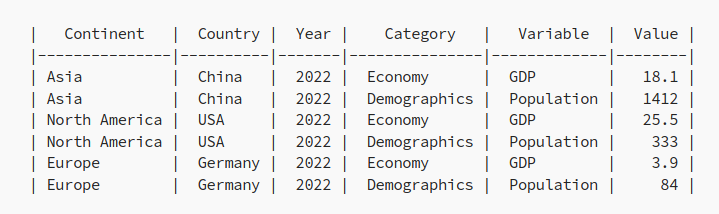
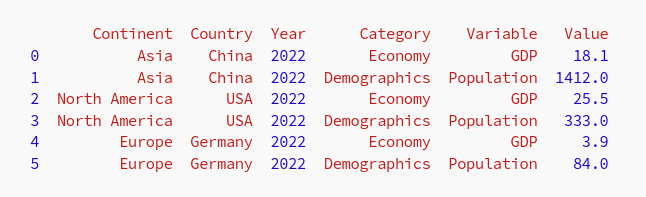
打开屏幕共享,差点直接被转账
今天和爸妈聊天端午回家的事情,突然说到最近AI诈骗的事情,千叮咛万嘱咐说要对方说方言才行,让他们充分了解一下现在骗子诈骗的手段,顺便也找了一下骗子还有什么其他的手段,打算一起和他们科普一下,结果就发现下面这一则新闻:
在辽宁大连务工的耿女士接到一名自称“大连市公安局民警”的电话,称其涉嫌广州一起诈骗案件,让她跟广州警方对接。耿女士在加上所谓的“广州警官”的微信后,这位“警官”便给耿女士发了“通缉令”,并要求耿女士配合调查,否则将给予“强制措施”。随后,对方与耿女士视频,称因办案需要,要求耿女士提供“保证金”,并将所有存款都集中到一张银行卡上,再把钱转到“安全账户”。
期间,通过 “屏幕共享”,对方掌握了耿女士银行卡的账号和密码。耿女士先后跑到多家银行,取出现金,将钱全部存到了一张银行卡上。正当她打算按照对方指示,进行下一步转账时,被民警及时赶到劝阻。在得知耿女士泄露了银行卡号和密码后,银行工作人员立即帮助耿女士修改了密码,幸运的是,银行卡的近6万元钱没有受到损失。
就这手段,我家里的老人根本无法预防,除非把手机从他们手里拿掉,与世隔绝还差不多,所以还是做APP的各大厂商努力一下吧!
希望各大厂商都能看看下面这个防劫持SDK,让出门在外打工的我们安心一点。
防劫持SDK
一、简介
防劫持SDK是具备防劫持兼防截屏功能的SDK,可有效防范恶意程序对应用进行界面劫持与截屏的恶意行为。
二、iOS版本
2.1 环境要求
| 条目 | 说明 |
|---|---|
| 兼容平台 | iOS 8.0+ |
| 开发环境 | XCode 4.0 + |
| CPU架构 | armv7, arm64, i386, x86_64 |
| SDK依赖 | libz, libresolv, libc++ |
2.2 SDK接入
2.2.1 DxAntiHijack获取
从官网下载SDK获取,下面是SDK的目录结构
DXhijack_xxx_xxx_xxx_debug.zip 防劫持debug 授权集成库 DXhijack_xxx_xxx_xxx_release.zip 防劫持release 授权集成库
解压
DXhijack_xxx_xxx_xxx_xxx.zip文件,得到以下文件
DXhijack文件夹
DXhijack.a已授权静态库Header/DXhijack.h头文件dx_auth_license.description授权描述文件DXhijackiOS.framework已授权framework 集成库
2.2.2 将SDK接入XCode
2.2.2.1 导入静态库及头文件
将SDK目录(包含静态库及其头文件)直接拖入工程目录中,或者右击总文件夹添加文件。 或者 将DXhijackiOS.framework 拖进framework存放目录
2.2.2.2 添加其他依赖库
在项目中添加 libc++.tbd 库,选择Target -> Build Phases,在Link Binary With Libraries里点击加号,添加libc++.tbd
2.2.2.3 添加Linking配置
在项目中添加Linking配置,选择Target -> Build Settings,在Other Linker Flags里添加-ObjC配置
2.3 DxAntiHijack使用
2.3.1 方法及参数说明
@interface DXhijack : NSObject
+(void)addFuzzy; //后台模糊效果
+(void)removeFuzzy;//后台移除模糊效果
@end
2.3.2 使用示例
在对应的AppDelegate.m 文件中头部插入
#import "DXhijack.h"
//在AppDelegate.m 文件中applicationWillResignActive 方法调用增加
- (void)applicationWillResignActive:(UIApplication *)application {
[DXhijack addFuzzy];
}
//在AppDelegate.m 文件中applicationDidBecomeActive 方法调用移除
- (void)applicationDidBecomeActive:(UIApplication *)application {
[DXhijack removeFuzzy];
}
三、Android版本
3.1 环境要求
| 条目 | 说明 |
|---|---|
| 开发目标 | Android 4.0+ |
| 开发环境 | Android Studio 3.0.1 或者 Eclipse + ADT |
| CPU架构 | ARM 或者 x86 |
| SDK三方依赖 | 无 |
3.2 SDK接入
3.2.1 SDK获取
- 访问官网,注册账号
- 登录控制台,访问“全流程端防控->安全键盘SDK”模块
- 新增App,填写相关信息
- 下载对应平台SDK
3.2.2 SDK文件结构
SDK目录结构
dx-anti-hijack-${version}.jarAndroid jar包armeabi,armeabi-v7a,arm64-v8a,x864个abi平台的动态库文件
3.2.3 Android Studio 集成
3.2.3.1 Android Studio导入jar, so
把dx-anti-hijack-x.x.x.jar, so文件放到相应模块的libs目录下
- 在该Module的build.gradle中如下配置:
android{
sourceSets {
main {
jniLibs.srcDirs = ['libs']
}
}
repositories{
flatDir{
dirs 'libs'
}
}
}
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
}
3.2.3.2 权限声明
Android 5.0(不包含5.0)以下需要在项目AndroidManifest.xml文件中添加下列权限配置:
<uses-permission android:name="android.permission.GET_TASKS"/>
3.2.3.3 混淆配置
-dontwarn *.com.dingxiang.mobile.**
-dontwarn *.com.mobile.strenc.**
-keep class com.security.inner.**{*;}
-keep class *.com.dingxiang.mobile.**{*;}
-keep class *.com.mobile.strenc.**{*;}
-keep class com.dingxiang.mobile.antihijack.** {*;}
3.3 DxAntiHijack 类使用
3.3.1 方法及参数说明
3.3.1.1 初始化
建议在Application的onCreate下調用
/**
* 使用API前必須先初始化
* @param context
*/
public static void init(Context context);
3.3.1.2 反截屏功能
/**
* 反截屏功能
* @param activity
*/
public static void DGCAntiHijack.antiScreen(Activity activity);
/**
* 反截屏功能
* @param dialog
*/
public static void DGCAntiHijack.antiScreen(Dialog dialog);
3.3.1.3 反劫持检测
/**
* 调用防劫持检测,通常现在activity的onPause和onStop调用
* @return 是否存在被劫持风险
*/
public static boolean DGCAntiHijack.antiHijacking();
3.3.2 使用示例
//使用反劫持方法
@Override
protected void onPause() {
boolean safe = DXAntiHijack.antiHijacking();
if(!safe){
Toast.makeText(getApplicationContext(), "App has entered the background", Toast.LENGTH_LONG).show();
}
super.onPause();
}
@Override
protected void onStop() {
boolean safe = DXAntiHijack.antiHijacking();
if(!safe){
Toast.makeText(getApplicationContext(), "App has entered the background", Toast.LENGTH_LONG).show();
}
super.onStop();
}
//使用反截屏方法
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DXAntiHijack.antiScreen(MainActivity.this);
}
以上。
结语
这种事情层出不穷,真的不是吾等普通民众能解决的,最好有从上至下的政策让相应的厂商(尤其是银行和会议类的APP)统一做处理,这样我们在外
来源:juejin.cn/post/7242145254057312311