前言

之前在我自己的项目中 打造属于你自己的 Mac(Next.js+Nest.js TS全栈项目)有同学问Terminal 组件是怎么实现的呢,现在我们就用 React+TS 写一个支持多种命令的 Terminal 终端吧。
每一步骤后都有对应的 commit 记录;
源码地址:github.com/ljq0226/my-… 欢迎 Star ⭐️⭐️⭐️
体验地址: my-terminal.netlify.app/
搭建环境
我们使用 vite 构建项目,安装所需要的依赖库:
- @neodrag/react (拖拽)
- tailwindcss
- lucide-react (图标)
步骤:
pnpm create vite
- 选择 React+TS 模版
- 安装依赖:
pnpm install @neodrag/react lucide-react && pnpm install -D tailwindcss postcss autoprefixer && npx tailwindcss init -p
配置 tailwind.config.js:
export default {
content: [
'./index.html',
'./src/**/*.{js,ts,jsx,tsx}',
],
theme: {
extend: {},
},
plugins: [],
}
仓库代码:commit1
开发流程
搭建页面

以上是终端的静态页面,样式这里就不在详细展开了,此次代码仓库 commit2 。 接下来我们为该终端添加拖拽效果:
···
import type { DragOptions } from '@neodrag/react'
import { useRef, useState } from 'react'
function APP(){
const [position, setPosition] = useState({ x: 0, y: 0 })
const draggableRef = useRef(null)
const options: DragOptions = {
position,
onDrag: ({ offsetX, offsetY }) => setPosition({ x: offsetX, y: offsetY }),
bounds: { bottom: -500, top: 32, left: -600, right: -600 },
handle: '.window-header',
cancel: '.traffic-lights',
}
useDraggable(draggableRef, options)
}
return (
<div ref={draggableRef}> //将 draggableRef 挂在到节点上
</div>
)
···
这样我们的 Terminal 终端就有了拖拽效果,其它 API 方法在@neodrag/react 官网中,代码仓库 commit3。

输入命令
一个终端最重要的当然是输入命令了,在这我们使用 input 框来收集收集输入命令的内容。
由于我们每次执行完一次命令之后,都会生成新的行,所以我们将新行封装成一个组件,Row 组件接收两个参数(id:当前 Row 的唯一标识;onkeydown:监听 input 框的操作):
interface RowProps {
id: number
onkeydown: (e: React.KeyboardEvent<HTMLInputElement>) => void
}
const Row: React.FC<RowProps> = ({ id, onkeydown }) => {
return (
<div className='flex flex-col w-full h-12'>
<div>
<span className="mr-2 text-yellow-400">funnycoder</span>
<span className="mr-2 text-green-400">@macbook-pro</span>
<span className="mr-2 text-blue-400">~{dir}</span>
<span id={`terminal-currentDirectory-${id}`} className="mr-2 text-blue-400"></span>
</div>
<div className='flex'>
<span className="mr-2 text-pink-400">$</span>
<input
type="text"
id={`terminal-input-${id}`}
autoComplete="off"
autoFocus={true}
className="flex-1 px-1 text-white bg-transparent outline-none"
onKeyDown={onkeydown}
/>
</div>
</div>
)
}
一开始的时候,我们通过初始化一个 Row 进行操作,我们所有生成的 Row 通过
const [content, setContent] = useState<JSX.Element[]>(
[<Row
id={0}
key={key()} // React 渲染列表时需要key
onkeydown={(e: React.KeyboardEvent<HTMLInputElement>) => executeCommand(e, 0)}
/>,
])
content 变量来存储,在后续我们经常要修改 content 的值,为了简化代码我们为 setContent 封装成 generateRow 方法:
const generateRow = (row: JSX.Element) => {
setContent(s => [...s, row])
}
问题来了,当我们获取到了输入的命令时,怎么执行对应的方法呢?
每一个 Row 组件都有 onKeyDown事件监听,当按下按键时就调用 executeCommand 方法,通过 input 框的 id 获取该 input 框 dom 节点, const [cmd, args] = input.value.trim().split(' ') 获取执行命令 cmd 和 参数 args,此时根据 event.key 按键操作执行对应的方法:
function executeCommand(event: React.KeyboardEvent<HTMLInputElement>, id: number) {
const input = document.querySelector(`#terminal-input-${id}`) as HTMLInputElement
const [cmd, args] = input.value.trim().split(' ')
if (event.key === 'ArrowUp')
alert(`ArrowUp,Command is ${cmd} Args is ${args}`)
else if (event.key === 'ArrowDown')
alert(`ArrowDown,Command is ${cmd} Args is ${args}`)
else if (event.key === 'Tab')
alert(`Tab,Command is ${cmd} Args is ${args}`)
else if (event.key === 'Enter')
alert(`Enter,Command is ${cmd} Args is ${args}`)
}
接下来我们测试一下,输入cd desktop,按下 Enter 键:
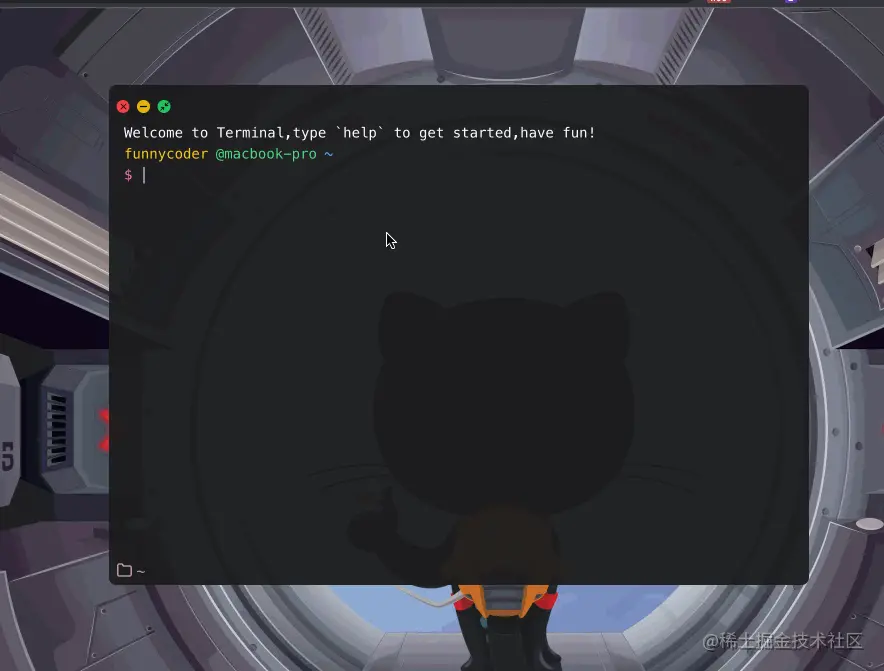
代码仓库 commit3。
构建文件夹系统
终端的最常用的功能就是操作文件,所以我们需要构建一个文件夹系统,起初,在我的项目中使用的是一个数组嵌套,类似下面这种
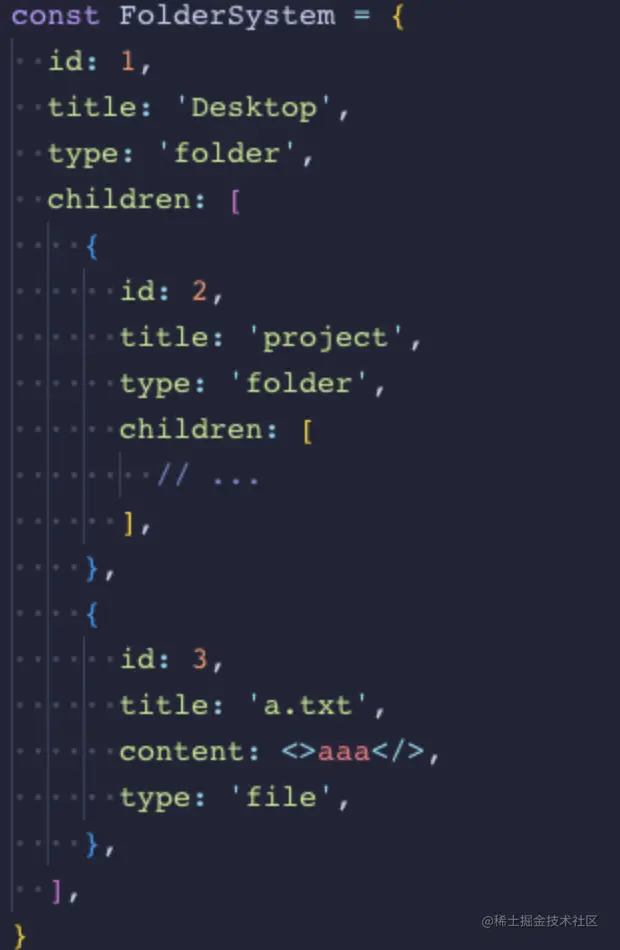
这种数据结构的话,每次寻找子项的都需要递归计算,非常麻烦。在这我们采用 map 进行存储,将数据扁平化:
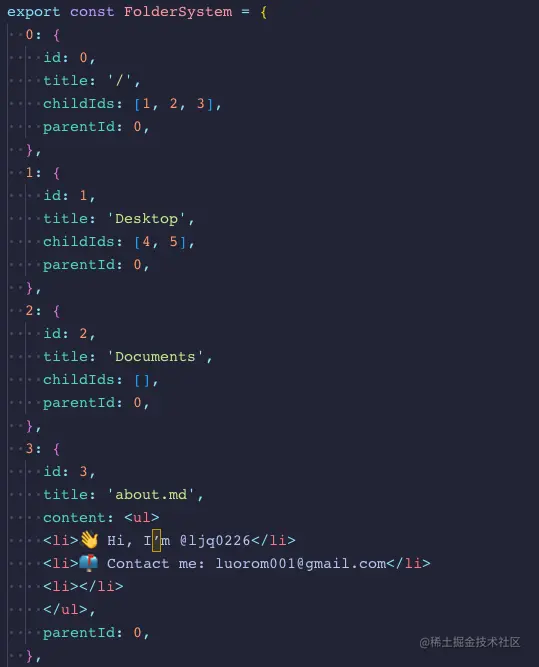
代码仓库 commit4 。
执行命令
准备工作
我们先介绍一下几个变量:
- currentFolderId :当前文件夹的 id,默认为 0 也就是最顶层的文件夹
- currentDirectory : 当前路径
- currentId : input 输入框的 id 标识
const [currentId, setCurrentId] = useState<number>(0)
const [currentFolderId, setCurrentFolderId] = useState(0)
const [currentDirectory, setCurrentDirectory] = useState<string>('')
并把一些静态组件封装在 components.tsx 文件中:
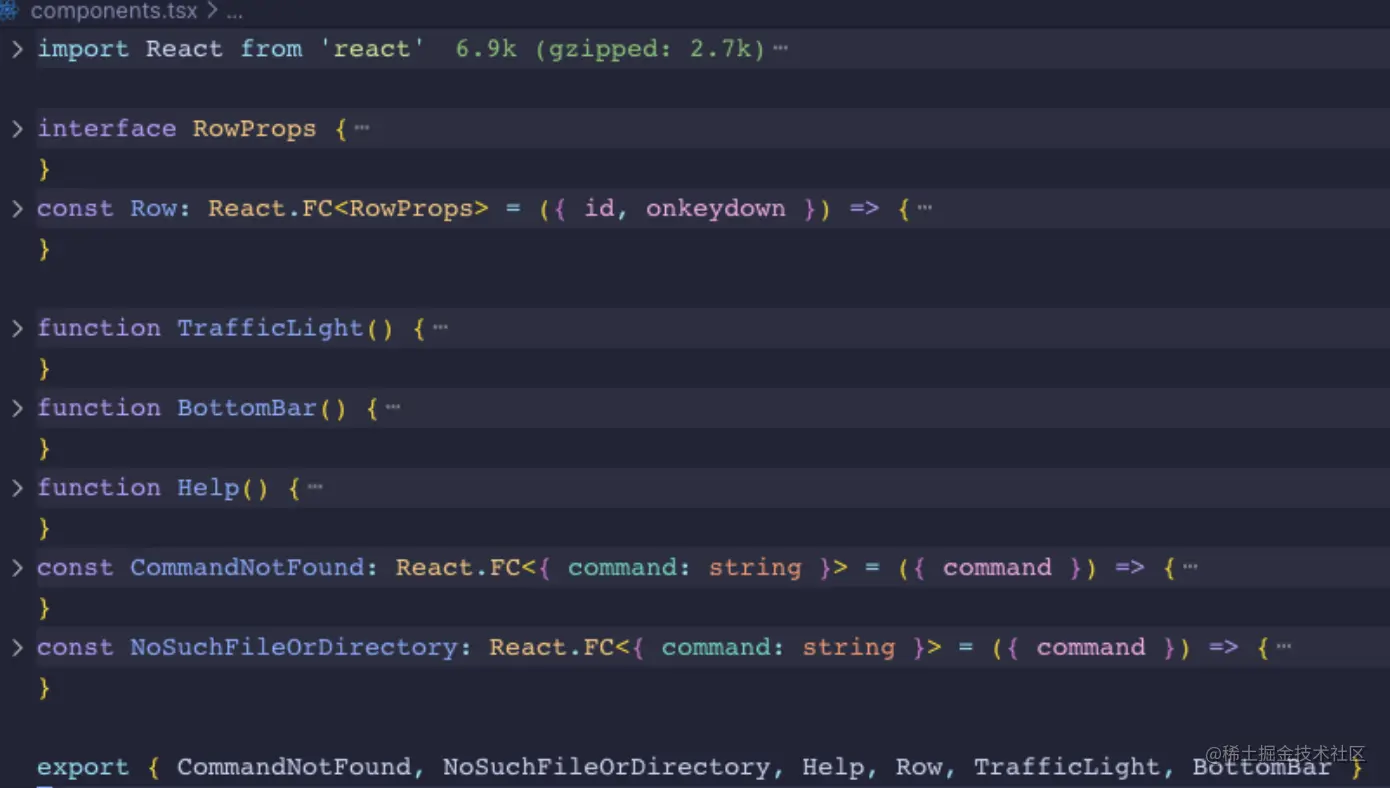
核心介绍
我们用一个对象来存储需要执行对应的方法:
const commandList: CommandList = {
cat,
cd,
clear,
ls,
help,
mkdir,
touch,
}
在executeCommand 方法中,如果用户按下的是'Enter' 键,我们首先判断下输入的 cmd 是否在 commandlist 中,如果存在,就直接执行该方法,如果不存在,就生成一个 CommandNotFound
行:
function executeCommand(){
else if (event.key === 'Enter') {
const newArr = commandHistory
newArr.push(input.value.trim())
setCommandHistory(newArr)
if (cmd && Object.keys(commandList).includes(cmd))
commandList[cmd](args)
else if (cmd !== '')
generateRow(<CommandNotFound key={key()} command={input.value.trim()} />)
setCurrentId(id => id + 1)
setTimeout(() => {
generateRow(
<Row
key={key()}
id={commandHistory.length}
onkeydown={(e: React.KeyboardEvent<HTMLInputElement>) => executeCommand(e, commandHistory.length)}
/>,
)
}, 100)
}
//...
}
help
当输入的 cmd 识别为'help'时就会调用该方法,生成在 components.tsx 里 Help()中定义好的静态数据:
const help = () => {
generateRow(<Help key={key()} />)
}
代码仓库:commit5
cd
首先,默认的currentFolderId为 0,也就是指向我们的根文件夹,我们可以通过 folderSysteam.get(currentFolderId) 来获取当前文件夹下的信息,包括该文件夹的 title,子文件的 id 数组 childIds 。
当我们获取到了参数 arg 时,首先要判断 是否为空或者'..',若是的话,即返回上一层目录,
如果是正常参数的话,通过 folderSysteam.get(currentFolderId) 获取子目录的 childIds 数组,遍历当前目录下的子目录,找到子目录中 title 和 arg 一样的目录并返回该子目录 id,将 currentFolderId 设置为该子目录 id 并且拼接文件路径:
const cd = (arg = '') => {
const dir: string = localStorage.getItem(CURRENTDIRECTORY) as string
if (!arg || arg === '..') {
const dirArr = dir.split('/')
dirArr.length = Math.max(0, dirArr.length - 2)
if (!dirArr.length)
setCurrentDirectory(`${dirArr.join('')}`)
else
setCurrentDirectory(`${dirArr.join('')}/`)
setCurrentFolderId(folderSysteam.get(`${currentFolderId}`)?.parentId as number)
return
}
const id = searchFile(arg)
if (id) {
const res = `${dir + folderSysteam.get(`${id}`)?.title}/`
setCurrentFolderId(id)
setCurrentDirectory(res)
}
else { generateRow(<NoSuchFileOrDirectory key={key()} command={arg}/>) }
}
const searchFile = (arg: string) => {
const args = [arg, arg.toUpperCase(), arg.toLowerCase(), arg.charAt(0).toUpperCase() + arg.slice(1)]
const childIds = getStorage(CURRENTCHILDIDS)
for (const item of folderSysteam.entries()) {
if (childIds.includes(item[1].id) && args.includes(item[1].title))
return item[1].id
}
}
ls
const ls = () => {
let res = ''
const ids = getStorage(CURRENTCHILDIDS)
for (const id of ids)
res = `${res + folderSysteam.get(`${id}`)?.title} `
if (!res) {
generateRow(<div key={key()} >There are no other folders or files in the current directory.</div>)
}
else {
res.split(' ').map((item: string) =>
generateRow(<div key={key()} className={item.includes('.') ? 'text-blue-500' : ''}>{item}</div>),
)
}
}
代码仓库:commit6| commit6.1
mkdir、touch
创建文件或文件夹,我们只需要创建该文件或文件夹对象,新对象的 parentId 指向当前目录,其新 id 加入到当前目录的 childIds 数组中,最后再更新一下 folderSysteam 变量:
const mkdir = (arg = '') => {
const currentFolderId = getStorage(CURRENTFOLDERID)
const size = folderSysteam.size.toString()
const newFolderSysteam = folderSysteam.set(`${size}`, {
id: +size,
title: arg,
childIds: [],
parentId: currentFolderId,
})
const childIds = (folderSysteam.get(`${currentFolderId}`) as FolderSysteamType).childIds as number[]
childIds && childIds.push(+size)
setStorage(CURRENTCHILDIDS, childIds)
setFolderSysteam(newFolderSysteam)
}
const touch = (arg = '') => {
const currentFolderId = getStorage(CURRENTFOLDERID)
const size = folderSysteam.size.toString()
const newFolderSysteam = folderSysteam.set(`${size}`, {
id: +size,
title: arg,
content: <div ><h1>
This is <span className='text-red-400 underline'>{arg}</span> file!
</h1>
<p>Imagine there's a lot of content here...</p>
</div>,
parentId: currentFolderId,
})
const childIds = (folderSysteam.get(`${currentFolderId}`) as FolderSysteamType).childIds as number[]
childIds && childIds.push(+size)
setStorage(CURRENTCHILDIDS, childIds)
setFolderSysteam(newFolderSysteam)
}
代码仓库:commit7
cat、clear
cat 命令只需要展示子文件的 content 属性值即可:
const cat = (arg = '') => {
const ids = getStorage(CURRENTCHILDIDS)
ids.map((id: number) => {
const item = folderSysteam.get(`${id}`) as FolderSysteamType
return item.title === arg ? generateRow(<div key={key()}>{item.content}</div> as JSX.Element) : ''
})
}
clear 命令只需要调用 setContent():
const clear = () => {
setContent([])
const input = document.querySelector('#terminal-input-0') as HTMLInputElement
input.value = ''
}
代码仓库:commit8
其它操作
准备工作
我们先介绍一下几个变量:
- commandHistory : 用于存储输入过的 command数组
- changeCount : 用来切换 command 计数
const [changeCount, setChangeCount] = useState<number>(0)
const [commandHistory, setCommandHistory] = useState<string[]>([])
上下键切换 command
上面定义的 changeCount 变量默认为 0,当我们按上🔼键时,changeCount-1,当我们按下🔽键时,changeCount+1。
而当 changeCount 变量变化时,获取当前 input dom 节点,设置其值为commandHistory[commandHistory.length + changeCount],这样我们的上下键切换 command 就实现了:
useEffect(() => {
const input = document.querySelector(`#terminal-input-${commandHistory.length}`) as HTMLInputElement
if (commandHistory.length)
input.value = commandHistory[commandHistory.length + changeCount]
if (!changeCount) {
input.value = ''
setChangeCount(0)
}
}, [changeCount])
function handleArrowUp() {
setChangeCount(prev => Math.max(prev - 1, -commandHistory.length))
}
function handleArrowDown() {
setChangeCount(prev => Math.min(prev + 1, 0))
}
function executeCommand(...) {
if (event.key === 'ArrowUp') {
handleArrowUp()
}
else if (event.key === 'ArrowDown') {
handleArrowDown()
}
Tab 键补全 command
根据历史记录补全 command ,利用 Array.filter() 和 String.startsWith() 就行:
const matchCommand = (inputValue: string): string | null => {
const matchedCommands = commandHistory.filter(command => command.startsWith(inputValue))
return matchedCommands.length > 0 ? matchedCommands[matchedCommands.length - 1] : null
}
代码仓库:commit9
最后
大家有兴趣的话可以自己再去二次改造或添加一些新玩法,此组件已通过 Netlify 部署上线,地址为 my-terminal.netlify.app/
项目源代码:github.com/ljq0226/my-… 欢迎 S
作者:Aphelios_
来源:juejin.cn/post/7248599585735098405
tar ⭐️⭐️⭐️











