








我们来说一说什么是联合索引最左匹配原则?
什么是联合索引?
首先,要理解最左匹配原则,得先知道什么是联合索引。
- 单列索引:只针对一个表列创建的索引。例如,为 users 表的 name 字段创建一个索引。
- 联合索引:也叫复合索引,是针对多个表列创建的索引。例如,为 users 表的 (last_name, first_name) 两个字段创建一个联合索引。
这个索引的结构可以想象成类似于电话簿或字典。电话簿是先按姓氏排序,在姓氏相同的情况下,再按名字排序。你无法直接跳过姓氏,快速找到一个特定的名字。
什么是最左匹配原则?
最左匹配原则指的是:在使用联合索引进行查询时,MySQL/SQL数据库从索引的最左前列开始,并且不能跳过中间的列,一直向右匹配,直到遇到范围查询(>、<、BETWEEN、LIKE)就会停止匹配。
这个原则决定了你的 SQL 查询语句是否能够使用以及如何高效地使用这个联合索引。
核心要点:
- 从左到右:索引的使用必须从最左边的列开始。
- 不能跳过:不能跳过联合索引中的某个列去使用后面的列。
- 范围查询右停止:如果某一列使用了范围查询,那么它右边的列将无法使用索引进行进一步筛选。
举例说明
假设我们有一个 users 表,并创建了一个联合索引 idx_name_age,包含 (last_name, age) 两个字段。
| id | last_name | first_name | age | city |
| 1 | Wang | Lei | 20 | Beijing |
| 2 | Zhang | Wei | 25 | Shanghai |
| 3 | Wang | Fang | 22 | Guangzhou |
| 4 | Li | Na | 30 | Shenzhen |
| 5 | Zhang | San | 28 | Beijing |
索引 idx_name_age 在磁盘上大致是这样排序的(先按 last_name 排序,last_name 相同再按 age 排序):
(Li, 30) (Wang, 20) (Wang, 22) (Zhang, 25) (Zhang, 28)
现在,我们来看不同的查询场景:
✅ 场景一:完全匹配最左列
SELECT * FROM users WHERE last_name = 'Wang';
- 分析:查询条件包含了索引的最左列 last_name。
- 索引使用情况:✅ 可以使用索引。数据库可以快速在索引树中找到所有 last_name = 'Wang' 的记录((Wang, 20) 和 (Wang, 22))。
✅ 场景二:匹配所有列
SELECT * FROM users WHERE last_name = 'Wang' AND age = 22;
- 分析:查询条件包含了索引的所有列,并且顺序与索引定义一致。
- 索引使用情况:✅ 可以高效使用索引。数据库先定位到 last_name = 'Wang',然后在这些结果中快速找到 age = 22 的记录。
✅ 场景三:匹配最左连续列
SELECT * FROM users WHERE last_name = 'Zhang';
- 分析:虽然只用了 last_name,但它是索引的最左列。
- 索引使用情况:✅ 可以使用索引。和场景一类似。
❌ 场景四:跳过最左列
SELECT * FROM users WHERE age = 25;
- 分析:查询条件没有包含索引的最左列 last_name。
- 索引使用情况:❌ 无法使用索引。这就像让你在电话簿里直接找所有叫“伟”的人,你必须翻遍整个电话簿,也就是全表扫描。
⚠️ 场景五:包含最左列,但中间有断档
-- 假设我们有一个三个字段的索引 (col1, col2, col3) -- 查询条件为 WHERE col1 = 'a' AND col3 = 'c';
- 分析:虽然包含了最左列 col1,但跳过了 col2 直接查询 col3。
- 索引使用情况:✅ 部分使用索引。数据库只能使用 col1 来缩小范围,找到所有 col1 = 'a' 的记录。对于 col3 的过滤,它无法利用索引,需要在第一步的结果集中进行逐行筛选。
⚠️ 场景六:最左列是范围查询
SELECT * FROM users WHERE last_name > 'Li' AND age = 25;
- 分析:最左列 last_name 使用了范围查询 >。
- 索引使用情况:✅ 部分使用索引。数据库可以使用索引找到所有 last_name > 'Li' 的记录(即从 Wang 开始往后的所有记录)。但是,对于 age = 25 这个条件,由于 last_name 已经是范围匹配,age 列在索引中是无序的,因此数据库无法再利用索引对 age 进行快速筛选,只能在 last_name > 'Li' 的结果集中逐行检查 age。
总结与最佳实践
最左匹配原则的本质是由索引的数据结构(B+Tree) 决定的。索引按照定义的字段顺序构建,所以必须从最左边开始才能利用其有序性。
如何设计好的联合索引?
- 高频查询优先:将最常用于 WHERE 子句的列放在最左边。
- 等值查询优先:将经常进行等值查询(=)的列放在范围查询(>, <, LIKE)的列左边。
- 覆盖索引:如果查询的所有字段都包含在索引中(即覆盖索引),即使不符合最左前缀,数据库也可能直接扫描索引来避免回表,但这通常发生在二级索引扫描中,效率依然不如最左匹配。
来源:juejin.cn/post/7565940210148868148
MyBatis 中 where1=1 一些替换方式
题记
生命中的风景千变万化,但我一直在路上。
风雨兼程,不是为了抵达终点,而是为了沿途的风景。
起因
今天闲来无事,翻翻看看之前的项目。
在看到一个项目的时候,项目框架用的是SpringMvc+Spring+Mybatis。项目里面注释时间写的是2018年,时间长了,里面有好多语法现在看起来好麻烦的样子呀!
说有它就有,这不就有一个吗?在Mybatis配置的xml中,有好多where 1=1 拼接Sql的方式,看的人头都大了。想着改一下吧,又一想,代码已经时间长了,如果出现问题找谁,就先不管了。
话是这样说,但在实际工作中,还是会有方法可以代替的,下面我们一起来看看吧!
替换方式
在 MyBatis 中,WHERE 1=1 通常用来在多条件查询情况下下进行SQL 拼接,其目的就是避免在没有条件时出现语法错误。
但这种写法不够优雅,可通过以下方式进行替代:
1. 使用 <where> 标签(推荐)
MyBatis 的 <where> 标签会自动处理 SQL 的 WHERE 语句,移除多余的 AND 或 OR 关键字。
看实例:
<select id="selectUsers" resultType="User">
SELECT * FROM user
<where>
<if test="username != null and username != ''">
AND username = #{username}
</if>
<if test="age != null">
AND age = #{age}
</if>
</where>
</select>
效果说明:
- 当无参数时,此时执行的Sql语句为:
SELECT * FROM user - 当仅传
username时,此时执行的Sql语句为:SELECT * FROM user WHERE username = ? - 当传
username和age时,此时执行的Sql语句为:SELECT * FROM user WHERE username = ? AND age = ?
2. 使用 <trim> 标签自定义
<trim> 可更灵活地处理 SQL 片段,通过设置 prefix 和 prefixOverrides 属性模拟 <where> 的功能。
看实例:
<select id="selectUsers" resultType="User">
SELECT * FROM user
<trim prefix="WHERE" prefixOverrides="AND |OR ">
<if test="username != null and username != ''">
AND username = #{username}
</if>
<if test="age != null">
AND age = #{age}
</if>
</trim>
</select>
说明:
prefix="WHERE":在条件前添加WHERE关键字。prefixOverrides="AND |OR ":移除条件前多余的AND或OR。
3. 使用 <choose>、<when>、<otherwise>
类似Java在进行判断中常用的 switch-case语句,此方式适用于多条件互斥的场景。
看实例:
<select id="selectUsers" resultType="User">
SELECT * FROM user
<where>
<choose>
<when test="username != null and username != ''">
username = #{username}
</when>
<when test="age != null">
age = #{age}
</when>
<otherwise>
1=1 <!-- 仅在无任何条件时使用 -->
</otherwise>
</choose>
</where>
</select>
4. Java代码判断控制
在 Service 层根据条件动态选择不同的 SQL 语句。
看实例:
public List<User> getUsers(String username, Integer age) {
if (username != null && !username.isEmpty()) {
return userMapper.selectByUsername(username);
} else if (age != null) {
return userMapper.selectByAge(age);
} else {
return userMapper.selectAll();
}
}
具体方式对比与选择
| 方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
<where> | 多条件动态组合 | 自动处理 WHERE 和 AND | 需MyBatis 框架支持 |
<trim> | 复杂 SQL 片段处理 | 灵活度比较高 | 配置稍繁琐 |
<choose> | 多条件互斥选择 | 逻辑清晰 | 无明确条件时仍需 1=1 |
| Java代码判断控制 | 条件逻辑复杂 | 完全可控 | 增加Service层代码复杂度 |
总结
推荐优先使用 <where> 标签,它能自动处理 SQL 语法,避免冗余代码。只有在需要更精细控制时,才考虑 <trim> 或其他方式。尽量避免在 XML 中使用 WHERE 1=1,保持 SQL 的简洁性和规范性。
展望
世间万物皆美好, 终有归途暖心潮。
在纷繁的世界里,保持内心的宁静与坚定,让每一步都走向完美的结局。
来源:juejin.cn/post/7534892673107804214
从RBAC到ABAC的进阶之路:基于jCasbin实现无侵入的SpringBoot权限校验
一、前言:当权限判断写满业务代码
几乎所有企业系统,都逃不过“权限”这道关。
从“谁能看”、“谁能改”到“谁能审批”,权限逻辑贯穿了业务的方方面面。
起初,大多数项目使用最常见的 RBAC(基于角色的访问控制) 模型
if (user.hasRole("admin")) {
documentService.update(doc);
}
逻辑简单、上手快,看似能解决 80% 的问题。
但随着业务复杂度上升,RBAC 很快会失控。
比如你可能遇到以下需求 👇
- “文档的作者可以编辑自己的文档”;
- “同部门的经理也可以编辑该文档”;
- “外部合作方仅能查看共享文档”;
- “项目归档后,所有人都只读”。
这些场景无法用“角色”简单定义,
于是权限判断开始蔓延在业务代码各处,像这样:
if (user.getId().equals(doc.getOwnerId())
|| (user.getDept().equals(doc.getDept()) && user.isManager())) {
// 编辑文档
} else {
throw new AccessDeniedException("无权限");
}
时间久了,这些判断像杂草一样蔓延。
权限逻辑与业务逻辑纠缠不清,修改一处可能引发连锁反应。
可维护性、可测试性、可演化性统统崩盘。
二、RBAC 的天花板:角色无法描述现实世界
RBAC 的问题在于:它过于静态。
“角色”可以描述一类人,但描述不了上下文。
举个例子:
研发经理能编辑本部门的文档,但不能编辑市场部的。
在 RBAC 下,你只能再创建新角色:
研发经理、市场经理、项目经理……
角色越来越多,最终爆炸。
而现实世界的权限,往往与“属性”有关:
- 用户的部门
- 资源的拥有者
- 操作发生的时间 / 状态
这些动态因素,是 RBAC 无法覆盖的。
于是我们需要一个更灵活的模型 —— ABAC。
三、ABAC:基于属性的访问控制
ABAC(Attribute-Based Access Control) 的核心理念是:
授权决策 = 函数(主体属性、资源属性、操作属性、环境属性)
| 概念 | 含义 | 示例 |
|---|---|---|
| Subject(主体) | 谁在访问 | 用户A,部门=研发部 |
| Object(资源) | 访问什么 | 文档1,ownerId=A,部门=研发部 |
| Action(操作) | 做什么 | edit / read / delete |
| Policy(策略) | 允许条件 | user.dept == doc.dept && act == "edit" |
一句话总结:
ABAC 不关心用户是谁,而关心“用户和资源具有什么属性”。
举例说明:
“用户可以编辑自己部门的文档,或自己创建的文档。”
简单、直观、灵活。
四、引入 JCasbin:让授权逻辑从代码中消失
JCasbin(github.com/casbin/jcas…) 是一个优秀的 Java 权限引擎,支持多种模型(RBAC、ABAC)。
它最大的价值在于:
把授权逻辑从代码中抽离,让代码只负责执行业务。
在 JCasbin 中,我们通过定义:
- 模型文件(model) :规则框架;
- 策略文件(policy) :具体规则。
然后由 Casbin 引擎来执行判断。
五、核心实现:几行配置搞定动态权限
模型文件 model.conf
[request_definition]
r = sub, obj, act
[policy_definition]
p = sub_rule, obj_rule, act
[policy_effect]
e = some(where (p.eft == allow))
[matchers]
m = eval(p.sub_rule) && eval(p.obj_rule) && r.act == p.act
策略文件 policy.csv
p, r.sub.dept == r.obj.dept, true, edit
p, r.sub.id == r.obj.ownerId, true, edit
p, true, true, read
解释:
- 同部门可编辑;
- 作者可编辑;
- 所有人可阅读。
在代码中调用
Enforcer enforcer = new Enforcer("model.conf", "policy.csv");
User user = new User("u1", "研发部");
Document doc = new Document("d1", "研发部", "u1");
boolean canEdit = enforcer.enforce(user, doc, "edit");
System.out.println("是否有编辑权限:" + canEdit);
输出:
是否有编辑权限:true
无需任何 if-else,逻辑全在外部配置中定义。
业务代码只需调用 Enforcer,简单又优雅。
六、在 Spring Boot 中实现“无感校验”
实际项目中,我们希望权限校验能“自动触发”,
这可以通过 注解 + AOP 切面 的方式实现。
定义注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CheckPermission {
String action();
}
编写切面
@Aspect
@Component
public class PermissionAspect {
@Autowired
private Enforcer enforcer;
@Before("@annotation(checkPermission)")
public void checkAuth(JoinPoint jp, CheckPermission checkPermission) {
Object user = getCurrentUser();
Object resource = getRequestResource(jp);
String action = checkPermission.action();
if (!enforcer.enforce(user, resource, action)) {
throw new AccessDeniedException("无权限执行操作:" + action);
}
}
}
在业务代码中使用
@CheckPermission(action = "edit")
@PostMapping("/doc/edit")
public void editDoc(@RequestBody Document doc) {
documentService.update(doc);
}
✅ 授权逻辑彻底从业务中解耦,权限统一由 Casbin 引擎处理。
七、策略动态化与分布式支持
在生产环境中,权限策略通常存储在数据库中,而非文件。
JCasbin 支持多种扩展方式:
JDBCAdapter adapter = new JDBCAdapter(dataSource);
Enforcer enforcer = new Enforcer("model.conf", adapter);
支持特性包括:
- 💽 MySQL / PostgreSQL 等持久化;
- 🔄 Redis Watcher 实现多节点策略热更新;
- ⚡ SyncedEnforcer 支持高并发一致性。
这样修改权限规则就无需重新部署代码,权限即改即生效
八、总结
引入 JCasbin 后,项目结构会发生显著变化👇
| 优势 | 描述 |
|---|---|
| 逻辑解耦 | 授权逻辑完全从业务代码中剥离 |
| 灵活配置 | 权限规则动态可改、可热更新 |
| 可扩展 | 可根据属性定义复杂条件 |
| 统一决策 | 所有权限判断走同一引擎 |
| 可测试 | 策略可单测,无需跑整套业务流程 |
最重要的是:新增规则无需改代码。
只要在策略表里加一条记录,就能实现全新的授权逻辑。
权限系统的复杂,不在于“能不能判断”,
而在于——“判断逻辑放在哪儿”。
当项目越做越大,你会发现:
真正的架构能力,不是多写逻辑,而是让逻辑有边界。
JCasbin 给了我们一个极好的解法:
一个统一的决策引擎,让权限系统既灵活又有秩序。
它不是银弹,但能让你在权限处理上的代码更纯净、系统扩展性更好。
来源:juejin.cn/post/7558094123812536361
研发排查问题的利器:一款方法调用栈跟踪工具
导语
本文从日常值班问题排查痛点出发,分析方法复用的调用链路和上下文业务逻辑,通过思考分析,借助栈帧开发了一个方法调用栈的链式跟踪工具,便于展示一次请求的方法串行调用链,有助于快速定位代码来源和流量入口,有效提升研发和运维排查定位效率。期望在大家面临类似痛点时可以提供一些实践经验和参考,也欢迎大家合适的场景下接入使用。
现状分析
在系统值班时,经常会有人拿着报错截图前来咨询,作为值班研发,我们则需要获取尽可能多的信息,帮助我们分析报错场景,便于排查识别问题。
例如,下图就是一个常见的的报错信息截图示例。
从图中,我们可以初步获取到一些信息:
•菜单名称:变更单下架,我们这是变更单下架操作时的一个报错提醒。
•报错信息:序列号状态为离库状态,请检查。
•其他辅助信息:例如用户扫描或输入的86开头编码,SKU、商品名称、储位等。
这时会有一些常见的排查思路:
1、根据提示,将用户输入的86编码,按照提示文案去检查用户数据,即作为序列号编码,去看一下序列号是否存在,是否真的是离库了。
2、如果86编码确实是序列号,而且真的是离库了,那么基本上可以快速结案了,这个86编码确实是序列号并且是已离库,正如提示文案所示,这时跟提问人做好解释答疑即可。
3、如果第2步排查完,发现86编码不是序列号编码,或并非离库状态,即与提示文案不符,这时就要定位报错文案的代码来源,继续查看代码逻辑来进行判案了。(这种也比较常见,一种是报错场景较多,但提示文案比较单一,不便于在提示文案中覆盖所有报错场景;另一种提示文案陈旧未跟随需求演变而更新。这两点可以通过细分场景细化对应的报错文案,或更新报错文案,使得报错文案更优更新,但不是本文讨论的重点。)
4、如何根据报错文案快速找到代码来源呢?一般我们会在代码库中搜索提示文案,或者在日志中检索报错信息,辅助定位代码来源,后者依赖于代码中打印了该报错信息,且日志级别配置能够确保该信息打印到日志文件中。
5、倘若我们根据提示文案搜索代码时,发现该提示文案有多处代码出现,此时就较为复杂了,我们需要进一步识别,哪个才与本次报错直接有关。

每个方法向上追溯,又发现调用来源众多:



在业务复杂的系统中,方法复用比较常见,不同的上下文和参数传递,也有着不同的业务逻辑判断和走向。
这时,基本上进入到本文要讨论的痛点:如何根据有限的提示信息快速定位代码来源?以便于分析报错业务场景,答疑解惑或快速处理问题。
屏幕前的小伙伴,如果你也经常值班排查问题,应该也会有类似的痛点所在。
启发
这是我想到了Exception异常机制,作为一名Coder,我们对异常堆栈再熟悉不过了,异常堆栈是一个“可爱”又“可恨”的东西,“可爱”在于异常堆栈确实可以帮助我们快速定位问题所在,“可恨”在于有异常基本上就是有问题,堆栈让我们审美疲劳,累觉不爱。
下面是一个Java语言的异常堆栈信息示例:

异常类体系和异常处理机制在本文中不是重点,不做过多赘述,本文重点希望能从异常堆栈中获取一些启发。
让我们近距离再观察一下我们的老朋友。
在异常堆栈信息中,主要有四类信息:
•全限定类名
•方法名
•文件名
•代码行号
这四类信息可以帮助我们有效定位代码来源,而且堆栈中记录行先后顺序,也表示着异常发生的第一现场、第二现场、第三现场、……,以此传递。
这让我想起了JVM方法栈中的栈帧。
每当一个方法被调用时,JVM会为该方法创建一个新的栈帧,并将其压入当前线程的栈(也称为调用栈或执行栈)中。栈帧包含了方法执行所需的所有信息,包括局部变量、操作数栈、常量池引用等。

思路
从Java中的Throwable中,可以看到staceTrace的get和set,这个StackTraceElement数组里面存放的信息就是我们在异常堆栈中经常看到的信息。



再次放一下这张图,方便对照着看。

StackTraceElement类的注释中赫然写着:
StackTraceElement represents a stack frame.
对,StackTraceElement代表着一个栈帧。
这个StackTraceElement就是我要找的东西,即使非异常情况下,每个线程在执行方法调用时都会记录栈帧信息。

按照方法调用先后顺序,将调用栈中方法依次串联起来,就像糖葫芦一样,就可以得到我想要的方法调用链了。
NEXT,我可以动工写个工具了。
工具开发
工具的核心代码并不复杂,StackTraceElement 也是 Java JDK 中现成的,我所做的工作主要是从中过滤出必要的信息,加工简化成,按照顺序整理成链式信息,方便我们一眼就可以看出来方法的调用链。

入参介绍
pretty: 表示是只拼接类和方法,不拼接文件名和行号,非 pretty 是四个都会拼接。
simple: 表示会过滤一些我们代码中场景的代理增强出来的方法的信息输出。
specifiedPrefix: 指定保留相应的包路径堆栈信息,去掉一些过多的中间件信息。
其他还会过滤一些常见代理的堆栈信息:
•FastClassBySpringCGLIB
•EnhancerBySpringCGLIB
•lambda$
•Aspect
•Interceptor
对此,还封装了一些默认参数的方法,使用起来更为方便。

还有一些其他工具方法也可以使用:

使用效果
1、不过滤中间件、代理增强方法的调用栈信息
Thread#run ==> ThreadPoolExecutorWorker#run ==> ThreadPoolExecutor#runWorker ==> BaseTask#run ==> JSFTask#doRun ==> ProviderProxyInvoker#invoke ==> FilterChain#invoke ==> SystemTimeCheckFilter#invoke ==> ProviderExceptionFilter#invoke ==> ProviderContextFilter#invoke ==> InstMethodsInter#intercept ==> ProviderContextFiltereone9f9kd21#call ==> ProviderContextFilter#eoneinvokeaccessorpclcbe2 ==> ProviderContextFilter#eoneinvokep882ot3 ==> ProviderGenericFilter#invoke ==> ProviderUnitValidationFilter#invoke ==> ProviderHttpGWFilter#invoke ==> ProviderInvokeLimitFilter#invoke ==> ProviderMethodCheckFilter#invoke ==> ProviderTimeoutFilter#invoke ==> ValidationFilter#invoke ==> ProviderConcurrentsFilter#invoke ==> ProviderSecurityFilter#invoke ==> WmsRpcExceptionFilter#invoke ==> WmsRpcExceptionFilter#invoke4provider ==> AdmissionControlJsfFilter#invoke ==> AdmissionControlJsfFilter#providerSide ==> AdmissionControlJsfFilter#processRequest ==> ChainedDeadlineJsfFilter#invoke ==> ChainedDeadlineJsfFilter#providerSide ==> JsfPerformanceMonitor#invoke ==> AbstractMiddlewarePerformanceMonitor#doExecute ==> PerformanceMonitorTemplateComposite#execute ==> PerformanceMonitorTemplateComposite#lambdaexecute0 ==> PerformanceMonitorTemplateUmp#execute ==> PerformanceMonitorTemplateComposite#lambdaexecute0 ==> PerformanceMonitorTemplatePayload#execute ==> JsfPerformanceMonitor#lambdainvoke0 ==> JsfPerformanceMonitor#doInvoke ==> ProviderInvokeFilter#invoke ==> ProviderInvokeFilter#reflectInvoke ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor1704#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> ExposeInvocationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor344#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor1276#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor868#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor869#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor1642#invoke ==> MagicAspect#magic ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxyCglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> ExposeInvocationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor868#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor869#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxyCglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor1295#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> ExposeInvocationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor868#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxyCglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> ExposeInvocationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxyCglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AnnotationAwareRetryOperationsInterceptor#invoke ==> RetryOperationsInterceptor#invoke ==> RetryTemplate#execute ==> RetryTemplate#doExecute ==> RetryOperationsInterceptor1#doWithRetry ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxyCglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> CglibAopProxyDynamicAdvisedInterceptor#intercept ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> ExposeInvocationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor1276#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> TransactionInterceptor#invoke ==> TransactionAspectSupport#invokeWithinTransaction ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> AspectJAroundAdvice#invoke ==> AbstractAspectJAdvice#invokeAdviceMethod ==> AbstractAspectJAdvice#invokeAdviceMethodWithGivenArgs ==> Method#invoke ==> DelegatingMethodAccessorImpl#invoke ==> GeneratedMethodAccessor869#invoke ==> MethodInvocationProceedingJoinPoint#proceed ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> PersistenceExceptionTranslationInterceptor#invoke ==> CglibAopProxyCglibMethodInvocation#proceed ==> ReflectiveMethodInvocation#proceed ==> CglibAopProxy$CglibMethodInvocation#invokeJoinpoint ==> MethodProxy#invoke ==> StackTraceUtils#trace
2、指定包路径过滤中间件后的调用栈栈信息
LockAspect#lock ==> StockTransferAppServiceImpl#increaseStock ==> MonitorAspect#monitor ==> StockRetryExecutor#operateStock ==> StockRetryExecutor5188d6e#invoke ==> BaseStockOperation9d76cd9a#invoke ==> StockTransferServiceImpl85bb181e#invoke ==> ValidationAspect#logAndReturn ==> LogAspect#log ==> ThreadLocalRemovalAspect#removal ==> ValidationAspect#validate ==> BaseStockOperation#go ==> StockRepositoryImpl1388ef12#operateStock ==> StockTransferAppServiceImpl1095eafa#increaseStock ==> StockRepositoryImpla1b4dae4#invoke ==> StockTransferServiceImpl#increaseStock ==> DataBaseExecutor#execute ==> StockRetryExecutorb42789a#operateStock ==> StockInitializer85faf510#go ==> StockTransferServiceImplafc21975#increaseStock ==> StockRepositoryImpl#operateStock ==> DataBaseExecutor#operate ==> StockTransferAppServiceImple348d8e1#invoke
3、去掉Spring代理增强之后的调用栈信息
LogAspect#log ==> LockAspect#lock ==> ValidationAspect#validate ==> ValidationAspect#logAndReturn ==> MonitorAspect#monitor ==> StockTransferAppServiceImpl#decreaseStock ==> ThreadLocalRemovalAspect#removal ==> StockTransferServiceImpl#decreaseStock ==> StockOperationLoader#go ==> BaseStockOperation#go ==> DataBaseExecutor#operate ==> DataBaseExecutor#execute ==> StockRetryExecutor#operateStock ==> StockRepositoryImpl#operateStock
4、去掉一些自定义代理之后的调用栈栈信息
StockTransferAppServiceImpl#increaseStock ==> StockTransferServiceImpl#increaseStock ==> BaseStockOperation#go ==> DataBaseExecutor#operate ==> DataBaseExecutor#execute ==> StockRetryExecutor#operateStock ==> StockRepositoryImpl#operateStock
5、如果带上文件名和行号后的调用栈栈信息
StockTransferAppServiceImpl#increaseStock(StockTransferAppServiceImpl.java:103) ==> StockTransferServiceImpl#increaseStock(StockTransferServiceImpl.java:168) ==> BaseStockOperation#go(BaseStockOperation.java:152) ==> BaseStockOperation#go(BaseStockOperation.java:181) ==> BaseStockOperation#go(BaseStockOperation.java:172) ==> DataBaseExecutor#operate(DataBaseExecutor.java:34) ==> DataBaseExecutor#operate(DataBaseExecutor.java:64) ==> DataBaseExecutor#execute(DataBaseExecutor.java:79) ==> StockRetryExecutor#operateStock(StockRetryExecutor.java:64) ==> StockRepositoryImpl#operateStock(StockRepositoryImpl.java:303)
线上应用实践

接入方法调用栈跟踪工具后,根据报错提示词,可以检索到对应日志,从 ImmediateTransferController#offShelf ==> AopConfig#pointApiExpression ==> TransferOffShelfAppServiceImpl#offShelf ==> TransferOffShelfAppServiceImpl#doOffShelf 中顺藤摸瓜可以快速找到流量入口的代码位置。


适用场景
该方法调用栈工具类,可以在一些堆栈信息进行辅助排查分析的地方进行预埋,例如:
•业务异常时输出堆栈到日志信息中。
•业务监控告警信息中加入调用栈信息。
•一些复用方法调用复杂场景下,打印调用栈信息,展示调用链,方便分析。
•其他一些场景等。
延伸
在《如何一眼定位SQL的代码来源:一款SQL染色标记的简易MyBatis插件》一文中,我发布了一款SQL染色插件,该插件目前已有statementId信息,还支持通过SQLMarkingThreadLocal传递自定义附加信息。其他BGBU的技术小伙伴,也有呼声,希望在statementId基础上可以继续追溯入口方法。通过本文引入的方法调用栈跟踪工具,我在SQL染色插件中增加了方法调用栈染色信息。
SQL染色工具新版特性,欢迎大家先在TEST和UAT环境尝鲜试用,TEST和UAT环境验证没问题后,再逐步推广正式环境。
升级方法:
1、sword-mybatis-plugins版本升级至1.0.8-SNAPSHOT。
2、同时新引入本文的工具依赖
<!-- http://sd.jd.com/article/45616?shareId=105168&isHideShareButton=1 -->
<dependency>
<groupId>com.jd.sword</groupId>
<artifactId>sword-utils-common</artifactId>
<version>1.0.3-SNAPSHOT</version>
</dependency>
3、mybatis config xml 配置文件按最新配置调整
<!-- http://sd.jd.com/article/42942?shareId=105168&isHideShareButton=1 -->
<!-- SQLMarking Plugin,放在第一个Plugin的位置,不影响其他组件,但不强要求位置,也可以灵活调整顺序位置 -->
<plugin interceptor="com.jd.sword.mybatis.plugin.sql.SQLMarkingInterceptor">
<!-- 是否开启SQL染色标记插件 -->
<property name="enabled" value="true"/>
<!-- 是否开启方法调用栈跟踪 -->
<property name="stackTraceEnabled" value="true"/>
<!-- 指定需要方法调用栈跟踪的package,减少信息量,value配置为自己工程的package路径,多个路径用英文逗号分割 -->
<property name="specifiedStackTracePackages" value="com.jdwl.wms.stock"/>
<!-- 忽略而不进行方法堆栈跟踪的类名列表,多个用英文逗号分割,减少信息量 -->
<property name="ignoredStackTraceClassNames" value=""/>
<!-- 结合CPU利用率和性能考虑,方法调用栈跟踪采集率配置采集率,配置示例: m/n,表示n个里面抽m个进行采集跟踪 -->
<!-- 预发环境和测试环境可以配置全采集,例如配置1/1,生产环境可以结合CPU利用率和性能考虑按需配置采集率 -->
<property name="stackTraceSamplingRate" value="1/2"/>
<!-- 是否允许SQL染色标记作为前缀,默认false表示仅作为后缀 -->
<property name="startsWithMarkingAllowed" value="false"/>
<!-- 方法调用栈跟踪最大深度,减少信息量 -->
<property name="maxStackDepth" value="10"/>
</plugin>
或代码配置方式
/**
* SQLMarking Plugin
* http://sd.jd.com/article/42942?shareId=105168&isHideShareButton=1
*
* @return
*/
@Bean
public SQLMarkingInterceptor sQLMarkingInterceptor() {
SQLMarkingInterceptor sQLMarkingInterceptor = new SQLMarkingInterceptor();
Properties properties = new Properties();
// 是否开启SQL染色标记插件
properties.setProperty("enabled", "true");
// 是否开启方法调用栈跟踪
properties.setProperty("stackTraceEnabled", "true");
// 指定需要方法调用栈跟踪的package,减少信息量,value配置为自己工程的package路径,多个路径用英文逗号分割
properties.setProperty("specifiedStackTracePackages", "com.jdwl.wms.picking");
// 结合CPU利用率和性能考虑,方法调用栈跟踪采集率配置采集率,配置示例: m/n,表示n个里面抽m个进行采集跟踪
// 预发环境和测试环境可以配置全采集,例如配置1/1,生产环境可以结合CPU利用率和性能考虑按需配置采集率
properties.setProperty("stackTraceSamplingRate", "1/2");
// 是否允许SQL染色标记作为前缀,默认false表示仅作为后缀
properties.setProperty("startsWithMarkingAllowed", "false");
sQLMarkingInterceptor.setProperties(properties);
return sQLMarkingInterceptor;
}
接入效果
SELECT
id,
tenant_code,
warehouse_no,
sku,
location_no,
container_level_1,
container_level_2,
lot_no,
sku_level,
owner_no,
pack_code,
conversion_rate,
stock_qty,
prepicked_qty,
premoved_qty,
frozen_qty,
diff_qty,
broken_qty,
status,
md5_value,
version,
create_user,
update_user,
create_time,
update_time,
extend_content
FROM
st_stock
WHERE
deleted = 0
AND warehouse_no = ?
AND location_no IN(?)
AND container_level_1 IN(?)
AND container_level_2 IN(?)
AND sku IN(?)
/* [SQLMarking] statementId: com.jdwl.wms.stock.infrastructure.jdbc.main.dao.StockQueryDao.selectExtendedStockByLocation, stackTrace: BaseJmqConsumer#onMessage ==> StockInfoConsumer#handle ==> StockInfoConsumer#handleEvent ==> StockExtendContentFiller#fillExtendContent ==> StockInitializer#queryStockByWarehouse ==> StockInitializer#batchQueryStockByWarehouse ==> StockInitializer#queryByLocationAndSku ==> StockQueryRepositoryImpl#queryExtendedStockByLocationAndSku, warehouseNo: 6_6_601 */
如何接入本文工具?
如果小伙伴也有类似使用诉求,大家可以先在测试、UAT环境接入试用,然后再逐步推广线上生产环境。
1、新引入本文的工具依赖
<dependency>
<groupId>com.jd.sword</groupId>
<artifactId>sword-utils-common</artifactId>
<version>1.0.3-SNAPSHOT</version>
</dependency>
2、使用工具类静态方法
com.jd.sword.utils.common.runtime.StackTraceUtils#simpleTrace()
com.jd.sword.utils.common.runtime.StackTraceUtils#simpleTrace(java.lang.String...)
com.jd.sword.utils.common.runtime.StackTraceUtils#trace()
com.jd.sword.utils.common.runtime.StackTraceUtils#trace(java.lang.String...)
com.jd.sword.utils.common.runtime.StackTraceUtils#trace(boolean)
com.jd.sword.utils.common.runtime.StackTraceUtils#trace(boolean, boolean, java.lang.String...)
来源:juejin.cn/post/7565423807570952198
再说一遍!不要封装组件库!
最近公司里事儿比较多,项目也比较杂,但是因为公司的项目主要是聚焦OA方面,很多东西可以复用。
比方说:表单、表格、搜索栏等等,这部分现阶段大部分都是各写各的,每个项目因为主要的开发不同,各自维护自己的一份。

但是领导现在觉得还是维护一套组件库来的比较方便,一来是减少重复工作量,提升开发效率,二来是方便新人加入团队以后尽量与老成员开发风格保持一致。
另外还有一个原因是项目内现在有的用AntDesign,有的用ElmentPlus,这些库的样式和UI设计出来的风格不搭,改起来也非常麻烦。
我听见这个提议以后后背冷汗都下来了。
我再跟大家强调一遍,不要封装组件库!
咱们说说为什么:
抬高开发成本
大部分人都感觉封装组件库是降低了开发成本,但实际上大部分项目并非如此,封装组件库大部分时候都是抬高了开发成本。
项目不同,面对的客户不同,需求也就不同,所以无论是客户方的需求还是UI设计稿都存在一定的差别,有些时候差距很大。
针对项目单独进行开发虽然在表面上看起来是浪费了人力资源,重复了很多工作,但是在后期开发和维护过程中会节省非常多的时间。
这部分都是成本。很多时候组件的开发并不是面对产品或者团队的,而是面向项目和客户的。
这也就导致了组件的开发会存在极大的不确定性,一方面是需求的不确定,另一方面是组件灵活度的不确定。
很多时候开发出来的组件库会衍生出N多个版本,切出N多个分支,最后在各个项目中引用,逐渐变成一个臃肿的垃圾代码集合体。
我不相信有人会在自己的项目上改完以后,还把修改的部分根据他人的反馈再进行调整,最后合并到 master 分支上去。
我从未见过有这个操作的兄弟。
技术达不到封装水平
团队内部技术不在一个水平线上,事实上也不可能在一个水平线上。
有些人的技术好,封装出来的组件确实很契合大多数的业务场景,有些人技术稍逊,封装出来的组件就不一定能契合项目。
但是如果你用他人封装的组件,牵扯到定制化需求的时候势必会改造,这时候改造就有可能会影响其他项目。
尤其一种情况,老项目升级,这是组件库最容易出问题的时候。可能上个版本封版的组件库在老项目运行的非常完美,但是需要升级的项目引用新的组件库的时候就会出现很多问题。
大部分程序员其实都达不到封装组件库的水准。
如果想要试一试可以参考ElmentUI老版本代码,自己封装一下Select、Input、Button这几个组件,看看和这些久经考验的开源组件库编码程序员还差多少。
技术负债严重
承接上一个问题,不是团队内每个人的水平都一样,并且每个人的编码风格也都是不一样的。(Ts最大的作用点)
可能组件库建立初期会节省非常多的重复工作,毕竟拿来就用,而且本身就是封装好的,简直可以为自己鼓掌了。
照着镜子问这是哪个天才编写的组件库,简直不要太棒了。
但是随着时间的推移,你会发现这个组件库越来越难用,需要考虑的方面越来越多,受影响的模块越来越多,你会变得越来越不敢动其中的代码。
项目越来越多,组件库中的分支和版本越来越多,团队中的人有些已经离开,有些人刚来,这时候技术负债就已经形成了。
更不要说大部分人没有写技术文档的习惯,甚至是连写注释的习惯都没有,功能全靠看代码和猜,技术上的负债越来越严重,这个阶段组件库离崩塌就已经不远了。
新项目在立项之初你就会本能的排斥使用组件库,但是对于老项目呢?改是不可能改动的,但是不维护Bug又挂在这儿。
那你到底是选择代码能跑,还是选择...

对个人发展不利
有些兄弟觉得能封装组件库,让自己的代码在这个团队,这个公司永远的流传下去,简直是跟青史留名差不多了。以后谁用到这个组件都会看到author后面写着我的名字。
但事实并非如此!
封装出的组件库大部分情况下会让你"青💩留名",因为后面的每个人用这个组件都会骂,这是哪个zz封装的组件,为啥这么写,这里不应该这么写嘛?
如果你一直呆在这个公司,由你一手搭建的这个组件库将伴随你在这个公司的整个职业生涯。
一时造轮子,一辈子维护轮子!
只要任何人用到你这个组件库,遇到了问题一定会来找你。不管你现在到底有没有在负责这个组件库!
这种通用性的组件库不可能没有问题,但是一旦有了问题找到你,你或者是解决不了,又或者是解决的不及时,都将或多或少的影响你的同事对你的评价。
当所有人都对你封装的这个组件库不满意,并且在开组会的时候提出来因为xx封装的组件库不好使,导致了项目延期,时间一长你的领导会对你有好印象?
结语
希望兄弟们还是要明白,对于一个职场人来说,挣钱最重要,能升上去最重要。其他的所有都是细枝末节,不必太在意。
对于客户和老板而言,能快速交付,把钱挣到手最重要,其他也都是无所谓的小事。
对于咱们自己来说,喜欢折腾是程序员的特质,但是要分清形势。
来源:juejin.cn/post/7532773597850206243
我发现很多程序员都不会打日志。。
大家好,我是程序员鱼皮。我发现很多程序员都不打日志,有的是 不想 打、有的是 意识不到 要打、还有的是 真不会 打日志啊!
前段时间的模拟面试中,我问了几位应届的 Java 开发同学 “你在项目中是怎么打日志的”,得到的答案竟然是 “支支吾吾”、“阿巴阿巴”,更有甚者,竟然表示:直接用 System.out.println() 打印一下吧。。。

要知道,日志是我们系统出现错误时,最快速有效的定位工具,没有日志给出的错误信息,遇到报错你就会一脸懵逼;而且日志还可以用来记录业务信息,比如记录用户执行的每个操作,不仅可以用于分析改进系统,同时在遇到非法操作时,也能很快找到凶手。
因此,对于程序员来说,日志记录是重要的基本功。但很多同学并没有系统学习过日志操作、缺乏经验,所以我写下这篇文章,分享自己在开发项目中记录日志的方法和最佳实践,希望对大家有帮助~
一、日志记录的方法
日志框架选型
有很多 Java 的日志框架和工具库,可以帮我们用一行代码快速完成日志记录。
在学习日志记录之前,很多同学应该是通过 System.out.println 输出信息来调试程序的,简单方便。
但是,System.out.println 存在很严重的问题!

首先,System.out.println 是一个同步方法,每次调用都会导致 I/O 操作,比较耗时,频繁使用甚至会严重影响应用程序的性能,所以不建议在生产环境使用。此外,它只能输出简单的信息到标准控制台,无法灵活设置日志级别、格式、输出位置等。
所以我们一般会选择专业的 Java 日志框架或工具库,比如经典的 Apache Log4j 和它的升级版 Log4j 2,还有 Spring Boot 默认集成的 Logback 库。不仅可以帮我们用一行代码更快地完成日志记录,还能灵活调整格式、设置日志级别、将日志写入到文件中、压缩日志等。
可能还有同学听说过 SLF4J(Simple Logging Facade for Java),看英文名就知道了,这玩意并不是一个具体的日志实现,而是为各种日志框架提供简单统一接口的日志门面(抽象层)。
啥是门面?
举个例子,现在我们要记录日志了,先联系到前台接待人员 SLF4J,它说必须要让我们选择日志的级别(debug / info / warn / error),然后要提供日志的内容。确认之后,SLF4J 自己不干活,屁颠屁颠儿地去找具体的日志实现框架,比如 Logback,然后由 Logback 进行日志写入。
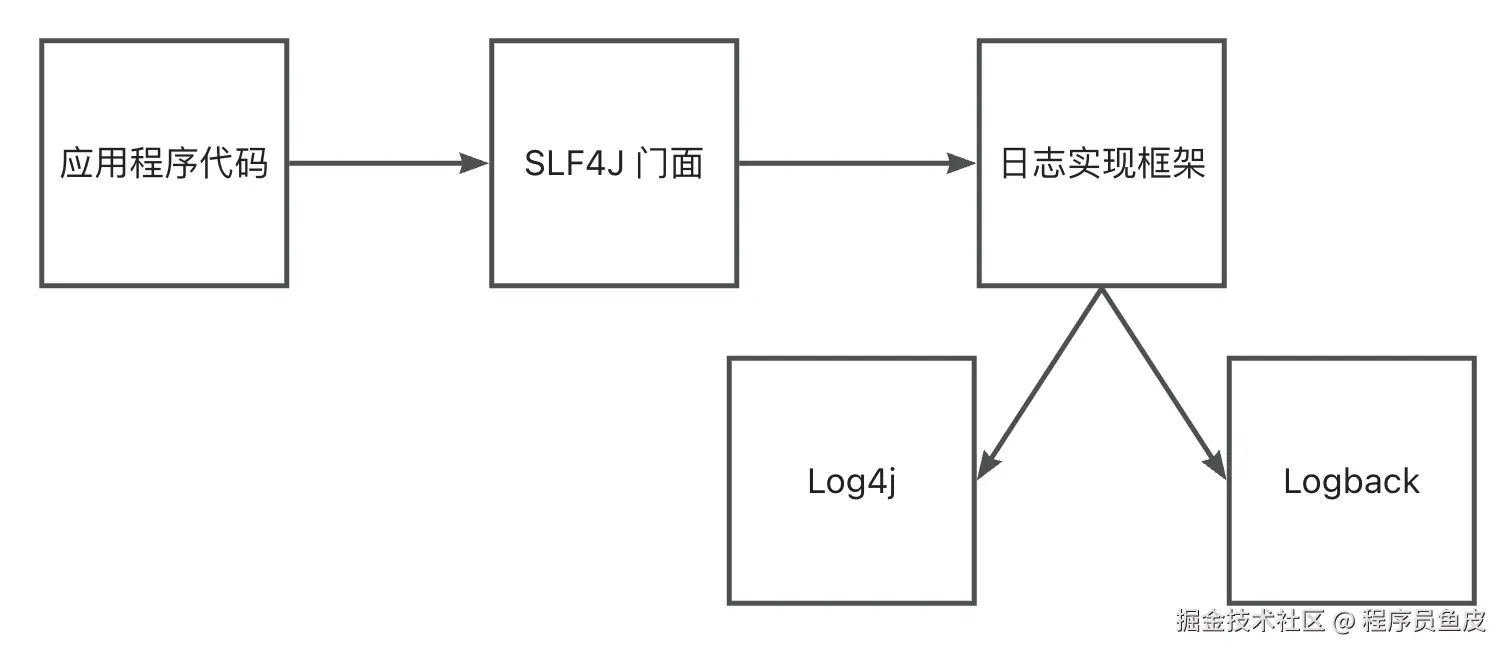
这样做有什么好处呢?无论我们选择哪套日志框架、或者后期要切换日志框架,调用的方法始终是相同的,不用再去更改日志调用代码,比如将 log.info 改为 log.printInfo。
既然 SLF4J 只是玩抽象,那么 Log4j、Log4j 2 和 Logback 应该选择哪一个呢?
值得一提的是,SLF4J、Log4j 和 Logback 竟然都是同一个作者(俄罗斯程序员 Ceki Gülcü)。
首先,Log4j 已经停止维护,直接排除。Log4j 2 和 Logback 基本都能满足功能需求,那么就看性能、稳定性和易用性。
- 从性能来说,Log4j 2 和 Logback 虽然都支持异步日志,但是 Log4j 基于 LMAX Disruptor 高性能异步处理库实现,性能更高。
- 从稳定性来说,虽然这些日志库都被曝出过漏洞,但 Log4j 2 的漏洞更为致命,姑且算是 Logback 得一分。
- 从易用性来说,二者差不多,但 Logback 是 SLF4J 的原生实现、Log4j2 需要额外使用 SLF4J 绑定器实现。
再加上 Spring Boot 默认集成了 Logback,如果没有特殊的性能需求,我会更推荐初学者选择 Logback,都不用引入额外的库了~
使用日志框架
日志框架的使用非常简单,一般需要先获取到 Logger 日志对象,然后调用 logger.xxx(比如 logger.info)就能输出日志了。
最传统的方法就是通过 LoggerFactory 手动获取 Logger,示例代码如下:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyService {
private static final Logger logger = LoggerFactory.getLogger(MyService.class);
public void doSomething() {
logger.info("执行了一些操作");
}
}
上述代码中,我们通过调用日志工厂并传入当前类,创建了一个 logger。但由于每个类的类名都不同,我们又经常复制这行代码到不同的类中,就很容易忘记修改类名。
所以我们可以使用 this.getClass 动态获取当前类的实例,来创建 Logger 对象:
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void doSomething() {
logger.info("执行了一些操作");
}
}
给每个类都复制一遍这行代码,就能愉快地打日志了。
但我觉得这样做还是有点麻烦,我连复制粘贴都懒得做,怎么办?
还有更简单的方式,使用 Lombok 工具库提供的 @Slf4j 注解,可以自动为当前类生成一个名为 log 的 SLF4J Logger 对象,简化了 Logger 的定义过程。示例代码如下:
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class MyService {
public void doSomething() {
log.info("执行了一些操作");
}
}
这也是我比较推荐的方式,效率杠杠的。

此外,你可以通过修改日志配置文件(比如 logback.xml 或 logback-spring.xml)来设置日志输出的格式、级别、输出路径等。日志配置文件比较复杂,不建议大家去记忆语法,随用随查即可。
二、日志记录的最佳实践
学习完日志记录的方法后,再分享一些我个人记录日志的经验。内容较多,大家可以先了解一下,实际开发中按需运用。
1、合理选择日志级别
日志级别的作用是标识日志的重要程度,常见的级别有:
- TRACE:最细粒度的信息,通常只在开发过程中使用,用于跟踪程序的执行路径。
- DEBUG:调试信息,记录程序运行时的内部状态和变量值。
- INFO:一般信息,记录系统的关键运行状态和业务流程。
- WARN:警告信息,表示可能存在潜在问题,但系统仍可继续运行。
- ERROR:错误信息,表示出现了影响系统功能的问题,需要及时处理。
- FATAL:致命错误,表示系统可能无法继续运行,需要立即关注。
其中,用的最多的当属 DEBUG、INFO、WARN 和 ERROR 了。
建议在开发环境使用低级别日志(比如 DEBUG),以获取详细的信息;生产环境使用高级别日志(比如 INFO 或 WARN),减少日志量,降低性能开销的同时,防止重要信息被无用日志淹没。
注意一点,日志级别未必是一成不变的,假如有一天你的程序出错了,但是看日志找不到任何有效信息,可能就需要降低下日志输出级别了。
2、正确记录日志信息
当要输出的日志内容中存在变量时,建议使用参数化日志,也就是在日志信息中使用占位符(比如 {}),由日志框架在运行时替换为实际参数值。
比如输出一行用户登录日志:
// 不推荐
logger.debug("用户ID:" + userId + " 登录成功。");
// 推荐
logger.debug("用户ID:{} 登录成功。", userId);
这样做不仅让日志清晰易读;而且在日志级别低于当前记录级别时,不会执行字符串拼接,从而避免了字符串拼接带来的性能开销、以及潜在的 NullPointerException 问题。所以建议在所有日志记录中,使用参数化的方式替代字符串拼接。
此外,在输出异常信息时,建议同时记录上下文信息、以及完整的异常堆栈信息,便于排查问题:
try {
// 业务逻辑
} catch (Exception e) {
logger.error("处理用户ID:{} 时发生异常:", userId, e);
}
3、控制日志输出量
过多的日志不仅会占用更多的磁盘空间,还会增加系统的 I/O 负担,影响系统性能。
因此,除了根据环境设置合适的日志级别外,还要尽量避免在循环中输出日志。
可以添加条件来控制,比如在批量处理时,每处理 1000 条数据时才记录一次:
if (index % 1000 == 0) {
logger.info("已处理 {} 条记录", index);
}
或者在循环中利用 StringBuilder 进行字符串拼接,循环结束后统一输出:
StringBuilder logBuilder = new StringBuilder("处理结果:");
for (Item item : items) {
try {
processItem(item);
logBuilder.append(String.format("成功[ID=%s], ", item.getId()));
} catch (Exception e) {
logBuilder.append(String.format("失败[ID=%s, 原因=%s], ", item.getId(), e.getMessage()));
}
}
logger.info(logBuilder.toString());
如果参数的计算开销较大,且当前日志级别不需要输出,应该在记录前进行级别检查,从而避免多余的参数计算:
if (logger.isDebugEnabled()) {
logger.debug("复杂对象信息:{}", expensiveToComputeObject());
}
此外,还可以通过更改日志配置文件整体过滤掉特定级别的日志,来防止日志刷屏:
<!-- Logback 示例 -->
<appender name="LIMITED" class="ch.qos.logback.classic.AsyncAppender">
<!-- 只允许 INFO 级别及以上的日志通过 -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<!-- 配置其他属性 -->
</appender>
4、把控时机和内容
很多开发者(尤其是线上经验不丰富的开发者)并没有养成记录日志的习惯,觉得记录日志不重要,等到出了问题无法排查的时候才追悔莫及。
一般情况下,需要在系统的关键流程和重要业务节点记录日志,比如用户登录、订单处理、支付等都是关键业务,建议多记录日志。
对于重要的方法,建议在入口和出口记录重要的参数和返回值,便于快速还原现场、复现问题。
对于调用链较长的操作,确保在每个环节都有日志,以便追踪到问题所在的环节。
如果你不想区分上面这些情况,我的建议是尽量在前期多记录一些日志,后面再慢慢移除掉不需要的日志。比如可以利用 AOP 切面编程在每个业务方法执行前输出执行信息:
@Aspect
@Component
public class LoggingAspect {
@Before("execution(* com.example.service..*(..))")
public void logBeforeMethod(JoinPoint joinPoint) {
Logger logger = LoggerFactory.getLogger(joinPoint.getTarget().getClass());
logger.info("方法 {} 开始执行", joinPoint.getSignature().getName());
}
}
利用 AOP,还可以自动打印每个 Controller 接口的请求参数和返回值,这样就不会错过任何一次调用信息了。
不过这样做也有一个很重要的点,注意不要在日志中记录了敏感信息,比如用户密码。万一你的日志不小心泄露出去,就相当于泄露了大量用户的信息。

5、日志管理
随着日志文件的持续增长,会导致磁盘空间耗尽,影响系统正常运行,所以我们需要一些策略来对日志进行管理。
首先是设置日志的滚动策略,可以根据文件大小或日期,自动对日志文件进行切分。比如按文件大小滚动:
<!-- 按大小滚动 -->
<rollingPolicy class="ch.qos.logback.core.rolling.SizeBasedRollingPolicy">
<maxFileSize>10MB</maxFileSize>
</rollingPolicy>
如果日志文件大小达到 10MB,Logback 会将当前日志文件重命名为 app.log.1 或其他命名模式(具体由文件名模式决定),然后创建新的 app.log 文件继续写入日志。
还有按照时间日期滚动:
<!-- 按时间滚动 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
上述配置表示每天创建一个新的日志文件,%d{yyyy-MM-dd} 表示按照日期命名日志文件,例如 app-2024-11-21.log。
还可以通过 maxHistory 属性,限制保留的历史日志文件数量或天数:
<maxHistory>30</maxHistory>
这样一来,我们就可以按照天数查看指定的日志,单个日志文件也不会很大,提高了日志检索效率。
对于用户较多的企业级项目,日志的增长是飞快的,因此建议开启日志压缩功能,节省磁盘空间。
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log.gz</fileNamePattern>
</rollingPolicy>
上述配置表示:每天生成一个新的日志文件,旧的日志文件会被压缩存储。
除了配置日志切分和压缩外,我们还需要定期审查日志,查看日志的有效性和空间占用情况,从日志中发现系统的问题、清理无用的日志信息等。
如果你想偷懒,也可以写个自动化清理脚本,定期清理过期的日志文件,释放磁盘空间。比如:
# 每月清理一次超过 90 天的日志文件
find /var/log/myapp/ -type f -mtime +90 -exec rm {} ;
6、统一日志格式
统一的日志格式有助于日志的解析、搜索和分析,特别是在分布式系统中。
我举个例子大家就能感受到这么做的重要性了。
统一的日志格式:
2024-11-21 14:30:15.123 [main] INFO com.example.service.UserService - 用户ID:12345 登录成功
2024-11-21 14:30:16.789 [main] ERROR com.example.service.UserService - 用户ID:12345 登录失败,原因:密码错误
2024-11-21 14:30:17.456 [main] DEBUG com.example.dao.UserDao - 执行SQL:[SELECT * FROM users WHERE id=12345]
2024-11-21 14:30:18.654 [main] WARN com.example.config.AppConfig - 配置项 `timeout` 使用默认值:3000ms
2024-11-21 14:30:19.001 [main] INFO com.example.Main - 应用启动成功,耗时:2.34秒
这段日志整齐清晰,支持按照时间、线程、级别、类名和内容搜索。
不统一的日志格式:
2024/11/21 14:30 登录成功 用户ID: 12345
2024-11-21 14:30:16 错误 用户12345登录失败!密码不对
DEBUG 执行SQL SELECT * FROM users WHERE id=12345
Timeout = default
应用启动成功
emm,看到这种日志我直接原地爆炸!

建议每个项目都要明确约定和配置一套日志输出规范,确保日志中包含时间戳、日志级别、线程、类名、方法名、消息等关键信息。
<!-- 控制台日志输出 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- 日志格式 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
也可以直接使用标准化格式,比如 JSON,确保所有日志遵循相同的结构,便于后续对日志进行分析处理:
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<!-- 配置 JSON 编码器 -->
</encoder>
此外,你还可以通过 MDC(Mapped Diagnostic Context)给日志添加额外的上下文信息,比如用户 ID、请求 ID 等,方便追踪。在 Java 代码中,可以为 MDC 变量设置值:
MDC.put("requestId", "666");
MDC.put("userId", "yupi");
logger.info("用户请求处理完成");
MDC.clear();
对应的日志配置如下:
<!-- 文件日志配置 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<!-- 包含 MDC 信息 -->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [%X{requestId}] [%X{userId}] %msg%n</pattern>
</encoder>
</appender>
这样,每个请求、每个用户的操作一目了然。
7、使用异步日志
对于追求性能的操作,可以使用异步日志,将日志的写入操作放在单独的线程中,减少对主线程的阻塞,从而提升系统性能。
除了自己开线程去执行 log 操作之外,还可以直接修改配置来开启 Logback 的异步日志功能:
<!-- 异步 Appender -->
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>500</queueSize> <!-- 队列大小 -->
<discardingThreshold>0</discardingThreshold> <!-- 丢弃阈值,0 表示不丢弃 -->
<neverBlock>true</neverBlock> <!-- 队列满时是否阻塞主线程,true 表示不阻塞 -->
<appender-ref ref="CONSOLE" /> <!-- 生效的日志目标 -->
<appender-ref ref="FILE" />
</appender>
上述配置的关键是配置缓冲队列,要设置合适的队列大小和丢弃策略,防止日志积压或丢失。
8、集成日志收集系统
在比较成熟的公司中,我们可能会使用更专业的日志管理和分析系统,比如 ELK(Elasticsearch、Logstash、Kibana)。不仅不用每次都登录到服务器上查看日志文件,还可以更灵活地搜索日志。
但是搭建和运维 ELK 的成本还是比较大的,对于小团队,我的建议是不要急着搞这一套。
OK,就分享到这里,洋洋洒洒 4000 多字,希望这篇文章能帮助大家意识到日志记录的重要性,并养成良好的日志记录习惯。学会的话给鱼皮点个赞吧~
日志不是写给机器看的,是写给未来的你和你的队友看的!
更多
来源:juejin.cn/post/7439785794917072896
微服务正在悄然消亡:这是一件美好的事
最近在做的事情正好需要系统地研究微服务与单体架构的取舍与演进。读到这篇文章《Microservices Are Quietly Dying — And It’s Beautiful》,许多观点直击痛点、非常启发,于是我顺手把它翻译出来,分享给大家,也希望能给同样在复杂性与效率之间权衡的团队一些参考。
微服务正在悄然消亡:这是一件美好的事
为了把我们的创业产品扩展到数百万用户,我们搭建了 47 个微服务。
用户从未达到一百万,但我们达到了每月 23,000 美元的 AWS 账单、长达 14 小时的故障,以及一个再也无法高效交付新功能的团队。
那一刻我才意识到:我们并没有在构建产品,而是在搭建一座分布式的自恋纪念碑。

我们都信过的谎言
五年前,微服务几乎是教条。Netflix 用它,Uber 用它。每一场技术大会、每一篇 Medium 文章、每一位资深架构师都在高喊同一句话:单体不具备可扩展性,微服务才是答案。
于是我们照做了。我们把 Rails 单体拆成一个个服务:用户服务、认证服务、支付服务、通知服务、分析服务、邮件服务;然后是子服务,再然后是调用服务的服务,层层套叠。
到第六个月,我们已经在 12 个 GitHub 仓库里维护 47 个服务。我们的部署流水线像一张地铁图,架构图需要 4K 显示器才能看清。
当“最佳实践”变成“最差实践”
我们不断告诫自己:一切都在运转。我们有 Kubernetes,有服务网格,有用 Jaeger 的分布式追踪,有 ELK 的日志——我们很“现代”。
但那些光鲜的微服务文章从不提的一点是:分布式的隐性税。
每一个新功能都变成跨团队的协商。想给用户资料加一个字段?那意味着要改五个服务、提三个 PR、协调两周,并进行一次像劫案电影一样精心编排的数据库迁移。
我们的预发布环境成本甚至高于生产环境,因为想测试任何东西,都需要把一切都跑起来。47 个服务在 Docker Compose 里同时启动,内存被疯狂吞噬。
那个彻夜崩溃的夜晚
凌晨 2:47,Slack 被消息炸翻。
生产环境宕了。不是某一个服务——是所有服务。支付服务连不上用户服务,通知服务不断超时,API 网关对每个请求都返回 503。
我打开分布式追踪面板:一万五千个 span,全线飘红。瀑布图像抽象艺术。我花了 40 分钟才定位出故障起点。
结果呢?一位初级开发在认证服务上发布了一个配置变更,只是一个环境变量。它让令牌校验多了 2 秒延迟,这个延迟在 11 个下游服务间层层传递,超时叠加、断路器触发、重试逻辑制造请求风暴,整个系统在自身重量下轰然倒塌。
我们搭了一座纸牌屋,却称之为“容错架构”。
我们花了六个小时才修复。并不是因为 bug 复杂——它只是一个配置的单行改动,而是因为排查分布式系统就像破获一桩谋杀案:每个目击者说着不同的语言,而且有一半在撒谎。
那个被忽略的低语
一周后,在复盘会上,我们的 CTO 说了句让所有人不自在的话:
“要不我们……回去?”
回到单体。回到一个仓库。回到简单。
会议室一片沉默。你能感到认知失调。我们是工程师,我们很“高级”。单体是给传统公司和训练营毕业生用的,不是给一家正打造未来的 A 轮初创公司用的。
但随后有人把指标展开:平均恢复时间 4.2 小时;部署频率每周 2.3 次(从单体时代的每周 12 次一路下滑);云成本增长速度比营收快 40%。
数字不会说谎。是架构在拖垮我们。
美丽的回归
我们用了三个月做整合。47 个服务归并成一个模块划分清晰的 Rails 应用;Kubernetes 变成负载均衡后面的三台 EC2;12 个仓库的工作流收敛成一个边界明确的仓库。
结果简直让人尴尬。
部署时间从 25 分钟降到 90 秒;AWS 账单从 23,000 美元降到 3,800 美元;P95 延迟提升了 60%,因为我们消除了 80% 的网络调用。更重要的是——我们又开始按时交付功能了。
开发者不再说“我需要和三个团队协调”,而是开始说“午饭前给你”。
我们的“分布式系统”变回了结构良好的应用。边界上下文变成 Rails 引擎,服务调用变成方法调用,Kafka 变成后台任务,“编排层”……就是 Rails 控制器。
它更快,它更省,它更好。
我们真正学到的是什么
这是真相:我们为此付出两年时间和 40 万美元才领悟——
微服务不是一种纯粹的架构模式,而是一种组织模式。Netflix 需要它,因为他们有 200 个团队。你没有。Uber 需要它,因为他们一天发布 4,000 次。你没有。
复杂性之所以诱人,是因为它看起来像进步。 拥有 47 个服务、Kubernetes、服务网格和分布式追踪,看起来很“专业”;而一个单体加一套 Postgres,看起来很“业余”。
但复杂性是一种税。它以认知负担、运营开销、开发者幸福感和交付速度为代价。
而大多数初创公司根本付不起这笔税。
我们花了两年时间为并不存在的规模做优化,同时牺牲了能让我们真正达到规模的简单性。
你不需要 50 个微服务,你需要的是自律
软件架构的“肮脏秘密”是:好的设计在任何规模都奏效。
一个结构良好的单体,拥有清晰的模块、明确的边界上下文和合理的关注点分离,比一团由希望和 YAML 勉强粘合在一起的微服务乱麻走得更远。
微服务并不是因为“糟糕”而式微,而是因为我们出于错误的理由使用了它。我们选择了分布式的复杂性而不是本地的自律,选择了运营的负担而不是价值的交付。
那些悄悄回归单体的公司并非承认失败,而是在承认更难的事实:我们一直在解决错误的问题。
所以我想问一个问题:你构建微服务,是在逃避什么?
如果答案是“一个凌乱的代码库”,那我有个坏消息——分布式系统不会修好坏代码,它只会让问题更难被发现。
来源:juejin.cn/post/7563860666349649970
Spring Boot 分布式事务高阶玩法:从入门到精通
嘿,各位 Java 小伙伴们!今天咱们要来聊聊 Spring Boot 里一个超酷炫但又有点让人头疼的家伙 —— 分布式事务。这玩意儿就像是一场大型派对的组织者,要确保派对上所有的活动(操作)要么都顺顺利利地进行,要么就一起取消,绝对不能出现有的活动进行了一半,有的却没开始的尴尬局面。
为啥要有分布式事务
在以前那种单体应用的小世界里,事务处理就像在自己家里整理东西,所有的东西(数据)都在一个地方,要保证操作的一致性很容易。但随着业务越来越复杂,应用变成了分布式的 “大杂烩”,各个服务就像住在不同房子里的小伙伴,这时候再想保证所有操作都一致,就需要分布式事务这个 “超级协调员” 出场啦。
Spring Boot 里的分布式事务支持
Spring Boot 对分布式事务的支持就像是给你配备了一套超级工具包。其中,@Transactional注解大家肯定都很熟悉,在单体应用里它就是事务管理的小能手。但在分布式场景下,我们还有更厉害的武器,比如基于 XA 协议的分布式事务管理器,以及像 Seata 这样的开源框架。
XA 协议的分布式事务管理器
XA 协议就像是一个国际通用的 “交流规则”,它规定了数据库和事务管理器之间怎么沟通。在 Spring Boot 里使用 XA 协议的分布式事务管理器,就像是给各个服务的数据库都请了一个翻译,让它们能准确地交流事务相关的信息。
下面我们来看一段简单的代码示例,假设我们有两个服务,一个是订单服务,一个是库存服务,我们要在创建订单的同时扣减库存,并且保证这两个操作要么都成功,要么都失败。
首先,我们需要配置 XA 数据源,这里以 MySQL 为例:
@Configuration
public class XADataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSourceProperties dataSourceProperties() {
return new DataSourceProperties();
}
@Bean
public DataSource dataSource() {
return dataSourceProperties().initializeDataSourceBuilder()
.type(com.mysql.cj.jdbc.MysqlXADataSource.class)
.build();
}
}
然后,配置事务管理器:
@Configuration
public class XATransactionConfig {
@Autowired
private DataSource dataSource;
@Bean
public PlatformTransactionManager transactionManager() throws SQLException {
return new JtaTransactionManager(new UserTransactionFactory(), new TransactionManagerFactory(dataSource));
}
}
接下来,在业务代码里使用@Transactional注解:
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private StockService stockService;
@Transactional
public void createOrder(Order order) {
orderRepository.save(order);
stockService.decreaseStock(order.getProductId(), order.getQuantity());
}
}
在这个例子里,createOrder方法上的@Transactional注解就像一个 “指挥官”,它会协调订单保存和库存扣减这两个操作,确保它们在同一个事务里执行。
Seata 框架
Seata 就像是一个更智能、更强大的 “事务指挥官”。它有三个重要的组件:TC(Transaction Coordinator)事务协调器、TM(Transaction Manager)事务管理器和 RM(Resource Manager)资源管理器。TC 就像一个调度中心,TM 负责发起和管理事务,RM 则负责管理资源和提交 / 回滚事务。
使用 Seata,我们首先要在项目里引入相关依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
然后,配置 Seata 客户端:
seata:
application-id: ${spring.application.name}
tx-service-group: my_test_tx_group
enable-auto-data-source-proxy: true
client:
rm:
async-commit-buffer-limit: 10000
lock:
retry-interval: 10
retry-times: 30
retry-policy-branch-rollback-on-conflict: true
tm:
commit-retry-count: 5
rollback-retry-count: 5
undo:
data-validation: true
log-serialization: jackson
log-table: undo_log
在业务代码里,我们使用@GlobalTransactional注解来开启全局事务:
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private StockService stockService;
@GlobalTransactional
public void createOrder(Order order) {
orderRepository.save(order);
stockService.decreaseStock(order.getProductId(), order.getQuantity());
}
}
这里的@GlobalTransactional注解就像是给整个分布式事务场景下了一道 “圣旨”,让所有涉及到的服务都按照统一的事务规则来执行。
总结
分布式事务虽然复杂,但有了 Spring Boot 提供的强大支持,以及像 Seata 这样优秀的框架,我们也能轻松应对。就像掌握了一门高超的魔法,让我们的分布式系统变得更加可靠和强大。希望今天的分享能让大家对 Spring Boot 中的分布式事务有更深入的理解,在开发的道路上一路 “开挂”,解决各种复杂的业务场景。
来源:juejin.cn/post/7490588889948061750
⚔️ ReentrantLock大战synchronized:谁是锁界王者?
一、选手登场!🎬
🔵 蓝方:synchronized(老牌选手)
// synchronized:Java自带的语法糖
public synchronized void method() {
// 临界区代码
}
// 或者
public void method() {
synchronized(this) {
// 临界区代码
}
}
特点:
- 📜 JDK 1.0就有了,资历老
- 🎯 简单粗暴,写法简单
- 🤖 JVM级别实现,自动释放
- 💰 免费午餐,不需要手动管理
🔴 红方:ReentrantLock(新锐选手)
// ReentrantLock:JDK 1.5引入
ReentrantLock lock = new ReentrantLock();
public void method() {
lock.lock(); // 手动加锁
try {
// 临界区代码
} finally {
lock.unlock(); // 必须手动释放!
}
}
特点:
- 🆕 JDK 1.5新秀,年轻有活力
- 🎨 功能丰富,花样多
- 🏗️ API级别实现,灵活强大
- ⚠️ 需要手动管理,容易忘记释放
二、底层实现对决 💻
Round 1: synchronized的底层实现
1️⃣ 对象头结构(Mark Word)
Java对象内存布局:
┌────────────────────────────────────┐
│ 对象头 (Object Header) │
│ ┌─────────────────────────────┐ │
│ │ Mark Word (8字节) │ ← 存储锁信息
│ ├─────────────────────────────┤ │
│ │ 类型指针 (4/8字节) │ │
│ └─────────────────────────────┘ │
├────────────────────────────────────┤
│ 实例数据 (Instance Data) │
├────────────────────────────────────┤
│ 对齐填充 (Padding) │
└────────────────────────────────────┘
Mark Word在不同锁状态下的变化:
64位虚拟机的Mark Word(8字节=64位)
┌──────────────────────────────────────────────────┐
│ 无锁状态 (001) │
│ ┌────────────┬─────┬──┬──┬──┐ │
│ │ hashcode │ age │0 │01│ 未锁定 │
│ └────────────┴─────┴──┴──┴──┘ │
├──────────────────────────────────────────────────┤
│ 偏向锁 (101) │
│ ┌────────────┬─────┬──┬──┬──┐ │
│ │ 线程ID │epoch│1 │01│ 偏向锁 │
│ └────────────┴─────┴──┴──┴──┘ │
├──────────────────────────────────────────────────┤
│ 轻量级锁 (00) │
│ ┌────────────────────────────┬──┐ │
│ │ 栈中锁记录指针 │00│ 轻量级锁 │
│ └────────────────────────────┴──┘ │
├──────────────────────────────────────────────────┤
│ 重量级锁 (10) │
│ ┌────────────────────────────┬──┐ │
│ │ Monitor对象指针 │10│ 重量级锁 │
│ └────────────────────────────┴──┘ │
└──────────────────────────────────────────────────┘
2️⃣ 锁升级过程(重点!)
锁升级路径
无锁状态 偏向锁 轻量级锁 重量级锁
│ │ │ │
│ 第一次访问 │ 有竞争 │ 竞争激烈 │
├──────────────→ ├──────────────→ ├──────────────→ │
│ │ │ │
│ │ CAS失败 │ 自旋失败 │
│ │ │ │
🚶 一个人 🚶 还是一个人 🚶🚶 两个人 🚶🚶🚶 一群人
走路 (偏向这个人) 抢着走 排队走
详细解释:
阶段1:无锁 → 偏向锁
// 第一次有线程访问synchronized块
Thread-1第一次进入:
1. 对象处于无锁状态
2. Thread-1通过CAS在Mark Word中记录自己的线程ID
3. 成功!升级为偏向锁,偏向Thread-1
4. 下次Thread-1再来,发现Mark Word里是自己的ID,直接进入!
(就像VIP通道,不用检查)✨
生活比喻:
你第一次去常去的咖啡店☕,店员记住了你的脸。
下次你来,店员一看是你,直接给你做你的老口味,不用问!
阶段2:偏向锁 → 轻量级锁
Thread-2也想进入:
1. 发现偏向锁偏向的是Thread-1
2. Thread-1已经退出了,撤销偏向锁
3. 升级为轻量级锁
4. Thread-2通过CAS在栈帧中创建Lock Record
5. CAS将对象头的Mark Word复制到Lock Record
6. CAS将对象头指向Lock Record
7. 成功!获取轻量级锁 🎉
生活比喻:
咖啡店来了第二个客人,店员发现需要排队系统了。
拿出号码牌,谁先抢到谁先点单(自旋CAS)🎫
阶段3:轻量级锁 → 重量级锁
Thread-3、Thread-4、Thread-5也来了:
1. 多个线程竞争,CAS自旋失败
2. 自旋一定次数后,升级为重量级锁
3. 没抢到的线程进入阻塞队列
4. 需要操作系统介入,线程挂起(park)😴
生活比喻:
咖啡店人太多了!需要叫号系统 + 座位等待区。
没叫到号的人坐下来等,不用一直站着抢(操作系统介入)🪑
3️⃣ 字节码层面
public synchronized void method() {
System.out.println("hello");
}
字节码:
public synchronized void method();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED ← 看这里!方法标记
Code:
stack=2, locals=1, args_size=1
0: getstatic #2
3: ldc #3
5: invokevirtual #4
8: return
同步块字节码:
public void method() {
synchronized(this) {
System.out.println("hello");
}
}
public void method();
Code:
0: aload_0
1: dup
2: astore_1
3: monitorenter ← 进入monitor
4: getstatic #2
7: ldc #3
9: invokevirtual #4
12: aload_1
13: monitorexit ← 退出monitor
14: goto 22
17: astore_2
18: aload_1
19: monitorexit ← 异常时也要退出
20: aload_2
21: athrow
22: return
Round 2: ReentrantLock的底层实现
基于AQS(AbstractQueuedSynchronizer)实现:
// ReentrantLock内部
public class ReentrantLock {
private final Sync sync;
// 抽象同步器
abstract static class Sync extends AbstractQueuedSynchronizer {
// ...
}
// 非公平锁实现
static final class NonfairSync extends Sync {
final void lock() {
// 先CAS抢一次
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1); // 进入AQS队列
}
}
// 公平锁实现
static final class FairSync extends Sync {
final void lock() {
acquire(1); // 直接排队,不插队
}
}
}
数据结构:
ReentrantLock
│
├─ Sync (继承AQS)
│ ├─ state: int (0=未锁,>0=重入次数)
│ └─ exclusiveOwnerThread: Thread (持锁线程)
│
└─ CLH队列
Head → Node1 → Node2 → Tail
↓ ↓
Thread2 Thread3
(等待) (等待)
三、功能对比大战 ⚔️
🏁 功能对比表
| 功能 | synchronized | ReentrantLock | 胜者 |
|---|---|---|---|
| 加锁方式 | 自动 | 手动lock/unlock | synchronized ✅ |
| 释放方式 | 自动(异常也会释放) | 必须手动finally | synchronized ✅ |
| 公平锁 | 不支持 | 支持公平/非公平 | ReentrantLock ✅ |
| 可中断 | 不可中断 | lockInterruptibly() | ReentrantLock ✅ |
| 尝试加锁 | 不支持 | tryLock() | ReentrantLock ✅ |
| 超时加锁 | 不支持 | tryLock(timeout) | ReentrantLock ✅ |
| Condition | 只有一个wait/notify | 可多个Condition | ReentrantLock ✅ |
| 性能(JDK6+) | 优化后差不多 | 差不多 | 平局 ⚖️ |
| 使用难度 | 简单 | 复杂,易出错 | synchronized ✅ |
| 锁信息 | 不易查看 | getQueueLength()等 | ReentrantLock ✅ |
🎯 详细功能对比
1️⃣ 可中断锁
// ❌ synchronized不可中断
Thread t = new Thread(() -> {
synchronized(lock) {
// 即使调用t.interrupt(),这里也不会响应
while(true) {
// 死循环
}
}
});
// ✅ ReentrantLock可中断
Thread t = new Thread(() -> {
try {
lock.lockInterruptibly(); // 可响应中断
// ...
} catch (InterruptedException e) {
System.out.println("被中断了!");
}
});
t.start();
Thread.sleep(100);
t.interrupt(); // 可以中断!
2️⃣ 尝试加锁
// ❌ synchronized没有tryLock
synchronized(lock) {
// 要么拿到锁,要么一直等
}
// ✅ ReentrantLock可以尝试
if (lock.tryLock()) { // 尝试获取,不阻塞
try {
// 拿到锁了
} finally {
lock.unlock();
}
} else {
// 没拿到,去做别的事
System.out.println("锁被占用,我去干别的");
}
// ✅ 还支持超时
if (lock.tryLock(3, TimeUnit.SECONDS)) { // 等3秒
try {
// 拿到了
} finally {
lock.unlock();
}
} else {
// 3秒还没拿到,放弃
System.out.println("等太久了,不等了");
}
3️⃣ 公平锁
// ❌ synchronized只能是非公平锁
synchronized(lock) {
// 后来的线程可能插队
}
// ✅ ReentrantLock可选公平/非公平
ReentrantLock fairLock = new ReentrantLock(true); // 公平锁
ReentrantLock unfairLock = new ReentrantLock(false); // 非公平锁(默认)
公平锁 vs 非公平锁:
非公平锁(吞吐量高):
Thread-1持锁 → Thread-2排队 → Thread-3排队
↓
释放锁!
↓
Thread-4刚好来了,直接抢!(插队)✂️
虽然Thread-2先来,但Thread-4先抢到
公平锁(先来后到):
Thread-1持锁 → Thread-2排队 → Thread-3排队
↓
释放锁!
↓
Thread-4来了,但要排队到最后!
Thread-2先到先得 ✅
4️⃣ 多个条件变量
// ❌ synchronized只有一个等待队列
synchronized(lock) {
lock.wait(); // 只有一个等待队列
lock.notify(); // 随机唤醒一个
}
// ✅ ReentrantLock可以有多个Condition
ReentrantLock lock = new ReentrantLock();
Condition notFull = lock.newCondition(); // 条件1:未满
Condition notEmpty = lock.newCondition(); // 条件2:非空
// 生产者
lock.lock();
try {
while (queue.isFull()) {
notFull.await(); // 等待"未满"条件
}
queue.add(item);
notEmpty.signal(); // 唤醒"非空"条件的线程
} finally {
lock.unlock();
}
// 消费者
lock.lock();
try {
while (queue.isEmpty()) {
notEmpty.await(); // 等待"非空"条件
}
queue.remove();
notFull.signal(); // 唤醒"未满"条件的线程
} finally {
lock.unlock();
}
四、性能对决 🏎️
JDK 1.5时代:ReentrantLock完胜
JDK 1.5性能测试(100万次加锁):
synchronized: 2850ms 😓
ReentrantLock: 1200ms 🚀
ReentrantLock快2倍多!
JDK 1.6之后:synchronized反击!
JDK 1.6对synchronized做了大量优化:
- ✅ 偏向锁(Biased Locking)
- ✅ 轻量级锁(Lightweight Locking)
- ✅ 自适应自旋(Adaptive Spinning)
- ✅ 锁粗化(Lock Coarsening)
- ✅ 锁消除(Lock Elimination)
JDK 1.8性能测试(100万次加锁):
synchronized: 1250ms 🚀
ReentrantLock: 1200ms 🚀
几乎一样了!
优化技术解析
1️⃣ 偏向锁
// 同一个线程反复进入
for (int i = 0; i < 1000000; i++) {
synchronized(obj) {
// 偏向锁:第一次CAS,后续直接进入
// 性能接近无锁!✨
}
}
2️⃣ 锁消除
public String concat(String s1, String s2) {
// StringBuffer是线程安全的,有synchronized
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
// JVM发现sb是局部变量,不可能有竞争
// 自动消除StringBuffer内部的synchronized!
// 性能大幅提升!🚀
3️⃣ 锁粗化
// ❌ 原代码:频繁加锁解锁
for (int i = 0; i < 1000; i++) {
synchronized(obj) {
// 很短的操作
}
}
// ✅ JVM优化后:锁粗化
synchronized(obj) { // 把锁提到循环外
for (int i = 0; i < 1000; i++) {
// 很短的操作
}
}
五、使用场景推荐 📝
优先使用synchronized的场景
1️⃣ 简单的同步场景
// 简单的计数器
private int count = 0;
public synchronized void increment() {
count++;
}
2️⃣ 方法级别的同步
public synchronized void method() {
// 整个方法同步,简单明了
}
3️⃣ 不需要高级功能
// 只需要基本的互斥,不需要tryLock、Condition等
synchronized(lock) {
// 业务代码
}
优先使用ReentrantLock的场景
1️⃣ 需要可中断的锁
// 可以响应中断,避免死锁
lock.lockInterruptibly();
2️⃣ 需要尝试加锁
// 拿不到锁就去做别的事
if (lock.tryLock()) {
// ...
}
3️⃣ 需要公平锁
// 严格按照先来后到
ReentrantLock fairLock = new ReentrantLock(true);
4️⃣ 需要多个条件变量
// 生产者-消费者模式
Condition notFull = lock.newCondition();
Condition notEmpty = lock.newCondition();
5️⃣ 需要获取锁的信息
// 查看等待的线程数
int waiting = lock.getQueueLength();
// 查看是否有线程在等待
boolean hasWaiters = lock.hasQueuedThreads();
六、常见坑点 ⚠️
坑1:ReentrantLock忘记unlock
// ❌ 危险!如果中间抛异常,永远不会释放锁
lock.lock();
doSomething(); // 可能抛异常
lock.unlock(); // 不会执行!💣
// ✅ 正确写法
lock.lock();
try {
doSomething();
} finally {
lock.unlock(); // 一定会执行
}
坑2:synchronized锁错对象
// ❌ 每次都是新对象,不起作用!
public void method() {
synchronized(new Object()) { // 💣 错误!
// 相当于没加锁
}
}
// ✅ 正确写法
private final Object lock = new Object();
public void method() {
synchronized(lock) {
// ...
}
}
坑3:锁的粒度太大
// ❌ 锁的范围太大,性能差
public synchronized void method() { // 整个方法都锁住
doA(); // 不需要同步
doB(); // 需要同步
doC(); // 不需要同步
}
// ✅ 缩小锁范围
public void method() {
doA();
synchronized(lock) {
doB(); // 只锁需要的部分
}
doC();
}
七、面试应答模板 🎤
面试官:synchronized和ReentrantLock有什么区别?
你的回答:
主要从实现层面和功能层面两个角度对比:
实现层面:
- synchronized是JVM层面的,基于monitor机制,通过对象头的Mark Word实现
- ReentrantLock是API层面的,基于AQS(AbstractQueuedSynchronizer)实现
功能层面,ReentrantLock更强大:
- 可中断:lockInterruptibly()可响应中断
- 可尝试:tryLock()非阻塞获取锁
- 可超时:tryLock(time)超时放弃
- 公平锁:可选择公平或非公平
- 多条件:支持多个Condition
- 可监控:可获取等待线程数等信息
性能对比:
- JDK 1.6之前ReentrantLock性能更好
- JDK 1.6之后synchronized做了大量优化(偏向锁、轻量级锁、锁消除、锁粗化),性能差不多
- synchronized优化包括:无锁→偏向锁→轻量级锁→重量级锁的升级路径
使用建议:
- 简单场景优先synchronized(代码简洁,自动释放)
- 需要高级功能时用ReentrantLock(可中断、超时、公平锁等)
举个例子:
如果只是简单的计数器,用synchronized即可。但如果是银行转账系统,需要可中断、可超时,就应该用ReentrantLock。
八、总结 🎯
选择决策树:
需要同步?
│
Yes
│
┌─────────────┴─────────────┐
│ │
简单场景 复杂场景
(计数器、缓存等) (可中断、超时等)
│ │
synchronized ReentrantLock
│ │
✅ 简单 ✅ 功能强
✅ 自动释放 ⚠️ 需手动
✅ 性能好 ✅ 灵活
记忆口诀:
简单场景synchronized,
复杂需求ReentrantLock,
性能现在差不多,
根据场景来选择!🎵
最后一句话:
synchronized是"自动挡"🚗,简单好用;
ReentrantLock是"手动挡"🏎️,灵活强大!
来源:juejin.cn/post/7563822304766427172
消息队列和事件驱动如何实现流量削峰
消息队列和事件驱动架构不仅是实现流量削峰的关键技术,它们之间更是一种相辅相成、紧密协作的关系。下面这个表格可以帮您快速把握它们的核心联系与分工。
| 特性 | 消息队列 (Message Queue) | 事件驱动架构 (Event-Driven Architecture) |
|---|---|---|
| 核心角色 | 实现事件驱动架构的技术工具和传输机制 | 一种架构风格和设计模式 |
| 主要职责 | 提供异步通信通道,负责事件的存储、路由和可靠传递 | 定义系统各组件之间通过事件进行交互的规范 |
| 与流量削峰关系 | 实现流量削峰的具体手段(作为缓冲区) | 流量削峰是其在处理突发流量时的一种自然结果和能力体现 |
| 协作方式 | 事件驱动架构中,事件的生产与消费通常依赖消息队列来传递事件消息 | 为消息队列的应用提供了顶层设计和业务场景 |
🔌 消息队列:流量削峰的实现工具
消息队列在流量削峰中扮演着“缓冲区”或“蓄水池”的关键角色 。其工作流程如下:
- 接收请求:当突发流量到来时,所有请求首先被作为消息发送到消息队列中暂存,而非直接冲击后端业务处理服务 。
- 平滑压力:后端服务可以按照自身的最佳处理能力,以固定的、可控的速度从消息队列中获取请求并进行处理 。
- 解耦与异步:这使得前端请求的接收和后端业务的处理完全解耦。用户可能瞬间收到“请求已接受”的响应,而实际任务则在后台排队有序执行 。
一个典型的例子是秒杀系统 。在短时间内涌入的海量下单请求会被放入消息队列。队列的长度可以起到限制并发数量的作用,超出系统容量的请求可以被快速拒绝,从而保护下游的订单、库存等核心服务不被冲垮,实现削峰填谷 。
🏗️ 事件驱动:流量削峰的指导架构
事件驱动架构是一种从更高层面设计系统交互模式的思想 。当某个重要的状态变化发生时(例如用户下单、订单支付成功),系统会发布一个事件 。其他关心此变化的服务会订阅这些事件,并触发相应的后续操作 。这种“发布-订阅”模式天然就是异步的。
在流量削峰的场景下,事件驱动架构的意义在于:
- 设计上的解耦:它将“触发动作的服务”和“执行动作的服务”从时间和空间上分离开。下单服务完成核心逻辑后,只需发布一个“订单已创建”的事件,而不需要同步调用库存服务、积分服务等。这本身就为引入消息队列作为事件总线来缓冲流量奠定了基础 。
- 结果的可达性:即使某个服务(如积分服务)处理速度较慢,也不会影响核心链路(如扣减库存)。事件会在消息队列中排队,等待积分服务按自己的能力处理,从而实现了服务间的流量隔离和削峰 。
🤝 协同工作场景
消息队列与事件驱动架构协同工作的场景包括:
- 异步任务处理:用户注册后,需要发送邮件和短信。注册服务完成核心逻辑后,发布一个“用户已注册”事件到消息队列。邮件服务和短信服务作为订阅者,异步消费该事件,实现异步处理 。
- 系统应用解耦:订单系统与库存系统之间通过消息队列解耦。订单系统下单后,将消息写入消息队列即可返回成功,库存系统再根据消息队列中的信息进行库存操作,即使库存系统暂时不可用,也不会影响下单 。
- 日志处理与实时监控:使用类似Kafka的消息队列收集应用日志,后续的日志分析、监控报警等服务订阅这些日志流进行处理,解决大量日志传输问题 。
💡 选型与注意事项
在选择和运用这些技术时,需要注意:
- 技术选型:不同消息队列有不同特点。RabbitMQ 以消息可靠性见长;Apache Kafka 专为高吞吐量的实时日志流和数据管道设计,尤其适合日志处理等场景 ;RocketMQ 在阿里内部经历了大规模交易场景的考验 。
- 潜在挑战:
- 复杂性增加:需要维护消息中间件,并处理可能出现的消息重复、丢失、乱序等问题 。
- 数据一致性:异步化带来了最终一致性,需要考虑业务是否能接受 。
- 系统延迟:请求需要排队处理,用户得到最终结果的时间会变长,不适合所有场景。
来源:juejin.cn/post/7563511245087506486
Java 中的 Consumer 与 Supplier 接口
异同分析
Consumer 和 Supplier 是 Java 8 引入的两个重要函数式接口,位于 java.util.function 包中,用于支持函数式编程范式。
相同点
- 都是函数式接口(只有一个抽象方法)
- 都位于
java.util.function包中 - 都用于 Lambda 表达式和方法引用
- 都在 Stream API 和 Optional 类中广泛使用
不同点
| 特性 | Consumer | Supplier |
|---|---|---|
| 方法签名 | void accept(T t) | T get() |
| 参数 | 接受一个输入参数 | 无输入参数 |
| 返回值 | 无返回值 | 返回一个值 |
| 主要用途 | 消费数据 | 提供数据 |
| 类比 | 方法中的参数 | 方法中的返回值 |
详细分析与使用场景
Consumer 接口
Consumer 表示接受单个输入参数但不返回结果的操作。
import java.util.function.Consumer;
import java.util.Arrays;
import java.util.List;
public class ConsumerExample {
public static void main(String[] args) {
// 基本用法
Consumer<String> printConsumer = s -> System.out.println(s);
printConsumer.accept("Hello Consumer!");
// 方法引用方式
Consumer<String> methodRefConsumer = System.out::println;
methodRefConsumer.accept("Hello Method Reference!");
// 集合遍历中的应用
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(printConsumer);
// andThen 方法组合多个 Consumer
Consumer<String> upperCaseConsumer = s -> System.out.println(s.toUpperCase());
Consumer<String> decoratedConsumer = s -> System.out.println("*** " + s + " ***");
Consumer<String> combinedConsumer = upperCaseConsumer.andThen(decoratedConsumer);
combinedConsumer.accept("functional interface");
// 在 Optional 中的使用
java.util.Optional<String> optional = java.util.Optional.of("Present");
optional.ifPresent(combinedConsumer);
}
}
Consumer 的使用场景:
- 遍历集合元素并执行操作
- 处理数据并产生副作用(如打印、保存到数据库)
- 在 Optional 中处理可能存在的值
- 组合多个操作形成处理链
Supplier 接口
Supplier 表示一个供应商,不需要传入参数但返回一个值。
import java.util.function.Supplier;
import java.util.List;
import java.util.Random;
import java.util.stream.Stream;
public class SupplierExample {
public static void main(String[] args) {
// 基本用法
Supplier<String> stringSupplier = () -> "Hello from Supplier!";
System.out.println(stringSupplier.get());
// 方法引用方式
Supplier<Double> randomSupplier = Math::random;
System.out.println("Random number: " + randomSupplier.get());
// 对象工厂
Supplier<List<String>> listSupplier = () -> java.util.Arrays.asList("A", "B", "C");
System.out.println("List from supplier: " + listSupplier.get());
// 延迟计算/初始化
Supplier<ExpensiveObject> expensiveObjectSupplier = () -> {
System.out.println("Creating expensive object...");
return new ExpensiveObject();
};
System.out.println("Supplier created but no object yet...");
// 只有在调用 get() 时才会创建对象
ExpensiveObject obj = expensiveObjectSupplier.get();
// 在 Stream 中生成无限流
Supplier<Integer> randomIntSupplier = () -> new Random().nextInt(100);
Stream.generate(randomIntSupplier)
.limit(5)
.forEach(System.out::println);
// 在 Optional 中作为备选值
java.util.Optional<String> emptyOptional = java.util.Optional.empty();
String value = emptyOptional.orElseGet(() -> "Default from supplier");
System.out.println("Value from empty optional: " + value);
}
static class ExpensiveObject {
ExpensiveObject() {
// 模拟耗时操作
try { Thread.sleep(1000); } catch (InterruptedException e) {}
}
}
}
Supplier 的使用场景:
- 延迟初始化或延迟计算
- 提供配置或默认值
- 生成测试数据或模拟对象
- 在 Optional 中提供备选值
- 创建对象工厂
- 实现惰性求值模式
实际应用示例
下面是一个结合使用 Consumer 和 Supplier 的示例:
import java.util.function.Consumer;
import java.util.function.Supplier;
import java.util.logging.Logger;
public class CombinedExample {
private static final Logger logger = Logger.getLogger(CombinedExample.class.getName());
public static void main(String[] args) {
// 创建一个数据处理器,结合了 Supplier 和 Consumer
processData(
() -> { // Supplier - 提供数据
// 模拟从数据库或API获取数据
return new String[] {"Data1", "Data2", "Data3"};
},
data -> { // Consumer - 处理数据
for (String item : data) {
System.out.println("Processing: " + item);
}
},
error -> { // Consumer - 错误处理
logger.severe("Error occurred: " + error.getMessage());
}
);
}
public static <T> void processData(Supplier<T> dataSupplier,
Consumer<T> dataProcessor,
Consumer<Exception> errorHandler) {
try {
T data = dataSupplier.get(); // 从Supplier获取数据
dataProcessor.accept(data); // 用Consumer处理数据
} catch (Exception e) {
errorHandler.accept(e); // 用Consumer处理错误
}
}
}
总结
- Consumer 用于表示接受输入并执行操作但不返回结果的函数,常见于需要处理数据并产生副作用的场景
- Supplier 用于表示无需输入但返回结果的函数,常见于延迟计算、提供数据和工厂模式场景
- 两者都是函数式编程中的重要构建块,可以组合使用创建灵活的数据处理管道
- 在 Stream API、Optional 和现代 Java 框架中广泛应用
理解这两个接口的差异和适用场景有助于编写更简洁、更表达力的 Java 代码,特别是在使用 Stream API 和函数式编程范式时。
来源:juejin.cn/post/7548717557531623464
线程安全过期缓存:手写Guava Cache🗄️
缓存是性能优化的利器,但如何保证线程安全、支持过期、防止内存泄漏?让我们从零开始,打造一个生产级缓存!
一、开场:缓存的核心需求🎯
基础需求
- 线程安全:多线程并发读写
- 过期淘汰:自动删除过期数据
- 容量限制:防止内存溢出
- 性能优化:高并发访问
生活类比:
缓存像冰箱🧊:
- 存储食物(数据)
- 定期检查过期(过期策略)
- 空间有限(容量限制)
- 多人使用(线程安全)
二、版本1:基础线程安全缓存
public class SimpleCache<K, V> {
private final ConcurrentHashMap<K, CacheEntry<V>> cache =
new ConcurrentHashMap<>();
// 缓存项
static class CacheEntry<V> {
final V value;
final long expireTime; // 过期时间戳
CacheEntry(V value, long ttl) {
this.value = value;
this.expireTime = System.currentTimeMillis() + ttl;
}
boolean isExpired() {
return System.currentTimeMillis() > expireTime;
}
}
/**
* 存入缓存
*/
public void put(K key, V value, long ttlMillis) {
cache.put(key, new CacheEntry<>(value, ttlMillis));
}
/**
* 获取缓存
*/
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
if (entry == null) {
return null;
}
// 检查是否过期
if (entry.isExpired()) {
cache.remove(key); // 惰性删除
return null;
}
return entry.value;
}
/**
* 删除缓存
*/
public void remove(K key) {
cache.remove(key);
}
/**
* 清空缓存
*/
public void clear() {
cache.clear();
}
/**
* 缓存大小
*/
public int size() {
return cache.size();
}
}
使用示例:
SimpleCache<String, User> cache = new SimpleCache<>();
// 存入缓存,5秒过期
cache.put("user:1", new User("张三"), 5000);
// 获取缓存
User user = cache.get("user:1"); // 5秒内返回User对象
Thread.sleep(6000);
User expired = cache.get("user:1"); // 返回null(已过期)
问题:
- ❌ 过期数据需要访问时才删除(惰性删除)
- ❌ 没有容量限制,可能OOM
- ❌ 没有定时清理,内存泄漏
三、版本2:支持定时清理🔧
public class CacheWithCleanup<K, V> {
private final ConcurrentHashMap<K, CacheEntry<V>> cache =
new ConcurrentHashMap<>();
private final ScheduledExecutorService cleanupExecutor;
static class CacheEntry<V> {
final V value;
final long expireTime;
CacheEntry(V value, long ttl) {
this.value = value;
this.expireTime = System.currentTimeMillis() + ttl;
}
boolean isExpired() {
return System.currentTimeMillis() > expireTime;
}
}
public CacheWithCleanup() {
this.cleanupExecutor = Executors.newSingleThreadScheduledExecutor(
new ThreadFactoryBuilder()
.setNameFormat("cache-cleanup-%d")
.setDaemon(true)
.build()
);
// 每秒清理一次过期数据
cleanupExecutor.scheduleAtFixedRate(
this::cleanup,
1, 1, TimeUnit.SECONDS
);
}
public void put(K key, V value, long ttlMillis) {
cache.put(key, new CacheEntry<>(value, ttlMillis));
}
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
if (entry == null || entry.isExpired()) {
cache.remove(key);
return null;
}
return entry.value;
}
/**
* 定时清理过期数据
*/
private void cleanup() {
cache.entrySet().removeIf(entry -> entry.getValue().isExpired());
}
/**
* 关闭缓存
*/
public void shutdown() {
cleanupExecutor.shutdown();
cache.clear();
}
}
改进:
- ✅ 定时清理过期数据
- ✅ 不依赖访问触发删除
问题:
- ❌ 还是没有容量限制
- ❌ 没有LRU淘汰策略
四、版本3:完整的缓存实现(LRU+过期)⭐
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class AdvancedCache<K, V> {
// 缓存容量
private final int maxSize;
// 存储:ConcurrentHashMap + LinkedHashMap(LRU)
private final ConcurrentHashMap<K, CacheEntry<V>> cache;
// 定时清理线程
private final ScheduledExecutorService cleanupExecutor;
// 统计信息
private final AtomicInteger hitCount = new AtomicInteger(0);
private final AtomicInteger missCount = new AtomicInteger(0);
// 缓存项
static class CacheEntry<V> {
final V value;
final long expireTime;
volatile long lastAccessTime; // 最后访问时间
CacheEntry(V value, long ttl) {
this.value = value;
this.expireTime = System.currentTimeMillis() + ttl;
this.lastAccessTime = System.currentTimeMillis();
}
boolean isExpired() {
return System.currentTimeMillis() > expireTime;
}
void updateAccessTime() {
this.lastAccessTime = System.currentTimeMillis();
}
}
public AdvancedCache(int maxSize) {
this.maxSize = maxSize;
this.cache = new ConcurrentHashMap<>(maxSize);
this.cleanupExecutor = Executors.newSingleThreadScheduledExecutor(
new ThreadFactoryBuilder()
.setNameFormat("cache-cleanup-%d")
.setDaemon(true)
.build()
);
// 每秒清理过期数据
cleanupExecutor.scheduleAtFixedRate(
this::cleanup,
1, 1, TimeUnit.SECONDS
);
}
/**
* 存入缓存
*/
public void put(K key, V value, long ttlMillis) {
// 检查容量
if (cache.size() >= maxSize) {
evictLRU(); // LRU淘汰
}
cache.put(key, new CacheEntry<>(value, ttlMillis));
}
/**
* 获取缓存
*/
public V get(K key) {
CacheEntry<V> entry = cache.get(key);
if (entry == null) {
missCount.incrementAndGet();
return null;
}
// 检查过期
if (entry.isExpired()) {
cache.remove(key);
missCount.incrementAndGet();
return null;
}
// 更新访问时间
entry.updateAccessTime();
hitCount.incrementAndGet();
return entry.value;
}
/**
* 带回调的获取(类似Guava Cache)
*/
public V get(K key, Callable<V> loader, long ttlMillis) {
CacheEntry<V> entry = cache.get(key);
// 缓存命中且未过期
if (entry != null && !entry.isExpired()) {
entry.updateAccessTime();
hitCount.incrementAndGet();
return entry.value;
}
// 缓存未命中,加载数据
try {
V value = loader.call();
put(key, value, ttlMillis);
return value;
} catch (Exception e) {
throw new RuntimeException("加载数据失败", e);
}
}
/**
* LRU淘汰:移除最久未访问的
*/
private void evictLRU() {
K lruKey = null;
long oldestAccessTime = Long.MAX_VALUE;
// 找出最久未访问的key
for (Map.Entry<K, CacheEntry<V>> entry : cache.entrySet()) {
long accessTime = entry.getValue().lastAccessTime;
if (accessTime < oldestAccessTime) {
oldestAccessTime = accessTime;
lruKey = entry.getKey();
}
}
if (lruKey != null) {
cache.remove(lruKey);
}
}
/**
* 定时清理过期数据
*/
private void cleanup() {
cache.entrySet().removeIf(entry -> entry.getValue().isExpired());
}
/**
* 获取缓存命中率
*/
public double getHitRate() {
int total = hitCount.get() + missCount.get();
return total == 0 ? 0 : (double) hitCount.get() / total;
}
/**
* 获取统计信息
*/
public String getStats() {
return String.format(
"缓存统计: 大小=%d, 命中=%d, 未命中=%d, 命中率=%.2f%%",
cache.size(),
hitCount.get(),
missCount.get(),
getHitRate() * 100
);
}
/**
* 关闭缓存
*/
public void shutdown() {
cleanupExecutor.shutdown();
cache.clear();
}
}
五、完整使用示例📝
public class CacheExample {
public static void main(String[] args) throws InterruptedException {
// 创建缓存:最大100个,5秒过期
AdvancedCache<String, User> cache = new AdvancedCache<>(100);
// 1. 基本使用
cache.put("user:1", new User("张三", 20), 5000);
User user = cache.get("user:1");
System.out.println("获取缓存: " + user);
// 2. 带回调的获取(自动加载)
User user2 = cache.get("user:2", () -> {
// 模拟从数据库加载
System.out.println("从数据库加载 user:2");
return new User("李四", 25);
}, 5000);
System.out.println("加载数据: " + user2);
// 3. 再次获取(命中缓存)
User cached = cache.get("user:2");
System.out.println("命中缓存: " + cached);
// 4. 等待过期
Thread.sleep(6000);
User expired = cache.get("user:1");
System.out.println("过期数据: " + expired); // null
// 5. 查看统计
System.out.println(cache.getStats());
// 6. 关闭缓存
cache.shutdown();
}
}
输出:
获取缓存: User{name='张三', age=20}
从数据库加载 user:2
加载数据: User{name='李四', age=25}
命中缓存: User{name='李四', age=25}
过期数据: null
缓存统计: 大小=1, 命中=2, 未命中=1, 命中率=66.67%
六、实战:用户Session缓存🔐
public class SessionCache {
private final AdvancedCache<String, UserSession> cache;
public SessionCache() {
this.cache = new AdvancedCache<>(10000); // 最大1万个session
}
/**
* 创建Session
*/
public String createSession(Long userId) {
String sessionId = UUID.randomUUID().toString();
UserSession session = new UserSession(userId, LocalDateTime.now());
// 30分钟过期
cache.put(sessionId, session, 30 * 60 * 1000);
return sessionId;
}
/**
* 获取Session
*/
public UserSession getSession(String sessionId) {
return cache.get(sessionId);
}
/**
* 刷新Session(延长过期时间)
*/
public void refreshSession(String sessionId) {
UserSession session = cache.get(sessionId);
if (session != null) {
// 重新设置30分钟过期
cache.put(sessionId, session, 30 * 60 * 1000);
}
}
/**
* 删除Session(登出)
*/
public void removeSession(String sessionId) {
cache.remove(sessionId);
}
static class UserSession {
final Long userId;
final LocalDateTime createTime;
UserSession(Long userId, LocalDateTime createTime) {
this.userId = userId;
this.createTime = createTime;
}
}
}
七、与Guava Cache对比📊
Guava Cache的使用
LoadingCache<String, User> cache = CacheBuilder.newBuilder()
.maximumSize(1000) // 最大容量
.expireAfterWrite(5, TimeUnit.MINUTES) // 写入后过期
.expireAfterAccess(10, TimeUnit.MINUTES) // 访问后过期
.recordStats() // 记录统计
.build(new CacheLoader<String, User>() {
@Override
public User load(String key) throws Exception {
return loadUserFromDB(key); // 加载数据
}
});
// 使用
User user = cache.get("user:1"); // 自动加载
功能对比
| 功能 | 自定义Cache | Guava Cache |
|---|---|---|
| 线程安全 | ✅ | ✅ |
| 过期时间 | ✅ | ✅ |
| LRU淘汰 | ✅ | ✅ |
| 自动加载 | ✅ | ✅ |
| 弱引用 | ❌ | ✅ |
| 统计信息 | ✅ | ✅ |
| 监听器 | ❌ | ✅ |
| 刷新 | ❌ | ✅ |
建议:
- 简单场景:自定义实现
- 生产环境:用Guava Cache或Caffeine
八、性能优化技巧⚡
技巧1:分段锁
public class SegmentedCache<K, V> {
private final int segments = 16;
private final AdvancedCache<K, V>[] caches;
@SuppressWarnings("unchecked")
public SegmentedCache(int totalSize) {
this.caches = new AdvancedCache[segments];
int sizePerSegment = totalSize / segments;
for (int i = 0; i < segments; i++) {
caches[i] = new AdvancedCache<>(sizePerSegment);
}
}
private AdvancedCache<K, V> getCache(K key) {
int hash = key.hashCode();
int index = (hash & Integer.MAX_VALUE) % segments;
return caches[index];
}
public void put(K key, V value, long ttl) {
getCache(key).put(key, value, ttl);
}
public V get(K key) {
return getCache(key).get(key);
}
}
技巧2:异步加载
public class AsyncCache<K, V> {
private final AdvancedCache<K, CompletableFuture<V>> cache;
private final ExecutorService loadExecutor;
public CompletableFuture<V> get(K key, Callable<V> loader, long ttl) {
return cache.get(key, () ->
CompletableFuture.supplyAsync(() -> {
try {
return loader.call();
} catch (Exception e) {
throw new CompletionException(e);
}
}, loadExecutor),
ttl
);
}
}
九、常见陷阱⚠️
陷阱1:缓存穿透
// ❌ 错误:不存在的key反复查询数据库
public User getUser(String userId) {
User user = cache.get(userId);
if (user == null) {
user = loadFromDB(userId); // 每次都查数据库
if (user != null) {
cache.put(userId, user, 5000);
}
}
return user;
}
// ✅ 正确:缓存空对象
public User getUser(String userId) {
User user = cache.get(userId);
if (user == null) {
user = loadFromDB(userId);
// 即使是null也缓存,但设置短过期时间
cache.put(userId, user != null ? user : NULL_USER, 1000);
}
return user == NULL_USER ? null : user;
}
陷阱2:缓存雪崩
// ❌ 错误:所有key同时过期
for (String key : keys) {
cache.put(key, value, 5000); // 5秒后同时过期
}
// ✅ 正确:过期时间随机化
for (String key : keys) {
long ttl = 5000 + ThreadLocalRandom.current().nextInt(1000);
cache.put(key, value, ttl); // 5-6秒随机过期
}
十、面试高频问答💯
Q1: 如何保证缓存的线程安全?
A:
- 使用
ConcurrentHashMap - volatile保证可见性
- CAS操作保证原子性
Q2: 如何实现过期淘汰?
A:
- 惰性删除:访问时检查过期
- 定时删除:定时任务扫描
- 两者结合
Q3: 如何实现LRU?
A:
- 记录访问时间
- 容量满时淘汰最久未访问的
Q4: 缓存穿透/击穿/雪崩的区别?
A:
- 穿透:查询不存在的key,缓存和DB都没有
- 击穿:热点key过期,大量请求打到DB
- 雪崩:大量key同时过期
十一、总结🎯
核心要点
- 线程安全:ConcurrentHashMap
- 过期策略:定时清理+惰性删除
- 容量限制:LRU淘汰
- 性能优化:分段锁、异步加载
- 监控统计:命中率、容量
生产建议
- 简单场景:自己实现
- 复杂场景:用Guava Cache
- 极致性能:用Caffeine
下期预告: 为什么双重检查锁定(DCL)是错误的?指令重排序的陷阱!🔐
来源:juejin.cn/post/7563511077180473386
Lambda 底层原理全解析
是否好奇过,这样一行代码,编译器背后做了什么?
auto lambda = [](int x) { return x * 2; };
本文将带你深入 Lambda 的底层
一、Lambda回顾
auto lambda = [](int x) { return x + 1; };
int result = lambda(5);
lambda我们很熟悉,是一个对象。
完整语法:[捕获列表] (参数列表) mutable 异常说明->返回类型{函数体}
基本的用法就不说,说几个用的时候注意的点
- & 捕获要注意悬垂引用,不要让捕获的引用,被销毁了还在使用
- this指针捕获,引起的悬垂指针
class MyClass {
int value = 42;
public:
auto getLambda() {
return [this]() { return value; }; //捕获 this 指针
}
};
MyClass* obj = new MyClass();
auto lambda = obj->getLambda();
delete obj;
lambda(); //this 指针悬垂
C++17解决:*this捕获,直接拷贝整个对象
return [*this]() { return value; }; // 拷贝整个对象
3.每个lambda都是唯一的
auto l1 = []() { return 1; };
auto l2 = []() { return 1; };
// l1 和 l2 类型不同!
// typeid(l1) != typeid(l2)
4.转换为函数指针
// 不捕获变量→可以转换
auto l1 = [](int x) { return x + 1; };
int (*fp)(int) = l1;//正确
// 捕获变量→不能转换
int a = 10;
auto l2 = [a](int x) { return a + x; };
int (*fp2)(int) = l2; //编译错误
记住这句话:函数指针=纯粹的代码地址,你一旦有成员变量,operator()就会依赖对象状态(a),无法转换为函数指针,函数指针调用时,不知道a的值从哪里来。
简单来说:lambda本质是对象+代码,而函数指针只能表示纯代码
解决方式:function(可以直接存储Lambda对象)
5.混淆了[=] 和 [&]
class MyClass {
int value = 100;
public:
void test() {
auto lambda = [=]() { //看起来按值捕获
std::cout << value << std::endl;
};
//等价于 [this],捕获的是this指针
//等价于this->value
}
};
6.lambda递归
auto factorial = [](int n) { //无法递归调用自己
return n <= 1 ? 1 : n * factorial(n - 1); // 错误:factorial 未定义
};
//正确做法:C++23显式对象参数
auto factorial = [](this auto self, int n) { // C++23
return n <= 1 ? 1 : n * self(n - 1);
};
7.移动捕获
void process(std::unique_ptr<int>&& ptr) {
auto lambda = [p = std::move(ptr)]() { //移动到 Lambda
std::cout << *p << std::endl;
};
//错误做法
//auto lambda = [&ptr]() { //捕获的是引用
//std::cout << *ptr << std::endl;
//可能导致ptr移动后lambda失效.
lambda();
}
二、Lambda 的本质
Lambda不是普通的函数,也不是普通的对象,它是一个重载了operator()的类对象。
现在来证明一下:代码如下
#include <iostream>
int main() {
auto lambda = [](int x) { return x * 2; };
int result = lambda(5);
std::cout << result << std::endl;
return 0;
}
gdb证明:
观察到lambda是一个结构体,且大小为1字节
引申出几个问题
- 为什么这里是一个空的结构体?
- 为什么大小为1字节?
- 还没有证明他是一个重载了operator()的对象
问题1:为什么这里是一个空的结构体?
我们来按值捕获参数试试:
int main() {
int y=2;
auto lambda = [=](int x) { return x * 2+y * 3; };
int result = lambda(5);
std::cout << result << std::endl;
return 0;
}
gdb:
哦,原来捕获对象会存在这个结构体中,同时我们发现大小为4字节,就为数据的大小。
那我们捕获引用试试呢?
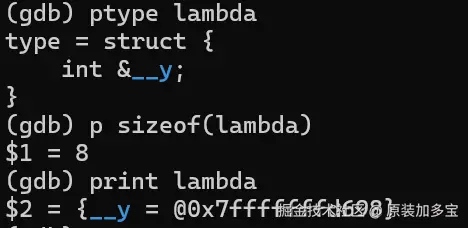
同样也是引用数据类型,但是由于引用底层是存着对象的地址,所以它的大小为8字节,是一个指针的大小。
回到上面,为什么我们一开始的结构体什么数据都没有还是为1字节呢,C++规定了空类大小不为0,最小为1字节(保证每个对象都有唯一的地址)
总结:引用或按值捕获的数据被存在lambda对象内部
问题2:证明他是一个重载了operator()的对象
(1)gdb继续调试:
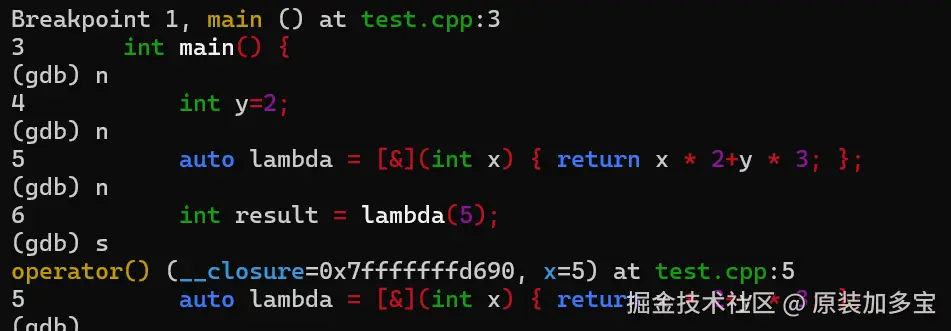
可以看到,确实是调用了一个operator()
(2)我们在用C++ Insights验证一下
访问:cppinsights.io/
可以查看编译器实际生成的完整类定义
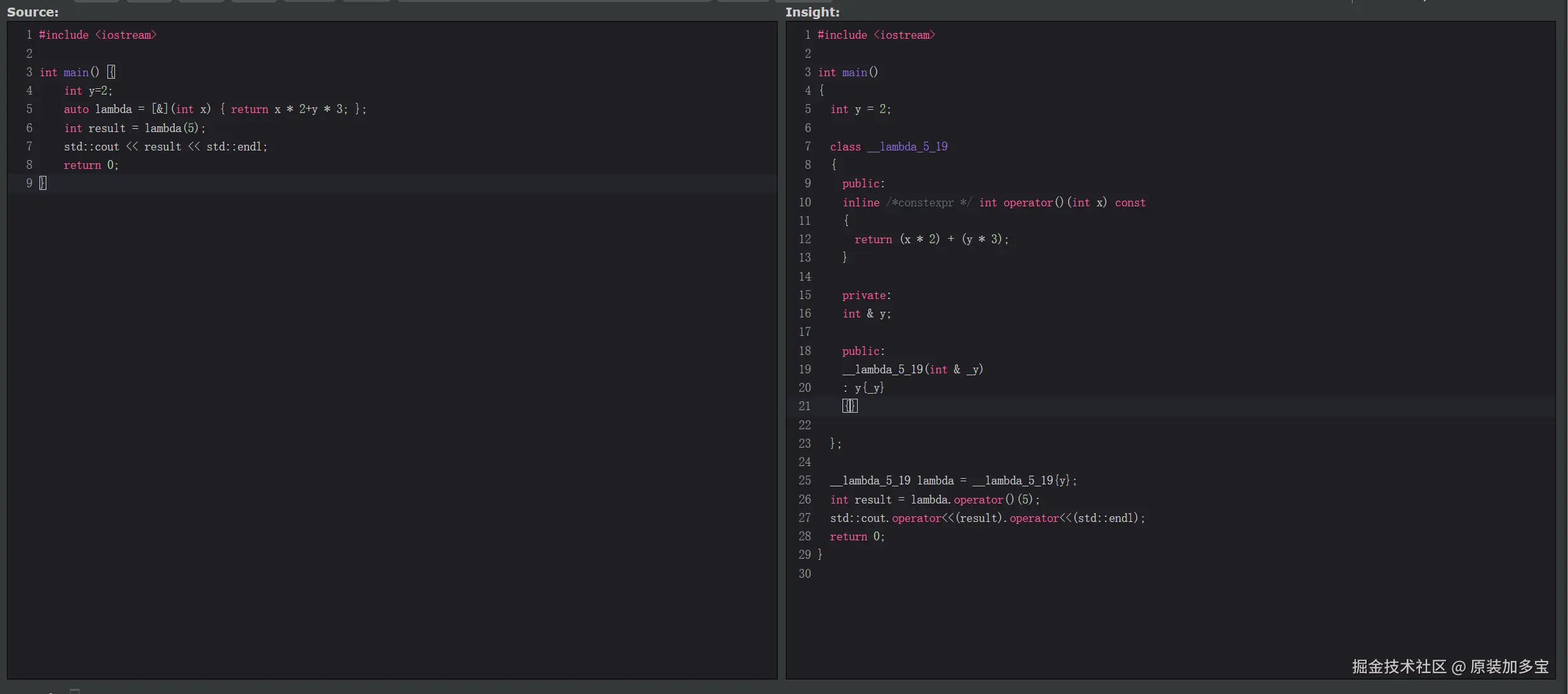
关注到operator()后面是一个const,说明不可以修改捕获的变量,mutable加上后const消失,可自行验证
来源:juejin.cn/post/7564694382999994406
从“写循环”到“写思想”:Java Stream 流的高级实战与底层原理剖析
引言
在实际开发中,很多工程师依然停留在“用 for 循环遍历集合”的思维模式。但在大型项目、复杂业务中,这种写法往往显得冗余、难以扩展,也不符合函数式编程的趋势。
Stream API 的出现,不只是“简化集合遍历”,而是把 声明式编程思想 带入了 Java,使我们能以一种更优雅、更高效、更可扩展的方式处理集合与数据流。
如果你还把 Stream 仅仅理解为 list.stream().map(...).collect(...),那就大错特错了。本文将从 高级用法、底层原理、业务实践、性能优化 四个维度,带你重新认识 Stream —— 让它真正成为你架构设计和代码表达的利器。
一、为什么要用 Stream?
在真实业务场景中,Stream 的价值不仅仅体现在“更少的代码量”,而在于:
- 声明式语义 —— 写“我要做什么”,而不是“怎么做”。
// 传统方式
List<String> result = new ArrayList<>();
for (User u : users) {
if (u.getAge() > 18) {
result.add(u.getName());
}
}
// Stream 写法:表达意图更清晰
List<String> result = users.stream()
.filter(u -> u.getAge() > 18)
.map(User::getName)
.toList();
后者的代码阅读体验更接近“业务规则”,而非“算法步骤”。
- 可扩展性 —— 同样的链式调用,可以无缝切换到 并行流(parallelStream)以提升性能,而无需修改核心逻辑。
- 契合函数式编程趋势 —— 在 Java 8 引入 Lambda 后,Stream 彻底释放了函数式编程的潜力。
二、Stream 的核心思想
Stream API 的设计核心可以用一句话概括:
把数据操作抽象成流水线,每一步都是一个中间操作,最终由终止操作触发执行。
- 数据源(Source) :集合、数组、I/O、生成器等。
- 中间操作(Intermediate Operations) :
filter、map、flatMap、distinct、sorted…,返回一个新的 Stream(惰性求值)。 - 终止操作(Terminal Operations) :
collect、forEach、reduce、count…,触发实际计算。
关键点:Stream 是惰性的。中间操作不会立即执行,直到遇到终止操作才会真正运行。
三、高级用法与最佳实践
1. 多级分组与统计
真实业务中,常见的场景是“按条件分组统计”。
// 按部门分组,并统计每个部门的人数
Map<String, Long> groupByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment, Collectors.counting()));
// 多级分组:按部门 -> 按职位
Map<String, Map<String, List<Employee>>> group = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.groupingBy(Employee::getTitle)));
2. flatMap 的威力
flatMap 可以把多层集合打平成单层流。
// 一个学生对应多个课程,如何获取所有课程的去重列表?
List<String> courses = students.stream()
.map(Student::getCourses) // Stream<List<String>>
.flatMap(List::stream) // Stream<String>
.distinct()
.toList();
3. reduce 高阶聚合
Stream 的 reduce 方法提供了更灵活的聚合方式。
// 求所有订单的总金额
BigDecimal total = orders.stream()
.map(Order::getAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add);
相比 Collectors.summingInt 等方法,reduce 更加灵活,适合需要自定义聚合逻辑的场景。
4. 结合 Optional 优雅处理空值
Stream 与 Optional 配合,可以消除 if-null 的丑陋写法。
// 找到第一个满足条件的用户
Optional<User> user = users.stream()
.filter(u -> u.getAge() > 30)
.findFirst();
与传统的 null 判断相比,这种写法更安全、更符合函数式语义。
5. 并行流与 ForkJoinPool
只需一行代码,就能让 Stream 自动并行处理
long count = bigList.parallelStream()
.filter(item -> isValid(item))
.count();
注意点:
- 并行流基于 ForkJoinPool,默认线程数 = CPU 核心数。
- 不适合小数据量,启动线程开销可能大于收益。
- 不适合有共享资源的场景(容易产生锁竞争)。
四、Stream 的底层原理
理解底层机制,才能在性能和架构上做出正确决策。
- 流水线模型(Pipeline Model)
- 每个中间操作都返回一个
Stream,但实际上内部是一个Pipeline。 - 只有终止操作才会触发数据逐步流经整个 pipeline。
- 每个中间操作都返回一个
- 内部迭代(Internal Iteration)
- 相比外部迭代(for 循环),Stream 将迭代逻辑交给框架本身,从而更容易做优化(如并行)。
- 短路操作(Short-circuiting)
anyMatch、findFirst等操作可以在满足条件时立刻返回,避免不必要的计算。
- 内存与性能
- 惰性求值减少不必要的计算。
- 但过度链式调用可能带来额外开销(对象创建、函数调用栈)。
五、业务场景中的最佳实践
1. 日志分析系统
日志按时间、级别分组统计:
Map<LogLevel, Long> logCount = logs.stream()
.filter(log -> log.getTimestamp().isAfter(start))
.collect(Collectors.groupingBy(Log::getLevel, Collectors.counting()));
2. 电商系统订单处理
对订单进行聚合,计算 GMV(成交总额):
BigDecimal gmv = orders.stream()
.filter(o -> o.getStatus() == OrderStatus.FINISHED)
.map(Order::getAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add);
3. 权限系统多对多关系处理
用户-角色-权限的映射去重:
Set<String> permissions = users.stream()
.map(User::getRoles)
.flatMap(List::stream)
.map(Role::getPermissions)
.flatMap(List::stream)
.collect(Collectors.toSet());
六、性能优化与陷阱
- 避免在 Stream 中修改外部变量
List<String> result = new ArrayList<>();
list.stream().forEach(e -> result.add(e)); //违反函数式编程
应该用 collect。
- 适度使用并行流
- 小集合别用并行流。
- 线程池可通过
ForkJoinPool.commonPool()自定义。
- 避免链式调用过长
虽然优雅,但可读性会下降,必要时拆分。 - Stream 不是万能的
- 对于简单循环,普通 for 循环更直观。
- 对性能敏感的底层操作(如数组拷贝),直接用原生循环更高效。
总结
Stream 并不是一个“语法糖”,而是 Java 向函数式编程迈进的重要里程碑。
它让我们能以声明式、可扩展、可并行的方式处理数据流,提升代码表达力和业务抽象能力。
对于中高级开发工程师来说,Stream 的价值在于:
- 提升业务逻辑的可读性和可维护性
- 利用底层并行能力提升性能
- 契合函数式思维,帮助团队写出更现代化的 Java 代码
未来的你,写业务逻辑时,应该少考虑“怎么遍历”,多去思考“我要表达的业务规则是什么”。
来源:juejin.cn/post/7538829865351036967
通信的三种基本模式:单工、半双工与全双工
在数据通信与网络技术中,信道的“方向性”是一个基础而核心的概念。它定义了信息在通信双方之间流动的方向与方式。根据其特性,我们通常将其归纳为三种基本模式:单工、半双工和全双工。清晰理解这三种模式,是掌握众多通信协议与网络技术的基石。
一、单工通信

单工通信代表了最单一、最直接的数据流向。
- 定义:数据只能在一个方向上传输,通信的一方固定为发送端,另一方则固定为接收端。
- 核心特征:方向不可改变。就像一条单行道,数据流只有一个固定的方向。
- 经典比喻:
- 广播电台:电台负责发送信号,广大听众的收音机只能接收信号,无法通过收音机向电台发送数据。
- 电视信号传输:电视台到家庭电视的信号传输。
- 键盘到计算机(在传统概念中):数据从键盘单向传入计算机。
单工通信模式简单、成本低,但交互性为零,无法实现双向信息交流。
二、半双工通信

半双工通信允许了双向交流,但增加了“轮流”的规则。
- 定义:数据可以在两个方向上传输,但在任一时刻,只能有一个方向在进行传输。它需要一种“切换”机制来改变数据传输的方向。
- 核心特征:双向交替,不能同时。
- 经典比喻:
- 对讲机:一方需要按下“通话键”说话,说完后必须说“完毕”并松开按键,切换到接收状态,才能听到对方的回复。双方不能同时讲话。
- 独木桥:同一时间只能允许一个人从一个方向通过。
半双工的局限性:
由于其交替通信的本质,半双工存在几个固有缺陷:
- 效率较低:存在信道空闲和状态切换的时间开销,总吞吐量低。
- 延迟较高:发送方必须等待信道空闲才能发送,接收方必须等待发送方完毕才能接收。
- 可能发生碰撞:在共享信道中,若多个设备同时开始发送,会导致数据冲突,必须重传,进一步降低效率。
- 需要冲突管理:必须引入如CSMA/CD(载波侦听多路访问/冲突检测)等协议来管理信道访问,增加了系统复杂度。
三、全双工通信

全双工通信实现了最自然、最高效的双向交互。
- 定义:数据可以在两个方向上同时进行传输。
- 核心特征:同时双向传输。
- 经典比喻:
- 电话通话:双方可以同时说话和聆听,交流过程自然流畅,无需等待。
- 双向多车道公路:两个方向的车流拥有各自独立的车道,可以同时、高速、互不干扰地行驶。
技术实现:全双工通常需要两条独立的物理信道(如网线中的两对线),或通过频分复用等技术在一条信道上逻辑地划分出上行和下行通道。其最大优势在于彻底避免了半双工中固有的碰撞问题。
三种模式对比总结
| 特性维度 | 单工 | 半双工 | 全双工 |
|---|---|---|---|
| 数据流向 | 仅单向 | 双向,但交替进行 | 双向,同时进行 |
| 经典比喻 | 广播 | 对讲机 | 电话 |
| 信道占用 | 一条单向信道 | 一条共享信道 | 两条独立信道或等效技术 |
| 效率 | 低(无交互) | 较低 | 高 |
| 交互性 | 无 | 有,但不流畅 | 有,且自然流畅 |
| 数据碰撞 | 无 | 可能发生 | 不可能发生 |
| 典型应用 | 广播、电视 | 早期以太网、对讲机 | 现代以太网、电话、视频会议 |
结论
从单工的“只读”模式,到半双工的“轮流对话”,再到全双工的“自由交谈”,通信模式的演进体现了人们对更高效率和更自然交互的不懈追求。全双工凭借其高吞吐量、低延迟和无碰撞的特性,已成为当今主流有线与无线网络(如交换式以太网、4G/5G移动通信)的标配。而半双工和单工则在物联网、传感器网络、广播等特定应用场景中,因其成本或功能需求,依然保有一席之地。理解这三种基础模式,是步入更复杂通信世界的第一步。
来源:juejin.cn/post/7563108340538507318
大数据-133 ClickHouse 概念与基础|为什么快?列式 + 向量化 + MergeTree 对比
TL;DR
场景:要做高并发低延迟 OLAP,且不想上整套 Hadoop/湖仓。
结论:ClickHouse 的核心在列式+向量化+MergeTree+近似统计;适合即席分析与近实时写入,不适合强事务与高频行级更新。
产出:选型决策表 + 分区/排序键速查卡 + 5 条查询模板(安装/集群放到下一章)。


简要概述
ClickHouse 是一个快速开源的OLAP数据库管理系统,它是面向列的,允许使用SQL查询实时生成分析报告。
随着物联网IOT时代的来临,IOT设备感知和报警存储数据越来越大,有用的价值数据需要数据分析师去分析。大数据分析成了非常重要的环节,开源也为大数据分析工程师提供了十分丰富的工具,但这也增加了开发者选择适合的工具的难度,尤其是新入行的开发者来说。
框架的多样化和复杂度成了很大的难题,例如:Kafka、HDFS、Spark、Hive等等组合才能产生最后的分析结果,把各种开源框架、工具、库、平台人工整合到一起所需的工作之复杂,是大数据领域开发和数据分析师常有的抱怨之一,也就是他们支持大数据分析简化和统一化的首要原因。

从业务维度来分析,用户需求会反向促使技术发展。
简要选型
| 需求/约束 | 适合 | 不适合 |
|---|---|---|
| 高并发、低延迟 OLAP | ✅ | |
| 重事务/强一致 OLTP | ❌ | |
| 近实时写入、即席分析 | ✅ | |
| 频繁行级更新/删除 | ⚠️(有 mutations 但代价高) |
- 需要强事务/OLTP → 不是 CH
- OLAP + 近实时 + 自建机房成本敏感 → CH 优先
- 只做离线、成本不敏感且现有湖仓成熟 → SparkSQL/Trino 也行
- 预计算立方体 + 报表固化 → Druid/Kylin 也可
OLTP
OLTP:Online Transaction Processing:联机事务处理过程。
应用场景
- ERP:Enterprise Resource Planning 企业资源计划
- CRM:Customer Relationship Management 客户关系管理
流程审批、数据录入、填报等
具体特点
线下工作线上化,数据保存在各自的系统中,互不相同(数据孤岛)
OLAP
OLAP:On-Line Analytical Processing:联机分析系统
分析报表、分析决策等。
应用场景
方案1:数仓

如上图所示,数据实时写入HBase,实时的数据更新也在HBase完成,为了应对OLAP需求,我们定时(通常是T+1或者T+H)将HBase数据写成静态的文件(如:Parquet)导入到 OLAP引擎(如HDFS,比较常见的是Impala操作Hive)。这一架构又能满足随机读写,又可以支持OLAP分析的场景,但是有如下缺点:
- 架构复杂:从架构上看,数据在HBase、消息队列、HDFS间流转,涉及到的环节过多,运维成本也很高,并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,对数据安全策略、监控都提出了挑战。
- 时效性低:数据从HBase导出静态文件是周期性的,一般这个周期一天(或者一小时),有时效性上不是很高。
- 难以应对后续的更新:真实场景中,总会有数据是延迟到达的,如果这些数据之前已经从HBase导出到HDFS,新到的变更数据更难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
方案2:ClickHouse、Kudu
实现方案2就是 ClickHouse、Kudu
发展历史
Yandex在2016年6月15日开源了一个数据分析数据库,叫做ClickHouse,这对保守的俄罗斯人来说是个特大事件。更让人惊讶的是,这个列式数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。如果你没有Vertica,那你一定听过Michael Stonebraker,2014年图灵奖的获得者,PostgreSQL和Ingres发明者(Sybase和SQL Server都是继承Ingres而来的),Paradigm4和SciDB的创办者。Micheal StoneBraker于2005年创办的Vertica公司,后来该公司被HP收购,HP Vertica成为MPP列式存储商业数据库的高性能代表,Facebook就购买了Vertica数据用于用户行为分析。
ClickHouse技术演变之路
Yandex公司在2011年上市,它的核心产品是搜索引擎。
我们知道,做搜索引擎的公司营收非常依赖流量和在线广告,所以做搜索引擎公司一般会并行推出在线流量分析产品,比如说百度的百度统计,Google的Google Analytics等,Yandex的Yandex.Metricah。ClickHouse就是在这种背景下诞生的。
- ROLAP:传统关系型数据库OLAP,基于MySQL的MyISAM表引擎
- MOLAP:借助物化视图的形式实现数据立方体,预处理的结果存在HBase这类高性能的分布式数据库中
- HOLAP:R和M的结合体H
- ROLAP:ClickHouse
ClickHouse 的核心特点
超高的查询性能
- 列式存储:只读取查询所需的列,减少了磁盘 I/O。
- 向量化计算:批量处理数据,提高了 CPU 使用效率。
- 数据压缩:高效的压缩算法,降低了存储成本。
水平可扩展性
- 分布式架构:支持集群部署,轻松处理 PB 级数据。
- 线性扩展:通过增加节点提升性能,无需停机。
实时数据写入
- 高吞吐量:每秒可插入数百万行数据。
- 低延迟:数据写入后立即可查询,满足实时分析需求。
丰富的功能支持
- 多样的数据类型:支持从基本类型到复杂类型的数据。
- 高级 SQL 特性:窗口函数、子查询、JOIN 等。
- 物化视图:预计算和存储查询结果,进一步提升查询性能。
典型应用场景
- 用户行为分析:电商、游戏、社交平台的实时用户行为跟踪。
- 日志和监控数据存储:处理服务器日志、应用程序日志和性能监控数据。
- 商业智能(BI):支持复杂的报表和数据分析需求。

部署与运维
- 单机部署:适合测试和小规模应用。
- 集群部署:用于生产环境,可通过 Zookeeper 进行协调。
- 运维工具:提供了监控和管理工具,如 clickhouse-client、clickhouse-copier。
最佳实践
- 数据分区:根据时间或其他字段进行分区,提高查询效率。
- 索引优化:使用主键和采样键,加速数据定位。
- 硬件配置:充分利用多核 CPU、高速磁盘和大内存。
ClickHouse支持特性
ClickHouse具体有哪些特性呢:
- 真正的面向列的DBMS
- 数据高效压缩
- 磁盘存储的数据
- 多核并行处理
- 在多个分布式服务器上分布式处理
- SQL语法支持
- 向量化引擎
- 实时数据更新
- 索引
- 适合在线查询
- 支持近似预估计算
- 支持嵌套的数据结构
- 支持数组作为数据类型
- 支持限制查询复杂性以及配额
- 复制数据和对数据完整性的支持
ClickHouse和其他对比
商业OLAP
例如:
- HP Vertica
- Actian the Vector
区别:
- ClickHouse 是开源而且免费的
云解决方案
例如:
- 亚马逊 RedShift
- 谷歌 BigQuery
区别:
- ClickHouse 可以使用自己机器部署,无需云付费
Hadoop生态
例如:
- Cloudera Impala
- Spark SQL
- Facebook Presto
- Apache Drill
区别:
- ClickHouse 支持实时的高并发系统
- ClickHouse不依赖于Hadoop生态软件和基础
- ClickHouse支持分布式机房的部署
开源OLAP数据库
例如:
- InfiniDB
- MonetDB
- LucidDB
区别:
- 应用规模小
- 没有在大型互联网服务中蚕尝试
非关系型数据库
例如:
- Druid
- Apache Kylin
区别:
- ClickHouse 可以支持从原始数据直接查询,支持类SQL语言,提供了传统关系型数据的便利。
真正的面向列DBMS
如果你想要查询速度变快:
- 减少数据扫描范围
- 减少数据传输时的大小
在一个真正的面向列的DBMS中,没有任何无用的信息在值中存储。
例如:必须支持定长数值,以避免在数值旁边存储长度数字,10亿个Int8的值应该大约消耗1GB的未压缩磁盘空间,否则这将强烈影响CPU的使用。由于解压的速度(CPU的使用率)主要取决于未压缩的数据量,即使在未压缩的情况下,紧凑的存储数据也是非常重要的。
因为有些系统可以单独存储独列的值,但由于其他场景的优化,无法有效处理分析查询,例如HBase、BigTable、Cassandra和HypeTable。在这些系统中,每秒可以获得大约十万行的吞吐量,但是每秒不会到达数亿行。
另外,ClickHouse是一个DBMS,而不是一个单一的数据库,ClickHouse允许运行时创建表和数据库,加载数据和运行查询,而不用重新配置或启动系统。


之所以称作 DBMS,因为ClickHouse:
- DDL
- DML
- 权限管理
- 数据备份
- 分布式存储
- 等等功能
数据压缩
一些面向列的DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩,但是数据压缩可以提高性能。
磁盘存储
许多面向列的DBMS(SAP HANA和GooglePower Drill)只能在内存中工作,但即使在数千台服务器上,内存也太小,无法在Yandex.Metrica中存储所有浏览和会话。
多核并行
多核并行进行大型的查询。
在多个服务器上分布式处理
上面列出的DBMS几乎不支持分布式处理,在ClickHouse中,数据可以驻留不同的分片上,每个分片可以是用于容错的一组副本,查询在所有分片上并行处理,这对用户来说是透明的。
SQL支持
- 支持的查询包括 GR0UP BY、ORDER BY
- 子查询在FROM、IN、JOIN子句中被支持
- 标量子查询支持
- 关联子查询不支持
- 真是因为ClickHouse提供了标准协议的SQL查询接口,使得现有可视化分析系统能够轻松的与它集成对接
向量化引擎
数据不仅案列存储,而且由矢量-列的部分进行处理,这使我们能够实现高CPU性能。
向量化执行时寄存器硬件层面上的特性,可以理解为消除程序中循环的优化。
为了实现向量化执行,需要利用CPU的SIMD指令(Single Instrution Multiple Data),即用单条指令处理多条数据。现代计算机系统概念中,它是利用数据并行度来提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据并行的实现原理。
实时数据更新
ClickHouse支持主键表,为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序,由于这个原因,数据可以不断的添加到表中,添加数据时无锁处理。
索引
例如,带有主键可以在特定的时间范围内为特定的客户端(Metrica计数器)抽取数据,并且延迟事件小于几十毫秒。
支持在线查询
我们可以使用该系统作为Web界面的后端,低延迟意味着可以无延迟的实时的处理查询。
支持近似计算
- 系统包含用于近似计算各种值,中位数和分位数的集合函数
- 支持基于部分(样本)数据运行查询并获得近似结果,在这种情况下,从磁盘检索比例较少的数据。
- 支持为有限数量的随机秘钥(而不是所有秘钥)运行聚合,在数据中秘钥分发的特定场景下,这提供了相对准确的结果,同时使用较少的资源。
数据复制和对数据完整性支持
使用异步多主复制,写入任何可用的副本后,数据将分发到所有剩余的副本,系统在不同的副本上保持相同的数据。
要注意的是,ClickHouse并不完美:
- 不支持事务
- 虽然已支持条件 Delete/Update(mutations),只是非事务型、异步、重写分片数据开销大;生产要谨慎,用 TTL/分区替代更常见。
- 支持有限的操作系统
最后总结
在大数据分析领域中,传统的大数据分析需要不同框架和技术组合才能达到最终效果,在人力成本、技术能力、硬件成本、维护成本上,让大数据分析变成了很昂贵的事情,很多中小企业非常痛苦,不得不被迫租赁第三方大型数据分析服务。
ClickHouse开源的出现让许多想做大数据且想做大数据分析的很多公司和企业都耳目一新。ClickHouse正是以不依赖Hadoop生态、安装维护简单、查询快速、支持SQL等特点,在大数据领域越走越远。
来源:juejin.cn/post/7563935896706957363
Maven高级
一. 分模块设计与开发
分模块设计的核心是 “高内聚,低耦合”。
- 高内聚:一个模块只负责一个独立的、明确的职责(如:订单模块只处理所有订单相关业务)。模块内部的代码关联性非常强。
- 低耦合:模块与模块之间的依赖关系尽可能的简单和清晰。一个模块的变化,应该尽量减少对其他模块的影响。
通过Maven,我们可以轻松地实现这一思想。每个模块都是一个独立的Maven项目,它们通过父子工程和依赖管理有机地组织在一起。
以一个经典的电商平台为例,我们可以将其拆分为以下模块:

将pojo和utils模块分出去

)
在tilas-web-management中的pom.xml中引入pojo,utils模块
<dependency>
<groupId>org.example</groupId>
<artifactId>tlias-pojo</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.example</groupId>
<artifactId>tlias-utils</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
分模块的好处
- 代码清晰,职责分明:每个开发人员可以专注于自己的模块,易于理解和维护。
- 并行开发,提升效率:多个模块可以由不同团队并行开发,只需约定好接口即可。
- 构建加速:Maven支持仅构建更改的模块及其依赖模块(使用 mvn -pl 命令),大大节省构建时间。
- 极高的复用性:像 core、dao 这样的模块,可以直接被其他新项目引用,避免重复造轮子。
- 便于单元测试:可以针对单个业务模块进行独立的、深入的测试。
二. 继承
2.1 继承配置
tlias-pojo、tlias-utils、tlias-web-management 中都引入了一个依赖 lombok 的依赖。我们在三个模块中分别配置了一次。

我们可以再创建一个父工程 tlias-parent ,然后让上述的三个模块 tlias-pojo、tlias-utils、tlias-web-management 都来继承这个父工程 。 然后再将各个模块中都共有的依赖,都提取到父工程 tlias-parent中进行配置,只要子工程继承了父工程,依赖它也会继承下来,这样就无需在各个子工程中进行配置了。

将tilas-parent中的pom.xml设置成pom打包方式
Maven打包方式:
- jar:普通模块打包,springboot项目基本都是jar包(内嵌tomcat运行)
- war:普通web程序打包,需要部署在外部的tomcat服务器中运行
- pom:父工程或聚合工程,该模块不写代码,仅进行依赖管理
<packaging>pom</packaging>
通过parent来配置父工程
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.8</version>
<!-- 父工程的pom.xml的相对路径 如果不配置就直接从中央仓库调取 -->
<relativePath/> <!-- lookup parent from repository -->
</parent>
子工程配置 通过relativePath配置父工程的路径
<parent>
<groupId>org.example</groupId>
<artifactId>tlias-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../tilas-parent/pom.xml</relativePath>
</parent>
2.2 版本锁定
如果项目拆分的模块比较多,每一次更换版本,我们都得找到这个项目中的每一个模块,一个一个的更改。 很容易就会出现,遗漏掉一个模块,忘记更换版本的情况。
在maven中,可以在父工程的pom文件中通过 来统一管理依赖版本。
<!--统一管理依赖版本-->
<dependencyManagement>
<dependencies>
<!--JWT令牌-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
······
</dependencies>
</dependencyManagement>
这样在子工程中就不需要进行version版本设置了
<dependencies>
<!--JWT令牌-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
</dependency>
</dependencies>
注意!!!
- 在父工程中所配置的 dependencyManagement只能统一管理依赖版本,并不会将这个依赖直接引入进来。 这点和 dependencies 是不同的。
- 子工程要使用这个依赖,还是需要引入的,只是此时就无需指定 版本号了,父工程统一管理。变更依赖版本,只需在父工程中统一变更。
2.3 自定义属性
<properties>
<lombok.version>1.18.34</lombok.version>
</properties>
通过${属性名}引用属性
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
三. 聚合
聚合(Aggregation) 和继承(Inheritance) 是Maven支持分模块设计的两个核心特性,它们目的不同,但又相辅相成。
简单来说,继承是为了统一管理,而聚合是为了统一构建。

在聚合工程中通过modules>module来配置聚合
<!-- 聚合其他模块 -->
<modules>
<module>你要聚合的模块路径</module>
</modules>
四. 私服
私服是一种特殊的远程仓库,它代理并缓存了位于互联网的公共仓库(如MavenCentral),同时允许企业内部部署自己的私有构件(Jar包)。
你可以把它理解为一个 “架设在公司内网里的Maven中央仓库”。

项目版本说明:
- RELEASE(发布版本):功能趋于稳定、当前更新停止,可以用于发行的版本,存储在私服中的RELEASE仓库中。
- SNAPSHOT(快照版本):功能不稳定、尚处于开发中的版本,即快照版本,存储在私服的SNAPSHOT仓库中。
4.1 私服下载
下载Nexus私服 help.sonatype.com/en/download…

在D:\XXXXXXXX\bin目录下 cmd运行nexus /run nexus 显示这个就表示开启成功啦!

浏览器输入localhost:8081

私服仓库说明:
- RELEASE:存储自己开发的RELEASE发布版本的资源。
- SNAPSHOT:存储自己开发的SNAPSHOT发布版本的资源。
- Central:存储的是从中央仓库下载下来的依赖
4.2 资源上传与下载
设置私服的访问用户名/密码(在自己maven安装目录下的conf/settings.xml中的servers中配置)
<server>
<id>maven-releases</id>
<username>admin</username>
<password>admin</password>
</server>
<server>
<id>maven-snapshots</id>
<username>admin</username>
<password>admin</password>
</server>
设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的mirrors中配置)
<mirror>
<id>maven-public</id>
<mirrorOf>*</mirrorOf>
<url>http://localhost:8081/repository/maven-public/</url>
</mirror>
设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的profiles中配置)
<profile>
<id>allow-snapshots</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>maven-public</id>
<url>http://localhost:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
IDEA的maven工程的pom文件中配置上传(发布)地址(直接在tlias-parent中配置发布地址)
<distributionManagement>
<!-- release版本的发布地址 -->
<repository>
<id>maven-releases</id>
<url>http://localhost:8081/repository/maven-releases/</url>
</repository>
<!-- snapshot版本的发布地址 -->
<snapshotRepository>
<id>maven-snapshots</id>
<url>http://localhost:8081/repository/maven-snapshots/</url>
</snapshotRepository>
</distributionManagement>
打开maven控制面板双击deploy

由于当前我们的项目是SNAPSHOT版本,所以jar包是上传到了snapshot仓库中
来源:juejin.cn/post/7549363056862756918
别再被VO、BO、PO、DTO、DO绕晕!今天用一段代码把它们讲透
大家好,我是晓凡。
前阵子晓凡的粉丝朋友面试,被问到“什么是VO?和DTO有啥区别?”
粉丝朋友:“VO就是Value Object,DTO就是Data Transfer Object……”
面试官点点头:“那你说说,一个下单接口里,到底哪个算VO,哪个算DTO?”
粉丝朋友有点犹豫了。
回来后粉丝朋友痛定思痛,把项目翻了个底朝天,并且把面试情况告诉了晓凡,下定决心捋清楚了这堆 XO 的真实含义。
于是乎,这篇文章就来了 今天咱们就用一段“用户下单买奶茶”的故事,把 VO、BO、PO、DTO、DO 全部聊明白。
看完保准你下次面试不卡壳,写代码不纠结。
一、先放结论
它们都是“为了隔离变化”而诞生的马甲
| 缩写 | 英文全称 | 中文直译 | 出现位置 | 核心目的 |
|---|---|---|---|---|
| PO | Persistent Object | 持久化对象 | 数据库 ↔ 代码 | 一张表一行记录的直接映射 |
| DO | Domain Object | 领域对象 | 核心业务逻辑层 | 充血模型,封装业务行为 |
| BO | Business Object | 业务对象 | 应用/服务层 | 聚合多个DO,面向用例编排 |
| DTO | Data Transfer Object | 数据传输对象 | 进程/服务间 | 精简字段,抗网络延迟 |
| VO | View Object | 视图对象 | 控制层 ↔ 前端 | 展示友好,防敏感字段泄露 |
一句话总结: PO 管存储,DO 管业务,BO 管编排,DTO 管网络,VO 管界面。
下面上代码,咱们边喝奶茶边讲。
二、业务场景
用户下一单“芋泥波波奶茶”
需求:
- 用户选好规格(大杯、少冰、五分糖)。
- 点击“提交订单”,前端把数据发过来。
- 后端算价格、扣库存、落库,返回“订单创建成功”页面。
整条链路里,我们到底需要几个对象?
三、从数据库开始:PO
PO是
Persistent Object的简写 PO 就是“一行数据一个对象”,字段名、类型和数据库保持一一对应,不改表就不改它。
// 表:t_order
@Data
@TableName("t_order")
public class OrderPO {
private Long id; // 主键
private Long userId; // 用户ID
private Long productId; // 商品ID
private String sku; // 规格JSON
private BigDecimal price; // 原价
private BigDecimal payAmount; // 实付
private Integer status; // 订单状态
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
注意:PO 里绝不能出现业务方法,它只是一个“数据库搬运工”。
四、核心业务:DO
DO 是“有血有肉的对象”,它把业务规则写成方法,让代码自己说话。
// 领域对象:订单
public class OrderDO {
private Long id;
private UserDO user; // 聚合根
private MilkTeaDO milkTea; // 商品
private SpecDO spec; // 规格
private Money price; // Money是值对象,防精度丢失
private OrderStatus status;
// 业务方法:计算最终价格
public Money calcFinalPrice() {
// 会员折扣
Money discount = user.getVipDiscount();
// 商品促销
Money promotion = milkTea.getPromotion(spec);
return price.minus(discount).minus(promotion);
}
// 业务方法:下单前置校验
public void checkBeforeCreate() {
if (!milkTea.hasStock(spec)) {
throw new BizException("库存不足");
}
}
}
DO 可以引用别的 DO,形成聚合根。它不关心数据库,也不关心网络。
五、面向用例:BO
BO 是“场景大管家”,把多个 DO 攒成一个用例,常出现在 Service 层。
@Service
public class OrderBO {
@Resource
private OrderRepository orderRepository; // 操作PO
@Resource
private InventoryService inventoryService; // RPC或本地
@Resource
private PaymentService paymentService;
// 用例:下单
@Transactional
public OrderDTO createOrder(CreateOrderDTO cmd) {
// 1. 构建DO
OrderDO order = OrderAssembler.toDO(cmd);
// 2. 执行业务校验
order.checkBeforeCreate();
// 3. 聚合逻辑:扣库存、算价格
inventoryService.lock(order.getSpec());
Money payAmount = order.calcFinalPrice();
// 4. 落库
OrderPO po = OrderAssembler.toPO(order, payAmount);
orderRepository.save(po);
// 5. 返回给前端需要的数据
return OrderAssembler.toDTO(po);
}
}
BO 的核心是编排,它把 DO、外部服务、PO 串成一个完整的业务动作。
六、跨进程/服务:DTO
DTO 是“网络快递员”,字段被压缩成最少,只带对方需要的数据。
1)入口 DTO:前端 → 后端
@Data
public class CreateOrderDTO {
@NotNull
private Long userId;
@NotNull
private Long productId;
@Valid
private SpecDTO spec; // 规格
}
2)出口 DTO:后端 → 前端
@Data
public class OrderDTO {
private Long orderId;
private String productName;
private BigDecimal payAmount;
private String statusDesc;
private LocalDateTime createTime;
}
DTO 的字段命名常带 UI 友好词汇(如 statusDesc),并且绝不暴露敏感字段(如 userId 在返回给前端时可直接省略)。
七、最后一步:VO
VO 是“前端专属快递”,字段可能二次加工,甚至带 HTML 片段。
@Data
public class OrderVO {
private String orderId; // 用字符串避免 JS long 精度丢失
private String productImage; // 带 CDN 前缀
private String priceText; // 已格式化为“¥18.00”
private String statusTag; // 带颜色:green/red
}
VO 通常由前端同学自己写 TypeScript/Java 类,后端只负责给 DTO,再让前端 BFF 层转 VO。如果你用 Node 中间层或 Serverless,VO 就出现在那儿。
八、一张图记住流转过程
前端页面
│ JSON
▼
CreateOrderVO (前端 TS)
│ 序列化
▼
CreateOrderDTO (后端入口)
│ BO.createOrder()
▼
OrderDO (充血领域模型)
│ 聚合、计算
▼
OrderPO (落库)
│ MyBatis
▼
数据库
返回时反向走一遍:
数据库
│ SELECT
OrderPO
│ 转换
OrderDTO
│ JSON
OrderVO (前端 TS 渲染)
九、常见疑问答疑
- 为什么 DO 和 PO 不合并? 数据库加索引、加字段不影响业务;业务改规则不改表结构。隔离变化。
- DTO 和 VO 能合并吗? 小项目可以,但一上微服务或多端(App、小程序、管理后台),立马爆炸。比如后台需要用户手机号,App 不需要,合并后前端会拿到不该看的数据。
- BO 和 Service 有什么区别? BO 更贴近用例,粒度更粗。Service 可能细分读写、缓存等。命名随意,关键看团队约定。
十、一句话背下来
数据库里叫 PO,业务里是 DO,编排靠 BO,网络走 DTO,前端看 VO。
下次面试官再问,你就把奶茶故事讲给他听,保证他频频点头。
本期内容到这儿就结束了
我是晓凡,再小的帆也能远航
我们下期再见 ヾ(•ω•`)o (●'◡'●)
来源:juejin.cn/post/7540472612595941422
后端仔狂喜!手把手教你用 Java 拿捏华为云 IoTDA,设备上报数据 so easy
作为天天跟接口、数据库打交道的后端博主,我之前总觉得 IoT 是 “硬件大佬的专属领域”—— 直到我踩坑华为云 IoTDA(物联网设备接入服务)后发现:这玩意儿明明就是 “后端友好型选手”!今天带大家从 0 到 1 玩转 IoTDA,从创建产品到 Java 集成,全程无废话,连小白都能看懂~
一、先唠唠:IoTDA 到底是个啥?
设备接入服务(IoTDA)是华为云的物联网平台,提供海量设备连接上云、设备和云端双向消息通信、批量设备管理、远程控制和监控、OTA升级、设备联动规则等能力,并可将设备数据灵活流转到华为云其他服务。
你可以把 IoTDA 理解成 “IoT 设备的专属管家”:
- 设备想连互联网?管家帮它搭好通道(MQTT/CoAP 等协议);
- 设备要上报数据(比如温湿度、电量)?管家负责接收、存着还能帮你分析;
- 你想给设备发指令(比如让灯关掉)?管家帮你把指令精准送到设备手里。
简单说:有了 IoTDA,后端不用管硬件怎么联网,专心写代码处理 “设备数据” 就行 —— 这不就是咱们的舒适区嘛!
相关的一些概念:
- 服务和物模型:
- 物模型:设备本身拥有的属性(功能数据),像电量,电池温度等等
- 服务:理解为不同物模型的分类(分组),比如电池服务(包含了电量、电池温度等等物模型), 定位服务(经纬度坐标,海拔高度物模型)
- 设备:真实看得见、摸得着的设备实物,设备的信息需要录入到华为云IoTDA平台里
二、实操第一步:给你的设备 “办张身-份-证”(创建产品)
产品:某一类具有相同能力或特征的设备的集合称为一款产品。帮助开发者快速进行产品模型和插件的开发,同时提供端侧集成、在线调试、自定义Topic等多种能力。比如,手表、大门通道门禁、紧急呼叫报警器、滞留报警器、跌倒报警器
就像人要办身-份-证才能出门,IoT 设备也得先在 IoTDA 上 “建档”(创建产品),步骤简单到离谱:
- 登录华为云控制台,搜 “IoTDA” 进入服务页面(记得先开服务,新用户有免费额度!);
- 左侧菜单点【产品】→【创建产品】,填这几个关键信息:

- 产品名称:比如 “我的温湿度传感器”(别起 “test123”,后续找起来头疼);

- 协议类型:选 “MQTT”(后端最常用,设备端也好对接);
- 数据格式:默认 “JSON”(咱们后端处理 JSON 不是手到擒来?);
- 点【确定】,搞定!此时你会拿到一个 “产品 ID”—— 记好它,后续要当 “钥匙” 用。

小吐槽:第一次创建时我把协议选错成 “CoAP”,结果设备端连不上,排查半小时才发现… 大家别学我!
三、设备接入:让传感器 “开口说话”(数据上报)
产品创建好后,得让具体的设备(比如你手里的温湿度传感器)连上来,核心就两步:注册设备→上报数据。 官方案例-设备接入:基于NB-IoT小熊派的智慧烟感
3.1 给单个设备 “上户口”(注册设备)
- 进入刚创建的产品详情页,点【设备】→【注册设备】;
- 填 “设备名称”(比如 “传感器 001”),其他默认就行;

- 注册成功后,会拿到两个关键信息:设备 ID和设备密钥(相当于设备的 “账号密码”,千万别泄露!)。
3.2 数据上报:让设备把数据 “发快递” 过来
前提条件:需要提前创建好产品和对应的物模型,以及该产品的设备
准备实例的接入地址
后续设备上报数据时,需要准备好接入地址。去哪里找接入地址呢?参考下图:

设备要上报数据,本质就是通过 MQTT 协议给 IoTDA 发一条 JSON 格式的消息,举个实际例子:
假设温湿度传感器要上报 “温度 25℃、湿度 60%”,数据格式长这样:
{
"Temperature": 25.0, // 温度
"Humidity": 60.0 // 湿度
}
设备端怎么发?不用你写 C 代码!华为云给了现成的 “设备模拟器”:
在设备详情页点【在线调试】→ 选 “属性上报”→ 把上面的 JSON 粘进去→ 点【发送】,刷新页面就能看到数据已经躺在 IoTDA 里了 —— 是不是比调接口还简单?
四、后端重头戏:Java 项目集成 IoTDA
前面都是控制台操作,后端真正要做的是 “用代码跟 IoTDA 交互”。华为云提供了 Java SDK,咱们不用重复造轮子,直接撸起袖子干!
4.1 先搞懂:关键参数从哪来?
集成前必须拿到这 3 个 “钥匙”,少一个都不行:
- Access Key/Secret Key:华为云账号的 “API 密钥”,在【控制台→我的凭证→访问密钥】里创建;
- 区域 ID:比如 “cn-north-4”(北京四区),IoTDA 控制台首页就能看到;
- 产品 ID / 设备 ID:前面创建产品、注册设备时拿到的(忘了就去控制台查!)。
友情提示:别把 Access Key 硬编码到代码里!用配置文件或者 Nacos 存,不然上线后哭都来不及~
4.2 项目集成:Maven 依赖先安排上
在 pom.xml 里加 IoTDA SDK 的依赖(版本选最新的就行):
<dependency>
<groupId>com.huaweicloud.sdkgroupId>
<artifactId>huaweicloud-sdk-iotdaartifactId>
<version>3.1.47version>
dependency>
<dependency>
<groupId>com.huaweicloud.sdkgroupId>
<artifactId>huaweicloud-sdk-coreartifactId>
<version>3.1.47version>
dependency>
4.3 核心功能实现:代码手把手教你写
先初始化 IoTDA 客户端(相当于建立连接),写个工具类:
import com.huaweicloud.sdk.core.auth.BasicCredentials;
import com.huaweicloud.sdk.iotda.v5.IoTDAClient;
import com.huaweicloud.sdk.iotda.v5.region.IoTDARegion;
public class IoTDAClientUtil {
// 从配置文件读参数,这里先写死方便演示
private static final String ACCESS_KEY = "你的Access Key";
private static final String SECRET_KEY = "你的Secret Key";
private static final String REGION_ID = "cn-north-4"; // 你的区域ID
public static IoTDAClient getClient() {
// 1. 配置凭证
BasicCredentials credentials = new BasicCredentials()
.withAk(ACCESS_KEY)
.withSk(SECRET_KEY);
// 2. 初始化客户端
return IoTDAClient.newBuilder()
.withCredentials(credentials)
.withRegion(IoTDARegion.valueOf(REGION_ID))
.build();
}
}
接下来实现咱们需要的 5 个核心功能,每个功能都带注释,一看就懂:
功能 1:从 IoT 平台同步产品列表
import com.huaweicloud.sdk.iotda.v5.model.ListProductsRequest;
import com.huaweicloud.sdk.iotda.v5.model.ListProductsResponse;
public class IoTDAService {
private final IoTDAClient client = IoTDAClientUtil.getClient();
// 同步产品列表(支持分页,这里查第一页,每页10条)
public void syncProductList() {
ListProductsRequest request = new ListProductsRequest()
.withLimit(10) // 每页条数
.withOffset(0); // 页码,从0开始
try {
ListProductsResponse response = client.listProducts(request);
System.out.println("同步到的产品列表:" + response.getProducts());
} catch (Exception e) {
System.err.println("同步产品列表失败:" + e.getMessage());
}
}
}
项目参考思路

功能 2:查询所有产品列表(分页查询封装)
// 查所有产品(自动分页,直到查完所有)
public void queryAllProducts() {
int offset = 0;
int limit = 20;
while (true) {
ListProductsRequest request = new ListProductsRequest()
.withLimit(limit)
.withOffset(offset);
ListProductsResponse response = client.listProducts(request);
if (response.getProducts().isEmpty()) {
break; // 没有更多产品了,退出循环
}
System.out.println("当前页产品:" + response.getProducts());
offset += limit; // 下一页
}
}
功能 3:注册设备(代码注册,不用手动在控制台点了)
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceRequest;
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceResponse;
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceRequestBody;
public void registerDevice(String productId, String deviceName) {
// 构造注册请求体
RegisterDeviceRequestBody body = new RegisterDeviceRequestBody()
.withDeviceName(deviceName);
RegisterDeviceRequest request = new RegisterDeviceRequest()
.withProductId(productId) // 关联的产品ID
.withBody(body);
try {
RegisterDeviceResponse response = client.registerDevice(request);
System.out.println("设备注册成功!设备ID:" + response.getDeviceId()
+ ",设备密钥:" + response.getDeviceSecret());
} catch (Exception e) {
System.err.println("设备注册失败:" + e.getMessage());
}
}
功能 4:查询设备详细信息(比如设备在线状态、最后上报时间)
import com.huaweicloud.sdk.iotda.v5.model.ShowDeviceRequest;
import com.huaweicloud.sdk.iotda.v5.model.ShowDeviceResponse;
public void queryDeviceDetail(String deviceId) {
ShowDeviceRequest request = new ShowDeviceRequest()
.withDeviceId(deviceId); // 要查询的设备ID
try {
ShowDeviceResponse response = client.showDevice(request);
System.out.println("设备在线状态:" + response.getStatus()); // ONLINE/OFFLINE
System.out.println("最后上报时间:" + response.getLastOnlineTime());
System.out.println("设备详细信息:" + response);
} catch (Exception e) {
System.err.println("查询设备详情失败:" + e.getMessage());
}
}
功能 5:查看设备上报的数据(关键!终于能拿到传感器数据了)
import com.huaweicloud.sdk.iotda.v5.model.ListDevicePropertiesRequest;
import com.huaweicloud.sdk.iotda.v5.model.ListDevicePropertiesResponse;
public void queryReportedData(String deviceId) {
// 查询设备最近上报的10条属性数据
ListDevicePropertiesRequest request = new ListDevicePropertiesRequest()
.withDeviceId(deviceId)
.withLimit(10)
.withAsc(false); // 倒序,最新的先看
try {
ListDevicePropertiesResponse response = client.listDeviceProperties(request);
response.getProperties().forEach(property -> {
System.out.println("数据上报时间:" + property.getReportTime());
System.out.println("上报的属性值:" + property.getPropertyValues());
// 比如取温度:property.getPropertyValues().get("Temperature")
});
} catch (Exception e) {
System.err.println("查询设备上报数据失败:" + e.getMessage());
}
}
五、踩坑总结:这些坑我替你们踩过了!
- 区域 ID 搞错:比如用 “cn-east-2”(上海二区)的客户端去连 “cn-north-4” 的 IoTDA,直接报 “连接超时”;
- 设备密钥泄露:一旦泄露,别人能伪装你的设备上报假数据,一定要存在安全的地方;
- SDK 版本太旧:有些老版本不支持 “查询设备历史数据” 接口,记得用最新版 SDK;
- 免费额度用完:新用户免费额度够测 1 个月,别上来就挂生产设备,先测通再说~
最后说两句
其实 IoTDA 对后端来说真的不难,核心就是 “调用 API 跟平台交互”,跟咱们平时调支付接口、短信接口没啥区别。今天的代码大家可以直接 copy 到项目里,改改参数就能跑通~
你们在集成 IoTDA 时遇到过啥坑?或者有其他 IoT 相关的需求(比如设备指令下发)?评论区聊聊,下次咱们接着唠!
(觉得有用的话,别忘了点赞 + 收藏,后端学 IoT 不迷路~)
来源:juejin.cn/post/7541667597285277731
Code Review 最佳实践 2:业务实战中的审核细节
🧠 本节谈
我们聚焦真实业务模块中的 Code Review,涵盖:
- 🔐 表单校验逻辑
- 🧩 动态权限控制
- 🧱 页面逻辑复杂度管理
- ⚠️ 接口调用规范
- ♻️ 组件解耦重构
- 🧪 单元测试提示
每一条都配备真实反面代码 + 改进建议 + 原因说明,并总结通用审核 checklist。
📍 场景 1:复杂表单校验逻辑
❌ 错误示例:耦合 + 不可维护
const onSubmit = () => {
if (!form.name || form.name.length < 3 || !form.age || isNaN(form.age)) {
message.error('请填写正确信息')
return
}
// ...
}
问题:
- 所有校验写死在事件里,不可复用
- 无法做提示区分
✅ 改进方式:抽离校验 + 可扩展
const validateForm = (form: UserForm) => {
if (!form.name) return '姓名不能为空'
if (form.name.length < 3) return '姓名过短'
if (!form.age || isNaN(Number(form.age))) return '年龄格式错误'
return ''
}
const onSubmit = () => {
const msg = validateForm(form)
if (msg) return message.error(msg)
// ...
}
👉 Review 要点:
- 校验逻辑是否可复用?
- 是否便于单测?
- 提示是否明确?
📍 场景 2:权限控制逻辑写死
❌ 反例
<Button v-if="user.role === 'admin'">删除</Button>
问题:
- 无法集中管理
- 用户身份切换时易出错
- 无法与服务端权限匹配
✅ 推荐:
const hasPermission = (perm: string) => user.permissions.includes(perm)
<Button v-if="hasPermission('can_delete')">删除</Button>
👉 Review 要点:
- 权限是否统一处理?
- 是否可扩展到路由、接口层?
- 是否易于调试?
📍 场景 3:复杂页面组件未解耦
❌ 嵌套组件塞一堆逻辑
// 页面结构
<Table data={data}>
{data.map(row => (
<tr>
<td>{row.name}</td>
<td>
<Button onClick={() => doSomething(row.id)}>操作</Button>
</td>
</tr>
))}
</Table>
- 所有数据/逻辑/视图耦合一起
- 无法复用
- 改动难以测试
✅ 推荐:
<TableRow :row="row" @action="handleRowAction" />
// TableRow.vue
<template>
<tr>
<td>{{ row.name }}</td>
<td><Button @click="emit('action', row.id)">操作</Button></td>
</tr>
</template>
👉 Review 要点:
- 是否具备清晰的“数据流 → 逻辑流 → 视图层”结构?
- 是否把组件职责划分清楚?
- 是否拆分足够颗粒度便于测试?
📍 场景 4:接口调用未封装
❌ 直接 axios 写在组件中:
axios.get('/api/list?id=' + id).then(res => {
this.list = res.data
})
问题:
- 接口不可复用
- 无法集中处理错误
- 改动接口时无法追踪引用
✅ 推荐:
// services/user.ts
export const getUserList = (id: number) =>
request.get('/api/list', { params: { id } })
// 页面中
getUserList(id).then(res => (this.list = res.data))
👉 Review 要点:
- 是否将接口层抽离为服务?
- 是否统一请求拦截、错误处理?
- 是否易于 Mock 和调试?
📍 场景 5:测试个锤子🔨
❌ 错误写法:组件中逻辑混杂难以测试
if (user.age > 18 && user.vipLevel > 3 && user.region === 'CN') {
return true
}
问题:
- 没有语义抽象
- 不可测试
✅ 改进写法:
const isPremiumUser = (user: User) =>
user.age > 18 && user.vipLevel > 3 && user.region === 'CN'
👉 Review 要点:
- 是否具备良好的可测试性?
- 是否便于 Jest/Vitest 测试用例编写?
✅ 最佳实践总结
Review 高级 Checklist
| 检查点 | 检查说明 |
|---|---|
| ✅ 表单逻辑 | 是否抽离,是否健壮 |
| ✅ 权限处理 | 是否统一管理,可扩展 |
| ✅ 页面复杂度 | 是否组件解耦,职责清晰 |
| ✅ 接口调用 | 是否封装为服务层,便于复用 |
| ✅ 可测试性 | 关键逻辑是否抽象、是否测试友好 |
🎯 尾声:从 Code Review 走向“架构推动者”
掌握 Code Review 不止是“找错”,而是:
- 帮助他人提升思维方式
- 用标准统一团队技术认知
- 用习惯推动系统演进
来源:juejin.cn/post/7530437804129239080
负载均衡 LVS vs Nginx 对比!还傻傻分不清?
- Nginx特点
- 正向代理与反向代理
- 负载均衡
- 动静分离
- Nginx的优势
- 可操作性大
- 网络依赖小
- 安装简单
- 支持健康检查以及请求重发
- LVS 的优势
- 抗负载能力强
- 配置性低
- 工作稳定
- 无流量
今天总结一下负载均衡中LVS与Nginx的区别,好几篇博文一开始就说LVS是单向的,Nginx是双向的,我个人认为这是不准确的,LVS三种模式中,虽然DR模式以及TUN模式只有请求的报文经过Director,但是NAT模式,Real Server回复的报文也会经过Director Server地址重写:
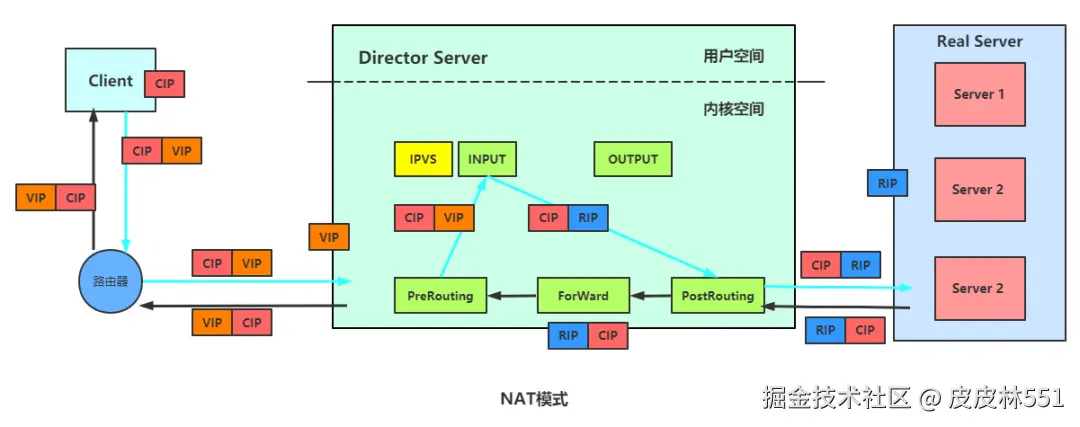
图片
首先要清楚的一点是,LVS是一个四层的负载均衡器,虽然是四层,但并没有TCP握手以及分手,只是偷窥了IP等信息,而Nginx是一个七层的负载均衡器,所以效率势必比四层的LVS低很多,但是可操作性比LVS高,后面所有的讨论都是基于这个区别。
为什么四册比七层效率高?
四层是TCP层,使用IP+端口四元组的方式。只是修改下IP地址,然后转发给后端服务器,TCP三次握手是直接和后端连接的。只不过在后端机器上看到的都是与代理机的IP的established而已,LVS中没有握手。
7层代理则必须要先和代理机三次握手后,才能得到7层(HTT层)的具体内容,然后再转发。意思就是代理机必须要与client和后端的机器都要建立连接。显然性能不行,但胜在于七层,人工可操作性高,能写更多的转发规则。
Nginx特点
Nginx 专为性能优化而开发,性能是其最重要的要求,十分注重效率,有报告 Nginx 能支持高达 50000 个并发连接数。
另外,Nginx 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
正向代理与反向代理
正向代理 :局域网中的电脑用户想要直接访问服务器是不可行的,服务器可能Hold不住,只能通过代理服务器来访问,这种代理服务就被称为正向代理,特点是客户端知道自己访问的是代理服务器。

图片
反向代理 :客户端无法感知代理,因为客户端访问网络不需要配置,只要把请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据,然后再返回到客户端。
此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器 IP 地址。
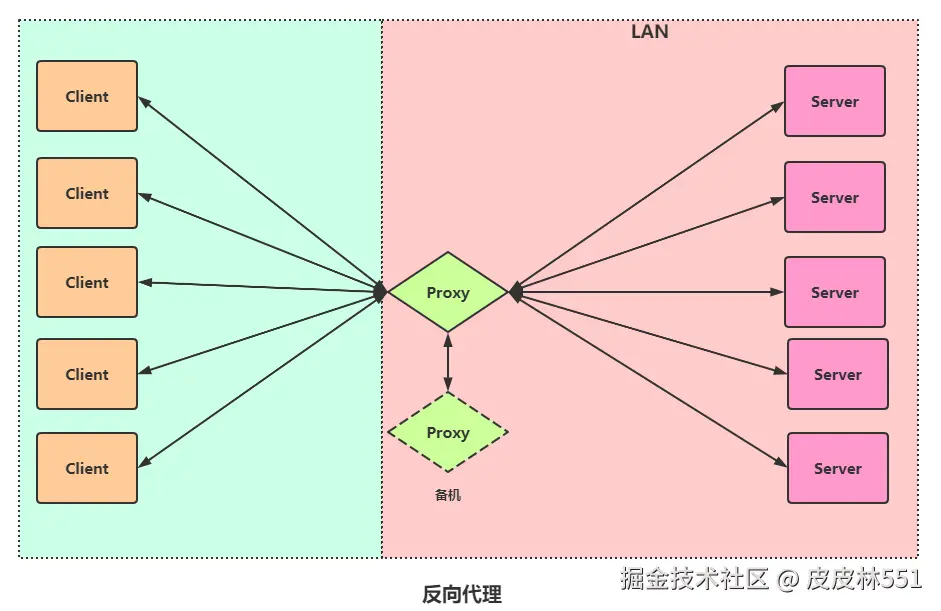
图片
负载均衡
客户端发送多个请求到服务器,服务器处理请求,有一些可能要与数据库进行交互,服务器处理完毕之后,再将结果返回给客户端。
普通请求和响应过程如下图:
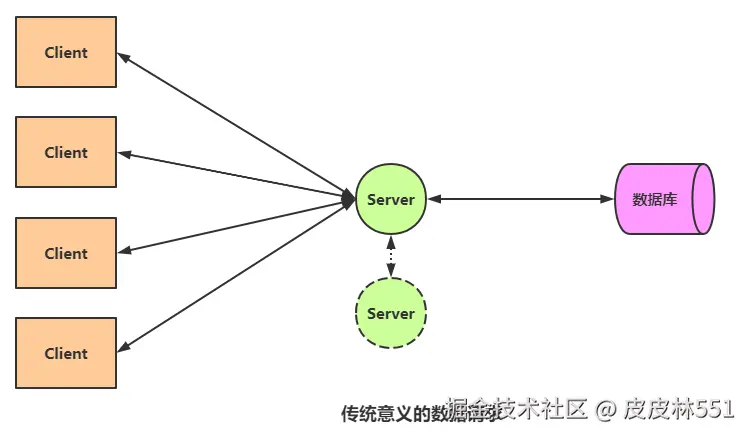
图片
但是随着信息数量增长,访问量和数据量增长,单台的Server以及Database就成了系统的瓶颈,这种架构无法满足日益增长的需求,这时候要么提升单机的性能,要么增加服务器的数量。
关于提升性能,这儿就不赘述,提提如何增加服务器的数量,构建集群,将请求分发到各个服务器上,将原来请求集中到单个服务器的情况改为请求分发到多个服务器,也就是我们说的负载均衡。
图解负载均衡:
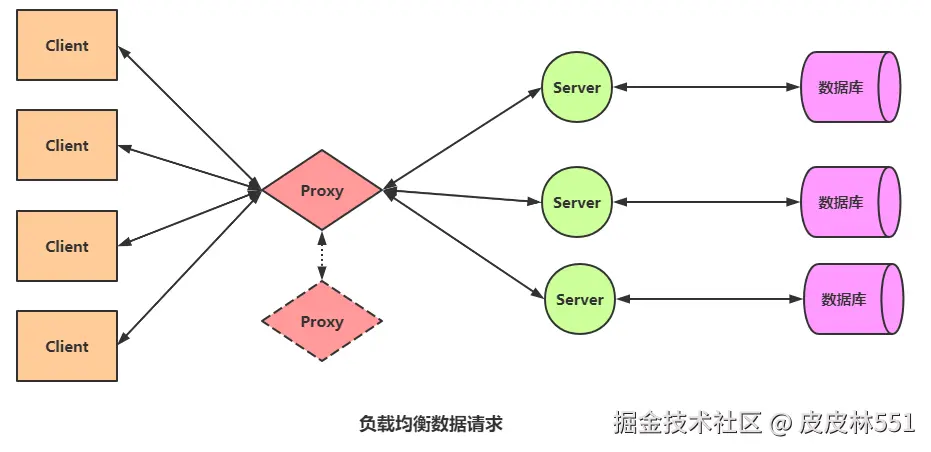
图片
关于服务器如何拆分组建集群,这儿主要讲讲负载均衡,也就是图上的Proxy,可以是LVS,也可以是Nginx。假设有 15 个请求发送到代理服务器,那么由代理服务器根据服务器数量,这儿假如是平均分配,那么每个服务器处理 5 个请求,这个过程就叫做负载均衡。
动静分离
为了加快网站的解析速度,可以把动态页面和静态页面交给不同的服务器来解析,加快解析的速度,降低由单个服务器的压力。
动静分离之前的状态
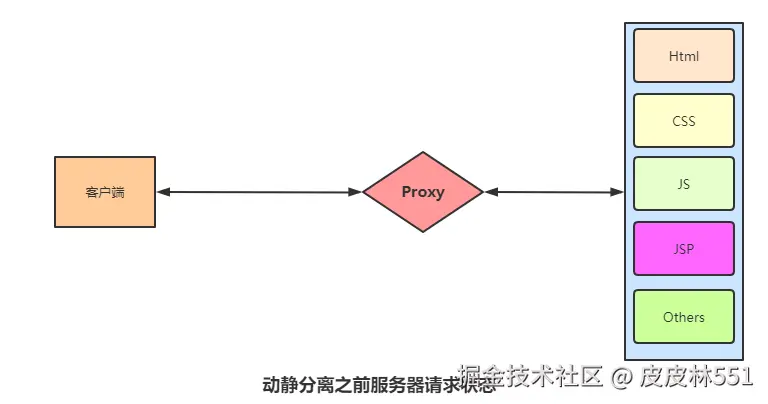
图片
动静分离之后

图片
光看两张图可能有人不理解这样做的意义是什么,我们在进行数据请求时,以淘宝购物为例,商品详情页有很多东西是动态的,随着登录人员的不同而改变,例如用户ID,用户头像,但是有些内容是静态的,例如商品详情页,那么我们可以通过CDN(全局负载均衡与CDN内容分发)将静态资源部署在用户较近的服务器中,用户数据信息安全性要更高,可以放在某处集中,这样相对于将说有数据放在一起,能分担主服务器的压力,也能加速商品详情页等内容传输速度。
Nginx的优势
可操作性大
Nginx是一个应用层的程序,所以用户可操作性的空间大得多,可以作为网页静态服务器,支持 Rewrite 重写规则;支持 GZIP 压缩,节省带宽;可以做缓存;可以针对 http 应用本身来做分流策略,静态分离,针对域名、目录结构等相比之下 LVS 并不具备这样的功能,所以 nginx 单凭这点可以利用的场合就远多于 LVS 了;但 nginx 有用的这些功能使其可调整度要高于 LVS,所以经常要去触碰,人为出现问题的几率也就大
网络依赖小
nginx 对网络的依赖较小,理论上只要 ping 得通,网页访问正常,nginx 就能连得通,nginx 同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;LVS 就比较依赖于网络环境,目前来看服务器在同一网段内并且 LVS 使用 direct 方式分流,效果较能得到保证。另外注意,LVS 需要向托管商至少申请多于一个 ip 来做 visual ip
安装简单
nginx 安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。LVS 的安装和配置、测试就要花比较长的时间,因为同上所述,LVS 对网络依赖性比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦的多
nginx 也同样能承受很高负载且稳定,但负载度和稳定度差 LVS 还有几个等级:nginx 处理所有流量所以受限于机器 IO 和配置;本身的 bug 也还是难以避免的;nginx 没有现成的双机热备方案,所以跑在单机上还是风险比较大,单机上的事情全都很难说
支持健康检查以及请求重发
nginx 可以检测到服务器内部的故障(健康检查),比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前 LVS 中 ldirectd 也能支持针对服务器内部的情况来监控,但 LVS 的原理使其不能重发请求。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx 会把上传切到另一台服务器重新处理,而 LVS 就直接断掉了。
LVS 的优势
抗负载能力强
因为 LVS 工作方式的逻辑是非常简单的,而且工作在网络的第 4 层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。LVS 一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU 等)出现问题导致 LVS 出现问题
配置性低
这通常是一大劣势同时也是一大优势,因为没有太多的可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率
工作稳定
因为其本身抗负载能力很强,所以稳定性高也是顺理成章的事,另外各种 LVS 都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,LVS 会自动判别,所以系统整体是非常稳定的
无流量
LVS 仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的 IO 性能不会受到大流量的影响
LVS 基本上能支持所有应用,因为 LVS 工作在第 4 层,所以它可以对几乎所有应用做负载均衡,包括 http、数据库、聊天室等。
来源:juejin.cn/post/7517644116592984102
SQL Join 中函数使用对性能的影响与优化方法
在日常开发中,经常会遇到这样的场景:
需要在 大小写不敏感 或 格式化字段 的情况下进行表关联。
如果在 JOIN 或 WHERE 中直接使用函数,往往会带来严重的性能问题。
本文用一个新的示例来说明问题和优化方法。
一、问题场景
假设我们有两张表:
- 用户表 user_info
user_id | username
----------+------------
1 | Alice
2 | Bob
3 | Charlie
- 订单表 order_info
order_id | buyer_name
----------+------------
1001 | alice
1002 | BOB
1003 | dave
我们希望根据用户名和买家名称进行关联(忽略大小写)。
原始写法(低效)
SELECT o.order_id, u.user_id, u.username
FROM order_info o
LEFT JOIN user_info u
ON LOWER(o.buyer_name) = LOWER(u.username);
问题:
LOWER()包裹了字段,导致数据库无法使用索引。- 每一行都要执行函数运算,性能下降。
二、优化方法
1. 子查询提前计算
通过子查询生成派生列,再进行关联。
SELECT o.order_id, u.user_id, u.username
FROM (
SELECT order_id, buyer_name, LOWER(buyer_name) AS buyer_name_lower
FROM order_info
) o
LEFT JOIN (
SELECT user_id, username, LOWER(username) AS username_lower
FROM user_info
) u
ON o.buyer_name_lower = u.username_lower;
优点:
- 避免在
JOIN时重复调用函数。 - 优化器有机会物化子查询并建立临时索引。
2. 建立函数索引(推荐)
如果这种需求非常频繁,可以在表上建立函数索引。
PostgreSQL 示例:
CREATE INDEX idx_username_lower ON user_info(LOWER(username));
CREATE INDEX idx_buyer_name_lower ON order_info(LOWER(buyer_name));
之后即使写:
SELECT ...
FROM order_info o
LEFT JOIN user_info u
ON LOWER(o.buyer_name) = LOWER(u.username);
数据库也能走索引,性能大幅提升。
3. 数据入库时统一格式
如果业务允许,可以在入库时统一转为小写,避免查询时做转换。
INSERT INTO user_info (user_id, username)
VALUES (1, LOWER('Alice'));
这样关联时直接比较即可:
ON o.buyer_name = u.username
三、总结
- 在
JOIN或WHERE中直接使用函数,会 导致索引失效,影响性能。 - 优化方法:
- 子查询提前计算,避免在关联时重复调用函数;
- 建立函数索引(或虚拟列索引);
- 入库时统一数据格式,彻底消除函数依赖。
📌 记忆要点:
- 函数写在
JOIN→ 慢 - 子查询提前算 → 好
- 函数索引 / 数据规范化 → 最优解
来源:juejin.cn/post/7555612267787550772
PaddleOCR-VL,超强文字识别能力,PDF的拯救者
转眼间已经是 2025 年的 Q4 了,年终越来越近,领导给予的 okr 压力越来越大,前段时间,领导提出了一个非常搞的想法,当然也是急需解决的痛点——线上一键翻译功能。
小包当前负责是开发开发面向全球各国的活动,因此活动中不免就会出现各种各样的语言,此时就出现了一个困扰已久的难题,线上体验的同学看不懂,体验过程重重受阻,很容易遗漏掉一些环节,导致一些问题很难暴露出来。
为了这个问题,小包跟进了一段时间了,主要有两个地方的文案来源
- 代码渲染的文本
- 切图中的静态文本
大多数文本来源于是切图中,因此如何应对各种各样的切图成为难题。由此小包提出了两种解决方案:
- 同时保存两种图片资源,分别为中文和当前区服语言
- 直接进行图片翻译
第一种方案被直接拒绝了,主要由于当前的技术架构和同事们的一些抵触,业务中使用的 img、txt 信息都存储在配置平台中,存储两份就需要维护两类配置,严重增加了心智负担。
那我是这么思考的,第一次上传图片资源时,自动进行图片翻译,存储在另一个配置字段中,当开启一键翻译功能后,切换翻译后的图片。
由于是内部使用的工具,因此不需要非常准确,为了节省 token,只在第一次进行翻译。
图片翻译需要两个过程,首先进行 OCR,识别出图片中的文字;其次对识别出的文字进行翻译。
尝试了好几款 OCR 工具,都有些不尽人意,整个过程中,体验最好的是上个月PaddleOCR推出的PP-OCRv5。
在一段时间内,都一直盯着 PaddleOCR 的最新进度,昨天,百度发布并开源自研多模态文档解析模型 PaddleOCR-VL,该模型在最新 OmniDocBench V1.5 榜单中,综合性能全球第一,四项核心能力SOTA,模型已登顶HF全球第一。
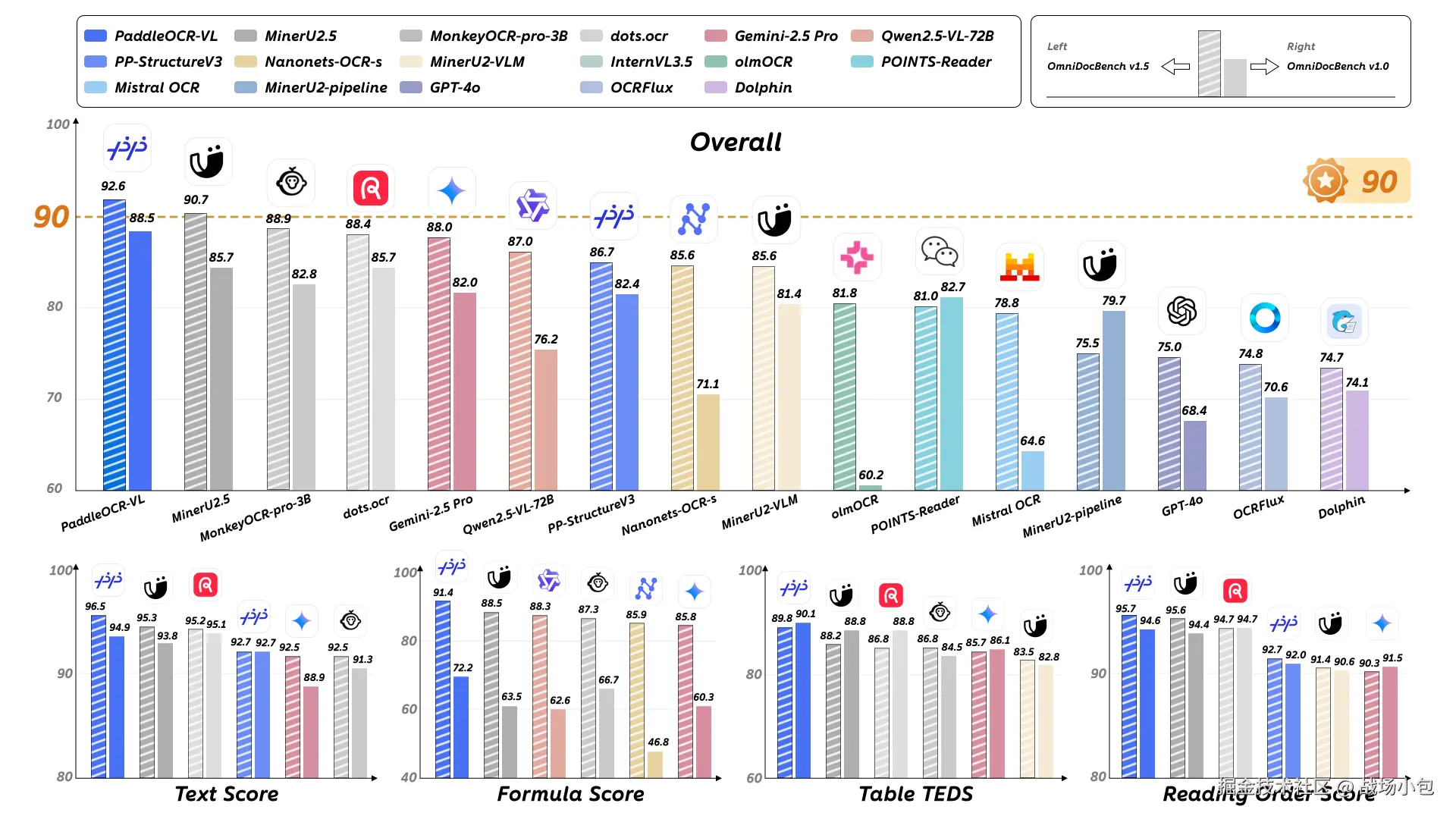
这么说我的 OKR 有救了啊,快马加鞭的来试一下。
对于线上翻译,有两种指标是必须要达到的
- 文字区域识别的准确性
- 支持语言的多样性
下面逐一地体验一下
OKR 需求测试
先随便找了一张较为简单的韩服的设计稿,识别效果见右图,识别的区域非常准确,精准的区分开文字区域和图像区域。
右侧有三个 tab,其中第一个 tab:Markdown Preview 预览还支持翻译功能,翻译的文案也是非常准确的
激动了啊,感觉 PaddleOCR-VL 自己就可以解决当前的需求啊。
再换一种比较复杂的语言,阿拉伯语。支持效果也是出奇的好啊,阿语活动开发过程和体验过程是最难受的啊,目前也是最严重的卡点
对于阿语的翻译的效果也非常好,这点太惊喜了,阿服的字体又细又长,字间距又窄,能做到这么好的识别真是让人惊艳
经过一番简单的测试,PaddleOCR-VL 完全可以应对领导的 OKR 要求了(毕竟天下第一难语言阿服都可以较为完美的应对,撒花),爽啊!只需要把 demo 跑出来,就可以去申请经费啦。
更多测试
作为一个程序员,除了要干好本职的工作,更要积极的探索啊,多来几个场景,倒要看看 PaddleOCR VL 能做到什么程度。
糊图识别
日常中经常有这种需求,领导给了一张扫描了一万次或者扫描的一点都不清楚的图片,阅读难度甚大,那时候就想能不能有一种方案直接把内容提取出来。
例如就像下面的糊糊的作文,连划去的内容都成功提取出来了,牛
元素级识别
PaddleOCR-VL 除了文档解析能力,还提供了元素级识别能力,例如公式识别、表格内容识别等,诸如此类都是图片识别中的超难点。
先来个简单公式试一下

效果这么好的吗,全对了,那就要上难度了啊
黑板中的公式繁杂,混乱,且是手写体,没想到识别的整体内容都是非常准确的,只有最后一个公式错误的乘在一起了,效果有些令人惊叹啊。
总结
PaddleOCR-VL 效果真是非常惊艳啊,年底的 okr 实现的信心大增。
PaddleOCR-VL 文字识别感觉像戴了高精度眼镜一般,后续遇到类似的文字识别需求,可以首选 PaddleOCR-VL 啊。
此外小小看了一下论文,PaddleOCR-VL 采用创新的两阶段架构:第一阶段由 PP-DocLayoutV2 模型负责版面检测与阅读顺序预测;第二阶段由 PaddleOCR-VL-0.9B 识别并结构化输出文字、表格、公式、图表等元素。相较端到端方案,能够在复杂版面中更稳定、更高效,有效避免多模态模型常见的幻觉与错位问题。
PaddleOCR-VL在性能、成本和落地性上实现最佳平衡,具备强实用价值。后续遇到文字识别的需求,PaddleOCR-VL 是当之无愧的首选。
体验链接:
- Github:github.com/PaddlePaddl…
- huggingface:huggingface.co/PaddlePaddl…
- Technical report:arxiv.org/pdf/2510.14…
- Technical Blog:
- English: ernie.baidu.com/blog/posts/…
- Chinese: ernie.baidu.com/blog/zh/pos…
来源:juejin.cn/post/7561954132011483188
知乎崩了?立即把网站监控起来!
今天早上(2025.10.17),知乎突然出现疑似大规模服务故障,导致多数用户无法访问,“知乎崩了”瞬间登上热搜榜。
一.当前故障表现为:
1.全平台功能异常:
- 网页端: 无法进入,显示 525 错误(服务器配置错误)。
- App 端: 首页可显示,但点击任何问题或回答均无法加载详情,部分用户还出现反复登出、匿名状态异常等。
2.技术特征分析:
- 故障表现似乎为核心数据接口响应失败,与 2023 年 4 月,2025 年 7 月的情况高度吻合,推测是中心化服务器集群在高压并发下的处理能力不足。
- 有部分用户提到 App 内出现 503 错误(服务不可用),这通常与服务器过载或后端服务中断有关。
二.网站崩溃可能造成的损失:
网站监控是保障业务稳定和用户体验的核心环节,其本质是提前发现问题、减少损失,做到“防患于未然”,避免因网站问题导致用户流失或业务损失。
根据最新的行业报告以及权威研究机构分析:
1.直接财务损失:
Gartner 指出
- 金融行业每分钟停机成本可达15 万美元。
- 电商与零售业每分钟停机成本可达 1 万美元。
- 制造业停产每分钟损失可达4 万美元。
2.隐形、持久损失:
- 客户信任与品牌声誉受损:一次严重的停机时间可能导致客户的永久丢失。负面舆情传播极快,会造成潜在客户“望而却步”
- 市场竞争力下降:竞争对手可能趁机抢占市场份额的事情屡见不鲜。像之前某旅游平台因预订系统故障,导致客户转而通过竞品平台下单;某打车软件长时间瘫痪,竞争对手趁机发布平台优惠福利,司机和乘客大面积流失,后通过超过半年的时间才恢复。
- 合规风险与法律责任:金融、医疗等受到严格监管的行业可能面临高额罚款、内部追责、未履行 SLA 造成的法律纠纷或赔偿等。
三.网站监控为什么重要?
| 保障可用性,减少停机损失 | 实时监测网站是否能正常访问(如服务器宕机、域名解析故障),一旦出现问题立即告警,缩短停机时间。 |
|---|---|
| 优化用户体验,提升留存 | 监测页面加载速度、接口响应时间等性能指标。若用户打开页面需等待 5 秒以上,流失率会大幅上升,监控能帮助定位慢加载的原因(如图片过大、服务器资源不足)。 |
| 防范安全风险,防止数据泄露 | 扫描 SQL 注入、XSS 攻击、服务器漏洞等安全威胁,提前拦截恶意访问,保护用户数据和网站核心资产。 |
| 支撑业务决策,发现潜在问题 | 通过监控访问量、转化率、用户地域分布等业务数据,及时发现异常(如某地区访问量骤降),为运维和运营策略调整提供依据。 |
1.通过Applications Manager监控网站
Applications Manager 是一款企业级应用性能监控(APM)与可观测性解决方案,能够监控到业务系统各个组成部分,支持 150 + 技术栈,覆盖 Java/.NET/Node.js 等应用服务器、Oracle/MySQL/MongoDB 等数据库、AWS/Azure/GCP 等云平台,以及 Kubernetes/Docker 容器环境。通过无侵入式字节码注入技术,实现从代码级到基础设施层的端到端性能追踪,精准定位慢事务、SQL 查询和线程瓶颈。
对于网站监控,通过卓豪 APM 能够实现:
2.网站可用性监控:
l HTTP 配置检查:
支持 POST/GET 方式。可以设置基于状态码的阈值告警。例如设置>200都作为告警触发,比如这次知乎响应状态码为 525,平台会立刻发出可用性 down 的告警;支持验证以及添加请求参数(可选)等。

l 内容检查:
在HTTP 配置检查均正常时,可以通过网站内容检查来识别“假运行”状态。支持正则表达式
3.应用性能监控:
URL监控能够监控网站上重要URL的可用性和性能,无论它们是在互联网上还是内部网上。这通过监控单个URL的响应时间来确保网站的顺利运行,在网站的页面加载时间出现任何延迟时提供即时通知。在URL序列监控的帮助下,可以模拟在线访问者通常访问的URL的序列,并分析它们以识别和解决任何潜在问题。
4.网站证书监控:
不断检查网站的SSL/TLS证书状态,以确保网站访问者的真实性、安全性和可靠性。如果网站证书接近到期日,会立即收到通知,以便采取必要措施按时续订。除此之外还可以查看SSL/TLS证书的域名、组织和组织单位等信息,以供快速参考。
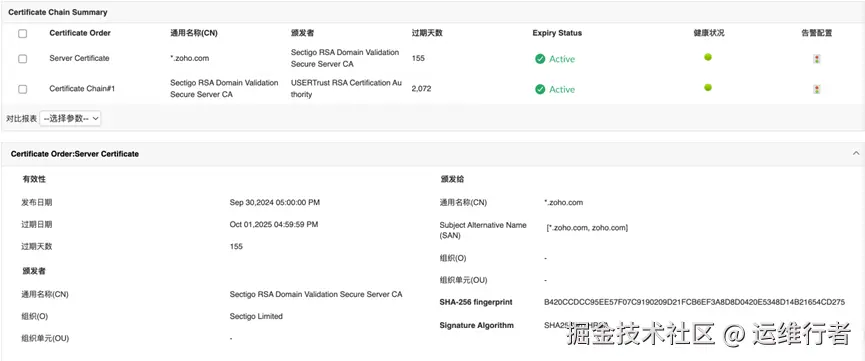
5.真实用户访问监控:
真实用户监控(RUM)能够通过实时见解增强网站的数字最终用户体验。它根据实际流量,从全球不同地点全天候监控网站的前端性能,跟踪关键指标,并提供有关真实用户如何与网站互动的深入见解。它根据浏览器、设备、ISP、地理等参数提供有关网站性能的详细信息。可以查看前端、后端和网络响应时间,还可以深入了解网络事务、用户会话、AJAX调用、Javascript错误等。
结语:
除了网站监控之外,APM还可以对业务系统从服务器/操作系统到中间件、数据库等各个组成部分的应用性能监控,保障业务正常运行,避免故障停机导致的损失。从基础架构到前端响应,立即发现、及时预警,保障用户访问网站畅通无阻!
来源:juejin.cn/post/7561781514922541066
e签宝亮相2025云栖大会:以签管一体化AI合同平台,构建数字信任“中国方案”

9月24日至9月26日,以“云智一体 · 碳硅共生”为主题的2025云栖大会在杭州召开。大会通过3大主论坛+超110场聚合话题,充分展示 Agentic AI(代理式AI)和 Physical AI(物理AI)的变革性突破,探讨AI 基础设施、大模型、Agent 开发、AI 应用等多个领域和层次的话题内容。
作为亚太地区电子签名领域的领军企业,e签宝受邀出席系列重要活动。在题为《AI Agent崛起,谁会赢得下一代企业服务市场?》的分享环节中,e签宝创始人兼CEO金宏洲先生全面介绍了公司在智能合同、全球合规签署以及数字信任基础设施建设方面的最新成果。

金宏洲强调,在面向ToB的AI Agent领域,要取得成功,需要三个关键:第一,数据闭环,在用户使用过程中积累数据,反哺Agent能力提升,形成数据飞轮,这是做好Agent产品的基础。第二,有领域知识,这是垂直Agent产品做厚的价值点,也是防止被通用Agent吞没的护城河。第三,最终的护城河是用户规模和网络效应,无论是新老创业者,在AI时代都有机会,但不拥抱AI的必然会被淘汰。

大会现场还有 4 万平米的智能科技展区以及丰富的创新活动,将为每一位参会者带来密集的 AI 新思想、新发布、新形态。

人工智能+馆全面呈现了从基础大模型、开发工具到全链路Agent服务的最新进展。通义大模型系列以“全尺寸、全模态”开源矩阵亮相,展示了其在多模态理解与生成上的全面布局;魔搭社区展示其超过7万个模型与1600万开发者的生态力量;瓴羊 AgentOne 提供客服、营销等场景化服务;AI Coding 展区核心展示开发者工作范式的变化……观众可现场体验阿里云百炼、无影AgentBay等智能体开发与应用场景,感受大模型如何从工具走向“数字伙伴”。

计算馆内,硬核技术不再冰冷,而是化作可感知、可交互的趣味场景。无影展区人气爆棚,一块巴掌大的“无影魔方Ultra”竟能流畅运行对GPU要求极高的3A游戏。现场观众坐上模拟驾驶座,即可与大屏幕联动,体验极速飙车的刺激;拿上手柄,闯入《黑神话:悟空》的游戏世界,与BOSS展开激战。“东数西算”展区,戴上VR设备,观众就能“空降”至贵州、内蒙古、青海等西部数据中心,近距离观摩真实运行的机房与算力设备,直观感受国家算力网的建设成果。

前沿应用馆彻底化身为机器人的“演武场”。一位“泰拳手”机器人凌厉出击后稳健收势,被“击倒”后竟能如人类般灵活爬起;另一侧,一只机器狗如履平地般攀上高台,完成后还俏皮地模仿起花滑运动员的庆祝动作;而在模拟工厂区域,一名“工人”指挥着数十只机械臂协同作业,宛若“千手观音”。
除了这些“能动”的机器人,更具渗透力的智能体也正在融入日常生活的方方面面。e签宝展示了基于Agent技术的“统一、智能、互信”的全球签署解决方案。

e签宝展区重点呈现了签管一体化AI合同平台和全球化信任服务体系eSignGlobal。e签宝以“统一签、统一管、统一AI”为核心建设理念,致力于打造企业级统一智能签管底座,帮助企业实现跨系统、跨地域、跨法域的合同签署与管理闭环,构建以技术为驱动力的全球数字信任基础设施。
智能合同Agent
2025年,e签宝发布智能合同Agent,实现从“会聊天”到“会干活”的跨越式发展,引领行业智能化升级。e签宝创始人兼CEO金宏洲先生表示,“智能合同Agent不仅是工具,更是企业数字信任体系的‘神经中枢’”。
针对合同文本结构复杂、多栏排版、嵌套条款等行业共性难题,e签宝自主研发了合同魔方引擎,融合多模态文档解析技术、长文本Chunking技术、合同结构化规范,实现跨栏位、跨页面的精准内容提取。该引擎使合同信息识别准确率高达97%,较通用大模型性能提升10%。
基于深度任务拆解需求,e签宝打造了合同Agent Hub平台,通过“工具增强CoT”技术,结合动态私域知识库与自研工具链,实现复杂合同任务的自动化调度与精准执行。平台可动态优化企业专属知识库,并智能调用嵌入式分析、信息抽取等AI工具,确保业务流程的高效适配。
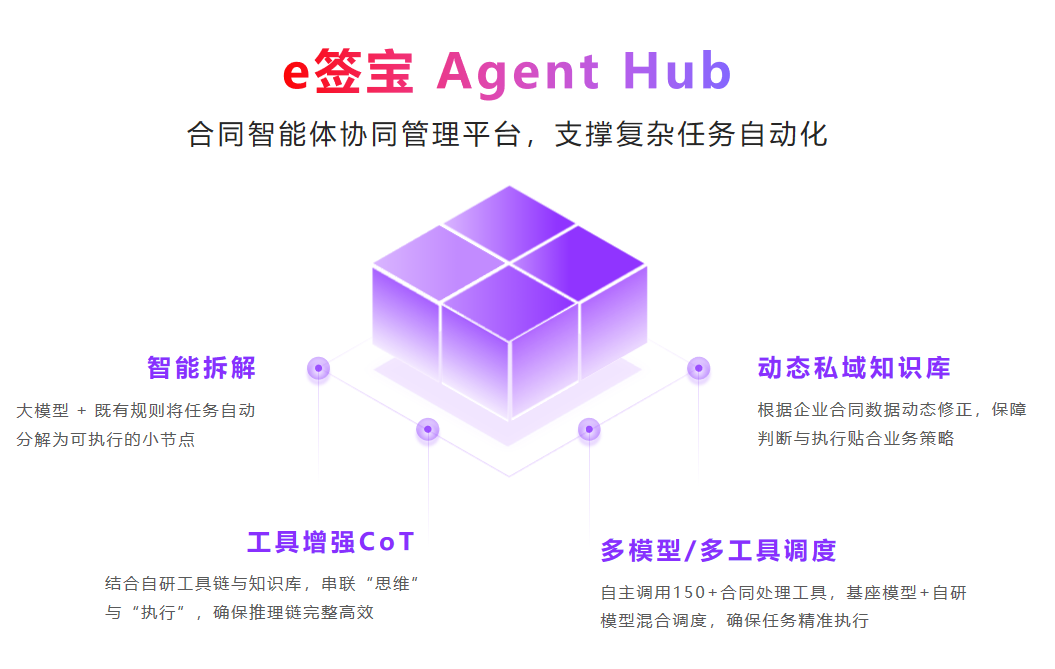
企业的统一智能签管底座
e签宝提出“统一、智能、互信”的全球签署网络理念,通过签管一体化AI合同平台,帮助企业实现合同全生命周期的数字化管理。

统一签:全流程覆盖、全场景适配、全渠道通用。企业使用e签宝后,无论合同来自于CRM、HR系统、OA还是任何业务系统,都能在一个平台上快捷完成签署。即开即用,复杂业务场景也能轻松适配。这种统一性为后续的合同管理、风险识别和AI赋能奠定了基础。
统一管:统管集团组织、统管业务资源、统管合规风控。e签宝平台能够集中管理企业的合同、印章和组织流程。AI会自动进行智能归档,高效检索合同,并提取关键信息方便后续自动化管理。智能印控中心可确保印章被安全使用,避免违规用印风险,保障体系稳定发展。
统一AI能力确保了企业合同数据的安全性与可靠性。e签宝将所有合同AI能力集中在同一平台上运行,串联全业务流程,避免数据外泄,确保在企业安全范围内处理敏感合同数据,保障安全合规。同时,这些AI能力通过API或MCP服务形式开放,可集成到企业各业务系统中。
eSignGlobal全球合规签署
面对企业全球化运营的需求,e签宝推出了eSignGlobal全球签署服务。eSignGlobal遵循全球各地的相关法规,在中国香港、新加坡、法兰克福设立独立数据中心,通过TrustHub服务连接各地权威的CA机构,确保电子签名的本地化合规性。
e签宝已经从单纯的电子签名服务发展为全方位的数字信任基础设施提供者。截至2025年8月,eSignGlobal已与16个国家和地区签约,服务覆盖全球97个国家和地区,构建起了跨地域、跨法域的“信任网络”。
根据全球权威机构MarketsandMarkets报告,e签宝以“亚太第一、全球第六”的排名跻身全球电子签名领域第一梯队,成为中国唯一跻身全球电子签名领域前十的企业。
AI普惠:让信任更简单的使命践行
“让签署更便捷,让信任更简单”是e签宝的使命。在AI技术赋能下,这一使命正得到更深层次地践行。
2023年,e签宝发布了自己的合同大模型,基于此开发的智能合同产品在商业化方面取得了显著成绩。AI收入占e签宝整体收入的比例已达到20%以上,公司从SaaS到AI的转型相当成功。

今年4月,e签宝在新加坡面向全球发布了AI合同Agent,将智能合同产品进一步升级为Chat交互为主的Agent方式。在过去的半年中,e签宝AI能力的调用量显著增长:智能归档能力达3425万次、智能台账850万次,风险审查11万次,合同比对33万次。
e签宝的AI技术正在深入生活的各个角落。年轻人利用e签宝的AI合同生成能力创建恋爱协议、分手协议、合租协议、宠物共养协议等。这些应用场景完全由用户自己创造,展现了AI技术的普惠价值

“让全球1/4的人用e签宝签合同”,这是e签宝十年前写下的愿景。经过10年努力,这一愿景已取得了显著进展。随着“技术+合规+生态”战略的持续深化,e签宝正以“中国方案”重塑全球信任体系。
如今,e签宝正在构建一个“统一、智能、互信”的全球签署网络,推动全球数字信任基础设施的演进与升级,更深层次地践行“让签署更便捷,让信任更简单”的使命。
什么是Java 的 Lambda 表达式?
一、前言
在Lambda表达式没有出现之前,很多功能的实现需要写冗长的匿名类,这样的代码不仅难以维护,还让人难以理解,用 Lambda 表达式后,代码变得更加简洁,易于维护。今天我们就来聊聊Lambda表达式的一些使用。
二、Lambda表达式的使用
我们之前的编程习惯是利用匿名类去实现一些接口的行为,比如线程的执行,然而,这种写法会导致代码膨胀和冗长,我们先来看看传统的写法:
public static void main(String[] args) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("hello world");
}
});
thread.start();
}
- Thread thread = new Thread(new Runnable() {...}); 这一行创建了一个新的线程,它接受一个
Runnable类型的对象作为参数,这里使用的是匿名类。
其实上面那段代码是非常冗长的,我们直接来对比一下Lambda表达式的写法就知道了:
public static void main(String[] args) {
//使用Lambda表达式
Thread thread = new Thread(() -> System.out.println("hello world"));
thread.start();
}
简洁明了,只用一行简洁的代码,我们就完成了线程的创建和启动。我们来看一下Lambda表达式的标准格式:
(parameters) -> expression
说明:
(parameters)是传递给 Lambda 表达式的参数,可以是零个或多个。例如,在我们上面的例子中传递的是() ->,表示没有参数。->是箭头操作符,表示 Lambda 表达式的开始,指向 Lambda 体。expression是 Lambda 表达式的主体,也就是我们要执行的代码。
使用前提
上文中提到,lambda表达式可以在⼀定程度上简化接口的实现。但是,并不是所有的接口都可以使用lambda表达式来简化接口的实现的。
先说结论,lambda表达式,只能实现函数式接口。lambda表达式毕竟只是⼀个匿名方法。
什么是函数式接口?
函数式接口在 Java 中是指: 有且仅有一个抽象方法的接口 。
函数式接口,即适用于函数式编程场景的接口。而 Java 中的函数式编程体现就是Lambda,所以函数式接口就是可以适用于Lambda使用的接口。只有确保接口中有且仅有一个抽象方法,Java中的 Lambda才能顺利地进行推导。
Java 8 中专门为函数式接口引入了一个新的注解:@FunctionalInterface。一旦使用该注解来定义接口,编译器将会强制检查该接口是否确实有且仅有一个抽象方法,否则将会报错。需要注意的是,即使不使用该注解,只要满足函数式接口的定义,这仍然是一个函数式接口。以下为示例代码:
@FunctionalInterface
public interface TestFunctionalInterface {
void testMethod();
}
语法简化
1.参数类型简化:由于在接口的方法中,已经定义了每⼀个参数的类型是什么。而且在使用lambda表达式实现接口的时候,必须要保证参数的数量和类 型需要和接口中的方法保持⼀致。因此,此时lambda表达式中的参数的类型可以省略不写。例子:
Test test = (name,age) -> {
System.out.println(name+" "+age);
};
2.参数小括号简化:如果方法的参数列表中的参数数量 有且只有⼀个,此时,参数列表的小括号是可以省略不写的。例子:
Test test = name -> {
System.out.println(name);
};
3.方法体部分的简化:当⼀个方法体中的逻辑,有且只有⼀句的情况下,大括号可以省略。例子:
Test test = name -> System.out.println(name);
4.return部分的简化:如果⼀个方法中唯⼀的⼀条语句是⼀个返回语句, 此时在省略掉大括号的同时, 也必须省略掉return。例子:
Test test = (a,b) -> a+b;
三、总结
本文从Lambda表达式的基础概念、基本使用几方面完整的讨论了这一Java8新增的特性,实际开发中确实为我们提供了许多便利,简化了代码。
来源:juejin.cn/post/7555051376284499978
kv数据库-leveldb (16) 跨平台封装-环境 (Env)
在上一章 过滤器策略 (FilterPolicy) 中,我们学习了 LevelDB 如何利用布隆过滤器这样的巧妙设计,在访问磁盘前就过滤掉大量不存在的键查询,从而避免了无谓的 I/O 操作。
至此,我们已经探索了 LevelDB 从用户接口到底层数据结构,再到性能优化的几乎所有核心组件。但我们忽略了一个最基础的问题:LevelDB 是一个 C++ 库,它需要运行在真实的操作系统上。它是如何在不同的操作系统(如 Linux, Windows, macOS)上读写文件、创建线程、获取当前时间的呢?难道 LevelDB 的核心代码里充斥着大量的 #ifdef __linux__ 和 #ifdef _WIN32 这样的条件编译指令吗?
如果真是这样,代码将会变得难以维护,移植到新平台也会是一场噩梦。为了优雅地解决这个问题,LevelDB 引入了它的基石——环境(Env)。
什么是环境 (Env)?
Env 是对操作系统底层功能的一个抽象层。你可以把它想象成一个万能工具箱。LevelDB 的核心逻辑(比如 合并 (Compaction) 线程、排序字符串表 (SSTable) 的读写)在工作时,并不直接调用操作系统的原生函数(如 open, read, CreateFileW),而是从这个标准的“工具箱”里取工具来用。
这个工具箱里有什么呢?它定义了一套标准的工具接口:
NewWritableFile(...): 给我一把能写文件的“扳手”。StartThread(...): 给我一个能启动新线程的“马达”。NowMicros(): 给我一个能读取当前微秒时间的“秒表”。SleepForMicroseconds(...): 让我休息一下的“闹钟”。
有了这个标准的工具箱接口,LevelDB 的核心逻辑就可以完全不关心自己到底运行在哪个操作系统上。它只管向 Env 索要工具。
那么,具体的工具是从哪里来的呢?LevelDB 为每个它支持的平台,都提供了一个具体的工具箱实现。
- 在 Linux/macOS (POSIX) 上,它提供一个
PosixEnv。这个工具箱里的“扳手”是用open()和write()实现的。 - 在 Windows 上,它提供一个
WindowsEnv。这个工具箱里的“扳手”则是用CreateFileA()和WriteFile()实现的。
这种设计带来了巨大的好处:可移植性。当需要将 LevelDB 移植到一个新的操作系统(比如 Fuchsia)时,开发者几乎不需要修改任何核心逻辑代码。他们只需要为新平台实现一个新的 Env 子类——也就是打造一个新的、符合标准的工具箱——然后整个 LevelDB 就可以在这个新平台上运行了。
graph BT
subgraph "具体的平台实现"
C["PosixEnv (Linux, macOS)"]
D["WindowsEnv (Windows)"]
E["MemEnv (用于测试)"]
end
subgraph "LevelDB 核心逻辑"
A["DBImpl, Compaction, SSTable, 等..."]
end
subgraph "Env 抽象接口 (标准工具箱)"
B(Env)
B -- "提供 NewWritableFile()" --> A
B -- "提供 StartThread()" --> A
end
A -- "调用" --> B
C -- "实现" --> B
D -- "实现" --o B
E -- "实现" --o B
style A fill:#cde
style B fill:#f9f
我们如何使用 Env?
对于绝大多数用户来说,你几乎不需要直接与 Env 交互。LevelDB 会在后台为你处理好一切。
当你打开一个数据库时,选项 (Options) 对象里有一个 env 成员。如果你不设置它,它的默认值就是 Env::Default()。
Env::Default() 是一个静态方法,它会根据编译时确定的操作系统,返回一个对应平台的 Env 单例对象。在 Linux 上,它返回 PosixEnv 的实例;在 Windows 上,它返回 WindowsEnv 的实例。
#include "leveldb/db.h"
#include "leveldb/env.h"
int main() {
leveldb::Options options;
// 我们没有设置 options.env,
// 所以 LevelDB 会自动使用 Env::Default()
// 在 Linux 上就是 PosixEnv,在 Windows 上就是 WindowsEnv
leveldb::DB* db;
// DB::Open 内部会从 options.env 获取环境对象,
// 并在需要时用它来操作文件、启动线程等。
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
// ...
delete db;
return 0;
}
所以,Env 虽然至关重要,但它就像空气一样,默默地支撑着一切,而我们通常感觉不到它的存在。
Env 内部是如何工作的?
Env 的强大之处在于它的多态设计。Env 本身是一个抽象基类,定义了所有平台都需要提供的功能接口。
1. Env 的接口定义 (include/leveldb/env.h)
Env 类定义了许多纯虚函数(以 = 0 结尾),这意味着任何想要成为一个“合格” Env 的子类都必须实现这些函数。
// 来自 include/leveldb/env.h (简化后)
class LEVELDB_EXPORT Env {
public:
virtual ~Env();
// 返回一个适合当前操作系统的默认 Env
static Env* Default();
// 创建一个用于顺序读取的文件对象
virtual Status NewSequentialFile(const std::string& fname,
SequentialFile** result) = 0;
// 创建一个用于随机读取的文件对象
virtual Status NewRandomAccessFile(const std::string& fname,
RandomAccessFile** result) = 0;
// 创建一个用于写操作的文件对象
virtual Status NewWritableFile(const std::string& fname,
WritableFile** result) = 0;
// 启动一个新线程
virtual void StartThread(void (*function)(void* arg), void* arg) = 0;
// 返回当前的微秒时间戳
virtual uint64_t NowMicros() = 0;
// ... 还有很多其他接口, 如文件删除、目录创建等 ...
};
这个接口就是 LevelDB 核心逻辑所依赖的“标准工具箱”的蓝图。
2. POSIX 平台的实现 (util/env_posix.cc)
PosixEnv 类继承自 Env,并使用 POSIX 标准的系统调用来实现这些接口。
让我们看看 NewWritableFile 的实现:
// 来自 util/env_posix.cc (简化后)
Status PosixEnv::NewWritableFile(const std::string& filename,
WritableFile** result) {
// 使用 POSIX 的 open() 系统调用来创建文件
int fd = ::open(filename.c_str(),
O_TRUNC | O_WRONLY | O_CREAT, 0644);
if (fd < 0) {
*result = nullptr;
return PosixError(filename, errno); // 返回错误状态
}
// 创建一个 PosixWritableFile 对象来包装文件描述符
*result = new PosixWritableFile(filename, fd);
return Status::OK();
}
这里,PosixEnv 将对“写文件”这个抽象请求,转换成了对 ::open() 这个具体的 POSIX 系统调用。
3. Windows 平台的实现 (util/env_windows.cc)
与之对应,WindowsEnv 则使用 Windows API 来实现同样的功能。
// 来自 util/env_windows.cc (简化后)
Status WindowsEnv::NewWritableFile(const std::string& filename,
WritableFile** result) {
// 使用 Windows API 的 CreateFileA() 来创建文件
ScopedHandle handle = ::CreateFileA(
filename.c_str(), GENERIC_WRITE, /*share_mode=*/0,
/*security=*/nullptr, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL,
/*template=*/nullptr);
if (!handle.is_valid()) {
*result = nullptr;
return WindowsError(filename, ::GetLastError());
}
// 创建一个 WindowsWritableFile 对象来包装文件句柄
*result = new WindowsWritableFile(filename, std::move(handle));
return Status::OK();
}
WindowsEnv 将同样的抽象请求,转换成了对 ::CreateFileA() 这个具体的 Windows API 调用。LevelDB 的上层代码完全不知道也不关心这些差异。
Env::Default() 的魔法
Env::Default() 是如何知道该返回哪个实现的呢?这通常是通过编译时的预处理宏来完成的。
// 位于 env.cc 或平台相关的 env_*.cc 文件中 (概念简化)
#include "leveldb/env.h"
#if defined(LEVELDB_PLATFORM_POSIX)
#include "util/env_posix.h"
#elif defined(LEVELDB_PLATFORM_WINDOWS)
#include "util/env_windows.h"
#endif
namespace leveldb {
Env* Env::Default() {
// 静态变量保证了全局只有一个实例
static SingletonEnv<
#if defined(LEVELDB_PLATFORM_POSIX)
PosixEnv
#elif defined(LEVELDB_PLATFORM_WINDOWS)
WindowsEnv
#else
// Fallback or error for unsupported platforms
#endif
> env_container;
return env_container.env();
}
} // namespace leveldb
在编译时,构建系统会根据目标平台定义 LEVELDB_PLATFORM_POSIX 或 LEVELDB_PLATFORM_WINDOWS,从而使得 Env::Default() 的代码在编译后,就“硬编码”为返回正确的平台特定 Env 实例。
用于测试的 MemEnv
Env 抽象层的另一个巨大好处是可测试性。LevelDB 提供了一个完全在内存中模拟文件系统的 MemEnv(位于 helpers/memenv/memenv.h)。在进行单元测试时,可以使用 MemEnv 来代替真实的 PosixEnv 或 WindowsEnv。这使得测试可以:
- 非常快:因为没有实际的磁盘 I/O。
- 完全隔离:不会在文件系统上留下任何垃圾文件。
- 可控:可以方便地模拟文件读写错误等异常情况。
总结与回顾
在本章中,我们探索了 LevelDB 的根基——Env 环境抽象层。
Env是一个对操作系统功能的抽象接口,它将 LevelDB 的核心逻辑与具体的平台实现解耦。- 这个“万能工具箱”的设计使得 LevelDB 具有极高的可移植性。
- 我们通常通过
Env::Default()间接使用它,它会自动返回适合当前操作系统的Env实现(如PosixEnv或WindowsEnv)。 Env的抽象也使得编写快速、隔离的单元测试成为可能,例如使用内存文件系统MemEnv。
至此,我们已经完成了 LevelDB 核心概念的探索之旅!让我们一起回顾一下走过的路:
我们从最基础的数据表示 数据切片 (Slice) 开始,学习了如何通过 选项 (Options)] 配置我们的 数据库实例 (DB)。我们掌握了如何使用 批量写 (WriteBatch) 和 迭代器 (Iterator) 与数据库高效交互。
然后,我们深入内部,揭开了数据持久化的第一道防线 预写日志 (Log / WAL),看到了数据在内存中的临时住所 内存表 (MemTable),并最终见证了它们在磁盘上的永久归宿 排序字符串表 (SSTable)。我们理解了 LevelDB 是如何通过后台的 合并 (Compaction) 任务来保持整洁,以及如何通过 版本集 (VersionSet / Version) 来管理数据快照。
我们还深入到了 SSTable 的微观世界,探索了 数据块 (Block) 的紧凑结构,并了解了 缓存 (Cache) 如何为读取加速。我们学会了用 比较器 (Comparator) 定义秩序,用 过滤器策略 (FilterPolicy) 避免无效查询。最后,我们认识了支撑这一切的平台基石 环境 (Env)。
希望这个系列能帮助你建立起对 LevelDB 内部工作原理的清晰理解。现在,你不仅知道如何使用 LevelDB,更重要的是,你明白了它为何能如此高效、稳定地工作。恭喜你完成了这段旅程!
来源:juejin.cn/post/7554961105325129771
Spec-Kit WBS:技术团队的项目管理新方式
Spec-Kit WBS:技术团队的项目管理新方式
📋 WBS基本概念
什么是WBS?
WBS (Work Breakdown Structure) = 工作分解结构
- 定义: 将项目可交付成果和项目工作分解成较小的、更易于管理的组件的过程
- 目标: 确保项目范围完整,工作不遗漏,便于估算、计划、执行和控制
- 本质: 把复杂项目像搭积木一样,一层一层地分解成可管理的小任务
WBS的核心价值
- 完整性保证 - 确保所有工作都被识别和分解
- 可管理性 - 将复杂项目分解为可管理的小任务
- 责任分配 - 每个任务可以分配给特定的人员
- 进度跟踪 - 可以跟踪每个任务的完成状态
- 成本估算 - 每个任务可以估算时间和成本
🔄 WBS与PDCA的关系
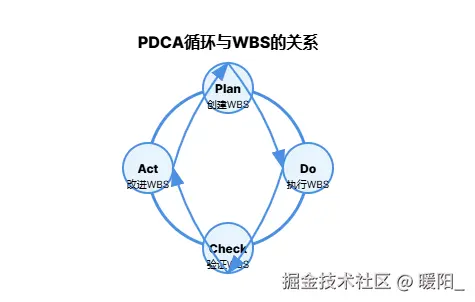
PDCA循环在项目管理中的应用
Plan (计划)
├── 项目范围定义
├── WBS创建 ← 关键工具
├── 时间估算
├── 资源分配
└── 风险管理
Do (执行)
├── 按WBS执行任务
├── 团队协作
├── 质量保证
└── 进度跟踪
Check (检查)
├── 里程碑检查
├── 质量审查
├── 进度评估
└── 偏差分析
Act (行动)
├── 纠正措施
├── 预防措施
├── 经验总结
└── 流程改进
WBS与PDCA的协同效应
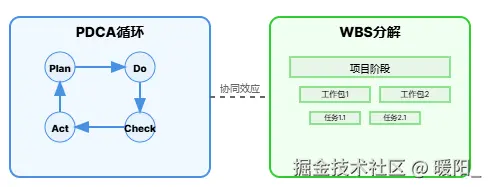
关键理解: WBS是PDCA循环中Plan阶段的核心工具,它将抽象的项目目标转化为具体的、可执行的任务,确保项目管理的系统性和完整性。
🏗️ WBS实际示例:开发一个电商网站
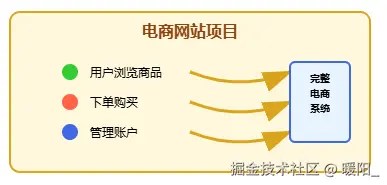
1. 项目概述
项目名称: 开发一个在线购物网站
项目目标: 让用户可以浏览商品、下单购买、管理账户
2. WBS分解过程
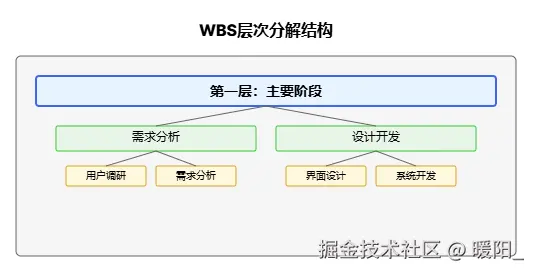
第一层:主要阶段
电商网站项目
├── 1. 需求分析阶段
├── 2. 设计阶段
├── 3. 开发阶段
├── 4. 测试阶段
└── 5. 部署上线阶段
第二层:每个阶段的工作包
电商网站项目
├── 1. 需求分析阶段
│ ├── 1.1 用户需求调研
│ ├── 1.2 功能需求分析
│ └── 1.3 技术需求分析
├── 2. 设计阶段
│ ├── 2.1 界面设计
│ ├── 2.2 数据库设计
│ └── 2.3 系统架构设计
├── 3. 开发阶段
│ ├── 3.1 前端开发
│ ├── 3.2 后端开发
│ └── 3.3 数据库开发
├── 4. 测试阶段
│ ├── 4.1 功能测试
│ ├── 4.2 性能测试
│ └── 4.3 安全测试
└── 5. 部署上线阶段
├── 5.1 服务器配置
├── 5.2 数据迁移
└── 5.3 上线发布
第三层:具体活动(最详细的任务)
电商网站项目
├── 1. 需求分析阶段
│ ├── 1.1 用户需求调研
│ │ ├── 1.1.1 设计用户问卷
│ │ ├── 1.1.2 进行用户访谈
│ │ └── 1.1.3 分析用户反馈
│ ├── 1.2 功能需求分析
│ │ ├── 1.2.1 列出所有功能点
│ │ ├── 1.2.2 确定功能优先级
│ │ └── 1.2.3 编写需求文档
│ └── 1.3 技术需求分析
│ ├── 1.3.1 确定技术栈
│ ├── 1.3.2 评估性能要求
│ └── 1.3.3 制定技术方案
├── 2. 设计阶段
│ ├── 2.1 界面设计
│ │ ├── 2.1.1 设计首页布局
│ │ ├── 2.1.2 设计商品列表页
│ │ ├── 2.1.3 设计购物车页面
│ │ └── 2.1.4 设计用户中心
│ ├── 2.2 数据库设计
│ │ ├── 2.2.1 设计用户表
│ │ ├── 2.2.2 设计商品表
│ │ ├── 2.2.3 设计订单表
│ │ └── 2.2.4 设计购物车表
│ └── 2.3 系统架构设计
│ ├── 2.3.1 设计整体架构
│ ├── 2.3.2 设计API接口
│ └── 2.3.3 设计安全方案
├── 3. 开发阶段
│ ├── 3.1 前端开发
│ │ ├── 3.1.1 搭建前端框架
│ │ ├── 3.1.2 开发首页组件
│ │ ├── 3.1.3 开发商品展示组件
│ │ ├── 3.1.4 开发购物车组件
│ │ └── 3.1.5 开发用户中心组件
│ ├── 3.2 后端开发
│ │ ├── 3.2.1 搭建后端框架
│ │ ├── 3.2.2 开发用户管理API
│ │ ├── 3.2.3 开发商品管理API
│ │ ├── 3.2.4 开发订单管理API
│ │ └── 3.2.5 开发支付接口
│ └── 3.3 数据库开发
│ ├── 3.3.1 创建数据库
│ ├── 3.3.2 创建数据表
│ ├── 3.3.3 插入测试数据
│ └── 3.3.4 优化数据库性能
├── 4. 测试阶段
│ ├── 4.1 功能测试
│ │ ├── 4.1.1 测试用户注册登录
│ │ ├── 4.1.2 测试商品浏览功能
│ │ ├── 4.1.3 测试购物车功能
│ │ └── 4.1.4 测试下单支付功能
│ ├── 4.2 性能测试
│ │ ├── 4.2.1 测试页面加载速度
│ │ ├── 4.2.2 测试并发用户处理
│ │ └── 4.2.3 测试数据库查询性能
│ └── 4.3 安全测试
│ ├── 4.3.1 测试SQL注入防护
│ ├── 4.3.2 测试XSS攻击防护
│ └── 4.3.3 测试用户数据安全
└── 5. 部署上线阶段
├── 5.1 服务器配置
│ ├── 5.1.1 购买云服务器
│ ├── 5.1.2 配置服务器环境
│ └── 5.1.3 安装必要软件
├── 5.2 数据迁移
│ ├── 5.2.1 备份开发数据
│ ├── 5.2.2 迁移到生产环境
│ └── 5.2.3 验证数据完整性
└── 5.3 上线发布
├── 5.3.1 部署代码到服务器
├── 5.3.2 配置域名和SSL
└── 5.3.3 监控系统运行状态
3. WBS编号规则
1. 第一层:1, 2, 3, 4, 5 (主要阶段)
2. 第二层:1.1, 1.2, 1.3 (工作包)
3. 第三层:1.1.1, 1.1.2, 1.1.3 (具体活动)
4. WBS与PDCA的结合
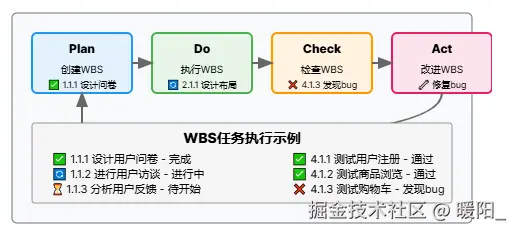
Plan阶段 (创建WBS)
✅ 1.1.1 设计用户问卷
✅ 1.1.2 进行用户访谈
✅ 1.1.3 分析用户反馈
Do阶段 (执行WBS)
🔄 2.1.1 设计首页布局
🔄 2.1.2 设计商品列表页
⏳ 2.1.3 设计购物车页面
Check阶段 (检查WBS)
✅ 4.1.1 测试用户注册登录 - 通过
✅ 4.1.2 测试商品浏览功能 - 通过
❌ 4.1.3 测试购物车功能 - 发现bug
Act阶段 (改进WBS)
🔧 修复购物车bug
📝 更新测试用例
🔄 重新测试购物车功能
5. 实际项目管理中的应用

任务分配表
| 任务编号 | 任务名称 | 负责人 | 开始时间 | 结束时间 | 状态 |
|---|---|---|---|---|---|
| 1.1.1 | 设计用户问卷 | 产品经理 | 2024-01-01 | 2024-01-03 | ✅完成 |
| 1.1.2 | 进行用户访谈 | 产品经理 | 2024-01-04 | 2024-01-10 | 🔄进行中 |
| 1.1.3 | 分析用户反馈 | 产品经理 | 2024-01-11 | 2024-01-15 | ⏳待开始 |
| 2.1.1 | 设计首页布局 | UI设计师 | 2024-01-16 | 2024-01-20 | ⏳待开始 |
进度跟踪
项目进度: 15%
├── 需求分析阶段: 60% (3/5个任务完成)
├── 设计阶段: 0% (0/8个任务开始)
├── 开发阶段: 0% (0/12个任务开始)
├── 测试阶段: 0% (0/9个任务开始)
└── 部署阶段: 0% (0/8个任务开始)
🎯 WBS的优势体现
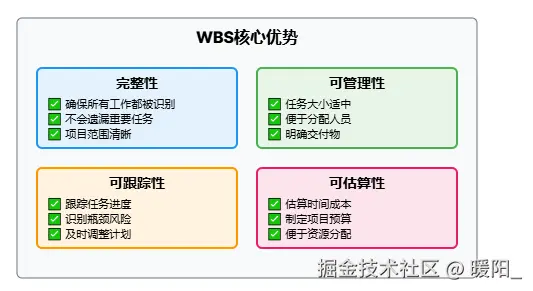
A. 完整性
- ✅ 确保所有工作都被识别
- ✅ 不会遗漏重要任务
- ✅ 项目范围清晰
B. 可管理性
- ✅ 每个任务都有明确的交付物
- ✅ 任务大小适中,便于管理
- ✅ 可以分配给不同的人员
C. 可跟踪性
- ✅ 可以跟踪每个任务的进度
- ✅ 识别瓶颈和风险点
- ✅ 及时调整计划
D. 可估算性
- ✅ 每个任务可以估算时间和成本
- ✅ 便于制定项目预算
- ✅ 便于资源分配
E. 责任分配
- ✅ 每个任务可以分配给特定的人员
- ✅ 明确的责任分工
- ✅ 便于团队协作
🔧 WBS在Spec-Kit中的应用

传统WBS vs Spec-Kit WBS
核心区别对比
分解思路
- 传统WBS:按项目阶段分解(需求→设计→开发→测试→部署)
- Spec-Kit WBS:按技术实现分解(环境→测试→实现→集成→完善)
测试策略
- 传统WBS:测试放在最后,问题发现太晚
- Spec-Kit WBS:测试先行(TDD),质量更有保障
任务标识
- 传统WBS:无特殊标识,按顺序执行
- Spec-Kit WBS:[P]标识并行任务,提高开发效率
适用场景
- 传统WBS:通用项目管理(建筑、市场、产品发布)
- Spec-Kit WBS:软件开发项目(API开发、系统集成、技术重构)
文件管理
- 传统WBS:通用描述,适合各种项目
- Spec-Kit WBS:具体文件路径,便于开发执行
传统WBS
电商网站项目
├── 1. 需求分析 (5个任务)
├── 2. 设计 (8个任务)
├── 3. 开发 (12个任务)
├── 4. 测试 (9个任务)
└── 5. 部署 (8个任务)
Spec-Kit的WBS
联调12个接口
├── 阶段 3.1: 环境设置 (3个任务)
├── 阶段 3.2: 测试先行 (13个任务) [P]
├── 阶段 3.3: 核心实现 (14个任务)
├── 阶段 3.4: 集成 (4个任务)
└── 阶段 3.5: 完善 (4个任务)
Spec-Kit WBS的特点
- 技术实现导向 - 更注重技术实现细节
- 测试先行 - 强调TDD (Test-Driven Development)
- 并行任务标识 - 明确标识可并行执行的任务 [P]
- 具体文件路径 - 每个任务都有明确的文件路径
- 依赖关系管理 - 清晰定义任务间的依赖关系
Spec-Kit WBS示例
联调12个接口
├── 阶段 3.1: 环境与项目设置
│ ├── T001: 创建目录结构
│ ├── T002: 初始化项目
│ └── T003 [P]: 配置工具
├── 阶段 3.2: 测试先行 (TDD)
│ ├── T004-T015: 12个接口的合约测试 [P]
│ └── T016: 集成测试
├── 阶段 3.3: 核心实现
│ ├── T017-T018: 数据模型和服务层
│ └── T019-T030: 12个接口实现
├── 阶段 3.4: 集成
│ ├── T031-T033: 服务连接和配置
│ └── T034: 集成测试
└── 阶段 3.5: 完善
├── T035-T037: 测试和文档
└── T038: 最终验证
📝 总结
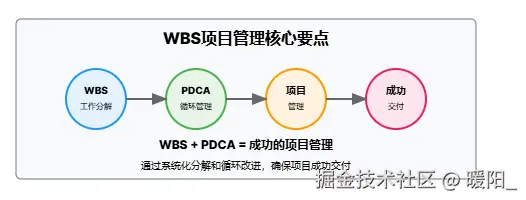
WBS是项目管理的核心工具,它将复杂的项目分解为可管理的小任务。与PDCA循环结合使用,可以确保项目的系统性、完整性和可跟踪性。
关键要点:
- WBS是PDCA循环中Plan阶段的核心工具
- 通过层次化分解确保项目完整性
- 每个任务都有明确的交付物和责任人
- 支持进度跟踪和风险管理
- 在Spec-Kit中与规范驱动开发完美结合
实际应用建议:
- 从项目目标开始,逐层分解
- 确保每个任务都有明确的交付物
- 合理分配任务给团队成员
- 定期检查进度,及时调整计划
- 总结经验,持续改进WBS模板
Changelog
V1.0 (2025-09-29)
- [新增] 初稿完成 - 文档基础框架建立
- [新增] 初稿完成 - 基础版本
- [新增] 添加WBS基本概念和实际应用示例
- [新增] 新增传统WBS vs Spec-Kit WBS对比分析
- [新增] 完善文档结构和可读性 - 用户体验
来源:juejin.cn/post/7555327916483870774
SpringBoot多模板引擎整合难题?一篇搞定JSP、Freemarker与Thymeleaf!
关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
在现代Web应用开发中,模板引擎是实现前后端分离和视图渲染的重要工具。SpringBoot作为流行的Java开发框架,天然支持多种模板引擎。
每一个项目使用单一的模板引擎是标准输出。但是,总有一些老项目经历多轮迭代,人员更替,不同的开发都只是用自己熟悉的模版引擎,导致一个项目中包含了多种模板引擎。从而相互影响,甚至出现异常。这也是小编正在经历的痛苦。
本文将详细介绍如何在SpringBoot项目中同时集成JSP、Freemarker和Thymeleaf三种模板引擎,包括配置方法、使用场景、常见问题及解决方案。
02 项目搭建
本文基于Springboot 3.0.13,因为不同版本(2.x)对于部分包的做了更改。由于JSP的配置会影响其他的模板引擎,所以JSP的配置,放到最后说明。
2.1 Maven依赖
<!-- freemarker 模版引擎 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
<!-- thymeleaf 模版引擎 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
2.3 配置
#配置freemarker
spring.freemarker.template-loader-path=classpath:/templates/ftl/
spring.freemarker.suffix=.ftl
spring.freemarker.cache=false
# 配置thymeleaf
spring.thymeleaf.prefix=classpath:/templates/html/
spring.thymeleaf.suffix=.html
spring.thymeleaf.cache=false
2.4 最佳实践
页面
控制层
@Controller
@RequestMapping("/page")
public class PageController {
@RequestMapping("{engine}")
public String toPage(@PathVariable("engine") String engine, Model model) {
model.addAttribute("date", new Date());
return engine + "_index";
}
}
2.5 测试
到这里,会发现一切顺利。Thymeleaf和Freemarker都可以顺利解析。但是,引入JSP之后,发现不能生效。
03 SpringBoot继续集成JSP
3.1 Maven依赖
<!-- JSP支持 -->
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
</dependency>
<!-- jstl 工具 -->
<dependency>
<groupId>jakarta.servlet.jsp.jstl</groupId>
<artifactId>jakarta.servlet.jsp.jstl-api</artifactId>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>jakarta.servlet.jsp.jstl</artifactId>
</dependency>
这里要说明的jstl,低版本(3.x一下)的需要引入:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
具体的依赖可以在Springboot官方文档中查看。
3.2 配置
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp
3.3 创建包结构
因为SpringBoot默认不支持JSP,所以需要我们自己配置支持JSP。
包的路径地址:\src\main\webapp\WEB-INF
3.4 修改pom打包
在build下增加resource
<resources>
<!-- 打包时将jsp文件拷贝到META-INF目录下-->
<resource>
<!-- 指定处理哪个目录下的资源文件 -->
<directory>src/main/webapp</directory>
<!--注意此次必须要放在此目录下才能被访问到-->
<targetPath>META-INF/resources</targetPath>
<includes>
<include>**/**</include>
</includes>
</resource>
</resources>
3.5 测试
其他两个不受影响,但是发现配置的JSP并不生效,根据报错信息来看,默认使用了Thymeleaf解析的。
04 源码追踪
关键的类:org.springframework.web.servlet.view.ContentNegotiatingViewResolver
断点调试发现,图中①根据jsp_index视图,可以发现两个候选的View:ThymelearView和JstlView。
图中②获取最优的视图返回了ThymelearView,从而解析错误。从getBestView()源码可以看到,仅仅做了遍历操作,并没有个给句特殊的规则去取。如图:
所以影响视图解析器的就是候选视图的顺序。
我们继续看候选视图的取值:
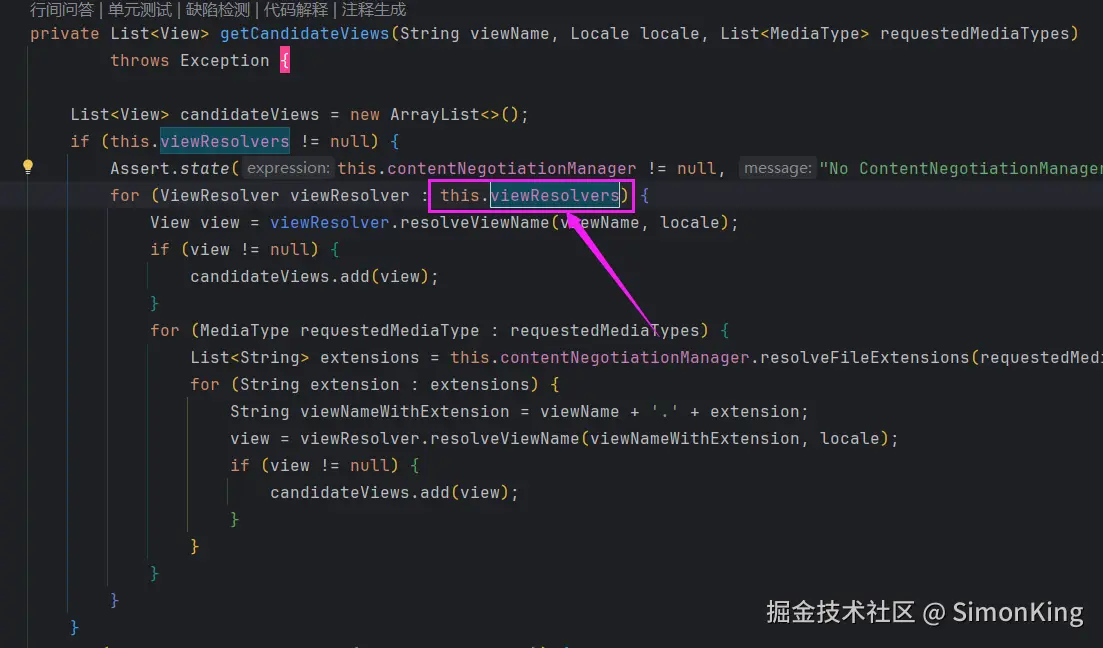
这里仍是只是遍历,我们需要继续追溯this.viewResolvers的来源:
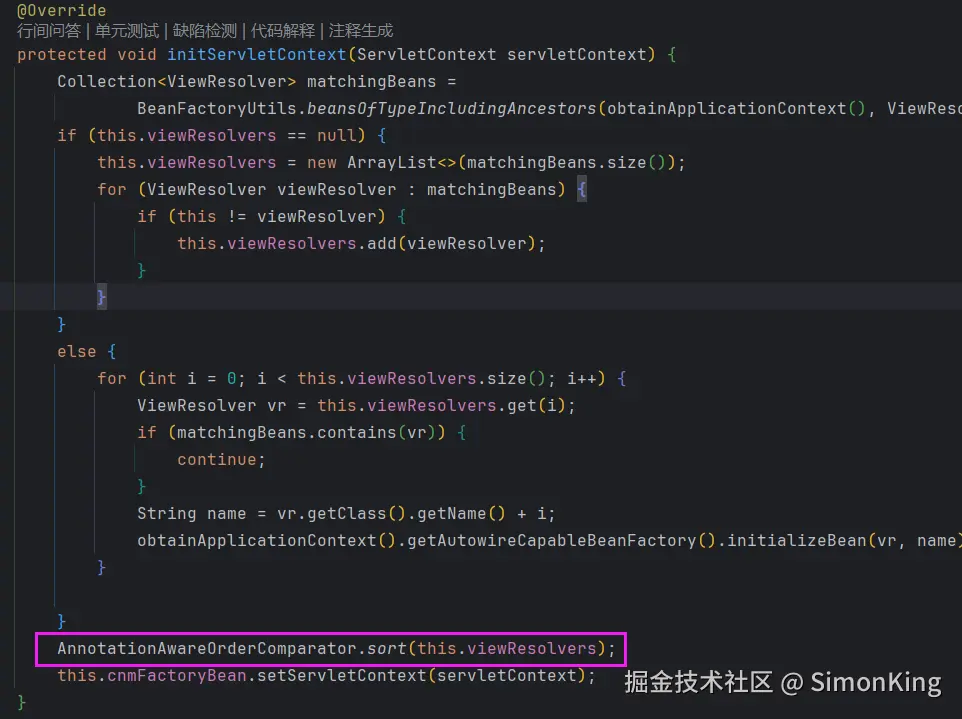
关键代码AnnotationAwareOrderComparator.sort(this.viewResolvers)会对所有的视图排序,所以我们只需要指定JSP的视图为第一个就可以了。
05 配置JSP视图的顺序
因为JSP的视图使用的是InternalResourceViewResolver,所以我们只需要设置其顺序即可。
@Configuration
public class BeanConfig {
@Autowired
InternalResourceViewResolver resolver;
@PostConstruct
public void init() {
resolver.setOrder(1);
}
由于其他的视图解析器默认是最级别,所以这里的设置只要比Integr.MAX小即可。
测试
我们发现源代码已经将JstlView变成了第一个,最优的视图自然也选择了JstlView,如图:
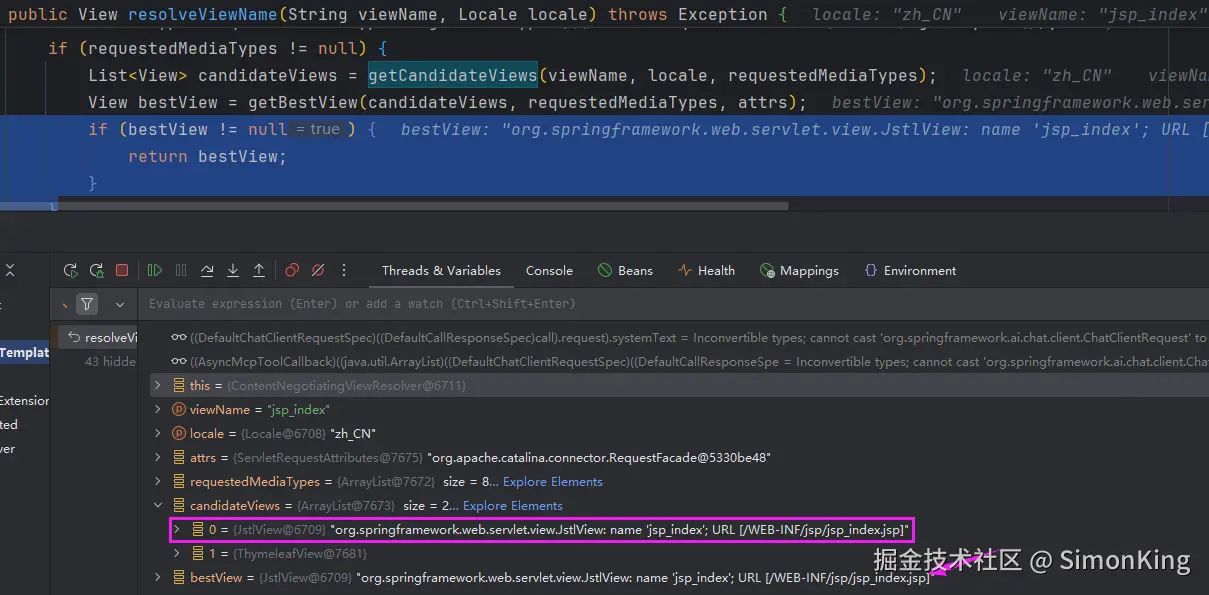
效果
我们发现JSP是正常显示了,但是其他两个又不好了。
真实让人头大!
06 解决JSP混合问题
6.1 解决方案
其实这里要使用一个属性可以永久的解决问题:viewName,
每一个ViewResolver都有一段关键的源码:

这里是匹配关系,可以通过配置的view-names过滤不符合条件的视图:

6.2 重新修改配置
###配置freemarker
spring.freemarker.template-loader-path=classpath:/templates/
spring.freemarker.view-names=ftl/*
spring.freemarker.suffix=.ftl
spring.freemarker.cache=false
#
### 配置thymeleaf
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.view-names=html/*
spring.thymeleaf.suffix=.html
spring.thymeleaf.cache=false
##
### 配置JSP
spring.mvc.view.prefix=/WEB-INF/
spring.mvc.view.suffix=.jsp
这里的和之前不同的就是增加了spring.thymeleaf.view-names、spring.freemarker.view-names,并且classpath的路径少了一部分移动到view-names里面了。
JSP的spring.mvc.view.prefix同样少了一部分需要配置。
6.3 重新修改Java配置
@Configuration
public class BeanConfig {
@Autowired
InternalResourceViewResolver resolver;
@PostConstruct
public void init() {
resolver.setViewNames("jsp/*");
}
也可以使用Bean定义。使用Bean定义需要删除配置文件关于JSP的配置。
@Bean
public ViewResolver jspViewResolver() {
InternalResourceViewResolver resolver = new InternalResourceViewResolver();
resolver.setPrefix("/WEB-INF/");
resolver.setSuffix(".jsp");
resolver.setViewNames("jsp/*");
return resolver;
}
6.4 修改控制层
@Controller
@RequestMapping("/page")
public class PageController {
@RequestMapping("{engine}")
public String toFtl(@PathVariable("engine") String engine, Model model) {
model.addAttribute("date", new Date());
return engine + "/" + engine + "_index";
}
}
6.5 效果
来源:juejin.cn/post/7555065224802861066
JVM内存公寓清洁指南:G1与ZGC清洁工大比拼
JVM内存公寓清洁指南:G1与ZGC清洁工大比拼 🧹
引言:当内存公寓遇上"清洁工天团"
当 Java 应用中的对象在"内存公寓"里肆意"开派对"后,未被引用的对象便成了散落各处的"垃圾",此时就需要专业的"清洁团队"——垃圾回收器登场。JVM 内存区域如同"内存公寓"的不同房间,其中线程共享区的堆是最大的"活动空间",按对象生命周期分为新生代(Eden 区占 8/10、Survivor 区各占 1/10)和老年代,如同公寓的"青年宿舍"与"长者公寓";方法区(元空间)则类似"物业档案室",存储类元数据等。
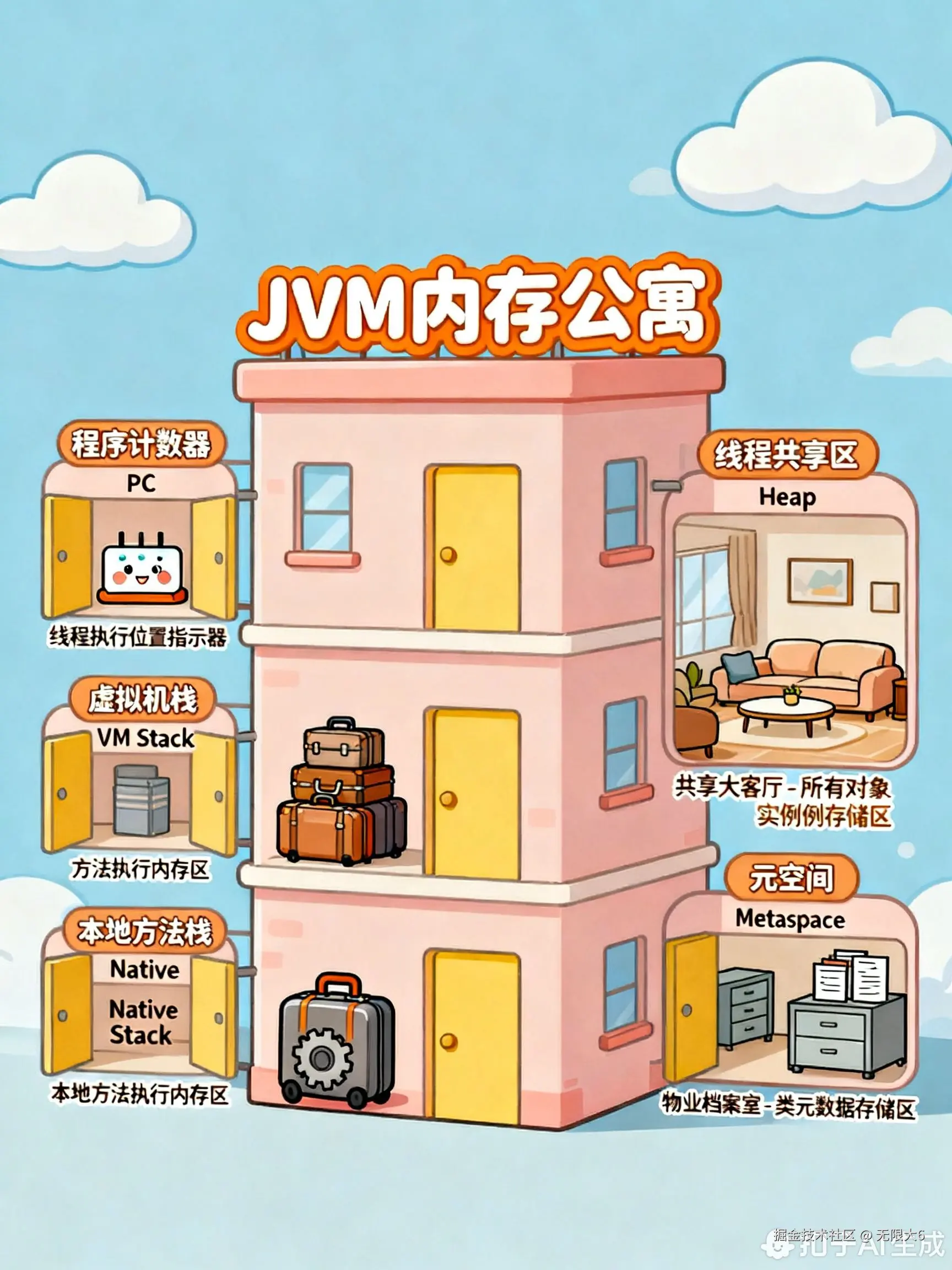
为什么有的"清洁工"习惯按区域分片打扫,有的却能以"闪电速度"完成全屋清洁?这就不得不提到 G1 和 ZGC 两位"王牌清洁工"——前者以"分区管理"策略著称,后者则追求"低延迟闪电清洁",其设计目标是将应用暂停(STW)时间控制在 10ms 以内,且停顿时间不会随堆大小或活跃对象增加而延长。

核心差异预告:G1 采用分代分区管理模式,擅长平衡吞吐量与停顿;ZGC 则通过创新算法突破堆大小限制,主打"毫秒级响应"。本文将拆解两者的"清洁秘籍"(垃圾回收算法)与"工资参数"(调优参数),揭秘谁能成为"内存公寓"的最优解。
G1回收器:精打细算的"分区清洁队长"

Garbage-First (G1) 垃圾收集器作为默认低延迟收集器,其核心设计理念可类比为"内存公寓"的分区清洁管理系统。与传统收集器将堆内存划分为固定大小新生代与老年代的方式不同,G1采用"分区垃圾袋"式的Region机制,将整个堆内存划分为最多2048个独立Region,每个Region容量可在1MB至32MB之间动态调整(默认根据堆大小自动选择)。这些Region并非固定归属新生代或老年代,而是根据应用内存分配模式动态标记为Eden区、Survivor区或Old区,实现内存资源的弹性调度。这种动态分区机制使G1能够灵活应对不同类型应用的内存需求,尤其适用于堆内存4GB至32GB的常规企业应用场景。
G1的垃圾回收策略采用"混合清洁模式"(Mixed GC),其工作流程可形象比喻为"先集中清理垃圾密集的房间(新生代),再抽空打扫老房间(老年代)"。G1优先对新生代Region执行Minor GC,通过复制算法快速回收短期存活对象;当老年代Region占比达到参数-XX:InitiatingHeapOccupancyPercent(默认45%)设定的阈值时,触发Mixed GC,在新生代收集的同时,选取部分垃圾占比高的老年代Region进行回收。这种选择性回收策略使G1能够集中资源处理垃圾密集区域,从而更精准地控制停顿时间,避免传统收集器对整个老年代进行全区域扫描的高昂成本。
在实际调优中,启用G1需通过JVM参数显式配置,基础命令示例如下:java -XX:+UseG1GC -Xms4g -Xmx4g -XX:MaxGCPauseMillis=200 -jar app.jar。某电商交易系统优化案例显示,在未调优状态下GC停顿时间常达300ms,通过设置MaxGCPauseMillis=200并调整Region大小后,停顿时间稳定降至180ms,同时吞吐量保持98%以上。核心调优参数及说明如下表所示:
| 参数 | 作用 | 幽默解读 |
|---|---|---|
-XX:+UseG1GC | 启用G1回收器 | "任命G1为清洁队长" |
-Xms/-Xmx | 初始/最大堆大小 | "初始/最大垃圾袋容量" |
-XX:MaxGCPauseMillis | 目标停顿时间 | "要求每次清洁不超过X毫秒" |
-XX:G1HeapRegionSize | Region大小 | "每个垃圾袋的容量" |
💡 调优技巧:设置合理的停顿目标(如200ms)是平衡延迟与吞吐量的关键。G1会根据历史回收数据动态调整Region回收数量,过度严苛的停顿目标(如50ms)会迫使收集器频繁进行小范围压缩,反而导致GC次数激增。建议通过-XX:G1HeapRegionSize参数将Region大小设置为堆内存的1/2048,确保每个Region既能容纳大对象,又避免过小Region导致的管理开销。
🚨 常见误区:不要将-Xms和-Xmx设置为不同值!动态堆扩容会导致"内存公寓"频繁调整垃圾袋大小,引发额外性能开销,就像清洁工频繁更换垃圾桶尺寸一样影响效率。
以下是G1调优前后的GC日志对比:
# 调优前(停顿300ms)
[GC pause (G1 Evacuation Pause) (young) 1024M->768M(4096M) 302.5ms]
# 调优后(停顿180ms)
[GC pause (G1 Evacuation Pause) (young) 1024M->768M(4096M) 178.3ms]
ZGC回收器:闪电般的"极速清洁特工"

ZGC作为JVM内存管理的"极速清洁特工",其核心竞争力体现在毫秒级停顿与超大堆支持两大特性上。设计目标明确为停顿时间不超过10ms,且该指标不会随堆大小或活跃对象数量的增加而退化,从根本上解决了传统回收器在大堆场景下的停顿痛点。
ZGC的"闪电清洁"秘籍
ZGC实现"边打扫边让住户正常活动"的核心技术在于染色指针与内存多重映射。染色指针技术在64位指针中嵌入4位元数据,可实时存储对象的标记状态与重定位信息,相当于清洁工佩戴的"AR智能眼镜",能在不中断住户活动的情况下完成垃圾标记。内存多重映射则通过将物理内存同时映射到Marked0、Marked1、Remapped三个虚拟视图,实现并发重定位操作,确保回收过程与应用线程几乎无干扰。实测数据显示,ZGC停顿时间平均仅1.09ms,99.9%分位值为1.66ms,远低于10ms的设计阈值。
大堆管理:从16MB到16TB的"超级公寓"
与G1固定大小的Region(最大32MB)不同,ZGC采用动态Region机制,将内存划分为小页(2MB)、中页(32MB)和大页(N×2MB,最大支持16TB),如同"能伸缩的智能垃圾袋",可根据对象大小自动调整容量。这种设计使其支持从8MB到16TB的堆内存范围,而G1在堆大小超过64GB时易出现停顿失控[1]。动态Region不仅提升了内存利用率,还解决了大对象分配效率问题,实现"小到零食包装,大到家具"的全覆盖管理。
调优参数实战
启用与核心参数配置
启用ZGC需在JDK15+环境中使用以下命令:
java -XX:+UseZGC -Xms16g -Xmx16g -XX:ZCollectionInterval=60 -jar app.jar
该配置指定16GB堆空间(初始与最大堆相同),至少每60秒执行一次回收。以下为核心参数说明:
| 参数 | 作用 | 幽默解读 |
|---|---|---|
-XX:+UseZGC | 启用ZGC回收器 | "召唤闪电清洁特工" |
-Xms/-Xmx | 初始/最大堆大小 | "清洁区域的固定边界" |
-XX:ZCollectionInterval | 最小回收间隔 | "至少每隔X秒打扫一次" |
-XX:ZAllocationSpikeTolerance | 分配尖峰容忍度 | "允许临时垃圾堆积倍数" |
💡 调优黄金法则:ZGC在32GB以上大堆场景优势显著,此时其停顿稳定性远超G1;而8GB以下小堆场景建议保留G1,因ZGC的吞吐量损失(通常<15%)在小堆下性价比更低。
🚨 误区警示:ZGC在JDK15才正式发布,JDK11-14为实验性版本,存在功能限制;JDK11以下版本完全不支持,切勿尝试在低版本JDK中启用。
性能对比与GC日志示例
在64GB堆环境下,ZGC与G1的表现差异显著:
# ZGC日志(停顿8ms)
[0.875s][info][gc] GC(0) Pause Relocate Start 1.56ms
[0.877s][info][gc] GC(0) Pause Relocate End 0.89ms
# G1日志(停顿520ms)
[GC pause (G1 Evacuation Pause) (mixed) 5890M->4520M(65536M) 520.3ms]
某支付系统迁移案例显示,将G1替换为ZGC后,峰值GC停顿从280ms降至8ms,交易成功率提升0.5%,验证了ZGC在关键业务场景的性能优势。
G1 vs ZGC:清洁团队终极PK
衡量垃圾收集器的三项重要指标包括内存占用(Footprint)、吞吐量(Throughput)和延迟(Latency)。吞吐量和延迟通常不可兼得,关注吞吐量的收集器和关注延迟的收集器在算法选择上存在差异。以下从核心能力与场景适配两方面对比 G1 与 ZGC 的差异:
核心能力对比表
| 能力维度 | G1(分区清洁工) | ZGC(闪电特工) |
|---|---|---|
| 停顿时间 | 100-300 ms | < 10 ms |
| 堆大小支持 | 最大 64 GB | 最大 16 TB |
| 吞吐量 | 较高 | 略低(因并发开销) |
| 适用场景 | 常规应用、中小堆 | 低延迟服务、超大堆 |
电商订单系统:用户下单高峰期需避免卡顿,ZGC 小于 10 ms 的停顿特性可保障交易流畅性。
大数据批处理:当堆大小适中(如 32 GB)且吞吐量优先时,G1 更具成本效益。
实时游戏服务:毫秒级响应要求下,ZGC 是唯一能满足低延迟需求的选择。
总结:选对清洁工,内存公寓更舒心
回到"内存公寓"的管理视角,垃圾回收器的选择本质是匹配"公寓规模"与"住户需求"的过程——正如现实中没有万能的清洁工,JVM 内存管理也不存在绝对最优解,只有最适配场景的选择。
G1 作为"精打细算的分区管理员",擅长处理 4GB~32GB 堆内存的常规企业应用,通过区域化内存布局与增量回收机制,在延迟控制与吞吐量之间取得平衡,成为大多数标准业务场景的默认选择。其设计理念如同经验丰富的物业经理,通过精细化分区管理确保日常运营的稳定高效。
ZGC 则是"追求极致速度的闪电特工",专为 8MB~16TB 超大堆场景打造,尤其适用于金融交易等对停顿时间(<10ms)要求严苛的低延迟应用。它突破传统回收器的性能瓶颈,如同配备尖端装备的特种清洁团队,能在不干扰住户正常活动的前提下完成超大空间的极速清理。
调优核心口诀:"小堆 G1 看停顿,大堆 ZGC 保延迟,参数设置要合理,日志监控不能停"。这一实践准则强调:堆内存规模与延迟需求是选型的首要依据,而持续的参数优化与监控分析则是维持长期稳定的关键。
选择合适的垃圾回收器并合理配置参数(如元空间大小、回收阈值等),是确保"内存公寓"长期整洁(避免内存溢出、减少 GC 停顿)的核心保障。你的内存公寓需要哪种清洁工?评论区聊聊你的调优故事吧!🎉
来源:juejin.cn/post/7552730198288564259
Mysql---领导让下班前把explain画成一张图
Explain总览图 这篇文章主要看图
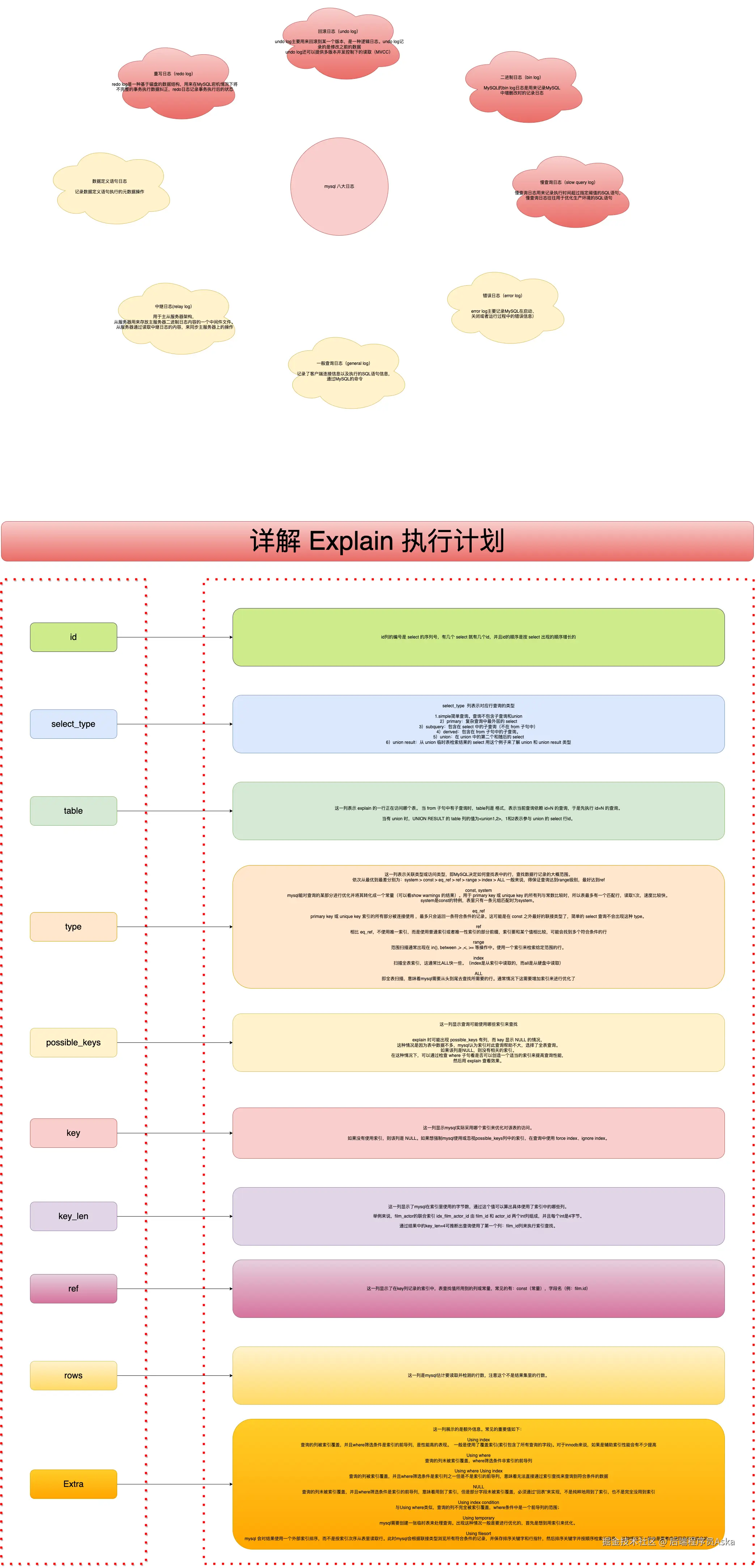
Explain是啥
1、Explain工具介绍
使用EXPLAIN关键字可以模拟优化器执行SQL语句,分析你的查询语句或是结构的性能瓶颈, 在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL。
注意:如果 from 中包含子查询,仍会执行该子查询,将结果放入临时表中。
2、Explain分析示例
参考官方文档:dev.mysql.com/doc/refman/…
# 示例表:
DROP TABLE IF EXISTS `actor`;
CREATE TABLE `actor` (
`id` int(11) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `actor` (`id`, `name`, `update_time`) VALUES (1,'a','2017‐12‐22
15:27:18'), (2,'b','2017‐12‐22 15:27:18'), (3,'c','2017‐12‐22 15:27:18');
DROP TABLE IF EXISTS `film`;
CREATE TABLE `film` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film` (`id`, `name`) VALUES (3,'film0'),(1,'film1'),(2,'film2');
DROP TABLE IF EXISTS `film_actor`;
CREATE TABLE `film_actor` (
`id` int(11) NOT NULL,
`film_id` int(11) NOT NULL,
`actor_id` int(11) NOT NULL,
`remark` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_film_actor_id` (`film_id`,`actor_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `film_actor` (`id`, `film_id`, `actor_id`) VALUES (1,1,1),(2,1,2),(3,2,1);
explain select * from actor;
# 在查询中的每个表会输出一行,如果有两个表通过 join 连接查询,那么会输出两行。
3、explain 两个变种
- 1)explain extended:
会在 explain 的基础上额外提供一些查询优化的信息。紧随其后通过 show warnings 命令可 以得到优化后的查询语句,从而看出优化器优化了什么。额外还有 filtered 列,是一个半分比的值,rows * filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)
explain extended select * from film where id = 1;
show warnings;
- 2)explain partitions:
相比 explain 多了个 partitions 字段,如果查询是基于分区表的话,会显示查询将访问的分区。
4、explain中的列
4.1. id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。 id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
4.2. select_type列
select_type 表示对应行是简单还是复杂的查询。
- 1)simple:简单查询。查询不包含子查询和union;
- 2)primary:复杂查询中最外层的select ;
- 3)subquery:包含在 select 中的子查询(不在 from 子句中);
- 4)derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中;
- 5)union:在 union 中的第二个和随后的 select;
explain select * from film where id = 2;
用这个例子来了解 primary、subquery 和 derived 类型:
#关闭mysql5.7新特性对衍生表的合并优化
set session optimizer_switch='derived_merge=off';
explain select (select 1 from actor where id = 1) from (select * from film where id = 1) der;
#还原默认配置
set session optimizer_switch='derived_merge=on';
explain select 1 union all select 1;
4.3. table列
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。当有 union 时,UNION RESULT 的 table 列的值为,1和2表示参与 union 的 select 行id。
4.4. type列
这一列表示关联类型或访问类型,即MySQL决定如何查找表中的行,查找数据行记录的大概范围。 依次从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL 。
一般来说,得保证查询达到range级别,最好达到ref ;
NULL:
mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可 以单独查找索引来完成,不需要在执行时访问表
mysql> explain select min(id) from film;
const, system:
mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于 primary key 或 unique key 的所有列与常数比较时,所以表最多有一个匹配行,读取1次,速度比较快。system是 const的特例,表里只有一条元组匹配时为system;
explain extended select * from (select * from film where id = 1) tmp;
show warnings;
eq_ref:
primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。这可能是在 const 之外最好的联接类型了,简单的 select 查询不会出现这种 type。
explain select * from film_actor left join film on film_actor.film_id = film.id;
ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会 找到多个符合条件的行。
简单 select 查询,name是普通索引(非唯一索引)
explain select * from film where name = 'film1';
关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
explain select film_id from film left join film_actor on film.id = film_actor.fi
lm_id;
range:
范围扫描通常出现在 in(), between ,> ,= 等操作中。使用一个索引来检索给定范围的行。
explain select * from actor where id > 1;
index:
扫描全索引就能拿到结果,一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接 对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这 种通常比ALL快一些。
explain select * from film;
ALL:
即全表扫描,扫描你的聚簇索引的所有叶子节点.通常情况下这需要增加索引来进行优化。
explain select * from actor;
4.5. possible_keys列
这一列显示查询可能使用哪些索引来查找 explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提 高查询性能,然后用 explain 查看效果。
4.6. key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。 如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index、ignore index。
4.7. key_len列
这一列显示了mysql在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。 举例来说,film_actor的联合索引 idx_film_actor_id 由 film_id 和 actor_id 两个int列组成,并且每个int是4字节。通 过结果中的key_len=4可推断出查询使用了第一个列:film_id列来执行索引查找。
explain select * from film_actor where film_id = 2;
key_len计算规则如下:
字符串:
char(n):如果存汉字长度就是 3n 字节
varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,
因为 varchar是变长字符串
char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,
如果是 utf-8,一个数字 或字母占1个字节,一个汉字占3个字节 ;
数值类型:
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型:
date:3字节
timestamp:4字节
datetime:8字节
如果字段允许为 NULL,需要1字节记录是否为 NULL ;索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
4.8. ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,
常见的有:const(常量),字段名(例:film.id)
4.9. rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
4.10. Extra列
这一列展示的是额外信息。常见的重要值如下:
1)Using index:使用覆盖索引
覆盖索引定义:mysql执行计划explain结果里的key有使用索引,如果select后面查询的字段都可以从这个索引的树中 获取,这种情况一般可以说是用到了覆盖索引,extra里一般都有using index;覆盖索引一般针对的是辅助索引,整个 查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值。
explain select film_id from film_actor where film_id = 1;
2)Using where:
使用 where 语句来处理结果,并且查询的列未被索引覆盖
explain select * from actor where name = 'a';
3)Using index condition:
查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
explain select * from film_actor where film_id > 1;
4)Using temporary:
mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索 引来优化。
actor.name没有索引,此时创建了张临时表来distinct
explain select distinct name from actor;
film.name建立了idx_name索引,此时查询时extra是using index,没有用临时表
explain select distinct name from film;
5)Using filesort:
将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一 般也是要考虑使用索引来优化的
- actor.name未创建索引,会浏览actor整个表,保存排序关键字name和对应的id,然后排序name并检索行记录
1 mysql> explain select * from actor order by name
2. film.name建立了idx_name索引,此时查询时extra是using index
explain select * from film order by name;
6)Select tables optimized away:
使用某些聚合函数(比如 max、min来访问存在索引的某个字段是
explain select min(id) from film;
索引最佳实践
# 示例表:
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei',
23,'dev',NOW());
INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
5.1.全值匹配
1 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei';
1 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22;
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
5.2.最左前缀法则
如果索引了多列,要遵守最左前缀法。则指的是查询从索引的最左前列开始并且不跳过索引中的列。
1 EXPLAIN SELECT * FROM employees WHERE name = 'Bill' and age = 31;
2 EXPLAIN SELECT * FROM employees WHERE age = 30 AND position = 'dev';
3 EXPLAIN SELECT * FROM employees WHERE position = 'manager'
5.3.不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
1 EXPLAIN SELECT * FROM employees WHERE name = 'LiLei';
2 EXPLAIN SELECT * FROM employees WHERE left(name,3) = 'LiLei';
给hire_time增加一个普通索引:
1 ALTER TABLE employees ADD INDEX idx_hire_time (hire_time) USING BTREE ;
2 EXPLAIN select * from employees where date(hire_time) ='2018‐09‐30';
转化为日期范围查询,有可能会走索引:
1 EXPLAIN select * from employees where hire_time >='2018‐09‐30 00:00:00' and hire_time <='2018‐09‐30 23:59:59';
还原最初索引状态
1 ALTER TABLE employees DROP INDEX idx_hire_time;
5.4.存储引擎不能使用索引中范围条件右边的列
1 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
2 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';
5.5.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少 select * 语句
1 EXPLAIN SELECT name,age FROM employees WHERE name= 'LiLei' AND age = 23 AND position='manager';
1 EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
5.6.mysql在使用不等于(!=或者<>),not in ,not exists 的时候无法使用索引会导致全表扫描 < 小于、 > 大于、 = 这些,mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引
1 EXPLAIN SELECT * FROM employees WHERE name != 'LiLei';
5.7.is null,is not null 一般情况下也无法使用索引
1 EXPLAIN SELECT * FROM employees WHERE name is null
5.8.like以通配符开头('$abc...')mysql索引失效会变成全表扫描操作
1 EXPLAIN SELECT * FROM employees WHERE name like '%Lei'
1 EXPLAIN SELECT * FROM employees WHERE name like 'Lei%'
问题:解决like'%字符串%'索引不被使用的方法?
a)使用覆盖索引,查询字段必须是建立覆盖索引字段
1 EXPLAIN SELECT name,age,position FROM employees WHERE name like '%Lei%';
b)如果不能使用覆盖索引则可能需要借助搜索引擎
5.9.字符串不加单引号索引失效
1 EXPLAIN SELECT * FROM employees WHERE name = '1000'; 2 EXPLAIN SELECT * FROM employees WHERE name = 1000;
5.10.少用or或in,
用它查询时,mysql不一定使用索引,mysql内部优化器会根据检索比例、表大小等多个因素整体评 估是否使用索引,详见范围查询优化
1 EXPLAIN SELECT * FROM employees WHERE name = 'LiLei' or name = 'HanMeimei';
5.11.范围查询优化 给年龄添加单值索引
1 ALTER TABLE employees ADD INDEX idx_age (age) USING BTREE ;
2 explain select * from employees where age >=1 and age <=2000;
没走索引原因:mysql内部优化器会根据检索比例、表大小等多个因素整体评估是否使用索引。比如这个例子,可能是 由于单次数据量查询过大导致优化器最终选择不走索引 。
优化方法:可以将大的范围拆分成多个小范围。
1 explain select * from employees where age >=1 and age <=1000;
2 explain select * from employees where age >=1001 and age <=2000;
还原最初索引状态
1 ALTER TABLE employees DROP INDEX idx_age;
6、索引使用总结
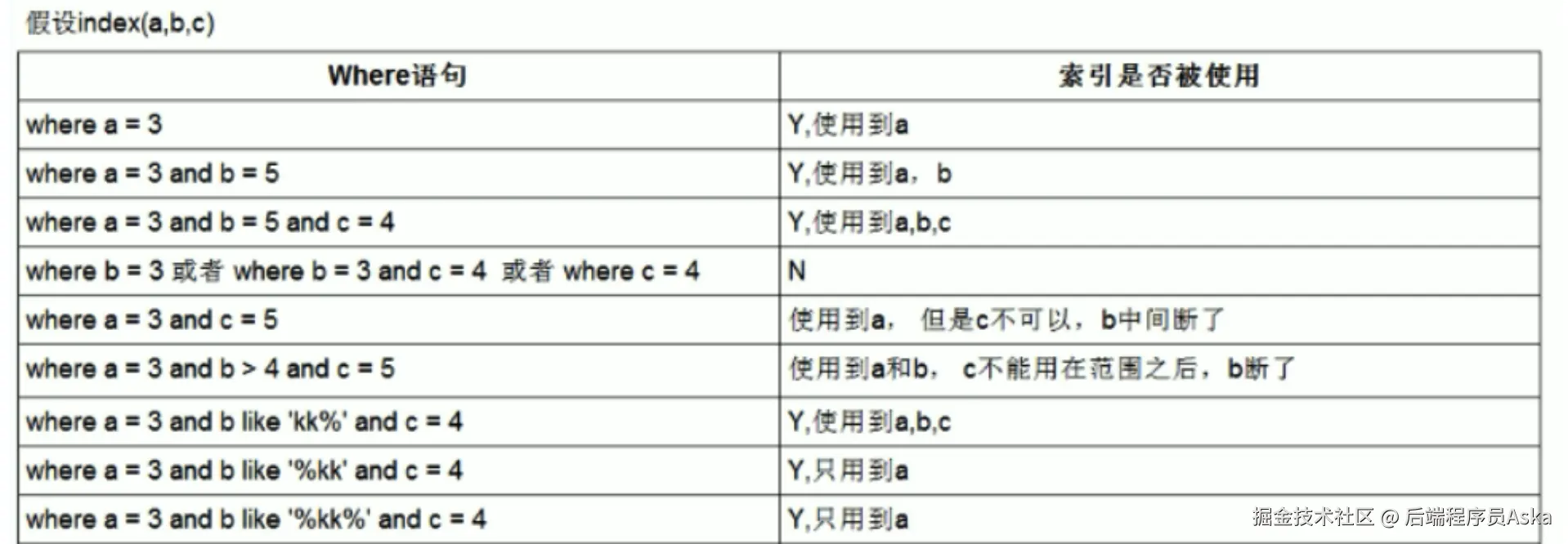
PS:like KK%相当于=常量,%KK和%KK% 相当于范围
来源:juejin.cn/post/7478888679231193125
叫你别乱封装,你看出事了吧
团队曾为一个订单状态显示问题加班至深夜:并非业务逻辑出错,而是前期封装的订单类过度隐藏核心字段,连获取支付时间都需多层调用,最终只能通过反射绕过封装临时解决,后续还需承担潜在风险。这一典型场景,正是 “乱封装” 埋下的隐患 —— 封装本是保障代码安全、提升可维护性的工具,但违背其核心原则的 “乱封装”,反而会让代码从 “易扩展” 走向 “高耦合”,成为开发流程中的阻碍。
一、乱封装的三类典型形态:偏离封装本质的错误实践
乱封装并非 “不封装”,而是未遵循 “最小接口暴露、合理细节隐藏” 原则,表现为三种具体形态,与前文所述的过度封装、虚假封装、混乱封装高度契合,且每一种都直接破坏代码可用性。
1. 过度封装:隐藏必要扩展点,制造使用障碍
为追求 “绝对安全”,将本应开放的核心参数或功能强行隐藏,仅保留僵化接口,导致后续业务需求无法通过正常途径满足。例如某文件上传工具类,将存储路径、上传超时时间等关键参数设为私有且未提供修改接口,仅支持默认配置。当业务需新增 “临时文件单独存储” 场景时,既无法调整路径参数,又不能复用原有工具类,最终只能重构代码,造成开发资源浪费。
反例代码:
// 文件上传工具类(过度封装)
public class FileUploader {
// 关键参数设为私有且无修改途径
private String storagePath = "/default/path";
private int timeout = 3000;
// 仅提供固定逻辑的上传方法,无法修改路径和超时时间
public boolean upload(File file) {
// 使用默认storagePath和timeout执行上传
return doUpload(file, storagePath, timeout);
}
// 私有方法,外部无法干预
private boolean doUpload(File file, String path, int time) {
// 上传逻辑
}
}
问题:当业务需要 "临时文件存 /tmp 目录" 或 "大文件需延长超时时间" 时,无法通过正常途径修改参数,只能放弃该工具类重新开发。
正确做法:暴露必要的配置接口,隐藏实现细节:
public class FileUploader {
private String storagePath = "/default/path";
private int timeout = 3000;
// 提供修改参数的接口
public void setStoragePath(String path) {
this.storagePath = path;
}
public void setTimeout(int timeout) {
this.timeout = timeout;
}
// 保留核心功能接口
public boolean upload(File file) {
return doUpload(file, storagePath, timeout);
}
2. 虚假封装:形式化隐藏细节,未实现数据保护
表面通过访问控制修饰符(如private)隐藏变量,也编写getter/setter方法,但未在接口中加入必要校验或逻辑约束,本质与 “直接暴露数据” 无差异,却增加冗余代码。以订单类为例,将orderStatus(订单状态)设为私有后,setOrderStatus()方法未校验状态流转逻辑,允许外部直接将 “已发货” 状态改为 “待支付”,违背业务规则,既未保护数据完整性,也失去了封装的核心价值。
反例代码:
// 订单类(虚假封装)
public class Order {
private String orderStatus; // 状态:待支付/已支付/已发货
// 无任何校验的set方法
public void setOrderStatus(String status) {
this.orderStatus = status;
}
public String getOrderStatus() {
return orderStatus;
}
}
// 外部调用可随意修改状态,违背业务规则
Order order = new Order();
order.setOrderStatus("已发货");
order.setOrderStatus("待支付"); // 非法状态流转,封装未阻止
问题:允许状态从 "已发货" 直接变回 "待支付",违反业务逻辑,封装未起到数据保护作用,和直接用 public 变量没有本质区别。
正确做法:在接口中加入校验逻辑:
public class Order {
private String orderStatus;
public void setOrderStatus(String status) {
// 校验状态流转合法性
if (!isValidTransition(this.orderStatus, status)) {
throw new IllegalArgumentException("非法状态变更");
}
this.orderStatus = status;
}
// 隐藏校验逻辑
private boolean isValidTransition(String oldStatus, String newStatus) {
// 定义合法的状态流转规则
return (oldStatus == null && "待支付".equals(newStatus)) ||
("待支付".equals(oldStatus) && "已支付".equals(newStatus)) ||
("已支付".equals(oldStatus) && "已发货".equals(newStatus));
}
}
3. 混乱封装:混淆职责边界,堆砌无关逻辑
将多个独立功能模块强行封装至同一类或组件中,未按职责拆分,导致代码耦合度极高。例如某项目的 “CommonUtil” 工具类,同时包含日期转换、字符串处理、支付签名校验三类无关功能,且内部逻辑相互依赖。后续修改支付签名算法时,误触日期转换模块的静态变量,导致多个依赖该工具类的功能异常,排查与修复耗时远超预期。
反例代码:
// 万能工具类(混乱封装)
public class CommonUtil {
// 日期处理
public static String formatDate(Date date) { ... }
// 字符串处理
public static String trim(String str) { ... }
// 支付签名(与工具类无关)
public static String signPayment(String orderNo, BigDecimal amount) {
// 使用了类内静态变量,与其他方法产生耦合
return MD5.encode(orderNo + amount + secretKey);
}
private static String secretKey = "default_key";
}
问题:当修改支付签名逻辑(如替换加密方式)时,可能误改 secretKey,导致日期格式化、字符串处理等无关功能异常,排查难度极大。
正确做法:按职责拆分封装:
// 日期工具类
public class DateUtil {
public static String formatDate(Date date) { ... }
}
// 字符串工具类
public class StringUtil {
public static String trim(String str) { ... }
}
// 支付工具类
public class PaymentUtil {
private static String secretKey = "default_key";
public static String signPayment(String orderNo, BigDecimal amount) { ... }
}
二、乱封装的核心危害:从开发效率到系统稳定性的双重冲击
乱封装的危害具有 “隐蔽性” 和 “累积性”,初期可能仅表现为局部开发不便,随业务迭代会逐渐放大,对系统造成多重影响。
1. 降低开发效率,增加需求落地成本
乱封装会导致接口设计与业务需求脱节,当需要调用核心功能或获取关键数据时,需额外编写适配代码,甚至重构原有封装。例如某报表功能需获取订单原始字段用于统计,但前期封装的订单查询接口仅返回加工后的简化数据,无法满足需求,开发团队只能协调原封装者新增接口,沟通与开发周期延长,直接影响项目进度。
2. 破坏系统可扩展性,引发连锁故障
未预留扩展点的乱封装,会让后续功能迭代陷入 “牵一发而动全身” 的困境。某项目的缓存工具类未设计 “缓存过期清除” 开关,当业务需临时禁用缓存时,只能修改工具类源码,却因未考虑其他依赖模块,导致多个功能因缓存逻辑变更而异常,引发线上故障。这种因封装缺陷导致的扩展问题,会随系统复杂度提升而愈发严重。
3. 提升调试难度,延长问题定位周期
内部细节的无序隐藏,会让问题排查失去清晰路径。例如某支付接口返回 “参数错误”,但封装时未在接口中返回具体错误字段,且内部日志缺失关键信息,开发人员需逐层断点调试,才能定位到 “订单号长度超限” 的问题,原本十分钟可解决的故障,耗时延长数倍。
三、避免乱封装的实践原则:回归封装本质,平衡安全与灵活
避免乱封装无需复杂的设计模式,核心是围绕 “职责清晰、接口合理” 展开,结合前文总结的经验,可落地为两大原则。
1. 按 “单一职责” 划分封装边界
一个类或组件仅负责一类核心功能,不堆砌无关逻辑。例如用户模块中,将 “用户注册登录”“信息修改”“地址管理” 拆分为三个独立封装单元,通过明确的接口交互(如用户 ID 关联),避免功能耦合。这种拆分方式既能降低修改风险,也让代码结构更清晰,便于后续维护。
2. 接口设计遵循 “最小必要 + 适度灵活”
- 最小必要:仅暴露外部必须的接口,隐藏内部实现细节(如工具类无需暴露临时变量、辅助函数);
- 适度灵活:针对潜在变化预留扩展点,避免接口僵化。例如短信发送工具类,核心接口sendSms(String phone, String content)满足基础需求,同时提供setTimeout(int timeout)方法允许调整超时时间,既隐藏签名验证、服务商调用等细节,又能应对不同场景的参数调整需求。
某商品管理项目的封装实践可作参考:商品查询功能同时提供两个接口 —— 面向前端的 “分页筛选简化接口” 和面向后端统计的 “完整字段接口”,既满足不同场景需求,又未暴露数据库查询逻辑,后续数据库表结构调整时,仅需维护内部实现,外部调用无需改动,充分体现了合理封装的价值。
结语
封装的本质是 “用合理的边界保障代码安全,用清晰的接口提升开发效率”,而非 “为封装而封装”。开发过程中,需避免过度追求形式化封装,也需警惕功能堆砌的混乱封装,多从后续维护、业务扩展的角度权衡接口设计。毕竟,好的封装是开发的 “助力”,而非 “阻力”—— 下次封装前,不妨先思考:“这样的设计,会不会给后续埋下隐患?”
来源:juejin.cn/post/7543911246166556715
苍穹外卖实现员工分页查询
员工分页查询功能开发
1. 需求分析
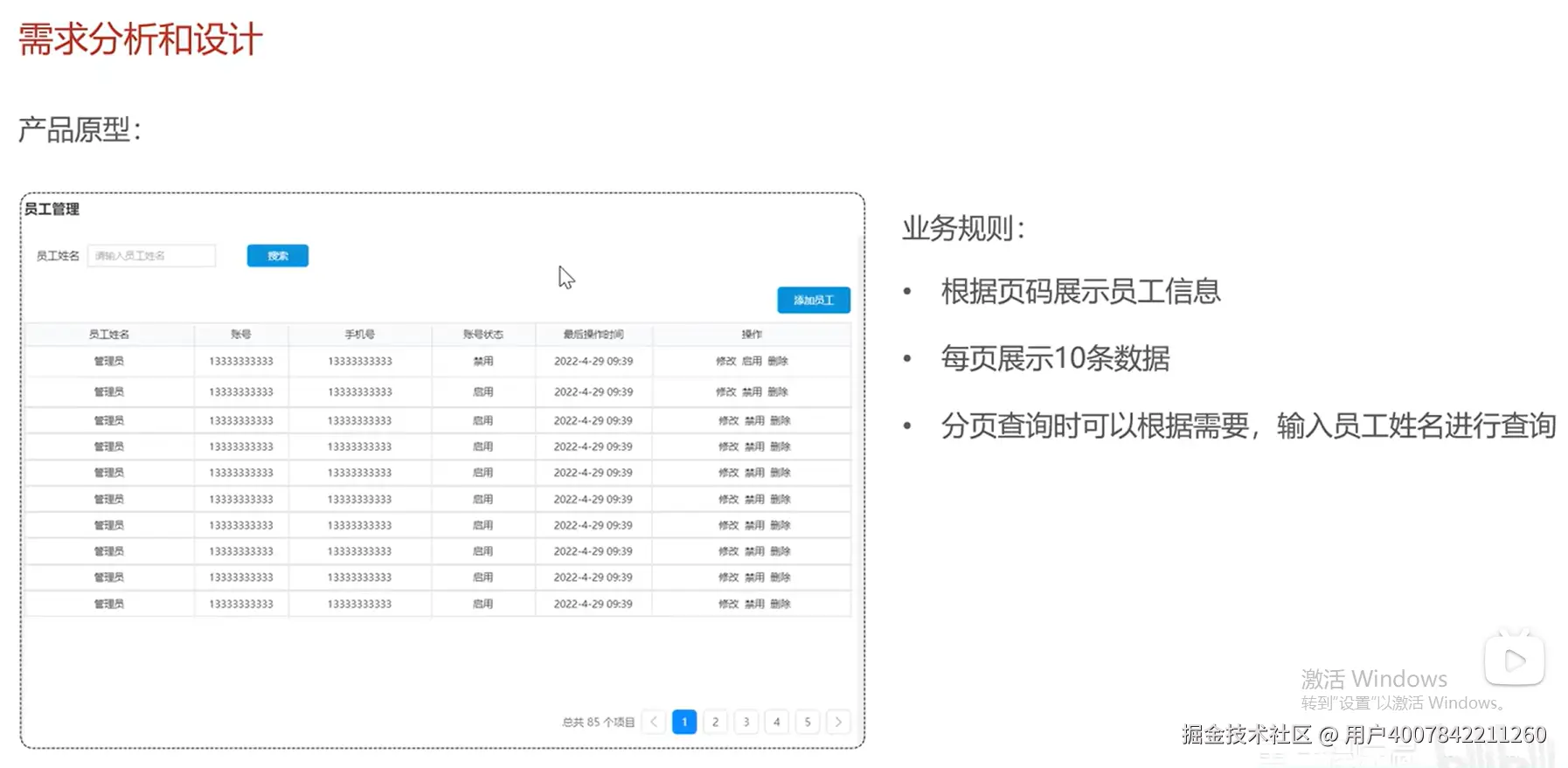
2. 代码开发
- 根据分页查询接口设计对应的DTO

- 设计controller层
@GetMapping("/page")
@ApiOperation(value = "员工分页查询")
public Result page(EmployeePageQueryDTO employeePageQueryDTO){
//输出日志
log.info("员工分页查询,查询参数: {}",employeePageQueryDTO);
//调用service层返回分页结果
PageResult pageResult = employeeService.pageQuery(employeePageQueryDTO);
//返回result
return Result.success(pageResult);
}
- 设计service层,使用Page Helper进行分页,并返回total和record
@Override
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
//开始分页
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
//调用mapper方法返回page对象,泛型为内容的类型,(page实际是一个List)
Page page = employeeMapper.pageQuery(employeePageQueryDTO);
//获取总的数据量
long total = page.getTotal();
//获取所有员工对象
List record = page.getResult();
//返回结果
return new PageResult(total,record);
}
- 设计Mapper层
Page pageQuery(EmployeePageQueryDTO employeePageQueryDTO);
- 使用动态SQL进行查询
<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
name like concat('%',#{name},'#')
if>
where>
order by create_time desc
select>
- 根据分页查询接口设计对应的DTO
- 设计controller层
@GetMapping("/page")
@ApiOperation(value = "员工分页查询")
public Result page(EmployeePageQueryDTO employeePageQueryDTO){
//输出日志
log.info("员工分页查询,查询参数: {}",employeePageQueryDTO);
//调用service层返回分页结果
PageResult pageResult = employeeService.pageQuery(employeePageQueryDTO);
//返回result
return Result.success(pageResult);
}
@Override
public PageResult pageQuery(EmployeePageQueryDTO employeePageQueryDTO) {
//开始分页
PageHelper.startPage(employeePageQueryDTO.getPage(), employeePageQueryDTO.getPageSize());
//调用mapper方法返回page对象,泛型为内容的类型,(page实际是一个List)
Page page = employeeMapper.pageQuery(employeePageQueryDTO);
//获取总的数据量
long total = page.getTotal();
//获取所有员工对象
List record = page.getResult();
//返回结果
return new PageResult(total,record);
}
Page pageQuery(EmployeePageQueryDTO employeePageQueryDTO);
<select id="pageQuery" resultType="com.sky.entity.Employee">
select * from employee
<where>
<if test="name != null and name != ''">
name like concat('%',#{name},'#')
if>
where>
order by create_time desc
select>
3. 功能测试
Swagger测试:
问题
createTime这种是数组形式传递的
前后端联调:
问题:
操作时间渲染格式问题
4. 代码完善

方式一:
代码:
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime createTime;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime updateTime;
数据返回:
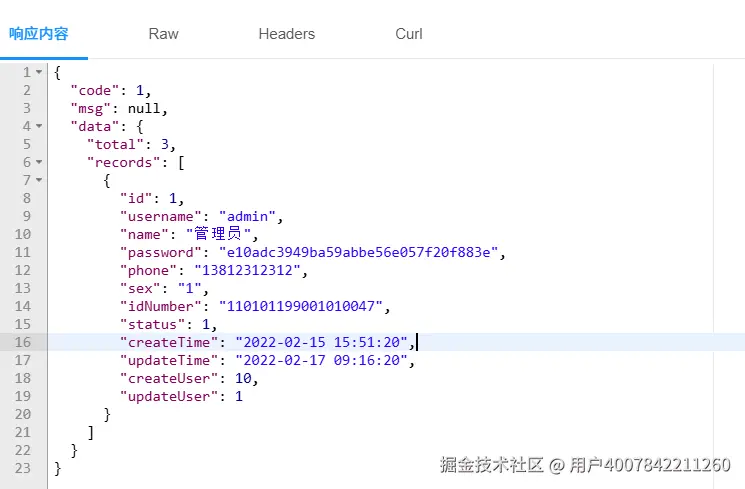
方式二:
代码:
需要在配置类中重写父类的方法,并配置添加消息转换器
@Override
protected void extendMessageConverters(List> converters) {
log.info("扩展消息转换器");
//创建一个消息转换器
MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();
//为消息转换器设置一个对象转换器,对象转换器可以将对象数据转换为json数据
converter.setObjectMapper(new JacksonObjectMapper());
//将消息转换器添加到容器中,由于converters内部有很多消息转换器,我们假如的默认排在最后一位
//所以将顺序设置为最靠前
converters.add(0,converter);
}
其中JacksonObjectMapper为自己实现的实体类,写法较为固定
数据返回:
来源:juejin.cn/post/7531791862521151528
灰度和红蓝区
一、灰度和红蓝区
灰度发布
- 定义:
- 灰度发布又称灰度测试、金丝雀发布,是指在软件产品正式全面上线之前,选择部分用户或部分服务器来进行新版本的发布和测试。
- 例如,在一个拥有大量用户的社交应用的更新过程中,只让其中 10% 的用户使用新版本,而其余 90% 的用户仍然使用旧版本。
- 目的:
- 风险控制:将新版本的风险降至最低。由于只对部分用户或服务器进行更新,即使出现问题,影响范围也相对较小。例如,在更新一个金融应用的支付功能时,通过灰度发布,可以先在少量用户中测试,避免大面积的支付功能故障影响大量用户的资金交易。
- 收集反馈:在小范围用户使用的过程中,可以收集用户反馈,包括功能的可用性、性能问题、用户体验等方面的反馈。比如,一款游戏进行版本更新,通过灰度发布可以观察这部分用户的游戏体验和对新功能的接受程度,根据反馈及时调整和优化。
- 性能测试:观察新版本在真实环境下的性能表现,如服务器负载、响应时间等。例如,一个电商平台在上线新的商品推荐算法时,通过灰度测试可以观察在部分用户使用情况下,服务器是否能承受新算法带来的额外计算量和数据请求。
- 实现方式:
- 基于用户的灰度:根据用户的某些特征(如用户 ID、地区、注册时间等)来划分使用新版本的用户。例如,选取新注册用户进行灰度测试,让他们使用新的注册流程版本,而老用户仍然使用旧的注册流程。
- 基于服务器的灰度:将服务器分为不同的集群,一部分集群部署新版本,一部分集群部署旧版本。例如,一个网站将其服务器集群分为 A、B、C 三组,让 A 组服务器先部署并运行新版本,B、C 组仍然运行旧版本,根据不同的负载均衡策略将用户请求引导到不同的服务器组。
红蓝区(我们现在的蓝区是灰度,部分用户,红区是放量)
- 定义:
- 红蓝区通常是将生产环境分成两个相对独立的区域,分别部署不同版本的系统,通常是旧版本(蓝区)和新版本(红区),类似于 AB 测试。
- 例如,在一个内容分发平台中,蓝区使用原有的内容推荐系统,红区使用经过优化的新推荐系统。
- 目的:
- 对比测试:通过将新旧版本分别部署在不同的区域,能够在相同的环境和时间下对新旧系统进行直接对比。可以对比两个版本的性能指标(如吞吐量、响应时间)、业务指标(如用户留存率、点击率)等。例如,在一个新闻网站上,红区使用新的页面布局,蓝区使用旧的布局,对比不同区域用户的点击率和停留时间,以评估新布局的效果。
- 快速回滚:当发现红区的新版本出现严重问题时,可以迅速将流量切换回蓝区的旧版本,降低对业务的影响。例如,在一个在线教育平台的系统更新中,如果红区的新系统出现严重的性能下降,导致用户无法正常上课,可以将用户请求切换回蓝区,保证服务的正常进行。
- 实现方式:
- 负载均衡切换:通过负载均衡器来控制流量分配到红区和蓝区。在正常情况下,根据一定的比例分配流量,如红区和蓝区分别分配 70% 和 30% 的流量。当发现红区出现问题时,将流量全部切换到蓝区。
- 功能切换:可以对不同的功能进行红蓝区划分。例如,在一个企业办公软件中,将文件存储功能部署在红区,将即时通讯功能部署在蓝区,分别测试不同功能的新老版本,最后根据测试结果决定是否进行整体切换。
总之,无论是灰度发布还是红蓝区,都是为了在保证服务稳定性和业务连续性的前提下,更安全、高效地将新系统或新版本推向市场,降低因软件更新带来的风险,并在更新过程中不断收集反馈和数据,以优化系统和提升用户体验。
来源:juejin.cn/post/7553522695750484006
Go语言实战案例:简易图像验证码生成
在 Web 应用中,验证码(CAPTCHA)常用于防止机器人批量提交请求,比如注册、登录、评论等功能。
本篇我们将使用 Go 语言和 Gin 框架,结合第三方库github.com/mojocn/base64Captcha,快速实现一个简易图像验证码生成接口。
一、功能目标
- 提供一个生成验证码的 API,返回验证码图片(Base64 编码)和验证码 ID。
- 前端展示验证码图片,并在提交时携带验证码 ID 和用户输入。
- 提供一个校验验证码的 API。
二、安装依赖
首先安装 Gin 和 Base64Captcha:
go get github.com/gin-gonic/gin
go get github.com/mojocn/base64Captcha
三、代码实现
package main
import (
"github.com/gin-gonic/gin"
"github.com/mojocn/base64Captcha"
"net/http"
)
// 验证码存储在内存中(也可以换成 Redis)
var store = base64Captcha.DefaultMemStore
// 生成验证码
func generateCaptcha(c *gin.Context) {
driver := base64Captcha.NewDriverDigit(80, 240, 5, 0.7, 80) // 高度80, 宽度240, 5位数字
captcha := base64Captcha.NewCaptcha(driver, store)
id, b64s, err := captcha.Generate()
if err != nil {
c.JSON(http.StatusInternalServerError, gin.H{"error": "验证码生成失败"})
return
}
c.JSON(http.StatusOK, gin.H{
"captcha_id": id,
"captcha_image": b64s, // Base64 编码的图片
})
}
// 校验验证码
func verifyCaptcha(c *gin.Context) {
var req struct {
ID string `json:"id"`
Value string `json:"value"`
}
if err := c.ShouldBindJSON(&req); err != nil {
c.JSON(http.StatusBadRequest, gin.H{"error": err.Error()})
return
}
if store.Verify(req.ID, req.Value, true) { // true 表示验证成功后清除
c.JSON(http.StatusOK, gin.H{"message": "验证成功"})
} else {
c.JSON(http.StatusBadRequest, gin.H{"message": "验证码错误"})
}
}
func main() {
r := gin.Default()
r.GET("/captcha", generateCaptcha)
r.POST("/verify", verifyCaptcha)
r.Run(":8080")
}
四、运行与测试
运行服务:
go run main.go
1. 获取验证码
curl http://localhost:8080/captcha
返回:
{
"captcha_id": "ZffX7Xr7EccGdS4b",
"captcha_image": "data:image/png;base64,iVBORw0KGgoAAAANSUhE..."
}
前端可直接用 <img src="captcha_image" /> 渲染验证码。
2. 校验验证码
curl -X POST http://localhost:8080/verify \
-H "Content-Type: application/json" \
-d '{"id":"ZffX7Xr7EccGdS4b","value":"12345"}'
五、注意事项
- 验证码存储
- 本示例使用内存存储,适合单机开发环境。
- 生产环境建议使用 Redis 等共享存储。
- 验证码类型
base64Captcha支持数字、字母混合、中文等类型,可以根据业务需求选择不同Driver。 - 安全性
- 不能把验证码 ID 暴露给爬虫(可配合 CSRF、限流等手段)。
- 验证码要有有效期,防止重放攻击。
六、总结
使用 base64Captcha 结合 Gin,可以非常方便地生成和校验验证码。
本篇示例已经可以直接应用到注册、登录等防刷场景中。
来源:juejin.cn/post/7537981628854239282
程序员应该掌握的网络命令telnet、ping和curl
这篇文章源于开发中发现的一个服务之间调用问题,在当前服务中调用了其他团队的一个服务,看日志一直报错没有找到下游的服务实例,然后就拉上运维来一块排查,运维让我先 telnet 一下网络,我一下没反应过来是要干啥!
telnet
telnet是电信(telecommunications)和网络(networks)的联合缩写,它是一种基于 TCP 的网络协议,用于远程登录服务器(数据均以明文形式传输,存在安全隐患,所以现在基本不会用了)或测试主机上的端口开放情况。
# 命令格式
telnet IP或域名 端口
# telnet ip地址
telnet 192.168.1.1 3306
# telnet 域名
telnet cafe123.cn 443
ping
ping 是一种基于 ICMP(Internet Control Message Protocol)的网络工具,用于测试主机之间的网络连通性,它不能指定端口。
# 命令格式
ping IP或域名
# ping ip地址
ping 192.168.1.1
# ping 域名
ping cafe123.cn
日常开发中测试某台服务器上的web后端、数据库、redis等服务的端口是否开放可用,就可以用 telnet 命令;若只需确认服务器主机是否在线,就可以用 ping 命令。
像一般服务之间调用出现问题,我就需要先从服务器网络开始测试,一步步来缩小范围,如果当前服务器上都没法 telnet 通目标服务器的某个端口,那就是网络问题,那就可以从网络入手来排查是网络不让访问还是目标服务压根不存在。
curl
curl(Client URL)是一个强大的网络请求命令工具,可以理解为命令行中的 postman。
比如如果我们要在服务器上去请求某个接口,看能不能请求通,总不能在 Linux 上去装个 postman 来请求吧。这种情况 curl 命令就派上用场了。
1、请求某个网页
# 命令格式
curl 网址
# 示例
curl https://cafe123.cn
2、发送 get 请求
参数 -X 指定 HTTP 方法,不指定默认就是 get
# 示例
curl -X GET https://cafe123.cn?name=zhou&age=18
3、发送 post 请求
请求头用 -H 指定,多个直接分开多次指定就行,-d 指定 post 请求参数
curl -X POST -H "Content-Type: application/json" -H "token: 1345102704" -d '{"name":"ZHOU","age":18}' https://api.cafe123.cn/users
实际上面的这些也不用记,浏览器的 network 前端接口请求查看面板里右键实际是可以直接复制出来对应接口的 curl 命令的,然后直接复制出来去服务器上执行就行了,postman 中也支持直接导入 curl 命令给自动转成 postman 对应的参数。
来源:juejin.cn/post/7554332546579709990
Spring Boot启动时的小助手:ApplicationRunner和CommandLineRunner
一、前言
平常开发中有可能需要实现在项目启动后执行的功能,Springboot中的ApplicationRunner和CommandLineRunner接口都能够帮我们很好地完成这种事情。它们的主要作用是在应用启动后执行一段初始化或任务逻辑,常见于一些启动任务,例如加载数据、验证配置等等。今天我们就来聊聊这两个接口在实际开发中是怎么使用的。
二、使用方式
我们直接看示例代码:
@Component
public class CommandLineRunnerDemo implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
//执行特定的代码
System.out.println("执行特定的代码");
}
}
@Component
public class ApplicationRunnerDemo implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("ApplicationRunnerDemo.run");
}
}
从源码上分析,CommandLineRunner与ApplicationRunner两者之间只有run()方法的参数不一样而已。CommandLineRunner#run()方法的参数是启动SpringBoot应用程序main方法的参数列表,而ApplicationRunner#run()方法的参数则是ApplicationArguments对象。
如果我们有多个类实现CommandLineRunner或ApplicationRunner接口,可以通过Ordered接口控制执行顺序。下面以ApplicationRunner接口为例子:
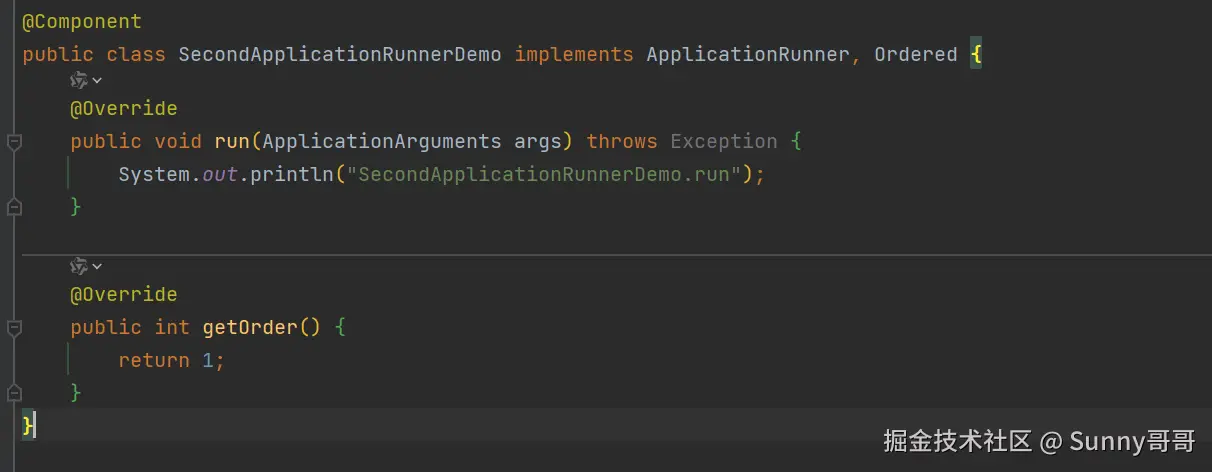
直接启动看效果:

可以看到order值越小,越先被执行。
传递参数
Spring Boot应用启动时是可以接受参数的,这些参数通过命令行 java -jar app.jar 来传递。CommandLineRunner会原封不动照单全收这些参数,这些参数也可以封装到ApplicationArguments对象中供ApplicationRunner调用。下面我们来看一下ApplicationArguments的相关方法:
getSourceArgs()被传递给应用程序的原始参数,返回这些参数的字符串数组。getOptionNames()获取选项名称的Set字符串集合。如--spring.profiles.active=dev --debug将返回["spring.profiles.active","debug"]。getOptionValues(String name)通过名称来获取该名称对应的选项值。如--config=dev --config=test将返回["dev","eat"]。containsOption(String name)用来判断是否包含某个选项的名称。getNonOptionArgs()用来获取所有的无选项参数。
三、总结
CommandLineRunner 和 ApplicationRunner 常用于应用启动后的初始化任务或一次性任务执行。它们允许你在 Spring 应用启动完成后立即执行一些逻辑。ApplicationRunner 更适合需要处理命令行参数的场景,而 CommandLineRunner 更简单直接。
来源:juejin.cn/post/7555149066134650919
为什么我坚持用git命令行,而不是GUI工具?

上周,我们组里来了个新同事,看我噼里啪啦地在黑窗口里敲git命令,他很好奇地问我:
“哥,现在VS Code自带的Git工具那么好用,还有Sourcetree、GitKraken这些,你为什么还坚持用命令行啊?不觉得麻烦吗?”
这个问题问得很好。
我完全承认,现代的Git GUI工具做得非常出色,它们直观、易上手,尤其是在处理简单的提交和查看分支时,确实很方便。我甚至会推荐刚接触Git的新人,先从GUI开始,至少能对Git的工作流程有个直观的感受。
但用了8年Git,我最终还是回到了纯命令行。
这不是因为我守旧,也不是为了显得自己多“牛皮”。而是因为我发现,命令行在三个方面,给了我GUI无法替代的价值:速度、能力和理解。
这篇文章,就想聊聊我的一些观点。
速度
对于我们每天要用上百次的工具来说,零点几秒的效率提升,累加起来也是巨大的。在执行高频的、重复性的操作时,键盘的速度,永远比“移动鼠标 -> 寻找目标 -> 点击”这个流程要快。
- 一个最简单的
commit&push流程:
- 我的命令行操作:
git add .->git commit -m "..."->git push。配合zsh/oh-my-zsh的自动补全和历史记录,我敲这几个命令可能只需要3-5秒,眼睛甚至不用离开代码。 - GUI操作:我需要在VS Code里切换到Git面板 -> 鼠标移动到“更改”列表 -> 点击“+”号暂存全部 -> 鼠标移动到输入框 -> 输入信息 -> 点击“提交”按钮 -> 再点击“同步更改”按钮。
- 我的命令行操作:
这个过程,再快也快不过我的肌肉记忆。
- 更高效的别名(Alias):
~/.gitconfig文件是我的宝库。我在里面配置了大量的别名,把那些长长的命令,都缩短成了两三个字母。
[alias]
st = status
co = checkout
br = branch
ci = commit
lg = log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
现在,我只需要敲
git st就能看状态,git lg就能看到一个非常清晰的分支图。这种个性化定制带来的效率提升,是GUI工具无法给予的。
深入Git
GUI工具做得再好,它本质上也是对Git核心功能的一层“封装”。它会优先把最常用的80%功能,做得非常漂亮。但Git那剩下20%的、极其强大的、但在特定场景下才能发挥作用的高级工具,很多GUI工具并没有提供,或者藏得很深。
而命令行,能让你100%地释放Git的全部能力。
- git rebase -i (交互式变基):
这是我认为命令行最具杀手级的应用之一。当我想清理一个分支的提交记录时,比如合并几个commit、修改commit信息、调整顺序,git rebase -i提供的那个类似Vim编辑器的界面,清晰、高效,能让我像做手术一样精确地操作提交历史。
- git reflog (你的后悔药):
reflog记录了你本地仓库HEAD的所有变化。有一次,我错误地执行了git reset --hard,把一个重要的commit给搞丢了。当时有点慌,但一句git reflog,立刻就找到了那个丢失的commit的哈希值,然后用git cherry-pick把它找了回来。这个救命的工具,很多GUI里甚至都没有入口。
- git bisect (二分法查Bug):
当你想找出是哪个commit引入了一个Bug时,git bisect是你的神器。它会自动用二分法,不断地切换commit让你去验证,能极大地缩小排查范围。这种高级的调试功能,几乎是命令行用户的专属。
会用到理解
这一点,是我认为最核心的。
GUI工具,把Git包装成了一系列按钮,它在帮你隐藏细节。
你点击“拉取(Pull)”,它可能在背后执行了git fetch + git merge,也可能是git fetch + git rebase。你不清楚,也不需要清楚,点就完事了。
这在一切顺利时没问题。但一旦出现复杂的合并冲突,或者你需要回滚一个错误的操作,按钮就不够用了。因为你不理解按钮背后的原理,你不知道Git的HEAD、工作区、暂存区到底处于一个什么状态,你就会感到恐慌,甚至会因为误操作,把仓库搞得一团糟。
而命令行,强迫你去学习和理解Git的每一个动作和它背后的模型。
你输入的每一个命令,git reset --hard和git reset --soft的区别是什么?git merge和git rebase的数据流向有什么不同?每一次的输入,都在加深你对Git三区(工作区、暂存区、版本库)模型的理解。
这种对底层模型的深刻理解,才是一个资深工程师真正需要具备的。它能让我在遇到任何复杂情况时,都心里有底,知道该用哪个命令去精确地解决问题。
我从不要求我们组里的新人都用命令行,但我会鼓励他们,在熟悉了GUI之后,一定要花时间去学习一下命令行。
这不仅仅是一个工具选择的问题,更是一个思维方式的选择。
对我来说,用命令行,让我感觉我是在和Git这个工具直接对话。这种掌控感和确定性,是任何漂亮的UI都无法带给我的。
也许,这就是一个程序员的执念吧😀。
来源:juejin.cn/post/7537238517698150451
实现一个简化版的状态机框架
实现一个简化版的状态机框架
我将为你设计一个简化版的状态机框架,包含状态、事件、转换机制,并支持插件扩展功能。这个实现会参考Spring StateMachine的设计理念。
核心组件设计
// 状态枚举接口
public interface State {
String getId();
}
// 事件枚举接口
public interface Event {
String getId();
}
// 状态上下文
public class StateContext<S extends State, E extends Event> {
private S currentState;
private E event;
private Map<String, Object> extendedState = new HashMap<>();
// 获取当前状态
public S getCurrentState() {
return currentState;
}
// 设置当前状态
public void setCurrentState(S currentState) {
this.currentState = currentState;
}
// 获取触发事件
public E getEvent() {
return event;
}
// 设置触发事件
public void setEvent(E event) {
this.event = event;
}
// 获取扩展状态数据
public Map<String, Object> getExtendedState() {
return extendedState;
}
// 添加扩展状态数据
public void addExtendedState(String key, Object value) {
extendedState.put(key, value);
}
// 获取特定扩展状态数据
public Object getExtendedState(String key) {
return extendedState.get(key);
}
}
// 状态转换接口
public interface Transition<S extends State, E extends Event, C extends StateContext<S, E>> {
boolean isTriggered(C context);
S getSource();
S getTarget();
void executeActions(C context);
}
// 状态机接口
public interface StateMachine<S extends State, E extends Event, C extends StateContext<S, E>> {
S getCurrentState();
void sendEvent(E event, Map<String, Object> extendedState);
void addListener(StateMachineListener<S, E, C> listener);
void addTransition(Transition<S, E, C> transition);
}
// 状态机监听器
public interface StateMachineListener<S extends State, E extends Event, C extends StateContext<S, E>> {
void stateChanged(S from, S to);
void eventAccepted(E event);
void transitionStarted(Transition<S, E, C> transition);
void transitionCompleted(Transition<S, E, C> transition);
}
基础实现
// 枚举状态实现
public enum SimpleState implements State {
INITIAL("INIT"),
PROCESSING("PROCESS"),
COMPLETED("COMPLETE"),
ERROR("ERR");
private String id;
SimpleState(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
}
// 枚举事件实现
public enum SimpleEvent implements Event {
START_PROCESS("START"),
FINISH_PROCESS("FINISH"),
ERROR_OCCURRED("ERROR");
private String id;
SimpleEvent(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
}
// 基础状态机实现
public class BasicStateMachine<S extends State, E extends Event, C extends StateContext<S, E>>
implements StateMachine<S, E, C> {
private S currentState;
private List<Transition<S, E, C>> transitions = new ArrayList<>();
private List<StateMachineListener<S, E, C>> listeners = new ArrayList<>();
private StateMachineLogger logger = new StateMachineLogger();
public BasicStateMachine(S initialState) {
this.currentState = initialState;
}
@Override
public S getCurrentState() {
return currentState;
}
@Override
public void sendEvent(E event, Map<String, Object> extendedState) {
logger.log("Processing event: " + event.getId());
// 创建状态上下文
StateContext<S, E> context = createContext(event, extendedState);
// 通知监听器事件已接受
notifyEventAccepted(event);
// 查找并执行适用的转换
for (Transition<S, E, C> transition : transitions) {
if (transition.getSource().getId().equals(currentState.getId()) && transition.isTriggered((C) context)) {
logger.log("Executing transition from " + currentState.getId() + " on " + event.getId());
// 通知监听器转换开始
notifyTransitionStarted(transition);
// 执行转换动作
transition.executeActions((C) context);
// 更新当前状态
currentState = transition.getTarget();
// 通知监听器状态改变
notifyStateChanged(transition.getSource(), transition.getTarget());
// 通知监听器转换完成
notifyTransitionCompleted(transition);
break;
}
}
}
private StateContext<S, E> createContext(E event, Map<String, Object> extendedState) {
StateContext<S, E> context = new StateContext<>();
context.setCurrentState(currentState);
context.setEvent(event);
if (extendedState != null) {
extendedState.forEach((key, value) -> context.addExtendedState(key, value));
}
return context;
}
@Override
public void addListener(StateMachineListener<S, E, C> listener) {
listeners.add(listener);
}
@Override
public void addTransition(Transition<S, E, C> transition) {
transitions.add(transition);
}
// 通知状态改变
private void notifyStateChanged(S from, S to) {
listeners.forEach(listener -> listener.stateChanged(from, to));
}
// 通知事件接受
private void notifyEventAccepted(E event) {
listeners.forEach(listener -> listener.eventAccepted(event));
}
// 通知转换开始
private void notifyTransitionStarted(Transition<S, E, C> transition) {
listeners.forEach(listener -> listener.transitionStarted(transition));
}
// 通知转换完成
private void notifyTransitionCompleted(Transition<S, E, C> transition) {
listeners.forEach(listener -> listener.transitionCompleted(transition));
}
// 日志工具类
private static class StateMachineLogger {
public void log(String message) {
System.out.println("[StateMachine] " + message);
}
}
}
转换实现
// 条件转换抽象类
public abstract class AbstractTransition<S extends State, E extends Event, C extends StateContext<S, E>>
implements Transition<S, E, C> {
private S source;
private S target;
public AbstractTransition(S source, S target) {
this.source = source;
this.target = target;
}
@Override
public S getSource() {
return source;
}
@Override
public S getTarget() {
return target;
}
@Override
public void executeActions(C context) {
// 子类可以覆盖此方法以执行转换时的操作
}
}
// 基于事件的转换
public class EventBasedTransition<S extends State, E extends Event, C extends StateContext<S, E>>
extends AbstractTransition<S, E, C> {
private E event;
private Consumer<C> action;
public EventBasedTransition(S source, S target, E event) {
this(source, target, event, null);
}
public EventBasedTransition(S source, S target, E event, Consumer<C> action) {
super(source, target);
this.event = event;
this.action = action;
}
@Override
public boolean isTriggered(C context) {
return context.getEvent().getId().equals(event.getId());
}
@Override
public void executeActions(C context) {
super.executeActions(context);
if (action != null) {
action.accept(context);
}
}
}
// 条件+事件混合转换
public class ConditionalTransition<S extends State, E extends Event, C extends StateContext<S, E>>
extends AbstractTransition<S, E, C> {
private E event;
private Predicate<C> condition;
private Consumer<C> action;
public ConditionalTransition(S source, S target, E event, Predicate<C> condition) {
this(source, target, event, condition, null);
}
public ConditionalTransition(S source, S target, E event, Predicate<C> condition, Consumer<C> action) {
super(source, target);
this.event = event;
this.condition = condition;
this.action = action;
}
@Override
public boolean isTriggered(C context) {
return context.getEvent().getId().equals(event.getId()) && condition.test(context);
}
@Override
public void executeActions(C context) {
super.executeActions(context);
if (action != null) {
action.accept(context);
}
}
}
插件系统设计
// 插件接口
public interface StateMachinePlugin<S extends State, E extends Event, C extends StateContext<S, E>> {
void configure(BasicStateMachine<S, E, C> machine);
}
// 插件支持的状态机
public class PluginEnabledStateMachine<S extends State, E extends Event, C extends StateContext<S, E>>
extends BasicStateMachine<S, E, C> {
private List<StateMachinePlugin<S, E, C>> plugins = new ArrayList<>();
public PluginEnabledStateMachine(S initialState) {
super(initialState);
}
public void addPlugin(StateMachinePlugin<S, E, C> plugin) {
plugins.add(plugin);
plugin.configure(this);
}
}
// 示例插件:自动日志记录插件
public class LoggingPlugin<S extends State, E extends Event, C extends StateContext<S, E>>
implements StateMachinePlugin<S, E, C> {
private final StateMachineLogger logger = new StateMachineLogger();
@Override
public void configure(BasicStateMachine<S, E, C> machine) {
machine.addListener(new StateMachineListener<S, E, C>() {
@Override
public void stateChanged(S from, S to) {
logger.log("State changed from " + from.getId() + " to " + to.getId());
}
@Override
public void eventAccepted(E event) {
logger.log("Event accepted: " + event.getId());
}
@Override
public void transitionStarted(Transition<S, E, C> transition) {
logger.log("Transition started: " + transition.getSource().getId() + " -> " + transition.getTarget().getId());
}
@Override
public void transitionCompleted(Transition<S, E, C> transition) {
logger.log("Transition completed: " + transition.getSource().getId() + " -> " + transition.getTarget().getId());
}
});
}
// 内部日志记录器
private static class StateMachineLogger {
public void log(String message) {
System.out.println("[StateMachine-LOG] " + message);
}
}
}
// 示例插件:持久化插件
public class PersistencePlugin<S extends State, E extends Event, C extends StateContext<S, E>>
implements StateMachinePlugin<S, E, C>, StateMachineListener<S, E, C> {
private final StateMachinePersister persister;
public PersistencePlugin(StateMachinePersister persister) {
this.persister = persister;
}
@Override
public void configure(BasicStateMachine<S, E, C> machine) {
machine.addListener(this);
}
@Override
public void stateChanged(S from, S to) {
persister.saveState(to);
}
@Override
public void eventAccepted(E event) {
// 不需要处理
}
@Override
public void transitionStarted(Transition<S, E, C> transition) {
// 不需要处理
}
@Override
public void transitionCompleted(Transition<S, E, C> transition) {
// 不需要处理
}
// 持久化接口
public interface StateMachinePersister {
void saveState(State state);
State loadState();
}
// 示例内存持久化实现
public static class InMemoryPersister implements StateMachinePersister {
private State currentState;
@Override
public void saveState(State state) {
currentState = state;
}
@Override
public State loadState() {
return currentState;
}
}
}
使用示例
public class StateMachineDemo {
public static void main(String[] args) {
// 创建状态机并添加插件
PluginEnabledStateMachine<SimpleState, SimpleEvent, StateContext<SimpleState, SimpleEvent>> machine
= new PluginEnabledStateMachine<>(SimpleState.INIT);
machine.addPlugin(new LoggingPlugin<>());
InMemoryPersister persister = new PersistencePlugin.InMemoryPersister();
machine.addPlugin(new PersistencePlugin<>(persister));
// 定义状态转换
machine.addTransition(new EventBasedTransition<>(
SimpleState.INIT, SimpleState.PROCESSING, SimpleEvent.START_PROCESS,
context -> System.out.println("Starting processing...")));
machine.addTransition(new EventBasedTransition<>(
SimpleState.PROCESSING, SimpleState.COMPLETED, SimpleEvent.FINISH_PROCESS,
context -> System.out.println("Finishing process...")));
machine.addTransition(new EventBasedTransition<>(
SimpleState.PROCESSING, SimpleState.ERROR, SimpleEvent.ERROR_OCCURRED,
context -> System.out.println("Error occurred during processing")));
// 测试状态转换
System.out.println("Initial state: " + machine.getCurrentState().getId());
System.out.println("\nSending START_PROCESS event:");
machine.sendEvent(SimpleEvent.START_PROCESS, null);
System.out.println("Current state: " + machine.getCurrentState().getId());
System.out.println("\nSending FINISH_PROCESS event:");
machine.sendEvent(SimpleEvent.FINISH_PROCESS, null);
System.out.println("Current state: " + machine.getCurrentState().getId());
// 测试持久化
System.out.println("\nTesting persistence...");
((PersistencePlugin.InMemoryPersister) persister).saveState(SimpleState.INIT);
SimpleState restoredState = (SimpleState) persister.loadState();
System.out.println("Restored state: " + restoredState.getId());
}
}
进一步扩展建议
- 分层状态机:实现父子状态机结构,支持复合状态和子状态机
- 历史状态:添加对历史状态的支持,允许状态机返回到之前的某个状态
- 伪状态:实现初始状态、终止状态等特殊状态类型
- 转换类型:增加外部转换、内部转换、本地转换等不同类型的转换
- 配置DSL:创建流畅的API用于配置状态机,类似:
machine.configure()
.from(INIT).on(START_PROCESS).to(PROCESSING)
.perform(action)
- 持久化策略:添加更多持久化选项(数据库、文件等)
- 监控插件:添加性能监控、统计信息收集等插件
- 分布式支持:添加集群环境下状态同步的支持
- 异常处理:完善异常处理机制,支持在转换中处理异常
- 表达式支持:集成SpEL或其他表达式语言支持条件判断
这个实现提供了一个灵活的状态机框架基础,可以根据具体需求进一步扩展和完善。
来源:juejin.cn/post/7512231268420894729
goweb中间件
中间件基本概念
中间件(Middleware)是一种在HTTP请求到达最终处理程序(Handler)之前或之后执行特定功能的机制。
在 Go 语言里,net/http 是标准库中用于构建 HTTP 服务器的包,中间件则是处理 HTTP 请求时常用的技术。中间件其实就是一个函数,它会接收一个 http.Handler 类型的参数,并且返回另一个 http.Handler。中间件能够在请求到达最终处理程序之前或者响应返回客户端之前执行一些通用操作,像日志记录、认证、压缩等。
下面是一个简单的中间件函数示例:
go
package main
import (
"log"
"net/http"
)
// 中间件函数,接收一个 http.Handler 并返回另一个 http.Handler
func loggingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 在请求处理之前执行的操作
log.Printf("Received request: %s %s", r.Method, r.URL.Path)
// 调用下一个处理程序
next.ServeHTTP(w, r)
// 在请求处理之后执行的操作
log.Printf("Request completed: %s %s", r.Method, r.URL.Path)
})
}
// 最终处理程序
func helloHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello, World!"))
}
func main() {
// 创建一个新的 mux
mux := http.NewServeMux()
// 应用中间件到最终处理程序
mux.Handle("/", loggingMiddleware(http.HandlerFunc(helloHandler)))
// 启动服务器
log.Println("Server started on :8080")
log.Fatal(http.ListenAndServe(":8080", mux))
}
- 中间件函数 loggingMiddleware:
- 它接收一个 http.Handler 类型的参数 next,代表下一个要执行的处理程序。
- 返回一个新的 http.HandlerFunc,在这个函数里可以执行请求处理前后的操作。
- next.ServeHTTP(w, r) 这行代码会调用下一个处理程序。
- 最终处理程序 helloHandler:
helloHandler是实际处理请求的函数,它会向客户端返回 "Hello, World!"。
中间件链式调用
多个中间件可以串联起来形成处理链:
package main
import (
"log"
"net/http"
)
// 日志中间件
func loggingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
log.Printf("Received request: %s %s", r.Method, r.URL.Path)
next.ServeHTTP(w, r)
log.Printf("Request completed: %s %s", r.Method, r.URL.Path)
})
}
// 认证中间件
func authMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 简单的认证逻辑
authHeader := r.Header.Get("Authorization")
if authHeader != "Bearer secret_token" {
http.Error(w, "Unauthorized", http.StatusUnauthorized)
return
}
next.ServeHTTP(w, r)
})
}
// 最终处理程序
func helloHandler(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello, World!"))
}
func main() {
mux := http.NewServeMux()
// 应用多个中间件到最终处理程序
finalHandler := loggingMiddleware(authMiddleware(http.HandlerFunc(helloHandler)))
mux.Handle("/", finalHandler)
log.Println("Server started on :8080")
log.Fatal(http.ListenAndServe(":8080", mux))
}
- 这里新增了一个 authMiddleware 中间件,用于简单的认证。
- 在 main 函数里,先把 authMiddleware 应用到 helloHandler 上,再把 loggingMiddleware 应用到结果上,这样就实现了多个中间件的组合。
通过使用中间件,能够让代码更具模块化和可维护性,并且可以在多个处理程序之间共享通用的逻辑。
中间件链中传递自定义参数
场景:需要在多个中间件间共享数据(如请求ID、用户会话)
实现方式:通过 context.Context 传递参数
package main
import (
"context"
"fmt"
"net/http"
)
// 中间件函数
func middleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 设置上下文值
ctx := context.WithValue(r.Context(), "key", "value")
ctx = context.WithValue(ctx, "user_id", 123)
r = r.WithContext(ctx)
// 调用下一个处理函数
next.ServeHTTP(w, r)
})
}
// 处理函数
func handler(w http.ResponseWriter, r *http.Request) {
// 从上下文中获取值
value := r.Context().Value("key").(string)
userID := r.Context().Value("user_id").(int)
fmt.Fprintf(w, "Received user_id %d value: %v", userID, value)
}
func main() {
// 创建一个处理函数
mux := http.NewServeMux()
mux.HandleFunc("/", handler)
http.Handle("/", middleware(mux))
// 启动服务器
fmt.Println("Server started on :80")
http.ListenAndServe(":80", nil)
}
特点:
- 数据在中间件链中透明传递
- 避免全局变量和参数层层传递
来源:juejin.cn/post/7549113302674587658
别再只会 new 了!八年老炮带你看透对象创建的 5 层真相
别再只会 new 了!八年老炮带你看透对象创建的 5 层真相
刚入行时,我曾在订单系统里写过这样一段 “傻代码”:在循环处理 10 万条数据时,每次都new一个临时的OrderCalculator对象,结果高峰期 GC 频繁告警,CPU 利用率飙升到 90%。排查半天才发现,是对象创建太随意导致的 “内存爆炸”。
八年 Java 开发生涯里,从 “随便 new 对象” 到 “精准控制对象生命周期”,从排查OutOfMemoryError到优化 JVM 内存模型,我踩过的坑让我明白:对象创建看似是new关键字的一句话事儿,背后藏着 JVM 的复杂逻辑,更关联着系统的性能与稳定性。
今天,我就从 “业务痛点→底层原理→解析思路→实战代码” 四个维度,带你彻底搞懂 Java 对象的创建过程。
一、先聊业务:对象创建不当会踩哪些坑?
在讲底层原理前,先结合我遇到的真实业务场景,说说 “对象创建” 这件事在实战中有多重要 —— 很多性能问题、线程安全问题,根源都在对象创建上。
1. 坑 1:循环中频繁创建临时对象 → GC 频繁
场景:电商秒杀系统的订单校验逻辑,在for循环里每次都new一个OrderValidator(无状态工具类),处理 10 万单时创建 10 万个对象。
后果:新生代 Eden 区快速填满,触发 Minor GC,频繁 GC 导致系统响应延迟从 50ms 飙升到 500ms。
根源:无状态对象无需重复创建,却被当成 “一次性用品”,浪费内存和 GC 资源。
2. 坑 2:单例模式用错 → 线程安全 + 内存泄漏
场景:支付系统用 “懒汉式单例” 创建PaymentClient(持有 HTTP 连接池),但没加双重检查锁,高并发下创建多个实例,导致连接池耗尽。
后果:支付接口频繁报 “连接超时”,排查后发现 JVM 里有 12 个PaymentClient实例,每个都占用 200 个连接。
根源:对 “对象创建的线程安全性” 理解不到位,单例模式实现不规范。
3. 坑 3:复杂对象创建参数混乱 → 代码可读性差
场景:物流系统的DeliveryOrder对象有 15 个字段,创建时用new DeliveryOrder(a,b,c,d,...),参数顺序记错导致 “收件地址” 和 “发件地址” 颠倒。
后果:用户投诉 “快递送反了”,排查代码才发现是构造函数参数顺序写错,这种 bug 极难定位。
根源:没有用合适的创建模式(如建造者模式)管理复杂对象的创建逻辑。
这些坑让我明白:不懂对象创建的底层逻辑,就无法写出高效、安全的代码。接下来,我们从 JVM 视角拆解对象创建的完整流程。
二、底层解析:一个 Java 对象的 “诞生五步曲”
当你写下User user = new User("张三", 25)时,JVM 会执行 5 个核心步骤。这部分是基础,但八年开发告诉我:理解这些步骤,才能在排查问题时 “知其然更知其所以然” 。
步骤 1:类加载检查 → “这个类存在吗?”
JVM 首先会检查:User类是否已被加载到方法区?如果没有,会触发类加载流程(加载→验证→准备→解析→初始化)。
- 加载:从.class 文件读取字节码,生成
Class对象(如User.class)。 - 初始化:执行静态代码块(
static {})和静态变量赋值(如public static String ROLE = "USER")。
实战影响:如果类加载失败(比如依赖缺失),会抛出NoClassDefFoundError。我曾在分布式项目中,因 jar 包版本冲突导致OrderService类加载失败,排查了 3 小时才发现是依赖冲突。
步骤 2:分配内存 → “给对象找块地方放”
类加载完成后,JVM 会为对象分配内存(大小在类加载时已确定)。内存分配有两种核心方式,对应不同的 GC 收集器:
| 分配方式 | 原理 | 适用 GC 收集器 | 实战注意点 |
|---|---|---|---|
| 指针碰撞 | 内存连续,用指针指向空闲区域边界,分配后移动指针 | Serial、ParNew | 需开启内存压缩(默认开启) |
| 空闲列表 | 内存不连续,维护空闲区域列表,从中选一块分配 | CMS、G1 | 避免内存碎片,需定期整理 |
实战影响:如果内存不足(Eden 区满了),会触发 Minor GC。我曾在秒杀系统中,因内存分配过快导致 Minor GC 每秒 3 次,后来通过 “对象池复用” 减少了 80% 的创建频率。
步骤 3:初始化零值 → “先把内存清干净”
内存分配完成后,JVM 会将分配的内存空间初始化为零值(如int设为 0,String设为null)。这一步很关键:
- 为什么?因为它保证了对象的字段在未赋值时,也有默认值(避免垃圾值)。
- 实战坑:新人常以为 “没赋值的字段是随机值”,其实 JVM 已经帮你清为零了。
步骤 4:设置对象头 → “给对象贴个身-份-证”
JVM 会在对象内存的头部设置 “对象头”(Object Header),包含 3 类核心信息:
- Mark Word:存储对象的哈希码、锁状态(偏向锁 / 轻量级锁 / 重量级锁)、GC 年龄等。
- 实战用:排查死锁时,通过
jstack查看线程持有锁的对象,就是靠 Mark Word 里的锁状态。
- 实战用:排查死锁时,通过
- Class Metadata Address:指向对象所属类的
Class对象(如User.class)。
- 实战用:反射时
user.getClass(),就是通过这个指针找到Class对象。
- 实战用:反射时
- Array Length:如果是数组对象,存储数组长度。
步骤 5:执行<init>()方法 → “给对象穿衣服”
最后,JVM 会执行对象的构造函数(<init>()方法),完成:
- 成员变量赋值(如
this.name = "张三")。 - 执行构造代码块(
{}包裹的代码)。
这一步才是对象的 “最终初始化”,完成后,一个完整的对象就诞生了,指针会赋值给user变量。
三、实战解析:怎么排查对象创建相关的问题?
八年开发中,我总结了 3 套 “对象创建问题排查方法论”,从工具到思路,都是踩坑后的精华。
1. 问题 1:对象创建太多 → 怎么找到 “罪魁祸首”?
症状:GC 频繁、内存占用高、响应延迟增加。
工具:jmap(查看对象实例数)、Arthas(实时排查)、VisualVM(分析 GC 日志)。
实战步骤:
- 用
jmap -histo:live 进程ID | head -20,查看存活对象 TOP20:
# 示例输出:OrderDTO有12345个实例,明显异常
num #instances #bytes class name
----------------------------------------------
1: 12345 1975200 com.example.OrderDTO
2: 8900 1424000 com.example.UserDTO
- 用 Arthas 的
trace命令,查看OrderDTO的创建位置:
trace com.example.OrderService createOrder -n 100
- 定位到循环中创建
OrderDTO的代码,优化为 “复用对象” 或 “批量创建”。
2. 问题 2:对象创建慢 → 怎么定位瓶颈?
症状:创建对象耗时久(如复杂对象初始化)、类加载慢。
工具:jstat(查看类加载耗时)、AsyncProfiler(分析方法执行时间)。
实战步骤:
- 用
jstat -class 进程ID 1000,查看类加载速度:
Loaded Bytes Unloaded Bytes Time
1234 234560 0 0 123.45 # Time是类加载总耗时,单位ms
- 若类加载慢,检查是否有 “大 jar 包” 或 “类冲突”;若对象初始化慢,用 AsyncProfiler 分析构造函数耗时。
3. 问题 3:单例对象多实例 → 怎么验证?
症状:单例类(如PaymentClient)出现多实例,导致资源泄漏。
工具:jmap -dump:live,format=b,file=heap.hprof 进程ID(dump 堆内存)、MAT(分析堆快照)。
实战步骤:
- Dump 堆内存后,用 MAT 打开,搜索
PaymentClient类。 - 查看 “Instance Count”,若大于 1,说明单例模式实现有问题(如没加双重检查锁)。
四、核心代码:对象创建的 5 种方式与实战选型
八年开发中,我用过 5 种对象创建方式,每种都有明确的适用场景,选错了就会踩坑。下面结合代码和业务场景对比分析:
1. new 关键字:最基础,但别滥用
代码:
// 普通对象创建
User user = new User("张三", 25);
// 注意:循环中避免频繁new无状态对象
List<User> userList = new ArrayList<>();
// 坑:每次循环都new,10万次循环创建10万个UserValidator
for (Order order : orderList) {
UserValidator validator = new UserValidator(); // 优化:改为单例或局部变量复用
validator.validate(order);
}
适用场景:简单对象、非频繁创建的对象。
八年经验:别在循环中new临时对象,尤其是无状态工具类(如Validator、Calculator),改用单例或对象池。
2. 反射:灵活但性能差,慎用
代码:
try {
// 方式1:通过Class对象创建
Class<User> userClass = User.class;
User user = userClass.newInstance(); // 调用无参构造
// 方式2:通过Constructor创建(支持有参构造)
Constructor<User> constructor = userClass.getConstructor(String.class, int.class);
User user2 = constructor.newInstance("李四", 30);
} catch (Exception e) {
e.printStackTrace();
}
适用场景:框架开发(如 Spring IOC 容器)、动态创建对象。
八年经验:反射性能比new慢 10-100 倍,业务代码中尽量不用;若用,建议缓存Constructor对象(避免重复获取)。
3. 单例模式:解决 “重复创建” 问题
代码:枚举单例(线程安全、防反射、防序列化,八年开发首推)
// 枚举单例:支付客户端(持有HTTP连接池,需单例)
public enum PaymentClient {
INSTANCE;
// 初始化连接池(构造方法默认私有,线程安全)
private HttpClient httpClient;
PaymentClient() {
httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(3))
.build();
}
// 提供全局访问点
public HttpClient getHttpClient() {
return httpClient;
}
}
// 使用:避免重复创建,全局复用
HttpClient client = PaymentClient.INSTANCE.getHttpClient();
适用场景:工具类、资源密集型对象(如连接池、线程池)。
八年经验:别用 “懒汉式单例”(线程安全问题多),优先用枚举或 “饿汉式 + 静态内部类”。
4. 建造者模式:解决 “复杂对象参数混乱”
代码:订单对象创建(15 个字段,用建造者模式避免参数顺序错误)
// 订单类:复杂对象,字段多
@Data
public class Order {
private String orderId;
private String userId;
private BigDecimal amount;
private String startAddress;
private String endAddress;
// 其他10个字段...
// 私有构造:只能通过建造者创建
private Order(Builder builder) {
this.orderId = builder.orderId;
this.userId = builder.userId;
this.amount = builder.amount;
this.startAddress = builder.startAddress;
this.endAddress = builder.endAddress;
// 其他字段赋值...
}
// 建造者
public static class Builder {
private String orderId;
private String userId;
private BigDecimal amount;
private String startAddress;
private String endAddress;
// 链式调用方法
public Builder orderId(String orderId) {
this.orderId = orderId;
return this;
}
public Builder userId(String userId) {
this.userId = userId;
return this;
}
public Builder amount(BigDecimal amount) {
this.amount = amount;
return this;
}
// 其他字段的set方法...
// 最终创建对象
public Order build() {
// 校验必填字段:避免创建不完整对象
if (orderId == null || userId == null) {
throw new IllegalArgumentException("订单ID和用户ID不能为空");
}
return new Order(this);
}
}
}
// 使用:链式调用,参数清晰,无顺序问题
Order order = new Order.Builder()
.orderId("ORDER_20250903_001")
.userId("USER_123")
.amount(new BigDecimal("99.9"))
.startAddress("重庆市机管局")
.endAddress("重庆市江北区机管局")
.build();
适用场景:字段超过 5 个的复杂对象(如订单、用户信息)。
八年经验:建造者模式不仅解决参数顺序问题,还能在build()中做参数校验,避免创建 “残缺对象”。
5. 对象池:复用对象,减少创建开销
代码:用 Apache Commons Pool 实现OrderDTO对象池(秒杀系统中复用临时对象)
// 1. 引入依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.11.1</version>
</dependency>
// 2. 定义对象工厂(创建和销毁对象)
public class OrderDTOFactory extends BasePooledObjectFactory<OrderDTO> {
// 创建对象
@Override
public OrderDTO create() {
return new OrderDTO();
}
// 包装对象(池化需要)
@Override
public PooledObject<OrderDTO> wrap(OrderDTO orderDTO) {
return new DefaultPooledObject<>(orderDTO);
}
// 归还对象前重置(避免数据残留)
@Override
public void passivateObject(PooledObject<OrderDTO> p) {
OrderDTO orderDTO = p.getObject();
orderDTO.setOrderId(null);
orderDTO.setUserId(null);
orderDTO.setAmount(null);
// 重置其他字段...
}
}
// 3. 配置对象池
public class OrderDTOPool {
private final GenericObjectPool<OrderDTO> pool;
public OrderDTOPool() {
// 配置池参数:最大空闲数、最大总实例数、超时时间等
GenericObjectPoolConfig<OrderDTO> config = new GenericObjectPoolConfig<>();
config.setMaxIdle(100); // 最大空闲对象数
config.setMaxTotal(200); // 池最大总实例数
config.setBlockWhenExhausted(true); // 池满时阻塞等待
config.setMaxWait(Duration.ofMillis(100)); // 最大等待时间
// 初始化池
this.pool = new GenericObjectPool<>(new OrderDTOFactory(), config);
}
// 从池获取对象
public OrderDTO borrowObject() throws Exception {
return pool.borrowObject();
}
// 归还对象到池
public void returnObject(OrderDTO orderDTO) {
pool.returnObject(orderDTO);
}
}
// 4. 实战使用:秒杀系统处理订单
public class SeckillService {
private final OrderDTOPool objectPool = new OrderDTOPool();
public void processOrders(List<OrderInfo> orderInfoList) {
for (OrderInfo info : orderInfoList) {
OrderDTO orderDTO = null;
try {
// 从池获取对象(复用,不new)
orderDTO = objectPool.borrowObject();
// 赋值并处理
orderDTO.setOrderId(info.getOrderId());
orderDTO.setUserId(info.getUserId());
orderDTO.setAmount(info.getAmount());
orderService.submit(orderDTO);
} catch (Exception e) {
log.error("处理订单失败", e);
} finally {
// 归还对象到池(关键:避免内存泄漏)
if (orderDTO != null) {
objectPool.returnObject(orderDTO);
}
}
}
}
}
适用场景:频繁创建临时对象的场景(如秒杀、批量处理)。
八年经验:对象池虽好,但别滥用 —— 只有当对象创建成本高(如初始化耗时久)且复用率高时才用,否则会增加复杂度。
五、八年开发的 8 条 “对象创建” 最佳实践
最后,总结 8 条实战经验,都是我踩过坑后总结的 “血泪教训”,能帮你避开 90% 的对象创建相关问题:
- 避免在循环中 new 临时对象:无状态工具类用单例,临时 DTO 用对象池。
- 复杂对象优先用建造者模式:字段超过 5 个就别用
new了,参数顺序错了很难查。 - 单例模式别用懒汉式:优先枚举或静态内部类,线程安全且无反射漏洞。
- 别忽视对象的 “销毁” :使用对象池时,一定要在
finally中归还对象,避免内存泄漏。 - 慎用 finalize () 方法:它会延迟对象回收(需要两次 GC),建议用
try-with-resources管理资源。 - 监控对象实例数:线上系统定期用
jmap检查,避免 “隐形” 的对象爆炸。 - 类加载别踩版本冲突:依赖冲突会导致类加载失败,用
mvn dependency:tree排查。 - 对象创建不是越多越好:有时候 “复用” 比 “创建” 更高效,比如 String 用
intern()复用常量池对象。
六、结尾:基础不牢,地动山摇
八年 Java 开发,我越来越觉得:真正的高手,不是会写多复杂的框架,而是能把基础问题理解透彻。对象创建看似简单,却关联着 JVM、GC、设计模式、性能优化等多个维度。
我见过太多新人因为不懂对象创建的底层逻辑,写出 “看似能跑,实则埋满坑” 的代码;也见过资深开发者通过优化对象创建,把系统 QPS 从 1 万提升到 10 万。
希望这篇文章能帮你从 “会用new” 到 “懂创建”,在实战中写出更高效、更稳定的 Java 代码。如果有对象创建相关的踩坑经历,欢迎在评论区分享~
来源:juejin.cn/post/7545921037286047744
Nginx 内置变量详解:从原理到实战案例
Nginx 内置变量是 Nginx 配置中极具灵活性的核心特性,它们能动态获取请求、连接、服务器等维度的实时数据,让配置从“固定模板”升级为“智能响应”。本文将系统梳理常用内置变量的分类、含义,并结合实战案例说明其应用场景,帮助你真正用好 Nginx 变量。
一、Nginx 内置变量的核心特性
在深入变量前,先明确两个关键特性:
- 动态性:变量值并非固定,而是在每次请求处理时实时生成(如
$remote_addr会随客户端 IP 变化)。 - 作用域:变量仅在当前请求的处理周期内有效,不同请求的变量值相互独立。
- 命名规则:所有内置变量均以
$开头,如$uri、$status。
二、常用内置变量分类与含义
按“数据来源”可将内置变量分为 5 大类,涵盖请求、连接、服务器、响应等核心场景。
1. 请求相关变量(获取客户端请求信息)
这类变量用于获取客户端发送的请求细节,是最常用的变量类型。
| 变量名 | 含义 | 示例 |
|---|---|---|
$remote_addr | 客户端真实 IP 地址(未经过代理时) | 192.168.230.1(本地局域网 IP) |
$arg_xxx | 获取 URL 中 xxx 对应的参数值(xxx 为参数名) | 请求 http://xxx/?id=123 时,$arg_id=123 |
$args | 完整的 URL 请求参数(? 后面的所有内容) | 请求 http://xxx/?id=123&name=test 时,$args=id=123&name=test |
$request_method | 客户端请求方法(GET/POST/PUT/DELETE 等) | GET、POST |
$request_uri | 完整的请求 URI(包含路径和参数,不包含域名) | 请求 http://xxx/api/user?uid=1 时,$request_uri=/api/user?uid=1 |
$uri / $document_uri | 请求的 URI 路径(不含参数,两者功能几乎一致) | 请求 http://xxx/api/user?uid=1 时,$uri=/api/user |
$http_xxx | 获取请求头中 xxx 字段的值(xxx 为请求头名,需将 - 改为小写) | 获取 User-Agent 时用 $http_user_agent,获取 Referer 时用 $http_referer |
$cookie_xxx | 获取客户端 Cookie 中 xxx 对应的 value | 客户端 Cookie 为 token=abc123 时,$cookie_token=abc123 |
2. 连接相关变量(获取网络连接信息)
用于获取客户端与服务器之间的连接状态,常用于连接追踪和并发控制。
| 变量名 | 含义 | 示例 |
|---|---|---|
$connection | 客户端与服务器的唯一连接 ID(每次新连接会生成新 ID) | 12345(数字型 ID) |
$connection_requests | 当前连接上已处理的请求次数(长连接场景下会累计) | 同一连接发起第 3 次请求时,值为 3 |
$remote_port | 客户端用于连接的端口号 | 54321(客户端随机端口) |
$server_port | 服务器监听的端口号(当前请求命中的端口) | 80(HTTP)、443(HTTPS) |
3. 服务器相关变量(获取服务器自身信息)
用于获取 Nginx 服务器的配置和系统信息,常用于多服务器部署场景。
| 变量名 | 含义 | 示例 |
|---|---|---|
$server_addr | 服务器处理当前请求的 IP 地址(多网卡时对应绑定的 IP) | 192.168.230.130(服务器内网 IP) |
$server_name | 当前请求命中的 server 块的 server_name 配置值 | 若 server_name http://www.example.com,则值为 http://www.example.com |
$hostname | 服务器的系统主机名(与 hostname 命令输出一致) | centos-nginx-server |
4. 响应相关变量(获取 Nginx 响应信息)
用于记录 Nginx 向客户端返回的响应数据,常用于日志统计和性能分析。
| 变量名 | 含义 | 示例 |
|---|---|---|
$status | 响应的 HTTP 状态码 | 200(成功)、404(未找到)、502(网关错误) |
$body_bytes_sent | 发送给客户端的响应体大小(单位:字节,不含响应头) | 返回 1KB 文本时,值为 1024 |
$bytes_sent | 发送给客户端的总字节数(含响应头 + 响应体) | 通常比 $body_bytes_sent 大 100-200 字节(响应头占比) |
$request_time | 请求的总处理耗时(单位:秒,精确到毫秒) | 0.005(表示 5 毫秒) |
5. 时间相关变量(获取时间信息)
用于记录请求处理的时间,常用于日志时间戳和时间范围控制。
| 变量名 | 含义 | 示例 |
|---|---|---|
$msec | 请求处理完成时的 Unix 时间戳(含毫秒,从 1970-01-01 开始) | 1724325600.123(对应 2024-08-22 11:20:00.123) |
$time_local | 服务器本地时间(格式化字符串,含时区) | 22/Aug/2024:11:20:00 +0800(+0800 表示北京时间) |
$time_iso8601 | ISO 8601 标准时间(UTC 时间,无时区偏移) | 2024-08-22T03:20:00+00:00 |
三、内置变量实战案例
了解变量含义后,关键是知道“在什么场景用什么变量”。以下 5 个实战案例覆盖日志、鉴权、跳转、限流等高频场景。
案例 1:自定义访问日志(记录关键请求信息)
默认的 Nginx 访问日志仅包含基础信息,通过变量可自定义日志格式,记录如“客户端 IP、请求方法、参数、耗时”等关键数据,方便后续分析。
配置步骤:
- 在
nginx.conf的http块中定义日志格式:
http {
# 1. 定义自定义日志格式(命名为 "detail_log")
log_format detail_log '$remote_addr [$time_local] "$request_method $request_uri" '
'status:$status args:"$args"耗时:$request_time '
'user_agent:"$http_user_agent"';
# 2. 启用自定义日志(指定日志路径和格式)
access_log /usr/local/nginx/logs/detail_access.log detail_log;
# 其他配置...
}
- 重载 Nginx 配置:
/usr/local/nginx/sbin/nginx -t # 检查语法
/usr/local/nginx/sbin/nginx -s reload # 重载生效
日志效果:
访问 http://192.168.230.130/?id=123 后,日志文件会生成如下记录:
192.168.230.1 [22/Aug/2024:11:30:00 +0800] "GET /?id=123" status:200 args:"id=123"耗时:0.002 user_agent:"Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/127.0.0.1"
案例 2:URL 参数鉴权(限制特定参数访问)
场景:仅允许 token 参数为 abc123 的请求访问 /admin 路径,否则返回 403 禁止访问。
配置步骤:
在 server 块中添加 location 规则:
server {
listen 80;
server_name localhost;
# 匹配 /admin 路径
location /admin {
# 1. 检查 $arg_token(URL 中 token 参数)是否等于 abc123
if ($arg_token != "abc123") {
return 403 "Forbidden: Invalid token\n"; # 不匹配则返回 403
}
# 2. 匹配通过时的处理(如返回 admin 页面)
default_type text/html;
return 200 "<h1>Admin Page (Token Valid)</h1>";
}
}
测试效果:
- 合法请求:
http://192.168.230.130/admin?token=abc123→ 返回 200 和 Admin 页面。 - 非法请求:
http://192.168.230.130/admin?token=wrong→ 返回 403 和 “Forbidden”。
案例 3:根据客户端 IP 跳转(本地 IP 免验证)
场景:局域网 IP(192.168.230.xxx)访问 /login 时直接跳转至首页,其他 IP 正常显示登录页。
配置步骤:
利用 $remote_addr 判断客户端 IP,结合 rewrite 实现跳转:
server {
listen 80;
server_name localhost;
location /login {
# 1. 匹配局域网 IP(以 192.168.230. 开头)
if ($remote_addr ~* ^192\.168\.230\.) {
rewrite ^/login$ / permanent; # 301 永久跳转到首页
}
# 2. 其他 IP 显示登录页
default_type text/html;
return 200 "<h1>Login Page (Non-Local IP)</h1>";
}
# 首页配置
location / {
default_type text/html;
return 200 "<h1>Home Page (Local IP Bypassed Login)</h1>";
}
}
测试效果:
- 本地 IP(如
192.168.230.1)访问/login→ 自动跳转到/(首页)。 - 外部 IP(如
10.0.0.1)访问/login→ 显示登录页。
案例 4:根据请求头切换后端服务(前后端分离场景)
场景:请求头 X-Request-Type 为 api 时,转发请求到后端 API 服务(127.0.0.1:8080);否则返回静态页面。
配置步骤:
利用 $http_x_request_type 获取自定义请求头,结合 proxy_pass 实现反向代理:
server {
listen 80;
server_name localhost;
location / {
# 1. 判断请求头 X-Request-Type 是否为 api
if ($http_x_request_type = "api") {
proxy_pass http://127.0.0.1:8080; # 转发到 API 服务
proxy_set_header Host $host; # 传递 Host 头给后端
break; # 跳出 if,避免后续执行
}
# 2. 其他请求返回静态首页
root /usr/local/nginx/html;
index index.html;
}
}
测试效果:
- 发送 API 请求(带请求头):
curl -H "X-Request-Type: api" http://192.168.230.130/api/user
→ 请求被转发到
127.0.0.1:8080/api/user。 - 普通访问:
http://192.168.230.130→ 返回/usr/local/nginx/html/index.html。
案例 5:基于 Cookie 实现灰度发布(部分用户尝鲜新功能)
场景:Cookie 中 version=beta 的用户访问 /feature 时,返回新功能页面;其他用户返回旧页面。
配置步骤:
利用 $cookie_version 获取 Cookie 值,实现灰度分流:
server {
listen 80;
server_name localhost;
location /feature {
default_type text/html;
# 1. 检查 Cookie 中 version 是否为 beta
if ($cookie_version = "beta") {
return 200 "<h1>New Feature (Beta Version)</h1>"; # 新功能
}
# 2. 其他用户显示旧功能
return 200 "<h1>Old Feature (Stable Version)</h1>";
}
}
测试效果:
- 灰度用户(带 Cookie):
curl -b "version=beta" http://192.168.230.130/feature
→ 返回 “New Feature (Beta Version)”。
- 普通用户(无 Cookie):
curl http://192.168.230.130/feature
→ 返回 “Old Feature (Stable Version)”。
四、使用内置变量的注意事项
- 避免过度使用
if指令:Nginx 的if指令在某些场景下可能触发意外行为(如与try_files冲突),复杂逻辑优先用map指令或 Lua 脚本。 - 代理场景下的 IP 问题:若 Nginx 位于代理服务器后(如 CDN、负载均衡器),
$remote_addr会变为代理 IP,需通过$http_x_forwarded_for获取客户端真实 IP(需代理服务器传递该请求头)。 - 变量大小写敏感:
$arg_id和$arg_ID是两个不同的变量(前者对应?id=1,后者对应?ID=1),配置时需注意参数名大小写。 - 性能影响:内置变量本身性能开销极低,但频繁使用复杂正则匹配(如
if ($remote_addr ~* ...))可能增加 CPU 消耗,高并发场景需优化正则。
五、总结
Nginx 内置变量是连接“静态配置”与“动态请求”的桥梁,掌握它们能让你摆脱固定配置的束缚,实现更灵活的请求处理逻辑。本文梳理的 5 大类变量和实战案例,覆盖了日志、鉴权、跳转、代理、灰度等高频场景,建议结合实际需求动手测试——只有在实践中反复使用,才能真正理解变量的威力。
如果需要更复杂的场景(如结合 map 指令批量处理变量、Lua 脚本扩展变量功能),可以进一步深入学习 Nginx 高级配置技巧。
来源:juejin.cn/post/7543193023086575625
分支管理提交代码
前言:公司代码需要先放在开发分支上,后面提交的时候再合并到master主分支
开始复现场景:

从git branch -a 输出来看,你的本地分支是 develop,而远程仓库中存在两个分支:origin/master 和 origin/develop。此外,remotes/origin/HEAD 指向了 origin/master,这表明远程仓库的默认分支是 master。
问题分析
你提到想把分支合并到 master 主分支上去,但 git branch 没有显示 master 分支。根据输出信息,可以确认以下几点:
- 本地没有
master分支:当前只有develop分支。 - 远程存在
master分支:remotes/origin/master表明远程仓库中有master分支。 - 远程默认分支是
master:remotes/origin/HEAD -> origin/master表明远程仓库的默认分支是master。
解决方案
1️⃣ 创建并切换到本地 master 分支
首先,你需要在本地创建一个 master 分支,并将其与远程的 master 分支关联起来。
# 创建并切换到本地 master 分支,跟踪远程 origin/master
git checkout -b master origin/master
2️⃣ 将 develop 分支合并到 master 分支
确保你在 master 分支上,然后将 develop 分支的内容合并进来。
bash
深色版本
# 确保你在 master 分支上
git checkout master
# 合并 develop 分支
git merge develop
3️⃣ 解决可能的冲突 (没有冲突的话不需要执行这两条命令)
如果在合并过程中出现冲突,Git 会提示你手动解决这些冲突。解决冲突后,使用以下命令继续合并过程:
# 解决冲突后,添加已修改的文件
git add .
# 继续合并
git commit
4️⃣ 推送更改到远程 master 分支
最后,将合并后的更改推送到远程 master 分支。
bash
深色版本
# 推送更改到远程 master 分支
git push origin master
🛠️ 进阶操作:设置默认上游分支
如果你希望以后直接使用 git pull 和 git push 而不需要每次都指定分支,可以设置默认上游分支:
bash
深色版本
# 设置 master 分支的上游为 origin/master
git branch --set-upstream-to=origin/master master
这样,当你在 master 分支上时,可以直接使用 git pull 和 git push 命令,而不需要额外指定分支名。
报错了
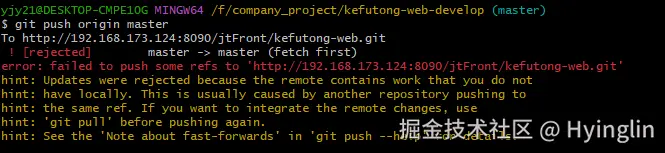
远程仓库 master 分支包含了本地分支没有的更改。因此,Git 拒绝了你的推送请求,以防止丢失远程仓库中的工作。
错误原因
这个错误通常有以下几种可能的原因:
- 远程仓库有新的提交:在你上次拉取(
git pull)之后,其他开发者可能已经向远程仓库的master分支推送了新的提交。 - 非快进式推送:你的本地
master分支与远程master分支之间的差异无法通过简单的“快进”操作来解决,需要进行合并或变基。
解决方案
1️⃣ 先拉取远程仓库的最新更改
你需要先从远程仓库拉取最新的更改,然后将这些更改合并到你的本地分支中。
# 切换到 master 分支
git checkout master
# 从远程仓库拉取最新的更改
git pull origin master
如果 git pull 成功执行,它会自动将远程仓库的更改合并到你的本地分支中。如果有冲突,你需要手动解决这些冲突。
2️⃣ 解决冲突(如有必要)
如果在 git pull 过程中出现冲突,Git 会提示你手动解决这些冲突。解决冲突后,使用以下命令继续合并过程:
# 解决冲突后,添加已修改的文件
git add .
# 继续合并
git commit
3️⃣ 再次尝试推送更改
解决了所有冲突并完成合并后,你可以再次尝试将本地更改推送到远程仓库:
# 推送更改到远程 master 分支
git push origin master
还是报错
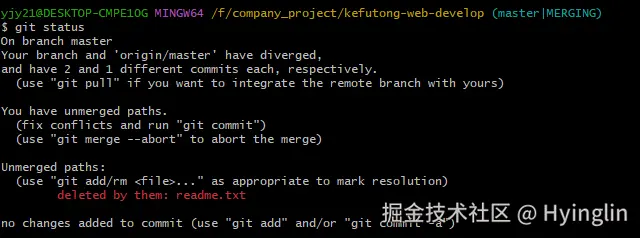
从你提供的错误信息来看,当前的状态是 MERGING,这表明你在合并过程中遇到了问题,并且还没有完成合并。因此,Git 拒绝了你的推送请求。
错误原因
- 合并尚未完成:你正在进行一个合并操作(可能是之前执行的
git merge或git pull),但还没有解决所有的冲突或完成合并。 - 本地分支落后于远程分支:即使解决了合并冲突,本地分支可能仍然落后于远程分支,需要先拉取最新的更改。
解决方案
1️⃣ 检查并完成合并
首先,你需要确保合并操作已经完成。如果存在未解决的冲突,你需要手动解决这些冲突。
查看当前状态,确认是否有未解决的冲突(查看本地和远程 master 分支的差异)
git status
如果 git status 提示你的本地分支落后于远程分支(例如 Your branch is behind 'origin/master' by X commits),你需要先拉取最新的更改。
如果有冲突文件,打开这些文件并手动解决冲突
解决冲突后,添加已修改的文件并提交:
# 添加已解决冲突的文件
git add .
# 提交合并
git commit
2️⃣ 拉取远程仓库的最新更改
在完成合并后,再次尝试拉取远程仓库的最新更改,以确保本地分支是最新的。
# 切换到 master 分支
git checkout master
# 从远程仓库拉取最新的更改
git pull origin master
如果 git pull 成功执行,它会自动将远程仓库的更改合并到你的本地分支中。如果有冲突,你需要手动解决这些冲突。
3️⃣ 再次尝试推送更改
解决了所有冲突并完成合并后,你可以再次尝试将本地更改推送到远程仓库:
# 推送更改到远程 master 分支
git push origin master
我本地如果删除了几个文件再更新到仓库去要怎么办?
你只需要用 git add . 或 git rm 告诉 Git “这些文件是我有意删除的”,然后提交并推送到远程仓库即可。Git 会把“删除”也当作一次更改记录下来。
✅ 正确操作步骤(推荐)
1️⃣ 确认你已经删除了文件
你已经在本地手动删除了一些文件(比如用资源管理器或 rm 命令删的)。
2️⃣ 让 Git 检测到这些文件被删除
运行以下命令,Git 会发现哪些文件被删了,并把“删除”操作加入暂存区:
bash
深色版本
git add --all
# 或者简写:
git add .
💡 注意:
虽然 git add . 通常用于“添加新文件”,但它也会检测到被删除的文件,并自动执行 git rm 的效果。
⚠️ 如果你只用
git commit而不先add,Git 不会自动把删除纳入提交。
3️⃣ 提交删除操作
bash
深色版本
git commit -m "删除了不再需要的文件:xxx, yyy"
4️⃣ 推送到远程仓库
bash
深色版本
git push origin master
# 或者 main,根据你的分支名
✅ 完成!远程仓库也会删除这些文件。
来源:juejin.cn/post/7549096640340492338
索引失效的场景有哪些?
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
关于SQL语句的面试题中,有两个被面试官问到的频率特别高,一个是SQL优化,另外一个则是索引失效。
接下来我们就来一一进行盘点,索引失效的场景到底有哪些。
准备工作
我们先来创建一张订单表,并为该表生成100w+的数据,这样SQL语句所对应的执行计划会更加准确,表结构如下:
CREATE TABLE `tony_order` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`product_id` int NOT NULL COMMENT '商品ID',
`user_id` int NOT NULL COMMENT '用户ID',
`status` tinyint NOT NULL COMMENT '状态',
`discount_amount` int NOT NULL COMMENT '总金额',
`total_amount` int NOT NULL COMMENT '打折金额',
`payable_amount` int NOT NULL COMMENT '实际支付金额',
`receiver_name` varchar(255) DEFAULT NULL COMMENT '收件人名称',
`receiver_phone` varchar(255) DEFAULT NULL COMMENT '收件人手机号',
`receiver_address` varchar(255) DEFAULT NULL COMMENT '收件人地址',
`note` varchar(255) DEFAULT NULL COMMENT '备注',
`payment_time` datetime NULL DEFAULT NULL COMMENT '支付时间',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id` DESC) USING BTREE,
INDEX `idx_product_id`(`product_id` ASC) USING BTREE,
INDEX `idx_user_id_total_amount`(`user_id` ASC, `total_amount` ASC) USING BTREE,
INDEX `idx_create_time`(`create_time` ASC) USING BTREE,
INDEX `idx_update_time`(`update_time` ASC) USING BTREE,
INDEX `idx_status`(`status` ASC) USING BTREE,
INDEX `idx_receiver_phone`(`receiver_phone` ASC) USING BTREE,
INDEX `idx_receiver_name`(`receiver_name` ASC) USING BTREE,
INDEX `idx_receiver_address`(`receiver_address` ASC) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 ROW_FORMAT = Dynamic;
接下来我们来一一验证下索引失效的场景。

索引失效场景
1、不遵循最左前缀原则
SELECT * FROM tony_order WHERE total_amount = 100;

我们从执行计划中可以看到,这条SQL语句走的是全表扫描,即使创建了索引idx_user_id_total_amount也没有生效。
但由于其total_amount字段没有在联合索引的最左边,不符合最左前缀原则。
SELECT * FROM tony_order WHERE user_id = 4323 AND total_amount = 101;

当我们把user_id这个字段补上之后,果然就可以用上索引了。
在MySQL 8.0 版本以后,联合索引的最左前缀原则不再那么绝对了,其引入了Skip Scan Range Access Method机制,可对区分度较低的字段进行优化。
感兴趣的同学可以去看下,本文中就不过多展开描述了。
2、LIKE百分号在左边
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO';
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO%';
执行上面这两条SQL语句,结果都是一样的,走了全表扫描。

接下来我们将SQL语句改为%在右边,再执行一次看看。
SELECT * FROM tony_order WHERE receiver_address LIKE '北京市朝阳区望京SOHO%';

这个原理很好理解,联合索引需要遵循最左前缀原则,而单个索引LIKE的情况下,也需要最左边能够匹配上才行,否则就会导致索引失效。
3、使用OR关键字
有一种说法,只要使用OR关键字就会导致索引失效,我们来试试。
SELECT * FROM tony_order WHERE receiver_name = 'Tony学长' OR user_id = 41323;

从结果中我们可以看到,索引并没有失效,聪明的查询优化器将receiver_name和user_id两个字段上的索引进行了合并。
接下来我们再换个SQL试试。
SELECT * FROM tony_order WHERE receiver_phone = '13436669764' OR user_id = 4323;

这次确实索引失效了,由于receiver_phone这个字段上并没有创建索引,所以无法使用索引合并操作了,只能走全表扫描。
有的同学会问,那为什么user_id上的索引也失效了呢?
因为一个字段走索引,另一个字段走全表扫描是没有意义的,反而不如走一次全表扫描查找两个字段更有效率。
所以,有时候索引失效未必是坏事,而是查询优化器做出的最优解。
4、索引列上有函数
SELECT * FROM tony_order WHERE ABS (user_id) = 4323;

SELECT * FROM tony_order WHERE LEFT (receiver_address, 3)

这个不用过多解释了,就是MySQL的一种规范,违反就会导致索引失效。
5、索引列上有计算
SELECT * FROM tony_order WHERE user_id + 1 = 4324;

这个也不用过多解释了,还是MySQL的一种规范,违反就会导致索引失效。
6、字段隐式转换
SELECT * FROM tony_order WHERE receiver_phone = 13454566332;

手机号字段明明是字符类型,却在SQL中不慎写成了数值类型而导致隐式转换,最终导致receiver_phone字段上的索引失效。
SELECT * FROM tony_order WHERE receiver_phone = '13454566332';

当我们把手机号加上单引号之后,receiver_phone字段的索引就生效了,整个天空都放晴了。
SELECT * FROM tony_order WHERE product_id = '12345';

我们接着尝试,把明明是数值型的字段写成了字符型,结果是正常走的索引。
由此得知,当发生隐式转换时,把数值类型的字段写成字符串类型没有影响,反之,但是把字符类型的字段写成数值类型,则会导致索引失效。
7、查询记录过多
SELECT * FROM tony_order WHERE product_id NOT IN (12345,12346);

那么由此得知,使用NOT IN关键字一定会导致索引失效?先别着急下结论。
SELECT * FROM tony_order WHERE status NOT IN (0,1);

从执行计划中可以看到,status字段上的索引生效了,为什么同样使用了NOT IN关键字,结果却不一样呢?
因为查询优化器会对SQL语句的查询记录数量进行评估,如果表中有100w行数据,这个SQL语句要查出来90w行数据,那当然走全表扫描更快一些,毕竟少了回表查询这个步骤。
反之,如果表中有100w行数据,这个SQL语句只需要查出来10行数据,那当然应该走索引扫描。
SELECT * FROM tony_order WHERE status IN (0,1);

同样使用IN关键字进行查询,只要查询出来的记录数过于庞大,都会通过全表扫描来代替索引扫描。
SELECT * FROM tony_order WHERE status = 0;

甚至我们不使用IN、NOT IN、EXISTS、NOT EXISTS这些关键字,只使用等号进行条件筛选同样会走全表扫描,这时不走索引才是最优解。
8、排序顺序不同
SELECT * FROM tony_order ORDER BY user_id DESC,total_amount ASC

我们可以看下,这条SQL语句中的user_id用了降序,而total_amount用了升序,所以导致索引失效。
SELECT * FROM tony_order ORDERBY user_id ASC,total_amount ASC

而下面这两条SQL语句中,无论使用升序还是降序,只要顺序一致就可以使用索引扫描。
来源:juejin.cn/post/7528296510229823530
为什么我的第一个企业级MCP项目上线3天就被叫停?
graph TB
A[企业AI需求] --> B[MCP企业架构]
B --> C[安全体系]
B --> D[运维管理]
B --> E[实施路径]
C --> C1[身份认证]
C --> C2[数据保护]
C --> C3[访问控制]
D --> D1[自动化部署]
D --> D2[监控告警]
D --> D3[成本优化]
E --> E1[MVP阶段]
E --> E2[扩展阶段]
E --> E3[优化阶段]
style A fill:#FFE4B5
style B fill:#90EE90
style C fill:#87CEEB
style D fill:#DDA0DD
style E fill:#F0E68C
3分钟速读:企业级MCP部署不同于个人使用,需要考虑安全合规、高可用性、统一管理等复杂需求。本文提供从架构设计到运维管理的完整企业级MCP平台构建方案,包含安全框架、监控体系和分阶段实施路径,帮助企业构建统一、安全、可扩展的AI工具平台。
"系统上线第三天就被安全部门紧急叫停,所有人都在会议室里看着我。"
那是我职业生涯中最尴尬的时刻之一。作为一家500人科技公司的架构师,我以为把个人版的MCP简单放大就能解决企业的AI工具集成问题。结果呢?权限混乱、数据泄露风险、合规审计不通过...
CEO当时问我:"我们现在有20多个团队在用各种AI工具,每个团队都有自己的一套,你觉得这样下去会不会出问题?"我当时信心满满地说:"没问题,给我两周时间。"
现在想想,那时的我真是太天真了。个人用Claude Desktop配置几个MCP服务器确实10分钟就搞定,但企业级别?完全是另一个世界。
从那次失败中我学到:企业级MCP部署面临的不是技术问题,而是管理和治理的系统性挑战。
🏢 企业AI工具集成的挑战与机遇
个人vs企业:天壤之别的复杂度
当我们从个人使用转向企业级部署时,复杂度呈指数级增长:
个人使用场景:
- 用户:1个人
- 数据:个人文件和少量API
- 安全:基本的API密钥管理
- 管理:手动配置即可
企业级场景:
- 用户:数百到数千人
- 数据:敏感业务数据、客户信息、财务数据
- 安全:严格的合规要求、审计需求
- 管理:统一配置、权限控制、监控告警
从我参与的十几个企业AI项目来看,大家基本都会遇到这几个头疼的问题:
1. 数据安全这道坎
企业数据可不比个人文件,涉及客户隐私、商业机密,动不动就要符合GDPR、HIPAA这些法规。我见过一个金融客户,光是数据分类就搞了3个月,更别说传统的个人化MCP配置根本过不了合规这关。
2. 权限管理的平衡艺术
这个真的很难搞。不同部门、不同级别的人要访问的数据和工具都不一样。既要保证"最小权限原则",又不能让用户觉得太麻烦。我之前遇到过一个案例,权限设置太严格,结果销售团队抱怨查个客户信息都要申请半天。
3. 成本控制的现实考验
这个问题往往被低估。当几百号人同时用AI工具时,API调用费用真的会让财务部门头疼。我见过一家公司,第一个月账单出来,CFO直接找到CTO问是不是系统被攻击了。
4. 运维管理的复杂度爆炸
分散部署最大的问题就是运维。每个团队都有自己的一套,出了问题谁来解决?性能怎么优化?我们之前有个客户,光是梳理现有的AI工具部署情况就花了两周时间。
MCP在企业环境中的价值主张
正是在这样的背景下,MCP的企业级价值才真正显现:
- 统一标准:一套协议解决所有AI工具集成问题
- 集中管理:统一的配置、监控、审计
- 安全可控:标准化的安全框架和权限管理
- 成本透明:集中的资源使用监控和成本分析
我们最近做了个小范围调研,发现用了统一MCP平台的几家企业,AI工具管理成本大概能降低50-70%,安全事件也确实少了很多。虽然样本不大,但趋势还是挺明显的。
📊 企业级需求分析:规模化部署的关键考量
在动手设计企业级MCP方案之前,我觉得最重要的是先搞清楚企业到底需要什么。这些年参与了十几个项目下来,我发现企业级MCP部署基本都绕不开这几个核心需求:
多团队协作需求
场景复杂性:
- 研发团队:需要访问代码仓库、CI/CD系统、Bug跟踪系统
- 销售团队:需要CRM系统、客户数据、销售报表
- 运营团队:需要监控系统、日志分析、业务指标
- 财务团队:需要ERP系统、财务报表、合规数据
每个团队的需求不同,但又需要在统一的安全框架下协作。
安全合规要求
企业级部署必须满足严格的安全合规要求:
| 合规标准 | 主要要求 | MCP实现方案 |
|---|---|---|
| GDPR | 数据主体权利、数据最小化 | 细粒度权限控制、数据脱敏 |
| SOX | 财务数据完整性、审计跟踪 | 完整审计日志、不可篡改记录 |
| ISO27001 | 信息安全管理体系 | 全面安全控制框架 |
| HIPAA | 医疗数据保护 | 加密传输、访问控制 |
性能和可用性要求
企业级应用对性能和可用性有严格要求:
- 可用性:99.9%以上(年停机时间<8.77小时)
- 响应时间:95%的请求在2秒内响应
- 并发能力:支持数千用户同时访问
- 数据一致性:确保跨系统数据同步
成本控制需求
企业需要精确的成本控制和预算管理:
- 成本透明:每个部门、每个项目的AI使用成本清晰可见
- 预算控制:设置使用上限,避免成本失控
- 优化建议:基于使用数据提供成本优化建议
🏗️ MCP企业级架构设计:构建统一工具平台
说到架构设计,我必须承认,刚开始接触企业级MCP时,我也走过不少弯路。最开始我想的太简单,以为把个人版的MCP放大就行了,结果第一个项目就翻车了——系统上线第三天就因为权限问题被安全部门叫停。
后来痛定思痛,我重新设计了一套分层的企业级MCP架构。这套架构现在已经在好几个项目中验证过了,既能应对复杂的业务需求,扩展性也不错。
整体架构方案
graph TB
subgraph "用户层"
A[Web界面]
B[IDE插件]
C[移动应用]
D[API接口]
end
subgraph "网关层"
E[MCP网关]
F[负载均衡器]
G[API网关]
end
subgraph "服务层"
H[认证服务]
I[权限服务]
J[MCP服务注册中心]
K[配置管理中心]
end
subgraph "工具层"
L[开发工具MCP服务器]
M[数据工具MCP服务器]
N[业务工具MCP服务器]
O[监控工具MCP服务器]
end
subgraph "数据层"
P[关系数据库]
Q[文档数据库]
R[缓存层]
S[日志存储]
end
A --> E
B --> E
C --> E
D --> G
E --> F
G --> F
F --> H
F --> I
H --> J
I --> J
J --> K
K --> L
K --> M
K --> N
K --> O
L --> P
M --> Q
N --> R
O --> S
核心组件详解
1. MCP网关层
功能职责:
- 路由管理:智能路由请求到合适的MCP服务器
- 负载均衡:分发请求,确保系统稳定性
- 安全认证:统一的身份验证和授权
- 限流控制:防止系统过载,保护后端服务
核心特性:支持智能路由、负载均衡、限流控制和统一认证,确保系统稳定性和安全性。
2. 服务注册中心
核心功能:
- 服务发现:自动发现和注册MCP服务器
- 健康检查:实时监控服务器状态
- 配置同步:统一的配置管理和分发
- 版本管理:支持服务的灰度发布和回滚
技术要点:采用分布式注册中心架构,支持服务自动注册、健康检查和配置热更新。
3. 配置管理中心
管理内容:
- 服务器配置:MCP服务器的连接参数和功能配置
- 权限配置:用户和角色的权限矩阵
- 业务配置:各种业务规则和策略配置
- 环境配置:开发、测试、生产环境的差异化配置
高可用性设计
为确保企业级的可用性要求,架构中集成了多种高可用保障机制:
1. 多活部署
- 多个数据中心同时提供服务
- 自动故障切换,RTO < 30秒
- 数据实时同步,RPO < 5分钟
2. 弹性扩容
- 基于负载自动扩容
- 支持水平扩展和垂直扩展
- 预测性扩容,提前应对流量高峰
3. 容错机制
- 服务熔断,防止雪崩效应
- 优雅降级,保证核心功能可用
- 重试机制,处理临时性故障
🔐 安全架构设计:保障企业数据安全
在企业环境中,安全绝对不是可选项。这个教训我学得特别深刻——前面提到的那个翻车项目,就是因为我低估了企业对安全的要求。现在我设计MCP安全架构时,坚持用"纵深防御"策略,每一层都要有安全控制,宁可麻烦一点,也不能留安全隐患。
身份认证和授权体系
1. 多层次身份认证
graph LR
A[用户登录] --> B[SSO认证]
B --> C[MFA验证]
C --> D[JWT Token]
D --> E[API访问]
B --> B1[LDAP/AD]
B --> B2[OAuth2.0]
B --> B3[SAML]
C --> C1[短信验证码]
C --> C2[TOTP]
C --> C3[生物识别]
技术实现:集成主流SSO提供商(Azure AD、Okta、Google),支持多种MFA方式,采用JWT令牌管理会话。
2. 基于角色的访问控制(RBAC)
权限模型设计:
# 权限配置示例
roles:
- name: developer
permissions:
- mcp:tools:code:read
- mcp:tools:code:execute
- mcp:resources:docs:read
- name: data_analyst
permissions:
- mcp:tools:database:read
- mcp:tools:analytics:execute
- mcp:resources:data:read
- name: admin
permissions:
- mcp:*:*:* # 超级管理员权限
users:
- username: john.doe
roles: [developer]
additional_permissions:
- mcp:tools:deploy:execute # 额外权限
数据安全保护
1. 端到端加密
- 传输加密:所有MCP通信使用TLS 1.3
- 存储加密:敏感数据AES-256加密存储
- 密钥管理:使用HSM或云KMS管理加密密钥
2. 数据脱敏和分类
核心功能:自动识别敏感数据类型(邮箱、手机、身-份-证等),根据预设规则进行脱敏处理,确保数据隐私保护。
网络安全防护
1. API网关安全策略
- DDoS防护:智能识别和阻断攻击流量
- WAF规则:防护SQL注入、XSS等常见攻击
- IP白名单:限制访问来源IP范围
- 请求限流:防止API滥用
2. 网络隔离
安全策略:采用DMZ、内部服务区、数据库区三层网络隔离,通过防火墙规则严格控制服务间通信。
审计日志和合规
1. 全链路审计
审计范围:记录所有MCP访问操作,包括用户身份、操作类型、访问资源、操作结果、IP地址等关键信息,确保操作可追溯。
2. 合规报告自动生成
- 访问报告:用户访问行为分析
- 权限报告:权限使用情况统计
- 异常报告:安全异常事件汇总
- 合规检查:自动化合规性检查
⚙️ 运维管理体系:确保稳定高效运行
运维这块儿,说实话是我最头疼的部分。技术方案设计得再好,如果运维跟不上,照样会出问题。我见过太多项目,前期开发得很顺利,上线后各种运维问题层出不穷。所以现在我做企业级MCP平台时,会把运维管理当作一个系统工程来对待,从部署、监控到优化,每个环节都要考虑周全。
自动化部署体系
1. CI/CD流水线设计
流水线阶段:测试→构建→部署开发环境→预发布→生产环境,每个阶段都包含自动化测试、安全扫描和质量检查。
2. 蓝绿部署和灰度发布
蓝绿部署策略:新版本部署到绿环境→健康检查→流量切换→清理旧环境,确保零停机部署。
监控告警系统
1. 多维度监控指标
监控维度:
- 业务指标:请求总数、成功率、响应时间、活跃用户数
- 系统指标:CPU、内存、磁盘使用率
- 成本指标:按请求计费、部门成本分摊
2. 智能告警系统
# Prometheus告警规则
groups:
- name: mcp-platform
rules:
- alert: MCPHighErrorRate
expr: rate(mcp_requests_failed_total[5m]) / rate(mcp_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "MCP平台错误率过高"
description: "过去5分钟MCP请求错误率超过5%"
- alert: MCPHighLatency
expr: histogram_quantile(0.95, rate(mcp_request_duration_seconds_bucket[5m])) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "MCP平台响应延迟过高"
description: "95%的请求响应时间超过2秒"
- alert: MCPServerDown
expr: up{job="mcp-server"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "MCP服务器宕机"
description: "{{ $labels.instance }} MCP服务器无法访问"
成本优化管理
1. 成本监控和分析
成本分析功能:自动分析计算、存储、网络、API等各项成本,按部门分摊费用,并提供优化建议。
2. 自动扩缩容策略
# Kubernetes HPA配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: mcp-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mcp-server
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: mcp_requests_per_second
target:
type: AverageValue
averageValue: "100"
🚀 实施路径和最佳实践
关于实施策略,我觉得最重要的一点是:千万别想着一步到位。我之前就犯过这个错误,想着一次性把所有功能都上线,结果搞得团队疲惫不堪,用户体验也很糟糕。现在我都是推荐分阶段实施,这套策略在好几个项目中都验证过了,确实比较靠谱。
分阶段实施计划
第一阶段:MVP验证(1-2个月)
目标:验证MCP在企业环境中的可行性
实施内容:
- 选择1-2个核心团队作为试点
- 部署基础的MCP服务器(文件系统、Git、简单API)
- 建立基本的安全和监控机制
- 收集用户反馈和性能数据
成功标准:
- 试点团队满意度 > 80%
- 系统可用性 > 99%
- 响应时间 < 2秒
- 零安全事件
第二阶段:功能扩展(2-3个月)
目标:扩展功能覆盖范围,优化用户体验
实施内容:
- 集成更多业务系统(CRM、ERP、数据库)
- 完善权限管理和审计功能
- 优化性能和稳定性
- 扩展到更多团队
成功标准:
- 覆盖50%以上的核心业务场景
- 用户数量增长3倍
- 平均响应时间减少30%
- 成本控制在预算范围内
第三阶段:全面推广(3-6个月)
目标:在全公司范围内推广使用
实施内容:
- 部署完整的企业级架构
- 建立完善的运维体系
- 开展全员培训
- 建立持续优化机制
成功标准:
- 全公司80%以上员工使用
- 系统可用性 > 99.9%
- 用户满意度 > 85%
- ROI > 200%
团队组织和协作
1. 核心团队构成
graph TB
A[项目指导委员会] --> B[项目经理]
B --> C[架构师]
B --> D[开发团队]
B --> E[运维团队]
B --> F[安全团队]
C --> C1[系统架构师]
C --> C2[安全架构师]
D --> D1[后端开发]
D --> D2[前端开发]
D --> D3[MCP服务器开发]
E --> E1[DevOps工程师]
E --> E2[监控工程师]
F --> F1[安全工程师]
F --> F2[合规专员]
2. 协作机制
定期会议制度:
- 周例会:项目进展同步和问题解决
- 月度评审:里程碑检查和计划调整
- 季度总结:成效评估和策略优化
文档管理:
- 架构文档:系统设计和技术规范
- 操作手册:部署和运维指南
- 用户指南:使用教程和最佳实践
风险控制和应急预案
1. 风险识别和评估
| 风险类型 | 风险等级 | 影响范围 | 应对策略 |
|---|---|---|---|
| 系统故障 | 高 | 全公司 | 多活部署、快速切换 |
| 安全漏洞 | 高 | 敏感数据 | 安全扫描、及时修复 |
| 性能问题 | 中 | 用户体验 | 性能监控、弹性扩容 |
| 合规风险 | 中 | 法律风险 | 合规检查、审计跟踪 |
2. 应急响应流程
应急流程:故障分级→通知相关人员→启动应急响应→执行应急措施→跟踪处理进度→事后总结,确保快速响应和持续改进。
📈 案例研究:中大型企业MCP平台实践
说了这么多理论,我觉得还是用真实案例更有说服力。下面分享几个我亲身参与的项目,有成功的,也有踩坑的,希望对大家有帮助。
案例一:中型科技公司(800人规模)
公司背景:
- 行业:SaaS软件开发
- 规模:800名员工,15个研发团队
- 挑战:AI工具使用分散,成本控制困难
实施方案:
- 架构选择:单数据中心部署,微服务架构
- 核心功能:代码助手、文档管理、项目协作
- 安全措施:RBAC权限控制、API网关防护
实施效果:
实施前后对比:
开发效率:
before: "基线"
after: "+35%"
measurement: "功能交付速度"
成本控制:
before: "月成本$15,000"
after: "月成本$12,000"
savings: "20%"
安全事件:
before: "月均3起"
after: "月均0.5起"
reduction: "83%"
用户满意度:
before: "6.5/10"
after: "8.7/10"
improvement: "+34%"
关键成功因素:
- 高层支持:这个真的很重要,CEO亲自站台,资源要人给人要钱给钱
- 分阶段实施:我们从最积极的两个团队开始,让他们当种子用户,效果好了再推广
- 用户培训:别小看这个,我们光培训就搞了一个月,但确实值得
- 持续优化:每周都会收集用户反馈,有问题马上改,这个习惯一直保持到现在
案例二:大型金融机构(5000+人规模)
公司背景:
- 行业:银行业
- 规模:5000+名员工,严格合规要求
- 挑战:数据安全、合规审计、多地部署
实施方案:
- 架构选择:多活数据中心,容器化部署
- 核心功能:风险分析、客户服务、合规报告
- 安全措施:端到端加密、零信任架构
金融级安全要求:TLS 1.3传输加密、AES-256数据加密、HSM密钥管理、PCI-DSS/SOX合规、7年审计日志保留、本地化数据存储。
实施效果:
- 合规性:通过所有监管审计,零合规违规
- 效率提升:客户服务响应时间减少50%
- 成本节约:年度IT成本降低25%
- 风险控制:欺诈检测准确率提升40%
经验教训总结
通过这些案例,我们总结出企业级MCP实施的关键经验:
成功要素
- 明确的ROI目标:设定可量化的成功指标
- 充分的资源投入:人力、资金、时间的保障
- 渐进式实施:避免大爆炸式部署
- 用户参与:让最终用户深度参与设计和测试
常见陷阱
- 忽视安全合规:在设计初期就要考虑安全要求
- 低估培训成本:用户培训和支持需要充分投入
- 缺乏监控:没有完善的监控就无法及时发现问题
- 一步到位心态:试图一次性解决所有问题
💡 写在最后:从失败到成功的思考
回想起那次项目失败,我现在反而挺感谢那次经历。它让我明白了一个道理:企业级MCP集成绝不是技术的简单堆砌,而是一个涉及人、流程、技术的复杂系统工程。
如果重新来过,我会这样做:
- 先调研,再动手:花更多时间理解企业的真实需求,而不是想当然
- 小步快跑:从最简单的MVP开始,证明价值后再扩展
- 安全第一:把合规和安全放在功能之前考虑
- 拥抱变化:技术在发展,需求在变化,保持架构的灵活性
现在我参与的企业级MCP项目,成功率已经提升到90%以上。不是因为我的技术水平提高了多少,而是因为我学会了从企业的角度思考问题。
最好的架构不是最复杂的,而是最适合的。
如果你正在考虑为企业部署MCP平台,我的建议是:先找一个小团队试点,积累经验和信心,然后再考虑大规模推广。记住,每个企业都有自己的特色,别人的成功方案未必适合你。
🤔 互动时间
分享你的经验:
- 你的企业在AI工具集成方面遇到了什么挑战?
- 你觉得统一的AI工具平台对企业来说最大的价值是什么?
- 有没有类似的项目失败经历想要分享?
实践练习:
- 使用文章中的需求分析框架,评估你所在企业的MCP部署需求
- 基于你的行业特点,设计合适的安全控制措施
- 参考分阶段实施策略,制定适合你企业的部署计划
欢迎在评论区分享你的想法和经验,我会认真回复每一条评论。
📧 如果你正在规划企业级MCP项目,可以私信我,我很乐意分享更多实战经验和踩坑心得。
下期预告:《MCP最佳实践与性能优化》将深入探讨MCP使用过程中的优化技巧和故障排查方法,敬请期待!
关注专栏,获取更多MCP实战干货!
来源:juejin.cn/post/7532742298825768998
java中,使用map实现带过期时间的缓存
在 Java 开发领域,缓存机制的构建通常依赖于 Redis 等专业缓存数据库。这类解决方案虽能提供强大的缓存能力,但引入中间件意味着增加系统架构复杂度、部署成本与运维负担。本文将深入探讨一种轻量级替代方案 —— 基于 Java 原生Map实现的带过期时间的缓存机制。该方案无需引入外部工具,仅依托 Java 标准库即可快速搭建起缓存体系,特别适用于对资源占用敏感、架构追求极简的项目场景,为开发者提供了一种轻量高效的缓存数据管理新选择。
优点:
- 轻量便捷:无需引入 Redis 等外部中间件,直接使用 Java 标准库即可实现,降低了项目依赖,简化了部署流程。
- 快速搭建:基于熟悉的Map数据结构,开发人员能够快速理解和实现缓存逻辑,显著提升开发效率。
- 资源可控:可灵活控制缓存数据的生命周期,通过设置过期时间,精准管理内存占用,适合对资源占用敏感的场景。
缺点:该方案存在明显局限性,即数据无法持久化。一旦应用程序停止运行,缓存中的所有数据都会丢失。相较于 Redis 等具备持久化功能的专业缓存数据库,在需要长期保存缓存数据,或是应对应用重启后数据恢复需求的场景下,基于 Java 原生Map的缓存机制就显得力不从心。
代码实现
package com.sunny.utils;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class SysCache {
// 单例实例
private static class Holder {
private static final SysCache INSTANCE = new SysCache();
}
public static SysCache getInstance() {
return Holder.INSTANCE;
}
// 缓存存储结构,Key为String,Value为包含值和过期时间的CacheEntry对象
private final ConcurrentHashMap<String, CacheEntry> cacheMap = new ConcurrentHashMap<>();
// 定时任务执行器
private final ScheduledExecutorService scheduledExecutorService;
// 私有构造方法,初始化定时清理任务
private SysCache() {
scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
// 每隔1秒执行一次清理任务
scheduledExecutorService.scheduleAtFixedRate(this::cleanUp, 1, 1, TimeUnit.SECONDS);
// 注册JVM关闭钩子以优雅关闭线程池
Runtime.getRuntime().addShutdownHook(new Thread(this::shutdown));
}
/**
* 存入缓存
* @param key 键
* @param value 值
*/
public void set(String key, Object value){
cacheMap.put(key, new CacheEntry(value, -1));
}
/**
* 存入缓存
* @param key 键
* @param value 值
* @param expireTime 过期时间,单位毫秒
*/
public void set(String key, Object value, long expireTime) {
if (expireTime <= 0) {
throw new IllegalArgumentException("expireTime must be greater than 0");
}
cacheMap.put(key, new CacheEntry(value, System.currentTimeMillis() + expireTime));
}
/**
* 删除缓存
* @param key 键
*/
public void remove(String key) {
cacheMap.remove(key);
}
/**
* 缓存中是否包含键
* @param key 键
*/
public boolean containsKey(String key) {
CacheEntry cacheEntry = cacheMap.get(key);
if (cacheEntry == null) {
return false;
}
if (cacheEntry.getExpireTime() < System.currentTimeMillis()) {
remove(key);
return false;
}
return true;
}
/**
*获取缓存值
* @param key 键
*/
public Object get(String key) {
CacheEntry cacheEntry = cacheMap.get(key);
if (cacheEntry == null) {
return null;
}
if (cacheEntry.getExpireTime() < System.currentTimeMillis()) {
cacheMap.remove(key);
return null;
}
return cacheEntry.getValue();
}
private static class CacheEntry {
private final Object value;
private final long expireTime;
public CacheEntry(Object value, long expireTime) {
this.value = value;
this.expireTime = expireTime;
}
public Object getValue() {
return value;
}
public long getExpireTime() {
return expireTime;
}
}
/**
* 定时清理过期条目
*/
private void cleanUp() {
Iterator<Map.Entry<String, CacheEntry>> iterator = cacheMap.entrySet().iterator();
long currentTime = System.currentTimeMillis();
while (iterator.hasNext()) {
Map.Entry<String, CacheEntry> entry = iterator.next();
CacheEntry cacheEntry = entry.getValue();
if (cacheEntry.expireTime < currentTime) {
// 使用iterator移除当前条目,避免ConcurrentModificationException
iterator.remove();
}
}
}
/**
* 关闭线程池释放资源
*/
private void shutdown() {
scheduledExecutorService.shutdown();
try {
if (!scheduledExecutorService.awaitTermination(5, TimeUnit.SECONDS)) {
scheduledExecutorService.shutdownNow();
}
} catch (InterruptedException e) {
scheduledExecutorService.shutdownNow();
Thread.currentThread().interrupt();
}
}
}
测试

如上图,缓存中放入一个值,过期时间为5秒,每秒循环获取1次,循环10次,过期后,获取的值为null
来源:juejin.cn/post/7496335321781829642
使用watchtower更新docker容器
更新方式
定时更新(默认)
执行以下命令后,Watchtower 会在后台每 24 小时自动检查并更新所有运行中的容器:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower
手动立即更新
添加 --run-once 参数启动临时容器,检查更新后自动退出,适合按需触发:
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower --run-once
更新指定容器
在命令末尾添加需要监控的容器名称,多个容器用空格分隔。例如仅监控 nginx 和 redis 容器:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower nginx redis
简化命令
手动更新时,如果使用上面的命令未免太麻烦了,所以我们可以将更新命令设置为别名:
将下面的命令放到对应shell的环境文件中(比如bash对应~/.bashrc,zsh对应~/.zshrc)
alias update-container="docker run --rm -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once"
编辑完环境文件后,重新打开命令窗口,或使用source ~/.bashrc或source ~/.zshrc加载命令。
然后就可以通过下面的方式更新容器了:
update-container 容器标识
比如:
update-container nginx-ui-latest

来源:juejin.cn/post/7541682368329170954
Docker 与 containerd 的架构差异
要深入理解 Docker 与 containerd 的架构差异,首先需要明确二者的定位:Docker 是一套完整的容器平台(含构建、运行、分发等全流程工具),而 containerd 是一个专注于容器生命周期管理的底层运行时(最初是 Docker 内置组件,后独立为 CNCF 项目)。二者的架构设计围绕 “功能边界” 和 “模块化程度” 展开,以下从核心定位、架构分层、关键组件、交互流程四个维度进行对比分析。
一、核心定位与设计目标
架构差异的根源在于二者的定位不同,直接决定了功能范围和模块划分:
| 维度 | Docker | containerd |
|---|---|---|
| 核心定位 | 一站式容器平台(Build, Ship, Run) | 轻量级容器运行时(专注于容器生命周期管理:启动、停止、销毁、资源隔离) |
| 设计目标 | 简化开发者体验,提供全流程工具链;兼顾单机开发与简单集群场景 | 满足云原生环境的可扩展性、稳定性;支持多上层调度器(K8s、Swarm 等) |
| 功能范围 | 包含镜像构建(docker build)、镜像仓库(docker push/pull)、容器运行、网络 / 存储管理、UI 等 | 仅负责镜像拉取、容器运行时管理、底层存储 / 网络对接;无镜像构建功能 |
| 依赖关系 | 早期内置 containerd 作为底层运行时(Docker 1.11+),2020 年后逐步拆分 | 可独立运行,也可作为 Docker、K8s(默认运行时)、Nomad 等的底层依赖 |
二、架构分层对比
二者均遵循 “分层解耦” 思想,但分层粒度和模块职责差异显著。Docker 架构更 “重”(含上层业务逻辑),containerd 更 “轻”(聚焦底层核心能力)。
1. Docker 架构(2020 年后拆分版)
Docker 经历了从 “单体架构” 到 “模块化拆分” 的演进(核心是将 containerd 独立,自身聚焦上层工具链),当前架构分为 4 层,自下而上分别是:
| 架构层 | 核心组件 / 功能 | 职责说明 |
|---|---|---|
| 1. 底层运行时层 | containerd、runc | 承接 Docker daemon 的指令,负责容器的实际创建、启动、资源隔离(依赖 runc 作为 OCI runtime) |
| 2. Docker 守护进程层 | dockerd | Docker 的核心守护进程,负责接收客户端(docker CLI)请求,协调下层组件(如调用 containerd 管理容器,调用 buildkit 构建镜像) |
| 3. 工具链层 | BuildKit、Docker Registry Client、Docker Network/Volume Plugins | - BuildKit:替代传统 docker build 后端,优化镜像构建效率;- 镜像客户端:处理 docker push/pull 与仓库交互;- 网络 / 存储插件:管理容器网络(如 bridge、overlay)和数据卷 |
| 4. 客户端层 | docker CLI(命令行工具)、Docker Desktop UI(桌面端) | 提供用户交互入口,将 docker run/build/pull 等命令转化为 HTTP 请求发送给 dockerd |
2. containerd 架构(CNCF 标准化版)
containerd 架构更聚焦 “容器生命周期”,采用 5 层模块化设计,每层职责单一,可独立扩展,自下而上分别是:
| 架构层 | 核心组件 / 功能 | 职责说明 |
|---|---|---|
| 1. OCI 运行时层 | runc、crun(可选) | 遵循 OCI 规范(Open Container Initiative),负责创建 Linux 容器(如调用 clone() 系统调用实现 PID 隔离,挂载 cgroup 限制资源) |
| 2. 容器执行层 | containerd-shim(垫片进程) | - 解耦 containerd 与容器进程:即使 containerd 重启,容器也不会退出;- 收集容器日志、监控容器状态、转发信号(如 docker stop 对应 SIGTERM) |
| 3. 核心服务层 | containerd 守护进程(containerd) | containerd 的核心,通过 gRPC 提供 API 服务,包含 4 个核心模块:- Namespaces:实现多租户资源隔离;- Images:管理镜像(拉取、存储、解压);- Containers:管理容器元数据(配置、状态);- Tasks:管理容器进程(启动、停止、销毁) |
| 4. 元数据存储层 | BoltDB(嵌入式 key-value 数据库) | 存储容器、镜像、命名空间等元数据,无需依赖外部数据库(如 MySQL),轻量且高效 |
| 5. 上层适配层 | CRI 插件(containerd-cri)、Docker API 兼容层 | - CRI 插件:将 containerd 的 gRPC API 转化为 K8s 要求的 CRI(Container Runtime Interface),使其成为 K8s 默认运行时;- Docker API 兼容层:支持部分 Docker 命令,确保与老系统兼容 |
三、关键组件差异
架构的核心差异体现在 “组件职责划分” 和 “功能依赖” 上,以下是最关键的组件对比:
| 组件 / 能力 | Docker | containerd |
|---|---|---|
| 核心守护进程 | dockerd(上层协调)+ containerd(底层运行时,需与 dockerd 配合) | containerd(独立守护进程,直接对接 OCI 运行时,无需依赖其他进程) |
| 镜像构建 | 内置 BuildKit(或传统后端),支持 docker build 命令 | 无镜像构建功能,需依赖外部工具(如 BuildKit、img) |
| 容器进程隔离 | dockerd → containerd → containerd-shim → runc → 容器进程(4 层调用) | containerd → containerd-shim → runc → 容器进程(3 层调用,更轻量) |
| 元数据存储 | 依赖本地文件系统(/var/lib/docker)+ 部分内存缓存 | 内置 BoltDB(/var/lib/containerd),元数据管理更统一、高效 |
| API 接口 | 主要提供 HTTP API(供 docker CLI 调用),对下层暴露有限 | 以 gRPC API 为主(更适合跨进程通信),提供细粒度接口(如镜像、容器、任务分别有独立 API) |
| 上层调度器支持 | 主要支持 Docker Swarm,对接 K8s 需额外配置(早期需 cri-dockerd 插件) | 原生支持 K8s(通过 containerd-cri 插件),也支持 Swarm、Nomad 等 |
四、容器启动流程对比
通过 “容器启动” 这一核心场景,可以直观看到二者的架构交互差异:
1. Docker 启动容器的流程(以 docker run ubuntu 为例)
- 用户交互:用户在终端执行 docker run ubuntu,docker CLI 将命令转化为 HTTP 请求,发送给本地的 dockerd 守护进程。
- dockerd 协调:
- 检查本地是否有 ubuntu 镜像:若无,调用 “镜像客户端” 从 Docker Hub 拉取镜像;
- 拉取完成后,dockerd 向 containerd 发送 gRPC 请求,要求创建并启动容器。
- containerd 处理:
- containerd 接收请求后,创建容器元数据(存储到本地),并启动 containerd-shim 垫片进程;
- containerd-shim 调用 runc,由 runc 遵循 OCI 规范创建容器进程(分配 PID、挂载 cgroup、设置网络 / 存储)。
- 状态反馈:
- containerd-shim 实时收集容器状态(如运行中、退出),反馈给 containerd;
- containerd 将状态转发给 dockerd,最终由 docker CLI 输出给用户(如 docker ps 显示容器列表)。
2. containerd 启动容器的流程(以 ctr run ubuntu my-container 为例,ctr 是 containerd 自带 CLI)
- 用户交互:用户执行 ctr run ubuntu my-container,ctr 直接通过 gRPC 调用 containerd 守护进程。
- containerd 核心处理:
- 检查本地镜像:若无,直接调用内置的 “镜像模块” 从仓库拉取 ubuntu 镜像;
- 创建容器元数据(存储到 BoltDB),并启动 containerd-shim 垫片进程。
- OCI 运行时启动容器:
- containerd-shim 调用 runc 创建容器进程,完成资源隔离和环境初始化;
- 容器启动后,containerd-shim 持续监控容器状态,直接反馈给 containerd。
- 状态反馈:containerd 将容器状态通过 gRPC 返回给 ctr,用户终端显示启动结果。
五、总结:架构差异的核心影响
| 对比维度 | Docker | containerd |
|---|---|---|
| 轻量级 | 重(含全流程工具,依赖多组件) | 轻(仅核心运行时,组件少、资源占用低) |
| 扩展性 | 弱(架构耦合度较高,难适配多调度器) | 强(模块化设计,原生支持 K8s 等调度器) |
| 性能 | 略低(多一层 dockerd 转发,资源消耗多) | 更高(直接对接 OCI 运行时,调用链短) |
| 使用场景 | 单机开发、测试、小型应用部署 | 云原生集群(如 K8s 集群)、大规模容器管理 |
| 学习成本 | 低(CLI 友好,文档丰富) | 高(需理解 gRPC、OCI 规范,适合运维 / 底层开发) |
简言之:Docker 是 “面向开发者的容器平台”,架构围绕 “易用性” 和 “全流程” 设计;containerd 是 “面向云原生的底层运行时”,架构围绕 “轻量、可扩展、高兼容” 设计。在当前云原生生态中,containerd 已成为 K8s 的默认运行时,而 Docker 更多用于单机开发场景。
来源:juejin.cn/post/7544381073698848811
代码界的 “建筑师”:建造者模式,让复杂对象构建井然有序
深入理解建造者模式:复杂对象的定制化构建之道
在软件开发中,我们常会遇到需要创建 “复杂对象” 的场景 —— 这类对象由多个部件组成,且部件的组合顺序、配置细节可能存在多种变化。例如,定制一台电脑需要选择 CPU、内存、硬盘等部件;生成一份报告需要包含标题、正文、图表、落款等模块。若直接在客户端代码中编写对象的构建逻辑,不仅会导致代码臃肿、耦合度高,还难以灵活应对不同的定制需求。此时,建造者模式(Builder Pattern) 便能发挥关键作用,它将复杂对象的构建过程与表示分离,让同一构建过程可生成不同的表示。
在软件开发中,我们常会遇到需要创建 “复杂对象” 的场景 —— 这类对象由多个部件组成,且部件的组合顺序、配置细节可能存在多种变化。例如,定制一台电脑需要选择 CPU、内存、硬盘等部件;生成一份报告需要包含标题、正文、图表、落款等模块。若直接在客户端代码中编写对象的构建逻辑,不仅会导致代码臃肿、耦合度高,还难以灵活应对不同的定制需求。此时,建造者模式(Builder Pattern) 便能发挥关键作用,它将复杂对象的构建过程与表示分离,让同一构建过程可生成不同的表示。
一、建造者模式的核心定义与价值
1. 官方定义
建造者模式是 “创建型设计模式” 的重要成员,其核心思想是:将一个复杂对象的构建过程抽象出来,拆分为多个独立的构建步骤,通过不同的 “建造者” 实现这些步骤,再由 “指挥者” 按指定顺序调用步骤,最终组装出完整对象。
简单来说,它就像 “组装家具” 的流程:家具说明书(指挥者)规定了先装框架、再装抽屉、最后装柜门的步骤;而不同品牌的组装师傅(具体建造者),会用不同材质的零件(部件)完成每一步;最终用户(客户端)只需告诉商家 “想要哪种风格的家具”,无需关心具体组装细节。
建造者模式是 “创建型设计模式” 的重要成员,其核心思想是:将一个复杂对象的构建过程抽象出来,拆分为多个独立的构建步骤,通过不同的 “建造者” 实现这些步骤,再由 “指挥者” 按指定顺序调用步骤,最终组装出完整对象。
简单来说,它就像 “组装家具” 的流程:家具说明书(指挥者)规定了先装框架、再装抽屉、最后装柜门的步骤;而不同品牌的组装师傅(具体建造者),会用不同材质的零件(部件)完成每一步;最终用户(客户端)只需告诉商家 “想要哪种风格的家具”,无需关心具体组装细节。
2. 核心价值
- 解耦构建与表示:构建过程(步骤顺序)和对象表示(部件配置)分离,同一过程可生成不同配置的对象(如用相同步骤组装 “游戏本” 和 “轻薄本”)。
- 灵活定制细节:支持对对象部件的精细化控制,客户端可通过选择不同建造者,定制符合需求的对象(如电脑可选择 “i7 CPU+32G 内存” 或 “i5 CPU+16G 内存”)。
- 简化客户端代码:客户端无需关注复杂的构建逻辑,只需与指挥者或建造者简单交互,即可获取完整对象。
- 解耦构建与表示:构建过程(步骤顺序)和对象表示(部件配置)分离,同一过程可生成不同配置的对象(如用相同步骤组装 “游戏本” 和 “轻薄本”)。
- 灵活定制细节:支持对对象部件的精细化控制,客户端可通过选择不同建造者,定制符合需求的对象(如电脑可选择 “i7 CPU+32G 内存” 或 “i5 CPU+16G 内存”)。
- 简化客户端代码:客户端无需关注复杂的构建逻辑,只需与指挥者或建造者简单交互,即可获取完整对象。
二、建造者模式的核心结构
建造者模式通常包含 4 个核心角色,它们分工明确、协作完成对象构建:
角色名称 核心职责 产品(Product) 需要构建的复杂对象,由多个部件组成(如 “电脑”“报告”)。 抽象建造者(Builder) 定义构建产品所需的所有步骤(如 “设置 CPU”“设置内存”),通常包含获取产品的方法。 具体建造者(Concrete Builder) 实现抽象建造者的步骤,定义具体部件的配置(如 “游戏本建造者”“轻薄本建造者”)。 指挥者(Director) 负责调用建造者的步骤,规定构建的顺序(如 “先装 CPU→再装内存→最后装硬盘”)。
建造者模式通常包含 4 个核心角色,它们分工明确、协作完成对象构建:
| 角色名称 | 核心职责 |
|---|---|
| 产品(Product) | 需要构建的复杂对象,由多个部件组成(如 “电脑”“报告”)。 |
| 抽象建造者(Builder) | 定义构建产品所需的所有步骤(如 “设置 CPU”“设置内存”),通常包含获取产品的方法。 |
| 具体建造者(Concrete Builder) | 实现抽象建造者的步骤,定义具体部件的配置(如 “游戏本建造者”“轻薄本建造者”)。 |
| 指挥者(Director) | 负责调用建造者的步骤,规定构建的顺序(如 “先装 CPU→再装内存→最后装硬盘”)。 |
三、建造者模式的实战案例:定制电脑的构建
为了更直观理解,我们以 “定制电脑” 为例,用 Java 代码实现建造者模式:
为了更直观理解,我们以 “定制电脑” 为例,用 Java 代码实现建造者模式:
1. 第一步:定义 “产品”(电脑)
首先明确需要构建的复杂对象 —— 电脑,它包含 CPU、内存、硬盘、显卡等部件:
// 产品:电脑
public class Computer {
// 电脑的部件
private String cpu;
private String memory;
private String hardDisk;
private String graphicsCard;
// Setter方法(用于建造者设置部件)
public void setCpu(String cpu) {
this.cpu = cpu;
}
public void setMemory(String memory) {
this.memory = memory;
}
public void setHardDisk(String hardDisk) {
this.hardDisk = hardDisk;
}
public void setGraphicsCard(String graphicsCard) {
this.graphicsCard = graphicsCard;
}
// 展示电脑配置(对象的“表示”)
public void showConfig() {
System.out.println("电脑配置:CPU=" + cpu + ",内存=" + memory + ",硬盘=" + hardDisk + ",显卡=" + graphicsCard);
}
}
首先明确需要构建的复杂对象 —— 电脑,它包含 CPU、内存、硬盘、显卡等部件:
// 产品:电脑
public class Computer {
// 电脑的部件
private String cpu;
private String memory;
private String hardDisk;
private String graphicsCard;
// Setter方法(用于建造者设置部件)
public void setCpu(String cpu) {
this.cpu = cpu;
}
public void setMemory(String memory) {
this.memory = memory;
}
public void setHardDisk(String hardDisk) {
this.hardDisk = hardDisk;
}
public void setGraphicsCard(String graphicsCard) {
this.graphicsCard = graphicsCard;
}
// 展示电脑配置(对象的“表示”)
public void showConfig() {
System.out.println("电脑配置:CPU=" + cpu + ",内存=" + memory + ",硬盘=" + hardDisk + ",显卡=" + graphicsCard);
}
}
2. 第二步:定义 “抽象建造者”(电脑建造者接口)
抽象出构建电脑的所有步骤,确保所有具体建造者都遵循统一规范:
// 抽象建造者:电脑建造者接口
public interface ComputerBuilder {
// 构建步骤1:设置CPU
void buildCpu();
// 构建步骤2:设置内存
void buildMemory();
// 构建步骤3:设置硬盘
void buildHardDisk();
// 构建步骤4:设置显卡
void buildGraphicsCard();
// 获取最终构建的电脑
Computer getComputer();
}
抽象出构建电脑的所有步骤,确保所有具体建造者都遵循统一规范:
// 抽象建造者:电脑建造者接口
public interface ComputerBuilder {
// 构建步骤1:设置CPU
void buildCpu();
// 构建步骤2:设置内存
void buildMemory();
// 构建步骤3:设置硬盘
void buildHardDisk();
// 构建步骤4:设置显卡
void buildGraphicsCard();
// 获取最终构建的电脑
Computer getComputer();
}
3. 第三步:实现 “具体建造者”(游戏本 / 轻薄本建造者)
针对不同需求,实现具体的部件配置。例如,“游戏本” 需要高性能 CPU 和显卡,“轻薄本” 更注重便携性(低功耗部件):
// 具体建造者1:游戏本建造者
public class GamingLaptopBuilder implements ComputerBuilder {
private Computer computer = new Computer(); // 持有产品实例
@Override
public void buildCpu() {
computer.setCpu("Intel i9-13900HX(高性能CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("32GB DDR5(高带宽内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("2TB SSD(高速硬盘)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("NVIDIA RTX 4080(高性能显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
// 具体建造者2:轻薄本建造者
public class UltrabookBuilder implements ComputerBuilder {
private Computer computer = new Computer();
@Override
public void buildCpu() {
computer.setCpu("Intel i5-1335U(低功耗CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("16GB LPDDR5(低功耗内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("1TB SSD(便携性优先)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("Intel Iris Xe(集成显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
针对不同需求,实现具体的部件配置。例如,“游戏本” 需要高性能 CPU 和显卡,“轻薄本” 更注重便携性(低功耗部件):
// 具体建造者1:游戏本建造者
public class GamingLaptopBuilder implements ComputerBuilder {
private Computer computer = new Computer(); // 持有产品实例
@Override
public void buildCpu() {
computer.setCpu("Intel i9-13900HX(高性能CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("32GB DDR5(高带宽内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("2TB SSD(高速硬盘)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("NVIDIA RTX 4080(高性能显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
// 具体建造者2:轻薄本建造者
public class UltrabookBuilder implements ComputerBuilder {
private Computer computer = new Computer();
@Override
public void buildCpu() {
computer.setCpu("Intel i5-1335U(低功耗CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("16GB LPDDR5(低功耗内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("1TB SSD(便携性优先)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("Intel Iris Xe(集成显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
4. 第四步:定义 “指挥者”(电脑组装指导者)
指挥者负责规定构建顺序,避免具体建造者与步骤顺序耦合。例如,统一按 “CPU→内存→硬盘→显卡” 的顺序组装:
// 指挥者:电脑组装指导者
public class ComputerDirector {
// 接收具体建造者,按顺序调用构建步骤
public Computer construct(ComputerBuilder builder) {
builder.buildCpu(); // 步骤1:装CPU
builder.buildMemory(); // 步骤2:装内存
builder.buildHardDisk();// 步骤3:装硬盘
builder.buildGraphicsCard();// 步骤4:装显卡
return builder.getComputer(); // 返回组装好的电脑
}
}
指挥者负责规定构建顺序,避免具体建造者与步骤顺序耦合。例如,统一按 “CPU→内存→硬盘→显卡” 的顺序组装:
// 指挥者:电脑组装指导者
public class ComputerDirector {
// 接收具体建造者,按顺序调用构建步骤
public Computer construct(ComputerBuilder builder) {
builder.buildCpu(); // 步骤1:装CPU
builder.buildMemory(); // 步骤2:装内存
builder.buildHardDisk();// 步骤3:装硬盘
builder.buildGraphicsCard();// 步骤4:装显卡
return builder.getComputer(); // 返回组装好的电脑
}
}
5. 第五步:客户端调用(定制电脑)
客户端只需选择 “具体建造者”,无需关心构建步骤,即可获取定制化电脑:
public class Client {
public static void main(String[] args) {
// 1. 创建指挥者
ComputerDirector director = new ComputerDirector();
// 2. 定制游戏本(选择游戏本建造者)
ComputerBuilder gamingBuilder = new GamingLaptopBuilder();
Computer gamingLaptop = director.construct(gamingBuilder);
gamingLaptop.showConfig(); // 输出:游戏本配置
// 3. 定制轻薄本(选择轻薄本建造者)
ComputerBuilder ultrabookBuilder = new UltrabookBuilder();
Computer ultrabook = director.construct(ultrabookBuilder);
ultrabook.showConfig(); // 输出:轻薄本配置
}
}
运行结果:
电脑配置:CPU=Intel i9-13900HX(高性能CPU),内存=32GB DDR5(高带宽内存),硬盘=2TB SSD(高速硬盘),显卡=NVIDIA RTX 4080(高性能显卡)
电脑配置:CPU=Intel i5-1335U(低功耗CPU),内存=16GB LPDDR5(低功耗内存),硬盘=1TB SSD(便携性优先),显卡=Intel Iris Xe(集成显卡)
客户端只需选择 “具体建造者”,无需关心构建步骤,即可获取定制化电脑:
public class Client {
public static void main(String[] args) {
// 1. 创建指挥者
ComputerDirector director = new ComputerDirector();
// 2. 定制游戏本(选择游戏本建造者)
ComputerBuilder gamingBuilder = new GamingLaptopBuilder();
Computer gamingLaptop = director.construct(gamingBuilder);
gamingLaptop.showConfig(); // 输出:游戏本配置
// 3. 定制轻薄本(选择轻薄本建造者)
ComputerBuilder ultrabookBuilder = new UltrabookBuilder();
Computer ultrabook = director.construct(ultrabookBuilder);
ultrabook.showConfig(); // 输出:轻薄本配置
}
}
运行结果:
电脑配置:CPU=Intel i9-13900HX(高性能CPU),内存=32GB DDR5(高带宽内存),硬盘=2TB SSD(高速硬盘),显卡=NVIDIA RTX 4080(高性能显卡)
电脑配置:CPU=Intel i5-1335U(低功耗CPU),内存=16GB LPDDR5(低功耗内存),硬盘=1TB SSD(便携性优先),显卡=Intel Iris Xe(集成显卡)
四、建造者模式的适用场景
并非所有对象创建都需要建造者模式,以下场景最适合使用:
- 复杂对象的定制化构建:对象由多个部件组成,且部件配置、组合顺序存在多种变化(如定制电脑、生成个性化报告、构建汽车)。
- 需要隐藏构建细节:客户端无需知道对象的具体构建步骤,只需获取最终结果(如用户无需知道电脑 “先装 CPU 还是先装内存”)。
- 同一构建过程生成不同表示:通过更换具体建造者,可让同一指挥者(步骤顺序)生成不同配置的对象(如同一组装流程,既做游戏本也做轻薄本)。
并非所有对象创建都需要建造者模式,以下场景最适合使用:
- 复杂对象的定制化构建:对象由多个部件组成,且部件配置、组合顺序存在多种变化(如定制电脑、生成个性化报告、构建汽车)。
- 需要隐藏构建细节:客户端无需知道对象的具体构建步骤,只需获取最终结果(如用户无需知道电脑 “先装 CPU 还是先装内存”)。
五、建造者模式的优缺点
优点
- 灵活性高:支持对对象部件的精细化定制,轻松扩展新的具体建造者(如新增 “工作站电脑建造者”,无需修改原有代码)。
- 代码清晰:将复杂构建逻辑拆分为独立步骤,职责单一,便于维护(构建步骤由指挥者管理,部件配置由建造者管理)。
- 解耦性强:客户端与具体构建步骤、部件配置分离,降低代码耦合度。
- 灵活性高:支持对对象部件的精细化定制,轻松扩展新的具体建造者(如新增 “工作站电脑建造者”,无需修改原有代码)。
缺点
- 增加类数量:每个具体产品需对应一个具体建造者,若产品类型过多,会导致类数量激增(如电脑有 10 种型号,需 10 个具体建造者)。
- 不适用于简单对象:若对象仅由少数部件组成(如 “用户” 对象仅含姓名、年龄),使用建造者模式会显得冗余,不如直接 new 对象高效。
- 增加类数量:每个具体产品需对应一个具体建造者,若产品类型过多,会导致类数量激增(如电脑有 10 种型号,需 10 个具体建造者)。
六、建造者模式与工厂模式对比表
建造者模式与工厂模式虽同属 “创建型模式”,但核心意图和适用场景差异显著,以下是两者的关键对比:
| 对比维度 | 建造者模式(Builder Pattern) | 工厂模式(Factory Pattern) |
|---|---|---|
| 核心意图 | 关注 “如何构建”:拆分复杂对象的构建步骤,定制部件细节 | 关注 “创建什么”:统一创建对象,隐藏实例化逻辑 |
| 产品复杂度 | 适用于复杂对象(由多个部件组成,需分步构建) | 适用于简单 / 标准化对象(单一完整对象,无需分步) |
| 客户端控制度 | 客户端可控制部件配置(选择不同建造者) | 客户端仅控制产品类型(告诉工厂 “要什么”,不关心细节) |
| 角色构成 | 产品、抽象建造者、具体建造者、指挥者(4 个角色) | 产品、抽象工厂、具体工厂(3 个角色,无指挥者) |
| 典型场景 | 定制电脑、组装汽车、生成个性化报告 | 生产标准化产品(如不同品牌的手机、不同类型的日志器) |
| 类比生活场景 | 按需求定制家具(选材质、定尺寸,分步组装) | 从工厂批量购买标准化家电(直接拿成品,不关心生产) |
来源:juejin.cn/post/7543448572341157927
用户请求满天飞,如何精准『导航』?聊聊流量路由那些事儿
嘿,各位未来的技术大佬们,我是老码小张。
不知道大家有没有遇到过这样的场景:你美滋滋地打开刚部署上线的应用 cool-app.com,在国内访问速度飞快。结果第二天,海外的朋友跟你吐槽,说访问你的应用慢得像蜗牛。或者更糟,某个区域的用户突然反馈说服务完全访问不了了!这时候你可能会挠头:用户来自天南海北,服务器也可能部署在不同地方,我怎么才能让每个用户都能又快又稳地访问到我的服务呢?

别慌!这其实就是咱们今天要聊的互联网流量路由策略要解决的问题。搞懂了它,你就掌握了给网络请求“精准导航”的秘诀,让你的应用在全球范围内都能提供更好的用户体验。
流量路由:不止是 DNS 解析那么简单
很多初级小伙伴可能觉得,用户访问网站不就是 浏览器 -> DNS 查询 IP -> 连接服务器 嘛?没错,DNS 是第一步,但现代互联网应用远不止这么简单。特别是当你的服务需要部署在多个数据中心、覆盖不同地理区域的用户时,仅仅返回一个固定的 IP 地址是远远不够的。
我们需要更智能的策略,来决定当用户请求 cool-app.com 时,DNS 服务器应该返回哪个(或哪些)IP 地址。这就引出了各种路由策略(Routing Policies)。你可以把它们想象成 DNS 服务器里的“智能导航系统”,根据不同的规则把用户导向最合适的目的地。
下面,咱们就来盘点几种最常见也最实用的路由策略。
策略一:按地理位置『就近安排』 (Geolocation Routing)
这是最直观的一种策略。顾名思义,它根据用户请求来源的 IP 地址,判断用户的地理位置(比如国家、省份甚至城市),然后将用户导向物理位置上距离最近或者预设好的对应区域的服务器。
工作原理示意:
sequenceDiagram
participant User as 用户 (来自北京)
participant DNS as 智能 DNS 服务器
participant ServerCN as 北京服务器 (1.1.1.1)
participant ServerUS as 美国服务器 (2.2.2.2)
User->>DNS: 查询 cool-app.com 的 IP 地址
activate DNS
DNS-->>DNS: 分析来源 IP,判断用户在北京
DNS-->>User: 返回北京服务器 IP (1.1.1.1)
deactivate DNS
User->>ServerCN: 连接 1.1.1.1
啥时候用?
- 需要为特定地区用户提供本地化内容或服务。
- 有合规性要求,比如某些数据必须存储在用户所在国家境内(像 GDPR)。
- 希望降低跨区域访问带来的延迟。
简单配置示例(伪代码):
// 类似 AWS Route 53 或其他云 DNS 的配置逻辑
RoutingPolicy {
Type: Geolocation,
Rules: [
{ Location: '中国', TargetIP: '1.1.1.1' },
{ Location: '美国', TargetIP: '2.2.2.2' },
{ Location: '*', TargetIP: '3.3.3.3' } // * 代表默认,匹配不到具体位置时使用
]
}
策略二:追求极致速度的『延迟优先』 (Latency-Based Routing)
这个策略的目标是:快! 它不关心用户在哪儿,只关心用户访问哪个服务器的网络延迟最低(也就是 RTT,Round-Trip Time 最短)。DNS 服务商会持续监测从全球不同网络到你各个服务器节点的网络延迟,然后把用户导向响应最快的那个节点。
工作原理示意:
sequenceDiagram
participant User as 用户
participant DNS as 智能 DNS 服务器
participant ServerA as 服务器 A (东京)
participant ServerB as 服务器 B (新加坡)
User->>DNS: 查询 cool-app.com 的 IP 地址
activate DNS
DNS-->>DNS: 检测用户到各服务器的延迟 (到 A: 50ms, 到 B: 30ms)
DNS-->>User: 返回延迟最低的服务器 B 的 IP
deactivate DNS
User->>ServerB: 连接服务器 B
啥时候用?
- 对响应速度要求极高的应用,比如在线游戏、实时通讯。
- 全球用户分布广泛,希望动态地为每个用户找到最快接入点。
注意点: 延迟是动态变化的,所以这种策略依赖于 DNS 服务商持续、准确的延迟探测。
策略三:灵活调度的『按权重分配』 (Weighted Routing)
这种策略允许你给不同的服务节点分配不同的权重(百分比),DNS 服务器会按照你设定的比例,把用户的请求随机分配到这些节点上。
工作原理示意:
假设你有两个版本的服务 V1 和 V2,部署在不同的服务器组上。
// 类似云 DNS 配置
RoutingPolicy {
Type: Weighted,
Targets: [
{ TargetIPGr0up: 'V1_Servers', Weight: 90 }, // 90% 流量到 V1
{ TargetIPGr0up: 'V2_Servers', Weight: 10 } // 10% 流量到 V2
]
}
DNS 会根据这个权重,概率性地返回 V1 或 V2 服务器组的 IP。
啥时候用?
- A/B 测试:想测试新功能?分一小部分流量(比如 5%)到新版本,看看效果。
- 灰度发布/金丝雀发布:新版本上线,先给 1% 的用户试试水,没问题再逐步增加权重到 10%、50%、100%。稳!
- 负载均衡:如果你的服务器配置不同(比如有几台是高性能的,几台是普通配置的),可以按性能分配不同权重,让高性能机器承担更多流量。
策略四:保障高可用的『故障转移』 (Failover Routing)
这个策略是为了高可用性。你需要设置一个主服务节点和一个或多个备用节点。DNS 服务器会持续对主节点进行健康检查(比如探测端口是否存活、HTTP 接口是否返回 200 OK)。
- 正常情况:所有流量都导向主节点。
- 主节点挂了:DNS 检测到主节点 N 次健康检查失败后,会自动把流量切换到备用节点。
- 主节点恢复:一旦主节点恢复健康,流量可以自动切回来(取决于你的配置)。
工作原理示意:
graph LR
A[用户请求] --> B{DNS 健康检查};
B -- 主节点健康 --> C[主服务器];
B -- 主节点故障 --> D[备用服务器];
C --> E[提供服务];
D --> E;
啥时候用?
- 任何对可用性要求高的关键服务。谁也不想服务宕机了用户还一直往坏掉的服务器上撞吧?
- 实现基本的灾备能力。
关键点: 健康检查的配置(频率、失败阈值)和 DNS 记录的 TTL(Time-To-Live,缓存时间)设置很关键。TTL 太长,故障切换就不够及时;TTL 太短,会增加 DNS 查询压力和成本。需要权衡。
策略五:CDN 和大厂最爱『任播』 (Anycast)
Anycast 稍微特殊一点,它通常是在更底层的网络层面(BGP 路由协议)实现的,但 DNS 经常与之配合。简单来说,就是你用同一个 IP 地址在全球多个地点宣告你的服务。用户的请求会被沿途的网络路由器自动导向“网络距离”上最近的那个宣告了该 IP 的节点。
效果: 用户感觉就像是连接到了离他最近的“入口”。
啥时候用?
- CDN 服务:为什么你访问各大 CDN 厂商(如 Cloudflare, Akamai)的资源总是很快?Anycast 是核心技术之一,让用户从最近的边缘节点获取内容。
- 公共 DNS 服务:像 Google 的
8.8.8.8和 Cloudflare 的1.1.1.1都使用了 Anycast,你在全球任何地方 ping 这个 IP,响应的都是离你最近的数据中心。
对于应用开发者来说,你可能不会直接配置 BGP,但你会选择使用提供了 Anycast 网络的服务商(比如某些云厂商的负载均衡器或 CDN 服务)。
选哪个?一张表帮你捋清楚
这么多策略,到底该怎么选呢?别急,我给你整理了个表格,对比一下:
| 策略名称 | 核心原理 | 主要应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 地理位置路由 | 基于用户 IP 判断地理位置 | 本地化内容、合规性、区域优化 | 实现区域隔离、满足合规 | IP 库可能不准、无法反映真实网络状况 |
| 延迟路由 | 基于网络延迟 (RTT) | 追求最低访问延迟、全球性能优化 | 用户体验好、动态适应网络变化 | 依赖准确探测、成本可能较高 |
| 权重路由 | 按预设比例分配流量 | A/B 测试、灰度发布、按能力负载均衡 | 灵活控制流量分配、上线平稳 | 无法基于用户体验动态调整(除非结合其他策略) |
| 故障转移路由 | 健康检查 + 主备切换 | 高可用、灾备 | 提升服务可靠性、自动化故障处理 | 切换有延迟(受 TTL 和检查频率影响) |
| 任播 (Anycast) | 同一 IP 多点宣告,网络路由就近转发 | CDN、公共 DNS、全球入口优化 | 显著降低延迟、抵抗 DDoS 攻击(分散) | 配置复杂(通常由服务商提供)、成本高 |
实战经验分享:组合拳出奇效!
在实际项目中,我们很少只用单一策略。更常见的是打组合拳:
- 地理位置 + 故障转移:先按区域分配流量(比如中国用户到上海,美国用户到硅谷),然后在每个区域内部署主备服务器,使用故障转移策略保障区域内的高可用。这是很多应用的标配。
- 地理位置 + 权重路由:在一个特定的地理区域内(比如只在中国区),对新上线的服务 V2 使用权重路由进行灰度发布。
- Anycast + 后端智能路由:使用 Anycast IP 作为全球统一入口,流量到达最近的接入点后,再根据后端服务的实际负载、延迟等情况,通过内部的负载均衡器或服务网格(Service Mesh)进行更精细的二次路由。
别忘了监控! 无论你用哪种策略,监控都至关重要。你需要关注:
- 各节点的健康状况。
- 用户的实际访问延迟(可以用 RUM - Real User Monitoring)。
- DNS 解析成功率和解析耗时。
- 流量分布是否符合预期。
有了监控数据,你才能知道你的路由策略是否有效,是否需要调整。
好了,今天关于互联网流量路由策略就先和大家聊这么多。希望这些内容能帮助你理解,当用户的请求“满天飞”时,我们是如何通过这些“智能导航”技术,确保他们能又快又稳地到达目的地的。这不仅仅是运维同学的事,作为开发者,理解这些原理,能让你在设计和部署应用时考虑得更周全。
我是老码小张,一个喜欢研究技术原理,并且在实践中不断成长的技术人。如果你觉得这篇文章对你有帮助,或者有什么想法想交流,欢迎在评论区留言!咱们下次再见!
来源:juejin.cn/post/7498292516493656098





