








摆动序列
摆动序列
一、问题描述
LeetCode:376. 摆动序列
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
例如,[1, 7, 4, 9, 2, 5] 是一个摆动序列,因为差值 (6, -3, 5, -7, 3) 是正负交替出现的。
相反,[1, 4, 7, 2, 5] 和 [1, 7, 4, 5, 5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数数组 nums,返回 nums 中作为摆动序列的最长子序列的长度。
二、解题思路
摆动序列的关键在于寻找数组中的峰和谷。每当序列发生方向变化时,摆动序列的长度就会增加。因此,可以通过遍历数组,统计方向变化的次数来得到最长摆动序列的长度。
- 记录初始趋势:计算数组前两个元素的差值作为最开始的变化趋势preTrend = nums[1] - nums[0],若差值不为 0,说明前两个元素构成了摆动序列的初始趋势,此时摆动序列长度初始化为 2;若差值为 0,意味着前两个元素相等,不构成摆动趋势,摆动序列长度初始化为 1。
- 遍历数组寻找变化趋势:记录当前变化趋势curTrend = nums[i] - nums[i - 1],若当前变化趋势curTrend 与之前的变化趋势preTrend 不同,preTrend <= 0 && curTrend > 0 或者 preTrend >= 0 && curTrend < 0 时 更新变化趋势preTrend ,摆动序列加1
三、代码实现
以下是使用 JavaScript 实现的代码:
var wiggleMaxLength = function (nums) {
// 统计波峰波谷的数量
// 若长度为1 或为 0
if (nums.length < 2) return nums.length;
let preTrend = nums[1] - nums[0];
let reLen = preTrend !== 0 ? 2 : 1;
for (let i = 2; i < nums.length; i++) {
let curTrend = nums[i] - nums[i - 1];
// 当出现波谷或者波峰时,更新preTrend
if ((preTrend <= 0 && curTrend > 0) || (preTrend >= 0 && curTrend < 0)) {
preTrend = curTrend;
reLen++;
}
}
return reLen;
};
四、注意事项
- 边界条件需谨慎:在处理数组前两个元素确定初始趋势时,要特别注意数组长度为 2 的情况。若两个元素相等,初始化摆动序列长度为 1,此时不能因为后续没有更多元素判断趋势变化,就错误认为长度还能增加。在遍历过程中,若遇到数组结尾,也应保证最后一次趋势变化能正确统计,避免遗漏。
- 趋势判断避免误判:在比较差值判断趋势变化时,条件 (preTrend <= 0 && curTrend > 0) 与 (preTrend >= 0 && curTrend < 0) 中的 “小于等于” 和 “大于等于” 不能随意替换为 “小于” 和 “大于”。例如,当出现连续相等元素后趋势改变的情况,若使用严格的 “小于” 和 “大于” 判断,可能会错过第一个有效趋势变化点,导致结果错误。
五、复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。只需要遍历一次数组。
- 空间复杂度:O(1),只需要常数级的额外空间。
来源:juejin.cn/post/7518198430662492223
绿盟科技重磅发布AI安全运营新成果,全面驱动智能攻防体系升级

8月29日,绿盟科技在北京成功举办以“智御新境·安全无界”为主题的AI赋能安全运营线上成果发布会,全面展示了公司在AI安全领域的最新技术成果与实践经验。
会议总结了“风云卫”AI安全能力平台上半年在客户侧的实际运营成效,介绍了AISOC平台的新特性与能力,进一步验证了“AI+安全运营”在降噪、研判、处置闭环以及未知威胁检测等核心场景中的规模化应用价值。
此外,还正式发布了“绿盟AI智能化渗透系统”,该系统依托AI技术全面赋能渗透测试全流程,可广泛应用于常态化扫描和日常安全运维等场景,有效帮助客户降本增效,显著降低渗透测试的专业门槛。
双底座多智能体架构,构建三位一体AI安全生态
2020年至2022年,绿盟科技连续发布三部AI安全白皮书《安全AI赋能安全运营白皮书》、《知识图谱白皮书》和《AI安全分析白皮书》,并于2023年推出“风云卫”安全大模型,深度融合AI与攻防知识。2025年,公司再度升级,构建“风云卫+DeepSeek”双底座与多智能体架构,打造AI驱动的安全生态,覆盖模型生产、场景适配与应用复制三大层面,全面提升安全检测、运营、数据安全及蓝军对抗能力,实现全域智能赋能。

安全运营实现“智防”质变,绿盟“风云卫”AI实战成效显著

绿盟科技产品BG总经理吴天昊
绿盟科技产品BG总经理吴天昊表示,安全运营人员每天面临几万到几十万不等的原始攻击告警,绿盟“风云卫”AI安全能力平台依托千亿级安全样本训练的大模型,能够自动识别系统日志中的无效告警与重复信息,达到百级左右的高价值告警的优先推荐。
针对不同攻击事件,可自动展开研判分析,精准解析攻击路径和手法,并通过可视化分析界面清晰呈现完整攻击链条。通过自主调查,智能开展横向溯源,自动关联跨端、跨网、跨身份数据,构建出完整的攻击图谱;同时进行并案分析,深度挖掘同类攻击线索,精准定位攻击组织;最后通过SOAR剧本自动生成与执行,实现分钟级事件闭环,并为未来同类事件建立自动化处置范式。
实际应用数据显示,绿盟科技的AI降噪率平均达到95%以上,AI综合辅助研判准确率超过90%。在处置响应方面,依托自主响应可实现超过40%的安全事件端到端的自动化响应处置。特别值得关注的是,经过实际观测和验证,针对13大类77小类的攻击类型,绿盟风云卫AI辅助识别准确率超过95%。
会上,绿盟科技全流程演示了AI赋能安全运营的过程,生动体现了AI技术在安全运营各环节的深度融合——从海量告警的智能降噪、攻击链路的自动重构,到复杂事件的自主研判和自动化响应,真正实现了安全运营从"人防"到"智防"的质变升级。

AI赋能安全检测:混淆检测+自主基线,让未知威胁检测变成可能
在攻防演练中,统计数据显示有76%的攻击属于“已知家族、未知变种”类型,这类攻击因具备一定家族特征又存在变异特性,给检测工作带来不小挑战。
绿盟“风云卫”AI安全能力平台在此类场景中展现出显著优势:在混淆检测方面,AI凭借强大的语义理解能力,能够深入剖析恶意程序的本质特征。即便攻击手段经过混淆处理,改变了表面形态,AI也能透过现象看本质,精准识别出其属于已知家族的核心属性,从而有效识破“未知变种”的伪装。
在自主基线构建上,AI能够自主解读并理解全量日志,从中提炼出账号、流量、进程等各类实体在正常时段的行为画像。基于这些画像,AI可以秒级输出动态阈值,形成精准的正常行为基线。当“已知家族、未知变种”的攻击出现,导致相关实体行为偏离动态阈值时,系统能快速察觉异常,为及时发现和应对威胁提供有力支撑。
智能体中心成效显著,20多个安全领域智能体协同赋能
绿盟“风云卫”AI安全能力平台汇聚绿盟安全专家经验,内置20+安全领域智能体,覆盖网络安全多个关键环节,包含钓鱼邮件检测、可疑样本分析、敏感数据识别、零配置日志解析、情报分析、报告生成等多个智能体。这些智能体既可以赋能产品,也可以独立运行。值得一提的是,智能体中心支持智能体可视化编排,这一特性为用户带来了极大便利。即便是非专业的技术人员,也能通过简单的拖拽、连线操作,如同搭建积木一般,将多个智能体按照企业自身的业务逻辑与安全需求,灵活组合成个性化的安全工作流程。
例如,用户可通过可视化方式自定义编排敏感信息检测智能体,将企业特定的敏感信息嵌入其中,从而实现更精准的自定义检测。这种低代码的编排方式不仅大幅降低了使用门槛,还能灵活应对企业不断变化的安全需求,实现安全防护的定制化与敏捷化,全面提升网络安全工作的效能。

多行业落地实践,安全运营效率大幅提升

绿盟科技鹰眼安全运营中心技术经理李昀磊
截至目前,绿盟科技已助力电信、金融、政府、高校等行业的多家客户实现安全运营智能化转型。在近期多项攻防演练中,公司依托“风云卫”AI安全能力平台,为客户提供全面支撑,多项智能体——包括未知威胁检测、行为分析、钓鱼邮件识别等——均发挥关键作用。
绿盟科技鹰眼安全运营中心技术经理李昀磊介绍,绿盟安全运营中心已持续为超2000家企业提供安全运营服务,并于2023年起全面融合“风云卫”大模型,AI赋能成效主要体现在三方面:
●高频场景AI全自动处置:对实时性要求极高的常见攻击,实现从检测、研判、通知到响应的全自动闭环,无需人工干预;
●复杂事件智能辅助调查:针对约占20%+的复杂事件,AI可自主拓展调查路径,完成情报搜集与初步总结,提升分析师决策效率;
●工具调度与客户交互自动化:AI统一调度多类分析工具,并自动完成工单发送、报告生成与客户反馈响应,显著节约人力。
截至目前,绿盟云端安全运营中心约77%的告警日志依托AI实现辅助研判与处置,在客户预授权条件下5分钟内发现确认并处置闭环事件,运营效率大幅提升。
绿盟AI智能化渗透系统发布

绿盟科技产品总监许伟强
绿盟科技产品总监许伟强表示,公司基于多年攻防实战经验与大模型技术,正式推出新一代绿盟AI智能化渗透系统。该系统全面覆盖常态化扫描与日常安全运维等多种场景,在国内首次实现AI智能体在真实网络环境中完成端到端渗透测试,显著提升渗透效率与响应能力。该系统具备四大核心能力:
●智能任务规划:通过多智能体分层协作,结合专业攻防知识库,实现对复杂渗透场景的智能化任务分解;
●智能工具调度:依托工具调度智能体,无缝调用并协同多种渗透工具,破除工具间壁垒,增强协同作战效能;
●渗透路径推荐:基于安全大模型技术,融合知识图谱与漏洞利用知识,提供渗透路径规划、过程可视化及标准化报告输出;
●AI智能对话:支持自然语言交互,可依据用户指令智能推荐并自动执行渗透工具,大幅降低操作门槛。
绿盟AI智能化渗透系统基于“风云卫”平台构建,采用“人在环路”安全机制与多智能体协同架构,具备“直接模式+深度模式”双轨机制,可快速响应常规攻击面,也可深入攻坚复杂高对抗场景,动态适应多样化的实战攻防需求。

随着国务院常务会议审议通过《关于深入实施“人工智能+”行动的意见》,“人工智能+”正成为产业升级的关键方向,各领域在快速发展的同时,安全问题将不容忽视。绿盟科技始终站在技术前沿,目前形成了以风云卫AI安全能力平台为核心,构建“模型生产、场景适配、应用赋智”的“三位一体”AI安全生态体系,可为不同用户提供全方位的智能安全保障。面向未来,绿盟科技将继续以创新为引擎,携手客户与合作伙伴,共同迎接智能安全新时代。
本地Docker部署Transmission,内网穿透无限远程访问教程
Transmission是一款开源、轻量且资源占用极低的BitTorrent客户端。借助Docker,可以在几分钟内把它跑起来;再借助贝锐花生壳的内网穿透功能,又能随时随地从外网安全访问。下面给出一条龙的部署与远程访问流程,全部命令可直接复制粘贴。

一、准备Docker环境
1. 一键安装最新版Docker(已包含阿里云镜像加速):


2. 启动并设为开机自启:


二、拉取Transmission镜像


如果拉取超时,可在 `/etc/docker/daemon.json` 中追加国内镜像源,例如:

三、运行Transmission容器
下面命令把Web端口9091、BT 监听端口41234(TCP/UDP)都映射出来,并把配置、下载目录、监控目录挂到宿主机持久化。按需替换UID/GID、时区、用户名密码以及宿主机路径。


启动后,浏览器访问 http://局域网IP:9091即可看到Transmission Web UI。

点击左上角图标即可上传种子或粘贴磁力链接开始下载。


四、安装并配置贝锐花生壳
1. 下载客户端
在同一内网任意设备上,从花生壳官网下载最新Linux版客户端,可根据实际情况,选择docker安装花生壳。(`phddns_5.x.x_amd64.deb`)。


2. 安装
根据不同位数的系统输入下面的命令进行安装,安装完成会自动生成SN码与登录密码。


3. 激活与登录
浏览器打开 [花生壳管理平台](http://b.oray.com),用SN和默认密码登录。

首次登录需激活设备,支持微信扫码或绑定贝锐账号。

4. 添加映射
激活成功后,进入「内网穿透」→「添加映射」,填写新增的映射信息。

保存后,贝锐花生壳会生成一个 `http://xxxx.hsk.oray.com:端口` 的外网地址。可访问外网地址访问transmission。

五、外网访问与日常使用
任何地点打开浏览器,输入花生壳提供的外网地址,即可远程管理Transmission:添加种子、查看进度、做种、限速等操作与局域网完全一致。

至此,借助贝锐花生壳内网穿透就可以使本地Docker版Transmission已可安全、便捷地实现远程访问。
收起阅读 »一文说透WebSocket协议(秒懂)
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
为避免同学们概念混淆,先声明一下,其实WebSocket和Socket之间是毫无关系的,就像北大青鸟和北大一样,大家不要被名字给带偏了。
WebSocket是一种建立在TCP底层连接上,使web客户端和服务器端可进行持续全双工通信的协议。
用大白话来说,WebSocket协议最大的特点是支持服务器端给客户端发送消息。
只需先通过HTTP协议进行握手并进行协议升级,即可让服务器端和客户端一直保持连接并实现通信,直到连接关闭。
如下图所示:
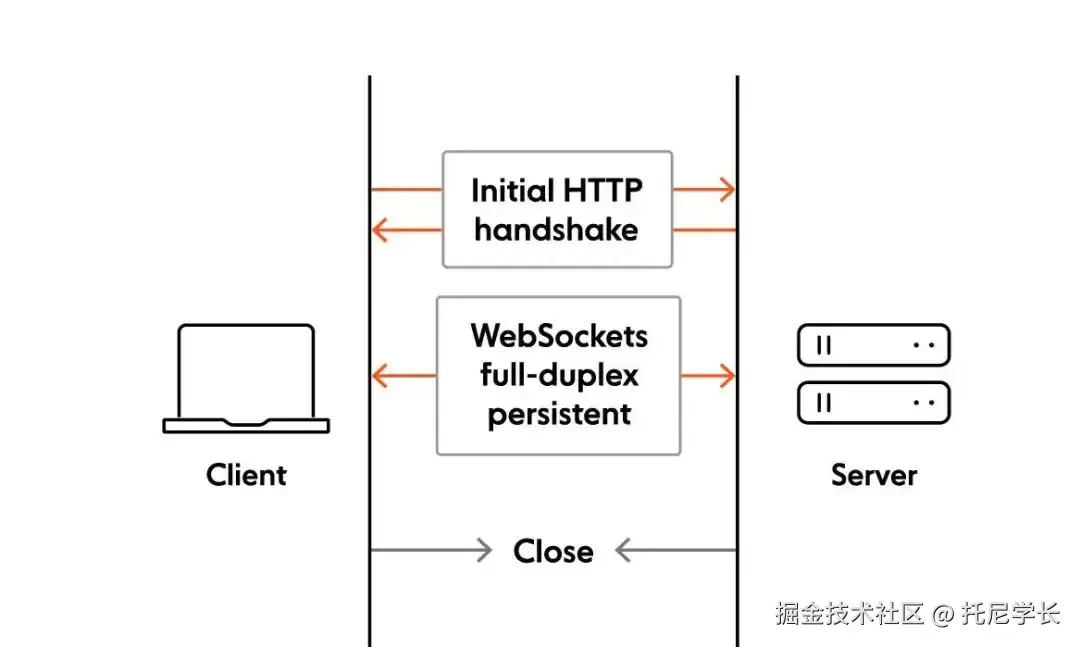
一定会有同学存在疑问,WebSocket协议所具备的“支持服务器端给客户端发送消息”的特点,具体适用场景是什么呢?
下面我们就来详细地讲解一下。
适用场景
对于这个问题,我们有必须逆向思考一下,WebSocket协议所适用的场景,必然是其他协议不适用的场景,这个协议就是HTTP。
由于HTTP协议是半双工模式,只能由客户端发起请求并由服务器端进行响应。
所以在线聊天、实时互动游戏、股票行情、物联网设备监控等业务场景下,只能通过客户端以轮询、长轮询的方式去服务器端获取最新数据。
股票行情场景,如下图所示:
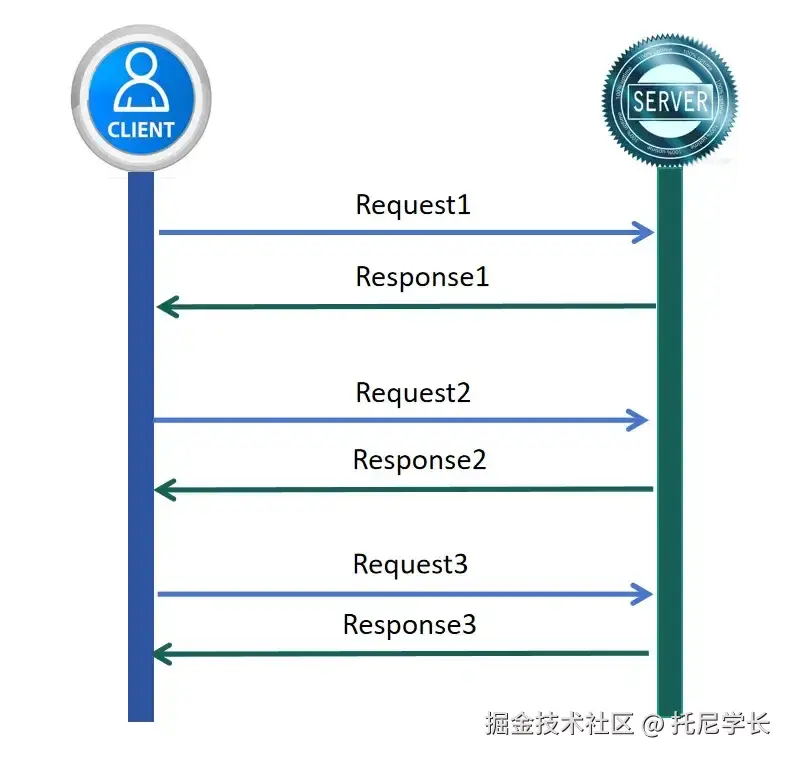
这种方式所带来的问题有两点:
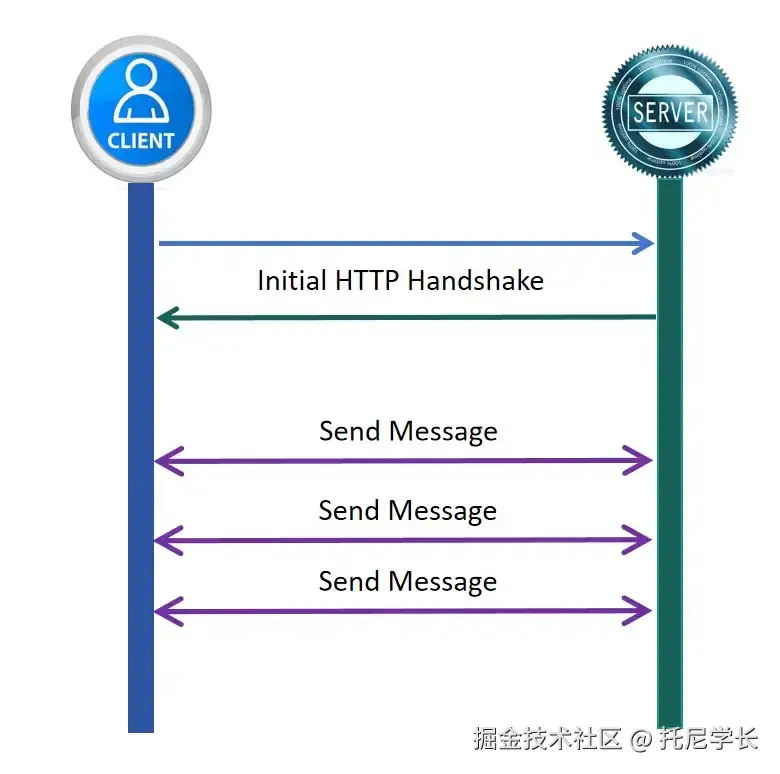
1、客户端频繁发送HTTP请求会带来网络开销,也会给服务器端带来负载压力;2、轮询间隔难以把控,间隔过短同样会带来问题(1)中提到的点,间隔过长会导致数据延迟。
而WebSocket协议只有在服务器端有事件发生的时候,才会第一时间给客户端发送消息,彻底杜绝了HTTP轮询所带来的网络开销、服务器负载和数据时延问题。
实现步骤
阶段一、客户端通过 HTTP 协议发送包含特殊头部的请求,触发协议升级:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Version: 13
- Upgrade: websocket明确请求升级协议。
- Sec-WebSocket-Key:客户端生成的随机字符串,用于安全验证。
- Sec-WebSocket-Version:指定协议版本(RFC 6455 规定为 13)。
阶段二、服务器端进行响应确认,返回 101 Switching Protocols 响应:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
- Sec-WebSocket-Accept:服务器将客户端的 Sec-WebSocket-Key 与固定字符串拼接后,计算 SHA-1 哈希并进行 Base64 编码,生成验证令牌。
阶段三、此时 TCP 连接从 HTTP 升级为 WebSocket 协议,后续数据可通过二进制帧进行传输。
阶段四、数据传输,WebSocket是一种全双工通信协议,客户端与服务端可同时发送/接收数据,无需等待对方请求,数据帧是以二进制格式进行传输的。
如下图所示:
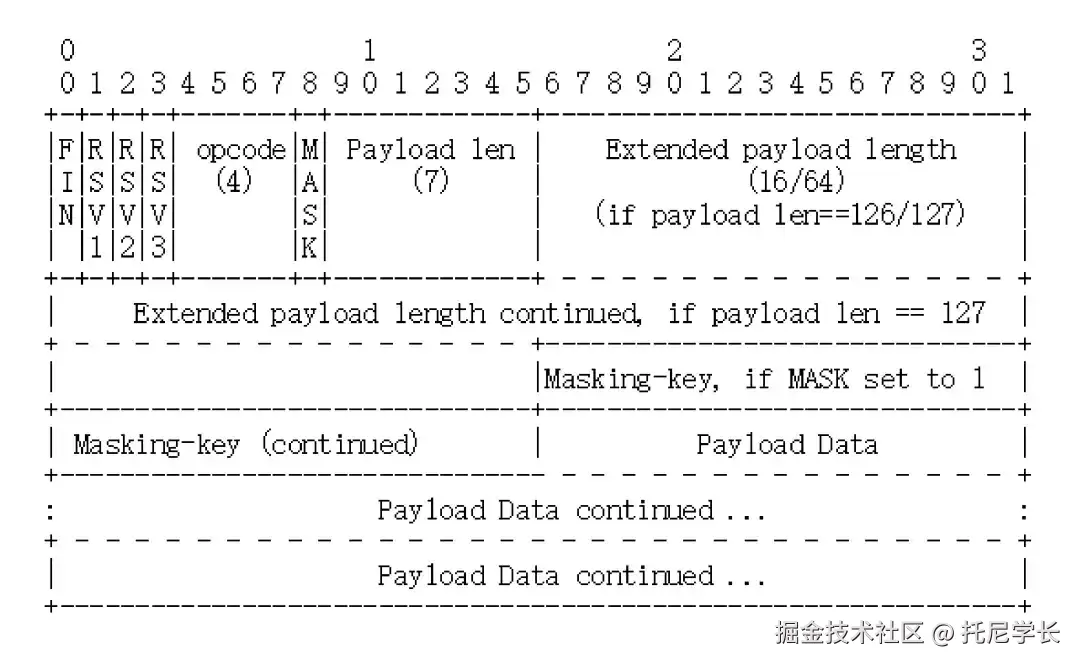
- FIN (1 bit):标记是否为消息的最后一个分片。
- Opcode (4 bits):定义数据类型(如文本 0x1、二进制 0x2、关闭连接 0x8、Ping 0x9、Pong 0xA)。
- Mask (1 bit):客户端发送的数据需掩码处理(防止缓存污染攻击),服务端发送的数据无需掩码。
- Payload Length (7 or 7+16 or 7+64 bits):帧内容的长度,支持最大 2^64-1 字节。
- Masking-key(32 bits),掩码密钥,由上面的标志位 MASK 决定的,如果使用掩码就是 4 个字节的随机数,否则就不存在。
- payload data 字段:这里存放的就是真正要传输的数据
阶段五、连接关闭,客户端或服务器端都可以发起关闭。
示例代码
前端代码:
<!DOCTYPE html>
<html>
<body>
<input type="text" id="messageInput" placeholder="输入消息">
<button onclick="sendMessage()">发送</button>
<div id="messages"></div>
<script>
// 创建 WebSocket 连接
const socket = new WebSocket('ws://localhost:8080/ws');
// 连接打开时触发
socket.addEventListener('open', () => {
logMessage('连接已建立');
});
// 接收消息时触发
socket.addEventListener('message', (event) => {
logMessage('收到消息: ' + event.data);
});
// 连接关闭时触发
socket.addEventListener('close', () => {
logMessage('连接已关闭');
});
// 错误处理
socket.addEventListener('error', (error) => {
logMessage('连接错误: ' + error.message);
});
// 发送消息
function sendMessage() {
const message = document.getElementById('messageInput').value;
socket.send(message);
logMessage('发送消息: ' + message);
}
// 日志输出
function logMessage(message) {
const messagesDiv = document.getElementById('messages');
const p = document.createElement('p');
p.textContent = message;
messagesDiv.appendChild(p);
}
</script>
</body>
</html>
我们通过 Spring WebSocket 来实现服务器端代码。
1、添加 Maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
<version>2.7.14</version>
</dependency>
2、配置类启用 WebSocket:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.config.annotation.EnableWebSocket;
import org.springframework.web.socket.config.annotation.WebSocketConfigurer;
import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry;
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(new MyWebSocketHandler(), "/ws")
.setAllowedOrigins("*");
}
}
3、消息处理器实现:
import org.springframework.web.socket.TextMessage;
import org.springframework.web.socket.WebSocketSession;
import org.springframework.web.socket.handler.TextWebSocketHandler;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
public class MyWebSocketHandler extends TextWebSocketHandler {
private static final Set<WebSocketSession> sessions =
Collections.synchronizedSet(new HashSet<>());
@Override
public void afterConnectionEstablished(WebSocketSession session) {
sessions.add(session);
log("新连接: " + session.getId());
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) {
String payload = message.getPayload();
log("收到消息: " + payload);
// 广播消息
sessions.forEach(s -> {
if (s.isOpen() && !s.equals(session)) {
try {
s.sendMessage(new TextMessage("广播: " + payload));
} catch (Exception e) {
log("发送消息失败: " + e.getMessage());
}
}
});
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) {
sessions.remove(session);
log("连接关闭: " + session.getId());
}
private void log(String message) {
System.out.println("[MyWebSocketHandler] " + message);
}
}
结语
在本文中,我们先是对WebSocket协议的概念进行了讲解,也对其适用场景、实现步骤进行描述,最后给出了实例代码,旨在帮助大家一站式熟悉WebSocket协议。
来源:juejin.cn/post/7503811248288661558
交替打印最容易理解的实现——同步队列
前言
原创不易,禁止转载!
本文旨在实现最简形式的交替打印。理解了同步队列,你可以轻松解决60%以上的多线程面试题。同步队列作为JUC提供的并发原语之一,使用了无锁算法,性能更好,但是却常常被忽略。
交替打印是一类常见的面试题,也是很多人第一次学习并发编程面对的问题,如:
- 三个线程T1、T2、T3轮流打印ABC,打印n次,如ABCABCABCABC.......
- 两个线程交替打印1-100的奇偶数
- N个线程循环打印1-100
很多文章(如: zhuanlan.zhihu.com/p/370130458 )总结了实现交替打印的多种做法:
- synchronized + wait/notify: 使用synchronized关键字和wait/notify方法来实现线程间的通信和同步。
- join() : 利用线程的join()方法来确保线程按顺序执行。
- Lock: 使用ReentrantLock来实现线程同步,通过锁的机制来控制线程的执行顺序。
- Lock + Condition: 在Lock的基础上,使用Condition对象来实现更精确的线程唤醒,避免不必要的线程竞争。
- Semaphore: 使用信号量来控制线程的执行顺序,通过acquire()和release()方法来管理线程的访问。
- 此外还有LockSupport、CountDownLatch、AtomicInteger 等实现方式。
笔者认为,在面试时能够选择一种无bug实现即可。
缺点
这些实现使用的都是原语,也就是并发编程中的基本组件,偏向于底层,同时要求开发者深入理解这些原语的工作原理,掌握很多技巧。
问题在于:如果真正的实践中实现,容易出现 bug,一般也不推荐在生产中使用;
这也是八股文的弊端之一:过于关注所谓的底层实现,忽略了真正的实践。
我们分析这些组件的特点,不外乎临界区锁定、线程同步、共享状态等。以下分析一个实现,看看使用到了哪些技巧:
class Wait_Notify_ACB {
private int num;
private static final Object LOCK = new Object();
private void printABC(int targetNum) {
for (int i = 0; i < 10; i++) {
synchronized (LOCK) {
while (num % 3 != targetNum) {
try {
LOCK.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
System.out.print(Thread.currentThread().getName());
LOCK.notifyAll();
}
}
}
public static void main(String[] args) {
Wait_Notify_ACB wait_notify_acb = new Wait_Notify_ACB ();
new Thread(() -> {
wait_notify_acb.printABC(0);
}, "A").start();
new Thread(() -> {
wait_notify_acb.printABC(1);
}, "B").start();
new Thread(() -> {
wait_notify_acb.printABC(2);
}, "C").start();
}
}
整体观之,使用的是 synchronized 隐式锁。使用等待队列实现线程同步,while 循环避免虚假唤醒,维护了多线程共享的 num 状态,此外需要注意多个任务的启动和正确终止。
InterruptedException 的处理是错误的,由于我们没有使用到中断机制,可以包装后抛出 IllegalStateException 表示未预料的异常。实践中,也可以设置当前线程为中断状态,待其他代码进行处理。
Lock不应该是静态的,可以改成非静态或者方法改成静态也行。
总之,经过分析可以看出并发原语的复杂性,那么有没有更高一层的抽象来简化问题呢?
更好的实现
笔者在项目的生产环境中遇到过类似的问题,多个线程需要协作,某些线程需要其他线程的结果,这种结果的交接是即时的,也就是说,A线程的结果直接交给B线程进行处理。
更好的实现要求我们实现线程之间的同步,同时应该避免并发修改。我们很自然地想到 SynchronousQueue,使用 CSP 实现 + CompletableFuture,可以减少我们考虑底层的心智负担,方便写出正确的代码。SynchronousQueue 适用于需要在生产者和消费者之间进行直接移交的场景,通常用于线程之间的切换或传递任务。
看一个具体例子:
以下是两个线程交替打印 1 - 100 的实现,由于没有在代码中使用锁,也没有状态维护的烦恼,这也是函数式的思想(减少状态)。
实现思路为:任务1从队列1中取结果,计算,提交给队列2。任务2同理。使用SynchronousQueue 实现直接交接。
private static Stopwatch betterImpl() {
Stopwatch sw = Stopwatch.createStarted();
BlockingQueue<Integer> q1 = new SynchronousQueue<>();
BlockingQueue<Integer> q2 = new SynchronousQueue<>();
int limit = 100;
CompletableFuture<Void> cf1 = CompletableFuture.runAsync(() -> {
while (true) {
Integer i = Uninterruptibles.takeUninterruptibly(q1);
if (i <= limit) {
System.out.println("thread1: i = " + i);
}
Uninterruptibles.putUninterruptibly(q2, i + 1);
if (i == limit - 1) {
break;
}
}
});
CompletableFuture<Void> cf2 = CompletableFuture.runAsync(() -> {
while (true) {
Integer i = Uninterruptibles.takeUninterruptibly(q2);
if (i <= limit) {
System.out.println("thread2: i = " + i);
}
if (i == limit) {
break;
}
Uninterruptibles.putUninterruptibly(q1, i + 1);
}
});
Uninterruptibles.putUninterruptibly(q1, 1);
CompletableFuture.allOf(cf1, cf2).join();
return sw.stop();
}
Uninterruptibles 是 Guava 中的并发工具,很实用,可以避免 try-catch 中断异常这样的样板代码。
线程池配置与本文讨论内容关系不大,故忽略。
一般实践中,阻塞方法都要设置超时时间,这里也忽略了。
这个实现简单明了,性能也不错。如果不需要即时交接,可以替换成缓冲队列(如 ArrayBlockingQueue)。
笔者简单比较了两种实现,结果如下:
private static Stopwatch bufferImpl() {
Stopwatch sw = Stopwatch.createStarted();
BlockingQueue<Integer> q1 = new ArrayBlockingQueue<>(2);
BlockingQueue<Integer> q2 = new ArrayBlockingQueue<>(2);
// ...
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
betterImpl();
bufferImpl();
// 预热
}
Stopwatch result1 = bufferImpl();
Stopwatch result2 = betterImpl();
System.out.println("result1 = " + result1);
System.out.println("result2 = " + result2);
}
// ...
thread2: i = 92
thread1: i = 93
thread2: i = 94
thread1: i = 95
thread2: i = 96
thread1: i = 97
thread2: i = 98
thread1: i = 99
thread2: i = 100
result1 = 490.3 μs
result2 = 469.1 μs
结论:使用 SynchronousQueue 性能更好,感兴趣的读者可以自己写 JMH 比对。
如果你觉得本文对你有帮助的话,欢迎给个点赞加收藏,也欢迎进一步的讨论。
后续我将继续分享并发编程、性能优化等有趣内容,力求做到全网独一份、深入浅出,一周两更,欢迎关注支持。
来源:juejin.cn/post/7532925096828026899
订单表超10亿数据,如何设计Sharding策略?解决跨分片查询和分布式事务?
订单表超10亿数据,如何设计Sharding策略?解决跨分片查询和分布式事务?
引言:
在电商平台高速发展的今天,海量订单处理已成为技术团队必须面对的挑战。当订单数据突破10亿大关,传统单库架构在查询性能、存储容量和运维复杂度上都会遇到瓶颈。
作为有8年经验的Java工程师,我曾主导多个日订单量百万级系统的分库分表改造。今天我将分享从Sharding策略设计到分布式事务落地的完整解决方案,其中包含核心代码实现和实战避坑指南。
一、业务场景分析
1.1 订单数据特点
- 数据量大:日增订单50万+,年增1.8亿
- 访问模式:
- 写操作:高频下单(峰值5000 TPS)
- 读操作:订单查询(用户端+运营端)
- 数据生命周期:热数据(3个月)占80%访问量
1.2 核心挑战
graph LR
A[10亿级订单] --> B[查询性能]
A --> C[存储瓶颈]
A --> D[跨分片聚合]
A --> E[分布式事务]
二、Sharding策略设计
2.1 分片键选择
| 候选方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 用户ID | 用户维度查询快 | 可能导致数据倾斜 | C端主导业务 |
| 订单ID | 数据分布均匀 | 用户订单需跨分片查询 | 均匀分布场景 |
| 商户ID | 商户维度查询快 | C端查询效率低 | B2B平台 |
| 创建时间 | 冷热数据分离 | 范围查询可能跨分片 | 推荐方案 |
最终方案:复合分片键(用户ID+创建时间)
2.2 分片算法设计
/**
* 自定义复合分片算法
* 分片键:user_id + create_time
*/
public class OrderShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final String USER_KEY = "user_id";
private static final String TIME_KEY = "create_time";
@Override
public Collection<String> doSharding(
Collection<String> availableTargetNames,
ComplexKeysShardingValue<Long> shardingValue) {
Map<String, Collection<Long>> columnMap = shardingValue.getColumnNameAndShardingValuesMap();
List<String> shardingResults = new ArrayList<>();
// 获取用户ID分片值
Collection<Long> userIds = columnMap.get(USER_KEY);
Long userId = userIds.stream().findFirst().orElseThrow();
// 获取时间分片值
Collection<Long> timestamps = columnMap.get(TIME_KEY);
Long createTime = timestamps.stream().findFirst().orElse(System.currentTimeMillis());
// 计算用户分片(16个分库)
int dbShard = Math.abs(userId.hashCode()) % 16;
// 计算时间分片(按月分表)
LocalDateTime dateTime = Instant.ofEpochMilli(createTime)
.atZone(ZoneId.systemDefault())
.toLocalDateTime();
String tableSuffix = dateTime.format(DateTimeFormatter.ofPattern("yyyyMM"));
// 构建目标分片
String targetDB = "order_db_" + dbShard;
String targetTable = "t_order_" + tableSuffix;
shardingResults.add(targetDB + "." + targetTable);
return shardingResults;
}
}
2.3 分片策略配置(ShardingSphere)
# application-sharding.yaml
spring:
shardingsphere:
datasource:
names: ds0,ds1,...,ds15
# 配置16个数据源...
sharding:
tables:
t_order:
actualDataNodes: ds${0..15}.t_order_${202301..202412}
tableStrategy:
complex:
shardingColumns: user_id,create_time
algorithmClassName: com.xxx.OrderShardingAlgorithm
keyGenerator:
column: order_id
type: SNOWFLAKE
三、跨分片查询解决方案
3.1 常见问题及对策
| 问题类型 | 传统方案痛点 | 优化方案 |
|---|---|---|
| 分页查询 | LIMIT 0,10 扫描全表 | 二次查询法 |
| 排序聚合 | 内存合并性能差 | 并行查询+流式处理 |
| 全局索引 | 无法直接建立 | 异步构建ES索引 |
3.2 分页查询优化实现
/**
* 跨分片分页查询优化(二次查询法)
* 原SQL:SELECT * FROM t_order WHERE user_id=1001 ORDER BY create_time DESC LIMIT 10000,10
*/
public Page<Order> shardingPageQuery(Long userId, int pageNo, int pageSize) {
// 第一步:全分片并行查询
List<Order> allShardResults = shardingExecute(
shard -> "SELECT order_id, create_time FROM t_order "
+ "WHERE user_id = " + userId
+ " ORDER BY create_time DESC"
);
// 第二步:内存排序取TopN
List<Long> targetIds = allShardResults.stream()
.sorted(Comparator.comparing(Order::getCreateTime).reversed())
.skip(pageNo * pageSize)
.limit(pageSize)
.map(Order::getOrderId)
.collect(Collectors.toList());
// 第三步:精准查询目标数据
return orderRepository.findByIdIn(targetIds);
}
/**
* 并行执行查询(使用CompletableFuture)
*/
private List<Order> shardingExecute(Function<Integer, String> sqlBuilder) {
List<CompletableFuture<List<Order>>> futures = new ArrayList<>();
for (int i = 0; i < 16; i++) {
final int shardId = i;
futures.add(CompletableFuture.supplyAsync(() -> {
String sql = sqlBuilder.apply(shardId);
return jdbcTemplate.query(sql, new OrderRowMapper());
}, shardingThreadPool));
}
return futures.stream()
.map(CompletableFuture::join)
.flatMap(List::stream)
.collect(Collectors.toList());
}
3.3 聚合查询优化
/**
* 分布式聚合计算(如:用户总订单金额)
* 方案:并行查询分片结果 + 内存汇总
*/
public BigDecimal calculateUserTotalAmount(Long userId) {
List<CompletableFuture<BigDecimal>> futures = new ArrayList<>();
for (int i = 0; i < 16; i++) {
futures.add(CompletableFuture.supplyAsync(() -> {
String sql = "SELECT SUM(amount) FROM t_order WHERE user_id = ?";
return jdbcTemplate.queryForObject(
sql, BigDecimal.class, userId);
}, shardingThreadPool));
}
return futures.stream()
.map(CompletableFuture::join)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
}
四、分布式事务解决方案
4.1 方案对比
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 2PC | 强一致 | 差 | 高 | 银行核心系统 |
| TCC | 强一致 | 中 | 高 | 资金交易 |
| Saga | 最终一致 | 优 | 中 | 订单系统(推荐) |
| 本地消息表 | 最终一致 | 良 | 低 | 低要求场景 |
4.2 Saga事务实现(订单创建场景)
sequenceDiagram
participant C as 应用
participant O as 订单服务
participant I as 库存服务
participant P as 支付服务
C->>O: 创建订单
O->>I: 预扣库存
I-->>O: 扣减成功
O->>P: 发起支付
P-->>O: 支付成功
O->>C: 返回结果
alt 支付失败
O->>I: 释放库存(补偿)
end
4.3 核心代码实现
/**
* Saga事务管理器(使用Seata框架)
*/
@Service
@Slf4j
public class OrderSagaService {
@Autowired
private InventoryFeignClient inventoryClient;
@Autowired
private PaymentFeignClient paymentClient;
@Transactional
public void createOrder(OrderCreateDTO dto) {
// 1. 创建本地订单(状态:待支付)
Order order = createPendingOrder(dto);
try {
// 2. 调用库存服务(Saga参与者)
inventoryClient.deductStock(
new DeductRequest(order.getOrderId(), dto.getSkuItems()));
// 3. 调用支付服务(Saga参与者)
paymentClient.createPayment(
new PaymentRequest(order.getOrderId(), order.getTotalAmount()));
// 4. 更新订单状态为已支付
order.paySuccess();
orderRepository.update(order);
} catch (Exception ex) {
// 触发Saga补偿流程
log.error("订单创建失败,触发补偿", ex);
handleCreateOrderFailure(order, ex);
throw ex;
}
}
/**
* 补偿操作(需要幂等)
*/
@Compensable(compensationMethod = "compensateOrder")
private void handleCreateOrderFailure(Order order, Exception ex) {
// 1. 释放库存
inventoryClient.restoreStock(order.getOrderId());
// 2. 取消支付(如果已发起)
paymentClient.cancelPayment(order.getOrderId());
// 3. 标记订单失败
order.cancel("系统异常: " + ex.getMessage());
orderRepository.update(order);
}
/**
* 补偿方法(幂等设计)
*/
public void compensateOrder(Order order, Exception ex) {
// 通过状态判断避免重复补偿
if (order.getStatus() != OrderStatus.CANCELLED) {
handleCreateOrderFailure(order, ex);
}
}
}
五、性能优化实践
5.1 分片路由优化
/**
* 热点用户订单查询优化
* 方案:用户分片路由缓存
*/
@Aspect
@Component
public class ShardingRouteCacheAspect {
@Autowired
private RedisTemplate<String, Integer> redisTemplate;
private static final String ROUTE_KEY = "user_route:%d";
@Around("@annotation(org.apache.shardingsphere.api.hint.Hint)")
public Object cacheRoute(ProceedingJoinPoint joinPoint) throws Throwable {
Long userId = getUserIdFromArgs(joinPoint.getArgs());
if (userId == null) {
return joinPoint.proceed();
}
// 1. 查询缓存
String cacheKey = String.format(ROUTE_KEY, userId);
Integer shardId = redisTemplate.opsForValue().get(cacheKey);
if (shardId == null) {
// 2. 计算分片ID(避免全表扫描)
shardId = calculateUserShard(userId);
redisTemplate.opsForValue().set(cacheKey, shardId, 1, TimeUnit.HOURS);
}
// 3. 设置分片Hint强制路由
try (HintManager hintManager = HintManager.getInstance()) {
hintManager.setDatabaseShardingValue(shardId);
return joinPoint.proceed();
}
}
private int calculateUserShard(Long userId) {
// 分片计算逻辑(与分片算法保持一致)
return Math.abs(userId.hashCode()) % 16;
}
}
5.2 冷热数据分离
-- 归档策略示例(每月执行)
CREATE EVENT archive_orders
ON SCHEDULE EVERY 1 MONTH
DO
BEGIN
-- 1. 创建归档表(按年月)
SET @archive_table = CONCAT('t_order_archive_', DATE_FORMAT(NOW(), '%Y%m'));
SET @create_sql = CONCAT('CREATE TABLE IF NOT EXISTS ', @archive_table, ' LIKE t_order');
PREPARE stmt FROM @create_sql; EXECUTE stmt;
-- 2. 迁移数据(6个月前)
SET @move_sql = CONCAT(
'INSERT INTO ', @archive_table,
' SELECT * FROM t_order WHERE create_time < DATE_SUB(NOW(), INTERVAL 6 MONTH)'
);
PREPARE stmt FROM @move_sql; EXECUTE stmt;
-- 3. 删除原表数据
DELETE FROM t_order WHERE create_time < DATE_SUB(NOW(), INTERVAL 6 MONTH);
END
六、避坑指南
6.1 常见问题及解决方案
| 问题类型 | 现象 | 解决方案 |
|---|---|---|
| 分片键选择不当 | 数据倾斜(70%数据在1个分片) | 增加分片基数(复合分片键) |
| 分布式事务超时 | 库存释放失败 | 增加重试机制+人工补偿台 |
| 跨分片查询性能差 | 分页查询超时 | 改用ES做全局搜索 |
| 扩容困难 | 增加分片需迁移数据 | 初始设计预留分片(32库) |
6.2 必须实现的监控项
graph TD
A[监控大盘] --> B[分片负载]
A --> C[慢查询TOP10]
A --> D[分布式事务成功率]
A --> E[热点用户检测]
A --> F[归档任务状态]
七、总结与展望
分库分表本质是业务与技术的平衡艺术,经过多个项目的实践验证,我总结了以下核心经验:
- 分片设计三原则:
- 数据分布均匀性 > 查询便捷性
- 业务可扩展性 > 短期性能
- 简单可运维 > 技术先进性
- 演进路线建议:
graph LR
A[单库] --> B[读写分离]
B --> C[垂直分库]
C --> D[水平分表]
D --> E[单元化部署]
- 未来优化方向:
- 基于TiDB的HTAP架构
- 使用Apache ShardingSphere-Proxy
- 智能分片路由(AI预测热点)
最后的话:
处理10亿级订单如同指挥一场交响乐——每个分片都是独立乐器,既要保证局部精准,又要实现全局和谐。
好的分库分表方案不是技术参数的堆砌,而是对业务深刻理解后的架构表达。
来源:juejin.cn/post/7519688814395719714
Nginx+Keepalive 实现高可用并启用健康检查模块
1. 目标效果
keepalived 负责监控 192.168.1.20 和 192.168.1.30 这两台负载均衡的服务器,并自动选择一台作为主服务器。用户访问 http://192.168.1.10 时,由主服务器接收该请求。当 keepalived 检测到主服务器不可访问时,会将备服务器升级为主服务器,从而实现高可用。
在主服务器中,通过 nginx(tengine)实现负载均衡,将访问请求分流到 192.168.1.100 和 192.168.1.200 这两台业务服务器。 nginx 中的健康检查模块会检测业务服务器状态,如果检测到 192.168.1.100 不可访问,则不再将访问请求发送给该服务器。
2. 部署 Keepalived
2.1 主机 IP
| 主机 | IP |
|---|---|
| 虚拟 IP | 192.168.1.10 |
| 主服务器 | 192.168.1.20 |
| 备服务器 | 192.168.1.30 |
2.2 主服务器设置
官方配置说明文档:Keepalived for Linux
yun install vim epel-release keepalived -y
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id nginx01
}
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass linalive
}
virtual_ipaddress {
192.168.1.10
}
track_script {
check_nginx
}
}
EOF
touch /etc/keepalived/nginx_check.sh && chmod +x /etc/keepalived/nginx_check.sh
cat > /etc/keepalived/nginx_check.sh <<EOF
#!/bin/bash
if ! pgrep -x "nginx" > /dev/null; then
systemctl restart nginx
sleep 2
if ! pgrep -x "nginx" > /dev/null; then
pkill keepalived
fi
fi
EOF
2.2 备服务器设置
yun install vim epel-release keepalived -y
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
cat > /etc/keepalived/keepalived.conf <<EOF
! Configuration File for keepalived
global_defs {
router_id nginx02
}
vrrp_script check_nginx {
script "/etc/keepalived/nginx_check.sh"
interval 2
weight 2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass linalive
}
virtual_ipaddress {
192.168.1.10
}
track_script {
check_nginx
}
}
EOF
touch /etc/keepalived/nginx_check.sh && chmod +x /etc/keepalived/nginx_check.sh
cat > /etc/keepalived/nginx_check.sh <<EOF
#!/bin/bash
if ! pgrep -x "nginx" > /dev/null; then
systemctl restart nginx
sleep 2
if ! pgrep -x "nginx" > /dev/null; then
pkill keepalived
fi
fi
EOF
3. 部署 Tengine (主备服务器)
3.1 准备 Tengine 压缩文件
下载 tengine 压缩文件,将文件上传到 /opt 文件夹下。下载地址:The Tengine Web Server
本文章编写时,最新版是:tengine-3.1.0.tar.gz
3.2 解压并编译
yum install -y gcc gcc-c++ make pcre-devel zlib-devel openssl-devel
tar zxvf /opt/tengine-3.1.0.tar.gz -C /opt
cd /opt/tengine-3.1.0
# configure 有众多的参数可设置,可使用 ./configure --help 进行查看
# 按照官方说法默认应该是开启了健康检查模块,但实测需要手动添加参数
./configure --add-module=modules/ngx_http_upstream_check_module/
make && make install
3.3 添加服务项
cat > /etc/systemd/system/nginx.service <<EOF
[Unit]
Description=The Tengine HTTP and reverse proxy server
After=network.target
[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStartPre=/usr/local/nginx/sbin/nginx -t
ExecStart=/usr/local/nginx/sbin/nginx
ExecReload=/usr/local/nginx/sbin/nginx -s reload
ExecStop=/usr/local/nginx/sbin/nginx -s stop
PrivateTmp=true
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
3.4 编辑 nginx 配置文件
此处配置的内容项可参考官方文档:ngx_http_upstream_check_module
# tengine 默认的安装路径是 /usr/local/nginx
# 配置文件路径: /usr/local/nginx/conf/nginx.conf
# /favicon.ico 是接口地址,需替换成真实的 api 接口
worker_processes auto;
events {
worker_connections 1024;
}
http {
upstream cluster1 {
server 192.168.1.100:8082;
server 192.168.1.200:8089;
check interval=3000 rise=2 fall=5 timeout=1000 type=http;
check_http_send "HEAD /favicon.ico HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx http_3xx;
}
server {
listen 80;
server_name localhost;
location / {
index Index.aspx;
proxy_pass http://cluster1;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
location /status {
check_status;
access_log off;
}
}
}
3.5 启动服务并访问
使用 systemctl start nginx启动服务,并访问 localhost:80/status查看健康检查报表页
4. 写在最后
来源:juejin.cn/post/7483314478957232138
创建型模式:抽象工厂模式
什么是抽象工厂模式
抽象工厂模式是一种创建型设计模式,它提供一个接口来创建一系列相关或相互依赖的对象家族,而无需指定它们的具体类。简单来说,抽象工厂模式是工厂模式的升级版,它不再只生产一种产品,而是生产一整套产品。
抽象工厂vs工厂方法:关键区别
- 工厂方法模式:关注单个产品的创建,一个工厂创建一种产品
- 抽象工厂模式:关注产品族的创建,一个工厂创建多种相关产品
这就像一个生产手机的工厂(工厂方法)和一个生产整套电子设备(手机、平板、耳机)的工厂(抽象工厂)的区别。
抽象工厂模式的核心实现
// 产品A接口
public interface ProductA {
void operationA();
}
// 产品B接口
public interface ProductB {
void operationB();
}
// 产品A1实现
public class ConcreteProductA1 implements ProductA {
@Override
public void operationA() {
System.out.println("产品A1的操作");
}
}
// 产品A2实现
public class ConcreteProductA2 implements ProductA {
@Override
public void operationA() {
System.out.println("产品A2的操作");
}
}
// 产品B1实现
public class ConcreteProductB1 implements ProductB {
@Override
public void operationB() {
System.out.println("产品B1的操作");
}
}
// 产品B2实现
public class ConcreteProductB2 implements ProductB {
@Override
public void operationB() {
System.out.println("产品B2的操作");
}
}
// 抽象工厂接口
public interface AbstractFactory {
ProductA createProductA();
ProductB createProductB();
}
// 具体工厂1 - 创建产品族1(A1+B1)
public class ConcreteFactory1 implements AbstractFactory {
@Override
public ProductA createProductA() {
return new ConcreteProductA1();
}
@Override
public ProductB createProductB() {
return new ConcreteProductB1();
}
}
// 具体工厂2 - 创建产品族2(A2+B2)
public class ConcreteFactory2 implements AbstractFactory {
@Override
public ProductA createProductA() {
return new ConcreteProductA2();
}
@Override
public ProductB createProductB() {
return new ConcreteProductB2();
}
}
抽象工厂模式的关键点
- 产品接口:为每种产品定义接口
- 具体产品:实现产品接口的具体类
- 抽象工厂接口:声明一组创建产品的方法
- 具体工厂:实现抽象工厂接口,创建一个产品族
- 产品族:一组相关产品的集合(例如PC系列组件、移动系列组件)
实际应用示例:跨平台UI组件库
下面通过一个跨平台UI组件库的例子来展示抽象工厂模式的强大应用:
// ===== 按钮组件 =====
public interface Button {
void render();
void onClick();
}
// Windows按钮
public class WindowsButton implements Button {
@Override
public void render() {
System.out.println("渲染Windows风格的按钮");
}
@Override
public void onClick() {
System.out.println("Windows按钮点击效果");
}
}
// MacOS按钮
public class MacOSButton implements Button {
@Override
public void render() {
System.out.println("渲染MacOS风格的按钮");
}
@Override
public void onClick() {
System.out.println("MacOS按钮点击效果");
}
}
// ===== 复选框组件 =====
public interface Checkbox {
void render();
void toggle();
}
// Windows复选框
public class WindowsCheckbox implements Checkbox {
@Override
public void render() {
System.out.println("渲染Windows风格的复选框");
}
@Override
public void toggle() {
System.out.println("Windows复选框切换状态");
}
}
// MacOS复选框
public class MacOSCheckbox implements Checkbox {
@Override
public void render() {
System.out.println("渲染MacOS风格的复选框");
}
@Override
public void toggle() {
System.out.println("MacOS复选框切换状态");
}
}
// ===== 文本框组件 =====
public interface TextField {
void render();
void getText();
}
// Windows文本框
public class WindowsTextField implements TextField {
@Override
public void render() {
System.out.println("渲染Windows风格的文本框");
}
@Override
public void getText() {
System.out.println("获取Windows文本框内容");
}
}
// MacOS文本框
public class MacOSTextField implements TextField {
@Override
public void render() {
System.out.println("渲染MacOS风格的文本框");
}
@Override
public void getText() {
System.out.println("获取MacOS文本框内容");
}
}
// ===== GUI工厂接口 =====
public interface GUIFactory {
Button createButton();
Checkbox createCheckbox();
TextField createTextField();
}
// Windows GUI工厂
public class WindowsFactory implements GUIFactory {
@Override
public Button createButton() {
return new WindowsButton();
}
@Override
public Checkbox createCheckbox() {
return new WindowsCheckbox();
}
@Override
public TextField createTextField() {
return new WindowsTextField();
}
}
// MacOS GUI工厂
public class MacOSFactory implements GUIFactory {
@Override
public Button createButton() {
return new MacOSButton();
}
@Override
public Checkbox createCheckbox() {
return new MacOSCheckbox();
}
@Override
public TextField createTextField() {
return new MacOSTextField();
}
}
如何使用抽象工厂模式
// 应用类 - 与具体工厂解耦
public class Application {
private Button button;
private Checkbox checkbox;
private TextField textField;
// 构造函数接收一个抽象工厂
public Application(GUIFactory factory) {
button = factory.createButton();
checkbox = factory.createCheckbox();
textField = factory.createTextField();
}
// 渲染表单
public void renderForm() {
System.out.println("=== 开始渲染表单 ===");
button.render();
checkbox.render();
textField.render();
System.out.println("=== 表单渲染完成 ===");
}
// 表单操作
public void handleForm() {
System.out.println("\n=== 表单交互 ===");
button.onClick();
checkbox.toggle();
textField.getText();
}
}
// 客户端代码
public class GUIDemo {
public static void main(String[] args) {
// 检测当前操作系统
String osName = System.getProperty("os.name").toLowerCase();
GUIFactory factory;
// 根据操作系统选择合适的工厂
if (osName.contains("windows")) {
factory = new WindowsFactory();
System.out.println("检测到Windows系统,使用Windows风格UI");
} else {
factory = new MacOSFactory();
System.out.println("检测到非Windows系统,使用MacOS风格UI");
}
// 创建并使用应用 - 注意应用不依赖于具体组件类
Application app = new Application(factory);
app.renderForm();
app.handleForm();
}
}
运行结果(Windows系统上)
检测到Windows系统,使用Windows风格UI
=== 开始渲染表单 ===
渲染Windows风格的按钮
渲染Windows风格的复选框
渲染Windows风格的文本框
=== 表单渲染完成 ===
=== 表单交互 ===
Windows按钮点击效果
Windows复选框切换状态
获取Windows文本框内容
运行结果(MacOS系统上)
检测到非Windows系统,使用MacOS风格UI
=== 开始渲染表单 ===
渲染MacOS风格的按钮
渲染MacOS风格的复选框
渲染MacOS风格的文本框
=== 表单渲染完成 ===
=== 表单交互 ===
MacOS按钮点击效果
MacOS复选框切换状态
获取MacOS文本框内容
抽象工厂模式的常见应用场景
- 跨平台UI工具包:为不同操作系统提供一致的界面组件
- 数据库访问层:支持多种数据库系统(MySQL、Oracle、MongoDB等)
- 游戏开发:创建不同主题的游戏元素(中世纪、未来、童话等)
- 多环境配置系统:为开发、测试、生产环境提供不同实现
- 电子设备生态系统:创建配套的产品(手机、耳机、手表都来自同一品牌)
- 多主题应用:切换应用的视觉主题(暗色模式/亮色模式)
抽象工厂模式的实际案例
许多知名框架和库使用抽象工厂模式,如:
- Java的JDBC:
ConnectionFactory创建特定数据库的连接 - Spring Framework:通过BeanFactory创建和管理各种组件
- javax.xml.parsers.DocumentBuilderFactory:创建DOM解析器
- Hibernate:
SessionFactory为不同数据库创建会话
抽象工厂模式的优点
- 产品一致性保证:确保一个工厂创建的产品相互兼容
- 隔离具体类:客户端与具体类隔离,只与接口交互
- 开闭原则:引入新产品族不需要修改现有代码
- 替换产品族:可以整体替换产品族(如UI主题切换)
抽象工厂模式的缺点
- 扩展困难:添加新的产品类型需要修改工厂接口及所有实现
- 复杂度增加:产品较多时,类的数量会急剧增加
- 接口污染:接口中可能包含部分工厂不支持的创建方法
抽象工厂的实现变体
使用反射简化工厂实现
public class ReflectiveFactory implements GUIFactory {
private String packageName;
public ReflectiveFactory(String stylePrefix) {
packageName = "com.example.gui." + stylePrefix.toLowerCase();
}
@Override
public Button createButton() {
return (Button) createComponent("Button");
}
@Override
public Checkbox createCheckbox() {
return (Checkbox) createComponent("Checkbox");
}
@Override
public TextField createTextField() {
return (TextField) createComponent("TextField");
}
private Object createComponent(String type) {
try {
Class<?> clazz = Class.forName(packageName + "." + type);
return clazz.getDeclaredConstructor().newInstance();
} catch (Exception e) {
throw new RuntimeException("无法创建组件", e);
}
}
}
带有默认实现的抽象工厂
public abstract class BaseGUIFactory implements GUIFactory {
// 提供默认实现
@Override
public TextField createTextField() {
return new DefaultTextField(); // 所有平台通用的默认实现
}
// 其他方法需要子类实现
@Override
public abstract Button createButton();
@Override
public abstract Checkbox createCheckbox();
}
实现抽象工厂的设计考虑
- 产品族边界:明确定义哪些产品属于同一族
- 接口设计:保持工厂接口精简,避免方法爆炸
- 工厂选择机制:考虑如何选择/切换具体工厂
- 扩展策略:提前考虑如何添加新产品类型
- 组合与单一职责:大型产品族可考虑拆分为多个子工厂
抽象工厂模式最佳实践
- 适度使用:当确实需要创建一系列相关对象时才使用
- 懒加载:考虑延迟创建产品,而不是一次创建所有产品
- 结合其他模式:与单例、原型、构建者等模式结合使用
- 依赖注入:通过依赖注入框架传递工厂
- 配置驱动:使用配置文件或注解选择具体工厂实现
// 使用配置驱动的工厂
public class ConfigurableGUIFactory {
public static GUIFactory getFactory() {
String factoryType = ConfigLoader.getProperty("ui.factory");
switch (factoryType) {
case "windows": return new WindowsFactory();
case "macos": return new MacOSFactory();
case "web": return new WebFactory();
default: throw new IllegalArgumentException("未知UI工厂类型");
}
}
}
抽象工厂与依赖倒置原则
抽象工厂是实现依赖倒置原则的绝佳方式:高层模块不依赖于低层模块,两者都依赖于抽象。
// 不好的设计:直接依赖具体类
public class BadForm {
private WindowsButton button; // 直接依赖具体实现
private WindowsCheckbox checkbox;
public void createUI() {
button = new WindowsButton(); // 硬编码创建具体类
checkbox = new WindowsCheckbox();
}
}
// 好的设计:依赖抽象
public class GoodForm {
private Button button; // 依赖接口
private Checkbox checkbox;
private final GUIFactory factory; // 依赖抽象工厂
public GoodForm(GUIFactory factory) {
this.factory = factory;
}
public void createUI() {
button = factory.createButton(); // 通过工厂创建
checkbox = factory.createCheckbox();
}
}
抽象工厂模式小结
抽象工厂模式是一种强大但需谨慎使用的创建型模式。它在需要一套相关产品且系统不应依赖于产品的具体类时非常有用。这种模式有助于确保产品兼容性,并为产品族提供统一的创建接口。
适当应用抽象工厂模式可以使代码更具灵活性和可维护性,但也要避免过度设计导致的复杂性。理解产品族的概念和如何设计良好的抽象工厂接口是掌握这一模式的关键。
来源:juejin.cn/post/7491963395284549669
Spring Boot Admin:一站式监控微服务,这个运维神器真香!
关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
在现代微服务架构中,应用实例的数量动辄成百上千。传统的逐个登录服务器查看日志、检查状态的方式早已变得低效且不现实。
因此,一个集中化、可视化、且能提供实时健康状态的管理平台变得至关重要。Spring Boot Admin (SBA) 正是为了满足这一需求而生的强大工具。
然而,各种厂商的云服务提供了各种监控服务解决客户的各种痛点。Spring Boot Admin这样的工具似乎关注度没有那么高。小编也是无意间发现这款产品,分享给大家。
02 简介
Spring Boot Admin 是一个用于管理和监控 Spring Boot 应用程序的开源社区项目。它并非官方 Spring 项目,但在社区中备受推崇并被广泛使用。
其核心原理是:一个作为“服务器”(Server)的中央管理端,通过收集并展示众多作为“客户端”(Client)的 Spring Boot 应用的监控信息。
Spring Boot Admin 通过集成 Spring Boot Actuator 端点来获取应用数据,并提供了一个友好的 Web UI 界面来展示这些信息。
主要分为两部分:
- 服务端:监控平台
- 客户端:业务端
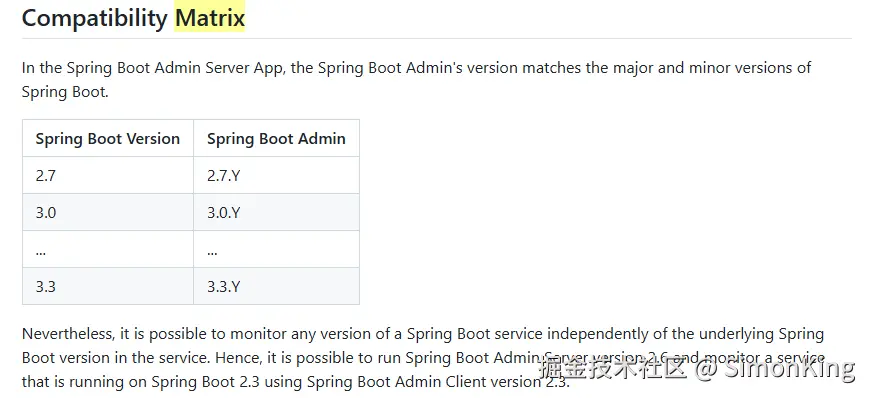
SpringBoot的版本和Spring Boot Admin有一定的对应关系:
GitHub地址:github.com/codecentric…
文档地址:docs.spring-boot-admin.com/
03 Admin服务端
服务的端配置相当简单,只需要引入依赖,启动增加注解。服务端的基础配置就算完成了。
3.1 基础配置
Maven依赖
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>${latest.version}</version>
</dependency>
增加注解
@EnableAdminServer
这两个配置就可访问项目的IP+端口,进入管理页面了。
3.2 增加鉴权
为了数据安全,可以增加鉴权。拥有账号和密码方可进入。
Maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
配置文件
# 设置自己的用户名和密码
spring.security.user.name=admin
spring.security.user.password=123456
输入对应的用户名和密码就可以进入了。
3.3 增加邮件推送
官方提供了各种通知,也可以自定义,如图:
我们以邮件通知为例。
Maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>
配置
# 邮箱配置
spring.mail.host=smtp.163.com
spring.mail.port=25
spring.mail.username=用户名
spring.mail.password=*****[授权码]
# 发送和接受邮箱
spring.boot.admin.notify.mail.to=wsapplyjob@163.com
spring.boot.admin.notify.mail.from=wsapplyjob@163.com
客户端下线之后会触发邮件:
04 Adamin客户端
因为服务端是依赖Spring Boot Actuator 端点来获取应用数据,所以我们需要开放期其所有的服务。
4.1 基础配置
Maven依赖
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-client</artifactId>
<version>${latest.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
# 服务端地址
spring.boot.admin.client.url=http://127.0.0.1:8081
# 鉴权信息
spring.boot.admin.client.username=admin
spring.boot.admin.client.password=123456
# 开发所有的暴漏的信息
management.endpoints.web.exposure.include=*
4.2 监控界面
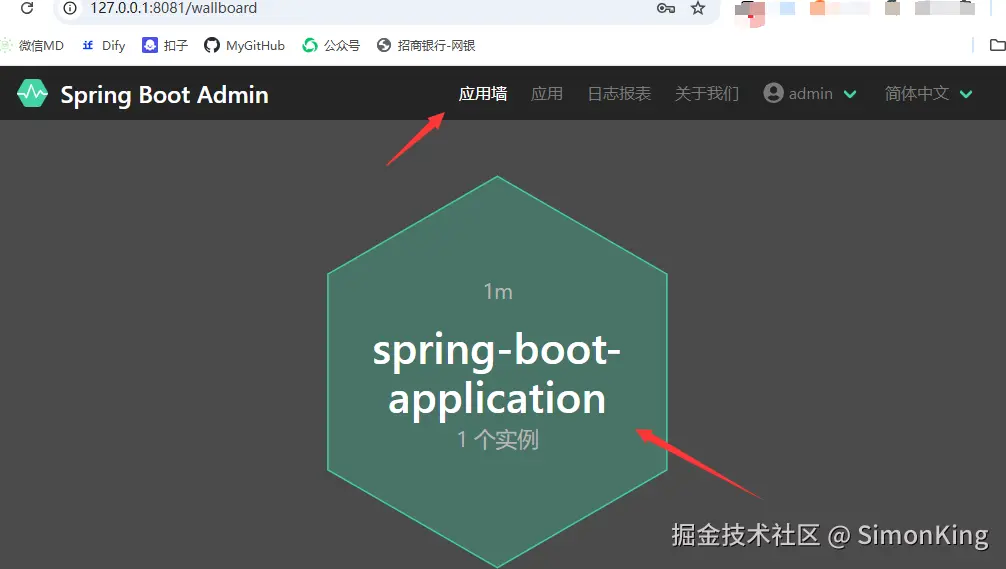
进入之后,我们就会发现上面的页面。点击应用墙,就会展示所有监控的实例。进入之后如图:
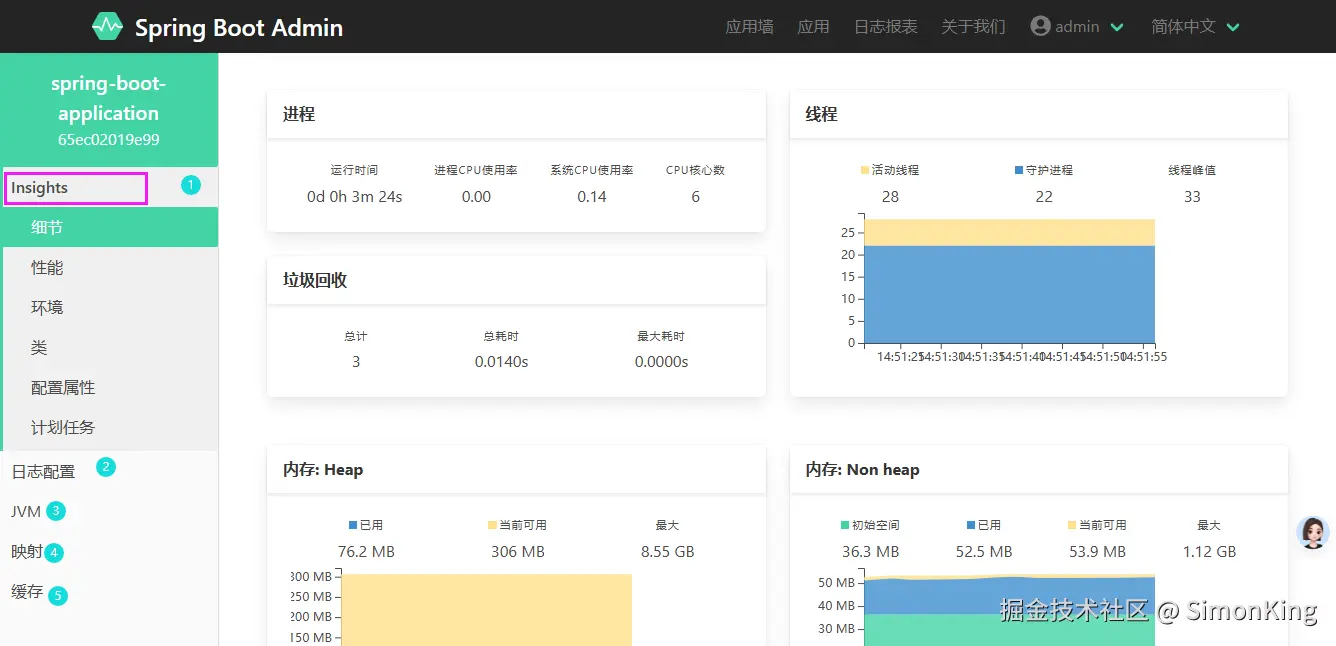
进入之后就可以看到五大块。其中②就是我们之前看到的日志级别的控制。还包含了缓存、计划任务、映射甚至类之间的依赖关系。
因为界面支持中文,里面具体的功能就不做描述,感兴趣的可以自己的探索。
4.3 日志配置增加日志
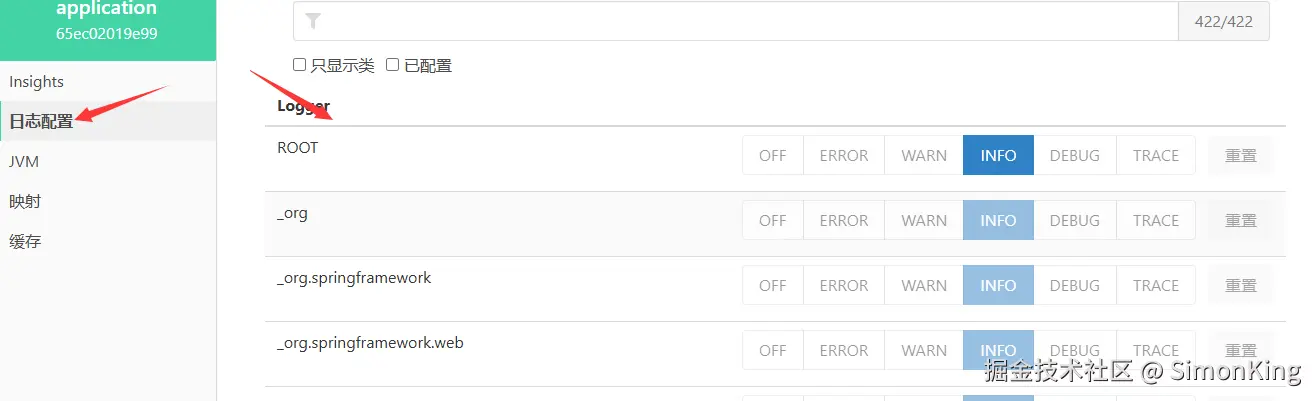
默认的日志进去只有日志的级别,并不会打印日志。
这是官方的描述:
我们增加配置:
logging.file.name=/var/log/boot-log.log
logging.pattern.file=%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%5p) %clr(${PID}){magenta} %clr(---){faint} %clr([.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n%wEx (2)
启动查看结果:
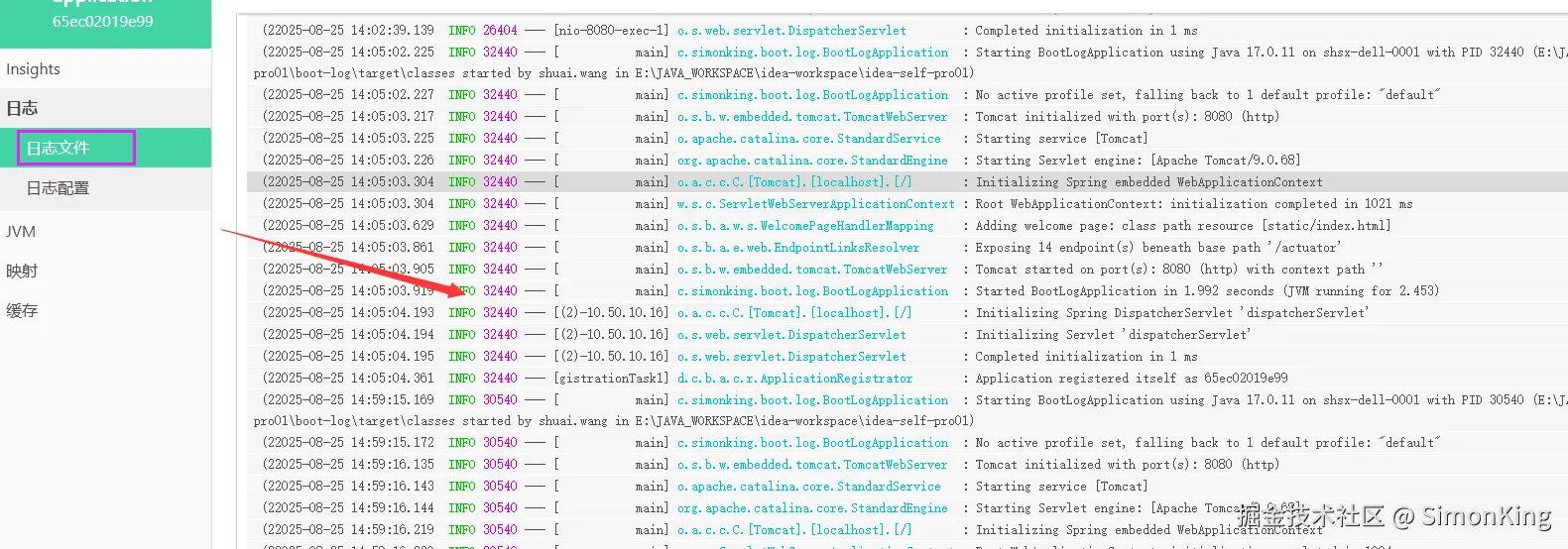
我们就可以看到信的菜单:日志文件
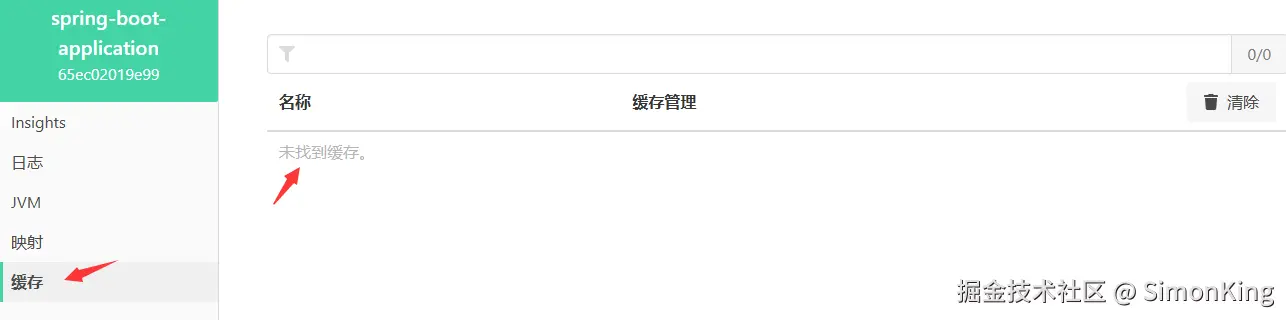
4.4 缓存
【缓存】是没有数据的:
缓存依赖
<!-- 监控缓存需要的依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
代码
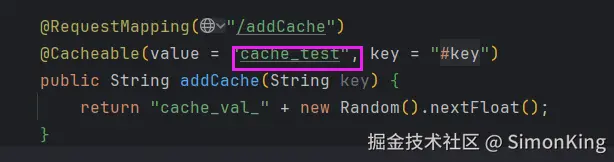
触发缓存任务之后,就会出现缓存的管理:
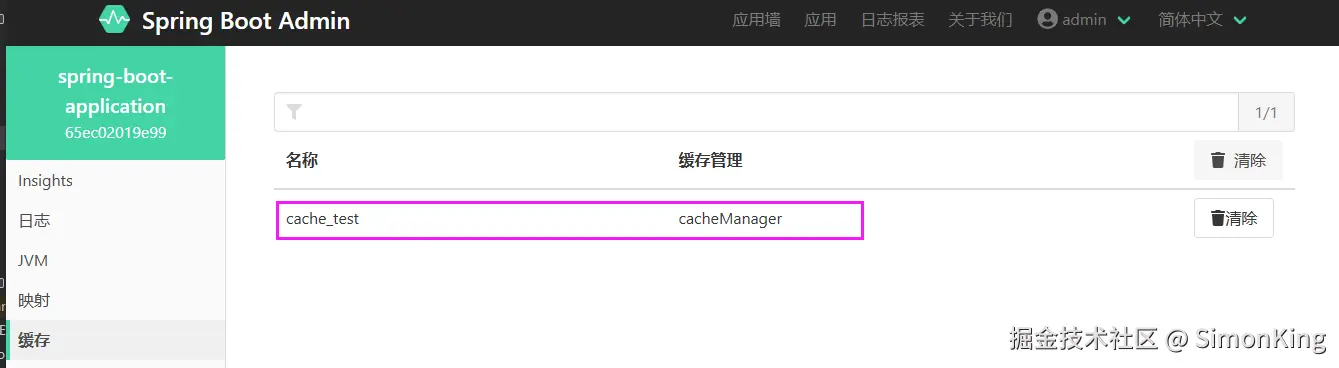
4.5 计划任务
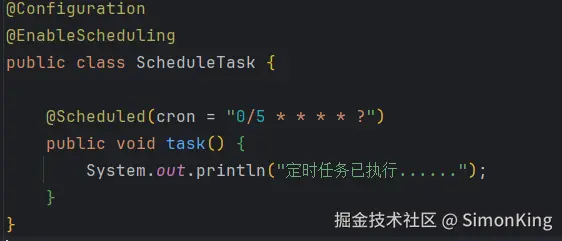
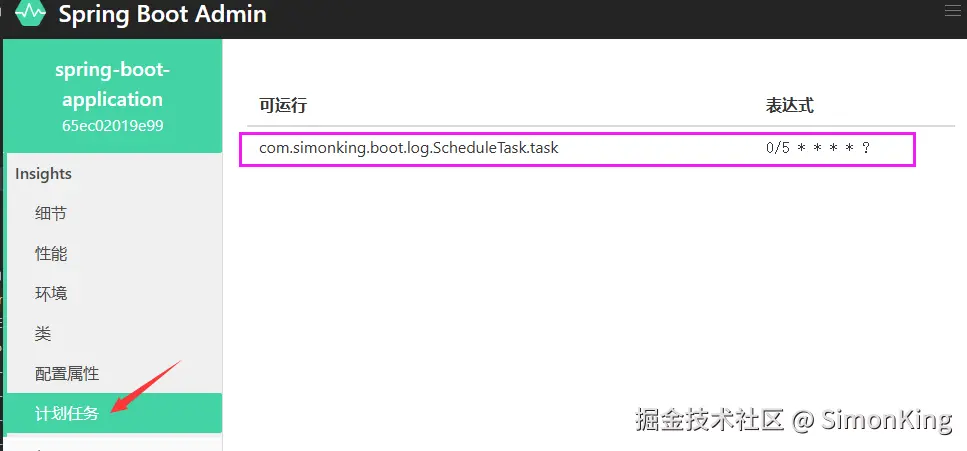
【计划任务】和缓存基本一样,但是无需引入第三方依赖。使用@Scheduled即可。
监控结果:
05 小结
Spring Boot Admin 以其简洁的配置、强大的功能和友好的界面,成为了 Spring Boot 微服务监控领域的事实标准。它极大地降低了监控和运维的复杂度,让开发者能够更专注于业务逻辑开发。
对于中小型规模的微服务集群,直接使用 SBA 是一个高效且成本低廉的解决方案。
赶快去探索里面不同的功能的吧!
来源:juejin.cn/post/7542450691911155762
别再混淆了!一文彻底搞懂System.identityHashCode与Object.hashCode的区别
在Java开发中,哈希码的使用无处不在,但许多开发者对
System.identityHashCode()和Object.hashCode()的区别仍然模糊不清。本文将深入剖析二者的核心区别,并通过实际代码演示它们在不同场景下的行为差异。
一、本质定义:两种哈希码的起源
- Object.hashCode()
- 所有Java对象的默认方法(定义在
Object类中) - 可被子类重写(通常基于对象内容计算)
// 默认实现(未重写时)
public native int hashCode();
- 所有Java对象的默认方法(定义在
- System.identityHashCode()
System类提供的静态工具方法- 无视任何重写,始终返回JVM原始哈希码
public static native int identityHashCode(Object x);
二、核心区别对比(表格速查)
| 特性 | Object.hashCode() | System.identityHashCode() |
|---|---|---|
| 是否可重写 | ✅ 子类可重写改变行为 | ❌ 行为固定不可变 |
| 对重写的敏感性 | 返回重写后的自定义值 | 永远返回JVM原始哈希码 |
null处理 | 调用抛NullPointerException | 安全返回0 |
| 返回值一致性 | 内容改变时可能变化 | 对象生命周期内永不改变 |
| 典型用途 | HashMap/HashSet等基于内容的集合 | IdentityHashMap等身份敏感操作 |
三、关键差异深度解析
1. 重写行为对比(核心区别)
class CustomObject {
private int id;
// 重写hashCode(基于内容)
@Override
public int hashCode() {
return id * 31;
}
}
public static void main(String[] args) {
CustomObject obj = new CustomObject();
obj.id = 100;
System.out.println("hashCode: " + obj.hashCode()); // 3100
System.out.println("identityHashCode: " + System.identityHashCode(obj)); // 356573597
}
输出说明:
✅ hashCode()返回重写后的计算值
✅ identityHashCode()无视重写,返回JVM原始哈希
2. null安全性对比
Object obj = null;
// 抛出NullPointerException
try {
System.out.println(obj.hashCode());
} catch (NullPointerException e) {
System.out.println("调用hashCode()抛NPE");
}
// 安全返回0
System.out.println("identityHashCode(null): "
+ System.identityHashCode(obj));
3. 哈希码不变性验证
String str = "Hello";
int initialIdentity = System.identityHashCode(str);
str = str + " World!"; // 修改对象内容
// 身份哈希码保持不变
System.out.println(initialIdentity == System.identityHashCode(str)); // true
四、经典应用场景
1. 使用Object.hashCode()的场景
// 在HashMap中作为键(依赖内容哈希)
Map<Student, Grade> gradeMap = new HashMap<>();
Student s = new Student("2023001", "张三");
gradeMap.put(s, new Grade(90));
// 重写需遵守规范:内容相同则哈希码相同
class Student {
private String id;
private String name;
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}
2. 使用identityHashCode()的场景
场景1:实现身份敏感的容器
// IdentityHashMap基于身份哈希而非内容
IdentityHashMap<Object, String> identityMap = new IdentityHashMap<>();
String s1 = new String("ABC");
String s2 = new String("ABC");
identityMap.put(s1, "第一对象");
identityMap.put(s2, "第二对象"); // 不同对象,均可插入
System.out.println(identityMap.size()); // 2
场景2:检测hashCode是否被重写
boolean isHashCodeOverridden(Object obj) {
return obj.hashCode() != System.identityHashCode(obj);
}
// 测试
System.out.println(isHashCodeOverridden(new Object())); // false
System.out.println(isHashCodeOverridden(new String("Test"))); // true
场景3:调试对象内存关系
Object objA = new Object();
Object objB = objA; // 指向同一对象
// 身份哈希相同证明是同一对象
System.out.println(System.identityHashCode(objA)
== System.identityHashCode(objB)); // true
五、底层机制揭秘
- 存储位置:身份哈希码存储在对象头中
- 生成时机:首次调用
hashCode()或identityHashCode()时生成 - 计算规则:通常基于内存地址,但JVM会优化(非直接地址)
- 不变性:一旦生成,在对象生命周期内永不改变
六、总结与最佳实践
| 方法 | 选用原则 |
|---|---|
Object.hashCode() | 需要基于对象内容的哈希逻辑时使用 |
System.identityHashCode() | 需要对象身份标识时使用 |
黄金准则:
- 当对象作为
HashMap等内容敏感容器的键时 → 重写hashCode()+equals() - 当需要对象身份标识(如调试、
IdentityHashMap)时 → 使用identityHashCode() - 永远不要在重写的
hashCode()中调用identityHashCode(),这违反哈希契约!
通过合理选择这两种哈希码,可以避免常见的
HashMap逻辑错误和身份混淆问题。理解它们的差异,将使你的Java代码更加健壮高效!
来源:juejin.cn/post/7519797197925367818
别再说你会 new Object() 了!JVM 类加载的真相,绝对和你想的不一样
当我们编写
new Object()时,JVM 背后到底发生了怎样的故事?类加载过程中的初始化阶段究竟暗藏哪些玄机?
一、引言:从一段简单代码说起
先来看一个看似简单的 Java 代码片段:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
当我们执行这段代码时,背后却隐藏着 JVM 复杂的类加载机制。.java 文件经过编译变成 .class 字节码文件,这些"静态"的字节码需要被 JVM 动态地加载、处理并最终执行。这就是类加载过程的神奇之处。
类加载机制是 Java 语言的核心基石,它赋予了 Java "一次编写,到处运行" 的能力。理解这一过程,不仅能帮助我们编写更高效的代码,更是面试中的高频考点。
二、类生命周期:七个阶段的完整旅程
在深入类加载过程之前,我们先来了解类的完整生命周期。一个类在 JVM 中从加载到卸载,总共经历七个阶段:
| 阶段 | 描述 | 是否必须 | 特点 | JVM规范要求 |
|---|---|---|---|---|
| 加载(Loading) | 查找并加载类的二进制数据 | 是 | 将字节码读入内存,生成Class对象 | 强制 |
| 验证(Verification) | 确保被加载的类正确无误 | 是 | 安全验证,防止恶意代码 | 强制 |
| 准备(Preparation) | 为类变量分配内存并设置初始零值 | 是 | 注意:不是程序员定义的初始值 | 强制 |
| 解析(Resolution) | 将符号引用转换为直接引用 | 否 | 可以在初始化后再进行 | 可选 |
| 初始化(Initialization) | 执行类构造器 <clinit>() 方法 | 是 | 初始化类而不是对象 | 强制 |
| 使用(Using) | 正常使用类的功能 | 是 | 类的使命阶段 | - |
| 卸载(Unloading) | 从内存中释放类数据 | 否 | 由垃圾回收器负责 | 可选 |
前五个阶段(加载、验证、准备、解析、初始化)统称为类加载过程。
三、类加载过程的五个步骤详解
3.1 加载阶段:寻找类的旅程
加载阶段是类加载过程的起点,主要完成三件事情:
- 通过类的全限定名获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表这个类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口
// 示例:不同的类加载方式
public class LoadingExample {
public static void main(String[] args) throws Exception {
// 通过类加载器加载
Class<?> clazz1 = ClassLoader.getSystemClassLoader().loadClass("java.lang.String");
// 通过Class.forName加载(默认会初始化)
Class<?> clazz2 = Class.forName("java.lang.String");
// 通过字面常量获取(不会触发初始化)
Class<?> clazz3 = String.class;
System.out.println("三种方式加载的类是否相同: " +
(clazz1 == clazz2 && clazz2 == clazz3));
}
}
3.2 验证阶段:安全的第一道防线
验证阶段确保 Class 文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息不会危害虚拟机自身的安全。
| 验证类型 | 验证内容 | 失败后果 |
|---|---|---|
| 文件格式验证 | 魔数(0xCAFEBABE)、版本号、常量池 | ClassFormatError |
| 元数据验证 | 语义验证、继承关系(如是否实现抽象方法) | IncompatibleClassChangeError |
| 字节码验证 | 逻辑验证、跳转指令合法性 | VerifyError |
| 符号引用验证 | 引用真实性、访问权限(如访问private方法) | NoSuchFieldError、NoSuchMethodError |
3.3 准备阶段:零值初始化的奥秘
这是最容易产生误解的阶段! 在准备阶段,JVM 为**类变量(static变量)**分配内存并设置初始零值,注意这不是程序员定义的初始值。
public class PreparationExample {
// 准备阶段后 value = 0,而不是 100
public static int value = 100;
// 准备阶段后 constantValue = 200(因为有final修饰)
public static final int constantValue = 200;
// 实例变量 - 准备阶段完全不管
public int instanceValue = 300;
}
各种数据类型的零值对照表:
| 数据类型 | 零值 | 数据类型 | 零值 |
|---|---|---|---|
| int | 0 | boolean | false |
| long | 0L | float | 0.0f |
| double | 0.0 | char | '\u0000' |
| 引用类型 | null | short | (short)0 |
关键区别:只有**类变量(static变量)**在准备阶段分配内存和初始化零值,实例变量会在对象实例化时随对象一起分配在堆内存中。
3.4 解析阶段:符号引用到直接引用的转换
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。这个过程可以在初始化之后再进行,这是为了支持Java的动态绑定特性。
解析主要针对以下四类符号引用:
| 引用类型 | 解析目标 | 可能抛出的异常 |
|---|---|---|
| 类/接口解析 | 将符号引用解析为具体类/接口 | NoClassDefFoundError |
| 字段解析 | 解析字段所属的类/接口 | NoSuchFieldError |
| 方法解析 | 解析方法所属的类/接口 | NoSuchMethodError |
| 接口方法解析 | 解析接口方法所属的接口 | AbstractMethodError |
3.5 初始化阶段:执行类构造器 <clinit>()
这是类加载过程的最后一步,也是真正开始执行类中定义的Java程序代码的一步。
JVM规范严格规定的六种初始化触发情况:
- 遇到new、getstatic、putstatic或invokestatic这四条字节码指令时
// new指令 - 创建类的实例
Object obj = new Object();
// getstatic指令 - 读取类的静态字段
int value = MyClass.staticField;
// putstatic指令 - 设置类的静态字段
MyClass.staticField = 100;
// invokestatic指令 - 调用类的静态方法
MyClass.staticMethod();
- 使用java.lang.reflect包的方法对类进行反射调用时
// 反射调用会触发类的初始化
Class<?> clazz = Class.forName("com.example.MyClass");
- 当初始化一个类时,发现其父类还没有进行过初始化
class Parent {
static { System.out.println("Parent初始化"); }
}
class Child extends Parent {
static { System.out.println("Child初始化"); }
}
// 初始化Child时会先初始化Parent
- 虚拟机启动时,用户指定的主类(包含main()方法的那个类)
// 执行 java MyApp 时,MyApp类会被初始化
public class MyApp {
public static void main(String[] args) {
System.out.println("应用程序启动");
}
}
- 使用JDK7新加入的动态语言支持时
// 使用MethodHandle等动态语言特性
MethodHandles.Lookup lookup = MethodHandles.lookup();
- 一个接口中定义了JDK8新加入的默认方法时,如果这个接口的实现类发生了初始化,要先将接口进行初始化
interface MyInterface {
// JDK8默认方法会触发接口初始化
default void defaultMethod() {
System.out.println("默认方法");
}
}
3.6 使用阶段:类的使命实现
当类完成初始化后,就进入了使用阶段。这是类生命周期中最长的阶段,类的所有功能都可以正常使用:
public class UsageStageExample {
public static void main(String[] args) {
// 类已完成初始化,进入使用阶段
MyClass obj = new MyClass(); // 创建对象实例
obj.instanceMethod(); // 调用实例方法
MyClass.staticMethod(); // 调用静态方法
int value = MyClass.staticVar;// 访问静态变量
}
}
class MyClass {
public static int staticVar = 100;
public int instanceVar = 200;
public static void staticMethod() {
System.out.println("静态方法");
}
public void instanceMethod() {
System.out.println("实例方法");
}
}
在使用阶段,类可以:
- 创建对象实例
- 调用静态方法和实例方法
- 访问和修改静态字段和实例字段
- 被其他类引用和继承
3.7 卸载阶段:生命的终结
类的卸载是生命周期的最后阶段,但并不是必须发生的。一个类被卸载需要满足以下条件:
- 该类所有的实例都已被垃圾回收
- 加载该类的ClassLoader已被垃圾回收
- 该类对应的java.lang.Class对象没有被任何地方引用
public class UnloadingExample {
public static void main(String[] args) throws Exception {
// 使用自定义类加载器加载类
CustomClassLoader loader = new CustomClassLoader();
Class<?> clazz = loader.loadClass("com.example.TemporaryClass");
// 创建实例并使用
Object instance = clazz.newInstance();
System.out.println("类已加载并使用: " + clazz.getName());
// 解除所有引用,使类和类加载器可被回收
clazz = null;
instance = null;
loader = null;
// 触发GC,可能卸载类
System.gc();
System.out.println("类和类加载器可能已被卸载");
}
}
class CustomClassLoader extends ClassLoader {
// 自定义类加载器实现
}
所以,在 JVM 生命周期内,由 jvm 自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
四、关键辨析:类初始化 vs. 对象实例化
这是本文的核心观点,也是大多数开发者容易混淆的概念。让我们通过一个对比表格来清晰区分:
| 特性 | 类初始化 (Initialization) | 对象实例化 (Instantiation) |
|---|---|---|
| 触发时机 | 类被首次"主动使用"时(JVM控制) | 遇到new关键字时(程序员控制) |
| 发生次数 | 一次(每个类加载器范围内) | 多次(可以创建多个对象实例) |
| 核心方法 | <clinit>()方法 | <init>()方法(构造函数) |
| 操作目标 | 类本身(初始化静态变量/类变量) | 对象实例(初始化实例变量) |
| 内存区域 | 方法区(元空间) | Java堆 |
| 执行内容 | 静态变量赋值、静态代码块 | 实例变量赋值、实例代码块、构造函数 |
public class InitializationVsInstantiation {
// 类变量 - 在<clinit>()方法中初始化
public static String staticField = initStaticField();
// 实例变量 - 在<init>()方法中初始化
public String instanceField = initInstanceField();
// 静态代码块 - 在<clinit>()方法中执行
static {
System.out.println("静态代码块执行");
}
// 实例代码块 - 在<init>()方法中执行
{
System.out.println("实例代码块执行");
}
public InitializationVsInstantiation() {
System.out.println("构造方法执行");
}
private static String initStaticField() {
System.out.println("静态变量初始化");
return "static value";
}
private String initInstanceField() {
System.out.println("实例变量初始化");
return "instance value";
}
public static void main(String[] args) {
System.out.println("=== 第一次创建对象 ===");
new InitializationVsInstantiation();
System.out.println("\n=== 第二次创建对象 ===");
new InitializationVsInstantiation();
}
}
输出结果:
静态变量初始化
静态代码块执行
=== 第一次创建对象 ===
实例变量初始化
实例代码块执行
构造方法执行
=== 第二次创建对象 ===
实例变量初始化
实例代码块执行
构造方法执行
五、深度实战:初始化顺序全面解析
现在,让我们通过一个综合示例来回答开篇的思考题:如果一个类同时包含静态变量、静态代码块、实例变量、实例代码块和构造方法,它们的执行顺序是怎样的?在存在继承关系时又会如何变化?
5.1 单类初始化顺序
public class InitializationOrder {
// 静态变量
public static String staticField = "静态变量";
// 静态代码块
static {
System.out.println(staticField);
System.out.println("静态代码块");
}
// 实例变量
public String field = "实例变量";
// 实例代码块
{
System.out.println(field);
System.out.println("实例代码块");
}
// 构造方法
public InitializationOrder() {
System.out.println("构造方法");
}
public static void main(String[] args) {
System.out.println("第一次实例化:");
new InitializationOrder();
System.out.println("\n第二次实例化:");
new InitializationOrder();
}
}
输出结果:
静态变量
静态代码块
第一次实例化:
实例变量
实例代码块
构造方法
第二次实例化:
实例变量
实例代码块
构造方法
关键发现:
- 静态代码块只在类第一次加载时执行一次
- 实例代码块在每次创建对象时都会执行
- 执行顺序:静态变量/代码块 → 实例变量/代码块 → 构造方法
5.2 继承关系下的初始化顺序
class Parent {
// 父类静态变量
public static String parentStaticField = "父类静态变量";
// 父类静态代码块
static {
System.out.println(parentStaticField);
System.out.println("父类静态代码块");
}
// 父类实例变量
public String parentField = "父类实例变量";
// 父类实例代码块
{
System.out.println(parentField);
System.out.println("父类实例代码块");
}
// 父类构造方法
public Parent() {
System.out.println("父类构造方法");
}
}
class Child extends Parent {
// 子类静态变量
public static String childStaticField = "子类静态变量";
// 子类静态代码块
static {
System.out.println(childStaticField);
System.out.println("子类静态代码块");
}
// 子类实例变量
public String childField = "子类实例变量";
// 子类实例代码块
{
System.out.println(childField);
System.out.println("子类实例代码块");
}
// 子类构造方法
public Child() {
System.out.println("子类构造方法");
}
public static void main(String[] args) {
System.out.println("第一次实例化子类:");
new Child();
System.out.println("\n第二次实例化子类:");
new Child();
}
}
输出结果:
父类静态变量
父类静态代码块
子类静态变量
子类静态代码块
第一次实例化子类:
父类实例变量
父类实例代码块
父类构造方法
子类实例变量
子类实例代码块
子类构造方法
第二次实例化子类:
父类实例变量
父类实例代码块
父类构造方法
子类实例变量
子类实例代码块
子类构造方法
关键发现:
- 父类静态代码块 → 子类静态代码块 → 父类实例代码块 → 父类构造方法 → 子类实例代码块 → 子类构造方法
- 静态代码块只执行一次,实例代码块每次创建对象都执行
- 父类优先于子类初始化
5.3 进阶案例:包含静态变量初始化的复杂情况
public class ComplexInitialization {
public static ComplexInitialization instance = new ComplexInitialization();
public static int staticVar = 100;
public int instanceVar = 200;
static {
System.out.println("静态代码块: staticVar=" + staticVar);
}
{
System.out.println("实例代码块: instanceVar=" + instanceVar + ", staticVar=" + staticVar);
}
public ComplexInitialization() {
System.out.println("构造方法: instanceVar=" + instanceVar + ", staticVar=" + staticVar);
}
public static void main(String[] args) {
System.out.println("main方法开始");
new ComplexInitialization();
}
}
输出结果:
实例代码块: instanceVar=200, staticVar=0
构造方法: instanceVar=200, staticVar=0
静态代码块: staticVar=100
main方法开始
实例代码块: instanceVar=200, staticVar=100
构造方法: instanceVar=200, staticVar=100
关键发现:
- 静态变量
staticVar在准备阶段被初始化为0 - 在初始化阶段,按顺序执行静态变量赋值和静态代码块
- 当执行
instance = new ComplexInitialization()时,staticVar还未被赋值为100(还是0) - 这解释了为什么第一次输出时
staticVar=0
六、面试常见问题与解答
6.1 高频面试题解析
Q1: 下面代码的输出结果是什么?为什么?
public class InterviewQuestion {
public static void main(String[] args) {
System.out.println(Child.value);
}
}
class Parent {
static int value = 100;
static { System.out.println("Parent静态代码块"); }
}
class Child extends Parent {
static { System.out.println("Child静态代码块"); }
}
A: 输出结果为:
Parent静态代码块
100
解析: 通过子类引用父类的静态字段,不会导致子类初始化,这是类加载机制的一个重要特性。
Q2: 接口的初始化与类有什么不同?
A: 接口的初始化与类类似,但有重要区别:
- 接口也有
<clinit>()方法,由编译器自动生成 - 接口初始化时不需要先初始化父接口
- 只有当程序首次使用接口中定义的非常量字段时,才会初始化接口
6.2 类加载机制的实际应用
1. 单例模式的优雅实现:
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
static {
System.out.println("SingletonHolder初始化");
}
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种实现利用了类加载机制的特性:只有在真正调用 getInstance() 时才会加载 SingletonHolder 类,实现了懒加载且线程安全。
2. 常量传播优化:
public class ConstantExample {
public static final String CONSTANT = "Hello";
public static void main(String[] args) {
System.out.println(CONSTANT);
}
}
编译时,常量 CONSTANT 的值会被直接内联到使用处,不会触发类的初始化。
七、总结与思考
通过本文的深入分析,我们可以总结出以下几个关键点:
- 类加载过程五个阶段:加载 → 验证 → 准备 → 解析 → 初始化,每个阶段都有其特定任务
- 关键区别:
- 初始化阶段是初始化类(执行
<clinit>()),而不是初始化对象(执行<init>()) - 类静态变量在准备阶段分配内存并设置零值,在初始化阶段赋实际值
- 实例变量在对象实例化时分配内存和初始化
- 初始化阶段是初始化类(执行
- 初始化顺序原则:
- 父类优先于子类
- 静态优先于实例
- 变量定义顺序决定初始化顺序
- 实际应用:理解类加载机制有助于我们编写更高效的代码,如实现懒加载的单例模式、理解常量内联优化等
希望本文能帮助你深入理解JVM类加载机制,下次遇到相关面试题时,相信你一定能游刃有余!
来源:juejin.cn/post/7541339617489797163
计算初始化内存总长度
计算初始化内存总长度
问题背景
在一个系统中,需要执行一系列的内存初始化操作。每次操作都会初始化一个特定地址范围的内存。这些操作范围可能会相互重叠。我们需要计算所有操作完成后,被初始化过的内存空间的总长度。
核心定义
- 操作范围: 每一次内存初始化操作由一个范围
[start, end]定义,它代表一个左闭右开的区间[start, end)。这意味着地址start被包含,而地址end不被包含。 - 内存长度: 对于一个操作
[start, end],其初始化的内存长度为end - start。
关键假设
- 所有初始化操作都会成功执行。
- 同一块内存区域允许被重复初始化。例如,操作
[2, 5)和[4, 7)是允许的,它们有重叠部分[4, 5)。
任务要求
给定一组内存初始化操作 cmdsOfMemInit,计算所有操作完成后,被初始化过的内存空间的总长度。这等同于计算所有给定区间的并集的总长度。
输入格式
cmdsOfMemInit: 一个二维数组(或列表的列表),代表一系列的内存初始化操作。
- 数组长度:
1 <= cmdsOfMemInit.length <= 100000 - 每个元素
cmdsOfMemInit[i]是一个包含两个整数[start, end]的数组。 - 区间范围:
0 <= start < end <= 10^9
- 数组长度:
输出格式
- 一个整数,表示最终被初始化过的内存空间的总长度。
样例说明
样例 1
- 输入:
[[2, 4], [3, 7], [4, 6]] - 输出:
5 - 解释:
- 我们有三个区间:
[2, 4),[3, 7),[4, 6)。 - 合并
[2, 4)和[3, 7): 因为它们有重叠部分([3, 4)),所以可以合并成一个更大的区间[2, 7)。 - 合并
[2, 7)和[4, 6): 新的区间[4, 6)完全被[2, 7)覆盖。合并后的结果仍然是[2, 7)。 - 所有操作完成后,最终被初始化的内存区域是
[2, 7)。 - 总长度为
7 - 2 = 5。
- 我们有三个区间:
样例 2
- 输入:
[[3, 7], [2, 4], [10, 30]] - 输出:
25 - 解释:
- 我们有三个区间:
[3, 7),[2, 4),[10, 30)。 - 合并
[3, 7)和[2, 4): 它们有重叠部分,合并后的区间为[2, 7)。 - 合并
[2, 7)和[10, 30): 这两个区间没有重叠,因为10大于7。它们是两个独立的初始化区域。 - 所有操作完成后,最终的初始化内存区域由两个不相交的区间组成:
[2, 7)和[10, 30)。 - 总长度是这两个独立区间长度之和:
(7 - 2) + (30 - 10) = 5 + 20 = 25。
- 我们有三个区间:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
/**
* 解决“内存空间长度”问题的方案类。
*/
public class Solution {
/**
* 计算一系列内存初始化操作覆盖的总内存空间长度。
*
* @param cmdsOfMemInit 一个二维数组,每个内部数组 [start, end] 代表一个左闭右开的内存初始化区间。
* @return 最终初始化的内存空间的总长度。
*/
public long totalInitializedLength(int[][] cmdsOfMemInit) {
// --- 1. 处理边界情况 ---
// 如果输入为空或没有操作,则总长度为 0。
if (cmdsOfMemInit == null || cmdsOfMemInit.length == 0) {
return 0;
}
// --- 2. 按区间的起始地址(start)对所有操作进行升序排序 ---
// 这是合并区间的关键前提步骤。
// Comparator.comparingInt(a -> a[0]) 是一个简洁的写法,表示按内部数组a的第一个元素排序。
Arrays.sort(cmdsOfMemInit, Comparator.comparingInt(a -> a[0]));
// --- 3. 合并重叠和连续的区间 ---
// 使用一个 List 来存储合并后的、不重叠的区间。
List<int[]> mergedIntervals = new ArrayList<>();
// 首先将第一个区间(起始地址最小)加入合并列表作为基础。
mergedIntervals.add(cmdsOfMemInit[0]);
// 遍历排序后的其余区间
for (int i = 1; i < cmdsOfMemInit.length; i++) {
int[] currentInterval = cmdsOfMemInit[i];
// 获取合并列表中的最后一个区间,用于比较
int[] lastMerged = mergedIntervals.get(mergedIntervals.size() - 1);
// 检查当前区间是否与最后一个合并区间重叠或连续。
// 因为区间是 [start, end) 左闭右开,所以当 currentInterval 的 start <= lastMerged 的 end 时,
// 它们就需要合并。例如 [2,4) 和 [4,6) 应该合并为 [2,6)。
if (currentInterval[0] <= lastMerged[1]) {
// --- 合并区间 ---
// 如果有重叠/连续,则更新最后一个合并区间的结束地址。
// 新的结束地址是两个区间结束地址中的较大者。
// 例如,合并 [2,7) 和 [4,6) 时,新的 end 是 max(7, 6) = 7,结果为 [2,7)。
lastMerged[1] = Math.max(lastMerged[1], currentInterval[1]);
} else {
// --- 不重叠,添加新区间 ---
// 如果没有重叠,则将当前区间作为一个新的、独立的合并区间添加到列表中。
mergedIntervals.add(currentInterval);
}
}
// --- 4. 计算合并后区间的总长度 ---
// 使用 long 类型来存储总长度,防止因数值过大(坐标可达10^9)而溢出。
long totalLength = 0;
// 遍历所有不重叠的合并区间
for (int[] interval : mergedIntervals) {
// 累加每个区间的长度 (end - start)
totalLength += (long) interval[1] - interval[0];
}
// --- 5. 返回结果 ---
return totalLength;
}
public static void main(String[] args) {
Solution sol = new Solution();
// 样例1
int[][] cmds1 = {{2, 4}, {3, 7}, {4, 6}};
System.out.println("样例1 输入: [[2, 4], [3, 7], [4, 6]]");
System.out.println("样例1 输出: " + sol.totalInitializedLength(cmds1)); // 预期: 5
// 样例2
int[][] cmds2 = {{3, 7}, {2, 4}, {10, 30}};
System.out.println("\n样例2 输入: [[3, 7], [2, 4], [10, 30]]");
System.out.println("样例2 输出: " + sol.totalInitializedLength(cmds2)); // 预期: 25
// 边界测试
int[][] cmds3 = {{1, 5}, {6, 10}};
System.out.println("\n边界测试 输入: [[1, 5], [6, 10]]");
System.out.println("边界测试 输出: " + sol.totalInitializedLength(cmds3)); // 预期: 8 (4+4)
}
*/
}
来源:juejin.cn/post/7527154276223336488
JMeter 多台压力机分布式测试(Windows)
JMeter 多台压力机分布式测试(Windows)
1. 背景
- 在单台压力机运行时,出现了端口冲突问题,如
JMeter port already in use。 - 压力机机器权限限制,无法修改默认端口配置。
- 为避免端口冲突且提升压力机的压力能力,考虑使用多台机器(多台JMeter压力机)分布式压测。
2.环境说明
- Master IP:
192.20.10.7 - Slave1 IP:
192.20.10.8 - Slave2 IP:
192.20.10.9 - JMeter版本均为 5.5
- Java版本均为 1.8+
- 网络可互通,防火墙端口放通
- RMI 注册端口:1099
- RMI 远程对象端口:50000(默认,可配置)
3. Master 节点配置
3.1 修改 jmeter.properties (JMETER_HOME/bin/jmeter.properties)
properties复制# 远程主机列表,逗号分隔
remote_hosts=192.20.10.8,192.20.10.9
# 禁用RMI SSL,避免额外复杂度
server.rmi.ssl.disable=true
# Master的回调地址,设置为本机可达IP(用于Slave回调)
client.rmi.localhostname=192.20.10.7
# 关闭插件联网上报,提升启动速度
jmeter.pluginmanager.report_stats=false
2.2 启动 JMeter GUI
- 直接运行
jmeter.bat打开GUI - 加载测试脚本(
*.jmx) - 确认脚本和依赖文件已同步到所有Slave节点同路径
3. Slave 节点配置(192.20.10.8 和 192.20.10.9)
3.1 修改各自的 jmeter.properties (JMETER_HOME/bin/jmeter.properties)
Slave1(192.20.10.8):
# 远程RMI服务监听端口
server_port=1099
# RMI通信本地端口(避免冲突,Slave1用50000)
server.rmi.localport=50000
# 禁用RMI SSL
server.rmi.ssl.disable=true
# 远程机器回调绑定IP(本机IP)
java.rmi.server.hostname=192.20.10.8
# 关闭插件联网上报
jmeter.pluginmanager.report_stats=false
Slave2(192.20.10.9):
server_port=1099
server.rmi.localport=50001
server.rmi.ssl.disable=true
java.rmi.server.hostname=192.20.10.9
jmeter.pluginmanager.report_stats=false
3.2 启动Slave服务
在每台Slave机器的 bin 目录,执行:
set JVM_ARGS=-Djava.rmi.server.hostname=192.20.10.8 #可选配置
jmeter-server.bat
(Slave2替换IP为 192.20.10.9)
看到类似 Using local port: 50002 Created remote object: UnicastServerRef2 [liveRef:XXXX 表示启动成功。
如启动异常,可以打开jmeter-server.log查看日志。
3.2 验证监听端口
netstat -an | findstr 1099
TCP 0.0.0.0:1099 0.0.0.0:0 LISTENING
TCP [::]:1099 [::]:0 LISTENING
netstat -an | findstr 50002
TCP 0.0.0.0:50002 0.0.0.0:0 LISTENING
TCP [::]:50002 [::]:0 LISTENING
4. 测试执行流程
- 确保Master和所有Slave机器的JMeter和Java版本一致。
- 确保测试脚本和依赖文件(如CSV等)在所有Slave路径相同。
- 启动所有Slave的
jmeter-server.bat,确保端口监听正常。 - 在Master GUI加载脚本。
- 点击菜单
Run -> Remote Start 或 Remote Start All,Master向所有Slave发起远程测试。 11.JMeter GUI的日志样例如下:
INFO o.a.j.e.ClientJMeterEngine: Sending properties {}
o.a.j.e.ClientJMeterEngine: sent run command to
o.a.j.e.DistributedRunner: Remote engines have been started
o.a.j.g.u.JMeterMenuBar: setRunning
o.a.j.g.u.JMeterMenuBar: setRunning
jmeter-server.bat的日志如下,出现如下字段
Starting the test on host ...
Finished the test on host ...
- Master GUI的 Listener(Summary Report等)会显示所有Slave合并的结果。
5. 其他注意事项
- 防火墙放通Master和Slave的
server_port(1099)、server.rmi.localport端口。 - Master
client.rmi.localhostname必须是Slave可访问的Master IP。 - 禁用插件联网统计,避免卡顿。
- 避免使用重型监听器,使用轻量级监听器提升性能。
来源:juejin.cn/post/7530141922499149862
Spring高级开发:状态机/事件/插件
Spring 状态机与事件机制插件开发示例
我将为您演示一个完整的 Spring 状态机实现,包含状态机配置、事件机制和可扩展的插件体系。以下是一个订单处理系统的示例:
1. 添加依赖(pom.xml)
<dependencies>
<!-- Spring State Machine -->
<dependency>
<groupId>org.springframework.statemachine</groupId>
<artifactId>spring-statemachine-starter</artifactId>
<version>4.2.0</version>
</dependency>
<!-- Spring Event 相关 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>6.0.9</version>
</dependency>
</dependencies>
2. 定义核心接口和类
2.1 状态和事件枚举
// 状态枚举
public enum OrderState {
NEW,
PAYMENT_PENDING,
PAID,
SHIPPED,
DELIVERED,
CANCELLED
}
// 事件枚举
public enum OrderEvent {
CREATE_ORDER,
INITIATE_PAYMENT,
PAYMENT_COMPLETED,
SHIP_ORDER,
DELIVERY_CONFIRMED,
CANCEL_ORDER
}
2.2 插件接口定义
// 状态变更监听器接口
public interface StateChangeListener {
void onStateChange(OrderState from, OrderState to, String orderId);
}
// 订单操作插件接口
public interface OrderOperationPlugin {
void execute(String orderId, OrderState currentState);
}
// 插件管理器接口
public interface PluginManager {
void registerStateChangeListener(StateChangeListener listener);
void notifyStateChange(OrderState from, OrderState to, String orderId);
void executePlugins(String orderId, OrderState currentState);
}
3. 实现状态机配置
@Configuration
@EnableStateMachine
public class OrderStateMachineConfig extends EnumStateMachineConfigurerAdapter<OrderState, OrderEvent> {
@Autowired
private List<OrderOperationPlugin> plugins;
@Override
public void configure(StateMachineStateConfigurer<OrderState, OrderEvent> states) throws Exception {
states
.withStates()
.initial(OrderState.NEW)
.state(OrderState.PAYMENT_PENDING)
.junction(OrderState.PAID)
.end(OrderState.DELIVERED)
.end(OrderState.CANCELLED)
.fork(OrderState.SHIPPED);
}
@Override
public void configure(StateMachineTransitionConfigurer<OrderState, OrderEvent> transitions) throws Exception {
transitions
.withExternal()
.source(OrderState.NEW).target(OrderState.PAYMENT_PENDING)
.event(OrderEvent.CREATE_ORDER)
.and().withExternal()
.source(OrderState.PAYMENT_PENDING).target(OrderState.PAID)
.event(OrderEvent.INITIATE_PAYMENT)
.and().withExternal()
.source(OrderState.PAID).target(OrderState.SHIPPED)
.event(OrderEvent.SHIP_ORDER)
.and().withExternal()
.source(OrderState.SHIPPED).target(OrderState.DELIVERED)
.event(OrderEvent.DELIVERY_CONFIRMED)
.and().withExternal()
.source(OrderState.NEW).target(OrderState.CANCELLED)
.event(OrderEvent.CANCEL_ORDER)
.and().withExternal()
.source(OrderState.PAYMENT_PENDING).target(OrderState.CANCELLED)
.event(OrderEvent.CANCEL_ORDER);
}
@Bean
public PluginManager pluginManager() {
return new DefaultPluginManager(plugins);
}
}
4. 插件实现
4.1 默认插件管理器
@Component
public class DefaultPluginManager implements PluginManager {
private final List<StateChangeListener> stateChangeListeners = new ArrayList<>();
private final List<OrderOperationPlugin> operationPlugins;
public DefaultPluginManager(List<OrderOperationPlugin> plugins) {
this.operationPlugins = plugins;
}
@Override
public void registerStateChangeListener(StateChangeListener listener) {
stateChangeListeners.add(listener);
}
@Override
public void notifyStateChange(OrderState from, OrderState to, String orderId) {
stateChangeListeners.forEach(listener -> listener.onStateChange(from, to, orderId));
}
@Override
public void executePlugins(String orderId, OrderState currentState) {
operationPlugins.forEach(plugin -> plugin.execute(orderId, currentState));
}
}
4.2 示例插件实现
// 日志记录插件
@Component
public class LoggingPlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
System.out.println("订单 " + orderId + " 当前状态: " + currentState + " - 正在记录日志");
}
}
// 邮件通知插件
@Component
public class EmailNotificationPlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
System.out.println("订单 " + orderId + " 当前状态: " + currentState + " - 发送邮件通知");
}
}
// 库存管理插件
@Component
public class InventoryUpdatePlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
if (currentState == OrderState.PAID) {
System.out.println("订单 " + orderId + " 已支付,正在更新库存");
}
}
}
5. 状态监听器实现
@Component
public class AuditStateChangeListener implements StateChangeListener {
@Override
public void onStateChange(OrderState from, OrderState to, String orderId) {
System.out.println("订单状态变更: " + orderId + " 从 " + from + " 到 " + to + " - 审计记录已创建");
}
}
6. 服务层实现
@Service
public class OrderService {
@Autowired
private StateMachine<OrderState, OrderEvent> stateMachine;
@Autowired
private PluginManager pluginManager;
public OrderService() {
// 注册监听器
pluginManager.registerStateChangeListener(new AuditStateChangeListener());
}
public void handleOrderEvent(String orderId, OrderEvent event) {
try {
stateMachine.start();
OrderState currentState = stateMachine.getState().getId();
// 发送事件
stateMachine.sendEvent(event);
OrderState newState = stateMachine.getState().getId();
// 触发状态变更监听器
if (currentState != newState) {
pluginManager.notifyStateChange(currentState, newState, orderId);
}
// 执行操作插件
pluginManager.executePlugins(orderId, newState);
} catch (Exception e) {
System.err.println("处理订单事件失败: " + e.getMessage());
} finally {
stateMachine.stop();
}
}
}
7. 控制器示例
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping("/{orderId}/events")
public ResponseEntity<String> sendEvent(@PathVariable String orderId, @RequestParam String event) {
try {
OrderEvent orderEvent = OrderEvent.valueOf(event.toUpperCase());
orderService.handleOrderEvent(orderId, orderEvent);
return ResponseEntity.ok("事件已处理: " + event);
} catch (IllegalArgumentException e) {
return ResponseEntity.badRequest().body("无效的事件类型: " + event);
}
}
@GetMapping("/{orderId}/status")
public ResponseEntity<String> checkStatus(@PathVariable String orderId) {
// 这里应该从存储中获取当前状态,为简化示例返回固定值
return ResponseEntity.ok("订单 " + orderId + " 当前状态: 示例状态");
}
}
8. 可扩展性说明
如何添加新插件:
@Component
public class NewFeaturePlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
// 新功能逻辑
}
}
如何添加新状态监听器:
@Component
public class NewStateChangeListener implements StateChangeListener {
@Override
public void onStateChange(OrderState from, OrderState to, String orderId) {
// 新监听器逻辑
}
}
使用示例:
# 创建订单
POST /orders/123/events?event=CREATE_ORDER
# 发起支付
POST /orders/123/events?event=INITIATE_PAYMENT
# 发货
POST /orders/123/events?event=SHIP_ORDER
# 确认送达
POST /orders/123/events?event=DELIVERY_CONFIRMED
# 取消订单
POST /orders/123/events?event=CANCEL_ORDER
这个实现具有以下特点:
- 灵活的状态机配置:使用 Spring StateMachine 配置订单状态流转
- 可扩展的插件系统:通过接口设计支持轻松添加新插件
- 事件驱动架构:利用状态变更事件触发相关业务逻辑
- 良好的分离关注点:核心状态机逻辑与业务插件解耦
- 易于维护和测试:各组件之间通过接口通信,便于单元测试和替换实现
您可以根据具体业务需求扩展更多状态、事件和插件功能。
来源:juejin.cn/post/7512237186647916571
docker容器增加或者修改容器映射端口
前言
在只有使用docker安装的容器,没有使用docker-compose或者其他客户端工具,如果要增加或者修改容器端口,也是可以增加或者修改容器端口映射=
容器端口映射
重新安装
这种方法简单粗暴,就是重新把docker容器移除,然后重新用
docker run -p
重新做端口映射
修改配置文件
这里以rabbitmq为例子
1、 首先使用
docker ps
查看容器id

2、 然后使用
docker inspace 容器id
查看容器配置文件放止于哪里

这里放置于/var/lib/docker/containers/29384a9aa22f4fb53eda66d672b039b997143dc7633694e3455fc12f7dbcac5d
然后使用Linux进入到该目录
3、先把docker容器停止了
systemctl stop docker.socket

4、 修改hostconfig文件,找到里面的json数据中的PortBindings

这里将5672端口修改为5673

保存文件
5、 修改config.v2.json文件中的内容,找到里面中的ExposedPorts,把5673端口开放出来

保存文件
6、 启动docker服务
systemctl start docker.socket
这个时候就会发现5673端口映射了

总结
修改docker容器映射开放端口方法很多,现在也有很多优秀的客户端可以进行配置
来源:juejin.cn/post/7456094963018006528
.NET 高级开发:反射与代码生成的实战秘籍
在当今快速发展的软件开发领域,灵活性和动态性是开发者不可或缺的能力。.NET 提供的反射机制和代码生成技术,为开发者提供了强大的工具,能够在运行时动态地探索和操作代码。这些技术不仅能够提升开发效率,还能实现一些传统静态代码无法完成的功能。本文将深入探讨 .NET 反射机制的核心功能、高级技巧以及代码生成的实际应用,帮助你在开发中更好地利用这些强大的工具。
.NET 反射:运行时的魔法
反射是 .NET 中一个极其强大的特性,它允许开发者在运行时动态地检查和操作类型信息。通过反射,你可以获取类型信息、动态创建对象、调用方法,甚至访问私有成员。这种能力在许多场景中都非常有用,比如实现插件系统、动态调用方法、序列化和反序列化等。
反射基础
反射的核心是 System.Type 类,它代表了一个类型的元数据。通过 Type 类,你可以获取类的名称、基类、实现的接口、方法、属性等信息。System.Reflection 命名空间提供了多个关键类,如 Assembly、MethodInfo、PropertyInfo 和 FieldInfo,帮助你更深入地探索类型信息。
获取 Type 对象有三种常见方式:
- 使用
typeof运算符:适用于编译时已知的类型。
Type type = typeof(string);
Console.WriteLine(type.Name); // 输出:String
- 调用
GetType()方法:适用于运行时已知的对象。
string name = "Hello";
Type type = name.GetType();
Console.WriteLine(type.Name); // 输出:String
- 通过类型名称动态加载:适用于运行时动态加载类型。
Type? type = Type.GetType("System.String");
if (type != null) {
Console.WriteLine(type.Name); // 输出:String
}
反射的常见操作
反射可以完成许多强大的操作,以下是一些常见的用法:
获取类型信息
通过 Type 对象,你可以获取类的各种信息,例如类名、基类、是否泛型等。
Type type = typeof(List<int>);
Console.WriteLine($"类名: {type.Name}"); // 输出:List`1
Console.WriteLine($"基类: {type.BaseType?.Name}"); // 输出:Object
Console.WriteLine($"是否泛型: {type.IsGenericType}"); // 输出:True
动态调用方法
假设你有一个类 Calculator,你可以通过反射动态调用它的方法。
public class Calculator
{
public int Add(int a, int b) => a + b;
}
Calculator calc = new Calculator();
Type type = calc.GetType();
MethodInfo? method = type.GetMethod("Add");
if (method != null) {
int result = (int)method.Invoke(calc, new object[] { 5, 3 })!;
Console.WriteLine(result); // 输出:8
}
访问私有成员
反射可以绕过访问修饰符的限制,访问私有字段或方法。
public class SecretHolder
{
private string _secret = "Hidden Data";
}
var holder = new SecretHolder();
Type type = holder.GetType();
FieldInfo? field = type.GetField("_secret", BindingFlags.NonPublic | BindingFlags.Instance);
if (field != null) {
string secret = (string)field.GetValue(holder)!;
Console.WriteLine(secret); // 输出:Hidden Data
}
动态创建对象
通过 Activator.CreateInstance 方法,你可以动态实例化对象。
Type type = typeof(StringBuilder);
object? instance = Activator.CreateInstance(type);
StringBuilder sb = (StringBuilder)instance!;
sb.Append("Hello");
Console.WriteLine(sb.ToString()); // 输出:Hello
高级反射技巧
反射的高级用法可以让你在开发中更加灵活,以下是一些进阶技巧:
调用泛型方法
如果方法带有泛型参数,你需要先使用 MakeGenericMethod 指定类型。
public class GenericHelper
{
public T Echo<T>(T value) => value;
}
var helper = new GenericHelper();
Type type = helper.GetType();
MethodInfo method = type.GetMethod("Echo")!;
MethodInfo genericMethod = method.MakeGenericMethod(typeof(string));
string result = (string)genericMethod.Invoke(helper, new object[] { "Hello" })!;
Console.WriteLine(result); // 输出:Hello
性能优化
反射调用比直接调用慢很多,因此在高性能场景下,可以缓存 MethodInfo 或使用 Delegate 来优化性能。
MethodInfo method = typeof(Calculator).GetMethod("Add")!;
var addDelegate = (Func<Calculator, int, int, int>)Delegate.CreateDelegate(
typeof(Func<Calculator, int, int, int>),
method
);
Calculator calc = new Calculator();
int result = addDelegate(calc, 5, 3);
Console.WriteLine($"result: {result}"); // 输出:8
动态加载插件
假设你有一个插件系统,所有插件都实现了 IPlugin 接口,你可以通过反射动态加载插件。
public interface IPlugin
{
void Execute();
}
public class HelloPlugin : IPlugin
{
public void Execute() => Console.WriteLine("Hello from Plugin!");
}
Assembly assembly = Assembly.LoadFrom("MyPlugins.dll");
var pluginTypes = assembly.GetTypes()
.Where(t => typeof(IPlugin).IsAssignableFrom(t) && !t.IsAbstract);
foreach (Type type in pluginTypes)
{
IPlugin plugin = (IPlugin)Activator.CreateInstance(type);
plugin.Execute();
}
代码生成:运行时的创造力
在某些高级场景中,你可能需要在运行时生成新的类型或方法。.NET 提供的 System.Reflection.Emit 命名空间允许你在运行时构建程序集、模块、类型和方法。
使用 Reflection.Emit 生成动态类
以下是一个示例,展示如何使用 Reflection.Emit 生成一个动态类 Person,并为其添加一个 SayHello 方法。
using System;
using System.Reflection;
using System.Reflection.Emit;
public class DynamicTypeDemo
{
public static void Main()
{
// 创建一个动态程序集
AssemblyName assemblyName = new AssemblyName("DynamicAssembly");
AssemblyBuilder assemblyBuilder =
AssemblyBuilder.DefineDynamicAssembly(assemblyName, AssemblyBuilderAccess.Run);
// 创建一个模块
ModuleBuilder moduleBuilder = assemblyBuilder.DefineDynamicModule("MainModule");
// 定义一个类:public class Person
TypeBuilder typeBuilder = moduleBuilder.DefineType(
"Person",
TypeAttributes.Public
);
// 定义一个方法:public void SayHello()
MethodBuilder methodBuilder = typeBuilder.DefineMethod(
"SayHello",
MethodAttributes.Public,
returnType: typeof(void),
parameterTypes: Type.EmptyTypes
);
// 生成 IL 代码,等价于 Console.WriteLine("Hello from dynamic type!");
ILGenerator il = methodBuilder.GetILGenerator();
il.Emit(OpCodes.Ldstr, "Hello from dynamic type!");
il.Emit(OpCodes.Call, typeof(Console).GetMethod("WriteLine", new[] { typeof(string) })!);
il.Emit(OpCodes.Ret);
// 创建类型
Type personType = typeBuilder.CreateType();
// 实例化并调用方法
object personInstance = Activator.CreateInstance(personType)!;
personType.GetMethod("SayHello")!.Invoke(personInstance, null);
}
}
运行上述代码后,你将看到输出:
Hello from dynamic type!
表达式树:更安全的代码生成
如果你希望在运行时生成代码行为,但又不想深入 IL 层,表达式树(System.Linq.Expressions)是一个更现代、更安全的替代方案。以下是一个示例,展示如何使用表达式树生成一个简单的 SayHello 方法。
using System;
using System.Linq.Expressions;
public class ExpressionTreeDemo
{
public static void Main()
{
// 表达式:() => Console.WriteLine("Hello from expression tree!")
var writeLineMethod = typeof(Console).GetMethod("WriteLine", new[] { typeof(string) });
// 构建常量表达式 "Hello from expression tree!"
var messageExpr = Expression.Constant("Hello from expression tree!");
// 调用 Console.WriteLine(string) 的表达式
var callExpr = Expression.Call(writeLineMethod!, messageExpr);
// 构建 lambda 表达式:() => Console.WriteLine(...)
var lambda = Expression.Lambda<Action>(callExpr);
// 编译成委托并执行
Action sayHello = lambda.Compile();
sayHello();
}
}
运行上述代码后,你将看到输出:
Hello from expression tree!
Source Generator:编译期代码生成
Source Generator 是 .NET 提供的一种编译期代码生成工具,可以在编译过程中注入额外的源代码。它不依赖反射,无运行时开销,适合构建高性能、可维护的自动化代码逻辑。
以下是一个简单的 Source Generator 示例,展示如何为类自动生成一个 SayHello 方法。
- 创建标记用的 Attribute
// HelloGenerator.Attributes.csproj
namespace HelloGenerator
{
[System.AttributeUsage(System.AttributeTargets.Class)]
public class GenerateHelloAttribute : System.Attribute { }
}
- 创建 Source Generator
// HelloGenerator.Source/HelloMethodGenerator.cs
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Text;
using System.Text;
[Generator]
public class HelloMethodGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context)
{
// 注册一个语法接收器,用于筛选出标记了 [GenerateHello] 的类
context.RegisterForSyntaxNotifications(() => new SyntaxReceiver());
}
public void Execute(GeneratorExecutionContext context)
{
if (context.SyntaxReceiver is not SyntaxReceiver receiver)
return;
// 遍历所有被标记的类,生成 SayHello 方法
foreach (var classDecl in receiver.CandidateClasses)
{
var model = context.Compilation.GetSemanticModel(classDecl.SyntaxTree);
var symbol = model.GetDeclaredSymbol(classDecl) as INamedTypeSymbol;
if (symbol is null) continue;
string className = symbol.Name;
string namespaceName = symbol.ContainingNamespace.ToDisplayString();
string source = $@"
namespace {namespaceName}
{{
public partial class {className}
{{
public void SayHello()
{{
System.Console.WriteLine(""Hello from Source Generator!"");
}}
}}
}}";
context.AddSource($"{className}_Hello.g.cs", SourceText.From(source, Encoding.UTF8));
}
}
// 语法接收器
class SyntaxReceiver : ISyntaxReceiver
{
public List<ClassDeclarationSyntax> CandidateClasses { get; } = new();
public void OnVisitSyntaxNode(SyntaxNode syntaxNode)
{
if (syntaxNode is ClassDeclarationSyntax classDecl &&
classDecl.AttributeLists.Count > 0)
{
CandidateClasses.Add(classDecl);
}
}
}
}
- 在主项目中使用 Source Generator
using HelloGenerator;
namespace MyApp
{
[GenerateHello]
public partial class Greeter { }
class Program
{
static void Main()
{
var g = new Greeter();
g.SayHello(); // 自动生成的方法
}
}
}
运行上述代码后,你将看到输出:
Hello from Source Generator!
总结
反射和代码生成是 .NET 中非常强大的特性,它们为开发者提供了运行时动态探索和操作代码的能力。反射机制允许你在运行时检查类型信息、动态创建对象、调用方法,甚至访问私有成员。代码生成技术则让你能够在运行时生成新的类型和方法,或者在编译期生成代码,从而提升开发效率和代码的灵活性。
在实际开发中,反射虽然功能强大,但需要注意性能开销。在需要高性能的场景下,可以考虑使用 Delegate 缓存、表达式树,或 .NET 6 的 Source Generators 来替代反射。通过合理使用这些技术,你可以在开发中更加灵活地应对各种复杂场景,提升代码的可维护性和性能。
希望这篇文章能帮助你更好地理解和应用 .NET 反射和代码生成技术,让你在开发中更加得心应手!
来源:juejin.cn/post/7527559658276323379
深入理解 Java 中的信号机制
观察者模式的困境
在Java中实现观察者模式通常需要手动管理监听器注册、事件分发等逻辑,这会带来以下问题:
- 代码侵入性高:需要修改被观察对象的代码(如添加
addListener()方法) - 紧耦合:监听器与被观察对象高度耦合,难以复用
- 类型安全缺失:传统
Observable只能传递Object类型参数,需强制类型转换 - 事件解耦困难:难以区分触发事件的具体属性变化
下面,我们用一个待办事项的例子说明这个问题。同时利用信号机制的方法改写传统方式,进行对比。
示例:待办事项应用
我们以经典的待办事项应用为例,需要监听以下事件:
- 当单个Todo项发生以下变化时:
- 标题变更
- 完成状态切换
- 当TodoList发生以下变化时:
- 新增条目
- 删除条目
传统实现方案
1. 基础监听器模式
// 监听器接口
public interface Listener {
void onTitleChanged(Todo todo);
void onCompletionChanged(Todo todo);
void onItemAdded(Todo entity, Collection<Todo> todos);
void onItemRemoved(Todo entity, Collection<Todo> todos);
}
// 具体实现
public class ConsoleListener implements Listener {
@Override
public void onTitleChanged(Todo todo) {
System.out.printf("任务标题变更为: %s%n", todo.getTitle());
}
// 其他事件处理...
}
// 被观察对象(侵入式改造)
public class TodosList {
private final List<Listener> listeners = new ArrayList<>();
public void addListener(Listener listener) {
listeners.add(listener);
}
public void removeListener(Listener listener) {
listeners.remove(listener);
}
public Todo add(String title) {
Todo todo = new Todo(UUID.randomUUID(), title, false);
listeners.forEach(l -> l.onItemAdded(todo, todos));
return todo;
}
// 其他操作方法...
}
2. Java 内置的 Observable(已弃用)
// 被观察的Todo类
@Getter @AllArgsConstructor
public class Todo extends Observable {
private UUID id;
@Setter private String title;
@Setter private boolean completed;
public void setTitle(String title) {
this.title = title;
setChanged();
notifyObservers(this); // 通知所有观察者
}
// 其他setter同理...
}
// 观察者实现
public class BasicObserver implements Observer {
@Override
public void update(Observable o, Object arg) {
if (o instanceof Todo todo) {
System.out.println("[Observer] 收到Todo更新事件: " + todo);
}
}
}
信号机制(Signals)解决方案
核心思想:将属性变化抽象为可观察的信号(Signal),通过声明式编程实现事件监听
1. 信号基础用法
// 信号定义(使用第三方库com.akilisha.oss:signals)
public class Todo {
private final Signal<String> title = Signals.signal("");
private final Signal<Boolean> completed = Signals.signal(false);
public void setTitle(String newTitle) {
title.set(newTitle); // 自动触发订阅的副作用
}
public void observeTitleChanges(Consumer<String> effect) {
Signals.observe(title, effect); // 注册副作用
}
}
2. 待办事项列表实现
public class TodosList {
private final SignalCollection<Todo> todos = Signals.signal(new ArrayList<>());
public Todo add(String title) {
Todo todo = Todo.from(title);
todos.add(todo); // 自动触发集合变更事件
// 声明式监听集合变化
Signals.observe(todos, (event, entity) -> {
switch (event) {
case "add":
System.out.printf("新增任务: %s%n", entity);
break;
case "remove":
System.out.printf("删除任务: %s%n", entity);
break;
}
});
return todo;
}
}
3. 效果注册与取消
public class Main {
public static void main(String[] args) {
TodosList list = new TodosList();
// 注册副作用(自动绑定到Todo属性)
list.add("学习Signals")
.observeTitleChanges(title ->
System.out.printf("任务标题变更为: %s%n", title)
);
list.add("实践Signals")
.observeCompletionChanges(completed ->
System.out.printf("任务完成状态: %s%n", completed)
);
// 触发事件
list.todos.get(0).getTitle().set("深入学习Signals");
}
}
技术对比
| 特性 | 传统监听器模式 | Java Observable | Signals机制 |
|---|---|---|---|
| 类型安全 | ❌ 需强制转换 | ❌ Object类型 | ✅ 泛型类型安全 |
| 事件解耦 | ❌ 难以区分属性变化 | ❌ 无法区分属性 | ✅ 明确属性变更事件 |
| 内存泄漏风险 | ⚠️ 需手动移除监听器 | ⚠️ 需手动移除观察者 | ✅ 自动取消订阅 |
| 代码侵入性 | ❌ 需修改被观察对象 | ❌ 需继承Observable | ✅ 零侵入 |
| 生态支持 | ✅ 成熟框架 | ❌ 已弃用 | ⚠️ 第三方库 |
关键优势
- 声明式编程:通过
.observe()方法直接声明副作用逻辑 - 精确事件解耦:可区分
add/remove/update等具体操作 - 组合式API:支持多信号组合(如
Signals.combineLatest()) - 类型安全:编译期检查事件类型匹配
使用建议
- 新项目推荐:优先考虑使用Signals机制
- 遗留系统改造:可通过适配器模式逐步替换传统监听器
- 复杂场景:结合RxJava等响应式流框架实现高级功能
通过这种现代化的事件处理方式,可以显著提升代码的可维护性和可测试性,特别适合需要精细控制状态变化的复杂业务场景。
来源:juejin.cn/post/7512657698408988713
搞懂 GO 的垃圾回收机制

速通 GO 垃圾回收机制
前言
垃圾回收(Garbage Collection,简称 GC)是编程语言中自动管理内存的一种机制。Go 语言从诞生之初就带有垃圾回收机制,经过多次优化,现在已经相当成熟。本文将带您深入了解 Go 语言的垃圾回收机制。
下面先一起了解下涉及到的垃圾回收相关知识。
标记清除
标记清除(Mark-Sweep)是最基础的垃圾回收算法,分为两个阶段:
- 标记阶段:从根对象出发,标记所有可达对象(可达性分析)
- 清除阶段:遍历整个堆,回收未被标记的对象
标记清除示例
考虑以下场景:
type Node struct {
next *Node
data int
}
func createLinkedList() *Node {
root := &Node{data: 1}
node2 := &Node{data: 2}
node3 := &Node{data: 3}
root.next = node2
node2.next = node3
return root
}
func main() {
list := createLinkedList()
// 此时内存中有三个对象,都是可达的
list.next = nil
// 此时node2和node3变成了不可达对象,将在下次GC时被回收
}
在这个例子中:
- 初始状态:root -> node2 -> node3 形成链表
- 标记阶段:从root开始遍历,标记所有可达对象
- 修改引用后:只有root是可达的
- 清除阶段:node2和node3将被回收
// 伪代码展示标记清除过程
func MarkSweep() {
// 标记阶段
for root := range roots {
mark(root)
}
// 清除阶段
for object := range heap {
if !marked(object) {
free(object)
}
}
}
标记清除算法的优点是实现简单,但存在以下问题:
- 需要 STW(Stop The World),即在垃圾回收时需要暂停程序运行
- 会产生内存碎片,因为清除后最终剩下的活跃对象在堆中的分布是零散不连续的
- 标记和清除的效率都不高
内存碎片示意图
%%{init: {"flowchart": {"htmlLabels": false}} }%%
flowchart LR
subgraph Before["GC前的堆内存"]
direction LR
A1["已分配"] --- B1["已分配"] --- C1["空闲"] --- D1["已分配"] --- E1["已分配"]
end
Before ~~~ After
subgraph After["GC后的堆内存"]
direction LR
A2["已分配"] --- B2["空闲"] --- C2["空闲"] --- D2["已分配"] --- E2["空闲"]
end
classDef default fill:#fff,stroke:#333,stroke-width:2px;
classDef allocated fill:#a8d08d,stroke:#333,stroke-width:2px;
classDef free fill:#f4b183,stroke:#333,stroke-width:2px;
class A1,B1,D1,E1 allocated;
class C1 free;
class A2,D2 allocated;
class B2,C2,E2 free;
如图所示,GC后的内存空间虽然有足够的总空间,但是由于碎片化,可能无法分配较大的连续内存块。
三色标记
为了优化标记清除算法,Go 语言采用了三色标记算法。主要的目的是为了缩短 STW 的时间,提高程序在垃圾回收过程中响应速度。
三色标记将对象分为三种颜色:
- 白色:未被标记的对象
- 灰色:已被标记但其引用对象未被标记的对象
- 黑色:已被标记且其引用对象都已被标记的对象
三色标记过程图解
graph TD
subgraph "最终状态"
A4[Root] --> B4[Object 1]
B4 --> C4[Object 2]
B4 --> D4[Object 3]
D4 --> E4[Object 4]
style A4 fill:#000000
style B4 fill:#000000
style C4 fill:#000000
style D4 fill:#000000
style E4 fill:#000000
end
subgraph "处理灰色对象"
A3[Root] --> B3[Object 1]
B3 --> C3[Object 2]
B3 --> D3[Object 3]
D3 --> E3[Object 4]
style A3 fill:#000000
style B3 fill:#808080
style C3 fill:#FFFFFF
style D3 fill:#FFFFFF
style E3 fill:#FFFFFF
end
subgraph "标记根对象为灰色"
A2[Root] --> B2[Object 1]
B2 --> C2[Object 2]
B2 --> D2[Object 3]
D2 --> E2[Object 4]
style A2 fill:#808080
style B2 fill:#FFFFFF
style C2 fill:#FFFFFF
style D2 fill:#FFFFFF
style E2 fill:#FFFFFF
end
subgraph "初始状态"
A1[Root] --> B1[Object 1]
B1 --> C1[Object 2]
B1 --> D1[Object 3]
D1 --> E1[Object 4]
style A1 fill:#D3D3D3
style B1 fill:#FFFFFF
style C1 fill:#FFFFFF
style D1 fill:#FFFFFF
style E1 fill:#FFFFFF
end
在垃圾回收器开始工作时,所有对象都为白色,垃圾回收器会先把所有根对象标记为灰色,然后后续只会从灰色对象集合中取出对象进行处理,把取出的对象标为黑色,并且把该对象引用的对象标灰加入到灰色对象集合中,直到灰色对象集合为空,则表示标记阶段结束了。
三色标记实际示例
type Person struct {
Name string
Friends []*Person
}
func main() {
alice := &Person{Name: "Alice"}
bob := &Person{Name: "Bob"}
charlie := &Person{Name: "Charlie"}
// Alice和Bob是朋友
alice.Friends = []*Person{bob}
bob.Friends = []*Person{alice, charlie}
// charlie没有朋友引用(假设bob的引用被删除)
bob.Friends = []*Person{alice}
// 此时charlie将在下次GC时被回收
}
详细标志过程如下:
- 初始时所有对象都是白色
- 从根对象开始,将其标记为灰色
- 从灰色对象集合中取出一个对象,将其引用对象标记为灰色,自身标记为黑色
- 重复步骤 3 直到灰色集合为空
- 清除所有白色对象
// 三色标记伪代码
func TriColorMark() {
// 初始化,所有对象设为白色
for obj := range heap {
setWhite(obj)
}
// 根对象入灰色队列
for root := range roots {
setGrey(root)
greyQueue.Push(root)
}
// 处理灰色队列
for !greyQueue.Empty() {
grey := greyQueue.Pop()
scan(grey)
setBlack(grey)
}
// 清除白色对象
sweep()
}
需要注意的是,三色标记清除算法本身是不支持和用户程序并行执行的,因为在标记过程中,用户程序可能会进行修改对象指针指向等操作,导致最终出现误清除掉活跃对象等情况,这对于内存管理而言,是十分严重的错误了。
并发标记的问题示例
func main() {
var root *Node
var finalizer *Node
// GC开始,root被标记为灰色
root = &Node{data: 1}
// 用户程序并发修改引用关系
finalizer = root
root = nil
// 如果这时GC继续运行,finalizer指向的对象会被错误回收
// 因为从root开始已经无法到达该对象
}
所以为了解决这个问题,在一些编程语言中,常见的做法是,三色标记分为 3 个阶段:
- 初始化阶段,需要 STW,包括标记根对象等操作
- 主要标记阶段,该阶段支持并行
- 结束标记阶段,需要 STW,确认对象标记无误
通过这样的设计,至少可以使得标记耗时较长的阶段可以和用户程序并行执行,大幅度缩短了 STW 的时间,但是由于最后一阶段需要重复扫描对象,所以 STW 的时间还是不够理想,因此引入了内存屏障等技术继续优化。
内存屏障技术
三色标记算法在并发环境下会出现对象丢失的问题,为了解决这个问题,Go 引入了内存屏障技术。
内存屏障技术是一种屏障指令,确保屏障指令前后的操作不会被越过屏障重排。
内存屏障工作原理图解
graph TD
subgraph "插入写屏障"
A1[黑色对象] -->|新增引用| B1[白色对象]
B1 -->|标记为灰色| C1[灰色对象]
end
subgraph "删除写屏障"
A2[黑色对象] -->|删除引用| B2[白色对象]
B2 -->|标记为灰色| C2[灰色对象]
end
垃圾回收中的屏障更像是一个钩子函数,在执行指定操作前通过该钩子执行一些前置的操作。
对于三色标记算法,如果要实现在并发情况下的正确标记,则至少要满足以下两种三色不变性中的其中一种:
- 强三色不变性: 黑色对象不指向白色对象,只会指向灰色或黑色对象
- 弱三色不变性:黑色对象可以指向白色对象,但是该白色对象必须被灰色对象保护着(被其他的灰色对象直接或间接引用)
插入写屏障
插入写屏障的核心思想是:在对象新增引用关系时,将被引用对象标记为灰色。
// 插入写屏障示例
type Object struct {
refs []*Object
}
func (obj *Object) AddReference(ref *Object) {
// 写屏障:在添加引用前将新对象标记为灰色
shade(ref)
obj.refs = append(obj.refs, ref)
}
// 插入写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(ptr) // 将新引用的对象标记为灰色
*slot = ptr
}
插入写屏障是一种相对保守的策略,相当于有可能存活的对象都会被标灰,满足了强三色不变行,缺点是会产生浮动垃圾(没有被引用但却没被回收的对象),要到下一轮垃圾回收时才会被回收。
浮动垃圾示例
func main() {
obj1 := &Object{}
obj2 := &Object{}
// obj1引用obj2
obj1.AddReference(obj2) // obj2被标记为灰色
// 立即删除引用
obj1.refs = nil
// 此时obj2虽然已经不可达
// 但因为已被标记为灰色,要等到下一轮GC才会被回收
}
栈上的对象在垃圾回收中也是根对象,但是如果栈上的对象也开启插入写屏障,那么对于写指针的操作会带来较大的性能开销,所以很多时候插入写屏障只针对堆对象启用,这样一来,要保证最终标记无误,在最终标记结束阶段就需要 STW 来重新扫描栈空间的对象进行查漏补缺。实际上这两种方式各有利弊。
删除写屏障
删除写屏障的核心思想是:在对象删除引用关系时,将被解引用的对象标记为灰色。
这种方法可以保证弱三色不变性,缺点是回收精度低,同样也会产生浮动垃圾。
// 删除写屏障示例
func (obj *Object) RemoveReference(index int) {
// 写屏障:在删除引用前将被删除的对象标记为灰色
shade(obj.refs[index])
obj.refs = append(obj.refs[:index], obj.refs[index+1:]...)
}
// 删除写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot) // 将被删除引用的对象标记为灰色
*slot = ptr
}
混合写屏障
Go 1.8 引入了混合写屏障,同时应用了插入写屏障和删除写屏障,结合了二者的优点:
// 混合写屏障示例
func (obj *Object) UpdateReference(index int, newRef *Object) {
// 删除写屏障
shade(obj.refs[index])
// 更新引用
obj.refs[index] = newRef
// 插入写屏障
shade(newRef)
}
// 混合写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot) // 删除写屏障
*slot = ptr
shade(ptr) // 插入写屏障
}
GO 中垃圾回收机制
大致演进与版本改进
- Go 1.3之前:传统标记-清除,全程STW(秒级停顿)。
- Go 1.5:引入并发三色标记,STW降至毫秒级。
- Go 1.8:混合写屏障优化,STW缩短至微秒级。
- Go 1.12+:并行标记优化,提升吞吐量。
在 GO 1.7 之前,主要是使用了插入写屏障来保证强三色不变性,由于垃圾回收的根对象包括全局变量、寄存器、栈对象,如果要对所有的 Goroutine 都开启写屏障,那么对于写指针操作肯定会造成很大的性能损耗,所以 GO 并没有针对栈开启写屏障。而是选择了在标记完成时 STW、重新扫描栈对象(将所有栈对象标灰重新扫描),避免漏标错标的情况,但是这一过程是比较耗时的,要占用 10 ~ 100 ms 时间。
于是,GO 1.8 开始就使用了混合写屏障 + 栈黑化 的方案优化该问题,GC 开始时全部栈对象标记为黑色,以及标记过程中新建的栈、堆对象也标记为黑色,防止新建的对象都错误回收掉,通过这样的机制,栈空间的对象都会为黑色,所以最后也无需重新扫描栈对象,大幅度地缩短了 STW 的时间。当然,与此同时也会有产生浮动垃圾等方面的牺牲,没有完成的方法,只有根据实际需求的权衡取舍。
主要特点
- 并发回收:GC 与用户程序同时运行
- 非分代式:不按对象年龄分代
- 标记清除:使用三色标记算法
- 写屏障:使用混合写屏障
- STW 时间短:平均在 100us 以内
垃圾回收触发条件
- 内存分配达到阈值
- 定期触发
- 手动触发(runtime.GC())
GC 过程
- STW,开启写屏障
- 并发标记
- STW,清除标记
- 并发清除
- 结束
GC触发示例
func main() {
// 1. 内存分配达到阈值触发
for i := 0; i < 1000000; i++ {
_ = make([]byte, 1024) // 大量分配内存
}
// 2. 定期触发
// Go运行时会自动触发GC
// 3. 手动触发
runtime.GC()
}
总结
Go 语言的垃圾回收机制经过多次优化,已经达到了很好的性能。它采用三色标记算法,配合混合写屏障技术,实现了高效的并发垃圾回收。虽然还有一些不足,如不支持分代回收,但对于大多数应用场景来说已经足够使用。
性能优化建议
要优化 Go 程序的 GC 性能,可以:
- 减少对象分配
// 不好的做法
for i := 0; i < 1000; i++ {
data := make([]int, 100)
process(data)
}
// 好的做法
data := make([]int, 100)
for i := 0; i < 1000; i++ {
process(data)
}
- 复用对象
// 使用sync.Pool复用对象
var pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
func process() {
buf := pool.Get().([]byte)
defer pool.Put(buf)
// 使用buf
}
- 使用合适的数据结构
// 不好的做法:频繁扩容
s := make([]int, 0)
for i := 0; i < 1000; i++ {
s = append(s, i)
}
// 好的做法:预分配容量
s := make([]int, 0, 1000)
for i := 0; i < 1000; i++ {
s = append(s, i)
}
- 控制内存使用量
// 设置GOGC环境变量控制GC频率
// GOGC=100表示当内存扩大一倍时触发GC
os.Setenv("GOGC", "100")
参考资料:
来源:juejin.cn/post/7523256725126873114
牛马的人生,需要Spring Shell
前言
“技术是人类对需求的回应。”
大家好,这里是知行小栈。
最近,一位运营的同学突然给我发来了一串加密的手机号,类似这样:
2f731fb2aea9fb5069adef6e4aa2624e
他让我帮忙解下密,想拿到具体的手机号。
我看了下,也不是啥大事儿。于是找到了对应的项目,直接调用里面的解密方法,将这些号码都打印了出来,给到了他。
本以为事情到此就结束了,结果他隔三岔五的让我去做这个操作(心里os)。判断了下情况,这种需求可能会不间断的发生。顿时,我的大脑就应激了,必须弄个一劳永逸的方案!
命令行
我最先想到的就是命令行。为啥呢?因为命令行有两个特点:
- 易于调用;
- 简短的命令就能完成指定的功能;

只要制作一个自定义的命令行工具,下次就可以通过这种方式减少繁琐的操作,增加摸鱼的时间。
原先项目中,已经有手机号加解密的功能。基于职业的基本素养(不重复造轮子),之前已有的功能我是不会重写的,而是想办法能直接通过命令行调用。类似:
java -jar xxx.jar
这个命令虽然看起来有点长,但可以通过为其起别名的方式,简化命名。实现 ll 等价于 ls -l 的效果。
Spring Shell
想要通过 shell 调用 Java 指定类中的指定方法,方式有许多。我思考了 秒,就决定采用 Spring Shell(因为它与我想要实现的场景匹配度高达 99.999%)。
首先,我仅需要在原先的项目中多引入一个依赖
<dependency>
<groupId>org.springframework.shell</groupId>
<artifactId>spring-shell-starter</artifactId>
<version>2.1.15</version>
</dependency>
然后,实现一个自定义的命令组件
// @ShellComponent 类似 @Component 表明是 Spring 中的一个组件
@ShellComponent
public class Cipher {
// @ShellMethod 定义了一个命令,key 属性是命令的名称,value 属性是命令的描述
// @ShellOption 定义了命令中的参数
@ShellMethod(key = "decrypt", value = "解密操作")
public String decrypt(@ShellOption String cipherText, @ShellOption String key) {
// 调用项目中已有的解密方法
return AesUtil.decrypt(cipherText, key);
}
@ShellMethod(key = "encrypt", value = "加密操作")
public String encrypt(@ShellOption String text, @ShellOption String key) {
// 调用项目中已有的加密方法
return AesUtil.encrypt(text, key);
}
}
最后,重新将 Shell 组件所在的项目打个包,运行项目

执行命令,验证

到这里,还不行。因为我可不会每次都去执行 java -jar xxx.jar 这么长的命令来启动 Spring Shell。windows 终端我一直用的 Git-Bash,这种类 Unix 的终端都可以采用相同的方式为长命令设置一个别名。
于是,我在 .bash_profile 文件中,给这段长命令起了一个别名:
alias shell='java -jar encrypt.jar'
接下来,就可以通过简单的 shell 命令调用 Spring Shell 终端,执行之前定义好的命令了

知行有话
Spring Shell 简直就是开发者的利器。试想一下,我们把日常学习或工作中频繁的操作都弄成这样的终端命令,是不是会节约我们大量的时间?还有一个值得提的点就是它对 Java 开发者十分友好。只要你懂 Java,就可以轻松上手开发自定义的终端命令。
来源:juejin.cn/post/7530521957666914346
docker容器如何打包镜像和部署
1、打包镜像
如图,参考执行步骤。打包你的工程镜像。
2、推送镜像
2.1 仓库申请
首先,你需要申请一个阿里云Docker镜像仓库 cr.console.aliyun.com/cn-beijing/…
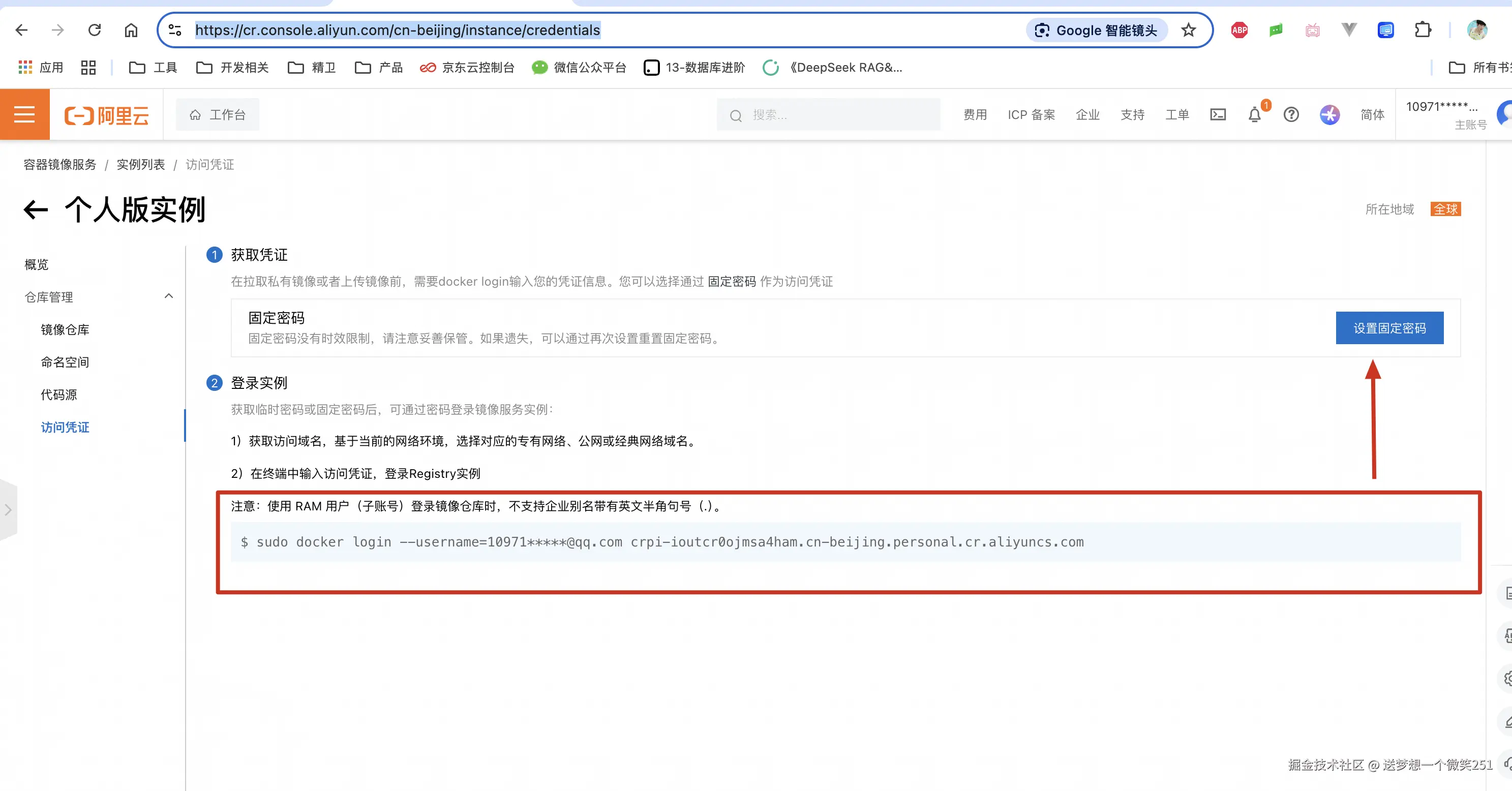
2.2 命名空间
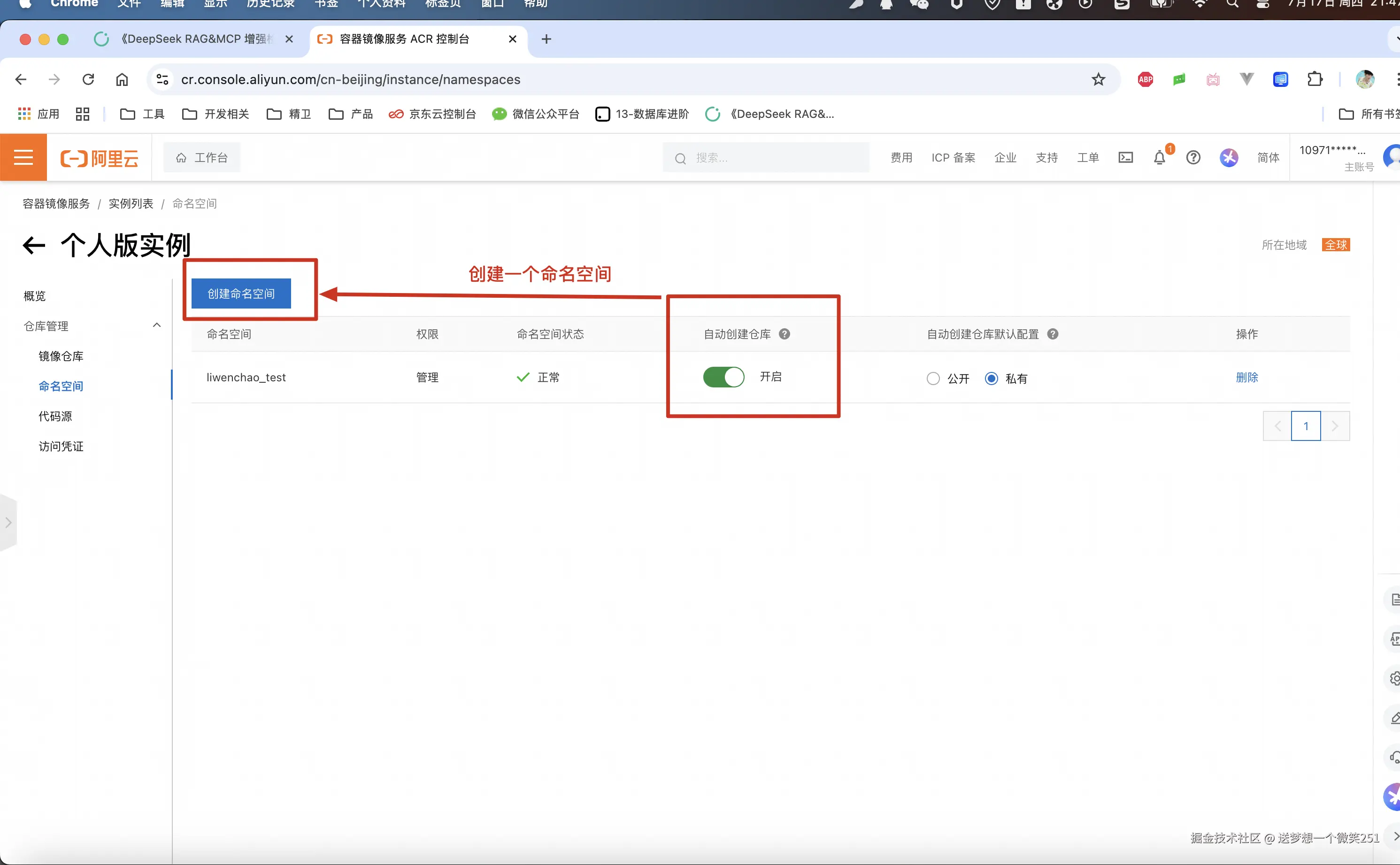
创建一个你的命名空间,后面使用到这个空间地址。
2.3 脚本配置
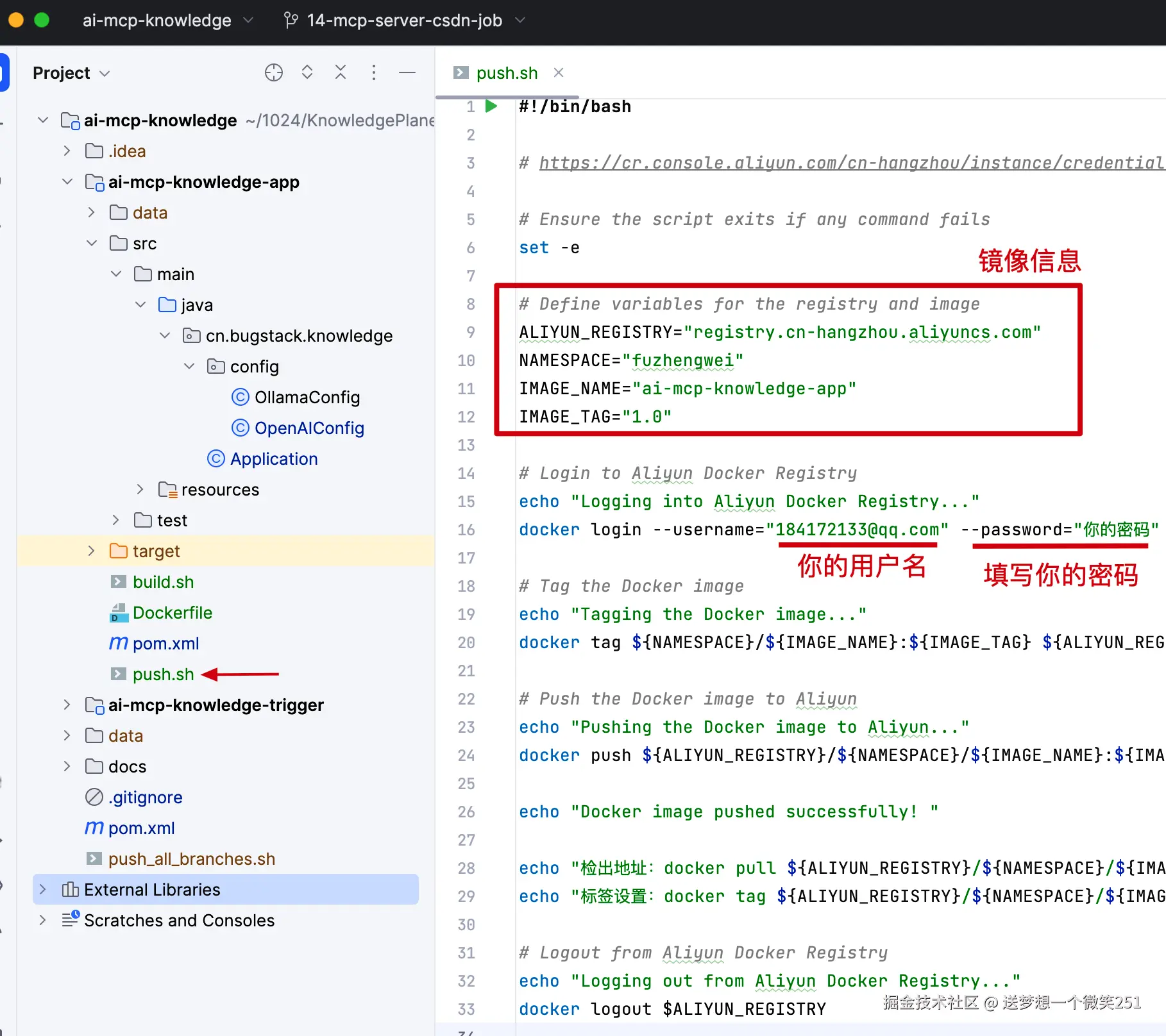
打开 push.sh 填写你的镜像信息,以及你的镜像仓库地址。
push.sh 脚本,需要通过 ./push.sh 运行,mac 电脑可以直接点击绿色小箭头运行。这个操作步骤完成后,会把镜像推送到你的阿里云Docker镜像仓库去。
拉取使用;docker pull crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT
设置名称;docker tag crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT liwenchao_test/riderwuyou-admin:1.0
注意;你可以重设镜像名称,可以把 liwenchao_test/riderwuyou-admin:1.0 的地方。
- 服务脚本
docker 项目的部署,具有一次构建,多地部署的通用性。所以,你可以在本地 docker 环境部署、nas环境部署、云服务器环境部署。
3.1 部署环境 - 脚本
通过以下脚本,安装mysql、redis等。
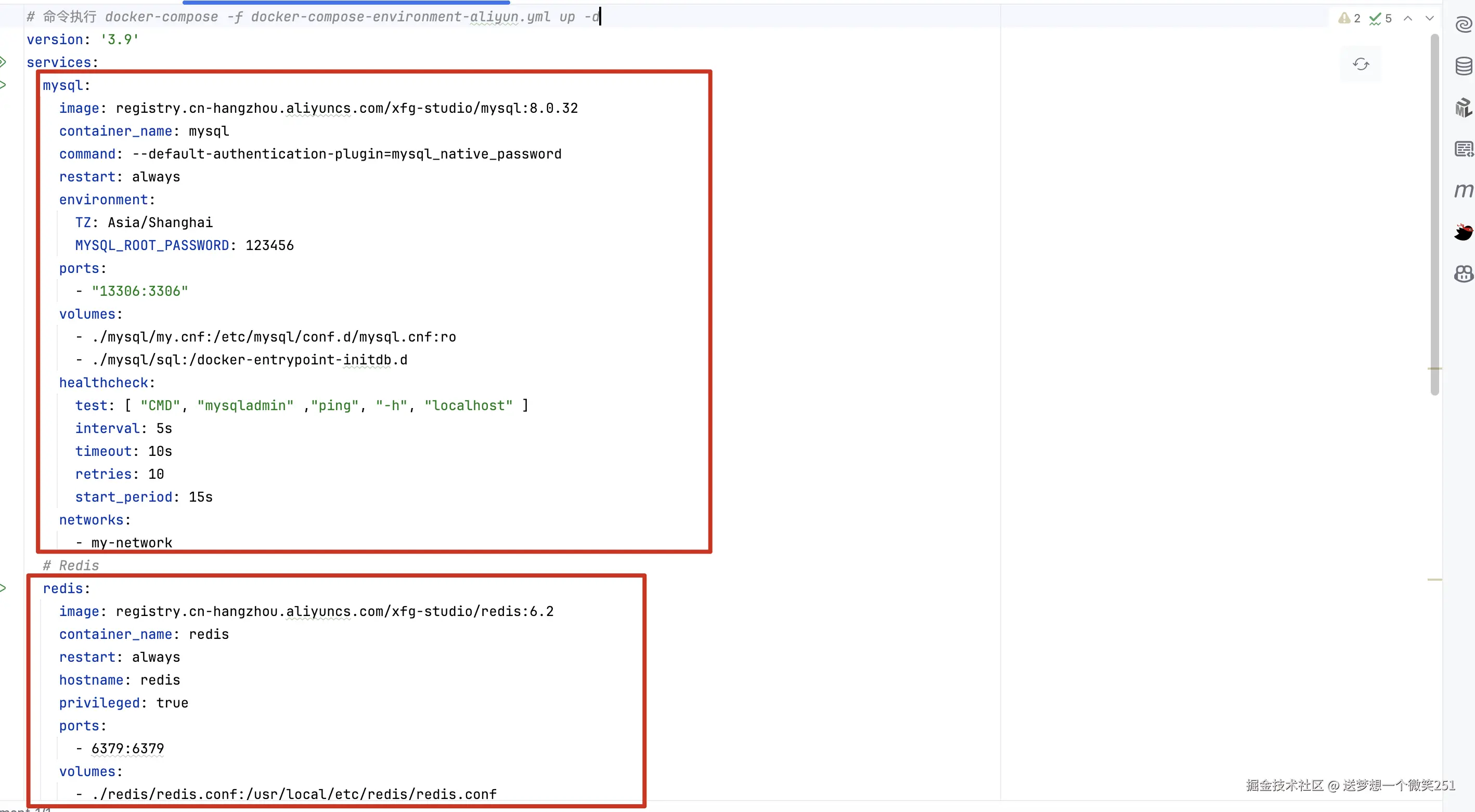
3.2 项目部署 - 脚本
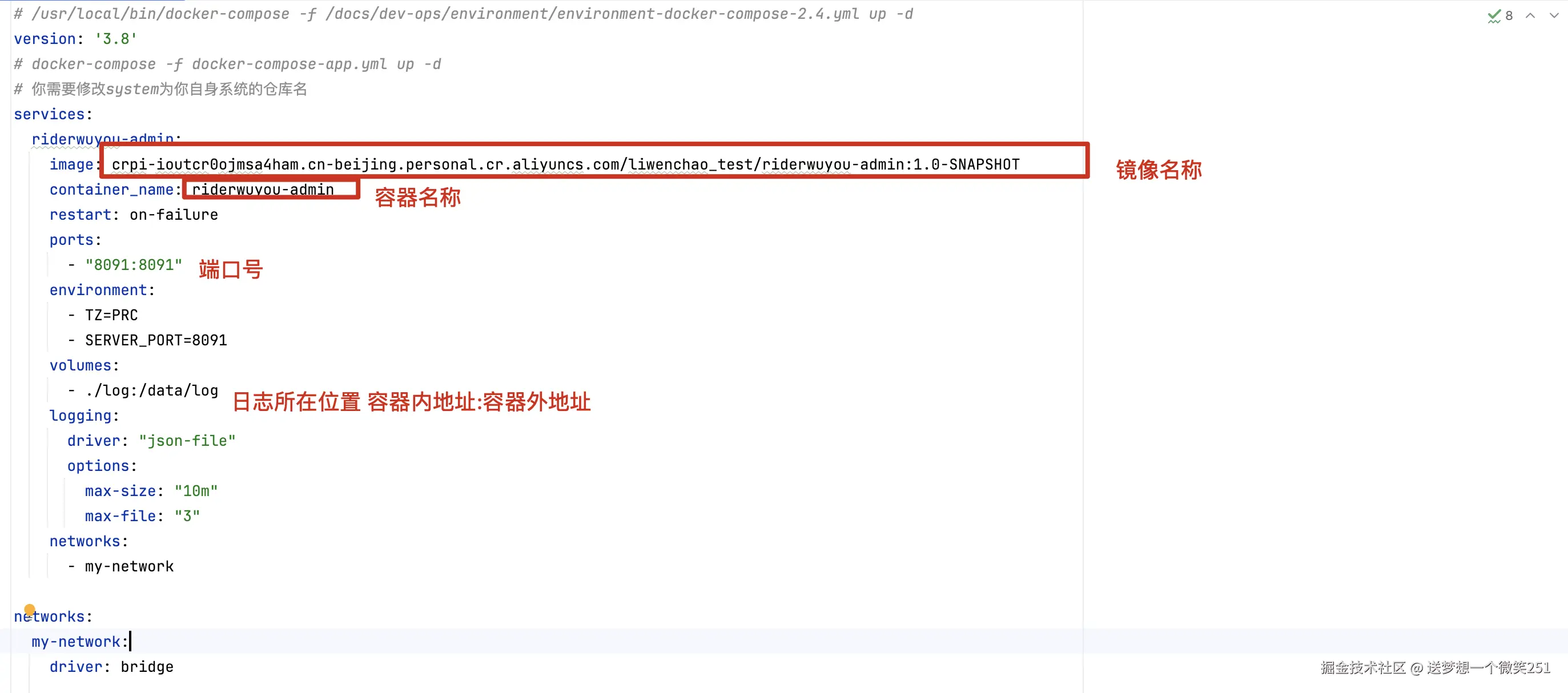
镜像,liwenchao_test/riderwuyou-admin:1.0 如果使用阿里云Docker仓库,那么可以使用 image: crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT 或者用 docker tag crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT liwenchao_test/riderwuyou-admin:1.0 设定镜像名称。
4. 服务部署
4.1 上传脚本
4.2 执行脚本
- 执行脚本01;
docker-compose -f docker-compose-environment-aliyun.yml up -d - 执行脚本02;
docker-compose -f docker-compose-app-v1.0.yml up -d - 运行完成后,就可以运行测试了
来源:juejin.cn/post/7529292244571897910
面试官:MySQL单表过亿数据,如何优化count(*)全表的操作?
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
最近有好几个同学跟我说,他在技术面试过程中被问到这个问题了,让我找时间系统地讲解一下。
其实从某种意义上来说,这并不是一个严谨的面试题,接下来 show me the SQL,我们一起来看一下。
如下图所示,一张有 3000多万行记录的 user 表,执行全表 count 操作需要 14.8 秒的时间。
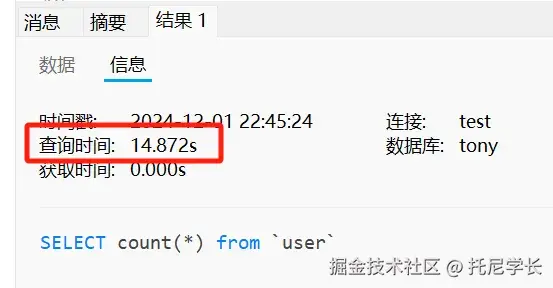
接下来我们稍作调整再试一次,神奇的一幕出现了,执行全表 count 操作竟然连 1 毫秒的时间都用不上。
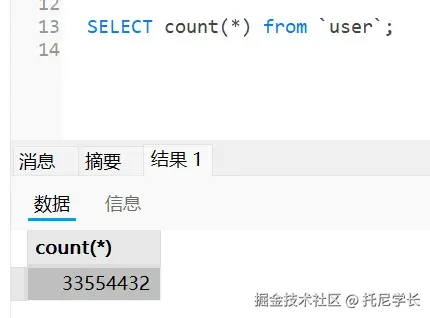
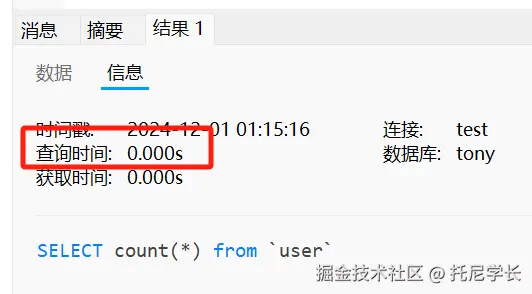
这是为什么呢?
其实原因很简单,第一次执行全表 count 操作的时候,我用的是 MySQL InnoDB 存储引擎,而第二次则是用的 MySQL MyISAM 存储引擎。
这两者的差别在于,前者在执行 count(*) 操作的时候,需要将表中每行数据读取出来进行累加计数,而后者已经将表的总行数存储下来了,只需要直接返回即可。
当然,InnoDB 存储引擎对 count(*) 操作也进行了一些优化,如果该表创建了二级索引,其会通过全索引扫描的方式来代替全表扫描进行累加计数,
毕竟,二级索引值只存储了索引列和主键列两个字段,遍历计数肯定比存储所有字段的数据表的 IO 次数少很多,也就意味着其执行效率更高。
而且,MySQL 的优化器会选择最小的那个二级索引的索引文件进行遍历计数。
所以,这个技术面试题严谨的问法应该是 —— MySQL InnoDB 存储引擎单表过亿数据,如何优化 count(*) 全表的操作?
下面我们就来列举几个常见的技术解决方案,如下图所示:

(1)Redis 累加计数
这是一种最主流且简单直接的实现方式。
由于我们基本上不会对数据表执行 delete 操作,所以当有新的数据被写入表的时候,通过 Redis 的 incr 或 incrby 命令进行累加计数,并在用户查询汇总数据的时候直接返回结果即可。
如下图所示:

该实现方式在查询性能和数据准确性上两者兼得,Redis 需要同时负责累加计数和返回查询结果操作,缺点在于会引入缓存和数据库间的数据一致性的问题。
(2)MySQL 累加计数表 + 事务
这种实现方式跟“Redis 累加计数”大同小异,唯一的区别就是将计数的存储介质从 Redis 换成了 MySQL。
如下图所示:
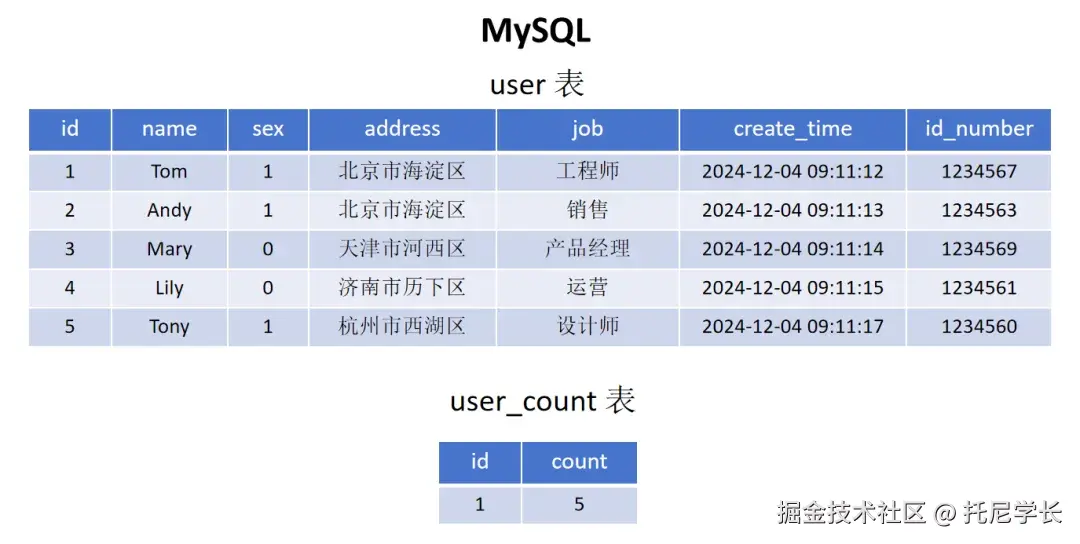
但这么一换,就可以将写入表操作和累加计数操作放在一个数据库事务中,也就解决了缓存和数据库间的数据一致性的问题。
该实现方式在查询性能和数据准确性上两者兼得,但不如“Redis 累加计数”方式的性能高,在高并发场景下数据库会成为性能瓶颈。
(3)MySQL 累加计数表 + 触发器
这种实现方式跟“MySQL 累加计数表 + 事务”的表结构是一样的,如下图所示:
**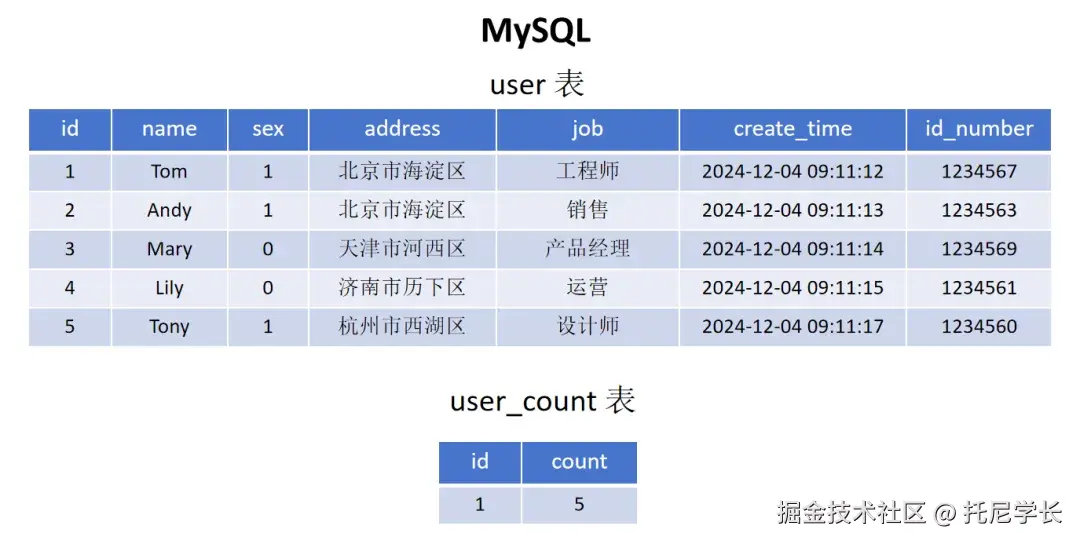 **
**
唯一的区别就是增加一个触发器,不用在工程代码中通过事务进行实现了。
CREATE TRIGGER `user_count_trigger` AFTER INSERT ON `user` FOR EACH ROW BEGIN UPDATE user_count SET count = count + 1 WHERE id = NEW.id;END
该实现方式在查询性能和数据准确性上两者兼得,与“MySQL 累加计数表 + 事务”方式相比,最大的好处就是不用污染工程代码了。
(4)MySQL 增加并行线程
在 MySQL 8.014 版本中,总算增加了并行查询的新特性,其通过参数 innodb_parallel_read_threads 进行设定,默认值为 4。
下面我们做个实验,将这个参数值调得大一些:
set local innodb_parallel_read_threads = 16;
然后,我们再来执行一次上文中那个 3000 多万行记录 user 表的全表 count 操作,结果如下所示:
参数调整后,执行全表 count 操作的时间由之前的 14.8 秒,降低至现在的 6.1 秒,是可以看到效果的。
接下来,我们继续将参数值调整得大一些,看看是否还有优化空间:
set local innodb_parallel_read_threads = 32;
然后,我们再来执行一次上文中那个 3000 多万行记录 user 表的全表 count 操作,结果如下所示:
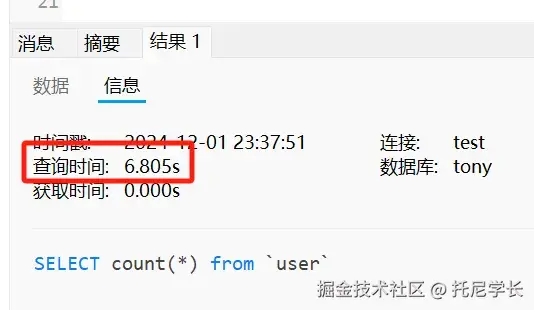
参数调整后,执行全表 count 操作的时间竟然变长了,从原来的 6.1 秒变成了 6.8 秒,看样子优化空间已经达到上限了,再多增加执行线程数量只会适得其反。
该实现方式一样可以保证数据准确性,在查询性能上有所提升但相对有限,其最大优势是只需要调整一个数据库参数,在工程代码上不会有任何改动。
不过,如果数据库此时的负载和 IOPS 已经很高了,那开启并行线程或者将并行线程数量调大,会加速消耗数据库资源。
(5)MySQL 增加二级索引
还记得我们在上文中说的内容吗?
InnoDB 存储引擎对 count() 操作也进行了一些优化,如果该表创建了二级索引,其会通过全索引扫描的方式来代替全表扫描进行累加计数,*
毕竟,二级索引值只存储了索引列和主键列两个字段,遍历计数肯定比存储所有字段的数据表的IO次数少很多,也就意味着执行效率更高。
而且,MySQL 的优化器会选择最小的那个二级索引的索引文件进行遍历计数。
为了验证这个说法,我们给 user 表中最小的 sex 字段加一个二级索引,然后通过 EXPLAIN 命令看一下 SQL 语句的执行计划:
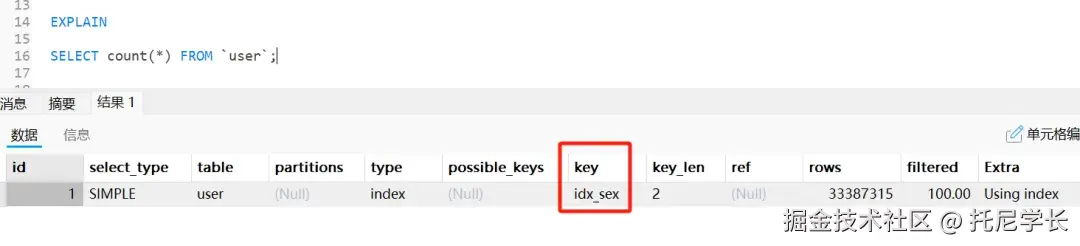
果然,这个 SQL 语句的执行计划会使用新建的 sex 索引,接下来我们执行一次看看时长:
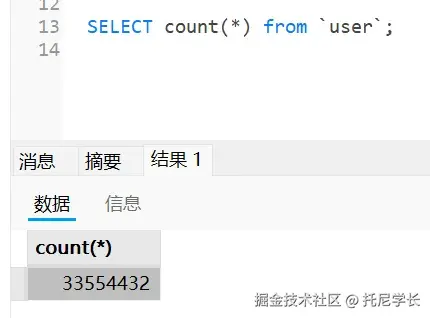
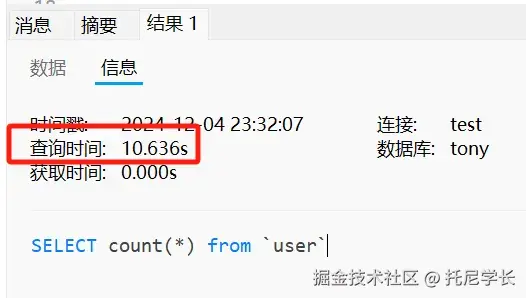
果不其然,执行全表 count 操作走了 sex 二级索引后,SQL 执行时间由之前的 14.8 秒降低至现在的 10.6 秒,还是可以看到效果的。
btw:大家可能会觉得效果并不明显,这是因为我们用来测试的 user 表中算上主键 ID 只有七个字段,而且没有一个大字段。
反之,user 表中的字段数量越多,且包含的大字段越多,其优化效果就会越明显。
该实现方式一样可以保证数据准确性,在查询性能上有所提升但相对有限,其最大优势是只需要创建一个二级索引,在工程代码上不会有任何改动。
(6)SHOW TABLE STATUS
如下图所示,通过 SHOW TABLE STATUS 命令也可以查出来全表的行数:
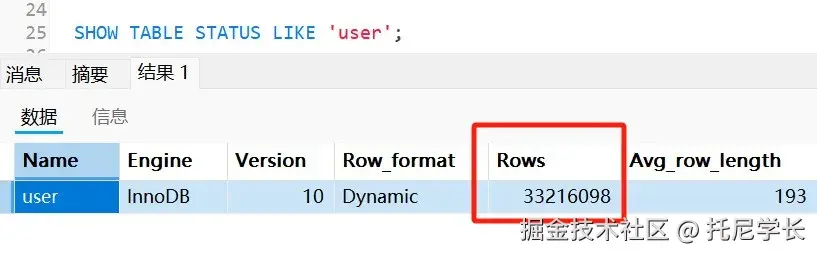
我们常用于查看执行计划的 EXPLAIN 命令也能实现:
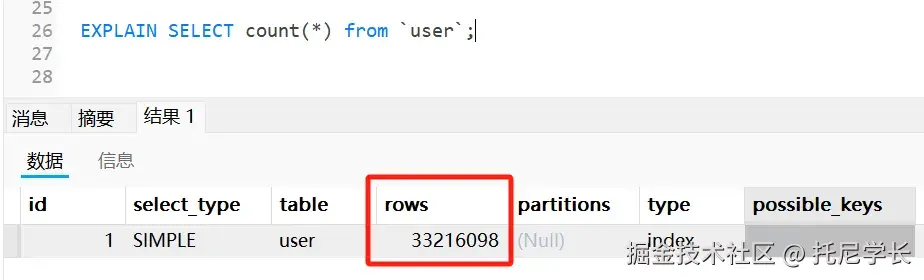
只不过,通过这两个命令得出来的表记录数是估算出来的,都不太准确。那到底有多不准确呢,我们来计算一下。
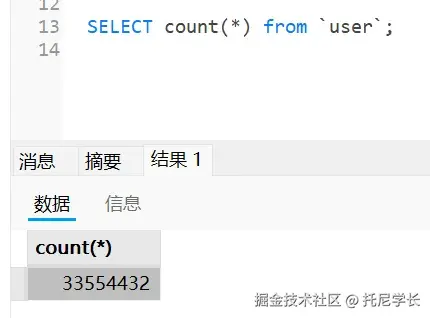
公式为:33554432 / 33216098 = 1.01
就这个 case 而言,误差率大概在百分之一左右。
该实现方式一样可以保证查询性能,无论表中有多大量级的数据都能毫秒级返回结果,且在工程代码方面不会有任何改动,但数据准确性上相差较多,只能用作大概估算。
来源:juejin.cn/post/7444919285170307107
Go实现超时控制
应用场景
交易、金融等事务系统往往会有各种下游,绝大多数时候我们会以同步方式进行访问,如调用RPC、HTTP等。
这些下游在通常延时相对稳定,但有时可能出现极端的超大延时,这些极端case可能具备特定的业务特征,也有可能单纯是硬件、网络的问题造成,最终表现在系统P99或者P999的延时出现了突刺,如果是面向C端的场景,也会向用户报出一些系统错误,造成用户体验的下降。
一种简易的解决方案是,针对关键的下游节点增加超时控制。在特定时间内,如果下游到期还未返回,不再暴露系统级错误,而是做特殊化处理,比如返回「处理中」状态。
Go实现方案
设计一个方法,使用闭包,传入时间和执行的任务,如果任务执行完未到时间,则直接返回,否则通知调用者超时。
为了保证代码简介和使用简单,我们仅定义一个Wrapper方法,方法定义如下
func TimeoutControlWrapper(duration time.Duration, fn func()) (timeout bool)
官方包time有一个After方法,可以在指定时间内,返回一个channel,基于此来判断是否超时。
另外,在Wrapper方法里异步化执行目标方法,执行完成后写入一个finish信号通知。
同时监听这两个channel,判断是否超时,代码如下
func TimeoutControlWrapper(duration time.Duration, fn func()) (timeout bool) {
finish := make(chan struct{})
go func() {
fn()
finish <- struct{}{}
}()
select {
case <-finish:
return false
case <-time.After(duration):
return true
}
}
结合场景,假设系统会调用一个支付系统的接口,接口本身延时不稳定,因此我们套用TimeoutControlWrapper
func CallPaymentSystem(param PayParam) (payStatus PayStatus) {
var payStatus PayStatus
timeout := TimeoutControlWrapper(time.Second, func() {
payStatus = PaymentSystemRPC.Pay(param)
})
if timeout {
warn() // WARN告警
return PROCESSING // 返回处理中
}
return payStatus
}
延伸思考
上述通过一个简单的Wrapper,来实现调用下游时的超时控制。但在引入的场景里,实现上是不严谨的。哪怕不增加超时控制,我们也无法确认请求是否真实到达了下游系统,这本质上是一个分布式事务的问题,需要我们设计更加健全的系统能力保证一致性,比如通过消息的方式、补偿机制、增加对账系统。
来源:juejin.cn/post/7524615282490441779
调试 WebView 旧资源缓存问题:一次从偶发到复现的实战经历
移动端 WebView 与浏览器最大的差异之一就是缓存机制:浏览器支持 DevTools 清理缓存、更新资源非常便利;而 WebView 在 App 中受系统 WebView 组件和应用缓存策略影响,经常会出现资源更新后,部分用户仍加载老版本 JS/CSS,引发奇怪的线上问题。
这类问题难点在于:不是所有用户都能复现,只有特定设备/网络环境/升级路径才会触发。以下是我们在一个活动页迭代中解决用户加载到老版本脚本的问题记录。
背景:活动页面更新后部分用户功能异常
活动页面上线后,我们修复了一个按钮点击无效的 bug,并发布了新 JS 资源。大部分用户恢复正常,但个别用户仍反馈点击无响应。
通过埋点数据统计,这类异常只占总 PV 的 1~2%,但因影响实际参与,必须解决。
第一步:判断用户是否加载到新资源
通过后端接口返回的页面版本号,我们在埋点中发现异常用户请求的是最新页面 HTML,但 HTML 中引用的 JS 文件版本却是旧文件。
我们用 Charles 配合 WebDebugX,在问题设备上连接调试,确认请求路径:
https://cdn.example.com/activity/v1.2.0/main.js
服务器早已上线 v1.3.0 文件,但部分设备仍强制加载 v1.2.0。这说明浏览器或 WebView 从缓存中读取了过期资源。
第二步:复现问题与验证缓存机制
通过 Charles 的 Map Local 功能,我们在真机上强制模拟返回旧版 main.js,验证页面表现是否与用户反馈一致。结果按钮再次失效,证明旧资源是问题根源。
然后用 WebDebugX 查看资源请求的响应 header,确认服务器已正确返回 Cache-Control:
Cache-Control: no-cache, max-age=0
理论上应强制重新拉取最新资源,但部分 Android WebView 未执行 no-cache,而是优先使用 local cache。
第三步:排查 WebView 缓存策略差异
我们协助移动端团队通过 Logcat 查看 WebView 请求日志,发现部分机型仍启用了 LOAD_DEFAULT 缓存模式,该模式下只要缓存有效期内,就会使用本地缓存资源,即便服务器指示不缓存也无法生效。
而大部分新系统使用了 LOAD_NO_CACHE 或 LOAD_CACHE_ELSE_NETWORK,能更好地遵循服务器缓存头。
第四步:修复方案设计
针对缓存策略问题,我们制定了双向修复方案:
短期前端方案
- 在资源引用 URL 中增加强制更新参数:
<script src="https://cdn.example.com/activity/main.js?v=20240601"></script>
- 每次版本发布更新
v参数,确保请求路径变化,从而绕开缓存。
中期后端方案
- 通过 CDN 配置给静态文件加上不可缓存策略,确保 CDN 节点不会继续提供过期资源。
长期客户端方案
- 移动端团队将 WebView 缓存策略统一改为
LOAD_NO_CACHE模式,彻底解决旧资源被缓存的问题。
第五步:验证全流程有效性
修复完成后,我们用以下方法进行多角度验证:
- 使用 Charles 观察请求地址是否携带新版本参数;
- 在 WebDebugX 中查看页面是否加载了最新资源;
- 在 QA 部门用多台低端机和慢网环境回归测试,模拟网络断开重连、App 冷启动后资源拉取表现;
- 监控埋点数据中页面版本和资源版本是否完全一致,确认没有用户再加载到老资源。
最终确认异常用户比例下降到 0%。
工具与协作流程
此次缓存问题排查中,我们的调试和分工是:
| 工具 | 用途 | 使用人 |
|---|---|---|
| WebDebugX | 查看资源加载路径、响应 header | 前端 / QA |
| Charles | 模拟缓存场景、观察真实请求 | 前端 |
| Logcat | 验证 WebView 缓存模式 | 移动端 |
| Vysor | 复现低端设备表现、录制操作过程 | QA |
总结:缓存问题的解决要从端到端出发
缓存问题不是“前端清理一下”就能解决,它涉及:
浏览器/WebView 端缓存策略;
后端或 CDN 返回的缓存头;
前端 URL 版本控制;
不同系统/厂商 WebView 兼容性。
要彻底消除老资源顽固缓存,必须让服务器、前端、客户端配置形成闭环。
调试工具(WebDebugX、Charles、Logcat)可以帮助我们还原资源加载链条,但核心是对缓存机制的整体认知与各端的配合。
来源:juejin.cn/post/7522187483762966579
用 Tauri + FFmpeg + Whisper.cpp 从零打造本地字幕生成器
背景:
最近开始尝试做自媒体,录点视频。刚开始就遇到了字幕的问题,于是想先搞个字幕生成工具(为了这点醋才包的这顿饺子😄):SubGen。
这个工具用 Tauri + Rust 做外壳,把 FFmpeg 和 Whisper.cpp 集成进去,能一键把视频转成 SRT 字幕。
这篇文章记录下笔者做这个工具的过程,也分享下用到的核心组件和代码结构。
架构设计
SubGen 采用分层架构,核心组件的交互关系如下:
┌─────────────┐ ┌──────────────┐
│ React UI │ │ Rust Core │
│ (TypeScript)│ <----> │ (Tauri API) │
└─────────────┘ └─────┬────────┘
│
┌─────────────┴───────────────┐
│ │
┌────▼────┐ ┌────▼────┐
│ FFmpeg │ │Whisper │
│ 提取音频 │ │ 离线识别 │
└─────────┘ └─────────┘
为什么用 Tauri?
最开始笔者也考虑过 Electron,但它打包太大了(动辄 100MB 起步),而且资源占用高。后来发现 Tauri,它用 Rust 做后端,前端还是用 React 或者任意 Web 技术,这样:
- 打包后体积很小(十几 MB)。
- 跨平台方便(Windows / macOS / Linux)。
- Rust 调用本地二进制(FFmpeg 和 Whisper)非常顺手。
笔者主要是用 React + TypeScript 写了一个简单的 UI,用户选视频、点按钮,剩下的活就交给 Rust。
FFmpeg:用它来“扒”音频
FFmpeg 是老牌的音视频处理工具了,笔者直接内置了一个编译好的 ffmpeg.exe/ffmpeg 到资源目录,调用它来:
- 从视频里抽出音频。
- 统一格式(16kHz,单声道 WAV),让 Whisper 可以直接处理。
Rust 这边的调用很简单:
use std::process::Command;
Command::new("resources/ffmpeg")
.args(["-i", &video_path, "-ar", "16000", "-ac", "1", "audio.wav"])
.status()
.expect("FFmpeg 执行失败");
这样一行命令就能把视频转成标准 WAV。
Whisper.cpp:核心的离线识别
笔者选的是 Whisper.cpp,因为它比 Python 版 Whisper 更轻量,直接编译一个 whisper-cli 就能用,不需要装乱七八糟的依赖。
更重要的一点是支持CPU运行,默认4个线程,即使用 ggml-large-v3 也可以跑出来结果,只是稍微慢点。这对于没有好的显卡的童鞋很有用!
调用命令大概是这样:
whisper-cli -m ggml-small.bin -f audio.wav -osrt -otxt
最后会输出一个 output.srt,直接能用。
Rust 里调用也是 Command::new() 一把梭:
Command::new("resources/whisper-cli")
.args(["-m", "resources/models/ggml-small.bin", "-f", "audio.wav", "-l", "zh", "--output-srt"])
.status()
.expect("Whisper 执行失败");
代码结构和流程
笔者的项目大概是这样分层的:
subgen/
├── src/ # 前端 React + TypeScript
│ └── main.tsx # UI入口
├── src-tauri/ # Tauri + Rust
│ ├── commands.rs # Rust命令逻辑
│ ├── resources/ # ffmpeg、whisper二进制、模型文件
│ └── main.rs # 程序入口
前端用 @tauri-apps/api 的 invoke 调 Rust:
import { invoke } from '@tauri-apps/api';
async function handleGenerate(videoPath: string) {
const result = await invoke<string>('extract_subtitles', { videoPath });
console.log('字幕生成完成:', result);
}
Rust 后端的核心命令:
#[tauri::command]
fn extract_subtitles(video_path: String) -> Result<String, String> {
// 1. 调 FFmpeg
// 2. 调 Whisper.cpp
// 3. 返回 SRT 路径
Ok("output.srt".to_string())
}
用下来的感受
整个工具现在已经能做到“拖进视频 → 等几十秒 → 出字幕”这种体验了。
几个感受:
- Tauri 真香:比 Electron 清爽太多,Rust 后端很适合做这些底层调用。
- FFmpeg 是万能的,直接抽音频,性能还不错。
- Whisper.cpp 虽然 CPU 跑慢点,但好在准确率挺高,还不用联网。
后续想做的事
- 支持批量处理视频。
- 集成一个简单的字幕编辑功能。
- 尝试 GPU 加速 Whisper(Metal / Vulkan)。
截图
主界面:
生成的 SRT:

如果你也想做个自己的字幕工具,可以直接参考 SubGen 的架构,自己改改就能用。
代码已开源:github.com/byteroycai/…
来源:juejin.cn/post/7528457291697012774
jwt,过滤器,拦截器用法和介绍
jwt,过滤器,拦截器介绍
JWT令牌
JWT介绍
JWT全称 JSON Web Token 。
jwt可以将原始的json数据格式进行安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT全称 JSON Web Token 。
jwt可以将原始的json数据格式进行安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT的组成
JWT令牌由三个部分组成,三个部分之间使用英文的点来分割
- 第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{"alg":"HS256","type":"JWT"}
- 第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{"id":"1","username":"Tom"}
- 第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
JWT令牌由三个部分组成,三个部分之间使用英文的点来分割
- 第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{"alg":"HS256","type":"JWT"}
- 第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{"id":"1","username":"Tom"}
- 第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
JWT将原始的JSON格式数据转变为字符串的方式:
- 其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
- Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
- 需要注意的是Base64是编码方式,而不是加密方式。
- 其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
- Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
- 需要注意的是Base64是编码方式,而不是加密方式。
生成和校验
1.要想使用JWT令牌,需要先引入JWT的依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验。
2.生成JWT代码实现:
@Test
public void testGenJwt() {
Map<String, Object> claims = new HashMap<>();
claims.put("id", 10);
claims.put("username", "itheima");
String jwt = Jwts.builder().signWith(SignatureAlgorithm.HS256, "aXRjYXN0")
.addClaims(claims)
.setExpiration(new Date(System.currentTimeMillis() + 12 * 3600 * 1000))
.compact();
System.out.println(jwt);
}
- 实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
@Test
public void testParseJwt() {
Claims claims = Jwts.parser().setSigningKey("aXRjYXN0")
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTcwMTkwOTAxNX0.N-MD6DmoeIIY5lB5z73UFLN9u7veppx1K5_N_jS9Yko")
.getBody();
System.out.println(claims);
}
1.要想使用JWT令牌,需要先引入JWT的依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验。
2.生成JWT代码实现:
@Test
public void testGenJwt() {
Map<String, Object> claims = new HashMap<>();
claims.put("id", 10);
claims.put("username", "itheima");
String jwt = Jwts.builder().signWith(SignatureAlgorithm.HS256, "aXRjYXN0")
.addClaims(claims)
.setExpiration(new Date(System.currentTimeMillis() + 12 * 3600 * 1000))
.compact();
System.out.println(jwt);
}
- 实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
@Test
public void testParseJwt() {
Claims claims = Jwts.parser().setSigningKey("aXRjYXN0")
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTcwMTkwOTAxNX0.N-MD6DmoeIIY5lB5z73UFLN9u7veppx1K5_N_jS9Yko")
.getBody();
System.out.println(claims);
}
篡改令牌中的任何一个字符,在对令牌进行解析时都会报错,所以JWT令牌是非常安全可靠的。
JWT令牌过期后,令牌就失效了,解析的为非法令牌。
过滤器Filter
Filter介绍
- Filter表示过滤器,是 JavaWeb三大组件(Servlet、Filter、Listener)之一。
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等。
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
定义过滤器
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
配置过滤器
在定义完Filter之后,Filter其实并不会生效,还需要完成Filter的配置,Filter的配置非常简单,只需要在Filter类上添加一个注解:@WebFilter,并指定属性urlPatterns,通过这个属性指定过滤器要拦截哪些请求
@WebFilter(urlPatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
在Filter类上面加了@WebFilter注解之后,还需要在启动类上面加上一个注解@ServletComponentScan,通过这个@ServletComponentScan注解来开启SpringBoot项目对于Servlet组件的支持。
@ServletComponentScan //开启对Servlet组件的支持
@SpringBootApplication
public class TliasManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasManagementApplication.class, args);
}
}
在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.doFilter(request, response);
过滤器的执行流程
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用 FilterChain对象当中的doFilter()方法,在调用doFilter()这个方法之前所编写的代码属于放行之前的逻辑。
测试代码:
@WebFilter(urlPatterns = "/*")
public class DemoFilter implements Filter {
@Override //初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("DemoFilter 放行前逻辑.....");
//放行请求
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("DemoFilter 放行后逻辑.....");
}
@Override //销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}
过滤器的拦截路径配置
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
测试代码:
@WebFilter(urlPatterns = "/login") //拦截/login具体路径
public class DemoFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("DemoFilter 放行前逻辑.....");
//放行请求
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("DemoFilter 放行后逻辑.....");
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
}
@Override
public void destroy() {
Filter.super.destroy();
}
}
过滤器链
过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
过滤器链上过滤器的执行顺序:注解配置的Filter,优先级是按照过滤器类名(字符串)的自然排序。 比如:
- AbcFilter
- DemoFilter
这两个过滤器来说,AbcFilter 会先执行,DemoFilter会后执行。
拦截器Interceptor
- 拦截器是一种动态拦截方法调用的机制,类似于过滤器。
- 拦截器是Spring框架中提供的,用来动态拦截控制器方法的执行。
- 拦截器的作用:拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
自定义拦截器
实现HandlerInterceptor接口,并重写其所有方法
//自定义拦截器
@Component
public class DemoInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}
- preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
- postHandle方法:目标资源方法执行后执行
- afterCompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器
在 com.itheima下创建一个包,然后创建一个配置类 WebConfig, 实现 WebMvcConfigurer 接口,并重写 addInterceptors 方法
@Configuration
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
@Autowired
private DemoInterceptor demoInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(demoInterceptor).addPathPatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}
拦截器的拦截路径配置
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过addPathPatterns("要拦截路径")方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。
@Configuration
public class WebConfig implements WebMvcConfigurer {
//拦截器对象
@Autowired
private DemoInterceptor demoInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(demoInterceptor)
.addPathPatterns("/**")//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
.excludePathPatterns("/login");//设置不拦截的请求路径
}
}
在拦截器中除了可以设置/**拦截所有资源外,还有一些常见拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
拦截器的执行流程
- 当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于我们当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问我们所定义的controller当中的接口方法。
- Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
- 当我们定义了拦截器后,会在执行Controller的方法之前,请求被拦截器拦截住。执行
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。 - 在controller当中的方法执行完毕之后,再回过来执行
postHandle()这个方法以及afterCompletion() 方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。postHandle()这个方法以及afterCompletion() 方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。过滤器和拦截器之间的区别:
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
作者:丧心病狂汤姆猫
来源:juejin.cn/post/7527869985345339392
来源:juejin.cn/post/7527869985345339392
从HTTP到HTTPS
当你在浏览器里输入 http://www.example.com 并按下回车,看似平平无奇的一次访问,其实暗藏着 SSL/TLS 的三次握手、对称与非对称加密的轮番上阵、CA 证书的“身份核验”以及防中间人攻击的多重机关。
一、SSL、TLS、HTTPS 到底是什么关系?
- SSL(Secure Sockets Layer):早期网景公司设计的加密协议,1999 年后停止更新。
- TLS(Transport Layer Security):SSL 的直系升级版,目前主流版本为 TLS 1.2/1.3。
- HTTPS:把 HTTP 报文塞进 TLS 的“安全信封”里,再交给 TCP 传输。简而言之,HTTPS = HTTP + TLS/SSL。
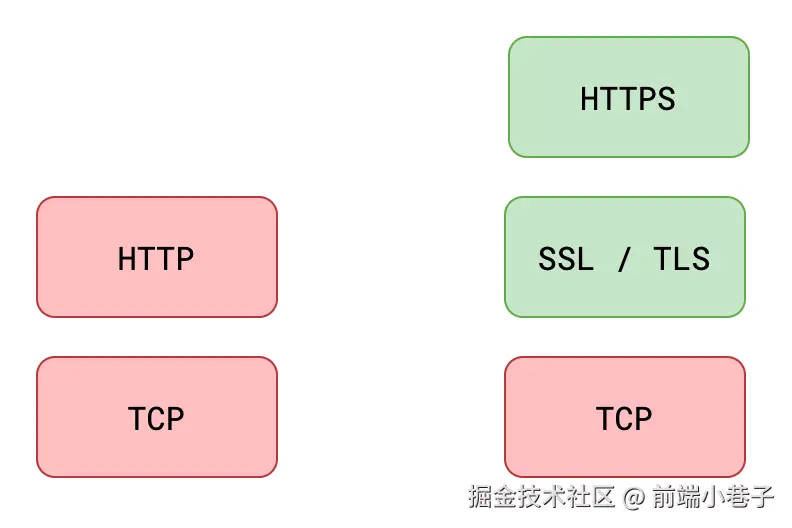
二、HTTPS 握手
- ClientHello
浏览器把支持的加密套件、随机数 A、TLS 版本号一起发给服务器。 - ServerHello + 证书
服务器挑一套加密算法,返回随机数 B,并附上自己的数字证书(含公钥)。 - 验证证书 + 生成会话密钥
浏览器先给证书“验明正身”——颁发机构是否可信、证书是否被吊销、域名是否匹配。
验证通过后,浏览器生成随机数 C(Pre-Master-Secret),用服务器证书里的公钥加密后发送。双方根据 A、B、C 算出同一把对称密钥。 - Finished
双方都用这把对称密钥加密一条“Finished”消息互发,握手完成。之后的所有 HTTP 数据都用这把对称密钥加解密,速度快、强度高。
三、为什么必须有 CA?
没有 CA,任何人都可以伪造公钥,中间人攻击将防不胜防。CA 通过可信第三方背书,把“公钥属于谁”这件事写死在证书里,浏览器才能放心地相信“这就是真正的服务器”。
四、证书到底怎么防伪?
证书 = 域名 + 公钥 + 有效期 + CA 数字签名。
CA(Certificate Authority)用自己的私钥对整个证书做哈希签名。浏览器内置 CA 公钥,可解密签名并对比哈希值,一旦被篡改就立即报警。
没有 CA 签名的自签证书?浏览器会毫不留情地显示“红色警告”。
五、对称与非对称加密的分工
- 非对称加密(RSA/ECC):只在握手阶段用一次,解决“如何安全地交换对称密钥”。
- 对称加密(AES/ChaCha20):握手完成后,所有 HTTP 报文都用对称密钥加解密,性能高、延迟低。
一句话:非对称加密“送钥匙”,对称加密“锁大门”。
六、中间人攻击的两张面孔
- SSL 劫持
攻击者伪造证书、偷梁换柱。浏览器会提示证书错误,但不少用户习惯性点击“继续访问”,于是流量被窃听。 - SSL 剥离
攻击者把用户的 HTTPS 请求降级成 HTTP,服务器以为在加密,客户端却在明文裸奔。HSTS(HTTP Strict Transport Security)能强制浏览器只走 HTTPS,遏制这种降级。
总结
- 证书是身-份-证,CA 是公安局。
- 非对称握手送钥匙,对称加密跑数据。
- 没有 CA 的 HTTPS,就像没有钢印的合同——谁都能伪造。
下次当你在地址栏看到那把绿色小锁时,背后是一场涉及四次握手、两把密钥、一张证书和全球信任链的加密大戏。
来源:juejin.cn/post/7527578862054899754
我在 pre 直接修改 bug,被领导批评了
大家好,我是石小石!
背景简介
前几天项目在pre回归时,测试发现一个bug,经过排查,我发现漏写了一行代码。

由于此时test、dev的代码已经进入新的迭代开发了,因此为了图方便,我直接在pre上修改了代码,并直接推送发布。
没想到,随后就收到了来自领导的批评:为什么不拉个hotfix分支修复合并?你直接修改代码会让代码难以追踪、回滚,以后上线全是隐患!
确实,即使只有一行代码的修改,也不应该直接在pre直接更改,我深刻的反思了自己。
分支管理与协作流程
一般来说,一个项目从开发到上线共包含四个环境。
| 环境 | 分支名示例 | 作用说明 |
|---|---|---|
| 开发环境 | dev | 日常开发,集成各功能分支的代码,允许不稳定,便于测试和联调 |
| 测试环境 | test | 提供给 QA 团队回归测试,要求相对稳定;一般从 dev合并而来 |
| 预发布环境 | pre | 模拟线上环境,临上线前验证,接近正式发布版本,禁止频繁变更 |
| 生产环境 | prod / main | 最终上线版本,代码必须安全稳定、经过充分测试 |
以我们公司为例,大致的协作规范流程如下:
1、dev功能开发
由于功能是几个人共同开发,每个人开发前都需要从 dev 分支拉出 feature/xxx 分支;本地开发完成后提合并回 dev;
- 提测
当功能开发完成dev 稳定后合并进 test,然后QA 回归测试环境;如发现问题,在 hotfix/xxx 修复后继续合并回 test(实际开发中,为了简化开发流程,大家都是直接在test修改bug)。
3. 预发布验证
测试通过,临近上线时,会从 test 合并进 pre。pre 仅用于业务验证、客户预览,不会在开发新功能;遇到bug的话,必须基于pre拉一个hotfix分支,修复完通过验证后,在合并回pre。
4. 正式上线
从 pre 合并到 prod ,并部署上线;
为什么不能直接在pre修改bug
pre 是预发布环境分支,作用是:模拟线上环境,确保代码上线前是可靠的,它应只接收已审核通过的改动,而不是“随便修的东西”。
如果直接在 pre 上修改,会出现很多意料之外的问题。如:
- 代码来源不清晰,审查流程被绕过
- 多人协作下容易引发冲突和覆盖(bug重现)
这样时间久了我们根本不知道哪个 bug 是从哪冒出来的,代码就会变得难以维护和溯源。
因此,基于pre拉一个hotfix/xxx 分支是团队开发的规范流程:
- 创建热修分支(hotfix 分支)
从 pre 分支上拉一个新的临时分支,命名建议规范些,如:
git checkout pre
git pull origin pre # 确保是最新代码
git checkout -b hotfix/fix-button-not-working
- 2在 hotfix 分支中修复 bug
进行代码修改、调试、测试。
- 创建合并请求
bug修复且通过qa验证后,我们就可以合并至pre等待审核。
使用hotfix,大家一看到这个分支名字,大家就知道这是线上急修的问题,容易跟踪、回溯和管理。你直接在 pre 改,其他人甚至都不知道发生了 bug。
总结
通过本文,大家应该也进一步了解pre环境的bug处理规范,如果你还觉得小问题在pre直接修改问题不大,可以看看这个示例:
你是一个信誉良好的企业老板,你的样品准备提交客户的时候突然发现了问题。你正常的流程应该是:
- 回原材料工厂排查修理
- 重新打样
- 提交新样品
- 送给客户
除非你是黑心老板,样品有问题直接凑合修一下直接给客户。
来源:juejin.cn/post/7501992214283370507
时间设置的是23点59分59秒,数据库却存的是第二天00:00:00
问题描述
昨天下班的时候,运营反馈了一个问题,明明设置的是两天后解封,为什么提示却是三天后呢。
比如今天(6.16)被拉入黑名单了,用户报名会提示 “6.19号恢复报名”,但是现在却提示6月20号才能报名,经过排查发现,就是解封的时间被多加了 1s 中,本来应该是存2025-06-18 23:59:59,但是数据库却是2025-06-19 00:00:00。
看了数据库有接近一半的数据是正确的,有一半的数据是第二天0晨(百思不得其解啊🤣)
代码逻辑实现:
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
❓看到上面的代码,有没有大佬已经发现问题了。确实上面的代码存在问题
昨天下班的时候,运营反馈了一个问题,明明设置的是两天后解封,为什么提示却是三天后呢。
比如今天(6.16)被拉入黑名单了,用户报名会提示 “6.19号恢复报名”,但是现在却提示6月20号才能报名,经过排查发现,就是解封的时间被多加了 1s 中,本来应该是存2025-06-18 23:59:59,但是数据库却是2025-06-19 00:00:00。
看了数据库有接近一半的数据是正确的,有一半的数据是第二天0晨(百思不得其解啊🤣)
代码逻辑实现:
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
❓看到上面的代码,有没有大佬已经发现问题了。确实上面的代码存在问题
解决过程
排查思路
一、排除代码问题
1.确认了项目中所有设置DeblockTime的地方 只有1出。排除了代码逻辑问题,被其他代码覆盖问题;
1.确认了项目中所有设置DeblockTime的地方 只有1出。排除了代码逻辑问题,被其他代码覆盖问题;
二、问问AI:
LocalDateTime futureTime = currentTime.plus(oaConfigActivityBlacklist.getBlockDay(), ChronoUnit.DAYS);
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
Date date = Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant());
这种写法能保证最后的date 的时分秒为 23时59分59秒么?
ai的答案如下 :
LocalDateTime futureTime = currentTime.plus(oaConfigActivityBlacklist.getBlockDay(), ChronoUnit.DAYS);
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
Date date = Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant());
这种写法能保证最后的date 的时分秒为 23时59分59秒么?
ai的答案如下 :
1. 夏令时(DST)影响
- 场景:若时区在目标日期存在夏令时调整(如时钟回拨或前拨),可能导致时间偏差。
- 示例:
- 假设系统时区为
Europe/Paris,2023 年 10 月 29 日凌晨 3 点时钟回拨到 2 点。 - 若
futureTime 是该日,设置 23:59:59 后,转换为 UTC 时可能变为 21:59:59Z 或 22:59:59Z,取决于时钟调整规则。
- 场景:若时区在目标日期存在夏令时调整(如时钟回拨或前拨),可能导致时间偏差。
- 示例:
- 假设系统时区为
Europe/Paris,2023 年 10 月 29 日凌晨 3 点时钟回拨到 2 点。 - 若
futureTime是该日,设置23:59:59后,转换为 UTC 时可能变为21:59:59Z或22:59:59Z,取决于时钟调整规则。
- 假设系统时区为
2. 时区转换问题
- 场景:若
currentTime 是其他时区的时间(如 UTC),直接转换可能导致时间偏移。 - 示例:
- 若
currentTime 是 UTC 时间 2023-10-01T16:00:00Z,系统时区为 Asia/Shanghai(UTC+8)。 - 添加 1 天后得到
2023-10-02T16:00:00Z,设置为 23:59:59 后转换为 Date,实际对应 UTC 时间 2023-10-02T15:59:59Z。
看了数据的时间分布,任何时间点 都存在 23:59:59 和 00:00:00的情况,就算创建时间相差几分钟的情况下,都存在这两种数据。
- 场景:若
currentTime是其他时区的时间(如 UTC),直接转换可能导致时间偏移。 - 示例:
- 若
currentTime是 UTC 时间2023-10-01T16:00:00Z,系统时区为Asia/Shanghai(UTC+8)。 - 添加 1 天后得到
2023-10-02T16:00:00Z,设置为23:59:59后转换为Date,实际对应 UTC 时间2023-10-02T15:59:59Z。
- 若
看了数据的时间分布,任何时间点 都存在
23:59:59和00:00:00的情况,就算创建时间相差几分钟的情况下,都存在这两种数据。
三、批量插入数据测试
看看能不能复现这个问题,会不会插入时候精度等其他问题:
for (int i = 0; i < 100; i++) {
Thread.sleep(100);
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊 LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
}
果然还真复现了,有一半的数据是2025-06-19 23:59:59 有一半的数据是2025-06-20 00:00:00
看看能不能复现这个问题,会不会插入时候精度等其他问题:
for (int i = 0; i < 100; i++) {
Thread.sleep(100);
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊 LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
}
果然还真复现了,有一半的数据是2025-06-19 23:59:59 有一半的数据是2025-06-20 00:00:00
定位问题
通过demo的复现,可以确认是在存数据库的时候出了问题。 因为Date的精度是控制在毫秒,pgsql 中TimeStamp 的精度用的默认值,精确到秒,所以在插入的时候Date的毫秒部分大于等于500的时候就会加1秒处理。入库之后就变成了第二天的00:00:00呢
通过demo的复现,可以确认是在存数据库的时候出了问题。 因为Date的精度是控制在毫秒,pgsql 中TimeStamp 的精度用的默认值,精确到秒,所以在插入的时候Date的毫秒部分大于等于500的时候就会加1秒处理。入库之后就变成了第二天的00:00:00呢
解决方案
要么将java对象的时间精度和 数据库的精度保持一致,要么就将java对象多余的精度置为0,解决方案如下:
- 方案1:代码中清空秒后面的数据
修改前: futureTime.withHour(23).withMinute(59).withSecond(59);
修改后: futureTime.withHour(23).withMinute(59).withSecond(59).withNano(0); - 方案2:调整数据库TimeStamp精度不小于java(date)对象的精度
修改前: 
修改后: 
要么将java对象的时间精度和 数据库的精度保持一致,要么就将java对象多余的精度置为0,解决方案如下:
- 方案1:代码中清空秒后面的数据
修改前:futureTime.withHour(23).withMinute(59).withSecond(59);
修改后:futureTime.withHour(23).withMinute(59).withSecond(59).withNano(0); - 方案2:调整数据库TimeStamp精度不小于java(date)对象的精度
修改前:
修改后:
知识扩展
1. Date 和 LocalDateTime
特性 java.util.Date (Java 1.0)java.time.LocalDateTime (Java 8+)精度 毫秒级(1/1000 秒) 纳秒级(1/1,000,000,000 秒) 包路径 java.util.Datejava.time.LocalDateTime可变性 可变(修改会影响原对象) 不可变(所有操作返回新对象) 时区感知 不存储时区,但内部时间戳基于 UTC 无时区,仅表示本地日期和时间
| 特性 | java.util.Date (Java 1.0) | java.time.LocalDateTime (Java 8+) |
|---|---|---|
| 精度 | 毫秒级(1/1000 秒) | 纳秒级(1/1,000,000,000 秒) |
| 包路径 | java.util.Date | java.time.LocalDateTime |
| 可变性 | 可变(修改会影响原对象) | 不可变(所有操作返回新对象) |
| 时区感知 | 不存储时区,但内部时间戳基于 UTC | 无时区,仅表示本地日期和时间 |
2. mysql 中的timestamp 和 datetime
特性 DATETIMETIMESTAMP存储范围 1000-01-01 00:00:00 到 9999-12-31 23:59:591970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC精度 5.6.4 版本后支持 fractional seconds(如DATETIME(6))最高精度微妙,设置0的话就表示精确到秒 同上(如TIMESTAMP(6)) 存储空间 8 字节 4 字节(时间戳范围小) 时区感知 不存储时区信息,直接存储字面量 自动转换时区:存储时转换为 UTC,读取时转换为会话时区 默认值 无默认值(除非显式设置DEFAULT) 支持DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP 自动更新 不支持 支持自动更新为当前时间(ON UPDATE)
| 特性 | DATETIME | TIMESTAMP |
|---|---|---|
| 存储范围 | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 | 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC |
| 精度 | 5.6.4 版本后支持 fractional seconds(如DATETIME(6))最高精度微妙,设置0的话就表示精确到秒 | 同上(如TIMESTAMP(6)) |
| 存储空间 | 8 字节 | 4 字节(时间戳范围小) |
| 时区感知 | 不存储时区信息,直接存储字面量 | 自动转换时区:存储时转换为 UTC,读取时转换为会话时区 |
| 默认值 | 无默认值(除非显式设置DEFAULT) | 支持DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP |
| 自动更新 | 不支持 | 支持自动更新为当前时间(ON UPDATE) |
3.适用场景建议
- java 中尽量用
LocalDateTime吧,毕竟LocalDateTime 主要就是用来取代Date对象的,区别如下
场景类型 java.util.Date(旧 API)java.time.LocalDateTime(新 API)简单本地时间记录 可使用,但 API 繁琐(需配合Calendar) 推荐使用(无需时区,代码简洁) 带时区的时间处理 不推荐(时区处理易混淆) 推荐使用ZonedDateTime或OffsetDateTime 多线程环境 不推荐(非线程安全) 推荐(不可变设计,线程安全) 数据库交互(JDBC 4.2+) 需转换为java.sql.Timestamp 直接支持(如pstmt.setObject(1, localDateTime)) 时间计算与格式化 需依赖SimpleDateFormat(非线程安全) 推荐(DateTimeFormatter线程安全) 高精度需求(纳秒级) 仅支持毫秒级 支持纳秒级(1/1,000,000,000 秒
- 数据库到底是用
timestamp 还是 datetime呢,跨国业务用timestamp 其他场景建议用datetime:
- java 中尽量用
LocalDateTime吧,毕竟LocalDateTime主要就是用来取代Date对象的,区别如下
| 场景类型 | java.util.Date(旧 API) | java.time.LocalDateTime(新 API) |
|---|---|---|
| 简单本地时间记录 | 可使用,但 API 繁琐(需配合Calendar) | 推荐使用(无需时区,代码简洁) |
| 带时区的时间处理 | 不推荐(时区处理易混淆) | 推荐使用ZonedDateTime或OffsetDateTime |
| 多线程环境 | 不推荐(非线程安全) | 推荐(不可变设计,线程安全) |
| 数据库交互(JDBC 4.2+) | 需转换为java.sql.Timestamp | 直接支持(如pstmt.setObject(1, localDateTime)) |
| 时间计算与格式化 | 需依赖SimpleDateFormat(非线程安全) | 推荐(DateTimeFormatter线程安全) |
| 高精度需求(纳秒级) | 仅支持毫秒级 | 支持纳秒级(1/1,000,000,000 秒 |
- 数据库到底是用
timestamp还是datetime呢,跨国业务用timestamp 其他场景建议用datetime:
| 场景 | 推荐类型 | 原因 |
|---|---|---|
| 存储历史事件时间(如订单创建时间) | DATETIME | 不依赖时区,固定记录用户输入的时间 |
| 记录服务器本地时间(如定时任务执行时间) | DATETIME | 无需时区转换,直接反映服务器时间 |
| 多时区应用(如跨国业务) | TIMESTAMP | 自动处理时区转换,确保数据一致性(如登录时间) |
| 需要自动更新时间戳 | TIMESTAMP | 支持ON UPDATE CURRENT_TIMESTAMP特性 |
| 存储范围超过 2038 年 | DATETIME | TIMESTAMP仅支持到 【2038】 年 |
| 微秒级精度需求 | DATETIME(6)或TIMESTAMP(6) | 根据是否需要时区转换选择 |
总结
本文主要讲述了在处理用户解封时间时,因 Java 代码中时间精度与数据库TIMESTAMP类型精度不一致,导致约一半数据存储时间比预期多 1 秒的问题。通过排查与测试,定位问题并给出了 Java 对象时间精度和调整数据库精度两种解决方案,同时对比了 Java 和数据库中多种时间类型的特性及适用场景 。
来源:juejin.cn/post/7517119131856191500
Postgres 杀疯了,堪称 “六边形战士”,还要 Redis 干啥?
我们需要谈谈困扰我几个月的事情。我一直看到独立黑客和初创公司创始人疯狂地拼凑各种技术栈,用 Redis 做缓存,用 RabbitMQ 做队列,用 Elasticsearch 做搜索,还有用 MongoDB……为什么?
我也犯过这种错误。当我开始构建UserJot(我的反馈和路线图工具)时,我的第一反应是规划一个“合适的”架构,为所有功能提供独立的服务。然后我停下来问自己:如果我把所有功能都用 Postgres 来做会怎么样?
事实证明,房间里有一头大象,但没人愿意承认:
| Postgres 几乎可以做到这一切。 |
|---|
而且它的效果比你想象的还要好。
“Postgres 无法扩展”的谬论正在让你损失金钱?
让我猜猜——有人告诉你,Postgres“只是一个关系数据库”,需要专门的工具来完成专门的工作。我以前也是这么想的,直到我发现 Instagram 可以在单个 Postgres 实例上扩展到 1400 万用户。Discord 处理数十亿条消息。Notion 的整个产品都是基于 Postgres 构建的。
但问题是:他们不再像 2005 年那样使用 Postgres。
队列系统
别再为 Redis 和 RabbitMQ 付费了。Postgres 原生支持LISTEN/NOTIFY并且比大多数专用解决方案更好地处理作业队列:
-- Simple job queue in pure Postgres
CREATETABLE job_queue (
id SERIAL PRIMARY KEY,
job_type VARCHAR(50),
payload JSONB,
status VARCHAR(20) DEFAULT'pending',
created_at TIMESTAMPDEFAULT NOW(),
processed_at TIMESTAMP
);
-- ACID-compliant job processing
BEGIN;
UPDATE job_queue
SET status ='processing', processed_at = NOW()
WHERE id = (
SELECT id FROM job_queue
WHERE status ='pending'
ORDERBY created_at
FORUPDATESKIP LOCKED
LIMIT 1
)
RETURNING *;
COMMIT;
这让你无需任何额外的基础设施就能实现 Exactly-Once 的处理。不妨试试用 Redis 来实现,会让你很抓狂。
在 UserJot 中,我正是使用这种模式来处理反馈提交、发送通知和更新路线图项目。只需一次事务,即可保证一致性,无需消息代理的复杂性。
键值存储
Redis 在大多数平台上的最低价格为 20 美元/月。Postgres JSONB 已包含在您现有的数据库中,可以满足您的大部分需求:
-- Your Redis alternative
CREATETABLE kv_store (
key VARCHAR(255) PRIMARY KEY,
value JSONB,
expires_at TIMESTAMP
);
-- GIN index for blazing fast JSON queries
CREATE INDEX idx_kv_value ON kv_store USING GIN (value);
-- Query nested JSON faster than most NoSQL databases
SELECT*FROM kv_store
WHEREvalue @>'{"user_id": 12345}';
运算符@>是 Postgres 的秘密武器。它比大多数 NoSQL 查询更快,并且数据保持一致。
全文搜索
Elasticsearch 集群价格昂贵且复杂。Postgres 内置的全文搜索功能非常出色:
-- Add search to any table
ALTERTABLE posts ADDCOLUMN search_vector tsvector;
-- Auto-update search index
CREATEOR REPLACE FUNCTION update_search_vector()
RETURNStriggerAS $
BEGIN
NEW.search_vector := to_tsvector('english',
COALESCE(NEW.title, '') ||' '||
COALESCE(NEW.content, '')
);
RETURNNEW;
END;
$ LANGUAGE plpgsql;
-- Ranked search results
SELECT title, ts_rank(search_vector, query) as rank
FROM posts, to_tsquery('startup & postgres') query
WHERE search_vector @@ query
ORDERBY rank DESC;
这可以处理模糊匹配、词干提取和相关性排名。
对于 UserJot 的反馈搜索,此功能可让用户跨标题、描述和评论即时查找功能请求。无需 Elasticsearch 集群 - 只需使用 Postgres 即可发挥其优势。
实时功能
忘掉复杂的 WebSocket 基础架构吧。Postgres LISTEN/NOTIFY无需任何附加服务即可为您提供实时更新:
-- Notify clients of changes
CREATEOR REPLACE FUNCTION notify_changes()
RETURNStriggerAS $
BEGIN
PERFORM pg_notify('table_changes',
json_build_object(
'table', TG_TABLE_NAME,
'action', TG_OP,
'data', row_to_json(NEW)
)::text
);
RETURNNEW;
END;
$ LANGUAGE plpgsql;
您的应用程序会监听这些通知并向用户推送更新。无需 Redis 的发布/订阅机制。
“专业”工具的隐性成本
我们来算一下。一个典型的“现代”堆栈的成本是:
- Redis:20美元/月
- 消息队列:25美元/月
- 搜索服务:50美元/月
- 监控 3 项服务:30 美元/月
- 总计:每月 125 美元
但这还只是托管成本。真正的痛点在于:
运营开销:
- 三种不同的服务用于监控、更新和调试
- 不同的缩放模式和故障模式
- 需要维护多种配置
- 单独的备份和灾难恢复程序
- 每项服务的安全考虑因素不同
开发复杂性:
- 客户端库和连接模式
- 多个服务的部署
- 间数据不一致
- 的测试场景
- 的性能调优方法
如果您自行托管,请添加服务器管理、安全补丁以及当 Redis 决定消耗所有内存时不可避免的凌晨 3 点调试会话。
Postgres 使用您已经管理的单一服务来处理所有这些。
扩展的单一数据库
大多数人可能没有意识到:单个 Postgres 实例就能处理海量数据。我们指的是每天数百万笔交易、数 TB 的数据以及数千个并发连接。
真实世界的例子:
- Airbnb:单个 Postgres 集群处理数百万个预订
- Robinhood:数十亿笔金融交易
- GitLab:Postgres 上的整个 DevOps 平台
Postgres 的架构魅力非凡。它被设计成具备极佳的垂直扩展能力,而当你最终需要水平扩展时,它也有以下成熟的方案可供选择:
- 用于查询扩展的读取副本
- 大表分区
- 并发连接池
- 分布式设置的逻辑复制
大多数企业从未达到过这些限制。在处理数百万用户或复杂的分析工作负载之前,单个实例可能就足够了。
将此与管理所有以不同方式扩展的单独服务进行比较 - 您的 Redis 可能会耗尽内存,而您的消息队列则会遇到吞吐量问题,并且您的搜索服务需要完全不同的硬件。
从第一天起就停止过度设计
现代开发中最大的陷阱是架构式的“宇航员”。我们设计系统时,面对的是我们从未遇到过的问题,我们面对的是从未见过的流量,我们可能永远无法达到的规模。
过度设计循环:
- “我们可能有一天需要扩大规模”
- 添加 Redis、队列、微服务、多个数据库
- 花费数月时间调试集成问题
- 向 47 位用户推出
- 每月支付 200 美元购买可在 5 美元 VPS 上运行的基础设施
与此同时,您的竞争对手的发货速度更快,因为他们在需要分布式系统之前并没有管理它。
更好的方法:
- 从 Postgres 开始
- 监控实际的瓶颈,而不是想象的瓶颈
- 当达到实际极限时扩展特定组件
- 仅在解决实际问题时才增加复杂性
你的用户并不关心你的架构。他们关心的是你的产品是否有效,是否能解决他们的问题。
当你真正需要专用工具时
别误会我的意思——专用工具自有其用处。但你可能在以下情况之前不需要它们:
- 您每分钟处理 100,000 多个作业
- 您需要亚毫秒级的缓存响应
- 您正在对数 TB 的数据进行复杂的分析
- 您有数百万并发用户
- 您需要具有特定一致性要求的全局数据分布
如果您在公众号上阅读强哥这篇文章,那么您可能还没有到达那一步。
为什么这真的很重要
让我大吃一惊的是:Postgres 可以同时充当您的主数据库、缓存、队列、搜索引擎和实时系统。同时还能在所有方面保持 ACID 事务。
-- One transaction, multiple operations
BEGIN;
INSERT INTO users (email) VALUES ('user@example.com');
INSERT INTO job_queue (job_type, payload)
VALUES ('send_welcome_email', '{"user_id": 123}');
UPDATE kv_store SET value = '{"last_signup": "2024-01-15"}'
WHERE key = 'stats';
COMMIT;
尝试在 Redis、RabbitMQ 和 Elasticsearch 上执行此操作,不要哭泣。
无聊的技术却能获胜
Postgres 并不引人注目。它没有华丽的网站,也没有在 TikTok 上爆红。但几十年来,在其他数据库兴衰更迭之际,它一直默默地支撑着互联网。
选择简单、可靠且有效的技术是有道理的。
下一个项目的行动步骤
- 仅从 Postgres 开始- 抵制添加其他数据库的冲动
- 使用 JSONB 实现灵活性- 借助 SQL 的强大功能,您可以获得无架构的优势
- 在 Postgres 中实现队列——节省资金和复杂性
- 仅当达到实际极限时才添加专用工具- 而不是想象中的极限
我的真实经历
UserJot 的构建是这一理念的完美测试案例。它是一个反馈和路线图工具,需要:
- 提交反馈时实时更新
- 针对数千个功能请求进行全文搜索
- 发送通知的后台作业
- 缓存经常访问的路线图
- 用于用户偏好和设置的键值存储
我的整个后端只有一个 Postgres 数据库。没有 Redis,没有 Elasticsearch,没有消息队列。从用户身份验证到实时 WebSocket 通知,一切都由 Postgres 处理。
结果如何?我的功能交付速度更快,需要调试的部件更少,而且基础设施成本也降到了最低。当用户提交反馈、搜索功能或获取路线图变更的实时更新时,一切都由 Postgres 完成。
这不再只是理论上的。它正在实际生产中,通过真实的用户和真实的数据发挥作用。
令人不安的结论
Postgres 或许好得过头了。它功能强大,以至于大多数其他数据库对于 90% 的应用程序来说都显得多余。业界一直说服我们,所有事情都需要专门的工具,但或许我们只是把事情弄得比实际需要的更难。
你的初创公司不必成为分布式系统的样板。它需要为真正的人解决真正的问题。Postgres 让你专注于此,而不是照看基础设施。
因此,下次有人建议添加 Redis 来“提高性能”或添加 MongoDB 来“提高灵活性”时,请问他们:“您是否真的先尝试过在 Postgres 中执行此操作?”
答案可能会让你大吃一惊。我知道,当我完全在 Postgres 上构建UserJot时,它就一直运行顺畅。
| 本文为译文,英文原文地址(可能需要使用魔法访问):dev.to/shayy/postg… |
|---|
来源:juejin.cn/post/7517200182725296178
为什么 Go 语言非常适合开发 AI Agent
原文:Alexander Belanger - 2025.06.03
如同地球上几乎所有人一样,过去的几个月里,我们也一直在关注着 Agent 的发展。
特别值得一提的是,我们观察到 Agent 的采用推动了我们编排平台的增长,这让我们对哪些技术栈和框架——或者干脆没有框架——在此领域表现良好有了一些见解。
我们看到的一个更有趣的现象是混合技术栈的激增:一个典型的 Next.js 或 FastAPI 后端,搭配着一个用 Go 语言编写的 Agent,甚至在非常早期阶段就如此。
作为一名长期的 Go 语言开发者,这着实令人兴奋;下面我将解释为何我认为这将成为未来更普遍的做法。
什么是 Agent?
这里的术语有些混乱,但通常我指的是一个在循环中执行的进程,该进程对其执行路径中的下一步操作拥有一定的自主权。这与预定义的执行路径(例如定义为有向无环图的一组步骤,我们称之为工作流)形成对比。Agent 通常包含一个基于最大深度或满足某个条件(如“测试通过”)的退出条件。

当 Agent 开始规模化(即:拥有实际用户)时,它们通常具有一些共同特征:
- 它们是长时间运行的——从几秒到几分钟甚至几小时不等。
- 每次执行的成本都很高——不仅仅是 LLM 调用的成本,Agent 的本质是取代通常需要人工操作员完成的任务。开发环境、浏览器基础设施、大型文档处理——这些都花费 $$$ 钱的。
- 在它们的执行周期中,经常需要在某个时刻接收用户(或另一个 Agent!)的输入。
- 它们花费大量时间等待 I/O 或人类输入。
让我们将这一系列特征转化为对运行时的要求。为了限定问题范围,假设我们正在处理一个在远程执行的 Agent,而非在用户本地机器上(尽管 Go 对于分发本地 Agent 也是一个绝佳选择)。在远程执行的情况下,为每次 Agent 执行运行一个单独的容器成本会高得惊人。因此,在大多数情况下(尤其是当我们的 Agent 主要是简单的 I/O 和 LLM 调用时),我们最终会得到大量并发运行的轻量级进程。每个进程可以处于特定状态(例如,“搜索文件中”、“生成代码中”、“测试中”)。请注意,不同 Agent 执行的状态顺序可能并不相同。

这种包含许多并发、长时间运行进程的系统,与大约十年前的传统 Web 架构截然不同。在传统架构中,对服务器的请求处理速度要快得多,使用一些缓存、高效的处理程序和 OLTP 数据库就能高效地服务数千名日活用户。
事实证明,这种架构转变非常适合 Go 语言的并发模型、依赖通道(channel)进行通信、集中的取消机制以及围绕 I/O 构建的工具链。
高并发性
让我们从最明显的一点开始——Go 拥有极其简单且强大的并发模型。创建一个新的 goroutine 所需的内存和时间成本非常低,因为每个 goroutine 只有 2KB 的预分配内存。

这实际上意味着你可以同时运行许多 goroutine 而开销很小,并且它们在底层运行在多个操作系统线程上,能够利用服务器中的所有 CPU 核心。这一点非常重要,因为如果你碰巧在某个 goroutine 中执行非常消耗 CPU 的操作(比如反序列化一个大型 JSON 结构),其影响会比你使用单线程运行时(如 Node.js)要小(在 Node.js 中,你需要为阻塞线程的操作创建 worker 线程或子进程),或者比使用 Python 的 async/await 也要好。
这对于 Agent 意味着什么?因为 Agent 的运行时间比典型的 Web 请求长得多,所以并发性就成为了一个更关键的问题。在 Go 中,相比于在 Python 中为每个 Agent 运行一个线程,或者在 Node.js 中为每个 Agent 运行一个 async 函数,你受到为每个 Agent 生成一个 goroutine 的限制要小得多。再加上较低的基础内存占用和编译成单一二进制文件的特点,在轻量级基础设施上同时运行数千个并发 Agent 执行变得异常简单。
通过通信共享内存
对于那些不了解的人,Go 语言有一个常见的习语:不要通过共享内存来通信;相反,通过通信来共享内存。
在实践中,这意味着不需要尝试跨多个并发进程同步内存内容(这是使用类似 Python 的 multithreading 库时的常见问题),每个进程可以通过在通道(channel)上获取和释放对象来获得该对象的所有权。这样做的效果是,每个进程只在拥有对象所有权时关心该对象的本地状态,而其他时候不需要协调所有权——无需互斥锁(mutex)!
老实说——在我编写过的大多数 Go 程序中,我使用等待组(wait groups)和互斥锁(mutexes)的次数往往比使用通道(channels)更多,因为这样通常更简单(这也符合 Go 社区的建议),并且只有一个地方需要并发访问数据。
但是,在建模 Agent 时,这种范式非常有用,因为 Agent 通常需要异步响应用户或其他 Agent 发来的消息,并且将应用程序实例视为一个 Agent 池来思考是很有帮助的。
为了更具体说明,让我们编写一些示例代码来表示 Agent 循环的核心逻辑:
// 注意:在真实世界的例子中,我们需要一种机制来优雅地
// 关闭循环并防止通道关闭;
// 这是一个简化示例。
func Agent(in <-chan Message, out chan<- Output, status chan<- State) {
internal := make(chan Message, 10) // 内部缓冲区大小为 10 的通道
for {
select {
case msg := <-internal: // 从内部通道读取消息
processMessage(msg, internal, out, status)
case msg := <-in: // 从外部输入通道读取消息
processMessage(msg, internal, out, status)
}
}
}
func processMessage(msg Message, internal chan<- Message, out chan<- Output, status chan<- State) {
result := execute(msg) // 执行消息处理
status <- State{msg.sessionId, result.status} // 发送状态更新
if next := result.next(); next != nil { // 获取下一步消息(如果有)
internal <- next // 将下一步消息发送到内部通道
}
out <- result // 发送处理结果
}
(请注意,<-chan 表示接收者只能从通道读取,而 chan<- 表示接收者只能向通道写入。)
这个 Agent 是一个长时间运行的进程,它等待消息到达 in 通道,处理消息,然后异步地将结果发送到 out 通道。status 通道用于发送关于 Agent 状态的更新,这对于监控或向用户发送增量结果很有用;而 internal 通道用于处理 Agent 的内部循环。例如,内部循环可以实现下图中的“直到测试通过”循环:

尽管我们使用 for 循环来运行 Agent,但该 Agent 的实例在消息之间不需要维护任何内部状态。它本质上是一个无状态归约器,其决策执行路径的下一步操作不依赖于某些内部状态。重要的是,这意味着任何 Agent 实例都能够处理下一条消息。这也允许 Agent 在消息之间使用持久化边界,例如将消息写入数据库或消息队列。
使用 context.Context 的集中取消机制
还记得 Agent 执行成本很高吗?假设一个用户触发了一个价值 10 美元的执行任务,但突然改变主意并点击“停止生成”——为了节省成本,你希望取消这次执行。
事实证明,在 Node.js 和 Python 中取消长时间运行的工作极其困难,原因有很多:
- 库之间缺乏统一的取消机制——虽然两种语言都支持中止信号(AbortSignal)和控制器(Controller),但这并不能保证你调用的第三方库会尊重这些信号。
- 如果信号取消失败,强行终止线程是个痛苦的过程,并可能导致线程泄漏或资源损坏。
幸运的是,Go 采用 context.Context 使得取消工作变得轻而易举,因为绝大多数库都预期并尊重这种模式。即使某些库不支持:由于 Go 只有一种并发模型,因此有像 goleak 这样的工具,可以更容易地检测出泄漏的 goroutine 和有问题的库。
丰富的标准库
当你开始使用 Go 时,你会立即注意到 Go 的标准库非常丰富且质量很高。它的许多部分也是为 Web I/O 构建的——比如 net/http、encoding/json 和 crypto/tls——这些对于 Agent 的核心逻辑非常有用。
Go 还有一个隐含的假设:所有 I/O 在 goroutine 内部都是阻塞的——再次强调,因为 Go 只有一种方式运行并发工作——这鼓励你将业务逻辑的核心编写为直线式程序。你不需要担心用 await 包装每个函数调用来将执行推迟给调度器。
与 Python 对比:库开发者需要考虑 asyncio、多线程(multithreading)、多进程(multiprocessing)、eventlet、gevent 以及其他一些模式,几乎不可能同等地支持所有并发模型。因此,如果你用 Python 编写 Agent,你需要研究每个库对你所采用的并发模型的支持情况,并且如果你的第三方库不完全支持你想要的模式,你可能需要采用多种模式。
(Node.js 的情况要好得多,尽管 Bun 和 Deno 等其他运行时的加入增加了一些不兼容的层面。)
性能剖析(Profiling)
由于其有状态性(statefulness)和大量长时间运行的进程,Agent 似乎特别容易出现内存泄漏和线程泄漏。Go 在 runtime/pprof 中提供了出色的工具,可以使用堆(heap)和分配(alloc)配置文件找出内存泄漏的来源,或者使用 goroutine 配置文件找出 goroutine 泄漏的来源。

额外优势:LLM 擅长编写 Go 代码
由于 Go 语法非常简单(一个常见的批评是 Go 有点“啰嗦”)并且拥有丰富的标准库,LLM 非常擅长编写符合 Go 语言习惯的代码。我发现它们在编写表格测试(table tests)方面尤其出色,这是 Go 代码库中的一种常见模式。
Go 工程师也往往反对框架(anti-framework),这意味着 LLM 不需要跟踪你使用的是哪个框架(或框架的哪个版本)。
不足之处
尽管有以上诸多好处,仍然有很多理由让你可能不会选择 Go 来开发你的 Agent:
- 第三方库支持仍然落后于 Python 和 Typescript。
- 使用 Go 进行任何涉及真正机器学习(real machine learning)的工作几乎是不可能的。
- 如果你追求最佳性能,那么有比 Go 更好的语言,如 Rust 和 C++。
- 你特立独行,不喜欢(显式)处理错误。
来源:juejin.cn/post/7514621534339055631
😡同事查日志太慢,我现场教他一套 grep 组合拳!
前言
最近公司来了个新同事,年轻有活力,就是查日志的方式让我有点裂开。
事情是这样的:他写的代码在测试环境报错了,报警信息也被钉钉机器人发到了我们群里。作为资深摸鱼战士,我寻思正好借机摸个鱼顺便指导一下新人,就凑过去看了眼。
结果越看我越急,差点当场喊出:“兄弟你是来写代码的,还是和日志谈恋爱的?”
来看看他是怎么查日志的
他先敲了一句:
tail -f a.log | grep "java.lang.NullPointerException"
想着等下次报错就能立刻看到。等了半天,终于蹦出来一行:
2025-07-03 11:38:48.339 [http-nio-8960-exec-1] [47gK4n32jEYvTYX8AYti48] [INFO] [GlobalExceptionHandler] java.lang.NullPointerException, ex: java.lang.NullPointerException
java.lang.NullPointerException: null
我提醒他:“这样看不到堆栈信息啊。”
他“哦”了一声,灵机一动,用 vi把整个文件打开,/NullPointerException 搜关键词,一个 n 一个 n 地翻……半分钟过去了,异常在哪都没找全,我都快给他跪下了。

于是我当场掏出了一套我压箱底的“查日志组合拳”,一招一式手把手教他。他当场就“悟了”,连连称妙,并表示想让我写成文章好让他发给他前同事看——因为他前同事也是这样查的……
现在,这套组合拳我也分享给你,希望你下次查日志的时候,能让你旁边的同事开开眼。
正式教学
核心的工具其实还是 grep 命令,下面我将分场景给你讲讲我的实战经验,保证你能直接套用!
场景一:查异常堆栈,不能只看一行!
Java 异常堆栈通常都是多行的,仅仅用 grep "NullPointerException" 只能看到最上面那一行,问题根源在哪你压根找不到。
这时候使用 **grep** 的 **-A** (After) 参数来显示匹配行之后的N行。
# 查找 NullPointerException,并显示后面 50 行
grep -A 50 "java.lang.NullPointerException" a.log
如果你发现异常太多,屏幕一闪而过,也可以用less加上分页查看:
grep -A 50 "java.lang.NullPointerException" a.log | less
在 less 视图中,你可以:
- 使用 箭头↑↓ 或 Page Up/Down 键来上下滚动
- 输入
G直接翻到末尾,方便快速查看最新的日志 - 输入
/Exception继续搜索 - 按
q键退出
这样你就能第一时间拿到完整异常上下文信息,告别反复 vi + / 的低效操作!

场景二:实时看新日志怎么打出来的
如果你的应用正在运行,并且你怀疑它会随时抛出异常,你可以实时监控日志文件的增长。
使用 tail -f 结合 grep:
# 实时监控 a.log 文件的新增内容,并只显示包含 "java.lang.NullPointerException" 的行及其后50行
tail -f a.log | grep -A 50 "java.lang.NullPointerException"
只要异常一出现,它就会自动打出来,堆栈信息也一并送到你面前!
- 想停下?
Ctrl + C - 想更准确?加
-i忽略大小写,防止大小写拼错找不到
场景三:翻历史日志 or 查压缩日志
服务器上的日志一般都会按天或按大小分割并压缩,变成 .log.2025-07-02.gz 这种格式,查找这些文件的异常信息怎么办?
🔍 查找当前目录所有 .log 文件:
# 在当前目录下查找所有以 .log 结尾的文件,-H 参数可以顺便打印出文件名
grep -H -A 50 "java.lang.NullPointerException" *.log
其中 -H 会帮你打印出是哪个文件中出现的问题,防止你找完还不知道是哪天的事。
🔍 查找 .gz 文件(压缩日志):
zgrep -H -A 50 "java.lang.NullPointerException" *.gz
zgrep 是专门处理 .gz 的 grep,它的功能和 grep 完全一样,无需手动解压,直接开整!
场景四:统计异常数量(快速判断异常是否频繁)
有时候你需要知道某个异常到底出现了多少次,是偶发还是成灾,使用 grep -c(count):
grep -c "java.lang.NullPointerException" a.log
如果你要统计所有日志里的数量:
grep -c "java.lang.NullPointerException" *.log
其他常用的 grep 参数
| 参数 | 作用 |
|---|---|
-B N | 匹配行之前的 N 行(Before) |
-A N | 匹配行之后的 N 行(After) |
-C N | 匹配行上下共 N 行(Context) |
-i | 忽略大小写 |
-H | 显示匹配的文件名 |
-r | 递归搜索目录下所有文件 |
比如:
grep -C 25 "java.lang.NullPointerException" a.log
这个命令就能让你一眼看到异常前后的上下文,帮助定位代码逻辑是不是哪里先出问题了。
尾声
好了,这套组合拳我已经传授给你了,要是别人问你在哪学的,记得报我杆师傅的大名(doge)。
其实还有其他查日志的工具,比如awk、wc 等。
但是我留了一手,没有全部教给我这个同事,毕竟江湖规则,哪有一出手就把看家本领全都交出去的道理?
如果你也想学,先拜个师交个学费(点赞、收藏、关注),等学费凑够了,我下次再开新课,传授给大家~

来源:juejin.cn/post/7524216834619408430
为什么我不再相信 Tailwind?三个月重构项目教会我的事
Tailwind 曾经是我最爱的工具,直到它让我维护不下去整个项目。
前情提要:我是如何变成 Tailwind 重度用户的
作为一个多年写 CSS 的前端,我曾经深陷“命名地狱”:
什么 .container-title, .btn-primary, .form-item-error,一个项目下来能写几百个类名,然后改样式时不知道该去哪动刀,甚至删个类都心慌。
直到我遇见了 Tailwind CSS——一切原子化,想改样式就加 class,别管名字叫什么,直接调属性即可。
于是我彻底拥抱它,团队项目里我把所有 SCSS 全部清除,组件中也只保留了 Tailwind class,一切都干净、轻便、高效。
但故事从这里开始转变。
三个月后的重构期,我被 Tailwind“反噬”
我们的后台管理系统迎来一次大版本升级,我负责重构 UI 样式逻辑,目标是:
- 统一设计规范;
- 提高代码可维护性;
- 降低多人协作时的样式冲突。
刚开始我信心满满,毕竟 Tailwind 提供了:
- 原子化 class;
@apply合成组件级 class;- 配置主题色/字体/间距系统;
- 插件支持动画/form 控件/typography;
但随着项目深入,我开始发现 几个巨大的问题,并最终决定停用 Tailwind。
一、class 污染:结构和样式纠缠成灾
来看一个真实例子:
<div class="flex items-center justify-between bg-white p-4 rounded-lg shadow-sm border border-gray-200">
<h2 class="text-lg font-semibold text-gray-800">订单信息</h2>
<button class="text-sm px-2 py-1 bg-blue-500 text-white rounded hover:bg-blue-600">编辑</button>
</div>
你能看出这个组件的“设计意图”吗?
你能快速改它的样式吗?
一个看似简单的按钮,一眼看不到设计语言,只看到一坨 class,你根本不知道:
px-2 py-1是从哪里决定的?bg-blue-500是哪个品牌色?hover:bg-blue-600是统一交互吗?
Tailwind 让样式变得快,但也让样式“变得不可读”。
二、复用失败:想复用样式还得靠 SCSS
我天真地以为 @apply 能帮我合成组件级样式,比如:
.btn-primary {
@apply text-white bg-blue-500 px-4 py-2 rounded;
}
但问题来了:
@apply不能用在媒体查询内;@apply不支持复杂嵌套、hover/focus 的组合;- 响应式、伪类写在 HTML 里更乱,如:
lg:hover:bg-blue-700; - 没法动态拼接 class,逻辑和样式混在组件逻辑层了。
最终结果就是:复用失败、样式重复、维护困难。
三、设计规范无法沉淀
我们设计系统中定义了若干基础变量:
- 主色:
#0052D9 - 次色:
#A0AEC0 - 字体尺寸规范:
12/14/16/18/20/24/32px - 组件间距:
8/16/24
本来我们希望 Tailwind 的 theme.extend 能承载这套设计系统,结果发现:
- tailwind.config.js 修改后,需要全员重启 dev server;
- 新增设计 token 非常繁琐,不如直接写 SCSS 变量;
- 多人改配置时容易冲突;
- 和设计稿同步代价高。
这让我明白:配置式设计系统不适合快速演进的产品团队。
四、多人协作混乱:Tailwind 并不直观
当我招了一位新同事,给他一个组件代码时,他的第一句话是:
“兄弟,这些 class 是从设计稿复制的吗?”
他根本看不懂 gap-6, text-gray-700, tracking-wide 分别是什么意思,只看到一堆“魔法 class” 。
更糟糕的是,每个人心中对 text-sm、text-base 的视觉认知不同,导致多个组件在微调时出现样式不一致、间距不统一的问题。
Tailwind 的语义脱离了设计意图,协作就失去了基础。
最终决定:我切回了 SCSS + BEM + 设计 token
我们开始回归传统模式:
- 所有组件都有独立
.scss文件; - 使用 BEM 命名规范:
.button,.button--primary,.button--disabled; - 所有颜色/间距/字体等统一放在
_variables.scss中; - 每个组件样式文件都注释设计规范来源。
这种模式虽然看起来“原始”,但它:
- 清晰分离结构和样式;
- 强制大家遵守设计规范;
- 组件样式可复用,可继承,可重写;
- 新人一眼看懂,不需要会 Tailwind 语法。
总结:Tailwind 不是错,是错用的代价太高
Tailwind 在以下场景表现极好:
- 个人项目 / 小程序:快速开发、无需复用;
- 组件库原型:试验颜色、排版效果;
- 纯前端工程师独立开发的项目:没有协作负担。
但在以下情况,Tailwind 会成为维护灾难:
- 多人协作;
- UI 不断迭代,设计语言需频繁调整;
- 有强复用需求(组件抽象);
- 与设计系统严格对齐的场景;
我为什么写这篇文章?
不是为了黑 Tailwind,而是为了让你在选择技术栈时更慎重。
就像当年我们争论 Sass vs Less,今天的 Tailwind vs 原子/语义 CSS 并没有标准答案。
Tailwind 很强,但不是所有团队都适合。
也许你正在享受它的爽感,但三个月后你可能会像我一样,把所有 .w-full h-screen text-gray-800 替换成 .layout-container。
尾声:如果你非要继续用 Tailwind,我建议你做这几件事
- 强制使用
@apply形成组件级 class,不允许直接使用长串 class; - 抽离公共样式,写在一个统一的组件样式文件中;
- 和设计团队对齐 Tailwind 的 spacing/font/color;
- 用 tailwind.config.js 做好 token 映射和语义名设计;
- 每个页面都进行 CSS code review,不然很快就会变垃圾堆。
来源:juejin.cn/post/7511602231508664361
用了十年 Docker,我为什么决定换掉它?
一、Docker 不再万能,我们该何去何从?
过去十年,Docker 改变了整个软件开发世界。它以“一次构建,到处运行”的理念,架起了开发者和运维人员之间的桥梁,推动了 DevOps 与微服务架构的广泛落地。
从自动化部署、持续集成到快速交付,Docker 一度是不可或缺的技术基石。
然而到了 2025 年,越来越多开发者开始重新审视 Docker。

系统规模在不断膨胀,开发场景也更加多元,不再是当初以单一后端应用为主的架构。
如今,开发者面临的不只是如何部署一个服务,更要关注架构的可扩展性、容器的安全性、本地与云端的适配性,以及资源的最优利用。
在这种背景下,Docker 开始显得不再那么“全能”,它在部分场景下的臃肿、安全隐患和与 Kubernetes 的解耦问题,使得不少团队正在寻找更轻、更适合自身的替代方案。
之所以写下这篇文章就是为了帮助你认清 Docker 当前的局限,了解新的技术趋势,并发现适用于不同场景的下一代容器化工具。
二、Docker 的贡献与瓶颈
不可否认,Docker 曾是容器化革命的引擎。从过去到现在,它的最大价值在于降低了环境配置的复杂度,让开发与运维团队之间的协作更加顺畅,带动了整个容器生态的发展。
很多团队正是依赖 Docker 才实现了快速构建镜像、构建流水线、部署微服务的能力。
但与此同时,Docker 本身也逐渐显露出局限性。比如,它高度依赖守护进程,导致资源占用明显高于预期,启动速度也难以令人满意。
更关键的是,Docker 默认以 root 权限运行容器,极易放大潜在攻击面,在安全合规日益严格的今天,这一点令人担忧。Kubernetes 的官方运行时也已从 Docker 切换为 containerd 与 runc,表明行业主流已在悄然转向。
这并不意味着 Docker 已过时,它依旧在许多团队中扮演重要角色。但如果你期待更高的性能、更低的资源消耗和更强的安全隔离,那么,是时候拓宽视野了。

三、本地开发的难题与新解法
特别是在本地开发场景中,Docker 的“不够轻”问题尤为突出。为了启动一个简单的 PHP 或 Node 项目,很多人不得不拉起庞大的容器,等待镜像下载、构建,甚至调试端口映射,最终电脑风扇轰鸣,开发体验直线下降。
一些开发者试图回归传统,通过 Homebrew 或 apt 手动配置开发环境,但这又陷入了“版本冲突”“依赖错位”等老问题。
这时,ServBay 的出现带来了新的可能。作为专为本地开发设计的轻量级工具,ServBay 不依赖 Docker,也无需繁琐配置。用户只需一键启动,即可在本地运行 PHP、Python、Golang、Java 等多种语言环境,并能自由切换版本与服务组合。它不仅启动迅速,资源占用也极低,非常适合 WordPress、Laravel、ThinkPHP 等项目的本地调试与开发。
更重要的是,ServBay 不再强制开发者理解复杂的镜像构建与容器编排逻辑,而是将本地开发流程变得像打开编辑器一样自然。对于 Web 后端和全栈开发者来说,它提供了一种“摆脱 Docker”的全新路径。
四、当 Docker 不再是运行时的唯一选择
容器运行时的格局也在悄然生变。containerd 和 runc 成为了 Kubernetes 官方推荐的运行时,它们更轻、更专注,仅提供核心的容器管理功能,剥离了不必要的附加组件。与此同时,CRI-O 正在被越来越多团队采纳,它是专为 Kubernetes 打造的运行时,直接对接 CRI 接口,减少了依赖层级。
另一款备受好评的是 Podman,它的最大亮点在于支持 rootless 模式,使容器运行更加安全。同时,它的命令行几乎与 Docker 完全兼容,开发者几乎不需要重新学习。
对于安全隔离要求极高的场景,还可以选择 gVisor 或 Kata Containers。前者通过用户态内核方式拦截系统调用,构建沙箱化环境;后者则将轻量虚拟机与容器结合,兼顾性能与隔离性。这些方案正在逐步替代传统 Docker,成为新一代容器架构的基石。
五、容器编排:Kubernetes 之后的路在何方?
虽然 Kubernetes 仍然是企业级容器编排的标准选项,但它的复杂性和陡峭的学习曲线也让不少中小团队望而却步。一个简单的应用部署可能涉及上百行 YAML 文件,过度的抽象与组件拆分反而拉高了运维门槛。
这也促使“微型 Kubernetes”方案逐渐兴起。K3s 是其中的代表,它对 Kubernetes 进行了极大简化,专为边缘计算和资源受限场景优化。此外,像 KubeEdge 等项目,也在积极拓展容器编排在边缘设备上的适配能力。
与此同时,AI 驱动的编排平台正在探索新路径。CAST AI、Loft Labs 等团队推出的智能调度系统,可以自动分析工作负载并进行优化部署,最大化资源利用率。更进一步,Serverless 与容器的融合也逐渐成熟,比如 AWS Fargate、Google Cloud Run 等服务,让开发者无需再关心节点管理,容器真正变成了“即用即走”的计算单元。
六、未来趋势:容器走向“定制化生长”
未来的容器化,我们将看到更细化的技术选型:开发环境选择轻量灵活的本地容器,测试环境强调快速重建与自动化部署,生产环境则关注安全隔离与高可用性。
安全性也会成为核心关键词。rootless 容器、沙箱机制和系统调用过滤将成为主流实践,容器从“不可信”向“可信执行环境”演进。与此同时,人工智能将在容器调度中发挥更大作用,不仅提升弹性伸缩的效率,还可能引领“自愈系统”发展,让集群具备自我诊断与恢复能力。
容器标准如 OCI 的持续完善,将让不同运行时之间更加兼容,为整个生态的整合提供可能。而在部署端,我们也将看到容器由本地向云端、再向边缘设备的自然扩展,真正成为“无处不在的基础设施”。

七、结语:容器化的新纪元已经到来
Docker 的故事并没有结束,它依然是很多开发者最熟悉的工具,也在部分场景中继续发挥作用。但可以确定的是,它不再是唯一选择。2025 年的容器世界,早已迈入了多元化、场景化、智能化的阶段。从轻量级的 ServBay 到更安全的 Podman,从微型编排到 Serverless 混合模式,我们手中可选的工具越来越丰富,技术栈的自由度也空前提升。
下一个十年,容器不只是为了“装下服务”,它将成为构建现代基础设施的关键砖块。愿你也能在这场演进中,找到属于自己的工具组合,打造更轻、更快、更自由的开发与部署体验。
来源:juejin.cn/post/7521927128524210212
放弃 JSON.parse(JSON.stringify()) 吧!试试现代深拷贝!
作者:程序员成长指北
原文:mp.weixin.qq.com/s/WuZlo_92q…
最近小组里的小伙伴,暂且叫小A吧,问了一个bug:
提示数据循环引用,相信不少小伙伴都遇到过类似问题,于是我问他:
我:你知道问题报错的点在哪儿吗
小A: 知道,就是下面这个代码,但不知道怎么解决。
onst a = {};
const b = { parent: a };
a.child = b; // 形成循环引用
try {
const clone = JSON.parse(JSON.stringify(a));
} catch (error) {
console.error('Error:', error.message); // 会报错:Converting circular structure to JSON
}
上面是我将小A的业务代码提炼为简单示例,方便阅读。
- 这里
a.child指向b,而b.parent又指回a,形成了循环引用。 - 用
JSON.stringify时会抛出 Converting circular structure to JSON 的错误。
我顺手查了一下小A项目里 JSON.parse(JSON.stringify()) 的使用情况:
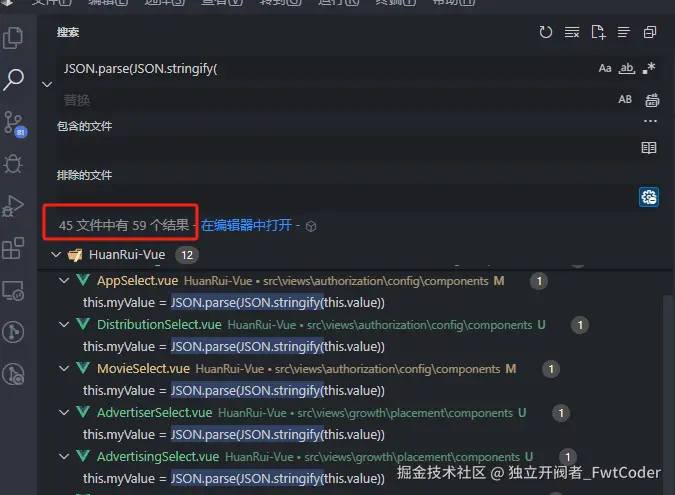
一看有50多处都使用了, 使用频率相当高了。
我继续提问:
我:你有找解决方案吗?
小A: 我看网上说可以自己实现一个递归来解决,但是我不太会实现
于是我帮他实现了一版简单的递归深拷贝:
function deepClone(obj, hash = new Map()) {
if (typeof obj !== 'object' || obj === null) return obj;
if (hash.has(obj)) return hash.get(obj);
const clone = Array.isArray(obj) ? [] : {};
hash.set(obj, clone);
for (const key in obj) {
if (obj.hasOwnProperty(key)) {
clone[key] = deepClone(obj[key], hash);
}
}
return clone;
}
// 测试
const a = {};
const b = { parent: a };
a.child = b;
const clone = deepClone(a);
console.log(clone.child.parent === clone); // true
此时,为了给他拓展一下,我顺势抛出新问题:
我: 你知道原生Web API 现在已经提供了一个深拷贝 API吗?
小A:???
于是我详细介绍了一下:
主角 structuredClone登场
structuredClone() 是浏览器原生提供的 深拷贝 API,可以完整复制几乎所有常见类型的数据,包括复杂的嵌套对象、数组、Map、Set、Date、正则表达式、甚至是循环引用。
它遵循的标准是:HTML Living Standard - Structured Clone Algorithm(结构化克隆算法)。
语法:
const clone = structuredClone(value);
一行代码,优雅地解决刚才的问题:
const a = {};
const b = { parent: a };
a.child = b; // 形成循环引用
const clone = structuredClone(a);
console.log(clone !== a); // true
console.log(clone.child !== b); // true
console.log(clone.child.parent === clone); // true,循环引用关系被保留
为什么增加 structuredClone?
在 structuredClone 出现之前,常用的深拷贝方法有:
| 方法 | 是否支持函数/循环引用 | 是否支持特殊对象 |
|---|---|---|
JSON.parse(JSON.stringify(obj)) | ❌ 不支持函数、循环引用 | ❌ 丢失 Date、RegExp、Map、Set |
第三方库 lodash.cloneDeep | ✅ 支持 | ✅ 支持,但体积大,速度较慢 |
| 手写递归 | ✅ 可支持 | ❌ 复杂、易出错 |
structuredClone 是 原生、极速、支持更多数据类型且无需额外依赖 的现代解决方案。
支持的数据类型
| 类型 | 支持 |
|---|---|
| Object | ✔️ |
| Array | ✔️ |
| Map / Set | ✔️ |
| Date | ✔️ |
| RegExp | ✔️ |
| ArrayBuffer / TypedArray | ✔️ |
| Blob / File / FileList | ✔️ |
| ImageData / DOMException / MessagePort | ✔️ |
| BigInt | ✔️ |
| Symbol(保持引用) | ✔️ |
| 循环引用 | ✔️ |
❌ 不支持:
- 函数(Function)
- DOM 节点
- WeakMap、WeakSet
常见使用示例
1. 克隆普通对象
const obj = { a: 1, b: { c: 2 } };
const clone = structuredClone(obj);
console.log(clone); // { a: 1, b: { c: 2 } }
console.log(clone !== obj); // true
2. 支持循环引用
const obj = { name: 'Tom' };
obj.self = obj;
const clone = structuredClone(obj);
console.log(clone.self === clone); // true
3. 克隆 Map、Set、Date、RegExp
const complex = {
map: new Map([["key", "value"]]),
set: new Set([1, 2, 3]),
date: new Date(),
regex: /abc/gi
};
const clone = structuredClone(complex);
console.log(clone);
兼容性
提到新的API,肯定得考虑兼容性问题:
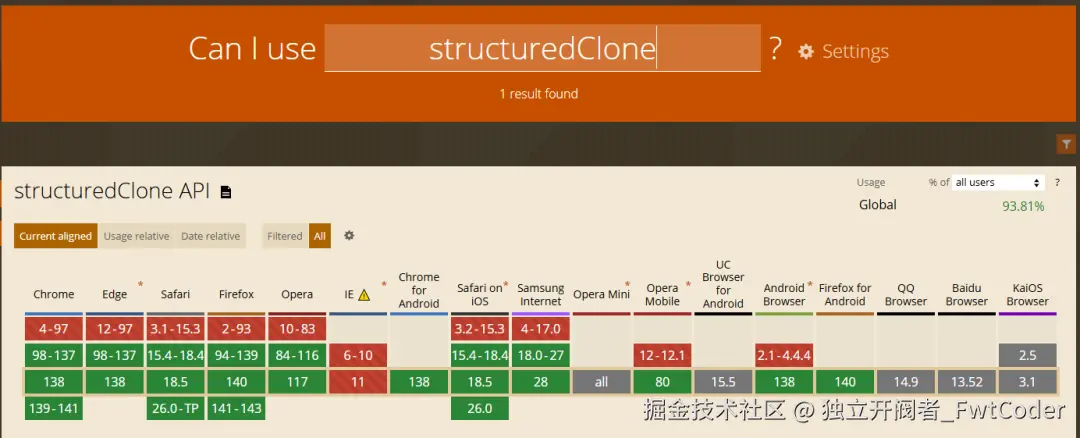
- Chrome 98+
- Firefox 94+
- Safari 15+
- Node.js 17+ (
global.structuredClone)
如果需要兼容旧浏览器:
- 可以降级使用
lodash.cloneDeep - 或使用 MessageChannel Hack
很多小伙伴一看到兼容性问题,可能心里就有些犹豫:
"新API虽然好,但旧浏览器怎么办?"
但技术的发展离不开新技术的应用和推广,只有更多人开始尝试并使用,才能让新API真正普及开来,最终成为主流。
建议:
如果你的项目运行在现代浏览器或 Node.js 环境,structuredClone 是目前最推荐的深拷贝方案。 Node.js 17+:可以直接使用 global.structuredClone。
来源:juejin.cn/post/7524232022124085257
localhost 和 127.0.0.1 到底有啥区别?
在开发中,我们经常会接触到 localhost 和 127.0.0.1。很多人可能觉得它们是一样的,甚至可以互换使用。实际上,它们确实有很多相似之处,但细究起来,也存在一些重要的区别。
本篇文章就带大家一起来深入了解 localhost 和 127.0.0.1,并帮助你搞清楚它们各自的特点和适用场景。
一、什么是 localhost?
localhost 是一个域名,它被广泛用于表示当前这台主机(也就是你自己的电脑)。当你在浏览器地址栏输入 localhost 时,操作系统会查找 hosts 文件(在 Windows 中通常位于 C:\Windows\System32\drivers\etc\hosts,在 MacOS 或者 Linux 系统中,一般位于 /etc/hosts),查找 localhost 对应的 IP 地址。如果没有找到,它将默认解析为 127.0.0.1。
特点:
- 是一个域名,默认指向当前设备。
- 不需要联网也能工作。
- 用于测试本地服务,例如开发中的 Web 应用或 API。
小知识 🌟:域名和 IP 地址的关系就像联系人名字和电话号码。我们用名字联系某个人,实际上是依赖后台的通讯录解析到实际号码来拨号。
二、什么是 127.0.0.1?
127.0.0.1 是一个特殊的 IP 地址,它被称为 回环地址(loopback address)。这个地址专门用于通信时指向本机,相当于告诉电脑“别出门,就在家里转一圈”。你可以试一试在浏览器中访问 127.0.0.2 看看会访问到什么?你会发现,它同样会指向本地服务!环回地址的范围是 127.0.0.0/8,即所有以 127 开头的地址都属于环回网络,但最常用的是 127.0.0.1。
特点:
- 127.0.0.1 不需要 DNS 解析,因为它是一个硬编码的地址,直接指向本地计算机。
- 是 IPv4 地址范围中的一个保留地址。
- 只用于本机网络通信,不能通过这个地址访问外部设备或网络。
- 是开发测试中最常用的 IP 地址之一。
小知识 🌟:所有从
127.0.0.0到127.255.255.255的 IP 地址都属于回环地址,但通常只用127.0.0.1。
三、两者的相似点
- 都指向本机
- 不管是输入
localhost还是127.0.0.1,最终都会将请求发送到你的电脑,而不是其他地方。
- 不管是输入
- 常用于本地测试
- 在开发中,我们需要在本机运行服务并测试,
localhost和127.0.0.1都是标准的本地访问方式。
- 在开发中,我们需要在本机运行服务并测试,
- 无需网络支持
- 即使你的电脑没有连接网络,这两个也可以正常使用,因为它们完全依赖于本机的网络栈。
四、两者的不同点
| 区别 | localhost | 127.0.0.1 |
|---|---|---|
| 类型 | 域名 | IP 地址 |
| 解析过程 | 需要通过 DNS 或 hosts 文件解析为 IP 地址 | 不需要解析,直接使用 |
| 协议版本支持 | 同时支持 IPv4 和 IPv6 | 仅支持 IPv4 |
| 访问速度 | 解析时可能稍慢(视 DNS 配置而定) | 通常更快,因为不需要额外的解析步骤 |
五、为什么 localhost 和 127.0.0.1 有时表现不同?
在大多数情况下,localhost 和 127.0.0.1 是等效的,但在一些特殊环境下,它们可能会表现出差异:
1. IPv4 和 IPv6 的影响
localhost 默认可以解析为 IPv4(127.0.0.1)或 IPv6(::1)地址,具体取决于系统配置。如果你的程序只支持 IPv4,而 localhost 被解析为 IPv6 地址,可能会导致连接失败。
示例:
# 测试 localhost 是否解析为 IPv6
ping localhost
可能的结果:
- 如果返回
::1,说明解析为 IPv6。 - 如果返回
127.0.0.1,说明解析为 IPv4。
2. hosts 文件配置
在某些情况下,你的 localhost 并不一定指向 127.0.0.1。这是因为域名解析优先会查找系统的 hosts 文件:
- Windows:
C:\Windows\System32\drivers\etc\hosts - Linux/macOS:
/etc/hosts
示例:自定义 localhost
# 修改 hosts 文件
127.0.0.1 my-local
之后访问 http://my-local 会指向 127.0.0.1,但如果 localhost 被误配置成其他地址,可能会导致问题。
3. 防火墙或网络配置的限制
某些网络工具或防火墙规则会区别对待域名和 IP 地址。如果只允许 127.0.0.1 通信,而不允许 localhost,可能会引发问题。
六、在开发中如何选择?
- 优先使用
localhost
因为它是更高层次的表示方式,更通用。如果将来需要切换到不同的 IP 地址(例如 IPv6),不需要修改代码。 - 需要精准控制时用
127.0.0.1
如果你明确知道程序只需要使用 IPv4 环境,或者想避免域名解析可能带来的问题,直接用 IP 地址更稳妥。
示例:用 Python 测试
# 使用 localhost
import socket
print(socket.gethostbyname('localhost')) # 输出可能是 127.0.0.1 或 ::1
# 使用 127.0.0.1
print(socket.gethostbyname('127.0.0.1')) # 输出始终是 127.0.0.1
七、总结
虽然 localhost 和 127.0.0.1 大部分情况下可以互换使用,但它们的本质不同:
localhost是域名,更抽象。127.0.0.1是 IP 地址,更具体。
在开发中,我们应根据场景合理选择,尤其是在涉及到跨平台兼容性或网络配置时,理解它们的差异性会让你事半功倍。
最后,记得动手实践,多跑几个测试。毕竟,编程是用代码说话的艺术!😄
如果你觉得这篇文章对你有帮助,记得点个赞或分享给更多人!有其他技术问题想了解?欢迎评论区留言哦~ 😊
来源:juejin.cn/post/7511583779578200115
都说了布尔类型的变量不要加 is 前缀,非要加,这不是坑人了嘛
开心一刻
今天心情不好,给哥们发语音
我:哥们,晚上出来喝酒聊天吧
哥们:咋啦,心情不好?
我:嗯,刚刚在公交车上看见前女友了
哥们:然后呢?
我:给她让座时,发现她怀孕了...
哥们:所以难受了?
我:不是她怀孕让我难受,是她怀孕还坐公交车让我难受
哥们:不是,她跟着你就不用坐公交车了?不还是也要坐,有区别吗?
我默默的挂断了语音,心情更难受了

Java开发手册
作为一个 javaer,我们肯定看过 Alibaba 的 Java开发手册,作为国内Java开发领域的标杆性编码规范,我们或多或少借鉴了其中的一些规范,其中有一点

我印象特别深,也一直在奉行,自己还从未试过用 is 作为布尔类型变量的前缀,不知道会有什么坑;正好前段时间同事这么用了,很不幸,他挖坑,我踩坑,阿西吧!

is前缀的布尔变量有坑
为了复现问题,我先简单搞个 demo;调用很简单,服务 workflow 通过 openfeign 调用 offline-sync,代码结构如下

qsl-data-govern-common:整个项目的公共模块
qsl-offline-sync:离线同步
- qsl-offline-sync-api:向外提供
openfeign接口
- qsl-offline-sync-common:离线同步公共模块
- qsl-offline-sync-server:离线同步服务
qsl-workflow:工作流
- qsl-workflow-api:向外提供
openfeign接口,暂时空实现
- qsl-workflow-common:工作流公共模块
- qsl-workflow-server:工作流服务
完整代码:qsl-data-govern
qsl-offline-sync-server 提供删除接口
/**
* @author 青石路
*/
@RestController
@RequestMapping("/task")
public class SyncTaskController {
private static final Logger LOG = LoggerFactory.getLogger(SyncTaskController.class);
@PostMapping("/delete")
public ResultEntity<String> delete(@RequestBody SyncTaskDTO syncTask) {
// TODO 删除处理
LOG.info("删除任务[taskId={}]", syncTask.getTaskId());
return ResultEntity.success("删除成功");
}
}
qsl-offline-sync-api 对外提供 openfeign 接口
/**
* @author 青石路
*/
@FeignClient(name = "data-govern-offline-sync", contextId = "dataGovernOfflineSync", url = "${offline.sync.server.url}")
public interface OfflineSyncApi {
@PostMapping(value = "/task/delete")
ResultEntity<String> deleteTask(@RequestBody SyncTaskDTO syncTaskDTO);
}
qsl-workflow-server 调用 openfeign 接口
/**
* @author 青石路
*/
@RestController
@RequestMapping("/definition")
public class WorkflowController {
private static final Logger LOG = LoggerFactory.getLogger(WorkflowController.class);
@Resource
private OfflineSyncApi offlineSyncApi;
@PostMapping("/delete")
public ResultEntity<String> delete(@RequestBody WorkflowDTO workflow) {
LOG.info("删除工作流[workflowId={}]", workflow.getWorkflowId());
// 1.查询工作流节点,查到离线同步节点(taskId = 1)
// 2.删除工作流节点,删除离线同步节点
ResultEntity<String> syncDeleteResult = offlineSyncApi.deleteTask(new SyncTaskDTO(1L));
if (syncDeleteResult.getCode() != 200) {
LOG.error("删除离线同步任务[taskId={}]失败:{}", 1, syncDeleteResult.getMessage());
ResultEntity.fail(syncDeleteResult.getMessage());
}
return ResultEntity.success("删除成功");
}
}
逻辑是不是很简单?我们启动两个服务,然后发起 http 请求
POST http://localhost:8081/data-govern/workflow/definition/delete
Content-Type: application/json
{
"workflowId": 99
}
此时 qsl-offline-sync-server 日志输出如下
2025-06-30 14:53:06.165|INFO|http-nio-8080-exec-4|25|c.q.s.s.controller.SyncTaskController :删除任务[taskId=1]
至此,一切都很正常,第一版也是这么对接的;后面 offline-sync 进行调整,删除接口增加了一个参数:isClearData
public class SyncTaskDTO {
public SyncTaskDTO(){}
public SyncTaskDTO(Long taskId, Boolean isClearData) {
this.taskId = taskId;
this.isClearData = isClearData;
}
private Long taskId;
private Boolean isClearData = false;
public Long getTaskId() {
return taskId;
}
public void setTaskId(Long taskId) {
this.taskId = taskId;
}
public Boolean getClearData() {
return isClearData;
}
public void setClearData(Boolean clearData) {
isClearData = clearData;
}
}
然后实现对应的逻辑
/**
* @author 青石路
*/
@RestController
@RequestMapping("/task")
public class SyncTaskController {
private static final Logger LOG = LoggerFactory.getLogger(SyncTaskController.class);
@PostMapping("/delete")
public ResultEntity<String> delete(@RequestBody SyncTaskDTO syncTask) {
// TODO 删除处理
LOG.info("删除任务[taskId={}]", syncTask.getTaskId());
if (syncTask.getClearData()) {
LOG.info("清空任务[taskId={}]历史数据", syncTask.getTaskId());
// TODO 清空历史数据
}
return ResultEntity.success("删除成功");
}
}
调整完之后,同事通知我,让我做对 qsl-workflow 做对应的调整。调整很简单,qsl-workflow 删除时直接传 true 即可
/**
* @author 青石路
*/
@RestController
@RequestMapping("/definition")
public class WorkflowController {
private static final Logger LOG = LoggerFactory.getLogger(WorkflowController.class);
@Resource
private OfflineSyncApi offlineSyncApi;
@PostMapping("/delete")
public ResultEntity<String> delete(@RequestBody WorkflowDTO workflow) {
LOG.info("删除工作流[workflowId={}]", workflow.getWorkflowId());
// 1.查询工作流节点,查到离线同步节点(taskId = 1)
// 2.删除工作流节点,删除离线同步节点
// 删除离线同步任务,isClearData直接传true
ResultEntity<String> syncDeleteResult = offlineSyncApi.deleteTask(new SyncTaskDTO(1L, true));
if (syncDeleteResult.getCode() != 200) {
LOG.error("删除离线同步任务[taskId={}]失败:{}", 1, syncDeleteResult.getMessage());
ResultEntity.fail(syncDeleteResult.getMessage());
}
return ResultEntity.success("删除成功");
}
}
调整完成之后,发起 http 请求,发现历史数据没有被清除,看日志发现
LOG.info("清空任务[taskId={}]历史数据", syncTask.getTaskId());
没有打印,参数明明传的是 true 吖!!!
offlineSyncApi.deleteTask(new SyncTaskDTO(1L, true));
这是哪里出了问题?

问题排查
因为 qsl-offline-sync-api 是直接引入的,并非我实现的,所以我第一时间找到了其实现者,反馈了问题后让其自测下;一开始他还很自信,说这么简单怎么会有问题
当他启动 qsl-offline-sync-server 后,发起 http 请求
POST http://localhost:8080/data-govern/sync/task/delete
Content-Type: application/json
{
"taskId": 123,
"isClearData": true
}
发现 isClearData 的值是 false
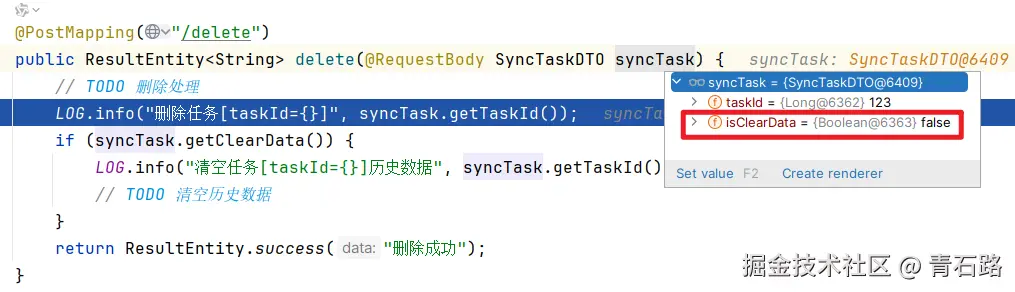
此刻,疑问从我的额头转移到了他的额头上,他懵逼了,我轻松了。为了功能能够正常交付,我还是决定看下这个问题,没有了心理压力,也许更容易发现问题所在。第一眼看到 isClearData,我就隐约觉得有问题,所以我决定仔细看下 SyncTaskDTO 这个类,发现 isClearData 的 setter 和 getter 方法有点不一样
private Boolean isClearData = false;
public Boolean getClearData() {
return isClearData;
}
public void setClearData(Boolean clearData) {
isClearData = clearData;
}
方法名是不是少了 Is?带着这个疑问我找到了同事,问他 setter 、getter 为什么要这么命名?他说是 idea 工具自动生成的(也就是我们平时用到的idea自动生成setter、getter方法的功能)
我让他把 Is 补上试试
private Boolean isClearData = false;
public Boolean getIsClearData() {
return isClearData;
}
public void setIsClearData(Boolean isClearData) {
this.isClearData = isClearData;
}
发现传值正常了,他回过头看着我,我看着他,两人同时提问
他:为什么加了
Is就可以了?
我:布尔类型的变量,你为什么要加
is前缀?
问题延申
作为一个严谨的开发,不只是要知其然,更要知其所以然;关于
为什么加了
Is就可以了
这个问题,我们肯定是要会上一会的;会这个问题之前,我们先来捋一下参数的流转,因为是基于 Spring MVC 实现的 Web 应用,所以我们可以这么问 deepseek
Spring MVC 是如何将前端参数转换成POJO的
能够查到如下重点信息
RequestResponseBodyMethodProcessor 的 resolveArgument
/**
* Throws MethodArgumentNotValidException if validation fails.
* @throws HttpMessageNotReadableException if {@link RequestBody#required()}
* is {@code true} and there is no body content or if there is no suitable
* converter to read the content with.
*/
@Override
public Object resolveArgument(MethodParameter parameter, @Nullable ModelAndViewContainer mavContainer,
NativeWebRequest webRequest, @Nullable WebDataBinderFactory binderFactory) throws Exception {
parameter = parameter.nestedIfOptional();
Object arg = readWithMessageConverters(webRequest, parameter, parameter.getNestedGenericParameterType());
String name = Conventions.getVariableNameForParameter(parameter);
if (binderFactory != null) {
WebDataBinder binder = binderFactory.createBinder(webRequest, arg, name);
if (arg != null) {
validateIfApplicable(binder, parameter);
if (binder.getBindingResult().hasErrors() && isBindExceptionRequired(binder, parameter)) {
throw new MethodArgumentNotValidException(parameter, binder.getBindingResult());
}
}
if (mavContainer != null) {
mavContainer.addAttribute(BindingResult.MODEL_KEY_PREFIX + name, binder.getBindingResult());
}
}
return adaptArgumentIfNecessary(arg, parameter);
}
正是解析参数的地方,我们打个断点,再发起一次 http 请求
很明显,readWithMessageConverters 是处理并转换参数的地方,继续跟进去会来到 MappingJackson2HttpMessageConverter 的 readJavaType 方法
此刻我们可以得到,是通过 jackson 完成数据绑定与数据转换的。继续跟进,会看到 isClearData 的赋值过程
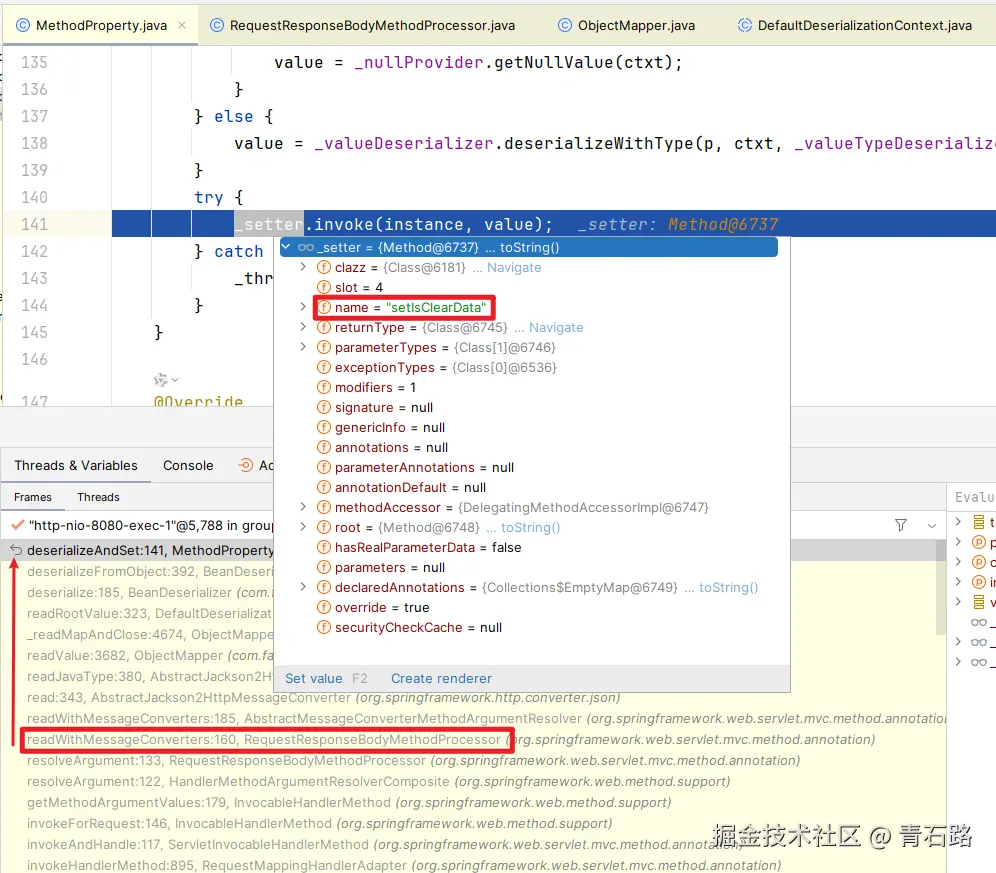
通过前端传过来的参数 isClearData 找对应的 setter方法是 setIsClearData,而非 setClearData,所以问题
为什么加了
Is就可以了
是不是就清楚了?
问题解决
- 按上述方式调整
isClearData的setter、getter方法
带上
is
public Boolean getIsClearData() {
return isClearData;
}
public void setIsClearData(Boolean isClearData) {
this.isClearData = isClearData;
}
- 布尔类型的变量,不用
is前缀
可以用
if前缀
private Boolean ifClearData = false;
public Boolean getIfClearData() {
return ifClearData;
}
public void setIfClearData(Boolean ifClearData) {
this.ifClearData = ifClearData;
}
- 可以结合
@JsonProperty来处理
@JsonProperty("isClearData")
private Boolean isClearData = false;
总结
Spring MVC对参数的绑定与转换,内容不同,采用的处理器也不同
- form表单数据(application/x-www-form-urlencoded)
处理器:
ServletModelAttributeMethodProcessor - JSON 数据 (application/json)
处理器:
RequestResponseBodyMethodProcessor
转换器:MappingJackson2HttpMessageConverter - 多部分文件 (multipart/form-data)
处理器:
MultipartResolver
- form表单数据(application/x-www-form-urlencoded)
POJO的布尔类型变量,不要加is前缀
命名不符合规范,集成第三方框架的时候就很容易出不好排查的问题
成不了规范的制定者,那就老老实实遵循规范!
来源:juejin.cn/post/7521642915278422070
这5种规则引擎,真香!
前言
核心痛点:业务规则高频变更与系统稳定性之间的矛盾
想象一个电商促销场景:
// 传统硬编码方式(噩梦开始...)
public BigDecimal calculateDiscount(Order order) {
BigDecimal discount = BigDecimal.ZERO;
if (order.getTotalAmount().compareTo(new BigDecimal("100")) >= 0) {
discount = discount.add(new BigDecimal("10"));
}
if (order.getUser().isVip()) {
discount = discount.add(new BigDecimal("5"));
}
// 更多if-else嵌套...
return discount;
}
当规则变成:"非VIP用户满200减30,VIP用户满150减40,且周二全场额外95折"时,代码将陷入维护地狱!
规则引擎通过分离规则逻辑解决这个问题:
- 规则外置存储(数据库/文件)
- 支持动态加载
- 声明式规则语法
- 独立执行环境
下面给大家分享5种常用的规则引擎,希望对你会有所帮助。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景题、面试真题、项目实战、工作内推什么都有。
核心痛点:业务规则高频变更与系统稳定性之间的矛盾
想象一个电商促销场景:
// 传统硬编码方式(噩梦开始...)
public BigDecimal calculateDiscount(Order order) {
BigDecimal discount = BigDecimal.ZERO;
if (order.getTotalAmount().compareTo(new BigDecimal("100")) >= 0) {
discount = discount.add(new BigDecimal("10"));
}
if (order.getUser().isVip()) {
discount = discount.add(new BigDecimal("5"));
}
// 更多if-else嵌套...
return discount;
}
当规则变成:"非VIP用户满200减30,VIP用户满150减40,且周二全场额外95折"时,代码将陷入维护地狱!
规则引擎通过分离规则逻辑解决这个问题:
- 规则外置存储(数据库/文件)
- 支持动态加载
- 声明式规则语法
- 独立执行环境
下面给大家分享5种常用的规则引擎,希望对你会有所帮助。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景题、面试真题、项目实战、工作内推什么都有。
1.五大常用规则引擎
1.1 Drools:企业级规则引擎扛把子
适用场景:
- 金融风控规则(上百条复杂规则)
- 保险理赔计算
- 电商促销体系
- 金融风控规则(上百条复杂规则)
- 保险理赔计算
- 电商促销体系
实战:折扣规则配置
// 规则文件 discount.drl
rule "VIP用户满100减20"
when
$user: User(level == "VIP")
$order: Order(amount > 100)
then
$order.addDiscount(20);
end
// 规则文件 discount.drl
rule "VIP用户满100减20"
when
$user: User(level == "VIP")
$order: Order(amount > 100)
then
$order.addDiscount(20);
end
Java调用代码:
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("discountSession");
kSession.insert(user);
kSession.insert(order);
kSession.fireAllRules();
优点:
- 完整的RETE算法实现
- 支持复杂的规则网络
- 完善的监控管理控制台
缺点:
- 学习曲线陡峭
- 内存消耗较大
- 需要依赖Kie容器
适合:不差钱的大厂,规则复杂度高的场景
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieSession kSession = kContainer.newKieSession("discountSession");
kSession.insert(user);
kSession.insert(order);
kSession.fireAllRules();
优点:
- 完整的RETE算法实现
- 支持复杂的规则网络
- 完善的监控管理控制台
缺点:
- 学习曲线陡峭
- 内存消耗较大
- 需要依赖Kie容器
适合:不差钱的大厂,规则复杂度高的场景
1.2 Easy Rules:轻量级规则引擎之王
适用场景:
- 参数校验
- 简单风控规则
- 审批流引擎
- 参数校验
- 简单风控规则
- 审批流引擎
注解式开发:
@Rule(name = "雨天打折规则", description = "下雨天全场9折")
public class RainDiscountRule {
@Condition
public boolean when(@Fact("weather") String weather) {
return "rainy".equals(weather);
}
@Action
public void then(@Fact("order") Order order) {
order.setDiscount(0.9);
}
}
@Rule(name = "雨天打折规则", description = "下雨天全场9折")
public class RainDiscountRule {
@Condition
public boolean when(@Fact("weather") String weather) {
return "rainy".equals(weather);
}
@Action
public void then(@Fact("order") Order order) {
order.setDiscount(0.9);
}
}
引擎执行:
RulesEngineParameters params = new RulesEngineParameters()
.skipOnFirstAppliedRule(true); // 匹配即停止
RulesEngine engine = new DefaultRulesEngine(params);
engine.fire(rules, facts);
优点:
- 五分钟上手
- 零第三方依赖
- 支持规则组合
缺点:
- 不支持复杂规则链
- 缺少可视化界面
适合:中小项目快速落地,开发人员不足时
RulesEngineParameters params = new RulesEngineParameters()
.skipOnFirstAppliedRule(true); // 匹配即停止
RulesEngine engine = new DefaultRulesEngine(params);
engine.fire(rules, facts);
优点:
- 五分钟上手
- 零第三方依赖
- 支持规则组合
缺点:
- 不支持复杂规则链
- 缺少可视化界面
适合:中小项目快速落地,开发人员不足时
1.3 QLExpress:阿里系脚本引擎之光
适用场景:
- 动态配置计算逻辑
- 财务公式计算
- 营销规则灵活变更
- 动态配置计算逻辑
- 财务公式计算
- 营销规则灵活变更
执行动态脚本:
ExpressRunner runner = new ExpressRunner();
DefaultContext context = new DefaultContext<>();
context.put("user", user);
context.put("order", order);
String express = "if (user.level == 'VIP') { order.discount = 0.85; }";
runner.execute(express, context, null, true, false);
ExpressRunner runner = new ExpressRunner();
DefaultContext context = new DefaultContext<>();
context.put("user", user);
context.put("order", order);
String express = "if (user.level == 'VIP') { order.discount = 0.85; }";
runner.execute(express, context, null, true, false);
高级特性:
// 1. 函数扩展
runner.addFunction("计算税费", new Operator() {
@Override
public Object execute(Object[] list) {
return (Double)list[0] * 0.06;
}
});
// 2. 宏定义
runner.addMacro("是否新用户", "user.regDays < 30");
优点:
- 脚本热更新
- 语法接近Java
- 完善的沙箱安全
缺点:
- 调试困难
- 复杂规则可读性差
适合:需要频繁修改规则的业务(如运营活动)
// 1. 函数扩展
runner.addFunction("计算税费", new Operator() {
@Override
public Object execute(Object[] list) {
return (Double)list[0] * 0.06;
}
});
// 2. 宏定义
runner.addMacro("是否新用户", "user.regDays < 30");
优点:
- 脚本热更新
- 语法接近Java
- 完善的沙箱安全
缺点:
- 调试困难
- 复杂规则可读性差
适合:需要频繁修改规则的业务(如运营活动)
1.4 Aviator:高性能表达式专家
适用场景:
- 实时定价引擎
- 风控指标计算
- 大数据字段加工
- 实时定价引擎
- 风控指标计算
- 大数据字段加工
性能对比(执行10万次):
// Aviator 表达式
Expression exp = AviatorEvaluator.compile("user.age > 18 && order.amount > 100");
exp.execute(map);
// Groovy 脚本
new GroovyShell().evaluate("user.age > 18 && order.amount > 100");
引擎 耗时 Aviator 220ms Groovy 1850ms
// Aviator 表达式
Expression exp = AviatorEvaluator.compile("user.age > 18 && order.amount > 100");
exp.execute(map);
// Groovy 脚本
new GroovyShell().evaluate("user.age > 18 && order.amount > 100");
| 引擎 | 耗时 |
|---|---|
| Aviator | 220ms |
| Groovy | 1850ms |
编译优化:
// 开启编译缓存(默认开启)
AviatorEvaluator.getInstance().useLRUExpressionCache(1000);
// 字节码生成模式(JDK8+)
AviatorEvaluator.setOption(Options.ASM, true);
优点:
- 性能碾压同类引擎
- 支持字节码生成
- 轻量无依赖
缺点:
- 只支持表达式
- 不支持流程控制
适合:对性能有极致要求的计算场景
// 开启编译缓存(默认开启)
AviatorEvaluator.getInstance().useLRUExpressionCache(1000);
// 字节码生成模式(JDK8+)
AviatorEvaluator.setOption(Options.ASM, true);
优点:
- 性能碾压同类引擎
- 支持字节码生成
- 轻量无依赖
缺点:
- 只支持表达式
- 不支持流程控制
适合:对性能有极致要求的计算场景
1.5 LiteFlow:规则编排新物种
适用场景:
- 复杂业务流程
- 订单状态机
- 审核工作流
- 复杂业务流程
- 订单状态机
- 审核工作流
编排示例:
<chain name="orderProcess">
<then value="checkStock,checkCredit"/>
<when value="isVipUser">
<then value="vipDiscount"/>
when>
<otherwise>
<then value="normalDiscount"/>
otherwise>
<then value="saveOrder"/>
chain>
<chain name="orderProcess">
<then value="checkStock,checkCredit"/>
<when value="isVipUser">
<then value="vipDiscount"/>
when>
<otherwise>
<then value="normalDiscount"/>
otherwise>
<then value="saveOrder"/>
chain>
Java调用:
LiteflowResponse response = FlowExecutor.execute2Resp("orderProcess", order, User.class);
if (response.isSuccess()) {
System.out.println("流程执行成功");
} else {
System.out.println("失败原因:" + response.getCause());
}
优点:
- 可视化流程编排
- 支持异步、并行、条件分支
- 热更新规则
缺点:
- 新框架文档较少
- 社区生态待完善
适合:需要灵活编排的复杂业务流
LiteflowResponse response = FlowExecutor.execute2Resp("orderProcess", order, User.class);
if (response.isSuccess()) {
System.out.println("流程执行成功");
} else {
System.out.println("失败原因:" + response.getCause());
}
优点:
- 可视化流程编排
- 支持异步、并行、条件分支
- 热更新规则
缺点:
- 新框架文档较少
- 社区生态待完善
适合:需要灵活编排的复杂业务流
2 五大规则引擎横向评测
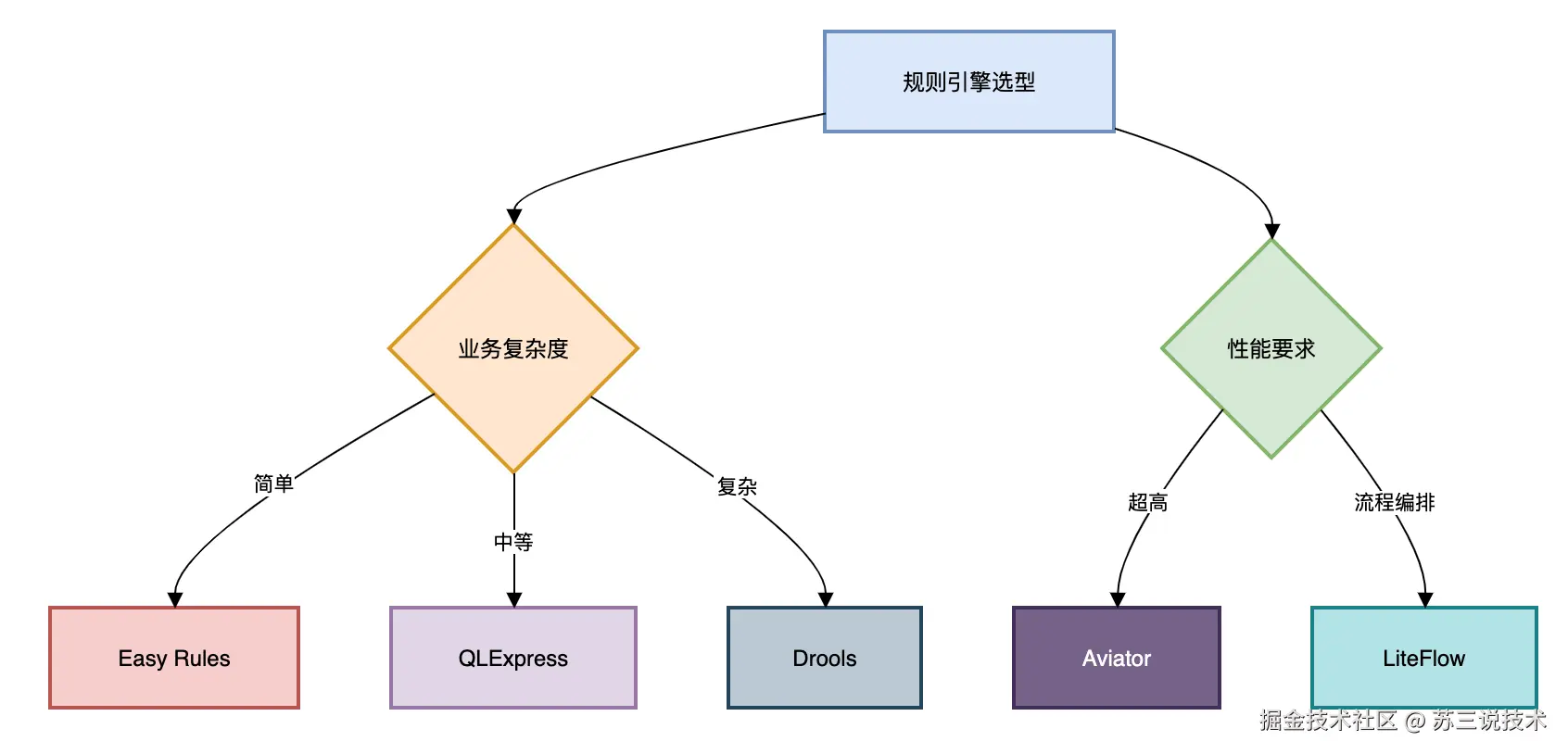
性能压测数据(单机1万次执行):
引擎 耗时 内存占用 特点 Drools 420ms 高 功能全面 Easy Rules 38ms 低 轻量易用 QLExpress 65ms 中 阿里系脚本引擎 Aviator 28ms 极低 高性能表达式 LiteFlow 120ms 中 流程编排专家
| 引擎 | 耗时 | 内存占用 | 特点 |
|---|---|---|---|
| Drools | 420ms | 高 | 功能全面 |
| Easy Rules | 38ms | 低 | 轻量易用 |
| QLExpress | 65ms | 中 | 阿里系脚本引擎 |
| Aviator | 28ms | 极低 | 高性能表达式 |
| LiteFlow | 120ms | 中 | 流程编排专家 |
3 如何技术选型?
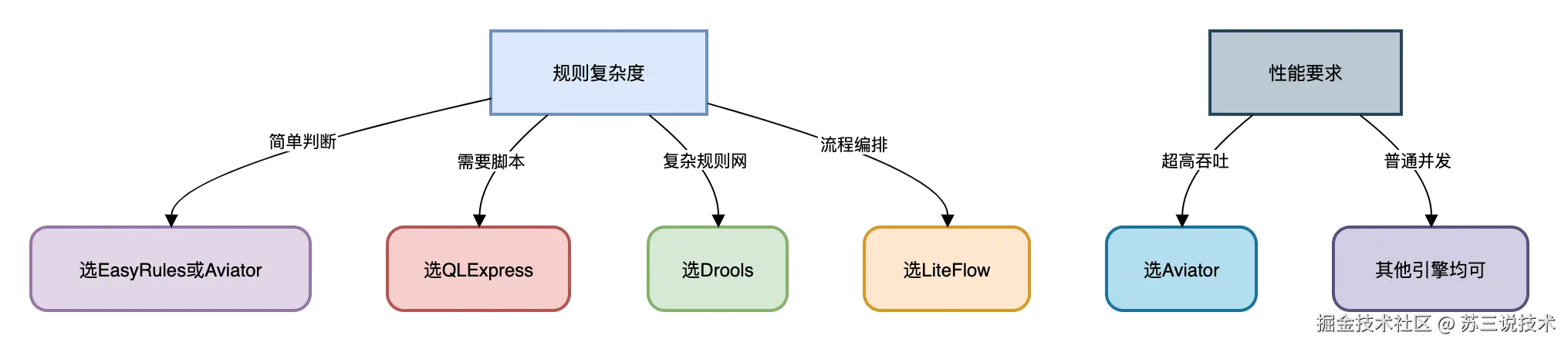
黄金法则:
- 简单场景:EasyRules + Aviator 组合拳
- 金融风控:Drools 稳如老狗
- 电商运营:QLExpress 灵活应变
- 工作流驱动:LiteFlow 未来可期
- 简单场景:EasyRules + Aviator 组合拳
- 金融风控:Drools 稳如老狗
- 电商运营:QLExpress 灵活应变
- 工作流驱动:LiteFlow 未来可期
4 避坑指南
- Drools内存溢出
// 设置无状态会话(避免内存积累)
KieSession session = kContainer.newStatelessKieSession();
- QLExpress安全漏洞
// 禁用危险方法
runner.addFunctionOfServiceMethod("exit", System.class, "exit", null, null);
- 规则冲突检测
// Drools冲突处理策略
KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration();
config.setProperty("drools.sequential", "true"); // 按顺序执行
- Drools内存溢出
// 设置无状态会话(避免内存积累)
KieSession session = kContainer.newStatelessKieSession();
- QLExpress安全漏洞
// 禁用危险方法
runner.addFunctionOfServiceMethod("exit", System.class, "exit", null, null);
// Drools冲突处理策略
KieSessionConfiguration config = KieServices.Factory.get().newKieSessionConfiguration();
config.setProperty("drools.sequential", "true"); // 按顺序执行
总结
- 能用:替换if/else(新手村)
- 用好:规则热更新+可视化(进阶)
- 用精:规则编排+性能优化(大师级)
- 能用:替换if/else(新手村)
- 用好:规则热更新+可视化(进阶)
- 用精:规则编排+性能优化(大师级)
曾有人问我:“规则引擎会不会让程序员失业?” 我的回答是:“工具永远淘汰不了思考者,只会淘汰手工作坊”。
真正的高手,不是写更多代码,而是用更优雅的方式解决问题。
最后送句话:技术选型没有最好的,只有最合适的。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
来源:juejin.cn/post/7517854096175988762
用户登录成功后,判断用户在10分钟内有没有操作,无操作自动退出登录怎么实现?
需求详细描述:用户登录成功后,默认带入10min的初始值,可针对该用户进行单独设置,单位:分钟,设置范围:1-15,用户在系统没有操作后满足该时长自动退出登录;
疑问:怎么判断用户在10分钟内有没有操作?
实现步骤
✅ 一、功能点描述:
默认超时时间,登录后默认为 10 分钟,
支持自定义设置 用户可修改自己的超时时间(1~15 分钟)
自动登出逻辑 用户在设定时间内没有“操作”,就触发登出.
✅ 二、关键问题:如何判断用户是否操作了?
🔍 操作的定义:
这里的“操作”可以理解为任何与页面交互的行为,
例如:
点击按钮、
鼠标移动、
键盘输入、
页面滚动、路由变化等。
✅ 三、解决方案:
使用全局事件监听器来检测用户的活跃状态,并重置计时器。
✅ 四、实现思路(Vue3 + Composition API)
我们可以通过以下步骤实现:
1. 定义一个响应式的 inactivityTime 变量(单位:分钟)
const inactivityTime = ref(10); // 默认10分钟
2. 创建一个定时器变量
let logoutTimer = null;
3. 重置定时器函数
function resetTimer() {
if (logoutTimer) {
clearTimeout(logoutTimer);
}
logoutTimer = setTimeout(() => {
console.log('用户已超时,执行登出');
// 这里执行登出操作,如清除 token、跳转到登录页等
store.dispatch('logout'); // 假设你用了 Vuex/Pinia
}, inactivityTime.value * 60 * 1000); // 转换为毫秒
}
4. 监听用户活动并重置定时器
function setupActivityListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.addEventListener(event, resetTimer, true);
});
}
function removeActivityListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.removeEventListener(event, resetTimer, true);
});
}
5. 在组件挂载时初始化定时器和监听器
<script setup>
import { ref, onMounted, onUnmounted } from 'vue';
import { useRouter } from 'vue-router';
const router = useRouter();
const inactivityTime = ref(10); // 默认10分钟
let logoutTimer = null;
function resetTimer() {
if (logoutTimer) {
clearTimeout(logoutTimer);
}
logoutTimer = setTimeout(() => {
alert('由于长时间未操作,您已被自动登出');
localStorage.removeItem('token'); // 清除 token
router.push('/login'); // 跳转到登录页
}, inactivityTime.value * 60 * 1000);
}
function setupActivityListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.addEventListener(event, resetTimer, true);
});
}
function removeActivityListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.removeEventListener(event, resetTimer, true);
});
}
onMounted(() => {
setupActivityListeners();
resetTimer(); // 初始化定时器
});
onUnmounted(() => {
removeActivityListeners();
if (logoutTimer) clearTimeout(logoutTimer);
});
</script>
✅ 四、支持用户自定义设置(进阶)
你可以通过接口获取用户的个性化超时时间:
// 假设你从接口获取到了用户的设置
api.getUserSettings().then(res => {
const userTimeout = res.autoLogoutTime; // 单位:分钟,假设值为 5-15
if (userTimeout >= 1 && userTimeout <= 15) {
inactivityTime.value = userTimeout;
resetTimer(); // 更新定时器
}
});
✅ 五、完整逻辑流程图(文字版)

✅ 六、注意事项
不要监听太少的事件,比如只监听 click,可能会漏掉键盘操作,
使用 true 参数添加事件监听器,表示捕获阶段监听,更可靠
多标签页场景,如果用户开了多个标签页,需考虑同步机制(比如使用 LocalStorage)
移动端适配,加入 touchstart 等移动端事件监听,
登出前最好加个提示,比如弹窗让用户选择是否继续会话。
✅ 七、推荐封装方式
你可以把这个逻辑封装成一个 Vue 自定义 Hook,例如 useAutoLogout.js,然后在需要的页面调用它即可。
// useAutoLogout.js
export function useAutoLogout(timeoutMinutes = 10) {
let timer = null;
function resetTimer() {
if (timer) clearTimeout(timer);
timer = setTimeout(() => {
alert('由于长时间未操作,您已被自动登出');
localStorage.removeItem('token');
window.location.href = '/login';
}, timeoutMinutes * 60 * 1000);
}
function setupListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.addEventListener(event, resetTimer, true);
});
}
function removeListeners() {
const events = ['click', 'mousemove', 'keydown', 'scroll', 'touchstart'];
events.forEach(event => {
window.removeEventListener(event, resetTimer, true);
});
}
onMounted(() => {
setupListeners();
resetTimer();
});
onUnmounted(() => {
removeListeners();
if (timer) clearTimeout(timer);
});
}
然后在组件中:
import { useAutoLogout } from '@/hooks/useAutoLogout'
export default {
setup() {
useAutoLogout(10); // 设置默认10分钟
}
}
✅ 八、总结:
实现方式:
判断用户是否有操作,监听 click、 mousemove、 keydown 等事件,
自动登出设置定时器,在无操作后触发,
用户自定义超时时间,接口获取后动态设置定时器时间,
页面间复用,封装为 Vue 自定义 Hook 更好维护。
使用优化
如果把它封装成一个自定义 Hook(如 useAutoLogout),这种写法确实需要在每个需要用到自动登出功能的页面里手动引入并调用它,麻烦且不优雅,不适合大型项目。
✅ 一、进阶方案:通过路由守卫自动注入
你可以利用 Vue Router 的 beforeEach 钩子,在用户进入页面时自动触发 useAutoLogout。
步骤如下:
- 创建一个可复用的方法(比如放到 utils.js 或 autoLogout.js 中)
// src/utils/autoLogout.js
import { useAutoLogout } from '@/hooks/useAutoLogout'
export function enableAutoLogout(timeout = 10) {
useAutoLogout(timeout)
}
2. 在路由配置中使用 meta 标记是否启用自动登出
// src/router/index.js
import { createRouter, createWebHistory } from 'vue-router';
import { useAutoLogout } from '@/hooks/useAutoLogout';
import store from './store'; // 假设你有一个 Vuex 或 Pinia 状态管理库用于保存用户设置
const routes = [
{
path: '/dashboard',
name: 'Dashboard',
component: () => import('@/views/Dashboard.vue'),
meta: { autoLogout: true } // 表示这个页面需要自动登出功能
},
{
path: '/login',
name: 'Login',
component: () => import('@/views/Login.vue')
// 不加 meta.autoLogout 表示不启用
}
];
const router = createRouter({
history: createWebHistory(),
routes,
});
router.beforeEach(async (to, from, next) => {
if (to.meta.autoLogout) {
// 获取用户的自定义超时时间
let timeout = 10; // 默认值
try {
// 这里假设从后端获取用户的自定义超时时间
const userSettings = await store.dispatch('fetchUserSettings'); // 根据实际情况调整
timeout = userSettings.autoLogoutTime || timeout;
} catch (error) {
console.error("Failed to fetch user settings:", error);
}
// 使用自定义超时时间初始化或重置计时器
const resetTimer = useAutoLogout(timeout);
resetTimer(); // 初始设置计时器
}
next();
});
export default router;
⚠️ 注意事项:
- 组件实例:
Vue 3 Composition API 中,不能直接在 beforeEach 中访问组件实例,需要把 enableAutoLogout 改为在组件内部调用,或者结合 Vuex/Pinia 做状态管理。 - 状态管理: 如果用户可以在应用运行期间更改其自动登出时间设置,你需要一种机制来实时更新这些设置。这通常涉及到状态管理库(如Vuex/Pinia)以及与后端同步用户偏好设置。
- 避免重复监听事件: 在每次导航时都添加新的事件监听器会导致内存泄漏。上述代码通过在组件卸载时移除监听器解决了这个问题,但如果你选择其他方式实现,请确保也处理了这一点。
- 用户体验: 在实际应用中,最好在即将登出前给用户提示,让用户有机会延长会话。
✅ 三、终极方案:创建一个全局插件(最优雅)
你可以把这个逻辑封装成一个 Vue 插件,这样只需要一次引入,就能全局生效。
示例:创建一个插件文件 autoLogoutPlugin.js
// src/plugins/autoLogoutPlugin.js
import { useAutoLogout } from '@/hooks/useAutoLogout'
export default {
install: (app, options = {}) => {
const timeout = options.timeout || 10
app.mixin({
setup() {
useAutoLogout(timeout)
}
})
}
}
使用插件:
// main.js
import AutoLogoutPlugin from './plugins/autoLogoutPlugin'
const app = createApp(App)
app.use(AutoLogoutPlugin, { timeout: 10 }) // 设置默认超时时间
app.mount('#app')
✅ 这样做之后,所有页面都会自动应用 useAutoLogout,无需手动导入。
插件使用解释
- ✅ export default 是一个 Vue 插件对象,必须包含 install 方法
Vue 插件是一个对象,它提供了一个 install(app, options) 方法。这个方法会在你调用 app.use(Plugin) 的时候执行。 - ✅ install: (app, options = {}) => { ... }
app: 是你的 Vue 应用实例(也就是通过 createApp(App) 创建的那个)
options: 是你在调用 app.use(AutoLogoutPlugin, { timeout: 10 }) 时传入的配置项
所以你可以在这里拿到你设置的超时时间 { timeout: 10 }。 - ✅ const timeout = options.timeout || 10
这是一个默认值逻辑:如果用户传了 timeout,就使用用户的;
否则使用默认值 10 分钟。 - ✅ app.mixin({ ... })
这是关键部分!
- 💡 什么是 mixin?
mixin 是 Vue 中的“混入”,可以理解为:向所有组件中注入一些公共的逻辑或配置。 - 举个例子:如果你有一个功能要在每个页面都启用,比如日志记录、权限检查、自动登出等,就可以用 mixin 实现一次写好,到处生效。
- ✅ setup() 中调用 useAutoLogout(timeout)
每个组件在创建时都会执行一次 setup() 函数。
在这里调用 useAutoLogout(timeout),相当于:
在每一个页面组件中都自动调用了 useAutoLogout(10)
也就是说,自动注册了监听器 + 自动设置了计时器
- 💡 什么是 mixin?
- 为什么这样就能全局监听用户操作?因为你在每个组件中都执行了 useAutoLogout(timeout),而这个函数内部做了以下几件事:
function useAutoLogout(timeout) {
// 设置定时器
// 添加事件监听器(点击、移动鼠标、键盘输入等)
// 组件卸载时清除监听器和定时器
}
因此,只要某个组件被加载,就会自动启动自动登出机制;组件卸载后,又会自动清理资源,避免内存泄漏。
总结一下整个流程
1️⃣ 在 main.js 中调用 app.use(AutoLogoutPlugin, { timeout: 10 })
2️⃣ 插件的 install() 被执行,获取到 timeout 值
3️⃣ 使用 app.mixin() 向所有组件中注入一段逻辑
4️⃣ 每个组件在 setup() 阶段自动调用 useAutoLogout(timeout)
5️⃣ 每个组件都注册了全局事件监听器,并设置了登出定时器
✅ 这样一来,所有组件页面都拥有了自动登出功能,不需要你手动去每个页面加代码。
注意事项
❗ 不是所有页面都需要自动登出 比如登录页、错误页可能不需要。可以在 mixin 中加判断,例如:根据路由或 meta 字段过滤
⚠️ 性能问题? 不会有明显影响,因为只添加了一次监听器,且组件卸载时会清理
🔄 登录后如何动态更新超时时间? 可以结合 Vuex/Pinia,在 store 改变时重新调用 useAutoLogout(newTimeout)
🧪 测试建议 手动测试几种情况:
• 页面切换是否重置计时
• 用户操作是否刷新倒计时
• 超时后是否跳转登录页
进阶建议:支持按需开启(可选)
如果你想只在某些页面启用自动登出功能,而不是全局启用,也可以这样改写:
app.mixin({
setup() {
// 判断当前组件是否启用了 autoLogout
const route = useRoute()
if (route.meta.autoLogout !== false) {
useAutoLogout(timeout)
}
}
})
然后在路由配置中:
{
path: '/dashboard',
name: 'Dashboard',
component: () => import('@/views/Dashboard.vue'),
meta: { autoLogout: true }
}
最终效果你只需要在 main.js 中引入插件并配置一次:
app.use(AutoLogoutPlugin, { timeout: 10 })
就能让整个项目中的所有页面都拥有自动登出功能,无需在每个页面单独导入和调用。
✅ 四、总结对比
🟢 大型项目、统一行为控制,所有页面都启用自动登出 ➜ 推荐使用 插件方式
🟡 中型项目、统一管理页面行为,只在某些页面启用 ➜ 推荐使用 路由守卫 + meta
🔴 小型项目、部分页面控制,只在个别页面启用 ➜ 继续使用 手动调用
来源:juejin.cn/post/7510044998433030180
如何优雅的防止按钮重复点击
1. 业务背景
在前端的业务场景中:点击按钮,发起请求。在请求还未结束的时候,一个按钮可以重复点击,导致接口重新请求多次(如果后端不做限制)。轻则浪费服务器资源,重则业务逻辑错误,尤其是入库操作。
传统解决方案:使用防抖函数,但是无法解决接口响应时间过长的问题,当接口一旦响应时间超过防抖时间,测试单身20年的手速照样还是可以点击多次。
更稳妥的方式:给button添加loadng,只有接口响应结果后才能再次点击按钮。需要在每个使用按钮的页面逻辑中单独维护loading变量,代码变得臃肿。
那如果是在react项目中,这种问题有没有比较优雅的解决方式呢?
vue项目解决方案参考:juejin.cn/post/749541…
在前端的业务场景中:点击按钮,发起请求。在请求还未结束的时候,一个按钮可以重复点击,导致接口重新请求多次(如果后端不做限制)。轻则浪费服务器资源,重则业务逻辑错误,尤其是入库操作。
传统解决方案:使用防抖函数,但是无法解决接口响应时间过长的问题,当接口一旦响应时间超过防抖时间,测试单身20年的手速照样还是可以点击多次。
更稳妥的方式:给button添加loadng,只有接口响应结果后才能再次点击按钮。需要在每个使用按钮的页面逻辑中单独维护loading变量,代码变得臃肿。
那如果是在react项目中,这种问题有没有比较优雅的解决方式呢?
vue项目解决方案参考:juejin.cn/post/749541…
2. useAsyncButton
在 React 项目中,对于这种按钮重复点击的问题,可以使用自定义 Hook 来优雅地处理。以下是一个完整的解决方案:
- 首先创建一个自定义 Hook
useAsyncButton:
import { useState, useCallback } from 'react';
interface RequestOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: RequestOptions = {}
) {
const [loading, setLoading] = useState(false);
const run = useCallback(
async (...args: any[]) => {
if (loading) return; // 如果正在加载,直接返回
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, requestFn, options]
);
return {
loading,
run
};
}
- 在组件中使用这个 Hook:
import { useAsyncButton } from '../hooks/useAsyncButton';
const MyButton = () => {
const { loading, run } = useAsyncButton(async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}, {
onSuccess: (data) => {
console.log('请求成功:', data);
},
onError: (error) => {
console.error('请求失败:', error);
}
});
return (
<button
onClick={() => run()}
disabled={loading}
>
{loading ? '加载中...' : '点击请求'}
button>
);
};
export default MyButton;
在 React 项目中,对于这种按钮重复点击的问题,可以使用自定义 Hook 来优雅地处理。以下是一个完整的解决方案:
- 首先创建一个自定义 Hook
useAsyncButton:
import { useState, useCallback } from 'react';
interface RequestOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: RequestOptions = {}
) {
const [loading, setLoading] = useState(false);
const run = useCallback(
async (...args: any[]) => {
if (loading) return; // 如果正在加载,直接返回
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, requestFn, options]
);
return {
loading,
run
};
}
- 在组件中使用这个 Hook:
import { useAsyncButton } from '../hooks/useAsyncButton';
const MyButton = () => {
const { loading, run } = useAsyncButton(async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}, {
onSuccess: (data) => {
console.log('请求成功:', data);
},
onError: (error) => {
console.error('请求失败:', error);
}
});
return (
<button
onClick={() => run()}
disabled={loading}
>
{loading ? '加载中...' : '点击请求'}
button>
);
};
export default MyButton;
这个解决方案有以下优点:
- 统一管理:将请求状态管理逻辑封装在一个 Hook 中,避免重复代码
- 自动处理 loading:不需要手动管理 loading 状态
- 防重复点击:在请求过程中自动禁用按钮或阻止重复请求
- 类型安全:使用 TypeScript 提供类型检查
- 灵活性:可以通过 options 配置成功/失败的回调函数
- 可复用性:可以在任何组件中重用这个 Hook
useAsyncButton直接帮你进行了try catch,你不用再单独去做异常处理。
是不是很简单?有的人可能有疑问了,为什么下方不就能拿到接口请求以后的数据吗?为什么还需要onSuccess呢?
async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}
3. onSuccess
确实我们可以直接在调用 run() 后通过 .then() 或 await 来获取数据。提供 onSuccess 回调主要有以下几个原因:
- 关注点分离:
// 不使用 onSuccess
const { run } = useAsyncButton(async () => {
const response = await fetch('/api/data');
return response.json();
});
const handleClick = async () => {
const data = await run();
// 处理数据的逻辑和请求逻辑混在一起
setData(data);
message.success('请求成功');
doSomethingElse(data);
};
// 使用 onSuccess
const { run } = useAsyncButton(async () => {
const response = await fetch('/api/data');
return response.json();
}, {
onSuccess: (data) => {
// 数据处理逻辑被清晰地分离出来
setData(data);
message.success('请求成功');
doSomethingElse(data);
}
});
const handleClick = () => {
run(); // 更清晰的调用方式
};
- 统一错误处理:
// 不使用 callbacks
const handleClick = async () => {
try {
const data = await run();
setData(data);
} catch (error) {
// 每个地方都需要写错误处理
message.error('请求失败');
}
};
// 使用 callbacks
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => setData(data),
onError: (error) => message.error('请求失败')
// 错误处理被集中管理
});
- 自动重试场景:
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => setData(data),
onError: (error) => {
if (retryCount < 3) {
retryCount++;
run(); // 可以在失败时自动重试
}
}
});
- 状态联动:
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => {
setData(data);
// 可能需要触发其他请求
refetchRelatedData();
// 或更新其他状态
setOtherState(true);
}
});
所以,虽然你完全可以不使用 onSuccess 回调,但它能帮助你:
- 更好地组织代码结构
- 统一管理成功/失败处理逻辑
- 方便进行状态联动
- 在需要扩展功能时更加灵活
选择使用与否取决于你的具体需求,如果是简单的场景,直接使用 await run() 也完全可以。
4. 禁止一段时间内点击
评论区有人说了,我要是想在某一段时间内防止重复点击怎么整?
我们可以扩展 useAsyncButton 的功能,添加一个防冷却时间(cooldown)的特性。这在一些特定场景下很有用,比如发送验证码按钮需要等待 60 秒才能再次点击:
import { useState, useCallback, useRef } from 'react';
interface AsyncButtonOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
cooldown?: number; // 冷却时间(毫秒)
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: AsyncButtonOptions = {}
) {
const [loading, setLoading] = useState(false);
const [cooldownRemaining, setCooldownRemaining] = useState(0);
const timerRef = useRef<NodeJS.Timeout>();
const startCooldown = useCallback(() => {
if (!options.cooldown) return;
setCooldownRemaining(options.cooldown / 1000);
const startTime = Date.now();
timerRef.current = setInterval(() => {
const elapsed = Date.now() - startTime;
const remaining = Math.ceil((options.cooldown! - elapsed) / 1000);
if (remaining <= 0) {
clearInterval(timerRef.current);
setCooldownRemaining(0);
} else {
setCooldownRemaining(remaining);
}
}, 1000);
}, [options.cooldown]);
const run = useCallback(
async (...args: any[]) => {
if (loading || cooldownRemaining > 0) return;
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
startCooldown();
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, cooldownRemaining, requestFn, options, startCooldown]
);
return {
loading,
cooldownRemaining,
run,
disabled: loading || cooldownRemaining > 0
};
}
使用示例:
import { useAsyncButton } from '../hooks/useAsyncButton';
const SendCodeButton = () => {
const { loading, cooldownRemaining, disabled, run } = useAsyncButton(
async () => {
// 发送验证码的接口请求
const response = await fetch('/api/send-code');
return response.json();
},
{
cooldown: 60000, // 60秒冷却时间
onSuccess: () => {
console.log('验证码发送成功');
},
onError: (error) => {
console.error('验证码发送失败', error);
}
}
);
return (
<button
onClick={() => run()}
disabled={disabled}
>
{loading ? '发送中...' :
cooldownRemaining > 0 ? `${cooldownRemaining}秒后重试` :
'发送验证码'}
button>
);
};
export default SendCodeButton;
来源:juejin.cn/post/7498646341460787211
为什么说不可信的Wi-Fi不要随便连接?
新闻中一直倡导的“不可信的Wi-Fi不要随便连接”,一直不知道里面的风险,即使是相关专业的从业人员,惭愧。探索后发现这里面的安全知识不少,记录下:
简单来说:
当用户连接上攻击者创建的伪造热点或者不可信的wifi后,实际上就进入了一个高度不可信的网络环境,攻击者可以进行各种信息窃取、欺骗和控制操作。
主要风险有:
🚨 1.中间人攻击(MITM)
攻击者拦截并转发你与网站服务器之间的数据,做到“你以为你连的是官网,其实中间有人”。
- 可窃取账号密码、聊天记录、信用卡信息
- 可篡改网页内容,引导你下载恶意应用
如果你和“正确”的网站之间是https,那么信息不会泄露,TLS能保证通信过程的安全,前提是你连接的这个https网站是“正确”的。正确的含义是:不是某些人恶意伪造的,不是一些不法份子通过DNS欺骗来重定向到的。
🪤 2.DNS欺骗 / 重定向
攻击者控制DNS,将合法网址解析到伪造网站。
- 你访问的“http://www.bank.com” 其实是假的银行网站,DNS域名解析到恶意服务上,返回和银行一样的登录的界面,这样用户输入账号密码就被窃取到了。
- 输入的账号密码被记录,后端没收到任何请求
这里多说一句:目前的登录方式中,采用短信验证码的方式,能避免真实的密码被窃取的风险,尽量用这种登录方式。
📥 3.强制HTTP连接,篡改内容
即使你访问的是HTTPS网站,攻击者可以强制降级为HTTP或注入恶意代码:
- 注入广告、木马脚本
- 启动钓鱼表单页面骗你输入账号密码
攻击者操作流程:
- 用户访问
http://example.com(明文) - 攻击者拦截请求,阻止它跳转到 HTTPS
- 返回伪造页面(比如仿登录页面),引导用户输入账号密码
- 用户完全不知道自己并未进入 HTTPS 页面
这里“降级”的意思是,虽然你访问的是http网站,网站正常会转为https的访问方式,但是被阻止了,一直使用的是http协议访问,能实现这种降级的前提有两个:
- 用户没有直接输入
https://baidu.com, 而是输入的http://baidu.com, 依赖浏览器自动跳转 - 访问的网站没有开启 HSTS(HTTP Strict Transport Security)
搭建安全的网站的启示:
- 网站访问用https,并且如果用户访问HTTP网站时被自动转到 HTTPS 网站
- 网站要启用HSTS
HSTS 是一种告诉浏览器“以后永远都不要使用 HTTP 访问我”的机制。
如何开启HSTS?
添加响应头(核心方式)
。在你的网站服务端(如 Nginx、Apache、Spring Boot、Express 等)添加以下 HTTP 响应头:
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
各参数含义如下:
| 参数 | 含义 |
|---|---|
max-age=31536000 | 浏览器记住 HSTS 状态的时间(单位:秒,31536000 秒 = 1 年) |
includeSubDomains | 所有子域名也强制使用 HTTPS(推荐) |
preload | 提交到浏览器 HSTS 预加载列表(详见下文) |
网站实现http访问转为了https访问:
1 网站服务器配置了自动重定向(HTTP to HTTPS)
- 这是最常见的做法。网站后台(如 Nginx、Apache、Tomcat 等)配置了规则,凡是 HTTP 请求都会返回 301/302 重定向到 HTTPS 地址。
- 目的是强制用户用加密的 HTTPS 访问,保障数据安全。
2 请求的http response中加入HSTS机制
- 网站通过 HTTPS 响应头发送了 HSTS 指令。
- 浏览器收到后会记住该网站在一定时间内只能用 HTTPS 访问。
- 即使你输入
http://,浏览器也会自动用https://访问,且不会发送 HTTP 请求。
📁 4.会话劫持(Session Hijacking)
如果你已登录某个网站(如微博/邮箱),攻击者可以窃取你与服务端之间的 Session Cookie,无需密码即可“冒充你”。
搭建web服务对于cookie泄密的安全启示:
1、开启 Cookie 的 Secure 和 HttpOnly
当一个 Cookie 设置了 Secure 标志后,它只会在 HTTPS 加密连接中发送,不会通过 HTTP 明文连接发送。
设置 HttpOnly 后,JavaScript 无法通过 document.cookie 访问该 Cookie,它只能被浏览器在请求时自动带上。如果站点存在跨站脚本漏洞(XSS),攻击者注入的 JS 可以读取用户的 Cookie。设置了 HttpOnly 后,即便 JS 被执行,也无法读取该 Cookie。
2、配合设置 SameSite=Strict 或 Lax 可进一步防止 CSRF 攻击。
Set-Cookie: sessionid=abc123; SameSite=Strict; Secure; HttpOnly
CSRF(Cross-Site Request Forgery) 攻击的原理示意
| 操作 | 说明 |
|---|---|
用户登录 bank.com,浏览器存有 bank.com 的 Cookie | Cookie 设置为非 HttpOnly 且未限制 SameSite 或 设置为 SameSite=Lax,正常携带 |
攻击网站 attacker.com,诱导用户访问 <img src="https://bank.com/transfer?to=attacker&amount=1000"> | 这个请求是向 bank.com 发送的跨域请求 |
浏览器自动带上 bank.com 的 Cookie | 因为请求的目标是 bank.com,Cookie 会被自动携带 |
bank.com 服务器收到请求,认为是用户本人操作,执行转账 | 服务器无法区分这个请求是不是用户主动发起的 |
重点是:你在浏览器中访问A网站,浏览器中存储A的cookie,此时你访问恶意的B网站,B网站向A网站发送请求,浏览器一般默认带上A网站的cookie,因此,相当于B网站恶意使用了你在A网站的身份,完成了攻击,比如获取信息,比如添加东西。设置SameSite=Strict能防止跨站伪造攻击,对A网站的请求只能在A网站下发送,在B网站发起对A网站请求的无法使用A的cookie
同源策略和Cookie的关系:
同源策略限制的是脚本访问另一个域的内容(比如 JS 不能读取别的网站 Cookie 或响应数据),但浏览器发送请求时,会自动携带目标域对应的 Cookie(只要该 Cookie 未被 SameSite 限制)。 也就是说,请求可以跨域发送,Cookie 也会随请求自动发送,但脚本无法读取响应。在没有设置SameSite时,B网站是可以直接往A网站发送请求并附带上A网站的cookie的。
关于SameSite三种取值详解:
| 值 | 说明 | 是否防CSRF | 是否影响用户体验 |
|---|---|---|---|
Strict | 最严格:完全阻止第三方请求携带 Cookie(即使用户点击链接跳转也不带) | ✅ 完全防止 | ❗️可能影响登录态保持等 |
Lax | 较宽松:阻止大多数第三方请求,但允许用户主动导航(点击链接)时携带 Cookie | ✅ 可防大部分场景 | ✅ 用户体验良好 |
| 不限制跨站请求,所有请求都携带 Cookie | ❌ 不防CSRF | ⚠️ 必须配合 Secure 使用 |
🛡 SameSite使用建议(最佳实践)
| 场景 | 建议配置 |
|---|---|
| 登录态/session Cookie | SameSite=Lax; Secure; HttpOnly ✅ 实用且安全 |
| 高安全需求(如金融后台) | SameSite=Strict; Secure; HttpOnly ✅ 更强安全性 |
| 跨域 OAuth / 第三方登录等 | SameSite=; Secure ⚠️ 必须使用 HTTPS,否则被浏览器拒绝 |
🧬 5.恶意软件传播
伪造热点可提供假的软件下载链接、更新提示等方式传播病毒或木马程序。
📡 6.网络钓鱼 + 社会工程攻击
攻击者可能弹出“需登录使用Wi-Fi”的界面,其实是钓鱼网站:
- 模拟常见的Wi-Fi登录界面(如酒店/机场门户)
- 用户一旦输入账号、手机号、验证码等敏感信息就被窃取
🔎 7.MAC地址、设备指纹收集
哪怕你没主动上网,连接伪热点后,攻击者也可能收集:
- 你的设备MAC地址、品牌型号
- 操作系统、语言、浏览器等指纹信息
- 用于后续追踪、精准广告投放,甚至诈骗定位
✅ 如何防范被伪热点攻击?
| 措施 | 说明 |
|---|---|
| 关闭“自动连接开放Wi-Fi” | 阻止设备自动连接伪热点 |
| 避免输入账号密码、支付信息 | 尤其在陌生Wi-Fi环境下 |
| 使用 VPN | 建立安全通道防止数据被截取 |
| 留意HTTPS证书异常 | 浏览器地址栏变红或提示“不安全”要立刻断开连接 |
| 使用手机流量热点 | 相对更可控安全 |
| 安装安全软件 | 检测钓鱼网站和网络攻击行为 |
来源:juejin.cn/post/7517468634194362387
瞧瞧别人家的判空,那叫一个优雅!
大家好,我是苏三,又跟大家见面了。
一、传统判空的血泪史
某互联网金融平台因费用计算层级的空指针异常,导致凌晨产生9800笔错误交易。
DEBUG日志显示问题出现在如下代码段:
// 错误示例
BigDecimal amount = user.getWallet().getBalance().add(new BigDecimal("100"));
此类链式调用若中间环节出现null值,必定导致NPE。
初级阶段开发者通常写出多层嵌套式判断:
if(user != null){
Wallet wallet = user.getWallet();
if(wallet != null){
BigDecimal balance = wallet.getBalance();
if(balance != null){
// 实际业务逻辑
}
}
}
这种写法既不优雅又影响代码可读性。
那么,我们该如何优化呢?
最近准备面试的小伙伴,可以看一下这个宝藏网站:www.susan.net.cn,里面:面试八股文、面试真题、工作内推什么都有。
二、Java 8+时代的判空革命
Java8之后,新增了Optional类,它是用来专门判空的。
能够帮你写出更加优雅的代码。
1. Optional黄金三板斧
// 重构后的链式调用
BigDecimal result = Optional.ofNullable(user)
.map(User::getWallet)
.map(Wallet::getBalance)
.map(balance -> balance.add(new BigDecimal("100")))
.orElse(BigDecimal.ZERO);
高级用法:条件过滤
Optional.ofNullable(user)
.filter(u -> u.getVipLevel() > 3)
.ifPresent(u -> sendCoupon(u)); // VIP用户发券
2. Optional抛出业务异常
BigDecimal balance = Optional.ofNullable(user)
.map(User::getWallet)
.map(Wallet::getBalance)
.orElseThrow(() -> new BusinessException("用户钱包数据异常"));
3. 封装通用工具类
public class NullSafe {
// 安全获取对象属性
public static <T, R> R get(T target, Function<T, R> mapper, R defaultValue) {
return target != null ? mapper.apply(target) : defaultValue;
}
// 链式安全操作
public static <T> T execute(T root, Consumer<T> consumer) {
if (root != null) {
consumer.accept(root);
}
return root;
}
}
// 使用示例
NullSafe.execute(user, u -> {
u.getWallet().charge(new BigDecimal("50"));
logger.info("用户{}已充值", u.getId());
});
三、现代化框架的判空银弹
4. Spring实战技巧
Spring中自带了一些好用的工具类,比如:CollectionUtils、StringUtils等,可以非常有效的进行判空。
具体代码如下:
// 集合判空工具
List<Order> orders = getPendingOrders();
if (CollectionUtils.isEmpty(orders)) {
return Result.error("无待处理订单");
}
// 字符串检查
String input = request.getParam("token");
if (StringUtils.hasText(input)) {
validateToken(input);
}
5. Lombok保驾护航
我们在日常开发中的entity对象,一般会使用Lombok框架中的注解,来实现getter/setter方法。
其实,这个框架中也提供了@NonNull等判空的注解。
比如:
@Getter
@Setter
public class User {
@NonNull // 编译时生成null检查代码
private String name;
private Wallet wallet;
}
// 使用构造时自动判空
User user = new User(@NonNull "张三", wallet);
四、工程级解决方案
6. 空对象模式
public interface Notification {
void send(String message);
}
// 真实实现
public class EmailNotification implements Notification {
@Override
public void send(String message) {
// 发送邮件逻辑
}
}
// 空对象实现
public class NullNotification implements Notification {
@Override
public void send(String message) {
// 默认处理
}
}
// 使用示例
Notification notifier = getNotifier();
notifier.send("系统提醒"); // 无需判空
7. Guava的Optional增强
其实Guava工具包中,给我们提供了Optional增强的功能。
比如:
import com.google.common.base.Optional;
// 创建携带缺省值的Optional
Optional<User> userOpt = Optional.fromNullable(user).or(defaultUser);
// 链式操作配合Function
Optional<BigDecimal> amount = userOpt.transform(u -> u.getWallet())
.transform(w -> w.getBalance());
Guava工具包中的Optional类已经封装好了,我们可以直接使用。
五、防御式编程进阶
8. Assert断言式拦截
其实有些Assert断言类中,已经做好了判空的工作,参数为空则会抛出异常。
这样我们就可以直接调用这个断言类。
例如下面的ValidateUtils类中的requireNonNull方法,由于它内容已经判空了,因此,在其他地方调用requireNonNull方法时,如果为空,则会直接抛异常。
我们在业务代码中,直接调用requireNonNull即可,不用写额外的判空逻辑。
例如:
public class ValidateUtils {
public static <T> T requireNonNull(T obj, String message) {
if (obj == null) {
throw new ServiceException(message);
}
return obj;
}
}
// 使用姿势
User currentUser = ValidateUtils.requireNonNull(
userDao.findById(userId),
"用户不存在-ID:" + userId
);
最近就业形势比较困难,为了感谢各位小伙伴对苏三一直以来的支持,我特地创建了一些工作内推群, 看看能不能帮助到大家。
你可以在群里发布招聘信息,也可以内推工作,也可以在群里投递简历找工作,也可以在群里交流面试或者工作的话题。
添加苏三的私人微信:li_su223,备注:掘金+所在城市,即可加入。
9. 全局AOP拦截
我们在一些特殊的业务场景种,可以通过自定义注解 + 全局AOP拦截器的方式,来实现实体或者字段的判空。
例如:
@Aspect
@Component
public class NullCheckAspect {
@Around("@annotation(com.xxx.NullCheck)")
public Object checkNull(ProceedingJoinPoint joinPoint) throws Throwable {
Object[] args = joinPoint.getArgs();
for (Object arg : args) {
if (arg == null) {
throw new IllegalArgumentException("参数不可为空");
}
}
return joinPoint.proceed();
}
}
// 注解使用
public void updateUser(@NullCheck User user) {
// 方法实现
}
六、实战场景对比分析
场景1:深层次对象取值
// 旧代码(4层嵌套判断)
if (order != null) {
User user = order.getUser();
if (user != null) {
Address address = user.getAddress();
if (address != null) {
String city = address.getCity();
// 使用city
}
}
}
// 重构后(流畅链式)
String city = Optional.ofNullable(order)
.map(Order::getUser)
.map(User::getAddress)
.map(Address::getCity)
.orElse("未知城市");
场景2:批量数据处理
List<User> users = userService.listUsers();
// 传统写法(显式迭代判断)
List<String> names = new ArrayList<>();
for (User user : users) {
if (user != null && user.getName() != null) {
names.add(user.getName());
}
}
// Stream优化版
List<String> nameList = users.stream()
.filter(Objects::nonNull)
.map(User::getName)
.filter(Objects::nonNull)
.collect(Collectors.toList());
七、性能与安全的平衡艺术
上面介绍的这些方案都可以使用,但除了代码的可读性之外,我们还需要考虑一下性能因素。
下面列出了上面的几种在CPU消耗、内存只用和代码可读性的对比:
| 方案 | CPU消耗 | 内存占用 | 代码可读性 | 适用场景 |
|---|---|---|---|---|
| 多层if嵌套 | 低 | 低 | ★☆☆☆☆ | 简单层级调用 |
| Java Optional | 中 | 中 | ★★★★☆ | 中等复杂度业务流 |
| 空对象模式 | 高 | 高 | ★★★★★ | 高频调用的基础服务 |
| AOP全局拦截 | 中 | 低 | ★★★☆☆ | 接口参数非空验证 |
黄金法则
- Web层入口强制参数校验
- Service层使用Optional链式处理
- 核心领域模型采用空对象模式
八、扩展技术
除了,上面介绍的常规判空之外,下面再给大家介绍两种扩展的技术。
Kotlin的空安全设计
虽然Java开发者无法直接使用,但可借鉴其设计哲学:
val city = order?.user?.address?.city ?: "default"
JDK 14新特性预览
// 模式匹配语法尝鲜
if (user instanceof User u && u.getName() != null) {
System.out.println(u.getName().toUpperCase());
}
总之,优雅判空不仅是代码之美,更是生产安全底线。
本文分享了代码判空的10种方案,希望能够帮助你编写出既优雅又健壮的Java代码。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的50万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
来源:juejin.cn/post/7478221220074504233
什么语言最适合用来游戏开发?
什么语言最适合用来游戏开发?
游戏开发,是一项结合了图形渲染、性能优化、系统架构与玩家体验的综合艺术,而“选用什么编程语言”这个问题,往往是新手开发者迈入这片领域时面临的第一个技术岔路口。
一、从需求出发:游戏开发对语言的核心要求
在选择语言之前,我们先明确一点:游戏类型不同,对语言的要求也大不一样。开发 3D AAA 大作和做一个像素风的休闲小游戏,使用的语言和引擎可能完全不同。
一般来说,语言选择需要考虑:
| 维度 | 说明 |
|---|---|
| 性能需求 | 是否要求极致性能(如大型 3D 游戏)? |
| 跨平台能力 | 是否要支持多个平台(Windows/Mac/Linux/iOS/Android/主机)? |
| 引擎生态 | 是否依赖成熟的游戏引擎(如 Unity、Unreal)? |
| 开发效率 | 团队大小如何?语言是否有丰富工具链、IDE 支持、调试便利性? |
| 学习曲线 | 是个人项目还是商业项目?是否有足够时间去掌握复杂语法或底层结构? |
二、主流语言实战解析
C++:3A最常用的语言
- 适合场景:大型 3D 游戏、主机平台、UE(Unreal Engine)项目
- 特点:
- 几乎所有主流游戏引擎底层都是用 C++ 编写的(UE4/5、CryEngine 等)
- 手动内存管理带来极致性能控制,但也带来更高的 bug 风险
- 编译时间长、语法复杂,不适合快速原型开发
如果你追求的是性能边界、需要对引擎源码进行改造,或者准备进入 3A 游戏开发领域,C++ 是必修课。
C#:Unity 的生态核心
- 适合场景:中小型游戏、独立游戏、跨平台移动/PC 游戏、Unity 项目
- 特点:
- Unity 的脚本语言就是 C#,生态丰富、社区活跃、教程资源丰富
- 开发效率高,语法现代,有良好的 IDE 支持(VS、Rider)
- 在性能上不如 C++,但对大多数项目而言“够用”
如果你是个人开发者或小团队,C# + Unity 几乎是性价比最高的方案之一。
JavaScript/TypeScript:Web 游戏与轻量跨平台
- 适合场景:H5 游戏、小程序游戏、跨平台 2D 游戏、快速迭代
- 特点:
- 配合 Phaser、PixiJS、Cocos Creator 等框架,可以高效制作 Web 游戏
- 原生支持浏览器平台,无需安装,天然适合传播
- 性能不及原生语言,但足以支撑休闲游戏
Web 平台的红利尚未过去,JS/TS + WebGL 仍然是轻量化游戏开发的稳定选择。
Python/Lua:脚本语言发力
- 适合场景:游戏逻辑脚本、AI 行为树、数据驱动配置、教学引擎
- 特点:
- 并不适合用来开发整款游戏,但常作为内嵌脚本语言
- Lua 广泛用于游戏脚本(如 WOW、GTA、Roblox),轻量、运行效率高
- Python 适合教学、原型设计、AI 模块等场景
他们更多是游戏开发的一环,而非“用来开发整款游戏”的首选语言。
三、主流引擎使用的主语言和适用语言
| 游戏引擎 | 主语言 | 适用语言 |
|---|---|---|
| Unreal Engine | C++ | C++ / Blueprint(可视化脚本) |
| Unity | C# | C# |
| Godot | GDScript | GDScript / C# / C++ / Python(部分支持) |
| Cocos Creator | TypeScript/JS | TypeScript / JavaScript |
| Phaser | JavaScript | JavaScript / TypeScript |
四、总结:如何选对“你的语言”?
语言没有好坏,只有适不适合你的项目定位与资源情况。
如果你是:
- 学习引擎开发/大作性能优化:优先掌握 C++,结合 Unreal 学习
- 做跨平台独立游戏/商业项目:优先 C# + Unity
- 做 Web 平台轻量游戏:TypeScript + Phaser/Cocos 是好选择
- 研究 AI、教学、逻辑脚本:Python/Lua 脚本语言
写游戏不是目的,做出好玩的游戏才是!
如果你打算正式进军游戏开发领域,不妨从一个引擎 + 一门主语言开始,结合一个小项目落地,再去拓展更多语言和引擎的协作模式。
来源:juejin.cn/post/7516784123693498378
被问到 NextTick 是宏任务还是微任务
NextTick
等待下一次 DOM 更新刷新的工具方法。
<https://cn.vuejs.org/api/general.html#nexttick>
从字面上看 就知道 肯定是个 异步的嘛。
然后面试官 那你来说说 js执行过程吧。 宏任务 微任务 来做做 宏任务 微任务输出的结果的题吧。
再然后 问问你 nextTick 既然几个异步的 那么他是 宏任务 还是个 微任务呀。
vue2 中
文件夹 src/core/util/next-tick.js 中
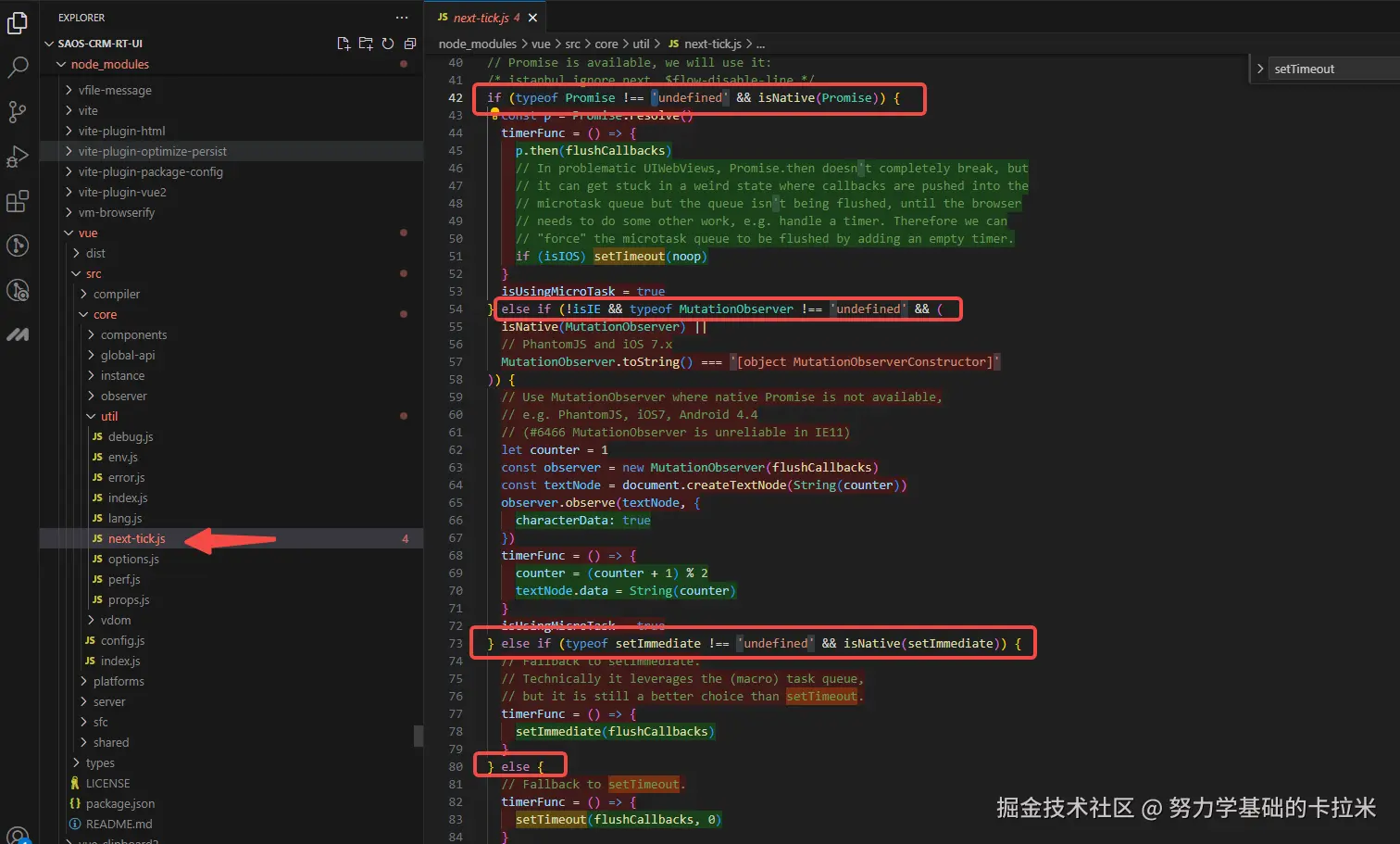
promise --> mutationObserver -> setImmediate -> setTimeout
支持 哪个走哪个
vue3 中
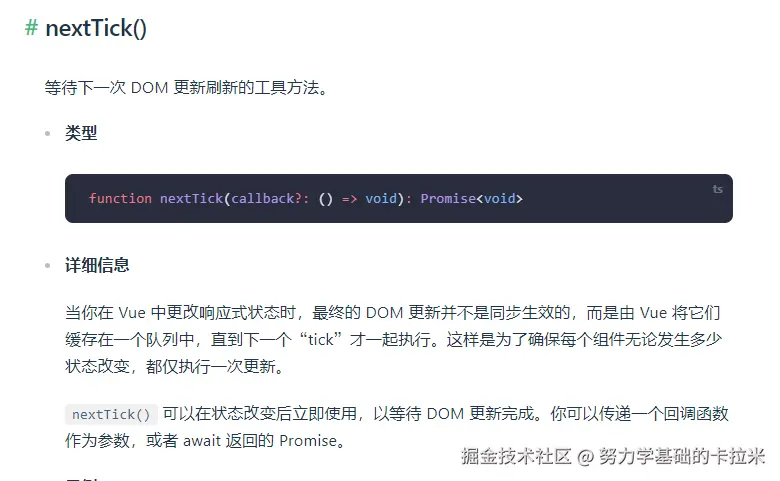
好吧 好吧 promise 了嘛
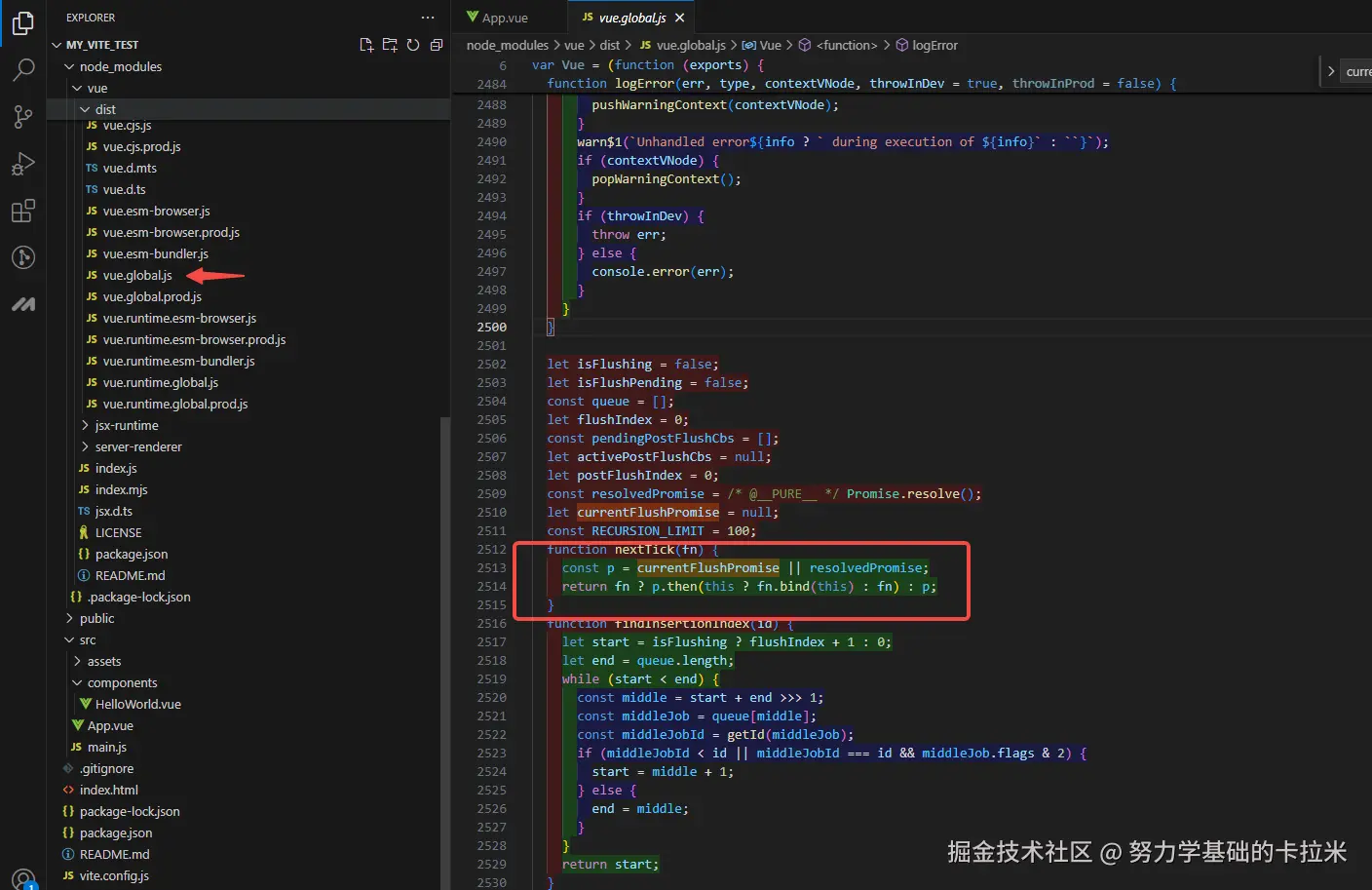
全程 promise
来源:juejin.cn/post/7418505553642291251
什么?localhost还能设置二级域名?
大家好,我是农村程序员,独立开发者,行业观察员,前端之虎陈随易。
我会在这里分享关于 独立开发、编程技术、思考感悟 等内容,欢迎关注。
- 个人网站 1️⃣:chensuiyi.me
- 个人网站 2️⃣:me.yicode.tech
- 技术群,搞钱群,闲聊群,自驾群,想入群的在我个人网站联系我。
如果你觉得本文有用,一键三连 (点赞、评论、转发),就是对我最大的支持~
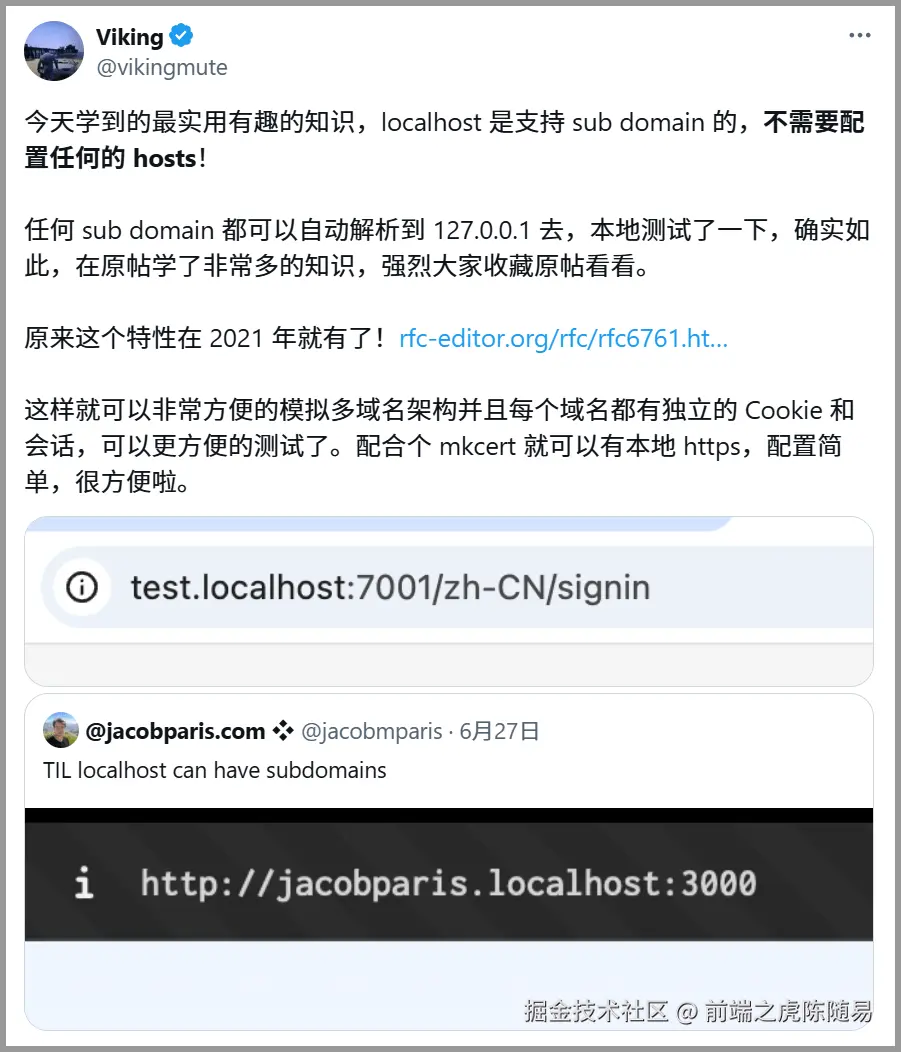
网上冲浪看到一个有趣且违背常识的帖子,用了那么多年的 localhost,没想到 localhost 还能设置子域名。
而且还不需要修改 hosts 文件,直接就能使用,这真是离谱他妈给离谱开门,离谱到家了。
先说说应用场景:
- 多用户/多会话隔离:在本地开发中模拟不同用户的 cookies 和 session storage,适合测试用户认证或个性化功能。
- 跨域开发与测试:模拟真实多域环境 (如 API 和前端分离),用于调试 CORS、单点登录或微服务架构。
- 简化开发流程:无需修改 hosts 文件即可快速创建子域名,适合快速原型设计或临时项目。
- 工具与服务器集成:与本地开发工具 (如 localias) 结合,支持 HTTPS 和自定义端口,增强开发体验。
- 灵活调试:通过自定义子域名和 IP (如 127.0.0.42) 进行高级调试或模拟复杂网络配置。
总得来说就是,localhsot 支持子域名比我们自己手动配置不同的域名并设置 hosts 文件方便多了。
接下来给大家实测一下。
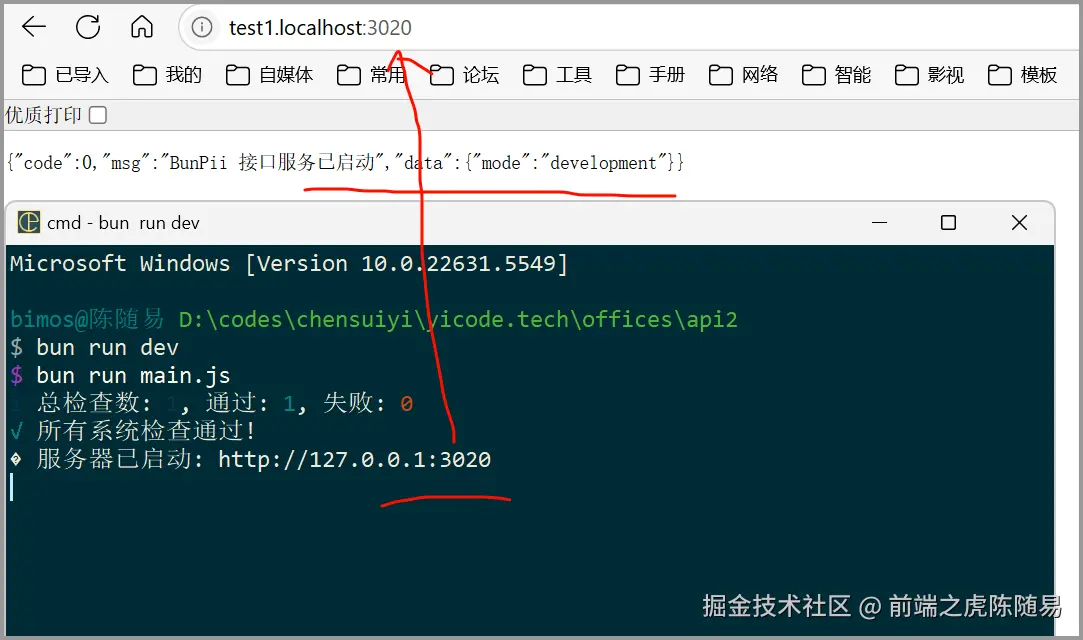
请看,这是我直接在浏览器输入 test1.localhost:3020 后,就能请求到我本地启动的监听 3020 端口的后端接口返回的数据。
我没有配置 hosts 文件,没有做过任何多余的配置工作,直接就生效了。
那么我们可以直接在本地就能调试多服务器集群,跨域 cookie 共享,SSO 单点登录,微服务架构等功能,非常方便。
另外,本公众号是 前端之虎陈随易 专门分享技术的公众号,目前关注量不多,希望大家点点小手指,来个大大的关注哦~
来源:juejin.cn/post/7521013717438758938
优雅!用了这两款插件,我成了整个公司代码写得最规范的码农
同事:你的代码写的不行啊,不够规范啊。

我:我写的代码怎么可能不规范,不要胡说。
于是同事打开我的 IDEA ,安装了一个插件,然后执行了一下,规范不规范,看报告吧。
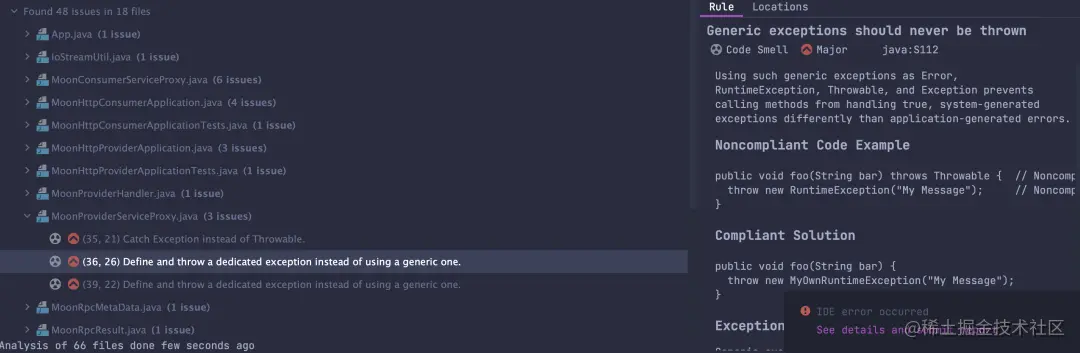
这可怎么是好,这玩意竟然给我挑出来这么多问题,到底靠谱不。
同事潇洒的走掉了,只留下我在座位上盯着屏幕惊慌失措。我仔细的查看了这个报告的每一项,越看越觉得这插件指出的问题有道理,果然是我大意了,竟然还给我挑出一个 bug 来。
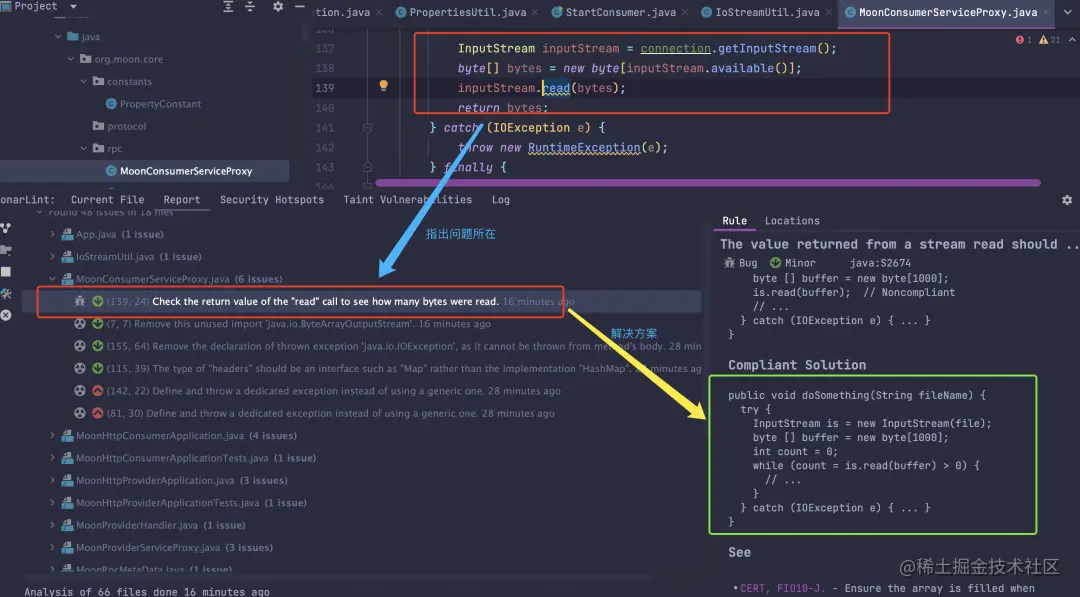
这是什么插件,review 代码无敌了。

这个插件就是 SonarLint,官网的 Slogan 是 clean code begins in your IDE with {SonarLint}。
作为一个程序员,我们当然希望自己写的代码无懈可击了,但是由于种种原因,有一些问题甚至bug都无法避免,尤其是刚接触开发不久的同学,也有很多有着多年开发经验的程序员同样会有一些不好的代码习惯。
代码质量和代码规范首先肯定是靠程序员自身的水平和素养决定的,但是提高水平的是需要方法的,方法就有很多了,比如参考大厂的规范和代码、比如有大佬带着,剩下的就靠平时的一点点积累了,而一些好用的插件能够时时刻刻提醒我们什么是好的代码规范,什么是好的代码。
SonarLint 就是这样一款好用的插件,它可以实时帮我们 review代码,甚至可以发现代码中潜在的问题并提供解决方案。
SonarLint 使用静态代码分析技术来检测代码中的常见错误和漏洞。例如,它可以检测空指针引用、类型转换错误、重复代码和逻辑错误等。这些都是常见的问题,但是有时候很难发现。使用 SonarLint 插件,可以在编写代码的同时发现这些问题,并及时纠正它们,这有助于避免这些问题影响应用程序的稳定性。
比如下面这段代码没有结束循环的条件设置,SonarLint 就给出提示了,有强迫症的能受的了这红下划线在这儿?
SonarLint 插件可以帮助我提高代码的可读性。代码应该易于阅读和理解,这有助于其他开发人员更轻松地维护和修改代码。SonarLint 插件可以检测代码中的代码坏味道,例如不必要的注释、过长的函数和变量名不具有描述性等等。通过使用 SonarLint 插件,可以更好地了解如何编写清晰、简洁和易于理解的代码。
例如下面这个名称为 hello_world的静态 final变量,SonarLint 给出了两项建议。
- 因为变量没有被使用过,建议移除;
- 静态不可变变量名称不符合规范;
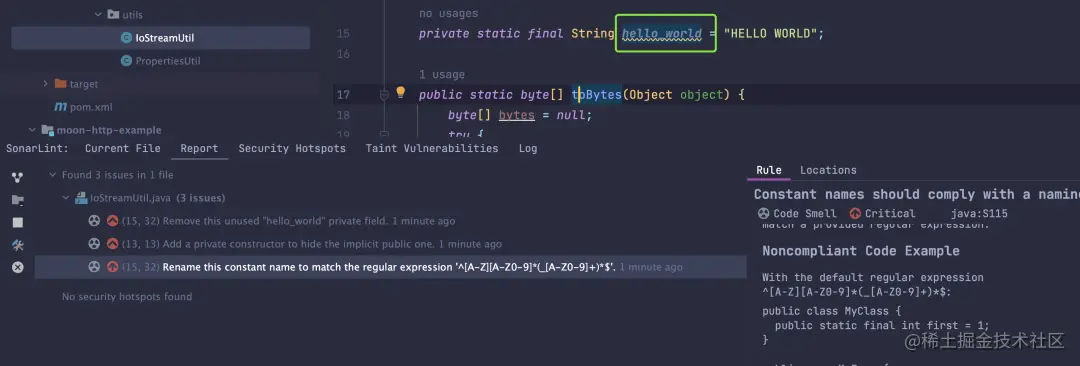
SonarLint 插件可以帮助我遵循最佳实践和标准。编写符合标准和最佳实践的代码可以确保应用程序的质量和可靠性。SonarLint 插件可以检测代码中的违反规则的地方,例如不安全的类型转换、未使用的变量和方法、不正确的异常处理等等。通过使用 SonarLint 插件,可以学习如何编写符合最佳实践和标准的代码,并使代码更加健壮和可靠。
例如下面的异常抛出方式,直接抛出了 Exception,然后 SonarLint 建议不要使用 Exception,而是自定义一个异常,自定义的异常可能让人直观的看出这个异常是干什么的,而不是 Exception基本类型导出传递。
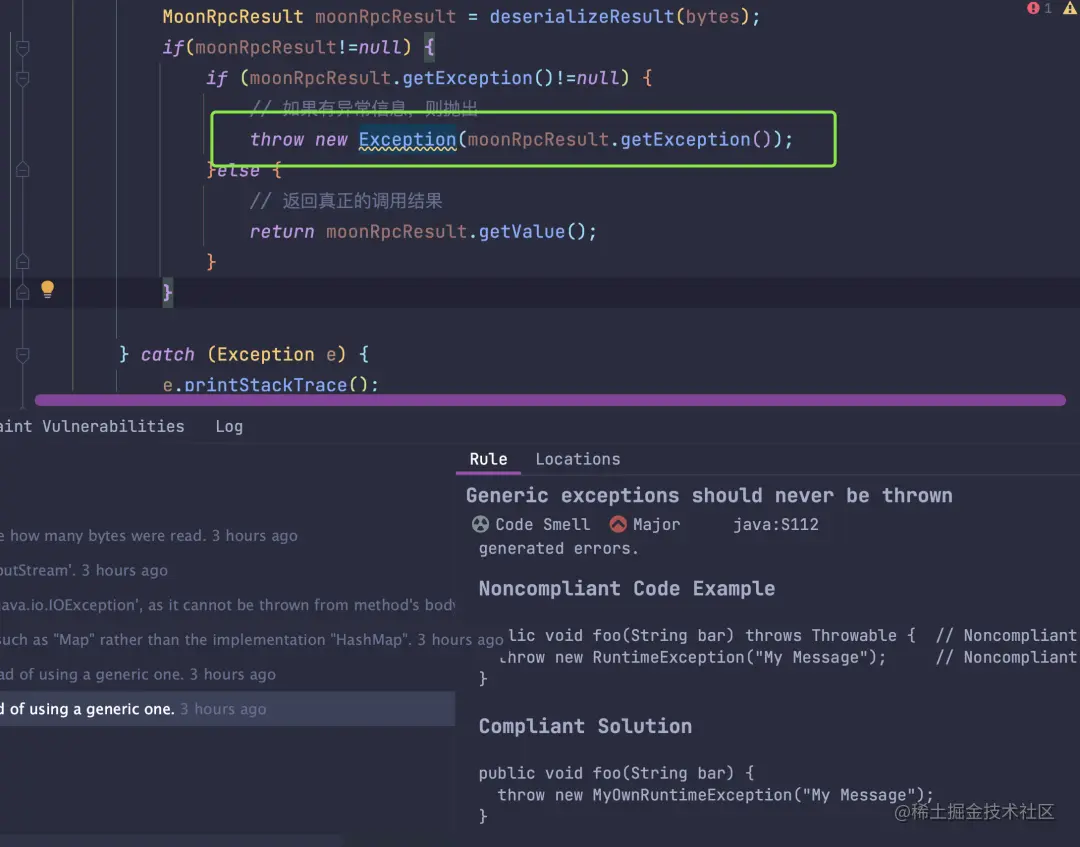
安装 SonarLint
可以直接打开 IDEA 设置 -> Plugins,在 MarketPlace中搜索SonarLint,直接安装就可以。
还可以直接在官网下载,打开页面http://www.sonarsource.com/products/so… EXPLORE即可到下载页面去下载了。虽然我们只是在 IDEA 中使用,但是它不只支持 Java 、不只支持 IDEA ,还支持 Python、PHP等众多语言,以及 Visual Studio 、VS Code 等众多 IDE。

在 IDEA 中使用
SonarLint 插件安装好之后,默认就开启了实时分析的功能,就跟智能提示的功能一样,随着你噼里啪啦的敲键盘,SonarLint插件就默默的进行分析,一旦发现问题就会以红框、红波浪线、黄波浪线的方式提示。
当然你也可以在某一文件中点击右键,也可在项目根目录点击右键,在弹出菜单中点击Analyze with SonarLint,对当前文件或整个项目进行分析。
分析结束后,会生成分析报告。
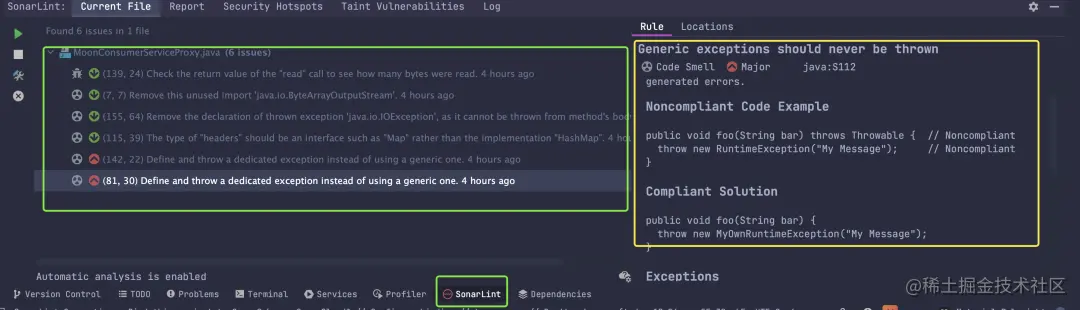
左侧是对各个文件的分析结果,右侧是对这个问题的建议和修改示例。
SonarLint 对问题分成了三种类型
类型说明Bug代码中的 bug,影响程序运行Vulnerability漏洞,可能被作为攻击入口Code smell代码意味,可能影响代码可维护性
问题按照严重程度分为5类
严重性说明BLOCKER已经影响程序正常运行了,不改不行CRITICAL可能会影响程序运行,可能威胁程序安全,一般也是不改不行MAJOR代码质量问题,但是比较严重MINOR同样是代码质量问题,但是严重程度较低INFO一些友好的建议
SonarQube
SonarLint 是在 IDE 层面进行分析的插件,另外还可以使用 SonarQube功能,它以一个 web 的形式展现,可以为整个开发团队的项目提供一个web可视化的效果。并且可以和 CI\CD 等部署工具集成,在发版前提供代码分析。
SonarQube是一个 Java 项目,你可以在官网下载项目本地启动,也可以以 docker 的方式启动。之后可以在 IDEA 中配置全局 SonarQube配置。
也可以在 SonarQube web 中单独配置一个项目,创建好项目后,直接将 mvn 命令在待分析的项目中执行,即可生成对应项目的分析报告,然后在 SonarQube web 中查看。
5
对于绝大多数开发者和开发团队来说,SonarQube 其实是没有必要的,只要我们每个人都解决了 IDE 中 SonarLint 给出的建议,当然最终的代码质量就是符合标准的。
阿里 Java 规约插件
每一个开发团队都有团队内部的代码规范,比如变量命名、注释格式、以及各种类库的使用方式等等。阿里一直在更新 Java 版的阿里巴巴开发者手册,有什么泰山版、终极版,想必各位都听过吧,里面的规约如果开发者都能遵守,那别人恐怕再没办法 diss 你的代码不规范了。
对应这个开发手册的语言层面的规范,阿里也出了一款 IDEA 插件,叫做 Alibaba Java Coding Guidelines,可以在插件商店直接下载。
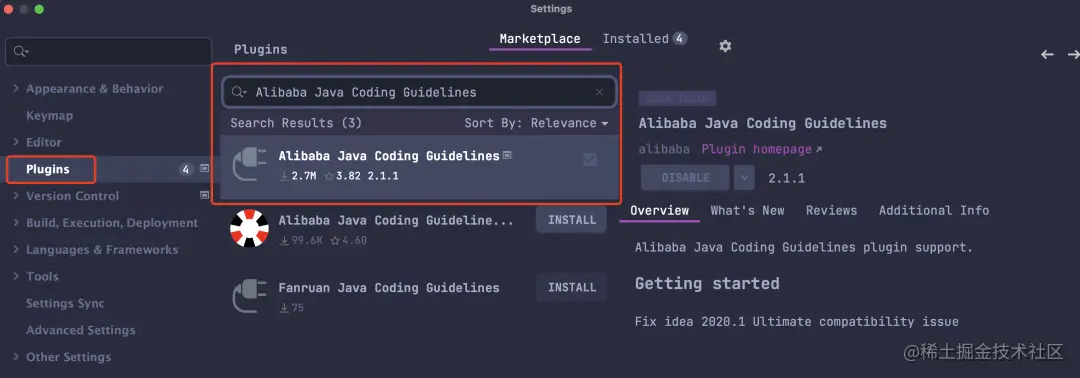
比如前面说的那个 hello_world变量名,插件直接提示「修正为以下划线分隔的大写模式」。
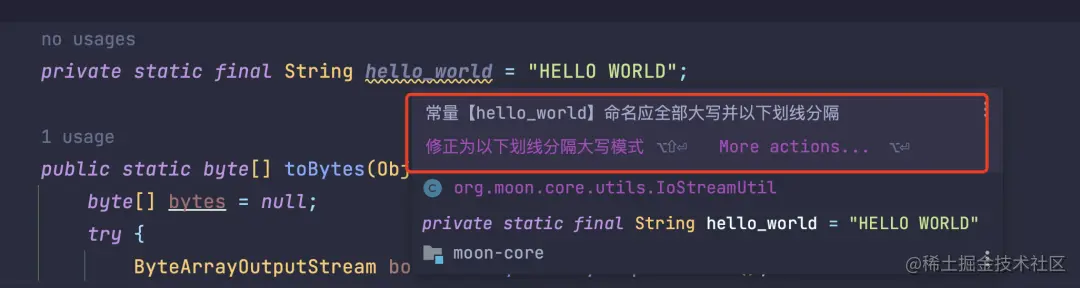
再比如一些注释上的提示,不建议使用行尾注释。
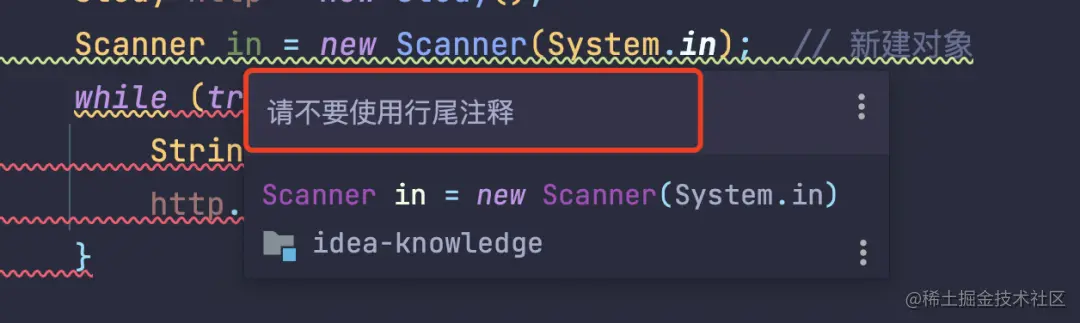
image-20230314165107639
还有,比如对线程池的使用,有根据规范建议的内容,建议自己定义核心线程数和最大线程数等参数,不建议使用 Excutors工具类。
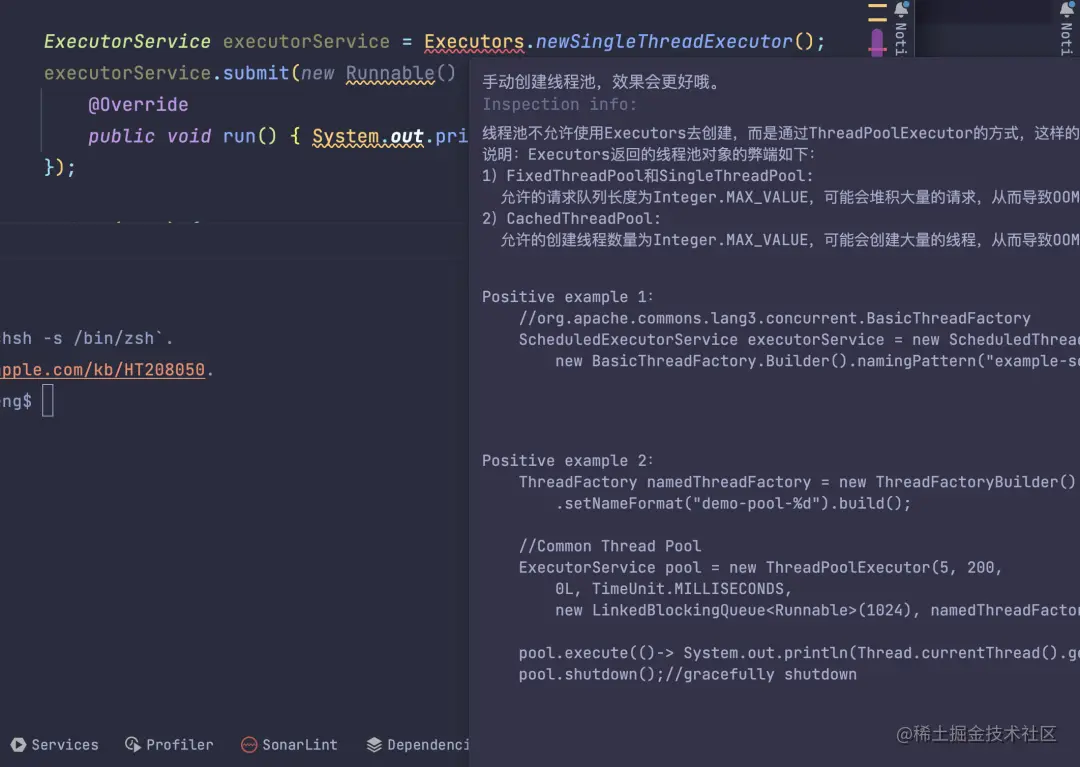
有了这俩插件,看谁还能说我代码写的不规范了。
来源:juejin.cn/post/7260314364876931131
本尊来!网易灰度发布系统揭秘:一天300次上线是怎么实现的?
你可能听过“网易每天上线几百次”,
但你是否知道:99%的发布都不是全量,而是按灰度批次推进。
今天从代码 + 场景双视角,拆解网易灰度发布的完整实现逻辑,让你真正搞懂:
- 发布是怎么分用户、分地域、分时间段的
- 如何回滚不影响线上用户
- 甚至如何模拟真实用户流量进行 A/B 实验
一、网易灰度系统整体架构图(简化)
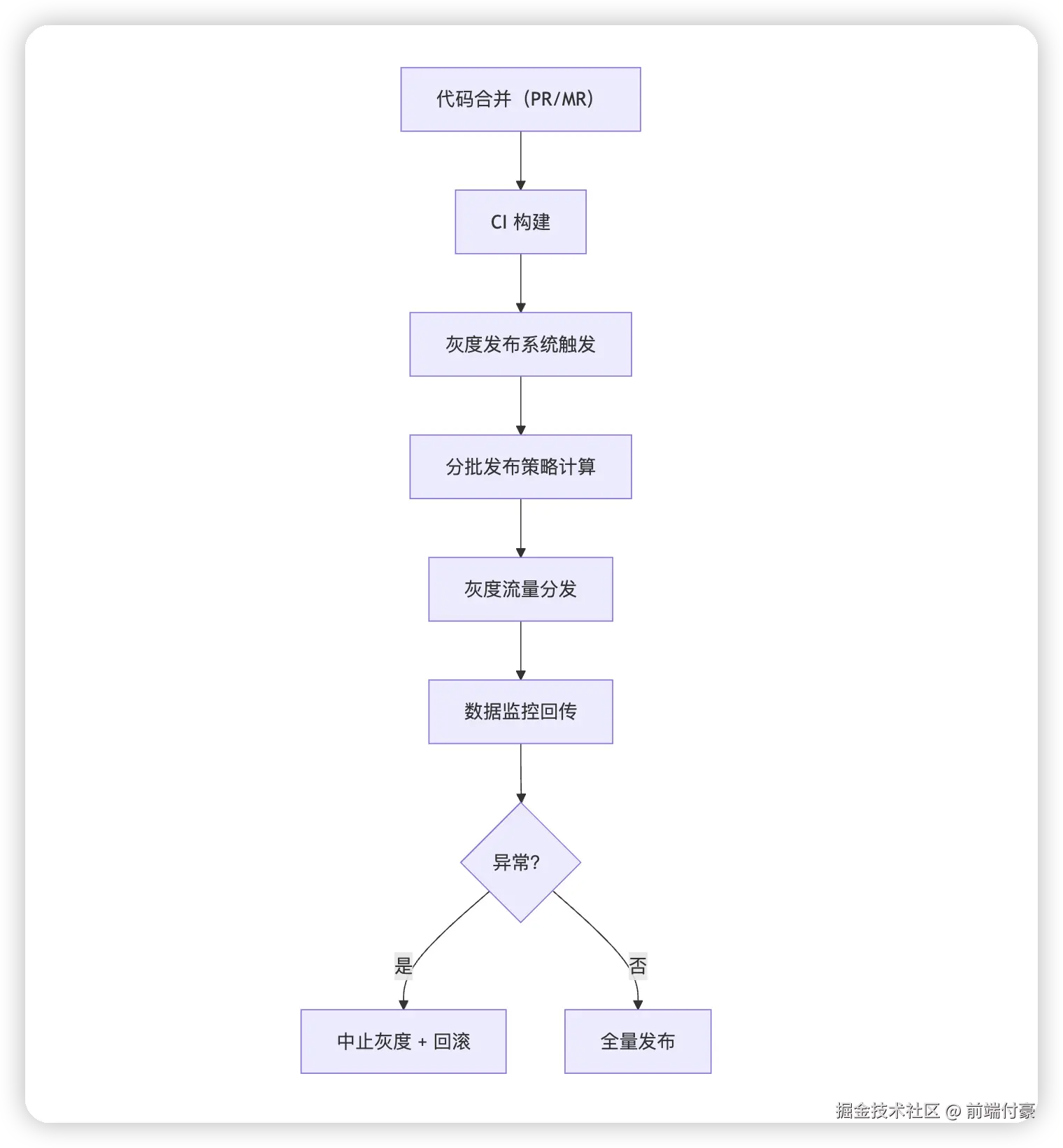
二、核心策略算法:如何选择灰度用户?
网易内部灰度用户分流引擎大致是这样:
interface User {
uid: string
region: string // 地域
isVip: boolean
loginTime: number // 最近登录时间
}
// 灰度策略配置
const strategy = {
percent: 10, // 灰度比例
regionInclude: ['华南'], // 地域包含
vipOnly: true // 只投放给 VIP
}
// 筛选函数
function filterUsers(users: User[], strategy) {
const filtered = users.filter(u =>
(!strategy.regionInclude || strategy.regionInclude.includes(u.region)) &&
(!strategy.vipOnly || u.isVip)
)
const count = Math.floor((strategy.percent / 100) * filtered.length)
return filtered.slice(0, count)
}
三、实际运行结果展示(模拟环境)
const users: User[] = Array.from({ length: 1000 }, (_, i) => ({
uid: `U${i}`,
region: ['华南', '华北', '华东'][i % 3],
isVip: i % 2 === 0,
loginTime: Date.now() - i * 10000,
}))
const selected = filterUsers(users, strategy)
console.log('灰度命中用户数:', selected.length)
console.log('前5个用户:', selected.slice(0, 5))
✅ 输出示例:
灰度命中用户数: 166
前5个用户: [
{ uid: 'U0', region: '华南', isVip: true, loginTime: 1717288879181 },
{ uid: 'U6', region: '华南', isVip: true, loginTime: 1717288819181 },
{ uid: 'U12', region: '华南', isVip: true, loginTime: 1717288759181 },
...
]
四、网易如何触发灰度?手动?自动?答案是:多触发源 + 策略组合
- ✅ 手动控制(管理员控制台)
- ✅ CI/CD 自动触发(合并主干自动上线)
- ✅ 实验平台触发(A/B 实验验证新功能)
示例:CI/CD 触发部署的逻辑(伪代码):
// Jenkinsfile 中执行灰度命令
steps {
script {
sh 'node deploy.js --env=prod --gray=10%'
}
}
五、监控数据如何决定“是否继续灰度”?
网易内部有自动指标监控,如:
| 指标名 | 作用 | 阈值 |
|---|---|---|
| error_rate | 错误率异常自动中止 | >0.05 |
| api_delay | 接口响应时间 | >300ms |
| login_success_ratio | 登录成功率 | <0.95 |
代码示例(灰度中控系统伪代码):
if (metrics.error_rate > 0.05 || metrics.login_success_ratio < 0.95) {
graySystem.stopDeployment()
graySystem.rollback()
console.log('灰度异常,中止并回滚')
} else {
graySystem.continue()
}
六、网易的灰度回滚机制非常丝滑,为什么?
他们采用了 “金丝雀版本+热切流量+自动恢复” 策略:
graySystem.deploy(version: '1.2.3', tag: 'canary')
// graySystem.rollback() 会回到上一个 tag=stable 的版本
而且每次发布都会打上 Git tag,并记录环境信息,回滚只需1行命令:
gray rollback --env prod --tag stable
七、你能学到什么?(总结)
- 灰度不等于“发布慢一点”,而是可控可观测的发布策略
- 用户维度灰度筛选逻辑要尽量结构化,避免硬编码
- 数据指标必须“事前定义”,不能出了问题再想怎么止损
- 所有灰度发布必须可回滚
彩蛋:
“上线不是勇气的象征,而是风控能力的体现。”
来源:juejin.cn/post/7511150244576837684
解锁企业高效未来|上海飞络Synergy AI开启智能体协作新时代
他/她可以有自己的电脑,可以有自己的邮箱号,可以有自己的企业微信号。只要赋予权限,他/她可以替你完成各种日常工作,他/她可以随时随地和你沟通并完成你安排的任务,他/她永远高效!他/她永不抱怨!
Synergy AI数字员工雇佣管理平台,以大语言模型驱动的AI Agent为核心,结合MCP工具集,并在数据安全、信息安全及行为安全的多维度监控下,为企业提供安全、合规、高效的“智能体员工”,重塑人机协作新范式!

为什么选择Synergy AI数字员工管理平台?
1、智能生产力升级
AI Agent数字员工深度融合语言理解、逻辑推理与工具调用能力,是能够自主感知环境、决策并执行任务的人工智能系统。它可以拥有自己的电脑、邮箱,微信号等所有员工的权限,同时也具备MCP工具集中的各种技能,能够像真人一样沟通,处理工作,但是能够实现更高的工作效率和更加低廉的成本!

2、根据职位定制AI员工工作流
通过“AIGC+Workflow”组合,实现任务自动化执行,响应速度大幅提升,成为企业降本增效的核心引擎。
同时基于企业人员、技能、文档、流程等六大核心信息库,AI数字员工可快速融入业务场景,提供从单职能支持、人机协同到多职能协作的全链路服务。

3、安全合规,全程可控
1)行为监测
实时检测AI数字员工是否存在权限越界、敏感数据操作,信息泄露,被黑客利用等安全合规隐患。
2)数据安全管控
智能识别、过滤、脱敏替换AI数字员工及大语言模型使用过程中触发的敏感数据,企业核心数据泄漏等风险。
3)效能可视化
通过工作流执行情况、人工干预度等指标,持续优化AI员工表现。

Synergy AI能实现什么效果?
1、AI销售助理
可协助销售管理日程、预约会议、统计CRM数字,甚至代替销售联络沟通回款问题。入职飞络销售部门后,内部数据显示客户响应效率提升3倍以上,人力成本降低60%,助力团队精准触达商机。

2、SOC安全及运维专员
在安全运营和运维场景中,AI员工可以迅速响应各个安全系统平台的告警,并根据制定的工作流程,进行下一步的沟通、交流、处置。让企业安全事件响应速度大幅提升,精准提高准确率,为企业筑牢数字防线。

3、更多AI人职位有待解锁
根据每家企业不同的场景需求,Synergy AI提供可以定制化的各种企业AI数字员工,让AI智能体真正能够匹配企业需求,为企业带来实际帮助。

Synergy AI如何落地实施?
1、分析岗位SOW/SOP
找到重复、需要与人互动的工作流,快速实现智能化并通过拟人化的AI员工来完成,逐步将AI工作流覆盖全业务。
2、无缝对接系统
支持OA、ERP、CRM、M365等主流平台MCP / API对接。
3、7×24小时护航
飞络安全运营中心全程监控,保障业务稳定运行。

企业的信息安全如何保护?
飞络基于自研发两大安全管理平台,为企业在使用AI的同时,极大限度保障企业的数据以及隐私安全:
企业AI安全事件监控管理平台
通过企业AI安全事件监控管理平台,我们可以实时提供AI系统以及AI Agents的运行状态,对于所发生的安全事件,实行7*24小时的安全监控及管理。
ASSA:企业AI数据过滤平台
通过ASSA,企业可以管理及管控企业内部信息传输到大语言模型上的数据,对于敏感信息、企业机密、个人信息等进行阻止、脱敏、模糊化等管理操作
7*24 SOC服务
基于飞络提供的7*24级别的SOC运营服务,可以协助客户一起实时监控及管理所有AI相关的安全事件,为企业的数据安全保驾护航!


Synergy AI数字员工雇佣管理平台,以自主研发技术为核心,为企业提供一站式智能解决方案。
收起阅读 »给前端小白的科普,为什么说光有 HTTPS 还不够?为啥还要请求签名?
今天咱们聊个啥呢?先设想一个场景:你辛辛苦苦开发了一个前端应用,后端 API 也写得杠杠的。用户通过你的前端界面提交一个订单,比如说买1件商品。请求发出去,一切正常。但如果这时候,有个“不开眼”的黑客老哥,在你的请求发出后、到达服务器前,悄咪咪地把“1件”改成了“100件”,或者把你用户的优惠券给薅走了,那服务器收到的就是个被篡改过的“假”请求。更狠一点,如果他拿到了你某个用户的合法请求,然后疯狂重放这个请求,那服务器不就炸了?
是不是想想都后怕?别慌,今天咱就来聊聊怎么给咱们的API请求加一把“锁”,让这种“中间人攻击”和“重放攻击”无处遁形。这把锁,就是大名鼎鼎的 HMAC-SHA256 请求签名。学会了它,你就能给你的应用穿上“防弹衣”!

一、光有 HTTPS 还不够?为啥还要请求签名?
可能有机灵的小伙伴会问:“老张,咱不都有 HTTPS 了吗?数据都加密了,还怕啥?”
问得好!HTTPS 确实牛,它能保证你的数据在传输过程中不被窃听和篡改,就像给数据修了条“加密隧道”。但它主要解决的是传输层的安全。可如果:
- 请求在加密前就被改了:比如黑客通过某种手段(XSS、恶意浏览器插件等)在你的前端代码执行时就修改了要发送的数据,那 HTTPS 加密的也是被篡改后的数据。
- 请求被合法地解密后,服务器无法验证“我是不是我”:HTTPS 保证了数据从A点到B点没被偷看,但如果有人拿到了一个合法的、加密的请求包,他可以原封不动地发给服务器100遍(重放攻击),服务器每次都会认为是合法的。
- API Key/Secret 直接在前端暴露: 有些简单的 API 认证,可能会把 API Key 直接写在前端,这简直就是“裸奔”,分分钟被扒下来盗用。
请求签名,则是在应用层做的一道防线。它能确保:
- 消息的完整性:数据没被篡改过。
- 消息的身份验证:确认消息确实是你授权的客户端发来的。
- 防止重放攻击:结合时间戳或 Nonce,让每个请求都具有唯一性。
它和 HTTPS 是好搭档,一个负责“隧道安全”,一个负责“货物安检”,双保险!
二、主角登场:HMAC-SHA256 是个啥?
HMAC-SHA256,听起来挺唬人,拆开看其实很简单:
- HMAC:Hash-based Message Authentication Code,翻译过来就是“基于哈希的消息认证码”。它是一种使用密钥(secret key)来生成消息摘要(MAC)的方法。
- SHA256:Secure Hash Algorithm 256-bit,一种安全的哈希算法,能把任意长度的数据转换成一个固定长度(256位,通常表示为64个十六进制字符)的唯一字符串。相同的输入永远得到相同的输出,输入有任何微小变化,输出都会面目全非。
所以,HMAC-SHA256 就是用一个共享密钥 (Secret Key),通过 SHA256 算法,给你的请求数据生成一个独一无二的“签名”。
三、签名的艺术:请求是怎么被“签”上和“验”货的?
整个流程其实不复杂,咱们用个图来说明一下:
sequenceDiagram
participant C as 前端 (Client)
participant S as 后端 (Server)
C->>C: 1. 准备请求参数 (如 method, path, query, body)
C->>C: 2. 加入时间戳 (timestamp) 和/或 随机数 (nonce)
C->>C: 3. 将参数按约定规则排序、拼接成一个字符串 (stringToSign)
C->>C: 4. 使用共享密钥 (Secret Key) 对 stringToSign 进行 HMAC-SHA256 运算,生成签名 (signature)
C->>S: 5. 将原始请求参数 + timestamp + nonce + signature 一起发送给后端
S->>S: 6. 接收到所有数据
S->>S: 7. 校验 timestamp/nonce (检查是否过期或已使用,防重放)
S->>S: 8. 从接收到的数据中,按与客户端相同的规则,提取参数、排序、拼接成 stringToSign'
S->>S: 9. 使用自己保存的、与客户端相同的 Secret Key,对 stringToSign' 进行 HMAC-SHA256 运算,生成 signature'
S->>S: 10. 比对客户端传来的 signature 和自己生成的 signature'
alt 签名一致
S->>S: 11. 验证通过,处理业务逻辑
S-->>C: 响应结果
else 签名不一致
S->>S: 11. 验证失败,拒绝请求
S-->>C: 错误信息 (如 401 Unauthorized)
end
简单来说,就是:
- 客户端:把要发送的数据(比如请求方法、URL路径、查询参数、请求体、时间戳等)按照事先约定好的顺序和格式拼成一个长长的字符串。然后用一个只有你和服务器知道的“秘密钥匙”(Secret Key)和 HMAC-SHA256 算法,给这个字符串算出一个“指纹”(签名)。最后,把原始数据、时间戳、签名一起发给服务器。
- 服务器端:收到请求后,用完全相同的规则和完全相同的“秘密钥匙”,对收到的原始数据(不包括客户端传来的签名)也算一遍“指纹”。然后比较自己算出来的指纹和客户端传过来的指纹。如果一样,说明数据没被改过,而且确实是知道秘密钥匙的“自己人”发的;如果不一样,那对不起,这请求有问题,拒收!
四、Talk is Cheap, Show Me The Code!
光说不练假把式,咱们来点实在的。
前端签名 (JavaScript - 通常使用 crypto-js 库)
// 假设你已经安装了 crypto-js: npm install crypto-js
import CryptoJS from 'crypto-js';
function generateSignature(params, secretKey) {
// 1. 准备待签名数据
const method = 'GET'; // 请求方法
const path = '/api/user/profile'; // 请求路径
const timestamp = Math.floor(Date.now() / 1000).toString(); // 时间戳 (秒)
const nonce = CryptoJS.lib.WordArray.random(16).toString(); // 随机数,可选
// 2. 构造待签名字符串 (规则很重要,前后端要一致!)
// 通常会对参数名按字典序排序
const sortedKeys = Object.keys(params).sort();
const queryString = sortedKeys.map(key => `${key}=${params[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${timestamp}\n${nonce}`;
console.log("String to Sign:", stringToSign); // 调试用
// 3. 使用 HMAC-SHA256 生成签名
const signature = CryptoJS.HmacSHA256(stringToSign, secretKey).toString(CryptoJS.enc.Hex);
console.log("Generated Signature:", signature); // 调试用
return {
signature,
timestamp,
nonce
};
}
// --- 使用示例 ---
const mySecretKey = "your-super-secret-key-dont-put-in-frontend-directly!"; // 强调:密钥不能硬编码在前端!
const requestParams = {
userId: '123',
role: 'user'
};
const { signature, timestamp, nonce } = generateSignature(requestParams, mySecretKey);
// 实际发送请求时,把 signature, timestamp, nonce 放在请求头或请求体里
// 例如:
// fetch(`${path}?${queryString}`, {
// method: method,
// headers: {
// 'X-Signature': signature,
// 'X-Timestamp': timestamp,
// 'X-Nonce': nonce,
// 'Content-Type': 'application/json'
// },
// // body: JSON.stringify(requestBody) // 如果是POST/PUT等
// })
// .then(...)
划重点! 上面代码里的 mySecretKey 绝对不能像这样直接写在前端代码里!这只是个演示。真正的 Secret Key 需要通过安全的方式分发和存储,比如在构建时注入,或者通过更安全的认证流程动态获取(但这又引入了新的复杂性,通常 Secret Key 是后端持有,客户端动态获取一个有时效性的 token)。对于纯前端应用,更常见的做法是后端生成签名所需参数,或者整个流程由 BFF (Backend For Frontend) 层处理。如果你的应用是 App,可以把 Secret Key 存储在原生代码中,相对安全一些。
后端验签 (Node.js - 使用内置 crypto 模块)
const crypto = require('crypto');
function verifySignature(requestData, clientSignature, clientTimestamp, clientNonce, secretKey) {
// 0. 校验时间戳 (例如,请求必须在5分钟内到达)
const serverTimestamp = Math.floor(Date.now() / 1000);
if (Math.abs(serverTimestamp - parseInt(clientTimestamp, 10)) > 300) { // 5分钟窗口
console.error("Timestamp validation failed");
return false;
}
// (可选) 校验 Nonce 防止重放,需要存储已用过的 Nonce,可以用 Redis 等
// if (isNonceUsed(clientNonce)) {
// console.error("Nonce replay detected");
// return false;
// }
// markNonceAsUsed(clientNonce, clientTimestamp); // 标记为已用,并设置过期时间
// 1. 从请求中提取参与签名的参数
const { method, path, queryParams } = requestData; // 假设已解析好
// 2. 构造待签名字符串 (规则必须和客户端完全一致!)
const sortedKeys = Object.keys(queryParams).sort();
const queryString = sortedKeys.map(key => `${key}=${queryParams[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${clientTimestamp}\n${clientNonce}`;
console.log("Server String to Sign:", stringToSign);
// 3. 使用 HMAC-SHA256 生成签名
const expectedSignature = crypto.createHmac('sha256', secretKey)
.update(stringToSign)
.digest('hex');
console.log("Server Expected Signature:", expectedSignature);
console.log("Client Signature:", clientSignature);
// 4. 比对签名 (使用 crypto.timingSafeEqual 防止时序攻击)
if (clientSignature.length !== expectedSignature.length) {
return false;
}
return crypto.timingSafeEqual(Buffer.from(clientSignature), Buffer.from(expectedSignature));
}
// --- Express 示例中间件 ---
// app.use((req, res, next) => {
// const clientSignature = req.headers['x-signature'];
// const clientTimestamp = req.headers['x-timestamp'];
// const clientNonce = req.headers['x-nonce'];
// // 实际项目中,secretKey 应该从环境变量或配置中读取
// const API_SECRET_KEY = process.env.API_SECRET_KEY || "your-super-secret-key-dont-put-in-frontend-directly!";
// // 构造 requestData 对象,包含 method, path, queryParams
// // 注意:如果是 POST/PUT 请求,请求体 (body) 通常也需要参与签名
// // 且 body 如果是 JSON,建议序列化后参与签名,而不是原始对象
// const requestDataForSig = {
// method: req.method.toUpperCase(),
// path: req.path,
// queryParams: req.query, // 对于GET;POST/PUT可能还需包含body
// // bodyString: req.body ? JSON.stringify(req.body) : "" // 如果body参与签名
// };
// if (!verifySignature(requestDataForSig, clientSignature, clientTimestamp, clientNonce, API_SECRET_KEY)) {
// return res.status(401).send('Invalid Signature');
// }
// next();
// });
五、细节是魔鬼:实施过程中的注意事项
- 密钥管理 (Secret Key):
- 绝对保密:这是最重要的!密钥泄露,签名机制就废了。
- 不要硬编码在前端:再次强调!对于B端或内部系统,可以考虑通过安全的构建流程注入。对于C端开放应用,通常结合用户登录后的 session token 或 OAuth token 来做,或者使用更复杂的 API Gateway 方案。
- 定期轮换:为了安全,密钥最好能定期更换。
- 时间戳 (Timestamp):
- 防止重放攻击:服务器会校验收到的时间戳与当前服务器时间的差值,如果超过一定阈值(比如5分钟),就认为是无效请求。
- 时钟同步:客户端和服务器的时钟要尽量同步,不然很容易误判。
- 随机数 (Nonce):
- 更强的防重放:Nonce 是一个只使用一次的随机字符串。服务器需要记录用过的 Nonce,在一定时间内(同时间戳窗口)不允许重复。可以用 Redis 等缓存服务来存。
- 哪些内容需要签名?
- HTTP 方法 (GET, POST, etc.)
- 请求路径 (Path, e.g.,
/users/123) - 查询参数 (Query Parameters, e.g.,
?name=zhangsan&age=18):参数名需要按字典序排序,确保客户端和服务端拼接顺序一致。 - 请求体 (Request Body):如果是
application/x-www-form-urlencoded或multipart/form-data,处理方式同 Query Parameters。如果是application/json,通常是将整个 JSON 字符串作为签名内容的一部分。注意空 body 和有 body 的情况。 - 关键的请求头:比如
Content-Type,以及自定义的一些重要 Header。 - 时间戳和 Nonce:它们本身也要参与签名,防止被篡改。
- 一致性是王道:客户端和服务端在选择哪些参数参与签名、参数的排序规则、拼接格式等方面,必须严格一致,一个空格,一个换行符不同,签名结果就天差地别。
六、HMAC-SHA256 vs. 其他方案?
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 仅 HTTPS | 传输层加密,防止窃听 | 无法防止应用层篡改(加密前)、无法验证发送者身份(应用层)、无法防重放 | 基础数据传输安全 |
| 简单摘要 (如MD5) | 实现简单 | 若无密钥,容易被伪造;MD5本身已不安全 | 文件完整性校验(非安全敏感) |
| HMAC-SHA256 | 消息完整性、身份验证(基于共享密钥)、可防重放(结合时间戳/Nonce) | 密钥管理是关键和难点;签名和验签有一定计算开销 | 需要保障API接口安全、防止未授权访问和篡改的场景 |
| JWT (JSON Web Token) | 无状态、可携带用户信息、标准化 | Token 可能较大;吊销略麻烦;主要用于用户认证和授权 | 用户登录、单点登录、API授权 |
HMAC-SHA256 更侧重于请求本身的完整性和来源认证,而 JWT 更侧重于用户身份的认证和授权。它们可以结合使用。
好啦,今天关于 HMAC-SHA256 请求签名的唠嗑就到这里。这玩意儿看起来步骤多,但一旦理解了原理,实现起来其实就是细心活儿。给你的 API 加上这把锁,晚上睡觉都能踏实点!
我是老码小张,一个喜欢研究技术原理,并且在实践中不断成长的技术人。希望今天的分享对你有帮助,咱们下回再聊!欢迎大家留言交流你的看法和经验哦!
来源:juejin.cn/post/7502641888970670080
聊聊四种实时通信技术:长轮询、短轮询、WebSocket 和 SSE
这篇文章,我们聊聊 四种实时通信技术:短轮询、长轮询、WebSocket 和 SSE 。
1 短轮询
浏览器 定时(如每秒)向服务器发送 HTTP 请求,服务器立即返回当前数据(无论是否有更新)。

- 优点:实现简单,兼容性极佳
- 缺点:高频请求浪费资源,实时性差(依赖轮询间隔)
- 延迟:高(取决于轮询频率)
- 适用场景:兼容性要求高,延迟不敏感的简单场景。
笔者职业生涯印象最深刻的短轮询应用场景是比分直播:

如图所示,用户进入比分直播界面,浏览器定时查询赛事信息(比分变动、黄红牌等),假如数据有变化,则重新渲染页面。
这种方式实现起来非常简单可靠,但是频繁的调用后端接口,会对后端性能会有影响(主要是 CPU)。同时,因为依赖轮询间隔,页面数据变化有延迟,用户体验并不算太好。
2 长轮询
浏览器发送 HTTP 请求后,服务器 挂起连接 直到数据更新或超时,返回响应后浏览器立即发起新请求。

- 优点:减少无效请求,比短轮询实时性更好
- 缺点:服务器需维护挂起连接,高并发时资源消耗大
- 延迟:中(取决于数据更新频率)
- 适用场景:需要较好实时性且无法用 WebSocket/SSE 的场景(如消息通知)
长轮询最常见的应用场景是:配置中心,我们耳熟能详的注册中心 Nacos 、阿波罗都是依赖长轮询机制。

客户端发起请求后,Nacos 服务端不会立即返回请求结果,而是将请求挂起等待一段时间,如果此段时间内服务端数据变更,立即响应客户端请求,若是一直无变化则等到指定的超时时间后响应请求,客户端重新发起长链接。
3 WebSocket
基于 TCP 的全双工协议,通过 HTTP 升级握手(Upgrade: websocket)建立持久连接,双向实时通信。 
- 优点:最低延迟,支持双向交互,节省带宽
- 缺点:实现复杂,需单独处理连接状态
- 延迟:极低
- 适用场景:聊天室、在线游戏、协同编辑等 高实时双向交互 需求
笔者曾经服务于北京一家电商公司,参与直播答题功能的研发。

直播答题整体架构见下图:

Netty TCP 网关的技术选型是:Netty、ProtoBuf、WebSocket ,选择 WebSocket 是因为它支持双向实时通信,同时 Netty 内置了 WebSocket 实现类,工程实现起来相对简单。
4 Server Send Event(SSE)
基于 HTTP 协议,服务器可 主动推送 数据流(如Content-Type: text/event-stream),浏览器通过EventSource API 监听。

- 优点:原生支持断线重连,轻量级(HTTP协议)
- 缺点:不支持浏览器向服务器发送数据
- 延迟:低(服务器可即时推送)
- 适用场景:股票行情、实时日志等 服务器单向推送 需求。
SSE 最经典的应用场景是 : DeepSeek web 聊天界面 ,如图所示:

当在 DeepSeek 对话框发送消息后,浏览器会发送一个 HTTP 请求 ,服务端会通过 SSE 方式将数据返回到浏览器。

5 总结
| 特性 | 短轮询 | 长轮询 | SSE | WebSocket |
|---|---|---|---|---|
| 通信方向 | 浏览器→服务器 | 浏览器→服务器 | 服务器→浏览器 | 双向通信 |
| 协议 | HTTP | HTTP | HTTP | WebSocket(基于TCP) |
| 实时性 | 低 | 中 | 高 | 极高 |
| 资源消耗 | 高(频繁请求) | 中(挂起连接) | 低 | 低(长连接) |
选择建议:
- 需要 简单兼容性 → 短轮询
- 需要 中等实时性 → 长轮询
- 只需 服务器推送 → SSE
- 需要 全双工实时交互 → WebSocket
来源:juejin.cn/post/7496375493329174591
BOE(京东方)第6代新型半导体显示器件生产线全面量产 打造全球显示产业新引擎
2025年5月26日,BOE(京东方)成功举办主题为“屏启未来 智显无界”的量产交付活动,开启第6代新型半导体显示器件生产线由建设转向运营的崭新篇章。这不仅标志着BOE(京东方)在LTPO、LTPS、Mini LED等高端显示领域实现跨越式突破,也为我国半导体显示产业注入强劲动能,加速助力北京打造国际科技创新中心。作为全球技术最先进、产能最大的VR用LCD生产基地,该生产线将充分发挥技术引领和产业集聚优势,进一步巩固BOE(京东方)行业龙头地位,加速全球虚拟现实产业和数字经济发展。BOE(京东方)科技集团董事长陈炎顺,BOE(京东方)首席执行官冯强,BOE(京东方)首席运营官王锡平,行业专家及生态伙伴出席现场仪式,共同见证这一荣耀时刻。

活动现场,BOE(京东方)科技集团董事长陈炎顺发表致辞,他表示,BOE(京东方)以“BOE速度”打造新型显示产业基地建设标杆,成功实现开工当年封顶、次年产品点亮的关键目标。与此同时,技术研发与产品准备也在同步推进,多款产品已完成客户送样并推进交付。BOE(京东方)特别感谢战略合作伙伴们对技术创新的追求和坚持,这也推动着BOE(京东方)不断超越自我,取得一个又一个新的突破。BOE(京东方)将始终以战略客户伙伴的前沿需求和技术标准为指引,在“屏之物联”战略指导下,用踏实奋斗和持续创新回馈各界支持。

作为全球技术最先进的液晶显示屏生产基地,BOE(京东方)第6代新型半导体显示器件生产线总投资290亿元,占地面积42万平方米,设计月产能达5万片。该生产线以LTPO(低温多晶氧化物)和LTPS(低温多晶硅)技术为核心,聚焦聚焦 VR 显示面板、中小尺寸高附加值 IT 显示面板、车载显示面板等高端产品研发与生产,采用1500mm×1850mm的6代线玻璃基板,配备当前最先进的生产设备,并整合京东方多条成熟产线的先进经验,大幅提升生产效率和产品精度。在技术创新方面,BOE(京东方)LTPO技术融合了LTPS的高迁移率和Oxide的低功耗优势,可实现1500PPI以上的超高像素密度,并大幅度降低面板功耗,为显示设备提供更流畅、更清晰的动态画面。
值得一提的是,BOE(京东方)第6代新型半导体显示器件生产线还充分赋能多元化的场景应用,多款产品凭借极具竞争力的产品性能和领先的技术优势,获得全球一线知名客户的高度认可。其中,BOE(京东方)自主设计开发的超高2117PPI Real RGB显示屏实现成功点亮,达到当前LCD行业最高分辨率。在此次交付活动上,BOE(京东方)展示了已具备量产条件的2.24英寸1500PPI以及2.24英寸1700PPI VR显示模组,16英寸240Hz电竞笔记本屏幕(分辨率2560×1600,100% DCI-P3色域),以及14.6英寸窄边框高端车载中控屏等产品,全面满足“元宇宙”、高端消费电子、智能出行等领域的需求。
更加值得关注的是,BOE(京东方)第6代新型半导体显示器件生产线还在可持续发展方面走在世界前列。通过洁净室气流集控、AI分区温湿度自调、用电集控等创新技术,BOE(京东方)实现供热回收使用率100%、实现纯水回用率达80%、污染物排放均值小于标准50%。此外,在“双碳”目标引领下,BOE(京东方)将绿色理念贯穿于研发、生产与回收全生命周期。例如,生产线生产的产品在提升画质的同时更加注重产品低功耗性能,为设备的长时间使用提供可持续支持。这些实践不仅呼应了全球绿色低碳转型趋势,更展现了BOE(京东方)作为行业领军者的责任担当。同时,依托AI赋能,BOE(京东方)第6代新型半导体显示器件生产线还实现了智能排产、预测性维护、智能缺陷管理等全流程优化,设备综合效率(OEE)提升0.5%,工艺稳定性提升20%,良率分析效率提升20%,为行业树立了绿色生产与智能制造的双重标杆,也有力地回应了BOE(京东方)“Open Next Earth”的可持续发展品牌内涵。
在虚实交融的数字文明浪潮中,屏幕已从信息媒介跃升为跨越现实与虚拟、链接当下与未来的纽带。BOE(京东方)将持续以“屏之物联”战略为核心,加速显示技术与物联网、人工智能等前沿技术的深度融合,深刻践行“科技创新+绿色发展”之道。面向未来,BOE(京东方)将与更多合作伙伴携手,以协同创新之力探寻合作路径,全力赋能万物互联的未来智能生态体系,共同迎接一个更智慧、更互联、更美好、更绿色的全新时代。





