



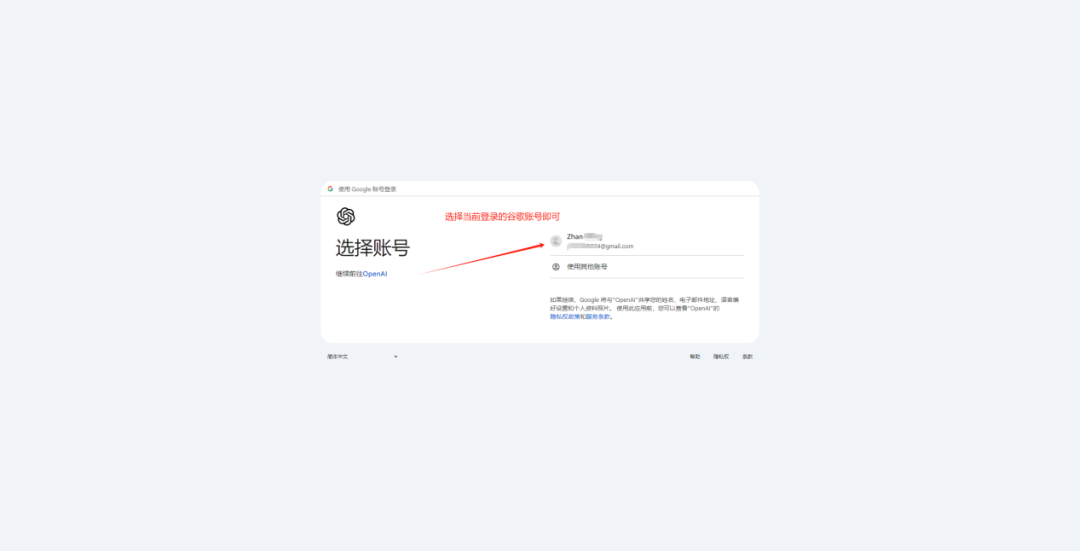
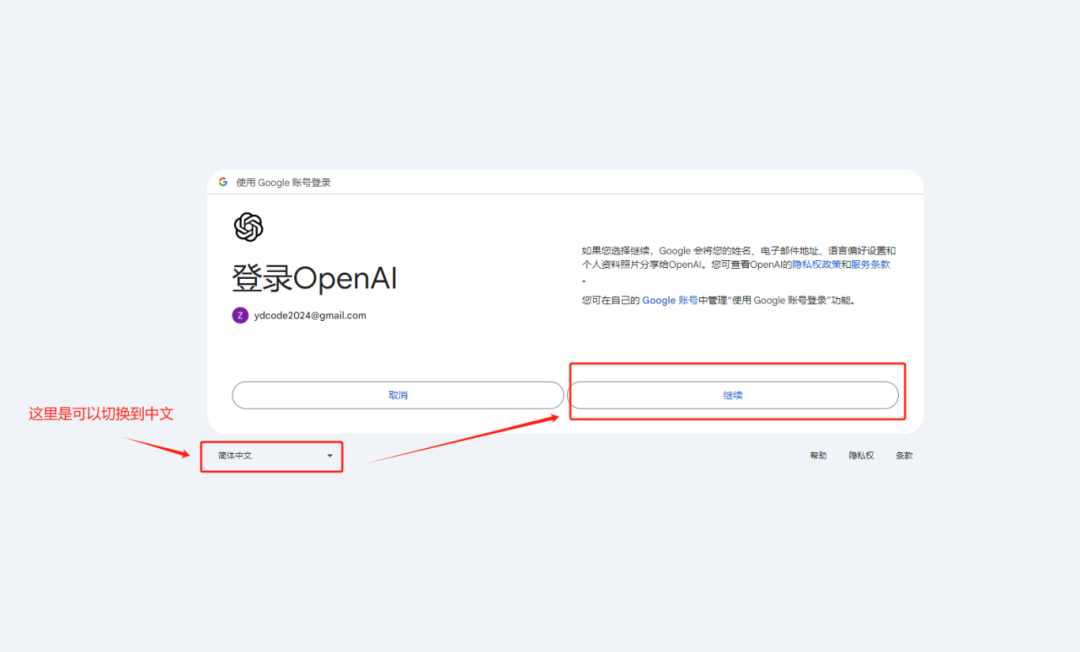
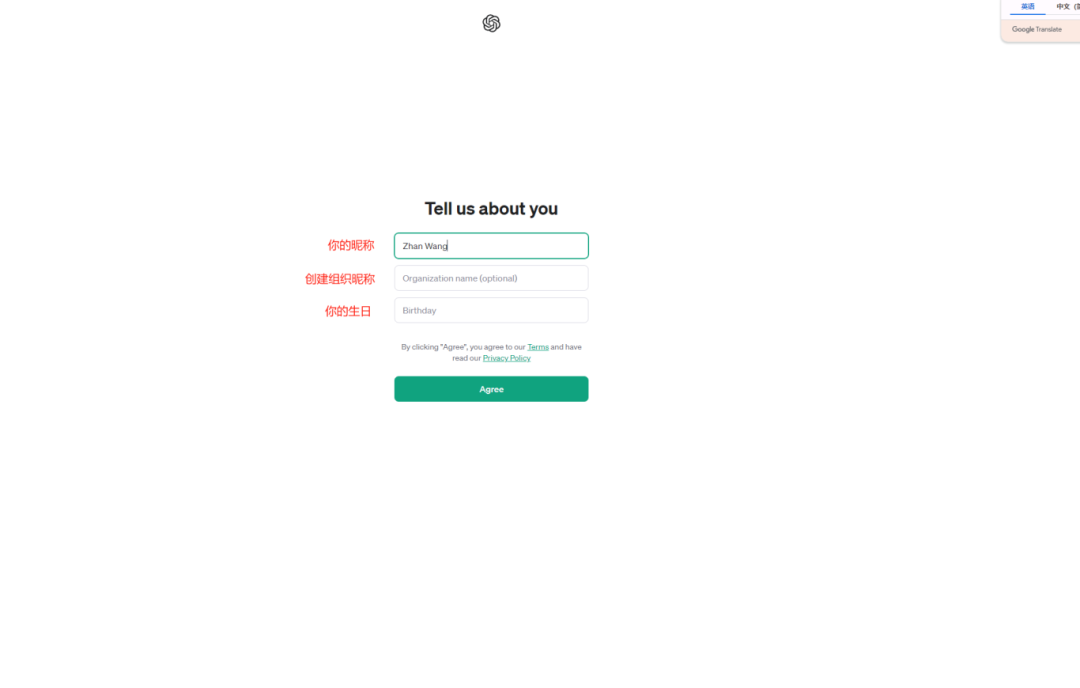
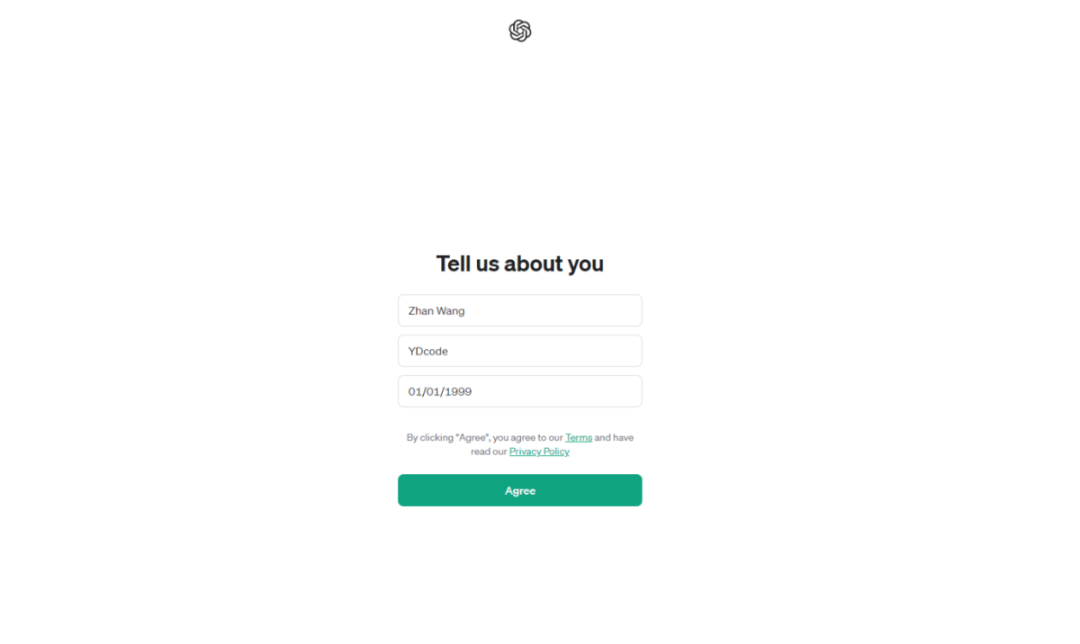




























![[舔屏]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/40/pcmoren_tian_org.png)





![[污]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/3c/pcmoren_wu_org.png)

![[坏笑]](http://img.t.sinajs.cn/t4/appstyle/expression/ext/normal/50/pcmoren_huaixiao_org.png)








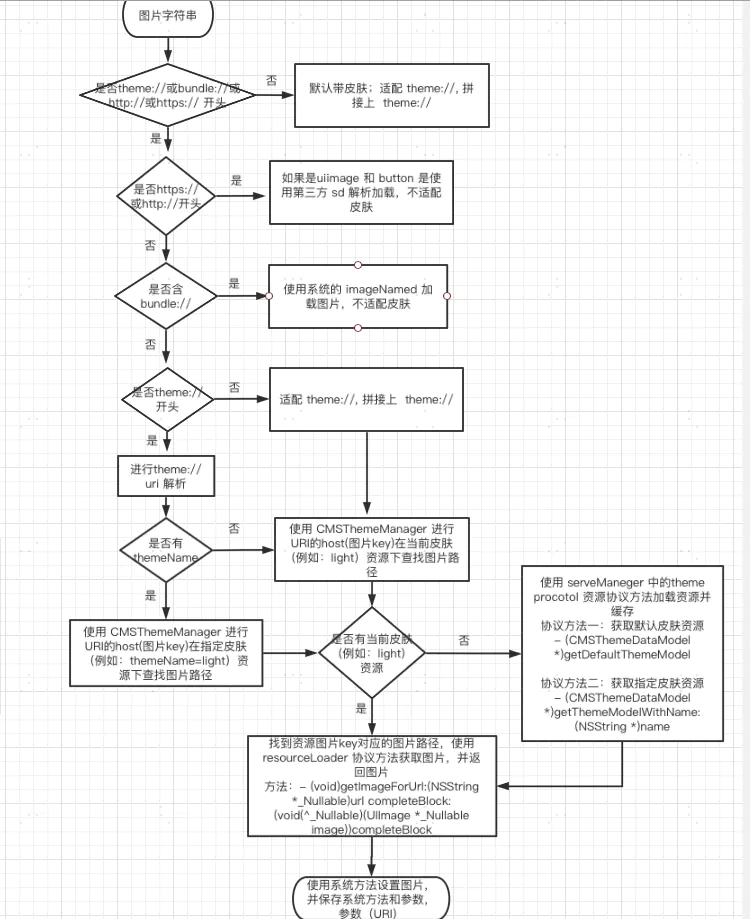
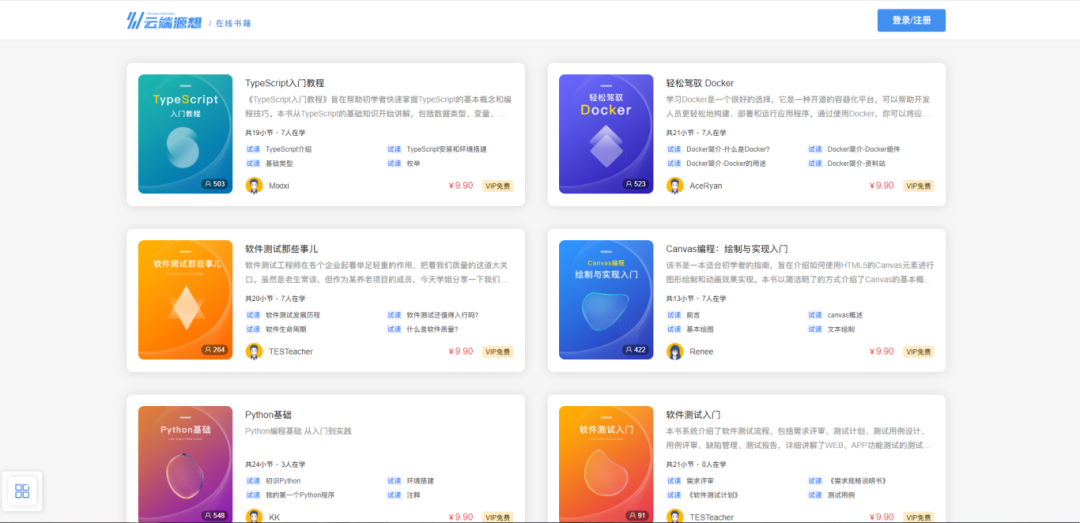
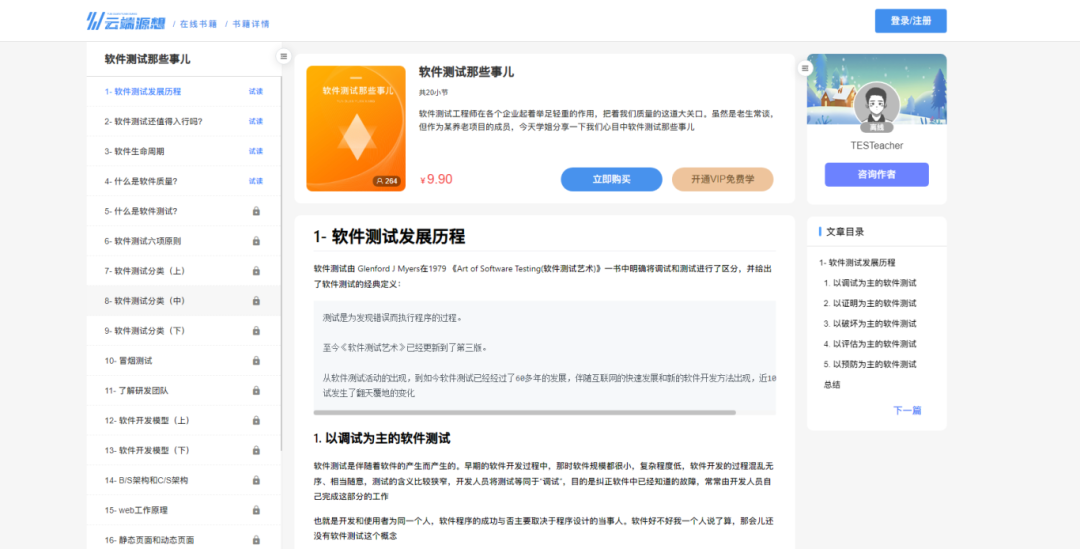
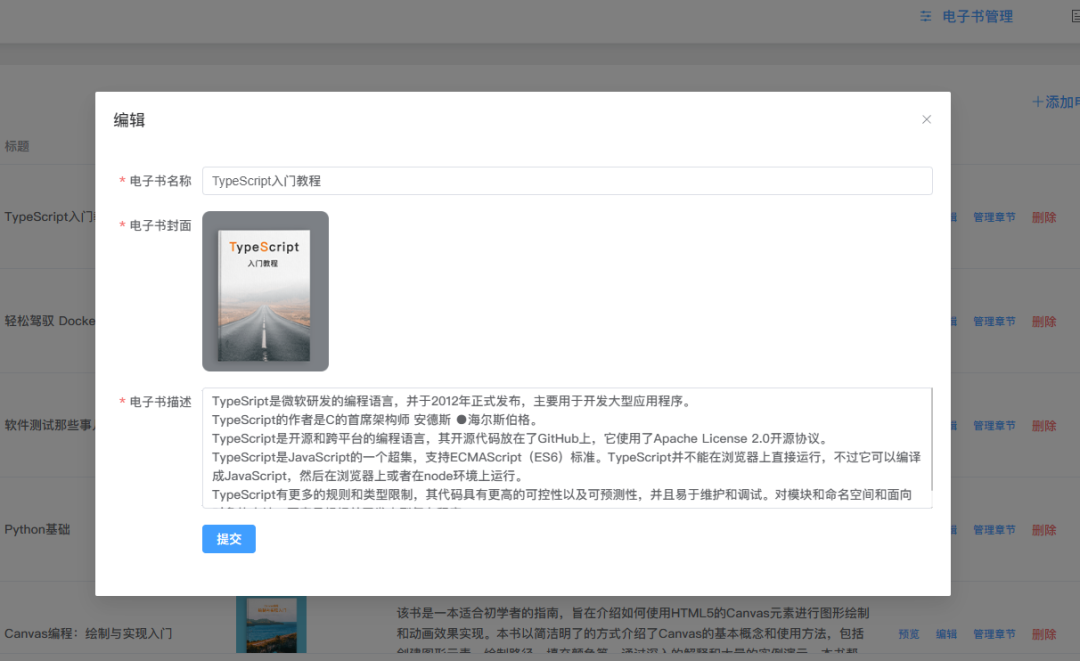
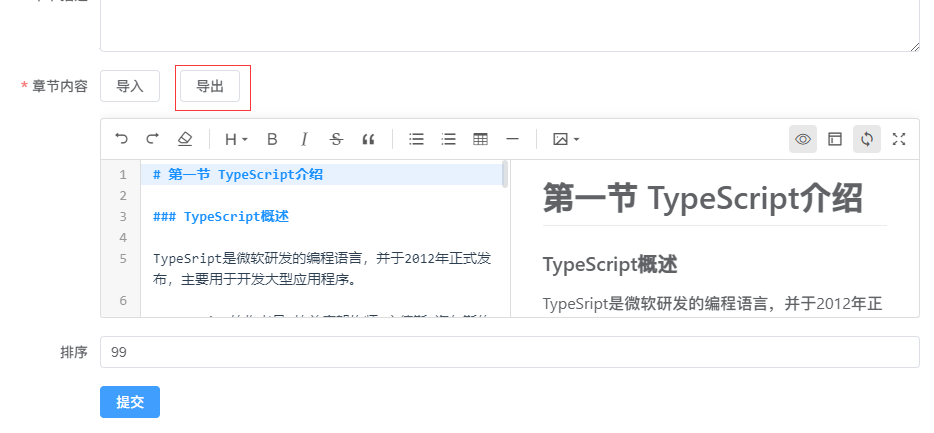
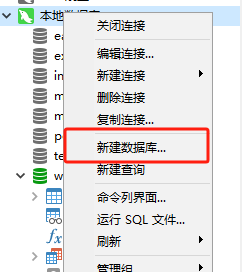
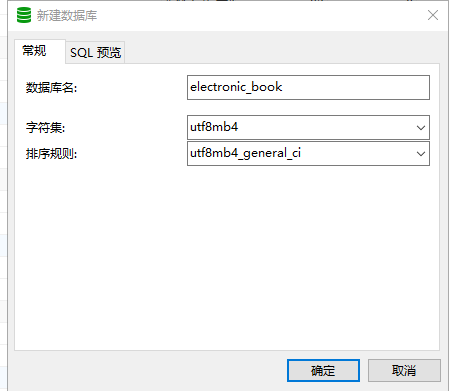
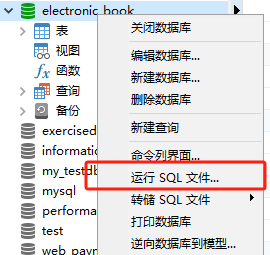
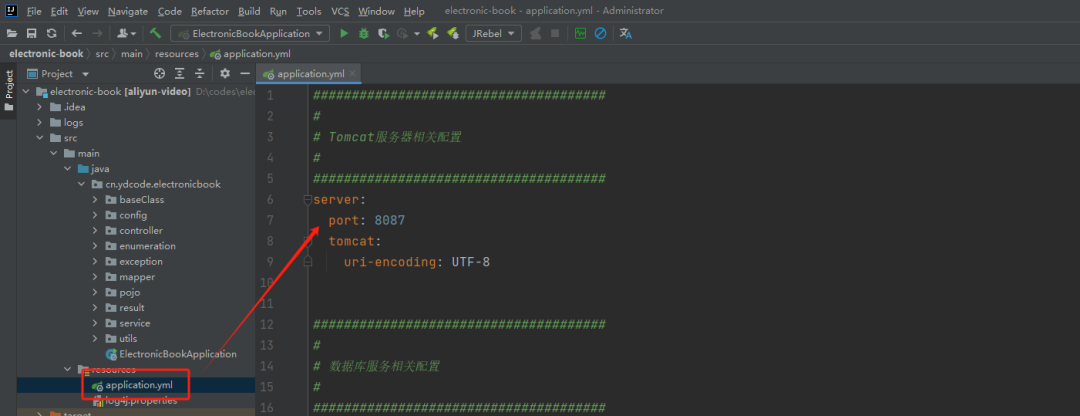
插件介绍
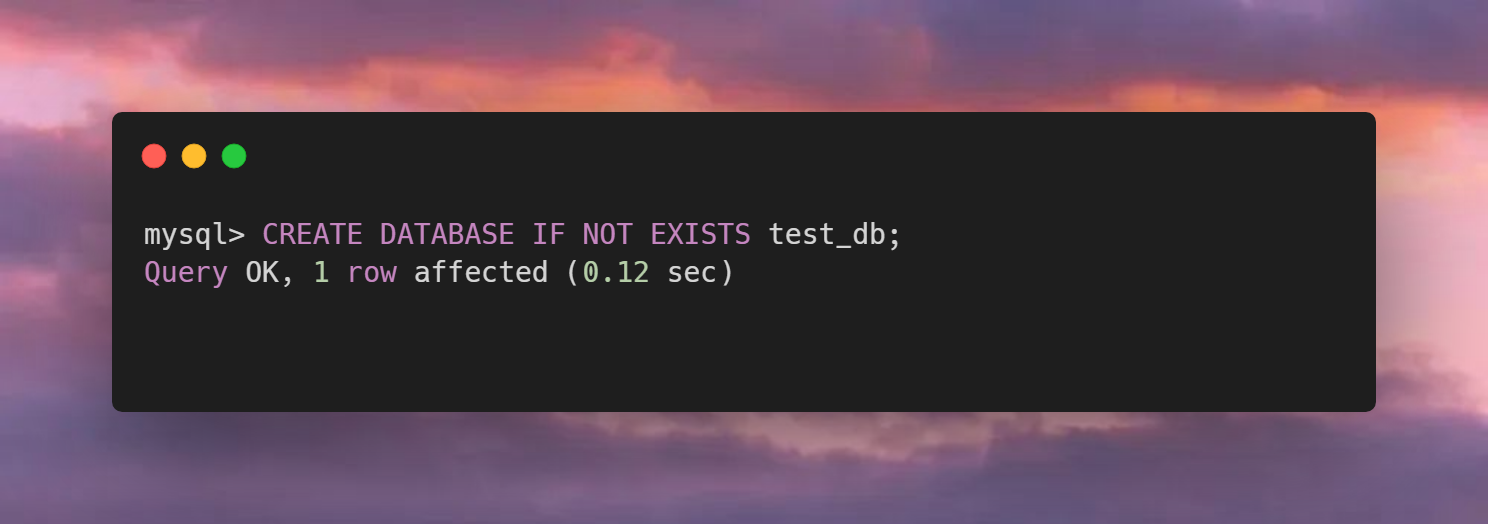
excel-2b-json 插件用于将 google excel 文件转化成 本地json文件。
适用场景: 项目国际化,配置多语言
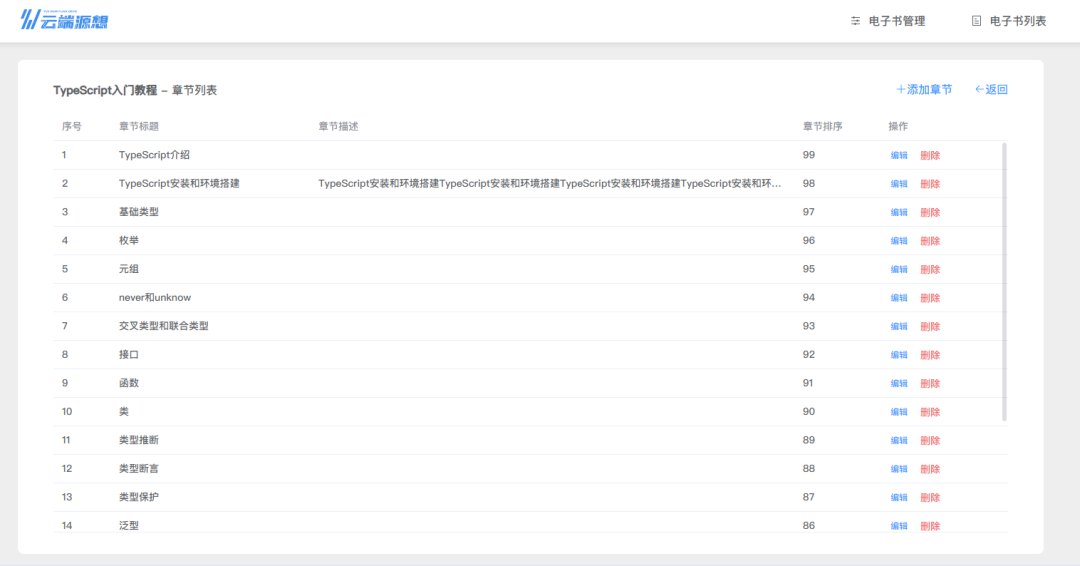
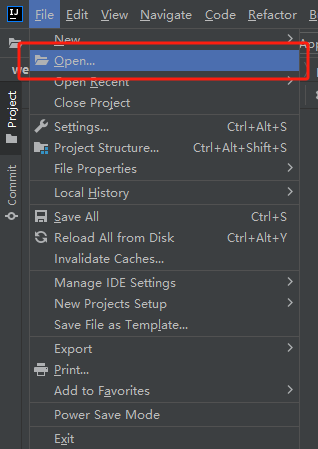
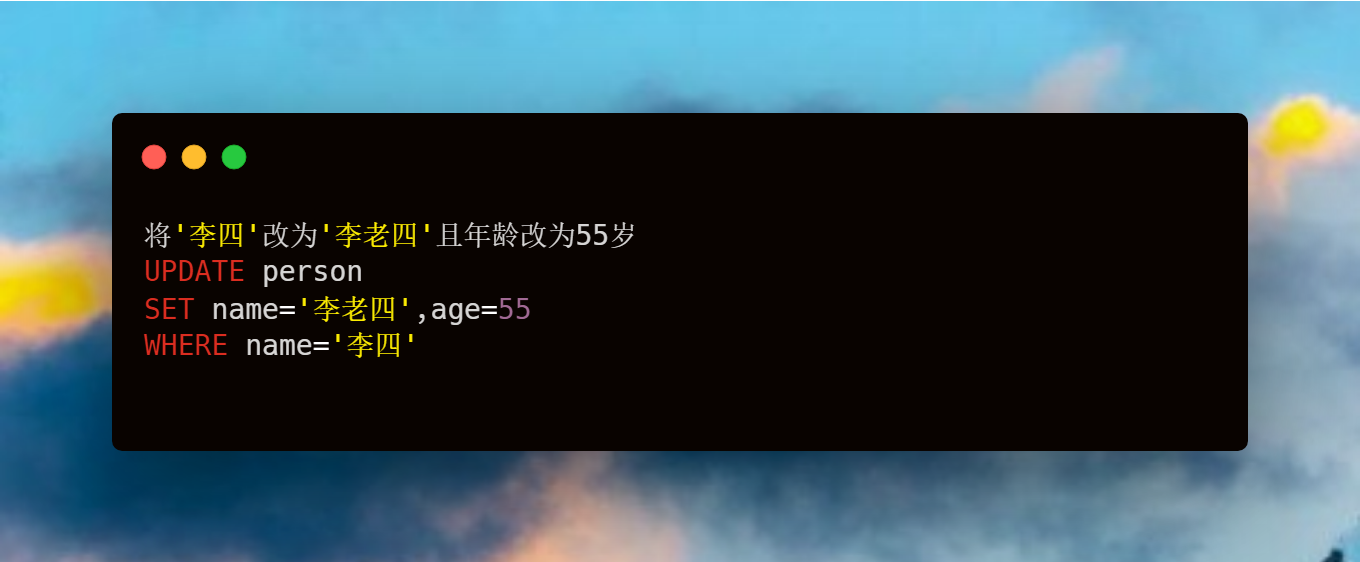
使用方法
1. 安装excel-2b-json
npm install excel-2b-json
2. 引入使用
const excelToJson = require('excel-2b-json');
// path 生成的json文件目录
excelToJson('https://docs.google.com/spreadsheets/d/12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM/edit#gid=0', path)
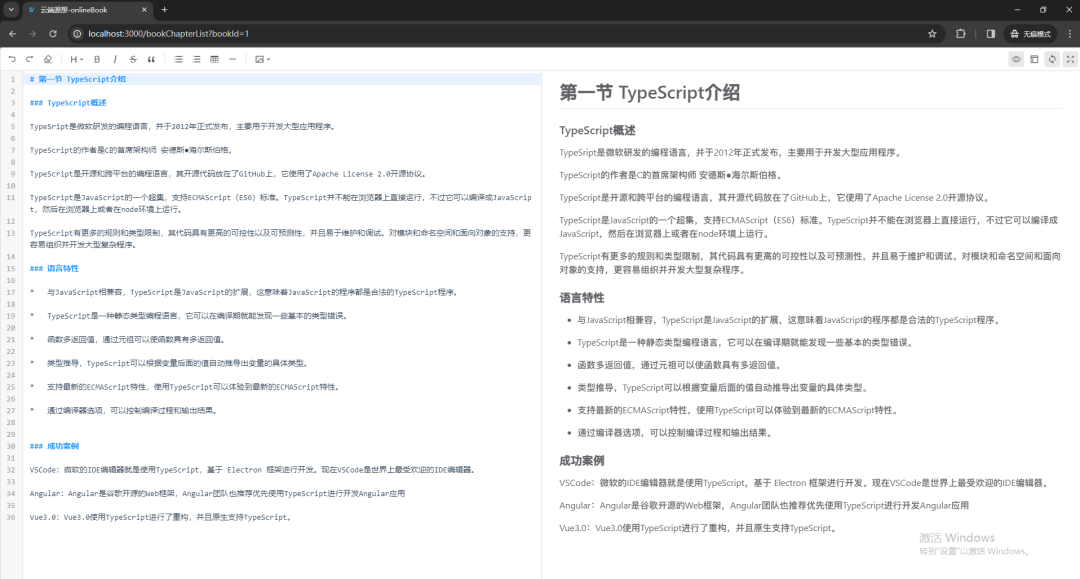
转化得到
下面是插件的实现
源码已放到github:github.com/Sunny-lucki…
一、涉及的算法
1. 26字母转换成数字,26进制,a为1,aa为27,ab为28
function colToInt(col) {
const letters = ['', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
col = col.trim().split('')
let n = 0
for (let i = 0; i < col.length; i++) {
n *= 26
n += letters.indexOf(col[i])
}
return n
}
2. 生成几行几列的二维空数组
function getEmpty2DArr(rows, cols) {
let arrs = new Array(rows);
for (var i = 0; i < arrs.length; i++) {
arrs[i] = new Array(cols).fill(''); //每行有cols列
}
return arrs;
}
3. 清除二维数组中空的数组
[
[1,2,3],
['','',''],
[7,8,9]
]
转化为
[
[1,4,7],
[3,6,9]
]
clearEmptyArrItem(matrix) {
return matrix.filter(function (val) {
return val.some(function (val1) {
return val1.replace(/\s/g, '') !== ''
})
})
}
4. 矩阵的翻转
[
[1,2,3],
[4,5,6],
[7,8,9]
]
转化为
[
[1,4,7],
[2,5,8],
[3,6,9]
]
算法实现
/**
*
* @param {array*2} matrix 一个二维数组,返回旋转后的二维数组。
*/
rotateExcelDate(matrix) {
if (!matrix[0]) return []
var results = [],
result = [],
i,
j,
lens,
len
for (i = 0, lens = matrix[0].length; i < lens; i++) {
result = []
for (j = 0, len = matrix.length; j < len; j++) {
result[j] = matrix[j][i]
}
results.push(result)
}
return results
}
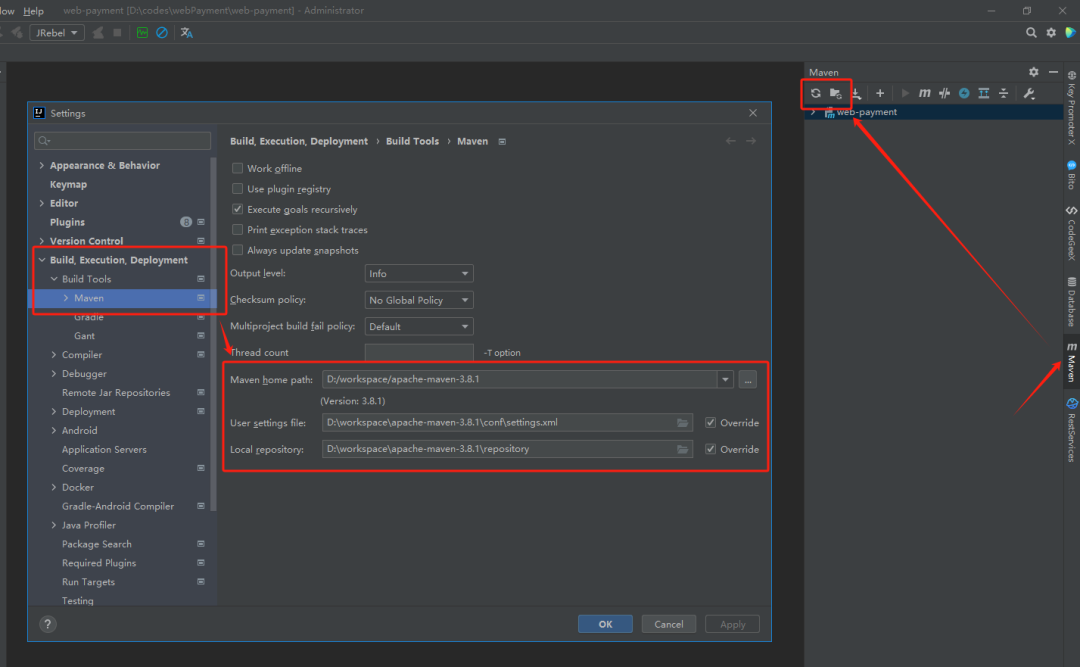
二、插件的实现
1. 下载google Excel文档到本地
我们先看看google Excel文档的url的组成
https://docs.google.com/spreadsheets/d/文档ID/edit#哈希值
例如下面这条,你可以尝试打开,下面这条链接是可以打开的。
https://docs.google.com/spreadsheets/d/12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM/edit#gid=0
下载google文档的步骤非常简单,只要获取原始的链接,然后拼接成下面的url,向这个Url发起请求,然后以流的方式写入生成文件就可以了。
https://docs.google.com/spreadsheets/d/ + "文档ID" + '/export?format=xlsx&id=' + id + '&' + hash
因此实现下载的方法非常简单,可以直接看代码
downLoadExcel.js
const fs = require('fs')
const request = require('superagent')
const rmobj = require('./remove')
/**
* 下载google excel 文档到本地
* @param {*} url // https://docs.google.com/spreadsheets/d/12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM/edit#gid=0
* @returns
*/
function downLoadExcel(url) {
// 记录当前下载文件的目录,方便删除
rmobj.push({
path: __dirname,
ext: 'xlsx'
})
return new Promise((resolve, reject) => {
var down1 = url.split('/')
var down2 = down1.pop() // edit#gid=0
var url2 = down1.join('/') // https://docs.google.com/spreadsheets/d/12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM
var id = down1.pop() // 12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM
var hash = down2.split('#').pop() // gid=0
var downurl = url2 + '/export?format=xlsx&id=' + id + '&' + hash // https://docs.google.com/spreadsheets/d/12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM/export?format=xlsx&id=12q3leiNxdmI_ZLWFj4LP_EA5PeJpLF18vViuyiSOuvM&gid=0
var loadedpath = __dirname + '/' + id + '.xlsx'
const stream = fs.createWriteStream(loadedpath)
const req = request.get(downurl)
req.pipe(stream).on('finish', function () {
resolve(loadedpath)
// 已经成功下载下来了,接下来将本地excel转化成json的工作就交给Excel对象来完成
})
})
}
module.exports = downLoadExcel
入口文件可以这样写
async function excelToJson(excelPathName, outputPath) {
if (Util.checkAddress(excelPathName) === 'google') {
// 1.判断是谷歌excel文档,需要交给Google对象去处理,主要是下载线上的,生成本地excel文件
const filePath = await downLoadExcel(excelPathName)
// 2.解析本地excel成二维数组
const data = await parseXlsx(filePath)
// 3.生成json文件
generateJsonFile(data, outputPath)
}
}
module.exports = excelToJson
之所以写if判断,是为了后面扩展,也许就不止是解析google文档了,或许也要解析腾讯等其他文档呢
第一步已经实现了,接下来就看第二步怎么实现
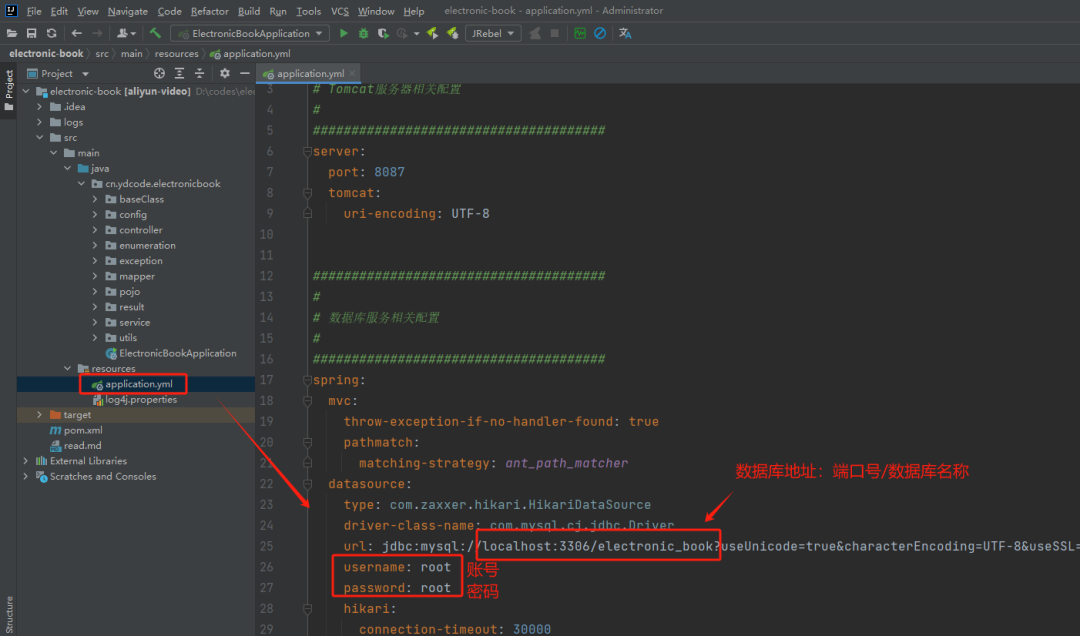
2. 解析本地excel成二维数组
解析本地excel文件,获取excel的sheet信息和strings信息
excel 文件其实本质上是多份xml文件的压缩文件。
xml是存储数据的,而html是显示数据的
而在这里我们只需要获取两份xml 文件,一份是strings,就是excel里的内容,一份是sheet,概括整个excel文件的信息。
async function parseXlsx(path) {
// 1. 解析本地excel文件,获取excel的sheet信息和content信息
const files = await extractFiles(path);
// 2. 根据strings和sheet解析成二维数组
const data = await extractData(files)
// 3. 处理二维数组的内容,
const fixData = handleData(data)
return fixData;
}
所以第一步我们看看怎么获取excel的sheet信息和strings信息
function extractFiles(path) {
// excel的本质是多份xml组成的压缩文件,这里我们只需要xl/sharedStrings.xml和xl/worksheets/sheet1.xml
const files = {
strings: {}, // strings内容
sheet: {},
'xl/sharedStrings.xml': 'strings',
'xl/worksheets/sheet1.xml': 'sheet'
}
const stream = path instanceof Stream ? path : fs.createReadStream(path)
return new Promise((resolve, reject) => {
const filePromises = [] // 由于一份excel文档,会被解析成好多分xml文档,但是我们只需要两份xml文档,分别是(xl/sharedStrings.xml和xl/worksheets/sheet1.xml),所以用数组接受
stream
.pipe(unzip.Parse())
.on('error', reject)
.on('close', () => {
Promise.all(filePromises).then(() => {
return resolve(files)
})
})
.on('entry', entry => {
// 每解析某个xml文件都会进来这里,但是我们只需要xl/sharedStrings.xml和xl/worksheets/sheet1.xml,并将内容保存在strings和sheet中
const file = files[entry.path]
if (file) {
let contents = ''
let chunks = []
let totalLength = 0
filePromises.push(
new Promise(resolve => {
entry
.on('data', chunk => {
chunks.push(chunk)
totalLength += chunk.length
})
.on('end', () => {
contents = Buffer.concat(chunks, totalLength).toString()
files[file].contents = contents
if (/�/g.test(contents)) {
throw TypeError('本次转化出现乱码�')
} else {
resolve()
}
})
})
)
} else {
entry.autodrain()
}
})
})
}
可以断点看看entry.path,你就会看到分别进来了好几次,然后我们会分别看到我们想要的那两个文件
两份xml文件解析之后就会到close方法里了,这时就可以看到strings和sheet都有内容了,而且内容都是xml
我们分别看看strings和sheet的内容
stream
.pipe(unzip.Parse())
.on('error', reject)
.on('close', () => {
Promise.all(filePromises).then(() => {
console.log(files.strings.contents);
console.log(files.sheet.contents);
return resolve(files)
})
})
格式化一下
strings
sheet
可以发现strings的内容非常简单,现在我们借助xmldom将内容解析为节点对象,然后用xpath插件来获取内容
xpath的用法:github.com/goto100/xpa…
const XMLDOM = require('xmldom')
const xpath = require('xpath')
const ns = { a: 'http://schemas.openxmlformats.org/spreadsheetml/2006/main' }
const select = xpath.useNamespaces(ns)
const valuesDoc = new XMLDOM.DOMParser().parseFromString(
files.strings.contents
)
// 把所有每个格子的内容都放进了values数组里。
values = select('//a:si', valuesDoc).map(string =>
select('.//a:t', string)
.map(t => t.textContent)
.join('')
)
'
//a:si' 是xpath语法,//表示选择当前节点下的所有子孙节点,a是schemas.openxmlformats.org/spreadsheet…
可以看到,xpath的用法很简单,就是找到si节点下的子节点t的内容,然后放进数组里
最终生成的values数组是[ 'lang', 'cn','en', 'lang001','我是阳光', 'i am sunny','lang002', '前端阳光','FE Sunny', 'lang003','带带我', 'ddw']
现在我们要获取sheet的内容了,我们先分析一下xml结构
可以看到sheetData节点其实就是记录strings的内容的信息的,strings的内容是我们真正输入的,而sheet则是类似一种批注。
我们分析看看
row就是表示表格中的行,c则表示的是列,属性t="s"表示的是当前这个格子有内容,r="A1"表示的是在第一行中的A列
。
而节点v则表示该格子是该表格的第几个有值的格子,不信?我们可以试试看
可以看到这打印出来的xml内容,strings中已经没有了那两个值,而sheet中的那两个格子的c节点的t属性没了,而且v节点也没有了。
现在我们可以知道,string只保存有值的格子里的值,而sheet则是一个网格,不管格子有没有值都会记录,有值的会有个序号存在v节点中。
现在就要收集c节点
const na = {
textContent: ''
}
class CellCoords {
constructor(cell) {
cell = cell.split(/([0-9]+)/)
this.row = parseInt(cell[1])
this.column = colToInt(cell[0])
}
}
class Cell {
constructor(cellNode) {
const r = cellNode.getAttribute('r')
const type = cellNode.getAttribute('t') || ''
const value = (select('a:v', cellNode, 1) || na).textContent
const coords = new CellCoords(r)
this.column = coords.column // 该格子所在列数
this.row = coords.row // 该格子所在行数
this.value = value // 该格子的顺序
this.type = type // 该格子是否为空
}
}
const cells = select('/a:worksheet/a:sheetData/a:row/a:c', sheet).map(
node => new Cell(node)
)
每个c节点用cell对象来表示
可以看到cell节点有四个属性。
你现在知道它为什么要保存顺序了吗?
因为这样才可以直接从strings生成的values数组中拿出对应顺序的值填充到网格中。
接下来要获取总共有多少列数和行数。这就需要获取最大最小行数列数,然后求差得到
// 计算该表格的最大最小列数行数
d = calculateDimensions(cells)
const cols = d[1].column - d[0].column + 1
const rows = d[1].row - d[0].row + 1
function calculateDimensions(cells) {
const comparator = (a, b) => a - b
const allRows = cells.map(cell => cell.row).sort(comparator)
const allCols = cells.map(cell => cell.column).sort(comparator)
const minRow = allRows[0]
const maxRow = allRows[allRows.length - 1]
const minCol = allCols[0]
const maxCol = allCols[allCols.length - 1]
return [{ row: minRow, column: minCol }, { row: maxRow, column: maxCol }]
}
接下来就根据列数和行数造空二维数组,然后再根据cells和values填充内容
// 计算该表格的最大最小列数行数
d = calculateDimensions(cells)
const cols = d[1].column - d[0].column + 1
const rows = d[1].row - d[0].row + 1
// 生成二维空数组
data = getEmpty2DArr(rows, cols)
// 填充二维空数组
for (const cell of cells) {
let value = cell.value
// s表示该格子有内容
if (cell.type == 's') {
value = values[parseInt(value)]
}
// 填充该格子
if (data[cell.row - d[0].row]) {
data[cell.row - d[0].row][cell.column - d[0].column] = value
}
}
return data
我们看看最终生成的data,可以发现,excel的网格已经被二维数组模拟出来了
所以我们看看extractData的完整实现
function extractData(files) {
let sheet
let values
let data = []
try {
sheet = new XMLDOM.DOMParser().parseFromString(files.sheet.contents)
const valuesDoc = new XMLDOM.DOMParser().parseFromString(
files.strings.contents
)
// 把所有每个格子的内容都放进了values数组里。
values = select('//a:si', valuesDoc).map(string =>
select('.//a:t', string)
.map(t => t.textContent)
.join('')
)
console.log(values);
} catch (parseError) {
return []
}
const na = {
textContent: ''
}
class CellCoords {
constructor(cell) {
cell = cell.split(/([0-9]+)/)
this.row = parseInt(cell[1])
this.column = colToInt(cell[0])
}
}
class Cell {
constructor(cellNode) {
const r = cellNode.getAttribute('r')
const type = cellNode.getAttribute('t') || ''
const value = (select('a:v', cellNode, 1) || na).textContent
const coords = new CellCoords(r)
this.column = coords.column // 该格子所在列数
this.row = coords.row // 该格子所在行数
this.value = value // 该格子的顺序
this.type = type // 该格子是否为空
}
}
const cells = select('/a:worksheet/a:sheetData/a:row/a:c', sheet).map(
node => new Cell(node)
)
// 计算该表格的最大最小列数行数
d = calculateDimensions(cells)
const cols = d[1].column - d[0].column + 1
const rows = d[1].row - d[0].row + 1
// 生成二维空数组
data = getEmpty2DArr(rows, cols)
// 填充二维空数组
for (const cell of cells) {
let value = cell.value
// s表示该格子有内容
if (cell.type == 's') {
value = values[parseInt(value)]
}
// 填充该格子
if (data[cell.row - d[0].row]) {
data[cell.row - d[0].row][cell.column - d[0].column] = value
}
}
return data
}
接下来就是要去除空行和空列,并将二维数组翻转成我们需要的格式
function handleData(data) {
if (data) {
data = clearEmptyArrItem(data)
data = rotateExcelDate(data)
data = clearEmptyArrItem(data)
}
return data
}
可以看到,现在数组的第一项子数组则是key列表了。
接下来就可以根据key来生成对应的json文件了。
3. 生成json数据
这一步非常简单
function generateJsonFile(excelDatas, outputPath) {
// 获得转化成json格式
const jsons = convertProcess(excelDatas)
// 生成写入文件
writeFile(jsons, outputPath)
}
首先就是获取json数据
先获取data数组的第一项数组,第一项数组是key,然后生成每种语言的json对象
/**
*
* @param {array*2} data
* 返回处理完后的多语言数组,每一项都是一个json对象。
*/
function convertProcess(data) {
var keys_arr = [],
data_arr = [],
result_arr = [],
i,
j,
data_arr_len,
col_data_json,
col_data_arr,
data_arr_col_len
// 表格合并处理,这是json属性列。
keys_arr = data[0]
// 第一例是json描述,后续是语言包
data_arr = data.slice(1)
for (i = 0, data_arr_len = data_arr.length; i < data_arr_len; i++) {
// 取出第一个列语言包
col_data_arr = data_arr[i]
// 该列对应的临时对象
col_data_json = {}
for (
j = 0, data_arr_col_len = col_data_arr.length;
j < data_arr_col_len;
j++
) {
col_data_json[keys_arr[j]] = col_data_arr[j]
}
result_arr.push(col_data_json)
}
return result_arr
}
我们可以看看生成的result_arr
可见已经成功生成每一种语言的json对象了。
接下来只需要生成json文件就可以了,注意把之前生成的excel文件删除
//得到的数据写入文件
function writeFile(datas, outputPath) {
for (let i = 0, len = datas.length; i < len; i++) {
fs.writeFileSync(outputPath +
(datas[i].filename || datas[i].lang) +
'.json',
JSON.stringify(datas[i], null, 4)
)
}
rmobj.flush();
}
到此,一个稍微完美的插件就此完成了。 撒花撒花!!!!