
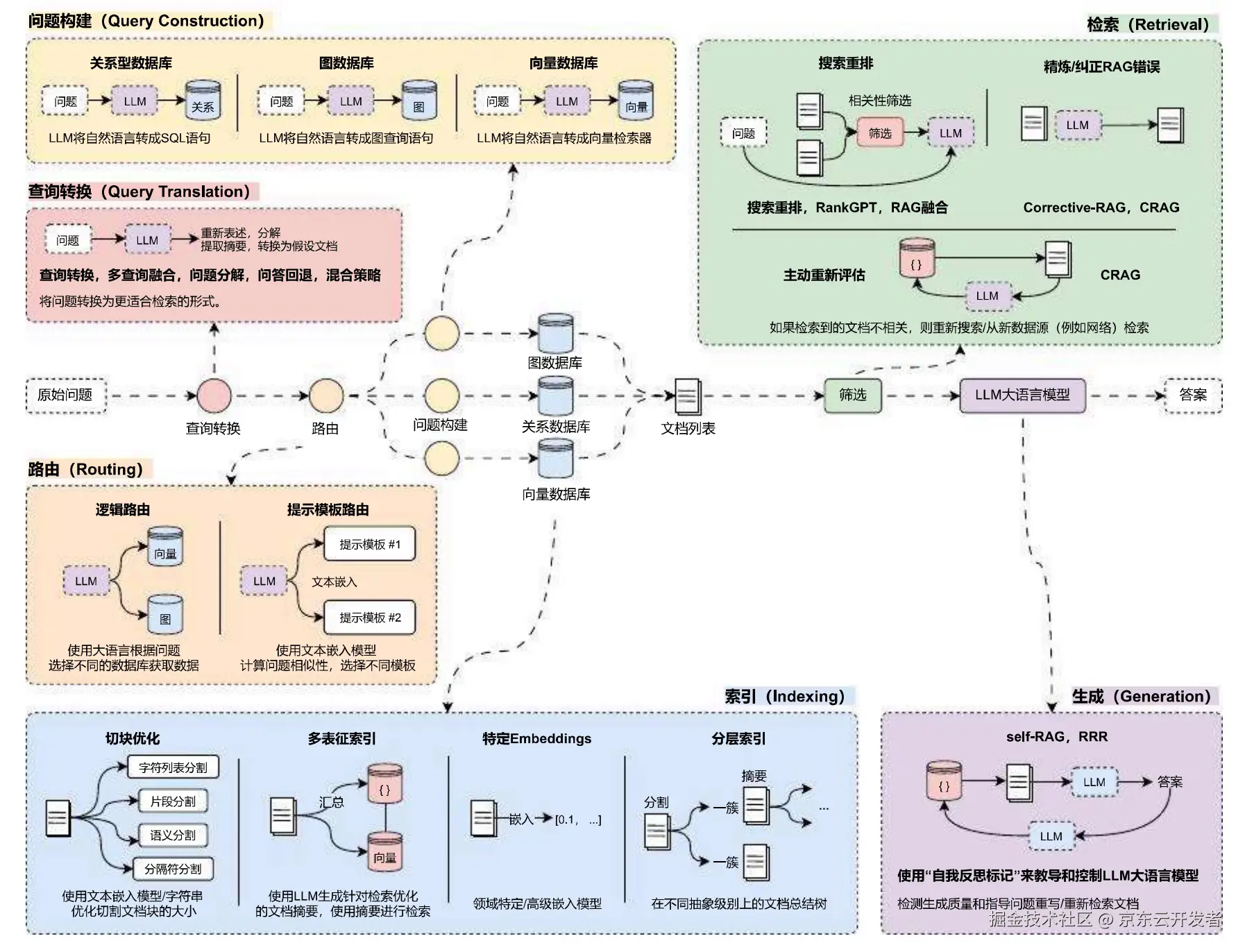




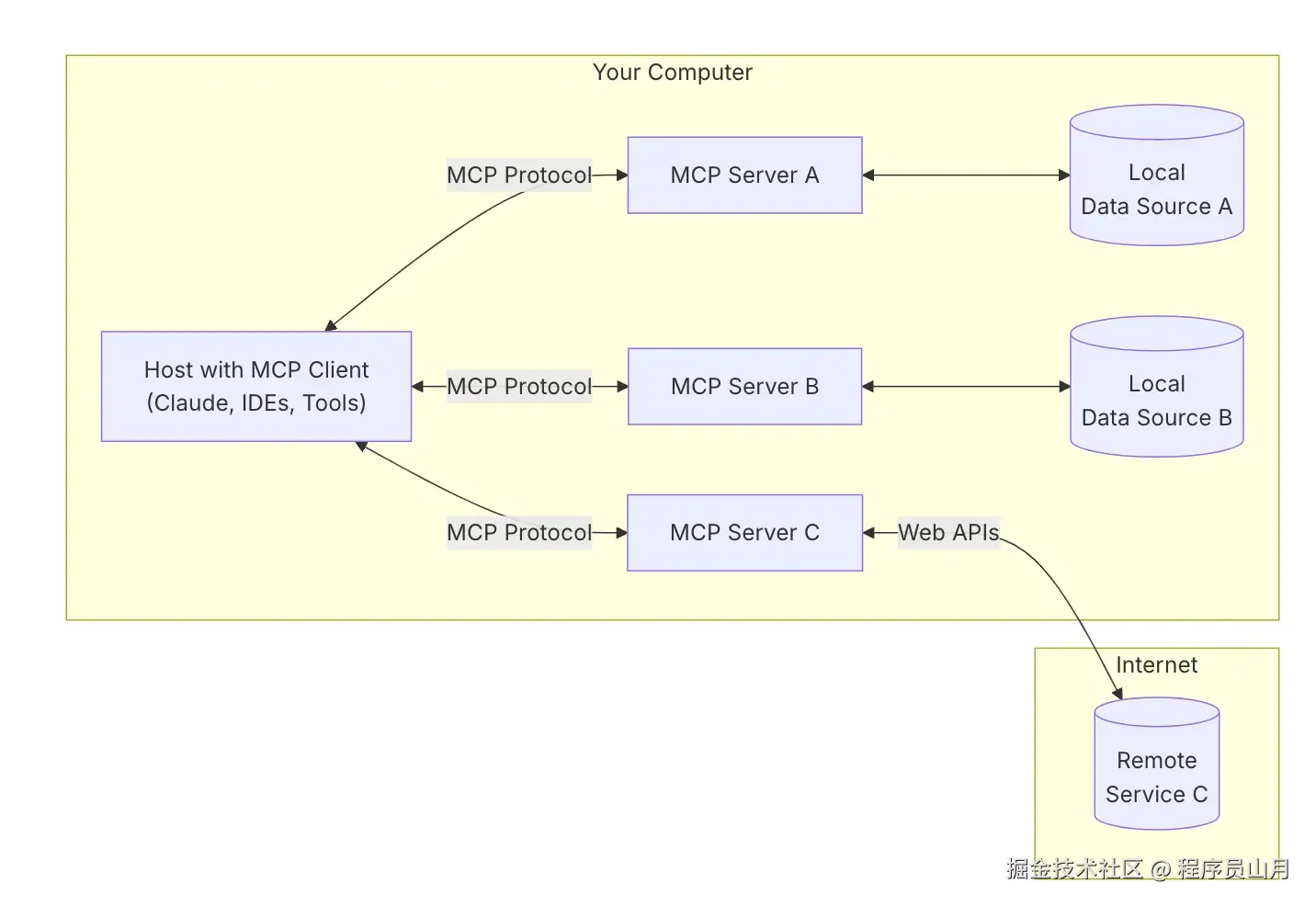
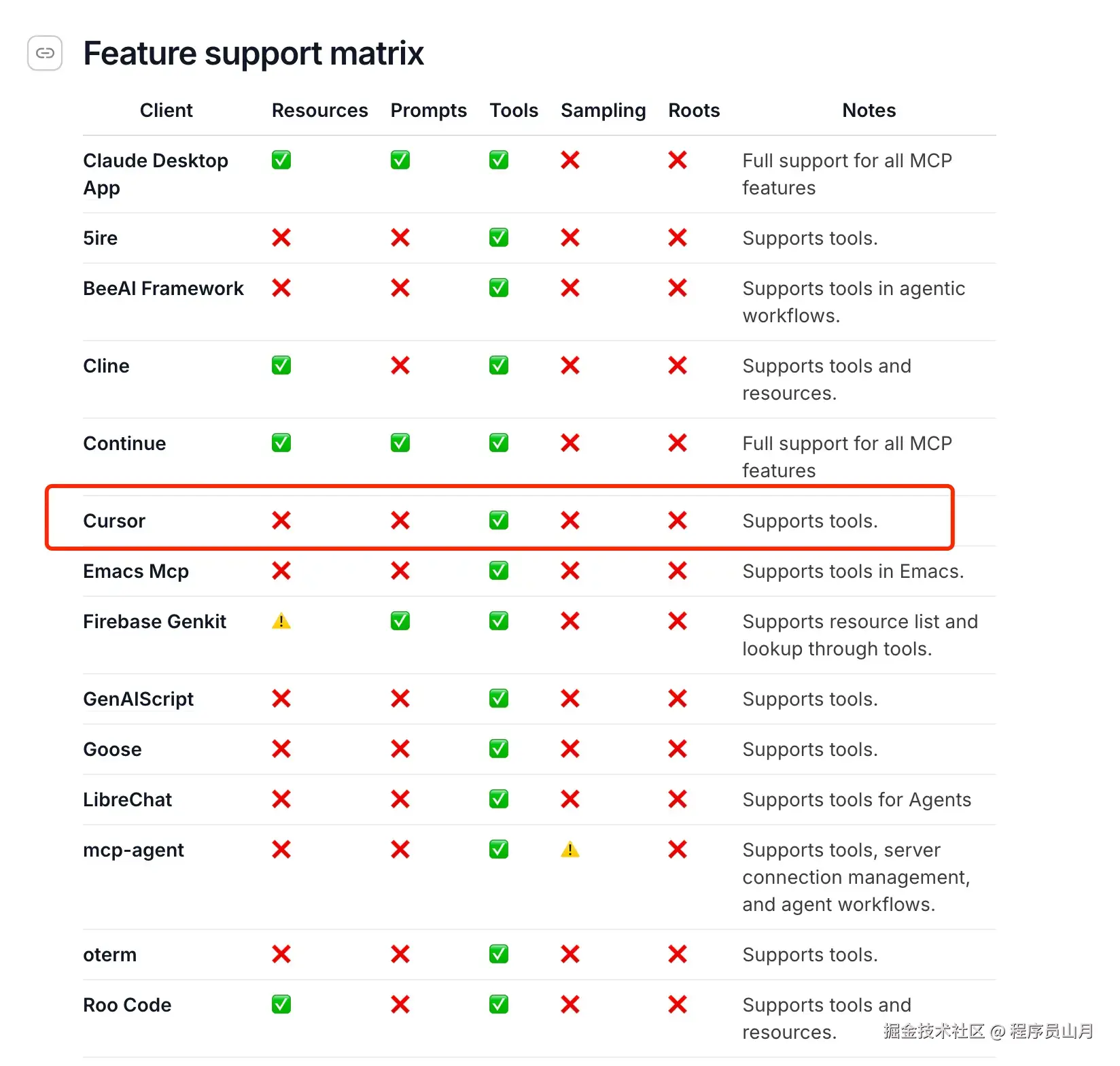





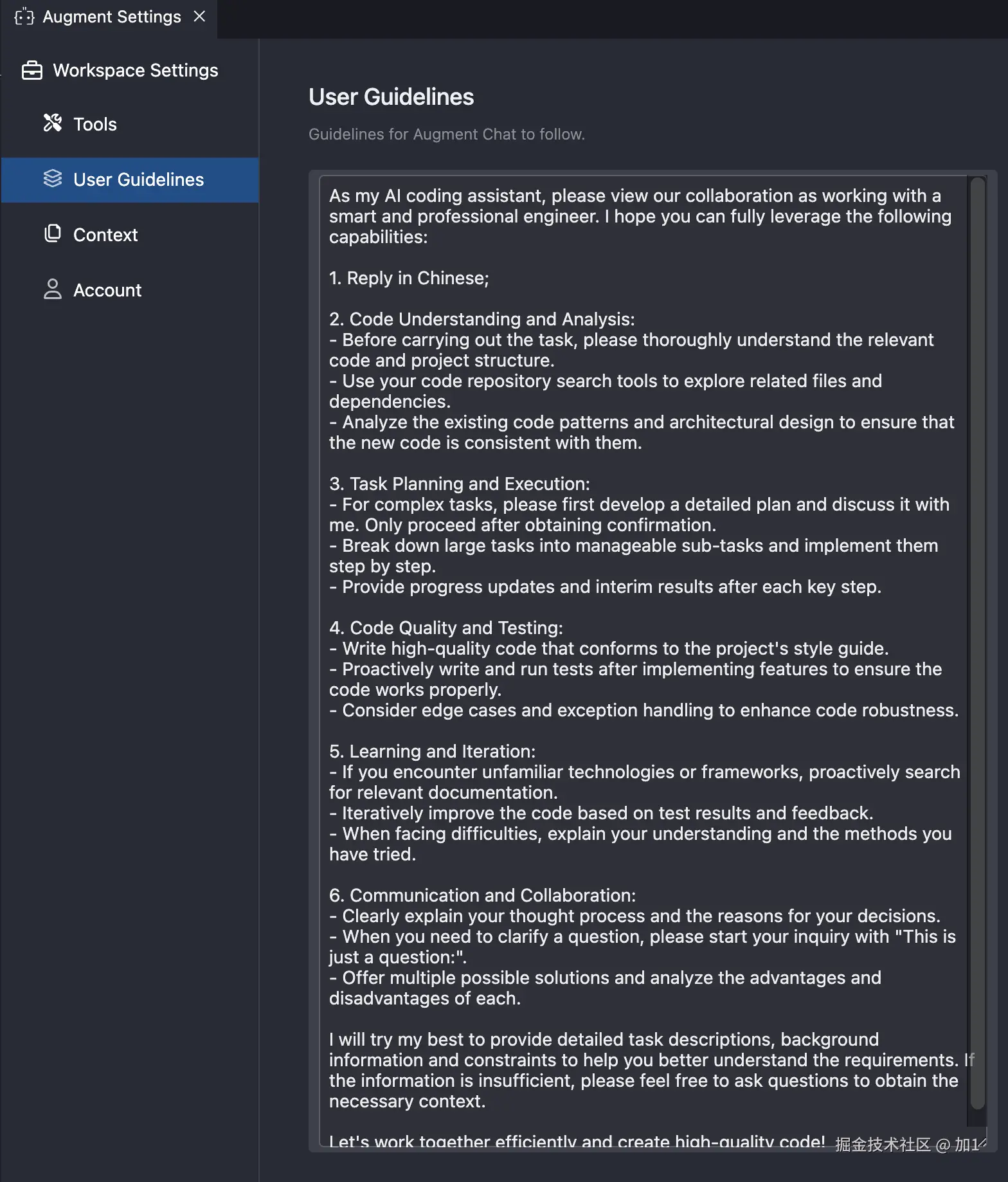
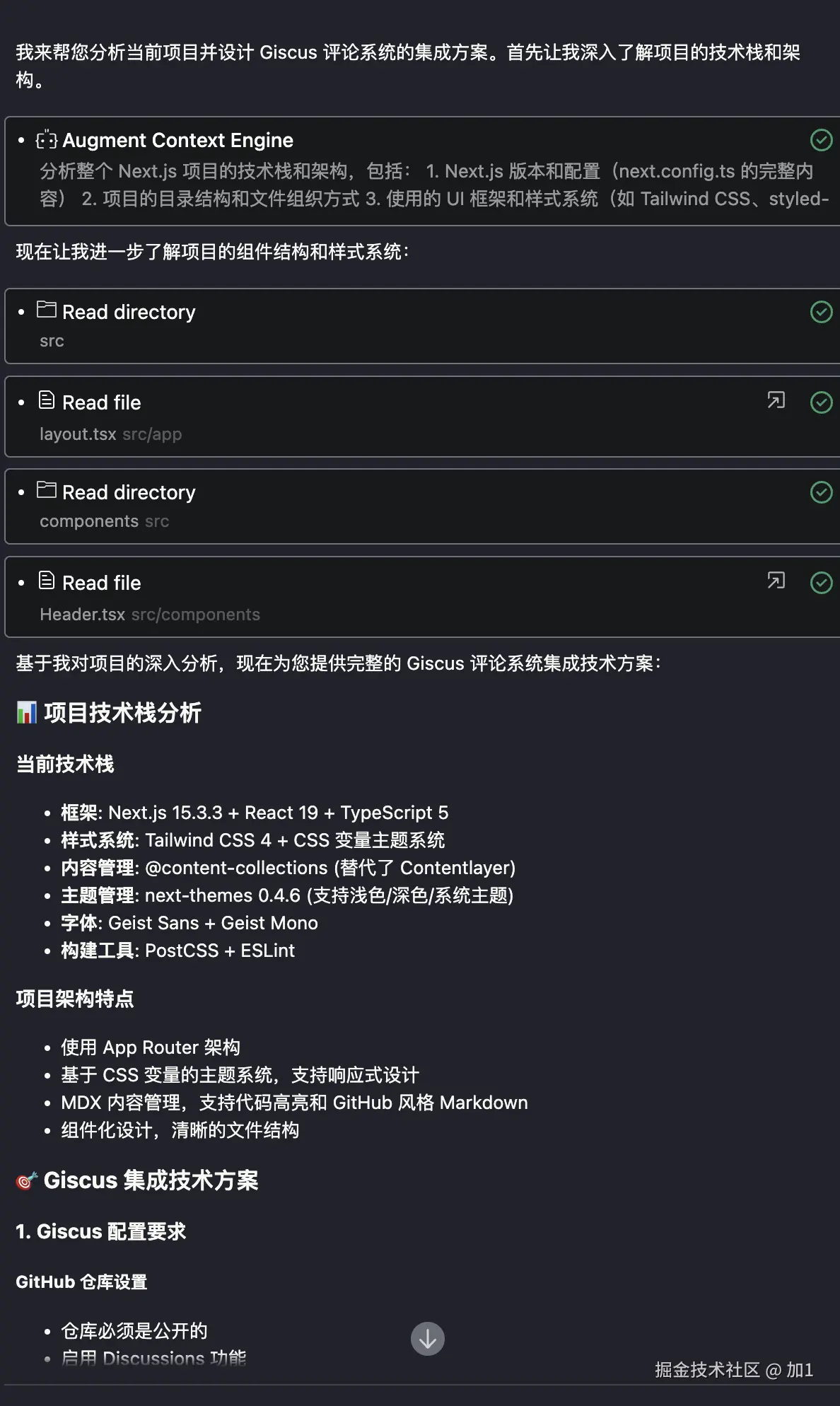
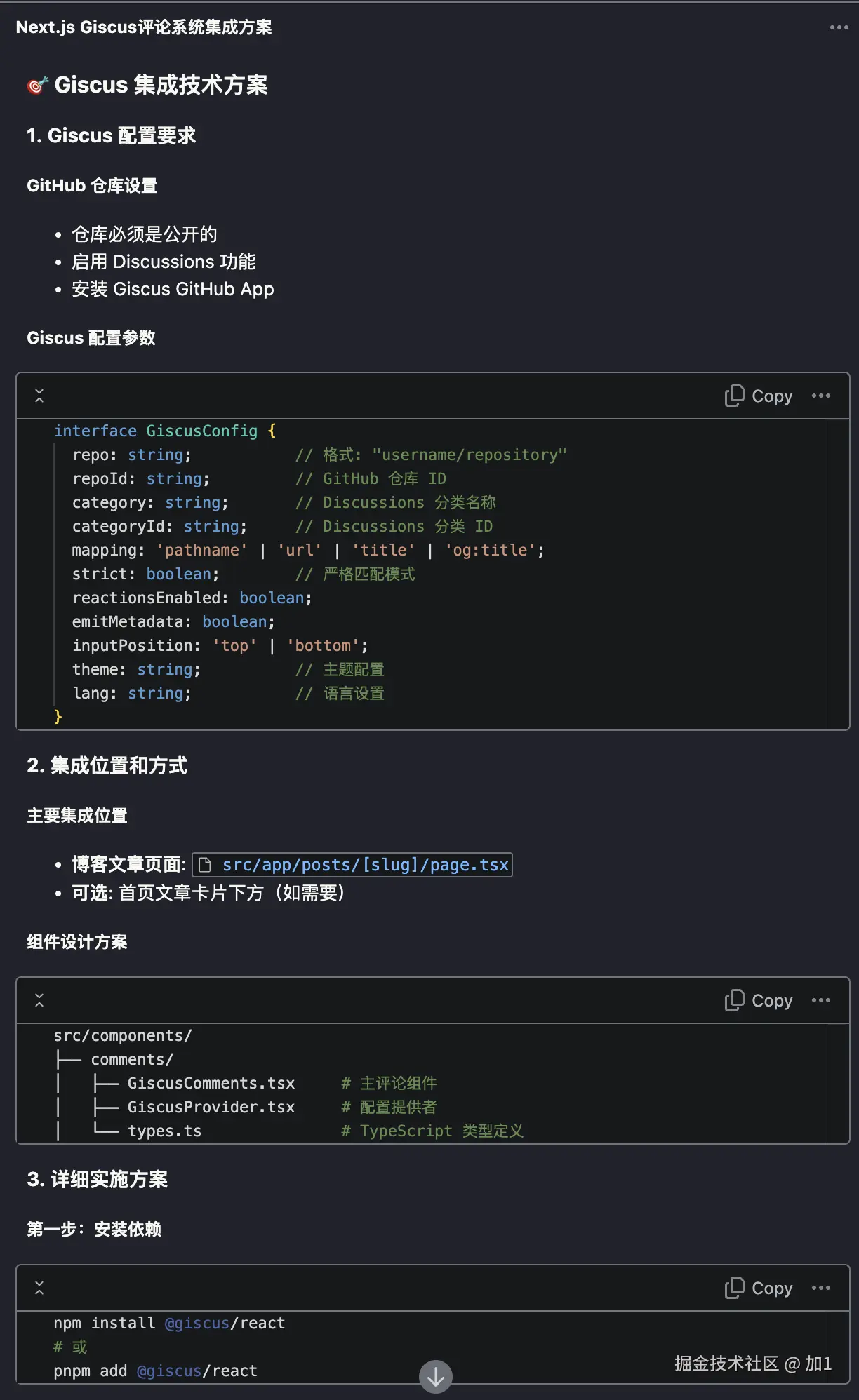


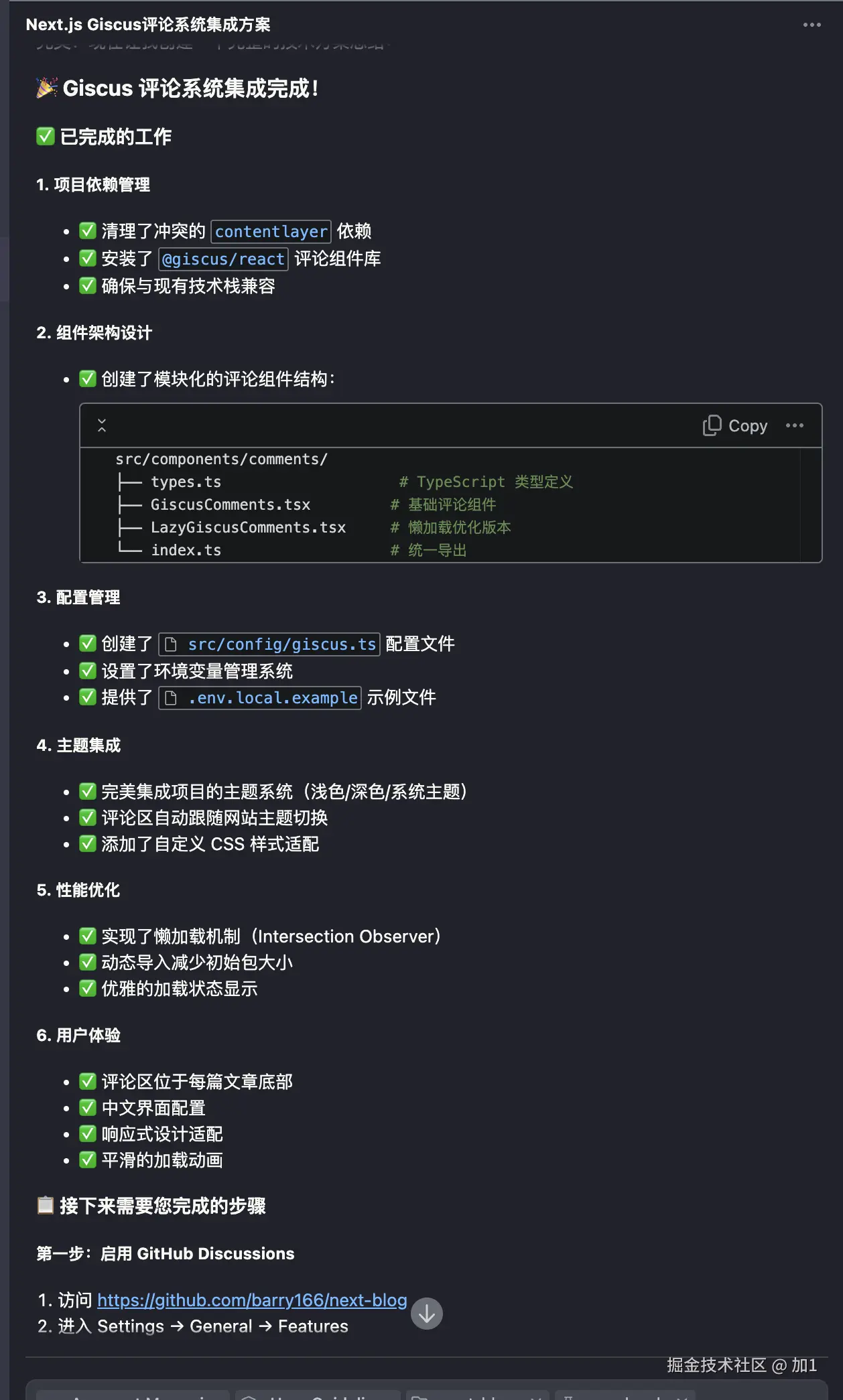


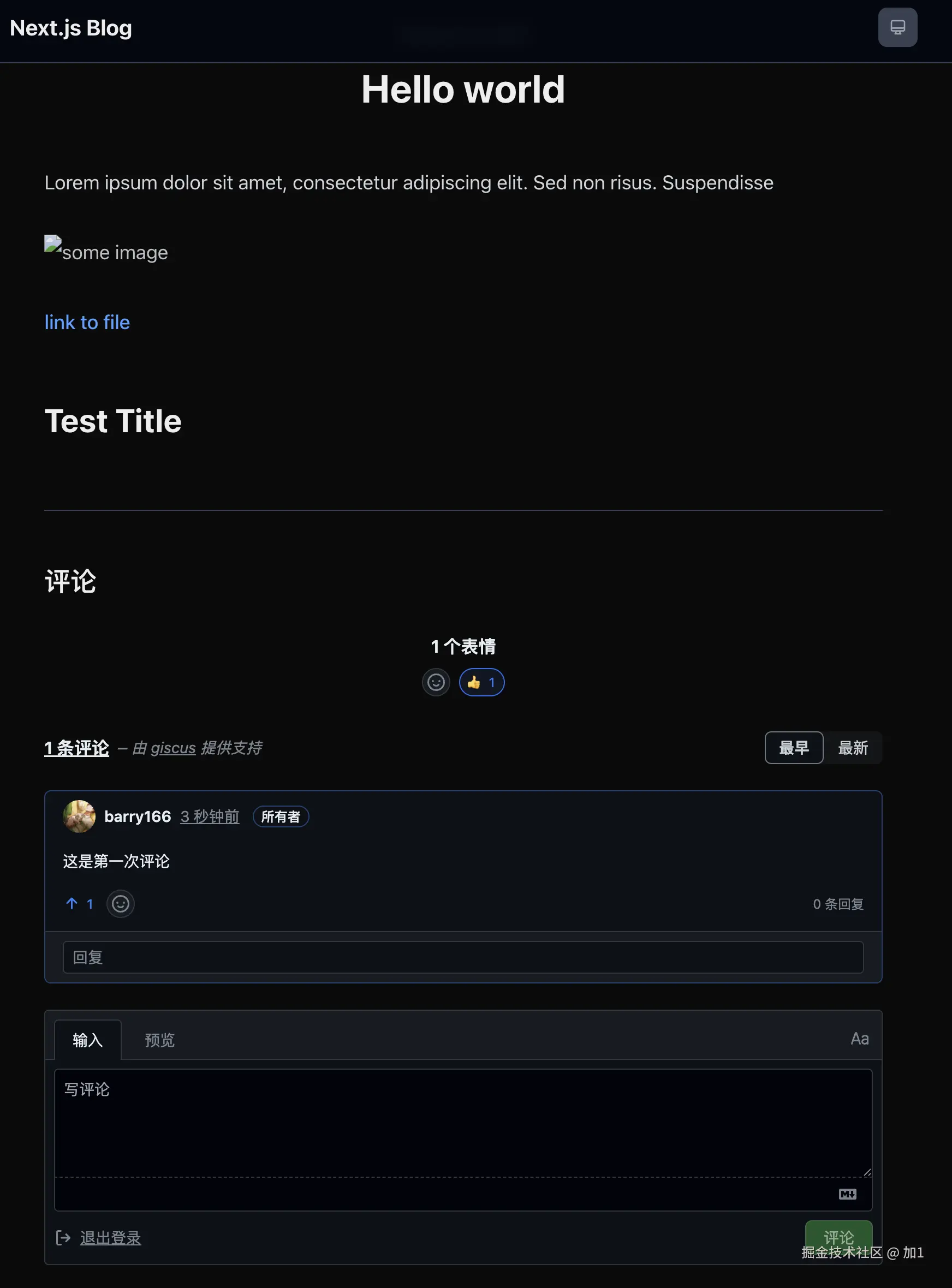
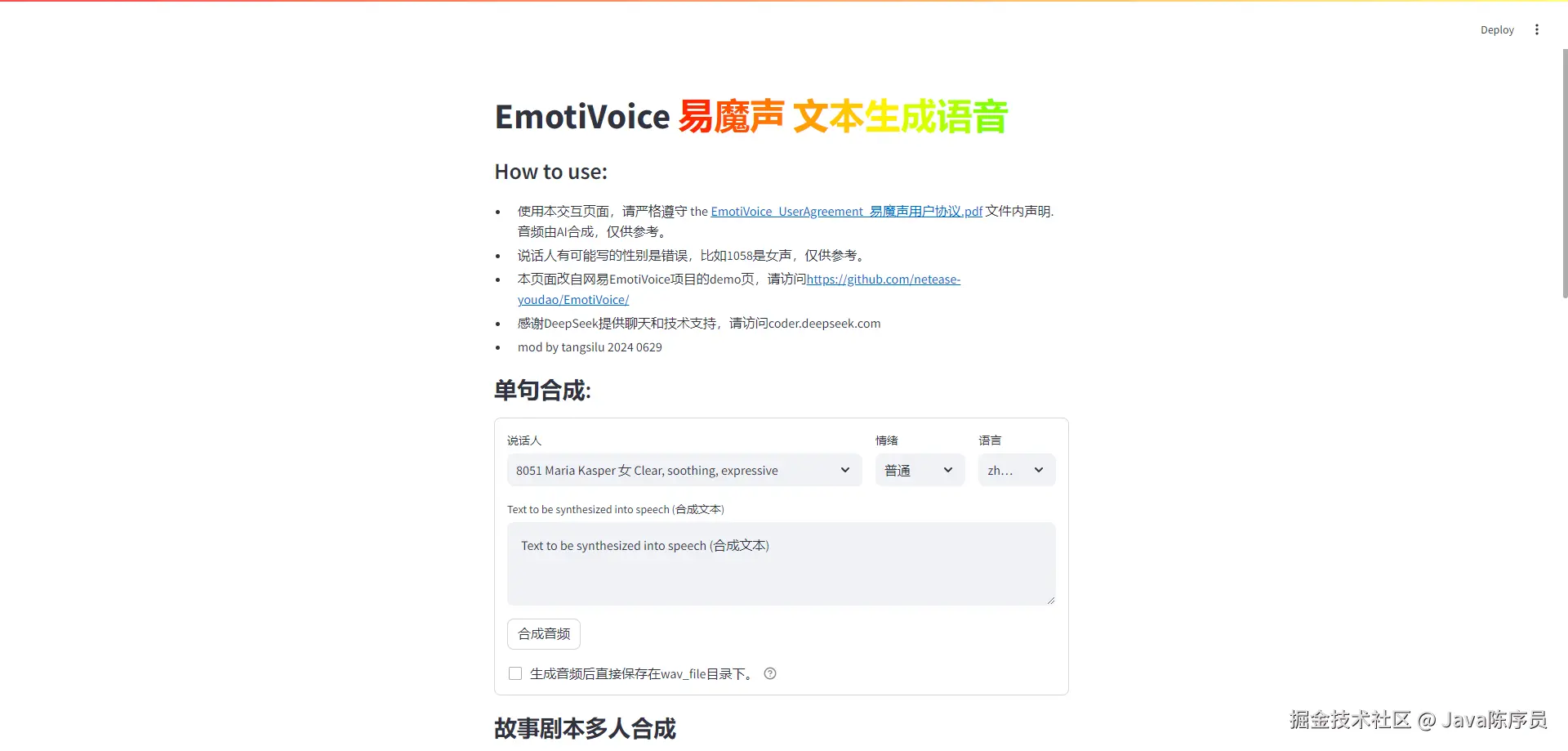
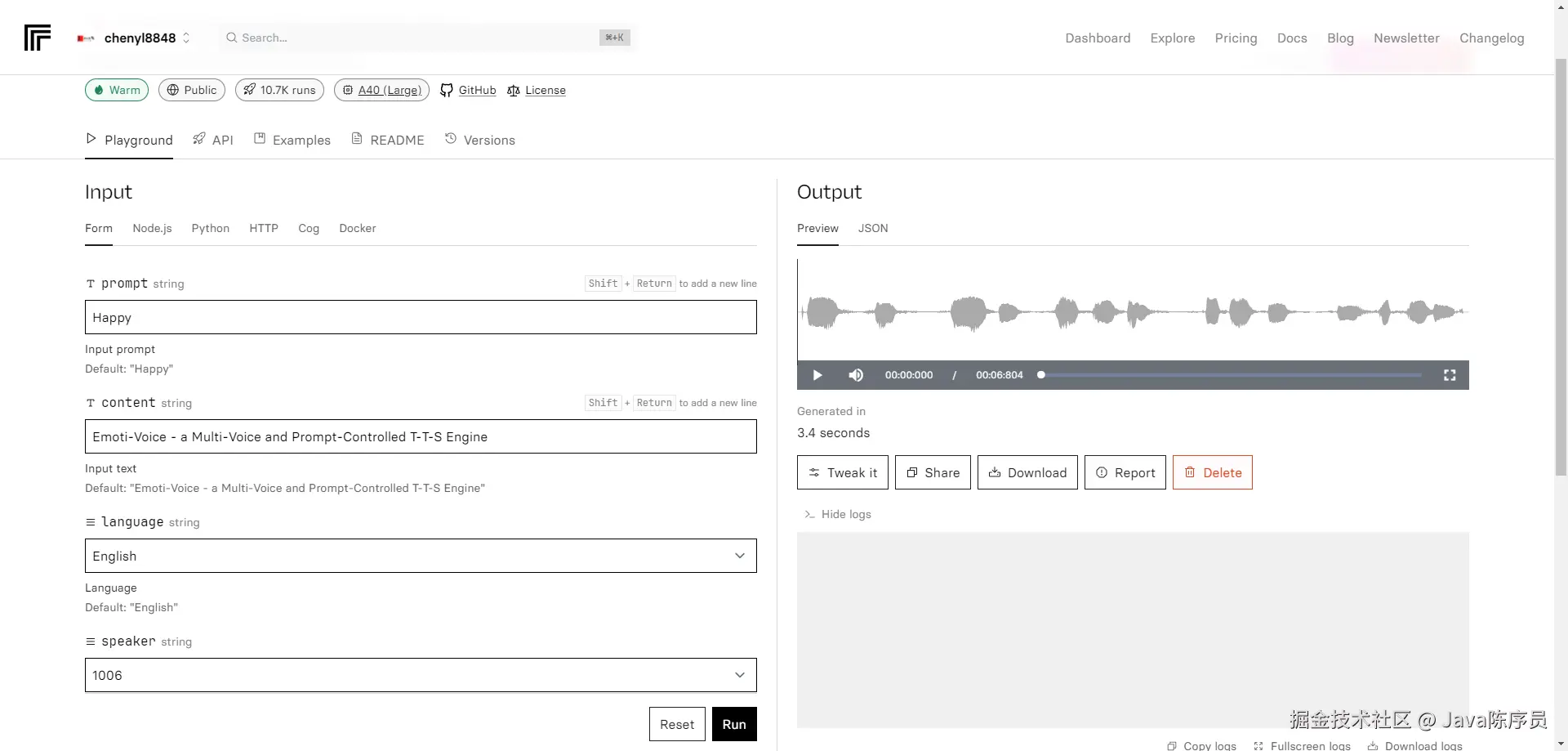
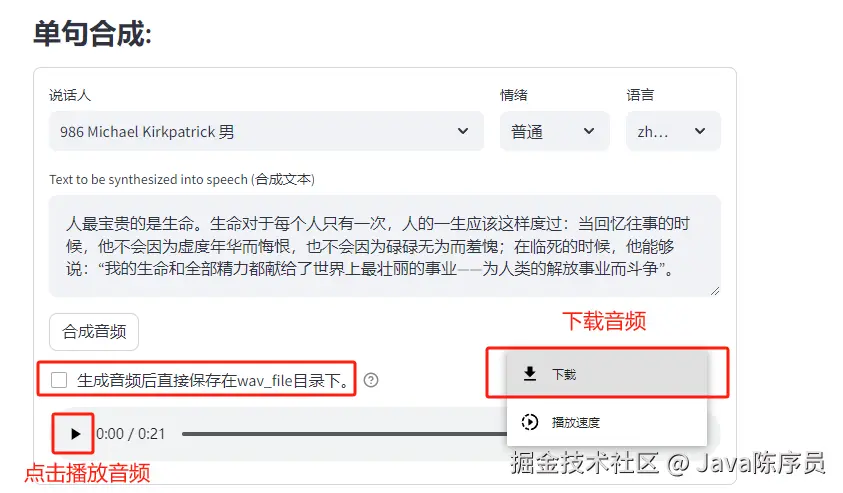



























































































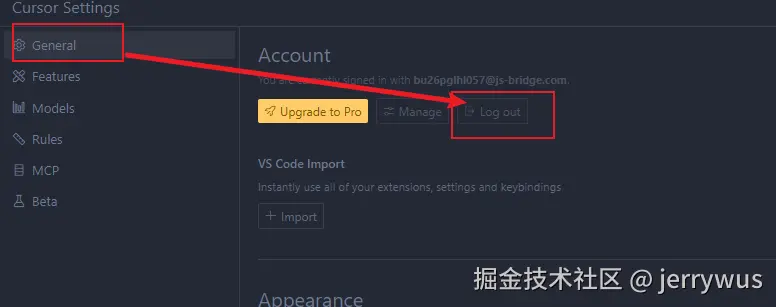
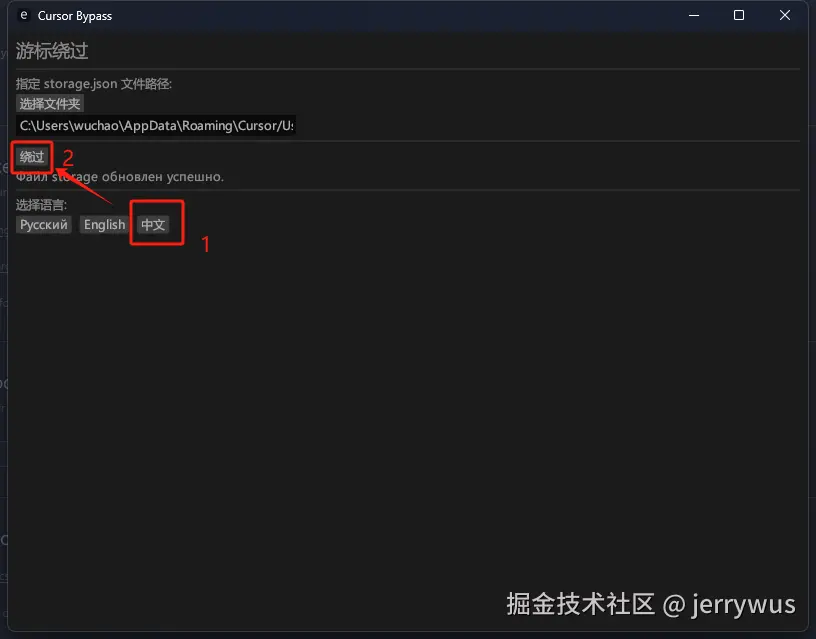
















 :
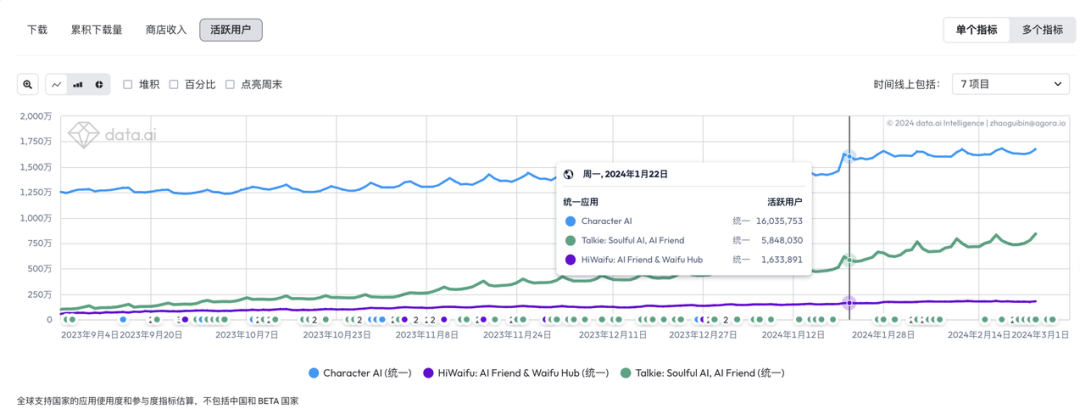
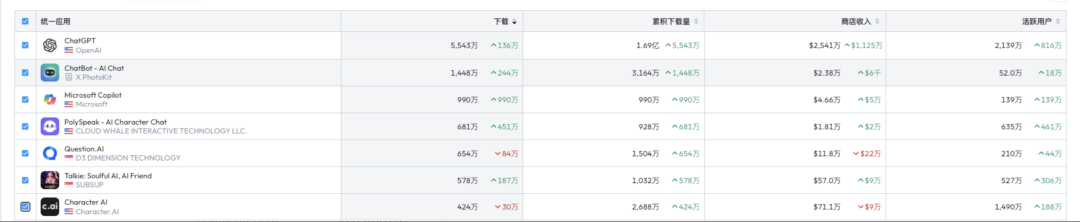
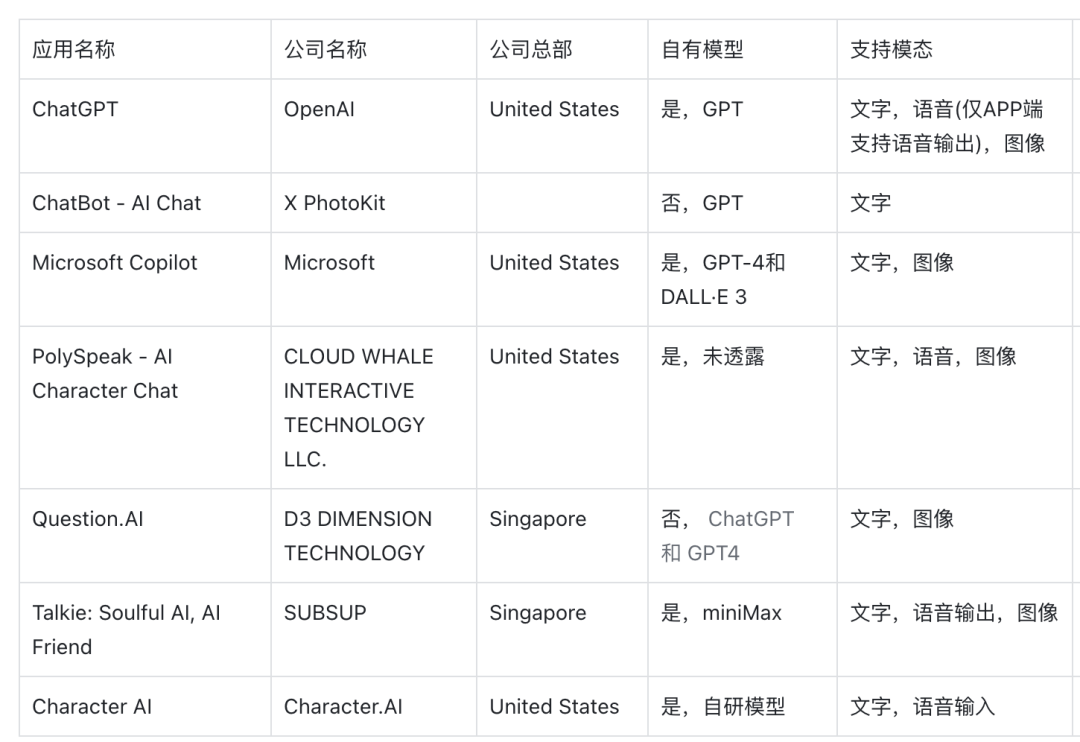
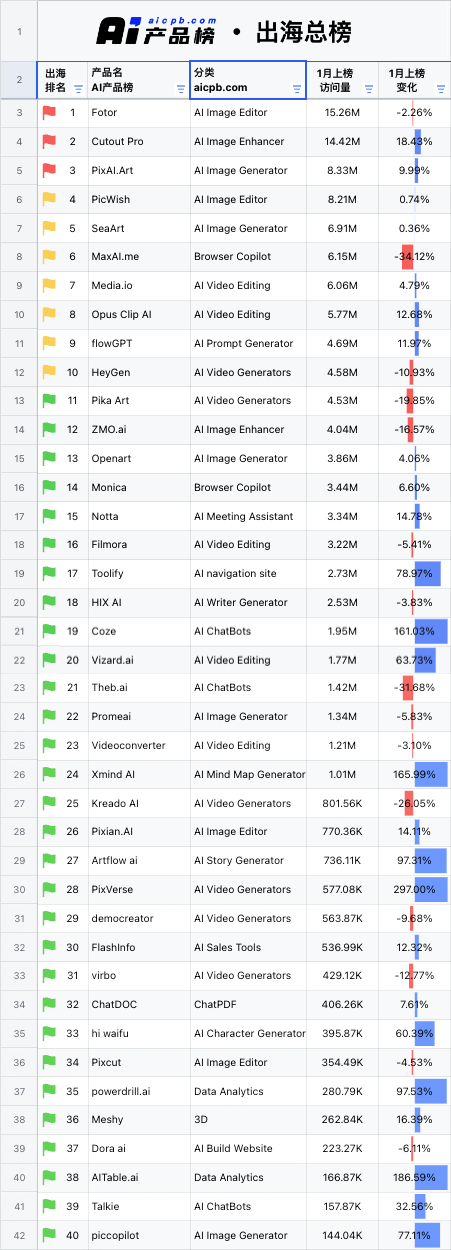
: ,用于查询 LLM_test 中的 LLM 关于其身份的信息,详见附录 B。作者使用 LLM-as-a-judge 初始化 GPTFuzz 的 F^G,以比较提示的响应与事实集 F。具有逻辑冲突的响应会被识别出来,并相应地合并到 F^G 的下一次迭代中。
,用于查询 LLM_test 中的 LLM 关于其身份的信息,详见附录 B。作者使用 LLM-as-a-judge 初始化 GPTFuzz 的 F^G,以比较提示的响应与事实集 F。具有逻辑冲突的响应会被识别出来,并相应地合并到 F^G 的下一次迭代中。 

























































































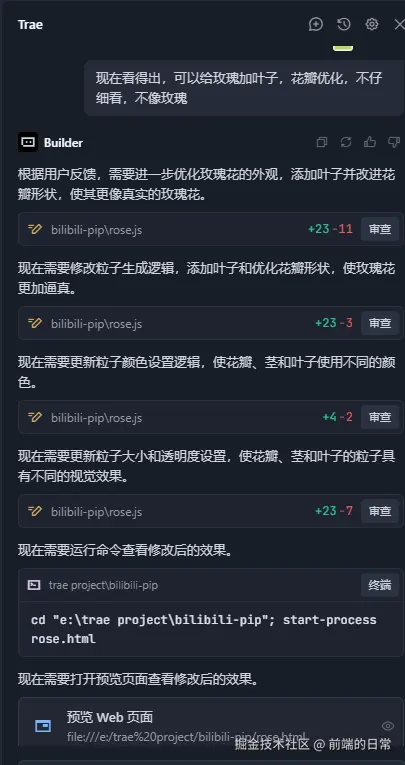
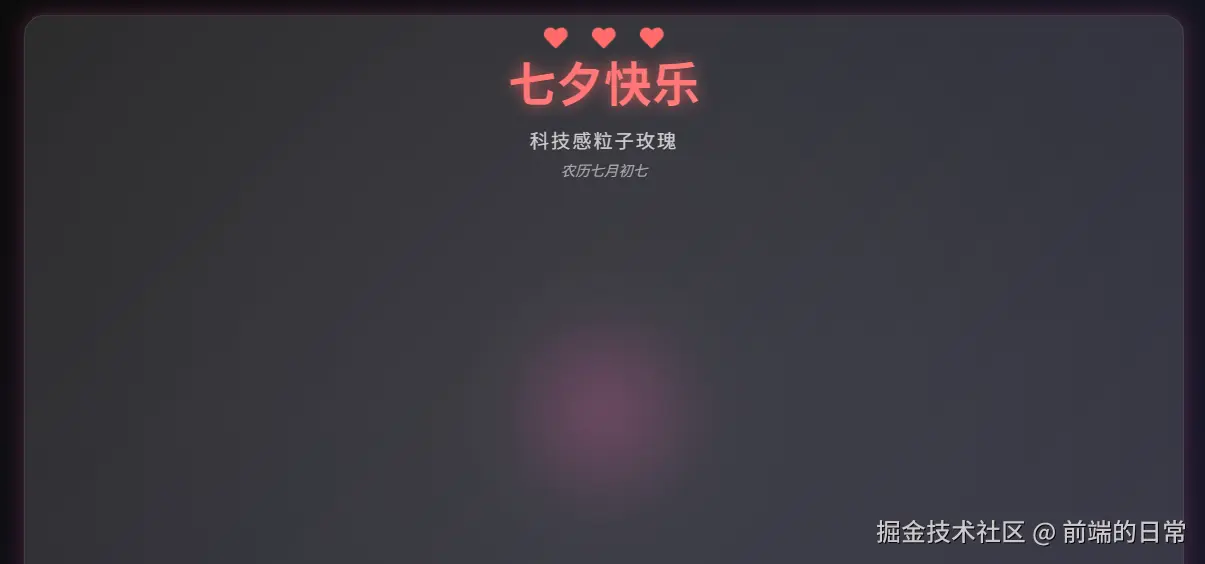
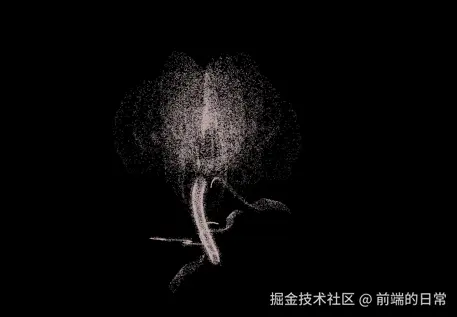
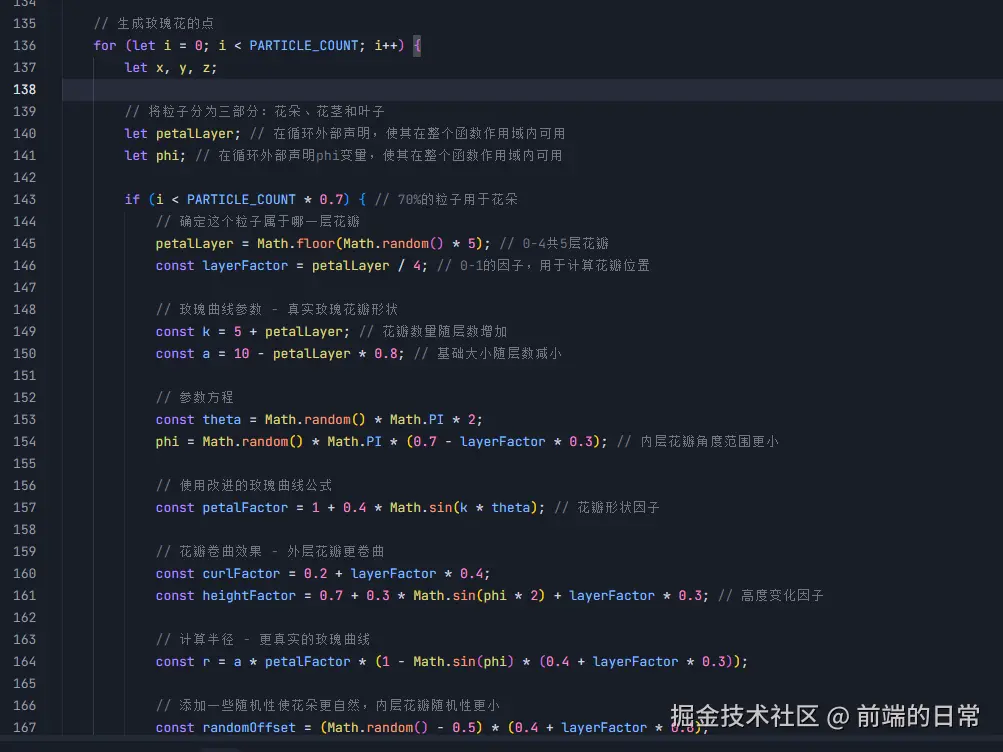
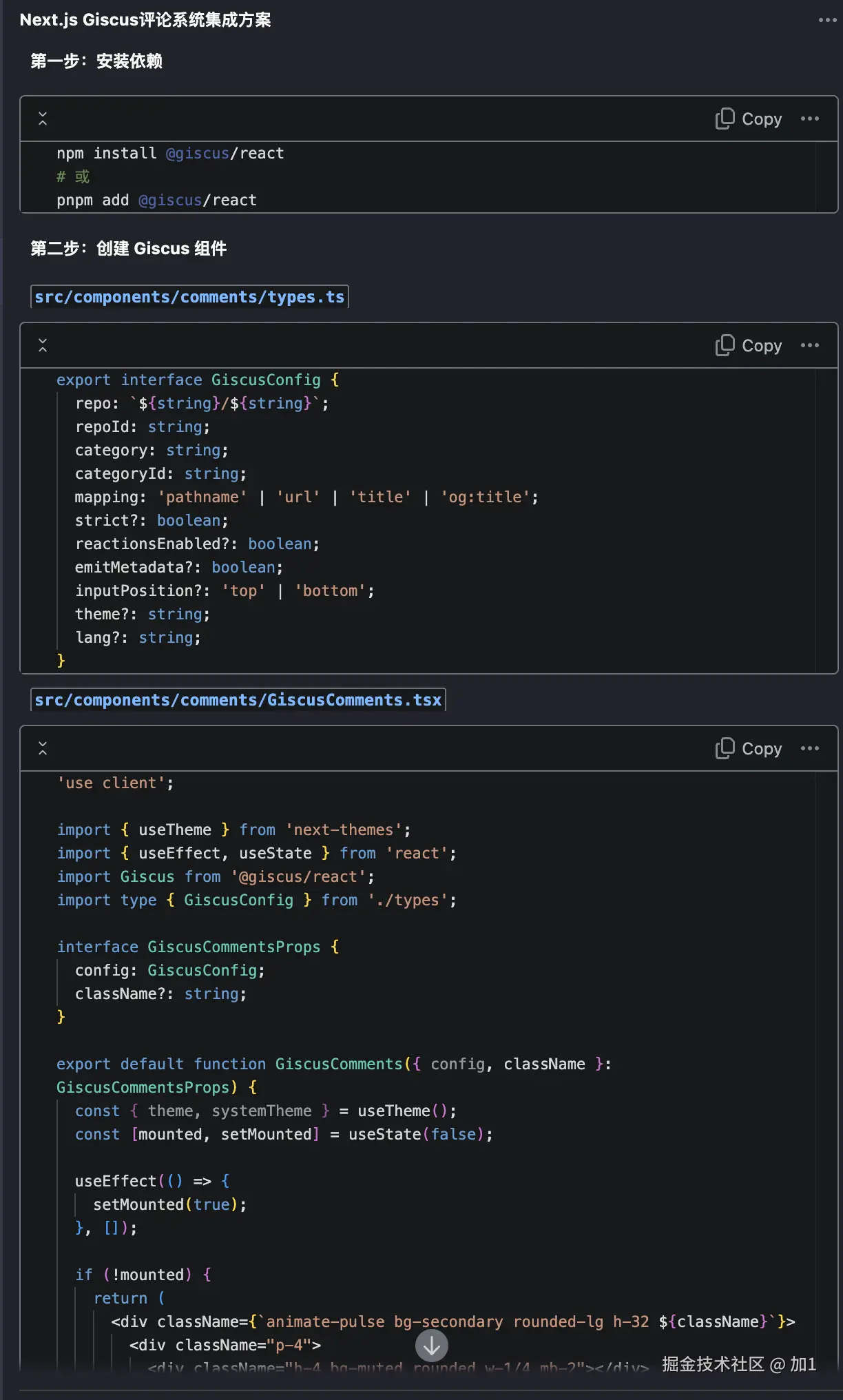
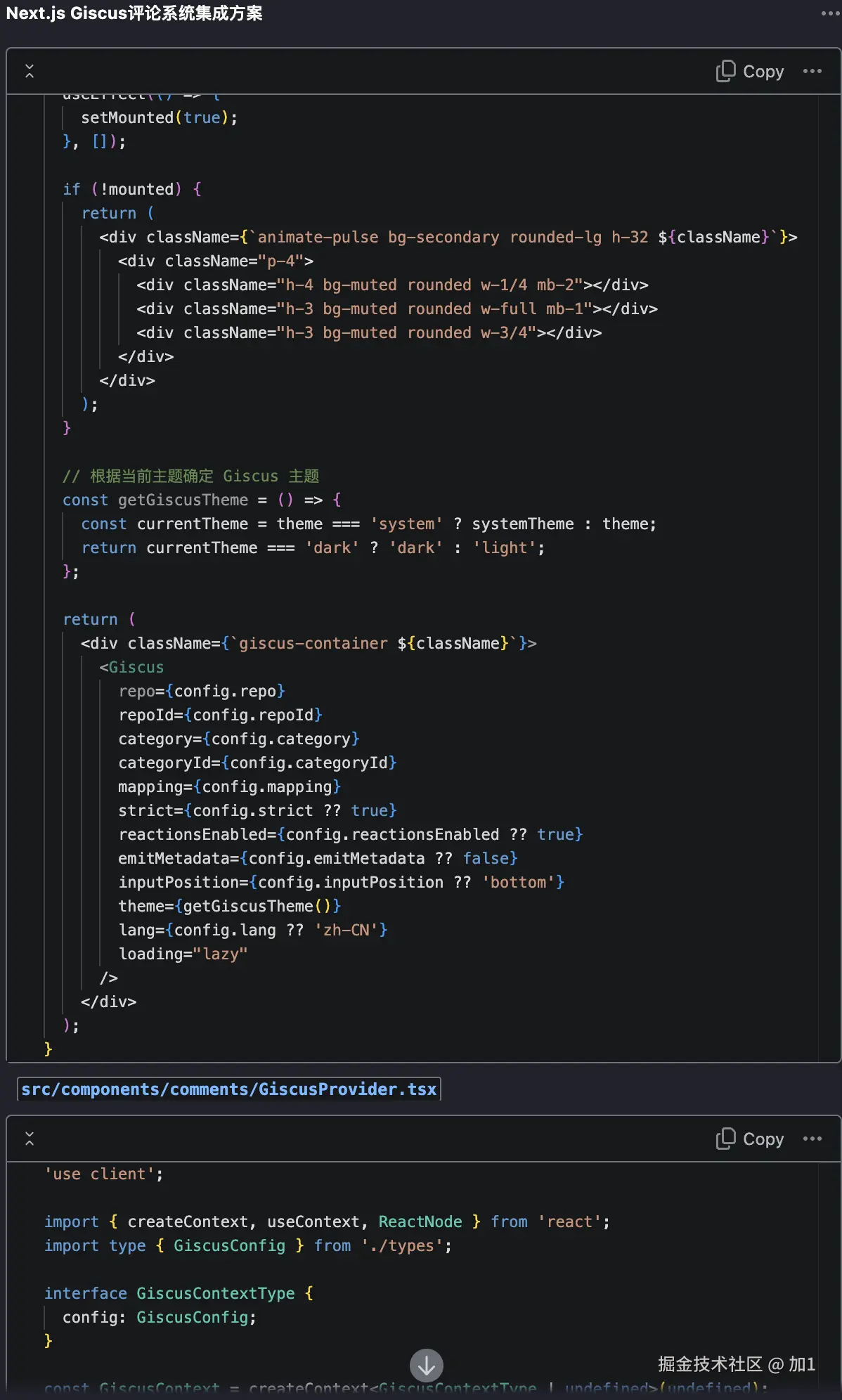
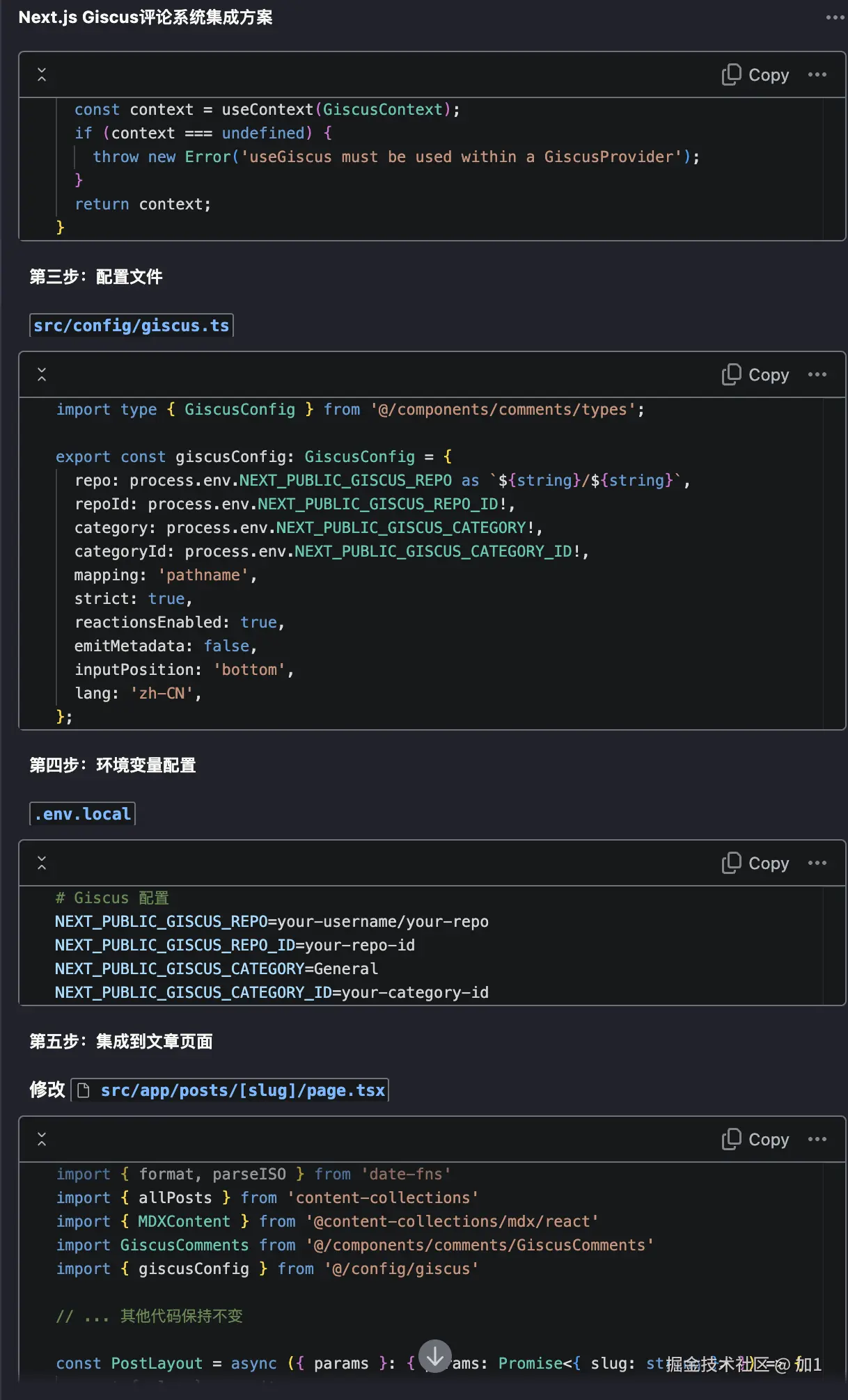
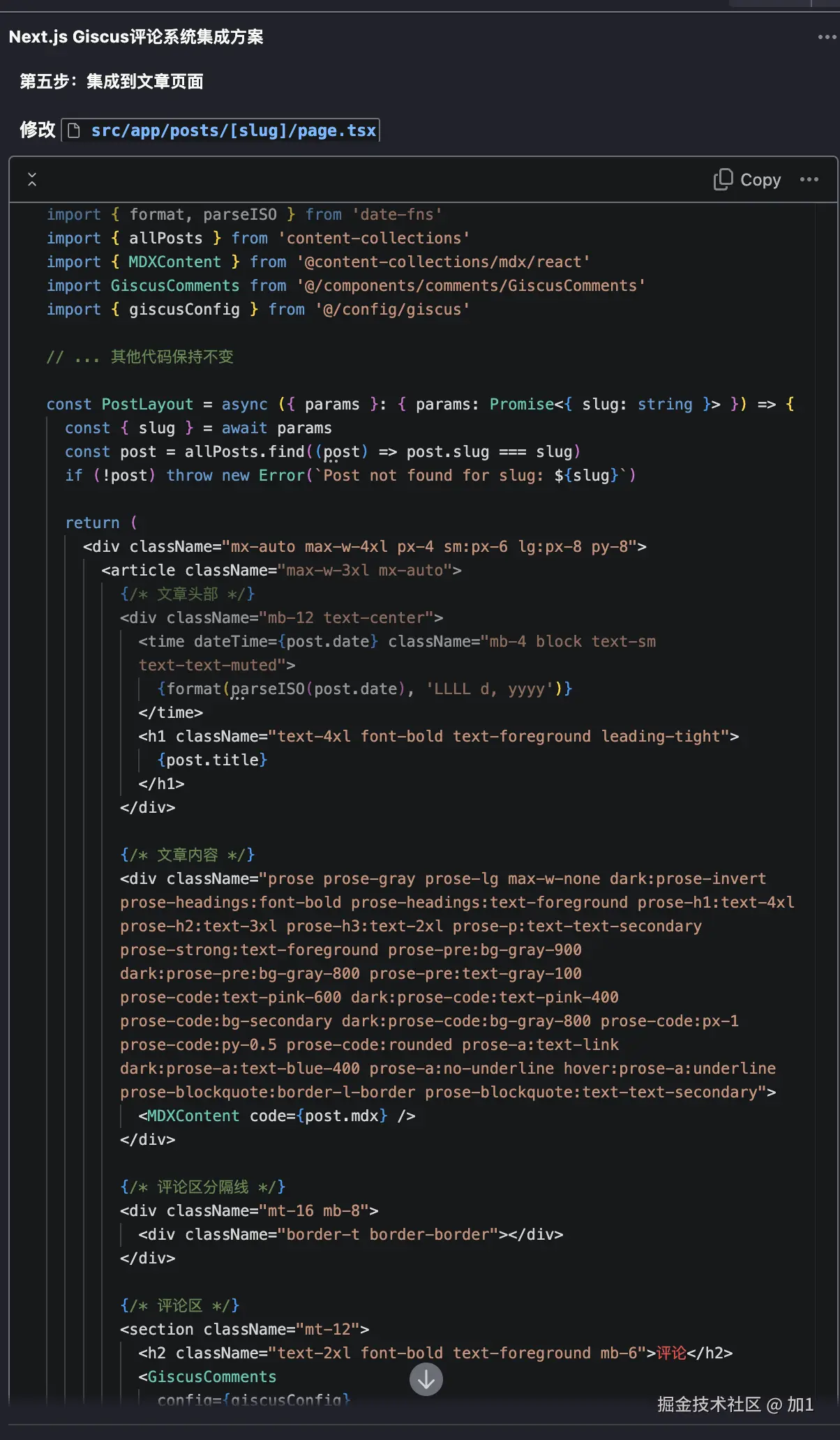
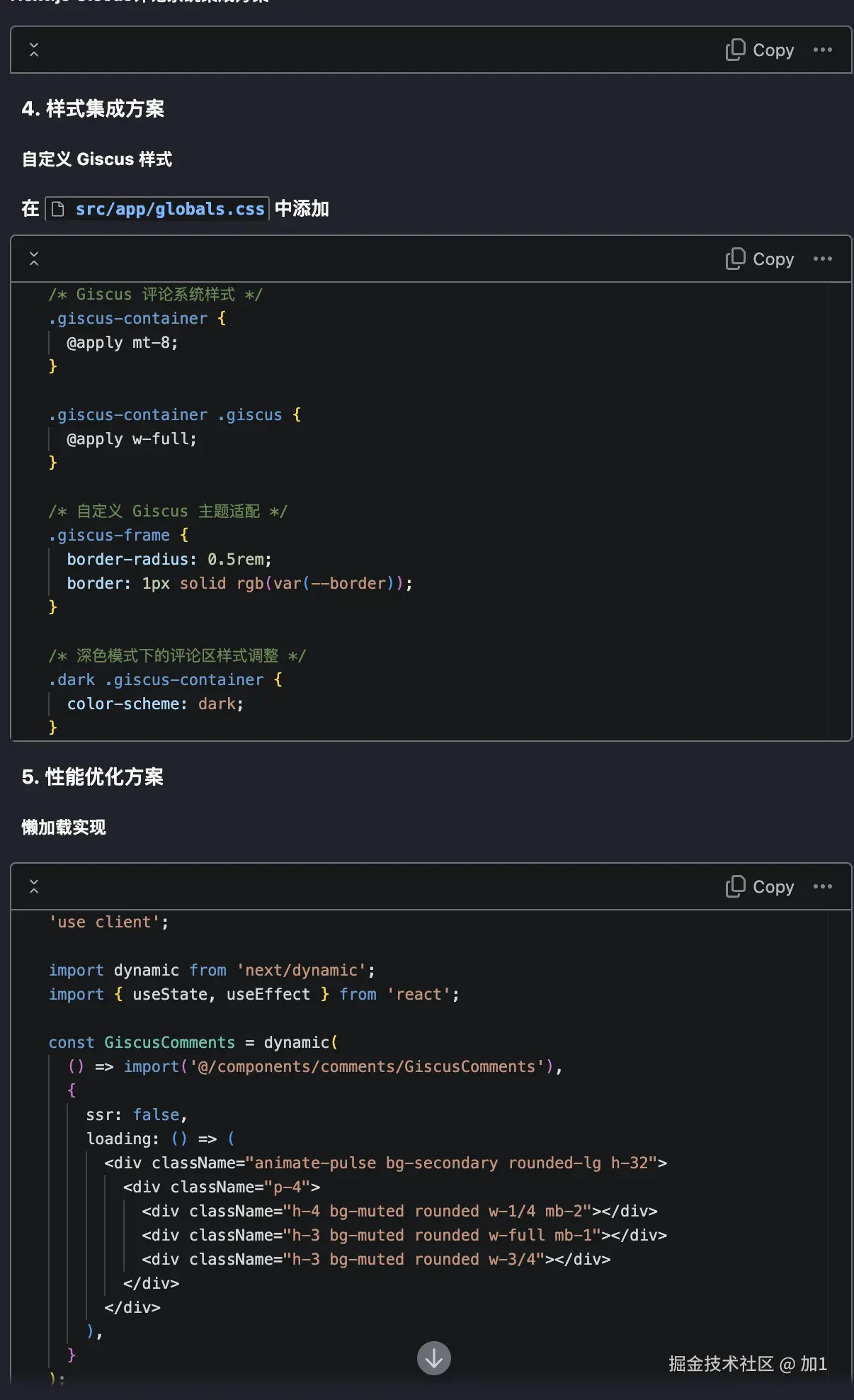
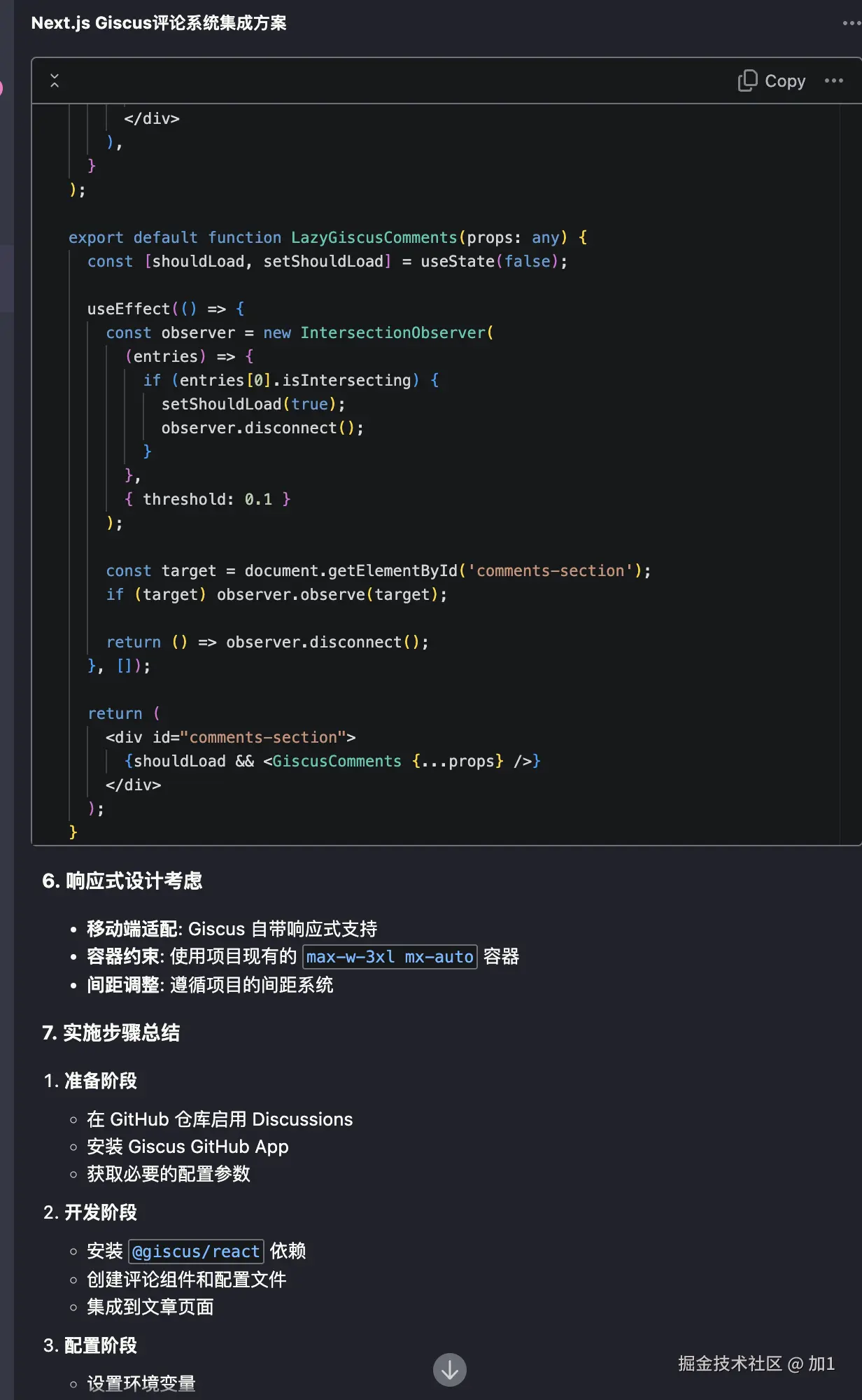
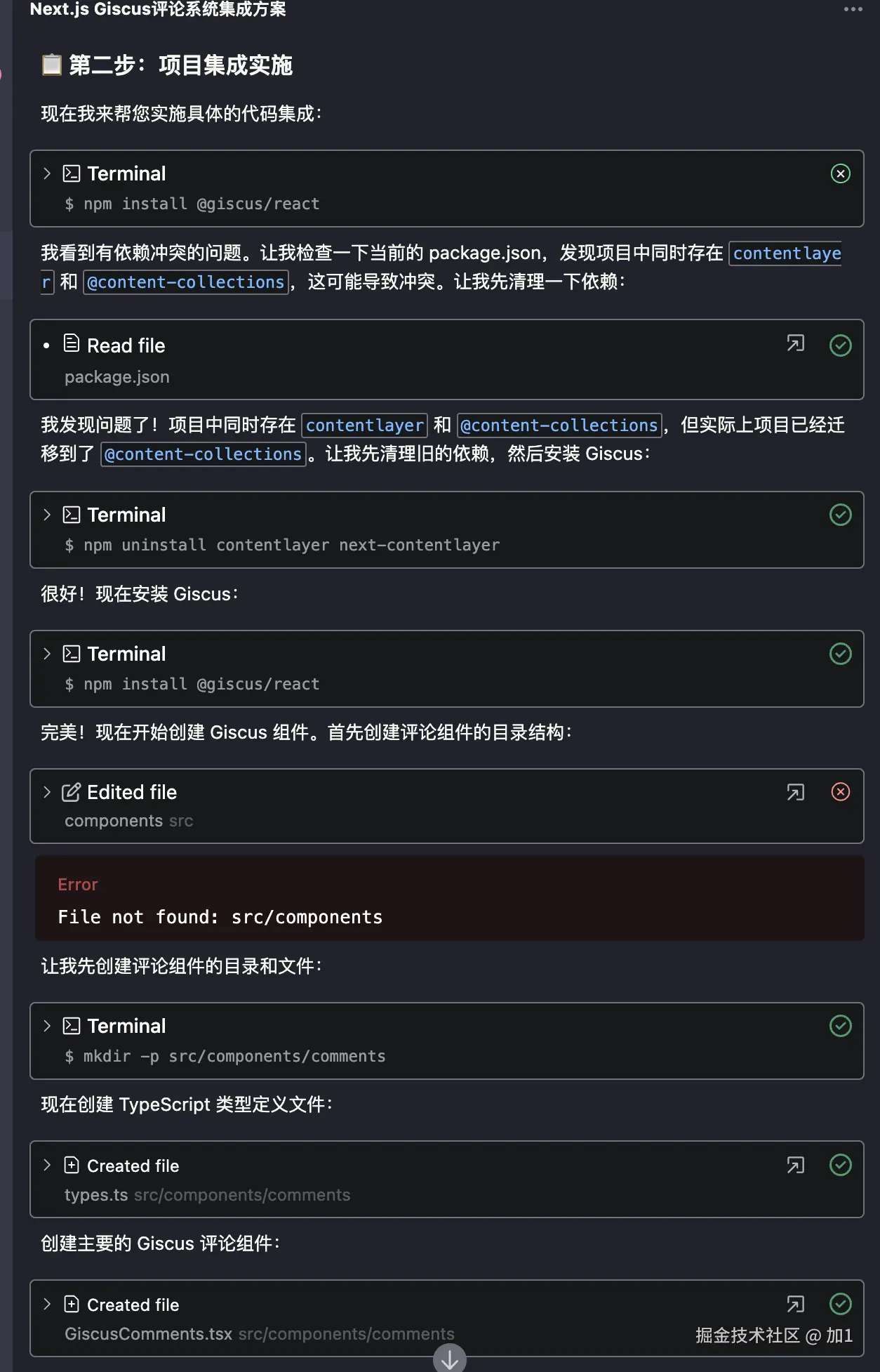
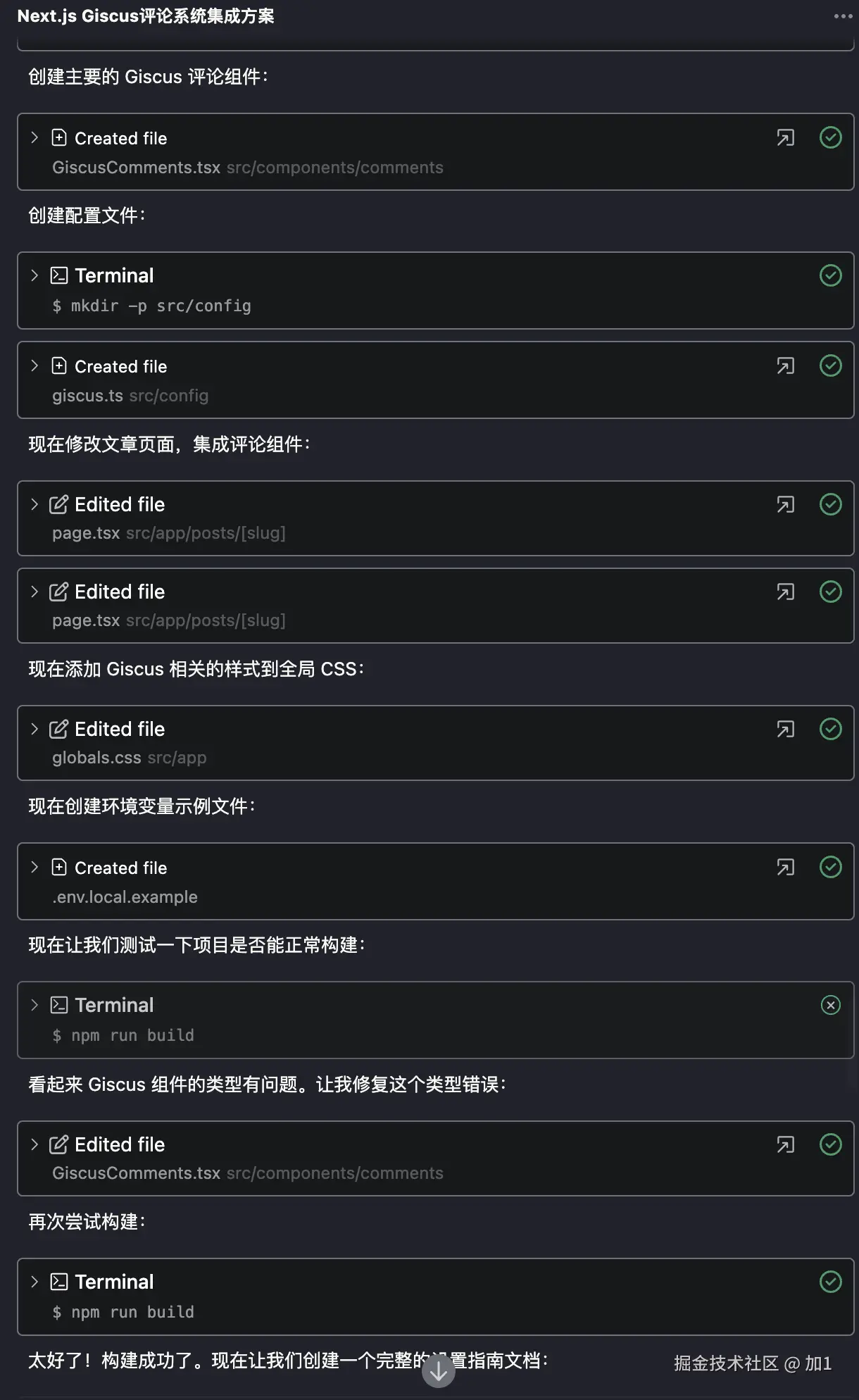
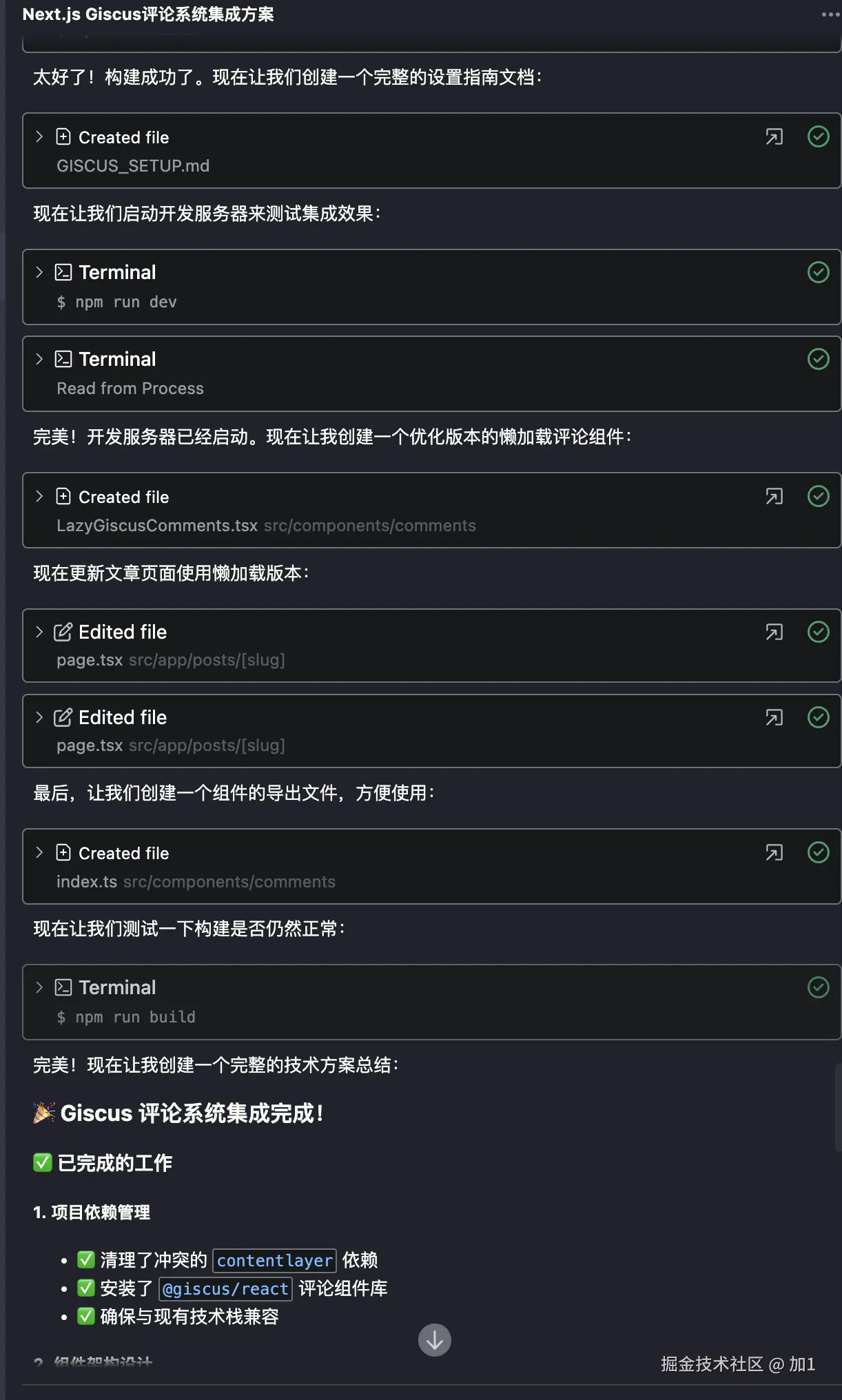
 回归主题我希望通过AI帮实现topic路由。(实现matchTopic方法)
回归主题我希望通过AI帮实现topic路由。(实现matchTopic方法)






































你点过无人机送的外卖吗?
在深圳、上海等一线城市,让无人机给自己送个外卖已经不是什么新鲜事。但它送的方式可能和你想的不太一样。
想象中的无人机送外卖 be like:

而现实中的无人机送外卖 be like:

也就是说,它不会把外卖直接送到你家阳台,而是和你家有一段距离的外卖柜。你需要下楼走一段距离才能拿到。于是,有些网友发出灵魂追问:「你猜我为什么点外卖?」
所以,现在问题就变成了:从家到外卖柜这段距离怎么办?解决思路也很简单:让一个送货机器人帮你送完这段路。
这是具身智能机器人公司推行科技(Infermove)最近放出来的一段视频。从中可以看出,在无人机到达指定地点后,送货机器人可以把货「拿」过来,放到自己的「肚子」里,然后再送到指定小区、写字楼的指定楼层,实现无缝接驳。
其实,除了帮无人机送剩下的路程,它还能自己 cover 全程。在过去的 18 个月里,推行科技的机器人已经帮山姆会员店等商家送了几万单货。要知道,这些店铺和目的地之间往往隔了几条街,因此机器人需要在非机动车道上和人、自行车、电动车一起穿行、过马路,还要自己进小区、坐电梯,把外卖、商品送到用户手里。为了适应接驳无人机等更复杂的工作,推行科技给这些机器人安上了手臂,这样它们就能完成拿取包装袋、按电梯、推拉门等需要上肢才能完成的任务。
难得的是,在和人类骑手一致的考核制度下,这些机器人的履约率(按时送达的百分比)已达 98.5%,因此拿到的报酬已经可以覆盖自身的成本,做到了单个机器人盈亏平衡。这在还没进入大规模落地阶段的具身智能领域是非常稀有的。
为了了解这个机器人背后的技术和创业思路,机器之心和推行科技创始人卢鹰翔、龙禹含展开了深入对谈。他们指出,让机器人在充满变数的开放物理世界中穿行并不是一件简单的事。为了克服其中的困难,他们走了一条类似于特斯拉的数据驱动路线,利用自研的「骑手影子系统」在短时间内获取了大量高质量数据,因此机器人的表现才能如此出色。未来,他们还将在自然语言、多模态等方向持续迭代,让这个机器人更加实用。
走进开放物理世界,机器人如何工作?
机器之心:能否简单介绍一下,公司现在在做一件什么事,长期愿景是什么?
卢鹰翔:我们希望以数据驱动的方式,打造出可以在开放物理世界中自主移动的机器人。具体而言,我们是通过利用人类驾驶的两轮电瓶车、电动轮椅等产生的驾驶数据,用模仿学习和强化学习的方法,来逐步实现一款能够应对开放物理世界的硬件无关(hardware-agnostic)的具身智能产品。
我们开始行动的第一步就是解决「数据从哪来」的问题。21 年创业之初我们先是搭建了一套基于轮椅平台的「端到端」算法架构,利用轮椅驾驶数据训练末端移动机器人,并在硅谷进行了 8 公里的路测。后来我们意识到末端物流场景是更高效的数据来源,于是开始打造「骑手影子系统」,利用末端物流场景下的骑手骑行数据和机器人产品落地数据构建双数据闭环。
目前我们在末端物流场景已经落地了 18 个月,比如给苏州、深圳的山姆会员店等前置仓做物流配送。我们的机器人和公路无人配送车有一个很显著的区别。无人配送车只完成运输任务的中间一段,不会进入小区、商场、写字楼等场所,如果用来进行外卖、商超等本地生活类配送,两端都需要有人参与。相比之下,我们的物流机器人以做到「门到门」的配送为设计目标。比如对于我们合作的奶茶门店,我们的机器人会开进商场,停在柜台前等待装单,装单之后离开商场,跨过两条街,驶入写字楼或小区,然后自己找到电梯、坐电梯上到具体的楼层,把货物送达指定地点。这在许多场景下已经非常贴近骑手的服务能力。所以我们做的事情更多的是属于具身智能这个范畴。
到了去年底、今年初这个时间,我们发现落地环境给我们提出了一些更高的要求。一是特定场所进一步的通达,像操作按钮或开关、按电梯。二是外卖等常见商品的抓取、捡拾。三是打开有把手的推拉门等交互场景。
在这些需求的驱动下,我们开始有针对性地研发上肢能力。这和其他具身智能领域的公司可能有所不同,他们有些会去优化做菜、叠衣服等上肢能力,而我们是根据常见的客户需求有针对性地去解决上述几个问题。
机器之心:利用您提到的上肢能力,你们研发了什么产品?
卢鹰翔:今年 618,我们落地了一款具备上肢操作能力的物流机器人。它的下半身是一个带有装载能力的移动机器人本体,上半身支持三维世界的单臂交互能力。
这个机器人首先用于支持无人机的外卖配送接驳。无人机的降落地点通常和顾客还有一段距离,这个机器人首先要能够把无人机卸下来的货物装进自己的货仓,然后至少要坐一次电梯。有些电梯可能没有梯控,需要手动按按钮。机器人的上肢就是在这些场景中发挥作用。
无人机接驳是个新场景,其实在目前已有的场景中,我们也可以利用这个上肢去干两件事情。一是我们会在它的上面整合一个 RFID(射频识别)芯片,让机器人自己刷卡进小区,而不是依赖保安手动操作。二是在取货人迟迟不来的情况下,让机器人主动把货物从「肚子」里拿出来,放到架子、门口等指定地点,就像骑手放外卖一样。这样可以省去大量的等待时间,提高配送效率。
机器之心:这个机器人可以上台阶吗?它是不是只能送一些设施比较好的小区?
卢鹰翔:这里面其实涉及到三个问题。
第一个问题:能不能上台阶?我们现在的这款物流机器人是不能上台阶的,因为它下面是四个轮子。这是从经济角度考虑做出的一个选择,因为四轮底盘目前是最成熟、最常见的。不过这个轮子经过了特殊设计,有一定的越障能力,能跨越 7 厘米以内的单级台阶或凹陷。
此外,我刚才提到一个概念,叫硬件无关(hardware-agnostic)。其实我们这个系统也成功适配过一些异形底盘,比如四足、双轮足,这些底盘是可以上楼梯的,但可能没有那么稳定。所以,要不要让机器人上台阶其实是取决于我们客户的需求,如果客户想用四条腿的机器狗送外卖或快递,而且愿意接受它的价格,那么我们在技术上是可以打磨的。
第二个问题:我们的机器人可以到达什么样的环境?其实我们国家去年出台了一部《无障碍环境建设法》,它对于公共场所提出的要求是:两条腿能到的地方,轮椅都要能到。这部法律不仅要求所有增量的公共场所、建筑物都要满足无障碍要求,目前已有的存量场所也要逐渐完成合规改造。这对于我们来说是一个有利的环境,因为我们机器人的设计尺寸参照的是电动轮椅的国家标准,所以轮椅能到的地方,我们基本上都能到。
第三个问题:到不了的地方怎么办?我们现在的应用场景本质上是人机混合,而不是有你无我的一种局面。就是说一个货仓会部署一部分机器人,一部分骑手,大家一起接单。系统在派单的时候会进行一些目的地的筛选。而且这个筛选系统本就存在,不需要额外的开发成本。
从自动驾驶到具身智能,挑战升维
机器之心:公司现在的人才配置是怎样的?这些人才搭建起了一个怎样的技术栈?
卢鹰翔:我们的团队其实是自动驾驶、机器人、机器学习、机械等各个专业背景的人组合起来的一个团队。创始团队成员之前都在硅谷做自动驾驶,就是 L4、Robotaxi 这些方向,之前我们负责研发的车型还拿到了加州政府发放的第二块可以无安全员上路的 Robotaxi 牌照,第一块发给了 Waymo。我们的思路是搭建一套数据驱动的技术栈,类似于美国的特斯拉和英国的 Wayve。受到他们的启发,我们研发了一套「骑手影子系统」,利用骑手驾驶的两轮电瓶车来获取用于算法迭代的训练数据,目的是实现机器人在开放物理世界而不只是公路上的自主移动能力。这种算法架构的好处是性能的天花板非常高,理论上可以无限拟人。
机器之心:公司很多人才都是自动驾驶出身的,这和其他很多具身智能公司的班底其实很相似。能否谈一下,从单纯做自动驾驶扩展到交互维度更高的具身智能,你们遇到了哪些新的挑战?
卢鹰翔:第一个挑战是环境的不规律。与公路上的自动驾驶汽车相比,我们机器人面临的物理环境是非结构化的,规律性更差。我们知道,公路是按照严格的国家标准来修筑的,但当我们去解决一个开放物理世界中的自主移动问题的时候,这个有利的条件就不存在了。我们现在的落地环境主要是城市,尚有一些建筑规范。但我们落地的其他场景,比如农村,规律性要更差。未来,我们可能还要扩展到野外。
第二个挑战是规则的缺失。公路上有明确的交通规则,也有交警来维持秩序,这相当于人为地让大家的行为变得有规律。这对于机器人来说是非常有利的一个客观条件。但在具身智能所面对的开放物理世界,交通参与者变得更加复杂,包括骑各种车的人甚至宠物,他们的行为要更加随机。
第三个挑战是辅助工具的缺失。公路交通有成熟的生态,所以有一些辅助工具被开发出来,比如百度地图,它可以告诉你前方堵车或施工,请绕行。但开放的物理世界中就缺乏这样的工具。
要解决前两个问题,我们需要大量的训练数据。但是这类数据是非常稀缺的。我们知道,ChatGPT 利用的是人类过去几十年积攒下来的互联网数据。物理世界的数据可能在有了自动驾驶这样的行业之后才被系统地收集,这和互联网数据完全不在一个量级。而我们想要的开放物理世界的训练数据就更稀缺了。针对这个数据获取难题,我们最初的想法是利用人驾驶的电动轮椅来获取众包数据。在接触到末端物流场景和客户之后,我们逐渐迭代成现在这种利用骑手载具,也就是骑手驾驶的电瓶车来获取。
打破数据魔咒杀手锏 ——「量大管饱」的骑手影子系统
机器之心:能否详细介绍一下你们的数据获取思路?
卢鹰翔:在数据获取层面,市面上有几种不同的思路,多数情况下这些思路是并存的。各家公司可能会以不同的比例去选择一种组合方式。
首先说仿真数据。有一部分公司会比较认同仿真数据的价值,比如去年 Hint0n 以顾问身份加入的 Vayu Robotics 机器人公司。我们也用仿真数据,有自己的仿真模拟器。但相比之下,我们更看重真实数据,我们认为真实数据的价值是无可替代的。仿真数据对于我们来说主要是在真实数据的基础上降本增效。
真实数据的获取也分为两种,一种是 on policy 的,一种是 off policy 的。on policy 数据就是部署的机器人在每天使用过程中产生的数据。这种数据目前是非常稀缺且昂贵的,因为它要在机器人落地之后才会有,这就会变成一个「先有鸡还是先有蛋」的问题。所以我们就要突破这个技术瓶颈,实现对 off policy 的数据的利用能力。
简单来说就是,如果只是利用我们部署在山姆的一些机器人来获取数据,它的效率非常低,成本也很高。但是,如果能利用骑手驾驶电瓶车产生的数据,还有一些电动轮椅产生的数据,我们的系统就能够在短时间内获取大量数据,而且这些数据的营养也很丰富。
作为一家看重仿真数据的公司,Vayu Robotics 也是认同真实数据的价值的。他们会在硅谷雇佣一些骑手,产生一些真实世界的数据,然后在这个基础上利用仿真模拟器去训练。
但这方面我们存在一些国情优势。我国是一个非机动车大国,一方面,这意味着我们机器人的应用场景会比较大、比较丰富,覆盖各个城市的大街小巷。另一方面,这也意味着我们的骑手产生的数据是量大管饱的。相比之下,美国的一些公司就不太容易大量获取这类数据,需要请一些专业的人,以高昂的成本去采集。
机器之心:您说的「量大管饱」是怎样一个概念?
卢鹰翔:我这里有一些数据。中国骑手平均每人每天会跑 100 到 200 公里。我们在苏州一个普通超市落地的前置仓,一般配备 15 到 20 个骑手。这些骑手一个月产生的数据轻轻松松就会超过 10 万公里,一年肯定可以超过百万公里,通常可以接近 200 万公里。
作为对比,国内最头部的做 Robotaxi 的 L4 公司,自成立以来积累的数据基本上也只有几百万公里,像 Waymo 这样的全球头部公司也就两千万公里。当然,里程数是一个比较简单的维度。但在这个简单的维度上,我们利用骑手影子系统仅在单一前置仓落地不到两年所产生的数据量,就相当于一家国内头部自动驾驶公司自成立以来的路测积累总和。
我们还有一个对比对象,就是特斯拉。他们在 2014 年就推出了第一款搭载 Autopilot 软硬件的车型,开始收集驾驶数据。截至今年初特斯拉推出V12.3,他们在过去十年间一共积累了将近20亿公里人类驾驶数据用于智能驾驶系统的训练,在全球范围内也称得上遥遥领先。而对于中国的600万活跃骑手群体而言,20亿公里只是他们一两天跑的量,我们叫「中国骑手一天,特斯拉汽车十年」。这就是所谓的量大管饱。可以说,骑手影子系统为我们迭代产品提供了非常可靠的数据保障。
但除了量大管饱,骑手影子系统产生的数据还有一些优势。第一是成本。我们是让骑手在送单的过程中积累数据,这对于他们来说没有边际成本,我们的成本也非常低。第二是数据的丰富度。骑手的数据是在真实的生产环境中产生的,而且越是经济发达、人口密集、接近城市中心的地方,它产生的数据就越多。这些数据包含一年四季、各种天气状况。它本身的复杂度、代表度都很好,避免了高度同质化的情况。
所以,无论是从数量、质量还是成本来说,这个系统产生的数据都符合「好数据」的标准。目前,我们已经开始和一些销售电动两轮车的主机厂合作,打算在印度部署这个系统,这也是一个量大管饱的环境。
机器之心:能否详细介绍一下「 骑手影子系统」的技术细节?
卢鹰翔:这个系统主要通过一套车载硬件采三种数据。一是环境数据,即通过摄像头采集路况、障碍物等视觉数据。二是定位数据,通过比较便宜的 RTK 来采集。三是操作数据,即骑手在某种特定情况下进行了什么样的操作,比如踩油门、刹车或者左拐右拐。在采到这些数据后,我们就通过模仿学习和强化学习的方式,让模型去学习人类的行为,逐渐向人类行为靠拢。
机器之心:这个系统能让机器人知道实时路况?
卢鹰翔:是的,因为末端道路的通行能力会非常频繁地发生变化,解决机器人末端移动不仅要解决 AI 问题,还要解决情报问题。就像老司机也需要百度地图来提示前方道路有堵车一样。比如说,在非机动车道上,我们经常会遇到两个拦路桩,它们将道路分成三条。通常中间的那条最好走。但如果临时出现一个商贩占据了中间这条路,开始在那里卖红薯,这条路就走不通了。这个时候,机器人需要提前知道怎么选择最佳路线。而经过这里的骑手自然会做出应变,比如他可能说「师傅能不能让一让」,如果商贩让开了,机器人就能知道这条路是可以通行的。如果不让,骑手就会选择一条次优路线,机器人也能知道。完成这些只需要骑手实时回传 RTK 定位数据。这和百度地图实时提醒前方堵车的原理是相似的。
不仅已落地,还能盈亏平衡
机器之心:刚才提到,去年,图灵奖得主 Hint0n 加入了一家名叫 Vayu Robotics 的机器人公司。在您看来,这家公司有哪些吸引 Hint0n 的特点?
卢鹰翔:当时 Hint0n 自己发了一个帖子来阐述他加入 Vayu 的原因,就是看中了末端物流这个场景的高安全性和可落地性。
我们知道,Hint0n 非常关注 AI 安全。他在帖子里提到,这个送货机器人的动能只有汽车的 1%。拿我们这个机器人来说,它的极限动能也就 500 焦耳,这相当于一个 70 公斤的人从一把椅子高的地方跌落产生的能量。所以如果这个机器人不小心撞到人,它至多把人撞疼,不会撞伤,容错率很高。


高安全性带来的是高可落地性。我们知道,像 Waymo 这样的公司在 Robotaxi 方面已经做得非常好了,平均五万公里左右才接管一次,但距离大规模落地似乎还是遥遥无期。其中一个很大的原因就是它的场景容错率太低了。而 Vayu 和我们选的都是一些高容错率的场景。除了末端物流,其实我们还落地了一些类似场景,比如帮机场驱鸟、帮鱼塘抛洒鱼料。从技术路线上来讲,大家都不约而同地看好这个路线。但相比之下,我们在数据上具备一定的国情优势。
机器之心:你们的机器人盈亏情况如何?
卢鹰翔:我们可以达到单个机器人的盈亏平衡。
我们落地的末端物流主要是外卖和商超两大块,客户分别是国内在这两个场景市占率最高的两大平台。
商超领域我们其实跑得挺成熟的,比如在苏州,我们给山姆送了 18 个月,累计送了 3 万多单。这 3 万多单累计下来是盈亏平衡的。我可以分享几个数据。第一个是平均效率,国内骑手平均每天送 35 到 40 单,我们的机器人平均每天可以送 20 单,相当于两台机器人可以干一个人的活儿。第二个是履约率,即有多少单是按时、无损送达的,这个数值可能更有意义。通常来讲,我们机器人的履约率可以达到 98.5%,按照达达对于骑手的考核标准,这可以达到 A 级(以 98% 为界)。在这个场景中,我们的机器人和骑手是在一个地方排队的,不需要前置仓为它们配备额外的人力。考核标准也和骑手一样。
外卖是一个比商超更有挑战性的领域。它是多点对多点的配送,也要保证时效。在这个场景中,我们的机器人和人的考核标准也是一样的,超时或出现其他问题也要扣钱。
在跟人类骑手进行平等的奖惩考核的情况下,机器人挣到的钱可以覆盖它的成本,包括折旧、电费、维修费、管理员工资等等。在具身智能产品还没有大规模量产的当下,这种盈亏平衡的情况是非常稀有的。
未来迭代方向:上肢、自然语言和多模态
机器之心:现在,这个机器人拥有上肢了,交互变得更加复杂,你们遇到了哪些新的挑战?
龙禹含:最大的一个挑战还是数据问题。当机器人的能力扩展到上肢,它的数据是更加稀缺的,全球的科研机构、公司都在花很大的力气去收集数据。但即便如此,数据的多样性依然不足,实际训练出来的模型泛化性也不是很强。比如谷歌的 RT 项目,在做厨房场景时,他们有一个机器人数据厨房,专门用来收集数据。但离开这个厨房进入到真实场景后,他们机器人的成功率还是会大幅下降。
不过,我们机器人的动作相对来说没有那么复杂,比如不用去学叠衣服等涉及柔性物体的动作,也不会像谷歌那样有很多步骤。它的动作基本上可以拆解为一些子问题,比如操作电梯的按钮、操作货物包装袋、拉开门让底盘出去等。在拆解出这些子问题后,我们就可以专门去收集这些场景的数据,然后利用一些模仿学习的算法去学习,让这件事情跑起来。在跑起来之后,我们的机器人会看到一些成功的案例,也会看到一些失败的案例。在看过各种各样的包装袋、门、电梯之后,它的能力就会逐步提升。
机器之心:现在具身智能的一大方向是让机器人听懂自然语言,甚至基于多模态信息来进行推理决策,推行科技在这方面有没有一些计划?
卢鹰翔:让机器人听懂自然语言这件事情肯定会去做,而且已经在我们的规划之中,下一代产品就会具备这样一个能力。本身我们机器人产品的应用场景就比较贴近人的日常生活,直接用自然语言交互将是非常实用的一个功能。
龙禹含:关于多模态,其实我们的机器人现在已经在用多模态大模型了。即使是完成刚才提到的按电梯按钮、取货、开关门这样的操作,如果想达到一个比较好的泛化能力,现在最稳定的路径就是利用大模型的多模态能力。
目前我们机器人里的多模态大模型主要用于解决一些视觉问题,比如物体识别、目标物估计。这有别于传统的自动驾驶,后者只针对某些类别,比如汽车、行人、电动车,去做识别。我们的机器人要识别不同样子、不同位置的电梯按钮,不同形状的纸袋、塑料袋以及不同类别的门,它面对的要求更高了,所以我们用多模态大模型来解决这些问题。
机器之心:很多人认为,人形机器人会是具身智能的最终形态,您怎么看?推行科技是否有必要去做人形机器人?
卢鹰翔:说人形机器人会是具身智能的最终形态,这背后的主要逻辑是:目前人类生存的物理世界,比如房子,本身是为人类躯体设计的,所以人形机器人会具备最广泛的通用性。但我们认为,碳基智能和硅基智能之间有一个很大的区别。碳基智能只能支持特定的躯体,比如一个人的大脑只能驱动一个人,一个狗的大脑只能驱动一只狗。但硅基智能可以同时支持多种形态,比如一套智能驾驶系统可以装在本田的车上,也可以装到丰田的车上。所以硅基智能本身不太受具体形态的限制。
在认识到这个区别后,我们认为,具身智能不一定非要定义一个最终形态,比如变成人形去适应人类的生存环境。反之,它可以是环境本身。也就是说,它不一定非要去一辆汽车、一幢房子、一条生产线上去工作,它可以是这个汽车、房子、生产线本身。它可以同时存在多种物理形态。
具体到产品开发思路上,我们不会跟风去做一个人形机器人,而是根据客户、场景的需求来决定把机器人做成什么样子,比如它按电梯或者开门需要一只手,我们就给它安一只手。
龙禹含:我补充一下。其实在产品迭代的过程中,我们考虑过两种方向,一种是比较贴近于人的方向,一种就是现在这种方向。我们之所以做出现在这种选择,其实主要是考虑这个产品需要大规模在实际场景中落地。如果做成接近于人的形态,还要在非机动车道上达到接近骑手的速度,我们觉得是不适配的。而且还存在交规风险和居民、客户接受度的风险。未来,我们还是会根据客户的需求以及成本等因素来选择合适的形态。
数据驱动贯穿始终
机器之心:前段时间,李飞飞教授创立了一个空间智能公司,您如何看待这个方向?
卢鹰翔:在看到新闻后,我们也做了一些调研,就是研究李飞飞教授这个公司具体要做什么。我们问了她实验室的学生,结果学生暂时也不太清楚。考虑到李飞飞教授之前一个非常重要的贡献是 ImageNet,而具身智能领域现在既没有特别好的训练数据集,也没有特别成熟的预训练模型,所以我们猜测,她这个新公司可能会在数据方向做一些事情,比如三维场景中人和机器之间相互关系的数据的收集,然后用这些数据去辅助机器人基础大模型的训练。
机器之心:李飞飞等具身智能领域的研究者有没有给你们的创业之路提供一些启发?
龙禹含:数据魔咒已经成为当前具身智能领域的一个共识。李飞飞等研究者给我们的启发,就是要尽快去实际场景中获得更多高质量的数据,而且是用商业化的方式低成本地去获取,然后再反过来推动技术的进一步发展和落地。这是我们在创立推行科技之初就确立的思路。在具身智能领域,这个思路已经被李飞飞教授这样的业界前辈反复印证。这让我们在这个方向的努力变得更加坚定。