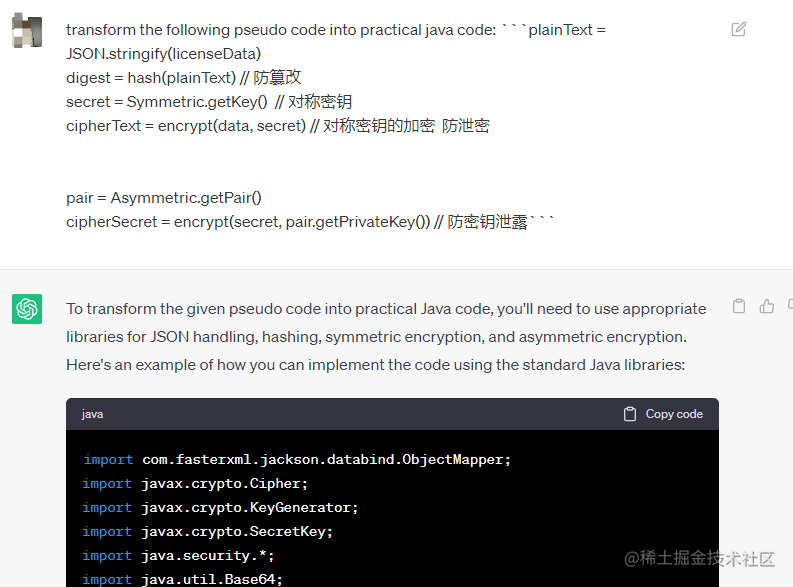
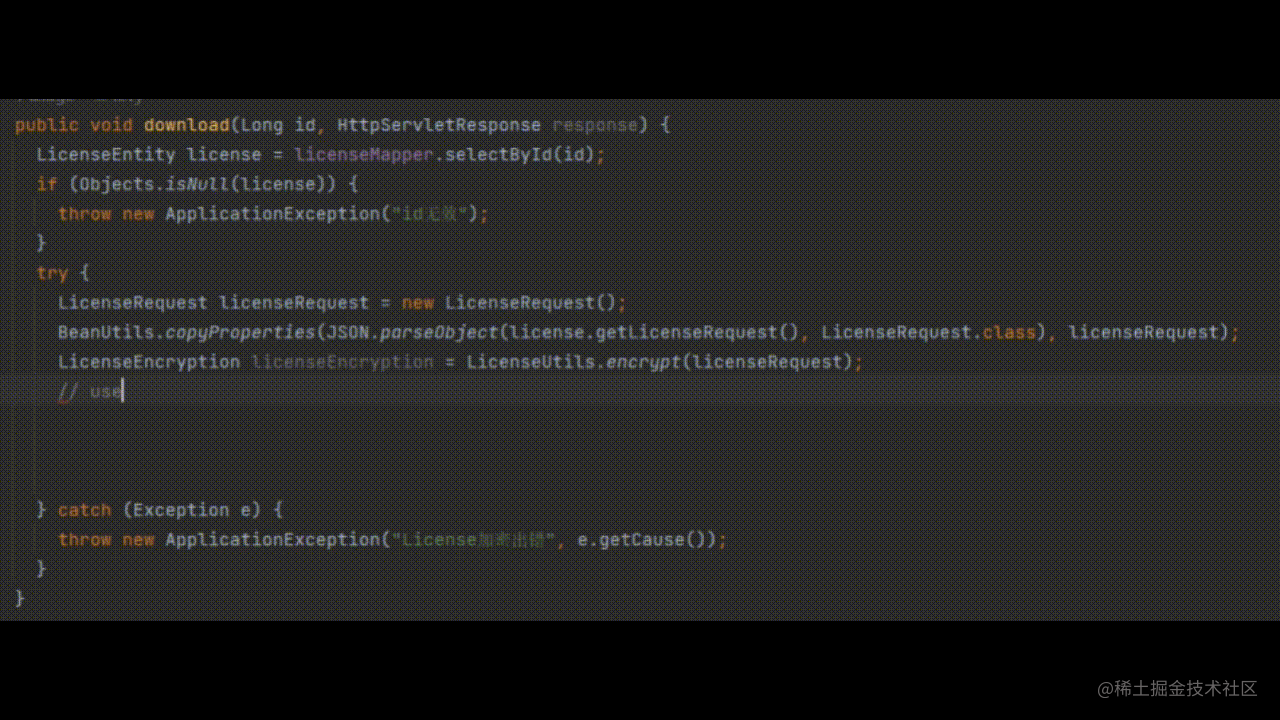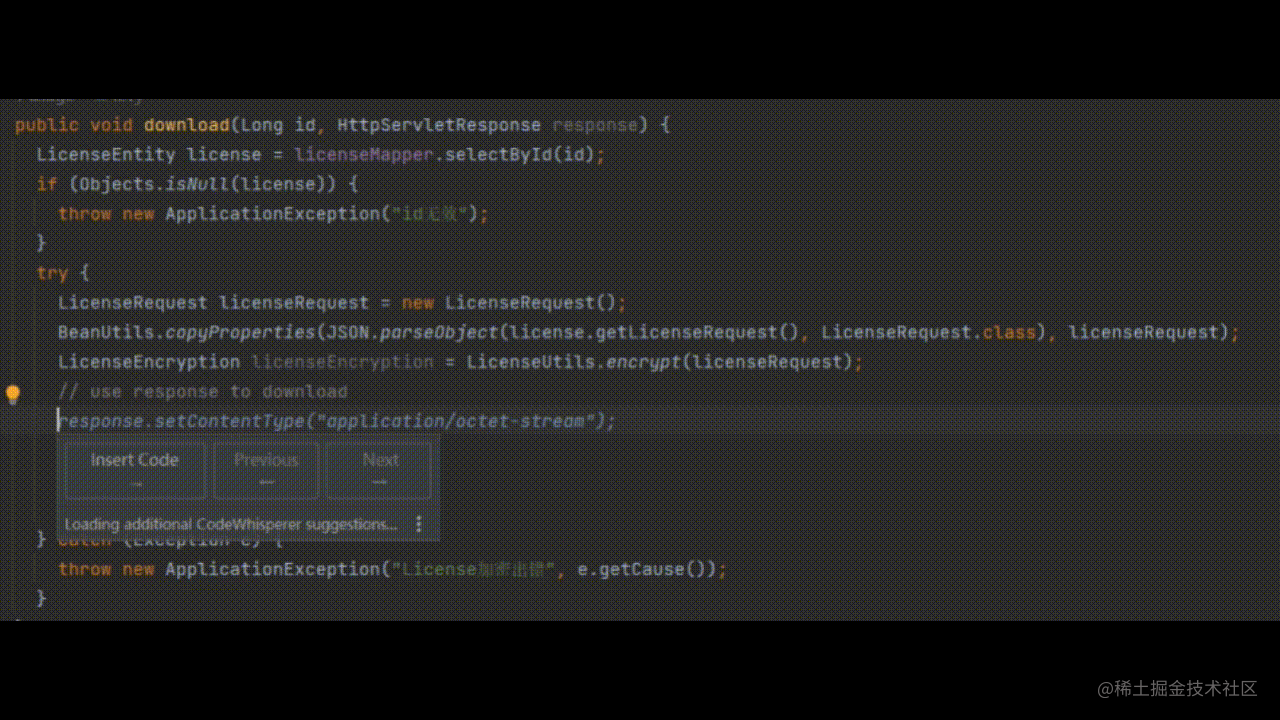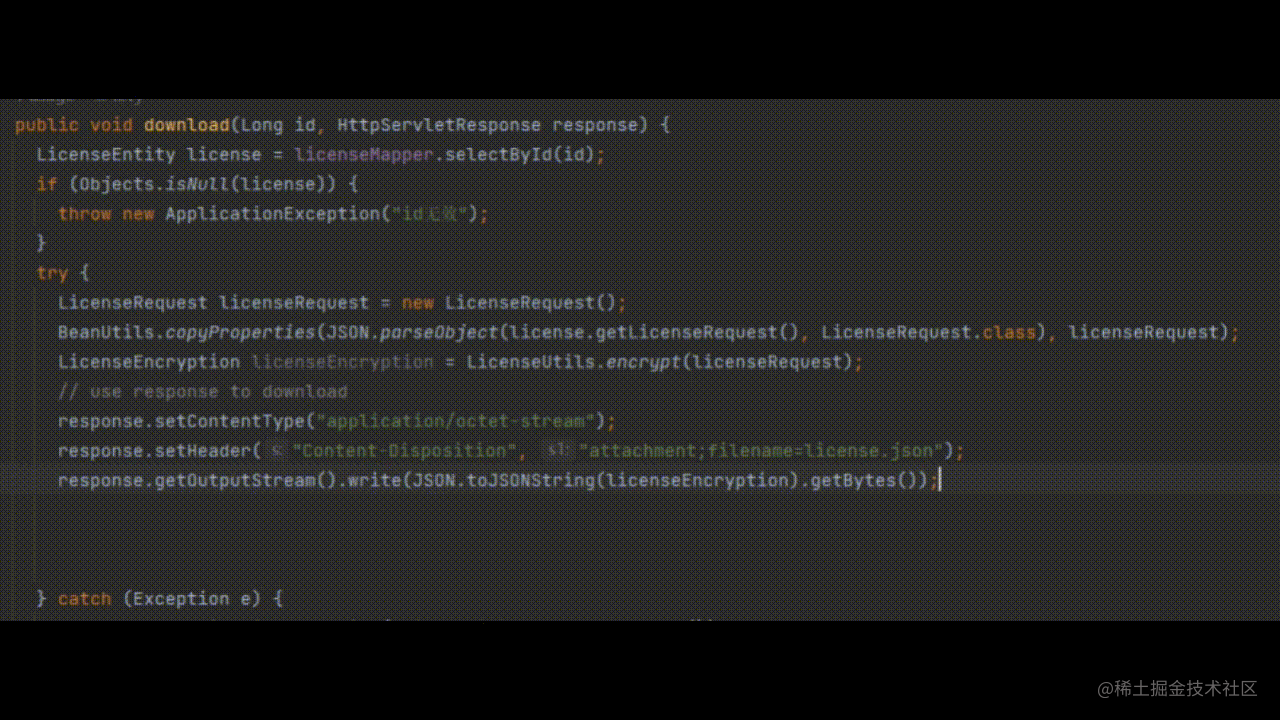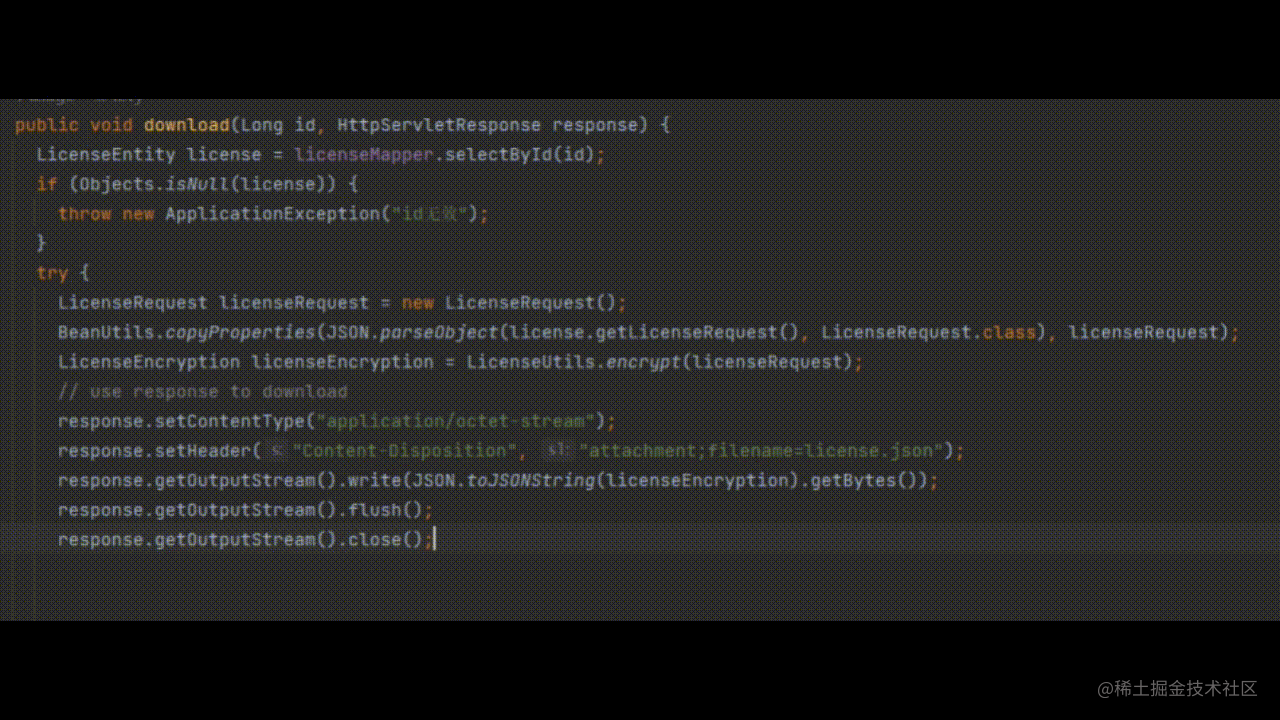
写在前面
目前已经上班快两个月了,对现在的工作很满意,甚至说更喜欢这的氛围吧。
如题所示,从今年5月开始,发生的所有事,都完全超出了我自己可以承受的范围,好在这一切都过去了,真的感谢上天安排,让我能更加确信自己要的是什么,以后该怎么生活。
爸爸被诊断为肺癌
我每年都会带父母去做体检,因为去年疫情全面放开后,担心被传染。寻思稳定稳定再去。
后爸爸因为走路崴脚在家养了三个月,就一直没去上体检。
有一天下班爸爸跟我说,心脏不得劲,心总疼,而且还上不来气,我说那明天去医院看看吧。
由于我工作项目忙还总加班,就让姐姐陪爸爸一起去检查了。
由于比较有名的医院,都没号了,姐姐就去了某国际医院(私立医院),做了全面检查,通过各种CT的检查结果汇总,医院给出的答案是小细胞癌晚期,建议转院。
当我姐哭着给我打电话告诉我这个消息时,我整个人都楞了几秒。
我跟姐姐说,你先别慌,我们再去其他医院看看,小医院技术不行,也许查错了呢!
你就跟我爸说,可能是上火引起的,CT上查出来有个黑点具体什么没看出来,建议我们去大医院看,那设备好一些,能看出来。
接下来,我和姐姐去约各大医院的专家号,某军区总院、某四院、某二院、某市中医院、某省总医院、某肿瘤医院等等。
最后,以上所有医院的结果,给出的答案都是小细胞癌晚期。
据我同学给介绍的医生说,我爸这样的情况,最多可能半年或1年,即使是化疗也意义不大,当我和姐姐知道这个消息的时候,一时我也接受不了这个消息,看到姐姐伤心痛哭的样子,我心里也难受极了.....
我强忍着跟姐姐说,咱们再看看,肯定可以治疗。
爸爸得知自己肺癌
对我们而言,怕爸爸知道自己肺癌,会因为舍不得钱而轻生的想法,不配合治疗,所以刚开始在没完全确诊之前,就一直瞒着他。
后来,随着去的医院越来越多,爸爸也逐渐开始起了疑心!
直到我们去某四院,做完肺活检,等结果。并告诉爸爸一周后才能出来(那时候我都佩服我自己撒谎的本事!),其实结果早就出了,只是 我和姐姐不死心,想拿着结果去其他医院再看看,总觉得是医院给看错了。
爸爸也是一直在关注着检查的结果,每天都会问结果到底什么时候能出来!
本来和妈妈、姐姐一直打算瞒着爸爸,让他开心的过完后面的时间。
当然,肯定这肯定是瞒不住的,只是能瞒着一天算一天。
后来,经商量后决定,还是跟爸爸说,觉得他也有知道的权利,而且我们相信爸爸可以接受,并且会积极配合治疗。
当爸爸知道自己得了肺癌后,刚开始那几天,每天都在那发呆,一句话也不说。
于是,我们就决定每天家里必须有个人在家,怕爸爸有轻生的想法,但怕他待在家比较闷,我们决定就带爸爸去旅游。
当然这期间,我们一直没有放弃,又通过关系找到某肿瘤医院主任医生,抱着试试看的态度就去了,听他说完,我们觉得还算靠谱,于是,我们决定就在这家医院治疗了。
随着时间的流逝,爸爸也开始慢慢接受了自己肺癌的事实,而且也选择积极配合治疗,最后也去了医院,这真的让我很开心。
千万不要去化疗
刚开始化疗的时候,我们都是早上7点多就到医院,晚上挂完点滴,到晚上9点-10点才能到家,第一次化疗大约5天左右。
和每个化疗患者一样,刚开始,爸爸也是开始掉头发、厌食。
爸爸最爱吃猪蹄,我每天都会买猪蹄,都后来干脆都不吃,说是没胃口,再到后面脸上也逐渐出现一些症状,有点发黑。
那一刻,我真的感觉化疗就和慢性自杀一样,看着一天天日渐消瘦的爸爸,我的心里真的很不是滋味。
就这样顺利的完成第一阶段,22天后,我们又开始进行了第二次化疗。
化疗的第一天开始,爸爸就开始感觉不舒服,说心脏不得劲,后来医生说有个药不给用了,再看看。
然后,到了第二天,爸爸又开始血压不稳定、心慌,开始不怎么吃饭了,也不怎么说话了,把我吓坏了,脸色也不好。
我一也没睡,就这样守着看到了第三天,抢矿更不好,爸爸开始吐,恶心。
后来和医生说我们要强制出院,不打了,化疗的反应真的太大了,医生也同意我们出院了。
回家后,过了两天稍微好些,第三天,爸爸开始高烧不退、拉肚子不止,脸色苍白,后来我就带爸爸去急诊,输液后好了一些,到急诊那医生,听医生说爸爸是化疗后引起的,没有血小板和白细胞了,建议我们回原医院好些。
然后,我们又去商量主治医师,跟她说了下我爸爸现在的状况,只想恢复正常,表示先不化疗了,并询问能再次接收我们住院治疗,医生最后同意了。
住院后,开始做各种检查,住院当天下午稍微稳定了一些,然后连续两天又开始连续高烧、血压不稳,查完指标说还是是血小板太低,白细胞是0,几乎没有免疫力,需要补。
这时,通过食补根本来不及,主要因为爸爸基本不怎么吃东西了,而且高烧起来,抽起来吓人,筷子都咬折了,真太吓人了,我当时真的希望我要是能替爸爸受这个罪该多好,当时真的强忍着眼泪,心里老难受了 !
最后,在我们的一再坚持下,请到了某二院的专家来帮忙会诊,老专家先让爸爸做了几项检查,并给换了药输液,大约也就一周左右,爸爸就好了,出院前,也去查了CT,发现肺部的肿瘤竟然没了!
医生说建议,过一阵再来接着化疗,后面再放疗会更好。其实我们也明白,因为小细胞癌的扩散速度很快,所以建议多观察治疗。
但是我们都坚持不会再去化疗了!
求医之路
爸爸出院回家后,开始进行食补,大约一周后,爸爸能正常走了,而且起色也好了许多。
我们开始四处求医,开启寻医之路,也是去了好多地方吧!
这期间遇到的,有一些老中医有个习惯,说是凡是化疗过的都不给看, 这让我表示很苦恼而且不理解。
再后来,爸爸的一位病友给推荐了一个老中医,我们还是照常打个电话过去,说明了情况,查看是否能治疗,结果开心的是能治疗。
刚开始,我们也是不相信的,抱着试试看的态度,我们去看了下,医生给开了半个月的药,结果爸爸喝中药俩礼拜后,就感觉明显走路有劲了,比以前强很多。
直到现在还在喝中药,之前化疗的副作用慢慢都好了,比如厌食、牙齿松动,吃甜的东西牙疼,头发也长出来了,而且每天还和之前一样,早晚去散步,连之前楼下的老太太,都说完全看不出来像生病一样,真的是好开心,也算是好事多磨吧,也可以说是遇到贵人了。
我失业了
从2022年开始年底就开始裁员,公司也是组织架构调整,人员变动也比较频繁。
我当时也是负责性能测试、自动化测试这两块,并行着三个项目,也是真的加班加点的干。
因为爸爸生病,跑医院检查,我总请假,赶上公司组织架构调整。检查、陪护一个人根本忙不过来,妈妈年龄大了不太方便,所以我辞职了,当然也失业了,"成功"地走进2023失业大军中。
好处就是,我终于可以全身心的去忙家里的事了。
找工作
出院后的一个月,爸爸这边病情算是稳定了,我便开始了积极找工作。
因为好久没找工作了,首先,我用了大约5天的时间去搞简历,搞完简历便开始找工作。
通过找工作才发现,真TM卷呀,都是统招本科起步,更过分的是有的公司还要求必须是计算机专业!
我一看我自己,大专自考本科,完全没竞争力,BOSS上、智联、脉脉上、拉钩、内推,基本都是被学历卡掉了!
而且,那会特别焦虑,除了这行还能干嘛,我还会做啥,离了这行,是不是完了?
那会女友找到了工作,而且收入也不错,我待业,顶着巨大压力,我还是继续努力的寻找的工作。
还好感谢上天眷顾 ,还有几个面试,让我有的选择,最终我选择了一家成功上岸工作了。
,还有几个面试,让我有的选择,最终我选择了一家成功上岸工作了。
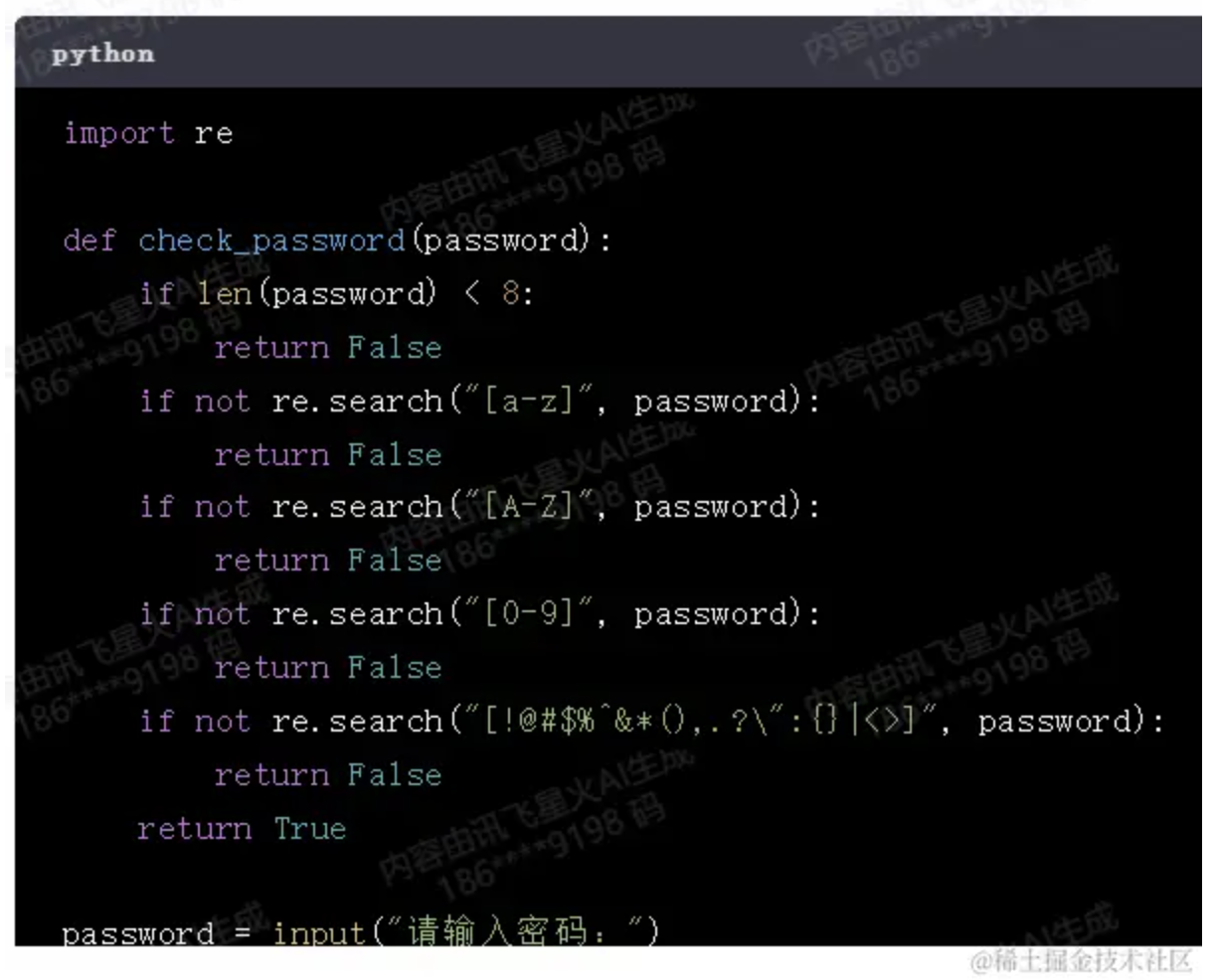
分享两个面试题:
StringBuilder和StringBuffer的区别?(我只用过他们拼接字符,结果凉了)
你性能测试中最大的QPS是多少?(这题我跟面试官,开始了杠精模式,我真没法回答)
我失恋了
每次写到这块,就感觉我像个怨妇一样呢,哈哈,真的不爱写。
我和女友是相亲认识的,3月相识直到今年10月长假彻底分手,分手是在吃完定亲饭开始黄的,听起来是不是很奇怪。
那会我已经上班一周,也是临近十一的一周,爸爸那会身体恢复的已经很好了,开始正常上班了。
因为在这之前她总跟我说,我们结婚把之类的话,我刚开始没往心里去,但是也就在那周,我接了话拆,并也耐心的跟他说了个初步沟通,寻问过彩礼和三金等等,当时,我看她也很开心的。
然后,回家我就跟家长说了这事,我爸说,那也行我这边身体现在也恢复的挺好,那就吃个定亲饭,把你俩的事定下来。
之后,爸爸给介绍人打了电话给介绍人,介绍人询问她家什么时候有时间,然后他妈妈给了个时间,当天晚上下班,女孩就跟我生气说,没正式通知她(也许差个求婚仪式吗?我可能直男了吧),完事我俩吵了一架。
然后呢,她告诉他妈说不行,然后又跟他妈妈吵架了,那意思说没告诉她 怎么就定了呢!
后来,我妥协了,我说那这样吧,时间你来定什么时候都行,不行怎么就先处着,你感觉行再订婚,你别有压力呢。
结果,也不到怎么她妈妈又给介绍人打电话定了个时间,完事又不行,来回会改了三次,我爸妈当时也说,要是人家不愿意就算了,再等等吧。
完事我还是跟女孩说,等你们定好,提前一天告诉我就行,你先和家长商量好就行的。
就因为吃定亲饭时间,他们家来回变定不下来,搞的我父母心情很复杂,但也是为了自己的儿子幸福,就等等了。 好在最后,定下来最后的时间了。
在吃定亲饭那天,给了定金,我感觉啥也没谈,介绍人问了女孩家有没有陪嫁,男方这边有房子,可以出装修等等,其他的我忘记了,当时他父母不吱声也不表态,我就感觉很奇怪吧。
当然,我作为晚辈在桌上没法发表意见。
于是,第二天,我们去自驾游回来的时候,我就说吃完定亲饭,介绍人问你父母你家有没有陪嫁,你爸妈没表态,我爸爸得了肺癌手头可能也不宽裕,我寻思问下你家有没有陪嫁,可以出点家电或者装修?因为都我家的话,可能会负债。
女孩问我是我的意思,还是我爸妈的意思,我说昨晚我们到家都很晚了,我晚上到家父母都睡觉了,一早我俩5点多出门去旅游,基本没说上话,我俩就是商量下。
女孩没说话,直接下车,并说 我现在就去找我爸妈,我去问问(当时生气的哭了,或许我不该问?)
之后,我回家和我爸妈说,我又把对象惹生气了,并说了事情的缘由,父母本着保全大局的原则,让我先去道歉。
我先去找女孩的妈妈,结果,到那后,他妈妈基本都不让我说话,大概那意思,就是她们不是卖女儿,娶媳妇还想让她们拿钱,能娶得起就娶,娶不起就不娶,要是有饥荒,女儿肯定不嫁。
我看这样,我就又去找女孩各种道歉努力,女孩最后说不处了,直接退定金,走介绍人流程。
之后,我回家跟父母学了一下,父母还是为了我,为了他们儿子,直接去找到女孩的父母,带着我去赔礼道歉。
到了后,我虽然离的很远都能听到,他妈妈跟我说的那些话,又跟我妈妈说了几遍,好在他爸爸是明事理的人,说也会帮着劝劝,但是他爸爸说了不算,尴尬。
随后,妈妈和我又去找到女孩去赔礼道歉,妈妈说了很多话,大概意思是,给阿姨个面子,我们家小孩不太会说话,别忘心里去。
那种乞求被原谅的感觉,我那一刻,眼泪唰就出来了,心里很不是滋味,完事我偷偷的快速擦掉眼泪。妈妈临出门时说,大概意思是,你俩好好聊聊,好好相处,我家小孩嘴笨,你多担待点!结果我说啥,她也不说话,我说,那你先忙。
那一刻的冷漠,让我感觉到这份感情真的太脆弱、卑微了。
接着到了第二天,我早上买完早点给他送去,从8点多一直说到11点多,她的态度依旧是那么坚决,说不想处了,我当时回家后,我就在那想,处了半年多,一点感情也没有吗?说分就分,真的就能放下?
虽然每次吵架她都说分手,我都去哄,去赔礼道歉,也习惯了,但是这次不一样,我感觉好像是真的无法挽回。
但是我真的觉得,我和女孩都相处了快7个月了,有啥不能谈呢,至于上升到家长层面吗?
回家后,我跟父母说了下,后来大家讨论后,得出的结论:
可能是因为得知我爸爸是肺癌,每个月都要喝中药治病,觉得可能会是个累赘,再一个就是为了给爸爸治病花了不少钱,可能我家没多少钱了,可能怕以后的日子不好过,受拖累!
接着又过了一天,介绍人把我叫去,聊了一下,问我还有多少钱,还有一些别的,然后,又说跟她妈妈约定了好了,具体啥我忘记了,和我聊完,又给女孩妈妈打了个电话。
又过了一个多小时,我接到女孩的电话,她没说话,说打错了,我寻思给了台阶我就下了,我说你在哪,等你到家,你告诉我我去找你吧。
当天晚上,我收到女孩微信,说让我一起去介绍人那再聊一下,他们聊了啥,我也不到,我被支开了,他们聊了很久吧,聊的啥我也不知道,完事我送她回家。
第二天,早上我去找他,我打算跟她好好聊一下,我知道她肯定是想和好,我就问了他几个问题:
- 我不能保证一直都有工作,或者说我以后可能会有待业期,或者赚的不多,或者说不能给你更好的物质生活,但是我肯定会努力赚钱,不会摆烂(大概意思),你愿意跟我结婚吗?(没想过,而且现在不想结婚,想两年后吧,或者明年?)
- 比如我上班要早起你上班比较晚,偶尔愿意帮我早起做个早饭吗?(不想起来)
- 以后相处模式,能跟我先沟通下,再到父母层面吗?(不说话)
- 我爸爸要喝中药,我不能不管我爸爸(她的意思是我把父母看的比她重)
其他我忘记了,总之基本不说话,虽然来抱我,表示和好,但是那一刻我发现,感觉真的变了!
然后跟我说,她会跟她妈妈说,我们和好了,但是不让我和我爸妈说,让我很吃惊!
难道我家长是因为好说话?就该不被重视?
“和好后”的两天,和之前一样,每天正常见面,都是我在找话题,她还是不说话,去她家,她基本不说话,在那工作,不说话,我就在那刷手机看视频。
然后又过去两天,我们出去散步,她还是不说话,甚至不牵我手。
想到带我去道歉的妈妈和她的冷漠态度, 突然,我好像想明白了。
又过了一天,晚上下班到家,我提出了分手,删除了她的微信,彻底分手了
我知道,如果我在跟她谈结婚,还是会遇到这样的问题,而且她也说过,
不想结婚,想再玩两年!
而我真玩不起了,从始至终,每次吵架,我都去道歉挽留,因为害怕失去,感觉在感情里,我被养成了讨好型的人格。
跳出来看,换位思考,如果我是女孩家长,可能也会让她嫁的更好,或者未来会有更好的物质生活,感情里,没有谁对谁错,只有愿不愿意吧,所以真的就是和平分手了!
但无论怎样,我也不会动父母养老的钱,没钱我就不娶!
可能有同学会说了,那你是娶不起吧。
没错,要是结个婚,要贷款梭哈的话,还是算了吧。
你有没有想过把父母老本都拿来,完事还让他们去借钱,他们都那么大岁数了,没有劳动力了,怎么还?
值得一说的是,她家并不是家境不好,只能说和我家差不多吧,后面我了解到,真的不是他们家没钱,只是他姐姐陪嫁还有个房子,到我这就一个人,让我们自己白手起家?还是瞧不起我?亦或许就不想跟我结婚?
写在最后
刚失恋那一个月,真的我天天失眠睡不着,而且担心光棍一辈子,去求助很多朋友帮忙介绍对象。
而现在呢,失眠是因为搞不到钱。真的才发现搞钱,才是这个世界上最有意义的事了吧。

作者:软件测试君
来源:juejin.cn/post/7300099522202009637