








前端部署,又有新花样?
大多数前端开发者在公司里,很少需要直接操心“部署”这件事——那通常是运维或 DevOps 的工作。
但一旦回到个人项目,情况就完全不一样了。写个小博客、搭个文档站,或者搞个 demo 想给朋友看,部署往往成了最大的拦路虎。
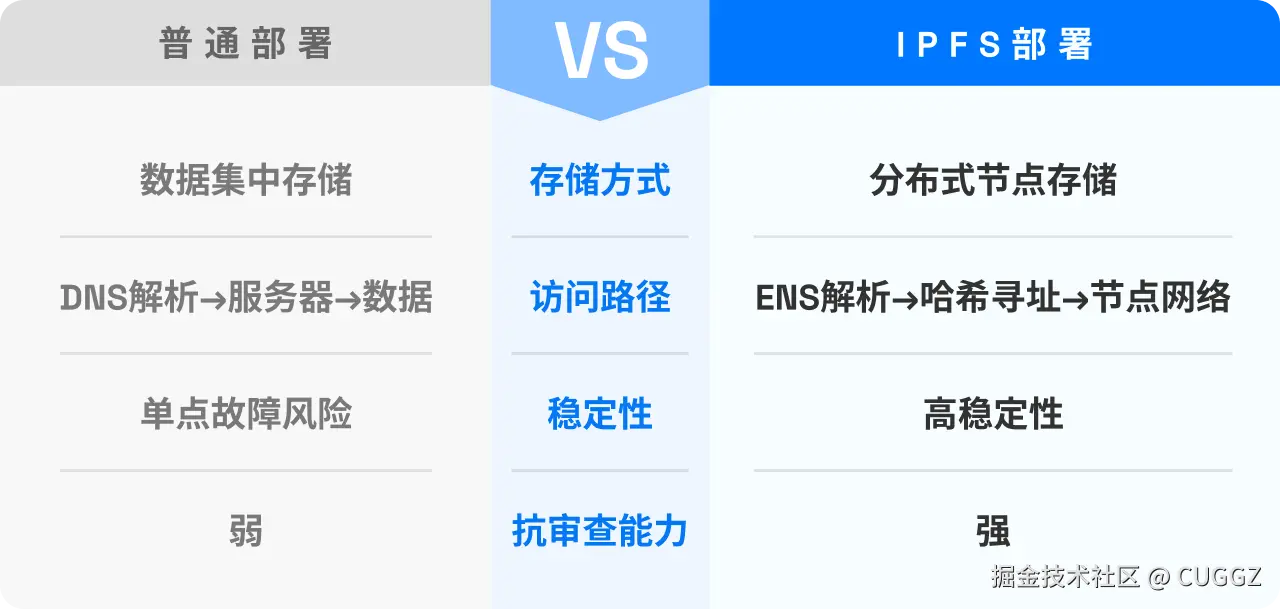
常见的选择无非是 Vercel、Netlify 或 GitHub Pages。它们表面上“一键部署”,但细节其实并不轻松:要注册平台账号、要配置域名,还得接受平台的各种限制。国内的一些云服务商(比如阿里云、腾讯云)管控更严格,操作门槛也更高。更让人担心的是,一旦平台宕机,或者因为地区网络问题导致访问不稳定,你的项目可能随时“消失”在用户面前。虽然这种情况不常见,但始终让人心里不踏实。
很多时候,我们只是想快速上线一个小页面,不想被部署流程拖累,有没有更好的方法?
一个更轻的办法
前段时间我发现了一个开源工具 PinMe,主打的就是“极简部署”。

它的使用体验非常直接:
- 不需要服务器
- 不用注册账号
- 在项目目录敲一条命令,就能把项目打包上传到 IPFS 网络
- 很快,你就能拿到一个可访问的地址
实际用起来的感受就是一个字:爽。
整个过程几乎没有繁琐配置,不需要绑定平台账号,也不用担心流量限制或收费。
这让很多场景变得顺手:
- 临时展示一个 demo,不必折腾服务器
- 写了个静态博客,不想搞 CI/CD 流程
- 做了个活动页或 landing page,随时上线就好
以前这些需求可能要纠结“用 GitHub Pages 还是 Vercel”,现在有了 PinMe,直接一键上链就行。
体验一把
接下来看看它在真实场景下的表现:部署流程有多简化?访问速度如何?和传统方案相比有没有优势?
测试项目
为了覆盖不同体量的场景,这次我选了俩类项目来测试:
- 小型项目:fuwari(开源的个人博客项目),打包体积约 4 MB。
- 中大型项目:Soybean Admin(开源的后台管理系统),打包体积约 15 MB。
部署项目
PinMe 提供了两种方式:命令行 和 可视化界面。
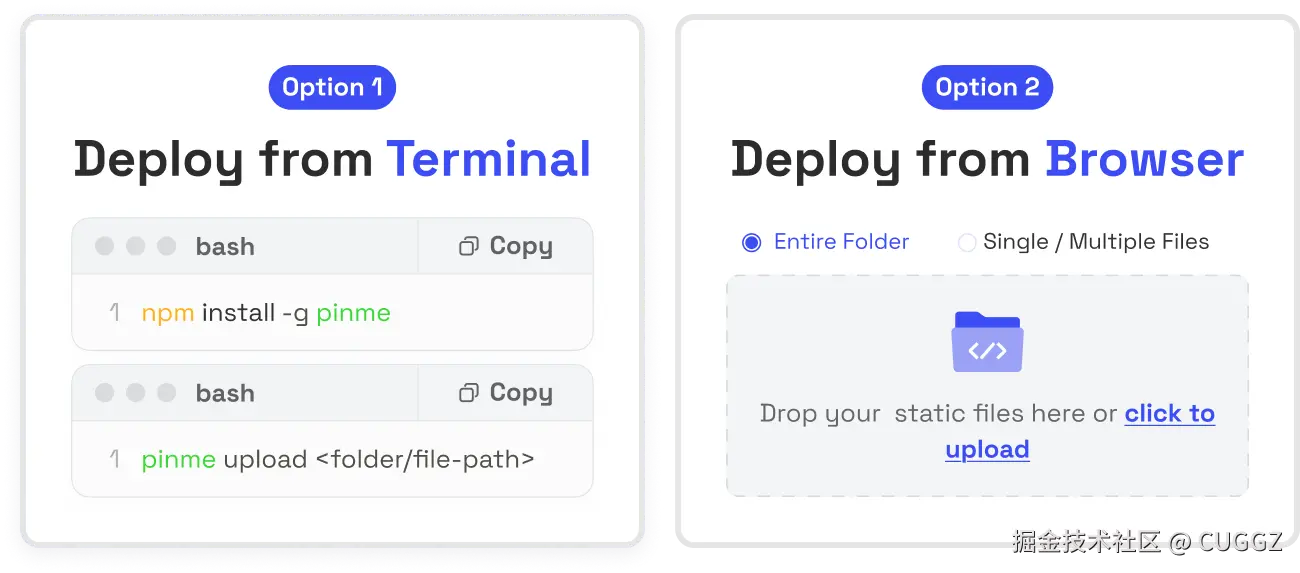
这两种方式我们都来试一下。
命令行部署
先全局安装:
npm install -g pinme
然后一条命令上传:
pinme upload <folder/file-path>
比如上传 Soybean Admin,文件大小 15MB:
输入命令之后,等着就可以了:

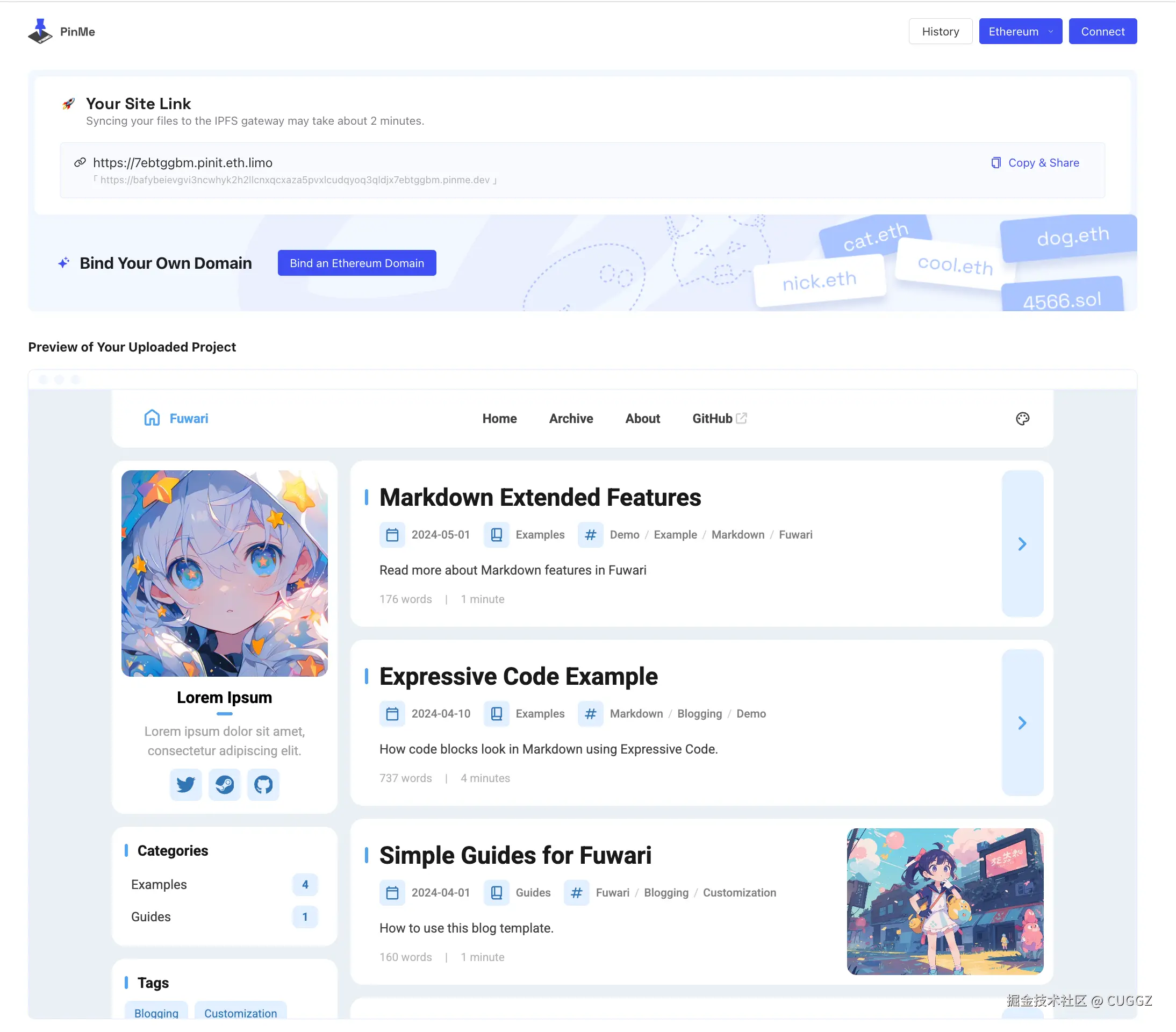
只用了两分钟,终端返回的 URL 就能直接访问项目的控制页面。还能绑定自己的域名:
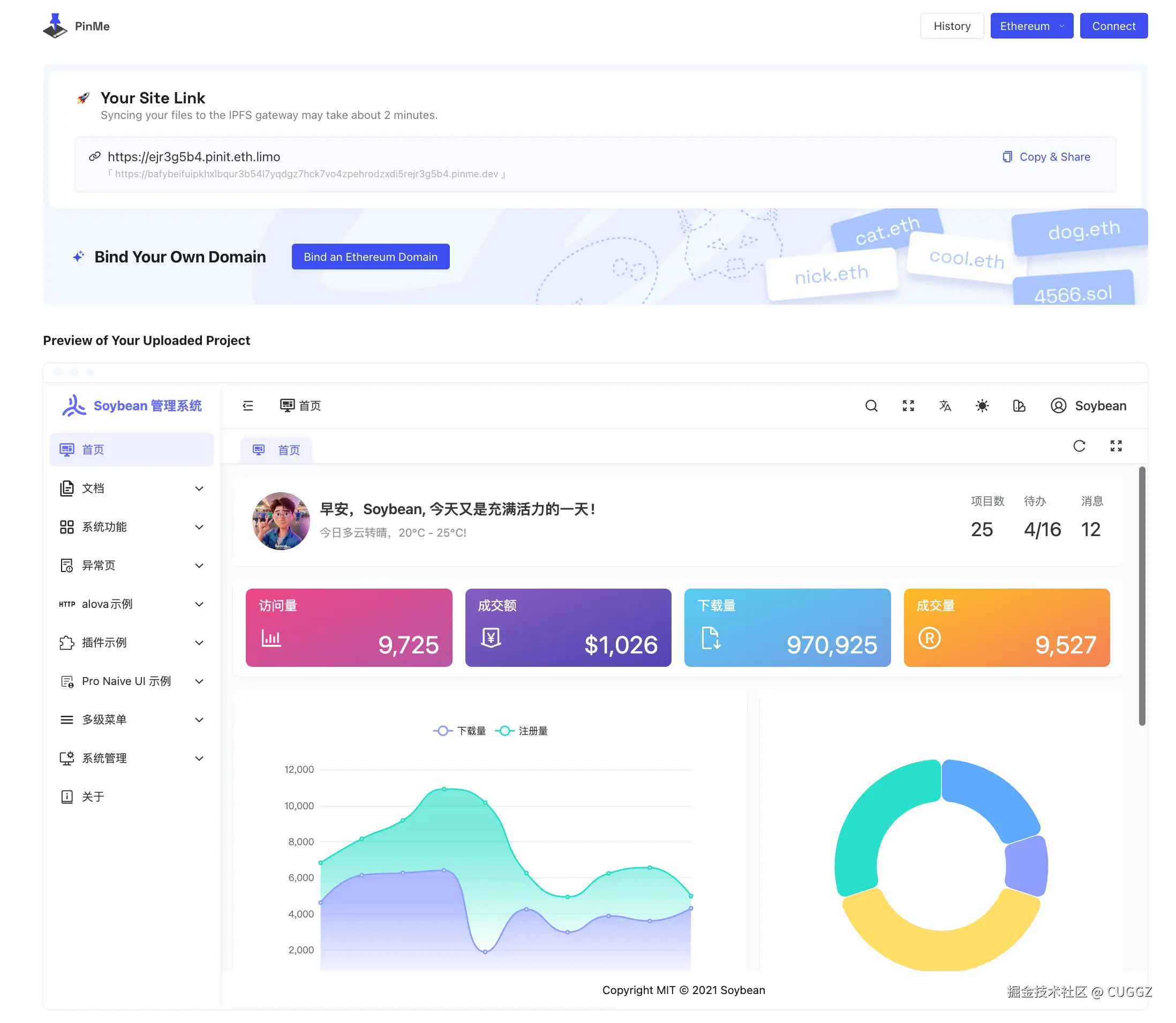
点击网站链接就可以看到已经部署好的项目,访问速度还是挺快的:
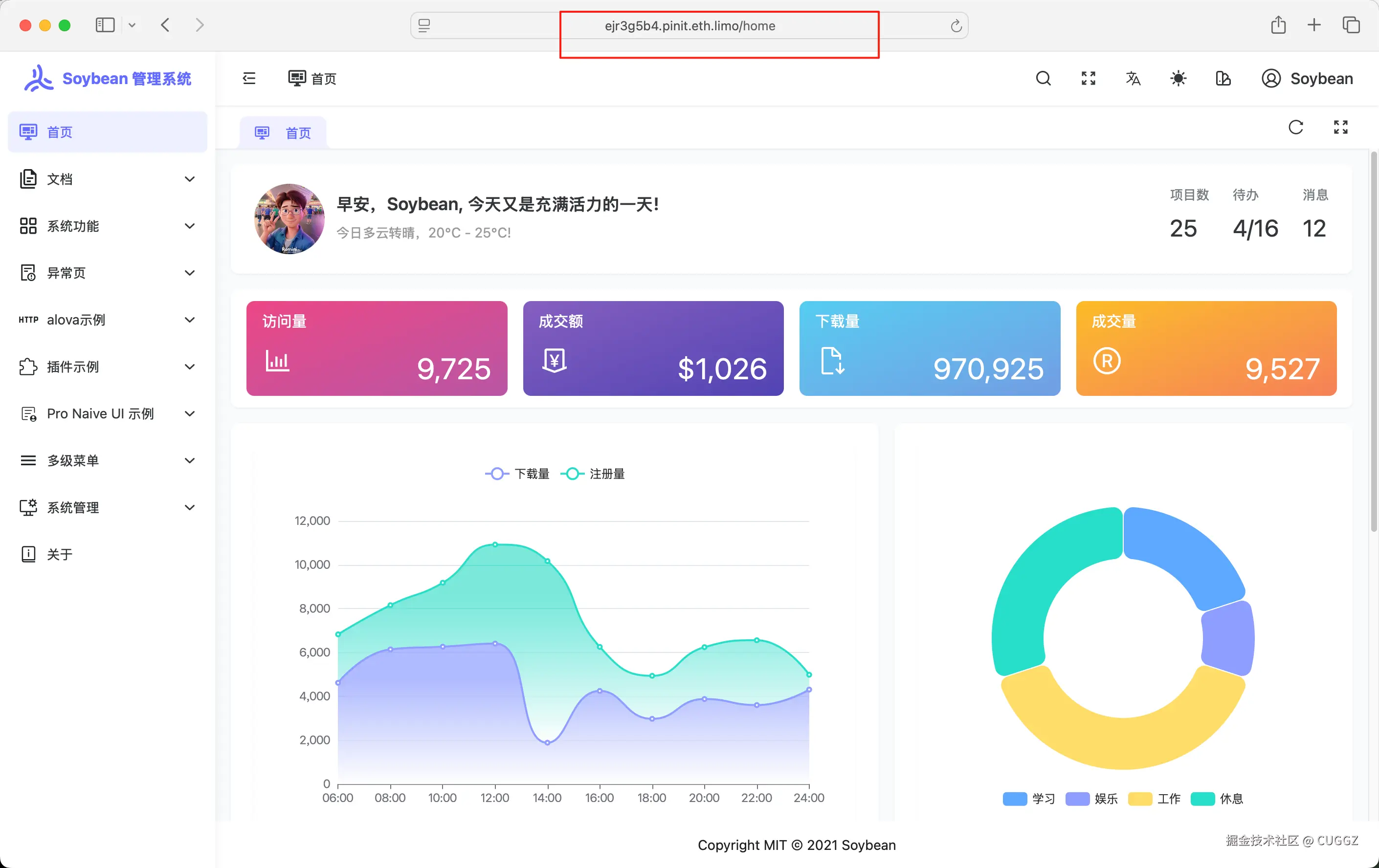
同样地,上传个人博客也是一样的流程。
部署完成:
可视化部署
不习惯命令行?PinMe 也提供了网页上传,进度条实时显示:
部署完成后会自动进入管理页面:
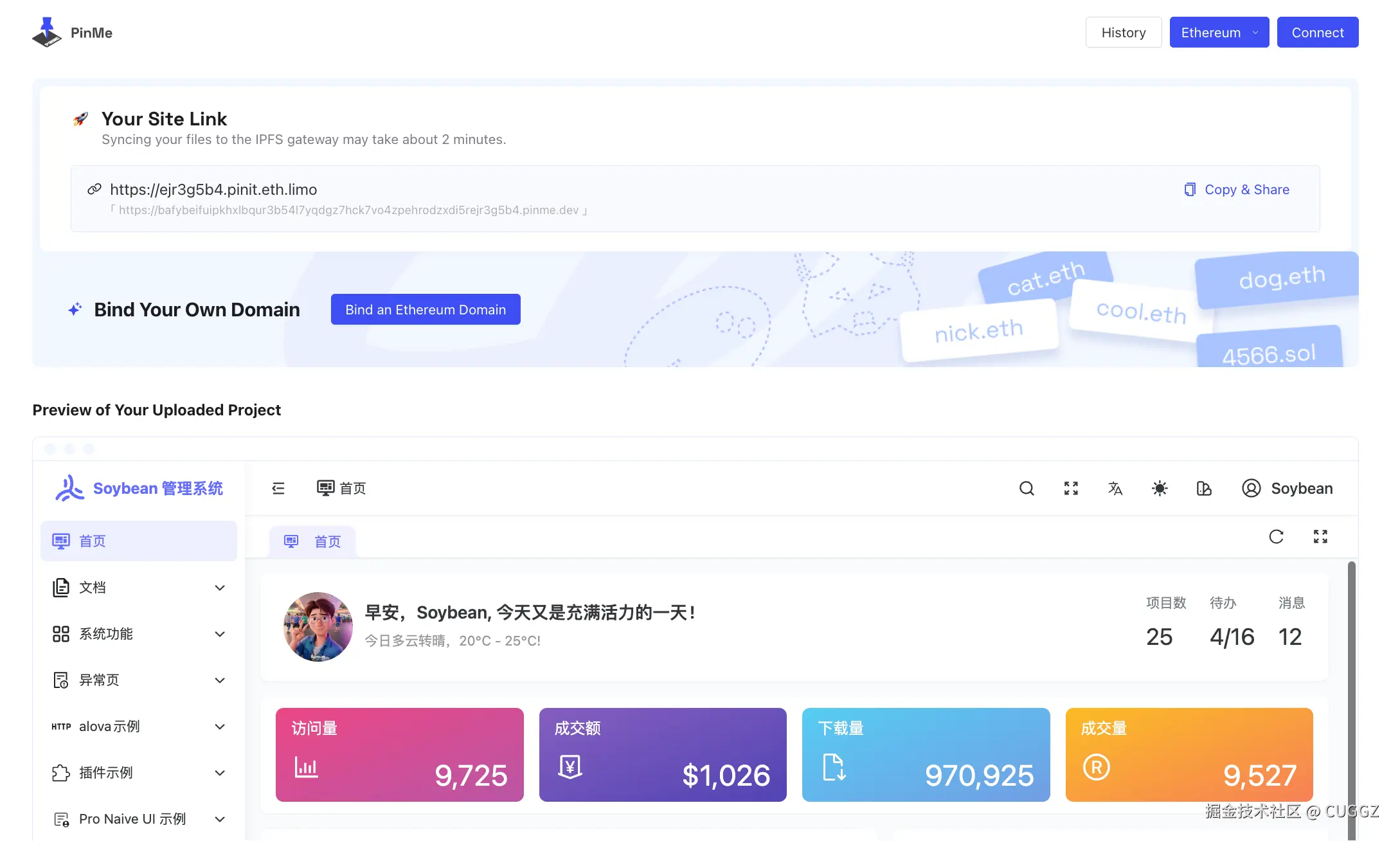
经过测试,部署速度和命令行几乎一致。
其他功能
历时记录
部署过的网站都能在主页的 History 查看:
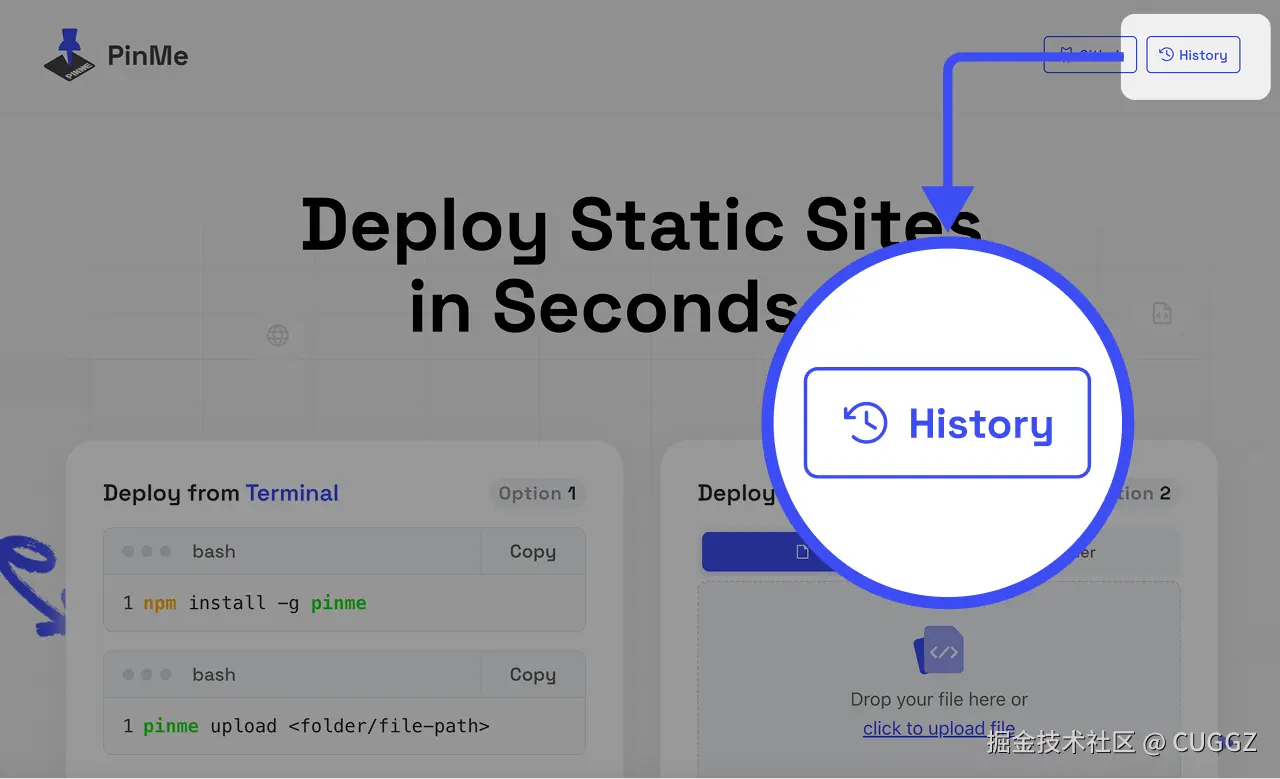
历史部署记录:
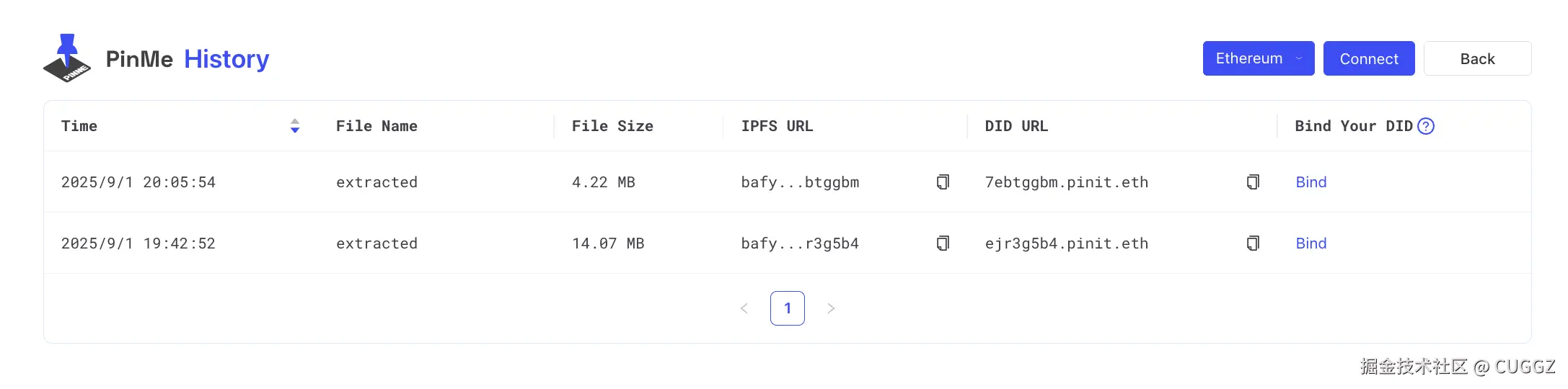
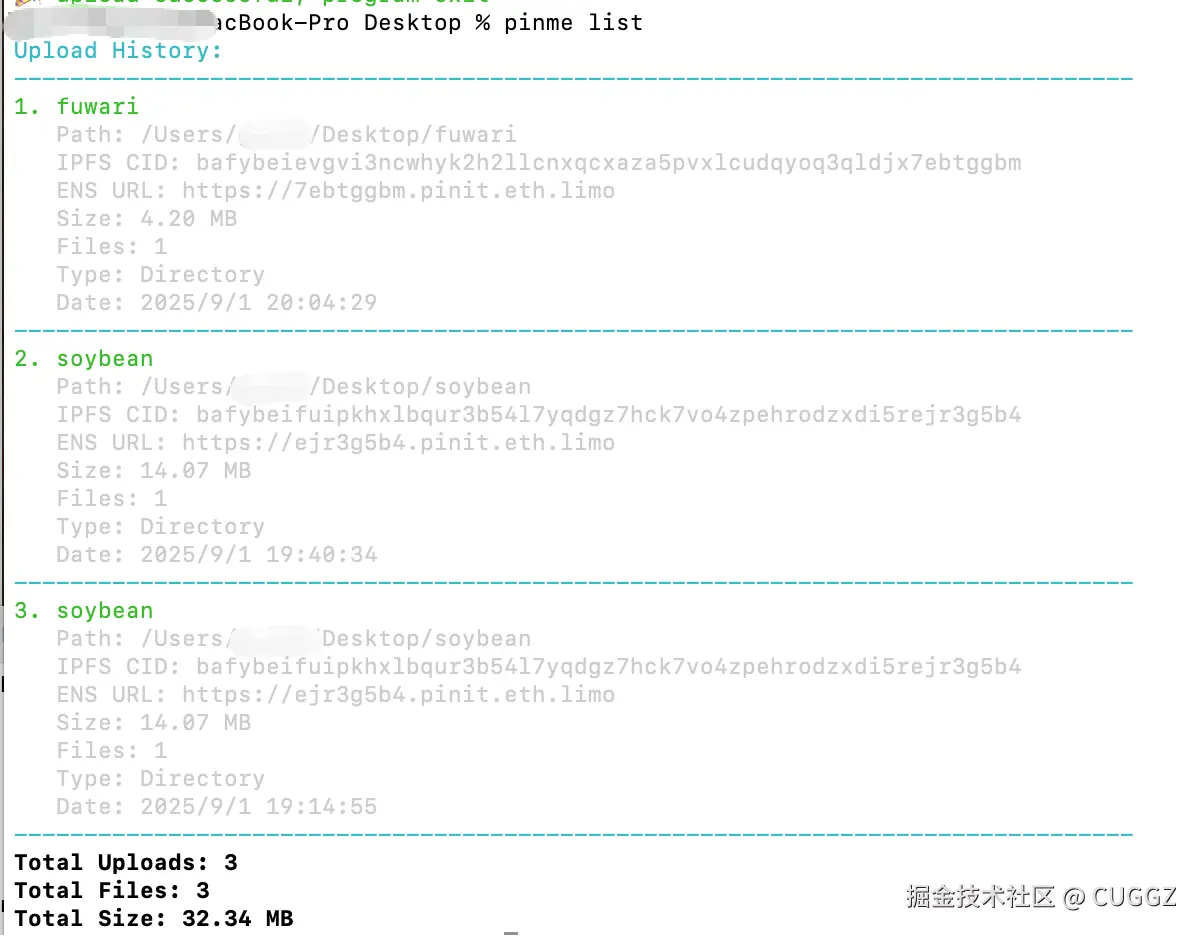
也可以用命令行:
pinme list
历史部署记录:
删除网站
如果不再需要某个项目,执行以下命令即可:
pinme rm
PinMe 背后的“硬核支撑”
如果只看表层,PinMe 就像一个极简的托管工具。但要理解它为什么能做到“不依赖平台”,还得看看它背后的底层逻辑。
PinMe 的底层依赖 IPFS,这是一个去中心化的分布式文件系统。
要理解它的意义,得先聊聊“去中心化”这个概念。
传统互联网是中心化的:你访问一个网站时,浏览器会通过 DNS 找到某台服务器,然后从这台服务器获取内容。这条链路依赖强烈,一旦 DNS 被劫持、服务器宕机、服务商下线,网站就无法访问。
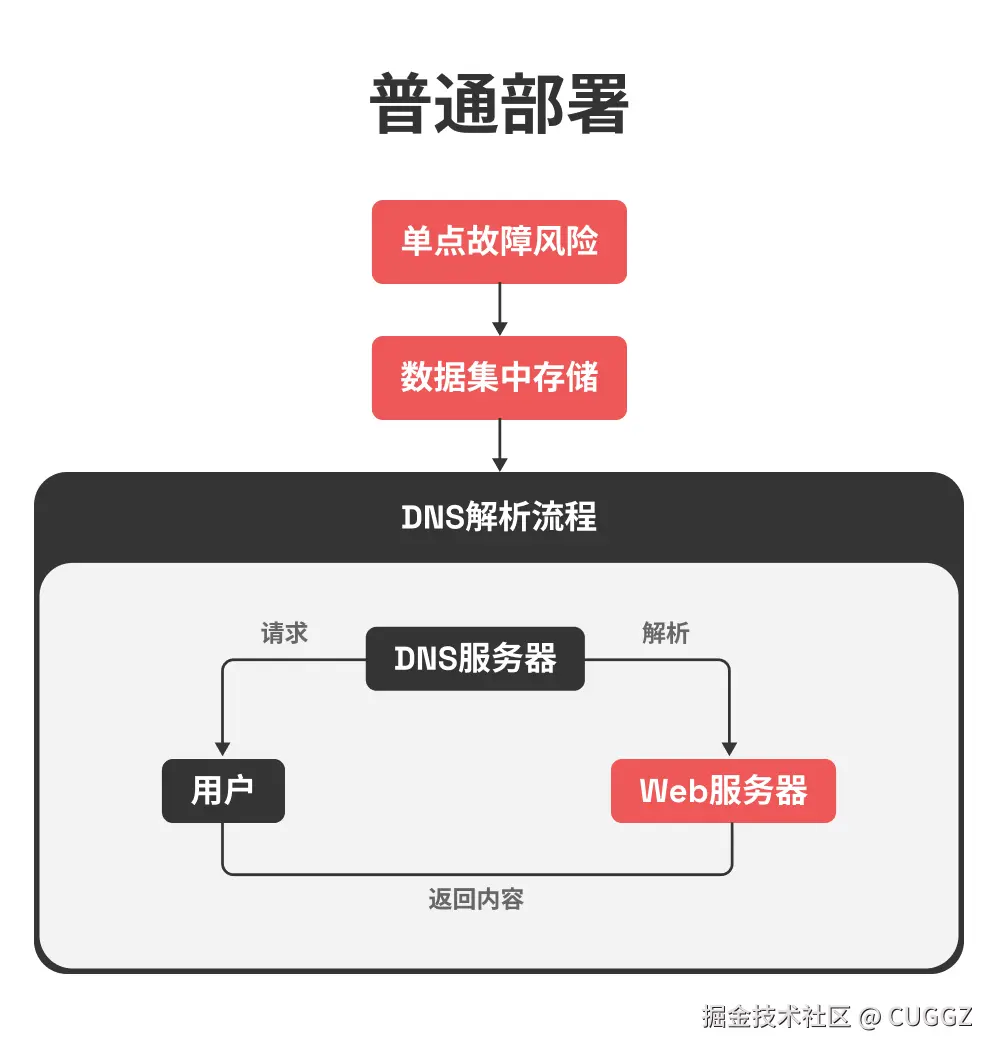
去中心化的思路完全不同:
- 数据不是放在单一服务器,而是分布在全球节点中
- 访问不依赖“位置”,而是通过内容哈希来检索
- 只要有节点存储这份内容,就能访问到,不怕单点故障
这意味着:
- 更稳定:即使部分节点宕机,内容依然能从其他节点获取。
- 防篡改:文件哪怕改动一个字节,对应的 CID 也会完全不同,从机制上保障了前端资源的完整性和安全性。
- 更自由:不再受制于中心化平台,文件真正由用户自己掌控。
当然,IPFS 地址(哈希)太长,不适合直接记忆和分享。这时候就需要 ENS(Ethereum Name Service)。它和 DNS 类似,但记录存储在以太坊区块链上,不可能被篡改。比如你可以把 myblog.eth 指向某个 IPFS 哈希,别人只要输入 ENS 域名就能访问,不依赖传统 DNS,自然也不会被劫持。
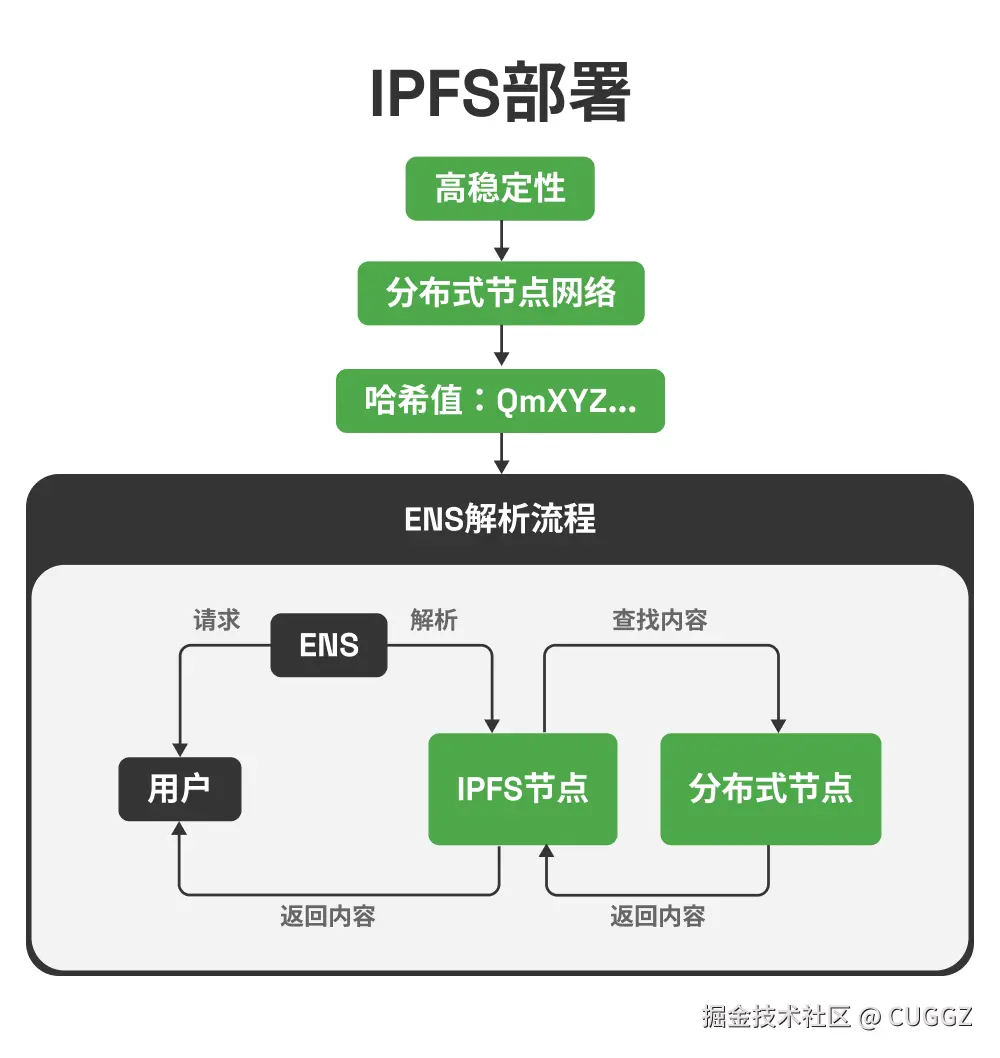
换句话说:
ENS + IPFS = 内容去中心化 + 域名去中心化
前端个人项目瞬间就有了更高的自由度和安全性。
一点初步感受
PinMe 并不是要取代 Vercel 这类成熟平台,但它带来了一种新的选择:更简单、更自由、更去中心化。
如果你只是想快速上线一个小项目,或者对去中心化部署感兴趣,PinMe 值得一试。
- 官网:pinme.eth.limo/
- Github:github.com/glitternetw…
这是一个完全开源的项目,开发团队也会持续更新。如果你在测试过程中有想法或需求,不妨去 GitHub 提个 Issue —— 这不仅能帮助项目成长,也能让它更贴近前端开发的实际使用场景!
来源:juejin.cn/post/7547515500453380136
antd 对 ai 下手了!Vue 开发者表示羡慕!

前端开发者应该对 Ant Design 不陌生,特别是 React 开发者,antd 应该是组件库的标配了。
近年来随着 AI 的爆火,凡是想要接入 AI 的都想搞一套自己的 AI 交互界面。专注于 AI 场景组件库的开源项目倒不是很多见,近日 antd 宣布推出 Ant Design X 1.0 🚀 ,这是一个基于 Ant Design 的全新 AGI 组件库,使用 React 构建 AI 驱动的用户交互变得更简单了,它可以无缝集成 AI 聊天组件和 API 服务,简化 AI 界面的开发流程。
该项目已在 Github 开源,拥有 1.6K Star!
看了网友的评论,看来大家还是需要的!当前的 Ant Design X 只支持 React 项目,看来 Vue 开发者要羡慕了...
ant-design-x 特性
- 🌈 源自企业级 AI 产品的最佳实践:基于 RICH 交互范式,提供卓越的 AI 交互体验
- 🧩 灵活多样的原子组件:覆盖绝大部分 AI 对话场景,助力快速构建个性化 AI 交互页面
- ⚡ 开箱即用的模型对接能力:轻松对接符合 OpenAI 标准的模型推理服务
- 🔄 高效管理对话数据流:提供好用的数据流管理功能,让开发更高效
- 📦 丰富的样板间支持:提供多种模板,快速启动 LUI 应用开发
- 🛡 TypeScript 全覆盖:采用 TypeScript 开发,提供完整类型支持,提升开发体验与可靠性
- 🎨 深度主题定制能力:支持细粒度的样式调整,满足各种场景的个性化需求
支持组件
以下圈中的部分为 ant-design-x 支持的组件。可以看到主要都是基于 AI Chat 场景的组件设计。现在你可以基于这些组件自由组装搭建一个自己的 AI 界面。
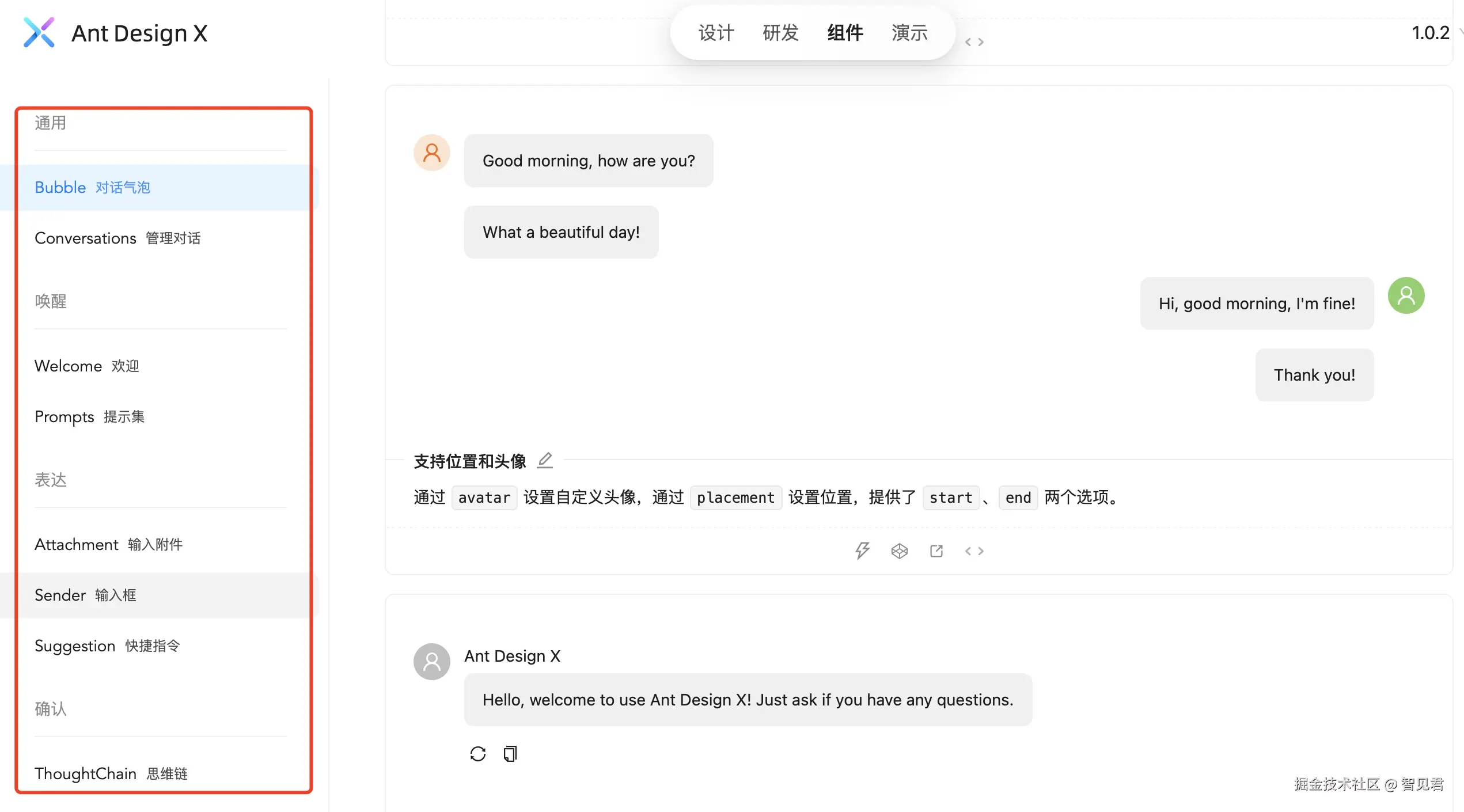
ant-design-x 也提供了一个完整 AI Chat 的 Demo 演示,可以查看 Demo 的代码并直接使用。
更多组件详细内容可参考 组件文档
使用
以下命令安装 @ant-design/x 依赖。
注意,ant-design-x 是基于 Ant Design,因此还需要安装依赖 antd。
yarn add antd @ant-design/x
import React from 'react';
import {
// 消息气泡
Bubble,
// 发送框
Sender,
} from '@ant-design/x';
const messages = [
{
content: 'Hello, Ant Design X!',
role: 'user',
},
];
const App = () => (
<div>
<Bubble.List items={messages} />
<Sender />
</div>
);
export default App;
Ant Design X 前生 ProChat
不知道有没有小伙伴们使用过 ProChat,这个库后面的维护可能会有些不确定性,其维护者表示 “24 年下半年后就没有更多精力来维护这个项目了,Github 上的 Issue 存留了很多,这边只能尽量把一些恶性 Bug 修复”
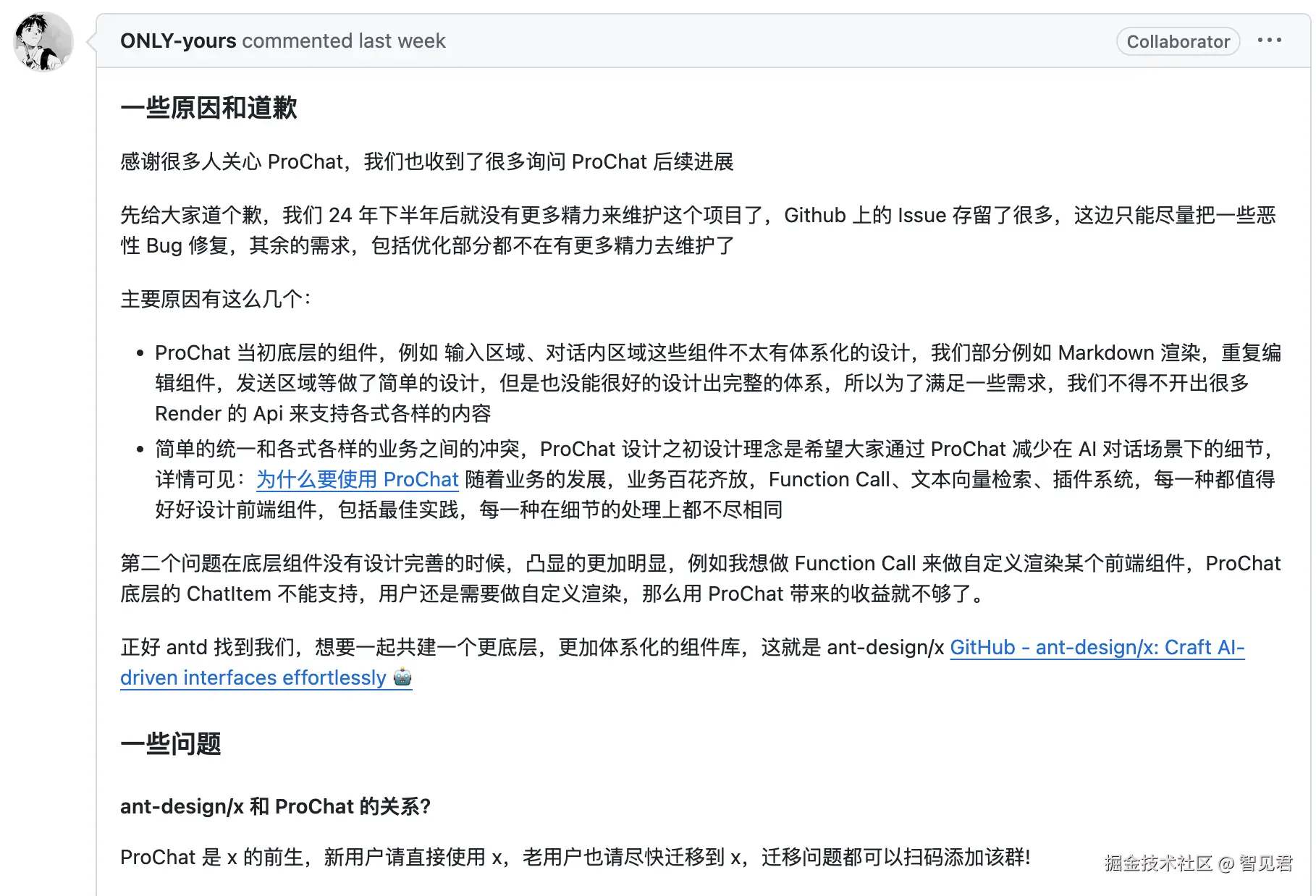
如上所示,也回答了其和 Ant Design X 的关系:ProChat 是 x 的前生,新用户请直接使用 x,老用户也请尽快迁移到 x。
感兴趣的朋友们可以去试试哦!
来源:juejin.cn/post/7444878635717443595
为什么 Electron 项目推荐使用 Monorepo 架构 🚀🚀🚀
最近在使用 NestJs 和 NextJs 在做一个协同文档 DocFlow,如果感兴趣,欢迎 star,有任何疑问,欢迎加我微信进行咨询 yunmz777
在现代前端开发中,Monorepo(单一代码仓库)架构已经成为大型项目的首选方案。对于Electron应用开发而言,Monorepo架构更是带来了诸多优势。本文将以一个实际的Electron项目为例,深入探讨为什么Electron项目强烈推荐使用Monorepo架构,以及它如何解决传统多仓库架构的痛点。
什么是Monorepo
Monorepo是一种软件开发策略,它将多个相关的项目或包存储在同一个代码仓库中。与传统的多仓库(Multi-repo)架构不同,Monorepo允许开发团队在单一代码库中管理多个相互依赖的模块。
Electron项目的复杂性分析
Electron应用通常包含以下核心组件:
- 主进程(Main Process):负责创建和管理应用窗口
- 渲染进程(Renderer Process):运行前端UI代码
- 预加载脚本(Preload Scripts):安全地桥接主进程和渲染进程
- 共享代码库:业务逻辑、工具函数、类型定义等
- 构建配置:Webpack、Vite等构建工具配置
- 打包配置:Electron Builder等打包工具配置
这种多层次的架构使得代码组织变得复杂,传统的多仓库架构往往无法很好地处理这些组件之间的依赖关系。
实际项目结构深度解析
让我们以您的项目为例,深入分析Monorepo架构的实际应用:
项目整体架构
electron-app/
├── apps/ # 应用层
│ ├── electron-app/ # Electron主应用
│ │ ├── src/
│ │ │ ├── main/ # 主进程代码
│ │ │ └── preload/ # 预加载脚本
│ │ ├── build/ # 构建配置
│ │ └── package.json # 应用依赖
│ └── react-app/ # React前端应用
│ ├── src/
│ │ ├── components/ # React组件
│ │ └── page/ # 页面组件
│ └── package.json # 前端依赖
├── packages/ # 共享包层
│ ├── electron-core/ # 核心业务逻辑
│ │ ├── src/
│ │ │ ├── base-app.ts # 基础应用类
│ │ │ ├── app-config.ts # 应用配置
│ │ │ ├── menu-config.ts # 菜单配置
│ │ │ └── ffmpeg-service.ts # FFmpeg服务
│ │ └── package.json
│ ├── electron-ipc/ # IPC通信封装
│ │ ├── src/
│ │ │ ├── ipc-handler.ts # IPC处理器
│ │ │ ├── ipc-channels.ts # IPC通道定义
│ │ │ └── ipc-config.ts # IPC配置
│ │ └── package.json
│ └── electron-window/ # 窗口管理
│ ├── src/
│ │ ├── window-manager.ts # 窗口管理器
│ │ └── window-factory.ts # 窗口工厂
│ └── package.json
├── scripts/ # 构建脚本
├── package.json # 根配置
├── pnpm-workspace.yaml # Workspace配置
├── turbo.json # Turbo构建配置
└── tsconfig.json # TypeScript配置
核心配置文件分析
1. pnpm-workspace.yaml - 工作空间配置
packages:
- 'apps/*'
- 'packages/electron-*'
这个配置定义了工作空间的范围,告诉pnpm哪些目录包含包。这种配置的优势:
- 统一依赖管理:所有包共享同一个
node_modules - 版本一致性:确保所有包使用相同版本的依赖
- 安装效率:避免重复安装相同的依赖
2. turbo.json - 构建管道配置
{
"$schema": "https://turbo.build/schema.json",
"globalDependencies": ["/.env.*local"],
"tasks": {
"build": {
"dependsOn": ["^build"],
"outputs": ["dist/", "out/", "build/", ".next/"]
},
"dev": {
"cache": false,
"persistent": true
},
"lint": {
"dependsOn": []
},
"typecheck": {
"dependsOn": ["^build"]
},
"test": {
"dependsOn": ["^build"]
},
"clean": {
"cache": false
},
"format": {
"cache": false
}
}
}
这个配置定义了构建管道,实现了:
- 依赖关系管理:
dependsOn: ["^build"]确保依赖包先构建 - 增量构建:只构建发生变化的包
- 并行执行:多个独立任务可以并行运行
- 缓存机制:避免重复构建
3. 根package.json - 统一脚本管理
{
"scripts": {
"build": "turbo run build",
"dev": "turbo run dev",
"lint": "turbo run lint -- --fix",
"typecheck": "turbo run typecheck",
"electron:dev": "turbo run dev --filter=@monorepo/react-app && turbo run dev --filter=my-electron-app",
"electron:build": "turbo run build --filter=@monorepo/react-app && turbo run build --filter=my-electron-app"
}
}
Monorepo架构的六大核心优势
1. 统一的依赖管理
传统多仓库架构的问题:
- 每个子项目都需要独立管理依赖
- 容易出现版本不一致的问题
- 重复安装相同的依赖,浪费磁盘空间
Monorepo解决方案:
在您的项目中,所有包都使用workspace:*协议引用内部依赖:
// apps/electron-app/package.json
{
"dependencies": {
"@monorepo/electron-core": "workspace:*",
"@monorepo/electron-window": "workspace:*",
"@monorepo/electron-ipc": "workspace:*"
}
}
这种配置的优势:
- 版本一致性:所有包使用相同版本的内部依赖
- 实时更新:修改共享包后,依赖包立即获得更新
- 避免重复:pnpm的符号链接机制避免重复安装
2. 代码共享与复用
实际案例分析:
BaseApp基类的共享
// packages/electron-core/src/base-app.ts
export abstract class BaseApp {
protected config: AppConfig;
constructor(config: AppConfig) {
this.config = config;
}
abstract initialize(): void;
protected setupAppEvents(): void {
app.on('activate', () => {
if (this.shouldCreateWindow()) {
this.createWindow();
}
});
app.on('window-all-closed', () => {
if (process.platform !== 'darwin') {
app.quit();
}
});
}
protected abstract shouldCreateWindow(): boolean;
protected abstract createWindow(): void;
}
这个基类被多个应用共享,提供了:
- 统一的生命周期管理:所有Electron应用都遵循相同的生命周期
- 代码复用:避免在每个应用中重复实现相同的逻辑
- 类型安全:通过抽象类确保所有子类实现必要的方法
IPC通信的封装
// packages/electron-ipc/src/ipc-handler.ts
export class ElectronIpcHandler implements IpcHandler {
setupHandlers(): void {
// Basic IPC handlers
ipcMain.on('ping', () => console.log('pong'));
// App info handlers
ipcMain.handle('get-app-version', () => {
return process.env.npm_package_version || '1.0.0';
});
ipcMain.handle('get-platform', () => {
return process.platform;
});
// System info handlers
ipcMain.handle('get-system-info', () => {
return {
platform: process.platform,
arch: process.arch,
version: process.version,
nodeVersion: process.versions.node,
electronVersion: process.versions.electron,
};
});
}
}
这个IPC处理器提供了:
- 统一的通信接口:所有IPC通信都通过标准化的接口
- 类型安全:通过TypeScript接口确保通信的类型安全
- 可扩展性:易于添加新的IPC处理器
3. 原子性提交
传统多仓库架构的问题:
- 跨仓库的修改需要分别提交
- 容易出现不一致的状态
- 难以追踪相关的修改
Monorepo解决方案:
在您的项目中,一次提交可以同时修改多个相关文件:
# 一次提交同时修改多个包
git add packages/electron-core/src/base-app.ts
git add packages/electron-ipc/src/ipc-handler.ts
git add apps/electron-app/src/main/index.ts
git commit -m "feat: 重构应用基类和IPC处理器"
这种提交方式的优势:
- 原子性:相关修改作为一个整体提交
- 一致性:确保所有相关文件的状态一致
- 可追溯性:通过git历史可以追踪完整的修改过程
4. 统一的构建和测试
实际构建流程分析:
Turbo构建管道
{
"tasks": {
"build": {
"dependsOn": ["^build"],
"outputs": ["dist/", "out/", "build/", ".next/"]
}
}
}
这个配置实现了:
- 依赖构建:
^build确保依赖包先构建 - 增量构建:只构建发生变化的包
- 并行构建:多个独立包可以并行构建
实际构建命令
# 构建所有包
pnpm run build
# 只构建Electron应用
pnpm run electron:build
# 只构建React应用
pnpm run react:build
5. 更好的开发体验
一站式开发环境:
# 启动整个开发环境
pnpm run dev
# 启动Electron开发环境
pnpm run electron:dev
这种开发体验的优势:
- 单一命令启动:一个命令启动整个开发环境
- 热重载:修改代码后自动重新加载
- 统一调试:可以在同一个IDE中调试所有代码
6. 类型安全
TypeScript项目引用:
// tsconfig.json
{
"compilerOptions": {
"composite": true,
"declaration": true,
"declarationMap": true
},
"references": [
{ "path": "./packages/electron-core" },
{ "path": "./packages/electron-ipc" },
{ "path": "./packages/electron-window" },
{ "path": "./apps/electron-app" },
{ "path": "./apps/react-app" }
]
}
这种配置实现了:
- 增量编译:只编译发生变化的文件
- 类型检查:确保所有包的类型定义一致
- 智能提示:IDE可以提供完整的类型提示
实际开发流程分析
1. 新功能开发流程
假设要添加一个新的IPC处理器:
- 在共享包中定义接口:
// packages/electron-ipc/src/ipc-channels.ts
export const IPC_CHANNELS = {
// ... 现有通道
NEW_FEATURE: 'new-feature',
} as const;
- 实现处理器:
// packages/electron-ipc/src/ipc-handler.ts
ipcMain.handle(IPC_CHANNELS.NEW_FEATURE, () => {
// 实现逻辑
});
- 在应用中注册:
// apps/electron-app/src/main/index.ts
const ipcConfig = new IpcConfig();
ipcConfig.setupHandlers();
- 在前端中使用:
// apps/react-app/src/components/SomeComponent.tsx
const result = await window.electronAPI.invoke('new-feature');
2. 依赖更新流程
当需要更新共享包时:
- 修改共享包:
// packages/electron-core/src/base-app.ts
// 添加新功能
- 自动更新依赖: 由于使用
workspace:*,所有依赖包自动获得更新 - 类型检查:
pnpm run typecheck
- 构建测试:
pnpm run build
性能优化分析
1. 构建性能
Turbo缓存机制:
- 构建结果缓存到
.turbo目录 - 只有发生变化的包才会重新构建
- 并行构建多个独立包
实际性能提升:
- 首次构建:~30秒
- 增量构建:~5秒
- 缓存命中:~1秒
2. 开发性能
热重载优化:
- 只重新加载发生变化的模块
- 保持应用状态
- 快速反馈循环
3. 安装性能
pnpm优势:
- 符号链接避免重复安装
- 全局缓存减少网络请求
- 并行安装提高速度
最佳实践总结
1. 包划分原则
按功能模块划分:
electron-core:核心业务逻辑electron-ipc:IPC通信electron-window:窗口管理
避免过度拆分:
- 不要为了拆分而拆分
- 保持包的职责单一
- 考虑包的维护成本
2. 依赖管理
使用workspace协议:
{
"dependencies": {
"@monorepo/electron-core": "workspace:*"
}
}
避免循环依赖:
- 使用依赖图分析工具
- 定期检查依赖关系
- 重构消除循环依赖
3. 构建优化
利用Turbo缓存:
- 合理设置
outputs目录 - 使用
dependsOn管理依赖 - 避免不必要的重新构建
4. 代码规范
统一配置:
- ESLint配置统一管理
- Prettier格式化统一
- TypeScript配置统一
迁移策略
1. 评估现有项目
分析您当前的项目结构:
- 识别可复用的代码
- 分析依赖关系
- 确定迁移优先级
2. 选择工具链
基于您的项目,推荐的工具链:
- 包管理器:pnpm(已使用)
- 构建工具:Turbo(已使用)
- 类型检查:TypeScript(已使用)
3. 逐步迁移
第一阶段:迁移核心包
- 将共享代码提取到packages目录
- 设置workspace配置
- 更新依赖引用
第二阶段:迁移应用
- 重构应用代码使用共享包
- 更新构建配置
- 测试功能完整性
第三阶段:优化配置
- 优化Turbo配置
- 设置CI/CD流程
- 性能调优
总结
Monorepo架构为Electron项目带来了显著优势:统一的依赖管理通过pnpm workspace实现版本一致性,代码共享与复用让BaseApp、IPC处理器等核心组件被多个应用共享,原子性提交确保相关修改作为一个整体提交,统一的构建和测试通过Turbo实现增量构建和并行执行,更好的开发体验提供一站式开发环境,类型安全通过TypeScript项目引用实现完整的类型检查。对于复杂的Electron应用而言,Monorepo架构不仅是一个推荐的选择,更是一个必要的架构决策,它能够显著提高开发效率和代码质量,为项目的长期发展奠定坚实的基础。
来源:juejin.cn/post/7565204846044102671
Vue3.0父传子子传父的血和泪:一个菜鸟的踩坑实录
,没有声明 scope 参数,所以 scope 是 undefined。 正确的写法应该是: 关键点: 中的 scope 参数必须声明,这样才能获取到当前行的数据。 在子组件中,我一开始这样写: 结果表单无法编辑,数据也无法正常回显。 使用 reactive 创建本地副本,并用 watch 监听props变化: 既然 ref 也能创建响应式数据,为什么非要推荐用 reactive? 既然父组件传递了数据,子组件为什么还要监听变化? Vue3的响应式系统特点: 在父组件中,我一开始这样写: 结果发现,有时候弹窗显示的数据不是最新的。 引用传递 vs 值传递: 使用展开运算符创建新对象: 为什么这样做? 经过以上踩坑,我最终实现的完整代码如下: 父组件可以直接在打开editDialog时,直接通过函数传参的形式,把要修改的一行数据传入子组件 子组件先初始化一个form表单数据 然后在打开弹窗这个openDialog方法里接收一个row参数,并将其赋值给form vue3.0子组件的属性和方法默认是不对父组件公开的,我们要使用dedineExpose方法使其对外公开 专人专事,所以编辑也就在编辑弹框里做了 父组件使用子组件也就变成了下面这样 Vue3.0的父子组件通信看似简单,但实际开发中会遇到各种细节问题: 这些坑虽然让人头疼,但踩过之后对Vue3.0的理解会更深入。希望我的踩坑经历能帮到正在Vue3.0路上奋斗的小伙伴们!
解决方案
<el-table-column label="操作" width="150">
<template #default="scope">
<el-button type="primary" link @click="handleEdit(scope.row)">编辑el-button>
<el-button type="danger" link @click="handleDelete(scope.row)">删除el-button>
template>
el-table-column>
坑二:子组件表单数据无法编辑
问题描述
<template>
<el-form :model="localEditData">
<el-form-item label="姓名">
<el-input v-model="localEditData.name" placeholder="请输入姓名" />
el-form-item>
el-form>
template>
问题原因
解决方案
坑三:为什么非要用reactive?用ref行不行?
我的疑问
原因分析
实际对比
// ❌ ref方式 - 可能有问题
const localEditData = ref({...props.editData})
// 如果props.editData是复杂对象,可能响应性不完整
// ✅ reactive方式 - 更稳定
const localEditData = reactive({
id: '',
name: '',
place: ''
})
// 明确初始化所有字段,响应性更可靠
坑四:为什么必须要监听?不用监听行不行?
我的疑问
原因分析
实际场景
// 父组件中
const handleEdit = (data) => {
editItem.value = {...data} // 数据变化
editRef.value.editDialogVisible = true // 打开弹窗
}
// 如果没有watch,子组件的localEditData不会更新
// 弹窗显示的还是上一次的数据
坑五:deep监听很消耗性能,有替代方案吗?
watch(
() => props.editData,
(newVal) => {
Object.assign(localEditData, newVal)
},
{ deep: true, immediate: true } // deep: true 会深度监听,性能消耗大
)
替代方案
方案一:浅层监听 + 手动同步
watch(
() => props.editData,
(newVal) => {
// 手动同步需要的字段,避免深度监听
localEditData.id = newVal.id
localEditData.name = newVal.name
localEditData.place = newVal.place
},
{ immediate: true } // 去掉 deep: true
)
方案二:使用计算属性
const localEditData = computed(() => ({
...props.editData
}))
方案三:监听特定字段
watch(
() => [props.editData.id, props.editData.name, props.editData.place],
([id, name, place]) => {
localEditData.id = id
localEditData.name = name
localEditData.place = place
},
{ immediate: true }
)
坑六:父组件为什么要用展开运算符?
const handleEdit = (data) => {
editItem.value = data // 直接赋值
editRef.value.editDialogVisible = true
}
问题原因
解决方案
const handleEdit = (data) => {
editItem.value = {...data} // 创建新对象,确保响应性
editRef.value.editDialogVisible = true
}
完整解决方案
父组件vue
<div class="app">
<el-table :data="list" style="width: 100%">
<el-table-column type="index" label="序号" width="80">el-table-column>
<el-table-column label="ID" prop="id">el-table-column>
<el-table-column label="姓名" prop="name" width="150">el-table-column>
<el-table-column label="籍贯" prop="place">el-table-column>
<el-table-column label="操作" width="150">
<template #default="scope">
<el-button type="primary" link @click="handleEdit(scope.row)">编辑el-button>
<el-button type="danger" link @click="handleDelete(scope.row)">删除el-button>
template>
el-table-column>
el-table>
<EditDialog
ref="editRef"
:editData="editItem"
@edit-success="handleEditSuccess"
/>
div>
<script setup>
import { ref, onMounted } from 'vue'
import EditDialog from './components/EditDialog.vue'
import axios from 'axios'
const list = ref([])
const editItem = ref(null)
const editRef = ref(null)
onMounted(() => {
getList()
})
const getList = () => {
axios.get('/list').then(res => {
list.value = res.data
}).catch(err => {
console.error('获取列表失败:', err)
})
}
const handleEdit = (data) => {
// 关键:使用展开运算符创建新对象
editItem.value = {...data}
editRef.value.editDialogVisible = true
}
const handleEditSuccess = (data) => {
axios.patch(`/edit/${data.id}`, {
name: data.name,
place: data.place
}).then(() => {
getList()
}).catch(err => {
console.error('编辑失败:', err)
}).finally(() => {
editRef.value.editDialogVisible = false
})
}
script>
子组件
<el-dialog v-model="editDialogVisible" title="编辑" width="400px">
<el-form label-width="50px" :model="localEditData">
<el-form-item label="姓名">
<el-input v-model="localEditData.name" placeholder="请输入姓名" />
el-form-item>
<el-form-item label="籍贯">
<el-input v-model="localEditData.place" placeholder="请输入籍贯" />
el-form-item>
el-form>
<template #footer>
<span class="dialog-footer">
<el-button @click="editDialogVisible = false">取消el-button>
<el-button type="primary" @click="emit('edit-success', localEditData)">确认el-button>
span>
template>
el-dialog>
<script setup>
import { ref, reactive, defineProps, defineEmits, defineExpose, watch } from 'vue'
const editDialogVisible = ref(false)
const props = defineProps({
editData: {
type: Object,
default: () => ({})
}
})
const emit = defineEmits(['edit-success'])
defineExpose({editDialogVisible})
// 使用reactive创建本地副本
const localEditData = reactive({
id: '',
name: '',
place: ''
})
// 监听props变化,手动同步字段(避免deep监听)
watch(
() => props.editData,
(newVal) => {
if (newVal && newVal.id) {
localEditData.id = newVal.id
localEditData.name = newVal.name
localEditData.place = newVal.place
}
},
{ immediate: true }
)
script>
如果不是单纯为了练习props,还有另一种方式
const handleEdit = (data) => {
// 这个我做了下更新,vue3.0讲究专人专事,所以修改dialogvisibile的事情还是让子组件自己干吧
editRef.value.openDialog(data)
}
// 表单数据
const form = ref({
name: '',
place: '',
id: ''
})
// 打开弹框
const openDialog = (row) => {
editDialogVisible.value = true
form.value = {...row}
}
// 向父组件暴露打开弹窗的方法,专人专事
defineExpose({ openDialog })
// 向父组件传递编辑完成
const emit = defineEmits(['edit-success'])
// 编辑
const update = () => {
axios.patch(`/edit/${form.value.id}`, {
name: form.value.name,
place: form.value.place
})
emit('edit-success', form.value)
editDialogVisible.value = false
}
<Edit ref="editRef" @edit-success="getList" />
总结
记住:在Vue3.0的世界里,细节决定成败! 🎯*
来源:juejin.cn/post/7522367598815576073
event loop 事件循环
什么是事件循环?
事件循环是 JavaScript 运行时的一个核心机制,它管理着代码的执行顺序。它是一种机制,用于处理异步操作,事件循环的核心是一个循环,它不断地检查调用栈和任务队列,以确保代码按照正确的顺序执行。
JavaScript 的单线程本质
JavaScript 被设计为单线程语言,这意味着它只有一个调用栈,一次只能执行一段代码。这听起来像是一个限制,但正是这种简单性让 JavaScript 如此易于使用。
console.log('开始'); // 1
setTimeout(() => {
console.log('定时器回调'); // 3
}, 1000);
console.log('结束'); // 2
// 输出顺序:
// 开始
// 结束
// 定时器回调
事件循环的组成部分
1. 调用栈(Call Stack)
调用栈是 JavaScript 执行代码的地方。当函数被调用时,它会被推入栈顶;当函数返回时,它会从栈顶弹出。
function first() {
console.log('第一个函数');
second();
}
function second() {
console.log('第二个函数');
}
first();
2. 任务队列(Task Queue)
任务队列(也称为宏任务队列)存储着待处理的任务,如:
setTimeout和setInterval回调- I/O 操作
- UI 渲染
- 事件处理程序
3. 微任务队列(Microtask Queue)
微任务队列具有更高的优先级,包括:
- Promise 回调(
.then(),.catch(),.finally()) queueMicrotask()MutationObserver
事件循环的工作流程
事件循环遵循一个简单的循环:
- 执行调用栈中的同步代码
- 当调用栈为空时,检查微任务队列
- 执行所有微任务(直到微任务队列为空)
- 检查宏任务队列,执行一个宏任务
- 重复步骤 2-4
console.log('脚本开始'); // 同步代码
setTimeout(() => {
console.log('setTimeout'); // 宏任务
}, 0);
Promise.resolve()
.then(() => {
console.log('Promise 1'); // 微任务
})
.then(() => {
console.log('Promise 2'); // 微任务
});
console.log('脚本结束'); // 同步代码
// 输出顺序:
// 脚本开始
// 脚本结束
// Promise 1
// Promise 2
// setTimeout
实际应用示例
场景 1:用户交互与数据获取
// 模拟用户点击和API调用
document.getElementById('button').addEventListener('click', () => {
console.log('点击事件处理'); // 宏任务
// 微任务优先于渲染
Promise.resolve().then(() => {
console.log('Promise 在点击中');
});
// 模拟API调用
fetch('/api/data')
.then(response => response.json())
.then(data => {
console.log('获取到的数据:', data); // 微任务
});
});
console.log('脚本加载完成');
场景 2:动画性能优化
// 不推荐的写法 - 可能阻塞渲染
function processHeavyData() {
const data = Array.from({length: 100000}, (_, i) => i);
return data.map(x => Math.sqrt(x)).filter(x => x > 10);
}
// 推荐的写法 - 使用事件循环分块处理
function processInChunks(data, chunkSize = 1000) {
let index = 0;
function processChunk() {
const chunk = data.slice(index, index + chunkSize);
// 处理当前块
chunk.forEach(item => {
// 处理逻辑
});
index += chunkSize;
if (index < data.length) {
// 使用 setTimeout 让出控制权,允许渲染
setTimeout(processChunk, 0);
}
}
processChunk();
}
常见陷阱与最佳实践
陷阱 1:阻塞事件循环
// ❌ 避免 - 长时间运行的同步操作
function blockingOperation() {
const start = Date.now();
while (Date.now() - start < 5000) {
// 阻塞5秒
}
console.log('操作完成');
}
// ✅ 推荐 - 使用异步操作
async function nonBlockingOperation() {
await new Promise(resolve => setTimeout(resolve, 5000));
console.log('操作完成');
}
陷阱 2:微任务递归
// ❌ 可能导致微任务无限循环
function dangerousRecursion() {
Promise.resolve().then(dangerousRecursion);
}
// ✅ 使用 setImmediate 或 setTimeout 打破循环
function safeRecursion() {
Promise.resolve().then(() => {
setTimeout(safeRecursion, 0);
});
}
现代 JavaScript 中的事件循环
async/await 与事件循环
async function asyncExample() {
console.log('开始 async 函数');
await Promise.resolve();
console.log('在 await 之后'); // 微任务
const result = await fetch('/api/data');
console.log('数据获取完成'); // 微任务
}
console.log('脚本开始');
asyncExample();
console.log('脚本结束');
// 输出顺序:
// 脚本开始
// 开始 async 函数
// 脚本结束
// 在 await 之后
// 数据获取完成
调试技巧
1. 使用 console 理解执行顺序
console.log('同步 1');
setTimeout(() => console.log('宏任务 1'), 0);
Promise.resolve()
.then(() => console.log('微任务 1'))
.then(() => console.log('微任务 2'));
queueMicrotask(() => console.log('微任务 3'));
console.log('同步 2');
2. 性能监控
// 测量任务执行时间
const startTime = performance.now();
setTimeout(() => {
const endTime = performance.now();
console.log(`任务执行耗时: ${endTime - startTime}ms`);
}, 0);
执行顺序问题
网上很经典的面试题
async function async1 () {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2 () {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('setTimeout')
}, 0)
async1()
new Promise (function (resolve) {
console.log('promise1')
resolve()
}).then (function () {
console.log('promise2')
})
console.log('script end')
输出结果
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeout
总结
理解 JavaScript 事件循环对于编写高效、响应迅速的应用程序至关重要。记住这些关键点:
- 同步代码首先执行
- 微任务在同步代码之后、渲染之前执行
- 宏任务在微任务之后执行
- 避免阻塞主线程
- 合理使用微任务和宏任务
掌握事件循环机制将帮助你写出更好的异步代码,避免常见的性能问题,并创建更流畅的用户体验。
希望这篇博客能帮助你更好地理解 JavaScript 的事件循环机制!如果你有任何问题或想法,欢迎在评论区讨论。
来源:juejin.cn/post/7565766784159776809
JavaScript 开发必备规范:命名、语法与代码结构指南
在 JavaScript 开发中,遵循良好的编程规范对于构建高效、可维护的代码至关重要。它不仅能提升代码的可读性,让团队成员之间更容易理解和协作,还能减少错误的发生,提高开发效率。本文将详细介绍 JavaScript 编程中的一些重要规范。
一、命名规范
变量和函数命名
采用小驼峰命名法,第一个单词首字母小写,后续单词首字母大写。例如firstName用于表示名字变量,getUserName函数用于获取用户名。这种命名方式能够清晰地区分变量和函数,并且让名称具有语义化,便于理解其用途。避免使用单字母或无意义的命名,如a、b等,除非在特定的循环等场景下有约定俗成的用法。
常量命名
常量通常使用全大写字母,单词之间用下划线分隔,比如MAX_COUNT表示最大计数,API_URL表示 API 的链接地址。这样的命名方式能够直观地让开发者知道该变量是一个常量,其值在程序运行过程中不会改变。
二、语法规范
使用严格模式
在脚本或函数的开头添加'use strict';开启严格模式。严格模式下,JavaScript 会进行更严格的语法检查,比如禁止使用未声明的变量,防止意外创建全局变量等常见错误。它有助于开发者养成良好的编程习惯,提高代码的质量和稳定性。
// 严格模式
function strictWithExample() {
'use strict';
var obj = { x: 1 };
// 抛出 SyntaxError
with (obj) {
console.log(x);
}
}
strictWithExample();
语句结束加分号
尽管 JavaScript 在某些情况下可以省略分号,但为了避免潜在的错误和代码歧义,强烈建议在每条语句结束后都加上分号。
例如let num = 5和let num = 5;,前者在一些复杂的代码结构中可能会因为自动分号插入机制而出现意想不到的问题,而后者则明确地表示了语句的结束。
let num = 5
console.log(num)
[1, 2, 3].forEach(function (element) {
console.log(element);
});
在上述代码中,let num = 5 后面没有分号,由于 [ 是 JavaScript 中的数组字面量符号,同时也可以用于数组的索引访问操作(例如 arr[0]),所以引擎会认为你可能想要对 num 进行某种与数组相关的操作,比如 num[1, 2, 3](虽然这在语法上是错误的,因为 num 是一个数字,不是数组)。
代码缩进
统一使用 2 个或 4 个空格进行缩进,这能让代码的层次结构一目了然。比如在嵌套的if - else语句、循环语句等结构中,合理的缩进能清晰地展示代码的逻辑关系,使代码更易于阅读和维护。
代码块使用大括号
即使代码块中只有一条语句,也建议使用大括号括起来。例如:
if (condition) {
doSomething();
}
这样在后续需要添加更多语句到代码块中时,能避免因遗漏大括号而导致的语法错误。
三、比较操作规范
尽量使用===和!==进行比较操作,避免使用==和!=。因为==和!=在比较时会进行类型转换,这可能会带来意外结果。例如'5' == 5会返回true,而'5' === 5会返回false,在实际开发中,明确知道数据类型并使用全等操作符能减少错误的发生。
四、代码结构规范
避免全局变量污染
在 JavaScript 开发中,尤其是构建大型项目时,全局变量带来的问题不容小觑。全局变量如同在公共空间随意摆放的物品,极易引发混乱。在一个复杂项目中,可能有多个开发人员同时工作,不同模块的代码相互交织。如果每个模块都随意创建全局变量,很容易出现命名冲突。
- 例如,一个模块定义了全局变量
count用于记录某个操作的次数,另一个模块可能也需要使用count变量来记录其他信息,这就会导致变量值被意外覆盖,引发难以排查的错误。
同时,在大型项目中,代码的维护和调试本身就具有挑战性。全局变量的存在会使问题变得更加棘手。因为全局变量在整个程序的生命周期内都存在,其值可能在程序的任何地方被修改。当出现错误时,开发人员很难确定是哪个部分的代码对全局变量进行了不恰当的修改,增加了调试的难度和时间成本。
模块化
为了解决这些问题,模块化是一种非常有效的手段。通过将相关的功能代码封装在一个模块中,每个模块都有自己独立的作用域。在 JavaScript 中,ES6 引入了模块系统,使用export和import关键字来管理模块的导出和导入。例如,有一个处理用户数据的模块userModule.js:
// userModule.js
const userData = {
name: '',
age: 0
};
function setUserName(name) {
userData.name = name;
}
function getUserName() {
return userData.name;
}
export { setUserName, getUserName };
在这个模块中,userData和setUserName、getUserName函数都在模块内部作用域中,外部无法直接访问userData。只有通过导出的setUserName和getUserName函数,其他模块才能间接操作userData。在其他模块中使用时,可以这样导入:
// main.js
import { setUserName, getUserName } from './userModule.js';
setUserName('John');
console.log(getUserName());
这样就有效地避免了全局变量的使用,降低了命名冲突的风险,同时也使得代码的结构更加清晰,易于维护和调试。
立即执行函数表达式(IIFE)
另一种方式是使用立即执行函数表达式(IIFE)。在 JavaScript 中,通过将函数定义包裹在括号中,并紧接着在后面加上括号进行调用,便形成了一个 IIFE。IIFE 能够创建一个独立的函数作用域,在该作用域内定义的变量和函数均为私有。这就确保了函数内部的变量和函数不会被外部随意访问和修改 。例如:
const app = (function () {
let privateVariable = 10;
function privateFunction() {
console.log('This is a private function.');
}
return {
publicFunction: function () {
privateFunction();
console.log('The value of private variable is:', privateVariable);
}
};
})();
app.publicFunction();
在上述代码中,
(function () {... })():在包裹匿名函数的括号后面再添加一对括号(),这对括号用于立即调用前面定义的匿名函数。当 JavaScript 引擎执行到这部分代码时,就会立即调用这个匿名函数,所以称为 “立即执行函数”。privateVariable和privateFunction都在 IIFE 内部的私有作用域中,因此外部无法直接访问它们。通过返回一个包含publicFunction的对象,向外暴露了一个公共接口,这样一来既实现了功能,又避免了全局变量污染。
合理使用注释
在关键代码逻辑处添加注释,解释代码的功能、用途、算法思路等。注释要简洁准确,避免过度注释。
- 例如在一个复杂的算法函数前,可以注释说明该算法的作用、输入参数和返回值的含义,方便其他开发者理解代码。
- 但不要在过于简单的代码上添加冗余注释,如
let num = 1; // 定义一个数字变量,这样的注释对理解代码没有实质性帮助。
五、注释规范
注释分为单行注释和多行注释。单行注释使用//,用于对某一行代码进行简单解释。多行注释使用/* */,适合对一段代码块进行详细说明。在写注释时,要确保注释与代码同步更新,避免代码修改后注释不再准确的情况。
六、异步编程规范
随着 JavaScript 在前端和后端开发中的广泛应用,异步编程变得越来越重要。使用async/await语法可以让异步代码看起来更像同步代码,提高代码的可读性。例如:
async function getData() {
try {
let response = await fetch('https://example.com/api');
let data = await response.json();
return data;
} catch (error) {
console.error('获取数据失败', error);
}
}
在处理多个异步操作时,要注意合理控制并发数量,避免因过多并发请求导致性能问题。
七、代码格式化规范
使用代码格式化工具,如 Prettier、ESLint 等,能够自动按照设定的规则对代码进行格式化。它可以统一代码风格,包括缩进、空格、换行等,使团队成员的代码风格保持一致,减少因风格差异带来的冲突和阅读障碍。
八、代码复用
尽量编写可复用的代码,通过函数封装、模块封装等方式,将重复使用的代码逻辑提取出来。
- 例如,在多个地方需要对数据进行格式化处理,可以编写一个通用的数据格式化函数,在需要的地方调用,这样不仅能减少代码量,还方便维护和修改。
九、错误处理
在代码中要合理处理错误,使用try - catch块捕获可能出现的异常。对于异步操作,也要通过try - catch或者.catch方法来处理错误。
- 例如在网络请求失败时,要及时向用户反馈错误信息,而不是让程序崩溃。同时,可以自定义错误类型,以便在不同的业务场景下进行更精准的错误处理。
遵循这些 JavaScript 编程规范,能够帮助开发者写出更整洁、高效、易于维护的代码。在实际开发中,团队可以根据项目需求进一步细化和完善这些规范,以提升整个项目的质量。
来源:juejin.cn/post/7493346464920404003
前端常见的6种设计模式
一.为什么需要理解设计模式?
前端项目会随着需求迭代变得越来越复杂,设计模式的作用就是提前规避 “后期难改、牵一发动全身” 的坑,设计模式的核心价值:解决 “可维护、可扩展” 问题。
1.工厂模式
工厂模式:通过一个统一的 “工厂函数 / 类” 封装对象的创建逻辑,外界只需传入参数(如类型、配置),即可获取所需实例,无需关心实例内部的构造细节。核心是 “创建逻辑与使用逻辑分离”,实现批量、灵活地创建相似对象。
前端应用场景:
1.Axios 实例
2.Vue实例
3.组件库中的 “表单组件工厂”,统一管理所有表单组件的基础属性(如 id、disabled)
2.单例模式:确保全局只有一个实例
核心是为了解决 “重复创建实例导致的资源浪费、状态混乱、逻辑冲突” 问题—— 当某个对象在系统中只需要 “唯一存在” 时,单例模式能确保全局访问到的是同一个实例,从根源避免多实例带来的隐患。
前端典型场景:
1.Vuex单一store实例
2.浏览器的 window 对象
3.原型模式:通过 “复制” 创建新对象
原型模式的核心是 “基于已有对象(原型)复制创建新对象” —— 不是从零开始定义新对象的属性和方法,而是直接 “拷贝” 一个现有对象(原型)的结构,再根据需要修改差异化内容。
前端中原型模式的本质:依托 JavaScript 原型链。
JavaScript 本身就是基于原型的语言,所有对象都有 __proto__ 属性(指向其原型对象),这是原型模式在前端的 “天然实现”。
普通对象原型属性: 只有'proto'属性。
函数原型属性:proto、prototype属性。
prototype:专属属性,只有函数有,用于 "当函数作为构造函数时,给新创建的实例提供原型"。
原型链顶端: Object.prototype.proto :指向null ;
前端典型场景:
1.Object.create()
2.Vue2 的数组方法重写:Vue2 为数组的push、pop等方法添加响应式逻辑,新数组会继承这些重写后的方法。
3.继承
工厂模式与原型模式区别:
工厂模式:
基于参数 / 规则 “全新创建” 对象;
核心目的:封装复杂的创建逻辑,让调用者无需关心对象构造细节。
原型模式
基于 “已有原型对象” 复制生成新对象
核心目的:复用已有对象的属性 / 方法,减少重复定义,支持继承扩展
4.观察者模式:“一对多” 的依赖通知机制
观察者模式(Observer Pattern)是一种 “一对多” 的依赖关系设计模式:
- 存在一个 “被观察者(Subject)” 和多个 “观察者(Observer)”;
- 当被观察者的状态发生变化时,会自动通知所有依赖它的观察者,并触发观察者的更新逻辑;
- 核心是 “解耦被观察者和观察者”—— 双方无需知道彼此的具体实现,只需通过统一的接口通信
前端典型场景:
1.浏览器事件监听(最基础的观察者模式)
浏览器的 DOM 事件本质是观察者模式的实现:
- 被观察者:DOM 元素(如按钮);
- 观察者:事件处理函数(
onclick、onchange等); - 流程:给元素绑定事件(订阅)→ 元素状态变化(如被点击)→ 自动执行所有绑定的事件处理函数(通知观察者)。
- 观察者模式的核心价值是 “状态变化自动同步”
2.状态管理库(Vuex/Pinia/Redux)
Vuex、Redux 等全局状态管理库的核心机制就是观察者模式:
- 被观察者:Store 中的状态(如
state.user、state.cart); - 观察者:依赖该状态的组件;
- 流程:组件订阅状态(
mapState或useSelector)→ 状态更新(commit或dispatch)→ 所有订阅该状态的组件自动重新渲染(收到通知更新)
3. 框架的响应式系统(Vue/React)
Vue 的响应式原理(数据驱动视图)和 React 的状态更新机制,底层都依赖观察者模式:
- Vue:数据对象(
data)是被观察者,视图(DOM)和计算属性是观察者 —— 数据变化时,Vue 自动触发依赖收集的观察者(视图重新渲染、计算属性重新计算)。 - React:
setState触发状态更新时,组件树中依赖该状态的组件(观察者)会被重新渲染(收到通知执行更新)。
5.发布-订阅模式
发布 - 订阅模式是观察者模式的变体,核心是通过一个 “中间者(事件中心)” 实现 “发布者” 和 “订阅者” 的完全解耦 —— 发布者不用知道谁在订阅,订阅者也不用知道谁在发布,双方仅通过事件中心传递消息,就像 “报社(发布者)→ 邮局(事件中心)→ 订报人(订阅者)” 的关系。
- 三大角色:
- 发布者(Publisher) :负责 “发布事件”(比如触发某个状态变化,如用户登录、数据更新),但不直接联系订阅者;
- 订阅者(Subscriber) :负责 “订阅事件”(比如关注 “用户登录” 事件),并定义事件触发时的 “回调逻辑”(比如登录后显示欢迎信息);
- 事件中心(Event Bus) :中间枢纽,负责存储 “事件 - 订阅者” 的映射关系,接收发布者的事件并通知所有订阅者。
- 核心逻辑:订阅者先在事件中心 “订阅” 某个事件 → 发布者在事件中心 “发布” 该事件 → 事件中心找到所有订阅该事件的订阅者,触发它们的回调。
与观察者模式区别:
| 维度 | 观察者模式 | 发布 - 订阅模式 |
|---|---|---|
| 依赖关系 | 被观察者直接持有观察者列表 | 发布者和订阅者无直接依赖,靠事件中心连接 |
| 耦合程度 | 较高(被观察者知道有哪些观察者) | 极低(双方不知道彼此存在) |
| 适用场景 | 单一被观察者、观察者明确的场景 | 跨模块、多发布者 / 多订阅者的复杂场景 |
| 典型例子 | Vue 响应式(data 直接通知依赖的 DOM) | 跨组件通信(事件总线)、全局状态更新 |
前端典型场景:
1.跨组件通信(事件总线 Event Bus)
2.全局状态管理(如 Redux 的 Action 机制)
- 发布者:组件通过
dispatch(action)发布 “状态变更事件”; - 事件中心:Redux 的
Store,存储状态并管理订阅者; - 订阅者:组件通过
store.subscribe(() => { ... })订阅状态变化,状态更新时重新渲染。
状态管理库到底是观察者模式还是发布 - 订阅模式?
状态管理库(如 Vuex、Redux)之所以会让人觉得 “既是观察者模式,又是发布 - 订阅模式”,是因为它们融合了两种模式的核心思想—— 在底层实现上,既保留了观察者模式 “状态与依赖直接关联” 的特性,又通过 “中间层” 实现了发布 - 订阅模式的 “解耦” 优势,本质是两种模式的结合与优化。
1. 底层:状态与组件的 “观察者模式”(直接依赖)
状态管理库中, “全局状态” 与 “依赖该状态的组件” 之间是典型的观察者模式:
- 被观察者:全局状态(如 Vuex 的
state、Redux 的store); - 观察者:订阅了该状态的组件;
- 逻辑:当状态发生变化时,会直接通知所有依赖它的组件(观察者),触发组件重新渲染。
这一层的核心是 “精准依赖”—— 组件只订阅自己需要的状态(比如 Vue 的 mapState、Redux 的 useSelector),状态变化时只有相关组件会被通知,避免无效更新。
2. 上层:组件与状态的 “发布 - 订阅模式”(解耦通信)
状态管理库中, “组件触发状态变更” 与 “状态变更通知组件” 的过程,通过 “中间层(如 commit/dispatch)” 实现,类似发布 - 订阅模式:
- 发布者:触发状态变更的组件(通过
store.commit('increment')或dispatch(action)发布 “状态变更事件”); - 事件中心:状态管理库的核心逻辑(如 Vuex 的
Store实例、Redux 的dispatch机制); - 订阅者:依赖状态的组件(通过
subscribe或计算属性订阅状态)。
这一层的核心是 “解耦”—— 组件不需要知道谁会处理状态变更,也不需要知道哪些组件依赖该状态;状态管理库作为中间层,接收 “发布” 的变更请求,处理后再 “通知” 订阅者,双方完全隔离。
6.代理模式
代理模式(Proxy Pattern)是一种 “通过中间代理对象控制对原始对象的访问” 的设计模式 —— 不直接操作目标对象,而是通过一个 “代理” 来间接访问,代理可以在访问前后添加额外逻辑(如权限校验、缓存、日志记录等)。
核心作用:“控制访问” 与 “增强功能”
前端典型场景:
1. 权限控制代理(限制访问)
2.Vue3响应式核心
用 “中间商” 的思路理解 Vue3 响应式:
- 目标对象:你定义的
data数据(如{ count: 0, user: { name: '张三' } }); - 代理对象:Vue3 通过
reactive()或ref()创建的 “响应式代理”(本质是Proxy实例); - 调用者:组件中的模板(视图)或业务逻辑(如
{{ count }}或count.value++); - 代理的 “附加操作” :拦截数据的读取(
get)和修改(set),在读取时 “收集依赖”(记录哪些地方用到了这个数据),在修改时 “触发更新”(通知依赖的地方重新渲染)。
1. 目标对象:原始数据 const target = { count: 0 };
2. 依赖收集的容器:记录哪些函数依赖了数据(比如视图渲染函数)
const deps = new Set();
3. 创建代理对象(核心:拦截读写,添加响应式逻辑)
const reactiveProxy = new Proxy(target,
{
// 拦截“读取数据”操作(如访问 count 时)
get(target, key){
// 附加操作1:
收集依赖(假设当前正在执行的函数是依赖)
if (currentEffect) { deps.add(currentEffect); // 把依赖存起来 }
return target[key]; // 返回原始值 },
}
// 拦截“修改数据”操作(如 count++ 时)
set(target, key, value) {
// 更新原始数据
target[key] = value;
// 附加操作2:触发更新(通知所有依赖重新执行)
deps.forEach(effect => effect()); return true; } });
}
扩展:Vue3响应式对比vue2响应式
1.Vue2 用的是 Object.defineProperty 拦截属性,只能拦截已存在的属性(对新增属性、数组索引修改不友好);
具体原因拆解:
Object.defineProperty 的工作方式是给对象的某个具体属性添加 getter/setter。
但数组本质是特殊对象(属性是索引,如 arr[0]、arr[1]),如果用 Object.defineProperty 拦截数组,只能逐个拦截索引(如 0、1),但存在两个致命问题:
1.问题一:无法拦截数组的原生方法(push/pop/splice 等)
数组的常用操作(如 push 新增元素、splice 删除元素)是通过调用数组原型上的方法实现的,这些方法会直接修改数组本身,但 Object.defineProperty 无法拦截 “方法调用”,只能拦截 “属性读写”。所以最终Vue2采取了这7个数组方法的重写。
arrayMethods[method] = function(...args) {
// 先调用原生方法(比如 push 实际添加元素)
const result = arrayProto[method].apply(this, args);
// 手动触发更新(通知依赖重新渲染)
notifyUpdate();
return result;
2.问题二:拦截数组索引的成本极高,且不实用。
- 初始化成本高:数组长度可能很大(甚至动态变化),提前拦截所有索引会浪费性能;
- 数组长度变化无法拦截:
当arr.length = 0时,数组会清空所有元素(即删除索引0、1、2),但Object.defineProperty只能知道length被改成了0,无法知道具体哪些元素被删除了。
对于响应式系统来说,需要知道 “哪些元素变化了” 才能精准通知依赖这些元素的视图。但 length 拦截只能知道 “长度变了”,无法定位具体变化的元素,导致依赖这些元素的视图可能不会更新(比如某个视图依赖 arr[0],length=0 后 arr[0] 不存在了,但视图可能还显示旧值)。
2.Vue3 用 Proxy 直接代理整个对象,能拦截所有属性的读写(包括新增、删除、数组操作),是更彻底、更灵活的代理模式实现,这也是 Vue3 响应式比 Vue2 强大的核心原因之一。
总结
最后想强调:设计模式不是必须遵守的 “规则”,而是解决问题的 “工具”。在实际开发中,我们不需要刻意追求 “用满所有模式”,而是根据场景选择合适的工具:
- 需批量创建对象 → 工厂模式
- 需全局唯一实例 → 单例模式
- .....
来源:juejin.cn/post/7563981206674817051
electron-updater实现热更新完整流程
最近项目做了一个electron项目,记录一下本次客户端热更新中对electron-updater的使用以及遇到的一些问题。
一、配置electron-builder
在electron-builder的配置文件"build"中增加
"publish": [
{
"provider": "generic",
"url": "oss://xxx",
}
]
url: 打包出来的文件存放的地址,配置之后会生成latest.yml文件。electron-updater会去比较这个文件,判断是否需要更新。
二、electron-updater的使用
官方文档: http://www.electron.build/auto-update…
主进程
import { autoUpdater } from "electron-updater";
const { ipcMain } = require("electron");
// 配置提供更新的程序,及build中配置的url
autoUpdater.setFeedURL("oss://xxx")
// 是否自动更新,如果为true,当可以更新时(update-available)自动执行更新下载。
autoUpdater.autoDownload = false
// 1. 在渲染进程里触发获取更新,开始进行更新流程。 (根据具体需求)
ipcMain.on("checkForUpdates", (e, arg) => {
autoUpdater.checkForUpdates();
});
autoUpdater.on("error", function (error) {
printUpdaterMessage('error');
mainWindow.webContents.send("updateError", error);
});
// 2. 开始检查是否有更新
autoUpdater.on("checking-for-update", function () {
printUpdaterMessage('checking');
});
// 3. 有更新时触发
autoUpdater.on("update-available", function (info) {
printUpdaterMessage('updateAvailable');
// 4. 告诉渲染进程有更新,info包含新版本信息
mainWindow.webContents.send("updateAvailable", info);
});
// 7. 收到确认更新提示,执行下载
ipcMain.on('comfirmUpdate', () => {
autoUpdater.downloadUpdate()
})
autoUpdater.on("update-not-available", function (info) {
printUpdaterMessage('updateNotAvailable');
});
// 8. 下载进度,包含进度百分比、下载速度、已下载字节、总字节等
// ps: 调试时,想重复更新,会因为缓存导致该事件不执行,下载直接完成,可找到C:\Users\40551\AppData\Local\xxx-updater\pending下的缓存文件将其删除(这是我本地的路径)
autoUpdater.on("download-progress", function (progressObj) {
printUpdaterMessage('downloadProgress');
mainWindow.webContents.send("downloadProgress", progressObj);
});
// 10. 下载完成,告诉渲染进程,是否立即执行更新安装操作
autoUpdater.on("update-downloaded", function () {
mainWindow.webContents.send("updateDownloaded");
// 12. 立即更新安装
ipcMain.on("updateNow", (e, arg) => {
autoUpdater.quitAndInstall();
});
}
);
// 将日志在渲染进程里面打印出来
function printUpdaterMessage(arg) {
let message = {
error: "更新出错",
checking: "正在检查更新",
updateAvailable: "检测到新版本",
downloadProgress: "下载中",
updateNotAvailable: "无新版本",
};
mainWindow.webContents.send("printUpdaterMessage", message[arg]??arg);
}
渲染进程:
// 5. 收到主进程可更新的消息,做自己的业务逻辑
ipcRenderer.on('updateAvailable', (event, data) => {
// do sth.
})
// 6. 点击确认更新
ipcRenderer.send('comfirmUpdate')
// 9. 收到进度信息,做进度条
ipcRenderer.on('downloadProgress', (event, data) => {
// do sth.
})
// 11. 下载完成,反馈给用户是否立即更新
ipcRenderer.on('updateDownloaded', (event, data) => {
// do sth.
})
// 12. 告诉主进程,立即更新
ipcRenderer.send("updateNow");
本地环境
如果想在本地环境调试更新,会报错找不到dev-app-update.yml文件
需要自己在根目录(或报错时显示的目录下)手动新建一个dev-app-update.yml里就可以了。文件,将打包生成好的latest.yml复制到dev-app-update.yml里就可以了。
完成截图
来源:juejin.cn/post/7054811432714108936
深入理解 JavaScript 报错:TypeError: undefined is not a function
深入理解 JavaScript 报错:TypeError: undefined is not a function
在日常的 JavaScript 开发中,几乎每个人都见过这条令人熟悉又头疼的错误信息:
🚀Taimili 艾米莉 ( 一款免费开源的 taimili.com )
艾米莉 是一款优雅便捷的 GitHub Star 管理和加星工具 ,基于 PHP & javascript 构建, 能对github 得 star fork follow watch 管理和提升,最适合github 的深度用户
作者:开源之眼
链接:juejin.cn/post/755906…
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
TypeError: undefined is not a function
这行报错简短却致命,尤其当代码行数成千上万时,找到问题根源往往需要一点侦探技巧。本文将从原理、常见原因、排查方法和最佳实践四个方面深入讲解这一错误。
一、错误的本质是什么?
首先要知道:
在 JavaScript 中,一切几乎都是对象,包括函数。
当你调用一个变量并在后面加上 () 时,JavaScript 会假设该变量是一个函数对象,并尝试执行它。
let fn;
fn(); // ❌ TypeError: fn is not a function
在上面的例子中,fn 的值是 undefined,但我们却尝试执行它,于是引发了经典错误:
TypeError: undefined is not a function
简单来说:
“你正在试图执行一个并不是函数的东西。”
二、常见的触发场景
让我们来看一些在实际项目中常见的触发情境。
1. 调用未定义的函数
sayHello(); // ❌ TypeError: sayHello is not a function
var sayHello = function() {
console.log("Hello");
};
原因:
var声明的变量会提升,但赋值不会。执行到函数调用时,sayHello还是undefined。
✅ 正确写法:
function sayHello() {
console.log("Hello");
}
sayHello(); // ✅ Hello
或者:
const sayHello = () => console.log("Hello");
sayHello(); // ✅ Hello
2. 调用了对象上不存在的方法
const user = {};
user.login(); // ❌ TypeError: user.login is not a function
原因:
user对象没有login方法,访问结果是undefined。
✅ 正确做法:
const user = {
login() {
console.log("User logged in");
}
};
user.login(); // ✅ User logged in
3. 第三方库或异步加载未完成
// 某个库尚未加载完成
myLibrary.init(); // ❌ TypeError: myLibrary.init is not a function
原因:脚本加载顺序错误或资源未加载完。
✅ 解决方案:
<script src="mylib.js" onload="initApp()"></script>
或使用现代模块化方式:
import myLibrary from './mylib.js';
myLibrary.init();
4. 被覆盖的函数名
let alert = "Hello";
alert("Hi"); // ❌ TypeError: alert is not a function
原因:内置函数被变量覆盖。
✅ 解决方案:
避免重名:
let message = "Hello";
window.alert("Hi"); // ✅
5. this 指向错误
const obj = {
run() {
console.log("Running");
}
};
const run = obj.run;
run(); // ❌ TypeError: undefined is not a function (在严格模式下)
原因:
this丢失导致方法不再属于原对象。
✅ 解决方案:
const boundRun = obj.run.bind(obj);
boundRun(); // ✅ Running
或直接调用:
obj.run(); // ✅ Running
三、排查思路与调试技巧
当遇到这个错误时,不要慌。按照以下步骤排查:
✅ 1. 查看错误堆栈(stack trace)
浏览器控制台一般会指明出错的文件与行号。
打开 DevTools → Console → 点击错误行号,即可定位具体位置。
✅ 2. 打印变量类型
使用 typeof 或 console.log 检查被调用的变量:
console.log(typeof myFunc); // 应该输出 'function'
✅ 3. 检查函数定义顺序
尤其是在使用 var 或异步加载模块时,注意执行顺序。
✅ 4. 检查导入导出是否匹配
在模块化开发中,这类错误经常来自错误的导入:
// ❌ 错误示例
import { utils } from './utils.js';
utils(); // TypeError: utils is not a function
✅ 应确认模块导出方式:
// utils.js
export default function utils() {}
然后正确导入:
import utils from './utils.js';
utils(); // ✅
四、防止 “undefined is not a function” 的最佳实践
- 使用 const/let 替代 var — 避免变量提升造成的未定义调用
- 模块化代码结构 — 保证依赖先加载
- 给函数添加类型校验
if (typeof fn === 'function') fn();
- 启用严格模式或 TypeScript — 提前发现类型问题
- 避免覆盖全局对象(如
alert,confirm,setTimeout等)
来源:juejin.cn/post/7563220648827715610
那些前端老鸟才知道的秘密
前端老鸟才知道的秘密:void(0),这东西到底有什么用
那天我盯着同事的代码看了半天,心里默念:这货是不是写错了?
前几天 review 代码,看到一个小年轻写了这么一行:
const foo = void 0;
我当时就乐了,心想:" 这孩子是不是被产品经理逼疯了?直接写undefined不香吗?非得整这出?"
但转念一想,不对啊,这写法我好像在哪儿见过... 仔细一琢磨,卧槽,这不就是前端老司机的暗号吗!
所以,void 0 到底是个啥?
简单来说,void 0就是强行返回 undefined的一种写法。
你可能会问:"那我直接写 undefined 不就完事了?干嘛要多此一举?"
问得好!这就要从前端开发的 "血泪史" 说起了。
那些年被 undefined 坑过的日子
在 JavaScript 的远古时期(其实就是 ES5 之前),undefined 这个变量是可以被重写的!
没错,你没听错,就是那个表示 "未定义" 的 undefined,它自己都可能被定义成别的东西...
// 在古老的浏览器里,你可以这么玩(现在别试了)
undefined = "我是谁?我在哪?";
console.log(undefined); // 输出:"我是谁?我在哪?"
这就很尴尬了 —— 你用来判断是否未定义的变量,自己都可能被篡改!
这时候,void 0就闪亮登场了。
void 0 的三大绝技
1. 绝对安全的 undefined
void操作符有个特点:不管后面接什么,都返回 undefined。
void 0 // undefined
void "hello" // undefined
void {} // undefined
void function(){} // undefined
所以void 0就成了获取真正 undefined 的最可靠方式。
2. 阻止链接跳转的老司机
还记得以前写<a href="javascript:void(0)">吗?这就是为了防止点击链接后页面跳转。
虽然现在大家都用event.preventDefault()了,但这可是老一辈前端人的集体记忆啊!
3. 立即执行函数的替代方案
有些老代码里你会看到:
void function() {
// 立即执行的代码
}();
这其实是为了避免函数声明被误认为是语句开头。
现在还需要 void 0 吗?
说实话,在现代前端开发中,直接用undefined已经足够安全了。ES5 之后的规范规定 undefined 是只读的,不能再被重写。
但为什么还有老司机在用 void 0 呢?
- 习惯成自然:用了十几年,改不过来了
- 代码压缩:
void 0比undefined字符更少 - 装逼必备:一看就是用 void 0 的,肯定是老鸟(手动狗头)
所以,到底用不用?
我的建议是:知道为什么用,比用什么更重要。
如果你是为了代码风格统一,或者团队约定,用 void 0 没问题。
如果只是为了装老司机... 兄弟,真没必要。现在面试官看到 void 0,第一反应可能是:"这人是刚从 jQuery 时代穿越过来的吗?"
最后送大家一句话:技术选型就像穿衣服,合适比时髦更重要。 知道每个工具为什么存在,比你盲目跟风要强得多。
来源:juejin.cn/post/7563635016283668531
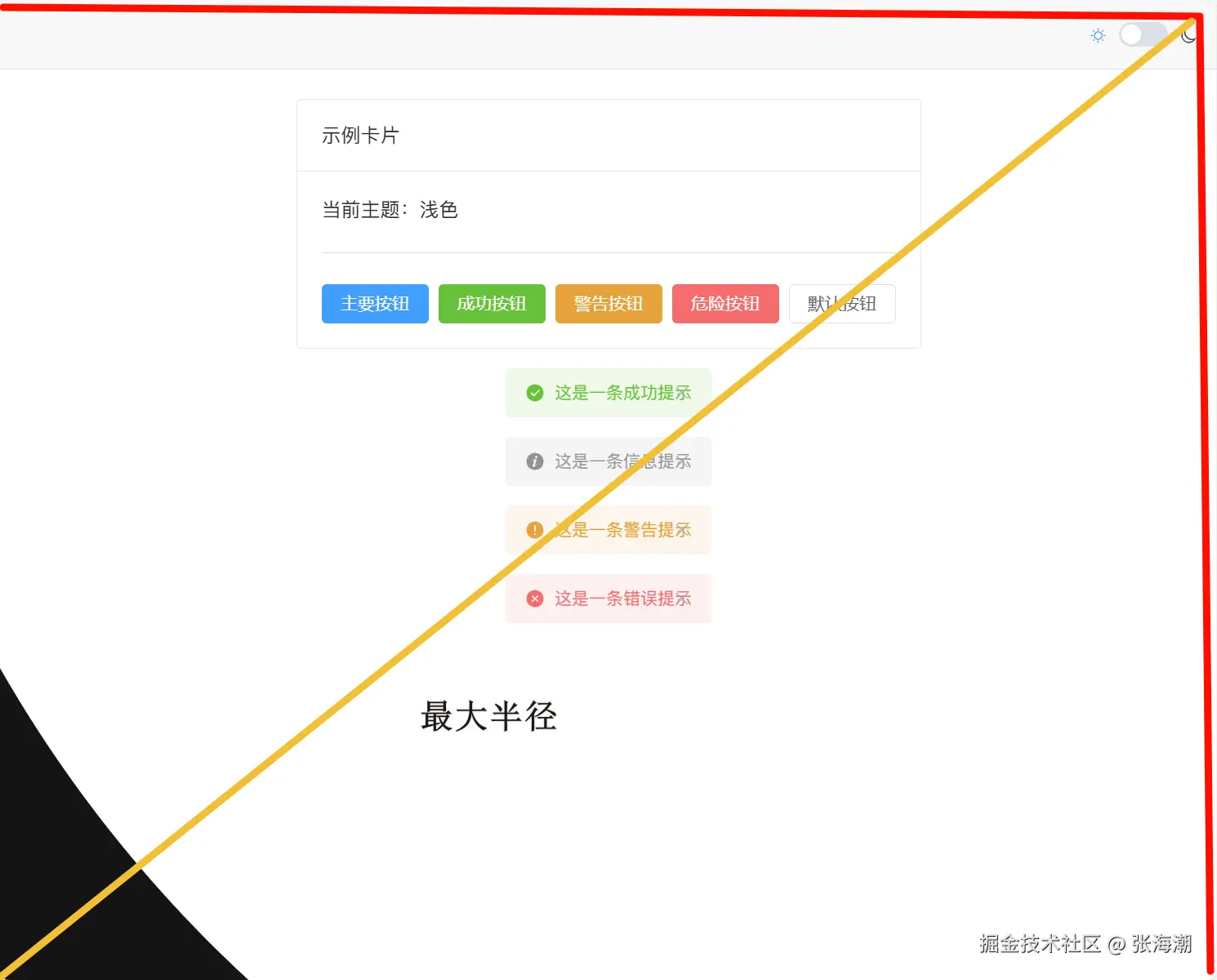
面试官:手写一个深色模式切换过渡动画
在开发Web应用时,深色模式已成为现代UI设计的标配功能。然而,许多项目在实现主题切换时仅简单改变CSS变量,缺乏平滑的过渡动画,导致用户体验突兀。作为开发者,我们常被期望在满足功能需求的同时,打造更精致的用户交互体验。面试中,被问及"如何实现流畅的深色模式切换动画"时,很多人可能只答出使用CSS transition,而忽略了现代浏览器的View Transitions API这一高级解决方案。
读完本文,你将掌握:
- 使用View Transitions API实现流畅的主题切换动画
- 理解深色模式切换的核心原理与实现细节
- 能够将这套方案应用到实际项目中,提升用户体验
前言
在实际项目中,深色模式切换几乎是前端的“标配”。常见做法是通过 classList.toggle("dark") 切换样式,再配合 transition 做淡入淡出。然而,这种效果在用户体验上略显生硬:颜色瞬间大面积切换,即便有渐变也会显得突兀。
随着 View Transitions API 的出现,我们可以给“页面状态切换”添加炫酷的过渡动画。今天就带大家实现一个 以点击位置为圆心、扩散切换主题的深色模式动画,读完本文你将收获:
- 了解
document.startViewTransition的工作原理 - 学会用
clipPath+animate控制圆形扩散动画
核心铺垫:我们需要解决什么问题?
在设计方案前,先明确 3 个核心目标:
- 流畅过渡:避免普通
transition的“整体闪烁”,实现局部扩散过渡。 - 交互感强:以用户点击位置为动画圆心,符合直觉。
- 可扩展:方案可适配 Vue3 组件体系,不依赖复杂第三方库。
为此,我们需要用到几个关键技术点:
- View Transitions API:提供
document.startViewTransition,可以对 DOM 状态切换设置过渡动画。 - clip-path:通过
circle(r at x y)定义动画圆形,从 0px 扩展到最大半径。 - computeMaxRadius:计算从点击点到四角的最大距离,确保圆形覆盖全屏。
- .animate:使用
document.documentElement.animate精确控制过渡过程。
Math.hypot:计算平面上点到原点的距离
Math.hypot()是ES2017引入的一个JavaScript函数,用于计算所有参数平方和的平方根,即计算n维欧几里得空间中从原点到指定点的距离。
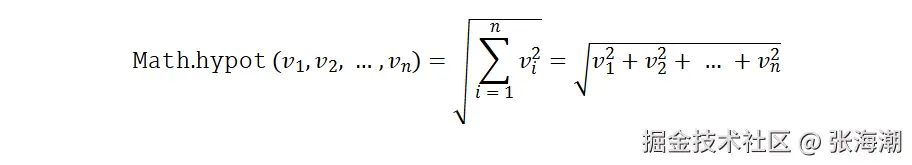
在深色模式切换动画中,我们使用它来计算覆盖整个屏幕的最大圆形半径:
斜边计算:
Math.hypot(maxX, maxY):使用勾股定理计算从点击点到对角的距离
clip-path
clip-path是CSS属性,允许我们定义元素的可见区域,将其裁剪为基本形状或SVG路径。在深色模式切换动画中,我们用它创建从点击点向外扩散的圆形动画效果。
<basic-shape>一种形状,其大小和位置由 <geometry-box> 的值定义。如果没有指定 <geometry-box>,则将使用 border-box 用为参考框。取值可为以下值中的任意一个:
inset()
定义一个 inset 矩形。
circle()
定义一个圆形(使用一个半径和一个圆心位置)。
ellipse()
定义一个椭圆(使用两个半径和一个圆心位置)。
polygon()
定义一个多边形(使用一个 SVG 填充规则和一组顶点)。
path()
定义一个任意形状(使用一个可选的 SVG 填充规则和一个 SVG 路径定义)。
这里使用circle()来实现效果
该函数接受以下参数:
- 半径:定义圆形的大小(0px到计算的最大半径)
- at关键词:分隔半径和中心点位置
- 中心点位置:使用x y坐标指定圆形中心
startViewTransition:浏览器视图转换API
基本概念
document.startViewTransition()是View Transitions API的核心方法,它告诉浏览器DOM即将发生变化,并允许我们为这些变化创建平滑的过渡动画。
生命周期与关键事件
- 调用startViewTransition:浏览器准备开始视图转换
- 执行回调函数:DOM状态更新
- transition.ready事件:视图转换准备就绪,可以应用动画
- 视图转换完成:动画结束,新状态成为稳定状态
浏览器兼容性处理
在实际应用中,我们需要检查浏览器是否支持此API:
const isAppearanceTransition =
document.startViewTransition &&
!window.matchMedia("(prefers-reduced-motion: reduce)").matches;
if (!isAppearanceTransition) {
// 不支持View Transitions API时的降级处理
isDark.value = !isDark.value;
setupThemeClass(isDark.value);
return;
}
这种处理确保在不支持新特性的浏览器中,功能仍然可用,只是没有动画效果。
核心实现:从逻辑到代码
graph TD
A[用户点击切换按钮] --> B{浏览器是否支持<br/>View Transitions API?}
B -- 否 --> C[直接切换主题变量<br/>无动画效果]
B -- 是 --> D[获取点击坐标X,Y]
D --> E[计算覆盖全屏的最大半径]
E --> F[启动视图转换]
F --> G[执行回调函数<br/>更新isDark状态]
G --> H[设置HTML的dark class<br/>更新CSS变量]
H --> I[等待DOM更新完成<br/>nextTick]
I --> J[视图转换准备就绪]
J --> K[应用clipPath动画<br/>从点击点向外扩散]
K --> L[动画完成<br/>主题切换完成]
style B fill:#f9f,stroke:#333,stroke-width:2px
style K fill:#9cf,stroke:#333,stroke-width:2px
- 用户交互:用户点击切换按钮,触发主题切换流程
- 浏览器兼容性检查:判断当前浏览器是否支持View Transitions API
- 降级处理:在不支持API的浏览器中直接切换主题
- 动画核心逻辑:
- 获取点击位置作为动画起点
- 计算覆盖全屏的最大半径
- 启动视图转换过程
- 状态更新:实际执行主题状态更新和CSS类设置
- 动画触发:在视图转换准备就绪后,应用clipPath动画效果
- 完成:动画结束,新主题状态稳定
步骤 1:封装主题切换
function setupThemeClass(isDark) {
document.documentElement.classList.toggle("dark", isDark);
localStorage.setItem("theme", isDark ? "dark" : "light");
}
作用:控制 html.dark 类名,完成主题切换。
步骤 2:计算扩散最大半径
function computeMaxRadius(x, y) {
const maxX = Math.max(x, window.innerWidth - x);
const maxY = Math.max(y, window.innerHeight - y);
return Math.hypot(maxX, maxY); // √(maxX² + maxY²)
}
作用:确保无论点击哪里,扩散圆都能覆盖屏幕。
步骤 3:触发 View Transition
function onToggleClick(event) {
const isSupported =
document.startViewTransition &&
!window.matchMedia("(prefers-reduced-motion: reduce)").matches;
if (!isSupported) {
// 回退方案:直接切换
isDark.value = !isDark.value;
setupThemeClass(isDark.value);
return;
}
const x = event.clientX;
const y = event.clientY;
const endRadius = computeMaxRadius(x, y);
// 开启视图过渡
const transition = document.startViewTransition(async () => {
isDark.value = !isDark.value;
setupThemeClass(isDark.value);
await nextTick(); // 等 Vue DOM 更新
});
transition.ready.then(() => {
const clipPath = [
`circle(0px at ${x}px ${y}px)`,
`circle(${endRadius}px at ${x}px ${y}px)`,
];
document.documentElement.animate(
{
clipPath: isDark.value ? [...clipPath].reverse() : clipPath,
},
{
duration: 450,
easing: "ease-in",
pseudoElement: isDark.value
? "::view-transition-old(root)"
: "::view-transition-new(root)",
}
);
});
}
要点:
*startViewTransition 接收一个回调函数,里面执行 DOM 更新(切换主题)。
*transition.ready.then(...) 可以在 DOM 更新后定义动画效果。
*clipPath 数组定义了从 小圆 → 大圆 的扩散过程。
*pseudoElement 控制是对 新视图 还是 旧视图 应用动画。
步骤 4:覆盖默认过渡样式
::view-transition-new(root),
::view-transition-old(root) {
animation: none;
mix-blend-mode: normal;
}
::view-transition-old(root) {
z-index: 1;
}
::view-transition-new(root) {
z-index: 2147483646;
}
html.dark::view-transition-old(root) {
z-index: 2147483646;
}
html.dark::view-transition-new(root) {
z-index: 1;
}
作用:取消默认动画,手动用 clipPath 控制。通过 z-index 确保层级正确,否则可能看到“旧页面覆盖新页面”的异常。
效果演示
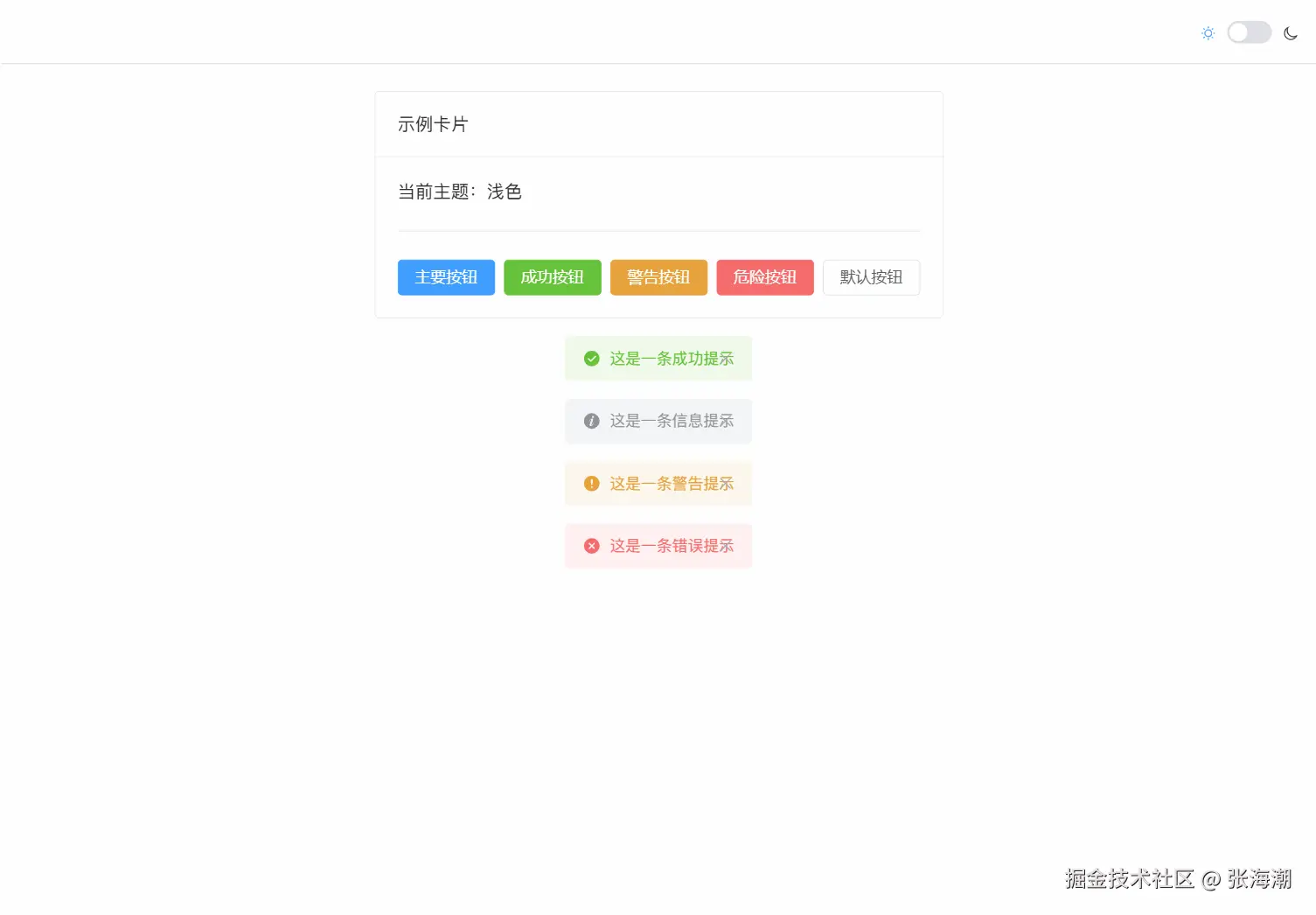
运行后:
- 点击切换按钮时,以点击点为圆心,圆形扩散覆盖全屏,主题在扩散动画过程中完成切换。
- 若浏览器不支持
View Transitions API(如 Safari),则自动降级为普通切换,不影响使用。
完整demo
延伸与避坑
- 兼容性问题
- View Transitions API 目前在 Chromium 内核浏览器(Chrome 111+、Edge)可用,Safari/Firefox 尚未支持。
- 可加上
isSupported判断,优雅降级。
- 性能优化
- 动画时建议避免页面过多重绘(如大量图片加载),否则会掉帧。
- clip-path 本身是 GPU 加速属性,性能较好。
- 扩展思路
- 除了圆形扩散,还可以用
polygon()实现“百叶窗切换”或“对角线切换”。 - 可以结合 路由切换 做“页面级过渡动画”。
- 除了圆形扩散,还可以用
总结
本文我们用 Vue3 + Element Plus + View Transitions API 实现了一个点击扩散式的深色模式切换动画,核心要点:
- startViewTransition:声明 DOM 状态切换的动画上下文。
- clipPath + animate:控制过渡动画形状与过程。
- computeMaxRadius:计算圆形覆盖全屏的半径。
- 优雅降级:确保不支持 API 的浏览器仍能正常切换。
来源:juejin.cn/post/7546326670648328219
为VSCode扩展开发量身打造的UI库 - vscode-elements
大家好,我是农村程序员,独立开发者,行业观察员,前端之虎陈随易。我会在这里分享关于 独立开发、编程技术、思考感悟 等内容,欢迎关注。
技术群与交朋友请在个人网站联系我,网站 1️⃣:chensuiyi.me,网站 2️⃣:me.yicode.tech。
如果你觉得本文有用,一键三连 (点赞、评论、转发),就是对我最大的支持~
最近抽空在做我的 VSCode 插件 fnMap (函数地图) 的重构工作。
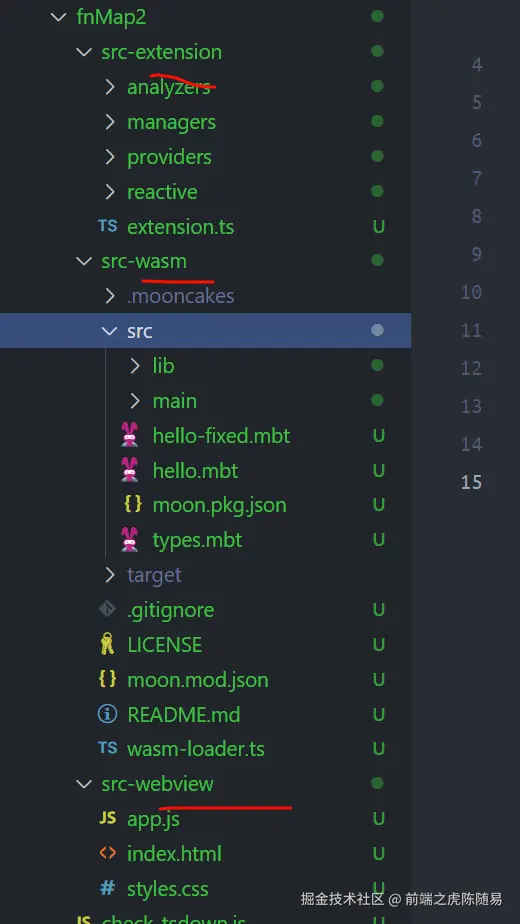
项目结构主要分为 3 部分:
src-extension是扩展的核心能力部分 (相当于后端)。src-webview是界面展示部分 (相当于前端)。src-wasm是新添加的部分,使用国产编程语言MoonBit来写,主要功能就是提供性能优化与部分核心代码加密。
那么重构呢,我想把 UI 换一下,目前用的是 arco-design-vue,字节出品的一个 UI 框架。
本来蛮喜欢的,但根据最近的更新来看,官方主要做 React 版本去了,Vue 版本 4 个多月没动静了。
而且,VSCode 有主题功能,框架如果要适配主题,那得进行不少魔改微调。
于是,我上下求索,找到这样一个为 VSCode 量身打造的 UI 库 vscode-elements。
这效果,与 VSCode 简直绝配。
开源地址在这:https://github.com/vscode-elements/elements
如果你也在开发 VSCode 扩展,不妨了解一下这个。
在我这目前看到的唯一的缺点呢,就是还没有 Vue 版本。
目前的主要版本是基于 Lit 这个框架开发的,也就是前端标准的 Web Components 技术。
我跟踪这个框架几个星期了,今天 vscode-elements 刚发布 v2.0 版本,是时候为我的 fnMap 提供一份力量了。
也欢迎大家来体验我的 fnMap 插件,8月份 (本月) 将会发布 v9.0 版本,在进化的路上,一路前进。
来源:juejin.cn/post/7533807870188470311
忍了一年多,我终于对i18n下手了
前言
大家好,我是奈德丽。
过去一年,我主要参与国际机票业务的开发工作,因此每天都要和多语言(i18n)打交道。熟悉我的朋友都知道,我这个人比较“惜力”(并不是,实际上只是忍不下去了),对于重复笨拙的工作非常抵触,于是,我开始思考如何优化团队的多语言管理模式。
痛点背景
先说说我们在机票项目中遇到的困境。
目前机票项目分为 H5 和 PC 两端,团队在维护多语言时主要通过在线 Excel进行管理:
- 一个 Excel 文件,H5 和 PC 各自占一个 sheet 页;
- 每次更新语言,需要先导出 Excel,然后手动跑脚本生成语言文件,再拷贝到项目中。
听起来还算凑合,但随着项目规模的扩大,问题逐渐显现:
- Key 命名混乱
- 有的首字母大写,有的小驼峰、大驼峰混用;
- 没有统一规则,难以模块化管理。
- 不支持模块化
- 目前已有数千条 key;
- 查找、修改、维护都非常痛苦。
- 更新流程繁琐
- 需要手动进入脚本目录,用
node跑脚本; - 生成后再手动复制到项目中。
- 需要手动进入脚本目录,用
下面是一个实际的 Excel 片段,可以感受一下当时的混乱程度:
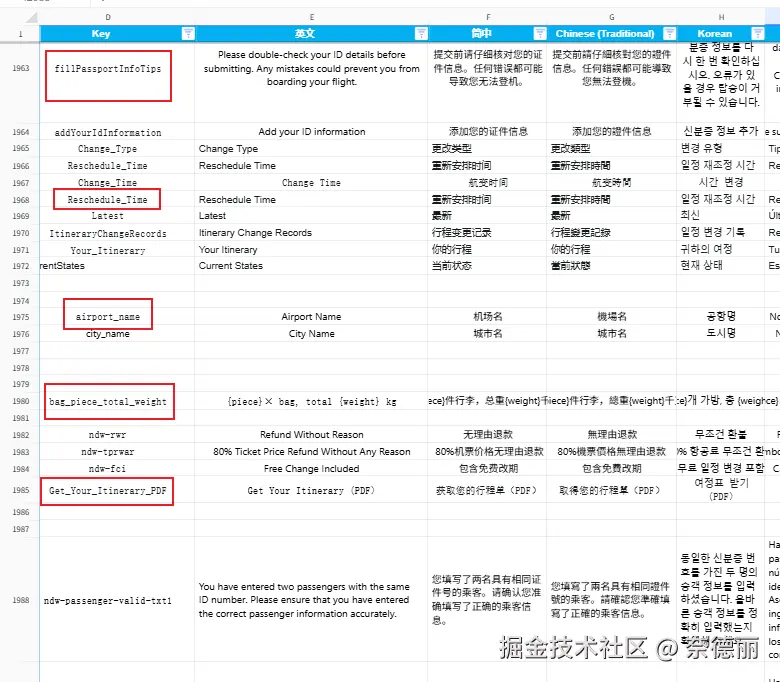
用原node脚本生成的语言文件如图
在这样的场景下,每次迭代多语言文件更新都像噩梦一样。
尤其是我们很多翻译是通过AI 机翻生成,后续频繁修改的成本极高。
然而,机票项目的代码量太大、历史包袱太重,短期内几乎不可能彻底改造。

新项目,新机会
机票项目虽然不能动,但在我们启动酒店业务新项目时,我决定不能再重蹈覆辙。
因此,在酒店项目中,我从零搭建了这套更高效的 i18n 管理方案。
目标很简单:
- 统一 key 规则,支持模块化,模块与内容间用.隔开,内容之间用下划线隔开;
- 自动化生成多语言 JSON 文件,集成到项目内,不再需要查找转化脚本的位置;
- 一条命令搞定更新,不需要手动拷贝。
于是,我在项目中新增了一个 scripts 目录,并编写了一个 excel-to-json.js 脚本。
在 package.json 中添加如下命令:
{
"scripts": {
"i18n:excel-to-json": "node scripts/excel-to-json.js"
}
}
以后,只需要运行下面一行命令,就能完成所有工作:
pnpm i18n:excel-to-json
再也不用手动寻找脚本路径,也不用手动复制粘贴,效率直接起飞 🚀。
脚本实现
核心逻辑就是:
从 Excel 读取内容 → 转换为 JSON → 输出到项目 i18n 目录。
完整代码如下:
import fs from 'node:fs'
import os from 'node:os'
import path from 'node:path'
import XLSX from 'xlsx'
/**
* 语言映射表:Excel 表头 -> 标准语言码
*/
const languageMap = {
'English': 'en',
'简中': 'zh-CN',
'Chinese (Traditional)': 'zh-TW',
'Korean': 'ko',
'Spanish': 'es',
'German Edited': 'de',
'Italian': 'it',
'Norwegian': 'no',
'French': 'fr',
'Arabic': 'ar',
'Thailandese': 'th',
'Malay': 'ms',
}
// 读取 Excel 文件
function readExcel(filePath) {
if (!fs.existsSync(filePath)) {
throw new Error(`❌ Excel 文件未找到: ${filePath}`)
}
const workbook = XLSX.readFile(filePath)
const sheet = workbook.Sheets[workbook.SheetNames[0]]
return XLSX.utils.sheet_to_json(sheet)
}
/**
* 清空输出目录
*/
function clearOutputDir(dirPath) {
if (fs.existsSync(dirPath)) {
fs.readdirSync(dirPath).forEach(file => fs.unlinkSync(path.join(dirPath, file)))
console.log(`🧹 已清空目录: ${dirPath}`)
} else {
fs.mkdirSync(dirPath, { recursive: true })
console.log(`📂 创建目录: ${dirPath}`)
}
}
/**
* 生成 JSON 文件
*/
function generateLocales(rows, outputDir) {
const locales = {}
rows.forEach(row => {
const key = row.Key
if (!key) return
// 遍历语言列
Object.entries(languageMap).forEach(([columnName, langCode]) => {
if (!locales[langCode]) locales[langCode] = {}
const value = row[columnName] || ''
const keys = key.split('.')
let current = locales[langCode]
keys.forEach((k, idx) => {
if (idx === keys.length - 1) {
current[k] = value
} else {
current[k] = current[k] || {}
current = current[k]
}
})
})
})
// 输出文件
Object.entries(locales).forEach(([lang, data]) => {
const filePath = path.join(outputDir, `${lang}.json`)
fs.writeFileSync(filePath, JSON.stringify(data, null, 2), 'utf-8')
console.log(`✅ 生成文件: ${filePath}`)
})
}
/**
* 检测缺失翻译
*/
function detectMissingTranslations(rows) {
const missing = []
rows.forEach(row => {
const key = row.Key
if (!key) return
Object.entries(languageMap).forEach(([columnName, langCode]) => {
const value = row[columnName]
if (!value?.trim()) {
missing.push({ key, lang: langCode })
}
})
})
return missing
}
function logMissingTranslations(missingList) {
if (missingList.length === 0) {
console.log('\n🎉 所有 key 的翻译完整!')
return
}
console.warn('\n⚠️ 以下 key 缺少翻译:')
missingList.forEach(item => {
console.warn(` - key: "${item.key}" 缺少语言: ${item.lang}`)
})
}
function main() {
const desktopPath = path.join(os.homedir(), 'Desktop', 'hotel多语言.xlsx')
const outputDir = path.resolve('src/i18n/locales')
const rows = readExcel(desktopPath)
clearOutputDir(outputDir)
generateLocales(rows, outputDir)
logMissingTranslations(detectMissingTranslations(rows))
}
main()
成果展示
这是在线语言原文档
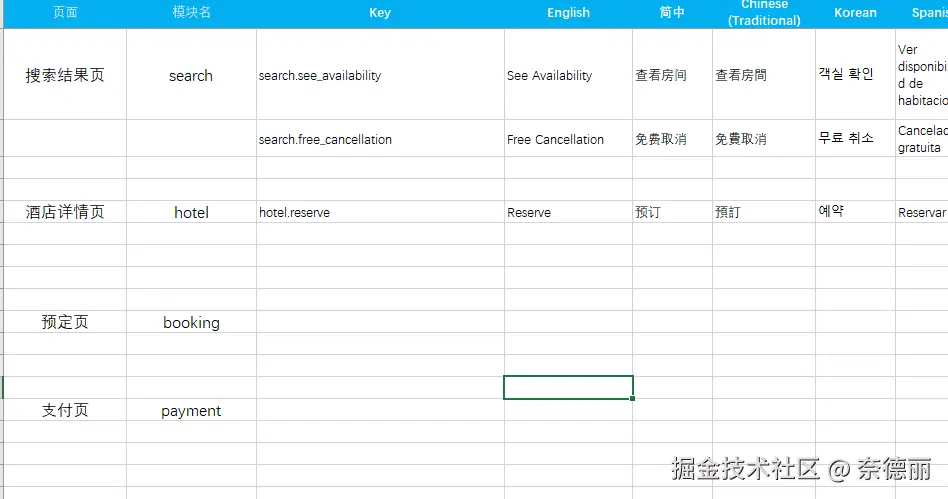
这是生成后的多语言文件和内容
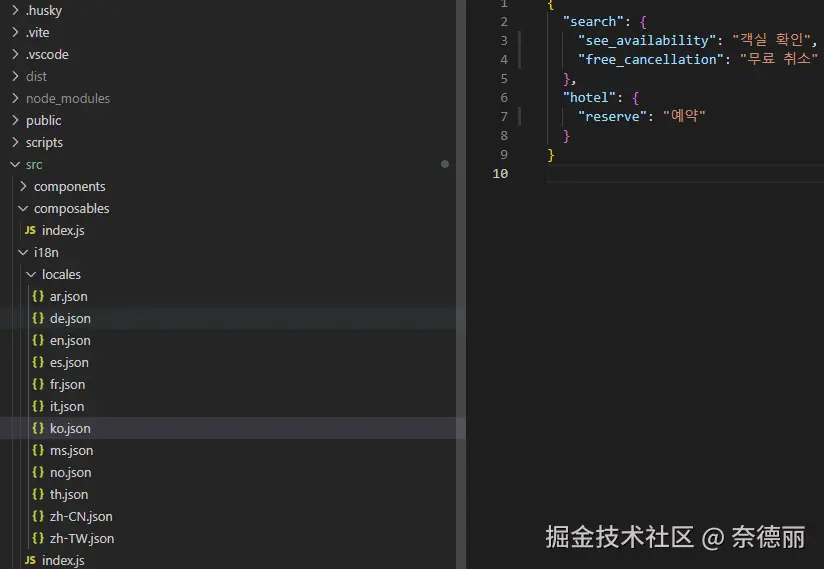
现在的工作流大幅简化:
| 操作 | 旧流程 | 新流程 |
|---|---|---|
| 运行脚本 | 手动找脚本路径 | pnpm i18n:excel-to-json |
| 文件生成位置 | 生成后手动拷贝 | 自动输出到项目 |
| 检测缺失翻译 | 无 | 自动提示 |
| key 命名管理 | 无统一规则 | 模块化、规范化 |
这套机制目前在酒店项目中运行良好,团队反馈也很积极。
总结
这次改造让我最大的感触是:
旧项目难以推翻重来,但新项目一定要趁早做好架构设计。
通过这次优化,我们不仅解决了多语言维护的痛点,还提升了团队整体开发效率。
而这套方案在未来如果机票项目有机会重构,也可以直接平滑迁移过去。
来源:juejin.cn/post/7553105607417053194
实现一个 AI 编辑器 - 行内代码生成篇
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:佳岚
什么是行内代码生成?
通过一组快捷键(一般为cmd + k)在选中代码块或者光标处唤起 Prompt 命令弹窗,并且快速的应用生成的代码。

提示词系统
首先是完成一个简易的提示词系统,不同功能对应的提示词与提供的上下文不同, 定义不同的功能场景:
export enum PromptScenario {
SYNTAX_COMPLETION = 'syntax_completion', // 语法补全
CODE_GENERATION = 'code_generation', // 代码生成
CODE_EXPLANATION = 'code_explanation', // 代码解释
CODE_OPTIMIZATION = 'code_optimization', // 代码优化
ERROR_FIXING = 'error_fixing', // 错误修复
}
每种场景都有对应的系统 prompt 和用户 prompt 模板:
export const PROMPT_TEMPLATES: Record<PromptScenario, PromptTemplate> = {
[PromptScenario.SYNTAX_COMPLETION]: {
id: 'syntax_completion',
scenario: PromptScenario.SYNTAX_COMPLETION,
title: 'SQL语法补全',
description: '基于上下文进行智能的SQL语法补全',
systemPromptTemplate: ``,
userPromptTemplate: `<|fim_prefix|>{prefix}<|fim_suffix|>{suffix}<|fim_middle|>`,
temperature: 0.2,
maxTokens: 256
},
[PromptScenario.CODE_GENERATION]: {
id: 'code_generation',
scenario: PromptScenario.CODE_GENERATION,
title: 'SQL代码生成',
description: '根据需求描述生成相应的SQL代码',
systemPromptTemplate: `你是{languageName}数据库专家。根据用户需求生成高质量的{languageName}代码。
语言特性:{languageFeatures}
生成要求:
1. 严格遵循 {languageName} 语法规范
2. {syntaxNotes}
3. 生成完整、可执行的SQL语句
4. {performanceTips}
5. 考虑代码的可读性和维护性
6. 回答不要包含任何对话解释内容
7. 保持缩进与参考代码一致`,
userPromptTemplate: `用户需求:{userPrompt}
参考代码:
\`\`\`sql
{selectedCode}
\`\`\`
请生成符合需求的{languageName}代码:`,
temperature: 0.3,
maxTokens: 512
},
// ...其他略
}
收集以下上下文信息并动态替换掉提示词模板的变量以生成最终传递给大模型的提示词:
/**
* 上下文信息
*/
export interface PromptContext {
/** 当前语言ID */
languageId: string;
/** 光标前的代码 */
prefix?: string;
/** 光标后的代码 */
suffix?: string;
/** 当前文件完整代码 */
fullCode?: string;
/** 当前打开的文件名 */
activeFile?: string;
/** 用户输入的提示 */
userPrompt?: string;
/** 选中的代码 */
selectedCode?: string;
/** 错误信息 */
errorMessage?: string;
/** 额外的上下文信息 */
metadata?: Record<string, any>;
}
ViewZone
观察该 Widget 可以发现它是实际占据了一段代码行高度,撑开了上下代码,但没有行号,这是通过 ViewZone实现的。

monaco-editor 中的 viewZone 是一种可以在编辑器的文本行之间自定义插入可视区域的机制,不属于实际代码内容,但可以渲染任意自定义 DOM 内容或空白空间。
核心只有一个changeViewZones,必须使用其回调中的accessor来实现新增删除ViewZone操作
新增示例:
editor.changeViewZones(function (accessor) {
accessor.addZone({
afterLineNumber: 10, // 插入在哪一行后(基于原始代码行号)
heightInLines: 3, // zone 的高度(按行数)
heightInPx: 10, // zone 的高度(按像素), 与heightInLines二选一
domNode: document.createElement('div'), // 需要插入的 DOM 节点
});
});
删除示例:
editor.changeViewZones(accessor => {
if (zoneIdRef.current !== null) {
accessor.removeZone(zoneIdRef.current);
}
});
但需要注意的是,ViewZones 的视图层级是在可编辑区之下的,我们通过 domNode 创建弹窗后,无法响应点击,所以需要手动为 domNode 添加 z-Index。

但我们咱不用 domNode 直接渲染我们的弹窗组件,而是通过 ViewZone 结合 OverlayWidget 的方式去添加我们要的元素。
OverlayWidget 的层级比可编辑区域的更高,无需考虑层级覆盖问题。
其次,我们需要将 Overlay 的元素通过绝对定位移动到 ViewZone 上,这需要利用 ViewZone 的 onDomNodeTop来实时同步两者的定位。

monaco-editor 中的代码行与 ViewZone 使用了虚拟列表,它们的 top 在滚动时会随着可见性不断变化,所以需要随时同步 ,onDomNodeTop会在每次 ViewZone 的top属性变化时执行。
此外,OverlayWidget 是以整个编辑器最左边为基准的,计算时需要考虑上
editorInstance.changeViewZones((changeAccessor) => {
viewZoneId = changeAccessor.addZone({
// ...略
onDomNodeTop: (top) => {
// 这里的domNode为overlayWidget所绑定创建的节点
if (domNode) {
// 获取编辑器左侧偏移量(行号、代码折叠等组件的宽度)
const layoutInfo = editorInstance.getLayoutInfo();
const leftOffset = layoutInfo.contentLeft;
domNode.style.top = `${top}px`;
domNode.style.left = `${leftOffset}px`;
domNode.style.width = `${layoutInfo.contentWidth}px`;
}
}
});
});
创建 OverlayWidget :
let overlayWidget: editor.IOverlayWidget | null = null;
let domNode: HTMLDivElement | null = null;
let reactRoot: any = null;
domNode = document.createElement('div');
domNode.className = 'code-generation-overlay-widget';
domNode.style.position = 'absolute';
reactRoot = createRoot(domNode);
reactRoot.render(<CodeGenerationWidget />)
overlayWidget = {
getId: () => `code-generation-overlay-${position.lineNumber}-${Date.now()}`,
getDomNode: () => domNode!,
getPosition: () => null
};
editorInstance.addOverlayWidget(overlayWidget);
// 唤起时,将 widget 滚动到视口
editorInstance.revealLineInCenter(targetLineNumber);
CodeGenerationWidget 动态高度
接下来我们实现 Prompt 输入框根据内容动态调整高度。

输入框部分我们可以直接用 rc-textarea 组件来实现回车自动新增高度。
监听整个容器高度变化触发 onHeightChange 以通知 ViewZone :
useEffect(() => {
if (!containerRef.current) return;
const observer = new ResizeObserver(() => {
onHeightChange?.();
});
observer.observe(containerRef.current);
return () => {
observer.disconnect();
};
}, [containerRef]);
注意 ViewZone 只能增或删,不能手动改变其高度,所以需要重新创建一个:
reactRoot.render(
<CodeGenerationWidget
editorInstance={editorInstance}
initialPosition={position}
initialSelection={selection}
widgetWidth={widgetWidth}
onClose={() => dispose()}
onHeightChange={() => {
// 高度变化时需要更新ViewZone
if (viewZoneId && domNode) {
const actualHeight = domNode.clientHeight;
editorInstance.changeViewZones((changeAccessor) => {
changeAccessor.removeZone(viewZoneId!);
viewZoneId = changeAccessor.addZone({
afterLineNumber: Math.max(0, targetLineNumber - 1),
heightInPx: actualHeight + 8,
domNode: document.createElement('div'),
onDomNodeTop: (top) => {
if (domNode) {
// 获取编辑器左侧偏移量(行号、代码折叠等组件的宽度)
const layoutInfo = editorInstance.getLayoutInfo();
const leftOffset = layoutInfo.contentLeft;
domNode.style.top = `${top}px`;
domNode.style.left = `${leftOffset}px`;
}
}
});
});
}
}}
/>
);
这里如果使用 ViewZone 的 domNode 来渲染组件的方法的话,由于每次高度变化创建新的 ViewZone , 其 domNode 会被重新挂载,那么就会导致每次高度变化时输入框都会失焦。
生成代码 diff 展示
对于选择了代码行后生成,会对原始代码进行编辑修改,我们需要配合行 diff 进行编辑应用结果的展示。对于删除的行使用 ViewZone 进行插入,对于新增的行使用 Decoration 进行高亮标记。

首先需要实现 diff 计算出这些行的信息。 我们需要以最少的操作实现从原始代码到目标代码的转化。

其核心问题是 最长公共子序列(LCS)。最长公共子序列(LCS )是指在两个或多个序列中,找出一个最长的子序列,使得这个子序列在这些序列中都出现过。与子串不同,子序列不需要在原序列中占用连续的位置。
如 ABCDEF 至 ACEFG , 那么它们的最长公共子序列是 ACEF 。
其算法可以参考 cloud.tencent.com/developer/a… 学习,这里我们直接就使用现成的库jsdiff 去实现了。
完整实现:
export enum DiffLineType {
UNCHANGED = 'unchanged',
ADDED = 'added',
DELETED = 'deleted'
}
export interface DiffLine {
type: DiffLineType;
originalLineNumber?: number; // 原始行号
newLineNumber?: number; // 新行号
content: string; // 行内容
}
/**
* 计算两个字符串数组的diff
*/
export const calculateDiff = (originalLines: string[], newLines: string[]): DiffLine[] => {
const result: DiffLine[] = [];
// 将字符串数组转换为字符串
const originalText = originalLines.join('\n');
const newText = newLines.join('\n');
// 使用 diff 库计算差异
const diffs = diffLines(originalText, newText);
let originalLineNumber = 1;
let newLineNumber = 1;
diffs.forEach(diff => {
if (diff.added) {
// 添加的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.ADDED,
newLineNumber: newLineNumber++,
content: line
});
});
} else if (diff.removed) {
// 删除的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.DELETED,
originalLineNumber: originalLineNumber++,
content: line
});
});
} else {
// 未变化的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.UNCHANGED,
originalLineNumber: originalLineNumber++,
newLineNumber: newLineNumber++,
content: line
});
});
}
});
return result;
};

那么接下来我们只要根据计算出的 diffLines 对删除行和新增行进行视觉展示即可。
我们封装一个 applyDiffDisplay 方法用来展示 diffLines 。
有以下步骤:
- 清除之前的结果
- 直接将选区内容替换为生成内容
- 遍历
diffLines中ADDED与DELETED的行:对于DELETED的行,可以多个连续行组成一个ViewZone创建以优化性能;对于ADDED的行,通过deltaDecorations添加背景装饰
const applyDiffDisplay =
(diffLines: DiffLine[]) => {
// 先清除之前的展示
clearDecorations();
clearDiffOverlays();
if (!initialSelection) return;
const model = editorInstance.getModel();
if (!model) return;
// 获取语言ID用于语法高亮
const languageId = getLanguageId();
// 首先替换原始内容为新内容(包含unchanged的行)
const newLines = diffLines
.filter((line) => line.type !== DiffLineType.DELETED)
.map((line) => line.content);
const newContent = newLines.join('\n');
// 执行替换
editorInstance.executeEdits('ai-code-generation-diff', [
{
range: initialSelection,
text: newContent,
forceMoveMarkers: true
}
]);
// 计算新内容的范围
const resultRange = new Range(
initialSelection.startLineNumber,
initialSelection.startColumn,
initialSelection.startLineNumber + newLines.length - 1,
newLines.length === 1
? initialSelection.startColumn + newContent.length
: newLines[newLines.length - 1].length + 1
);
let currentLineNumber = initialSelection.startLineNumber;
let deletedLinesGr0up: DiffLine[] = [];
for (const diffLine of diffLines) {
if (diffLine.type === DiffLineType.DELETED) {
// 收集连续的删除行
deletedLinesGr0up.push(diffLine);
} else {
if (deletedLinesGr0up.length > 0) {
addDeletedLinesViewZone(deletedLinesGr0up, currentLineNumber - 1, languageId);
deletedLinesGr0up = [];
}
if (diffLine.type === DiffLineType.ADDED) {
// 添加绿色背景色
const addedDecorations = editorInstance.deltaDecorations(
[],
[
{
range: new Range(
currentLineNumber,
1,
currentLineNumber,
model.getLineContent(currentLineNumber).length + 1
),
options: {
className: 'added-line-decoration',
isWholeLine: true
}
}
]
);
decorationsRef.current.push(...addedDecorations);
}
currentLineNumber++;
}
}
// 处理最后的删除行组
if (deletedLinesGr0up.length > 0) {
addDeletedLinesViewZone(deletedLinesGr0up, currentLineNumber - 1, languageId);
}
return resultRange;
}
删除行的视觉呈现
删除行使用 ViewZone 插入到 originalLineNumber - 1 的位置, 对于删除行直接使用 ViewZone 自身的 domNode 进行展示了,因为不太需要考虑层级问题。
export const createDeletedLinesOverlayWidget = (
editorInstance: editor.IStandaloneCodeEditor,
deletedLines: DiffLine[],
afterLineNumber: number,
languageId: string,
onDispose?: () => void
): { dispose: () => void } => {
let domNode: HTMLDivElement | null = null;
let reactRoot: any = null;
let viewZoneId: string | null = null;
domNode = document.createElement('div');
domNode.className = 'deleted-lines-view-zone-container';
reactRoot = createRoot(domNode);
reactRoot.render(<DeletedLineViewZone lines={deletedLines} languageId={languageId} />);
const heightInLines = Math.max(1, deletedLines.length);
editorInstance.changeViewZones((changeAccessor) => {
viewZoneId = changeAccessor.addZone({
afterLineNumber,
heightInLines,
domNode: domNode!
});
});
const dispose = () => {
// 清除
};
return { dispose };
};
添加命令快捷键
使用 cmd + k 唤起弹窗
editorInstance.onKeyDown((e) => {
if ((e.ctrlKey || e.metaKey) && e.keyCode === KeyCode.KeyK) {
e.preventDefault();
e.stopPropagation();
const selection = editorInstance.getSelection();
const position = selection ? selection.getPosition() : editorInstance.getPosition();
if (!position) return;
// 如果有选择范围,则将其传递给widget供后续替换使用
const selectionRange = selection && !selection.isEmpty() ? selection : null;
// 如果已经有viewZone,先清理
if (activeCodeGenerationViewZone) {
activeCodeGenerationViewZone.dispose();
activeCodeGenerationViewZone = null;
}
// 创建新的ViewZone
activeCodeGenerationViewZone = createCodeGenerationOverlayWidget(
editorInstance,
position,
selectionRange,
undefined, // widgetWidth
() => {
// 当viewZone被dispose时清理全局状态
activeCodeGenerationViewZone = null;
}
);
}
最终实现效果:

未来优化方向:
- 实现流式生成:对于未选区的代码生成,我们不需要应用diff,所以流式很好实现,但对于进行选区后进行的代码修改,每次输出一行就要执行一次diff计算与展示,diff结果可能不同,会产生视觉上的重绘,实现起来也相对比较麻烦。

- 接收或者拒绝后能够进行撤回,回到等待响应生成结果时的状态
其他计划
- [已完成] 行内补全
- [已完成] 代码生成
- 行内补全的缓存设计
- 完善的上下文系统
- 实现 Agent 模式
在线预览
jackwang032.github.io/monaco-sql-…
仓库代码:github1s.com/JackWang032…
最后
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
来源:juejin.cn/post/7545087770776616986
【前端效率工具】:告别右键另存,不到 50 行代码一键批量下载网页图片
前端还原页面你肯定干过吧?像仿 xxx 首页那种。收素材时最烦的就是一张张存图,慢不说还老漏。
跟我用 10 分钟做个chrome小插件,点一下,整页图片全下到本地
先看效果:在素材网站一键批量保存所有图片

废话不多说,直接上手!
项目结构
image-downloader-extension
├── manifest.json # 扩展的"身-份-证"
└── background.js # 插件后台脚本
创建文件夹
image-downloader-extension创建manifest.json文件
这个文件是插件的身-份-证,告诉浏览器你的插件是谁、能干啥。
{
"manifest_version": 3,
"name": "我的下载插件",
"version": "1.0.0",
"permissions": ["contextMenus", "downloads", "scripting"],
"host_permissions": ["" ],
"background": {
"service_worker": "background.js"
}
}
关键点解读:
| 字段 | 说明 |
|---|---|
| manifest_version: 3 | 使用最新的 Manifest V3 扩展规范 |
| name | 插件名称 |
| version | 插件版本号 |
| permissions | 申请权限(contextMenus 创建右键菜单,downloads下载) |
创建background.js文件
background.js后台脚本负责创建并响应右键菜单等事件来下载页面图片
// 1. 插件安装时创建右键菜单
chrome.runtime.onInstalled.addListener(() => {
chrome.contextMenus.create({
id: 'downloadAllImages', // 菜单唯一标识
title: '我要下载所有图片', // 菜单显示的文字
contexts: ['page'], // 在页面任意位置右键时显示
});
});
// 2. 监听右键菜单点击事件
chrome.contextMenus.onClicked.addListener((info, tab) => {
if (info.menuItemId === 'downloadAllImages') {
// 使用 scripting API 在当前页面执行脚本获取所有图片
chrome.scripting.executeScript(
{
target: { tabId: tab.id },
func: getImagesFromPage,
},
(results) => {
// 获取执行结果
if (!results || !results[0]?.result || results[0].result.length === 0) {
console.log('未找到图片');
return;
}
const images = results[0].result;
// 批量下载图片
images.forEach((url, index) => {
setTimeout(() => {
chrome.downloads.download({
url: url,
filename: `images/image_${index + 1}.jpg`, // 保存路径
saveAs: false, // 不弹出保存对话框
});
}, index * 500); // 每张图片间隔 500ms,避免浏览器限制
});
}
);
}
});
// 在页面中执行的函数,用于获取所有图片URL
function getImagesFromPage() {
const images = Array.from(document.images)
.map((img) => img.src)
.filter((src) => src.startsWith('http'));
return images;
}
API 文档速查
- chrome.runtime(扩展生命周期/事件)
- chrome.contextMenus(右键菜单)
- chrome.scripting(脚本执行)
- chrome.downloads(下载管理)
- 权限声明(MV3)
4. 加载插件到浏览器
接下来我们将插件加载到浏览器中

步骤:
4.1 打开扩展管理页面 在 Chrome 地址栏输入 chrome://extensions/ 并回车
4.2 开启开发者模式
4.3 点击 “加载未打包的扩展程序”
选择刚刚创建的image-downloader-extension文件夹进行加载
4.4 插件加载成功
你会看到插件出现在列表中

至此,我们的下载插件就搞完了,是不是非常容易?
测试(验证功能)
接下来我们随便打开一个网站,点击鼠标右键,就会发现右键菜单多了一个选项

点击“我要下载所有图片” 即可实现我们的需求了
调试(查看 background.js日志与断点)
如下图:点击插件的 Service Worker 入口,会弹出调试面板。
在该面板中你可以:
- 实时查看 background.js 的 console日志输出;
- 在代码中设置断点调试以排查问题。

总结
这一次带你用一个小巧的 Chrome 插件,一键把当前网页的所有图片下载下来,希望对你有所帮助
来源:juejin.cn/post/7559124639323242506
Token已过期,我是如何实现无感刷新Token的?

我们来想象一个场景:你正在一个电商网站上,精心挑选了半小时的商品,填好了复杂的收货地址,满心欢喜地点击提交订单 Button。
突然,页面Duang🎈地一下,跳转到了登录页,并提示你:“登录状态已过期,请重新登录”。
那一刻,你的内心是什么感受?我想大概率是崩溃的,并且想把这个网站拉进黑名单。
这就是一个典型的、因为Token过期处理不当,而导致的灾难级用户体验。作为一个负责任的开发者,这是我们绝对不能接受的。
今天就聊聊,我们团队是如何通过请求拦截和队列控制,来实现无感刷新Token的。让用户即使在Token过期的情况下,也能无缝地继续操作,就好像什么都没发生过一样。
先讲基础知识
为什么需要两个Token?
要实现无感刷新,我们首先需要后端同学的配合,采用双Token的认证机制。
accessToken: 这是我们每次请求业务接口时,都需要在请求头里带上的令牌。它的特点是生命周期短(比如1小时),因为暴露的风险更高。refreshToken: 它的唯一作用,就是用来获取一个新的accessToken。它的特点是生命周期长(比如7天),并且需要被安全地存储(比如HttpOnly的Cookie里)。
流程是这样的:用户登录成功后,后端会同时返回accessToken和refreshToken。前端将accessToken存在内存(或LocalStorage)里,然后在后续的请求中,通过refreshToken来刷新。

解决思路,利用axios的请求拦截器
我们整个方案的核心,是利用axios(或其他HTTP请求库)提供的请求拦截器(Interceptor) 。它就像一个哨兵,可以在请求发送前和响应返回后,对请求进行拦截和改造。
我们的目标是:
- 在响应拦截器里,捕获到后端返回的
accessToken已过期的错误(通常是401状态码)。 - 当捕获到这个错误时,暂停所有后续的API请求。
- 使用
refreshToken,悄悄地在后台发起一个获取新accessToken的请求。 - 拿到新的
accessToken后,更新我们本地存储的Token。 - 最后,把之前失败的请求和被暂停的请求,用新的
Token重新发送出去。
这个过程对用户来说,是完全透明的。他们最多只会感觉到某一次API请求,比平时慢了一点点。
具体怎么实现?
下面是我们团队在项目中,实际使用的axios拦截器伪代码。
import axios from 'axios';
// 创建一个新的axios实例
const api = axios.create({
baseURL: '/api',
timeout: 5000,
});
// ------------------- 请求拦截器 -------------------
api.interceptors.request.use(config => {
const accessToken = localStorage.getItem('accessToken');
if (accessToken) {
config.headers.Authorization = `Bearer ${accessToken}`;
}
return config;
}, error => {
return Promise.reject(error);
});
// ------------------- 响应拦截器 -------------------
// 用于标记是否正在刷新token
let isRefreshing = false;
// 用于存储因为token过期而被挂起的请求
let requestsQueue = [];
api.interceptors.response.use(
response => {
return response;
},
async error => {
const { config, response } = error;
// 如果返回的HTTP状态码是401,说明access_token过期了
if (response && response.status === 401) {
// 如果当前没有在刷新token,那么我们就去刷新token
if (!isRefreshing) {
isRefreshing = true;
try {
// 调用刷新token的接口
const { data } = await axios.post('/refresh-token', {
refreshToken: localStorage.getItem('refreshToken')
});
const newAccessToken = data.accessToken;
localStorage.setItem('accessToken', newAccessToken);
// token刷新成功后,重新执行所有被挂起的请求
requestsQueue.forEach(cb => cb(newAccessToken));
// 清空队列
requestsQueue = [];
// 把本次失败的请求也重新执行一次
config.headers.Authorization = `Bearer ${newAccessToken}`;
return api(config);
} catch (refreshError) {
// 如果刷新token也失败了,说明refreshToken也过期了
// 此时只能清空本地存储,跳转到登录页
console.error('Refresh token failed:', refreshError);
localStorage.removeItem('accessToken');
localStorage.removeItem('refreshToken');
// window.location.href = '/login';
return Promise.reject(refreshError);
} finally {
isRefreshing = false;
}
} else {
// 如果当前正在刷新token,就把这次失败的请求,存储到队列里
// 返回一个pending的Promise,等token刷新后再去执行
return new Promise((resolve) => {
requestsQueue.push((newAccessToken) => {
config.headers.Authorization = `Bearer ${newAccessToken}`;
resolve(api(config));
});
});
}
}
return Promise.reject(error);
}
);
export default api;
这段代码的关键点,也是面试时最能体现你思考深度的地方:
- isRefreshing 状态锁:
这是为了解决并发问题。想象一下,如果一个页面同时发起了3个API请求,而accessToken刚好过期,这3个请求会同时收到401。如果没有isRefreshing这个锁,它们会同时去调用/refresh-token接口,发起3次刷新请求,这是完全没有必要的浪费,甚至可能因为并发问题导致后端逻辑出错。
有了这个锁,只有第一个收到401的请求,会真正去执行刷新逻辑。
- requestsQueue 请求队列:
当第一个请求正在刷新Token时(isRefreshing = true),后面那2个收到401的请求怎么办?我们不能直接抛弃它们。正确的做法,是把它们的resolve函数推进一个队列(requestsQueue)里,暂时挂起。
等第一个请求成功拿到新的accessToken后,再遍历这个队列,把所有被挂起的请求,用新的Token重新执行一遍。
无感刷新Token这个功能,用户成功的时候,是感知不到它的存在的。
但恰恰是这种无感的细节,区分出了一个能用的应用和一个好用的应用。
因为一个资深的开发者,他不仅关心功能的实现,更应该关心用户体验和整个系统的健壮性。
希望这一套解决思路,能对你有所帮助🤞😁。
来源:juejin.cn/post/7550943000689950774
前端仔如何在公司搭建 AI Review 系统
一、前言
在上一篇 《AI 应用开发入门:前端也可以学习 AI》中,我给大家分享了前端学习 AI 应用开发的入门相关知识。我相信很多同学,看完应该都有了一定的收获。未来我会把关于前端学习 AI 的文章都放在这个 《前端学习 AI 之路》 专栏进行更新~
本篇会更偏向实际的应用,我将会运用之前分享的技术和概念,给大家分享如何通过 nodejs + LLM 搭建一个简易的 AI Review 系统的。
在本篇你将收获到:
- 设计 AI 应用的思路
- 设计提示词的思路
- 如何用 NodeJS 结合 LLM 分析代码
在上一篇 《AI 应用开发入门:前端也可以学习 AI》中,我给大家分享了前端学习 AI 应用开发的入门相关知识。我相信很多同学,看完应该都有了一定的收获。未来我会把关于前端学习 AI 的文章都放在这个 《前端学习 AI 之路》 专栏进行更新~
本篇会更偏向实际的应用,我将会运用之前分享的技术和概念,给大家分享如何通过 nodejs + LLM 搭建一个简易的 AI Review 系统的。
在本篇你将收获到:
- 设计 AI 应用的思路
- 设计提示词的思路
- 如何用 NodeJS 结合 LLM 分析代码
二、背景
我相信大家在团队中,都会有 Code Review 这个流程。但是有时候随着人手不够、项目周期紧张,就会出现 review 流程被忽视、或者 review 质量不高的问题。于是,我就在想,是否可以把这种费时、费精力且需要专注的事情,交给一个专门的“AI 员工”去完成呢?答案是可以的。
我相信大家在团队中,都会有 Code Review 这个流程。但是有时候随着人手不够、项目周期紧张,就会出现 review 流程被忽视、或者 review 质量不高的问题。于是,我就在想,是否可以把这种费时、费精力且需要专注的事情,交给一个专门的“AI 员工”去完成呢?答案是可以的。
三、整体效果
目前在我们团队,已经全面的在使用 AI 进行 Review 了,涵盖了前端、后端大大小小 20 + 的项目。得益于在集团内可以使用像(“GPT-4.1、 Calude”)这样更大上下文、更强推理能力的模型,所以整体效果是非常不错的。有时候一些很细微的安全隐患、性能、业务逻辑等问题,AI 都能比人更容易发现。
下面是我用演示的项目呈现的效果,也就是我们即将动手搭建的这个项目。
目前在我们团队,已经全面的在使用 AI 进行 Review 了,涵盖了前端、后端大大小小 20 + 的项目。得益于在集团内可以使用像(“GPT-4.1、 Calude”)这样更大上下文、更强推理能力的模型,所以整体效果是非常不错的。有时候一些很细微的安全隐患、性能、业务逻辑等问题,AI 都能比人更容易发现。
下面是我用演示的项目呈现的效果,也就是我们即将动手搭建的这个项目。
3.1 评论模式
通过 AI 分析提交的代码,然后会在有问题的代码下,评论出问题类型以及问题的具体原因。

通过 AI 分析提交的代码,然后会在有问题的代码下,评论出问题类型以及问题的具体原因。
3.2 报告模式
还一种是报告的展示形式。它会在提交的 MR 下输出一个评审报告,列出所有问题的标题、所在位置、以及具体原因。但是,这两种模式实现的本质都一样,只不过是展示结果的方式有不同,这个看你个人喜欢。


还一种是报告的展示形式。它会在提交的 MR 下输出一个评审报告,列出所有问题的标题、所在位置、以及具体原因。但是,这两种模式实现的本质都一样,只不过是展示结果的方式有不同,这个看你个人喜欢。
四、思路分析
那这个 AI Code Review 应用要怎么实现呢?下面给大家分享一下具体的思路。
那这个 AI Code Review 应用要怎么实现呢?下面给大家分享一下具体的思路。
4.1 人为流程
首先要做的,就是分析你现有团队人工 review 代码的规范,然后总结出一个具体流程。为什么要这样做?因为让 AI 帮你做事的本质,就是让它模仿你做事。如果连你自己都不清楚具体的执行流程,就更别期待 AI 能把这个事情做好了。
下面是我举例的一个 review 流程,看完后你可以思考一下,自己平时是怎么 review 代码的,有没有一个固定的流程或者方案。如果有,则按照下面的这个“行为 + 目的”的格式记录下来。
- 行为:收到的 MR 的提示了;目的:知道有需要 review 的 MR 提交

- 行为:查看 commit message;目的:确认本次提交的主题是什么。
首先要做的,就是分析你现有团队人工 review 代码的规范,然后总结出一个具体流程。为什么要这样做?因为让 AI 帮你做事的本质,就是让它模仿你做事。如果连你自己都不清楚具体的执行流程,就更别期待 AI 能把这个事情做好了。
下面是我举例的一个 review 流程,看完后你可以思考一下,自己平时是怎么 review 代码的,有没有一个固定的流程或者方案。如果有,则按照下面的这个“行为 + 目的”的格式记录下来。
- 行为:收到的 MR 的提示了;目的:知道有需要 review 的 MR 提交
- 行为:查看 commit message;目的:确认本次提交的主题是什么。

- 行为:查看改动哪些文件;目的:确认改动范围,主要判断改了哪些业务模块、是否改了公共、或者高风险文件等

- 行为:查看文件路径;目的:确认该文件关联的业务、所属的模块等信息,当做后续 diff 评审的前置判断信息。

- 行为:查看 diff 内容;目的:判断改动代码的逻辑、安全、性能是否存在问题。结合相关的业务和需求信息,判断是否有实现不合理的地方。
- 行为:在有问题的相关代码下,发出评论;目的:在有问题的代码下面,给出修改建议,让开发的同事能够注意和修改一下当前的问题。

4.2 程序流程
上面列举的是一个完整的人为评审代码的流程。但是,如果想让 AI 完全模仿,其实是存在一定的复杂性的。比如,人在评审某处 diff 时,会思考关联的业务、模块等前置信息,然后再做出评论。而不单单只是评审代码表面的编码问题。如果想要 AI 也这样做,还需要引入 RAG 等相关的技术,目的则是为了补充给更多的上下文信息。
为了不增加大家的实现和理解难度,本篇我们实现的是一个简化版本的 AI Code Review。下面是我梳理的 review 流程和与之对应的 AI 应用流程。

4.2 核心问题
这次搭建的 AI Code Review 应用,本质上是一个 NodeJS 服务。这个服务通过感知 MR 事件,获取 diff 交给 LLM 分析,得到结论以后,会输出评论到 GitLab。整体流程图如下:

所以,我们要面对这些核心问题是
- node 服务如何感知 GitLab 的 MR 提交
- 如何获取 MR 中每个文件改动的 diff
- 如何让编写提示词,让大模型评审和分析并输出结构化的数据
- 如何解析数据以及异常的处理
- 如何发送评论到 gitlab
- 如何推送状态到企微
接下来,我们带着上面的问题,来一步步实现这个 AI Code Review 应用。
五、具体实现
5.1 创建项目
创建一个 NestJS 的项目(用什么技术框架都可以,你可以使用你最熟悉的 Node 开发框架。重点是关注实现的核心步骤和思路,这个演示的项目我开源了,可以在 GitHub 上查看完整的代码)
nvm use 20
使用 nest 命令初始化一个项目
nest new mr-agent
5.2 实现 webhook 接口
首先我们来解决 node 服务如何感知 MR 事件的问题
Webhook
像 GitLab、GitHub 都会允许用户在项目中配置 webhook。它是干嘛的呢? webhook 可以让外部的服务,感知到 git 操作的相关事件(如 push 、merge 等事件)。比如我在合并代码时,gitlab 就会把 MR 事件,通过这个 hook 发送到我们搭建的服务上。

以 GitLab 为例,它会允许开发者在每个项目中配置多个 webhook 接口。比如,咱们配置一个 http://example.com/webhook/trigger 的地址。当发生相关 git 事件时,GitLab 就会往这个地址推送消息。

代码实现
所以,我们要做的第一件事,就是定义一个接口 url,用于接收 GitLab 的 webhook 事件。下面的代码中,实现了一个处理/webhook/trigger路由的 controller,它的主要职责是接收 MR 事件并且解析 body 和 header 中的参数,代码如下(完整代码)

Body
body 中会包含很多有用的的信息,如 Git 仓库信息、分支信息、MR 信息、提交者信息等,这些数据是 GitLab 调用 webhook 接口时发送过来的,在后续的逻辑中,都会用到里面的数据。

- object_type/object_kind:描述的事件的类型,例如 merge 事件、push 事件等。
- project:主要是描述仓库相关的信息,例如项目 id、名称等
- object_attributes: 主要包含本次 MR 相关的信息,如目标分支、源分支、mr 的 id 等等
- user:提交者的信息
Header
header 中是我们自己目定义的配置信息,核心有三个
- x-ai-mode:评论的模式(report 报告模式、 comment 评论模式)
- x-push-url:用于推送状态的地址(推送到企微、或者飞书的机器人)
- x-gitlab-token:gitlab 中的 access token,用于后续 GitLab API 调用鉴权

调试问题
调试开发的这个接口确实是一个比较麻烦的问题。因为 GitLab 基本都是内网部署,想要真实调试接口,一是需要真实代码仓库,二是需要想办法把 GitLab 的请求转发到本地来。这里我给大家分享三个办法:
内网转发
使用内网转发的办法,第三方的例如 ngrok、localtunnel、frp 等。如果你们公司的部署平台本身支持流量转发到本地,那就更好了(我用的是这个办法)。
ApiFox、Postman
先将服务部署到你们公司 GitLab 可以访问的服务器上,手动触发 MR 事件

然后在日志上打印完整的 header 和 body,然后复制到 ApiFox、Postman 上在本地模拟请求

问 AI
😁 最后一个办法就是,根据你的场景,问问 AI 怎么做 
5.3 获取 diff 内容
在能够接受到 GitLab 发送的 MR 事件后,就要解决如何获取 diff 的问题。这一步很简单, 调用 GitLab 官方的 API 就可以。重点就是两个核心逻辑:
- 获取全部文件的 diff 内容
- 过滤非代码文件

获取 diff 内容
gitlab 的 api 路径一般是一样的。唯一的区别就是不同公司的部署域名不同。baseUrl 需要配置成你公司的域名,projectId 和 mrId 都可以在 body 中取到(完整代码)

调用成功以后,获取的数据如下,changes 中会包含每个文件的 diff

过滤文件
因为并不是所有的文件都需要让 LLM 进行 review ,例如像 package.json、package-lock.json 等等。所以需要把这部分非代码文件过滤出来。

5.4 设计提示词
有了每个文件的 diff 数据以后,就是解决如何分析 diff 内容并输出有效结论的问题。其实这个问题的本质,就是如何设计系统提示词。
提示词思路
首先我们先思考一下编写提示词的目的是什么?我们期望的是,通过提示词指引 LLM,当输入 diff 文本的时候,它能够分析里面的代码并输出结构化的数据。

我们希望 LLM 返回的是一个数组,数组的每一项是对每一个问题的描述,里面包含标题、文件路径、行号、具体的内容等,数据结构如下:
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}
之所以需要这种结构化的数据,是因为后续在调用 GitLab API 发送评论的时候,需要用到这些参数。

整体思路确定好了,接下来我们就来编写具体的系统提示词。
角色设定
角色设定就是告诉 LLM 扮演什么角色以及它的具体要做什么事情
你是一个代码 MR Review 专家,你的任务是评审 Git Merge Request 中提交的代码,如果存在有问题的代码,你要提供有价值、有建设性值的建议。
注意,你评审时,应重点关注 diff 中括号后面带 + 或 - 的代码。
输入内容
上面有说到,我们不仅需要 LLM 分析代码的问题,还需要它把问题代码所在的文件路径、行号分析出来。
但是,如果你直接把原生的 diff 内容输入给它,它是不知道这些信息。因为原生的 diff 并没有具体的行号、新旧文件路径信息的。
@@ -1,16 +1,13 @@
import { Injectable } from '@nestjs/common';
-interface InputProps {
- code_diff: string;
- code_context: string;
- rules?: string;
-}
+type InputProps = Record;
interface CallDifyParams {
所以我们需要扩展输入的 diff,给它增加新旧文件的路径、以及每一行具体的行号,例如 (1, 1) 表示的是当前行,是旧文件中的第 1 行,新文件中的第 1 行。这个后面会说如何扩展,这里我们只是要先设计好,并告诉 LLM 我们会输入什么格式的内容
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
(9, 9)
(10, 10) interface CallDifyParams {
有了这些完善的信息,LLM 才知道有问题的代码在哪个文件以及它所在的具体行号
加解释
diff 经过我们的扩展以后,就不再是标准的描述 diff 的 Unified Format 格式了,所以必须向 LLM 解释一下格式的含义,增强它对输入的理解,避免它随便臆想。
我们将使用下面的格式来呈现 MR 代码的 diff 内容:
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record
(9, 9)
(10, 10) interface CallDifyParams {
- 以 ”## new_path“ 开头的行内容,表示修改后的文件路径
- 以 ”## old_path“ 开头的行内容,表示修改前的文件路径
- @@ -1,16 +1,13 @@ 是统一差异格式(Unified Diff Format)中的hunk header,用于描述文件内容的具体修改位置和范围
- 每一行左侧括号内的两个数字,左边表示旧代码的行号,右边表示新代码的行号
- 括号后的 + 表示的是新增行
- 括号后的 - 表示的是删除行
- 引用代码中的变量、名称或文件路径时,请使用反引号(`)而不是单引号(')。
加限制
加限制的主要目的是指引 LLM 按照固定的数据类型进行输出。这里我们会告诉 LLM 具体的 TS 类型,避免它输出一些乱七八糟的类型,导致后续在代码中解析和使用的时候报异常。例如,数字变成字符串、字符串变成数组等。
你必须根据下面的 TS 类型定义,输出等效于MRReview类型的YML对象:
```ts
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}
```
在限制的类型中,最好是增加一些注解,让 LLM 能够理解每个字段的含义。
加示例
加示例的主要目的是告诉 LLM 按照固定的文件格式进行输出,这样我们就可以直接拿 LLM 的输出,进行标准化的解析,转换成实例的数据进行使用,伪代码如下:
// 调用 LLM 的接口
const result = await callLLM('xxxxx');
// 解析数据
const data = yaml.load(result);
// 操作数据
data.reviews.forEach(() => { })
提示词描述如下
输出模板(注意,我只需要 yaml 格式的内容。yaml 内容的前后不要有其他内容):
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 1
endLine: 1
type: |
old
issueHeader: |
逻辑错误
issueContent: |
...
- newPath: |
src/webhook/decorators/advanced-header.decorator.ts
oldPath: |
src/webhook/decorators/commmon-header.decorator.ts
startLine: 1
endLine: 1
type: |
new
issueHeader: |
性能风险
issueContent: |
...
```
这里简单说一下,为什么选择 yaml 而不是 json。因为在实践的过程中,我们发现 json 解析异常的概率会比 yaml 高很多,因为 json 的 key 和 value 是需要双引号("")包裹的,如果 issueContent 中包含了代码相关的内容且存在一些双引号、单引号之类的符号,就很容易导致报错,而且比较难通过一些替换规则进行兜底处理。
最后完整的提示词这里:提示词
调试
这里再告诉大家一个提示词的调试技巧,你可以先在 Coze、Dify 这样的平台上,通过工作台不断调试你的提示词,直到它能够稳定的输出你满意的结果。

5.5 扩展、组装 diff
上面我们有说到,通过 GitLab 获取的原始 diff 是没有新旧文件路径和具体的新旧行号的,这个需要通过代码计算来补全这些信息。这一小节,我们就来解决 diff 的扩展、组装问题。
扩展
扩展主要做两个事:
- 在 diff 头部加新旧文件的路径
- 在每一行加新旧文件中的行号
加路径比较简单,可以在获取每个文件的 diff 数据的时候,拿到新旧文件的路径的,取值后加上即可。
 加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。
加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。

为了防止有些同学不清楚 diff 格式的结构,我这里简单标注一下。 在下面这个 diff 中,像 “@@ -1,16 +1,13 @@” 这样的内容就是 Hunk Head,用于描述后续 diff 内容在新旧文件中的起始行号。用框住的第一个 hunk 为例:
- -1,16: 表示
import { Injectable } from '@nestjs/common';是在旧文件中的第 1 行,改动范围是往后的一共 16 行,需要忽略 “+” 加号开头的行。- +1,13:表示是
import { Injectable } from '@nestjs/common';在新文件中的第 1 行,改动范围是往后的一共 13 行,需要忽略 “-” 加号开头的行。然后图中被我用红框标注的连续代码片段就是 hunk,它一般由 hunk header + 连续的代码组成。一个文件的 diff 可能会有多个 hunk。
- hunk 中 “+” 开头的行,表示新文件中增加的行
- “-” 开头的行,表示旧文件中被删除的行

这里需要先遍历每个文件的 diff,然后按 hunk head 来分割内容块。
const hunks = splitHunk(diffFile.diff);
代码如下:

逻辑是将 diff 按 “\n” 分割成包含所有行的数组,然后遍历每一行。每当遍历到一个 hunk head 就创建一个新的 hunk 结构,然后通过正则提取里面的起始行号,并将后续遍历到的行都保存起来,直到它遇到一个新的 hunk head。
接着就是遍历 hunk,计算每个 hunk 中每一行的具体行号。

comptuedHunkLineNumer 的代码如下:

核心逻辑是:
- 使用 oldLineNumber、newLineNumber 两个独立计数器,记录新旧文件的当前行号
- 遍历到 “-” 开头的行,oldLineNumber + 1,记录行号(oldLineNumber + 1, )
- 遍历到 “+” 开头的行,newLineNumber + 1,记录行号( , newLineNumber + 1)
- 遍历常规的行,oldLineNumber 和 newLineNumber 都 + 1,记录行号(oldLineNumber + 1, newLineNumber + 1)
为了让你更清晰理解这个逻辑,我在 diff 中标注一下。下面是计算旧文件中的行号,我们只会对“-”开头的行和普通的行进行计数,忽律 “+” 开头的行。

计算新文件中的行,此时我将不计算 “-” 开头的行。所以type InputProps = Record这行代码,在合并后的新文件中,真正的行号是在第 15 行。

处理后 diff 的每一行,都会带上新旧文件中的行号
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
(9, 9)
(10, 10) interface CallDifyParams {
(11, 11) input: InputProps;
(12, 12) query: string;
(13, 13) conversation_id?: string;
(14, 14) user: string;
( , 15) + apiKey: string;
(16, 16) }
(17, 17)
组装
得到每个文件扩展的 diff 以后,便是将 commit message 和所有文件 diff 拼接到一个字符串中,后续会把这个拼接好的字符串直接输入给 LLM 进行分析。
commit message: feat: 调整 review 触发逻辑,增加请求拦截器
##new_path: src/agent/agent.service.ts
##old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
## new_path: src/webhook/decorators/advanced-header.decorator.ts
## old_path: src/webhook/decorators/advanced-header.decorator.ts
@@ -0,0 +1,152 @@
( , 1) +import {
( , 2) + createParamDecorator,
( , 3) + ExecutionContext,
( , 4) + BadRequestException,
( , 5) +} from '@nestjs/common';
( , 6) +
( , 7) +/**
( , 8) + * 高级 Header 装饰器,支持类型转换和验证
( , 9) + */
( , 10) +export const AdvancedHeader = createParamDecorator(
5.6 对接 LLM
现在我们已经有了系统提示词、处理好的 diff 内容,接着就是如何调用 LLM 分析结果。

申请 DeepSeek
演示的案例中,我用的是 DeepSeek-v3 的模型。如果能够使用 GPT-4.1 或者 Calude 模型的同学,你可以优先选择使用这两个模型。
这里你需要去到 DeepSeek 官网申请一个 API Key

然后去充值个几块钱,你就可以使用 DeepSeek 这个模型了。

具体申请和使用步骤,官网文档都讲得很清楚了,这里不过多赘述。
调用 LLM
申请完 DeepSeek 的 API Key 以后,就可以通过接口调用了

这里主要关注一下调用接口的入参:
- model: 如果是 deepseek 的话,你选择
deepseek-chat还是deepseek-reasoner都可以 - messages: 这里我们输入两个 message,一个是系统提示词,一个是扩展的 diff
- temperature:设置成 0.2,提高输出的精确性
如果一切调用成功的话,你应该会得到 LLM 一个这样的回复:
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 8
endLine: 8
type: |
new
issueHeader: |
类型定义不严谨
issueContent: |
将 `InputProps` 从具体的接口类型改为 `Record`,虽然提升了灵活性,但丢失了原有的类型约束,容易导致后续代码中出现属性拼写错误或类型不一致的问题。建议保留原有字段定义,并在需要扩展时通过继承或联合类型实现更好的类型安全。
- newPath: |
src/webhook/webhook.controller.ts
oldPath: |
src/webhook/webhook.controller.ts
startLine: 38
endLine: 40
type: |
new
issueHeader: |
参数注入冗余与未使用参数
issueContent: |
在 `trigger` 方法中注入了 `@GitlabToken()`、`@QwxRobotUrl()` 等参数,但实际方法体内并未使用这些参数,而是继续从 headers 中解析相关信息(已被删除)。建议移除未用到的装饰器参数,或者直接替换原有 header 获取逻辑,避免混乱和冗余。
```
5.7 数据解析和异常处理
有了 LLM 回复的数据以后,接着要做的就是将字符串解析成数据,以及处理解析过程中的异常问题
数据解析
这里主要做两个是事,一个是提取 yaml 的内容

提取完字符串以后,然后通过 js-yaml这个包解析数据
const mrReview = yaml.load(yamlContent) as MRReview;
至此,你已经得到一份经过 LLM 分析后产生的实例化的数据了
异常处理
但是你以为到这里就结束了吗?实际的情况却是 LLM 会因为它的黑盒性和不确定性,偶然的输出一些奇奇怪怪的字符或格式,导致出现解析的异常。
场景1:多余的 '\n' 符号
有时候 LLM 在输出的时候,会给 type 字段多加一个 '\n' 符号
{
newPath: "src/agent/agent.service.ts",
oldPath: "src/agent/agent.service.ts",
startLine: 10,
endLine: 12,
type: "new\n"
....
}
看日志的时候,感觉一直没问题。可是到一些具体场景判断的时候,就会开始怀疑人生。当时一些关于 type 的判断,我想破脑袋也没想明白为什么 new 会走到 old 的逻辑里面,结果仔细一看,还有一个换行符……

所以针对这个场景,需要单独加一些处理逻辑。通过 replace 把字符串中的换行符全部去掉。

场景2:多余的空格符号
我们知道 yaml 的字段结构是按空格来控制的,但有时候 LLM 偏偏就在某些字段前面少一个或者多个空格,排查的时候也是非常的头痛,例如下面的 issueHeader、issueContent 因为少了空格,而导致 yaml 解析异常…

我的办法就是让 AI 写了一个兜底处理方法。在解析异常的时候,通过兜底方法再解析一次。 具体代码(查看里面的 fixYamlFormatIssues 方法)
更多场景
因为 LLM 偶现的不稳定性,会导致出现各种奇奇怪怪的问题。目前的解决思路有三个:
- 使用更强大的模型,并调低 temperature 参数
- 调试出更完善的提示词,通过加限制、加示例等技巧,提高提示词的准确性
- 特殊场景,特殊手段。例如通过编码等手段,提前防范这些异常
5.8 上下文分割
还有一个需要解决的问题就 LLM 的上下文长度的限制。像 GPT-4.1 上下文长度有 100w 个 token,但是你用 deepseek 的话,可能只有 64000 个。
一旦你输入的提示词 + diff 内容超过这个上下文,就会报错导致 LLM 无法正常解析。这时我们就不得不把输入的 diff 拆分成多份,然后并行调用 LLM,最后整合数据。

解决这个问题的思路也很简单,每次调用 LLM 前,计算一下系统提示词 + Diff 内容需要消耗的 token,如果超了就把 diff 多差几份。
import { encoding_for_model, TiktokenModel } from '@dqbd/tiktoken';
const encoding = encoding_for_model(this.modelName);
const tokens = encoding.encode(text);
const count = tokens.length;
encoding.free();
我用的是 @dqbd/tiktoken 这个包计算 token,它里面包含了大多数模型的 token 计算方式。
5.9 发送结果
在有了处理好的 review 数据以后,我们就可以调用 GitLab 的接口发送评论了

从上面方法的入参可以看到,newPath、oldPath、endLine、issuceContent 等数据,都是在通过 LLM 分析以后得出来的。
5.10 小结
至此,这个 AI Code Review 的关键流程,我已经讲完了。下面再来总结一下两个流程:
- 逻辑流程
- 使用流程
逻辑流程
- 部署 NodeJS 服务
- 开发 webhook 接口,接受 MR 事件
- 收到事件后,获取 Diff 内容
- 有了 Diff 内容后,扩展行号、文件路径,拼成一个字符串
- 进行 token 分析,超了就分多份进行分析
- 调用 LLM,输入系统提示词、Diff
- 拿到 YAML 结构的分析数据
- 解析数据、处理异常
- 发送评论到 GitLab
使用流程
- 申请 access token
- 配置 webhook
- 发起 MR
- 收到 AI 分析的评论
六、最后
6.1 期待
本篇给大家分享了一个 AI Code Review 应用开发的简单案例。我希望大家可以看完以后,可以在自己的业务或者个人项目中去实践落地,然后再回到评论区给与反馈,展示你的成果。
6.2 学习方法
如果看到文章中有任何不懂的,我建议你都可以直接问 AI。我看掘金自带的这个 AI 助手也挺方便的。我们既然要学习 AI,就要多用 AI 的方式去学习。当然,你也可以直接留言问我。

6.3 关注
最后呢,也是希望大家关注我,我会持续在这个专栏更新我的文章。本想着坚持能够一个月输出两篇,但是在工作忙碌 + 文章质量的不断权衡中,还是写了很久,才写出这一篇。原创不易,需转载请私信我~
这个演示的项目地址:github.com/zixingtangm… (可以的话,也帮忙点点 star ⭐️ 哈哈)
来源:juejin.cn/post/7532596434031149106
使用 AI 助手提升前端代码质量:自动代码审查实战
最近在带团队的时候,发现代码审查(Code Review)总是成为项目进度的一个瓶颈。一方面,高级工程师的时间很宝贵,不可能审查每一行代码;另一方面,初级工程师又急需及时的反馈来提升。于是我就在想:能不能用 AI 来解决这个问题?
经过一番研究和实践,我搭建了一个 AI 代码审查助手,效果出乎意料的好!今天就来分享下这个小工具是怎么做的。
为什么需要 AI 代码审查?
说实话,最开始团队里有不少质疑的声音:"AI 能审查什么代码?""能发现真正的问题吗?"但是经过一段时间的使用,大家发现 AI 代码审查确实能解决很多痛点:
- 人工审查的问题
- 😫 审查疲劳:谁能一直盯着代码看?
- ⏰ 反馈延迟:等高级工程师有空可能需要好几天
- 🤔 标准不一:每个人的审查重点和标准都不太一样
- AI 审查的优势
- 🤖 24/7 全天候服务,随时可用
- 🎯 审查标准统一且可配置
- ⚡️ 秒级反馈,再也不用等人了
- 📚 会不断学习和改进
实战:搭建 AI 代码审查助手
温馨提示:这个项目用到了 OpenAI API,需要自己准备 API Key。新账号有免费额度,够用来测试了。
1. 项目初始化
mkdir ai-code-review
cd ai-code-review
npm init -y
npm install openai eslint prettier
2. 核心代码实现
这是最关键的部分,我们需要:
- 处理各种代码格式
- 设置合适的提示词(prompt)
- 处理 API 限流和错误
// src/codeReviewer.ts
import { Configuration, OpenAIApi } from 'openai'
import { rateLimit } from '@/utils/rate-limit'
class AICodeReviewer {
private openai: OpenAIApi
private reviewCache: Map<string, string>
constructor(apiKey: string) {
const configuration = new Configuration({
apiKey: apiKey
})
this.openai = new OpenAIApi(configuration)
this.reviewCache = new Map() // 缓存常见问题的反馈
}
private async generateReviewPrompt(code: string, language: string): string {
// 根据不同语言定制提示词
const basePrompt = `作为一个资深的${language}开发专家,请审查以下代码,重点关注:
1. 代码质量和最佳实践
2. 潜在的性能问题
3. 安全隐患
4. 可维护性
5. 错误处理
请用中文回复,按严重程度排序,并给出具体的修改建议。
代码:
${code}`
return basePrompt
}
async reviewCode(code: string, language: string = 'JavaScript'): Promise<string> {
try {
// 检查缓存
const cacheKey = this.generateCacheKey(code)
if (this.reviewCache.has(cacheKey)) {
return this.reviewCache.get(cacheKey)!
}
// 限流检查
if (!await rateLimit.check()) {
throw new Error('请求太频繁,请稍后再试')
}
const prompt = await this.generateReviewPrompt(code, language)
const completion = await this.openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [
{
role: 'system',
content: '你是一个资深的代码审查专家,擅长发现代码中的问题并提供建设性的改进建议。'
},
{ role: 'user', content: prompt }
],
temperature: 0.7, // 让回复更有创意一些
})
const review = completion.data.choices[0].message?.content || ''
// 缓存结果
this.reviewCache.set(cacheKey, review)
return review
} catch (error: any) {
console.error('代码审查失败:', error)
throw new Error(this.formatError(error))
}
}
private generateCacheKey(code: string): string {
// 简单的缓存 key 生成
return code.trim().substring(0, 100)
}
private formatError(error: any): string {
if (error.response?.status === 429) {
return '当前请求较多,请稍后再试'
}
return '代码审查服务暂时不可用,请重试'
}
}
export default AICodeReviewer
3. VSCode 扩展实现
这是我们团队最常用的功能,可以直接在编辑器里获取 AI 反馈:
// extension.ts
import * as vscode from 'vscode'
import AICodeReviewer from './codeReviewer'
export function activate(context: vscode.ExtensionContext) {
// 注册命令
let disposable = vscode.commands.registerCommand('aiCodeReview.review', async () => {
const editor = vscode.window.activeTextEditor
if (!editor) {
vscode.window.showErrorMessage('请先打开要审查的代码文件')
return
}
// 获取当前文件的语言
const language = editor.document.languageId
const code = editor.document.getText()
// 显示加载状态
const statusBarItem = vscode.window.createStatusBarItem(
vscode.StatusBarAlignment.Left
)
statusBarItem.text = '$(sync~spin) AI 正在审查代码...'
statusBarItem.show()
try {
const reviewer = new AICodeReviewer(
vscode.workspace.getConfiguration().get('aiCodeReview.apiKey') as string
)
const review = await reviewer.reviewCode(code, language)
// 在侧边栏显示结果
const panel = vscode.window.createWebviewPanel(
'aiCodeReview',
'AI 代码审查报告',
vscode.ViewColumn.Two,
{}
)
panel.webview.html = `
<!DOCTYPE html>
<html>
<head>
<style>
body { padding: 15px; }
.review { white-space: pre-wrap; }
.severity-high { color: #d73a49; }
.severity-medium { color: #e36209; }
.severity-low { color: #032f62; }
</style>
</head>
<body>
<h2>AI 代码审查报告</h2>
<div class="review">${this.formatReview(review)}</div>
</body>
</html>
`
} catch (error: any) {
vscode.window.showErrorMessage(error.message)
} finally {
statusBarItem.dispose()
}
})
context.subscriptions.push(disposable)
}
实战经验分享
经过几个月的使用,我总结了一些经验:
1. 提示词(Prompt)很重要
- 🎯 要让 AI 关注特定领域的最佳实践
- 📝 提供具体的评审标准和格式要求
- 🌐 针对不同编程语言定制提示词
2. 合理的使用场景
- ✅ 适合:代码风格检查、基本的逻辑问题、文档完整性
- ❌ 不适合:业务逻辑正确性、系统架构决策、性能调优
3. 成本控制
在实际使用中,我发现几个控制成本的好办法:
- 缓存常见问题
- 类似的代码问题可以复用审查结果
- 显著减少 API 调用次数
- 合理的调用策略
- 不是每次保存都触发审查
- 设置合适的调用间隔
- 批量处理多个文件的审查
- 优化 token 使用
- 只发送必要的代码片段
- 限制单次审查的代码长度
- 选择合适的模型(3.5 通常就够用)
实际效果
使用这个工具后,我们团队有了一些明显的改善:
- 代码质量
- 基础问题大幅减少
- 代码风格更统一
- 新人学习曲线变缓
- 开发效率
- PR 审查时间减少 50%
- 反馈速度提升
- 开发体验更好
- 团队氛围
- 减少了代码审查的争议
- 新人更敢提问和讨论
- 代码审查不再是负担
写在最后
这个 AI 代码审查助手现在已经成为我们团队日常开发的好帮手了。它不是来替代人工代码审查的,而是帮我们过滤掉那些基础问题,让我们能把精力放在更有价值的讨论上。
如果你也想尝试,建议从小范围开始,慢慢调整和优化。毕竟每个团队的情况都不一样,找到最适合自己团队的方式才是关键。
如果觉得有帮助,别忘了点赞关注!之后我还会分享更多提升开发效率的实战经验~
来源:juejin.cn/post/7440818887455604736
小红书小组件开发 最早踩坑版
前言

是这样的,这段小红书逛的多,发现有一篇关于小红书小组件的介绍,介绍里提到的是[AI调酒]这款小组件,在内容里可以直接挂载。我试玩了一下,还挺有趣,交互感挺强的。
然后下面提到说,留言即可有机会获取内测开发资格,内测时可以免费使用里面的AI功能。
想着能白嫖就报名了,正好加入小红书生态,好宣传自己的app一波,hhh
没想到过一天就受到了科技署的邀请,加入了内测群!
开发
进群后,就令我感到有点诧异了,群里陆续进去了21个人,有15个工作人员,6个被邀请的开发。进去后,组织者发了一个操作文档:
各位好,我们是小组件项目的产品和研发,各位可以先提供下自己的小红书账号,我们为大家添加测试白名单
添加后需要完成的事项:
1、前往小红书开放平台创建开发者账号(开白后可申请个人主体账号,若已有账号可忽略)
https://miniapp.xiaohongshu.com/home
2、查阅小组件和智能体的开发文档,下载开平IDE工具,进行设计和开发
小组件开发介绍:https://miniapp.xiaohongshu.com/doc/DC026740
智能体开发介绍(如果需要在小组件中内嵌AI服务):https://miniapp.xiaohongshu.com/doc/DC783288
最佳实践:https://miniapp.xiaohongshu.com/doc/DC246551
3、由于小组件是无需备案的,因此平台会承担一定风险,因此有明确的创作方向后,需要开发者提供简易的demo图,我们会做内部的产品&研发&安全的可行性评估
🌟🌟 在过程中,大家如果有流程、开发、设计上的问题,都可以群内和我们沟通,由于这是小组件第一波内测,所以不可避免地可能还有些问题,大家提出来后我们也会及时处理优化,也感谢大家理解[合十]
🌟🌟 也辛苦各位重点关注:小组件整体的定位是「轻量、简单」,以及整体的UI设计也希望能「简介、美观」,更符合小红书社区氛围,这样更容易在社区总传播

意思就是,大家按照文档操作就行,基本没什么大问题。
但是小问题还是挺多的。
里面的很多开发,基本都有小红书小程序的开发经验了,这次感觉纯属了为了捧场或者是和我一样,做完后有没有什么推流。他们基本上很快就做完了。
我就不一样了,有主职工作而且一直做的是移动原生,虽然之前学过一丢丢微信小程序开发,但都已经过了差不多3年了。
但来都来了。
小组件

小组件开发可以独立进行,不依赖其他的三方。如果可以的话,你可以开发个很简易的demo上去,当然你还得经过小红书官方的审核,如果太基础的话就不太行,这个大家都懂得。
一般来讲,小组件需要依赖后台服务,或者是小红书他们提供AI智能体,毕竟咋们是奔着它去的。而且给的demo也是关于智能体。
第一步下载编辑器

编辑器好像是需要这个版本才行,是官方人员直接在群里发的。最新版本的编辑器融合了AI功能,真的很给力,我自己写好了核心的逻辑后,让它来美化UI真是太省事了,而且美化的UI和小红书官方的小组件交互效果有点类似,有点红薯风,对于我这种没有UI审美的开发来说是一大福星,而且比免费版本的cursor好用。
跟着文档开发后
跟着文档开发,这里就不贴具体的过程了,因为文档也会更新,会更完善。因为我们是第一版本,所以文档里有很多遗漏的和错误的,这里补充一下这部分,如果再有人开发到这一步,可能会用的到。
隐私协议:
xhs.openClipLegalPolicy();
小组件核心代码:
因为我是调用的是智能体,调用智能体的代码用官方的那样写是有问题的,写了好久有跑不通,咨询了很久才得到正确的代码:
初始化agent
// 初始化 Agent env: 'production'按需选择线上和测试
async initAgent() {
try {
const agentId = "test6baffa154e6db2d96e64ef310a6e";
const agent = xhs.cloud.AI.createAgent({
agentId,
env: 'production',
version: '0.1.8'
});
this.setData({
agent: agent
});
console.log("Agent初始化成功");
} catch (error) {
console.error("Agent初始化失败: ", error);
xhs.showToast({
title: "Agent初始化失败",
icon: "none",
});
}
},
// 调用智能体 解梦
if (this.data.agent == null) return;
const agentInfo = this.data.agent.getAgentInfo();
console.log("res", agentInfo);
// 使用回调方式发送消息
const { message, onMessage, onSuccess, onError } = this.data.agent.sendMessage({
msg: dreamContent,
history: [],
});
onSuccess((result) => {
this.setData({
isOver:true
})
console.log("请求成功:", result);
console.log("API调用成功,返回结果:", result);
// result.data.data
xhs.hideLoading();
});
// 监听流式消息
onMessage((chunkStr) => {
// console.log("收到消息块:", chunkStr, "api-message", message);
xhs.hideLoading();
if (chunkStr === "[DONE]") {
return;
}
let chunk = null;
try {
chunk = JSON.parse(chunkStr);
} catch (error) {
console.error("解析消息块失败:", error);
return;
}
// 解析消息块
if (chunk!=null&&chunk.choices && chunk.choices[0] && chunk.choices[0].message) {
const message = chunk.choices[0].message;
console.log("收到消息块 message:", message.content);
// 处理回复内容
if (message.content) {
this.setData({
dreamInterpretation:this.data.dreamInterpretation + message.content
})
this.setData({
isLoading: false,
showResult: true,
resultDream: dreamContent,
dreamInterpretation: this.data.dreamInterpretation
});
}
}
});
// 监听错误回调
onError((error) => {
console.error("请求失败:", error);
xhs.hideLoading();
xhs.showToast({
title: "生成失败,请重试",
icon: "none",
});
});
智能体

智能体分为流式和非流式的。
看具体的业务需求了,如果是很快的生成 和 生成的文本很短,就像[AI调酒],只需要简单的json即可,那就可以用非流式的。
像我这种需要生成长文本的就有点不太适合了,所以这里选择的是流式输出的形式。
核心代码:
// {user_mood: '开心',user_taste: '随便'}
async sendMessage(input) {
console.log('message -- '+ JSON.stringify(input))
console.log('--')
console.log('msg -- '+ input.msg)
const model = this.createModel('deepseek-v3')
const messages = [
{
role:'system',
content: systemPrompt
},
{
role:'user',
content:{
type:'text',
content: input.msg
// content: JSON.stringify(input)
// content: '{\'user_mood\': \'开心\', \'user_taste\': \'随便\'}'
}
}
]
const modelResponse = await model.streamText({
enable_thinking:false,
temperature:1,
messages: [
{
role: 'system',
content: systemPrompt
},
{
role: 'user',
content: {
type: 'text',
// JSON.stringify(input.msg)
content: JSON.stringify(input)
// context:input.msg
}
}
]}
)
console.log('aaaa')
for await (const chunk of modelResponse) {
this.sseSender.send({ data: chunk });
}
console.log('bbbb')
this.sseSender.end();
}
systemPrompt 指的是提示词,提示词是ai的核心,这里可以返回json或者是markdown或是html样式。如果不会写提示词,也可以让ai给你写提示词,hhh
End

最后附一张截图。各位大佬有兴趣可以在小红书里搜索AI解梦小组件 ,里面有笔记进行挂载。
发布后发现,官方根本没有推流,而且后续也没提小组件这回事了🤡。
不过就当自己玩玩了,可以使用免费的ai服务进行快速解梦~
来源:juejin.cn/post/7564540677478301759
为了搞一个完美的健身APP,我真是费尽心机
作为一个强迫症患者,当我需要一个简单、好用、流畅、无广告的健身记录软件时,撸铁记就诞生了。
为什么我要开发撸铁记
我应该是2018年接触健身的,那个时候我的教练每次给我上课,都会拿着一个文件夹记录我的每一次训练。但是纸制记录最大的问题是难保存,而且只能教练一个人看,于是我写了第一个健身记录软件,叫FitnessRecord,然后我就在知乎上分享了自己的应用,没想到真的有人用!
后来,在朋友的撺掇下,我正式决定将撸铁记推上线,然后就是(巴拉巴拉极其费劲的上线了!)
个人开发者有多痛苦
一个完美的软件,最重要的,不仅要好看,还得好用,于是,就出现了下面这些设计
暗黑模式
一个 APP,如果不支持暗黑模式,那你让强迫症怎么活?


但是...你以为这就完了吗?细节藏在魔鬼里😄
绝对黑
记得前两年各大手机厂商还在卷屏幕的时候,苹果率先推出了“绝对黑”,强调OLED屏幕通过像素关闭实现的物理级纯黑效果。so~为了实现在暗黑模式下,软件用的更爽,撸铁记的 APP 的背景色使用了#000000,也就是纯黑色
这样做的好处是在暗黑模式下,撸铁记可以与屏幕完美的融为一体。但是!问题来了。纯黑色真的很难设计,作为一个程序员出身的我,头发都抓掉了好几把。
有细心的小伙伴们或许已经发现了,亮色模式下跟暗黑模式的主题色其实不是一个颜色:

我们发现在暗黑模式下,亮色模式下的主题色与黑色之间的对比度不够明显,导致整体色调暗沉,因此,亮色模式的主题色是:#3B7AEF 暗黑模式下则是:#2E6FEC
虚拟导航键适配
Android 的虚拟导航键如果适配不好,有多丑相信懂得都懂,为了能够在弹窗模式下也能够让弹窗与导航栏完美无瑕的融为一体,我设计了一个 BaseDialog,专门用来管理弹窗状态,确保在任何页面,虚拟导航栏都不会影响到 APP 的整体颜值!

左滑展示更多功能
作为一个专业的记录软件,各种各样的功能总要有吧?
全部堆叠到更多菜单中是不是很傻?如果在屏幕排列出来展示是不是更傻?所以,左滑删除这种很合理的交互是不是得有?
IOS 设备是常态,但是能够完美的搬到 Android 机器上,该怎么做?鸿蒙系统又该怎么适配?!
但是!我说的是但是,为了更漂亮的 UI,更合理的交互,我又熬了个通宵,最终完美解决!

好的交互就得多看,多学
每个人的习惯都不同,比如有的用户希望能够在倒计时 120s 之后有一个声音提示,有的则希望可以按照训练顺序,对卡片自动排序,那么问题来了,这些功能又该堆叠在哪里呢?
我的灵感来源是一款不太出名的 P 图软件
在训练详情页面的左侧,有一根很不起眼的线,当你触摸这条线的时候,就会弹出训练设置的总菜单啦!(不用担心很难触摸,我已经将触摸范围调整到了最合适的大小,既不会误触,也不会很难点👍)

其实,APP 还有很多为了“好看”而做的设计,但是一个好的 APP,只是静态的好看怎么能行!
完美的入场动效
我该如何像您吹嘘这系统级的丝滑动效?请看 VCR(希望掘金支持视频链接😂):
http://www.bilibili.com/video/BV1sb…
http://www.bilibili.com/video/BV1Pb…
如何?是否足够丝滑???
当然,功能性才是核心
除了记录的易用性和强大复杂的功能,为了能够 360° 覆盖健身所需要的所有场景,我还开发了各种各样的功能
赛博智能
赛博智能,我希望这个功能可以像赛博机器人一样,对我的身体状况进行 360° 评估。
鄙人不才,晒一下我的身体状态评估分析:

一个超级大长图,几乎涵盖了你想要知道的一切~当然,后续还会继续丰富其他功能😁
日历统计

这个月你偷懒了吗
是的,你的每一滴汗水,都会浓缩破到这一张小小的日历表格中,如果你偷懒了,那就是一张空空的日历,那么,你会努力填满每一天的,对吧?
最后的最后
按原本的计划,我想要从设计到功能,认真的介绍一下撸铁记的所有方方面面,但是回头看看,文章真的太长了,所以,就留一点悬念给大家,希望需要的小伙伴自行探索😁
其实,每一个细节,我都改过很多次,后续依旧会不断的改来改去,因为我只想要最好~
最后,祝愿所有喜欢健身的朋友,都可以收获自己成功~
来源:juejin.cn/post/7524504350250205238
Electron 内网离线打包全攻略
一、背景与问题核心
近期维护一个内网传统网页开发项目,该项目采用「网页+Electron壳」的架构。由于原Electron版本过旧,导致项目中依赖的Antv G6 v5图表库出现兼容性问题(表现为图表渲染异常或功能报错)。升级Electron本身可参考官方文档快速实现,但内网环境下打包时无法联网下载预编译二进制文件,成为本次迁移的核心难点。本文将详细记录完整解决方案,帮助有类似需求的开发者避坑。
二、完整实操流程
整个过程分为「依赖安装配置」和「离线缓存准备」两大步骤,确保开发环境运行与内网打包均正常。
Step 1:安装并配置Electron依赖
Electron默认会根据当前系统自动下载对应平台的预编译包,但内网环境需提前指定下载参数,避免后续打包时依赖网络。
1.1 创建.npmrc文件固定下载参数
在项目根目录新建.npmrc文件,写入以下内容(根据实际需求修改平台和架构,此处以Windows x64为例):
# .npmrc 配置
# 系统架构(x64/arm64等)
arch=x64
# 操作系统(win32/mac/linux等)
platform=win32
# 可选:设置npm镜像(非必需,若内网有镜像可配置)
# registry=https://your-internal-npm-mirror.com/
1.2 安装核心依赖
执行以下命令安装Electron及打包工具@electron-forge/cli(用于后续打包操作):
# 安装开发依赖
npm install electron @electron-forge/cli --save-dev
# 将项目导入Electron Forge(自动生成打包配置文件forge.config.js)
npx electron-forge import
1.3 验证开发环境
确保package.json中已指定Electron入口文件(通过main字段配置,如"main": "main.js"),随后运行以下命令启动项目,验证Antv G6兼容性是否解决:
npm run start
💡 注意:若启动后图表仍异常,可检查Antv G6是否与当前Electron版本匹配(参考G6官方兼容性说明),或清除node_modules后重新安装依赖。
Step 2:准备离线缓存文件
Electron打包时需依赖预编译二进制文件,内网环境无法联网下载,因此需提前在外网环境下载对应文件并配置缓存路径。
2.1 下载对应版本的Electron预编译包
- 查看项目中实际安装的Electron版本:在package.json中找到electron的版本号(如"electron": "^38.4.0");
- 访问Electron镜像地址:npmmirror.com/mirrors/ele…
- 下载以下文件(以win32-x64为例):
- electron-v38.4.0-win32-x64.zip(对应系统的预编译包)
- SHASUMS256.txt(文件校验码,用于验证完整性)
2.2 校验文件完整性(可选但推荐)
下载完成后,通过校验工具(如Windows的PowerShell、Linux/macOS的终端)验证文件哈希值是否与SHASUMS256.txt一致,避免文件损坏:
Windows PowerShell示例(替换文件名和版本号)
Get-FileHash .\electron-v38.4.0-win32-x64.zip -Algorithm SHA256 | Select-Object Hash
将输出的哈希值与SHASUMS256.txt中对应文件名的哈希值对比,一致则文件完整。
2.3 配置forge.config.js离线缓存路径
在项目根目录创建electron-cache文件夹,将下载的预编译包和校验文件放入其中。然后修改forge.config.js,在packagerConfig中添加缓存配置:
const { FusesPlugin } = require("@electron-forge/plugin-fuses");
const { FuseV1Options, FuseVersion } = require("@electron/fuses");
const path = require("path");
module.exports = {
packagerConfig: {
asar: true, // 启用asar打包(可选,用于压缩和保护资源)
download: {
// 本地缓存镜像路径(绝对路径更稳妥)
mirror: path.resolve(__dirname, "electron-cache"),
cache: path.resolve(__dirname, "electron-cache"),
focus: false, // 禁用下载进度聚焦(避免终端干扰)
},
electronZipDir: path.resolve(__dirname, "electron-cache/"), // 预编译包所在目录
},
// ... 其他配置
};
2.4 执行内网离线打包
完成上述配置后,在项目根目录执行打包命令,Electron Forge将从本地缓存读取预编译包,无需联网:
npm run make
打包成功后,可在项目根目录的out文件夹中找到对应系统的安装包或绿色版程序。
三、关键注意事项
- 路径必须准确:配置中使用path.resolve生成绝对路径,避免相对路径导致的缓存找不到问题;
- 文件名严格匹配:本地缓存的预编译包文件名需与官方一致(如electron-v{version}-{platform}-{arch}.zip),否则无法识别;
- 多系统适配:若需打包多个系统(如Windows和macOS),需下载对应平台的预编译包放入缓存文件夹,无需修改配置;
- 版本号统一:确保package.json中的Electron版本与下载的预编译包版本完全一致,避免兼容性问题。
四、总结
本次Electron升级及内网打包的核心是「提前配置下载参数+本地缓存预编译包」。通过固定.npmrc参数确保依赖安装时匹配目标系统,再通过配置Forge的缓存路径实现离线打包,最终解决了Antv G6的兼容性问题和内网环境限制。若后续需升级Electron版本,只需重复「下载对应版本预编译包→更新缓存文件夹」的步骤即可。
如果遇到其他特殊场景(如内网npm镜像配置、asar包解压问题),欢迎在评论区交流讨论!
来源:juejin.cn/post/7564472484067835923
【深入浅出Nodejs】异步非阻塞IO
概览:本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
I/O模式
I/O模式介绍
1.文件描述符
类unix操作系统将I/O抽象为文件描述符(file description,下面简称fd),可读/可写流都可以看做读一个“文件”,打开文件和创建Socket等都是获取到一个fd文件描述符。
2.操作I/O时发生了什么
操作流就是读和写(read/write),下面用read进行说明。read时需要CPU进入内核态等待操作系统处理数据,等操作系统完成后会响应结果。用户态切换到内核态仅仅是CPU执行模式切换,线程本身并未改变,CPU进入内核态才能进行外部设备(外设)的准备工作,从而支持后续数据复制到内核缓冲区,完成后再切换回用户态,然后真正的读数据到用户程序。
3.五种I/O模式

如图,操作系统有5种I/O模式。
- blocking
- nonblocking
- multiplexing
- signal-driven (很少使用,不介绍)
- async I/O
可以的话,不妨看完下面详细介绍后再回过头看这张图,对5种模式进行对比,相信你认识一定会更加深刻。
阻塞I/O (blocking)
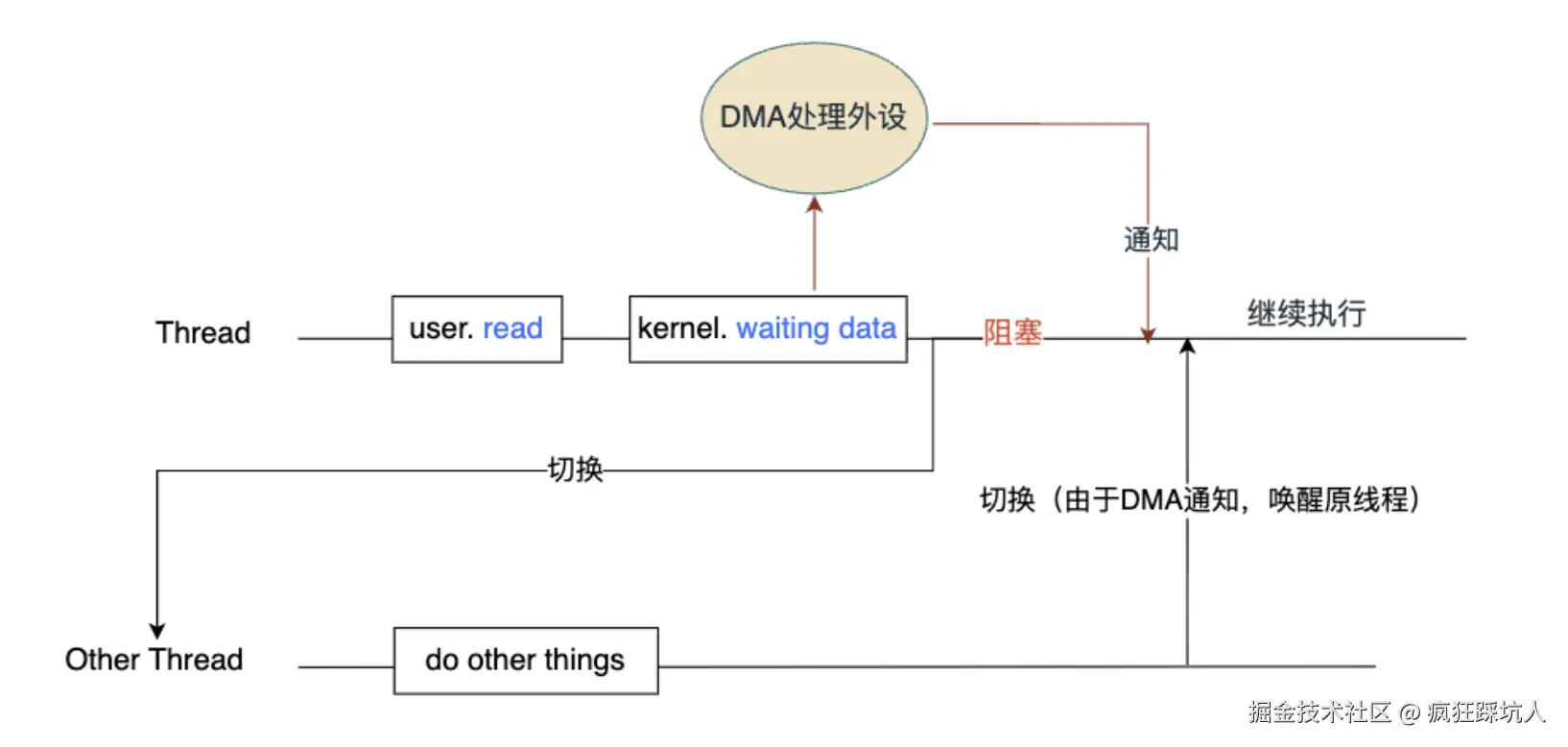
- 当用户态调用read API读流时,操作系统陷入内核态开始准备数据。
- 此时read是阻塞的。CPU是会切换到其他线程,做其他事的。原因就是现代计算机(采用了DMA技术)对于这种磁盘读取工作中的数据传输部分CPU是不参与的,交给了DMA控制器负责,等处理好了DMA会发出一个CPU中断,通知CPU切换回原来的线程继续处理。
- 所以线程一定是阻塞的,当前线程的执行权让出去了,也就是说没有CPU时间片继续执行当前线程。
- 内核态数据准备完成,原来的Thread被唤醒,继续执行,表现为API读流返回了数据。
P.S. DMA是通知操作系统,唤醒原来Thread,继续执行。并不是通知Thread的具体某段程序执行,而是之前被阻塞时执行到哪,现在就继续执行哪里。
非阻塞I/O (non-blocking)
为甚么还要有非阻塞I/O?
显然,阻塞I/O会导致后面的代码不能继续执行,在要处理多个I/O的情况下就是串行发起I/O操作了。而非阻塞I/O就是希望发起I/O操作是并发的(不用等上一个流操作结束才发起下一个)。
非阻塞I/O: 调用read去读fd的数据时,立即返回fd的状态结果,不阻塞后面代码的执行。此时操作系统就需要考虑如何实现这种非阻塞,如管理多个I/O流。
/*伪代码*/
fd = openStream(); //打开文件,创建Socket等都能获得一个fd,不阻塞
n = read(fd); //读取这个fd的数据,不阻塞
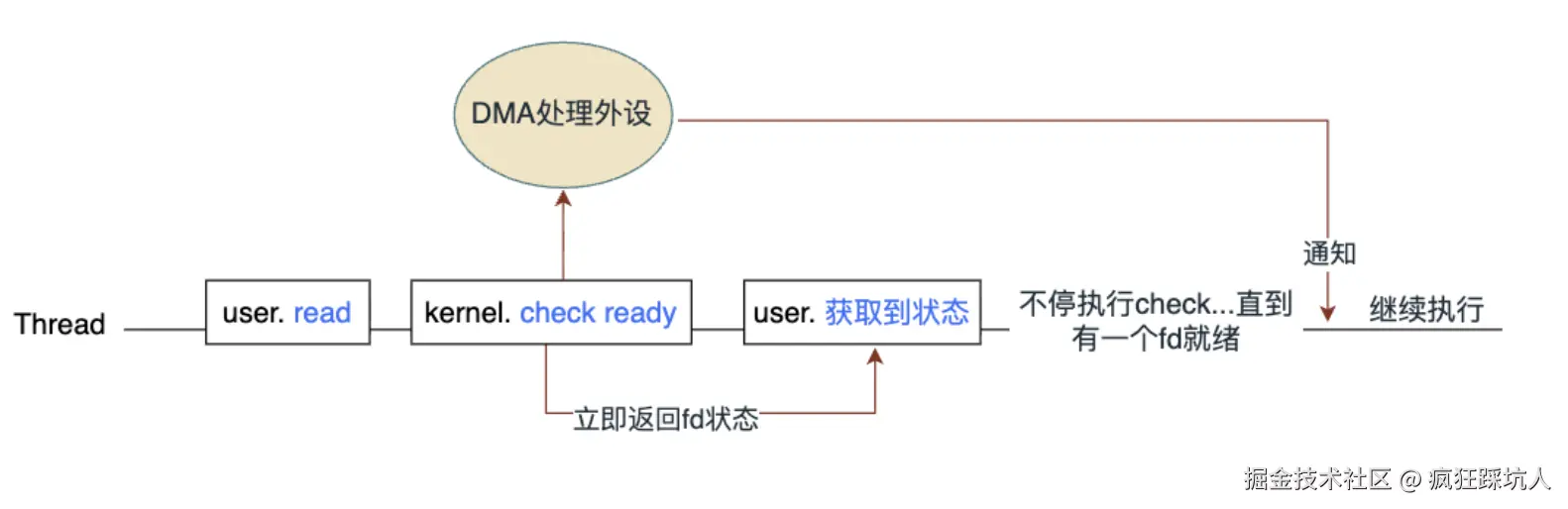
- 当用户态调用read API读流时,操作系统陷入内核态检查数据是否就绪。
- 此时read是不阻塞的,可以继续执行后面的代码。但是后续需要不断「check」(就是read)来检查数据是否就绪。
- DMA通知唤醒Thread(如果Thread一直都是激活状态,不存在被唤醒这一动作)。「check」发现有fd的数据就绪,就进行数据处理。
非阻塞I/O 是指read读数据能立即返回fd状态,而不用等待,但是需要你主动去read。如下图所示(图来自《深入浅出Nodejs》):
C++伪代码实现
// 文件描述符集合
std::vector<int> fds = {fd1, fd2, fd3}; // 假设有3个需要监控的文件描述符
// 设置为非阻塞模式
for(auto& fd : fds) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
// 轮询循环
while(true) {
bool all_done = true;
// 应用层轮询每个文件描述符
for(auto fd : fds) {
char buffer[1024];
ssize_t n = read(fd, buffer, sizeof(buffer)); // 非阻塞调用
if(n > 0) {
// 成功读取到数据
process_data(buffer, n);
}
else if(n == 0) {
// 连接关闭
remove_fd(fd);
}
else if(n < 0) {
if(errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据未就绪,立即返回 - 继续轮询其他fd
continue;
} else {
// 真实错误
handle_error(fd);
}
}
// 检查是否还有需要处理的数据
if(has_pending_operations()) {
all_done = false;
}
}
// 可选的短暂休眠避免CPU占用过高
if(all_done) {
usleep(1000); // 1s休眠
}
// 退出条件
if(should_exit) break;
}
此时,还需要我们手动一个个检查fd的状态。下面就介绍I/O多路复用,它做到了批量监听多个fd状态,不用我们手动去管理监听每一个fd了。
I/O多路复用(multiplexing)
类unix操作系统下,多路复用的方式有 select, poll, epoll(macos/freeBSD 上的替代品是 kqueue)。而在windows下面则直接使用IOCP(基于线程池的异步I/O方式),下面会介绍。
select、poll分别早在1983年、1986年就出现了,而epoll知道Linux2.6(大约2003)年才出现。
现代系统都是非阻塞I/O大都采用epoll或者IOCP的方式作为主流I/O并发方案了。
select
通过select()系统调用来监视多个fd的数组,返回一个int值(表示了fd就绪的个数),当调用select会阻塞,直到有一个fd就绪。
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
//maxfdp:被监听的文件描述符的总数;
//readset:读fd集合
//writeset:写fd集合
//exceptset
//timeout:用于设置select函数的超时时间,即告诉内核select等待多长时间之后就放弃等待。
//返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。
下图展示了select方式(图来自《深入浅出Nodejs》):
具体过程大致如下:
1、调用select()方法,上下文切换转换为内核态
2、将fd从用户空间复制到内核空间
3、内核遍历所有fd,查看其对应事件是否发生
4、如果没发生,将进程阻塞,当设备驱动产生中断或者timeout时间后,将进程唤醒,再次进行遍历
5、返回遍历后的fd
6、将fd从内核空间复制到用户空间
poll
poll是对select差不多,当调用poll会阻塞。但进行了一定改进:使用链表维护fd集合(select内是使用数组),这样没有了maxfdp的限制。
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// fds:polld结构体集合,每个结构体描述了fd及其事件
// nfs:指定 `fds`数组中的元素个数,类型 `nfds_t`通常为无符
// timeout:等待时间,`-1`表示阻塞等待直到有事件发生;`0`表示立即返回(非阻塞);大于 `0`则表示最长等待时间
// 返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要监视的事件(输入) */
short revents; /* 实际发生的事件(输出) */
};
下图展示了poll方式(图来自《深入浅出Nodejs》):
poll方式伪代码
// 主循环
while (1) {
int ret = poll(fds, nfds, 3000); // 等待 3 秒
if (ret < 0) {
perror("poll error");
break;
} else if (ret == 0) {
printf("[poll] 超时,没有事件\n");
continue;
}
// 遍历所有 fd,检查哪些 revents 有标志
for (int i = 0; i < nfds; i++) {
if (fds[i].revents & POLLIN) {
char buf[1024];
ssize_t n = read(fds[i].fd, buf, sizeof(buf) - 1);
if (n > 0) {
buf[n] = '\0';
process_data(buf, n, fds[i].fd);
} else if (n == 0) {
// EOF,连接关闭
remove_fd(fds, &nfds, i);
i--; // 数组被压缩,重新检查当前位置
} else if (n < 0 && errno != EAGAIN && errno != EWOULDBLOCK) {
perror("read error");
remove_fd(fds, &nfds, i);
i--;
}
}
}
if (nfds == 0) {
printf("所有 fd 都关闭了,退出。\n");
break;
}
}
poll和select的区别不大,都是要遍历fd看是否有就绪。最大的区别在于poll没有监视的fd集合大小限制(因为采用的链表),而select有大小限制(因为内部采用的数组存储,可以通过参数maxfdp修改,默认1024)。
epoll
epoll_create创建一个 epoll 实例,同时返回一个引用该实例的文件描述符
int epoll_create(int size);
epoll_ctl 会将文件描述符 fd 添加到 epoll 实例的监听列表里,同时为 fd 设置一个回调函数,并监听事件 event,如果红黑树中已经存在立刻返回。当 fd 上发生相应事件时,会调用回调函数,将 fd 添加到 epoll 实例的就绪队列上。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// 表示要监听的目标文件描述符
// op 表示要对 fd 执行的操作, 例如为 fd 添加一个监听事件 event
// event 表示要监听的事件
// 返回值 0 或 -1,表示上述操作成功与否。
epoll 模型的主要函数epoll_wait,功能相当于 select。调用该函数时阻塞,等待事件通知唤醒进程。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// events 是一个数组,保存就绪状态的文件描述符,其空间由调用者负责申请
// maxevents 指定 events 的大小
// timeout 类似于 select 中的 timeout。如果没有文件描述符就绪,即就绪队列为空,则 epoll_wait 会阻塞 timeout 毫秒。如果 timeout 设为 -1,则 epoll_wait 会一直阻塞,直到有文件描述符就绪;如果 timeout 设为 0,则 epoll_wait 会立即返回
// 返回值表示 events 中存储的就绪描述符个数,最大不超过 maxevents。
下图展示了epoll方式(图来自《深入浅出Nodejs》):
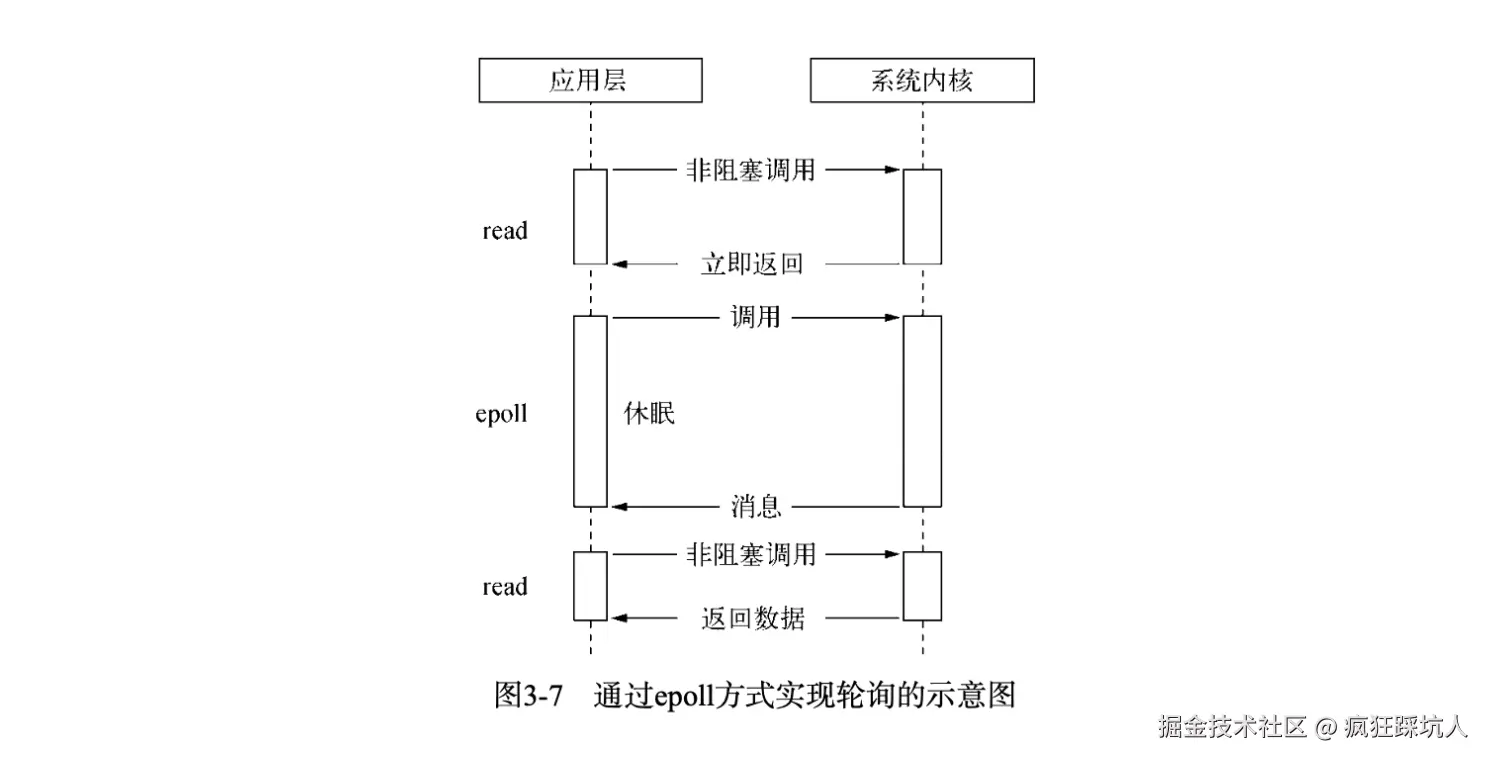
epoll方式伪代码
int epfd = epoll_create(1024);
struct epoll_event ev, events[MAX_CONN];
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &ev);
while (1) {
int n = epoll_wait(epfd, events, MAX_CONN, -1);
for (int i = 0; i < n; i++) {
if (events[i].events & EPOLLIN) {
// 处理可读事件
}
}
}
select和poll存在的缺点:
- 内核线程需要遍历一遍fd集合,返回给用户空间后需要应用层再遍历一遍fd数组。
- 每次select/poll都会内核空间到用户空间拷贝fd集合。
- 性能开销随fd线性增加,时间复杂度O(n)
epoll主要改进点:
- 通过
epoll_ctl提前给fd设置一个事件回调函数,fd上有事件触发了就执行回调函数,把fd放到一个就绪队列上,这样在内核线程是不存在遍历fd集合的,时间复杂度O(1)。 epoll_wait不会对fd集合在内核空间和用户空间拷贝, 而是“利用mmap()文件映射内存加速与内核空间的消息传递,减少拷贝开销。”
到这里,我们可以试着总结non-blocking和多路复用区别和联系。
区别:
- non-blocking I/O:靠不断“主动轮询”实现不阻塞
- I/O 多路复用:靠“事件通知 + 轮询”实现更高效的不阻塞
个人理解,广义的来说,多路复用本身也是一种非阻塞I/O。
异步I/O
尽管epoll已经利用了事件来降低CPU的耗用,但是休眠期间CPU几乎是闲置的,对于当前线程而言利用率不够,那么是否有一种理想的异步I/O呢?
下图展示了理想的异步I/O(图来自《深入浅出Nodejs》):
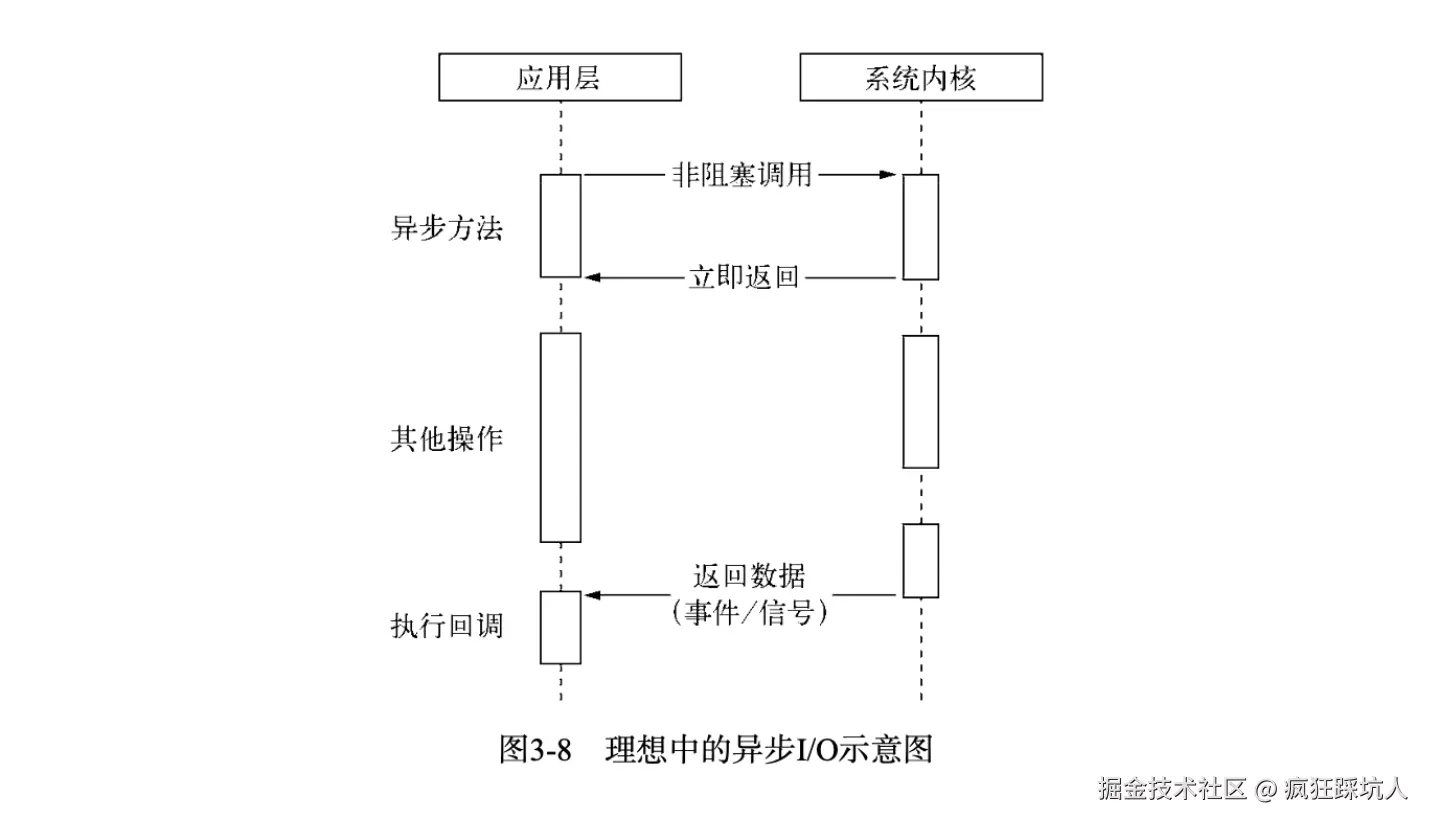
真正的异步I/O是在操作流时(发起异步操作)即不阻塞后续的代码执行,又不需要自己去主动轮询(read),只需要内核通知应用层执行回调(并且数据从内核空间读取到用户空间也是不阻塞的)。很遗憾,这种异步I/O几乎不存在(之所以说几乎,是因为Linux原生提供了一种这样的异步I/O——AIO,但存在缺陷)。
现实中的异步I/O,基本上都是通过线程池的方式来实现的,windows的IOCP也是内核级别实现了线程池。
在Node单线程中,通过让其他部分线程进行「阻塞I/O」或者「非阻塞I/O+轮询技术」来完成数据获取,等数据获取完成后通知主线程执行回调。此时主线程是不会让出CPU执行权的,可以一直继续执行其他代码。这样就实现了异步I/O。
下图展示了线程池模拟的异步I/O(图来自《深入浅出Nodejs》):
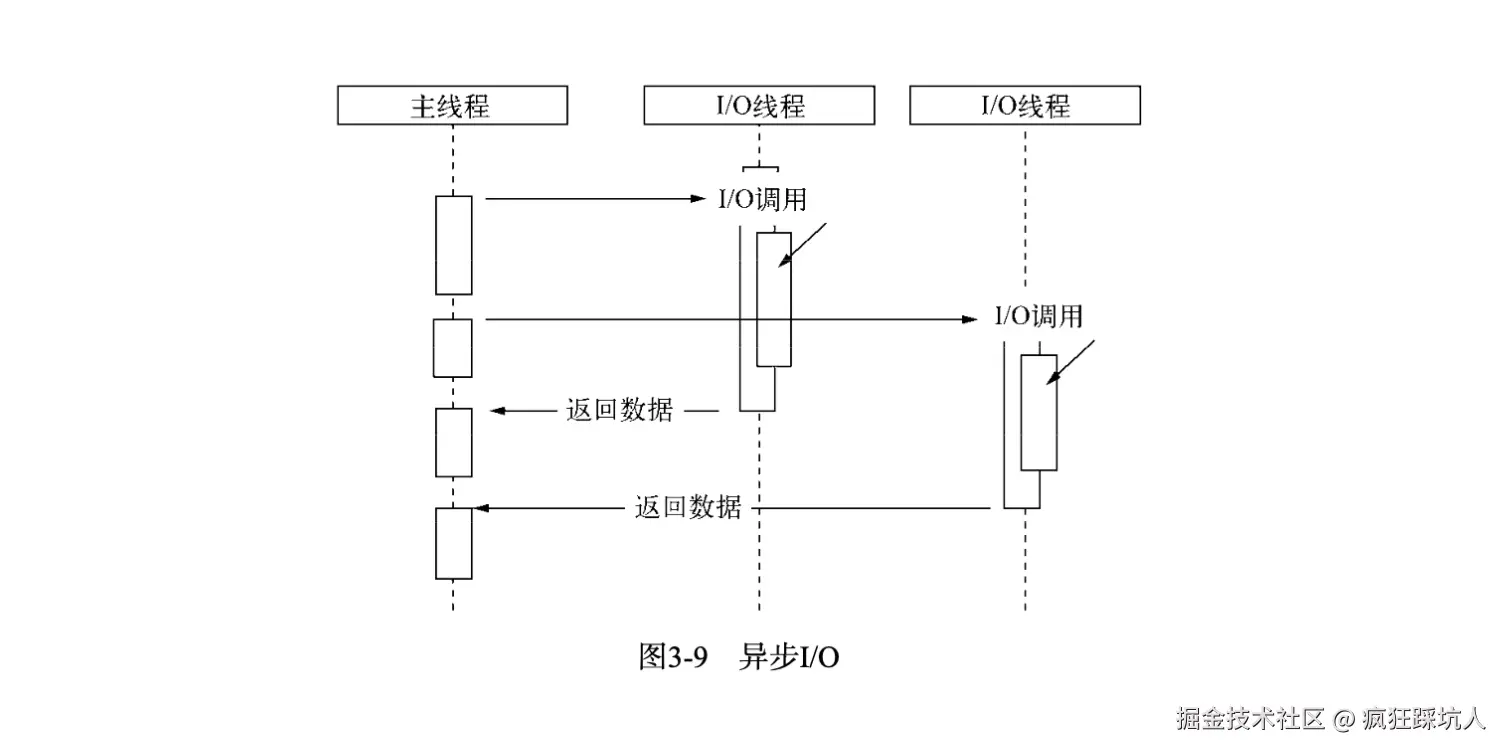
由于Windows和*nix的平台差异,Node提供了libuv作为抽象封装层来对不同平台做兼容性判断。
下图展示了Node的libuv架构(图来自《深入浅出Nodejs》):
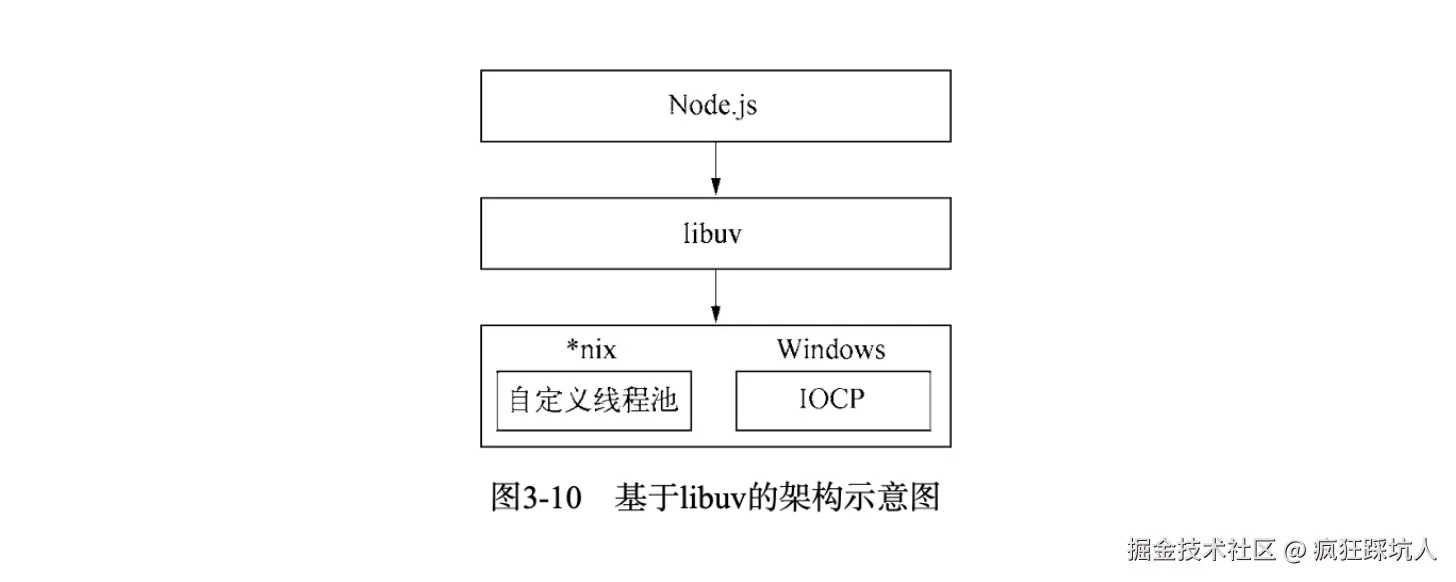
Node的事件循环
请求对象 :一个异步I/O的发起,libuv会产生一个封装好的请求对象。比如fs.open会产生一个FSReqWrap的对象。
观察者: 可以理解成观察者模式中的观察者,它主要是观察判断事件队列中是否有事件了,当有事件了就需要去处理这个事件。
这里我用一张流程图说明发起异步I/O是如何被线程池执行,然后通过事件通知主线程的流程。
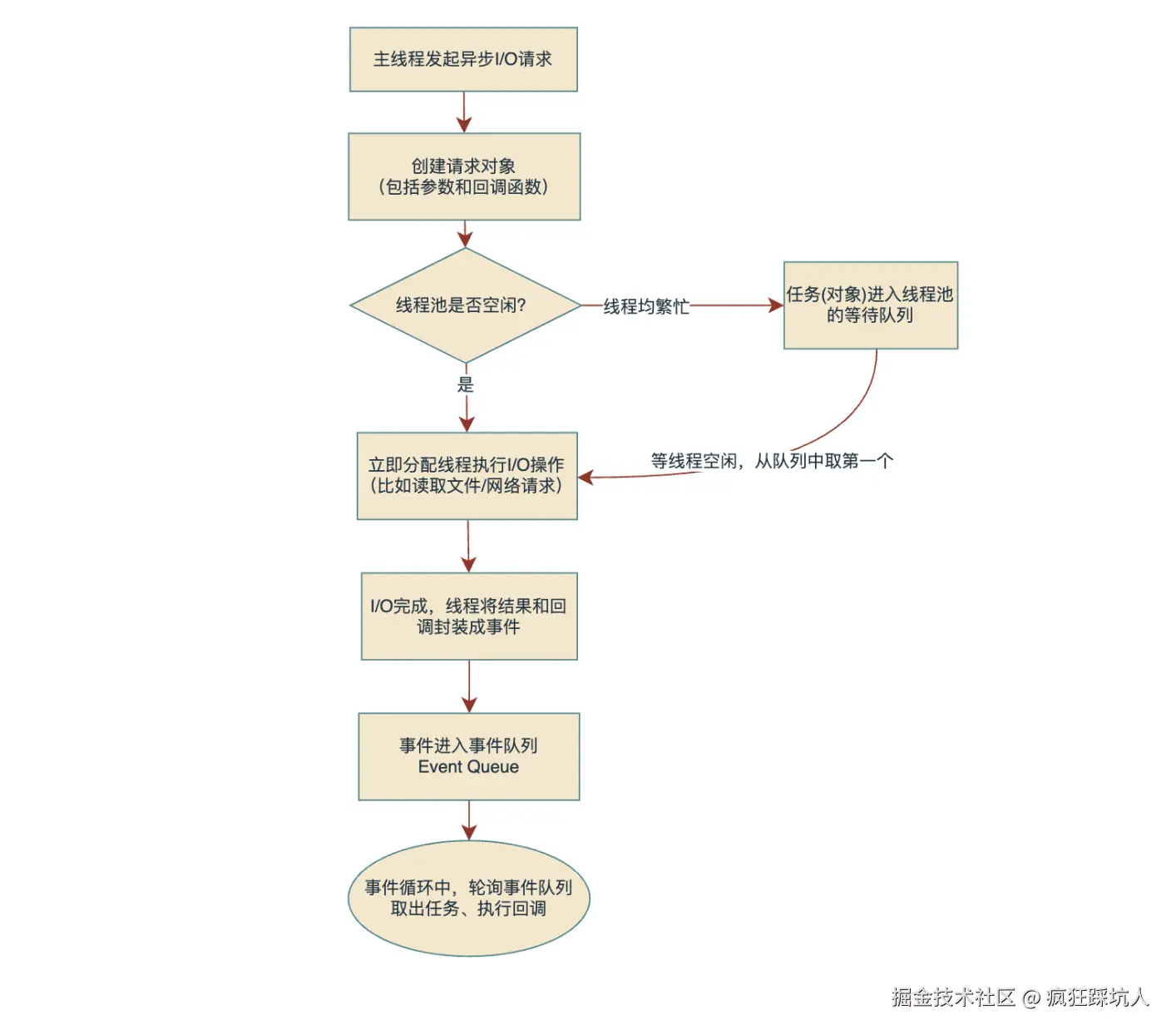
当异步任务执行的结果放入了事件队列,此时观察者会在主线程同步任务执行完后,查看事件队列中是否有事件任务,有则取出执行。等这个任务(同步代码)执行完后接着取下一个任务执行,一直循环,这就是Node的事件循环
P.S.这里的事件队列是一个笼统的队列概念,可以理解成包括宏任务队列和微任务队列。
总结
本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
在多路复用中,结合C++伪代码和图示的方式展示了select/poll/epoll的原理和差异,Linux中通常使用epoll(mac中有类似的kqueue)来实现非阻塞I/O,具备不用遍历fd集合和反复拷贝fd集合的性能优点。
最后,介绍了基于线程池的异步非阻塞I/O的实现原理,再结合事件队列和观察者实现了Node事件循环。
参考资料
Select、Poll、Epoll、 异步IO 介绍
【操作系统】I/O 多路复用,select / poll / epoll 详解
深入浅出Nodejs
来源:juejin.cn/post/7564614473962733577
Vue3 后台分页写腻了?我用 1 个 Hook 删掉 90% 重复代码(附源码)
实战推荐:
还在为每个列表页写重复的分页代码而烦恼吗? 还在复制粘贴 currentPage、pageSize、loading 等状态吗? 一个 Hook 帮你解决所有分页痛点,减少90%重复代码
背景与痛点
在后台管理系统开发中,分页列表查询非常常见,我们通常需要处理:
- 当前页、页大小、总数等分页状态
- 加载中、错误处理等请求状态
- 搜索、刷新、翻页等分页操作
- 数据缓存和重复请求处理
这些重复逻辑分散在各个组件中,维护起来很麻烦。
为了解决这个烦恼,我专门封装了分页数据管理 Hook。现在只需要几行代码,就能轻松实现分页查询,省时又高效,减少了大量重复劳动
使用前提 - 接口格式约定
查询接口返回的数据格式:
{
list: [ // 当前页数据数组
{ id: 1, name: 'user1' },
{ id: 2, name: 'user2' }
],
total: 100 // 数据总条数
}
先看效果:分页查询只需几行代码!
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList, // 查询API
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
这样子每次分页查询只需要引入hook,然后传入查询接口就好了,减少了大量重复劳动
解决方案
我设计了两个相互配合的 Hook:
- useFetch:基础请求封装,处理请求状态和缓存
- usePageFetch:分页逻辑封装,专门处理分页相关的状态和操作
usePageFetch (分页业务层)
├── 管理 page / pageSize / total 状态
├── 处理搜索、刷新、翻页逻辑
├── 统一错误处理和用户提示
└── 调用 useFetch (请求基础层)
├── 管理 loading / data / error 状态
├── 可选缓存机制(避免重复请求)
└── 成功回调适配不同接口格式
核心实现
useFetch - 基础请求封装
// hooks/useFetch.js
import { ref } from 'vue'
const Cache = new Map()
/**
* 基础请求 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {*} options.initValue - 初始值
* @param {string|Function} options.cache - 缓存配置
* @param {Function} options.onSuccess - 成功回调
*/
function useFetch(fn, options = {}) {
const isFetching = ref(false)
const data = ref()
const error = ref()
// 设置初始值
if (options.initValue !== undefined) {
data.value = options.initValue
}
function fetch(...args) {
isFetching.value = true
let promise
if (options.cache) {
const cacheKey = typeof options.cache === 'function'
? options.cache(...args)
: options.cache || `${fn.name}_${args.join('_')}`
promise = Cache.get(cacheKey) || fn(...args)
Cache.set(cacheKey, promise)
} else {
promise = fn(...args)
}
// 成功回调处理
if (options.onSuccess) {
promise = promise.then(options.onSuccess)
}
return promise
.then(res => {
data.value = res
isFetching.value = false
error.value = undefined
return res
})
.catch(err => {
isFetching.value = false
error.value = err
return Promise.reject(err)
})
}
return {
fetch,
isFetching,
data,
error
}
}
export default useFetch
usePageFetch - 分页逻辑封装
// hooks/usePageFetch.js
import { ref, onMounted, toRaw, watch } from 'vue'
import useFetch from './useFetch' // 即上面的hook ---> useFetch
import { ElMessage } from 'element-plus'
/**
* 分页数据管理 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {Object} options.params - 默认参数
* @param {boolean} options.initFetch - 是否自动初始化请求
* @param {Ref} options.formRef - 表单引用
*/
function usePageFetch(fn, options = {}) {
// 分页状态
const page = ref(1)
const pageSize = ref(10)
const total = ref(0)
const data = ref([])
const params = ref()
const pendingCount = ref(0)
// 初始化参数
params.value = options.params
// 使用基础请求 Hook
const { isFetching, fetch: fetchFn, error, data: originalData } = useFetch(fn)
// 核心请求方法
const fetch = async (searchParams, pageNo, size) => {
try {
// 更新分页状态
page.value = pageNo
pageSize.value = size
params.value = searchParams
// 发起请求
await fetchFn({
page: pageNo,
pageSize: size,
// 使用 toRaw 避免响应式对象问题
...(searchParams ? toRaw(searchParams) : {})
})
// 处理响应数据
data.value = originalData.value?.list || []
total.value = originalData.value?.total || 0
pendingCount.value = originalData.value?.pendingCounts || 0
} catch (e) {
console.error('usePageFetch error:', e)
ElMessage.error(e?.msg || e?.message || '请求出错')
// 清空数据,提供更好的用户体验
data.value = []
total.value = 0
}
}
// 搜索 - 重置到第一页
const search = async (searchParams) => {
await fetch(searchParams, 1, pageSize.value)
}
// 刷新当前页
const refresh = async () => {
await fetch(params.value, page.value, pageSize.value)
}
// 改变页大小
const onSizeChange = async (size) => {
await fetch(params.value, 1, size) // 重置到第一页
}
// 切换页码
const onCurrentChange = async (pageNo) => {
await fetch(params.value, pageNo, pageSize.value)
}
// 组件挂载时自动请求
onMounted(() => {
if (options.initFetch !== false) {
search(params.value)
}
})
// 监听表单引用变化(可选功能)
watch(
() => options.formRef,
(formRef) => {
if (formRef) {
console.log('Form ref updated:', formRef)
}
}
)
return {
// 分页状态
currentPage: page,
pageSize,
total,
pendingCount,
// 数据状态
data,
originalData,
isFetching,
error,
// 操作方法
search,
refresh,
onSizeChange,
onCurrentChange
}
}
export default usePageFetch
完整使用示例
用element ui举例
<template>
<el-form :model="searchForm" >
<el-form-item label="用户名">
<el-input v-model="searchForm.username" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSearch">搜索</el-button>
</el-form-item>
</el-form>
<!-- 表格数据展示,绑定 data 和 loading 状态 -->
<el-table :data="data" v-loading="isFetching">
<!-- ...表格列定义... -->
</el-table>
<!-- 分页组件,绑定当前页、页大小、总数,并响应切换事件 -->
<el-pagination
v-model:current-page="currentPage"
v-model:page-size="pageSize"
:total="total"
@size-change="onSizeChange"
@current-change="onCurrentChange"
/>
</template>
<script setup>
import { ref } from 'vue'
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 搜索表单数据,响应式声明
const searchForm = ref({
username: ''
})
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList,
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
/**
* 处理搜索操作
*/
const handleSearch = () => {
search({ username: searchForm.value.username })
}
</script>
高级用法
带缓存
const {
data,
isFetching,
search
} = usePageFetch(getUserList, {
cache: (params) => `user-list-${JSON.stringify(params)}` // 自定义缓存 key
})
设计思路解析
- 职责分离:useFetch 专注请求状态管理,usePageFetch 专注分页逻辑
- 统一错误处理:在 usePageFetch 层统一处理错误
- 智能缓存机制:支持多种缓存策略
- 生命周期集成:自动在组件挂载时请求数据
总结
这套分页管理 Hook 的优势:
- 开发效率高,减少90%的重复代码,新增列表页从 30 分钟缩短到 5 分钟
- 状态管理完善,自动处理加载、错误、数据状态
- 缓存机制,避免重复请求
- 错误处理统一,用户体验一致
- 易于扩展,支持自定义配置和回调
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下!
来源:juejin.cn/post/7549096640340426802
识别手写数字,居然可以只靠前端?
前言
之前一篇的神经网络文章,居然意外的受欢迎,有一万多的掘友们看过。github 的 star 数也是破了新高,非常感谢~
文章链接:当一个前端学了很久的神经网络...👈🤣
github 链接:github.com/imoo666/neu…
但是之前边调研边写代码,还是有些乱的,我重新组织了一下代码,让大家能更清晰的了解前端使用神经网络的流程。
不过只是重新讲解一下流程就太水了,这篇就再来一个识别手写数字的项目,顺便理一下我们的思路。
步骤
很多同学反馈 担心前端入坑神经网络很难,但其实就是按部就班的几步,许多步骤都是调用 api,并不需要我们全部手写,还是比较容易的。
核心步骤有下:
- 加载和准备数据
- 定义模型
- 训练模型
- 使用模型进行预测
加载和准备数据
既然是手写数字识别,我们首先还是需要一些手写数字的图片,数据集我一般是去 kaggle 找的。
下载链接:http://www.kaggle.com/code/cdeott…
不过这次的数据是 csv 而非图片压缩包,先下载打开看看怎么个事。
可以观察到是一个 784 * n 的一个表格,表格中的数在 0-255 之间,对图片敏感的同学应该已经反应过来了,784 === 28 * 28,也就是每一行代表了一个 28 * 28 的灰度 图片。
可以简单写一个渲染图片的方法来看一下效果:

看起来跟我们猜想的一样,另外,第一行是表头,第一列是该行的实际数字,用于做验证。
知道这些,那就可以开始加载数据了,目标是将这堆数据转化为可以供 模型训练 的数据。
const loadCsvData = async () => {
// 先加载
const response = await fetch("src/pages/mnist/assets/mnist.csv");
const text = await response.text();
// 忽略第一行的表头
const lines = text.trim().split("\n").slice(1);
// 将每一行都转化为张量
const samples: DigitSample[] = lines.map((line) => {
const values = line.split(",").map(Number);
const label = values[0];
const pixels = tf
.tensor3d(values.slice(1), [28, 28, 1])
.div(255) as tf.Tensor3D;
return { pixels, label };
});
// 打乱数组
tf.util.shuffle(samples);
// 将后 50 条作为测试集,其余作为训练集
const train = samples.slice(0, samples.length - 50);
const test = samples.slice(-50);
// 独热编码,一共 10 个可能
const xTrain = tf.stack(train.map((s) => s.pixels)) as tf.Tensor4D;
const yTrain = tf.oneHot(
train.map((s) => s.label),
10
) as tf.Tensor2D;
return { xTrain, yTrain, test };
};
定义模型
这次是手写数字的识别,我们需要用到图片识别比较经典的 卷积层 + 最大池化层 的组合,除此之外,这次还添加了一个防止过拟合的 dropout 层。
const defineModel = () => {
const model = tf.sequential({
layers: [
// 最大池化层,用于降低图片大小
tf.layers.maxPooling2d({
poolSize: 2,
strides: 2,
inputShape: [28, 28, 1],
}),
// 卷积层,用 32个卷积核进行提取特征
tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: "relu",
padding: "same",
}),
// 将提取结果平铺
tf.layers.flatten(),
// 一个普通的隐藏层计算关系
tf.layers.dense({ units: 64, activation: "relu" }),
// 防止过拟合
tf.layers.dropout({ rate: 0.3 }),
// 分类
tf.layers.dense({
units: 10,
activation: "softmax",
}),
],
});
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: ["accuracy"],
});
return model;
};
训练模型
训练模型没什么需要写的,只是需要配置几个参数(如轮数,批处理数量等),然后按照固定逻辑调用 api 即可
const trainModel = async () => {
setModelState({ model: null, isTraining: true, logs: [] });
const model = defineModel();
const { xTrain, yTrain, test } = await loadCsvData();
await model.fit(xTrain, yTrain, {
epochs: 20, // 轮数
batchSize: 8, // 批处理数量
validationSplit: 0.2, // 用于验证的比例
callbacks: {
onEpochEnd: (epoch, logs) => {
if (!logs) return;
setModelState((prev) => ({
...prev,
logs: [
...prev.logs,
{
epoch: epoch + 1,
loss: Number(logs.loss?.toFixed(4)),
accuracy: Number((logs.acc ?? logs.accuracy ?? 0).toFixed(4)),
},
],
}));
},
},
});
predict(model, test);
setModelState((prev) => ({ ...prev, model, isTraining: false }));
tf.dispose([xTrain, yTrain]);
};
等待模型训练完毕后,model 就是可用的模型,可以用其去预测不同的图片,我选择了 50 张图片用于我们测试正确率。
使用模型进行预测
核心就是调用一下 model.predict() 这个方法用于预测,不过最后给出的结果会是一个十个元素的数组,分别代表是某个数字的概率,我们需要手动取出最高概率的一个作为我们的预测结果。
const predict = (model: tf.Sequential, samples: DigitSample[]) => {
const results: PredictionResult[] = samples.map((sample) => {
const input = sample.pixels.expandDims(0); // 格式化
const output = model.predict(input) as tf.Tensor; // 预测
const probs = output.dataSync(); // 张量转数组
const predicted = output.argMax(1).dataSync()[0]; // 拿到最大的位
const confidence = Number((probs[predicted] * 100).toFixed(1));
tf.dispose([input, output]);
return {
imageTensor: sample.pixels,
actual: sample.label,
predicted,
confidence,
correct: predicted === sample.label,
};
});
setPredictions(results);
};
其他
最后可以看一下我们的完整页面
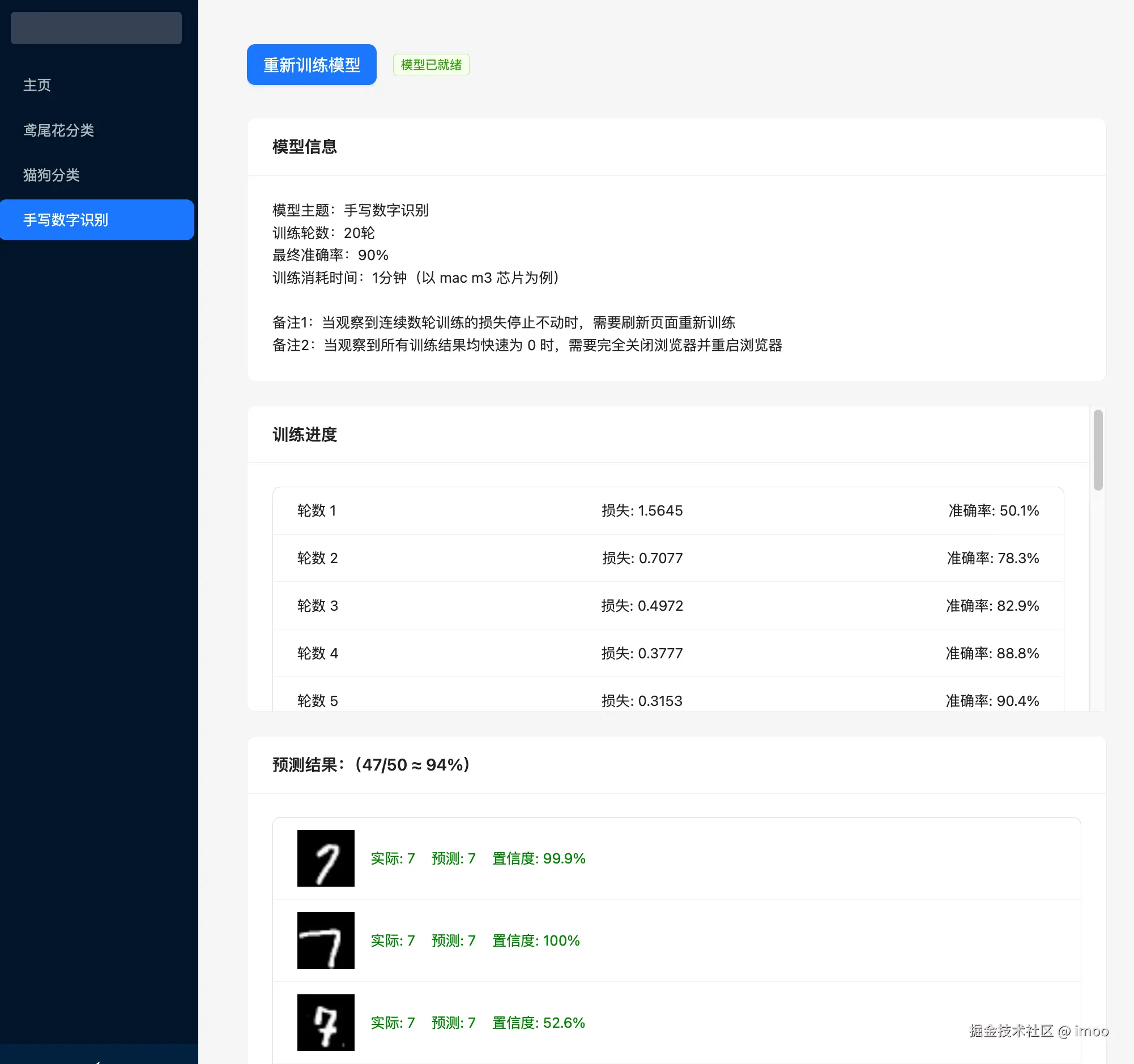
感兴趣的同学可以查看源码,相较于之前的版本做了许多整理工作,都按照本文的步骤进行了函数的划分:github.com/imoo666/neu…
又变强了一步!一起加油前端仔!

来源:juejin.cn/post/7514250027041964083
TabFlow: 一款简洁的 Chrome 标签页域名分类器
TabFlow:打造智能化的Chrome标签页管理扩展
前言
在日常的Web开发和浏览过程中,我们经常会同时打开大量的标签页。当标签页数量超过10个时,浏览器的标签栏就会变得拥挤不堪,找到特定的页面变得困难。为了解决这个痛点,我开发了TabFlow——一个智能的Chrome标签页分组管理扩展。
项目概述
TabFlow是一个基于Chrome Extension Manifest V3的标签页管理工具,它能够:
- 🏷️ 智能分组:自动按域名对标签页进行分组
- 🎨 视觉区分:为不同域名分配独特的颜色标识
- 📊 实时统计:显示标签页数量和域名统计
- ⚡ 性能优化:采用防抖、缓存等技术确保流畅体验
技术架构
1. 项目结构
TabFlow/
├── manifest.json # 扩展配置文件
├── background.js # 后台服务脚本
├── popup.html # 弹窗界面
├── popup.js # 弹窗逻辑
└── icons/ # 图标资源
├── icon16.png
├── icon48.png
└── icon128.png
2. 核心技术栈
- Chrome Extensions API:标签页和分组管理
- Manifest V3:最新的扩展开发标准
- Service Worker:后台处理逻辑
- Modern CSS:毛玻璃效果和渐变设计
核心功能实现
1. 智能域名解析
首先,我们需要从URL中提取有意义的域名信息:
function parseUrl(url) {
if (domainCache.has(url)) {
return domainCache.get(url);
}
try {
const urlObj = new URL(url);
let hostname = urlObj.hostname;
// 移除www前缀
if (hostname.startsWith('www.')) {
hostname = hostname.substring(4);
}
// 提取主域名
const parts = hostname.split('.');
let mainDomain = hostname;
if (parts.length >= 2) {
const commonTLDs = ['com', 'org', 'net', 'edu', 'gov', 'cn', 'jp', 'uk'];
const lastPart = parts[parts.length - 1];
if (commonTLDs.includes(lastPart)) {
mainDomain = parts.slice(-2).join('.');
} else {
mainDomain = parts.slice(-3).join('.');
}
}
const displayName = mainDomain.split('.')[0].toUpperCase();
const result = { mainDomain, displayName };
// 缓存结果,限制缓存大小
if (domainCache.size > 100) {
const firstKey = domainCache.keys().next().value;
domainCache.delete(firstKey);
}
domainCache.set(url, result);
return result;
} catch (e) {
return null;
}
}
技术亮点:
- 使用Map缓存解析结果,避免重复计算
- 智能处理各种TLD(顶级域名)
- 限制缓存大小防止内存泄漏
2. 自动分组机制
当检测到同域名的多个标签页时,自动创建或更新分组:
async function autoGr0upTabsByDomain(mainDomain, displayName, tabs, color) {
try {
// 使用缓存的分组信息
let existingGr0ups;
if (groupCache.has('groups')) {
existingGr0ups = groupCache.get('groups');
} else {
existingGr0ups = await chrome.tabGr0ups.query({});
groupCache.set('groups', existingGr0ups);
setTimeout(() => groupCache.delete('groups'), 5000);
}
const targetGr0up = existingGr0ups.find(group =>
group.title.includes(displayName)
);
if (targetGr0up) {
// 添加到现有分组
const ungroupedTabs = tabs.filter(tab => tab.groupId === -1);
if (ungroupedTabs.length > 0) {
const tabIds = ungroupedTabs.map(tab => tab.id);
await chrome.tabs.group({ tabIds, groupId: targetGr0up.id });
// 获取分组中的实际标签页数量
const groupTabs = await chrome.tabs.query({ groupId: targetGr0up.id });
await chrome.tabGr0ups.update(targetGr0up.id, {
title: `${displayName} (${groupTabs.length})`
});
}
} else if (tabs.length > 1) {
// 创建新分组
const tabIds = tabs.map(tab => tab.id);
const groupId = await chrome.tabs.group({ tabIds });
await chrome.tabGr0ups.update(groupId, {
title: `${displayName} (${tabs.length})`,
color: GR0UP_COLORS[color] || 'grey',
collapsed: false
});
}
groupCache.delete('groups');
} catch (e) {
console.log('分组失败:', e);
}
}

3. 实时数量更新
这是项目中的一个技术难点。Chrome的标签页分组API在标签页数量变化时不会自动更新分组标题,需要我们主动监听和更新:
// 监听标签页移除,更新分组标题
chrome.tabs.onRemoved.addListener(async (tabId, removeInfo) => {
try {
const groups = await chrome.tabGr0ups.query({});
for (const group of groups) {
const groupTabs = await chrome.tabs.query({ groupId: group.id });
if (groupTabs.length > 0) {
const titleMatch = group.title.match(/^(.+?)\s*\(/);
if (titleMatch) {
const displayName = titleMatch[1];
await chrome.tabGr0ups.update(group.id, {
title: `${displayName} (${groupTabs.length})`
});
}
}
}
} catch (e) {
console.log('更新分组标题失败:', e);
}
});
// 定期更新分组标题(每5秒检查一次)
async function updateAllGr0upTitles() {
try {
const groups = await chrome.tabGr0ups.query({});
for (const group of groups) {
const groupTabs = await chrome.tabs.query({ groupId: group.id });
const titleMatch = group.title.match(/^(.+?)\s*\(/);
if (titleMatch && groupTabs.length > 0) {
const displayName = titleMatch[1];
const currentTitle = `${displayName} (${groupTabs.length})`;
if (group.title !== currentTitle) {
await chrome.tabGr0ups.update(group.id, {
title: currentTitle
});
}
}
}
} catch (e) {
console.log('更新分组标题失败:', e);
}
}
setInterval(updateAllGr0upTitles, 5000);
技术亮点:
- 多重监听机制确保数量实时更新
- 正则表达式解析分组标题
- 定时器作为兜底方案
4. 现代化UI设计
采用了Apple设计语言,实现了毛玻璃效果和流畅的动画:
.container {
padding: 20px;
backdrop-filter: blur(20px);
-webkit-backdrop-filter: blur(20px);
}
.stats {
display: flex;
justify-content: space-between;
margin-bottom: 20px;
padding: 16px 20px;
background: rgba(255, 255, 255, 0.85);
backdrop-filter: blur(20px);
border-radius: 16px;
border: 1px solid rgba(255, 255, 255, 0.2);
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.08);
}
.domain-item {
display: flex;
align-items: center;
padding: 14px 16px;
margin-bottom: 10px;
background: rgba(255, 255, 255, 0.9);
backdrop-filter: blur(20px);
border-radius: 12px;
transition: all 0.3s cubic-bezier(0.25, 0.46, 0.45, 0.94);
}
.domain-item:hover {
transform: translateY(-2px);
box-shadow: 0 8px 25px rgba(0, 0, 0, 0.12);
}

性能优化策略
1. 缓存机制
let domainCache = new Map(); // 缓存域名解析结果
let groupCache = new Map(); // 缓存分组信息
let pendingUpdates = new Set(); // 防止重复处理
2. 防抖处理
let updateTimeout;
function debounceTabUpdate(callback, delay = 500) {
clearTimeout(updateTimeout);
updateTimeout = setTimeout(callback, delay);
}
3. 批量操作
// 并行处理分组
const groupPromises = Object.entries(domainGr0ups)
.filter(([, domainTabs]) => domainTabs.length > 1)
.map(async ([mainDomain, domainTabs]) => {
const urlInfo = parseUrl(domainTabs[0].url);
if (urlInfo) {
const color = assignColorToDomain(mainDomain);
return autoGr0upTabsByDomain(mainDomain, urlInfo.displayName, domainTabs, color);
}
});
await Promise.all(groupPromises);
图标设计
为了让扩展更具视觉吸引力,我设计了一套现代化的图标:

图标采用了:
- 蓝紫色到粉色的渐变背景
- 多层标签页卡片效果
- 流动箭头指示分组功能
- 现代化的扁平设计风格
开发过程中的挑战与解决方案
1. Manifest V3迁移
Chrome Extensions从V2迁移到V3带来了一些挑战:
问题:Background Scripts改为Service Worker
解决:重构代码结构,使用事件驱动模式
// Manifest V3配置
{
"manifest_version": 3,
"background": {
"service_worker": "background.js",
"type": "module"
},
"permissions": [
"tabs",
"storage",
"tabGr0ups"
]
}
2. 分组标题实时更新
问题:Chrome API不会自动更新分组标题中的数量
解决:实现多重监听机制 + 定时同步
3. 性能优化
问题:频繁的API调用导致性能问题
解决:引入缓存、防抖、批量处理等优化策略
安装TabFlow后,用户可以:
- 自动按域名分组标签页
- 通过颜色快速识别不同网站
- 实时查看每个分组的标签页数量
- 一键整理所有标签页
技术总结
通过开发TabFlow,我深入学习了:
- Chrome Extensions API:掌握了标签页、分组、存储等核心API
- 性能优化:学会了缓存、防抖、批量处理等优化技术
- 现代CSS:实践了毛玻璃效果、渐变、动画等现代设计
- 用户体验:理解了如何设计直观易用的界面
项目地址
- GitHub仓库:github.com/wajuejinaji…
- Chrome商店:(待上架)
未来规划
- 智能分组算法:基于用户习惯的智能分组
- 标签页搜索:快速搜索和定位标签页
- 数据同步:跨设备同步分组配置
- 快捷键支持:键盘快捷键操作
结语
TabFlow不仅解决了我个人的标签页管理痛点,也是一次完整的Chrome扩展开发实践。从需求分析到技术实现,从性能优化到用户体验,每一个环节都充满了学习和挑战。
希望这个项目能够帮助更多开发者提高浏览效率,也欢迎大家提出建议和贡献代码!
如果你觉得这篇文章对你有帮助,欢迎点赞和分享。如果你有任何问题或建议,也欢迎在评论区讨论!
来源:juejin.cn/post/7554979158435643407
可重试接口请求
概述
日常开发中,接口数据请求失败是很常见的需求,因此我们有时候可能需要对失败的请求进行重试,提高用户体验。
实现
如下案例通过fetch方法做请求,项目中肯定使用axios居多,思路都是一致的
原理
要想实现请求重试,我们需要清楚如下问题:
- R: 什么时候重试?
- A: 请求失败的时候
- R:请求重试次数?
- A:外部传入
- R:如何失败后重新请求?
- A:利用请求promise状态和递归重新请求实现
程序
/**
* @Description 发送请求,返回promise
* @param { string } url 请求地址
* @param { number } maxCount 最大重试次数
* @returns { Promise<any> } 返回请求结果的promise
**/
// 定义
function sendRequest(url, maxCount = 3) {
return fetch(url).catch((error) => {
return maxCount <= 0
? Promise.reject(error)
: sendRequest(url, maxCount - 1);
});
}
// 使用
sendRequest("https://api.example.com/data").then((response) => {
console.log("Request succeeded:", response);
});
来源:juejin.cn/post/7535765649114808339
🥳Elx开源升级:XMarkdown 组件加入、Storybook 预览体验升级
Element Plus XV1.3.0上新XMarkdown 组件
🙊大家好,我是嘉悦。经过一周 beta 版本的测试,我们推出了 v1.3.0 主版本,并且将 main 分支的代码进行了替换。移除了旧的 playground 代码,换成了新的 storybook 在线预览体验更好。同时我们也在我们的👉仿豆包模版项目 中升级了最新的自建库依赖,并集成了 xmd 组件
🥪现在的在线预览:可以在右侧进行调试,实时预览,让你更快理解组件属性
🫕最新的模版项目代码已经更新,请大家酌情拉取,可能会和你本地的已修改的代码有冲突
这一次主版本的更新,主要是给 XMarkdown 组件进行了优化升级,我们内置了更多功能
🍍内置更多功能,支持自定义
| 功能 | 描述 | 是否支持 |
|---|---|---|
| 增量渲染 | 极致的性能 | ✅ |
| 自定义插槽 | 可以是 h 函数的组件,也可以是 template 模版组件,上手更简单 | ✅ |
| 行级代码块高亮 | 内置样式,可自定义 | ✅ |
| 代码块高亮 | 内置折叠、切换主题色、复制代码块、滚动吸顶功能 | ✅ |
| 数学公式 | 支持行级公式和块级公式 | ✅ |
| mermaid 图表 | 内置切换查看代码、缩放、归位、下载、复制代码块功能 | ✅ |
| 自定义 echarts | 自定义渲染 | ✅ |
| 拦截 ``` 后面的标识符 | 拦截后可获取内容进行自定义渲染 | ✅ |
| 拦截标签 | 拦截后可进行自定义渲染 | ✅ |
| 支持预览 html 代码块 | 内置对 html 标签的预览功能 | ✅ |
🐝在项目中使用后,大概是这个样子
💌 mermaid 图表
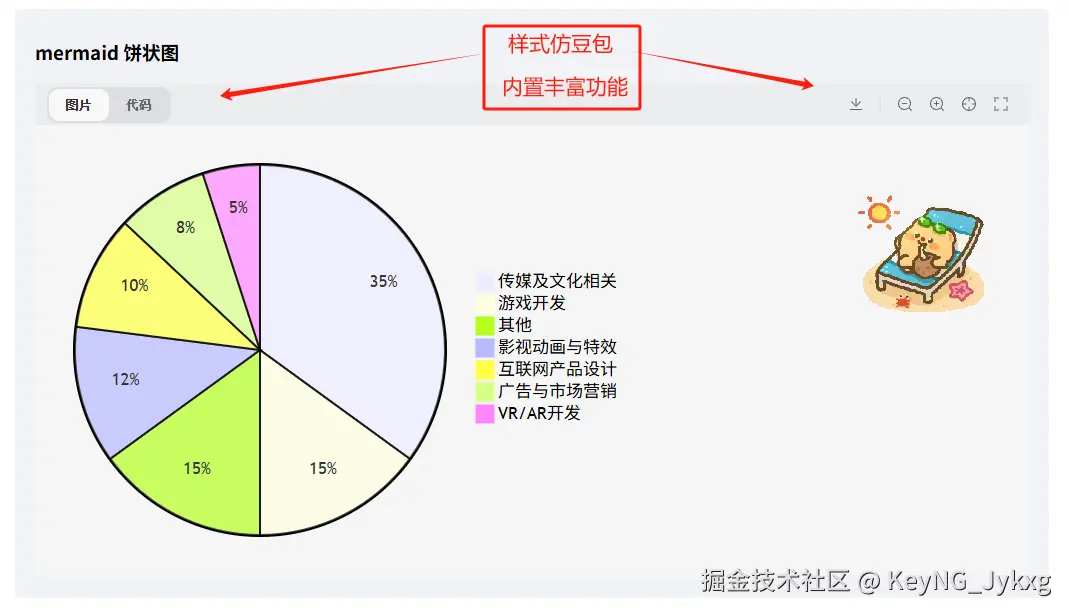
💌 数学公式

💌 预览 html
💌 代码块
💌 自定义代码块
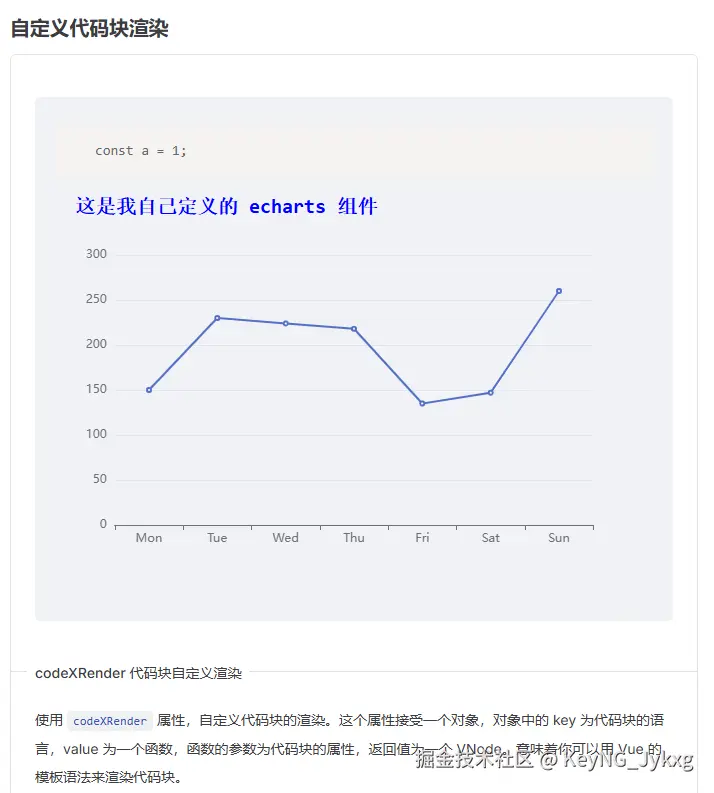
💌 自定义属性
💌 自定义标签
目前,我们已经将组件上新到组件库 main 分支开源,请大家及时fork最新的 main 分支代码。💐欢迎大家升级体验最新V1.3.0版本
pnpm add vue-element-plus-x@1.3.0
V1.3.0版本更新内容速递:
🍉 后续计划
- 😁我们近期会对组件库的官网进行更新
- 🥰预计下周,我们将会推出一个对 vue2 的支持库,并负责维护下去
- 🐒预计下下周,我们将会推出 编辑发送框组件,这个组件已经在测试阶段
- 🙉同时已经组建了一个30+人的开发者群,后续会在开发者群中开放更多的贡献任务
- 💩对这个项目感兴趣的朋友,可以加交流群或者作者微信 👉交流邀请
📢 项目地址,快速链接体验
这里是最全的项目地址,方便大家跳转查看
| 名称 | 链接 |
|---|---|
| 👀 模版项目 预览 | 👉 在线预览 |
| 🍉 模版项目 源码 | 👉 github 👉 gitee |
| 🎀 模版项目 开发文档 | 👉 模版项目 开发文档 |
| 💟 Element-Plus-X 组件库 | 👉 Element-Plus-X 组件库 开发文档 |
| 🎃 Element-Plus-X 组件库交流群 | 👉 交流4群二维码地址 github 👉 交流4群二维码地址 gitee 💖加入交流群,获取最新的技术支持💖 |
| 🚀 若依AI项目 源码 | 👉 github 👉 gitee |
| 🔥 Hook-fetch 超优雅请求库 | 👉 源码学习 |
来源:juejin.cn/post/7527034544663461898
🔥 enum-plus:前端福利!介绍一个天花板级的前端枚举库

像原生 enum 一样,但更强大!
简介
enum-plus是一个增强版的枚举类库,完全兼容原生enum的基本用法,同时支持扩展显示文本、绑定到 UI 组件以及提供丰富的扩展方法,是原生enum的一个直接替代品。它是一个轻量级、零依赖、100% TypeScript 实现的工具,适用于多种前端框架,并支持本地化。
枚举项列表可以用来一键生成下拉框、复选框等组件,可以轻松遍历枚举项数组,获取某个枚举值的显示文本,判断某个值是否存在等。支持本地化,可以根据当前语言环境返回对应的文本,轻松满足国际化的需求。
还有哪些令人兴奋的特性呢?请继续探索吧!或者不妨先看下这个使用视频。

特性
- 完全兼容原生
enum的用法 - 支持
number、string等多种数据类型 - 增强的枚举项,支持自定义显示文本
- 内置
本地化能力,枚举项文本可实现国际化,可与任何 i18n 库集成 - 支持枚举值转换为显示文本,代码更简洁
- 可扩展设计,允许在枚举项上添加自定义字段
- 支持将枚举绑定到 Ant Design、ElementPlus、Material-UI 等 UI 库,一行代码枚举变下拉框
- 支持 Node.js 环境,支持服务端渲染(SSR)
- 零依赖,纯原生 JavaScript,可用于任何前端框架
- 100% TypeScript 实现,具有全面的类型推断能力
- 轻量(gzip 压缩后仅 2KB+)
安装
npm install enum-plus
枚举定义
本节展示了使用 Enum 函数初始化枚举的多种方式,你可以根据不同的使用场景选择最合适的方法
1. 基础格式,与原生枚举用法基本一致
import { Enum } from 'enum-plus';
const Week = Enum({
Sunday: 0,
Monday: 1,
} as const);
Week.Monday; // 1
as const类型断言用于将枚举值变成字面量类型,类型更精确,否则它们将被作为number类型。如果你使用的是JavaScript,请删除as const
2. 标准格式(推荐)
为每个枚举项指定 value (枚举值) 和 label(显示文本)字段,这是最常用的格式,也是推荐的格式。这种格式允许你为每个枚举项设置显示文本,这些文本可以在UI组件中使用
import { Enum } from 'enum-plus';
const Week = Enum({
Sunday: { value: 0, label: '星期日' },
Monday: { value: 1, label: '星期一' },
} as const);
Week.Sunday; // 0
Week.label(0); // 星期日
3. 数组格式
数组格式在需要动态创建枚举时很有用,例如从 API 获取数据中动态创建一个枚举。这种方式还允许自定义字段映射,这增加了灵活性,可以适配不同的数据格式
import { Enum } from 'enum-plus';
const petTypes = await getPetsData();
// [ { value: 1, key: 'dog', label: '狗' },
// { value: 2, key: 'cat', label: '猫' },
// { value: 3, key: 'rabbit', label: '兔子' } ];
const PetTypes = Enum(petTypes);
4. 原生枚举格式
如果你已经有一个原生的枚举,你可以直接传递给Enum函数,它会自动转换为增强版的枚举,这样可以借用原生枚举的枚举值自动递增特性
import { Enum } from 'enum-plus';
enum init {
Sunday = 0,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
}
const Week = Enum(init);
Week.Sunday; // 0
Week.Monday; // 1
Week.Saturday; // 6
Week.label('Sunday'); // Sunday
API
💎 拾取枚举值
像原生enum一样,直接拾取一个枚举值
Week.Sunday; // 0
Week.Monday; // 1
💎 items
获取一个包含全部枚举项的只读数组,可以方便地遍历枚举项。由于符合 Ant Design 组件的数据规范,因此支持将枚举一键转换成下拉框、复选框等组件,只需要一行代码!
💎 keys
获取一个包含全部枚举项Key的只读数组
💎 label
根据某个枚举值或枚举 Key,获取该枚举项的显示文本。如果设置了本地化,则会返回本地化后的文本。
Week.label(1); // 星期一
Week.label('Monday'); // 星期一
💎 key
根据枚举值获取该枚举项的 Key,如果不存在则返回undefined
Week.key(1); // 'Monday'
💎 has
判断某个枚举项(值或 Key)是否存在
Week.has(1); // true
Week.has('Sunday'); // true
Week.has(9); // false
Week.has('Birthday'); // false
💎 toSelect
toSelect与items相似,都是返回一个包含全部枚举项的数组。区别是,toSelect返回的元素只包含label和value两个字段,同时,toSelect方法支持在数组头部插入一个可自定义的默认元素,一般用于下拉框等组件的默认选项
💎 toMenu
生成一个对象数组,可以绑定给 Ant Design 的Menu、Dropdown等组件
import { Menu } from 'antd';
<Menu items={Week.toMenu()} />;
数据数据格式为:
[
{ key: 0, label: '星期日' },
{ key: 1, label: '星期一' },
];
💎 toFilter
生成一个对象数组,可以直接传递给 Ant Design Table 组件的列配置,在表头中显示一个下拉筛选框,用来过滤表格数据
数据数据格式为:
[
{ text: '星期日', value: 0 },
{ text: '星期一', value: 1 },
];
💎 toValueMap
生成一个符合 Ant Design Pro 规范的枚举集合对象,可以传递给 ProFormField、ProTable 等组件。
数据格式为:
{
0: { text: '星期日' },
1: { text: '星期一' },
}
💎 raw
方法重载^1 raw(): Record<K, T[K]>
方法重载^2 raw(keyOrValue: V | K): T[K]
第一个重载方法,返回枚举集合的初始化对象,即用来初始化 Enum 原始 init 对象。
第二个重载方法,用来处理单个枚举项,根据获取单个枚举项的原始初始化对象。
这个方法主要作用是,用来获取枚举项的自定义字段,支持无限扩展字段
const Week = Enum({
Sunday: { value: 0, label: '星期日', happy: true },
Monday: { value: 1, label: '星期一', happy: false },
} as const);
Week.raw(0).happy // true
Week.raw(0); // { value: 0, label: '星期日', happy: true }
Week.raw('Monday'); // { value: 1, label: '星期一', happy: false }
Week.raw(); // { Sunday: { value: 0, label: '星期日', happy: true }, Monday: { value: 1, label: '星期一', happy: false } }
⚡️ valueType TypeScript ONLY
在 TypeScript 中,提供了一个包含所有枚举值的联合类型,用于缩小变量或组件属性的数据类型。这种类型替代了像 number 或 string 这样宽泛的原始类型,使用精确的值集合,防止无效赋值,同时提高代码可读性和编译时类型安全性。
type WeekValues = typeof Week.valueType; // 0 | 1
const weekValue: typeof Week.valueType = 1; // ✅ 类型正确,1 是一个有效的周枚举值
const weeks: (typeof Week.valueType)[] = [0, 1]; // ✅ 类型正确,0 和 1 是有效的周枚举值
const badWeekValue: typeof Week.valueType = 8; // ❌ 类型错误,8 不是一个有效的周枚举值
const badWeeks: (typeof Week.valueType)[] = [0, 8]; // ❌ 类型错误,8 不是一个有效的周枚举值
注意,这只是一个 TypeScript 类型,只能用来约束类型,不可在运行时调用,运行时调用会抛出异常
用法
• 基本用法,与原生枚举用法一致
const Week = Enum({
Sunday: { value: 0, label: '星期日' },
Monday: { value: 1, label: '星期一' },
} as const);
Week.Sunday; // 0
Week.Monday; // 1
• 支持为枚举项添加 Jsdoc 注释,代码提示更友好
在代码编辑器中,将光标悬停在枚举项上,即可显示关于该枚举项的详细 Jsdoc 注释,而不必再转到枚举定义处查看
const Week = Enum({
/** 星期日 */
Sunday: { value: 0, label: '星期日' },
/** 星期一 */
Monday: { value: 1, label: '星期一' },
} as const);
Week.Monday; // 将光标悬浮在 Monday 上

可以看到,不但提示了枚举项的释义,还有枚举项的值,无需跳转离开当前光标位置,在阅读代码时非常方便
• 获取包含全部枚举项的数组
Week.items; // 输出如下:
// [
// { value: 0, label: '星期日', key: 'Sunday', raw: { value: 0, label: '星期日' } },
// { value: 1, label: '星期一', key: 'Monday', raw: { value: 1, label: '星期一' } }
// ]
• 获取第一个枚举值
Week.items[0].value; // 0
• 检查一个值是否一个有效的枚举值
Week.has(1); // true
Week.items.some(item => item.value === 1); // true
1 instanceof Week; // true
• 支持遍历枚举项数组,但不可修改
Week.items.length; // 2
Week.items.map((item) => item.value); // [0, 1],✅ 可遍历
Week.items.forEach((item) => {}); // ✅ 可遍历
for (const item of Week.items) {
// ✅ 可遍历
}
Week.items.push({ value: 2, label: '星期二' }); // ❌ 不可修改
Week.items.splice(0, 1); // ❌ 不可修改
Week.items[0].label = 'foo'; // ❌ 不可修改
• 枚举值(或Key)转换为显示文本
Week.label(1); // 星期一,
Week.label(Week.Monday); // 星期一
Week.label('Monday'); // 星期一
• 枚举值转换为Key
Week.key(1); // 'Monday'
Week.key(Week.Monday); // 'Monday'
Week.key(9); // undefined, 不存在此枚举项
• 添加扩展字段,不限数量
const Week = Enum({
Sunday: { value: 0, label: '星期日', active: true, disabled: false },
Monday: { value: 1, label: '星期一', active: false, disabled: true },
} as const);
Week.raw(0).active // true
Week.raw(Week.Sunday).active // true
Week.raw('Sunday').active // true
🔥 转换成 UI 组件
- 生成 Select 下拉框
- Ant Design | Arco Design
Select
import { Select } from 'antd';
<Select options={Week.items} />;
- Material-UI Select
import { MenuItem, Select } from '@mui/material';
<Select>
{Week.items.map((item) => (
<MenuItem key={item.value} value={item.value}>
{item.label}
</MenuItem>
))}
</Select>;
- Kendo UI Select
import { DropDownList } from '@progress/kendo-react-dropdowns';
<DropDownList data={Week.items} textField="label" dataItemKey="value" />;
- ElementPlus Select
<el-select>
<el-option v-for="item in Week.items" v-bind="item" />
</el-select>
- Ant Design Vue | Arc Design Select
<a-select :options="Week.items" />
- Vuetify Select
<v-select :items="Week.items" item-title="label" />
- Angular Material Select
<mat-select>
<mat-option *ngFor="let item of Week.items" [value]="item.value">{{ item.label }}</mat-option>
</mat-select>
- NG-ZORRO Select
<nz-select>
<nz-option *ngFor="let item of Week.items" [nzValue]="item.value">{{ item.label }}</nz-option>
</nz-select>
- Ant Design | Arco Design
- 生成下拉菜单
toMenu方法可以为 Ant Design Menu、Dropdown 等组件生成数据源,格式为:{ key: number|string, label: string } []
import { Menu } from 'antd';
<Menu items={Week.toMenu()} />;
- 生成表格列筛选
toFilter方法可以生成一个对象数组,为表格绑定列筛选功能,列头中显示一个下拉筛选框,用来过滤表格数据。对象结构遵循 Ant Design 的数据规范,格式为:{ text: string, value: number|string } []
import { Table } from 'antd';
const columns = [
{
title: 'week',
dataIndex: 'week',
filters: Week.toFilter(),
},
];
// 在表头中显示下拉筛选项
<Table columns={columns} />;
- 支持 Ant Design Pro 组件生成
toValueMap方法可以为 Ant Design Pro 的ProFormFields、ProTable等组件生成数据源,这是一个类似 Map 的数据结构,格式为:{ [key: number|string]: { text: string } }
import { ProFormSelect, ProFormCheckbox, ProFormRadio, ProFormTreeSelect, ProTable } from '@ant-design/pro-components';
<ProFormSelect valueEnum={Week.toValueMap()} />; // 下拉框
<ProFormCheckbox valueEnum={Week.toValueMap()} />; // 复选框
<ProFormRadio.Gr0up valueEnum={Week.toValueMap()} />; // 单选框
<ProFormTreeSelect valueEnum={Week.toValueMap()} />; // 树选择
<ProTable columns={[{ dataIndex: 'week', valueEnum: Week.toValueMap() }]} />; // ProTable
• 枚举合并(或者扩展枚举)
const myWeek = Enum({
...Week.raw(),
Friday: { value: 5, label: '星期五' },
Saturday: { value: 6, label: '星期六' },
});
• 使用枚举值序列来缩小 number 取值范围 [TypeScript ONLY]
使用 valueType 类型约束,可以将数据类型从宽泛的number或string类型缩小为有限的枚举值序列,这不但能减少错误赋值的可能性,还能提高代码的可读性
const weekValue: number = 8; // 👎 任意数字都可以赋值给周枚举,即使错误的
const weekName: string = 'Birthday'; // 👎 任意字符串都可以赋值给周枚举,即使错误的
const goodWeekValue: typeof Week.valueType = 1; // ✅ 类型正确,1 是一个有效的枚举值
const goodWeekName: typeof Week.keyType = 'Monday'; // ✅ 类型正确,'Monday' 是一个有效的枚举名
const badWeekValue: typeof Week.valueType = 8; // ❌ 类型报错,8 不是一个有效的枚举值
const badWeekName: typeof Week.keyType = 'Birthday'; // ❌ 类型报错,'Birthday' 不是一个有效的枚举值
type FooProps = {
value?: typeof Week.valueType; // 👍 组件属性类型约束,可以防止错误赋值,还能智能提示取值范围
names?: (typeof Week.keyType)[]; // 👍 组件属性类型约束,可以防止错误赋值,还能智能提示取值范围
};
本地化
enum-plus 本身不内置国际化能力,但支持通过 localize 可选参数传入一个自定义方法,来实现本地化文本的转化。这是一个非常灵活的方案,这使你能够实现自定义的本地化函数,根据当前的语言环境将枚举的 label 值转换为适当的翻译文本。语言状态管理仍由您自己负责,您的 localize 方法决定返回哪种本地化文本。对于生产环境的应用程序,我们强烈建议使用成熟的国际化库(如 i18next),而不是创建自定义解决方案。
以下是一个简单的示例,仅供参考。请注意,第一种方法由于缺乏灵活性,不建议在生产环境中使用,它仅用于演示基本概念。请考虑使用第二种及后面的示例。
import { Enum } from 'enum-plus';
import i18next from 'i18next';
import Localize from './Localize';
let lang = 'zh-CN';
const setLang = (l: string) => {
lang = l;
};
// 👎 这不是一个好例子,仅供演示,不建议生产环境使用
const sillyLocalize = (content: string) => {
if (lang === 'zh-CN') {
switch (content) {
case 'enum-plus.options.all':
return '全部';
case 'week.sunday':
return '星期日';
case 'week.monday':
return '星期一';
default:
return content;
}
} else {
switch (content) {
case 'enum-plus.options.all':
return 'All';
case 'week.sunday':
return 'Sunday';
case 'week.monday':
return 'Monday';
default:
return content;
}
}
};
// 👍 建议使用 i18next 或其他国际化库
const i18nLocalize = (content: string | undefined) => i18next.t(content);
// 👍 或者封装成一个基础组件
const componentLocalize = (content: string | undefined) => <Localize value={content} />;
const Week = Enum(
{
Sunday: { value: 0, label: 'week.sunday' },
Monday: { value: 1, label: 'week.monday' },
} as const,
{
localize: sillyLocalize,
// localize: i18nLocalize, // 👍 推荐使用i18类库
// localize: componentLocalize, // 👍 推荐使用组件形式
}
);
setLang('zh-CN');
Week.label(1); // 星期一
setLang('en-US');
Week.label(1); // Monday
当然,每个枚举类型都这样设置可能比较繁琐,enum-plus 提供了一种全局设置方案,可以通过 Enum.localize 全局方法,来全局设置本地化。如果两者同时存在,单个枚举的设置会覆盖全局设置。
Enum.localize = i18nLocalize;
全局扩展
虽然 Enum 提供了一套全面的内置方法,但如果这些还不能满足你的需求,你可以使用 Enum.extends API 扩展其功能,添加自定义方法。这些扩展会全局应用于所有枚举实例,包括在扩展应用之前创建的实例,并且会立即生效,无需任何其它设置。
Enum.extends({
toMySelect(this: ReturnType<typeof Enum>) {
return this.items.map((item) => ({ value: item.value, title: item.label }));
},
reversedItems(this: ReturnType<typeof Enum>) {
return this.items.reverse();
},
});
Week.toMySelect(); // [{ value: 0, title: '星期日' }, { value: 1, title: '星期一' }]
兼容性
enum-plus 提供了完善的兼容性支持。
- 浏览器环境:
- 现代打包工具:对于支持 exports 字段的打包工具(如 Webpack 5+、Vite、Rollup),enum-plus 的目标是
ES2020。如果需要更广泛的浏览器支持,可以在构建过程中使用@babel/preset-env转译为更早期的语法。 - 旧版打包工具:对于不支持
exports字段的工具(如 Webpack 4),enum-plus 会自动回退到main字段的入口点,其目标是ES2016。 - Polyfill 策略:为了最小化包的体积,enum-plus 不包含任何 polyfill。如果需要支持旧版浏览器,可以引入以下内容:
core-js- 配置适当的
@babel/preset-env和useBuiltIns设置 - 其他替代的 polyfill 实现
- 现代打包工具:对于支持 exports 字段的打包工具(如 Webpack 5+、Vite、Rollup),enum-plus 的目标是
- Node.js 兼容性:enum-plus 需要至少
ES2016的特性,兼容 Node.jsv7.x及以上版本。
意犹未尽,还期待更多?不妨移步 Github官网,你可以发现更多的高级使用技巧。
相信我,一定会让你感觉相见恨晚!
如果你喜欢这个项目,欢迎在GitHub上给项目点个Star⭐ —— 这是程序员表达喜爱的通用语言😜~ 可以让更多开发者发现它!
来源:juejin.cn/post/7493721453537116169
一个 4.7 GB 视频把浏览器拖进 OOM
你给一家在线教育平台做「课程视频批量上传」功能。
需求听起来很朴素:讲师后台一次性拖 20 个 4K 视频,浏览器要稳、要快、要能断网续传。
你第一版直接 <input type="file"> + FormData,结果上线当天就炸:
- 讲师 A 上传 4.7 GB 的
.mov,Chrome 直接 内存溢出 崩溃; - 讲师 B 网断了 3 分钟,重新上传发现进度条归零,心态跟着归零;
- 运营同学疯狂 @ 前端:“你们是不是没做分片?”
解决方案:三层防线,把 4 GB 切成 2 MB 的“薯片”
1. 表面用法:分片 + 并发,浏览器再也不卡
// upload.js
const CHUNK_SIZE = 2 * 1024 * 1024; // 🔍 2 MB 一片,内存友好
export async function* sliceFile(file) {
let cur = 0;
while (cur < file.size) {
yield file.slice(cur, cur + CHUNK_SIZE);
cur += CHUNK_SIZE;
}
}
// uploader.js
import pLimit from 'p-limit';
const limit = pLimit(5); // 🔍 最多 5 并发,防止占满带宽
export async function upload(file) {
const hash = await calcHash(file); // 🔍 秒传、断点续传都靠它
const tasks = [];
for await (const chunk of sliceFile(file)) {
tasks.push(limit(() => uploadChunk({ hash, chunk })));
}
await Promise.all(tasks);
await mergeChunks(hash, file.name); // 🔍 通知后端合并
}
逐行拆解:
sliceFile用file.slice生成 Blob 片段,不占额外内存;p-limit控制并发,避免 100 个请求同时打爆浏览器;calcHash用 WebWorker 算 MD5,页面不卡顿(后面细讲)。
2. 底层机制:断点续传到底续在哪?
| 角色 | 存储位置 | 内容 | 生命周期 |
|---|---|---|---|
| 前端 | IndexedDB | hash → 已上传分片索引数组 | 浏览器本地,清缓存即失效 |
| 后端 | Redis / MySQL | hash → 已接收分片索引数组 | 可配置 TTL,支持跨端续传 |
sequenceDiagram
participant F as 前端
participant B as 后端
F->>B: POST /prepare {hash, totalChunks}
B-->>F: 200 OK {uploaded:[0,3,7]}
loop 上传剩余分片
F->>B: POST /upload {hash, index, chunkData}
B-->>F: 200 OK
end
F->>B: POST /merge {hash}
B-->>F: 200 OK
Note over B: 按顺序写磁盘
- 前端先
POST /prepare带 hash + 总分片数; - 后端返回已上传索引
[0, 3, 7]; - 前端跳过这 3 片,只传剩余;
- 全部完成后
POST /merge,后端按顺序写磁盘。
3. 设计哲学:把“上传”做成可插拔的协议
interface Uploader {
prepare(file: File): Promise<PrepareResp>;
upload(chunk: Blob, index: number): Promise<void>;
merge(): Promise<string>; // 🔍 返回文件 URL
}
我们实现了三套:
BrowserUploader:纯前端分片;TusUploader:遵循 tus.io 协议,天然断点续传;AliOssUploader:直传 OSS,用 OSS 的断点 SDK。
| 方案 | 并发控制 | 断点续传 | 秒传 | 代码量 |
|---|---|---|---|---|
| 自研 | 手动 | 自己实现 | 手动 | 300 行 |
| tus | 内置 | 协议级 | 需后端 | 100 行 |
| OSS | 内置 | SDK 级 | 自动 | 50 行 |
应用扩展:拿来即用的配置片段
1. WebWorker 算 Hash(防卡顿)
// hash.worker.js
importScripts('spark-md5.min.js');
self.onmessage = ({ data: file }) => {
const spark = new SparkMD5.ArrayBuffer();
const reader = new FileReaderSync();
for (let i = 0; i < file.size; i += CHUNK_SIZE) {
spark.append(reader.readAsArrayBuffer(file.slice(i, i + CHUNK_SIZE)));
}
self.postMessage(spark.end());
};
2. 环境适配
| 环境 | 适配点 |
|---|---|
| 浏览器 | 需兼容 Safari 14 以下无 File.prototype.slice(用 webkitSlice 兜底) |
| Node | 用 fs.createReadStream 分片,Hash 用 crypto.createHash('md5') |
| Electron | 渲染进程直接走浏览器方案,主进程可复用 Node 逻辑 |
举一反三:3 个变体场景
- 秒传
上传前先算 hash → 调后端/exists?hash=xxx→ 已存在直接返回 URL,0 流量完成。 - 加密上传
在uploadChunk里加一层AES-GCM加密,后端存加密块,下载时由前端解密。 - P2P 协同上传
用 WebRTC 把同局域网学员的浏览器变成 CDN,分片互传后再统一上报,节省 70% 出口带宽。
小结
大文件上传的核心不是“传”,而是“断”。
把 4 GB 切成 2 MB 的薯片,再配上一张能续命的“进度表”,浏览器就能稳稳地吃下任何体积的视频。
来源:juejin.cn/post/7530868895768838179
让 Vue 动画如德芙般丝滑!这个 FLIP 动画组件绝了!
“还在为 Vue 动画卡顿掉帧烦恼?只需 3 行代码,让你的元素切换丝滑到飞起!🚀”
今天给大家安利一个我最近发现的宝藏 Vue 组件——vue-flip-motion!它基于 FLIP 动画技术(First Last Invert Play),能轻松实现高性能、无卡顿的过渡效果,无论是列表重排、元素缩放还是颜色渐变,统统搞定!
🌟 核心亮点:
- ⚡️ 性能狂魔:FLIP 技术减少布局抖动,60fps 流畅到窒息!
- 🎨 傻瓜式操作:数据驱动动画,改个
mutation就能触发效果! - 🔄 双版本兼容:Vue 2 和 Vue 3 一把梭,无缝迁移!
- 🎚️ 高度可定制:支持嵌套动画、自定义缓动函数,想怎么玩就怎么玩!
(GIF 展示:点击按钮瞬间触发的丝滑重排/颜色变化)
(GIF 展示:运动轨迹叠加动画)
🛠️ 快速上手:
安装:
npm install vue-flip-motion
代码示例(Vue 3):
<template>
<Flip
:mutation="styles"
:styles="['backgroundColor']"
:animate-option="{ duration: 1000 }"
>
<div
class="box"
@click="handleClick"
:style="{ height: styles.height, background: styles.bgColor }"
/>
</Flip>
</template>
<script setup>
import { ref } from 'vue';
import Flip from 'vue-flip-motion';
const styles = ref({ height: '100px', bgColor: '#42b983' });
const handleClick = () => {
styles.value = { height: '200px', bgColor: '#ff0000' }; // 点我触发动画!
};
</script>
💥 高级玩法:
1. 嵌套动画:叠加缩放+旋转效果,轻松实现「多重影分身」!
2. 自定义选择器:精准控制子元素动画,比如列表重排时的「交错入场」特效!
3. 精细化配置:animateOption 支持 easing、delay 等参数,连贝塞尔曲线都能玩!
:animate-option="{
duration: 800,
easing: 'cubic-bezier(0.68, -0.6, 0.32, 1.6)', // 弹跳效果
iterations: Infinity // 无限循环
}"
❓ 为什么选它?
- 对比原生 CSS 动画:无需手动计算关键帧,数据一变自动补间!
- 对比 GSAP:更轻量(压缩后仅 5KB),专为 Vue 定制!
- 对比其他 FLIP 库:API 设计更符合 Vue 生态,上手零成本!
📢 行动号召:
👉 GitHub 地址:github.com/qianyuanjia…
👉 npm 地址:http://www.npmjs.com/package/vue…
现在就用起来,让你的项目动画体验提升 200%! 🚀
来源:juejin.cn/post/7553245651938066467
useReducer : hook 中的响应式状态管理
在前端开发中,状态管理是构建复杂应用的核心能力之一,而React作为主流框架,它提供了多种状态管理方案.
然而,随着应用规模扩大,组件层级加深,传统的状态传递方式似乎优点捉襟见肘了,于是,为了解决这种问题,
useReducer和useContext诞生了。
今天,我将从组件通信的不足开始,逐渐深入地讲解如何通过
useReducer实现高效、可维护的全局状态管理。
一、组件通信简单介绍
1.1 组件通信的常见方式:
- 父子组件通信:通过
props传递数据,子组件通过props接收父组件的数据。 - 子父组件通信:子组件通过
props传递回调函数(自定义事件)给父组件,实现数据反向传递。 - 兄弟组件通信:通过父组件作为中间人进行传递数据。
- 跨层级通信:使用
useContext创建共享上下文(Context),直接跨层级传递状态,详细讲解可以看我之前的文章《useContext : hook中跨层级通信的优雅方案》。
1.2 Context 的不足:
然而,尽管useContext解决了跨层级传递状态的问题,避免了数据臃肿,但是,它在以下场景中仍存在一些缺陷:
- 当Context频繁更新时,所有依赖该Context的组件都会重新渲染,即使某些组件并未使用更新后的数据,容易导致性能问题。
- Context能解决标签的跨级传输,然而,多个Context嵌套也会导致组件层级臃肿(比如
<LoginContext.Provider>中包裹<ThemeContext.Provider>)。 - Context本身只提供数据共享能力,它并不涉及到状态更新逻辑,需结合
useState或useReducer使用,这就导致了状态管理分散问题。
因此,当应用状态逻辑变得复杂、需集中管理时,useReducer就成为了更优的选择。
二、useReducer详解
2.1 useReducer的定义与作用
useReducer,响应式状态管理,它是React提供的用于管理复杂状态逻辑的Hook。
useReducer通过将状态(state)交由一个纯函数(reducer)进行统一管理,并通过派发动作(dispatch action)触发状态更新,而非直接修改状态。
2.2 useReducer的参数与返回值
const [state, dispatch] = useReducer(reducer, initialState);
- 参数1:reducer函数:根据当前状态和传入的action,返回新的状态。
- 参数2:initialState:初始状态对象。
- 返回值:
state:表示当前状态值。dispatch:用于触发状态更新的函数,接受一个action对象作为参数。
2.3 纯函数(Pure Function)
useReducer的参数里面,其中,要求reducer函数必须是一个纯函数。
纯函数的特性:
- 相同输入,相同输出:给定相同的输入参数,纯函数始终返回相同的结果。
- 无副作用:函数内部不修改外部变量、不依赖或修改全局状态、不发起网络请求或操作DOM。
- 不可变更新:函数不会直接修改输入参数,而是通过创建新对象或数组返回结果。
举个例子:
// 不纯的函数
let total = 0;
function addToTotal(a) {
total += a; // 修改了外部变量
return total;
}
// 纯函数
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 }; // 返回新对象
default:
return state;
}
}
代码功能说明:
addToTotal函数直接修改了外部变量total,导致结果不可预测。- 而
reducer函数通过返回新对象的方式更新状态,符合纯函数的要求。
三、用计数器案例讲解useReducer
3.1 代码实现的功能
以下代码实现了一个计数器功能,它通过按钮点击+1或-1修改Count值,输入自定义数值后,通过+???按钮,将该数值加到Count上。
效果如下:
关键代码片段:
import { useState,useReducer } from 'react'
import './App.css'
const initialState ={
count :0,
}
//关键代码
const reducer = (state ,action)=>{
switch(action.type){
case 'increment':
return {
count:state.count +1
};
case 'decrement':
return {
count:state.count -1
};
case 'incrementByNum':
return{
count:state.count +parseFloat(action.payload)
}
default:
return state
}
}
function App(){
const [count ,setCount] = useState(0)
const [state, dispatch]= useReducer(reducer, initialState)
return (
<>
<p>Count:{state.count}</p>
<input type="text" value={count} onChange={(e)=>setCount(e.target.value)}/>
<button onClick={()=>dispatch({type:'increment'})}> +1 </button>
<button onClick={()=>dispatch({type:'decrement'})}> -1</button>
<button onClick={()=>dispatch({type:'incrementByNum',payload:count})}> +??? </button>
</>
)
}
export default App
3.2 代码讲解:
- 在第9行中,
reducer函数通过switch语句处理三种类型的action即当触发increment、decrement、incrementByNum行为时,分别返回不同的新的状态对象。 - 而
dispatch函数用于触发状态更新,例如第35行,dispatch({ type: 'increment' })函数会在我们触发increment行为时,将计数器值增加1。 - 用户可以通过输入框输入自定义数值,并通过
incrementByNum操作将其加到当前计数器上。
关键部分:
- reducer函数的设计:
action.type决定了状态更新的逻辑,例如'increment'对应递增操作。action.payload用于传递额外参数(如自定义数值)。
- 不可变更新:
- 所有状态更新均通过创建新对象实现(如
{ count: state.count + 1 }),而非直接修改state。
- 所有状态更新均通过创建新对象实现(如
- dispatch的使用:
dispatch接受一个action对象,触发状态更新。例如,dispatch({ type: 'incrementByNum', payload: inputValue })会将输入框中的值加到计数器上。
四、总结
4.1 useReducer的适用场景
- 复杂状态逻辑:当状态更新逻辑涉及多个条件分支或嵌套结构时(如计数器的
incrementByNum操作)。 - 集中管理状态:通过将状态更新规则统一到
reducer中,避免分散在多个组件或回调函数中。
4.2 实际应用建议
- 结合useContext:通过
useContext创建共享状态,useReducer管理状态更新,形成轻量级全局状态管理方案。 - 模块化设计:将不同功能的
reducer拆分为独立文件(如counterReducer.js、formReducer.js),提升代码可维护性。
来源:juejin.cn/post/7527585340145713206
el-table实现可编辑表格的开发历程
写在前面的话
想直接看代码的朋友可以省略下面的历程直接翻到最底下,我把完整示例代码放在最下面
引子
笔者最近在做项目中遇到了一件事,某个迭代我们需要对项目进行UI改造,特别是把当前正在使用的一个可编辑表格换一下UI。说是换UI,其实是换表格,因为当前在用的表格组件是项目组花钱买的,但老板应该是对这个组件的UI有别的想法(其实就是觉得丑),然后经过老大的决定,我们需要换成Element-UI的组件(Element打钱~~ )。
虽说组件要换,但是我们要尽可能的保留原先的功能,原来的组件,在使用上面非常贴近于Excel表格。然后,笔者开始库库干了。。。
初步实现
为了快速实现功能,我们首先选择的是把这个可编辑表格的所有编辑项全部展示出来,这样用户就可以直接进行表格的编辑,就像这样:
但很快,我们就发现了第一个问题。
我们的表格中,有两列下拉框使用了远端搜索功能,同时使用了一个封装的下拉选择组件。这就使得当下拉框有值的时候,它会尝试用value在下拉选项中去匹配对应的label,而下拉选项需要通过远端搜索即调接口获取。这两列调的是同一个接口,哪怕这里做了分页并且默认一页10条,仍然默认会调同一个接口20次,这是一个很影响性能的问题,如果切换成一页20条、30条、50条的话,后果不堪设想。。。
考虑到这种情况,我们首先采取的方法是只调一次接口,把选项数据全部拉回来本地,然后让使用这些选项的下拉框直接引用。但在这里,我们又发现,这些下拉框是这样的:
是的,label和value同时展示出来,而且在远程搜索中,可以搜索label或value来找对应项。
那这里我们就得使用filter-method自定义搜索方法咯,但这里有个问题,那就是搜索结果得要是独立的才行,即:第一次搜索的选项结果,不能出现在第二次的搜索选项里,意思就是每次搜索完,需要把选项还原到默认状态。这好办,visible-change事件可以实现。
当我们把实现的功能交付出去后,产品给我们带来了一个噩耗:用户非得要跟Excel一样的,也就是说为了满足用户的使用习惯,我们需要尽可能还原出原来的表格组件来

解决之道
第一步
事已至此,先吃饭吧,啊,不是,先百度吧
在某次冲浪中,我发现了一篇文章,里面提到使用el-table组件的cell-dblclick事件来实现双击进入编辑状态的做法,也就是下面这样:
通过列的prop和行的id一起来定位到双击选中的单元格的位置,然后通过v-if使得输入框渲染出来
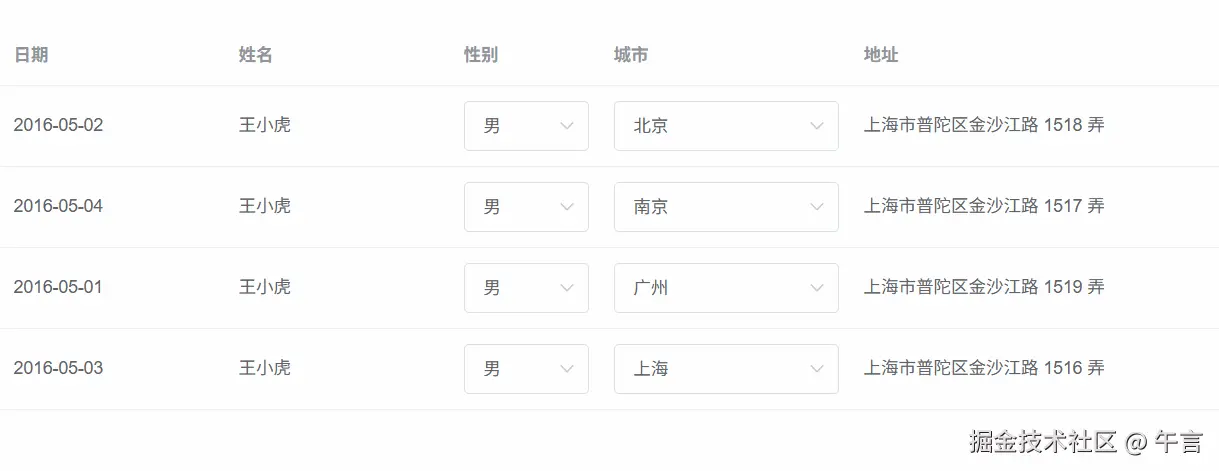
<template>
<el-table
:data="tableData"
style="width: 100%"
@cell-dblclick="cellDblclick"
>
<el-table-column prop="name" label="姓名" width="180">
<template slot-scope="scope">
<el-input v-if="formViewMethod(scope)" v-model="scope.row.name"></el-input>
<span v-else>{{ scope.row.name }}</span>
</template>
</el-table-column>
</el-table>
</template>
<script>
export default {
data() {
return {
editColumnProp: null,
editRowId: null
}
},
methods: {
cellDblclick(row, column, cell) {
cell.style.background = 'pink'
this.editColumnProp = column.property
this.editRowId = row.id
},
formViewMethod(scope) {
const { row, column } = scope
return (
row.id === this.editRowId &&
this.editColumnProp === column.property
)
}
}
}
</script>
这方法确实可行!在默认是text的情况下,也就不会去调接口,这样,哪怕是用回远端搜索功能,也能保证对性能没有那种压力。
第一步走出了,另一个问题就摆在眼前了:当我点击编辑框以外的地方,该怎么让它恢复默认那种文本状态呢?文章的作者并没有给出答案,那就得自己去寻找了
新的曙光
最近在冲浪中,我了解到有一个名为ClickOutside的指令,这是一个vue3中的自定义指令,顾名思义,就是点击外面的意思。这下子灵感就来了:在cell-dblclick事件中,我们可以获取到当前单元格的dom,那如果我们在获取dom的时候,给它加上一个点击事件,当点击到外面的时候,就清空当前单元格的选中状态,那是不是就可以实现了呢?说干就干,上代码:
cellDblclick(row, column, cell) {
cell.style.background = 'pink'
cell.__clickOutside__ = (e) => {
if (cell.contains(e.target)) {
return console.log('点击了自己')
}
console.log('点击了外面')
cell.__clickOutside__ && document.removeEventListener('click', cell.__clickOutside__)
}
document.addEventListener('click', cell.__clickOutside__)
this.editColumnProp = column.property
this.editRowId = row.id
}
在这里我们使用了dom的contains()方法,这个方法用于检测一个元素是否包含另一个元素,返回的是一个布尔值。也就是当点击的时候,判断被点击元素B是否在双击的时候绑定点击事件的元素A之内,如果返回true的话,就是点击自己了,否则就是点击外面,这样就能实现清空选中状态的方法了。就像下面这样子:
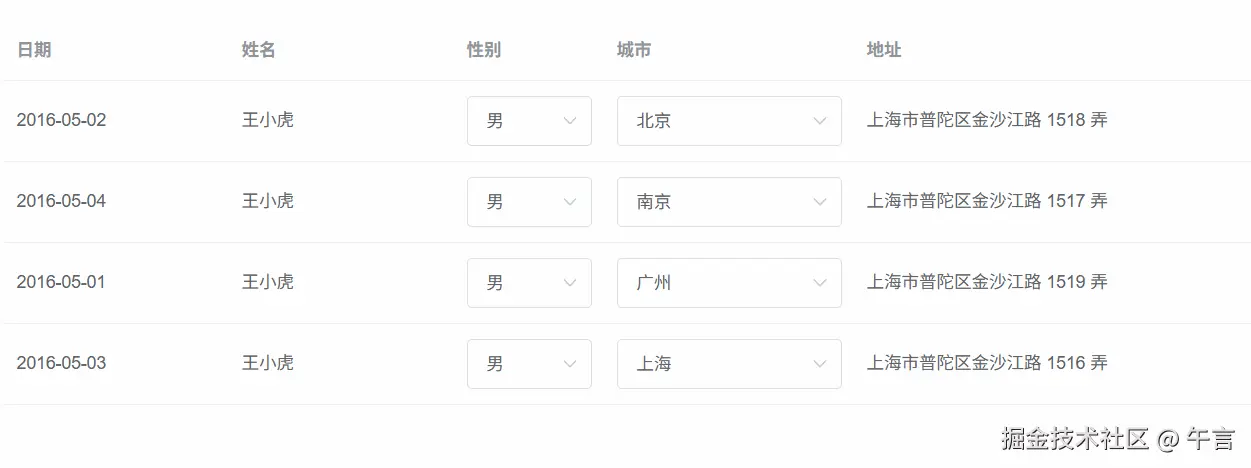
到这里,可编辑表格的功能就算实现了,谢谢大家观看,下面会贴上完整的示例代码,大伙儿可以直接复制粘贴来看看效果。
完整代码
<template>
<div class="irregular-table-container">
<div class="custom-table">
<!-- 表格区域 -->
<el-table
:data="tableData"
style="width: 100%"
@cell-dblclick="cellDblclick"
>
<el-table-column
prop="date"
label="日期"
width="180">
</el-table-column>
<el-table-column prop="name" label="姓名" width="180">
<template slot-scope="scope">
<el-input v-if="formViewMethod(scope)" v-model="scope.row.name"></el-input>
<span v-else>{{ scope.row.name }}</span>
</template>
</el-table-column>
<el-table-column
prop="gender"
label="性别"
width="120"
:formatter="formatGender"
>
</el-table-column>
<el-table-column
prop="city"
label="城市"
width="200"
:formatter="formatCity"
>
</el-table-column>
<el-table-column prop="address" label="地址"/>
</el-table>
</div>
</div>
</template>
<script>
export default {
name: "EditableTable",
data() {
return {
tableData: [
{
id: 1,
date: '2016-05-02',
name: '王小虎',
gender: '男',
city: 'Beijing',
address: '上海市普陀区金沙江路 1518 弄'
}, {
id: 2,
date: '2016-05-04',
name: '王小虎',
gender: '男',
city: 'Nanjing',
address: '上海市普陀区金沙江路 1517 弄'
}, {
id: 3,
date: '2016-05-01',
name: '王小虎',
gender: '男',
city: 'Guangzhou',
address: '上海市普陀区金沙江路 1519 弄'
}, {
id: 4,
date: '2016-05-03',
name: '王小虎',
gender: '男',
city: 'Shanghai',
address: '上海市普陀区金沙江路 1516 弄'
}
],
options: [
{ label: '男', value: 1 },
{ label: '女', value: 0 }
],
cities: [
{
value: 'Beijing',
label: '北京'
}, {
value: 'Shanghai',
label: '上海'
}, {
value: 'Nanjing',
label: '南京'
}, {
value: 'Chengdu',
label: '成都'
}, {
value: 'Shenzhen',
label: '深圳'
}, {
value: 'Guangzhou',
label: '广州'
}
],
editColumnProp: null,
editRowId: null
}
},
computed: {},
created() {},
methods: {
formatName(row) {
const input = (
<el-input v-model={row.name} clearable />
)
return input
},
formatGender(row) {
const select = (
<el-select v-model={row.gender}>
{this.options.map(item => {
return (
<el-option
key={item.value}
label={item.label}
value={item.value}
/>
)
})}
</el-select>
)
return select
},
formatCity(row) {
const select = (
<el-select v-model={row.city}>
{this.cities.map(item => {
return (
<el-option
key={item.value}
label={item.label}
value={item.value}
>
<span style="float: left">{ item.label }</span>
<span style="float: right; color: #8492a6; font-size: 13px">{ item.value }</span>
</el-option>
)
})}
</el-select>
)
return select
},
cellDblclick(row, column, cell) {
cell.style.background = 'pink'
cell.__clickOutside__ = (e) => {
if (cell.contains(e.target)) {
return console.log('点击了自己')
}
// console.log('点击了外面')
this.editColumnProp = null
this.editRowId = null
cell.__clickOutside__ && document.removeEventListener('click', cell.__clickOutside__)
}
document.addEventListener('click', cell.__clickOutside__)
this.editColumnProp = column.property
this.editRowId = row.id
},
formViewMethod(scope) {
const { row, column } = scope
return (
row.id === this.editRowId &&
this.editColumnProp === column.property
)
}
}
}
</script>
感谢名单
写完一看时间,嚯,好家伙,凌晨4点了,赶紧碎觉,狗命要紧~~
最后的最后,这里要感谢两位给我提供灵感和思路的大大,我把他们的文章链接放到下面了,感兴趣的小伙伴可以过去学习下。
vue对el-table的二次封装,双击单元格编辑,避免表格输入框过多卡顿
vue自定义指令(v-clickoutside)-点击当前区域之外的位置
来源:juejin.cn/post/7552789573735907328
event.currentTarget 、event.target 傻傻分不清楚?
在前端开发中,事件处理是交互逻辑的核心。但你是否会遇到这样的困惑:绑定事件时明明用的是父元素,触发时却总获取到子元素的信息?或是想优化大量子元素的事件绑定,却不知从何下手?
这一切的答案,都藏在 event.currentTarget和 event.target这对“双胞胎”属性里。
一、核心概念:谁在触发?谁在处理?
要理解这两个属性,首先需要明确事件流的基本概念。当用户与页面交互(如点击)时,事件会经历 捕获阶段 → 目标阶段 → 冒泡阶段 传播。而 event.currentTarget和 event.target的差异,正源于它们在这场“事件旅行”中的不同角色。
1. event.target:事件的“起点”
定义:触发事件的最深层元素,即用户实际交互的对象。
特点:
- 从事件触发到结束,始终指向最初的“罪魁祸首”(即使事件冒泡到父元素,它也不会变)。
- 可能是按钮、文本节点,甚至是动态生成的元素。
示例:点击一个嵌套的 <div>内部的 <span>,event.target始终是 <span>。
2. event.currentTarget:事件的“处理者”
定义:当前正在执行事件处理程序的元素,即绑定事件监听器的那个元素。
特点:
- 随着事件在捕获/冒泡阶段流动,它的值会动态变化(从外层元素逐渐向内,或从内层向外)。
- 在非箭头函数的回调中,
this等价于event.currentTarget。
示例:父元素绑定点击事件,子元素被点击时,父元素的回调函数中 event.currentTarget是父元素,而 event.target是子元素。
二、一张图看懂:事件流中的身份切换
为了更直观理解二者的差异,我们通过一个三层嵌套结构的交互演示:
<div id="outer" class="box">外层(绑定事件)
<div id="middle" class="box">中层
<div id="inner" class="box">内层(点击我)</div>
</div>
</div>
当点击最内层的 inner元素时,事件流的三个阶段中,currentTarget和 target的变化如下:
| 阶段 | event.currentTarget(处理者) | event.target(触发者) |
|---|---|---|
| 捕获阶段 | outer → middle → inner | inner(始终不变) |
| 目标阶段 | inner | inner |
| 冒泡阶段 | inner → middle → outer | inner(始终不变) |
关键结论:
target是“事件的源头”,永远指向用户点击的那个元素。currentTarget是“事件的搬运工”,随事件传播阶段变化,指向当前处理事件的元素。
三、为什么需要事件委托?用差异解决实际问题
传统事件绑定方式为每个子元素单独添加监听器,但在动态列表、表格等场景下,这会导致 内存浪费、动态元素难维护、代码冗余 三大痛点。而事件委托的出现,正是利用 currentTarget和 target的差异,提供了一种“集中管理、按需处理”的优化方案。
事件委托的核心逻辑
原理:将子元素的事件监听绑定在父元素上,利用事件冒泡机制,由父元素统一处理子元素的事件。
关键依赖:
- 父元素(
currentTarget)负责接收事件。 - 通过
event.target识别实际触发的子元素,执行针对性逻辑。
经典场景实战
场景 1:动态待办列表的点击交互
需求:点击待办项标记完成,支持动态添加新任务。
传统方式的问题:每次新增任务都要重新绑定事件,代码冗余且易出错。
事件委托方案:
<ul id="todoList">
<li class="todo-item">任务 1(点击标记完成)</li>
<li class="todo-item">任务 2(点击标记完成)</li>
</ul>
<button id="addTodo">添加新任务</button>
const todoList = document.getElementById('todoList');
const addTodoBtn = document.getElementById('addTodo');
// 父元素 todoList 绑定唯一点击事件(冒泡阶段)
todoList.addEventListener('click', function(event) {
// event.target 是实际点击的元素(可能是 li 或其子元素)
const target = event.target.closest('.todo-item'); // 向上查找最近的 li
if (!target) return; // 非目标元素,跳过
// 标记完成(切换类名)
target.classList.toggle('completed');
// 若点击删除按钮(假设子元素有 .delete-btn)
if (target.querySelector('.delete-btn')) {
target.remove(); // 直接删除父元素 li
}
});
// 动态添加新任务(无需重新绑定事件)
addTodoBtn.addEventListener('click', () => {
const newTodo = document.createElement('li');
newTodo.className = 'todo-item';
newTodo.innerHTML = `新任务 ${Date.now()} <button class="delete-btn">删除</button>`;
todoList.appendChild(newTodo);
});
优势:
- 仅需绑定一次父元素事件,内存占用极低。
- 新增任务自动继承事件处理能力,无需额外代码。
场景 2:表格单元格的双击编辑
需求:双击表格单元格(td)转换为输入框编辑。
事件委托方案:
<table id="dataTable">
<thead><tr><th>ID</th><th>名称</th></tr></thead>
<tbody>
<tr><td>1</td><td>苹果</td></tr>
<tr><td>2</td><td>香蕉</td></tr>
</tbody>
</table>
const dataTable = document.getElementById('dataTable');
// 父元素 tbody 监听双击事件(冒泡到 tbody)
dataTable.addEventListener('dblclick', function(event) {
// event.target 是实际双击的元素(可能是文本或 td)
const td = event.target.closest('td');
if (!td) return;
// 转换为输入框编辑
const originalText = td.textContent;
td.innerHTML = `<input type="text" value="${originalText}" class="edit-input">`;
const input = td.querySelector('.edit-input');
input.focus();
// 输入完成后保存(监听输入框失焦)
input.addEventListener('blur', () => {
td.textContent = input.value;
});
});
优势:
- 无论表格有多少行,只需绑定一次
tbody事件。 - 新增行(如 AJAX 加载数据后插入)自动支持编辑功能。
四、避坑指南:事件委托的注意事项
- 选择合适的父元素
父元素应尽可能靠近目标子元素(如列表用
ul而非body),避免不必要的事件判断逻辑,减少性能损耗。 - 精确过滤目标元素
使用
event.target.closest(selector)或event.target.matches(selector)确保只处理目标子元素。例如:
if (event.target.matches('.todo-item')) { ... }或
const target = event.target.closest('.todo-item'); if (target) { ... } - 处理事件冒泡的中断
若子元素调用了
event.stopPropagation(),事件不会冒泡到父元素,委托会失效。需避免在关键子元素中阻止冒泡,或改用捕获阶段监听(addEventListener第三个参数为true)。 - 性能优化的边界
对于极少量子元素(如 5 个以内),直接绑定可能更简单;但对于动态或大量子元素,事件委托是更优选择。
五、总结:从“混淆”到“精通”的关键
event.currentTarget和 event.target的核心差异,本质是 “处理者”与“触发者” 的分工:
target是用户交互的起点,始终指向实际触发的元素。currentTarget是事件处理程序的载体,随事件传播阶段变化。
而事件委托,正是利用这一差异,通过父元素(currentTarget)集中处理子元素事件,解决了动态内容、批量操作的维护难题。
掌握这对属性和事件委托模式,不仅能写出更高效的代码,更能让你在前端交互设计中游刃有余。下次遇到大量子元素的事件绑定需求时,不妨试试事件委托——它会是你最可靠的“效率工具”。
来源:juejin.cn/post/7553245651939131427
前端数据请求对决:Axios 还是 Fetch?
在 2025 年的现代前端开发中,高效可靠的数据请求依然是核心挑战。Axios 和 Fetch API 作为两大主流解决方案,一直让开发者难以抉择。本文将深入剖析两者特点,通过实际对比助你做出技术选型决策。
原生之力:Fetch API
Fetch 是浏览器原生提供的请求接口,无需安装即可使用:
// 基础 GET 请求
fetch('https://api.example.com/data')
.then(response => {
if (!response.ok) throw new Error('Network error');
return response.json(); // 需手动解析JSON
})
.then(data => console.log(data))
.catch(error => console.error('Request failed:', error));
核心特性:
- 原生内置:现代浏览器(包括IE11+)全面支持
- Promise 架构:告别回调地狱,支持 async/await
- 精简设计:无额外依赖,项目体积零负担
2025 年增强特性:
- AbortController:支持请求取消(原生能力已普及)
const controller = new AbortController();
fetch(url, { signal: controller.signal });
controller.abort(); // 取消请求
- Streams API:直接处理数据流(适用于大文件)
- 请求优先级:通过
priority: 'high'参数优化关键请求
全能战士:Axios
Axios 作为久经考验的第三方库,提供了更完善的功能封装:
// 完整特性的 POST 请求
axios.post('https://api.example.com/users', {
name: 'John',
age: 30
}, {
headers: { 'X-Custom-Header': 'value' },
timeout: 5000
})
.then(response => console.log(response.data)) // 自动解析JSON
.catch(error => {
if (axios.isCancel(error)) {
console.log('Request canceled');
} else {
console.error('Request error:', error);
}
});
不可替代的优势:
- 开箱即用的 JSON 处理:自动转换响应数据
- 拦截器机制:全局管理请求/响应
// 身份验证拦截器
axios.interceptors.request.use(config => {
config.headers.Authorization = `Bearer ${token}`;
return config;
});
// 错误统一处理
axios.interceptors.response.use(
response => response,
error => {
alert(`API Error: ${error.response.status}`);
return Promise.reject(error);
}
);
- 便捷的取消机制:
const source = axios.CancelToken.source();
axios.get(url, { cancelToken: source.token });
source.cancel('Operation canceled');
- 客户端防御:内置 XSRF 防护
- 进度跟踪:上传/下载进度监控
- 多环境支持:浏览器与 Node.js 通用
关键决策因素对比
| 特性 | Axios | Fetch |
|---|---|---|
| 安装需求 | 需安装 (13KB gzip) | 浏览器内置 |
| JSON 处理 | 自动转换 | 需手动 response.json() |
| 错误处理 | 捕获所有HTTP错误 | 需检查 response.ok |
| 取消请求 | 专用CancelToken | 使用AbortController |
| 拦截器 | ✅ | ❌ |
| 超时设置 | 原生支持 timeout 参数 | 需结合AbortController实现 |
| 请求进度追踪 | ✅ | 通过response.body实现 |
| 浏览器兼容性 | IE10+ (需polyfill) | 现代浏览器(IE11+) |
| XSRF防护 | ✅自动 | 需手动配置 |
| TypeScript支持 | 完善的类型定义 | 需额外声明 |
2025 年选型建议
- 选择 Fetch 当:
- 项目无复杂请求逻辑
- 追求零依赖和最小打包体积
- 目标平台均为现代浏览器
- 使用框架内置封装(如 Next.js 的 fetch 增强)
- 选择 Axios 当:
- 需要统一处理错误/权限
- 项目涉及文件上传等复杂场景
- 服务端渲染(SSR)应用
- 团队已有Axios使用规范
- 需要TypeScript深度支持
融合解决方案
在大型项目中,可以采用混合方案:
// 封装原生fetch获得axios式体验
const http = async (url, options = {}) => {
const controller = new AbortController();
const config = {
...options,
signal: controller.signal,
headers: { 'Content-Type': 'application/json', ...options.headers }
};
const timeoutId = setTimeout(() => controller.abort(), 8000);
try {
const response = await fetch(url, config);
clearTimeout(timeoutId);
if (!response.ok) throw new Error(`HTTP ${response.status}`);
return await response.json();
} catch (error) {
if (error.name === 'AbortError') console.error('Request timed out');
throw error;
}
};
结论
在 2025 年的技术背景下,Fetch API 的原生能力得到大幅增强,对于小型项目和简单场景愈发得心应手。但对于企业级应用,Axios 仍然凭借其人性化设计和功能完备性保持不可替代的地位。建议开发者根据项目的规模、运行环境、团队习惯三大核心因素制定技术决策,必要时可进行混合封装以平衡开发效率与性能要求。
来源:juejin.cn/post/7535907433278226474
ts的迭代器和生成器
在 TypeScript(以及 JavaScript)中,迭代器和生成器是用于处理集合数据(如数组、对象等)的强大工具。它们允许你按顺序访问集合中的元素,并提供了一种控制数据访问的方式。
迭代器(Iterator)
迭代器是一个对象,它定义了一个序列,并且提供了一种方法来访问这个序列的元素。迭代器对象实现了 Iterator 接口,该接口要求它有一个 next() 方法。
Iterable 接口
一个对象如果实现了Iterable接口,那么它就是可迭代的。这个接口要求对象必须有一个Symbol.iterator方法,这个方法返回一个迭代器对象。
Iterator 接口
迭代器对象必须实现Iterator接口。这个接口定义了next()方法,该方法返回一个对象,这个对象有两个属性:value和done。value表示当前的元素值,done是一个布尔值,表示是否还有更多的元素可以迭代。
1.可迭代对象(Iterable)
一个对象如果实现了[Symbol.iterator]方法,它就是可迭代的。这个方法必须返回一个迭代器对象。常见的内置可迭代对象包括:Array,String,Map,Set,arguments对象(可通过Array.from()或扩展运算符使用),DOM的NodeList(部分浏览器)。
const arr = [1, 2, 3];
console.log(arr[Symbol.iterator]);

这些对象之所以能被for...of循环遍历,正是因为它们实现了Symbol.iterator方法。
2.迭代器(Iterator)
迭代器是一个带有next()方法的对象,调用next()返回{value,done}.
value:当前值(当done:true时,value可省略或为undefined)
done:布尔值,表示是否遍历完成。
const arr = [10, 20];
const iterator = arr[Symbol.iterator]();
console.log(iterator.next());
console.log(iterator.next());
console.log(iterator.next());
注意:迭代器本身通常也是可迭代的(即它自己也有[Symbol.iterator()]),这样它就可以用于for...of。
3.for...of与展开运算符的工作原理
for (const item of [1, 2, 3]) {
console.log(item);
}
背后的逻辑:
- 获取
[1,2,3][Symbol.iterator]() - 不断调用.next()直到done:true
同理:
const str = "hi";
const chars = [...str];
console.log(chars)

手动实现一个可迭代对象
class Countdown {
constructor(private start: number) {}
[Symbol.iterator](): Iterator<number> {
let current = this.start;
return {
next(): { value: number; done: boolean } {
if (current < 0) {
return { value: undefined, done: true };
}
return { value: current--, done: false };
},
// 可选:支持 return() 方法用于提前终止(如 break)
return() {
console.log("迭代被中断");
return { value: undefined, done: true };
}
};
}
}
// 使用
const countdown = new Countdown(3);
for (const n of countdown) {
console.log(n);
}
生成器(Generator):简化迭代器创建
生成器函数是创建迭代器的便捷方式。使用function* 定义,内部用yield暂停执行。
function* idGenerator() {
let id = 1;
while (true) {
yield id++;
}
}
const gen = idGenerator();
console.log(gen.next().value);
console.log(gen.next().value);

生成器函数返回一个生成器对象,它即是迭代器,也是可迭代对象。
你甚至可以让一个对象使用生成器作为[Symbol.iterator]
const myRange = {
from: 1,
to: 5,
*[Symbol.iterator]() {
for (let i = this.from; i <= this.to; i++) {
yield i;
}
}
};
console.log([...myRange]);
迭代器协议总结:
协议:Iterable
方法:
[Symbol.iterator]():Iterator
返回值:迭代器对象
说明:表示可被遍历
协议:Iterator
方法:
next():{value,done}
返回值:状态对象
说明:提供下一个值
协议:可选
方法:
return?():{value,done}
返回值:状态对象
说明:处理提前退出
协议:可选
方法:
throw?():{value,done}
返回值:状态对象
说明:处理异常抛出
来源:juejin.cn/post/7547346633400221747
仿照豆包实现 Prompt 变量模板输入框
先前在使用豆包的Web版时,发现在“帮我写作”模块中用以输入Prompt的模板输入框非常实用,既可以保留模板输入的优势,来调优指定的写作方向,又能够不失灵活地自由编辑。其新对话的输入交互也非常细节,例如选择“音乐生成”后技能提示本身也是编辑器的嵌入模块,不可以直接删除。
虽然看起来这仅仅是一个文本内容的输入框,但是实现起来并不是那么容易,细节的交互也非常重要。例如技能提示节点直接作为输入框本身模块,多行文本就可以在提示下方排版,而不是类似网格布局需要在左侧留空白内容。那么在这里我们就以豆包的交互为例,来实现Prompt的变量模板输入框。
概述
当我们开发AI相关的应用时,一个常见的场景便是需要用户输入Prompt,或者是在管理后台维护Prompt模板提供给其他用户使用。此时我们就需要一个能够支持内容输入或者模板变量的输入框,那么常见的实现方式有以下几种:
- 纯文本输入框,类似于
<input>、<textarea>等标签,在其DOM结构周围实现诸如图片、工具选择等按钮的交互。 - 表单变量模板,类似于填空的形式,将
Prompt模板以表单的形式填充变量,用户只需要填充所需要的变量内容即可。 - 变量模板输入框,同样类似于填空的形式,但是其他内容也是可以编辑的,以此实现模版变量调优以及灵活的自由指令。
在这里有个有趣的事情,豆包的这个模板输入框是用slate做的,而后边生成文档的部分却又引入了新的富文本框架。也就是其启用分步骤“文档编辑器”模式的编辑器框架与模板输入框的编辑器框架并非同一套实现,毕竟引入多套编辑器还是会对应用的体积还是有比较大的影响。
因此为什么不直接使用同一套实现则是非常有趣的问题,虽然一开始可能是想着不同的业务组实现有着不同的框架选型倾向。但是仔细研究一下,想起来slate对于inline节点是特殊类型实现,其内嵌的inline左右是还可以放光标的,重点是inline内部也可以放光标。
这个问题非常重要,如果不能实现空结构的光标位置,那么就很难实现独立的块结构。而这里的实现跟数据结构和选区模式设计非常相关,若是针对连续的两个DOM节点位置,如果需要实现多个选区位置,就必须有足够的选区表达,而如果是纯线性的结构则无法表示。
// <em>text</em><strong>text</strong>
// 完全匹配 DOM 结构的设计
{ path: [0], offset: 4 } // 位置 1
{ path: [1], offset: 0 } // 位置 2
// 线性结构的设计
{ offset: 4 } // 位置 1
对于类似的光标位置问题,开源的编辑器编辑器例如Quill、Lexical等,甚至商业化的飞书文档、Notion都没有直接支持这种模式。这些编辑器的schema设计都是两个字符间仅会存在一个caret的光标插入点,验证起来也很简单,只要看能否单独插入一个空内容的inline节点即可。
在这里虽然我们主要目标是实现变量模板的输入框形式,但是其他的形式也非常有意思,例如GitHub的搜索输入框高亮、CozeLoop的Prompt变量调时输入等。因此我们会先将这些形式都简单叙述一下,在最后再重点实现变量模板输入框的形式,最终的实现可以参考 BlockKit Variables 以及 CodeSandbox。
纯文本输入框
纯文本输入框的形式就比较常见了,例如<input>、<textarea>等标签,当前我们平时使用的输入框也都是类似的形式,例如DeepSeek就是单纯的textarea标签。当然也有富文本编辑器的输入框形式,例如Gemini的输入框,但整体形式上基本一致。
文本 Input
单纯的文本输入框的形式自然是最简单的实现了,直接使用textarea标签即可,只不过这里需要实现一些控制形式,例如自动计算文本高度等。此外还需要根据业务需求实现一些额外的交互,例如图片上传、联网搜索、文件引用、深度思考等。
+-------------------------------------------+
| |
| DeepThink Search ↑ |
+-------------------------------------------+
文本高亮匹配
在这里更有趣的是GitHub的搜索输入框,在使用综合搜索、issue搜索等功能时,我们可以看到如果关键词不会会被高亮。例如is:issue state:open 时,issue和open会被高亮,而F12检查时发现其仅是使用input标签,并没有引入富文本编辑器。
在这里GitHub的实现方式就非常有趣,实际上是使用了div渲染格式样式,来实现高亮的效果,然后使用透明的input标签来实现输入交互。如果在F12检查时将input节点的color透明隐藏掉,就可以发现文本的内容重叠了起来,需要关注的点在于怎么用CSS实现文本的对齐。
我们也可以实现一个类似的效果,主要关注字体、spacing的文本对齐,以及避免对浮层的事件响应,否则会导致鼠标点击落到浮层div而不是input导致无法输入。其实这里还有一些其他的细节需要处理,例如可能存在滚动条的情况,不过在这里由于篇幅问题我们就不处理了。
<div class="container">
<div id="$$1" class="overlay"></div>
<input id="$$2" type="text" class="input" value="变量文本{{vars}}内容" />
</div>
<script>
const onInput = () => {
const text = $$2.value;
const html = text.replace(/{{(.*?)}}/g, `<span style="color: blue;">{{$1}}</span>`);
$$1.innerHTML = html;
};
$$2.oninput = onInput;
onInput();
</script>
<style>
.container { position: relative; height: 30px; width: 800px; border: 1px solid #aaa; border-radius: 3px; }
.container > * { width: 800px; height: 30px; font-size: 16px; box-sizing: border-box; font-family: inherit; }
.overlay { pointer-events: none; position: absolute; left: 0; top: 0; height: 100%; width: 100%; }
.overlay { white-space: pre; display: flex; align-items: center; word-break: break-word; }
.input { padding: 0; border-width: 0; word-spacing: 0; letter-spacing: 0; color: #0000; caret-color: #000; }
</style>
表单变量模板
变量模板的形式非常类似于表单的形式,在有具体固定的Prompt模板或者具体的任务时,这种模式非常合适。还有个有意思的事情,这种形式同样适用于非AI能力的渐进式迭代,例如文档场景常见的翻译能力,原有的交互形式是提交翻译表单任务,而在这里可以将表单形式转变为Prompt模板来使用。
表单模板
表单模版的交互形式比较简单,通常都是左侧部分编写纯文本并且预留变量空位,右侧部分会根据文本内容动态构建表单,CozeLoop中有类似的实现形式。除了常规的表单提交以外,将这种交互形式融入到LLms融入到流程编排中实现流水线,以提供给其他用户使用,也是常见的场景。
此外,表单模版适用于比较长的Prompt模版场景,从易用性上来说,用户可以非常容易地专注变量内容的填充,而无需仔细阅读提供的Prompt模版。并且这种形式还可以实现变量的复用,也就是在多个位置使用同一个变量。
+--------------------------------------------------+------------------------+
| 请帮我写一篇关于 {{topic}} 的文章,文章内容要 | 主题: ________________ |
| 包含以下要点: {{points}},文章风格符合 {{style}}, | 要点: ________________ |
| 文章篇幅为 {{length}},并且要包含一个吸引人的标题。 | 风格: ________________ |
| | 长度: ________________ |
+--------------------------------------------------+------------------------+
行内变量块
行内变量块就相当于内容填空的形式,相较表单模版来说,行内变量块则会更加倾向较短的Prompt模板。整个Prompt模板绘作为整体,而变量块则作为行内的独立块结构存在,用户可以直接点击变量块进行内容编辑,注意此处的内容是仅允许编辑变量块的内容,模板的文本是不能编辑的。
+---------------------------------------------------------------------------+
| 请帮我写一篇关于 {{topic}} 的文章,文章内容要包含以下要点: {{points}}, |
| 文章风格符合 {{style}},文章篇幅为 {{length}},并且要包含一个吸引人的标题。 |
+---------------------------------------------------------------------------+
这里相对豆包的变量模板输入框形式来说,最大的差异就是非变量块不可编辑。那么相对来说这种形式就比较简单了,普通的文本就使用span节点,变量节点则使用可编辑的input标签即可。看起来没什么问题,然而我们需要处理其自动宽度,类似arco的实现,否则交互起来效果会比较差。
实际上input的自动宽度并没有那么好实现,通常来说这种情况需要额外的div节点放置文本来同步计算宽度,类似于前文我们聊的GitHub搜索输入框的实现方式。那么在这里我们使用Editable的span节点来实现内容的编辑,当然也会存在其他问题需要处理,例如避免回车、粘贴等。
<div id="$$0" class="container"><span>请帮我写一篇关于</span><span class="input" placeholder="{{topic}}" ></span><span>的文章,文章内容要包含以下要点:</span><span class="input" placeholder="{{points}}" ></span>,<span>文章风格符合</span><span class="input" placeholder="{{style}}" ></span><span>,文章篇幅为</span><span class="input" placeholder="{{length}}" ></span><span>,并且要包含一个吸引人的标题。</span></div>
<style>
.container > * { font-size: 16px; display: inline-block; }
.input { outline: none; margin: 3px 2px; border-radius: 4px; padding: 2px 5px; }
.input { color: #0057ff; background: rgba(0, 102, 255, 0.06); }
.input::after { content: attr(data-placeholder); cursor: text; opacity: 0.5; pointer-events: none; }
</style>
<script>
const inputs = document.querySelectorAll(".input");
inputs.forEach(input => {
input.setAttribute("contenteditable", "true");
const onInput = () => {
!input.innerText ? input.setAttribute("data-placeholder", input.getAttribute("placeholder"))
: input.removeAttribute("data-placeholder");
}
onInput();
input.oninput = onInput;
});
</script>
变量模板输入框
变量模板输入框可以认为是上述实现的扩展,主要是支持了文本的编辑,这种情况下通常就需要引入富文本编辑器来实现了。因此,这种模式同样适用于较短的Prompt模版场景,并且用户可以在模板的基础上进行灵活的调整,参考下面的示例实现的 DEMO 效果。
+---------------------------------------------------------------------------+
| 我是一位 {{role}},帮我写一篇关于 {{theme}} 内容的 {{platform}} 文章, |
| 需要符合该平台写作风格,文章篇幅为 {{space}} 。 |
+---------------------------------------------------------------------------+
方案设计
实际上只要涉及到编辑器相关的内容,无论是富文本编辑器、图形编辑器等,都会比较复杂,其中的都涉及到了数据结构、选区模式、渲染性能等问题。而即使是个简单的输入框,也会涉及到其中的很多问题,因此我们必须要做好调研并且设计好方案。
开篇我们就讲述了为何slate可以实现这种交互,而其他的编辑器框架则不行,主要是因为slate的inline节点是特殊类型实现。具体来说,slate的inline节点是一个children数组,因此这里看起来是同个位置的选区可以通过path的不同区分,child内会多一层级。
[
{
type: "paragraph",
children: [{
type: "badge",
children: [{ text: "Approved" }],
}],
},
]
因此既然slate本身设计上支持这种选区行为,那么实现起来就会非常方便了。然而我对于slate编辑器实在是太熟悉了,也为slate提过一些PR,所以在这里我并不太想继续用slate实现,而恰好我一直在写 从零实现富文本编辑器 的系列文章,因此用自己做的框架BlockKit实现是个不错的选择。
而实际上,用slate的实现并非完全没有问题,主要是slate的数据结构完全支持任意层级的嵌套,那么也就是说,我们必须要用很多策略来限制用户的行为。例如我们复制了嵌入节点,是完全可以将其贴入到其他块结构内,造成更多级别的children嵌套,类似这种情况必须要写完善的normalize方法处理。
那么在BlockKit中并不支持多层级的嵌套,因为我们的选区设计是线性的结构,即使有多个标签并列,大多数情况下我们会认为选区是在偏左的DOM节点末尾。而由于某些情况下节点在浏览器中的特殊表现,例如Embed类型的节点,我们才会将光标放置在偏右的DOM位置。
// 左偏选区设计
{ offset: 4 }
// <em>text[caret]</em><strong>text</strong>
{ offset: 5 }
// <em>text</em><strong>t[caret]ext</strong>
因此我们必须要想办法支持这个行为,而更改架构设计则是不可行的,毕竟如果需要修改诸如选区模式、数据结构等模块,就相当于修改了地基,上层的所有模块都需要重新适配。因此我们需要通过其他方式来实现这个功能,而且还需要在整体编辑器的架构设计基础上实现。
那么这里的本质问题是我们的编辑器不支持独立的空结构,其中主要是没有办法额外表示一个选区位置,如果能够通过某些方式独立表达选区位置,理论上就可以实现这个功能。沿着这个思路,我们可以比较容易地想出来下面的两个方式:
- 在变量块周围维护配对的
Embed节点,即通过额外的节点构造出新的选区位置,再来适配编辑器的相关行为。 - 变量块本身通过独立的
Editable节点实现,相当于脱离编辑器本身的控制,同样需要适配内部编辑的相关行为。
方案1的优点是其本身并不会脱离编辑器的控制,整体的选区、历史记录等操作都可以被编辑器本身管理。缺点是需要额外维护Embed节点,整体实现会比较复杂,例如删除末尾Embed节点时需要配对删除前方的节点、粘贴的时候也需要避免节点被重复插入、需要额外的包装节点处理样式等。
方案2的优点是维护了独立的节点,在DOM层面上不需要额外的处理,将其作为普通可编辑的Embed节点即可。缺点是脱离了编辑器框架本身的控制,必须要额外处理选区、历史记录等操作,相当于本身实现了内部的不受控的新编辑器,独立出来的编辑区域自然需要额外的Case需要处理。
最终比较起来,我们还是选择了方案2,主要是其实现起来会比较简单,并且不需要额外维护复杂的约定式节点结构。虽然脱离了编辑器本身的控制,但是我们可以通过事件将其选区、历史记录等操作同步到编辑器本身,相当于半受控处理,虽然会有一些边界情况需要处理,但是整体实现起来还比较可控。
Editable 组件
那么在方案2的基础上,我们就首先需要实现一个Editable组件,来实现变量块的内容编辑。由于变量块的内容并不需要支持任何加粗等操作,因此这里我们并不需要嵌套富文本编辑器本身,而是只需要支持一个纯文本的可编辑区域即可,通过事件通信的形式实现半受控处理。
因此在这里我们就只需要一个span标签,并且设置其contenteditable属性为true即可。至于为什么不使用input来实现文本的输入框,主要是input的宽度跟随文本长度变化需要自己测量,而直接使用可编辑的span标签是天然支持的。
<div
className="block-kit-editable-text"
contentEditable
suppressContentEditableWarning
></div>
可输入的变量框就简单地实现出来了,而仅仅是可以输入文本并不够,我们还需要空内容时的占位符。由于Editable节点本身并不支持placeholder属性,因此我们必须要自行注入DOM节点,而且还需要避免占位符节点被选中、复制等,这种情况下伪元素是最合适的选择。
.block-kit-editable-text {
display: inline-block;
outline: none;
&::after {
content: attr(data-vars-placeholder);
cursor: text;
opacity: 0.5;
pointer-events: none;
user-select: none;
}
}
当然placeholder的值可以是动态设置的,并且placeholder也仅仅是在内容为空时才会显示,因此我们还需要监听input事件来动态设置data-vars-placeholder属性。
const showPlaceholder = !value && placeholder && !isComposing;
<div
className="block-kit-editable-text"
data-vars-placeholder={showPlaceholder ? placeholder : void 0}
></div>
这里的isComposing状态可以注意一下,这个状态是用来处理输入法IME的。当唤醒输入法输入的时候,编辑器通常会处于一个不受控的状态,这点我们先前在处理输入的文章中讨论过,然而此时文本区域是存在候选词的,因此这个情况下不应该显示占位符。
const [isComposing, setIsComposing] = useState(false);
const onCompositionStart = useMemoFn(() => {
setIsComposing(true);
});
const onCompositionEnd = useMemoFn((e: CompositionEvent) => {
setIsComposing(false);
});
接下来需要处理内容的输入,在此处的半受控主要是指的我们并不依靠BeforeInput事件来阻止用户输入,而是在允许用户输入后,主动通过onChange事件将内容同步到外部。而外部编辑器接收到变更后,会触发该节点的rerender,在这里我们再检查内容是否一致决定更新行为。
在这里不使用input标签其实也会存在一些问题,主要是DOM标签本身内部是可以写入很多复杂的HTML内容的,而这里我们是希望将其仅仅作为普通的文本输入框来使用,因此我们在检查到DOM节点不符合要求的时候,需要将其重置为纯文本内容。
useEffect(() => {
if (!editNode) return void 0;
if (isDOMText(editNode.firstChild)) {
if (editNode.firstChild.nodeValue !== props.value) {
editNode.firstChild.nodeValue = props.value;
}
for (let i = 1, len = editNode.childNodes.length; i < len; i++) {
const child = editNode.childNodes[i];
child && child.remove();
}
} else {
editNode.innerText = props.value;
}
}, [props.value, editNode]);
const onInput = useMemoFn((e: InputEvent) => {
if (e.isComposing || isNil(editNode)) {
return void 0;
}
const newValue = editNode.textContent || "";
newValue !== value && onChange(newValue);
});
对于避免Editable节点出现非文本的HTML内容,我们还需要在onPaste事件中阻止用户粘贴非文本内容,这里需要阻止默认行为,并且将纯文本的内容提取出来重新插入。这里还涉及到了使用旧版的浏览器API,实际上L0的编辑器就是基于这些旧版的浏览器API实现的,例如pell编辑器。
此外,我们还需要避免用户按下Enter键导致换行,在Editable里回车各大浏览的支持都不一致,因此这里即使是真的需要支持换行,我们也最好是使用\n来作为软换行使用,然后将white-space设置为pre-wrap来实现换行。我们可以回顾一下浏览器的不同行为:
- 在空
contenteditable编辑器的情况下,直接按下回车键,在Chrome中的表现是会插入<div><br></div>,而在FireFox(<60)中的表现是会插入<br>,IE中的表现是会插入<p><br></p>。 - 在有文本的编辑器中,如果在文本中间插入回车例如
123|123,在Chrome中的表现内容是123<div>123</div>,而在FireFox中的表现则是会将内容格式化为<div>123</div><div>123</div>。 - 同样在有文本的编辑器中,如果在文本中间插入回车后再删除回车,例如
123|123->123123,在Chrome中的表现内容会恢复原本的123123,而在FireFox中的表现则是会变为<div>123123</div>。
const onPaste = useMemoFn((e: ClipboardEvent) => {
preventNativeEvent(e);
const clipboardData = e.clipboardData;
if (!clipboardData) return void 0;
const text = clipboardData.getData(TEXT_PLAIN) || "";
document.execCommand("insertText", false, text.replace(/\n/g, " "));
});
const onKeyDown = useMemoFn((e: KeyboardEvent) => {
if (isKeyCode(e, KEY_CODE.ENTER) || isKeyCode(e, KEY_CODE.TAB)) {
preventNativeEvent(e);
return void 0;
}
})
至此Editable变量组件就基本实现完成了,接下来我们就可以实现一个变量块插件,将其作为Embed节点Schema集合进编辑器框架当中。在编辑器的插件化中,我们主要是将当前的值传递到编辑组件中,并且在onChange事件中将变更同步到编辑器本身,这就非常类似于表单的输入框处理了。
export class EditableInputPlugin extends EditorPlugin {
public key = VARS_KEY;
public options: EditableInputOptions;
constructor(options?: EditableInputOptions) {
super();
this.options = options || {};
}
public destroy(): void {}
public match(attrs: AttributeMap): boolean {
return !!attrs[VARS_KEY];
}
public onTextChange(leaf: LeafState, value: string, event: InputEvent) {
const rawRange = leaf.toRawRange();
if (!rawRange) return void 0;
const delta = new Delta().retain(rawRange.start).retain(rawRange.len, { [VARS_VALUE_KEY]: value });
this.editor.state.apply(delta, { autoCaret: false, });
}
public renderLeaf(context: ReactLeafContext): React.ReactNode {
const { attributes: attrs = {} } = context;
const varKey = attrs[VARS_KEY];
const placeholders = this.options.placeholders || {};
return (
<Embed context={context}>
<EditableTextInput
className={cs(VARS_CLS_PREFIX, `${VARS_CLS_PREFIX}-${varKey}`)}
value={attrs[VARS_VALUE_KEY] || ""}
placeholder={placeholders[varKey]}
onChange={(v, e) => this.onTextChange(context.leafState, v, e)}
></EditableTextInput>
</Embed>
);
}
}
然而,当我们将Editable节点集成后出现了问题,特别是选区无法设置到变量编辑节点内。主要是这里的选区会不受编辑器控制,因此我们还需要在编辑器的核心包里,避免选区被编辑器框架强行拉取到leaf节点上,这还是需要编辑器本身支持的。
同样的,很多事件同样需要避免编辑器框架本身处理,得益于浏览器DOM事件流的设计,我们可以比较轻松地通过阻止事件冒泡来避免编辑器框架处理这些事件。当然还有一些不冒泡的如Focus等事件,以及SelectionChange等全局事件,我们还需要在编辑器本身的事件中心中处理这些事件。
/**
* 独立节点嵌入 HOC
* - 独立区域 完全隔离相关事件
* @param props
*/
export const Isolate: FC<IsolateProps> = props => {
const [ref, setRef] = useState<HTMLSpanElement | null>(null);
useEffect(() => {
// 阻止事件冒泡
}, [ref]);
return (
<span
ref={setRef}
{...{ [ISOLATED_KEY]: true }}
contentEditable={false}
>
{props.children}
</span>
);
};
/**
* 判断选区变更时, 是否需要忽略该变更
* @param node
* @param root
*/
export const isNeedIgnoreRangeDOM = (node: DOMNode, root: HTMLDivElement) => {
for (let n: DOMNode | null = node; n !== root; n = n.parentNode) {
// node 节点向上查找到 body, 说明 node 并非在 root 下, 忽略选区变更
if (!n || n === document.body || n === document.documentElement) {
return true;
}
// 如果是 ISOLATED_KEY 的元素, 则忽略选区变更
if (isDOMElement(n) && n.hasAttribute(ISOLATED_KEY)) {
return true;
}
}
return false;
};
到这里,模板输入框基本已经实现完成了,在实际使用中问题太大的问题。然而在测试兼容性时发现一个细节,在Firefox和Safari中,按下方向键从非变量节点跳到变量节点时,不一定能够成功跳入或者跳出,具体的表现在不同的浏览器都有差异,只有Chrome是完全正常的。
因此为了兼容浏览器的处理,我们还需要在KeyDown事件中主动处理在边界上的跳转行为。这部分的实现是需要适配编辑器本身的实现的,需要完全根据DOM节点来处理新的选区位置,因此这里的实现主要是根据预设的DOM结构类型来处理,这里实现代码比较多,因此举个左键跳出变量块的例子。
const onKeyDown = useMemoFn((e: KeyboardEvent) => {
LEFT_ARROW_KEY: if (
!readonly &&
isKeyCode(e, KEY_CODE.LEFT) &&
sel &&
sel.isCollapsed &&
sel.anchorOffset === 0 &&
sel.anchorNode &&
sel.anchorNode.parentElement &&
sel.anchorNode.parentElement.closest(`[${LEAF_KEY}]`)
) {
const leafNode = sel.anchorNode.parentElement.closest(`[${LEAF_KEY}]`)!;
const prevNode = leafNode.previousSibling;
if (!isDOMElement(prevNode) || !prevNode.hasAttribute(LEAF_KEY)) {
break LEFT_ARROW_KEY;
}
const selector = `span[${LEAF_STRING}], span[${ZERO_SPACE_KEY}]`;
const focusNode = prevNode.querySelector(selector);
if (!focusNode || !isDOMText(focusNode.firstChild)) {
break LEFT_ARROW_KEY;
}
const text = focusNode.firstChild;
sel.setBaseAndExtent(text, text.length, text, text.length);
preventNativeEvent(e);
}
})
最后,我们还需要处理History的相关操作,由于变量块本身是脱离编辑器框架的,选区实际上是并没有被编辑器本身感知的。所以这里的undo、redo等操作实际上是无法处理变量块选区的变更,因此这里我们就简单处理一下,避免输入组件undo本身的操作被记录到编辑器内。
public onTextChange(leaf: LeafState, value: string, event: InputEvent) {
this.editor.state.apply(delta, {
autoCaret: false,
// 即使不记录到 History 模块, 仍然存在部分问题
// 但若是受控处理, 则又存在焦点问题, 因为此时焦点并不在编辑器
undoable: event.inputType !== "historyUndo" && event.inputType !== "historyRedo",
});
}
选择器组件
选择器组件主要是固定变量的值,例如上述的的例子中我们将篇幅这个变量固定为短篇、中篇、长篇等选项。这里的实现就比较简单了,主要是选择器组件本身不需要处理选区的问题,其本身就是常规的Embed类型节点,因此只需要实现选择器组件,并且在onChange事件中将值同步到编辑器本身即可。
export class SelectorInputPlugin extends EditorPlugin {
public key = SEL_KEY;
public options: SelectorPluginOptions;
constructor(options?: SelectorPluginOptions) {
super();
this.options = options || {};
}
public destroy(): void {}
public match(attrs: AttributeMap): boolean {
return !!attrs[SEL_KEY];
}
public onValueChange(leaf: LeafState, v: string) {
const rawRange = leaf.toRawRange();
if (!rawRange) return void 0;
const delta = new Delta().retain(rawRange.start).retain(rawRange.len, {
[SEL_VALUE_KEY]: v,
});
this.editor.state.apply(delta, { autoCaret: false });
}
public renderLeaf(context: ReactLeafContext): React.ReactNode {
const { attributes: attrs = {} } = context;
const selKey = attrs[SEL_KEY];
const value = attrs[SEL_VALUE_KEY] || "";
const options = this.options.selector || {};
return (
<Embed context={context}>
<SelectorInput
value={value}
optionsWidth={this.options.optionsWidth || SEL_OPTIONS_WIDTH}
onChange={(v: string) => this.onValueChange(context.leafState, v)}
options={options[selKey] || [value]}
/>
</Embed>
);
}
}
SelectorInput组件则是常规的选择器组件,这里需要注意的是避免该组件被浏览器的选区处理,因此会在MouseDown事件中阻止默认行为。而弹出层的DOM节点则是通过Portal的形式挂载到编辑器外部的节点上,这样自然不会被选区影响。
export const SelectorInput: FC<{ value: string; options: string[]; optionsWidth: number; onChange: (v: string) => void; }> = props => {
const { editor } = useEditorStatic();
const [isOpen, setIsOpen] = useState(false);
const onOpen = (e: React.MouseEvent<HTMLSpanElement>) => {
if (isOpen) {
MountNode.unmount(editor, SEL_KEY);
} else {
const target = (e.target as HTMLSpanElement).closest(`[${VOID_KEY}]`);
if (!target) return void 0;
const rect = target.getBoundingClientRect();
const onChange = (v: string) => {
props.onChange && props.onChange(v);
MountNode.unmount(editor, SEL_KEY);
setIsOpen(false);
};
const Element = (
<SelectorOptions
value={props.value}
width={props.optionsWidth}
left={rect.left + rect.width / 2 - props.optionsWidth / 2}
top={rect.top + rect.height}
options={props.options}
onChange={onChange}
></SelectorOptions>
);
MountNode.mount(editor, SEL_KEY, Element);
const onMouseDown = () => {
setIsOpen(false);
MountNode.unmount(editor, SEL_KEY);
document.removeEventListener(EDITOR_EVENT.MOUSE_DOWN, onMouseDown);
};
document.addEventListener(EDITOR_EVENT.MOUSE_DOWN, onMouseDown);
}
setIsOpen(!isOpen);
};
return (
<span className="editable-selector" onMouseDownCapture={preventReactEvent} onClick={onOpen}>
{props.value}
</span>
);
};
总结
在本文中我们调研了用户Prompt输入的相关场景实现,且讨论了纯文本输入框模式、表单模版输入模式,还观察了一些有趣的实现方案。最后重点基于富文本编辑器实现了变量模板输入框,特别适配了我们从零实现的编辑器框架BlockKit,并且实现了Editable变量块、选择器变量块等插件。
实际上引入富文本编辑器总是会比较复杂,在简单的场景下直接使用Editable自然也是可行的,特别是类似这种简单的输入框场景,无需处理复杂的性能问题。然而若是要实现更复杂的交互形式,以及多种块结构、插件化策略等,使用富文本编辑器框架还是更好的选择,否则最终还是向着编辑器实现了。
每日一题
参考
来源:juejin.cn/post/7551995949503840292
关于排查问题的总结
1. 写在最前面
用了这么久的 Cursor ,还是会时不时的感慨科技使人类进步。尤其是最近的「Claude Sonnet 4」 好用的不得了,在丢给它一个需求之后,从设计方案、到 coding、以及编写 tase case 、修复验证逻辑、甚至还记的 lint 一下,无比贴心。但是随之而来的坏处就是,过分相信 Cursor 之后,不在去理解库是否符合业务场景。
注:尽信书,则不如无书。看来在提升 coding 效率的同时,也要更为慎重的思考每个使用 场景是否符合最初设计的预期。
2. 问题小计
2.1 aiohttp 库
前置说明,笔者并不是很熟悉 Python ,属于一边用,一边学习的状态。接的需求是,在使用 aiohttp 库的时候,能够复用 http client ,无需每次请求都重新建立连接,以达到最终减少请求和返回的耗时的目的。
笔者实现的方式:
def _get_session(self) -> aiohttp.ClientSession:
if self._session is not and not self._session.closed:
return self._session
new_session = aiohttp.ClientSession(
timeout=aiohttp.ClientTimeout(total=30),
connector=aiohttp.TCPConnector(limit=100, enable_cleanup_closed=True),
trace_configs=[self.trace_config],
)
self._session = new_session
return self._session
注:这当然是 cursor 帮忙给的思路。但是笔者当时大意了,没有细细的深究 aiohttp.ClientTimeout 这字段的意思。
不推卸责任,问题当时是实现代码人的问题,记录在这里,方便下次在类似的改动前,能够在深入探究一步,减少后续返工以及故障的可能性。
先解释一下 aiohttp.ClientTimeout 字段的意思
timeout = aiohttp.ClientTimeout(
total=, # 总超时时间
connect=, # 连接超时时间
sock_connect=, # Socket 连接超时时间
sock_read= # Socket 读取超时时间
)
各参数详细说明
- total (float | )
- 整个请求的总超时时间(秒),包括连接建立、发送请求、接收响应的全部时间,默认值:5 分钟 (300 秒),设置为 表示无限制
- connect (float | )
- 建立连接的超时时间(秒),包括 DNS 解析、TCP 连接建立、SSL 握手等,默认值:无限制 ()
- sock_connect (float | )
- 底层 socket 连接的超时时间(秒),仅针对 TCP socket 连接建立阶段,默认值:无限制 ()
- sock_read (float | )
- Socket 读取数据的超时时间(秒),在连接建立后读取响应数据的超时,默认值:无限制 ()
先解释了参数的含义之后,就可以推测到现象是,如果 response 持续返回的时间超过 30s ,就会主动断开连接。
注:除了 aiohttp.ClientTimeout,建议再用 aiohttp.TCPConnector 字段时也要先确认字段的生效规则后使用。
2.2 奇怪的问题
笔者本次提测改动的功能很少,但是 QA 测试的时候报了很多跟功能无关的 jira ,比如:
- start 的时候返回超时报错
- 启动的任务,自动退出查询不到了
注:这种跟改动无任何关系的问题,查起来真的有点子费人……
问题1:start 的时候返回超时报错
结论:最终查下来, start 超时是因为请求的机器,磁盘读写耗时极高,分析下来,可能是因为混用的测试环境,其他服务的测试写入了过多的音视频文件导致……
还好,公司的机器是有 cpu、memery、磁盘等 Zeus 监控的,不然都没办法自证业务的清白了。
注:不过这里虽然机器有问题的可能性比较高,但有一点,我还是没有想通的为什么磁盘耗时高会表现 start 超时呢?印象中业务的 start 行为中没有任何写入磁盘的行为。
cursor 一个比较符合的原因的回答是:
- 依赖库加载:Python模块、动态库加载需要磁盘I/O
- 超时连锁反应:磁盘I/O慢 → 启动步骤延迟 → 健康检查超时 → 服务被认为启动失败
问题2: 启动的任务,自动退出查询不到了
结论:是因为业务消耗的资源的内存变多了,之前 pod 设置的 memory 是 1G,导致 oom 了……

为了能够按时交付版本,本次的改动是先调整部署的 chart ,将 memory 从 1G 调整 2G
至此,那些奇怪的问题就排查完成了。还好,虽然排查的过程有点痛苦,但是还是从中学到了之前不知道的支持,比如dmesg -T 查看内核的输出信息。
3. 碎碎念
终于在十一前,挤出时间来整理了一下最近遇到有些奇怪的问题。希望这个十一能够玩的开心。
- 到底是什么伟大前程,值得我们把每个四季都错过?(ps:读的时候,心理酸酸的
- 人一旦有退路,无论是你愿意还是不愿意接受的退路,就不会用全力了。
来源:juejin.cn/post/7554979158435364879
VitePress 博客变身 APP,支持离线访问,只需这一招。
大家好,我是不如摸鱼去,uni-app vue3 组件库 wot-ui 的主要维护者,欢迎来到我的工具分享专栏。
前阵子解决网站国内访问慢的问题之前,总有朋友问:“网站太慢了,能离线使用吗?”
答案是:“可以!” 这需求正是 PWA 能解决的嘛!今天我们花几分钟时间,将我的个人博客改造为 PWA ,支持安装到本地并且可以离线访问,我的博客地址: blog.wot-ui.cn/。
PWA 是什么?
渐进式 Web 应用(Progressive Web App,PWA)是一个使用 web 平台技术构建的应用程序,但它提供的用户体验就像一个特定平台的应用程序。
它像网站一样,PWA 可以通过一个代码库在多个平台和设备上运行。它也像一个特定平台的应用程序一样,可以安装在设备上,可以离线和在后台运行,并且可以与设备和其他已安装的应用程序集成。
说句题外话,国内 PWA 的生态位其实是被各大 APP 的小程序占据了,不过小程序各自为战的标准实在是令人头疼,写小程序会让人变得烦恼,写多个平台的小程序会让人变得不幸。你可能会笑,而我却真的在写,wot-ui 组件库为了兼容多平台小程序不知道让我掉了多少头发。
具体定义见: developer.mozilla.org/zh-CN/docs/…
PWA 可以安装到本地,支持离线访问,并将快捷方式放到启动台中。

VitePress 添加 PWA 支持
我博客是使用 VitePress 搭建的,生态里有个现成的插件 @vite-pwa/vitepress,可以为 VitePress 项目添加 PWA 能力。
VitePress 是一个静态站点生成器 (SSG),专为构建快速、以内容为中心的站点而设计。简而言之,VitePress 获取用 Markdown 编写的内容,对其应用主题,并生成可以轻松部署到任何地方的静态 HTML 页面。 信息来自 vitepress 官网。
1. 安装
# 我用的pnpm,快!
pnpm add @vite-pwa/vitepress -D
# npm/yarn用户自己替换一下
2. 配置(.vitepress/config.mts)
这是核心步骤,直接上我改完的配置,关键地方我加了个**“唠叨版”注释**,解释下为啥这么设:
import { defineConfig } from 'vitepress'
import { withPwa } from '@vite-pwa/vitepress'
export default withPwa(defineConfig({
// 博客基础信息,老样子
title: '不如摸鱼去',
description: '不如摸鱼去的博客,分享前端、uni-app、AI编程相关知识',
// PWA 配置区,重点来了!
pwa: {
base: '/',
scope: '/',
includeAssets: ['favicon.ico', 'logo.png', 'images/**/*'], // 告诉插件,这些静态资源要缓存起来
registerType: 'prompt', // 有更新别偷偷刷新,得问问我(用户)同不同意
injectRegister: 'auto',
// 开发环境专用,关掉烦人的警告
devOptions: {
enabled: true,
suppressWarnings: true, // 开发时警告太多,眼花,先屏蔽
navigateFallback: '/',
type: 'module'
},
// Service Worker 配置,缓存策略的灵魂
workbox: {
globPatterns: ['**/*.{js,css,html,ico,png,jpg,jpeg,gif,svg,woff2}'], // 需要缓存哪些类型的文件
cleanupOutdatedCaches: true, // 老缓存?清理掉!别占地方
clientsClaim: true, // 新的Service Worker来了,立刻接管页面
skipWaiting: true, // 新SW别等了,赶紧干活
maximumFileSizeToCacheInBytes: 10 * 1024 * 1024, // 单个文件最大10MB,再大就不缓存了
// 针对不同资源,用不同缓存策略(这里踩过坑)
runtimeCaching: [
// Google Fonts这类外部字体:缓存优先,存久点(一年),反正不常变
{
urlPattern: /^https:\/\/fonts\.googleapis\.com\/.*/i,
handler: 'CacheFirst',
options: {
cacheName: 'google-fonts-cache',
expiration: {
maxEntries: 10,
maxAgeSeconds: 60 * 60 * 24 * 365
}
}
},
// 图片:也缓存优先,但别存太久(30天),万一我换了图呢?
{
urlPattern: /\.(?:png|jpg|jpeg|svg|gif)$/,
handler: 'CacheFirst',
options: {
cacheName: 'images-cache',
expiration: {
maxEntries: 100,
maxAgeSeconds: 60 * 60 * 24 * 30
}
}
}
// 注意:JS/CSS/HTML Workbox默认会处理,通常用 StaleWhileRevalidate 策略(缓存优先,后台更新)
]
},
// App清单,告诉系统“我是个App!”
manifest: {
name: '不如摸鱼去', // 完整名
short_name: '摸鱼去', // 桌面图标下面显示的短名,太长显示不全
description: '分享前端、uni-app、AI编程相关知识',
theme_color: '#ffffff', // 主题色,影响状态栏、启动画面背景
background_color: '#ffffff', // 启动画面背景色
display: 'standalone', // 独立显示模式(全屏,无浏览器UI)
orientation: 'portrait', // 默认竖屏
scope: '/', // PWA能管哪些页面
start_url: '/', // 点开图标从哪开始
icons: [ // 图标!重中之重!
{
src: '/logo.png',
sizes: '192x192',
type: 'image/png'
},
{
src: '/logo.png',
sizes: '512x512',
type: 'image/png'
},
{
src: '/logo.png',
sizes: '512x512',
type: 'image/png',
purpose: 'any maskable' // 这个重要!告诉系统这图标能被裁剪成各种形状(圆的、方的)
}
]
}
}
}))
看看效果
部署上线后,浏览器打开 blog.wot-ui.cn/ 会发现地址栏旁边会提示安装应用。
安装后将我们的app放到启动台中就可以快捷访问了,断网后也可以访问,很方便。
搞完之后,有啥变化?
说实话,效果比我预期的好:
- 快! 二次访问(尤其是同一设备)快多了,静态资源直接读本地缓存,秒开。在没网的地方(比如电梯里),打开博客,之前看过的文章照样能看,体验不掉线。
- 体验升级: 全屏阅读,没有浏览器边框干扰,沉浸感强不少。
- 方便访问: 可以在桌面、启动台创建快捷方式,方便读者找到我们,不需要记忆网址。
- 服务器压力小点: 缓存命中率高了,请求自然少了点。
总结
给 VitePress 博客加PWA,投入产出比真挺高的。主要就是装个插件、改改配置、准备个图标。过程不算复杂,但带来的体验提升是实打实的。如果你的网站访问速度比较慢,或者期望提高用户的粘性,提供一下 PWA 能力还是很不错的。读到这里还不把「不如摸鱼去」博客添加到桌面吗(偷笑)?
参考资料
- VitePress 官网: vitepress.dev/
- @vite-pwa/vitepress: github.com/vite-pwa/vi…
- PWA的MDN: developer.mozilla.org/zh-CN/docs/…
往期精彩
uni-app vue3 也能使用 Echarts?Wot Starter 是这样做的!
当年偷偷玩小霸王,现在偷偷用 Trae Solo 复刻坦克大战
告别 HBuilderX,拥抱现代化!这个模板让 uni-app 开发体验起飞
Vue3 uni-app 主包 2 MB 危机?1 个插件 10 分钟瘦身
欢迎评论区沟通讨论👇👇
来源:juejin.cn/post/7554204108154159156
🚀 告别 Electron 的臃肿:用 Tauri 打造「轻如鸿毛」的桌面应用
Tauri:从300MB到5MB!这才是桌面应用的未来
你有没有这样的体验?
打开一个用 Electron 写的桌面工具,任务管理器瞬间飙出 300MB+ 内存占用,启动要等好几秒,系统风扇呼呼作响……而它的功能,可能只是一个简单的 Markdown 编辑器。
今天,我要向你介绍一位 Electron 的「性能杀手」——Tauri。
它不仅能让你用 React/Vue/Svelte 构建界面,还能把最终应用打包成 小于 5MB 的安装包,启动速度接近原生!
🚀 什么是 Tauri?颠覆性的轻量级方案
Tauri 是一个基于 Rust 构建的开源框架,允许开发者使用前端技术创建安全、轻量、高性能的跨平台桌面应用。
- ✅ 支持 Windows / macOS / Linux
- ✅ 前端任意框架:React、Vue、Svelte、Solid.js 等
- ✅ 核心逻辑由 Rust 编写,极致安全与性能
- ✅ 即将支持移动端,迈向全平台统一
📊 性能对比:数字会说话
| 指标 | Electron | Tauri | 优势 |
|---|---|---|---|
| 应用体积 | 80~200MB | <5MB | 减少95% |
| 内存占用 | 150~300MB | <30MB | 减少85% |
| 启动时间 | 2~5秒 | <0.5秒 | 快5-10倍 |
| 安全性 | Node.js 全权限 | Rust + 权限控制 | 企业级安全 |
Tauri 的秘诀在于:利用操作系统自带的 WebView,而不是捆绑整个 Chromium。
🛡️ 安全架构:Rust 原生的降维打击
多层安全防护
- 内存安全:Rust 编译时防止空指针、数据竞争等漏洞
- 权限控制:细粒度的能力声明,前端只能访问明确授权的系统功能
- 沙箱机制:前端代码运行在隔离环境中,无法直接调用系统 API
// Rust 后端:类型安全的系统调用
#[tauri::command]
fn read_file(path: String) -> Result<String, String> {
std::fs::read_to_string(&path)
.map_err(|e| format!("读取文件失败: {}", e))
}
即使前端遭遇 XSS 攻击,攻击者也无法越权访问系统资源。
💻 实战演示:5分钟构建文件管理器
1. 项目初始化
npm create tauri-app@latest my-files-app
cd my-files-app
npm install
2. 前端界面(React示例)
import { invoke } from '@tauri-apps/api/tauri';
function FileManager() {
const [files, setFiles] = useState([]);
const listFiles = async (path) => {
const fileList = await invoke('list_files', { path });
setFiles(fileList);
};
return (
<div>
<button onClick={() => listFiles('/')}>浏览文件</button>
<ul>
{files.map(file => (
<li key={file.name}>{file.name}</li>
))}
</ul>
</div>
);
}
3. Rust 后端实现
use std::fs;
#[tauri::command]
fn list_files(path: String) -> Result<Vec<FileInfo>, String> {
let entries = fs::read_dir(path)
.map_err(|e| e.to_string())?;
let mut files = Vec::new();
for entry in entries {
if let Ok(entry) = entry {
files.push(FileInfo {
name: entry.file_name().to_string_lossy().to_string(),
size: entry.metadata().map(|m| m.len()).unwrap_or(0),
});
}
}
Ok(files)
}
4. 构建发布
npm run tauri build
# 生成 3.8MB 的安装包!
🎯 Tauri 的适用场景
✅ 强烈推荐
- 效率工具:笔记软件、截图工具、翻译软件
- 开发工具:API 测试、数据库管理、日志查看器
- 内部系统:监控面板、数据可视化、配置工具
- 轻量应用:计算器、单位转换、密码管理器
⚠️ 谨慎选择
- 复杂图形渲染(游戏、3D 编辑)
- 重度依赖 Chrome 扩展生态
- 需要支持老旧操作系统
🔮 生态展望:不只是桌面
Tauri 正在快速进化:
- 移动端支持:一套代码,多端部署
- 插件生态:官方维护的常用功能模块
- 云集成:无缝对接云服务
- AI 集成:本地模型推理能力
💡 迁移策略:从 Electron 平滑过渡
如果你已有 Electron 项目,可以这样迁移:
- 渐进式迁移:先移植核心功能模块
- 并行开发:保持 Electron 版本,逐步替换
- 性能对比:AB 测试验证用户体验提升
- 用户反馈:收集真实使用数据优化方向
🌟 总结:为什么 Tauri 是未来?
| 维度 | Electron | Tauri | 结论 |
|---|---|---|---|
| 用户体验 | 笨重缓慢 | 轻快流畅 | Tauri 胜出 |
| 开发体验 | 成熟稳定 | 现代高效 | 各有优势 |
| 资源消耗 | 浪费严重 | 极致优化 | Tauri 完胜 |
| 安全性能 | 依赖配置 | 内置安全 | Tauri 领先 |
Tauri 不是另一个 Electron,而是桌面应用开发的范式革命。
它证明了:Web 技术的灵活性 + 原生语言的性能 = 最佳桌面开发方案。
🚀 立即开始
# 1. 安装 Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
# 2. 创建项目
npm create tauri-app@latest my-app
# 3. 开始开发
npm run tauri dev
💬 互动讨论
- 你在项目中用过 Tauri 吗?体验如何?
- 你认为 Tauri 会取代 Electron 吗?
- 最期待 Tauri 的哪些新特性?
欢迎在评论区分享你的观点!如果觉得这篇文章有帮助,请点赞支持~
来源:juejin.cn/post/7553912808804384818
异步函数中return与catch的错误处理
详细解释:
- 加
return的情况:
return createRequest(...)返回一个 Promise 链。- 当
createRequest失败时,.catch会捕获错误,并抛出新的错误。 - 由于整个 Promise 链被返回,
beforeSubmit的 Promise 会被 reject,错误会传递到调用方,从而中断后续操作。
- 不加
return的情况:
createRequest(...)会启动一个 Promise 链,但未被返回。beforeSubmit函数不会等待这个 Promise 链完成,而是立即返回一个 resolved 的 Promise(因为async函数默认返回一个 resolved Promise,除非有await或return)。- 即使
.catch捕获了错误并抛出,也只是在内部的 Promise 链中处理,不会影响beforeSubmit的返回值。因此,外部调用者认为beforeSubmit成功完成,后续代码会继续执行。
总结:
- 当前代码中使用了
return createRequest(...),这是正确的做法,可以确保错误被传播并阻止后续执行。 - 如果不加
return,即使 URL 校验失败,beforeSubmit也会成功返回,表单提交可能会继续,这不符合预期。
来源:juejin.cn/post/7546105524095696947
前端性能基准测试入门:用 Benchmark.js 做出数据驱动的选择
前端性能基准测试入门:用 Benchmark.js 做出数据驱动的选择
背景
在前端开发过程中,会有一些需要注重代码性能的场景,比如:一个复杂功能依赖的数据基于嵌套数组实现(比如支持拖拽的行程规划需要有行程单、日期、时间、地点等多种维度的数据)、一个功能需要前端来做大量数据的计算。
在这些场景中,同样的操作我们会针对不同的实现方式进行测试,来得到不同实现方式的性能差异,便于选择最优的实现方式。
为什么使用 Benchmark.js
我最开始其实也有这样的疑问,为什么不能 直接在本地执行一遍代码,然后自己计算执行时间来 测试性能?
详细了解相关资料后发现会有以下几个问题:
- 计时精度问题: JavaScript 自带的 Date.now() 最小单位是毫秒,对于 CPU 执行代码的耗时来说精度是不够的。同时,如果代码执行时间过短,可能无法准确测量。
- 引擎优化问题: JavaScript 引擎会对代码进行优化,比如:一段代码会有“冷启动”和“热状态”的差异,有些没有被使用到的执行结果会被直接优化掉等等。
- 单次测试不具备参考性: 单次测试可能会受到很多因素的影响,可能一段代码第一次的执行用了 3 毫秒,第二次只用了 1 毫秒等等。
专业的事情还是要交给专业的人去做,就好像在实验室进行专业温度测量不会使用体温计一样。我们可以使用 Benchmark.js 为我们进行更加精确的基准测试。
Benchmark.js 基本使用
Benchmark.js 官方的文档写的比较晦涩,不太利于新手阅读,下面会通过一个简单的例子来介绍如何使用 Benchmark.js 进行性能测试。
引入或安装 Benchmark.js
在浏览器环境中可以使用 CDN 引入,在 Node.js 环境中可以使用 npm 安装。
需要特别注意的是:benchmark.js 依赖于 lodash.js,所以通过 Script 引入时需要先引入 lodash.js。(使用 npm 安装时会自动处理依赖,无需手动引入 lodash)
<script src="https://cdn.jsdelivr.net/npm/lodash@4.17.21/lodash.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/benchmark@2.1.4/benchmark.min.js"></script>
npm install benchmark
创建套件
Benchmark.js 默认提供了一个构造函数,我们可以通过这个构造函数来创建一个性能测试的实例,通常会把这个内容叫做 suite 套件。在 Benchmark.js 里,每次测试都是以一个 suite 套件为范围的。
const Benchmark = require("benchmark");
const suite = new Benchmark.Suite();
添加测试用例
有了套件之后,我们就可以往套件中添加测试用例了。假设我们有一段简单的数据,需要计算出数组中每个元素的平方最后加和。那实现方式可能会包含以下两种:
- 提前定义好一个变量,使用
for循环遍历数组,然后计算每个元素的平方最后加到这个变量中。 - 使用
reduce方法,直接计算出数组中每个元素的平方最后加和。
我们可以使用 suite.add 方法来往套件中添加测试用例。这个方法接收两个参数:第一个参数是测试用例的名称,第二个参数是测试用例的函数。
const suite = new Benchmark.Suite();
const arr = [1, 2, 3, 4, 5]; // 测试数据
suite.add("使用 for 循环", () => {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i] * arr[i];
}
});
suite.add("使用 reduce 方法", () => {
const sum = arr.reduce((acc, val) => acc + val * val, 0);
});
监听测试过程中的事件
suite 还提供了 on 方法,可以监听测试用例的开始、结束、完成等事件。
suite.on("事件的名字", 触发的回调函数);
常见的监听事件包括:
start:整个测试环节开始时触发cycle:每个测试用例完成一个循环周期时触发complete:所有测试用例都执行完毕时触发
比如:如果给之前添加的测试用例添加 cycle 事件,那么每次单个测试用例执行完,都会触发 cycle 事件。我们也可以在 complete 事件中统计并输出本次测试中最快的用例。
suite.on("cycle", (event) => {
const result = event.target;
const name = result.name;
const hz = Math.round(result.hz);
const mean = result.stats.mean;
console.log(`[CYCLE] ${name}: ${hz} 次/秒 平均耗时: ${mean}s`);
});
suite.on("complete", function () {
const fastest = this.filter("fastest").map("name");
console.log(`[COMPLETE] 最快的是: ${fastest}`);
});
cycle 事件的回调函数参数中提供了很多有用的信息,比如 event.target.hz 表示当前测试用例的执行频率,event.target.stats.mean 表示当前测试用例的平均执行时间。我们可以在回调函数中打印出这些信息,来查看测试用例的执行情况。
执行测试
有了套件和测试用例之后,我们就可以执行测试了。执行测试的命令是 suite.run()。执行测试后,会自动触发 start 事件,然后依次触发 cycle 事件,最后触发 complete 事件。
suite.run 方法接收一个对象作为参数,这个对象中可以配置一些选项。通常情况下,我们只需要配置 async: true 以异步方式启动测试,避免长时间阻塞页面交互。
suite.run({ async: true });
完整代码
const suite = new Benchmark.Suite();
// 更大的数据规模能更好地放大实现差异
const arr = Array.from({ length: 100000 }, (_, i) => i + 1);
suite
.add("使用 for 循环", () => {
let sum = 0;
for (let i = 0; i < arr.length; i++) {
sum += arr[i] * arr[i];
}
})
.add("使用 reduce 方法", () => {
const sum = arr.reduce((acc, val) => acc + val * val, 0);
});
suite
.on("start", () => {
console.log("[START] 开始基准测试");
})
.on("cycle", (event) => {
const r = event.target;
console.log(
`[CYCLE] ${r.name}: ${Math.round(r.hz)} 次/秒 平均耗时: ${r.stats.mean}s`
);
})
.on("complete", function () {
console.log(`[COMPLETE] 最快的是: ${this.filter("fastest").map("name")}`);
});
suite.run({ async: true });
// [START] 开始基准测试
// [CYCLE] 使用 for 循环: 15875 次/秒 平均耗时: 0.00006299306622951745s
// [CYCLE] 使用 reduce 方法: 1936 次/秒 平均耗时: 0.0005163982717989002s
// [COMPLETE] 最快的是: 使用 for 循环
由上述代码测试结果可见,在更大的数据规模下,使用 for 方法的执行速度比使用 reduce 方法的执行速度快很多。
总结
本文从为什么不能直接用 Date.now() 计时出发,说明了 Benchmark.js 在计时精度、引擎优化与多次运行统计上的优势,并给出 suite、add、on、run 的基本实践路径。
更多内容可以参考 Benchmark.js 官方文档
来源:juejin.cn/post/7554402481913315328
<a>标签下载文件 download 属性无效?原来问题出在这里
最近在开发中遇到一个小坑:我想用 <a> 标签下载文件,并通过 download 属性来自定义文件名。代码写好后,却发现文件名始终是默认的,根本没有按照我设置的来。
一番调查后才发现,这里面还真有点门道。
1. download 的正常使用方式
在同源环境下,给 <a> 标签设置 download 属性,确实能生效。比如:
const downloadFile = (url, fileName) => {
const a = document.createElement('a');
a.href = url;
a.download = fileName;
a.click();
};
这段代码会触发浏览器下载,并且文件名会按我们设置的 fileName 来保存。
2. 为何文件名没有生效?
关键点在于:跨域下载时,浏览器出于安全策略,会忽略 download 设置的文件名。
这么设计是有原因的:
- 假设某个网站偷偷嵌入了一段恶意代码,让用户下载一个木马文件。
- 如果它能随意改文件名(比如改成 resume.pdf),用户就可能在不知情的情况下打开恶意程序。
为了避免这种“文件欺骗”,浏览器在 跨域资源 上直接禁用了 download 属性的文件重命名能力。
3. 怎么解决?
既然浏览器对跨域有限制,那解决思路就是:想办法让文件下载看起来是同源的。常见有两种方法。
方法一:前端先拉取文件,再触发下载
思路是:
- 通过 fetch / XHR 把文件以 blob 的形式拉到本地(前提是目标服务允许跨域访问,需正确配置 CORS)。
- 用 URL.createObjectURL 生成临时链接,再用 a.download 触发下载。
示例代码:
const fetchFile = (url, callback) => {
const xhr = new XMLHttpRequest();
xhr.open('GET', url);
xhr.responseType = 'blob'; // 以二进制形式拿到数据
xhr.onload = () => {
if (xhr.status === 200) {
const blob = new Blob([xhr.response], {
type: 'application/octet-stream'
});
callback(blob);
}
};
xhr.send();
};
const downloadFile = (url, fileName) => {
fetchFile(url, (blob) => {
const objectURL = URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = objectURL;
link.download = fileName; // ✅ 现在可以自定义文件名了
link.click();
URL.revokeObjectURL(objectURL); // 释放内存
});
};
这种方法的前提是:服务端必须配置了允许跨域的 CORS 响应头,否则浏览器会拦截请求。
方法二:服务端做代理,转发请求
如果目标服务不支持 CORS,或者你不想暴露原始文件地址,可以在自己的后端加一层代理。
流程:
- 前端请求自己的服务 /server-proxy?originalURL=xxx
- 后端去目标服务下载文件,再流式返回给前端
- 由于下载来源变成了“同源”,download 属性就能生效
前端代码
const downloadFile = (url, fileName) => {
const a = document.createElement('a');
a.href = `http://localhost:3000/server-proxy?originalURL=${encodeURIComponent(url)}`;
a.download = fileName;
a.click();
};
Node.js 服务端(纯 http/https 实现)
import http from 'http';
import https from 'https';
import { URL } from 'url';
const server = http.createServer((req, res) => {
const parsedUrl = url.parse(req.url, true);
if (parsedUrl.pathname === '/server-proxy') {
const originalURL = parsedUrl.query?.originalURL || '';
if (!originalURL) {
res.writeHead(400, { 'Content-Type': 'application/json' });
return res.end(JSON.stringify({ error: 'Missing originalURL' }));
}
//待转发的原始URL
console.log('originalURL', originalURL);
// 发起请求到目标服务
const urlOptions = new URL(originalURL);
const client = urlOptions.protocol === 'https:' ? https : http;
const proxyReq = client.request(urlOptions, (proxyRes) => {
res.writeHead(proxyRes.statusCode || 200, proxyRes.headers);
proxyRes.pipe(res);
});
proxyReq.on('error', (err) => {
console.error('Proxy error:', err);
res.writeHead(500);
res.end('Proxy error');
});
proxyReq.end();
} else {
res.writeHead(404, { 'Content-Type': 'application/json' });
res.end(JSON.stringify({ error: 'Not found' }));
}
});
server.listen(3000, () => {
console.log('Server running at http://localhost:3000');
});
4. 小结
- a.download 生效条件:
- 资源必须是同源,或者 CORS 允许访问
- 否则浏览器会忽略自定义文件名
- 解决方案:
- 前端 fetch + blob 下载,再触发保存
- 后端做代理,转发文件
这样就能既保证安全,又能灵活设置下载文件名。
📌 补充:
- 某些情况下,服务端返回的 Content-Disposition: attachment; filename="xxx" 头也会影响最终文件名,如果设置了,它会覆盖前端的 download。
- 如果文件非常大,前端 fetch + blob 可能会占用较多内存,建议使用服务端代理方案。
- fetch + blob 可能会被打断,文件尚未下载完毕时刷新浏览器会导致下载中断,如果不希望被打断可以考虑服务端代理方案。
来源:juejin.cn/post/7554677260344950847
每天一个知识点——dayjs常用的语法示例
日期时间处理需求
- 关于时间的处理,一般来说使用公共库更加优雅、方便
- 否则的话,自己就要写一堆处理时间的函数
- 比如:我需要一个将当前时间,转换成年月日时分秒格式的函数
- 如下:
function formatCurrentTimeFn() {
const now = new Date();
const year = now.getFullYear();
const month = String(now.getMonth() + 1).padStart(2, '0'); // 月份从0开始,所以要+1
const day = String(now.getDate()).padStart(2, '0');
const hours = String(now.getHours()).padStart(2, '0');
const minutes = String(now.getMinutes()).padStart(2, '0');
const seconds = String(now.getSeconds()).padStart(2, '0');
return `${year}-${month}-${day} ${hours}:${minutes}:${seconds}`;
}
// 使用示例
console.log(formatCurrentTimeFn()); // 输出类似:2025-06-04 14:30:45
- 而使用了时间日期处理的库后,直接:
dayjs().format('YYYY-MM-DD HH:mm:ss'))即可
dayjs VS momentjs
dayjs获取当前的年月日时分秒
假设今天是2025年6月4日
新建一个html文件,而后引入cdn:
<script src="https://cdn.bootcdn.net/ajax/libs/dayjs/1.11.13/dayjs.min.js"></script>
获取时间日期相关信息:
// 获取当前时间的年份
console.log('当前年份:', dayjs().year()); // 2025年
// 获取当前时间的月份(0-11)
console.log('当前月份:', dayjs().month() + 1); // 6月 // 月份从0开始,所以加1
// 获取当前时间的日期几号
console.log('当前日期几号:', dayjs().date()); // 4号
// 获取当前时间的星期几(0-6,0表示星期日,6表示星期六)
console.log('当前星期几:', dayjs().day()); // 3 // 星期三
// 获取当前时间的小时(几点)
console.log('当前小时:', dayjs().hour()); // 12时
// 获取当前时间的分钟
console.log('当前分钟:', dayjs().minute()); // 35分
// 获取当前时间的秒钟
console.log('当前秒:', dayjs().second()); // 4秒
// 获取当前时间的毫秒
console.log('当前毫秒:', dayjs().millisecond()); // 667
注意:dayjs的语法中:dayjs()[unit]() === dayjs().get(unit)
所以,还可以这样写:
console.log(dayjs().get('year')); // 2025
console.log(dayjs().get('month')); // 5 // 月份从0开始,所以是5
console.log(dayjs().get('date')); // 4
console.log(dayjs().get('day')); // 3 // 星期三
console.log(dayjs().get('hour')); // 12
console.log(dayjs().get('minute')); // 35
console.log(dayjs().get('second')); // 4
console.log(dayjs().get('millisecond')); // 667
dayjs的format格式化
// 国际化时间格式(ISO 8601)默认带时区
const ISO8601 = dayjs().format();
console.log('ISO 8601国际化时间格式:', ISO8601); // 2025-06-04T09:35:04+08:00
// 自定义格式化时间【 dayjs()不传时间,就表示当前】
console.log('四位数年月日时分秒格式:', dayjs().format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:35:04
// 两位数年月日时分秒格式
console.log('两位数年月日时分秒格式:', dayjs().format('YY-MM-DD HH:mm:ss')); // 25-06-04 09:35:04
console.log('横杠年月日格式:', dayjs().format('YYYY-MM-DD')); // 2025-06-04
console.log('斜杠年月日格式:', dayjs().format('DD/MM/YYYY')); // 04/06/2025
console.log('时分秒格式:', dayjs().format('HH:mm:ss')); // 09:35:04
console.log('时分格式:', dayjs().format('HH:mm')); // 09:35
// 自定义格式化时间【 dayjs()传时间,就格式化传递进去的时间】
console.log('年月日格式:', dayjs('2025-06-04 10:25:20').format('YYYY-MM-DD')); // 2025-06-04
console.log('时分秒格式:', dayjs('2025-06-04 10:25:20').format('HH:mm:ss')); // 09:35:04
console.log('时分格式:', dayjs('2025-06-04 10:25:20').format('HH:mm')); // 09:35
// 当然,也可以传递时间戳毫秒数之类的,不赘述
console.log('时分格式:', dayjs(1749013684020).format('HH:mm')); // 09:35
dayjs的日期加减
// 获取当前时间
console.log('当前时间:', dayjs().format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:35:04
// 获取当前时间的前一天
console.log('前一天:', dayjs().subtract(1, 'day').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-03 09:35:04
// 获取当前时间的后一天
console.log('后一天:', dayjs().add(1, 'day').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-05 09:35:04
// 获取当前时间的前一周
console.log('前一周:', dayjs().subtract(1, 'week').format('YYYY-MM-DD HH:mm:ss')); // 2025-05-28 09:35:04
// 获取当前时间的后一周
console.log('后一周:', dayjs().add(1, 'week').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-11 09:35:04
// 获取当前时间的前一个月
console.log('前一个月:', dayjs().subtract(1, 'month').format('YYYY-MM-DD HH:mm:ss')); // 2025-05-04 09:35:04
// 获取当前时间的后一个月
console.log('后一个月:', dayjs().add(1, 'month').format('YYYY-MM-DD HH:mm:ss')); // 2025-07-04 09:35:04
// 获取当前时间的前一年
console.log('前一年:', dayjs().subtract(1, 'year').format('YYYY-MM-DD HH:mm:ss')); // 2024-06-04 09:35:04
// 获取当前时间的后一年
console.log('后一年:', dayjs().add(1, 'year').format('YYYY-MM-DD HH:mm:ss')); // 2026-06-04 09:35:04
// 获取当前时间的前一个小时
console.log('前一个小时:', dayjs().subtract(1, 'hour').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 08:35:04
// 获取当前时间的后一个小时
console.log('后一个小时:', dayjs().add(1, 'hour').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 10:35:04
// 获取当前时间的前一分钟
console.log('前一分钟:', dayjs().subtract(1, 'minute').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:34:04
// 获取当前时间的后一分钟
console.log('后一分钟:', dayjs().add(1, 'minute').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:36:04
// 获取当前时间的前一秒
console.log('前一秒:', dayjs().subtract(1, 'second').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:35:03
// 获取当前时间的后一秒
console.log('后一秒:', dayjs().add(1, 'second').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-04 09:35:05
// 获取当前时间的前一毫秒
console.log('前一毫秒:', dayjs().subtract(1, 'millisecond').format('YYYY-MM-DD HH:mm:ss.SSS')); // 2025-06-04 09:35:04.003
// 获取当前时间的后一毫秒
console.log('后一毫秒:', dayjs().add(1, 'millisecond').format('YYYY-MM-DD HH:mm:ss.SSS')); // 2025-06-04 09:35:04.005
日期前后相等比较
/**
* 假设今天是6月5号
* */
console.log('是否日期相同', dayjs().isSame(dayjs('2025-06-05'), 'day')); // true
console.log('是否在日期之前', dayjs().isBefore(dayjs('2025-06-06'), 'day')); // true
console.log('是否在日期之后', dayjs().isAfter(dayjs('2025-06-03'), 'day')); // true
日期的差值diff
计算两个日期之间,差了多久时间
const date1 = dayjs('2019-01-25 12:00:02')
const date2 = dayjs('2019-01-25 12:00:01')
console.log('date1和date2差了:', date1.diff(date2)); // 默认差值单位毫秒数 1000
const date3 = dayjs('2019-01-25')
const date4 = dayjs('2019-02-25')
console.log(date4.diff(date3, 'month')) // 1
指定以月份为单位,可选单位有 'year', 'month', 'week', 'day', 'hour', 'minute', 'second', 'millisecond' 想要支持季度,需额外下载QuarterOfYear插件
获取时间戳毫秒数
// 获取当前时间的时间戳,单位为毫秒
console.log('毫秒时间戳', dayjs().valueOf()); // 1749113764926
获取时间戳秒数
// 获取当前时间的时间戳,单位为秒
console.log('秒时间戳', dayjs().unix()); // 1749113764
获取月份有多少天
// 获取某个时间的月份有多少天
console.log('dayjs().daysInMonth()', dayjs().daysInMonth()); // 30 // 现在是6月份,所以30天
开始时间和结束时间
// 获取当前时间所在天的开始时间
console.log('开始时间', dayjs().startOf('day').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-05 00:00:00
// 获取当前时间所在天的结束时间
console.log('结束时间', dayjs().endOf('day').format('YYYY-MM-DD HH:mm:ss')); // 2025-06-05 23:59:59
每天一个知识点...
来源:juejin.cn/post/7512270432213876762
【小程序】迁移非主包组件以减少主包体积
代码位置
问题及背景
- 微信小程序主包体积最大为
2M,超出体积无法上传。 - 组件放在不同的目录下的表现不同:
src/components目录中的组件会被打包到主包中,可以被所有页面引用。src/pages/about/components目录中的组件会被打印到对应分包中,只能被当前分包引用(只考虑微信小程序的话可以用分包异步化,我这边因为需要做不同平台所以不考虑这个方案)。
在之前的项目结构中,所有的组件都放在 src/components 目录下,因此所有组件都会被打包到主包中,这导致主包体积超出了 2M 的限制。
后续经过优化,将一些与主包无关的组件放到了对应分包中,但是有一些组件,在主包页面中没有被引用,但是被多个不同的分包页面引用,因此只能放到 src/components 目录下打包到主包中。
本文的优化思路就是将这一部分组件通过脚本迁移到不同的分包目录中,从而减少主包体积,这样做的缺点也显而易见:会增加代码包的总体积(微信还有总体积小于 20M 的限制 🤮)。
实现思路
项目中用 gulp 做打包流程管理,因此将这个功能封装成一个 task,在打包之前调用。
1. 分析依赖
分析 src/components 组件是否主包页面引用,有两种情况:
- 直接被主页引用。
- 间接被主页引用:主页引用
a,a引用b,此时a为直接引用,b为间接引用。
const { series, task, src, parallel } = require("gulp");
const tap = require("gulp-tap");
const path = require("path");
const fs = require("fs");
const pages = require("../src/pages.json");
// 项目根目录
const rootPath = path.join(__dirname, "../");
const srcPath = path.join(rootPath, "./src");
const componentsPath = path.join(rootPath, "./src/components");
// 组件引用根路径
const componentRootPath = "@/components"; // 替换为 pages 页面中引入组件的路径
// 组件依赖信息
let componentsMap = {};
// 从 pages 文件中获取主包页面路径列表
const mainPackagePagePathList = pages.pages.map((item) => {
let pathParts = item.path.split("/");
return pathParts.join(`\\${path.sep}`);
});
/**
* 组件信息初始化
*/
function initComponentsMap() {
// 为所有 src/components 中的组件创建信息
return src([`${srcPath}/@(components)/**/**.vue`]).pipe(
tap((file) => {
let filePath = transferFilePathToComponentPath(file.path);
componentsMap[filePath] = {
refers: [], // 引用此组件的页面/组件
quotes: [], // 此组件引用的组件
referForMainPackage: false, // 是否被主包引用,被主包引用时不需要 copy 到分包
};
})
);
}
/**
* 分析依赖
*/
function analyseDependencies() {
return src([`${srcPath}/@(components|pages)/**/**.vue`]).pipe(
tap((file) => {
// 是否为主包页面
const isMainPackagePageByPath = checkIsMainPackagePageByPath(file.path);
// 分析页面引用了哪些组件
const componentsPaths = Object.keys(componentsMap);
const content = String(file.contents);
componentsPaths.forEach((componentPath) => {
if (content.includes(componentPath)) {
// 当前页面引用了这个组件
componentsMap[componentPath].refers.push(file.path);
if (file.path.includes(componentsPath)) {
// 记录组件被引用情况
const targetComponentPath = transferFilePathToComponentPath(
file.path
);
componentsMap[targetComponentPath].quotes.push(componentPath);
}
// 标记组件是否被主页引用
if (isMainPackagePageByPath) {
componentsMap[componentPath].referForMainPackage = true;
}
}
});
})
);
}
/**
* 分析间接引用依赖
*/
function analyseIndirectDependencies(done) {
for (const componentPath in componentsMap) {
const componentInfo = componentsMap[componentPath];
if (!componentInfo.referForMainPackage) {
const isIndirectReferComponent =
checkIsIndirectReferComponent(componentPath);
if (isIndirectReferComponent) {
console.log("间接引用组件", componentPath);
componentInfo.referForMainPackage = true;
}
}
}
done();
}
/**
* 是否为被主页间接引用的组件
*/
function checkIsIndirectReferComponent(componentPath) {
const componentInfo = componentsMap[componentPath];
if (componentInfo.referForMainPackage) {
return true;
}
for (const filePath of componentInfo.refers) {
if (filePath.includes(componentsPath)) {
const subComponentPath = transferFilePathToComponentPath(filePath);
const result = checkIsIndirectReferComponent(subComponentPath);
if (result) {
return result;
}
}
}
}
/**
* 将文件路径转换为组件路径
*/
function transferFilePathToComponentPath(filePath) {
return filePath
.replace(componentsPath, componentRootPath)
.replaceAll(path.sep, "/")
.replace(".vue", "");
}
/**
* 判断页面路径是否为主包页面
*/
function checkIsMainPackagePageByPath(filePath) {
// 正则:判断是否为主包页面
const isMainPackagePageReg = new RegExp(
`(${mainPackagePagePathList.join("|")})`
);
return isMainPackagePageReg.test(filePath);
}
经过这一步后会得到一个 json,包含被引用文件信息和是否被主页引用,格式为:
{
"@/components/xxxx/xxxx": {
"refers": [
"D:\\code\\miniPrograme\\xxxxxx\\src\\pages\\xxx1\\index.vue",
"D:\\code\\miniPrograme\\xxxxxx\\src\\pages\\xxx2\\index.vue",
"D:\\code\\miniPrograme\\xxxxxx\\src\\components\\xxx\\xxx\\xxx.vue"
],
"referForMainPackage": false
}
}
2. 分发组件
经过第一步的依赖分析,我们知道了 referForMainPackage 值为 false 的组件是不需要放在主包中的,在这一步中将这些组件分发到对应的分包中。
思路:
- 遍历所有
referForMainPackage值为false的组件。 - 遍历所有组件的
refers列表,如果refer能匹配到分包,做以下动作:
- 在分包根目录下创建
componentsauto目录,将组件复制到这里。 - 复制组件中引用的相对路径资源。
- 在分包根目录下创建
- 删除
pages/components中的当前组件。
const taskMap = {};
const changeFileMap = {};
const deleteFileMap = {};
// 分发组件
async function distributionComponents() {
for (let componentPath in componentsMap) {
const componentInfo = componentsMap[componentPath];
// 未被主包引用的组件
for (const pagePath of componentInfo.refers) {
// 将组件复制到分包
if (pagePath.includes(pagesPath)) {
// 将组件复制到页面所在分包
await copyComponent(componentPath, pagePath);
}
}
}
}
/**
* 复制组件
* @param {*} componentPath
* @param {*} targetPath
* @returns
*/
async function copyComponent(componentPath, pagePath) {
const componentInfo = componentsMap[componentPath];
if (componentInfo.referForMainPackage) return;
const key = `${componentPath}_${pagePath}`;
// 避免重复任务
if (taskMap[key]) return;
taskMap[key] = true;
const subPackageRoot = getSubPackageRootByPath(pagePath);
if (!subPackageRoot) return;
const componentFilePath = transferComponentPathToFilePath(componentPath);
const subPackageComponentsPath = path.join(subPackageRoot, "componentsauto");
const newComponentFilePath = path.join(
subPackageComponentsPath,
path.basename(componentFilePath)
);
const newComponentsPath = newComponentFilePath
.replace(srcPath, "@")
.replaceAll(path.sep, "/")
.replaceAll(".vue", "");
// 1. 复制组件及其资源
await copyComponentWithResources(
componentFilePath,
subPackageComponentsPath,
componentInfo
);
// 2. 递归复制引用的组件
if (componentInfo.quotes.length > 0) {
let tasks = [];
componentInfo.quotes.map((quotePath) => {
// 复制子组件
tasks.push(copyComponent(quotePath, pagePath));
const subComponentInfo = componentsMap[quotePath];
if (!subComponentInfo.referForMainPackage) {
// 2.1 修改组件引用的子组件路径
const newSubComponentFilePath = path.join(
subPackageComponentsPath,
path.basename(quotePath)
);
const newSubComponentsPath = newSubComponentFilePath
.replace(srcPath, "@")
.replaceAll(path.sep, "/")
.replaceAll(".vue", "");
updateChangeFileInfo(
newComponentFilePath,
quotePath,
newSubComponentsPath
);
}
});
await Promise.all(tasks);
}
// 3. 修改页面引用当前组件路径
updateChangeFileInfo(pagePath, componentPath, newComponentsPath);
// 4. 删除当前组件
updateDeleteFileInfo(componentFilePath);
}
/**
* 更新删除文件信息
* @param {*} filePath
*/
function updateDeleteFileInfo(filePath) {
deleteFileMap[filePath] = true;
}
/**
* 更新修改文件内容信息
* @param {*} filePath
* @param {*} oldStr
* @param {*} newStr
*/
function updateChangeFileInfo(filePath, oldStr, newStr) {
if (!changeFileMap[filePath]) {
changeFileMap[filePath] = [];
}
changeFileMap[filePath].push([oldStr, newStr]);
}
/**
* 删除文件任务
*/
async function deleteFile() {
for (const filePath in deleteFileMap) {
try {
await fs.promises.unlink(filePath).catch(console.log); // 删除单个文件
// 或删除目录:await fs.rmdir('path/to/dir', { recursive: true });
} catch (err) {
console.error("删除失败:", err);
}
}
}
/**
* 复制组件及其资源
* @param {*} componentFilePath
* @param {*} destPath
*/
async function copyComponentWithResources(componentFilePath, destPath) {
// 复制主组件文件
await new Promise((resolve) => {
src(componentFilePath).pipe(dest(destPath)).on("end", resolve);
});
// 处理组件中的相对路径资源
const content = await fs.promises.readFile(componentFilePath, "utf-8");
const relativePaths = extractRelativePaths(content);
await Promise.all(
relativePaths.map(async (relativePath) => {
const resourceSrcPath = path.join(componentFilePath, "../", relativePath);
const resourceDestPath = path.join(destPath, path.dirname(relativePath));
await new Promise((resolve) => {
src(resourceSrcPath).pipe(dest(resourceDestPath)).on("end", resolve);
});
})
);
}
/**
* 修改页面引用路径
*/
async function changePageResourcePath() {
for (const pagePath in changeFileMap) {
const list = changeFileMap[pagePath];
await new Promise((resolve) => {
src(pagePath)
.pipe(
tap((file) => {
let content = String(file.contents);
for (const [oldPath, newPath] of list) {
content = content.replaceAll(oldPath, newPath);
}
file.contents = Buffer.from(content);
})
)
.pipe(dest(path.join(pagePath, "../")))
.on("end", resolve);
});
}
}
// 获取分包根目录
function getSubPackageRootByPath(pagePath) {
for (const subPackagePagePath of subPackagePagePathList) {
const rootPath = `${path.join(pagesPath, subPackagePagePath)}`;
const arr = pagePath.replace(pagesPath, "").split(path.sep);
if (arr[1] === subPackagePagePath) {
return rootPath;
}
}
}
注意事项
引用资源时不能用相对路径
避免使用相对路径引入资源,可以通过代码规范来限制(处理起来比较麻烦,懒得写了)。
不同操作系统未验证
代码仅在 windows 10 系统下运行,其他操作系统未验证,可能会存在资源路径无法匹配的问题。
uniapp 项目
本项目是 uniapp 项目,因此迁移的组件后缀为 .vue,原生语言或其他框架不能直接使用。
来源:juejin.cn/post/7518758885273829413
【吃瓜】这可能是2025年最荒谬的前端灾难:一支触控笔"干掉"了全球CSS预处理器
作为mockm项目的维护者,这几天我一直在优化CI/CD流水线。终于把自动化测试和发布流程都搞定了,心想着可以安心写代码了。结果今天早上一看GitHub Actions,我傻眼了...
项目突然构建失败了
昨天还好好的CI/CD流水线,今天突然就红了一片!
刚刚合并完dev分支的代码,准备发布新版本,结果Deploy Documentation and Release Package这个workflow直接失败了。作为一个有洁癖的开发者,看到Actions页面一片红色真的很崩溃。
第一反应:又是我的配置问题?
点开失败的job详情,看到build-and-release这一步挂了。心想肯定又是我的docker-compose配置有问题,或者是某个环境变量没设对。
毕竟刚优化完CI/CD,出问题很正常嘛...
但是当我仔细查看错误日志时,发现了一个让我摸不着头脑的错误:
stylus包不存在?什么鬼?
我重新运行了一遍workflow,还是同样的错误。然后我在本地试了试 npm install,结果更震惊了——NPM告诉我这个用了好几年的CSS预处理器库,突然从地球上消失了。
从GitHub Actions红屏到全网灾难
看到这个错误,我的第一反应不是恐慌,而是怀疑自己的CI配置:
npm ERR! 404 'stylus@https://registry.npmjs.org/stylus/-/stylus-0.64.0.tgz' is not in this registry
"是不是我的workflow配置有问题?"我检查了一遍deploy.yml文件,docker-compose配置也重新看了遍。
"是不是环境变量没设对?"我在Actions的Secrets里确认了一遍,没有问题。
"是不是依赖版本冲突了?"我看了看package.json,stylus版本一直没变过啊。
然后我想到,也许是GitHub Actions的runner环境问题?我在本地试了试:
npm install stylus
npm ERR! 404 'stylus@*' is not in this registry.
WTF?本地也不行了!
这时候我才意识到,这不是我的mockm项目的问题,不是我的CI/CD配置的问题,而是整个NPM生态出大问题了。
直到我打开Twitter,看到满屏的哀嚎,才意识到这不是我一个人的问题。这是一场全球性的前端灾难。
当我意识到这不是我的CI问题时...
说实话,刚开始我还暗自庆幸——至少不是我的自动化流程配置有问题。毕竟刚花了好几天时间优化CI/CD,要是出bug了那真是太丢人了。
但当我看到GitHub上那些issue的时候,笑不出来了:
- Nx框架的用户在哭
- TypeScript项目在崩溃
- 连Vue的生态都受到了影响
- 我的mockm项目构建也挂了
这让我想起了2016年的left-pad事件,但这次更严重。left-pad至少只是一个小工具函数,而Stylus是整个CSS预处理生态的重要组成部分。
我开始担心:不光是我的mockm项目发布不了,全世界有多少个项目的CI/CD都在今天红屏了?有多少开发者像我一样,以为是自己的配置问题,结果查了半天发现是外部依赖炸了?
全球开发者陷入恐慌
GitHub Issues 爆炸式增长
短短几小时内,与Stylus相关的错误报告如雨后春笋般涌现:
- [Nx框架] -
'stylus@https://registry.npmjs.org/stylus/-/stylus-0.64.0.tgz' is not in this registry on npm install nrwl/nx#32031 - [TypeScript CSS Modules] -
Stylus contained malicious code and was removed from the registry by the npm security team mrmckeb/typescript-plugin-css-modules#287 - [ShadCN Vue] -
ERR_PNPM_NO_MATCHING_VERSION due to yanked package unovue/shadcn-vue#1344
社交媒体上的恐慌
Twitter、Reddit、Discord等平台上充斥着开发者的求助和抱怨:
"我的整个项目都跑不起来了,Stylus到底发生了什么?"
"生产环境部署失败,老板在催进度,Stylus你什么时候能回来?"
"这是我见过最离谱的NPM事故,一个CSS预处理器居然能让半个前端圈瘫痪"
然后我发现了最荒谬的真相...
花了一个上午收集信息后,我发现了这个让人哭笑不得的真相:
NPM把CSS预处理器和ChromeOS的触控笔搞混了!
没错,你没看错。导致Stylus被封禁的CVE-2025-6044,说的是ChromeOS设备上的物理触控笔存在安全漏洞。而NPM的安全团队,可能是用了某种自动化工具,看到"Stylus"这个名字,就把我们前端开发者天天用的CSS预处理器给ban了。
我第一次看到这个解释的时候,真的以为是在看洋葱新闻。
让我们来对比一下这个绝世乌龙:
真正有漏洞的"Stylus":
- ChromeOS设备上的物理触控笔工具
- 需要物理接触设备才能攻击
- 和前端开发一毛钱关系都没有
被误杀的"stylus":
- 前端开发者的CSS预处理器
- 纯软件库,连UI都没有
- 被全世界几百万项目依赖
这就好比因为苹果公司出了安全问题,就把超市里的苹果都下架了一样荒谬。
我为这个维护者感到心疼
看到Stylus维护者@iChenLei在GitHub上的无助求助,说实话我挺心疼的。
作为一个也维护过开源项目的人,我太能理解那种感受了:你辛辛苦苦维护了这么多年的项目,服务了全球这么多开发者,结果因为一个莫名其妙的错误就被封禁,而且申诉无门。
他在Issue里写道:
"这影响了很多人。虽然这不是我的错,但我向每个人道歉。"
这句话让我特别感动。明明是NPM搞错了,但他还是在为用户的困扰道歉。这就是开源维护者的责任感。
而且你看他做的这些努力:
- 立即提交官方ticket
- 在Twitter上求助
- 甚至还展示了自己的2FA截图证明账户安全
但NPM官方到现在还没有任何回应。这让我想起那句话:"开源开发者用爱发电,平台方用AI管理"。
临时解决方案:前端社区的自救行动
面对官方的无回应,社区开始了自救。说实话,这种时候最能看出开源社区的凝聚力。
我试过的几种方法
方法一:直接用GitHub源
npm install https://github.com/stylus/stylus/archive/refs/tags/0.64.0.tar.gz
这个方法管用,但感觉不太优雅。而且每次安装都要下载整个repo,速度慢得要命。
方法二:Package.json override
{
"overrides": {
"postcss-styl>stylus": "https://github.com/stylus/stylus/archive/refs/tags/0.64.0.tar.gz"
}
}
这个比较适合已有项目,但对新项目来说还是很麻烦。
方法三:换注册表
npm config set registry https://registry.npmmirror.com/
试了几个国内镜像,大部分还有缓存,可以正常安装。但总感觉不是长久之计。
让我感动的社区互助
在各种群和论坛里,大家都在分享解决方案,没有人在抱怨,更没有人在指责维护者。这让我想起了为什么我当初会爱上开源社区。
有个老哥甚至建议大家去转发维护者的Twitter求助,我觉得这个主意不错。毕竟有时候社交媒体的影响力比正式渠道还管用。
这件事让我重新思考了很多问题
说实话,这次事件让我开始重新审视我们前端开发的生态。
NPM真的靠谱吗?
作为一个在前端圈混了这么多年的老司机,我一直觉得NPM已经足够成熟稳定了。但这次事件让我意识到,我们可能过于依赖这个中心化的平台了。
想想看:
- 一个错误的安全判断,就能让全球项目停摆
- 维护者申诉无门,只能在社交媒体求助
- 没有任何预警机制,用户只能被动承受
这真的合理吗?

开源维护者太难了
@iChenLei的遭遇让我想起了很多开源维护者的心酸。他们用爱发电,服务全世界,但遇到问题时却如此无助。
我觉得我们作为受益者,应该:
- 多给开源项目捐赠
- 积极参与社区建设
- 在这种时候给维护者更多支持
而不是只会在出问题时抱怨。
前端生态的脆弱性
这次事件也暴露了现代前端开发的一个问题:我们的依赖树太复杂了。
一个简单的项目,动不动就有几百个依赖。每个依赖都是一个潜在的故障点。虽然这种模块化的开发方式很高效,但风险也确实不小。
我开始思考:
- 是不是应该减少一些不必要的依赖?
- 关键依赖是不是应该做备份?
- 公司是不是应该建立私有NPM镜像?
从left-pad到stylus,我们学到了什么?
2016年的left-pad事件,曾经让整个JavaScript生态停摆了一天。当时大家说要吸取教训,要建立更稳定的包管理机制。
现在2025年了,类似的事情又发生了,而且更严重。
这让我意识到,单纯依靠技术手段可能解决不了根本问题。我们需要的是:
- 更透明的治理机制:NPM的决策过程应该更开放
- 更快速的申诉渠道:不能让维护者只能在Twitter求助
- 更多元化的生态:不能把鸡蛋都放在一个篮子里
left-pad事件:
left-pad 是一个由 Javascript 程序员 Azer 编写的 npm 包,功能是为字符串添加左侧填充,代码仅有 11 行,但却被上千个项目使用,其中包括著名的 babel 和 react-native 等。
Azer 收到 kik 公司的邮件,对方称要发布名为 kik 的封包,但 kik 这个名字已被 Azer 占用,希望他能改名。Azer 拒绝后,kik 公司多次与他沟通无果,便向 npm 公司发邮件。最终,npm 公司将 kik 封包转给了 kik 公司。
Azer 因 npm 公司的这一决定感到愤怒,一怒之下将自己在 npm 上的 273 个封包全部撤下,其中包括 left-pad 封包。这导致依赖 left-pad 的成千上万个项目瞬间崩溃,大量开发者的项目构建失败。
我的一些建议
作为一个用户,我觉得我们可以:
短期内:
- 建立项目的依赖备份机制
- 使用多个注册表镜像
- 关键项目使用package-lock.json
长期来看:
- 支持去中心化的包管理方案
- 推动NPM改进治理机制
- 给开源项目更多的资金和技术支持~逃~~~
资金支持?之前为了让 mockm 项目的文档能让网络“不方便”的大家也能快速访问,自己花钱买的域名、服务器。但是这么多年工资也没有涨,可能是我没有好好工作。撑不下去了(本来好像也没几个用户),所以我打算把文档部署在 GITHUB PAGE 上了,网络不方便?爱谁谁!
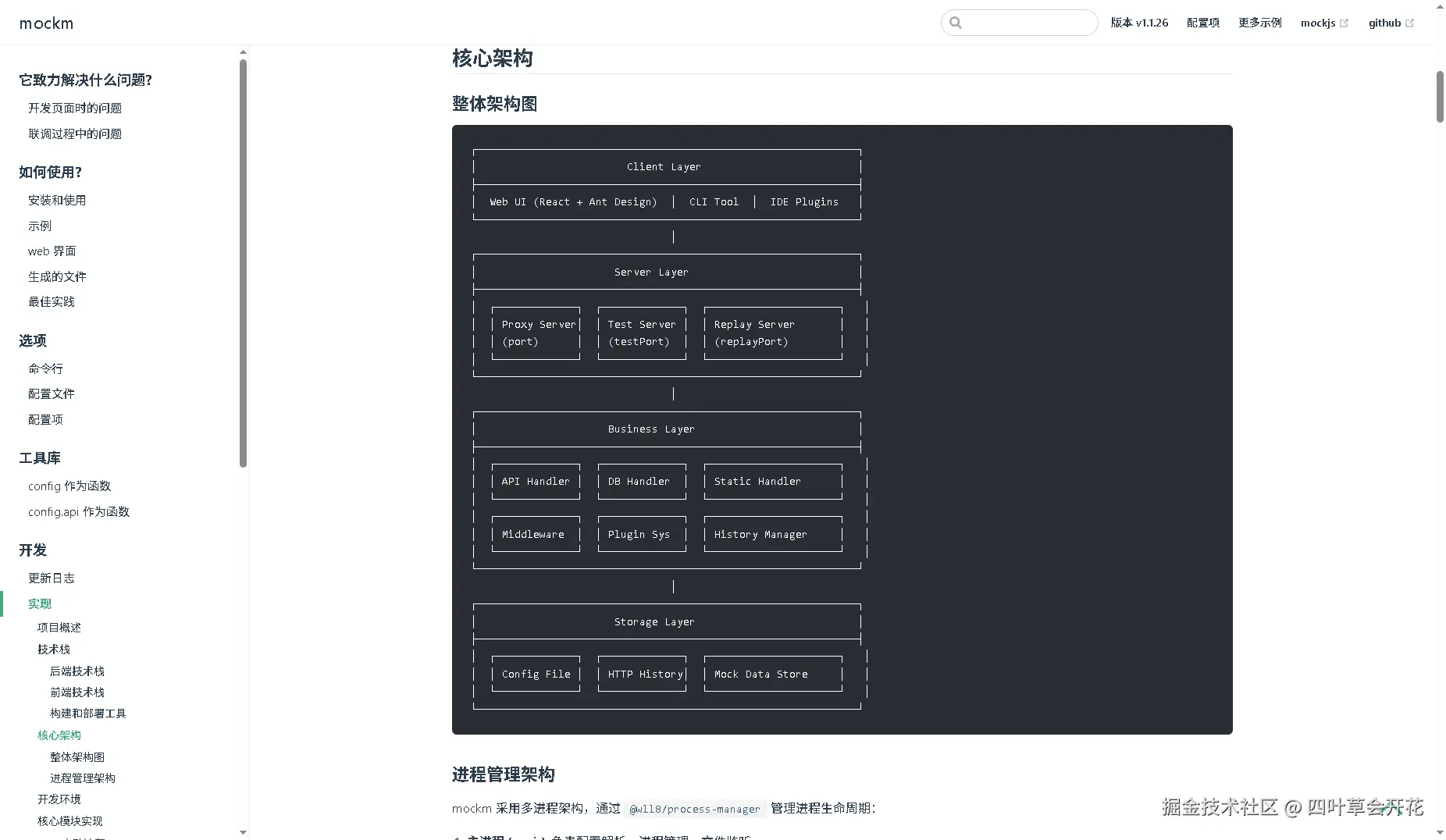
写在最后
这次事件提醒我们,我们的工作比想象中更脆弱。但也让我看到了社区的力量:当官方渠道失效时,我们依然能够相互帮助,共度难关。PS:这就是为什么我爱这个行业的原因。
然而一个又产生一个新想法:一个小小的名称混淆,就能让全球的前端开发陷入混乱。那么,"软件正在吞噬世界,但谁来守护软件?"
相关链接
- 吃瓜地址: github.com/stylus/styl…
- MOCKM 文档: wll8.github.io/mockm/
来源:juejin.cn/post/7529903134296653839
🔥 滚动监听写到手抽筋?IntersectionObserver让你躺平实现懒加载
🎯 学习目标:掌握IntersectionObserver API的核心用法,解决滚动监听性能问题,实现高效的懒加载和可见性检测
📊 难度等级:中级
🏷️ 技术标签:#IntersectionObserver#懒加载#性能优化#滚动监听
⏱️ 阅读时间:约8分钟
🌟 引言
在日常的前端开发中,你是否遇到过这样的困扰:
- 滚动监听卡顿:addEventListener('scroll')写多了页面卡得像PPT
- 懒加载复杂:图片懒加载逻辑复杂,还要手动计算元素位置
- 无限滚动性能差:数据越来越多,滚动越来越卡
- 可见性检测麻烦:想知道元素是否进入视口,代码写得头疼
今天分享5个IntersectionObserver的实用场景,让你的滚动监听更加丝滑,告别性能焦虑!
💡 核心技巧详解
1. 图片懒加载:告别手动计算位置的痛苦
🔍 应用场景
当页面有大量图片时,一次性加载所有图片会严重影响页面性能,需要实现图片懒加载。
❌ 常见问题
传统的滚动监听方式性能差,需要频繁计算元素位置。
// ❌ 传统滚动监听写法
window.addEventListener('scroll', () => {
const images = document.querySelectorAll('img[data-src]');
images.forEach(img => {
const rect = img.getBoundingClientRect();
if (rect.top < window.innerHeight) {
img.src = img.dataset.src;
img.removeAttribute('data-src');
}
});
});
✅ 推荐方案
使用IntersectionObserver实现高性能的图片懒加载。
/**
* 创建图片懒加载观察器
* @description 使用IntersectionObserver实现高性能图片懒加载
* @param {string} selector - 图片选择器
* @param {Object} options - 观察器配置选项
* @returns {IntersectionObserver} 观察器实例
*/
const createImageLazyLoader = (selector = 'img[data-src]', options = {}) => {
// 推荐写法:使用IntersectionObserver
const defaultOptions = {
root: null, // 使用视口作为根元素
rootMargin: '50px', // 提前50px开始加载
threshold: 0.1 // 元素10%可见时触发
};
const config = { ...defaultOptions, ...options };
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = entry.target;
// 加载图片
img.src = img.dataset.src;
img.removeAttribute('data-src');
// 停止观察已加载的图片
observer.unobserve(img);
}
});
}, config);
// 观察所有待加载的图片
document.querySelectorAll(selector).forEach(img => {
observer.observe(img);
});
return observer;
};
💡 核心要点
- rootMargin:提前加载,避免用户看到空白
- threshold:设置合适的触发阈值
- unobserve:加载完成后停止观察,释放资源
🎯 实际应用
在Vue3项目中的完整应用示例:
<template>
<div class="image-gallery">
<img
v-for="(image, index) in images"
:key="index"
:data-src="image.url"
:alt="image.alt"
class="lazy-image"
src="data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' width='300' height='200'%3E%3Crect width='100%25' height='100%25' fill='%23f0f0f0'/%3E%3C/svg%3E"
/>
</div>
</template>
<script setup>
import { onMounted, onUnmounted } from 'vue';
let observer = null;
onMounted(() => {
observer = createImageLazyLoader('.lazy-image');
});
onUnmounted(() => {
observer?.disconnect();
});
</script>
2. 无限滚动:数据加载的性能优化
🔍 应用场景
实现无限滚动列表,当用户滚动到底部时自动加载更多数据。
❌ 常见问题
传统方式需要监听滚动事件并计算滚动位置,性能开销大。
// ❌ 传统无限滚动实现
window.addEventListener('scroll', () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight - 100) {
loadMoreData();
}
});
✅ 推荐方案
使用IntersectionObserver监听底部哨兵元素。
/**
* 创建无限滚动观察器
* @description 监听底部哨兵元素实现无限滚动
* @param {Function} loadMore - 加载更多数据的回调函数
* @param {Object} options - 观察器配置
* @returns {Object} 包含观察器和控制方法的对象
*/
const createInfiniteScroll = (loadMore, options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '100px', // 提前100px触发加载
threshold: 0
};
const config = { ...defaultOptions, ...options };
let isLoading = false;
const observer = new IntersectionObserver(async (entries) => {
const [entry] = entries;
if (entry.isIntersecting && !isLoading) {
isLoading = true;
try {
await loadMore();
} catch (error) {
console.error('加载数据失败:', error);
} finally {
isLoading = false;
}
}
}, config);
return {
observer,
// 开始观察哨兵元素
observe: (element) => observer.observe(element),
// 停止观察
disconnect: () => observer.disconnect(),
// 获取加载状态
getLoadingState: () => isLoading
};
};
💡 核心要点
- 哨兵元素:在列表底部放置一个不可见的元素作为触发器
- 防重复加载:使用loading状态防止重复请求
- 错误处理:加载失败时的异常处理
🎯 实际应用
Vue3组件中的使用示例:
<template>
<div class="infinite-list">
<div v-for="item in items" :key="item.id" class="list-item">
{{ item.title }}
</div>
<!-- 哨兵元素 -->
<div ref="sentinelRef" class="sentinel"></div>
<div v-if="loading" class="loading">加载中...</div>
</div>
</template>
<script setup>
import { ref, onMounted, onUnmounted } from 'vue';
const items = ref([]);
const loading = ref(false);
const sentinelRef = ref(null);
let infiniteScroll = null;
// 加载更多数据
const loadMoreData = async () => {
loading.value = true;
// 模拟API请求
const newItems = await fetchData();
items.value.push(...newItems);
loading.value = false;
};
onMounted(() => {
infiniteScroll = createInfiniteScroll(loadMoreData);
infiniteScroll.observe(sentinelRef.value);
});
onUnmounted(() => {
infiniteScroll?.disconnect();
});
</script>
3. 元素可见性统计:精准的用户行为分析
🔍 应用场景
统计用户对页面内容的浏览情况,比如广告曝光、内容阅读时长等。
❌ 常见问题
手动计算元素可见性复杂且不准确。
// ❌ 手动计算可见性
const isElementVisible = (element) => {
const rect = element.getBoundingClientRect();
return rect.top >= 0 && rect.bottom <= window.innerHeight;
};
✅ 推荐方案
使用IntersectionObserver精准统计元素可见性。
/**
* 创建可见性统计观察器
* @description 统计元素的可见性和停留时间
* @param {Function} onVisibilityChange - 可见性变化回调
* @param {Object} options - 观察器配置
* @returns {IntersectionObserver} 观察器实例
*/
const createVisibilityTracker = (onVisibilityChange, options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '0px',
threshold: [0, 0.25, 0.5, 0.75, 1.0] // 多个阈值,精确统计
};
const config = { ...defaultOptions, ...options };
const visibilityData = new Map();
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const element = entry.target;
const elementId = element.dataset.trackId || element.id;
if (!visibilityData.has(elementId)) {
visibilityData.set(elementId, {
element,
startTime: null,
totalTime: 0,
maxVisibility: 0
});
}
const data = visibilityData.get(elementId);
if (entry.isIntersecting) {
// 元素进入视口
if (!data.startTime) {
data.startTime = Date.now();
}
data.maxVisibility = Math.max(data.maxVisibility, entry.intersectionRatio);
} else {
// 元素离开视口
if (data.startTime) {
data.totalTime += Date.now() - data.startTime;
data.startTime = null;
}
}
// 触发回调
onVisibilityChange({
elementId,
isVisible: entry.isIntersecting,
visibilityRatio: entry.intersectionRatio,
totalTime: data.totalTime,
maxVisibility: data.maxVisibility
});
});
}, config);
return observer;
};
💡 核心要点
- 多阈值监听:使用多个threshold值精确统计可见比例
- 时间统计:记录元素在视口中的停留时间
- 数据持久化:将统计数据存储到Map中
🎯 实际应用
广告曝光统计的实际应用:
// 实际项目中的广告曝光统计
const trackAdExposure = () => {
const tracker = createVisibilityTracker((data) => {
const { elementId, isVisible, visibilityRatio, totalTime } = data;
// 曝光条件:可见比例超过50%且停留时间超过1秒
if (visibilityRatio >= 0.5 && totalTime >= 1000) {
// 发送曝光统计
sendExposureData({
adId: elementId,
exposureTime: totalTime,
visibilityRatio: visibilityRatio
});
}
});
// 观察所有广告元素
document.querySelectorAll('.ad-banner').forEach(ad => {
tracker.observe(ad);
});
};
4. 动画触发控制:精准的视觉效果
🔍 应用场景
当元素进入视口时触发CSS动画或JavaScript动画,提升用户体验。
❌ 常见问题
使用滚动监听触发动画,性能差且时机不准确。
// ❌ 传统动画触发方式
window.addEventListener('scroll', () => {
const elements = document.querySelectorAll('.animate-on-scroll');
elements.forEach(el => {
const rect = el.getBoundingClientRect();
if (rect.top < window.innerHeight * 0.8) {
el.classList.add('animate');
}
});
});
✅ 推荐方案
使用IntersectionObserver精准控制动画触发时机。
/**
* 创建动画触发观察器
* @description 当元素进入视口时触发动画
* @param {Object} options - 观察器和动画配置
* @returns {IntersectionObserver} 观察器实例
*/
const createAnimationTrigger = (options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '-10% 0px', // 元素完全进入视口后触发
threshold: 0.3,
animationClass: 'animate-in',
once: true // 只触发一次
};
const config = { ...defaultOptions, ...options };
const triggeredElements = new Set();
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const element = entry.target;
if (entry.isIntersecting) {
// 添加动画类
element.classList.add(config.animationClass);
if (config.once) {
// 只触发一次,停止观察
observer.unobserve(element);
triggeredElements.add(element);
}
// 触发自定义事件
element.dispatchEvent(new CustomEvent('elementVisible', {
detail: { intersectionRatio: entry.intersectionRatio }
}));
} else if (!config.once) {
// 允许重复触发时,移除动画类
element.classList.remove(config.animationClass);
}
});
}, {
root: config.root,
rootMargin: config.rootMargin,
threshold: config.threshold
});
return observer;
};
💡 核心要点
- rootMargin负值:确保元素完全进入视口后才触发
- once选项:控制动画是否只触发一次
- 自定义事件:方便其他代码监听动画触发
🎯 实际应用
配合CSS动画的完整实现:
/* CSS动画定义 */
.fade-in-element {
opacity: 0;
transform: translateY(30px);
transition: all 0.6s ease-out;
}
.fade-in-element.animate-in {
opacity: 1;
transform: translateY(0);
}
// JavaScript动画控制
const initScrollAnimations = () => {
const animationTrigger = createAnimationTrigger({
animationClass: 'animate-in',
threshold: 0.2,
once: true
});
// 观察所有需要动画的元素
document.querySelectorAll('.fade-in-element').forEach(element => {
animationTrigger.observe(element);
// 监听动画触发事件
element.addEventListener('elementVisible', (e) => {
console.log(`元素动画触发,可见比例: ${e.detail.intersectionRatio}`);
});
});
};
5. 虚拟滚动优化:大数据列表的性能救星
🔍 应用场景
处理包含大量数据的列表,只渲染可见区域的元素,提升性能。
❌ 常见问题
渲染大量DOM元素导致页面卡顿,滚动性能差。
// ❌ 渲染所有数据
const renderAllItems = (items) => {
const container = document.getElementById('list');
items.forEach(item => {
const element = document.createElement('div');
element.textContent = item.title;
container.appendChild(element);
});
};
✅ 推荐方案
结合IntersectionObserver实现简化版虚拟滚动。
/**
* 创建虚拟滚动观察器
* @description 只渲染可见区域的列表项,优化大数据列表性能
* @param {Array} data - 数据数组
* @param {Function} renderItem - 渲染单个项目的函数
* @param {Object} options - 配置选项
* @returns {Object} 虚拟滚动控制器
*/
const createVirtualScroll = (data, renderItem, options = {}) => {
const defaultOptions = {
itemHeight: 60, // 每项高度
bufferSize: 5, // 缓冲区大小
container: null // 容器元素
};
const config = { ...defaultOptions, ...options };
const visibleItems = new Map();
// 创建占位元素
const createPlaceholder = (index) => {
const placeholder = document.createElement('div');
placeholder.style.height = `${config.itemHeight}px`;
placeholder.dataset.index = index;
placeholder.classList.add('virtual-item-placeholder');
return placeholder;
};
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const placeholder = entry.target;
const index = parseInt(placeholder.dataset.index);
if (entry.isIntersecting) {
// 元素进入视口,渲染真实内容
if (!visibleItems.has(index)) {
const realElement = renderItem(data[index], index);
realElement.style.height = `${config.itemHeight}px`;
placeholder.replaceWith(realElement);
visibleItems.set(index, realElement);
}
} else {
// 元素离开视口,替换为占位符
const realElement = visibleItems.get(index);
if (realElement) {
const newPlaceholder = createPlaceholder(index);
realElement.replaceWith(newPlaceholder);
observer.observe(newPlaceholder);
visibleItems.delete(index);
}
}
});
}, {
root: config.container,
rootMargin: `${config.bufferSize * config.itemHeight}px`,
threshold: 0
});
// 初始化列表
const init = () => {
const container = config.container;
container.innerHTML = '';
data.forEach((_, index) => {
const placeholder = createPlaceholder(index);
container.appendChild(placeholder);
observer.observe(placeholder);
});
};
return {
init,
destroy: () => observer.disconnect(),
getVisibleCount: () => visibleItems.size
};
};
💡 核心要点
- 占位符机制:使用固定高度的占位符保持滚动条正确
- 缓冲区:通过rootMargin提前渲染即将可见的元素
- 内存管理:及时清理不可见的元素,释放内存
🎯 实际应用
Vue3组件中的虚拟滚动实现:
<template>
<div ref="containerRef" class="virtual-scroll-container">
<!-- 虚拟滚动内容将在这里动态生成 -->
</div>
</template>
<script setup>
import { ref, onMounted, onUnmounted } from 'vue';
const containerRef = ref(null);
let virtualScroll = null;
// 大量数据
const largeDataset = ref(Array.from({ length: 10000 }, (_, i) => ({
id: i,
title: `列表项 ${i + 1}`,
content: `这是第 ${i + 1} 个列表项的内容`
})));
// 渲染单个列表项
const renderListItem = (item, index) => {
const element = document.createElement('div');
element.className = 'list-item';
element.innerHTML = `
<h3>${item.title}</h3>
<p>${item.content}</p>
`;
return element;
};
onMounted(() => {
virtualScroll = createVirtualScroll(
largeDataset.value,
renderListItem,
{
itemHeight: 80,
bufferSize: 3,
container: containerRef.value
}
);
virtualScroll.init();
});
onUnmounted(() => {
virtualScroll?.destroy();
});
</script>
📊 技巧对比总结
| 技巧 | 使用场景 | 优势 | 注意事项 |
|---|---|---|---|
| 图片懒加载 | 大量图片展示 | 性能优秀,实现简单 | 需要设置合适的rootMargin |
| 无限滚动 | 长列表数据加载 | 避免频繁滚动监听 | 防止重复加载,错误处理 |
| 可见性统计 | 用户行为分析 | 精确统计,多阈值监听 | 数据存储和上报策略 |
| 动画触发 | 页面交互效果 | 时机精准,性能好 | 动画只触发一次的控制 |
| 虚拟滚动 | 大数据列表 | 内存占用低,滚动流畅 | 元素高度固定,复杂度较高 |
🎯 实战应用建议
最佳实践
- 合理设置rootMargin:根据实际需求提前或延迟触发观察
- 及时清理观察器:使用unobserve()和disconnect()释放资源
- 错误处理机制:为异步操作添加try-catch保护
- 性能监控:在开发环境中监控观察器的性能表现
- 渐进增强:为不支持IntersectionObserver的浏览器提供降级方案
性能考虑
- 观察器数量控制:避免创建过多观察器实例
- threshold设置:根据实际需求设置合适的阈值
- 内存泄漏防护:组件销毁时及时清理观察器
- 兼容性处理:使用polyfill支持旧版浏览器
💡 总结
这5个IntersectionObserver实用场景在日常开发中能显著提升页面性能,掌握它们能让你的滚动监听:
- 图片懒加载:告别手动位置计算,性能提升显著
- 无限滚动:避免频繁滚动监听,用户体验更佳
- 可见性统计:精准的用户行为分析,数据更准确
- 动画触发:完美的视觉效果时机控制
- 虚拟滚动:大数据列表的性能救星
希望这些技巧能帮助你在前端开发中告别滚动监听的性能焦虑,写出更丝滑的交互代码!
🔗 相关资源
- MDN IntersectionObserver文档
- Can I Use - IntersectionObserver兼容性
- IntersectionObserver Polyfill
- Web性能优化最佳实践
💡 今日收获:掌握了5个IntersectionObserver实用场景,这些知识点在实际开发中非常实用。
如果这篇文章对你有帮助,欢迎点赞、收藏和分享!有任何问题也欢迎在评论区讨论。 🚀
来源:juejin.cn/post/7549102542833631267
你一定疑惑JavaScript中的this绑定的究竟是什么?😵💫
想要了解this的绑定过程,首先要理解调用方式。
调用方式
调用方式被描述为函数被触发执行时语法形式。
主要有以下几种基本模式:
- 直接调用(独立函数调用):
f1() - 方法调用:
f1.f2() - 构造函数调用:
new f1() - 显示绑定调用:
f1.call(f2)或者f1.apply(f2) - 间接调用:
(0,f1)()
第五点可能很多人没有见过,其实这是应用了逗号操作符,(0,f1)()其实等同于f1(),但它有什么区别呢?我放在显式绑定的最后来阐述吧。
有的人会用调用位置来解释this的绑定,但我感觉那个不太好用,可能是我没理解到位吧,如果有人知道怎么用它来解释this的绑定,希望能告诉我。总之,我们先用调用方式来解释this的绑定吧。
四种绑定规则
接下来介绍四种绑定规则。
默认绑定
首先要介绍的是默认绑定,当使用了最常用的函数调用类型:直接调用(独立函数调用) 时,便应用默认绑定。可以把这条规则看作是无法应用其他规则时的默认规则。
在默认绑定时,this绑定的是全局作用域。
var a = 0;
function f1(){
var a = 1;
console.log(this.a); //输出为0
}
f1(); //直接调用,应用默认绑定
多个函数内部层层调用也是一样的。
var a = 0;
function f1(){
var a = 1;
f2();
}
function f2(){
var a = 2;
console.log(this.a); //输出的是0
}
f1();
隐式绑定
当函数被当作对象的属性被调用时(例如通过obj.f1()的形式),this会自动绑定到该对象上,这个绑定是隐式发生的,不需要显式使用call、apply或bind。
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //this绑定的是f2这个对象字面量
}
var obj = {
a : 2,
f1 : f1
// 也可以直接在obj内部定义f1
// function f1() {
// var a = 1;
// }
};
obj.f1(); // 输出为2
对象层层引用只有最后一个对象会影响this的绑定
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //最后输出为2
}
var obj1 = {
a : 2,
f1 : f1
};
var obj2 = {
a : 3,
obj1 : obj1
}
obj2.obj1.f1();
可以发现这里有两个对象一个是obj1,一个是obj2,obj2中的属性为obj1。先通过ob2.obj1调用obj1,再通过ob2.obj1.f1()调用f1函数,可以发现对象属性引用链中的最后一个对象为this所绑定的对象
隐性丢失
但隐式绑定可能会导致this丢失所绑定的对象,也就是会应用默认绑定(this绑定到全局作用域) 造成隐性丢失主要有两个方面,一个是给函数取别名,一个是回调函数。
- 函数取别名
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //最后输出为0
}
var obj = {
a : 2,
f1 : f1
}
var fOne = obj.f1; // 给f1取了一个fOne的别名
fOne();
虽然函数fOne是obj.f1的一个引用,但实际上,它引用的是f1函数本身,因此它执行的就是f1()。所以会使用默认绑定。
- 回调函数
var a = 0;
// f1为回调函数,将obj.f2作为参数传递给f1
function f1(f2) {
var a = 1;
f2();
}
function f2() {
var a = 2;
console.log(this.a); //结果为0
}
var obj = {
a : 3,
f2 : f2
}
f1(obj.f2);
原因很简单,f1(obj.f2)把obj.f2赋值给了function f1(f2) {...}中的f2(形参),就像上面讲的函数取了一个别名一样,实际执行的就是直接调用,所以应用默认绑定。
显式绑定
显式绑定很好理解,显式绑定让我们可以自定义this的绑定。我们通过使用函数的apply、call或bind方法,让我们可以自定义this的绑定。
var a = 0;
function f1 () {
var a = 1;
console.log(this.a);
}
//apply方法绑定this apply(对象,参数数组)
f1.apply({a:2}); //输出2
//call方法绑定this call(对象,参数1,参数2,...)
f1.call({a:3}); //输出3
//bind方法绑定this bind(对象,参数1,参数2,...),bind会返回一个函数,需要调用
boundf1 = f1.bind({a:4});
boundf1(); //输出4
但用apply、call来进行显示绑定并不能避免隐性丢失的问题。下面有两个方法来解决这个问题。
1.硬绑定
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
var bar = function() {
return f1.apply({a:2});
};
setTimeout(bar, 1000);//输出为2
让我们来分析分析这个代码。我们创建了函数bar,这个函数负责返回绑定好this的f1函数,并立即执行它。 这种绑定我们称之为硬绑定。
这种绑定方法会使用在一个i可以重复使用的辅助函数 例如
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
function bind(fn, obj) {
return function () {
return fn.apply(obj, arguments);
};
}
var bar = bind(f1,{a:2});
bar();
可以很明显发现这和我们js自带的函数bind方法很像。是的,在ES5中提供了内置的方法Function.prototype.bind。它的用法我再提一次吧。
var a = 0;
function f1 () {
var a = 1;
console.log(this.a);
}
//bind方法绑定this
//bind(对象,参数1,参数2,...),bind会返回一个函数,需要调用
boundf1 = f1.bind({a:2});
boundf1(); //输出2
2.API调用的“上下文”
第三方库的许多函数,以及JavaScript语言和宿主环境中许多内置函数,都提供了一个可选参数,通常被称为“上下文”,其作用和bind方法一样,都是为了防止隐性丢失。
现在来举个例子吧。
function f1(el) {
console.log(el, this.id);
}
var obj = {
id : "awesome"
};
[1,2,3].forEach(f1,obj);
//最后输出的结果为
// 1 'awesome'
// 2 'awesome'
// 3 'awesome'
逗号操作符
在文章开头我们提到了这样一种表达式(0,f1)(),这是逗号操作符的应用,逗号操作符会依次计算所有的表达式,然后返回最后一个表达式的值。这里(0,f1)会先计算0(无实际意义),然后再返回f1,所以最后为f1()。
理解了逗号操作符的使用,那如果我们把f1改为obj.f1呢,即(0,obj.f1)(),这时f1中的this绑定的是谁呢?
直接说结论,绑定的是全局对象。(0,obj.f1)()先计算0,然后返回obj.f1即f1函数本身,所以它返回的是一个解绑this的函数,其相当于f1.call(window)——window是全局对象。
下面我们来验证一下吧。
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
var obj = {
a : 2,
f1 : f1
};
(0,obj.f1)(); //输出0
完全正确哈哈,注意这种方式不算作隐性丢失哦。
- 这个操作只是调用了
obj.f1,并没有阻止垃圾回收(GC)。 - 如果
obj或f1没有其他引用,它们仍然会被正常回收。
如果对其具体的工作流程感兴趣,可以去网上再找些资料。本篇就不讲太详细了。
new 绑定
这是this绑定的最后一条规则。
new绑定通常的形式为:... = new MyClass(参数1,参数2,...)
JavaScript中的new操作符的机制和那些面向类的语言的new操作符有些不一样,因为JavaScript是基于原型的语言(这个也许以后我会谈谈哈哈)。在JavaScript中,“构造函数”仅仅只是你使用new操作符时被调用的函数。
使用new来调用函数,会自动执行以下操作。
- 创建(或者说构造)一个全新的对象。
- 这个新对象会被执行原型连接。
- 这个新对象会绑定到函数调用的this。
- 如果函数没有返回其他对象,那么new表达式中的函数调用会自动返回这个新对象。
我们现在重点要关注的是第三点。
function f1(a){
this.a = a;
}
var bar = new f1(2);
console.log(bar.a); //输出为2
console.log(f1.a); //输出为undefined
这段代码就可以很明显的看出来new会创建一个新对象bar,并把this绑定到这个bar上,所以才会在bar上创建a这个属性。而原来的f1上则没有a这个属性,所以是undefined。
四条规则的优先级
- 如果某个调用位置应用了多条规则该怎么办?这时我们就需要知道它们的优先级了。 首先,默认绑定的优先级是最低的。我们先来测试一下它们隐式绑定和显式绑定哪个优先级高吧,这里我偷个懒,就引用一下《你不知道的JavaScript(上卷)》这本书的测试代码
function foo() {
console.log( this.a );
}
var obj1 = {
a: 2,
foo: foo
};
var obj2 = {
a: 3,
foo: foo
};
obj1.foo(); // 2
obj2.foo(); // 3
obj1.foo.call( obj2 ); // 3
obj2.foo.call( obj1 ); // 2
稍微分析一下吧,obj1.foo()和obj2.foo()为隐式调用,this分别绑定的为obj1,obj2,所以会打印2,3。接着我们调用了obj1.foo.call(obj2)发现结果输出为obj2中的a属性2,所以这里应用的是显式绑定。
所以显式绑定的优先级是高于隐式绑定的。
- 再来看看
new绑定和隐式绑定的优先级谁更高吧。
function foo(something) {
this.a = something;
}
var obj1 = {
foo: foo
};
obj1.foo(1);
console.log( obj1.a ); // 1
var bar = new obj1.foo(2);
console.log( obj1.a ); // 1
console.log( bar.a ); // 2
var bar = new obj1.foo(2)这段代码,如果隐式绑定的优先级会大于new绑定,就会在obj1里把属性a赋值为2; 如果new绑定的优先级大于隐式绑定,就会在bar中创建一个属性a,值为2,最后看obj1.a和bar.a谁输出为2,谁的优先级就更高,很明显bar.a输出为2,所以new绑定的优先级高于隐式绑定的。
所以new调用的优先级要高于隐式调用的优先级。
- 再来看看new调用和显式调用的优先级谁高谁低吧。
new不能和apply和call方法同时使用,但我们可以用bind方法进行硬绑定,再用bind返回的新函数再new一下以此来判断谁的优先级高。
function foo(something) {
this.a = something;
}
var obj1 = {};
var bar = foo.bind( obj1 );
bar( 2 );
console.log( obj1.a ); // 2
var baz = new bar(3);
console.log( obj1.a ); // 2
console.log( baz.a ); // 3
首先硬绑定了obj1,在obj1中创建了a属性,值为2,bar接收返回的bind函数。之后new bar并给a赋值为3,用baz来接收new的对象,这时如果baz.a为3就说明this应用的绑定规则是new绑定。
所以new绑定的优先级是高于显示调用的优先级的。
现在知道了四种规则,又知道了这四个规则的优先级,我们就能很清晰的判断this的绑定了。
判断this的流程
以后判断this我们可以按以下顺序来判断:
- 函数是否在
new中调用(new绑定)?如果是的话this绑定的是新创建的对象。var bar = new foo() //这里bar为this绑定的对象
- 函数是否通过
call、apply(显式绑定)或者硬绑定(bind)调用?如果是的话,this绑定的是指定的对象。var bar = foo.call(obj) //这里obj为this绑定的对象
- 函数是否在某个上下文对象中调用(隐式绑定)如果是的话,
this绑定的是那个上下文对象。var bar = obj.foo() //这里obj为this绑定的对象
- 如果都不是,则应用默认绑定,
this绑定到全局对象上。var bar = foo() //this绑定的为全局对象
凡事都有例外,还有一些十分特殊的情况不满足上面的四条规则,我们需要单独拎出来记忆。
绑定例外
绑定例外主要有3种。
null导致的绑定意外
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
f1.apply(null); //输出为0
var bar = f1.bind(null);
bar() //输出为0
当我们使用显式绑定(使用apply、call、bind方法)的时候,如果我们显式绑定一个null,就会发现this绑定的不是null而是应用默认绑定,绑定全局对象。这会导致变量全局渗透的问题。
有的人可能会说,那我们不用null来绑定this不就好了吗?但有的时候我们还真不得不使用null来绑定this,下面我来介绍一下什么时候会使用这种情况。
一种常见的做法是使用apply(..)来“展开”一个数组,并当作参数传入一个函数。类似地,bind(..)可以对参数进行柯里化(预先设置一些参数),这种方法有时很好用的。
function f1 (a , b) {
console.log("a:" + a + ",b:" + b);
}
f1.apply(null,[2,3]) //输出为a:2,b:3
//bind的柯里化
var bar = f1.bind(null,2);
bar(3); //输出为a:2,b:3
现在来简单地来介绍一下柯里化是什么?柯里化是将一个接收多个参数的函数转换为一系列只接受单个参数的函数。这时bind和null的作用就体现出来了。
然而,在apply,call,bind使用null会导致全局溢出,在一些有this的函数中,给这个this绑定null,会让this绑定全局对象。该如何解决这个问题呢?
更安全的this
我们可手动创建一个空的对象,这个空的对象我们称作“DMZ”(demilitarized zoo,非军事区)对象——它是一个空的非委托的对象。
如果我们在想要忽略this绑定时总是传入一个DMZ对象,那就不用担心this会溢出到全局了,这个this绑定的就是DMZ对象。
在JavaScript中创建一个空对象最简单的方法是Object.create(null)——它会返回一个空对象,Object.create(null)。Object.create(null)和{}很像,并不会创建Object.prototype这个委托,所以它比{}“更空”。
var c = 0;
function f1 (a , b) {
this.c = 1;
console.log("a:" + a + ",b:" + b);
}
//创建自己的空对象
var myNull = Object.create(null);
f1.apply(myNull,[2,3]) //输出为a:2,b:3
console.log(c); //输出为0
//bind的柯里化
var bar = f1.bind(myNull,2);
bar(3); //输出为a:2,b:3
console.log(c); //输出为0
可以发现这段代码中,我们创建了自己的空对象通过apply和bind方法把this绑定到这个空对象了。最后的输出的c是0,说明this.c并没有修改全局变量c的值。所以这个方法可以防止全局溢出。
接下来谈谈另外一个绑定的例外吧。
间接引用
有的时候你可能(有意或无意地)创建了一个函数的“间接引用”,在这种情况下,调用这个函数应用默认绑定规则。
var a = 0;
function f1() {
console.log(this.a);
}
var obj1 = {
a : 1,
f1 : f1
};
var obj2 = {
a : 2,
};
obj1.f1(); // 1
(obj2.f1 = obj1.f1)(); // 0
我们来看看这个代码。obj1中有a和f1属性或方法,a的值为1;obj2中只有a属性,值为2。我们先隐式绑定obj1,this绑定obj1,最后输出为1,这个我们可以理解。关键是下面这行代码(obj2.f1 = obj1.f1)(),obj2中没有f1,所以它在obj2中创建一个f1,然后将obj1中的f1函数赋值给obj2的f1,然后执行这个赋值表达式。那为什么输出的是0而不是obj2中的2或者obj1中的1呢? 🤔
其实这和赋值表达式的返回值有关系,因为赋值表达式会返回等号右边的值。 所以(obj2.f1 = obj1.f1)实际上返回的obj1.f1中的f1函数,实际执行的是f1()。所以应用的是默认绑定,this绑定全局对象,结果输出为0。
我们继续看绑定的下一个例外。
箭头函数
在ES6中介绍了一种无法使用这些规则的特殊函数类型:箭头函数。
箭头函数和一般的函数不一样,它不是用function来定义的,而是使用被称作“胖箭头”的操作符=>定义的。
定义格式:(参数) => {函数体}
箭头函数不使用this的四条规则,而是继承外层(定义时所在)函数或全局作用域的this的值,this在箭头函数创建时就被确定,且永远不会被改变,new也不行。
var a = 0;
(()=>{
var a = 1;
console.log(this.a); // 结果输出为0
})();
很明显该箭头函数外部就是全局作用域,所以继承全局对象的this就是它本身,所以输出为0。
再看看如果在其他函数中定义箭头函数this如何绑定
var a = 0;
function f1() {
var a = 1;
(()=>{
var a = 2;
console.log(this.a);
})();
}
f1();//输出0
//给f1绑定一个对象
f1.apply({a:3}); // 输出3
可以发现f1内部的箭头函数继承了其外部函数f1的this的绑定。所以一开始没给f1绑定this时,f1的this绑定的是全局对象,箭头函数的也是全局对象;当给f1的this绑定一个对象时,箭头函数的this也绑定该对象。
小结
以上是我的学习分享,希望对你有所帮助。
还有本篇的四条规则只适用于非严格模式,严格模式的this的绑定我日后再出一篇吧,其实只是有点懒😂。
参考书籍
《你所不知道的JavaScript(上卷)》
来源:juejin.cn/post/7504237094283526178
svg按钮渐变边框
共用css
body {
padding: 50px;
background-color: black;
color: white;
}
svg {
--text_fill: orange;
--svg_width: 120px;
--svg_height: 40px;
width: var(--svg_width);
height: var(--svg_height);
cursor: pointer;
/* 创建图层 */
will-change: transform;
&:hover {
--text_fill: #fed71a;
}
text {
fill: var(--text_fill);
font-size: 1rem;
transform: translate(50%, 50%);
text-anchor: middle;
dominant-baseline: middle;
stroke: yellowgreen;
stroke-width: .5px;
cursor: pointer;
}
rect {
--stroke_width: 4px;
width: calc(var(--svg_width) - var(--stroke_width));
height: calc(var(--svg_height) - var(--stroke_width));
stroke-width: var(--stroke_width);
rx: calc(var(--svg_height)/2);
x: calc(var(--stroke_width)/2);
y: calc(var(--stroke_width)/2);
fill: none;
cursor: pointer;
}
}
移入执行、移出暂停
<body>
<svg style='position:absolute;left:-9999px;width:0;height:0;visibility:hidden;'>
<defs>
<linearGradient id='strokeColor1' x1='0%' y1='0%' x2='100%' y2='0%'>
<stop offset='0%' stop-color="#00ccff" stop-opacity="1" />
<stop offset='50%' stop-color="#d400d4" stop-opacity="1" />
<stop offset='100%' stop-color="#ff00ff" stop-opacity=".7" />
</linearGradient>
</defs>
</svg>
<svg id="svg1">
<text>渐变按钮</text>
<rect stroke='url(#strokeColor1)' />
<animateTransform id="ani1" href="#strokeColor1" attributeName='gradientTransform' dur='5s' type="rotate"
form="0,.5,.5" to="360,.5,.5" repeatCount='indefinite' begin="indefinite" />
</svg>
</body>
<script>
svg1.addEventListener('mouseover', function () {
if (!this.beginMark) {
ani1.beginElement();
this.beginMark = true;
return;
}
this.unpauseAnimations();
})
svg1.addEventListener('mouseleave', function () {
this.pauseAnimations();
})
</script>
svg1效果图

移入暂停、移出执行
<body>
<svg style='position:absolute;left:-9999px;width:0;height:0;visibility:hidden;'>
<defs>
<linearGradient id='strokeColor2' x1='0%' y1='0%' x2='100%' y2='0%'>
<stop offset='0%' stop-color="#ec261b" />
<stop offset='50%' stop-color="#ff9f43" />
<stop offset='100%' stop-color="#ffe66d" stop-opacity="1" />
</linearGradient>
</defs>
</svg>
<svg id="svg2">
<text>渐变按钮</text>
<rect stroke='url(#strokeColor2)' />
<animateTransform id="ani2" href="#strokeColor2" attributeName='gradientTransform' dur='5s' type="rotate"
form="0,.5,.5" to="360,.5,.5" repeatCount='indefinite' begin="0s" />
</svg>
</body>
<script>
svg2.addEventListener('mouseover', function () {
this.pauseAnimations();
})
svg2.addEventListener('mouseleave', function () {
this.unpauseAnimations();
})
</script>
sv2效果图

总结
个人感觉svg实现渐变边框相比较css的实现来说,相对代码量更大一些,但是svg其实还有很多好玩的地方。
用svg来做渐变边框也是另外的一种思路,也许以后能够用的上。
来源:juejin.cn/post/7488575555048161332
Java String.replace()原理,你真的了解吗?
大家好呀,我是猿java。
String.replace()是我们日常开发中经常用到的一个方法,那么,你有看过其底层的源码实现吗?你知道String.replace()是如何工作的吗?String.replace()的性能到底怎么样?这篇文章我们来深入地分析。
在开始今天的问题之前,让我们先来看一个问题:
String original = "Hello, World!";
// 替换字符
String result = original.replace('World', 'Java');
original.replace('World', 'Java'),是把 original的内容直接修改成Hello, Java了,还是重新生成了一个 Hello, Java的 String并返回?
1. String.replace()是什么?
String.replace()位于java.lang包中,它是 Java中的一个重要方法,用于替换字符串中的某些字符或子字符串。以下String.replace()的源码截图。

String.replace()方法用于替换字符串中的某些字符或子字符串。它有多个重载版本,常见的有:
// 用于替换单个字符
public String replace(char oldChar, char newChar);
// 用于替换子字符串
public String replace(CharSequence target, CharSequence replacement);
下面是一个简单的示例,演示了replace方法的用法:
public class ReplaceExample {
public static void main(String[] args) {
String original = "Hello, World!";
// 替换字符
String replacedChar = original.replace('o', 'a');
System.out.println(replacedChar); // 输出: "Hella, Warld!"
// 替换子字符串
String replacedString = original.replace("World", "Java");
System.out.println(replacedString); // 输出: "Hello, Java!"
}
}
在上面的例子中,我们演示了如何使用replace方法替换字符和子字符串。需要注意的是,String对象在Java中是不可变的(immutable),因此replace方法会返回一个新的字符串,而不会修改原有字符串。
2. 源码分析
上述示例,我们演示了replace方法的用法,接下来,我们来分析下replace方法的实现原理。
2.1 String的不可变性
Java中的String类是不可变的,这意味着一旦创建了一个String对象,其内容不能被改变。这样的设计有助于提高性能和安全性,尤其在多线程环境下。String源码说明如下:

2.2 replace()工作原理
让我们深入了解replace方法的内部实现。以replace(CharSequence target, CharSequence replacement)为例,以下是其基本流程:
- 检查目标和替换内容:方法首先检查传入的
target和replacement是否为null,如果是,则抛出NullPointerException。 - 搜索目标子字符串:在原始字符串中查找所有符合目标子字符串的地方。
- 构建新的字符串:基于找到的位置,将原始字符串分割,并用替换字符串进行拼接,生成一个新的字符串。
2.3 源码解析
让我们看一下String类中replace方法的源码(简化版):
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
String ret = isLatin1() ? StringLatin1.replace(value, oldChar, newChar)
: StringUTF16.replace(value, oldChar, newChar);
if (ret != null) {
return ret;
}
}
return this;
}
public String replace(CharSequence target, CharSequence replacement) {
String tgtStr = target.toString();
String replStr = replacement.toString();
int j = indexOf(tgtStr);
if (j < 0) {
return this;
}
int tgtLen = tgtStr.length();
int tgtLen1 = Math.max(tgtLen, 1);
int thisLen = length();
int newLenHint = thisLen - tgtLen + replStr.length();
if (newLenHint < 0) {
throw new OutOfMemoryError();
}
StringBuilder sb = new StringBuilder(newLenHint);
int i = 0;
do {
sb.append(this, i, j).append(replStr);
i = j + tgtLen;
} while (j < thisLen && (j = indexOf(tgtStr, j + tgtLen1)) > 0);
return sb.append(this, i, thisLen).toString();
}
解析步骤
- 参数校验:首先检查
target和replacement是否为null,避免后续操作出现NullPointerException。 - 查找目标字符串:使用
indexOf方法查找目标子字符串首次出现的位置。如果未找到,直接返回原字符串。 - 替换逻辑:
- 使用
StringBuilder来构建新的字符串,这是因为StringBuilder在拼接字符串时效率更高。 - 通过循环查找所有目标子字符串的位置,并将其替换为替换字符串。
- 最后,拼接剩余的字符串部分,返回最终结果。
- 使用
性能考虑
由于String的不可变性,每次修改都会创建新的String对象。如果需要进行大量的字符串替换操作,推荐使用StringBuilder或StringBuffer来提高性能。
三、实际示例演示
接下来,我们将通过几个实际的例子,来更好地理解String.replace()的使用场景和效果。
示例1:替换字符
public class ReplaceCharDemo {
public static void main(String[] args) {
String text = "banana";
String result = text.replace('a', 'o');
System.out.println(result); // 输出: "bonono"
}
}
解释:将所有的'a'替换为'o',得到"bonono"。
示例2:替换子字符串
public class ReplaceStringDemo {
public static void main(String[] args) {
String text = "I love Java. Java is versatile.";
String result = text.replace("Java", "Python");
System.out.println(result); // 输出: "I love Python. Python is versatile."
}
}
解释:将所有的"Java"替换为"Python",结果如上所示。
示例3:替换多个不同的子字符串
有时,我们可能需要在一个字符串中替换多个不同的子字符串。例如,将文中的标点符号替换为空格:
public class ReplaceMultipleDemo {
public static void main(String[] args) {
String text = "Hello, World! Welcome to Java.";
String result = text.replace(",", " ")
.replace("!", " ")
.replace(".", " ");
System.out.println(result); // 输出: "Hello World Welcome to Java "
}
}
解释:通过链式调用replace方法,依次将,、!和.替换为空格。
示例4:替换不匹配的情况
public class ReplaceNoMatchDemo {
public static void main(String[] args) {
String text = "Hello, World!";
String result = text.replace("Python", "Java");
System.out.println(result); // 输出: "Hello, World!"
}
}
解释:由于"Python"在原字符串中不存在,replace方法不会做任何替换,直接返回原字符串。
四、String.replace()的技术架构图
虽然文字描述已能帮助我们理解replace方法的工作原理,但通过一个简化的技术架构图,可以更直观地抓住其核心流程。
+---------------------------+
| String对象 |
| "Hello, World!" |
+------------+--------------+
|
| 调用replace("World", "Java")
v
+---------------------------+
| 搜索目标子字符串 "World" |
+------------+--------------+
|
| 找到位置 7
v
+---------------------------+
| 构建新的字符串 "Hello, Java!" |
+---------------------------+
|
| 返回新字符串
v
+---------------------------+
| 新的 String对象 |
| "Hello, Java!" |
+---------------------------+
图解说明
- 调用
replace方法:在原始String对象上调用replace("World", "Java")。 - 搜索目标:方法内部使用
indexOf找到"World"的位置。 - 构建新字符串:使用
StringBuilder将"Hello, "与"Java"拼接,形成新的字符串"Hello, Java!"。 - 返回新字符串:最终返回一个新的
String对象,原始字符串保持不变。
五、总结
通过本文的介绍,相信你对Java中String.replace()方法有了更深入的理解。从基本用法到内部原理,再到实际应用示例,每一步都帮助你全面掌握这个重要的方法。
记住,String的不可变性设计虽然带来了安全性和线程安全性,但在频繁修改字符串时,可能影响性能。因此,合理选择使用String还是StringBuilder,根据具体场景优化代码,是每个Java开发者需要掌握的技能。
希望这篇文章能对你在Java编程的道路上提供帮助。如果有任何疑问或更多的讨论,欢迎在评论区留言!
8. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7543147533368229903
一万行代码实现的多维分析表格,让数据处理效率提升 300%
上个月在 趣谈AI 发布了我实现的多维表格1.0版本,没有用到任何第三方组件,完全组件化设计。最近对多维表格进行了进一步的升级优化,满打满算花了接近3个月时间,累计代码接近1w行。

接下来就和大家聊聊我做的 flowmix/mute多维表格 的核心功能和技术实现。
核心功能介绍
1. 多视图模式

目前多维表格支持多种视图模式:表格视图,看板视图,人员分配视图。用户可以轻松在不同视图下切换并进行可视化操作数据。
2. 多条件筛选功能

我们可以基于不同维度进行筛选和排序,并支持组合筛选。
3. 多维度分组功能

表格视图中,我们可以基于用户,优先级,状态,对数据进行分组管理,提高表格数据的查看效率。
4. 表格字段管理功能

多维表格中不仅支持字段的管理控制,同时还支持添加自定义字段:

5. 表格行列支持自定义拖拽排序功能

表格我们不仅仅支持列的宽度拖拽,还支持拖拽调整列的排序,同时表格的行也支持拖拽,可以跨分组进行拖拽,也支持在组内进行拖拽排序,极大的提高了数据管理的效率。
6. 表格支持一键编辑

我们可以在菜单按钮中开启编辑模式,也可以双击编辑单元格一键编辑表格内容,同时大家还可以进行扩展。
7. 表格支持一键转换为可视化分析视图表

我们可以将表格数据转换为可视化分析图表,帮助管理者更好地掌握数据动向。
8. 表格支持一键导入任务数据

目前多维表格支持导出和导入json数据,并一键渲染为多维表格。技术实现多维表格的设计我采用了组件化的实现的方式, 并支持数据持久化,具体使用如下:
<div className="flex-1 bg-gray-50">
{currentView === "tasks" && <TaskManagementTable sidebarOpen={sidebarOpen} setSidebarOpen={setSidebarOpen} />}
{currentView === "statistics" && <StatisticsView />}
{currentView === "documentation" && <DocumentationView />}
{currentView === "assignment" && <AssignmentView />}
{currentView === "deployment" && <DeploymentView />}
</div>
在开发多维表格的过程中其实需要考虑很多复杂逻辑,比如表格用什么方式渲染,如何优化表格性能,如何实现表格的列排序,行排序,表格编辑等。传统表格组件大多基于div模拟行列,虽然灵活但渲染性能差。所以可以做如下优化:
- 虚拟滚动当数据量超过 500 行时,启用虚拟滚动机制,仅渲染可见区域的 DOM 节点,内存占用降低 70%;
- 行列冻结通过固定定位
position: sticky实现表头和固定列冻结,解决大数据表格的滚动迷失问题; - 异步加载采用
Intersection Observer监听表格滚动事件,动态加载可视区域外的数据,避免一次性请求全量数据。
接下来分享一下简版的虚拟滚动的实现方案:
// 虚拟滚动核心代码(简化版)
function renderVirtualTable(data, visibleHeight) {
const totalRows = data.length;
const rowHeight = 40; // 行高固定
const visibleRows = Math.ceil(visibleHeight / rowHeight);
const startIndex = scrollTop / rowHeight | 0;
const endIndex = startIndex + visibleRows;
// 渲染可见区域数据
const fragment = document.createDocumentFragment();
for (let i = startIndex; i < endIndex; i++) {
const row = document.createElement('tr');
row.innerHTML = data[i].cells.map(cell => `<td>${cell.value}</td>`).join('');
fragment.appendChild(row);
}
// 更新滚动条高度和偏移量
table.scrollHeight = totalRows * rowHeight;
table.innerHTML = `<thead>${header}</thead><tbody>${fragment}</tbody>`;
}
对于大表格数据量需要在本地缓存,所以需要设计表格数据的缓存处理逻辑,目前我采用的是hooks的实现方案,具体实现如下:
import { useState, useEffect } from "react"
export function useLocalStorage<T>(key: string, initialValue: T): [T, (value: T | ((val: T) => T)) => void] {
// 初始化状态
const [storedValue, setStoredValue] = useState<T>(() => {
try {
// 获取本地存储中的值
if (typeof window === "undefined") {
return initialValue
}
const item = window.localStorage.getItem(key)
// 解析存储的JSON或返回初始值
return item ? JSON.parse(item) : initialValue
} catch (error) {
// 如果出错,返回初始值
console.error(`Error reading localStorage key "${key}":`, error)
return initialValue
}
})
// 返回一个包装版本的 useState setter 函数
// 将新值同步到 localStorage
const setValue = (value: T | ((val: T) => T)) => {
try {
// 允许值是一个函数
const valueToStore = value instanceof Function ? value(storedValue) : value
// 保存到 state
setStoredValue(valueToStore)
// 保存到 localStorage
if (typeof window !== "undefined") {
window.localStorage.setItem(key, JSON.stringify(valueToStore))
}
} catch (error) {
console.error(`Error setting localStorage key "${key}":`, error)
}
}
// 监听其他标签页的变化
useEffect(() => {
const handleStorageChange = (e: StorageEvent) => {
if (e.key === key && e.newValue) {
try {
setStoredValue(JSON.parse(e.newValue))
} catch (error) {
console.error(`Error parsing localStorage item "${key}":`, error)
}
}
}
// 添加事件监听器
if (typeof window !== "undefined") {
window.addEventListener("storage", handleStorageChange)
}
// 清理事件监听器
return () => {
if (typeof window !== "undefined") {
window.removeEventListener("storage", handleStorageChange)
}
}
}, [key])
return [storedValue, setValue]
}
其实在实现多维表格的过程中,我也调研了很多开源的方案,但是对于扩展性,灵活度和功能复杂度上,都略显简单,所以我才考虑花时间来实现这款多维表格方案。另一个比较复杂的逻辑是表格的列拖拽和排序,我们需要对可展开折叠的表格支持排序和拖拽,并保持优秀的用户体验:

技术实现如下:
import { useState, useEffect } from "react"
export function useLocalStorage<T>(key: string, initialValue: T): [T, (value: T | ((val: T) => T)) => void] {
// 初始化状态
const [storedValue, setStoredValue] = useState<T>(() => {
try {
// 获取本地存储中的值
if (typeof window === "undefined") {
return initialValue
}
const item = window.localStorage.getItem(key)
// 解析存储的JSON或返回初始值
return item ? JSON.parse(item) : initialValue
} catch (error) {
// 如果出错,返回初始值
console.error(`Error reading localStorage key "${key}":`, error)
return initialValue
}
})
// 返回一个包装版本的 useState setter 函数
// 将新值同步到 localStorage
const setValue = (value: T | ((val: T) => T)) => {
try {
// 允许值是一个函数
const valueToStore = value instanceof Function ? value(storedValue) : value
// 保存到 state
setStoredValue(valueToStore)
// 保存到 localStorage
if (typeof window !== "undefined") {
window.localStorage.setItem(key, JSON.stringify(valueToStore))
}
} catch (error) {
console.error(`Error setting localStorage key "${key}":`, error)
}
}
// 监听其他标签页的变化
useEffect(() => {
const handleStorageChange = (e: StorageEvent) => {
if (e.key === key && e.newValue) {
try {
setStoredValue(JSON.parse(e.newValue))
} catch (error) {
console.error(`Error parsing localStorage item "${key}":`, error)
}
}
}
// 添加事件监听器
if (typeof window !== "undefined") {
window.addEventListener("storage", handleStorageChange)
}
// 清理事件监听器
return () => {
if (typeof window !== "undefined") {
window.removeEventListener("storage", handleStorageChange)
}
}
}, [key])
return [storedValue, setValue]
}
多维表格还支持多种视图的转换,比如可以将表格视图一键转换为可视化分析图表:

对用户和团队进行多维度的数据分析。技术实现如下:
import { PieChart, Pie, Cell, Tooltip, Legend, ResponsiveContainer } from "recharts"
import type { Task } from "@/lib/types"
interface PriorityDistributionChartProps {
tasks: Task[]
}
export function PriorityDistributionChart({ tasks }: PriorityDistributionChartProps) {
// 计算每个优先级的任务数量
const priorityCounts: Record<string, number> = {}
tasks.forEach((task) => {
const priority = task.priority || "未设置"
priorityCounts[priority] = (priorityCounts[priority] || 0) + 1
})
// 转换为图表数据格式
const chartData = Object.entries(priorityCounts).map(([priority, count]) => ({
priority,
count,
}))
// 为不同优先级设置不同颜色
const COLORS = ["#FF8042", "#FFBB28", "#00C49F", "#0088FE"]
return (
<div className="w-full h-[300px]">
<ResponsiveContainer width="100%" height="100%">
<PieChart>
<Pie
data={chartData}
cx="50%"
cy="50%"
labelLine={true}
outerRadius={80}
fill="#8884d8"
dataKey="count"
nameKey="priority"
label={({ priority, percent }) => `${priority}: ${(percent * 100).toFixed(0)}%`}
>
{chartData.map((entry, index) => (
<Cell key={`cell-${index}`} fill={COLORS[index % COLORS.length]} />
))}
</Pie>
<Tooltip formatter={(value, name, props) => [`${value} 个任务`, props.payload.priority]} />
<Legend />
</PieChart>
</ResponsiveContainer>
</div>
)
}
项目的体验地址:mute.turntip.cn
如果大家有好的想法,欢迎评论区留言反馈~
来源:juejin.cn/post/7511649092658577448




