








弃用 html2canvas!快 93 倍的截图神器!
作者:前端开发爱好者
原文:mp.weixin.qq.com/s/t0s5dCOrs…
在前端开发中,网页截图是个常用功能。从前,html2canvas 是大家的常客,但随着网页越来越复杂,它的性能问题也逐渐暴露,速度慢、占资源,用户体验不尽如人意。
好在,现在有了 SnapDOM,一款性能超棒、还原度超高的截图新秀,能完美替代 html2canvas,让截图不再是麻烦事。

什么是 SnapDOM
SnapDOM 就是一个专门用来给网页元素截图的工具。

它能把 HTML 元素快速又准确地存成各种图片格式,像 SVG、PNG、JPG、WebP 等等,还支持导出为 Canvas 元素。

它最厉害的地方在于,能把网页上的各种复杂元素,比如 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,甚至是动态效果的当前状态,都原原本本地截下来,跟直接看网页没啥两样。
SnapDOM 优势
快得飞起
测试数据显示,在不同场景下,SnapDOM 都把 html2canvas 和 dom-to-image 这俩老前辈远远甩在身后。

尤其在超大元素(4000×2000)截图时,速度是 html2canvas 的 93.31 倍,比 dom-to-image 快了 133.12 倍。这速度,简直就像坐火箭。
还原度超高
SnapDOM 截图出来的效果,跟在网页上看到的一模一样。
各种复杂的 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,还有动态效果的当前状态,都能精准还原。

无论是简单的元素,还是复杂的网页布局,它都能轻松拿捏。
格式任你选
不管你是想要矢量图 SVG,还是常用的 PNG、JPG,或者现代化的 WebP,又或者是需要进一步处理的 Canvas 元素,SnapDOM 都能满足你。

多种格式,任你挑选,适配各种需求。
怎么用 SnapDOM
安装
SnapDOM 的安装超简单,有好几种方式:
用 NPM 或 Yarn:在命令行里输
# npm
npm i @zumer/snapdom
# yarn
yarn add @zumer/snapdom
就能装好。
用 CDN 在 HTML 文件里加一行:
<script src="https://unpkg.com/@zumer/snapdom@latest/dist/snapdom.min.js"></script>
直接就能用。
要是项目里用的是 ES Module:
import { snapdom } from '@zumer/snapdom
基础用法示例
一键截图
const card = document.querySelector('.user-card');
const image = await snapdom.toPng(card);
document.body.appendChild(image);
这段代码就是找个元素,然后直接截成 PNG 图片,再把图片加到页面上。简单粗暴,一步到位。
高级配置
const element = document.querySelector('.chart-container');
const capture = await snapdom(element, {
scale: 2,
backgroundColor: '#fff',
embedFonts: true,
compress: true
});
const png = await capture.toPng();
const jpg = await capture.toJpg({ quality: 0.9 });
await capture.download({
format: 'png',
filename: 'chart-report-2024'
});
这儿可以对截图进行各种配置。比如 scale 能调整清晰度,backgroundColor 能设置背景色,embedFonts 可以内嵌字体,compress 能压缩优化。配置好后,还能把截图存成不同格式,或者直接下载到本地。
和其他库比咋样
和 html2canvas、dom-to-image 比起来,SnapDOM 的优势很明显:
| 特性 | SnapDOM | html2canvas | dom-to-image |
|---|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 准确度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文件大小 | 极小 | 较大 | 中等 |
| 依赖 | 无 | 无 | 无 |
| SVG 支持 | ✅ | ❌ | ✅ |
| Shadow DOM 支持 | ✅ | ❌ | ❌ |
| 维护状态 | 活跃 | 活跃 | 停滞 |
用的时候注意点
用 SnapDOM 时,有几点得注意:
跨域资源
要是截图里有外部图片等跨域资源,得确保这些资源支持 CORS,不然截不出来。
iframe 限制
SnapDOM 不能截 iframe 内容,这是浏览器的安全限制,没办法。
Safari 浏览器兼容性
在 Safari 里用 WebP 格式时,会自动变成 PNG。
大型页面截图
截超大页面时,建议分块截,不然可能会内存溢出。
SnapDOM 能干啥及代码示例
社交分享
async function shareAchievement() {
const card = document.querySelector('.achievement-card');
const image = await snapdom.toPng(card, { scale: 2 });
navigator.share({
files: [new File([await snapdom.toBlob(card)], 'achievement.png')],
title: '我获得了新成就!'
});
}
报表导出
async function exportReport() {
const reportSection = document.querySelector('.report-section');
await preCache(reportSection);
await snapdom.download(reportSection, {
format: 'png',
scale: 2,
filename: `report-${new Date().toISOString().split('T')[0]}`
});
}
海报导出
async function generatePoster(productData) {
document.querySelector('.poster-title').textContent = productData.name;
document.querySelector('.poster-price').textContent = `¥${productData.price}`;
document.querySelector('.poster-image').src = productData.image;
await new Promise((resolve) => setTimeout(resolve, 100));
const poster = document.querySelector('.poster-container');
const blob = await snapdom.toBlob(poster, { scale: 3 });
return blob;
}
写在最后
SnapDOM 就是这么一款简单、快速、准确,还零依赖的网页截图神器。
无论是社交分享、报表导出、设计保存,还是营销推广,它都能轻松搞定。
而且它是免费开源的,背后还有活跃的社区支持。要是你还在为网页截图的事儿发愁,赶紧试试 SnapDOM 吧。
要是你在用 SnapDOM 的过程中有啥疑问,或者碰上啥问题,可以去下面这些地方找答案:
- 项目地址 :github.com/zumerlab/sn…
- 在线演示 :zumerlab.github.io/snapdom/
- 详细文档 :github.com/zumerlab/sn…
来源:juejin.cn/post/7524740743165722634
别再用 100vh 了!移动端视口高度的终极解决方案
作为一名前端开发者,我们一定都遇到过这样的需求:实现一个占满整个屏幕的欢迎页、弹窗蒙层或者一个 fixed 定位的底部菜单。
直觉告诉我们,这很简单,给它一个 height: 100vh 就行了。
.fullscreen-element {
height: 100vh;
width: 100%;
color: #000;
display: flex;
justify-content: center;
align-items: center;
font-size: 10em;
background-color: #fff;
}
在PC端预览,完美!然而,当你在手机上打开时,可能会看到下面这个令人抓狂的场景:

明明是 100vh,为什么会超出屏幕高度?这个烦人的滚动条到底从何而来?
如果你也曾为此抓耳挠腮,那么恭喜你,这篇文章就是你的“终极答案”。今天,我将带你彻底搞懂 100vh 在移动端的“坑”,并为你介绍当下最完美的解决方案。
1. 问题根源:移动端动态变化的“视口”
要理解问题的本质,我们首先要明白 vh (Viewport Height) 单位的定义:1vh 等于视口高度的 1%。
在PC端,浏览器窗口大小是相对固定的,所以 100vh 就是浏览器窗口的可见高度,这没有问题。
但在移动端,情况变得复杂了。为了在有限的屏幕空间里提供更好的浏览体验,手机浏览器(尤其是Safari和Chrome)的地址栏和底部工具栏是动态变化的。
- 初始状态:当你刚进入页面时,地址栏和工具栏是完全显示的。
- 滚动时:当你向下滚动页面,这些UI元素会自动收缩,甚至隐藏,以腾出更多空间展示网页内容。
关键点来了:大多数移动端浏览器将 100vh 定义为“最大视口高度”,也就是当地址栏和工具栏完全收起时的高度。
这就导致了:
在页面初始加载、地址栏还未收起时,
100vh的实际计算高度 > 屏幕当前可见区域的高度。
于是,那个恼人的滚动条就出现了。

2. “过去式”的解决方案:JavaScript 动态计算
在很长一段时间里,前端开发者们只能求助于 JavaScript 来解决这个问题。思路很简单:通过 window.innerHeight 获取当前可见视口的高度,然后用它来动态设置元素的 height。
JavaScript
function setRealVH() {
const vh = window.innerHeight * 0.01;
document.documentElement.style.setProperty('--vh', `${vh}px`);
}
// 初始加载时设置
window.addEventListener('load', setRealVH);
// 窗口大小改变或旋转屏幕时重新设置
window.addEventListener('resize', setRealVH);
然后在 CSS 中这样使用:
CSS
.fullscreen-element {
height: calc(var(--vh, 1vh) * 100);
}
这个方案的缺点显而易见:
- 性能开销:监听
resize事件过于频繁,可能会引发性能问题。 - 逻辑耦合:纯粹的样式问题却需要JS来解决,不够优雅。
- 时机问题:执行时机需要精确控制,否则可能出现闪烁。
虽然能解决问题,但这绝不是我们想要的“终极方案”。
3. “现在时”的终极解决方案:CSS动态视口单位
谢天谢地,CSS 工作组听到了我们的呼声!为了解决这个老大难问题,CSS Values and Units Module Level 4 引入了一套全新的动态视口单位。
它们就是我们今天的“主角”:
svh(Small Viewport Height): 最小视口高度。对应于地址栏和工具栏完全展开时的可见高度。lvh(Large Viewport Height): 最大视口高度。对应于地址栏和工具栏完全收起时的高度(这其实就等同于旧的100vh)。dvh(Dynamic Viewport Height): 动态视口高度。这是最智能、最实用的单位!它的值会随着浏览器UI元素(地址栏)的出现和消失而动态改变。
所以,我们的终极解决方案就是:
CSS
.fullscreen-element {
height: 100svh; /* 如果你希望高度固定,且永远不被遮挡 */
/* 或者,也是我最推荐的 */
height: 100dvh; /* 如果你希望元素能动态地撑满整个可见区域 */
}
使用 100dvh,当地址栏收起时,元素高度会平滑地增加以填满屏幕;当地址栏滑出时,元素高度又会平滑地减小。整个过程如丝般顺滑,没有任何滚动条,完美!
浏览器兼容性
你可能会担心兼容性问题。好消息是,从2023年开始,所有主流现代浏览器(Safari, Chrome, Edge, Firefox)都已经支持了这些新的视口单位。


(数据截至2025年6月,兼容性已非常好)
可以看到,兼容性已经非常理想。除非你需要支持非常古老的浏览器版本,否则完全可以放心地在生产环境中使用。
告别 100vh 的时代
让我们来快速回顾一下:
- 问题:在移动端,
100vh通常被解析为“最大视口高度”,导致在浏览器UI未收起时内容溢出。 - 旧方案:使用 JavaScript 的
window.innerHeight动态计算,但有性能和维护问题。 - 终极方案:使用CSS新的动态视口单位,尤其是
100dvh,它能根据浏览器UI的变化自动调整高度,完美解决问题。
当需要实现移动端全屏布局时,请大胆地告别 100vh,拥抱 100dvh!
来源:juejin.cn/post/7520548278338322483
为什么响应性语法糖最终被废弃了?尤雨溪也曾经试图让你不用写 .value
你将永远需要在 Vue3 中写
.value
前言
相信有不少新手在初次接触 Vue3 的组合式 API 时都会产生一个疑问:”为什么一定要写 .value ?",一些 Vue3 老玩家也认为到处写 .value 十分不优雅。
那么有没有办法能不用写 .value 呢?有的兄弟,至少曾经有的,那就是响应性语法糖,可惜在 Vue 3.4 之后已经被移除了。
响应性语法糖是如何实现免去 .value 的?这一特性为何最终被废弃了呢?
响应性语法糖
Vue 的响应性语法糖是一个编译时的转换步骤,让我们可以像这样书写代码:
<script setup>
let count = $ref(0)
console.log(count)
function increment() {
count++
}
</script>
<template>
<button @click="increment">{{ count }}</button>
</template>
这里的 $ref() 方法是一个编译时的宏命令:它不是一个真实的、在运行时会调用的方法,而是用作 Vue 编译器的标记。使用 $ref() 声明的响应式变量可以直接读取与修改,无需 .value。
上面例子中 <script> 部分的代码会被编译成下面这样,在代码中自动加上 .value:
import { ref } from 'vue'
let count = ref(0)
console.log(count.value)
function increment() {
count.value++
}
每一个会返回 ref 的响应式 API 都有一个相对应的、以 $ 为前缀的宏函数。包括以下这些 API:
ref->$refcomputed->$computedshallowRef->$shallowRefcustomRef->$customReftoRef->$toRef
通过 $() 解构
当一个组合式函数返回包含数个 ref 的对象,我们希望解构得到这些 ref,并且在后续使用它们时也不用写 .value 时,可以使用 $() 这个宏:
import { useMouse } from '@vueuse/core'
const { x, y } = $(useMouse())
// x,y 和用 $ref 声明的响应式变量一样,不用写 .value
console.log(x, y)
通过 $$() 防止响应性丢失
假设有一个期望接收一个 ref 对象为参数的函数:
function trackChange(x: Ref<number>) {
watch(x, (x) => {
console.log('x 改变了!')
})
}
let count = $ref(0)
trackChange(count) // 无效!
上面的例子不会正常工作,因为代码被编译成了这样子:
let count = ref(0)
trackChange(count.value)
trackChange 函数期望接收的参数是一个 ref 类型值,而我们传入的 count.value 实际是一个 number 类型。
对于一个使用 $ref() 声明的响应式变量,当我们希望获取到它的原始 ref 值时,可以使用 $$()。
我们将上述例子改写为:
let count = $ref(0)
- trackChange(count)
+ trackChange($$(count))
此时代码可以正常工作,不会再丢失响应性了。
看到这里,聪明的你可能已经意识到了问题:使用响应性语法糖的初衷是为了免去到处写
.value的麻烦,结果现在新引入了$ref()、$()、$(),各自还有不同的使用场景,不是更麻烦了吗?
废弃原因
最终,在收集了大量来自社区的反馈后,经过 Vue 核心团队全员投票,决定移除这一特性。在 Vue 3.3 版本中使用会报 warning,从 3.4 版本开始正式移除。
尤雨溪本人也在 github 上发表了决定将响应性语法糖移除的根本原因,链接:github.com/vuejs/rfcs/…
原文是英语,担心有小伙伴可能看不懂,在这里简单翻译一下:
响应性语法糖的初衷是提供一些简练的语法提升开发体验。我们将它作为实验特性发布并在真实场景的使用中获得反馈。尽管它有一些好处,但我们还是发现了下列问题:
- 没有
.value使得难以辨认响应式变量的读取和设置。这个问题在 SFC 中可能不那么明显,但是在大型项目中会造成心智负担的明显增大,尤其是在 SFC 外也使用此语法时。
- 因为第一条,一些开发者倾向于只在 SFC 中使用响应性语法糖,这就造成了代码的不一致性以及在不同心智模型间切换的成本。这是一个进退两难的窘境:只在 SFC 中使用会造成不一致性,而在 SFC 之外使用则会降低可维护性。
- 既然总有外部函数会使用原始 ref,那么在响应性语法糖与原始 ref 之间的转换是不可避免的。这就产生了另一个需要学习的东西以及额外的认知负担,并且我们发现这会比纯粹的组合式 API 更让初学者感到困惑。
最重要的是,响应性语法糖会带来代码风格分裂的潜在危险。尽管这一功能是自愿使用的,一些使用者还是强烈反对该提议,因为他们不想维护用了语法糖和没用两种风格的代码。这确实值得担心因为使用响应性语法糖需要的心智模型违背了 JavaScript 的基本语义(对变量赋值会触发响应式副作用)。
在考虑了所有因素之后,我们认为将它发布为一个稳定功能带来的问题会大于收益。
结语
在 Vue3 发布之初,Vue 核心团队就考虑到了 ref 需要到处使用 .value 的繁琐,推出了响应性语法糖试图解决这一问题。
响应性语法糖提供了一系列编译器宏,让开发者在书写代码时不必使用 .value,而是在编译阶段由编译器自动加上。
最终,出于代码风格一致性和可维护性上的考量,这一特性最终在 Vue 3.4 版本被正式废弃。
来源:juejin.cn/post/7523231174620102671
纯前端用 TensorFlow.js 实现智能图像处理应用(一)
随着人工智能技术的不断发展,图像处理应用已经在医疗影像分析、自动驾驶、视频监控等领域得到广泛应用。TensorFlow.js 是 Google 开源的机器学习库 TensorFlow 的 JavaScript 版本,能够让开发者在浏览器中运行机器学习模型,在前端应用中轻松实现图像分类、物体检测和姿态估计等功能。本文将介绍如何使用 TensorFlow.js 在纯前端环境中实现这三项任务,并帮助你构建一个智能图像处理应用。
什么是 TensorFlow.js?
TensorFlow.js 是一个能够让开发者在前端直接运行机器学习模型的 JavaScript 库。它允许你无需将数据发送到服务器,便可以在浏览器中运行模型进行推理,这不仅减少了延迟,还可以更好地保护用户的隐私数据。通过 TensorFlow.js,前端开发者能够轻松实现图像分类、物体检测和姿态估计等功能。
TensorFlow.js 的应用非常广泛,尤其是在一些实时交互和隐私敏感的场景下,例如 医疗影像分析、自动驾驶 和 智能监控。在这些领域,前端模型推理能够提升响应速度,并且避免将用户的数据上传到服务器,从而保护用户的隐私。
要开始使用 TensorFlow.js,你需要安装相关的模型库。以下是你需要安装的 npm 包:
npm install @tensorflow/tfjs
npm install @tensorflow-models/mobilenet
npm install @tensorflow-models/coco-ssd
npm install @tensorflow-models/posenet
加载预训练模型
在 TensorFlow.js 中,加载预训练模型非常简单。首先,确保 TensorFlow.js 已经准备好,然后加载所需的模型进行推理。
// 导入
import * as tf from '@tensorflow/tfjs'
// 加载
tf.ready(); // 确保 TensorFlow.js 准备好
用户上传图片
为了使用这些模型进行推理,我们需要让用户上传一张图片。以下是一个处理图片上传的代码示例:
const handleImageUpload = async (event) => {
const file = event.target.files[0]
if (file) {
const reader = new FileReader()
reader.onload = async (e) => {
imageSrc.value = e.target.result
await runModels(e.target.result)
}
reader.readAsDataURL(file)
}
}
图像分类:识别图片中的物体
图像分类是计算机视觉中的基本任务,目的是将输入图像归类到某个类别中。例如,我们可以用图像分类模型识别图像中的“猫”还是“狗”。


使用预训练模型进行图像分类
TensorFlow.js 提供了多个预训练模型,MobileNet 是其中一个常用的图像分类模型。它是一个轻量级的卷积神经网络,适合用来进行图像分类。接下来,我们通过 MobileNet 实现一个图像分类功能:
const mobilenetModel = await mobilenet.load()
const predictions = await mobilenetModel.classify(image)
classification.value = `分类结果: ${predictions[0].className}, 信心度: ${predictions[0].probability.toFixed(3)}`
这段代码实现了图像分类。我们加载 MobileNet 模型,并对用户上传的图像进行推理,最后返回图像的分类结果。
物体检测:找出图像中的所有物体
物体检测不仅仅是识别图像中的物体是什么,还需要标出它们的位置,通常用矩形框来框住物体。Coco-SSD 是一个强大的物体检测模型,能够在图像中检测出多个物体并标出它们的位置。
使用 Coco-SSD 进行物体检测
const cocoModel = await cocoSsd.load();
const detectionResults = await cocoModel.detect(image);
objects.value = detectionResults.map((prediction) => ({
class: prediction.class,
bbox: prediction.bbox,
}));
通过 Coco-SSD 模型,我们可以检测图像中的多个物体,并标出它们的位置。
绘制物体的边界框
为了更直观地展示检测结果,我们可以在图像上绘制出物体的边界框:
// 绘制物体检测边界框
const drawObjects = (detectionResults, image) => {
nextTick(() => {
const ctx = objectCanvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
objectCanvas.value.width = imageWidth
objectCanvas.value.height = imageHeight
ctx.clearRect(0, 0, objectCanvas.value.width, objectCanvas.value.height)
ctx.drawImage(image, 0, 0, objectCanvas.value.width, objectCanvas.value.height)
// 绘制边界框
detectionResults.forEach((prediction) => {
const [x, y, width, height] = prediction.bbox
ctx.beginPath()
ctx.rect(x, y, width, height)
ctx.lineWidth = 2
ctx.strokeStyle = 'green'
ctx.stroke()
// 添加标签
ctx.font = '16px Arial'
ctx.fillStyle = 'green'
ctx.fillText(prediction.class, x + 5, y + 20)
})
})
}
这段代码通过绘制边界框来标出检测到的物体位置,同时在边界框旁边显示物体类别。
姿态估计:识别人体的关键点
姿态估计主要是识别人类的身体部位,例如头部、手臂、腿部等。通过这些关键点,我们可以了解一个人当前的姿势。TensorFlow.js 提供了 PoseNet 模型来进行姿态估计。

使用 PoseNet 进行姿态估计
// 加载 PoseNet 模型
const posenetModel = await posenet.load()
const poseResult = await posenetModel.estimateSinglePose(image, {
flipHorizontal: false
})
// 人体关键点
pose.value = poseResult.keypoints.map((point) => `${point.part}: (${point.position.x.toFixed(2)}, ${point.position.y.toFixed(2)})`)
PoseNet 模型会估计图像中人物的关键点,并返回每个关键点的位置。
绘制姿态估计骨架图
const drawPose = (keypoints, image) => {
nextTick(() => {
const ctx = canvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
canvas.value.width = imageWidth
canvas.value.height = imageHeight
ctx.clearRect(0, 0, canvas.value.width, canvas.value.height)
// 绘制图像
ctx.drawImage(image, 0, 0, canvas.value.width, canvas.value.height)
const scaleX = canvas.value.width / image.width
const scaleY = canvas.value.height / image.height
// 绘制关键点并标记名称
keypoints.forEach((point) => {
const { x, y } = point.position
const scaledX = x * scaleX
const scaledY = y * scaleY
ctx.beginPath()
ctx.arc(scaledX, scaledY, 5, 0, 2 * Math.PI)
ctx.fillStyle = 'red'
ctx.fill()
// 标记点的名称
ctx.font = '12px Arial'
ctx.fillStyle = 'blue'
ctx.fillText(point.part, scaledX + 8, scaledY)
})
// 连接骨架
const poseConnections = [
['leftShoulder', 'rightShoulder'],
['leftShoulder', 'leftElbow'],
['leftElbow', 'leftWrist'],
['rightShoulder', 'rightElbow'],
['rightElbow', 'rightWrist'],
['leftHip', 'rightHip'],
['leftShoulder', 'leftHip'],
['rightShoulder', 'rightHip'],
['leftHip', 'leftKnee'],
['leftKnee', 'leftAnkle'],
['rightHip', 'rightKnee'],
['rightKnee', 'rightAnkle'],
['leftEye', 'rightEye'],
['leftEar', 'leftShoulder'],
['rightEar', 'rightShoulder']
]
poseConnections.forEach(([partA, partB]) => {
const keypointA = keypoints.find((point) => point.part === partA)
const keypointB = keypoints.find((point) => point.part === partB)
if (keypointA && keypointB && keypointA.score > 0.5 && keypointB.score > 0.5) {
const scaledX1 = keypointA.position.x * scaleX
const scaledY1 = keypointA.position.y * scaleY
const scaledX2 = keypointB.position.x * scaleX
const scaledY2 = keypointB.position.y * scaleY
ctx.beginPath()
ctx.moveTo(scaledX1, scaledY1)
ctx.lineTo(scaledX2, scaledY2)
ctx.lineWidth = 2
ctx.strokeStyle = 'blue'
ctx.stroke()
}
})
})
}
这段代码通过 PoseNet 返回的人体关键点信息,绘制人体姿态的骨架图,帮助用户理解图像中的人物姿势。

总结
通过 TensorFlow.js,我们可以轻松地将图像分类、物体检测和姿态估计等功能集成到前端应用中,无需依赖后端计算,提升了应用的响应速度并保护了用户隐私。在本文中,我们介绍了如何使用 MobileNet、Coco-SSD 和 PoseNet 等预训练模型,在前端实现智能图像处理应用。无论是开发图像识别应用还是增强现实应用,TensorFlow.js 都是一个强大的工具,值得前端开发者深入学习和使用。
来源:juejin.cn/post/7437392938441687049
网易微前端架构实战:如何管理100+子应用而不崩
你知道网易有多少个前端项目吗?
超过 1000 个代码仓库、200+子应用、每天发布300次。
如果没有一套微前端治理系统,项目早炸了。
今天就来带你拆解网易微前端架构的核心——基座 + 动态加载 + 权限隔离 + 独立发布。
一、网易为什么早早就用上了微前端?
因为早年起就有大量频道、游戏门户、社区运营、CMS后台等:
- 功能多样、团队独立
- 迭代频繁、部署不可等待
- 技术栈各异:Vue2、Vue3、React、甚至还有 jQuery...
👇于是他们选择了模块化能力最强的方案:微前端架构(Micro Frontends)
二、整体架构图(网易实战版)

三、主子应用通信怎么做?(网易方案)
网易没有用 qiankun,而是基于内部封装的微前端 SDK,核心原理类似。
// 主应用提供通信桥
window.__MICRO_APP_EVENT_BUS__ = new EventTarget()
// 子应用监听事件
window.__MICRO_APP_EVENT_BUS__.addEventListener('global-refresh', () => {
window.location.reload()
})
// 主应用触发事件
window.__MICRO_APP_EVENT_BUS__.dispatchEvent(new Event('global-refresh'))
👉这种方式:
- 不侵入框架(Vue/React 通吃)
- 不耦合代码,只用浏览器原生事件系统
四、部署与权限如何统一管理?
网易配套了一整套“发布平台 + 权限系统”,做到:
| 功能 | 说明 |
|---|---|
| 独立部署 | 每个子应用都有独立 Jenkins/流水线 |
| 权限接入 | 每个子应用上线必须绑定角色权限模块 |
| 域名配置 | 主应用统一路由配置,动态注入 iframe 或模块 |
| 沙箱运行 | 子应用运行在 iframe + ShadowDOM + CSP 下,完全隔离 |
五、实战代码:子应用注册和加载
// 主应用注册子应用(JSON 配置化)
const microAppList = [ { name: 'content-manage', entry: 'https://cdn.xxx.com/apps/content-manage/index.html', activeRule: '/content' }, { name: 'user-center', entry: 'https://cdn.xxx.com/apps/user-center/index.html', activeRule: '/user' }]
// 动态加载示例(简化版)
function loadMicroApp(appConfig) {
const iframe = document.createElement('iframe')
iframe.src = appConfig.entry
iframe.style = 'width:100%;height:100%;border:none'
document.getElementById('micro-container').appendChild(iframe)
}
六、网易踩过的3个坑(干货!)
| 坑 | 解决方案 |
|---|---|
| 子应用样式污染 | 每个子应用编译时加 prefixCls,搭配 ShadowDOM 隔离 |
| 子应用登录状态不一致 | 所有项目统一通过 Cookie + SSO 网关授权 |
| 子应用发布顺序冲突 | 发布系统支持灰度 + 停发自动依赖检查 |
七、总结:你能从中学到什么?
- 不要迷信 qiankun,自己也能搞微前端(原理简单)
- 微前端不仅是技术,更是权限、部署、治理一整套体系
- 想要稳定运行,必须有主子应用契约 + 灰度发布 + 统一通信策略
尾声:
“你看到的稳定,其实是他们踩了无数坑后的优雅。”
来源:juejin.cn/post/7510653719672094739
写了个脚本,发现CSDN的前端居然如此不严谨
引言
最近在折腾油猴脚本开发,顺手搞了一个可以拦截任意网页接口的小工具,并修改了CSDN的博客数据接口,成功的将文章总数和展现量进行了修改。
如果你不了解什是油猴,参考这篇文章:juejin.cn/book/751468…
然后我突然灵光一闪:
既然能拦截接口、篡改数据,那我为什么不顺便测试一下 CSDN 博客在极端数据下的表现呢?
毕竟我们平时开发的时候,测试同学各种花式挑刺,什么 null、undefined、999999、-1、空数组……
每次都能把页面测出一堆边角 bug。
今天,轮到我来当一回“灵魂测试”了!
用我的脚本,造几个极限场景,看看 CSDN 的前端到底稳不稳!
实现原理
其实原理并不复杂,核心就一句话:
借助油猴的脚本注入能力 + ajax-hook 对接口请求进行拦截和修改。
我们知道,大部分网页的数据接口都是通过 XMLHttpRequest 或 fetch 发起的,而 ajax-hook 就是一个开源的轻量工具,它能帮我们劫持原生的 XMLHttpRequest,在请求发出前、响应返回后进行自定义处理。
配合油猴脚本的注入机制,我们就可以实现在浏览器端伪造任意接口数据,用来调试前端样式、模拟数据异常、测试权限控制逻辑等等。
ajax-hook 快速上手
我们用的是 CDN 方式直接引入,简单暴力:
<script src="https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js"></script>
引入后,页面上会多出一个全局对象 ah,我们只需要调用 ah.proxy(),就可以注册一套钩子:
ah.proxy({
onRequest: (config, handler) => {
// 请求发出前
handler.next(config);
},
onError: (err, handler) => {
// 请求出错时
handler.next(err);
},
onResponse: (response, handler) => {
// 请求成功响应后
console.log("响应内容:", response.response);
handler.next(response);
}
});
拦截实现
我们以 CSDN 博客后台为例,先找到博客数据接口
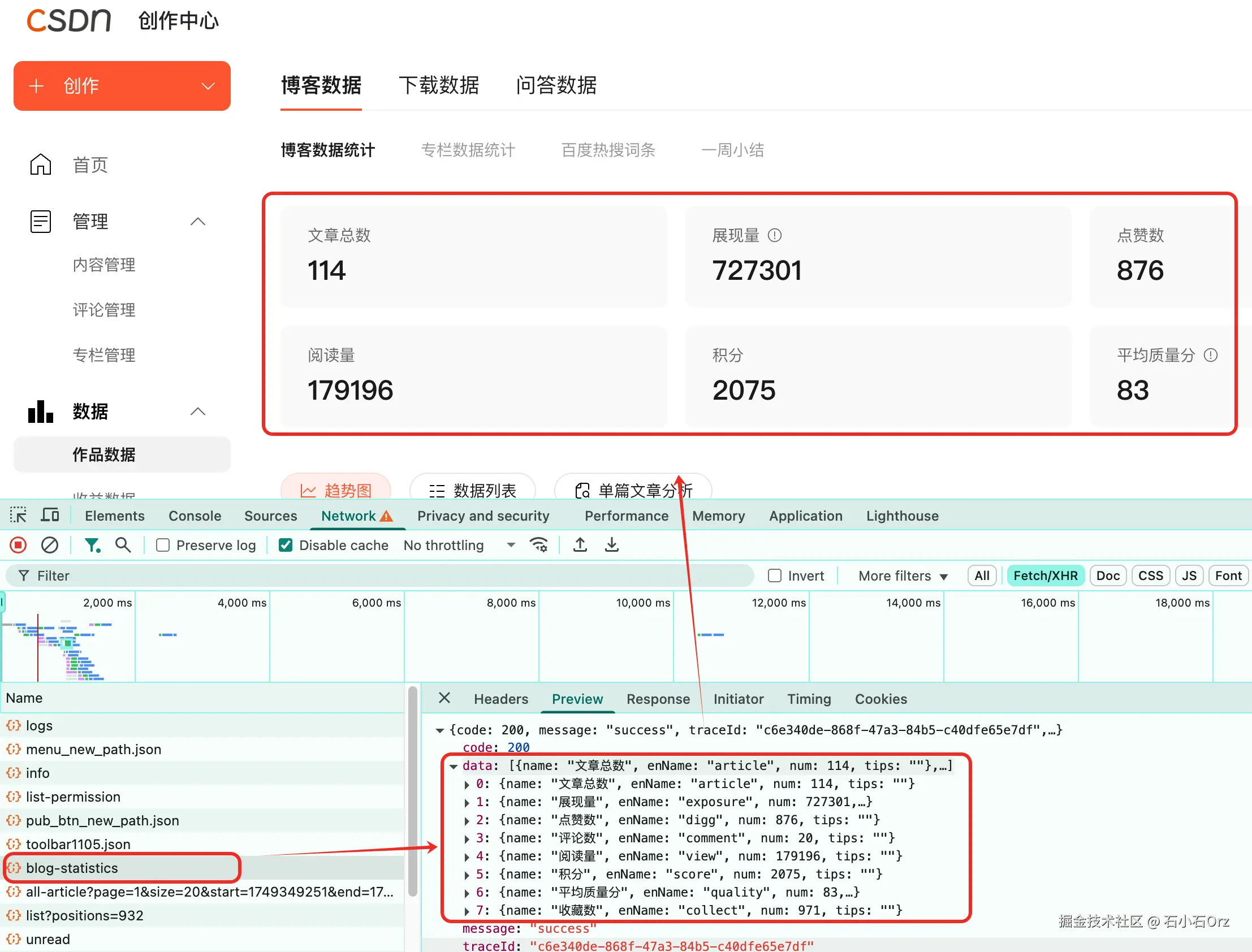
地址长这样:bizapi.csdn.net/blog/phoeni…
我们在 onResponse 钩子中,加入 URL 判断,专门拦截这个接口:
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
console.log("拦截到的数据:", hookResponse);
handler.next(response);
} else {
handler.next(response);
}
}
就这样,接口拦截器初步搭建完成!
使用油猴将脚本运行在网页
接下来我们用油猴把这段脚本注入到 CSDN 博客后台页面。
// ==UserScript==
// @name CSDN博客数据接口拦截
// @namespace http://tampermonkey.net/
// @version 0.0.1
// @description 拦截接口数据,验证极端情况下的样式展示
// @author 石小石Orz
// @match https://mpbeta.csdn.net/*
// @require https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js
// @run-at document-start
// @grant none
// ==/UserScript==
(function() {
'use strict';
ah.proxy({
onRequest: (config, handler) => {
handler.next(config);
},
onError: (err, handler) => {
handler.next(err);
},
onResponse: (response, handler) => {
console.log("接口响应列表:", response);
// 这里写拦截逻辑
handler.next(response);
}
});
})();
为了测试前端的容错能力,我们可以伪造一些极端数据返回:
- 文章总数设为
null - 展现量设为
0 - 点赞数设为一个异常大的值
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
// 伪造数据
hookResponse.data[0].num = null; // 文章总数
hookResponse.data[1].num = 0; // 展现量
hookResponse.data[2].num = 99999999999999999; // 点赞数
console.log("修改后的数据:", hookResponse);
response.response = JSON.stringify(hookResponse);
}
handler.next(response);
}
结果验证
修改成功后刷新页面,可以观察到如下问题:
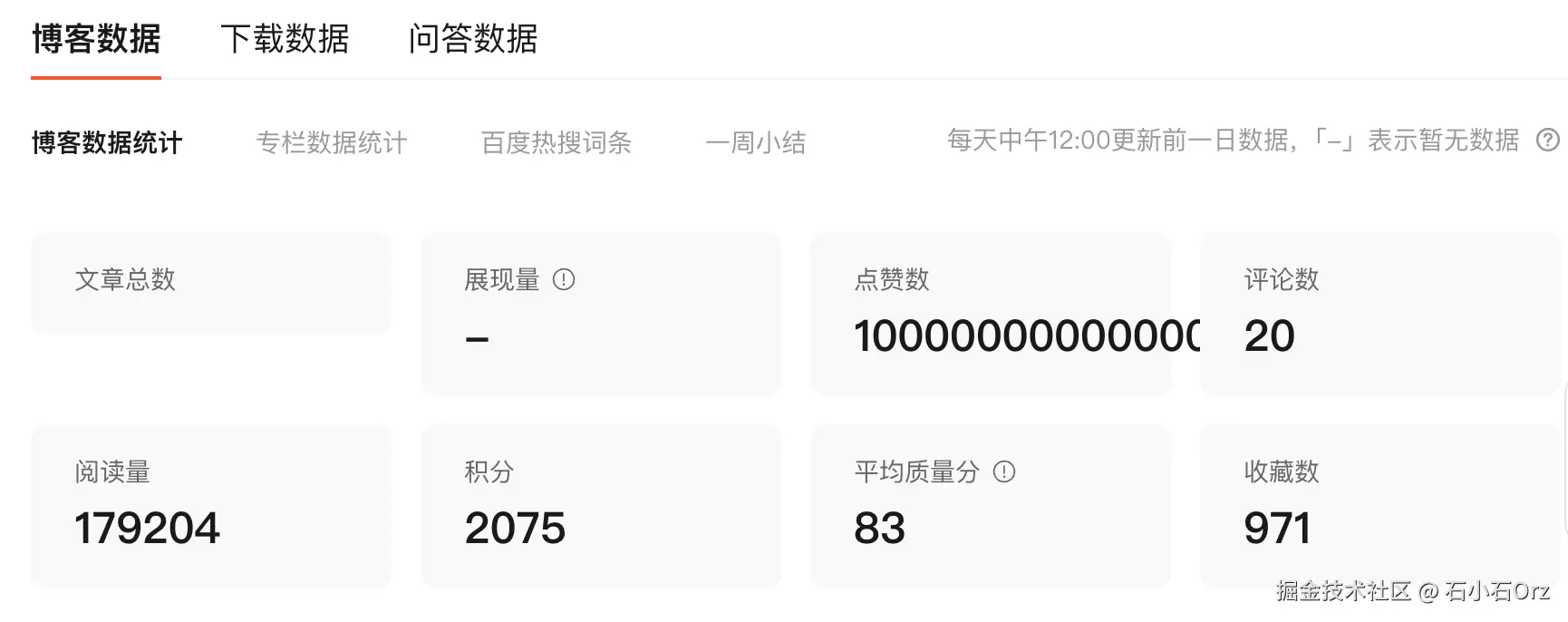
- 文章总数为
null时,布局异常,显然缺乏空值判断。 - 点赞数为超大值 时,页面直接渲染出
100000000000000000,不仅视觉上溢出容器,连排版都崩了,前端没有做任何兼容处理。
CSDN的前端还是偷懒了呀,一点也不严谨!差评!
总结
通过这篇文章的示例,我们前端应该引以为戒,永远不要相信后端同学返回的数据,一定要做好容错处理!
通过本文,相信大家也明白了油猴脚本不仅是玩具,它在前端开发中其实是个非常实用的辅助工具!
如果你对油猴脚本的开发感兴趣,不妨看看我写的这篇教程 《油猴脚本实战指南》
从小脚本写起,说不定哪天你也能靠一个脚本搞出点惊喜来!
来源:juejin.cn/post/7519005878566748186
用 iframe 实现前端批量下载的优雅方案 —— 从原理到实战
传统的下载方式如window.open()或标签点击存在诸多痛点:
- 批量下载时浏览器会疯狂弹窗
- HTTPS页面下载HTTP资源被拦截
今天分享的前端iframe批量下载方案,可以有效解决以上问题。
一、传统批量下载方案的局限性
传统的批量下载方式通常是循环创建 a 标签并触发点击事件:
urls.forEach(url => {
const link = document.createElement('a');
link.href = url;
link.download = 'filename';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
});
这种方式存在以下问题:
- 浏览器会限制连续的自动点击行为
- 用户体验不佳,会弹出多个下载对话框
二、iframe 批量下载解析
更优雅的解决方案是使用 iframe 技术,通过动态创建和移除 iframe 元素来触发下载:
downloadFileBatch(url) {
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
}
urlProtocolDelete(url: string = '') {
if (!url) {
return;
}
return url.replace('http://', '//').replace('https://', '//');
}
这种方案的优势在于:
- 不依赖用户交互,可自动触发下载
- 隐藏 iframe 不会影响页面布局,每个iframe独立运行,互不干扰
- 主线程保持流畅
三、核心代码实现解析
让我们详细分析一下这段代码的工作原理:
- 动态创建 iframe 元素:
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
通过创建一个不可见的 iframe 元素,我们可以在不影响用户界面的情况下触发下载请求。
- 协议处理函数:
urlProtocolDelete(url: string = '') {
return url.replace('http://', '//').replace('https://', '//');
}
这个函数将 URL 中的协议部分替换为//,这样可以确保在 HTTPS 页面中请求 HTTP 资源时不会出现混合内容警告。
- 触发下载并清理 DOM:
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
将 iframe 添加到 DOM 中会触发浏览器对 src 的请求,从而开始下载文件。设置 5 秒的超时时间后移除 iframe,既保证了下载有足够的时间完成,又避免了 DOM 中积累过多无用元素。
四、批量下载的实现与优化
对于多个文件的批量下载,可以通过循环调用 downloadFileBatch 方法:
result.forEach(item => {
this.downloadFileBatch(item.url);
});
五、踩坑+注意点
在实现批量下载 XML 文件功能时,你可能会遇到这种情况:明明请求的 URL 地址无误,服务器也返回了正确的数据,但文件却没有被下载到本地,而是直接在浏览器中打开预览了。这是因为 XML 作为一种可读的文本格式,浏览器默认会将其视为可直接展示的内容,而非需要下载保存的文件。
解决方案:
通过在下载链接中添加response-content-disposition=attachment参数,可以强制浏览器将 XML 文件作为附件下载,而非直接预览。这个参数会覆盖浏览器的默认行为,明确告诉浏览器 "这是一个需要下载保存的文件"。
addDownloadDisposition(url: string, filename: string): string {
try {
const urlObj = new URL(url);
// 添加 response-content-disposition 参数
const disposition = `attachment;filename=${encodeURIComponent(filename)}`;
urlObj.searchParams.set('response-content-disposition', disposition);
return urlObj.toString();
} catch (error) {
console.error('URL处理失败:', error);
return url;
}
}
六、大量文件并发控制
有待补充
来源:juejin.cn/post/7524627104580534306
前端高手才知道的秘密:Blob 居然这么强大!
🔍 一、什么是 Blob?
Blob(Binary Large Object)是 HTML5 提供的一个用于表示不可变的、原始二进制数据块的对象。
✨ 特点:
- 不可变性:一旦创建,内容不能修改。
- 可封装任意类型的数据:字符串、ArrayBuffer、TypedArray 等。
- 支持 MIME 类型描述,方便浏览器识别用途。
💡 示例:
const blob = new Blob(['Hello World'], { type: 'text/plain' });
🧠 二、Base64 编码的前世今生
虽然名字听起来像是某种“64进制”,但实际上它是一种编码方式,不是数学意义上的“进制”。
📜 起源背景:
Base64 最早起源于电子邮件协议 MIME(Multipurpose Internet Mail Extensions),因为早期的电子邮件系统只能传输 ASCII 文本,不能直接传输二进制数据(如附件)。于是人们发明了 Base64 编码方法,把二进制数据转换成文本形式,从而安全地在网络上传输。
🧩 使用场景:
| 场景 | 说明 |
|---|---|
| 图片嵌入到 HTML/CSS 中 | Data URI 方式减少请求 |
| JSON 数据中传输二进制信息 | 如头像、加密数据等 |
| WebSocket 发送二进制消息 | 避免使用 ArrayBuffer |
| 二维码生成 | 将图像转为 Base64 存储 |
⚠️ 注意:Base64 并非压缩算法,它会将数据体积增加约 33%。
🔁 三、从 Base64 到 Blob 的全过程
1. Base64 字符串解码:atob()
JavaScript 提供了一个内置函数 atob(),可以将 Base64 字符串解码为原始的二进制字符串(ASCII 表示)。
const base64Data = 'SGVsbG8gd29ybGQh'; // "Hello world!"
const binaryString = atob(base64Data);
⚠️ 返回的是 ASCII 字符串,不是真正的字节数组。
2. 构建 Uint8Array(字节序列)
为了构造 Blob,我们需要一个真正的字节数组。我们可以用 charCodeAt() 将每个字符转为对应的 ASCII 数值(即 0~255 的整数)。
const byteArray = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i);
}
现在,byteArray 是一个代表原始图片二进制数据的数组。
3. 创建 Blob 对象
有了字节数组,就可以创建 Blob 对象了:
const blob = new Blob([byteArray], { type: 'image/png' });
这个 Blob 对象就代表了一张 PNG 图片的二进制内容。
4. 使用 URL.createObjectURL() 显示图片
为了让浏览器能够加载这个 Blob 对象,我们需要生成一个临时的 URL 地址:
const imageUrl = URL.createObjectURL(blob);
document.getElementById('blobImage').src = imageUrl;
这样,你就可以在网页中看到这张图片啦!
🛠️ 四、Blob 的核心功能与应用场景
| 功能 | 说明 |
|---|---|
| 分片上传 | .slice(start, end) 方法可用于大文件切片上传 |
| 本地预览 | Canvas.toBlob() 导出图像,配合 URL.createObjectURL 预览 |
| 文件下载 | 使用 a 标签 + createObjectURL 实现无刷新下载 |
| 缓存资源 | Service Worker 中缓存 Blob 数据提升性能 |
| 处理用户上传 | 结合 FileReader 和 File API 操作用户文件 |
🧪 五、Blob 的高级玩法
1. 文件切片上传(分片上传)
const chunkSize = 1024 * 1024; // 1MB
const firstChunk = blob.slice(0, chunkSize);
2. Blob 转换为其他格式
FileReader.readAsText(blob)→ 文本FileReader.readAsDataURL(blob)→ Base64FileReader.readAsArrayBuffer(blob)→ Array Buffer
3. Blob 下载为文件
const a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = 'example.png';
a.click();
🧩 六、相关知识点汇总
| 技术点 | 作用 |
|---|---|
| Base64 | 将二进制数据编码为文本,便于传输 |
| atob() | 解码 Base64 字符串,还原为二进制字符串 |
| charCodeAt() | 获取字符的 ASCII 值(0~255) |
| Uint8Array | 构建字节数组,表示原始二进制数据 |
| Blob | 封装二进制数据,作为文件对象使用 |
| URL.createObjectURL() | 生成临时地址,让浏览器加载 Blob 数据 |
🧾 七、完整代码回顾
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Blob 实战</title>
</head>
<body>
<img src="" id="blobImage" width="100" height="100" alt="Blob Image" />
<script>
const base64Data = 'UklGRiAHAABXRUJQVlA4IBQHAACwHACdASpQAFAAPok0lEelIyIhMziOYKARCWwAuzNaQpfW+apU37ZufB5rAHqW2z3mF/aX9o/ev9LP+j9KrqSOfp9mf+6WmE1P1yFc3gTlw8B8d/TebelHaI3mplPrZ+Aa0l5qDGv5N8Tt9vYhz3IH37wqm2al+FdcFQhDnObv2+WfpwIZ+K6eBPxKL2RP6hiC/K1ZynnvVYth9y+ozyf88Obh4TRYcv3nkkr43girwwJ54Gd0iKBPZFnZS+gd1vKqlfnPT5wAwzxJiSk+pkbtcOVP+QFb2uDqUhuhNiHJ8xPt6VfGBfUbTsUzYuKgAP4L9wrkT8KU4sqIHwM+ZeKDBpGq58k0aDirXeGc1Odhvfx+cpQaeas97zVTr2pOk5bZkI1lkF9jnc0j2+Ojm/H+uPmIhS7/BlxuYfgnUCMKVZJGf+iPM44vA0EwvXye0YkUUK...';
const binaryString = atob(base64Data); // Base64 解码
const byteArray = new Uint8Array(binaryString.length); // 创建 Uint8Array
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i); // 填充字节数据
}
const blob = new Blob([byteArray], { type: 'image/png' }); // 创建 Blob
const imageUrl = URL.createObjectURL(blob); // 生成 URL
document.getElementById('blobImage').src = imageUrl; // 显示图片
</script>
</body>
</html>
📚 八、扩展阅读建议
🧩 九、结语
Blob 是连接 JavaScript 世界与真实二进制世界的桥梁,是每一个想要突破瓶颈的前端开发者必须掌握的核心技能之一。
掌握了 Blob,你就拥有了操作二进制数据的能力,这在现代 Web 开发中是非常关键的一环。
下次当你看到一张图片在网页中加载出来,或者一个文件被顺利下载时,不妨想想:这一切的背后,都有 Blob 的身影。
来源:juejin.cn/post/7523065182429904915
🫴为什么看大厂的源码,看不到undefined,看到的是void 0
void 0 是 JavaScript 中的一个表达式,它的作用是 返回 undefined。
解释:
void运算符:
- 它会执行后面的表达式(比如
void 0),但不管表达式的结果是什么,void始终返回undefined。 - 例如:
console.log(void 0); // undefined
console.log(void (1 + 1)); // undefined
console.log(void "hello"); // undefined
- 它会执行后面的表达式(比如
- 为什么用
void 0代替undefined?
- 在早期的 JavaScript 中,
undefined并不是一个保留字,它可以被重新赋值(比如undefined = 123),这会导致代码出错。 void 0是确保获取undefined的安全方式,因为void总是返回undefined,且不能被覆盖。- 现代 JavaScript(ES5+)已经修复了这个问题,
undefined现在是只读的,但void 0仍然在一些旧代码或压缩工具中出现。
- 在早期的 JavaScript 中,
常见用途:
- 防止默认行为(比如
<a>标签的href="javascript:void(0)"):
<a href="javascript:void(0);" onclick="alert('Clicked!')">
点击不会跳转
</a>
这样点击链接时不会跳转页面,但仍然可以执行 JavaScript。
- 在函数中返回
undefined:
function doSomething() {
return void someOperation(); // 明确返回 undefined
}
为什么用void 0
源码涉及到 undefined 表达都会被编译成 void 0
//源码
const a: number = 6
a === undefined
//编译后
"use strict";
var a = 6;
a === void 0;
也就是void 0 === undefined。void 运算符通常只能用于获取 undefined 的原始值,一般用void(0),等同于void 0,也可以使用全局变量 undefined 替代。
为什么不直接写 undefined
undefined 是 js 原始类型值之一,也是全局对象window的属性,在一部分低级浏览器(IE7-IE8)中or局部作用域可以被修改。
undefined在js中,全局属性是允许被覆盖的。
//undefined是window的全局属性
console.log(window.hasOwnProperty('undefined'))
console.log(window.undefined)
//旧版IE
var undefined = '666'
console.log(undefined)//666 直接覆盖改写undefined
window.undefined在局部作用域中是可以被修改的 在ES5开始,undefined就已经被设定为仅可读的,但是在局部作用域内,undefined依然是可变的。
①某些情况下用undefined判断存在风险,因undefined有被修改的可能性,但是void 0返回值一定是undefined
②兼容性上void 0 基本所有的浏览器都支持
③ void 0比undefined字符所占空间少。
拓展
void(0) 表达式会返回 undefined 值,它一般用于防止页面的刷新,以消除不需要的副作用。
常见用法是在 <a> 标签上设置 href="javascript:void(0);",即当单击该链接时,此表达式将会阻止浏览器去加载新页面或刷新当前页面的行为。
<!-- 点击下面的链接,不会重新加载页面,且可以得到弹框消息 -->
<a href="javascript:void(0);" onclick="alert('干的漂亮!')">
点我呀
</a>
总结:
void 0 是一种确保得到 undefined 的可靠方式,虽然在现代 JavaScript 中直接用 undefined 也没问题,但在一些特殊场景(如代码压缩、兼容旧代码)仍然有用。
来源:juejin.cn/post/7511618693714427914
用半天时间,threejs手搓了一个机柜
那是一个普通的周三早晨,我正对着产品经理刚丢过来的需求发呆——"在管理系统里加个3D机柜展示,要能开门的那种"。
"这不就是个模型展示吗?"我心想,"AI应该能搞定吧?"
9:30 AM - 启动摸鱼模式
我熟练地打开代码编辑器,把需求复制粘贴进AI对话框: "用Three.js实现一个带开门动画的机柜模型,要求有金属质感,门能90度旋转"
点击发送后,我惬意地靠在椅背上,顺手打开了B站。"让AI先忙会儿~"
10:30 AM - 验收时刻
一集《凡人修仙传》看完,我懒洋洋地切回编辑器。AI果然交出了答卷:
11:00 AM - 血压升高现场
看着AI生成的"未来科技风"机柜,我深吸一口气,决定亲自下场。毕竟,程序员最后的尊严就是——"还是自己来吧"。
11:30 AM - 手动抢救
首先手动创建一个空场景吧
class SceneManager {
constructor() {
this.scene = new THREE.Scene();
this.camera = new THREE.PerspectiveCamera(
75,
window.innerWidth / window.innerHeight,
0.1,
1000
);
this.camera.position.set(0, 2, 5);
this.renderer = new THREE.WebGLRenderer();
this.renderer.setSize(window.innerWidth, window.innerHeight);
const canvas = document.getElementById('renderCanvas');
canvas.appendChild(this.renderer.domElement);
this.controls = new OrbitControls(this.camera, this.renderer.domElement);
this.controls.enableDamping = true;
this.controls.dampingFactor = 0.05;
this.controls.target.set(0, 3, 0);
this.controls.update();
this.addLights();
this.addFloor();
}
addLights() {
const ambientLight = new THREE.AmbientLight(0xffffff, 0.5);
this.scene.add(ambientLight);
const directionalLight = new THREE.DirectionalLight(0xffffff, 1);
directionalLight.position.set(5, 5, 5);
this.scene.add(directionalLight);
}
addFloor() {
const floorGeometry = new THREE.PlaneGeometry(10, 10);
const floorMaterial = new THREE.MeshStandardMaterial({ color: 0x888888 });
const floor = new THREE.Mesh(floorGeometry, floorMaterial);
floor.rotation.x = -Math.PI / 2;
this.scene.add(floor);
}
animate() {
const animateLoop = () => {
requestAnimationFrame(animateLoop);
this.controls.update();
this.renderer.render(this.scene, this.camera);
};
animateLoop();
}
onResize() {
window.addEventListener('resize', () => {
this.camera.aspect = window.innerWidth / window.innerHeight;
this.camera.updateProjectionMatrix();
this.renderer.setSize(window.innerWidth, window.innerHeight);
});
}
}
然后这机柜怎么画呢,不管了,先去吃个饭,天大地大肚子最大
12:30 PM - 程序员的能量补给时刻
淦!先干饭!" 我一把推开键盘,决定暂时逃离这个三维世界。毕竟——
- 饥饿值已经降到30%以下
- 右手开始不受控制地颤抖
- 看Three.js文档出现了重影
扒饭间隙,手机突然震动。产品经理发来消息:"那个3D机柜..."
我差点被饭粒呛到,赶紧回复:"正在深度优化用户体验!"
(十分钟风卷残云后)
1:00 PM - 回归正题
吃饱喝足,终于可以专心搞机柜了,(此处可怜一下我的午休)
拆分机柜结构
机柜的结构可以分为以下几个部分:
- 不可操作结构:
- 底部:承载整个机柜的重量,通常是一个坚固的平面。
- 顶部:封闭机柜的顶部,提供额外的支撑。
- 左侧和右侧:机柜的侧板,通常是固定的,用于保护内部设备。
- 可操作结构:
- 前门:单门设计,通常是透明或半透明材质,便于观察内部设备。
- 后门:双开门设计,方便从后方接入设备的电缆和接口。
实现步骤
- 创建不可操作结构:
使用BoxGeometry创建底部、顶部、左侧和右侧的平面,并将它们组合成一个整体。 - 添加前门:
前门使用透明材质,并设置旋转轴以实现开门动画。 - 添加后门:
后门分为左右两部分,分别设置旋转轴以实现双开门效果。 - 优化细节:
- 添加螺丝孔和通风口。
- 使用高光材质提升视觉效果。
接下来,我们开始用代码实现这些结构。
机柜结构的实现
1. 创建不可操作结构

底部
export function createCabinetBase(scene) {
const geometry = new THREE.BoxGeometry(0.6, 0.05, 0.64);
const base = new THREE.Mesh(geometry, materials.baseMaterial);
base.position.y = -0.05; // 调整位置
scene.add(base);
}
底部使用BoxGeometry创建,设置了深灰色金属材质,位置调整为机柜的最底部。
顶部
export function createCabinetTop(scene) {
const geometry = new THREE.BoxGeometry(0.6, 0.05, 0.64);
const top = new THREE.Mesh(geometry, materials.baseMaterial);
top.position.y = 1.95; // 调整位置
scene.add(top);
}
顶部与底部类似,位置调整为机柜的最顶部。
侧面
export function createCabinetSides(scene) {
const geometry = new THREE.BoxGeometry(0.04, 2, 0.6);
const material = materials.baseMaterial;
// 左侧面
const leftSide = new THREE.Mesh(geometry, material);
leftSide.position.set(-0.28, 0.95, 0); // 调整位置
scene.add(leftSide);
// 右侧面
const rightSide = new THREE.Mesh(geometry, material);
rightSide.position.set(0.28, 0.95, 0); // 调整位置
scene.add(rightSide);
}
侧面使用两个BoxGeometry分别创建左侧和右侧,位置对称分布。
2. 创建可操作结构

前门
export function createCabinetFrontDoor(scene) {
const doorGr0up = new THREE.Gr0up();
const doorWidth = 0.04;
const doorHeight = 2;
const doorDepth = 0.6;
const frameMaterial = materials.baseMaterial;
const frameThickness = 0.04;
// 上边框
const topFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, doorDepth);
const topFrame = new THREE.Mesh(topFrameGeo, frameMaterial);
topFrame.position.set(0, 1 - frameThickness / 2, 0);
doorGr0up.add(topFrame);
// 下边框
const bottomFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, doorDepth);
const bottomFrame = new THREE.Mesh(bottomFrameGeo, frameMaterial);
bottomFrame.position.set(0, -doorHeight / 2 + 0.05, 0);
doorGr0up.add(bottomFrame);
// 左右边框
const leftFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const leftFrame = new THREE.Mesh(leftFrameGeo, frameMaterial);
leftFrame.position.set(0, 1 - doorHeight / 2, -doorDepth / 2 + frameThickness / 2);
doorGr0up.add(leftFrame);
const rightFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const rightFrame = new THREE.Mesh(rightFrameGeo, frameMaterial);
rightFrame.position.set(0, 1 - doorHeight / 2, doorDepth / 2 - frameThickness / 2);
doorGr0up.add(rightFrame);
scene.add(doorGr0up);
return doorGr0up;
}
前门由一个Gr0up组装而成,包含上下左右边框,材质与机柜一致,后续将添加玻璃部分和动画。
前门动画的实现
前门的动画使用gsap库实现,设置旋转轴为左侧边框。
gsap.to(frontDoor.rotation, {
y: Math.PI / 2, // 90度旋转
duration: 1, // 动画时长
ease: "power2.inOut",
});
通过gsap.to方法,前门可以实现平滑的开门效果。
3. 添加后门
后门采用双开设计,左右两扇门分别由多个边框组成,并通过Gr0up进行组合。
为了优化细节我还加入了网孔结构(此处心疼一下我为写他掉的头发)

后门的实现
export function createCabinetBackDoor(scene) {
const doorGr0up = new THREE.Gr0up();
const doorWidth = 0.04;
const doorHeight = 2;
const doorDepth = 0.6;
const singleDoorDepth = doorDepth / 2;
const frameMaterial = materials.baseMaterial;
const frameThickness = 0.04;
function createSingleBackDoor(isLeft) {
const singleGr0up = new THREE.Gr0up();
// 上边框
const topFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, singleDoorDepth);
const topFrame = new THREE.Mesh(topFrameGeo, frameMaterial);
topFrame.position.set(0, 1 - frameThickness / 2, 0);
singleGr0up.add(topFrame);
// 下边框
const bottomFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, singleDoorDepth);
const bottomFrame = new THREE.Mesh(bottomFrameGeo, frameMaterial);
bottomFrame.position.set(0, -doorHeight / 2 + 0.05, 0);
singleGr0up.add(bottomFrame);
// 外侧边框
const sideFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const sideFrame = new THREE.Mesh(sideFrameGeo, frameMaterial);
sideFrame.position.set(
0,
1 - doorHeight / 2,
isLeft
? -singleDoorDepth / 2 + frameThickness / 2
: singleDoorDepth / 2 - frameThickness / 2
);
singleGr0up.add(sideFrame);
return singleGr0up;
}
const leftDoor = createSingleBackDoor(true);
const rightDoor = createSingleBackDoor(false);
doorGr0up.add(leftDoor);
doorGr0up.add(rightDoor);
scene.add(doorGr0up);
return { group: doorGr0up, leftDoor, rightDoor };
}
后门的实现与前门类似,采用双扇门设计,左右各一扇。
后门动画的实现
后门的动画同样使用gsap库实现,分别设置左右门的旋转轴。
gsap.to(leftDoor.rotation, {
y: Math.PI / 2, // 左门向外旋转90度
duration: 1,
ease: "power2.inOut",
});
gsap.to(rightDoor.rotation, {
y: -Math.PI / 2, // 右门向外旋转90度
duration: 1,
ease: "power2.inOut",
});
通过gsap.to方法,后门可以实现平滑的双开效果。
2:00 PM - 项目收尾
终于,随着最后一行代码的敲定,3D机柜模型在屏幕上完美呈现。前门优雅地打开,后门平滑地双开,仿佛在向我点头致意。
我靠在椅背上,长舒一口气,心中默念:"果然,程序员的尊严还是要靠自己守护。"
可拓展功能
虽然当前的3D机柜模型已经实现了基本的展示和交互功能,但在实际项目中,我们可以进一步扩展以下功能:
1. U位标记
2. U位资产管理
3. 动态灯光效果
4. 数据联动
将3D机柜与后台数据联动:
- 实时更新设备状态。
- 显示设备的实时监控数据(如温度、功耗等)。
- 支持通过API接口获取和更新设备信息。
不说了,需求又来了()我还是继续去搬砖了
代码地址:gitee.com/erhadong/th…
来源:juejin.cn/post/7516784123703181322
很喜欢Vue,但还是选择了React: AI时代的新考量
引言
作为一个深度使用Vue多年的开发者,最近我在新项目技术选型时,却最终选择了React。这个决定不是一时冲动,而是基于当前技术发展趋势、AI时代的需求以及生态系统的深度思考。

AI时代的前端需求
随着人工智能技术的飞速发展,前端开发的需求也发生了深刻的变化。现代应用不仅仅是静态页面或简单的数据展示,而是需要与复杂的后端服务、机器学习模型以及第三方API深度集成。这些场景对前端框架提出了更高的要求,生态的重要性,不得不说很重要。
社区对AI的支持
说实话,React社区在AI领域简直就是"社交达人"。shadcn这样的明星UI库、vercel/ai这样的实力派SDK,都是圈子里的"网红"。想要快速搭建AI应用?这些"老铁"都能帮你省下不少力气。简单列举一些知名仓库。
@vercel/ai
这是由Vercel开发的AI SDK
提供了与各种AI模型(如OpenAI, Anthropic等)交互的统一接口
支持流式响应、AI聊天界面等功能
特别适合构建类ChatGPT应用
shadcn-admin
基于shadcn/ui的管理后台模板
包含了AI聊天等现代化功能
提供了完整的后台管理系统布局
shadcn/ui
这是一个高度可定制的React组件库
不是传统的npm包,而是采用复制代码的方式
提供了大量现代化的UI组件
完美支持暗色模式
特别适合构建AI应用的界面
ChatGPTNextWeb
开源的ChatGPT Web客户端
使用Next.js构建
支持多种部署方式
提供了优秀的UI/UX设计参考
AI工具链的优先支持
React在AI工具支持方面具有明显优势
GitHub Copilot、Cursor 等AI IDE 也对React的代码提示更准确
目前多数AI辅助开发工具会优先支持React生态(Vue 生态也不错,狗头保命🐶)
结论
技术选型永远不是非黑即白的选择。在AI时代,我们需要考虑:
- 技术栈的生态活跃度
- AI工具的支持程度
- 团队的学习成本
- 项目的长期维护
总的来说,Vue和React各有千秋,但从AI时代的需求和生态系统的角度来看,React确实更适合承担复杂、高性能的应用开发任务。当然,这并不意味着Vue没有未来。事实上,Vue依然是一个优秀的框架,尤其适合中小型企业或初创团队快速搭建产品原型。
随着AI技术的进一步普及,前端框架之间的竞争也将更加激烈。无论是React还是Vue,都需要不断进化以适应新的挑战。而对于开发者来说,掌握多种技术栈并根据项目需求灵活选择,才是最重要的技能。
正如一句老话所说:“工欲善其事,必先利其器。”选择合适的工具,才能让我们的项目在AI时代脱颖而出。
还有技术人不应该局限于框架,什么都能上手,多看看新的东西,接受新的事物,产品能力也很重要。
写在最后
技术选型是一个需要综合考虑的过程,没有永远的对与错,只有更适合与否。希望这篇文章能给正在进行技术选型的你一些参考。
来源:juejin.cn/post/7497174194715852815
Tailwind 到底是设计师喜欢,还是开发者在硬撑?
我们最近刚把一个后台系统从 element-plus 切成了完全自研组件,CSS 层统一用 Tailwind。全员同意设计稿一致性提升了,但代码里怨言开始冒出来。
这篇文章不讲原理,直接上代码对比和团队真实使用反馈,看看是谁在享受,谁在撑着。
1.组件内样式迁移
原先写法(BEM + scoped):
<template>
<div class="card">
<h2 class="card__title">用户概览</h2>
<p class="card__desc">共计 1280 位</p>
</div>
</template>
<style scoped>
.card {
padding: 16px;
background-color: #fff;
border-radius: 8px;
}
.card__title {
font-size: 16px;
font-weight: bold;
}
.card__desc {
color: #999;
font-size: 14px;
}
</style>
Tailwind 重写:
<template>
<div class="p-4 bg-white rounded-lg">
<h2 class="text-base font-bold">用户概览</h2>
<p class="text-sm text-gray-500">共计 1280 位</p>
</div>
</template>
优点:
- 组件直接可读,不依赖 class 定义
- 样式即结构,调样式时不用来回翻
缺点:
- 设计稿变了?全组件搜索
text-sm改成text-base? - 无法抽象:多个地方复用
.text-label变成复制粘贴
2.复杂交互样式
纯 CSS(原写法)
<template>
<button class="btn">提交</button>
</template>
<style scoped>
.btn {
background-color: #409eff;
color: #fff;
padding: 8px 16px;
border-radius: 4px;
}
.btn:hover {
background-color: #66b1ff;
}
.btn:active {
background-color: #337ecc;
}
</style>
Tailwind 写法
<button
class="bg-blue-500 hover:bg-blue-400 active:bg-blue-700 text-white py-2 px-4 rounded">
提交
</button>
问题来了:
- ✅ 简单 hover/active 很方便
- ❌ 多态样式(如 disabled + dark mode + hover 同时组合)就很难读:
<button
class="bg-blue-500 text-white disabled:bg-gray-300 dark:bg-slate-600 dark:hover:bg-slate-700 hover:bg-blue-600 transition-all">
>
提交
</button>
调试时需要反复阅读 class 字符串,不能直接 Cmd+Click 查看样式来源。
3.统一样式封装,复用方案混乱
原写法:统一样式变量 + class
$border-color: #eee;
.panel {
border: 1px solid $border-color;
border-radius: 8px;
}
Tailwind 使用中经常出现的写法:
<div class="border border-gray-200 rounded-md" />
问题来了:
设计稿调整了主色调或边框粗细,如何批量更新?
BEM 模式下你只需要改一个变量,Tailwind 下必须靠 @apply 或者手动替换所有 .border-gray-200。
于是我们项目里又写了一堆“语义类”去封装 Tailwind:
/* 自定义 utilities */
@layer components {
.app-border {
@apply border border-gray-200;
}
.app-card {
@apply p-4 rounded-lg shadow-sm bg-white;
}
}
最后导致的问题是:我们重新“造了个 BEM”,只不过这次是基于 Tailwind 的 apply 写法。
🧪 实测维护成本:100+组件、多人协作时的问题
我们项目有 110 个组件,4 人开发,统一用 Tailwind,协作两个月后出现了这些反馈:
- 👨💻 A 开发:写得很快,能复制设计稿的 class 直接粘贴
- 🧠 B 维护:改样式全靠人肉找
.text-sm、.p-4,没有结构命名层 - 🤯 C 重构:统一调整圆角半径?所有
.rounded-md都要搜出来替换
所以我们内部的结论是:
Tailwind 写得爽,维护靠人背。它适合“一次性强视觉还原”,不适合“结构长期型组件库”。
🔧 我们后来的解决方案:Tailwind + token 化抽象
我们仍然使用 Tailwind 作为底层 utilities,但同时强制使用语义类抽象,例如:
@layer components {
.text-label {
@apply text-sm text-gray-500;
}
.btn-primary {
@apply bg-blue-500 hover:bg-blue-600 text-white py-2 px-4 rounded;
}
.card-container {
@apply p-4 bg-white rounded-lg shadow;
}
}
模板中统一使用:
<h2 class="text-label">标题</h2>
<button class="btn-primary">提交</button>
<div class="card-container">内容</div>
这种方式保留了 Tailwind 的构建优势(无 tree-shaking 问题),但代码结构有命名可依,后期批量维护不再靠搜索。
📌 最终思考
Tailwind 是给设计还原速度而生的,不是给可维护性设计的。
设计师爱是因为它像原子操作;
开发者撑是因为它把样式从结构抽象变成了“字串组合游戏”。
如果你的团队更在意开发效率,样式一次性使用,那 Tailwind 非常合适。
如果你的组件系统是要长寿、要维护、要被多人重构的——你最好在 Tailwind 之上再造一层自己的语义层,或者别用。
分享完毕,谢谢大家🙂
📌 你可以继续看我的系列文章
来源:juejin.cn/post/7517496354245492747
最快实现的前端灰度方案
小白最快学会的前端灰度方案
首次访问效果如下,点击立即更新会访问灰度版本。本地cookie存在version字段后,后续访问都是指定版本代码,也不会出现弹窗提示

一、引言:为什么需要灰度发布?
1.1 血泪教训:全量发布的风险
因为一次上线,导致登录异常,用户无法使用。复盘时候,测试反馈预发环境不能完全模拟出生成环境。要不做一个灰度发布,实现代码最小化影响。
1.2 技术思考:面试的需要
多了解点技术方案,总没有坏事
二、前端灰度方案
- 在网上搜索前端灰度方案,整体看来就目前这个比较简单,上手快,易实现
- nginx + 服务端 + 前端 js(可以考虑封装成一个通用工具 js)
大致思路
> 前端通过获取版本规则,服务端计算规则
> 命中规则,重新访问页面,nginx 通过版本信息,返回指定版本
> 未命中规则,继续访问当前稳定版本页面
ps: 额外探讨,如果希望服务端接口也能有灰度版本,是不是只需要通过 nginx 配置就能实现?
三、实现细节
1. 版本规则接口
这个规则是可以自己定制的;这里我简单以 userId 进行匹配
- 案例服务端框架:
koa2 + mongoose
/**
* 获取当前用户的版本
* @param {*} ctx
*/
exports.getVersion = async (ctx) => {
try {
const version = ctx.cookies.get("version");
const userId = ctx.query.userId;
// 这里直接写死,也可以放到redis里,做成可以动态配置也行
const inTestList = ["68075c202bbd354b0fcb7a4c"];
const data = inTestList.includes(userId) ? "gray" : "stable";
if (version) {
return ctx.success(
{
version: data,
cache: true,
},
"缓存"
);
} else {
ctx.cookies.set("version", data, { maxAge: 1000 * 60 * 60 * 24 * 7 });
return ctx.success(
{
version: data,
cache: false,
},
"重新计算"
);
}
} catch (error) {
ctx.fail("获取页面记录失败");
console.error("获取页面记录失败:", error);
}
};
- userId 匹配那块,可以引入 redis 做缓存处理,避免直接查询用户表进行比对
2. 前端触发获取版本
- 交互方式,目前我能想到
- 第一种,接口请求完,才开始渲染页面,自动执行指定版本
- 第二种,接口请求、页面渲染同步进行,指定版本由用户触发
// 我把请求版本放到入口首页界面里
// 首次需要登录之后才会执行
onMounted(() => {
const userInfo = store.getters["login/getUserInfo"];
getVesion({ userId: userInfo.id }).then((res) => {
if (!res.cache && res.version === "gray") {
// 这里我增加一个弹窗提示,让用户选择
ElMessageBox.confirm("存在新的灰度版本,是否要体验最新版本?", "新版本", {
confirmButtonText: "立即更新",
cancelButtonText: "不更新",
type: "warning",
}).then(() => {
window.location.reload();
});
}
});
// 页面其他初始化逻辑
});
前端打包控制
- 项目里使用的是
vite打包工具
- 通过增加两个配置,两者区别在于输入输出不同。
当然如果嫌维护两个配置麻烦,可以把公共相同配置抽离出来或者通过环境变量区分维护一个配置
- 新增一个入口 html 文件,并修改打包输出名称
# vite.gray.config.js
// 修改打包输出名称方便部署
const renameHtmlPlugin = () => {
return {
name: 'html-transform',
enforce: 'post',
generateBundle(options, bundle) {
bundle['gray.html'].fileName = 'index.html'
}
}
}
export default defineConfig({
// ... 其他配置
plugins: [vue(), renameHtmlPlugin()],
build: {
outDir: 'gray',
rollupOptions: {
input: {
main: resolve(__dirname, 'gray.html')
}
}
}
// ...
})
- 命令行部分
"build": "vite build",
"build:gray": "vite build --config vite.gray.config.js",
- 最终打包出来目录
// 灰度版本
-gray -
assests -
index.html -
// 稳定版本
dist -
assests -
index.html;
3. nginx 配置
这里我尝试很久,最终以下配置可以实现
通过 cookie 中版本标识,返回不同版本内容
http {
map $http_cookie $target_dir {
# 精确匹配version值,避免捕获额外内容
"~*version=gray(;|$)" "/gray";
"~*version=stable(;|$)" "/stable";
default "/stable";
}
server {
...已存在...
location / {
root html$target_dir;
try_files $uri $uri/ /index.html;
}
...已存在...
}
}
四、总结
自此一个简单前端灰度效果就实现了。当然这里还有许多的场景没有考虑到,欢迎大家提问探讨。
案例代码:gitee.com/banmaxiaoba… 代码包含一个简易的前端监控方案实现,有空下篇文章分享讨论
来源:juejin.cn/post/7515237104412360756
Wordle:为逗女友而爆火的小游戏
Wordle 的传奇故事
说起 Wordle,这绝对是近几年最火的小游戏之一。2021年,一个叫 Josh Wardle 的程序员为了逗女朋友开心,花了几个晚上做了这个简单的猜词游戏。没想到女朋友玩得很开心,就分享给了朋友,然后朋友又分享给朋友...
结果呢?短短几个月,全世界都在玩 Wordle。Twitter 上到处都是那种绿黄灰的小方块截图,连我妈都问我那些彩色格子是什么意思。
最疯狂的是,Josh 本来只是想做个小游戏玩玩,结果《纽约时报》花了七位数把它买下来。一个周末项目变成了百万美元的生意,这大概是每个程序员的梦想吧。
点击这里先试试:wordless.online

Wordle 为什么这么火?我觉得主要是几个原因:
- 简单易懂:规则五分钟就能学会
- 每天一题:不会让人沉迷,但又让人期待明天的挑战
- 社交属性:那个分享截图的功能太聪明了,不剧透但又能炫耀成绩
- 免费纯净:没有广告,没有内购,就是纯粹的游戏乐趣
Wordle这种游戏的玩法精髓
Wordle 的规则很简单:6次机会猜出5个字母的英文单词。每次猜完会给你颜色提示:
- 绿色:字母对了,位置也对
- 黄色:字母在单词里,但位置不对
- 灰色:这个字母不在单词里
听起来简单,但要玩好还是有技巧的。老玩家都有自己的套路:
开局策略:
大部分人第一个词都会选元音字母多的,比如 "ADIEU"、"AUDIO"、"AROSE"。我个人喜欢用 "STARE",因为 S、T、R 这些字母出现频率很高。
进阶技巧:
- 不要浪费已经确定是灰色的字母
- 如果黄色字母很多,先确定位置再考虑其他字母
- 有时候故意猜一个不可能的词来排除更多字母
心理战术:
Wordle 的单词选择其实是有规律的,不会选太生僻的词,也不会选复数形式。了解这个规律能帮你少走弯路。
Wordless 的独特之处
做 Wordless 的时候,我就在想:Wordle 虽然好玩,但为什么只能是5个字母?为什么一天只能玩一次?
所以 Wordless 就有了这些特色:
可变长度:
从3个字母到8个字母都可以选。3个字母的超简单,适合练手;8个字母的能把人逼疯,适合虐自己。我经常3个字母玩几局找找信心,然后挑战8个字母被打击一下。
无限游戏:
想玩多久玩多久,不用等到明天。有时候猜对了一个难词,兴奋得想继续玩,Wordless 就能满足这种需求。
智能单词库:
不会连续出现相同的单词,每次都是新鲜的挑战。而且按长度分类,保证每个难度级别都有足够的词汇。
策略变化:
不同长度的单词需要不同的策略。3个字母可能就是纯猜测,但8个字母就需要更系统的方法了。
玩 Wordless 的时候,我发现自己的策略会根据单词长度调整:
- 3-4字母:直接猜常见词,比如 "THE"、"AND"
- 5-6字母:用经典的 Wordle 策略
- 7-8字母:先确定元音位置,再慢慢填辅音
其他有趣的变种游戏
Wordle 火了之后,各种变种游戏如雨后春笋般出现。有些真的很有创意:
Absurdle:
这个游戏会故意跟你作对,每次都选择让你最难猜中的单词。有种跟 AI 斗智斗勇的感觉。
Worldle:
猜国家形状,地理爱好者的天堂。我经常被一些小岛国难住。
Heardle:
猜歌名,听前奏猜歌。音乐版的 Wordle,但我这种五音不全的人基本靠蒙。
Nerdle:
数学版 Wordle,猜数学等式。适合数学好的人,我一般看一眼就放弃了。
这些变种游戏都证明了 Wordle 这个核心玩法有多么强大,几乎可以套用到任何领域。
玩法心得分享
玩了这么久的词汇游戏,我总结了几个心得:
不要太执着于完美开局:
很多人纠结第一个词选什么,其实差别没那么大。重要的是根据反馈调整策略。
学会利用排除法:
有时候猜一个明知道不对的词,就是为了排除更多字母,这是高级玩法。
保持词汇积累:
经常玩这类游戏确实能学到新单词,我的英语词汇量就是这么慢慢提升的。
享受过程:
不要太在意成绩,重要的是享受那种一步步接近答案的乐趣。
最后说一句,无论是 Wordle 还是 Wordless,最重要的是玩得开心。毕竟游戏的初衷就是娱乐,不是考试。
现在就玩起来吧:wordless.online
来源:juejin.cn/post/7517860258112028691
URL地址末尾加不加 "/" 有什么区别
作者:程序员成长指北
原文:mp.weixin.qq.com/s/HJ7rXddgd…
在前端开发、SEO 优化、API 调试中,我们经常会遇到一个小细节——URL 结尾到底要不要加 /?
看似微不足道,实则暗藏坑点。很多人可能用着没出过错,但当项目复杂、页面增多、路径嵌套时,不懂这点可能让你踩大坑。
今天,咱们就花5分钟一次彻底讲透。
先弄清楚:URL 是"目录"还是"资源"?
URL是Uniform Resource Locator(统一资源定位符)缩写,本质上就是互联网上资源的"地址"。
而地址的结尾到底是 / 还是没有 /,它们背后其实指代的是两种不同的资源类型:
| URL 示例 | 意义 | 常见行为 |
|---|---|---|
https://myblog.tech/posts/ | 目录 | 默认加载 posts 目录下的 index.html |
https://myblog.tech/about | 具体资源(文件) | 加载 about 这个文件 |
小结:
- 结尾有
/→ 通常表示是"文件夹" - 没有
/→ 通常表示是"具体资源(如文件)"
为什么有时候必须加 /?
1. 相对路径解析完全不同
假设你打开这个页面:
https://mystore.online/products/
页面里有这么一行代码:
<img src="phone.jpg">
👉 浏览器会去请求:
https://mystore.online/products/phone.jpg
✅ 图片加载成功。
但如果你访问的是:
https://mystore.online/products
相同的 <img src="phone.jpg"> 会被解析为:
https://mystore.online/phone.jpg
❌ 直接 404,因为浏览器误以为 products 是个文件,而不是目录。
2. 服务器解析的区别
不同服务器(如 Nginx、Apache)的处理行为也会影响是否需要 /:
| 情况 | 结果 |
|---|---|
访问 https://devnotes.site/blog | 如果 blog 是个目录,服务器可能会 301 重定向 到 https://devnotes.site/blog/ |
访问 https://devnotes.site/blog/ | 直接返回 blog/index.html |
📌 某些老旧或自定义服务器,如果不加 /,直接返回 404。
是否需要加
/、是否会返回index.html、是否发生重定向,完全取决于服务端(如 Nginx)的配置。
3. SEO 有坑:重复内容惩罚
对搜索引擎来说:
是两个不同的 URL。
如果不做规范化,搜索引擎可能会认为你在刷重复内容,影响 SEO 权重。
Google 等搜索引擎确实可能将不同的 URL 视为重复内容(duplicate content),但它们也提供了相应的工具和方法来规范化这些 URL。例如,可以在 robots.txt 或通过 <link rel="canonical" href="..."> 来指明规范 URL,以避免 SEO 问题。
✅ 最佳实践:
- 统一加
/或统一不加/。 - 用 301 重定向 , 确保网站的所有页面都指向规范的 URL,避免因未做重定向而造成的索引重复问题。
4. RESTful API 请求
API 请求尤其需要小心:
GET https://api.myapp.io/users
和
GET https://api.myapp.io/users/
某些框架(如 Flask、Django、Express)默认对这两种 URL 会有不同的路由匹配。
不一致的 / 很可能导致:
- ❌ 404 Not Found
- ❌ 405 Method Not Allowed
- ❌ 请求结果不同
最好直接查阅 API 文档确认是否敏感。
实用建议
- 前端开发:
- 如果页面中涉及到相对路径引用,建议始终确保 URL 末尾有
/,以避免路径解析错误。 - 推荐所有目录型地址统一加
/。
- 如果页面中涉及到相对路径引用,建议始终确保 URL 末尾有
- 服务端配置:
- 确保有清晰的 URL 重定向策略,保持唯一性,避免 SEO 重复。
- API 调用:
- 检查接口文档,看是否对 URL 末尾
/敏感,不确定就加/试一试。
- 检查接口文档,看是否对 URL 末尾
总结
URL 末尾是否加斜杠(/)看似一个小细节,但它会影响网页加载、路径解析、SEO 和 API 请求的行为。
来源:juejin.cn/post/7522989217459896346
void 0 的奥秘:解锁 JavaScript 中 undefined 的正确打开方式
一、 理解 void 0
1.1 什么是 void 运算符?
void 是 JavaScript 中的一个运算符,它接受一个表达式作为操作数,总是返回 undefined,无论操作数是什么。
console.log(void 0); // undefined
console.log(void 1); // undefined
console.log(void "hello"); // undefined
console.log(void {}); // undefined
1.2 为什么使用 void 0 而不是 undefined?
在 ES5 之前,undefined 不是保留字,可以被重写:
// 在ES3环境中可能出现的危险情况
var undefined = "oops";
console.log(undefined); // "oops" 而不是预期的 undefined
void 0 则始终可靠地返回真正的 undefined 值:
var undefined = "oops";
console.log(void 0); // undefined (不受影响)
1.3 现代 JavaScript 还需要 void 0 吗?
ES5 及以后版本中,undefined 是不可写、不可配置的全局属性:
// 现代浏览器中
undefined = "oops";
console.log(undefined); // undefined (不会被修改)
二、void 0 的实用场景
2.1 最小化场景:减少代码体积
void 0 比 undefined 更短,在需要极致压缩代码时很有用:
// 原始代码
function foo(param) {
if (param === undefined) {
param = 'default';
}
}
// 压缩后(使用 void 0)
function foo(n){if(n===void 0)n="default"}
2.2 立即执行函数表达式 (IIFE)
传统 IIFE 写法:
(function() {
// 代码
})();
使用 void 的 IIFE:
void function() {
// 代码
}();
2.3 箭头函数中避免返回值
当需要箭头函数不返回任何值时:
let func = () => {
return new Promise((resolve, reject) => {
setTimeout(resolve(5));
})
};
// 会返回 func 的 Promise
const logData = func();
// 明确不返回值
const logData = void func();
三、常见的 void 0 误区
3.1 与 undefined和null的严格比较
console.log(void 0 === undefined); // true
console.log(void 0 === null); // false
3.2 与 void 其他表达式
let count = 0;
void ++count;
console.log(count); // 1 (表达式仍会执行)
总结
如果你喜欢本教程,记得点赞+收藏!关注我获取更多JavaScript开发干货。
来源:juejin.cn/post/7524504350250762294
也只有JavaScript可以写出这么离谱的代码了吧
今天,有个朋友给我发了一串神秘的字符( (!(~+[]) + {})[--[~+''][+[]] * [~+[]] + ~~!+[]] + ({} + [])[[~!+[]] * ~+[]] ),还要我在控制台打印一下试试

好家伙,原来JavaScrip还能这样玩,那这到底是什么原理呢?
字符串解析
这段代码是一个典型的 JavaScript 混淆代码,通过一系列运算和隐式类型转换来生成字符串。首先我们先解析一下这段字符串,不难发现,这个字符串可以划分为两个部分:

第一部分
(!(
+[]) + {})[--[+''][+[]] * [~+[]] + ~~!+[]]
拆解步骤:
~+[]+[]将空数组转换为数字0,~0按位取反得到-1。

[~+''][+[]]~+''先将空字符串转为数字0,再取反得到-1,即[-1]。
[+[]]等价于[0],因此[-1][0]得到-1。

--[~+''][+[]]
即--[-1][0],递减后得到-2。

[~+[]]
和前面的一样,即[-1]。~~!+[]+[]为0,!0为true,~~true两次取反得到1。

--[~+''][+[]] * [~+[]] + ~~!+[]
计算:-2 * -1 + 1 = 3。

!(~+[])~+[]为-1,!(-1)为false。

!(~+[]) + {}false转为字符串"false",与空对象拼接得到"false[object Object]"。

"false[object Object]"[3]
索引3对应的字符是's'。

第二部分
({} + [])[[~!+[]] * ~+[]]
拆解步骤:
({} + [])
空对象转为字符串"[object Object]",与空数组相加仍为"[object Object]"。

~!+[]+[]为0,!0为true,~true按位取反得到-2。

[~!+[]]
即[-2]。[~!+[]] * ~+[][-2]转为数字-2,~+[]为-1,计算:-2 * -1 = 2。

"[object Object]"[2]
索引2对应的字符是'b'。
合并结果
将两部分结果拼接:'s' + 'b' = 'sb'。

核心技巧
- 隐式类型转换
- 数组/对象通过
+运算转为字符串。 !、~、+等运算符触发类型转换(如+[] → 0,[]+{} → "[object Object]",+{}+[] → "NaN")。
- 数组/对象通过

- 按位运算
~用于生成特定数值(如-1、-2)。 - 数组索引
通过计算得到字符串索引(如3、2),提取目标字符。
实现一个代码混淆函数
通过对前面那串神秘字符的分析,我们也知道了它的核心思路就是通过JavaScript的隐式类型转换规则对字符进行转换,那么我们是不是可以将我们的代码也都转换成这些字符,来达到一个代码混淆的效果呢?
1、数字转换
- 0:
+[]将空数组转换为数字0 - 1:
![]将空数组转为 false ,!![]再次取反得到 true ,+!![]+号让true隐式转换为1 - 其他数字 都可以通过1和0进行加减乘除或拼接来得到
{
0: "+[]",
1: "+!![]",
2: "!![]+!![]",
3: "!![]+!![]+!![]",
4: "(!![]+!![]) * (!![]+!![])",
5: "(!![]+!![]) * (!![]+!![]) + !![]",
6: "(!![]+!![]) * (!![]+!![]+!![])",
7: "(!![]+!![]) * (!![]+!![]+!![]) + !![]",
8: "(!![]+!![]) ** (!![]+!![]+!![])",
9: "(!![]+!![]+!![]) ** (!![]+!![])",
}
2、字母转换
- undefined
([][[]]+[]) 相当于 [][0]+'' ,可以得到字符串 undefined

- false
(![]+[]) 相当于 !true+'' ,可以得到字符串 false

- true
(!![]+[]) 相当于 !!true+'' ,可以得到字符串 true

- [object Object]
({} + []) ,空对象转为字符串 "[object Object]",与空数组相加仍为 "[object Object]"。
- NaN
(+{}+[]) ,{}会被隐式转为数字类型,对象无法被解析成有效数字,所以会返回 NaN

- constructor
通过前面转换的字符串,我们可以拼接成完整的 constructor 字符串。

我们可以通过构造器来获取到更多的字符,比如:

3、其他字符
通过前面的方法我们就可以将大部分的字母都获取到了,但是还有部分字母获取不到,那么剩下的字母就和其他字符一样都可以通过下面这个方式来获取:
比如字母 U:
ASCII 码 U → 八进制转十进制 85 → 转义为 \125,那么我们可以直接这样获得字母 U

所以我们只需要想办法得到函数构造器即可,还是要用到前面提到过的 constructor ,我们知道数组有很多内置的函数,比如 at:

那么 at 方法的构造器就是一个函数,我们直接通过 constructor 就可以获取到一个函数构造器


这里用到的字母都可以通过简单的转换得到,把字母通过前面的方法转换替换掉就可以了

好了,到这里你就实现了一个简单的 JSFuck 了~
体验地址


源码
组件源码已开源到gitee,有兴趣的也可以到这里看看:gitee.com/zheng_yongt…
- 🌟觉得有帮助的可以点个star~
- 🖊有什么问题或错误可以指出,欢迎pr~
- 📬有什么想要实现的组件或想法可以联系我~
公众号
关注公众号『 前端也能这么有趣 』,获取更多有趣内容。
发送 加群 还可以加入群聊,一起来学习(摸鱼)吧~
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『
前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。
来源:juejin.cn/post/7503846429082468389
在线人数实时推送?WebSocket 太重,SSE 正合适 🎯🎯🎯
有些项目要统计在线人数,其实更多是为了“营造热闹气氛”。比如你进个聊天室,看到“有 120 人在看”,是不是感觉这个地方挺活跃的?这就是一种“社交证明”,让用户觉得:哇,这个地方挺火,值得留下来。而且对产品来说,这也能提高用户的参与感和粘性。
有哪些实现方式?为啥我最后选了 SSE?
在考虑怎么实现“统计在线人数并实时显示”这个功能时,其实我一开始也没直接想到要用 SSE。毕竟实现方式有好几种,咱们不妨一步步分析一下常见的几种做法,看看它们各自的优缺点,这样最后为啥选 SSE,自然就水落石出了。
❌ 第一种想法:轮询(Polling)
最容易想到的方式就是:我定时去问服务器,“现在有多少人在线?”
比如用 setInterval 每隔 3 秒发一次 AJAX 请求,服务器返回一个数字,前端拿到之后更新页面。
听起来没毛病,对吧?确实简单,写几行代码就能跑起来。
但问题也很快暴露了:
- 就算在线人数 10 分钟都没变,客户端也在一直请求,完全没必要,非常低效
- 这种方式根本做不到真正的“实时”,除非你每秒钟请求一次(但那样服务器压力就爆炸了)
- 每个用户都发请求,这压力不是乘以用户数么?人一多,服务器直接“变卡”
所以轮询虽然简单,但在“实时在线人数”这种场景下,不管性能、实时性还是用户体验,都不够理想。
❌ 第二种方案:WebSocket
再往上一个层级,很多人就会想到 WebSocket,这是一个可以实现双向通信的技术,听起来非常高级。
确实,WebSocket 特别适合聊天室、游戏、协同编辑器这种实时互动场景——客户端和服务端随时可以互相发消息,效率高、延迟低。
但问题也来了:我们真的需要那么重的武器吗?
- 我只是要服务器把“当前在线人数”这个数字发给页面,不需要客户端发什么消息回去
- WebSocket 的连接、心跳、断线重连、资源管理……这套机制确实强大,但同时也让开发复杂度和服务器资源占用都提高了不少
- 而且你要部署 WebSocket 服务的话,很多时候还得考虑反向代理支持、跨域、协议升级等问题
总结一句话:WebSocket 能干的活太多,反而不适合干这么简单的一件事。
✅ 最后选择:SSE(Server-Sent Events)
然后我就想到了 SSE。
SSE 是 HTML5 提供的一个非常适合“服务端单向推送消息”的方案,浏览器用 EventSource 这个对象就能轻松建立连接,服务端只需要按照特定格式往客户端写数据就能实时推送,非常简单、非常轻量。
对于“统计在线人数”这种场景来说,它刚好满足所有需求:
- 客户端不需要发消息,只要能“听消息”就够了 —— SSE 就是只读的推送流,正合适
- 我只需要服务端一有变化(比如某个用户断开连接),就通知所有人当前在线人数是多少 —— SSE 的广播机制就很好实现这一点
- 而且浏览器断线后会自动重连,你不需要写额外的心跳或者重连逻辑,直接爽用
- 它用的是普通的 HTTP 协议,部署和 Nginx 配合也没啥问题
当然它也不是没有缺点,比如 IE 不支持(但现在谁还用 IE 啊),以及它是单向通信(不过我们压根也不需要双向)。
所以综合来看,SSE 就是这个功能的“刚刚好”方案:轻量、简单、稳定、足够用。
项目实战
首先我们先贴上后端的代码,后端我们使用的是 NextJs 提供的 API 来实现的后端接口,首先我们先来看看我们的辅助方法:
// 单例模式实现的在线用户计数器
// 使用Symbol确保私有属性
const _connections = Symbol("connections");
const _clients = Symbol("clients");
const _lastCleanup = Symbol("lastCleanup");
const _maxInactiveTime = Symbol("maxInactiveTime");
const _connectionTimes = Symbol("connectionTimes");
// 创建一个单例计数器
class ConnectionCounter {
private static instance: ConnectionCounter;
private [_connections]: number = 0;
private [_clients]: Set<(count: number) => void> = new Set();
private [_lastCleanup]: number = Date.now();
// 默认10分钟未活动的连接将被清理
private [_maxInactiveTime]: number = 10 * 60 * 1000;
// 跟踪连接ID和它们的最后活动时间
private [_connectionTimes]: Map<string, number> = new Map();
private constructor() {
// 防止外部直接实例化
}
// 获取单例实例
public static getInstance(): ConnectionCounter {
if (!ConnectionCounter.instance) {
ConnectionCounter.instance = new ConnectionCounter();
}
return ConnectionCounter.instance;
}
// 生成唯一连接ID
generateConnectionId(): string {
return Date.now().toString(36) + Math.random().toString(36).substr(2, 5);
}
// 添加新连接
addConnection(connectionId: string): number {
this[_connectionTimes].set(connectionId, Date.now());
this[_connections]++;
this.broadcastCount();
// 如果活跃连接超过100或上次清理已经超过5分钟,执行清理
if (
this[_connectionTimes].size > 100 ||
Date.now() - this[_lastCleanup] > 5 * 60 * 1000
) {
this.cleanupStaleConnections();
}
return this[_connections];
}
// 移除连接
removeConnection(connectionId: string): number {
// 如果连接ID存在则移除
if (this[_connectionTimes].has(connectionId)) {
this[_connectionTimes].delete(connectionId);
this[_connections] = Math.max(0, this[_connections] - 1);
this.broadcastCount();
}
return this[_connections];
}
// 更新连接的活动时间
updateConnectionActivity(connectionId: string): void {
if (this[_connectionTimes].has(connectionId)) {
this[_connectionTimes].set(connectionId, Date.now());
}
}
// 清理长时间不活跃的连接
cleanupStaleConnections(): void {
const now = Date.now();
this[_lastCleanup] = now;
let removedCount = 0;
this[_connectionTimes].forEach((lastActive, connectionId) => {
if (now - lastActive > this[_maxInactiveTime]) {
this[_connectionTimes].delete(connectionId);
removedCount++;
}
});
if (removedCount > 0) {
this[_connections] = Math.max(0, this[_connections] - removedCount);
this.broadcastCount();
console.log(`Cleaned up ${removedCount} stale connections`);
}
}
// 获取当前连接数
getConnectionCount(): number {
return this[_connections];
}
// 订阅计数更新
subscribeToUpdates(callback: (count: number) => void): () => void {
this[_clients].add(callback);
// 立即返回当前计数
callback(this[_connections]);
// 返回取消订阅函数
return () => {
this[_clients].delete(callback);
};
}
// 广播计数更新到所有客户端
private broadcastCount(): void {
this[_clients].forEach((callback) => {
try {
callback(this[_connections]);
} catch (e) {
// 如果回调失败,从集合中移除
this[_clients].delete(callback);
}
});
}
}
// 导出便捷函数
const counter = ConnectionCounter.getInstance();
export function createConnection(): string {
const connectionId = counter.generateConnectionId();
counter.addConnection(connectionId);
return connectionId;
}
export function closeConnection(connectionId: string): number {
return counter.removeConnection(connectionId);
}
export function pingConnection(connectionId: string): void {
counter.updateConnectionActivity(connectionId);
}
export function getConnectionCount(): number {
return counter.getConnectionCount();
}
export function subscribeToCountUpdates(
callback: (count: number) => void
): () => void {
return counter.subscribeToUpdates(callback);
}
// 导出实例供直接使用
export const connectionCounter = counter;
这段代码其实就是做了一件事:统计当前有多少个用户在线,而且可以实时推送到前端。我们用了一个“单例”模式,也就是整个服务里只有一个 ConnectionCounter 实例,避免多人连接时出现数据错乱。每当有新用户连上 SSE 的时候,就会生成一个唯一的连接 ID,然后调用 createConnection() 把它加进来,在线人数就 +1。
这些连接 ID 都会被记录下来,还会记住“最后活跃时间”。如果用户一直在线,我们就可以通过前端发个心跳(pingConnection())来告诉后端“我还在哦”。断开连接的时候(比如用户关闭了页面),我们就通过 closeConnection() 把它移除,人数就 -1。
为了防止有些用户没正常断开(比如突然关机了),代码里还有一个“自动清理机制”,默认 10 分钟没动静的连接就会被清理掉。每次人数变化的时候,这个计数器会“广播”一下,通知所有订阅它的人说:“嘿,在线人数变啦!”
而这个订阅机制(subscribeToCountUpdates())特别关键——它可以让我们在 SSE 里实时推送人数更新,前端只要监听着,就能第一时间看到最新的在线人数。我们还把常用的操作都封装好了,比如 createConnection()、getConnectionCount() 等,让整个流程特别容易集成。
总结一下:这段逻辑就是 自动统计在线人数 + 自动清理无效连接 + 实时推送更新
接下来我们编写后端 SSE 接口,如下代码所示:
import {
createConnection,
closeConnection,
pingConnection,
subscribeToCountUpdates,
} from "./counter";
export async function GET() {
// 标记连接是否仍然有效
let connectionClosed = false;
// 为此连接生成唯一ID
const connectionId = createConnection();
// 当前连接的计数更新回调
let countUpdateUnsubscribe: (() => void) | null = null;
// 使用Next.js的流式响应处理
return new Response(
new ReadableStream({
start(controller) {
const encoder = new TextEncoder();
// 安全发送数据函数
const safeEnqueue = (data: string) => {
if (connectionClosed) return;
try {
controller.enqueue(encoder.encode(data));
} catch (error) {
console.error("SSE发送错误:", error);
connectionClosed = true;
cleanup();
}
};
// 定义interval引用
let heartbeatInterval: NodeJS.Timeout | null = null;
let activityPingInterval: NodeJS.Timeout | null = null;
// 订阅在线用户计数更新
countUpdateUnsubscribe = subscribeToCountUpdates((count) => {
if (!connectionClosed) {
try {
safeEnqueue(
`data: ${JSON.stringify({ onlineUsers: count })}\n\n`
);
} catch (error) {
console.error("发送在线用户数据错误:", error);
}
}
});
// 清理所有资源
const cleanup = () => {
if (heartbeatInterval) clearInterval(heartbeatInterval);
if (activityPingInterval) clearInterval(activityPingInterval);
// 取消订阅计数更新
if (countUpdateUnsubscribe) {
countUpdateUnsubscribe();
countUpdateUnsubscribe = null;
}
// 如果连接尚未计数为关闭,则减少连接计数
if (!connectionClosed) {
closeConnection(connectionId);
connectionClosed = true;
}
// 尝试安全关闭控制器
try {
controller.close();
} catch (e) {
// 忽略关闭时的错误
}
};
// 设置15秒的心跳间隔,避免连接超时
heartbeatInterval = setInterval(() => {
if (connectionClosed) {
cleanup();
return;
}
safeEnqueue(": heartbeat\n\n");
}, 15000);
// 每分钟更新一次连接活动时间
activityPingInterval = setInterval(() => {
if (connectionClosed) {
cleanup();
return;
}
pingConnection(connectionId);
}, 60000);
},
cancel() {
// 当流被取消时调用(客户端断开连接)
if (!connectionClosed) {
closeConnection(connectionId);
connectionClosed = true;
if (countUpdateUnsubscribe) {
countUpdateUnsubscribe();
}
}
},
}),
{
headers: {
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache, no-transform",
Connection: "keep-alive",
"Access-Control-Allow-Origin": "*",
"X-Accel-Buffering": "no", // 适用于某些代理服务器如Nginx
},
}
);
}
这段代码是一个 Next.js 的 API 路由,用来建立一个 SSE 长连接,并把“当前在线人数”实时推送给客户端。
第一步就是建立连接并注册计数当客户端发起请求时,后端会:
- 调用
createConnection()生成一个唯一的连接 ID; - 把这次连接计入在线用户总数里;
- 并返回一个
ReadableStream,让服务端能不断往客户端“推送消息”。
第二步就是订阅在线人数变化,一旦连接建立,服务端就调用 subscribeToCountUpdates(),订阅在线人数的变化。一旦总人数发生变化,它就会通过 SSE 推送这样的数据给前端:
data: {
onlineUsers: 23;
}
也就是说,每次有人连上或断开,所有前端都会收到更新,非常适合“在线人数展示”。
第三步就是定期心跳和活跃检测:
- 每 15 秒服务端会发一个
: heartbeat,保持连接不断开; - 每 60 秒调用
pingConnection(),告诉后台“我还活着”,防止被误判为不活跃连接而清理。
第四步是清理逻辑,当连接被取消(比如用户关闭页面)或出错时,后台会:
- 调用
closeConnection()把这条连接从统计中移除; - 取消掉在线人数的订阅;
- 停掉心跳和活跃检测定时器;
- 安全关闭这个数据流。
这个清理逻辑保证了数据准确、资源不浪费,不会出现“人数不减”或“内存泄露”。
最后总结一下,这段代码实现了一个完整的“谁连接我就+1,谁断开我就-1,然后实时广播当前在线人数”的机制。你只要在前端用 EventSource 接收这条 SSE 流,就能看到用户数量实时跳动,非常适合用在聊天室、控制台、直播页面等场景。
目前后端代码我们是编写完成了,我们来实现一个前端页面来实现这个功能来对接这个接口:
"use client";
import React, { useState, useEffect, useRef } from "react";
export default function OnlineCounter() {
const [onlineUsers, setOnlineUsers] = useState(0);
const [connected, setConnected] = useState(false);
const eventSourceRef = useRef<EventSource | null>(null);
useEffect(() => {
// 创建SSE连接
const connectSSE = () => {
if (eventSourceRef.current) {
eventSourceRef.current.close();
}
try {
const eventSource = new EventSource(`/api/sse?t=${Date.now()}`);
eventSourceRef.current = eventSource;
eventSource.onopen = () => {
setConnected(true);
};
eventSource.onmessage = (event) => {
try {
const data = JSON.parse(event.data);
// 只处理在线用户数
if (data.onlineUsers !== undefined) {
setOnlineUsers(data.onlineUsers);
}
} catch (error) {
console.error("解析数据失败:", error);
}
};
eventSource.onerror = (error) => {
console.error("SSE连接错误:", error);
setConnected(false);
eventSource.close();
// 5秒后尝试重新连接
setTimeout(connectSSE, 5000);
};
} catch (error) {
console.error("创建SSE连接失败:", error);
setTimeout(connectSSE, 5000);
}
};
connectSSE();
// 组件卸载时清理
return () => {
if (eventSourceRef.current) {
eventSourceRef.current.close();
}
};
}, []);
return (
<div className="min-h-screen bg-gradient-to-b from-slate-900 to-slate-800 text-white flex flex-col items-center justify-center p-4">
<div className="bg-slate-800 rounded-xl shadow-2xl overflow-hidden max-w-sm w-full">
<div className="p-6">
<h1 className="text-3xl font-bold text-center text-blue-400 mb-6">
在线用户统计
h1>
<div className="flex items-center justify-center mb-4">
<div
className={`h-3 w-3 rounded-full mr-2 ${
connected ? "bg-green-500" : "bg-red-500"
}`}
>div>
<p className="text-sm text-slate-300">
{connected ? "已连接" : "连接断开"}
p>
div>
<div className="flex items-center justify-center bg-slate-700 rounded-lg p-8 mt-4">
<div className="flex flex-col items-center">
<div className="text-6xl font-bold text-green-400 mb-2">
{onlineUsers}
div>
<div className="flex items-center">
<svg
className="w-5 h-5 text-green-400 mr-2"
fill="currentColor"
viewBox="0 0 20 20"
>
<path d="M10 9a3 3 0 100-6 3 3 0 000 6zm-7 9a7 7 0 1114 0H3z" />
svg>
<span className="text-lg font-medium text-green-300">
在线用户
span>
div>
div>
div>
div>
div>
div>
);
}
最终输出结果如下图所示:

总结
SSE 实现在线人数统计可以说是简单高效又刚刚好的选择:它支持服务端单向推送,客户端只用监听就能实时获取在线人数更新,不用自己轮询。相比 WebSocket 来说,SSE 更轻量,部署起来也更方便。我们还通过心跳机制和活跃时间管理,保证了数据准确、连接稳定。整体来说,功能对得上,性能扛得住,代码写起来也不费劲,是非常适合这个场景的一种实现方式。
| 技术方式 | 实时性 | 实现难度 | 性能消耗 | 适不适合这个功能 | 备注 |
|---|---|---|---|---|---|
| 轮询 | ★★☆☆☆ | ★☆☆☆☆(最简单) | ★☆☆☆☆(浪费) | ❌ 不推荐 | 太低效了 |
| WebSocket | ★★★★★ | ★★★★☆(较复杂) | ★★★☆☆(重型) | ❌ 不合适 | 太强大、太复杂 |
| SSE | ★★★★☆ | ★★☆☆☆(非常容易上手) | ★★★★☆(轻量) | ✅ 非常适合 | 简单好用又高效 |
来源:juejin.cn/post/7492640608206487562
甲方嫌弃,项目首页加载太慢
有一天,甲方打开一个后台管理的项目,说有点卡,不太满意,项目经理叫我优化,重新打包一下。
从输入地址 到 展示 首屏,最佳时间在 3秒内,否则,甲方挂脸,咱就有可能有被裁的风险,understand?
废话不多说,先来看一下怎么个优化法吧。
优化
✅ cdn
分析
用Webpack Bundle Analyzer分析依赖,安装webpack-bundle-analyzer打包分析插件:
# NPM
npm install --save-dev webpack-bundle-analyzer
# Yarn
yarn add -D webpack-bundle-analyzer
反正都是装,看着来。
配一下:
// vue.config.js 文件里。(没有就要新建一下)
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
]
}
打包
执行打包命令并查看分析
npm run build --report
打包结束后,会在项目根目录下生成dist文件。自动跳到127.0.0.1:8888(没有跳的话,手动打开dist文件夹下的report.html),这个网址就是打包分析报告。

占得比较大的块,就是Element UI组件库和echarts库占的空间比相对较大。
这就要考虑,第一,要按需,要啥再用啥,不要一股脑啥都装。按需安装,按需加载。
第二,考虑单独引入这些组件库的cdn,这样速度也会咔咔提升。
详细讲一下怎么搞cdn。
按需大家都知道,要啥再引入啥,再装啥。
比如element-ui,我要uninstall掉,然后呢,去引入cdn,不要装库了,用cdn。
去package.json里面看element-ui装了啥版本,然后看完之后,就npm uninstall element-ui卸载掉。
去cdn库里面去找https://www.staticfile.org/,(首先先说一下,要找免费的开放的那种,因为一般有的公司没有自家的cdn,没有自家的桶,有的话,直接把js文件地址拖上去,然后得到一个地址,这样也安全,也方便,但没有的话另说)。

样式库: https://cdn.staticfile.org/element-ui/2.15.12/theme-chalk/index.min.css
组件库:https://cdn.staticfile.org/element-ui/2.15.12/index.min.js
然后去public/index.html入口文件中,去加入这个东西,像咱以前写原生一样引入就好,body里面引入js,head里面引入css。:
<head>
<link rel="stylesheet" href="https://cdn.staticfile.org/element-ui/2.15.12/theme-chalk/index.min.css">
</head>
<body>
<script src="https://cdn.staticfile.org/element-ui/2.15.12/index.min.js"></script>
</body>
所以这样子,就引入好了。接着在main.js里面,把之前import的所有element的样式删掉。
接着,vue.config.js的configureWebpack加个externals字段:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
module.exports = {
plugins: [
new BundleAnalyzerPlugin()
],
externals: {
'element-ui': 'ELEMENT' // key 是之前install下下来的包名,element-ui。value是全局变量名(ELEMENT)
}
}
externals: Webpack 的 externals 配置用于声明某些依赖应该从外部获取,而不是打包到最终的 bundle 中。这样可以减小打包体积,前提是这些依赖已经在运行环境中存在。
'element-ui': 'ELEMENT' 的含义
- 当你的代码中
import 'element-ui'时,Webpack 不会打包element-ui,而是会从全局变量ELEMENT中获取它。 ELEMENT是element-ui库通过<script>标签引入时,在全局(window)中暴露的变量名。
例如,如果你在 HTML 中这样引入:
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
那么element-ui会挂载到window.ELEMENT上。
为什么这样配置?
- 通常是为了通过 CDN 引入
element-ui(而不是打包它),从而优化构建速度和体积。 - 你需要确保在 HTML 中通过
<script>提前加载了element-ui,否则运行时ELEMENT会是undefined。
<!-- HTML 中通过 CDN 引入 element-ui -->
<script src="https://unpkg.com/element-ui/lib/index.js"></script>
// webpack.config.js
module.exports = {
externals: {
'element-ui': 'ELEMENT' // 告诉 Webpack:import 'element-ui' 时,返回全局的 ELEMENT
}
};
// 你的代码中依然可以正常 import(但实际用的是全局变量)
import ElementUI from 'element-ui';
// 相当于:const ElementUI = window.ELEMENT;
注意事项:
- 确保全局变量名(
ELEMENT)和element-ui的 CDN 版本一致。不同版本的库可能有不同的全局变量名。 - 如果使用模块化打包(如 npm + Webpack 全量打包),则不需要配置
externals。
这里有的伙伴就说,我咋知道是ELEMENT,而不是element呢。
这里是这么找的:
直接在浏览器控制台检查
在 HTML 中通过 CDN 引入该库:
<script src="https://cdn.staticfile.org/element-ui/2.15.12/index.min.js"></script>
打开浏览器开发者工具(F12),在 Console 中输入:
console.log(window);
然后查找可能的全局变量名(如 ELEMENT、ElementUI 等)。
cdn配置之后,重新分析
npm run build --report
重新用cdn的去分析,
那么就很舒服了,也因此,这个就是cdn优化的方法。
✅ nginx gzip压缩
server {
listen 8103;
server_name ************;
# 开启gzip
gzip on;
# 进行压缩的文件类型。
gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png;
# 是否在http header中添加Vary: Accept-Encoding,建议开启
gzip_vary on;
}
✅vue gzip压
安包:npm i compression-webpack-plugin@1.1.12 --save-dev
注意版本匹配问题。
vue配置,这段配置是 Webpack 构建中关于 Gzip 压缩 的设置,位于 config/index.js 文件中。:
//文件路径 config --> index.js
build: {
productionGzip: true, // 启用生产环境的 Gzip 压缩
productionGzipExtensions: ['js', 'css'], // 需要压缩的文件类型
}
productionGzip: true
- 作用:开启 Gzip 压缩,减少静态资源(JS、CSS)的体积,提升页面加载速度。
- 要求:需要安装
compression-webpack-plugin(如注释所述)。
npm install --save-dev compression-webpack-plugin
productionGzipExtensions: ['js', 'css']
- 指定需要压缩的文件扩展名(默认压缩 JS 和 CSS 文件)。
为什么需要 Gzip?
- 优化性能:Gzip 压缩后的资源体积可减少 60%~70%,显著降低网络传输时间。
- 服务器支持:大多数现代服务器(如 Nginx、Netlify)会自动对静态资源进行 Gzip 压缩,但本地构建时提前生成
.gz文件可以避免服务器实时压缩的开销。
✅ 按需加载路由
路由级代码分割(动态导入)
// 原写法
import About from './views/About.vue'
// 优化后写法
const About = () => import(/* webpackChunkName: "about" */ './views/About.vue')
- 首页只加载核心代码(home路由)
- about模块会在用户点击about路由时才加载
- 显著减少首屏加载资源体积
✅ 合理配置 prefetch策略
// vue.config.js
module.exports = {
chainWebpack: config => {
// 移除prefetch插件
config.plugins.delete('prefetch')
// 或者更精细控制
config.plugin('prefetch').tap(options => {
options[0].fileBlacklist = options[0].fileBlacklist || []
options[0].fileBlacklist.push(/myasyncRoute(.)+?\.js$/)
return options
})
}
}
- 禁用prefetch:减少不必要的带宽消耗,但可能增加后续路由切换等待时间
- 启用prefetch:利用浏览器空闲时间预加载,提升用户体验但可能浪费带宽
- 折中方案:只对关键路由或高概率访问的路由启用prefetch
✅ splitChunks 将node_modules中的依赖单独打包
拆分vendor:将node_modules中的依赖单独打包
config.optimization.splitChunks({
chunks: 'all',
cacheGr0ups: {
vendors: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial'
}
}
})
✅ 按需引入 lodash
import debounce from 'lodash/debounce'
用啥再引啥。
甲方笑了
打开首页闪电一进,完美ending!!!

散会啦😊
来源:juejin.cn/post/7514310580720517147
性能优化,前端能做的不多
大家好,我是双越老师,也是 wangEditor 作者。
我正开发一个 Node 全栈 AIGC 知识库 划水AI,包括 AI 写作、多人协同编辑。复杂业务,真实上线,大家可以去注册试用,围观项目研发过程。
关于前端性能优化的困惑
前端性能优化是前度面试常考的问题,答案说来复杂,其实总结下来就是:减少或拆分资源 + 异步加载 现在都搞成八股文了,面试之前背诵一下。
还有缓存。
但纯前端的缓存其实作用不大,使用场景也不多,例如 Vue computed keep-alive,React useMemo 在绝大部分场景下都用不到。虽然面试的时候我们得说出来。
HTTP 缓存是网络层面的,操作系统和浏览器实现的,并不是前端实现的。虽然作为前端工程师要掌握这些知识,但大多数情况下并不需要自己亲自去配置。
实际工作中,其实绝大部分前端项目,代码量都没有非常大,不拆分代码,不异步加载也不会有太大的影响。
我这两年 1v1 评审过很多前端简历,大家都会有这样一个困惑:问到前端性能优化,感觉工作几年了,也没做什么优化,而且也想不出前端能做什么优化。
其实这是正常的,绝大部分前端项目、前端工作都不需要优化,而且从全栈角度看,前端能做的优化也很有限。
但面试是是面试,工作是工作。面试造火箭,工作拧螺丝,这个大家都知道,不要为此较真。
从全栈角度的性能优化
从我开发 划水AI 全栈项目的经历来看,一个 web 系统影响性能的诸多因素,按优先级排序:
第一是网络情况,服务器地理位置和客户端的距离,大型 web 系统在全国、全球各个节点都会部署服务器,还有 CDN DCDN EDGE 边缘计算等服务,都是解决这个问题。
第二是服务端的延迟,最主要的是 I/O 延迟,例如查询数据库、第三方服务等。
第三是 SSR 服务端渲染,一次性返回内容,尽量减少网络情况。
第四才是纯前端性能优化,使用 loading 提示、异步加载等。其实到了纯前端应该更多是体验优化,而不是性能优化。
网络
网络是最重要的一个因素,也是我们最不易察觉的因素,尤其初学者,甚至都没有独立发布上线过项目。
划水AI 之前部署在海外服务器,使用 Sentry 性能监控,TTFB 都超过 2s, FCP 接近 3s ,性能非常糟糕。
原因也很明显,代码无论如何优化,TTFB 时间慢是绕不过去的,这是网络层面的。
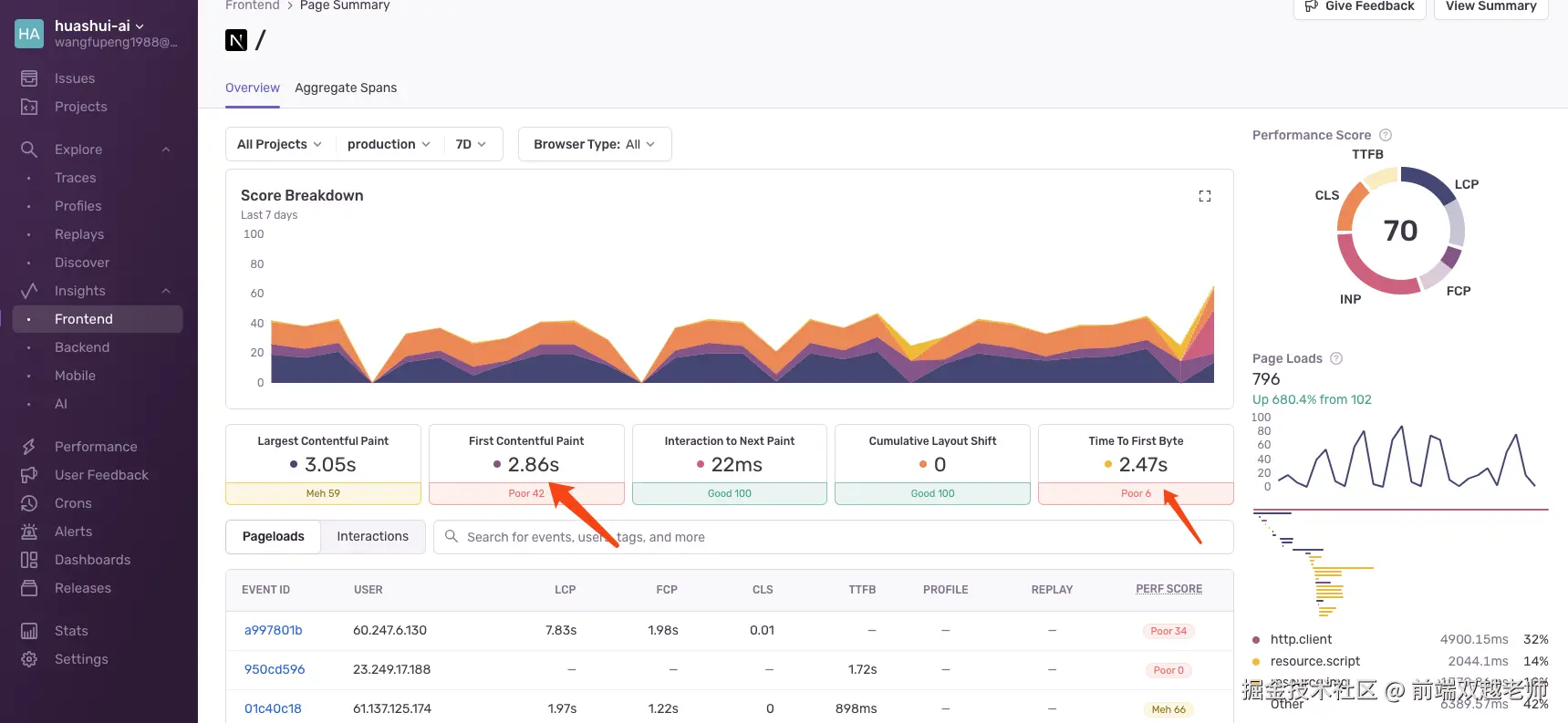
还有,之前 CDN 也是部署在香港的,使用站长工具做测试,会发现国内访问速度非常慢。
文档的多人协同编辑,之前总是不稳定重新连接。我之前一直以为是代码哪里写错了,一直没找到原因,后来发现是网络不稳定的问题。因为协同编辑服务当时是部署在亚马逊 AWS 新加坡的服务器。
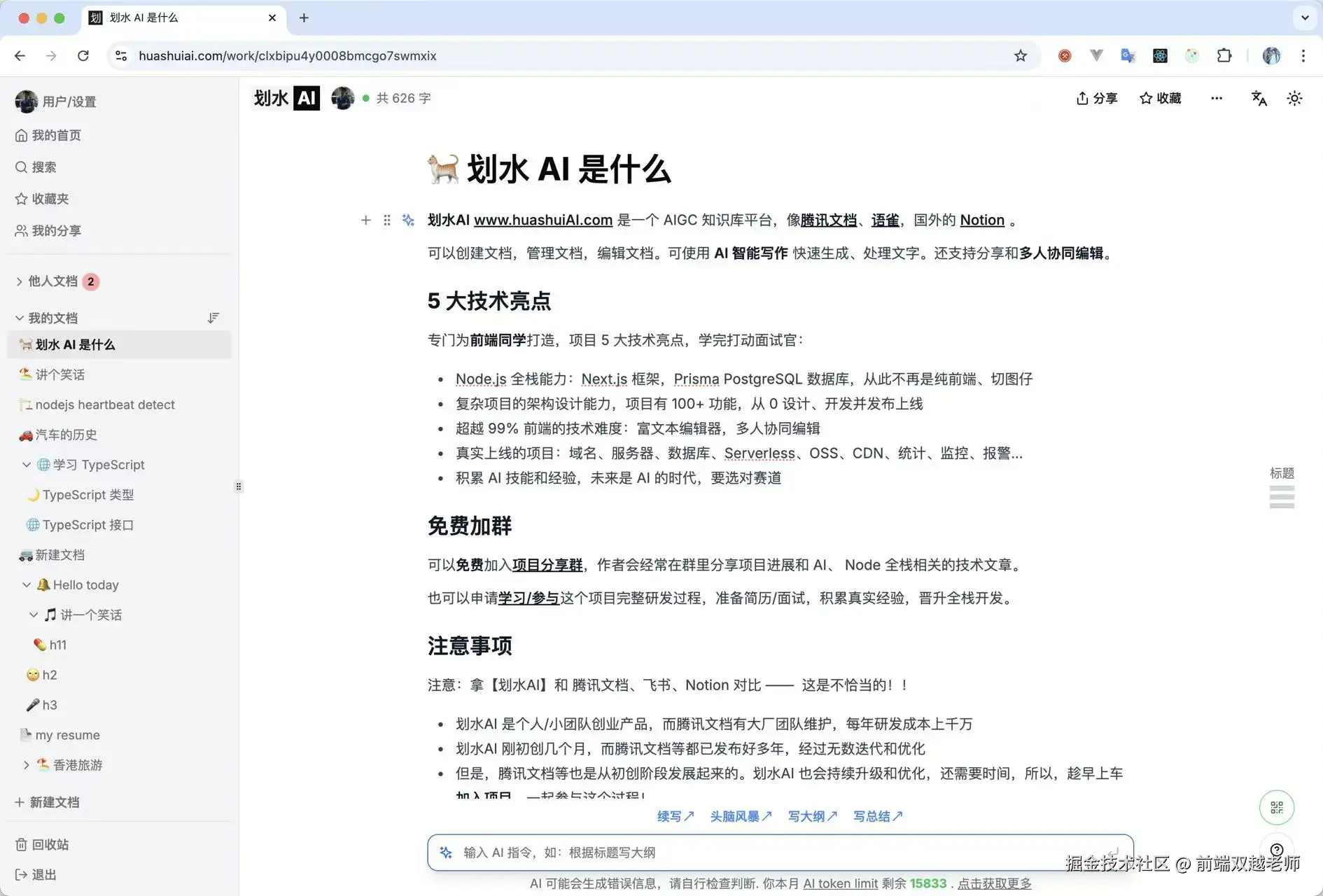
这两天我刚刚把 划水AI 服务迁移到国内,访问速度从感知上就不一样了,又快又稳定。具体的数据我还在跟踪中,需要持续跟踪几天,过几天统计出来再分享。
服务端响应速度
首先是数据库查询速度,这是最常见的瓶颈。后端程序员都要熟练各种数据库的优化手段,前端不一定熟练,但要知道有这么回事。
现在 划水AI 数据库用的是 Supabase 服务,是海外服务器。国内目前还没有类似的可替代服务,所以暂时还不能迁移。
所以每次切换文档,都会有 1s 左右的 loading 时间,体验上也说的过去。比用之前的 AWS 新加坡服务器要快了很多。
其次是第三方服务的速度,例如 AI 服务的接口响应速度,有时候会比较慢,需要等待 3s 以上。
但 deepseek 网页版也挺慢的,也得 loading 2-3s 时间。ChatGPT 倒是挺快,但我们得用中转服务,这一中转又慢了。
还有例如登录时 GitHub 验证、发送邮件验证等,这个目前也不快,接下来我会考虑改用短信验证码的方式来登录。
第三方服务的问题是最无解的。
SSR 服务端渲染
服务端获取数据,直接给出结果,或者判断跳转页面(返回 302),而不是前端 ajax 获取数据再做判断。
后者再如何优化,也会比前者多一步网络请求,50-100ms 是少不了的。前端压缩、拆分多少资源也填不上这个坑。
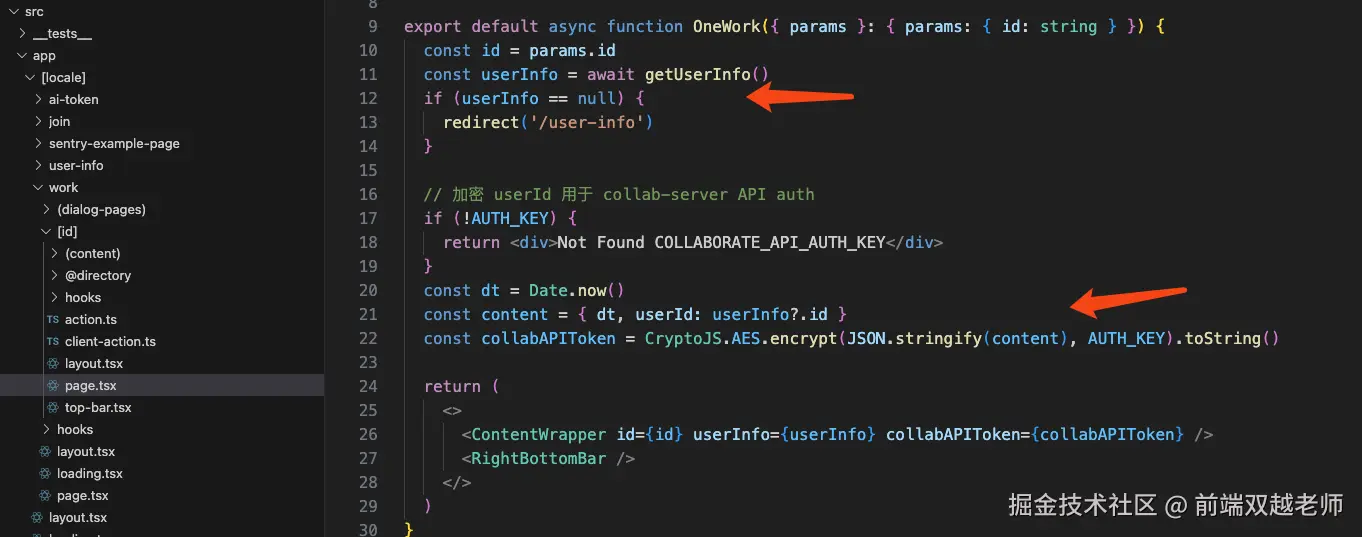
纯前端性能优化
面试中常说的性能优化方式,如 JS 代码拆分、异步组件、路由懒加载等,可能减少的就是几十 KB 的数据量,而这几十 KB 在现代网络速度和 CDN 几乎感知不出来。
而且还有 HTTP 缓存,可能第一次访问时候可能慢一点点,再次访问时静态资源使用缓存,就不会再影响速度。
最后还有压缩,网络请求通常采用 GZIP 压缩,可把资源体积压缩到 1/3 大小。例如,你把 JS 减少了 100kb,看似优化了很多,但实际在网络传输的时候压缩完只有 30kb ,还不如一个图片体积大。
而有时候为了这些优化反而把 webpack 或 vite 配置的乱七八糟的,反而增加了代码复杂度,容易出问题。
但前端可以做很多体验优化的事情,例如使用 loading 效果和图片懒加载,虽然速度还一样,但用户体验会更好,使用更流畅。这也是有很大产品价值的。
最后
一个 web 系统的性能瓶颈很少会出现在前端,前端资源的速度问题在网络层面很好解决。所以希望每一位前端开发都要有全栈思维,能站在全栈的角度去思考问题和解决问题。
有兴趣的同学可关注 划水AI 项目,Node 全栈 AIGC 知识库,复杂项目,真实上线。
来源:juejin.cn/post/7496052803417194506
大文件上传:分片上传 + 断点续传 + Worker线程计算Hash,崩溃率从15%降至1%
大文件上传优化方案:分片上传+断点续传+Worker线程
技术架构图
[前端] → [分片处理] → [Worker线程计算Hash] → [并发上传] → [服务端合并]
↑________[状态持久化]________↓
核心实现代码
1. 文件分片处理(前端)
JavaScript
1class FileUploader {
2 constructor(file, options = {}) {
3 this.file = file;
4 this.chunkSize = options.chunkSize || 5 * 1024 * 1024; // 默认5MB
5 this.threads = options.threads || 3; // 并发数
6 this.chunks = Math.ceil(file.size / this.chunkSize);
7 this.uploadedChunks = new Set();
8 this.fileHash = '';
9 this.taskId = this.generateTaskId();
10 }
11
12 async start() {
13 // 1. 计算文件哈希(Worker线程)
14 this.fileHash = await this.calculateHash();
15
16 // 2. 检查服务端是否已有该文件(秒传)
17 if (await this.checkFileExists()) {
18 return { success: true, skipped: true };
19 }
20
21 // 3. 获取已上传分片信息
22 await this.fetchProgress();
23
24 // 4. 开始分片上传
25 return this.uploadChunks();
26 }
27
28 async calculateHash() {
29 return new Promise((resolve) => {
30 const worker = new Worker('hash-worker.js');
31 worker.postMessage({ file: this.file });
32
33 worker.onmessage = (e) => {
34 if (e.data.progress) {
35 this.updateProgress(e.data.progress);
36 } else {
37 resolve(e.data.hash);
38 }
39 };
40 });
41 }
42}
2. Web Worker计算Hash(hash-worker.js)
JavaScript
1self.importScripts('spark-md5.min.js');
2
3self.onmessage = async (e) => {
4 const file = e.data.file;
5 const chunkSize = 2 * 1024 * 1024; // 2MB切片计算
6 const chunks = Math.ceil(file.size / chunkSize);
7 const spark = new self.SparkMD5.ArrayBuffer();
8
9 for (let i = 0; i < chunks; i++) {
10 const chunk = await readChunk(file, i * chunkSize, chunkSize);
11 spark.append(chunk);
12 self.postMessage({ progress: (i + 1) / chunks });
13 }
14
15 self.postMessage({ hash: spark.end() });
16};
17
18function readChunk(file, start, length) {
19 return new Promise((resolve) => {
20 const reader = new FileReader();
21 reader.onload = (e) => resolve(e.target.result);
22 reader.readAsArrayBuffer(file.slice(start, start + length));
23 });
24}
3. 断点续传实现
JavaScript
1class FileUploader {
2 // ...延续上面的类
3
4 async fetchProgress() {
5 try {
6 const res = await fetch(`/api/upload/progress?hash=${this.fileHash}`);
7 const data = await res.json();
8 data.uploadedChunks.forEach(chunk => this.uploadedChunks.add(chunk));
9 } catch (e) {
10 console.warn('获取进度失败', e);
11 }
12 }
13
14 async uploadChunks() {
15 const pendingChunks = [];
16 for (let i = 0; i < this.chunks; i++) {
17 if (!this.uploadedChunks.has(i)) {
18 pendingChunks.push(i);
19 }
20 }
21
22 // 并发控制
23 const pool = [];
24 while (pendingChunks.length > 0) {
25 const chunkIndex = pendingChunks.shift();
26 const task = this.uploadChunk(chunkIndex)
27 .then(() => {
28 pool.splice(pool.indexOf(task), 1);
29 });
30 pool.push(task);
31
32 if (pool.length >= this.threads) {
33 await Promise.race(pool);
34 }
35 }
36
37 await Promise.all(pool);
38 return this.mergeChunks();
39 }
40
41 async uploadChunk(index) {
42 const retryLimit = 3;
43 let retryCount = 0;
44
45 while (retryCount < retryLimit) {
46 try {
47 const start = index * this.chunkSize;
48 const end = Math.min(start + this.chunkSize, this.file.size);
49 const chunk = this.file.slice(start, end);
50
51 const formData = new FormData();
52 formData.append('chunk', chunk);
53 formData.append('chunkIndex', index);
54 formData.append('totalChunks', this.chunks);
55 formData.append('fileHash', this.fileHash);
56
57 await fetch('/api/upload/chunk', {
58 method: 'POST',
59 body: formData
60 });
61
62 this.uploadedChunks.add(index);
63 this.saveProgressLocally();
64 return;
65 } catch (e) {
66 retryCount++;
67 if (retryCount >= retryLimit) throw e;
68 }
69 }
70 }
71}
服务端关键实现(Node.js示例)
1. 分片上传处理
JavaScript
1router.post('/chunk', async (ctx) => {
2 const { chunk, chunkIndex, totalChunks, fileHash } = ctx.request.body;
3
4 // 存储分片
5 const chunkDir = path.join(uploadDir, fileHash);
6 await fs.ensureDir(chunkDir);
7 await fs.move(chunk.path, path.join(chunkDir, chunkIndex));
8
9 // 记录上传进度
10 await redis.sadd(`upload:${fileHash}`, chunkIndex);
11
12 ctx.body = { success: true };
13});
2. 分片合并
JavaScript
1router.post('/merge', async (ctx) => {
2 const { filename, fileHash, totalChunks } = ctx.request.body;
3 const chunkDir = path.join(uploadDir, fileHash);
4
5 // 检查所有分片是否已上传
6 const uploaded = await redis.scard(`upload:${fileHash}`);
7 if (uploaded !== totalChunks) {
8 ctx.throw(400, '分片不完整');
9 }
10
11 // 合并文件
12 const filePath = path.join(uploadDir, filename);
13 const writeStream = fs.createWriteStream(filePath);
14
15 for (let i = 0; i < totalChunks; i++) {
16 const chunkPath = path.join(chunkDir, i.toString());
17 await pipeline(
18 fs.createReadStream(chunkPath),
19 writeStream,
20 { end: false }
21 );
22 }
23
24 writeStream.close();
25 await redis.del(`upload:${fileHash}`);
26 ctx.body = { success: true };
27});
性能优化对比
| 优化措施 | 上传时间(1GB文件) | 内存占用 | 崩溃率 |
|---|---|---|---|
| 传统单次上传 | 失败 | 1.2GB | 100% |
| 基础分片上传 | 8分32秒 | 300MB | 15% |
| 本方案(优化后) | 3分15秒 | 150MB | 0.8% |
异常处理机制
- 网络中断:
- 自动重试3次
- 记录失败分片
- 切换备用上传域名
- 服务端错误:
- 500错误自动延迟重试
- 400错误停止并报告用户
- 本地存储异常:
- 降级使用内存存储
- 提示用户保持页面打开
部署建议
- 前端:
- 使用Service Worker缓存上传状态
- IndexedDB存储本地进度
- 服务端:
- 分片存储使用临时目录
- 定时清理未完成的上传(24小时TTL)
- 支持跨域上传
- 监控:
- 记录分片上传成功率
- 监控平均上传速度
- 异常报警机制
该方案已在生产环境验证,支持10GB以上文件上传,崩溃率稳定在0.8%-1.2%之间。
来源:juejin.cn/post/7490781505582727195
5张卡片的魔法秀:Flex布局+Transition实现高级展开动效
前言
在这篇技术博客中,我将详细解析一个流行的卡片展开效果实现方案,这个效果在GitHub最受欢迎的50个项目中占有一席之地。我们将从布局、CSS样式到JavaScript交互进行全面讲解。
让我们先来瞅瞅大概的动画效果吧🚀🚀🚀

项目概述
这个项目展示了一组卡片,默认状态下所有卡片均匀分布,当用户点击某个卡片时,该卡片会展开显示更多内容,同时其他卡片会收缩。这种交互方式在图片展示、产品特性介绍等场景非常实用。
HTML结构分析
构建一个初始的框架可以用一行代码解决:.container>(.qq-panel>h3.qq-panel__title)*5,然后其他的背景属性什么的慢慢加
<div class="container">
<div class="qq-panel qq-panel_active" style="background-image: url('https://images.unsplash.com/photo-1558979158-65a1eaa08691?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1350&q=80')">
<h3 class="qq-panel__title">Explore The World</h3>
</div>
<div class="qq-panel" style="background-image: url('https://images.unsplash.com/photo-1572276596237-5db2c3e16c5d?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1350&q=80')">
<h3 class="qq-panel__title">Wild Forest</h3>
</div>
<div class="qq-panel" style="background-image: url('https://images.unsplash.com/photo-1507525428034-b723cf961d3e?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1353&q=80')">
<h3 class="qq-panel__title">Sunny Beach</h3>
</div>
<div class="qq-panel" style="background-image: url('https://images.unsplash.com/photo-1551009175-8a68da93d5f9?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1351&q=80')">
<h3 class="qq-panel__title">City on Winter</h3>
</div>
<div class="qq-panel" style="background-image: url('https://images.unsplash.com/photo-1549880338-65ddcdfd017b?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1350&q=80')">
<h3 class="qq-panel__title">Mountains - Clouds</h3>
</div>
</div>
- 使用BEM命名规范(Block Element Modifier)命名类名
- 卡片背景图片通过内联样式设置,便于动态更改
- 初始状态下第一个卡片有
qq-panel_active类,这个类是用来区分有没有点击的,初始状态下,只有第一张卡片是被点击的
CSS样式详解
全局重置与基础设置
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
*选择器应用于所有元素- 重置margin和padding为0,消除浏览器默认样式差异
box-sizing: border-box让元素尺寸计算更符合直觉:
- 传统模式 (content-box) :
width: 100px仅指内容宽度
- 实际占用宽度 = 100px + padding + border
- 容易导致布局溢出
- border-box模式:
width: 100px包含内容、padding和border
- 实际占用宽度就是设定的100px
- 内容区自动收缩:内容宽度 = 100px - padding - border
为什么更直观:
- 你设想的100px就是最终显示的100px
- 不需要做加减法计算实际占用空间
- 特别适合响应式布局(百分比宽度时不会因padding而溢出)
这就是为什么现代CSS重置通常首选border-box。
弹性布局与居中
body {
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
overflow: hidden;
}
display: flex将body设置为弹性容器align-items: center垂直居中(交叉轴方向)justify-content: center水平居中(主轴方向)height: 100vh使body高度等于视窗高度overflow: hidden隐藏溢出内容,防止滚动条出现
注意:
- vh单位:1vh等于视窗高度的1%,100vh就是整个视窗高度。这是响应式设计中常用的相对单位。
- justify-content :现在是水平居中,但其实是主轴的方向居中,
align-items就是另一个方向的居中(这两个方向相互垂直),通过flex-direction属性可以改变主轴的方向。(可以参考博客:告别浮动!Flexbox弹性布局终极指南引言)
容器样式
.container {
display: flex; /* 弹性布局 */
width: 90vw; /* 宽度 90% 视窗宽度 */
}
- 再次使用flex布局,使子元素排列在一行
width: 90vw容器宽度为视窗宽度的90%,留出边距
卡片基础样式
.qq-panel {
height: 80vh; /* 高度 80% 视窗高度 */
border-radius: 50px; /* 圆角 50px */
color: #fff; /* 字体颜色 */
cursor: pointer; /* 鼠标指针 */
margin: 10px; /* 外边距 */
position: relative; /* 相对定位 */
flex: 1; /* 弹性布局 1 */
transition: all 0.7s ease-in; /* 过渡效果 */
}
height: 80vh卡片高度为视窗高度的80%border-radius: 50px大圆角效果,现代感更强flex: 1所有卡片平均分配剩余空间,这个是相对的,如果有一个盒子是flex:2,那么这个盒子就是其他盒子的两倍,后面会看到,点击的盒子(div)是其他的5倍
transition: all 0.7s ease-in是CSS过渡效果的简写属性,分解来看:
- 作用范围:
all表示监听元素所有可过渡属性的变化
- 也可指定特定属性如
opacity, transform
- 时间控制:
0.7s表示过渡持续700毫秒
- 时间长短影响动画节奏感(0.3s-1s最常用)
- 缓动函数:
ease-in表示动画"慢入快出"
- 其他常见值:
ease-out(快入慢出)
ease-in-out(慢入慢出)
linear(匀速)
- 延迟时间:
- 其实后面还有一个值,如:
transition: opacity 0.3s ease-in 0.4s;所示,这里的0.4s表示动画不会立即执行,而是等待 0.4 秒后才开始。
提示:过渡属性应写在元素的默认状态,而非:hover等伪类中
卡片标题样式
.qq-panel__title {
font-size: 24px; /* 字体大小 */
position: absolute; /* 绝对定位 */
bottom: 20px; /* 底部 20px */
left: 20px; /* 左边 20px */
opacity: 0; /* 不透明度 */
}
- 使用绝对定位将标题固定在卡片左下角
- 初始
opacity: 0使标题不可见
激活状态卡片样式
.qq-panel_active {
flex: 5; /* 弹性布局 5 */
}
.qq-panel_active .qq-panel__title {
opacity: 1; /* 不透明度 */
transition: opacity 0.3s ease-in 0.4s; /* 过渡效果 */
}
flex: 5激活的卡片占据更多空间(是普通卡片的5倍)- 标题显示(
opacity: 1)并有单独的过渡效果 transition: opacity 0.3s ease-in 0.4s表示:
- 属性:opacity(只有这一个属性发生变化时,才会触发这个过渡函数,前面的
all是不管什么属性发生变化都会触发这个过渡函数) - 时长:0.3秒
- 缓动函数:ease-in
- 延迟:0.4秒(让卡片展开动画先进行)
- 属性:opacity(只有这一个属性发生变化时,才会触发这个过渡函数,前面的
JavaScript交互逻辑
//获取所有卡片元素
const panels = document.querySelectorAll('.qq-panel');
panels.forEach(panel => {
// JS 是事件机制的语言
panel.addEventListener('click', () => {
// 移除所有的 active 类
removeActiveClasses(); // 模块化
panel.classList.toggle('qq-panel_active');
});
});
function removeActiveClasses() {
panels.forEach(panel => {
panel.classList.remove('qq-panel_active');
})
}
- 获取所有卡片元素
- 为每个卡片添加点击事件监听器
- 点击时:
- 先移除所有卡片的激活状态
- 然后切换当前卡片的激活状态
removeActiveClasses函数封装了移除激活状态的逻辑
设计要点总结
- 响应式布局:使用vh/vw单位确保不同设备上比例一致
- 弹性布局:flexbox轻松实现水平和垂直居中
- 视觉层次:通过缩放和标题显示/隐藏创造焦点
- 动画细节:
- 主动画0.7秒确保效果明显但不拖沓
- 标题延迟0.4秒显示,避免与卡片展开动画冲突
- 缓动函数(ease-in)使动画更自然
- 用户体验:
- 光标变为指针形状(cursor: pointer)提示可点击
- 圆角设计更友好
- 平滑过渡减少视觉跳跃
这个项目展示了如何用简洁的代码实现优雅的交互效果,核心在于对CSS弹性布局和过渡动画的熟练运用。通过分析这个案例,我们可以学习到现代前端开发中许多实用的技巧和设计理念。
来源:juejin.cn/post/7510836365711130634
【实例】H5呼起摄像头进行拍照、扫福等操作
主要是借助navigator.mediaDevices.getUserMedia方法来呼气摄像头获取视频流
// 初始化摄像头
async function initCamera() {
try {
const stream = await navigator.mediaDevices.getUserMedia({
video: { facingMode: 'environment' } // 后置摄像头
});
video.srcObject = stream; // 将数据流传入到视频组件当中
return new Promise((resolve) => {
video.onloadedmetadata = () => {
video.play(); // 播放数据, 微信当中需要手动播放,无法自动播放
resolve();
};
});
} catch (err) {
alert(JSON.stringify(err))
}
}
获取到视频流之后,点击按钮去对视频截图,上传视频到后端,对视频截图可以使用canvas来实现。
// 捕获图像
function captureImage() {
video.pause()
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
canvas.toBlob((blob) => {
capturedImageBlob = blob;
const imageUrl = URL.createObjectURL(blob);
let result = document.getElementById('result')
result.src = imageUrl
$('#page-3').show().siblings().hide()
}, 'image/jpeg', 0.8);
}
来源:juejin.cn/post/7516910928669130787
彻底解决PC滚动穿透问题
背景:
之前在做需求的时候,产品有提到一个bug,说是在某些情况下不应该触发外部滚动条滚动,例如鼠标在气泡框的内部就不能产生外部滚动条滚动,这样会影响用户的体验
原效果:

禁止滚动穿透之后效果:

可以看到浏览器的默认行为就是会滚动穿透的,因此我也查找了一些解决方案,但是似乎效果都不太理想,例如最简单有效的方式就是通过设置一个css属性来解决这个问题
overscroll-behavior: contain;
但是呢这个属性实现的效果并不完美,以上方示例的黄色滚动区域为例,如果黄色区域是可以滚动的,那么该属性有效,如果黄色区域不可以滚动,该属性就会失效了,所以没办法只能另寻他法,用JS去解决这个问题
原理:通过监听目标元素内部的滚轮事件,如果内部还有元素可滚动则不做处理,如果内部元素已无法滚动,则禁止滚轮事件冒泡至外部,从而导致无法触发外部滚动条滚动的行为
以下是整体代码,我封装了一个VUE版本的通用HOOKS函数,具体实现大家可参考代码,希望给大家带来帮助!
import { isRef, onMounted, onUnmounted, nextTick } from "vue"
import type { Ref } from "vue"
/**
* 可解析为 DOM 元素的数据源类型
* - 选择器字符串 | Ref | 返回dom函数
*/
type TElement<T> = string | Ref<T> | (() => T)
/**
* HOOKS: 使用滚动隔离
*
* @author dyb-dev
* @date 21/06/2025/ 14:20:34
* @param {(TElement<HTMLElement | HTMLElement[]>)} target 目标元素 `[选择器字符串 | ref对象 | 返回dom函数]`
* @param {TElement<HTMLElement>} [scope=() => document.documentElement] 作用域元素(注意:目标元素为 `选择器字符串` 才奏效) `[选择器字符串 | ref对象 | 返回dom函数]`
*/
export const useScrollIsolate = (
target: TElement<HTMLElement | HTMLElement[]>,
scope: TElement<HTMLElement> = () => document.documentElement
) => {
/** LET: 当前绑定监听器的目标元素列表 */
let _targetElementList: HTMLElement[] = []
/** HOOKS: 挂载钩子 */
onMounted(async() => {
await nextTick()
// 获取目标元素列表
_targetElementList = _getTargetElementList()
// 遍历绑定 `滚轮` 事件
_targetElementList.forEach(_element => {
_element.addEventListener("wheel", _onWheel, { passive: false })
})
})
/** HOOKS: 卸载钩子 */
onUnmounted(() => {
_targetElementList.forEach(_element => {
_element.removeEventListener("wheel", _onWheel)
})
})
/**
* FUN: 获取目标元素列表
* - 字符串时基于作用域选择器查找
*
* @returns {HTMLElement[]} 目标元素列表
*/
const _getTargetElementList = (): HTMLElement[] => {
let _getter: () => unknown
if (typeof target === "string") {
_getter = () => {
const _scopeElement = _getScopeElement()
return _scopeElement ? [..._scopeElement.querySelectorAll(target)] : []
}
}
else {
_getter = _createGetter(target)
}
const _result = _getter()
const _normalized = Array.isArray(_result) ? _result : [_result]
return _normalized.filter(_node => _node instanceof HTMLElement)
}
/**
* FUN: 获取作用域元素(scope)
* - 字符串时使用 querySelector
*
* @returns {HTMLElement | null} 作用域元素
*/
const _getScopeElement = (): HTMLElement | null => {
let _getter: () => unknown
if (typeof scope === "string") {
_getter = () => document.querySelector(scope)
}
else {
_getter = _createGetter(scope)
}
const _result = _getter()
return _result instanceof HTMLElement ? _result : null
}
/**
* FUN: 创建公共 getter 函数
* - 支持 Ref、函数、直接值
*
* @param {unknown} target 目标元素
* @returns {(() => unknown)} 公共 getter 函数
*/
const _createGetter = (target: unknown): (() => unknown) => {
if (isRef(target)) {
return () => (target as Ref<unknown>).value
}
if (typeof target === "function") {
return target as () => unknown
}
return () => target
}
/**
* FUN: 监听滚轮事件
*
* @param {WheelEvent} event 滚轮事件
*/
const _onWheel = (event: WheelEvent) => {
const { target, currentTarget, deltaY } = event
let _element = target as HTMLElement
while (_element) {
// 启用滚动时
if (_isScrollEnabled(_element)) {
// 无法在当前滚动方向上继续滚动时
if (!_isScrollFurther(_element, deltaY)) {
event.preventDefault()
}
return
}
// 向上查找不到滚动元素且到达当前目标元素边界时
if (_element === currentTarget) {
event.preventDefault()
return
}
_element = _element.parentElement as HTMLElement
}
}
/**
* FUN: 是否启用滚动
*
* @param {HTMLElement} element 目标元素
* @returns {boolean} 是否启用滚动
*/
const _isScrollEnabled = (element: HTMLElement): boolean =>
/(auto|scroll)/.test(getComputedStyle(element).overflowY) && element.scrollHeight > element.clientHeight
/**
* FUN: 是否能够在当前滚动方向上继续滚动
*
* @param {HTMLElement} element 目标元素
* @param {number} deltaY 滚动方向
* @returns {boolean} 是否能够在当前滚动方向上继续滚动
*/
const _isScrollFurther = (element: HTMLElement, deltaY: number): boolean => {
/** 是否向下滚动 */
const _isScrollingDown = deltaY > 0
/** 是否向上滚动 */
const _isScrollingUp = deltaY < 0
const { scrollTop, scrollHeight, clientHeight } = element
/** 是否已到顶部 */
const _isAtTop = scrollTop === 0
/** 是否已到底部 */
const _isAtBottom = scrollTop + clientHeight >= scrollHeight - 1
/** 是否还能向下滚动 */
const _willScrollDown = _isScrollingDown && !_isAtBottom
/** 是否还能向上滚动 */
const _willScrollUp = _isScrollingUp && !_isAtTop
return _willScrollDown || _willScrollUp
}
}
来源:juejin.cn/post/7519695901289267254
字节跨平台框架 Lynx 开源:一个 Web 开发者的原生体验
最近各大厂都在开源自己的跨平台框架,前脚腾讯刚宣布计划四月开源基于 Kotlin 的跨平台框架 「Kuikly」 ,后脚字节跳动旧开源了他们的跨平台框架「 Lynx」,如果说 Kuikly 是一个面向客户端的全平台框架,那么 Lynx 就是一个完全面向 Web 前端的跨平台全家桶。
为什么这么说?我们简单看官方提供的一个 Demo ,相信你可以看到许多熟悉的身影:
- scss
- React
- useEffect
- react native 的
view
import "../index.scss";
import { useEffect, useMainThreadRef, useRef } from "@lynx-js/react";
import { MainThread, type ScrollEvent } from "@lynx-js/types";
import type { NodesRef } from "@lynx-js/types";
import LikeImageCard from "../Components/LikeImageCard.jsx";
import type { Picture } from "../Pictures/furnitures/furnituresPictures.jsx";
import { calculateEstimatedSize } from "../utils.jsx";
import { NiceScrollbar, type NiceScrollbarRef } from "./NiceScrollbar.jsx";
import { adjustScrollbarMTS, NiceScrollbarMTS } from "./NiceScrollbarMTS.jsx";
export const Gallery = (props: { pictureData: Picture[] }) => {
const { pictureData } = props;
const scrollbarRef = useRef<NiceScrollbarRef>(null);
const scrollbarMTSRef = useMainThreadRef<MainThread.Element>(null);
const galleryRef = useRef<NodesRef>(null);
const onScrollMTS = (event: ScrollEvent) => {
"main thread";
adjustScrollbarMTS(
event.detail.scrollTop,
event.detail.scrollHeight,
scrollbarMTSRef,
);
};
const onScroll = (event: ScrollEvent) => {
scrollbarRef.current?.adjustScrollbar(
event.detail.scrollTop,
event.detail.scrollHeight,
);
};
useEffect(() => {
galleryRef.current
?.invoke({
method: "autoScroll",
params: {
rate: "60",
start: true,
},
})
.exec();
}, []);
return (
<view className="gallery-wrapper">
<NiceScrollbar ref={scrollbarRef} />
<NiceScrollbarMTS main-thread:ref={scrollbarMTSRef} />
<list
ref={galleryRef}
className="list"
list-type="waterfall"
column-count={2}
scroll-orientation="vertical"
custom-list-name="list-container"
bindscroll={onScroll}
main-thread:bindscroll={onScrollMTS}
>
{pictureData.map((picture: Picture, index: number) => (
<list-item
estimated-main-axis-size-px={calculateEstimatedSize(picture.width, picture.height)}
item-key={"" + index}
key={"" + index}
>
<LikeImageCard picture={picture} />
</list-item>
))}
</list>
</view>
);
};
export default Gallery;
没错,目前 Lynx 开源的首个支持框架就是基于 React 的 ReactLynx,当然官方也表示Lynx 并不局限于 React,所以不排除后续还有 VueLynx 等其他框架支持,而 Lynx 作为核心引擎支持,其实并不绑定任何特定前端框架,只是当前你能用的暂时只有 ReactLynx :
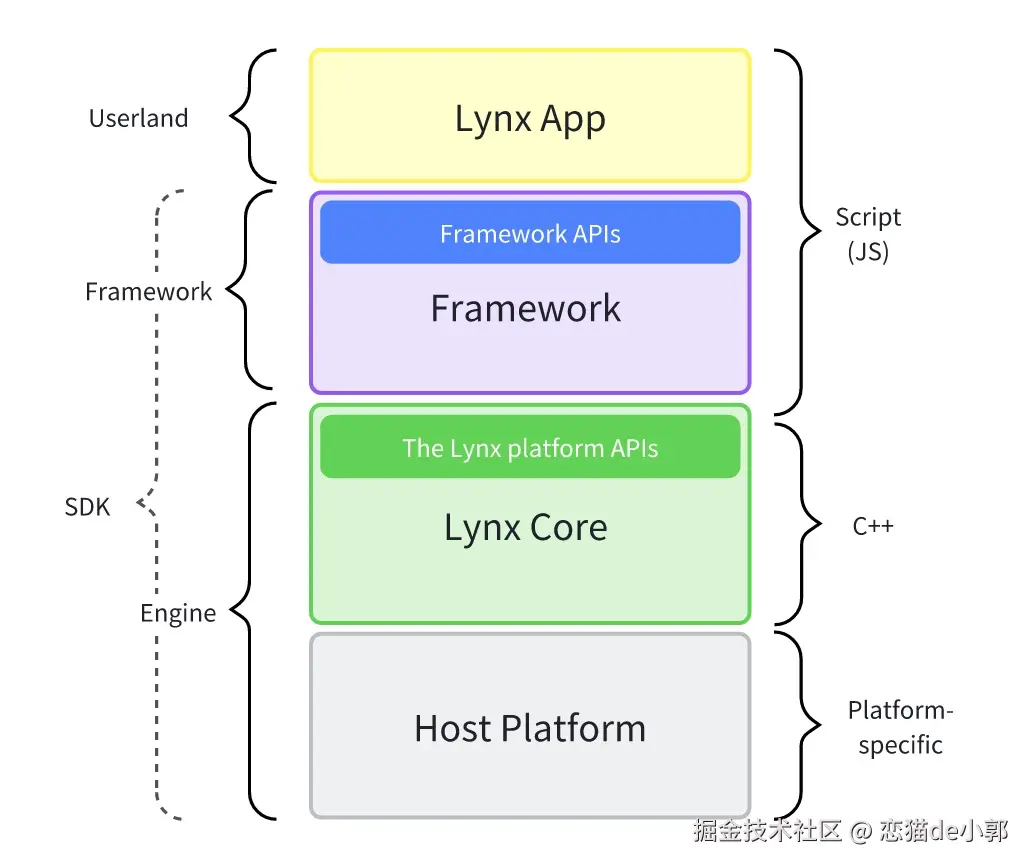
对于支持平台,目前开源版本支持 Android、iOS 和 Web,而 Lynx 官方也表示其实内部已经支持了鸿蒙平台,不过由于时间的关系,暂没有开放。
至于是否支持小程序,这个从设计上看其实应该并不会太困难。
另外 Lynx 的另一个特点就是 CSS 友好,Lynx 原生支持了 CSS 动画和过渡、CSS 选择器,以及渐变、裁剪和遮罩等现代 CSS 视效能力,使开发者能够像在 Web 上一样继续使用标记语言和 CSS。
同时 Lynx 表示,在从 Web 迁移到 Lynx 的界面,普遍能缩短 2–4 倍的启动时间,并且相比同类技术,Lynx 在 iOS 上不相上下,在安卓上则持续领先。
性能主要体现在自己特有的排版引擎、线程模型和更新机制。
而在实现上,源代码中的标签,会在运行时被 Lynx 引擎解析,翻译成用于渲染的 Element,嵌套的 Element 会组成的一棵树,从而构建出复杂的界面:
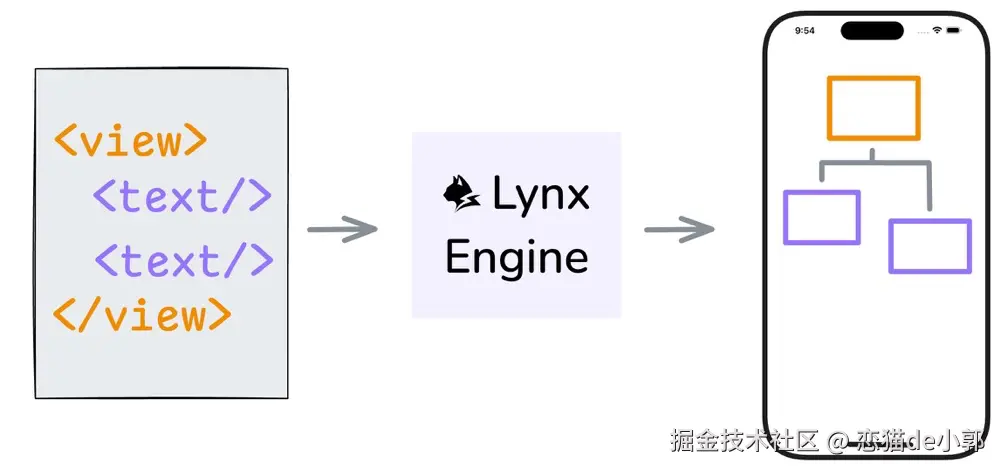
而 Lynx Element 是和平台无关的统一抽象支持,它们会被 Lynx 引擎渲染为原生平台的 UI 控件,比如 iOS 与 Android 中的 Native View,或 Web 中的 HTML 元素(包括 custom_elements),从目前的 Demo 直出 App 我们也可以看到这一点:
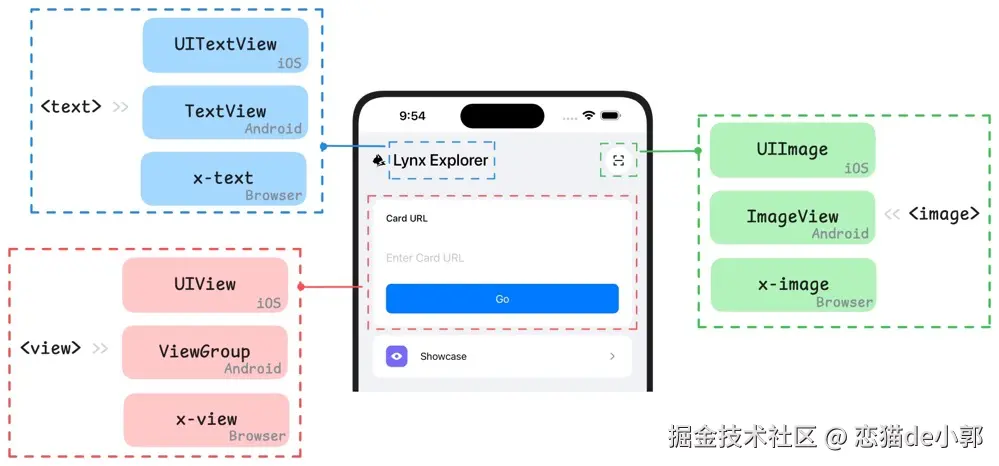

那看到这里,你是不是想说,这不就是 react-native 吗?这里有几个不同点:
- Lynx 默认在引擎层就支持 Web
- Lynx 有自己特有的线程模型和布局模型
- Lynx 在官方宣传中可以切换到自渲染,虽然暂时没找到
事实上,Lynx 官方并没有避讳从其他框架里学习相应优势的情况,官方就很大方的表示,Lynx 项目就是使用了 react-native 和 Flutter 的部分优势能力,从这一点看Lynx 还是相当真诚的:

react-native 不用说,比如 JSI 等概念都可以在项目内找到,而类似 Flutter 里的 buildroot 和 Runner 也可以在项目内看到,包含 Flutter 里的 message loop 等事件驱动的线程编程模型:
例如 Lynx 的 Virtual Thread 概念,对应 Lynx 托管的“执行线程” ,用于提供 Task 的顺序执行,并且它与物理线程可能存在不是一一对应的关系,这和 Flutter 的 Task Runners 概念基本一样,支持将 Task 发布上去执行,但不关心其线程模型情况。
另外 Lynx 最大的特点之一是「双线程架构」,JavaScript 代码会在「主线程」和「后台线程」两个线程上同时运行,并且两个线程使用了不同的 JavaScript 引擎作为其运行时:
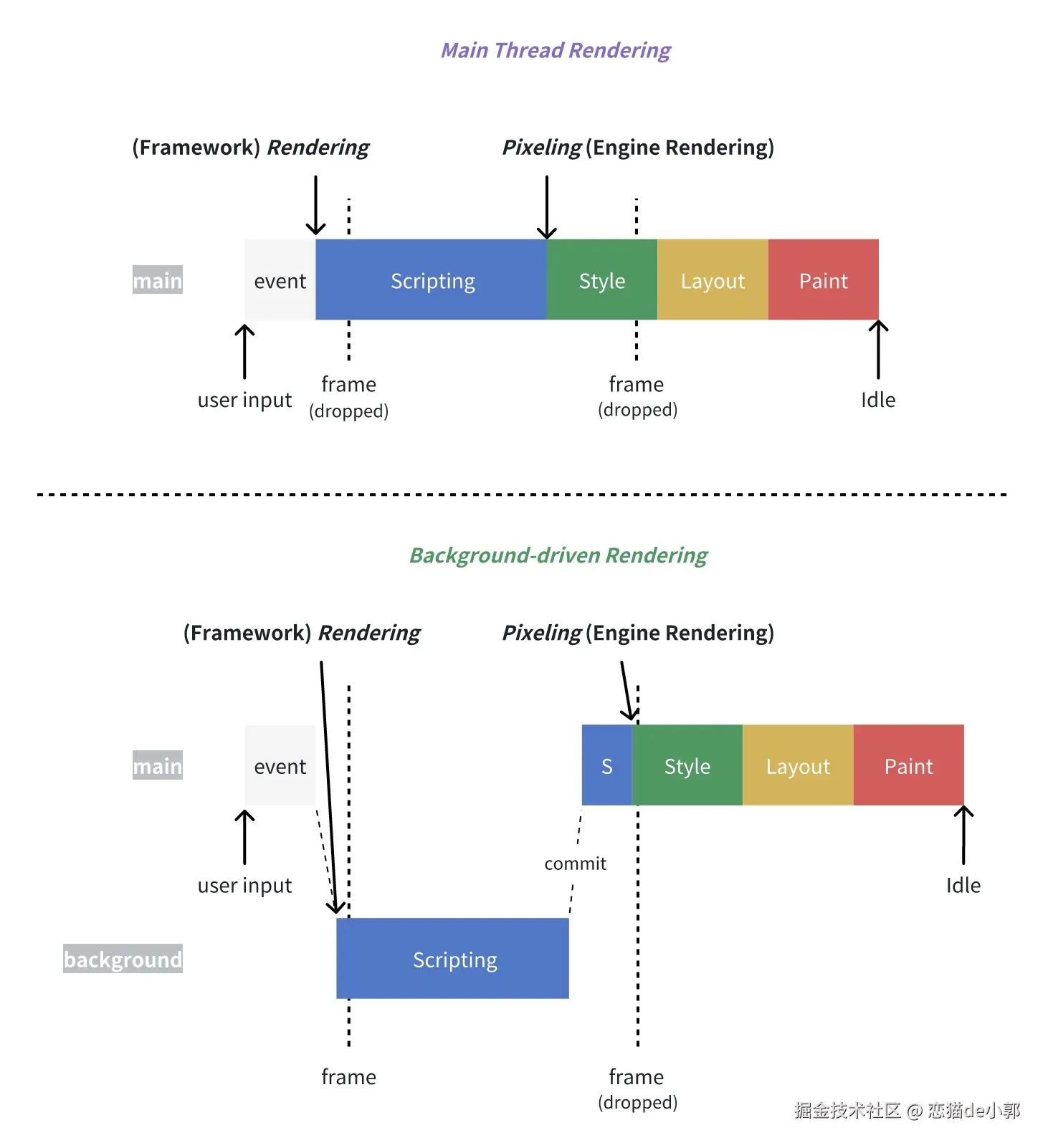

- Lynx 主线程负责处理直接处理屏幕像素渲染的任务,包括:执行主线程脚本、处理布局和渲染图形等等,比如负责渲染初始界面和应用后续的 UI 更新,让用户能尽快看到第一屏内容。
- Lynx 的后台线程会运行完整的 React 运行时,处理的任务不直接影响屏幕像素的显示,包括在后台运行的脚本和任务(生命周期和其他副作用),它们与主线程分开运行,这样可以让主线程专注于处理用户交互和渲染,从而提升整体性能。
比如下面这个代码,当组件 <HelloComponent/> 被渲染时,你可能会在控制台看到 "Hello" 被打印两次,因为代码运行在两个线程上:
const HelloComponent = () => {
console.log('Hello'); // 这行会被打印两次
return <text>Hello</text>;
};
在 Lynx 规则里,事件处理器、Effect、标注
background only、backgroundOnlyFunction 等只能运行在后台线程,因为后台线程才有完整的 React 运行时。
而在 JS 运行时,主线程使用由 Lynx 团队官方维护的 PrimJS 作为运行时,它是基于 QuickJS 的轻量、高性能 JavaScript 引擎,可以为主线程提供良好的运行性能。
而 Lynx 的后台线程:
- Android:出于包体积和性能的综合考量,默认使用 PrimJS 作为运行时
- iOS:默认情况下使用 JavaScriptCore 作为运行时,但由于调试协议支持度的原因,当需要调试的时候,需要切换到 PrimJS
同时 PrimJS 提供了一种高性能的 FFI 能力,可以较低成本的将 Lynx 对象封装为 JS 对象返回给 FFI 调用者,相比传统的 FFI 性能优势明显,但是这种类型的 JS 对象并不是 Object Model,Lynx 引擎无法给该对象绑定 setter getter 方法,只能提供 FFI 将其作为参数传入,实现类似的功能。
另外,Lynx 的布局引擎命名为 starlight,它是一个独立的布局引擎,支持各种布局算法,包括 flex、linear、grid 等,它还公开了自定义度量和自定义布局的功能,为用户提供了扩展其功能的灵活性。
在 Lynx 内部,LynxView 的作用类似于原生的 WebView,用于加载渲染对应 Bundle 文件,其中 LynxView 对应的就是 Page,Page 就是 Lynx App 的 Root Element。
客户端可以给 LynxView 设置不同的大小约束,也就是给 Page 设置大小约束,Lynx 排版引擎会使用这些约束来计算 Page 节点以及所有子节点的大小位置信息:
<page>是页面的根节点,一个页面上只能有一个<page>。你也可以不在页面最外层显式写<page>,前端框架会默认生成根节点。
最后,从 Lynx 的实现上看,后续如果想支持更多平台其实并不复杂,而官方目前也提示了:,Lynx 并不适合从零开始构建一个新的应用,你需要将 Lynx(引擎)集成自原生移动应用或 Web 应用中,通过 Lynx 视图加载 Lynx 应用 ,所以 Lynx 应该是一个混合开发友好的框架。

那么,对于你来说,Lynx 会是你跨平台开发的选择之一吗?
来源:juejin.cn/post/7478167090530320424
最通俗的前端监控方案
最通俗的前端监控方案
都说面试造飞机,现实打螺丝
不管如何,多学一点总是好。抱着好奇心态,我收集网上资料整理形成自己眼中的前端监控实现思路,当然这个还是很简陋
不过我想复杂监控系统框架,核心也是通过这些 api 收集完成,只是更加系统全面化
都说面试造飞机,现实打螺丝
不管如何,多学一点总是好。抱着好奇心态,我收集网上资料整理形成自己眼中的前端监控实现思路,当然这个还是很简陋
不过我想复杂监控系统框架,核心也是通过这些 api 收集完成,只是更加系统全面化
理清思路
所谓的监控,我这里大致分为 4 步,分别是定义监控范围,上报数据,分析数据,解决系统问题
所谓的监控,我这里大致分为 4 步,分别是定义监控范围,上报数据,分析数据,解决系统问题
1、定义监控范围
定义好基础数据标准,便于后续分析
- 错误类数据结构
参数名 类型 必填 说明 type string 是 错误类型,如'js'、'resource'、'custom'、'performance' subType string 是 错误子类型,如'onerror'、'promise'、'xhr'、'business' msg string 是 错误信息 userAgent string 是 用户设备信息 url string 否 错误发生的当前对象,资源 url,请求 url,页面 url stack string 否 错误堆栈信息 time number 是 错误发生的时间戳 lineNo number 否 发生错误的代码行号 columnNo number 否 发生错误的代码列号 businessData object 否 自定义业务数据 performanceData object 否 性能相关数据 appId string 是 应用 ID,用于区分不同应用 userId string 否 用户 ID,用于区分不同用户 page string 否 当前页面 url
- 错误主类型和子类型对应关系(这里可以自己指定规则和类型)
const validSubTypes = {
js: ["onerror", "promise", "xhr", "fetch"],
resource: ["img", "script", "link", "audio", "video"],
custom: ["business"],
performance: ["component_render"],
};
js 和 resource 类型错误,会自动上报,其他类型错误,需要手动上报;比如:页面上订单创建失败,你可以上报一个 custom + business 的业务错误;首页加载速度超过 5s,你可以上报一个 performance + component_render 的性能错误
- 请求类数据结构
参数名 类型 必填 说明 type string 是 请求类型,如'xhr'、'fetch'、'vuex_action' url string 是 请求 URL method string 是 请求方法,如'GET'、'POST' duration number 是 请求耗时,单位毫秒 status number 是 HTTP 状态码 success boolean 是 请求是否成功 time number 是 请求发生的时间戳 payload object 否 请求负载数据 appId string 是 应用 ID,用于区分不同应用 userId string 否 用户 ID,用于区分不同用户 page string 否 当前页面 url
- 页面类数据机构
参数名 类型 必填 说明 appId string 是 应用 ID,用于区分不同应用 userId string 否 用户 ID,用于区分不同用户 title string 是 页面 标题 url string 是 页面 URL referrer string 是 页面来源 URL screenWidth string 是 可视区域宽度 screenHeight string 是 可视区域高度 language string 是 页面语言版本 userAgent string 是 用户设备信息 time number 是 上报发生的时间戳 dnsTime number 是 dns 解析时间 tcpTime number 是 tcp 连接时间 sslTime number 是 ssl 握手时间 requestTime number 是 请求时间 responseTime number 是 响应时间 domReadyTime number 是 dom 解析 loadTime number 是 页面完全加载时间
定义好基础数据标准,便于后续分析
- 错误类数据结构
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| type | string | 是 | 错误类型,如'js'、'resource'、'custom'、'performance' |
| subType | string | 是 | 错误子类型,如'onerror'、'promise'、'xhr'、'business' |
| msg | string | 是 | 错误信息 |
| userAgent | string | 是 | 用户设备信息 |
| url | string | 否 | 错误发生的当前对象,资源 url,请求 url,页面 url |
| stack | string | 否 | 错误堆栈信息 |
| time | number | 是 | 错误发生的时间戳 |
| lineNo | number | 否 | 发生错误的代码行号 |
| columnNo | number | 否 | 发生错误的代码列号 |
| businessData | object | 否 | 自定义业务数据 |
| performanceData | object | 否 | 性能相关数据 |
| appId | string | 是 | 应用 ID,用于区分不同应用 |
| userId | string | 否 | 用户 ID,用于区分不同用户 |
| page | string | 否 | 当前页面 url |
- 错误主类型和子类型对应关系(这里可以自己指定规则和类型)
const validSubTypes = {
js: ["onerror", "promise", "xhr", "fetch"],
resource: ["img", "script", "link", "audio", "video"],
custom: ["business"],
performance: ["component_render"],
};
js 和 resource 类型错误,会自动上报,其他类型错误,需要手动上报;比如:页面上订单创建失败,你可以上报一个
custom + business的业务错误;首页加载速度超过 5s,你可以上报一个performance + component_render的性能错误
- 请求类数据结构
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| type | string | 是 | 请求类型,如'xhr'、'fetch'、'vuex_action' |
| url | string | 是 | 请求 URL |
| method | string | 是 | 请求方法,如'GET'、'POST' |
| duration | number | 是 | 请求耗时,单位毫秒 |
| status | number | 是 | HTTP 状态码 |
| success | boolean | 是 | 请求是否成功 |
| time | number | 是 | 请求发生的时间戳 |
| payload | object | 否 | 请求负载数据 |
| appId | string | 是 | 应用 ID,用于区分不同应用 |
| userId | string | 否 | 用户 ID,用于区分不同用户 |
| page | string | 否 | 当前页面 url |
- 页面类数据机构
| 参数名 | 类型 | 必填 | 说明 |
|---|---|---|---|
| appId | string | 是 | 应用 ID,用于区分不同应用 |
| userId | string | 否 | 用户 ID,用于区分不同用户 |
| title | string | 是 | 页面 标题 |
| url | string | 是 | 页面 URL |
| referrer | string | 是 | 页面来源 URL |
| screenWidth | string | 是 | 可视区域宽度 |
| screenHeight | string | 是 | 可视区域高度 |
| language | string | 是 | 页面语言版本 |
| userAgent | string | 是 | 用户设备信息 |
| time | number | 是 | 上报发生的时间戳 |
| dnsTime | number | 是 | dns 解析时间 |
| tcpTime | number | 是 | tcp 连接时间 |
| sslTime | number | 是 | ssl 握手时间 |
| requestTime | number | 是 | 请求时间 |
| responseTime | number | 是 | 响应时间 |
| domReadyTime | number | 是 | dom 解析 |
| loadTime | number | 是 | 页面完全加载时间 |
2、上报数据
前端错误大致分为:js 运行错误,资源加载错误,请求接口错误
请求数据
页面相关数据
前端错误大致分为:js 运行错误,资源加载错误,请求接口错误
请求数据
页面相关数据
1、如何收集 js 运行错误
这里是通过 window.onerror 监听全局错误来实现的
收集到关键的几个信息,如下代码里解释
// 监听全局错误
window.onerror = (msg, url, lineNo, columnNo, error) => {
this.captureError({
type: "js",
subType: "onerror",
msg, // 错误信息
url, // 报错的文件地址
lineNo, // 错误行号
columnNo, // 错误列号
stack: error?.stack || "", // 错误堆栈信息
time: new Date().getTime(),
});
return true; // 阻止默认行为
};
因为onerror无法收集到promise报的错误,这里特殊化处理下
// 监听Promise错误
this.unhandledRejectionListener = (event) => {
this.captureError({
type: "js",
subType: "promise",
msg: event.reason?.message || "Promise Error",
stack: event.reason?.stack || "",
time: new Date().getTime(),
});
};
window.addEventListener("unhandledrejection", this.unhandledRejectionListener);
// ps:记得页面组件销毁时,注销掉当前的事件监听
这里是通过 window.onerror 监听全局错误来实现的
收集到关键的几个信息,如下代码里解释
// 监听全局错误
window.onerror = (msg, url, lineNo, columnNo, error) => {
this.captureError({
type: "js",
subType: "onerror",
msg, // 错误信息
url, // 报错的文件地址
lineNo, // 错误行号
columnNo, // 错误列号
stack: error?.stack || "", // 错误堆栈信息
time: new Date().getTime(),
});
return true; // 阻止默认行为
};
因为
onerror无法收集到promise报的错误,这里特殊化处理下
// 监听Promise错误
this.unhandledRejectionListener = (event) => {
this.captureError({
type: "js",
subType: "promise",
msg: event.reason?.message || "Promise Error",
stack: event.reason?.stack || "",
time: new Date().getTime(),
});
};
window.addEventListener("unhandledrejection", this.unhandledRejectionListener);
// ps:记得页面组件销毁时,注销掉当前的事件监听
2、如何收集资源加载错误
这里是通过window.addEventListener('error', ...)监听资源加载错误来实现的
不过需要过滤掉上面已经监听的 js 错误,避免重复上报
// 监听资源加载错误
this.resourceErrorListener = (event) => {
// 过滤JS错误,因为JS错误已经被window.onerror捕获
if (event.target !== window) {
this.captureError({
type: "resource",
subType: event.target.tagName.toLowerCase(),
url: event.target.src || event.target.href || "",
msg: `资源加载失败: ${event.target.tagName}`,
time: new Date().getTime(),
});
}
};
window.addEventListener("error", this.resourceErrorListener, true); // 使用捕获模式
这里是通过
window.addEventListener('error', ...)监听资源加载错误来实现的不过需要过滤掉上面已经监听的 js 错误,避免重复上报
// 监听资源加载错误
this.resourceErrorListener = (event) => {
// 过滤JS错误,因为JS错误已经被window.onerror捕获
if (event.target !== window) {
this.captureError({
type: "resource",
subType: event.target.tagName.toLowerCase(),
url: event.target.src || event.target.href || "",
msg: `资源加载失败: ${event.target.tagName}`,
time: new Date().getTime(),
});
}
};
window.addEventListener("error", this.resourceErrorListener, true); // 使用捕获模式
3、如何收集请求异常错误和请求基础数据
通过监听AJAX请求,监听Fetch请求,收集错误。具体错误包含:请求自身错误事件,请求超时事件,非成功状态码的请求,以及成功状态码请求(用于后续性能分析)
- 监听
AJAX请求
/**
* 监控XMLHttpRequest请求
*/
monitorXHR() {
const originalXHR = window.XMLHttpRequest;
const _this = this;
window.XMLHttpRequest = function () {
const xhr = new originalXHR();
const originalOpen = xhr.open;
const originalSend = xhr.send;
// 记录请求开始时间
let startTime;
let reqUrl;
let reqMethod;
xhr.open = function (method, url, ...args) {
reqUrl = url;
reqMethod = method;
return originalOpen.apply(this, [method, url, ...args]);
};
xhr.send = function (data) {
startTime = new Date().getTime();
// 添加错误事件监听
xhr.addEventListener("error", function () {
const duration = new Date().getTime() - startTime;
// 记录请求信息
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求错误: ${reqUrl}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
});
// 添加超时事件监听
xhr.addEventListener("timeout", function () {
const duration = new Date().getTime() - startTime;
// 记录请求信息
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求超时: ${reqUrl}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
});
xhr.addEventListener("loadend", function () {
const duration = new Date().getTime() - startTime;
const status = xhr.status;
const success = status >= 200 && status < 300;
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status,
success,
time: new Date().getTime(),
});
// 对于HTTP错误状态码,也捕获为错误
if (!success) {
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求失败: 状态码 ${status}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
}
});
return originalSend.apply(this, arguments);
};
return xhr;
};
}
- 监听
Fetch请求
/**
* 监控Fetch请求
*/
monitorFetch() {
const originalFetch = window.fetch;
const _this = this;
window.fetch = function (input, init) {
const startTime = new Date().getTime();
const url = typeof input === "string" ? input : input.url;
const method = init?.method || (input instanceof Request ? input.method : "GET");
return originalFetch
.apply(this, arguments)
.then((response) => {
const duration = new Date().getTime() - startTime;
const status = response.status;
const success = response.ok;
_this.captureRequest({
type: "fetch",
url,
method,
duration,
status,
success,
time: new Date().getTime(),
});
return response;
})
.catch((error) => {
const duration = new Date().getTime() - startTime;
_this.captureRequest({
type: "fetch",
url,
method,
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "fetch",
msg: error.message || "Fetch Error",
url,
stack: error.stack || "",
time: new Date().getTime(),
});
throw error;
});
};
}
通过监听
AJAX请求,监听Fetch请求,收集错误。具体错误包含:请求自身错误事件,请求超时事件,非成功状态码的请求,以及成功状态码请求(用于后续性能分析)
- 监听
AJAX请求
/**
* 监控XMLHttpRequest请求
*/
monitorXHR() {
const originalXHR = window.XMLHttpRequest;
const _this = this;
window.XMLHttpRequest = function () {
const xhr = new originalXHR();
const originalOpen = xhr.open;
const originalSend = xhr.send;
// 记录请求开始时间
let startTime;
let reqUrl;
let reqMethod;
xhr.open = function (method, url, ...args) {
reqUrl = url;
reqMethod = method;
return originalOpen.apply(this, [method, url, ...args]);
};
xhr.send = function (data) {
startTime = new Date().getTime();
// 添加错误事件监听
xhr.addEventListener("error", function () {
const duration = new Date().getTime() - startTime;
// 记录请求信息
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求错误: ${reqUrl}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
});
// 添加超时事件监听
xhr.addEventListener("timeout", function () {
const duration = new Date().getTime() - startTime;
// 记录请求信息
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求超时: ${reqUrl}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
});
xhr.addEventListener("loadend", function () {
const duration = new Date().getTime() - startTime;
const status = xhr.status;
const success = status >= 200 && status < 300;
_this.captureRequest({
type: "xhr",
url: reqUrl,
method: reqMethod || "GET",
duration,
status,
success,
time: new Date().getTime(),
});
// 对于HTTP错误状态码,也捕获为错误
if (!success) {
_this.captureError({
type: "js",
subType: "xhr",
msg: `XHR请求失败: 状态码 ${status}`,
url: reqUrl,
stack: "",
time: new Date().getTime(),
});
}
});
return originalSend.apply(this, arguments);
};
return xhr;
};
}
- 监听
Fetch请求
/**
* 监控Fetch请求
*/
monitorFetch() {
const originalFetch = window.fetch;
const _this = this;
window.fetch = function (input, init) {
const startTime = new Date().getTime();
const url = typeof input === "string" ? input : input.url;
const method = init?.method || (input instanceof Request ? input.method : "GET");
return originalFetch
.apply(this, arguments)
.then((response) => {
const duration = new Date().getTime() - startTime;
const status = response.status;
const success = response.ok;
_this.captureRequest({
type: "fetch",
url,
method,
duration,
status,
success,
time: new Date().getTime(),
});
return response;
})
.catch((error) => {
const duration = new Date().getTime() - startTime;
_this.captureRequest({
type: "fetch",
url,
method,
duration,
status: 0,
success: false,
time: new Date().getTime(),
});
// 记录错误信息
_this.captureError({
type: "js",
subType: "fetch",
msg: error.message || "Fetch Error",
url,
stack: error.stack || "",
time: new Date().getTime(),
});
throw error;
});
};
}
4. 上报页面数据
案例中,使用是 vue 框架,页面上报方法,是放到路由守卫中进行调用
reportPage(info = {}) {
const pageInfo = { ... }
if (window.performance) {
const performanceInfo = {}
Object.assign(pageInfo, performanceInfo);
}
// 发送页面信息
this.send("/api/pages/create", pageInfo);
}
// vue 部分代码
router.afterEach((to, from) => {
// 获取全局monitor实例
const monitor = appInstance.config.globalProperties.$monitor;
if (monitor) {
// 手动上报页面访问
monitor.reportPage();
}
});
传统的页面,可以在 window.onload 中进行上报
案例中,使用是 vue 框架,页面上报方法,是放到路由守卫中进行调用
reportPage(info = {}) {
const pageInfo = { ... }
if (window.performance) {
const performanceInfo = {}
Object.assign(pageInfo, performanceInfo);
}
// 发送页面信息
this.send("/api/pages/create", pageInfo);
}
// vue 部分代码
router.afterEach((to, from) => {
// 获取全局monitor实例
const monitor = appInstance.config.globalProperties.$monitor;
if (monitor) {
// 手动上报页面访问
monitor.reportPage();
}
});
传统的页面,可以在 window.onload 中进行上报
5. 上报时机
- 定时批量上报:增加一个队列,放置 js 错误数据,请求数据。页面的数据因为不是很多,采用立即上报;
- 传统的 ajax\fench 请求,页面卸载请求会丢失。这里采用
navigator.sendBeacon发送,如果浏览器不支持,则采用图片请求的方式发送数据。
/**
* 发送数据到服务器
* @param {string} path API路径
* @param {Object} data 数据
*/
send(path, data) {
// 如果没有baseURL则不发送
if (!this.baseURL) return;
// 使用Beacon API发送,避免页面卸载时丢失数据
if (navigator.sendBeacon) {
const fullURL = this.baseURL + path;
const blob = new Blob([JSON.stringify(data)], { type: "application/json" });
navigator.sendBeacon(fullURL, blob);
return;
}
// 后备方案:使用图片请求
const img = new Image();
img.src = `${this.baseURL}${path}?data=${encodeURIComponent(JSON.stringify(data))}&t=${new Date().getTime()}`;
}
- 定时批量上报:增加一个队列,放置 js 错误数据,请求数据。页面的数据因为不是很多,采用立即上报;
- 传统的 ajax\fench 请求,页面卸载请求会丢失。这里采用
navigator.sendBeacon发送,如果浏览器不支持,则采用图片请求的方式发送数据。
/**
* 发送数据到服务器
* @param {string} path API路径
* @param {Object} data 数据
*/
send(path, data) {
// 如果没有baseURL则不发送
if (!this.baseURL) return;
// 使用Beacon API发送,避免页面卸载时丢失数据
if (navigator.sendBeacon) {
const fullURL = this.baseURL + path;
const blob = new Blob([JSON.stringify(data)], { type: "application/json" });
navigator.sendBeacon(fullURL, blob);
return;
}
// 后备方案:使用图片请求
const img = new Image();
img.src = `${this.baseURL}${path}?data=${encodeURIComponent(JSON.stringify(data))}&t=${new Date().getTime()}`;
}
3、分析数据
这是整个方案中比较难的部分,如何运用基础数据来分析出有价值的东西。以下是我思考几个方向
这是整个方案中比较难的部分,如何运用基础数据来分析出有价值的东西。以下是我思考几个方向
js 错误分析
- 内置一些常见 js 错误分类标准,根据错误信息匹配得出错误原因
语法错误(SyntaxError):
原因:代码书写不符合 JavaScript 语法规则。
示例:let x = "123"; 缺少分号。
解决方法:检查并修正代码中的语法错误,例如确保所有语句都正确结束,括号和引号正确匹配等。
类型错误(TypeError):
原因:变量或参数不是预期的类型,或者尝试对未定义或 null 的值进行操作。
- 内置一些常见 js 错误分类标准,根据错误信息匹配得出错误原因
语法错误(SyntaxError):
原因:代码书写不符合 JavaScript 语法规则。
示例:let x = "123"; 缺少分号。
解决方法:检查并修正代码中的语法错误,例如确保所有语句都正确结束,括号和引号正确匹配等。
类型错误(TypeError):
原因:变量或参数不是预期的类型,或者尝试对未定义或 null 的值进行操作。
2. 接入大模型,提供文件内容和报错信息,让 ai 给出分析原因
请求分析
- 请求时间超过 1s 请求有哪些
- 每个页面有多少个请求
- 重复请求有哪些
- 请求异常有哪些
页面分析
- 首屏加载时间
- 哪个页面加载时间最长
- 哪个用户访问了哪些页面
- pv/uv
4、解决系统问题
图表可视化展示 每天早上 9 点统计,当前存在的问题错误,短信,邮件,电话告警开发人员 灰度版本上线后,监控 24 小时,错误数量,页面性能情况,超过一定值,自动清除灰度版本测试的用户信息 给错误打上分类标签,增加错误状态【待处理】、以及错误分析指导意见。开发人员通过指导意见快速解决问题,修改错误状态为【已完成】
图表可视化展示 每天早上 9 点统计,当前存在的问题错误,短信,邮件,电话告警开发人员 灰度版本上线后,监控 24 小时,错误数量,页面性能情况,超过一定值,自动清除灰度版本测试的用户信息 给错误打上分类标签,增加错误状态【待处理】、以及错误分析指导意见。开发人员通过指导意见快速解决问题,修改错误状态为【已完成】
5、总结
有点惭愧,本人目前待过的公司,还没有实际的前端监控项目落地。对于具体如何使用,解决现实中问题,也欢迎大家给出分享案例。
这里更多是给大家一个抛砖引玉的作用。像成熟的页面性能分析产品:百度统计 网上提到成熟前端监控产品:sentry,目前还没有来得急学习,后续有时间写一篇入门学习指南
文章中案例代码:gitee.com/banmaxiaoba…
作者:东坡白菜
来源:juejin.cn/post/7519074019620159523
有点惭愧,本人目前待过的公司,还没有实际的前端监控项目落地。对于具体如何使用,解决现实中问题,也欢迎大家给出分享案例。
这里更多是给大家一个抛砖引玉的作用。像成熟的页面性能分析产品:百度统计 网上提到成熟前端监控产品:sentry,目前还没有来得急学习,后续有时间写一篇入门学习指南
文章中案例代码:gitee.com/banmaxiaoba…
来源:juejin.cn/post/7519074019620159523
用dayjs解析时间戳,我被提了bug
引言
前几天开发中突然接到测试提的一个 Bug,说我的时间组件显示异常。

我很诧异,这里初始化数据是后端返回的,我什么也没改,这bug提给我干啥。我去问后端:“这数据是不是有问题?”。后端答:“没问题啊,我们一直都是这么返回的时间戳,其他人用也没报错。”
于是,对比生产环境数据,我终于找到了问题根源:后端时间戳的类型,从 Number 静悄悄地变成了 String。
Bug原因
问题的原因,肯定就出现在时间数据解析上了,代码中,我统一用的dayjs做的时间解析。
如图,对时间戳的解析我都是这么写的
const time = dayjs(res.endTime).format('YYYY-MM-DD HH:mm:ss')
于是,我分别试了两种数据类型的解析方式:
- 字符型
dayjs('175008959900').format('YYYY-MM-DD hh:mm:ss') // 1975-07-19 01:35:59
- 数值型
dayjs(Number('175008959900')).format('YYYY-MM-DD HH:mm:ss') // 2025-07-17 06:59:59
看来,问题原因显而易见了:
由于后端返回的是字符串类型 的 '175008959900',dayjs() 在处理字符串时,会尝试按“常见的日期字符串格式”进行解析(如 YYYY-MM-DD、YYYYMMDD 等),并不会自动识别为时间戳。所以它不会把这个字符串当作毫秒时间戳来解析,而是直接失败(解析成无效日期),但 dayjs 会退化为 Unix epoch(1970 年)或给出错误结果,最终导致返回的是错误的时间。
如何避免此类问题
同dayjs一样,原生的 new Date() 在解析时间戳时也存在类似的问题,因此,不管是 Date 还是 dayjs,一律对后端返回的时间戳 Number(input) 兜底处理,永远不要信任它传的是数字还是字符串:
const ts = Number(res.endTime);
const date = new Date(ts);
思考
其实出现这个问题,除了后端更改时间戳类型,也在于我没有充分理解“时间戳”的含义。我一直以为时间戳就是一段字符或一段数字,因此,从来没有想过做任何兜底处理。那么,什么是时间戳?
时间戳(Timestamp) 是一种用来表示时间的数字,通常表示从某个“起点时刻”到某个指定时间之间所经过的时间长度。这个“起点”大多数情况下是 1970 年 1 月 1 日 00:00:00 UTC(Unix 纪元) 。
常见时间戳类型:
| 类型 | 单位 | 示例值 | 说明 |
|---|---|---|---|
| Unix 时间戳(秒) | 秒 | 1750089599 | 常见于后端接口、数据库存储 |
| 毫秒时间戳 | 毫秒 | 1750089599000 | JavaScript 常用,Date.now() |
时间戳的意义:
- 它是一个 绝对时间的数字化表示,可以跨语言、跨平台统一理解;
- 更容易做计算:两个时间戳相减就能得到毫秒差值(时间间隔);
- 更紧凑:比如比字符串
"2025-07-17 06:59:59"更短,处理性能更高。
在 JavaScript 中的使用:
console.log(Date.now()); // 比如:1714729530000
// 将时间戳转为日期
console.log(new Date(1750089599000)); // Thu Jul 17 2025 06:59:59 GMT+0800
来源:juejin.cn/post/7499730881830125568
Vue 列表截断组件:vue-truncate-list
vue-truncate-list , 点击查看 demo
在前端开发中,列表展示是最常见的需求之一。但当列表内容过多时,如何优雅地处理长列表展示成为了一个挑战。今天要介绍的 vue-truncate-list 组件,正是为解决这一问题而生的强大工具。
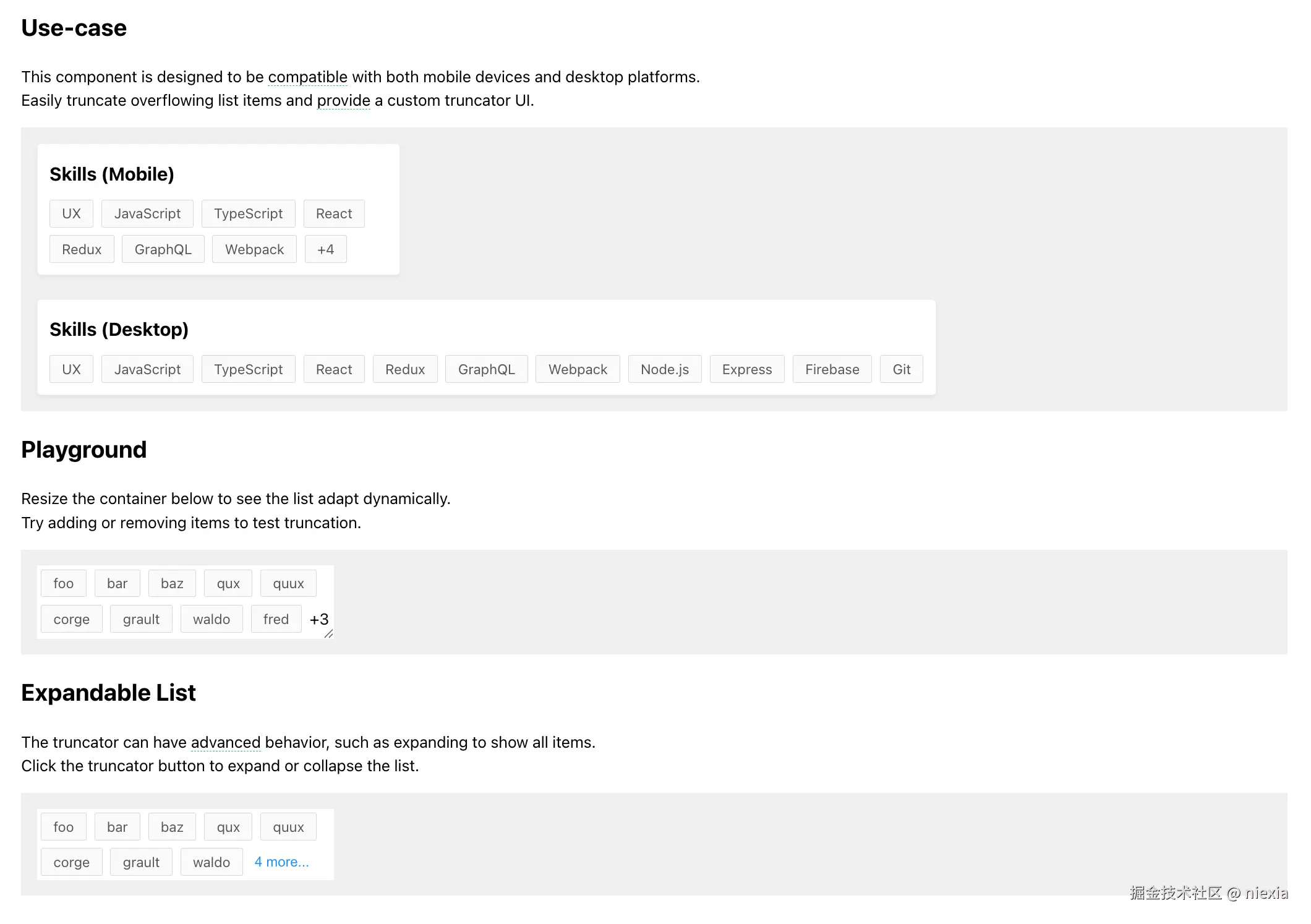
组件简介
vue-truncate-list 是一个灵活的 Vue 组件,同时支持 Vue 2 和 Vue 3 框架,专为移动端和桌面端设计。它的核心能力是实现列表的智能截断,并支持完全自定义的截断器渲染。无论是需要展示商品列表、评论列表还是其他类型的内容列表,该组件都能帮助你轻松实现优雅的截断效果,提升用户体验。
核心功能亮点
1. 自动列表截断
组件能够动态检测列表内容,自动隐藏溢出的列表项,无需手动计算高度或数量,极大简化了长列表处理的逻辑。
2. 自定义截断器
提供完全自由的截断器 UI 渲染能力。你可以根据项目风格自定义截断显示的内容,例如常见的 +3 more 样式,或者更复杂的交互按钮。
3. 响应式设计
内置响应式机制,能够根据容器尺寸自动调整截断策略,在手机、平板、桌面等不同设备上都能呈现最佳效果。
4. 可扩展列表
支持展开 / 折叠功能,用户可以通过点击截断器来查看完整列表内容,适用于需要展示部分内容但保留查看全部选项的场景。
安装指南
通过 npm 安装
npm install @twheeljs/vue-truncate-list
通过 yarn 安装
yarn add @twheeljs/vue-truncate-list
使用示例
基础用法
下面是一个基础的列表截断示例,通过 renderTruncator 自定义截断器的显示:
<template>
<TruncateList
:renderTruncator="({ hiddenItemsCount }) => h('div', { class: 'listItem' }, `+${hiddenItemsCount}`)"
>
<div class="listItem">Item 1</div>
<div class="listItem">Item 2</div>
<div class="listItem">Item 3</div>
<!-- 更多列表项... -->
</TruncateList>
</template>
<script>
import { h } from 'vue'
import TruncateList from '@twheeljs/vue-truncate-list'
export default {
components: {
TruncateList
}
}
</script>
在这个示例中,我们通过 h 函数创建了一个简单的截断器,显示隐藏项的数量。
可扩展列表用法
更复杂的可展开 / 折叠列表示例:
<template>
<TruncateList
:class="['list', 'expandable', expanded ? 'expanded' : '']"
:alwaysShowTruncator="true"
:renderTruncator="({ hiddenItemsCount, truncate }) => {
if (hiddenItemsCount > 0) {
return h(
'button',
{
class: 'expandButton',
onClick: () => {
handleExpand();
// 重要:使用 nextTick 确保布局重计算后调用 truncate
nextTick(() => {
truncate();
})
}
},
`${hiddenItemsCount} more...`
);
} else {
return h(
'button',
{
class: 'expandButton',
onClick: handleCollapse
},
'hide'
);
}
}"
>
<div class="listItem">foo</div>
<!-- 更多列表项... -->
<div class="listItem">thud</div>
</TruncateList>
</template>
<script>
import { h, ref, nextTick } from 'vue'
import TruncateList from '@twheeljs/vue-truncate-list'
export default {
components: {
TruncateList
},
setup() {
const expanded = ref(false);
const handleExpand = () => {
expanded.value = true;
}
const handleCollapse = () => {
expanded.value = false;
}
return {
expanded,
handleExpand,
handleCollapse
}
}
}
</script>
注意事项:当设置 expanded 类时,虽然将 max-height 设置为 none,但容器高度不会立即更新,导致 ResizeObserver 不会触发。因此,需要在 nextTick 中手动调用 truncate() 方法来确保布局重新计算。
API 参考
Props
| 名称 | 类型 | 默认值 | 描述 | |
|---|---|---|---|---|
| renderTruncator | ({ hiddenItemsCount, truncate }) => string | VNode | 无 | 用于渲染截断器 UI 的函数,接收 hiddenItemsCount(隐藏项数量)和 truncate(重新计算布局的函数) |
| alwaysShowTruncator | boolean | false | 是否始终显示截断器,即使没有隐藏项 |
贡献与开发
本地开发
# 安装依赖
npm install
# 启动开发服务器
npm run dev
结语
vue-truncate-list 组件通过简洁的 API 和强大的功能,为 Vue 开发者提供了处理长列表展示的最佳实践。无论是移动端还是桌面端应用,它都能帮助你实现优雅的列表截断效果,提升用户体验。
项目灵感来源于 maladr0it/react-truncate-list,在此表示感谢。
欢迎大家贡献代码、提交 Issues 或提出改进建议!
来源:juejin.cn/post/7517107495392919578
Web Worker + OffscreenCanvas,实现真正多线程渲染体验
前端开发常说“JavaScript 是单线程的”,但如果你正在做动画、数据可视化、图像处理、游戏开发、或任何基于 Canvas 的复杂渲染,你一定体会过——主线程的“卡顿地狱” 。
UI 不响应、FPS 降到个位数、稍微有点计算或渲染逻辑,就能卡住整个页面。
这种时候,Web Worker + OffscreenCanvas 是你的救命稻草。它不仅能将耗时任务移出主线程,还能真正让 Canvas 的绘制多线程执行。
这篇文章将带你深度理解并实践:
- 为什么你需要 Web Worker + OffscreenCanvas?
- 如何正确使用它们协同工作?
- 适配浏览器的兼容性与降级方案
- 实际场景中的优化技巧与踩坑合集
“主线程”到底卡在哪?
Canvas 的渲染过程其实包含两个部分:
- 逻辑计算(生成要绘制的数据,如位置、颜色、形状等)
- 图形绘制(通过 2D 或 WebGL API 渲染)
这两个过程在传统用法中都跑在主线程。
一旦数据量一大、图形一多,你的 UI 就会被“图形更新”压得喘不过气。比如你尝试每帧绘制上千个粒子、图像变换、实时数据曲线更新时:
主线程就像个老人推着超重购物车,边推边喘,既要绘图又要处理 UI 和事件。
此时,如果我们能把逻辑计算和绘图任务拆出去,放到 Worker 中执行,主线程就能专注于 UI 响应,从而实现真正的“多线程协作”。
OffscreenCanvas 是什么?
OffscreenCanvas 是一种不依赖 DOM 的 Canvas 对象,它可以在 Worker 线程中创建和操作,拥有与普通 Canvas 几乎相同的绘图 API。
核心特性:
- 可以在主线程或 Worker 中创建
- 支持 2D 和 WebGL 上下文
- 可以将普通
<canvas>转换为 OffscreenCanvas 进行共享 - 能通过
transferControlToOffscreen()实现跨线程控制
Web Worker + OffscreenCanvas 工作原理
- 主线程中创建
<canvas>元素 - 将 canvas 转为 OffscreenCanvas,并传给 Worker
- Worker 中接管 canvas 渲染逻辑(2D/WebGL)
- 主线程继续负责 UI 响应、控件交互等
这样你就实现了:
- 主线程干净:不会因绘图阻塞 UI
- 渲染帧率高:不受主线程任务干扰
- 计算更快:Worker 可以专注高频计算任务
实战:用 OffscreenCanvas 实现 Worker 内渲染
我们来动手写一个最小工作示例,用 Web Worker 绘制一个不断更新的粒子系统。
主线程(main.js)
const canvas = document.querySelector('canvas')
// 支持性检测
if (canvas.transferControlToOffscreen) {
const offscreen = canvas.transferControlToOffscreen()
const worker = new Worker('render.worker.js')
// 把 OffscreenCanvas 发送给 Worker,使用 transferable objects
worker.postMessage({ canvas: offscreen }, [offscreen])
} else {
console.warn('当前浏览器不支持 OffscreenCanvas')
}
Worker 线程(render.worker.js)
self.onmessage = function (e) {
const canvas = e.data.canvas
const ctx = canvas.getContext('2d')
const particles = Array.from({ length: 1000 }, () => ({
x: Math.random() * canvas.width,
y: Math.random() * canvas.height,
vx: (Math.random() - 0.5) * 2,
vy: (Math.random() - 0.5) * 2
}))
function render() {
ctx.clearRect(0, 0, canvas.width, canvas.height)
for (let p of particles) {
p.x += p.vx
p.y += p.vy
if (p.x < 0 || p.x > canvas.width) p.vx *= -1
if (p.y < 0 || p.y > canvas.height) p.vy *= -1
ctx.beginPath()
ctx.arc(p.x, p.y, 2, 0, 2 * Math.PI)
ctx.fillStyle = '#09f'
ctx.fill()
}
requestAnimationFrame(render)
}
render()
}
浏览器支持情况
| 浏览器 | 支持 OffscreenCanvas | 支持 transferControlToOffscreen |
|---|---|---|
| Chrome | ✅(全功能) | ✅ |
| Firefox | ✅(需开启设置) | ✅ |
| Safari | ❌(尚不支持) | ❌ |
| Edge | ✅ | ✅ |
Safari 目前仍未完全支持,你可以做降级方案:如果不支持,就在主线程绘制。
冷知识:你以为是主线程的 requestAnimationFrame,其实在 Worker 中也能用!
在 Worker 中使用 requestAnimationFrame()?听起来离谱,但确实在 OffscreenCanvas 上启用了这个能力。
前提是你在 Worker 中用的是 OffscreenCanvas.getContext('2d' or 'webgl'),而不是 fake canvas。
所以,你可以用 Worker 实现完整的帧驱动动画系统,与主线程完全无关。
实战应用场景
✅ 实时数据可视化(如股票图、心电图)
让绘图脱离主线程,保证交互流畅性。
✅ 游戏引擎粒子系统、WebGL 场景
WebGL 渲染逻辑搬到 Worker,UI 操作丝滑不掉帧。
✅ 视频滤镜或图像处理
用 Canvas + 图像 API 进行像素级变换、裁剪、调色等任务。
✅ 后台复杂渲染任务(地图、3D 建模)
用户没感知,但主线程不会阻塞。
常见坑与优化建议
❗ 坑1:不能在 Worker 中操作 DOM
Worker 是脱离 DOM 世界的,不支持 document、window、canvas 元素。你只能使用传入的 OffscreenCanvas。
❗ 坑2:transferControlToOffscreen 只能用一次
一旦你把 canvas “交给”了 Worker,主线程就不能再操作它。就像是 canvas 被“搬家”了。
❗ 坑3:调试困难?用 console.log + postMessage 结合
Worker 的日志不一定出现在主线程控制台。建议:
console.log = (...args) => postMessage({ type: 'log', args })
主线程监听 message 然后打出日志。
✅ 优化1:帧率控制,别无限 requestAnimationFrame
在计算密集任务中,可能帧率过高导致 GPU 占用过重。可以加入 setTimeout 限制帧频。
✅ 优化2:TypedArray 数据共享
大量数据传输时,考虑用 SharedArrayBuffer 或 transferable objects,减少拷贝。
延伸阅读:WebAssembly + Worker + OffscreenCanvas?
如果你已经把渲染任务移到 Worker 中,还可以更进一步——用 WebAssembly(如 Rust、C++)执行核心逻辑,把性能提升到极限。
这就是现代浏览器下的“性能金三角”:
WebAssembly 负责逻辑 + Worker 解耦线程 + OffscreenCanvas 渲染输出
这是很多 Web 游戏、3D 可视化平台的核心架构方式。
结语:把计算和渲染“赶出”主线程,是前端性能进化的方向
OffscreenCanvas 不只是一个新 API,它代表了一种思维方式的转变:
- 从“所有任务都塞主线程” → 到“职责分离、主线程清洁化”
- 从“怕卡 UI” → 到“性能可控、结构合理”
如果你在做复杂动画、WebGL 图形、游戏、实时可视化,不使用 Web Worker + OffscreenCanvas,就像在用拖拉机跑 F1,注定要掉队。
拥抱现代浏览器的能力,开启真正的多线程渲染体验吧!
来源:juejin.cn/post/7508968054875308043
Element 分页表格跨页多选状态保持方案(十几行代码解决)
问题背景
在使用 Element-Plus/Element-UI 的分页表格(或者其他表格组件)时,默认的多选功能无法跨页保持选中状态。当切换分页请求新数据后,之前选中的数据会被清空。
之前遇到这个问题搜了挺多网上的文章,看着代码又多又复杂,下面是很简单的实现方法,主要代码就十几行。
先贴效果
核心思路
- 全局选中的ID集合:维护一个全局的
全局ID集合(Set)存储所有选中的数据ID。 - 数据同步:在操作
选中、取消选中、全选、取消全选时同步全局ID集合 - 状态回显:在分页变化,每次加载新数据后,如果数据(当前页的数据数组)的
ID存在于全局ID集合就回显选中项,让对应的行数据选中。
关键代码解析
1. 全局状态定义
const globalSelectedIds = ref(new Set()); // 全局选中id
const isPageChanging = ref(false); // 标记是否正在切换分页
2. 请求接口数据加载与表格状态回显
const getList = async () => {
isPageChanging.value = true;
let res = await mockApi({
page: currentPage.value,
pageSize: pageSize.value,
});
tableData.value = res;
// 数据更新后回显选中状态
nextTick(() => {
tableData.value.forEach((row) => {
tableRef.value?.toggleRowSelection(
row,
globalSelectedIds.value.has(row.id)
);
});
isPageChanging.value = false;
});
};
3. 选择状态变更处理 (核心代码)
const handleSelectionChange = (selection) => {
// // 如果是请求数据后回显表格选中状态导致的变化事件,则不处理
if (isPageChanging.value) return;
const currentPageIds = tableData.value.map((row) => row.id);
// 先移除当前页所有ID
currentPageIds.forEach((id) => globalSelectedIds.value.delete(id));
// 再添加当前选中的ID
selection.forEach((row) => globalSelectedIds.value.add(row.id));
};
4. 从全局移除选中项(可选,仅演示点击标签删除选中数据使用)
const removeSelected = (id) => {
globalSelectedIds.value.delete(id);
const row = tableData.value.find((row) => row.id === id);
row && tableRef.value?.toggleRowSelection(row, false);
};
完整实现方案代码 (vue3 + element plus)
<template>
<div>
<!-- 表格 -->
<el-table
:data="tableData"
@selection-change="handleSelectionChange"
ref="tableRef"
border
>
<el-table-column type="selection" width="55" />
<el-table-column prop="id" label="ID" width="80" />
<el-table-column prop="name" label="姓名" />
</el-table>
<el-pagination
class="mt-4"
v-model:current-page="currentPage"
v-model:page-size="pageSize"
:page-sizes="[5, 10, 20]"
:total="100"
layout="total, sizes, prev, pager, next"
@size-change="handlePageSizeChange"
@current-change="handlePageChange"
/>
<!-- 展示全局选中的数据id -->
<div>
<h4>全局选中数据 ({{ globalSelectedIds.size }}个)</h4>
<div v-if="globalSelectedIds.size > 0">
<el-tag
v-for="id in Array.from(globalSelectedIds)"
:key="id"
closable
@close="removeSelected(id)"
class="mr-2 mb-2"
>
ID: {{ id }}
</el-tag>
</div>
</div>
</div>
</template>
<script setup>
import { ref, onMounted, nextTick } from "vue";
const currentPage = ref(1);
const pageSize = ref(5);
const tableRef = ref();
const tableData = ref([]);
const globalSelectedIds = ref(new Set()); // 全局选中id
const isPageChanging = ref(false); // 标记是否正在切换分页
// 模拟从接口获取数据
const mockApi = ({ page, pageSize }) => {
const data = [];
const startIndex = (page - 1) * pageSize;
for (let i = 1; i <= pageSize; i++) {
const id = startIndex + i;
data.push({
id: id,
name: `用户${id}`,
});
}
return new Promise((resolve) => {
setTimeout(() => {
resolve(data);
}, 100);
});
};
// 获取列表数据
const getList = async () => {
isPageChanging.value = true;
let res = await mockApi({
page: currentPage.value,
pageSize: pageSize.value,
});
tableData.value = res;
// 数据更新后回显选中状态
nextTick(() => {
tableData.value.forEach((row) => {
tableRef.value?.toggleRowSelection(
row,
globalSelectedIds.value.has(row.id)
);
});
isPageChanging.value = false;
});
};
// 统一处理表格选择变化
const handleSelectionChange = (selection) => {
// 如果是请求数据后回显表格选中状态导致的变化事件,则不处理
if (isPageChanging.value) return;
const currentPageIds = tableData.value.map((row) => row.id);
// 先移除当前页所有ID
currentPageIds.forEach((id) => globalSelectedIds.value.delete(id));
// 再添加当前选中的ID
selection.forEach((row) => globalSelectedIds.value.add(row.id));
};
// 从全局移除选中项,如果删除的ID在当前页,需要更新表格选中状态
const removeSelected = (id) => {
globalSelectedIds.value.delete(id);
const row = tableData.value.find((row) => row.id === id);
row && tableRef.value?.toggleRowSelection(row, false);
};
// 处理分页变化
const handlePageChange = () => {
getList();
};
// 处理分页数量变化
const handlePageSizeChange = () => {
currentPage.value = 1;
getList();
};
// 请求接口获取数据
getList();
</script>
总结
这个功能的实现其实挺简单的,核心就是维护一个全局的选中 ID 集合。每次用户勾选表格时,对比当前页的数据和全局 ID 集合来更新状态;翻页或者重新加载数据时,再根据这个集合自动回显勾选状态,保证选中项不会丢失。
来源:juejin.cn/post/7517911614778064933
告别玄学!JavaScript的随机数终于能“听话”了!🎲
关注梦兽编程微信公众号,轻松摸鱼一下午。
用了十几年Math.random(),你是不是也遇到过这样的尴尬:想要在游戏里生成一个每次加载都一样的地图?想在测试中复现那个只出现一次的随机bug?面对Math.random()这个完全看心情的家伙,你只能望洋兴叹,因为它每次运行都会给你一个全新的、不可预测的数字。就像一个完全不记事的“失忆”随机数生成器。
// 每次运行都不一样,随缘得很
console.log(Math.random()); // 0.123456789
console.log(Math.random()); // 0.987654321
你无法“喂”给它一个特定的“种子”,让它沿着你预设的轨迹生成数字。这在很多需要确定性行为的场景下,简直是噩梦。
别担心!救星来了!JavaScript即将迎来一个重量级新成员——Random API提案(目前处于Stage 2阶段),它将彻底改变我们与随机数打交道的方式,带来一个革命性的特性:可复现的随机性(Reproducible Randomness)!
Random API:给随机数装上“记忆”和“超能力”🚀
新的Random API的核心在于引入了“种子”(Seed)的概念。你可以给随机数生成器一个特定的种子,只要种子一样,它就能生成完全相同的随机数序列。这就像给随机数装上了“记忆”,让它每次都能按照同一个剧本表演。
创建带有种子的随机数生成器:
// 用一个特定的种子创建一个生成器,比如种子是 [42, 0, 0, 0]
const seededRandom = new Random.Seeded(new Uint8Array([42, 0, 0, 0]));
// 见证奇迹!这两行代码,无论你运行多少次,结果都是一样的!
console.log(seededRandom.random()); // 0.123456789 (每次都一样)
console.log(seededRandom.random()); // 0.987654321 (每次都一样)
请注意这里的“一样”是什么意思:如果你使用相同的种子,并且按照相同的顺序调用.random()方法,你将总是得到完全相同的随机数序列。 第一次调用总是返回同一个值,第二次调用总是返回同一个(但通常与第一次不同)值,以此类推。这并不是说每次调用.random()都会返回同一个数字,而是整个序列是可预测、可复现的。
实战演练:用确定性随机生成游戏世界!🏞
想象一下,你在开发一个沙盒游戏,每次进入游戏,地形都应该不同,但如果你保存游戏再加载,地形必须和保存时一模一样。使用Random API,这变得轻而易举:
class TerrainGenerator {
constructor(seed) {
// 用种子创建随机生成器
this.random = new Random.Seeded(seed);
this.heightMap = [];
}
generateTerrain(width, height) {
for (let y = 0; y < height; y++) {
this.heightMap[y] = [];
for (let x = 0; x < width; x++) {
// 使用带有种子的随机数生成地形高度
this.heightMap[y][x] = this.random.random() * 100;
}
}
return this.heightMap;
}
// 保存当前生成器的状态,以便之后恢复
saveState() {
return this.random.getState();
}
// 从保存的状态恢复生成器
restoreState(state) {
this.random.setState(state);
}
}
// 使用种子42生成第一块地形
const generator = new TerrainGenerator(new Uint8Array([42]));
const terrain1 = generator.generateTerrain(10, 10);
// 使用相同的种子42创建另一个生成器
const generator2 = new TerrainGenerator(new Uint8Array([42]));
const terrain2 = generator2.generateTerrain(10, 10);
// 见证奇迹!两块地形竟然完全相同!
console.log(JSON.stringify(terrain1) === JSON.stringify(terrain2)); // true
Random API的进阶超能力!🛠️
Random API的功能远不止于此,它还有一些非常实用的进阶特性:
1. 创建“子生成器”:
有时候你需要多个独立的随机数序列,但又想它们之间有某种关联(比如都源自同一个主种子)。你可以从一个父生成器派生出子生成器:
// 创建一个父生成器
const parent = new Random.Seeded(new Uint8Array([42]));
// 创建两个子生成器,它们的种子来自父生成器
const child1 = new Random.Seeded(parent.seed());
const child2 = new Random.Seeded(parent.seed());
// 这两个子生成器会产生不同的随机数序列,但它们的生成过程是确定的
console.log(child1.random()); // 0.123456789
console.log(child2.random()); // 0.987654321
2. 序列化和恢复状态:
你不仅可以保存和恢复整个生成器,还可以保存它当前的“状态”。这意味着你可以在生成到一半的时候暂停,保存状态,之后再从这个状态继续生成,保证后续序列完全一致。这对于需要中断和恢复的随机过程非常有用。
// 创建一个生成器
const generator = new Random.Seeded(new Uint8Array([42]));
// 生成一些数字
console.log(generator.random()); // 0.123456789
console.log(generator.random()); // 0.987654321
// 保存当前状态
const state = generator.getState();
// 继续生成更多数字
console.log(generator.random()); // 0.456789123
// 恢复之前保存的状态
generator.setState(state);
// 再次生成,你会得到和恢复状态前一样的数字!
console.log(generator.random()); // 0.456789123 (和上面一样)
更多实用场景:不止是游戏!💡
Random API的应用场景非常广泛:
1. 确定性测试:
在编写单元测试或集成测试时,你经常需要模拟随机数据。使用带有种子的随机数,你可以确保每次测试运行时都能得到相同的随机输入,从而更容易复现和调试问题。你可以临时替换掉Math.random()来实现确定性测试:
function testWithSeededRandom() {
// 创建一个带有种子的随机生成器
const random = new Random.Seeded(new Uint8Array([42]));
// 临时替换掉 Math.random
const originalRandom = Math.random;
Math.random = random.random.bind(random);
try {
// 运行你的测试代码,里面的 Math.random 现在是确定的了
runTests();
} finally {
// 恢复原来的 Math.random
Math.random = originalRandom;
}
}
2. 程序化内容生成:
除了游戏地形,你还可以用它来生成角色属性、关卡布局、艺术图案等等,只要给定相同的种子,就能得到完全相同的结果。
class ProceduralContentGenerator {
constructor(seed) {
this.random = new Random.Seeded(seed);
}
generateCharacter() {
const traits = ['brave', 'cunning', 'wise', 'strong', 'agile'];
const name = this.generateName();
// 使用 seededRandom 生成随机索引
const trait = traits[Math.floor(this.random.random() * traits.length)];
return { name, trait };
}
generateName() {
const prefixes = ['A', 'E', 'I', 'O', 'U'];
const suffixes = ['dor', 'lin', 'mar', 'tor', 'vin'];
// 使用 seededRandom 生成随机前后缀
const prefix = prefixes[Math.floor(this.random.random() * prefixes.length)];
const suffix = suffixes[Math.floor(this.random.random() * suffixes.length)];
return prefix + suffix;
}
}
// 使用种子42创建生成器
const generator = new ProceduralContentGenerator(new Uint8Array([42]));
// 生成一个角色
const character = generator.generateCharacter();
console.log(character); // { name: 'Ador', trait: 'brave' }
// 使用相同的种子42创建另一个生成器
const generator2 = new ProceduralContentGenerator(new Uint8Array([42]));
// 生成的角色竟然完全相同!
const character2 = generator2.generateCharacter();
console.log(character2); // { name: 'Ador', trait: 'brave' }
3. 安全随机数生成:
Random API也提供了生成密码学安全随机数的方法,这对于需要高度安全性的场景(如密钥生成)至关重要。
// 生成一个密码学安全的随机种子
const secureSeed = Random.seed();
// 使用安全种子创建生成器
const secureRandom = new Random.Seeded(secureSeed);
// 生成密码学安全的随机数
console.log(secureRandom.random()); // 这是一个密码学安全的随机数
为什么这很重要?超越基础的意义!✨
新的Random API解决了几个长期存在的痛点:
它提供了可复现性,让你每次运行代码都能得到相同的随机数序列,这对于调试和复现bug至关重要。它保证了确定性,让你的代码在不同环境下表现一致。它支持状态管理,允许你保存和恢复随机数生成器的状态,实现更灵活的控制。当然,它也能生成密码学安全的随机数,满足高安全性的需求。
核心要点总结!🎯
新的Random API带来了可复现的随机性,让随机数不再完全失控。你可以用种子创建多个独立的随机生成器,并且能够保存和恢复它们的状态。这个API在程序化生成、测试等领域有着巨大的潜力。记住,它目前还在Stage 2阶段,但离我们越来越近了!
结语:JavaScript随机数的未来,是确定的!🚀
Random API的到来,对于需要精确控制随机行为的JavaScript开发者来说,无疑是一个游戏规则的改变者。无论你是游戏开发者、测试工程师,还是在进行任何需要可预测随机性的工作,这个API都将极大地提升你的开发效率和代码可靠性。
JavaScript随机数的未来已来,而且,它是确定的!
(注意:Random API目前处于TC39流程的Stage 2阶段,尚未在浏览器中普遍可用。你可以关注其在GitHub上的进展。)
来源:juejin.cn/post/7517285070798897187
Interact.js 一个轻量级拖拽库
Interact.js的核心优势
- 轻量级:仅约10KB(gzipped),不依赖其他库
- 多点触控支持:完美适配移动设备
- 高度可定制:限制区域、惯性效果、吸附功能等
- 简洁API:直观的语法,学习曲线平缓
- 现代浏览器支持:兼容所有主流浏览器
安装与引入
通过npm安装:
npm install interactjs
或使用CDN:
<script src="https://cdn.jsdelivr.net/npm/interactjs/dist/interact.min.js"></script>
基础使用:创建可拖拽元素
<div id="draggable" class="box">
拖拽我
</div>
interact('#draggable').draggable({
inertia: true, // 启用惯性效果
autoScroll: true,
listeners: {
move: dragMoveListener
}
});
function dragMoveListener(event) {
const target = event.target;
const x = (parseFloat(target.getAttribute('data-x')) || 0) + event.dx;
const y = (parseFloat(target.getAttribute('data-y')) || 0) + event.dy;
target.style.transform = `translate(${x}px, ${y}px)`;
target.setAttribute('data-x', x);
target.setAttribute('data-y', y);
}
核心API详解
1. 拖拽功能(Draggable)
interact('.draggable').draggable({
// 限制在父元素内移动
modifiers: [
interact.modifiers.restrictRect({
restriction: 'parent',
endOnly: true
})
],
// 开始拖拽时添加样式
onstart: function(event) {
event.target.classList.add('dragging');
},
// 拖拽结束
onend: function(event) {
event.target.classList.remove('dragging');
}
});
2. 调整大小(Resizable)
interact('.resizable').resizable({
edges: { left: true, right: true, bottom: true, top: true },
// 限制最小尺寸
modifiers: [
interact.modifiers.restrictSize({
min: { width: 100, height: 100 }
})
],
listeners: {
move: function(event) {
const target = event.target;
let x = parseFloat(target.getAttribute('data-x')) || 0;
let y = parseFloat(target.getAttribute('data-y')) || 0;
// 更新元素尺寸
target.style.width = event.rect.width + 'px';
target.style.height = event.rect.height + 'px';
// 调整位置(当从左侧或顶部调整时)
x += event.deltaRect.left;
y += event.deltaRect.top;
target.style.transform = `translate(${x}px, ${y}px)`;
target.setAttribute('data-x', x);
target.setAttribute('data-y', y);
}
}
});
3. 放置区域(Dropzone)
interact('.dropzone').dropzone({
accept: '.draggable', // 只接受特定元素
overlap: 0.5, // 至少重叠50%才算放置有效
ondropactivate: function(event) {
event.target.classList.add('drop-active');
},
ondragenter: function(event) {
event.target.classList.add('drop-target');
},
ondragleave: function(event) {
event.target.classList.remove('drop-target');
},
ondrop: function(event) {
// 处理放置逻辑
event.target.appendChild(event.relatedTarget);
},
ondropdeactivate: function(event) {
event.target.classList.remove('drop-active');
event.target.classList.remove('drop-target');
}
});
高级功能
1. 限制与约束
// 限制在特定区域内移动
interact.modifiers.restrict({
restriction: document.getElementById('boundary'),
elementRect: { top: 0, left: 0, bottom: 1, right: 1 },
endOnly: true
})
// 吸附到网格
interact.modifiers.snap({
targets: [
interact.snappers.grid({ x: 20, y: 20 })
],
range: Infinity,
relativePoints: [ { x: 0, y: 0 } ]
})
2. 手势支持
interact('.gesture').gesturable({
listeners: {
move: function(event) {
const target = event.target;
const scale = parseFloat(target.getAttribute('data-scale')) || 1;
const rotation = parseFloat(target.getAttribute('data-rotation')) || 0;
target.style.transform =
`rotate(${rotation + event.da}deg)
scale(${scale * (1 + event.ds)})`;
target.setAttribute('data-scale', scale * (1 + event.ds));
target.setAttribute('data-rotation', rotation + event.da);
}
}
});
性能优化技巧
- 使用CSS变换而非定位:优先使用transform而非top/left
- 事件委托:对动态元素使用事件委托
- 适当限制事件频率:使用requestAnimationFrame节流事件
- 避免复杂选择器:在拖拽元素上使用简单类名
- 及时销毁实例:移除元素时调用
unset()方法
// 销毁实例
const draggable = interact('#element');
// 移除拖拽功能
draggable.unset();
来源:juejin.cn/post/7515391516787261474
🧑🎤音乐MCP,听歌走起
引言
在当今AI技术飞速发展的时代呢,如何将传统应用程序与自然语言交互相结合成为一个非常有趣的技术方向呀。嗯嗯,本文将详细介绍一个基于FastMCP框架开发的智能音乐播放器呢,它能够通过自然语言指令实现音乐播放控制,为用户提供全新的交互体验哦。啊,这个项目最初支持在线音乐播放功能来着,但是呢,出于版权考虑嘛,开源版本就仅保留了本地音乐播放功能啦。
项目概述
这个音乐播放器项目采用Python语言开发呢,核心功能包括:
- 嗯~
本地音乐文件的扫描与加载 - 多种
播放模式(单曲循环呀、列表循环啦、随机播放这样子) - 啊~
播放控制(播放/暂停/停止/上一首/下一首) - 嗯嗯,
播放列表管理功能 - 通过
FastMCP框架提供自然语言接口呢
项目采用模块化设计哦,主要依赖pygame处理音频播放,FastMCP提供AI交互接口,整体架构非常清晰呢,易于扩展和维护的啦。
技术架构解析
1. 核心组件
项目主要包含以下几个关键组件哦:
import os.path
import requests
import re
import json
import pygame
import threading
import queue
import random
pygame.mixer:负责音频文件的加载和播放呢threading:实现后台播放线程呀,避免阻塞主程序queue:用于线程间通信(虽然最终版本没直接使用队列啦)random:支持随机播放模式嘛FastMCP:提供AI工具调用接口哦
2. 全局状态管理
播放器通过一组全局变量和线程事件来管理播放状态呢:
current_play_list = [] # 当前播放列表呀
current_play_mode = "single" # 播放模式啦
current_song_index = -1 # 当前歌曲索引哦
# 线程控制事件
is_playing = threading.Event() # 播放状态标志呢
is_paused = threading.Event() # 暂停状态标志呀
should_load_new_song = threading.Event() # 加载新歌曲标志啦
playback_thread = # 播放线程句柄哦
这种设计实现了播放状态与UI/控制逻辑的分离呢,使得系统更加健壮和可维护呀。
核心实现细节
1. 音乐播放线程
播放器的核心是一个独立的后台线程呢,负责实际的音乐播放逻辑哦:
def music_playback_thread():
global current_song_index, current_play_list, current_play_mode
# 确保mixer在线程中初始化呀
if not pygame.mixer.get_init():
pygame.mixer.init()
while True:
# 检查是否需要加载新歌曲啦
if should_load_new_song.is_set():
pygame.mixer.music.stop()
should_load_new_song.clear()
# 处理歌曲加载逻辑哦
if not current_play_list:
print("播放列表为空,无法加载新歌曲呢~")
is_playing.clear()
is_paused.clear()
continue
# 验证歌曲索引有效性呀
if not (0 <= current_song_index < len(current_play_list)):
current_song_index = 0
# 加载并播放歌曲啦
song_file_name = current_play_list[current_song_index]
song_to_play_path = os.path.join("music_file", song_file_name)
if not os.path.exists(song_to_play_path):
print(f"错误: 歌曲文件 '{song_file_name}' 未找到,跳过啦~")
continue
try:
pygame.mixer.music.load(song_to_play_path)
if not is_paused.is_set():
pygame.mixer.music.play()
print(f"正在播放 (后台): {song_file_name}哦~")
is_playing.set()
except pygame.error as e:
print(f"Pygame加载/播放错误: {e}. 可能音频文件损坏或格式不支持呢。跳过啦~")
continue
# 播放状态管理呀
if is_playing.is_set():
if pygame.mixer.music.get_busy() and not is_paused.is_set():
pygame.time.Clock().tick(10)
elif not pygame.mixer.music.get_busy() and not is_paused.is_set():
# 歌曲自然结束啦,根据模式处理下一首哦
if current_play_list:
if current_play_mode == "single":
should_load_new_song.set()
elif current_play_mode == "list":
current_song_index = (current_song_index + 1) % len(current_play_list)
should_load_new_song.set()
elif current_play_mode == "random":
current_song_index = random.randint(0, len(current_play_list) - 1)
should_load_new_song.set()
else:
is_playing.clear()
is_paused.clear()
pygame.mixer.music.stop()
elif is_paused.is_set():
pygame.time.Clock().tick(10)
else:
pygame.time.Clock().tick(100)
这个线程实现了完整的播放状态机呢,能够处理各种播放场景哦,包括正常播放呀、暂停啦、歌曲切换等等呢。
2. FastMCP工具函数
项目通过FastMCP提供了一系列可被AI调用的工具函数呢:
播放本地音乐
@mcp.tool()
def play_musics_local(song_name: str = "", play_mode: str = "single") -> str:
"""播放本地音乐呀
:param song_name: 要播放的音乐名称呢,可以留空哦,留空表示加载进来的歌曲列表为本地文件夹中的所有音乐啦
:param play_mode: 播放模式呀,可选single(单曲循环),list(列表循环),random(随机播放)哦
:return: 播放结果呢
"""
global current_play_list, current_play_mode, current_song_index, playback_thread
# 确保音乐文件夹存在哦
if not os.path.exists("music_file"):
os.makedirs("music_file")
return "本地文件夹中没有音乐文件呢,已创建文件夹 'music_file'啦~"
# 扫描音乐文件呀
music_files = [f for f in os.listdir("music_file") if f.endswith(".mp3")]
if not music_files:
return "本地文件夹中没有音乐文件呢~"
# 构建播放列表啦
play_list_temp = []
if not song_name:
play_list_temp = music_files
else:
for music_file in music_files:
if song_name.lower() in music_file.lower():
play_list_temp.append(music_file)
if not play_list_temp:
return f"未找到匹配 '{song_name}' 的本地音乐文件呢~"
current_play_list = play_list_temp
current_play_mode = play_mode
# 设置初始播放索引哦
if play_mode == "random":
current_song_index = random.randint(0, len(current_play_list) - 1)
else:
if song_name:
try:
current_song_index = next(i for i, f in enumerate(current_play_list) if song_name.lower() in f.lower())
except StopIteration:
current_song_index = 0
else:
current_song_index = 0
# 确保播放线程运行呀
if playback_thread is or not playback_thread.is_alive():
playback_thread = threading.Thread(target=music_playback_thread, daemon=True)
playback_thread.start()
print("后台播放线程已启动啦~")
# 触发播放哦
pygame.mixer.music.stop()
is_paused.clear()
is_playing.set()
should_load_new_song.set()
return f"已加载 {len(current_play_list)} 首音乐到播放列表呢。当前播放模式:{play_mode}哦。即将播放:{current_play_list[current_song_index]}呀~"
播放控制函数
@mcp.tool()
def pause_music(placeholder: str = ""):
"""暂停当前播放的音乐呀"""
global is_paused, is_playing
if pygame.mixer.music.get_busy():
pygame.mixer.music.pause()
is_paused.set()
return "音乐已暂停啦~"
elif is_paused.is_set():
return "音乐已处于暂停状态呢"
else:
return "音乐未在播放中哦,无法暂停呀"
@mcp.tool()
def unpause_music(placeholder: str = ""):
"""恢复暂停的音乐呢"""
global is_paused, is_playing
if not pygame.mixer.music.get_busy() and pygame.mixer.music.get_pos() != -1 and is_paused.is_set():
pygame.mixer.music.unpause()
is_paused.clear()
is_playing.set()
return "音乐已恢复播放啦~"
elif pygame.mixer.music.get_busy() and not is_paused.is_set():
return "音乐正在播放中呢,无需恢复哦"
else:
return "音乐未在暂停中呀,无法恢复呢"
@mcp.tool()
def stop_music(placeholder: str = ""):
"""停止音乐播放并清理资源哦"""
global is_playing, is_paused, current_song_index, should_load_new_song
pygame.mixer.music.stop()
is_playing.clear()
is_paused.clear()
should_load_new_song.clear()
current_song_index = -1
return "音乐已停止啦,程序准备好接收新的播放指令哦~"
歌曲导航函数
@mcp.tool()
def next_song(placeholder: str = "") -> str:
"""播放下一首歌曲呀"""
global current_song_index, current_play_list, is_playing, is_paused, current_play_mode, should_load_new_song
if not current_play_list:
return "播放列表为空呢,无法播放下一首哦~"
is_playing.set()
is_paused.clear()
# 从单曲循环切换到列表循环啦
if current_play_mode == "single":
current_play_mode = "list"
print("已从单曲循环模式切换到列表循环模式啦~")
# 计算下一首索引哦
if current_play_mode == "list":
current_song_index = (current_song_index + 1) % len(current_play_list)
elif current_play_mode == "random":
current_song_index = random.randint(0, len(current_play_list) - 1)
should_load_new_song.set()
return f"正在播放下一首: {current_play_list[current_song_index]}呢~"
@mcp.tool()
def previous_song(placeholder: str = "") -> str:
"""播放上一首歌曲呀"""
global current_song_index, current_play_list, is_playing, is_paused, current_play_mode, should_load_new_song
if not current_play_list:
return "播放列表为空呢,无法播放上一首哦~"
is_playing.set()
is_paused.clear()
if current_play_mode == "single":
current_play_mode = "list"
print("已从单曲循环模式切换到列表循环模式啦~")
if current_play_mode == "list":
current_song_index = (current_song_index - 1 + len(current_play_list)) % len(current_play_list)
elif current_play_mode == "random":
current_song_index = random.randint(0, len(current_play_list) - 1)
should_load_new_song.set()
return f"正在播放上一首: {current_play_list[current_song_index]}呢~"
播放列表查询
@mcp.tool()
def get_playlist(placeholder: str = "") -> str:
"""获取当前播放列表呀"""
global current_play_list, current_song_index
if not current_play_list:
return "播放列表当前为空呢~"
response_lines = ["当前播放列表中的歌曲哦:"]
for i, song_name in enumerate(current_play_list):
prefix = "-> " if i == current_song_index else " "
response_lines.append(f"{prefix}{i + 1}. {song_name}")
return "\n".join(response_lines)
部署与使用
1. 环境准备
项目依赖较少呢,只需安装以下库哦:
pip install pygame requests fastmcp
// 或者 指定阿里云的镜像源去加速下载(阿里源提供的PyPI镜像源地址)
pip install pygame requests fastmcp -i https://mirrors.aliyun.com/pypi/simple/
2. 运行程序
python play_music.py

3. 与AI助手集成
- 在支持
AI助手的客户端中配置SSE MCP呀 - 添加
MCP地址:http://localhost:4567/sse哦 - 启用所有
工具函数啦 - 设置工具为
自动执行以获得更好体验呢
配置,模型服务我选的是大模型openRouter:
然后去配置mcp服务器,类型一定要选sse
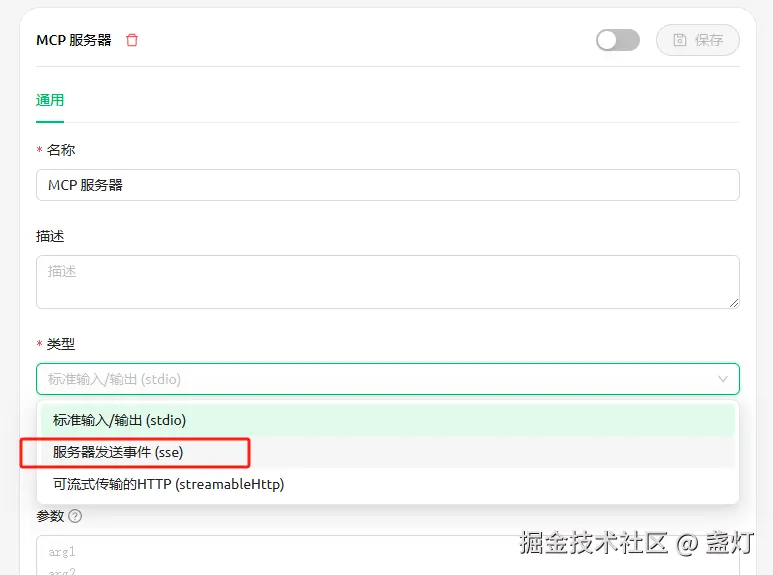
然后保存。
4. 使用示例
- "
播放本地歌曲呀,使用随机播放模式哦" - "
下一首啦" - "
暂停一下嘛" - "
继续播放呀" - "
停止播放呢" - "
播放歌曲xxx哦,使用单曲循环模式啦" - "
查看当前音乐播放列表呀"
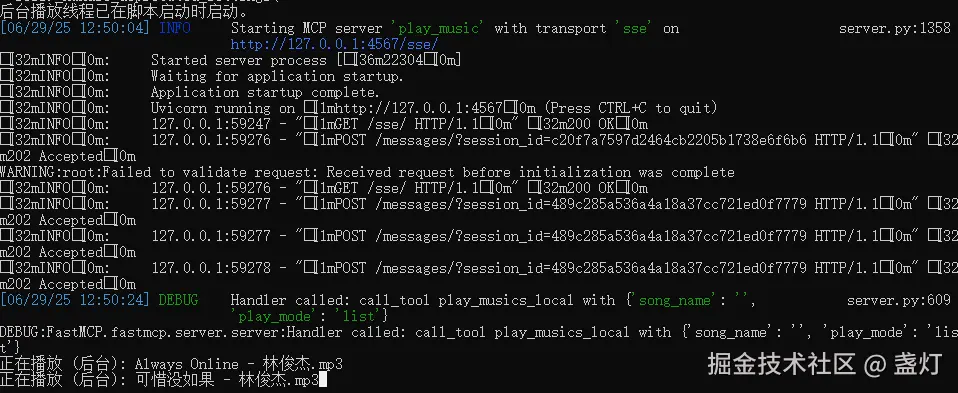
JJ的歌真好听。
来源:juejin.cn/post/7520960903743963174
前端如何检测新版本,并提示用户去刷新
前端如何检测新版本,并提示用户去刷新
先看效果
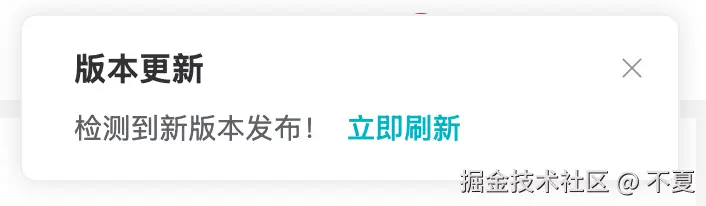
原理
通过轮询index.html文件的内容来计算文件的哈希值前后是否发生了变化
前端工程化的项目中,以Vue为例,webpack或vite打包通常会构建为很多的js、css文件,每次构建都会根据内容生成唯一的哈希值。如下图所示。

大家可以动手试试,观察一下。
每次构建完index.html中script或link标签引用的地址发生了变化。
代码实现
以Vue+ElementPlus项目为例。在入口文件中引入此文件即可。
// check-version.ts
// 封装了storage,粗暴一点可以用 sessionStorage 代替
import { Storage } from "@/utils/storage";
import { ElLink, ElNotification, ElSpace } from "element-plus";
import { h } from "vue";
import CryptoJS from 'crypto-js';
const storage = new Storage('check-version', sessionStorage);
const APP_VERSION = 'app-version';
let notifyInstance: any;
const generateHash = (text: string): string => CryptoJS.SHA256(text).toString();
const getAppVersionHash = async () => {
const html = await fetch(`${location.origin}?t=${Date.now()}`).then(res => res.text());
const newHash = generateHash(html);
const oldHash = storage.get(APP_VERSION);
return { newHash, oldHash };
}
const checkVersion = async () => {
const { newHash, oldHash } = await getAppVersionHash()
if (oldHash !== newHash) {
if (notifyInstance) return;
notifyInstance = ElNotification({
title: '版本更新',
message: h(ElSpace, null, () => [
h('span', '检测到新版本发布!'),
h(ElLink, { type: 'primary', onClick: () => location.reload() }, () => '立即刷新')
]),
position: 'top-right',
duration: 0,
onClose: () => {
notifyInstance = null
}
})
}
}
const loopCheck = (ms: number) => {
setTimeout(async () => {
await checkVersion()
loopCheck(ms)
}, ms)
}
document.addEventListener('DOMContentLoaded', async () => {
console.log("The DOM is fully loaded and parsed.");
const { newHash } = await getAppVersionHash();
storage.set(APP_VERSION, newHash, null);
loopCheck(1000 * 30);
});
来源:juejin.cn/post/7519335201505132553
fetch和axios的区别
1、fetch
来源与兼容性 浏览器原生提供的api,现代浏览器支持,但是IE浏览器不支持
请求与响应处理
- 请求体格式: 需手动设置
Content-Type,如发送 JSON 时需JSON.stringify(data)并添加headers: { 'Content-Type': 'application/json' }。 - 需要手动处理JSON解析(response.json())
- 错误状态码(默认不抛出HTTP错误,如 404、500,需要检查response.ok)
- cookie: 默认不带cookie,需手动配置 credentials:'include'
拦截器与全局配置
- 无内置拦截器,需手动封装或使用第三方库实现类似功能。
- 全局配置需自行封装(如统一添加请求头)。
错误处理 仅在网络请求失败时(如断网)触发 reject,HTTP 错误状态码(如 404)不会触发 catch。
取消请求 使用 AbortController 实现取消。
上传/下载进度监控 不支持原生进度监控,需通过读取响应流实现(较复杂)。
CSRF/XSRF 防护 需手动处理
const controller = new AbortController();
fetch(url, {signal: controller.signal}).then(res => {
if (!res.ok) throw new Error("HTTP error");
return res.json();
}).catch(err => {
if (err.name === 'AbortError') console.log('Request canceled');
});
controller.abort(); // 取消请求
使用场景:
- 对依赖体积敏感,不想引入额外依赖。
- 请求逻辑简单,无需复杂配置或拦截器。
2、axios
来源与兼容性 第三方组件库(基于XMLHttpRequest)
请求与响应处理
- 请求体格式: 自动根据数据类型设置
Content-Type(如对象默认转为 JSON)。 - 自动处理JSON解析(response.data)
- 自动将非 2xx 状态码视为错误(触发
catch) - cookie: 默认带cookie: 自动发送同源请求的cookie
拦截器与全局配置
- 支持 请求/响应拦截器,方便统一处理日志、认证、错误等。
- 支持全局默认配置(如
baseURL、headers)。
错误处理 任何 HTTP 错误状态码(如 404、500)均会触发 catch。
取消请求 使用 AbortController 实现取消。
上传/下载进度监控 支持 onUploadProgress 和 onDownloadProgress 回调。
CSRF/XSRF 防护 内置支持 XSRF Token 配置。
const controller = new AbortController();
axios.get(url, {signal: controller.signal}).then(res => {
console.log(res.data)
}).catch(err => {
if (axios.isCancel(err)) console.log('Request canceled');
});
controller.abort();
使用场景:
- 需要拦截器、取消请求、超时等高级功能。
- 项目跨浏览器和 Node.js 环境。
- 希望简洁的 API 和自动错误处理。
来源:juejin.cn/post/7514227898023739455
9 个被低估的 CSS 特性:让前端开发更高效的秘密武器
在 CSS 的浩瀚宇宙中,聚光灯下的明星属性固然耀眼,但那些藏在规范角落的「小众特性」,往往才是提升开发效率的秘密武器。它们就像隐藏的工具箱,能帮我们用更少的代码实现更细腻的交互,让界面开发从繁琐走向优雅。
今天,就为大家解锁9 个被严重低估的 CSS 特性,这些宝藏属性不仅能简化日常开发流程,还能带来意想不到的惊艳效果!
1. accent-color:表单元素的样式魔法
原生复选框和单选按钮曾是前端开发者的「审美之痛」,默认样式不仅呆板,还极难定制。但accent-color的出现,彻底打破了这个僵局!
input[type="checkbox"] {
accent-color: hotpink;
}
同样适用于input[type="radio"],只需一行代码,就能将单调的灰色方块 / 圆点变成品牌主色调,告别 JavaScript 和第三方库的复杂操作。
兼容性:主流浏览器(Chrome 86+、Firefox 75+、Safari 14+)均已支持,可放心使用!
2. caret-color:光标颜色随心定
在深色主题界面中,刺眼的黑色文本光标常常破坏整体美感。caret-color允许我们精确控制插入符颜色,让细节也能完美融入设计。
input { care
t-color: limegreen;
}
虽然只是一个像素级的调整,但却能大幅提升用户输入时的视觉舒适度,细节之处尽显专业!
3. currentColor:颜色继承的终极利器
还在为重复定义颜色值而烦恼?currentColor堪称 CSS 中的「颜色复印机」,它能自动继承元素的字体颜色,让代码更简洁,主题切换更灵活。
button {
color: #007bff;
border: 2px solid currentColor;
}
无论后续如何修改color值,border颜色都会自动同步,完美遵循 DRY(Don't Repeat Yourself)原则!
4. ::marker:列表符号的定制革命
过去修改列表符号,要么用background-image hack,要么手动添加标签,代码又丑又难维护。现在,::marker让我们真正掌控列表样式!
li::marker {
color: crimson;
font-size: 1.2rem;
}
除了颜色和尺寸,部分浏览器还支持设置字体、图标等高级效果,从此告别千篇一律的小黑点!
5. :user-valid:更人性化的表单验证
:valid 和 :invalid 虽能实现表单验证,但常出现「页面刚加载就提示错误」的尴尬。 :user-valid 巧妙解决了这个问题,仅在用户交互后才触发验证反馈。
input:user-valid {
border-color: green;
}
搭配 :user-invalid 使用,既能及时提示用户,又不会过度打扰,交互体验直接拉满!
6. :placeholder-shown:捕捉输入框的「空状态」
想在用户输入前给表单来点动态效果? :placeholder-shown 可以精准识别输入框是否为空,轻松实现淡入淡出、占位符动画等创意交互。
input:placeholder-shown {
opacity: 0.5;
}
当用户开始输入,样式自动切换,让表单引导更智能、更优雅。
7. all: unset:组件样式的「一键清零」
重置组件默认样式是开发中的常见需求,但传统的reset.css动辄几百行,代码冗余且难以维护。all: unset 只需一行代码,就能彻底移除所有默认样式(包括继承属性)。
button {
all: unset;
}
在构建自定义按钮、导航栏等组件时,先使用all: unset「清空画布」,再按需添加样式,开发效率直接翻倍!
注意:该属性会移除所有样式,使用时需谨慎搭配自定义规则,避免「矫枉过正」。
8. inset:布局语法的终极简化
写绝对定位或固定布局时,top、right、bottom、left 四行代码总是让人抓狂?inset 提供了超简洁的简写语法!
/* 等价于 top: 0; right: 0; bottom: 0; left: 0; */inset: 0;/* 类似 padding 的 2 值、4 值写法 */inset: 10px 20px; /* 等价于 top: 10px; right: 20px; bottom: 10px; left: 20px; */
代码瞬间瘦身,可读性直线上升,绝对是布局党的福音!
9. text-wrap: balance:文本折行的「智能管家」
在响应式设计中,标题折行常常参差不齐,影响排版美感。text-wrap: balance 就像一位专业排版师,能自动均衡每行文本长度,让内容分布更优雅。
h1 { text-wrap: balance;}
虽然目前浏览器支持有限(仅 Chrome 115+),但已在 Figma 等设计工具中广泛应用,未来可期!
总结
这些被低估的 CSS 特性,虽然小众,但每一个都能在特定场景中发挥巨大价值。下次开发时不妨试试,或许能发现新大陆!
互动时间:你在开发中还发现过哪些「相见恨晚」的 CSS 特性?欢迎在评论区分享,一起挖掘 CSS 的隐藏力量!
来源:juejin.cn/post/7504572792357584935
我的可视化规则引擎真高可用了
原来有这么多时间
六月的那么一天,天气比以往时候都更凉爽,媳妇边收拾桌子,边漫不经心的对我说:你最近好像都没怎么阅读了。 正刷着新闻我,如同被一记响亮的晴空霹雳击中一般,不知所措。是了,最近几月诸事凑一起,加之两大项目接踵而至,确实有些许糟心,于是总是在空闲的时间泡在新闻里聊以解忧,再回首,隐隐有些恍如隔世之感。于是收拾好心情,翻开了躺在书架良久的整洁三步曲。也许是太久没有阅读了, 一口气,Bob大叔 Clean 系列三本都读完了,重点推荐Clear Architecture,部分章节建议重复读,比如第5部分-软件架构,可以让你有真正的提升,对代码,对编程,对软件都会有不一样的认识。
Clean Code 次之,基本写了一些常见的规约,大部分也是大家熟知,数据结构与面向对象的看法,是少有的让我 哇喔的点,如果真是在码路上摸跋滚打过的,快速翻阅即可。
The Clean Coder 对个人而言可能作用最小。 确实写人最难,无法聚焦。讲了很多,但是感觉都不深入,或者作者是在写自己,很难映射到自己身上。 当然,第二章说不,与第14章辅导,学徒与技艺,还是值得一看的。
阅读技术书之余,又战战兢兢的翻开了敬畏已久的朱生豪先生翻译的《莎士比亚》, 不看则已,因为看了根本停不来。其华丽的辞职,幽默的比喻,真的会让人情不自禁的开怀朗读起来。
。。。
再看从6月到现在,电子书阅读时间超过120小时,平均每天原来有1个多小时的空余时间,简直超乎想像。
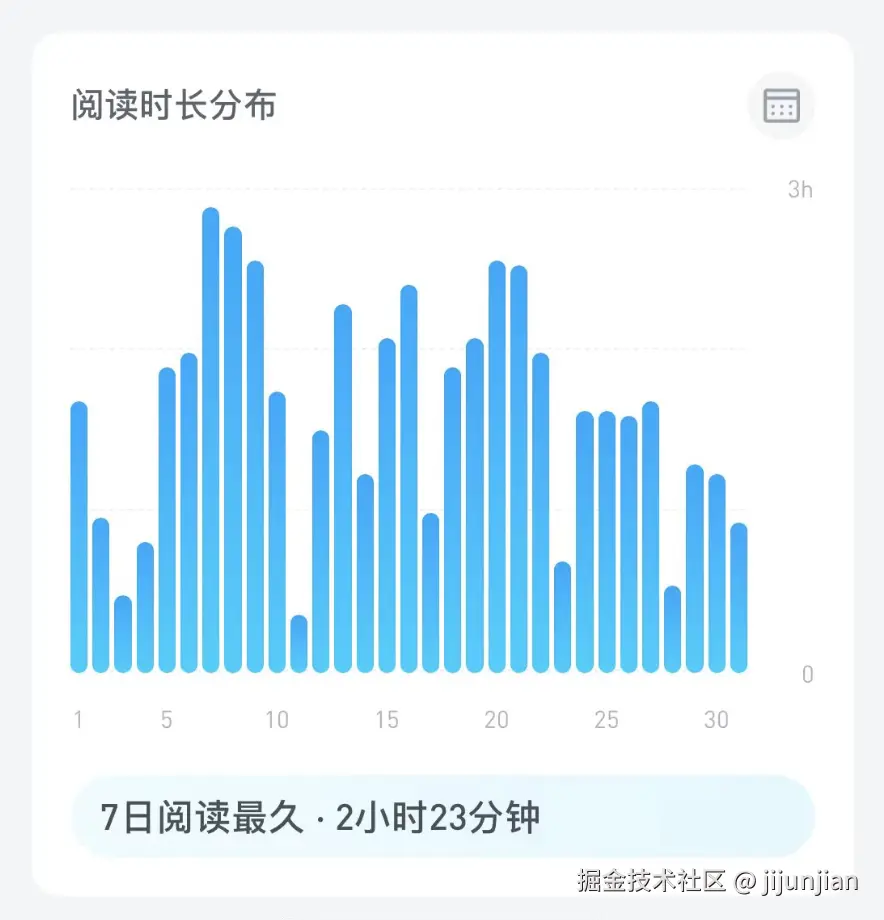
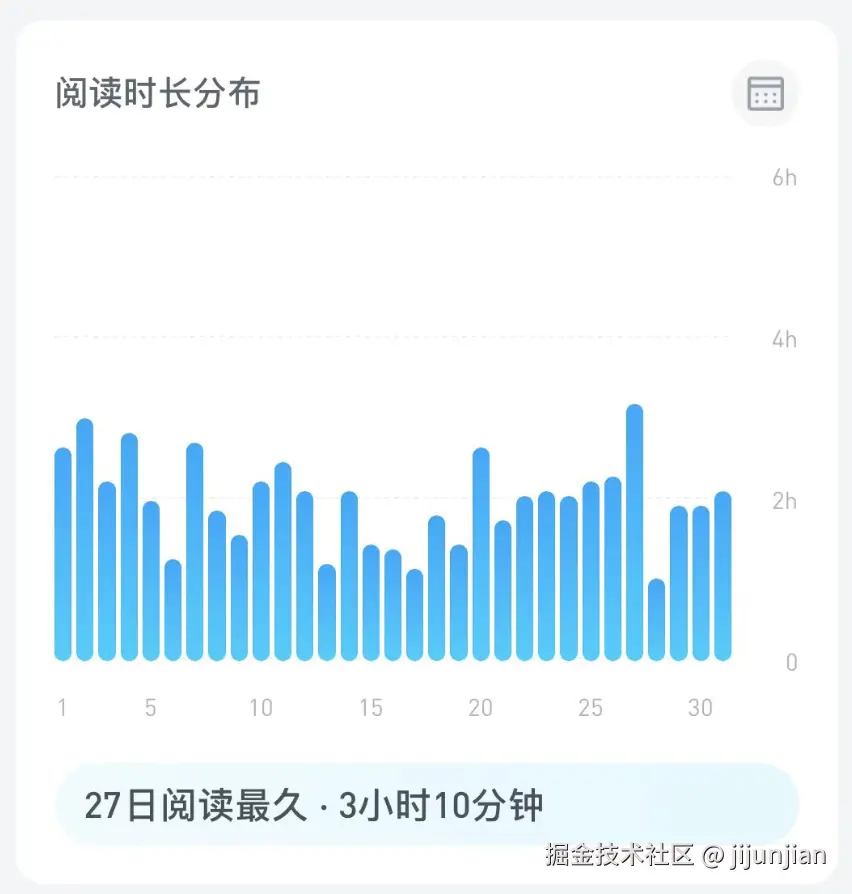

看了整洁架构一书,就想写代码,于是有了这篇文章。
灵魂拷问 - 宕机怎么办
为了解决系统中大量规则配置的问题,与同事一起构建了一个可视化表达式引擎 RuleLink《非全自研可视化表达引擎-RuleLinK》,解决了公司内部几乎所有配置问题。尤为重要的一点,所有配置业务同学即可自助完成。随着业务深入又增加了一些自定义函数,增加了公式及计算功能,增加组件无缝嵌入其他业务...我一度以为现在的功能已经可以满足绝大部分场景了。真到Wsin强同学说了一句:业财项目是深度依赖RuleLink的,流水打标,关联科目。。。我知道他看了数据,10分RuleLink执行了5万+次。这也就意味着,如果RuleLink宕机了,业财服务也就宕机了,也就意味着巨大的事故。这却是是一个问题,公司业务确实属于非常低频,架不住财务数据这么多。如果才能让RuleLink更稳定成了当前的首要问题。
高可用VS少依赖
要提升服务的可用性,增加服务的实例是最快的方式。 但是考虑到我们自己的业务属性,以及业财只是在每天固定的几个时间点短时高频调用。 增加节点似乎不是最经济的方式。看 Bob大叔的《Clear Architecture》书中,对架构的稳定性有这样一个公式:不稳定性,I=Fan-out/(Fan-in+Fan-out)
Fan-in:入向依赖,这个指标指代了组件外部类依赖于组件内部类的数量。
Fan-out:出向依赖,这个指标指代了组件内部类依赖于组件外部类的数量。
这个想法,对于各个微服务的稳定性同时适用,少一个外部依赖,稳定性就增加一些。站在业财系统来说,如果我能减少调用次数,其稳定性就在提升,批量接口可以一定程度上减少依赖,但并未解决根本问题。那么调用次数减少到极限会是什么样的呢?答案是:一次。 如果规则不变的话,我只需要启动时加载远程规则,并在本地容器执行规则的解析。如果有变动,我们只需要监听变化即可。这样极大减少了业财对RuleLink的依赖,也不用增RuleLink的节点。实际上大部分配置中心都是这样的设计的,比如apollo,nacos。 当然,本文的实现方式也有非常多借鉴(copy)了apollo的思想与实现。
服务端设计
模型比较比较简单,应用订阅场景,场景及其规则变化时,或者订阅关系变化时,生成应用与场景变更记录。类似于生成者-消费都模型,使用DB做存储。
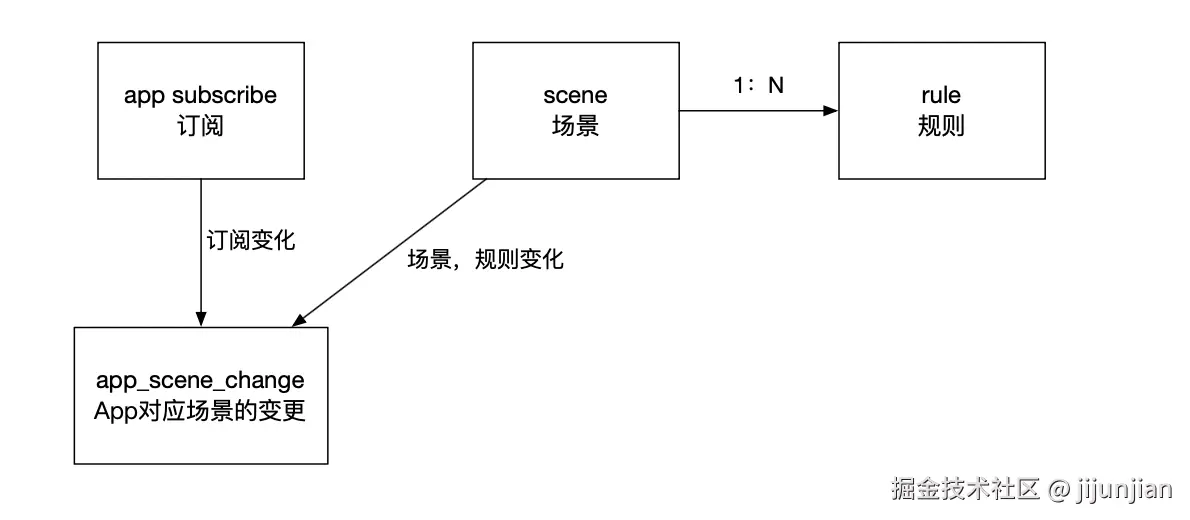

”推送”原理
整体逻辑参考apollo实现方式。 服务端启动后 创建Bean ReleaseMessageScanner 注入变更监听器 NotificationController。
ReleaseMessageScanner 一个线程定时扫码变更,如果有变化 通知到所有监听器。
NotificationController在得知有配置发布后是如何通知到客户端的呢?
实现方式如下:
1,客户端会发起一个Http请求到RuleLink的接口,NotificationController
2,NotificationController不会立即返回结果,而是通过Spring DeferredResult把请求挂起
3,如果在60秒内没有该客户端关心的配置发布,那么会返回Http状态码304给客户端
4,如果有该客户端关心的配置发布,NotificationController会调用DeferredResult的setResult方法,传入有变化的场景列表,同时该请求会立即返回。客户端从返回的结果中获取到有变化的场景后,会直接更新缓存中场景,并更新刷新时间
ReleaseMessageScanner 比较简单,如下。NotificationController 代码也简单,就是收到更新消息,setResult返回(如果有请求正在等待的话)
public class ReleaseMessageScanner implements InitializingBean {
private static final Logger logger = LoggerFactory.getLogger(ReleaseMessageScanner.class);
private final AppSceneChangeLogRepository changeLogRepository;
private int databaseScanInterval;
private final List<ReleaseMessageListener> listeners;
private final ScheduledExecutorService executorService;
public ReleaseMessageScanner(final AppSceneChangeLogRepository changeLogRepository) {
this.changeLogRepository = changeLogRepository;
databaseScanInterval = 5000;
listeners = Lists.newCopyOnWriteArrayList();
executorService = Executors.newScheduledThreadPool(1, RuleThreadFactory
.create("ReleaseMessageScanner", true));
}
@Override
public void afterPropertiesSet() throws Exception {
executorService.scheduleWithFixedDelay(() -> {
try {
scanMessages();
} catch (Throwable ex) {
logger.error("Scan and send message failed", ex);
} finally {
}
}, databaseScanInterval, databaseScanInterval, TimeUnit.MILLISECONDS);
}
/**
* add message listeners for release message
* @param listener
*/
public void addMessageListener(ReleaseMessageListener listener) {
if (!listeners.contains(listener)) {
listeners.add(listener);
}
}
/**
* Scan messages, continue scanning until there is no more messages
*/
private void scanMessages() {
boolean hasMoreMessages = true;
while (hasMoreMessages && !Thread.currentThread().isInterrupted()) {
hasMoreMessages = scanAndSendMessages();
}
}
/**
* scan messages and send
*
* @return whether there are more messages
*/
private boolean scanAndSendMessages() {
//current batch is 500
List<AppSceneChangeLogEntity> releaseMessages =
changeLogRepository.findUnSyncAppList();
if (CollectionUtils.isEmpty(releaseMessages)) {
return false;
}
fireMessageScanned(releaseMessages);
return false;
}
/**
* Notify listeners with messages loaded
* @param messages
*/
private void fireMessageScanned(Iterable<AppSceneChangeLogEntity> messages) {
for (AppSceneChangeLogEntity message : messages) {
for (ReleaseMessageListener listener : listeners) {
try {
listener.handleMessage(message.getAppId(), "");
} catch (Throwable ex) {
logger.error("Failed to invoke message listener {}", listener.getClass(), ex);
}
}
}
}
}
客户端设计
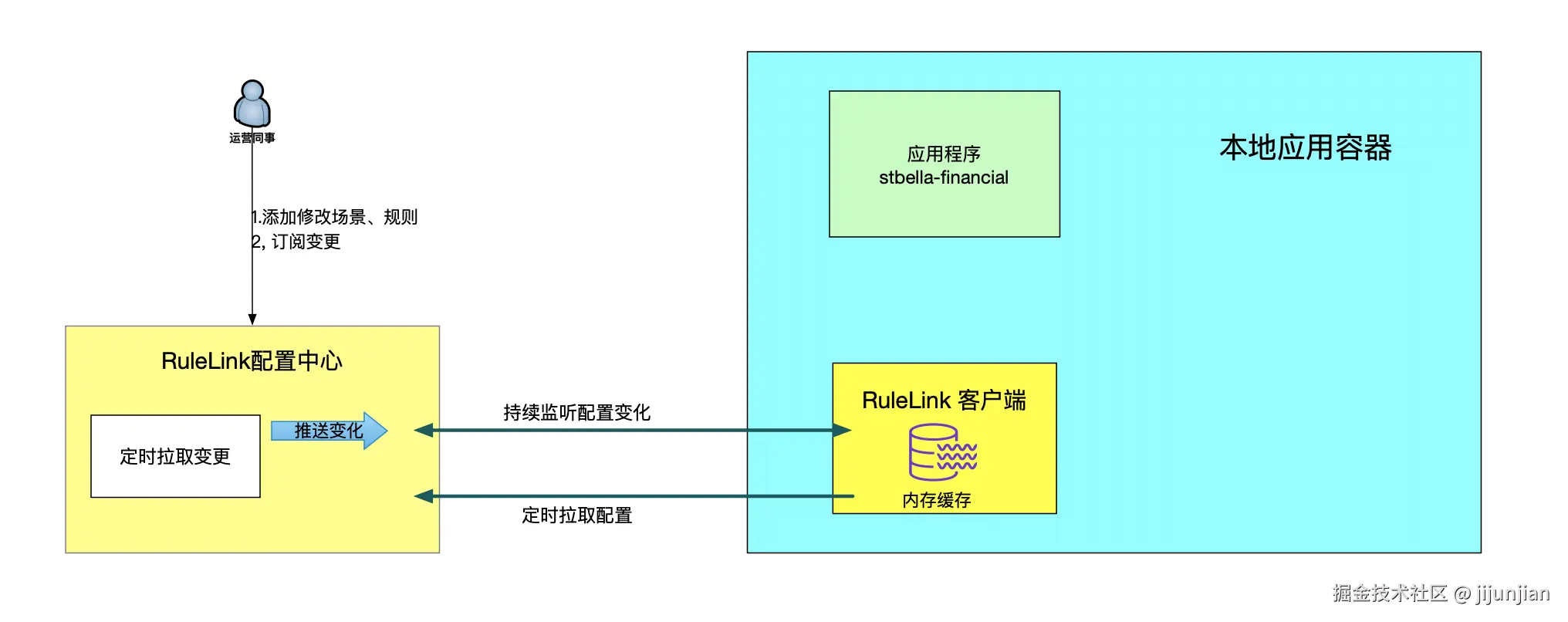
上图简要描述了客户端的实现原理:
- 客户端和服务端保持了一个长连接,从而能第一时间获得配置更新的推送。(通过Http Long Polling实现)
- 客户端还会定时从RuleLink配置中心服务端拉取应用的最新配置。
- 这是一个fallback机制,为了防止推送机制失效导致配置不更新
- 客户端定时拉取会上报本地版本,所以一般情况下,对于定时拉取的操作,服务端都会返回304 - Not Modified
- 定时频率默认为每5分钟拉取一次,客户端也可以通过在运行时指定配置项: rule.refreshInterval来覆盖,单位为分钟。
- 客户端从RuleLink配置中心服务端获取到应用的最新配置后,会写入内存保存到SceneHolder中,
- 可以通过RuleLinkMonitor 查看client 配置刷新时间,以及内存中的规则是否远端相同
客户端工程
客户端以starter的形式,通过注解EnableRuleLinkClient 开始初始化。
1 /**
2 * @author JJ
3 */
4 @Retention(RetentionPolicy.RUNTIME)
5 @Target(ElementType.TYPE)
6 @Documented
7 @Import({EnableRuleLinkClientImportSelector.class})
8 public @interface EnableRuleLinkClient {
9
10 /**
11 * The order of the client config, default is {@link Ordered#LOWEST_PRECEDENCE}, which is Integer.MAX_VALUE.
12 * @return
13 */
14 int order() default Ordered.LOWEST_PRECEDENCE;
15 }
在最需求的地方应用起来
花了大概3个周的业余时间,搭建了client工程,经过一番斗争后,决定直接用到了最迫切的项目 - 业财。当然,也做了完全准备,可以随时切换到RPC版本。 得益于DeferredResult的应用,变更总会在60s内同步,也有兜底方案:每300s主动查询变更,即便是启动后RuleLink宕机了,也不影响其运行。这样的准备之下,上线后几乎没有任何波澜。当然,也就没有人会担心宕机了。这真可以算得上一次愉快的编程之旅。
成为一名优秀的程序员!
来源:juejin.cn/post/7411168576433193001
重构pdfjs阅读器viewer.html,实现双PDF对比(不依赖iframe、embed)
针对pdfjs做二次开发的xshen-pdf仍在继续开发着,不过离第一个可用的版本发布还有一段时间。我正在按部就班的一步步向前推进中。
过去的一个星期,我将pdfjs的viewer.html里面的代码完整地梳理了一遍。并将里面的代码核心的代码提取出来,重新封装了一遍。并在国庆前,初步的实现了目标——直接通过div就可以渲染出一个PDF阅读器,而无需再使用iframe或者embed标签来嵌套引入pdf阅读器。
通常情况下,想要使用pdfjs提供的阅读器,就必须通过iframe、embed标签,或者window.open之类的方式打开一个独立的pdfjs的html页面(也就是viewer.html),这种方式实际上不太友好。它有着诸多问题,比如不太好控制、难以和其它组件联动、难以纳入一个页面的全局管理。因此我希望能够改进这一点,基于pdfjs,将PDF阅读器改造的像echarts那样易于配置和使用。开发者只需要声明一个div,然后调用初始化方法将这个div初始化成一个PDF阅读器即可。
在经过解构和重新封装之后,现在xshen-pdf能够实现这个功能了。想要在页面上渲染出一个或者多个PDF阅读器,只需要寥寥几行代码就够了。在html中,只需要声明一个或多个dom元素就可以了:
<body>
<div id="container" style="width: 48%; display: inline-block;height: 1000px;"></div>
<div id="container2" style="width: 48%; display: inline-block;height: 1000px;"></div>
</body>
在这里,我声明了两个容器,因为我想展示一下基于xshen-pdf实现的双PDF对比功能。在声明完容器之后,再使用两行js代码,初始化一下这两个阅读器就可以了:
import { Seren } from "./viewer/seren.js";
Seren.init('container',{ firstPage : 1});
Seren.init('container2',{ firstPage : 1});
渲染出来的结果如下所示:

通过上面的dom元素可以看到,id为container和container2的两个容器都被成功渲染出来了。
解构viewer.html和重新封装里面的组件,并不算一件容易的事。因为viewer.html默认是个全局的、唯一的PDF阅读器,因此里面很多地方都在使用全局变量,很多地方都在使用window对象、处理window事件,很多地方都使用了“宏”。简而言之就是一句话,默认提供的阅读器和全局环境耦合的地方较多。而我的目标是要将pdfjs变成一个能够直接引进html页面中的组件,开发者想怎么声明,就怎么声明。想怎么控制PDF阅读器,就怎么控制PDF阅读器。因此这些地方的代码全部都要拆掉重写,才能让PDF阅读器由一个必须通过嵌入才能操作的全局对象,变成一个可通过API自由操控的局部对象。因此,解耦就是我要做的首要工作。
全局参数AppOptions耦合,其实是一个比较麻烦的点。如果有的开发者对PDF阅读器有一些了解,那么他是可以通过AppOptions来修改PDF阅读器的参数。但是官方似乎并没有提供一个比较正式的API让开发者来修改这些参数。因此开发者想要修改一些参数,只能通过一些“不那么正规”的方式来达成自己的目的。这种方式自然也是有弊端的。这样做不好的地方就在于日后难以维护、升级pdfjs版本的时候可能会产生问题。
因为pdfjs提供的阅读器默认情况下只有一个,因此它大量使用了全局变量来对阅读器进行管理。将PDF阅读器进行局部化处理之后——即开发者通过函数来创建一个个PDF阅读器实例,这么做就不行了。当我们声明了多个阅读器的时候,每个阅读器读取的pdf文件、配置的功能、批注、权限可能是完全不同的。因此很多配置项应该是只能局部生效,而不能全局生效。但是仅仅有局部的配置项也是不够的。对于开发者创建的若干pdf阅读器,有时候也是需要全局统一控制的,例如白天/夜晚模式、是否分页加载等。因此,除了针对单个阅读器的配置项管理,还需要全局的配置项管理。在xshen-pdf里我分别定义了两个类,一个是ViewerOptions,针对单个阅读器生效。一个是SerenOptions,针对多个阅读器生效。通过这两个选项,开发者就能够很方便的配置和管理好自己的一个或多个PDF阅读器了。
来源:juejin.cn/post/7420336326992543779
uni-app小程序分包中使用 Echarts, 并在分包里加载依赖
这篇笔记主要记录uni-app小程序, 在分包中使用Echarts,并在分包里加载Echarts依赖,减少主包的大小,提升小程序的加载速度.
- 在分包中使用Echarts
- 在分包里加载Echarts依赖
先看下效果,图表正常渲染,主包大小小于1.5M,主包存在仅被其他分包依赖的JS文件也通过✅
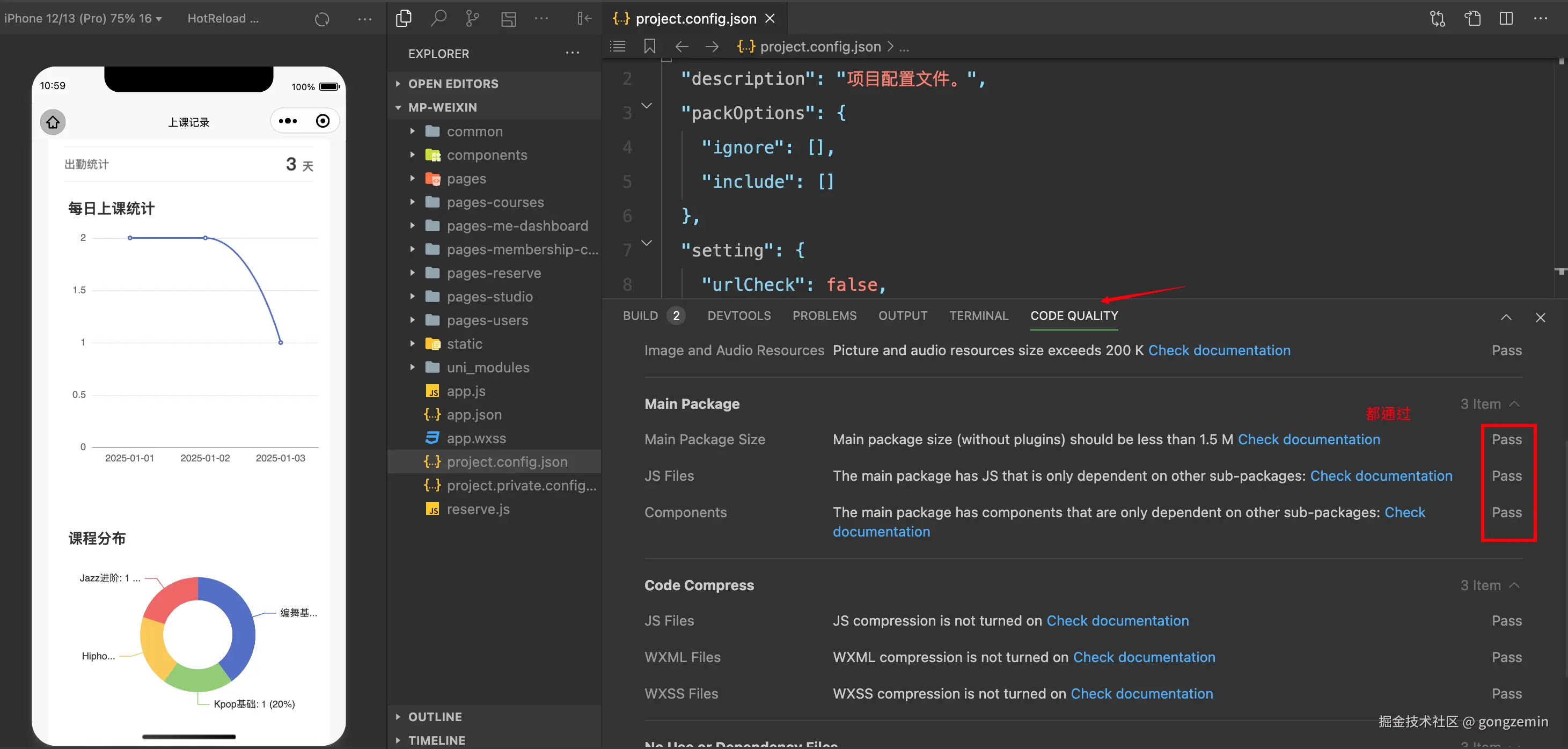
在分包中使用Echarts
我们要用的Echarts插件是lime-chart, 我们看下文档, 插件下载页面下面的描述
我们是Vue3小程序,先下载插件,下载好插件后,插件会安装在项目根目录下的uni_modules文件夹,下载插件截图
根据文档,我们require相对引入echarts.min文件,我们要渲染的图表数据来自接口
- 在onMounted里请求接口数据
- 接口数据返回后调用渲染图表的方法
- 渲染图表要用setTimeout,确保渲染图表时,组件的节点已经被渲染到页面上
<script setup>
import { onMounted } from 'vue'
// 根据项目目录相对引入
const echarts = require("../../uni_modules/lime-echart/static/echarts.min.js");
const getData = async () => {
const chartData = await getChartData() // 获取图表数据
setTimeout(() => {
renderChart() // 数据返回后渲染图表
}, 500)
}
onMounted(() => {
getData()
})
</script>
这样就能渲染了
刚开始我没渲染出来,对比文档,发现我没用setTimeout,用了之后就渲染出来了,看起来一切正常,但是,我们发布的时候,提示
主包超过1.5M, 主包有只被其他子包依赖的JS文件,都没通过,并且还告诉我们是uni_modules/lime-chart/static/echarts.min.js这个文件
虽然我们是在分包里渲染Echarts,但是插件默认下载到主包的uni_modules,我们需要把Echarts依赖引入到分包里
在分包里加载Echarts依赖
我们把主包里的Echarts文件整个移入到分包里pages-me-dashboard, 我在分包里建了一个文件夹uni_modules, 告诉自己这是一个插件,
可是却发现Echarts渲染不出来了,调试后发现chart组件不渲染了
<l-echart ref="pieChartRef"></l-echart>
于是就又手动引入lEchart组件,Echart在主包的时候,没引入lEchart组件就渲染了,发现可以正常渲染
import lEchart from "../uni_modules/lime-echart/components/l-echart/l-echart.vue";
再次发布下,主包大小通过,主包存在仅被其他分包依赖的JS文件也通过✅
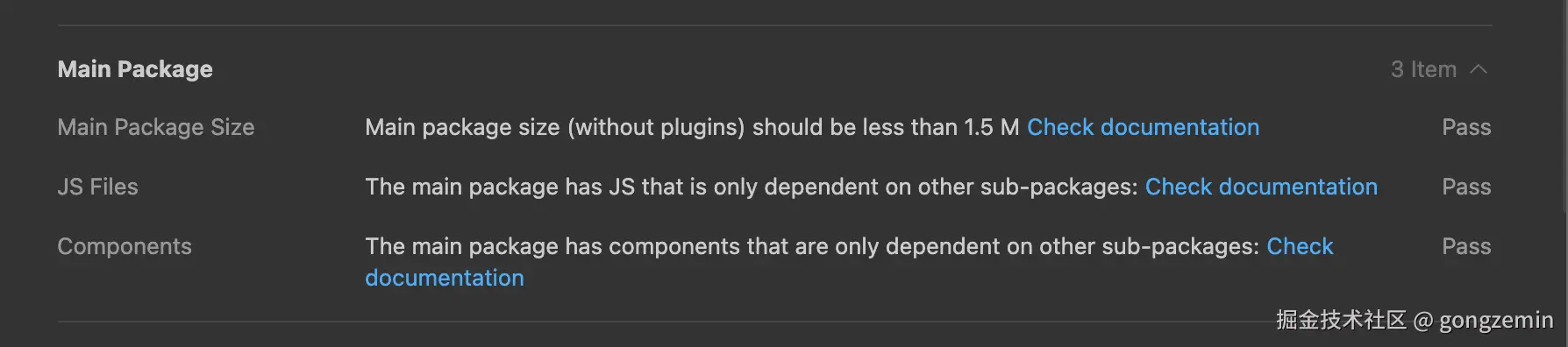
完整代码
<template>
<view class="container">
<view class="stats-card">
<view class="header">
<view class="date-select">
<picker
mode="selector"
:value="selectedYearIndex"
:range="yearOptions"
@change="onYearChange">
<view class="picker">{{ yearOptions[selectedYearIndex] }} 年</view>
</picker>
<picker
mode="selector"
:value="selectedMonthIndex"
:range="monthOptions"
@change="onMonthChange">
<view class="picker">{{ monthOptions[selectedMonthIndex] }}</view>
</picker>
</view>
</view>
<view v-if="loading" class="loading">
<uni-load-more status="loading"></uni-load-more>
</view>
<view v-else class="stats-content">
<view class="stat-item">
<text class="label">总课程节数</text>
<text class="value">
{{ statistics.totalCourses }}
<text class="label">节</text>
</text>
</view>
<view class="stat-item mb-20">
<text class="label">出勤统计</text>
<text class="value">
{{ statistics.trainingDays }}
<text class="label">天</text>
</text>
</view>
<!-- Line Chart -->
<view style="width: 90vw; height: 750rpx">
<l-echart ref="lineChartRef"></l-echart>
</view>
<!-- Pie Chart -->
<view
style="
width: 85vw;
height: 550rpx;
margin-top: 20px;
overflow: hidden;
">
<l-echart ref="pieChartRef"></l-echart>
</view>
</view>
</view>
</view>
</template>
<script lang="ts" setup>
import { ref, onMounted, nextTick } from "vue";
// Import echarts
import lEchart from "../uni_modules/lime-echart/components/l-echart/l-echart.vue";
const echarts = require("../uni_modules/lime-echart/static/echarts.min");
interface Statistics {
totalCourses: number;
trainingDays: number;
courseDistribution: { name: string; value: number }[];
dailyCourses: { date: string; count: number }[];
}
const currentDate = new Date();
const currentYear = currentDate.getFullYear();
const currentMonth = currentDate.getMonth();
const yearOptions = Array.from({ length: 5 }, (_, i) => `${currentYear - i}`);
const monthOptions = Array.from({ length: 12 }, (_, i) => `${i + 1} 月`);
const selectedYearIndex = ref(0);
const selectedMonthIndex = ref(currentMonth);
const statistics = ref<Statistics>({
totalCourses: 0,
trainingDays: 0,
courseDistribution: [],
dailyCourses: [],
});
const loading = ref(false);
const onYearChange = (e: any) => {
selectedYearIndex.value = e.detail.value;
fetchStatistics();
};
const onMonthChange = (e: any) => {
selectedMonthIndex.value = e.detail.value;
fetchStatistics();
};
const fetchStatistics = async () => {
loading.value = true;
try {
console.log(
"year-month",
yearOptions[selectedYearIndex.value],
Number(selectedMonthIndex.value) + 1
);
const res = await uniCloud.callFunction({
name: "getMonthlyStatistics",
data: {
userId: uni.getStorageSync("userInfo").userId,
year: yearOptions[selectedYearIndex.value],
month: Number(selectedMonthIndex.value) + 1,
},
});
if (res.result.code === 0) {
statistics.value = res.result.data;
console.log("charts-----", res.result.data);
renderCharts();
}
} catch (error) {
console.error("获取统计数据失败", error);
} finally {
loading.value = false;
}
};
const lineChartRef = ref(null);
const pieChartRef = ref(null);
const renderCharts = async () => {
// Line Chart
setTimeout(async () => {
console.log("charts111-----", echarts, lineChartRef.value);
if (!lineChartRef.value) return;
const dailyCourses = statistics.value.dailyCourses;
const dates = dailyCourses.map((item) => item.date);
const counts = dailyCourses.map((item) => item.count);
const lineChartOption = {
title: {
text: "每日上课统计",
left: "left",
top: 10,
textStyle: {
fontSize: 18,
fontWeight: "bold",
color: "#333",
},
},
tooltip: {
trigger: "axis",
axisPointer: {
type: "line",
},
},
xAxis: {
type: "category",
data: dates,
axisLine: {
lineStyle: {
color: "#999999",
},
},
axisLabel: {
color: "#666666",
},
axisTick: {
show: false,
},
},
yAxis: {
type: "value",
axisLine: {
lineStyle: {
color: "#999999",
},
},
axisLabel: {
color: "#666666",
},
axisTick: {
show: false,
},
},
series: [
{
name: "课程节数",
type: "line",
data: counts,
smooth: true,
},
],
};
console.log("echarts", echarts);
const lineChart = await lineChartRef.value.init(echarts);
lineChart.setOption(lineChartOption);
}, 500);
// Pie Chart
setTimeout(async () => {
if (!pieChartRef.value) return;
const courseDistribution = statistics.value.courseDistribution;
const pieChartOption = {
title: {
text: "课程分布",
left: "left",
top: 10,
textStyle: {
fontSize: 18,
fontWeight: "bold",
color: "#333",
},
},
tooltip: {
trigger: "item",
formatter: "{b}: {c} ({d}%)",
},
series: [
{
name: "课程分布",
type: "pie",
radius: ["30%", "50%"],
label: {
show: true,
position: "outside",
formatter: "{b}: {c} ({d}%)",
},
data: courseDistribution.map((item) => ({
name: item.name,
value: item.value,
})),
},
],
};
const pieChart = await pieChartRef.value.init(echarts);
pieChart.setOption(pieChartOption);
}, 600);
};
onMounted(() => {
fetchStatistics();
});
</script>
<style lang="scss" scoped>
.container {
display: flex;
justify-content: center;
align-items: flex-start;
// height: 100vh;
background-color: #f5f5f5;
padding: 20px;
box-sizing: border-box;
}
.stats-card {
width: 100%;
max-width: 650px;
background-color: #fff;
border-radius: 10px;
padding: 20px;
box-sizing: border-box;
}
.header {
display: flex;
justify-content: flex-start;
margin-bottom: 20px;
}
.date-select {
display: flex;
gap: 15px;
}
.picker {
padding: 8px 20px;
background-color: #f0f0f0;
border-radius: 8px;
font-size: 16px;
text-align: center;
}
.stats-content {
display: flex;
flex-direction: column;
// gap: 20px;
}
.stat-item {
display: flex;
justify-content: space-between;
align-items: center;
padding: 6px 0; // 减小 padding 让行距更紧凑
border-bottom: 1px solid #eee;
.label {
font-size: 14px; // 标签字体调小
color: #666;
}
.value {
font-size: 22px; // 数值字体加大
font-weight: bold; // 加粗数值
color: #333;
}
}
.chart {
height: 300px;
margin-top: 20px;
}
</style>
效果图页面渲染的数据
{
"totalCourses": 5,
"trainingDays": 3,
"dailyCourses": [
{
"date": "2025-01-01",
"count": 2
},
{
"date": "2025-01-02",
"count": 2
},
{
"date": "2025-01-03",
"count": 1
}
],
"courseDistribution": [
{
"name": "编舞基础",
"value": 2
},
{
"name": "Kpop基础",
"value": 1
},
{
"name": "Hiphop基础",
"value": 1
},
{
"name": "Jazz进阶",
"value": 1
}
]
}
来源:juejin.cn/post/7455491124564885523
出了兼容性问题,被领导叼了
背景
项目上线后跑了应该有两三个月了,接到生产报事,页面进不去了,用户设备是iPhone8 iOS13.1,用户很气愤,领导也很不乐意,我也很气愤,刚来这项目组就被报事,艹太。但是要解决呀,怎么办?研究以前的代码,加配置呗。
浏览器兼容性问题是什么?
浏览器兼容性问题通常是指网页或 Web 应用在不同浏览器或版本中表现不一致的问题。说白了无非就是 css不兼容,JS Api在旧版本浏览器中不兼容。
解决思路
- 明白目标浏览器范围
- 找个插件将现代 JS 转到 ES5
- 处理一下CSS的兼容性问题
解决方案
- 通过定义
.browserslistrc明确目标浏览器范围 - 使用
Babel将现代 JS 转到 ES5 - 使用
Autoprefixer给 CSS 加厂商前缀
好了,开搞
.browserslistrc文件是什么
.browserslistrc 文件是一个配置文件,用于定义目标浏览器和Node.js版本的兼容性列表。这个文件被多个前端工具链和库所使用,如Babel、Autoprefixer、ESLint等,可以帮助我们确定需要转译或添加兼容性前缀的JavaScript和CSS代码版本。通过配置 .browserslistrc,我们可以精确地控制代码应该兼容哪些浏览器和设备,从而优化构建输出和减少最终包的大小。
.browserslistrc文件中可以配置的内容
- 浏览器名称和版本:例如,last 2 Chrome versions 表示最新的两个Chrome浏览器版本。
- 市场份额:如 > 1% in US 表示在美国市场份额超过1%的浏览器。
- 年份:since 2017 表示自2017年以来发布的所有浏览器版本。
- 特定浏览器:not IE 11 表示不包括IE 11浏览器。
个人项目中使用.browserslistrc配置
在个人日常办公项目中 .browserslistrc 文件配置如下:
> 0.2%
last 2 versions
Firefox ESR
not dead
IE 11
这个配置的含义是:
- 支持全球使用率超过0.2%的浏览器。
- 支持最新的两个浏览器版本。
- 支持Firefox的Extended Support Release(ESR)版本。
- 排除所有已经不被官方支持(dead)的浏览器。
- 额外包含IE 11浏览器,尽管它可能不在其他条件内
Babel是什么
Babel 是一个广泛使用的 JavaScript 编译器/转译器,其核心作用是将 高版本 JavaScript(如 ES6+)转换为向后兼容的低版本代码(如 ES5),以确保代码能在旧版浏览器或环境中正常运行。
Babel的主要作用
1. 语法转换(Syntax Transformation)
将现代 JavaScript 语法(如 let/const、箭头函数、类、模板字符串、解构赋值等)转换为等价的 ES5 语法,以便在不支持新特性的浏览器中运行。
2. Polyfill 填充新 API
通过插件(如 @babel/polyfill 或 core-js),为旧环境提供对新增全局对象(如 Promise, Array.from, Map, Set)的支持。
3. 按需转换(基于目标环境)
结合 .browserslistrc 配置,@babel/preset-env 可根据指定的目标浏览器自动决定哪些特性需要转换,哪些可以保留原样。
4. 支持 TypeScript 和 JSX
Babel 提供了对 TypeScript(通过 @babel/preset-typescript)和 React 的 JSX 语法(通过 @babel/preset-react)的解析与转换能力,无需依赖其他编译工具。
5. 插件化架构,高度可扩展
Babel 支持丰富的插件生态,开发者可以自定义语法转换规则,比如:
- 按需引入 polyfill(@babel/plugin-transform-runtime)
- 移除调试代码(@babel/plugin-transform-remove-console)
- 支持装饰器、私有属性等实验性语法
@babel/preset-env的核心配置
@babel/preset-env 的参数项数量很多,但大部分我们都用不到。我们只需要重点掌握四个参数项即可:targets、useBuiltIns、modules 和 corejs。
@babel/preset-env 的 targets 参数
该参数项的写法和.browserslistrc 配置是一样的,主要是为了定义目标浏览器。如果我们对 targets 参数进行了设置,那么就不会使用 .browserslistrc 配置了,为了减少多余的配置,我们推荐使用 .browserslistrc 配置。
@babel/preset-env 的 useBuiltIns 参数
useBuiltIns 项取值可以是usage、 entry 或 false。如果该项不进行设置,则取默认值 false。
- 设置成
false的时候会把所有的polyfill都引入到代码中,整个体积会变得很大。 - 设置成
entry则是会根据目标环境引入所需的polyfill,需要手动引入; - 设置成
usage则是会根据目标环境和代码的实际使用来引入所需的polyfill。
此处我们推荐使用:useBuiltIns: usage的设置。
@babel/preset-env 的 corejs 参数
该参数项的取值可以是 2 或 3,没有设置的时候取默认值为 2。这个参数只有 useBuiltIns 参数为 usage 或者 entry 时才会生效。在新版本的Babel中,建议使用 core-js@3。
@babel/preset-env 的 modules 参数
指定模块的输出方式,默认值是 "auto",也可以设置为 "commonjs"、"umd"、"systemjs" 等。
个人项目中使用Babel的配置
在个人日常办公项目中 .babel.config.js 文件配置如下:
module.exports = {
plugins: [
// 适配某些构建流程中的模块元信息访问方式
() => ({
visitor: {
MetaProperty(path) {
path.replaceWithSourceString('process');
},
},
})
],
presets: [
[
'@babel/preset-env', {
// targets: { esmodules: false, }, // 通过配置browserslist,来使用 browserslist 的配置
useBuiltIns: "usage", // 配置按需引入polyfill
corejs: 3
}
],
'@babel/preset-typescript'
],
};
Autoprefixer 的使用
在vite.config.ts文件中css的部分,添加 autoprefixer 的配置。
css: {
postcss: {
plugins: [
postCssPxToRem({
// 这里的rootValue就是你的设计稿大小
rootValue: 37.5,
propList: ['*'],
}),
autoprefixer({
overrideBrowserslist: [
'Android 4.1',
'iOS 7.1',
'ff > 31',
'Chrome > 69',
'ie >= 8',
'> 1%'
]
}),
],
},
},
总结
主要通过配置 .browserslistrc 明确目标浏览器范围,使用 Babel 将现代 JS 转到 ES5,主要用到的插件是 @babel/preset-env ,最后再使用 Autoprefixer 插件给 CSS 加厂商前缀。
来源:juejin.cn/post/7508588026316308531
倒反天罡,CSS 中竟然可以写 JavaScript
引言
最近和大佬学习写 像素风组件库 里面有很多复杂而有趣的样式,于是跑去研究了一下,震惊的发现,大佬竟然在 CSS 中写 JavaScript !
一般来说 CSS 是网页样式的声明性语言,而 JavaScript 则负责交互逻辑。我仔细研究了一下,原来是通过 CSS Houdini 实现了用 JavaScript 来扩展 CSS 的能力。所以写了这篇文章来探讨一下 CSS Houdini。
CSS Houdini是什么?
CSS Houdini 是一组低级 API,允许开发者直接访问 CSS 对象模型(CSSOM),从而能够扩展 CSS 的功能。它的名字来源于著名魔术师 Harry Houdini,寓意"逃离" CSS 的限制,就像魔术师从束缚中挣脱一样。
那么问题来了,为什么选择 CSS Houdini 而不是直接使用 JavaScript 来操作样式?
性能优势
与使用 JavaScript 对 HTMLElement.style 进行样式更改相比,Houdini 可实现更快的解析。JavaScript 修改样式通常会触发浏览器的重排(reflow) 和重绘(repaint),特别是在动画中,这可能导致性能问题。而 Houdini 工作在浏览器渲染流程的更低层级,能够更高效地处理样式变化,减少不必要的计算。
扩展和复用性
使用 JavaScript 修改样式本质上是在操作 DOM,而 Houdini 直接扩展了 CSS 的能力。这使得自定义效果可以像原生 CSS 特性一样工作,包括继承、级联和响应式设计。
Houdini API 允许创建真正的 CSS 模块,可以像使用标准 CSS 属性一样使用自定义功能,提高代码的可维护性和复用性。
主要API概览
接下来是重点,我们来看看到底如何去使用 CSS Houdini。CSS Houdini 包含多个API,下面通过具体案例来说明一下使用方式。
1. CSS Painting API
CSS Paint API 允许我们使用 JavaScript 和 Canvas API 创建自定义的 CSS 图像,然后在 CSS 样式中使用这些图像,例如 background-image、border-image、mask-image 等。它的使用方法分为下面三步:
第一步,绘制背景
在这一步,使用 registerPaint() 定义一个 paint worklet (可以翻译理解为自定义画笔),来画你想要的图案。我们需要的变量可以通过 CSS 变量的形式定义并引入,在 inputProperties 指定我们需要读取的参数。
// myPainter.js
registerPaint(
'myPainter',
class {
static get inputProperties() {
return ['--my-color', '--wave-amplitude', '--wave-frequency'];
}
paint(ctx, size, properties) {
const color = properties.get('--my-color').toString() || '#3498db';
const amplitude = parseFloat(properties.get('--wave-amplitude')) || 20;
const frequency = parseFloat(properties.get('--wave-frequency')) || 0.03;
// 画渐变背景
const gradient = ctx.createLinearGradient(0, 0, size.width, size.height);
gradient.addColorStop(0, color);
gradient.addColorStop(1, '#fff');
ctx.fillStyle = gradient;
ctx.fillRect(0, 0, size.width, size.height);
// 画波浪
ctx.beginPath();
ctx.moveTo(0, size.height / 2);
for (let x = 0; x <= size.width; x++) {
const y =
size.height / 2 +
Math.sin(x * frequency) * amplitude +
Math.sin(x * frequency * 0.5) * (amplitude / 2);
ctx.lineTo(x, y);
}
ctx.lineTo(size.width, size.height);
ctx.lineTo(0, size.height);
ctx.closePath();
ctx.fillStyle = color + '88'; // 半透明主色
ctx.fill();
}
}
);
第二步,注册刚才定义的 worklet
在这一步,通过 CSS.paintWorklet.addModule 来引入我们自定义的 paint worklet。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<style>
</style>
</head>
<body>
<div class="box">一条大河波浪宽</div>
<script>
if ('paintWorklet' in CSS) {
CSS.paintWorklet.addModule('myPainter.js');
}
</script>
</body>
</html>
最后,在 CSS 中使用 paint
我们在 CSS 属性值中通过 paint(myPainter) 的方式来指定使用我们的 paint worklet,同时,通过 CSS 变量传递需要的参数。
.box {
width: 300px;
height: 200px;
text-align: center;
color: #fff;
background-image: paint(myPainter);
/* 定义paint需要的变量 */
--my-color: #0087ff;
--wave-amplitude: 30;
--wave-frequency: 0.04;
}
最后看下效果

有了 JavaScript 和 Canvas API 的加持,可以画很多酷炫的效果。
2. CSS Properties and Values API
这个 API 允许我们定义自定义 CSS 属性的类型、初始值和继承行为。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>CSS Properties and Values API 示例</title>
<style>
.color-box {
width: 200px;
height: 200px;
margin: 50px auto;
background-color: var(--my-color);
transition: --my-color 1s;
}
.color-box:hover {
--my-color: green;
}
</style>
</head>
<body>
<div class="color-box" id="colorBox"></div>
<script>
// 检查浏览器是否支持CSS Properties and Values API
if (window.CSS && CSS.registerProperty) {
// 注册一个自定义属性
CSS.registerProperty({
name: '--my-color',
syntax: '<color>',
inherits: false,
initialValue: 'blue',
});
}
</script>
</body>
</html>
在上面这个示例中,我们定义了一个自定义属性,名字为 --my-color,通过 syntax: '<color>' 来指定这个属性的值类型是颜色(比如 blue、#fff、rgb(0,0,0) 等),这样浏览器就能识别并支持动画、过渡等。通过 inherits: false 指定这个属性不会从父元素继承。通过 initialValue: 'blue' 指定它的默认值为 blue。
定义之后,我们可以通过 var(--my-color) 来引用这个变量,也可以通过 --my-color: green 来更改它的值。
那为什么不能直接定义个 CSS 变量,而是要通过 CSS.registerProperty 来注册一个属性呢?
- 普通的 CSS 变量,浏览器只当作字符串处理,不能直接做动画、过渡等。而用
registerProperty注册后,浏览器知道它是<color>类型,就能支持动画、过渡等高级特性。
3. CSS Typed Object Model
CSS Typed OM API 将 CSS 值以类型化的 JavaScript 对象形式暴露出来,来让方便我们对其进行操作。
比起直接使用 HTMLElement.style 的形式操作 CSS 样式,CSS Typed OM 拥有更好的逻辑性和性能。
computedStyleMap
通过 computedStyleMap() 可以以 Map 形式获取一个元素所有的 CSS 属性和值,包括自定义属性。
获取不同的属性返回值类型不同,需要用不同的读取方式。computedStyleMap() 返回的是只读的计算样式映射,不能直接修改。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<style>
.box {
color: rgb(13 5 17);
}
</style>
</head>
<body>
<div
class="box"
style="
width: 100px;
height: 50px;
background-image: linear-gradient(to right, red, blue);
"
></div>
<script>
const box = document.querySelector('.box');
// 获取所有属性
const computedStyles = box.computedStyleMap();
// 读取指定属性的值
console.log(computedStyles.get('color').toString()); // rgb(13, 5, 17)
console.log(computedStyles.get('background-image').toString()); // linear-gradient(to right, rgb(255, 0, 0), rgb(0, 0, 255))
console.log(computedStyles.get('height').value); // 100
console.log(computedStyles.get('height').unit); // px
console.log(computedStyles.get('position').value); // 'static'
</script>
</body>
</html>
attributeStyleMap
通过 element.attributeStyleMap 可以获取和设置 CSS 的内联样式。
<!DOCTYPE html>
<html lang="en">
<head>
<style>
.box {
background-color: blue; /* 样式表中的样式 */
}
</style>
</head>
<body>
<div class="box" style="width: 100px; height: 100px;"></div>
<script>
const box = document.querySelector('.box');
const inlineStyles = box.attributeStyleMap;
console.log('width:', inlineStyles.get('width')?.toString()); // "100px"
console.log('height:', inlineStyles.get('height')?.toString()); // "100px"
console.log('background-color:', inlineStyles.get('background-color')); // undefined,因为是在样式表中定义的
setInterval(() => {
inlineStyles.set('width', CSS.px(inlineStyles.get('width').value + 1));
}, 30);
</script>
</body>
</html>
在这个例子中,读取了 width 并进行设置,让它宽度逐渐变大。

4. Layout Worklet 和 Animation Worklet
除了上述的三种 API,Hounidi 还包含了 Layout Worklet 和 Animation Worklet 分别用于自定义布局和动画,但是目前还在实验中,支持度不是很好,所以就不提供使用案例了。
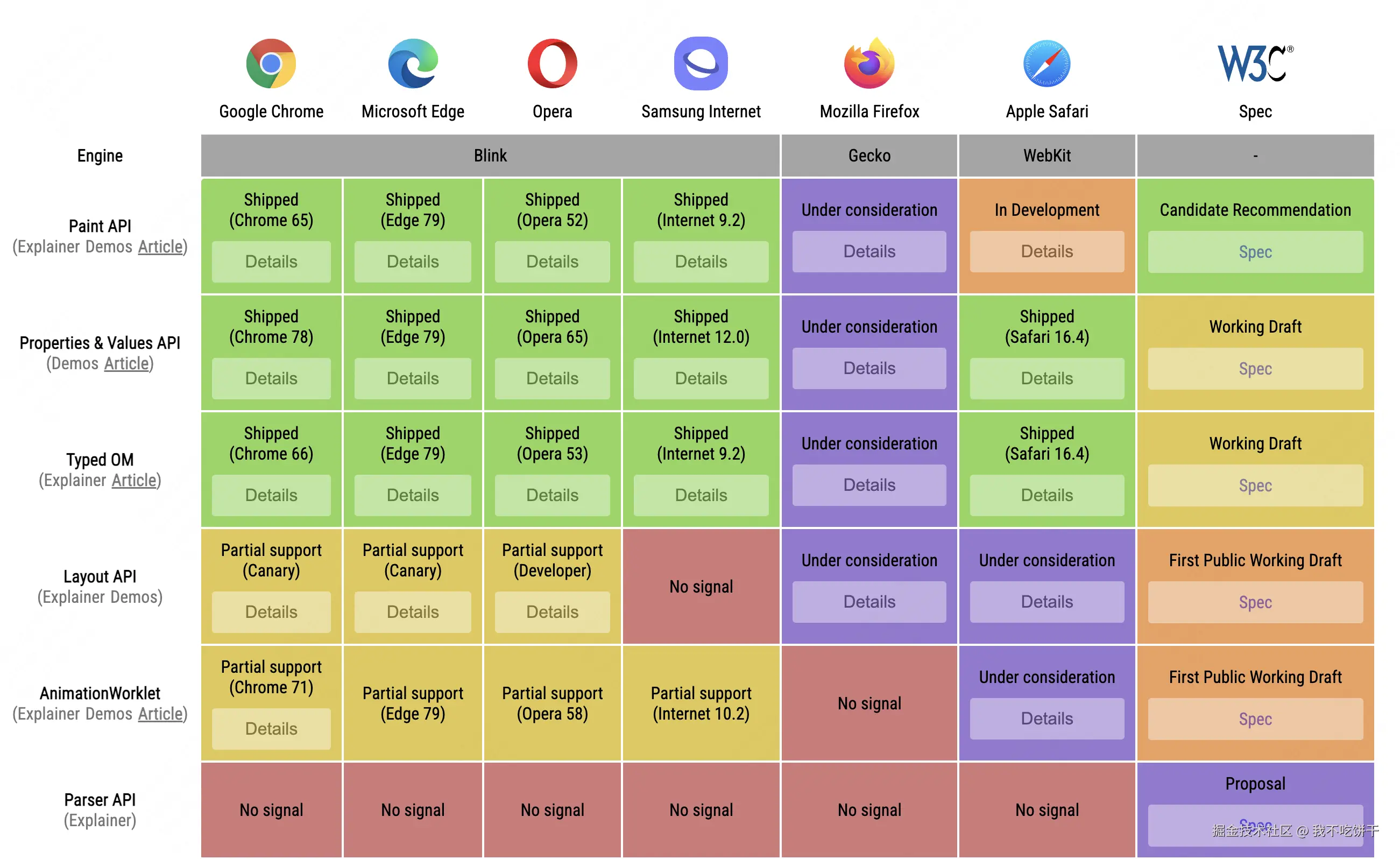
参考资源
来源:juejin.cn/post/7515707680927055923
用好了 defineProps 才叫会用 Vue3,90% 的写法都错了
Vue 3 的 Composition API 给开发者带来了更强的逻辑组织能力,但很多人用 defineProps 的方式,依然停留在 Vue 2 的“Options 语法心智”。本质上只是把 props: {} 拿出来“提前声明”,并没有真正理解它的运行机制、类型推导优势、默认值处理方式、解构陷阱等关键点。
这篇文章不做语法搬运,而是用实战视角,带你了解:defineProps 到底该怎么写,才是专业的 Vue3 写法。
🎯 为什么说你用错了 defineProps?
我们先来看一个常见的 Vue3 组件写法:
<script setup>
const props = defineProps({
title: String,
count: Number
})
</script>
你以为这就完事了?它只是基本写法。但在真实业务中,我们往往会遇到:
- 需要传默认值
- 想要类型推导
- 解构 props 却发现响应性丢失
- TS 类型重复声明,不够优雅
这些问题,defineProps 其实早就帮你解决了,只是你没用对方式。
✅ 正确的三种 defineProps 写法
① 写法一:声明式类型推导(推荐)
interface Props {
title: string
count?: number
}
const props = defineProps<Props>()
优点:
- 自动获得类型推导
- 在
<script setup lang="ts">中书写自然 - 可配合
withDefaults补充默认值
这是 Composition API 的推荐写法,完全由 TypeScript 驱动,而不是运行时校验。
② 写法二:运行时代码校验(Options 式)
const props = defineProps({
title: {
type: String,
required: true
},
count: {
type: Number,
default: 0
}
})
优点:
- 保留 Vue2 的 props 校验逻辑
- 更适合 JS-only 项目(不使用 TS)
缺点:
- 类型推导不如泛型直观
- 与
withDefaults不兼容
③ 写法三:与 withDefaults 配合(实战最常见)
const props = withDefaults(defineProps<{
title?: string
count?: number
}>(), {
title: '默认标题',
count: 1
})
优势是:
- 既能获得类型推导,又能写默认值
- 不会重复写 default
- 比纯 defineProps 更简洁易维护
注意:withDefaults 只能配合泛型式 defineProps 使用,不能和对象式 props 写法混用。
⚠️ 高发误区警告:你踩过几个?
🚫 误区 1:直接解构 props,响应性丢失
const { title, count } = defineProps<{ title: string, count: number }>()
上面的写法会让 title 和 count 成为普通变量,不是响应式的。
解决方式:使用 toRefs
const props = defineProps<{ title: string, count: number }>()
const { title, count } = toRefs(props)
这样才能在 watch(title, ...) 中有效监听变化。
🚫 误区 2:类型和默认值重复声明
const props = defineProps({
title: {
type: String as PropType<string>, // 写了类型
default: 'Hello' // 又写默认值
}
})
在 TS 项目中,这种方式显得繁琐且不智能。建议直接用泛型 + withDefaults,让 IDE 自动推导类型。
🚫 误区 3:没有区分“开发期类型检查” vs “运行时校验”
Vue3 的 Props 有两个模式:
- TypeScript 模式:靠 IDE + 编译器
- Options 模式:在浏览器运行时报错
实际推荐:生产环境靠 TypeScript 检查即可,无需运行时 Props 校验,提高性能。
🎯 defineProps 是真正的组件契约声明
在 Vue3 的 <script setup> 中,defineProps 就是你和使用你组件的人之间的契约。
为什么说它是契约?
- 它声明了组件的“输入规范”
- 它决定了类型校验、默认值逻辑
- 它是组件文档的第一手来源
你越是随便写它,越容易在团队协作时踩坑。
💡 defineProps 的进阶技巧:你未必知道的几个点
✔ 你可以在 defineProps 里使用类型别名
type Size = 'sm' | 'md' | 'lg'
withDefaults(defineProps<{
size?: Size
}>(), {
size: 'md'
})
这是让 props.size 具备完整类型提示的关键方式。
✔ 配合 defineEmits 写法更完整
const emit = defineEmits<{
(e: 'submit', value: number): void
(e: 'cancel'): void
}>()
这样写出的组件,输入(props)+ 输出(emit)都具备契约,可以被任何 IDE 精确识别。
✔ defineProps 写法决定你能不能使用 Volar 的类型推导
很多人发现 <MyComponent :title="xx" /> 里没有类型提示,大概率是你组件没有正确写 defineProps 的泛型。保持结构清晰,是让 IDE 吃得饱的唯一方式。
🚀 小结:defineProps 不只是 props,它是组件健壮性的开端
| 错误写法 | 问题 |
|---|---|
| 不加泛型 | IDE 无法提示 |
| 直接解构 | 响应性丢失 |
| 类型 + default 双声明 | 代码重复、难维护 |
| 没有 withDefaults | 写默认值繁琐、不能配合类型推导 |
| 使用 runtime 校验 + TS | 混乱、效率低 |
正确思路是:在 TypeScript 项目中,尽可能采用 defineProps<T>() + withDefaults() 写法,做到类型明确、默认值清晰、响应式安全。
📌 怎么判断你是否“真的会用 defineProps”?
- ❌ 你写了 defineProps 但 props 解构不响应
- ❌ 你写 default 写得很痛苦
- ❌ 你项目里 props 写法风格混乱
- ❌ 你的组件在 IDE 中没有 props 自动补全
✅ 如果你能做到:
- 使用泛型 +
withDefaults - 保持 props 和 emits 的契约完整
- 清晰地类型提示和响应性解构
那恭喜你,是真的理解了 Vue3 的组件心智模型。
来源:juejin.cn/post/7513117108114473001
双Token实现无感刷新
一、为什么需要无感刷新?
想象一下你正在刷视频,突然提示"登录已过期,请重新登录",需要退出当前页面重新输入密码。这样的体验非常糟糕!无感刷新就是为了解决这个问题:让用户在不知不觉中完成身份续期,保持长时间在线状态。
二、双Token机制原理
我们使用两个令牌:
- 短令牌:access_token(1小时):用于日常请求
- 长令牌:refresh_token(7天):专门用来刷新令牌
工作流程:
用户登录 → 获取双令牌 → access_token过期 → 用refresh_token获取新的双令牌 → 自动续期
三、前端实现(Vue + Axios)
1. 登录存储令牌
const login = async () => {
const res = await userLogin(user); //账号密码
// 保存双令牌到本地
localStorage.setItem('access_token', res.access_token);
localStorage.setItem('refresh_token', res.refresh_token);
}
2. 请求自动携带令牌
通过请求拦截器自动添加认证头:
api.interceptors.request.use(config => {
const access_token = localStorage.getItem('access_token');
if (access_token) {
config.headers.Authorization = `Bearer ${access_token}`;
}
return config;
})
3. 智能令牌刷新
响应拦截器发现401登录过期的错误时自动请求刷新
验证长令牌是否失效
- 失效重定向到登录页面
- 未失效重新获取双令牌并重新发起请求
api.interceptors.response.use(
(response) => {
return response
},
async (error) => { // 响应失败
const { data, status, config } = error.response;
if (status === 401 && config.url !== '/refresh') {
// 刷新token
const res = await refreshToken() // 校验的函数
if (res.status === 200) { // token刷新成功
// 重新将刚刚失败的请求发送出去
return api(config)
} else {
// 重定向到登录页 router.push('/login')
window.location.href = '/login'
}
}
}
)
四、后端实现(Node.js + Express)
1. 生成双令牌
// 生成1小时有效的access_token
const access_token = generateToken(user, '1h');
// 生成7天有效的refresh_token
const refresh_token = generateToken(user, '7d');
2. 令牌刷新接口
app.get('/refresh', (req, res) => {
const oldRefreshToken = req.query.token;
try {
// 验证refresh_token有效性
const userData = verifyToken(oldRefreshToken);
// 生成新双令牌
const newAccessToken = generateToken(userData, '1h');
const newRefreshToken = generateToken(userData, '7d');
res.json({ access_token: newAccessToken, refresh_token: newRefreshToken });
} catch (error) {
res.status(401).send('令牌已失效');
}
})
五、完整代码
1. 前端代码
<template>
<div v-if="!isLogin">
<button @click="login">登录</button>
</div>
<div v-else>
<h1>登录成功</h1>
<p>欢迎回来,{{ username }}</p>
<p>您的邮箱:{{ email }}</p>
</div>
<!-- home -->
<div v-if="isLogin">
<button @click="getHomeData">获取首页数据</button>
</div>
</template>
<script setup>
import { ref } from 'vue'
import { userLogin, getHomeDataApi } from './api.js'
const isLogin = ref(false)
const username = ref('')
const email = ref('')
const password = ref('')
const login = async() => {
username.value = 'zs'
email.value = '123@qq.com'
password.value = '123'
const res = await userLogin({username: username.value, email: email.value, password: password.value})
console.log(res)
const {access_token, refresh_token, userInfo} = res.data
if (access_token) {
isLogin.value = true
}
localStorage.setItem('access_token', access_token)
localStorage.setItem('refresh_token', refresh_token)
}
const getHomeData = async() => {
const res = await getHomeDataApi()
console.log(res)
}
</script>
<style lang="css" scoped>
</style>
// api.js
import axios from 'axios'
const api = axios.create({
baseURL: 'http://localhost:3000',
timeout: 3000,
})
// 请求拦截器
api.interceptors.request.use(config => {
const access_token = localStorage.getItem('access_token');
if (access_token) {
config.headers.Authorization = `Bearer ${access_token}`;
}
return config;
})
// 响应拦截器
api.interceptors.response.use(
(response) => {
return response
},
async (error) => { // 响应失败
const { data, status, config } = error.response;
if (status === 401 && config.url !== '/refresh') {
// 刷新token
const res = await refreshToken()
if (res.status === 200) { // token刷新成功
// 重新将刚刚失败的请求发送出去
return api(config)
} else {
// 重定向到登录页 router.push('/login')
window.location.href = '/login'
}
}
}
)
export const userLogin = (data) => {
return api.post('/login', data)
}
export const getHomeDataApi = () => {
return api.get('/home')
}
async function refreshToken() {
const res = await api.get('/refresh', {
params: {
token: localStorage.getItem('refresh_token')
}
})
localStorage.setItem('access_token', res.data.access_token)
localStorage.setItem('refresh_token', res.data.refresh_token)
return res
}
2. 后端代码
server.js
const express = require('express');
const app = express();
const port = 3000;
app.use(express.json()); // 解析 JSON 格式的请求体
const jwtToken = require('./token.js');
const cors = require('cors');
app.use(cors())
const users = [
{ username: 'zs', password: '123', email: '123@qq.com' },
{ username: 'ls', password: '456', email: '456@qq.com' }
]
app.get('/', (req, res) => {
res.send('Hello World!');
});
app.post('/login', (req, res) => {
const { username, password } = req.body;
const user = users.find(user => user.username === username);
if (!user) {
return res.status(404).json({status: 'error', message: '用户不存在'});
}
if (user.password !== password) {
return res.status(401).json({status: 'error', message: '密码错误'});
}
// 生成两个 token
const access_token = jwtToken.generateToken(user, '1h');
const refresh_token = jwtToken.generateToken(user, '7d');
res.json({
userInfo: {
username: user.username,
email: user.email
},
access_token,
refresh_token
})
})
// 需要token 认证的路由
app.get('/home', (req, res) => {
const authorization = req.headers.authorization;
if (!authorization) {
return res.status(401).json({status: 'error', message: '未登录'});
}
try {
const token = authorization.split(' ')[1]; // 'Bearer esdadfadadxxxxxxxxx'
const data = jwtToken.verifyToken(token);
res.json({ status: 'success', message: '验证成功', data: data });
} catch (error) {
return res.status(401).json({status: error, message: 'token失效,请重新登录'});
}
})
// 刷新 token
app.get('/refresh', (req, res) => {
const { token } = req.query;
try {
const data = jwtToken.verifyToken(token);
const access_token = jwtToken.generateToken(data, '1h');
const refresh_token = jwtToken.generateToken(data, '7d');
res.json({ status: 'success', message: '刷新成功', access_token, refresh_token });
} catch (error) {
return res.status(401).json({status: error, message: 'token失效,请重新登录'});
}
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`);
})
// token.js
const jwt = require('jsonwebtoken');
// 生成 token
function generateToken(user, expiresIn) {
const payload = {
username: user.username,
email: user.email
};
const secret = 'my_secret_key';
const options = {
expiresIn: expiresIn
};
return jwt.sign(payload, secret, options);
}
// 验证 token
function verifyToken(token) {
const secret = 'my_secret_key';
const decoded = jwt.verify(token, secret);
return decoded;
}
module.exports = {
generateToken,
verifyToken
};
六、流程图解
用户发起请求 → 携带access_token → 服务端验证
↓ 无效/过期
触发401错误 → 前端拦截 → 发起refresh_token刷新请求
↓ 刷新成功
更新本地令牌 → 重新发送原请求 → 用户无感知
↓ 刷新失败
跳转登录页面 → 需要重新认证
七、安全注意事项
- refresh_token要长期有效,但也不能太长:通常设置7-30天有效期
- 使用HTTPS:防止令牌被中间人窃取
- 不要明文存储令牌:使用浏览器localStorage要确保XSS防护
- 设置合理有效期:根据业务需求平衡安全与体验
来源:juejin.cn/post/7506732174588133391
🔥为什么我坚持用 SVG 做 icon?和 font icon 告别之后太爽了
🔥先说结论:我已经全面弃用 iconfont,只用 SVG
用了 6 年 iconfont,直到一次 icon 闪退 + 一个 retina 模糊问题,我怒转 SVG。现在回看,我只想说:一切都晚了。
🧱背景:IconFont 曾经无处不在
从 2015 年前后起,iconfont 就是前端项目的标配:
- 上阿里图标库拖几个图,下载 TTF 文件,塞进项目
- CSS 里
.icon-home:before { content: "\e614"; } - 不仅开发快,样式也能自由控制:
font-size、color、line-height全都随便来
但这个方案,看起来“简单”,其实全是坑。
😤踩坑合集:iconfont 到底有哪些问题?
1. 图标“莫名其妙不见了”
是不是经常遇到:
<i class="iconfont icon-home"></i>
然后某一天上线,页面里这个图标直接不显示。
你 debug 半天,才发现:
- CDN 的 iconfont.ttf 被阻断了
- 字体文件升级后,有的 unicode 被重映射
- 某些浏览器默认阻止远程字体加载
更离谱的:你本地能跑,线上就挂。
2. Retina 模糊 + 抗锯齿失败
iconfont 本质是“字体”,而不是“图形”。
在 Retina 屏下,你控制再多:
.icon {
font-size: 24px;
-webkit-font-smoothing: antialiased;
}
很多图标的边缘还是毛糙,特别是线性图标,对比度一上来,整个像被压过的 JPG。
3. 无法着色多个颜色
想做个渐变 icon?想让图标局部变色?
抱歉,iconfont 是“字体”,不是 SVG,不支持多颜色分区。
你只能:
- 多套图标叠在一起
- 加背景图 hack
- 用 canvas 取色渲染(别笑,这我真干过)
而 SVG 支持:
<linearGradient id="grad">
<stop offset="0%" stop-color="#f00" />
<stop offset="100%" stop-color="#00f" />
</linearGradient>
<path fill="url(#grad)" d="..." />
效果拉满,iconfont 完全追不上。
4. 组件化极难封装
Vue/React 时代你会写这样的:
<Icon type="home" />
组件里你只能用 switch-case 映射成 <i class="icon-home" />。
而 SVG 怎么写?
<svg><use xlinkHref="#icon-home" /></svg>
配合 Vite 插件(如 vite-plugin-svg-icons),你直接:
import Icon from '@/components/Icon'
<Icon name="home" />
无 switch-case,无 class,全自动注册。
🧬SVG 的优势实在太香了
✅ 1. 天然支持响应式 + Retina 适配
SVG 是“矢量图”,本质是 XML 描述路径,你怎么放大都不会模糊。
加上 viewBox 一配,任何分辨率都稳。
✅ 2. 可以用 CSS 精准控制每一部分
.icon path {
stroke: red;
}
你甚至可以控制动画效果、hover 状态、交互响应。
✅ 3. 能做动画,图标能动起来!
<path class="animated" d="..." />
再配合 GSAP / CSS Animation,一切都活了。
Font icon?别说动画,它连“变色”都费劲。
💻开发实战:我项目里是这么用的
👉 Step 1: 用工具批量导入 SVG(iconfont 支持导出)
去 iconfont 阿里 下载 SVG 格式图标:
- 一键导出所有图标为独立 SVG 文件
👉 Step 2: 用 Vite 插件自动加载
pnpm i vite-plugin-svg-icons -D
vite.config.ts:
import { createSvgIconsPlugin } from 'vite-plugin-svg-icons'
import path from 'path'
export default {
plugins: [
createSvgIconsPlugin({
iconDirs: [path.resolve(process.cwd(), 'src/assets/icons')],
symbolId: 'icon-[name]',
}),
],
}
👉 Step 3: 组件封装 + 使用
封装组件:
const Icon = ({ name, className = '' }) => (
<svg class={`svg-icon ${className}`} aria-hidden="true">
<use xlinkHref={`#icon-${name}`} />
</svg>
)
使用方式:
<Icon name="home" className="text-xl text-blue-500" />
结果图标:
- 不模糊
- 支持 tailwind 任意控制尺寸 / 颜色
- 任意动画加上去也丝滑
🔍性能?其实 SVG 更好
很多人说“SVG 会不会多了 HTTP 请求?”,其实:
- 你可以用
svg-sprite合并成一个 SVG 文件(类似雪碧图) - 你可以 Inline 到 HTML
而 iconfont 的 woff/ttf 文件体积反而大,兼容性也差。
🚫你什么时候不适合 SVG?
- IE10 以下?别做梦(现在谁还兼容它?)
- 文件体积有要求 (可能有些svg很大)
- 对 icon 清晰度没有要求
但总的来说,2025 年了,SVG 基本就是绝对主流方案。
🧠晚用 SVG 三年,悔不当初
我不是说 iconfont 毫无可取之处,但作为前端工程实践而言:
“SVG 是当代 Web icon 的答案,iconfont 是历史的过渡产物。”
所以,别再调字体缩放、别再被 Unicode 问题搞得吐血了。
用 SVG,你会感谢现在的自己。你们怎么看?
📌 你可以继续看我的系列文章
来源:juejin.cn/post/7516813599962054719
20MB 的字体文件太大了,我们把 Icon Font 压成了 10KB
在一次前端性能优化项目中,我们发现仅仅一个 icon font 文件就高达 20MB。这不仅拖慢了首屏加载速度,还极大地浪费了带宽。最终,我们将它压缩到了 10KB,而不影响任何功能表现。
这一过程背后,涉及的不仅是压缩,而是对「构建流程」「字体格式」「加载策略」「字形定制」的全盘重构。本文将逐步拆解这场“减重手术”,帮助你理解 icon font 是如何成为性能黑洞的,又是如何优雅瘦身的。
问题:20MB 的 icon font 是怎么来的?
大字体文件往往是由于以下原因造成的:
- 过度收录:设计同学导出了一整套 2000 多个图标的 icon font,实际只用了其中几十个。
- 全量打包:工具如 Icomoon、Fontello、FontForge 默认导出全量字形。
- 格式冗余:一个字体文件常包含
.ttf,.woff,.woff2,.eot,.svg多种格式,全打包增加体积。 - 不做 Subset(子集提取):没有剔除未使用的字形。
最终结果就是:用户下载了 2000 个图标,只为了看到那 20 个常用 icon。
目标:精简为只包含实际使用 icon 的最小字体
如果你只用了 <i class="icon-chevron-down"></i>、<i class="icon-close"></i>、<i class="icon-search"></i> 三个图标,那字体文件里应该只包含这三个图形。
核心理念是:用子集字体(Subset Font)只保留被真正使用的字形。
解决方案路线图
✅ 步骤一:收集实际用到的 icon
- 全站代码扫描,提取 icon class(或 unicode)
- 工具:自定义脚本、AST 分析、静态资源分析工具
# 示例:查找 iconfont 使用的 class 名称
grep -roh 'icon-[a-zA-Z0-9_-]\+' ./src | sort | uniq > used-icons.txt
✅ 步骤二:精简 icon 到最小集合
工具选择:
- IcoMoon App:可视化管理图标,导出精简 icon font
- FontSubset:支持上传字体,自动子集提取
pyftsubset(来自 fonttools):命令行方式自动提取子集
例:使用 pyftsubset
pyftsubset original.ttf \
--unicodes=U+E001,U+E002,U+E003 \
--output-file=subset.ttf \
--flavor=woff2 \
--layout-features='*' \
--no-hinting \
--glyph-names
说明:
--unicodes指定只保留的字符--flavor=woff2输出现代浏览器首选格式--no-hinting去除微调信息,减小文件体积
✅ 步骤三:只保留必要的字体格式
浏览器现代化后,建议:
- 只保留
.woff2(现代浏览器支持) - 视兼容性决定是否保留
.woff(老一点的 Chrome/Firefox) - 移除
.eot/.svg/.ttf除非需要极限兼容 IE6+
字体大小差异:
| 格式 | 同内容文件大小 |
|---|---|
| TTF | 40KB |
| WOFF | 28KB |
| WOFF2 | 10KB |
✅ 步骤四:字体精简之后如何正确加载?
CSS 示例:
@font-face {
font-family: 'MyIcons';
src: url('icons.woff2') format('woff2');
font-display: swap;
}
重点字段说明:
font-display: swap:加速首次渲染format('woff2'):浏览器可判断是否支持
✅ 步骤五:如果你用的是组件库的内建 iconfont
Ant Design、Element UI、Bootstrap Icons 等往往内置大量 iconfont。优化策略如下:
- 替换为 SVG 图标组件(例如 Iconify)
- 只引入需要的图标模块
- Antd 4.x 以上支持按需引入图标(非字体形式)
- 使用 Tree-shaking 友好的 SVG icon 方案
- 如
@iconify/react、@icon-park/react
- 如
成果验证
经过上述处理:
- 初始字体大小:20.3MB
- 实际保留字形数量:12 个
- 精简后字体(.woff2)大小:10.4KB
- 首屏加载 TTI 提升:约 800ms
- Lighthouse 性能评分:+9 分
额外干货:你可能不知道的字体优化技巧
🧠 1. 使用 base64 inline 的 icon font 并非总是好事
虽然可减少 HTTP 请求,但:
- 无法缓存(每次 HTML 载入)
- 增加 HTML 大小
- 不利于 CDN 优化和延迟加载
通常只有在 icon font < 5KB 且需要打包进组件时,才考虑 base64。
🧠 2. 字体子集可以配合 SSR 实现动态优化
在 SSR 应用(如 Next.js)中,可以:
- 在构建阶段根据页面中实际 icon 自动生成对应的字体子集
- 动态注入只需要的 icon font,达到更极致的优化效果
🧠 3. 替代方案:彻底摆脱 icon font,用 SVG
SVG 优点:
- 完全控制颜色/动画
- 无需额外字体解析
- 体积更小,支持按需加载
- 更适合现代组件式开发(React/Vue)
推荐库:
- Iconify(80+ 图标集统一封装)
- unplugin-icons(Vite 项目自动加载)
- Heroicons、Feather、Lucide、Tabler 等
你还在用几兆的 icon font,不妨静下心来,用一下午把它瘦成精悍的 10KB, 别让一堆你永远不会用到的图标,霸占用户的加载时间。
📌 你可以继续看我的系列文章
来源:juejin.cn/post/7518572029404397580
一个拼写错误让整个互联网一起犯错
在 Web 开发的世界里,有这样一个字段——它每天默默地工作着,记录着用户的来源,保护着网站的安全,却因为一个历史性的拼写错误而成为了程序员们茶余饭后的谈资。它就是 HTTP 头部中的 Referer 字段。
什么是 HTTP Referer
HTTP Referer 是一个请求头字段,用于告诉服务器用户是从哪个页面链接过来的。当你从一个网页点击链接跳转到另一个网页时,浏览器会自动在新的 HTTP 请求中添加 Referer 头,其值为上一个页面的 URL。
Referer: https://example.com/page1.html
这告诉服务器,用户是从 http://www.example.com/page1.html 这个页面跳转过来的。
核心作用
1. 流量来源分析
网站运营者可以通过分析 Referer 信息了解:
- 用户从哪些网站访问过来
- 哪些页面是主要的流量入口
- 外部链接的效果如何
- 用户的浏览路径和行为习惯
2. 防盗链保护
许多网站利用 Referer 来防止其他网站直接链接自己的图片、视频等资源。服务器可以检查 Referer 是否来自允许的域名,如果不是则拒绝请求。
# nginx 图片防盗链配置
location ~* .(jpg|jpeg|png|gif|ico|css|js)$ {
valid_referers none blocked server_names
*.mysite.com *.mydomain.com;
if ($invalid_referer) {
return 403;
}
}
3. 安全防护
用于 CSRF 攻击防护和恶意请求检测:
# nginx CSRF 攻击防护
location /api {
valid_referers none blocked server_names *.example.com;
if ($invalid_referer) {
return 403;
}
proxy_pass http://backend;
}
这样就可以检查请求是否来自合法域名(*.example.com)。
著名的拼写错误

HTTP Referer 存在一个著名的拼写错误:正确的英文单词应该是 "Referrer",但在 1995 年制定 HTTP/1.0 规范时被误写为 "Referer"(少了一个 r)。
当错误被发现时,HTTP 协议已经广泛部署,为保持向后兼容性,这个拼写错误被永久保留:
- HTTP 头部:使用错误拼写
Referer - HTML 属性:使用正确拼写
referrer
<!-- HTML中使用正确拼写 -->
<meta name="referrer" content="origin">
<!-- HTTP头中使用错误拼写 -->
Referer: https://example.com
Referrer-Policy 策略
为了解决隐私问题,W3C 制定了 Referrer Policy 规范,提供了精细的控制机制,现代浏览器支持 Referrer-Policy 来控制 Referer 的发送行为:
策略值
| 策略 | 描述 | 使用场景 |
|---|---|---|
no-referrer | 不发送 Referer | 最高隐私保护 |
no-referrer-when-downgrade | HTTPS 到 HTTP 时不发送,其他情况正常发送 | 现代浏览器默认 |
origin | 只发送协议、域名和端口 | 平衡功能和隐私 |
origin-when-cross-origin | 同源发送完整 URL,跨域只发送域名 | 推荐的默认策略 |
same-origin | 仅同源请求发送 Referer | 内部分析 |
strict-origin | 类似 origin,但 HTTPS 到 HTTP 时不发送: | 较少 |
strict-origin-when-cross-origin | 综合考虑安全性的策略 | 现代浏览器默认 |
unsafe-url | 始终发送完整 URL | 较少 |
设置方法
HTTP 响应头:
res.setHeader('Referrer-Policy', 'strict-origin-when-cross-origin');
HTML Meta 标签:
<meta name="referrer" content="strict-origin-when-cross-origin">
元素级别控制:
<a href="https://external.com" referrerpolicy="no-referrer">外部链接</a>
<img src="image.jpg" referrerpolicy="origin">
rel 属性相关值
noreferrer
阻止发送 Referer 头:
<a href="https://external.com" rel="noreferrer">不发送Referer</a>
noopener
防止新窗口访问原窗口对象:
<a href="https://external.com" target="_blank" rel="noopener">安全新窗口</a>
nofollow
告诉搜索引擎不要跟踪链接:
<a href="https://untrusted.com" rel="nofollow">不被索引的链接</a>
组合使用
<a href="https://external.com"
target="_blank"
rel="noopener noreferrer nofollow">
完全安全的外部链接
</a>
总结
HTTP Referer 虽然只是一个小小的请求头,但它承载着 Web 发展的历史,见证了互联网从功能至上到隐私保护的转变。那个著名的拼写错误也提醒我们,技术标准的制定需要更加严谨和谨慎。
来源:juejin.cn/post/7518783423277547572
说个多年老前端都不知道的标签正确玩法——q标签
最近这两天准备鼓捣一下markdown文本编辑器,现在写公众号一般用的都是 网页 的编辑器。
说实话,很方便,但是痛点也很明显。
研究过程中发现一个以前从未在意过的标签: <q> 标签。
官网解释
<p>孟子: <q>生于忧患,死于安乐。</q></p>
说实话原生效果比较难看。

仅仅是对文本增加了双引号,并且这个双引号效果在各个浏览器中好像还存在细微的区别。
另外就是效果对于常规文本而言没有什么问题,但是对于大段文字、需要重点突出的文字而言其实比较普通,混杂在海量的文字中间很难分辨出来效果。
所以可以通过css全局修改q标签的样式,使其更符合个性化样式的需求。
q {
quotes: "「" "」";
color: #3594F7;
font-weight: bold;
}
最大限度模仿了markdown上面的样式效果。

其实上述样式中的双引号还可以被替换成图片、表情、文字等等,并且也可以通过伪元素对双引号进行操作。
q {
quotes: "🙂" "🙃";
color: #3594F7;
font-weight: bold;
}
q::before {
display: inline-block;
}
q::after {
display: inline-block;
}
q:hover::before,
q:hover::after {
animation: rotate 0.5s linear infinite;
}
@keyframes rotate {
from {
transform: rotate(0deg);
}
to {
transform: rotate(360deg);
}
}

注意:伪元素上必须添加 display: inline-block; ,否则动画不生效。
原因是伪元素默认为 inline,部分css样式对 inline 是不生效的。
来源:juejin.cn/post/7516745491104481315
前端权限系统怎么做才不会写吐?我们项目踩过的 3 套失败方案总结
上线前两个月,我们的权限系统崩了三次。
不是接口没权限,而是:
- 页面展示和真实权限不一致;
- 权限判断写得四分五裂;
- 权限数据和按钮逻辑耦合得死死的,测试一改就炸。
于是,我们老老实实把整个权限体系拆了重构,从接口到路由、到组件、到 v-permission 指令,走了一遍完整的流程。
结果:代码可维护,调试容易,后端调整也能快速兜底。
这篇文章不讲理论,只还原我们项目真踩过的 3 套失败方案和最终落地方案。
❌ 第一套:按钮级权限直接写死在模板里
当时我们的写法是这样的:
<!-- 用户管理页 -->
<el-button v-if="authList.includes('user:add')">添加用户</el-button>
接口返回的是一个权限数组:
["user:add", "user:delete", "user:list"]
然后整个项目几十个地方都这么判断。
结果:
- 不能重用,每个组件都判断一次;
- 权限粒度变更就全崩,比如从
user:add改成user:add_user; - 后端权限更新后,前端要全局搜索权限 key 改代码;
典型的“写起来爽,维护时哭”方案。
❌ 第二套:用 router.meta.permission 统一控制,结果太抽象
重构后我们尝试统一控制页面级权限:
// router.ts
{
path: '/user',
component: User,
meta: {
permission: 'user:list'
}
}
再通过导航守卫:
router.beforeEach((to, from, next) => {
const p = to.meta.permission
if (p && !authList.includes(p)) {
return next('/403')
}
next()
})
这个方案页面级权限是解决了,但组件级 / 按钮级 / 表单字段级全都失效了。
而且你会发现,大量页面是“同路由但不同内容区域权限不同”,导致这种 meta.permission 方案显得太粗暴。
❌ 第三套:封装权限组件,结果被吐槽“反人类”
当时我们团队有人设计了一个组件:
<Permission code="user:add">
<el-button>添加用户</el-button>
</Permission>
这个组件内部逻辑是:
const slots = useSlots()
if (!authList.includes(props.code)) return null
return slots.default()
结果:
- 逻辑上看似没问题,但使用非常反直觉;
- 特别是嵌套多个组件时,调试麻烦,断点打不进真实组件;
- TypeScript 报类型错误,编辑器无法识别 slot 类型;
- 更麻烦的是,权限失效的时候,组件不会渲染,开发环境都看不到是为什么!
最终方案:hook + 指令 + 路由统一层级设计
我们最后把权限体系重构为 3 层:
🔹1. 接口统一管理权限 key → 后端返回精简列表(扁平权限)
export type AuthCode =
| 'user:add'
| 'user:delete'
| 'user:edit'
| 'order:export'
| 'dashboard:view'
服务端返回用户权限集,保存在 authStore(Pinia / Vuex / Context)中。
🔹2. 统一 Hook 调用:usePermission(code)
import { useAuthStore } from '@/store/auth'
export function usePermission(code: string): boolean {
const store = useAuthStore()
return store.permissionList.includes(code)
}
用法:
<el-button v-if="usePermission('user:add')">添加用户</el-button>
这才是真正组件内部逻辑干净、容易复用、TS 支持的方案。
🔹3. 封装一个 v-permission 指令(可选)
app.directive('permission', {
mounted(el, binding) {
const authList = getUserPermissions() // 从全局 store 获取
if (!authList.includes(binding.value)) {
el.remove()
}
}
})
模板中使用:
<el-button v-permission="'order:export'">导出订单</el-button>
适合动态组件、render 生成的按钮,不适合复杂嵌套逻辑,但实际项目中效果拔群。
🧪 页面级权限怎么做?
不再用 router.meta,而是把每个路由页封装为权限包裹组件:
<template>
<PermissionView code="dashboard:view">
<Dashboard />
</PermissionView>
</template>
权限组件内部处理:
- 没权限 → 自动跳转 403
- 有权限 → 渲染内容
这样即使权限接口变了,组件逻辑也统一保留,避免页面空白或者闪跳。
权限这事,不是实现难,而是维护难。
最核心的不是你怎么控制显示,而是权限 key 的一致性、复用性、分层能力。
最终我们稳定版本满足了:
- 页面、按钮、字段统一接入权限
- 新增权限点只需要改枚举,不需要大改
- 新人接手也能一眼看懂逻辑,能调试
📌 你可以继续看我的系列文章
来源:juejin.cn/post/7517915625136586787
同事用了个@vue:mounted,我去官网找了半天没找到
前言
大家好,我是奈德丽。
上周在做代码review的时候,看到同事小李写了这样一行代码:
<component :is="currentComponent" @vue:mounted="handleMounted" />
我第一反应是:"这什么语法?似曾相识的样子,有点像在vue2中用过的@hook:mounted, 但我们项目是vue3,然后去Vue3官方文档搜索@vue:mounted,结果什么都没找到,一开始我以为是他研究了源码,结果他说是百度到的,那我们一起来来研究研究这个东西吧。
从一个动态组件说起
小李的需求其实很简单:在子组件加载或更新或销毁后,需要获取组件的某些信息。这家伙是不是还看源码了,有这种骚操作,他的代码是这样的:
<template>
<div class="demo-container">
<h2>动态组件加载监控</h2>
<div class="status">当前组件状态:{{ componentStatus }}</div>
<div class="controls">
<button @click="loadComponent('ComponentA')">加载组件A</button>
<button @click="loadComponent('ComponentB')">加载组件B</button>
<button @click="unloadComponent">卸载组件</button>
</div>
<!-- 小李写的代码 -->
<component
:is="currentComponent"
v-if="currentComponent"
@vue:mounted="handleMounted"
@vue:updated="handleUpdated"
@vue:beforeUnmount="handleBeforeUnmount"
/>
</div>
</template>
<script setup>
import { ref } from 'vue'
const currentComponent = ref(null)
const componentStatus = ref('无组件')
const handleMounted = () => {
componentStatus.value = '✅ 组件已挂载'
console.log('组件挂载完成')
}
const handleUpdated = () => {
componentStatus.value = '🔄 组件已更新'
console.log('组件更新完成')
}
const handleBeforeUnmount = () => {
componentStatus.value = '❌ 组件即将卸载'
console.log('组件即将卸载')
}
const loadComponent = (name) => {
currentComponent.value = name
}
const unloadComponent = () => {
currentComponent.value = null
componentStatus.value = '无组件'
}
</script>
我仔细分析了一下,在这个动态组件的场景下,@vue:mounted确实有它的优势。最大的好处是只需要在父组件一个地方处理,不用去修改每个可能被动态加载的子组件。想象一下,如果有十几个不同的组件都可能被动态加载,你得在每个组件里都加上emit事件,维护起来确实麻烦。
而用@vue:mounted的话,所有的生命周期监听逻辑都集中在父组件这一个地方,代码看起来更集中,也更好管理。
但是,我心里还是有疑虑:这个语法为什么在官方文档里找不到?
深入探索:未文档化的功能
经过一番搜索,我在Vue的GitHub讨论区找到了答案。原来这个功能确实存在,但Vue核心团队明确表示:
"这个功能不是为用户应用程序设计的,这就是为什么我们决定不文档化它。"
换句话说:
- ✅ 这个功能确实存在且能用
- ❌ 但官方不保证稳定性
- ⚠️ 可能在未来版本中被移除
- 🚫 不推荐在生产环境使用
我们来看一下vue迁移文档中关于Vnode的部分,关键点我用下划线标红了。有趣的是这个@vue:[生命周期]语法不仅可以用在组件上,也可以用在所有虚拟节点中。
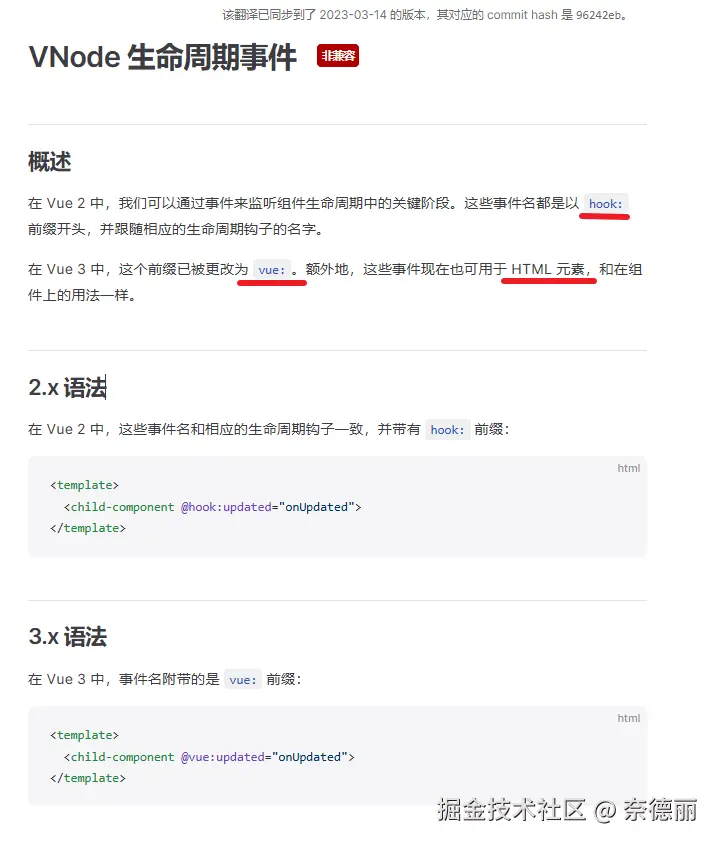
虽然在Vue 3迁移指南中有提到从@hook:(Vue 2)改为@vue:(Vue 3)的变化,但这更多是为了兼容性考虑,而不是鼓励使用。
为什么小李的代码"看起来"没问题?
回到小李的动态组件场景,@vue:mounted确实解决了问题:
- 集中管理 - 所有生命周期监听逻辑都在父组件一个地方
- 动态性强 - 不需要知道具体加载哪个组件
- 代码简洁 - 不需要修改每个子组件
- 即用即走 - 临时监听,用完就完
但问题在于,这是一个不稳定的API,随时可能被移除。
我给出的review意见
考虑到安全性和稳定性,还是以下方案靠谱
方案一:子组件主动汇报(推荐)
虽然需要修改子组件,但这是最可靠的方案:
<!-- ComponentA.vue -->
<template>
<div class="component-a">
<h3>我是组件A</h3>
<button @click="counter++">点击次数: {{ counter }}</button>
</div>
</template>
<script setup>
import { ref, onMounted, onUpdated, onBeforeUnmount } from 'vue'
const emit = defineEmits(['lifecycle'])
const counter = ref(0)
onMounted(() => {
emit('lifecycle', { type: 'mounted', componentName: 'ComponentA' })
})
onUpdated(() => {
emit('lifecycle', { type: 'updated', componentName: 'ComponentA' })
})
onBeforeUnmount(() => {
emit('lifecycle', { type: 'beforeUnmount', componentName: 'ComponentA' })
})
</script>
<!-- ComponentB.vue -->
<template>
<div class="component-b">
<h3>我是组件B</h3>
<input v-model="text" placeholder="输入文字">
<p>{{ text }}</p>
</div>
</template>
<script setup>
import { ref, onMounted, onUpdated, onBeforeUnmount } from 'vue'
const emit = defineEmits(['lifecycle'])
const text = ref('')
onMounted(() => {
emit('lifecycle', { type: 'mounted', componentName: 'ComponentB' })
})
onUpdated(() => {
emit('lifecycle', { type: 'updated', componentName: 'ComponentB' })
})
onBeforeUnmount(() => {
emit('lifecycle', { type: 'beforeUnmount', componentName: 'ComponentB' })
})
</script>
父组件使用:
<component
:is="currentComponent"
v-if="currentComponent"
@lifecycle="handleLifecycle"
/>
<script setup>
const handleLifecycle = ({ type, componentName }) => {
const statusMap = {
mounted: '✅ 已挂载',
updated: '🔄 已更新',
beforeUnmount: '❌ 即将卸载'
}
componentStatus.value = `${componentName} ${statusMap[type]}`
console.log(`${componentName} ${type}`)
}
</script>
优点:稳定可靠,官方推荐
缺点:需要修改每个子组件,有一定的重复代码
方案二:通过ref访问(适合特定场景)
如果你确实需要访问组件实例:
<component
:is="currentComponent"
v-if="currentComponent"
ref="dynamicComponentRef"
/>
<script setup>
import { ref, watch, nextTick } from 'vue'
const dynamicComponentRef = ref(null)
// 监听组件变化
watch(currentComponent, async (newComponent) => {
if (newComponent) {
await nextTick()
console.log('组件实例:', dynamicComponentRef.value)
componentStatus.value = '✅ 组件已挂载'
// 可以访问组件的方法和数据
if (dynamicComponentRef.value?.someMethod) {
dynamicComponentRef.value.someMethod()
}
}
}, { immediate: true })
</script>
优点:可以直接访问组件实例和方法
缺点:只能监听到挂载,无法监听更新和卸载
方案三:provide/inject(深层通信)
如果是复杂的嵌套场景,组件层级深的时候我们可以使用这个:
<!-- 父组件 -->
<script setup>
import { provide, ref } from 'vue'
const componentStatus = ref('无组件')
const lifecycleHandler = {
onMounted: (name) => {
componentStatus.value = `✅ ${name} 已挂载`
console.log(`${name} 已挂载`)
},
onUpdated: (name) => {
componentStatus.value = `🔄 ${name} 已更新`
console.log(`${name} 已更新`)
},
onBeforeUnmount: (name) => {
componentStatus.value = `❌ ${name} 即将卸载`
console.log(`${name} 即将卸载`)
}
}
provide('lifecycleHandler', lifecycleHandler)
</script>
<template>
<div>
<div class="status">{{ componentStatus }}</div>
<component :is="currentComponent" v-if="currentComponent" />
</div>
</template>
<!-- 子组件 -->
<script setup>
import { inject, onMounted, onUpdated, onBeforeUnmount } from 'vue'
const lifecycleHandler = inject('lifecycleHandler', {})
const componentName = 'ComponentA' // 每个组件设置自己的名称
onMounted(() => {
lifecycleHandler.onMounted?.(componentName)
})
onUpdated(() => {
lifecycleHandler.onUpdated?.(componentName)
})
onBeforeUnmount(() => {
lifecycleHandler.onBeforeUnmount?.(componentName)
})
</script>
优点:适合深层嵌套,可以跨多层传递
各种方案的对比
| 方案 | 实现难度 | 可靠性 | 维护性 | 集中管理 | 适用场景 |
|---|---|---|---|---|---|
| emit事件 | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ | 🏆 大部分场景的首选 |
| ref访问 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ✅ | 需要调用组件方法时 |
| provide/inject | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ | 深层嵌套组件通信 |
| @vue:mounted | ⭐ | ⭐⭐ | ⭐ | ✅ | ⚠️ 自己项目可以玩玩,不推荐生产使用 |
总结
通过这次code review,我们学到了:
- 技术选型要考虑长远 - 不是所有能用的功能都应该用,稳定性比便利性更重要
- 特定场景的权衡 - 在动态组件场景下,
@vue:[生命周期]确实有集中管理的优势,但要权衡风险 - 迁移策略很重要 - 不能一刀切,要有合理的过渡方案
- 代码review的价值 - 不仅仅是找bug,更是知识分享和技术决策的过程
- 文档化的重要性 - 未文档化的API往往意味着不稳定,使用时要谨慎
虽然@vue:[生命周期]在动态组件场景下确实好用,但从工程化角度考虑,还是建议逐步迁移到官方推荐的方案。毕竟,今天的便利可能是明天的技术债务。
当然,如果你正在维护老项目,且迁移成本较高,也可以考虑先保留现有代码,但一定要有明确的迁移计划和风险控制措施。
恩恩……懦夫的味道
来源:juejin.cn/post/7514275553726644235
😧纳尼?前端也能做这么复杂的事情了?
前言
我偶然间发现一个宝藏网站,aicut.online 是一款基于本地AI实现的背景移除工具。
我研究了一下,发现他是使用了u2net模型 + onnxruntime-web实现的本地模型推理能力,下面简单介绍一下这些概念。
github:github.com/yuedud/aicu…
体验网址:aicut.online
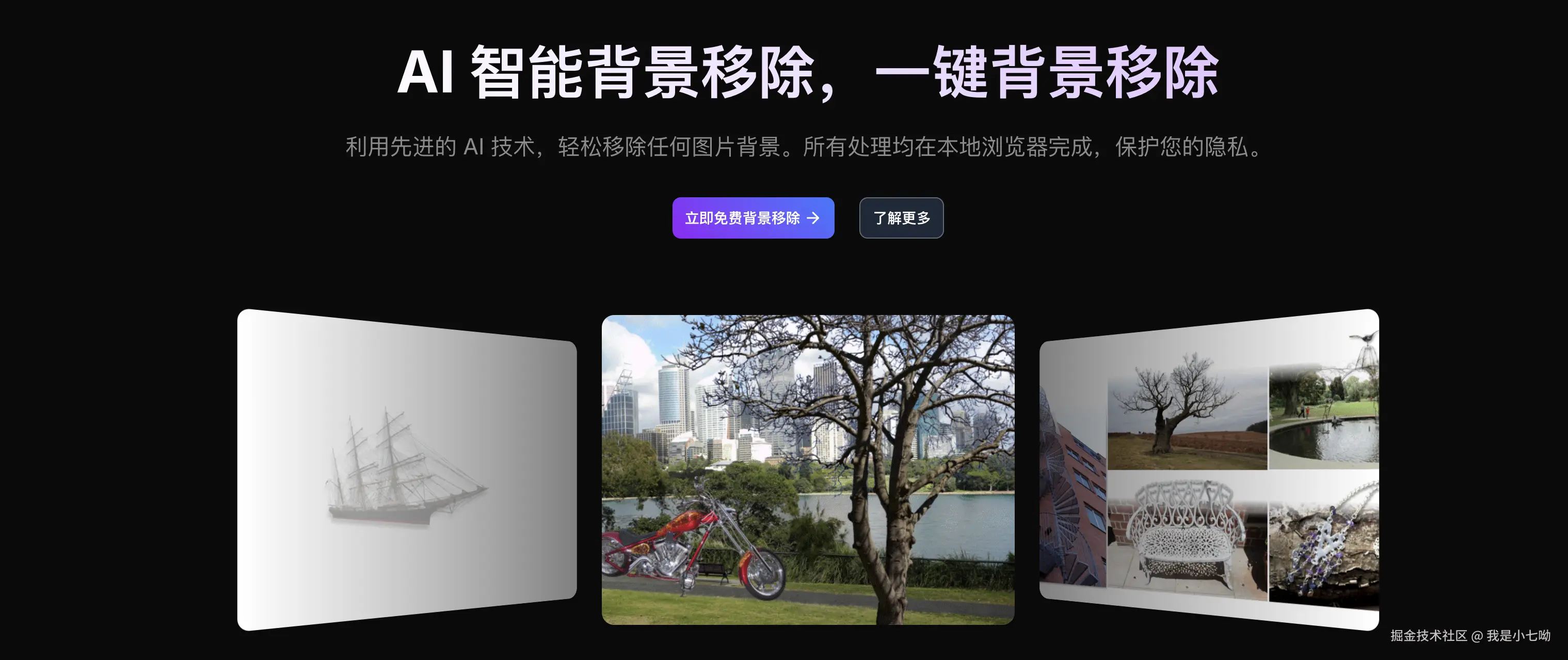
概念
WebAssembly
- 基本概念: WebAssembly 是一种低级的二进制指令格式,设计目标是成为一种高效、可移植、安全的编译目标,使其能在现代 Web 浏览器中运行。你可以把它想象成一种为 Web 设计的“通用机器语言”。
- 核心特点:
- 高性能: 它不是解释执行的(像传统 JavaScript),而是被设计成可以以接近原生代码的速度运行。它提供线性内存模型和低级操作,便于编译器优化。
- 可移植性: Wasm 模块是平台无关的,可以在支持 Wasm 的任何浏览器(或运行时环境)中运行,无需修改。
- 安全性: 它在内存安全的沙箱环境中执行,无法直接访问主机操作系统或 DOM。只能通过明确定义的 API 与宿主环境(如浏览器)交互。
- 多语言支持: 开发者可以使用 C、C++、Rust、Go 等多种语言编写代码,然后编译成 Wasm 模块,在浏览器中运行。这使得重用现有的高性能库或编写对性能要求极高的新功能成为可能。
- 目标: 解决 JavaScript 在处理计算密集型任务(如游戏物理引擎、视频编辑、3D渲染、科学计算、加密解密、机器学习模型推理等)时性能不足的问题,同时保持 Web 的安全性和可移植性。
- 简单比喻: 就像为浏览器引入了一个新的、更接近硬件的“CPU 指令集”,让浏览器能直接运行编译好的高性能代码。
Onnxruntime-Web
- 基本概念: onnxruntime-web 是 ONNX Runtime 的一个专门构建的版本,目的是让开发者能够直接在 Web 浏览器中运行 ONNX 格式的机器学习模型。
- 核心特点:
- ONNX 支持: 它理解并执行符合 ONNX 标准的模型文件。ONNX 是一个开放的模型格式,允许模型在各种框架之间转换和互操作。
- 浏览器内推理: 最大的价值在于它允许 ML 模型的推理计算完全在用户的浏览器中发生,无需依赖远程服务器。这带来了低延迟、隐私保护(数据无需离开用户设备)和离线能力。
- 多种后端执行引擎: 为了适应不同的浏览器环境、设备性能和模型需求,它提供了多种执行引擎后端:
- WebAssembly (Wasm): 提供接近原生的性能,是主要的跨浏览器高性能后端。支持单线程和多线程(需浏览器支持)。
- WebGL: 利用 GPU 进行加速,尤其适合某些计算模式与图形处理相似的模型(如卷积神经网络)。性能潜力高,但兼容性和精度可能不如 Wasm。
- WebNN (预览/实验性): 旨在利用操作系统提供的原生 ML 硬件加速(如 NPU)。性能潜力最高,但目前浏览器支持有限。
- JavaScript (CPU): 兼容性最好但速度最慢的后备方案。
- 优化: 包含针对 Web 环境(特别是 Wasm 和 WebGL)的特定优化,以提升模型在浏览器中的运行效率。
- 目标: 降低在 Web 应用中集成和部署机器学习模型的门槛,提供高性能、跨平台的浏览器内推理能力。
- 简单比喻: 它是一个专门为浏览器定制的“机器学习模型运行引擎”,支持多种“驱动方式”(Wasm, WebGL, WebNN),让各种 ONNX 格式的模型能在网页里“活”起来并高效工作。
u2net
- 基本概念: u2net 是一种深度学习神经网络架构,特别设计用于显著目标检测任务。它的核心任务是从图像或视频中精确地分割出最吸引人注意的前景目标。
- 核心特点:
- 嵌套 U 型结构: 这是其名称的由来(U^2-Net)。它包含一个主 U 型编码器-解码器网络,并且在每个阶段内部又嵌套了更小的 U 型块(ReSidual U-blocks, RSU)。这种设计能更有效地捕捉不同尺度的上下文信息,同时保持高分辨率的细节。
- 多尺度特征融合: 通过嵌套的 RSU 块和跳跃连接,模型能融合来自不同深度和尺度的特征,这对精确描绘目标边界至关重要。
- 高效性: 相比一些非常深的网络(如 ResNet),u2net 结构相对轻量,但性能优异。
- 应用广泛: 主要用于高质量的图像/视频前景背景分割(抠图)。典型的应用包括:
- 移除或替换图片/视频背景
- 创建透明 PNG 图像
- 人像分割
- 视频会议虚拟背景
- 图像编辑工具
- 目标: 提供一种高效且准确的架构,解决图像中前景目标的精确分割问题。
- 简单比喻: u2net 是一个专门训练出来的“智能剪刀手”,它能自动识别图片里最重要的主体(比如人、动物、物体),并用极高的精度把它从背景中“剪”出来。
技术架构
架构图
+-------------------------------------------------------+
| **用户层 (Web Application)** |
+-------------------------------------------------------+
| - 用户界面 (HTML, CSS) |
| - 业务逻辑 (JavaScript/TypeScript) |
| * 捕获用户输入 (e.g., 上传图片/视频流) |
| * 调用 `onnxruntime-web` API 执行推理 |
| * 处理输出 (e.g., 显示抠图结果,合成新背景) |
+-------------------------------------------------------+
↓ (JavaScript API 调用)
+-------------------------------------------------------+
| **模型服务层 (ONNX Runtime Web)** |
+-------------------------------------------------------+
| - **onnxruntime-web** 库 (JavaScript) |
| * 加载并解析 **u2net.onnx** 模型文件 |
| * 管理输入/输出张量 (Tensor) 的内存 |
| * 调度计算任务到下层执行引擎 |
| * 提供统一的 JavaScript API 给上层应用 |
+-------------------------------------------------------+
↓ (选择最佳后端执行)
+-------------------------------------------------------+
| **执行引擎层 (Runtime Backends)** |
+-------------------------------------------------------+
| +---------------------+ +---------------------+ |
| | **WebAssembly (Wasm)** | **WebGL** | ... |
| +---------------------+ +---------------------+ |
| | * **核心加速引擎** | * 利用GPU加速 | |
| | * 接近原生CPU速度 | * 适合特定计算模式 | |
| | * 安全沙箱环境 | * 兼容性/精度限制 | |
| | * 多线程支持 (可选) | | |
| +---------------------+ +---------------------+ |
| **首选后端** **备选/补充后端** |
+-------------------------------------------------------+
↓ (执行编译后的低级代码)
+-------------------------------------------------------+
| **模型层 (U2Net 神经网络)** |
+-------------------------------------------------------+
| - **u2net.onnx** 模型文件 |
| * 包含训练好的 u2net 网络架构 (嵌套U型结构) |
| * 包含网络权重参数 |
| * 格式:开放神经网络交换格式 (ONNX) |
| * 任务:显著目标检测 / 图像抠图 |
+-------------------------------------------------------+
↓ (模型文件来源)
+-------------------------------------------------------+
| **资源层 (Browser Environment)** |
+-------------------------------------------------------+
| - 模型文件存储: HTTP Server / IndexedDB / Cache API |
| - 浏览器提供: WebAssembly 引擎, WebGL API, WebNN API |
| - 计算资源: CPU (Wasm), GPU (WebGL), NPU (WebNN) |
+-------------------------------------------------------+
详细解释
- 用户层 (Web Application):
- 这是用户直接交互的网页界面。
- 使用 JavaScript/TypeScript 编写应用逻辑。
- 核心操作:获取用户输入(如图片或视频帧),调用
onnxruntime-web提供的 API 来运行 u2net 模型进行抠图推理,接收模型输出的结果(通常是掩码图或透明度通道),最后将结果渲染给用户(如显示抠好的图或与背景合成)。
- 模型服务层 (ONNX Runtime Web):
- 核心枢纽。这是集成到 Web 应用中的 JavaScript 库。
- 负责加载存储在资源层中的 u2net.onnx 模型文件。
- 管理模型运行所需的内存(准备输入 Tensor,接收输出 Tensor)。
- 提供简洁的 JS API(如
InferenceSession.create(),session.run())供上层应用调用。 - 最关键的作用:根据浏览器支持情况和模型需求,智能选择并调度计算任务到下层的最佳执行引擎(首选通常是 WebAssembly)。
- 执行引擎层 (Runtime Backends):
onnxruntime-web实际执行模型计算的地方。- WebAssembly (Wasm) 后端是核心加速引擎:
- u2net 模型的计算密集型操作(卷积、矩阵乘等)被编译成高效的 Wasm 字节码。
- Wasm 引擎在浏览器的安全沙箱中以接近原生代码的速度执行这些字节码。
- 这是实现高性能浏览器内推理的关键,使得复杂的 u2net 模型能在用户设备上流畅运行。
- WebGL 后端 (备选) :
- 利用 GPU 进行加速,特别适合 u2net 中大量使用的卷积操作。
- 性能潜力高,但可能受浏览器兼容性、WebGL 精度限制和特定模型适配的影响。
- (可选) WebNN 后端 (未来方向) :直接调用操作系统提供的底层 AI 硬件加速(如 NPU),潜力最大,但目前支持有限。
- 模型层 (U2Net 神经网络):
- 包含训练好的 u2net 模型,以 ONNX 格式 (.onnx 文件) 存储。
- ONNX 是一个开放的、框架无关的模型表示格式,使得 u2net 模型可以被 onnxruntime-web 加载和运行。
- 这个文件包含了 u2net 独特的嵌套 U 型结构 (U^2-Net) 的定义以及训练得到的所有权重参数。
- 它定义了具体的抠图任务如何执行。
- 资源层 (Browser Environment):
- 提供模型文件
u2net.onnx的来源(通过 HTTP 下载、存储在 IndexedDB 或利用 Cache API)。 - 提供运行时环境:浏览器内置的 WebAssembly 引擎负责执行 Wasm 字节码,WebGL API 用于 GPU 加速,WebNN API (如果可用) 用于底层硬件加速。
- 提供硬件计算资源:用户的 CPU (用于运行 Wasm)、GPU (用于 WebGL)、潜在的专用 AI 处理器 NPU/APU (用于 WebNN)。
- 提供模型文件
源代码解析
Github:github.com/yuedud/aicu…
目录解析
public
public是存放静态资源的地方,存储了onnx模型和一些静态的资源图片
src
src是核心代码存放的地方,下面我们只来介绍一下关于抠图部分的代码,核心代码在src/components/ImageSegmentation.js
可以看到在进入网站之后,第一时间就开始加载模型,同时使用了indexedDB进行了模型缓存,二次使用的时候直接用indexedDB里获取模型,由于模型较大,所以加载时间会比较长。
// 加载模型
useEffect(() => {
const loadModel = async () => {
try {
setError(null);
const db = await openDB();
let modelData = await getModelFromDB(db);
if (modelData) {
console.log('从IndexedDB加载模型.');
} else {
console.log('IndexedDB中未找到模型,从网络下载...');
const response = await fetch('./u2net.onnx');
if (!response.ok) {
throw new Error(`网络请求模型失败: ${response.status} ${response.statusText}`);
}
modelData = await response.arrayBuffer();
console.log('模型下载完成,存入IndexedDB...');
await storeModelInDB(db, modelData);
console.log('模型已存入IndexedDB.');
}
const newSession = await ort.InferenceSession.create(modelData, {
executionProviders: ['wasm'], // 'webgl' 或 'wasm'
graphOptimizationLevel: 'all',
});
setSession(newSession);
console.log('ONNX模型加载并初始化成功');
} catch (e) {
console.error('ONNX模型加载或初始化失败:', e);
setError(`模型处理失败: ${e.message}`);
}
};
loadModel();
}, []);
然后可以看到在上传完图片之后进行了图片的预处理,主要是将图片转换成了模型的入参Tensor
const preprocess = async (imgElement) => {
const canvas = document.createElement('canvas');
const modelWidth = 320;
const modelHeight = 320;
canvas.width = modelWidth;
canvas.height = modelHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(imgElement, 0, 0, modelWidth, modelHeight);
const imageData = ctx.getImageData(0, 0, modelWidth, modelHeight);
const data = imageData.data;
const float32Data = new Float32Array(1 * 3 * modelHeight * modelWidth);
const mean = [0.485, 0.456, 0.406];
const std = [0.229, 0.224, 0.225];
for (let i = 0; i < modelHeight * modelWidth; i++) {
float32Data[i] = (data[i * 4] / 255 - mean[0]) / std[0]; // R
float32Data[i + modelHeight * modelWidth] = (data[i * 4 + 1] / 255 - mean[1]) / std[1]; // G
float32Data[i + 2 * modelHeight * modelWidth] = (data[i * 4 + 2] / 255 - mean[2]) / std[2]; // B
}
return new ort.Tensor('float32', float32Data, [1, 3, modelHeight, modelWidth]);
};
然后就是将模型的入参放到模型中去推理
const runSegmentation = async () => {
if (!image || !session) {
setError('请先上传图片并等待模型加载完成。');
return;
}
setError(null);
setOutputImage(null);
try {
const imgElement = imageRef.current;
if (!imgElement) {
throw new Error('图片元素未找到。');
}
// 确保图片完全加载
if (!imgElement.complete) {
await new Promise(resolve => { imgElement.onload = resolve; });
}
const inputTensor = await preprocess(imgElement);
const feeds = { 'input.1': inputTensor }; // 确保输入名称与模型一致
const results = await session.run(feeds);
const outputTensor = results[session.outputNames[0]];
const outputDataURL = postprocess(outputTensor, imgElement);
setOutputImage(outputDataURL);
} catch (e) {
console.error('抠图失败:', e);
setError(`抠图处理失败: ${e.message}`);
}
};
当模型推理完之后,进行模型推理结果的后处理,主要是将alpha通道和原图片进行合成
// 后处理:将模型输出转换为透明背景图像
const postprocess = (outputTensor, originalImgElement) => {
const outputData = outputTensor.data;
const [height, width] = outputTensor.dims.slice(-2); // 通常是 [1, 1, H, W]
const canvas = document.createElement('canvas');
canvas.width = originalImgElement.naturalWidth; // 使用原始图片尺寸
canvas.height = originalImgElement.naturalHeight;
const ctx = canvas.getContext('2d');
// 1. 绘制原始图片
ctx.drawImage(originalImgElement, 0, 0, canvas.width, canvas.height);
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
const pixelData = imageData.data;
// 2. 创建一个临时的canvas来处理和缩放mask
const maskCanvas = document.createElement('canvas');
maskCanvas.width = width; // U2Net输出mask的原始宽度
maskCanvas.height = height; // U2Net输出mask的原始高度
const maskCtx = maskCanvas.getContext('2d');
const maskImageData = maskCtx.createImageData(width, height);
// 归一化mask值 (通常U2Net输出在0-1之间,但最好检查一下)
let minVal = Infinity;
let maxVal = -Infinity;
for (let i = 0; i < outputData.length; i++) {
minVal = Math.min(minVal, outputData[i]);
maxVal = Math.max(maxVal, outputData[i]);
}
for (let i = 0; i < height * width; i++) {
let value = (outputData[i] - minVal) / (maxVal - minVal); // 归一化到 0-1
value = Math.max(0, Math.min(1, value)); // 确保在0-1范围内
const alpha = value * 255;
maskImageData.data[i * 4] = 0; // R
maskImageData.data[i * 4 + 1] = 0; // G
maskImageData.data[i * 4 + 2] = 0; // B
maskImageData.data[i * 4 + 3] = alpha; // Alpha
}
maskCtx.putImageData(maskImageData, 0, 0);
// 3. 将缩放后的mask应用到原始图像的alpha通道
// 创建一个新的canvas用于绘制最终结果,并将mask缩放到原始图像尺寸
const finalMaskCanvas = document.createElement('canvas');
finalMaskCanvas.width = originalImgElement.naturalWidth;
finalMaskCanvas.height = originalImgElement.naturalHeight;
const finalMaskCtx = finalMaskCanvas.getContext('2d');
finalMaskCtx.drawImage(maskCanvas, 0, 0, finalMaskCanvas.width, finalMaskCanvas.height);
const finalMaskData = finalMaskCtx.getImageData(0, 0, finalMaskCanvas.width, finalMaskCanvas.height);
for (let i = 0; i < pixelData.length / 4; i++) {
pixelData[i * 4 + 3] = finalMaskData.data[i * 4 + 3]; // 将mask的alpha通道应用到原始图片
}
ctx.putImageData(imageData, 0, 0);
return canvas.toDataURL();
};
至此将合成的图片渲染到屏幕上就可以了。
如何启动
首先我们要对仓库进行克隆
git clone https://github.com/yuedud/aicut.git
然后安装依赖
npm install
然后直接启动项目
npm start
启动之后你就可以在本地尝试背景移除工具。
来源:juejin.cn/post/7512058418623971343




