








我在团队内部提倡禁用 css margin
新的文章已经写完了,从技术角度详详细细的介绍了我的理由,朋友们在阅读完本文之后,如果还有兴趣可继续深入阅读
juejin.cn/post/747896…
一一一分割线一一一
目前社区也有不少人提倡禁用 margin,大概原因有什么奇怪的边距融合、责任区域划分不明确等等,我今天从另一个角度来说明为什么不要使用 margin
我们现在处于协同化时代,基本都是靠 figma、motiff 这类在线设计工具看设计稿的。这类工具有写特点
- 没有 margin 概念
- 只有自动布局和约束布局两种方式
- 有研发模式
自动布局等同于 flex 布局,支持设置主轴方向,主轴辅轴对其方式,间距(gap),边距(padding)等等

下面是我随手画的一个例子,在研发模式下,鼠标 hover 到容器上面,会出现蓝色和粉色区域。蓝色就代表 padding,粉色就代表 gap。

约束就是绝对定位,这个很简单,不详细阐述

所以,由于工具的天然限制,设计师在画稿的时候,不会像写代码一些,条条大路通罗马。比如我想让两个 div 相距 100px,css 起码得有 10 种方式。所以我们作为前端开发,拿到设计稿的时候可以放心的相信设计师的打组结构,设计稿一个框,你就写一个 div。因为他们不会有天马行空的骚操作,两个设计师是有很大概率画出结构一样的设计稿的。
实战
我在 figma 画了一个移动端界面

然后切换到研发模式,从外向内开始选中图层查看细节

可以看到结构是一套四,竖向 flex 布局,间距是 29px padding 是 0
// frame 7
<div class='flex flex-col gap-29px'>
// frame 8
<div></div>
// frame 9
<div></div>
// frame 10
<div></div>
// frame 10
<div></div>
</div>
然后直接看最后一个图层,前面的简单就不看了

可以一看看出结构是 flex 横向布局,padding 13px 34px,justify-content: space-between
然后可以继续无脑的写代码了
// frame 7
<div class='flex flex-col gap-29px'>
// frame 8
<div></div>
// frame 9
<div></div>
// frame 10
<div></div>
// frame 10
<div class='flex px-13px py-34px justify-between'>
// star 3
<div></div>
// star 4
<div></div>
// star 5
<div></div>
// star 6
<div></div>
</div>
</div>
然后增加一个回到顶部的 float button,约束为右、下。

hover 到 button 上

发现出现了两条线,指向右和下,这就代表这是一个相对于父元素的右下角的绝对定位图层。只需要无脑写代码即可
// frame 7
<div class='relative flex flex-col gap-29px'>
.....
<div class='absolute right-xxx bottom-xxx w-10 h-10'></div>
</div>
总结
在使用 figma、motiff 这类的工具的情况下,
- 前端程序员可以无脑的根据设计稿分组来写自己的 html,绝大部分情况他们应该是一对一的。
- 应该跟随工具,只使用 flex 布局,绝对定位布局
- 绝大部分情况不应该使用 margin
确实存在一些情况使用 margin 会更方便,我也真实遇到了一些 case。如果你们有想聊的 case 可以发到评论区
来源:juejin.cn/post/7478182398409965620
微信小程序包体积治理
背景
微信考虑到小程序的体验和性能问题限制主包不能超过2M。哈啰微信小程序也随着业务线在主包中由简到复杂,体积越来越大,前期业务野蛮增长阶段npm库缺乏统一管理,第三方组件库本身工程复杂等问题导致包体积长期处于2M临界卡点,目前存在以下痛点:
- 阻塞各业务正常微信小程序端需求排期。
- 迭代需求需要人肉搜索包体积的增长点,推动增长业务线去优化对应的包体积,治标不治本。
- 缺乏微信端包体积统一管理平台来限制各业务包体积增长。
- 微信包体积太大导致加载时间长、体验差。
所以主要从包体积优化和长期控制包体积增长两个方面让微信包体积达到平衡状态,长期运行。
包体积优化
微信包体积优化是个老生常谈的话题,只要是公司业务体积达到一定的量级都会不可避免的碰到主包体积超出和体验问题,关于怎么解决官方和网上也给出了比较多的解决方案。知其然知其所以然,那我们就从小程序的原理层面去看解决方案。主要也分为常规的优化方案和结合业务优化技术方案。
常规优化方案
按照微信小程序官网介绍,我们把小程序的性能优化分为启动性能优化和运行时性能优化:
- 启动性能 :小程序的启动过程以「用户打开小程序」为起点,到小程序「首页渲染完成」为止。小程序「首页渲染完成」的标志是首个页面 Page.onReady 事件触发。
- 运行时性能:小程序的运行时性能直接决定了用户在使用小程序功能时的体验。如果运行时性能出现问题,很容易出现页面滚动卡顿、响应延迟等问题,影响用户使用。如果内存占用过高,还会出现黑屏、闪退等问题。
1.启动性能优化
在进行启动性能优化之前,先介绍下小程序启动流程,小程序的启动流程主要包括以下几个环节:

1.1 资源准备
a. 小程序相关信息准备:微信客户端需要从微信后台获取小程序的头像、昵称、版本、配置、权限等基本信息,这些信息会在本地缓存,并通过一定的机制进行更新。
b. 环境预加载(受到场景、设备资源和操作系统调度的影响,并不能保证每次启动一定命中)
为了尽可能的降低运行环境准备对启动耗时的影响,微信客户端会根据用户的使用场景和设备资源的使用情况,依照一定策略在小程序启动前对运行环境进行部分地预加载,以降低启动耗时。

c. 代码包准备
从微信后台获取代码包的地址,从CDN下载小程序代码包,并对代码包进行校验。
为了提高下载耗时,微信本身就做了一些优化:
- 代码包压缩
- 增量更新
- 更高效的网络协议:下载代码包优先使用 QUIC 和 HTTP/2
- 预先建立连接:在下载发生前,提前和 CDN 建立连接,降低下载过程中 DNS 请求和连接建立的耗时。
- 代码包复用:对每个代码包都会计算 MD5 签名。即使发生了版本更新,如果代码包的 MD5 没有发生变化,则不需要重新进行下载。
1.2 小程序代码注入
小程序启动时需要从代码包内读取小程序的配置和代码,并注入到 JavaScript 引擎中,同时WXSS 和 WXML 会编译成 JavaScript 代码注入到视图层,视图层和逻辑层的小程序代码注入是并行进行的。
微信客户端会使用 V8 引擎的 Code Caching 技术对代码编译结果进行缓存,降低非首次注入时的编译耗时(Code Caching:V8会把编译和解析的结果缓存下来,等到下次遇到相同的文件时,直接使用缓存数据)
1.3 首屏渲染\

视图层和逻辑层都是从start并行进行初始化操作,视图层初始化完毕后会发送notify给逻辑层,自身进入等待状态,逻辑层收到信号后会结合自身初始化状态(第一种没初始化完,继续初始化。第二种初始化完进入等待状态)发送初始数据Data到视图层,结合初始数据和视图层得到的页面结构和样式信息,小程序框架会进行小程序首页的渲染,展示小程序首屏,并触发首页的 Page.onReady 事件。
1.4 优化方案
a. 控制包体积:降低代码包大小是最直接的手段,代码包大小直接影响了下载耗时,影响用户启动小程序时的体验。
- 分包:使用 分包加载 是优化小程序启动耗时效果最明显的手段。及时清理无用代码和资源。
- 独立分包。
- 分包预下载:在使用「分包加载」后,虽然能够显著提升小程序的启动速度,但是当用户在使用小程序过程中跳转到分包内页面时,需要等待分包下载完成后才能进入页面,造成页面切换的延迟,影响小程序的使用体验
- 分包异步化:「分包异步化」将小程序的分包从页面粒度细化到组件甚至文件粒度。
b. 代码注入优化:
- 按需引入:在小程序启动时,启动页面依赖的所有代码包(主包、分包、插件包、扩展库等)的所有 JS 代码会全部合并注入,包括其他未访问的页面以及未用到自定义组件,同时所有页面和自定义组件的 JS 代码会被立刻执行。这造成很多没有使用的代码在小程序运行环境中注入执行,影响注入耗时和内存占用。
- 用时注入:在开启「按需注入」特性的前提下,「用时注入」可以指定一部分自定义组件不在小程序启动时注入,而是在真正渲染的时候才进行注入。
c. 首屏渲染优化:
- 启用【初始渲染缓存】:启用初始渲染缓存,可以使视图层不需要等待逻辑层初始化完毕,而直接提前将页面初始 data 的渲染结果展示给用户,这可以使得页面对用户可见的时间大大提前。
- 数据预拉取:预拉取能够在小程序冷启动的时候通过微信后台提前向第三方服务器拉取业务数据,当代码包加载完时可以更快地渲染页面,减少用户等待时间,从而提升小程序的打开速度 。
- 周期性更新:周期性更新能够在用户未打开小程序的情况下,也能从服务器提前拉取数据,当用户打开小程序时可以更快地渲染页面,减少用户等待时间,增强在弱网条件下的可用性。
- 骨架屏:如果首页内容是通过接口异步获取的,用户不一定立即看到完整的界面,需要等待接口返回后调用setData进行页面更新,才能看到真实内容,避免过长时间白屏可以选择骨架屏来提高用户体验。
2.运行时性能优化
2.1 优化方案:
a. 合理使用setData:小程序的逻辑层和视图层是两个独立的运行环境,通讯通过Native层实现。具体的实现原理和bridge实现一致,ios利用WKWebView提供的messageHandlers,安卓是往webview的window对象注入一个原生方法,所以数据传输的耗时和数据量的大小成正比。
b. 页面切换优化:页面切换的性能影响用户操作的连贯性和流畅度,是小程序运行时性能的一个重要组成部分。
请求前置:小程序不同于H5,在跳转本身就需要消耗比较多的时间,特别是在安卓机上,所以我们可以在页面跳转的同时进行数据并行请求。

c. 控制预加载下个页面的时机(仅安卓):
小程序页面加载完成后,会预加载下一个页面。默认情况下,小程序框架会在当前页面 onReady 触发 200ms 后触发预加载。
在安卓上,小程序渲染层所有页面的 WebView 共享同一个线程。很多情况下,小程序的初始数据只包括了页面的大致框架,并不是完整的内容。页面主体部分需要依靠 setData 进行更新。因此,预加载下一个页面可能会阻塞当前页面的渲染,造成 setData 和用户交互出现延迟,影响用户看到页面完整内容的时机。

我们本次拉齐两轮、数科、普惠,分别进行部分页面分包,下掉0流量页面及其依赖的npm包,把仅有单个业务线引用的npm从主小程序移植到分包下从而不占用主包体积,删除无用文件等操作才从2M体积减少到1.88M,这个收益对于反复优化过的主小程序而言已经算是不错的收益,但是很难满足未来各业务线对小程序主包体积的迭代诉求,所以我们还需要更优的解决方案来减少更多的包体积和限制各业务线在现有体积上进行置换而不是无限扩张。
关于这两个问题我们就在结合业务优化方案和长期控制包体积机制中探讨。
结合业务优化方案
1.第三方组件库异步分包
微信小程序为考虑体验问题主包被限制到了2M,但随着小程序业务线接入越来越多,npm库缺乏统一管理,第三方组件库本身工程比较复杂等问题导致主包超过1M+都被npm库所占用掉,留给业务的空间不足1M,所以可以从vendor.js中进行部分拆分优化,在不占用主包体积下主包也能够使用这些第三方库。
这样操作的意义在于可以把部分第三方npm库抽离到分包中,主包内只剩核心业务和不能拆的npm库。
实现原理:小程序的分包异步化就是来实现这种功能的,按照微信官方文档提供可以使用require来异步引入包含第三方npm的分包。

但是我们的小程序是使用taro,通过webpack进行编译的,静态产物不支持CommonJS模块的写法,所以require在编译的时候会进行报错,解决方法有两种:
- 自定义webpack插件,将require关键字替换为customRequireKey(自定义key值,在解析的时候替换成require就可以)。

- webpack提供的__non_webpack_require__代替require,不会被webpack解析。
注意点1:如果把第三方npm库改成异步引用后,对于之前通过import同步引用的代码需要进行改造,不然可能会出现在包引入前提前调用包内部方法的问题,对于这个问题可以创建缓存队列解决。
注意点2:分包因为网络波动等原因会加载失败,但是概率极低,可以使用重试机制解决。
2.封面方案
封面方案相比于第三方组件异步分包方案更好理解,就是把业务全部抽离到分包中,主包中只保留各业务线所依赖的基础库和公共文件,在小程序启动的时候做个启动界面,页面一旦加载就立即跳转到真正承载业务的页面中, 而这个页面被放在分包中。
这么做的好处在于主包中的2M体积只用来放基础库和公共文件,包体积始终控制在1M左右,对小程序性能优化和体验上都有很大的提升。而其他业务都放在业务的主分包中进行管理。

长期控制包体积机制
主包体积优化后如果缺乏标准的控制方法,在未来还是会随着各业务迭代增加不停的增加直到超出2M。所以一套标准的管理机制也是至关重要的。
小程序包体积治理主要从两个方面:
- 业务线管理机制后台
- 发布系统管理机制
业务线管理机制后台
业务线size管理机制后台主要集临时资源申请和图标展示于一体,以解决业务线临时size压力。可以通过后台系统进行临时size申请,提出申请后说明申请原因、资源需要时长、size大小,到达审批人时可酌情考虑,审批通过\不通过后都会钉钉通知申请。在管理平台也能看到当前业务线的永久size、临时size、临时size到期时间、申请理由和各业务每迭代包体积大小等信息。

a. 申请临时资源流程:用户根据自己的诉求进入后台选择对应业务线点击新增按钮去申请临时资源、申请临时资源时需在申请弹窗中明确以下几点内容:
- 申请资源大小:最大申请资源为当前包体积剩余的最大值
- 使用时间:最多为2个迭代就要把临时资源退回、否则限制发布流程
- 申请理由:在理由中需要明确填写申请资源后带来的业务价值、由平台的产品侧和研发侧共同衡量价值。
- prd地址:链接地址。
b. 申请临时资源最长路径:最多为2个迭代就要把申请的临时资源进行退回、否则在发布时限制发布。
c. 临时申请最大包体积:申请最大资源为当前包体积剩余的最大值
d. 包体积到期通知:提前一个迭代时间钉钉通知对应的申请人和leader包体积到期时间进行优化,申请资源到期后后台系统会自动把申请的资源状态改为已到期,并减少对应申请的资源大小,如果未归还对应体积大小,在发布流程阶段会做体积大小卡口,限制发布。
发布系统管理机制
发布系统管理机制主要流程是developer在AppHelloBikeWXSS项目上每次通过feature分支merge到release分支的时候都会触发gitlab的钩子函数,然后触发jenkins的job进行编译、计算现在各业务线在主包中所占的体积,在通过包体积管理后台申请的体积进行比对,如果超出会钉钉通知到开发者并且在发布系统限制发布,如果没超出正常发布。

(本文作者:董恒磊)
来源:juejin.cn/post/7381657886801805312
前端页面怎么限制用户打开浏览器控制台?
说在前面
作为一名开发,相信大家对于浏览器控制台都是不陌生的,平时页面一出问题第一反应总是先打开控制台看看报错信息,而且还可以在控制台里插入自己的脚本信息来修改页面逻辑,那么你有没有想过 怎么限制用户打开控制台 呢?
禁用右键菜单 🔨

添加图片注释,不超过 140 字(可选)
在页面上点击鼠标右键我们可以看到有个 检查 选项,通过这个菜单可以直接打开控制台,我们可以直接在这个页面上禁用右键菜单。
document.addEventListener("contextmenu", e => e.preventDefault());
加上这段代码后用户在页面上点击右键就不会有反应了。
拦截快捷键 🛑
除了右键菜单栏,还有最经典的 F12 ,通过 F12 快捷键也可以快速打开控制台,所以我们也可以将这个快捷键给拦截掉
document.addEventListener("keydown", e => {
if (e.keyCode === 123) {
e.preventDefault();
}
});
那么除了 F12 你知道还有什么快捷键可以打开控制台吗?
- Ctrl+Shift+C
- Ctrl+Shift+I
上面这两个快捷键也可以打开控制台,还有一个快捷键 Ctrl+U 可以打开源码页面,这里我们也可以一起把它给拦截掉。
document.addEventListener("keydown", e => {
if (e.keyCode === 123 || // F12
(e.ctrlKey && e.shiftKey && e.keyCode === 67) || // Ctrl+Shift+C
(e.ctrlKey && e.shiftKey && e.keyCode === 73) || // Ctrl+Shift+I
(e.ctrlKey && e.keyCode === 85)) { // Ctrl+U
e.preventDefault();
}
});
加上这段代码后用户在页面上按下这些快捷键就不会有反应了。
检测窗口变化🔷
加上前面的拦截之后,其实我们还是有办法打开控制台,可以通过浏览器设置来打开控制台,这里的入口我们并无法监听拦截到

添加图片注释,不超过 140 字(可选)
let lastWidth = window.innerWidth;
let lastHeight = window.innerHeight;
window.addEventListener("resize", () => {
const widthDiff = Math.abs(window.innerWidth - lastWidth);
const heightDiff = Math.abs(window.innerHeight - lastHeight);
// 如果窗口尺寸变化但不是全屏切换,可能是控制台打开
if ((widthDiff > 50 || heightDiff > 50) && !isFullScreen()) {
//跳转到空白页面
window.location.href = "about:blank";
alert("检测到异常窗口变化,请关闭开发者工具");
}
lastWidth = window.innerWidth;
lastHeight = window.innerHeight;
});
function isFullScreen() {
return (
document.fullscreenElement ||
document.webkitFullscreenElement ||
document.msFullscreenElement
);
}
通常默认是会在页面内靠边打开控制台,所以可以通过监听页面大小变化来简单判断是否打开控制台,监听到打开后直接跳转到空白页面。

添加图片注释,不超过 140 字(可选)
但是还有这么两种情况
- 全屏切换时的尺寸变化可能被误判
- 独立打开控制台页面时无法监听到
无限Debugger⚡
我们还可以通过 Function("debugger") 来动态生成断点(动态生成是为了防断点禁用),通过无限循环生成断点,让页面一直处于断点状态。
(() => {
function block() {
setInterval(() => {
(function(){return false;})["constructor"]("debugger")["call"]();
}, 50);
}
try { block(); } catch (err) {}
})();

添加图片注释,不超过 140 字(可选)
虽然我们可以通过一些技术手段,给用户打开控制台设置一些障碍,但对于经验老到的用户而言,绕过这些限制并非难事。依赖前端技术拦截控制台访问是一种典型的“防君子不防小人”策略,不能想着靠这些手段来保障自己网站的安全。
公众号
关注公众号『 前端也能这么有趣 』,获取更多有趣内容。
发送 加群 还可以加入群聊,一起来学习(摸鱼)吧~
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。
来源:juejin.cn/post/7508362269586063360
前端遇到高并发如何解决重复请求
在前端开发中遇到高并发场景时,若不加控制容易出现重复请求,这可能导致接口压力增加、数据异常、用户体验变差等问题。以下是前端防止/解决重复请求的常见方法,按不同场景归类总结:
🌟 一、常见重复请求场景
- 用户频繁点击按钮:多次触发相同请求(例如提交表单、下载操作)。
- 路由短时间内多次跳转或刷新:导致重复加载数据。
- 多次调用 debounce/throttle 未正确控制函数执行时机。
- 轮询或 WebSocket 消息导致并发访问同一接口。
🚀 二、常用解决方案
✅ 1. 禁用按钮防止多次点击
const [loading, setLoading] = useState(false);
const handleClick = async () => {
if (loading) return;
setLoading(true);
try {
await fetchData();
} finally {
setLoading(false);
}
};
<Button loading={loading} onClick={handleClick}>提交</Button>
✅ 2. 使用请求缓存 + Map 记录请求状态
原理:在请求发出前先检查是否已有相同请求在进行。
const requestCache = new Map();
const requestWithDeduplication = (url: string, options: any = {}) => {
if (requestCache.has(url)) {
return requestCache.get(url); // 复用已有请求
}
const req = fetch(url, options).finally(() => {
requestCache.delete(url); // 请求结束后清除缓存
});
requestCache.set(url, req);
return req;
};
适合统一封装
fetch、axios请求,避免相同参数的并发请求。
✅ 3. 使用 Axios 的 CancelToken 取消上一次请求
let controller: AbortController | null = null;
const request = async (url: string) => {
if (controller) {
controller.abort(); // 取消上一个请求
}
controller = new AbortController();
try {
const res = await fetch(url, { signal: controller.signal });
return await res.json();
} catch (e) {
if (e.name === 'AbortError') {
console.log('Request canceled');
}
}
};
适合搜索联想、快速切换 tab 等需要 只保留最后一次请求 的场景。
✅ 4. 使用 debounce/throttle 防抖节流
import { debounce } from 'lodash';
const fetchData = debounce((params) => {
// 实际请求
}, 300);
<input onChange={(e) => fetchData(e.target.value)} />
控制高频输入类请求频率,减少并发请求量。
✅ 5. 后端幂等 + 前端唯一请求 ID(可选高级方案)
- 给每次请求生成唯一 ID(如 UUID),发送给后端。
- 后端对相同 ID 请求只处理一次。
- 前端避免再做复杂状态判断,适合交易、支付类场景。
🧠 小结对照表
| 场景 | 推荐方案 |
|---|---|
| 按钮多次点击 | 禁用按钮 / loading 状态 |
| 相同请求并发 | 请求缓存 Map / Axios CancelToken |
| 输入频繁调用接口 | debounce 防抖 |
| 只保留最后一个请求 | AbortController / CancelToken |
| 表单提交 /交易请求幂等 | 请求唯一 ID + 后端幂等处理 |
如果你告诉我你遇到的具体是哪个页面或场景(例如点击下载、搜索联想、多 tab 切换等),我可以给出更加定制化的解决方案。
来源:juejin.cn/post/7507560729609830434
她说:JSON 没错,但就是 parse 不过?我懂了!
技术纯享版:《不规范 JSON 怎么办?三种修复思路+代码实现》
开篇:夜色渐浓,佳人亦在
那天晚上,办公室的灯已经灭了大半,只剩几个工位发出轻轻的蓝光。中央空调早就熄了,但显示器的热度依然在屏幕前形成一圈圈淡淡的光晕。
我坐在靠窗的位置,刚把代码提交推送完,正打算收键盘走人。
这时,小语走过来,端着还冒着热气的速溶咖啡——她果然又是那个留下来最晚的人之一。
“诶~”她蹲在我旁边的桌子边上,语气带着一丝挫败,“你这边有没有遇到 JSON 字符串明明格式看着没错,却死活 JSON.parse 不过的情况?”
一个普通的错误,却不是普通的崩溃
原来她在调试一个用户日志上传模块,前端接收到的日志数据是从后端来的 JSON 字符串。
问题出在一个看似再平常不过的解析操作上——
const logData = JSON.parse(incomingString);
可是控制台总是报错:Unexpected token。数据一眼看去也没问题,{'name': 'Tom', 'age': 30} —— 结构清晰,属性齐全,但偏偏就是“坏掉了”。
她抿了一口咖啡,苦笑,“我知道是引号的问题,可这种数据是从破旧的系统里吐出来的,量还特别大,我不可能一个个手动改。”
风起 · JSON.parse 不是万灵药
我们一起回顾了她的实现方式。她用的是最基础的 JSON.parse(),这是我们在项目里默认的处理方式——简单、直接、快速。
但这个方法对 JSON 格式的要求极其严格:
- 只能使用双引号
" - 属性名必须加引号
- 不容忍任何额外字符或注释
一旦出现诸如单引号、缺少逗号、多余空格这些“微小过失”,就直接抛错了。
小语叹气,“很多时候这些 JSON 是设备端拼出来的,不规范,又没有错误提示,我根本不知道该怎么修。”
我翻了翻之前的代码,从夹缝中找出来一张破旧的黄皮纸,我们俩一起瞅了上去,看到上面写着
function tryParseJSON(jsonString) {
try {
return JSON.parse(jsonString);
} catch (e) {
// 尝试简单修复:去除可能的多余字符
const cleaned = jsonString.replace(/[^\x20-\x7E]/g, '').trim();
try {
return JSON.parse(cleaned);
} catch (e2) {
console.error("无法解析JSON:", e2);
return null;
}
}
}
下面备注了一行小字:此法在一些更轻量的场景里,做一些“简陋修复“,对于简单的问题有时能奏效,但对于更复杂的错误,比如混合了单引号和双引号的情况,只能再实现另一个方法可以做更针对性的修复方法:
function fixQuotes(jsonString) {
// 将单引号替换为双引号(简单情况)
return jsonString.replace(/'/g, '"');
}
小语感叹一声:“没有更好的了吗?”
解决篇 · 来自大佬的一句话
恰好这时,阿杰从会议室出来,耳机还挂在脖子上。
他听了一耳朵后随口说了句:“你们试过 jsonrepair 吗?那玩意能把坏 JSON 修回来,就像修车。”
“json... repair?”小语一脸困惑。
我忽然想起,之前有个日志监控服务也碰到类似的问题,当时就是用了这个库一把梭。
我打开编辑器,快速翻出来了这一段:
npm install jsonrepair
const { jsonrepair } = require('jsonrepair');
const damaged = "{name: 'John', age: 30}";
const fixed = jsonrepair(damaged); // => {"name":"John","age":30}
const obj = JSON.parse(fixed);
小语凑过来看了一眼,眼睛一亮:“它真的把引号补好了?”
我点头。这个工具是为了解决类似“非标准 JSON”问题的,它会尽可能地补全缺失引号、逗号,甚至处理 Unicode 异常字符。
当然,也不是所有情况都适用。
比如碰到乱码或者非法嵌套结构,jsonrepair 有时也会无能为力。这时可以退一步——用更宽松的解析器,比如 JSON5:
const JSON5 = require('json5');
const result = JSON5.parse("{name: 'John', age: 30}"); // 也能解析
我看着认真学习的小语,语重心长的讲道:它不是修复,而是扩展 JSON 标准,让一些非标准写法也能解析(JSON5 能容忍的内容包括:单引号、尾逗号、注释、未加引号的属性名、十六进制、科学计数法等数字格式),
接着我们还讨论了更复杂的修复方式,比如用正则处理批量日志,甚至用 AST 工具逐步构建 JSON 树。但那是更远的故事了。
面对当前的问题,我们准备搞一套组合拳:
function parseJson(jsonString) {
// 第一步:尝试标准JSON解析
try {
return JSON.parse(jsonString);
} catch (e) {
console.log("标准JSON解析失败,尝试修复...");
// 第二步:尝试使用jsonrepair修复
try {
const { jsonrepair } = require('jsonrepair');
const fixedJson = jsonrepair(jsonString);
return JSON.parse(fixedJson);
} catch (e2) {
console.log("修复失败,尝试使用JSON5解析...");
// 第三步:尝试使用JSON5解析
try {
const JSON5 = require('json5');
return JSON5.parse(jsonString);
} catch (e3) {
// 最后:如果所有方法都失败,返回错误信息
console.error("所有解析方法都失败了:", e3);
throw new Error("无法解析JSON数据");
}
}
}
}
结局
一段时间后,小语在前端监控日志里贴了段截图:原本一天上千条的 parse error 错误,几乎消失了。
她补了一句:“终于不用再一个个点开调日志了。”
我回头看她的工位,屏幕亮着,浏览器里是一个模拟器页面,console 正在缓缓输出内容。
她突然抬起头看着我,问道:“AST是什么?听说也能实现json修复?”
来源:juejin.cn/post/7506754146894168118
Flutter - 聊天键盘与面板丝滑切换的强势升级 🍻
欢迎关注微信公众号:FSA全栈行动 👋

BiliBili: http://www.bilibili.com/video/BV1yT…
一、概述
距离 chat_bottom_container 首个可用版本 (0.0.2) 的发布已经过去了 1 个多月,在这期间根据大家的使用反馈,我们也做了一些优化调整,今天就来盘点一下到底做了哪些优化,新增了什么功能,以及一些常见操作。
请注意
- 本篇仅介绍更新的优化及功能,基础使用请查看: Flutter - 实现聊天键盘与功能面板的丝滑切换 🍻
- 截至本篇发布时,最新版本为
0.2.0,可以关注我们的微信公众号 FSA全栈行动 获取最新的资讯
开源不易,如果你也觉得这个库好用,请不吝给个
Star👍 ,并多多支持!
二、使用
调整键盘高度监听管理逻辑
0.1.0 版本前,只考虑了页面栈这种常规情况,当键盘高度变化时只处理栈顶的监听。
但其实还有一种常见打破该规则的场景,就是悬浮聊天页,它会一直在页面上,可能为了能快速从悬浮小球展开聊天页面,收起时只是做了隐藏,而不会销毁页面,在这种情况下,它依旧在监听管理里的栈顶,所以在收起后,上一个聊天页的键盘高度监听就会失效。
这个在 0.1.0 版本中得到修复,内部会倒序遍历调用所有的监听回调。
不过你不用担心这一改动会导致其它聊天页面出现多余的视图刷新,因为在键盘高度监听回调里会先判断输入框是否有焦点,若无则直接返回了。
兼容外接键盘
当连接外接键盘时,软键盘会消失,高度会降为 0,这里可以用 iOS 模拟器结合 Toggle Software Keyboard (快捷键: cmd + k) 来模拟连接与断开外接键盘的效果。

隐藏面板
有小伙伴提出,不知道如何程序式的隐藏面板,其实很简单,就两步
- 让输入框失去焦点
- 更新内部状态为
ChatBottomPanelType.none
hidePanel() {
// 0.2.0 前
inputFocusNode.unfocus();
if (ChatBottomPanelType.none == controller.currentPanelType) return;
controller.updatePanelType(ChatBottomPanelType.none);
// 0.2.0 后,可以这么写
controller.updatePanelType(
ChatBottomPanelType.none,
forceHandleFocus: ChatBottomHandleFocus.unfocus,
);
}
自定义底部安全区高度
在默认情况下,chat_bottom_container 在收起模式 (.none) 下会自动帮你添加底部安全区高度,但在一些场景下你可能不希望如此。比如:
- 安卓的底部安全区的高度,很多小伙伴都是简单粗暴的设置个高度了事
App首页有底部BottomNavigationBar,不需要安全区高度
在此,你可以通过将 safeAreaBottom 参数来自定义这个高度,如下设置为 0。
return ChatBottomPanelContainer<PanelType>(
...
safeAreaBottom: 0,
...
);
调整键盘面板高度
如示例中位于首页的聊天页面

在键盘弹出时,如下图所示
| 实际 | 期望 |
|---|---|
 |  |
很明显,我们希望键盘容器高度能够减去外层底部固定的 BottomNavigationBar 高度。
ChatBottomPanelContainer 提供了 changeKeyboardPanelHeight 回调,在回调中可以拿到当前的键盘高度,经过计算后,将合适的键盘容器高度返回即可。
return ChatBottomPanelContainer<PanelType>(
...
changeKeyboardPanelHeight: (keyboardHeight) {
final renderObj = bottomNavigationBarKey.currentContext?.findRenderObject();
if (renderObj is! RenderBox) return keyboardHeight;
return keyboardHeight - renderObj.size.height;
},
...
);
缓存键盘高度
先来看未做键盘高度缓存处理之前,会发生什么?

上图一共进入了三次聊天页
- 第一次是先点击键盘,再切到表情面板,体验起来还是挺不错的。
- 为了避免一闪而过,没有注意到,所以第二次和第三次的操作是一样的,先唤起表情面板,再切到键盘,可以看到在切到键盘时会抖动。
这是因为每次进入聊天页,键盘的高度为初始值 0,在 0.2.0 版本中对此进行了优化,加入了键盘高度缓存逻辑,从而尽量避免该抖动问题的出现。
❗️ 但需要注意的是,假如你卸载重装
App,该缓存会丢失,即你还是有可能会看到最多一次的抖动。
除此之外,你还可以使用这个缓存的键盘高度来实现表情面板与键盘高度保持一致的效果,这样在切换的时候体验上会更好些。😉
Widget _buildEmojiPickerPanel() {
// 如果键盘高度还没有缓存过,则使用默认高度 300
double height = 300;
final keyboardHeight = controller.keyboardHeight;
if (keyboardHeight != 0) {
height = keyboardHeight;
}
return Container(
padding: EdgeInsets.zero,
height: height,
color: Colors.blue[50],
child: const Center(
child: Text('Emoji Panel'),
),
);
}
效果如下

支持表情面板与输入框焦点共存
这也是提升用户体验的重要一点,效果见上图。
先按如下设置你的输入框
bool readOnly = false;
TextEditingController textEditingController = TextEditingController();
...
TextField(
controller: textEditingController,
focusNode: inputFocusNode,
// 为 true 时不显示键盘,默认为 false
readOnly: readOnly,
// 获取焦点后显示光标,设置为 true 才不受 readOnly 的影响
showCursor: true,
),
...
接下来就是切换表情面板的操作
switchToEmojiPanel() {
readOnly = true;
// 这里你可以只刷新输入框
setState(() {});
// 等待下一帧
WidgetsBinding.instance.addPostFrameCallback((timeStamp) {
controller.updatePanelType(
// 内部切至 other 状态
ChatBottomPanelType.other,
// 关联外部的面板类型为表情面板
data: PanelType.emoji,
// 输入框获取焦点
forceHandleFocus: ChatBottomHandleFocus.requestFocus,
);
});
}
在 updatePanelType 方法中,如果是切至 .other 状态,是会帮你执行失去焦点操作的,所以这里提供了一个 forceHandleFocus 参数,如果你对方法内部对焦点的处理不满意,你可以使用它来强制指定焦点的处理方式。
三、最后
好了,上述便是该库的更新内容, 惯例附上 GitHub 地址: github.com/LinXunFeng/… ,如果接入上有什么问题,可以在链接中查看 demo 演示代码。
开源不易,如果你也觉得这个库好用,请不吝给个 Star 👍 ,并多多支持!
本篇到此结束,感谢大家的支持,我们下次再见! 👋
如果文章对您有所帮助, 请不吝点击关注一下我的微信公众号:FSA全栈行动, 这将是对我最大的激励. 公众号不仅有
iOS技术,还有Android,Flutter,Python等文章, 可能有你想要了解的技能知识点哦~
来源:juejin.cn/post/7399045497002328102
一个js库带你看懂AI+前端的发展方向
前言
随着技术的发展,人工智能正逐渐渗透到我们生活的方方面面,从前端开发到后端服务,从数据分析到用户体验设计。特别是在前端领域,AI 的应用正成为一个不可忽视的趋势。本文将探讨 AI 在前端领域的应用,并重点介绍一个在浏览器端即可运行的神经网络库——Brain.js。
随着技术的发展,人工智能正逐渐渗透到我们生活的方方面面,从前端开发到后端服务,从数据分析到用户体验设计。特别是在前端领域,AI 的应用正成为一个不可忽视的趋势。本文将探讨 AI 在前端领域的应用,并重点介绍一个在浏览器端即可运行的神经网络库——Brain.js。
Brain.js:浏览器端的神经网络库
Brain.js 是一个专为前端开发者设计的 JavaScript 库,它允许开发者在浏览器或 Node.js 环境中轻松创建和训练神经网络。以下是 Brain.js 的几个核心能力:
- 投喂数据训练
- Brain.js 支持以 JSON 数组的形式投喂数据,这使得准备训练数据变得非常简单。例如,可以准备一个包含输入和期望输出的数据集,用于训练神经网络。
const trainingData = [
{ input: [0, 0], output: { zero: 1 } },
{ input: [0, 1], output: { one: 1 } },
{ input: [1, 0], output: { one: 1 } },
{ input: [1, 1], output: { zero: 1 } }
];
- 实例化神经网络
- Brain.js 提供了多种类型的神经网络,包括前馈神经网络(Feedforward Neural Networks)和循环神经网络(Recurrent Neural Networks)。对于文本处理和序列数据,推荐使用
brain.recurrent.LSTM(),这是一种长短期记忆网络,特别适合处理时间序列数据。
- 训练模型
- 训练神经网络非常简单,只需调用
train 方法并传入训练数据即可。Brain.js 会自动调整网络参数,使模型逐步学会从输入数据中提取特征并作出准确的预测。
- 推理能力
- 训练完成后,可以使用
run 方法对新的输入数据进行推理。例如,在 NLP 场景中,可以使用训练好的模型对用户输入的文本进行情感分析或分类。
- 结果分类
- Brain.js 支持多分类任务,可以将输入数据归类到多个预定义的类别中。这对于内容推荐、垃圾邮件过滤等应用场景非常有用。
Brain.js 是一个专为前端开发者设计的 JavaScript 库,它允许开发者在浏览器或 Node.js 环境中轻松创建和训练神经网络。以下是 Brain.js 的几个核心能力:
- 投喂数据训练
- Brain.js 支持以 JSON 数组的形式投喂数据,这使得准备训练数据变得非常简单。例如,可以准备一个包含输入和期望输出的数据集,用于训练神经网络。
const trainingData = [
{ input: [0, 0], output: { zero: 1 } },
{ input: [0, 1], output: { one: 1 } },
{ input: [1, 0], output: { one: 1 } },
{ input: [1, 1], output: { zero: 1 } }
];
- 实例化神经网络
brain.recurrent.LSTM(),这是一种长短期记忆网络,特别适合处理时间序列数据。train 方法并传入训练数据即可。Brain.js 会自动调整网络参数,使模型逐步学会从输入数据中提取特征并作出准确的预测。run 方法对新的输入数据进行推理。例如,在 NLP 场景中,可以使用训练好的模型对用户输入的文本进行情感分析或分类。开始使用 Brain.js:
要开始使用 Brain.js,首先需要安装它。如果你是在 Node.js 环境下工作,可以通过 npm 安装:
npm install brain.js
如果你在浏览器中使用,可以直接通过 CDN 引入:
<script src="https://cdn.jsdelivr.net/npm/brain.js">script>
然后可以按照官方文档提供的示例代码来构建你的第一个神经网络模型。
示例1:
// 创建一个神经网络
const network = new brain.NeuralNetwork();
// 用 4 个输入对象训练网络
network.train([
{ input: [0, 0], output: { zero: 1 } },
{ input: [0, 1], output: { one: 1 } },
{ input: [1, 0], output: { one: 1 } },
{ input: [1, 1], output: { zero: 1 } }
]);
// [1, 0] 的预期输出是什么?
const result = network.run([1, 0]);
// 显示 "zero" 和 "one" 的概率
console.log(result["one"] + " " + result["zero"]);
- 使用
new brain.NeuralNetwork() 创建一个神经网络。 - 使用
network.train([examples]) 训练网络。 examples 表示 4 个输入值及其对应的输出值。- 使用
network.run([1, 0]) 询问 "[1, 0] 的可能输出是什么?"
// 创建一个神经网络
const network = new brain.NeuralNetwork();
// 用 4 个输入对象训练网络
network.train([
{ input: [0, 0], output: { zero: 1 } },
{ input: [0, 1], output: { one: 1 } },
{ input: [1, 0], output: { one: 1 } },
{ input: [1, 1], output: { zero: 1 } }
]);
// [1, 0] 的预期输出是什么?
const result = network.run([1, 0]);
// 显示 "zero" 和 "one" 的概率
console.log(result["one"] + " " + result["zero"]);
new brain.NeuralNetwork() 创建一个神经网络。network.train([examples]) 训练网络。examples 表示 4 个输入值及其对应的输出值。network.run([1, 0]) 询问 "[1, 0] 的可能输出是什么?"网络的输出是:
- one: 93%(接近 1)
- zero: 6%(接近 0)
使用 CSS,颜色可以通过 RGB 设置:
示例2:
| 颜色 | RGB |
|---|---|
| 黑色 | RGB(0,0,0) |
| 黄色 | RGB(255,255,0) |
| 红色 | RGB(255,0,0) |
| 白色 | RGB(255,255,255) |
| 浅灰色 | RGB(192,192,192) |
| 深灰色 | RGB(65,65,65) |
下面的代码展示了如何预测颜色的深浅:
// 创建一个神经网络
const net = new brain.NeuralNetwork();
// 用 4 个输入对象训练网络
net.train([
// 白色 RGB(255, 255, 255)
{ input: [255 / 255, 255 / 255, 255 / 255], output: { light: 1 } },
// 浅灰色 (192, 192, 192)
{ input: [192 / 255, 192 / 255, 192 / 255], output: { light: 1 } },
// 深灰色 (64, 64, 64)
{ input: [65 / 255, 65 / 255, 65 / 255], output: { dark: 1 } },
// 黑色 (0, 0, 0)
{ input: [0, 0, 0], output: { dark: 1 } }
]);
// 深蓝色 (0, 0, 128) 的预期输出是什么?
let result = net.run([0, 0, 128 / 255]);
// 显示 "dark" 和 "light" 的概率
console.log(result["dark"] + " " + result["light"]);
- 使用
new brain.NeuralNetwork()创建一个神经网络。 - 使用
network.train([examples])训练网络。 examples表示 4 个输入值及其对应的输出值。- 使用
network.run([0, 0, 128 / 255])询问 "深蓝色的可能输出是什么?"
网络的输出是:
- Dark: 95%
- Light: 4%
示例3:
下面这个例子演示如何使用 Brain.js 创建并训练一个基本的神经网络,该网络学习从摄氏度转换为华氏度:
const brain = require('brain.js');
// 创建一个 LSTM 神经网络实例
const net = new brain.recurrent.LSTM();
// 准备训练数据
const trainingData = [
{ input: '0', output: '32' }, // 0°C -> 32°F
{ input: '100', output: '212' } // 100°C -> 212°F
];
// 训练神经网络
net.train(trainingData, {
iterations: 20000, // 训练迭代次数
log: (stats) => console.log(`Training progress: ${stats.iterations}/${stats.error}`) // 训练日志
});
// 使用训练好的模型进行推理
const output = net.run('50'); // 预测 50°C 对应的华氏温度
console.log(output); // 输出结果接近 "122"
其他用于创建神经网络的js库
TensorFlow.js、Synaptic.js、ConvNetJS、Keras.js、Deeplearn.js (现更名为 TensorFlow.js)、 ML.js等。 这些js库作为在浏览器端即可运行的神经网络库,为前端开发者提供了强大的工具,使得我们能够在不深入数学和机器学习理论的前提下,快速实现和应用机器学习功能。无论是简单的分类任务、预测建模,还是更复杂的自然语言处理和图像识别,它们都能帮助你轻松应对。
结语
你发现了吗,通过brain.js,你也可以轻松地将机器学习功能集成到你的项目中。未来,随着模型的小型化、边缘计算的发展以及多模态融合的推进,AI + 前端将更加普及和成熟。

点个赞再走吧~
来源:juejin.cn/post/7438876948762066980
请放弃使用JPEG、PNG、GIF格式的图片!
随着互联网的发展,图片作为最直观的内容展示方式逐渐在系统中占用越来越多的版面,但是随之而来的就是系统性能的大幅度下滑。传统的JPEG、PNG、GIF各有优点,也各有弊端,“大一统”的图片格式被需要,于是WebP诞生了。
需求
WebP格式文件产生的原因主要是源于对网络图像传输效率的需求以及现有图像格式在某些方面的局限性。
在现代互联网网页中图片和视频占据了很大比例。为了提供更吸引人的用户体验,网站需要加载大量的高质量图像。

同时智能手机和平板电脑的普及推动了移动互联网的快速发展。在移动设备上,网络速度通常比桌面端慢,且用户的流量是有限的。
而JPEG、PNG和GIF等传统图像格式各有其优点,但也存在不足之处。
例如,JPEG虽然非常适合照片,但仅支持有损压缩且不支持透明度;PNG支持透明度但文件大小通常较大;GIF支持动画但色彩范围有限,且文件体积相对较大。
产生
WebP是一种由Google开发的图像文件格式,旨在提供更高效的图片压缩,适用于网络图像传输和展示。
- 高压缩效率:WebP采用了先进的压缩算法,可以提供比JPEG更高的压缩率而不会明显损失图像质量。这意味着使用WebP格式可以在不牺牲视觉体验的情况下显著减少图片文件的大小,从而加快网页加载速度。
- 支持透明度:与JPEG不同,WebP支持alpha通道(即透明度),这使得它在需要背景透明效果的应用场景中成为PNG的一个有力替代者,同时还能以更低的文件大小实现这一功能。
- 动画支持:除了静态图像外,WebP还支持动画,作为一种更加有效的替代GIF的方案。相比GIF,WebP能够以更小的文件尺寸提供更高品质的动画效果和更多的色彩支持。
- 广泛兼容性:虽然WebP最初由Google推出,但它逐渐获得了广泛的浏览器和其他平台的支持,包括Chrome、Firefox、Edge、Safari等主流浏览器,以及各种操作系统和图像处理软件。

局限
- 浏览器兼容性:虽然大多数现代浏览器已经支持WebP格式,但仍有少数旧版浏览器可能不完全支持或根本不支持这种格式。在转换的同时也需要准备适当的回退方案(如提供JPEG或PNG版本的图像)。
- 性能问题:尽管WebP通常能提供更好的压缩率和质量比,但在某些情况下,转换过程可能会增加服务器负载,尤其是在需要实时生成WebP图像的情况下。
- 特定需求和偏好:一些网站可能基于设计、品牌或其他技术要求而选择特定的图像格式。例如,对于需要极高保真度的专业摄影展示,可能仍然倾向于使用TIFF或高质量JPEG格式。
使用
在线格式转换
- SO JSON 在线格式转换 http://www.sojson.com/image/forma…
- Convertio convertio.co/zh/image-co…
- ILoveImg http://www.iloveimg.com/zh-cn/featu…
- ALL TO ALL http://www.alltoall.net/

程序格式转换
Python:可以使用Pillow库(PIL的一个分支)结合webp的支持来进行转换。
// 安装 pip install Pillow
from PIL import Image
im = Image.open("input.png")
im.save("output.webp", "WEBP")
也可以使用Node.js来转换。
这里使用egg.js作为服务端框架
前端
<template>
<div class="wrap">
<a-upload
v-model:file-list="fileList"
name="file"
action="/api/uploadImg"
:accept="['.jpeg','.png','.jpg','.gif']"
@change="handleChange"
>
<a-button>
上传文件
</a-button>
</a-upload>
<div class="diff-wrap">
<div class="old-img">
<img style="max-width: 400px;max-height: 500px;" :src="oldImg" alt=""/>
</div>
<div class="new-img">
<img style="max-width: 400px;max-height: 500px;" :src="newImg" alt=""/>
</div>
</div>
</div>
</template>
<script setup>
import { ref } from 'vue';
const oldImg = ref('');
const newImg = ref('');
const handleChange = info => {
const file = info.file;
// 使用 FileReader 进行本地文件预览(无论上传是否成功)
const reader = new FileReader();
reader.onload = () => {
oldImg.value = reader.result; // 将本地文件的 Base64 赋值给 oldImg
};
reader.readAsDataURL(file.originFileObj); // 读取原始文件对象
// 原有上传完成逻辑可保留用于处理服务器返回结果
if (file.status === 'done' && file.response) {
console.log(file)
newImg.value = file.response.url; // 如果上传成功,使用服务器返回的 URL
}
};
const fileList = ref([]);
</script>
<style scoped>
.diff-wrap {
width: 800px;
margin: 20px auto;
border: 1px solid #ddd;
display: flex;
}
.old-img {
flex: 1;
height: 500px;
border-right: 1px solid #ddd;
}
.new-img {
flex: 1;
height: 500px;
}
</style>
服务端
使用 Node.js 的图像处理库 sharp 进行格式转换,安装 sharp。
npm install sharp
示例代码
const { Service } = require('egg');
const fs = require('fs');
const path = require('path');
const sharp = require('sharp');
class HomeService extends Service {
async index() {
return 'hello world';
}
async uploadImg() {
const { ctx } = this;
try {
// 1. 获取上传的文件流
const stream = await ctx.getFileStream();
// 2. 检查是否为支持的图片格式(可选)
const allowedMimes = [ 'image/jpeg', 'image/png', 'image/gif', 'image/webp' ];
if (!allowedMimes.includes(stream.mime)) {
throw new Error('Unsupported image format');
}
// 3. 定义路径
const tempInputPath = path.join(this.config.baseDir, 'app/public', `temp_${Date.now()}.tmp`);
const outputFilename = `converted_${Date.now()}.webp`;
const outputFilePath = path.join(this.config.baseDir, 'app/public', outputFilename);
// 4. 写入临时原始文件
const writeStream = fs.createWriteStream(tempInputPath);
await new Promise((resolve, reject) => {
stream.pipe(writeStream);
stream.on('end', resolve);
stream.on('error', reject);
});
// 5. 使用 sharp 转换为 webp
await sharp(tempInputPath)
.webp({ quality: 80 }) // 可设置压缩质量
.toFile(outputFilePath);
// 6. 清理临时文件
fs.unlinkSync(tempInputPath);
// 7. 返回 WebP 图片地址
return {
url: `/public/${outputFilename}`,
filename: outputFilename,
};
} catch (err) {
ctx.logger.error('Image upload or conversion failed:', err);
throw new Error('Image processing failed: ' + err.message);
}
}
}
module.exports = HomeService;
来源:juejin.cn/post/7503017777064362010
Vue3 首款 3D 数字孪生编辑器 正式开源!
作者:前端开发爱好者
对于多数前端开发者而言,用 ThreeJS 打造炫酷的数字孪生场景并非易事,需掌握大量专业知识。

如今,一款基于 Vue3、ThreeJS 和 Naive UI 的数字孪生开发框架 ——Astral 3D Editor 正式开源,为 Web3D 开发带来新转机。
Astral 3D Editor 是什么?
Astral 3D Editor 是一款免费开源的三维可视化孪生场景编辑器,主要服务于 Web3D 开发,支持多种常见 3D 模型格式

还具备轻量化 BIM 模型解析及 CAD 图纸预览功能。

Astral 3D Editor 的优势
- 功能丰富 :支持多种 3D 模型格式,可导入导出多类型模型,方便资源整合。它还提供插件系统,可扩展更多功能。同时,支持在线预览 BIM 模型和 CAD 图纸,为建筑、工程等领域提供便利。粒子系统、动画编辑器等功能一应俱全,满足多样化创作需求。
- 技术先进 :以 ThreeJS 为底层 3D 渲染库,结合 Vue3 响应式编程和组件化开发,以及 Naive UI 的丰富组件,构建高效稳定的编辑器框架。其场景数据无损压缩和网络分包渐进存取技术,优化了大规模场景的加载效率。
- 开发门槛低 :作为 3D 低代码创作工具,降低了 Web3D 开发难度,前端开发者无需深入掌握 3D 图形学知识,也能快速创建高质量 3D 场景,提高开发效率。
- 开源友好 :采用 Apache-2.0 License 开源协议,吸引众多开发者参与,形成活跃开源社区,便于交流分享和共同推动项目发展。
Astral 3D Editor 快速上手
环境准备
在开始使用 Astral 3D Editor 之前,确保已经安装了以下软件和工具:
- Node.js :建议安装 Node.js ≥ 18.x,可以通过官方链接下载安装。
- Yarn :一个高效的包管理工具,可以通过官方链接进行安装。

项目克隆与安装
通过 Git 将 Astral 3D Editor 的项目代码克隆到本地:
git clone https://github.com/mlt131220/Astral3DEditor.git
进入项目目录:
cd Astral3DEditor
使用 Yarn 安装项目依赖:
yarn install
项目运行与构建
在开发环境中启动项目:
yarn run dev
这将启动本地开发服务器,通常会自动在浏览器中打开 Astral 3D Editor 的界面,若未自动打开,可在浏览器中访问 http://localhost:3000。
基础操作指南
Astral 3D Editor 的界面简洁直观,主要包含以下几个关键区域:
- 工具栏 :提供了各种工具按钮,可进行模型导入、视图切换、对象选择和变换等操作。

- 视图区域 :用于显示和编辑 3D 场景,支持多种视图模式,如透视图、正交图,以及前置、后置、左置、右置等不同视角的切换。

- 属性面板 :用于查看和编辑当前选中对象的属性,可根据不同对象类型进行相应属性的调整。

Astral 3D Editor 在线编辑器
Astral 3D Editor 的在线编辑器是其一大亮点,提供了便捷的在线 3D 场景创作体验。

在线编辑器无需安装额外软件,只要有浏览器和网络连接,用户就能直接在浏览器中打开: https://editor.astraljs.com/#/,随时随地进行 3D 场景的创作和编辑。

界面设计简洁直观,操作流程简单易懂,降低了学习成本,初学者也能快速上手,轻松进行模型导入、场景编辑、动画添加等操作,迅速构建出想要的 3D 场景。

此外,在线编辑器还具有出色的跨平台兼容性,支持在 Windows、macOS 以及 Linux 等多种操作系统上运行,兼容各大主流浏览器,包括 Chrome、Firefox、Safari 等,用户可自由选择浏览器进行创作。
值得一提的是,在线编辑器支持通过拖拉拽形式创建场景,操作简单直观,大大降低了 3D 场景创作的门槛。
同时,官方还提供了大量可视化案例展示,这些案例不仅丰富多样,而且具有很高的学习价值,可供用户参考学习,帮助用户更好地掌握 3D 场景创作的技巧和方法。
Astral 3D Editor 的开源,为 Web3D 领域注入新活力。
其功能、技术、开发难度、应用场景和开源优势,使其有望在数字孪生领域发挥重要作用,推动 Web3D 技术持续进步。
- Astral 3D Editor Github 地址:
https://github.com/mlt131220/Astral3DEditor - Astral 3D Editor 在线编辑器:
https://editor.astraljs.com/#/ - Astral 3D Editor 官方文档:
http://editor-doc.astraljs.com/
来源:juejin.cn/post/7497821254205816858
✨说说私活,前端特效开发,以及报价策略✨
为啥要写
最能唬人的前端工种是啥?最能出活的前端模块是啥?跟大家讲,真的是搞动画那一块,搞特效那一块,搞3d、webgl那一块。出活,真的出活。
吭哧吭哧一些高深的框架或者死磕一个难啃的技术硬骨头老半天,给不懂技术的人看,他未必能懂,可能他还会心想:”做老半天,啊?就这...要我来我也会(翻白眼🙄)“。真是这样的。
所以说,唬得住人的,绝b有视觉滚动这一块。
搜一些外国佬的一些产品官网,十个有八个是类似这样的。我们熟悉的苹果官网也是这样的。


再多的,我不举例了。
那身为前端的,切图仔的,小卡拉米的,千千万万个我,绝不能说不会。一般人会看到一个官网有这种视差效果,就会打开给你看,问:”你说你是前端,那你会做这个效果吗“。
这个时候,咱一定得把这个ac中间那个字母给支棱起来。不能丢了面。去搜库搜包,借助工具给它搞出来。
不要说不行
要做这种视觉滚动效果,给jym推荐一个库,啥库呢?gsap
这个玩意,能通过最少的代码实现令人惊叹的滚动动画。
外国佬很多网站,甚至我们国内很多官网,搞这种装ac中间那个字母的官网,离不开这个库。
咋用
写原生,不搞框架的:
就用cdn,引就行了:
<script src="https://cdn.jsdelivr.net/npm/gsap@3.12/dist/gsap.min.js"></script>
引完这个gsap的库的js呢,完呢,再引入一个插件,叫ScrollTrigger,两者一结合,啥滚动动画能做不出来你说,官网都说了:GSAP的ScrollTrigger插件通过最少的代码实现令人惊叹的滚动动画。
<html lang="en">
// 每个section都有个背景,和一个h1的文字
<section>
<h1>111</h1>
</section>
<section>
<h1>222</h1>
</section>
<section>
<h1>333</h1>
</section>
<body>
<script src="https://cdn.jsdelivr.net/npm/gsap@3.12/dist/gsap.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/gsap@3.12.7/dist/ScrollTrigger.min.js"></script>
</body>
</html>
上面就把html那一块写完了,接着写js:
const sections = document.querySelectorAll('section'); // 获取页面中所有的<section>元素
sections.forEach(se => {
// 从初始到目标的动画
gsap.fromTo(se, {
backgroundPositionY: `-${window.innerHeight / 2}px`, // 向上偏移(初始背景垂直位置为视口高度一般的负值)
}, {
backgroundPositionY: `${window.innerHeight / 2}px`, // 向下偏移(视口高度的一般的正值)
duration: 3, // 动画持续3s
ease: 'none', // 线性曲线
})
})
接下来用到ScrollTrigger插件:
const sections = document.querySelectorAll('section'); // 获取页面中所有的<section>元素
gsap.registerPlugin(ScrollTrigger); // gsap注册插件ScrollTrigger
sections.forEach(se => {
// 从初始到目标的动画
gsap.fromTo(se, {
backgroundPositionY: `-${window.innerHeight / 2}px`, // 向上偏移(初始背景垂直位置为视口高度一般的负值)
}, {
backgroundPositionY: `${window.innerHeight / 2}px`, // 向下偏移(视口高度的一般的正值)
duration: 3, // 动画持续3s
ease: 'none', // 线性曲线
scrollTrigger: {
trigger: se, // 触发的是当前的section
scrub: true, // 按滚动条去做这个视觉效果
}
})
})
总结
好了,如果你觉得神奇,停止往下看,自个儿去官网瞅一眼,别听我在这瞎叨叨,自己去瞅一眼,它啊,不单单是我说的这种视差滚动效果可以做,还有很多动画可以搞,它是一个动画库,我只是说的其一。
动画滴本质实质上就是数字的变动。动来动去就有了动画。这个库帮我们做了很多活,我们拿来用,我们就关注应该怎么变动数字,哪些数字,就完事。前人栽树,后人乘凉,有时候有效地聪明地灵活地有思路地去运用一些库一些包会让事情事半功倍,让效率提升,让时间缩减,让效果更美妙。
特效
往往,玩这些特效的,💰会报得高:
- 视差滚动(Parallax Scrolling):通过背景层与内容层滚动速度差异营造空间感,适用于官网、营销页等场景,开发成本低但感知价值高。
- 3D交互(Three.js/WebGL):如产品展示、虚拟展厅等,结合Canvas或WebGL实现,技术门槛较高但报价可达数万元。
- 粒子动画(Particles.js/GSAP):用于登录页、Loading动画等,开发周期短但视觉效果突出,适合按模块打包报价。
- SVG路径动画:适用于图标、数据可视化等场景,通过GreenSock等工具实现,复杂度可控且客户感知专业性强。
推荐大家工具,或许对你当前比较恼火的无法着手的特效,可能有思路:GSAP(动画库)、Three.js(3D渲染)、Pixi.js(2D渲染)。
报价策略:优先选择视觉效果显著、开发效率高的特效类型(如视差滚动、3D交互),报价可以溢出点,客户会觉得干了很多活才出这么牛的效果,交付的时候,特别是官网,也不会说太干巴巴,就只是图垒字,字垒图这种。有动画的官网,会使得更多的阅览量,触动更多的购买欲。
来源:juejin.cn/post/7495938507212177448
阮一峰推荐to-unocss,尤雨溪点赞


这个网站可以直接将 style 转换成 UnoCss 语法, 他内部使用了 transform-to-unocss 的库,可以直接将 SFC 页面转换成 UnoCss SFC,这个特性,它能带来的收益就是,可以将你原本 sass、less、class、inline-style 转换成 UnoCss 然后原子化这样 class 能够最大限度被复用,对于 inline-style 被转换后还能带来性能收益,其他转换后能极大程度上减少打包后 css 体积, 当然 transform-to-unocss 底层还有一个 ]transform-to-unocss-core 的支持,能够将一长串的 style 输入,编译成 UnoCss 语法的输出,他已经用在用户量不错的 figma 插件的 fubukicss-tool 之中,当然处理 UnoCss,我同样做了 Tailwind 的一套,如果你是 UnoCss 新手,你一定要试试这个网站 to-unocss ,如果你是 vscode 用户可以按住 Unot 这个插件,他提供了 vscode hover inline-style 提示转换和整个 SFC page 转换的强大能力
来源:juejin.cn/post/7499251236128342067
2025 跨平台框架更新和发布对比,这是你没看过的全新版本
2025 年可以说又是一个跨平台的元年,其中不妨有「鸿蒙 Next」 平台刺激的原因,也有大厂技术积累“达到瓶颈”的可能,又或者“开猿截流、降本增笑”的趋势的影响,2025 年上半年确实让跨平台框架又成为最活跃的时刻,例如:
- Flutter Platform 和 UI 线程合并和Android Impeller 稳定
- React Native 优化 Skia 和发布全新 WebGPU 支持
- Compose Multiplatform iOS 稳定版发布,客户端全平台稳定
- 腾讯 Kotlin 跨平台框架 Kuikly 正式开源
- 字节跨平台框架 Lynx 正式开源
- uni-app x 跨平台框架正式支持鸿蒙
- ····
而本篇也是基于上面的内容,对比当前它们的情况和未来可能,帮助你在选择框架时更好理解它们的特点和差异。
就算你不用,也许面试的时候就糊弄上了?
Flutter
首先 Flutter 大家应该已经很熟悉了,作为在「自绘领域」坚持了这么多年的跨平台框架,相信也不需要再过多的介绍,因为是「自绘」和 「AOT 模式」,让 Flutter 在「平台统一性」和「性能」上都有不错的表现。
开发过程过程中的 hotload 的支持程度也很不错。
而自 2025 以来的一些更新也给 Flutter 带来了新的可能,比如 Flutter Platform 和 UI 线程合并 ,简单来说就是以前 Dart main Thread 和 Platform UI Thread 是分别跑在独立线程,它们的就交互和数据都需要经过 Channel 。

而合并之后,Dart main 和 Platform UI 在 Engine 启动完成后会合并到一个线程,此时 Dart 和平台原生语言就支持通过同步的方式去进行调用,也为 Dart 和 Kotlin/Java,Swift/OC 直接同步互操作在 Framework 提供了进一步基础支持。
当然也带来一些新的问题,具体可见线程合并的相关文章。
另外在当下,其实 Flutter 的核心竞争力是 Impeller ,因为跨平台框架不是系统“亲儿子”,又是自绘方案,那么在性能优化上,特别 iOS 平台,就不得不提到着色器预热或者提前编译。
传统 Skia 需要把「绘制命令」编译成可在 GPU 执行代码的过程,一般叫做着色器编译, Skia 需要「动态编译」着色器,但是 Skia 的着色器「生成/编译」与「帧工作」是按顺序处理,如果这时候着色器编译速度不够快,就可能会出现掉帧(Jank)的情况,这个我们也常叫做「着色器卡顿」
而 Impeller 正是这个背景的产物,简单说,App 所需的所有着色器都在 Flutter 引擎构建时进行离线编译,而不是在应用运行时编译。

这其实才是目前是 Flutter 的核心竞争力,不同于 Skia 需要考虑多场景和平台通用性,需要支持各种灵活的额着色器场景,Impeller 专注于 Flutter ,所以它可以提供更好的专注支持和问题修复,更多可见:着色器预热?为什么 Flutter 需要?
当然 Skia 也是 Google 项目,对于着色器场景也有 Graphite 后端在推进支持,它也在内部也是基于 Impeller 为原型去做的改进,所以未来 Skia 也可以支持部分场景的提前编译。
而在鸿蒙平台,华为针对 Flutter 在鸿蒙的适配,在华为官方过去的分享里,也支持了 Flutter引擎Impeller鸿蒙化,详细可见:b23.tv/KKNDAQB
甚至,Flutter 在类游戏场景支持也挺不错,如果配合 rive 的状态机和自适应,甚至可以开发出很多出乎意料的效果,而官方也有 Flutter 的游戏 SDK 或者 Flame 第三方游戏包支持:

最后,那么 Flutter 的局限性是什么呢?其实也挺多的,例如:
- 文字排版能力不如原生
- PC平台推进交给了 Canonical 团队负责,虽然有多窗口雏形,但是推进慢
- 不支持官方热更新,shorebird 国内稳定性一般
- 内存占用基本最高
- Web 只支持 wasm 路线
- 鸿蒙版本落后主版本太多
- 不支持小程序,虽然有第三方实现,但是力度不大
- ····
所以,Flutter 适合你的场景吗?
React Native
如果你很久没了解过 RN ,那么 2025 年的 RN 会超乎你的想象,可以说 Skia 和 WebGPU 给了它更多的可能。

RN 的核心之一就是对齐 Web 开发体验,其中最重要的就是 0.76 之后 New Architecture 成了默认框架,例如 Fabric, TurboModules, JSI 等能力解决了各种历史遗留的性能瓶颈,比如:
- JSI 让 RN 可以切换 JS 引擎,比如
Chakra、v8、Hermes,同时允许 JS 和 Native 线程之间的同步相互执行 - 全新的 Fabric 取代了原本的 UI Manager,支持 React 的并发渲染能力,特别是现在的新架构支持 React 18 及更高版本中提供的并发渲染功能,对齐 React 最新版本,比如 Suspense & Transitions:

- Hermes JS 引擎预编译的优化字节码,优化 GC 实现等
- TurboModules 按需加载插件
- ····
另外现在新版 RN 也支持热重载,同时可以更快对齐新 React 特性,例如 React 19 的 Actions、改进的异步处理等 。
而另一个支持就是 RN 在 Skia 和 WebGPU 的探索和支持,使用 Skia 和 WebGPU 不是说 RN 想要变成自绘,而是在比如「动画」和「图像处理」等场景增加了强力补充,比如:
React Native Skia Video 模块,实现了原生纹理(iOS Metal, Android OpenGL)到 React Native Skia 的直接传输,优化了内存和渲染速度,可以被用于视频帧提取、集成和导出等,生态中还有 React Native Vision Camera 和 React Native Video (v7) 等支持 Skia 的模块:

还有是 React Native 开始引入 WebGPU 支持,其效果将确保与 Web 端的 WebGPU API 完全一致,允许开发者直接复制代码示例的同时,实现与 Web Canvas API 对称的 RN Canvas API:

最后,WebGPU 的引入还可以让 React Native 开发者能够利用 ThreeJS 生态,直接引入已有的 3D 库,这让 React Native 的能力进一步对齐了 Web :

最后,RN 也是有华为推进的鸿蒙适配,会采用 XComponent 对接到 ArkUI 的后端接口进行渲染,详细可见:鸿蒙版 React Native 正式开源 。
而在 PC 领域 RN 也有一定支持,比如微软提供的 windows 和 macOS 支持,社区提供的 web 和 Linux 支持,只是占有并不高,一般忽略。
而在小程序领域,有京东的 Taro 这样的大厂开源支持,整体在平台兼容上还算不错。
当然,RN 最大的优势还在于成熟的 code-push 热更新支持。
那么使用 RN 有什么局限性呢?最直观的肯定是平台 UI 的一致性和样式约束,这个是 OEM 框架的场景局限,而对于其他的,目前存在:
- 第三方库在新旧框架支持上的风险
- RN 版本升级风险,这个相信大家深有体会
- 平台 API 兼容复杂度较高
- 0.77 之后才支持 Google Play 的 16 KB 要求
- 可用性集中在 Android 和 iOS ,鸿蒙适配和维度成本更高
- 小程序能力支持和客户端存在一定割裂
- ····
事实上, RN 是 Cordova 之后我接触的第一个真正意义上的跨平台框架,从我知道它到现在应该有十年了,那么你会因为它的新架构和 WebGPU 能力而选择 RN 么?
更多可见:
Compose Multiplatform
Compose Multiplatform(CMP) 近期的热度应该来自 Compose Multiplatform iOS 稳定版发布 ,作为第二个使用 Skia 的自绘框架,除了 Web 还在推进之外, CMP 基本完成了它的跨平台稳定之路。

Compose Multiplatform(CMP) 是 UI,Kotlin Multiplatform (KMP) 是语言基础。
CMP 使用 Skia 绘制 UI ,甚至在 Android 上它和传统 View 体系的 UI 也不在一个渲染树,并且 CMP 通过 Skiko (Skia for Kotlin) 这套 Kotlin 绑定库,进而抹平了不同架构(Kotlin Native,Kotlin JVM ,Kotlin JS,Kotlin wasm)调用 skia 的差异。
所以 CMP 的优势也来自于此,它可以通过 skia 做到不同平台的 UI 一致性,并且在 Android 依赖于系统 skia ,所以它的 apk 体积也相对较小,而在 PC 平台得益于 JVM 的成熟度,CMP 目前也做到了一定的可用程度。
其中和 Android JVM 模式不同的是,Kotlin 在 iOS 平台使用的是 Kotlin/Native ,Kotlin/Native 是 KMP 在 iOS 支持的关键能力,它负责将 Kotlin 代码直接编译为目标平台的机器码或 LLVM 中间表示 (IR),最终为 iOS 生成一个标准 .framework ,这也是为什么 Compose iOS 能实现接近原生的性能。
实现鸿蒙支持目前主流方式也是 Kotlin/Native ,不得不说 Kotlin 最强大的核心价值不是它的语法糖,而是它的编译器,当然也有使用 Kotlin/JS 适配鸿蒙的方案。
所以 CMP 最大的优势其实是 Kotlin ,Kotlin 的编译器很强大,支持各种编译过程和产物,可以让 KMP 能够灵活适配到各种平台,并且 Kotlin 语法的优势也让使用它的开发者忠诚度很高。
不过遗憾的是,目前 CMP 鸿蒙平台的适配上都不是 Jetbrains 提供的方案,华为暂时也没有 CMP 的适配计划,目前已知的 CMP/KMP 适配基本是大厂自己倒腾的方案,有基于 KN 的 llvm 方案,也有基于 Kotlin/JS 的低成本方案,只是大家的路线也各不相同。
在小程序领域同样如此。
另外现在 CMP 开发模式下的 hot reload 已经可以使用 ,不过暂时只支持 desktop,原理大概是只支持 jvm 模式。
而在社区上,klibs.io 的发布也补全了 Compose Multiplatform 在跨平台最后一步,这也是 Compose iOS 能正式发布的另外一个原因:

那么聊到这里,CMP 面临的局限性也很明显:
- 鸿蒙适配成本略高,没有官方支持,低成本可能会选择 Kotlin/JS,为了性能的高成本可能会考虑 KN,但是 KN 在 iOS 和鸿蒙的 llvm 版本同步适配也是一个需要衡量的成本
- 小程序领域需要第三方支持
- iOS 平台可能面临的着色器等问题暂无方案,也许未来等待 Skia 的 Graphite 后端
- 在 Android JVM 模式和 iOS 的 KN 模式下,第三方包适配的难度略高
- hotload 暂时只支持 PC
- 桌面内存占用问题-
- 没有官方热更新条件
- kjs、kn、kjvm、kwasm 之间的第三方包兼容支持问题
- ····
相信 2025 年开始,CMP 会是 Android 原生开发者在跨平台的首选之一,毕竟 Kotlin 生态不需要额外学习 Dart 或者 JS 体系,那么你会选择 CMP 吗?
Kuikly
Kuikly 其实也算是 KMP 体系的跨平台框架,只是腾讯在做它的时候还没 CMP ,所以一开始 Kuikly 是通过 KMM 进行实现,而后在 UI 层通过自己的方案完成跨平台。

这其实就是 Kuikly 和 CMP 最大的不同,底层都是 KMP 方案,但是在绘制上 Kuikly 采用的是类 RN 的方式,目前 Kuikly 主要是在 KMP 的基础上实现的自研 DSL 来构建 UI ,比如 iOS 平台的 UI 能力就是 UIkit ,而大家更熟悉的 Compose 支持,目前还处于开发过程中:

SwiftUI 和 Compose 无法直接和 Kuikly 一起使用,但是 Kuikly 可以在 DSL 语法和 UI 组件属性对齐两者的写法,变成一个类 Compose 和 SwiftUI 的 UI 框架,也就是 Compose DSL 大概就是让 Kuikly 更像 Compose ,而不是直接适配 Compose 。
那么,Kuikly 和 RN 之间又什么区别?
第一,Kuikly 支持 Kotlin/JS 和 Kotlin/Native 两种模式,也就是它可以支持性能很高的 Native 模式
第二,Kuikly 实现了自己的一套「薄原生层」,Kuikly 使用“非常薄”的原生层,该原生层只暴露最基本和无逻辑的 UI 组件(原子组件),也就是 Kuikly 在 UI 上只用了最基本的原生层 UI ,真正的 UI 逻辑主要在共享的 Kotlin 代码来实现:
通过将 UI 逻辑抽象到共享的 Kotlin 层,减少平台特定 UI 差异或行为差异的可能性,「薄原生层」充当一致的渲染目标,确保 Kotlin 定义的 UI 元素在所有平台上都以类似的方式显示。

也就是说,Kuikly 虽然会依赖原生平台的控件,但是大部分控件的实现都已经被「提升」到 Kuikly 自己的 Kotlin 共享层,目前 Kuikly 实现了 60% UI 组件的纯 Kotlin 组合封装实现,不需要 Native 提供原子控件 。
另外 Kuikly 表示后续会支持全平台小程序,这也是优势之一。
最后,Kuikly 还在动态化热更新场景, 可以和自己腾讯的热更新管理平台无缝集成,这也是优势之一。
那么 Kuikly 存在什么局限性?首先就是动态化场景只支持 Kotlin/JS,而可动态化类型部分:
- 不可直接依赖平台能力
- 不可使用多线程和协程
- 不可依赖内置部分
其他的还有:
- UI 不是 CMP ,使用的是类 RN 方式,所谓需要稍微额外理解成本
- 不支持 PC 平台
- 基于原生 OEM,虽然有原子控件,但是还是存在部分不一致情况
- 在原有 App 集成 Kuikly ,只能把它简单当作如系统 webview 的概念来使用
另外,腾讯还有另外一个基于 CMP 切适配鸿蒙的跨平台框架,只是何时开源还尚不明确
那么,你会为了小程序和鸿蒙而选择 Kuikly 吗?
更多可见:腾讯 Kuikly 正式开源
Lynx
如果说 Kuikly 是一个面向客户端的全平台框架,那么 Lynx 就是一个完全面向 Web 前端的跨平台全家桶。

目前 Lynx 开源的首个支持框架就是基于 React 的 ReactLynx,当然官方也表示Lynx 并不局限于 React,所以不排除后续还有 VueLynx 等其他框架支持,而 Lynx 作为核心引擎支持,其实并不绑定任何特定前端框架,只是当前你能用的暂时只有 ReactLynx :

而在实现上,源代码中的标签,会在运行时被 Lynx 引擎解析,翻译成用于渲染的 Element,嵌套的 Element 会组成的一棵树,从而构建出UI界面:

所以从这里看,初步开源的 Lynx 是一个类 RN 框架,不过从官方的介绍“选择在移动和桌面端达到像素级一致的自渲染” ,可以看出来宣传中可以切换到自渲染,虽然暂时还没看到。
而对于 Lynx 主要的技术特点在于:
- 「双线程架构」,思路类似 react-native-reanimated ,JavaScript 代码会在「主线程」和「后台线程」两个线程上同时运行,并且两个线程使用了不同的 JavaScript 引擎作为其运行时:

- 另外特点就是 PrimJS ,一个基于 QuickJS 深度定制和优化的 JavaScript 引擎,主要有模板解释器(利用栈缓存和寄存器优化)、与 Lynx 对象模型高效集成的对象模型(减少数据通信开销)、垃圾回收机制(非 QuickJS 的引用计数 RC,以提升性能和内存分析能力)、完整实现了 Chrome DevTools Protocol (CDP) 以支持 Chrome 调试器等
- “Embedder API” 支持直接与原生 API 交互 ,提供多平台支持
所以从 Lynx 的宏观目标来看,它即支持类 RN 实现,又有自绘计划,同时除了 React 模式,后期还适配 Vue、Svelte 等框架,可以说是完全针对 Web 开发而存在的跨平台架构。
另外支持平台也足够,Android、iOS、鸿蒙、Web、PC、小程序都在支持列表里。
最后,Lynx 对“即时首帧渲染 (IFR)”和“丝滑流畅”交互体验有先天优势,开发双线程模型及主线程脚本 (MTS) 让 Lynx 的启动和第一帧渲染速度还挺不错,比如:
- Lynx 主线程负责处理直接处理屏幕像素渲染的任务,包括:执行主线程脚本、处理布局和渲染图形等等,比如负责渲染初始界面和应用后续的 UI 更新,让用户能尽快看到第一屏内容
- Lynx 的后台线程会运行完整的 React 运行时,处理的任务不直接影响屏幕像素的显示,包括在后台运行的脚本和任务(生命周期和其他副作用),它们与主线程分开运行,这样可以让主线程专注于处理用户交互和渲染,从而提升整体性能
而在多平台上,Lynx 是自主开发的渲染后端支持 Windows、tvOS、MacOS 和 HarmonyOS ,但是不确实是否支持 Linux:

那 Lynx 有什么局限性?首先肯定是它非常年轻,虽然它的饼很大,但是对应社区、生态系统、第三方库等都还需要时间成长。
所以官方也建议 Lynx 最初可能更适合作为模块嵌入到现有的原生应用中,用于构建特定视图或功能,而非从零开始构建一个完整的独立应用 。
其次就是对 Web 前端开发友好,对客户端而言学习成本较高,并且按照目前的开源情况,除了 Android、iOS 和 Web 的类 RN 实现外,其他平台的支持和自绘能力尚不明确:


最后,Lynx 的开发环境最好选 macOS,关于 Windows 和 Linux 平台目前工具链兼容性还需要打磨。
那么,总结下来,Lynx 应该会是前端开发的菜,那你觉得 Lynx 是你的选择么?
更多可见:字节跨平台框架 Lynx 开源
uni-app x
说到 uni-app 大家第一印象肯定还是小程序,而虽然 uni-app 也可以打包客户端 app,甚至有基于 weex 的 nvue 支持,但是其效果只能说是“一言难尽”,而这里要聊的 uni-app x ,其实就是 DCloud 在跨平台这两年的新尝试。
具体来说,就是 uni-app 不再是运行在 jscore 的跨平台框架,它是“基于 Web 技术栈开发,运行时编译为原生代码”的模式,相信这种模式大家应该也不陌生了,简单说就是:js(uts) 代码在打包时会直接编译成原生代码:
| 目标平台 | uts 编译后的原生语言 |
|---|---|
| Android | Kotlin |
| iOS | Swift |
| 鸿蒙 | ArkTS |
| Web / 小程序 | JavaScript |
甚至极端一点说,uni-app x 可以不需要单独写插件去调用平台 API,你可以直接在 uts 代码里引用平台原生 API ,因为你的代码本质上也是会被编译成原生代码,所以 uts ≈ native code ,只是使用时需要配置上对应的条件编译(如 APP-ANDROID、APP-IOS )支持:
import Context from "android.content.Context";
import BatteryManager from "android.os.BatteryManager";
•
import { GetBatteryInfo, GetBatteryInfoOptions, GetBatteryInfoSuccess, GetBatteryInfoResult, GetBatteryInfoSync } from '../interface.uts'
import IntentFilter from 'android.content.IntentFilter';
import Intent from 'android.content.Intent';
•
import { GetBatteryInfoFailImpl } from '../unierror';
•
/**
* 获取电量
*/
export const getBatteryInfo : GetBatteryInfo = function (options : GetBatteryInfoOptions) {
const context = UTSAndroid.getAppContext();
if (context != null) {
const manager = context.getSystemService(
Context.BATTERY_SERVICE
) as BatteryManager;
const level = manager.getIntProperty(
BatteryManager.BATTERY_PROPERTY_CAPACITY
);
•
let ifilter = new IntentFilter(Intent.ACTION_BATTERY_CHANGED);
let batteryStatus = context.registerReceiver(null, ifilter);
let status = batteryStatus?.getIntExtra(BatteryManager.EXTRA_STATUS, -1);
let isCharging = status == BatteryManager.BATTERY_STATUS_CHARGING || status == BatteryManager.BATTERY_STATUS_FULL;
•
const res : GetBatteryInfoSuccess = {
errMsg: 'getBatteryInfo:ok',
level,
isCharging: isCharging
}
options.success?.(res)
options.complete?.(res)
} else {
let res = new GetBatteryInfoFailImpl(1001);
options.fail?.(res)
options.complete?.(res)
}
}
•
比如上方代码,通过 import BatteryManager from "android.os.BatteryManager" 可以直接导入使用 Android 的 BatteryManager 对象。
可以看到,在 uni-app x 你是可以“代码混写”的,所以与传统的 uni-app 不同,uni-app 依赖于定制 TypeScript 的 uts 和 uvue 编译器:
- uts 和 ts 有相同的语法规范,并支持绝大部分 ES6 API ,在编译时会把内置的如
Array、Date、JSON、Map、Math、String等内置对象转为 Kotlin、Swift、ArkTS 的对象等,所以也不需要有 uts 之类的虚拟机,另外 uts 编译器在处理特定平台时,还会调用相应平台的原生编译器,例如 Kotlin 编译器和 Swift 编译器 - uvue 编译器基于 Vite 构建,并对它进行了扩展,大部分特性(如条件编译)和配置项(如环境变量)与 uni-app 的 Vue3 编译器保持一致,并且支持 less、sass、ccss 等 CSS 预处理器,例如 uvue 的核心会将开发者使用 Vue 语法和 CSS 编写的页面,编译并渲染为 ArkUI
而在 UI 上,目前除了编译为 ArkUI 之外,Android 和 iOS 其实都是编译成原生体系,目前看在 Android 应该是编译为传统 View 体系而不是 Compose ,而在 iOS 应该也是 UIKit ,按照官方的说法,就是性能和原生相当。
所以从这点看,uni-app x 是一个类 RN 的编译时框架,所以,它的局限性问题也很明显,因为它的优势在于编译器转译得到原生性能,但是它的劣势也是在于转译:
- 不同平台翻译成本较高,并不支持完整的语言,阉割是必须的,API 必然需要为了转译器而做删减,翻译后的细节对齐于优化会是最大的挑战
- iOS 平台还有一些骚操作,保留了可选 js 老模式和新 swift 模式,核心是因为插件生态,官方表示 js 模式可以大幅降低插件生态的建设难度, 插件作者只需要特殊适配 Android 版本,在iOS和Web端仍使用 ts/js 库,可以快速把 uni-app/web 的生态迁移到 uni-app x
- 生态支持割裂,uni-app 和 uni-app x 插件并不通用
- 不支持 PC
- HBuilderX IDE
- ·····
那么,你觉得 uni-app x 会是你跨平台选择之一么?
更多可见:uni-app x 正式支持鸿蒙
最后
最后,我们简单做个总结:
| 框架 (Framework) | 开发语言 | 渲染方式 | 特点 | 缺点 | 支持平台 | 维护企业 |
|---|---|---|---|---|---|---|
| Flutter | Dart | 自绘,Impeller | 自绘,多平台统一,未来支持 dart 和平台语言直接交互,Impeller 提供竞争力,甚至支持游戏场景 | 占用内存大,文本场景略弱,Impeller 还需要继续打磨 | android、iOS、Web、Windows、macOS、Linux、鸿蒙(华为社区提供) | |
| React Native | JS 体系 | 原生 OEM + Skia/WebGPU 支持 | 新架构提供性能优化,对齐 Web,引入 skia 和 webGPU 补充,code-push 热更新 | UI 一致性和新旧架构的第三方支持 | android、iOS、鸿蒙(华为社区提供),额外京东 Taro 支持小程序,web、windows、macOS、Linux 第三方支持 | |
| Compose Multiplatform | Kotlin体系 | Skia 自绘 | Kotlin 体系,skia 自绘,多平台统一,支持 kn、kjs、kwasm 、kjvm 多种模式 | KN JVM、JS、Wasm 生态需要整合,没有着色器预编方案 | android、iOS、Web、Windows、macOS、Linux | Jetbrains |
| Kuikly | Kotlin体系 | 原生 OEM ,「薄原生层」 | 基于 KMP 的类 RN 方案,在动态化有优势 | 小部分 UI 一致性场景,UI 与 CMP 脱轨 | android、iOS、Web、鸿蒙、小程序 | 腾讯 |
| Lynx | JS 体系 | 原生 OEM,未来也有自绘 | 对齐 Web 开发首选,秒开优化,规划丰富 | 非常早期 ,生态发展中,客户端不友好 | android、iOS、Web、Windows、macOS、鸿蒙、小程序 | 字节 |
| uni-app x | uts | 原生 OEM,直接翻译为原生语言 | 支持混写 uts 和原生代码,直接翻译为原生 | 生态插件割裂,UI 一致性问题,翻译 API 长期兼容成本 | android、iOS、Web、鸿蒙、小程序 | DCloud |
什么,你居然看完了?事实上我写完都懒得查错别字了,因为真的太长了。
来源:juejin.cn/post/7505578411492474915
前端何时能出个"秦始皇"一统天下?我是真学不动啦!
前端何时能出个"秦始皇"一统天下?我是真学不动啦!
引言
前端开发的世界,就像历史上的战国时期一样,各种框架、库、工具层出不穷,形成了一个百花齐放但也令人眼花缭乱的局面。
而且就因为百家争鸣,导致各种鄙视链出现
比如 React 和 Vue 互喷
v:你react 这么难用,不如我vue 简单
r:你一点都不灵活,我想咋用咋用
v:你useEffect 心智负担太重,一点都好用
r:啥心智负担,那是你太笨了,我就喜欢这种什么都掌握在自己手里的感觉
v:你内部更是混乱,一个状态管理就那么多种 啥redux、mobx、recoil。。。。不像我们一个pinia 走天下
r:你管我 我想用哪个用哪个,你还说我,你内部对一个 用ref还是用reactive 都吵得不可开交!
......

1. 框架之争
- React: 由Facebook维护的一个用于构建用户界面的JavaScript库。其设计理念是通过组件化的方式简化复杂的UI开发。
- 官网: reactjs.org/
- GitHub: github.com/facebook/re…
- GitHub Stars: 超过235k(截至2025年4月)
- Vue.js: 一种渐进式JavaScript框架,非常适合用来构建单页应用。Vue的核心库只关注视图层,易于上手。
- 官网: vuejs.org/
- GitHub: github.com/vuejs/vue
- GitHub Stars: 约209k(截至2025年4月)
- Angular: Google支持的一个开源Web应用框架,适用于大型企业级项目。它提供了一个全面的解决方案来创建动态Web应用程序。
- 官网: angular.io/
- GitHub: github.com/angular/ang…
- GitHub Stars: 大约97.5k(截至2025年4月)
- Solid.js: 一个专注于性能和简单性的声明式UI库,采用细粒度的响应式系统,提供了极高的运行效率。
- 官网: http://www.solidjs.com/
- GitHub: github.com/solidjs/sol…
- GitHub Stars: 约33.3k(截至2025年4月)
- Svelte: 一种新兴的前端框架,通过在编译时将组件转换为高效的原生代码,从而避免了运行时开销。
- 官网: svelte.dev/
- GitHub: github.com/sveltejs/sv…
- GitHub Stars: 约82.3k(截至2025年4月)
- Ember.js: 一个旨在帮助开发者构建可扩展的Web应用的框架,尤其适合大型团队协作。
- 官网: emberjs.com/
- GitHub: github.com/emberjs/emb…
- GitHub Stars: 约22.6k(截至2025年4月)
2. 样式处理满花齐放
样式处理方面可以进一步细分,包括CSS预处理器、CSS-in-JS、Utility-First CSS框架以及CSS Modules等。
- CSS预处理器
- Sass: 提供变量、嵌套规则等高级功能,极大地提高了CSS代码的可维护性。
- 官网: sass-lang.com/
- GitHub: github.com/sass/sass
- GitHub Stars: 约15.2k(截至2025年4月)
- Less: 另一种流行的CSS预处理器,支持类似的功能但语法稍有不同。
- 官网: lesscss.org/
- GitHub: github.com/less/less.j…
- GitHub Stars: 约17k(截至2025年4月)
- Stylus: 一款灵活且功能强大的CSS预处理器,允许省略括号和分号等符号,使代码更加简洁。
- 官网: stylus-lang.com/
- GitHub: github.com/stylus/styl…
- GitHub Stars: 约11.2k(截至2025年4月)
- Sass: 提供变量、嵌套规则等高级功能,极大地提高了CSS代码的可维护性。
- CSS-in-JS
- styled-components: 允许你通过JavaScript编写CSS,并将样式直接附加到组件上。
- 官网: styled-components.com/
- GitHub: github.com/styled-comp…
- GitHub Stars: 约40.8k(截至2025年4月)
- Emotion: 类似于styled-components,但提供了更多的灵活性和性能优化。
- 官网: emotion.sh/
- GitHub: github.com/emotion-js/…
- GitHub Stars: 约17.7k(截至2025年4月)
- styled-components: 允许你通过JavaScript编写CSS,并将样式直接附加到组件上。
- 原子化css
- Tailwind CSS: 一种实用优先的CSS框架,让你可以通过低级实用程序类构建定制设计。
- 官网: tailwindcss.com/
- GitHub: github.com/tailwindlab…
- GitHub Stars: 约87.2k(截至2025年4月)
- UnoCSS: 新一代的原子化CSS引擎,旨在提供极致的性能和灵活性。
- 官网: uno.antfu.me/
- GitHub: github.com/unocss/unoc…
- GitHub Stars: 约17.5k(截至2025年4月)
- Windi CSS: 一个基于Tailwind CSS的即时按需CSS框架,提供了更快的开发体验。
- 官网: windicss.org/
- GitHub: github.com/windicss/wi…
- GitHub Stars: 约6.5k(截至2025年4月)
- Tailwind CSS: 一种实用优先的CSS框架,让你可以通过低级实用程序类构建定制设计。
3. 构建工具五花八门
构建工具是现代前端开发不可或缺的一部分,它们负责将源代码转换为生产环境可用的形式,并优化性能。
- Webpack: 一个模块打包工具,广泛用于复杂的前端项目中。它支持多种文件类型的处理,并具有强大的插件生态。
- 官网: webpack.js.org/
- GitHub: github.com/webpack/web…
- GitHub Stars: 约65.2k(截至2025年4月)
- Vite: 由Vue.js作者尤雨溪开发的下一代前端构建工具,以其极快的冷启动速度和热更新闻名。
- 官网: vitejs.dev/
- GitHub: github.com/vitejs/vite
- GitHub Stars: 约72.1k(截至2025年4月)
- Rollup: 一个专注于JavaScript库的打包工具,特别适合构建小型库或框架。
- 官网: rollupjs.org/
- GitHub: github.com/rollup/roll…
- GitHub Stars: 约25.7k(截至2025年4月)
- Rspack: 一个基于Rust实现的高性能构建工具,兼容Webpack配置,旨在提供更快的构建速度。
- 官网: rspack.dev/
- GitHub: github.com/web-infra-d…
- GitHub Stars: 约11.3k(截至2025年4月)
- esbuild: 一个用Go语言编写的极速打包工具,专为现代JavaScript项目设计。
- 官网: esbuild.github.io/
- GitHub: github.com/evanw/esbui…
- GitHub Stars: 约38.8k(截至2025年4月)
- Turbopack: 由Next.js团队推出的下一代构建工具,号称比Webpack快700倍。
- 官网: turbo.build/docs
- GitHub: github.com/vercel/turb…
- GitHub Stars: 约27.5k(截至2025年4月)
- Rolldown: 一个基于Rust的Rollup替代方案,旨在提供更快的构建速度和更高的性能。
- 官网: rolldown.dev/
- GitHub: github.com/rolldown/ro…
- GitHub Stars: 约10.7k(截至2025年4月)
对比分析:
- Webpack 是目前最成熟的构建工具,生态系统庞大,但配置复杂度较高。
- Vite 凭借其快速的开发体验迅速崛起,尤其在中小型项目中表现优异。
- Rollup 更适合轻量级项目或库的构建,虽然社区规模较小,但在特定场景下非常高效。
- Rspack 和 esbuild 利用高性能语言(如Rust和Go)实现了极快的构建速度,适合对性能要求较高的项目。
- Turbopack 是新兴工具,主打极速构建,未来可能成为Webpack的有力竞争者。
- Rolldown 提供了另一种基于Rust的高速构建解决方案,特别针对Rollup用户群体。
4. 包管理工具逐步更新
- npm: Node.js默认的包管理器,允许开发者轻松地安装、共享和分发代码。
- 官网: http://www.npmjs.com/
- GitHub: github.com/npm/cli
- cnpm: npm在中国的镜像站,由于网络问题,很多中国开发者更倾向于使用cnpm。
- GitHub: github.com/cnpm/cnpm
- Yarn: Facebook推出的一个快速、可靠、安全的依赖管理工具。
- 官网: yarnpkg.com/
- GitHub: github.com/yarnpkg/yar…
- pnpm: 快速且节省磁盘空间的包管理器。
- 官网: pnpm.io/
- GitHub: github.com/pnpm/pnpm
5. 状态管理百家争鸣
状态管理是前端开发中的重要组成部分,它帮助开发者有效地管理应用的状态变化。
- Redux: 经典的Flux实现,广泛用于React生态系统中,适合管理大型应用的状态。
- 官网: redux.js.org/
- GitHub: github.com/reduxjs/red…
- GitHub Stars: 约61.1k(截至2025年4月)
- MobX: 响应式状态管理库,通过可观察对象实现自动化的状态更新。
- 官网: mobx.js.org/
- GitHub: github.com/mobxjs/mobx
- GitHub Stars: 约27.8k(截至2025年4月)
- Zustand: 轻量级的状态管理解决方案,API简单且易于使用。
- 官网: zustand-demo.pmnd.rs/
- GitHub: github.com/pmndrs/zust…
- GitHub Stars: 约51.7k(截至2025年4月)
- Jotai: 原子化状态管理库,专注于轻量级和灵活性。
- 官网: jotai.org/
- GitHub: github.com/pmndrs/jota…
- GitHub Stars: 约19.8k(截至2025年4月)
- Recoil: Facebook推出的实验性状态管理库,专为React设计。
- 官网: recoiljs.org/
- GitHub: github.com/facebookexp…
- GitHub Stars: 约19.6k(截至2025年4月)
- Pinia: Vue的下一代状态管理库,设计简洁且与Vue 3完美集成。
- 官网: pinia.vuejs.org/
- GitHub: github.com/vuejs/pinia
- GitHub Stars: 约13.8k(截至2025年4月)
6. JavaScript运行时环境都有好几种
JavaScript运行时环境是现代前端和后端开发的核心部分,它决定了代码如何被解析和执行。以下是几种主流的JavaScript运行时环境:
- Node.js:
- Node.js 是一个基于Chrome V8引擎的JavaScript运行时,广泛用于构建服务器端应用、命令行工具以及全栈开发。
- 它拥有庞大的生态系统,npm作为其默认包管理器,已经成为全球最大的软件注册表。
- 官网: nodejs.org/
- GitHub: github.com/nodejs/node
- GitHub Stars: 约111k(截至2025年4月)
- Deno:
- Deno 是由Node.js的原作者Ryan Dahl创建的一个现代化JavaScript/TypeScript运行时,旨在解决Node.js的一些设计缺陷。
- 它内置了对TypeScript的支持,并提供了更安全的权限模型(如文件系统访问需要显式授权)。
- Deno还集成了标准库,无需依赖第三方模块即可完成许多常见任务。
- 官网: deno.land/
- GitHub: github.com/denoland/de…
- GitHub Stars: 约103k(截至2025年4月)
- Bun:
- Bun 是一个新兴的JavaScript运行时,旨在提供更快的性能和更高效的开发体验。
- 它不仅可以用作运行时环境,还可以替代npm、Yarn等包管理工具,同时支持ES Modules和CommonJS。
- Bun的目标是成为Node.js和Deno的强大竞争者,特别适合高性能需求的场景。
- 官网: bun.sh/
- GitHub: github.com/oven-sh/bun
- GitHub Stars: 约77.5k(截至2025年4月)
对比分析:
- Node.js 是目前最成熟且广泛应用的JavaScript运行时,尤其在企业级项目中占据主导地位。
- Deno 提供了更现代化的设计理念,特别是在安全性、TypeScript支持和内置工具方面表现突出。
- Bun 是一个新兴的选手,凭借其极速的性能和多功能性迅速吸引了开发者关注,未来潜力巨大。
7. 跨平台开发
随着移动设备和多终端生态的普及,跨平台开发成为现代应用开发的重要方向。以下是几种主流的跨平台开发工具和技术:
- React Native:
- React Native 是由Facebook推出的一个基于React的跨平台移动应用开发框架,允许开发者使用JavaScript和React构建原生性能的iOS和Android应用。
- 它提供了丰富的社区支持和插件生态,适合需要快速迭代的项目。
- 官网: reactnative.dev/
- GitHub: github.com/facebook/re…
- GitHub Stars: 约122k(截至2025年4月)
- Flutter:
- Flutter 是由Google开发的一个开源UI框架,使用Dart语言构建高性能的跨平台应用。
- 它通过自绘引擎渲染UI,提供了一致的用户体验,并支持Web、iOS、Android以及桌面端开发。
- 官网: flutter.dev/
- GitHub: github.com/flutter/flu…
- GitHub Stars: 约170k(截至2025年4月)
- Electron:
- Electron 是一个用于构建跨平台桌面应用的框架,基于Node.js和Chromium,广泛应用于桌面端应用开发。
- 它允许开发者使用Web技术(HTML、CSS、JavaScript)构建功能强大的桌面应用,但可能会导致较大的应用体积。
- 官网: http://www.electronjs.org/
- GitHub: github.com/electron/el…
- GitHub Stars: 约116k(截至2025年4月)
- Tauri:
- Tauri 是一个轻量级的跨平台桌面应用框架,旨在替代Electron,提供更小的应用体积和更高的安全性。
- 它利用系统的原生Webview来渲染UI,同时支持Rust作为后端语言,从而实现更高的性能。
- 官网: tauri.app/
- GitHub: github.com/tauri-apps/…
- GitHub Stars: 约91.5k(截至2025年4月)
- Capacitor:
- Capacitor 是由Ionic团队推出的一个跨平台工具,允许开发者将Web应用封装为原生应用。
- 它支持iOS、Android和Web,并提供了丰富的插件生态,方便调用原生设备功能。
- 官网: capacitorjs.com/
- GitHub: github.com/ionic-team/…
- GitHub Stars: 约13.1k(截至2025年4月)
- UniApp:
- UniApp 是一个基于 Vue.js 的跨平台开发框架,能够将代码编译到多个平台,包括微信小程序、H5、iOS、Android以及其他小程序(如支付宝小程序、百度小程序等)。
- 它的优势在于一次编写,多端运行,特别适合需要覆盖多个小程序平台的项目。
- 官网: uniapp.dcloud.io/
- GitHub: github.com/dcloudio/un…
- GitHub Stars: 约40.6k(截至2025年4月)
对比分析:
- React Native 和 Flutter 是移动端跨平台开发的两大主流选择,分别适合熟悉JavaScript和Dart的开发者。
- Electron 是桌面端跨平台开发的经典解决方案,虽然体积较大,但易于上手。
- Tauri 提供了更轻量化的桌面端开发方案,适合对性能和安全性有更高要求的项目。
- Capacitor 则是一个灵活的工具,特别适合将现有的Web应用快速迁移到移动端。
- UniApp 非常适合需要覆盖多种小程序平台的项目,尤其在国内的小程序生态中表现出色。
结论
你看我这还是只是列举了一部分,都这么多了,学前端的是真的命苦啊,真心学不动了。

而且最近 尤雨溪宣布成立 VoidZero 说是一代JavaScript工具链,能够统一前端 开发构建工具,如果真能做到,真是一件令人振奋的事情,希望尤雨溪能做到跟 spring 一样统一java 天下 把前端的天下给统一了,大家觉得有可能么?
来源:juejin.cn/post/7493420166878822450
脱裤子放屁 - 你们讨厌这样的页面吗?
前言
平时在逛掘金和少数派等网站的时候,经常有跳转外链的场景,此时基本都会被中转到一个官方提供的提示页面。
掘金:

知乎:

少数派:

这种官方脱裤子放屁的行为实在令人恼火。是、是、是、我当然知道这么做有很多冠冕堂皇的理由,比如:
- 防止钓鱼攻击
- 增强用户意识
- 品牌保护
- 遵守法律法规
- 控制流量去向
(以上5点是 AI 告诉我的理由)
但是作为混迹多年的互联网用户,什么链接可以点,什么最好不要点(悄悄的点) 我还是具备判断能力的。
互联网的本质就是自由穿梭,一个 A 标签就可以让你在整个互联网翱翔,现在你每次起飞的时候都被摁住强迫你阅读一次免责声明,多少是有点恼火的。
解决方案
这些中转站的实现逻辑基本都是将目标地址挂在中转地址的target 参数后面,在中转站做免责声明,然后点击继续跳转才跳到目标网站。
掘金:
少数派:
https://sspai.com/link?target=https%3A%2F%2Fgeoguess.games%2F
知乎:
https://link.zhihu.com/?target=https%3A//asciidoctor.org/
所以我们就可以写一个浏览器插件,在这些网站中,找出命中外链的 A 标签,替换掉它的 href 属性(只保留 target 后面的真实目标地址)。
核心函数:
function findByTarget() {
if (!hostnames.includes(location.hostname)) return;
const linkKeyword = "?target=";
const aLinks = document.querySelectorAll(
`a[href*="${linkKeyword}"]:not([data-redirect-skipper])`
);
if (!aLinks) return;
aLinks.forEach((a) => {
const href = a.href;
const targetIndex = href.indexOf(linkKeyword);
if (targetIndex !== -1) {
const newHref = href.substring(targetIndex + linkKeyword.length);
a.href = decodeURIComponent(newHref);
a.setAttribute("data-redirect-skipper", "true");
}
});
}
为此我创建了一个项目仓库 redirect-skipper ,并且将该浏览器插件发布在谷歌商店了 安装地址 。
安装并启用这个浏览器插件之后,在这些网站中点击外链就不会看到中转页面了,而是直接跳转到目标网站。
因为我目前明确需要修改的就是这几个网站,如果大家愿意使用这个插件,且有其他网站需要添加到替换列表的,可以给 redirect-skipper 仓库 提PR。
如果需要添加的网站的转换规则是和 findByTarget 一致的,那么仅需更新 sites.json 文件即可。
如果需要添加的网站的转换规则是独立的,那么需要更新插件代码,合并之后,由我向谷歌商店发起更新。
为了后期可以灵活更新配置(谷歌商店审核太慢了),我默认将插件应用于所有网站,然后在代码里通过 hostname 来判断是否真的需要执行。
{
"$schema": "https://json.schemastore.org/chrome-manifest.json",
"name": "redirect-skipper",
"manifest_version": 3,
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["./scripts/redirect-skipper.js"],
"run_at": "document_end"
}
],
}
在当前仓库里维护一份 sites.json 的配置表,格式如下:
{
"description": "远程配置可以开启 Redirect-Skipper 插件的网站 (因为谷歌商店审核太慢了,否则无需通过远程配置,增加复杂性)",
"sites": [
{
"hostname": "juejin.cn",
"title": "掘金"
},
{
"hostname": "sspai.com",
"title": "少数派"
},
{
"hostname": "www.zhihu.com",
"title": "知乎"
}
]
}
这样插件在拉取到这份数据的时候,就可以根据这边描述的网站配置,决定是否执行具体代码。
插件完整代码:
function replaceALinks() {
findByTarget();
}
function observerDocument() {
const mb = new MutationObserver((mutationsList) => {
for (const mutation of mutationsList) {
if (mutation.type === "childList") {
if (mutation.addedNodes.length) {
replaceALinks();
}
}
}
});
mb.observe(document, { childList: true, subtree: true });
}
// 监听路由等事件
["hashchange", "popstate", "load"].forEach((event) => {
window.addEventListener(event, async () => {
replaceALinks();
if (event === "load") {
observerDocument();
await updateHostnames();
replaceALinks(); // 更新完数据后再执行一次
}
});
});
let hostnames = ["juejin.cn", "sspai.com", "www.zhihu.com"];
function updateHostnames() {
return fetch(
"https://raw.githubusercontent.com/dogodo-cc/redirect-skipper/master/sites.json"
)
.then((response) => {
if (response.ok) {
return response.json();
}
throw new Error("Network response was not ok");
})
.then((data) => {
// 如果拉到了远程数据,就用远程的
hostnames = data.sites.map((site) => {
return site.hostname;
});
})
.catch((error) => {
console.error(error);
});
}
// 符合 '?target=' 格式的链接
// https://link.juejin.cn/?target=https%3A%2F%2Fdeveloper.apple.com%2Fcn%2Fdesign%2Fhuman-interface-guidelines%2Fapp-icons%23macOS/
// https://sspai.com/link?target=https%3A%2F%2Fgeoguess.games%2F
// https://link.zhihu.com/?target=https%3A//asciidoctor.org/
function findByTarget() {
if (!hostnames.includes(location.hostname)) return;
const linkKeyword = "?target=";
const aLinks = document.querySelectorAll(
`a[href*="${linkKeyword}"]:not([data-redirect-skipper])`
);
if (!aLinks) return;
aLinks.forEach((a) => {
const href = a.href;
const targetIndex = href.indexOf(linkKeyword);
if (targetIndex !== -1) {
const newHref = href.substring(targetIndex + linkKeyword.length);
a.href = decodeURIComponent(newHref);
a.setAttribute("data-redirect-skipper", "true");
}
});
}
更详细的流程可以查看 redirect-skipper 仓库地址
标题历史
- 浏览器插件之《跳过第三方链接的提示中转页》
来源:juejin.cn/post/7495977411273490447
前端实现画中画超简单,让网页飞出浏览器
Document Picture-in-Picture 介绍
今天,我来介绍一个非常酷的前端功能:文档画中画 (Document Picture-in-Picture, 本文简称 PiP)。你有没有想过,网页上的任何内容能悬浮在桌面上?😏
🎬 视频流媒体的画中画功能
你可能已经在视频平台(如腾讯视频、哔哩哔哩等网页)见过这种效果:视频播放时,可以点击画中画后。无论你切换页面,它都始终显示在屏幕的最上层,非常适合上班偷偷看电视💻

在今天的教程中,不仅仅是视频,我将教你如何将任何 HTML 内容放入画中画模式,无论是动态内容、文本、图片,还是纯炫酷的 div,统统都能“飞”起来。✨
一个如此有趣的功能,在网上却很少有详细的教程来介绍这个功能的使用。于是我决定写一篇详细的教程来教大家如何实现画中画 (建议收藏)😁
体验网址:Treasure-Navigation
📖 Document Picture-in-Picture 详细教程
🛠 HTML 基本代码结构
首先,我们随便写一个简单的 HTML 页面,后续的 JS 和样式都会基于它实现。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document Picture-in-Picture API 示例</title>
<style>
#pipContent {
width: 600px;
height: 300px;
background: pink;
font-size: 20px;
}
</style>
</head>
<body>
<div id="container">
<div id="pipContent">这是一个将要放入画中画的 div 元素!</div>
<button id="clickBtn">切换画中画</button>
</div>
<script>
// 在这里写你的 JavaScript 代码
</script>
</body>
</html>
1️. 请求 PiP 窗口
PiP 的核心方法是 window.documentPictureInPicture.requestWindow。它是一个 异步方法,返回一个新创建的 window 对象。
PIP 窗口可以将其看作一个新的网页,但它始终悬浮在屏幕上方。
document.getElementById("clickBtn").addEventListener("click", async function () {
// 获取将要放入 PiP 窗口的 DOM 元素
const pipContent = document.getElementById("pipContent");
// 请求创建一个 PiP 窗口
const pipWindow = await window.documentPictureInPicture.requestWindow({
width: 200, // 设置窗口的宽度
height: 300 // 设置窗口的高度
});
// 将原始元素添加到 PiP 窗口中
pipWindow.document.body.appendChild(pipContent);
});
演示:

👏 现在,我们已经成功创建了一个画中画窗口!
这段代码展示了如何将网页中的元素放入一个新的画中画窗口,并让它悬浮在最上面。非常简单吧
关闭PIP窗口
可以直接点右上角关闭PIP窗口,如果我们想在代码中实现关闭,直接调用window上的api就可以了
window.documentPictureInPicture.window.close();
2️. 检查是否支持 PiP 功能
一切不能兼容浏览器的功能介绍都是耍流氓,我们需要检查浏览器是否支持PIIP功能。
实际就是检查documentPictureInPicture属性是否存在于window上 🔧
if ('documentPictureInPicture' in window) {
console.log("🚀 浏览器支持 PiP 功能!");
} else {
console.warn("⚠️ 当前浏览器不支持 PiP 功能,更新浏览器或者换台电脑吧!");
}
如果是只需要将视频实现画中画功能,视频画中画 (Picture-in-Picture) 的兼容性会好一点,但是它只能将<video>元素放入画中画窗口。它与本文介绍的 文档画中画(Document Picture-in-Picture) 使用方法也是十分相似的。


3️. 设置 PiP 样式
我们会发现刚刚创建的画中画没有样式,一点都不美观。那是因为我们只放入了dom元素,没有添加css样式。
3.1. 全局样式同步
假设网页中的所有样式如下:
<head>
<style>
#pipContent {
width: 600px;
height: 300px;
background: pink;
font-size: 20px;
}
</style>
<link rel="stylesheet" type="text/css" href="https://abc.css">
</head>
为了方便,我们可以直接把之前的网页的css样式全部赋值给画中画。
// 1. document.styleSheets获取所有的css样式信息
[...document.styleSheets].forEach((styleSheet) => {
try {
// 转成字符串方便赋值
const cssRules = [...styleSheet.cssRules].map((rule) => rule.cssText).join('');
// 创建style标签
const style = document.createElement('style');
// 设置为之前页面中的css信息
style.textContent = cssRules;
console.log('style', style);
// 把style标签放到画中画的<head><head/>标签中
pipWindow.document.head.appendChild(style);
} catch (e) {
// 通过 link 引入样式,如果有跨域,访问styleSheet.cssRules时会报错。没有跨域则不会报错
const link = document.createElement('link');
/**
* rel = stylesheet 导入样式表
* type: 对应的格式
* media: 媒体查询(如 screen and (max-width: 600px))
* href: 外部样式表的 URL
*/
link.rel = 'stylesheet';
link.type = styleSheet.type;
link.media = styleSheet.media;
link.href = styleSheet.href ?? '';
console.log('error: link', link);
pipWindow.document.head.appendChild(link);
}
});
演示:

3.2. 使用 link 引入外部 CSS 文件
向其他普通html文件一样,可以通过link标签引入特定css文件:
创建 pip.css 文件:
#pipContent {
width: 600px;
height: 300px;
background: skyblue;
}
js引用:
// 其他不变
const link = document.createElement('link');
link.rel = 'stylesheet';
link.href = './pip.css'; // 引入外部 CSS 文件
pipWindow.document.head.appendChild(link);
pipWindow.document.body.appendChild(pipContent);
演示:

3.3. 媒体查询的支持
可以设置媒体查询 @media (display-mode: picture-in-picture)。在普通页面中会自动忽略样式,在画中画模式会自动渲染样式
<style>
#pipContent {
width: 600px;
height: 300px;
background: pink;
font-size: 20px;
}
<!-- 普通网页中会忽略 -->
@media (display-mode: picture-in-picture) {
#pipContent {
background: lightgreen;
}
}
</style>
在普通页面中显示为粉色,在画中画自动变为浅绿色
演示:

4️. 监听进入和退出 PiP 模式的事件
我们还可以为 PiP 窗口 添加事件监听,监控画中画模式的 进入 和 退出。这样,你就可以在用户操作时,做出相应的反馈,比如显示提示或执行其他操作。
// 进入 PIP 事件
documentPictureInPicture.addEventListener("enter", (event) => {
console.log("已进入 PIP 窗口");
});
const pipWindow = await window.documentPictureInPicture.requestWindow({
width: 200,
height: 300
});
// 退出 PIP 事件
pipWindow.addEventListener("pagehide", (event) => {
console.log("已退出 PIP 窗口");
});
演示

5️. 监听 PiP 焦点和失焦事件
const pipWindow = await window.documentPictureInPicture.requestWindow({
width: 200,
height: 300
});
pipWindow.addEventListener('focus', () => {
console.log("PiP 窗口进入了焦点状态");
});
pipWindow.addEventListener('blur', () => {
console.log("PiP 窗口失去了焦点");
});
演示

6. 克隆节点画中画
我们会发现我们把原始元素传入到PIP窗口后,原来窗口中的元素就不见了。
我们可以把原始元素克隆后再传入给PIP窗口,这样原始窗口中的元素就不会消失了
const pipContent = document.getElementById("pipContent");
const pipWindow = await window.documentPictureInPicture.requestWindow({
width: 200,
height: 300
});
// 核心代码:pipContent.cloneNode(true)
pipWindow.document.body.appendChild(pipContent.cloneNode(true));
演示

PIP 完整示例代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document Picture-in-Picture API 示例</title>
<style>
#pipContent {
width: 600px;
height: 300px;
background: pink;
font-size: 20px;
}
</style>
</head>
<body>
<div id="container">
<div id="pipContent">这是一个将要放入画中画的 div 元素!</div>
<button id="clickBtn">切换画中画</button>
</div>
<script>
// 检查是否支持 PiP 功能
if ('documentPictureInPicture' in window) {
console.log("🚀 浏览器支持 PiP 功能!");
} else {
console.warn("⚠️ 当前浏览器不支持 PiP 功能,更新浏览器或者换台电脑吧!");
}
// 请求 PiP 窗口
document.getElementById("clickBtn").addEventListener("click", async function () {
const pipContent = document.getElementById("pipContent");
// 请求创建一个 PiP 窗口
const pipWindow = await window.documentPictureInPicture.requestWindow({
width: 200, // 设置窗口的宽度
height: 300 // 设置窗口的高度
});
// 将原始元素克隆并添加到 PiP 窗口中
pipWindow.document.body.appendChild(pipContent.cloneNode(true));
// 设置 PiP 样式同步
[...document.styleSheets].forEach((styleSheet) => {
try {
const cssRules = [...styleSheet.cssRules].map((rule) => rule.cssText).join('');
const style = document.createElement('style');
style.textContent = cssRules;
pipWindow.document.head.appendChild(style);
} catch (e) {
const link = document.createElement('link');
link.rel = 'stylesheet';
link.type = styleSheet.type;
link.media = styleSheet.media;
link.href = styleSheet.href ?? '';
pipWindow.document.head.appendChild(link);
}
});
// 监听进入和退出 PiP 模式的事件
pipWindow.addEventListener("pagehide", (event) => {
console.log("已退出 PIP 窗口");
});
pipWindow.addEventListener('focus', () => {
console.log("PiP 窗口进入了焦点状态");
});
pipWindow.addEventListener('blur', () => {
console.log("PiP 窗口失去了焦点");
});
});
// 关闭 PiP 窗口
// pipWindow.close(); // 可以手动调用关闭窗口
</script>
</body>
</html>
总结
🎉 你现在已经掌握了如何使用 Document Picture-in-Picture API 来悬浮任意 HTML 内容!
希望能带来更灵活的交互体验。✨
如果你有什么问题,或者对 PiP 功能有更多的想法,欢迎在评论区与我讨论!👇📬
来源:juejin.cn/post/7441954981342036006
还在每次都写判断?试试惰性函数,让你的代码更聪明!
什么是惰性函数?
先来看个例子
function addEvent(el, type, handler) {
if (window.addEventListener) {
el.addEventListener(type, handler, false);
} else {
el.attachEvent('on' + type, handler);
}
}
上面这段代码中,每次调用 addEvent 都会进行一遍判断。实际上,我们并不需要每次都进行判断,只需要执行一次就够了,当然,我们也可以存个全局的flag来记录,但是,有更好的办法了
function addEvent(el, type, handler) {
if (window.addEventListener) {
addEvent = function(el, type, handler) {
el.addEventListener(type, handler, false);
}
} else {
addEvent = function(el, type, handler) {
el.attachEvent('on' + type, handler);
}
}
return addEvent(el, type, handler); // 调用新的函数
}
这就是惰性函数:第一次执行时会根据条件覆盖自身,后续调用直接执行更新后的逻辑。
惰性函数的实现方式
惰性函数一般情况下有两种实现方式
在函数内部重写自身
这种实现方式就是上面我们介绍的那样
function foo() {
console.log('初始化...');
foo = function() {
console.log('后续逻辑');
}
}
大多数情况下,这种实现方式都可以覆盖
用函数表达式赋值
const foo = (function() {
if (someCondition) {
return function() { console.log('A'); }
} else {
return function() { console.log('B'); }
}
})();
这种情况适用于模块或者立即执行的情况,其实就是用闭包做了个封装
惰性函数的应用场景
兼容性判断
我们在做适配的时候,很多时候需要进行浏览器特性的判断,比如之前提到的事件绑定
性能优化
其实惰性函数说起来很像单例,他的原理就是只执行一次,那么如果想要避免一些重复操作,尤其是重复初始化,就可以想一下是不是可以用惰性函数来处理,比如Canvas渲染引擎,加载某些外部依赖、判断登录状态等等
注意事项
- 写好注释,一定要写好注释,因为函数在执行后会变化,不写注释如果除了一些问题,可能后面维护的人会骂街,会大大增加你的不可替代性,咳咳,千万不要这么操作,一定要写好注释
- 不适合频繁修改逻辑和复杂上下文的场景,会增加复杂度
一句话总结:能判断一次就不要判断两次,惰性函数让你的代码更聪明
来源:juejin.cn/post/7490850417976508428
Electron 应用太重?试试 PakePlus 轻装上阵

Electron 作为将 Web 技术带入桌面应用领域的先驱框架,让无数开发者能够使用熟悉的 HTML、CSS 和 JavaScript 构建跨平台应用。然而,随着应用规模的扩大,Electron 应用的性能问题逐渐显现——内存占用高、启动速度慢、安装包体积庞大,这些都成为了用户体验的绊脚石。不过,现在有了 PakePlus,这些烦恼都将迎刃而解。
PakePlus官网文档:PakePlus
PakePlus开源地址:github.com/Sjj1024/Pak…
首先要轻
以一款基于 Electron 的文档编辑应用为例,在使用 PakePlus 优化前,安装包大小达 200MB,启动时间超过 10 秒。但是使用PakePlus重新打包之后,安装包大小控制在5M左右,缩小了将近40倍!启动时间也做到了2秒以内!这就是PakePLus的魅力所在。
开发者反馈:"迁移过程出乎意料的顺利,大部分代码无需修改,性能提升却立竿见影。"

其次都是其次
- 🚀 基于 Rust Tauri,PakePlus 比基于 JS 的框架更轻量、更快。
- 📦 内置丰富功能包——支持快捷方式、沉浸式窗口、极简自定义。
- 👻 PakePlus 只是一个极简的软件,用 Tauri 替代旧的打包方式,支持跨平台桌面,将很快支持手机端。
- 🤗 PakePlus 易于操作使用,只需一个 GitHub Token,即可获得桌面应用。
- 🌹 不需要在本地安装任何复杂的依赖环境,使用 Github Action 云端自动打包。
- 🧑🤝🧑 支持国际化,对全球用户都非常友好,并且会自动跟随你的电脑系统语言。
- 💡 支持自定义 js 注入。你可以编写自己的 js 代码注入到页面中。
- 🎨 ui 界面更美观更友好对新手更实用,使用更舒适,支持中文名称打包。
- 📡 支持网页端直接使用,但是客户端功能更强大,更推荐客户端。
- 🔐 数据安全,你的 token 仅保存在你本地,不会上传服务器,你的项目也都在你自己的 git 中安全存储。
- 🍀 支持静态文件打包,将 Vue/React 等项目编译后的 dist 目录或者 index.html 丢进来即可成为客户端,何必是网站。
- 🐞 支持 debug 调试模式,无论是预览阶段还是发布阶段,都可以找到 bug 并消灭 bug
使用场景
你有一个网站,想把它立刻变成跨平台桌面应用和手机APP,立刻高大尚。
你有一个 Vue/React 等项目,不想购买服务器,想把它打包成桌面应用。
你的 Cocos 游戏是不是想要跨平台客户端运行?完全没有问题。
你的 Unity 项目是不是想要跨平台打包为客户端?也完全没有问题。
隐藏你的网站地址,不被随意传播和使用,防止爬虫程序获取你的网站内容。
公司内网平台,不想让别人知道你的网站地址,只允许通过你的客户端访问。
想把某个网站变成自己的客户端,实现自定义功能,比如注入 js 实现自动化操作。
网站广告太多?想把它隐藏起来,用无所不能的 js 来屏蔽它们吧。
需要使用 tauri2 打包,但是依赖环境太复杂,本地电脑硬盘不够用,就用 PakePlus
热门包

PakePLus 支持 arm 和 inter 架构的安装包,流行的程序安装包仅仅包含了 mac 的 arm(M 芯片)版本 和 windows 的 Inter(x64)版本 和 Linux 的 x64 版本,如果需要更多架构的安装包,请使用 PakePlus 单独编译自己需要的安装包。热门包的下载地址请到官方文档下载体验
常见问题
mac提示:应用已随坏

这是因为没有给苹果给钱,所以苹果会拒绝你的应用。
解决办法:
Mac 用户可能在安装时看到“应用已损坏”的警告。 请点击“取消”,然后运行以下命令,输入电脑密码后,再重新打开应用:(这是由于应用需要官方签名,才能避免安装后弹出“应用已损坏”的提示,但官方签名的费用每年 99 美元...因此,需要手动绕过签名以正常使用)
sudo xattr -r -d com.apple.quarantine /Applications/PakePlus.app当你打包应用时,Mac 用户可能在安装时看到“应用已损坏”的警告。 请点击“取消”,然后运行以下命令,再重新打开应用:
sudo xattr -r -d com.apple.quarantine /Applications/你的软件名称.app来源:juejin.cn/post/7490876486292389914
只需一行代码,任意网页秒变可编辑!
大家好,我是石小石!
在我们日常工作中,可能会遇到截图页面的场景,有时页面有些内容不符合要求,我们可能需要进行一些数值或内容的修改。如果你会PS,修改内容难度不高,如果你是前端,打开控制台也能通过修改dom的方式进行简单的文字修改。
今天,我就来分享一个冷门又实用的前端技巧 —— 只需一行 JavaScript 代码,让任何网页瞬间变成可编辑的! 先看看效果:
甚至,还可以插入图片等媒体内容

如何实现
很难想象,这么炫酷的功能,居然只需要在控制台输入一条指令:
document.designMode = "on";
打开浏览器控制台(F12),复制粘贴这行代码,回车即可。

如果你想关闭此功能,输入document.designMode = "off"即可。
Document:designMode 属性
MDN是这样介绍的:
document.designMode 控制整个文档是否可编辑。有效值为 "on" 和 "off"。根据规范,该属性默认为 "off"。Firefox 遵循这一标准。早期版本的 Chrome 和 IE 默认为 "inherit"。从 Chrome 43 开始,默认为 "off" 并不再支持 "inherit"。在 IE6-10 中,该值为大写。
兼容性方面,基本上所有浏览器都是支持的。

借助次API,我们也能实现Iframe嵌套页面的编辑:
iframeNode.contentDocument.designMode = "on";
关联API
与designMode关联的API其实还有contentEditable和execCommand(已弃用,但部分浏览器还可以使用)。
contentEditable与designMode功能类似,不过contentEditable可以使特定的 DOM 元素变为可编辑,而designMode只能使整个文档可编辑。
| 特性 | contentEditable | document.designMode |
|---|---|---|
| 作用范围 | 可以使单个元素可编辑 | 可以使整个文档可编辑 |
| 启用方式 | 设置属性为 true或 false | 设置 document.designMode = "on" |
| 适用场景 | 用于指定某些元素,如 <div>, <span>等 | 用于让整个页面变为可编辑 |
| 兼容性 | 现代浏览器都支持 | 现代浏览器都支持,部分老旧浏览器可能不支持 |
document.execCommand() 方法允许我们在网页中对内容进行格式化、编辑或操作。它主要用于操作网页上的可编辑内容(如 <textarea> 或通过设置 contentEditable 或 designMode 属性为 "true" 的元素),例如加粗文本、插入链接、调整字体样式等。由于它已经被W3C弃用,所以本文也不再介绍了。
来源:juejin.cn/post/7491188995164897320
老板花一万大洋让我写的艺术工作室官网?! HeroSection 再度来袭!(Three.js)
引言.我不是鸽子大王!!
哈喽大家好!距离我上次发文已经过去半个月了,差点又变回了那只熟悉的“老鸽子”。不行,我不能堕落!我还没有将 Web3D 推广到普罗大众,还没有让更多人感受到三维图形的魅力 (其实是还没有捞着米)。怀着这样的心情,我决定重新振作,继续为大家带来更多关于 Three.js 和 Shader 的进阶内容。
0.前置条件
欢迎阅读本篇文章!在深入探讨 Three.js 和 Shader (GLSL) 的进阶内容之前,确保您已经具备以下基础知识:
- Three.js 基础:您需要熟悉
Three.js的基本概念和使用方法,包括场景(Scene)、相机(Camera)、渲染器(Renderer)、几何体(Geometry)、材质(Material)和网格(Mesh)等核心组件。如果您还不熟悉这些内容,建议先学习Three.js的入门教程。 - Shader 语法:本文涉及
GLSL(OpenGL Shading Language)的编写,因此您需要了解GLSL的基本语法,包括顶点着色器(Vertex Shader)和片元着色器(Fragment Shader)的编写,以及如何在Three.js中使用自定义着色器。
1. Hero Section 概览
Hero Section 是网页设计中的一个术语,通常指页面顶部的一个大型横幅区域。但对于开发人员而言,这个概念可以更直观地理解为用户在访问网站的瞬间所感受到的视觉冲击,或者促使用户停留在该网站的关键原因因素。
话说这天老何接到了一个私活

起始钱不钱的无所谓!主要是想挑战一下自己(不是)。最后的成品如图所示 (互动方式为鼠标滑动 + 鼠标点击 GIF 压缩太多了内容了,实际要好看很多)。

PC端在线预览地址: fluid-light.vercel.app
Debug调试界面: fluid-light.vercel.app/#debug
2.基础场景搭建
首先我来为你解读一下这个场景里面有什么,他非常简单。只有一个可以接受光照影响的平面几何体以及数个点光源构成,仅此而已。
让我去掉后处理以及一些页面文本元素展示给你看

构建这样的一个基础场景不难。
2.1 构建平面几何体
让我们先来解决平面几何体
值得注意的是,为了让显示效果更好,我使用了正交相机并让平面覆盖整个视窗大小
this.geometry = new THREE.PlaneGeometry(2 * 屏幕宽高比, 2);
然后构建相应的物理材质,可以去 polyhaven 下载一些自己喜欢的texture 并下载下来。

根据右边的分类选择纹理大类细分,随后选择想要下载的纹理点击下载。
因为我们本质是需要 Displacement Texture置换贴图 & Normal Texture 法线贴图
所以不需要太在意这个纹理是作用在什么物件上面的

随后将纹理导入后赋予材质相应的属性,并对部分参数进行调整。通常直接赋予displacementMap 后 Threejs 中显示平面的凹凸会特别明显。所以记得通过
displacementScale来调整相应的大小。
this.material = new THREE.MeshPhysicalMaterial({
color: '#121423',
metalness: 0.59,
roughness: 0.41,
displacementMap: 下载的纹理贴图,
displacementScale: 0.1,
normalMap: 下载的法线贴图,
normalScale: new THREE.Vector2(0.68, 0.75),
side: THREE.FrontSide
});
最后将物体加入场景即可
this.mesh = new THREE.Mesh(this.geometry, this.material);
scene.add(this.mesh);
(tips:MeshStandardMaterial 和 MeshPhysicalMaterial 适合需要真实感光照和复杂物理特性的场景,但性能消耗较高。如果您的电脑出现卡顿可以选择消耗较少性能的物理材质)
2.2 灯光加入战场
在本案例中,高级感的来源之一就是灯光的变换。如果您足够细心,可能会注意到一些更微妙的细节:场景中的灯光并不是简单地从 A Color 切换到 B Color,而是同时存在多个光源,并且它们的强度也在动态变化。这种设计使得场景的光影效果更加丰富和立体。

如果场景中只有一个光源,效果可能会显得单调。而本案例中,灯光的变化呈现出一种层次感:中间是白色,周围还有一层类似年轮的光圈,最后逐渐扩散为纯色背景。这种效果的关键在于同一时间场景中存在多个点光源。虽然多个光源会显著增加性能消耗,但为了实现唯美的视觉效果,这是值得的。
让我们逐步分析灯光是如何实现的。
1. 封装创建点光源的函数
为了简化代码并提高复用性,我们可以先封装一个创建点光源的函数。这个函数会返回一个包含光源对象和目标颜色的对象。
createPointLight(intensity) {
const light = new THREE.PointLight(
0xff_ff_ff,
intensity,
100,
Math.random() * 10
);
light.position.copy(this.lightPosition); //所有的光源都同步在一个位置
return {
object: light,
targetColor: new THREE.Color()
};
}
2. 生成多个点光源
接下来,我们可以调用这个函数生成多个点光源,并将它们添加到场景中。
this.colors = [
new THREE.Color('orange'),
new THREE.Color('red'),
new THREE.Color('red'),
new THREE.Color('orange'),
new THREE.Color('lightblue'),
new THREE.Color('green'),
new THREE.Color('blue'),
new THREE.Color('blue')
];
this.lights = [
this.createPointLight(2),
this.createPointLight(3),
this.createPointLight(2.5),
this.createPointLight(10),
this.createPointLight(2),
this.createPointLight(3),
];
// 初始化灯光颜色
const numberLights = this.lights.length;
for (let index = 0; index < numberLights; index++) {
const colorIndex = Math.min(index, this.colors.length - 1);
this.lights[index].object.color.copy(this.colors[colorIndex]);
}
for (const light of this.lights) this.scene.add(light.object);
3. 动态调整光源强度
在场景中,所有光源同时存在,但它们的强度会有所不同。每次由光照强度为 10 的光源担任场景的主色。当用户点击场景时,灯光会像上楼梯或者传送带一样逐步切换,即由新的点光源担任场景主色。
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa,
8 8"b, "Ya
8 8 "b, "Ya
8 aa=D光源=a8, "b, "Ya
8 8"b, "Ya "8""""""8
8 8 "b, "Ya 8 8
8 a=C光源=8, "b, "Ya8 8
8 8"b, "Ya "8""""""" 8
8 8 "b, "Ya 8 8
8 a=B光源=8, "b, "Ya8 8
8 8"b, "Ya "8""""""" 8
8 8 "b, "Ya 8 8
8=A光源=, "b, "Ya8 8
8"b, "Ya "8""""""" 8
8 "b, "Ya 8 8
8, "b, "Ya8 8
"Ya "8""""""" 8
"Ya 8 8
"Ya8 8
"""""""""""""""""""""""""""""""""""""
让我们看看代码是如何实现的吧
window.addEventListener('click', () => {
// 打乱颜色数组(看个人喜好)
this.colors = [...this.colors.sort(() => Math.random() - 0.5)];
// 标记开始颜色过渡
this.colorTransition = true;
// 为每个灯光设置目标颜色
const numberLights = this.lights.length;
for (let index = 0; index < numberLights; index++) {
const colorIndex = Math.min(index, this.colors.length - 1);
this.lights[index].targetColor = this.colors[colorIndex].clone();
}
});
然后再Render函数中以easeing方式更新颜色
update() {
// 只在需要时更新颜色
if (this.colorTransition) {
const numberLights = this.lights.length;
const baseSmooth = 0.25;
const smoothIncrement = 0.05;
let allTransitioned = true; // 检查所有颜色是否已完成过渡
for (let index = 0; index < numberLights; index++) {
const smoothTime = baseSmooth + index * smoothIncrement;
// 使用目标颜色进行平滑过渡
const currentColor = this.lights[index].object.color;
const targetColor = this.lights[index].targetColor;
this.dampC(currentColor, targetColor, smoothTime, delta);
// 检查是否还在过渡
if (!this.isColorClose(currentColor, targetColor)) {
allTransitioned = false;
}
}
// 如果所有颜色都已完成过渡,停止更新
if (allTransitioned) {
this.colorTransition = false;
}
}
}
3.后处理完善场景
在完成了场景的基本构建之后,我们已经实现了大约 80% 的内容。即使现在加上 UI,效果也不会太差。不过,为了让场景更具视觉冲击力和艺术感,我们可以通过后处理(Post Processing)技术来进一步提升质感。

使用 UnrealBloomPass 和 FilmPass
在本文中,我们将使用 UnrealBloomPass(辉光效果)和 FilmPass(电影滤镜)来增强场景的视觉效果。以下是具体的实现步骤:
- 引入后处理库:首先,我们需要引入
Three.js的后处理库EffectComposer以及相关的Pass类。 - 创建
EffectComposer:EffectComposer是后处理的核心类,用于管理和执行各种后处理效果。 - 添加
RenderPass:RenderPass用于将场景渲染到后处理管道中。 - 添加
UnrealBloomPass:UnrealBloomPass用于实现辉光效果,可以使场景中的亮部区域产生光晕。 - 添加
FilmPass:FilmPass用于模拟电影胶片的效果,增加颗粒感和复古风格。
这里的具体参数需要看个人品味进行调试。同款参数可以从这里看我的源码。具体路径位于src\js\world\effect.js
this.composer = new EffectComposer(this.renderer);
this.composer.addPass(this.renderPass);
this.composer.addPass(this.bloomPass);
this.composer.addPass(this.filmPass);
此时页面的质感是不是一下就上来了呢?

最后我们需要添加最关键的一部,就是画面扭曲。
这里我们需要用到 Threejs 的 ShaderPass,让我们来创建一个初始的ShaderPass,仅将 EffectComposer 的读取缓冲区的图像内容复制到其写入缓冲区,而不应用任何效果。
具体内容你可以从 Threejs 后处理中了解到更多
import { ShaderPass } from 'three/addons/postprocessing/ShaderPass.js';
const BaseShader = {
name: 'BaseShader',
uniforms: {
'tDiffuse': { value: null },
'opacity': { value: 1.0 }
},
vertexShader: /* glsl */`
varying vec2 vUv;
void main() {
vUv = uv;
gl_Position = projectionMatrix * modelViewMatrix * vec4( position, 1.0 );
}`,
fragmentShader: /* glsl */`
uniform float opacity;
uniform sampler2D tDiffuse;
varying vec2 vUv;
void main() {
vec4 texel = texture2D( tDiffuse, vUv );
gl_FragColor = opacity * texel;
}`
};
const BasePass = new ShaderPass( BaseShader );
此时画面不会有任何变化
让我们对uv进行简单操纵,让其读取tDiffuse时可以发生扭曲
vec2 uv = vUv;
uv.y += sin(uv.x * frequency + offset) * amplitude;
gl_FragColor = texture2D(tDiffuse, uv);
最后得到效果

4.最后一些话
技术的未来与前端迁移
随着 AI 技术的快速发展,各类技术的门槛正在大幅降低,以往被视为高门槛的 3D 技术也不例外。与此同时,过去困扰开发者的数字资产构建成本问题,也正在被最新的 3D generation 技术所攻克。这意味着,在不久的将来,前端开发将迎来一次技术迁移,开发者需要掌握更新颖的交互方式和更出色的视觉效果。
为什么选择 Three.js?
Three.js 作为最流行的 WebGL 库之一,不仅简化了三维图形的开发流程,还提供了丰富的功能和强大的扩展性。无论是创建复杂的 3D 场景,还是实现炫酷的视觉效果,Three.js 都能帮助开发者快速实现目标。
本专栏的愿景
本专栏的愿景是通过分享 Three.js 的中高级应用和实战技巧,帮助开发者更好地将 3D 技术应用到实际项目中,打造令人印象深刻的 Hero Section。我们希望通过本专栏的内容,能够激发开发者的创造力,推动 Web3D 技术的普及和应用。
加入社区,共同成长
如果您对 Threejs 这个 3D 图像框架很感兴趣,或者您也深信未来国内会涌现越来越多 3D 设计风格的网站,欢迎加入 ice 图形学社区。这里是国内 Web 图形学最全的知识库,致力于打造一个全新的图形学生态体系!您可以在认证达人里找到我这个 Threejs 爱好者和其他大佬。
此外,如果您很喜欢 Threejs 又在烦恼其原生开发的繁琐,那么我诚邀您尝试 Tresjs 和 TvTjs, 他们都是基于 Vue 的 Threejs 框架。 TvTjs 也为您提供了大量的可使用案例,并且拥有较为活跃的开发社区,在这里你能碰到志同道合的朋友一起做开源!
5.下期预告
未来科技?机器人概念官网来袭 !!!

6. 往期回顾
2025 年了,我不允许有前端不会用 Trae 让页面 Hero Section 变得高级!!!(Threejs)
2024年了,前端人是时候给予页面一点 Hero Section 魔法了!!! (Three.js)
来源:juejin.cn/post/7478403990141796352
前端如何优雅通知用户刷新页面?
前言
老板:新的需求不是上线了嘛,怎么用户看到的还是老的页面呀
窝囊废:让用户刷新一下页面,或者清一下缓存
老板:那我得告诉用户,刷新一下页面,或者清一下缓存,才能看到新的页面呀,感觉用户体验不好啊,不能直接刷新页面嘛?
窝囊废:可以解决(OS:一点改的必要没有,用户全是大聪明)
老板:新的需求不是上线了嘛,怎么用户看到的还是老的页面呀
窝囊废:让用户刷新一下页面,或者清一下缓存
老板:那我得告诉用户,刷新一下页面,或者清一下缓存,才能看到新的页面呀,感觉用户体验不好啊,不能直接刷新页面嘛?
窝囊废:可以解决(OS:一点改的必要没有,用户全是大聪明)
产品介绍
c端需要经常进行一些文案调整,一些老版的文字字眼可能会导致一些舆论问题,所以就需要更新之后刷新页面,让用户看到新的页面。
c端需要经常进行一些文案调整,一些老版的文字字眼可能会导致一些舆论问题,所以就需要更新之后刷新页面,让用户看到新的页面。
思考问题为什么产生
项目是基于vue的spa应用,通过nginx代理静态资源,配置了index.html协商缓存,js、css等静态文件Cache-Control,按正常前端重新部署后, 用户重新访问系统,已经是最新的页面。
但是绝大部份用户都是访问页面之后一直停留在此页面,这时候前端部署后,用户就无法看到新的页面,需要用户刷新页面。
项目是基于vue的spa应用,通过nginx代理静态资源,配置了index.html协商缓存,js、css等静态文件Cache-Control,按正常前端重新部署后, 用户重新访问系统,已经是最新的页面。
但是绝大部份用户都是访问页面之后一直停留在此页面,这时候前端部署后,用户就无法看到新的页面,需要用户刷新页面。
产生问题
- 如果后端接口有更新,前端重新部署后,用户访问老的页面,可能会导致接口报错。
- 如果前端部署后,用户访问老的页面,可能无法看到新的页面,需要用户刷新页面,用户体验不好。
- 出现线上bug,修复完后,用户依旧访问老的页面,仍会遇到bug。
- 如果后端接口有更新,前端重新部署后,用户访问老的页面,可能会导致接口报错。
- 如果前端部署后,用户访问老的页面,可能无法看到新的页面,需要用户刷新页面,用户体验不好。
- 出现线上bug,修复完后,用户依旧访问老的页面,仍会遇到bug。
解决方案
- 前后端配合解决
- WebSocket
- SSE(Server-Send-Event)
- 纯前端方案 以下示例均以vite+vue3为例;
- 轮询html Etag/Last-Modified
- 前后端配合解决
- WebSocket
- SSE(Server-Send-Event)
- 纯前端方案 以下示例均以vite+vue3为例;
在App.vue中添加如下代码
const oldHtmlEtag = ref();
const timer = ref();
const getHtmlEtag = async () => {
const { protocol, host } = window.location;
const res = await fetch(`${protocol}//${host}`, {
headers: {
"Cache-Control": "no-cache",
},
});
return res.headers.get("Etag");
};
oldHtmlEtag.value = await getHtmlEtag();
clearInterval(timer.value);
timer.value = setInterval(async () => {
const newHtmlEtag = await getHtmlEtag();
console.log("---new---", newHtmlEtag);
if (newHtmlEtag !== oldHtmlEtag.value) {
Modal.destroyAll();
Modal.confirm({
title: "检测到新版本,是否更新?",
content: "新版本内容:",
okText: "更新",
cancelText: "取消",
onOk: () => {
window.location.reload();
},
});
}
}, 30000);
- versionData.json
自定义plugin,项目根目录创建/plugins/vitePluginCheckVersion.ts
import path from "path";
import fs from "fs";
export function checkVersion(version: string) {
return {
name: "vite-plugin-check-version",
buildStart() {
const now = new Date().getTime();
const version = {
version: now,
};
const versionPath = path.join(__dirname, "../public/versionData.json");
fs.writeFileSync(versionPath, JSON.stringify(version), "utf8", (err) => {
if (err) {
console.log("写入失败");
} else {
console.log("写入成功");
}
});
},
};
}
在vite.config.ts中引入插件
import { checkVersion } from "./plugins/vitePluginCheckVersion";
plugins: [
vue(),
checkVersion(),
]
在App.vue中添加如下代码
const timer = ref()
const checkUpdate = async () => {
let res = await fetch('/versionData.json', {
headers: {
'Cache-Control': 'no-cache',
},
}).then((r) => r.json())
if (!localStorage.getItem('demo_version')) {
localStorage.setItem('demo_version', res.version)
} else {
if (res.version !== localStorage.getItem('demo_version')) {
localStorage.setItem('demo_version', res.version)
Modal.confirm({
title: '检测到新版本,是否更新?',
content: '新版本内容:' + res.content,
okText: '更新',
cancelText: '取消',
onOk: () => {
window.location.reload()
},
})
}
}
}
onMounted(()=>{
clearInterval(timer.value)
timer.value = setInterval(async () => {
checkUpdate()
}, 30000)
})
Use
// vite.config.ts
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import { webUpdateNotice } from '@plugin-web-update-notification/vite'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
webUpdateNotice({
logVersion: true,
}),
]
})
来源:juejin.cn/post/7439905609312403483
部署项目,console.log为什么要去掉?
console.log的弊端
1. 影响性能(轻微但可优化)
console.log 会占用 内存 和 CPU 资源,尤其是在循环或高频触发的地方(如 mousemove 事件)。
虽然现代浏览器优化了 console,但大量日志仍可能导致 轻微性能下降。
2. 暴露敏感信息(安全风险)
可能会 泄露 API 接口、Token、用户数据 等敏感信息,容易被恶意利用。
3. 干扰调试(影响开发者体验)
生产环境日志过多,可能会 掩盖真正的错误信息,增加调试难度。
开发者可能会误以为某些 console.log 是 预期行为,而忽略真正的 Bug。
4. 增加代码体积(影响加载速度)
即使 console.log 本身很小,但 大量日志 会增加打包后的文件体积,影响 首屏加载速度。
解决方案:移除生产环境的 console.log
1. 使用 Babel 插件
在 babel.config.js 中配置:
module.exports = {
presets: [
'@vue/cli-plugin-babel/preset',
],
plugins: [
['@babel/plugin-proposal-optional-chaining'],
...process.env.NODE_ENV === 'production' ? [['transform-remove-console', { exclude: ['info', 'error', 'warn'] }]] : []
]
}
特点:
- 不影响源码,仅在生产环境生效,开发环境保留完整
console。 - 配置简单直接,适合快速实现基本需求。
- 依赖 Babel 插件
2. 使用 Terser 压缩时移除(Webpack/Vite 默认支持)
在 vite.config.js 或 webpack.config.js 中配置:
module.exports = {
chainWebpack: (config) => {
config.optimization.minimizer("terser").tap((args) => {
args[0].terserOptions.compress = {
...args[0].terserOptions.compress,
drop_console: true, // 移除所有 console
pure_funcs: ["console.log"], // 只移除 console.log,保留其他
};
return args;
});
},
};
特点:
- 不影响源码,仅在生产环境生效,开发环境保留完整
console。 - 避免 Babel 插件兼容性问题
- 需要额外配置
3. 自定义 console 包装函数(按需控制)
// utils/logger.js
const logger = {
log: (...args) => {
if (process.env.NODE_ENV !== "production") {
console.log("[LOG]", ...args);
}
},
warn: (...args) => {
console.warn("[WARN]", ...args);
},
error: (...args) => {
console.error("[ERROR]", ...args);
},
};
export default logger;
使用方式
import logger from "./utils/logger";
logger.log("Debug info"); // 生产环境自动不打印
logger.error("Critical error"); // 始终打印
特点:
- 可以精细控制日志,可控性强,可以自定义日志级别。
- 不影响
console.warn和console.error。 - 需要手动替换
console.log
来源:juejin.cn/post/7485938326336766003
因网速太慢我把20M+的字体压缩到了几KB
于水增
故事背景
事情起源于之前做的海报编辑器,自己调试时无意中发现字体渲染好慢,第一反应就是网怎么变慢了,断网了?仔细一看才发现,淦!这几个字体资源咋这么大,难怪网速变慢了呢😁😁。

图片中的海报包含6种字体,其中最大的字体文件超过20M,而最长的网络加载时长已接近20s。所以海报实际效果图展示耗时太久,很影响用户体验。那就趁此机会跟大家聊聊 字体 这件小事。
字体文件为什么那么大?
🙋 DeepSeek同学来回答下大家:
这里所说的大体积的字体资源多数是指中文主要原因下边两点
- 中文字符数量庞大,英文仅 26 个字母 + 符号,中文(全字符集)包含 70,000+ 字符
- 字形结构复杂,字体文件需为每个字符存储独立的矢量轮廓数据,而汉字笔画复杂,每个字符需存储数百个控制点坐标(例如「龍」字的轮廓点数量可能是「A」的 10 倍以上)
总结下来就是咱们不光汉字多,书法也是五花八门,它是真小不了。如果你硬要压缩,我们只能从第一点入手,将字符数量进行缩减,比如保留 1000 个常用汉字。
web网站中常见字体格式

由于我司物料部门提供的为TTF格式,所以这里通过 思源黑体 给一个直观的对比:
- TTF 文件:16.9 MB
- WOFF2 文件:7.4 MB(压缩率约 60%)
两者为什么会差这么多,其实WOFF2 只是在 TTF/OTF 基础上添加了压缩和 Web 专用元数据,且WOFF2支持增量解码,也就是边下载边解析,文本可更快显示(即使字体未完全加载,不过有待考证)。
TTF有办法优化吗?
回归问题本身
首先来简单回顾下我们自定义的字体是如何在浏览器中完成渲染的
一般情况下我们对字体文件的引用方式为下边三种
- 通过绝对路径来引用,这种就是将字体文件打包在工程内,所以带来的结果就是工程打包文件体积太大
@font-face {
font-family: 'xxx';
src: url('../../assets/fonts.woff2')
}
- 第二种就是 CDN 中存放的字体文件,一般是通过这种方式来减少工程的编译后体积
@font-face {
font-family: 'xxx';
src: url('https://xxx.woff2')
}
- 通过 FontFace 构造一个字体对象
前两种一般是在浏览器构建 CSSOM 时,当遇到**<font style="color:rgba(0, 0, 0, 0.9);background-color:rgb(243, 243, 243);">url()</font>** 引用时会发起资源请求。第三种则是通过 js 来控制字体的加载流程,所以归根结底就是字体文件太大,导致网络资源下载速度慢,我们只能从优化字体大小的方向入手
确定解决方向
下面汇总下查到的具体几个优化方案,诸如提高网络传输效率,增加缓存之类的就不讲了,能够立竿见影的主要下边这两个方案
| 方案 | 方法/原理 | 适用场景 |
|---|---|---|
| 字体子集化 | 通过工具将字体文件进行提取(支持动态),返回指定的字符集的字体文件,其根本就是减少单次资源请求的体积,需要服务端支持 | 这个方案是所有优化场景的基础 |
| 按需加载 | 通过设置 unicode-range 属性,浏览器在进行css样式计算时候,会根据页面中的字符与设置的字符范围进行比对,匹配上会加载对应的字体文件 | 前提是资源已经被子集化,比较适用多语言切换的场景 |
简单来说,字体子集化可单独食用,按需加载则必须要将字体前置子集化。才能完美实现按需加载。就我的这个项目而言,动态子集化方案不要太完美,毕竟一张海报本身就没几个字儿!所以我们这次将抛弃 CDN,通过动态的将服务本地中的字体资源子集化来实现字体的压缩效果。

这里我们使用python中的一个字体工具库 fontTools 来实现一个动态子集化,类似于 Google Fonts 的实现。核心思路就是将字符传给服务端,通过工具将传入的字符在本地字体文件中提取并返回给客户端,通过fontTools 还可以将TTF格式转化为和Web更搭的WOFF2格式。实现细节如下述代码所示
@app.route('/font/<font_name>', methods=['GET'])
def get_font_subset(font_name):
# 获取本地字体文件路径
font_path = os.path.join(FONTS_DIR, f"{font_name}.ttf")
# 获取子集字符
chars = request.args.get('text', '')
# 字体文件格式
format = request.args.get('format', 'woff2').lower()
# 处理字符,去重
unique_chars = ''.join(sorted(set(chars)))
try:
# 配置子集化选项
options = Options()
options.flavor = format if format in {'woff', 'woff2'} else
options.desubroutinize = True # 增强兼容性
subsetter = Subsetter(options=options)
# 加载字体并生成子集
font = TTFont(font_path)
subsetter.populate(text=unique_chars)
subsetter.subset(font)
# 保存为指定格式
buffer = io.BytesIO()
font.save(buffer)
buffer.seek(0)
# 确定MIME类型
mime_type = {
'woff2': 'font/woff2',
'woff': 'font/woff',
}[format]
# 创建响应并设置
response = Response(buffer.read(), mimetype=mime_type)
# 其他设置...
return response
except Exception as e:
# 子集化失败...
前端代码中增加了一些字符提取的工作,我本身就是通过 FontFace Api 来请求字体资源的,所以我仅需将资源链接替换为子集化字体的接口就可以了,下面代码来描述字体的加载过程
// ...其他逻辑
Toast.loading('字体加载中')
// 遍历海报中的字体对象
[...new Set(fontFamilies)].forEach((fontName) => {
// 在字体库中找到对应字体详细信息
const obj = fontLibrary.find((el) => el?.value === fontName) ?? {};
if (obj.value && obj.src) {
// 处理海报中提取的文案集合
const text = textMap[obj.value].join('');
// 构建字体对象
const font = new FontFace(
obj.value,
`url(http://127.0.0.1:5000/font/${obj.value}?text=${text}&format=woff2)`
);
// 加载字体
font.load();
// 添加到文档字体集中
document.fonts.add(font);
}
});
// 文档所有字体加载完毕后返回成功的 Promise
return document.fonts.ready.finally(() => Toast.destory());
好了,刷新下浏览器,来看看最终的效果:

这这 真立竿见影(主要是基数大😁😁),最终得到的结果就是,实际 22.4M 的字体文件,子集化后缩减到 3.6KB。实际效果图生成的时间由 20s+ 缩减到毫秒级(300ms 以内)。这下就无惧网速了吧!
结语
总的来说,优化字体加载的方案有很多,我们需要结合自己的实际业务场景来进行选型,字体子集化确实是一种高效且实用的优化手段,更多的实践思路可以参考下 Google fonts。
来源:juejin.cn/post/7490337281866317836
面试官:前端倒计时有误差怎么解决
前言
去年遇到的一个问题,也是非常经典的面试题了。能聊的东西还蛮多的
倒计时为啥不准
一个最简单的常用倒计时:
const [count, setCount] = useState(0)
let total = 10 // 倒计时10s
const countDown = ()=>{
if(total > 0){
setCount(total)
total--
setTimeout(countDown ,1000)
}
}

稍微有几毫秒的误差,但是问题不大。
原因:JavaScript是单线程,setTimeout 的回调函数会被放入事件队列,既然要排队,就可能被前面的任务阻塞导致延迟 。且任务本身从call stack中拿出来执行也要耗时。所以有1000变1002也合理。就算setTimeout的第二个参数设为0,也会有至少有4ms的延迟。
如果切换了浏览器tab,或者最小化了浏览器,那误差就会变得大了。

倒计时10s,实际时间却经过了15s,误差相当大了。(不失为一种穿越时间去到未来的方法)
原因:当页面处于后台时,浏览器会降低定时器的执行频率以节省资源,导致 setTimeout 的延迟增加。切回来后又正常了
目标:解决切换后台导致的倒计时不准问题
解决方案1
监听 visibilitychange 事件,在切回tab时修正。
页面从后台离开或者切回来,都能触发visibilitychange事件。只需在document.visibilityState === 'visible'时去修正时间,删掉旧的计时器,设置正确的计时,计算下一次触发的差值,然后创建新的计时器。
// 监听页面切换
useEffect(() => {
const handleVisibilityChange = () => {
console.log('Page is visible:', document.visibilityState);
if(document.visibilityState === 'visible'){
updateCount()
}
};
// 添加事件监听器
document.addEventListener('visibilitychange', handleVisibilityChange);
// 清理函数:移除事件监听器
return () => {
document.removeEventListener('visibilitychange', handleVisibilityChange);
};
}, []);
// 修正倒计时
const updateCount = ()=>{
clearTimeout(timer) // 清除
const nowStamp = Date.now()
const pastTime = nowStamp - firstStamp
const remainTime = CountSeconds * 1000 - pastTime
if(remainTime > 0){
setCount(Math.floor(remainTime/1000))
total = Math.floor(remainTime/1000)
timer = setTimeout(countDown,remainTime%1000)
}else{
setCount(0)
console.log('最后时间:',new Date().toLocaleString(),'总共耗时:', nowStamp-firstStamp)
}
}
特点:会跳过一些时刻计数,可能会错过一些关键节点上事件触发。如果长时间离开,误差变大,实际时间结束,倒计时仍在,激活页面时才结束。

解决方案2
修改回调函数,自带修正逻辑,每次执行时都去修正
// 每次都修正倒计时
const countDown = ()=>{
const nowDate = new Date()
const nowStamp = nowDate.getTime()
firstStamp = firstStamp || nowStamp
lastStamp = lastStamp || nowStamp
const nextTime = firstStamp + (CountSeconds-total) * 1000
const gap = nextTime - nowStamp ;
// 如果当前时间超过了下一次应该执行的时间,就修正时间
if(gap < 1){
clearTimeout(timer)
if(total == 0){
setCount(0)
console.log('最后时间:',nowDate.toLocaleString(),'总共耗时:', nowStamp-firstStamp)
}else{
console.log('left',total, 'time:',nowDate.toLocaleString(),'间隔:',nowStamp-lastStamp)
lastStamp = nowStamp
setCount(total)
total--
countDown()
}
}else{
timer = setTimeout(countDown,gap)
}
}
结果:

特性:每个倒计时时刻都触发,最后更新更精准。(顺便一提,edge浏览器后台状态timeout间隔最低是1000)
解决方案3
上面的都依赖Date模块,改本地时间就会爆炸,一切都乱套了。(可以用performance.now 来缺相对值判断时间)
有没有方案让时钟像邓紫棋一样一直倒数的

有的,就是用web worker,单独的线程去计时,不会受切tab影响
let intervalId;
let count = 0;
self.onmessage = function (event) {
const data = event.data; // 接收主线程传递的数据
console.log('Worker received:', data);
count = data;
intervalId = setInterval(countDown,1000); // 这里用了interval
};
function countDown() {
count--
self.postMessage(count); // 将结果发送回主线程
if (count == 0) {
clearInterval(intervalId);
}
}
const [worker, setWorker] = useState(null);
// 初始化 Web Worker
useEffect(() => {
const myWorker = new Worker(new URL('./worker.js', import.meta.url));
// 监听 Worker 时钟 返回的消息
myWorker.onmessage = (event) => {
// console.log('Main thread received:', event.data);
const left = event.data
const nowDate = new Date()
const nowStamp = nowDate.getTime()
if(left > 0){
const gap = nowStamp - lastStamp
console.log('left',left, 'time:',nowDate.toLocaleString(),'间隔:',gap)
lastStamp = nowStamp
setCount(left)
}else{
setCount(0)
console.log('最后时间:',nowDate.toLocaleString(),'总共耗时:', nowStamp-firstStamp)
}
};
setWorker(myWorker);
// 清理函数:关闭 Worker
return () => {
myWorker.terminate();
};
}, []);

缺点:worker的缺点 ;优点:精准计时
总结:
方案1 大修正
方案2 小修正
方案3 无修正
三种方式来使倒计时更准确
来源:juejin.cn/post/7478687361737768986
Electron实现静默打印小票
Electron实现静默打印小票
静默打印流程

1.渲染进程通知主进程打印
//渲染进程 data是打印需要的数据
window.electron.ipcRenderer.send('handlePrint', data)
2.主进程接收消息,创建打印页面
//main.ts
/* 打印页面 */
let printWindow: BrowserWindow | undefined
/**
* @Author: yaoyaolei
* @Date: 2024-06-07 09:27:22
* @LastEditors: yaoyaolei
* @description: 创建打印页面
*/
const createPrintWindow = () => {
return new Promise<void>((resolve) => {
printWindow = new BrowserWindow({
...BASE_WINDOW_CONFIG,
title: 'printWindow',
webPreferences: {
preload: join(__dirname, '../preload/index.js'),
sandbox: false,
nodeIntegration: true,
contextIsolation: false
}
})
printWindow.on('ready-to-show', () => {
//打印页面创建完成后不需要显示,测试时可以调用show查看页面样式(下面有我处理的样式图片)
// printWindow?.show()
resolve()
})
printWindow.webContents.setWindowOpenHandler((details: { url: string }) => {
shell.openExternal(details.url)
return { action: 'deny' }
})
if (is.dev && process.env['ELECTRON_RENDERER_URL']) {
printWindow.loadURL(`${process.env['ELECTRON_RENDERER_URL']}/print.html`)
} else {
printWindow.loadFile(join(__dirname, `../renderer/print.html`))
}
})
}
ipcMain.on('handlePrint', (_, obj) => {
//主进程接受渲染进程消息,向打印页面传递数据
if (printWindow) {
printWindow!.webContents.send('data', obj)
} else {
createPrintWindow().then(() => {
printWindow!.webContents.send('data', obj)
})
}
})
3.打印页面接收消息,拿到数据渲染页面完成后通知主进程开始打印
<!doctype html>
<html>
<head>
<meta charset="UTF-8" />
<title>打印</title>
<style>
</style>
</head>
<body>
</body>
<script>
window.electron.ipcRenderer.on('data', (_, obj) => {
//这里是接受的消息,处理完成后将html片段放在body里面完成后就可以开始打印了
//样式可以写在style里,也可以内联
console.log('event, data: ', obj);
//这里自由发挥
document.body.innerHTML = '处理的数据'
//通知主进程开始打印
window.electron.ipcRenderer.send('startPrint')
})
</script>
</html>
这个是我处理完的数据样式,这个就是print.html


4,5.主进程接收消息开始打印,并且通知渲染进程打印状态
ipcMain.on('startPrint', () => {
//这里如果不指定打印机使用的是系统默认打印机,如果需要指定打印机,
//可以在初始化的时候使用webContents.getPrintersAsync()获取打印机列表,
//然后让用户选择一个打印机,打印的时候将打印机名称传过来
printWindow!.webContents.print(
{
silent: true,
margins: { marginType: 'none' }
//deviceName:如果要指定打印机传入打印机名称
},
(success) => {
//通知渲染进程打印状态
if (success) {
mainWindow.webContents.send('printStatus', 'success')
} else {
mainWindow.webContents.send('printStatus', 'error')
}
}
)
})

完毕~
来源:juejin.cn/post/7377645747448365091
富文本选型太难了,谁来帮帮我!
前言
在管理平台中,富文本编辑器是信息输入和内容编辑的重要工具,几乎是必不可少的功能模块。它不仅能帮助用户轻松创建和格式化文档、邮件、模版等内容,还支持多样化的输入方式,提升了内容管理的便捷性和效率。
遇事不决扔个富文本,随心所欲不逾矩
富文本编辑器的实现虽然为用户提供了极大的便利,但其背后的技术复杂度也不容小觑。实现一个全面且高效的富文本编辑器,涉及到跨浏览器兼容性、复杂的格式化操作、多媒体支持等多个技术难题,往往需要花费大量的人力物力。即便如此,富文本编辑器也不可能满足所有用户的需求。不同的用户对功能有着各自的偏好.对于用户来说,选择富文本编辑器时,也需要在功能性与操作便捷性之间进行取舍,找到最适合自己需求的解决方案。
碰到说做一个和word相同功能的富文本的领导,直接上砖头
我认为选择富文本要考虑以下这些重要的功能:
- 页面简洁美观(不难看是前提,不要说功能好用 - 不好看的界面,我连用都不用)
- 支持从
Word中复制、粘贴 - 格式化功能丰富,尽可能的支持各种文本和段落的样式
- 多媒体功能丰富,支持对
图片大小、位置的处理 - 支持
html代码与显示切换 - 支持并满足复杂的
表格功能 - 插件拓展
- 多端兼容
- 编辑器不能基于某一种编程语言,迁移成本小
- 多语言支持(对于部分海外客户可能有需求)
你很难想象竟然有不会英文的客户,强烈要求我们更换富文本编辑器
富文本测评
Tinymce
Tinymce是一个老牌做富文本的公司,文档和插件配置的自由度都不错,也支持自定义拓展。功能强大,可以完全作为用户的首选
免费版如下图所示:

评测一下Tinymce的优缺点:
优点:
- 老牌做富文本的公司,且不断保持更新和维护,值得信赖
- UI也做的蛮好看的(吐槽一下5.X好丑)
- 免费版功能强大,基本能满足日常需要(开源版本支持商用,nice)
- 功能强大:如导出,自定义插件,表格功能强大,文件上传,复制粘贴,数学方程等等
- 对非技术用户友好: 所见所得,拖动即可完成所有
- 支持多端,移动端友好
- 社区丰富,文档友好,集成简单
- 支持多种语言,阿拉伯这种程序员的噩梦也支持
缺点:
图片上传需要自定义- 超链接不友好并且很丑
- UI不是很好看 - 我们领导吐槽好丑
- 复杂的word复制过去格式会变化,需要重新编辑
打开缓慢,需要开发者和使用者有相当的耐心
我司从5.X开始使用,目前已迭代到7.X(UI好看了好多)
不知道怎么选的情况下,选Tinymce肯定没错,当然也不能对Tinymce有太大要求,你会失望的
CKEditor
CKEditor也是一个老牌做富文本的公司, 5.0版本无论是功能还是UI做的相当不错,毫不夸张的说,这是我见过插件最丰富的富文本了
完整版如下图所示:

评测一下CKEditor的优缺点:
优点:
- 老牌做富文本的公司,且不断保持更新和维护,值得信赖
- UI简洁美观
- 功能强大:100多个插件,如导出,自定义插件,表格功能强大,文件上传,复制粘贴,数学方程等等
- 对非技术用户友好: 所见所得,拖动即可完成所有
- 支持多主题配置
- 支持多端,移动端友好
- 支持多人协作
- 支持多种语言,阿拉伯这种程序员的噩梦也支持
缺点:
- 价格比较贵,
免费版功能太少,可能不会满足日常使用 - API太多,
文档对于国内不是很友好, 开发成本高 - V38.0.0起,
免费版会显示“Powered by CKEditor”logo(这也是我司最后放弃使用CKEditor的原因之一)
最基础的免费版如下:

基于CKEditor的优缺点,推荐复杂文档编辑及格式化的业务使用
白嫖党不推荐,适合人民币玩家
Tiptap
Tiptap是一个模块化的编辑器, 官方解释是tipTap是一个无头编辑器,无头特征决定了完全自由。
自由扩展,自由定义。
它基于Prosemirror,完全可扩展且无渲染。可以轻松地将自定义外观、样式、位置等等
可以像这样:

也可以像这样:

灵活的API,不仅可以让你进行天马行空的布局,各种事件也可以让你用到飞起。作为一个后起之秀,迅速占领市场,赢得了大量客户的好评。真心推荐大家去使用一下!
下面评测一下Tiptap富文本
优点:
- 高度可定制的UX
- 功能强大,插件丰富
- 可快速搭建,集成简单
- 和element适配度高,使用element-ui不要太爽
支持多人协作
缺点:
- 自由度太高,配置较复杂,需要对API有一定的了解
不支持markdown
经查阅资料,tiptap插件支持markdown格式,感谢 李里_lexy 和 imber的指正
想要多人协作的,不要考虑了:用它,用它,用它!
Quill
我司最开始使用的一款富文本。配置简单,UI也还不错。中文文档丰富,一天的时间就可以集成到项目中。

评测一下Quill的优缺点
优点:
- UI还可以(虽说排版看起来有点乱)
- API和文档简单,一天的时间就可以集成到项目中
- 支持word的复制,粘贴操作
(加分项) - 持续更新,从发布到至今,已13年之久,不用担心不维护的问题
缺点:
- 对图片非常不友好,不支持图片拖拽
- 不支持表格
- 不支持html与界面的切换(在文档中统一替换很困难,需要技术人员配合)
在v-if中显示文本到编辑文本切换后,会无法输入文本,官方bug且没有被修复
全局改样式的时候,从控制台中取一下html代码,然后全局替换一下忍忍也就算了。随着图片上传后,文档排版越来越麻烦,真的不能忍了。只能宣布这个富文本的倒计时了!
适合对图片没有太多需求,并且对文档没有太大格式需求的公司
个人开发蛮推荐的
wangEditor
国产之光,个人能做成这个样子,我还是由衷的佩服的。

有兴趣的掘友们可以看下为什么都说富文本编辑器是天坑?。觉得自己还可以的掘友可以试着做做下面这两个小功能?
- 输入一个Hello, world!
- Hello加粗,llo斜体,world加粗,ld下划线
- 选中hello,取消选择,复制,粘贴,全选,删除
- 兼容主流浏览器
- 看一下标签至少符合规范(加粗斜体不能嵌套,p标签不能包块元素,是否有空标签...)
不要小看这个小功能,我敢打赌,95%的程序员至少一周的时间或者压根做不出来
赌一包辣条,立贴为证
好了,回到正题。我们评测一下wangEditor富文本
优点:
- 简单易用,可以快速集成
- 中文文档友好
- 支持图片和表格拖拽
- 社区友好,可以在github提交意见和反馈
- 多语言支持
缺点:
- 个人开源,相对专门做富文本的公司,相对配置型和丰富性不足
- 移动端不适配,Android下有严重bug,可能会影响使用
暂停维护了
首先向wangEditor开源作者双越老师表示敬意,因为开源想盈利太不容易了,基本都是为爱发电
不考虑移动端的,并且不介意暂停维护的可以使用
否则直接pass吧,
用Jodit或者wangEditor-next替代吧
wangEditor-next
wangEditor-next的作者cycleccc在简介中这样写道:
wangeditor 因作者个人原因短期不再维护,wangEditor-next为fork版本,将在尽量不 Breaking change 的前提下继续维护。
此外,wangEditor-next也不再是个人单打独斗了,开始多人团队协作。最近几个月更新也很频繁,近3000次commit也能看出该团队的活跃度和持续产出,这种高频次的更新不仅反映了团队对用户反馈的响应速度,确保项目能够持续迭代并满足用户需求。

期待wangEditor-next能够在开源和盈利中找到平衡点,期待国人的产品能够获得广泛认可,为用户提供优质的体验。
Jodit
免费版功能如下:

- 风格和wangEditor类似,但功能要比wangEditor强大的多。
- 项目持续维护中,不用担心跑路的问题
- 支持图片和表格拖拽
- 支持word复制和粘贴
- 支持
打印 - 适配
移动端,可预览 - 支持多语言
白嫖党的福音
大招:收费版来了

在原有的基础上又增加了以下实用的功能
- 支持
文档翻译和谷歌地图 - 支持
预览和导出pdf - 支持自定义button
- 支持插入iframe
- 支持恢复功能(
不是撤销,是真的回档) - 支持查找和替换(很nice的功能)
一次性付费99$(一个项目),399$(无限项目)即可解锁,我觉得超值
相比于wangEditor,我更推荐Jodit。无论是免费版,还是付费版,都值得拥有和尝试
Editor.js
Editor也是一个模块化编辑器。与Tiptap有很多相似之处,如模块化设计,可拓展性等等。这里不详细展开了,主要说一下两个编辑器的不同点:
- Editor.js
默认生成 JSON 格式的数据,便于解析和存储。适合保存结构化的数据,如文档管理等等等。
Tiptap 功能更强大,适合需要精细控制的富文本编辑器应用,尤其适合需要所见即所得体验的场景,如
博客编辑器等等 - Tiptap的社区及文档更友好,非常适合 Vue 或 React 项目集成,更适合初次开发者
- Editor功能较少,可能不满足使用
Editorbug比较多,虽然已经修复了好多,但建议还是慎选
Editor默认使用JSON格式的数据,更易于展示和分析,除非有强烈需求,否则慎选
Slate
引用一下原文:
Slate是一个 完全 可定制的富文本编辑器框架。
Slate 让你构建像 Medium, Dropbox Paper或者是 Google Docs(它们正成为web应用的标杆)这样丰富,直观的编辑器,而不会让你在代码实现上深陷复杂度的泥潭。
文档介绍的很酷,但目前是beta版本,且仍没有计划发布正式版。我没有用过,不做过多的评价,有兴趣的可以自己去体验一下
开源项目,没有大公司的支持,完全是自愿奉献。30k的star用户默默的支持,期待早日发布
很酷的架构设计,推荐大家去体验一下,期待Slate的早日发布
medium-editor

一款轻量级的编辑器,压缩后约为28KB, 除了工具栏可以显示在文本上方,支持内联编辑外,我没有找到其他的优点。4年没有更新, 插件拓展非常不友好。对不起这16K的star
如果你喜欢这种编辑方式,还可以体验一下。除此外,直接Pass
Squire

又是一款轻量级的编辑器,压缩完才11.5kb,相对于其它的富文本来说是非常的小了,推荐功能不复杂的场景使用
轻量级的编辑器,相较于medium-editor更符合用户习惯,推荐功能不复杂的场景使用
UEditor

看到上面这个图片,估计很多用户直接就断绝了使用的想法吧。确实,UI设计的真不好看,不符合当今的审美。可是在小10年前,用百度UEditor的比比皆是,只能说此一时彼一时。
我们评测一下UEditor富文本
优点:
- 发布之初,功能强大,但是放在现在,已经有点弱了
- 支持从word复制粘贴
- 中文文档友好
缺点:
- 无力吐槽的UI
- 官方已经不维护了,gg
- 不支持图片和表格拖拽
- ...
不吐槽了,直接用省略号吧。祭奠我的青春
久远的富文本,官方已经不维护了,不推荐使用
UEditor Plus
UEditor Plus 是基于 UEditor 二次开发的富文本编辑器

让人诟病的UI风格终于焕新了,还算在我的审美点上了,简单评测一下
优点:
- UI风格焕新还是蛮清新的(
功能平铺还是感觉有点乱,太占空间了) - 支持图片拖拽
- 表格功能强大(虽然有些功能我不太会用)
- 兼容现有UEditor
缺点:
- 作为开发者,很多功能都不会用,更别提普通用户了,估计一脸懵
- 为了功能而功能,忽视了用户体验
- 更新迭代比较慢,社区不友好,不是很关心用户的反馈
试用了1天,总给我不踏实的感觉,担心某一天又不维护了
编辑器的功能体验不是很好,有些功能是为了功能而功能,真心希望提升一下用户体验
Summernote

一款韩国人做的开源编辑器。基于 jQuery 和 Bootstrap 构建,支持快捷键操作,提供大量可定制的选项,乍一看,页面挺清新简洁的。但使用下来非常让人之气愤。用户提的bug和优化项目完全不理,格式化也是做的很差劲。搞不懂11k的star是怎么出来的
不推荐用。除非你喜欢用hook去擦屁股
lexical

Facebook出品的编辑器,大厂出品,值得信赖。
lexical是draft-js的升级版。由于draft-js只作维护,不做开发。整体功能已迁移到Lexical新框架。
github这样写道:
该项目目前处于维护模式。它不会收到任何功能更新,只会收到关键的安全漏洞补丁。2022 年 12 月 31 日,该仓库将完全归档。
对于寻找开源替代方案的用户,Meta 一直致力于迁移到一个名为Lexical的新框架。它仍处于实验阶段,我们正在努力添加迁移指南,但我们相信,它提供了一种更高效、更易于访问的替代方案。
样式见上图,很清爽,很漂亮。多而不乱,我蛮喜欢的。
功能上也很强大,图片拖拽、表格拖拽、导入导出,分享,还能进行涂鸦,绘图。还可以选中文本设置文本样式,同时还能对文本进行评论...功能上没得说,由于React是 Facebook的亲儿子,lexical也是基于React的编辑器 。虽然可以在vue上用,但官方支持主要集中在 React 上,因此在 Vue 中的集成需要额外处理一些兼容性问题。违背了我们选择不依赖框架语言的初衷。因此将lexical放在最后,不做过多的评价,也不会放在简评中。只是让我们多了解一下,尤其是React用户,可以作为备选方案
但要注意:Lexical 不支持 Internet Explorer 或旧版本的 Edge。需要兼容IE以及Edge浏览器的业务就不要选了
Facebook出品,可以作为React全家桶使用
简评
强烈推荐
Tinymce: 不知道怎么去选的时候,就用Tinymce!不求有功,但求无过
CKEditor: 文档格式化内容众多,追求使用效率,并且土豪公司或者人民币玩家就用它
Tiptap: 喜欢diy样式的,追求美观和别具一格的开发者首选
Jodit: 一次性付款,你值得拥有
比较推荐
Quill: 集成简单,小项目够用,大项目不推荐
wangEditor: 国人之光
wangEditor-next: wangEditor的升级版,持续迭代,持续为您服务
Editor: 存储,解析JSON数据的首选,其他慎选
Slate: 很棒的架构设计,期待早上发布
UEditor Plus: 基于 UEditor 二次开发的富文本编辑器,UI和功能都做了升级,初步体验还是蛮不错的,个人建议还是要慎用
不推荐
UEditor: 百度的烂尾项目,不够打了
Squire: 轻量级编辑器,格式文本还是可以的
Summernote: 韩国佬开发的项目,大爷级别的,反人类,还不搭理你
medium-editor 除了在文档上方显示,找不到其他的优点
总结
优秀的富文本编辑器不仅要页面美观,而且要格式化功能强大,使用方便快捷。非技术用户也能轻松排版、编辑、上传多媒体内容,从而提升管理平台的整体易用性和用户体验。因此,选择合适的富文本编辑器,不仅关系到内容生产的效率,更直接影响到平台的用户满意度和运营效果。
同时,我们也要认识到,不可能有一个编辑器能百分百满足我们的需求,理解开发富文本编辑器是一个巨难,且很难盈利的项目。只能尽可能的满足我们的痛点,在使用体验和需求功能上找到一个平衡点,权衡选择。
最后,祝开发找到适合自己公司的编辑器,早日脱坑
参考资料
来源:juejin.cn/post/7434373084747333658
十年跨平台开发,Electron 凭什么占据一席之地?

大家好,我是徐徐。今天我们来认识认识 Electron。
前言
其实一直想系统的写一写 Electron 相关的文章,之前在掘金上写过,但是现在来看那些文章都写得挺粗糙的,所以现在我决定系统整理相关的知识,输出自己更多 Electron 开发相关的经验。这一节我们主要是来认识一下 Electron,这个已经有 10 年历史的跨端开发框架。我将从诞生背景,优劣势,生态,案例以及和其他框架的对比这几个方面带大家来认识 Electron。
Electron 诞生背景

Electron 的背景还是很强劲的,下面我们就来看看它是如何诞生的。
起源
Electron 的前身 Atom Shell,由 GitHub 的开发者在 2013 年创建的,当时 Atom 需要一个能够在桌面环境中运行的跨平台框架,同时能够利用 web 技术构建现代化的用户界面,于是就有了 Electron 的雏形。
需求 & Web 技术的发展
互联网的兴起使得桌面端的需求日益增长,传统的桌面应用开发需要针对每个操作系统(Windows、macOS、Linux)分别编写代码,这增加了开发和维护成本,所以非常需要可以通过一次开发实现多平台支持的框架。
随着 HTML5、CSS3 和 JavaScript 的快速发展,web 技术变得越来越强大和灵活。开发者希望能够利用这些技术构建现代化的用户界面,并且享受 web 开发工具和框架带来的便利。这使得更加需要一款跨端大杀器架来支持开发者,Electron 应运而生。
发展历程

- 2013 年:Atom Shell 诞生,最初用于 GitHub 的 Atom 编辑器。
- 2014 年 2 月:Atom 编辑器对外发布,Atom Shell 作为其核心技术。
- 2015 年 4 月:Atom Shell 更名为 Electron,并作为一个独立项目发布。随着时间的推移,Electron 的功能和社区支持不断增强。
- 2016 年:Electron 的应用开始广泛传播,许多公司和开发者开始使用 Electron 构建跨平台桌面应用。
- 2020 年:Electron 发布 10.0 版本,进一步增强了稳定性和性能。
- 2023 年:Electron 10 周年
更多可以参考:
http://www.electronjs.org/blog/electr…
Electron 优势
Electron 的优势非常的明显,大概总结为下面四个方面。
跨平台支持
Electron 的最大优势在于其跨平台特性。开发者可以编写一次代码,Electron 会处理不同操作系统之间的差异,使应用能够在 Windows、macOS 和 Linux 上无缝运行。
前端技术栈
Electron 应用使用 HTML、CSS 和 JavaScript 构建界面。开发者可以使用流行的前端框架和工具(如 React、Vue.js、Angular)来开发应用,提高开发效率和代码质量。
Node.js 集成
Electron 将 Chromium 和 Node.js 集成在一起,这使得应用不仅可以使用 web 技术构建界面,还可以使用 Node.js 访问底层系统资源,如文件系统、网络、进程等。
强大社区
Electron 拥有丰富的文档、教程、示例和强大的社区支持。开发者可以很容易地找到解决问题的方法和最佳实践,从而加快开发速度。
Electron 劣势
当然,一个东西都有两面性,有优势肯定也有劣势,劣势大概总结为以下几个方面。
性能问题
Electron 应用由于需要运行一个完整的 Chromium 实例,通常会占用较高的内存和 CPU 资源,性能相对较差。这在资源有限的设备上(如老旧计算机)尤为明显。
打包体积大
由于需要包含 Chromium 和 Node.js 运行时,Electron 应用的打包体积较大。一个简单的 Electron 应用的打包体积可能达到几十到上百 MB,这对于一些应用场景来说是不小的负担。
安全性
Electron 应用需要处理 web 技术带来的安全问题,如跨站脚本(XSS)攻击和远程代码执行(RCE)漏洞。开发者需要特别注意安全性,采取适当的防护措施(如使用 contextIsolation、sandbox、Content Security Policy 等)。
生态
上面谈到了 Electron 的优势和劣势,下面我们来看看 Electron 的生态。对于一款开源框架,生态是非常关键的,社区活跃度以及相应的配套工具非常影响框架的生态,如果有众多的开发者支持和维护这个框架,那么它的生态才会越来越好。Electron 的生态依托于 Node.js 发展出了很多很多开源工具,其生态是相当的繁荣。下面可以看看两张图就知道其生态的繁荣之处。
- GitHub 情况

- NPM 情况

下面是一些常见的相关生态工具。
打包和分发工具
- electron-packager:用于将 Electron 应用打包成可执行文件。支持多平台打包,简单易用。
- electron-builder:一个功能强大的打包工具,支持自动更新、多平台打包和安装程序制作。
测试工具
- Spectron:基于 WebDriver,用于 Electron 应用的端到端测试。支持模拟用户操作和验证应用行为。
- electron-mocha:用于在 Electron 环境中运行 Mocha 测试,适合进行单元测试和集成测试。
开发工具
- Electron Forge:一个集成开发工具,简化了 Electron 应用的开发、打包和分发流程。支持脚手架、插件系统和自动更新。
- Electron DevTools:调试和分析 Electron 应用性能的工具,帮助开发者优化应用性能。
案例

用 Electron开发的软件非常多,国内外都有很多知名的软件,有了成功的案例才会吸引更多的开发者使用它,下面是一些举例。
国内
- 微信开发者工具
- 百度网盘
- 语雀
- 网易灵犀办公
- 网易云音乐
国外
- Visual Studio Code
- Slack
- Discord
- GitHub Desktop
- Postman
其他更多可参考:http://www.electronjs.org/apps
一个小技巧,Mac 电脑检测应用是否是 Electron 框架,在命令行运行如下代码:
for app in /Applications/*; do;[ -d $app/Contents/Frameworks/Electron\ Framework.framework ] && echo $app; done
和其他跨端框架的对比

一个框架的诞生避免不了与同类型的框架对比,下面是一个对比表格,展示了 Electron 与其他流行的跨端桌面应用开发框架(如 NW.js、Proton Native、Tauri 和 Flutter Desktop)的优缺点和特性:
| 特性 | Electron | NW.js | Proton Native | Tauri | Flutter Desktop |
|---|---|---|---|---|---|
| 开发语言 | JavaScript, HTML, CSS | JavaScript, HTML, CSS | JavaScript, React | Rust, JavaScript, HTML, CSS | Dart |
| 框架大小 | 大(几十到几百 MB) | 中等(几十 MB) | 中等(几十 MB) | 小(几 MB) | 大(几十到几百 MB) |
| 性能 | 中等 | 中等 | 中等 | 高 | 高 |
| 跨平台支持 | Windows, macOS, Linux | Windows, macOS, Linux | Windows, macOS, Linux | Windows, macOS, Linux | Windows, macOS, Linux |
| 使用的技术栈 | Chromium, Node.js | Chromium, Node.js | React, Node.js | Rust, WebView | Flutter Engine |
| 生态系统和社区 | 非常活跃,生态丰富 | 活跃 | 停滞了 | 新兴,快速增长 | 活跃,现阶段更新不频繁 |
| 开发难度 | 易于上手 | 易于上手 | 需要 React 知识 | 需要 Rust 和前端知识 | 需要 Dart 知识 |
| 自动更新支持 | 内置支持 | 需要手动实现 | 需要手动实现 | 需要手动实现 | 需要手动实现 |
| 原生功能访问 | 通过 Node.js 模块访问 | 通过 Node.js 模块访问 | 通过 Node.js 和原生模块访问 | 通过 Rust 原生模块访问 | 通过插件和原生模块访问 |
| 热重载和开发体验 | 支持(需要配置) | 支持(需要配置) | 支持(需要配置) | 支持(需要配置) | 支持(内置支持) |
| 打包和发布 | Electron Builder, Forge | nw-builder | 需要手动配置打包工具 | Tauri 打包工具 | Flutter build tools |
| 常见应用场景 | 聊天应用、生产力工具、IDE | 聊天应用、生产力工具 | 小型工具和实用程序 | 轻量级、性能要求高的应用 | 跨平台移动和桌面应用 |
| 知名应用 | VS Code, Slack, Discord, 知名应用 | WebTorrent, 其他工具 | 小型 React 工具和应用 | 新兴应用和工具 | 仅少数桌面应用,Flutter主打移动应用 |
结语
Electron 是一个强大的跨平台开发框架,其诞生对前端开发者的意义非常大,让很多从事前端的开发者也有机会开发桌面客户端,扩大了前端开发工程师的岗位需求。当然,它不一定是最好的框架,因为适合自己的才是最好的,主要还是看自己的业务场景和技术需要,优势和劣势都是需要考虑的,仁者见仁,智者见智。
来源:juejin.cn/post/7416902812251111476
Electron调用dll的新姿势
之前旧的系统在浏览器中调用dll都是使用IE的activex控件实现。进而通过dll脚本和硬件发生交互。现在IE浏览器已经不在默认预制在系统中,且对windows的操作系统有限制,win10之前的版本才能正常访问。
在不断的业务迭代过程中,已经成了制约系统扩展的最大阻碍。调研后选择了electron-egg框架来进行业务功能尝试,主要是dll的嵌入调用和设备交互。
ElectronEgg

作为一个对前端不是那么擅长的后端来说,electron-egg已经包装了大部分操作,且拥有非常详尽的中文开发文档。可以无缝切换,低成本代码的开发。
框架设计

具体的业务逻辑还是放在后台服务中,electron只负责透传交互指令和硬件设备进行交互。这里调用dll用的js库是koffi。
Koffi
Koffi 是一个快速且易于使用的 Node.js C FFI 模块。实现了在Node中调用dll的功能。
koffi版本2.8.0
DLL配置
按照官方文档dll文件放置在extraSources文件中。
DLL加载
const lib = koffi.load(path.join(Ps.getExtraResourcesDir(), "dll", "dcrf32.dll"));
DLL调用
dll调用有两种方式。分别为经典语法和类c原型方式。
- 经典语法
定义函数名,返回参数类型,入参类型constprintf=lib.func('printf','int', ['str','...']);
- 类C语法
在类中定义方法类似,lib.func('int printf(const char *fmt, ...)');
推荐使用类C语法更加方便,不受参数的限制,更易于修改。
DLL调用类型
- 同步调用
本机函数,您就可以像调用任何其他 JS 函数一样简单地调用它。
const atoi = lib.func('int atoi(const char *str)');
let value = atoi('1257');
- 异步调用
有一些耗时的操作,可以使用异步调用回调的方式处理。
const atoi = lib.func('int atoi(const char *str)');
atoi.async('1257', (err, res) => {
console.log('Result:', res);
})
JS类型值传递
JS基础类型时不支持值传递的,遇到需要传递指针变量时,直接调用是无法获取到变更后的值。相应的koffi也提供了非常方便的值包装。
- 数组包装
项目中采用比较方便的数组包装来进行值传递。包装基础对象到数组中,变更后取出第一位就能获取到变更后的值。

需要定义返回的值的获取长度,防止出现只获取到部分的返回结果。
- 引用类型包装
把基础类型包装成引用对象。传递到函数中。
let cardsenr = koffi.alloc('int', 64);
let cardRet = dcCard(icdev, 0, cardsenr);
这种就更方便,调用后也不需要转换。在调用完后需要通过free方法进行内存释放。
- Buffer对象
如果遇到接收中文数据时,koffi可以结合Node中的Buffer进行对象传递。
let text = Buffer.alloc(1024);
let ret = read(text);
部分dll默认读出来的编码是gbk格式,需要将buffer对象转换成utf8格式的字符串进行展示。 就需要通过iconv组件进行gbk解码。
iconv.decode(text, 'gbk')
如果需要把utf8转成gbk,使用相反的方式就可以
iconv.encode(build/photos/${id_number}.bmp, "gbk")
结构体调用
JS中只有引用对象,如果遇到结构体参数需要进行JS包装。
// C
typedef struct A {
int a;
char b;
const char *c;
struct {
double d1;
double d2;
} d;
} A;
// JS
const A = koffi.struct('A', {
a: 'int',
b: 'char',
c: 'const char *', // Koffi does not care about const, it is ignored
d: koffi.struct({
d1: 'double',
d2: 'double'
})
});
如果调用出现对齐不对的情况,可以使用pack方法进行手动对齐类型。
// This struct is 3 bytes long
const PackedStruct = koffi.pack('PackedStruct', {
a: 'int8_t',
b: 'int16_t'
});
常规dll的调用都可以轻易的在JS中实现。
Node后端
底层调用已经通过koffi来实现。后面就需要借助electron-egg框架能力进行业务代码指令透传。
service层
'use strict';
const { Service } = require('ee-core');
/**
* 示例服务(service层为单例)
* @class
*/
class ExampleService extends Service {
constructor(ctx) {
super(ctx);
}
/**
* test
*/
async test(args) {
let obj = {
status:'ok',
params: args
}
return obj;
}
}
ExampleService.toString = () => '[class ExampleService]';
module.exports = ExampleService;
定义我们需要交互的方法
controller层
'use strict';
const { Controller } = require('ee-core');
const Log = require('ee-core/log');
const Services = require('ee-core/services');
/**
* example
* @class
*/
class ExampleController extends Controller {
constructor(ctx) {
super(ctx);
}
/**
* 所有方法接收两个参数
* @param args 前端传的参数
* @param event - ipc通信时才有值。详情见:控制器文档
*/
/**
* test
*/
async test () {
const result = await Services.get('example').test('electron');
Log.info('service result:', result);
return 'hello electron-egg';
}
}
ExampleController.toString = () => '[class ExampleController]';
module.exports = ExampleController;
JS前端
通过ipc的方式,乡调用api一样调用node后端接口。
定义路由
import { ipc } from '@/utils/ipcRenderer';
const ipcApiRoute = {
test: 'controller.d8.test',
init: 'controller.d8.init',
reset: 'controller.d8.reset',
exit: 'controller.d8.exit',
command:'controller.d8.command'
}
调用
ipc.invoke(this.ipcApiRoute.init).then(r => {
// r为返回的数据
if(r >= 0) {
this.setInitRet(r);
this.scrollToBottom("连接成功,返回码:" + r);
this.connectStr = "连接成功";
this.setDeviceStatus('success');
} else {
this.scrollToBottom("连接失败,返回码:" + r);
}
})
通过ipc的invode方法调用方法即可。后续就可以愉快的编写我们的业务代码了。
参照
来源:juejin.cn/post/7352075771534868490
AI对话的逐字输出:流式返回才是幕后黑手
AI应用已经渗透到我们生活的方方面面。其中,AI对话系统因其自然、流畅的交流方式而备受瞩目。前段时间有人在交流群中问到,如何实现AI对话中那种逐字输出的效果,这背后,流式返回技术发挥了关键作用。

欢迎加入前端筱园交流群:点击加入交流群
其实这背后并不是前端做了什么特效,而是采用的流式返回,而不是一次性返回完整的响应。流式返回允许服务器在一次连接中逐步发送数据,而不是一次性返回全部结果。这种方式使得前端可以在等待完整响应的过程中,逐步展示生成的内容,从而极大地提升了用户体验。
那么,前端接收流式返回具体有哪些方式呢?接下来,本文将详细探讨几种常见的技术手段,帮助读者更好地理解并应用流式返回技术。
使用 Axios
大多数场景下,前端用的最多的就是axios来发送请求,但是axios 只有在在Node.js环境中支持设置 responseType: 'stream' 来接收流式响应。
const axios = require('axios');
const fs = require('fs');
axios.get('http://localhost:3000/stream', {
responseType: 'stream', // 设置响应类型为流
})
.then((response) => {
// 将响应流写入文件
response.data.pipe(fs.createWriteStream('output.txt'));
})
.catch((error) => {
console.error('Stream error:', error);
});
特点
- 仅限 Node.js:浏览器中的
axios不支持responseType: 'stream'。 - 适合文件下载:适合处理大文件下载。
使用 WebSocket
WebSocket 是一种全双工通信协议,适合需要双向实时通信的场景。
前端代码:
const socket = new WebSocket('ws://localhost:3000');
socket.onopen = () => {
console.log('WebSocket connected');
};
socket.onmessage = (event) => {
console.log('Received data:', event.data);
};
socket.onerror = (error) => {
console.error('WebSocket error:', error);
};
socket.onclose = () => {
console.log('WebSocket closed');
};
服务器代码
const WebSocket = require('ws');
const wss = new WebSocket.Server({ port: 3000 });
wss.on('connection', (ws) => {
console.log('Client connected');
let counter = 0;
const intervalId = setInterval(() => {
counter++;
ws.send(JSON.stringify({ message: 'Hello', counter }));
if (counter >= 5) {
clearInterval(intervalId);
ws.close();
}
}, 1000);
ws.on('close', () => {
console.log('Client disconnected');
clearInterval(intervalId);
});
});
虽然WebSocket作为一种在单个TCP连接上进行全双工通信的协议,具有实时双向数据传输的能力,但AI对话情况下可能并不选择它进行通信。主要有以下几点原因:
- 在AI对话场景中,通常是用户向AI模型发送消息,模型回复消息的单向通信模式,WebSocket的双向通信能力在此场景下并未被充分利用
- 使用WebSocket可能会引入不必要的复杂性,如处理双向数据流、管理连接状态等,也会增加额外的部署与维护工作

特点
- 双向通信:适合实时双向数据传输
- 低延迟:基于 TCP 协议,延迟低
- 复杂场景:适合聊天、实时游戏等复杂场景
使用 XMLHttpRequest
虽然 XMLHttpRequest 不能直接支持流式返回,但可以通过监听 progress 事件模拟逐块接收数据
const xhr = new XMLHttpRequest();
xhr.open('GET', '/stream', true);
xhr.onprogress = (event) => {
const chunk = xhr.responseText; // 获取当前接收到的数据
console.log(chunk);
};
xhr.onload = () => {
console.log('Request complete');
};
xhr.send();
服务器代码(Koa 示例):
router.get("/XMLHttpRequest", async (ctx, next) => {
ctx.set({
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
});
// 创建一个 PassThrough 流
const stream = new PassThrough();
ctx.body = stream;
let counter = 0;
const intervalId = setInterval(() => {
counter++;
ctx.res.write(
JSON.stringify({ message: "Hello", counter })
);
if (counter >= 5) {
clearInterval(intervalId);
ctx.res.end();
}
}, 1000);
ctx.req.on("close", () => {
clearInterval(intervalId);
ctx.res.end();
});
});
可以看到以下的输出结果,在onprogress中每次可以拿到当前已经接收到的数据。它并不支持真正的流式响应,用于AI对话场景中,每次都需要将以显示的内容全部替换,或者需要做一些额外的处理。

如果想提前终止请求,可以使用 xhr.abort() 方法;
setTimeout(() => {
xhr.abort();
}, 3000);

特点
- 兼容性好:支持所有浏览器。
- 非真正流式:
XMLHttpRequest仍然需要等待整个响应完成,progress事件只是提供了部分数据的访问能力。 - 内存占用高:不适合处理大文件。
使用 Server-Sent Events (SSE)
SSE 是一种服务器向客户端推送事件的协议,基于 HTTP 长连接。它适合服务器向客户端单向推送实时数据
前端代码:
const eventSource = new EventSource('/sse');
eventSource.onmessage = (event) => {
console.log('Received data:', event.data);
};
eventSource.onerror = (event) => {
console.error('EventSource failed:', event);
};
服务器代码(Koa 示例):
router.get('/sse', (ctx) => {
ctx.set({
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
});
let counter = 0;
const intervalId = setInterval(() => {
counter++;
ctx.res.write(`data: ${JSON.stringify({ message: 'Hello', counter })}\n\n`);
if (counter >= 5) {
clearInterval(intervalId);
ctx.res.end();
}
}, 1000);
ctx.req.on('close', () => {
clearInterval(intervalId);
ctx.res.end();
});
});

EventSource 也具有主动关闭请求的能力,在结果没有完全返回前,用户可以提前终止内容的返回。
// 在需要时中止请求
setTimeout(() => {
eventSource.close(); // 主动关闭请求
}, 3000); // 3 秒后中止请求

虽然EventSource支持流式请求,但AI对话场景不使用它有以下几点原因:
- 单向通信
- 仅支持
get请求:在 AI 对话场景中,通常需要发送用户输入(如文本、文件等),这需要使用 POST 请求 - 无法自定义请求头:
EventSource不支持自定义请求头(如Authorization、Content-Type等),在 AI 对话场景中,通常需要设置认证信息(如 API 密钥)或指定请求内容类型
注意点
返回给 EventSource 的值必须遵循 data: 开头并以 \n\n 结尾的格式,这是因为 Server-Sent Events (SSE) 协议规定了这种格式。SSE 是一种基于 HTTP 的轻量级协议,用于服务器向客户端推送事件。为了确保客户端能够正确解析服务器发送的数据,SSE 协议定义了一套严格的格式规范。SSE 协议规定,服务器发送的每条消息必须遵循以下格式:
field: value\n
其中 field 是字段名,value 是对应的值。常见的字段包括:
data::消息的内容(必须)。event::事件类型(可选)。id::消息的唯一标识符(可选)。retry::客户端重连的时间间隔(可选)。
每条消息必须以 两个换行符 (\n\n) 结尾,表示消息结束
以下是一个完整的 SSE 消息示例:
id: 1\n
event: update\n
data: {"message": "Hello", "counter": 1}\n\n
特点
- 单向通信:适合服务器向客户端推送数据。
- 简单易用:基于 HTTP 协议,无需额外协议支持。
- 自动重连:
EventSource会自动处理连接断开和重连
使用 fetch API
fetch API 是现代浏览器提供的原生方法,支持流式响应。通过 response.body,可以获取一个 ReadableStream,然后逐块读取数据。
前端代码:
// 发送流式请求
fetch("http://localhost:3000/stream/fetch", {
method: "POST",
signal,
})
.then(async (response: any) => {
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
console.log(new TextDecoder().decode(value));
}
})
.catch((error) => {
console.error("Fetch error:", error);
});
服务器代码(Koa 示例):
router.post("/fetch", async (ctx) => {
ctx.set({
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
});
// 创建一个 PassThrough 流
const stream = new PassThrough();
ctx.body = stream;
let counter = 0;
const intervalId = setInterval(() => {
counter++;
ctx.res.write(JSON.stringify({ message: "Hello", counter }));
if (counter >= 5) {
clearInterval(intervalId);
ctx.res.end();
}
}, 1000);
ctx.req.on("close", () => {
clearInterval(intervalId);
ctx.res.end();
});
});

fetch也同样可以在客户端主动关闭请求。
// 创建一个 AbortController 实例
const controller = new AbortController();
const { signal } = controller;
// 发送流式请求
fetch("http://localhost:3000/stream/fetch", {
method: "POST",
signal,
})
.then(async (response: any) => {
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
console.log(new TextDecoder().decode(value));
}
})
.catch((error) => {
console.error("Fetch error:", error);
});
// 在需要时中止请求
setTimeout(() => {
controller.abort(); // 主动关闭请求
}, 3000); // 3 秒后中止请求
打开控制台,可以看到在Response中可以看到返回的全部数据,在EventStream中没有任何内容。


这是由于返回的信息SSE协议规范,具体规范见上文的 Server-Sent Events 模块中有介绍到
ctx.res.write(
`data: ${JSON.stringify({ message: "Hello", counter })}\n\n`
);

但是客户端fetch请求中接收到的数据也包含了规范中的内容,需要前端对数据进一步的处理一下

特点
- 原生支持:现代浏览器均支持
fetch和ReadableStream。 - 逐块处理:可以实时处理每个数据块,而不需要等待整个响应完成。
- 内存效率高:适合处理大文件或实时数据。
总结
综上所述,在 AI 对话场景中,fetch 请求 是主流的技术选择,而不是 XMLHttpRequest 或 EventSource。以下是原因和详细分析:
fetch是现代浏览器提供的原生 API,基于 Promise,代码更简洁、易读fetch支持ReadableStream,可以实现流式请求和响应fetch支持自定义请求头、请求方法(GET、POST 等)和请求体fetch结合AbortController可以方便地中止请求fetch的响应对象提供了response.ok和response.status,可以更方便地处理错误
| 方式 | 特点 | 适用场景 |
|---|---|---|
fetch | 原生支持,逐块处理,内存效率高 | 大文件下载、实时数据推送 |
XMLHttpRequest | 兼容性好,非真正流式,内存占用高 | 旧版浏览器兼容 |
| Server-Sent Events (SSE) | 单向通信,简单易用,自动重连 | 服务器向客户端推送实时数据 |
| WebSocket | 双向通信,低延迟,适合复杂场景 | 聊天、实时游戏 |
axios(Node.js) | 仅限 Node.js,适合文件下载 | Node.js 环境中的大文件下载 |
最后来看一个接入deekseek的完整例子:
resource.dengzhanyong.com/mp4/7823928…
服务器代码(Koa 示例):
const openai = new OpenAI({
baseURL: "https://api.deepseek.com",
apiKey: "这里是你申请的deepseek的apiKey",
});
// 流式请求 DeepSeek 接口并流式返回
router.post("/fetchStream", async (ctx) => {
// 设置响应头
ctx.set({
"Content-Type": "text/event-stream",
"Cache-Control": "no-cache",
Connection: "keep-alive",
});
try {
// 创建一个 PassThrough 流
const stream = new PassThrough();
ctx.body = stream;
// 调用 OpenAI API,启用流式输出
const completion = await openai.chat.completions.create({
model: "deepseek-chat", // 或 'gpt-3.5-turbo'
messages: [{ role: "user", content: "请用 100 字介绍 OpenAI" }],
stream: true, // 启用流式输出
});
// 逐块处理流式数据
for await (const chunk of completion) {
const content = chunk.choices[0]?.delta?.content || ""; // 获取当前块的内容
ctx.res.write(content);
process.stdout.write(content); // 将内容输出到控制台
}
ctx.res.end();
} catch (err) {
console.error("Request failed:", err);
ctx.status = 500;
ctx.res.write({ error: "Failed to stream data" });
}
});
前端代码:
const controller = new AbortController();
const { signal } = controller;
const Chat = () => {
const [text, setText] = useState<string>("");
const [message, setMessage] = useState<string>("");
const [loading, setLoading] = useState<boolean>(false);
function send() {
if (!message) return;
setText(""); // 创建一个 AbortController 实例
setLoading(true);
// 发送流式请求
fetch("http://localhost:3000/deepseek/fetchStream", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
message,
}),
signal,
})
.then(async (response: any) => {
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const data = new TextDecoder().decode(value);
console.log(data);
setText((t) => t + data);
}
})
.catch((error) => {
console.error("Fetch error:", error);
})
.finally(() => {
setLoading(false);
});
}
function stop() {
controller.abort();
setLoading(false);
}
return (
<div>
<Input
value={message}
onChange={(e) => setMessage(e.target.value)}
/>
<Button
onClick={send}
type="primary"
loading={loading}
disabled={loading}
>
发送
</Button>
<Button onClick={stop} danger>
停止回答
</Button>
<div>{text}</div>
</div>
);
};
写在最后
欢迎加入前端筱园交流群:点击加入交流群
关注我的公众号【前端筱园】,不错过每一篇推送
来源:juejin.cn/post/7478109057044299810
electron+node-serialport串口通信
electron+node-serialport串口通信
公司项目需求给客户开发一个能与电子秤硬件通信的Win7客户端,提供数据读取、处理和显示功能。项目为了兼容win7使用了
electron 22.0.0版本,串口通信使用了serialport 12.0.0版本
//serialport的基本使用方法
//安装 npm i serialport
import { SerialPort } from 'serialport'
SerialPort.list()//获取串口列表
/** 创建一个串口连接
path(必需):串口设备的路径。例如,'/dev/robot' 或 'COM1'。
baudRate(必需):波特率,即每秒传输的比特数。常见值有 9600、19200、38400、57600、115200 等。
autoOpen(可选):是否在创建对象时自动打开串口。默认为 true。如果设置为 false,你需要手动调用 port.open() 来打开串口。
dataBits(可选):每字节的数据位数。可以是 5、6、7、8。默认值是 8。
stopBits(可选):停止位的位数。可以是 1 或 2。默认值是 1。
parity(可选):校验位类型。可以是 'none'、'even'、'odd'、'mark'、'space'。默认值是 'none'。
rtscts(可选):是否启用硬件流控制(RTS/CTS)。布尔值,默认值是 false。
xon(可选):是否启用软件流控制(XON)。布尔值,默认值是 false。
xoff(可选):是否启用软件流控制(XOFF)。布尔值,默认值是 false。
xany(可选):是否启用软件流控制(XANY)。布尔值,默认值是 false。
highWaterMark(可选):用于流控制的高水位标记。默认值是 16384(16KB)。
lock(可选):是否锁定设备文件,防止其他进程访问。布尔值,默认值是 true。
**/
const serialport = new SerialPort({ path: '/dev/example', baudRate: 9600 })
serialport.open()//打开串口
serialport.write('ROBOT POWER ON')//向串口发送数据
serialport.on('data', (data) => {//接收数据
//data为串口接收到的数据
})
获取串口列表
//主进程main.ts
import { SerialPort, SerialPortOpenOptions } from 'serialport'
//初始化先获取串口列表,提供给页面选择
ipcMain.on('initData', async () => {
const portList = await SerialPort.list()
mainWindow.webContents.send('initData', {portList})
})
//渲染进程
window.electron.ipcRenderer.once('initData', (_,{portList}) => {
//获取串口列表后存入本地,登录页直接做弹窗给客户选择串口,配置波特率
window.localStorage.setItem('portList', JSON.stringify(portList))
})
串口选择

波特率配置

读取数据
公司秤和客户的秤串口配置不一样,所以做了model1和model2区分
//主进程main.ts
let P: SerialPort | undefined
ipcMain.on('beginSerialPort', (_, { path, baudRate }) => {
//区分配置
const portConfig: SerialPortOpenOptions<AutoDetectTypes> =
import.meta.env.VITE_MODE == 'model1'
? {
path: path || 'COM1',
baudRate: +baudRate || 9600, //波特率
autoOpen: true,
dataBits: 8
}
: {
path: path || 'COM1',
baudRate: +baudRate || 115200, //波特率
autoOpen: true,
dataBits: 8,
stopBits: 1,
parity: undefined
}
if (P) {
P.close((error) => {
if (error) {
console.log('关闭失败:', error)
} else {
P = new SerialPort(portConfig)
P?.write('SIR\r\n', 'ascii')//告诉秤端开始发送信息,具体看每个秤的配置,有的不需要
P.on('data', (data) => {
//接收到的data为Buffer类型,直接转为字符串就可以使用了
mainWindow.webContents.send('readingData', data.toString())
})
}
})
} else {
P = new SerialPort(portConfig)
P?.write('SIR\r\n', 'ascii')
P.on('data', (data) => {
mainWindow.webContents.send('readingData', data.toString())
})
}
})
解析数据
<!--渲染进程解析数据-->
<template>
<div class="weight-con">
<div class="weight-con-main">
<div>
<el-text class="wei-title" type="primary">毛<br />重</el-text>
</div>
<div class="weight-panel">
<el-text id="wei-num">{{ weightNum!.toFixed(2) }}</el-text>
<div class="weight-con-footer">当前最大称重:600公斤</div>
</div>
<div>
<el-text class="wei-title" type="primary">公<br />斤</el-text>
</div>
</div>
</div>
</template>
<script setup lang="ts">
import { weightModel } from '@/utils/WeightReader'
const emits = defineEmits(['zeroChange'])
const weightNum = defineModel<number>()
window.electron.ipcRenderer.on('readingData', (_, data: string) => {
//渲染进程接收到主进程数据,根据环境变量解析数据
weightNum.value = weightModel[import.meta.env.VITE_MODE](data)
if (weightNum.value == 0) {
emits('zeroChange')
}
})
</script>
//weightReader.ts 解析配置
export type Mode = 'model1' | 'model2'
let str = ''
export const weightModel = {
model1: (weightStr: string) => {
const rev = weightStr.split('').reverse().join('')
return +rev.replace('=', '')
},
module2: (weightStr: string) => {
str += weightStr
if (str.match(/S\s+[A-Za-z]\s*(-?\d*.?\d+)\s*kg/g)) {
const num = str.match(/S\s+[A-Za-z]\s*(-?\d*.?\d+)\s*kg/m)![1]
str = ''
return Number(num)
} else {
return 0
}
}
}

完活~下班!
来源:juejin.cn/post/7387701265796562980
无虚拟DOM到底能快多少?
相信大家都跟我一样有这样一个疑问:之前都说虚拟DOM是为了性能,怎么现在又反向宣传了?无虚拟DOM怎么又逆流而上成为了性能的标杆了呢?
下篇文章我们会仔细分析无虚拟DOM与虚拟DOM之间的区别,本篇文章我们先看数据。首先是体积,由于没有了虚拟DOM以及vDOM diff算法,所以体积肯定能小不少。当然不是说无虚拟DOM就彻底不需要diff算法了,我看过同为无虚拟DOM框架的Svelte和Solid源码,无虚拟DOM只是不需要vDOM间的Diff算法,列表之间还是需要diff的。毕竟再怎么编译,你从后端获取到的数组,编译器也不可能预测得到。
那么官方给出的数据是:

虽然没有想象中的那么多,但33.6%也算是小不少了。当然这个数据指的是纯Vapor模式,如果你把虚拟DOM和Vapor混着用的话,体积不仅不会减小反而还会增加。毕竟会同时加载Vapor模式的runtime和虚拟DOM模式的runtime,二者一相加就大了。
Vapor模式指的就是无虚拟DOM模式,如果你不太清楚二者之间有何关联的话,可以看一眼这篇:《无虚拟DOM版Vue为什么叫Vapor》
那性能呢?很多人对体积其实并不敏感,觉得多10K少10k都无所谓,毕竟现在都是5G时代了。所以我们就来看一眼官方公布的性能数据:


从左到右依次为:
- 原生
JS:1.01 Solid:1.09Svelte:1.11- 无虚拟
DOM版Vue:1.24 - 虚拟
DOM版Vue:1.32 React:1.55
数字越小代表性能越高,但无论再怎么高都不可能高的过手动优化过的原生JS,毕竟无论什么框架最终打包编译出来的还是JS。不过框架的性能其实已经挺接近原生的了,尤其是以无虚拟DOM著称的Solid和Svelte。但无虚拟DOM版Vue和虚拟DOM版Vue之间并没有拉开什么很大的差距,1.24和1.32这两个数字证明了其实二者的性能差距并不明显,这又是怎么一回事呢?

一个原因是Vue3本来就做了许多编译优化,包括但不限于静态提升、大段静态片段将采用innerHTML渲染、编译时打标记以帮助虚拟DOM走捷径等… 由于本来的性能就已经不错了,所以可提升的空间自然也没多少。
看完上述原因肯定有人会说:可提升的空间没多少可以理解,那为什么还比同为无虚拟DOM的Solid和Svelte差那么多?如果Vapor和Solid性能差不多的话,那可提升空间小倒是说得过去。但要是像现在这样差的还挺多的话,那这个理由是不是就有点站不住脚了?之所以会出现这样的情况是因为Vue Vapor的作者在性能优化和快速实现之间选择了后者,毕竟尤雨溪第一次公布要开始做无虚拟DOM版Vue的时间是在2020年:

而如今已经是2025年了。也就是说如果一个大一新生第一次满心欢喜的听到无虚拟DOM版Vue的消息后,那么他现在大概率已经开始毕业工作了都没能等到无虚拟DOM版Vue的发布。这个时间拖的有点太长了,甚至从Vue2到Vue3都没用这么久。

可以看到Vue3从立项到发布也就不到两年的时间,而Vapor呢?从立项到现在已经将近5年的光阴了,已经比Vue3所花费的时间多出一倍还多了。所以现在的首要目标是先实现出来一版能用的,后面再慢慢进行优化。我们工作不也是这样么?先优先把功能做出来,优化的事以后再说。那么具体该怎么优化呢:

现在的很多渲染逻辑继承自原版Vue3,但无虚拟DOM版Vue可以采用更优的渲染逻辑。而且现在的Vapor是跟着原版Vue的测试集来做的,这也是为了实现和原版Vue一样的行为。但这可能并不是最优解,之后会慢慢去掉一些不必要的功能,尤其是对性能产生较大影响的功能。
往期精彩文章:
来源:juejin.cn/post/7480069116461088822
leaflet+天地图+更换地图主题

先弄清楚leaflet和天地图充当的角色
- leaflet是用来在绘制、交互地图的
- 天地图是纯粹用来当个底图的,相当于在leaflet中底部的一个图层而已
- 进行Marker打点、geojson绘制等操作都是使用leaflet实现
1. 使用天地图当底图
- 在token处填自己的token
- 我这里用的是天地图的
影像底图,如果需要可自行更换或添加底图 - 天地图底图网址:lbs.tianditu.gov.cn/server/MapS…
- 只用替换我代码里的天地图链接里的
http://{s}.tianditu.com/img_c/里的img_c为我图中圈起来的编号,其他不用动

const token = "填自己的天地图token";
// 底图
const VEC_C ="http://{s}.tianditu.com/img_c/wmts?layer=vec&style=default&tilematrixset=c&Service=WMTS&Request=GetTile&Version=1.0.0&Format=tiles&TileMatrix={z}&TileCol={x}&TileRow={y}&tk=";
// 文字标注
// const CVA_C = "http://{s}.tianditu.com/cia_c/wmts?layer=cva&style=default&tilematrixset=c&Service=WMTS&Request=GetTile&Version=1.0.0&Format=tiles&TileMatrix={z}&TileCol={x}&TileRow={y}&tk=";
let map = L.map("map", {
minZoom: 3,
maxZoom: 17,
center: [34.33213, 109.00945],
zoomSnap: 0.1,
zoom: 3.5,
zoomControl: false,
attributionControl: false,
crs: L.CRS.EPSG4326,
});
L.tileLayer(VEC_C + token, {
zoomOffset: 1,
subdomains: ["t0", "t1", "t2", "t3", "t4", "t5", "t6", "t7"],
opacity: 0.2,
}).addTo(map);
// 添加文字标注
// L.tileLayer(CVA_C + token, {
// tileSize: 256,
// zoomOffset: 1,
// subdomains: ["t0", "t1", "t2", "t3", "t4", "t5", "t6", "t7"],
// }).addTo(map);
2. 绘制中国地图geojson
- 这里我需要国的边界和省的边界线颜色不一样,所以用了一个国的geojson和另一个包含省的geojson叠加来实现
- 获取geojson数据网站:datav.aliyun.com/portal/scho…
L.geoJson(sheng, {
style: {
color: "#0c9fb8",
weight: 1,
fillColor: "#028297",
fillOpacity: 0.1,
},
}).addTo(map);
L.geoJson(guo, {
style: {
color: "#b8c3c8",
weight: 2,
fillOpacity: 0,
},
}).addTo(map);
3. 更换背景主题色
我的实现思路比较简单粗暴,直接给天地图的图层设置透明度,对div元素设置背景色,如果UI配合,可以叫UI给个遮罩层的背景图,比如我这里就是用了四周有黑边渐变阴影,中间是透明的背景图。
<div id="map"></div>
<div class="mask"></div>
#map {
height: 100vh;
width: 100vw;
background: #082941;
z-index: 2;
}
.mask {
width: 100%;
height: 100%;
position: absolute;
left: 0;
top: 0;
background: url("./mask.png") no-repeat;
background-size: 100% 100%;
z-index: 1;
}
4. 完整代码
- 写自己天地图的token
- 自己下载geojson文件
- 自己看需要搞个遮罩层背景图,不需要就注释掉mask
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<link
href="https://cdn.bootcdn.net/ajax/libs/leaflet/1.9.4/leaflet.css"
rel="stylesheet"
/>
</head>
<style>
* {
margin: 0;
padding: 0;
}
#map {
height: 100vh;
width: 100vw;
background: #082941;
z-index: 2;
}
.mask {
width: 100%;
height: 100%;
position: absolute;
left: 0;
top: 0;
background: url("./mask.png") no-repeat;
background-size: 100% 100%;
z-index: 1;
}
</style>
<body>
<div id="map"></div>
<div class="mask"></div>
</body>
<script src="https://cdn.bootcdn.net/ajax/libs/leaflet/1.9.4/leaflet.js"></script>
<script src="./china.js"></script>
<script src="./guo.js"></script>
<script>
const token = "写自己天地图的token";
// 底图
const VEC_C =
"http://{s}.tianditu.com/img_c/wmts?layer=vec&style=default&tilematrixset=c&Service=WMTS&Request=GetTile&Version=1.0.0&Format=tiles&TileMatrix={z}&TileCol={x}&TileRow={y}&tk=";
// 文字标注
// const CVA_C =
// "http://{s}.tianditu.com/cia_c/wmts?layer=cva&style=default&tilematrixset=c&Service=WMTS&Request=GetTile&Version=1.0.0&Format=tiles&TileMatrix={z}&TileCol={x}&TileRow={y}&tk=";
let map = L.map("map", {
minZoom: 3,
maxZoom: 17,
center: [34.33213, 109.00945],
zoomSnap: 0.1,
zoom: 3.5,
zoomControl: false,
attributionControl: false, //版权控制器
crs: L.CRS.EPSG4326,
});
L.tileLayer(VEC_C + token, {
zoomOffset: 1,
subdomains: ["t0", "t1", "t2", "t3", "t4", "t5", "t6", "t7"],
opacity: 0.2,
}).addTo(map);
// L.tileLayer(CVA_C + token, {
// tileSize: 256,
// zoomOffset: 1,
// subdomains: ["t0", "t1", "t2", "t3", "t4", "t5", "t6", "t7"],
// }).addTo(map);
L.geoJson(sheng, {
style: {
color: "#0c9fb8",
weight: 1,
fillColor: "#028297",
fillOpacity: 0.1,
},
}).addTo(map);
L.geoJson(guo, {
style: {
color: "#b8c3c8",
weight: 2,
fillOpacity: 0,
},
}).addTo(map);
</script>
</html>
来源:juejin.cn/post/7485482994989596722
怎么将中文数字转为阿拉伯数字?
说在前面
最近实现了一个b站插件,可以通过语音来控制播放页面上指定的视频,在语音识别的过程中遇到了需要将中文数字转为阿拉伯数字的情况,在这里分享一下具体事例和处理过程。
功能背景
先介绍一下功能背景,页面渲染的时候会先对视频进行编号处理,具体如下:

比如我们想要播放第4个视频的话,我们只需要说“第4个”,插件就能帮我们选择第四个视频进行播放。
问题描述
功能背景我们已经了解了,那么问题是出在哪里呢?

如上图,这里识别出来的语音文本数字是中文数字,这样跟页面的视频编号无法对应上,因此我们需要实现一个方法来将中文转为阿拉伯数字。
方法实现
1、个位级映射表
const numMap = {
零: 0,一: 1,壹: 1,二: 2,两: 2,
三: 3,叁: 3,四: 4,肆: 4,五: 5,
伍: 5,六: 6,陆: 6,七: 7,柒: 7,
八: 8,捌: 8,九: 9,玖: 9,
};
2、单位映射表
const unitMap = {
十: { value: 10, sec: false },
拾: { value: 10, sec: false },
百: { value: 100, sec: false },
佰: { value: 100, sec: false },
千: { value: 1000, sec: false },
仟: { value: 1000, sec: false },
万: { value: 10000, sec: true },
萬: { value: 10000, sec: true },
亿: { value: 100000000, sec: true },
億: { value: 100000000, sec: true }
};
3、处理流程
- 遇到数字:先存起来(比如「三」记作3)
if (hasZero && current > 0) {
current *= 10;
hasZero = false;
}
current += numMap[char];
- 遇到单位:
- 如果是十/百/千:把存着的数字乘上倍数
(如「三百」→3×100=300)
current = current === 0 ? unit.value : current * unit.value;
section += current;
current = 0;
- 遇到万/亿:先结算当前数字,将当前数字加到总数上
processSection();
section = (section + current) * unit.value;
total += section;
section = 0;
- 如果是十/百/千:把存着的数字乘上倍数
- 遇到零:做个标记,提醒下个数字要占位
(如「三百零五」→300 + 0 +5=305)
if (char === "零") {
hasZero = true;
continue;
}
4、完整代码
function chineseToArabic(chineseStr) {
// 映射表(支持简繁)
const numMap = {
零: 0,一: 1,壹: 1,二: 2,两: 2,
三: 3,叁: 3,四: 4,肆: 4,五: 5,
伍: 5,六: 6,陆: 6,七: 7,柒: 7,
八: 8,捌: 8,九: 9,玖: 9,
};
//单位映射表
const unitMap = {
十: { value: 10, sec: false },
拾: { value: 10, sec: false },
百: { value: 100, sec: false },
佰: { value: 100, sec: false },
千: { value: 1000, sec: false },
仟: { value: 1000, sec: false },
万: { value: 10000, sec: true },
萬: { value: 10000, sec: true },
亿: { value: 100000000, sec: true },
億: { value: 100000000, sec: true }
};
let total = 0; // 最终结果
let section = 0; // 当前小节
let current = 0; // 当前累加值
let hasZero = false; // 零标记
const processSection = () => {
section += current;
current = 0;
};
for (const char of chineseStr) {
if (numMap.hasOwnProperty(char)) {
if (char === "零") {
hasZero = true;
continue;
}
if (hasZero && current > 0) {
current *= 10;
hasZero = false;
}
current += numMap[char];
} else if (unitMap.hasOwnProperty(char)) {
const unit = unitMap[char];
if (unit.sec) {
// 处理万/亿分段
processSection();
section = (section + current) * unit.value;
total += section;
section = 0;
} else {
current = current === 0 ? unit.value : current * unit.value;
section += current;
current = 0;
}
hasZero = false;
}
}
const last2 = chineseStr.slice(-2)[0];
const last2Unit = unitMap[last2];
if (last2Unit) {
current = (current * last2Unit.value) / 10;
}
return total + section + current;
}
功能测试
柒億零捌拾萬

十萬三十

十萬三

二百五

二百零五

八

插件信息
对我上述提到的插件感兴趣的同学可以看下我前面发的这篇文章:
公众号
关注公众号『 前端也能这么有趣 』,获取更多有趣内容。
发送 加群 还可以加入群聊,一起来学习(摸鱼)吧~
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『
前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。
来源:juejin.cn/post/7485936146071765030
npm和npx的区别
npx 和 npm 是 Node.js 生态中两个密切相关的工具,但它们的功能和用途有显著区别:
1. npm(Node Package Manager)
- 定位:Node.js 的包管理工具,用于安装、管理和发布 JavaScript 包。
- 核心功能:
- 安装依赖:通过
npm install <package>安装包到本地或全局。 - 管理项目依赖:通过
package.json文件记录依赖版本。 - 运行脚本:通过
npm run <script>执行package.json中定义的脚本。 - 发布包:通过
npm publish将代码发布到 npm 仓库。
- 安装依赖:通过
- 示例:
npm install lodash # 安装 lodash 到本地 node_modules
npm install -g typescript # 全局安装 TypeScript
npm run start # 运行 package.json 中的 "start" 脚本
2. npx(Node Package Executor)
- 定位:
npm的配套工具,用于直接执行包中的命令,无需全局或本地安装。 - 核心功能:
- 临时执行包:自动下载远程包并运行,完成后删除。
- 运行本地已安装的包:直接调用本地
node_modules/.bin中的命令。 - 切换包版本:指定特定版本运行(如
npx node@14 myscript.js)。
- 示例:
npx create-react-app my-app # 临时下载并运行 create-react-app
npx eslint . # 运行本地安装的 eslint
npx http-server # 启动一个临时 HTTP 服务器
关键区别
| 特性 | npm | npx |
|---|---|---|
| 主要用途 | 安装和管理依赖 | 直接执行包中的命令 |
| 是否需要安装包 | 需要提前安装(本地或全局) | 可临时下载并执行,无需提前安装 |
| 典型场景 | 管理项目依赖、运行脚本、发布包 | 运行一次性命令、测试工具、脚手架 |
| 执行本地包命令 | 需通过 npm run 或完整路径调用 | 直接通过 npx <command> 调用 |
| 全局包依赖 | 依赖全局安装的包 | 不依赖全局包,可指定版本运行 |
为什么需要 npx?
- 避免全局污染:
例如运行create-react-app时,无需全局安装,直接通过npx临时调用最新版本。 - 简化本地包调用:
本地安装的工具(如eslint、jest)可以直接用npx执行,无需配置package.json脚本或输入冗长路径。 - 兼容多版本:
可指定版本运行,如npx node@14 myscript.js,避免全局版本冲突。
使用建议
- 用
npm:
管理项目依赖、定义脚本、发布包。 - 用
npx:
运行脚手架工具(如create-react-app)、临时工具(如http-server)或本地已安装的命令。
示例场景
# 使用 npm 安装依赖
npm install axios
# 使用 npx 运行一次性工具
npx json-server db.json # 临时启动一个 REST API 服务器
# 使用 npm 运行脚本(需在 package.json 中定义 "scripts")
npm run build
# 使用 npx 调用本地已安装的包
npx webpack --config webpack.config.js
通过合理使用 npm 和 npx,可以更高效地管理依赖和执行命令。
来源:juejin.cn/post/7484992785952096267
TypeScript 官方宣布弃用 Enum?Enum 何罪之有?
1. 官方真的不推荐 Enum 了吗?
1.1 事情的起因
起因是看到 科技爱好者周刊(第 340 期) 里面推荐了一篇文章,说是官方不再推荐使用 enum 语法,原文链接在 An ode to TypeScript enums,大致是说 TS 新出了一个 --erasableSyntaxOnly 配置,只允许使用可擦除语法,但是 enum 不可擦除,因此推断官方已不再推荐使用 enum 了。官方并没有直接表达不推荐使用,那官方为什么要出这个配置项呢?

1.2 什么是可擦除语法
就在上周,TypeScript 发布了 5.8 版本,其中有一个改动是添加了 --erasableSyntaxOnly 配置选项,开启后仅允许使用可擦除语法,否则会报错。enum 就是一个不可擦除语法,开启 erasableSyntaxOnly 配置后,使用 enum 会报错。
例如,如果在 tsconfig 文件中配置 "erasableSyntaxOnly": true(只允许可擦除语法),此时使用不可擦除语法,将会得到报错:

可擦除语法就是可以直接去掉的、仅在编译时存在、不会生成额外运行时代码的语法,例如 type,interface。不可擦除语法就是不能直接去掉的、需要编译为JS且会生成额外运行时代码的语法,例如 enum,namesapce(with runtime code)。 具体举例如下:
可擦除语法,不生成额外运行时代码,比如 type、let n: number、interface、as number 等:

不可擦除语法,生成额外运行时代码,比如 enum、namespace(具有运行时行为的)、类属性参数构造语法糖(Class Parameter properties)等:
// 枚举类型
enum METHOD {
ADD = 'add'
}
// 类属性参数构造
class A {
constructor(public x: number) {}
}
let a: number = 1
console.log(a)

需要注意,具有运行时行为的 namespace 才属于不可擦除语法。
// 不可擦除,具有运行时逻辑
namespace MathUtils {
export function add(a: number, b: number): number {
return a + b;
}
}
// 可擦除,仅用于类型声明,不包含任何运行时逻辑
namespace Shapes {
export interface Rectangle {
width: number;
height: number;
}
}

1.3 TS 官方为什么要出 erasableSyntaxOnly?
官方既然没有直接表达不推荐 enum,那为什么要出 erasableSyntaxOnly 配置来排除 enum 呢?
我找到了 TS 官方文档(The --erasableSyntaxOnly Option)说明:

大致意思是说之前 Node 新版本中支持了执行 TS 代码的能力,可以直接运行包含可擦除语法的 TypeScript 文件。Node 将用空格替换 TypeScript 语法,并且不执行类型检查。总结下来就是:
在 Node 22 版本:
- 需要配置
--experimental-transform-types执行支持 TS 文件 - 要禁用 Node 这种特性,使用参数
--no-experimental-strip-types
在 Node 23.6.0 版本:
- 默认支持直接运行可擦除语法的 TS 文件,删除参数
--no-experimental-strip-types - 对于不可擦除语法,使用参数
--experimental-transform-types
综上所述,TS 官方为了配合 Node.js 这次改动(即默认允许直接执行不可擦除语法的 TS 代码),才添加了一个配置项 erasableSyntaxOnly,只允许可擦除语法。
2. Enum 的三大罪行
自 Enum 从诞生以来,它一直是前端界最具争议的特性之一,许多前端开发者乃至不少大佬都对其颇有微词,纷纷发起了 DO NOT USE TypeScript Enum 的吐槽。那么enum 真的有那么难用吗?我认为是的,这玩意坑还挺多的,甲级战犯 Enum,出列!
2.1 枚举默认值
enum 默认的枚举值从 0 开始,这还不是最关键的,你传入了默认枚举值时,居然是合法的,这无形之中带来了类型安全问题。
enum METHOD {
ADD
}
function doAction(method: METHOD) {
// some code
}
doAction(METHOD.ADD) // ✅ 可以
doAction(0) // ✅ 可以
2.2 不支持枚举值字面量
还有一种场景,我要求既可以传入枚举类型,又要求传入枚举值字面量,如下所示,但是他又不合法了?(有人说你定义传枚举类型就要传相应的枚举,这没问题,但是上面提到的问题又是怎么回事呢?这何尝不是 Enum 的双标?)
enum METHOD {
ADD = 'add'
}
function doAction(method: METHOD) {
// some code
}
doAction(METHOD.ADD) // ✅ 可以
doAction('add') // ❌ 不行
2.3 增加运行时开销
TypeScript 的 enum 在编译后会生成额外的 JavaScript 双向映射数据,这会增加运行时的开销。

3. Enum 的替代方案
众所周知,TS 一大特性是类型变换,我们可以通过类型操作组合不同类型来达到目标类型,又称为类型体操。下面的四种解决方案,可以根据实际需求来选择。
3.1 const enum
const enum 是解决产生额外生成的代码和额外的间接成本有效且快捷的方法,但不推荐使用。
const enum由于编译时内联带来了性能优化,但在.d.ts文件、isolatedModules兼容性、版本不匹配及运行时缺少.js文件等场景下存在隐藏陷阱,可能导致难以发现的 bug。详见官方说明:const-enum-pitfalls
const enum METHOD {
ADD = 'add',
DELETE = 'delete',
UPDATE = 'update',
QUERY = 'query',
}
function doAction(method: METHOD) {
// some code
}
doAction(METHOD.ADD) // ✅ 可行
doAction('delete') // ❌ 不行
const enum 解析后的代码中引用 enum 的地方将直接被替换为对应的枚举值:

3.2 模板字面量类型
将枚举类型包装为模板字面量类型(Template Literal Types),从而即支持枚举类型,又支持枚举值字面量,但是没有解决运行时开销问题。
enum METHOD {
ADD = 'add',
DELETE = 'delete',
UPDATE = 'update',
QUERY = 'query',
}
type METHOD_STRING = `${METHOD}`
function doAction(method: METHOD_STRING) {
// some code
}
doAction(METHOD.ADD) // ✅ 可行
doAction('delete') // ✅ 可行
doAction('remove') // ❌ 不行

3.3 联合类型(Union Types)
使用联合类型,引用时可匹配的值限定为指定的枚举值了,但同时也没有一个地方可以统一维护枚举值,如果一旦枚举值有调整,其他地方都需要改。
type METHOD =
| 'add'
/**
* @deprecated 不再支持删除
*/
| 'delete'
| 'update'
| 'query'
function doAction(method: METHOD) {
// some code
}
doAction('delete') // ✅ 可行,没有 TSDoc 提示
doAction('remove') // ❌ 不行

3.4 类型字面量 + as const(推荐)
类型字面量就是一个对象,将一个对象断言(Type Assertion)为一个 const,此时这个对象的类型就是对象字面量类型,然后通过类型变换,达到即可以传入枚举值,又可以传入枚举类型的目的。
const METHOD = {
ADD:'add',
/**
* @deprecated 不再支持删除
*/
DELETE:'delete',
UPDATE: 'update',
QUERY: 'query'
} as const
type METHOD_TYPE = typeof METHOD[keyof typeof METHOD]
function doAction(method: METHOD_TYPE) {
// some code
}
doAction(METHOD.DELETE) // ✅ 可行,有 TSDoc 提示
doAction('delete') // ✅ 可行
doAction('remove') // ❌ 不行

3.5 Class 类静态属性自定义实现
还有一种方法,参考了 @Hamm 提供的方法,即利用 TS 面向对象的特性,自定义实现一个枚举类,实际上这很类似于后端定义枚举的一般方式。这种方式具有很好的扩展性,自定义程度更高。
- 定义枚举基类
/**
* 枚举基类
*/
export default class EnumBase {
/**
* 枚举值
*/
private value!: string
/**
* 枚举描述
*/
private label!: string
/**
* 记录枚举
*/
private static valueMap: Map<string, EnumBase> = new Map();
/**
* 构造函数
* @param value 枚举值
* @param label 枚举描述
*/
public constructor(value: string, label: string) {
this.value = value
this.label = label
const cls = this.constructor as typeof EnumBase
if (!cls.valueMap.has(value)) {
cls.valueMap.set(value, this)
}
}
/**
* 获取枚举值
* @param value
* @returns
*/
public getValue(): string | null {
return this.value
}
/**
* 获取枚举描述
* @param value
* @returns
*/
public getLabel(): string | null {
return this.label
}
/**
* 根据枚举值转换为枚举
* @param this
* @param value
* @returns
*/
static convert<E extends EnumBase>(this: new(...args: any[]) => E, value: string): E | null {
return (this as any).valueMap.get(value) || null
}
}
- 继承实现具体的枚举(可根据需要扩展)
/**
* 审核状态
*/
export class ENApproveState extends EnumBase {
/**
* 未审核
*/
static readonly NOTAPPROVED = new ENApproveState('1', '未审核')
/**
* 已审核
*/
static readonly APPROVED = new ENApproveState('2', '已审核')
/**
* 审核失败
*/
static readonly FAILAPPROVE = new ENApproveState('3', '审核失败')
/***
* 审核中
*/
static readonly APPROVING = new ENApproveState('4', '审核中')
}
- 使用
test('ENCancelState.NOCANCEL equal 1', () => {
expect(ENApproveState.NOTAPPROVED.getValue()).toBe('1')
expect(ENApproveState.APPROVING.getValue()).toBe('4')
expect(ENApproveState.FAILAPPROVE.getLabel()).toBe('审核失败')
expect(ENApproveState.convert('2')).toBe(ENApproveState.APPROVED)
expect(ENApproveState.convert('99')).toBe(null)
})

4. 总结
- TS 可擦除语法 是指
type、interface、n:number等可以直接去掉的、仅在编译时存在、不会生成额外运行时代码的语法 - TS 不可擦除语法 是指
enum、constructor(public x: number) {}等不可直接去除且会生成额外运行时代码的语法 - Node.js 23.6.0 版本开始 默认支持直接执行可擦除语法 的 TS 文件
enum的替代方案有多种,取决于实际需求。用字面量类型 +as const是比较常用的一种方案。
TS 官方为了兼容 Node.js 23.6.0 这种可执行 TS 文件特性,出了 erasableSyntaxOnly 配置禁用不可擦除语法,反映了 TypeScript 官方对减少运行时开销和优化编译输出的关注,而不是要放弃 enum。
但或许未来就是要朝着这个方向把 enum 优化掉也说不定呢?
5. 参考链接
来源:juejin.cn/post/7478980680183169078
AI时代下,我用陌生技术栈两天开发完一个App后的总结
AI时代下,我用陌生技术栈两天开发完一个App后的总结
今年的 AI 应用赛道简直是热火朝天,大街上扔一把核桃能砸到三个在讨论 AI 的,更有不少类似于零编程经验用 AI 三天开发 App 登榜 App Store的标题在各大平台的AI话题圈子里刷屏,作为一个在互联网行业摸爬滚打多年的程序员,我做过开源项目,也做过多个小型独立商业项目,最近两年也是在 AI 相关公司任职,对此我既感到兴奋又难免焦虑——为什么我还没遇到这样的机遇?
刚好最近想到了一个点子,是一个结合了屏幕呼吸灯 + 轻音乐 + 白噪声的辅助睡眠移动端 A 应用,我将其命名为“音之梦”,是我某天晚上睡不着看到路由器闪烁的灯光照耀在墙壁上之后突然爆发的灵感。
这是个纯客户端应用,没有太多外部依赖,体量小,正好拿来试一下是不是真的有可能完全让 AI 来将它实现,而为了尽量模拟“编程小白”这个身份,这次我选择用我比较陌生的 Swift UI。
先上结论:
对于小体量的应用,或者只考虑业务实现而不需要考虑架构合理性/可维护性的稍大体量的应用,在纯编码层面确实是完全可以实现的,作为一个不会 Swift UI 的开发者,我确实在不到 2 天时间内完全借助 AI 完成了这个应用的开发,而且已经上架苹果App Store。
以下是应用截图:
感兴趣的朋友们也访问下面的链接或者上App Store搜索 ”音之梦“ 下载体验。
我做了哪些事情?
工具准备
开发工具使用的是Cursor + XCode,开发语言选的 Swift UI,模型自然选择最适合编码的Claude 3.7。
为什么不选择Trae?因为下一个开坑项目准备用Trae + Deepseek来进行效果对比。
产品设计
上面截图展示的其实是第二版, UI和交互流程是我根据产品需求仔细思考琢磨设计出来的。
而第一版则完全由AI生成的,我只是描述了我期望的功能,交互方式和UI效果都是AI来生成的,那自然和我心目中期望的差距很大,不过最开始只是想验证AI的快速编码能力,所以首次上架的还是还是用的这一版的样式,可以看下面的截图:
而因为国区上架需要备案,在等待备案的过程中,我又诞生了很多新的想法,加上对于第一版的UI和交互流程也是越看越不爽,所以就重新思考了整个应用的UI和交互流程,并重新用figma画了设计稿,然后交由AI来实现。
当然每个人的审美和需求都不一样,也并不是每个人都有不错的UI和交互设计能力,对于大部分人来说现阶段的AI设计水平已经是能满足需要了的。
开发过程
使用AI来进行开发,那最重要的就是提示词,而如何编写提示词来让AI更了解你的需求、尽可能不走弯路去实现,其实是很不容易的。
这里我的经验是,先自己思考清楚,用markdown整理好需求,包括主要功能、需要有哪些页面、每个页面的大致布局,以及一些需要额外强调的细节等等,然后让AI先根据你整理的需求文档来描述一下它对这个需求的理解,也可以让它反过来问你一些在需求文档无法确定的问题,补全到文档中,直到他能八九不离十的把你想要的结果描述出来。
此外,你也可以先在chat模式里面简单一句话描述需求,选择claude 3.7 thinking模型,或者deepseek r1模型,然后你们俩一起交流来把需求逐步完善和明确。
需求明确之后,也不要马上就让AI直接开始开发,因为如果整个过程很长的话,大模型目前的上下文肯定是不够的,就算是基于codebase,后续也必然会丢失细节,甚至完全忘记了你们之前定好的需求。
这里的建议是,先让AI根据需求文档把目录和文件创建好,并为每个代码文件建立一个md文件,用于标记每个代码文件里面包含的关键变量、方法名、和其他模块的依赖关系等,这样相比完整的代码文件,数据量要小很多,后续觉得大模型忘事儿了,就让他根据md来进行分析,这要比让他分析完整的代码文件要靠谱很多。另外在后续开发过程中也一定要让AI及时更新md文件。
可以在Cursor的规则配置文件中明确上面的要求。
由于Cursor中的Claude 3.7不支持输入图片作为参考,所以如果你需要基于现有的设计图进行开发,可以先选择Claude 3.5,传入参考图,让它先帮你把不带交互的UI代码实现,然后再使用claude 3.7 来进一步完善设计的业务逻辑。
开发过程中,每一次迭代可能都大幅改动之前已经实现的部分,所以切记一定要及时git commit,尤其是已经完成了某个小功能之后,一定要提交代码!这也是我使用AI进行全流程开发的最大的教训!
音频资源的获取
这个App中有很多音频资源,包括轻音乐、环境声、白噪声等,在以往,个人开发者要获取这些资源其实是很费时间的,而且需要付出的成本也比较高,但是随着AI的发展,现在获取这些资源已经变得非常容易了。
比如轻音乐,我用的是Suno AI来生成的,十几美元一个月,就能生成足够多的轻音乐,而且质量还不错,可以满足大部分场景的需求。
白噪声,则是让AI帮我编写的nodejs脚本来生成的,直接本地生成mp3音乐文件。
环境声、物品音效之类的,可以使用Eleven Lab来生成,价格也很便宜,不过我这里是先用的开源项目Moodist中的资源,而且也对作者进行了捐赠支持。
另外,在讲这些音频资源打包到应用的时候,从体积角度考虑,我对这些音频都做了压缩,在以往可能需要找一些格式工厂之类的软件来完成,现在直接让AI帮你基于Macos内置的音频处理模块生成命令行脚本,轻松完成格式转换和比率压缩,非常方便。
非AI的部分
虽然我全程几乎没有写一行代码,但是还是有一些非AI的部分,需要手动来完成。
比如应用的启动图标设计、App Store上架资料的准备、关键词填写、技术支持网址、隐私协议内容、应用截图的准备等等,虽然这其中有一些也能借助AI辅助进行,但是最终还是免不了要手动进行处理。
隐私协议内容可以让AI生成,不过一定要自己过一遍,而技术支持网站,可以用在线问卷的形式,不用自己准备网站。
在App Store上架审核的时候,也需要时刻关注审核进度和反馈,一般来说新手第一次上架审核就过审的概率很低,苹果那边也有很多规范或者要求甚至是红线,需要踩坑多次才能了解清楚。我之前已经上架过好几款应用了,这一次提审第一次没过居然是因为内购项目忘记一并提审了,笑死,不然就是一把过了,后面更新的几个版本最快半小时不到就过审了。
另外还有国区上架备案的问题,实际要准备的资料也不多,流程其实也不复杂,但是就是需要等待,而且等待的时间不确定,我这次等了近5天才通过。
有朋友可能会咨询安卓版的问题,我只能说一言难尽,目前安卓的上架流程和资质要求对独立开发者太不友好了,不确定项目有商业价值之前,不建议考虑安卓(就算是出海上google play,也比上苹果应用商店麻烦多了)。
总结
以往我作为全栈工程师,在开发产品的时候,编码始终是我最核心的工作,而这一次,我最重要的编码过程交给了 AI,我则是充当了产品设计师和测试工程师的角色,短短几天,我已经体会了很多专职产品设计师在和开发人员沟通时候的感受,也体会到了测试工程师在测试产品时候的感受,这确实是一个非常有趣和有意义的过程。
作为产品设计师,我需要能够准备描述需求、考虑到尽可能多的场景和细节,才能让 AI 更加敏捷和高质量的完成需求的开发,而作为测试工程师,我需要学会如何准确地描述问题的表现和复现步骤,才能让 AI 更加精准的给出解决方案。
虽然我确实没有写一行代码,但是在开发过程中,遇到一些复杂场景或者问题,Cursor 也会原地踏步甚至把问题越改越严重,这个时候还是需要我去分析一下它实现的代码,跳出它的上下文来来给他提示,然后他就会恍然大悟一般迅速解决问题,这确确实实依赖了我多年来的开发经验和直觉,我相信在开发复杂应用的时候,这是必不可少的。
而且开发 App 是一回事,上架 App 又是另外一回事了,备案、审核、隐私协议准备、上架配图准备等等等等,这些可能要花的时间比开发的时间还长。
在这次实践的过程中,我虽然是借助了自己的以往的独立开发经验解决了很多问题,并因此缩短了从开始开发到真正完成审核上架的周期,但我相信最核心的编码问题已经完全能交给AI了的话,那对于大部想要做一个自己的应用的人来说,真正的技术门槛确实已经不存在了。
因此我可以对大家说,准备好面对一个人人都能编程做应用的新时代吧!
再回到关于零编程经验用 AI 三天开发 App 登榜 App Store这个话题,我只能说,这确实是一个非常吸引眼球的话题,但是它也确实存在一定的误导性,不管用 AI 还是纯人工编码,做出来好的 APP 和成为爆款 APP 其实是两回事。
事实上我体验过一些此类爆款产品,在产品完成度和交互设计上实际上还很初级,甚至可以说很粗糙,但是它们却能够获得巨大的成功,除了运气和时机之外,营销上的成功其实是更重要的。
需要清醒认识的是,App Store 榜单是产品力、运营策略和市场机遇的综合产物。作为开发者,更应该关注 AI 如何重构我们的能力边界,而非简单对标营销案例。
最后再说点
总有人会问AI会不会取代程序员,我觉得不会,被AI淘汰的,只会是那些害怕使用AI,不愿意学习使用AI的人。我相信经常逛掘金的朋友们也都是不甘于只做一颗螺丝钉的,快让借助AI来拓展你的能力边界吧,
最后再再再说一句
一定要记得及时git commit!!!
来源:juejin.cn/post/7484530047866355766
🔥🔥什么?LocalStorage 也能被监听?为什么我试了却不行?
引言:最近,团队的伙伴需要实现监听
localStorage数据变化,但开发中却发现无法直接监听。
在团队的一个繁重项目中,我们发现一个新功能的实现成本很大,因此开始思考:能否通过实时监听 LocalStorage 的变化并自动触发相关操作。我们尝试使用 addEventListener 来监听 localStorage 的变化,但令人意外的是,这种方法仅在不同浏览器标签页之间有效,而在同一标签页内却无法实现监听。这是怎么回事?

经过调研了解到,浏览器确实提供了 storage 事件机制,但它仅适用于同源的不同标签页之间。对于同一标签页内的 LocalStorage 变化,却没有直接的方法来实现实时监听。最初,我们考虑使用 setInterval 进行定时轮询来获取变化,但这种方式要么导致性能开销过大,要么无法第一时间捕捉到变化。
今天,我们探讨下几种高效且实用的解决方案,是否可以帮助轻松应对LocalStorage这种监听需求?希望对你有所帮助,有所借鉴!
传统方案的痛点🎯🎯
先来看看浏览器是如何帮助我们处理不同页签的 LocalStorage 变化:
window.addEventListener("storage", (event) => {
if (event.key === "myKey") {
// 执行相应操作
}
});
通过监听 storage 事件,当在其他页签修改 LocalStorage 时,你可以在当前页签捕获到这个变化。但问题是:这种方法只适用于跨页签的 LocalStorage 修改,在同一页签下无法触发该事件。于是,很多开发者开始寻求替代方案,比如:
1、轮询(Polling)
轮询是一种最直观的方式,它定期检查 localStorage 的值是否发生变化。然而,这种方法性能较差,尤其在高频轮询时会对浏览器性能产生较大的影响,因此不适合作为长期方案。
let lastValue = localStorage.getItem('myKey');
setInterval(() => {
const newValue = localStorage.getItem('myKey');
if (newValue !== lastValue) {
lastValue = newValue;
console.log('Detected localStorage change:', newValue);
}
}, 1000); // 每秒检查一次
这种方式实现简单,不依赖复杂机制。但是性能较差,频繁轮询会影响浏览器性能。
2、监听代理(Proxy)或发布-订阅模式
这种方式通过创建一个代理来拦截 localStorage.setItem 的调用。每次数据变更时,我们手动发布一个事件,通知其他监听者。
(function() {
const originalSetItem = localStorage.setItem;
const subscribers = [];
localStorage.setItem = function(key, value) {
originalSetItem.apply(this, arguments);
subscribers.forEach(callback => callback(key, value));
};
function subscribe(callback) {
subscribers.push(callback);
}
subscribe((key, value) => {
if (key === 'myKey') {
console.log('Detected localStorage change:', value);
}
});
localStorage.setItem('myKey', 'newValue');
})();
这种比较灵活,可以用于复杂场景。但是需要手动拦截 setItem,维护成本高(但也是值得推荐的)。

然而,这些方案往往存在性能问题或者开发的复杂度,在高频数据更新的情况下,有一定的性能问题,而且存在一定的风险性。那么有没有可以简单快速,风险性还小的方案呢?
高效的解决方案 🚀🚀
既然浏览器不支持同一页签的 storage 事件,我们可以手动触发事件,以此来实现同一页签下的 LocalStorage 变化监听。
1、自定义 Storage 事件
通过手动触发 StorageEvent,你可以在 LocalStorage 更新时同步分发事件,从而实现同一页签下的监听。
localStorage.setItem('myKey', 'value');
// 手动创建并分发 StorageEvent
const storageEvent = new StorageEvent('storage', {
key: 'myKey',
url: window.location.href
});
window.dispatchEvent(storageEvent);
你可以使用相同的监听逻辑来处理数据变化,无论是同一页签还是不同页签:
window.addEventListener("storage", (event) => {
if (event.key === "myKey") {
// 处理 LocalStorage 更新
}
});
这种实现简单、轻量、快捷。但是需要手动触发事件。
2、基于 CustomEvent 的自定义事件
与 StorageEvent 类似,你可以使用 CustomEvent 手动创建并分发事件,实现 localStorage 的同步监听。
localStorage.setItem('myKey', 'newValue');
const customEvent = new CustomEvent('localStorageChange', {
detail: { key: 'myKey', value: 'newValue' }
});
window.dispatchEvent(customEvent);
这种方式适合更加灵活的事件触发场景。CustomEvent不局限于 localStorage 事件,可以扩展到其他功能。
window.addEventListener('localStorageChange', (event) => {
const { key, value } = event.detail;
if (key === 'myKey') {
console.log('Detected localStorage change:', value);
}
});
3、MessageChannel(消息通道)
MessageChannel API 可以在同一个浏览器上下文中发送和接收消息。我们可以通过 MessageChannel 将 localStorage 的变化信息同步到其他部分,起到类似事件监听的效果。
const channel = new MessageChannel();
channel.port1.onmessage = (event) => {
console.log('Detected localStorage change:', event.data);
};
localStorage.setItem('myKey', 'newValue');
channel.port2.postMessage(localStorage.getItem('myKey'));
适合组件通信和复杂应用场景,消息机制较为灵活。相对复杂的实现,可能不适合简单场景。
4、BroadcastChannel
BroadcastChannel 提供了一种更高级的浏览器通信机制,允许多个窗口或页面之间广播消息。你可以通过这个机制将 localStorage 变更同步到多个页面或同一页面的不同部分。
const channel = new BroadcastChannel('storage_channel');
channel.onmessage = (event) => {
console.log('Detected localStorage change:', event.data);
};
localStorage.setItem('myKey', 'newValue');
channel.postMessage({ key: 'myKey', value: 'newValue' });
支持跨页面通信,方便在不同页面间同步数据,易于实现。适用场景较为具体,通常用于复杂的页面通信需求。
这4个方法,主打的就是一个见缝插针,简单快速,风险性低。但是客观角度来讲,每种方案都是有各自优势的。
优势对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 轮询 | 实现简单,适合低频监控需求 | 性能差,频繁轮询影响浏览器性能 | 简单场景或临时方案 |
| 监听代理/发布-订阅模式 | 灵活扩展,适合复杂项目 | 需要手动拦截 setItem,维护成本高 | 需要手动事件发布的场景 |
自定义 StorageEvent | 实现简单,原生支持 storage 事件监听 | 需要手动触发事件 | 同页签下 localStorage 监听 |
| 自定义事件 | 灵活的事件管理,适合不同场景 | 需要手动触发事件 | 需要自定义触发条件的场景 |
MessageChannel | 适合组件通信和复杂应用场景 | 实现复杂,不适合简单场景 | 高级组件通信需求 |
BroadcastChannel | 跨页面通信,适合复杂通信需求 | 使用场景较具体 | 复杂的多窗口通信 |
如何在 React / Vue 使用
在主流前端框架(如 React 和 Vue)中,监听 LocalStorage 变化并不困难。无论是 React 还是 Vue,你都可以使用自定义的 StorageEvent 或其他方法来实现监听。在此,我们以自定义 StorageEvent 为例,展示如何在 React 和 Vue 中实现 LocalStorage 的监听。

1. 在 React 中使用自定义 StorageEvent
React 是一个基于组件的框架,我们可以使用 React 的生命周期函数(如 useEffect)来监听和处理 LocalStorage 的变化。
import React, { useEffect } from 'react';
const LocalStorageListener = () => {
useEffect(() => {
// 定义 storage 事件监听器
const handleStorageChange = (event) => {
if (event.key === 'myKey') {
console.log('Detected localStorage change:', event.newValue);
}
};
// 添加监听器
window.addEventListener('storage', handleStorageChange);
// 模拟触发自定义的 StorageEvent
const triggerCustomStorageEvent = () => {
const storageEvent = new StorageEvent('storage', {
key: 'myKey',
newValue: 'newValue',
url: window.location.href,
});
window.dispatchEvent(storageEvent);
};
// 组件卸载时移除监听器
return () => {
window.removeEventListener('storage', handleStorageChange);
};
}, []); // 空依赖数组表示该 effect 只会在组件挂载时运行
return (
<div>
<button onClick={() => localStorage.setItem('myKey', 'newValue')}>
修改 localStorage
</button>
<button onClick={() => window.dispatchEvent(new StorageEvent('storage', {
key: 'myKey',
newValue: localStorage.getItem('myKey'),
url: window.location.href,
}))}>
手动触发 StorageEvent
</button>
</div>
);
};
export default LocalStorageListener;
useEffect是 React 的一个 Hook,用来处理副作用,在这里我们用它来注册和清除事件监听器。- 我们手动触发了
StorageEvent,以便在同一页面中监听 LocalStorage 的变化。
2. 在 Vue 中使用自定义 StorageEvent
在 Vue 3 中,我们可以使用 onMounted 和 onUnmounted 这两个生命周期钩子来管理事件监听器。(Vue 3 Composition API):
<template>
<div>
<button @click="updateLocalStorage">修改 localStorage</button>
<button @click="triggerCustomStorageEvent">手动触发 StorageEvent</button>
</div>
</template>
<script lang="ts" setup>
import { onMounted, onUnmounted } from 'vue';
const handleStorageChange = (event: StorageEvent) => {
if (event.key === 'myKey') {
console.log('Detected localStorage change:', event.newValue);
}
};
const updateLocalStorage = () => {
localStorage.setItem('myKey', 'newValue');
};
const triggerCustomStorageEvent = () => {
const storageEvent = new StorageEvent('storage', {
key: 'myKey',
newValue: 'newValue',
url: window.location.href,
});
window.dispatchEvent(storageEvent);
};
onMounted(() => {
window.addEventListener('storage', handleStorageChange);
});
onUnmounted(() => {
window.removeEventListener('storage', handleStorageChange);
});
</script>
- 使用了 Vue 的 Composition API,其中
onMounted和onUnmounted类似于 React 的useEffect,用于在组件挂载和卸载时管理副作用。 - 同样手动触发了
StorageEvent来监听同一页面中的 LocalStorage 变化。
提炼封装一下 🚀🚀
无论是 React 还是 Vue,将自定义 StorageEvent 实现为一个组件或工具函数是常见的做法。你可以将上面的逻辑提取到一个独立的 hook 或工具函数中,方便在项目中多次使用。
在 React 中提取为 Hook
import { useEffect } from 'react';
const useLocalStorageListener = (key, callback) => {
useEffect(() => {
const handleStorageChange = (event) => {
if (event.key === key) {
callback(event.newValue);
}
};
window.addEventListener('storage', handleStorageChange);
return () => {
window.removeEventListener('storage', handleStorageChange);
};
}, [key, callback]);
};
export default useLocalStorageListener;
在 Vue 中提取为工具函数
import { onMounted, onUnmounted } from 'vue';
export const useLocalStorageListener = (key: string, callback: (value: string | null) => void) => {
const handleStorageChange = (event: StorageEvent) => {
if (event.key === key) {
callback(event.newValue);
}
};
onMounted(() => {
window.addEventListener('storage', handleStorageChange);
});
onUnmounted(() => {
window.removeEventListener('storage', handleStorageChange);
});
};
- 在 React 中,我们创建了一个自定义 Hook
useLocalStorageListener,通过传入监听的 key 和回调函数来捕获 LocalStorage 的变化。 - 在 Vue 中,我们创建了一个工具函数
useLocalStorageListener,同样通过传入 key 和回调函数来监听变化。
总结

在同一个浏览器页签中监听 localStorage 的变化并非难事,但不同场景下需要不同的方案。从简单的轮询到高级的 BroadcastChannel,本文介绍的几种方案各有优缺点。根据你的实际需求,选择合适的方案可以帮助你更高效地解决问题。
- 简单需求:可以考虑使用自定义
StorageEvent或CustomEvent实现监听。 - 复杂需求:对于更高级的场景,如跨页面通信,
MessageChannel或BroadcastChannel是更好的选择。
如果你有其他的优化技巧或问题,欢迎在评论区分享,让我们一起交流更多的解决方案!
来源:juejin.cn/post/7418117491720323081
CSS换行最容易出现的bug,半天被提了两个😭😭
引言
大家好,我是石小石!
文字超出换行应该是大家项目中高频的css样式了,它也是非常容易出现样式bug的一个地方。
分享一下我工作中遇到的问题。前几天开发代码的时候,突然收到两个测试提的bug:

bug的内容大致就是我的文字换行出现了问题
我的第一反应就是线上代码不是最新的,因为自测的时候,我注意过这个问题,我在本地还测试过
然而经过验证,最后我还是被打脸了,确实是自己的问题!
问题原因分析
在上述的问题代码中,我没有做任何换行的规则
.hover-content {
max-width: 420px;
max-height: 420px;
}
因此,此时弹框内的换行规则遵循的是浏览器的默认换行规则(white-space:normal):
浏览器换行遵循 单词完整性优先 的规则,即尽可能不在单词或数字序列内部断行;而中文是固定宽度字符,每个汉字视为独立的可断点,因此换行非常自然,展示不下浏览器会将其移动到下一行。
那么,出现上述bug的原因就非常简单了,基于浏览器的默认换行规则,这种胡乱输入、没有规则的连续纯英文或数字不换行,而汉字会换行。
white-space:normal 指定文本能够换行,是css的默认值,后文我们会继续讲解
解决方案
解决上述问题其实非常简单,一行css就可以解决🤗
word-break: break-all
word-break: break-all 可以打破浏览器的默认规则,允许在任何字符间断行(包括英文单词和数字序列)。
word-break
- 作用:指定如何对单词进行断行。
- 取值:
normal(默认值):使用浏览器默认规则,中文按字断行,英文按单词断行。break-all:强制在任何字符间断行(适用于中文、英文、数字)。keep-all:中文按字断行,英文和数字不允许在单词或数字中断行。
与换行关联的css属性
除了word-break,你可能还会对white-space、word-wrap有疑问,他们与文本换行又有什么关系呢?
white-space
white-space大家一定不陌生,做文本超出显示...的时候,它是老熟人了。
white-space: nowrap; /* 禁止文本换行 */
overflow: hidden; /* 隐藏溢出内容 */
text-overflow: ellipsis; /* 使用省略号表示溢出内容 */
white-space 用于指定如何处理元素内的空白字符和如何控制文本的换行。简单来说,它的作用就是是否应该允许文本自动换行,它的默认值normal,代表文本允许换行。
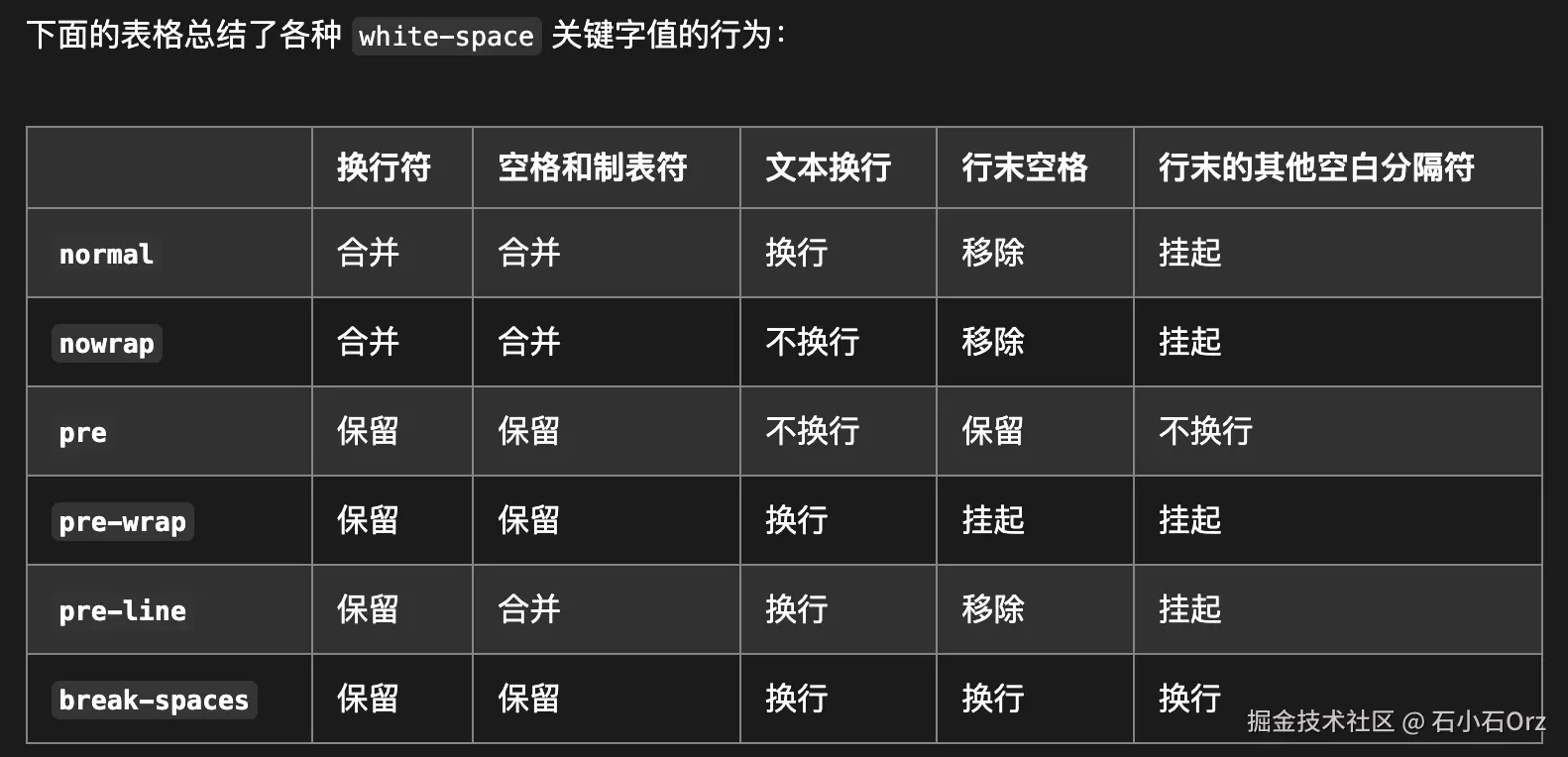
所有能够换行的文本,一定拥有此默认属性white-space:normal,如果你设置nowrap,那么不管是中文还是数字或者英文,都是不会出现换行的。
white-space的换行遵循的是单词完整性优先 的规则,如果我们要使单词可以在其内部被截断,就需要使用 overflow-wrap、word-break 或 hyphens。
word-break我们已经说过了,我们介绍下
overflow-wrap
这个属性原本属于微软扩展的一个非标准、无前缀的属性,叫做 word-wrap,后来在大多数浏览器中以相同的名称实现。目前它已被更名为 overflow-wrap,word-wrap 相当于其别称。
作用:控制单词过长时是否允许断行。
常用值:
normal:单词超出容器宽度时不换行。break-word:允许在单词中断行以防止溢出。anywhere:类似break-word,但优先级更高。
实际开发中,overflow-wrap:break-word的效果同word-break: break-all

但他们存在一点点差异
换行方式:
overflow-wrap: break-word允许在单词内部进行断行,但会尽量保持单词的完整性。word-break: break-all则强制在任意字符间进行换行,不考虑单词的完整性。
因此,使用verflow-wrap: break-word 会比word-break: break-all更好一些!
推荐实践
通过本文,相信大家对css文本换行有了新的认识,个人比较推荐的实践如下:
- 中文为主:可以默认使用
word-break: normal;。 - 中英文混排:
overflow-wrap: break-word;。 - 主要为英文或数字:需要强制换行时,使用
word-break: break-all;。
- 中文为主:可以默认使用
考虑到场景的复杂新,大家可以word-break: break-all走天下。
来源:juejin.cn/post/7450110698728816655
token泄漏产生的悲剧!Vant和Rspack被注入恶意代码,全网大面积被感染
一、事件
2024年12月19号,在前端圈发生了一件匪夷所思的事情,前端开源项目Vant的多个版本被注入恶意代码后,发布到了npm上,导致全网大面积被感染。
随后Vant团队人员出来发声说:经排查可能是我们团队一名成员的 token 被盗用,他们正在紧急处理。 What?token还能被别人盗用的么,这安全性真的是差点惊掉我的下巴。
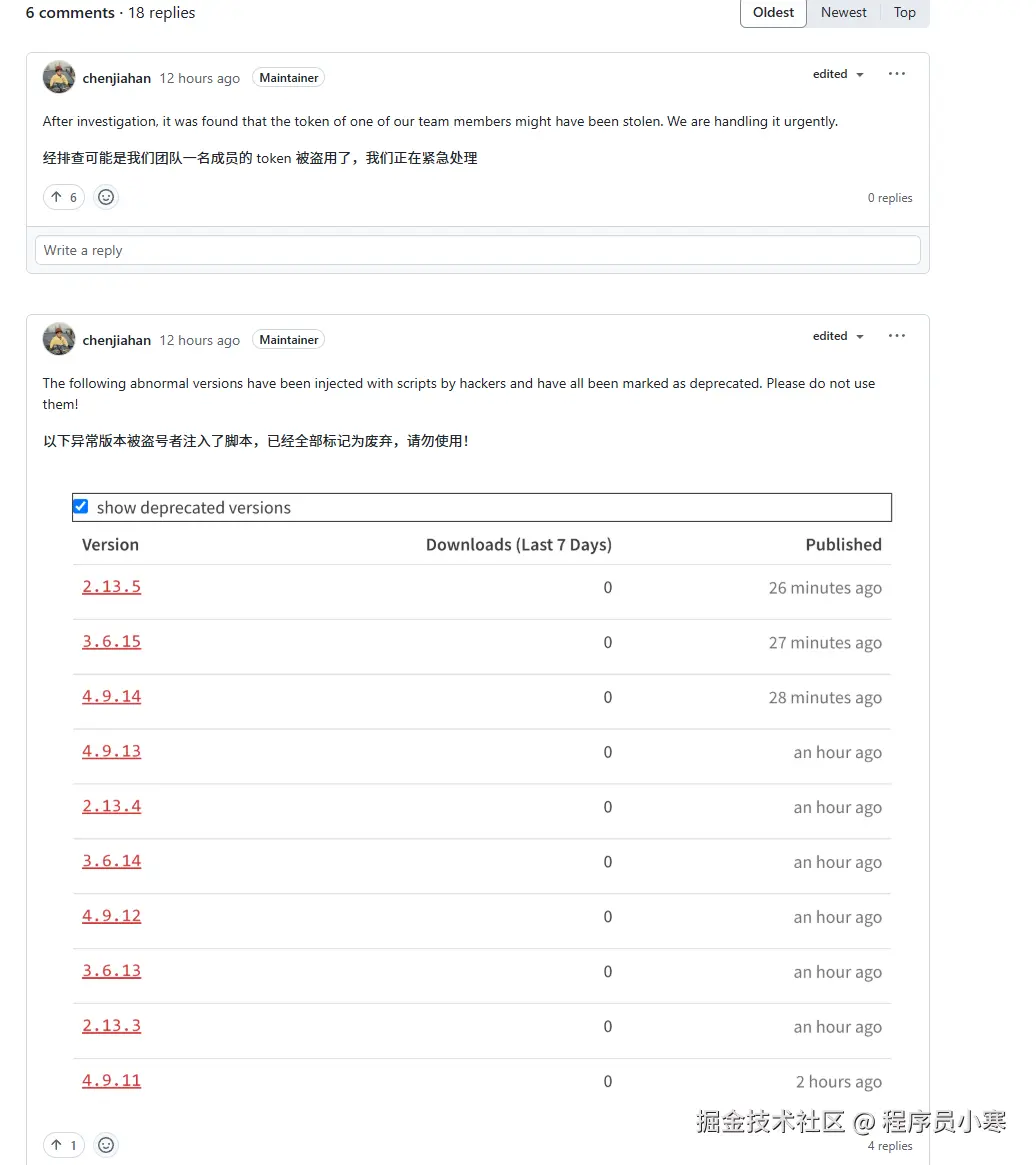
然后Vant团队人员废弃了有问题的版本,并在几个大版本2、3、4上都发布了新的安全版本2.13.6、3.6.16、4.9.15,我刚试了下,现在使用npm i vant@latest安装的是最新的4.9.15版本,事件就算是告一段落了。
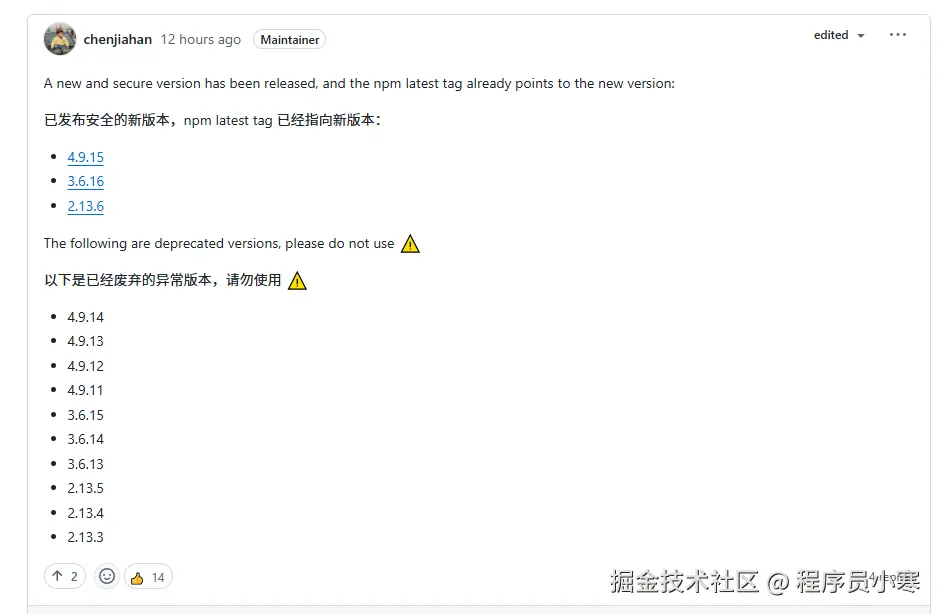
二、关联事件:Rspack躺枪
攻击者拿到了vant成员的token后,进一步拿到了同个GitHub组织下另一个成员的token,并发布了同样带有恶意代码的Rspack@1.1.7版本。
这里简单介绍下Rspack,它是一个基于Rust编写打的高性能javascript打包工具,相比于webpack、rollup等打包工具,它的构建性能有很大的提升,是字节团队为了解决构建性能的问题而研发的,后开源在github。
Rspack这波属实是躺枪了,不过Rspack团队反应很快,已经在一小时内完成该版本的废弃处理,并发布了1.1.8修复版本,字节的问题处理速度还是可以的。目前Rspack的1.1.7版本在npm上已经删除了,无法安装。
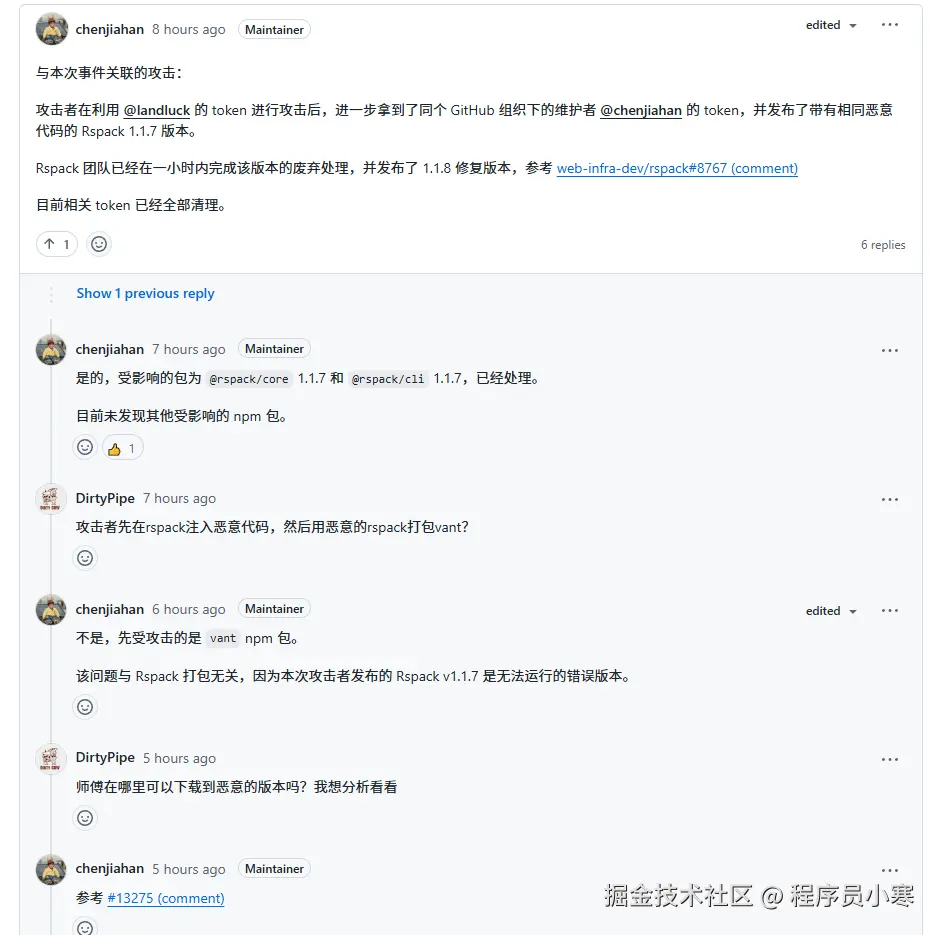
三、带来的影响
Vant作为一个老牌的国产移动端组件库,由有赞团队负责开发和维护,在github上已经拥有23.4k的Star,是一款很优秀的组件库,其在国内的前端项目中应用是非常广泛的,几乎是开发H5项目的首选组件库。vant官方目前提供了 Vue 2 版本、Vue 3 版本和微信小程序版本,微信小程序版本本次不受影响,遭受攻击的是Vue2和Vue3版本。
如果在发布恶意版本还未修复的期间,正好这时候有项目发布安装到了这些恶意版本,那后果不堪设想。要知道Vant可是面向用户端(C端)的组件库,其杀伤力是十分大的。
我们公司很多前端移动端项目也用了Vant组件库,不过我们项目都用了package-lock.json,所以对于我们来说问题不大,这里也简单介绍下package-lock.json,也推荐大家都用一下。
四、package-lock.json介绍
比如你在package.json中写了一个依赖^3.7.0,你用npm install安装到了3.7.0版本,然后过了一段时间后,你同事把这个代码克隆到本地,然后也执行npm install,由于此时依赖包已经更新到了3.8.0版本,所以此时你同事安装到的是3.8.0版本。
这时候问题就来了,这个依赖的开发团队“不讲武德”,在3.8.0对一个API做了改动,并且做好向后兼容,于是代码报错了,项目跑不起来了,你同事找了半天,发现是依赖更新了,很无语,浪费半天开发时间,又得加班赶项目了!
按理来说,npm install就应该向纯函数(相同的输入产生相同的输入,无副作用的函数)一样,产出相同node_modules,然而依赖是会更新的,这会导致npm install产出的结果不一样,而如果依赖开发人员不按规范升级版本,或者升级后的新版本有bug,尽管业务代码一行没改,项目再次发布时也可能会出现问题。
package-lock.json就是为了解决这个问题的,在npm install的时候,会根据package.json中的依赖版本,默认生成一份package-lock.json文件,你可以把这个lock文件上传到git仓库上,下次npm install的时候,会根据一定规则选择最终安装的版本:
- npm v5.0.x版本:不管package.json文件中的依赖项是否有更新,都会按照package-lock.json文件中的依赖版本进行下载。
- npm v5.1.0 - v5.4.2:当package.json的依赖版本有符合的更新版本时,会忽略package-lock.json,按照package.json安装,并更新package-lock.json文件。
- npm v5.4.2以上:当package.json声明的的依赖版本与package-lock.json中的版本兼容时,会按照package-lock.json的版本安装,反之,如果不兼容则按照package.json安装,并更新package-lock.json文件。
npm v5.4.2这个版本已经很旧了,我们用的npm版本几乎都在这之上,所以如果用了package-lock.json文件,应该就能避免这个问题,不要怕麻烦,我觉得为了项目的稳定性,这个还是需要用的。
这个事件就介绍到这里了,对此大家怎么看呢?
来源:juejin.cn/post/7450080841546121243
你知道JS中有哪些“好用到爆”的一行代码?
哈喽,各位小伙伴们,你们好呀,我是喵手。
今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
前言
偶尔帮同事开发点前端页面,每次写代码,总会遇到一些能让人直呼nb的代码。今天,我们就来盘点一下那些 “好用到爆”的 JavaScript 一行代码。省去复杂的多行代码,直接用一行或者简洁的代码进行实现。也能在同事面前秀一波(当然是展示技术实力,而不是装X 🤓)。
也许你会问:“一行代码真的能有这么强吗?” 别急,接着往下看,保证让你大呼—— 这也行?! 哈哈,待看完之后,你可能会心一笑,原来一行代码还能发挥的如此优雅!核心就是要简洁高效快速实现。
目录
- 妙用之美:一行代码的魅力
- 实用案例:JS 一行代码提升开发效率
- 生成随机数
- 去重数组
- 检查变量类型
- 深拷贝对象
- 交换两个变量的值
- 生成 UUID
- 延伸知识:一行代码背后的原理
- 总结与感悟
妙用之美:一行代码的魅力
为什么“一行代码”如此让人着迷?因为它是 简洁、高效、优雅 的化身。在日常开发中,我们总希望能用更少的代码实现更多的功能,而“一行代码”就像是开发者智慧的结晶,化繁为简,带来极致的编码体验。
当然,别以为一行代码就等同于简单。事实上,这些代码往往利用了 JavaScript 中的高级技巧,比如 ES6+ 的特性、函数式编程的思维、甚至对底层机制的深入理解。它们既是技巧的体现,也是对语言掌控力的证明。
接下来,让我们通过一些实用案例,感受“一行代码”的高优雅吧!
实用案例:JS 一行代码提升开发效率
1. 生成随机数
在日常开发中,生成随机数是非常常见的需求。但是我可以一句代码就能搞定,示例如下:
const random = (min, max) => Math.floor(Math.random() * (max - min + 1)) + min;
用法示例:
console.log(random(1, 100)); // 输出 1 到 100 之间的随机整数
解析:代码核心是 Math.random(),它生成一个 0 到 1 的随机数。通过数学公式将其映射到指定范围,并利用 Math.floor() 确保返回的是整数。
2. 数组去重
数组去重的方法有很多种,但下面这种方式极其优雅,不信你看!
const unique = (arr) => [...new Set(arr)];
用法示例:
console.log(unique([1, 2, 2, 3, 4, 4, 5])); // [1, 2, 3, 4, 5]
解析:Set 是一种集合类型,能自动去重。而 ... 是扩展运算符,可以将 Set 转换为数组,省去手动遍历的步骤。
3. 检查变量类型
判断变量类型也是日常开发中的常见操作,但是下面这一行代码就足够满足你的需求:
const type = (value) => Object.prototype.toString.call(value).slice(8, -1).toLowerCase();
用法示例:
console.log(type(123)); // 'number'
console.log(type([])); // 'array'
console.log(type(null)); // 'null'
解析:通过 Object.prototype.toString 可以准确获取变量的类型信息,而 slice(8, -1) 是为了提取出 [object Type] 中的 Type 部分。
4. 深拷贝对象
经常会碰到拷贝的场景,但是对于需要深拷贝的对象,下面的一行代码简单且高效:
const deepClone = (obj) => JSON.parse(JSON.stringify(obj));
用法示例:
const obj = { a: 1, b: { c: 2 } };
const copy = deepClone(obj);
console.log(copy); // { a: 1, b: { c: 2 } }
注意:这种方法不适用于循环引用的对象。如果需要处理复杂对象,建议使用 Lodash 等库。
5. 交换两个变量的值
日常中,如果是传统写法,可能会采用需要引入临时变量,但是,今天,我可以教你一个新写法,使用解构赋值就简单多了:
let a = 1, b = 2;
[a, b] = [b, a];
用法示例:
console.log(a, b); // 2, 1
解析:利用 ES6 的解构赋值语法,可以轻松实现两个变量的值交换,代码简洁且直观。
6. 生成 UUID
这个大家都不陌生,且基本所有的项目中都必须有,UUID ,它是开发中常用的唯一标识符,下面这段代码可以快速生成一个符合规范的 UUID,对,就一行搞定:
const uuid = () => 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, (c) => {
const r = (Math.random() * 16) | 0;
return c === 'x' ? r.toString(16) : ((r & 0x3) | 0x8).toString(16);
});
用法示例:
console.log(uuid()); // 类似 'e4e6c7c4-d5ad-4cc1-9be8-d497c1a9d461'
解析:通过正则匹配字符 x 或 y,并利用 Math.random() 生成随机数,再将其转换为符合 UUID 规范的十六进制格式。
延伸知识
如上这些“一行代码”的实现主要得益于 ES6+ 的特性,如:
- 箭头函数:让函数表达更简洁。
- 解构赋值:提升代码的可读性。
- 扩展运算符:操作数组和对象时更加优雅。
- Set 和 Map:提供高效的数据操作方式。
所以说,深入理解这些特性,不仅能让你更轻松地掌握这些代码,还能将它们灵活地应用到实际开发中,在日常开发中游刃有余,用最简洁的代码实现最复杂的也无需求。
总结与感悟
一行代码的背后,藏着开发者的智慧和对 JavaScript 代码的深入理解。通过这些代码,我们不仅能提升开发效率,还能在细节中感受代码的优雅与美感,这个也是我们一致的追求。
前端开发的乐趣就在于此——简单的代码,却能带来无限可能。如果你有更好用的一行代码,欢迎分享,让我们一起玩耍 JavaScript 的更多妙用!体验其中的乐趣。
... ...
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
... ...
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。
来源:juejin.cn/post/7444829930175905855
做定时任务,一定要用这个神库!!
说实话,作为前端开发者,我们经常需要处理一些定时任务,比如轮询接口、定时刷新数据、自动登出等功能。
过去我总是用 setTimeout 和 setInterval,但这些方案在复杂场景下并不够灵活。
我寻找了更可靠的方案,最终发现了 cron 这个 npm 包,为我的前端项目(特别是 Node.js 环境下运行的那部分)带来了专业级的定时任务能力。
cron 包:不只是个定时器
安装超级简单:
npm install cron
基础用法也很直观:
import { CronJob } from 'cron';
const job = new CronJob(
'0 */30 * * * *', // 每30分钟执行一次
function () {
console.log('刷新用户数据...');
// 这里放刷新数据的代码
},
null, // 完成时的回调
true, // 是否立即启动
'Asia/Shanghai' // 时区
);
看起来挺简单的,对吧?
但这个小包却能解决前端很多定时任务的痛点。
理解 cron 表达式,这个"魔法公式"
刚开始接触 cron 表达式时,我觉得这简直像某种加密代码。* * * * * * 这六个星号到底代表什么?
在 npm 的 cron 包中,表达式有六个位置(比传统的 cron 多一个),分别是:
秒 分 时 日 月 周
比如 0 0 9 * * 1 表示每周一早上 9 点整执行。
我找到一个特别好用的网站 crontab.guru 来验证表达式。
不过注意,那个网站是 5 位的表达式,少了"秒"这个位置,所以用的时候需要自己在前面加上秒的设置。
月份和星期几还可以用名称来表示,更直观:
// 每周一、三、五的下午5点执行
const job = new CronJob('0 0 17 * * mon,wed,fri', function () {
console.log('工作日提醒');
});
前端开发中的实用场景
作为前端开发者,我在这些场景中发现 cron 特别有用:
1. 在 Next.js/Nuxt.js 等同构应用中刷新数据缓存
// 每小时刷新一次产品数据缓存
const cacheRefreshJob = new CronJob(
'0 0 * * * *',
async function () {
try {
const newData = await fetchProductData();
updateProductCache(newData);
console.log('产品数据缓存已更新');
} catch (error) {
console.error('刷新缓存失败:', error);
}
},
null,
true,
'Asia/Shanghai'
);
2. Electron 应用中的定时任务
// 在 Electron 应用中每5分钟同步一次本地数据到云端
const syncJob = new CronJob(
'0 */5 * * * *',
async function () {
if (navigator.onLine) {
// 检查网络连接
try {
await syncDataToCloud();
sendNotification('数据已同步');
} catch (err) {
console.error('同步失败:', err);
}
}
},
null,
true
);
3. 定时检查用户会话状态
// 每分钟检查一次用户活动状态,30分钟无活动自动登出
const sessionCheckJob = new CronJob(
'0 * * * * *',
function () {
const lastActivity = getLastUserActivity();
const now = new Date().getTime();
if (now - lastActivity > 30 * 60 * 1000) {
console.log('用户30分钟无活动,执行自动登出');
logoutUser();
}
},
null,
true
);
踩过的那些坑
使用 cron 包时我踩过几个坑,分享给大家:
- 时区问题:有次我设置了一个定时提醒功能,但总是提前 8 小时触发。一查才发现是因为没设置时区。所以国内用户一定要设置
'Asia/Shanghai'!
// 这样才会在中国时区的下午6点执行
const job = new CronJob('0 0 18 * * *', myFunction, null, true, 'Asia/Shanghai');
- this 指向问题:如果你用箭头函数作为回调,会发现无法访问 CronJob 实例的 this。
// 错误示范
const job = new CronJob('* * * * * *', () => {
console.log('执行任务');
this.stop(); // 这里的 this 不是 job 实例,会报错!
});
// 正确做法
const job = new CronJob('* * * * * *', function () {
console.log('执行任务');
this.stop(); // 这样才能正确访问 job 实例
});
- v3 版本变化:如果你从 v2 升级到 v3,要注意月份索引从 0-11 变成了 1-12。
实战案例:构建一个智能通知系统
这是我在一个电商前端项目中实现的一个功能,用 cron 来管理各种用户通知:
import { CronJob } from 'cron';
import { getUser, getUserPreferences } from './api/user';
import { sendNotification } from './utils/notification';
class NotificationManager {
constructor() {
this.jobs = [];
this.initialize();
}
initialize() {
// 新品上架提醒 - 每天早上9点
this.jobs.push(
new CronJob(
'0 0 9 * * *',
async () => {
if (!this.shouldSendNotification('newProducts')) return;
const newProducts = await this.fetchNewProducts();
if (newProducts.length > 0) {
sendNotification('新品上架', `今天有${newProducts.length}款新品上架啦!`);
}
},
null,
true,
'Asia/Shanghai'
)
);
// 限时优惠提醒 - 每天中午12点和晚上8点
this.jobs.push(
new CronJob(
'0 0 12,20 * * *',
async () => {
if (!this.shouldSendNotification('promotions')) return;
const promotions = await this.fetchActivePromotions();
if (promotions.length > 0) {
sendNotification('限时优惠', '有新的限时优惠活动,点击查看详情!');
}
},
null,
true,
'Asia/Shanghai'
)
);
// 购物车提醒 - 每周五下午5点提醒周末特价
this.jobs.push(
new CronJob(
'0 0 17 * * 5',
async () => {
if (!this.shouldSendNotification('cartReminder')) return;
const cartItems = await this.fetchUserCart();
if (cartItems.length > 0) {
sendNotification('周末将至', '别忘了查看购物车中的商品,周末特价即将开始!');
}
},
null,
true,
'Asia/Shanghai'
)
);
console.log('通知系统已初始化');
}
async shouldSendNotification(type) {
const user = getUser();
if (!user) return false;
const preferences = await getUserPreferences();
return preferences?.[type] === true;
}
// 其他方法...
stopAll() {
this.jobs.forEach(job => job.stop());
console.log('所有通知任务已停止');
}
}
export const notificationManager = new NotificationManager();
写在最后
作为前端开发者,我们的工作不只是构建漂亮的界面,还需要处理各种复杂的交互和时序逻辑。
npm 的 cron 包为我们提供了一种专业而灵活的方式来处理定时任务,特别是在 Node.js 环境下运行的前端应用(如 SSR 框架、Electron 应用等)。
它让我们能够用简洁的表达式设定复杂的执行计划,帮助我们构建更加智能和用户友好的前端应用。
来源:juejin.cn/post/7486390904992890895
Browser.js:轻松模拟浏览器环境
什么是Browser.js
Browser.js是一个小巧而强大的JavaScript库,它模拟浏览器环境,使得原本只能在浏览器中运行的代码能够在Node.js环境中执行。这意味着你可以在服务器端运行前端代码,而不需要依赖真实浏览器
Browser.js的核心原理
Browser.js通过实现与浏览器兼容的API(如window、document、navigator等)来创建一个近似真实的浏览器上下文。它还支持fetch API用于网络请求,支持Promise,使得异步操作更加方便
Browser.js的用途
Browser.js主要用于以下场景:
- 服务器端测试:在服务端运行前端单元测试,无需依赖真实浏览器,从而提高测试效率
// 示例:使用Browser.js进行服务器端测试
const browser = require('browser.js');
const window = browser.window;
const document = browser.document;
// 在Node.js中模拟浏览器环境
console.log(window.location.href);
- 构建工具:编译或预处理只能在浏览器运行的库,例如基于DOM的操作,如CSS处理器或模板引擎
// 示例:使用Browser.js处理CSS
const browser = require('browser.js');
const document = browser.document;
// 创建一个CSS样式表
const style = document.createElement('style');
style.textContent = 'body { background-color: #f2f2f2; }';
document.head.appendChild(style);
- 离线应用:将部分业务逻辑放在客户端和服务端之外,在本地环境中执行1。
// 示例:使用Browser.js在本地环境中执行业务逻辑
const browser = require('browser.js');
const window = browser.window;
// 在本地环境中执行JavaScript代码
window.alert('Hello, World!');
- 自动化脚本:对网页进行自动化操作,如爬虫、数据提取等,而不必依赖真实浏览器1。
// 示例:使用Browser.js进行网页爬虫
const browser = require('browser.js');
const fetch = browser.fetch;
// 发送HTTP请求获取网页内容
fetch('https://example.com')
.then(response => response.text())
.then(html => console.log(html));
解决的问题
Browser.js解决了以下问题:
- 跨环境执行:使得原本只能在浏览器中运行的JavaScript代码能够在Node.js环境中执行,扩展了JavaScript的应用边界
- 兼容性问题:通过模拟浏览器环境,减少了不同浏览器之间的兼容性问题,提高了代码的可移植性
- 测试效率:提高了前端代码在服务端的测试效率,减少了对真实浏览器的依赖
Browser.js的特点
- 轻量级:体积小,引入方便,不会过多影响项目整体性能
- 兼容性:模拟的浏览器环境高度兼容Web标准,能够运行大部分浏览器代码
- 易用性:提供简单直观的API接口,快速上手
- 可扩展:支持自定义插件,可以根据需求扩展功能
- 无依赖:不依赖其他大型库或框架,降低项目复杂度
来源:juejin.cn/post/7486845198485585935
Vue 首个 AI 组件库发布!
人工智能(AI)已深度融入我们的生活,如今 Vue 框架也迎来了首个 AI 组件库 —— Ant Design X Vue,为开发者提供了强大的 AI 开发工具。
Ant Design X Vue 概述
Ant Design X Vue 是基于 Vue.js 的 AI 组件库,旨在简化 AI 集成开发。

它包含高度定制化的 AI 组件和 API 解决方案,支持无缝接入 AI 服务,是构建智能应用的理想选择。
组件库亮点
丰富多样的 AI 组件
通用组件:
- Bubble:显示会话消息气泡,支持多种布局。
- Conversations:管理多个会话,查看历史记录。
唤醒组件:
- Welcome:会话加载时插入欢迎语。
- Prompts:展示上下文相关的问题或建议。
表达组件:
- Sender:构建会话输入框,支持自定义样式。
- Attachments:展示和管理附件信息。
- Suggestion:提供快捷输入提示。
确认组件:
- ThoughtChain:展示 AI 的思维过程或结果。
工具组件:
- useXAgent:对接 AI 模型推理服务。
- useXChat:管理 AI 对话应用的数据流。
- XStream:处理数据流,支持流式传输。
- XRequest:向 AI 服务发起请求。
- XProvider:全局化配置管理。
RICH 设计范式
基于 RICH 设计范式,提供丰富、沉浸式、连贯和人性化的交互体验,适应不同 AI 场景。
AGI 混合界面(Hybrid-UI)
融合 GUI 和自然会话交互,用户可在同一应用中自由切换交互方式,提升体验。
适用场景
- 智能聊天应用:构建多轮对话界面,支持复杂会话逻辑。
- 企业级 AI 系统:快速搭建智能客服、知识管理等系统。
如何使用 Ant Design X Vue
安装与引入
npm install ant-design-x-vue --save
引入组件库及样式:
import Vue from 'vue';
import Antd from 'ant-design-x-vue';
import 'ant-design-x-vue/dist/antd.css';
Vue.use(Antd);
使用组件
示例:使用 Bubble 组件展示对话气泡
<template>
<div>
<a-bubble content="欢迎使用 Ant Design X Vue!" />
</div>
</template>
官方文档与示例
访问 Ant Design X Vue 官方文档:https://antd-design-x-vue.netlify.app/ 获取更多信息。
Ant Design X Vue 为 Vue 开发者提供了强大的 AI 组件库,助力高效构建智能应用。
无论是聊天应用还是企业级系统,都值得一试。
最后
如果觉得本文对你有帮助,希望能够给我点赞支持一下哦 💪 也可以关注wx公众号:
前端开发爱好者回复加群,一起学习前端技能 公众号内包含很多实战精选资源教程,欢迎关注
来源:juejin.cn/post/7475978280841543716
前端如何彻底解决重复请求问题
背景
- 保存按钮点击多次,造成新增多个单据
- 列表页疯狂刷新,导致服务器压力大
如何彻底解决
方案:我的思路从请求层面判断相同请求只发送一次,将结果派发给各个订阅者
实现思路
- 对请求进行数据进行hash
- 添加store 存储 hash => Array promise
- 相同请求,直接订阅对应的promise
- 请求取消,则将store中对应的promise置为null
- 请求返回后,调用所有未取消的订阅
核心代码
private handleFinish(key: string, index: number) {
const promises = this.store.get(key);
// 只有一个promise时则删除store
if (promises?.filter((item) => item).length === 1) {
this.store.delete(key);
} else if (promises && promises[index]) {
// 还有其他请求,则将当前取消的、或者完成的置为null
promises[index] = null;
}
}
private async handleRequest(config: any) {
const hash = sha256.create();
hash.update(
JSON.stringify({
params: config.params,
data: config.data,
url: config.url,
method: config.method,
}),
);
const fetchKey = hash.hex().slice(0, 40);
const promises = this.store.get(fetchKey);
const index = promises?.length || 0;
let promise = promises?.find((item) => item);
const controller = new AbortController();
if (config.signal) {
config.signal.onabort = (reason: any) => {
const _promises = this.store.get(fetchKey)?.filter((item) => item);
if (_promises?.length === 1) {
controller.abort(reason);
this.handleFinish(fetchKey, index);
}
};
}
if (!promise) {
promise = this.instance({
...config,
signal: controller.signal,
headers: {
...config.headers,
fetchKey,
},
}).catch((error) => {
console.log(error, "请求错误");
// 失败的话,立即删除,可以重试
this.handleFinish(fetchKey, index);
return { error };
});
}
const newPromise = Promise.resolve(promise)
.then((result: any) => {
if (config.signal?.aborted) {
this.handleFinish(fetchKey, index);
return result;
}
return result;
})
.finally(() => {
setTimeout(() => {
this.handleFinish(fetchKey, index);
}, 500);
});
this.store.set(fetchKey, [...(promises || []), newPromise]);
return newPromise;
}
以下为完整代码(仅供参考)
index.ts
import axios, { AxiosInstance, AxiosRequestConfig, AxiosResponse } from "axios";
import { sha256 } from "js-sha256";
import transformResponseValue, { updateObjTimeToUtc } from "./utils";
type ErrorInfo = {
message: string;
status?: number;
traceId?: string;
version?: number;
};
type MyAxiosOptions = AxiosRequestConfig & {
goLogin: (type?: string) => void;
onerror: (info: ErrorInfo) => void;
getHeader: () => any;
};
export type MyRequestConfigs = AxiosRequestConfig & {
// 是否直接返回服务端返回的数据,默认false, 只返回 data
useOriginData?: boolean;
// 触发立即更新
flushApiHook?: boolean;
ifHandleError?: boolean;
};
type RequestResult<T, U> = U extends { useOriginData: true }
? T
: T extends { data?: infer D }
? D
: never;
class LmAxios {
private instance: AxiosInstance;
private store: Map<string, Array<Promise<any> | null>>;
private options: MyAxiosOptions;
constructor(options: MyAxiosOptions) {
this.instance = axios.create(options);
this.options = options;
this.store = new Map();
this.interceptorRequest();
this.interceptorResponse();
}
// 统一处理为utcTime
private interceptorRequest() {
this.instance.interceptors.request.use(
(config) => {
if (config.params) {
config.params = updateObjTimeToUtc(config.params);
}
if (config.data) {
config.data = updateObjTimeToUtc(config.data);
}
return config;
},
(error) => {
console.log("intercept request error", error);
Promise.reject(error);
},
);
}
// 统一处理为utcTime
private interceptorResponse() {
this.instance.interceptors.response.use(
(response): any => {
// 对响应数据做处理,以下根据实际数据结构改动!!...
const [checked, errorInfo] = this.checkStatus(response);
if (!checked) {
return Promise.reject(errorInfo);
}
const disposition =
response.headers["content-disposition"] ||
response.headers["Content-Disposition"];
// 文件处理
if (disposition && disposition.indexOf("attachment") !== -1) {
const filenameReg =
/filename\*?=['"]?(?:UTF-\d['"]*)?([^;\r\n"']*)['"]?;?/g;
const filenames: string[] = [];
disposition.replace(filenameReg, (r: any, r1: string) => {
filenames.push(decodeURIComponent(r1));
});
return Promise.resolve({
filename: filenames[filenames.length - 1],
data: response.data,
});
}
if (response) {
return Promise.resolve(response.data);
}
},
(error) => {
console.log("request error", error);
if (error.message.indexOf("timeout") !== -1) {
return Promise.reject({
message: "请求超时",
});
}
const [checked, errorInfo] = this.checkStatus(error.response);
return Promise.reject(errorInfo);
},
);
}
private checkStatus(
response: AxiosResponse<any>,
): [boolean] | [boolean, ErrorInfo] {
const { code, message = "" } = response?.data || {};
const { headers, status } = response || {};
if (!status) {
return [false];
}
// 单地登录判断,弹出不同提示
if (status === 401) {
this.options?.goLogin();
return [false];
}
if (code === "ECONNABORTED" && message?.indexOf("timeout") !== -1) {
return [
false,
{
message: "请求超时",
},
];
}
if ([108, 109, 401].includes(code)) {
this.options.goLogin();
return [false];
}
if ((code >= 200 && code < 300) || code === 304) {
// 如果http状态码正常,则直接返回数据
return [true];
}
if (!code && ((status >= 200 && status < 300) || status === 304)) {
return [true];
}
let errorInfo = "";
const _code = code || status;
switch (_code) {
case -1:
errorInfo = "远程服务响应失败,请稍后重试";
break;
case 400:
errorInfo = "400: 错误请求";
break;
case 401:
errorInfo = "401: 访问令牌无效或已过期";
break;
case 403:
errorInfo = message || "403: 拒绝访问";
break;
case 404:
errorInfo = "404: 资源不存在";
break;
case 405:
errorInfo = "405: 请求方法未允许";
break;
case 408:
errorInfo = "408: 请求超时";
break;
case 500:
errorInfo = message || "500: 访问服务失败";
break;
case 501:
errorInfo = "501: 未实现";
break;
case 502:
errorInfo = "502: 无效网关";
break;
case 503:
errorInfo = "503: 服务不可用";
break;
default:
errorInfo = "连接错误";
}
return [
false,
{
message: errorInfo,
status: _code,
traceId: response?.data?.requestId,
version: response.data.ver,
},
];
}
private handleFinish(key: string, index: number) {
const promises = this.store.get(key);
if (promises?.filter((item) => item).length === 1) {
this.store.delete(key);
} else if (promises && promises[index]) {
promises[index] = null;
}
}
private async handleRequest(config: any) {
const hash = sha256.create();
hash.update(
JSON.stringify({
params: config.params,
data: config.data,
url: config.url,
method: config.method,
}),
);
const fetchKey = hash.hex().slice(0, 40);
const promises = this.store.get(fetchKey);
const index = promises?.length || 0;
let promise = promises?.find((item) => item);
const controller = new AbortController();
if (config.signal) {
config.signal.onabort = (reason: any) => {
const _promises = this.store.get(fetchKey)?.filter((item) => item);
if (_promises?.length === 1) {
controller.abort(reason);
this.handleFinish(fetchKey, index);
}
};
}
if (!promise) {
promise = this.instance({
...config,
signal: controller.signal,
headers: {
...config.headers,
fetchKey,
},
}).catch((error) => {
console.log(error, "请求错误");
// 失败的话,立即删除,可以重试
this.handleFinish(fetchKey, index);
return { error };
});
}
const newPromise = Promise.resolve(promise)
.then((result: any) => {
if (config.signal?.aborted) {
this.handleFinish(fetchKey, index);
return result;
}
return result;
})
.finally(() => {
setTimeout(() => {
this.handleFinish(fetchKey, index);
}, 500);
});
this.store.set(fetchKey, [...(promises || []), newPromise]);
return newPromise;
}
// add override type
public async request<T = unknown, U extends MyRequestConfigs = {}>(
url: string,
config: U,
): Promise<RequestResult<T, U> | null> {
// todo
const options = {
url,
// 是否统一处理接口失败(提示)
ifHandleError: true,
...config,
headers: {
...this.options.getHeader(),
...config?.headers,
},
};
const res = await this.handleRequest(options);
if (!res) {
return null;
}
if (res.error) {
if (res.error.message && options.ifHandleError) {
this.options.onerror(res.error);
}
throw new Error(res.error);
}
if (config.useOriginData) {
return res;
}
if (config.headers?.feTraceId) {
window.dispatchEvent(
new CustomEvent<{ flush?: boolean }>(config.headers.feTraceId, {
detail: {
flush: config?.flushApiHook,
},
}),
);
}
// 默认返回res.data
return transformResponseValue(res.data)
}
}
export type MyRequest = <T = unknown, U extends MyRequestConfigs = {}>(
url: string,
config: U,
) => Promise<RequestResult<T, U> | null>;
export default LmAxios;
utils.ts(这里主要用来处理utc时间,你可能用不到删除相关代码就好)
import moment from 'moment';
const timeReg =
/^\d{4}([/:-])(1[0-2]|0?[1-9])\1(0?[1-9]|[1-2]\d|30|31)($|( |T)(?:[01]\d|2[0-3])(:[0-5]\d)?(:[0-5]\d)?(\..*\d)?Z?$)/;
export function formatTimeValue(time: string, format = 'YYYY-MM-DD HH:mm:ss') {
if (typeof time === 'string' || typeof time === 'number') {
if (timeReg.test(time)) {
return moment(time).format(format);
}
}
return time;
}
// 统一转化如参
export const updateObjTimeToUtc = (obj: any) => {
if (typeof obj === 'string') {
if (timeReg.test(obj)) {
return moment(obj).utc().format();
}
return obj;
}
if (toString.call(obj) === '[object Object]') {
const newObj: Record<string, any> = {};
Object.keys(obj).forEach((key) => {
newObj[key] = updateObjTimeToUtc(obj[key]);
});
return newObj;
}
if (toString.call(obj) === '[object Array]') {
obj = obj.map((item: any) => updateObjTimeToUtc(item));
}
return obj;
};
const utcReg = /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.*Z$/;
const transformResponseValue = (res: any) => {
if (!res) {
return res;
}
if (typeof res === 'string') {
if (utcReg.test(res)) {
return moment(res).format('YYYY-MM-DD HH:mm:ss');
}
return res;
}
if (toString.call(res) === '[object Object]') {
const result: any = {};
Object.keys(res).forEach((key) => {
result[key] = transformResponseValue(res[key]);
});
return result;
}
if (toString.call(res) === '[object Array]') {
return res.map((item: any) => transformResponseValue(item));
}
return res;
};
export default transformResponseValue;
来源:juejin.cn/post/7484202915390718004
[译]为什么我选择用Tauri来替代Electron
原文地址:Why I chose Tauri instead of Electron
以下为正文。
关于我为什么在Tauri上创建Aptakube的故事,我与Electron的斗争以及它们之间的简短比较。
大约一年前,我决定尝试构建一个桌面应用程序。
我对自己开发的小众应用并不满意,我想我可以开发出更好的应用。我作为全栈开发人员工作了很长时间,但我以前从未构建过桌面应用程序。
我的第一个想法是用 SwiftUI 来构建。开发者喜欢原生应用,我也一直想学习 Swift。然而,在 SwiftUI 上构建会将我的受众限制为 macOS 用户。虽然我有一种感觉,大多数用户无论如何都会使用 macOS,但当我可以构建跨平台应用程序时,为什么要限制自己呢?
现在回想起来,我真的很庆幸当初放弃了 SwiftUI。看看人们在不同的操作系统上使用我的应用就知道了。
Windows和Linux代表了超过35%的用户。这相当于放弃了35%的收入。
那么 Electron 怎么样呢?
我不是与世隔绝的人,所以我知道 Electron 是个好东西,我每天使用的很多流行应用都是基于 Electron 开发的,包括我现在用来写这篇文章的编辑器。它似乎非常适合我想做的事情,因为:
- 单个代码库可以针对多个平台。
- 支持 React + TypeScript + Tailwind 配合使用,每个我都非常熟练。
- 非常受欢迎 = 很多资源和指南。
- NPM 是最大的(是吧?)软件包社区,这意味着我可以更快地发布。
在 Electron 上开发的另一个好处是,我可以专注于开发应用程序,而不是学习一些全新的东西。我喜欢学习新的语言和框架,但我想快速构建一些有用的东西。我仍然需要学习 Electron 本身,但它不会像学习 Swift 和 SwiftUI 那样困难。
好了,我们开始吧!
我决定了。Aptakube 将使用 Electron 来构建。
我通常不看文档。我知道我应该看,但我没有。不过,每当我第一次选择一个框架时,我总会阅读 “入门(Getting Started)” 部分。
流行的框架都有一个 npx create {framework-name},可以为我们快速一个应用程序。Next.js、Expo、Remix 和许多其他框架都有这样的功能。我发现这非常有用,因为它们可以让你快速上手,而且通常会给你提供很多选项,例如:
- 你想使用 TypeScript 还是 JavaScript?
- 你想使用 CSS 框架吗?那 Tailwind 呢?
- Prettier 和/或 ESLint?
- 你要这个还是那个?
这样的例子不胜枚举。这是一种很棒的开发体验,我希望每个框架都有一个。
我可以直接 npx create electron-app 吗?
显然,我不能,或者至少我还没有找到一种方法来做到这一点,除了在 Getting Started 里。
相反,我找到的是一个“快速启动(quick-start)”模板,我可以从 Git 上克隆下来,安装依赖项,然后就可以开始我的工作了。
然而,它不是 TypeScript,没有打包工具,没有 CSS 框架,没有检查,没有格式化,什么都没有。它只是一个简单的打开窗口的应用程序。
我开始用这个模板构建,并添加了所有我想让它使用的东西。我以为会很容易,但事实并非如此。
一个 electron 应用程序有三个入口点: main、preload(预加载),和render(渲染)。把所有这些和 Vite 连接起来是很痛苦的。我花了大约两周的空闲时间试图让所有东西都工作起来。我失败了,这让我很沮丧。
之后我为 Electron 找到了几十个其他的样板。我试了大约五个。有些还可以,但大多数模板都太固执己见了,而且安装了太多的依赖项,我甚至不知道它们是用来做什么的,这让我不太喜欢。有些甚至根本不工作,因为它们已经被遗弃多年了。
总之,对于刚接触 Electron 的人来说,开发体验低于平均水平。Next.js 和 Expo 将标准设置得如此之高,以至于我开始期待每个框架都能提供类似的体验。
那现在怎么办?
在漫无目的刷 Twitter 的时候,我看到了一条来自 Tauri 的有关 1.0 版本的推文。那时他们已经成立 2 年了,但我完全不知道 Tauri 是什么。我去看了他们的网站,我被震撼了 🤯 这似乎就是我正在寻找的东西。
你知道最棒的是什么吗?他们把一条 npm create tauri-app 命令放在了主页上。

Tauri 用
npx create Tauri -app命令从一开始就抓住了开发体验。
我决定尝试一下。我运行了 create the tauri-app 命令,体验与 Next.js 非常相似。它问了我几个问题,然后根据我的选择为我创建了一个新项目。
在这之后,我可以简单地运行 npm run dev,然后我就有了一个带有热加载、TypeScript、Vite 和 Solid.js 的可以运行的应用程序,几乎包含了我开始使用所需的一切。这让我印象深刻,并且很想了解更多。我仍然不得不添加 Prettier、Linters、Tailwind 等类似的东西,但我已经习惯了,而且它比 Electron 容易太多了。
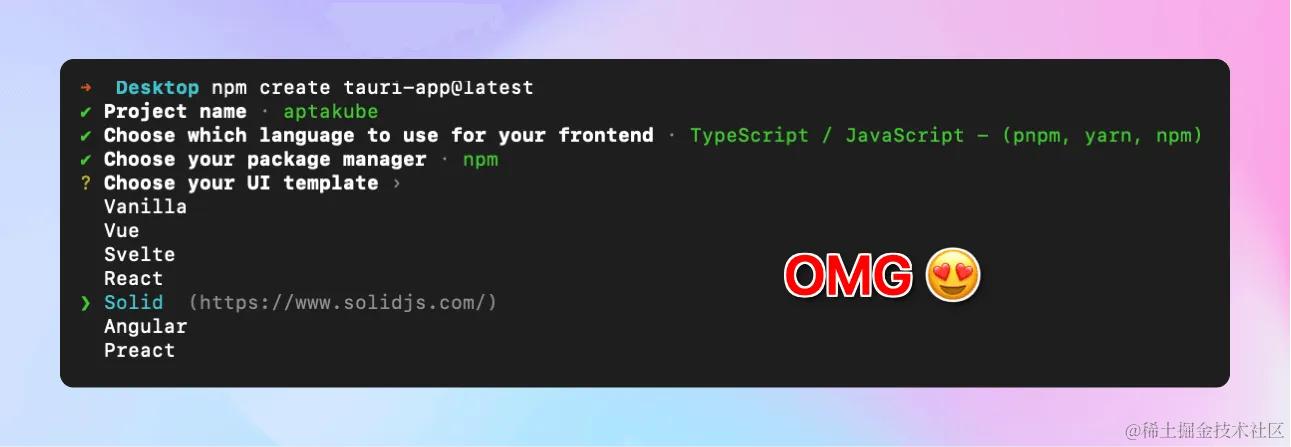
开始(再一次😅),但与 Tauri 一起
虽然在 Electron 中,我可以只用 JavaScript/HTML/CSS 构建整个应用程序,但在 Tauri 中,后端是 Rust,只有前端是 JavaScript。这显然意味着我必须学习 Rust,这让我很兴奋,但也不想花太多时间,因为我想快速构建原型。
我在使用过 7 种以上专业的编程语言,所以我认为学习 Rust 是轻而易举的事。
我错了。我大错特错了。Rust 是很难的,真的很难,至少对我来说是这样!
一年后,在我的应用发布了 20 多个版本之后,我仍然不能说我真正了解 Rust。我知道要不断地定期发布新功能,但每次我必须用 Rust 写一些东西时,我仍然能学到很多新知识。GitHub Copilot 和 ChatGPT 帮了我大忙,我现在还经常使用它们。

像使用字符串这样简单的事情在Rust中要比在其他语言中复杂得多🤣
不过,Tauri 中有一些东西可以让这一过程变得简单许多。
Tauri 有一个“command 命令”的概念,它就像前端和后端之间的桥梁。你可以用 Rust 在你的 Tauri 后端定义“命令”,然后在 JavaScript 中调用它们。Tauri 本身提供了一系列可以开箱即用的命令。例如,你可以通过 JavaScript 打开一个文件选择器(file dialog),读取/更新/删除文件,发送 HTTP 请求,以及其他很多与操作系统进行的交互,而无需编写任何 Rust 代码。
那么,如果你需要做一些在 Tauri 中没有的事情呢?这就是“Plugins插件”的用武之地。插件是 Rust 库,它定义了你可以在 Tauri 应用中使用的命令。稍后我会详细介绍插件,但现在你只需将它们视为扩展 Tauri 功能的一种方式就可以了。
事实上,我已经询问了很多使用 Tauri 构建应用程序的人,问他们是否必须编写 Rust 代码来构建他们的应用程序。他们中的大多数表示,他们只需要为一些特定的使用情况编写非常少的 Rust 代码。完全可以在不编写任何 Rust 代码的情况下构建一个 Tauri 应用程序!
那么 Tauri 与 Electron 相比又如何呢?
1. 编程语言和社区
在 Electron 中,你的后端是一个 Node.js 进程,而前端是 Chromium,这意味着 Web 开发人员可以仅使用 JavaScript/HTML/CSS 来构建桌面应用程序。NPM 上有着庞大的库社区,并且在互联网上有大量与此相关的内容,这使得学习过程变得更加容易。
然而,尽管通常认为能够在后端和前端之间共享代码是一件好事,但也可能会导致混淆,因为开发人员可能会尝试在前端使用后端函数,反之亦然。因此,你必须小心不要混淆。
相比之下,Tauri 的后端是 Rust,前端也是一个 Webview(稍后会详细介绍)。虽然有大量的 Rust 库,但它们远远不及 NPM 的规模。Rust 社区也比 JavaScript 社区小得多,这意味着关于它的内容在互联网上较少。但正如上面提到的,取决于你要构建的内容,你甚至可能根本不需要编写太多的 Rust 代码。
我的观点: 我只是喜欢我们在 Tauri 中得到的明确的前后端的分离。如果我在 Rust 中编写一段代码,我知道它将作为一个操作系统进程运行,并且我可以访问网络、文件系统和许多其他内容,而我在 JavaScript 中编写的所有内容都保证在一个 Webview 上运行。学习 Rust 对我来说并不容易,但我很享受这个过程,而且总的来说我学到了很多新东西!Rust 开始在我心中生根了。😊
2. Webview
在 Electron 中,前端是一个与应用程序捆绑在一起的 Chromium Webview。这意味着无论操作系统如何,您都可以确定应用程序使用的 Node.js 和 Chromium 版本。这带来了重大的好处,但也有一些缺点。
最大的好处是开发和测试的便利性,您知道哪些功能可用,如果某些功能在 macOS 上可用,那么它很可能也可以在 Windows 和 Linux 上使用。然而,缺点是由于所有这些二进制文件捆绑在一起,您的应用程序大小会更大。
Tauri 采用了截然不同的方法。它不会将 Chromium 与您的应用程序捆绑在一起,而是使用操作系统的默认 Webview。这意味着在 macOS 上,您的应用程序将使用 WebKit(Safari 的引擎),在 Windows 上将使用 WebView2(基于 Chromium),在 Linux 上将使用WebKitGTK(与 Safari 相同)。
最终结果是一个感觉非常快速的极小型应用程序!
作为参考,我的 Tauri 应用程序在 macOS 上只有 24.7MB 大小,而我的竞争对手的应用程序(Electron)则达到了 1.3GB。
为什么这很重要?
- 下载和安装速度快得多。
- 主机和分发成本更低(我在 AWS 上运行,所以我需要支付带宽和存储费用)。
- 我经常被问到我的应用是否使用 Swift 构建,因为用户通常在看到如此小巧且快速的应用时会有一种“这感觉像是本地应用”的时候。
- 安全性由操作系统处理。如果 WebKit 存在安全问题,苹果将发布安全更新,我的应用将简单地使用它。我不必发布我的应用的更新版本来修复它。
我的观点: 我喜欢我的应用如此小巧且快速。起初,我担心操作系统之间缺乏一致性会导致我需要在所有 3 个操作系统上测试我的应用,但到目前为止我没有遇到任何问题。无论如何,Web开发人员已经习惯了这种情况,因为我们长期以来一直在构建多浏览器应用程序。打包工具和兼容性填充也在这方面提供了很大帮助!
3. 插件
我之前简要提到过这一点,但我认为它值得更详细地讨论,因为在我看来,这是 Tauri 最好的特性之一。插件是由 Rust 编写的一组命令集,可以从 JavaScript 中调用。它允许开发人员通过组合不同的插件来构建应用程序,这些插件可以是开源的,也可以在您的应用程序中定义。
这是一种很好的应用程序组织结构的方式,它也使得在不同应用程序之间共享代码变得容易!
在 Tauri 社区中,您会找到一些插件的示例:
- tauri-plugin-log - 可配置的日志记录。
- tauri-plugin-store - 存储用户偏好/设置。
- tauri-plugin-window-state - 保存窗口大小和位置。
- window-vibrancy - 使您的窗口生动起来。
- tauri-plugin-sql - 连接任何 SQL 数据库。
- tauri-plugin-aptabase - 用于 Tauri 应用程序的分析。
- 还有更多……
这些特性本来可能可以成为 Tauri 本身的一部分,但将它们单独分开意味着您可以挑选和选择您想要使用的功能。这也意味着它们可以独立演变,并且如果有更好的替代品发布,可以被替换。
插件系统是我选择 Tauri 的第二大原因;它让开发者的体验提升了 1000 倍!
4. 功能对比
就功能而言,Electron 和 Tauri 非常相似。Electron 仍然具有一些更多的功能,但 Tauri 正在迅速赶上。至少对于我的使用情况来说,Tauri 具有我所需要的一切。
唯一给我带来较大不便的是缺乏一个“本地上下文菜单”API。这是社区强烈要求的功能,它将使 Tauri 应用程序感觉更加本地化。我目前是用 JS/HTML/CSS 来实现这一点,虽然可以,但还有提升的空间。希望我们能在 Tauri 2 中看到这个功能的实现 🤞
但除此之外,Tauri 还有很多功能。开箱即用,您可以得到通知、状态栏、菜单、对话框、文件系统、网络、窗口管理、自动更新、打包、代码签名、GitHub actions、辅助组件等。如果您需要其他功能,您可以编写一个插件,或者使用现有的插件之一。
5. 移动端
这个消息让我感到惊讶。在我撰写这篇文章时,Tauri 已经实验性地支持 iOS 和 Android。似乎这一直是计划的一部分,但当我开始我的应用程序时并不知道这一点。我不确定自己是否会使用它,但知道它存在感到很不错。
这是 Electron 所不可能实现的,并且可能永远也不会。因此,如果您计划构建跨平台的移动和桌面应用程序,Tauri 可能是一种不错的选择,因为您可能能够在它们之间共享很多代码。利用网络技术设计移动优先界面多年来变得越来越容易,因此构建一个既可以作为桌面应用程序又可以作为移动应用程序运行的单一界面并不像听起来那么疯狂。
我只是想提一句,让大家对 Tauri 的未来感到兴奋。

watchOS 上的 Tauri 程序?🤯
正如 Jonas 在他的推文中所提到的,这只是实验性的和折衷的;它可能需要很长时间才能达到生产状态,但看到这个领域的创新仍然非常令人兴奋!
结论
我对选择使用 Tauri 感到非常满意。结合 Solid.js,我能够制作出一个真正快速的应用程序,人们喜欢它!我不是说它总是比 Electron 好,但如果它具有您需要的功能,我建议尝试一下!如前所述,您甚至可能不需要写那么多 Rust 代码,所以不要被吓倒!您会惊讶地发现,只用 JavaScript 就能做的事情有多少。
如果你对 Kubernetes 感兴趣,请查看 Aptakube,这是一个使用 Tauri 构建的 Kubernetes 桌面客户端 😊
我现在正在开发一个面向桌面和移动应用的开源且注重隐私的分析平台。它已经具有各种框架的 SDK,包括 Tauri 和 Electron。顺便说一句,Tauri SDK 被打包为一个 Tauri 插件! 😄
最后,我也活跃在 Twitter 上。如果您有任何问题或反馈,请随时联系我。我喜欢谈论 Tauri!
感谢阅读!👋
来源:juejin.cn/post/7386115583845744649
前端の骚操作代码合集 | 让你的网页充满恶趣味
1️⃣ 永远点不到的幽灵按钮
效果描述:按钮会跟随鼠标指针,但始终保持微妙距离
<button id="ghostBtn" style="position:absolute">点我试试?</button>
<script>
const btn = document.getElementById('ghostBtn');
document.addEventListener('mousemove', (e) => {
btn.style.left = `${e.clientX + 15}px`;
btn.style.top = `${e.clientY + 15}px`;
});
</script>
2️⃣ 极简黑客帝国数字雨
代码亮点:仅用 20 行代码实现经典效果
<canvas id="matrix"></canvas>
<script>
const canvas = document.getElementById('matrix');
const ctx = canvas.getContext('2d');
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
const chars = '01';
const drops = Array(Math.floor(canvas.width/20)).fill(0);
function draw() {
ctx.fillStyle = 'rgba(0,0,0,0.05)';
ctx.fillRect(0,0,canvas.width,canvas.height);
ctx.fillStyle = '#0F0';
drops.forEach((drop, i) => {
ctx.fillText(chars[Math.random()>0.5?0:1], i*20, drop);
drops[i] = drop > canvas.height ? 0 : drop + 20;
});
}
setInterval(draw, 100);
</script>
运行建议:按下 F11 进入全屏模式效果更佳
下面是优化版:
<script>
const canvas = document.getElementById('matrix');
const ctx = canvas.getContext('2d');
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
const chars = '01'; // 显示的字符
const columns = Math.floor(canvas.width / 20); // 列数
const drops = Array(columns).fill(0); // 每列的起始位置
const speeds = Array(columns).fill(0).map(() => Math.random() * 10 + 5); // 每列的下落速度
function draw() {
// 设置背景颜色并覆盖整个画布,制造渐隐效果
ctx.fillStyle = 'rgba(0, 0, 0, 0.05)';
ctx.fillRect(0, 0, canvas.width, canvas.height);
// 设置字符颜色
ctx.fillStyle = '#0F0'; // 绿色
ctx.font = '20px monospace'; // 设置字体
// 遍历每一列
drops.forEach((drop, i) => {
// 随机选择一个字符
const char = chars[Math.random() > 0.5 ? 0 : 1];
// 绘制字符
ctx.fillText(char, i * 20, drop);
// 更新下落位置
drops[i] += speeds[i];
// 如果超出画布高度,重置位置
if (drops[i] > canvas.height) {
drops[i] = 0;
speeds[i] = Math.random() * 10 + 5; // 重置速度
}
});
}
// 每隔100毫秒调用一次draw函数
setInterval(draw, 100);
</script>
3️⃣ 元素融化动画
交互效果:点击元素后触发扭曲消失动画
<div onclick="melt(this)"
style="cursor:pointer; padding:20px; background:#ff6666;">
点我融化!
</div>
<script>
function melt(element) {
let pos = 0;
const meltInterval = setInterval(() => {
element.style.borderRadius = `${pos}px`;
element.style.transform = `skew(${pos}deg) scale(${1 - pos/100})`;
element.style.opacity = 1 - pos/100;
pos += 2;
if(pos > 100) clearInterval(meltInterval);
}, 50);
}
</script>
4️⃣ 控制台藏宝图
彩蛋效果:在开发者工具中埋入神秘信息
console.log('%c🔮 你发现了秘密通道!',
'font-size:24px; color:#ff69b4; text-shadow: 2px 2px #000');
console.log('%c输入咒语 %c"芝麻开门()" %c获得力量',
'color:#666', 'color:#0f0; font-weight:bold', 'color:#666');
console.debug('%c⚡ 警告:前方高能反应!',
'background:#000; color:#ff0; padding:5px;');
5️⃣ 重力反转页面
魔性交互:让页面滚动方向完全颠倒
window.addEventListener('wheel', (e) => {
e.preventDefault();
window.scrollBy(-e.deltaX, -e.deltaY);
}, { passive: false });
慎用警告:此功能可能导致用户怀疑人生 ( ̄▽ ̄)"
6️⃣ 实时 ASCII 摄像头
技术亮点:将摄像头画面转为字符艺术
<pre id="asciiCam" style="font-size:8px; line-height:8px;"></pre>
<script>
navigator.mediaDevices.getUserMedia({ video: true })
.then(stream => {
const video = document.createElement('video');
video.srcObject = stream;
video.play();
const chars = '@%#*+=-:. ';
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
video.onplaying = () => {
canvas.width = 80;
canvas.height = 40;
setInterval(() => {
ctx.drawImage(video, 0, 0, 80, 40);
const imgData = ctx.getImageData(0,0,80,40).data;
let ascii = '';
for(let i=0; i<imgData.length; i+=4) {
const brightness = (imgData[i]+imgData[i+1]+imgData[i+2])/3;
ascii += chars[Math.floor(brightness/25.5)]
+ (i%(80*4) === (80*4-4) ? '\n' : '');
}
document.getElementById('asciiCam').textContent = ascii;
}, 100);
};
});
</script>
⚠️ 使用注意事项
- 摄像头功能需 HTTPS 环境或 localhost 才能正常工作
- 反向滚动代码可能影响用户体验,建议仅在整蛊场景使用
- 数字雨效果会持续消耗 GPU 资源
- 控制台彩蛋要确保不会暴露敏感信息
这些代码就像前端的"复活节彩蛋",适度使用能让网站充满趣味性,但千万别用在生产环境哦!(≧∇≦)ノ
https://codepen.io/ 链接 CodePen)
希望这篇博客能成为程序员的快乐源泉!🎉
来源:juejin.cn/post/7477573759254675507
别再追逐全新框架了,先打好基础再说......
Hello,大家好,我是 Sunday
如果大家做过一段时间的前端开发,就会发现相比其他的技术圈而言,前端圈总显得 “乱” 的很。
因为,每隔几个月,圈里就会冒出一个“闪闪发光的全新 JavaScript 框架”,声称能解决你所有问题,并提供各种数据来证明它拥有:更快的性能!更简洁的语法!更多的牛批特性!
而对应的,很多同学都会开始 “追逐” 这些全新的框架,并大多数情况下都会得出一个统一的评论 “好牛批......”
但是,根据我的经验来看,通常情况下 过于追逐全新的框架,毫无意义。 特别是对于 前端初学者 而言,打好基础会更加的重要!
PS:我这并不是在反对新框架的创新,出现更多全新的框架,全新的创新方案肯定是好的。但是,我们需要搞清楚一点,这一个所谓的全新框架 究竟是创新,还是只是通过一个不同的方式,重复的造轮子?
全新的框架是追逐不完的
我们回忆一下,是不是很多所谓的全新框架,总是按照以下的方式在不断的轮回?
- 首先,网上出现了某个“全新 JS 框架”发布,并提供了:更小、更快、更优雅 的方案,从而吸引了大量关注
- 然后,很多技术人开始追捧,从 掘金、抖音、B 站 开始纷纷上线各种 “教程”
- 再然后,几乎就没有然后了。国内大厂不会轻易使用这种新的框架作为生产工具,因为大厂会更加看重框架的稳定性
- 最后,无非会出现两种结果,第一种就是:热度逐渐消退,最后停止维护。第二种就是:不断的适配何种业务场景,直到这种全新的框架也开始变得“臃肿不堪”,和它当年要打败的框架几乎一模一样。
- 重新开始轮回:另一个“热门”框架出现,整个循环再次启动。
Svelte 火了那么久,大家有见到过国内有多少公司在使用吗?可能有很多同学会说“国外有很多公司在使用 Svelte 呀?” 就算如此,它对比 Vue 、React、Angular(国外使用的不少) 市场占有率依然是寥寥无几的。并且大多数同学的主战场还不在国外。
很多框架只是语法层面发生了变化
咱们以一个 “点击计数” 的功能为例,分别来看下在 Vue、React、Svelte 三个框架中的实现(别问为啥没有 angular,问就是不会😂)
Vue3 实现
<template>
<button @click="count++">点击了 {{ count }} 次</button>
</template>
<script setup>
import { ref } from 'vue';
const count = ref(0);
</script>
React 实现
import { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
return (
<button onClick={() => setCount(count + 1)}>
点击了 {count} 次
</button>
);
}
export default Counter;
Svelte 实现
<script>
let count = 0;
</script>
<button on:click={() => count += 1}>
点击了 {count} 次
</button>
这三个版本的核心逻辑完全一样,只是语法不同。
那么这就意味着:如果换框架,都要重新学习这些新的语法细节(哪里要写冒号、哪里要写大括号、哪里要写中括号)。
如果你把时间都浪费着这些地方上(特别是前端初学者),是不是就意味着 毫无意义,浪费时间呢?
掌握好基础才是王道
如果我们去看了大量的 国内大厂的招聘面经之后,就会发现,无论是 校招 || 社招,大厂的考察重点 永远不在框架,而在于 JS 基础、网络、算法、项目 这四个部分。至于你会的是 vue || react 并没有那么重要!
PS:对于大厂来说
vue 和 react都有不同的团队在使用。所以不用担心你学的框架是什么,这并不影响你进大厂
因此,掌握好基础就显得太重要了。
所以说:不用过于追逐新的技术框架。
针对于 在校生 而言 打好基础,练习算法,多去做更多有价值的项目,研究框架底层源码 ,并且一定要注意 练习表达,这才是对你将来校招最重要的事情!
而对于 社招的同学 而言 多去挖掘项目的重难点,尝试通过 输出知识的方式 帮助你更好的梳理技术。多去思考 技术如何解决业务问题,这才是关键!
来源:juejin.cn/post/7484960608782336027
让你辛辛苦苦选好的筛选条件刷新页面后不丢失,该怎么做?
你有遇到过同样的需求吗?告诉我你的第一想法。存 Session storage ?可以,但是我更建议你使用 router.replace 。
为什么建议使用 router.replace 而不是浏览器自带的存储空间呢?
增加实用性,你有没有考虑过这种场景,也就是当我筛选好之后进行搜索,我需要将它发给我的同事。当使用storage时是实现不了的,同事只会得到一个初始的页面。那我们将这个筛选结果放入url中是不是就可以解决这个问题了。
router.replace
先给大家介绍一下 router.replace 的用法吧。
router.replace 是 Vue Router 提供的一个方法,用于替换当前的历史记录条目。与 router.push 不同的是,replace 不会在浏览器历史记录中添加新记录,而是替换当前的记录。这对于需要在 URL 中保存状态但不想影响浏览器导航历史的场景非常有用。
// 假设我们正在使用 Vue 2 和 Vue Router
methods: {
updateFilters(newFilters) {
// 将筛选条件编码为查询字符串参数
const query = {
...this.$route.query,
...newFilters,
};
// 使用 router.replace 更新 URL
this.$router.replace({ query });
}
}
在这个示例中,updateFilters 方法接收新的筛选条件,并将它们合并到当前的查询参数中。然后使用 router.replace 更新 URL,而不会在历史记录中添加新条目。
具体实现
将筛选条件转换为适合 URL 的格式,例如 JSON 字符串或简单的键值对。以下是一个更详细的实现:
methods: {
applyFilters(filters) {
const encodedFilters = JSON.stringify(filters);
this.$router.replace({
path: this.$route.path,
query: { ...this.$route.query, filters: encodedFilters },
});
},
getFiltersFromUrl() {
const filters = this.$route.query.filters;
return filters ? JSON.parse(filters) : {};
}
}
在这个实现中,applyFilters 方法将筛选条件编码为 JSON 字符串,并将其存储在 URL 的查询参数中。getFiltersFromUrl 方法用于从 URL 中读取筛选条件,并将其解析回 JavaScript 对象。
注意事项
- 编码和解码:在将复杂对象存储到 URL 时,确保使用
encodeURIComponent和decodeURIComponent来处理特殊字符。 - URL 长度限制:浏览器对 URL 长度有一定的限制,确保不要在 URL 中存储过多数据。
- 数据安全性:考虑 URL 中数据的敏感性,避免在 URL 中存储敏感信息。
- url重置:不要忘了在筛选条件重置时也将
url重置,在取消筛选时同时去除url上的筛选。
一些其他的应用场景
- 重定向用户:
- 当用户访问一个不再存在或不推荐使用的旧路径时,可以使用
router.replace将他们重定向到新的路径。这避免了用户点击“返回”按钮时再次回到旧路径。
- 当用户访问一个不再存在或不推荐使用的旧路径时,可以使用
- 处理表单提交后清理 URL:
- 在表单提交后,可能会在 URL 中附加查询参数。使用
router.replace可以在处理完表单数据后清理这些参数,保持 URL 的整洁。
- 在表单提交后,可能会在 URL 中附加查询参数。使用
- 登录后跳转:
- 在用户登录后,将他们重定向到一个特定的页面(如用户主页或仪表盘),并且不希望他们通过“返回”按钮回到登录页面。使用
router.replace可以实现这一点。
- 在用户登录后,将他们重定向到一个特定的页面(如用户主页或仪表盘),并且不希望他们通过“返回”按钮回到登录页面。使用
- 错误页面处理:
- 当用户导航到一个不存在的页面时,可以使用
router.replace将他们重定向到一个错误页面(如 404 页面),并且不希望这个错误路径保留在浏览历史中。
- 当用户导航到一个不存在的页面时,可以使用
- 动态内容加载:
- 在需要根据用户操作动态加载内容时,使用
router.replace更新 URL,而不希望用户通过“返回”按钮回到之前的状态。例如,在单页应用中根据选项卡切换更新 URL。
- 在需要根据用户操作动态加载内容时,使用
- 多步骤流程:
- 在多步骤的用户流程中(如注册或购买流程),使用
router.replace可以在用户完成每一步时更新 URL,而不希望用户通过“返回”按钮回到上一步。
- 在多步骤的用户流程中(如注册或购买流程),使用
- 清理查询参数:
- 在用户操作完成后,使用
router.replace清理不再需要的查询参数,保持 URL 简洁且易于阅读。
- 在用户操作完成后,使用
小结
简单来说就是把你的
url当成浏览器的sessionstorage了。其实这就是我上周收到的任务,当时我甚至纠结的是该用localStorage还是sessionStorage,忙活半天,不停转类型,然后在开周会我讲了下我的思路。我的tl便说出了我的问题,讲了更加详细的需求,我才开始尝试router.replace,又是一顿忙活。。
来源:juejin.cn/post/7424034641379098663
做了个渐变边框的input输入框,领导和客户很满意!
需求简介
前几天需求评审的时候,产品说客户希望输入框能够好看一点。由于我们UI框架用的是Elemnt Plus,input输入框的样式也比较中规中矩,所以我们组长准备拒绝这个需求
但是,喜欢花里胡哨的我立马接下了这个需求!我自信的告诉组长,放着我来,包满意!
经过一番折腾,我通过 CSS 的技巧实现了一个带有渐变边框的 Input 输入框,而且当鼠标悬浮在上面时,边框颜色要更加炫酷并加深渐变效果。

最后,领导和客户对最后的效果都非常满意~我也成功获得了老板给我画的大饼,很开心!
下面就来分享我的实现过程和代码方案,满足类似需求的同学可以直接拿去用!
实现思路
实现渐变边框的原理其实很简单,首先实现一个渐变的背景作为底板,然后在这个底板上加上一个纯色背景就好了。

当然,我们在实际写代码的时候,不用专门写两个div来这么做,利用css的 background-clip 就可以实现上面的效果。
background-clip属性详解
background-clip是一个用于控制背景(background)绘制范围的 CSS 属性。它决定了背景是绘制在 内容区域、内边距区域、还是 边框区域。
background-clip: border-box | padding-box | content-box | text;
代码实现
背景渐变
<template>
<div class="input-container">
<input type="text" placeholder="请输入内容" class="gradient-input" />
</div>
</template>
<script setup>
</script>
<style>
/* 输入框容器 */
.input-container {
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
width: 100vw;
background: #f4f4f9;
}
/* 渐变边框输入框 */
.gradient-input {
width: 400px;
height: 40px;
padding: 5px 12px;
font-size: 16px;
color: #333;
outline: none;
/* 渐变边框 */
border: 1px solid transparent;
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
border-radius: 20px;
}
/* Placeholder 样式 */
.gradient-input::placeholder {
color: #aaa;
font-style: italic;
}
</style>

通过上面的css方法,我们成功实现了一个带有渐变效果边框的 Input 输入框,它的核心代码是
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
padding-box:限制背景在内容区域显示,防止覆盖输入框内容。
border-box:渐变背景会显示在边框位置,形成渐变边框效果。
这段代码分为两层背景:
- 第一层背景:
linear-gradient(white, white)是一个纯白色的线性渐变,用于覆盖输入框的内容区域(padding-box)。 - 第二层背景:
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3)是一个多色的渐变,用于显示在输入框的边框位置(border-box)。
背景叠加后,最终效果是:内层内容是白色背景,边框区域显示渐变颜色。
Hover 效果
借助上面的思路,我们在添加一些hover后css样式,通过 :hover 状态改变渐变的颜色和 box-shadow 的炫光效果:
/* Hover 状态 */
.gradient-input:hover {
background: linear-gradient(white, white) padding-box,
linear-gradient(135deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 5px rgba(255, 0, 118, 0.5), 0 0 20px rgba(30, 174, 255, 0.5);
}

过渡似乎有点生硬,没关系,加个过渡样式
/* 渐变边框输入框 */
.gradient-input {
// .....
/* 平滑过渡 */
transition: background 0.3s ease, box-shadow 0.3s ease;
}
非常好看流畅~

激活样式
最后,我们再添加一个激活的Focus 状态:当用户聚焦输入框时,渐变变得更加灵动,加入额外的光晕。
/* Focus 状态 */
.gradient-input:focus {
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 15px rgba(255, 0, 118, 0.7), 0 0 25px rgba(30, 174, 255, 0.7);
color: #000; /* 聚焦时文本颜色 */
}
现在,我们就实现了一个渐变边框的输入框,是不是非常好看?

完整代码
<template>
<div class="input-container">
<input type="text" placeholder="请输入内容" class="gradient-input" />
</div>
</template>
<style>
/* 输入框容器 */
.input-container {
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
width: 100vw;
background: #f4f4f9;
}
/* 渐变边框输入框 */
.gradient-input {
width: 400px;
height: 40px;
padding: 5px 12px;
font-size: 16px;
font-family: 'Arial', sans-serif;
color: #333;
outline: none;
/* 渐变边框 */
border: 1px solid transparent;
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
border-radius: 20px;
/* 平滑过渡 */
transition: background 0.3s ease, box-shadow 0.3s ease;
}
/*
/* Hover 状态 */
.gradient-input:hover {
background: linear-gradient(white, white) padding-box,
linear-gradient(135deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 5px rgba(255, 0, 118, 0.5), 0 0 20px rgba(30, 174, 255, 0.5);
}
/* Focus 状态 */
.gradient-input:focus {
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 15px rgba(255, 0, 118, 0.7), 0 0 25px rgba(30, 174, 255, 0.7);
color: #000; /* 聚焦时文本颜色 */
}
/* Placeholder 样式 */
.gradient-input::placeholder {
color: #aaa;
font-style: italic;
}
</style>
总结
通过上述方法,我们成功实现了一个带有渐变效果边框的 Input 输入框,并且在 Hover 和 Focus 状态下增强了炫彩效果。
大家可以根据自己的需求调整渐变的方向、颜色或动画效果,让你的输入框与众不同!
来源:juejin.cn/post/7442216034751545394
几行代码,优雅的避免接口重复请求!同事都说好!
背景简介
我们日常开发中,经常会遇到点击一个按钮或者进行搜索时,请求接口的需求。
如果我们不做优化,连续点击按钮或者进行搜索,接口会重复请求。

首先,这会导致性能浪费!最重要的,如果接口响应比较慢,此时,我们在做其他操作会有一系列bug!
那么,我们该如何规避这种问题呢?
如何避免接口重复请求
防抖节流方式(不推荐)
使用防抖节流方式避免重复操作是前端的老传统了,不多介绍了
防抖实现
<template>
<div>
<button @click="debouncedFetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const timeoutId = ref(null);
function debounce(fn, delay) {
return function(...args) {
if (timeoutId.value) clearTimeout(timeoutId.value);
timeoutId.value = setTimeout(() => {
fn(...args);
}, delay);
};
}
function fetchData() {
axios.get('http://api/gcshi) // 使用示例API
.then(response => {
console.log(response.data);
})
}
const debouncedFetchData = debounce(fetchData, 300);
</script>
防抖(Debounce) :
- 在setup函数中,定义了timeoutId用于存储定时器ID。
- debounce函数创建了一个闭包,清除之前的定时器并设置新的定时器,只有在延迟时间内没有新调用时才执行fetchData。
- debouncedFetchData是防抖后的函数,在按钮点击时调用。
节流实现
<template>
<div>
<button @click="throttledFetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const lastCall = ref(0);
function throttle(fn, delay) {
return function(...args) {
const now = new Date().getTime();
if (now - lastCall.value < delay) return;
lastCall.value = now;
fn(...args);
};
}
function fetchData() {
axios.get('http://api/gcshi') //
.then(response => {
console.log(response.data);
})
}
const throttledFetchData = throttle(fetchData, 1000);
</script>
节流(Throttle) :
- 在setup函数中,定义了lastCall用于存储上次调用的时间戳。
- throttle函数创建了一个闭包,检查当前时间与上次调用时间的差值,只有大于设定的延迟时间时才执行fetchData。
- throttledFetchData是节流后的函数,在按钮点击时调用。
节流防抖这种方式感觉用在这里不是很丝滑,代码成本也比较高,因此,很不推荐!
请求锁定(加laoding状态)
请求锁定非常好理解,设置一个laoding状态,如果第一个接口处于laoding中,那么,我们不执行任何逻辑!
<template>
<div>
<button @click="fetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const laoding = ref(false);
function fetchData() {
// 接口请求中,直接返回,避免重复请求
if(laoding.value) return
laoding.value = true
axios.get('http://api/gcshi') //
.then(response => {
laoding.value = fasle
})
}
const throttledFetchData = throttle(fetchData, 1000);
</script>
这种方式简单粗暴,十分好用!
但是也有弊端,比如我搜索A后,接口请求中;但我此时突然想搜B,就不会生效了,因为请求A还没响应!

因此,请求锁定这种方式无法取消原先的请求,只能等待一个请求执行完才能继续请求。
axios.CancelToken取消重复请求
基本用法
axios其实内置了一个取消重复请求的方法:axios.CancelToken,我们可以利用axios.CancelToken来取消重复的请求,爆好用!
首先,我们要知道,aixos有一个config的配置项,取消请求就是在这里面配置的。
<template>
<div>
<button @click="fetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
let cancelTokenSource = null;
function fetchData() {
if (cancelTokenSource) {
cancelTokenSource.cancel('取消上次请求');
cancelTokenSource = null;
}
cancelTokenSource = axios.CancelToken.source();
axios.get('http://api/gcshi',{cancelToken: cancelTokenSource.token}) //
.then(response => {
laoding.value = fasle
})
}
</script>
我们测试下,如下图:可以看到,重复的请求会直接被终止掉!

CancelToken官网示例
官网使用方法传送门:http://www.axios-http.cn/docs/cancel…
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// 取消请求(message 参数是可选的)
source.cancel('Operation canceled by the user.');
也可以通过传递一个 executor 函数到 CancelToken 的构造函数来创建一个 cancel token:
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// executor 函数接收一个 cancel 函数作为参数
cancel = c;
})
});
// 取消请求
cancel();
注意: 可以使用同一个 cancel token 或 signal 取消多个请求。
在过渡期间,您可以使用这两种取消 API,即使是针对同一个请求:
const controller = new AbortController();
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token,
signal: controller.signal
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// 取消请求 (message 参数是可选的)
source.cancel('Operation canceled by the user.');
// 或
controller.abort(); // 不支持 message 参数
来源:juejin.cn/post/7380185173689204746
最近 React Scan 太火了,做了个 Vue Scan
在 React Scan 的 github 有这么一张 gif 图片。当用户在页面上操作时,对应的组件会有一个闪烁,表示当前组件更新了。用这样的方式来排查程序的性能是一个很直观的方式。

根据 React Scan 自己的介绍,React Scan 可以 通过自动检测和突出显示导致性能问题的渲染。
Vue Scan
但是我主要使用 vue 来开发我的应用,看到这个功能非常眼馋,所以就动手自己做了一个 demo,目前也构建了一个 chrome 扩展,不过扩展仅支持识别 vue3 项目 现在已经支持 vue2 和 vue3 项目了。
项目地址:Vue Scan
简单介绍,Vue Scan 通过组件的 onBeforUpdate 钩子,当组件更新时,在组件对应位置绘制一个闪烁的边框。看起来的效果就像这样。

用法
我更推荐在开发环境使用它,Vue Scan 提供一个 vue plugin,允许你在 mount 之前注入相关的内容。
// vue3
import { createApp } from 'vue'
import VueScan, { type VueScanOptions } from 'z-vue-scan/src'
import App from './App.vue'
const app = createApp(App)
app.use<VueScanOptions>(VueScan, {})
app.mount('#app')
// vue2
import Vue from 'vue'
import VueScan, { type VueScanBaseOptions } from 'z-vue-scan/vue2'
import App from './App.vue'
Vue.use<VueScanBaseOptions>(VueScan, {})
new Vue({
render: h => h(App),
}).$mount('#app')
浏览器扩展
如果你觉得看自己的网站没什么意思,那么我还构建了一个浏览器扩展,允许你注入相关方法到别人的 vue 程序中。
你可以在 Github Release 寻找一下最新版的安装包,然后解压安装到浏览器中。
安装完成后,你的扩展区域应该会多一个图标,点击之后会展开一个面板,允许你控制是否注入相关的内容。

这是如果你进入一个使用 vue 构建的网站,可以看控制台看到相关的信息,当你在页面交互时,页面应该也有相应的展示。

缺陷
就像 React Scan 的介绍中提到的,它能自动识别性能问题,单目前 Vue Scan 只是真实地反映组件的更新,并不会区分和识别此次更新是否有性能问题。
结语
通过观察网站交互时组件的更新状态,来尝试发现网站的性能问题,我觉得这是一个很好的方式。希望这个工具可以给大家带来一点乐趣和帮助。
来源:juejin.cn/post/7444449353165488168




