








🌿一个vue3指令让el-table自动轮播

前言
本文开发的工具,是vue3 element-plus ui库专用的,需要对vue3指令概念有一定的了解
最近开发的项目中,需要对项目中大量的列表实现轮播效果,经过一番折腾.最终决定不使用第三方插件,手搓一个滚动指令.
效果展示

实现思路
第一步先确定功能
- 列表自动滚动
- 鼠标移入停止滚动
- 鼠标移出继续滚动
- 滚轮滚动完成,还可以继续在当前位置滚动
- 元素少于一定条数时,不滚动
滚动思路


通过观察el-table的结构可以发现el-scrollbar__view里面放着所有的元素,而el-scrollbar__wrap是一个固定高度的容器,那么只需要获取到el-scrollbar__wrap这个DOM,并且再给一个定时器,不断的改变它的scrollTop值,就可以实现自动滚动的效果,这个值必须要用一个变量来存储,不然会失效
停止和继续滚动思路
设置一个boolean类型变量,每次执行定时器的时候判断一下,true就滚动,否则就不滚动
滚轮事件思路
为了每次鼠标在列表中滚动之后,我们的轮播还可以在当前滚动的位置,继续轮播,只需要在鼠标移出的时候,将当前el-scrollbar__wrap的scrollTop赋给前面存储的变量,这样执行定时器的时候,就可以继续在当前位置滚动
不滚动的思路
只需要判断el-scrollbar__view这个容器的高度,是否大于el-scrollbar__wrap的高度,是就可以滚动,不是就不滚动。
大致的思路是这样的,下面上源码
实现代码
文件名:tableAutoScroll.ts
interface ElType extends HTMLElement {
timer: number | null
isScroll: boolean
curTableTopValue: number
}
export default {
created(el: ElType) {
el.timer = null
el.isScroll = true
el.curTableTopValue = 0
},
mounted(el: ElType, binding: { value?: { delay?: number } }) {
const { delay = 15 } = binding.value || {}
const tableDom = el.getElementsByClassName(
'el-scrollbar__wrap'
)[0] as HTMLElement
const viewDom = el.getElementsByClassName(
'el-scrollbar__view'
)[0] as HTMLElement
const onMouseOver = () => (el.isScroll = false)
const onMouseOut = () => {
el.curTableTopValue = tableDom.scrollTop
el.isScroll = true
}
tableDom.addEventListener('mouseover', onMouseOver)
tableDom.addEventListener('mouseout', onMouseOut)
el.timer = window.setInterval(() => {
const viewDomClientHeight = viewDom.scrollHeight
const tableDomClientHeight = el.clientHeight
if (el.isScroll && viewDomClientHeight > tableDomClientHeight) {
const curScrollPosition = tableDom.clientHeight + el.curTableTopValue
el.curTableTopValue =
curScrollPosition === tableDom.scrollHeight
? 0
: el.curTableTopValue + 1
tableDom.scrollTop = el.curTableTopValue
}
}, delay)
},
unmounted(el: ElType) {
if (el.timer !== null) {
clearInterval(el.timer)
}
el.timer = null
const tableDom = el.getElementsByClassName(
'el-scrollbar__wrap'
)[0] as HTMLElement
tableDom.removeEventListener('mouseover', () => (el.isScroll = false))
tableDom.removeEventListener('mouseout', () => {
el.curTableTopValue = tableDom.scrollTop
el.isScroll = true
})
},
}
上面代码中,我在 created中初始化了三个变量,分别用于存储,定时器对象 、是否滚动判断、滚动当前位置。
在 mounted中我还获取了一个options,主要是为了可以定制滚动速度
用法
- 将这段代码放在你的文件夹中
- 在
main.ts中注册这个指令
import tableAutoScroll from './modules/tableAutoScroll.ts'
const directives: any = {
tableAutoScroll,
}
/**
* @function 批量注册指令
* @param app vue 实例对象
*/
export const install = (app: any) => {
Object.keys(directives).forEach((key) => {
app.directive(key, directives[key]) // 将每个directive注册到app中
})
}


我这边是将自己的弄了一个批量注册,正常使用就像官网里面注册指令就可以了
在需要滚动的el-table上使用这个指令就可以

<!-- element 列表滚动指令插件 -->
<template>
<div class="container">
<el-table v-tableAutoScroll :data="tableData" height="300">
<el-table-column prop="date" label="时间" />
<el-table-column prop="name" label="名称" />
<el-table-column prop="address" label="Address" />
</el-table>
<!-- delay:多少毫秒滚动一次 -->
<el-table
v-tableAutoScroll="{
delay: 50,
}"
:data="tableData"
height="300"
>
<el-table-column prop="date" label="时间" />
<el-table-column prop="name" label="名称" />
<el-table-column prop="address" label="Address" />
</el-table>
</div>
</template>
<script setup lang="ts">
import { ref, onMounted } from 'vue'
const tableData = ref<any>([])
onMounted(() => {
tableData.value = Array.from(Array(100), (item, index) => ({
date: '时间' + index,
name: '名称' + index,
address: '地点' + index,
}))
console.log('👉 ~ tableData.value=Array.from ~ tableData:', tableData)
})
</script>
<style lang="scss" scoped>
.container {
height: 100%;
display: flex;
align-items: flex-start;
justify-content: center;
gap: 100px;
.el-table {
width: 500px;
}
}
</style>
上面这个例子,分别演示两种调用方法,带参数和不带参数
最后
做了这个工具之后,突然有很多思路,打算后面再做几个,做成一个开源项目,一个开源的vue3指令集
来源:juejin.cn/post/7452667228006678540
马上2025年了,你还在用组件式弹窗? 来看看这个吧~
闲言少叙,直切正题。因为我喜欢命令式弹窗,所以就封装了它做为了业务代码的插件!如今在实际项目中跑了大半年,挺方便也挺灵活的!
如何使用
// vue2
npm install @e-dialog/v2
// main.js 入口文件
import Vue from 'vue'
import App from './App'
//导包
import eDialog from '@e-dialog/v2'
//注册插件
Vue.use(eDialog, {
width:'50%',//全局配置
top:'15vh',
//...省略
})
new Vue({
el: '#app',
render: h => h(App)
})
// vue3
npm install @e-dialog/v3
// main.js 入口文件
import { createApp } from 'vue'
import App from './App.vue'
//导包
import eDialog from '@e-dialog/v3'
// 创建实例
const setupAll = async () => {
const app = createApp(App)
app.use(eDialog,{
width:'50%',//全局配置
top:'15vh',
//...省略
})
app.mount('#app')
}
setupAll()
插件简介
vue2是基于element ui elDialog组件做的二次封装,vue3则是基于element-plus elDialog组件做的二次封装,属性配置这一块可以全部参考element UI文档!

扩展的属性配置
| 参数 | 说明 | 类型 | 默认值 |
|---|---|---|---|
| isBtn | 是否显示底部操作按钮 | boolean | true |
| draggable | 是否开启拖拽,vue3版本element-plus内置了该属性 | boolean | true |
| floorBtnSize | 底部操作按钮的尺寸 | medium、small、mini | small |
| sureBtnText | 确定按钮的文案 | string | 确定 |
| closeBtnText | 关闭按钮的文案 | string | 关闭 |
| footer | 底部按钮的插槽,是一个函数返回值必须是JSX | function | - |
底部插槽用法
// index.vue
<template>
<!-- vue2示例 -->
<div>
<el-button @click="handleDialog">弹窗</el-button>
</div>
</template>
<script>
//弹窗内容
import Edit form './edit.vue'
export default {
methods: {
handleDialog() {
this.$Dialog(Edit, props,function(vm,next){
//vm可以通过vm.formData拿到数据
},{
isBtn:false //如果定义了插槽,建议关闭底部操作按钮,不然会出现布局问题
footer:function(h,next){
return (
<el-button onClick={()=>{this.handleCheck(next)}}>按钮</el-button>
)
}
})
},
//按钮点击触发
handleCheck(next){
//next是一个手动关闭函数
console.log('业务逻辑')
}
}
}
</script>
页面使用:vue2
// index.vue
<template>
<!-- vue2示例 -->
<div>
<el-button @click="handleDialog">弹窗</el-button>
</div>
</template>
<script>
//弹窗内容
import Edit form './edit.vue'
export default {
methods: {
handleDialog() {
/**
* @function $Dialog是一个全局方法,自动挂载到了vue的原型
* @description 它总共接收4个参数
* @param 组件实例 | html字符串
* @param props要传递到组件的参数对象。
* @param 点击确定按钮的回调,回调里面的第一个参数是弹窗内容的组件实例,第二个参数是关闭弹窗的执行函数
* @param 配置对象,可以覆盖全局的配置
* @return void
*/
this.$Dialog(Edit, props,function(vm,next){
//vm可以通过vm.formData拿到数据
},{
//配置对象
})
}
}
}
</script>
//edit.vue
<template>
<div>弹窗内容!</div>
</template>
<script>
export default {
props:[/*这里可以接收$Dialog第二个参数props的数据*/]
data() {
return {
formData:{
a:'',
b:'',
c:''
}
}
},
}
</script>
页面使用:vue3
// index.vue
<template>
<!-- vue2示例 -->
<div>
<el-button @click="handleDialog">弹窗</el-button>
</div>
</template>
<script setup>
//弹窗内容
import Edit form './edit.vue'
const { proxy } = getCurrentInstance();
const $Dialog = proxy.useDialog()
function handleDialog() {
/**
* @function $Dialog是一个全局方法,自动挂载到了vue的原型
* @description 它总共接收4个参数
* @param 组件实例 | html字符串
* @param props要传递到组件的参数对象。
* @param 点击确定按钮的回调,回调里面的第一个参数是弹窗内容的组件实例,第二个参数是关闭弹窗的执行函数
* @param 配置对象,可以覆盖全局的配置
* @return void
*/
$Dialog(Edit, props,function(vm,next){
//vm可以通过vm.formData拿到数据
},{
//配置对象
})
}
</script>
//edit.vue
<template>
<div>弹窗内容!</div>
</template>
<script setup>
const formData = reactive({
a:'',
b:'',
c:''
})
defineExpose({ formData }) //这里注意一点要把外部要用的抛出去,如果不抛,则$Dialog回调将拿不到任何数据
</script>
函数参数设计理念
- 如果你弹窗内容比较复杂,例如涉及一些表单操作。最好建议抽离成一个组件,导入到Dialog第一个入参里面,如果只是简单的静态文本,则直接可以传HTML。
- 如果你Dialog导入的是组件,那么你有可能需要给组件传参。所以Dialog第二个入参就是给你开放的入口。
- 如果你点击确认按钮可能需要执行一些逻辑,例如调用API接口。所以你可能在Dialog第三个回调函数里面写入逻辑。回调函数会把第一个入参组件的实例给你传递回来,你拿到实例就可以干任何事情咯!
- Dialog第四个参数考虑到不同页面的配置不同。可以灵活设置。
vue2源码地址(github.com/zy1992829/e…)
vue3源码地址(github.com/zy1992829/e…)
喜欢的朋友可以去看一看,顺便帮忙点个星星。这个就不贴源码了。。
来源:juejin.cn/post/7448661024440401957
Vue3.5正式上线,父传子props用法更丝滑简洁
前言
Vue3.5在2024-09-03正式上线,目前在Vue官网显最新版本已经是Vue3.5,其中主要包含了几个小改动,我留意到日常最常用的改动就是props了,肯定是用Vue3的人必用的,所以针对性说一下props的两个小改动使我们日常使用更加灵活。

一、带响应式Props解构赋值
简述: 以前我们对Props直接进行解构赋值是会失去响应式的,需要配合使用toRefs或者toRef解构才会有响应式,那么就多了toRefs或者toRef这工序,而最新Vue3.5版本已经不需要了。
这样直接解构,testCount能直接渲染显示,但会失去响应式,当我们修改testCount时页面不更新。
<template>
<div>
{{ testCount }}
</div>
</template>
<script setup>
import { defineProps } from 'vue';
const props = defineProps({
testCount: {
type: Number,
default: 0,
},
});
const { testCount } = props;
</script>
保留响应式的老写法,使用
toRefs或者toRef解构
<template>
<div>
{{ testCount }}
</div>
</template>
<script setup>
import { defineProps, toRef, toRefs } from 'vue';
const props = defineProps({
testCount: {
type: Number,
default: 0,
},
});
const { testCount } = toRefs(props);
// 或者
const testCount = toRef(props, 'testCount');
</script>
最新
Vue3.5写法,不借助”外力“直接解构,依然保持响应式
<template>
<div>
{{ testCount }}
</div>
</template>
<script setup>
import { defineProps } from 'vue';
const { testCount } = defineProps({
testCount: {
type: Number,
},
});
</script>
相比以前简洁了真的太多,直接解构使用省去了toRefs或者toRef
二、Props默认值新写法
简述: 以前默认值都是用default: ***去设置,现在不用了,现在只需要解构的时候直接设置默认值,不需要额外处理。
先看看旧的
default: ***默认值写法
如下第12就是旧写法,其它以前Vue2也是这样设置默认值
<template>
<div>
{{ props.testCount }}
</div>
</template>
<script setup>
import { defineProps } from 'vue';
const props = defineProps({
testCount: {
type: Number,
default: 1
},
});
</script>
最新优化的写法
如下第9行,解构的时候直接一步到位设置默认值,更接近js语法的写法。
<template>
<div>
{{ testCount }}
</div>
</template>
<script setup>
import { defineProps } from 'vue';
const { testCount=18 } = defineProps({
testCount: {
type: Number,
},
});
</script>
小结
这次更新其实props的本质功能并没有改变,但写法确实变的更加丝滑好用了,props使用非常高频感觉还是有必要跟进这种更简洁的写法。如果那里写的不对或者有更好建议欢迎大佬指点啊。
来源:juejin.cn/post/7410333135118090279
2024 年了! CSS 终于加入了 light-dark 函数!
一. 前言
随着 Web 技术的不断发展,用户体验成为了设计和开发过程中越来越重要的因素之一。为了更好地适应用户的视觉偏好,CSS 在 2024 年正式引入了一项新的功能 —— light-dark() 函数。
这项功能的加入主要在于简化网页对于浅色模式(Light Mode)与深色模式(Dark Mode)的支持,使得我们能够更快更轻松轻松地实现不同的主题切换。
接下来,我们就来详细了解一下我们在开发网页是如何实现主题切换的!
以下 Demo 示例,支持跟随系统模式和自定义切换主题,先一睹为快吧!

二. 传统方式
在 light-dark() 函数出现之前,开发者通常需要通过 JavaScript 或者 CSS 变量配合媒体查询来实现主题切换。例如:
使用 CSS 变量 + 媒体查询:
开发者会定义一套 CSS 变量,然后基于用户的偏好设置(如:prefers-color-scheme: dark 或 prefers-color-schema: light)来改变这些变量的值。
/* 默认模式 */
:root {
--background-color: white;
--text-color: black;
}
/* dark模式 */
@media (prefers-color-scheme: dark) {
:root {
--background-color: #333;
--text-color: #fff;
}
}
也可以使用 JavaScript 监听主题切换:
JavaScript 可以监听用户更改其操作系统级别的主题设置,并相应地更新网页中的类名或样式表链接。
// 检测是否启用了dark模式
if (window.matchMedia && window.matchMedia('(prefers-color-scheme: dark)').matches) {
document.body.classList.add('dark-mode')
} else {
document.body.classList.remove('dark-mode')
}
以上这种方法虽然有效,但增加了代码复杂度,特别是当需要处理多个元素的颜色变化时,我们可能需要更多的代码来支持主题。
接下来我们看一下 light-dark 是如何实现的?
三. 什么是 light-dark?

light-dark() 是在 2024 年新加入的一种新的 CSS 函数,它允许我们根据用户的系统颜色方案(浅色或深色模式)来自动选择合适的颜色值。这个函数的引入简化了创建响应用户偏好主题的应用程序和网站的过程,而无需使用媒体查询或其他复杂的逻辑。
1. 基本用法
具体的说,light-dark() 函数接受两个参数,分别对应于浅色模式下的颜色值和深色模式下的颜色值。
- 第一个参数是在浅色模式下使用的颜色。
- 第二个参数是在深色模式下使用的颜色。
当用户的设备设置为浅色模式时,light-dark() 会返回第一个参数的颜色;当用户的设备设置为深色模式时,则返回第二个参数的颜色。
基本语法如下:
color: light-dark(浅色模式颜色, 深色模式颜色);
因此,light-dark() 提供了一种更简洁的方式来直接在 CSS 中指定两种模式下的颜色,而不需要额外的脚本或复杂的 CSS 结构。例如:
body {
background-color: light-dark(white, #333);
color: light-dark(black, #fff);
}
这里的 light-dark(白色, 深灰色) 表示如果用户处于浅色模式下,则背景色为白色;如果是深色模式,则背景色为深灰色。同样适用于文本颜色等其他属性。
2. 结合其他 CSS 特性
light-dark() 可以很好地与其他 CSS 特性结合使用,如变量、渐变等,以创造更加丰富多样的效果。当结合其他 CSS 特性使用 light-dark() 将更加灵活的创造页面的效果。
(1) 结合 CSS 变量
你可以利用 CSS 变量来存储颜色值,然后在 light-dark() 内引用这些变量,这样就能够在一处更改颜色方案并影响整个站点。
CSS 变量(也称为自定义属性)允许你存储可重复使用的值,这使得在不同的主题之间切换变得非常方便。你可以设置基础颜色变量,然后利用 light-dark() 来决定这些变量的具体值。
:root {
--primary-color: light-dark(#007bff, #6c757d);
--background-color: light-dark(white, #212529);
--text-color: light-dark(black, white);
}
body {
background-color: var(--background-color);
color: var(--text-color);
}
(2) 结合媒体查询
虽然 light-dark() 本身就可以根据系统偏好自动调整颜色,但有时候你可能还需要针对特定的屏幕尺寸或分辨率进行额外的样式调整。这时可以将 light-dark() 与媒体查询结合使用。
@media (max-width: 600px) {
body {
--button-bg: light-dark(#f8f9fa, #343a40); /* 更小的屏幕上按钮背景色 */
--button-text: light-dark(black, white);
}
button {
background-color: var(--button-bg);
color: var(--button-text);
}
}
(3) 结合伪类
light-dark() 也可以与伪类一起工作,比如 :hover, :focus 等,以实现不同状态下的颜色变化。
button {
background-color: light-dark(#007bff, #6c757d);
color: light-dark(white, black);
}
button:hover,
button:focus {
background-color: light-dark(#0056b3, #5a6268);
}
(4) 结合渐变
如果你希望在浅色模式和深色模式下使用不同的渐变效果,同样可以通过 light-dark() 来实现。
.header {
background: linear-gradient(light-dark(#e9ecef, #343a40), light-dark(#dee2e6, #495057));
}
(5) 结合阴影
对于元素的阴影效果,你也可以根据不同主题设置不同的阴影颜色和强度。
.box-shadow {
box-shadow: 0 4px 8px rgba(light-dark(0, 255), light-dark(0, 255), light-dark(0, 255), 0.1);
}
通过上述方法,你可以充分利用 light-dark() 函数的优势,并与其他 CSS 特性结合,创造出既美观又具有高度适应性的网页设计。这样不仅提高了用户体验,还简化了开发过程中的复杂度。
四. 兼容性
在 2024 年初时,light-dark() 函数作为 CSS 的一个新特性被加入到规范中,并且开始得到一些现代浏览器的支持。

其实,通过上图我们可以看到,light-dark() 在主流浏览器在大部分版本下都是支持了,所以我们可以放心的使用它。
但是同时我们也要注意,在一些较低的浏览器版本上仍然不被支持,比如 IE。因此,为了确保兼容性,在生产环境中使用该功能前需要检查目标浏览器是否支持这一特性。
如果浏览器不支持 light-dark(),可能需要提供回退方案,比如使用传统的媒体查询 @media (prefers-color-scheme: dark) 或者通过 JavaScript 来动态设置颜色。
五. 总结
通过本文,我们了解到,light-dark() 函数是 CSS 中的一个新特性,它允许开发者根据用户的系统偏好(浅色或深色模式)来自动切换颜色。
通过与传统模式开发深浅主题的比较,我们可以总结出 light-dark() 的优势应该包括:
- 使用简洁:不需要编写额外的媒体查询,简洁高效。
- 自动响应:能够随着系统的颜色方案改变而自动切换颜色。
- 易于维护:所有与颜色相关的样式可以在同一处定义。
- 减少代码量:相比使用多个媒体查询,可以显著减少 CSS 代码量。
light-dark() 函数是 CSS 领域的一项进步,它不仅简化了响应式设计的过程,也体现了对终端用户个性化体验的重视。随着越来越多的现代浏览器开始支持这一特性,我们未来可以在更多的应用场景中使用这一特性!
文档链接
码上掘金演示
可以点击按钮切换主题,也可以切换系统的暗黑模式跟随:
🔥 我正在参加2024年度人气创作者评选,每投2票可以抽奖! 点击链接投票
来源:juejin.cn/post/7443828372775764006
⚡聊天框 - 微信加载历史数据的效果原来这样实现的
前言
我记得2021年的时候做过聊天功能,那时业务也只限微信小程序
那时候的心路历程是:
卧槽,让我写一个聊天功能这么高大上??
嗯?这么简单,不就画画页面来个轮询吗,加个websocket也还行吧
然后,卧槽?这查看历史聊天记录什么鬼,页面闪一下不太好啊,真的能做到微信的那种效果吗
然后一堆调研加测试,总算在小程序中查看历史记录没那么鬼畜了,但是总是感觉不是最佳解决方案。
那时打出的子弹,一直等到现在击中了我
最近又回想到了这个痛点,于是网上想看看有没有大佬发解决方案,结果还真被我找到了。

正文开始
1,效果展示
上才艺~~~

2,聊天页面
2.1,查看历史聊天记录的坑
常规写法加载历史记录拼接到聊天主体的顶部后,滚动条会回到顶部、不在原聊天页面
直接上图

而我们以往的解决方案也只是各种利用缓存、scroll的滚动定位把回到顶部的滚动条重新拉回加载历史记录前的位置,好让我们可以继续在原聊天页面。
但即使我们做了很多优化,也会有安卓和苹果部分机型适配问题,还是不自然,可能会出现页面闪动。
其实吧,解决方案只有两行css代码~~~
2.2,解决方案:flex神功
想优雅顺滑的在聊天框里查看历史记录,这两行css代码就是flex的这个翻转属性
dispaly:flex;
flex-direction: column-reverse
灵感来源~~~

小伙伴可以看到,在加载更多数据时
滚动条位置没变、加载数据后还是原聊天页面的位置
这不就是我们之前的痛点吗~~~
所以,我们只需要翻转位置,用这个就可以优雅流畅的实现微信的加载历史记录啦
flex-direction: column-reverse
官方的意思:指定Flex容器中子元素的排列方向为列(从上到下),并且将其顺序反转(从底部到顶部)
如果感觉还是抽象,不好理解的话,那就直接上图,不加column-reverse的样子

加了column-reverse的样子

至此,我们用column-reverse再搭配data数据的位置处理就完美解决加载历史记录的历史性问题啦
代码放最后啦~~~
2.3,其他问题
2.3.1,数据过少时第一屏展示
因为用了翻转,数据少的时候会出现上图的问题
只需要.mainArea加上height:100%
然后额外写个适配盒子就行
flex-grow: 1;
flex-shrink: 1;

2.3.2,用了scroll-view导致的问题
这一part是因为我用了uniapp里 scroll-view组件导致的坑以及解决方案,小伙伴们没用这个组件的可忽略~~~
如下图,.mainArea使用了height:100%后,继承了父级高度后scroll-view滚动条消失了。

.mainArea去掉height:100%后scroll-view滚动条出现,但是第一屏数据过多时不会滚动到底部展示最新信息

解决方案:第一屏手动进行滚动条置顶
scrollBottom() {
if (this.firstLoad) return;
// 第一屏后不触发
this.$nextTick(() => {
const query = uni.createSelectorQuery().in(this);
query
.select("#mainArea")
.boundingClientRect((data) => {
console.log(data);
if (data.height > +this.chatHeight) {
this.scrollTop = data.height; // 填写个较大的数
this.firstLoad = true;
}
})
.exec();
});
},
3,服务端
使用koa自己搭一个websocket服务端
3.1 服务端项目目录

package.json
{
"name": "websocketapi",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"koa": "^2.14.2",
"koa-router": "^12.0.1",
"koa-websocket": "^7.0.0"
}
}
koa-tcp.js
const koa = require('koa')
const Router = require('koa-router')
const ws = require('koa-websocket')
const app = ws(new koa())
const router = new Router()
/**
* 服务端给客户端的聊天信息格式
* {
id: lastid,
showTime: 是否展示时间,
time: nowDate,
type: type,
userinfo: {
uid: this.myuid,
username: this.username,
face: this.avatar,
},
content: {
url:'',
text:'',
w:'',
h:''
},
}
消息数据队列的队头为最新消息,以次往下为老消息
客户端展示需要reverse(): 客户端聊天窗口最下面需要为最新消息,所以队列尾部为最新消息,以此往上为老消息
*/
router.all('/websocket/:id', async (ctx) => {
// const query = ctx.query
console.log(JSON.stringify(ctx.params))
ctx.websocket.send('我是小服,告诉你连接成功啦')
ctx.websocket.on('message', (res) => {
console.log(`服务端收到消息, ${res}`)
let data = JSON.parse(res)
if (data.type === 'chat') {
ctx.websocket.send(`我也会说${data.text}`)
}
})
ctx.websocket.on('close', () => {
console.log('服务端关闭')
})
})
// 将路由中间件添加到Koa应用中
app.ws.use(router.routes()).use(router.allowedMethods())
app.listen(9001, () => {
console.log('socket is connect')
})
切到server目录下yarn
然后执行nodemon koa-tcp.js
没有nodemon的小伙伴要装一下

代码区
聊天页面的核心代码如下(包含data数据的位置处理和与服务端联动)
完结
这篇文章我尽力把我的笔记和想法放到这了,希望对小伙伴有帮助。
到这里,想给小伙伴分享两句话
现在搞不清楚的事,不妨可以先慢下来,不要让自己钻到牛角尖了
一些你现在觉得解决不了的事,可能需要换个角度
欢迎转载,但请注明来源。
最后,希望小伙伴们给我个免费的点赞,祝大家心想事成,平安喜乐。

来源:juejin.cn/post/7337114587123335180
在高德地图上实现建筑模型动态单体化
前言
前段时间系统性地学习了国内知名GIS平台的三维应用解决方案,受益匪浅,准备分几期对所学内容进行整理归纳和分享,今天来讲讲城市3D模型的处理方案。
城市3D模型图层在Web GIS平台中能够对地面物体进行单独选中、查询、空间分析等操作,是属于比较普遍的功能需求。这样的图层一般不会只有单一的数据来源,而是个集成了倾斜投影、BIM建模、动态参数建模的混合型图层,并且需要对模型进行适当的处理优化以提升其性能,因此在GIS平台不会选择支持单独地选中地图,我们需要对模型进行拆分——即单体化处理。
对建筑模型单体化处理通常有三种方案,各有其优点和适用场景,对比如下:
| 方案 | 实现原理 | 优势 | 缺陷 |
|---|---|---|---|
| 切割单体化 | 将三维模型与二维面进行切割操作成为单独可操作对象 | 能够实现非常精细的单体化效果,适用于精细度要求高的场景 | 数据处理量大,对计算机性能要求较高 |
| ID 单体化 | 预先为每个三维模型对象和二维矢量数据分配一个可关联的 ID | 数据处理相对简单,不需要进行复杂的几何运算,适用于数据量相对较小、模型结构相对简单的场景 | 可能会出现 ID 管理困难的情况,且对于模型的几何形状变化适应性较差 |
| 动态单体化 | 实时判断鼠标点击或选择操作的位置与三维模型的关系,动态地将选中的部分从整体模型中分离出来进行单独操作 | 无需预先处理数据,可根据用户的交互实时进行单体化操作,适用于需要快速响应用户交互的场景 | 对计算机的图形处理能力和性能要求较高 |
在这些方案中,动态单体化无需对模型进行预处理,依数据而变化使用较为灵活,接下来我们通过一个简单的例子来演示该方案的整体实现过程,源代码在这里供下载交流。

需求分析
假设我们拿到一个城市行政区域内的三维建筑数据,对里面该区域里面的几栋关键型建筑进行操作管理,我们需要把建筑模型放置到对应的地图位置上,可宏观地浏览模型;支持通过鼠标选中建筑的楼层,查看当前楼层的相关数据;楼层数据支持动态变更,且可以进行结构性存储。因此我们得到以下功能需求:
- 在Web地图上建立3D区域模型图层
- 根据当前光标位置动态高亮楼层,并展示楼层基本信息
- 建筑单体化数据为通用geoJSON格式,方便直接转换为csv或导入数据库
技术栈说明
| 工具名称 | 版本 | 用途 |
|---|---|---|
| 高德地图 JSAPI | 2.0 | 为GIS平台提供基础底图和服务 |
| three.js | 0.157 | 主流webGL引擎之一,负责实现展示层面的功能 |
| QGIS | 3.32.3 | GIS数据处理工具,用于处理本文的矢量化数据 |
| cesiumlab | 3.1.11 | 三维数据处理工具集,用于将模型转换为互联网可用的3DTiles |
| blender | 3.6 | 模型处理工具,用于对BIM模型进行最简单的预处理 |
实现步骤
制作3DTiles
城市级的三维模型通常以无人机倾斜投影获取到的数据最为快捷,数据格式为OSGB且体积巨大不利于分享,由于手头没有合适的倾斜投影数据,我们以一个小型的BIM模型为例进行三维瓦片化处理也是一样的。
- 模型预处理。从sketchfab寻找到一个合适的建筑模型,下载其FBX格式并导入到模型处理工具(C4D、blender等)进行简单的预处理,调整模型的大小、重置坐标轴原点的位置到模型的几何中心,然后导出带材质的FBX模型备用,这里blender如何带材质地导出模型有一些技巧。

- 启动cesiumlab,点击“通用模型切片”选项,选择预处理好的模型,指定它的地理位置(ENU: 维度,经度),点击确认

- 在最后的“数据存储”设置原始坐标为打开、存储类型为散列(最终输出多个文件)、输出路径,提交处理等待3DTiles生成

- 生成过程结束后我们来到分发服务选项,点击chrome的图标就能够进入3DTiles的预览了,注意看路径这一列,这里面包含了入口文件tileset.json的两个路径(文件存储目录和静态资源服务地址),后面开发中我们会用到它。

- 至此模型准备完毕,我们可以把输出出的3Tiles目录放到开发i工程中,也可以单独部署为静态资源服务,保证tileset.json可访问即可。

- 开发3DTiles图层,详细的教程之前已经分享过了,这里直接上代码。
// 默认地图状态
const mapConf = {
name: '虚拟小区',
tilesURL: '../static/tiles/small-town/tileset.json',
//...
}
// 添加3DTiles图层
async function initTilesLayer() {
const layer = new TilesLayer({
container,
id: 'tilesLayer',
map: getMap(),
center: [113.536206, 22.799285],
zooms: [4, 22],
zoom: mapConf.zoom,
tilesURL: mapConf.tilesURL,
alone: false,
interact: false
})
layer.on('complete', ({ scene }) => {
// 调整模型的亮度
const aLight = new THREE.AmbientLight(0xffffff, 3.0)
scene.add(aLight)
})
layerManger.add(layer)
}
- 这一阶段实现的效果如下

创建单体化数据
- 使用QGIS处理矢量数据,绘制建筑模型轮廓的矢量面。由于本示例是虚拟的,我们需要自己创建矢量数据,把上一个步骤完成的内容高空垂直截图导入到QGIS上配准位置,作为描绘的参考图。

- 创建形状文件图层,进入编辑模式绘制建筑轮廓

- 选择图层右键打开属性表,开始编辑每个建筑的基础数据,导出为monobuildingexample1.geojson

- 对关键建筑“商业办公楼A”和“商业办公楼B”的楼层数据进行进一步编辑(bottomAltitude为每层楼的离地高度,extendAltitude为楼层高度),这块数据与GIS无关,我直接用wps图表去做了,完成后将csv文件转换成为json格式,然后与monobuildingexample1.geojson做一个组合,得到最终的geoJSON数据。

开发动态单体化图层
底座和数据准备好,终于可以进行动态单体化图层开发了,实现原理其实非常简单,根据上一步获得的建筑矢量和楼层高度数据,我们就可以在于模型匹配的地理位置上创建若干个“罩住”楼栋模型的盒状网格体,并监听网格体的鼠标拾取状态,即可实现楼层单体化交互。

- 我们的数据来自monobuildingexample1.geojson,生成每个楼层侧面包围盒的核心代码如下,通过path数据和bottomAltitued、extendAltitude就能得到网格体的所有顶点。
/**
* 根据路线创建侧面几何面
* @param {Array} path [[x,y],[x,y],[x,y]...] 路线数据
* @param {Number} height 几何面高度,默认为0
* @returns {THREE.BufferGeometry}
*/
createSideGeometry (path, region) {
if (path instanceof Array === false) {
throw 'createSideGeometry: path must be array'
}
const { id, bottomAltitude, extendAltitude } = region
// 保持path的路线是闭合的
if (path[0].toString() !== path[path.length - 1].toString()) {
path.push(path[0])
}
const vec3List = [] // 顶点数组
let faceList = [] // 三角面数组
let faceVertexUvs = [] // 面的UV层队列,用于纹理和几何信息映射
const t0 = [0, 0]
const t1 = [1, 0]
const t2 = [1, 1]
const t3 = [0, 1]
for (let i = 0; i < path.length; i++) {
const [x1, y1] = path[i]
vec3List.push([x1, y1, bottomAltitude])
vec3List.push([x1, y1, bottomAltitude + extendAltitude])
}
for (let i = 0; i < vec3List.length - 2; i++) {
if (i % 2 === 0) {
// 下三角
faceList = [
...faceList,
...vec3List[i],
...vec3List[i + 2],
...vec3List[i + 1]
]
// UV
faceVertexUvs = [...faceVertexUvs, ...t0, ...t1, ...t3]
} else {
// 上三角
faceList = [
...faceList,
...vec3List[i],
...vec3List[i + 1],
...vec3List[i + 2]
]
// UV
faceVertexUvs = [...faceVertexUvs, ...t3, ...t1, ...t2]
}
}
const geometry = new THREE.BufferGeometry()
// 顶点三角面
geometry.setAttribute(
'position',
new THREE.BufferAttribute(new Float32Array(faceList), 3)
)
// UV面
geometry.setAttribute(
'uv',
new THREE.BufferAttribute(new Float32Array(faceVertexUvs), 2)
)
return geometry
}
- 经过前面步骤,得到网格体如下

- 添加默认状态和选中状态下材质
initMaterial () {
const { initial, hover } = this._conf.style
// 顶部材质
this._mt = {}
this._mt.initial = new THREE.MeshBasicMaterial({
color: initial.color,
transparent: true,
opacity: initial.opacity,
side: THREE.DoubleSide,
wireframe: true
})
this._mt.hover = new THREE.MeshBasicMaterial({
color: hover.color,
transparent: true,
opacity: hover.opacity,
side: THREE.DoubleSide
})
}
- 添加拾取事件,对选中的网格体Mesh设置选中材质,并对外派发事件
// 处理拾取事件
onPicked ({ targets, event }) {
let attrs = null
if (targets.length > 0) {
const cMesh = targets[0]?.object
if (cMesh?.type == 'Mesh') {
// 设置选中状态
this.setLastPick(cMesh)
attrs = cMesh._attrs
} else {
// 移除选中状态
this.removeLastPick()
}
} else {
this.removeLastPick()
}
/**
* 外派模型拾取事件
* @event ModelLayer#pick
* @type {object}
* @property {Number} screenX 图层场景
* @property {Number} screenY 图层相机
* @property {Object} attrs 模型属性
*/
this.handleEvent('pick', {
screenX: event?.pixel?.x,
screenY: event?.pixel?.y,
attrs
})
}
- 外部监听到拾取事件,调动浮层展示详情
/**
* 建筑单体化图层
* @return {Promise<void>}
*/
async function initMonoBuilding() {
const data = await fetchData('../static/mock/monobuildingexample1.geojson')
const layer = new MonoBuildingLayer({
//...
data
})
layerManger.add(layer)
layer.on('pick', (event) => {
updateMarker(event)
})
}
// 更新浮标
function updateMarker(event) {
const { screenX, screenY, attrs } = event
if (attrs) {
// 更新信息浮层
const { id, name, belong, bottomAltitude, extendAltitude } = attrs
tip.style.left = screenX + 20 + 'px'
tip.style.top = screenY + 10 + 'px'
tip.innerHTML = `
<ul>
<li>id: ${id}</li>
<li>楼层: ${name}</li>
<li>离地高度: ${bottomAltitude}米</li>
<li>楼层高度: ${extendAltitude}米</li>
<li>所属: ${belong}</li>
</ul>
`
tip.style.display = 'block'
// 更新鼠标手势
container.classList.add('mouse_hover')
} else {
tip.style.display = 'none'
container.classList.remove('mouse_hover')
}
}
- 最终得到的交互效果如下

- 把3DTiles图层和点标记图层加上叠加显示,得到本示例最终效果

待拓展功能
- 对建筑模型单体的进一步细化
楼层功能还可以细化到每个楼层中各个户型,也许每个楼层都有独特的户型分布图,这个应该结合内部的墙体轮廓一起展示,选个弹窗在子内容页进行下一步操作,还是直在当前场景下钻到楼层内部?具体交互流程我还没想好。
- 如何处理异体模型
目前的方案仅针对规规矩矩的立方体建筑楼栋,而对于鸟巢、大裤衩、小蛮腰之类的异形地标性建筑,每个楼层的轮廓可能都是不一样的,因此在数据和代码方面仍需再做改进。

本示例使用到的高德JSAPI
相关工具链接
来源:juejin.cn/post/7404007685643501595
震惊,开源项目vant 2.13.5 被投毒,挖矿!
2024年12月19日,vant仓库新增一条issue,vant 2.13.5 被投毒,挖矿。
具体原因
可能是团队一名成员的 token 被盗用
与本次事件关联的攻击
攻击者在利用 @landluck 的 token 进行攻击后,进一步拿到了同个 GitHub 组织下的维护者 @chenjiahan 的 token,并发布了带有相同恶意代码的 Rspack 1.1.7 版本。
Rspack 团队已经在一小时内完成该版本的废弃处理,并发布了 1.1.8 修复版本,参考 web-infra-dev/rspack#8767 (comment)
目前相关 token 已经全部清理。
相关版本
以下异常版本被盗号者注入了脚本,已经全部标记为废弃,请勿使用!

有使用的大家可以升级版本,降低影响。
来源:juejin.cn/post/7450001084067627058
禁止调试,阻止浏览器F12开发者工具
写在前面
这两天突然想看看文心一言的http通信请求接口,于是想着用F12看看。

谁知道刚打开开发者工具,居然被动debugger了。

直接被JS写死的debugger关键字下了断点。行吧,不让调试就不让调试吧,关闭开发者工具之后,直接跳到了空白页。

其实几年之前就碰到过类似的情况,不过当时才学疏浅,也没当回事,就没研究过。这次又碰到了,毕竟已经不是当年的我了,于是便来研究研究。
分析
大家都知道浏览器的开发者工具能干啥,正经的用法:开发时调试代码逻辑,修改布局样式;不正经的用法:改改元素骗骗人,找找网站接口写爬虫,逆向js破解加密等等,所以说前端不安全,永远不要相信用户的输入。
而这次碰到的这个情况确实可以在用户端做一些防御操作,但是也可以绕过。 (PS:感谢评论区大佬指教:开发者工具Ctrl+F8可以禁用断点调试,学到了)
先做一波分析。
首先,防止你用F12调试,先用debugger关键字阻止你进行任何操作。随后,在你关闭之后,又直接跳转到空白页,不让你接着操作。
这就需要一个开发者工具检测的机制了,发现你打开了开发者工具,就给你跳走到空白页。
所以,关键就是要实现开发者工具的检测。
实现
经过查阅一番,发现原来这个debugger可能并不仅仅是阻止你进行调试的功能,同时还兼具判断开发者工具是否打开的作用。怎么实现?
debugger本身只是调试,阻止你继续对前端进行调试,但是代码中并不知道用户是否打开了开发者工具,所以就无法进行更进一步的操作,例如文心一言的跳转到空白页。
但是,有一点,你打开开发者工具之后,debugger下了断点,程序就停到那里了,如果你不打开开发者工具,程序是不会停止到断点的。没错,这就是我们可以判断的方式,时间间隔。正常情况下debugger前后的时间间隔可以忽略不计。但是,当你打开开发者工具之后,这个时间间隔就产生了,判断这个时间间隔,就可以知道是否打开了开发者工具。
直接上示例代码
<!DOCTYPE html>
<html>
<header>
<title>test</title>
</header>
<body>
<h1>test</h1>
</body>
<script>
setInterval(function() {
var startTime = performance.now();
// 设置断点
debugger;
var endTime = performance.now();
// 设置一个阈值,例如100毫秒
if (endTime - startTime > 100) {
window.location.href = 'about:blank';
}
}, 100);
</script>
</html>
通过设置一个定时循环任务来进行检测。
在不打开发者工具的情况下,debugger是不会执行将页面卡住,而恰恰是利用debugger的这一点,如果你打开开发者工具一定会被debugger卡住,那么上下文时间间隔就会增加,在对时间间隔进行判断,就能巧妙的知道绝对开了开发者工具,随后直接跳转到空白页,一气呵成。
测试

现在来进行测试,打开F12
 关闭开发者工具。
关闭开发者工具。

完美!
写在后面
这样确实可以阻挡住通过在开发者工具上获取信息,但是仅仅是浏览器场景。我想要拿到对话的api接口也不是只有这一种方法。
感谢评论区大佬指教:开发者工具Ctrl+F8可以禁用断点调试
或者说,开个代理抓包不好吗?hhh

来源:juejin.cn/post/7337188759055663119
Cesium从入门到入坟
大扎好,我系渣渣辉,斯一扔,介四里没有挽过的船新版本,挤需体验三番钟,里造会干我一样,爱象节款js裤
Cesium 概述
Cesium是国外一个基于JavaScript编写的使用WebGL的地图引擎,支持3D,2D,2.5D形式的地图展示,也是目前最流行的三维数字地球渲染引擎。
Cesium 基础介绍
首先我们需要登录上Cesium的官网,网址是 cesium.com/ ,获取源代码可以在Platform菜单项的Downloads中下载 。
接下来,第一个比较重要的事情就是我们需要注册一个免费账户以获取Cesium世界地形资产所需的访问令牌,而这个账户的token决定了哪些资产咱们可以使用;而第二个比较重要的事情就是Cesium的文档中心( cesium.com/learn/cesiu… ),我们在实际使用的过程中会经常来查阅这些API。
Cesium 的使用
由于我是使用的vue-cli生成的项目,所以直接安装vite-plugin-cesium依赖项,当然你也可以使用直接下载源码,在HTML中引入的方式。如果使用的是vite-plugin-cesium,你还需要在vite.config.ts中添加一下Cesium的引用。
import { fileURLToPath, URL } from 'node:url'
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
import vueJsx from '@vitejs/plugin-vue-jsx'
import VueDevTools from 'vite-plugin-vue-devtools'
// add this line
import cesium from 'vite-plugin-cesium';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
vueJsx(),
VueDevTools(),
// add this line
cesium()
],
resolve: {
alias: {
'@': fileURLToPath(new URL('./src', import.meta.url))
}
}
})
初始化地球
<script setup lang="ts">
import { onMounted } from 'vue'
import * as Cesium from 'cesium'
onMounted(() => {
const defaultToken = 'your access token'
Cesium.Ion.defaultAccessToken = defaultToken
const viewer = new Cesium.Viewer('cesiumContainer', {
//这里是配置项
})
})
</script>
<template>
<div id="cesiumContainer" class="cesium-container"></div>
</template>
<style scoped>
#cesiumContainer {
width: 100vw;
height: 100vh;
}
</style>
效果如下:

现在我们就可以看到Cesium生成的地球了,可以对其进行二维和三维状态的切换,也可以用其自带的播放器,对时间轴进行一个播放,支持正放和倒放,Cesium还自带了搜索地理位置组件,并且兼容了中文。
Cesium 常用的类
1. Viewer
它是Cesium展示三维要素内容的主要窗口,不仅仅包含了三维地球的视窗,还包含了一些基础控件,在定义Viewer对象的时候需要设定基础部件、图层等的初始化状态,下面演示一下部分属性的使用。
const viewer = new Cesium.Viewer('cesiumContainer', {
// 这里是配置项
// 动画播放控件
animation: false,
// 时间轴控件
timeline: false,
// 全屏按钮
fullscreenButton: true,
// 搜索位置按钮
geocoder: true,
// 帮助按钮
navigationHelpButton: false,
// VR按钮
vrButton: true
})
除了上述的控件属性之外,还有entities这种实体合集属性,主要用于加载实体模型,几何图形并对其进行样式设置,动效修改等,我们可以通过下述代码生成一个绿色的圆点。
const entity = viewer.entities.add({
position: Cesium.Cartesian3.fromDegrees(116.39, 39.9, 400),
point: {
pixelSize: 100,
color: new Cesium.Color(0, 1, 0, 1)
}
})
viewer.trackedEntity = entity
效果如下:

当然,我们也可以用entities来加载模型文件,下面我们用飞机模型试试
/** 通过entities加载一个飞机模型 */
const orientation = Cesium.Transforms.headingPitchRollQuaternion(
position,
new Cesium.HeadingPitchRoll(-90, 0, 0)
)
const entity = viewer.entities.add({
position: position,
orientation: orientation,
model: {
uri: '/Cesium_Air.glb',
minimumPixelSize: 100,
maximumScale: 10000,
show: true
}
})
viewer.trackedEntity = entity
效果如下:

2. Camera
Cesium中可以通过相机来描述和操作场景的视角,而通过相机Camera操作场景的视角还有下面的几种方法
- 飞行fly,比如flyTo,flyHome,flyToBoundingSphere
- 缩放zoom,比如zoomIn,zoomOut
- 移动move,比如moveBackward,moveDown,moveForward,moveLeft,moveRight,moveUp
- 视角look,比如lookDown,lookLeft,lookRight,lookUp
- 扭转twist,比如twistLeft,twistRight
- 旋转rotate,比如rotateDown,rotateLeft,rotateRight,rotateUp
- 其他方法,比如setView,lookAt
viewer.scene.camera.setView({
// 设定相机的目的地
destination: position,
// 设定相机视口的方向
orientation: {
// 控制视口方向的水平旋转,即沿着Y轴旋转
heading: Cesium.Math.toRadians(0),
// 控制视口方向的上下旋转,即沿着X轴旋转
pitch: Cesium.Math.toRadians(-20),
// 控制视口的翻转角度,即沿着Z轴旋转
roll: 0
}
})
我们尝试使用setView后可以发现,相机视角直接被定位到了下图的位置

3. DataSourceCollection
DataSourceCollection是Cesium中加载矢量数据的主要方式之一,它最大的特点是支持加载矢量数据集和外部文件的调用,主要有三种调用方法,分别为 CzmlDataSource,KmlDataSource,GeoJsonDataSource,分别对应加载Czml,Kml,GeoJSON格式的数据,在使用过程中我们只需要将矢量数据转换为以上任意一种格式就可以在Cesium中实现矢量数据的加载和存取。
viewer.dataSources.add(Cesium.GeoJsonDataSource.load('/ne_10m_us_states.topojson'))
效果如下:

这时候我们看到图层已经被加载上去了~
Cesium的坐标体系
通过上面的示例我们可以得知Cesium具有真实地理坐标的三维球体,但是用户是通过二维屏幕与Cesium进行操作的,假设我们需要将一个三维模型绘制到三维球体上,我们就需要再地理坐标和屏幕坐标之间做转换,而这就需要涉及到Cesium的坐标体系。
Cesium主要有5种坐标系:
- WGS84经纬度坐标系
- WGS84弧度坐标系
- 笛卡尔空间直角坐标系
- 平面坐标系
- 4D笛卡尔坐标系
他们的基础概念大家感兴趣的可以百度查阅一下,我也说不太清楚,问我他们的区别我也只能用 恰特鸡屁踢 敷衍你,下面我们演示一下怎么将WGS84左边西转换为笛卡尔空间直角坐标系:
const cartesian3 = Cesium.Cartesian3.fromDegrees(longitude, latitude, height)
我们可以通过经纬度进行转换,当然我们还有其他的方式,比如Cesium.Cartesian3.fromDegreesArray(coordinates),这里的coordinates格式为不带高度的数组。
Cesium加载地图和地形
加载地图
我们使用ArcGis地图服务来加载新地图,Cesium也给其提供了相关的加载方法:
const esri = await Cesium.ArcGisMapServerImageryProvider.fromUrl(
'https://services.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer'
)
/** 这里是配置项 */
const viewer = new Cesium.Viewer('cesiumContainer', {
baseLayerPicker: false,
})
// 加载ArcGis地图
viewer.imageryLayers.addImageryProvider(esri)
效果如下:

我们再来看一下之前的地球效果来对比对比:

可以明显看出来ArcGisMapServer提供的地图更加的清晰和立体。
注:加载ArcGis地图服务请使用我上述提供的代码,从Cesium中文网看到的示例代码可能很久没更新了,使用会报错~
当然我们还可以加载一些特定场景的地图,比如夜晚的地球,官网上直接给出了示例代码:
// addImageryProvider方法用于添加一个新的图层
viewer.imageryLayers.addImageryProvider(await Cesium.IonImageryProvider.fromAssetId(3812))
效果如下:

加载地形
我们回到刚刚的ArcGis地图,我们进入到地球内部查看一些山脉,会发现从俯视角度来看山脉是有轮廓的,但是当我们旋转相机后会发现,实际上地球表面是平的,并没有显示出地形,效果如下:

这时候我们就需要加载出地形数据了
const esri = await Cesium.ArcGisMapServerImageryProvider.fromUrl(
'https://services.arcgisonline.com/ArcGIS/rest/services/World_Imagery/MapServer'
)
/** 这里是配置项 */
const viewer = new Cesium.Viewer('cesiumContainer', {
baseLayerPicker: false,
terrainProvider: await Cesium.CesiumTerrainProvider.fromIonAssetId(1, {
// 可以增加法线,用于提高光照效果
requestVertexNormals: true,
// 可以增加水面特效
requestWaterMask: true
})
})
// 加载ArcGis地图
viewer.imageryLayers.addImageryProvider(esri)
效果如下:


可以看到原先的平面通过加载了地形数据,已经有了山势起伏,河流湖泊~
Cesium加载建筑体
我们在实际开发中,比如搭建一个智慧城市,光有地图和地形是远远不够的,还需要加载城市中的建筑模型信息,这时候我们就需要用到Cesium中建筑体的添加和使用的相关功能了,我们以官网的纽约市的模型数据为例:
/** 添加建筑物 */
const tileset = viewer.scene.primitives.add(await Cesium.Cesium3DTileset.fromIonAssetId(75343))
/** 添加相机信息 */
const position = Cesium.Cartesian3.fromDegrees(-74.006, 40.7128, 100)
viewer.camera.setView({
destination: position,
orientation: {
heading: 0,
pitch: 0,
roll: 0.0
}
})
效果如下:

我们看到纽约市建筑物的数据已经加载出来了,但是看起来都是白白的过于单调,我们还可以通过style来修改建筑物的样式
tileset.style = new Cesium.Cesium3DTileStyle({
color: {
conditions: [
['${Height} >= 300', 'rgba(45,0,75,0.5)'],
['${Height} >= 100', 'rgb(170,162,204)'],
['${Height} >= 50', 'rgb(102,71,151)'],
['true', 'rgb(127,59,8)']
]
},
show: '${Height} > 0',
meta: {
description: '"Building id ${id} has height ${Height}."'
}
})
现在我们再来看一下效果:

可以看出我们根据建筑物的不同高度,设定了不同的颜色,比如超过300米的建筑就带有透明效果了,比较上图的效果更有层次感。
最后
关于Cesium我也是初窥门径,具体的学习和使用大家还是要以 英文官网 为准,中文网上很多都过时了,使用的时候可能会报错,我已经帮大家踩好坑了😭,也欢迎大家在评论区里多沟通交流,互相学习~

来源:juejin.cn/post/7392558409742925874
震惊!🐿浏览器居然下毒!
发生什么事了
某天,我正在愉快的摸鱼,然后我看到测试给我发了条消息,说我们这个系统在UC浏览器中有问题,没办法操作,点了经常没反应(测试用得iPhone14,是一个h5的项目)。我直接懵了,这不是都测了好久了吗,虽然不是在uc上测得,chrome、safari、自带浏览器等,都没这个问题,代码应该是没问题的,uc上为啥会没有反应呢?难道是有什么隐藏的bug,需要一定的操作顺序才能触发?我就去找了测试,让他重新操作一下,看看是啥样的没反应。结果就是,正常进入列表页(首页),正常点某一项,正常进入详情页,然后点左上角返回,没反应。我上手试了下,确实,打开vconsole看了下,也没有报错。在uc上看起来还是必现的,我都麻了,这能是啥引起的啊。
找问题
在其他浏览器上都是好好的,uc上也不报错,完全看不出来代码有啥bug,完全没有头绪啊!那怎么办,刷新看看:遇事不决,先刷新,还不行就清空缓存刷新。刷新了之后,哎,好了!虽然不知道是什么问题,但现在已经好了,就当作遇到了灵异事件,我就去做其他事了。
过了一会,测试来找我了,说又出现了,不止是详情页,进其他页面也返回不了。这就难受住了呀,说明肯定是有问题的,只是还没找到原因。我就只好打开vconsole,一遍一遍的进入详情页点返回;刷新再进;清掉缓存,再进。
然后,我就发现,network中,出现了一个没有见过的请求


根据track、collect这些单词来判断,这应该是uc在跟踪、记录某些操作,requestType还是个ping;我就在想,难道是这个请求的问题?但是请求为啥会导致,我页面跳转产生问题?然后我又看到了intercept(拦截)、pushState(history添加记录),拦截了pushState?
这个项目确实使用的是history路由,问题也确实出在路由跳转的时候;而且出现问题的时候,路由跳转,浏览器地址栏中的地址是没有变化的,返回就g了(看起来是后退没有反应,实际是前进时G了)。这样看,uc确实拦截了pushState的操作。那它是咋做到的?
原来如此
然后,我想起来,前段时间在掘金上看到了一篇,讲某些第三方cdn投毒的事情,那么uc是不是在我们不知情的情况下,改了我们的代码。然后我切到了vconsole的element,展开head,发现了一个不属于我们项目的script,外链引入了一段js,就挂在head的最顶上。通过阅读,发现它在window的history上加了点料,覆写了forward和pushState(forward和pushState是继承来的方法)
正常的history应该是这样:

复写的类似这样:

当然,有些系统或框架,为了实现某些功能,比如实现触发popstate的效果,也会复写
但uc是纯纯的为了记录你的操作,它这玩意主要还有bug,会导致路由跳转出问题,真是闹麻了
如何做
删掉就好了,只要删掉uc添加的,当我们调用相关方法时,history就会去继承里找
// 判断是否是uc浏览器
if (navigator.userAgent.indexOf('UCBrowser') > -1) {
if (history.hasOwnProperty('pushState')) {
delete window.history.forward
delete window.history.pushState
}
// 找到注入的script
const ucScript = document.querySelector('script[src*="ucbrowser_script"]')
if (ucScript) {
document.head.removeChild(ucScript)}
}
}
吐槽
你说你一个搞浏览器的,就不能在底层去记录用户行为吗,还不容易被发现。主要是你这玩意它有bug呀,这不是更容易被发现吗。(这是23年11月份遇到的问题,当时产品要求在qq/百度/uc这些浏览器上也都测一下才发现的,现在记录一下,希望能帮助到其他同学)
来源:juejin.cn/post/7411358506048766006
耗时6个月做的可视化大屏编辑器, 开源!
hi, 大家好, 我是徐小夕.
5年前就开始着手设计和研发可视化大屏编辑器, 当时低代码在国内还没有现在那么火, 有人欢喜有人哀, 那个时候我就比较坚定的认为无码化搭建未来一定是个趋势, 能极大的帮助企业提高研发效率和降低研发成本, 所以 all in 做了2年, 上线了一个相对闭环的MVP可视化大屏搭建平台——V6.Dooring.

通过在技术社区不断的分享可视化搭建的技术实践和设计思路, 也参与了很多线上线下的技术分享, 慢慢市场终于“热了”起来.(机缘巧合)
从V6.Dooring的技术架构的设计, 到团队组建, 再到帮助企业做解决方案, 当时几乎所有的周末都花在这上面了, 想想收获还是挺大的, 接触到了形形色色的企业需求, 也不断完整着可视化大屏编辑器的功能, 最后推出了一个还算通用的解决方案:

当然上面介绍的还都不是这篇文章的重点.
重点是, 时隔4年, 我们打算把通用的可视化大屏解决方案, 开源!
一方面是供大家学习参考, 更好的解决企业自身的业务需求, 另一方面可以提供一个技术交流的平台, 大家可以对可视化搭建领域的技术实践, 提出自己的想法和观点, 共同打造智能化, 体验更好的搭建产品.
先上github地址: github.com/MrXujiang/v…
V6.Dooring开源大屏编辑器演示

其实最近几年我在掘金专栏分享了很多零代码和可视化搭建的技术实现和产品设计:
这里为了让大家更近一步了解V6-Dooring可视化大屏编辑器, 我还是会从技术设计到产品解决方案设计的角度, 和大家详细分享一下, 让大家在学习我们可视化大屏开源方案的过程中, 对可视化搭建技术产品, 有更深入的理解.
如果大家觉得有帮助, 不要忘记点赞 + 收藏哦, 后面我会持续分享最干的互联网干货.
你将收获
- 可视化大屏产品设计思路
- 主流可视化图表库技术选型
- 大屏编辑器设计思路
- 大屏可视化编辑器Schema设计
- 用户数据自治探索
方案实现
1.可视化大屏产品设计思路
目前很多企业或多或少的面临“信息孤岛”问题,各个系统平台之间的数据无法实现互通共享,难以实现一体化的数据分析和实时呈现。
相比于传统手工定制的图表与数据仪表盘,可视化大屏制作平台的出现,可以打破抵消的定制开发, 数据分散的问题,通过数据采集、清洗、分析到直观实时的数据可视化展现,能够多方位、多角度、全景展现各项指标,实时监控,动态一目了然。
针对以上需求, 我们设计了一套可视化大屏解决方案, 具体包含如下几点:

上图是笔者4个月前设计的基本草图, 后期会持续更新. 通过以上的设计分解, 我们基本可以搭建一个可自己定制的数据大屏.
2.主流可视化图表库技术选型

目前我调研的已知主流可视化库有:
- echart 一个基于 JavaScript 的老牌开源可视化图表库
- D3.js 一个数据驱动的可视化库, 可以不需要其他任何框架独立运行在现代浏览器中,它结合强大的可视化组件来驱动 DOM 操作
- antv 包含一套完整的可视化组件体系
- Chart.js 基于 HTML5 的 简单易用的 JavaScript 图表库
- metrics-graphics 建立在D3之上的可视化库, 针对可视化和布置时间序列数据进行了优化
- C3.js 通过包装构造整个图表所需的代码,使生成基于D3的图表变得容易
我们使用以上任何一个库都可以实现我们的可视化大屏搭建的需求, 各位可以根据喜好来选择.
3.大屏编辑器设计思路
在上面的分析中我们知道一个大屏编辑器需要有个编辑器核心, 主要包含以下部分:
- 组件库
- 拖拽(自由拖拽, 参考线, 自动提示)
- 画布渲染器
- 属性编辑器
如下图所示:

组件库我们可以用任何组件封装方式(react/vue等), 这里沿用H5-Dooring的可视化组件设计方式, 对组件模型进行优化和设计.
类似的代码如下:
import { Chart } from '@antv/f2';
import React, { memo, useEffect, useRef } from 'react';
import styles from './index.less';
import { IChartConfig } from './schema';
const XChart = (props:IChartConfig) => {
const { data, color, size, paddingTop, title } = props;
const chartRef = useRef(null);
useEffect(() => {
const chart = new Chart({
el: chartRef.current || undefined,
pixelRatio: window.devicePixelRatio, // 指定分辨率
});
// step 2: 处理数据
const dataX = data.map(item => ({ ...item, value: Number(item.value) }));
// Step 2: 载入数据源
chart.source(dataX);
// Step 3:创建图形语法,绘制柱状图,由 genre 和 sold 两个属性决定图形位置,genre 映射至 x 轴,sold 映射至 y 轴
chart
.interval()
.position('name*value')
.color('name');
// Step 4: 渲染图表
chart.render();
}, [data]);
return (
<div className={styles.chartWrap}>
<div className={styles.chartTitle} style={{ color, fontSize: size, paddingTop }}>
{title}
</div>
<canvas ref={chartRef}></canvas>
</div>
);
};
export default memo(XChart);
以上只是一个简单的例子, 更具业务需求的复杂度我们往往会做更多的控制, 比如动画(animation), 事件(event), 数据获取(data inject)等.

当然实际应用中大屏展现的内容和形式远比这复杂, 我们从上图可以提炼出大屏页面的2个直观特征:
- 可视化组件集
- 空间坐标关系
因为我们可视化大屏载体是页面, 是html, 所以还有另外一个特征: 事件/交互。综上我们总结出了可视化大屏的必备要素:

我们只要充分的理解了可视化大屏的组成和特征, 我们才能更好的设计可视化大屏搭建引擎, 基于以上分析, 我设计了一张基础引擎的架构图:

接下来我就带大家一起来拆解并实现上面的搭建引擎。
大屏搭建引擎核心功能实现
俗话说: “好的拆解是成功的一半”, 任何一个复杂任务或者系统, 我们只要能将其拆解成很多细小的子模块, 就能很好的解决并实现它. (学习也是一样)
接下来我们就逐一解决上述基础引擎的几个核心子模块:
- 拖拽器实现
- 物料中心设计
- 动态渲染器实现
- 配置面板设计
- 控制中心概述
- 功能辅助设计
1.拖拽器实现
拖拽器是可视化搭建引擎的核心模块, 也是用来解决上述提到的大屏页面特征中的“空间坐标关系”这一问题。我们先来看一下实现效果:

组件拖拽可以采用市面已有的 Dragable 等插件, 也可以采用 H5-Dooring 的智能网格拖拽. 这里笔者选择自由拖拽来实现. 已有的有:
- rc-drag
- sortablejs
- react-dnd
- react-dragable
- vue-dragable
等等. 具体拖拽呈现流程如下:

具体拖拽流程就是:
- 使用H5 dragable API拖拽左侧组件(component data)进入目标容器(targetBox)
- 监听拖拽结束事件拿到拖拽事件传递的
data来渲染真实的可视化组件 - 可视化组件挂载,
schema注入编辑面板, 编辑面板渲染组件属性编辑器 - 拖拽, 属性修改, 更新
- 预览, 发布
组件的schema参考H5-Dooring DSL设计.
2.物料中心设计
物料中心主要为大屏页面提供 “原材料”。为了设计健壮且通用的物料, 我们需要设计一套标准组件结构和属性协议。并且为了方便物料管理和查询, 我们还需要对物料进行分类, 我的分类如下:
- 可视化组件 (柱状图, 饼图, 条形图, 地图可视化等)
- 修饰型组件 (图片, 轮播图, 修饰素材等)
- 文字类组件 (文本, 文本跑马灯, 文字看板)
具体的物料库演示如下:

这里我拿一个可视化组件的实现来举例说明:
import React, { memo, useEffect } from 'react'
import { Chart } from '@antv/g2'
import { colors } from '@/components/BasicShop/common'
import { ChartConfigType } from './schema'
interface ChartComponentProps extends ChartConfigType {
id: string
}
const ChartComponent: React.FC<ChartComponentProps> = ({
id, data, width, height,
toggle, legendPosition, legendLayout, legendShape,
labelColor, axisColor, multiColor, tipEvent, titleEvent,
dataType, apiAddress, apiMethod, apiData, refreshTime,
}) => {
useEffect(() => {
let timer:any = null;
const chart = new Chart({
container: `chart-${id}`,
autoFit: true,
width,
height
})
// 数据过滤, 接入
const dataX = data.map(item => ({ ...item, value: Number(item.value) }))
chart.data(dataX)
// 图表属性组装
chart.legend(
toggle
? {
position: legendPosition,
layout: legendLayout,
marker: {
symbol: legendShape
},
}
: false,
)
chart.tooltip({
showTitle: false,
showMarkers: false,
})
// 其他图表信息源配置, 方法雷同, 此处省略
// ...
chart.render()
}, [])
return <div id={`chart-${id}`} />
}
export default memo(ChartComponent)
以上就是我们的基础物料的实现模式, 可视化组件采用了g2, 当然大家也可以使用熟悉的echart, D3.js等. 不同物料既有通用的 props , 也有专有的 props, 取决于我们如何定义物料的Schema。
在设计 Schema 前我们需要明确组件的属性划分, 为了满足组件配置的灵活性和通用性, 我做了如下划分:
- 外观属性 (组件宽高, 颜色, 标签, 展现模式等)
- 数据配置 (静态数据, 动态数据)
- 事件/交互 (如单击, 跳转等)
有了以上划分, 我们就可以轻松设计想要的通用Schema了。我们先来看看实现后的配置面板:

这些属性项都是基于我们定义的schema配置项, 通过 解析引擎 动态渲染出来的, 有关 解析引擎 和配置面板, 我会在下面的章节和大家介绍。我们先看看组件的 schema 结构:
const Chart: ChartSchema = {
editAttrs: [
{
key: 'layerName',
type: 'Text',
cate: 'base',
},
{
key: 'y',
type: 'Number',
cate: 'base',
},
...DataConfig, // 数据配置项
...eventConfig, // 事件配置项
],
config: {
width: 200,
height: 200,
zIndex: 1,
layerName: '柱状图',
labelColor: 'rgba(188,200,212,1)',
// ... 其他配置初始值
multiColor: ['rgba(91, 143, 249, 1)', 'rgba(91, 143, 249, 1)', 'rgba(91, 143, 249,,1)', 'rgba(91, 143, 249, 1)'],
data: [
{
name: 'A',
value: 25,
},
{
name: 'B',
value: 66,
}
],
},
}
其中 editAttrs 表示可编辑的属性列表, config 为属性的初始值, 当然大家也可以根据自己的喜好, 设计类似的通用schema。
我们通过以上设计的标准组件和标准schema, 就可以批量且高效的生产各种物料, 还可以轻松集成任何第三方可视化组件库。
3.动态渲染器实现
我们都知道, 一个页面中元素很多时会影响页面整体的加载速度, 因为浏览器渲染页面需要消耗CPU / GPU。对于可视化页面来说, 每一个可视化组件都需要渲染大量的信息元, 这无疑会对页面性能造成不小的影响, 所以我们需要设计一种机制, 让组件异步加载到画布上, 而不是一次性加载几十个几百个组件(这样的话页面会有大量的白屏时间, 用户体验极度下降)。
动态加载器就是提供了这样一种机制, 保证组件的加载都是异步的, 一方面可以减少页面体积, 另一方面用户可以更早的看到页面元素。目前我们熟的动态加载机制也有很多, Vue 和 React 生态都提供了开箱即用的解决方案(虽然我们可以用 webpack 自行设计这样的动态模型, 此处为了提高行文效率, 我们直接基于现成方案封装)。我们先看一下动态渲染组件的过程:

上面的演示可以细微的看出从左侧组件菜单拖动某个组件图标到画布上后, 真正的组件才开始加载渲染。
这里我们以 umi3.0 提供的 dynamic 函数来最小化实现一个动态渲染器. 如果不熟悉 umi 生态的朋友, 也不用着急, 看完我的实现过程和原理之后, 就可以利用任何熟悉的动态加载机制实现它了。实现如下:
import React, { useMemo, memo, FC } from 'react'
import { dynamic } from 'umi'
import LoadingComponent from '@/components/LoadingComponent'
const DynamicFunc = (cpName: string, category: string) => {
return dynamic({
async loader() {
// 动态加载组件
const { default: Graph } = await import(`@/components/materies/${cpName}`)
return (props: DynamicType) => {
const { config, id } = props
return <Graph {...config} id={id} />
}
},
loading: () => <LoadingComponent />
})
}
const DynamicRenderEngine: FC<DynamicType> = memo((props) => {
const {
type,
config,
// 其他配置...
} = props
const Dynamic = useMemo(() => {
return DynamicFunc(config)
}, [config])
return <Dynamic {...props} />
})
export default DynamicRenderEngine
是不是很简单? 当然我们也可以根据自身业务需要, 设计更复杂强大的动态渲染器。
4.配置面板设计
实现配置面板的前提是对组件 Schema 结构有一个系统的设计, 在介绍组件库实现中我们介绍了通用组件 schema 的一个设计案例, 我们基于这样的案例结构, 来实现 动态配置面板。

由上图可以知道, 动态配置面板的一个核心要素就是 表单渲染器。表单渲染器的目的就是基于属性配置列表 attrs 来动态渲染出对应的表单项。我之前写了一篇文章详细的介绍了表单设计器的技术实现的文章, 大家感兴趣也可以参考一下: Dooring可视化之从零实现动态表单设计器。
我这里来简单实现一个基础的表单渲染器模型:
const FormEditor = (props: FormEditorProps) => {
const { attrs, defaultValue, onSave } = props;
const onFinish = (values: Store) => {
// 保存配置项数据
onSave && onSave(values);
};
const handlechange = (value) => {
// 更新逻辑
}
const [form] = Form.useForm();
return (
<Form
form={form}
{...formItemLayout}
onFinish={onFinish}
initialValues={defaultValue}
onValuesChange={handlechange}
>
{
attrs.map((item, i) => {
return (
<React.Fragment key={i}>
{item.type === 'Number' && (
<Form.Item label={item.name} name={item.key}>
<InputNumber />
</Form.Item>
)}
{item.type === 'Text' && (
<Form.Item label={item.name} name={item.key}>
<Input placeholder={item.placeholder} />
</Form.Item>
)}
{item.type === 'TextArea' && (
<Form.Item label={item.name} name={item.key}>
<TextArea rows={4} />
</Form.Item>
)}
// 其他配置类型
</React.Fragment>
);
})}
</Form>
);
};
如果大家想看更完整的配置面板实现, 可以参考开源项目 H5-Dooring | H5可视化编辑器
我们可以看看最终的配置面板实现效果:

5.控制中心概述 & 功能辅助设计
控制中心的实现主要是业务层的, 没有涉及太多复杂的技术, 所以这里我简单介绍一下。因为可视化大屏页面展示的信息有些可能是私密数据, 只希望一部分人看到, 所以我们需要对页面的访问进行控制。其次由于企业内部业务战略需求, 可能会对页面进行各种验证, 状态校验, 数据更新频率等, 所以我们需要设计一套控制中心来管理。最基本的就是访问控制, 如下:

功能辅助设计 主要是一些用户操作上的优化, 比如快捷键, 画布缩放, 大屏快捷导航, 撤销重做等操作, 这块可以根据具体的产品需求来完善。大家后期设计搭建产品时也可以参考实现。
可视化大屏数据自治探索
目前我们实现的搭建平台可以静态的设计数据源, 也可以注入第三方接口, 如下:

我们可以调用内部接口来实时获取数据, 这块在可视化监控平台用的场景比较多, 方式如下:

参数(params)编辑区可以自定义接口参数. 代码编辑器笔者这里推荐两款, 大家可以选用:
- react-monaco-editor
- react-codemirror2
使用以上之一可以实现mini版vscode, 大家也可以尝试一下.
辅助功能
可视化大屏一键截图 一键截图功能还是沿用H5-Dooring 的快捷截图方案, 主要用于对大屏的分享, 海报制作等需求, 我们可以使用以下任何一个组件实现:
- dom-to-image
- html2canvas
撤销重做撤销重做功能我们可以使用已有的库比如react-undo, 也可以自己实现, 实现原理: 有点链表的意思, 我们将每一个状态存储到数组中, 通过指针来实现撤销重做的功能, 如果要想更健壮一点, 我们可以设计一套“状态淘汰机制”, 设置可保留的最大状态数, 之前的自动淘汰(删除, 更高大上一点的叫出栈). 这样可以避免复杂操作中的大量状态存储, 节约浏览器内存.
有点链表的意思, 我们将每一个状态存储到数组中, 通过指针来实现撤销重做的功能, 如果要想更健壮一点, 我们可以设计一套“状态淘汰机制”, 设置可保留的最大状态数, 之前的自动淘汰(删除, 更高大上一点的叫出栈). 这样可以避免复杂操作中的大量状态存储, 节约浏览器内存.
标尺参考线 标尺和参考线这里我们自己实现, 通过动态dom渲染来实现参考线在缩放后的动态收缩, 实现方案核心如下:
arr.forEach(el => {
let dom = [...Array.from(el.querySelectorAll('.calibrationNumber'))][0] as HTMLElement;
if (dom) {
dom.style.transform = `translate3d(-4px, -8px, 0px) scale(${(multiple + 0.1).toFixed(
1,
)})`;
}
});
详细源码可参考: H5-Dooring | 参考线设计源码
如果大家有好的建议也欢迎随时交流反馈, 开源不易, 别忘了star哦~
github地址: github.com/MrXujiang/v…
来源:juejin.cn/post/7451246345568387091
从前端的角度出发,目前最具性价比的全栈路线是啥❓❓❓
今年大部分时间都是在编码上和写文章上,但是也不知道自己都学到了啥,那就写篇文章来盘点一下目前的技术栈吧,也作为下一年的参考目标,方便知道每一年都学了些啥。

我的技术栈
首先我先来对整体的技术做一个简单的介绍吧,然后后面再对当前的一些技术进行细分吧。
React、Typescript、React Native、mysql、prisma、NestJs、Redis、前端工程化。
React
React 这个框架我花的时间应该是比较多的了,在校期间已经读了一遍源码了,对这些原理已经基本了解了。在随着技术的继续深入,今年毕业后又重新开始阅读了一遍源码,对之前的认知有了更深一步的了解。
也写了比较多跟 React 相关的文章,包括设计模式,原理,配套生态的使用等等都有一些涉及。
在状态管理方面,redux,zustand 我都用过,尤其在 Zustand 的使用上,我特别喜欢 Zustand,它使得我能够快速实现全局状态管理,同时避免了传统 Redux 中繁琐的样板代码,且性能更优。也对 Zustand 有比较深入的了解,也对其源码有过研究。
NextJs
Next.js 是一个基于 React 的现代 Web 开发框架,它为开发者提供了一系列强大的功能和工具,旨在优化应用的性能、提高开发效率,并简化部署流程。Next.js 支持多种渲染模式,包括服务器端渲染(SSR)、静态生成(SSG)和增量静态生成(ISR),使得开发者可以根据不同的需求选择合适的渲染方式,从而在提升页面加载速度的同时优化 SEO。
在路由管理方面,Next.js 采用了基于文件系统的路由机制,这意味着开发者只需通过创建文件和文件夹来自动生成页面路由,无需手动配置。这种约定优于配置的方式让路由管理变得直观且高效。此外,Next.js 提供了动态路由支持,使得开发者可以轻松实现复杂的 URL 结构和参数化路径。
Next.js 还内置了 API 路由,允许开发者在同一个项目中编写后端 API,而无需独立配置服务器。通过这种方式,前后端开发可以在同一个代码库中协作,大大简化了全栈开发流程。同时,Next.js 对 TypeScript 提供了原生支持,帮助开发者提高代码的可维护性和可靠性。
Typescript
今年所有的项目都是在用 ts 写了,真的要频繁修改的项目就知道用 ts 好处了,有时候用 js 写的函数修改了都不知道怎么回事,而用了 ts 之后,哪里引用到的都报红了,修改真的非常方便。
今年花了一点时间深入学习了一下 Ts 类型,对一些高级类型以及其实现原理也基本知道了,明年还是多花点时间在类型体操上,除了算法之外,感觉类型体操也可以算得上是前端程序员的内功心法了。
React Native
不得不说,React Native 不愧是接活神器啊,刚学完之后就来了个安卓和 ios 的私活,虽然没有谈成。
React Native 和 Expo 是构建跨平台移动应用的两大热门工具,它们都基于 React,但在功能、开发体验和配置方式上存在一些差异。React Native 是一个开放源代码的框架,允许开发者使用 JavaScript 和 React 来构建 iOS 和 Android 原生应用。Expo 则是一个构建在 React Native 之上的开发平台,它提供了一套工具和服务,旨在简化 React Native 开发过程。
React Native 的核心优势在于其高效的跨平台开发能力。通过使用 React 语法和组件,开发者能够一次编写应用的 UI 和逻辑,然后部署到 iOS 和 Android 平台。React Native 提供了对原生模块的访问,使开发者能够使用原生 API 来扩展应用的功能,确保性能和用户体验能够接近原生应用。
Expo 在此基础上进一步简化了开发流程。作为一个开发工具,Expo 提供了许多内置的 API 和组件,使得开发者无需在项目中进行繁琐的原生模块配置,就能够快速实现设备的硬件访问功能(如摄像头、位置、推送通知等)。Expo 还内置了一个开发客户端,使得开发者可以实时预览应用,无需每次都进行完整的构建和部署。
另外,Expo 提供了一个完全托管的构建服务,开发者只需将应用推送到 Expo 服务器,Expo 就会自动处理 iOS 和 Android 应用的构建和发布。这大大简化了应用的构建和发布流程,尤其适合不想处理复杂原生配置的开发者。
然而,React Native 和 Expo 也有各自的局限性。React Native 提供更大的灵活性和自由度,开发者可以更自由地集成原生代码或使用第三方原生库,但这也意味着需要更多的配置和维护。Expo 则封装了很多功能,简化了开发,但在需要使用某些特定原生功能时,开发者可能需要“弹出”Expo 的托管环境,进行额外的原生开发。
样式方案的话我使用的是 twrnc,大部分组件都是手撸,因为有 cursor 和 chatgpt 的加持,开发效果还是杠杠的。
rn 原理也争取明年能多花点时间去研究研究,不然对着盲盒开发还是不好玩。
Nestjs
NestJs 的话没啥好说的,之前也都写过很多篇文章了,感兴趣的可以直接观看:
对 Nodejs 的底层也有了比较深的理解了:
Prisma & mysql
Prisma 是一个现代化的 ORM(对象关系映射)工具,旨在简化数据库操作并提高开发效率。它支持 MySQL 等关系型数据库,并为 Node.js 提供了类型安全的数据库客户端。在 NestJS 中使用 Prisma,可以让开发者轻松定义数据库模型,并通过自动生成的 Prisma Client 执行类型安全的查询操作。与 MySQL 配合时,Prisma 提供了一种简单、直观的方式来操作数据库,而无需手动编写复杂的 SQL 查询。
Prisma 的核心优势在于其强大的类型安全功能,所有的数据库操作都能通过 Prisma Client 提供的自动生成的类型来进行,这大大减少了代码中的错误,提升了开发的效率。它还包含数据库迁移工具 Prisma Migrate,能够帮助开发者方便地管理数据库结构的变化。此外,Prisma Client 的查询 API 具有很好的性能,能够高效地执行复杂的数据库查询,支持包括关系查询、聚合查询等高级功能。
与传统的 ORM 相比,Prisma 使得数据库交互更加简洁且高效,减少了配置和手动操作的复杂性,特别适合在 NestJS 项目中使用,能够与 NestJS 提供的依赖注入和模块化架构很好地结合,提升整体开发体验。
Redis
Redis 和 mysql 都仅仅是会用的阶段,目前都是直接在 NestJs 项目中使用,都是已经封装好了的,直接传参调用就好了:
import { Injectable, Inject, OnModuleDestroy, Logger } from "@nestjs/common";
import Redis, { ClientContext, Result } from "ioredis";
import { ObjectType } from "../types";
import { isObject } from "@/utils";
@Injectable()
export class RedisService implements OnModuleDestroy {
private readonly logger = new Logger(RedisService.name);
constructor(@Inject("REDIS_CLIENT") private readonly redisClient: Redis) {}
onModuleDestroy(): void {
this.redisClient.disconnect();
}
/**
* @Description: 设置值到redis中
* @param {string} key
* @param {any} value
* @return {*}
*/
public async set(
key: string,
value: unknown,
second?: number
): Promise<Result<"OK", ClientContext> | null> {
try {
const formattedValue = isObject(value)
? JSON.stringify(value)
: String(value);
if (!second) {
return await this.redisClient.set(key, formattedValue);
} else {
return await this.redisClient.set(key, formattedValue, "EX", second);
}
} catch (error) {
this.logger.error(`Error setting key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取redis缓存中的值
* @param key {String}
*/
public async get(key: string): Promise<string | null> {
try {
const data = await this.redisClient.get(key);
return data ? data : null;
} catch (error) {
this.logger.error(`Error getting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置自动 +1
* @param {string} key
* @return {*}
*/
public async incr(
key: string
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.incr(key);
} catch (error) {
this.logger.error(`Error incrementing key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 删除redis缓存数据
* @param {string} key
* @return {*}
*/
public async del(key: string): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.del(key);
} catch (error) {
this.logger.error(`Error deleting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置hash结构
* @param {string} key
* @param {ObjectType} field
* @return {*}
*/
public async hset(
key: string,
field: ObjectType
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.hset(key, field);
} catch (error) {
this.logger.error(`Error setting hash for key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取单个hash值
* @param {string} key
* @param {string} field
* @return {*}
*/
public async hget(key: string, field: string): Promise<string | null> {
try {
return await this.redisClient.hget(key, field);
} catch (error) {
this.logger.error(
`Error getting hash field ${field} from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 获取所有hash值
* @param {string} key
* @return {*}
*/
public async hgetall(key: string): Promise<Record<string, string> | null> {
try {
return await this.redisClient.hgetall(key);
} catch (error) {
this.logger.error(
`Error getting all hash fields from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 清空redis缓存
* @return {*}
*/
public async flushall(): Promise<Result<"OK", ClientContext> | null> {
try {
return await this.redisClient.flushall();
} catch (error) {
this.logger.error("Error flushing all Redis data", error);
return null;
}
}
/**
* @Description: 保存离线通知
* @param {string} userId
* @param {any} notification
*/
public async saveOfflineNotification(
userId: string,
notification: any
): Promise<void> {
try {
await this.redisClient.lpush(
`offline_notifications:${userId}`,
JSON.stringify(notification)
);
} catch (error) {
this.logger.error(
`Error saving offline notification for user ${userId}`,
error
);
}
}
/**
* @Description: 获取离线通知
* @param {string} userId
* @return {*}
*/
public async getOfflineNotifications(userId: string): Promise<any[]> {
try {
const notifications = await this.redisClient.lrange(
`offline_notifications:${userId}`,
0,
-1
);
await this.redisClient.del(`offline_notifications:${userId}`);
return notifications.map((notification) => JSON.parse(notification));
} catch (error) {
this.logger.error(
`Error getting offline notifications for user ${userId}`,
error
);
return [];
}
}
/**
* 获取指定 key 的剩余生存时间
* @param key Redis key
* @returns 剩余生存时间(秒)
*/
public async getTTL(key: string): Promise<number> {
return await this.redisClient.ttl(key);
}
}
前端工程化
前端工程化这块花了很多信息在 eslint、prettier、husky、commitlint、github action 上,现在很多项目都是直接复制之前写好的过来就直接用。
后续应该是投入更多的时间在性能优化、埋点、自动化部署上了,如果有机会的也去研究一下 k8s 了。
全栈性价比最高的一套技术
最近刷到一个帖子,讲到了

我目前也算是一个小全栈了吧,我也来分享一下我的技术吧:
- NextJs
- React Native
- prisma
- NestJs
- taro (目前还不会,如果有需求就会去学)
剩下的描述也是和他下面那句话一样了(毕业后对技术态度的转变就是什么能让我投入最小,让我最快赚到钱的就是好技术)
总结
学无止境,任重道远。
最后再来提一下这两个开源项目,它们都是我们目前正在维护的开源项目:
如果你想参与进来开发或者想进群学习,可以添加我微信 yunmz777,后面还会有很多需求,等这个项目完成之后还会有很多新的并且很有趣的开源项目等着你。
来源:juejin.cn/post/7451483063568154639
📊 弃用 Echarts!这一次我选择 - Vue Data UI!
大家好,我是
xy👨🏻💻。今天,我要向大家隆重推荐一款令人惊艳的可视化图表库——Vue Data UI,一个赋予用户权力的数据可视化Vue3组件库!🎉
🌈 前言
Vue Data UI 诞生于一个问题:如果你的仪表板这么好,为什么你的用户要求 CSV 导出功能?

这个开源库的目的是为最终用户提供一组围绕图表和表格的内置工具,以减少重新计算导出数据的麻烦。当然,Vue Data UI 保留了导出为 CSV 和 PDF 的选项,以防万一。
数据,是现代商业决策的基石。但如何将复杂的数据转化为直观、易理解的视觉信息?这正是 Vue Data UI 致力于解决的问题。
🚀 丰富的图表类型,颜值爆表
探索数据的无限可能,Vue Data UI 带你领略数据之美!目前官方共提供 54 种 可视化组件,满足您的各种需求:
- 🌟 迷你图表:小巧精致,适合快速展示数据。
- 📈 折线图:流畅的线条,清晰展现数据趋势。
- 🍕 饼图:直观展示数据占比,一目了然。
- 📋 仪表盘:动态展示关键指标,提升决策效率。
- 🔍 雷达图:全面展示多变量数据,洞察数据全貌。
- 🎨 3D 图表:立体展示数据,增强视觉冲击力。
- 🚀 其它:更多组件查看-vue-data-ui.graphieros.com/examples。





📊 强大的图表生成器
告别繁琐,迎接效率!Vue Data UI 提供了一款超强大的图表可视化生成器,可视化编辑,所见即所得
- 通过直观的可视化界面,编写数据集,调整配置设置。
- 一切配置皆可可视化,无需再翻阅大量 API 文档。
- 直接复制组件代码,快速集成到您的项目中。


一键复制组件代码,重点:组件代码

📈 提供高定制化 APi
Vue Data UI 不仅仅是一个图表库,它是您项目中的定制化利器。提供了丰富的 API 和 插槽 属性,确保您的每一个独特需求都能得到满足。
- 利用提供的 API,您可以对图表的每一个细节进行精细调整。
- 插槽属性让您能够插入自定义的
HTML或Vue组件,实现真正的个性化设计。

比如我们需要在一个图表中注入另外一个图表:

注入一个箭头:

🛠️ 易于集成,快速上手
官方文档有很显眼的一句:1 import , 3 props , 54 components

安装
npm i vue-data-ui
# or
yarn add vue-data-ui
组件使用
<script setup>
import { ref } from "vue";
import { VueDataUi } from "vue-data-ui";
import "vue-data-ui/style.css";
const dataset = ref([...]);
const config = ref({...});
</script>
<template>
<div style="width:600px;">
<VueDataUi
component="VueUiXy"
:dataset="dataset"
:config="config"
/>
</div>
</template>
如果您也是一名前端开发,请一定要尝试下这个可视化组件库,因为这个可视化库真的太酷啦!
最后给大家送上官网地址:vue-data-ui.graphieros.com/
写在最后
如果觉得本文对你有帮助,希望能够给我点赞支持一下哦 💪 也可以关注wx公众号:
前端开发爱好者回复加群,一起学习前端技能 公众号内包含很多实战精选资源教程,欢迎关注
来源:juejin.cn/post/7419272082595708955
🌿一个vue3指令让el-table自动轮播

前言
本文开发的工具,是vue3 element-plus ui库专用的,需要对vue3指令概念有一定的了解
最近开发的项目中,需要对项目中大量的列表实现轮播效果,经过一番折腾.最终决定不使用第三方插件,手搓一个滚动指令.
效果展示

实现思路
第一步先确定功能
- 列表自动滚动
- 鼠标移入停止滚动
- 鼠标移出继续滚动
- 滚轮滚动完成,还可以继续在当前位置滚动
- 元素少于一定条数时,不滚动
滚动思路


通过观察el-table的结构可以发现el-scrollbar__view里面放着所有的元素,而el-scrollbar__wrap是一个固定高度的容器,那么只需要获取到el-scrollbar__wrap这个DOM,并且再给一个定时器,不断的改变它的scrollTop值,就可以实现自动滚动的效果,这个值必须要用一个变量来存储,不然会失效
停止和继续滚动思路
设置一个boolean类型变量,每次执行定时器的时候判断一下,true就滚动,否则就不滚动
滚轮事件思路
为了每次鼠标在列表中滚动之后,我们的轮播还可以在当前滚动的位置,继续轮播,只需要在鼠标移出的时候,将当前el-scrollbar__wrap的scrollTop赋给前面存储的变量,这样执行定时器的时候,就可以继续在当前位置滚动
不滚动的思路
只需要判断el-scrollbar__view这个容器的高度,是否大于el-scrollbar__wrap的高度,是就可以滚动,不是就不滚动。
大致的思路是这样的,下面上源码
实现代码
文件名:tableAutoScroll.ts
interface ElType extends HTMLElement {
timer: number | null
isScroll: boolean
curTableTopValue: number
}
export default {
created(el: ElType) {
el.timer = null
el.isScroll = true
el.curTableTopValue = 0
},
mounted(el: ElType, binding: { value?: { delay?: number } }) {
const { delay = 15 } = binding.value || {}
const tableDom = el.getElementsByClassName(
'el-scrollbar__wrap'
)[0] as HTMLElement
const viewDom = el.getElementsByClassName(
'el-scrollbar__view'
)[0] as HTMLElement
const onMouseOver = () => (el.isScroll = false)
const onMouseOut = () => {
el.curTableTopValue = tableDom.scrollTop
el.isScroll = true
}
tableDom.addEventListener('mouseover', onMouseOver)
tableDom.addEventListener('mouseout', onMouseOut)
el.timer = window.setInterval(() => {
const viewDomClientHeight = viewDom.scrollHeight
const tableDomClientHeight = el.clientHeight
if (el.isScroll && viewDomClientHeight > tableDomClientHeight) {
const curScrollPosition = tableDom.clientHeight + el.curTableTopValue
el.curTableTopValue =
curScrollPosition === tableDom.scrollHeight
? 0
: el.curTableTopValue + 1
tableDom.scrollTop = el.curTableTopValue
}
}, delay)
},
unmounted(el: ElType) {
if (el.timer !== null) {
clearInterval(el.timer)
}
el.timer = null
const tableDom = el.getElementsByClassName(
'el-scrollbar__wrap'
)[0] as HTMLElement
tableDom.removeEventListener('mouseover', () => (el.isScroll = false))
tableDom.removeEventListener('mouseout', () => {
el.curTableTopValue = tableDom.scrollTop
el.isScroll = true
})
},
}
上面代码中,我在 created中初始化了三个变量,分别用于存储,定时器对象 、是否滚动判断、滚动当前位置。
在 mounted中我还获取了一个options,主要是为了可以定制滚动速度
用法
- 将这段代码放在你的文件夹中
- 在
main.ts中注册这个指令
import tableAutoScroll from './modules/tableAutoScroll.ts'
const directives: any = {
tableAutoScroll,
}
/**
* @function 批量注册指令
* @param app vue 实例对象
*/
export const install = (app: any) => {
Object.keys(directives).forEach((key) => {
app.directive(key, directives[key]) // 将每个directive注册到app中
})
}


我这边是将自己的弄了一个批量注册,正常使用就像官网里面注册指令就可以了
在需要滚动的el-table上使用这个指令就可以

<!-- element 列表滚动指令插件 -->
<template>
<div class="container">
<el-table v-tableAutoScroll :data="tableData" height="300">
<el-table-column prop="date" label="时间" />
<el-table-column prop="name" label="名称" />
<el-table-column prop="address" label="Address" />
</el-table>
<!-- delay:多少毫秒滚动一次 -->
<el-table
v-tableAutoScroll="{
delay: 50,
}"
:data="tableData"
height="300"
>
<el-table-column prop="date" label="时间" />
<el-table-column prop="name" label="名称" />
<el-table-column prop="address" label="Address" />
</el-table>
</div>
</template>
<script setup lang="ts">
import { ref, onMounted } from 'vue'
const tableData = ref<any>([])
onMounted(() => {
tableData.value = Array.from(Array(100), (item, index) => ({
date: '时间' + index,
name: '名称' + index,
address: '地点' + index,
}))
console.log('👉 ~ tableData.value=Array.from ~ tableData:', tableData)
})
</script>
<style lang="scss" scoped>
.container {
height: 100%;
display: flex;
align-items: flex-start;
justify-content: center;
gap: 100px;
.el-table {
width: 500px;
}
}
</style>
上面这个例子,分别演示两种调用方法,带参数和不带参数
最后
做了这个工具之后,突然有很多思路,打算后面再做几个,做成一个开源项目,一个开源的vue3指令集
来源:juejin.cn/post/7452667228006678540
大屏适配方案--scale
CSS3的scale等比例缩放
宽度比率 = 当前网页宽度 / 设计稿宽度
高度比率 = 当前网页高度 / 设计稿高度
设计稿: 1920 * 1080
适配屏幕:1920 * 1080 3840 * 2160(2 * 2) 7680 * 2160(4 * 2)
方案一:根据宽度比率进行缩放(超宽屏比如9/16的屏幕会出现滚动条)
方案二:动态计算网页的宽高比,决定根据宽度比率还是高度比率进行缩放
首先基于1920 * 1080进行基础的布局,下面针对两种方案进行实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
body,
ul {
margin: 0;
padding: 0;
}
body {
width: 1920px;
height: 1080px;
box-sizing: border-box;
/* 在js中添加translate居中 */
position: relative;
left: 50%;
/* 指定缩放的原点在左上角 */
transform-origin: left top;
}
ul {
width: 100%;
height: 100%;
list-style: none;
display: flex;
flex-direction: row;
flex-wrap: wrap;
}
li {
width: 33.333%;
height: 50%;
box-sizing: border-box;
border: 2px solid rgb(198, 9, 135);
font-size: 30px;
}
</style>
</head>
<body>
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
<li>6</li>
</ul>
<script>
// ...实现适配方案
</script>
</body>
</html>
方案一:根据宽度比率进行缩放
// 设计稿尺寸以及宽高比
let targetWidth = 1920;
// html的宽 || body的宽
let currentWidth =
document.documentElement.clientWidth || document.body.clientWidth;
console.log(currentWidth);
// 按宽度计算缩放比率
let scaleRatio = currentWidth / targetWidth;
// 进行缩放
document.body.style = `transform: scale(${scaleRatio})`;
实现效果如下:

这时我们发现在7680 * 2160尺寸下,屏幕根据宽度缩放会出现滚动条,为了解决这个问题,我们就要动态的选择根据宽度缩放还是根据高度缩放。
方案二:动态计算网页的宽高比,决定根据宽度比率还是高度比率进行缩放
// 设计稿尺寸以及宽高比
let targetWidth = 1920;
let targetHeight = 1080;
let targetRatio = 16 / 9; // targetWidth /targetHeight
// 当前屏幕html的宽 || body的宽
let currentWidth =
document.documentElement.clientWidth || document.body.clientWidth;
// 当前屏幕html的高 || body的高
let currentHeight =
document.documentElement.clientHeight || document.body.clientHeight;
// 当前屏幕宽高比
let currentRatio = currentWidth / currentHeight;
// 默认 按宽度计算缩放比率
let scaleRatio = currentWidth / targetWidth;
if (currentRatio > targetRatio) {
scaleRatio = currentHeight / targetHeight;
}
// 进行缩放
document.body.style = `transform: scale(${scaleRatio}) translateX(-50%);`;
效果如下:

这样就可以解决在超宽屏幕下出现滚动条的问题,另外我们做了居中的样式处理,这样在超宽屏幕时,两边留白,内容居中展示显得更加合理些。
来源:juejin.cn/post/7359077652416725018
WebSocket太笨重?试试SSE的轻量级魅力!
一、 前言
Hello~ 大家好。我是秋天的一阵风~
关注我时间长一点的同学们应该会了解,我最近算是跟旧项目 “较上劲” 了哈哈哈。
刚发布了一篇清除项目里的“僵尸”文件文章,这不,我又发现了旧项目上的一个问题。请听我慢慢说来~
在2024年12月18日的午后,两点十八分,阳光透过窗帘的缝隙,洒在键盘上。我像往常一样,启动了那个熟悉的本地项目。浏览器的network面板静静地打开,准备迎接那个等待修复的bug。就在这时,一股尿意突然袭来,我起身,走向了厕所。
当我回来,坐回那把椅子,眼前的一幕让我愣住了。network面板上,不知何时,跳出了一堆http请求,它们像是一场突如其来的雨,让人措手不及。我的头皮开始发麻,那种麻,是那种从心底里涌上来的,让人无法忽视的麻。这堆请求,它们似乎在诉说着什么,又或许,它们只是在提醒我,这个世界,有时候,比我们想象的要复杂得多。
好了,矫情的话咱不说了,直接步入正题。😄😄😄

在查看代码以后发现这些频繁的请求是因为我们的项目首页有一个待办任务数量和消息提醒数量的展示,所以之前的同事使用了定时器,每隔十秒钟发送一次请求到后端接口拿数据,这也就是我们常说的轮询做法。
1. 轮询的缺点
我们都知道轮询的缺点有几种:
资源浪费:
- 网络带宽:频繁的请求可能导致不必要的网络流量,增加带宽消耗。
- 服务器负载:每次请求都需要服务器处理,即使是空返回,也会增加服务器的CPU和内存负载。
用户体验:
- 界面卡顿:频繁的请求和更新可能会造成用户界面的卡顿,影响用户体验。
2. websocket的缺点
那么有没有替代轮询的做法呢? 聪明的同学肯定会第一时间想到用websocket,但是在目前这个场景下我觉得使用websocket是显得有些笨重。我从以下这几方面对比:
- 客户端实现:
- WebSocket 客户端实现需要处理连接的建立、维护和关闭,以及可能的重连逻辑。
- SSE 客户端实现相对简单,只需要处理接收数据和连接关闭。
- 适用场景:
- WebSocket 适用于需要双向通信的场景,如聊天应用、在线游戏等。
- SSE 更适合单向数据推送的场景,如股票价格更新、新闻订阅等。
- 实现复杂性:
- WebSocket 是一种全双工通信协议,需要在客户端和服务器之间建立一个持久的连接,这涉及到更多的编程复杂性。
- SSE 是单向通信协议,实现起来相对简单,只需要服务器向客户端推送数据。
- 浏览器支持:
- 尽管现代浏览器普遍支持 WebSocket,但 SSE 的支持更为广泛,包括一些较旧的浏览器版本。
- 服务器资源消耗:
- WebSocket 连接需要更多的服务器资源来维护,因为它们是全双工的,服务器需要监听来自客户端的消息。
- SSE 连接通常是单向的,服务器只需要推送数据,减少了资源消耗。
二、 详细对比
对于这三者的详细区别,你可以参考下面我总结的表格:
以下是 WebSocket、轮询和 SSE 的对比表格:
| 特性 | WebSocket | 轮询Polling | Server-Sent Events (SSE) |
|---|---|---|---|
| 定义 | 全双工通信协议,支持服务器和客户端之间的双向通信。 | 客户端定期向服务器发送请求以检查更新。 | 服务器向客户端推送数据的单向通信协议。 |
| 实时性 | 高,服务器可以主动推送数据。 | 低,依赖客户端定时请求。 | 高,服务器可以主动推送数据。 |
| 开销 | 相对较高,需要建立和维护持久连接。 | 较低,但频繁请求可能导致高网络和服务器开销。 | 相对较低,只需要一个HTTP连接,服务器推送数据。 |
| 浏览器支持 | 现代浏览器支持,需要额外的库来支持旧浏览器。 | 所有浏览器支持。 | 现代浏览器支持良好,旧浏览器可能需要polyfill。 |
| 实现复杂性 | 高,需要处理连接的建立、维护和关闭。 | 低,只需定期发送请求。 | 中等,只需要处理服务器推送的数据。 |
| 数据格式 | 支持二进制和文本数据。 | 通常为JSON或XML。 | 仅支持文本数据,通常为JSON。 |
| 控制流 | 客户端和服务器都可以控制消息发送。 | 客户端控制请求发送频率。 | 服务器完全控制数据推送。 |
| 安全性 | 需要wss://(WebSocket Secure)来保证安全。 | 需要https://来保证请求的安全。 | 需要SSE通过HTTPS提供,以保证数据传输的安全。 |
| 适用场景 | 需要双向交互的应用,如聊天室、实时游戏。 | 适用于更新频率不高的场景,如轮询邮箱。 | 适用于服务器到客户端的单向数据流,如股票价格更新。 |
| 跨域限制 | 默认不支持跨域,需要服务器配置CORS。 | 默认不支持跨域,需要服务器配置CORS。 | 默认不支持跨域,需要服务器配置CORS。 |
| 重连机制 | 客户端可以实现自动重连逻辑。 | 需要客户端实现重连逻辑。 | 客户端可以监听连接关闭并尝试重连。 |
| 服务器资源 | 较高,因为需要维护持久连接。 | 较低,但频繁的请求可能增加服务器负担。 | 较低,只需要维护一个HTTP连接。 |
这个表格概括了 WebSocket、轮询和 SSE 在不同特性上的主要对比点。每种技术都有其适用的场景和限制,选择合适的技术需要根据具体的应用需求来决定。
三、 SSE(Server-Sent Events)介绍
我们先来简单了解一下什么是Server-Sent Events ?
Server-Sent Events (SSE) 是一种允许服务器主动向客户端浏览器推送数据的技术。它基于 HTTP 协议,但与传统的 HTTP 请求-响应模式不同,SSE 允许服务器在建立连接后,通过一个持久的连接不断地向客户端发送消息。
工作原理
- 建立连接:
- 客户端通过一个普通的 HTTP 请求订阅一个 SSE 端点。
- 服务器响应这个请求,并保持连接打开,而不是像传统的 HTTP 响应那样关闭连接。
- 服务器推送消息:
- 一旦服务器端有新数据可以发送,它就会通过这个持久的连接向客户端发送一个事件。
- 每个事件通常包含一个简单的文本数据流,遵循特定的格式。
- 客户端接收消息:
- 客户端监听服务器发送的事件,并在收到新数据时触发相应的处理程序。
- 连接管理:
- 如果连接由于任何原因中断,客户端可以自动尝试重新连接。
著名的计算机科学家林纳斯·托瓦兹(Linus Torvalds) 曾经说过:talk is cheap ,show me your code 。
我们直接上代码看看效果:
java代码
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.servlet.mvc.method.annotation.SseEmitter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
@RestController
@RequestMapping("platform/todo")
public class TodoSseController {
private final ExecutorService executor = Executors.newCachedThreadPool();
@GetMapping("/endpoint")
public SseEmitter refresh(HttpServletRequest request) {
final SseEmitter emitter = new SseEmitter(Long.MAX_VALUE);
executor.execute(() -> {
try {
while (true) { // 无限循环发送事件,直到连接关闭
// 发送待办数量更新
emitter.send(SseEmitter.event().data(5));
// 等待5秒
TimeUnit.SECONDS.sleep(5);
}
} catch (IOException e) {
emitter.completeWithError(e);
} catch (InterruptedException e) {
// 当前线程被中断,结束连接
Thread.currentThread().interrupt();
emitter.complete();
}
});
return emitter;
}
}
前端代码
beforeCreate() {
const eventSource = new EventSource('/platform/todo/endpoint');
eventSource.onmessage = (event) => {
console.log("evebt:",event)
};
eventSource.onerror = (error) => {
console.error('SSE error:', error);
eventSource.close();
};
this.$once('hook:beforeDestroy', () => {
if (eventSource) {
eventSource.close();
}
});
},
改造后的效果


可以看到,客户端只发送了一次http请求,后续所有的返回结果都可以在event.data里面获取,先不谈性能,对于有强迫症的同学是不是一个很大改善呢?
总结
虽然 SSE(Server-Sent Events)因其简单性和实时性在某些场景下提供了显著的优势,比如在需要服务器向客户端单向推送数据时,它能够以较低的开销维持一个轻量级的连接,但 SSE 也存在一些局限性。例如,它不支持二进制数据传输,这对于需要传输图像、视频或复杂数据结构的应用来说可能是一个限制。此外,SSE 只支持文本格式的数据流,这可能限制了其在某些数据传输场景下的应用。还有,SSE 的兼容性虽然在现代浏览器中较好,但在一些旧版浏览器中可能需要额外的 polyfill 或者降级方案。
考虑到这些优缺点,我们在选择数据通信策略时,应该基于项目的具体需求和上下文来做出决策。如果项目需要双向通信或者传输二进制数据,WebSocket 可能是更合适的选择。
如果项目的数据更新频率不高,或者只需要客户端偶尔查询服务器状态,传统的轮询可能就足够了。
而对于需要服务器频繁更新客户端数据的场景,SSE 提供了一种高效的解决方案。
总之,选择最合适的技术堆栈需要综合考虑项目的需求、资源限制、用户体验和未来的可维护性。
来源:juejin.cn/post/7451991754561880115
让同事用Cesium写一个测量工具并支持三角测量,他说有点难。。
大家好,我是日拱一卒的攻城师不浪,致力于技术与艺术的融合。这是2024年输出的第39/100篇文章。
可视化&Webgis交流群+V:brown_7778(备注来意)
前言
最近在开发智慧城市的项目,产品想让同事基于Cesium开发一个测量工具,需要支持长度测量、面积测量以及三角测量,但同事挠了挠头,说做这个有点费劲,还反问了产品:做这功能有啥意义?
产品经理:测量工具在智慧城市中发挥了重要的作用,通过对城市道路,地形,建筑物,场地等的精确测量,确保施工规划能够与现实场景精准吻合,节省人力以及施工成本。
对桥梁、隧道、地铁、管网等城市基础设施进行结构健康监测,安装传感器,实时监测结构体震动以及结构体偏移量等数据,确保设施安全运行并能够提前发现问题,防患于未然。
开发同事听完,觉得还蛮有道理,看向我:浪浪,如何应对?
我:呐,拿走直接抄!下班请吃铜锅涮肉!

三角测量
先来了解下三角测量:是一种基于三角形几何原理的测量方法,用于确定未知点的位置。它通过已知基线(即两个已知点之间的距离)和从这两个已知点测量的角度,计算出目标点的精确位置。
例如在建筑施工中,工程师使用三角测量法来测量楼体高度、桥梁等结构的位置和角度,确保建筑的精准施工。

代码解析
接下来看下这个MeasureTool类,主要包含以下功能:
- 坐标转换:整理了地理坐标(WGS84)与笛卡尔坐标(Cartesian)之间的转换功能。
- 拾取功能:通过屏幕坐标拾取场景中的三维位置,并判断该位置是位于模型上、地形上还是椭球体表面。
- 距离测量:绘制线段,并在场景中显示起点和终点之间的距离。
- 面积测量:通过给定的一组坐标,计算它们组成的多边形面积。
- 三角测量:绘制一个三角形来测量水平距离、直线距离和高度差。
坐标转换功能
transformWGS84ToCartesian: 将WGS84坐标(经度、纬度、高度)转换为Cesium中的三维笛卡尔坐标。transformCartesianToWGS84: 将Cesium的三维笛卡尔坐标转换为WGS84坐标。
核心代码:
transformWGS84ToCartesian(position, alt) {
return position
? Cesium.Cartesian3.fromDegrees(
position.lng || position.lon,
position.lat,
(position.alt = alt || position.alt),
Cesium.Ellipsoid.WGS84
)
: Cesium.Cartesian3.ZERO;
}
transformCartesianToWGS84(cartesian) {
var ellipsoid = Cesium.Ellipsoid.WGS84;
var cartographic = ellipsoid.cartesianToCartographic(cartesian);
return {
lng: Cesium.Math.toDegrees(cartographic.longitude),
lat: Cesium.Math.toDegrees(cartographic.latitude),
alt: cartographic.height,
};
}
Cesium的Cartesian3.fromDegrees和Ellipsoid.WGS84.cartesianToCartographic方法分别用于实现经纬度与笛卡尔坐标系的相互转换。
拾取功能
拾取功能允许通过屏幕像素坐标来获取3D场景中的位置。主要依赖scene.pickPosition和scene.globe.pick来实现拾取。
核心代码:
getCatesian3FromPX(px) {
var picks = this._viewer.scene.drillPick(px);
var cartesian = this._viewer.scene.pickPosition(px);
if (!cartesian) {
var ray = this._viewer.scene.camera.getPickRay(px);
cartesian = this._viewer.scene.globe.pick(ray, this._viewer.scene);
}
return cartesian;
}
这里首先尝试从3D模型或地形上拾取位置,如果未能拾取到模型或地形上的点,则尝试通过射线投射到椭球体表面。
距离测量

通过拾取点并记录每个点的坐标,计算相邻两个点的距离,并显示在Cesium场景中。通过ScreenSpaceEventHandler来捕获鼠标点击和移动事件。
核心代码:
drawLineMeasureGraphics(options = {}) {
var positions = [];
var _handlers = new Cesium.ScreenSpaceEventHandler(this._viewer.scene.canvas);
_handlers.setInputAction(function (movement) {
var cartesian = this.getCatesian3FromPX(movement.position);
positions.push(cartesian);
}, Cesium.ScreenSpaceEventType.LEFT_CLICK);
_handlers.setInputAction(function (movement) {
var cartesian = this.getCatesian3FromPX(movement.endPosition);
positions.pop();
positions.push(cartesian);
}, Cesium.ScreenSpaceEventType.MOUSE_MOVE);
_handlers.setInputAction(function () {
_handlers.destroy();
}, Cesium.ScreenSpaceEventType.RIGHT_CLICK);
}
测距的基本思想是通过鼠标点击获取多个点的坐标,然后计算每两个相邻点的距离。
面积测量

面积测量通过计算多个点围成的多边形的面积,基于Cesium的PolygonHierarchy实现多边形绘制。
核心代码:
getPositionsArea(positions) {
let ellipsoid = Cesium.Ellipsoid.WGS84;
let area = 0;
positions.push(positions[0]); // 闭合多边形
for (let i = 1; i < positions.length; i++) {
let p1 = ellipsoid.cartographicToCartesian(this.transformWGS84ToCartographic(positions[i - 1]));
let p2 = ellipsoid.cartographicToCartesian(this.transformWGS84ToCartographic(positions[i]));
area += p1.x * p2.y - p2.x * p1.y;
}
return Math.abs(area) / 2.0;
}
这里通过一个简单的多边形面积公式(叉乘)来计算笛卡尔坐标下的面积。
三角测量
三角测量通过拾取三个点,计算它们之间的直线距离、水平距离以及高度差,构建一个三角形并在场景中显示这些信息。
核心代码:
drawTrianglesMeasureGraphics(options = {}) {
var _positions = [];
var _handler = new Cesium.ScreenSpaceEventHandler(this._viewer.scene.canvas);
_handler.setInputAction(function (movement) {
var position = this.getCatesian3FromPX(movement.position);
_positions.push(position);
if (_positions.length === 3) _handler.destroy();
}, Cesium.ScreenSpaceEventType.LEFT_CLICK);
}
该方法核心思想是获取三个点的坐标,通过高度差来构建水平线和垂线,然后显示相应的距离和高度差信息。
使用
封装好,之后,使用起来就非常简单了。
import MeasureTool from "@/utils/cesiumCtrl/measure.js";
const measure = new MeasureTool(viewer);
**
* 测距
*/
const onLineMeasure = () => {
measure.drawLineMeasureGraphics({
clampToGround: true,
callback: (e) => {
console.log("----", e);
},
});
};
/**
* 测面积
*/
const onAreaMeasure = () => {
measure.drawAreaMeasureGraphics({
clampToGround: true,
callback: () => {},
});
};
/**
* 三角量测
*/
const onTrianglesMeasure = () => {
measure.drawTrianglesMeasureGraphics({
callback: () => {},
});
};
最后
这些测量工具都是依赖于Cesium提供的坐标转换、拾取以及事件处理机制,核心思路是通过ScreenSpaceEventHandler捕捉鼠标事件,获取坐标点,并通过几何算法计算距离、面积和高度。
【完整源码地址】:github.com/tingyuxuan2…
如果认为有帮助,希望可以给我们一个免费的star,激励我们持续开源更多代码。
如果想系统学习Cesium,可以看下作者的Cesium系列教程
《Cesium从入门到实战》,将Cesium的知识点进行串联,让不了解Cesium的小伙伴拥有一个完整的学习路线,学完后直接上手做项目,+作者:brown_7778(备注来意)了解课程细节。
另外有需要进
可视化&Webgis交流群可以加我:brown_7778(备注来意),也欢迎数字孪生可视化领域的交流合作。
来源:juejin.cn/post/7424902468243669029
因离线地图引发的惨案
小王最近接到了一个重要的需求,要求在现有系统上实现离线地图功能,并根据不同的经纬度在地图上显示相应的标记(marks)。老板承诺,如果小王能够顺利完成这个任务,他的年终奖就有着落了。
为了不辜负老板的期望并确保自己能够拿到年终奖,小王开始了马不停蹄的开发工作。他查阅了大量文档,研究了各种离线地图解决方案,并一一尝试。经过48小时的连续奋战,凭借着顽强的毅力和专业的技术能力,小王终于成功完成了需求。
他在系统中集成了离线地图,并实现了根据经纬度显示不同区域标记的功能。每个标记都能准确地反映地理位置的信息,系统的用户体验得到了极大的提升。小王的心中充满了成就感和对未来奖励的期待。
然而,天有不测风云。当小王准备向老板汇报工作成果时,却得知一个令人震惊的消息:老板因涉嫌某些违法行为(爬取不当得利)被逮捕了,公司也陷入了一片混乱。年终奖的承诺随之泡汤,甚至连公司未来的发展都蒙上了一层阴影。
尽管如此,小王并没有因此而气馁。这次通过技术让老板成功的获得了编制,他深知只有不断技术的积累和经验的增长才能更好的保护老板。
1.离线地图
首先需要怎么做呢,你需要一个地图瓦片生成器(爬取谷歌、高德、百度等各个平台的地图瓦片,其实就是一张张缩小的图片,这里爬取可以用各种技术手段,但是违法偶,老板就是这么进去的),有个工具推荐:

链接:pan.baidu.com/s/1nflY8-KL…
提取码:yqey
下载解压打开下面的文件

打开了界面就长这样

可以调整瓦片样式

下载速度龟慢,建议开启代理,因为瓦片等级越高数量越多,需要下载的包越大,这里建议下载到11-16级别,根据自己需求
下载完瓦片会保存在自己定义的文件夹,这里不建议放在c盘,会生成以下文件

使用一个文件服务去启动瓦片额静态服务,可以使用http-server
安装http-server
yarn add http-server -g
cd到下载的mapabc目录下
http-server roadmap

本地可以这么做上线后需要使用nginx代理这个静态服务
server {
listen 80;
server_name yourdomain.com; # 替换为你的域名或服务器 IP
root /var/www/myapp/public; # 设置根目录
index index.html; # 设置默认文件
location / {
try_files $uri $uri/ =404;
}
# 配置访问 roadmap 目录下的地图瓦片
location ^~/roloadmap/{
alias /home/d5000/iot/web/roloadmap/;
autoindex on; # 如果你想列出目录内容,可以开启这个选项
}
# 配置其他静态文件的访问(可选)
location /static/ {
alias /var/www/myapp/public/static/;
}
# 其他配置,例如反向代理到应用服务器等
# location /api/ {
# proxy_pass http://localhost:3000;
# proxy_set_header Host $host;
# proxy_set_header X-Real-IP $remote_addr;
# proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# proxy_set_header X-Forwarded-Proto $scheme;
# }
}
配置完重启一下ngix即可
对于如何将瓦片结合成一张地图并在vue2中使用,这里采用vueLeaflet,它是在leaflet基础上进行封装的
这个插件需要安装一系列包
yarn add leaflet vue2-leaflet leaflet.markercluster
<l-tile-layer url="http://192.168.88.211:8080/{z}/{x}/{y}.png" ></l-tile-layer>
这里的url就是上面启动的服务,包括端口和ip,要能访问到瓦片
编写代码很简单
<template>
<div class="map">
<div class="search">
<map-search @input_val="inputVal" @select_val="selectVal" />
</div>
<div class="map_container">
<l-map
:zoom="zoom"
:center="center"
:max-bounds="bounds"
:min-zoom="9"
:max-zoom="15"
:key="`${center[0]}-${center[1]}-${zoom}`"
style="height: 100vh; width: 100%"
>
<l-tile-layer
url="http://192.168.88.211:8080/{z}/{x}/{y}.png"
></l-tile-layer>
<l-marker-cluster>
<l-marker
v-for="(marker, index) in markers"
:key="index"
:lat-lng="marker.latlng"
:icon="customIcon"
@click="handleMarkerClick(marker)"
>
<l-tooltip :offset="tooltipOffset">
<div class="popup-content">
<p>设备名称: {{ marker.regionName }}</p>
<p>主线设备数量: {{ marker.endNum }}</p>
<p>边缘设备数量: {{ marker.edgNum }}</p>
</div>
</l-tooltip>
</l-marker>
</l-marker-cluster>
</l-map>
</div>
</div>
</template>
<script>
import { LMap, LTileLayer, LMarker, LPopup, LTooltip, LMarkerCluster } from "vue2-leaflet";
import mapSearch from "./search.vue";
import "leaflet/dist/leaflet.css";
import L from "leaflet";
// import geojsonData from "./city.json"; // 确保这个路径是正确的
import geoRegionData from "./equip.json"; // 确保这个路径是正确的
// 移除默认的图标路径
delete L.Icon.Default.prototype._getIconUrl;
L.Icon.Default.mergeOptions({
iconRetinaUrl: require("leaflet/dist/images/marker-icon-2x.png"),
iconUrl: require("leaflet/dist/images/marker-icon.png"),
shadowUrl: require("leaflet/dist/images/marker-shadow.png"),
});
export default {
name: "Map",
components: {
LMap,
LTileLayer,
LMarker,
LPopup,
LTooltip,
mapSearch,
LMarkerCluster
},
data() {
return {
zoom: 9,
center: [32.0617, 118.7636], // 江苏省的中心坐标
bounds: [
[30.7, 116.3],
[35.1, 122.3],
], // 江苏省的地理边界
markers: geoRegionData,
customIcon: L.icon({
iconUrl: require("./equip.png"), // 自定义图标的路径
iconSize: [21, 27], // 图标大小
iconAnchor: [12, 41], // 图标锚点
popupAnchor: [1, -34], // 弹出框相对于图标的锚点
shadowSize: [41, 41], // 阴影大小(如果有)
shadowAnchor: [12, 41], // 阴影锚点(如果有)
}),
tooltipOffset: L.point(10, 10), // 调整偏移值
};
},
methods: {
inputVal(val) {
// 处理输入值变化
this.center = val;
this.zoom = 15;
},
selectVal(val) {
// 处理选择值变化
this.center = val;
this.zoom = 15;
},
handleMarkerClick(marker) {
this.center = marker.latlng;
this.zoom = 15;
},
},
};
</script>
<style scoped lang="less">
@import "~leaflet/dist/leaflet.css";
@import "~leaflet.markercluster/dist/MarkerCluster.css";
@import "~leaflet.markercluster/dist/MarkerCluster.Default.css";
.map {
width: 100%;
height: 100%;
position: relative;
.search {
position: absolute;
z-index: 1000;
left: 20px;
top: 10px;
padding: 10px; /* 设置内边距 */
}
}
.popup-content {
font-family: Arial, sans-serif;
text-align: left;
}
.popup-content h3 {
margin: 0;
font-size: 16px;
font-weight: bold;
}
.popup-content p {
margin: 4px 0;
font-size: 14px;
}
/deep/.leaflet-control {
display: none !important; /* 隐藏默认控件 */
}
/deep/.leaflet-control-zoom {
display: none !important; /* 隐藏默认控件 */
}
</style>
这里使用遇到一个坑,需要切换地图中心center,需要给l-map绑定一个key="${center[0]}-${center[1]}-${zoom}",不然每次切换第一次会失败,第二次才能成功
可以给行政区添加范围,这里需要geojson数据,可以在阿里云数据平台上获取
通过组件加载即可
<l-geo-json :geojson="geojson"></l-geo-json>
效果如下

以上方法,不建议使用,如果是商业使用,不建议使用,不然容易被告侵权,最好能是使用官方合法的地图api,例如谷歌、百度、腾讯、高德,这里我使用高德api给兄弟们们展示一下
2.高德在线地图
2.1首先需要在高德的开放平台申请一个账号
创建一个项目,如下,我们需要使用到这个key和密钥,这里如果是公司使用可以使用公司的信息注册一个账号,公司的账号权限高于个人,具体区别如下参看官网
developer.amap.com/api/faq/acc…

2.2如何在框架中使用


因为不想在创建一个react应用了,这里还是用vue2演示,vue2需要下载一个高德提供的npm包
yarn add @amap/amap-jsapi-loader
编写代码
<template>
<div class="map">
<div class="serach">
<map-search @share_id="shareId" @input_val="inputVal" @select_val="selectVal" @change_theme="changeTheme" />
</div>
<div class="map_container" id="container"></div>
</div>
</template>
<script>
import AMapLoader from "@amap/amap-jsapi-loader";
import mapSearch from "./search.vue";
import cityJson from "../../assets/area.json";
window._AMapSecurityConfig = {
//这里是高德开放平台创建项目时生成的密钥
securityJsCode: "xxxx",
};
export default {
name: "mapContainer",
components: { mapSearch },
mixins: [],
props: {},
data() {
return {
map: null,
autoOptions: {
input: "",
},
auto: null,
AMap: null,
placeSearch: null,
searchPlaceInput: "",
polygons: [],
positions: [],
//地图样式配置
inintMapStyleConfig: {
//设置地图容器id
viewMode: "3D", //是否为3D地图模式
zoom: 15, //初始化地图级别
rotateEnable: true, //是否开启地图旋转交互 鼠标右键 + 鼠标画圈移动 或 键盘Ctrl + 鼠标左键画圈移动
pitchEnable: true, //是否开启地图倾斜交互 鼠标右键 + 鼠标上下移动或键盘Ctrl + 鼠标左键上下移动
mapStyle: "amap://styles/whitesmoke", //设置地图的显示样式
center: [118.796877, 32.060255], //初始化地图中心点位置
},
//地图配置
mapConfig: {
key: "xxxxx", // 申请好的Web端开发者Key,首次调用 load 时必填
version: "2.0", // 指定要加载的 JSAPI 的版本,缺省时默认为 1.4.15
plugins: [
"AMap.AutoComplete",
"AMap.PlaceSearch",
"AMap.Geocoder",
"AMap.DistrictSearch",
], // 需要使用的的插件列表,如比例尺'AMap.Scale'等
},
// 实例化DistrictSearch配置
districtSearchOpt: {
subdistrict: 1, //获取边界不需要返回下级行政区
extensions: "all", //返回行政区边界坐标组等具体信息
},
//这里是mark中的设置
icon: {
type: "image",
image: require("../../assets/equip.png"),
size: [15, 21],
anchor: "bottom-center",
fitZoom: [14, 20], // Adjust the fitZoom range for scaling
scaleFactor: 2, // Zoom scale factor
maxScale: 2, // Maximum scale
minScale: 1 // Minimum scale
}
};
},
created() {
this.initMap();
},
methods: {
//初始化地图
async initMap() {
this.AMap = await AMapLoader.load(this.mapConfig);
this.map = new AMap.Map("container", this.inintMapStyleConfig);
//根据地理位置查询经纬度
this.positions = await Promise.all(cityJson.map(async item => {
try {
const dot = await this.queryGeocodes(item.cityName, this.AMap);
return {
...item,
dot: dot
};
} catch (error) {
}
}));
//poi查询
this.addMarker();
//显示安徽省的区域
this.drawBounds("安徽省");
},
//查询地理位置
async queryGeocodes(newValue, AMap) {
return new Promise((resolve, reject) => {
//加载行政区划插件
const geocoder = new AMap.Geocoder({
// 指定返回详细地址信息,默认值为true
extensions: 'all'
});
// 使用地址进行地理编码
geocoder.getLocation(newValue, (status, result) => {
if (status === 'complete' && result.geocodes.length) {
const geocode = result.geocodes[0];
const latitude = geocode.location.lat;
const longitude = geocode.location.lng;
resolve([longitude, latitude]);
} else {
reject('无法获取该地址的经纬度');
}
});
});
},
//结合输入提示进行POI搜索
shareId(val) {
this.autoOptions.input = val;
},
//根据设备搜索
inputVal(val) {
if (val?.length === 0) {
//poi查询
this.addMarker();
//显示安徽省
this.drawBounds("安徽省");
return;
}
var position = val
this.icon.size = [12, 18]
this.map.setCenter(position)
this.queryPoI()
this.map.setZoom(12, true, 1);
},
//修改主题
changeTheme(val) {
const styleName = "amap://styles/" + val;
this.map.setMapStyle(styleName);
},
//区域搜索
selectVal(val) {
if (val && val.length > 0) {
let vals = val[val?.length - 1];
vals = vals.replace(/\s+/g, '');
this.queryPoI()
this.placeSearch.search(vals);
this.drawBounds(vals);
this.map.setZoom(15, true, 1);
}
},
//添加marker
addMarker() {
const icon = this.icon
let layer = new this.AMap.LabelsLayer({
zooms: [3, 20],
zIndex: 1000,
collision: false,
});
// 将图层添加到地图
this.map.add(layer);
// 普通点
let markers = [];
this.positions.forEach((item) => {
const content = `
<div class="custom-info-window">
<div class="info-window-header"><b>${item.cityName}</b></div>
<div class="info-window-body">
<div>边设备数 : ${item.edgNum} 台</div>
<div>端设备数 : ${item.endNum} 台</div>
</div>
</div>
`;
let labelMarker = new AMap.LabelMarker({
position: item.dot,
icon: icon,
rank: 1, //避让优先级
});
const infoWindow = new AMap.InfoWindow({
content: content, //传入字符串拼接的 DOM 元素
anchor: "top-left",
});
labelMarker.on('mouseover', () => {
infoWindow.open(this.map, item.dot);
});
labelMarker.on('mouseout', () => {
infoWindow.close();
});
labelMarker.on('click', () => {
this.map.setCenter(item.dot)
this.queryPoI()
this.map.setZoom(15, true, 1);
})
markers.push(labelMarker);
});
// 一次性将海量点添加到图层
layer.add(markers);
},
//POI查询
queryPoI() {
this.auto = new this.AMap.AutoComplete(this.autoOptions);
this.placeSearch = new this.AMap.PlaceSearch({
map: this.map,
}); //构造地点查询类
this.auto.on("select", this.select);
this.addMarker();
},
//选择数据
select(e) {
this.placeSearch.setCity(e.poi.adcode);
this.placeSearch.search(e.poi.name); //关键字查询查询
this.map.setZoom(15, true, 1);
},
// 行政区边界绘制
drawBounds(newValue) {
//加载行政区划插件
if (!this.district) {
this.map.plugin(["AMap.DistrictSearch"], () => {
this.district = new AMap.DistrictSearch(this.districtSearchOpt);
});
}
//行政区查询
this.district.search(newValue, (_status, result) => {
if (Object.keys(result).length === 0) {
this.$message.warning("未查询到该地区数据");
return
}
if (this.polygons != null) {
this.map.remove(this.polygons); //清除上次结果
this.polygons = [];
}
//绘制行政区划
result?.districtList[0]?.boundaries?.length > 0 &&
result.districtList[0].boundaries.forEach((item) => {
let polygon = new AMap.Polygon({
strokeWeight: 1,
path: item,
fillOpacity: 0.1,
fillColor: "#22886f",
strokeColor: "#22886f",
});
this.polygons.push(polygon);
});
this.map.add(this.polygons);
this.map.setFitView(this.polygons); //视口自适应
});
},
},
};
</script>
<style lang="less" scoped>
.map {
width: 100%;
height: 100%;
position: relative;
.map_container {
width: 100%;
height: 100%;
}
.serach {
position: absolute;
z-index: 33;
left: 20px;
top: 10px;
}
}
</style>
<style>
//去除高德的logo
.amap-logo {
right: 0 !important;
left: auto !important;
display: none !important;
}
.amap-copyright {
right: 70px !important;
left: auto !important;
opacity: 0 !important;
}
/* 自定义 infoWindow 样式 */
.custom-info-window {
font-family: Arial, sans-serif;
padding: 10px;
border-radius: 8px;
background-color: #ffffff;
max-width: 250px;
}
</style>
在子组件中构建查询
<template>
<div class="box">
<div class="input_area">
<el-input placeholder="请输入设备名称" :id="search_id" v-model="input" size="mini" class="input_item" />
<img src="../../assets/input.png" alt="" class="img_logo" />
<span class="el-icon-search search" @click="searchMap"></span>
</div>
<div class="select_area">
<el-cascader :options="options" size="mini" placeholder="选择地域查询" :show-all-levels="false" :props="cityProps"
clearable v-model="cityVal" @change="selectCity"></el-cascader>
</div>
<div class="date_area">
<el-select v-model="themeValue" placeholder="请选择地图主题" size="mini" @change="changeTheme">
<el-option v-for="item in themeOptions" :key="item.value" :label="item.label" :value="item.value">
</el-option>
</el-select>
</div>
</div>
</template>
<script>
import cityRegionData from "../../assets/area"
import cityJson from "../../assets/city.json";
export default {
name: "search",
components: {},
mixins: [],
props: {},
data() {
return {
search_id: "searchId",
input: "",
options: cityRegionData,
cityProps: {
children: "children",
label: "business_name",
value: "business_name",
checkStrictly: true
},
cityVal: "",
themeOptions: [
{ label: "标准", value: "normal" },
{ label: "幻影黑", value: "dark" },
{ label: "月光银", value: "light" },
{ label: "远山黛", value: "whitesmoke" },
{ label: "草色青", value: "fresh" },
{ label: "雅士灰", value: "grey" },
{ label: "涂鸦", value: "graffiti" },
{ label: "马卡龙", value: "macaron" },
{ label: "靛青蓝", value: "blue" },
{ label: "极夜蓝", value: "darkblue" },
{ label: "酱籽", value: "wine" },
],
themeValue: ""
};
},
computed: {},
watch: {},
mounted() {
this.sendId();
},
methods: {
sendId() {
this.$emit("share_id", this.search_id);
},
searchMap() {
console.log(this.input,'ssss');
if (!this.input) {
this.$emit("input_val", []);
return
}
let val = cityJson.find(item => item.equipName === this.input)
if (val) {
this.$emit("input_val", val.dot);
return
}
this.$message.warning("未查询到该设备,请输入正确的设备名称");
},
selectCity() {
this.$emit("select_val", this.cityVal);
},
changeTheme(val) {
this.$emit("change_theme", val);
}
},
};
</script>
<style lang="less" scoped>
.box {
display: flex;
.input_area {
position: relative;
width: 170px;
height: 50px;
display: flex;
align-items: center;
.input_item {
width: 100%;
/deep/ .el-input__inner {
padding-left: 30px !important;
}
}
.img_logo {
position: absolute;
left: 5px;
top: 50%;
transform: translateY(-50%);
width: 20px;
height: 20px;
margin-right: 10px;
}
span {
position: absolute;
right: 10px;
top: 50%;
transform: translateY(-50%);
font-size: 16px;
color: #ccc;
cursor: pointer;
}
}
.select_area {
width: 150px;
display: flex;
align-items: center;
height: 50px;
margin-left: 10px;
}
.date_area {
width: 150px;
display: flex;
align-items: center;
height: 50px;
margin-left: 10px;
}
}
</style>
效果如下

来源:juejin.cn/post/7386650134744596532
用Three.js搞个炫酷雷达扩散和扫描特效
1.画点建筑模型
添加光照,开启阴影
//开启renderer阴影
this.renderer.shadowMap.enabled = true;
this.renderer.shadowMap.type = THREE.PCFSoftShadowMap;
//设置环境光
const light = new THREE.AmbientLight(0xffffff, 0.6); // soft white light
this.scene.add(light);
//夜晚天空蓝色,假设成蓝色的平行光
const dirLight = new THREE.DirectionalLight(0x0000ff, 3);
dirLight.position.set(50, 50, 50);
this.scene.add(dirLight);
平行光设置阴影
//开启阴影
dirLight.castShadow = true;
//阴影相机范围
dirLight.shadow.camera.top = 100;
dirLight.shadow.camera.bottom = -100;
dirLight.shadow.camera.left = -100;
dirLight.shadow.camera.right = 100;
//阴影影相机远近
dirLight.shadow.camera.near = 1;
dirLight.shadow.camera.far = 200;
//阴影贴图大小
dirLight.shadow.mapSize.set(1024, 1024);
- 平行光的阴影相机跟正交相机一样,因为平行光的光线是平行的,就跟视线是平行一样,切割出合适的阴影视角范围,用于计算阴影。
- shadow.mapSize设置阴影贴图的宽度和高度,值越高,阴影的质量越好,但要花费计算时间更多。
增加建筑
//添加一个平面
const pg = new THREE.PlaneGeometry(100, 100);
//一定要用受光材质才有阴影效果
const pm = new THREE.MeshStandardMaterial({
color: new THREE.Color('gray'),
transparent: true,//开启透明
side: THREE.FrontSide//只有渲染前面
});
const plane = new THREE.Mesh(pg, pm);
plane.rotateX(-Math.PI * 0.5);
plane.receiveShadow = true;//平面接收阴影
this.scene.add(plane);
//随机生成建筑
this.geometries = [];
const helper = new THREE.Object3D();
for (let i = 0; i < 100; i++) {
const h = Math.round(Math.random() * 15) + 5;
const x = Math.round(Math.random() * 50);
const y = Math.round(Math.random() * 50);
helper.position.set((x % 2 ? -1 : 1) * x, h * 0.5, (y % 2 ? -1 : 1) * y);
const geometry = new THREE.BoxGeometry(5, h, 5);
helper.updateWorldMatrix(true, false);
geometry.applyMatrix4(helper.matrixWorld);
this.geometries.push(geometry);
}
//长方体合成一个形状
const mergedGeometry = BufferGeometryUtils.mergeGeometries(this.geometries, false);
//建筑贴图
const texture = new THREE.TextureLoader().load('assets/image.jpg');
texture.wrapS = texture.wrapT = THREE.RepeatWrapping;
const material = new THREE.MeshStandardMaterial({ map: texture,transparent: true });
const cube = new THREE.Mesh(mergedGeometry, material);
//形状产生阴影
cube.castShadow = true;
//形状接收阴影
cube.receiveShadow = true;
this.scene.add(cube);

效果就是很多高楼大厦的样子,为什么楼顶有窗?别在意这些细节,有的人就喜欢开天窗呢~
2.搞个雷达扩散和扫描特效
改变建筑材质shader,计算建筑的俯视uv
material.onBeforeCompile = (shader, render) => {
this.shaders.push(shader);
//范围大小
shader.uniforms.uSize = { value: 50 };
shader.uniforms.uTime = { value: 0 };
//修改顶点着色器
shader.vertexShader = shader.vertexShader.replace(
'void main() {',
` uniform float uSize;
varying vec2 vUv;
void main() {`
);
shader.vertexShader = shader.vertexShader.replace(
'#include <fog_vertex>',
`#include <fog_vertex>
//计算相对于原点的俯视uv
vUv=position.xz/uSize;`
);
//修改片元着色器
shader.fragmentShader = shader.fragmentShader.replace(
'void main() {',
`varying vec2 vUv;
uniform float uTime;
void main() {`
);
shader.fragmentShader = shader.fragmentShader.replace(
'#include <dithering_fragment>',
`#include <dithering_fragment>
//渐变颜色叠加
gl_FragColor.rgb=gl_FragColor.rgb+mix(vec3(0,0.5,0.5),vec3(1,1,0),vUv.y);`
);
};

然后你将同样的onBeforeCompile函数赋值给平面的时候,没有对应的效果。
因为平面没有z,只有xy,而且经过了-90度旋转后,坐标位置也要对应反转,由此可以得出平面的uv计算公式
vUv=vec2(position.x,-position.y)/uSize;

至此,建筑和平面的俯视uv一致了。
雷达扩散特效
- 雷达扩散就是一段渐变的环,随着时间扩大。
- 顶点着色器不变,改一下片元着色器,增加扩散环颜色uColor,对应shader.uniforms也要添加
shader.uniforms.uColor = { value: new THREE.Color('#00FFFF') };
const fragmentShader1 = `varying vec2 vUv;
uniform float uTime;
uniform vec3 uColor;
uniform float uSize;
void main() {`;
const fragmentShader2 = `#include <dithering_fragment>
//计算与中心的距离
float d=length(vUv);
if(d >= uTime&&d<=uTime+ 0.1) {
//扩散圈
gl_FragColor.rgb = gl_FragColor.rgb+mix(uColor,gl_FragColor.rgb,1.0-(d-uTime)*10.0 )*0.5 ;
}`;
shader.fragmentShader = shader.fragmentShader.replace('void main() {', fragmentShader1);
shader.fragmentShader = shader.fragmentShader.replace(
'#include <dithering_fragment>',
fragmentShader2);
//改变shader的时间变量,动起来
animateAction() {
if (this.shaders?.length) {
this.shaders.forEach((shader) => {
shader.uniforms.uTime.value += 0.005;
if (shader.uniforms.uTime.value >= 1) {
shader.uniforms.uTime.value = 0;
}
});
}
}

噔噔噔噔,完成啦!是立体化的雷达扩散,看起来很酷的样子。
雷达扫描特效
跟上面雷达扩散差不多,只要修改一下片元着色器
- 雷达扫描是通过扇形渐变形成的,还要随着时间旋转角度,shaderToy参考链接
const fragmentShader1 = `varying vec2 vUv;
uniform float uTime;
uniform vec3 uColor;
uniform float uSize;
//旋转角度矩阵
mat2 rotate2d(float angle)
{
return mat2(cos(angle), - sin(angle),
sin(angle), cos(angle));
}
//雷达扫描渐变扇形
float vertical_line(in vec2 uv)
{
if (uv.y > 0.0 && length(uv) < 1.2)
{
float theta = mod(180.0 * atan(uv.y, uv.x)/3.14, 360.0);
float gradient = clamp(1.0-theta/90.0,0.0,1.0);
return 0.5 * gradient;
}
return 0.0;
}
void main() {`;
const fragmentShader2 = `#include <dithering_fragment>
mat2 rotation_matrix = rotate2d(- uTime*PI*2.0);
//将雷达扫描扇形渐变混合到颜色中
gl_FragColor.rgb= mix( gl_FragColor.rgb, uColor, vertical_line(rotation_matrix * vUv)); `;

GitHub地址
来源:juejin.cn/post/7349837128508964873
粒子特效particles.js
效果图

版本:"particles.js": "^2.0.0"
npm i particles.js
Vue2版本
组件代码:src/App.vue
<template>
<div class="particles-js-box">
<div id="particles-js"></div>
</div>
</template>
<script>
import particlesJs from "particles.js";
import particlesConfig from "./assets/particles.json";
export default {
data() {
return {};
},
mounted() {
this.init();
},
methods: {
init() {
particlesJS("particles-js", particlesConfig);
document.body.style.overflow = "hidden";
},
},
};
</script>
<style scoped>
.particles-js-box {
position: fixed;
width: 100%;
height: 100%;
top: 0;
left: 0;
z-index: -1;
}
#particles-js {
background-color: #18688d;
width: 100%;
height: 100%;
}
</style>
代码里的json数据:
目录:src/assets/particles.json
{
"particles": {
"number": {
"value": 60,
"density": {
"enable": true,
"value_area": 800
}
},
"color": {
"value": "#ddd"
},
"shape": {
"type": "circle",
"stroke": {
"width": 0,
"color": "#000000"
},
"polygon": {
"nb_sides": 5
},
"image": {
"src": "img/github.svg",
"width": 100,
"height": 100
}
},
"opacity": {
"value": 0.5,
"random": false,
"anim": {
"enable": false,
"speed": 1,
"opacity_min": 0.1,
"sync": false
}
},
"size": {
"value": 3,
"random": true,
"anim": {
"enable": false,
"speed": 40,
"size_min": 0.1,
"sync": false
}
},
"line_linked": {
"enable": true,
"distance": 150,
"color": "#ffffff",
"opacity": 0.4,
"width": 1
},
"move": {
"enable": true,
"speed": 4,
"direction": "none",
"random": false,
"straight": false,
"out_mode": "out",
"bounce": false,
"attract": {
"enable": false,
"rotateX": 100,
"rotateY": 1200
}
}
},
"interactivity": {
"detect_on": "Window",
"events": {
"onhover": {
"enable": true,
"mode": "grab"
},
"onclick": {
"enable": true,
"mode": "push"
},
"resize": true
},
"modes": {
"grab": {
"distance": 140,
"line_linked": {
"opacity": 1
}
},
"bubble": {
"distance": 400,
"size": 40,
"duration": 2,
"opacity": 8,
"speed": 3
},
"repulse": {
"distance": 200,
"duration": 0.4
},
"push": {
"particles_nb": 4
},
"remove": {
"particles_nb": 2
}
}
},
"retina_detect": true
}
Vue3版本
{
"name": "vue3-test",
"version": "0.0.0",
"private": true,
"type": "module",
"scripts": {
"dev": "vite",
"build": "vite build",
"preview": "vite preview",
"lint": "eslint . --fix",
"format": "prettier --write src/"
},
"dependencies": {
"particles.js": "^2.0.0",
"vue": "^3.5.13"
},
"devDependencies": {
"@eslint/js": "^9.14.0",
"@vitejs/plugin-vue": "^5.2.1",
"@vue/eslint-config-prettier": "^10.1.0",
"eslint": "^9.14.0",
"eslint-plugin-vue": "^9.30.0",
"prettier": "^3.3.3",
"sass-embedded": "^1.83.0",
"vite": "^6.0.1",
"vite-plugin-vue-devtools": "^7.6.5"
}
}
需要修改 /node_modules/particles.js/particles.js 的代码



修改此 2 处,
我是把它拷贝到 src 目录下
组件使用:跟 vue2 一样,就是上面第8行引入不一样
import particlesJs from "@/particles.js";
来源:juejin.cn/post/7452931747785883684
为什么Rust 是 web 开发的理想选择
为什么Rust 是 web 开发的理想选择
Rust 经常被视为仅仅是一种系统编程语言,但实际上它是一种多用途的通用语言。像 Tauri(用于桌面应用)、Leptos(用于前端开发)和 Axum(用于后端开发)这样的项目表明 Rust 的用途远不止于系统编程。
当我开始学习 Rust 时,我构建了一个网页应用来练习。因为我主要是一名后端工程师,这是我最为熟悉的领域。很快我就意识到 Rust 非常适合做网页开发。它的特性让我有信心构建出可靠的应用程序。让我来解释一下为什么 Rust 是网页编程的理想选择。
错误处理
一段时间以前,我开始学习 Python,那时我被机器学习的热潮所吸引,甚至是在大型语言模型(LLM)热潮之前。我需要让机器学习模型可以被使用,因此我选择了编写一个 Django REST API。在 Django 中获取请求体,你可能会这样写代码:
class User(APIView):
def post(self, request):
body = request.data
这段代码大多数时候都能正常工作。然而,当我意外地发送了一个格式不正确的请求体时,它就不再起作用了。访问数据时抛出了异常,导致返回了 500 状态码的响应。我没有意识到这种访问可能会抛出异常,并且也没有明确的提示。
Rust 通过不抛出异常而是以 Result 形式返回错误作为值来处理这种情况。Result 同时包含值和错误,你必须处理错误才能访问该值。
let body: RequestBody = serde_json::from_slice(&requestData)?;
问号 (?) 表示你想在调用函数中处理错误,将错误向上一级传播。
我认为任何将错误作为值来处理的语言都是正确处理错误的方式。这种方法允许你编写代码时避免出现意外的情况,就像 Python 示例中的那样。
默认不可变性
最近,我的一位同事在我们的一个开源项目上工作,他需要替换一个客户端库为另一个。这是他使用的代码:
newClient(
WithHTTPClient(httpClient), // &http.Client{}
WithEndpoint(config.ApiBasePath),
)
突然间,集成测试开始抛出竞态条件错误,他搞不清楚为什么会这样。他向我求助,我们一起追踪问题回到了这行代码。我们在其他客户端之间共享了这个HTTP客户端,这导致了错误的发生。多个协程在读取客户端,而 WithHttpClient 函数修改了客户端的状态。在同一资源上同时有读线程和写线程会导致未定义的行为或在 Go 语言中引发恐慌。
这又是一个令人不悦的意外。而在 Rust 中,所有变量默认是不可变的。如果你想修改一个变量,你需要显式地声明它,使用 mut 关键字。这有助于 API 客户端理解发生了什么,并避免了意外的修改。
fn with_httpclient(client: &mut reqwest::Client) {}
宏
在像 Java 和 Python 这样的语言中,你们有注解;而在 Rust 中,我们使用宏。注解可以在某些环境下如 Spring 中带来优雅的代码,其中大量的幕后工作是通过反射完成的。虽然 Rust 的宏提供的“魔法”较少,但也同样能产生更清晰的代码。这里有一个 Rust 宏的例子:
sqlx::query_as!(Student, "DELETE FROM student WHERE id = ? RETURNING *", id)
Rust 中的宏会在后台生成代码,编译器在构建过程中会检查这些代码的正确性。通过宏,你甚至可以在编译时扩展编译器检查并验证 SQL 查询,方法是在编译期间生成运行查询的真实数据库上的代码。
这种能够在编译时检查代码正确性的能力开辟了新的可能性,特别是在 web 开发中,我们经常编写原始的数据库语句或 HTML 和 CSS 代码。它帮助我们写出更少 bug 的代码。
这里提到的宏被称为声明式宏。Rust 还有过程式宏,它们更类似于其他语言中的注解。
#[instrument(name = "UserRepository::begin")]
pub async fn begin(&self) {}
核心思想保持不变:在后台生成代码,并在方法调用前后执行一些逻辑,从而确保代码更加健壮和易于维护。
Chaining
来看看这段在 Rust 中优雅的代码:
let key_value = request.int0_inner()
.key_value
.ok_or_else(|| ServerError::InvalidArgument("key_value must be set".to_string()))?;
与这种更为冗长的方法相比:
Optional<KeyValue> keyValueOpt = request.getInner().getKeyValue();
if (!keyValueOpt.isPresent()) {
throw new IllegalArgumentException("key_value must be set");
}
KeyValue keyValue = keyValueOpt.get();
在 Rust 中,我们可以将操作链接在一起,从而得到简洁且易读的代码。但是,为了实现这种流畅的语法,我们通常需要实现诸如 From 这样的特质。
功能性技术大佬们可能会认识并欣赏这种方法,他们有这样的见解是有道理的。我认为任何允许混合函数式和过程式编程的语言都是走在正确的道路上。它为开发者提供了灵活性,让他们可以选择最适合其特定应用场景的方式。
线程安全
这里有没有人曾经因为竞态条件而在生产环境中触发过程序崩溃?我羞愧地承认,我有过这样的经历。是的,这是一个技能问题。当你在启动多个线程的同时对同一内存地址进行修改和读取时,很难不去注意到这个问题。但让我们考虑这样一个例子:
type repo struct {
m map[int]int
}
func (r *repo) Create(i int) {
r.m[i] = i
}
type Server struct {
repo *repo
}
func (s *Server) handleRequest(w http.ResponseWriter, r *http.Request) {
s.repo.Create(1)
}
没有显式启动任何线程,乍一看,一切似乎都很好。然而实际上,HTTP 服务器是在多个线程上运行的,这些线程被抽象隐藏了起来。在 web 开发中,这种抽象可能会掩盖与多线程相关的潜在问题。现在,让我们用 Rust 实现相同的功能:
struct repo {
m: std::collections::HashMap<i8, i8>
}
#[post("/maps")]
async fn crate_entry(r: web::Data<repo>) -> HttpResponse {
r.m.insert(1, 2);
HttpResponse::Ok().json(MessageResponse {
message: "good".to_string(),
})
}
当我们尝试编译这个程序时,Rust 编译器将会抛出一个错误:

error[E0596]: cannot
borrow data in an
`Arc` as mutable
--> src\main.rs:117:5
|
117 | r.m.insert(1, 2);
| ^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Arc<repo>`
很多人说 Rust 的错误信息通常是很有帮助的,这通常是正确的。然而,在这种情况下,错误信息可能会让人感到困惑并且不是立即就能明白。幸运的是,如果知道如何解决,修复方法很简单:只需要添加一个小的互斥锁:
struct repo {
m: HashMap<i8, i8>
}
#[post("/maps")]
async fn create_entry(r: web::Data<Mutex<repo>>) -> HttpResponse {
let mut map = r.lock().await();
map.m.insert(1, 2);
HttpResponse::Ok().json(MessageResponse {
message: "good".to_string(),
})
}
确实非常美妙,编译器能够帮助我们避免这些问题,让我们的代码保持安全和可靠。
空指针解引用
大多数人认为这个问题只存在于 C 语言中,但你也会在像 Java 或 Go 这样的语言中遇到它。这里是一个典型问题的例子:
type valueObject struct {
value *int
}
func getValue(vo *valueObject) int {
return *vo.value
}
你可能会说,“在使用值之前检查它是否为 nil 就好了。”这是 Go 语言中最大的陷阱之一 —— 它的指针机制。有时候我们会优化内存分配,有时候我们使用指针来表示可选值。
空指针解引用的风险在处理接口时尤其明显。
type Repository interface {
Get() int
}
func getValue(r Repository) int {
return r.Get()
}
func main() {
getValue(nil)
}
在许多语言中,将空值作为接口的有效选项传递是可以的。虽然代码审查通常会发现这类问题,但我还是见过一些空接口进入开发阶段的情况。在 Rust 中,这类问题是不可能发生的,这是对我们错误的另一层保护:
trait Repository {
fn get(&self) -> i32;
}
fn get_value(r: impl Repository) -> i32 {
r.get()
}
fn main() {
get_value(std::ptr::null());
}
Not to mention that it does not compile.
更不用说这段代码根本无法编译。
我承认,我是端口和适配器模式的大粉丝,这些模式包括了一些抽象概念。根据复杂度的不同,这些抽象可能是必要的,以便在你的应用程序中创建清晰的边界,从长远来看提高单元测试性和可维护性。批评者的一个论点是性能会下降,因为通常需要动态调度,因为在编译时无法确定具体的接口实现。让我们来看一个 Java 的例子:
@Service
public class StudentServiceImpl implements StudentService {
private final StudentRepository studentRepository;
@Autowired
public StudentServiceImpl(StudentRepository studentRepository) {
this.studentRepository = studentRepository;
}
}
Spring 为我们处理了很多幕后的事务。其中一个特性就是使用 @Autowired 注解来进行依赖注入。当应用程序启动时,Spring 会进行类路径扫描和反射。然而,这种便利性却伴随着性能成本。
在 Rust 中,我们可以创建这些清晰的抽象而不付出性能代价,这得益于所谓的零成本抽象:
struct ServiceImpl<T: Repository> {
repo: T,
}
trait Service{}
fn new_service<T: Repository>(repo: T) -> impl Service {
ServiceImpl { repo: repo }
}
这些抽象在编译时就被处理好,确保在运行时不会有任何性能开销。这使我们能够在不牺牲性能的情况下保持代码的整洁和高效。
数据转换
在企业级应用中,我们经常使用端口和适配器模式来处理复杂的业务需求。这种模式涉及将数据转换成不同层次所需的表示形式。我们可能通过异步通信接收到用户数据作为事件,或者通过同步通信接收到用户数据作为请求。然后,这些数据被转换成领域模型并通过服务和适配器层进行传递。
这就提出了一个问题:数据转换的逻辑应该放在哪里?应该放在领域包中吗?还是放在数据映射所在的包中?我们应该如何调用方法来转换数据?这些问题常常导致整个代码库中出现不一致性。
Rust 在提供一种清晰的方式来处理数据转换方面表现出色,使用 From 特质。如果我们需要将数据从适配器转换到领域,我们只需在适配器中实现 From 特质:
impl From<UserRequest> for domain::DomainUser {
fn from(user: UserRequest) -> Self {
domain::DomainUser {}
}
}
impl From<domain::DomainUser> for UserResponse {
fn from(user: domain::DomainUser) -> Self {
UserResponse {}
}
}
fn create_user(user: UserRequest) -> Result<()> {
let domain_user = domain::upsert_user(user.int0());
send_response(domain_user.int0())?;
Ok(())
}
通过在需要的地方实现 From 特质,Rust 提供了一种一致且直接的方式来处理数据转换,减少了不一致性,并使代码库更加易于维护。
性能
当然,Rust 很快这一点毋庸置疑,但它实际上给我们带来了哪些好处呢?我记得第一次将我的 Django 应用部署到 Kubernetes 上,并使用 kubectl top pods 命令来检查 CPU 和内存使用情况的时候。我很震惊地发现,即使没有任何负载,这个应用也几乎占用了 1GB 的 RAM。Java 也没好到哪里去。后来我发现了像 Rust 和 Go 这样的新语言,意识到事情可以做得更高效。
我查找了一些性能和资源使用方面的基准测试,并发现使用能够高效利用资源的语言可以节省很多成本。这里有一个例子:

Link to the original article

Link to the original article
想象一下,有一个 Lambda 函数被创建用来列出 AWS 账户中的所有存储桶,并确定每个存储桶所在的区域。你可能会认为,进行一些 REST API 调用并使用 for 循环在性能上不会有太大的区别。任何语言都应该能够合理地处理这个任务,对吧?
然而,测试显示 Rust 在执行这项任务时比 Python 快得多,并且使用更少的内存来达到这些执行时间。事实上,他们每百万次调用节省了 6 美元。
来自 web 和 Kubernetes 的背景,在那里我们根据用户负载进行扩缩容,我可以确认高效的资源使用能够节省成本并提高系统的可靠性。每个副本使用较少的资源意味着更多的容器可以装入一个节点。如果每个副本能够处理更多的请求,则总体上需要的副本数量就会减少。高性能和高效的资源利用对于构建成本效益高且可靠的系统至关重要。
我已经在 web 开发领域使用 Rust 三年了,对此我非常满意。那些具有挑战性的方面,比如编写异步代码或宏,都被我们使用的库很好地处理了。例如,如果你研究过 Tokio 库,你会知道它可能相当复杂。但在 web 开发中,我们专注于业务逻辑并与外部系统(如数据库或消息队列)交互,我们得以享受更简单的一面,同时受益于 Rust 出色的安全特性。
试试 Rust 吧;你可能会喜欢它,甚至成为一名更好的程序员。
来源:juejin.cn/post/7399288740908531712
我:CSS,你怎么变成紫色了?CSS:别管这些,都快2025了,这些新特性你还不知道吗?🤡
事情起因是这样的,大二的苦逼学生在给老外做页面的时候,做着做着无意间瞥见了css的图标。

wait!你不是我认识的css!你是谁?

我的天呐,你怎么成了这种紫色方块?(如果只关心为什么图标换了,可以直接跳到文章末尾)

这提起了我的兴趣,立马放下手中的工作去了解。查才知道,这是有原因的,而且在这之间CSS也更新了很多新特性。
不过看了许多博客,发现没啥人说这件事(也可能是我没找到),所以到我来更新了!😄
这里主要谈谈我认为还算有点用的新特性,全文不长,如果对您有用的话,麻烦给个赞和收藏加关注呗🙏!如果可以的话,掘金人气作者评选活动给孩子投一票吧😭
先叠个甲:所有观点纯本菜🐔意淫,各位大佬地方看个乐呵就行。
参考文献:张鑫旭的个人主页 » 张鑫旭-鑫空间-鑫生活
和MDN Web Docs
块级元素居中新方式:Align Content for Block Elements
元素垂直居中对齐终于有了专门的CSS属性,之前Flex布局和Grid布局中使用的align-content属性,现在已经可以在普通的block块级元素中使用。
垂直居中的快级元素不再需要 flex 或 grid,注意是在垂直居中!!!
display: block; <-非块级元素请加上这个代码
align-content: center;
不过我好像以前用过,不过用的很少,不知道是不是发生了改变造成了这种效果🤡
请看如下代码
<style>
.father {
display: block;
align-content: center;
background-color: aqua;
width: 300px;
height: 300px
}
.son {
width: 100px;
height: 100px;
background-color: red;
}
</style>
可以发现是div是垂直居中显示的

实现效果和用flex是一样的
<style>
.father {
display: flex;
align-item:center
background-color: aqua;
width: 300px;
height: 300px
}
.son {
width: 100px;
height: 100px;
background-color: red;
}
</style>

提醒一下,目前普通元素并不支持justify-content属性,必须Flex布局或者Grid布局。
subgrid
额,这个特性似乎国内没有很多文章讲解,但是我记得之前看过一个统计这个特性在老外那里很受欢迎,所以我还是讲解一下。
subgrid并不是一个CSS属性,而是 grid-template-columns和grid-template-rows属性支持的关键字,其使用的场景需要外面已经有个Grid布局,否则……嗯,虽然语法上不会识别为异常,但是渲染结果上却是没有区别的。
例如
.container {
display: grid;
}
.item {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-template-rows: subgrid;
}
那我们什么时候使用它呢?🤔
当我们想实现这种效果

Grid布局负责大的组织结构,而里面更细致的排版对齐效果,则可以使用subgrid布局。,这对于复杂的嵌套布局特别有用,在 subgrid 出现之前,嵌套网格往往会导致 CSS 变得复杂冗长。(其实你用flex也可以)
子网格允许子元素与父网格无缝对齐,从而简化了这一过程。
.container {
display: grid;
gap: 1rem;
grid-template-columns: repeat(auto-fill, minmax(240px, 1fr));
}
.item {
display: grid;
grid-template-rows: subgrid;
grid-row: span 4;
gap: .5rem;
}
/* 以下CSS与布局无关 */
.item {
padding: .75rem;
background: #f0f3f9;
}
.item blockquote {
background-color: skyblue;
}
.item h4 {
background-color: #333;
color: #fff;
}
<div class="container">
<section class="item">
<h4>1</h4>
<p>负责人:张三</p>
<blockquote>脑子和我只能活一个</blockquote>
<footer>3人参与 12月21日</footer>
</section>
<section class="item">
<h4>1</h4>
<p>负责人:张三</p>
<blockquote>脑子和我只能活一个</blockquote>
<footer>3人参与 12月21日</footer>
</section>
</div>
效果

@property
@property规则属于CSS Houdini中的一个特性,可以自定义CSS属性的类型,这个特性在现代CSS开发中还是很有用的,最具代表性的例子就是可以让CSS变量支持动画或过渡效果。
我个人认为这个东西最大的作用就是在我们写颜色渐变的时候很好避免使用var()不小心造成颜色继承的,而导致效果不理想。
用法
@property --rotation {
syntax: "<angle>";
inherits: false;
initial-value: 45deg;
}
描述符
syntax描述已注册自定义属性允许的值类型的字符串。可以是数据类型名称(例如<color>、<length>或<number>等),带有乘数(+、#)和组合符(|),或自定义标识。inherits一个布尔值,控制指定的自定义属性注册是否默认@property继承。initial-value设置属性的起始值的值。
描述
注意
简单演示
@property --box-pink {
syntax: "<color>";
inherits: false;
initial-value: pink;
}
.box {
width: 100px;
height: 100px;
background-color: var(--box-pink);
}

使用它进行颜色渐变
@property --colorA {
syntax: "<color>";
inherits: false;
initial-value: red;
}
@property --colorB {
syntax: "<color>";
inherits: false;
initial-value: yellow;
}
@property --colorC {
syntax: "<color>";
inherits: false;
initial-value: blue;
}
.box {
width: 300px;
height: 300px;
background: linear-gradient(45deg,
var(--colorA),
var(--colorB),
var(--colorC));
animation: animate 3s linear infinite alternate;
}
@keyframes animate {
20% {
--colorA: blue;
--colorB: #F57F17;
--colorC: red;
}
40% {
--colorA: #FF1744;
--colorB: #5E35B1;
--colorC: yellow;
}
60% {
--colorA: #E53935;
--colorB: #1E88E5;
--colorC: #4CAF50;
}
80% {
--colorA: #76FF03;
--colorB: teal;
--colorC: indigo;
}
}
</style>

transition-behavior让display none也有动画效果
大家都知道我们在设置一个元素隐藏和出现是一瞬间的,那有没有办法让他能出现类似于淡入淡出的动画效果呢?
这里我们就要介绍transition-behavior了,但是也有其他方法,这里就只介绍它。
语法如下:
transition-behavior: allow-discrete;
transition-behavior: normal;
allow-discrete表示允许离散的CSS属性也支持transition过渡效果,其中,最具代表性的离散CSS属性莫过于display属性了。
使用案例
仅使用transition属性,实现元素从 display:inline ↔ none 的过渡效果。
img {
transition: .25s allow-discrete;
opacity: 1;
height: 200px;
}
img[hidden] {
opacity: 0;
}
<button id="trigger">图片显示与隐藏</button>
<img id="target" src="./1.jpg" />
trigger.onclick = function () {
target.toggleAttribute('hidden');
};

这里我们可以发现消失的时候是有淡出效果的,但是出现却是一瞬间的,这是为什么?
原因是:
display:none到display:block的显示是突然的,在浏览器的渲染绘制层面,元素display计算值变成block和opacity设为1是在同一个渲染帧完成的,由于没有起始opacity,所以看不到动画效果。
那有没有什么办法能解决呢?🤔
使用@starting-style规则声明过渡起点
@starting-style顾名思义就是声明起始样式,专门用在transition过渡效果中。
例如上面的例子,要想让元素display显示的时候有淡出效果,很简单,再加三行代码就可以了:
img {
transition: .25s allow-discrete;
opacity: 1;
@starting-style {
opacity: 0;
}
}
或者不使用CSS嵌套语法,这样写也是可以的:
img {
transition: .25s allow-discrete;
opacity: 1;
}
@starting-style {
img {
opacity: 0;
}
}
此时,我们再点击按钮让图片显示,淡入淡出效果就都有了。

注意:
@starting-style仅与 CSS 过渡相关。使用CSS 动画实现此类效果时,@starting-style就不需要。
light-dark
先说明一下,我认为 CSS 的新 light-dark() 函数是 2024 年实现暗模式的最佳方式!
你自 2019 年以来,开发人员只需一行 CSS 就可以为整个站点添加暗模式?只需在 :root 中添加 color-scheme: light dark;,就可以获得全站暗模式支持——但它只适用于未指定颜色的元素,因此使用默认的浏览器颜色。
如果你想让自定义颜色的暗模式生效(大多数网站都需要),你需要将每个颜色声明包装在笨拙的 @media (prefers-color-scheme: ...) 块中:
@media (prefers-color-scheme: dark) {
body {
color: #fff;
background-color: #222;
}
}
@media (prefers-color-scheme: light) {
body {
color: #333;
background-color: #fff;
}
}
基本上,你需要把每个颜色声明写两遍。糟糕!这种冗长的语法使得编写和维护都很麻烦。因此,尽管 color-scheme 已发布五年,但从未真正流行起来。
light-dark很好解决了这个问题
基本语法
/* Named color values */
color: light-dark(black, white);
/* RGB color values */
color: light-dark(rgb(0 0 0), rgb(255 255 255));
/* Custom properties */
color: light-dark(var(--light), var(--dark));
body {
color-scheme: light dark; /* 启用浅色模式和深色模式 */
color: light-dark(#333, #fff); /* 文本浅色和深色颜色 */
background-color: light-dark(#fff, #222); /* 背景浅色和深色颜色 */
}
在这个示例代码中,正文文本在浅色模式下定义为 #333,在深色模式下定义为 #fff,而背景色则分别定义为 #fff 和 #222。就这样!浏览器会根据用户的系统设置自动选择使用哪种颜色。
无需 JavaScript 逻辑、自定义类或媒体查询。一切都能正常工作!
:user-vaild pseudo class
:user-validCSS伪类表示任何经过验证的表单元素,其值根据其验证约束正确验证。然而,与:valid此不同的是,它仅在用户与其交互后才匹配。
有什么用呢?🤔
这就很好避免了我们在进行表单验证的时候,信息提示在你交互之前出现的尴尬。
<form>
<label for="email">Email *: </label>
<input
id="email"
name="email"
type="email"
value="test@example.com"
required />
<span></span>
</form>
input:user-valid {
border: 2px solid green;
}
input:user-valid + span::before {
content: "😄";
}
在以下示例中,绿色边框和😄仅在用户与字段交互后显示。我们将电子邮件地址更改为另一个有效的电子邮件地址就可以看到了

interpolate-size
interpolate-size和calc-size()函数属性的设计初衷是一致的,就是可以让width、height等尺寸相关的属性即使值是auto,也能有transition过渡动画效果。
最具代表性的就是height:auto的过渡动画实现。
p {
height: 0;
transition: height .25s;
overflow: hidden;
}
.active+p {
height: auto;
height: calc-size(auto, size);
}
<button onClick="this.classList.toggle('active');">点击我</button>
<p>
<img src="./1.jpg" width="256" />
</p>
其实,要让height:auto支持transition过渡动画,还有个更简单的方法,就是在祖先容器上设置:
interpolate-size: allow-keywords;
换句话说,calc-size()函数是专门单独设置,而interpolate-size是全局批量设置。
interpolate-size: allow-keywords;
interpolate-size: numeric-only;
/* 全局设置 */
/* :root {
interpolate-size: allow-keywords;
} */
div {
width: 320px;
padding: 1em;
transition: width .25s;
/* 父级设置 */
interpolate-size: allow-keywords;
background: deepskyblue;
}
.active+div {
width: 500px;
}
</style>
<button onClick="this.classList.toggle('active');">点击我</button>
<div>
<img src="./1.jpg" width="256" />
</div>

全新的CSS相对颜色语法-使用from
from的作用我认为是简化了我们让文字自动适配背景色的步骤
我们先来看看用法
p {
color: rgb(from red r g b / alpha);
}

原因:r g b 以及 alpha 实际上是对red的解构,其计算值分别是255 0 0 / 1(或者100%)。
注意:实际开发,我们不会使用上面这种用法,这里只是为了展示语法作用。
使用from让文字适配背景色
<button id="btn" class="btn">我是按钮</button>
<p>请选择颜色:<input
type="color"
value="#2c87ff"
onInput="btn.style.setProperty('--color', this.value);"
></p>
<p>请选择颜色:<input
type="color"
value="#2c87ff"
onInput="btn.style.setProperty('--color', this.value);"
></p>

rebecca purple(#663399)
好了,最重要的东西来了,关于为什么变成了紫色,其实他们把它叫做rebecca紫,为什么叫这个名字呢?这其实是一个令人悲伤的故事😭。
在关于css这个新颜色以及logo的时候,内部发生了许多争议。
但是相信大部分人都读过CSS The Definitive guide,他的作者Eric A.Myer的女儿在这期间因为癌症去世了
在她去世的前几周,Rebecca说她即将成为一个六岁大的女孩,而becca是一个婴儿的名字。六岁后,他希望每个人都叫他Rebecca,而不是becca。
而那个女孩和病魔抗争,一直坚持到她到六岁,
我无法想象假如我是父亲,失去一个那么可爱的一个六岁的孩子,那个心情有多么痛苦。
最终社区被他的故事感动了,css的logo也就变成了这样。
总结
新特性多到让人麻木,真的非常非常多!!!!😵💫
这些新特性出现的速度比某四字游戏出皮肤的速度还快🚀,关键这些特性浏览器支持情况参差不齐,短时间无法在生产环境应用。
我真的看了非常都非常久,从早上五点起来开始看文档,除去吃饭上课,加上去写文章一直弄到凌晨三点,才选出这么几个我认为还算有点作用的新特性。
而且现有的JavaScript能力已经足够应付目前所有的交互场景,很多新特性没有带来颠覆性的改变,缺少迫切性和必要性,很难被重视。
最后的最后,希望大家的身边的亲人身体都健健康康的,也希望饱受癌症折磨的人们能够早日康复🙏
来源:juejin.cn/post/7450434330672234530
Nuxt 3手写一个搜索页面
Nuxt 3手写一个搜索页面
前言
前面做了一个小型搜索引擎,虽然上线了,但总体来说还略显粗糙。所以最近花了点时间打磨了一下这个搜索引擎的前端部分,使用的技术是Nuxt,UI组件库使用的是Vuetify,关于UI组件库的选择,你也可以查看我之前写的这篇对比。
本文不会介绍搜索引擎的其余部分,算是一篇前端技术文...
重要的:开源地址,应用部分的代码我也稍微整理了一下开源了,整体来说偏简单,毕竟只有一个页面,算是真正的“单页面应用”了🤣🤣🤣
演示

为什么要重写
这次重写的目的如下:
- 之前写的代码太乱了,基本一个页面就只写了一个文件,维护起来有点困难;
- 之前的后端使用nest单独写的,其实就调调API,单独起一个后端服务感觉有点重;
- 最后一点也是最重要的:使用SSR来优化一下SEO
具体如下:
- 比如当用户输入搜索之后,对应的url路径也会发生变化,比如ssgo.app/?page=1&que…,
- 如果用户将该url分享到其他平台被搜索引擎抓取之后,搜索引擎得到的数据将不再是空白的搜索框,而是包含相关资源的结果页,
- 这样有可能再下一次用户在其他搜索引擎搜索对应资源的时候,有可能会直接跳转到该应用的搜索结果页,这样就可以大大提高该应用的曝光率。
这样,用户之后不仅可以通过搜索“阿里云盘搜索引擎”能搜到这个网站,还有可能通过其他资源的关键词搜索到该网站
页面布局
首先必须支持移动端,因为从后台的访问数据看,移动端的用户更多,所以整体布局以竖屏为主,至于宽屏PC,则增加一个类似于max-width的效果。
其次为了整体实现简单,采取的还是搜索框与搜索结果处在一个页面,而非google\baidu之类的搜索框主页与结果页分别是两个页面,笔者感觉主页也没啥存在的必要(单纯对于搜索功能而言)
页面除了搜索框、列表项,还应该有logo,菜单,最终经过排版如下图所示:

左右两边为移动端的效果演示图,中间为PC端的效果演示。
nitro服务端部分
这里只需要实现两个API:
- 搜索接口,如
/api/search - 搜索建议的接口,如
/api/search/suggest
说到这里就不得不夸一下nuxt的开发者体验,新建一个API是如此的方便:

对比nest-cli中新建一个service/controller要好用不少,毕竟我在nest-cli中基本要help一下。
回到这里,我的server目录结构如下:
├─api
│ └─search # 搜索接口相关
│ index.ts # 搜索
│ suggest.ts # 搜索建议
│
└─elasticsearch
index.ts # es客户端
在elasticsearch目录中,我创建了一个ES的客户端,并在search中使用:
// elasticsearch/index.ts
import { Client } from '@elastic/elasticsearch';
export const client = new Client({
node: process.env.ES_URL,
auth: {
username: process.env.ES_AUTH_USERNAME || '',
password: process.env.ES_AUTH_PASSWORD || ''
}
});
然后使用,使用部分基本上没有做任何的特殊逻辑,就是调用ES client提供的api,然后组装了一下参数就OK了:
// api/search/index
import { client } from "~/server/elasticsearch";
interface ISearchQuery {
pageNo: number;
pageSize: number;
query: string;
}
export default defineEventHandler(async (event) => {
const { pageNo = 1, pageSize = 10, query }: ISearchQuery = getQuery(event);
const esRes = await client.search({
index: process.env.ES_INDEX,
body: {
from: (pageNo - 1) * pageSize, // 从哪里开始
size: pageSize, // 查询条数
query: {
match: {
title: query, // 搜索查询到的内容
},
},
highlight: {
pre_tags: ["<span class='highlight'>"],
post_tags: ['</span>'],
fields: {
title: {},
},
fragment_size: 40,
},
},
});
const finalRes = {
took: esRes.body.took,
total: esRes.body.hits.total.value,
data: esRes.body.hits?.hits.map((item: any) => ({
title: item._source.title,
pan_url: item._source.pan_url,
extract_code: item._source.extract_code,
highlight: item.highlight?.title?.[0] || '',
})),
};
return finalRes;
});
// api/search/suggest
import { client } from "~/server/elasticsearch";
interface ISuggestQuery {
input: string;
}
export default defineEventHandler(async (event) => {
const { input }: ISuggestQuery = getQuery(event);
const esRes = await client.search({
index: process.env.ES_INDEX,
body: {
suggest: {
suggest: {
prefix: input,
completion: {
field: "suggest"
}
}
}
},
});
const finalRes = esRes.body.suggest.suggest[0]?.options.map((item: any) => item._source.suggest)
return finalRes;
});
值得注意的是,客户端的ES版本需要与服务端的ES版本相互对应,比如我服务端使用的是ES7,这路也当然得使用ES7,如果你是ES8,这里需要安装对应版本得ES8,并且返回参数有些变化,ES8中上述esRes就没有body属性,而是直接使用后面的属性
page界面部分
首先为了避免出现之前所有代码均写在一个文件中,这里稍微封装了几个组件以使得page/index这个组件看起来相对简单:
/components
BaseEmpty.vue
DataList.vue
LoadingIndicator.vue
MainMenu.vue
PleaseInput.vue
RunSvg.vue
SearchBar.vue
具体啥意思就不赘述了,基本根据文件名就能猜得大差不差了...
然后下面就是我的主页面部分:
<template>
<div
class="d-flex justify-center bg-grey-lighten-5 overflow-hidden overflow-y-hidden"
>
<v-sheet
class="px-md-16 px-2 pt-4"
:elevation="2"
height="100vh"
:width="1024"
border
rounded
>
<v-data-iterator :items="curItems" :page="curPage" :items-per-page="10">
<template #header>
<div class="pb-4 d-flex justify-space-between">
<span
class="text-h4 font-italic font-weight-thin d-flex align-center"
>
<RunSvg style="height: 40px; width: 40px"></RunSvg>
<span>Search Search Go...</span>
</span>
<MainMenu></MainMenu>
</div>
<SearchBar
:input="curInput"
@search="search"
@clear="clear"
></SearchBar>
</template>
<template #default="{ items }">
<v-fade-transition>
<DataList
v-if="!pending"
:items="items"
:total="curTotal"
:page="curPage"
@page-change="pageChange"
></DataList>
<LoadingIndicator v-else></LoadingIndicator>
</v-fade-transition>
</template>
<template #no-data>
<template v-if="!curInput || !pending">
<v-slide-x-reverse-transition>
<BaseEmpty v-if="isInput"></BaseEmpty>
</v-slide-x-reverse-transition>
<v-slide-x-transition>
<PleaseInput v-if="!isInput"></PleaseInput>
</v-slide-x-transition>
</template>
</template>
</v-data-iterator>
</v-sheet>
</div>
</template>
<script lang="ts" setup>
const route = useRoute();
const { query = "", page = 1 } = route.query;
const router = useRouter();
const defaultData = { data: [], total: 0 };
const descriptionPrefix = query ? `正在搜索“ ${query} ”... ,这是` : "";
useSeoMeta({
ogTitle: "SearchSearchGo--新一代阿里云盘搜索引擎",
ogDescription: `${descriptionPrefix}一款极简体验、优雅、现代化、资源丰富、免费、无需登录的新一代阿里云盘搜索引擎,来体验找寻资源的快乐吧~`,
ogImage: "https://ssgo.app/logobg.png",
twitterCard: "summary",
});
interface IResultItem {
title: string;
pan_url: string;
extract_code: string;
highlight: string;
}
interface IResult {
data: IResultItem[];
total: number;
}
const curPage = ref(+(page || 1));
const curInput = ref((query || "") as string);
const isInput = computed(() => !!curInput.value);
let { data, pending }: { data: Ref<IResult>; pending: Ref<boolean> } =
await useFetch("/api/search", {
query: { query: curInput, pageNo: curPage, pageSize: 10 },
immediate: !!query,
});
data.value = data.value || defaultData;
const curItems = computed(() => data.value.data);
const curTotal = computed(() => data.value.total);
function search(input: string) {
curPage.value = 1;
curInput.value = input;
router.replace({ query: { ...route.query, query: input, page: 1 } });
}
function pageChange(page: number) {
curPage.value = page;
router.replace({ query: { ...route.query, page: page } });
}
function clear() {
curInput.value = "";
data.value = defaultData;
// 这里就不替换参数了,保留上一次的感觉好一些
}
</script>
大部分代码都是调用相关的子组件,传递参数,监听事件之类的,这里也不多说了。比较关键的在于这两部分代码:
useSeoMeta({
ogTitle: "SearchSearchGo--新一代阿里云盘搜索引擎",
ogDescription: `${descriptionPrefix}一款极简体验、优雅、现代化、资源丰富、免费、无需登录的新一代阿里云盘搜索引擎,来体验找寻资源的快乐吧~`,
ogImage: "https://ssgo.app/logobg.png",
twitterCard: "summary",
});
这里的SEO显示的文字是动态的,比如当前用户正在搜索AI,那么url路径参数也会增加AI,分享出去的页面描述就会包含AI,在twitter中的显示效果如下:

还有部分代码是这一部分:
let { data, pending }: { data: Ref<IResult>; pending: Ref<boolean> } =
await useFetch("/api/search", {
query: { query: curInput, pageNo: curPage, pageSize: 10 },
immediate: !!query,
});
其中immediate: !!query表示如果当前路径包含搜索词,则会请求数据,渲染结果页,否则不立即执行该请求,而是等一些响应式变量如curInput、 curPage发生变化后执行请求。
子组件部分这里就不详细解释了,具体可以查看源码,整体来说并不是很复杂。
其他
除此之外,我还增加了google analytics和百度 analytics,代码都非常简单,在plugins/目录下,如果你需要使用该项目,记得将对应的id改为你自己的id。
最后
这次也算是第一次使用nuxt来开发一个应用,总体来说安装了nuxt插件之后的开发体验非常不错,按照目录规范写代码也可以少掉很多导入导出的一串串丑代码。
关于笔者--justin3go.com
来源:juejin.cn/post/7327938054240780329
又报gyp ERR!为什么有那么多人被node-sass 坑过?
前言
node-sass: Command failed., gyp ERR! build error 这几个词相信很多小伙伴一定看着眼熟,当你的终端出现这些词时那么毫无疑问,你的项目跑不起来了。。。。。。
你可能通过各种方式去解决了这个报错,但是应该没有人去深究到底是咋回事,接下来让我们彻底弄懂,再遇到类似问题时能够举一反三,顺利解决。
关键词:node-sass libsass node-gyp
先来看个截图感受一下


熟悉吧?截图里我们看到了几个关键词 node-sass libsass node-gyp .cpp,我们一一来解释一下
node-sass
node-sass 是一个用于在 Node.js 中编译 Sass 文件的库,node-sass 可以将 .scss 或 .sass 文件编译为标准的 .css 文件,供浏览器或其他工具使用。
- node-sass 可以看作是 libsass 的一个包装器(wrapper)或者说是 nodejs 和 libsass 之间的桥梁。
- 它提供了一个 Node.js 友好的接口来使用 libsass 的功能。
- 当你使用 node-sass 时,实际的 Sass 编译工作是由底层的 libsass 完成的。
当你的项目中使用 sass 来写样式时,会直接或间接地引入这个这个库。
libsass
一个用 C++ 编写的高性能 Sass 编译器,这就是为什么你能在终端日志中看到 .cpp 的文件。
注意,搞这么麻烦就是为了高性能编译sass。
node-gyp
node-sass引入了 c++ 编写的库,那么直接在 node 中肯定是使用不了的,毕竟是两种不同的语言嘛,那么就需要 node-gyp 登场了。
node-gyp 是一个用于编译和构建原生 Node.js 模块的工具,这些原生模块通常是用 C++ 编写的。
node-sass 需要在安装时编译 libsass 的 C++ 代码,以生成可以在本地机器上运行的二进制文件。在这个编译过程中,node-gyp 就被用作构建工具,它负责调用 C++ 编译器(如 g++ 或 clang++),并将 libsass 的源代码编译为与当前系统兼容的二进制文件。
node-gyp 本身是一个用 JavaScript 编写的工具。它使用 Node.js 的标准模块(如 fs 和 path)来处理构建和配置任务,但是需要一些外部工具来实际进行编译和构建,例如 make、gcc等,这些工具必须安装在系统中,node-gyp 只是协调和使用这些工具。
普通模块(JavaScript/TypeScript)
普通模块是用 JavaScript 或 TypeScript 编写的,Node.js 本身可以直接执行或通过编译(如 TypeScript 编译器)转换为可执行代码,Node.js 使用 V8 引擎执行 JavaScript 代码。
原生模块(C/C++ 编写)
原生模块是用 C/C++ 编写的代码,这些模块通常用于高性能需求或需要直接与底层系统 API 交互的场景。它们通过 node-gyp 进行编译,并在 Node.js 中以二进制文件的形式加载。
例如以下模块:
- node-sass:编译 Sass 文件,依赖 libsass 进行高性能的样式编译。
- sharp:处理图像文件,使用 libvips(c++库) 提供高效的图像操作。
- bcrypt:进行加密处理,提供安全的密码哈希功能。
- fsevents:用于 macOS 系统的文件系统事件监听。
许多现有的高性能库和工具是用 C++ 编写的。为了利用这些库的功能,Node.js 可以通过模块接口调用这些 C++ 库,尤其某些高级功能,如加密算法、图像处理等,已经在 C++ 中得到了成熟的实现,Node.js 可以直接集成这些功能,而不必再重新造轮子而且性能还肯定不如用 c++ 写的库。
所谓的原生模块接口就是 node-gyp(还有Node-API (N-API)等),感兴趣的可以看看 node-gyp 的实现,或者了解下包信息
npm info node-gyp
node-gyp 基于 gyp,并在其之上添加了 Node.js 特定的功能,以支持 Node.js 模块的编译。
gyp
gyp(Generate Your Projects)是一个用于生成构建配置文件的工具,它负责将源代码(C++ 代码)转换为特定平台的构建配置文件(如 Makefile、Visual Studio 项目文件等),生成构建文件后,使用生成的构建文件来编译项目。例如,在 Unix 系统上,运行 make;在 Windows 上,使用 Visual Studio 编译项目。
从前端的角度来看,你可以把gyp理解成 webpack,而 make 命令则是 npm run build
为什么报错?
现在,我们已经了解了一些基本概念,并且知道了c++原生模块是需要在安装时编译才能使用的,那么很明显,上面的错误就是在编译时出错了,一般出现这个错误都是因为我们有一些老的项目的 node 版本发生了变化,例如上面的报错就是,在 node14 还运行的好好的,到了 node16 就报错了,我们再来看一下报错细节

这个错误发生在编译 node-sass 的过程中,具体是在编译 binding.cpp 文件时。
binding.cpp 是 node-sass 的一部分,用于将 libsass 与 Node.js 接口连接起来。
报错发生在 v8-internal.h 文件里,大概意思是这个c++头文件里使用了比较高级的语法,node-sass中的c++标准不支持这个语法,导致报错,就相当于你在 js 项目里引入一个三方库,这个三方库使用了 es13 的新特性(未编译为es5),但是你的项目只支持 es6,从而导致你的项目报错。
所以解决思路就很清晰了,要么降级 node 版本,要么升级 node-sass,要么干脆就不用node-sass了
解决方案
rebuild 大法
npm rebuild node-sass 重新编译模块,对于其他编译错误该方法可能会有效果,但是如果 node-sass 和 node 版本不匹配那就没得办法了,适合临时使用,不推荐。
升级node-sass
以下是 node-sass 支持的最低和最高版本的指南,找对应的版本升级就好了

但是!node-sass 与node版本强绑定,还得去想着保持版本匹配,心智负担较重,所以使用 sass 更好
更换为 sass
官方也说了,不再释放新版本,推荐使用 Dart Sass

Sass 和 node-sass 的区别
实现语言:
- Sass:Sass 是一个用 Ruby 编写的样式表语言,最初是基于 Ruby 的实现(ruby-sass)。在 Ruby 版本被弃用后,Sass 社区推出了 Dart 语言实现的版本,称为 dart-sass。这个版本是当前推荐的实现,提供了最新的功能和支持。
- node-sass:node-sass 封装了 libsass,一个用 C++ 编写的 Sass 编译器。node-sass 使用 node-gyp 编译 C++ 代码和链接 libsass 库。
构建和编译:
- Sass:dart-sass 是用 Dart 语言编写的,直接提供了一个用 JavaScript 实现的编译器,因此不需要 C++ 编译过程。它在 Node.js 环境中作为纯 JavaScript 模块运行,避免了编译问题。
- node-sass:node-sass 依赖于 libsass(C++ 编写),需要使用 node-gyp 进行编译。很容易导致各种兼容性问题。
功能和维护:
- Sass:dart-sass 是 Sass 的官方推荐实现,拥有最新的功能和最佳的支持。它的更新频繁,提供了对最新 Sass 语言特性的支持。
- node-sass:由于 node-sass 依赖于 libsass,而 libsass 的维护在 2020 年已停止,因此 node-sass 逐渐不再接收新的功能更新。它的功能和特性可能滞后于 dart-sass。
性能:
- Sass:dart-sass 的性能通常比 node-sass 更佳,因为 Dart 编译器的性能优化更加现代。
- node-sass:虽然 libsass 在性能上曾经表现良好,但由于它不再更新,可能不如现代的 Dart 实现高效。
总结
gyp ERR! 和 node-sass 问题是由 node-sass 与 node 版本兼容引起的编译问题,推荐使用 sass 替代,如果老项目不方便改的话就采用降级 node 版本或升级 node-sass 的办法。
其实这种问题没太大必要刨根究底的,但是如果这次简单解决了下次遇到类似的问题还是懵逼,主要还是想培养自己解决问题的思路,再遇到类似天书一样的坑时不至于毫无头绪,浪费大量时间。
来源:juejin.cn/post/7408606153393307660
Tauri+MuPDF 实现 pdf 文件裁剪,侄子再也不用等打印试卷了🤓
基于
MuPDF.js实现的 PDF 文件 A3 转 A4 小工具。(其实就是纵切分成2份🤓)
开发背景
表哥最近经常找我给我侄子的试卷 pdf 文件 A3 转 A4(因为他家只有 A4 纸,直接打印字太小了)。

WPS提供了pdf的分割工具,不过这是会员功能,我也不是总能在电脑前操作。于是我想着直接写一个小工具,拿Tauri打包成桌面应用就好了。

在掘金里刷到了柒八九大佬的文章:Rust 赋能前端:PDF 分页/关键词标注/转图片/抽取文本/抽取图片/翻转... 。发现MuPDF.js这个包有截取pdf文件的API,并且提供了编译好的wasm文件,这意味着可以在浏览器中直接体验到更高的裁切性能,于是我果断选择了基于MuPDF开发我的小工具。
项目简介
MuPDF-Crop-Kit是一个基于MuPDF.js、React、Vite和Tauri开发的小工具,用于将 PDF 文件从 A3 纸张大小裁切为 A4 纸张大小。它具有以下特点:
- 免费使用:无需任何费用;
- 无需后台服务:可以直接在浏览器中运行,无需依赖服务器;
- 高性能:利用 WebAssembly (WASM) 技术,提供高效的文件裁切性能;
- 轻量级桌面应用:通过 Tauri 打包成桌面软件,安装包体积小,方便部署;
- 开源项目:欢迎社区贡献代码和建议,共同改进工具。
项目代码地址
Github:MuPDF-Crop-Kit
开发过程与踩坑
MuPDF.js只支持ESM,官网中给出的要么使用.mjs文件,要么需要项目的type改成module:
npm pkg set type=module
我在我的
Rsbuild搭建的项目中都没有配置成功🤷♂️,最后发现用Vite搭建的项目直接就可以用...- 因为没有直接提供我想要的功能,肯定是要基于现有的
API手搓了。但是截取页面的API会修改原页面,那么自然想到是要复制一份出来,一个截左边一个截右边了。但是MuPDF.js的copyPage复制出来的pdf页修改之后,原pdf页居然也会被修改。
于是我想到了,一开始就new两个PDFDocument对象,一个截左边一个截右边,最后再合并到一起,我很快实现了两个文档的分别截取,并通过转png图片之后再合并,完成了裁切后的文档的浏览器预览。
然后我考虑直接使用jspdf把png图片转pdf文件,结果2MB的原文件转换后变成了12MB,并且如果原文件是使用扫描全能王扫描出来的,生成的pdf文件会很糊。
最后,终于让我在文档中发现merge方法:

不过依赖包提供的方法很复杂:
merge(sourcePDF, fromPage = 0, toPage = -1, startAt = -1, rotate = 0, copyLinks = true, copyAnnotations = true) {
if (this.pointer === 0) {
throw new Error("document closed");
}
if (sourcePDF.pointer === 0) {
throw new Error("source document closed");
}
if (this === sourcePDF) {
throw new Error("Cannot merge a document with itself");
}
const sourcePageCount = sourcePDF.countPages();
const targetPageCount = this.countPages();
// Normalize page numbers
fromPage = Math.max(0, Math.min(fromPage, sourcePageCount - 1));
toPage = toPage < 0 ? sourcePageCount - 1 : Math.min(toPage, sourcePageCount - 1);
startAt = startAt < 0 ? targetPageCount : Math.min(startAt, targetPageCount);
// Ensure fromPage <= toPage
if (fromPage > toPage) {
[fromPage, toPage] = [toPage, fromPage];
}
for (let i = fromPage; i <= toPage; i++) {
const sourcePage = sourcePDF.loadPage(i);
const pageObj = sourcePage.getObject();
// Create a new page in the target document
const newPageObj = this.addPage(sourcePage.getBounds(), rotate, this.newDictionary(), "");
// Copy page contents
const contents = pageObj.get("Contents");
if (contents) {
newPageObj.put("Contents", this.graftObject(contents));
}
// Copy page resources
const resources = pageObj.get("Resources");
if (resources) {
newPageObj.put("Resources", this.graftObject(resources));
}
// Insert the new page at the specified position
this.insertPage(startAt + (i - fromPage), newPageObj);
if (copyLinks || copyAnnotations) {
const targetPage = this.loadPage(startAt + (i - fromPage));
if (copyLinks) {
this.copyPageLinks(sourcePage, targetPage);
}
if (copyAnnotations) {
this.copyPageAnnotations(sourcePage, targetPage);
}
}
}
}
而且在循环调用这个
MuPDF.js提供的merge方法时,wasm运行的内存被爆了🤣。
仔细阅读代码发现其核心实现就是:
addPage新增页面;put("Resources")复制原文档页面中的内容到新页面;insertPage将新增的页面插入到指定文档中。
因为我并没有后续添加的
link和annotation,所以经过设计后,决定使用一个空的pdf文档,逐页复制原文档两次到空白文档中。主要逻辑如下:
- 加载 PDF 文件:读取并解析原始 A3 PDF 文件。
- 复制页面:创建两个新的 PDF 文档,分别截取每页的左半部分和右半部分。
- 合并页面:将两个新文档中的页面合并到一个新的 PDF 文档中。
- 设置裁剪框:根据 A4 纸张尺寸设置裁剪框(CropBox)和修整框(TrimBox)。
export function merge(
targetPDF: mupdfjs.PDFDocument,
sourcePage: mupdfjs.PDFPage
) {
const pageObj = sourcePage.getObject();
const [x, y, width, height] = sourcePage.getBounds();
// Create a new page in the target document
const newPageObj = targetPDF.addPage(
[x, y, width, height],
0,
targetPDF.newDictionary(),
""
);
// Copy page contents
const contents = pageObj.get("Contents");
if (contents) newPageObj.put("Contents", targetPDF.graftObject(contents));
// Copy page resources
const resources = pageObj.get("Resources");
if (resources) newPageObj.put("Resources", targetPDF.graftObject(resources));
// Insert the new page at the specified position
targetPDF.insertPage(-1, newPageObj);
}
export function generateNewDoc(PDF: mupdfjs.PDFDocument) {
const count = PDF.countPages();
const mergedPDF = new mupdfjs.PDFDocument();
for (let i = 0; i < count; i++) {
const page = PDF.loadPage(i);
merge(mergedPDF, page);
merge(mergedPDF, page);
}
for (let i = 0; i < count * 2; i++) {
const page = mergedPDF.loadPage(i); // 使用 mergedPDF 的页码
const [x, y, width, height] = page.getBounds();
if (i % 2 === 0)
page.setPageBox("CropBox", [x, y, x + width / 2, y + height]);
else page.setPageBox("CropBox", [x + width / 2, y, x + width, y + height]);
page.setPageBox("TrimBox", [0, 0, 595.28, 841.89]);
}
return mergedPDF;
}
完成以上核心方法后,便可以成功将我侄子的试卷裁切为
A4大小进行打印了✅。
体验与安装使用
浏览器版
- 直接访问网页链接(MuPdf-Crop-Kit)。

桌面版
- 下载并安装
Tauri打包的桌面应用(Release tauri-x64-exe-0.1.0 · HyaCiovo/MuPdf-Crop-Kit); - 使用源码自行打包需要的安装包。
使用教程
使用本工具非常简单,只需几个步骤即可完成 PDF 文件的裁切:
- 选择需要裁切的 A3 PDF 文件;

- 点击裁切按钮;

- 下载裁切后的 A4 PDF 文件。

不足
- 项目所使用的
wasm文件大小有10MB,本工具真正用到的并没有那么多,但是优化需要修改原始文件并重新编译; - 浏览器端的性能受限,并且
wasm运行可以使用的内存也是有限的; - 没有使用
Web Worker,理论上转换这种高延迟的任务应当放在Woker线程中进行来防止堵塞主线程。
替代方案
如果在使用过程中遇到问题或需要更多功能,可以尝试以下在线工具:
- Split PDF Down the Middle A3 to A4 Online:每小时可以免费转换3次,作者亲测好用👍。
来源:juejin.cn/post/7451252126255382543
9个要改掉的TypeScript坏习惯
为了提升TypeScript技能并避免常见的坏习惯,以下是九个需要改掉的坏习惯,帮助你编写更高效和规范的代码。
1. 不使用严格模式
错误做法: 不启用tsconfig.json中的严格模式。
正确做法: 启用严格模式。
原因: 更严格的规则有助于未来代码的维护,修复代码的时间会得到回报。

2. 使用 || 确定默认值
错误做法: 使用 || 处理可选值。

正确做法: 使用 ?? 运算符或在参数级别定义默认值。
原因: ?? 运算符只对 null 或 undefined 进行回退,更加精确。

3. 使用 any 作为类型
错误做法: 使用 any 类型处理不确定的数据结构。

正确做法: 使用 unknown 类型。
原因: any 禁用类型检查,可能导致错误难以捕获。

4. 使用 val as SomeType
错误做法: 强制编译器推断类型。

正确做法: 使用类型守卫。
原因: 类型守卫确保所有检查都是明确的,减少潜在错误。

5. 在测试中使用 as any
错误做法: 在测试中创建不完整的替代品。

正确做法: 将模拟逻辑移到可重用的位置。
原因: 避免在多个测试中重复更改属性,保持代码整洁。

6. 可选属性
错误做法: 将属性定义为可选。

正确做法: 明确表达属性的组合。
原因: 更明确的类型可以在编译时捕获错误。

7. 单字母泛型
错误做法: 使用单字母命名泛型。

正确做法: 使用描述性的类型名称。
原因: 描述性名称提高可读性,便于理解。

8. 非布尔判断
错误做法: 直接将值传递给 if 语句。
正确做法: 明确检查条件。
原因: 使代码逻辑更清晰,避免误解。

9. 感叹号操作符
错误做法: 使用 !! 将非布尔值转换为布尔值。

正确做法: 明确检查条件。
原因: 提高代码可读性,避免混淆。

来源:juejin.cn/post/7451586771781861426
低成本创建数字孪生场景-数据篇
众所周知在做数字孪生相关项目的时候,会划出相当一部分费用会用于做建模工作,然而有一天老板跑过来告诉我,由于客户地处于偏远经济欠发达地区,没有多少项目经费,因此不会花很大的价钱做建模,换言之如果这个项目连建模师都请不起了,阁下该如何应对。
常规的场景建模方式无非就是CAD、激光点云辅助、倾斜摄影建模,人工建模的成本自不必说,几百平方公理的场景如果用无人机倾斜等等建模也是一笔不小的开销,在客户对场景还原度和模型精细度不高的前提下,最省成本的办法还是尽肯能让程序自动建模。经过几天摸索,我终于找到一些稍微靠谱的应对方法,本篇着重讲述如何获取场景的数据,以及处理为展示所需的数据格式。

准备工作
使用的工具
| 工具 | 用途 | 成本 |
|---|---|---|
| 水经注 | 获取全国GIS数据 | 部分免费 |
| 地理空间数据云 | 获取地形高程图 | 免费 |
| QGIS | 空间数据编辑 | 开源 |
| cityEingine | 自动生成建筑和道路模型 | 部分免费 |
| CesiumLab3 | 转换地理模型 | 部分免费 |
| CesiumJS | 3D地图引擎,用于做最终场景展示 | 开源 |
QGIS(全称Quantum GIS)是一个开源的地理信息系统, 提供了一种可视化、编辑和分析地理数据的途径。它支持各种矢量、栅格和数据库格式,并且支持丰富的GIS功能,包括地图制作、空间数据编辑、地图浏览等。
CesiumLab3是一款强大的3D地理信息数据处理软件,可以将各种类型的数据,如点云、模型、影像、地形等,转换为3D Tiles格式,以便在CesiumJS中可视化。此外,CesiumLab3还提供了一套完整的数据管理和分发服务,使得大规模3D地理信息数据的存储、管理和服务变得更加便捷。
CesiumJS是一款开源的JavaScript库,它用于创建世界级的3D地球和地图的Web应用程序。无论是高精度的地形、影像,还是高度详细的3D模型,CesiumJS都可以轻松地将它们集成到一个统一的地理空间上下文中。该库提供了丰富的接口和功能,让开发者可以轻松实现地理信息可视化、虚拟地球等应用。
基础数据
| 图层 | 数据形态 | 数据格式 | 文件格式 |
|---|---|---|---|
| 卫星影像 | 图片 | 栅格 | TIF |
| 水域分布 | 多边形 | 矢量 | SHP |
| 建筑面轮廓 | 多边形 | 矢量 | SHP |
| 植被分布 | 散点 | 矢量 | SHP |
| 地形高程图 | 图片 | 栅格 | TIF |
数据处理
1. 影像和地形
带有地形信息的卫星影像作为底图可以说是非常重要,所有其他图层都是它的基础上进行搭建,因此我们必须尽可保证在处理数据时的底图和最终展示时使用的底图是一致的,至少空间参考坐标系必须是一致的。
由于在后面步骤用到的cityEgine工具可选坐标系里没有ESPG43226,这里使用EPSG32650坐标系。
在编辑过程中需要用到TIF格式的卫星底图,可以使用QGIS对栅格图层,图层的数据在平面模式下进行编辑,主要工作是对齐数据、查漏补缺。
地形处理步驟如下:
- 打开地理空间数据云,登录并进入“高级检索”
- 设置过数据集和过滤条件后会自动返回筛选结果,点击结果项右侧的下载图标即可下载。

- 在 QGIS 中打开菜单栏 Raster > Miscellaneous > Merge,并将下载的高程文件添加到 Input layers 中。

- 可以使用 Processing Toolbox 中的 Clip raster by mask layer 工具来裁剪高程图层,处理好之后导出TIF格式备用

- 使用esiumlab3做地形转换,在这里会涉及到转换算法的选择,VCG算法适合用于小范围,对精度要求高的地形;CTD算法则适合用于大范围,对精度要求低的地形。根据具体情况选择即可。地形具体步骤看 高程地形切片和制作水面效果


2. 建筑轮廓
建筑轮廓通常为矢量数据,在2D模式下它就是由多个内封闭多边形组成的图层,而在3D模式下可以对这些多边形进行挤压形成体力几何体,并在此基础上做变形和贴图,形成大量城市建筑的视觉效果。
这部分数据很难在互联网上拿到,即使有免费的渠道(比如OMS下载),数据也是较为老旧的或者残缺的,有条件的话建议让业主提供或者购买水经注VIP会员下载。即使这样,我们还需要使用QGIS等工具进行二次编辑。
操作步骤如下:
- 在QGIS处理数据,对数据进行筛选、补充、填充基本信息等处理,导出SHP格式数据,建议将卫星影像和地形底图一并导出,用于做模型位置对齐。为方便后面的自动化建模,需要将每个建筑面的基本信息(比如名称和建筑高度)录入到每个多边形中,如果对建筑高度要求没有那么精细也可以用QGIS自带的方法随机生成高度数值。

- 在cityEngine中新建工程(存放各种数据、图层、规则文件)和场景(从工程中抽取素材搭建场景)
- 使用cityEngine进行自动程序化建模,有了建筑面轮廓和高度,就可以直接使用规则生成建筑了,建筑的风格也是可以灵活配置的,比如商业区住宅区,或者CBD风格城乡结合部风格等等。 具体操作看 CityEngine-建筑自动化程序建模


- 将模型导出为FBX,并使用cesiumlab3转换为3Dtiles ,具体操作见 常见3D模型转3Dtiles文件。这里要注意空间参考必须设置为与在QGIS处理数据时的坐标系一致,这里有个坑的地方就是非授权(收费)用户是无法使用ENU之外的其他坐标系将FBX或OBJ文件转为3DTiles的,只能用SHP转出3DTiles白模。这就是为什么很多人反映导出3DTiles后放到地图里又对不上的原因。

3. 绿地和植被图层
绿地和植被图层为我们展示了特定区域内的自然或人工绿地及植被分布情况,包括公园、森林、草地、田地等各类植被区域。获取数据通常可以通过遥感卫星图像,或者通过地面调查和采集。这些数据经过处理后,可以以矢量或栅格的形式在GIS中进行展示和分析。
在本文案例中为了制作立体茂密树林的视觉效果,我们将植被图层数据转换为LOD图层,即在不同的地图缩放尺度下有不同的细节呈现。基本原理就是在指定的范围内随机生成一个树模型的大量实例操作步骤如下:
- 获取植被区域多边形,使用QGIS通过数据导入或手绘的方式得到植被的覆盖区域,可以給区域增加一些快速计算的属性,比如area

- 在覆盖区域内生成随机分布点,调整点的数量和密度达到满意状态即可

- 如有需要,可以手动调整随机生成的点数据,确认无误后导出文件shp

- 准备好带LOD的树模型(cesiumlab3\tools\lodmodel\yangshuchun有自带一个示例模型可用)和地形高程信息文件(.pak格式)

- 使用cesiumlab3创建实例模型切片,具体的流程可以看这里 CesiumLab3实例模型切片

以上方法适合创建模型单一、更新频度低、且数据量巨大的模型图层,比如树木、城市设备如路灯、垃圾桶、井盖等等。
4. 水域分布
地理上水域包括湖泊、河流、海洋和各种人工水体,在专业领域项目水域的分布对研究环境生态有重大意义,而比较通用的场景就是跟卫星影像、地形底图结合展示,我们同样需要矢量数据绘制多边形,并加上动态材质出效果。
由于最终展示的地图引擎cesium自带水域材质效果,这里的操作也变得简单,只要把水域多边形获取到手就行:
- 打开QGIS,导入从水经注下载的水域数据或者对着卫星影像地图手动绘制水域数据,导出为shp文件格式
- 在cesiumlab3 生成地形切片,在cesium里,水域是作为地形的一部分进行处理的,所以将地形高程图tif文件和水域shp文件一起上传处理即可。具体步骤看 高程地形切片和制作水面效果

组合数据
至此数据篇就介绍完了,由于cesiumlab3自带分发服务,我们可以直接在上面新建一个场景,将上文生成的数据图层组合到一个场景里作展示。另外还可以测试一些场景效果比如天气、轮廓、泛光等等,还挺有意思的。后续的单模型加载、可视化图层加载、鼠标事件交互等等就留在开发篇吧,今天就先这样。
- 叠加地形、建筑白模、植被实例切片图层

- 测试建筑模型积雪效果

相关链接
来源:juejin.cn/post/7329322608212885555
wasm真的比js快吗?
一. 前言
首先提一句话,本人是Rust新手!如果有什么不足的地方麻烦指出哈!
最近一直在玩Rust(摸鱼),本来是想着,多学一点,多练一练,之后把我们这边的一些可视化项目里面核心的代码用Rust重构一下。但是我最近在练习一个demo的时候,发现了跟我预期不一样的地方。

具体如何,我用下面几个案例展开细说。
二. 案例1: 使用canvas绘制十万个不同颜色的圆
首先我想到的是,把canvas的复杂图像绘制功能用Rust重写一下。这里我用canvas绘制大量的圆形为例子。
2.1 Rust绘制canvas
跟上一篇文章的流程差不多,我们需要先新建一个Rust项目:
cargo new canvas_circel_random --lib
然后更新一下Cargo.toml文件里面的依赖内容:
[package]
name = "canvas_circle_random"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib"]
[dependencies]
wasm-bindgen = "0.2"
js-sys = "0.3"
web-sys = { version = "0.3", features = ["HtmlCanvasElement", "CanvasRenderingContext2d"] }
完成之后,我们简单在src/lib.rs写一点代码:
// 引入相关的依赖
use wasm_bindgen::prelude::*;
use web_sys::{CanvasRenderingContext2d, HtmlCanvasElement};
use js_sys::Math;
// 给js调用的方法
#[wasm_bindgen]
pub fn draw_circles(canvas: HtmlCanvasElement) {
// 获取ctx绘画上下文
let context = canvas.get_context("2d").unwrap().unwrap().dyn_int0::<CanvasRenderingContext2d>().unwrap();
let width = canvas.client_width() as f64;
let height = canvas.client_height() as f64;
// 循环绘制
for _ in 0..100_0000 {
// 设置一下写x,y的位置
let x = Math::random() * width;
let y = Math::random() * height;
let radius = 10.0;
let color = format!(
"rgba({}, {}, {}, {})",
(Math::random() * 255.0) as u8,
(Math::random() * 255.0) as u8,
(Math::random() * 255.0) as u8,
Math::random()
);
draw_circle(&context, x, y, radius, &color);
}
}
fn draw_circle(context: &CanvasRenderingContext2d, x: f64, y: f64, radius: f64, color: &str) {
// 调用canvas的API绘制
context.begin_path();
context.arc(x, y, radius, 0.0, 2.0 * std::f64::consts::PI).unwrap();
context.set_fill_style(&JsValue::from_str(color));
context.fill();
context.stroke();```
}
简单解释一下代码:
0..100_0000创建了一个从0开始到999,999结束的范围注意,Rust 的范围是左闭右开的,这意味着它包含起始值但不包含结束值。&JsValue::from_str(color)从变量中取值。
完成之后,我们去打包一下。
wasm-pack build --target web
然后我们得到一个pkg包,如下图:

然后我们在项目中引入一下,具体流程可以看我上一篇文章。
回到我们的Vue项目中,我们引入一下:
import init, { draw_circles } from 'canvas_circle_random/canvas_circle_random'
onMounted(async () => {
await init();
const begin = new Date().getTime();
drawWasmCircle();
const end = new Date().getTime();
console.log('wasm cost time: ' + (end - begin) + 'ms');
})
之后我们打开一下页面:

多次加载了几次,加载范围大概在2750ms~2900ms之间。
2.2 使用js绘制canvas
const drawJsCircle = () => {
const canvas = document.getElementById('my-canvas') as HTMLCanvasElement;
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D;
for (let i = 0; i < 1000000; i++) {
drawRandomCircle(ctx, 800, 600);
}
}
const drawRandomCircle = (ctx: CanvasRenderingContext2D, width: number, height: number) => {
const radius = 10;
const x = Math.random() * (width - 2 * radius) + radius;
const y = Math.random() * (height - 2 * radius) + radius;
const color = `rgba(${Math.floor(Math.random() * 256)}, ${Math.floor(Math.random() * 256)}, ${Math.floor(Math.random() * 256)}, ${Math.random().toFixed(2)})`;
ctx.beginPath();
ctx.arc(x, y, radius, 0, Math.PI * 2);
ctx.fillStyle = color;
ctx.fill();
ctx.stroke();
}
没什么好说的,有手就会。
然后我们在页面上试一下:

加载范围大概在1950ms~2200ms之间。
卧槽,难道说js的性能比wasm快???
然后我又对绘制的数量和绘制的形状做了多次实验:
绘制10000个圆,wasm用时大概在1000ms,js用时大概在700ms。绘制100000个长方形,wasm用时大概在1700ms,js用时在1100ms。
无一例外,在绘制canvas上面,js的性能确实优于wasm。
三. 案例2:算法性能
考虑到通过canvas绘制图形来判断性能,有点太前端化了,我想可不可以通过写一些算法来做一下性能的比较。
试了很多算法,这里我用一下斐波那契算法,比较简单也比较有代表性。
在同级目录下新建一个Rust项目:
cargo new fb-lib --lib
然后在fb-lib中修改一下Cargo.toml:
[package]
name = "fb-lib"
version = "0.1.0"
edition = "2021"
[lib]
crate-type = ["cdylib", "rlib"]
[dependencies]
wasm-bindgen = "0.2"
把斐波那契数列代码写到src/lib.rs文件中:
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub fn fb_wasm(n: i32) -> i32 {
if n <= 1 {
1
}
else {
fb_wasm(n - 1) + fb_wasm(n - 2)
}
}
很简单,没什么好说的。完成之后,我们在项目中使用一下。
<script setup lang="ts">
import init, { fb_wasm } from 'fb-lib/fb_lib'
import { onMounted } from 'vue';
onMounted(async () => {
await init();
const begin = new Date().getTime();
fb_wasm(42);
const end = new Date().getTime();
console.log('wasm cost time: ' + (end - begin) + 'ms');
})
</script>

大概试了一下时间在1700ms~1850ms左右。
然后我们用js实现一下:代码如下:
import init, { fb_wasm } from 'fb-lib/fb_lib'
import { onMounted } from 'vue';
onMounted(async () => {
await init();
const begin = new Date().getTime();
fn_js(42);
const end = new Date().getTime();
console.log('js cost time: ' + (end - begin) + 'ms');
})
const fn_js = (n: number): number => {
if (n <= 1) {
return 1;
} else {
return fn_js(n - 1) + fn_js(n - 2);
}
}
然后我们在页面上看一下:

大概试了一下时间在2550ms~2700ms左右。
很明显,这时的wasm的性能是要优秀于js。
四. 总结
大概试了一下canvas,dom操作,高性能算法(排序、递归)等。我大概得出了一个这样的结论:
Wasm代码比JavaScript代码更加精简,因此从网络上获取Wasm代码的速度更快。- 对于一些高性能的算法,在基数足够大的情况下,
wasm的性能确实高于js,但是当基数比较小的时候,两者其实差不多。 - 由于Wasm是一种二进制格式,需要将
DOM操作的数据进行转换,才能在Wasm和js之间进行传递。这个数据转换过程可能导致额外的开销。以及Wasm操作DOM时,需要通过js提供的API进行通信。每次调用js的API都会引入一定的开销,从而影响性能。所以在一些页面交互操作上,wasm的性能并不会优于js。
综上,个人觉得wasm和js之间是一种互相选择互相依靠的关系,并不是取代的关系。日常开发中,也要结合实际情况选择不同的方式进行开发。
往期文章:前端仔,用rust来写canvas
来源:juejin.cn/post/7444450769488674825
原来科技感的三维地图可以这么简单实现
前言

2024.02.20
下午摸鱼时接到一个客户的数字孪生项目的需求,客户什么也没说,就要求“炫酷”和“科技感”地图,还要把他们的模型都放上去,起初我以为又是一个可视化大屏的项目,准备用高德地图应付过去,然后他们又在群里发什么要求高之类的,我们的数据种类多,说什么高德、百度、Mapbox、Cesium之类框架都试过了,满足不了需求,好嘛,这下给我犯了难了,会的技术栈全都给我排除了, 手撸Three.js源码我可不干,于是就在网上晃悠,尝试找一些灵感
2024.02.24
又试了几个地图框架,还是不行,被客户和经理催了一顿,再不行他们要换人了
2024.02.28
在QQ群里闲逛,发现了群友发的一个叫 Mapmost SDK for WebGL 的地图框架,于是抱着试一试的态度做了一下,好家伙,一下就对客户味了

2024.03.04
后面我发现这个SDK蛮有意思,于是把我实现客户需求的过程记录下来,分享给大家
初始化
这个SDK看似是个商用软件,不过目前是免费试用,官网上申请一下就行了,然后按照他们的文档,填一下参数,就能初始化一个地图,和一般的地图SDK用法差不多


<script src ='https://delivery.mapmost.com/cdn/sdk/webgl/v3.5.0/mapmost-webgl-min.js'></script>
<script>
let mapmost = window.mapmost
/*
* 初始化地图
*/
let map = new mapmost.Map({
container: 'map', //地图容器
style:'http://192.168.126.44/mms-style/darkMap.json', //矢量底图
center: [120.74014004382997, 31.32975410974069], //地图中心点
bearing: 50.399999999999636, //方位
pitch: 78.99999999999993, //倾斜角
zoom: 19.964625761228117, //缩放
userId: '***',
})
</script>

不过,在此之前,要把底图中的矢量建筑图层隐藏掉,客户要加载真正的建筑三维模型。
代码和效果图如下:
const buildingLayers = [
'buildings-di',
'buildings-faguang-1',
'buildings-faguang-2',
'buildings-faguang-3',
'buildings-high',
'buildings-high-top',
'buildings-low',
'buildings-low-top',
'buildings-lowmid',
'buildings-lowmid-top',
'buildings-mid',
'buildings-mid-top',
'buildings-midhigh',
'buildings-midhigh-copy',
]
map.on('load', (e) => {
buildingLayers.forEach((layer, index) => {
let layerObj = map.getLayer(layer)
map.setLayoutProperty(layerObj.id, 'visibility', 'none');
})
})

加载建筑三维模型
这里我们准备了城市建筑的模型,格式为glb,按照文档描述,我们添加一个id为modelLayer的三维图层,代码和效果图如下
//...
/*
* 加城市f载建筑模型
*/
let Gr0up = null
let Layer = null
let models = ["./model/YQ.glb"].map(item => ({
type: 'glb',
url: item
}));
map.on('load',(e) => {
let modelOptions = {
id: 'modelLayer',
type: 'model',
models: models,
sky: "./sky/satara_night_no_lamps_2k.hdr",
exposure: 2.4,
center: [120.74155610348487, 31.328251735532746, 0],
callback: (group, layer) => {
Gr0up = group
Layer = layer
}
};
map.addLayer(modelOptions);
})


添加三维效果
接下来就是客户的G点了,为三维场景添加特效:
添加建筑流光渐变效果
参考SDK的接口文档,给建筑加上流光渐变的效果


定义一个添加特效的函数addModelEffect,然后按照文档上的参数说明来配置相关属性
const addModelEffect = () =>{
Layer.addModelEffect(Gr0up, [{
type: "gradient",
startColor: "rgba(63, 177, 245,.5)",
endColor: "rgba(58, 142, 255,.8)",
opacity: 0.8,
percent: 0.5
}, {
type: "flow",
speed: 1,
color: "rgba(241, 99, 114, .4)",
opacity: 0.8,
percent: 0.05
}])
Gr0up.addFrame(0x3FB1F5);
}
然后我们在模型加载完成后调用这个函数:
//...
map.on('load',(e) => {
let modelOptions = {
id: 'modelLayer',
type: 'model',
models: models,
sky: "./sky/satara_night_no_lamps_2k.hdr",
exposure: 2.4,
center: [120.74155610348487, 31.328251735532746, 0],
callback: (group, layer) => {
Gr0up = group
Layer = layer
addModelEffect()
}
};
map.addLayer(modelOptions);
})
效果如下:


添加粒子飞线
同样,在SDK的文档上找到添加流动线的接口,定义一个addFlowLine的函数,然后按照要求配置参数:
这里我们借助了一个生成贝塞尔曲线的函数,以及一些随机的坐标点位数据。
他们的作用是为我们提供必要的模拟数据
import { getBSRPoints } from './bezierFunction.js'
import { flowLineData } from './flowLineData.js'
//...
const addFlowLine = () => {
//生成贝塞尔曲线测试数据
let data_trail1 = getBSRPoints(120.71541557869517, 31.316503949907542,
120.73787560336916, 31.321925190347713, 800);
let data_trail2 = getBSRPoints(120.71541557869517, 31.316503949907542,
120.72619950480242, 31.33360076088249, 1500);
let data_trail3 = getBSRPoints(120.71541557869517, 31.316503949907542,
120.69933418653403, 31.332725809914024, 900);
[data_trail1, data_trail2, data_trail3].map(data => {
Layer.addFlowLine({
type: "trail",
color: '#1ffff8',
speed: 4,
opacity: 0.9,
width: 8,
data: {
coordinate: data
}
});
})
flowLineData.map(data => {
Layer.addFlowLine({
type: "flow",
color: '#ff680d',
speed: 4,
opacity: 1,
percent: 0.08,
gradient: 0.02,
width: 5,
data: {
coordinate: data
}
});
})
}
同样,我们在模型加载完成后调用这个函数:
//...
map.on('load',(e) => {
let modelOptions = {
id: 'modelLayer',
type: 'model',
models: models,
sky: "./sky/satara_night_no_lamps_2k.hdr",
exposure: 2.4,
center: [120.74155610348487, 31.328251735532746, 0],
callback: (group, layer) => {
Gr0up = group
Layer = layer
addModelEffect()
addFlowLine()
}
};
map.addLayer(modelOptions);
})
效果图如下:


添加特效球
类似的,文档上的添加特效球的接口,给场景里添加两个”能量半球“

代码和效果图如下:
const addSphere = () => {
let sphere = Layer.addSphere({
color: "rgb(53, 108, 222)",
radius: 3300, //半径,单位米,默认为10米
segment: 256, //构成圆的面片数
phiLength: Math.PI,
speed: 3,
opacity: 1,
center: [120.67727020663829, 31.31997024841401, 0.0]
});
let sphere2 = Layer.addSphere({
color: "rgb(219, 74, 51)",
radius: 2300, //半径,单位米,默认为10米
segment: 256, //构成圆的面片数
phiLength: Math.PI,
speed: 6,
opacity: 1,
center: [120.67727020663829, 31.31997024841401, 0.0]
});
}
//...
map.on('load',(e) => {
let modelOptions = {
id: 'modelLayer',
type: 'model',
models: models,
sky: "./sky/satara_night_no_lamps_2k.hdr",
exposure: 2.4,
center: [120.74155610348487, 31.328251735532746, 0],
callback: (group, layer) => {
Gr0up = group
Layer = layer
addModelEffect()
addFlowLine()
addSphere()
}
};
map.addLayer(modelOptions);
})

环境效果调优
仔细看整个环境,发现天是白的,和整体环境不搭配

更改一下地图初始化时的参数,将天空设置为暗色:
let map = new mapmost.Map({
container: 'map', //地图容器
style: 'http://192.168.126.44/mms-style/darkMap.json', //矢量底图
center: [120.74014004382997, 31.32975410974069], //地图中心点
bearing: 60.399999999999636, //方位
pitch: 78.99999999999993, //倾斜角
zoom: 14.964625761228117, //缩放
sky: 'dark' //天空颜色
})
然后整体效果如下:

如果觉得场景本身太亮,可以降低添加模型时的曝光度:
let modelOptions = {
exposure: .4,
callback: (group, layer) => {
//...
}
};
这样整体环境就会偏暗一点,更有黑夜下的赛博朋克城市的味道

当然,在这我又换了一张更暗的底图:

最后,再调整一下特效球的半径和位置,行了,这就是客户喜欢的样子,哈哈哈,2小时搞定,而且不用手撸Three.js代码:
const addSphere = () => {
let sphere = Layer.addSphere({
color: "rgb(53, 108, 222)",
radius: 3300, //半径,单位米,默认为10米
segment: 256, //构成圆的面片数
phiLength: 180,
speed: 3,
opacity: 1,
center: [120.67943361712065, 31.306450929918768]
});
let sphere2 = Layer.addSphere({
color: "rgb(219, 74, 51)",
radius: 2300, //半径,单位米,默认为10米
segment: 256, //构成圆的面片数
phiLength: 180,
speed: 6,
opacity: 1,
center: [120.67727020663829, 31.31997024841401, 0.0]
});
}

总结
仔细看,不难发现,这个SDK集成了 Mapbox 和 Three.js 的核心功能,主打的是一个高颜值的三维地图引擎,当然除了好看之外,其他地图框架该有的功能它也具备,只是官网给人的感觉过于粗糙,不够吸引人;另外产品试用的门槛有些高,希望后面能优化吧


来源:juejin.cn/post/7342279484488138802
盘点一下用了这么长时间遇到的Wujie 无界微前端的坑
目前也用无界微前端很长时间了,当时选择无界没有选择乾坤的原因就是无界的保活模式更加丝滑,客户就想要这种方式,但是在这段过程也遇到了很多问题,甚至有些就是无界目前解决不了的问题,所以希望大家今后遇到了也能提前避免
已经解决的问题
1、子应用使用wangEditor 在主应用中无法编辑 ,无法粘贴,工具栏无法正常使用
✨问题复现
- 子项目中正常

- 主项目无法选中,无法粘贴

✨出现这种问题的原因:
- 子应用运行在 iframe内,dom在主应用的shadowdom中,当选中文字时,在主应用监听selectionchange,并且通过 document.getSelection()获取选中的selection,在wangEditor中 会判断这个 selection instanceof window.Selection,很明显主应用的selection 不可能是 iframe 里面window Selection的实例,所以出现了问题
- shadowDom 大坑,在shadowDom中 Selection.isCollapsed永远为true,相当于永远没有选中,所以只能修改 wangEditor 的代码,让读取 isCollapsed 修改成 baseOffset 和 focusOffset的对比,就知道是否选中了文字了
✨解决方案
1、将 wangeditor 替换成 wangEditor-next,因为wangeditor 作者大大已经说因为种种原因后面不会再继续更新了,所以担心更新的同学可以使用 wangEditor-next 这个还有人在继续更新
2、直接替换一个富文本组件 vue-quill,我使用的就是这个,因为我们项目对富文本的需求没有那么重,只要能用就行,所以你也可以替换一个在无界中没有问题的富文本组件
3、由此我们知道了在无界中getSelection是有问题的 如果遇到了可以用这个插件尝试解决 wujie-polyfill.github.io/doc/plugins…
2、子应用使用vue-office 的 pdf 预览,在主应用中白屏
✨问题复现
- 子应用 正常显示

- 主应用直接加载不出来

✨解决方案:
直接换个轮子,因为vue-office 源码不对外开放,你根本不知道是它内部做了何种处理,所以最好的办法就是直接换个其他的能够预览pdf 的方式,我这边选择的是 kkfile 的方式,kkfile 不仅可以预览pdf 还可以预览很多其他的格式的文件,让后端去生成预览地址 然后前端直接用 iframe 去打开即可
3、开发环境下 vite4 或者 vite5 子应用的 element-plus的样式丢失或者自己写的:root 不生效
✨问题复现
- 子应用正常

- 主应用样式丢失

✨出现这种问题的原因:
主要的原因是因为子应用的 :root 失效了,因为无界中是将:root 转成了:host ,但是如果你是在main.js 中外链的样式
import 'element-plus/dist/index.css'
这样的话无界将无法劫持到将 :root 转成:host

✨解决办法:
增加插件
<WujieVue
width="100%"
height="100%"
name="pro1"
:url
:sync="true"
:exec="true"
:alive="true"
:props="{ jump }"
:plugins="[{
patchElementHook(element, iframeWindow) {
if (element.nodeName === "STYLE") {
element.insertAdjacentElement = function (_position, ele) {
iframeWindow.document.head.appendChild(ele);
};
}
},
}]"
></WujieVue>
如果不生效请清除缓存重新启动,多试几次就行
4、el-select 位置偏移以及 el-table tootip 位置偏移的问题
✨问题复现:

✨出现这种问题的原因:
el中依赖了poper.js 的fixed定位偏移,子应用的dom挂载在shadowRoot上,导致计算错误
官网解决办法

试了,发现没啥用,所以维护官网的大大请更新快点,要不然哪个还想用无界啊!!
✨最后解决办法:
使用插件 wujie-polyfill.github.io/doc/plugins…
// import { DocElementRectPlugin } from "wujie-polyfill";
<WujieVue
width="100%"
height="100%"
name="xxx"
:url="xxx"
:plugins="[DocElementRectPlugin()]"
></WujieVue>
我的element-plus 的版本:"element-plus": "^2.9.0",
这个版本比较新,如果你们使用的是比较老的版本或者使用的是element-ui的话,上面的插件可能不生效,可以看下面的解决方案
总结下来无非是几个办法,要么是改element-ui 中的源码,然后在项目中打补丁
要么直接在子应用加代码
body{position: relative !important}
.el-popper {position: absolute !important}
大家都可以都试一下,说不准哪个生效了
5、异步获取e.target 的 e.target 变成了 wujie-app
✨问题复现:


官网文档方法

上面尝试了不行
✨最后解决办法:
使用 插件 wujie-polyfill.github.io/doc/plugins…
import { EventTargetPlugin } from "wujie-polyfill";
// vue
<WujieVue
width="100%"
height="100%"
name="xxx"
:url="xxx"
:plugins=“[EventTargetPlugin()]”
></WujieVue>
完美解决
6、全局样式污染了子应用元素的样式
✨问题复现:


✨最后解决办法:
比如主项目中你给 html 或者 body 文字居中,在子项目中也会受影响,其实这个不算是框架的问题,因为你写了这个是全局样式,那就说明了这个会影响所有的,所以建议大家样式尽量写scope 并且对全局的样式尽量主项目和子项目同步,不要出现不一样的情况,要不然很难去排查这种问题
目前还没找到解决办法的问题:
1、自定义事件
很多项目集成了第三方sdk 比如埋点、错误监控、数据通信,其中sdk 可能会使用了js 的自定义事件,这个时候在子组件中会失效
✨问题复现:
const customEvent = new CustomEvent('update', {
bubbles: true,
composed: true,
detail: {
msg:'我的数据更新喽'
}
})
setTimeout(() => {
console.log(window.__WUJIE_RAW_WINDOW__,'window.__WUJIE_RAW_WINDOW__');
window.dispatchEvent(customEvent)
window.__WUJIE_RAW_WINDOW__ && window.__WUJIE_RAW_WINDOW__.dispatchEvent(customEvent)
}, 2000)
window.addEventListener('update', function(event) {
// 主应用没有反应,子组件中正常
console.log(event)
})
window.__WUJIE_RAW_WINDOW__ && window.__WUJIE_RAW_WINDOW__ .addEventListener('testEvent', function(event) {
// 主应用没有反应,子组件中正常
console.log(event)
})
会发现使用 window.addEventListener 或者 window.WUJIE_RAW_WINDOW .addEventListener 都没有用
✨出现这种问题的原因:
看了issue中作者说这个是无界中的bug ,所以如果有子组件用到这个自定义事件的,只能先将子组件用iframe 嵌入进去,等作者更新了再改回来
2、主应用路由切换和子应用路由切换点击浏览器退回没反应
✨问题复现:
官方示例:wujie-micro.github.io/demo-main-v…
大家也可以试一下,先点击主应用中的左侧vite 下的页面切换,然后再点击子应用中中间的页面切换,会发现需要点击两次浏览器的返回才能正常返回,可以看到我录屏下的点击返回前进和退回都没反应,只有多点一次才可以,目前还没找到好的解决办法,如果大家有办法解决可以告诉我。

结语
用了无界这么长时间给我的感觉还是比较好的,子应用保活非常丝滑,开箱即用,子应用基本上不需要更改任何代码直接可以继承到无界之中,这个优点真的是非常棒!不像qiankun 还得写很多适配的代码,当然qiankun 的社区真的比无界强大很多,很多问题你都能找到解决方案,只能说各有优缺点吧,主要看你自己怎么选择了
来源:juejin.cn/post/7444134659719610380
把鸽鸽放到地图上唱跳rap篮球需要几步?
事情的起因
最近在做地图类的创意应用没什么灵感,有一天晚上看到我弟弟玩游戏,发现机箱里有个ikun手办,这创作灵感就来了,鸽鸽+唱歌跳舞有没有搞头?

说做就做,WebStorm启动

1.初始化地图
这里的地图框架我用的是Mapmost SDK for WebGL,代码和效果如下
<script src="https://delivery.mapmost.com/cdn/sdk/webgl/v9.3.0/mapmost-webgl-min.js"></script>
<script>
let map = new mapmost.Map({
container: 'map',
style: 'https://www.mapmost.com/cdn/styles/sample_data.json',
center: [120.71330725753552, 31.29683781822105],
zoom: 16,
userId: '*******************', //填入你自的授权码
pitch: 60,
bearing: 75,
sky:"light",
env3D:{
exposure:0.3,
defaultLights: true,
envMap: "./yun.hdr",
}
});
</script>

2.设置地图样式
这里为了和模型本身的颜色契合,我隐藏了一些图层,然后把水系、道路、和陆地的颜色改了,代码和效果如下

//更改背景、水系、道路配色
map.setPaintProperty('bacground', 'background-color', 'rgb(159, 208, 137)')
map.setPaintProperty('ground_grass2', 'fill-color', 'rgb(103, 173, 144)')
map.setPaintProperty('water_big', 'fill-color', 'rgb(106, 190, 190)')
map.setPaintProperty('water_samll', 'fill-color', '#ADDCDF')
map.setPaintProperty('road_city_polygon-tex', 'fill-color', '#F1ECCC')
map.setPaintProperty('ground_playground', 'fill-color', '#FBD9E1')
//隐藏道路名
map.setLayoutProperty('road_metroline_line','visibility','none')
map.setLayoutProperty('road_metro_line', 'visibility', 'none')
map.setLayoutProperty('road_metroline_name', 'visibility', 'none')
map.setLayoutProperty('road_metro_name', 'visibility', 'none')
map.setLayoutProperty('road_city_name', 'visibility', 'none')
map.setLayoutProperty('road_country_name', 'visibility', 'none')
map.setLayoutProperty('road_others_name', 'visibility', 'none')

3.加载模型和图标
然后从网上下载了鸽鸽的obj模型

直接加载上去,这里作为模型图层添加,用法参考下面的文档:
http://www.mapmost.com/mapmost_doc…
//定义模型对象
let models_obj = [{
type: 'obj',
url: "./XHJ.obj",
mtl: "./XHJ.mtl",
}]
//配置模型图层参数
let options = {
id: 'model_id',
type: 'model',
models: models_obj,
center: [120.71482081366986, 31.299511106127838, 145],
callback: function (group, layer) {
}
};
//添加图层
map.addLayer(options);
鸽鸽就这样水灵灵的出现了

然后我们加几个图标上去,这里利用geojson数据,添加的自定义图层

//增加ikun图标
map.addSource("ikun", {
"type": "geojson",
"data": "./ikun.geojson"
})
map.loadImage('./111.png', (error, image) => {
if (error) {
throw error;
}
map.addImage('icon', image)
map.addLayer({
"id": "icon_ikun",
"type": "symbol",
"source": "ikun",
"layout": {
"icon-image": "icon",
"icon-size": 0.15,
"visibility": "visible"
}
})
})
好了,大功告成了

后续:如何实现唱跳rap篮球?
当然只看模型肯定不行,主要得让鸽鸽动起来,唱、跳、rap、篮球一样不能少
怎么办,MasterGO启动, 急的我UI和交互都给一起做了,不会UI设计的开发不是好前端。


后面越想功能越多,干脆搞个小游戏算了,游戏名字我都想好了,叫:唤醒鸽鸽,输入不同的口令,激活鸽鸽不一样的动作,伴随着地图一起舞动。

但是开发遇到了点困难,手机和模型材质的适配还在解决中....,另外模型骨骼动画有点僵硬,这个等我解决了再给大家分享,目前的效果还比较粗糙:


如果大家想到什么好玩的功能,也可以评论区讨论一下,不过一定要与地图结合才好玩。
关于代码:源码地址在这
基础场景的代码我先发给大家:
链接: pan.baidu.com/s/1G-r5qIXN… 提取码: y1p5
完整的代码等我解决掉bug了再分享
来源:juejin.cn/post/7449599345371283482
来自全韩国最好的程序员的 Nest.js 中 TypeSafe 方案
Nest.js 中的 TypeSafe 方案
在现代 Web 开发中,类型安全(TypeSafe)是提升代码质量和减少运行时错误的关键因素。
Nest.js 作为一个渐进式的 Node.js 框架,结合了 TypeScript 的强大功能,提供了构建高效、可扩展服务器端应用的理想平台。
笔者在使用 Nest.js 构建全栈应用时最大的痛点是写了这么多类型检查,好像没有办法和前端通用啊~。相信许多人也有这个问题,所以也冒出了在 Nest.js 中集成 tRPC 的教程。
而本文介绍的 Nestia,一个专为 Nest.js 设计的类型安全解决方案,帮助开发者在构建应用时实现更高的类型安全性和开发效率。
韩国最好的程序员
Jeongho Nam,GitHub用户名为 samchon,他在 README 中自称为韩国最好的程序员。他自1998年开始编程,拥有25年的丰富经验。在这段时间里,他开发了许多程序,并不断提升自己的技能。他不仅在工作中开发程序,还在业余时间开发开源项目,以满足自身需求或改进现有功能。这些开源项目逐渐形成了新的开源库,其中最著名的就是 typia 和 nestia。
什么是Nestia?
Nestia 是一个专为 Nest.js 开发的库,旨在通过利用 TypeScript 的类型系统,提供更高效和类型安全的开发体验。Nestia 的核心目标是简化数据传输对象(DTOs)的定义和验证,减少类型错误,并提升代码的可维护性。
Nestia的主要功能
- 类型安全的 DTO 定义和验证:
Nestia 利用 TypeScript 的类型系统,允许开发者定义类型安全的 DTOs。通过自动生成的类型定义,Nestia 确保了数据在传输和处理过程中的一致性,避免了常见的类型错误。
NestJS需要三个重复的 DTO 模式定义。第一个是定义 TypeScript 类型,第二个和第三个是调用
class-validator和@nestjs/swagger的装饰器函数。这不仅繁琐,而且容易出错。如果你在第 2 或第 3 处写错了的话,TypeScript 编译器是无法检测到的。只有在运行时才能检测到。换句话说,它并不是类型安全的。 - 自动生成API客户端:
Nestia 可以根据服务器端的 API 定义,自动生成类型安全的 API 客户端。这种方式不仅减少了手动编写客户端代码的工作量,还确保了前后端的一致性。
这一功能与著名的 tRPC 库有相似之处。tRPC 是一个端到端类型安全的 RPC 框架,它允许你轻松构建和使用完全类型安全的 API,无需模式或代码生成。tRPC 的主要作用是在全栈 TypeScript 项目中提供类型安全的 API 调用,大大提高了开发效率和代码质量。但 tRPC 的问题是通常要求前后端代码位于同一个 monorepo 中,以便共享类型定义。这种紧耦合的架构可能不适合所有项目,特别是那些前后端分离开发或需要为第三方提供 API 的场景。相比之下,Nestia 通过自动生成独立的 API 客户端解决了这个问题。它允许你在保持类型安全的同时,将生成的 SDK 作为独立的包分发给客户端开发者。这种方式既保留了类型安全的优势,又提供了更大的灵活性,使得 Nestia 在更广泛的项目结构和开发场景中都能发挥作用。
- 高效的JSON序列化和反序列化:
Nestia 提供了高效的 JSON 序列化和反序列化功能,利用 TypeScript 的类型信息,显著提升了性能和类型安全性。
如何使用Nestia
安装Nestia
你可以运行以下命令通过模版代码来快速上手 Nestia。
模板将自动构建在<directory>中。作为参考,这是一个最小的模板项目,只集中于从 NestJS 服务器生成 SDK。它不包含数据库连接。
npx nestia start <directory>
你也可以运行下面的命令来将 Nestia 集成至现有的项目中。设置向导将自动安装并配置所有内容。
npx nestia setup
定义类型安全的DTO
你不需要掌握特殊的语法只使用 TypeScript 就可以编写一个带有类型检查的 DTO。当然,Nestia 也通过 Typia 提供了编写复杂类型检查的可能,例如,我们可以定义一个论坛完整的 DTO:
import { tags } from "typia";
export interface IBbsArticle {
/* Primary Key. */
id: string & tags.Format<"uuid">;
/* Title of the article. */
title: null | (string & tags.MinLength<5> & tags.MaxLength<100>);
/* Main content body of the article. */
body: string;
/* Creation time of article. */
created_at: string & tags.Format<"date-time">;
}
在 Controller 中调用 Nestia 的装饰器
NestJS 原生的装饰器(如 @Get(), @Post() 等)虽然使用方便,但在性能和类型安全方面存在一些局限:
- 使用 class-validator 和 class-transformer 进行验证和转换,性能相对较低
- 需要定义额外的 DTO 类和装饰器,增加了代码量
- 类型安全性不够强,运行时可能出现类型错误
Nestia 的装饰器(如 @TypedRoute.Get(), @TypedBody() 等)则解决了这些问题:
- 利用 typia 库进行高性能的运行时类型验证,比 class-validator 快 20,000 倍
- 支持使用纯 TypeScript 接口定义 DTO,无需额外的类定义
- 在编译时进行类型检查,提供更强的类型安全性
- JSON 序列化速度比 class-transformer 快 200 倍
import { TypedRoute } from "@nestia/core";
import { Controller } from "@nestjs/common";
import { IBbsArticle } from "./IBbsArticle";
@Controller("bbs/articles")
export class BbsArticlesController {
@TypedRoute.Get("random")
public async random(): Promise<IBbsArticle> {
return {
id: "2b5e21d8-0e44-4482-bd3e-4540dee7f3d6",
title: "Hello nestia users",
body: "Just use `TypedRoute.Get()` function like this",
created_at: "2023-04-23T12:04:54.168Z",
files: [],
};
}
@TypedRoute.Post()
public async store(
@TypedBody() input: IBbsArticle.IStore,
): Promise<IBbsArticle> {
return {
...input,
id: "2b5e21d8-0e44-4482-bd3e-4540dee7f3d6",
created_at: "2023-04-23T12:04:54.168Z",
};
}
}
自动生成API客户端
Nestia可以根据服务器端的API定义,自动生成类型安全的API客户端。在根目录配置 nestia.config.ts 文件
import { INestiaConfig } from '@nestia/sdk';
import { NestFactory } from '@nestjs/core';
import { FastifyAdapter } from '@nestjs/platform-fastify';
import { AppModule } from './src/app.module';
const NESTIA_CONFIG: INestiaConfig = {
input: async () => {
const app = await NestFactory.create(AppModule, new FastifyAdapter());
app.setGlobalPrefix('api');
return app;
},
output: 'src/api',
clone: true,
distribute: 'sdk',
};
export default NESTIA_CONFIG;
运行命令 npx nestia sdk 即可生成 SDK package,你可以直接在 Monorepo 中使用它,也可以将其分发到 npm.
尝试使用生成的 SDK 看到类型提示的那一刻,整个人都通畅了~

结论
Nestia 作为一个专为 Nest.js 设计的类型安全解决方案,通过简化 DTO 定义和验证、自动生成 API 客户端以及高效的 JSON 序列化和反序列化功能,帮助开发者在构建应用时实现更高的类型安全性和开发效率。无论是大型企业级应用还是个人项目,Nestia 都是提升代码质量和开发效率的理想选择。
通过本文的介绍,希望您对 Nestia 有了更深入的了解,并能在您的 Nest.js 项目中尝试使用这一强大的工具,享受类型安全带来的诸多好处。
来源:juejin.cn/post/7385728319738216488
Taro v4框架开发微信小程序(配置)
环境变量文件

将 .env.dev 文件重命名为 .env.development,以及将 .env.prod 文件重命名为 .env.production,以适配环境配置。

为了演示如何使用环境变量,我们在 .env.development 文件中添加两个变量 TARO_APP_ID 和 TARO_APP_API,然后在源代码中读取这些变量的值。
TARO_APP_ID="xxxxxxxxxxxxxxxxxx"
TARO_APP_API="https://api.tarojs.com"

接下来需要在 project.config.json 文件中更新 appid 的值。因为上一章节中为了测试修改了这个值,现在我们需要把它改回原来的 appid:
"appid": "touristappid",
在完成以上操作后,重新启动项目(使用命令 pnpm dev:weapp),控制台会显示相关的提示信息,并且可以看到 dist/project.config.json 文件中的 appid 已经变成了我们在 .env.development 文件中指定的 TARO_APP_ID 值。


为了在代码中使用环境变量,可以在 src/pages/index/index.tsx 文件的 useLoad 钩子中添加 console.log 语句来打印 TARO_APP_API 的值:
console.log(process.env.TARO_APP_API)
这样做的结果是,当程序运行时,可以在微信开发者工具的控制台中看到 TARO_APP_API 环境变量的值被成功打印出来。

这里需要记得将环境变量的appid改为你正常使用的appid,否则小程序会报错。
之后运行程序,并在微信开发者工具中浏览:

需要注意的是,只有以 TARO_APP_ 开头的环境变量才会被 webpack 的 DefinePlugin 插件静态嵌入到客户端代码中。这是为了避免环境变量与系统内置变量冲突。在构建过程中,代码中的 process.env.TARO_APP_API 会被替换为实际的环境变量值。例如,我们在小程序开发者工具中查看编译后的代码,会看到 console.log(process.env.TARO_APP_API) 被替换成了 console.log("https://api.tarojs.com");。

编译配置
编译配置是 Taro 项目开发过程中重要的一部分,它决定了项目的编译行为。Taro 的编译配置主要存放在项目根目录下的 config 文件夹内,由 index.ts 文件统一导出。其中,index.ts 通过合并 dev.ts 和 prod.ts 来分别处理开发时的配置和构建时的生产配置。dev.js 适用于项目预览时的设置,而 prod.js 则适用于项目打包时的设置。
在 Taro 的编译配置中,可以设置项目名称、创建日期、设计稿尺寸、源码目录等基本配置信息。下面的代码片段展示了一部分编译配置的内容:
const config = {
// 项目名称
projectName: 'learn-taro-wxapp',
// 项目创建日期
date: '2024-3-11',
// 设计稿尺寸
designWidth: 750,
// 设计稿尺寸换算规则
deviceRatio: {
640: 2.34 / 2,
750: 1,
375: 2,
828: 1.81 / 2
},
// 项目源码目录
sourceRoot: 'src',
// 项目产出目录
outputRoot: 'dist',
// Taro 插件配置
plugins: [],
// 全局变量设置
defineConstants: {},
// 文件 copy 配置
copy: {
patterns: [],
options: {},
},
// 框架,react,nerv,vue, vue3 等
framework: 'react',
// 使用 webpack5 编译
compiler: 'webpack5',
cache: {
enable: false // Webpack 持久化缓存配置,建议开启
},
// 小程序端专用配置
mini: {
postcss: {
pxtransform: {
enable: true,
config: {
}
},
autoprefixer: {
enable: true,
},
cssModules: {
enable: false, // 默认为 false,如需使用 css modules 功能,则设为 true
config: {
namingPattern: 'module', // 转换模式,取值为 global/module
generateScopedName: '[name]__[local]___[hash:base64:5]',
},
},
},
// 自定义 Webpack 配置
webpackChain(chain) {
chain.resolve.plugin('tsconfig-paths').use(TsconfigPathsPlugin)
}
},
// H5 端专用配置
h5: {
publicPath: '/',
staticDirectory: 'static',
postcss: {
autoprefixer: {
enable: true,
},
cssModules: {
enable: false, // 默认为 false,如需使用 css modules 功能,则设为 true
config: {
namingPattern: 'module', // 转换模式,取值为 global/module
generateScopedName: '[name]__[local]___[hash:base64:5]',
},
},
},
// 自定义 Webpack 配置
webpackChain(chain, webpack) {},
devServer: {},
},
rn: {
appName: 'taroDemo',
postcss: {
cssModules: {
enable: false, // 默认为 false,如需使用 css modules 功能,则设为 true
}
}
}
}
module.exports = function (merge) {
if (process.env.NODE_ENV === 'development') {
return merge({}, config, require('./dev'))
}
return merge({}, config, require('./prod'))
}
在编译配置文件中,alias 被用来设置路径别名,避免在代码中书写过多的相对路径。在配置文件中,默认已经将 @ 设置为指向 src 目录,这样,在代码中就可以使用 @ 快捷引用 src 下的文件了。
我们还可以增加额外的配置,例如:
alias: {
'@/components': path.resolve(__dirname, '..', 'src/components'),
}
使用 defineConstants 可以定义全局常量,例如,可以基于不同的环境设置不同的全局变量。
defineConstants: {
__DEV__: JSON.stringify(process.env.NODE_ENV === 'development'),
__PROD__: JSON.stringify(process.env.NODE_ENV === 'production')
}
等等...
如果想要查阅每个配置项的具体意义和用法,可以按住 Ctrl + 鼠标左键 点击属性名,跳转到 project.d.ts 类型声明文件中查看对应注释和示例代码。

designWidth 用于指定设计稿的宽度,这里设置的是 750px,这意味着使用的 UI 设计稿的宽度标准是 750px。Taro 提供了多个设计稿尺寸的换算规则,当前项目中已经设置了几种不同尺寸对应的换算比例。如下所示:
// 设计稿尺寸换算规则
deviceRatio: {
640: 2.34 / 2,
750: 1,
375: 2,
828: 1.81 / 2
},
对于 UI 设计师而言,推荐使用 750px 作为设计尺寸标准,它便于开发者使用 Taro 进行开发时,进行适配和转换。
对于更详细的编译配置,可以查询官方文档中的编译配置详情。
app.config.ts 通用配置文件
在 Taro 框架中,app.config.ts 是小程序的通用配置文件,其主要职责是定义小程序的页面及其全局属性。以下是针对 app.config.ts 文件中一些关键配置项的说明:
pages
pages 数组用于指明组成小程序的页面列表,每个元素都指向一个页面的路径加文件名,无需包含文件扩展名。由于 Taro 会自动处理寻找文件,这会带来方便。改变小程序页面结构时,如新增或删除页面,都应相应地更新 pages 配置。
pages: [
'pages/index/index',
'pages/other/other',
// ... 其他页面路径
]
其中,数组中的第一个条目表示小程序的入口页面(首页)。
window
window 对象用于设置小程序的状态栏、导航条、标题和窗口背景色等界面表现。
window: {
navigationBarBackgroundColor: '#ffffff',
navigationBarTextStyle: 'black',
backgroundColor: '#eeeeee',
// ... 其他窗口属性
}

查看属性详细信息和支持程度,你可以通过按住 Ctrl + 鼠标左键 点击任意属性,跳转至 taro.config.d.ts 类型声明文件。支持程度不同的平台详细请查阅官方文档。
tabBar
对于包含多个 tab(在客户端窗口底部或顶部有 tab 栏切换页面的)的小程序,tabBar 配置用于定义 tab 栏的外观以及每个 tab 对应的页面。
tabBar: {
color: "#434343",
selectedColor: "#333333",
// ... tabBar 属性和 tab 列表
}
tabBar 中的 list 属性是一个包含若干对象的数组,每个对象定义了一个 tab 项的页面路径、图标和文字等。点击 tab 时,应用会切换到对应的页面。
关于 tabBar 的更多详细配置项,也可以通过点击属性,跳转至 TypeScript 的类型声明文件中查看功能描述。

支持程度不同的平台详细请查阅官方文档
页面的config.ts配置文件
单个页面也可以有自己的配置文件,通常是 config.ts。页面配置会被 definePageConfig 函数包裹,并作为参数传入,其参数类型是 Taro.PageConfig。PageConfig 继承自 CommonConfig 类型。
export default definePageConfig({
navigationBarTitleText: '页面标题'
})

project.config.json 微信小程序配置文件
除了 Taro 的配置外,微信小程序也需一个 project.config.json,这个配置文件包含了微信小程序的专有配置。关于此配置你可以参考微信小程序官方文档。
来源:juejin.cn/post/7345063548705718312
站住!送你一个漂亮的毛玻璃渐变背景
大家好呀,我是 HOHO。
不知道你之前有没有接触过这种需求,实现一个下面这样的背景:

一层毛玻璃,然后后面有一些渐变的色块动来动去。这种效果大家应该都比较熟悉,之前有段时间 Apple 很热衷于使用类似的特效,说实话确实挺好看。我们一般管这种效果叫做 blurry gradient、或者模糊渐变、磨砂渐变、毛玻璃渐变。
本来以为一个背景而已,有什么难度,没成想一路走来还真踩到了不少的坑。本着我摔了一身泥不能让大家再摔一次的原则。我把这种效果封装成了一个 React 组件 react-blurry-gradient,大家可以直接拿来用,省的再抄代码浪费脑细胞。
在讲组件之前,我先来介绍一下都踩了哪些坑,如果你急用的话,前面直接无视就行。OK 话不多说,我们现在开始。
心路历程
1、shader gradient
其实一开始和 UI 沟通的时候,这个效果并不是典型的模糊渐变。而是一个 Shader,你可以在 这个网站 看到类似的效果,这个 Shader Gradient 还有对应的 Figma 插件。
这个效果其实实现起来不难,因为它提供了对应的 react 插件 ruucm/shadergradient: Create beautiful moving gradients on Framer, Figma and React。只需要把 UI 给的参数填进去就可以了。
但是事情并没有想象的那么简单,单纯的复刻效果倒没什么问题,问题出在这玩意居然自带一个十分离谱的入场特效:

可以看到,这个效果初始化的时候会有个旋转缩放的“入场动画”,让人忍俊不禁。不仅如此,这个背景还非常离谱的是可以拖动和缩放的:

这两个问题在组件的文档里并没有任何说明,我猜测这个效果组件是基于 threejs 实现的,出现这两个问题应该是 threejs 的一些默认设置没有关闭导致的。
不过这些也不是什么大问题,我们可以通过控制入场透明度和添加蒙层来解决。真正阻止我继续使用的是性能问题。因为这个项目要支持 H5 端,而老板的破水果手机打开这个效果都要燃起来了。没办法只能作罢。
2、css-doodle
听说这个效果差点让老板换手机之后,UI 挠了挠头,说要不我给你点颜色,你干脆写个毛玻璃渐变得了。我觉得他说的有道理,随手一搜,这不就来了:妙用滤镜构建高级感拉满的磨砂玻璃渐变背景。
css-doodle 我之前研究过,虽然不太喜欢这种写法风格,但是谁能拒绝直接抄的代码呢?三下五除二就搞成了 React 版本:
import 'css-doodle';
import styles from './index.module.less';
const DOODLE_RULES = `
:doodle {
@grid: 1x8 / 100vmin;
width: 100vw;
height: 100vh;
}
@place-cell: center;
width: @rand(40vw, 80vw);
height: @rand(40vh, 80vh);
transform: translate(@rand(-50%, 50%), @rand(-60%, 60%)) scale(@rand(.8, 1.8)) skew(@rand(45deg));
clip-path: polygon(
@r(0, 30%) @r(0, 50%),
@r(30%, 60%) @r(0%, 30%),
@r(60%, 100%) @r(0%, 50%),
@r(60%, 100%) @r(50%, 100%),
@r(30%, 60%) @r(60%, 100%),
@r(0, 30%) @r(60%, 100%)
);
background: @pick(#FBF1F7, #B27CEE, #E280AE, #c469ee, #a443ee, #e261bb, #e488ee);
opacity: @rand(.3, .8);
position: relative;
top: @rand(-80%, 80%);
left: @rand(-80%, 80%);
animation: pos-change @rand(4.1s, 10.1s) infinite 0s linear alternate;
@keyframes pos-change {
100% {
left: 0;
top: 0;
transform: translate(@rand(-50%, 50%), @rand(-60%, 60%)) scale(@rand(.8, 1.8)) skew(@rand(45deg))
}
}`;
export const Bg = () => {
return (
<div className={styles.loginBg}>
{/* eslint-disable-next-line @typescript-eslint/ban-ts-comment */}
{/* @ts-ignore */}
<css-doodle>{DOODLE_RULES}</css-doodle>
</div>
);
};
index.module.less
.loginBg {
position: absolute;
margin: 0;
width: 100%;
height: 100%;
display: flex;
align-items: center;
justify-content: center;
overflow: hidden;
background-color: #fff;
z-index: -1;
&::after {
content: '';
position: absolute;
top: -200%;
left: -200%;
right: -200%;
bottom: -200%;
backdrop-filter: blur(200px);
z-index: 1;
}
}
windows 上打开正常,但是 Safari 打开之后发现毛玻璃效果直接消失了,就像下面这样:

这给我整不会了,按理说 Safari 是支持 backdrop-filter 的。是 css-doodle 在 safari 上有什么兼容性问题?还是 react 和 css-doodle 的集成上出了什么毛病?我没深入了解,再加上本来不小的包体积,于是 css-doodle 方案也被我放弃了。

看看新组件 react-blurry-gradient
OK,踩了一圈子坑,下面该请出本文的主角 react-blurry-gradient 了,我们直接看效果:

如果 GIF 比较模糊的话可以试一下这个 codesandbox 在线 demo。
用法也很简单,安装,然后引入组件和对应的 css 文件即可:
npm install react-blurry-gradient
import { BlurryGradient } from 'react-blurry-gradient';
import 'react-blurry-gradient/style.css';
const colors = ['#bfdbfe', '#60a5fa', '#2563eb', '#c7d2fe', '#818cf8', '#4f46e5'];
export default function App() {
return (
<div style={{ width: '100vw', height: '100vh' }}>
<BlurryGradient colors={colors} />
</div>
);
}
组件会自动的从你指定的颜色列表中随机挑选颜色来生成渐变和动效。
如果你颜色也不想找,没问题,组件还内置了一套渐变颜色组,直接用就行了(目前包含红黄蓝绿紫五套):
import { BlurryGradient, COLORS } from 'react-blurry-gradient';
import 'react-blurry-gradient/style.css';
export default function App() {
return (
<div style={{ width: '100vw', height: '100vh' }}>
<BlurryGradient colors={COLORS.BLUE} />
</div>
);
}
这些颜色就是单纯的字符串数组,所以你可以把这些颜色兑在一起来实现撞色的效果:
<BlurryGradient colors={[...COLORS.BLUE, ...COLORS.RED]} />


如果你想设置背景色,没问题,react-blurry-gradient 本身就是透明的,也就是说你背景用什么都可以,直接设置给父元素就行了:
export default function App() {
return (
<div style={{ backgroundColor: COLORS.BLUE[0], width: '100vw', height: '100vh' }}>
<BlurryGradient colors={COLORS.BLUE} />
</div>
);
}
预设的 COLORS 第一个元素都是颜色最淡的,你可以直接拿来当作背景。
把这个背景色设置给 BlurryGradient 组件的 style 也可以,不过这样会在边缘形成一圈扩散的效果,而设置给父元素的话背景色就会更均一。
另外毛玻璃的模糊效果也是可以调整的,只需要设置 blur 参数即可,比如你可以调低一点,我觉得也挺好看的:
<BlurryGradient colors={[...COLORS.BLUE, ...COLORS.RED]} blur='20px' />


除此之外还有很多额外参数,例如可以通过 itemNumber 来控制生成色块的数量。可以通过 itemTop、itemLeft 来控制色块随机生成的位置范围。更多的属性可以在 react-blurry-gradient 配置参数 找到。
如果你不希望随机生成,想精确控制每个色块的颜色、尺寸、位置和运动轨迹,没问题,BlurryGradient 组件的 items 参数允许你指定每个色块的详细配置。参数说明可以看 这里。但是要注意,启用了 items 之后,colors 的配置就会被忽视了。
零依赖 & 极小体积
这个组件从一开始就以够轻量为宗旨,所以你可以看到它没有依赖任何第三方包,只要你项目里有 React,那它就能用:

而包本身也足够的清爽,不会往你电脑里拉屎:

组件所有的代码加起来只有 4Kb 不到。

当然,如果你真的不想因为这种小事再引一个包,没问题,都帮你收拾好了,把 这个文件夹 直接复制到你的项目里就能用,给个 star 意思一下就行~
来源:juejin.cn/post/7446018863504506907
都快2025年了,你们的前端代码都上装饰器了没?
可能很多人都听说过 TypeScript 的装饰器,也可能很多人已经在很多 NestJS 项目中使用装饰器了,也有一些前端开发者可能在某些前端框架中使用过一些简单的装饰器,那么你真的知道装饰器在前端还能玩出哪些花吗?
我们今天不讲基础概念,也不写一些你可能在很多文章里都看到过的没有意义的示例代码,我们直接拿装饰器来实战实现一些需求:
一、类装饰器
虽然很多前端对于类和面向对象是排斥的、抵触的,但不影响我们这篇文章继续来基于面向对象通过装饰器玩一些事情。
我已经写了很多关于面向对象在前端的使用了,实在是不想在这个问题上继续扯了,可以参考本专栏内的其他文章。
虽然但是,不论如何,你可以不用,但你不能不会,更不能不学。
不管在前端还是后端,我们可能都会用到类的实例来做一些事情,比如声明一个用户的类,让用户的类来完成一些事情。
我们可能会为类配置名称,比如给 User 类定义为 用户:
// 声明一个装饰器,用来保存类的文案
function Label(label: string) {
return (target: any) => {
Reflect.set(target, "label", label)
}
}
@Label("用户")
class User {
}
我们不限制被标记的类,你可以把any 用泛型约束一下,限制这个装饰器可以标记到哪些类的子类上。
我们可以通过 Reflect 来获取到类上的元数据,比如 Label 这个类上的 name 属性,通过 Reflect.getMetadata('name', User) 来获取到:
// 将打印 "用户"
console.log(Reflect.get(User, "label"))
通过这种方式,我们可以为类标记很多配置,然后在使用的时候就不会在代码里再出现很多类似 “用户” 的魔法值了。如果有改动的话,也只需要将 @Label("用户") 改成 @Label("XXX") 就好了。
当然,事实上我们不会单独为了一个小功能去声明一个装饰器,那样到时候会给类上标记很多的 @ 看着难受,于是我们可以直接声明一个 ClassConfig 的装饰器,用来保存类的各种配置:
interface IClassConfig {
// 刚才的 label
label?: string
// 添加一些其他的配置
// 表格的空数据文案
tableEmptyText?: string
// 表格删除提醒文案
tableDeleteTips?: string
}
function ClassConfig(config: IClassConfig){
return (target: any) => {
Reflect.set(target, "config", config)
}
}
@ClassConfig({
label: "用户",
tableEmptyText: "用户们都跑光啦",
tableDeleteTips: "你确定要删除这个牛逼的人物吗?"
})
当然,我们可以通过 Reflect.getMetadata('config', User) 来获取到 ClassConfig 这个类上的配置,然后就可以在代码里使用这些配置了.
比如,我们还封装了一个 Table 组件,我们就只需要将
User这个类传过去,表格就自动知道没数据的时候应该显示什么文案了:
<Table :model="User" :list="list" />
上面的表格内部,可以获取 model 传入的类,再通过 Reflect 来获取到这些配置进行使用,如果没有配置装饰器或者装饰器没有传入这个参数,那么就使用默认值。
二、属性装饰器
很多人都知道,装饰器不仅仅可以配置到类上,属性上的装饰器用处更多。
这个和上面第一点中的一样,也可以为属性做一些配置,比如给用户的账号属性做配置,而且我们还可以根据主要功能来声明不同的装饰器,比如表单的 @Form,表格的 @Table 等等。
class User {
@Field({
label: "账号",
// 如果下面的没有配置,那我来兜底。
isEmail: true,
})
@Form({
// 表单验证的时候必须是邮箱
isEmail: true,
// 表单验证的时候不能为空
isRequired: true,
placeholder: "请输入你牛逼的邮箱账号"
})
@Table({
// 表示表格列的邮箱点击后会打开邮件 App
isEmail: true,
// 表格列的宽度
width: 200,
// 需要脱敏显示
isMask: true
})
account!: string
}
当然,属性的装饰器声明和类的声明方式不太一致:
interface IFieldConfig {
label?: string
isEmail?: boolean
}
function Field(config: any) {
return (target: any, propertyKey: string) => {
Reflect.set(target, propertyKey, config)
}
}
使用 Reflect 获取的时候也不太一致:
const fieldConfig = Reflect.get(User.prototype, "account")
// 将打印出 `@Field` 配置的属性对象
console.log(fieldConfig)
想象一下,你封装的表格我也这么使用,我虽然没有传入有哪些表格列,但你是不是能够通过属性是否标记了 @Table 装饰器来判断是否需要显示这个邮箱列呢?
<Table :model="User" :list="list" />
你也可以再封装一些其他的组件,比如表单,比如搜索等等等等,像这样:
<Input :model="User" :field="account" />
上面的 Input 组件就会自动读取 User 这个类上的 account 属性的配置,然后根据配置来渲染表单和验证表单,是不是美滋滋?
三、方法装饰器和参数装饰器
这两个方式的装饰器我们在这篇文章不细讲,等装饰器这玩意在前端能被大家接受,或者前端娱乐圈骂面向对象不再那么狠的时候再细化一下吧,今天我们只讲讲简单使用:
3.1 方法装饰器
说到方法装饰器,我想先提一嘴 AOP 编程范式。
AOP(Aspect Oriented Programming) 是一种编程范式,它把应用程序切面化,即把应用程序的各个部分封装成可重用的模块,然后通过组合这些模块来构建应用程序。
举个简单的例子,我们最开始写好了很多代码和方法:
class User {
add(name: string) {
console.log("user " + name + " added!")
}
delete(name: string) {
console.log("user " + id + " deleted!")
}
}
const user = new User();
user.add("Hamm")
user.delete("Hamm")
以前调用这些方法都是正常的,突然有一天需求变了,只允许超级管理员才能调用这两个方法,你可能会这么写:
class User {
add(name: string) {
checkAdminPermission()
console.log("user " + name + " added!")
}
// 其他方法
}
function checkAdminPermission() {
if(!你的条件){
throw new Error("没有权限")
}
}
const user = new User();
user.add("Hamm")
虽然也没毛病,但需要去方法内部添加代码,这属于改动了已有的逻辑。
而 AOP 存在的意义,就是通过切面来修改已有的代码,比如在方法执行前,执行一段代码,在方法执行后,执行一段代码,在方法执行出错时,执行一段代码,等等。用更小的粒度来减少对已有代码的入侵。像这样:
class User {
@AdminRequired
add(name: string) {
console.log("user " + name + " added!")
}
}
function AdminRequired(target: any, propertyKey: string, descriptor: PropertyDescriptor) {
const originalMethod = descriptor.value
descriptor.value = function (...args: any[]) {
if (你的条件) {
return originalMethod.apply(this, args)
}
throw new Error("没有权限")
}
}
const user = new User()
console.log(user.add("Hamm"))
乍一看,我就知道又会有人说:“你这代码不是更多了么?” 看起来好像是。
但事实上,从代码架构上来说,这没有对原有的代码做任何改动,只是通过 AOP 的方式,在原有代码的基础上,添加了一些前置方法处理,所以看起来好像多了。但当我再加上一些后置的方法处理的话,代码量并没有添加多少,但结构会更清晰,代码入侵也没有。
传统写法(入侵)
class Test{
张三的方法(){
// 李四的前置代码
// 张三巴拉巴拉写好的代码
// 李四的后置代码
}
}
张三:“李四,你为什么用你的代码包围了我的代码!”
装饰器写法(不入侵)
class Test {
@LiSiWantToDoSomething
张三的方法() {
// 张三巴拉巴拉写好的代码
}
}
function LiSiWantToDoSomething(target: any, propertyKey: string, descriptor: PropertyDescriptor) {
const originalMethod = descriptor.value
descriptor.value = function (...args: any[]) {
console.log("李四的前置代码")
const result = originalMethod.apply(this, args)
console.log("张三干完了,结果是" + result)
return "我是李四,张三的结果被我偷走了"
}
}
这时,张三的代码完全在不改动的情况下添加了前置和后置代码。
3.2 参数装饰器
参数装饰器的使用场景在前端比较少,在 Nest 中比较多,这篇文章就不过多介绍了,如果后续大伙有兴趣我们再聊。
四、总结
装饰器是一种新的语法,可以让你的前端代码更加的架构化,增加代码的可维护性。
如果你有兴趣,还可以阅读本专栏内的这些文章:
TypeScript中如何用装饰器替代JSON配置项封装表单
当然,其他文章也很有意思哟~
今天就这样,欢迎继续关注我们的专栏 《用TypeScript写前端》
也欢迎关注我们的开源项目: AirPower4T,里面有很多装饰器在前端的应用场景,也许可以让你耳目一新。
Bye.
来源:juejin.cn/post/7449313175920459811
不要再二次封装 axios 了,它真的是“灵丹妙药”吗?
引言
最近,看到不少开发者在讨论如何“优雅地”封装 axios 时,我的内心不禁发出一声叹息——“收手吧阿祖,别再封装了!”我们都知道,axios 是一个轻量级的 http 客户端库,广泛用于前端和 node.js 环境中,因其简洁易用、功能丰富而备受喜爱。但问题来了:为什么那么多人非要二次封装它?是想追求什么“优雅”代码,还是只是满足某种程序员的“封装癖”?在我看来,二次封装 axios 的行为,其实更多的是“低效”和“麻烦”!
在这篇文章中,我将分析二次封装 axios 的现象,揭示它的弊端,并提出更合理的解决方案。
二次封装 axios 背后的动机
首先,得承认,在许多开发者的心目中,二次封装 axios 是“提升代码复用性”、“提升可维护性”的一种手段。究竟是什么驱动他们这么做呢?让我们来看看,通常的封装动机有哪些。
- 全局配置管理
很多人为了避免在每个请求中都写重复的配置(如 baseURL、timeout、headers 等),于是将 axios 封装成一个单独的模块,统一管理。这样一来,代码看似简洁了。 - 请求/响应拦截器
除了常见的全局配置外,二次封装通常还会加入请求和响应拦截器,用于做统一的错误处理、日志记录、token 刷新等。这听起来很有吸引力,似乎让项目更加“健壮”了。 - 封装错误处理
统一处理 HTTP 错误,诸如 400、500 错误等,这让开发者避免了在每个请求中重复编写错误处理逻辑。 - 功能扩展
比如:增加一些额外的功能,比如请求重试、自动刷新 token、请求取消等。
这些动机听起来有理有据,似乎是为了减少重复代码、提高效率。但,二次封装真的是解决问题的最佳方法吗?
二次封装 axios 的弊端:看似优雅,实际繁琐
虽然二次封装看起来很“高级”,但它带来的问题也是显而易见的。
1. 失去灵活性,降低可维护性
当我们通过二次封装 axios 将所有请求逻辑集中到一个地方时,代码复用的确得到了提高,但灵活性却大大下降。每当我们需要调整请求方式、处理特殊错误、或者添加新的请求功能时,必须在封装层修改代码,这意味着对每一个新请求的修改都变得更加复杂,导致代码膨胀,维护成本上升。
举个例子,假设你有一个简单的请求需要添加一个额外的请求头或参数,但你的封装类已经把一切都“包裹”得很严实,你不得不进入封装类的内部进行修改。这种情况下,封装的意义反而变得虚假。
2. 过度封装,增加不必要的复杂性
封装本应是为了简化代码,但过度封装反而让事情变得更加复杂。例如,很多二次封装的 axios 都包含了一堆的“自定义配置”,导致请求时你不得不先了解封装类的具体实现,甚至可能在不同项目之间迁移时也要重新学习一套封装规范。每次需要调用 api 的时候,都要与一个封装层打交道,这显然不是开发者想要的高效体验。
3. 性能问题:拦截器是双刃剑
请求和响应拦截器的设计初衷无疑是为了统一处理请求逻辑,但过多的拦截器往往会导致性能瓶颈。特别是在大型项目中,拦截器的链式执行可能带来额外的延迟。此外,拦截器中常常会加入错误处理、token 刷新等额外逻辑,这会影响整个请求链的执行效率。
4. 可能引发版本兼容性问题
随着项目的不断迭代,封装的代码与 axios 原生的更新频繁不一致,导致二次封装的代码容易发生维护上的“断层”或兼容性问题。每当 axios 更新时,可能需要你手动修复封装类中的依赖,甚至重构整个封装层,造成额外的开发工作量。
为什么我们不需要二次封装 axios?
那么,既然二次封装带来了这么多麻烦,我们应该如何解决 axios 使用中的痛点呢?
1. 使用 axios 的内置功能
axios 本身就有非常强大的功能,很多二次封装中提到的配置(比如 baseURL、headers 等)都可以直接通过 axios 的实例化来轻松解决。例如:
const axiosInstance = axios.create({
baseURL: 'https://api.example.com',
timeout: 1000,
headers: {'X-Custom-Header': 'foobar'}
});
这样,所有请求都可以通过统一的实例管理,无需复杂的封装,且灵活性保持不变。
2. 合理使用拦截器
axios 的请求和响应拦截器非常强大,用得好可以让你的代码更简洁。错误处理、token 刷新、请求取消等功能,都可以直接在 axios 拦截器中完成,而不需要一个额外的封装类。
axios.interceptors.response.use(
response => response,
error => {
if (error.response.status === 401) {
// Token 刷新逻辑
}
return Promise.reject(error);
}
);
通过这种方式,我们在全局进行处理,而不需要一层一层的封装,让代码保持简洁并且具有良好的扩展性。
3. 利用第三方库增强功能
如果你确实需要一些特殊的功能(比如请求重试、缓存、自动重定向等),可以使用现成的第三方库,而不是自己重复造轮子。比如:
- axios-retry:轻松实现请求重试
- axios-cache-adapter:请求缓存
- axios-auth-refresh:自动刷新 token
这些库都能与 axios 配合得很好,帮助你解决二次封装中出现的某些功能问题,避免在项目中增加冗余的封装层。
4. 模块化的请求管理
而对于需要统一管理的 api 请求,推荐将每个请求模块化,分层管理,而不是在一个封装类中把所有请求都硬编码。你可以根据需求将每个 api 的请求抽象成一个独立的函数或模块,保持高内聚低耦合的设计。
// api/user.js
export function getUserInfo(userId) {
return axios.get(`/users/${userId}`);
}
这样做的好处是,当某个接口发生变化时,只需要修改相应的模块,而不需要担心影响到其他的请求。
总结
二次封装 axios 是一种源自“代码复用”的良好初衷,但它往往带来了灵活性不足、复杂度增加、性能损失等一系列问题。在面对实际开发中的 http请求时,我们可以通过直接使用 axios 的内置功能、合理利用拦截器、借助现成的第三方库以及模块化管理等方式来更高效、更优雅地解决问题。
所以,不要再二次封装 axios 了,它并不是“灵丹妙药”。让我们回归简单,享受 axios 原生的优雅与高效吧!
来源:juejin.cn/post/7441853217522204681
不懂这些GIS基础,开发Cesium寸步难行!
大家好,我是日拱一卒的攻城师不浪,专注可视化、数字孪生、前端提效、nodejs、AI学习、GIS等学习沉淀,这是2024年输出的第30/100篇文章。
前言
想学Cesium开发,你如果对一些GIS基础,特别是坐标系概念不了解的话,会让你非常难受,今天我们就来聊聊WebGiser开发过程中常用到的一些坐标系概念。
GIS坐标系
要熟悉Cesium中常用到的一些坐标类型以及它们之间是如何进行转换的,到了真正用到的时候可以再返回来细看,加深理解。
经纬度坐标(球面坐标)
经纬度坐标通常被称为地理坐标或地球坐标,它是一种基于地球表面的坐标系统,用于确定地球上任何点的位置。这种坐标系统使用两个主要的数值来表示位置:经度和纬度。

- 经度(Longitude):表示从本初子午线(通常通过英国伦敦的格林尼治天文台)向东或向西的角度距离。经度的范围是从 -180° 到 +180°,其中 0° 表示本初子午线。
- 纬度(Latitude):表示从赤道向北或向南的角度距离。纬度的范围是从 -90°(南极点)到 +90°(北极点),其中 0° 表示赤道。
经纬度坐标也常常被称为:
- 球面坐标(Spherical Coordinates):因为地球近似为一个球体,经纬度坐标可以看作是在球面上确定点的位置。
- 大地坐标(Geodetic Coordinates):在大地测量学中,这种坐标系统用于描述地球表面的点。
- WGS84坐标:WGS84(World Geodetic System 1984)是一种广泛使用的全球地理坐标系统,它提供了一个标准化的参考框架,用于地理定位。
经纬度坐标广泛应用于地图制作、导航、地理信息系统(GIS)、航空和海洋导航等领域。在数字地图服务和应用程序中,经纬度坐标是最常见的位置表示方式之一。
地理坐标(弧度)
在地理信息系统(GIS)中,地理坐标通常指的是地球上某个点的位置,使用经纬度来表示。然而,由于地球是一个近似的椭球体,使用弧度而非角度来表示经纬度坐标可以避免在计算中引入的某些复杂性,尤其是在进行距离和面积的测量时。

弧度是一种角度的度量单位,它基于圆的周长和半径之间的关系。一个完整的圆周被定义为 2π弧度。弧度与角度的转换关系如下:

在GIS中,使用弧度的地理坐标可以简化一些数学运算,尤其是涉及到三角函数和地球曲率的计算。例如,计算两点之间的大圆距离(即地球表面的最短路径)时,使用弧度可以更直接地应用球面三角学公式。
地理坐标(弧度)的应用
- 距离计算:使用球面三角学公式,可以更准确地计算出两点之间的距离。
- 方向计算:确定从一个点到另一个点的方向,使用弧度可以简化计算过程。
- 地图投影:在某些地图投影中,使用弧度可以更自然地处理地球表面的曲率。
屏幕坐标系
屏幕坐标系(Screen Coordinate System)是一种二维坐标系统,它用于描述屏幕上的点或区域的位置。屏幕坐标系通常以屏幕的左上角为原点,水平向右为 x 轴正方向,垂直向下为 y 轴正方向。

屏幕坐标系在Cesium中叫做二维笛卡尔平面坐标。
new Cesium.Cartesian2(x, y)
屏幕坐标系的特点:
- 原点位置:屏幕坐标系的原点(0,0)位于屏幕的
左上角。 - 正方向:x 轴正方向向右,y 轴正方向向下。
- 单位:通常使用像素(px)作为单位。
- 范围:坐标值的范围取决于屏幕或窗口的大小。
空间直角坐标系
在地理信息系统(GIS)中,空间直角坐标系(Spatial Cartesian Coordinate System)是一种三维坐标系统,用于在三维空间中精确地表示点、线、面的位置。这种坐标系通常由三个正交的坐标轴组成:X、Y 和 Z 轴。

空间直角坐标系的特点:
- 正交性:X、Y 和 Z 轴相互垂直,形成一个直角坐标系。
- 三维性:可以表示三维空间中的任何位置,包括高度或深度信息。
- 标准化:通常以地球的质心或某个参考点为原点,建立一个标准化的坐标系统。
- 应用广泛:广泛应用于地理测量、城市规划、建筑设计、3D 建模等领域。
Cesium中的坐标系
Cesium中支持两种坐标系:3D笛卡尔坐标系和经纬度坐标系;
3D笛卡尔坐标系
先来了解下笛卡尔空间直角坐标系,它的X、Y、Z三个轴的正方向如下图所示:

坐标系的原点位于地球的中心。因此,这些坐标通常是负的。单位通常是米。
Cesium.Cartesian3(x, y, z)
地理坐标系
是一种基于经度和纬度的坐标系,它使用度数来表示位置。
在Cesium中,地理坐标可以通过将经度、纬度和高度值传递给Cartographic对象来表示。
其中经度和纬度是以度数表示的,高度值可以是以米或其他单位表示的。
Cesium将地理坐标转换为笛卡尔坐标以在地球表面上进行可视化。
坐标系转换
Cesium提供了很多坐标系互相转换的大类。
经纬度转空间直角
const cartesian3 = Cesium.Cartesian3.fromDegrees(lng, lat, height);
经纬度转地理坐标(弧度)
const radians = Cesium.Math.toRadians(degrees)
地理坐标(弧度)转经纬度
const degrees = Cesium.Math.toDegrees(radians)
空间直角转经纬度
// 先将3D笛卡尔坐标转为地理坐标(弧度)
const cartographic = Cesium.Cartographic.fromCartesian(cartesian3);
// 再将地理坐标(弧度)转为经纬度
const lat = Cesium.Math.toDegrees(cartographic.latitude);
const lng = Cesium.Math.toDegrees(cartographic.longitude);
const height = cartographic.height;
屏幕坐标转经纬度
// 监听点击事件,拾取坐标
const handler = new Cesium.ScreenSpaceEventHandler(viewer.scene.canvas);
handler.setInputAction((e) => {
const clickPosition = viewer.scene.camera.pickEllipsoid(e.position);
const randiansPos = Cesium.Cartographic.fromCartesian(clickPosition);
console.log(
"经度:" +
Cesium.Math.toDegrees(randiansPos.longitude) +
", 纬度:" +
Cesium.Math.toDegrees(randiansPos.latitude)
);
}, Cesium.ScreenSpaceEventType.LEFT_CLICK);
屏幕坐标转空间直角坐标
var cartesian3 = viewer.scene.globe.pick(viewer.camera.getPickRay(windowPostion), viewer.scene);
世界坐标转屏幕坐标
windowPostion = Cesium.SceneTransforms.wgs84ToWindowCoordinates(viewer.scene, cartesian3);
结语
作者的Cesium系列课程**《Cesium从入门到实战》**即将完结,课程介绍:ww7rybwvygd.feishu.cn/docx/PG1TdA…
如果想自学Cesium的也可以参考我的【开源项目】:github.com/tingyuxuan2…
有需要进技术产品开发交流群(可视化&GIS)可以加我:brown_7778(备注来意),也欢迎
数字孪生可视化领域的交流合作。
最后,如果觉得文章对你有帮助,也希望可以一键三连👏👏👏,支持我持续开源和分享~
来源:juejin.cn/post/7404091675666055209
苹果 visionOS for web
苹果的 Vision Pro 已经发布了,虽然没有拿到手,但我还是对它的操作界面充满了好奇。
我看到很多小伙伴写了 Windows for Web,Mac OS for Web,所以我也想来实现一下 Vision Pro 的系统主页。
一开始,我以为这不会太难,当头一棒的就是苹果祖传优势: 动画。

这动画,这模糊,还是从中心点开始逐渐向外层扩散,应该根据人眼的视觉特征进行设计的。
问题是,该如何实现呢?
模糊我知道怎么实现,
filter: blur(15px);
从中心点开始逐渐向外层扩散的效果,我直接来个
transition-delay: 0.1s;
一通操作之下,也实现就似是而非的效果。而且边缘处app图标的缓缓落下的效果也不好。

然后就是光影效果的实现,因为它的很美,让人很难忽略。
在 Vision Pro 系统演示中可以看出,为了模拟菜单栏使用了磨砂玻璃材质,而为了营造真实感,会模拟光照射到玻璃上而形成的光线边框。
我不知道这是不是菲涅尔效应,但问题是,这又该如何在前端实现呢?
我想到了 CSS Houdini,可以利用 Houdini 开放的底层能力 paint 函数来实现一个菜单栏效果。
if ('paintWorklet' in CSS) {
CSS.paintWorklet.addModule('data:text/javascript,' + encodeURIComponent(`
class FresnelAppRectPainter {
static get inputProperties() { return ['--light-angle']; }
paint(ctx, size, properties) {
const borderRadius = 30;
const fresnelColor = 'rgba(255, 255, 255, .9)';
const lightAngle = parseFloat(properties.get('--light-angle')[0]) || 0;
// 绘制圆角矩形
ctx.beginPath();
ctx.moveTo(borderRadius, 0);
ctx.lineTo(size.width - borderRadius, 0);
ctx.arcTo(size.width, 0, size.width, borderRadius, borderRadius);
ctx.lineTo(size.width, size.height - borderRadius);
ctx.arcTo(size.width, size.height, size.width - borderRadius, size.height, borderRadius);
ctx.lineTo(borderRadius, size.height);
ctx.arcTo(0, size.height, 0, size.height - borderRadius, borderRadius);
ctx.lineTo(0, borderRadius);
ctx.arcTo(0, 0, borderRadius, 0, borderRadius);
ctx.closePath();
ctx.fillStyle = 'rgba(163, 163, 163)';
ctx.fill();
// 模拟光照效果
const gradient = create360Gradient(ctx, size, lightAngle)
ctx.fillStyle = gradient;
ctx.fill();
// 添加菲涅尔效果
const borderGradient = ctx.createLinearGradient(0, 0, size.width, size.height);
borderGradient.addColorStop(0, fresnelColor);
borderGradient.addColorStop(0.2, 'rgba(255,255,255, 0.7)');
borderGradient.addColorStop(1, fresnelColor);
ctx.strokeStyle = borderGradient;
ctx.lineWidth = 1.5;
ctx.stroke();
}
}
registerPaint('fresnelAppRect', FresnelAppRectPainter);
`));
}
结果效果还可以,我甚至可以接收一个光的入射角度,来实时绘制光影效果。
function create360Gradient(ctx, size, angle) {
// 将角度转换为弧度
const radians = angle * Math.PI / 180;
// 计算渐变的起点和终点
const x1 = size.width / 2 + size.width / 2 * Math.cos(radians);
const y1 = size.height / 2 + size.height / 2 * Math.sin(radians);
const x2 = size.width / 2 - size.width / 2 * Math.cos(radians);
const y2 = size.height / 2 - size.height / 2 * Math.sin(radians);
// 创建线性渐变
const gradient = ctx.createLinearGradient(x1, y1, x2, y2);
gradient.addColorStop(0, 'rgba(255, 255, 255, 0.2)');
gradient.addColorStop(1, 'rgba(255, 255, 255, 0)');
return gradient;
}

演示效果图
哦对了,还有一个弹层底边角的缩放效果,我目前还没想到什么好办法来实现,年底还得抓紧搬砖,只能先搁置了,如果小伙伴们有好办法,欢迎告知或者讨论。

最终效果图
这里是 Demo 地址。
本来是冲着纯粹娱乐(蹭流量)来写的,但写着写着就发现好像没那么简单,三个晚上过去,也只写了个首页,不得不感慨苹果真的太细了呀。
以上。
来源:juejin.cn/post/7329280514627600425
美女运营老师,天天找我改配置,我用node给她写了个脚本,终于安静了
美女运营老师,天天找我改配置,给她写了个脚本,终于安静了
事情的起因是,加入到新的小组中,在开发低代码后台管理页面的需求,需要配置一些下拉选项,后端因为一些特殊的原因,没法提供api接口,所以需要前端写成配置选项。这样问题就来了,新增了选项,但是没有给前端配置。美女运营老师都会来找开发,说:为什么新导入的数据没有显示啊,是不是有bug。。找了一圈发现是配置没加

我让运营老师,把新增数据表格给我配置下,丢过来新增数据上来就是1000+,手动加要哭死。于是我就想能否用脚本生成一个。
刚开始借用在线CSV转换JSON
把csv下载到本地,转换成json,返回数据倒是能返回,但是不符合运营老师的要求,key值需要是 key: ${data.value}-${data.key}


于是我就写了下面第一个简单版的node脚本
const fs = require('fs')
const csv = require('csv-parser');
const uidsfilePath = './uids.json';
const datas = [`复制生成的json数据`];
let newarr = [];
format(datas);
fs.writeFile(uidsfilePath, JSON.stringify(newarr), () => {
console.log('done')
})
const format = (results) => {
newarr = results.map(item => {
return {
label: `${item.value}-${item.key}`,
value: item.value
}
})
}
okok 到这里可以生成了。但是吧,想把这个事情还给运营老师,嘿
于是我又在这个基础上加上了读取CSV文件,格式化数据,输出JSON文件
使用 csv-parser读取 csv文件
csv-parser 是一个为Node.js设计的高效且流线型库,专注于快速解析CSV数据。它旨在提供最小的开销,保持简单轻量,特别适配于Node.js的流处理。此库遵循RFC 4180标准,并通过csv-spectrum的酸性测试套件,确保了对各种CSV变体的广泛兼容性和正确性。性能方面,csv-parser在处理大文件时表现出色,无论是带引号还是不带引号的CSV数据。
快速使用csv-parser
开始使用csv-parser,首先确保你的环境中已安装Node.js。接着,通过npm安装
csv-parser:
npm install csv-parser
示例代码
const fs = require('fs');
const parse = require('csv-parser');
fs.createReadStream('yourfile.csv')
.pipe(parse({ headers: true }))
.on('data', (row) => {
console.log(row);
})
.on('end', () => {
console.log('CSV file successfully processed');
});
第二版脚本
直接获取csv文件,生成输出JSON
const fs = require('fs')
const csv = require('csv-parser');
const csvfilePath = './新增UID.csv';
const uidsfilePath = './uids.json';
const results = [];
let newarr = [];
fs.createReadStream(csvfilePath)
.pipe(csv({ headers: true }))
.on('data', (data) => {
results.push(data);
})
.on('end',async () => {
await format(results);
fs.writeFile(uidsfilePath, JSON.stringify(newarr), () => {
console.log('done')
})
});
const format = (results) => {
newarr = results.map(item => {
if(item._0 === 'key' || item._1 === 'value') {
return {}
}
return {
label: `${item._1}-${item._0}`,
value: item._1
}
})
}
部分生成的数据

到这里又节省了一些时间,但是运营老师既不会安装node,也不会使用命令执行node CSVtoJSON.js,太复杂了不会弄。。。我说你提个需求吧,后面给您做成页面上传csv文件,返回JSON数据,点击一键复制好不好。
仅供娱乐,欢迎吐槽
未完待续,持续更新中...
感谢关注点赞评论~
来源:juejin.cn/post/7442489501590044672
【环信uniapp uikit】手把手教你uniapp uikit运行到鸿蒙
写在前面:
好消息好消息,环信uniapp出uikit啦~
更好的消息,环信uniapp sdk也支持鸿蒙系统啦!!!!那么我们一起来看看uniapp uikit如何运行到鸿蒙系统~~let's go
uniapp uikit以及支持鸿蒙系统的uniapp sdk版本都是`4.11.0`
准备工作
1. HBuilderX 4.36
2. DevEco-Studio 5.0.5.310
3. sass:sass-loader 10.1.1 及之前版本
4. node:12.13.0 - 17.0.0,推荐 LTS 版本 16.17.0
5. npm:版本需与 Node.js 版本匹配
6. 已经在环信即时通讯云控制台创建了有效的环信即时通讯 IM 开发者账号,并获取了App Key
7. 了解uniapp创建运行鸿蒙系统
8. 了解uniapp UIkit各功能以及api调用
开始集成:
第一步:创建一个uniapp+vue3项目进度10%
第二步:安装依赖 进度15%npm init -y
npm i easemob-websdk@4.11.0 pinyin-pro@3.26.0 mobx@6.13.4 --save
第三步:下载uniapp uikit源码 进度20%git clone https://github.com/easemob/easemob-uikit-uniapp.git
第四步:拷贝uikit组件 进度50%
mkdir -p ./ChatUIKit
# macOS
mv ${组件项目路径}/ChatUIKit/* ./ChatUIKit
# windows
move ${组件项目路径}/ChatUIKit/* .\ChatUIKit
第五步:替换pages/index/index.vue文件 进度70%
第六步:替换app.vue文件 进度80%
第七步:在pages.json配置路由 进度90%
{
"pages": [
{
"path": "pages/index/index",
"style": {
"navigationBarTitleText": "uni-app"
}
},
{
"path": "ChatUIKit/modules/Chat/index",
"style": {
"navigationStyle": "custom",
// #ifdef MP-WEIXIN
"disableScroll": true,
// #endif
"app-plus": {
"bounce": "none",
"softinputNavBar": "none"
}
}
},
{
"path": "ChatUIKit/modules/VideoPreview/index",
"style": {
"navigationBarTitleText": "Video Preview",
"app-plus": {
"bounce": "none"
}
}
}
]
}
第八步:运行到chrome浏览器看下效果 进度90% 
第九步:运行到鸿蒙并发送一条消息 进度100%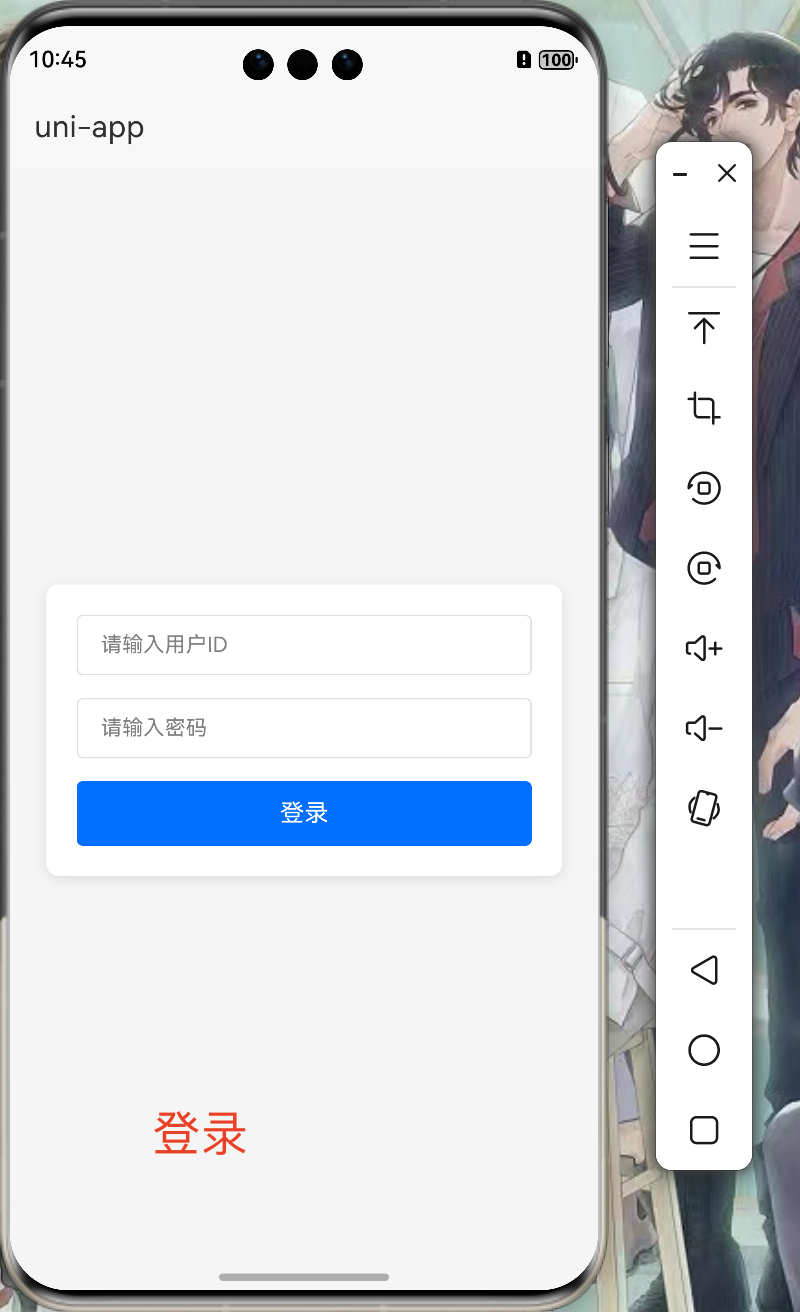
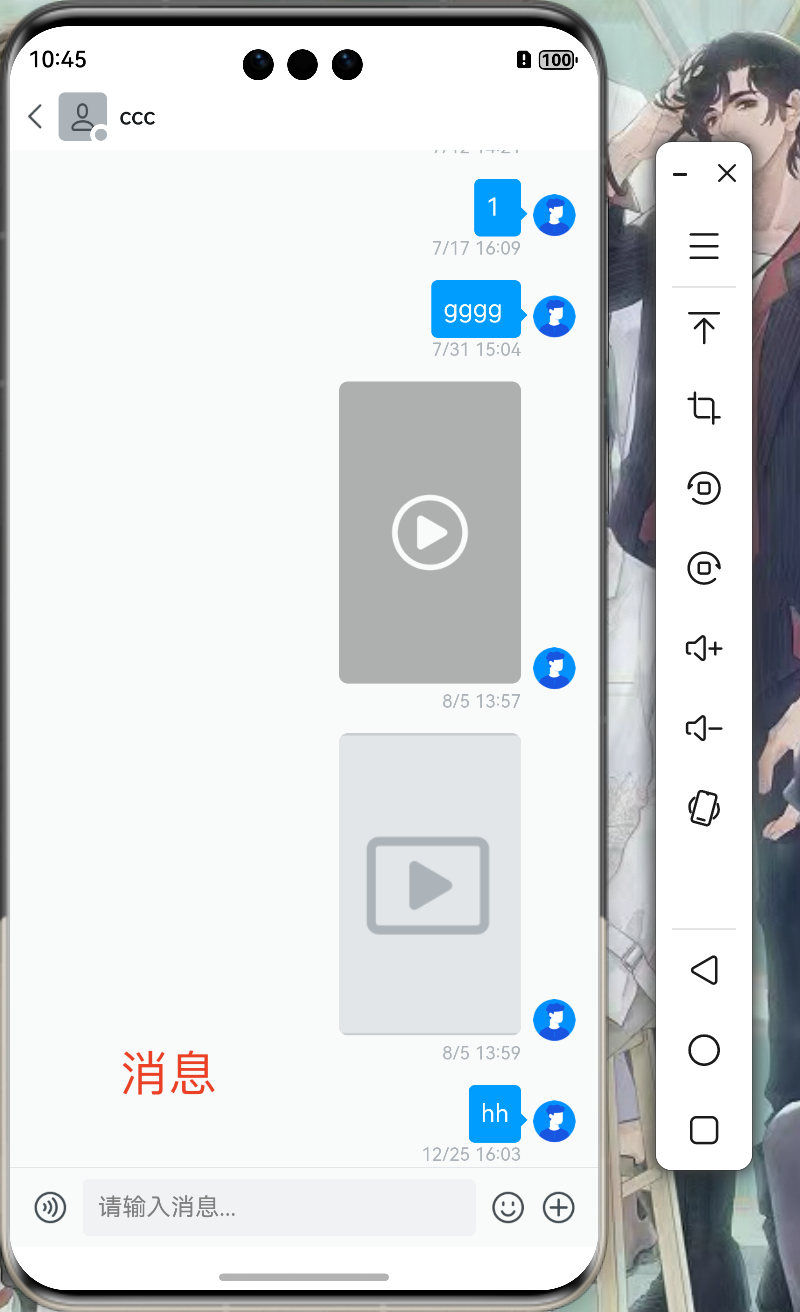
遇到的问题:
问题1:
详细报错信息如下
hvigor ERROR: Invalid product for target 'default'.
Detail: Check the target applyToProducts field for 'default': [ 'default', 'release' ].
at /Users/admin/Desktop/ouyeel_worksheet/unpackage/debug/app-harmony-2f573459/build-profile.json5
解决方案:
在harmony-configs/build-profile.json5文件,复制default配置,将default改为relese,参考
问题2:
登录报错
解决方案:
在/harmony-configs/entry/src/main/module.json5文件添加以下代码
"requestPermissions": [ {"name": "ohos.permission.GET_NETWORK_INFO"}, { "name": "ohos.permission.INTERNET"}, ],
问题3:
HBuilderX无限重连
解决方案:
看看sdk 是不是最新版,无限重连的问题已经在 4.12.0版本的sdk修复~
总结:
初步运行到鸿蒙的话问题会比较多,大家可以善用百度大法解决掉它!!!
老板不让用ECharts,还想让我画很多圆环!
需求简介
这几天下来个新需求:要在页面上动态渲染多个表格,每个表格内还要实现若干圆环!

刚拿到这个需求的时候,我第一反应是用echarts实现,简单快捷

然而,老板无情的拒绝了我!他说:
咱这个项目就一个独立页面,你引入个ECharts项目又要大很多!而且一个页面这么多ECharts实例,性能怎么保障?不准用ECharts,用CSS实现!
没办法,我只好百度如何用CSS画圆环。幸运的是,我确实找到了类似的文章:

不幸的事,效果和我的差异很大,代码根本 无法复用!没办法,只能用别的办法实现了。经过一番研究,最终借助Canvas搞出来了,简单的分享一下我的实现思路吧。
圆环组件简介
为了方便复用,我把这个功能封装成了项目可直接复用的组件。并支持自定义圆环大小、圆环宽度和圆环颜色比例配置属性。
<Ring
:storkWidth="5"
:size="60"
:ratioList="[
{ ratio: 0.3, color: '#FF5733' },
{ ratio: 0.6, color: '#33FF57' },
{ ratio: 0.1, color: '#3357FF' }
]"
></Ring>

技术方案
实现目标
根据我们的UX需求,我们需要实现一个简单的组件,该组件可以展示一个圆环图表,并根据外部传入的比例数据(如 ratioList)绘制不同颜色的环形区域。
- 使用 Vue 3 和 TypeScript。
- 动态绘制环形图,根据传入的数据绘制多个环。
- 支持自定义环形图的大小和环宽。
创建 Vue 组件框架
首先,我们创建一个名为 RingChart.vue的组件。组件的初始结构非常简单,只包含一个 canvas 元素。
<template>
<!-- 创建一个 canvas 元素,用于绘制图表 -->
<canvas ref="canvasDom"></canvas>
</template>
<script lang="ts" setup>
import { ref, onMounted } from 'vue';
// 获取 canvas DOM 元素的引用
const canvasDom = ref<HTMLCanvasElement | null>(null);
// 初始化 canvas 和上下文变量
let ctx: CanvasRenderingContext2D | null = null;
let width: number, height: number;
// 初始化 canvas 尺寸和绘图环境
const initCanvas = () => {
const dom = canvasDom.value;
if (!dom) return;
ctx = dom.getContext('2d');
if (!ctx) return;
// 设置 canvas 的宽高
dom.width = dom.offsetWidth;
dom.height = dom.offsetHeight;
width = dom.offsetWidth;
height = dom.offsetHeight;
};
// 在组件挂载后执行初始化
onMounted(() => {
initCanvas();
});
</script>
<style scoped>
canvas {
width: 100%;
height: 100%;
}
</style>
上述代码中,我们初始化了 canvas 元素,并且设定了 width 和 height 属性。
绘制基本的圆环
接下来,我们添加绘制圆环的功能:通过 arc 方法来绘制圆环,设置 lineWidth 来调整环的宽度。
<script lang="ts" setup>
import { ref, onMounted } from 'vue';
// 获取 canvas DOM 元素的引用
const canvasDom = ref<HTMLCanvasElement | null>(null);
// 初始化 canvas 和上下文变量
let ctx: CanvasRenderingContext2D | null = null;
let width: number, height: number;
// 初始化 canvas 尺寸和绘图环境
const initCanvas = () => {
const dom = canvasDom.value;
if (!dom) return;
ctx = dom.getContext('2d');
if (!ctx) return;
// 设置 canvas 的宽高
dom.width = dom.offsetWidth;
dom.height = dom.offsetHeight;
width = dom.offsetWidth;
height = dom.offsetHeight;
// 调用绘制圆环的方法
drawCircle({
ctx,
x: width / 2,
y: height / 2,
radius: 8,
lineWidth: 4,
color: '#C4C9CF4D',
startAngle: -Math.PI / 2,
endAngle: Math.PI * 1.5,
});
};
// 绘制一个圆环的方法
const drawCircle = ({
ctx,
x,
y,
radius,
lineWidth,
color,
startAngle,
endAngle,
}: {
ctx: CanvasRenderingContext2D;
x: number;
y: number;
radius: number;
lineWidth: number;
color: string;
startAngle: number;
endAngle: number;
}) => {
ctx.beginPath();
ctx.arc(x, y, radius, startAngle, endAngle);
ctx.lineWidth = lineWidth;
ctx.strokeStyle = color;
ctx.stroke();
ctx.closePath();
};
onMounted(() => {
initCanvas();
});
</script>
drawCircle函数是绘制圆环的核心。我们通过arc方法绘制圆形路径,使用lineWidth来调整环的宽度,并用strokeStyle给圆环上色。startAngle和endAngle参数决定了圆环的起始和结束角度,通过改变它们可以控制环的覆盖区域。
绘制多个环形区域
现在,我们来实现绘制多个环形区域的功能。我们将通过传入一个 ratioList 数组来动态生成多个环,每个环代表不同的比例区域。
<script lang="ts" setup>
import { ref, computed, onMounted } from 'vue';
// 定义 props 的类型
interface RatioItem {
ratio: number;
color: string;
}
const props = defineProps<{
size?: number; // 画布大小
storkWidth?: number; // 环的宽度
ratioList?: RatioItem[]; // 比例列表
}>();
// 默认值
const defaultSize = 200;
const defaultStorkWidth = 4;
const defaultRatioList: RatioItem[] = [
{ ratio: 1, color: '#C4C9CF4D' },
];
// canvas DOM 和上下文
const canvasDom = ref<HTMLCanvasElement | null>(null);
let ctx: CanvasRenderingContext2D | null = null;
// 动态计算 canvas 的中心点和半径
const size = computed(() => props.size || defaultSize);
const center = computed(() => ({
x: size.value / 2,
y: size.value / 2,
}));
const radius = computed(() => size.value / 2 - (props.storkWidth || defaultStorkWidth));
// 初始化 canvas
const initCanvas = () => {
const dom = canvasDom.value;
if (!dom) return;
ctx = dom.getContext('2d');
if (!ctx) return;
dom.width = size.value;
dom.height = size.value;
drawBackgroundCircle();
drawDataRings();
};
// 绘制背景圆环
const drawBackgroundCircle = () => {
if (!ctx) return;
drawCircle({
ctx,
x: center.value.x,
y: center.value.y,
radius: radius.value,
lineWidth: props.storkWidth || defaultStorkWidth,
color: '#C4C9CF4D',
startAngle: -Math.PI / 2,
endAngle: Math.PI * 1.5,
});
};
// 绘制数据圆环
const drawDataRings = () => {
const { ratioList = defaultRatioList } = props;
if (!ctx) return;
let startAngle = -Math.PI / 2;
ratioList.forEach(({ ratio, color }) => {
const endAngle = startAngle + ratio * Math.PI * 2;
drawCircle({
ctx,
x: center.value.x,
y: center.value.y,
radius: radius.value,
lineWidth: props.storkWidth || defaultStorkWidth,
color,
startAngle,
endAngle,
});
startAngle = endAngle;
});
};
// 通用绘制函数
const drawCircle = ({
ctx,
x,
y,
radius,
lineWidth,
color,
startAngle,
endAngle,
}: {
ctx: CanvasRenderingContext2D;
x: number;
y: number;
radius: number;
lineWidth: number;
color: string;
startAngle: number;
endAngle: number;
}) => {
ctx.beginPath();
ctx.arc(x, y, radius, startAngle, endAngle);
ctx.lineWidth = lineWidth;
ctx.strokeStyle = color;
ctx.stroke();
ctx.closePath();
};
// 监听画布大小变化
onMounted(() => {
initCanvas();
});
</script>
上述代码中,我们通过 ratioList 数组传递每个环的比例和颜色,使用 startAngle 和 endAngle 来控制每个环的绘制区域。其中,drawDataRings 函数遍历 ratioList,根据每个数据项的比例绘制环形区域。
现在,我们的组件就实现完毕了,可以在其他地方引入使用了
<RingChart
:storkWidth="8"
:size="60"
:ratioList="[
{ ratio: 0.3, color: '#F8766F' },
{ ratio: 0.6, color: '#69CD90' },
{ ratio: 0.1, color: '#FFB800' }
]"
></RRingChart>

组件代码
<template>
<canvas ref="canvasDom"></canvas>
</template>
<script lang="ts" setup>
import { ref, computed, onMounted, watchEffect } from 'vue';
// 定义 props 的类型
interface RatioItem {
ratio: number;
color: string;
}
const props = defineProps<{
size?: number; // 画布大小
storkWidth?: number; // 环的宽度
ratioList?: RatioItem[]; // 比例列表
}>();
// 默认值
const defaultSize = 200; // 默认画布宽高
const defaultStorkWidth = 4;
const defaultRatioList: RatioItem[] = [{ ratio: 1, color: '#C4C9CF4D' }];
// canvas DOM 和上下文
const canvasDom = ref<HTMLCanvasElement | null>(null);
let ctx: CanvasRenderingContext2D | null = null;
// 动态计算 canvas 的中心点和半径
const size = computed(() => props.size || defaultSize);
const center = computed(() => ({
x: size.value / 2,
y: size.value / 2
}));
const radius = computed(() => size.value / 2 - (props.storkWidth || defaultStorkWidth));
// 初始化 canvas
const initCanvas = () => {
const dom = canvasDom.value;
if (!dom) return;
ctx = dom.getContext('2d');
if (!ctx) return;
dom.width = size.value;
dom.height = size.value;
drawBackgroundCircle();
drawDataRings();
};
// 绘制背景圆环
const drawBackgroundCircle = () => {
if (!ctx) return;
drawCircle({
ctx,
x: center.value.x,
y: center.value.y,
radius: radius.value,
lineWidth: props.storkWidth || defaultStorkWidth,
color: '#C4C9CF4D',
startAngle: -Math.PI / 2,
endAngle: Math.PI * 1.5
});
};
// 绘制数据圆环
const drawDataRings = () => {
const { ratioList = defaultRatioList } = props;
if (!ctx) return;
let startAngle = -Math.PI / 2;
ratioList.forEach(({ ratio, color }) => {
const endAngle = startAngle + ratio * Math.PI * 2;
drawCircle({
ctx,
x: center.value.x,
y: center.value.y,
radius: radius.value,
lineWidth: props.storkWidth || defaultStorkWidth,
color,
startAngle,
endAngle
});
startAngle = endAngle;
});
};
// 通用绘制函数
const drawCircle = ({
ctx,
x,
y,
radius,
lineWidth,
color,
startAngle,
endAngle
}: {
ctx: CanvasRenderingContext2D;
x: number;
y: number;
radius: number;
lineWidth: number;
color: string;
startAngle: number;
endAngle: number;
}) => {
ctx.beginPath();
ctx.arc(x, y, radius, startAngle, endAngle);
ctx.lineWidth = lineWidth;
ctx.strokeStyle = color;
ctx.stroke();
ctx.closePath();
};
// 监听画布大小变化
watchEffect(() => {
initCanvas();
});
onMounted(() => {
initCanvas();
});
</script>
<style scoped>
canvas {
display: block;
margin: auto;
border-radius: 50%;
}
</style>
使用
<Ring
:storkWidth="5"
:size="60"
:ratioList="[
{ ratio: 0.3, color: '#FF5733' },
{ ratio: 0.6, color: '#33FF57' },
{ ratio: 0.1, color: '#3357FF' }
]"
></Ring>
总结
累了,今天不想写总结!
来源:juejin.cn/post/7444014749321510963
一种简单粗暴的大屏自适应方案,原理及案例
现状
现在最流行的大屏自适应手法: scale缩放
为了解决2d/3d的点击交互问题,通常设计成了2个层容器。图表层和2d/3d层。图表层负责缩放,2d/3d层保持100%显示,避免缩放引起的交互事件event问题。
下图是一个1920*1080的大屏示意图

使用常规的缩放方法,让大屏在窗口内最大化显示。大屏在不同的窗口中出现了空白区域,并没有充满整个屏幕。


新的方法
在缩放的基础上,对指定的要素进行贴边处理。我们希望上下吸附到窗口最上面和最下面。左右图表吸附到窗口的最左边和最右边。
这里面需要简单的计算,其中a是图表层 scale属性
var halftop = (window.innerHeight- (1080*a.scaleY))/2/a.scaleY;
var halfleft = (window.innerWidth- (1920*a.scaleX))/2/a.scaleX;
对指定id的容器,在resize事件中设置上下左右浮动。如下图



实战项目效果
注,下面图片中的数据指标、城市名、姓名、图像均为虚拟数据。
在实际应用中,一般1920*1080设计稿已宽屏为主,如果是竖屏大屏(下图6),需要设计竖屏UI。






你也可以下载该项目demo, 对窗口进行缩放查看效果 pan.baidu.com/s/1hE_C9x9i…
来源:juejin.cn/post/7444378390843768843
还在等后端接口?自己写得了
前言
前端:芜湖~静态页面写完,起飞
前端:接口能不能搞快点
后端:没空
前端:emmmmmm
迭代结束.....
老板:前端你怎么回事?搞这么慢
前端:
A:跳起来打老板
B:跳起来打后端
C:不干了
D:自己全干
E:继续挨骂
CABABABABABBABABABABBABD
当然是选择
Mock.js啦(骗你的,我自己也不用)






Mock.js 的使用教程
一、什么是 Mock.js?
Mock.js 是一个用于生成随机数据的 JavaScript 库,它可以帮助开发者快速模拟后台接口返回的数据,常用于前端开发中的接口调试和数据展示。通过使用 Mock.js,前端开发者无需依赖后端接口就可以模拟真实的接口数据,提升开发效率。
Mock.js 支持的数据类型非常丰富,包括字符串、数字、日期、图片等,并且可以对数据进行自定义设置,模拟出不同的场景。
二、安装 Mock.js
Mock.js 是一个轻量级的库,可以通过 npm 或 yarn 安装:
# 使用 npm 安装
npm install mockjs --save
# 使用 yarn 安装
yarn add mockjs
如果你没有使用包管理工具,也可以直接在 HTML 页面中通过 <script> 标签引入 Mock.js:
<script src="https://cdn.jsdelivr.net/npm/mockjs@1.1.0/dist/mock.min.js"></script>
三、Mock.js 的基本使用
Mock.js 提供了一个全局的 Mock 对象,使用 Mock 对象,你可以轻松地创建模拟数据。
1. 使用 Mock.mock() 方法
Mock.mock() 是 Mock.js 的核心方法,用于创建模拟数据。它接受一个模板作为参数,根据这个模板生成相应的模拟数据。
示例:生成简单的随机数据
const Mock = require('mockjs');
// 模拟一个简单的用户数据对象
const userData = Mock.mock({
'name': '@name', // 随机生成姓名
'age|18-60': 25, // 随机生成 18-60 之间的年龄
'email': '@email', // 随机生成邮箱地址
});
console.log(userData);
在这个例子中,@name、@email 等是 Mock.js 内置的随机数据生成规则,'age|18-60': 25 是一种范围随机生成规则,它会生成 18 到 60 之间的随机数。
模拟输出:
{
"name": "张三",
"age": 34,
"email": "example@example.com"
}
2. 模拟数组数据
Mock.js 还可以生成数组数据,支持定义数组长度以及每个元素的生成规则。
const Mock = require('mockjs');
// 模拟一个包含多个用户的数组
const userList = Mock.mock({
'users|3-5': [{ // 随机生成 3 到 5 个用户对象
'name': '@name',
'age|20-30': 25,
'email': '@email'
}]
});
console.log(userList);
模拟输出:
{
"users": [
{ "name": "李四", "age": 22, "email": "user1@example.com" },
{ "name": "王五", "age": 28, "email": "user2@example.com" },
{ "name": "赵六", "age": 25, "email": "user3@example.com" }
]
}
3. 使用自定义规则生成数据
Mock.js 还支持自定义规则,你可以定义数据生成的规则,或者通过函数来生成特定的数据。
const Mock = require('mockjs');
// 使用自定义函数生成随机数据
const customData = Mock.mock({
'customField': () => {
return Math.random().toString(36).substr(2, 8); // 返回一个随机的 8 位字符串
}
});
console.log(customData);
模拟输出:
{
"customField": "rkf7hbw8"
}
四、常用的 Mock.js 模板规则
Mock.js 提供了丰富的数据生成规则,下面列出一些常用的规则。
1. 字符串相关规则
@name:生成一个随机的中文名字。@cname:生成一个随机的中文全名。@word(min, max):生成一个随机的单词,min和max控制长度。@sentence(min, max):生成一个随机的句子,min和max控制单词数量。@email:生成一个随机的邮箱地址。@url:生成一个随机的 URL 地址。
2. 数字相关规则
@integer(min, max):生成一个随机整数,min和max控制范围。@float(min, max, dmin, dmax):生成一个随机浮点数,min和max控制范围,dmin和dmax控制小数点位数。@boolean:生成一个随机布尔值。@date(format):生成一个随机日期,format为日期格式,默认是yyyy-MM-dd。@time(format):生成一个随机时间。
3. 其他类型
@image(size, background, foreground):生成一张图片,size控制图片大小,background控制背景色,foreground控制前景色。@guid:生成一个 GUID。@id:生成一个随机的身-份-证号。@province、@city、@county:生成随机的省、市、区名称。
五、Mock.js 用于模拟接口数据
Mock.js 常用于前端开发中模拟接口数据,帮助前端开发人员在没有后端接口的情况下进行开发和调试。可以通过 Mock.mock() 来拦截 HTTP 请求,并返回模拟的数据。
示例:模拟一个接口请求
假设我们有一个接口需要返回用户数据,我们可以使用 Mock.js 来模拟这个接口。
const Mock = require('mockjs');
// 模拟接口请求
Mock.mock('/api/users', 'get', {
'users|5-10': [{ // 随机生成 5 到 10 个用户数据
'id|+1': 1, // id 从 1 开始递增
'name': '@name',
'email': '@email',
'age|18-60': 25,
}]
});
console.log('接口已模拟,发送请求查看结果');
在上面的代码中,Mock.mock() 拦截了对 /api/users 的 GET 请求,并返回一个包含随机用户数据的对象。当前端代码请求 /api/users 时,Mock.js 会自动返回模拟的数据。
六、Mock.js 高级用法
1. 延迟模拟
有时你可能希望模拟网络延迟,Mock.js 支持使用 timeout 配置来延迟接口响应。
Mock.mock('/api/data', 'get', {
'message': '成功获取数据'
}).timeout = 2000; // 设置延迟时间为 2000ms (2秒)
2. 使用正则表达式生成数据
Mock.js 还支持通过正则表达式来生成数据。例如,生成一个特定格式的电话号码。
const phoneData = Mock.mock({
'phone': /^1[3-9]\d{9}$/ // 正则表达式生成一个中国大陆手机号
});
console.log(phoneData);
3. 动态修改数据
Mock.js 还允许你在数据生成后对其进行动态修改,可以通过调用 Mock.Random 对象来获取随机数据,并进一步自定义。
const random = Mock.Random;
const customData = {
name: random.name(),
email: random.email(),
phone: random.phone(),
};
console.log(customData);
七、总结
Mock.js 是一个强大的工具,可以帮助你快速生成模拟数据,尤其适用于前后端分离的开发模式,前端开发人员可以独立于后端接口进行开发和调试。Mock.js 提供了灵活的数据生成规则,支持随机数、日期、图片等多种类型,并且能够模拟 HTTP 接口请求,极大地提高了开发效率。
掌握 Mock.js 的基本用法,可以帮助你在开发过程中更加高效,减少对后端开发的依赖,提升整个项目的开发速度。
各位彦祖亦菲再见ヾ( ̄▽ ̄)ByeBye

来源:juejin.cn/post/7442515129173262351
threejs 仿抖音漂移停车特效
最近刷到了抖音的漂移停车2的视频,感觉还蛮有趣的

乍一看,实现这个漂移停车的效果需要一些东西:
- 一辆一直往前开的小车和一个停车点,这里就做成一个小车库吧
- 漂移停车逻辑。这个小游戏是通过往左往右触屏滑动来刹车,附带了转向
- 和车库的碰撞处理
- 停车后的计分逻辑
之前的文章实现了基于threejs的3d场景和一辆麻雀虽小五脏俱全的小车,咱们拿来接着用一下
行车物理模拟
其实之前自己实现的自车行驶超级简单,加减速、转弯都做的比较粗糙,这里引入物理库 cannon-es(cannon.js 的增强版)来帮忙做这块逻辑。物理库的作用其实就是模拟一些真实的物理效果,比如行车、物理碰撞、重力等。具体api文档 戳这里,不过只有英文文档
npm install cannon-es
先初始化一个物理世界,其实和 threejs 场景的初始化有点像,之后也是需要将物理世界的物体和 threejs 的物体一一对应地关联起来,比如这里的地面、小车和车库,这样后面物理库做计算后,再将作用后的物体的位置信息赋值到 threejs 对应物体的属性上,最后通过循环渲染(animate)就能模拟行车场景了
import * as CANNON from "cannon-es";
// ...
const world = new CANNON.World();
// 物理世界预处理,这个可以快速排除明显不发生碰撞的物体对,提高模拟效率
world.broadphase = new CANNON.SAPBroadphase(world);
// 物理世界的重力向量
world.gravity.set(0, -9.8, 0);
// 刚体之间接触面的默认摩擦系数
world.defaultContactMaterial.friction = 0;
小车对象
cannon-es 的 RaycastVehicle 类可以辅助我们管理物理世界的小车对象,它提供了很多蛮好用的api,不仅可以帮助我们更好地管理车轮,而且能很好地根据地形运动
物理世界物体的基本要素有形状(常见的有Box长方体/Plane平面/Sphere球体)、材质 Material 和刚体 Body,类比 threejs 中的几何体、材质和 Mesh。创建刚体后别忘了将它添加到物理世界里,和 threejs 将物体添加到 scene 场景里类似
// 创建小车底盘形状,这里就是一个长方体
const chassisShape = new CANNON.Box(new CANNON.Vec3(1, 0.3, 2));
// 创建质量为150kg的小车刚体。物理世界的质量单位是kg
const chassisBody = new CANNON.Body({ mass: 150 });
// 关联刚体和形状
chassisBody.addShape(chassisShape);
// 设定刚体位置
chassisBody.position.set(0, 0.4, 0);
// 基于小车底盘创建小车对象
const vehicle = new CANNON.RaycastVehicle({
chassisBody,
// 定义车辆的方向轴(0:x轴,1:y轴,2:z轴),让它符合右手坐标系
// 车辆右侧
indexRightAxis: 0,
// 车辆上方
indexUpAxis: 1,
// 车辆前进方向
indexForwardAxis: 2,
});
// 将小车添加到物理世界里,类比 threejs 的 scene.add()
vehicle.addToWorld(world);
四个车轮
接下来定义下车轮对象,用到了 Cylinder 这种圆柱体的形状,然后要注意做好旋转值 Quaternion 的调整。这部分会稍微复杂些,可以耐心看下注释:
// 车轮配置,详情配置参考 https://pmndrs.github.io/cannon-es/docs/classes/RaycastVehicle.html#addWheel
const options = {
radius: 0.4, // 轮子半径
directionLocal: new CANNON.Vec3(0, -1, 0), // 轮子方向向量,指轮子从中心点出发的旋转方向
suspensionStiffness: 45,
suspensionRestLength: 0.4,
frictionSlip: 5, // 滑动摩擦系数
dampingRelaxation: 2.3,
dampingCompression: 4.5,
maxSuspensionForce: 200000,
rollInfluence: 0.01,
axleLocal: new CANNON.Vec3(-1, 0, 0),
chassisConnectionPointLocal: new CANNON.Vec3(1, 1, 0),
maxSuspensionTravel: 0.25,
customSlidingRotationalSpeed: -30,
useCustomSlidingRotationalSpeed: true,
};
const axlewidth = 0.7;
// 设置第一个车轮的连接点位置
options.chassisConnectionPointLocal.set(axlewidth, 0, -1);
// 按指定配置给小车添加第一个车轮,其他车轮类似
vehicle.addWheel(options);
options.chassisConnectionPointLocal.set(-axlewidth, 0, -1);
vehicle.addWheel(options);
options.chassisConnectionPointLocal.set(axlewidth, 0, 1);
vehicle.addWheel(options);
options.chassisConnectionPointLocal.set(-axlewidth, 0, 1);
vehicle.addWheel(options);
// 四个车轮
const wheelBodies: CANNON.Body[] = [];
const wheelVisuals: THREE.Mesh[] = [];
vehicle.wheelInfos.forEach(function (wheel) {
const shape = new CANNON.Cylinder(
wheel.radius,
wheel.radius,
wheel.radius / 2,
20
);
const body = new CANNON.Body({ mass: 1, material: wheelMaterial });
// 刚体可以是动态(DYNAMIC)、静态(STATIC)或运动学(KINEMATIC)
body.type = CANNON.Body.KINEMATIC;
// 0表示这个刚体将与所有其他未设置特定过滤组的刚体进行碰撞检测
body.collisionFilterGr0up = 0;
// 使用setFromEuler方法将欧拉角转换为四元数,欧拉角的值为-Math.PI / 2(即-90度或-π/2弧度)
const quaternion = new CANNON.Quaternion().setFromEuler(
-Math.PI / 2,
0,
0
);
body.addShape(shape, new CANNON.Vec3(), quaternion);
wheelBodies.push(body);
// 创建3d世界的车轮对象
const geometry = new THREE.CylinderGeometry(
wheel.radius,
wheel.radius,
0.4,
32
);
const material = new THREE.MeshPhongMaterial({
color: 0xd0901d,
emissive: 0xaa0000,
flatShading: true,
side: THREE.DoubleSide,
});
const cylinder = new THREE.Mesh(geometry, material);
cylinder.geometry.rotateZ(Math.PI / 2);
wheelVisuals.push(cylinder);
scene.add(cylinder);
});
这一步很关键,需要在每次物理模拟计算结束后 (postStep事件的回调函数) 更新车轮的位置和转角
// ...
world.addEventListener("postStep", function () {
for (let i = 0; i < vehicle.wheelInfos.length; i++) {
vehicle.updateWheelTransform(i);
const t = vehicle.wheelInfos[i].worldTransform;
// 更新物理世界车轮对象的属性
wheelBodies[i].position.copy(t.position);
wheelBodies[i].quaternion.copy(t.quaternion);
// 更新3d世界车轮对象的属性
wheelVisuals[i].position.copy(t.position);
wheelVisuals[i].quaternion.copy(t.quaternion);
}
});
车辆行驶和转向
监听键盘事件,按下上下方向键给一个前后的引擎动力,按下左右方向键给车轮一个转角值
// 引擎动力值
const engineForce = 3000;
// 转角值
const maxSteerVal = 0.7;
// 刹车作用力
const brakeForce = 20;
// ...
// 刹车
function brakeVehicle() {
// 四个车轮全部加刹车作用力
vehicle.setBrake(brakeForce, 0);
vehicle.setBrake(brakeForce, 1);
vehicle.setBrake(brakeForce, 2);
vehicle.setBrake(brakeForce, 3);
}
function handleNavigate(e: any) {
if (e.type != "keydown" && e.type != "keyup") {
return;
}
const isKeyup = e.type === "keyup";
switch (e.key) {
case "ArrowUp":
// 给第2/3个车轮加引擎动力
vehicle.applyEngineForce(isKeyup ? 0 : engineForce, 2);
vehicle.applyEngineForce(isKeyup ? 0 : engineForce, 3);
break;
case "ArrowDown":
vehicle.applyEngineForce(isKeyup ? 0 : -engineForce, 2);
vehicle.applyEngineForce(isKeyup ? 0 : -engineForce, 3);
break;
case "ArrowLeft":
// 设置车轮转角
vehicle.setSteeringValue(isKeyup ? 0 : -maxSteerVal, 2);
vehicle.setSteeringValue(isKeyup ? 0 : -maxSteerVal, 3);
break;
case "ArrowRight":
vehicle.setSteeringValue(isKeyup ? 0 : maxSteerVal, 2);
vehicle.setSteeringValue(isKeyup ? 0 : maxSteerVal, 3);
break;
}
brakeVehicle();
}
window.addEventListener("keydown", handleNavigate);
window.addEventListener("keyup", handleNavigate);
然后在每一帧里重新计算物体的物理值,并赋值给 3d 世界的小车属性,就可以实现行车效果
function updatePhysics() {
world.step(1 / 60);
egoCar.position.copy(chassisBody.position);
egoCar.quaternion.copy(chassisBody.quaternion);
}
// ...
const animate = () => {
stats.begin();
// ...
updatePhysics();
// ...
stats.end();
requestAnimationFrame(animate);
};
animate();
地面优化
地面看起来太光滑,显得有点假,咱们先给地面加上有磨砂质感的纹理贴图,同时隐藏掉辅助网格
// ...
// 加载纹理贴图
textureLoader.load("/gta/floor.jpg", (texture) => {
const planeMaterial = new THREE.MeshLambertMaterial({
// 将贴图对象赋值给材质
map: texture,
side: THREE.DoubleSide,
});
const plane = new THREE.Mesh(planeGeometry, planeMaterial);
// 地面接受阴影
plane.receiveShadow = true;
plane.rotation.x = Math.PI / 2;
scene.add(plane);
});
加载完贴图,生成3d场景的地面对象后,别忘了创建地面刚体并关联。这里还要定义地面刚体的物理材质,类比 threejs 的材质,会影响不同刚体之间摩擦和反弹的效果
// ...
// 定义地板的物理材质
const groundMaterial = new CANNON.Material("groundMaterial");
// 定义车轮的物理材质,其实之前代码用过了,可以留意下
const wheelMaterial = new CANNON.Material("wheelMaterial");
// 定义车轮和地板之间接触面的物理关联,在这里定义摩擦反弹等系数
const wheelGroundContactMaterial = new CANNON.ContactMaterial(
wheelMaterial,
groundMaterial,
{
// 摩擦系数
friction: 0.5,
// 反弹系数,0表示没有反弹
restitution: 0,
}
);
world.addContactMaterial(wheelGroundContactMaterial);
// ...
textureLoader.load("/gta/floor.jpg", (texture) => {
// ...
// 地面刚体
const q = plane.quaternion;
const planeBody = new CANNON.Body({
// 0说明物体是静止的,发生物理碰撞时不会相互移动
mass: 0,
// 应用接触面材质
material: groundMaterial,
shape: new CANNON.Plane(),
// 和3d场景的旋转值保持一致。在Cannon.js中,刚体的旋转可以通过四元数来表示,而不是传统的欧拉角或轴角表示法
quaternion: new CANNON.Quaternion(-q._x, q._y, q._z, q._w),
});
world.addBody(planeBody);
});
这回开起来可顺畅许多了,场景和自车旋转也变得更自然一些,感谢开源 ~

搭建车库
咱就搭个棚,一个背景墙、两个侧边墙、加一个屋顶和地板,其实都是些立方体,拼装成网格对象 Mesh 后,按照一定的位置和旋转拼在一起组成小车库,参考代码:
createParkingHouse() {
if (!this.scene || !this.world) return;
// 创建背景墙
const background = new THREE.Mesh(
new THREE.BoxGeometry(3, 4, 0.1),
new THREE.MeshBasicMaterial({ color: 0xcccccc })
);
background.position.set(0, 0, -53);
this.scene.add(background);
// 创建侧墙
const sider1 = new THREE.Mesh(
new THREE.BoxGeometry(6, 4, 0.3),
new THREE.MeshBasicMaterial({ color: 0xcccccc })
);
sider1.rotation.y = Math.PI / 2;
sider1.position.set(-1.5, 0.1, -50);
this.scene.add(sider1);
const sider2 = new THREE.Mesh(
new THREE.BoxGeometry(6, 4, 0.3),
new THREE.MeshBasicMaterial({ color: 0xcccccc })
);
sider2.rotation.y = Math.PI / 2;
sider2.position.set(1.5, 0.1, -50);
this.scene.add(sider2);
// 创建屋顶
const roof = new THREE.Mesh(
new THREE.BoxGeometry(3, 6, 0.1),
new THREE.MeshBasicMaterial({
color: 0xcccccc,
// 注意:这个值不为true的话,设置opacity是没用的
transparent: true,
opacity: 0.8,
})
);
roof.rotation.x = Math.PI / 2;
roof.position.set(0, 2, -50);
this.scene.add(roof);
// 创建地板
const floor = new THREE.Mesh(
new THREE.BoxGeometry(3, 6, 0.1),
new THREE.MeshBasicMaterial({ color: 0x666666 })
);
floor.rotation.x = Math.PI / 2;
floor.position.set(0, 0.1, -50);
this.scene.add(floor);
}
好了,一个稍微有点模样的小车库就大功告成

创建车库刚体
先加个背景墙的物理刚体
createParkingHouse() {
if (!this.scene || !this.world) return;
// 创建背景墙
const background = new THREE.Mesh(
new THREE.BoxGeometry(3, 4, 0.1),
new THREE.MeshBasicMaterial({ color: 0xcccccc })
);
background.position.set(0, 0, -53);
this.scene.add(background);
// 创建侧墙
// ...
// physic
const houseShape = new CANNON.Box(new CANNON.Vec3(1.5, 4, 0.1));
const houseBody = new CANNON.Body({ mass: 0 });
houseBody.addShape(houseShape);
houseBody.position.set(0, 0, -53);
this.world.addBody(houseBody);
}
// ...
其他的墙体类似的处理,屋顶先不管吧,小车应该也够不着。来,先撞一下试试

漂移停车
其实达到一定速度,通过方向键就能做一个甩尾漂移倒车入库
- 提供一个弹射的初始动力
// ...
animate();
setTimeout(() => {
// 给后轮上点动力
vehicle.applyEngineForce(2000, 2);
vehicle.applyEngineForce(2000, 3);
}, 100);
- 电脑端根据方向键触发漂移,这里注意要消除后轮的动力
// ...
case "ArrowLeft":
vehicle.setSteeringValue(keyup ? 0 : -maxSteerVal, 2);
vehicle.setSteeringValue(keyup ? 0 : -maxSteerVal, 3);
// 漂移停车游戏需要消除后轮动力,如果要正常行驶,需要去掉下面俩行
vehicle.applyEngineForce(0, 2);
vehicle.applyEngineForce(0, 3);
break;
case "ArrowRight":
vehicle.setSteeringValue(keyup ? 0 : maxSteerVal, 2);
vehicle.setSteeringValue(keyup ? 0 : maxSteerVal, 3);
// 漂移停车游戏需要消除后轮动力,如果要正常行驶,需要去掉下面俩行
vehicle.applyEngineForce(0, 2);
vehicle.applyEngineForce(0, 3);
break;
// ...
- 移动端根据触屏方向触发。需要注意此时要把相机控制器关掉,避免和触屏操作冲突。计算触发方向的逻辑参考
// 计算划过的角度
function getAngle(angx: number, angy: number) {
return (Math.atan2(angy, angx) * 180) / Math.PI;
}
// 计算触屏方向
function getDirection(
startx: number,
starty: number,
endx: number,
endy: number
): ESlideDirection {
const angx = endx - startx;
const angy = endy - starty;
let result = ESlideDirection.;
if (Math.abs(angx) < 2 && Math.abs(angy) < 2) {
return result;
}
const angle = getAngle(angx, angy);
if (angle >= -135 && angle <= -45) {
result = ESlideDirection.Top;
} else if (angle > 45 && angle < 135) {
result = ESlideDirection.Bottom;
} else if (
(angle >= 135 && angle <= 180) ||
(angle >= -180 && angle < -135)
) {
result = ESlideDirection.Left;
} else if (angle >= -45 && angle <= 45) {
result = ESlideDirection.Right;
}
return result;
}
let startx = 0;
let starty = 0;
document.addEventListener("touchstart", (e) => {
startx = e.touches[0].pageX;
starty = e.touches[0].pageY;
});
document.addEventListener("touchend", function (e) {
const endx = e.changedTouches[0].pageX;
const endy = e.changedTouches[0].pageY;
const direction = getDirection(startx, starty, endx, endy);
// 根据方向做转向和刹车的处理,和上面电脑侧左右键的逻辑一致就行了
// ...
})
计算分数
根据小车和车库角度偏差和中心点偏差来综合得分,这里就不细究了,浅浅定个规则:
- 不入库或没倒车:0分
- 其他情况:50分 + 角度分(20比例) + 中心分(30比例)
车停住后,先算出分数,再加个数字递增的效果,用 setInterval 实现就好了。不过这里要注意用回调函数的方式更新 state 值,避免闭包引起值不更新的问题
计分组件实现代码参考:
export const Overlay = observer(() => {
const [score, setScore] = useState(0);
useEffect(() => {
if (vehicleStore.score) {
// 计分动画
const timer = setInterval(() => {
// 回调方式更新state
setScore((score) => {
if (score + 1 === vehicleStore.score) {
clearInterval(timer);
}
return score + 1;
});
}, 10);
}
}, [vehicleStore.score]);
if (!vehicleStore.isStop) {
return null;
}
return (
<div className={styles["container"]}>
<div className={styles["score-box"]}>
<div className={styles["score-desc"]}>得分div>
<div>{score}div>
div>
div>
);
});
那么问题来了,怎么监听它停下了?可以加一个速度的阈值 velocityThreshold,如果小车刚体的速度低于这个阈值就判定小车停下了。然后通过 mobx 状态库建立一个 vehicleStore,主要是维护 isStop(是否停止) 和 score(分数) 这两个变量,变化后自动通知计分组件更新,这部分逻辑可以参考源码实现 ~
// ...
const velocityThreshold = 0.01;
function updatePhysics() {
world.step(1 / 60);
// ...
// 检查刚体的速度,小于阈值视为停止
if (
chassisBody.velocity.length() < velocityThreshold &&
// 停车标识
!vehicleStore.isStop
) {
console.log("小车已经停止");
vehicleStore.stop();
// 触发计分逻辑,自行参考源码
// ...
vehicleStore.setScore(score);
}
}
// ...

传送门
来源:juejin.cn/post/7331070678693380122
入职第一天,看了公司代码,牛马沉默了
入职第一天就干活的,就问还有谁,搬来一台N手电脑,第一分钟开机,第二分钟派活,第三分钟干活,巴适。。。。。。

打开代码发现问题不断
- 读取配置文件居然读取两个配置文件,一个读一点,不清楚为什么不能一个配置文件进行配置


 一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
prop_c.setProperty(key, value);
value获取外部配置为空的时候会抛出异常;properties底层集合用的是hashTable
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
}
- 很多参数写死在代码里,如果有改动,工作量会变得异常庞大,举例权限方面伪代码
role.haveRole("ADMIN_USE")
- 日志打印居然sout和log混合双打


先不说双打的事,对于上图这个,应该输出包括堆栈信息,不然定位问题很麻烦,有人可能会说e.getMessage()最好,可是生产问题看多了发现还是打堆栈好;还有如果不是定向返回信息,仅仅是记录日志,完全没必要catch多个异常,一个Exception足够了,不知道原作者这么写的意思是啥;还是就是打印日志要用logger,用sout打印在控制台,那我日志文件干啥;
4.提交的代码没有技术经理把关,下发生产包是个人就可以发导致生产环境代码和本地代码或者数据库数据出现不一致的现象,数据库数据的同步是生产最容易忘记执行的一个事情;比如我的这家公司上传文件模板变化了,但是没同步,导致出问题时开发环境复现问题真是麻烦;
5.随意更改生产数据库,出不出问题全靠开发的职业素养;
6.Maven依赖的问题,Maven引pom,而pom里面却是另一个pom文件,没有生成的jar供引入,是的,我们可以在dependency里加上
<type>pom
来解决这个问题,但是公司内的,而且实际也是引入这个pom里面的jar的,我实在不知道这么做的用意是什么,有谁知道;求教 
以上这些都是我最近一家公司出现的问题,除了默默接受还能怎么办;
那有什么优点呢:
- 不用太怎么写文档
- 束缚很小
- 学到了js的全局调用怎么写的(下一篇我来写,顺便巩固一下)
解决之道
怎么解决这些问题呢,首先对于现有的新项目或升级的项目来说,spring的application.xml/yml 完全可以写我们的配置,开发环境没必要整外部文件,如果是生产环境我们可以在脚本或启动命令添加 nohup java -Dfile.encoding=UTF-8 -Dspring.config.location=server/src/main/config/application.properties -jar xxx.jar & 来告诉jar包引哪里的配置文件;也可以加上动态配置,都很棒的,
其次就是规范代码,养成良好的规范,跟着节奏,不要另辟蹊径;老老实实的,如果原项目上迭代,不要动源代码,追加即可,没有时间去重构的;
我也曾是个快乐的童鞋,也有过崇高的理想,直到我面前堆了一座座山,脚下多了一道道坑,我。。。。。。!
来源:juejin.cn/post/7371986999164928010
金价大跳水?写一个金价监控脚本
说在前面
😶🌫️国庆过后,金价就大跳水,一直往下跌,看样子暂时是停不下来了,女朋友之前也入手了一点黄金,因此对黄金价格的变化比较关心,为了让她不用整天盯着实时金价,所以就搞了一个金价监控工具,超出设置的阈值就会发送邮件提醒✉。

一、金价信息获取方案
金价实时信息有两种方案可以获取到:
1、网页信息爬取
我们可以先找到一些官方的金价信息网站,然后直接利用爬虫直接爬取,比如:quote.cngold.org/gjs/jjs.htm…

2、通过接口获取
例如nowapi中就有黄金数据信息接口,我们可以直接通过接口来获取:

二、提醒阈值设置
1、创建数据库

2、监控页面编写
简单编写一个页面用于添加和调整提醒内容。

三、修改配置信息
1、邮箱配置
这里我使用的qq邮箱作为发件账号,需要开启邮箱授权,获取授权码。
{
host: "smtp.qq.com", // 主机
secureConnection: true, // 使用 SSL
port: 465, // SMTP 端口
auth: {
user: "jyeontu@qq.com", // 自己用于发送邮件的账号
pass: "jyeontu", // 授权码(这个是假的,改成自己账号对应即可,获取方法: QQ邮箱-->设置-->账户-->POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务-->IMAP/SMTP开启 复制授权码)
}
}
- (1)打开pc端qq邮箱,点击设置,再点击帐户

- (2)往下拉 可开启POP3/SMTP服务 根据提示即可获取qq邮箱授权码

- (3)将获取到的授权码复制到配置信息里即可

2、数据库配置
填写数据库对应的配置信息。
{
host: "localhost",
user: "root", //数据库账号
password: "jyeontu", //数据库密码
database: "test", //数据库名称
}
3、nowapi配置
免费开通后将AppKey和Sign替换成自己的就可以了。

{
AppKey: AppKey,
Sign: "Sign",
}
四、脚本功能编写
1、获取金价信息
我直接使用nowapi的免费试用套餐,配额是10 次/小时。

const { nowapiConfig } = require("./config.js");
async function getGoldPrice() {
const result = await axios.get(
`https://sapi.k780.com/?app=finance.gold_price&goldid=1053&appkey=${nowapiConfig.AppKey}&sign=${nowapiConfig.Sign}&format=json`
);
return result.data.result.dtList["1053"];
}
获取到的数据如下:

2、获取消息提醒阈值
(1)连接数据库
使用填写好的数据库配置信息连接数据库
const mysql = require("mysql");
const { dbConfig } = require("./config.js");
const connection = mysql.createConnection(dbConfig);
function connectDatabase() {
return new Promise((resolve) => {
connection.connect((error) => {
if (error) throw error;
console.log("成功连接数据库!");
resolve("成功连接数据库!");
});
});
}
(2)查询数据
function mysqlQuery(sqlStr) {
return new Promise((resolve) => {
connection.query(sqlStr, (error, results) => {
if (error) throw error;
resolve(results);
});
});
}
async function getMessage() {
const sqlStr =
"select * from t_message where isShow = 1 and isActive = 1 and type = '金价监控';";
const res = await mysqlQuery(sqlStr);
return { ...res[0] };
}
获取到的数据如下:

3、发送提醒邮件
(1)创建邮件传输对象
使用填写好的邮箱配置信息,创建邮件传输对象
const nodemailer = require("nodemailer");
const { mail } = require("./config.js");
const smtpTransport = nodemailer.createTransport(mail);
const sendMail = (options) => {
return new Promise((resolve) => {
const mailOptions = {
from: mail.auth.user,
...options,
};
// 发送邮件
smtpTransport.sendMail(mailOptions, function (error, response) {
if (error) {
console.error("发送邮件失败:", error);
} else {
console.log("邮件发送成功");
}
smtpTransport.close(); // 发送完成关闭连接池
resolve(true);
});
});
};
module.exports = sendMail;
(2)阈值判断
判断获取到的金价信息是否超出阈值范围来决定是否发送邮件提醒
async function mail(messageInfo, goldInfo) {
let { minVal = -Infinity, maxVal = Infinity } = messageInfo;
let { buy_price } = goldInfo;
minVal = parseFloat(minVal);
maxVal = parseFloat(maxVal);
buy_price = parseFloat(buy_price);
if (minVal < buy_price && maxVal > buy_price) {
return;
}
const mailOptions = {
to: messageInfo.mail.replaceAll("、", ","), // 接收人列表,多人用','隔开
subject: "金价监控",
text: `当前金价为${buy_price.toFixed(2)}`,
};
await sendMail(mailOptions);
}
五、定时执行脚本
可以使用corn编写一个定时任务来定时执行脚本即可。
* * * * * *分别对应:秒、分钟、小时、日、月、星期。- 每个字段可以是具体的值、范围、通配符(*表示每一个)或一些特殊的表达式。
例如:
0 0 * * *:每天午夜 0 点执行。
0 30 9 * * 1-5:周一到周五上午 9:30 执行。
你可以根据自己的需求设置合适的 cron 表达式来定时执行特定的任务。
六、效果展示
如果金价不在我们设置的阈值内时,我们就会收到邮件告知当前金价:



七、脚本使用
1、源码下载
git clone https://gitee.com/zheng_yongtao/node-scripting-tool.git
- 源码已经上传到gitee仓库
- 具体目录如下:

2、依赖下载
npm install
3、配置数据填写

这里的配置信息需要修改为你自己的信息,数据库、gitee仓库、nowapi配置。
4、脚本运行
node index.js
更多脚本
该脚本仓库里还有很多有趣的脚本工具,有兴趣的也可以看看其他的:gitee.com/zheng_yongt…
🌟觉得有帮助的可以点个star~
🖊有什么问题或错误可以指出,欢迎pr~
📬有什么想要实现的工具或想法可以联系我~
公众号
关注公众号『前端也能这么有趣』,获取更多有趣内容。
说在后面
🎉 这里是 JYeontu,现在是一名前端工程师,有空会刷刷算法题,平时喜欢打羽毛球 🏸 ,平时也喜欢写些东西,既为自己记录 📋,也希望可以对大家有那么一丢丢的帮助,写的不好望多多谅解 🙇,写错的地方望指出,定会认真改进 😊,偶尔也会在自己的公众号『
前端也能这么有趣』发一些比较有趣的文章,有兴趣的也可以关注下。在此谢谢大家的支持,我们下文再见 🙌。
来源:juejin.cn/post/7437006854122815497
程序员设计不出精美的 UI 界面?让 V0 来帮你
大家好,我是双越,也是 wangEditor 作者。
今年我致力于开发一个 Node 全栈 AIGC 知识库 划水AI,包括 AI 写作、多人协同编辑。复杂业务,真实上线,大家可以去注册试用。
本文分享一下前端实用的 AI 工具 v0.dev 以及我在 划水AI 中的实际应用经验,非常推荐这款工具。
不同 AI 工具写代码
ChatGPT 不好直接写代码
去年 ChatGPT 发布,但它一直是一个聊天工具,直接让它来写代码,用一问一答的形式,体验其实并不是非常友好。
可以让它来生成一些单一的代码或工具,例如 生成一个 nodejs 发送 Email 的函数 。然后我们把生成的代码复制粘贴过来,自己调整一下。
它可以作为一个导师或助理,指导你如何写代码,但它没法直接帮你写,尤其是在一个项目环境中。

PS. 这里只是说 ChatGPT 这种问答方式不适合直接写代码,但 ChatGPT 背后的 LLM 却未后面各种 AI 写代码工具提供了支持。
Cursor 非专业程序员
Cursor 其实去年我就试用过,它算是 AI 工具 + VSCode ,付费试用。没办法,AI 接口服务现在都是收费的。
前段时间 Cursor 突然在社区中很火爆,国内外都有看过它的宣传资料,我记得看过一个国外的 8 岁小女孩,用 Cursor 写 AI 聊天工具的视频,非常有意思,我全程看完了。

Cursor 可能会更加针对于非专业编程人员,去做一些简单的 demo ,主要体验编程的逻辑和过程,不用关心其中的 bug 。
例如,对于公司的 PM UI 人员,或者创业公司的老板。它真的可以产生价值,所以它也可以收费。
Copilot 针对专业程序员
我们是专业程序员,我更加推荐 Copilot ,直接在 vscode 安装插件即可。
我一直在使用 Copilot ,而且我现在都感觉自己有点依赖它了,每次写代码的时候都会停顿下来等待它帮我生成。
在一些比较明确的问题上,它的生成是非常精准的,可以大大节省人力,提高效率。

如果你遇到 Copilot 收费的问题,可以试试 Amazon CodeWhisper ,同样的功能,目前是免费的,未来不知道是否收费。
UI 很重要!!!
对于一个前端人员,有 UI 设计稿让他去还原开发这并不难,但你让他从 0 设计一个精美的 UI 页面,这有点困难。别说精美,能做到 UI 的基本美观就已经很不容易了。
举个例子,这是我偶遇一个笔记软件,这个 UI 真的是一言难尽:左上角无端的空白,左侧不对齐,icon 间距过大,字号不统一,tab 间距过小 …… 这种比较随性的 UI 设计,让人看了就没有任何试用的欲望。

可以在对比看一下 划水AI 的 UI 界面,看颜色、字号、艰巨、icon 等这些基础的 UI ,会否更加舒适一些?专业一些?

PS. 无意攻击谁(所以打了马赛克),只是做一个对比,强调 UI 的重要性。
V0 专业生成 UI 代码
V0 也是专业写代码的,不过它更加专注于一个方向 —— 生成 UI 代码 ,能做到基本的美观、舒适、甚至专业。
给一个指令 a home page like notion.com 生成了右侧的 UI 界面,我觉得已经非常不错了。要让我自己设计,我可设计不出来。

这一点对于很多人来说都是极具价值的,例如中小公司、创业公司的前端人员,他们负责开发 UI 但是没有专业的 UI 设计师,或者说他们开发的是一些 toB 的产品,也不需要招聘一个专职的 UI 设计师。
你可以直接拷贝 React 代码,也可以使用 npx 命令一键将代码转移到你自己的项目中。

它甚至还会考虑到响应式布局和黑白主题,这一点很惊艳

再让 V0 生成一个登录页,看看能做到啥效果。在首页输入指令 A login form like Github login page

等待 1-2 分钟,生成了如下效果,我个人还是挺满意的。如果让我自己写,我还得去翻阅一些 UI 组件库文档,看 form 表单怎么写,怎么对齐,宽度多少合适 …… 光写 UI 也得搞半天。

划水AI 中“我的首页” 就是 V0 生成的,虽然这个页面很简洁,但是我个人对 UI 要求很高,没有工具帮助,我无法短时间做到满意。

最后
任何行业和领域,看它是否成熟、是否能发展壮大,一个很重要的特点就是:是否有庞大的细分领域。例如现代医学、现代制造业、计算机领域…… 专业细分及其周密,大家各司其职,整个领域才能欣欣向荣。
AI 领域也是一样,AI 编程将是一个细分领域,再往下还有更多细分领域,像针对 UI 的、针对数据库的、针对云服务的,未来会有更多这方面的发展。
来源:juejin.cn/post/7438647233219903542
用 vue 给女主播写了个工具,榜一大哥爱上了她,她爱上了我
用 vue 写了个直播助手,榜一大哥爱上了她,她爱上了我
这是一个什么样的程序?这是一个使用 sys-shim/vue3/vite 开发的一个 windows 程序。用于向网站注入自己的代码以实现一些自动化功能。
sys-shim 是什么?它是一个我开发的个人工具,力求前端人员无需了解其他语言的情况下快速制作轻量的 windows 程序,详情请移步 electron 和 tauri 都不想用,那就自己写个想用的吧 。
为什么要开发这样的程序
虽然已经过去了很久,但那天的场景还是历历在目。
那天是在周五晚上 23 点过,大楼的中央空调都关了,我搓了搓手,看着还未完成的工作,想了想再不回去公车就没了,到家的话饭店也关门了。
然后按了一下显示器的电源按钮,让电脑继续工作着,准备回家吃饭后远程继续工作。
在大楼电梯遇到一个长得很挺好看的女生,由于这一层我们公司,然后看样子好像是直播部门的同事,虽然平时也都不怎么遇见,更没什么交集,只是公司偶尔让大家去主播间刷下人气,有点印象,猜想应该是直播部门的吧啦吧啦**蕾。
虽然是同事,却不熟悉,想打个招呼都不知道说啥,有点尴尬。然后我索性无所是事刷微信列表去了,虽然微信列表里一条消息也没有。。。
突然她给我来了句:“小哥哥你是我们公司的吧,你们平时下班都这么晚的吗?”一边哈气搓手。
我礼貌性笑了一下:“嗯,不是每天都这么晚。”,然后继续低头无所是事的刷微信列表。
大约一两秒之后,她说:“哦”。然后再停顿一会,好像又找到了什么话题:“那你们最近工作也很忙吗?但是我前两几天也没基本没遇到我们公司这么晚下班的人”。
这句话听起来好像传达了很多信息。但时间可不允许我慢慢思考每个信息应该如何正确应对,就像领导给的项目开发时间根据来不及完善好每一个细节一样。
我只能粗略回答:“没有特别忙,只是有时候我喜欢弄些小工具啥的,一不小心就已很晚了”。我心里想:感觉有点像面试,没有说公司不好,又显得自己爱学习,是一个能沉浸于思考的人,应该没问题吧。
“真好,看得出来你还十分热爱你这份职业。能够愿意花自己的时候去研究它们。”听语气好像是有一点羡慕我,感觉还有一点就是她不太喜欢她现在的工作。是呀,我也经常在想,做直播的那些人,有多少是喜欢整蛊自己,取悦别人,有多少是喜欢见人就哥哥好,哥哥帅,哥哥真的好可爱?
“只是觉得,能有一些工具,能帮助减少些重复劳动,就挺好”。
“对对对,小哥哥你说得太对了,就是因为有工具,减少了很多像机器一样的工作,人才可以去做更多有意义的,不像是机器那样的事情。”
当她说这句话的时候,我想,有一种不知道是不是错觉的错觉,真是个有想法的人!还有,这难道是在夸我们这些做工具的人吗?但是她说这句时的微笑,一下子就让人感到了她的热情和礼貌。
我心想,竟然这么有亲和力,很想有愿意继续沟通的想法。对!不然人家怎么能做主播?要换我上去做主播,绝对场也冷了,人也散了。
我一边告诉自己,因为能做主播,所以她本身就很有亲和力,所以你感觉她很热情,是因为这个热情是固有属性,并不是对于你热情。
一边竟开始好奇,这么漂亮又有亲和力的妹子,谁的下属?忍心让她上班这么晚?谁的女朋友?忍心让她上班这么晚?
好奇心害死猫。我竟然还是问出那句话:
“为什么你这么晚才下班呢?”
“最近销售量有点下滑,我想保住我销售额前一至少前二名的位置。”听到这句话的时候,我有点惊讶。我靠,居然是销冠。然后我不温不火的说到:“是啊,快过年了,得拿年终奖。”
“不是,就是想着让成绩保持着,马上快一年了。”尴尬,人家只是想保持成绩。是我肤浅了。等等!保持快一年?没记错的话她好像也才在公司直播一年不到吧!这就是传说中的入职即巅峰吗?我突然觉得我好菜!好想快点自觉走开,奈何地铁还没到!
“原来是销冠,这么厉害!我以为是年底为了冲年终奖,是我肤浅了~”我简单表达一下敬意和歉意。有颜值有能力,突然人与人之间的距离一下就拉开了。
“没有没有!钱也重要,钱也重要!”她噗呲一笑。然后用期盼的眼神看着我,“对了,你喜欢研究小工具来着,你有没有知道哪种可以在直播时做一些辅助的小工具?我网上找了好多,都是只能用在抖音斗鱼这些大公司的辅助工具,我们公司的这个直播平台的一直没有找到。哎呀!好烦~”
完犊子了,这题我不会。看着她好像是工具花了很久没有找到,焦急得好像就要跺脚的样子,我只感觉头皮发麻,要掉头发了!怎么办?怎么办?哪里有这种工具?
但话题还是要接着啊!我开始答非所问:“到没关注过这方面的小工具,但我听说现在有些自动直播的工具,可以克隆人像和声音二十四小时直播。”
“不需要不需要,我不需要这么高端的工具,而且那些自动播的很缺少粉丝互动的。我只要可以帮我定时上下架商品啥的就好。”
我心想,这不搞个脚本 setInterval 一下就行?虽然但是要做得方便他们使用的形式还是得折腾下。我们这个直播平台又不是大平台,网上肯定也没有现成的,不过要做一个没什么难度。
我回答说:“那我帮你找找。”
“谢谢谢谢小哥哥!你人真好!”看着她一边开心的笑着一边双手拜托的样子,我既感觉完犊子了入坑了,又恨不得现在就给她做一个出来!
车来了。她转头看了一下,然后又转过头来问我“小哥哥可以加下你微信吗?你有消息的话随随时通知我,我都在的。”
我:“行的。”
她:“我加你我加你~”
我竟然一下子没有找到我的微信二维码名片在哪,确实,从来就没有其他女生加过我,没什么经验倒也正常,是吧?她又转头看了看停车的车,我知道她是她的车,可她还告诉我没事的慢慢来。
她加上了我的微信,然后蹦上滴滴滴快要关门的列车,在窗口笑着向我挥手告别。在转角那一刻她指了指手机,示意我看微信。
“我叫李蕾^_^”。
“收到”。

功能设计
在上一节为什么要开发这样的程序花费了一定量的与技术无关的笔墨,可能有些读者会反感。对此我表示:你以为呢?接到一个项目哪那么容易?手动狗头。
在功能方面,主要考虑以下特性:
开发时方便
不方便肯定会影响开发进度啦。热更新热部署啥的,如果没有这些开发体验那可是一点都不快乐~
使用时点开就能用
解压、下一步下一步安装了都不要了。
多设备下多平台下多配置支持
如果不做设备隔离,万一主播把这软件发给别人用,岂不是乱套了。多平台的考虑是因为反正都是注入脚本,就统一实现。多配置主要实现每个配置是不同的浏览器配置和数据隔离。
便于更新
减少文件发来发去、版本混乱等问题。
便于风控
如果改天主播说这软件不想用了,那我远程关闭就行。
看下总体界面

一个设备支持多个主配置,每个主配置可以绑定密钥进行验证。
主配置验证通过之后,才是平台配置,平台配置表示系统已支持自动化的平台,例如疼训、筷手这些平台。这些每个平台对应自己的 logo、自动化脚本文件和状态。
自动化脚本文件在开发过程中可以修改,用户侧不可见,直接使用即可。
每个平台下有多个配置,比如疼训这个平台下,创建配置A作为账号A的自动化程序,配置B作为账号B的自动化程序。因为每个配置启动的是不同的浏览器实例,所以疼训理论上不会认为多个账号在同一浏览器下交叉使用。反正我司的平台肯定不会认为~
然后配置下有一些通用的功能:例如智能客服可以按关键字进行文字或语音回复。
例如假设你配置了一个关键字列表为
keys = [`小*姐姐`, `漂亮`]
reply = [`谢谢大哥`, `大哥你好呀`, `你也好帅`]
当你进入直播间,发了一句小*姐姐真漂亮时,就可能会自动收到小*姐姐的语音谢谢大哥, 你也好帅。
在场控助手这边,根据场控需求,直播间可以按指定规则进行自动发言,自动高亮评论(就是某个评论或系统设定的内容以很抢眼的形式展示在屏幕上),这是防止直播间被粉丝门把话题逐渐带偏的操作方法之一。
商品助手这边,有一些按指定规则、时间或顺序等配置展示商品的功能。
技术选型
- 使用 vue3/vite 进行界面开发。这部分众所周知是热更新的,并且可以在浏览器中进行调试。
- 使用 sys-shim 提供的 js api 进行浏览器窗口创建、读写操作系统的文件。当创建浏览器窗口后,需要关闭窗口。
- 使用 mockm 进行接口开发,自动实现多设备、平台、配置的 crud 逻辑支持。
在 vue3 进行界面开发的过程中,这个过程可以在浏览器里面也可以 sys-shim 的 app 容器中。因为界面与 sys-shim 进行通信主要是通过 websocket 。前端调用某个函数,例如打开计算器,然后这个函数在内部构造成 websocket 的消息体传给 sys-shim 去调用操作系统的 api 打开计算器。就像是前端调用后端提供的 api 让后端调用数据库查询数据,返回数据给前端。
在界面完成之后,把界面部署在服务器上,这样如果有更新的话,就像普通的前端项目一样上传 dist 中内容在服务器上即可。发给主播的 app 读取服务器内容进行界面展示和功能调用。
计划安排
- 周五加加班,用两小时完成数据模型、API实现
- 周六完成主要功能界面、交互开发
- 周日上午进行体验完善、发布测试
开发过程
由于我只是个做前端的,并且只是个实习生。所以用到的技术都很简单,下面是具体实现:
数据模型、API实现
由于是多设备、多平台、多配置,所以数据模型如下:
const db = util.libObj.mockjs.mock({
// 设备
'device|3-5': [
{
'id|+1': 1,
电脑名: `@cname`,
},
],
// 主配置
'config|10': [
{
'id|+1': 1,
deviceId() {
const max = 3
return this.id % max || 3
},
名称: `@ctitle`,
卡密: `@uuid`,
激活时间: `@date`,
过期时间: `@date`,
},
],
// 平台
platform: [
{
id: 1,
封面: [
{
label: `@ctitle`,
value: `@image().jpg`,
},
],
网址: `https://example.com/`,
状态: `可使用`,
脚本文件: [
{
label: `@ctitle().js`,
value: `@url().js`,
},
],
名称: `豆印`,
},
],
'devicePlatformConfig|1-3': [
{
'id|+1': 1,
名称: `默认`,
deviceId() {
const max = 3
return this.id % max || 3
},
platformId() {
const max = 3
return this.id % max || 3
},
configId() {
const max = 3
return this.id % max || 3
},
数据目录() {
return `data/${this.id}`
},
// 功能配置
action: {
智能客服: {
文字回复: {
频率: `@integer(1, 5)-@integer(6, 10)`,
启用: `@boolean`,
'配置|1-5': [
{
关键词: `@ctitle`,
回复: `@ctitle`,
},
],
},
// ... 省略更多配置
},
// ... 省略更多配置
},
},
],
}),
观察上面的数据模型, 例如主配置中有一个 deviceId,由于这个字段是以驼峰后缀的 Id 结尾,所以会自动与 device 表进行关联。
platform 这张表由于没有与其他表有关联关系,所以无需添加含有 ...Id 的字段。
devicePlatformConfig 平台设备配置这张表,是某设备创建的针对于某一主配置下的某平台下的某一配置,所以会有 deviceId / platformId / configId 。
这样如何要查某设备下的所有平台的配置,直接 /devicePlatformConfig?deviceId=查某设备ID 即可。
由于上面这些表声明关联关系之后,模拟数据和接口都是自动生成的,所以这一块并没有其他步骤。
在 api 层面,有一个需要处理的小地方,就是类似于登录(token/用户标识)的功能。由于这个程序并不需要登录功能,所以使用设备ID作为用户标记。
const api = {
async 'use /'(req, res, next) {
// 不用自动注入用户信息的接口, 一般是系统接口, 例如公用字典
const publicList = [`/platform`]
const defaultObj =
!publicList.includes(req.path) &&
Object.entries({ ...req.headers }).reduce((acc, [key, value]) => {
const [, name] = key.match(/^default-(.*)$/) || []
if (name) {
const k2 = name.replace(/-([a-z])/g, (match, group) => group.toUpperCase())
acc[k2] = value
}
return acc
}, {})
if (req.method !== `GET`) {
req.body = {
...defaultObj,
...req.body,
}
}
req.query = {
...defaultObj,
...req.query,
}
next()
},
}
在后端 api 入口上,我们添加了一个拦截器,含有 default- 开头的键会被当成接口的默认参数。如果传设备 id 就相当于给每个接口带上设备标记,后面这个设备创建和修改、查询配置都会被限定在改设备下,实现了类似某用户只能或修改查看某用户的数据的功能。对于之前提到的公用数据,例如 /platform 这个接口的数据是所有用户都能看到,那直接配置到上面的 publicList 中即可。
前端的请求拦截器是这样的:
http.interceptors.request.use(
(options) => {
options.headers[`default-device-id`] = globalThis.userId
return options
},
(error) => {
Promise.reject(error)
},
)
什么?并不严谨?啊对对对!
界面实现:首先做一个浏览器
由于只会一些简单的跑在浏览器里的 js/css ,所以我们要先做一个浏览器来显示我们的软件界面。
经常用 google chrome,用习惯了,并且听说它还不错。所以打算做一个和它差不多的浏览器。
它封装了 chromium 作为内核,那我们也封装 chromium 吧。
微软听说大家都想要做个基于 chromium 的的界面渲染程序,于是微软就给我们做好了,叫 microsoft-edge/webview2 。
听说大家都在用这个渲染引擎,那么微软干脆把它内置于操作系统中,目前 win10/win11 都有,win7/8 也可以在程序内自动在线安装或引用安装程序离线安装。
不知不觉的浏览器就做好了。
如何使用这个做好的浏览器
由于只会 js ,所以目前我使用 js 创建这个 webview 实例是这样的:
const hwnd = await hook.openUrl({
url: platformInfo.value.网址,
preloadScript,
userDataDir: row.数据目录 || `default`,
})
可以看到,上面的 js 方法支持传入一个网址、预加载脚本和数据目录。
在这个方法的内部,我们通过构造一个 aardio 代码片段来创建 winform 窗口嵌入 webview 实例。
至于要构造什么 aardio 片段,是 aardio 已经做好相关示例了。复制粘贴就能跑,需要传参的地方,底层是使用 ipc 或 rpc 进行通信的。
ipc 是进程之前通知,可以简单的理解为一个基于事件的发布订阅程序。
rpc 是远程调用,可以简单理解为我们前端经常调用的 api。服务端封装好的 api,暴露给前端,直接调用就好了。
aardio示意片段
var winform = win.form({text: `sys-shim-app`}) // 创建一个 windows 窗口
var wbPage = web.view(winform, arg.userDataDir, arg.browserArguments) // 使用指定配置启动一个浏览器示例
wbPage.external = { // 向浏览器注入全局变量
wsUrl: global.G.wsUrl;
}
wbPage.preloadScript(arg.preloadScript) // 向浏览器注入 js 脚本
wbPage.go(arg.url) // 使用创建的浏览器打开指定 url
winform.show() // 显示窗口
有了上面的代码,已经可以做很多事情了。因为向浏览器注入了一个全局变量 wsUrl,这是服务端的接口地址。然后在注入的脚本里去连接这个接口地址。
脚本由于是先于 url 被加载的,所以首先可以对页面上的 fetch 或者页面元素这些进行监听,实现拦截或代理。另外 webview 也提供了 cdp 层面实现的数据监听。
功能实现:让宿主与实现分离
这里的宿主是指除开 注入自定义脚本 的所有功能。根据之前的设计,网站地址是用户配置的,脚本也是用户上传的。所以一切都是用户行为,与平台无关?
啊对对对就这样!
把自动化这块功能分离出去,让其他人写(我不会!手动狗头)。然后我们在程序里为现有功能做一个事件发布。当用户开启了某个功能,脚本可以知道,并可以得到对应配置的值,然后去做对应功能的事。
const keyList = Object.keys(flatObj(getBase()))
keyList.forEach((key) => {
watch(
() => {
return deepGet(devicePlatformConfig.value, key)
},
(newVal, oldVal) => {
keyByValueUpdate(key, newVal, oldVal)
},
{
immediate: true,
},
)
})
getBase 是一个配置的基础结构对象。把这个对象扁平化,就能等到每个对象的 key,使用 vue 的 watch 监听每个 key 的变化,变化后分别发布 [key, 当前值, 占值, 整个配置对象] 。
这样在自动化脚本那边只需要订阅一下他关心的 key 即可。
例如:当 场控助手.直播间发言.频率 从 2 变成 6 。

ws.on(`action.场控助手.直播间发言.频率`, (...arg) => {
console.log(`变化了`, ...arg)
})
好了,接下来的内容就是在群里 v50 找人写写 js 模拟事件点击、dom监听啥的了(具体自动化脚本略,你懂的~手动狗头)。

测试过程
总算赶在了周一完成了功能,终于可以进行测试啦~

她同事进行功能测试的时候,提出了一些修改意见(还好是自己写的,不然真改不动一点),然后有个比较折腾的是原来我的配置窗口和平台直播页面是分别在不同的 windows 窗口下的,可以相互独立进行拖拽、最小化等控制,因为想着独立开来的话配置窗口就不会挡住直播页面的窗口了。
没想到她希望配置窗口可以悬浮在直播平台的页面上,并且可以展开折叠拖动。这对于之前设计的架构有一些差异,修改花了点时间。



最终结果

我很满意,手动狗头。
相关内容
- 源码地址: https://github.com/wll8/sys-shim/tree/main-open/store/demo/live-control-robot
- sys-shim 文档: https://wll8.github.io/sys-shim-doc/
- 视频(发布在的bilibili上,首次发视频,支持一下?)
- 安装、运行、开发 https://www.bilibili.com/video/BV1E5qbY2EbX/
- 打包、发布 https://www.bilibili.com/video/BV1J5qbY2EVX/
- 运行打包后的程序 https://www.bilibili.com/video/BV1jJqbYVEZx/
声明:本文仅作为 sys-shim 的程序开发技术交流,本人没有也不提供可以自动化操作某直播平台的脚本。
来源:juejin.cn/post/7448951076685119529
BOE(京东方)“向新2025”年终媒体智享会首站落地上海 六大维度创新开启产业发展新篇章
12月17日,BOE(京东方)以“向新2025”为主题的年终媒体智享会在上海启动。正值BOE(京东方)新三十年的开局之年,活动全面回顾了2024年BOE(京东方)在各领域所取得的领先成果,深度解读了六大维度的“向新”发展格局,同时详细剖析了BOE(京东方)在智能制造领域的领先实践。BOE(京东方)执行委员会委员、副总裁贠向南,BOE(京东方)副总裁、首席品牌官司达出席活动并发表主旨演讲。

经过三十年创新发展,秉持着对技术的尊重和对创新的坚持,在“屏之物联”战略指导下,BOE(京东方)从半导体显示领域当之无愧的领军巨擘迅速蝶变,成功转型为全球瞩目的物联网创新企业,并不断引领行业发展风潮。面对下一发展周期,BOE(京东方)将从战略、技术、应用、生态、模式、ESG六大方面全方位“向新”突破,以实现全面跃迁,并为产业高质发展注入强劲动力。
战略向新:自2021年“屏之物联”战略重磅发布以来,BOE(京东方)又于2024年京东方全球创新伙伴大会(BOE IPC·2024)上发布了基于“屏之物联”战略升维的“第N曲线”理论,以半导体显示技术、玻璃基加工、大规模集成智能制造三大核心优势为基础,精准布局玻璃基封装、钙钛矿光伏器件等前沿新兴领域,全力塑造业务增长新赛道。目前,玻璃基封装领域,BOE(京东方)已布局试验线,成立了玻璃基先进封装项目组,实现样机产出;钙钛矿领域,仅用38天就已成功产出行业首片2.4×1.2m中试线样品,标志着钙钛矿产业化迈出了重要一步。
技术向新:2021年,BOE(京东方 )发布了中国半导体显示领域首个技术品牌,开创了产业“技术+品牌”双价值驱动的新纪元。以技术品牌为着力点,BOE(京东方)深入赋能超5000家全球顶尖品牌厂商和生态合作伙伴,包括AOC、ROG、创维、华硕、机械师、雷神、联想等,助力行业向高价值增长的路径迈进,也为用户提供了众多行业领先、首发的更优选择。 BOE(京东方)还将全力深化人工智能与半导体显示技术以及产业发展的深度融合,并在AI+产品、AI+制造、AI+运营三大关键领域持续深耕,并依托半导体显示、物联网创新、传感器件三大技术策源地建设,与产业伙伴和产学研合作伙伴共同创新,为产业高质量可持续发展保驾护航。
应用向新: BOE(京东方)不仅是半导体显示领域的领军企业,也是应用场景创新领域的领跑者,BOE(京东方)秉持“屏之物联”战略,以全面领先的显示技术为基础,通过极致惊艳的显示效果、颠覆性的形态创新,为智慧座舱、电竞、视觉艺术、户外地标等场景注入了新鲜血液,带给用户更加美好智慧的使用体验。以智慧座舱为例,根据市场调研机构Omdia最新数据显示,2024年前三季度京东方车载显示出货量及出货面积持续保持全球第一,在此基础上BOE(京东方)还推出“HERO”车载场景创新计划,进一步描绘智能化时代汽车座舱蓝图。
生态向新: BOE(京东方)持续深化与电视、手机、显示器、汽车等众多品牌伙伴的合作,共同打造“Powered by BOE”产业生态集群,赢得众多客户的认可与赞誉。与此同时,BOE(京东方)还持续拓展跨产业生态,通过与上海电影集团、故宫博物院、微博等文化产业领先机构展开跨界合作,以创新技术赋能传统文化艺术与影像艺术。此外,通过战略直投、产业链基金等股权投资方式协同众多生态合作伙伴,通过协同合作、资源聚合共同构筑产业生态发展圈层。
模式向新: 为适配公司国际化、市场化、专业化的长远发展,BOE(京东方)持续深化“1+4+N+生态链”的业务发展架构,以及“三横三纵”组织架构和运营机制。在充分市场化和充分授权的机制保障下,形成了以半导体显示核心业务为牵引,传感、物联网创新、MLED业务、智慧医工四大高潜航道全面开花,聚焦包括智慧车联、工业互联、数字艺术、3D光场等规模化应用场景,生态链确保产业上下游合作伙伴协同跃迁的“万马奔腾”的发展图景。此外,BOE(京东方)还鼓励员工创新创业,通过激发人才创新热情,共同为集团发展注入强劲内生动力。
ESG向新: 2024年,BOE(京东方)承诺将在2050年实现自身运营碳中和,并通过坚持“Green+”、“Innovation+”、“Community+”可持续发展理念,推动全球显示产业高质永续发展。“Green+”方面,BOE(京东方)依托 16 家国家级绿色工厂、1 座灯塔工厂及1座零碳工厂,以绿色产品、制造与运营践行低碳路径;“Innovation+”方面,BOE(京东方)凭借全部为自主创新的9万件专利的行业佳绩,以及技术策源地、技术公益池等举措,携手产业上下游伙伴协同创新;“Community+”方面,BOE(京东方)在教育、医疗、环境等公益领域持续投入,积极履行社会责任,例如,在“照亮成长路”公益项目中,BOE(京东方)十年间在偏远地区建设的智慧教室已经突破120所。
BOE(京东方)智能制造:铸就行业新典范
BOE(京东方)智能制造在引领标准、数字化变革、AI+制造和可持续发展四个方面,树立了全球智能制造卓越标杆,并引领产业迈向智能化、绿色化新时代。在引领标准方面,BOE(京东方)已建立起遍布全球的智能制造体系,包括18条半导体显示生产线和6大全球智能终端服务平台,并荣膺全球智能制造最高荣誉——世界经济论坛“灯塔工厂”。为应对布局全球的产供销业务体系,BOE(京东方)已构建起设供产销集成管理系统,可实现业财一体的全生命周期智能决策;在数字化变革方面,BOE(京东方)正致力于打造“一个、数字化、可视的京东方”,包括流程、组织、IT、数据四大管理要素,通过建立一个基于流程的、端到端的、高效的数字化管理体系为智能制造赋能;在AI+制造方面,通过系统化运用AI、大数据等技术,BOE(京东方)结合生产制造痛点难点问题,聚焦效率领先、品质卓越,务实高效地执行AI+制造规划。在品质把控方面,BOE(京东方)打造的IDM质检平台(Intelligence defect management)是面向业务人员开发的系统,功能覆盖工业质检全场景及AI建模全流程,引入大模型标注、判定技术,打通场景、工序、代际壁垒,极大提升了人机协同下的复判效率和判定准确率,在确保产品高质量的同时实现成本的有效控制;在可持续发展方面,BOE(京东方)始终秉承“以绿色科技推动生产发展理念”,旗下16家工厂获得国家级“绿色工厂”称号,以绿色制造助力产业可持续升维发展。
“向新2025”年终媒体智享会,是BOE(京东方)2024创新营销的收官之作和全新实践,系统深化了大众对BOE(京东方)品牌和技术创新实力的认知与理解。近年来,BOE(京东方)通过多种创意独具的品牌破圈推广,包括“你好BOE”系列品牌线下活动、技术科普综艺《BOE解忧实验室》等生动鲜活地传递出BOE(京东方)以创新科技赋能美好生活的理念,为企业业务增长提供了强大动力,也为科技企业品牌推广打造了全新范式。据了解,BOE(京东方)该“向新2025”主题系列活动还将于12月20日和12月27日分别落地成都和深圳。
面向未来,BOE(京东方)将胸怀“Best on Earth”宏伟愿景,坚持“屏之物联”战略引领,持续推动显示技术和物联网、AI等前沿技术的深度融合。从提升产品视觉体验到优化产业生态协同,从升级智能制造体系到践行社会责任担当,BOE(京东方)将砥砺奋进、创新不辍,为全球用户呈献超凡科技体验,领航全球产业创新发展的新篇章。
收起阅读 »BOE(京东方)北京京东方医院主体结构开工 打造医工融合创新典范
12月12日,BOE(京东方)旗下北京京东方医院主体结构正式开工。北京京东方医院是2024年北京市“3个100”重点工程项目,定位为BOE(京东方)智慧物联网医院总院,位于房山区京东方生命科技产业基地,总占地面积约152亩, 总床位1500张,其中一期建设1000床,预计2026年建成开诊。北京京东方医院的建设将打造分级诊疗体系区域样板,为大众提供优质便捷高效的医疗服务,同时积极构建医工融合的产业集群,为区域医疗产业的智慧转型注入强劲动力。

京东方科技集团党委书记、副董事长冯强在致辞中表示,智慧医工业务作为BOE(京东方)在大健康领域的重要战略布局,历经十年发展,形成了以健康管理为核心,医工产品为牵引、数字医院为支撑的健康物联生态系统,并按照医工融合的发展理念,在房山布局了集“医教研产用”于一体的生命科技产业基地,北京京东方医院正是基地的核心支撑平台。医院以三级综合医院为基础,结合BOE(京东方)在显示、物联网、智慧医工等方面的核心优势,按照“补缺、合作、差异化”的原则,着力打造“技术领先、数字驱动、模式创新”的BOE(京东方)智慧物联网医院总院。

北京京东方医院将聚焦重症康复、急诊急救等重点学科,积极引进顶尖技术,推动诊疗技术向精准医学方向发展,做卓越医疗的践行者,并充分利用物联网和人工智能技术,建立数字孪生医院,做智慧医疗的引领者。同时,建立开放创新的平台化体系,汇聚专家资源,建立核心能力,将服务体系延伸到社区和家庭,做新型服务模式的创建者。作为生命科技产业基地的核心支撑,北京京东方医院将持续与全国一流高校、医疗机构、创新企业等有机协同,共同构建“从临床来,到临床去”的创新转化体系,推动生命科技产业新质生产力发展。
多年来,BOE(京东方)不断探索未来医疗健康产业的高潜发展方向,通过科技与医学融合创新,打通了“防治养”的全链条,实现了“医”为“工”提供需求来源和临床转化,“工”为“医”的技术提升持续赋能。目前,BOE(京东方)已在北京、合肥、成都、苏州四地建设并运营5家数字医院。面向未来,BOE(京东方)将坚持以“屏之物联”战略为牵引,积极推动医疗健康产业的智慧转型,以创新驱动和科技赋能开启医工融合发展的崭新篇章。
收起阅读 »



