这篇也是我分享里为数不多 “进阶” 与 “成长经历” 的文章之一。被别人送到嘴边的食物永远是最香的,但是咱们还是得学会主动去"如何找吃的",授人以鱼不如授人以渔嘛,我希望通过这篇文章能给正在努力的你,迷茫的你,焦虑的你,带来或多或少的参考、建议或者指引。
十年,谁来成就你?
离开校园,一晃已十年,时日深久,现在我已成为程序员老鸟了,从软件工程师到系统架构师,从被管理者到部门负责人,每一段经历的艰辛,如今回忆仍历历在目。各位同行你们可能正在经历的迷茫,焦虑与取舍,我也都曾经历过。
今天我打算跟大家分享下我这些年的一个成长经历,以此篇文章为我十年的职业历程画上一个完满的句号。这篇文章虽说不是什么“绝世武功”秘籍,更没法在短时间内把我十年的“功力”全部分享于你。篇幅受限,今天我会结合过往种种挑重点说一说,大家看的过程中,记住抓重点、捋框架思路就行了。希望在茫茫人海之中,能够给到正在努力的你或多或少的帮助,亦或启发与思考。
试问,你的核心竞争力在哪?
你曾经是否怕被新人卷或者代替?如果怕、担忧、焦虑,我可以很负责任地告诉你,那是因为你的核心竞争力还不够!这话并不好听,但,确是实在话。认清现状,踏实走好当下就行,谁能一开始或者没破茧成蝶时就一下子有所成就。
实质上,可以这么说,经验才是我们职场老鸟的优势。 但是,经验并不是把同一件事用同一种方式重复做多少年,而是把咱们过往那么多年头的实践经验,还有被验证的理论,梳理成属于自己的知识体系,建立一套自己的思维模式,从而提升咱们的核心竞争力。
核心竞争力的形成,并非一蹴而就,我们因为积累所以专业,因为专业所以自信,因为自信所以才有底气。积累、专业、自信、底气之间的关系,密不可分。
 核心竞争力,祭出三板斧
核心竞争力,祭出三板斧
道理咱们都懂,能不能来点实在的?行!每当身边朋友或者后辈们,希望我给他们传授一些“功力”时,我都会给出这样的三个建议:
- 多面试,验本事。
- 写博客,而且要坚持写。
- 拥有自己的 Github 项目。
其中,博客内容和 Github 项目,将会成为咱们求职道路上的门面,这两者也是实实在在记录你曾经的输出,是非常有力有价值的证明。此外,面试官可以通过咱们的博客和 Github,在短时间内快速地了解你的能力水平等。或许你没有足够吸引、打动人的企业背景,也没有过硬的学历。但!必须有不逊于前两者的作品跟经历。
再说说面试,我认为,它是我们接受市场与社会检验的一种有效方式。归根结底,咱们所付出的一切,都是为了日后在职业发展上走得越来越好。有朋友会说,面试官看这俩“门面”几率不大,没错,从我多年的求职经历来看,愿意看我作品的面试官也只占了 30%。
但是,谁又能预判到会不会遇到个好机会呢?有准备,总比啥也没有强,千里马的亮点是留给赏识它的伯乐去发现的。
PS:拥有自己 Github 项目与写博,都属于一种输出的方式,本文就以写博作为重点分享。写博与面试会在下文继续展开。
记忆与思考,经验与思维
武器(三板斧)咱们已经有了,少了“内功心法”也不行。这里分享下我的一些观点,也便于大家后续能够更好地参与到具体的实践中。
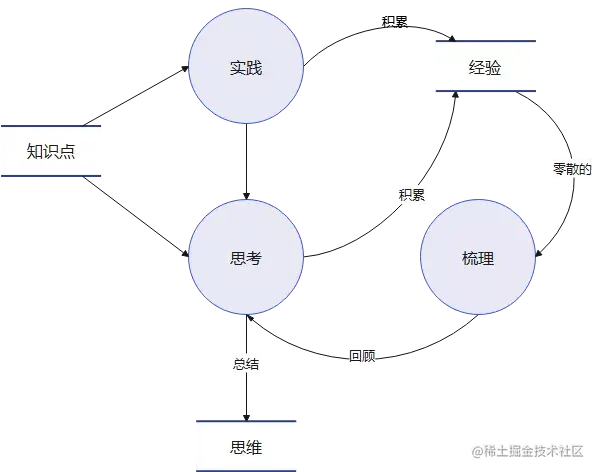
日常工作中,就拿架构设计当例子。作为架构师是需要针对现有的问题场景提出解决方案,作为架构师的思考输入是业务场景、团队成员、技术选型等,而它的输出就是基于前面的多种输入参数从而产出的短期或长期的解决方案,而且最终会以文档形式保存下来。
保存下来的目的,是为方便我们日后检索、回忆、复用。因此,在业余学习中同理,给与我们的输入是书籍、网络的资料或同行的传递等,而作为输出则是咱们记录下来的笔记、博客甚至是 Github 的项目 Demo。
基于上述,我们需要深刻意识到心法三要素:
- 带着明确的输出目的,才会真正地促进自己的思考。蜻蜓点水、泛泛而谈,是无法让自己形成对事物的独特见解和具象化输出,长期如此,并无良益。
- 只有尽可能通过深度思考过后的产出,才能够形成属于自己真正的经验。
- 知识的点与点之间建立联系,构成明晰的知识体系,经验与经验则形成了自己独有的思维模式。
多面试,验本事
既然“武器”和“内功心法”咱们都有了,那么接下来得开始练“外功”了,而这一招叫"多面试,验本事"。
我身边的同行与朋友,对我的面试行为感到奇怪:你每隔一段时间就去面试,有时拿到了 offer 还挺不错的,但是又没见想着跳槽,这是为何?
风平浪静,居安思危
回应这个疑问之前,我想反问大家 4 个问题:
- 是否曾遇到过在一家公司呆了太久过于安逸,也阶段性想过离开,发现真要走可却没了跳槽的勇气?
- 再想一想,日子一久,你们是不是就不清楚行业与市场上,对人才能力的需求了?
- 是否有经历过公司意外裁员,你在找工作的时段里有没有强烈感受到那种焦虑、无助?
- 是否对来之不易的 offer,纠结不知道如何抉择,又或者,最终因为迫于各方面压力,勉为其难接受了不太中意的那个?

刚提到的种种问题,那份焦虑、无助、纠结与妥协,我曾经在职场都经历过。我们想象一下,如果你现在随随便便出去面试五个公司能拿到三四个 offer,你还会有那失业的焦虑么?如果现在拿到的那几个 offer 正好都不喜欢,你全部放弃了,难道你会愁后续没有其他机会了么?显然不会!因为你有了更多底气和信心。
我再三思考,还是觉得有必要给大家分享一个我的真实经历。希望或多或少可以给你一点启发:
2019 年,因为 A 公司业务原因,我离开了工作 3 年的安逸的环境,市场对人才的需求我已经是模糊的了,当我真正面临时,我焦虑、我无助。幸好曾经跟我合作过的老领导注意到了这我这些年的成长,向我施予援手。入职 B 公司后,我重新审视自己,并给与自己定了个计划——每半年选一批公司面试。
一年以后,因为 B 公司因疫情原因,我再次离职。这次,我没有了焦虑,取而代之的是自信与底气,裸辞在家开始了我的休假计划。在整个休假期,我拒绝了两个满足我的高薪 offer,期间我接了个技术顾问的兼职,剩余时间把以前囤下来的书看了个遍,并实践了平常没触碰到的技术盲区。三个月后,我带着饱满的精神面貌再次"出山",入职了现在这家公司。
有人会问:你现在还有没有坚持自己的面试计划?毫无避讳回答:有!仍然是半年一次。
乘风破浪,未雨绸缪
就前面这些问题、情况,这里结合我自己多年来的一些经验,也希望给到大家一点破局建议:保持一定的面试频率,就如上文提到的“三板斧”,面试是接受市场与社会检验,非常直接、快速、有效的一种好方式。 当然,我可不是怂恿你频繁跳槽,没有多少公司能够欣然接受不稳定的员工,特别是岗位越做越高时。
看到这里,有些伙伴可能会想,我现在稳稳当当的、好端端的,干嘛要去面试,何必折腾自己。假若你在体制内,我这点建议或许参考意义不大。抛开体制内的讨论,大家认为真的有所谓的“稳定”的工作吗?
我认为所谓的“稳定”,都是只是暂时的,甚至虚幻的,没有任何的人、资本、企业能给你实打实的承诺,唯一能让你“稳定”持续发展下去的,只有你的能力与眼界、格局等。
疫情也有几年了,相信大家也有了更多思考,工作上,副业上等等各方面吧。人无远虑,必有近忧,未雨绸缪,实属必要!

放平心态,查缺补漏
面试是相对“主观的”,这是因为“人性”的存在,你可能会听过让人哭笑不得的拒绝你的理由:
- 连这么基础的知识都回答不上,还想应聘这岗位
- 你的性格并不适合当管理,过于主动对团队不好
咱们先抛开这观点的对与错。人无完人,每个人都有自己的优点与缺点,甚至你的优点可能是你的缺点。职场长路漫漫,要是把每一次的面试都当成人生中胜负的较量,那咱们最后可能会输的体无完肤。咱们付出任何的努力,也只是单纯提高“成功率”而已。听我一句劝,放平心态,以沟通交流为主,查漏补缺为辅。
近几年我以面架构师和负责人的岗位为主,面试官大多数喜欢问思想和方法论这类的问题,他们拥有不同的细节的侧重点,因此我们以梳理这些“公共”的点出发,事后复盘自己回答的完整性与逻辑性,对于含糊不清的及时找资料补全清晰,尝试模拟当时回答的场景。每一段面试,如此反复。
作为技术人我建议,除了会干,还得会说,我们不仅有硬实力,还得有软技能。
PS:篇幅有限,具体面试经历就不展开了,如果大家对具体的面试经历感兴趣,有机会我给大家来一篇多年的"面经"。
持续进步
编程语言本身在不断进步,对于菜鸟开发者来说,需要较高的学习成本。但低代码平台天然就具备全栈开发能力,低代码程序员天然就是全栈程序员。
这里非常推荐大家试试JNPF快速开发平台,依托的是低代码开发技术原理,因此区别于传统开发交付周期长、二次开发难、技术门槛高的痛点,在JNPF后台提供了丰富的解决方案和功能模块,大部分的应用搭建都是通过拖拽控件实现,简单易上手,在JNPF搭建使用OA系统,工作响应速度更快。可一站式搭建生产管理系统、项目管理系统、进销存管理系统、OA办公系统、人事财务等等。
开源链接:http://www.yinmaisoft.com/?from=jueji…
狠下心来,坚持到底
锲而舍之,朽木不折;锲而不舍,金石可镂——荀况
要是把"多面试"比喻成以"攻"为主的招式,而"写博客"则是以"守"为主的绝招。
回头看,今年,是我写博客的第八个年头了,虽说写博频率不高,但整体时间跨度还是挺大的。至今我还记得我写博客的初心,用博客记录我的学习笔记,同时抛砖引玉,跟同行来个思维上的碰撞。
随着工作年限的增长,我写博客的内容慢慢从学习笔记变成了实战记录,也越来越倾向于输出经验总结和实践心得。实质上,都是在传达我的观点与见解。
而这,至关重要。反过来看,后面机会来了,平台联系人也可以借此快速评估、判断这人会不会讲、能不能讲,讲得怎么样,成的话,人家也就快速联系咱了。进一步讲,每一次,于个人而言,都是好机会。
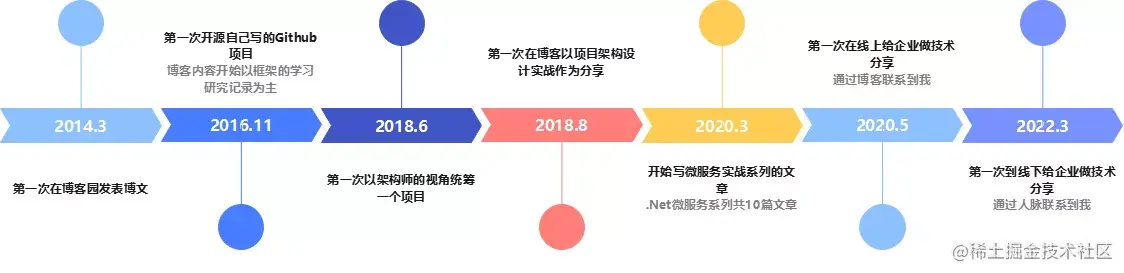
写博第一步,从记笔记开始
我相信不少的同行曾经面临这样的境况,都有产生过写博客的念头,有些始终没有迈出第一步,有些中途停了下来,这里可能有不少的原因:要么不知道写什么、要么觉得写了也没人看、还有一种是想写但是比较懒等等。
我觉得,一切的学习,前期都是从模仿开始的 。 学习笔记,它就是很好的便于着手的一种最佳方式。相信大家在学生年代或多或少都写过日记,就算是以流水账的方式输出,博客也可以作为非常好的开启平台。
由于在写博客的时候,潜意识里会认为写出来的东西会给更多人看,因此自己写的内容在不明确的地方都会去找资料再三确认,这是很有效的一种督促方法。确认的过程中,也会找到许多相关的知识点,自然而然就会进一步补充、完善、丰富我们自己原有或现在的知识体系。
幸运,需要自己争取
在写博客的这段时间里,除了梳理自己的知识体系之外,还能结交了一些拥有共同目标的同行,我想,这就是真正的志同道合吧。
甚至在你的博客质量达到了一定程度——有深度与广度,会有一些意象不到的额外小收获。例如有一些兼职找到自己,各大社区平台会邀请自己合作,也会收到成就证明与礼物等等。

意外地成为了讲师
到目前为止,正式作为讲师或者是技术顾问,以这样不同于往常的既有角色,我真切地经历了几次。虽次数不多,但每一次过后,即便时日深久,可现在回想起来,于我的成长而言,那都是一次又一次新的蜕变,真实而猛烈,且带给我一次次新生力量。
话说回来,前面提到几次分享,有的伙伴可能会说了,这本来就性格好又爱分享的人,个例罢了,不一定适合大多数啊。说到这儿,我想,我有必要简短地跟你聊一下我自己。
跌跌撞撞,逆水行舟
对于过往的自己,我的评价是从小就闷骚、内向的那种性格,只要在人多的时候发言就会慌会怂会紧张,自己越慌就越容易表达出错,如此恶性循环。随着我写博的篇幅越多,慢慢地我发现自己讲话时喜欢准备与思考,想好了再去表达,又慢慢地讲话就具有条理性与逻辑性了。
当代著名哲学家陈嘉映先生,他曾在一本书里说过这样一句话,放到这里再合适不过了—— "成长无时无刻不是在克服某些与生俱来的感觉和欲望"
回头看,一路走来,我从最初的摸索、探索、琢磨,到看到细微变化,到明显感知到更大层面的进步,再到后来的游刃有余,输出很有见地的思考,分享独到观点。
我想,这背后,离不开一次次尝试,一次次给自己机会,一次次认真、负责地探索突破自己。其实,大多数人,还真是这么跌跌撞撞挺过来的。
伺机而动,用心准备
2020 年,我第一次被某企业找到邀请我作为技术顾问是通过我的博客,这一次算是小试牛刀,主要以线上回答问题、交流为主。因为事先收集好了需要讨论的话题与问题,整个沟通持续了两个小时,最终也得到了对方老板的高度认可。
此事过后,我重新审视了自己,虽然我口才并不突出,但是我基于过往积累的丰富经验与知识融合,并能够正确无误地传达输出给对方,我认为是合格的了。坦率来讲,从那之后我不再怀疑自己的表达能力。同时有另外一件事件更值得重视,基于让自己得到更多更广泛的一个关注,思前想后,概括来讲,我还是觉得落到这句话上更合适,就是:建立个人 IP。
建立个人 IP
那么,我希望打造个人 IP 的原因是什么呢?希望或多或少也可以给你提供一点可供借鉴、探讨的方向。
我个人而言,侧重这样几个层面吧。
- 破局: 一个是我希望打破 35 岁魔咒,这本质上是想平稳快速度过职业发展瓶颈期;
- 觅友: 希望结识到拥有同样目标的同行,深度交流,构建技术圈人脉资源网;
- 动力 : 从中获取更多与工作不一样的成就感。有了强驱动力,也会使我在分享这条路上变得更坚定。
链接资源,提影响力
在《人民的名义》里祁同伟说过一句话,咱们就是人情的社会。增加了人脉,就是增加自己的机会。当然前提是,咱们自己得需要有这个实力。
建立个人 IP,最要提高知名度,而提知名度的主要方式是两种:写书、做讲师。后面我会展开讲,写书无疑是宣传自己的最好方式之一,但整个过程不容易,周期比较长。作为写书的简化版,我们写博客就是一种捷径了。
主动出击,勿失良机
而作为讲师,线上线下各类形式参与各种社区峰会露脸,这也是一种方式。不过这种一般会设有门槛。
这里不得不多提一句,就是建立 IP 它是一个循序渐进的过程,欲速则不达,任何时候咱们都得靠内容作品来说话, 当你输出的质量够了,自然而然社区人员、企业就会找到你,机会顺理成章来了。反过来讲,我们也得常盯着,或者说多留心关注业内各平台的内容风格,利用好业余零碎时间,好好梳理下某个感兴趣的内容平台,看看他们到底都倾向于打造什么样的东西。做到知己知彼,很重要。
我认识的一个前辈,之前阿里的,他非常乐于在博客上分享自己的经验与见解,随着他分享的干货越多,博客影响力越大,某内容付费平台找到他合作出了个专栏,随着专栏的完结,他基于专栏内容又出了一本书,而现在的他已经离开了阿里,成为了自由职业者。
追求成就感,倒逼突破自我
每一次写博客、做讲师,都能更大程度上填满我内心深处的空洞,或许是每一个支持我的留言与点赞,或许是每一节分享停顿间的掌声。如果我们抱着非常强的目的去做的时候,可能会事与愿违。就以我做讲师来说,因为我是一个新手,在前期资料准备所花费的精力与时间跟后续的课酬是不成正比的。
作为动力源,当时我会把侧重点放到结交同行上,同时利用“费曼学习法”重新梳理知识,另外寻找机会突破自己的能力上限。
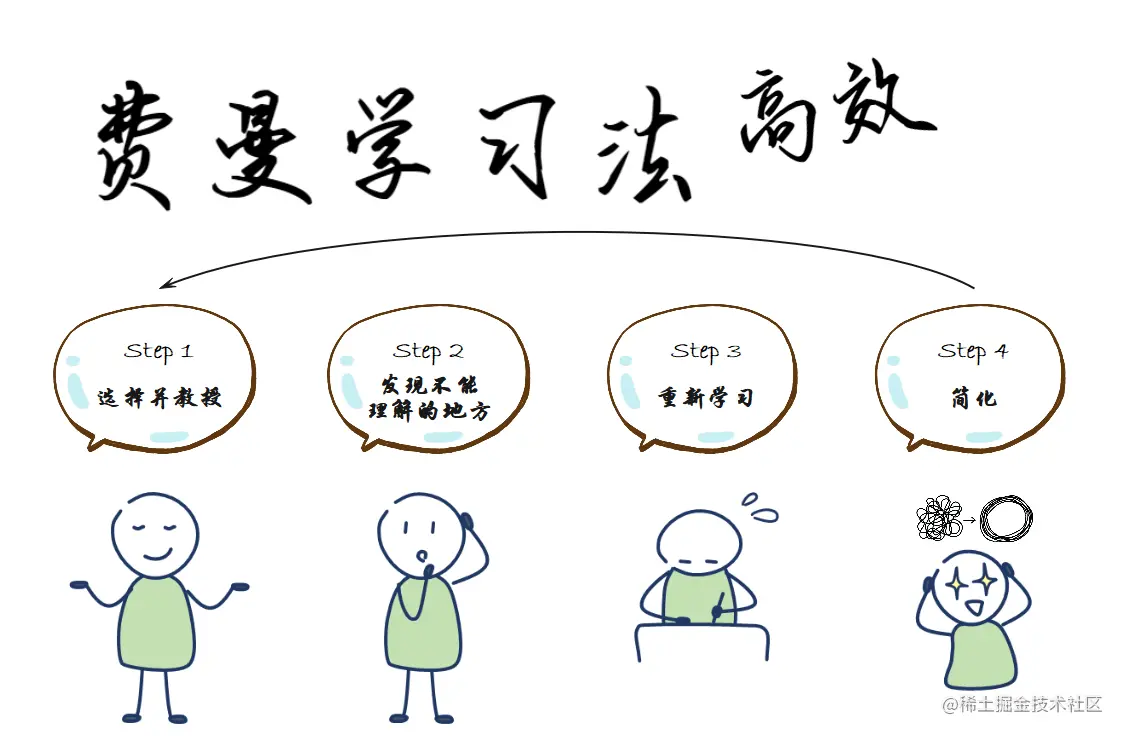
大家有没有想过,讲课最终受益者的是谁?有些朋友会回答“双方”。但是我很负责任地告诉你,作者、讲师自己才是最大的知识受益者。
如前面所讲,写博客为了更好地分享出更具价值性的内容,为保证专业性,咱们得再三确认不明确的点,而讲课基于写博客的基础上,还得以听众的角度,去思考、衡量、迭代,看看怎么让人家更好地理解、吸收、用得上这些知识点,甚至讲师得需要提前模拟、预估可能会在课后被提的问题。
这里总结一下,写博客与讲课的方式完全不同,因为博客是以图、文、表的方式展现,读者看不明白可以回头去看,但是讲课则没有回头路,是一环套一环的,所以梳理知识线的连贯性要求更强。
我个人认为,日常工作大多数是重复的、枯燥的,或者说,任何兴趣成了职业,那将不再是兴趣,或许只有在业余的时候获取那些许的成就感,才会重新燃起自己的那一份初心 ——行之于途而应于心。
源不深而望流之远,根不固而求木之长
求木之长者,必固其根本;欲流之远者,必浚其源泉——魏徵
有些同行或许会问:”打铁还需自身硬“这道理咱们都懂,成长进阶都离不开学习,但这要是天天写 BUG 的哪来那么多时间学?究竟学习的方向该怎么走呢?在这里分享下我的实际做法,以及一些切身的个人体会,希望可以提供一点借鉴、参考。
零碎时间,稳中求进
6 年前,我确定往系统架构师这个目标发展的时候,每天都会做这么两件事:碎片化时间学习,及时产出笔记。
- 上班通勤与中午休息,我会充分利用这些碎片时间(各 30 分钟)尽可能地学习与吸收知识,每天坚持一小时的积累,积少成多,两年后你会发现,效果非常可观,这就是一个量变到质变的过程。
而且有神经科学相关表明,”间歇式模块化学习的效果最佳,通勤路上就是实践这种模式的理想世界。“大家也可以多试试看。当然,一开始你学习某个领域的知识,可能效率没那么高,我建议你可以反复地把某一节掰开了揉碎了看或者听,直到看明白听懂了为止,接着得怎么做?如我前面说,咱们得要有输出!
看过这样一段话,”写和想是不同的,书写本身就是逻辑推演和信息梳理的过程。“而且,研究表明,”人的记忆力会在 17-24 岁达到高峰,25 岁之后会下降,理解力的发展曲线会延后 5 年,也就是说在 30 岁之后也会下降。“
你看,这个也直接或者间接告诉我们,还是趁早多做记录、多学习。文字也好,视频也罢,到底啥形式不重要,适合自己能长久坚持的就行,我相信你一定能从中受益。毕竟,这些累积的,可都是你自己实实在在的经验和思考沉淀!
话说回来,其实做笔记能花多长时间,就算在工作时间花半小时也有良效,而这时间并不会对自己的工作进度造成多么大的影响,但!一定时日深久,受益良多。
构建知识 体系 , 丰富 思维 模式
由于我们日常需要快速解决技术难题,很多时候从外界吸收到的知识点相对来说很零散,而知识体系是由点、线、面、体四个维度构造而成的。
那怎么做能够快速把知识串联起来呢?这里我举个简单的例子,方便大家理解。
以我们系统性能调优出发,首先我们需要了解系统相关性能瓶颈的业务场景是什么?该功能是 I/O 密集型还是 CPU 密集型?如果是 I/O 密集型多数的性能瓶颈在数据库,这个时候我们就得了解数据库瓶颈的原因,究竟是数据量大还是压力大?如果是数据量大,基于现有的业务场景应该选择数据归档、临时表还是分库分表,这之间的方案优缺点有什么不同?适用场景怎么样?假如是数据压力大了,我们是否能用 Redis 做缓存抗压就行?
再接着从 Redis 这个点继续思考,假如 Redis 内存满了会怎样?我们又了解到了 Redis 的内存淘汰策略,设置了 volatile-lru 策略,由于我们基本功扎实回忆起 LUR 算法是基于链表的数据结构,虽然链表的写的时间复杂度是 O(1),但是读是 O(n),不过我们得先读后写,所以为了高性能又选择 Hash 这种 O(1)的数据结构辅助读的处理。
你看,我们是不是从问题出发到架构设计,再从数据库优化方案到 Redis 的使用,最后到数据结构,这一些系统的知识就串联起来了?













