因为要学着写渗透工具,这几天都在上python编程基础课,听得我打瞌睡,毕竟以前学过嘛。
最后sherry老师留了作业,其中一道题是这样的:
题目:编写python程序找出10-30之间的质数。
太简单了,我直接给出答案:
Prime = [11, 13, 17, 19, 23, 29]
print(Prime)
输出结果:
[11, 13, 17, 19, 23, 29]
当然,这样做肯定会在下节课被sherry老师公开处刑的,所以说还是要根据上课时学的知识写个算法。
1.穷举法
回想一下上课时学了变量、列表、循环语句之类的东西,sherry老师还亲自演示了多重死循环是怎么搞出来的(老师是手滑了还是业务不熟练啊),所以我们还是要仔细思考一下不要重蹈覆辙。
思路:首先要构造一个循环,遍历所有符合条件的自然数,然后一个一个验证是否为质数,最后把符合条件的质数列出来。
import time
t0 = time.time()
Min = 10
Max = 30
Result = []
for N in range(Min, Max):
for P in range(2, N):
if (N % P == 0):
break
else:
Result.append(N)
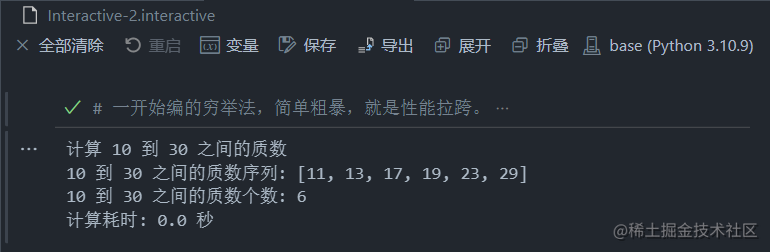
print('计算', Min, '到', Max, '之间的质数')
print(Min, '到', Max, '之间的质数序列:', Result)
print(Min, '到', Max, '之间的质数个数:', len(Result))
print('计算耗时:', time.time() - t0, '秒')
执行结果(计算耗时是最后加上去的):
到这里作业就搞定了。然后把其他几道题也做完了,发现很无聊,就又切回来想搞点事。这么点计算量,0秒真的有点少,不如趁这个机会烤一烤笔记本的性能,所以直接在Min和Max的值后面加几个0。试试100000-200000。
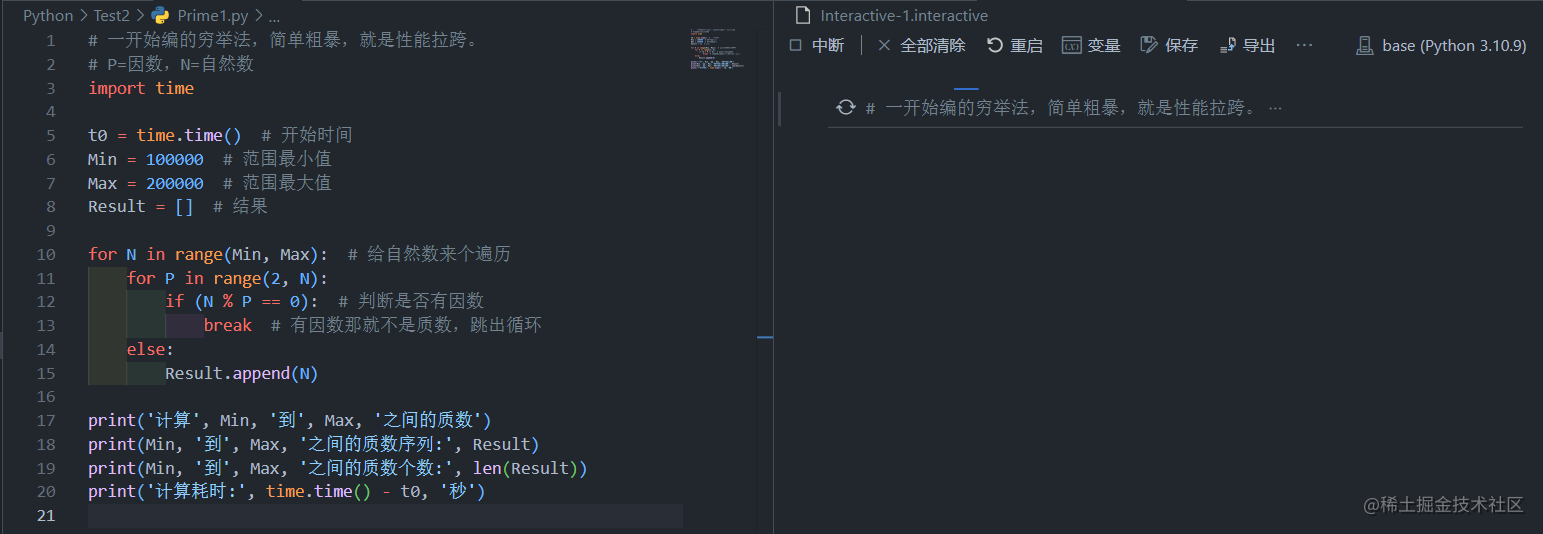
很尴尬,直接卡住了,这代码有点拉跨啊,完全不符合我的风格。
倒了杯咖啡,终于跑完了。
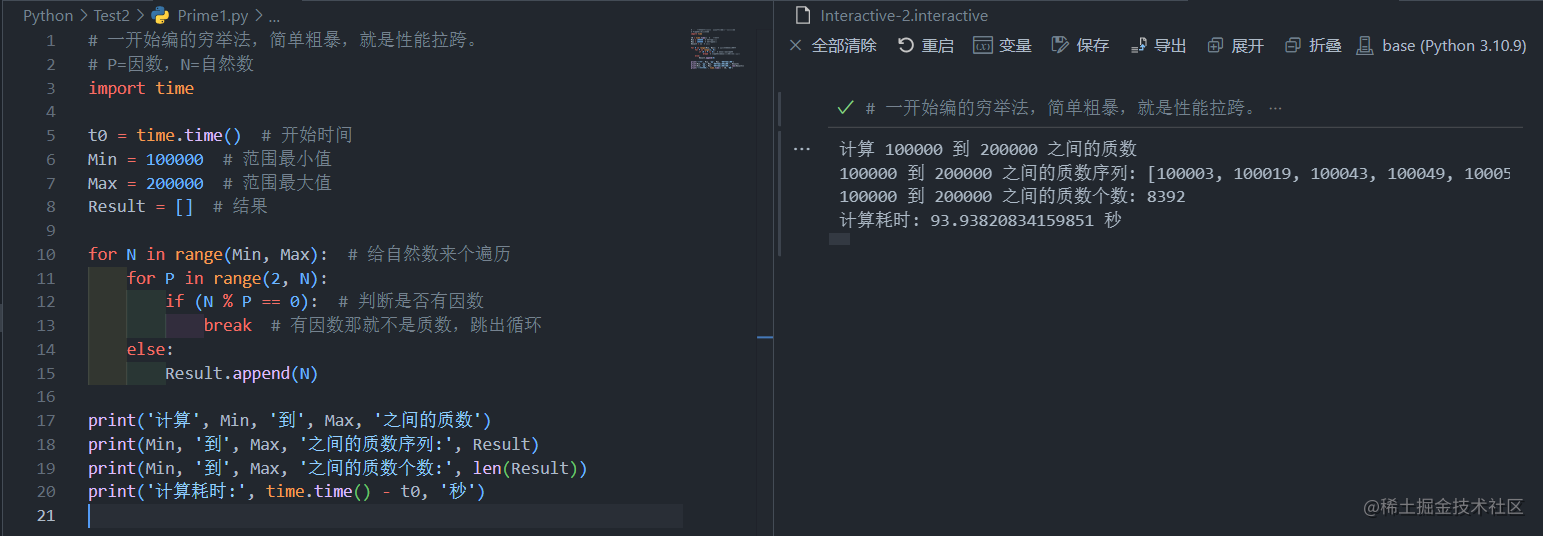
这个也太夸张,一定是哪里出了问题,很久以前用C写的代码我记得也没那么慢啊。反正周末挺闲的,不如仔细研究一下。
2.函数(CV)大法
为了拓宽一下思路,我决定借鉴一下大佬的代码。听说函数是个好东西,所以就CV了两个函数。
一个函数判断质数,另一个求范围内的所有质数,把它们拼一起,是这个样子:
import time
t0 = time.time()
Min = 100000
Max = 200000
def is_prime(n): return 0 not in [n % i for i in range(2, n//2+1)]
def gen_prime(a, b): return [n for n in range(
a, b+1) if 0 not in [n % i for i in range(2, n//2+1)]]
print('计算', Min, '到', Max, '之间的质数')
print(Min, '到', Max, '之间的质数序列:', gen_prime(Min, Max))
print('计算耗时:', time.time() - t0, '秒')
稍微改动了一下,还是100000-200000,我们试试看。
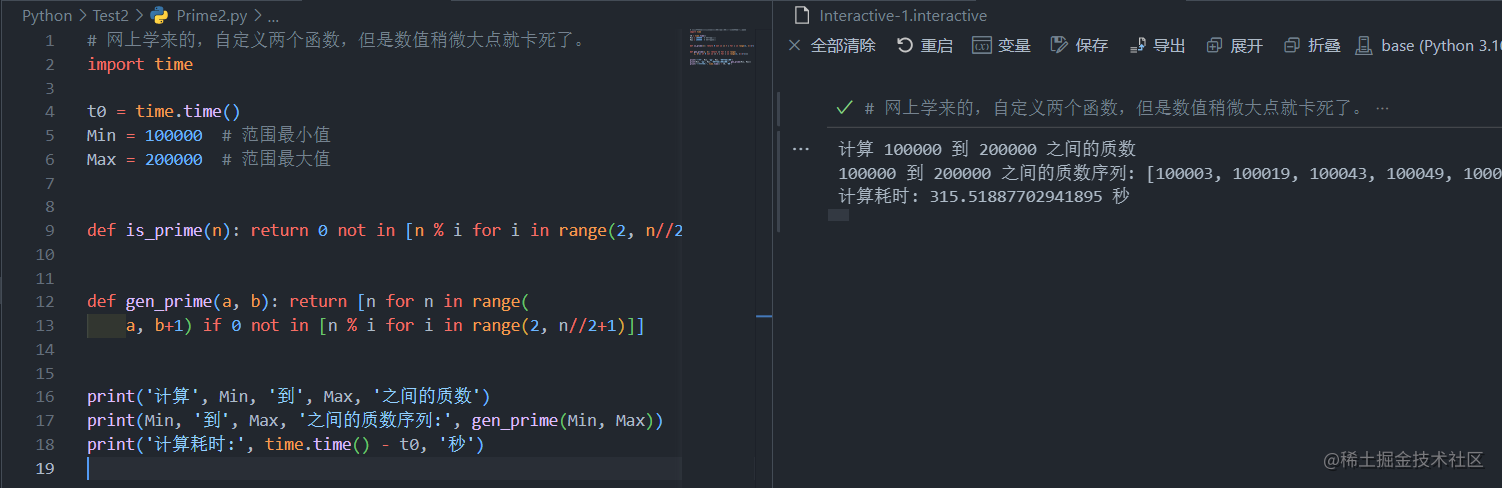
嗯,一运行风扇就开始啸叫,CPU都快烤炸了。看来CV大法也不行啊。
经过漫长的烤机,这次结果比上次还惨,300多秒,这两个函数本质上还是穷举法,看来这条路也走不通。
3.穷举法改
我们可以分析一下穷举法的代码,看看有没有什么改进的方法。
首先,通过九年义务教育掌握的数学知识,我们知道,质数中只有2是偶数,所以计算中可以把偶数忽略掉,只计算奇数,工作量立马减半!
其次,在用因数P判断N是否为质数时,如果P足够大的话,比如说PxP>=N的时候,那么后面的循环其实是重复无意义的。因为假设PxQ>=N,那么P和Q必然有一个小于sqrt(N),只需要计算P<=sqrt(N)的情况就行了。
因为2作为唯一一个偶数,夹在循环里面处理起来很麻烦,所以放在开头处理掉。最终的代码如下:
import time
t0 = time.time()
Min = 100000
Max = 200000
Prime = [2, 3]
Result = []
Loop = 0
if Min <= 2:
Result.append(2)
if Min <= 3:
Result.append(3)
for N in range(5, Max, 2):
for P in range(3, int(N**0.5)+2, 2):
Loop += 1
if (N % P == 0):
break
else:
Prime.append(N)
if N > Min:
Result.append(N)
print('计算', Min, '到', Max, '之间的质数')
print(Min, '到', Max, '之间的质数序列:', Result)
print(Min, '到', Max, '之间的质数个数:', len(Result))
print('循环次数:', Loop)
print('计算耗时:', time.time() - t0, '秒')
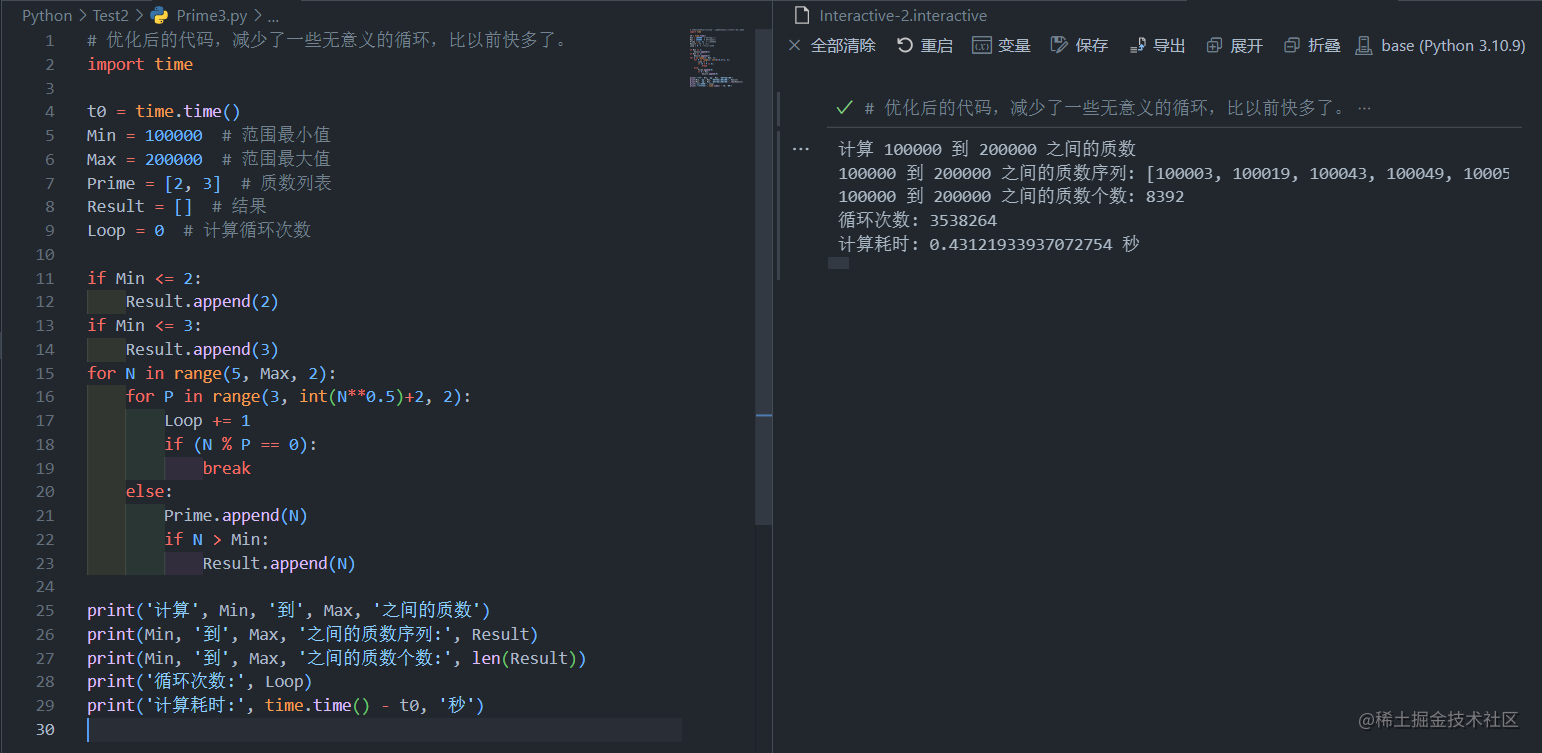
代码量虽然多了,但是效果还是很明显,100000-200000才0.4秒,快了不知道多少,看来我们的思路是对的。
我决定再加到1000000-5000000,看看能不能撑住。因为输出太多了控制台会卡死,所以改一下,只输出最后一个质数。
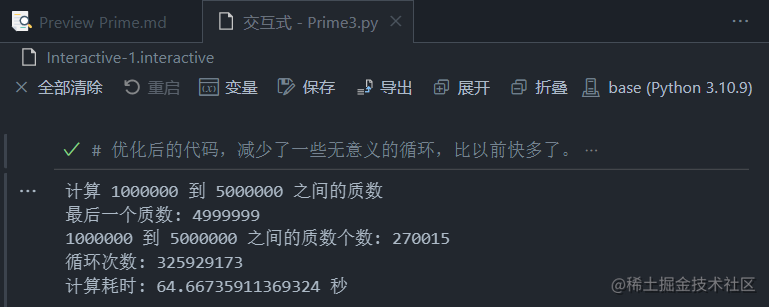
总共花了64秒,看来还是有点费劲。
4.穷举法魔改
我们再来分析一下,如果我们用于判断的因数,不是用奇数列表,而是用生成的Prime列表里面的质数,因为质数的个数远远少于奇数,所以第二个循环会少一些工作量呢?可以试试看。但是因为这个改动,需要加一些判断语句进去,所以节省的时间比较有限。
import time
t0 = time.time()
Min = 1000000
Max = 5000000
Prime = [2, 3]
Result = []
Loop = 0
if Min <= 2:
Result.append(2)
if Min <= 3:
Result.append(3)
for N in range(5, Max, 2):
M = int(N**0.5)
for P in range(len(Prime)):
Loop += 1
L = Prime[P+1]
if (N % L == 0):
break
elif L >= M:
Prime.append(N)
if N > Min:
Result.append(N)
break
print('计算', Min, '到', Max, '之间的质数')
print('最后一个质数:', Result[-1])
print(Min, '到', Max, '之间的质数个数:', len(Result))
print('循环次数:', Loop)
print('计算耗时:', time.time() - t0, '秒')
还是1000000-5000000再试试看
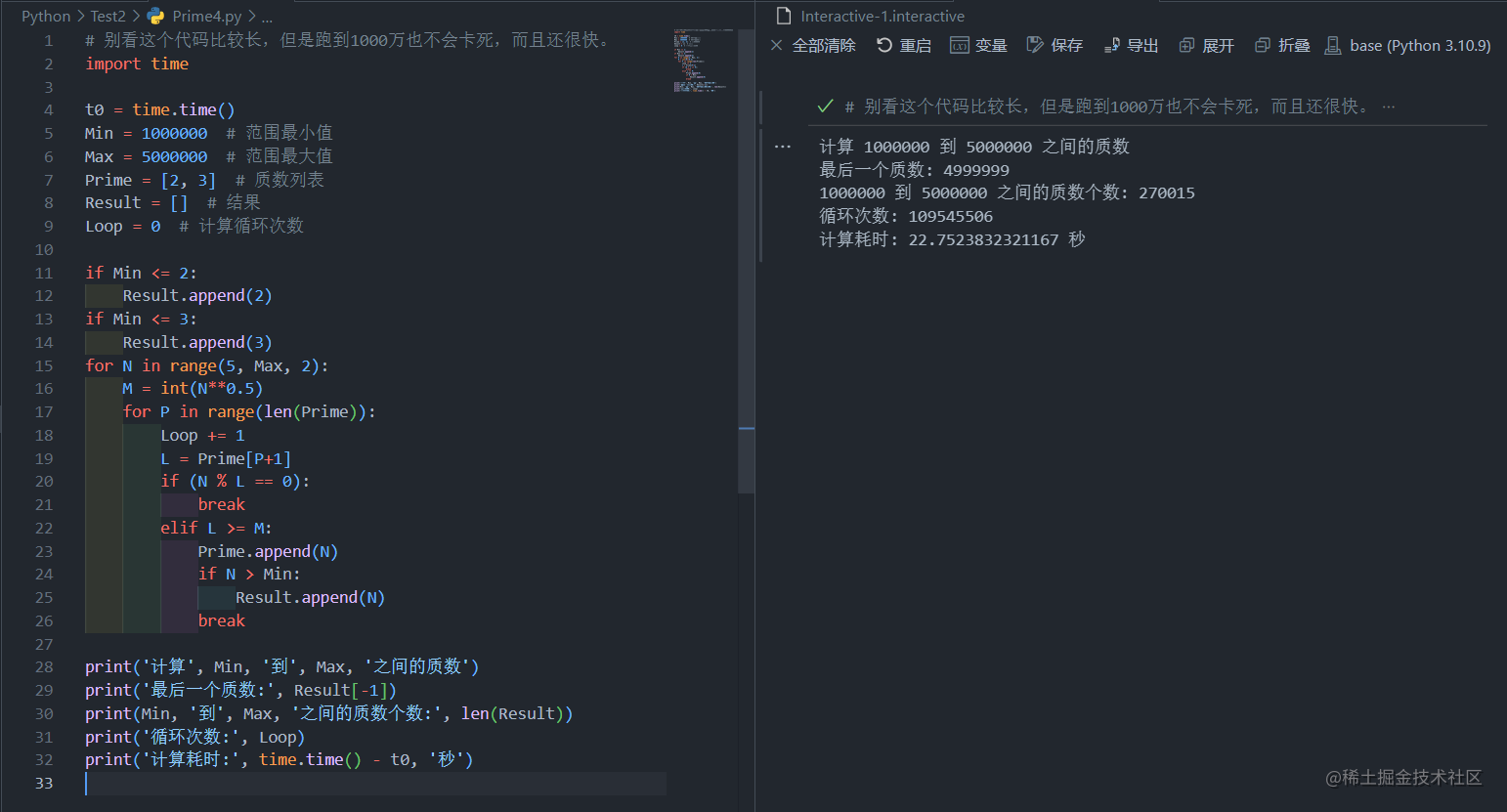
这次耗时22秒,时间又缩短了一大半,但是好像已经没多少改进的空间了,感觉穷举法已经到头了,需要新的思路。
5.埃氏筛法
其实初中数学我们就学过埃氏筛法:
如果P是质数,那么大于P的N的倍数一定不是质数。把所有的合数排除掉,那么剩下的就都是质数了。
我们可以生成一个列表用来储存数字是否是质数,初始阶段都是质数,每次得出一个质数就将它的倍数全部标记为合数。
import time
t0 = time.time()
Min = 1000000
Max = 2000000
Loop = 0
Result = []
Natural = [True for P in range(Max)]
for P in range(2, Max):
if Natural[P]:
if P >= Min:
Result.append(P)
for N in range(P*2, Max, P):
Loop += 1
Natural[N] = False
print('计算', Min, '到', Max, '之间的质数')
print('最后一个质数:', Result[-1])
print(Min, '到', Max, '之间的质数个数:', len(Result))
print('循环次数:', Loop)
print('计算耗时:', time.time() - t0, '秒')
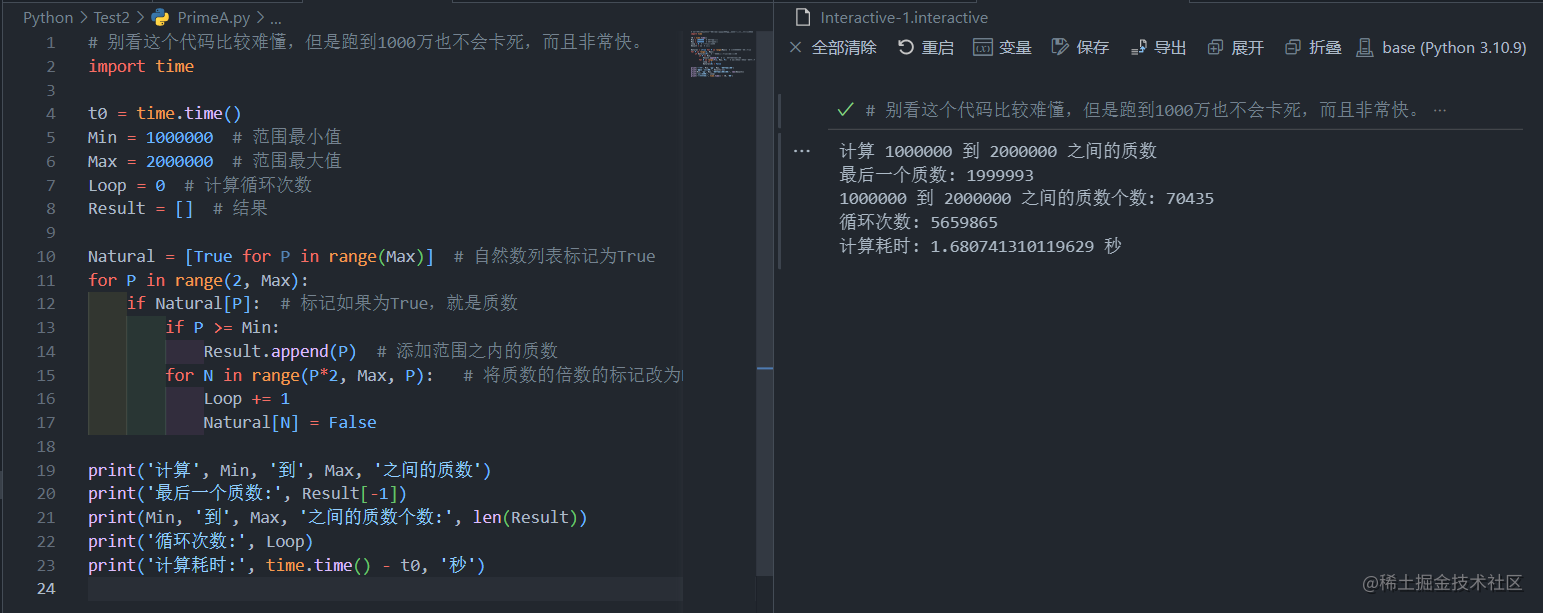
1.6秒,比最高级的穷举法还要快上10多倍,这是数学的胜利。
再试试1-50000000。
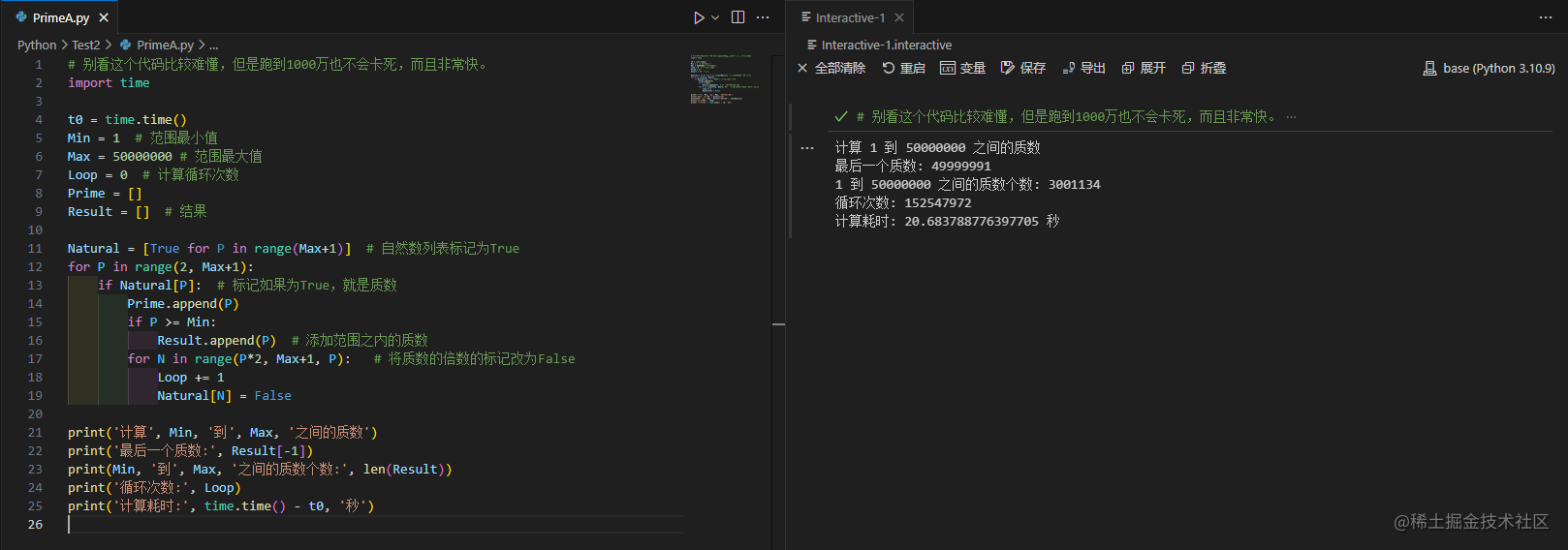
很不错,只需要20秒。因为筛法的特性,忽略内存的影响,数值越大,后面的速度反而越快了。
6.欧拉筛法
我们可以仔细分析一下,上面的埃氏筛法在最后标记的时候,还是多算了一些东西,N会重复标记False,比如77,既是7的倍数又是11的倍数,这样会被标记两次,后面的大合数会重复标记多次,浪费了算力,所以标记的时候要排除合数。另外就是P*N大于Max时,后面的计算已经无意义了,也要跳出来。把这些重复的动作排除掉,就是欧拉筛法,也叫线性筛。
import time
t0 = time.time()
Min = 1
Max = 50000000
Loop = 0
Prime = [2]
Result = []
if Min <= 2:
Result.append(2)
Limit = int(Max/3)+1
Natural = [True for P in range(Max+1)]
for P in range(3, Max+1, 2):
if Natural[P]:
Prime.append(P)
if P >= Min:
Result.append(P)
if P > Limit:
continue
for N in Prime:
Loop += 1
if P*N > Max:
break
Natural[P * N] = False
if P % N == 0:
break
print('计算', Min, '到', Max, '之间的质数')
print('最后一个质数:', Result[-1])
print(Min, '到', Max, '之间的质数个数:', len(Result))
print('循环次数:', Loop)
print('计算耗时:', time.time() - t0, '秒')
(因为之前的版本缩进错了,所以更新了这段代码)
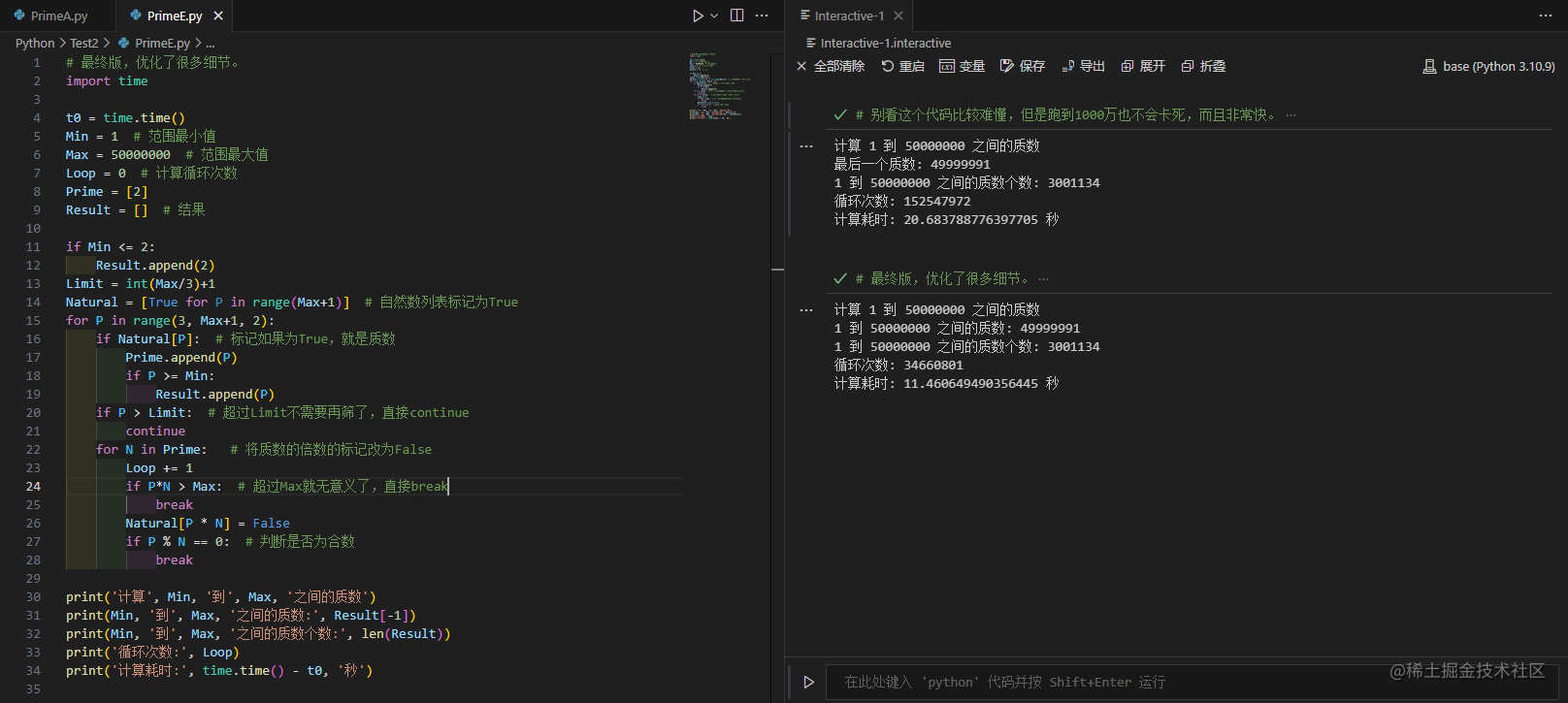
同样的条件下耗时11.46秒。这是因为多了一个列表和几行判断语句,加上python的解释型特性,所以实际上并不会快好几倍,但是总体效率还是有50%左右的提升。
好了,这次把老师课堂上讲的变量、列表、循环语句什么的都用上了,算是现买现卖、活学活用吧。我觉得这次的作业怎么说也能拿满分吧,sherry老师记得下次上课夸夸我。
作者:ReisenSS
来源:juejin.cn/post/7238199999732695097