








毕业5年了还不知道热修复?
前言
热修复到现在2022年已经不是一个新名词,但是作为Android开发核心技术栈的一部分,我这里还得来一次冷饭热炒。
随着移动端业务复杂程度的增加,传统的版本更新流程显然无法满足业务和开发者的需求,
热修复技术的推出在很大程度上改善了这一局面。国内大部分成熟的主流 App都拥有自己的热更新技术,像手淘、支付宝、微信、QQ、饿了么、美团等。
可以说,一个好的热修复技术,将为你的 App助力百倍。对于每一个想在 Android 开发领域有所造诣的开发者,掌握热修复技术更是必备的素质。
热修复是 Android 大厂面试中高频面试知识点,也是我们必须要掌握的知识点。热修复技术,可以看作 Android平台发展成熟至一定阶段的必然产物。
Android热修复了解吗?修复哪些东西?
常见热修复框架对比以及各原理分析?
1.什么是热修复
热修复说白了就是不再使用传统的应用商店更新或者自更新方式,使用补丁包推送的方式在用户无感知的情况下,修复应用bug或者推送新的需求
传统更新和热更新过程对比如下:
热修复优缺点:
- 优点:
- 1.只需要打补丁包,不需要重新发版本。
- 2.用户无感知,不需要重新下载最新应用
- 3.修复成功率高
- 缺点:
- 补丁包滥用,容易导致应用版本不可控,需要开发一套完整的补丁包更新机制,会增加一定的成本
2.热修复方案
首先我们得知道热修复修复哪些东西?
- 1.代码修复
- 2.资源修复
- 3.动态库修复
2.1:代码修复方案
从技术角度来说,我们的目的是非常明确的:把错误的代码替换成正确的代码。
注意这里的替换,并不是直接擦写dx文件,而是提供一份新的正确代码,让应用运行时绕过错误代码,执行新的正确代码。
想法简单直接,但实现起来并不容易。目前主要有三类技术方案:
2.1.1.类加载方案
之前分析类加载机制有说过:
加载流程先是遵循双亲委派原则,如果委派原则没有找到此前加载过此类,
则会调用CLassLoader的findClass方法,再去BaseDexClassLoader下面的dexElements数组中查找,如果没有找到,最终调用defineClassNative方法加载
代码修复就是基于这点:
将新的做了修复的dex文件,通过反射注入到BaseDexClassLoader的dexElements数组的第一个位置上dexElements[0],下次重新启动应用加载类的时候,会优先加载做了修复的dex文件,这样就达到了修复代码的目的。原理很简单
代码如下:
public class Hotfix {
public static void patch(Context context, String patchDexFile, String patchClassName)
throws ClassNotFoundException, NoSuchFieldException, IllegalAccessException, InstantiationException, NoSuchMethodException, InvocationTargetException {
//获取系统PathClassLoader的"dexElements"属性值
PathClassLoader pathClassLoader = (PathClassLoader) context.getClassLoader();
Object origDexElements = getDexElements(pathClassLoader);
//新建DexClassLoader并获取“dexElements”属性值
String otpDir = context.getDir("dex", 0).getAbsolutePath();
Log.i("hotfix", "otpdir=" + otpDir);
DexClassLoader nDexClassLoader = new DexClassLoader(patchDexFile, otpDir, patchDexFile, context.getClassLoader());
Object patchDexElements = getDexElements(nDexClassLoader);
//将patchDexElements插入原origDexElements前面
Object allDexElements = combineArray(origDexElements, patchDexElements);
//将新的allDexElements重新设置回pathClassLoader
setDexElements(pathClassLoader, allDexElements);
//重新加载类
pathClassLoader.loadClass(patchClassName);
}
private static Object getDexElements(ClassLoader classLoader) throws ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
//首先获取ClassLoader的“pathList”实例
Field pathListField = Class.forName("dalvik.system.BaseDexClassLoader").getDeclaredField("pathList");
pathListField.setAccessible(true);//设置为可访问
Object pathList = pathListField.get(classLoader);
//然后获取“pathList”实例的“dexElements”属性
Field dexElementField = pathList.getClass().getDeclaredField("dexElements");
dexElementField.setAccessible(true);
//读取"dexElements"的值
Object elements = dexElementField.get(pathList);
return elements;
}
//合拼dexElements
private static Object combineArray(Object obj, Object obj2) {
Class componentType = obj2.getClass().getComponentType();
//读取obj长度
int length = Array.getLength(obj);
//读取obj2长度
int length2 = Array.getLength(obj2);
Log.i("hotfix", "length=" + length + ",length2=" + length2);
//创建一个新Array实例,长度为ojb和obj2之和
Object newInstance = Array.newInstance(componentType, length + length2);
for (int i = 0; i < length + length2; i++) {
//把obj2元素插入前面
if (i < length2) {
Array.set(newInstance, i, Array.get(obj2, i));
} else {
//把obj元素依次放在后面
Array.set(newInstance, i, Array.get(obj, i - length2));
}
}
//返回新的Array实例
return newInstance;
}
private static void setDexElements(ClassLoader classLoader, Object dexElements) throws ClassNotFoundException, NoSuchFieldException, IllegalAccessException {
//首先获取ClassLoader的“pathList”实例
Field pathListField = Class.forName("dalvik.system.BaseDexClassLoader").getDeclaredField("pathList");
pathListField.setAccessible(true);//设置为可访问
Object pathList = pathListField.get(classLoader);
//然后获取“pathList”实例的“dexElements”属性
Field declaredField = pathList.getClass().getDeclaredField("dexElements");
declaredField.setAccessible(true);
//设置"dexElements"的值
declaredField.set(pathList, dexElements);
}
}
类加载过程如下:
微信Tinker,QQ 空间的超级补丁、手 QQ 的QFix 、饿了 么的 Amigo 和 Nuwa 等都是使用这个方式
缺点:因为类加载后无法卸载,所以类加载方案必须重启App,让bug类重新加载后才能生效。
2.1.2:底层替换方案
底层替换方案不会再次加载新类,而是直接在 Native 层 修改原有类,
这里我们需要提到Art虚拟机中ArtMethod:
每一个Java方法在Art虚拟机中都对应着一个 ArtMethod,ArtMethod记录了这个Java方法的所有信息,包括所属类、访问权限、代码执行地址等。
结构如下:
// art/runtime/art_method.h
class ArtMethod FINAL {
...
protected:
GcRoot<mirror::Class> declaring_class_;
GcRoot<mirror::PointerArray> dex_cache_resolved_methods_;
GcRoot<mirror::ObjectArray<mirror::Class>> dex_cache_resolved_types_;
uint32_t access_flags_;
uint32_t dex_code_item_offset_;
uint32_t dex_method_index_;
uint32_t method_index_;
struct PACKED(4) PtrSizedFields {
void* entry_point_from_interpreter_; // 1
void* entry_point_from_jni_;
void* entry_point_from_quick_compiled_code_; //2
} ptr_sized_fields_;
...
}
在 ArtMethod结构体中,最重要的就是 注释1和注释2标注的内容,从名字可以看出来,他们就是方法的执行入口。
我们知道,Java代码在Android中会被编译为 Dex Code。
Art虚拟机中可以采用解释模式或者 AOT机器码模式执行 Dex Code
- 解释模式:
就是去除Dex Code,逐条解释执行。
如果方法的调用者是以解释模式运行的,在调用这个方法时,就会获取这个方法的 entry_point_from_interpreter_,然后跳转执行。 - AOT模式:
就会预先编译好 Dex Code对应的机器码,然后在运行期直接执行机器码,不需要逐条解释执行Dex Code。
如果方法的调用者是以AOT机器码方式执行的,在调用这个方法时,就是跳转到 entry_point_from_quick_compiled_code_中执行。
那是不是只需要替换这个几个 entry_point_* 入口地址就能够实现方法替换了呢?
并没有那么简单,因为不论是解释模式还是AOT模式,在运行期间还会需要调用ArtMethod中的其他成员字段
AndFix采用的是改变指针指向:
// AndFix/jni/art/art_method_replace_6_0.cpp
void replace_6_0(JNIEnv* env, jobject src, jobject dest) {
art::mirror::ArtMethod* smeth =
(art::mirror::ArtMethod*) env->FromReflectedMethod(src); // 1
art::mirror::ArtMethod* dmeth =
(art::mirror::ArtMethod*) env->FromReflectedMethod(dest); // 2
...
// 3
smeth->declaring_class_ = dmeth->declaring_class_;
smeth->dex_cache_resolved_methods_ = dmeth->dex_cache_resolved_methods_;
smeth->dex_cache_resolved_types_ = dmeth->dex_cache_resolved_types_;
smeth->access_flags_ = dmeth->access_flags_ | 0x0001;
smeth->dex_code_item_offset_ = dmeth->dex_code_item_offset_;
smeth->dex_method_index_ = dmeth->dex_method_index_;
smeth->method_index_ = dmeth->method_index_;
smeth->ptr_sized_fields_.entry_point_from_interpreter_ =
dmeth->ptr_sized_fields_.entry_point_from_interpreter_;
smeth->ptr_sized_fields_.entry_point_from_jni_ =
dmeth->ptr_sized_fields_.entry_point_from_jni_;
smeth->ptr_sized_fields_.entry_point_from_quick_compiled_code_ =
dmeth->ptr_sized_fields_.entry_point_from_quick_compiled_code_;
LOGD("replace_6_0: %d , %d",
smeth->ptr_sized_fields_.entry_point_from_quick_compiled_code_,
dmeth->ptr_sized_fields_.entry_point_from_quick_compiled_code_);
}
缺点:存在一些兼容性问题,由于ArtMethod结构体是Android开源的一部分,所以每个手机厂商都可能会去更改这部分的内容,这就可能导致ArtMethod替换方案在某些机型上面出现未知错误。
Sophix为了规避上面的AndFix的风险,采用直接替换整个结构体。这样不管手机厂商如何更改系统,我们都可以正确定位到方法地址
2.4.3:install run方案
Instant Run 方案的核心思想是——插桩,在编译时通过插桩在每一个方法中插入代码,修改代码逻辑,在需要时绕过错误方法,调用patch类的正确方法。
首先,在编译时Instant Run为每个类插入IncrementalChange变量
IncrementalChange $change;
为每一个方法添加类似如下代码:
public void onCreate(Bundle savedInstanceState) {
IncrementalChange var2 = $change;
//$change不为null,表示该类有修改,需要重定向
if(var2 != null) {
//通过access$dispatch方法跳转到patch类的正确方法
var2.access$dispatch("onCreate.(Landroid/os/Bundle;)V", new Object[]{this, savedInstanceState});
} else {
super.onCreate(savedInstanceState);
this.setContentView(2130968601);
this.tv = (TextView)this.findViewById(2131492944);
}
}
如上代码,当一个类被修改后,Instant Run会为这个类新建一个类,命名为xxx&override,且实现IncrementalChange接口,并且赋值给原类的$change变量。
public class MainActivity$override implements IncrementalChange {
}
此时,在运行时原类中每个方法的var2 != null,通过accessdispatch(参数是方法名和原参数)定位到patch类MainActivitydispatch(参数是方法名和原参数)定位到patch类MainActivityoverride中修改后的方法。
Instant Run是google在AS2.0时用来实现“热部署”的,同时也为“热修复”提供了一个绝佳的思路。美团的Robust就是基于此。
2.2:资源修复方案
这里我们来看看install run的原理即可,市面上的常见修复方案大部分都是基于此方法。
public static void monkeyPatchExistingResources(Context context,
String externalResourceFile, Collection<Activity> activities) {
if (externalResourceFile == null) {
return;
}
try {
// 创建一个新的AssetManager
AssetManager newAssetManager = (AssetManager) AssetManager.class
.getConstructor(new Class[0]).newInstance(new Object[0]); // ... 1
Method mAddAssetPath = AssetManager.class.getDeclaredMethod(
"addAssetPath", new Class[] { String.class }); // ... 2
mAddAssetPath.setAccessible(true);
// 通过反射调用addAssetPath方法加载外部的资源(SD卡资源)
if (((Integer) mAddAssetPath.invoke(newAssetManager,
new Object[] { externalResourceFile })).intValue() == 0) { // ... 3
throw new IllegalStateException(
"Could not create new AssetManager");
}
Method mEnsureStringBlocks = AssetManager.class.getDeclaredMethod(
"ensureStringBlocks", new Class[0]);
mEnsureStringBlocks.setAccessible(true);
mEnsureStringBlocks.invoke(newAssetManager, new Object[0]);
if (activities != null) {
for (Activity activity : activities) {
Resources resources = activity.getResources(); // ... 4
try {
// 反射得到Resources的AssetManager类型的mAssets字段
Field mAssets = Resources.class
.getDeclaredField("mAssets"); // ... 5
mAssets.setAccessible(true);
// 将mAssets字段的引用替换为新创建的newAssetManager
mAssets.set(resources, newAssetManager); // ... 6
} catch (Throwable ignore) {
...
}
// 得到Activity的Resources.Theme
Resources.Theme theme = activity.getTheme();
try {
try {
// 反射得到Resources.Theme的mAssets字段
Field ma = Resources.Theme.class
.getDeclaredField("mAssets");
ma.setAccessible(true);
// 将Resources.Theme的mAssets字段的引用替换为新创建的newAssetManager
ma.set(theme, newAssetManager); // ... 7
} catch (NoSuchFieldException ignore) {
...
}
...
} catch (Throwable e) {
Log.e("InstantRun",
"Failed to update existing theme for activity "
+ activity, e);
}
pruneResourceCaches(resources);
}
}
/**
* 根据SDK版本的不同,用不同的方式得到Resources 的弱引用集合
*/
Collection<WeakReference<Resources>> references;
if (Build.VERSION.SDK_INT >= 19) {
Class<?> resourcesManagerClass = Class
.forName("android.app.ResourcesManager");
Method mGetInstance = resourcesManagerClass.getDeclaredMethod(
"getInstance", new Class[0]);
mGetInstance.setAccessible(true);
Object resourcesManager = mGetInstance.invoke(null,
new Object[0]);
try {
Field fMActiveResources = resourcesManagerClass
.getDeclaredField("mActiveResources");
fMActiveResources.setAccessible(true);
ArrayMap<?, WeakReference<Resources>> arrayMap = (ArrayMap) fMActiveResources
.get(resourcesManager);
references = arrayMap.values();
} catch (NoSuchFieldException ignore) {
Field mResourceReferences = resourcesManagerClass
.getDeclaredField("mResourceReferences");
mResourceReferences.setAccessible(true);
references = (Collection) mResourceReferences
.get(resourcesManager);
}
} else {
Class<?> activityThread = Class
.forName("android.app.ActivityThread");
Field fMActiveResources = activityThread
.getDeclaredField("mActiveResources");
fMActiveResources.setAccessible(true);
Object thread = getActivityThread(context, activityThread);
HashMap<?, WeakReference<Resources>> map = (HashMap) fMActiveResources
.get(thread);
references = map.values();
}
//遍历并得到弱引用集合中的 Resources ,将 Resources mAssets 字段引用替换成新的 AssetManager
for (WeakReference<Resources> wr : references) {
Resources resources = (Resources) wr.get();
if (resources != null) {
try {
Field mAssets = Resources.class
.getDeclaredField("mAssets");
mAssets.setAccessible(true);
mAssets.set(resources, newAssetManager);
} catch (Throwable ignore) {
...
}
resources.updateConfiguration(resources.getConfiguration(),
resources.getDisplayMetrics());
}
}
} catch (Throwable e) {
throw new IllegalStateException(e);
}
}
- 在注释1处创建一个新的 AssetManager ,
- 在注释2 和注释3 处通过反射调用 addAssetPath 方法加载外部( SD 卡)的资源。
- 在注释4 处遍历 Activity 列表,得到每个 Activity 的 Resources ,
- 在注释5 处通过反射得到 Resources 的 AssetManager 类型的 rnAssets 字段 ,
- 注释6处改写 mAssets 字段的引用为新的 AssetManager 。
采用同样的方式,
- 在注释7处将 Resources. Theme 的 m Assets 字段 的引用替换为新创建的 AssetManager 。
- 紧接着 根据 SDK 版本的不同,用不同的方式得到 Resources 的弱引用集合,
- 再遍历这个弱引用集合, 将弱引用集合中的 Resources 的 mAssets 字段引用都替换成新创建的 AssetManager 。
资源修复原理:
- 1.创建新的AssetManager,通过反射调用addAssetPath方法,加载外部资源,这样新创建的AssetManager就含有了外部资源
- 2.将AssetManager类型的mAsset字段全部用新创建的AssetManager对象替换。这样下次加载资源文件的时候就可以找到包含外部资源文件的AssetManager。
2.3:动态链接库so的修复
1.接口调用替换方案:
sdk提供接口替换System默认加载so库接口
SOPatchManager.loadLibrary(String libName) -> System.loadLibrary(String libName)
SOPatchManager.loadLibrary接口加载 so库的时候优先尝试去加载sdk 指定目录下的补丁so,
加载策略如下:
如果存在则加载补丁 so库而不会去加载安装apk安装目录下的so库
如果不存在补丁so,那么调用System.loadLibrary去加载安装apk目录下的 so库。
我们可以很清楚的看到这个方案的优缺点:
优点:不需要对不同 sdk 版本进行兼容,因为所有的 sdk 版本都有 System.loadLibrary 这个接口。
缺点:调用方需要替换掉 System 默认加载 so 库接口为 sdk提供的接口, 如果是已经编译混淆好的三方库的so 库需要 patch,那么是很难做到接口的替换
虽然这种方案实现简单,同时不需要对不同 sdk版本区分处理,但是有一定的局限性没法修复三方包的so库同时需要强制侵入接入方接口调用,接着我们来看下反射注入方案。
2、反射注入方案
前面介绍过 System. loadLibrary ( "native-lib"); 加载 so库的原理,其实native-lib 这个 so 库最终传给 native 方法执行的参数是 so库在磁盘中的完整路径,比如:/data/app-lib/com.taobao.jni-2/libnative-lib.so, so库会在 DexPathList.nativeLibraryDirectories/nativeLibraryPathElements 变量所表示的目录下去遍历搜索
sdk<23 DexPathList.findLibrary 实现如下
可以发现会遍历 nativeLibraryDirectories数组,如果找到了 loUtils.canOpenReadOnly (path)返回为 true, 那么就直接返回该 path, loUtils.canOpenReadOnly (path)返回为 true 的前提肯定是需要 path 表示的 so文件存 在的。那么我们可以采取类似类修复反射注入方式,只要把我们的补丁so库的路径插入到nativeLibraryDirectories数组的最前面就能够达到加载so库的时候是补丁 库而不是原来so库的目录,从而达到修复的目的。
sdk>=23 DexPathList.findLibrary 实现如下
sdk23 以上 findLibrary 实现已经发生了变化,如上所示,那么我们只需要把补丁so库的完整路径作为参数构建一个Element对象,然后再插入到nativeLibraryPathElements 数组的最前面就好了。
- 优点:可以修复三方库的so库。同时接入方不需要像方案1 —样强制侵入用 户接口调用
- 缺点:需要不断的对 sdk 进行适配,如上 sdk23 为分界线,findLibrary接口实现已经发生了变化。
对于 so库的修复方案目前更多采取的是接口调用替换方式,需要强制侵入用户 接口调用。
目前我们的so文件修复方案采取的是反射注入的方案,重启生效。具有更好的普遍性。
如果有so文件修复实时生效的需求,也是可以做到的,只是有些限制情况。
常见热修复框架?
| 特性 | Dexposed | AndFix | Tinker/Amigo | QQ Zone | Robust/Aceso | Sophix |
|---|---|---|---|---|---|---|
| 技术原理 | native底层替换 | native底层替换 | 类加载 | 类加载 | Instant Run | 混合 |
| 所属 | 阿里 | 阿里 | 微信/饿了么 | QQ空间 | 美团/蘑菇街 | 阿里 |
| 即时生效 | YES | YES | NO | NO | YES | 混合 |
| 方法替换 | YES | YES | YES | YES | YES | YES |
| 类替换 | NO | NO | YES | YES | YES | YES |
| 类结构修改 | NO | NO | YES | NO | NO | YES |
| 资源替换 | NO | NO | YES | YES | NO | YES |
| so替换 | NO | NO | YES | NO | NO | YES |
| 支持gradle | NO | NO | YES | YES | YES | YES |
| 支持ART | NO | YES | YES | YES | YES | YES |
可以看出,阿里系多采用native底层方案,腾讯系多采用类加载机制。其中,Sophix是商业化方案;Tinker/Amigo支持特性较多,同时也更复杂,如果需要修复资源和so,可以选择;如果仅需要方法替换,且需要即时生效,Robust是不错的选择。
总结:
尽管热修复(或热更新)相对于迭代更新有诸多优势,市面上也有很多开源方案可供选择,但目前热修复依然无法替代迭代更新模式。有如下原因:
热修复框架多多少少会增加性能开销,或增加APK大小
热修复技术本身存在局限,比如有些方案无法替换so或资源文件
热修复方案的兼容性,有些方案无法同时兼顾Dalvik和ART,有些深度定制系统也无法正常工作
监管风险,比如苹果系统严格限制热修复
所以,对于功能迭代和常规bug修复,版本迭代更新依然是主流。一般的代码修复,使用Robust可以解决,如果还需要修复资源或so库,可以考虑Tinker。
作者:高级攻城狮
链接:https://juejin.cn/post/7142481619604111390
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
LinkedList源码解析
LinkedList源码解析
目标
- 理解LinkedList底层数据结构
- 深入源码掌握LinkedList查询慢,新增快的原因
1.简介
List 接口的链接列表实现。实现所有可选的列表操作,并且允许所有元素(包括 null )。除了实现 List 接口外, LinkedList 类还为在列表的开头及结尾 get 、 remove 和 insert 元素提供了统一 的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
特点 :
- 有序性 : 存入和取出的顺序是一致的
- 元素可以重复
- 含有带索引的方法
- 独有特点 : 数据结构是链表,可以作为栈、队列或者双端队列!
2.LinkedList原理分析
双向链表
底层数据结构源码
public class LinkedList<E> {
transient int size = 0;
//双向链表的头结点
transient Node<E> first;
//双向链表的最后一个节点
transient Node<E> last;
//节点类【内部类】
private static class Node<E> {
E item;//数据元素
Node<E> next;//下一个节点
Node<E> prev;//上一个节点
//节点的构造方法
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} /
/...
}
2.1 LinkedList的数据结构
LinkedList是双向链表,在代码中是一个Node类。内部并没有数组的结构。双向链表肯定存在一个头节 点和一个尾部节点。node节点类,是以内部类的形式存在于LinkedList中的。Node类都有两个成员变 量:
- prev : 当前节点上一个节点,头节点的上一个节点是null
- next : 当前节点下一个节点,尾结点的下一个节点是null
链表数据结构的特点 : 查询慢,增删快!
- 链表数据结构基本构成,是一个node类
- 每个node类中,有上一个节点【prev】和下一个节点【next】
- 链表一定存在至少两个节点,first和last节点
- 如果LinkedList没有数据,first和last都是为null
2.2 LinkedList默认容量&最大容量
没有默认容量,也没有最大容量
2.3 LinkedList扩容机制
无需扩容机制,只要你的内存足够大,可以无限制扩容下去。前提是不考虑查询的效率。
2.4 为什么LinkedList查询慢,增删快?
LinkedList的数据结构的特点,链表的数据结构就是这样的特点!
- 链表是一种查询慢的结构【相对于数组来说】
- 链表是一种增删快的结构【相对于数组来说】
2.5 LinkedList源码剖析-为什么增删快?
新增add
//想LinkedList添加一个元素
public boolean add(E e){
//连接到链表的末尾
linkLast(e);
return true;
}/
/连接到最后一个节点上去
void linkLast(E e){
//将全局末尾节点赋值给l
final Node<E> l=last;
//创建一个新节点 : (上一个节点, 当前插入元素, null)
final Node<E> newNode=new Node<>(l,e,null);
//将当前节点作为末尾节点
last=newNode;
//判断l节点是否为null
if(l==null)
//既是尾结点也是头节点
first=newNode;
else
//之前的末尾节点,下一个节点时末尾节点!
l.next=newNode;
size++;//当前集合的元素数量+1
modCount++;//操作集合数+1。modCount属性是修改技术器
}/
/------------------------------------------------------------------
//向链表中部添加
//参数1,添加的索引位置,添加元素
public void add(int index,E element){
//检查索引位是否符合要求
checkPositionIndex(index);
//判断当前所有是否是存储元素个数
if(index==size)//true,最后一个元素
linkLast(element);
else
//连接到指定节点的后面【链表中部插入】
linkBefore(element,node(index));
}/
/根据索引查询链表中节点!
Node<E> node(int index){
// 判断索引是否小于 已经存储元素个数的1/2
if(index< (size>>1)){//二分法查找 : 提高查找节点效率
Node<E> x=first;
for(int i=0;i<index; i++)
x=x.next;
return x;
}else{
Node<E> x=last;
for(int i=size-1;i>index;i--)
x=x.prev;
return x;
}
}/
/将当前元素添加到指定节点之前
void linkBefore(E e,Node<E> succ){
// 取出当前节点的前一个节点
final Node<E> pred=succ.prev;
//创建当前元素的节点 : 上一个节点,当前元素,下一个节点
final Node<E> newNode=new Node<>(pred,e,succ);
//为指定节点上一个节点重新值
succ.prev=newNode;
//判断当前节点的上一个节点是否为null
if(pred==null)
first=newNode;//当前节点作为头部节点
else
pred.next=newNode;//将新插入节点作为上一个节点的下个节点
size++;//新增元素+1
modCount++;//操作次数+1
}
remove删除指定索引元素
//删除指定索引位置元素
public E remove(int index){
//检查元素索引
checkElementIndex(index);
//删除元素节点,
//node(index) 根据索引查到要删除的节点
//unlink()删除节点
return unlink(node(index));
}//根据索引查询链表中节点!
Node<E> node(int index){
// 判断索引是否小于 已经存储元素个数的1/2
if(index< (size>>1)){//二分法查找 : 提高查找节点效率
Node<E> x=first;
for(int i=0;i<index; i++)
x=x.next;
return x;
}else{
Node<E> x=last;
for(int i=size-1;i>index;i--)
x=x.prev;
return x;
}
}/
/删除一个指定节点
E unlink(Node<E> x){
//获取当前节点中的元素
final E element=x.item;
//获取当前节点的上一个节点
final Node<E> next=x.next;
//获取当前节点的下一个节点
final Node<E> prev=x.prev;
//判断上一个节点是否为null
if(prev==null){
//如果为null,说明当前节点为头部节点
first=next;
}else{
//上一个节点,的下一个节点改为下下节点
prev.next=next;
//将当前节点的上一个节点置空
x.prev=null;
}/
/判断下一个节点是否为null
if(next==null){
//如果为null,说明当前节点为尾部节点
last=prev;
}else{
//下一个节点的上节点,改为上上节点
next.prev=prev;
//当前节点的上节点置空
x.next=null;
}/
/删除当前节点内的元素
x.item=null;
size--;//集合中的元素个数-1
modCount++;//当前集合操作数+1。modCount计数器,记录当前集合操作次数
return element;//返回删除的元素
}
2.6 LinkedList源码剖析-为什么查询慢?
查询快和慢是一个相对概念!相对于数组来说
//根据索引查询一个元素
public E get(int index){
//检查索引是否存在
checkElementIndex(index);
// node(index)获取索引对应节点,获取节点中的数据item
return node(index).item;
}/
/根据索引获取对应节点对象
Node<E> node(int index){
//二分法查找索引对应的元素
if(index< (size>>1)){
Node<E> x=first;
//前半部分查找【遍历节点】
for(int i=0;i<index; i++)
x=x.next;
return x;
}else{
Node<E> x=last;
//后半部分查找【遍历】
for(int i=size-1;i>index;i--)
x=x.prev;
return x;
}
}/
/查看ArrayList里的数组获取元素的方式
public E get(int index){
rangeCheck(index);//检查范围
return elementData(index);//获取元素
}E
elementData(int index){
return(E)elementData[index];//一次性操作
}作者:会飞的汤姆猫
链接:https://juejin.cn/post/7139026562154201125
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
最安全的加密算法 Bcrypt,再也不用担心数据泄密了~
这是《Spring Security 进阶》专栏的第三篇文章,给大家介绍一下Spring Security 中内置的加密算法BCrypt,号称最安全的加密算法,究竟有着什么魔力能让黑客闻风丧胆
哈希(Hash)与加密(Encrypt)
哈希(Hash)是将目标文本转换成具有相同长度的、不可逆的杂凑字符串(或叫做消息摘要),而加密(Encrypt)是将目标文本转换成具有不同长度的、可逆的密文。
- 哈希算法往往被设计成生成具有相同长度的文本,而加密算法生成的文本长度与明文本身的长度有关。
- 哈希算法是不可逆的,而加密算法是可逆的。
HASH 算法是一种消息摘要算法,不是一种加密算法,但由于其单向运算,具有一定的不可逆性,成为加密算法中的一个构成部分。
JDK的String的Hash算法。代码如下:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
从JDK的API可以看出,它的算法等式就是s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1],其中s[i]就是索引为i的字符,n为字符串的长度。
HashMap的hash计算时先计算hashCode(),然后进行二次hash。代码如下:
// 计算二次Hash
int hash = hash(key.hashCode());
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
可以发现,虽然算法不同,但经过这些移位操作后,对于同一个值使用同一个算法,计算出来的hash值一定是相同的。
那么,hash为什么是不可逆的呢?
假如有两个密码3和4,我的加密算法很简单就是3+4,结果是7,但是通过7我不可能确定那两个密码是3和4,有很多种组合,这就是最简单的不可逆,所以只能通过暴力破解一个一个的试。
在计算过程中原文的部分信息是丢失了。一个MD5理论上是可以对应多个原文的,因为MD5是有限多个而原文是无限多个的。
不可逆的MD5为什么是不安全的?
因为hash算法是固定的,所以同一个字符串计算出来的hash串是固定的,所以,可以采用如下的方式进行破解。
- 暴力枚举法:简单粗暴地枚举出所有原文,并计算出它们的哈希值,看看哪个哈希值和给定的信息摘要一致。
- 字典法:黑客利用一个巨大的字典,存储尽可能多的原文和对应的哈希值。每次用给定的信息摘要查找字典,即可快速找到碰撞的结果。
- 彩虹表(rainbow)法:在字典法的基础上改进,以时间换空间。是现在破解哈希常用的办法。
对于单机来说,暴力枚举法的时间成本很高(以14位字母和数字的组合密码为例,共有1.24×10^25种可能,即使电脑每秒钟能进行10亿次运算,也需要4亿年才能破解),字典法的空间成本很高(仍以14位字母和数字的组合密码为例,生成的密码32位哈希串的对照表将占用5.7×10^14 TB的存储空间)。但是利用分布式计算和分布式存储,仍然可以有效破解MD5算法。因此这两种方法同样被黑客们广泛使用。
如何防御彩虹表的破解?
虽然彩虹表有着如此惊人的破解效率,但网站的安全人员仍然有办法防御彩虹表。最有效的方法就是“加盐”,即在密码的特定位置插入特定的字符串,这个特定字符串就是“盐(Salt)”,加盐后的密码经过哈希加密得到的哈希串与加盐前的哈希串完全不同,黑客用彩虹表得到的密码根本就不是真正的密码。即使黑客知道了“盐”的内容、加盐的位置,还需要对H函数和R函数进行修改,彩虹表也需要重新生成,因此加盐能大大增加利用彩虹表攻击的难度。
一个网站,如果加密算法和盐都泄露了,那针对性攻击依然是非常不安全的。因为同一个加密算法同一个盐加密后的字符串仍然还是一毛一样滴!
一个更难破解的加密算法Bcrypt
BCrypt是由Niels Provos和David Mazières设计的密码哈希函数,他是基于Blowfish密码而来的,并于1999年在USENIX上提出。
除了加盐来抵御rainbow table 攻击之外,bcrypt的一个非常重要的特征就是自适应性,可以保证加密的速度在一个特定的范围内,即使计算机的运算能力非常高,可以通过增加迭代次数的方式,使得加密速度变慢,从而可以抵御暴力搜索攻击。
Bcrypt可以简单理解为它内部自己实现了随机加盐处理。使用Bcrypt,每次加密后的密文是不一样的。
对一个密码,Bcrypt每次生成的hash都不一样,那么它是如何进行校验的?
- 虽然对同一个密码,每次生成的hash不一样,但是hash中包含了salt(hash产生过程:先随机生成salt,salt跟password进行hash);
- 在下次校验时,从hash中取出salt,salt跟password进行hash;得到的结果跟保存在DB中的hash进行比对。
在Spring Security 中 内置了Bcrypt加密算法,构建也很简单,代码如下:
@Bean
public PasswordEncoder passwordEncoder(){
return new BCryptPasswordEncoder();
}
生成的加密字符串格式如下:
$2b$[cost]$[22 character salt][31 character hash]
比如:
$2a$10$N9qo8uLOickgx2ZMRZoMyeIjZAgcfl7p92ldGxad68LJZdL17lhWy
\__/\/ \____________________/\_____________________________/
Alg Cost Salt Hash
上面例子中,$2a$ 表示的hash算法的唯一标志。这里表示的是Bcrypt算法。
10 表示的是代价因子,这里是2的10次方,也就是1024轮。
N9qo8uLOickgx2ZMRZoMye 是16个字节(128bits)的salt经过base64编码得到的22长度的字符。
最后的IjZAgcfl7p92ldGxad68LJZdL17lhWy是24个字节(192bits)的hash,经过bash64的编码得到的31长度的字符。
PasswordEncoder 接口
这个接口是Spring Security 内置的,如下:
public interface PasswordEncoder {
String encode(CharSequence rawPassword);
boolean matches(CharSequence rawPassword, String encodedPassword);
default boolean upgradeEncoding(String encodedPassword) {
return false;
}
}
这个接口有三个方法:
encode方法接受的参数是原始密码字符串,返回值是经过加密之后的hash值,hash值是不能被逆向解密的。这个方法通常在为系统添加用户,或者用户注册的时候使用。matches方法是用来校验用户输入密码rawPassword,和加密后的hash值encodedPassword是否匹配。如果能够匹配返回true,表示用户输入的密码rawPassword是正确的,反之返回fasle。也就是说虽然这个hash值不能被逆向解密,但是可以判断是否和原始密码匹配。这个方法通常在用户登录的时候进行用户输入密码的正确性校验。upgradeEncoding设计的用意是,判断当前的密码是否需要升级。也就是是否需要重新加密?需要的话返回true,不需要的话返回fasle。默认实现是返回false。
例如,我们可以通过如下示例代码在进行用户注册的时候加密存储用户密码
//将User保存到数据库表,该表包含password列
user.setPassword(passwordEncoder.encode(user.getPassword()));
BCryptPasswordEncoder 是Spring Security推荐使用的PasswordEncoder接口实现类
public class PasswordEncoderTest {
@Test
void bCryptPasswordTest(){
PasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
String rawPassword = "123456"; //原始密码
String encodedPassword = passwordEncoder.encode(rawPassword); //加密后的密码
System.out.println("原始密码" + rawPassword);
System.out.println("加密之后的hash密码:" + encodedPassword);
System.out.println(rawPassword + "是否匹配" + encodedPassword + ":" //密码校验:true
+ passwordEncoder.matches(rawPassword, encodedPassword));
System.out.println("654321是否匹配" + encodedPassword + ":" //定义一个错误的密码进行校验:false
+ passwordEncoder.matches("654321", encodedPassword));
}
}
上面的测试用例执行的结果是下面这样的。(注意:对于同一个原始密码,每次加密之后的hash密码都是不一样的,这正是BCryptPasswordEncoder的强大之处,它不仅不能被破解,想通过常用密码对照表进行大海捞针你都无从下手),输出如下:
原始密码123456
加密之后的hash密码:$2a$10$zt6dUMTjNSyzINTGyiAgluna3mPm7qdgl26vj4tFpsFO6WlK5lXNm
123456是否匹配$2a$10$zt6dUMTjNSyzINTGyiAgluna3mPm7qdgl26vj4tFpsFO6WlK5lXNm:true
654321是否匹配$2a$10$zt6dUMTjNSyzINTGyiAgluna3mPm7qdgl26vj4tFpsFO6WlK5lXNm:false
BCrypt 产生随机盐(盐的作用就是每次做出来的菜味道都不一样)。这一点很重要,因为这意味着每次encode将产生不同的结果。
作者:码猿技术专栏
链接:https://juejin.cn/post/7143054506614489101
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android DIY你的菜单栏
前言
个人打算开发个视频编辑的APP,然后把一些用上的技术总结一下,这次主要是APP的底部菜单栏用到了一个自定义View去绘制实现的,所以这次主要想讲讲自定义View的一些用到的点和自己如何去DIY一个不一样的自定义布局。
实现的效果和思路
可以先看看实现的效果
两个页面的内容还没做,当前就是一个Demo,可以看到底部的菜单栏是一个绘制出来的不规则的一个布局,那要如何实现呢。可以先来看看它的一个绘制区域:
就是一个底部的布局和3个子view,底部的区域当然也是个规则的区域,只不过我们是在这块区域上去进行绘制。
可以把整个过程分为几个步骤:
1. 绘制底部布局
(1) 绘制矩形区域
(2) 绘制外圆形区域
(3) 绘制内圆形区域
2. 添加子view进行布局
3. 处理事件分发的区域 (底部菜单上边的白色区域不触发菜单的事件)
4. 写个动画意思意思
1. 绘制底部布局
这里做的话就没必要手动去添加view这些了,直接全部手动绘制就行。
companion object{
const val DIMENS_64 = 64.0
const val DIMENS_96 = 96.0
const val DIMENS_50 = 50.0
const val DIMENS_48 = 48.0
interface OnChildClickListener{
fun onClick(index : Int)
}
}
private var paint : Paint ?= null // 绘制蓝色区域的画笔
private var paint2 : Paint ?= null // 绘制白色内圆的画笔
private var allHeight : Int = 0 // 总高度,就是绘制的范围
private var bgHeight : Int = 0 // 背景的高度,就是蓝色矩阵的范围
private var mRadius : Int = 0 // 外圆的高度
private var mChildSize : Int = 0
private var mChildCenterSize : Int = 0
private var mWidthZone1 : Int = 0
private var mWidthZone2 : Int = 0
private var mChildCentre : Int = 0
private var childViews : MutableList<View> = mutableListOf()
private var objectAnimation : ObjectAnimator ?= null
var onChildClickListener : OnChildClickListener ?= null
init {
initView()
}
private fun initView(){
val lp = ViewGroup.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT,
DimensionUtils.dp2px(context, DIMENS_64).toInt())
layoutParams = lp
allHeight = DimensionUtils.dp2px(context, DIMENS_96).toInt()
bgHeight = DimensionUtils.dp2px(context, DIMENS_64).toInt()
mRadius = DimensionUtils.dp2px(context, DIMENS_50).toInt()
mChildSize = DimensionUtils.dp2px(context, DIMENS_48).toInt()
mChildCenterSize = DimensionUtils.dp2px(context, DIMENS_64).toInt()
setWillNotDraw(false)
initPaint()
}
private fun initPaint(){
paint = Paint()
paint?.isAntiAlias = true
paint?.color = context.resources.getColor(R.color.kylin_main_color)
paint2 = Paint()
paint2?.isAntiAlias = true
paint2?.color = context.resources.getColor(R.color.kylin_third_color)
}
上边是先把一些尺寸给定义好(我这边是没有设计图,自己去直接调整的,所以可能有些视觉效果不太好,如果有设计师帮忙的话效果肯定会好些),绘制流程就是绘制3个形状,然后代码里也加了些注释哪个变量有什么用,这步应该不难,没什么可以多解释的。
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
val wSize = MeasureSpec.getSize(widthMeasureSpec)
// 拿到子view做操作的,和这步无关,可以先不看
if (childViews.size <= 0) {
for (i in 0 until childCount) {
val cView = getChildAt(i)
initChildView(cView, i)
childViews.add(cView)
if (i == childCount/2){
val ms: Int = MeasureSpec.makeMeasureSpec(mRadius, MeasureSpec.AT_MOST)
measureChild(cView, ms, ms)
}else {
val ms: Int = MeasureSpec.makeMeasureSpec(mChildSize, MeasureSpec.AT_MOST)
measureChild(cView, ms, ms)
}
}
}
setMeasuredDimension(wSize, allHeight)
}
这步其实也很简单,就是说给当前自定义view设置高度为allHeight
override fun onDraw(canvas: Canvas?) {
super.onDraw(canvas)
// 绘制长方形区域
canvas?.drawRect(left.toFloat(), ((allHeight - bgHeight).toFloat()),
right.toFloat(), bottom.toFloat(), paint!!)
// 绘制圆形区域
paint?.let {
canvas?.drawCircle(
(width/2).toFloat(), mRadius.toFloat(),
mRadius.toFloat(),
it
)
}
// 绘制内圆区域
paint2?.let {
canvas?.drawCircle(
(width/2).toFloat(), mRadius.toFloat(),
(mRadius - 28).toFloat(),
it
)
}
}
最后进行绘制, 就是上面说的绘制3个图形,代码里的注释也说得很清楚。
2. 添加子view
我这里是外面布局去加子view的,想弄得灵活点(但感觉也不太好,后面还是想改成里面定义一套规范来弄会好些,如果自由度太高的话去做自定义就很麻烦,而且实际开发中这种需求也没必要把扩展性做到这种地步,基本就是整个APP只有一个地方使用)
但是这边也只是一个Demo先做个演示。
<com.kylin.libkcommons.widget.BottomMenuBar
android:id="@+id/bv_content"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
>
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:src="@drawable/home"
/>
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:src="@drawable/video"
/>
<ImageView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:src="@drawable/more"
/>
</com.kylin.libkcommons.widget.BottomMenuBar>
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
val wSize = MeasureSpec.getSize(widthMeasureSpec)
if (childViews.size <= 0) {
for (i in 0 until childCount) {
val cView = getChildAt(i)
initChildView(cView, i)
childViews.add(cView)
if (i == childCount/2){
val ms: Int = MeasureSpec.makeMeasureSpec(mRadius, MeasureSpec.AT_MOST)
measureChild(cView, ms, ms)
}else {
val ms: Int = MeasureSpec.makeMeasureSpec(mChildSize, MeasureSpec.AT_MOST)
measureChild(cView, ms, ms)
}
}
}
setMeasuredDimension(wSize, allHeight)
}
拿到子view进行一个管理,做一些初始化的操作,主要是设点击事件这些,这里不是很重要。
override fun onLayout(changed: Boolean, l: Int, t: Int, r: Int, b: Int) {
if (mChildCentre == 0){
mChildCentre = width / 6
}
// 辅助事件分发区域
if (mWidthZone1 == 0 || mWidthZone2 == 0) {
mWidthZone1 = width / 2 - mRadius / 2
mWidthZone2 = width / 2 + mRadius / 2
}
// 设置每个子view的显示区域
for (i in 0 until childViews.size) {
if (i == childCount/2){
childViews[i].layout(mChildCentre*(2*i+1) - mChildCenterSize/2 ,
allHeight/2 - mChildCenterSize/2,
mChildCentre*(2*i+1) + mChildCenterSize/2 ,
allHeight/2 + mChildCenterSize/2)
}else {
childViews[i].layout(mChildCentre*(2*i+1) - mChildSize/2 ,
allHeight - bgHeight/2 - mChildSize/2,
mChildCentre*(2*i+1) + mChildSize/2 ,
allHeight - bgHeight/2 + mChildSize/2)
}
}
}
进行布局,这里比较重要,因为能看出,中间的图标会更大一些,所以要做一些适配。其实这里就是把宽度分为6块,然后3个view分别在1,3,5这三个左边点,y的话就是除中间那个,其它两个都是bgHeight绘制高度的的一半,中间那个是allHeight总高度的一半,这样3个view的x和y坐标都能拿到了,再根据宽高就能算出l,t,r,b四个点,然后布局。
3. 处理事件分发
可以看出我们的区域是一个不规则的区域,按照我们用抽象的角度去思考,我们希望这个菜单栏的区域只是显示蓝色的那个区域,所以蓝色区域上面的白色区域就算是我们自定义view的范围,他触发的事件也应该是后面的view的事件(Demo中后面的View是一个ViewPager),而不是菜单栏。
// 辅助事件分发区域
if (mWidthZone1 == 0 || mWidthZone2 == 0) {
mWidthZone1 = width / 2 - mRadius / 2
mWidthZone2 = width / 2 + mRadius / 2
}
这两块是圆外的x的区域。
/**
* 判断点击事件是否在点击区域中
*/
private fun isShowZone(x : Float, y : Float) : Boolean{
if (y >= allHeight - bgHeight){
return true
}
if (x >= mWidthZone1 && x <= mWidthZone2){
// 在圆内
val relativeX = abs(x - width/2)
val squareYZone = mRadius.toDouble().pow(2.0) - relativeX.toDouble().pow(2.0)
return y >= mRadius - sqrt(squareYZone)
}
return false
}
先判断y如果在背景的矩阵中(上面说了自定义view分成矩阵,外圆,内圆),那肯定是菜单的区域。如果不在,那就要判断y在不在圆内,这里就必须用勾股定理去判断。
override fun onTouchEvent(event: MotionEvent?): Boolean {
// 点击区域进行拦截
if (event?.action == MotionEvent.ACTION_DOWN && isShowZone(event.x, event.y)){
return true
}
return super.onTouchEvent(event)
}
最后做一个事件分发的拦截。除了计算区域那可能需要去想想,其它地方我觉得都挺好理解的吧。
4. 做个动画
给子view设点击事件让外部处理,然后给中间的按钮做个动画效果。
private fun initChildView(cView : View?, index : Int) {
cView?.setOnClickListener {
if (index == childViews.size/2) {
startAnim(cView)
}else {
onChildClickListener?.onClick(index)
}
}
}
private fun startAnim(view : View){
if (objectAnimation == null) {
objectAnimation = ObjectAnimator.ofFloat(view,
"rotation", 0f, -15f, 180f, 0f)
objectAnimation?.addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(p0: Animator) {
}
override fun onAnimationEnd(p0: Animator) {
onChildClickListener?.onClick(childViews.size / 2)
}
override fun onAnimationCancel(p0: Animator) {
onChildClickListener?.onClick(childViews.size / 2)
}
override fun onAnimationRepeat(p0: Animator) {
}
})
objectAnimation?.duration = 1000
objectAnimation?.interpolator = AccelerateDecelerateInterpolator()
}
objectAnimation?.start()
}
注意做释放操作。
fun onDestroy(){
try {
objectAnimation?.cancel()
objectAnimation?.removeAllListeners()
}catch (e : Exception){
e.printStackTrace()
}finally {
objectAnimation = null
}
}
5. 小结
其实代码都挺简单的,关键是你要去想出一个方法来实现这个场景,然后感觉这个自定义viewgroup也是比较经典的,涉及到measure、layout、draw,涉及到动画,涉及到点击冲突。
这个Demo表示你要实现怎样的效果都可以,只要是draw能画出来的,你都能实现,我这个是中间凸出来,你可以实现凹进去,你可以实现波浪的样子,可以实现复杂的曲线,都行,你用各种基础图形去做拼接,或者画贝塞尔等等,其实都不难,主要是要有个计算和调试的过程。但是你的形状要和点击区域关联起来,你设计的图案越复杂,你要适配的点击区域计算量就越大。
甚至我还能做得效果更屌的是,那3个子view的图标,我都能画出来,就不用ImagerView,直接手动画出来,这样做的好处是什么呢?我对子view的图标能做各种炫酷的属性动画,我在切换viewpager时对图标做属性动画,那不得逼格再上一层。 为什么我没做呢,因为没有设计,我自己做的话要花大量的时间去调,要是有设计的话他告诉我尺寸啊位置啊这些信息,做起来就很快。我的APP主要是打算实现视频的编辑为主,所以这些支线就没打算花太多时间去处理。
作者:流浪汉kylin
链接:https://juejin.cn/post/7142350663907803144
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin中 Flow、SharedFlow与StateFlow区别
一、简介
了解过协程Flow 的同学知道是典型的冷数据流,而SharedFlow与StateFlow则是热数据流。
- 冷流:只有当订阅者发起订阅时,事件的发送者才会开始发送事件。
- 热流:不管订阅者是否存在,只要发送了事件就会被消费,意思是不管接受方是否能够接收到,在这一点上有点像我们Android的
LiveData。
解释:LiveData新的订阅者不会接收到之前发送的事件,只会收到之前发送的最后一条数据,这个特性和SharedFlow的参数replay设置为1相似
二、使用分析
最好的分析是从使用时入手冷流flow,热流SharedFlow和StateFlow热流的具体的实现类分别是MutableSharedFlow和MutableStateFlow
用一个简单的例子来说明什么是冷流,什么是热流。
冷流flow:
private fun testFlow() {
val flow = flow<Int> {
(1..5).forEach {
delay(1000)
emit(it)
}
}
mBind.btCollect.setOnClickListener {
lifecycleScope.launch {
flow.collect {
Log.d(TAG, "testFlow 第一个收集器: 我是冷流:$it")
}
}
lifecycleScope.launch {
delay(5000)
flow.collect {
Log.d(TAG, "testFlow:第二个收集器 我是冷流:$it")
}
}
}
}
我点击收集按钮响应事件后,打印结果如下图:
这就是冷流,需要去触发收集,才能接收到结果。
从上图时间可知flow每次重新订阅收集都会将所有事件重新发送一次
热流MutableSharedFlow和
private fun testSharedFlow() {
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 0,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.SUSPEND
)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("collect1 received ago shared flow $it")
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
sharedFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a 100
delay(100)
launch {
sharedFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
第二个流收集被延迟,晚了100毫秒后就收不到了,想当于不管是否订阅,流都会发送,只管发,而collect1能够收集到是因为他在发送之前进行了订阅收集。
三、分析MutableSharedFlow中参数的具体含义
以上面testSharedFlow()方法中对象为例,上面的配置就是,当前对象的默认配置
源码如下图:
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 0,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.SUSPEND //产生背压现象后的,执行策略
)
3.1、 reply:事件粘滞数
reply:事件粘滞数以testSharedFlow方法为例如果设置了数目的话,那么其他订阅者不管什么时候订阅都能够收到replay数目的最新的事件,reply=1的话有点类似Android中使用的livedata。
eg:和testSharedFlow方法区别在于 replay = 2
private fun testSharedFlowReplay() {
val sharedFlow = MutableSharedFlow<Int>(
replay = 2,//相当于粘性数据
extraBufferCapacity = 0,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.SUSPEND
)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("collect1 received ago shared flow $it")
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
sharedFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a minute
delay(100)
launch {
sharedFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
按照上面的解释collect2会收集到最新的4,5两个事件如下图:
3.2 extraBufferCapacity:缓存容量
extraBufferCapacity:缓存容量,就是先发送几个事件,不管已经订阅的消费者是否接收,这种只管发不管消费者消费能力的情况就会出现背压,参数onBufferOverflow就是用于处理背压问题
eg:和testSharedFlow方法区别在于 extraBufferCapacity = 2
private fun testSharedFlowCapacity() {
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 2,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.SUSPEND
)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("collect1 received ago shared flow $it")
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
sharedFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a minute
delay(100)
launch {
sharedFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
结果如下图:
优先发送将其缓存起来,testSharedFlow测试中发送与接收在没有干扰(延时之类的干扰)的情况下 是一条顺序链,而设置了extraBufferCapacity优先发送两条,不管消费情况,不设置的话(extraBufferCapacity = 0)这时如果在collect1里面设置延时delay(100),send会被阻塞(因为默认是 onBufferOverflow = BufferOverflow.SUSPEND的策略)
3.3、onBufferOverflow
onBufferOverflow:由背压就有处理策略,sharedflow默认为BufferOverflow.SUSPEND
,也即是如果当事件数量超过缓存,发送就会被挂起,上面提到了一句,DROP_OLDEST销毁最旧的值,DROP_LATEST销毁最新的值
三种参数含义
public enum class BufferOverflow {
/**
* 在缓冲区溢出时挂起。
*/
SUSPEND,
/**
* 在缓冲区溢出时删除** *旧的**值,添加新的值到缓冲区,不挂起。
*/
DROP_OLDEST,
/**
* 在缓冲区溢出时,删除当前添加到缓冲区的最新的**值\
*(使缓冲区内容保持不变),不要挂起。
*/
DROP_LATEST
}
eg:和testSharedFlowCapacity方法区别在于 多了个delay(100)
- SUSPEND模式
private fun testSharedFlow2() {
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 2,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.SUSPEND
)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("collect1 received ago shared flow $it")
delay(100)
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
sharedFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a minute
delay(100)
launch {
sharedFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
SUSPEND情况下从第一张图知道collect1都收集了,第二张图发现collect2也打印了两次,为什么只有两次呢?
因为 extraBufferCapacity = 2,等于2,错过了两次的事件发送的接收,不信的话可以试一下extraBufferCapacity = 0,这时候肯定打印了4次,可能有人问为什么是4次呢,因为collect2的订阅者延时了100毫秒才开始订阅,
- DROP_LATEST模式
private fun testSharedFlow2() {
val sharedFlow = MutableSharedFlow<Int>(
replay = 0,//相当于粘性数据
extraBufferCapacity = 2,//接受的慢时候,发送的入栈
onBufferOverflow = BufferOverflow.DROP_LATEST
)
lifecycleScope.launch {
launch {
sharedFlow.collect {
println("collect1 received ago shared flow $it")
delay(100)
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
sharedFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a minute
delay(100)
launch {
sharedFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
发送过快的话,销毁最新的,只保留最老的两条事件,我们可以知道1,2,肯定保留其他丢失
要想不丢是怎么办呢,很简单不要产生背压现象就行,在emit中延时delay(200),比收集耗时长就行。
- DROP_OLDEST模式
该模式同理DROP_LATEST模式,保留最新的extraBufferCapacity = 2(多少)的数据就行。
四、StateFlow
初始化
val stateFlow = MutableStateFlow<Int>(value = -1)
由上图的继承关系可知stateFlow其实就是一种特殊的SharedFlow,它多了个初始值value
由上图可知:每次更新数据都会和旧数据做一次比较,只有不同时候才会更新数值。
SharedFlow和StateFlow的侧重点
- StateFlow就是一个replaySize=1的sharedFlow,同时它必须有一个初始值,此外,每次更新数据都会和旧数据做一次比较,只有不同时候才会更新数值。
- StateFlow重点在状态,ui永远有状态,所以StateFlow必须有初始值,同时对ui而言,过期的状态毫无意义,所以stateFLow永远更新最新的数据(和liveData相似),所以必须有粘滞度=1的粘滞事件,让ui状态保持到最新。
另外在一个时间内发送多个事件,不会管中间事件有没有消费完成都会执行最新的一条.(中间值会丢失) - SharedFlow侧重在事件,当某个事件触发,发送到队列之中,按照挂起或者非挂起、缓存策略等将事件发送到接受方,在具体使用时,SharedFlow更适合通知ui界面的一些事件,比如toast等,也适合作为viewModel和repository之间的桥梁用作数据的传输。
eg测试如下中间值丢失:
private fun testSharedFlow2() {
val stateFlow = MutableStateFlow<Int>(value = -1)
lifecycleScope.launch {
launch {
stateFlow.collect {
println("collect1 received ago shared flow $it")
}
}
launch {
(1..5).forEach {
println("emit1 send ago flow $it")
stateFlow.emit(it)
println("emit1 send after flow $it")
}
}
// wait a minute
delay(100)
launch {
stateFlow.collect {
println("collect2 received shared flow $it")
}
}
}
}
由下图可知,中间值丢失,collect2结果可知永远有状态
好了到这里文章就结束了,源码分析后续再写。
作者:五问
链接:https://juejin.cn/post/7142038525997744141
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
为什么B站的弹幕可以不挡人物

那天在B站看视频的时候偶然发现当字幕遇到人物的时候就被裁切了,不会挡住人物,觉得很神奇,于是决定一探究竟。
高端的效果,往往只需要采用最朴素的实现方式,忙碌了两个小时,陈师傅打开了F12,豁然开朗。一张图片+一个属性,直接搞定。
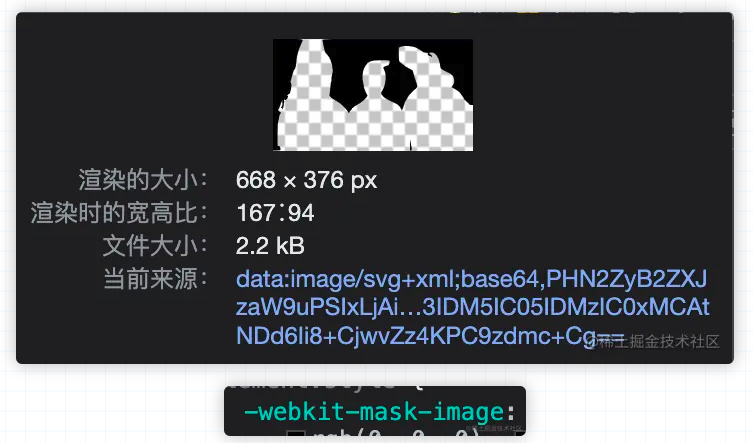
为了印证我的想法,我决定自己写一个demo
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
.video {
width: 668px;
height: 376px;
position: relative;
-webkit-mask-image: url("mask.svg");
-webkit-mask-size: 668px 376px;
}
.bullet {
position: absolute;
font-size: 20px;
}
</style>
</head>
<body>
<div class="video">
<div class="bullet" style="left: 100px; top: 0;">元芳,你怎么看</div>
<div class="bullet" style="left: 200px; top: 20px;">你难道就是传说中的奶灵</div>
<div class="bullet" style="left: 300px; top: 40px;">你好,我是胖灵</div>
<div class="bullet" style="left: 400px; top: 60px;">这是第一集,还没有舔灵</div>
</div>
</body>
</html>效果是这样的

加一个红背景,看的清楚一些

至此我们就实现了B站同款的不遮挡人物的弹幕。至于这张图片是怎么来的,肯定是AI识别出来然后生成的,一张图片也就一两K,一次加载很多张也不会造成很大的负担。
最后来看看这个神奇的css属性吧
所以在开发需求的时候可以把它当成一个亮点使用,但是不能强依赖于这个属性做需求。
原文链接:https://juejin.cn/post/7141012605535010823
收起阅读 »项目中第三方库并不是必须的
前言
有时候集成一个特定的库(比如 PayPal)是必须的,有时候是避免去开发一些非常复杂的功能,有时候仅仅只是避免重复造轮子。
虽然这些都是合理的考量,但使用第三方库的风险和相关成本往往被忽视或误解。在某些情况下,风险是值得的,但是在决定冒险之前,首先要能够明确的定义风险。为了使风险评估更加的透明和一致,我们制定了一个流程来衡量我们将其集成到app有多大的风险。
风险
大多数大型组织,包括我们,都有某种形式的代码审查,作为开发实践的一部分。对这些团队来说,添加一个第三方库就相当于添加了一堆由不属于团队成员开发,未经审查的代码。这破坏了团队一直坚持的代码审查原则,交付了质量未知的代码。这给app的运行方式以及长期开发带来了风险,对于大型团队而言,更是对整体业务带来了风险。
运行时风险
库代码通常来说,对于系统资源,和app拥有相同级别的访问权限,但它们不一定应用团队为管理这些资源而制定的最佳实践。这意味着它们可以在没有限制的情况下访问磁盘,网络,内存,CPU等等,因此,它们可以(过度)将文件写入磁盘,使用未优化的代码占用内存或CPU,导致死锁或主线程延迟,下载(和上传!)大量数据等等。更糟糕的是他们会导致崩溃,甚至崩溃循环。两次。
其中许多情况直到 app 已经上架才被发现,在这种情况下,修复它需要创建一个新版本,并通过审核,这通常需要大量时间和成本。这种风险可以通过一个变量控制是否调用来进行一定程度的控制,但是这种方法也并非万无一失(看下文)。
开发风险
引用一个同事的话:“每一行代码都是一种负担”,对不是你自己写的代码而言,这句话更甚。库在适配新技术或API时可能很慢,这阻碍了代码开发,或者太快,导致开发的版本过高。
库在采用新技术或API时可能很慢,阻碍了代码库,或者太快,导致部署目标太高。每当 Apple 和 Google 每年发布一个新 OS 版本时,他们通常要求开发人员根据SDK的变化更新代码,库开发人员也必须这样做。这需要协调一致的努力、优先事项的一致性以及及时完成工作的能力。
随着移动平台的不断变化,以及团队(成员)也不是一成不变,这将会成为一个持续不断的风险。当被集成的库不存在了,而库又需要更新时,会花很多时间来决定谁来做。事实证明一旦一个库存在,就很少也很难被移除,因此我们将其视为长期维护成本。
商业风险
如同我上面所说,现代的操作系统并没有对 app 代码和库代码进行区分,因此除了系统资源之外,它们还可以访问用户信息。作为 app 的开发者,我们负责恰当的使用这部分信息,也需要为任何第三方库负责。
如果用户给了 Lyft app 地理位置授权,任何第三方库也将自动得获得授权。他们可以将那些(地理位置)数据上传到自己服务器,竞对服务器,或者谁知道还有什么地方。当一个库需要我们没有的权限时,那问题就更大了。
同样,一个系统的安全取决于其最薄弱的环节,但如果其中包含未经审核的代码,那么你就不知道它到底有多安全。你精心设计的安全编码实践可能会被一个行为不当的库所破坏。苹果和谷歌实施的任何政策都是如此,例如“你不得对用户追踪”。
减少风险
当对一个库(是否)进行使用评估时,我们首先要问几个问题,以了解对库的需求。
我们内部能做么?
有时候我们只需要简单的粘贴复制真正需要的部分。在更复杂的场景中,库与自定义后端通信,我们对该API进行了逆向,并自己构建了一个迷你SDK(同样,只构建了我们需要的部分)。在90%的情况下,这是首选,但在与非常特定的供应商或需求集成时并不总是可行。
有多少用户从该库中受益?
在一种情况下,我们正在考虑添加一个风险很大的库(根据下面的标准),旨在为一小部分用户提供服务,同时将我们的所有用户都暴露在该库中。对于我们认为会从中受益的一小部分客户,我们冒了为我们所有用户带来问题的风险。
这个库有什么传递依赖?
我们还需要评估库的所有依赖项的以下标准。
退出标准是什么?
如果集成成功,是否有办法将其转移到内部?如果不成功,是否有办法删除?
评价标准
如果此时团队仍然希望集成库,我们要求他们根据一组标准对库进行“评分”。下面的列表并不全面,但应该能很好地说明我们希望看到的。
阻断标准
这些标准将阻止我们从技术上或者公司政策上集成此库,在进行下一步之前,我们必须解决:
过高的 deployment target/target SDKs。 我们支持过去4年主流的操作系统(版本),所以第三方库至少也需要支持一样多。
许可证不正确/缺失。 我们将许可文件与应用捆绑在一起,以确保我们可以合法使用代码并将其归属于许可持有人。
没有冲突的传递依赖关系。 一个库不能有一个我们已经包含但版本不同的传递依赖项。
不显示它自己的 UI 。 我们非常小心地使我们的产品看起来尽可能统一,定制用户界面对此不利。
它不使用私有 API 。 我们不愿意冒 app 因使用私有 API 而被拒绝的风险。
主要关注点
闭源。 访问源代码意味着我们可以选择我们想要包含的库的哪些部分,以及如何将该源代码与应用程序的其余部分捆绑在一起。对于我们来说,一个封闭源代码的二进制发行版更难集成。
编译时有警告。 我们启用了“警告视为错误”,具有编译警告的库是库整体质量(下降)的良好指示。
糟糕的文档。 我们希望有高质量的内联文档,外部”如何使用“文档,以及有意义的更新日志。
二进制体积。 这个库有多大?一些库提供了很多功能,而我们只需要其中的一小部分。尤其是在没有访问源码权限的情况下,这通常是一个全有或全无的情况。
外部的网络流量。 与我们无法控制的上游服务器/端点通信的库可能会在服务器关闭、错误数据被发回等时关闭整个应用程序。这也与我上面提到的隐私问题相同。
技术支持。 当事情不能正常工作时,我们需要能够报告/上报问题,并在合理的时间内解决问题。开源项目通常由志愿者维护,也很难有一个时间线,但至少我们可以自己进行修改。这在闭源项目是不可能的。
无法禁用。 虽然大多数库特别要求我们初始化它,但有些库在实例化时更“主动”,并且在我们不调用它的情况下可以自己执行工作。这意味着当库导致问题时,我们无法通过功能变量或其他机制将其关闭。
我们为所有这些(和其他一些)标准分配了点数,并要求工程师为他们想要集成的库汇总这些点数。虽然默认情况下,低分数并不难被拒绝,但我们通常会要求更多的理由来继续前进。
最后
虽然这个过程看起来非常严格,在许多情况下,潜在风险是假设的,但我们有我在这篇博文中描述的每个场景的实际例子。将评估记录下来并公开,也有助于将相对风险传达给不熟悉移动平台工作方式的人,并证明我们没有随意评估风险。
Kotlin 协程 Select:看我如何多路复用
前言
协程通信三剑客:Channel、Select、Flow,上篇已经分析了Channel的深水区,本篇将会重点分析Select的使用及原理。
通过本篇文章,你将了解到:
- Select 的引入
- Select 的使用
- Invoke函数 的妙用
- Select 的原理
- Select 注意事项
1. Select 的引入
多路数据的选择
串行执行
如今的二维码识别应用场景越来越广了,早期应用比较广泛的识别SDK如zxing、zbar,它们各有各的特点,也存在识别不出来的情况,为了将两者优势结合起来,我们想到的方法是同一份二维码图片分别给两者进行识别。
如下:
//从zxing 获取二维码信息
suspend fun getQrcodeInfoFromZxing(bitmap: Bitmap?): String {
//模拟耗时
delay(2000)
return "I'm fish"
}
//从zbar 获取二维码信息
suspend fun getQrcodeInfoFromZbar(bitmap: Bitmap?): String {
delay(1000)
return "I'm fish"
}
fun testSelect() {
runBlocking {
var bitmap = null
var starTime = System.currentTimeMillis()
var qrcoe1 = getQrcodeInfoFromZxing(bitmap)
var qrcode2 = getQrcodeInfoFromZbar(bitmap)
println("qrcode1=$qrcoe1 qrcode2=$qrcode2 useTime:${System.currentTimeMillis() - starTime} ms")
}
}
查看打印,最后花费的时间:
qrcode1=I'm fish qrcode2=I'm fish useTime:3013 ms
当然这是串行的方式效率比较低,我们想到了用协程来优化它。
协程并行执行
如下:
fun testSelect1() {
var bitmap = null;
var starTime = System.currentTimeMillis()
var deferredZxing = GlobalScope.async {
getQrcodeInfoFromZxing(bitmap)
}
var deferredZbar = GlobalScope.async {
getQrcodeInfoFromZbar(bitmap)
}
runBlocking {
//挂起等待识别结果
var qrcoe1 = deferredZxing.await()
//挂起等待识别结果
var qrcode2 = deferredZbar.await()
println("qrcode1=$qrcoe1 qrcode2=$qrcode2 useTime:${System.currentTimeMillis() - starTime} ms")
}
}
查看打印,最后花费的时间:
qrcode1=I'm fish qrcode2=I'm fish useTime:2084 ms
可以看出,花费时间明显变少了。
与上个Demo 相比,虽然识别过程是放在协程里并行执行的,但是在等待识别结果却是串行的。我们引入两个识别库的初衷是哪个识别快就用哪个的结果,为了达成这个目的,传统的方式是:
同时监听并记录识别结果的返回。
同时监听多路结果
如下:
fun testSelect2() {
var bitmap = null;
var starTime = System.currentTimeMillis()
var deferredZxing = GlobalScope.async {
getQrcodeInfoFromZxing(bitmap)
}
var deferredZbar = GlobalScope.async {
getQrcodeInfoFromZbar(bitmap)
}
var isEnd = false
var result: String? = null
GlobalScope.launch {
if (!isEnd) {
//没有结束,则继续识别
var resultTmp = deferredZxing.await()
if (!isEnd) {
//识别没有结束,说明自己是第一个返回结果的
result = resultTmp
println("zxing recognize ok useTime:${System.currentTimeMillis() - starTime} ms")
//标记识别结束
isEnd = true
}
}
}
GlobalScope.launch {
if (!isEnd) {
var resultTmp = deferredZbar.await()
if (!isEnd) {
//识别没有结束,说明自己是第一个返回结果的
result = resultTmp
println("zbar recognize ok useTime:${System.currentTimeMillis() - starTime} ms")
isEnd = true
}
}
}
//检测是否有结果返回
runBlocking {
while (!isEnd) {
delay(1)
}
println("recognize result:$result")
}
}
通过检测isEnd 标记来判断是否有某个模块返回结果。
结果如下:
- zbar recognize ok useTime:1070 ms
- recognize result:I'm fish
由于模拟设定的zbar 解析速度快,因此每次都是采纳的是zbar的结果,所花费的时间大幅减少了,该结果符合预期。
Select 闪亮登场
虽说上个Demo结果符合预期,但是多了很多额外的代码、多引入了其它协程,并且需要子模块对标记进行赋值(对"isEnd"进行赋值),没有达到解耦的目的。我们希望子模块的任务是单一且闭环的,如果能在一个函数里统一检测结果的返回就好了。
Select 就是为了解决多路数据的选择而生的。
来看看它是怎么解决该问题的:
fun testSelect3() {
var bitmap = null;
var starTime = System.currentTimeMillis()
var deferredZxing = GlobalScope.async {
getQrcodeInfoFromZxing(bitmap)
}
var deferredZbar = GlobalScope.async {
getQrcodeInfoFromZbar(bitmap)
}
runBlocking {
//通过select 监听zxing、zbar 结果返回
var result = select<String> {
//监听zxing
deferredZxing.onAwait {value->
//value 为deferredZxing 识别的结果
"zxing result $value"
}
//监听zbar
deferredZbar.onAwait { value->
"zbar result $value"
}
}
//运行到此,说明已经有结果返回
println("result from $result useTime:${System.currentTimeMillis() - starTime}")
}
}
结果如下:
result from zbar result I'm fish useTime:1079
符合预期,同时可以看出:相比上个Demo,这样写简洁了许多。
2. Select 的使用
除了可以监听async的结果,Select 还可以监听Channel的发送方/接收方 数据,我们以监听接收方数据为例:
fun testSelect4() {
runBlocking {
var bitmap = null;
var starTime = System.currentTimeMillis()
var receiveChannelZxing = produce {
//生产数据
var result = getQrcodeInfoFromZxing(bitmap)
//发送数据
send(result)
}
var receiveChannelZbar = produce {
var result = getQrcodeInfoFromZbar(bitmap)
send(result)
}
var result = select<String> {
//监听是否有数据发送过来
receiveChannelZxing.onReceive {
value->"zxing result $value"
}
receiveChannelZbar.onReceive {
value->"zbar result $value"
}
}
println("result from $result useTime:${System.currentTimeMillis() - starTime}")
}
}
结果如下:
result from zbar result I'm fish useTime:1028
不论是async还是Channel,Select 都可以监听它们的数据,从而形成多路复用的效果。
在监听协程里调用select 表达式,表达式{}内声明需要监听的协程的数据,对于select 来说有两种场景:
- 没有数据,则select 挂起协程并等待直到其它协程数据准备完成后再次恢复select 所在的协程。
- 有数据,则select 正常执行并返回获取的数据。
3. Invoke函数 的妙用
在分析Select 原理之前,需要弄明白invoke函数的原理。
对于Kotlin 类来说,都可以重写其invoke函数。
operator fun invoke():String {
return "I'm fish"
}
如上,重写了SelectDemo里的invoke函数,和普通成员函数一样,我们可以通过对象调用它。
fun main(args: Array<String>) {
var selectDemo = SelectDemo()
var result = selectDemo.invoke()
println("result:$result")
}
当然,可以进一步简化:
fun main(args: Array<String>) {
var selectDemo = SelectDemo()
var result = selectDemo()
println("result:$result")
}
这里涉及到了kotlin的语法糖:对象居然可以像函数一样调用。
作为函数,invoke 当然也可以接收高阶函数作为参数:
operator fun invoke(block: (Int) -> String): String {
return block(3)
}
fun main(args: Array<String>) {
var selectDemo = SelectDemo()
var result = selectDemo { age ->
when (age) {
3 -> "I'm fish3"
4 -> "I'm fish4"
else -> "error"
}
}
println("result:$result")
}
因此,当看到对象作为函数调用时,实际上调用的是invoke函数,具体的逻辑需要查看其invoke函数的实现。
4. Select 的原理
上篇分析过Channel,因此本篇趁热打铁,通过Select 监听Channel数据的变化来分析其原理,为方便讲解,我们先以监听一个Channel的为例。
先从select 表达式本身入手。
fun testSelect5() {
runBlocking {
var starTime = System.currentTimeMillis()
var receiveChannelZxing = produce {
//发送数据
send("I'm fish")
}
//确保channel 数据已经send
delay(1000)
var result = select<String> {
//监听是否有数据发送过来
receiveChannelZxing.onReceive { value ->
"zxing result $value"
}
}
println("result from $result useTime:${System.currentTimeMillis() - starTime}")
}
}
select 是挂起函数,因此协程运行到此有可能被挂起。
#Select.kt
public suspend inline fun <R> select(crossinline builder: SelectBuilder<R>.() -> Unit): R {
//...
return suspendCoroutineUninterceptedOrReturn { uCont ->
//传入父协程体
val scope = SelectBuilderImpl(uCont)
try {
//执行builder
builder(scope)
} catch (e: Throwable) {
scope.handleBuilderException(e)
}
//通过返回值判断是否需要挂起协程
scope.getResult()
}
}
重点看builder(scope),builder 是高阶函数,实际上就是执行了select花括号里的内容,而它里面就是监听数据是否返回。
receiveChannelZxing.onReceive
刚开始看的时候势必以为onReceive是个函数,然而它是ReceiveChannel 里的成员变量:
#Channel.kt
public val onReceive: SelectClause1<E>
通过上一节的分析可知,关键是要找到SelectClause1 的invoke的实现。
#Select.kt
public interface SelectBuilder<in R> {
//block 有个入参
//声明了SelectClause1的扩展函数invoke
public operator fun <Q> SelectClause1<Q>.invoke(block: suspend (Q) -> R)
}
override fun <Q> SelectClause1<Q>.invoke(block: suspend (Q) -> R) {
//SelectBuilderImpl 实现了 SelectClause1 的invoke函数
registerSelectClause1(this@SelectBuilderImpl, block)
}
再看onReceive 的赋值:
#AbstractChannel.kt
final override val onReceive: SelectClause1<E>
get() = object : SelectClause1<E> {
@Suppress("UNCHECKED_CAST")
override fun <R> registerSelectClause1(select: SelectInstance<R>, block: suspend (E) -> R) {
registerSelectReceiveMode(select, RECEIVE_THROWS_ON_CLOSE, block as suspend (Any?) -> R)
}
}
因此,简单总结调用栈如下:
当调用receiveChannelZxing.onReceive{},实际上调用了SelectClause1.invoke(),而它里面又调用了SelectClause1.registerSelectClause1(),最终调用了AbstractChannel.registerSelectReceiveMode。
AbstractChannel. registerSelectReceiveMode
#AbstractChannel.kt
private fun <R> registerSelectReceiveMode(select: SelectInstance<R>, receiveMode: Int, block: suspend (Any?) -> R) {
while (true) {
//如果已经有结果了,则直接返回------->①
if (select.isSelected) return
if (isEmptyImpl) {
//没有发送者在等待,则入队等待,并返回 ------->②
if (enqueueReceiveSelect(select, block, receiveMode)) return
} else {
//直接取出值------->③
val pollResult = pollSelectInternal(select)
when {
pollResult === ALREADY_SELECTED -> return
pollResult === POLL_FAILED -> {} // retry
pollResult === RETRY_ATOMIC -> {} // retry
//调用block------->④
else -> block.tryStartBlockUnintercepted(select, receiveMode, pollResult)
}
}
}
}
分为4个点,接着来一一分析。
①
select 同时监听多个值,若是有1个符合要求的数据返回了,那么该isSelected 标记为true,当检测到该标记为true时直接退出。
结合之前的Demo,zbar 已经识别出结果了,当select 检测zxing的结果时直接返回。
②
#AbstractChannel.kt
private fun <R> enqueueReceiveSelect(
select: SelectInstance<R>,
block: suspend (Any?) -> R,
receiveMode: Int
): Boolean {
//构造为Node元素
val node = AbstractChannel.ReceiveSelect(this, select, block, receiveMode)
//添加到Channel队列里
val result = enqueueReceive(node)
if (result) select.disposeOnSelect(node)
return result
当select 时,发现Channel里没有数据,说明Channel还没有开始send,因此构造了Node(ReceiveSelect)加入到Channel queue里。当send数据时,会查找queue里是否有接收者等待,若有则调用Node(ReceiveSelect.completeResumeReceive):
#AbstractChannel.kt
override fun completeResumeReceive(value: E) {
block.startCoroutineCancellable(
if (receiveMode == RECEIVE_RESULT) ChannelResult.success(value) else value,
select.completion,
resumeOnCancellationFun(value)
)
}
block 被调度执行,最后会恢复select 协程的执行。
③
取出数据,并尝试恢复send协程。
④
在③的基础上,拿到数据后,直接执行block(此时并没有切换线程进行调度)。
小结一下select 原理:
可以看出:
select 本身执行并不耗时,若最终没有数据返回则挂起等待,若是有数据返回则不会挂起协程。
我们从头再捋一下select 配合Channel 的原理:
虽然以Channel为例讲解了select 原理,实际上async等结合select 原理大致差不多,重点都是利用了协程的挂起/恢复做文章。
5. Select 注意事项
如果select有多个数据同时到达,select 默认会选择第一个数据,若想要随机选择数据,可做如下处理:
var result = selectUnbiased<String> {
//监听是否有数据发送过来
receiveChannelZxing.onReceive { value ->
"zxing result $value"
}
}
想要知道select 还可以监听哪些数据,可查看该数据是否实现了SelectClauseX(X 表示0、1、2)。
以上即为Select 的原理及其使用,下篇将会进入协程的精华部分:Flow的运用,该部分内容较多,可能会分几篇分析,敬请期待。
本文基于Kotlin 1.5.3,文中完整Demo请点击
作者:小鱼人爱编程
链接:https://juejin.cn/post/7142083646822809607
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin协程:flowOn与线程切换
本文分析示例代码如下:
launch(Dispatchers.Main) {
flow {
emit(1)
emit(2)
}.flowOn(Dispatchers.IO).collect {
delay(1000)
withContext(Dispatchers.IO) {
Log.d("liduo", "$it")
}
Log.d("liduo", "$it")
}
}
一.flowOn方法
flowOn方法用于将上游的流切换到指定协程上下文的调度器中执行,同时不会把协程上下文暴露给下游的流,即flowOn方法中协程上下文的调度器不会对下游的流生效。如下面这段代码所示:
launch(Dispatchers.Main) {
flow {
emit(2) // 执行在IO线程池
}.flowOn(Dispatchers.IO).map {
it + 1 // 执行在Default线程池
}.flowOn(Dispatchers.Default).collect {
Log.d("liduo", "$it") //执行在主线程
}
}
接下来,分析一下flowOn方法,代码如下:
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
// 检查当前协程没有执行结束
checkFlowContext(context)
return when {
// 为空,则返回自身
context == EmptyCoroutineContext -> this
// 如果是可融合的Flow,则尝试融合操作,获取新的流
this is FusibleFlow -> fuse(context = context)
// 其他情况,包装成可融合的Flow
else -> ChannelFlowOperatorImpl(this, context = context)
}
}
// 确保Job不为空
private fun checkFlowContext(context: CoroutineContext) {
require(context[Job] == null) {
"Flow context cannot contain job in it. Had $context"
}
}
在flowOn方法中,首先会检查方法所在的协程是否执行结束。如果没有结束,则会执行判断语句,这里flowOn方法传入的上下文不是空上下文,且通过flow方法构建出的Flow对象也不是FusibleFlow类型的对象,因此这里会走到else分支,将上游flow方法创建的Flow对象和上下文包装成ChannelFlowOperatorImpl类型的对象。
1.ChannelFlowOperatorImpl类
ChannelFlowOperatorImpl类继承自ChannelFlowOperator类,用于将上游的流包装成一个ChannelFlow对象,它的继承关系如下图所示:
通过上图可以知道,ChannelFlowOperatorImpl类最终继承了ChannelFlow类,代码如下:
internal class ChannelFlowOperatorImpl<T>(
flow: Flow<T>,
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = Channel.OPTIONAL_CHANNEL,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
) : ChannelFlowOperator<T, T>(flow, context, capacity, onBufferOverflow) {
// 用于流融合时创建新的流
override fun create(context: CoroutineContext, capacity: Int, onBufferOverflow: BufferOverflow): ChannelFlow<T> =
ChannelFlowOperatorImpl(flow, context, capacity, onBufferOverflow)
// 若当前的流不需要通过Channel即可实现正常工作时,会调用此方法
override fun dropChannelOperators(): Flow<T>? = flow
// 触发对下一级流进行收集
override suspend fun flowCollect(collector: FlowCollector<T>) =
flow.collect(collector)
}
二.collect方法
在Kotlin协程:Flow基础原理中讲到,当执行collect方法时,内部会调用最后产生的Flow对象的collect方法,代码如下:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})
这个最后产生的Flow对象就是ChannelFlowOperatorImpl类对象。
1.ChannelFlowOperator类的collect方法
ChannelFlowOperatorImpl类没有重写collect方法,因此调用的是它的父类ChannelFlowOperator类的collect方法,代码如下:
override suspend fun collect(collector: FlowCollector<T>) {
// OPTIONAL_CHANNEL为默认值,这里满足条件,之后会详细讲解
if (capacity == Channel.OPTIONAL_CHANNEL) {
// 获取当前协程的上下文
val collectContext = coroutineContext
// 计算新的上下文
val newContext = collectContext + context
// 如果前后上下文没有发生变化
if (newContext == collectContext)
// 直接触发对下一级流的收集
return flowCollect(collector)
// 如果上下文发生变化,但不需要切换线程
if (newContext[ContinuationInterceptor] == collectContext[ContinuationInterceptor])
// 切换协程上下文,调用flowCollect方法触发下一级流的收集
return collectWithContextUndispatched(collector, newContext)
}
// 调用父类的collect方法
super.collect(collector)
}
// 获取当前协程的上下文,该方法会被编译器处理
@SinceKotlin("1.3")
@Suppress("WRONG_MODIFIER_TARGET")
@InlineOnly
public suspend inline val coroutineContext: CoroutineContext
get() {
throw NotImplementedError("Implemented as intrinsic")
}
ChannelFlowOperator类的collect方法在设计上与协程的withContext方法设计思路是一致的:在方法内根据上下文的不同情况进行判断,在必要时才会切换线程去执行任务。
通过flowOn方法创建的ChannelFlowOperatorImpl类对象,参数capacity为默认值OPTIONAL_CHANNEL。因此代码在执行时会进入到判断中,但因为我们指定了上下文为Dispatchers.IO,因此上下文发生了变化,同时拦截器也发生了变化,所以最后会调用ChannelFlowOperator类的父类的collect方法,也就是ChannelFlow类的collect方法。
2.ChannelFlow类的collect方法
ChannelFlow类的代码如下:
override suspend fun collect(collector: FlowCollector<T>): Unit =
coroutineScope {
collector.emitAll(produceImpl(this))
}
在ChannelFlow类的collect方法中,首先通过coroutineScope方法创建了一个作用域协程,接着调用了produceImpl方法,代码如下:
public open fun produceImpl(scope: CoroutineScope): ReceiveChannel<T> =
scope.produce(context, produceCapacity, onBufferOverflow, start = CoroutineStart.ATOMIC, block = collectToFun)
produceImpl方法内部调用了produce方法,并且传入了待执行的任务collectToFun。
produce方法在Kotlin协程:协程的基础与使用中曾提到过,它是官方提供的启动协程的四个方法之一,另外三个方法为launch方法、async方法、actor方法。代码如下:
internal fun <E> CoroutineScope.produce(
context: CoroutineContext = EmptyCoroutineContext,
capacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
start: CoroutineStart = CoroutineStart.DEFAULT,
onCompletion: CompletionHandler? = null,
@BuilderInference block: suspend ProducerScope<E>.() -> Unit
): ReceiveChannel<E> {
// 根据容量与溢出策略创建Channel对象
val channel = Channel<E>(capacity, onBufferOverflow)
// 计算新的上下文
val newContext = newCoroutineContext(context)
// 创建协程
val coroutine = ProducerCoroutine(newContext, channel)
// 监听完成事件
if (onCompletion != null) coroutine.invokeOnCompletion(handler = onCompletion)
// 启动协程
coroutine.start(start, coroutine, block)
return coroutine
}
在produce方法内部,首先创建了一个Channel类型的对象,接着创建了类型为ProducerCoroutine的协程,并且传入Channel对象作为参数。最后,produce方法返回了一个ReceiveChannel接口指向的对象,当协程执行完毕后,会通过Channel对象将结果通过send方法发送出来。
至此,可以知道flowOn方法的实现实际上是利用了协程拦截器的拦截功能。
在这里之后,代码逻辑分成了两部分,一部分是block在ProducerCoroutine协程中的执行,另一部分是通过ReceiveChannel对象获取执行的结果。
3.flow方法中代码的执行
在produceImpl方法中,调用了produce方法,并且传入了collectToFun对象,这个对象将会在produce方法创建的协程中执行,代码如下:
internal val collectToFun: suspend (ProducerScope<T>) -> Unit
get() = { collectTo(it) }
当调用collectToFun对象的invoke方法时,会触发collectTo方法的执行,该方法在ChannelFlowOperator类中被重写,代码如下:
protected override suspend fun collectTo(scope: ProducerScope<T>) =
flowCollect(SendingCollector(scope))
在collectTo方法中,首先将参数scope封装成SendingCollector类型的对象,接着调用了flowCollect方法,该方法在ChannelFlowOperatorImpl类中被重写,代码如下:
override suspend fun flowCollect(collector: FlowCollector<T>) =
flow.collect(collector)
ChannelFlowOperatorImpl类的flowCollect方法内部调用了flow对象的collect方法,这个flow对象就是最初通过flow方法构建的对象。根据Kotlin协程:Flow基础原理的分析,这个flow对象类型为SafeFlow,最后会通过collectSafely方法,触发flow方法中的block执行。代码如下:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
// 触发执行
collector.block()
}
}
当flow方法在执行过程中需要向下游发出值时,会调用emit方法。根据上面flowCollect方法和collectTo方法可以知道,collectSafely方法的collector对象就是collectTo方法中创建的SendingCollector类型的对象,代码如下:
@InternalCoroutinesApi
public class SendingCollector<T>(
private val channel: SendChannel<T>
) : FlowCollector<T> {
// 通过Channel类对象发送值
override suspend fun emit(value: T): Unit = channel.send(value)
}
当调用SendingCollector类型的对象的emit方法时,会通过调用类型为Channel的对象的send方法,将值发送出去。
接下来,将分析下游如何接收上游发出的值。
4.接收flow方法发出的值
回到ChannelFlow类的collect方法,之前提到collect方法中调用produceImpl方法,开启了一个新的协程去执行任务,并且返回了一个ReceiveChannel接口指向的对象。代码如下:
override suspend fun collect(collector: FlowCollector<T>): Unit =
coroutineScope {
collector.emitAll(produceImpl(this))
}
在调用完produceImpl方法后,接着调用了emitAll方法,将ReceiveChannel接口指向的对象作为emitAll方法的参数,代码如下:
public suspend fun <T> FlowCollector<T>.emitAll(channel: ReceiveChannel<T>): Unit =
emitAllImpl(channel, consume = true)
emitAll方法是FlowCollector接口的扩展方法,内部调用了emitAllImpl方法对参数channel进行封装,代码如下:
private suspend fun <T> FlowCollector<T>.emitAllImpl(channel: ReceiveChannel<T>, consume: Boolean) {
// 用于保存异常
var cause: Throwable? = null
try {
// 死循环
while (true) {
// 挂起,等待接收Channel结果或Channel关闭
val result = run { channel.receiveOrClosed() }
// 如果Channel关闭了
if (result.isClosed) {
// 如果有异常,则抛出
result.closeCause?.let { throw it }
// 没有异常,则跳出循环
break
}
// 获取并发送值
emit(result.value)
}
} catch (e: Throwable) {
// 捕获到异常时抛出
cause = e
throw e
} finally {
// 执行结束关闭Channel
if (consume) channel.cancelConsumed(cause)
}
}
emitAllImpl方法是FlowCollector接口的扩展方法,而这里的FlowCollector接口指向的对象,就是collect方法中创建的匿名对象,代码如下:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})
在emitAllImpl方法中,当通过receiveOrClosed方法获取到上游发出的值时,会调用emit方法通知下游,这时就会触发collect方法中block的执行,最终实现值从流的上游传递到了下游。
三.flowOn方法与流的融合
假设对一个流连续调用两次flowOn方法,那么流最终会在哪个flowOn方法指定的调度器中执行呢?代码如下:
launch(Dispatchers.Main) {
flow {
emit(2)
// emit方法是在IO线程执行还是在主线程执行呢?
}.flowOn(Dispatchers.IO).flowOn(Dispatchers.Main).collect {
Log.d("liduo", "$it")
}
}
答案是在IO线程执行,为什么呢?
根据本篇上面的分析,当第一次调用flowOn方法时,上游的流会被包裹成ChannelFlowOperatorImpl对象,代码如下:
public fun <T> Flow<T>.flowOn(context: CoroutineContext): Flow<T> {
// 检查当前协程没有执行结束
checkFlowContext(context)
return when {
// 为空,则返回自身
context == EmptyCoroutineContext -> this
// 如果是可融合的Flow,则尝试融合操作,获取新的流
this is FusibleFlow -> fuse(context = context)
// 其他情况,包装成可融合的Flow
else -> ChannelFlowOperatorImpl(this, context = context)
}
}
而当第二次调用flowOn方法时,由于此时上游的流——ChannelFlowOperatorImpl类型的对象,实现了FusibleFlow接口,因此,这里会触发流的融合,直接调用上游的流的fuse方法,并传入新的上下文。这里容量和溢出策略均为默认值。
根据Kotlin协程:Flow的融合、Channel容量、溢出策略的分析,这里会调用ChannelFlow类的fuse方法。相关代码如下:
public override fun fuse(context: CoroutineContext, capacity: Int, onBufferOverflow: BufferOverflow): Flow<T> {
...
// 计算融合后流的上下文
// context为下游的上下文,this.context为上游的上下文
val newContext = context + this.context
...
}
再根据之前在Kotlin协程:协程上下文与上下文元素中的分析,当两个上下文进行相加时,后一个上下文中的拦截器会覆盖前一个上下文中的拦截器。在上面的代码中,后一个上下文为上游的流的上下文,因此会优先使用上游的拦截器。代码如下:
public operator fun plus(other: CoroutineDispatcher): CoroutineDispatcher = other
四.总结
粉线为使用时代码编写顺序,绿线为下游触发上游的调用顺序,红线为上游向下游发送值的调用顺序,蓝线为线程切换的位置。
作者:李萧蝶
链接:https://juejin.cn/post/7139135208267186213
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Koltin协程:Flow的触发与消费
本文分析示例代码如下:
launch(Dispatchers.Main) {
val task = flow {
emit(2)
emit(3)
}.onEach {
Log.d("liduo", "$it")
}
task.collect()
}
一.Flow的触发与消费
在Kotlin协程:Flow基础原理的分析中,流的触发与消费都是同时进行的。每当调用collect方法时,会触发流的执行,并同时在collect方法中对流发出的值进行消费。
而在协程中,其实还提供了分离流的触发与消费的操作——onEach方法。通过使用onEach方法,可以将原本在collect方法中的消费过程的移动到onEach方法中。这样在构建好一个Flow对象后,不会立刻去执行onEach方法,只有当调用collect方法时,才会真正的去触发流的执行。这样就实现了流的触发与消费的分离。
接下来,将对onEach方法进行分析。
1.onEach方法
onEach方法用于预先构建流的消费过程,只有在触发流的执行后,才会对流进行消费,代码如下:
public fun <T> Flow<T>.onEach(action: suspend (T) -> Unit): Flow<T> = transform { value ->
action(value)
return@transform emit(value)
}
onEach方法是一个Flow接口的扩展方法,返回一个类型为Flow的对象。Flow方法内部通过transform方法实现。
2.transform方法
transform方法是onEach方法的核心实现,代码如下:
public inline fun <T, R> Flow<T>.transform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = flow { // 创建Flow对象
collect { value -> // 触发collect
return@collect transform(value)
}
}
transform方法也是Flow接口的扩展方法,同样会返回一个类型为Flow的对象。并且在transform方法内部,首先构建了一个类型为Flow的对象,并且在这个Flow对象的执行体内,调用上游的流的collect来触发消费过程,并通过调用参数transform来实现消费。这个collect方法是一个扩展方法,在Kotlin协程:Flow基础原理分析过,因此不再赘述。
这就是onEach方法实现触发与消费分离的核心,它将对上游的流的消费过程包裹在了一个新的流内,只有当这个新的流或其下游的流被触发时,才会触发这个新的流自身的执行,从而实现对上游的流的消费。
接下来分析一下流的消费过程。
3.collect方法
collect方法用于触发流的消费,我们这里调用的collect方法,是一个无参数的方法,代码如下:
public suspend fun Flow<*>.collect(): Unit = collect(NopCollector)
这里的无参数collect方法是Flow接口的扩展方法。在无参数collect方法中,调用了另一个有参数的collect方法,这个有参数的collect方法在Kotlin协程:Flow基础原理中提到过,就是Flow接口中定义的方法,并且传入了NopCollecor对象,代码如下:
internal object NopCollector : FlowCollector<Any?> {
override suspend fun emit(value: Any?) {
// 什么都不做
}
}
NopCollecor是一个单例类,它实现了FlowCollector接口,但是emit方法为空实现。
因此,这里会调用onEach方法返回的Flow对象的collect方法,这部分在Kotlin协程:Flow基础原理进行过分析,最后会触发flow方法中的block参数的执行。而这个Flow对象就是transform方法返回的Flow对象。代码如下:
public inline fun <T, R> Flow<T>.transform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = flow { // 创建Flow对象
collect { value -> // 触发collect
return@collect transform(value)
}
}
通过上面的transform方法可以知道,在触发flow方法中的block参数执行后,会调用collect方法。上面提到transform方法是Flow接口的扩展方法,因此这里有会继续调用上游Flow对象的collect方法。这个过程与刚才分析的类似,这里调用的上游的Flow对象,就是我们在示例代码中通过flow方法构建的Flow对象。
此时,会触发上游flow方法中block参数的执行,并在执行过程中,通过emit方法将值发送到下游。
接下来,在transform方法中,collect方法的block参数会被会被回调执行,处理上游发送的值。这里又会继续调用transform方法中参数的执行,这部分逻辑在onEach方法中,代码如下:
public fun <T> Flow<T>.onEach(action: suspend (T) -> Unit): Flow<T> = transform { value ->
action(value)
return@transform emit(value)
}
这里会调用参数action的执行,流在这里最终被消费。同时,onEach方法会继续调用emit方法,将上游返回的值再原封不动的传递到下游,交由下游的流处理。
二.多消费过程的执行
首先看下面这段代码:
launch(Dispatchers.Main) {
val task = flow {
emit(2)
emit(3)
}.onEach {
Log.d("liduo1", "$it")
}.onEach {
Log.d("liduo2", "$it")
}
task.collect()
}
根据上面的分析,两个onEach方法会按顺序依次执行,打印出liduo1:2、liduo2:2、liduo1:3、liduo2:3。就是因为onEach方法会将上游的值继续向下游发送。
同样的,还有下面这段代码:
launch(Dispatchers.Main) {
val task = flow {
emit(2)
emit(3)
}.onEach {
Log.d("liduo1", "$it")
}
task.collect {
Log.d("liduo2", "$it")
}
}
这段代码也会打印出liduo1:2、liduo2:2、liduo1:3、liduo2:3。虽然使用了onEach方法,但也可以调用有参数的collect方法来对上游发送的数据进行最终的处理。
三.总结
粉线为代码编写顺序,绿线为下游触发上游的调用顺序,红线为上游向下游发送值的调用顺序,蓝线为onEach方法实现的核心。
作者:李萧蝶
链接:https://juejin.cn/post/7139427332602724365
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
错的不是世界,是我
本人是95前端菜鸟一枚,目前在广州打工混口饭吃。刚好换了工作,感觉生活节奏变得慢了下来,打了这么多年工总觉得想纪录些什么,怕以后自己老了忘记自己还有这么一些风流往事。书接上回。
楔子
"咕咚,咕咚,咕咚",随着桶装水一个个气泡涌上来,我的水杯虽已装满,但摸鱼太久的我却似木头般木讷,溢出的水从杯口流了下来,弄湿了我的new balance。问:此处描写代表了作者什么心情(5分)。
阳春三月,摸鱼的好季节,我拿起水杯小抿了一口,还是那个甘甜的味道。怡宝,永远的神。这个公司虽然没人陪我说话,工作量也不饱和,但是只要它一天不换怡宝,我便一直誓死效忠这个公司。我的水杯是个小杯,这样每次便能迅速喝完水走去装水,提高装水频率,极大提升摸鱼时长,我不自暗叹我真是一个大聪明。装水回到座位还没坐下,leader便带来一个新来的前端给每位组员介绍,我刚入职三个月,便又来了一位新人。leader瞥了我一眼,跟新人介绍说我也是刚入职的前端开发做题家,我看了新人一眼,脑海闪过几句诗词——眼明正似琉璃瓶,心荡秋水横波清,面如凝脂,眼如点漆,她呆呆的看着我,我向她点头示意,说了声,你好。她的名字,叫作小薇小月。
天眼
"小饿,过来天若有情找我一下",钉钉弹出来一条消息,正是HRBP红姐发来的,我的心里咯噔了一下,我正在做核酸,跟她同步后她让我做完核酸找她。其实下楼做核酸的时候我看到跟我负责同个项目的队友被红姐拉去谈话,公司找我聊天,除了四年前技术leader莫名奇妙帮我加薪有兴趣可看往期文章,其他都没有发生过好事。我的心里其实已经隐隐约约知道了什么事情,一边做着核酸一边想着对策,一边惶恐一边又有几分惊喜,心里想着不会又要拿大礼包了吧,靠着拿大礼包发家致富不是梦啊。
来到天若有情会议室,我收拾了一下心情,走了进去,"坐吧"。红姐冷冷的说了一声,我腿一软便坐了下来。"知道我找你是什么原因吗?"红姐率先发问,"公司是要裁员吗?"我直球回击。红姐有点出乎意料笑了一下,"啪"的一声,很快,我大意了,没有闪。一堆文件直接拍到了桌面,就犹如拍在我的脸上。"这是你上个月的离开工作位置时长,你自己核对一下,签个名"。
我震惊。没想到对面一上来就放大。我自己的情况我是知道的,早上拉个屎,下午喝杯茶,悠然混一日。加上嘘嘘偶尔做做核酸每天离开工作岗位大约2个小时左右。"为什么呀,你入职的时候表现不是这样子的呀,为什么会变成这样呢?是被带坏了吗?没有需求吗?还是个人原因?"。既然你诚心诚意发问,那我就大发慈悲告诉你吧。
为什么呢?
从入职新公司后,我的心感觉就不属于这里,公司指派的任务都有尽心尽责完成,但是来了公司大半年,做了一个项目上线后没落地便夭折,另外一个项目做了一半被公司业务投诉也立刻中断,我没有产出,公司当我太子一样供着。自己从上家公司拿了大礼包后,机缘巧合又能快速进入新的公司,其实自己是有点膨胀的,到了新公司完成任务空闲时便会到掘金写写小说,晚上回家杀杀狼人。有时动一下腰椎,也会传来噼里啪啦的声响,似乎提醒我该去走走了。不过不学无术,游手好闲,的确是我自己的问题。每天摸两小时,资本家看了也会流泪。当然,这些都是马后炮自己事后总结的。
"是我个人原因"。虽说极大部分归于没有需求做,但是没有需求做也不代表着能去摸鱼,而且更不能害了leader,我心里明白,这次是我错了。太子被废了。我在"犯罪记录"上面签了字,问了句如何处理,回复我说看上面安排。我出来后发现有两个同事也来询问我情况,我也一五一十说了,发现大家都是相同问题。我默默上百度查了下摸鱼被裁的话题,发现之前tx也有过一次案例,虽然前两次都是败诉,最后又胜诉了。
我晚上回去躺在床上翻来覆去睡不着觉,心中似乎知道结局,避无可避,但错在我身,这次的事件就当做是一个教训,我能接受,挨打立正。闲来无事打开BOSS刷了又刷,岗位寥寥无几,打开脉脉,第一条便是广州找工作怎么这么难啊,下面跟着一大群脉友互相抱团取暖,互相安慰,在寒冬下,大家都知道不容易,大家都互相鼓励,互相给出希望,希望就像一道道暖风,吹走压在骆驼身上的稻草,让我们在时间的流逝下找到花明。
第二天,红姐让我去江湖再见会议室。"其实是个坏消息啦,X总容忍不了,这是离职协议,签一下吧"。我看了厚厚的离职协议,默不作声,"签个人原因离职后背调也可以来找我,我这边来协助安排"。弦外之音声声割心,但其实我心里也明白,我也没有底气,不如利索点出来后看看能不能尽快找个工作。
晚宴
leader知道我们几个明天last day后,拉个小群请我们吃饭。也是在这次宴席中,leader透露出他也会跟着我们一起走,我大为吃惊,随后leader便娓娓道来,我知道了很多不为人知的秘密。这次总共走了四个人,都是前端,其中涉及了帮派的斗争,而我们也成为斗争中的牺牲品。我一边听着leader诉说公司的前尘往事,一边给各位小伙伴倒茶,心里也明白,就算内斗,如果自己本身没有犯错,没有被抓到把柄,其实也不会惹祸上身。leader也跟我说因为他个人原因太忙没有分配给我适合的工作量,导致我的确太闲,也让我给简历给他帮忙内推各种大厂,我心里十分感激。
期间有位小伙伴拍着我肩膀说,"我知道你是个很好的写手,但是这些东西最好不要写出来"。我一愣,他接着说,之前有位前端老员工识别到是你的文章,发出来了。凉了,怪不得我变成砧板的鱼肉,原来我的太子爽文都有可能传到老板手里了。我突然心里一惊,问了一句不会是因为的Best 30 年中总结征文大赛才导致大家今晚这场盛宴吧?leader罢了罢手,说我想多了。我也万万想不到,我的杰作被流传出去,可能点赞的人里面都藏着CEO。就怕太子爽文帮我拿到了电热锅,却把我饭碗给弄丢了。不过我相信,上帝为你关上一扇门,会为你打开一扇窗。
不过掘金的奖牌着实漂亮,谢谢大家的点赞,基层程序员一个,写的文章让大家有所动容,有所共鸣,实乃吾之大幸。天窗
自愿离职后的我开始准备简历,准备复习资料,同时老东家也传来裁员消息。心里不禁感叹,老东家这两次裁员名单,都有我的名字。我刷了下boss,投了一份简历,便准备面试题去了,因为我觉得我的简历很能打,但是面试的机会不多,每一次面试都是一个黄金机会,不能再像上次一样错过。当天一整天都很down,朋友约出来玩,我也拒绝了,但是朋友边邀请边骂边安慰我,我想了一下就当放松一下了,于是便出去浪了一天。第二天睡醒发现两个未接来电,回拨过去后是我投递简历的公司打来的,虽然我没有看什么面试题,但是好在狼人杀玩的够多,面对着几位面试官夸夸其谈,聊东南西北,最终也成功拿下offer。虽然offer一般,但在这个行情下,我一心求稳,便同意入职,所以也相当于无缝衔接。对这位朋友也心怀感激,上次也是他的鼓励,让我走出心中的灰暗,这次也是让我在沮丧中不迷失自我。那天我玩的很开心,让我明白工作没了可以再找,错误犯了可以改回来,但人一旦没了信心迷失方向,便容易坠入深渊。
THE END
其实很多人都跟我说,互联网公司只要结果,这次其实我没犯啥毛病,大家都会去摸鱼。我经过几天思考我也明白,不过,有时候真要从自己身上找下原因,知道问题根本所在,避免日后无论是在工作还是生活中,都能避免在同一个地方再次跌倒。其实大多时候,错的不是世界,而是我。
过了几天,leader请了前端组吃一顿他的散伙饭,因为他交接比较多,所以他走的比较晚。菜式十分丰富,其中有道羊排深得我心,肥而不腻,口有余香,难以言喻。小月坐在我的隔壁,在一块羊排上用海南青金桔压榨滴了几滴,拍了拍我的肩膀,让我试一下。我将这块羊排放入口中,金桔的微酸带苦,孜然的点点辛辣,羊排本身浓郁的甜味,原来,这就是人生啊。仔细品尝后,我对小月点了点头,说了声谢谢。
作者:很饿的男朋友
来源:juejin.cn/post/7138117808516235300
uniapp使用canvas实现二维码分享
实现使用canvas在小程序H5页面进行二维码分享 如下图效果 可以保存并扫码
总体思路:使用canvas进行绘制,为了节省时间固定部分采用背景图绘制 只有二维码以及展示图片及标题绘制,绘制完成后调用uni.canvasToTempFilePath将其转为图片展示
1.组件调用,使用ref调用组件内部相应的canvas绘制方法,传入相关参数 包括名称 路由 展示图片等。
<SharePoster v-if='showposter' ref='poster' @close='close'/>
<script>
import SharePoster from "@/components/share/shareposter.vue"
export default {
components: {
SharePoster,
},
methods:{
handleShare(item){
this.showposter=true
if(this.showvote){
this.showvote=false
}
this.$nextTick(() => {
this.$refs.poster.drawposter(item.name, `/pagesMore/voluntary/video/player?schoolId=${item.id}`,item.cover)
})
},
}
</script>2.组件模板放置canvas容器并赋予id以及宽度高度等,使用iscomplete控制是显示canvas还是显示最后调用uni.canvasToTempFilePath生成的图片
<div class="poster-wrapper" @click="closePoster($event)">
<div class='poster-content'>
<canvas canvas-id="qrcode"
v-if="qrShow"
:style="{opacity: 0, position: 'absolute', top: '-1000px'}"
></canvas>
<canvas
canvas-id="poster"
:style="{ width: cansWidth + 'px', height: cansHeight + 'px' ,opacity: 0, }"
v-if='!iscomplete'
></canvas>
<image
v-if="iscomplete"
:style="{ width: cansWidth + 'px', height: cansHeight + 'px' }"
:src="tempFilePath"
@longpress="longpress"
></image>
</div>
</div>3.data内放置相应配置参数
data() {
return {
bgImg:'https://cdn.img.up678.com/ueditor/upload/image/20211130/1638258070231028289.png', //画布背景图片
cansWidth:288, // 画布宽度
cansHeight:410, // 画布高度
projectImgWidth:223, // 中间展示图片宽度
projectImgHeight:167, // 中间展示图片高度
qrShow:true, // 二维码canvas
qrData: null, // 二维码数据
tempFilePath:'',// 生成图路径
iscomplete:false, // 是否生成图片
}
},4.在created生命周期内调用uni.createCanvasContext创建canvas实例 传入模板内canvas容器id
created(){
this.ctx = uni.createCanvasContext('poster',this)
},5.调用对应方法,绘制分享作品
// 绘制分享作品
async drawposter(name='重庆最美高校景象',url,projectImg){
uni.showLoading({
title: "加载中...",
mask: true
})
// 生成二维码
await this.createQrcode(url)
// 背景
await this.drawWebImg({
url: this.bgImg,
x: 0, y: 0, width: this.cansWidth, height: this.cansHeight
})
// 展示图
await this.drawWebImg({
url: projectImg,
x: 33, y: 90, width: this.projectImgWidth, height: this.projectImgHeight
})
await this.drawText({
text: name,
x: 15, y: 285, color: '#241D4A', size: 15, bold: true, center: true,
shadowObj: {x: '0', y: '4', z: '4', color: 'rgba(173,77,0,0.22)'}
})
// 绘制二维码
await this.drawQrcode()
//转为图片
this.tempFilePath = await this.saveCans()
this.iscomplete = true
uni.hideLoading()
},6.绘制图片方法,注意 this.ctx.drawImage方法第一个参数不能放网络图片 必须执行下载后绘制
drawWebImg(conf) {
return new Promise((resolve, reject) => {
uni.downloadFile({
url: conf.url,
success: (res) => {
this.ctx.drawImage(res.tempFilePath, conf.x, conf.y, conf.width?conf.width:"", conf.height?conf.height:"")
this.ctx.draw(true, () => {
resolve()
})
},
fail: err => {
reject(err)
}
})
})
},7.绘制文本标题
drawText(conf) {
return new Promise((resolve, reject) => {
this.ctx.restore()
this.ctx.setFillStyle(conf.color)
if(conf.bold) this.ctx.font = `normal bold ${conf.size}px sans-serif`
this.ctx.setFontSize(conf.size)
if(conf.shadowObj) {
// this.ctx.shadowOffsetX = conf.shadowObj.x
// this.ctx.shadowOffsetY = conf.shadowObj.y
// this.ctx.shadowOffsetZ = conf.shadowObj.z
// this.ctx.shadowColor = conf.shadowObj.color
}
let x = conf.x
conf.text=this.fittingString(this.ctx,conf.text,280)
if(conf.center) {
let len = this.ctx.measureText(conf.text)
x = this.cansWidth / 2 - len.width / 2 + 2
}
this.ctx.fillText(conf.text, x, conf.y)
this.ctx.draw(true, () => {
this.ctx.save()
resolve()
})
})
},
// 文本标题溢出隐藏处理
fittingString(_ctx, str, maxWidth) {
let strWidth = _ctx.measureText(str).width;
const ellipsis = '…';
const ellipsisWidth = _ctx.measureText(ellipsis).width;
if (strWidth <= maxWidth || maxWidth <= ellipsisWidth) {
return str;
} else {
var len = str.length;
while (strWidth >= maxWidth - ellipsisWidth && len-- > 0) {
str = str.slice(0, len);
strWidth = _ctx.measureText(str).width;
}
return str + ellipsis;
}
},8.生成二维码
createQrcode(qrcodeUrl) {
// console.log(window.location.origin)
const config={host:window.location.origin}
return new Promise((resolve, reject) => {
let url = `${config.host}${qrcodeUrl}`
// if(url.indexOf('?') === -1) url = url + '?sh=1'
// else url = url + '&sh=1'
try{
new qrCode({
canvasId: 'qrcode',
usingComponents: true,
context: this,
// correctLevel: 3,
text: url,
size: 130,
cbResult: (res) => {
this.qrShow = false
this.qrData = res
resolve()
}
})
} catch (err) {
reject(err)
}
})
},9.画二维码,this.qrData为生成的二维码资源
drawQrcode(conf = { x: 185, y: 335, width: 100, height: 50}) {
return new Promise((resolve, reject) => {
this.ctx.drawImage(this.qrData, conf.x, conf.y, conf.width, conf.height)
this.ctx.draw(true, () => {
resolve()
})
})
},10.将canvas绘制内容转为图片并显示,在H5平台下,tempFilePath 为 base64
// canvs => images
saveCans() {
return new Promise((resolve, reject) => {
uni.canvasToTempFilePath({
x:0,
y:0,
canvasId: 'poster',
success: (res) => {
resolve(res.tempFilePath)
},
fail: (err) => {
uni.hideLoading()
reject(err)
}
}, this)
})
},11.组件全部代码
作者:ArvinC
来源:juejin.cn/post/7041087990222815246
人生中的第一次被辞退
2022年8月26日下午5点半得到的通知,有10天的缓冲但没有补偿,理由是没有没有过试用期,离试用期还有10天。
一、咋进的公司?
公司与甲方签的一个单子快到时间了公司没人写,没怎么面试问了我以前写的项目就让我通过了,工资是不打折的。
二、进公司干了啥?
目前是80天,30天开发后台管理(81张设计稿,60个接口,vue写的),10天修改后台管理第二版,后面40天就是噩梦了,维护前后端不分离的和前后端分离的jq。(时间只是大概,具体不记得了)
三、辞退原因
公司给的原因:维护开发效率太低。
个人认为的原因:
1、之前没接触jq(进来前没说用jq和要维护前后端不分离的项目)。之前那哥们是一毕业就在这家公司写了两年半jq工资没加第二年还降了,与之相比我这之前没接触jq项目的,我开的工资比他还高但我维护的效率比他低太多了。
2、状态不好。我加了上个前端的微信,他当时走了2个月但他现在还没找到工作在家学习vue,我离职了他都没找到工作,这jq我越写越焦虑,我怕有一天忘记vue、react、uniapp就只会jq,简历上全是jq项目我下份工作怎么找。在这种焦虑中工作不在状态想离职但又怕找不到工作,有点摆烂。
四、感受
1、失落。居然被这样一份工作辞退,开始怀疑自己能不能干这行业,自己怕不是个垃圾(虽然确实是菜狗...)。
2、担忧。目前了解到的找工作的前端,一个找了5个月在家学vue的(这公司上个前端),一个找了6个月的,一个找了2个月但找了比较好的工作,我丫的不会也找几个月吧(看来要练习一下捡瓶子,防止饿死)。
3、解脱、丫的,终于10天后不用维护这些垃圾代码了,焯!!!爽!!!
五、有什么打算?
1、先到杭州见一下老朋友,当然也可能约不出来(尴尬),顺便去面试。
2、回老家一趟,两年没回去想家了。
3、去深圳那个唯一叫我靓仔的地方,之后可能就饿死在那。
作者:张二河
链接:https://juejin.cn/post/7136214855777779749
收起阅读 »
是时候改变了,日本政府决定将停止使用软盘和光盘
什么?日本要向软盘宣战了?
该国数字大臣河野太郎在推特上公开表示:
日本政府有太多业务都需要人们通过软盘、CD等老设备来提交表格和申请了,数量高达1900个!
现在,他们要更改规定,弃用软盘,让大家进行在线提交!
我没看错吧?
2022年了,软盘这种东西早就成为了时代的眼泪。
怎么日本——
一个堂堂的发达国家,以电子产业、机器人技术乃至赛博文化等标签闻名,还在用这东西?

软盘居然还在日本活着
是的,你没看错。
在日本政府,目前还有需要各方商业伙伴用软盘、CD等老式存储介质来传输数据。
最近日本也确实发生了几起软盘丢失的事件,侧面证明此事一点不假。
比如去年12月27日,日本警视厅对外承认:他们丢失了38位公民的个人数据。
这些公民申请了东京都下辖目黑区的公共住房,政府需要与警方确认申请人中是否与犯罪集团有关联。
在调查中,他们就是靠软盘传送申请人数据。
谁知软盘不慎丢失,申请人的个人信息也没了。
此事一出,全球网友都看傻了,有人甚至怀疑这是假新闻。
当然一些日本网友也表示很震惊,没想到自己国家的政务机构还在用这种老古董。
除了政府,软盘也被银行体系大量使用。
日经新闻去年的一篇消息就指出,仅山形银行,一个月内就有1000多家客户在使用软盘传输职工的工资数据。

当然,这些客户中,还是以政府和中小企业居多,尤其是政府。
而在几天前,日本的一个组织对300名15至29岁的人群做了一个小调查——
结果发现还是有近20%的年轻人用过软盘,没错,真的在「用」,相比下,中国00后们认识软盘的都不多…
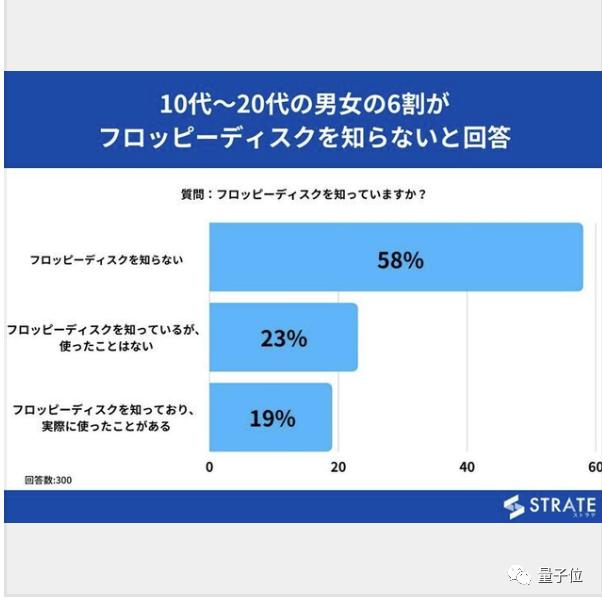
事实上,日本人与软盘还有些渊源。
该产品1971年就诞生了。当时它还有足足32寸,因携带不方便,被IBM改到了8寸。
真正将其发扬光大的正是日本名企,索尼。
1981年,索尼首次推出了经典款3.5英寸盘,后被广泛生产使用,1984年苹果那款知名的MAC,就带有3.5英寸软盘的驱动。

到90年代,软盘盛极一时,在1996年就有50亿张软盘被使用。
但很快,内存只有1.44MB、容易损坏的软盘被更大容量、更可靠的产品(比如U盘等)迅速取代。
2011年,索尼就已停止生产这种风靡一时的产品。
如今,十一年过去,日本社会对软盘依赖还这么高,或许索尼高层也没想到(手动狗头)。
可是,为什么软盘内存小、效率低,还是不摒弃?
究其原因,有当地网友认为,是因为软盘更安全。
它的存储空间很小,大多病毒都不足以容身,也不用担心网络攻击。

当然,也有更清奇的思路表示——
正因为它被用得少,即便被捡到了,对方也难以找到专门的读取设备。那么最终只能落回政府和机构手里。
但更为重要的也许是,很多使用者们自己不愿改变习惯。
日本官僚群体在软盘使用上一直比较坚持。某负责公共资金管理的政府工作者就曾对日经新闻一再强调软盘的可靠性,称它「几乎从未损坏和丢失数据」。
不光政府官僚。也有金融行业从事技术的工程师指出,他们20年前就在劝说客户改换存储媒介,但怎么说都劝不动。
对于银行、政府等服务机构来说,若有客户坚持认为邮寄软盘比网络传输更安全,作为服务方,他们也只能「向下兼容」,保留相应设备。
由此,也就造成软盘在日本“苟活”到今天。

其实……也早想抛弃
当然,还是有人考虑到现实因素,提出弃用软盘。
比如软盘读取设备停产导致无法处理数据的问题。
已有银行觉得专门的读取和归还软盘的费用很高,实在不想忍了,决定在承接软盘相关业务时收取每月5万日元 (约合2477元人民币)费用。
有些银行则已经开始摒弃软盘业务,将数据转移到其他在线存储格式。
也有一些政府机构也开始这种数字化转型,不过它们可能要到2026年才全面停止使用。
这回,雷厉风行的数字化大臣河野太郎上任后,就一直在公开场合敦促同僚们「走进发达社会」——
终于在这两天在社交网站正式用「宣战」一词,开启全面的抛弃软盘行动。
根据已披露的信息,数字厅将推动更多行政程序以在线方式完成,而非用邮寄软盘、CD、U盘等方式传数据。此外,他们还会敦促各部门机构自我审查,计划在年底发布更具体的政策。

那么,对河野太郎的宣战,各方反馈如何?
拍手称快的日本网友不少,还有一位在日本工作的印度人表示:
顺便也管管日本银行的工作效率吧。
比如你们那个瑞穗(日本三大行之一),每次办丁点儿业务都要去线下分行操作。在我们印度都不这样了,线上搞定一切!
另一方面,“唱衰”的声音仍然存在。
就比如有位朋友就说了:
谢谢您老的建议。
2022:软盘战 ;2052:网络安全打击战
你就等着瞧吧~
再去日网上一看,这种声音还并非个例。

关于河野太郎为什么会遇到较大阻力,身在中国的我们可能难以理解——
一位留学日本,并对该国文化有长期观察的媒体朋友分享了她的看法:
日本是全球第一个进入超高龄社会的国家,老年人又是最积极的投票群体,因此从对选票负责的角度来讲,日本政府需要尽可能地维持老年人所熟悉的社会,而不是迅速改变它。
并且,日本政府系统身居高位的人,绝大多数都是老年人。很多大臣连电脑都用不明白,更别说意识到数字化的重要性了。
翻盖手机等老古董同样流行
其实不止软盘,日本在IT方面总体都比较「怀旧」,或者说保守。
比如一些中小企业和政府机关还在用传真而不是E-mail发文件。
有人进行电商发货时,还要在快递里的清单上盖上每个负责人的印章。
由此,也诞生了一个名为“昭和三大遗物”的戏称,指的就是这俩玩意以及前文所说的软盘。
(嗯,昭和时代可是1926年-1989年了。)
此外,显示器习惯用古老的VGA接口,笔记本坚持用网线接口上网……这种情况在日本也不算稀罕。

还有,一些国际公司的网站一到日本就会改成上个世纪的设计。
比如当地重要门户雅虎,完全是00年代风:
B站日本兄弟站niconico,也还是有种多年前味道:
除了上面这些,还不得不提另一个在日本仍然焕发生命的老古董——
翻盖手机。
在咱们国家,大部分老年人基本都不用这种产品,而在该国,市场上每年都还有好几款新翻盖机上市,比如夏普、日本电信公司KDDI这些公司就在出。
(不过日本的翻盖机在智能化上确实做的很好。
和国内的老年机/功能机不同,它们在2003年刚普及的时候,就被陆续附上了wifi、扫码、移动支付、视频等功能。
现在更是早就普及了安卓系统,一些常用App都可以安装。)

曾在日留学的95后同事也分享了她的奇葩见闻——
在其就读的学校,40岁以上的日本老师都不用智能手机,都是翻盖手机挂脖子上,他们自己还觉得挺方便。
此外,学校办公方面也相对「原始」,当时都2017年了,还没有电子选课系统,而是纸质申请选课。
她还特别强调了支付方式方面,「他们一直在用硬币这种东西…就知道他们有多不怕麻烦了…」
……
看完上述现象,你是不是能理解日本人为什么不愿放弃软盘了……
最后,你觉得日本向软盘「宣战」能成功么?
来源:丰色 詹士 发自 凹非寺
收起阅读 »这一次,放下axios,使用基于rxjs的响应式HTTP客户端
众所周知,在浏览器端和 Node.js 端使用最广泛的 HTTP 客户端为 axios 。想必大家都对它很熟悉,它是一个用于浏览器和 Node.js 的、基于 Promise 的 HTTP 客户端,但这次的主角不是它。
起源
axios 的前身其实是 AngularJS 的 $http 服务。
为了避免混淆,这里需要澄清一下:
AngularJS并不等于Angular,AngularJS是特指 angular.js v1.x 版本,而Angular特指 angular v2+ (没有 .js)和其包含的一系列工具链。
这样说可能不太严谨,但 axios 深受 AngularJS 中提供的$http 服务的启发。归根结底,axios 是为了提供一个类似独立的服务,以便在 AngularJS 之外使用。
发展
但在 Angular 中,却没有继续沿用之前的 $http 服务,而是选择与 rxjs 深度结合,设计出了一个比 $http 服务更先进的、现代化的,响应式的 HTTP 客户端。 在这个响应式的 HTTP Client 中,发送请求后接收到的不再是一个 Promise ,而是来自 rxjs 的 Observable,我们可以订阅它,从而侦听到请求的响应:
const observable = http.get('url');
observable.subscribe(o => console.log(o));有关它的基本形态及详细用法,请参考官方文档。
正文
@ngify/http 是一个形如 Angular HttpClient 的响应式 HTTP 客户端。@ngify/http的目标与 axios 相似:提供一个类似独立的服务,以便在 Angular 之外使用。
@ngify/http 提供了以下主要功能:
先决条件
在使用 @ngify/http 之前,您应该对以下内容有基本的了解:
JavaScript / TypeScript 编程。
HTTP 协议的用法。
RxJS Observable 相关技术和操作符。请参阅 Observables 指南。
API
有关完整的 API 定义,请访问 ngify.github.io/ngify.
可靠性
@ngify/http 使用且通过了 Angular HttpClient 的单元测试(测试代码根据 API 的细微差异做出了相应的更改)。
安装
npm i @ngify/http基本用法
import { HttpClient, HttpContext, HttpContextToken, HttpHeaders, HttpParams } from '@ngify/http';
import { filter } from 'rxjs';
const http = new HttpClient();
http.get<{ code: number, data: any, msg: string }>('url', 'k=v').pipe(
filter(({ code }) => code === 0)
).subscribe(res => console.log(res));
http.post('url', { k: 'v' }).subscribe(res => console.log(res));
const HTTP_CACHE_TOKEN = new HttpContextToken(() => 1800000);
http.put('url', null, {
context: new HttpContext().set(HTTP_CACHE_TOKEN)
}).subscribe(res => console.log(res));
http.patch('url', null, {
params: { k: 'v' }
}).subscribe(res => console.log(res));
http.delete('url', new HttpParams('k=v'), {
headers: new HttpHeaders({ Authorization: 'token' })
}).subscribe(res => console.log(res));拦截请求和响应
借助拦截机制,你可以声明一些拦截器,它们可以检查并转换从应用中发给服务器的 HTTP 请求。这些拦截器还可以在返回应用的途中检查和转换来自服务器的响应。多个拦截器构成了请求/响应处理器的双向链表。
@ngify/http会按照您提供拦截器的顺序应用它们。
import { HttpClient, HttpHandler, HttpRequest, HttpEvent, HttpInterceptor, HttpEventType } from '@ngify/http';
import { Observable, tap } from 'rxjs';
const http = new HttpClient([
new class implements HttpInterceptor {
intercept(request: HttpRequest<unknown>, next: HttpHandler): Observable<HttpEvent<unknown>> {
// 克隆请求以修改请求参数
request = request.clone({
headers: request.headers.set('Authorization', 'token')
});
return next.handle(request);
}
},
{
intercept(request: HttpRequest<unknown>, next: HttpHandler) {
request = request.clone({
params: request.params.set('k', 'v')
});
console.log('拦截后的请求', request);
return next.handle(request).pipe(
tap(response => {
if (response.type === HttpEventType.Response) {
console.log('拦截后的响应', response);
}
})
);
}
}
]);虽然拦截器有能力改变请求和响应,但 HttpRequest 和 HttpResponse 实例的属性是只读的,因此让它们基本上是不可变的。
有充足的理由把它们做成不可变对象:应用可能会重试发送很多次请求之后才能成功,这就意味着这个拦截器链表可能会多次重复处理同一个请求。 如果拦截器可以修改原始的请求对象,那么重试阶段的操作就会从修改过的请求开始,而不是原始请求。 而这种不可变性,可以确保这些拦截器在每次重试时看到的都是同样的原始请求。
如果你需要修改一个请求,请先将它克隆一份,修改这个克隆体后再把它传递给 next.handle()。
替换 HTTP 请求类
@ngify/http 内置了以下 HTTP 请求类:
| HTTP 请求类 | 描述 |
|---|---|
HttpXhrBackend | 使用 XMLHttpRequest 进行 HTTP 请求 |
HttpFetchBackend | 使用 Fetch API 进行 HTTP 请求 |
HttpWxBackend | 在 微信小程序 中进行 HTTP 请求 |
默认使用 HttpXhrBackend,可以通过修改配置切换到其他的 HTTP 请求类:
import { HttpFetchBackend, HttpWxBackend, setupConfig } from '@ngify/http';
setupConfig({
backend: new HttpFetchBackend()
});你还可使用自定义的 HttpBackend 实现类:
import { HttpBackend, HttpClient, HttpRequest, HttpEvent, setupConfig } from '@ngify/http';
import { Observable } from 'rxjs';
// 需要实现 HttpBackend 接口
class CustomHttpBackend implements HttpBackend {
handle(request: HttpRequest<any>): Observable<HttpEvent<any>> {
// ...
}
}
setupConfig({
backend: new CustomHttpBackend()
});如果需要为某个 HttpClient 单独配置 HttpBackend,可以在 HttpClient 构造方法中传入:
const http = new HttpClient(new CustomHttpBackend());
// 或者
const http = new HttpClient({
interceptors: [/* 一些拦截器 */],
backend: new CustomHttpBackend()
});在 Node.js 中使用
@ngify/http 默认使用浏览器实现的 XMLHttpRequest 与 Fetch API。要在 Node.js 中使用,您需要进行以下步骤:
XMLHttpRequest
如果需要在 Node.js 环境下使用 XMLHttpRequest,可以使用 xhr2,它在 Node.js API 上实现了 W3C XMLHttpRequest 规范。
要使用 xhr2 ,您需要创建一个返回 XMLHttpRequest 实例的工厂函数,并将其作为参数传递给 HttpXhrBackend 构造函数:
import { HttpXhrBackend, setupConfig } from '@ngify/http';
import * as xhr2 from 'xhr2';
setupConfig({
backend: new HttpXhrBackend(() => new xhr2.XMLHttpRequest())
});Fetch API
如果需要在 Node.js 环境下使用 Fetch API,可以使用 node-fetch 和 abort-controller。
要应用它们,您需要分别将它们添加到 Node.js 的 global:
import fetch from 'node-fetch';
import AbortController from 'abort-controller';
import { HttpFetchBackend, HttpWxBackend, setupConfig } from '@ngify/http';
global.fetch = fetch;
global.AbortController = AbortController;
setupConfig({
backend: new HttpFetchBackend()
});传递额外参数
为保持 API 的统一,需要借助 HttpContext 来传递一些额外参数。
Fetch API 额外参数
import { HttpContext, FETCH_TOKEN } from '@ngify/http';
// ...
// Fetch API 允许跨域请求
http.get('url', null, {
context: new HttpContext().set(FETCH_TOKEN, {
mode: 'cors',
// ...
})
});微信小程序额外参数
import { HttpContext, WX_UPLOAD_FILE_TOKEN, WX_DOWNLOAD_FILE_TOKEN, WX_REQUSET_TOKEN } from '@ngify/http';
// ...
// 微信小程序开启 HTTP2
http.get('url', null, {
context: new HttpContext().set(WX_REQUSET_TOKEN, {
enableHttp2: true,
})
});
// 微信小程序文件上传
http.post('url', null, {
context: new HttpContext().set(WX_UPLOAD_FILE_TOKEN, {
filePath: 'filePath',
fileName: 'fileName'
})
});
// 微信小程序文件下载
http.get('url', null, {
context: new HttpContext().set(WX_DOWNLOAD_FILE_TOKEN, {
filePath: 'filePath'
})
});更多
有关更多用法,请访问 angular.cn。
作者:Sisyphus
来源:juejin.cn/post/7079724273929027597
第一波元宇宙公司发不出工资了
元宇宙已经成为了近几年的热门概念,但是投注这个概念之后,企业真的可以“一本万利”吗?答案显然是否定的。近期,便有元宇宙概念相关公司被曝存在拖欠工资等情况。所以就目前形势来看,元宇宙也许是一个不错的先进概念,但企业也需要谨慎投入,做好相应的发展规划。
又要给元宇宙泼冷水了。
近日,一家号称要成为“元宇宙时代的微软”的元宇宙公司影创科技被曝欠薪200多人,时间最长达半年,人均被拖欠10万元,社保公积金也断交。
影创科技公司大群也被创始人兼董事长孙立强制解散,连公司HR也加入讨薪队伍。讨薪员工纷纷申请仲裁。
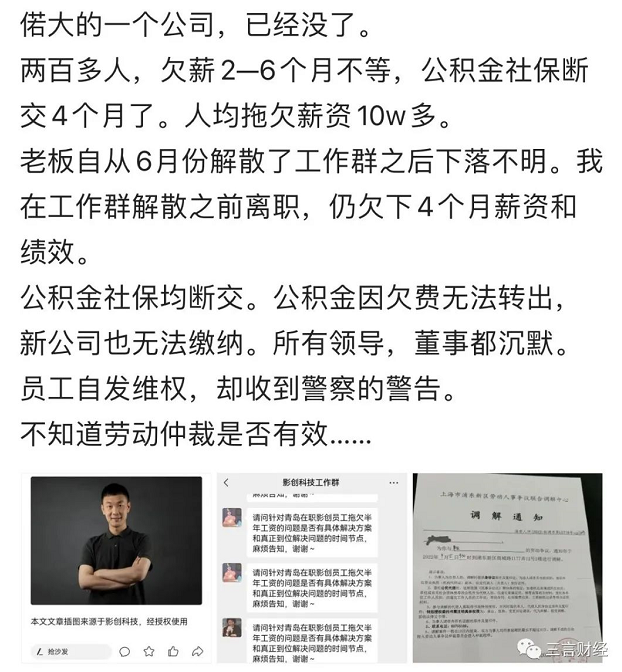
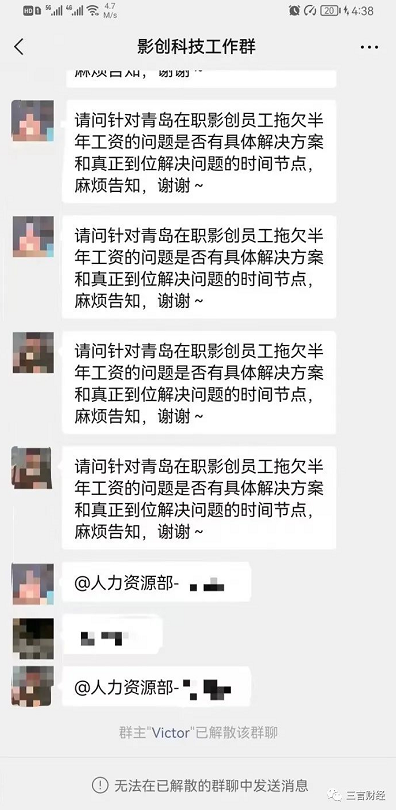
在某职场社交平台上,有不少人反映影创科技拖欠工资,时间最早追溯到今年6月份。
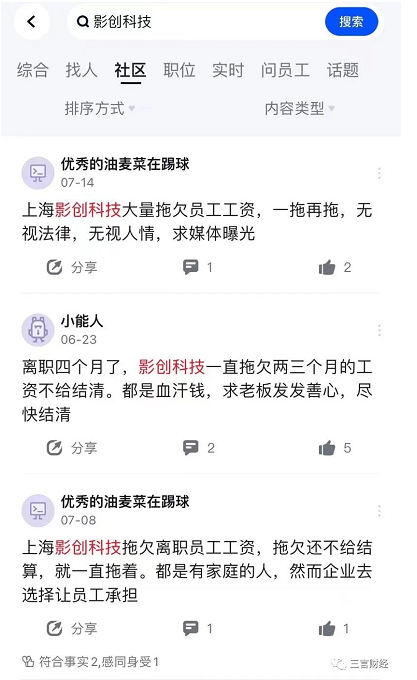
影创科技在VR圈内有一定的影响力和知名度。
世界VR产业大会是中国以及全球虚拟现实产业专业展会,大会每年都会发布“中国VR50强”榜单。而在过去的三年影创都在榜,19年第13名,20年第9名,21年第27名。
公开信息显示,影创曾获6轮融资,最近一轮融资是在2020年9月份。就在今年3月份,影创官网一篇报道中还写道“无论是技术还是出货量,我们基本都可以排到全球第二,第一是Meta”,影创还豪言要成为元宇宙的“微软”。
外面看着发展还不错,怎么却被曝大规模、长时间欠薪,员工大量离职?
一、今年3月份开始停发工资,讨薪群近200人,而在职员工不到50人
“影创在正常情况下是每月15日发薪,但在去年10月份开始出现拖欠情况,只发基本工资,期间偶尔会在月末补齐”,一位已离职影创员工对三言财经表示。
这名员工离职前是影创的开发工程师,他称到今年3月份,工资就不发了,同时社保、公积金也停了。
所以从今年4月份开始,陆续有人离职。据上述员工介绍,公司最多的时候大约有480人,2022年3月已不到300人,目前仍在职的应该不到50人。
大部分员工都已经离职,但离职并不能结算工资。该员工称自己本来在年前就拿到了两个offer,但因为老板进行了一系列“稳定军心”的动作,自己感觉公司还有希望就留了下来。
但是没想到后续事情的发展并未能如他所想。这名员工提到一个小细节,当时劝他留下来的HR比他还早离开了,“挺讽刺的”。后来HR也加入到了讨薪行列。
该员工还透露,自己离职时只是有一张离职证明。而后来离职员工还签了一份离职协议。协议的主要内容就是公司承诺将于8月、9月份陆续付清所欠薪资。

不过该员工指出,即使签了上述协议,但还是有很多人未能获得薪资。
“约200名员工,欠薪2—6个月,平均欠薪10w左右不等。很多年前离职的也没有结清工资”,他指出为了讨薪这些离职员工自发组织了一个群,用来讨论仲裁以及讨薪方式,群成员近200人。
据上述员工透露,200人讨薪队伍里,已有近100人申请了劳动仲裁。仲裁时间为8月份、9月中旬不等,最快的据说已经走到法院程序。

三言财经拨打了影创官网的400热线及工商预留电话,均无法接通。笔者也试图拨打了影创创始人孙立的电话,但是无人接听。
种种迹象表明,影创似乎正经历着巨大危机。
二、影创为什么走到今天这步?元宇宙不行了?
据公开报道,影创科技创始人孙立曾在游戏行业创业多年,2014年以1.5亿卖掉游戏公司,转到虚拟现实VR行业。
从影创的官网我们能大概看出它的业务范围。其中影创产品为VR眼镜硬件产品;软件服务下的点云平台还在开发中;解决方案具体指混合现实(MR)在具体领域的软件方案;开放平台则是影创的VR操作系统。
在今年4月份的一个关于孙立的专访中,对于影创的商业模式有这样的描述:一是MR智能眼镜硬件和软件的整体解决方案,应用在教育、工业、医疗等多个领域,这部分占整体业务的20%-30%。
二是以操作系统的服务和授权费用为主,这部分占营收的70%。
在专访中,孙立还介绍,影创科技近三年的营收基本上实现了年复合增长率达到260%。2022年预期收入能达到5亿元左右,目前公司盈利整体上还在处于亏损的状态,但亏损的金额在逐年递减,大约在2024年实现正向盈利。
在今年的多篇报道中都强调,影创要做元宇宙的“微软”。大意就是将影创VR操作系统授权给厂商使用,自己充当类似手机中安卓,或者PC中Windows的角色。
单纯只看上述报道,影创可谓前路光明,想象无限。但在员工眼里,却是另一番光景。
上述爆料员工表示,公司一开始主要做AR眼镜,号称国内版的HoloLens。但是缺乏应用场景,也没有完整的配套系统,C端用户不买账,C端市场销量几乎为零。
三言财经在京东搜索“影创”,排名靠前的几款影创智能眼镜基本都没有任何评价。

而长期的研发投入都是AR,但是产出跟投资不成正比,不断推出的新品AR眼镜打不开市场,公司决定转型。
该员工还透露,在2020年之后,趁着元宇宙的热潮,公司往VR方向转型。因为没有产品积淀,所以先做了B端,为其他公司定制软硬件的开发。
具体来说就是为第三方公司定制全套VR设备的开发,包括系统和VR设备。
该员工表示合作的公司大概3个,而且有一个项目原计划金额在上千万,但是项目开发到一半却被放弃了,干脆把源代码都交给了客户,交付前连测试都没有,所以最终公司只收到了400万。
在这名员工看来,公司迟迟融不到资,市场上没有走出困境,入不敷出,暴雷是迟早的事情,只是走的很不体面。
提到难有融资,这位员工称可能与一位投资人有关。他表示这位投资人因为某些原因和公司打官司,闹得很不愉快,受此影响,融资变得更加困难。
三言财经查询发现,2021年影创确实与公司的一名股东有多起诉讼和仲裁案件,涉及财产保全、股东知情权纠纷、公司决议纠纷、民间借贷纠纷。
其中股东知情权纠纷的法律文书中提到,该股东曾从影创财务负责人处得知,影创经营业绩存在严重虚报的情况。

在民间借贷纠纷中,曾提到该股东是此前是影创的第二大股东,同时担任公司的董事、总裁。2018年下半年,公司出现资金困难,该股东将数十万资金借给公司发放员工工资。
三、一边是元宇宙裁员潮,一边是高薪招人,其实并不矛盾
事实上,自从Facebook改名Meta押注元宇宙后,元宇宙瞬间成了风口,这也难怪如此多的公司都爱蹭点元宇宙的热点。
而像影创这样公司,转型元宇宙更是顺理成章。在元宇宙的世界里,VR正是其中一个大的切入点。
据央视财经报道,自去年开始,VR虚拟现实行业进入了发展快车道。2021年,VR头戴式显示器的全球出货量达1095万台,突破年出货一千万台的行业拐点,今年一季度,VR头显保持热销,全球出货量同比增长了241.6%。
而在国内,VR行业的热度也正在逐渐提升。数据显示,2022年上半年,中国VR市场零售额突破8亿元,同比增长81%,
风口之下,这两年元宇宙人才吃香,受到追捧,人才流动也加快。在招聘平台,元宇宙研发总监的月薪甚至达到10万。
但今年元宇宙的老大哥Meta则开始缩减招聘、计划裁员。
今年5月,Meta曾宣布暂停某些部门的招聘。7月初,又有报道称Meta取消了硅谷总部的后勤服务外包合同,导致数百名工人下岗。
扎克伯格也表示,Meta下调了2022年工程师目标数量,从原先的10000名缩减到6000-7000,砍掉了超3000人的招聘计划。
此外还有报道称,Meta预计今年将最多裁员10%。
一边是裁员,一边是高薪招人,看似矛盾,其实不然。风口效应仍Meta这类的企业想要快速占领行业高地,但大环境不再允许这样的冒进方式。
像影创这样追逐风口的中小公司更是数不胜数,他们没有大公司的雄厚实力,有时候断臂求生看起来也像是生死大劫。
风口之下,大家都想冲一波,但是死掉的是绝大多数。大量曾因元宇宙股价暴涨的概念股迎来暴跌;NFT热潮退去,不少巨头退出;元宇宙炒房泡沫破裂……
在消费市场,线下VR店运营情况不容乐观,不少网友反映冲了会员,店却突然倒闭了。
目前,元宇宙还是在初级阶段,没有现象级的爆发应用,也不够普及,还是小众消费。
不过在风口中,人才却可能是最大的受益者。
上文中的那位爆料员工在离职前就找好了下家,他表示自己收到了圈内多家offer,最终选择一家相对稳定的。
对于元宇宙,他这样看:
元宇宙,最重要的是应用场景和需求。一个技术脱离了实际场景,不管噱头多高级,都是空中楼阁。
正面例子有很多,VR类游戏,这抓住了高端游戏玩家的需求。比如半条命alyx VR这款游戏的诞生,吸引了很多玩家,带动了VR头戴设备的销量。绝大多数购买VR头盔的都是因为这个游戏。
还有VR观影,这也是一部分需求。
类似的,爱奇艺的奇遇VR,做的挺好。PICO主打串联,可以畅玩SteamVR,这也是很好的方向。
但是不管怎么说,这些都是高端玩家的需求市场。对于普通用户来说,不管元宇宙怎么发展都跟他们没关系,除非元宇宙切实的解决了他的一些需求。毕竟在虚拟世界里拥有一个房,远比不上现实环境的一片瓦。
最后他透露终于发现了影创创始人、董事长孙立的踪迹。
原来孙立将于8月26日参加AWE Asia 世界XR产业博览会。
影创是参展商,且排在第一位。孙立也是此次博览会的重要嘉宾,博览会首日的活动中,孙立也是也第一演讲的厂商,排在他前面的是三位活动主办方的高管。

在讨薪群里,离职员工商量着直播弹幕讨薪。
有员工说道,“以前看农民工讨薪觉得很遥远,怎想自己也有那么一天”。
作者:丰收;来源公众号:三言财经(ID:sycaijing)
收起阅读 »前端怎么样限制用户截图?
做后台系统,或者版权比较重视的项目时,产品经常会提出这样的需求:能不能禁止用户截图?有经验的开发不会直接拒绝产品,而是进行引导。
先了解初始需求是什么?是内容数据过于敏感,严禁泄漏。还是内容泄漏后,需要溯源追责。不同的需求需要的方案也不同。来看看就限制用户截图,有哪些脑洞?
有哪些脑洞
v站和某乎上的大佬给出了不少脑洞,我又加了点思路。
1.基础方案,阻止右键保存和拖拽。
这个方案是最基础,当前可只能阻拦一些小白用户。如果是浏览器,分分钟调出控制台,直接找到图片url。还可以直接ctrl+p,进入打印模式,直接保存下来再裁减。
2.失焦后加遮罩层
这个方案有点意思,看敏感信息时,必须鼠标点在某个按钮上,照片才完整显示。如果失去焦点图片显示不完整或者直接遮罩盖住。
3.高速动态马赛克
这个方案是可行的,并且在一些网站已经得到了应用,在视频或者图片上随机插像素点,动态跑来跑去,对客户来说,每一时刻屏幕上显示的都是完整的图像,靠用户的视觉残留看图或者视频。即时手机拍照也拍不完全。实际应用需要优化的点还是挺多的。比如用手机录像就可以看到完整内容,只是增加了截图成本。
下面是一个知乎上的方案效果。(原地址):
正经需求vs方案
其实限制用户截图这个方案本身就不合理,除非整个设备都是定制的,在软件上阉割截图功能。为了这个需求添加更复杂的功能对于一些安全性没那么高的需求来说,有点本末倒置了。
下面聊聊正经方案:
1.对于后台系统敏感数据或者图片,主要是担心泄漏出去,可以采用斜45度七彩水印,想要完全去掉几乎不可能,就是观感比较差。
2.对于图片版权,可以使用现在主流的盲水印,之前看过腾讯云提供的服务,当然成本比较高,如果版权需求较大,使用起来效果比较好。
3.视频方案,tiktok下载下来的时候会有一个水印跑来跑去,当然这个是经过处理过的视频,非原画,画质损耗也比较高。Netflix等视频网站采用的是服务端权限控制,走的视频流,每次播放下载加密视频,同时获得短期许可,得到许可后在本地解密并播放,一旦停止播放后许可失效。
总之,除了类似于Android提供的截图API等底层功能,其他的功能实现都不完美。即使是底层控制了,一样可以拍照录像,没有完美的方案。不过还是可以做的相对安全。
作者:正经程序员
来源:juejin.cn/post/7127829348689674253
大厂B端登录页,让我打开新思路了
登录页这个东西,因为感觉很简单,所以经常不被重视。
但是登录页作为一个产品的门面,直接影响用户第一印象,又是非常重要的存在。
最近研究了一下我电脑上那一堆桌面端的登录页,还真发现了一些之前没想清楚的门道来。
\0. 不登录
很多产品会提供部分功能给未登录账号使用。
比较谨慎的,Zoom 会给一个直接加入会议的按钮:
极端一些的,会像 WPS 这样打开后直接进入,不需要登录页:
给未登录用户太多功能会影响注册用户占比,强制登录又会把使用门槛拉得太高,这个主要看产品定位吧。
接下来,咱们主要针对必须登录的情况来讲吧。
\1. 填写项
这有什么好说的,登录填写项不就是用户名/邮箱/手机号+密码吗?
没错,最典型的却是如此。例如百度网盘和钉钉:
但是我发现,有的产品会故意分两步让你填,这样就可以把注册和登录合并到一个步骤了(输入后看看注册过没,没有就走注册流程,有就走登录流程)。例如飞书和 Google:
还有的,甚至不把填写项放出来,非要你点击入口才行。例如微云和 CCtalk:
我个人是比较喜欢一打开就是填写项,一次填完的,不知道大家怎么看?
\2. 二维码
我发现把二维码放到右上角的方式蛮常见的。
例如钉钉就做得很好看:
飞书用高亮色做有点生硬,但也还行:
微云这个感觉中间突然被切了一角,有点奇怪:
\3. 登录方式
如果登录方式只有 2 种,tab 是最常用的切换方式。例如微云:
如果比较多,用图标在底部列出来是最常用的方式。例如腾讯会议和 Zoom:
但也有一些产品,可能比较纠结,两种方式混合一下。比如飞书:
但是记住一定要在图标下加文字说明,否则就会像 CCtalk 一样看不懂第一个图标是什么(悬停提示也没有):
\4. 注册与忘记密码
这两个按钮几乎所有登录页都需要,但又不是特别重要的信息。
一般两种布局最常见,一是将这两个按钮都放在输入框下面。例如微云和钉钉:
二是把忘记密码放在密码框里面,然后注册就放在右下角某个地方。例如 Zoom、腾讯会议:
也如果把输入邮箱/手机号和密码分成两步,就可以省略一个这两个入口,不过登录就得多一步操作了。例如飞书:
\5. 勾选项
登录页一般有两个勾选项,一个是自动登录、一个是同意协议条款的,大多默认不勾选。
一般都放到登录按钮的下面,虽然不符合操作顺序(先勾选了才能确定),但是排版好看些。例如飞书:
其实像微云这样把勾选项放到登录按钮上其实更加符合操作顺序,因为这是在登录之前要确认的内容:
Zoom 在底部写上登录即代表同意政策和条款,就省略一个勾选项了:
但谁都比不上百度网盘,它们干脆一个勾选项都没有,至今还不是好好的?
\6. 登录按钮
基本上登录页都少不了登录按钮,除非是像钉钉这样登录方式有限的:
有的产品会让登录按钮置灰,直至用户填写完成为止。例如飞书和 Zoom:
\7. 设置项
很多产品会在用户登录之前就提供设置项目,主要是网络设置和语言设计。
例如飞书就两个都给了(左下角),做得挺到位的:
Zoom 就没有提供,跟着我的系统语言用中文,这个思路页也能理解:
腾讯会议比较实诚,把整个设置面板的入口都放到登录页了,包括语言选项在内:
\8. Logo
大部分产品的登录页都会放上 logo,这个感觉是常识。例如腾讯会议、百度网盘:
但其实也有不少只写名字不放 logo 的。例如微云、飞书:
钉钉就比较奇特,既没有 logo 也没有名字,不去状态栏查看一下都不知道这是什么软件:
总结一下
登录页表面看上去简单,经常不受重视,但仔细这么对比下来,发现可变因素还真是挺多的。
不知道大家对于这个页面有什么困惑的地方,可以在评论区讨论一下。
作者:设计师ZoeYZ
来源:juejin.cn/post/7138631923068305422
收起阅读 »实现一个简易的 npm install
现在写代码我们一般不会全部自己实现,更多是基于第三方的包来进行开发,这体现在目录上就是 src 和 node_modules 目录。
src 和 node_modules(第三方包) 的比例不同项目不一样。
运行时查找第三方包的方式也不一样:
在 node 环境里面,运行时就支持 node_modules 的查找。所以只需要部署 src 部分,然后安装相关的依赖。

在浏览器环境里面不支持 node_modules,需要把它们打包成浏览器支持的形式。
跨端环境下,它是上面哪一种呢?
都不是,不同跨端引擎的实现会有不同,跨端引擎会实现 require,可以运行时查找模块(内置的和第三方的),但是不是 node 的查找方式,是自己的一套。

和 node 环境下的模块查找类似,但是目录结构不一样,所以需要自己实现 xxx install。
思路分析
npm 是有自己的 registry server 来支持 release 的包的下载,下载时是从 registry server 上下载。我们自己实现的话没必要实现这一套,直接用 git clone 从 gitlab 上下载源码即可。
依赖分析
要实现下载就要先确定哪些要下载,确定依赖的方式和打包工具不同:
打包工具通过 AST 分析文件内容确定依赖关系,进行打包
依赖安装工具通过用户声明的依赖文件 (package.json / bundle.json)来确定依赖关系,进行安装
这里我们把包的描述文件叫做 bundle.json,其中声明依赖的包
{
"name": "xxx",
"dependencies": {
"yyyy": "aaaa/bbbb#release/1111"
}
}通过分析项目根目录的 bundle.json 作为入口,下载每一个依赖,分析 bundle.json,然后继续下载每一个依赖项,递归这个过程。这就是依赖分析的过程。
这样依赖分析的过程中进行包的下载,依赖分析结束,包的下载也就结束了。这是一种可行的思路。
但是这种思路存在问题,比如:版本冲突怎么办?循环依赖怎么办?
解决版本冲突
版本冲突是多个包依赖了同一个包,但是依赖的版本不同,这时候就要选择一个版本来安装,我们可以简单的把规则定为使用高版本的那个。
解决循环依赖
包之间是可能有循环依赖的(这也是为什么叫做依赖图,而不是依赖树),这种问题的解决方式就是记录下处理过的包,如果同个版本的包被分析过,那么久不再进行分析,直接拿缓存。
这种思路是解决循环依赖问题的通用思路。
我们解决了版本冲突和循环依赖的问题,还有没有别的问题?
版本冲突时会下载版本最高的包,但是这时候之前的低版本的包已经下载过了,那么就多了没必要的下载,能不能把这部分冗余下载去掉。
依赖分析和下载分离
多下载了一些低版本的包的原因是我们在依赖分析的过程中进行了下载,那么能不能依赖分析的时候只下载 bundle.json 来做分析,分析完确定了依赖图之后再去批量下载依赖?
从 gitlab 上只下载 bundle.json 这一个文件需要通过 ssh 协议来下载,略微复杂,我们可以用一种更简单的思路来实现:
git clone --depth=1 --branch=bb xxx加上 --depth 以后 git clone 只会下载单个 commit,速度会很快,虽然比不上只下载 bundle.json,但是也是可用的(我试过下载全部 commit 要 20s 的时候,下载单个 commit 只要 1s)。
这样我们在依赖分析的时候只下载一个 commit 到临时目录,分析依赖、解决冲突,确定了依赖图之后,再去批量下载,这时候用 git clone 下载全部的 commit。最后要把临时目录删除。
这样,通过分离依赖分析和下载,我们去掉了没必要的一些低版本包的下载。下载速度会得到一些提升。
全局缓存
当本地有多个项目的时候,每个项目都是独立下载自己的依赖包的,这样对于一些公用的包会存在重复下载,解决方式是全局缓存。
分析完依赖进行下载每一个依赖包的时候,首先查找全局有没有这个包,如果有的话,直接复制过来,拉取下最新代码。如果没有的话,先下载到全局,然后复制到本地目录。
通过多了一层全局缓存,我们实现了跨项目的依赖包复用。
代码实现
为了思路更清晰,下面会写伪代码
依赖分析
依赖分析会递归处理 bundle.json,分析依赖并下载到临时目录,记录分析出的依赖。会解决版本冲突、循环依赖问题。
const allDeps = {};
function installDeps(projectDir) {
const bundleJsonPath = path.resolve(projectDir, 'bundle.json');
const bundleInfo = JSON.parse(fs.readFileSync(bundleJsonPath));
const bundleDeps = bundleInfo.dependencies;
for (let depName in bundleDeps) {
if(allDeps[depName]) {
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本一样) {
continue;// 跳过安装
}
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本不一样){
if (bundleDeps[depName] 版本 < allDeps[depName] 版本 ) {
continue;
} else {
// 记录下版本冲突
allDeps[depName].conflit = true;
}
}
}
childProcess.exec(`git clone --depth=1 ${临时目录/depName}`);
allDeps[depName] = {
name: depName
url: xxx
branch: xxx
version: xxx
}
installDeps(`${临时目录/depName}`);
}
}下载
下载会基于上面分析出的 allDeps 批量下载依赖,首先下载到全局缓存目录,然后复制到本地。
function batchInstall(allDeps) {
allDeps.forEach(dep => {
const 全局目录 = path.resolve(os.homedir(), '.xxx');
if (全局目录/dep.name 存在) {
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
} else {
// 下载到全局
childProcess.exec(`git clone --depth=1 ${全局目录/dep.name}`);
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
}
});
}这样,我们就完成了依赖的分析和下载,实现了全局缓存。
总结
我们首先梳理了不同环境(浏览器、node、跨端引擎)对于第三方包的处理方式不同,浏览器需要打包,node 是运行时查找,跨端引擎也是运行时查找,但是用自己实现的一套机制。
然后明确了打包工具确定依赖的方式是 AST 分析,而依赖下载工具则是基于包描述文件 bundl.json(package.json) 来分析。然后我们实现了递归的依赖分析,解决了版本冲突、循环依赖问题。
为了减少没必要的下载,我们做了依赖分析和下载的分离,依赖分析阶段只下载单个 commit,后续批量下载的时候才全部下载。下载方式没有实现 registry 的那套,而是直接从 gitlab 来 git clone。
为了避免多个项目的公共依赖的重复下载,我们实现了全局缓存,先下载到全局目录,然后再复制到本地。
作者:zxg_神说要有光
链接:https://juejin.cn/post/6963855043174858759
如果你一层一层一层地剥开洋葱模型,你会明白
关于洋葱模型你知道多少?经过短时间接触NodeJS,浅浅地了解了NodeJS的相关知识,很多不太理解,但是对于洋葱模型,个人觉得挺有意思的,不仅是出于对名字的熟悉。刚接触NodeJS不久,今天就浅浅谈谈koa里的洋葱模型吧。
koa是一个精简的Node框架,被认为是第二代Node框架,其最大的特点就是`独特的中间件`流程控制,是一个典型的`洋葱模型`,
它的核心工作包括下面两个方面:
(1) 将Node原生的request和response封装成为一个context对象。
(2) 基于async/await的中间件洋葱模型机制。中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。
中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。(晦涩难懂了)
重点:
//这是一个中间件(app.use(fun)里的fun),有两个参数,ctx和next
app.use(async (ctx,next)=>{
console.log('<<one');
await next();
console.log('one>>');
})
中间件和路由处理器的参数中都有回调函数,这个函数有2,3,4个参数
如果有两个参数就是req和res;
如果有三个参数就是request,response和next
如果有四个参数就是error,request,response,next1、koa写接口
为了更好地引入洋葱模型,我们先从使用koa为切入口。且看下面代码:
// 写接口
const Koa = require('koa')//说明安装koa
const app = new Koa()
const main = (ctx) => {
// console.log(ctx.request);
if(ctx.request.url=='/home'){//localhost:3000/home访问
ctx.response.body={data:1}
}else if(ctx.request.url=='/user'){//localhost:3000/user访问
ctx.response.body={name:'fieemiracle'}
}else{//localhost:3000访问
ctx.response.body='texts'
}
}
app.use(main)
app.listen(3000)以上代码,当我们在后端(终端)启动这个项目,可以通过localhost:3000 || localhost:3000/home || localhost:3000/user访问,页面展示的内容不一样,分别对应分支里的内容。
模拟创建接口,虽然通过if分支让代码跟直观易懂,但是不够优雅,当需要创建多个不同接口时,代码冗长且不优雅,需要改进,我们这采用路由(router):
// 优化5.js
const Koa = require('koa')
const app = new Koa()
const fs=require('fs') ;
// 路由
const router=require('koa-route')//安装koa-router
// 中间件:所有被app.use()掉的函数
const main = (ctx) => {
ctx.response.body = 'hello'
}
// 中间件:所有被app.use()掉的函数
const about=(ctx)=>{
ctx.response.type='html';
ctx.response.body='<a href="https://koa.bootcss.com/">About</a>'
// ctx.response.body='<a href="/">About</a>'
}
// 中间件:所有被app.use()掉的函数
const other=(ctx)=>{
ctx.response.type='json';
ctx.response.body=fs.createReadStream('./6.json')
}
app.use(router.get('/',main));
app.use(router.get('/about',about));
app.use(router.get('/other',other));
// 路由内部有中间件,不需要第二个参数next
app.listen(3000);const Koa = require('koa');
const app=new Koa();
// 洋葱模型(koa中间件的执行顺序)
const one=(ctx,next)=>{
console.log('<<one');
next();//执行two()
console.log('one>>');
}
const two=(ctx,next)=>{
console.log('<<two');
next();//执行three()
console.log('two>>');
}
const three=(ctx,next)=>{
console.log('<<three');
next();//没有下一个函数,执行下一个打印
console.log('three>>');
}
app.use(one)
app.use(two)
app.use(three)
app.listen(3000,function(){
console.log('start');
})上面代码的执行顺序是什么?
<<one
<<two
<<three
three>>
two>>
one>>这就是koa的洋葱模型的执行过程:先走近最外层(one),打印'<<one'-->next(),走进第二层(two),打印'<<two'-->next(),走进第三层,打印'<<three'-->next(),没有下一个中间件,打印'three>>'-->第三层执行完毕,走出第三层,打印'two>>'-->第二层执行完毕,走出第二层,打印'one>>'。如图:
这个轮廓是不是就很像洋葱的亚子。简而言之,洋葱模型的执行过程就是:从外面一层一层的进去,再一层一层的从里面出来。
洋葱模型与路由的区别在于:路由内部有内置中间件,不需要第二个参数next。
洋葱模型执行原理
上面提到过,中间件:所有被app.use()掉的函数。也就是说,没有被app.use()掉,就不算是中间件。
//新建一个数组,存放中间件
cosnt middleware=[];当我们使用中间件的时候,首先是使用use方法,use方法会将传入的中间件回调函数存储到middleware中间件数组中。所以我们可以通过app.use()添加中间件,例如:
app.use(function){
middleware.push(function);
}监听,当执行app.listen去监听端口的时候,其实其内部调用了http模块的createServer方法,然后传入内置的callback方法,这个callback方法就会将use方法存储的middleware中间件数组传给compose函数(后期补充该内容)。
那么我们将上面的洋葱模型,利用其原理改造一下吧:
const Koa = require('koa');
const app=new Koa();
// 添加三个中间件
app.use(async (ctx,next)=>{
console.log('<<one');
await next();
console.log('one>>');
})
app.use(async (ctx,next)=>{
console.log('<<two');
await next();
console.log('two>>');
})
app.use(async (ctx,next)=>{
console.log('<<three');
await next();
console.log('three>>');
})
app.listen(3000,function(){
console.log('start');
})
//<<one
//<<two
//<<three
//three>>
//two>>
//one>>看!打印结果一样。async和洋葱模型的结合可谓是yyds了,其实,不用async也是一样的。这下明白什么是洋葱模型了吧。
compose方法是洋葱模型的核心,compose方法中有一个dispatch方法,第一次调用的时候,执行的是第一个中间件函数,中间件函数执行的时候就是再次调用dispatch函数,也就说形成了一个递归,这就是next函数执行的时候会执行下一个中间件的原因。
function compose (middleware) {
return function (context, next) {
let index = -1
// 一开始的时候传入为 0,后续递增
return dispatch(0)
//compose方法中的dispatch方法
function dispatch (i) {
// 假如没有递增,则说明执行了多次
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i;
// 拿到当前的中间件
let fn = middleware[i];
if (i === middleware.length) fn = next
// 当 fn 为空的时候,就会开始执行 next() 后面部分的代码
if (!fn) return Promise.resolve()
try {
// 执行 next() 的时候就是调用 dispatch 函数的时候
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}洋葱模型存在意义
当在一个app里面有很多个中间件,有些中间件需要依赖其他中间件的结果时,洋葱模型可以保证执行的顺序,如果没有洋葱模型,执行顺序可能出乎我们的预期。
结尾
看到第一个koa写接口的例子,我们知道上下文context(简写ctx)有两个属性,一个是request,另一个是response,洋葱模型就是以函数第二个参数next()为切割点,由外到内执行request逻辑,再由内到外执行response逻辑,这样中间件的交流就更加简单。专业一点说就是:
Koa的洋葱模型是以next()函数为分割点,先由外到内执行Request的逻辑,然后再由内到外执行Response的逻辑,这里的request的
逻辑,我们可以理解为是next之前的内容,response的逻辑是next函数之后的内容,也可以说每一个中间件都有两次处理时机。洋葱
模型的核心原理主要是借助compose方法。链接:https://juejin.cn/post/7124601052153774093
来源:稀土掘金
没有二十年功力,写不出Thread.sleep(0)这一行“看似无用”的代码!
你好呀,我是喜提七天居家隔离的歪歪。
这篇文章要从一个奇怪的注释说起,就是下面这张图:
我们可以不用管具体的代码逻辑,只是单单看这个 for 循环。
在循环里面,专门有个变量 j,来记录当前循环次数。
第一次循环以及往后每 1000 次循环之后,进入一个 if 逻辑。
在这个 if 逻辑之上,标注了一个注释:prevent gc.
prevent,这个单词如果不认识的同学记一下,考试肯定要考的:
这个注释翻译一下就是:防止 GC 线程进行垃圾回收。
具体的实现逻辑是这样的:
核心逻辑其实就是这样一行代码:
Thread.sleep(0);
这样就能实现 prevent gc 了?
懵逼吗?
懵逼就对了,懵逼就说明值得把玩把玩。
这个代码片段,其实是出自 RocketMQ 的源码:
org.apache.rocketmq.store.logfile.DefaultMappedFile#warmMappedFile
事先需要说明的是,我并没有找到写这个代码的人问他的意图是什么,所以我只有基于自己的理解去推测他的意图。如果推测的不对,还请多多指教。
虽然这是 RocketMQ 的源码,但是基于我的理解,这个小技巧和 RocketMQ 框架没有任何关系,完全可以脱离于框架存在。
我给出的修改意见是这样的:
把 int 修改为 long,然后就可以直接把 for 循环里面的 if 逻辑删除掉了。
这样一看是不是更加懵逼了?
不要慌,接下来,我给你抽丝剥个茧。
另外,在“剥茧”之前,我先说一下结论:
提出这个修改方案的理论立足点是 Java 的安全点相关的知识,也就是 safepoint。
官方最后没有采纳这个修改方案。
官方采没采纳不重要,重要的是我高低得给你“剥个茧”。
探索
当我知道这个代码片段是属于 RocketMQ 的时候,我想到的第一个点就是从代码提交记录中寻找答案。
看提交者是否在提交代码的时候说明了自己的意图。
于是我把代码拉了下来,一看提交记录是这样的:
我就知道这里不会有答案了。
因为这个类第一次提交的时候就已经包含了这个逻辑,而且对应这次提交的代码也非常多,并没有特别说明对应的功能。
从提交记录上没有获得什么有用的信息。
于是我把目光转向了 github 的 issue,拿着关键词 prevent gc 搜索了一番。
除了第一个链接之外,没有找到什么有用的信息:
而第一个链接对应的 issues 是这个:
这个 issues 其实就是我们在讨论这个问题的过程中提出来的,也就是前面出现的修改方案:
也就是说,我想通过源码或者 github 找到这个问题权威的回答,是找不到了。
于是我又去了这个神奇的网站,在里面找到了这个 2018 年提出的问题:
问题和我们的问题一模一样,但是这个问题下面就这一个回答:
这个回答并不好,因为我觉得没答到点上,但是没关系,我刚好可以把这个回答作为抓手,把差的这一点拉通对齐一下,给它赋能。
先看这个回答的第一句话:It does not(它没有)。
问题就来了:“它”是谁?“没有”什么?
“它”,指的就是我们前面出现的代码。
“没有”,是说没有防止 GC 线程进行垃圾回收。
这个的回答说:通过调用 Thread.sleep(0) 的目的是为了让 GC 线程有机会被操作系统选中,从而进行垃圾清理的工作。它的副作用是,可能会更频繁地运行 GC,毕竟你每 1000 次迭代就有一次运行 GC 的机会,但是好处是可以防止长时间的垃圾收集。
换句话说,这个代码是想要“触发”GC,而不是“避免”GC,或者说是“避免”时间很长的 GC。从这个角度来说,程序里面的注释其实是在撒谎或者没写完整。
不是 prevent gc,而是对 gc 采取了“打散运行,削峰填谷”的思想,从而 prevent long time gc。
但是你想想,我们自己编程的时候,正常情况下从来也没冒出过“这个地方应该触发一下 GC”这样想法吧?
因为我们知道,Java 程序员来说,虚拟机有自己的 GC 机制,我们不需要像写 C 或者 C++ 那样得自己管理内存,只要关注于业务代码即可,并没有特别注意 GC 机制。
那么本文中最关键的一个问题就来了:为什么这里要在代码里面特别注意 GC,想要尝试“触发”GC 呢?
先说答案:safepoint,安全点。
关于安全点的描述,我们可以看看《深入理解JVM虚拟机(第三版)》的 3.4.2 小节:
注意书里面的描述:
有了安全点的设定,也就决定了用户程序执行时并非在代码指令流的任意位置都能够停顿下来开始垃圾收集,而是强制要求必须执行到达安全点后才能够暂停。
换言之:没有到安全点,是不能 STW,从而进行 GC 的。
如果在你的认知里面 GC 线程是随时都可以运行的。那么就需要刷新一下认知了。
接着,让我们把目光放到书的 5.2.8 小节:由安全点导致长时间停顿。
里面有这样一段话:
我把划线的部分单独拿出来,你仔细读一遍:
是HotSpot虚拟机为了避免安全点过多带来过重的负担,对循环还有一项优化措施,认为循环次数较少的话,执行时间应该也不会太长,所以使用int类型或范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。这种循环被称为可数循环(Counted Loop),相对应地,使用long或者范围更大的数据类型作为索引值的循环就被称为不可数循环(Uncounted Loop),将会被放置安全点。
意思就是在可数循环(Counted Loop)的情况下,HotSpot 虚拟机搞了一个优化,就是等循环结束之后,线程才会进入安全点。
反过来说就是:循环如果没有结束,线程不会进入安全点,GC 线程就得等着当前的线程循环结束,进入安全点,才能开始工作。
什么是可数循环(Counted Loop)?
书里面的这个案例来自于这个链接:
juejin.cn/post/684490… HBase实战:记一次Safepoint导致长时间STW的踩坑之旅
如果你有时间,我建议你把这个案例完整的看一下,我只截取问题解决的部分:
截图中的 while(i < end) 就是一个可数循环,由于执行这个循环的线程需要在循环结束后才进入 Safepoint,所以先进入 Safepoint 的线程需要等待它。从而影响到 GC 线程的运行。
所以,修改方案就是把 int 修改为 long。
原理就是让其变为不可数循环(Uncounted Loop),从而不用等循环结束,在循环期间就能进入 Safepoint。
接着我们再把目光拉回到这里:
这个循环也是一个可数循环。
Thread.sleep(0) 这个代码看起来莫名其妙,但是我是不是可以大胆的猜测一下:故意写这个代码的人,是不是为了在这里放置一个 Safepoint 呢,以达到避免 GC 线程长时间等待,从而加长 stop the world 的时间的目的?
所以,我接下来只需要找到 sleep 会进入 Safepoint 的证据,就能证明我的猜想。
你猜怎么着?
本来是想去看一下源码,结果啪的一下,在源码的注释里面,直接找到了:
注释里面说,在程序进入 Safepoint 的时候, Java 线程可能正处于框起来的五种不同的状态,针对不同的状态有不同的处理方案。
本来我想一个个的翻译的,但是信息量太大,我消化起来有点费劲儿,所以就不乱说了。
主要聚焦于和本文相关的第二点:Running in native code。
When returning from the native code, a Java thread must check the safepoint _state to see if we must block.
第一句话,就是答案,意思就是一个线程在运行 native 方法后,返回到 Java 线程后,必须进行一次 safepoint 的检测。
同时我在知乎看到了 R 大的这个回答,里面有这样一句,也印证了这个点:
那么接下来,就是见证奇迹的时刻了:
根据 R 大的说法:正在执行 native 函数的线程看作“已经进入了safepoint”,或者把这种情况叫做“在safe-region里”。
sleep 方法就是一个 native 方法,你说巧不巧?
所以,到这里我们可以确定的是:调用 sleep 方法的线程会进入 Safepoint。
另外,我还找到了一个 2013 年的 R 大关于类似问题讨论的帖子:
这里就直接点名道姓的指出了:Thread.sleep(0).
这让我想起以前有个面试题问:Thread.sleep(0) 有什么用。
当时我就想:这题真难(S)啊(B)。现在发现原来是我道行不够,小丑竟是我自己。
还真的是有用。
实践
前面其实说的都是理论。
这一部分我们来拿代码实践跑上一把,就拿我之前分享过的《真是绝了!这段被JVM动了手脚的代码!》文章里面的案例。
public class MainTest {
public static AtomicInteger num = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Runnable runnable=()->{
for (int i = 0; i < 1000000000; i++) {
num.getAndAdd(1);
}
System.out.println(Thread.currentThread().getName()+"执行结束!");
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();
t2.start();
Thread.sleep(1000);
System.out.println("num = " + num);
}
}这个代码,你直接粘到你的 idea 里面去就能跑。
按照代码来看,主线程休眠 1000ms 后就会输出结果,但是实际情况却是主线程一直在等待 t1,t2 执行结束才继续执行。
这个循环就属于前面说的可数循环(Counted Loop)。
这个程序发生了什么事情呢?
1.启动了两个长的、不间断的循环(内部没有安全点检查)。
2.主线程进入睡眠状态 1 秒钟。
3.在1000 ms之后,JVM尝试在Safepoint停止,以便Java线程进行定期清理,但是直到可数循环完成后才能执行此操作。
4.主线程的 Thread.sleep 方法从 native 返回,发现安全点操作正在进行中,于是把自己挂起,直到操作结束。
所以,当我们把 int 修改为 long 后,程序就表现正常了:
受到 RocketMQ 源码的启示,我们还可以直接把它的代码拿过来:
这样,即使 for 循环的对象是 int 类型,也可以按照预期执行。因为我们相当于在循环体中插入了 Safepoint。
另外,我通过不严谨的方式测试了一下两个方案的耗时:
在我的机器上运行了几次,时间上都差距不大。
但是要论逼格的话,还得是右边的 prevent gc 的写法。没有二十年功力,写不出这一行“看似无用”的代码!
额外提一句
再说一个也是由前面的 RocketMQ 的源码引起的一个思考:
这个方法是在干啥?
预热文件,按照 4K 的大小往 byteBuffer 放 0,对文件进行预热。
byteBuffer.put(i, (byte) 0);
为什么我会对这个 4k 的预热比较敏感呢?
去年的天池大赛有这样的一个赛道:
其中有两个参赛选大佬都提到了“文件预热”的思路。
我把链接放在下面了,有兴趣的可以去细读一下:
最后,谢谢你“点赞”、“评论”我的文章,给我满满的正反馈。谢谢!
来源:juejin.cn/post/7139741080597037063
收起阅读 »敢在我工位装摄像头?吃我一套JS ➕ CSS组合拳!!👊🏻
前言
大家好,我是HoMeTown
不知道大家最近有没有看到过封面上的这张图,某公司在个人工位安装监控,首先我个人认为,第一每个行业有每个行业的规定,如果公司和员工提前做好沟通,并签过合同协议的话,问题不大,比如银行职员这种岗位。第二是私人企业和员工如果签订了补偿协议?协议里明确说明工资翻3倍?4倍?5倍?或者其他的对员工有利的条件?(如果一个探头能翻3倍工资,那我觉得我可以装满)
但是如果是公司在没有和员工沟通的前提下,未经员工同意强制在工位上安装这个破玩意,那我觉得这公司有点太不人道了,违不违法这个咱确实不懂,也不做评论。
类似这样的操作,我本着好奇的心态,又搜了搜,发现这种情况好像不在少数,比如这样:
再或者这样:
作为一个程序员,这点探头能难得到我?我能因为你这点儿探头止步不前了?
话不多说,是时候给你秀秀肌肉💪🏻了,开干!
组合拳拳谱
封装函数lick作为主函数直接 export,让广大的友友们开箱即用!
lick函数内置: init初始化方法、move移动方法、setupEvent事件注册方法以及setupStyle等关键函数,实现事件上的可控制移动。
lick!重卷出击!
export function lick(lickdogWords) {
setupStyle();
// 偏移值
let left = 0;
//声明定时器
let timer = null;
// 文字
let lickWord = "";
const out = document.querySelector("#lickdog-out_wrap");
out.innerHTML = `
<div id="lickdog-inner_wrap">
<div id="text-before">${lickWord}</div>
<div id="text-after">${lickWord}</div>
</div>
`;
const inner = document.querySelector("#lickdog-inner_wrap");
const textBefore = document.querySelector("#text-before");
init();
setupEvent();
// 初始化
function init() {
// 开启定时器之前最好先清除一下定时器
clearInterval(timer);
//开始定时器
timer = setInterval(move, speed);
}
function setupStyle() {
const styleTag = document.createElement("style");
styleTag.type = "text/css";
styleTag.innerHTML = `
#lickdog-out_wrap{
width: 100%;
height: 100px;
position: fixed;
overflow: hidden;
text-overflow: ellipsis;
/* 颜色一定要鲜艳 */
background-color: #ff0000;
border-radius: 8px;
/* 阴影也一定要够醒目 */
box-shadow: rgba(255, 0, 0, 0.4) 5px 5px, rgba(255, 0, 0, 0.3) 10px 10px, rgba(255, 0, 0, 0.2) 15px 15px, rgba(255, 0, 0, 0.1) 20px 20px, rgba(255, 0, 0, 0.05) 25px 25px;
}
#lickdog-inner_wrap {
// padding: 0 12px;
width: 100%;
height: 100%;
display: flex;
align-items: center;
position: absolute;
left: 0;
top: 0;
}
.text{
white-space:nowrap;
box-sizing: border-box;
color: #fff;
font-size: 48px;
font-weight:bold;
/* 文字一定要立体 */
text-shadow:0px 0px 0 rgb(230,230,230),1px 1px 0 rgb(215,215,215),2px 2px 0 rgb(199,199,199),3px 3px 0 rgb(184,184,184),4px 4px 0 rgb(169,169,169), 5px 5px 0 rgb(154,154,154),6px 6px 5px rgba(0,0,0,1),6px 6px 1px rgba(0,0,0,0.5),0px 0px 5px rgba(0,0,0,.2);
}
`;
document.head.appendChild(styleTag)
}
//封装移动函数
function move() {
if (left >= textBefore.offsetWidth) {
left = 0;
} else {
left++;
}
inner.style.left = `${-left}px`;
}
function setupStyle() { ... }
}通过简单的代码,我们基本实现了我们的这一套组合拳,可能说到这,有的朋友还不知道这段代码到底有什么作用,意义在哪,有什么实际的用途...
接下来建一个html进行才艺展示!:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
html, body {
margin: 0;
padding: 0;
}
</style>
</head>
<body>
<div id="lickdog-out_wrap"><div>
<script>
(async function() {
const lickdog = await import('./lickdog.js')
lickdog.lick(
// 重点!
[
"问题到我为止,改变从我开始",
"人在一起叫聚会,心在一起叫团队",
"工作创造价值,奉献带来快乐,态度决定一切",
"怠惰是贫穷的制造厂",
"一个优秀的员工必须培养自己对工作的兴趣,使工作成为愉快的旅程",
"一朵鲜花打扮不出美丽的春天,一个人先进总是单枪匹马,众人先进才能移山填海",
"抓住今日,尽可能少的依赖明天",
"行动是成功的开始,等待是失败的源头",
"强化竞争意识,营造团队精神",
"迅速响应,马上行动",
"去超越那个比你牛逼,更比你努力的人",
"不为失败找理由,只为成功找方法",
"含泪播种的人一定能含笑收获",
"不经历风雨,怎么见彩虹",
"路,要一步一步足踏实地地往前走,才能获得成功",
]
)
})()
</script>
</body>
</html>Duang!
Duang!
Duang!
效果来辽!
嗯,按照上面的代码,你可以通过最简单、最快的方式,立即在你的网页中获得一个置顶的!可以无限轮播公司标语的跑马灯!
而且色彩足够鲜艳,监控器一眼就能看到!!!
咱一整个就是说,这玩意儿往上面一放,老板看到不得夸你两句?给你提提薪资?给你放俩天假?
不够满意?
如果你觉的上面的功能还不够完美,我们可以添加一个空格事件,当你发现你觉得不错的标语(你想让老板给你涨薪的标语)时,仅仅只需要动动你的大拇指敲下空格键,呐,如你所愿,暂停⏸了!该标语会一直停留在展示区域,让老板仔细观看!(你品,你细品!)
function setupEvent() {
// 如果遇到自己喜欢的句子,不妨空格⏸,让老板多看看
document.onkeydown = function (e) {
var keyNum = window.event ? e.keyCode : e.which; //获取被按下的键值
if (keyNum == 32) {
if (timer) {
clearInterval(timer);
timer = null;
} else {
timer = setInterval(move, speed);
}
}
};
}效果如下:
还不够满意?
如果你觉得太慢,你甚至可以完全自定义设置滚动速度,让标语滚动更快或者更慢,像这样:
...
const speed = config?.speed ?? 10;
...
//开始定时器
timer = setInterval(move, speed);觉得自己的句子不够斗志昂扬?不够有激情?没问题,开启beautify,自动为你添加!。
lickdog.lick({
[ ... ],
{
speed: 1,
enableBeautify: true,
}
})不想用!?没问题!使用beautifyText!去自定义吧,自定义你想表达的情绪;自定义不被自定义的自定义:
lickdog.lick({
[ ... ],
{
speed: 1,
enableBeautify: true,
beautifyText: '!***、'
}
})完结
以玩笑的方式跟大家分享一个了知识点:文字的横向滚动轮播。
最后呢,关于这个话题,如果有朋友不幸遇到了,自己决定提不提桶就好。
愿好㊗️。
挣钱嘛,生意,不寒碜 --《让子弹飞》
来源:juejin.cn/post/7135994466006990856
收起阅读 »中秋~
中秋,是一个令我们耳熟能详的词,中秋博饼,相信大家也并不陌生。当然了,今年中秋我也有博饼。就让我来跟大家讲讲吧!
今年中秋,我随着爸爸妈妈来到好清香饭店,嘿嘿,这个饭店我可熟悉了,过年、生日、中秋……我都会和爸爸妈妈来这与他的好友及妻儿一起共聚。今年也不例外。大家吃完了一桌丰盛的美食后,面带微笑,准备开始接下来的博饼。我帮着妈妈把礼品都放到桌面上,开始博饼!我们从晨阳哥哥轮起,因为他创造了一个奇迹!从学校中的倒数几名,变成了一中全校唯有的一名可以到北京人民大学文科的学生。报纸上、电视上,都有报道呢!希望它能为我们大家开一个好头。
结果不太理想,噢,什么都没有。接下去大家一直都没有什么好起色。过了不久,再次轮到了我,我闭紧眼睛,双手抓起骰子用力放入碗中,骰子在碗中欢快地跳跃,眼看就要跳出碗了,我的目光顿时灰暗下来,移开视线,心想:前面博了一个二举,一个一秀,这次更惨,什么都没有,一会儿会不会还是这样?过了一会,四周顿时寂静无声,不知是谁大喊了一声:“对堂!”我不可置信地转过头来,“一、二、三、四、五、六!”真的是对堂,我高兴的欢呼起来。就这样,我为我们家博了一瓶酒。接下去就是我妈妈博了,大家呐喊着:“状元!状元!”只听几声骰子与碗碰撞出的清脆的响声,又一个对堂出现在大家眼前。大家“啧啧”地赞叹着。
眼见着桌上的东西越博越少,只剩下两个四进与状元了,大家目不转睛地盯着,仿佛下了天大的决心要博过来。一个四进被我博了,又一个四进被叶伯伯博了,开始博状元了!几轮无果的博饼后,叶伯伯说了句:“唉,今年的状元架子还真大呢!”大家都笑了起来。轮到我了,我满怀希望的投下去,额,四个一两个四,真是的,一和四都反了!,到我妈妈了,妈妈含笑着扔下去,三个四和五、一都已经停住了脚步,还有一个骰子欢快的舞蹈,只见那个骰子精疲力尽了,慢慢停住了脚步。“啊!状元带六”我大声欢呼着,是啊,按照规矩,可以再轮一圈抢状元,如果都没有,状元就归我们家了呢……哈哈,果然不出我所料,状元是我们家的了!妈妈不好意思的笑着说:“呵呵,都是我买来又都被我们家给博走了。”大家都笑着说没事。
随着骰子在碗里跳跃的声音越来越疏远,我知道,中秋拖着她的长裙慢慢走远了……
【中秋随手拍 | imgeek专属活动鼠标耳机免费送】我的中秋我做主,快来分享你的中秋趣事吧!
一年一度中秋时,合家齐聚把月赏。中秋节是中华民族的传统节日,每年农历八月十五,亲朋好友们都会合家团聚,围坐于桌前食月饼和赏月。而中秋节的月亮也是一年之中最圆的,似乎也寓意着合家美满、幸福团圆的意思。现诚邀广大环友一起来参与中秋随手拍线上活动,和家人团聚的时候也别忘了和大家分享一下你的中秋趣事和计划哦!!!!
本次活动福利多多,只要发布符合条件的话题,就可领取各种丰厚大奖,得奖概率超级大!
#中秋随手拍#参与方式
我的中秋我做主,回帖分享自己的中秋趣事或中秋计划、中秋福利等参与活动(主题不限,和中秋节有关即可)。
活动时间:9月6日—9月13日 17:59
活动奖励:
最充实中秋奖 1人 JBL无线蓝牙耳机 奖励精彩评论

幸运参与奖 1人 罗技 无线蓝牙鼠标 回帖中随机抽取一名

幸运陪跑奖 5名 游戏鼠标垫 奖励活动群内5波红包手气王

抽奖须知:
1、所有回复须为原创,不得转载网络图文。否则将不参与评选。
2、所有参与回帖用户请扫码进群,群内开奖时间: 9月13日 18点
3、最充实中秋奖评选标准:认真回复,内容丰富,感情真挚,表述清晰,阅读性高。。
4、群红包中奖但是没有参与话题活动,获奖无效,奖励将顺延给后面参加活动的群友
欢迎广大用户加入中秋随手拍活动群
前端四年,迷茫、无激情、躺平的人生,路在何方?
前途一片迷茫,路在何方? 今天我来分享一下我的职业囧途,借此告诫新人,少走弯路,多想出路。
我是2018年普通本科软件工程毕业,算上实习已经工作五年了。大学期间教的课程都是后台语言,C语言、C++、Java、ASP.NET等。但是教程安排的不太合理,本来大学期间很喜欢Java(大二第一学期),后面一整年时间都没Java相关的课程,教的是ASP、MFC和安卓等。以至于我到大四出来实习还没选好就业方向,胡乱海投简历,面试过Java、ASP.NET和前端岗位。最后选了某家居企业担任前端开发一职(月薪5-7k),虽然仅在此工作一年,但我还是很怀念那里,在那里学到挺多知识(基础差,学得多),认识很多小伙伴(现在还天天联系)。PS:刚出来工作打基础阶段找前端岗位多的平台,可以相互学习,共同进步。一定要多学多问,多做事。
2019年年初裸辞,回家结婚,瞬间感觉肩上的负担重了很多。那时候心想一定要努力学习,好好工作争取拿到高薪。3月中出广州找工作,那时候比较容易找吧!都是企业HR找上门,约面试。自己投的中大厂毫无音信,简历石沉大海。然后去面了两家自己找上门的公司,一家是港资(7-8k),一家就是目前工作这家(8k),也是家居行业的。港资那家其实我比较喜欢的(香港李某某儿子的公司),但是技术栈是Jquery+Node,我学的和做的大多数是Vue相关的,而且还要去香港出差。后面拒绝了(过了几天就后悔了,起码是中大厂背景呀!)。刚开始入职时候只有我一个前端,问组长会不会继续招前端,他说计划再招一个(忽悠的)。一个人硬着头皮干吧!开始遇到很多没做过的项目,VR 720°全景漫游,做了整个试用期才成功上线。头半年虽然是一个人在拼搏,没人教,没共同语言(他们都是后台),不懂就百度,慢慢摸索,工期不急,收获了挺多干货。PS:找工作有条件优先选择规模大背景好的企业。换好工作涨薪更容易。
2022年跑了一半了,我还是在原来的那家公司(3.5年),还是我一个前端,因为公司的项目更多的偏向于后端,前端工作我一个人就能处理完。工资相比入职那时涨了75%,我都不敢看掘金/抖音/小红书大佬们评论的工资了,感觉你们年薪最低都二三十万。我承认,严重拖后腿了。这三年多项目做得挺多挺杂的,有APP(HBuilder打包的)、微信小程序、公众号、网站、桌面应用(Electron套壳)、VR全景图(Three.js)、看板(Echart.js)、PDA/扫码枪相关的项目,还有最最最烦的ERP系统,因为它是开发了好几年的老旧系统,用Jquery开发,当时是后台做的,他们没有模块化的概念,公共组件、公共函数、公共样式啥都没有。MVC的开发模式,自我感觉,对自身职业发展毛用都没。我颓了,由于很多项目的前端都是我独自完成的,没有团队的意识,为了追求速度,没用Eslint代码规范,没用git建分支,没有代码冲突的体验。我目前的技术栈主要是Vue相关的(可以看我发的文章),React/Koa/TypeScript有学习但是工作上没用到,隔几个月就忘记了。平时逛掘金经常看到某某某一两年经验面试心得,那些面试题我看得一脸懵逼,很多题都是表面上知道,但是都不会作答的。我沉思了,心里想我现在都比不上刚出社会的实习生了吗?我跳槽出去还能找到工作吗?不如待在原公司做到退休吧(30+)??? 由于疫情影响,今年很多以前的同事都说公司裁员,大环境不好,有工作就不错了,铺天盖地的消极论。我上有老,下有小,老婆在家带娃,真的不敢跳出舒适圈。今年公司跟我签了第二次合同(5年),这家没年终奖,工作基本能胜任,绰绰有余那种,好处就是每年加一次薪(最少1k)。而我上家公司的前端同事,经过自身不断地努力都找到比较好的平台。一位去了某办公软件,听说年薪 有三四十W,真心羡慕呀! PS:如果你年轻,还没结婚,建议您尽快跳出舒适圈,找一个更好更大的平台深造。年轻是资本,错过了没有回头路,且行且珍惜
我现在好迷茫,没有了刚出社会那种冲劲,一直求稳,没太多的学习热情,很容易分心。每天闲余时间都会刷刷文章,但是没认真思考,没实操,没做笔记,过一段时间又忘了。这就是我毕业到现在的职业生涯。希望看到的新人能以此为鉴,避坑,少走弯路。
前段时间带老婆小孩去海陵岛玩了几天,心情愉悦了很多。最近老婆说她去上班赚钱减轻我的负担,其实我不太想她出去上班的,等小孩读幼儿园再去也不迟。这段时间思考了许久,下定决心,下半年要恶补一下技术,待大环境好点,找份高薪能学到更多技术的平台。希望掘金平台的大佬们能指引一下学习方向,我会努力向你们学习。
前路漫漫,道阻且长,行则将至,做则必成!愿未来无忧,心之所向,身之所往,终至所归!
作者:陌上花開等雨來
来源:juejin.cn/post/7115699180571459620
获取个验证码居然还可以这样玩
介绍
之前在抖音上看的某个脑洞大开的产品设想的几种别具特色的后端看了抓狂前端看了想打人的阴间交互效果,其中一个脑洞是让用户拉一下拉杆如同抽奖的形式获取到验证码,本期就咱们就还原出这个交互效果看看它到底有多疯狂。
演示
效果就是这样喵~
提前说明下,咱们仅仅实现交互效果不需要考虑后端交互验证和安全这些,所以数字是每次拉动前端随机生成的,也没有加混淆和干扰。
正文
绘制背景
通过上面的演示可以看到,背景svg云纹的效果,那它是怎么实现的呢?不卖关子了,我是用了一个专门生成svg背景的网站(heropatterns.com/) 来实现的,里面有各种各样的svg背景可以定制颜色,然后拷贝css代码出来就为你所用了。
拉杆绘制
<div class="submit-btn">
<div class="btn-ball"></div>
<div class="btn-rod"></div>
<div class="btn-stand"></div>
</div>拉杆主要分别由头,杆,底座三个部分组成,而我们触发事件后赋给容器应该 active 样式,然后由他去控制头和杆执行一段css动画来实现其拉动的效果。
.submit-btn{
&.active{
.btn-rod{
animation:rod-down .32s linear;
}
.btn-ball{
animation:ball-down .32s linear;
}
}
}
@keyframes rod-down{
0%{
transform: scaleY(1);
}
60%{
transform: scaleY(0);
}
80%{
transform:scaleY(-.2);
}
100%{
transform:scaleY(1);
}
}
@keyframes ball-down{
0%{
transform: translateY(0);
}
60%{
transform: translateY(40px);
}
80%{
transform: translateY(60px);
}
100%{
transform: translateY(0);
}
}至于,事件的绑定则非常容易,就说判断鼠标点击滑动抬起事件,看看两点间的变化量是否大于3px,如果大于则向容器赋予 active 样式触发css动画。
生成条带
让数字转动之前我们先要生成一下条带,当然我们可以直接使用图片,但是咱们没有设计,所以前端自己动手丰衣足食吧。就用 canvas 拼接出一个图片数字条带出来。
function createBackgroundImage(w, h) {
let canvas = document.createElement("canvas");
let ctx = canvas.getContext("2d");
canvas.width = ctx.width = w;
canvas.height = ctx.height = h * 10;
let BackgroundImage = new Array(10).fill(0);
BackgroundImage.forEach((n, i) => {
ctx.save();
ctx.textAlign = "center";
ctx.textBaseline = "middle";
ctx.font = "bold 36px Baloo Bhaijaan";
ctx.fillText(i, w / 2, h * i + h / 2 + 5, w);
ctx.restore();
});
return convertCanvasToImage(canvas);
}
function convertCanvasToImage(canvas) {
var image = new Image();
image.src = canvas.toDataURL("image/png");
return image;
}在项目初始化的时候,就会执行这个方法,利用 canvas 绘制出0到9,10个数字纵向排列出来,最后用 toDataURL 方法导出图片,赋给需要转动区域内的做背景图。
数字转动
上一步操作背景图都生成出来了,不难想到我们将会通过改变 backgroundPositionY 的形式来实现转动。当然,我们还要让动画不停加速最后在慢慢停下来,所以要加入缓动,这里推荐一个动画库 animejs ,它非常的小巧且灵活好用。
import anime from "https://cdn.skypack.dev/animejs@3.2.1";
function play() {
let nums = createNums();
code = nums.join("");
[].forEach.call(list.children, (el, index) => {
setTimeout(() => {
let y = parseInt(el.style.backgroundPositionY || "0", 10);
anime({
targets: el,
backgroundPositionY: [y, y + h * 30 + (10 - nums[index]) * h],
loop: false, // 循环播放
direction: "normal",
easing: "easeOutCirc", // 时间曲线
duration: 2000, // 播放时间2s
autoplay: true, // 是否立即播放
complete: (anim) => {
if (index == 3) isActive = false;
}
});
}, index * 200);
});
}
function createNums(l = 4) {
let num = random(1, 9999);
let res = (num + "").split("");
let len = res.length;
if (len < l) {
for (let i = 0; i < l - len; i++) {
res.unshift("0");
}
}
return res;
}先获取到要返回来的验证码,我这里用随机数来模拟,然后遍历那四个转动区域,生成好 anime 动画,其backgroundPositionY 最后的结果以刚刚获取到的验证码的数字获取到对应位置来计算得到,当然遍历的同时为了效果更好,我们是用 setTimeout 定时器每隔200ms再让开启下一个转动块执行的。
来源:juejin.cn/post/7124205596655484965
收起阅读 »前端vue实现打印、下载
分享一下几个后台管理系统比较常用的插件:下载、打印
html2canvas介绍
html2canvas是在浏览器上对网页进行截图操作,实际上是操作DOM,这个插件也有好长时间了,比较稳定,目前使用还没有遇到什么bug
jspdf介绍
如果下载出来是pdf文件,可以加上jspdf插件,会先通过html2canvas把页面转化成base64图片,再通过jspdf导出
安装
npm i html2canvas jspdf
或
yarn add html2canvas jspdf使用
注意点: 1、能使用ref来获取html结构就用ref,尽量不使用id。如果使用的地方比较多可以挂载到vue实例上 2、导出的pdf空白情况:检查dom结构有没有获取到,还有就是css样式要写在导出区域内的元素中
printjs介绍
之前是使用vue-print-nb插件的,但是这个插件有点猫病,有时候会出现样式跨域的问题,有时候又正常,后面在GitHub上找到的一个,用到现在也没出现过什么问题
在utils文件里面创建一个print.js文件
// 打印类属性、方法定义
/* eslint-disable */
const Print = function (dom, options) {
if (!(this instanceof Print)) return new Print(dom, options);
this.options = this.extend({
'noPrint': '.no-print'
}, options);
if ((typeof dom) === "string") {
this.dom = document.querySelector(dom);
} else {
this.isDOM(dom)
this.dom = this.isDOM(dom) ? dom : dom.$el;
}
this.init();
};
Print.prototype = {
init: function () {
var content = this.getStyle() + this.getHtml();
this.writeIframe(content);
},
extend: function (obj, obj2) {
for (var k in obj2) {
obj[k] = obj2[k];
}
return obj;
},
getStyle: function () {
var str = "",
styles = document.querySelectorAll('style,link');
for (var i = 0; i < styles.length; i++) {
str += styles[i].outerHTML;
}
str += "";
return str;
},
getHtml: function () {
var inputs = document.querySelectorAll('input');
var textareas = document.querySelectorAll('textarea');
var selects = document.querySelectorAll('select');
for (var k = 0; k < inputs.length; k++) {
if (inputs[k].type == "checkbox" || inputs[k].type == "radio") {
if (inputs[k].checked == true) {
inputs[k].setAttribute('checked', "checked")
} else {
inputs[k].removeAttribute('checked')
}
} else if (inputs[k].type == "text") {
inputs[k].setAttribute('value', inputs[k].value)
} else {
inputs[k].setAttribute('value', inputs[k].value)
}
}
for (var k2 = 0; k2 < textareas.length; k2++) {
if (textareas[k2].type == 'textarea') {
textareas[k2].innerHTML = textareas[k2].value
}
}
for (var k3 = 0; k3 < selects.length; k3++) {
if (selects[k3].type == 'select-one') {
var child = selects[k3].children;
for (var i in child) {
if (child[i].tagName == 'OPTION') {
if (child[i].selected == true) {
child[i].setAttribute('selected', "selected")
} else {
child[i].removeAttribute('selected')
}
}
}
}
}
return this.dom.outerHTML;
},
writeIframe: function (content) {
var w, doc, iframe = document.createElement('iframe'),
f = document.body.appendChild(iframe);
iframe.id = "myIframe";
//iframe.style = "position:absolute;width:0;height:0;top:-10px;left:-10px;";
iframe.setAttribute('style', 'position:absolute;width:0;height:0;top:-10px;left:-10px;');
w = f.contentWindow || f.contentDocument;
doc = f.contentDocument || f.contentWindow.document;
doc.open();
doc.write(content);
doc.close();
var _this = this
iframe.onload = function(){
_this.toPrint(w);
setTimeout(function () {
document.body.removeChild(iframe)
}, 100)
}
},
toPrint: function (frameWindow) {
try {
setTimeout(function () {
frameWindow.focus();
try {
if (!frameWindow.document.execCommand('print', false, null)) {
frameWindow.print();
}
} catch (e) {
frameWindow.print();
}
frameWindow.close();
}, 10);
} catch (err) {
console.log('err', err);
}
},
isDOM: (typeof HTMLElement === 'object') ?
function (obj) {
return obj instanceof HTMLElement;
} :
function (obj) {
return obj && typeof obj === 'object' && obj.nodeType === 1 && typeof obj.nodeName === 'string';
}
};
const MyPlugin = {}
MyPlugin.install = function (Vue, options) {
// 4. 添加实例方法
Vue.prototype.$print = Print
}
export default MyPluginprintjs源码在这里
在main.js中注册
import Vue from "vue";
import print from "./src/utils/print.js";
Vue.use(print)在需要的地方使用
注意:需使用ref获取dom节点,若直接通过id或class获取则webpack打包部署后打印内容为空
指定不打印区域 方法
方法一. 添加no-print样式类
="no-print">不要打印我方法二. 自定义类名
不要打印我
this.$print(this.$refs.print,{'no-print':'.do-not-print-me-xxx'}) // 使用作者:搬砖小能手丶
来源:juejin.cn/post/7131702669852278814
成都核酸系统崩溃原因分析
前言
这两天成都核酸检测系统接连崩溃,让工作人员和广大市民苦不堪言,因此决定对其背后的技术进行分析,看看这个系统复杂不复杂,是什么原因导致的崩溃
系统架构分析
核酸结果查询服务正常,核酸检测记录无法录入,因此推断分析此系统主要分为核酸录入服务和核酸结果查询服务,架构如下
核酸检查结果通过数据同步任务从数据库同步到redis里面,来支撑高并发访问,由于核酸结果查询正常,主要分析核酸录入的瓶颈在哪
指标计算
并发量
2千w人,6小时采样完,系统响应时间为2s,那么并发量为:2千万/(6 * 3600) * 2s=1850,如果考虑到时间在短一点,就按照2小时做完,2千万/(2 * 3600) * 2s=5555
带宽
1M宽带理论速度=1Mbit/s=1024 Kbit/s=128 KByte/s,带宽的计算公式为:并发量*平均报文大小/112KB,假设每个报文大小是2KB,那么带宽为1850 *2KB/112KB=33M
瓶颈分析
带宽
经过前面计算带宽为33M,即使需要100M,这块也不是压力,可能会有人说查询服务带宽没考虑在内,因为查询服务正常,所以不需要考虑,如果是共用一个带宽,那么查询服务也会出现问题
数据库
如果使用单台数据库,没做分库分表,每秒1850次访问写入,如果在数据库配置不高的情况下会出现问题(cpu、内存、io)都有可能出现瓶颈点,其次数据量也会快速膨胀,每天晚上有2千万人做核酸,那么会有2千万甚至更多数据插入,经验值mysql 单表在1千万左右性能最佳,如果在往上增长性能就会逐渐下降,所以如果是单点有可能会出现瓶颈,如果要优化一般会进行不同服务器进行分库存储,如下图master和slave都是独立服务器
应用服务器
核酸写入服务节点如果前期不够,会出现性能瓶颈,但是这个还是比较容易扩容的,不应该在连续2天还会出现这种问题,所以应该不是此问题。
负载均衡器
1850的并发对nginx也是能轻松支撑的,所以不是这块问题
网络
看到网络上说是运营商的网络问题导致的,作为从业多年的技术人员,这种情况我遇到过,运营商的网络有可能出现这种情况,但是几率不高而且会很快恢复
总结
经过分析系统功能点不多,业务逻辑不是特别复杂,并发量也不高,数据库的出现瓶颈几率大点,网络的几率很小。。。
以上内容如果不对,请指正,谢谢!
作者:dweizhao
来源:juejin.cn/post/7139156745682845709
Uniapp 多端开发经验整理
文档说明:
本文档目的在于帮助基于 Uniapp 进行移动开发的人员 快速上手、规避问题、提升效率。将以流程提纲的方式,整理开发过程各阶段可能出现的问题点以及思路。对官方文档中已有内容,会贴附链接,尽量不做过多阐述以免冗余。
使用时可根据需求和自身掌握情况,从目录跳转查看。
Uniapp 使用 Vue 语法+微信小程序 API,有二者基础可快速上手,开发 APP 还会用到 HTML5+规范 ,有非常丰富的原生能力。在此还是建议尽量安排时间通读官方文档,至少留下既有功能的印象,来增强对 Uniapp 开发的掌握,游刃有余的应对各类开发需求。
开发准备
小程序
后台配置
小程序个别类目需要行业资质,需要一定时间来申请,根据项目自身情况尽早进行
服务类目的设置以免影响上线时间。必须在后台进行 服务器域名配置,域名必须 为
https。否则无法进行网络请求。注意 每月只有 5 次修改机会。在开发工具中可配置不验证 https,这样可以临时使用非 https 接口进行开发。非 https 真机预览时需要从右上角打开调试功能。
如果有 webview 需求,必须在小程序管理后台配置域名白名单。
开发工具
下载 微信开发者工具
设置 → 安全 → 打开“服务端口”。打开后方可用 HbuilderX 运行并更新到微信开发者工具。
APP
证书文件
准备苹果开发账号
ios 证书、描述文件 申请方法
证书和描述文件分为开发(Development)和发布(Distribution)两种,Distribution 用来打正式包,Development 用来打自定义基座包。
ios 测试手机需要在苹果开发后台添加手机登录的 Apple 账号,且仅限邮箱方式注册的账号,否则无法添加。
Uniapp
创建 Uni-app 项目
根据 文档 操作即可,新建时建议先不选择模板,因为模板后期也可以作为插件导入。这里推荐一个 UI 框架 uView,兼容 Nvue 的 Uniapp 生态框架。
路由
配置: 路由的开发方式与 Vue 不同,不再是 router,而是参照小程序原生开发规则在 pages.json 中进行 配置,注意 path 前面不加"/"。
跳转: 路由的 跳转方式,同样参照了小程序 有 navigator 标签 和 API 两种。
navigator 标签: 推荐使用 有助于 SEO(搜索引擎优化)。
API: 常用跳转方式
uni.navigateTo()、uni.redirectTo()、uni.switchTab(),即可处理大部分路由情况。
需注意:
tabBar 页面 仅能通过
uni.switchTab、如需求特殊可以自定义开发 tabBar,即 pages.json 中不要设置 tabBar,这样也就不需要使用
uni.switchTab了。url 前面需要加"/"
问题点: 小程序页面栈最多 10 层。也就是说使用
uni.navigateTo最多只能跳转 9 层页面。解决: 这里不推荐直接使用
uni.redirectTo取代来处理,会影响用户体验,除非产品设计如此。建议在会出现同页面跳转的页面(例:产品详情 → 点击底部更多产品 → 产品详情 →...),封装一下页面跳转方法,使用getCurrentPages()方法获取当前页面栈的列表,根据列表长度去判断使用什么路由方法。路由方法的选择根据实际情况决定 官方文档。//页面跳转
toPage(url){
let pages=getCurrentPages()
if(pages.length<9){
uni.navigateTo({url})
}else{
uni.redirectTo({url})//根据实际情况选择路由方法
}
}
分包加载
提前规划好分包,使代码文件更加规整,全局思路更加清晰。可以根据业务流程或者业务类型来设计分包。官方文档
分包加载的使用场景:
主包大小超过 2m。
访问落地页启动较慢(因为需要下载整个主包)。
分包优化:
除页面可以分包配置,静态文件、js 也可以配置分包。可以进一步优化落地页加载速度。
在
manifest.json中对应平台下配置"optimization":{"subPackages":true}来开启分包优化。开启后分包目录下可以放置 static 内容。//manifest.json源码
{
...,
"mp-weixin" : {//这里以微信为例,如有其他平台需要分别添加
...,
"optimization" : {
"subPackages" : true
}
}
}分包预载
通过分包进入落地页后,可能会有跳转其他分包页面的需求。开启分包预载,在落地页分包数据加载完后,提前加载后续分包页面,详见 官方文档
生命周期
Uniapp 的页面生命周期建议使用
onLoad、onShow、onReady、onHide等,也可以使用 vue 生命周期created、mounted等,但是组件的生命周期仅支持vue 生命周期的写法。
easycom 组件模式
说明: 只要组件安装在项目的
components目录下或uni_modules目录下,并符合components/组件名称/组件名称.vue的目录结构,就可以不用引用、注册,直接在页面中使用。easycom为默认开启状态,可关闭。可以根据需求配置其他路径规则。详见 官方文档代码举例:
非 easycom 模式
<template>
<view>
<goods-list>goods-list>
view>
template>
<script>
import goodsList from '@/component/goods-list'; //引用组件
export default {
components: {
goodsList //注册组件
}
};
script>使用 easycom 模式
<template>
<view>
<goods-list>goods-list>
view>
template>
<script>
export default {};
script>
是否使用 Nvue
Nvue 开发
优点:原生渲染,性能优势明显(性能优势主要体现在长列表)、启用纯原生渲染模式(
manifest里设置app-plus下的renderer:"native") 可进一步减少打包体积(去除了小程序 webview 渲染相关模块)缺点:与 Vue 开发存在 差异,上手难度相对较高。并且设备兼容性问题较多。
使用:适合仅开发 APP,并且项目对性能有较高要求、组件有复杂层级需求的情况下使用。
Nvue+vue 混合开发
优点:性能与开发难度折中的选择,即大部分页面使用 Vue 开发,部分有性能要求的页面用 Nvue 开发。
缺点:同 Nvue 开发。并且当应用没有长列表时,与 Vue 开发相比性能提升不明显。
使用:适合需要同时开发 APP+小程序或 H5,并且项目有长列表的情况下使用。
Vue 开发
优点:直接使用 Vue 语法进行开发,所有开发平台皆可兼容。
缺点:在 APP 平台,使用 webview 渲染,性能比较 Nvue 相对差。
使用:适合除需要 Nvue 开发外的所有情况。如果 APP 没有性能要求可使用 vue 一锅端。
跨域
如需开发 H5 版本,本地调试会碰到跨域问题。
3 种解决方案:
使用 HbuilderX 内置浏览器预览。内置浏览器经过处理,不存在跨域问题。
在
manifest.json中配置,然后在封装的接口中判断 url// manifest.json
{
"h5": {
"devServer": {
"proxy": {
"/api": {
"target": "https://***.***.com",
"pathRewrite": {
"^/api": ""
}
}
}
}
}
}//判断当前是否生产环境
let url = (process.env.NODE_ENV == 'production' ? baseUrl : '/api') + api;创建一个
vue.config.js文件,并在里面配置 devServer// vue.config.js
module.exports = {
devServer: {
proxy: {
'/api': {
target: 'https://***.***.com',
pathRewrite: {
'^/api': ''
}
}
}
}
};如果 2、3 方法同时使用,2 会覆盖 3。
一键登录
5+APP 一键登录,顾名思义:使用了 HTML5+规范、仅 APP 能用。官方指南
小程序、H5 没有 HTML5+扩展规范。小程序可以使用
推送
既然在 uniapp 生态,就直接使用 UniPush 推送服务。
该服务由个推提供,但必须向 DCloud 重新申请账号,不能用个推账号。
开发中
CSS
建议使用 flex 布局开发。因为 flex 布局更灵活高效,且便于适配 Nvue(Nvue 仅支持 flex 布局)。
小程序 css 中 background 背景图不支持本地路径。解决办法改为网络路径或 base64。
图片设置
display:block。否则图片下方会有 3px 的空隙,会影响 UI 效果。多行文字需要限制行数溢出隐藏时,Nvue 和非 Nvue 写法不同。
Nvue 写法
.text {
lines: 2; //行数
text-overflow: ellipsis;
word-wrap: break-word;
}非 Nvue 写法
.text {
display: -webkit-box;
-webkit-line-clamp: 2; //行数
-webkit-box-orient: vertical;
overflow: hidden;
text-overflow: ellipsis;
}
图片
mode
Uniapp 的
mode属性,用来设置图片的裁剪、缩放模式。在开发中尽量养成每一个
mode的习惯。可以规避掉很多 UI 显示异常的问题。一般只需要使用
widthFix、aspectFill这两个属性即可应对绝大多数情况。即只需设置宽度自动撑起高度的图片用
widthFix;需要固定尺寸设置宽高,并保持图片不被拉伸的图片用aspectFill。例如:所有 icon、文章详情里、产品详情里的详情图一般会用
widthFix,用户头像、缩略图一般会用aspectFill。属性详情见 官方文档 。
lazy-load
图片懒加载,小程序支持,只针对 page 与 scroll-view 下的 image 有效。
图片压缩
静态图片未压缩。该问题不限于 Uniapp 开发,也包括其他开发方式。是非常常见的问题。
图片压缩前后,包体大小可差距 50%甚至更多。对编译和加载速度提升显著!
滚动穿透
弹窗遮罩显示时,底层页面仍可滚动。给遮罩最外层 view 增加事件
@touchmove.stop.prevent
底部安全区
问题: iOS 全面屏设备的屏幕底部有黑色横条显示,会对 UI 造成遮挡,影响事件点击和视觉效果。Android 没有横条,不受影响。
场景: 各页面底部悬浮菜单、相对于底部距离固定的悬浮按钮、长列表的最后一个内容。
解决方案:
使用 css 样式
constant(safe-area-inset-bottom)env(safe-area-inset-bottom)来处理,兼容 iOS11.2+,根据 iOS 系统版本占比,可放心使用。需注意该方法小程序模拟器不支持,真机正常。
如果使用
nvue,则不支持以上方案。可使用 HTML5+规范 的方法来处理。
交互反馈
移动端比 PC 画面小很多,但是要展示的内容并不少,甚至更多。为了让用户正常使用,并获得优良体验。交互反馈的设置是必不可少的。并且在 UI 设计评审时就应该确定好,所有交互反馈是否齐全。
缺省样式: 所有数量可能为空的数据展示,都应添加缺省样式,乃至缺省样式后的后续引导。
例如:评论区没有评论,不应显示空白,而是显示(具体按 UI 设计):一个 message 的 icon,下方跟一句"快来发表你的高见",下方再跟一个发表按钮。这样不仅体现了评论区的状态,还做了评论的引导,增加了互动概率。
状态提醒: 所有需要时间相应的状态变化,或者逻辑变化。都应对用户提供状态提醒。同样需要在 UI 设计评审时确认。
例如:无网络时,显示网络异常,点击重试。各种等待、 下拉刷新、上拉加载、上传、下载、提交成功、失败、内容未加载完成时的骨架屏。甚至可以在点赞时加一个
vibrateShort等等。
分享
除非特别要求不分享,或者订单等特殊页面。否则在开发时各个页面中一定要有设置分享的习惯。可以使应用的功能更完整更合理并且有助于搜索引擎优化。是必须考虑但又容易忽略的地方。
在页面的生命周期中添加
onShareAppMessage并配置其参数,否则点击右上角三个点,分享相关按钮是不可点击状态。小程序可以通过右上角胶囊按钮或者页面中
代码示例:
return 的 Object 中
imageUrl必须为宽高比例 5:4 的图片,并且图片大小尽量小于 20K。imageUrl 可不填,会自动截取当前页面画面。另外 button 有默认样式,需要清除一下。
获取用户手机号
小程序通过点击 button 获取 code 来跟后端换取手机号。在开发者工具中无法获取到 code。真机预览中可以获取到。
苹果登录
APP 苹果登录需要使用自定义基座打包才能获得 Apple 的登录信息进行测试
iOS 自定义基座打包需要用开发(Development)版的证书和描述文件
H5 唤起 App
两种实现方式:
URL Sheme
优点:配置简单
缺点:会弹窗询问“是否打开***”,未安装时网页没有回调,而且会弹窗“打不开网页,因为网址无效”;微信微博 QQ 等应用中被禁用,用户体验一般。
Universal Link
优点:没有额外弹窗,体验更优。
缺点:配置门槛更高,需要一个不同于 H5 域名的 https 域名(跨域才出发 UL);iOS9 以上有效,iOS9 一下还是要用 URL Sheme 来解决;未安装 App 时会跳转到 404 需要单独处理。
打包发布
摇树优化
H5 打包时去除未引用的组件、API。
摇树优化(treeShaking)
//manifest.json
"h5" : {
"optimization":{
"treeShaking":{
"enable":true //启用摇树优化
}
}
}
启动图标
让 UI 帮忙切一个符合以下标准的图片,在 APP 图标配置中自动生成即可。
格式为 png
UI 切图时不要带圆角
分辨率不小于 1024×1024
启动图
如没有特殊要求,直接使用通用启动页面即可。
如需自定义启动图:
Android 可直接使用普通 png,也可配置.9.png,可减少包体积,避免缩放影响清晰度。为了更好的效果和体验建议使用.9 图。
如何制作.9.png?使用 Android studio、ps。或者找 UI 同事帮忙
iOS 需要制作storyboard,如所需效果与 uni 提供的 storyboard 模板类似,可直接使用模板修改代码即可(xml 格式)。否则需要使用 xcode 进行更深度的修改,以实现效果并适配各机型。
权限配置
HBuilderX 默认会勾选一些不需要的权限,为避免审核打回,需要注意以下权限配置
manifest.json 中的【App 权限配置】取消勾选“Android 自动添加第三方 SDK 需要的权限”,然后在下方配置处根据参考文档取消勾选没有用到的权限,额外注意核对推送、分享等功能的权限需求。
manifest.json 中的【App 模块配置】仅勾选所需模块(容易漏掉,也会影响权限)
补充
SEO(搜索引擎优化)
用户流量是衡量产品的重要指标之一,受到很多方面影响,SEO 就是其中之一。在没有额外推广的情况下,搜索引擎带来的流量基本就是产品流量的主要来源。传统 web 开发通过设置 TDK、sitemap 等,现阶段移动开发方法有所变化,但是万变不离其宗,核心还是一样的。
小程序:
被动方式:
确保 URL 可直接打开,通俗说就是 url 要有效,不能是 404。
页面跳转优先采用 navigator 组件
清晰简洁的页面参数
必要的时候才请求用户进行授权、登录、绑定手机号等
不收录 web-view,若非不需 seo 内容(用户协议之类)、或已有 H5 页面节省开发,否则尽量不要用 web-view。
配置sitemap
设置标题和分享缩略图 类似于传统 web 中设置 TDK。在百度小程序中有专门的接口来传递 SEO 信息。
主动方式:
使用页面路径推送能力让微信收录内容。
内容详情请查看 优化指南。所有被动方式可以作为开发习惯来养成。
H5: 因为 Uniapp 是基于 Vue 语法来开发,这种 SPA 对于 SEO 并不友好。业界有
SSR(服务端渲染)方法,等了很久 Uniapp 官方也终于提供了 SSR 的方法,但是需要使用 uniCloud。所以如果没有使用 uniCloud,暂时没有更合适的方法来处理该问题。APP: 方式脱离前端范畴,不做讨论。
作者:Tigger
来源:juejin.cn/post/7138221718518595621
如何写出不可维护的Vue代码
前言
不止一次接手过复杂业务功能模块,开端总是深陷其中难以自拔,无数个深夜抚摸着头皮在内心暗暗咒骂。
相信你也有过类似的经历,面对复杂的业务逻辑,看代码俩小时,写代码五分钟,没有点胆识和谋略都不敢下手。
最近总结复盘了一下,以备后用,如果有喜欢的同事想坑他一把,可以按照此方法实践(不保证100%成功),个人拙见,如有不当望指正。
目录
data属性数量过多
组件入参数量过多
mixins和业务代码耦合
不要封装纯函数
数据结构尽量复杂
不写注释或写无法理解的注释
将前端逻辑变重
不封装mixins与组件
正文
1、data属性数量过多
要多用data属性,放置一些用不到的key,让属性看起来更丰富,增加理解成本。
最好一打开页面前100行都是data属性,让维护或者参与该组件开发的人员望而生畏,瞬间对组件肃然起敬。
这符合代码的坏味道所描述的:
良药与毒药的区别在于剂量。有少量的全局数据或许无妨,但数量越多,处理的难度就会指数上升。
如图所示,效果更佳:
2、组件入参数量过多
data属性的问题是在一个组件内,看多了加上注释可能就理解,而组件增加过多的props入参恰好能避免这个问题,过多的入参可以让理解变得更困难,要先理解父组件内绑定的值是什么,再理解子组件内的入参用做什么。
当然了,还有高阶一点的用法,就是让父组件的值和子组件的props名称不一致,这样做就更有趣了,难度陡增。
3、mixins与业务代码耦合
合理封装mixins能让代码变得更容易复用和理解,这不是我们想要的,让mixins与业务组件的代码耦合在一起,可以达到事倍功半的效果。
常规的做法是业务组件调用mixins的方法和变量,我们反其道而行之,让mixins调用组件中的方法和变量,然后让mixins多出引用,虽然看起来像mixins,但是并没有mixins的功能,让后期有心想抽离封装的人也无从下手。
小Tips:常见的mixins方法会加上特殊前缀与组件方法区分,我们可以不使用这个规范,让mixins方法更难被发现。
4、不要封装纯函数
如果有一个很重要的业务组件可读性很差,势必要小步快跑的迭代重构,这种情况也不用怕,我们一个微小的习惯就可以让这件事情变得困难重重,那就是不要封装纯函数方法。
纯函数的好处是不引用其他变量,可以轻易的挪动和替换; 让每个方法尽量引用data属性,当他人想迁移或替换你的方法时,就要先理解引用的属性和全局变量,再进一步,可以在方法里再引入mixnins里的变量和方法,这个小习惯就会让他们望而却步。
5、数据结构尽量复杂
让数据结构变复杂绝对是一个必杀技,数据结构随随便便循环嵌套几层,自己都能绕晕。
再加上一些骚操作,递归遍历加一些判断和删减,写上让人难以琢磨的注释,哪怕是高级工程师或是资深工程师都需要狠狠的磕上一段时间才能摸清真正的业务逻辑是什么。
这种方式还有另外一个优点,就是自己可能也会被绕晕,一起陷入有趣的逻辑梳理游戏。
6、不写注释或写无法理解的注释
如果其他方式都复杂且耗时,那这种方法简直是高效的存在,只需要胡乱的写一些让别人看不懂或容易误解的注释,就可轻松把接手代码的同事KO掉。
这个技能也看个人发挥的水平了,你也可以在注释中恐吓、劝阻参与开发人员改动功能代码,煽动开发人员放弃修改,让其内心崩溃。
7、让前端逻辑变重
良好的分层设计能够让系统变得简洁和健壮;为了凸显前端的重要性,应该将逻辑一股脑的承接到前端,让前端逻辑变重,尤其是写一些特殊的编码配置和奇葩规则。
不要和产品、后端讲述这件事情的不合理性,统统塞到前端,当需求被重新讨论时,他们会把特殊逻辑忘的一干二净,而你可以根据代码翻出一大堆,这样你就显得尤为重要了。
8、不封装mixins与组件
如果要让功能变得复杂,就不要拆分UI组件和业务组件,更不要按照业务抽离可复用的mixins方法,让组件尽量大,轻则一两千行,重则五六千行,不设上限,统统塞到一个组件里。
结尾
结合自己的踩坑经历写了这边偏笔记,调侃之处,纯属娱乐。 你有没有遇上过类似的场景,你的感受如何?又是如何解决的呢?敢不敢点个赞,一起评论区讨论。
作者:愚坤
来源:juejin.cn/post/7119692905123414029
Kotlin Sealed Class 太香了,Java 8 也想用怎么办?
为避免数据在分发过程中被恶意篡改,Kotlin 将 SealedClass 参数设置为 val 即可,
Java 17 以下未引入 SealedClass,且若实现 Kotlin val 同等效果,样板代码瞬间飙出许多,等于解决了数据一致性的同时,滋生了更多 “不一致” 问题,例如日后修改某字段,而忘配置构造方法等等。
痛定思痛,SealedClass4Java 应运而生,通过注解自动生成 SealedClass,像 Kotlin 一样使用 SealedClass。
献给喜欢 Kotlin 但又不得不维护 Java 老项目的朋友。
Github:SealedClass4Java
使用说明
1.创建一个接口,添加 SealedClass 注解,且接口名开头 _ 下划线,
@SealedClass
public interface _TestEvent {
void resultTest1(String a, int b);
void resultTest2(String a, int b, int c);
}
2.编译即可生成目标类,例如 TestEvent,然后像 Kotlin 一样使用该类:
TestEvent event = TestEvent.ResultTest1("textx");
switch (event.id) {
case TestEvent.ResultTest1.ID:
TestEvent.ResultTest1 event1 = (TestEvent.ResultTest1) event;
event1.copy(1);
event1.paramA;
event1.resultB;
break;
case TestEvent.ResultTest2.ID:
break;
}
进阶使用
本框架是 MVI-Dispatcher 项目优化过程中,为消除 “消息分流场景 final 样板代码” 而萌生的产物,所以我们不妨以 MVI-Dispatcher 使用场景为例:
注:“消息(message)、事件(event)、意图(intent)”,不同场景,叫法不同,但本质上是指同一东西,即 “可被消费的一次性数据”。
A.纯粹消息分发场景
1.定义一个接口,例如 _Messages,在方法列表中定义不携带参数的纯粹消息,定义完 build 生成对应 Messages 类。
@SealedClass
public interface _Messages {
void refreshNoteList();
void finishActivity();
}
2.在 MVI-View 中发送一个 Messages.RefreshNoteList( ) 纯粹消息
public class TestFragment {
public void onInput() {
MVI-Model.input(Messages.RefreshNoteList());
}
}
3.在 MVI-Model 中转发消息
public class PageMessenger extends MVI-Disptacher {
protected void onHandle(Messages intent){
sendResult(intent);
}
}
4.在 MVI-View 中响应消息
public class TestFragment {
public void onOutput() {
MVI-Model.output(this, intent-> {
switch(intent.id) {
case Messages.RefreshNoteList.ID: ... break;
case Messages.FinishActivity.ID: ... break;
}
});
}
}
B.带参数的意图分发场景
该场景十分普遍,例如页面向后台请求一数据,通过意图来传递参数,后台处理好结果,将结果注入到意图中,回传给页面。
所以该场景下,意图会携带 “参数” 和 “结果”,且发送场景下只需注入参数,回推场景下只需注入结果,
因而使用方法即,
1.定义接口,为参数添加 @Param 注解,
@SealedClass
public interface _NoteIntent {
void addNote(@Param Note note, boolean isSuccess);
void removeNote(@Param Note note, boolean isSuccess);
}
build 生成的静态方法,比如 AddNote 方法中,只提供 “参数” 列表,不提供结果列表,结果字段皆赋予默认值,以符合意图发送场景的使用。
public static NoteIntent AddNote(Note note) {
return new AddNote(note, false);
}
2.在 MVI-View 中发送一个 NoteIntent.AddNote(note) 意图,
public class TestFragment {
public void onInput() {
MVI-Model.input(NoteIntent.AddNote(note));
}
}
3.在 MVI-Model 中处理业务逻辑,注入结果和回推意图。
由于意图为确保 “数据一致性” 而不可修改,因此在注入结果的场景下,可通过 copy 方法拷贝一份新的意图,而 copy 方法的入参即 “结果” 列表,以符合意图回推场景的使用。
public class NoteRequester extends MVI-Disptacher {
protected void onHandle(NoteIntent intent){
switch(intent.id) {
case NoteIntent.AddNote.ID:
DataRepository.instance().addNote(result -> {
NoteIntent.AddNote addNote = (NoteIntent.AddNote) intent;
sendResult(addNote.copy(result.isSuccess));
});
break;
case NoteIntent.RemoveNote.ID:
...
break;
}
}
}
4.在 MVI-View 中响应意图
public class TestFragment {
public void onOutput() {
MVI-Model.output(this, intent-> {
switch(intent.id) {
case NoteIntent.AddNote.ID:
updateUI();
break;
case NoteIntent.RemoveNote.ID:
...
break;
}
});
}
}
C.不带参的事件分发场景
也即没有初值传参,只用于结果分发的情况。
这种场景和 “带参数意图分发场景” 通常重叠和互补,所以使用上其实大同小异。
1.定义接口,方法不带 @Param 注解。那么该场景下 NoteIntent.GetNotes 静态方法提供无参和有参两种,我们通常是使用无参,也即事件在创建时结果是被给到默认值。
@SealedClass
public interface _NoteIntent {
void getNotes(List<Note> notes);
}
2.在 MVI-View 中发送一个 NoteIntent.GetNotes() 事件,
public class TestFragment {
public void onInput() {
MVI-Model.input(NoteIntent.GetNotes());
}
}
3.在 MVI-Model 中处理业务逻辑,注入结果和回推意图。
由于意图为确保 “数据一致性” 而不可修改,因此在注入结果的场景下,可通过 copy 方法拷贝一份新的意图,而 copy 方法的入参即 “结果” 列表,以符合意图回推场景的使用。
public class NoteRequester extends MVI-Disptacher {
protected void onHandle(NoteIntent intent){
switch(intent.id) {
case NoteIntent.GetNotes.ID:
DataRepository.instance().getNotes(result -> {
NoteIntent.GetNotes getNotes = (NoteIntent.GetNotes) intent;
sendResult(getNotes.copy(result.notes));
});
break;
case NoteIntent.RemoveNote.ID:
...
break;
}
}
}
4.在 MVI-View 中响应事件
public class TestFragment {
public void onOutput() {
MVI-Model.output(this, intent-> {
switch(intent.id) {
case NoteIntent.GetNotes.ID:
updateUI();
break;
case NoteIntent.RemoveNote.ID:
...
break;
}
});
}
}
作者:KunMinX
链接:https://juejin.cn/post/7137571636781252622
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose制作“抖音”、“快手”视频进度条Loading动画效果
现在互联网产品,感觉谁家的App不整点视频功能,严格意义上都不能说是一个现代互联网App了😂,我们知道最火的是抖音、快手这类短视频App,在刷视频的同时,他们的App交互上面的一些特色能让我们一直沉浸在刷视频中;
比如,我们今天要聊的,短视频翻页流列表,视频加载缓冲的时候,Loading的设计:
它设计:在视频底部,进度条上面,当视频缓冲加载等待的时候,它有一个波纹的扩散效果,
即不干扰用户刷视频的操作,也没有很明显的突兀效果
(比如:突兀的屏幕中间大圆圈Loading,就很突兀)
一定要记得:『点赞❤️+关注❤️+收藏❤️』起来,划走了可就再也找不到了😅😅🙈🙈
我们先来看一下“抖音、快手App”的视频进度条Loading效果(GIF图稍微失真了点)
快手短视频首页的视频Loading
从视频里面可以看出来在视频底部,出现缓冲加载视频的时候,会有一个:“从中间往2边扩散”的效果。
GIF图放慢了一点,方便大家观看,实际研究过程,我一般是通过录制完视频,通过相册的视频编辑,去一帧一帧看,做了哪些动作,如下:
看完,我们发现:
1、一开始是在屏幕中间的位置,大概是20dp左右的宽度开始显示;
2、从中间扩散到屏幕边缘之后,会执行渐隐;
3、渐隐到透明,又开始从中间往2边扩散;
有了上面的前奏,我们就可以开始我们的编码了,那么在开始编码前,肯定需要知道宽度是多少,这里我们拿BoxWithConstraints来包我们的child composable,
我们可以看到BoxWithConstraints的代码如下:
// 代码来自:androidx.compose.foundation.layout
@Composable
@UiComposable
fun BoxWithConstraints(
modifier: Modifier = Modifier,
contentAlignment: Alignment = Alignment.TopStart,
propagateMinConstraints: Boolean = false,
content:
@Composable @UiComposable BoxWithConstraintsScope.() -> Unit
) {
val measurePolicy = rememberBoxMeasurePolicy(contentAlignment, propagateMinConstraints)
SubcomposeLayout(modifier) { constraints ->
val scope = BoxWithConstraintsScopeImpl(this, constraints)
val measurables = subcompose(Unit) { scope.content() }
with(measurePolicy) { measure(measurables, constraints) }
}
}
里面用到了SubcomposeLayout,来推迟内容组合,我们可以在BoxWithConstraintsScope里面获取到最大宽度maxWidth (单位dp)。
Loading线条,我们可以用DrawScope.drawLine来画,扩散效果肯定需要有动画来更新。
我们使用 rememberInfiniteTransition() 执行无限动画,使用animateFloat来获取动画更新的值:
// 代码来自:androidx.compose.animation.core
@Composable
fun InfiniteTransition.animateFloat(
initialValue: Float,
targetValue: Float,
animationSpec: InfiniteRepeatableSpec<Float>
): State<Float>
初始值(initialValue)可以定义成50F(读者可自行修改),目标值(targetValue)定义多少合适呢?
通过慢镜头查看“抖音、快手”的效果,发现它扩散完,会“渐隐到透明”,然后再从intialValue处开始重新扩散。
targetValue定义成maxWidth不行,那么我们拉大这个数值,可以定义成大概1.8倍的maxWidth;
由于maxWidth获取到的是dp单位的,我们需要转换成px,下面我们统一叫:width
val width = with(LocalDensity.current) { maxWidth.toPx() }
然后,我们的线条动画值就变成下面这样:
val lineProgressAnimValue by infiniteTransition.animateFloat(
initialValue = 100F,
targetValue = width * 1.8F,
animationSpec = infiniteRepeatable(
animation = tween(
durationMillis = TIME_PERIOD,
easing = FastOutLinearInEasing
)
)
)
private const val TIME_PERIOD = 1100
线条扩散到屏幕边缘的时候,需要执行渐隐,得出下面的alpha
val lineAlphaValue = if(lineProgressAnimValue <= width) {
// 读者可以根据自己体验
lineProgressAnimValue * 1.0F/ width * 1.0F
// 读者可以根据自己体验
//Math.min((lineProgressAnimValue.value) * 1.0F / width * 1.0F, 0.7F)
// 抖音、快手看效果都是1F,根据自己体验来设置吧
// 1F
} else {
// 扩散到屏幕边缘的时候,开始触发:渐隐
(width * 1.8F - lineProgressAnimValue) / width * 0.8F
}
// 线条宽度
val lineWidth = if(lineProgressAnimValue <= width) {
lineProgressAnimValue / 2
} else {
width / 2
}
最后,我们通过Canvas来绘制这个线条
Canvas(modifier = modifier) {
drawLine(
color = Color.White.copy(alpha = lineAlphaValue),
start = Offset(x = size.width / 2 - lineWidth, y = 0F),
end = Offset(x = size.width / 2 + lineWidth, y = 0F),
strokeWidth = 2.5F
)
}
来看看我们的最终效果吧:
作者:Halifax
链接:https://juejin.cn/post/7133793654912581639
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Kotlin学习快速入门—— 属性委托
委托其实是一种设计模式,但Kotlin把此特性编写进了语法中,可以方便开发者快速使用,本篇也来具体讲解下关于Kotlin中属性委托的使用
委托对应的关键字是by
属性委托
先讲下属性委托吧,首先,复习下kotlin中设置set和get方法
默认的set和get我们可以隐藏,实际上一个简单的类代码如下:
class Person {
var personName = ""
// 这是默认的 get/set(默认是隐藏的)
get() = field
set(value) {
field = value
}
}
这里具体知识点可以查看之前所说Kotlin学习快速入门(3)——类 继承 接口 - Stars-One的杂货小窝
当然,如果是数据bean类,我们会将get和set方法隐藏(或者使用data关键字来声明一个数据类)
若我们需要在get或set方法的时候做一下逻辑处理,比如说上面的personName字段,我们只允许接收长度小于等于10的字符串,超过10长度的字符串就不接收(即不设置新数值),则是应该这样写:
class Person{
var personName = ""
// 这是重写的 get/set
get() = "PersonName $field"
set(value) {
field = if (value.length <= 10) value else field
}
}
然后,我们再延伸出来,如果此规则不止应用于personName字段,还可用到其他类的字段中,这个时候就是使用到属性委托。
简单描述: 我们将此规则抽取出来,需要应用到此规则的字段的get/set方法委托给规则去做,这就叫属性委托
延迟加载(懒加载)
在开始讲属性委托之前,先说明下延迟加载
Kotlin中提供了lazy方法,使用by+lazy{}联用,我们就实现延迟加载(也可称作懒加载)
fun main() {
val demo = Demo()
val textContent = demo.textContent
val result = demo.textContent.substring(1)
println(result)
println("打印:$textContent")
}
class Demo{
val textContent by lazy { loadFile() }
}
fun loadFile(): String {
println("读取文件...")
//模拟读取文件返回数据
return "读取的数据"
}
这里的关键词by出现在属性名后面,表示属性委托,即将属性的读和写委托给另一个对象,被委托的对象必须满足一定的条件:
- 对于
val修饰的只读变量进行属性委托时,被委托的对象必须实现getValue()接口,即定义如何获取变量值。 - 对于
var修饰的读写变量进行属性委托时,被委托对象必须实现getValue()和setValue()接口,即定义如何读写变量值。
lazy()方法,接收一个lambda函数,返回值是一个Lazy对象,所以就可以简写成上面的样子,其只实现了getValue()接口,所以,当你尝试将textContent改为var类型,IDE会提示报错!!
也是因为这点,属于延迟加载的字段,是不可被再次修改了,所以采用lazy懒加载的方式,其实就是单例模式
lazy函数默认是线程安全的,而且是通过加锁实现的。如果你的变量不会涉及到多线程,那么请务必使用LazyThreadSafetyMode.NONE参数,避免不必要的性能开销,如下示例代码
val name:String by lazy(LazyThreadSafetyMode.NONE) { "Karl" }
Delegates.vetoable
还记得上述我们要实现的规则吗,其实Kotlin中已经有了几个默认的委托规则供我们快速使用(上述的lazy其实也是一个)
Delegates.vetoable()的规则就是上述规则的通用封装,解释为:
但会在属性被赋新值生效之前会传递给Delegates.vetoable()进行处理,依据Delegates.vetoable()的返回的布尔值判断要不要赋新值。
如下面例子:
class Person {
var personName by Delegates.vetoable("") { property, oldValue, newValue ->
//当设置的新值满足条件,则会设置为新值
newValue.length <= 10
}
}
Delegates.notNull
设置字段不能为null,不过想不到具体的应用情景
class Person {
var personName by Delegates.notNull<String>()
}
Delegates.observable
使用Delegates.observable可以帮我们快速实现观察者模式,只要字段数值发生改变,就会触发
class Person{
var age by Delegates.observable(0){ property, oldValue, newValue ->
//这里可以写相关的逻辑
if (newValue >= 18) {
tip = "已成年"
}else{
tip = "未成年"
}
}
var tip =""
}
上面的例子就比较简单,设置age同时更新提示,用来判断是否成年
val person = Person()
person.age = 17
println(person.tip)
补充-自定义委托
上述都是官方定义好的一些情形,但如果不满足我们的需求,这就需要自定义委托了
官方提供了两个基础类供我们自定义委托使用:
ReadWriteProperty 包含get和set方法,对应var关键字
ReadOnlyProperty 只有get方法,对应val关键字
PS:实际上,我们自己随意创建个委托类也是可以的,不过这样写不太规范,所以我们一般直接实现官方给的上述两个类即可
ReadWriteProperty和ReadOnlyProperty都需要传两个泛型,分别为R,T
R持有属性的类型T字段类型
可能上面描述不太明白,下面给个简单例子,Person类中有个name字段(String),首字母需要大写:
class Person {
var name by NameToUpperCase("")
}
class NameToUpperCase(var value:String) :ReadWriteProperty<Person,String>{
//NameToUpperCase类中默认有个属性字段,用来存数据
override fun getValue(thisRef: Person, property: KProperty<*>): String {
return this.value
}
override fun setValue(thisRef: Person, property: KProperty<*>, value: String) {
//在设置数值的时候,将第一个字母转为大写,一般推荐在setValue里编写逻辑
this.value = value.substring(0,1).toUpperCase()+value.substring(1)
}
}
个人看法,一般在setValue的时候进行设置数值比较好,因为getValue作操作的话,会触发多次,处理的逻辑复杂的话可能会浪费性能...
当然,再提醒下,上面的逻辑也可以直接去字段里的setValue()里面改,使用委托的目的就是方便抽取出去供其他类使用同样的规则,减少模板代码
PS: 如果你的委托不是针对特定的类,R泛型可以改为Any
类委托
这个一般与多态一起使用,不过个人想不到有什么具体的应用情景,暂时做下简单的记录
interface IDataStorage{
fun add()
fun del()
fun query()
}
class SqliteDataStorage :IDataStorage{
override fun add() {
println("SqliteDataStorage add")
}
override fun del() {
println("SqliteDataStorage del")
}
override fun query() {
println("SqliteDataStorage query")
}
}
假如现在我们有个MyDb类,查询的方法与SqliteDataStorage这个里的方法有所区别,但其他方法都是没有区别,这个时候就会用到类委托了
有以下几种委托的使用方式
1.委托类作为构造器形参传入(常用)
class MyDb(private val storage:IDataStorage) : IDataStorage by storage{
override fun add() {
println("mydb add")
}
}
val db = MyDb(SqliteDataStorage())
db.add()
db.query()
输出结果:
mydb add
SqliteDataStorage query
如果是全部都是委托给SqliteDataStorage的话,可以简写为这样:
class MyDb(private val storage:IDataStorage) : IDataStorage by storage
2.新建委托类对象
class MyDb : IDataStorage by SpDataStorage(){
override fun add() {
println("mydb add")
}
}
这里测试的效果与上文一样,不在重复赘述
参考
作者:Stars-One
链接:https://juejin.cn/post/7134886417934581768
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter开发·async await原理解析
async await 与 Future
在异步调用中有三个关键词,async、await、Future,其中async和await需要一起使用。在Dart中可以通过async和await进行异步操作,async表示开启一个异步操作,也可以返回一个Future结果。如果没有返回值,则默认返回一个返回值为null的Future。
await的操作,不会影响方法外后续代码的执行;只会阻塞async方法的后续代码
例子1
_testAsyncKeyword() {
print("test函数开始了:${DateTime.now()}");
_testString().then((value) => print(value));
print("test函数结束了:${DateTime.now()}");
}
Future<String> _testString() async {
Future f = Future.delayed(Duration(milliseconds: 300), () {
return "我是测试字符串===1";
});
String result = await f;
print("我是测试字符串===2");
return result;
}
// flutter: test函数开始了:
// flutter: test函数结束了:
// flutter: 我是测试字符串===2
// flutter: 我是测试字符串===1
在代码示例中,执行到_testString()方法,会同步进入方法内部进行执行,当执行到await时就会停止async内部的执行,从而继续执行外面的代码。所以await的操作,不会影响后面代码的执行("test函数结束了"会先于_testString()内部打印)。
当await有返回后,会继续从await的位置继续执行(所以先打印出了 "我是测试字符串===2" ,然后返回Future的结果,并通过print打印出 "我是测试字符串===1")。
例子2
_testAsyncKeyword() async {
print("test函数开始了:${DateTime.now()}");
print(await _testString());
print("test函数结束了:${DateTime.now()}");
}
Future<String> _testString() async {
Future f = Future.delayed(Duration(milliseconds: 300), () {
return "我是测试字符串===1";
});
String result = await f;
print("我是测试字符串===2");
return result;
}
// flutter: test函数开始了:
// flutter: 我是测试字符串===2
// flutter: 我是测试字符串===1
// flutter: test函数结束了:
在代码示例中, _testAsyncKeyword() 本身内部就有一个await操作,当执行到await时就会停止_testAsyncKeyword() async内部的执行.等待_testString()有结果返回之后,继续执行.
_testString()内部也是有一个await操作,当执行到await时就会停止_testString() async内部的执行,等待300毫秒,Future有结果后,打印字符串2
_testAsyncKeyword() 继续执行 打印 字符串1 及 结束
例子3
_testAsyncKeyword() {
print("test函数开始了:${DateTime.now()}");
firstString().then((value) => print(value));
secondString().then((value) => print(value));
thirdString().then((value) => print(value));
print("test函数结束了:${DateTime.now()}");
}
_testKeyword2() async{
print("test函数开始了:${DateTime.now()}");
print(await firstString());
print(await secondString());
print(await thirdString());
print("test函数结束了:${DateTime.now()}");
}
Future<String> firstString() {
return Future.delayed(Duration(milliseconds: 300), () {
return "我是一个字符串";
});
}
Future<String> secondString() {
return Future.delayed(Duration(milliseconds: 200), () {
return "我是二个字符串";
});
}
Future<String> thirdString() {
return Future.delayed(Duration(milliseconds: 100), () {
return "我是三个字符串";
});
}
//_testAsyncKeyword() 的打印:
//flutter: test函数开始了:
//flutter: test函数结束了:
//flutter: 我是三个字符串
//flutter: 我是二个字符串
//flutter: 我是一个字符串
//_testKeyword2() 的打印:
//flutter: test函数开始了:
//flutter: 我是一个字符串
//flutter: 我是二个字符串
//flutter: 我是三个字符串
//flutter: test函数结束了:
通过上面三个例子 , 可以看出 await async 和 then之间的区别和联系了.
async、await的原理
async、await的操作属于**"假异步"**,这是为什么呢?
如果想要得到这个问题的答案,首先我们需要了解async、await的原理,了解协程的概念,因为async、await本质上就是协程的一种语法糖。协程,也叫作coroutine,是一种比线程更小的单元。如果从单元大小来说,基本可以理解为 进程->线程->协程。
任务调度
在弄懂协程之前,首先要明白并发和并行的概念
- 并发: 指的是由系统来管理多个IO的切换,并交由CPU去处理。
- 并行: 指的是多核CPU在同一时间里执行多个任务。
并发的实现由非阻塞操作+事件通知来完成,事件通知也叫做“中断”。操作过程分为两种,一种是CPU对IO进行操作,在操作完成后发起中断告诉IO操作完成。另一种是IO发起中断,告诉CPU可以进行操作。
线程: 本质上也是依赖于中断来进行调度的,线程还有一种叫做“阻塞式中断”,就是在执行IO操作时将线程阻塞,等待执行完成后再继续执行,通过单线程并发可以进行大量并发操作。但线程的消耗是很大的,并不适合大量并发操作的处理,且单个线程只能使用到单个CPU。当多核CPU出现后,单个线程就无法很好的利用多核CPU的优势了,所以又引入了线程池的概念,通过线程池来管理大量线程。当需要同时执行多项任务的时候,我们就会采用多线程并发执行.
Dart单线程运行模型: 输入单吸纳成运行机制,主要是通过消息循环机制来实现任务调度和处理的.
协程coroutine
多线程并发 操作系统在线程等待IO的时候,会阻塞当前线程,切换到其它线程,这样在当前线程等待IO的过程中,其它线程可以继续执行。当系统线程较少的时候没有什么问题,但是当线程数量非常多的时候,却产生了问题。一是系统线程会占用非常多的内存空间,二是过多的线程切换会占用大量的系统时间。
协程 运行在线程之上,当一个协程执行完成后,可以选择主动让出,让另一个协程运行在当前线程之上。协程并没有增加线程数量,只是在线程的基础之上通过分时复用的方式运行多个协程,而且协程的切换在用户态完成,切换的代价比线程从用户态到内核态的代价小很多。
协程分为无线协程和有线协程.
- 无线协程在离开当前调用位置时,会将当前变量放在 堆区,当再次回到当前位置时,还会继续从堆区中获取到变量。所以,一般在执行当前函数时就会将变量直接分配到堆区,而async、await就属于无线协程的一种。
- 有线协程则会将变量继续保存在 栈区,在回到指针指向的离开位置时,会继续从栈中取出调用。
async、await原理
之所以说async/await是假异步,是因为他在执行过程中并没有开启新的线程更没有并发执行,而是通过单线程上的任务调度(协程,没有并发执行功能)实现的:
当代码执行到async则表示进入一个协程,会同步执行async的代码块。async的代码块本质上也相当于一个函数,并且有自己的上下文环境。当执行到await时,则表示有任务需要等待,CPU则去调度执行其他IO,也就是后面的代码或其他协程代码。过一段时间CPU就会轮询一次,看某个协程是否任务已经处理完成,有返回结果可以被继续执行,如果可以被继续执行的话,则会沿着上次离开时指针指向的位置继续执行,也就是await标志的位置。
由于并没有开启新的线程,只是进行IO中断改变CPU调度,所以网络请求这样的异步操作可以使用async、await,但如果是执行大量耗时同步操作的话,应该使用isolate开辟新的线程去执行。
作者:单总不会亏待你
链接:https://juejin.cn/post/7025200193729462302
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
动图图解GC算法 - 让垃圾回收动起来!
提到Java中的垃圾回收,我相信很多小伙伴和我一样,第一反应就是面试必问了,你要是没背过点GC算法、收集器什么的知识,出门都不敢说自己背过八股文。说起来还真是有点尴尬,工作中实际用到这方面知识的场景真是不多,并且这东西学起来也很枯燥,但是奈何面试官就是爱问,我们能有什么办法呢?
既然已经卷成了这样,不学也没有办法,Hydra牺牲了周末时间,给大家画了几张动图,希望通过这几张图,能够帮助大家对垃圾收集算法有个更好的理解。废话不多说,首先还是从基础问题开始,看看怎么判断一个对象是否应该被回收。
判断对象存活
垃圾回收的根本目的是利用一些算法进行内存的管理,从而有效的利用内存空间,在进行垃圾回收前,需要判断对象的存活情况,在jvm中有两种判断对象的存活算法,下面分别进行介绍。
1、引用计数算法
在对象中添加一个引用计数器,每当有一个地方引用它时计数器就加 1,当引用失效时计数器减 1。当计数器为0的时候,表示当前对象可以被回收。
这种方法的原理很简单,判断起来也很高效,但是存在两个问题:
堆中对象每一次被引用和引用清除时,都需要进行计数器的加减法操作,会带来性能损耗
当两个对象相互引用时,计数器永远不会0。也就是说,即使这两个对象不再被程序使用,仍然没有办法被回收,通过下面的例子看一下循环引用时的计数问题:
public void reference(){
A a = new A();
B b = new B();
a.instance = b;
b.instance = a;
}引用计数的变化过程如下图所示:
可以看到,在方法执行完成后,栈中的引用被释放,但是留下了两个对象在堆内存中循环引用,导致了两个实例最后的引用计数都不为0,最终这两个对象的内存将一直得不到释放,也正是因为这一缺陷,使引用计数算法并没有被实际应用在gc过程中。
2、可达性分析算法
可达性分析算法是jvm默认使用的寻找垃圾的算法,需要注意的是,虽然说的是寻找垃圾,但实际上可达性分析算法寻找的是仍然存活的对象。至于这样设计的理由,是因为如果直接寻找没有被引用的垃圾对象,实现起来相对复杂、耗时也会比较长,反过来标记存活的对象会更加省时。
可达性分析算法的基本思路就是,以一系列被称为GC Roots的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,证明该对象不再存活,可以作为垃圾被回收。
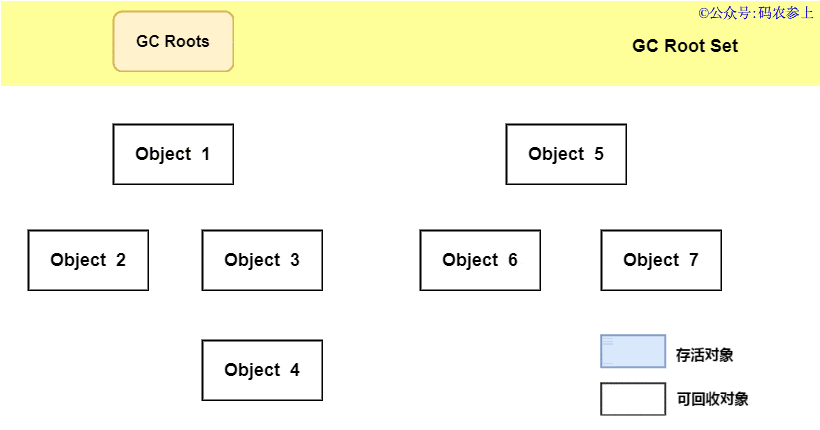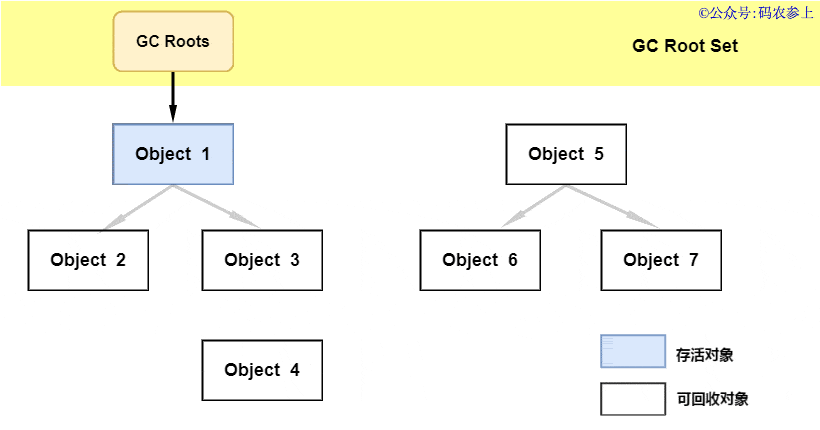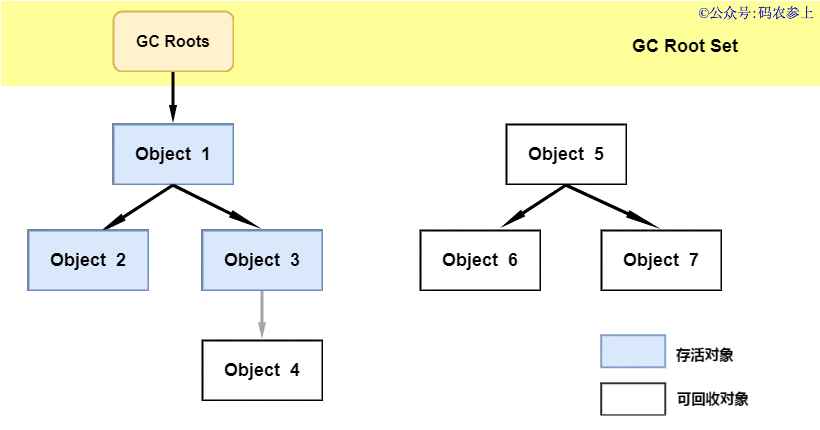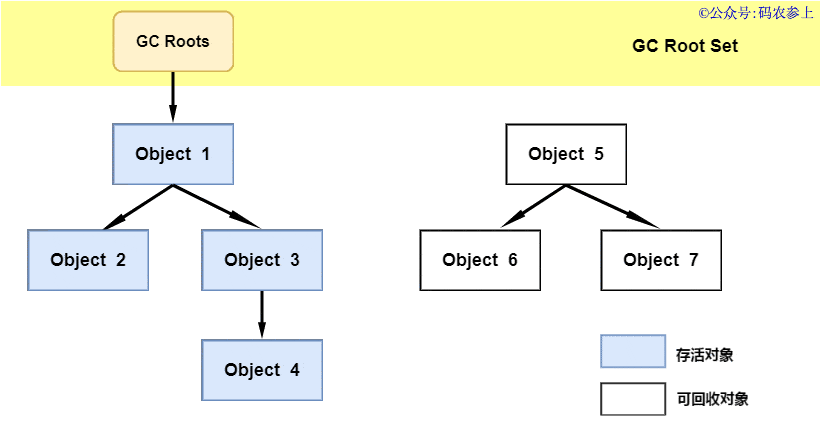
在java中,可作为GC Roots的对象有以下几种:
在虚拟机栈(栈帧的本地变量表)中引用的对象
在方法区中静态属性引用的对象
在方法区中常量引用的对象
在本地方法栈中JNI(
native方法)引用的对象jvm内部的引用,如基本数据类型对应的Class对象、一些常驻异常对象等,及系统类加载器
被同步锁
synchronized持有的对象引用反映jvm内部情况的
JMXBean、JVMTI中注册的回调本地代码缓存等此外还有一些临时性的GC Roots,这是因为垃圾收集大多采用分代收集和局部回收,考虑到跨代或跨区域引用的对象时,就需要将这部分关联的对象也添加到GC Roots中以确保准确性
其中比较重要、同时提到的比较多的还是前面4种,其他的简单了解一下即可。在了解了jvm是如何寻找垃圾对象之后,我们来看一看不同的垃圾收集算法的执行过程是怎样的。
垃圾收集算法
1、标记-清除算法
标记清除算法是一种非常基础的垃圾收集算法,当堆中的有效内存空间耗尽时,会触发STW(stop the world),然后分标记和清除两阶段来进行垃圾收集工作:
标记:从GC Roots的节点开始进行扫描,对所有存活的对象进行标记,将其记录为可达对象
清除:对整个堆内存空间进行扫描,如果发现某个对象未被标记为可达对象,那么将其回收
通过下面的图,简单的看一下两阶段的执行过程:
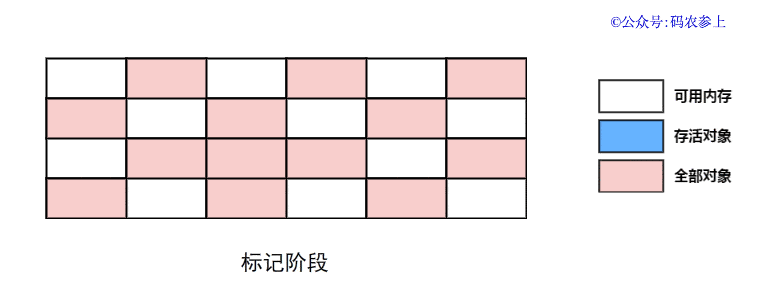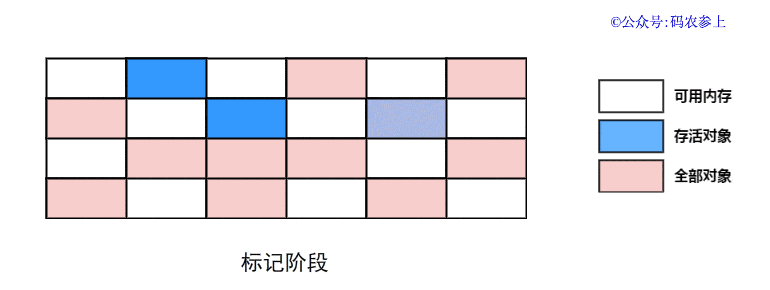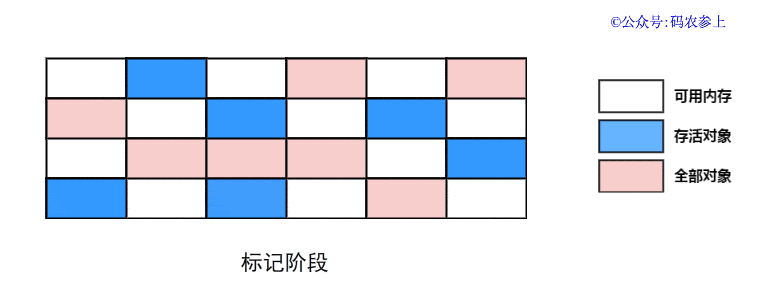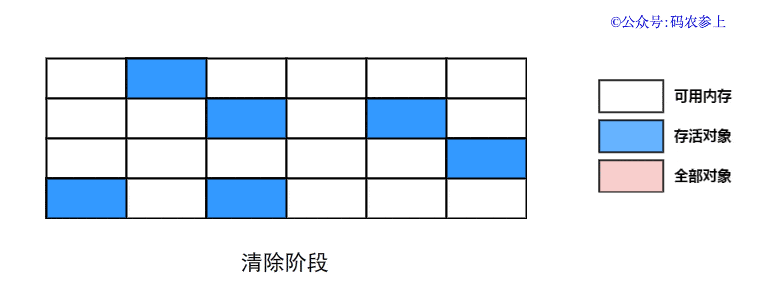
但是这种算法会带来几个问题:
在进行GC时会产生STW,停止整个应用程序,造成用户体验较差
标记和清除两个阶段的效率都比较低,标记阶段需要从根集合进行扫描,清除阶段需要对堆内所有的对象进行遍历
仅对非存活的对象进行处理,清除之后会产生大量不连续的内存碎片。导致之后程序在运行时需要分配较大的对象时,无法找到足够的连续内存,会再触发一次新的垃圾收集动作
此外,jvm并不是真正的把垃圾对象进行了遍历,把内部的数据都删除了,而是把垃圾对象的首地址和尾地址进行了保存,等到再次分配内存时,直接去地址列表中分配,通过这一措施提高了一些标记清除算法的效率。
2、复制算法
复制算法主要被应用于新生代,它将内存分为大小相同的两块,每次只使用其中的一块。在任意时间点,所有动态分配的对象都只能分配在其中一个内存空间,而另外一个内存空间则是空闲的。复制算法可以分为两步:
当其中一块内存的有效内存空间耗尽后,jvm会停止应用程序运行,开启复制算法的gc线程,将还存活的对象复制到另一块空闲的内存空间。复制后的对象会严格按照内存地址依次排列,同时gc线程会更新存活对象的内存引用地址,指向新的内存地址
在复制完成后,再把使用过的空间一次性清理掉,这样就完成了使用的内存空间和空闲内存空间的对调,使每次的内存回收都是对内存空间的一半进行回收
通过下面的图来看一下复制算法的执行过程:
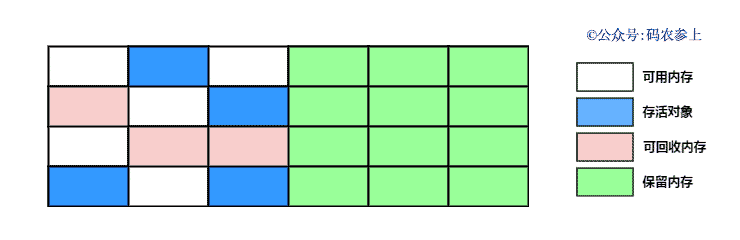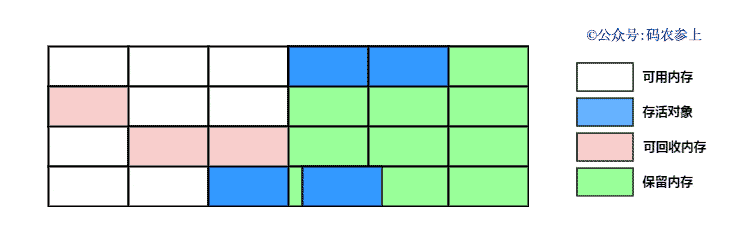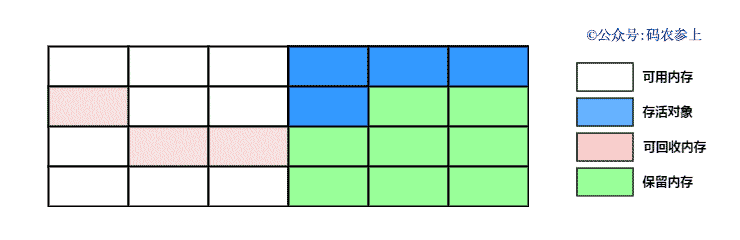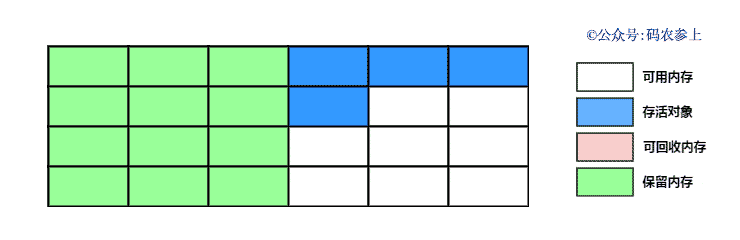
复制算法的的优点是弥补了标记清除算法中,会出现内存碎片的缺点,但是它也同样存在一些问题:
只使用了一半的内存,所以内存的利用率较低,造成了浪费
如果对象的存活率很高,那么需要将很多对象复制一遍,并且更新它们的应用地址,这一过程花费的时间会非常的长
从上面的缺点可以看出,如果需要使用复制算法,那么有一个前提就是要求对象的存活率要比较低才可以,因此,复制算法更多的被用于对象“朝生暮死”发生更多的新生代中。
3、标记-整理算法
标记整理算法和标记清除算法非常的类似,主要被应用于老年代中。可分为以下两步:
标记:和标记清除算法一样,先进行对象的标记,通过GC Roots节点扫描存活对象进行标记
整理:将所有存活对象往一端空闲空间移动,按照内存地址依次排序,并更新对应引用的指针,然后清理末端内存地址以外的全部内存空间
标记整理算法的执行过程如下图所示:
可以看到,标记整理算法对前面的两种算法进行了改进,一定程度上弥补了它们的缺点:
相对于标记清除算法,弥补了出现内存空间碎片的缺点
相对于复制算法,弥补了浪费一半内存空间的缺点
但是同样,标记整理算法也有它的缺点,一方面它要标记所有存活对象,另一方面还添加了对象的移动操作以及更新引用地址的操作,因此标记整理算法具有更高的使用成本。
4、分代收集算法
实际上,java中的垃圾回收器并不是只使用的一种垃圾收集算法,当前大多采用的都是分代收集算法。jvm一般根据对象存活周期的不同,将内存分为几块,一般是把堆内存分为新生代和老年代,再根据各个年代的特点选择最佳的垃圾收集算法。主要思想如下:
新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要复制少量对象以及更改引用,就可以完成垃圾收集
老年代中,对象存活率比较高,使用复制算法不能很好的提高性能和效率。另外,没有额外的空间对它进行分配担保,因此选择标记清除或标记整理算法进行垃圾收集
通过图来简单看一下各种算法的主要应用区域:
至于为什么在某一区域选择某种算法,还是和三种算法的特点息息相关的,再从3个维度进行一下对比:
执行效率:从算法的时间复杂度来看,复制算法最优,标记清除次之,标记整理最低
内存利用率:标记整理算法和标记清除算法较高,复制算法最差
内存整齐程度:复制算法和标记整理算法较整齐,标记清除算法最差
尽管具有很多差异,但是除了都需要进行标记外,还有一个相同点,就是在gc线程开始工作时,都需要STW暂停所有工作线程。
总结
本文中,我们先介绍了垃圾收集的基本问题,什么样的对象可以作为垃圾被回收?jvm中通过可达性分析算法解决了这一关键问题,并在它的基础上衍生出了多种常用的垃圾收集算法,不同算法具有各自的优缺点,根据其特点被应用于各个年代。
虽然这篇文章唠唠叨叨了这么多,不过这些都还是基础的知识,如果想要彻底的掌握jvm中的垃圾收集,后续还有垃圾收集器、内存分配等很多的知识需要理解,不过我们今天就介绍到这里啦,希望通过这一篇图解,能够帮助大家更好的理解垃圾收集算法。
来源:mp.weixin.qq.com/s/DvPaMfn7xEKIilv-_Ojk8g
收起阅读 »裸辞回家遇见了她
22年,连续跳了二三家公司,辗转七八个城市。
可能还是太年轻,工作上特别急躁,加班太多会觉得太累,没事情做又觉得无聊烦躁。去年年末回老家过年因为一些巧合遇见了她。年初就润,回到了老家。当时因为苏州疫情就没回去,就开始在老家这边的坎坷之旅。
年初千里见网友
说起来也是缘分,去年年末的时候,一个人加了我微信,当时也是一头雾水,还以为是传销或者什么。一看名字微信名:“xxx”,也不像是啊。当时没放在心上就随便聊了聊,也没咋放心上。后来我朋友告诉我他推的(因为觉得我挺清秀人品也还行),就把她推给了我。但是我这人自卑又社恐,加上她在我老家那边,就想反正自己好多年也不想回老家那个地方。现在即使网恋也是耽误人家,后面就没咋搭理她。
到过年的时候,我和我妈匆匆忙忙回到了老家,当时家里宅基地刚好重建装修完,背了一屁股的债务,当时很多人劝我不要建房子在老家,有钱直接在省会那边付个首付也比老家强,可我一直觉得这个房子是我奶奶心心念念了一辈子的事情,一辈人有一辈人的使命。最多就是自己在多奋斗几年就没多去计较。
后面过年期间,我和她某明奇妙的聊起来了,可能是我觉得离她近了就有一丝丝念想吧,当时因为一些特殊原因,过年的时候她也在上班。那几天基本每天从早聊到晚,稍微有点暧昧,之后还一起玩游戏,玩了几局,我也很菜没能赢。这样算是更深一步了解她吧,当时也不好断定她是怎样的人。就觉得她很温柔、活泼、可爱、直爽,后面想了想好像很久好久没用遇到这样的女孩子了吧,前几年也遇到不少女孩子都没有这种感觉。是不是自己单身太久产生的幻觉。经过一段时间的发酵我向我朋友打听了下她。
我朋友说人品没问题,就是有点矮,我想着女孩子没啥影响,反正我也矮。就决定去见见她,她也没拒绝我。缘分到了如果不抓住的话也不知道下一次是什么时候。其实那时候我们还只是看过照片,彼此感觉都是那种一般人,到了这个年纪(毕业二三年)其实都不是太在乎颜值,只有不是丑得不能见人(颜值好的话肯定是加分项)。虽然我们都在老家她兼职那边还是有点远,需要转很多车,但也没什么,也许这就是大多数人奔现的样子吧(但我心里是比较排斥这个词的)。
那天早上一大早我就急冲冲起来了,洗个了头,吹了个自认为很帅的发型,戴上小围巾就出发了(那晚上其实下了很大的雪)。因为老家比较远我都比较害怕那边没有班车,因为当时才大年初三,我们那边的习俗是过年几天不跑车,跑车一年的财运都会受影响。果然没让我失望,路上一辆车都没有。也是运气好,我前几天刚好听到我表姐说要去城里,我就问了问,果真就今天去(就觉得很巧合,跟剧本一样),他们把我送到高铁站,道了个谢,就跑去赶了最早一班的高铁。
怀着忐忑的心情出发了,那时差不多路上就是这个样子吧(手机里视频传不上去)。
在路上的时候她一直强调说自己这样不行,那样不可以怕我嫌弃,我当时倒是不自卑,直接对人家就是一顿安慰。到了省会那边,又辗转几个地方去买花,那时过年基本没什么花店开门。转了几个大的花店市场才发现一家花店,订了一束不大不小的花, 又去超市买了个玩偶和巧克力,放了几颗德芙在衣服包里面(小心机)。前前后后忙完这些已经下午一点了,对比下行程,可能有点赶不上车了。匆忙坐了班车到了她上班那个市区 ,本以为一切都会很顺利,结果到了那边转车的班车停运了,当时其实是迷茫的。不知道要不要住宿等到第二天。
那时我想起本来就是一腔热情才跑过来的,也许过了那个劲就不会有那个动力去面对了,心里默想:“所爱隔山海,山海皆可平”。心疼的打了个车花了差不多五百块(大冤种过年被宰)。就这样踏上最后一段路程。路上见到不一样的山峰,矮而尖而且很密集,那个司机天眼好像就是建筑在这边吧,我想着:即使人家见了我嫌弃我这段旅行也算很划算的吧。最终晚上七点到达了目的地,下车了还是有点紧张,我害怕她不喜欢我这样的,毕竟了解不多,也许就是你一厢情愿的认为这就是缘分和命运的安排。
终将相遇
最后一刻,我都还在想,她会不会看到我就跑了,然后不来见我。但应该不至于此,毕竟我相信我的老朋友(七年死党),也相信她的人品。我看见一个人从前面走来我还以为是她,都准备迎上去了,走近一看咋是个阿姨(吓我一跳还以为被骗了),等我反应过来那个阿姨已经走远了。然后一个声音从我对面传来:“我在这,我在这边”,我转头过去惊艳到我了,这这这是本人吗?短发到肩部,用蝴蝶结将一些头发丝束起,一身长白棉袄,精致的脸蛋。我还来不及细想,我就迎了过去,提前想好的台词都没有说出来,倒是显得有一些尴尬。
当时就开始自卑觉得,自己配不上她。寒暄了几句我将花递给她,没有惊喜的表情,只有一句:我都没给你准备什么礼物,你这样我会很不好意思的,她这样说我该是开心还是难过呢?我心里觉得大概要凉了。就怕一句:你是个好人,我们就这样吧。其实当时我们也没说啥喜欢啥的就是有点暧昧。所幸没有发生她嫌弃我的事情,我们延着路边一路闲聊下去,一开始我还有点拘谨,毕竟常年当程序员社交能力就不是很行。
慢慢的,我们说了很多很多,她请我吃了个饭(之前说过请她没倔过她),一路走着走着,说着大学的事,小时候的事,已经工作的事,一时间显得我们不是陌生人,而是多年未见的好友,一下子就觉得很轻松很幸福,反正我已经深深的迷上她的人美心善。她也说了离家老远跑来这边上班的原因(不方便透露)。走着走着我发现她的手有点红,就说道:我还给你准备了个惊喜,把手伸进我衣服包里吧,我在里面放了几颗糖,上班那么辛苦有点糖就不苦了。后面我有点唐突抓住她的手,我说给她暖一下太冰了。她说放我包里就暖和了,我看她脸都红了,也觉得有点唐突了。后面发现还是太冰了,没多想就用牵住了她,嘿嘿!她直接害羞的低下了头。一下子幸福感就涌上来了。
后面很晚的时候要分别了,送他回了宿舍,并把包里的玩偶,剩下的零食一并给了她。她说第二天来送我。
第二天我们两随便吃了点东西(依旧很害羞没敢坐我对面);就送我上车了,临走时送了我一个发带,并对我说:我们有缘再见。也许是想着我在苏州她在遵义太远了吧,可能就是最后一面了,有点伤心也没多问。
感情生活波折
回去的第二天我便回到苏州那边,但是很久之前就谋划着辞职,一方面是觉得在这边技术得不到提升,一方面是觉得想换个环境吧,毕竟这边太闲了让我找不到价值。可能年轻急躁当时没多想就直接裸辞了,期间我对她说:我辞职后来看她,她有点不愿意(说感觉我们的感情有点空中楼阁),可能觉得一面不足以确定什么吧,我可能觉得给不了他幸福也舍不得割舍吧。
后面裸辞后,蹭着苏州没有因为疫情封禁,直接带了二件衣服就回了老家。(具体细节不说了)
第二次见她,可能觉得有点陌生吧,不过慢慢的就过了那个尴尬期,我们一起去逛公园、去逛街、彼此送小礼物、一起吃饭,即使现在回来依旧觉得很美好。但是我依旧没有表白,可能我觉得这些事顺理成章的不需要。一次巧合我去了她家帮她做家务、洗头、做饭。哈哈哈,像一个家庭主男一样。可能就是那次她才真的喜欢上我的吧。
有一次见面之后因为一些很严重的事我们吵架了,本来以为就要在此结束了。后来我又去见她了,我觉得女孩子有什么顾虑很正常的,也许是不够喜欢啥的,准备最后见一面吧,但见面之后准备好的说辞一句没说还是像原来那样相处,一下子心里就有点矛盾,后面敞开心扉说开了心里纠结的问题也就解决了。慢慢的我们也彼此接受了,从一见钟情到建立关系,真的经历很多东西。不管是少了那一段经历我和她都不会有以后。我的果决她的温柔都是缺一不可的。
后续
她考研上岸,我离开苏州在贵阳上班。我们依旧还有很长一段路要走。后续把工作篇发出来(干web前端的)
作者:辰酒
来源:juejin.cn/post/7137973046563831838
android 自定义View: 视差动画
废话不多说,先来看今天要完成的效果:
在上一篇:android setContentView()解析中我们介绍了,如何通过Factory2来自己解析View,
那么我们就通过这个机制,来完成今天的效果《视差动画》,
回顾
先来回顾一下如何在Fragment中自己解析View
class MyFragment : Fragment(), LayoutInflater.Factory2 {
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?,
): View {
val newInflater = inflater.cloneInContext(activity)
LayoutInflaterCompat.setFactory2(newInflater, this)
return newInflater.inflate(R.layout.my_fragment, container, false)
}
// 重写Factory2的方法
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet,
): View? {
val view = createView(parent, name, context, attrs)
// 此时的view就是自己创建的view!
// ...................
return view
}
// 重写Factory2的方法
override fun onCreateView(name: String, context: Context, attrs: AttributeSet): View? {
return onCreateView(null, name, context, attrs)
}
// SystemAppCompatViewInflater() 复制的系统源码
private var mAppCompatViewInflater = SystemAppCompatViewInflater()
private fun createView(
parent: View?, name: String?, mContext: Context,
attrs: AttributeSet,
): View? {
val is21 = Build.VERSION.SDK_INT < 21
// 自己去解析View
return mAppCompatViewInflater.createView(parent, name, mContext, attrs, false,
is21, /* Only read android:theme pre-L (L+ handles this anyway) */
true, /* Read read app:theme as a fallback at all times for legacy reasons */
false /* Only tint wrap the context if enabled */
)
}
}
如果对这段代码有兴趣的,可以去看 上一篇:android setContentView()解析,
思路分析
viewpager + fragment
自定义属性:
- 旋转: parallaxRotate
- 缩放 : parallaxZoom
- 出场移动:parallaxTransformOutX,parallaxTransformOutY
- 入场移动:parallaxTransformInX,parallaxTransformInY
给需要改变变换的view设置属性
在fragment的时候自己创建view,并且通过AttributeSet解析所有属性
将需要变换的view保存起来,
在viewpager滑动过程中,通过addOnPageChangeListener{} 来监听viewpager变化,当viewpager变化过程中,设置对应view对应变换即可!
viewPager+Fragment
首先先实现最简单的viewpager+Fragment
代码块1.1
class ParallaxBlogViewPager(context: Context, attrs: AttributeSet?) : ViewPager(context, attrs) {
fun setLayout(fragmentManager: FragmentManager, @LayoutRes list: ArrayList<Int>) {
val listFragment = arrayListOf<C3BlogFragment>()
// 加载fragment
list.map {
C3BlogFragment.instance(it)
}.forEach {
listFragment.add(it)
}
adapter = ParallaxBlockAdapter(listFragment, fragmentManager)
}
private inner class ParallaxBlockAdapter(
private val list: List<Fragment>,
fm: FragmentManager
) : FragmentPagerAdapter(fm) {
override fun getCount(): Int = list.size
override fun getItem(position: Int) = list[position]
}
}
C3BlogFragment:
代码块1.2
class C3BlogFragment private constructor() : Fragment(), LayoutInflater.Factory2 {
companion object {
@NotNull
private const val LAYOUT_ID = "layout_id"
fun instance(@LayoutRes layoutId: Int) = let {
C3BlogFragment().apply {
arguments = bundleOf(LAYOUT_ID to layoutId)
}
}
}
private val layoutId by lazy {
arguments?.getInt(LAYOUT_ID) ?: -1
}
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?,
): View {
val newInflater = inflater.cloneInContext(activity)
LayoutInflaterCompat.setFactory2(newInflater, this)
return newInflater.inflate(layoutId, container, false)
}
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet,
): View? {
val view = createView(parent, name, context, attrs)
/// 。。。 在这里做事情。。。
return view
}
private var mAppCompatViewInflater = SystemAppCompatViewInflater()
override fun onCreateView(name: String, context: Context, attrs: AttributeSet): View? {
return onCreateView(null, name, context, attrs)
}
private fun createView(
parent: View?, name: String?, mContext: Context,
attrs: AttributeSet,
): View? {
val is21 = Build.VERSION.SDK_INT < 21
return mAppCompatViewInflater.createView(parent, name, mContext, attrs, false,
is21,
true,
false
)
}
}
这个fragment目前的作用就是接收传过来的布局,展示,
并且自己解析view即可!
xml与调用:
R.layout.c3_1.item,这些布局很简单,就是
- 一张静态图片
- 一张动态图片
其他的布局都是一样的,这里就不看了.
来看看当前的效果
自定义属性
通常我们给一个view自定义属性,我们会选择在attrs.xml 中来进行,例如这样:
但是很明显,这么做并不适合我们的场景,因为我们想给任何view都可以设置属性,
那么我们就可以参考ConstraintLayout中的自定义属性:
我们自己定义属性:
并且给需要变换的view设置值
- app:parallaxRotate="10" 表示在移动过程中旋转10圈
- app:parallaxTransformInY="0.5" 表示入场的时候,向Y轴方向偏移 height * 0.5
- app:parallaxZoom="1.5" 表示移动过程中慢慢放大1.5倍
Fragment中解析自定义属性
我们都知道,所有的属性都会存放到AttributeSet中,先打印看一看:
(0 until attrs.attributeCount).forEach {
Log.i("szj属性",
"key:${attrs.getAttributeName(it)}\t" +
"value:${attrs.getAttributeValue(it)}")
}
这样一来就可以打印出所有的属性,并且找到需要用的属性!
那么接下来只需要将这些属性保存起来,在当viewpager滑动过程中取出用即可!
这里我们的属性是保存到view的tag中,
需要注意的是,如果你的某一个view需要变换,那么你的view就一定得设置一个id,因为这里是通过id来存储tag!
监听ViewPager滑动事件
# ParallaxBlogViewPager.kt
// 监听变化
addOnPageChangeListener(object : OnPageChangeListener {
// TODO 滑动过程中一直回调
override fun onPageScrolled(
position: Int,
positionOffset: Float,
positionOffsetPixels: Int,
) {
Log.e("szjParallaxViewPager",
"onPageScrolled:position:$position\tpositionOffset:${positionOffset}\tpositionOffsetPixels:${positionOffsetPixels}")
}
//TODO 当页面切换完成时候调用 返回当前页面位置
override fun onPageSelected(position: Int) {
Log.e("szjParallaxViewPager", "onPageSelected:$position")
}
//
override fun onPageScrollStateChanged(state: Int) {
when (state) {
SCROLL_STATE_IDLE -> {
Log.e("szjParallaxViewPager", "onPageScrollStateChanged:页面空闲中..")
}
SCROLL_STATE_DRAGGING -> {
Log.e("szjParallaxViewPager", "onPageScrollStateChanged:拖动中..")
}
SCROLL_STATE_SETTLING -> {
Log.e("szjParallaxViewPager", "onPageScrollStateChanged:拖动停止了..")
}
}
}
})
这三个方法介绍一下:
onPageScrolled(position:Int , positionOffset:Float, positionOffsetPixels)
@param position: 当前页面下标@param positionOffset:当前页面滑动百分比@param positionOffsetPixels: 当前页面滑动的距离
在这个方法中需要注意的是,当假设当前是第0个页面,从左到右滑动,
- position = 0
- positionOffset = [0-1]
- positionOffsetPixels = [0 - 屏幕宽度]
当第1个页面的时候,从左到右滑动,和第0个页面的状态都是一样的
但是从第1个页面从右到左滑动的时候就不一样了,此时
- position = 0
- positionOffset = [1-0]
- positionOffsetPixels = [屏幕宽度 - 0]
onPageSelected(position:Int)
@param position: 但页面切换完成的时候调用
onPageScrollStateChanged(state:Int)
@param state:但页面发生变化时候调用,一共有3种状体
- SCROLL_STATE_IDLE 空闲状态
- SCROLL_STATE_DRAGGING 拖动状态
- SCROLL_STATE_SETTLING 拖动停止状态
了解了viewpager滑动机制后,那么我们就只需要在滑动过程中,
获取到刚才在tag种保存的属性,然后改变他的状态即可!
# ParallaxBlogViewPager.kt
// 监听变化
addOnPageChangeListener(object : OnPageChangeListener {
// TODO 滑动过程中一直回调
override fun onPageScrolled(
position: Int,
positionOffset: Float,
positionOffsetPixels: Int,
) {
// TODO 当前fragment
val currentFragment = listFragment[position]
currentFragment.list.forEach { view ->
// 获取到tag中的值
val tag = view.getTag(view.id)
(tag as? C3Bean)?.also {
// 入场
view.translationX = -it.parallaxTransformInX * positionOffsetPixels
view.translationY = -it.parallaxTransformInY * positionOffsetPixels
view.rotation = -it.parallaxRotate * 360 * positionOffset
view.scaleX =
1 + it.parallaxZoom - (it.parallaxZoom * positionOffset)
view.scaleY =
1 + it.parallaxZoom - (it.parallaxZoom * positionOffset)
}
}
// TODO 下一个fragment
// 防止下标越界
if (position + 1 < listFragment.size) {
val nextFragment = listFragment[position + 1]
nextFragment.list.forEach { view ->
val tag = view.getTag(view.id)
(tag as? C3Bean)?.also {
view.translationX =
it.parallaxTransformInX * (width - positionOffsetPixels)
view.translationY =
it.parallaxTransformInY * (height - positionOffsetPixels)
view.rotation = it.parallaxRotate * 360 * positionOffset
view.scaleX = (1 + it.parallaxZoom * positionOffset)
view.scaleY = (1 + it.parallaxZoom * positionOffset)
}
}
}
}
//TODO 当页面切换完成时候调用 返回当前页面位置
override fun onPageSelected(position: Int) {...}
override fun onPageScrollStateChanged(state: Int) { ... }
})
来看看现在的效果:
此时效果就基本完成了
但是一般情况下,引导页面都会在最后一个页面有一个跳转到主页的按钮
为了方便起见,我们只需要将当前滑动到的fragment页面返回即可!
这么一来,我们就可以在layout布局中为所欲为,因为我们可以自定义属性,并且自己解析,可以做任何自己想做的事情!
原创不易,您的点赞与关注就是对我最大的支持!
作者:史大拿
链接:https://juejin.cn/post/7137925163336597517
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter EventBus事件总线的应用
前言
flutter项目中,有许多可以实现跨组件通讯的方案,其中包括InheritedWidget,Notification,EventBus等。本文主要探讨的是EventBus事件总线实现跨组件通讯的方法。
EventBus的简介
EventBus的核心是基于Streams。它允许侦听器订阅事件并允许发布者触发事件,使得不同组件的数据不需要一层层传递,可以直接通过EventBus实现跨组件通讯。
EventBus最主要是通过触发事件和监听事件两项操作来实现不同页面的跨层访问。触发事件是通过fire(event)方法进行,监听事件则是通过on<T>()方法进行的,其中泛型可以传入指定类型,事件总线将进行针对性监听,如果泛型传值为空,则默认监听所有类型的事件:
void fire(event) {
streamController.add(event);
}
Stream<T> on<T>() {
if (T == dynamic) {
return streamController.stream as Stream<T>;
} else {
return streamController.stream.where((event) => event is T).cast<T>();
}
}
EventBus的实际应用
1、在
pubspec.yaml文件中引用eventBus事件总线依赖;
2、创建一个全局的
EventBus实例;
3、使用
fire(event)方法在事件总线上触发一个新事件(触发事件);
4、为事件总线注册一个监听器(监听事件);
5、取消EventBus事件订阅,防止内存泄漏。
// 1、在pubspec.yaml文件中引用eventBus事件总线依赖;
dependencies:
event_bus: ^2.0.0
// 2、创建一个全局的EventBus实例;
EventBus myEventBus = EventBus();
// 3、使用fire(event)方法在事件总线上触发一个新事件(触发事件);
Center(
child: ElevatedButton(
onPressed: () {
myEventBus.fire('通过EventBus触发事件');
},
child: Text('触发事件'),
),
)
var getData;
@override
void initState() {
// TODO: implement initState
super.initState();
// 4、为事件总线注册一个监听器(监听事件);
getData = myEventBus.on().listen((event) {
print(event);
});
}
@override
void dispose() {
// TODO: implement dispose
super.dispose();
// 5、取消EventBus事件订阅,防止内存泄漏。
getData.cancel();
}
总结
EventBus遵循的是发布/订阅模式,能够通过事件的触发和监听操作,有效实现跨组件通讯的功能。
作者:Zheng
链接:https://juejin.cn/post/7137327139061727262
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter 状态管理 | 业务逻辑与构建逻辑分离
1. 业务逻辑和构建逻辑
对界面呈现来说,最重要的逻辑有两个部分:业务数据的维护逻辑 和 界面布局的构建逻辑 。其中应用运行中相关数据的获取、修改、删除、存储等操作,就是业务逻辑。比如下面是秒表的三个界面,核心 数据 是秒表的时刻。在秒表应用执行功能时,数据的变化体现在秒数的变化、记录、重置等。
| 默认情况 | 暂停 | 记录 |
|---|---|---|
界面的构建逻辑主要体现在界面如何布局,维持界面的出现效果。另外,在界面构建过程中,除了业务数据,还有一些数据会影响界面呈现。比如打开秒表时,只有一个启动按钮;在运行中,显示暂停按钮和记录按钮;在暂停时,记录按钮不可用,重置按钮可用。这样在不同的交互场景中,有不同的界面表现,也是构建逻辑处理的一部分。
2. 数据的维护
所以的逻辑本身都是对 数据 的维护,界面能够显示出什么内容,都依赖于数据进行表现。理解需要哪些数据、数据存储在哪里,从哪里来,要传到哪里去,是编程过程中非常重要的一个环节。由于数据需要在构建界面时使用,所以很自然的:在布局写哪里,数据就在哪里维护。
比如默认的计数器项目,其中只有一个核心数据 _counter ,用于表示当前点击的次数。
代码实现时, _counter 数据定义在 _MyHomePageState 中,改数据的维护也在状态类中:
对于一些简单的场景,这样的处理无可厚非。但在复杂的交互场景中,业务逻辑和构建逻辑杂糅在 State 派生类中,会导致代码复杂,逻辑混乱,不便于阅读和维护。
3.秒表状态数据对布局的影响
现在先通过代码来实现如下交互,首先通过 StopWatchType 枚举来标识秒表运行状态。在初始状态 none 时,只有一个开始按钮;点击开始,秒表在运行中,此时显示三个按钮,重置按钮是灰色,不可点击,点击旗子按钮,可以记录当前秒表值;暂停时,旗子按钮不可点击,点击重置按钮时,回到初始态。
enum StopWatchType{
none, // 初始态
stopped, // 已停止
running, // 运行中
}
如下所示,通过 _buildBtnByState 方法根据 StopWatchState 状态值构建底部按钮。根据不同的 state 情况处理不同的显示效果,这就是构建逻辑的体检。而此时的关键数据就是 StopWatchState 对象。
Widget _buildBtnByState(StopWatchType state) {
bool running = state == StopWatchType.running;
bool stopped = state == StopWatchType.stopped;
Color activeColor = Theme.of(context).primaryColor;
return Wrap(
spacing: 20,
children: [
if(state!=StopWatchType.none)
FloatingActionButton(
child: const Icon(Icons.refresh),
backgroundColor: stopped?activeColor:Colors.grey,
onPressed: stopped?reset:null,
),
FloatingActionButton(
child: running?const Icon(Icons.stop):const Icon(Icons.play_arrow_outlined),
onPressed: onTapIcon,
),
if(state!=StopWatchType.none)
FloatingActionButton(
backgroundColor: running?activeColor:Colors.grey,
child: const Icon(Icons.flag),
onPressed: running?onTapFlag:null,
),
],
);
}
这样按照常理,应该在 _HomePageState 中定义 StopWatchType 对象,并在相关逻辑中维护 state 数据的值,如下 tag1,2,3 处:
StopWatchType state = StopWatchState.none;
void reset(){
duration.value = Duration.zero;
setState(() {
state = StopWatchState.none; // tag1
});
}
void onTapIcon() {
if (_ticker.isTicking) {
_ticker.stop();
lastDuration = Duration.zero;
setState(() {
state = StopWatchType.stopped; // tag2
});
} else {
_ticker.start();
setState(() {
state = StopWatchType.running; // tag3
});
}
}
4.秒表记录值的维护
如下所示,在秒表运行时点击旗子,可以记录当前的时刻并显示在右侧:
由于布局界面在 _HomePageState 中,事件的触发也在该类中定义。按照常理,又需要在其中维护 durationRecord 列表数据,进行界面的展现。
List<Duration> durationRecord = [];
final TextStyle recordTextStyle = const TextStyle(color: Colors.grey);
Widget buildRecordeList(){
return ListView.builder(
itemCount: durationRecord.length,
itemBuilder: (_,index)=>Center(child:
Padding(
padding: const EdgeInsets.all(4.0),
child: Text(
durationRecord[index].toString(),style: recordTextStyle,
),
)
));
}
void onTapFlag() {
setState(() {
durationRecord.add(duration.value);
});
}
void reset(){
duration.value = Duration.zero;
durationRecord.clear();
setState(() {
state = StopWatchState.none;
});
}
其实到这里可以发现,随着功能的增加,需要维护的数据会越来越多。虽然全部塞在 _HomePageState 类型访问和修改比较方便,但随着代码的增加,状态类会越来越臃肿。所以分离逻辑在复杂的场景中是非常必要的。
5. 基于 flutter_bloc 的状态管理
状态类的核心逻辑应该在于界面的 构建逻辑,而业务数据的维护,我们可以提取出来。这里通过 flutter_bloc 来将秒表中数据的维护逻辑进行分离,由 bloc 承担。
我们的目的是为 _HomePageState 状态类 "瘦身" ,如下,其中对于数据的处理逻辑都交由 StopWatchBloc 通过 add 相关事件来触发。_HomePageState 自身就无须书写维护业务数据的逻辑,可以在很大程度上减少 _HomePageState 的代码量,从而让状态类专注于界面构建逻辑。
class _HomePageState extends State<HomePage> {
StopWatchBloc get stopWatchBloc => BlocProvider.of<StopWatchBloc>(context);
void onTapIcon() {
stopWatchBloc.add(const ToggleStopWatch());
}
void onTapFlag() {
stopWatchBloc.add(const RecordeStopWatch());
}
void reset() {
stopWatchBloc.add(const ResetStopWatch());
}
首先创建状态类 StopWatchState 来维护这三个数据:
part of 'bloc.dart';
enum StopWatchType {
none, // 初始态
stopped, // 已停止
running, // 运行中
}
class StopWatchState {
final StopWatchType type;
final List<Duration> durationRecord;
final Duration duration;
const StopWatchState({
this.type = StopWatchType.none,
this.durationRecord = const [],
this.duration = Duration.zero,
});
StopWatchState copyWith({
StopWatchType? type,
List<Duration>? durationRecord,
Duration? duration,
}) {
return StopWatchState(
type: type ?? this.type,
durationRecord: durationRecord??this.durationRecord,
duration: duration??this.duration,
);
}
}
然后定义先关的行为事件,比如 ToggleStopWatch 用于开启或暂停秒表;ResetStopWatch 用于重置秒表;RecordeStopWatch 用于记录值。这就是最核心的三个功能:
abstract class StopWatchEvent {
const StopWatchEvent();
}
class ResetStopWatch extends StopWatchEvent{
const ResetStopWatch();
}
class ToggleStopWatch extends StopWatchEvent {
const ToggleStopWatch();
}
class _UpdateDuration extends StopWatchEvent {
final Duration duration;
_UpdateDuration(this.duration);
}
class RecordeStopWatch extends StopWatchEvent {
const RecordeStopWatch();
}
最后在 StopWatchBloc 中监听相关的事件,进行逻辑处理,产出正确的 StopWatchState 状态量。这样就将数据的维护逻辑封装到了 StopWatchBloc 中。
part 'event.dart';
part 'state.dart';
class StopWatchBloc extends Bloc<StopWatchEvent,StopWatchState>{
Ticker? _ticker;
StopWatchBloc():super(const StopWatchState()){
on<ToggleStopWatch>(_onToggleStopWatch);
on<ResetStopWatch>(_onResetStopWatch);
on<RecordeStopWatch>(_onRecordeStopWatch);
on<_UpdateDuration>(_onUpdateDuration);
}
void _initTickerWhenNull() {
if(_ticker!=null) return;
_ticker = Ticker(_onTick);
}
Duration _dt = Duration.zero;
Duration _lastDuration = Duration.zero;
void _onTick(Duration elapsed) {
_dt = elapsed - _lastDuration;
add(_UpdateDuration(state.duration+_dt));
_lastDuration = elapsed;
}
@override
Future<void> close() async{
_ticker?.dispose();
_ticker = null;
return super.close();
}
void _onToggleStopWatch(ToggleStopWatch event, Emitter<StopWatchState> emit) {
_initTickerWhenNull();
if (_ticker!.isTicking) {
_ticker!.stop();
_lastDuration = Duration.zero;
emit(state.copyWith(type:StopWatchType.stopped));
} else {
_ticker!.start();
emit(state.copyWith(type:StopWatchType.running));
}
}
void _onUpdateDuration(_UpdateDuration event, Emitter<StopWatchState> emit) {
emit(state.copyWith(
duration: event.duration
));
}
void _onResetStopWatch(ResetStopWatch event, Emitter<StopWatchState> emit) {
_lastDuration = Duration.zero;
emit(const StopWatchState());
}
void _onRecordeStopWatch(RecordeStopWatch event, Emitter<StopWatchState> emit) {
List<Duration> currentList = state.durationRecord.map((e) => e).toList();
currentList.add(state.duration);
emit(state.copyWith(durationRecord: currentList));
}
}
6. 组件状态类对状态的访问
这样 StopWatchBloc 封装了状态的变化逻辑,那如何在构建时让 组件状态类 访问到 StopWatchState 呢?实现需要在 HomePage 的上层包裹 BlocProvider 来为子节点能访问 StopWatchBloc 对象。
BlocProvider(
create: (_) => StopWatchBloc(),
child: const HomePage(),
),
比如构建表盘是通过 BlocBuilder 替代 ValueListenableBuilder ,这样当状态量 StopWatchState 发生变化是,且满足 buildWhen 条件时,就会 局部构建 来更新 StopWatchWidget 组件 。其他两个部分同理。这样在保证功能的实现下,就对逻辑进行了分离:
Widget buildStopWatch() {
return BlocBuilder<StopWatchBloc, StopWatchState>(
buildWhen: (p, n) => p.duration != n.duration,
builder: (_, state) => StopWatchWidget(
duration: state.duration,
radius: 120,
),
);
}
另外,由于数据已经分离,记录数据已经和 _HomePageState 解除了耦合。这就意味着记录面板可以毫无顾虑地单独分离出来,独立维护。这又进一步简化了 _HomePageState 中的构建逻辑,简化代码,便于阅读,这就是一个良性的反馈链。
到这里,关于通过状态管理如何分离 业务逻辑 和构建逻辑 就介绍的差不多了,大家可以细细品味。其实所有的状态管理库都大同小异,它们的目的不是在于 优化性能 ,而是在于 优化结构层次 。这里用的是 flutter_bloc ,你完全也可以使用其他的状态管理来实现类似的分离。工具千变万化,但思想万变不离其宗。谢谢观看 ~
作者:张风捷特烈
链接:https://juejin.cn/post/7137851060231602184
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter 3.3 正式发布,快来看看有什么新功能吧
Flutter 3.3 正式发布啦,本次更新带来了 Flutter Web、桌面、文本性能处理等相关更新,另外,本次还为 go_router 、DevTools 和 VS Code 扩展引入了更多更新。
Framework
Global Selection
Flutter Web 在之前的版本中,经常会有选择文本时与预期的行为不匹配的情况,因为与 Flutter App 一样,原生 Web 是由 elements 树组成。
在传统的 Web 应用中,开发者可以通过一个拖动手势选择多个 Web 元素,但这在 Flutter Web 上无法轻松完成。
但是从 3.3 开始,随着SelectableArea 的引入, SelectableArea Widget 的任何 Child 都可以自由启用改能力。
要利用这个强大的新特性,只需使用 SelectionArea 嵌套你的页面,比如路由下的 Scaffold,然后让 Flutter 就会完成剩下的工作。
要更全面地深入了解这个新功能,请访问
SelectableAreaAPI
触控板输入
Flutter 3.3 改进了对触控板输入的支持,这不仅提供了更丰富和更流畅的控制逻辑,还减少了某些情况下的错误识别。
举个例子,在 Flutter cookbook 中拖动 UI 元素页面,滚动到页面底部,然后执行以下步骤:
- 缩小窗口大小,使上部呈现滚动条
- 悬停在上部
- 使用触控板滚动
- 在 Flutter 3.3 之前,在触控板上滚动会拖动项目,因为 Flutter 正在调度模拟的一般事件
- Flutter 3.3 后,在触控板上滚动会正确滚动列表,因为 Flutter 提供的是“滚动”手势,卡片无法识别,但滚动可以被识别。
有关更多信息,请参阅 Flutter 触控板手势 设计文档,以及 GitHub 上的以下 PR:
- PR 89944:在框架中支持触控板手势
- PR 31591:iPad 触控板手势
- PR 34060:“ChromeOS/Android 触控板手势”
- PR 31594:Win32 触控板手势
- PR 31592:Linux 触控板手势
- PR 31593:Mac 触控板手势macOS
Scribble
感谢社区成员fbcouch的贡献,Flutter 现在支持在 iPadOS 上使用 Apple Pencil 进行 Scribble 手写输入。
默认情况下,此功能在 CupertinoTextField、TextField 和 EditableText 上启用,启用此功能,只需升级到 Flutter 3.3。
Text input
为了改进对富文本编辑的支持,该版本引入了平台的 TextInputPlugin,以前,TextInputClient 只交付新的编辑状态,没有新旧之间的差异信息,而 TextEditingDeltas 填补了 DeltaTextInputClient 这个信息空白。
通过访问这些增量,开发者可以构建一个带有样式范围的输入字段,该范围在用户键入时会扩展和收缩。
要了解更多信息,请查看富文本编辑器演示。
Material Design 3
Flutter 团队继续将更多 Material Design 3 组件迁移到 Flutter。此版本包括对IconButton、Chips以及AppBar.
要监控 Material Design 3 迁移的进度,请查看GitHub 上的将 Material 3 带到 Flutter。
图标按钮
Chip
Medium and large AppBar
Desktop
Windows
以前,Windows 的版本由特定于 Windows 应用的文件设置,但这个行为与其他平台设置其版本的方式不一致。
但现在开发者可以在项目 pubspec.yaml 文件和构建参数中设置 Windows 桌面应用程序版本。
有关设置应用程序版本的更多信息,请遵循 docs.flutter.dev上的文档和 迁移指南
Packages
go_router
为了扩展 Flutter 的原生导航 API,团队发布了一个新版本的 go_router 包,它的设计使得移动端、桌面端和 Web 端的路由逻辑变得更加简单。
go router包由 Flutter 团队维护,通过提供声明性的、基于 url 的 API 来简化路由,从而更容易导航和处理深层链接。
最新版本 (5.0) 下应用能够使用异步代码进行重定向,并包括迁移指南中描述的其他重大更改.有关更多信息,请查看 docs.flutter.dev 上的导航和路由页面。
VS Code 扩展增强
Flutter 的 Visual Studio Code 扩展有几个更新,包括添加依赖项的改进,开发者现在可以使用Dart: Add Dependency一步添加多个以逗号分隔的依赖项。
Flutter 开发者工具更新
自上一个稳定的 Flutter 版本以来,DevTools 进行了许多更新,包括对数据显示表的 UX 和性能改进,以便更快、更少地滚动大型事件列表 ( #4175 )。
有关 Flutter 3.0 以来更新的完整列表,请在此处查看各个公告:
Performance
光栅缓存改进
此版本通过消除拷贝和减少 Dart 垃圾收集 (GC) 压力来提高从资产加载图像的性能。
以前在加载资产图像时,ImageProvider API 需要多次复制压缩数据,当打开 assets 并将其作为类型化数据数组公开给 Dart 时,它会被复制到 native 堆中,然后当该类型化数据数组会被它被第二次复制到内部 ui.ImmutableBuffer。
通过 #32999,压缩的图像字节可以直接加载到ui.ImmutableBuffer.fromAsset用于解码的结构中,这种方法 需要 更改ImageProviders,这个过程也更快,因为它绕过了先前方法基于通道的加载器所需的一些额外的调度开销,特别是在我们的微基准测试中,图像加载时间提高了近 2 倍。
有关更多信息和迁移指南,请参阅在 docs.flutter.dev 上ImageProvider.loadBuffer 。
Stability
iOS 指针压缩已禁用
在 2.10 稳定版本中,我们在 iOS 上启用了 Dart 的指针压缩优化,然而 GitHub 上的Yeatse提醒我们 优化的结果并不好。
Dart 的指针压缩通过为 Dart 的堆保留一个大的虚拟内存区域来工作,由于 iOS 上允许的总虚拟内存分配少于其他平台,因此这一大预留量减少了可供其他保留自己内存的组件使用的内存量,例如 Flutter 插件。
虽然禁用指针压缩会增加 Dart 对象消耗的内存,但它也增加了 Flutter 应用程序的非 Dart 部分的可用内存,这总体上更可取的方向。
Apple 提供了一项可以增加应用程序允许的最大虚拟内存分配的权利,但是此权利仅在较新的 iOS 版本上受支持,目前这并且不适用于运行 Flutter 仍支持的 iOS 版本的设备。
API 改进
PlatformDispatcher.onError
在以前的版本中,开发者必须手动配置自定义 Zone 项才能捕获应用程序的所有异常和错误,但是自定义 Zone 对 Dart 核心库中的一些优化是有害的,这会减慢应用程序的启动时间。
在此版本中,开发者可以通过设置回调来捕获所有错误和异常,而不是使用自定义。
有关更多信息,请查看docs.flutter.dev 上 Flutter 页面中更新的 PlatformDispatcher.onError
FragmentProgram changes
用 GLSL 编写并在 shaders: 应用文件的 Flutter 清单中列出的片段着色器,pubspec.yaml 现在将自动编译为引擎可以理解的正确格式,并作为 assets 与应用捆绑在一起。
通过此次更改,开发者将不再需要使用第三方工具手动编译着色器,未来应该是将 Engine 的FragmentProgram API 视为仅接受 Flutter 构建工具的输出,当然目前还没有这种情况,但计划在未来的版本中进行此更改,如 FragmentProgram API 支持改进设计文档中所述。
有关此更改的示例,请参阅此Flutter 着色器示例。
Fractional translation
以前,Flutter Engine 总是将 composited layers 与精确的像素边界对齐,因为它提高了旧款(32 位)iPhone 的渲染性能。
自从添加桌面支持以来,我们注意到这导致了可观察到的捕捉行为,因为屏幕设备像素比通常要低得多,例如,在低 DPR 屏幕上,可以看到工具提示在淡入时明显捕捉。
在确定这种像素捕捉对于新 iPhone 型号的性能不再必要后,#103909 从 Flutter 引擎中删除了这种像素捕捉以提高桌面保真度。
此外,我们还发现,去除这种像素捕捉可以稳定我们的一些黄金图像测试,这些测试会经常随着细微的细线渲染差异而改变。
对支持平台的更改
32 位 iOS 弃用
正如我们之前在3.0 版本里宣布的一样 ,由于使用量减少,该版本是最后一个支持 32 位 iOS 设备和 iOS 版本 9 和 10的版本。
此更改影响 iPhone 4S、iPhone 5、iPhone 5C 以及第 2、3d 和第 4 代 iPad 设备。
Flutter 3.3 稳定版本和所有后续稳定版本不再支持 32 位 iOS 设备以及 iOS 9 和 10 版本,这意味着基于 Flutter 3.3 及更高版本构建的应用程序将无法在这些设备上运行。
停用 macOS 10.11 和 10.12
在 2022 年第四季度稳定版本中,我们预计将放弃对 macOS 版本 10.11 和 10.12 的支持。
这意味着在那之后针对稳定的 Flutter SDK 构建的应用程序将不再在这些版本上运行,并且 Flutter 支持的最低 macOS 版本将增加到 10.13 High Sierra。
Bitcode deprecation
在即将发布的 Xcode 14 版本中,iOS 应用程序提交将不再接受 Bitcode ,并且启用了 bitcode 的项目将在此版本的 Xcode 中发出构建警告。鉴于此,Flutter 将在未来的稳定版本中放弃对位码的支持。
默认情况下,Flutter 应用程序没有启用 Bitcode,我们预计这不会影响许多开发人员。
但是,如果你在 Xcode 项目中手动启用了 bitcode,请在升级到 Xcode 14 后立即禁用它,可以通过打开 ios/Runner.xcworkspace 构建设置Enable Bitcode并将其设置为No来做到这一点,Add-to-app 开发者应该在宿主 Xcode 项目中禁用它。
作者:恋猫de小郭
链接:https://juejin.cn/post/7137845252139778084
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
前端主题切换方案
前端主题切换方案
现在我们经常可以看到一些网站会有类似
暗黑模式/白天模式的主题切换功能,效果也是十分炫酷,在平时的开发场景中也有越来越多这样的需求,这里大致罗列一些常见的主题切换方案并分析其优劣,大家可根据需求综合分析得出一套适用的方案。
方案1:link标签动态引入
其做法就是提前准备好几套CSS主题样式文件,在需要的时候,创建link标签动态加载到head标签中,或者是动态改变link标签的href属性。
表现效果如下:
网络请求如下:
优点:
实现了按需加载,提高了首屏加载时的性能
缺点:
动态加载样式文件,如果文件过大网络情况不佳的情况下可能会有加载延迟,导致样式切换不流畅
如果主题样式表内定义不当,会有优先级问题
各个主题样式是写死的,后续针对某一主题样式表修改或者新增主题也很麻烦
方案2:提前引入所有主题样式,做类名切换
这种方案与第一种比较类似,为了解决反复加载样式文件问题提前将样式全部引入,在需要切换主题的时候将指定的根元素类名更换,相当于直接做了样式覆盖,在该类名下的各个样式就统一地更换了。其基本方法如下:
/* day样式主题 */
body.day .box {
color: #f90;
background: #fff;
}
/* dark样式主题 */
body.dark .box {
color: #eee;
background: #333;
}
.box {
width: 100px;
height: 100px;
border: 1px solid #000;
}<div class="box">
<p>hello</p>
</div>
<p>
选择样式:
<button onclick="change('day')">day</button>
<button onclick="change('dark')">dark</button>
</p>function change(theme) {
document.body.className = theme;
}表现效果如下:
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
缺点:
首屏加载时会牺牲一些时间加载样式资源
如果主题样式表内定义不当,也会有优先级问题
各个主题样式是写死的,后续针对某一主题样式表修改或者新增主题也很麻烦
方案小结
通过以上两个方案,我们可以看到对于样式的加载问题上的考量就类似于在纠结是做SPA单页应用还是MPA多页应用项目一样。两种其实都误伤大雅,但是最重要的是要保证在后续的持续开发迭代中怎样会更方便。因此我们还可以基于以上存在的问题和方案做进一步的增强。
在做主题切换技术调研时,看到了网友的一条建议:
因此下面的几个方案主要是针对变量来做样式切换
方案3:CSS变量+类名切换
灵感参考:Vue3官网
在Vue3官网有一个暗黑模式切换按钮,点击之后就会平滑地过渡,虽然Vue3中也有一个v-bind特性可以实现动态样式绑定,但经过观察以后Vue官网并没有采取这个方案,针对Vue3的v-bind特性在接下来的方案中会细说。
大体思路跟方案2相似,依然是提前将样式文件载入,切换时将指定的根元素类名更换。不过这里相对灵活的是,默认在根作用域下定义好CSS变量,只需要在不同的主题下更改CSS变量对应的取值即可。
顺带提一下,在Vue3官网还使用了color-scheme: dark;将系统的滚动条设置为了黑色模式,使样式更加统一。
html.dark {
color-scheme: dark;
}实现方案如下:
/* 定义根作用域下的变量 */
:root {
--theme-color: #333;
--theme-background: #eee;
}
/* 更改dark类名下变量的取值 */
.dark{
--theme-color: #eee;
--theme-background: #333;
}
/* 更改pink类名下变量的取值 */
.pink{
--theme-color: #fff;
--theme-background: pink;
}
.box {
transition: all .2s;
width: 100px;
height: 100px;
border: 1px solid #000;
/* 使用变量 */
color: var(--theme-color);
background: var(--theme-background);
}表现效果如下:
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用var()绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改CSS变量即可,在var()绑定样式变量的地方就会自动更换
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源
方案4:Vue3新特性(v-bind)
虽然这种方式存在局限性只能在Vue开发中使用,但是为Vue项目开发者做动态样式更改提供了又一个不错的方案。
简单用法
<script setup>
// 这里可以是原始对象值,也可以是ref()或reactive()包裹的值,根据具体需求而定
const theme = {
color: 'red'
}
</script>
<template>
<p>hello</p>
</template>
<style scoped>
p {
color: v-bind('theme.color');
}
</style>Vue3中在style样式通过v-bind()绑定变量的原理其实就是给元素绑定CSS变量,在绑定的数据更新时调用CSSStyleDeclaration.setProperty更新CSS变量值。
实现思考
前面方案3基于CSS变量绑定样式是在:root上定义变量,然后在各个地方都可以获取到根元素上定义的变量。现在的方案我们需要考虑的问题是,如果是基于JS层面如何在各个组件上优雅地使用统一的样式变量?
我们可以利用Vuex或Pinia对全局样式变量做统一管理,如果不想使用类似的插件也可以自行封装一个hook,大致如下:
// 定义暗黑主题变量
export default {
fontSize: '16px',
fontColor: '#eee',
background: '#333',
};// 定义白天主题变量
export default {
fontSize: '20px',
fontColor: '#f90',
background: '#eee',
};import { shallowRef } from 'vue';
// 引入主题
import theme_day from './theme_day';
import theme_dark from './theme_dark';
// 定义在全局的样式变量
const theme = shallowRef({});
export function useTheme() {
// 尝试从本地读取
const localTheme = localStorage.getItem('theme');
theme.value = localTheme ? JSON.parse(localTheme) : theme_day;
const setDayTheme = () => {
theme.value = theme_day;
};
const setDarkTheme = () => {
theme.value = theme_dark;
};
return {
theme,
setDayTheme,
setDarkTheme,
};
}使用自己封装的主题hook
<script setup lang="ts">
import { useTheme } from './useTheme.ts';
import MyButton from './components/MyButton.vue';
const { theme } = useTheme();
</script>
<template>
<div class="box">
<span>Hello</span>
</div>
<my-button />
</template>
<style lang="scss">
.box {
width: 100px;
height: 100px;
background: v-bind('theme.background');
color: v-bind('theme.fontColor');
font-size: v-bind('theme.fontSize');
}
</style><script setup lang="ts">
import { useTheme } from '../useTheme.ts';
const { theme, setDarkTheme, setDayTheme } = useTheme();
const change1 = () => {
setDarkTheme();
};
const change2 = () => {
setDayTheme();
};
</script>
<template>
<button class="my-btn" @click="change1">dark</button>
<button class="my-btn" @click="change2">day</button>
</template>
<style scoped lang="scss">
.my-btn {
color: v-bind('theme.fontColor');
background: v-bind('theme.background');
}
</style>表现效果如下:
其实从这里可以看到,跟Vue的响应式原理一样,只要数据发生改变,Vue就会把绑定了变量的地方通通更新。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用v-bind绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改JS变量即可,在v-bind()绑定样式变量的地方就会自动更换
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源
这种方式只要是在组件上绑定了动态样式的地方都会有对应的编译成哈希化的CSS变量,而不像方案3统一地就在:root上设置(不确定在达到一定量级以后的性能),也可能正是如此,Vue官方也并未采用此方式做全站的主题切换
方案5:SCSS + mixin + 类名切换
主要是运用SCSS的混合+CSS类名切换,其原理主要是将使用到mixin混合的地方编译为固定的CSS以后,再通过类名切换去做样式的覆盖,实现方案如下:
定义SCSS变量:
/* 字体定义规范 */
$font_samll:12Px;
$font_medium_s:14Px;
$font_medium:16Px;
$font_large:18Px;
/* 背景颜色规范(主要) */
$background-color-theme: #d43c33;//背景主题颜色默认(网易红)
$background-color-theme1: #42b983;//背景主题颜色1(QQ绿)
$background-color-theme2: #333;//背景主题颜色2(夜间模式)
/* 背景颜色规范(次要) */
$background-color-sub-theme: #f5f5f5;//背景主题颜色默认(网易红)
$background-color-sub-theme1: #f5f5f5;//背景主题颜色1(QQ绿)
$background-color-sub-theme2: #444;//背景主题颜色2(夜间模式)
/* 字体颜色规范(默认) */
$font-color-theme : #666;//字体主题颜色默认(网易)
$font-color-theme1 : #666;//字体主题颜色1(QQ)
$font-color-theme2 : #ddd;//字体主题颜色2(夜间模式)
/* 字体颜色规范(激活) */
$font-active-color-theme : #d43c33;//字体主题颜色默认(网易红)
$font-active-color-theme1 : #42b983;//字体主题颜色1(QQ绿)
$font-active-color-theme2 : #ffcc33;//字体主题颜色2(夜间模式)
/* 边框颜色 */
$border-color-theme : #d43c33;//边框主题颜色默认(网易)
$border-color-theme1 : #42b983;//边框主题颜色1(QQ)
$border-color-theme2 : #ffcc33;//边框主题颜色2(夜间模式)
/* 字体图标颜色 */
$icon-color-theme : #ffffff;//边框主题颜色默认(网易)
$icon-color-theme1 : #ffffff;//边框主题颜色1(QQ)
$icon-color-theme2 : #ffcc2f;//边框主题颜色2(夜间模式)
$icon-theme : #d43c33;//边框主题颜色默认(网易)
$icon-theme1 : #42b983;//边框主题颜色1(QQ)
$icon-theme2 : #ffcc2f;//边框主题颜色2(夜间模式)定义混合mixin:
@import "./variable.scss";
@mixin bg_color(){
background: $background-color-theme;
[data-theme=theme1] & {
background: $background-color-theme1;
}
[data-theme=theme2] & {
background: $background-color-theme2;
}
}
@mixin bg_sub_color(){
background: $background-color-sub-theme;
[data-theme=theme1] & {
background: $background-color-sub-theme1;
}
[data-theme=theme2] & {
background: $background-color-sub-theme2;
}
}
@mixin font_color(){
color: $font-color-theme;
[data-theme=theme1] & {
color: $font-color-theme1;
}
[data-theme=theme2] & {
color: $font-color-theme2;
}
}
@mixin font_active_color(){
color: $font-active-color-theme;
[data-theme=theme1] & {
color: $font-active-color-theme1;
}
[data-theme=theme2] & {
color: $font-active-color-theme2;
}
}
@mixin icon_color(){
color: $icon-color-theme;
[data-theme=theme1] & {
color: $icon-color-theme1;
}
[data-theme=theme2] & {
color: $icon-color-theme2;
}
}
@mixin border_color(){
border-color: $border-color-theme;
[data-theme=theme1] & {
border-color: $border-color-theme1;
}
[data-theme=theme2] & {
border-color: $border-color-theme2;
}
}<template>
<div @click="changeTheme">
<div>
<slot name="left">左边</slot>
</div>
<slot name="center">中间</slot>
<div>
<slot name="right">右边</slot>
</div>
</div>
</template>
<script>
export default {
name: 'Header',
methods: {
changeTheme () {
document.documentElement.setAttribute('data-theme', 'theme1')
}
}
}
</script>
<style scoped lang="scss">
@import "../assets/css/variable";
@import "../assets/css/mixin";
.header{
width: 100%;
height: 100px;
font-size: $font_medium;
@include bg_color();
}
</style>表现效果如下:
可以发现,使用mixin混合在SCSS编译后同样也是将所有包含的样式全部加载:
这种方案最后得到的结果与方案2类似,只是在定义主题时由于是直接操作的SCSS变量,会更加灵活。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用mixin混合绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改SCSS变量即可,经过编译后会将所有主题全部编译出来
缺点:
首屏加载时会牺牲一些时间加载样式资源
方案6:CSS变量+动态setProperty
此方案较于前几种会更加灵活,不过视情况而定,这个方案适用于由用户根据颜色面板自行设定各种颜色主题,这种是主题颜色不确定的情况,而前几种方案更适用于定义预设的几种主题。
方案参考:vue-element-plus-admin
主要实现思路如下:
只需在全局中设置好预设的全局CSS变量样式,无需单独为每一个主题类名下重新设定CSS变量值,因为主题是由用户动态决定。
:root {
--theme-color: #333;
--theme-background: #eee;
}定义一个工具类方法,用于修改指定的CSS变量值,调用的是CSSStyleDeclaration.setProperty
export const setCssVar = (prop: string, val: any, dom = document.documentElement) => {
dom.style.setProperty(prop, val)
}在样式发生改变时调用此方法即可
setCssVar('--theme-color', color)表现效果如下:
vue-element-plus-admin主题切换源码:
这里还用了vueuse的useCssVar不过效果和Vue3中使用v-bind绑定动态样式是差不多的,底层都是调用的CSSStyleDeclaration.setProperty这个api,这里就不多赘述vueuse中的用法。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
仔细琢磨可以发现其原理跟方案4利用Vue3的新特性v-bind是一致的,只不过此方案只在
:root上动态更改CSS变量而Vue3中会将CSS变量绑定到任何依赖该变量的节点上。需要切换主题的地方只用在
:root上动态更改CSS变量值即可,不存在优先级问题新增或修改主题方便灵活
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源(相对于前几种预设好的主题,这种方式的样式定义在首屏加载基本可以忽略不计)
方案总结
说明:两种主题方案都支持并不代表一定是最佳方案,视具体情况而定。
| 方案/主题样式 | 固定预设主题样式 | 主题样式不固定 |
|---|---|---|
| 方案1:link标签动态引入 | √(文件过大,切换延时,不推荐) | × |
| 方案2:提前引入所有主题样式,做类名切换 | √ | × |
| 方案3:CSS变量+类名切换 | √(推荐) | × |
| 方案4:Vue3新特性(v-bind) | √(性能不确定) | √(性能不确定) |
| 方案5:SCSS + mixin + 类名切换 | √(推荐,最终呈现效果与方案2类似,但定义和使用更加灵活) | × |
| 方案6:CSS变量+动态setProperty | √(更推荐方案3) | √(推荐) |
作者:四相前端团队
来源:juejin.cn/post/7134594122391748615
收起阅读 »【视频教程】集成环信Unity SDK教程,附Demo
教程地址:https://www.imgeek.org/video/115
本教程讲述以下两点:
1.跟着文档快速集成环信 IM Unity SDK,实现单聊功能
2.集成SDK时需要注意的点
Demo下载:链接: https://pan.baidu.com/s/1cWsUTO5oZQIWqKw3YyM7EA 密码: 27kn
收起阅读 »只想做开源项目、技术项目,不想做业务,有办法吗?
连续两期视频都有朋友问类似问题:“我只对开源项目、技术项目感兴趣,不想做业务,怎么办?”。
这种工作可能是所有人梦寐以求的,又能提升自己前端技术,又能提升社区知名度,还不用被业务左右。这么好的工作怎么找?今天我们来分析分析~
为什么公司需要做技术项目
首先我们从公司角度看看,为什么公司需要做技术项目?
我们需要先明确一点,公司是逐利的,不管是做技术项目,还是做业务,一定是要给公司带来价值的。业务的价值就不必说了,那技术项目能给公司带来什么价值?
举个知名开源库 ant design 的例子吧~
公司有几千个中后台应用,antd design 组件库的诞生,统一了此类应用的设计风格,同时极大提升了开发效率,对公司来讲,节省了极大的人力成本,这就是技术项目给公司带来的实打实的价值。
技术项目的价值一般是要这么计算的:覆盖了 xx 项目,提升了 xx% 效率,为公司节省了 xx 人力。
你不会以为做 ant design,最终汇报的时候,就是说自己做了 xx 个组件吧~
你不会以为做 ahooks,最终汇报的时候,就是说自己做了 xx 个 Hooks 吧~
所以公司为什么要做技术项目?那就是技术项目能给公司节省成本,带来价值。
为什么公司要把技术项目开源
答案很简单,因为开源能给公司带来价值。那价值是什么?
还是举 ant design 的例子,公司把 ant design 开源之后,收益至少有两部分
借社区无穷的力量,打磨 ant design 组件库,把它里面隐藏的 bug 都捉出来
吸引人才。君不见多少优秀的前端是被 ant design 吸引进去的?
技术项目是怎么诞生的
举几个我熟悉的开源项目,让大家看看技术项目都是怎么诞生的吧。
ahooks
最开始我负责了 N 个中后台项目,整天就是 CRUD,表格表单一把梭。
随着 React Hooks 的诞生,我开始在项目中引入 Hooks,我发现表格的逻辑、网络请求的逻辑都是类似的,可以封装起来,然后就封装了几个原始的 Hooks,在我的 N 个项目中复用。
后来我在组内组外分享了一下,发现大家都有同类诉求,还是很乐意尝试用用我封装的东西的。
再然后我就开始基于我的业务经验,封装了更多好用的 Hooks,一步一步走到了今天。
qiankun
再来讲讲著名微前端框架 qiankun 的诞生故事吧。
大概就是 qiankun 作者负责了一个比较特殊的项目,需要把几十个前端项目组合到一起,类似阿里云那样。这几十个项目都使用不同的域名,切换之后域名变来变去,浏览器还会刷新白屏,用户体验贼差。
为了解决这个问题,大佬怒而创造了一套微前端架构,解决前端项目组合问题。解决了自己的问题之后,他把通用能力抽取出来,就成为了我们看到的 qiankun~
从以上两个技术项目中,大家发现了什么共同点?那就是技术项目都是从业务中诞生出来的!
如果没有深入做过几年业务,都不知道业务的痛点在什么地方,怎么造轮子?万地高楼平地起,空中楼阁不可取。
很多朋友向我抱怨业务太多,整天 CRUD 没意思,其实你们在守着金矿,试着挖掘一下!
细想一下,如果现在你来负责 ahooks,你会加入哪些新的功能?如果你没做业务,你都没有输入来源。
另外我还要打击你的一点就是,公司内大部分有开源项目的同学,仍然有 60% 以上时间是做业务的,基本上很少很少有人全职做技术项目的(至少我没见过)。
建议
基于以上内容,我的建议是:多做业务,多做业务,多做业务!业务做的多,痛点自然有了,那技术项目自然而然就来了。
不做业务,只造轮子,先问问自己做什么轮子?做出来给谁用?
番外
当然啦,还是有一类岗位是比较适合这个朋友诉求的,那就是前端基建团队,比如 Web IDE、Serverless、前端流程管控平台、低代码等。这种项目不同于我们常见的业务,它们的目标用户是前端开发人员。
这类项目的一般都是前端开发一把梭,深度使用 Node.js,可以极大提升前端技能。
但这类项目做起来其实很难,可能做了好多年,发现投入产出比极低,没有给公司带来价值。
最终我还是建议先深入做几年业务,发现业务痛点,去解决它,技术项目、开源项目自然而然就来了!
作者:brickspert
来源:juejin.cn/post/7136893477681381407
我好像,正在经历职场PUA……
怎么别人都能干,你连这点小事都做不好?
经常加班是因为你的工作方法不对,效率太低了。
怎么现在的你和面试的时候相差了这么多,你太让我失望了……
上述这些话觉不觉得似曾相识呢?
如果有过,别怀疑,TA在PUA你!!
PUA,原本泛指恋爱关系中的一方通过精神打压等方式,对另一方进行情感控制,使他们对其迷恋,从而心甘情愿地为其付出。
说白了就是“我骂你,但你爱我”。
衍生到现在,PUA早已不局限在爱情里。
职场PUA、亲情PUA、友情PUA…应有尽有。
根据智联招聘发布的《2021年白领生活状况调研报告》显示,63.65%的受访者表示遭遇过职场PUA。
今天带大家从一次漂亮的回怼开始,向PUA说不可能!
一、偶遇渣男/渣女篇
感情中如果遇到PUA你的渣男/渣女,别客气,直接怼回去,然后就分手!
总之,小摹劝各位小伙伴一句,在感情中,一旦发现有PUA的苗头就要及时遏制住,找自己需要的爱情才对~
二、甲方爸爸PUA篇
面对甲方爸爸时,我们总不能硬碰硬的回怼,所以就得体现咱们说话的艺术啦~
甲方爸爸毕竟是金主,当然得说好听的话供着了!
三、回怼公司PUA篇
当你遇到了职场PUA,千万别忍着,否则别人只会认为你好欺负,一定要怼!回!去!
在此,小摹想提醒各位一句,职场PUA和要求严格最大的区别在于究竟是对事还是对人。
要求严格是对事不对人,希望你能将事情做好;职场PUA是对人不对事,针对你个人下结论。愿大家能珍惜对你严格的领导,远离PUA你的领导~
四、反PUA指南
对于正在遭受PUA的伙伴们,我也给大家整理了3个摆脱的方法,希望可以有所帮助:
设定边界,坚定自己的原则的底线;
学会用正确的方式疏导/释放自己的情绪;
敢于说不,及时向家人/朋友/外界寻求帮助。
最后,我想说,别让工资/依赖成为精神补偿,无论你在遭受职场or情感PUA,要么反击,要么离去!
作者:摹客
来源:juejin.cn/post/7133038800766566437
一个普通而立之年的女猿 の 年中总结
古人说,三十而立,意思是30岁可以自立于世,即做事合于礼,言行都很得当。
反观自己,真是一点边不沾,做事莽撞易炸毛,言行冒昧不妥帖。
先把个人问题放一边,以职业为口子,聊聊年中总结。
不得不说的裁员
现在互联网裁员越来越年轻化了,以前说35岁危机,现在看来,每天都可能有危机,特别是疫情这几年,动不动一条产品线没了,动不动项目开发完成但是由于X种原因不能上线了,动不动行业暴雷了。
认识一个朋友,同前端,再北京工作6年,换了5份工作,第一份试用期没过被裁,第二份被裁,第三份裁员时候庆幸自己留下来了,最后先被裁的都有了补偿,留下的拖欠了工资,直到倒闭也没有发出来,开始仲裁路,回老家休养生息1年。再次来北京,第四份干了一年多又被裁,第五份躲过了裁员潮,现在每天加班到十点以后。。
说实话,我挺佩服他,屡战屡败,越战越勇,最后也坚持下来了。好像在北京,没有裁员过的人生也是不完整的,多数人都有被裁员的经历。
还认识一个朋友,聪明且勤奋,在小厂磨砺3年,从bug满天飞,到没有一个bug,从部门被人吐槽的开发走到了领导者,工资一路涨,最后跳槽去了大厂,反而在大厂难以出头,最后平平无奇郁郁寡欢呆了2年,带着大厂光环进入小厂找到了存在感,确实能力强者。
还有一个朋友,就是平平无奇的我自己,6年换了2份工作,无大厂光环,每份薪水都处于平局线,没有被裁过,也没有光辉过。
我们,都同岁,有着不同的24岁到30岁,有着不同的三十而立。也是漂在北京的同龄人的缩影。
今年所在的公司由于黑天鹅事件踩雷被迫开始裁员,很多同事都领了大礼包,风波还在继续,指不定什么时候就轮到自己,早就做好心里准备,等待着这一天到来,然后拿着大礼包出去玩,年纪再大,也得学会排解自己。
以前找工作,hr总问,你住哪里?公司离你住所比较远,这点你怎么考虑?我都会说:房子么,也不是自己的,以工作为主,搬个家就可以了。
现在80后建议,买房子一定要买离工作单位近的,上下班方便,我都会说:工作么,早晚都会被裁的,还是以家庭为主。
就好像看的多了,格局就打开了,裁员不丢人,且干且珍惜,希望真轮到自己的时候也能这么豁达。
回顾年初立的flag
年初的时候立了几个flag
晋升
看书*5
源码
考证
减肥
出去玩
存款
晋升
晋升完成,这个属于意料之内,不出意外的正常发生(当然也有planB,就是头也不回的滚蛋)。
毕竟入职满一年,做的业务项目业绩不错,做的技术项目效果还行,给过去忙碌的一年一个交代。也有可能是因为这个,躲过了前2波的裁员。
这里还是给 年轻人点建议,踏踏实实巩固自己的技术基础,有能力的多了解下流行框架设计思想与底层原理,很多看似很难解决的bug,对基础和原理了解的多,很容易就解决了,我来的做的第一个技术项目就是这样,这里困扰fe很久的编译问题,其实知道原理和基础,200行代码就解决了,所以才给大家留下了印象。
说实话我不是聪明的那个人,只是努力做到普通罢了。
看书
《底层逻辑》--------done
《认知红利》—-—---done
《进化的力量》——--done
《你的灯还亮着吗》—done
《向上生长》—done
《跃迁:成为高手的技术》-ing
这里看的都是闲书,扩展下自己的思维,也不能说自己理解的多透彻,不细说了,都是好书,值得二刷,三刷。
感兴趣的可以评论,再出读后感。
这里分享几句我划线的句子。
人脉,不是能帮到你的人,而是你能帮到的人。 --《进化的力量》
在学习的前期,一个人是没有方向,没有思路,没有全局感的,最重要的就是不断地投入时间,过一段时间就会突然清晰了。很多人学习新技能一无所成,就是死在了这个时间点前。--《向上生长》
这个时代真正的高手,几乎都有一个特点———他们既懂得如何驱动自己持续地努力和积累,也懂得借助社会和科技趋势放大自己努力的收益。所有这些取得重大成就的人,最明显的共同特点,就是阶段性的非线性成长,跃迁式的上升,每隔几年,他们突然上一个台阶,眼界、想法、能力、调用的资源和身价都完全不同,这就是利用规律放大个人努力的结果。 --《跃迁:成为高手的技术》
源码
这可是一个跨越3年的flag,每次牟足了劲看一段时间,工作比较忙又搁置了一段时间,进度缓慢,看的没有忘得快。今年努努力吧~
考证
公司是做金融的,建议考《基金从业资格证》,除了买书,无进展。
大概率也不会有啥进展了,工作日没时间看,周末就像泄了气的皮球,懒到没边,所以这里应该相信我真的只是努力做到普通罢了。
减肥
掉了5斤,等于没有成功,因为虚胖,少吃几顿5斤就下来了,一直来来回回,反反复复,拉拉扯扯,都是这5斤。
不成功,能怎么办?
谁让这世界有这么多好吃的,我大概是不会抑郁的,不高兴的时候就会吃东西,吃东西就会发胖,胖了就会不高兴。 如此循环,如何享瘦?
出去玩
青春有几年,疫情占3年。
各地防疫政策比女生翻脸还快,一不小心就容易被隔离在外地,别说出去玩了,就连过年回家都得各种打报告。
好不容易到了兜里有点款子,范围内可以浪一浪的阶段,但是疫情确告诉你,年轻的时候没钱见的人,现在有钱了你也见不到。
疫情下的民生,有丑态毕露,也有温暖涌现,不能一句话去总结这人间万象,所以别去想,踏踏实实过好这现在的日子吧。
对下半年说点什么?
对下半年说点什么?我也不知道哎。
大概率还是跟过去的180几天一样。
计划永远赶不上变化,但是重要的几步还是要走,比如回家看父母,比如和男朋友规划未来。
还是要多看书,多锻炼,未完成的跨年falg继续,减肥继续,学习继续。
想到哪,说到哪吧~
留不留?
现在想法比较多的是,到底在这个公司死磕直到领一个丰厚的大礼包,还是少赚点钱去一个7点前下班的公司,毕竟,要考虑成家了,男朋友也是程序员,总的有一个顾家的。
在这说实话是有点压力的,被裁的人里面也有我觉得能力很强的人,之所以被裁,我觉得可能是敢于对不懂技术的领导的命令给予反抗,还有的是不爱出风头的,只知道门头干活的高t。
所以说,在一个公司长久,真的是一件缘分(dddd)。
还是两手准备吧
你们觉得呢?
来源:范小饭 juejin.cn/post/7119052137589375012
收起阅读 »前端好还是后端好,看看7年前端和后端怎么说
本篇文章是 B 站视频《# 前端好还是后端好,看看7年前端和后端怎么说》的文字版。
有朋友在上一期视频评论区问 “选前端好,还是选后端好”。这个问题我自己也挺好奇,如果我当初选了后端,现在是什么样子?
回答这个问题最好的方式,就是找两个有比较长工作经验的前端和后端,让他们来讲讲各自的从业感受,对比下发展现状。当然,前提是尽量减少他们的其它差异。
嘿,正好,我有一个非常好的朋友青果,我俩除了他做后端,我做前端之外,其它变量都高度一致。一致到什么程度呢?
我俩都是山西人,11 年考入杭州的大学,我俩一个专业,一个班级,一个寝室,头对头睡了 4 年。
14 年我俩一起去面试了同一家小公司,一起去实习,一起入职,每天一起上下班,一起在这个公司工作了 4 年,我俩在这个公司的薪资也一模一样。
我俩唯一的区别就是,他实习就做 JAVA,然后一直坚持在做,他一开始就认准了方向,即使公司让他做 PHP、做前端,他也是拒绝的。
相比之下,我就没主见了,先做 JAVA,然后公司需要 PHP,就去做了一年多 PHP,然后公司需要前端了,就去做了一年多前端,最终误打误撞进入了前端行业。
18 年前后,他离职去了杭州某中大厂,继续做了四年后端开发。
几个月之后,我也离职去了另外一个大厂,继续做了四年前端开发。
到目前为止,我们工作了 7 年多,站在这个节点上,正好对比一下,看看各自的从业感受,我也挺好奇结果的。
接下来,我会准备一些问题,我俩分别来回答一下。
1. 你后悔选 前端/后端 了吗?
砖家回答:
不后悔,我还挺庆幸当初转成前端的,在我的前端生涯发展中,虽然有磕绊,但整体上还是挺顺利的,前端带给了我很多东西,并且整体上来看,前端社区会更活泼一点。
如果现在让我回去 7 年前,我还会无脑选前端的。
青果回答:
谈不上后悔不后悔吧,选择总是基于当下的认知以及结合自身情况。因为当时自学过一段时间安卓开发,且后端体系比较庞大,个人觉得后续的发展空间可能更大,就一直坚持了后端工作。
现在后悔的是,大学期间心智开的太晚,在休闲娱乐上浪费了不少时间。
2. 你觉得 前端/后端 的技术发展快吗?需要一直学新东西吗?
砖家回答:
前端这些年发展太快了,天天出新东西,三个月不学习就落后了,一年不学习就已经不会写了,真正的是活到老学到老。
刚毕业的时候我还快乐的使用 jQuery,然后发展成 Angular,然后发展成 React、Vue 的天下,最近 Vercel 等新势力又冒出来了。框架层还算慢的,各种小的解决方案,那真的是层出不穷。
构建工具从 gulp 到 webpack,再到 esbuild、vite,真的是跟不上了。css 解决方案也是一大堆:css modules、styled-components、tailwind css 等等。
总之,前端最近几年的发展是坐火箭一样的,想不学习吃老本是不行的。另外发展快也有好处,就是机会多,可以造各种轮子。
青果回答:
技术总是推陈出新的,作为开发人员感知到的快与慢,跟能否及时在实际工作中使用新技术、新特性有关。
公司拥抱新技术,会从稳定性、收益成本等多角度考虑,规模越大的公司顾虑越多,也就越难使用新技术。比如各大厂还在大规模使用 2014 年发行的 java 8,而 java 现在已经进化到第 17 个版本了;后端框架仍然还是 SSM(Spring、Spring MVC、Mybatis)为主流。所以站在这个角度,即便技术更迭再快,后端业务开发能接触到的新技术也是很有限的。
在这套”陈旧“的技术上,一般 1、2 年就能驾轻就熟的实现各种业务。如果不持续学习底层原理、核心设计,很容易只停留在知道、会用的境地,当遇到技术难题时,就会不知从何下手。
3. 你推荐自己的好朋友学前端还是后端?
砖家回答:
如果他喜欢和数据打交道,那我可能推荐他去学后端。
大部分情况下,我还是会推荐他学前端,因为前端入门简单,并且上限也不低。 另外就是前端总是和用户交互界面打交道,会比较活泼一点~
青果回答:
如果是纯 IT 小白,可以先从前端找找感觉,入门相对简单,也能及时带来成就感。如果是科班出身的朋友,可以从其他几个问题上综合考量。
4. 你觉得现在市场上 前端/后端 饱和了吗?前端/后端 好找工作吗?
砖家回答:
我自己感觉,前端市场远远没有饱和,还是比较好找工作的,尤其是优质前端更缺。
大家可以想想,以前前端只是做网页的,但现在 IOS 开发、Android 开发、桌面端应用都逐渐使用前端技术栈开发了,前端已经吃掉了部分客户端开发同学的机会。
并且随着浏览器性能提升,前端能做的事情更多了,各种 3D、游戏都可以用前端技术做了。
所以我觉得前端还是有非常大的市场的。
青果回答:
实话实说,今年市场行情是工作以来最差的一年,很多战友都被动离开了,再加上后端从业人数大,想在这么多人中脱颖而出,找到一份称心的工作,确实比以往更难。
但我认为数字化浪潮还没有褪去,未来还有很多机会,个人努力培养核心竞争力,仍然能够如鱼得水。
5. 你觉得前端和后端的薪资差别大吗?
砖家回答:
因为工资一般在公司属于机密,所以大家都不会交流的,但是我感觉前端和后端工资都差不多的。
青果回答:
前期的话,总体来说薪资是差不多的,可以从各大招聘网站上了解各个职级的薪资水平。后期就要看自己的造化了,个人认为主要是决策力、不可替代性、能力影响范围等会提升你的薪水。
6. 你觉得 前端/后端 的发展上限高吗?你碰到瓶颈了吗?
砖家回答:
大部分前端都是业务开发,发展路线大概是这样的:
先跟着别人做业务
自己能独立承担业务开发
能虚线带一两个同学承担多个业务开发
带团队
带更大的团队
当然也有专门做技术,不靠带团队晋升到很高级别的,但真的比较少。
以我目前的阶段看,我目前的阶段还属于比较初级的,前面的人有非常非常非常多,所以并没有达到瓶颈。
然后我觉得前端的上限对我们普通人来说,是足够高的,两辈子可能都走不到头。
青果回答:
后端的上限肯定是高的,重点是如何不断突破自己的上限。
现代企业都需要复合型人才,也就是”T”型人才。作为后端开发,纵向需要培养解决疑难问题、设计复杂系统的能力,把技术向下做深、做透;横向需需要培养产品思维、业务分析、领导力等。如果个人遇到了瓶颈,可以参考《工程师职级胜任力框架》,去看看下个职级需要重点培养什么能力。
7. 你觉得 前端/后端 容易学吗?
砖家回答:
我觉得前端算是比较好学的,上手非常简单,可能学个几天就会写页面了。
然后说实话,前端的技术没有太多高深的东西,只要肯下功夫,是一定能掌握的,这是一个确定的事情。
青果回答:
我认为学习最难的,就是认知半径限制了应该去学啥,即不知道“应该学啥”。没有目标,不会检索,就很难学。
java 作为发展了接近 30 年的语言,世面上的学习资料可太多了,所以从“应该学啥”的角度,java 还是容易的。
8. 你觉得前端需要会一点后端吗?你觉得后端要会一点前端吗?
砖家回答:
我觉得是的,前端需要掌握一定的后端知识。
因为工作内外,我们可能都有独立开发一个小工具的诉求,后端知识必不可少的,虽然前端学学 Node.js 还是挺简单的,但是对 nginx、数据库、负载均衡 等后端知识也是要有一定涉猎的。
青果回答:
技术人员了解软件工程的全流程是大有裨益的,不光是要会一点前端,还要从业务分析和建模、编码和测试、上线和运营等多维度拓宽知识的边界,不仅利于与各职能之间的沟通协作,也给自己带来更高的看问题视角。这也是思特沃克中国区 CTO——徐昊比较推崇的,我们要努力成为全流工程师,感兴趣的可以去看看。
9. 你觉得你能做一辈子前端/后端吗?
砖家回答:
目前来看,是的,前端是可以做一辈子的,现在转行也没任何必要。并且我也不讨厌前端,挺好玩的还!这碗饭我吃定了~
青果回答:
首先不会限定自己只做后端,现在的物联网等行业也不存在所谓的前后端之分。
IT 这个行业是要做一辈子的,主要是个人的性格确实适合这个行业。如果你还在犹豫是否要从事这个行业,可以去做做 MBTI 测试。
10. 你有什么想对新人程序员,或者即将从业程序员的同学嘱咐的吗?
砖家回答:
工作前几年,不要太着急限定自己的发展方向,可以都尝试尝试,工作两年之后再做选择。
这个在小公司比较好实施,在大公司一进来工种基本就限定了。
另外就是,迷茫是正常的,是大家都会经历的,可以多找前辈聊一聊,可能会豁然开朗。
青果回答:
保持好奇心。
不要过早的给自己设限。
尽早搭建个人知识体系,可以通过思维导图构建技能树,补齐短板。
11. 你有什么想对对方讲的吗?
砖家回答:
缘分妙不可言,期待未来还有机会共事。这顿饭我请定了,但是下一顿得你请我。😄
青果回答:
没有,下一个问题。 开个玩笑,手动狗头,希望有机会向你学习前端技术。
总结
做这期内容,付出了一顿饭的代价,希望能给大家带来帮助,尤其是新人程序员。
也许不能带来实质性的帮助,但让大家看到了真实的工作了 7 年的前端和后端同学的想法。同时在看这篇内容的朋友也藏龙卧虎,大家也可以各抒己见,说说自己对当前工种的看法,给新同学一点帮助。
最后欢迎大家关注我,大家有任何问题,都可以在评论区留言,简单的我就直接回复了,复杂的我会记在小本本上,后面会专门做内容来回复!
来源:brickspert juejin.cn/post/7134283105627537444
收起阅读 »裁员、结婚、买房、赡养父母.....即将30岁,焦虑扑面而来
前言:
大家好,我是春风。
不知道你是否有过这样的经历,就是在临近30岁的这几年,可能是28,可能是29,会突然有一天,你就不得不以一个顶梁柱的角色去审视自己。
就算此时你还没有结婚,但面对即将不得不结婚的压力,面对已经老去的父母。时间突然就变得紧迫起来,你也突然就不再属于你自己,我们会不自觉的扮演起家庭的依靠,而且还是唯一的依靠。这种压力完全是在自己还没准备的时候就突袭了你。
就像我这一周都是在这种压力和焦虑中度过...
失眠
我不知道自己为什么会突然一下就想这么多,但年龄就像一个雷管,突然就炸开了赤裸裸的现实,或者是按下了一个倒计时。我不自觉的去想家庭,去想父母,去想我30岁40岁50|岁是什么样子。
这周的每天晚上我想着这些都失眠到三四点,当然如果这个时候你还像我一样去看下确切时间,你很大可能会失眠到五点。
尝试心理学
所以这几天上班也是一行代码都没敲,幸好需求不多。最后我迫切的觉得我应该找个办法解决一下,索性今天摸鱼一天,听了一天的心理学讲座的音频。
果然,心病还需心药医!!!
下面我给大家分享一下自己的治疗过程,希望也能对焦虑的你有所启发。
一、我为什么焦虑
解决焦虑的第一步就是先要弄清楚我们为什么焦虑?我们究竟在焦虑什么?可能很多人都是焦虑经济,焦虑结婚,焦虑生活中的各种琐事。
但我们也可以试着站在上帝视角,更深层次的解剖一下自己。
1. 焦虑多年努力没有换来想要的生活
比如我,我最大的焦虑也是钱,我从农村出来,没有任何背景,毕业到现在已经工作六年,20年在广州买房上车,但好巧不巧买的是恒大的房子,买完就暴雷,现在每个月有房贷,还要结婚。
所以我总是在想,这些年我算努力吗,为什么还是没有挣到钱。
三十而立近在眼前,可我这些年究竟立了什么呢?遥想刚毕业那会给自己定下的目标,虽然是天方夜谭,但对比现在,也太天方夜谭了吧。
不是说好的天道酬勤吗?不是说努力就会有收获吗?
所以我焦虑,我表面是焦虑钱,但何尝不是在焦虑自己这么多年的努力却没有得到我想要的结果呢?
2. 攀比带来的自我嫌弃
我们都知道攀比是不好的,尤其是在这个动辄年薪百万年薪的互联网世界,但也是这些网络信息的无孔不入,让我们不得不攀比,不得不怀疑自己是为什么会差这么多。
我承认自己是一个争强好胜的人,我会在读书时非常想要好的名次,因为我体验过那种胜利感一次之后,便会上瘾。所以现在工作,我也时常不自觉的攀比起来,因此,我也深深陷入了自我怀疑和自我嫌弃的枣泥。
为什么我努力学习,辛苦工作,一年下来却不如人家卖一个月炒饭,为什么那个做销售的同学两三个月就赚到了我两年的财富,为什么我工作六年攒下的钱,却还不及人家父母一个月的收租?
和我一样没背景的比我赚的多,有背景的赚的更多。这种怀疑病入膏肓的时候,我都会病态的想,那些富二代肯定都是花花公子,懒惰而不自知,毕竟电影里不都这样演吗?但现实是,别人会比你接受更好的家庭教育,环境教育。别人谈吐自如还努力学习。不仅赢在了起跑线,还比你努力。就是这种对比,越来越让我们自己嫌弃自己,厌恶自己。所以也就总是想要求自己必须去做更好的自己。
二、生命的意义
应该所有人都思考过这个问题吧,来这人间一趟,可都不想白来一趟。我们都想在这个世界留下点什么,就像战国时士人对君主,知道会被烹杀却勇于进言,只为留下一个劝谏名士的美名。人活一世,究竟为了什么呢?生前获利?死后留名?
但对于我们大多数的普通人呢?
待我们死去,我们的名字最多就被孙子辈的人知道,等到他们也故去,那这个世界还会有你来过的痕迹吗?
人生代代无穷已,江月年年望相似。
所以夜深人静的时候,我们总会在想,自己生命的意义?似乎一切都没有意义,我们注定就是会拥有一个低价值甚至无价值的人生。
三、结婚的压力
我们九零后,比零零后环境是不是更好不确定,但对比八零后,肯定要差,八零后结婚,印象里还不太谈房子,车子,但我们结婚,确是一个必考题。
所以我们结婚率低,不仅有不婚族,还有现在的丁克族。
我自己来自农村,我们那里男女比例就严重失衡,村里的男孩子结婚的不超过一半。但是我爸着急,不知道你们是否有过这种催婚的经历,父母会反复的告诉你大龄剩男剩女有多丢人,你们的不婚不仅是你自己的问题,还会让家里人都抬不起头。是的,父母含辛茹苦养育了你们,现在因为你,让他们在别人面前抬不起头来,失去了自尊。
四、知道该做什么,但拖延没做后就会更加的自我嫌弃
我们擅长给自己定下很多目标,但有时候就是逃不过人性,孔子说,食色性也。我们在被创造的时候就是被设计为不断的追求多巴胺的动物。所以我们沉迷游戏,沉迷追剧。总是在周五的晚上选择放松自己。而不会因为定下了目标就去学习。
总之,我们的目标定的越美好,我们的行动往往越低效。最后,两者的差距越来越远。我们离自己期望中的那个自己判若两人。
我们又会厌恶自己,嫌弃自己。甚至痛骂自己的不自律。
以上是我分析的自己的焦虑点。相信很多也是屏幕前的你曾经或者当下也有的吧。接下来,就看看我是怎么在心理学上找到解决的办法的吧!
给自己的建议
关于攀比、努力没有想要的结果、不自律等等带来的自我嫌弃。我们或许应该这样看
1、承认自己的普通
有远大报负,有远大理想。追求自由和生命的绚丽是我们每个人都会有也应该有的念想。但当暂时还没有结果的时候。我们不应该及早否定自己。而是勇于承认自己的普通。我们都想成为这个世界上独一无二的人。事实上从某种意义上来说。我们也是独一无二的人。但从金钱,名望这些大家公认的层面来看。99.99%的人都是普通人。我们这一生很大可能就会这样平凡的过完一生。接受自己的普通,活在当下。这才是体验这趟生命之旅最应该有的态度。只要今天比昨天好。我们不就是在进步吗?
为什么一定要有个结果??
人生最大的悲哀就是跨越知道和做到的鸿沟,当一个人承认自己是个普通人的时候,他才是人格完整,真正成熟的时候。
我们追求美好的事物,追求自己喜欢的东西,金钱也好,名望也罢,这都是无可厚非的。因为人就是需要被不断满足的,人因为有欲望才会想活下去。但是当暂时没有结果的时候。我们也不应该为此感到自责和焦虑。一旦我们队美好事物的追求变成了一种压力。我们就会陷入一种有负担的内缩状态,反而会跑不快。
我们都害怕浪费生命,因为生命只有一次。我们想让自己的生命在这个世界留下来过的痕迹。所以我们追寻那些热爱的东西,但其实追求的过程才是最应该留下的痕迹,结果反而只是别人眼里的痕迹。
当然也有一种理解认为活在当下就是躺平。恰好现在网络上也是躺平之语频频入耳。我想说关于是努力追求理想还是躺平的一点观点。
在禅宗里有这样一句话说的非常好:身无所住而生其心。
这里的住 代表的就是追求的一种执念。
身无所住而生其心,说的就是要避免有执和无执的两种极端状态。有执就是我们我都要要要。我要钱 我要名 我要豪车豪宅。无执就是觉得什么都没有意义。生命终会归于尘土。所以努力追求的再多,又有什么用呢?大多数人生命注定是无意义的。这也是很多人躺平的一部分原因吧!
但是就该这样躺平的度过一生吗?每天都陷入低价值的人生?
身无所住而生其心。我们的生命不应该陷入有执和无执这两种极端。花开了,虽然它终会化作春泥。但花开的此刻,它是真美啊!
2、关于结婚生子
关于结婚生子,为什么我要在所有人都结婚的年龄就结婚,为什么三十岁生孩子就是没出息。生育这个问题,其实是为了什么 我爸老说,你不生小孩或者很晚生小孩,到时候老了都没人照顾你,那养儿真的就是为了防老吗?其实这是一个伪命题,先还不说到时候,儿女孝不孝顺的问题,就说我爸,这么多年,他为了倾其所有,花我身上的钱不说几千万也有上百万了,如果真是要防老,那这个钱存银行,每年光吃利息就有几十万,几十万在一个农村来说晚年怎么都富足了,两三个人照顾你都够,而我到现在每年有给过我爸几十万吗?
再说养儿为了到时候不孤独,能享受天伦之乐,这算是感情上的需求吧。那既然这样,我在准备好的节奏里欣然的生育,不比我在年龄和周遭看法的压力下强行生育更加的好吗,当我想体验一下为人父的生命体验了,我顺其自然的要小孩儿,快快乐乐的养育他,而不是我已经三十岁了,别人小孩儿都打酱油了,大家都在说是不是我有问题,所以即使我现在经济,心理,精力上都没准备好,我也必须要一个小孩儿。
所以大人们说的并不是真正的理由,而人类或者动物,之所以热衷繁衍,最原始的动力是想把自己的基因流下去,是想在这个世界上留下一点记忆。
为别人而活。尤其是在农村,很多人一辈子就认识村里那些人,祖祖辈辈就只见过那些活法,在他们眼里,多少岁结婚,多少岁生孩子,这辈子就这么过去了。但是但凡有一点出格,那在其他人眼里就会抬不起头,因为,其他人出现意外的时候,自己也是这样看其他人的。所以大家都只为活在别人眼里而活,打个比方,我现在很想很想吃一个红薯,明明我吃完这个红薯,内心就会得到满足,但是我不会,因为别人会觉得我是不是穷,都只能吃红薯,这不单单是大家说的死要面子活受罪,其实是我们很多人骨子里的自卑,尤其是我们农村,经济条件都不好,没有什么值得炫耀的,所以我们就尽可能找大家能达成共识的去炫耀。很简单的一个例子。假如一个亿万富翁去到农村,他的身价已经足够自信了,即使他不结婚生子,其他人会看不起他吗?
结尾:
1、心理学是治愈,也是哲学上的思考。这种思考很多都能跳脱出现实而给到我们解决现实中问题的办法
2、再重复一遍:身无所住而生其心!
3、要爱具体的人,不要爱抽象的人,要爱生活,不要爱生活的意义。
来源:程序员春风 juejin.cn/post/7119863033920225287
收起阅读 »组员老是忘记打卡,我开发了一款小工具,让全组三个月全勤!
我司使用钉钉考勤打卡,人事要求的比较严格,两次未打卡记缺勤一天。但我们组醉心于工作,老是上下班忘记打卡,每月的工资被扣到肉疼。
开始的时候我们都设置了一个打卡闹铃,下班后准时提醒,但有的时候加班,加完班回家又忘记打卡了。还有的时候迷之自信的以为自己打卡了,第二天看考勤记录发现没打卡。
为了彻底解决这个问题,守住我们的钱袋子,我开发了一款打卡提醒工具,让全组连续三个月全勤!
下面介绍一下,这个小工具是如何实现的。
小工具实现思路
首先思考一下:闹铃提醒为什么不能百分之百有用?
机械的提醒
闹铃提醒很机械,每天一个点固定提醒,时间久了人就会免疫。就像起床闹铃用久了,慢慢的那个声音对你不起作用了,此时不得不换个铃声才行。
不能重复提醒
闹铃只会在固定时间提醒一次,没有办法判断是否打卡,更不会智能地发现你没有打卡,再提醒一次。
既然闹铃做不到,那我们就用程序来实现吧。按照上述两个原因,我们要实现的提醒工具必须包含两个功能:
检测用户是否打卡,未打卡则提醒,已打卡不提醒。
对未打卡用户循环检测,重复提醒,直到打卡为止。
如果能实现这两个功能,那么忘记打卡的问题多半也就解决了。
打卡数据需要从钉钉获取,并且钉钉有推送功能。因此我们的方案是:利用 Node.js + 钉钉 API 来实现打卡状态检测和精准的提醒推送。
认识钉钉 API
钉钉是企业版的即时通讯软件。与微信最大的区别是,它提供了开放能力,可以用 API 来实现创建群组,发送消息等功能,这意味使着用钉钉可以实现高度定制的通讯能力。
我们这里用到的钉钉 API 主要有以下几个:
获取凭证
获取用户 ID
检查打卡状态
群内消息推送
@某人推送
在使用钉钉 API 之前,首先要确认有公司级别的钉钉账号(使用过钉钉打卡功能一般就有公司账号),后面的步骤都是在这个账号下实现。
申请开放平台应用
钉钉开发第一步,先去钉钉开放平台申请一个应用,拿到 appKey 和 appSecret。
钉钉开放平台地址:open.dingtalk.com/developer
进入平台后,点击“开发者后台”,如下图:
开发者后台就是管理自己开发的钉钉应用的地方,进入后选择“应用开发->企业内部开发”,如下图:
进入这个页面可能提示暂无权限,这是因为开发企业钉钉应用需要开发者权限,这个权限需要管理员在后台添加。
管理员加开发者权限方式:
进入 OA 管理后台,选择设置-权限管理-管理组-添加开发者权限下的对应权限。
进入之后,选择【创建应用 -> H5 微应用】,根据提示创建应用。创建之后在【应用信息】中可以看到两个关键字段:
AppKey
AppSecret
这两个字段非常重要,获取接口调用凭证时需要将它们作为参数传递。AppKey 是企业内部应用的唯一身份标识,AppSecret 是对应的调用密钥。
搭建服务端应用
钉钉 API 需要在服务端调用。也就是说,我们需要搭建一个服务端应用来请求钉钉 API。
切记不可以在客户端直接调用钉钉 API,因为 AppKey 和 AppSecret 都是保密的,绝不可以直接暴露在客户端。
我们使用 Node.js 的 Express 框架来搭建一个简单的服务端应用,在这个应用上与钉钉 API 交互。搭建好的 Express 目录结构如下:
|-- app.js // 入口文件
|-- catch // 缓存目录
|-- router // 路由目录
| |-- ding.js // 钉钉路由
|-- utils // 工具目录
| |-- token.js // token相关app.js 是入口文件,也是应用核心逻辑,代码简单书写如下:
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const cors = require('cors');
app.use(bodyParser.json());
app.use(cors());
// 路由配置
app.use('/ding', require('./router/ding'));
// 捕获404
app.use((req, res, next) => {
res.status(404).send('Not Found');
});
// 捕获异常
app.use((err, req, res, next) => {
console.error(err);
res.status(err.status || 500).send(err.inner || err.stack);
});
app.listen(8080, () => {
console.log(`listen to http://localhost:8080`);
});另一个 router/ding.js 文件是 Express 标准的路由文件,在这里编写钉钉 API 的相关逻辑,代码基础结构如下:
// router/ding.js
var express = require('express');
var router = express.Router();
router.get('/', (req, res, next) => {
res.send('钉钉API');
});
module.exports = router;现在将应用运行起来:
$ node app.js然后访问 http://localhost:8080/ding,浏览器页面显示出 “钉钉 API” 几个字,表示运行成功。
对接钉钉应用
一个简单的服务端应用搭建好之后,就可以准备接入钉钉 API 了。
接入步骤参考开发文档,文档地址在这里。
1. 获取 API 调用凭证
钉钉 API 需要验证权限才可以调用。验证权限的方式是,根据上一步拿到的 AppKey 和 AppSecret 获取一个 access_token,这个 access_token 就是钉钉 API 的调用凭证。
后续在调用其他 API 时,只要携带 access_token 即可验证权限。
钉钉 API 分为新版和旧版两个版本,为了兼容性我们使用旧版。旧版 API 的 URL 根路径是https://oapi.dingtalk.com,下文用 baseURL 这个变量替代。
根据文档,获取 access_token 的接口是 ${baseURL}/gettoken。在 utils/ding.js 文件中定义一个获取 token 的方法,使用 GET 请求获取 access_token,代码如下:
const fetchToken = async () => {
try {
let params = {
appkey: 'xxx',
appsecret: 'xxx',
};
let url = `${baseURL}/gettoken`;
let result = await axios.get(url, { params });
if (result.data.errcode != 0) {
throw result.data;
} else {
return result.data;
}
} catch (error) {
console.log(error);
}
};上述代码写好之后,就可以调用 fetchToken 函数获取 access_token 了。
获取到 access_token 之后需要持久化的存储起来供后续使用。在浏览器端,我们可以保存在 localStorage 中,而在 Node.js 端,最简单的方法是直接保存在文件中。
写一个将 access_token 保存为文件,并且可读取的类,代码如下:
var fs = require('fs');
var path = require('path');
var catch_dir = path.resolve(__dirname, '../', 'catch');
class DingToken {
get() {
let res = fs.readFileSync(`${catch_dir}/ding_token.json`);
return res.toString() || null;
}
set(token) {
fs.writeFileSync(`${catch_dir}/ding_token.json`, token);
}
}写好之后,现在我们获取 access_token 并存储:
var res = await fetchToken();
if (res) {
new DingToken().set(res.access_token);
}在下面的接口调用时,就可以通过 new DingToken().get() 来获取到 access_token 了。
2. 查找组员 ID
有了 access_token 之后,第一个调用的钉钉 API 是获取员工的 userid。userid 是员工在钉钉中的唯一标识。
有了 userid 之后,我们才可以获取组员对应的打卡状态。最简单的方法是通过手机号获取员工的 userid,手机号可以直接在钉钉上查到。
根据手机号查询用户文档在这里。
接口调用代码如下:
let access_token = new DingToken().get();
let params = {
access_token,
};
axios
.post(
`${baseURL}/topapi/v2/user/getbymobile`,
{
mobile: 'xxx', // 用户手机号
},
{ params },
)
.then((res) => {
console.log(res);
});通过上面请求方法,逐个获取所有组员的 userid 并保存下来,我们在下一步使用。
3. 获取打卡状态
拿到组员的 userid 列表,我们就可以获取所有组员的打卡状态了。
钉钉获取打卡状态,需要在 H5 应用中申请权限。打开前面创建的应用,点击【权限管理 -> 考勤】,批量添加所有权限:
接着进入【开发管理】,配置一下服务器出口 IP。这个 IP 指的是我们调用钉钉 API 的服务器 IP 地址,开发的时候可以填为 127.0.0.1,部署后更换为真实的 IP 地址。
做好这些准备工作,我们就可以获取打卡状态了。获取打卡状态的 API 如下:
API 地址:${baseURL}/attendance/list
请求方法:POST
这个 API 的请求体是一个对象,对象必须包含的属性如下:
workDateFrom:查询考勤打卡记录的起始工作日。workDateTo:查询考勤打卡记录的结束工作日。userIdList:查询用户的用户 ID 列表。offset:数据起始点,用于分页,传 0 即可。limit:获取考勤条数,最大 50 条。
这里的字段解释一下。workDateFrom 和 workDateTo 表示查询考勤的时间范围,因为我们只需要查询当天的数据,因此事件范围就是当天的 0 点到 24 点。
userIdList 就是我们上一步取到的所有组员的 userid 列表。
将获取打卡状态写为一个单独的方法,代码如下:
const dayjs = require('dayjs');
const access_token = new DingToken().get();
// 获取打卡状态
const getAttendStatus = (userIdList) => {
let params = {
access_token,
};
let body = {
workDateFrom: dayjs().startOf('day').format('YYYY-MM-DD HH:mm:ss'),
workDateTo: dayjs().endOf('day').format('YYYY-MM-DD HH:mm:ss'),
userIdList, // userid 列表
offset: 0,
limit: 40,
};
return axios.post(`${baseURL}/attendance/list`, body, { params });
};查询考勤状态的返回结果是一个列表,列表项的关键字段如下:
userId:打卡人的用户 ID。userCheckTime:用户实际打卡时间。timeResult:用户打卡结果。Normal:正常,NotSigned:未打卡。checkType:考勤类型。OnDuty:上班,OffDuty:下班。
其他更多字段的含义请参考文档
上面的 4 个字段可以轻松判断出谁应该打卡,打卡是否正常,这样我们就能筛选出没有打卡的用户,对这些未打卡的用户精准提醒。
筛选打卡状态分为两种情况:
上班打卡
下班打卡
上下班打卡要筛选不同的返回数据。假设获取的打卡数据存储在变量 attendList 中,获取方式如下:
// 获取上班打卡记录
const getOnUids = () =>
attendList
.filter((row) => row.checkType == 'OnDuty')
.map((row) => row.userId);
// 获取下班打卡记录
const getOffUids = () =>
attendList
.filter((row) => row.checkType == 'OffDut')
.map((row) => row.userId);获取到已打卡的用户,接着找到未打卡用户,就可以发送通知提醒了。
4. 发送提醒通知
在钉钉中最常用的消息推送方式是:在群聊中添加一个机器人,向这个机器人的 webhook 地址发送消息,即可实现自定义推送。
还是进入前面创建的 H5 应用,在菜单中找到【应用功能 -> 消息推送 -> 机器人】,根据提示配置好机器人。
创建好机器人后,打开组员所在的钉钉群(已有群或新建群都可)。点击【群设置 -> 智能群助手 -> 添加机器人】,选择刚才创建的机器人,就可以将机器人绑定在群里了。
绑定机器人后,点击机器人设置,会看到一个 Webhook 地址,请求这个地址即可向群聊发送消息。对应的 API 如下:
API 地址:${baseURL}/robot/send?access_token=xxx
请求方法:POST
现在发送一条“我是打卡机器人”,实现代码如下:
const sendNotify = (msg, atuids = []) => {
let access_token = 'xxx'; // Webhook 地址上的 access_token
// 消息模版配置
let infos = {
msgtype: 'text',
text: {
content: msg,
},
at: {
atUserIds: atuids,
},
};
// API 发送消息
axios.post(`${baseURL}/robot/send`, infos, {
params: { access_token },
});
};
sendNotify('我是打卡机器人');解释一下:代码中的 atUserIds 属性表示要 @ 的用户,它的值是一个 userid 数组,可以 @ 群里的某几个成员,这样消息推送就会更精准。
发送之后会在钉钉群收到消息,效果如下:
综合代码实现
前面几步创建了钉钉应用,获取了打卡状态,并用机器人发送了群通知。现在将这些功能结合起来,写一个检查考勤状态,并对未打卡用户发送提醒的接口。
在路由文件 router/ding.js 中创建一个路由方法实现这个功能:
var dayjs = require('dayjs');
router.post('/attend-send', async (req, res, next) => {
try {
// 需要检测打卡的 userid 数组
let alluids = ["xxx", "xxxx"];
// 获取打卡状态
let attendList = await getAttendStatus(alluids);
// 是否9点前(上班时间)
let isOnDuty = dayjs().isBefore(dayjs().hour(9).minute(0));
// 是否18点后(下班时间)
let isOffDuty = dayjs().isAfter(dayjs().hour(18).minute(0));
if (isOnDuty) {
// 已打卡用户
let uids = getOnUids(attendList);
if (alluids.length > uids.length) {
// 未打卡用户
let txuids = alluids.filter((r) => !uids.includes(r));
sendNotify("上班没打卡,小心扣钱!", txuids);
}
} else if (isOffDuty) {
// 已打卡用户
let uids = getOffUids(attendList);
if (alluids.length > uids.length) {
// 未打卡用户
let txuids = alluids.filter((r) => !uids.includes(r));
sendNotify("下班没打卡,小心扣钱!", txuids);
}
} else {
return res.send("不在打卡时间");
}
res.send("没有未打卡的同学");
} catch (error) {
res.status(error.status || 500).send(error);
}
});上述接口写好之后,我们只需要调用一下这个接口,就能实现自动检测上班或下班的打卡情况。如果有未打卡的组员,那么机器人会在群里发通知提醒,并且 @ 未打卡的组员。
# 调用接口
$ curl -X POST http://localhost:8080/ding/attend-send检查打卡状态并提醒的功能实现了,现在还差一个“循环提醒”功能。
循环提醒的实现思路是,在某个时间段内,每隔几分钟调用一次接口。如果检测到未打卡的状态,就会循环提醒。
假设上下班时间分别是上午 9 点和下午 18 点,那么检测的时间段可以划分为:
上班:8:30-9:00 之间,每 5 分钟检测一次;
下班:18:00-19:00 之间,每 10 分钟检测一次;
上班打卡相对比较紧急,所以时间检测短,频率高。下班打卡相对比较宽松,下班时间也不固定,因此检测时间长,频率低一些。
确定好检测规则之后,我们使用 Linux 的定时任务 crontab 来实现上述功能。
首先将上面写好的 Node.js 代码部署到 Linux 服务器,部署后可在 Linux 内部调用接口。
crontab 配置解析
简单说一下 crontab 定时任务如何配置。它的配置方式是一行一个任务,每行的配置字段如下:
// 分别表示:分钟、小时、天、月、周、要执行的命令
minute hour day month weekday cmd每个字段用具体的数字表示,如果要全部匹配,则用 * 表示。上班打卡检测的配置如下:
29-59/5 8 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send上面的 29-59/5 8 表示在 8:29 到 8:59 之间,每 5 分钟执行一次;1-5 表示周一到周五,这样就配置好了。
同样的道理,下班打卡检测的配置如下:
*/10 18-19 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send在 Linux 中执行 crontab -e 打开编辑页面,写入上面的两个配置并保存,然后查看是否生效:
$ crontab -l
29-59/5 8 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send
*/10 18-19 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send看到上述输出,表示定时任务创建成功。
现在每天上班前和下班后,小工具会自动检测组员的打卡状态并循环提醒。最终效果如下:
总结
这个小工具是基于钉钉 API + Node.js 实现,思路比较有意思,解决了实际问题。并且这个小项目非常适合学习 Node.js,代码精简干净,易于理解和阅读。
小项目已经开源,开源地址为:
作者:杨成功
来源:juejin.cn/post/7136108565986541598
孩子起名愁死了,各位环子们,帮帮我们吧
女娃:虎年生,姓张









