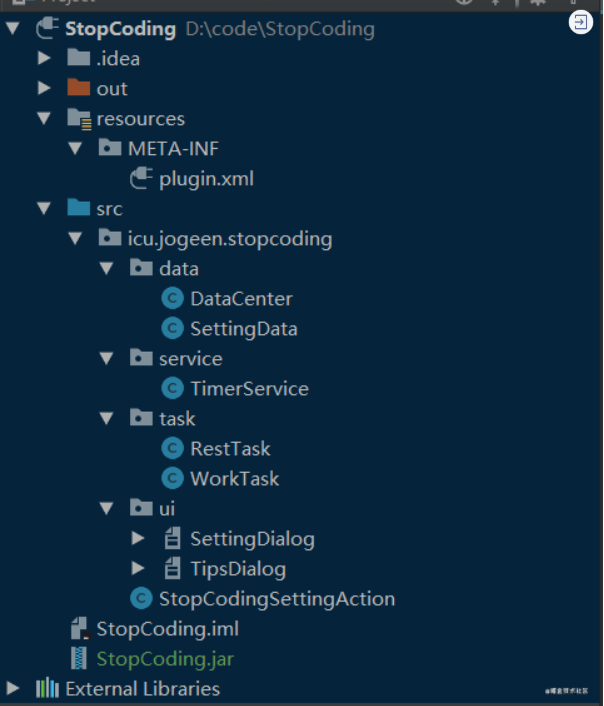
前言
今天继续探索绘制与手势的组合实践,之前在看电子书切换页面时会有一个模拟纸质书籍翻页效果,这是典型的绘制和手势的结合实现的效果,那么今天我们就用Flutter也实现这样的一个效果吧。
原理
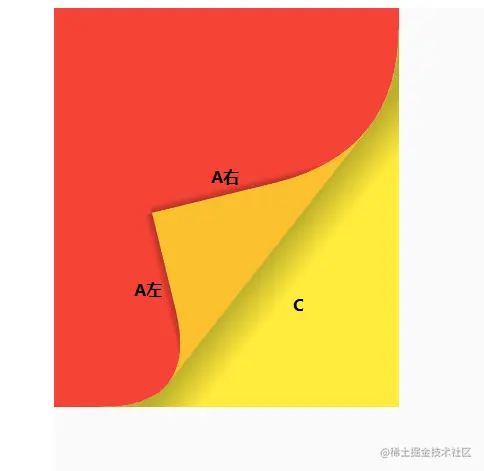
大家可以找本书翻页到一半看下效果,从右下角翻到一半时,我们可以将可视区域分为下图A、B、C三部分区域。
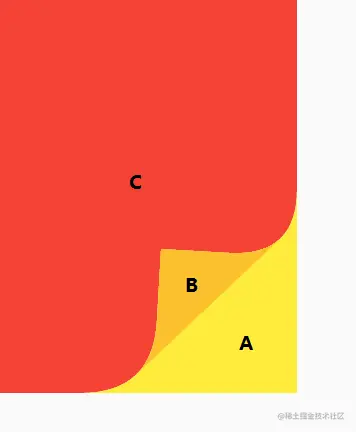
A:下一页可视区域。
B:当前页不可视区域,翻的页不可见的区域。
C:当前页可视区域,也就是需要翻的页的可视区域。
原理分解:
我们可以先将A区域和B区域合为一个区域计算,那么根据路径联合C区域自然就可以得到,至于A、B区域区分后面再讲,看下图:
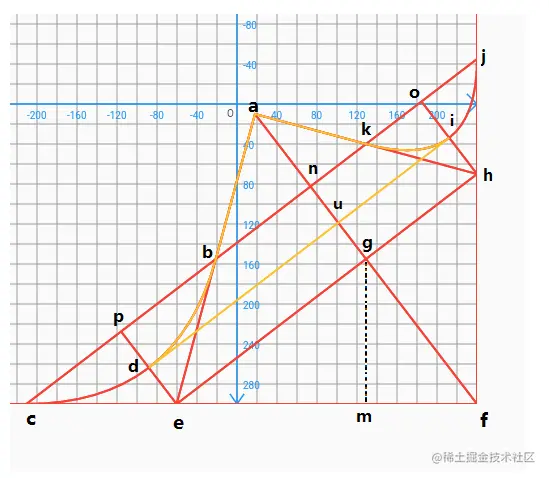
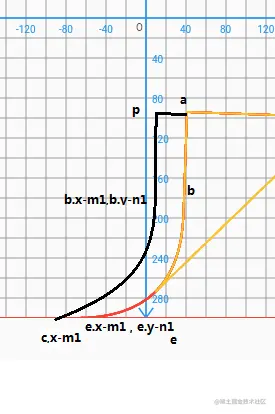
a为手指触摸点,表示翻页右下角位置。【已知】
f为固定书籍右下角位置。【已知】
a点和f已知,连接af,我们令g点为af的中点,过g点连接eh垂直af,为af中垂线, 可得 g = Point((a.x + f.x) / 2, (a.y + f.y) / 2);
并且知道△egf、△emg、△mfg为三个直角三角形,由直角三角形相似原理可知这三个三角型两两相似,所以,△emg相似△mfg,可知:
em/gm = gm/mf;
em = gm*gm/mf;
因为:gm = f.y-a.y; mf=f.x-g.x;
可得 e = Point(g.x - (pow(f.y - g.y, 2) / (f.x - g.x)), f.y);
同理过g点做fh垂直线可得h点坐标。略...
从上方理论图可知,cdb是一条二阶贝塞尔曲线,控制点为e点, ab和ak为直线线段,接下来我们令n为ag的中点,同理过n点垂直于af连接cj,可知ce等于ef的一半;(可以画辅助线过gf中点垂直af得出)。
所以可得 c = Point(e.x - (f.x - e.x) / 2, f.y);
j点坐标同理。略...
接下来我们看下b点,目前我们已知 a、e、c、j点坐标,现在b点就是ae和cj的相交点。
那么问题来了:
用我们九年义务教育学的数学知识解决以下两个问题。
1、在坐标系中,已知两点(x1,y1)、(x2,y2)坐标,求过这两点直线函数?
2、已知两条直线函数求两条直线的相交点?
我们知道直线函数表达式为:y=kx+b;,假设k为正常值,我们可求得k和b的值,
static double towPointKb(Point p1, Point p2,
{bool isK = true}) {
double k = 0;
double b = 0;
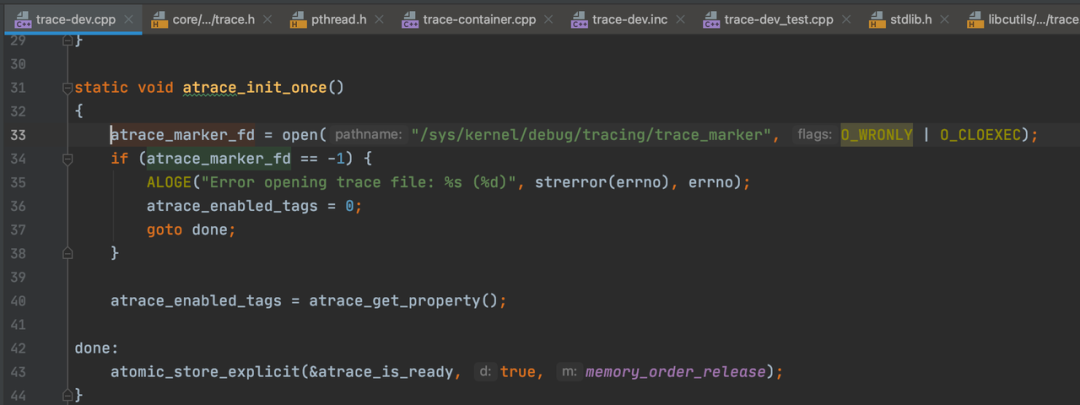
if (p1.x == p2.x) {
k = (p1.y - p2.y) / (p1.x - p2.x-1);
} else {
k = (p1.y - p2.y) / (p1.x - p2.x);
}
b = p1.y - k * p1.x;
if (isK)
return k;
else
return b;
}
通过两条直线表达式的k值和b值,我们就可以求出两条直线是否平行、相交、重合等情况,若相交则可求出。
k相同b不同:平行无交点。
k相同b相同:重合。
k不同无论b相不相同,相交必有一交点。
那么就可得出b点坐标:(假设k永不相等)
b = Point((b2 - b1) / (k1 - k2), (b2 - b1) / (k1 - k2) * k1 + b1);
k点坐标同理。略...
绘制
以上AB区域的关键点已经全部得到了,我们将辅助线去掉将这些点连接起来看下效果。
得到AB区域的同时,我们间接的就得到了C区域,
Path mPathC = Path.combine(PathOperation.reverseDifference, mPathAB, mPath);
接下来将AB区域进行区分,再回到上方,坐标图黄色线条部分,我们可以看到d点和i点坐标。
通过原理解析我们可知d点为pe的中点,而p点为cb的中点,那么就可以得出:
p.x = (e.x -c.x)/2; ,d.x = (e.x-p.x)/2;
p.y = (e.y -b.y)/2; ,d.y = (e.y-p.y)/2;
所以可得 d = Point(((c.x + b.x) / 2 + e.x) / 2, ((c.y + b.y) / 2 + e.y) / 2);
i点坐标同理。略...
接下来我们连接d、a、i三角形区域,得到以下图形,
同理通过路径联合我们就可以将AB区域进行分开,
Path mPath1 = Path();
mPath1.moveTo(p.value.d.x, p.value.d.y);
mPath1.lineTo(p.value.a.x, p.value.a.y);
mPath1.lineTo(p.value.i.x, p.value.i.y);
mPath1.close();
Path mPathB = Path.combine(PathOperation.intersect, mPathAB, mPath1);
得到以下图形,
到这里梳理一下,目前我们A、B、C三个path路径区域已经全部得到,剩下的就是填充书籍颜色,接下来我们将画笔设置为填充不同颜色,通过手势不断变化a点坐标看下效果。

是不是有点翻书的意思了,这里有一个问题,书籍的左下角也就是c点坐标在我们翻页的过程中会跑到页面之外,一般书籍都是左侧装订,这里我们希望达到一个真实的翻页效果就需要将c点的x轴最小值设置为书籍最左侧0。

这里涉及到相似图形的数学知识,手指触摸点是在不断变化的,当c点x轴达到临界值固定的时候,我们需要重新计算a点坐标,
见下图,
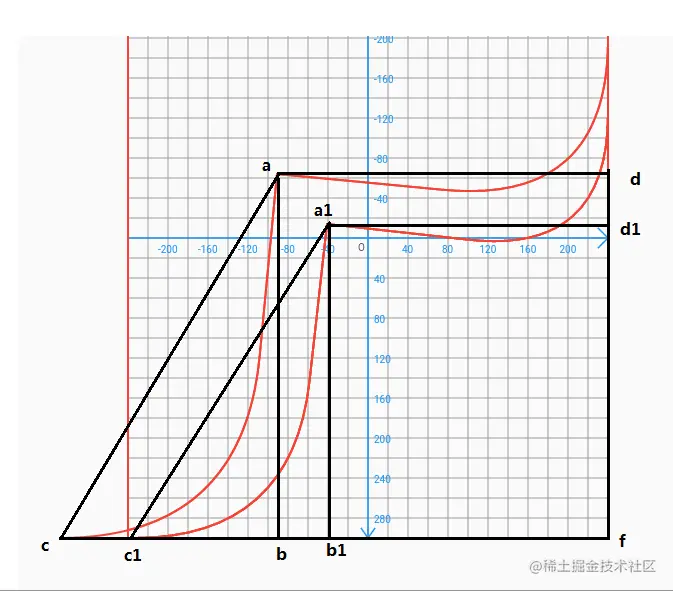
a是我们真实的手指触碰的坐标,a1则为我们需要计算出来的触碰坐标,从上图可知,△acb相似△a1b1c1,并且acfd区域相似a1c1d1f,那么通过相似原理我们可以得到fb1/fc1 = fb/fc;
从而得到,fb1= fb * fc1/fc;,
已知:
fb = f.x - a.x;
fc1 = size.width;
fc = f.x-c.x;
同理 fd1/fd = fb1/fb; 得到,fd1 = fb1 * fd/fb; 即可得到a1点坐标。
计算代码:
double fc = f.x - cx;
double fa = f.x - a.x;
double bb1 = size.width * fa / fc;
double fd1 = f.y - a.y;
double fd = bb1 * fd1 / fa;
a1 = Point(f.x - bb1, f.y - fd);
这时候我们再来看下效果,

c点坐标被我们设定最小值为书籍最左侧,所以左侧不会被翻出区域,看起来更像真实的翻页效果。
添加阴影
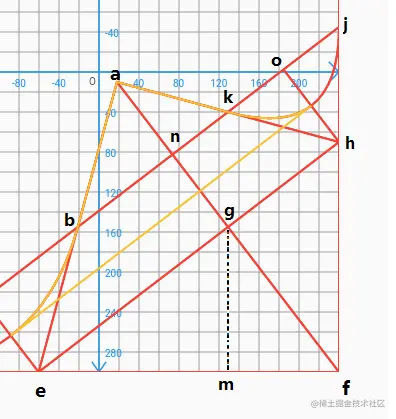
我们可以在灯光下找本书翻页看下阴影效果,差不多是这个样子,这里我将阴影分为三个部分,A区域两个和C区域一个。
我们先添加A左区域的阴影,A左区域的阴影可以认为是从ha方向由h向a进行色值渐变,所以这里我们需要得到A左阴影区域左上角坐标点,也就是ha直线向外延伸固定数值的坐标。
可以理解为数学题表达:
已知ha直线方程式和a点坐标, 以a为圆心,画半径为r(r>0)的圆,
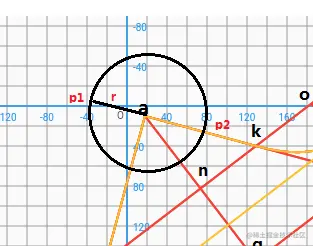
求:此圆和ha直线的相交的坐标。
设交点为坐标xy,可得 x²+y² =r²; y = kx+b;(k、b 、r)已知,最终我们得到一个一元二次方程。会解出两个坐标点,这里我们只需要往外延伸的坐标点就行,具体可以跟a点坐标判断得出,之后我们令double m1 = a.x-p1.x;double n1 = a.y-p1.y;
那么阴影外部曲线就可以用下方代码表示。
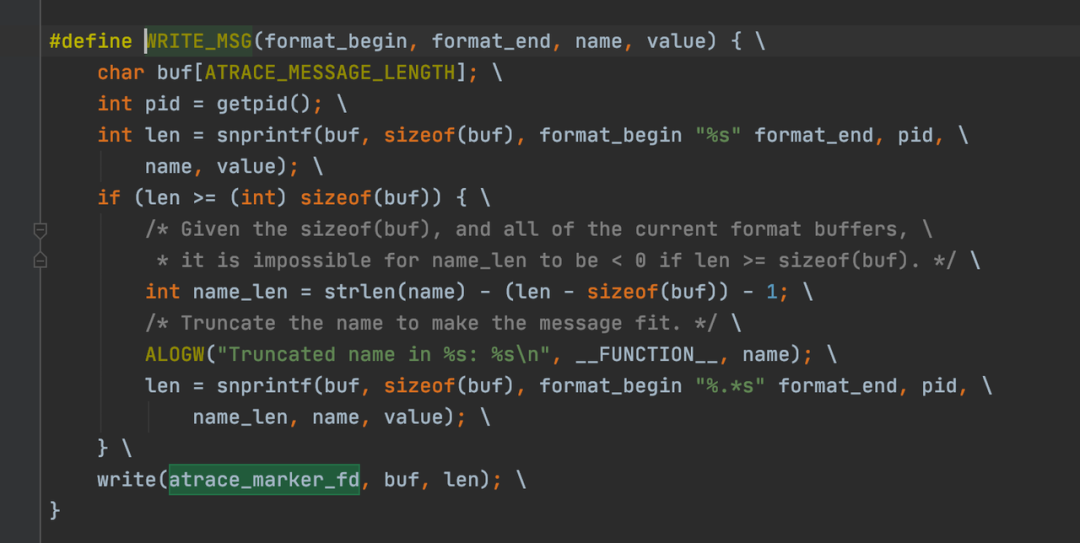
pyy1.moveTo(p.value.c.x - m1, p.value.c.y);
pyy1.quadraticBezierTo(p.value.e.x - m1, p.value.e.y - n1,
p.value.b.x - m1, p.value.b.y - n1);
pyy1.lineTo(p.value.p.x, p.value.p.y);
pyy1.lineTo(p.value.k.x, p.value.k.y);
pyy1.lineTo(p.value.f.x, p.value.f.y);
pyy1.close();
绘制出来看下效果

同理路径联合下:
Path startYY =
Path.combine(PathOperation.reverseDifference, mPathA, pyy1);
得到:

接下来通过设置画笔属性由a点向p1点进行渐变。
..shader = ui.Gradient.linear(
Offset(p.value.a.x, p.value.a.y),
Offset(p.value.p.x, p.value.p.y),
[Colors.black26, Colors.transparent]
效果:

这里我设置了由 black26,向透明渐变。延伸长度为10的效果,这里可以根据半径和色值调整影深。
A右同理,略...
效果:

接下来我们绘制C区域的阴影,C区域可以看到他是跟eh是平行的,那么我们连接c、j、h、e点,
Path pr = Path();
pr.moveTo(p.value.c.x, p.value.c.y);
pr.lineTo(p.value.j.x, p.value.j.y);
pr.lineTo(p.value.h.x, p.value.h.y);
pr.lineTo(p.value.e.x, p.value.e.y);
pr.close();
得到下面效果:

继续与AB区域进行路径联合,
Path p1 = Path.combine(PathOperation.intersect, pr, mPathAB);
得到下面效果:

继续与B区域再次联合,
Path p2 = Path.combine(PathOperation.difference, p1, mPathB);
最终得到我们想要的阴影区域。

接下来就是跟A区域操作一样了,设置线性渐变色和渐变方向,这里渐变方向的坐标点我们为u点和g点,g点已知,主要求u点坐标,u点坐标为af和di直线的相交点。
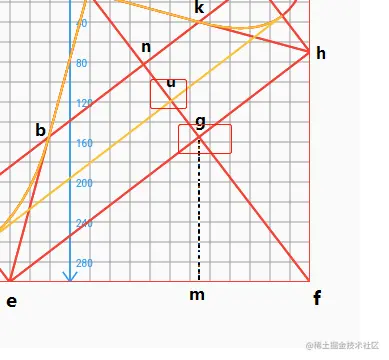
通过两条直线方程求相交点,得到u点以后,设置渐变色和渐变方向。
核心代码:
Path pc = Path();
pc.moveTo(p.value.c.x, p.value.c.y);
pc.lineTo(p.value.j.x, p.value.j.y);
pc.lineTo(p.value.h.x, p.value.h.y);
pc.lineTo(p.value.e.x, p.value.e.y);
pc.close();
Path p1 = Path.combine(PathOperation.intersect, pc, mPathA);
Path p2 = Path.combine(PathOperation.difference, p1, mPathB);
Offset u = Offset(
PaperPoint.toTwoPoint(p.value.a, p.value.f, p.value.d, p.value.i)
.x,
PaperPoint.toTwoPoint(p.value.a, p.value.f, p.value.d, p.value.i)
.y);
canvas.drawPath(
p2,
paint
..style = PaintingStyle.fill
..shader = ui.Gradient.linear(
u, Offset(p.value.g.x,p.value.g.y), [Colors.black26, Colors
.transparent]));
最后得到我们最终的效果。

这里阴影部分可能有些瑕疵,尤其上方a点坐标的处理有点生硬,但是没找到好的方式。以后有时间再优化。
翻页动画、回弹动画
目的: 我们希望可以滑动过程中页码可以自动翻过去,并且误触的情况下不要翻页。
这里我简单的判断当翻过去书籍宽度的3/1就理解为用户想翻页,当手势松开时自动翻过去;
当翻过去书籍宽度小于1/3,理解为用户误触并不想翻页,当手势松开自动回弹回去。
这里判断还可以根据用户滑动的速度进行判断,比如按下和松开之间的时间很快并且有想左滑动的距离,我们就可以判定用户想要翻页,不过这里就需要不断的调试优化达到一个比较理想的交互。
初始化动画
回弹动画,我们希望松开手指时,a点坐标回到和f点重合,这里我们需要在点击或移动的过程中保存当前手指触摸的坐标a,
var move = d.localPosition;
if (move.dx >= size.width ||
move.dx < 0 ||
move.dy >= size.height ||
move.dy < 0) {
return;
}
currentA = Point(move.dx, move.dy);
...
if ((size.width - move.dx) / size.width > 1 / 3) {
isNext = false;
} else {
isNext = true;
}
然后通过动画将a点坐标置位f点;
Point currentA = Point(0, 0);
late AnimationController _controller = AnimationController(
vsync: this, duration: Duration(milliseconds: 800))
..addListener(() {
if (isNext) {
_p.value = PaperPoint(
Point(
currentA.x + (size.width - currentA.x) * _controller.value,
currentA.y + (size.height - currentA.y) * _controller.value,
),
size);
} else {
_p.value = PaperPoint(
Point(currentA.x - (currentA.x + size.width) * _controller.value,
currentA.y + (size.height - currentA.y) * _controller.value),
size);
}
});
翻页,我们希望a点坐标和(-f.x,f.y)重合,也就是f.x为负值,相当也我们书籍彻底翻过去,
这里需要注意的是当a.x<0时,也就是书籍左侧外面区域,这里需要将我们之前设定c值的最小值放开,否则无法彻底翻过去。
只有a.x>0才限制cx坐标点
if (a.x > 0) {
if (cx <= 0) {
// // 临界点
double fc = f.x - cx;
double fa = f.x - a.x;
double bb1 = size.width * fa / fc;
double fd1 = f.y - a.y;
double fd = bb1 * fd1 / fa;
a = Point(f.x - bb1, f.y - fd);
g = Point((a.x + f.x) / 2, (a.y + f.y) / 2);
e = Point(g.x - (pow((f - g).y, 2) / (f - g).x), f.y);
cx = 0;
}
}
ok,有了这些数据以后,我们看下效果。

填充内容
最后一步,填充内容,模拟书籍嘛,当然不能是这些纯色翻页了,上面我们有了A B C三个路径的区域,接下来就需要对书籍内容Widget进行裁剪,这里我们需要路径裁剪类ClipPath类,
final CustomClipper? clipper;
const ClipPath({
Key? key,
this.clipper,
this.clipBehavior = Clip.antiAlias,
Widget? child,
}) : assert(clipBehavior != null),
super(key: key, child: child);
可以看到构造里有三个参数,除了子组件,clipBehavior是裁剪方式,可以设置抗锯齿等,clipper则是我们的核心裁剪方法,需要实现CustomClipper类里的Path getClip(Size size);方法。
通过它返回一个Path路径,即可将child进行自定义裁剪。
ok, 有了方法,接下来我们开始实现,首先我们将之前A区域的Path路径拿出来,裁剪当前页,通过Stack帧布局加载当前页和下一页内容,下一页内容永远在第一页内容下面,当翻过去动画结束时将下方页置位当前页,刷新第二页数据。
翻页动画结束当前页index+1;
if (status == AnimationStatus.completed) {
if (!isNext) {
setState(() {
currentIndex++;
});
}
}
填充内容布局代码:
List dataList = [
"第一页数据",
"第二页数据",
"第三页数据",
];
GestureDetector(
child: Stack(
children: [
currentIndex == dataList.length - 1
? SizedBox()
: ClipPath(
child: Container(
alignment: Alignment.center,
color: Colors.blue,
width: size.width,
height: size.height,
child: Text(
dataList[currentIndex + 1],
style: TextStyle(fontSize: 20),
),
),
),
ClipPath(
child: Container(
alignment: Alignment.center,
width: size.width,
height: size.height,
color: Colors.blue,
child: Text(
dataList[currentIndex],
style: TextStyle(fontSize: 20),
),
),
clipper: CurrentPaperClipPath(_p),
),
CustomPaint(
size: size,
painter: _BookPainter(
_p,
),
),
],
),
onPanDown: (d) {
if (currentIndex == dataList.length - 1) {
ToastUtil.show("最后一页了");
return;
}
isNext = false;
var down = d.localPosition;
_p.value = PaperPoint(Point(down.dx, down.dy), size);
currentA = Point(down.dx, down.dy);
},
onPanUpdate: currentIndex == dataList.length - 1
? null
: (d) {
var move = d.localPosition;
if (move.dx >= size.width ||
move.dx < 0 ||
move.dy >= size.height ||
move.dy < 0) {
return;
}
currentA = Point(move.dx, move.dy);
_p.value = PaperPoint(Point(move.dx, move.dy), size);
if ((size.width - move.dx) / size.width > 1 / 3) {
isNext = false;
} else {
isNext = true;
}
},
onPanEnd: currentIndex == dataList.length - 1
? null
: (d) {
_controller.forward(
from: 0,
);
},
),
class CurrentPaperClipPath extends CustomClipper {
ValueNotifier p;
CurrentPaperClipPath(
this.p,
) : super(reclip: p);
@override
Path getClip(Size size) {
Path mPath = Path();
mPath.addRect(Rect.fromCenter(
center: Offset(size.width / 2, size.height / 2),
width: size.width,
height: size.height));
Path mPathA = Path();
if (p.value.a != p.value.f && p.value.a.x > -size.width) {
print("当前页 ${p.value.a} ${p.value.f}");
mPathA.moveTo(p.value.c.x, p.value.c.y);
mPathA.quadraticBezierTo(
p.value.e.x, p.value.e.y, p.value.b.x, p.value.b.y);
mPathA.lineTo(p.value.a.x, p.value.a.y);
mPathA.lineTo(p.value.k.x, p.value.k.y);
mPathA.quadraticBezierTo(
p.value.h.x, p.value.h.y, p.value.j.x, p.value.j.y);
mPathA.lineTo(p.value.f.x, p.value.f.y);
mPathA.close();
Path mPathC =
Path.combine(PathOperation.reverseDifference, mPathA, mPath);
return mPathC;
}
return mPath;
}
@override
bool shouldReclip(covariant CurrentPaperClipPath oldClipper) {
return p != oldClipper.p;
}
}
最终看下效果.
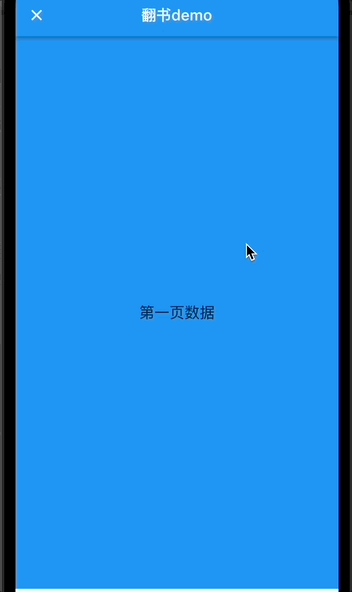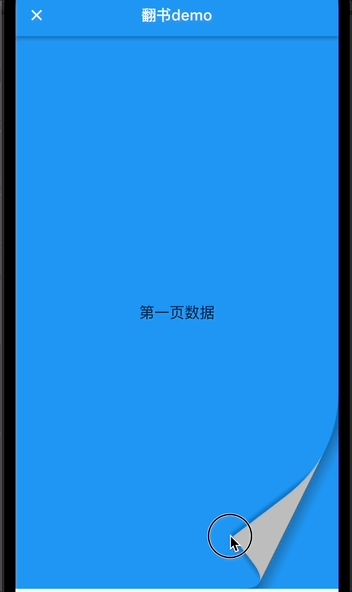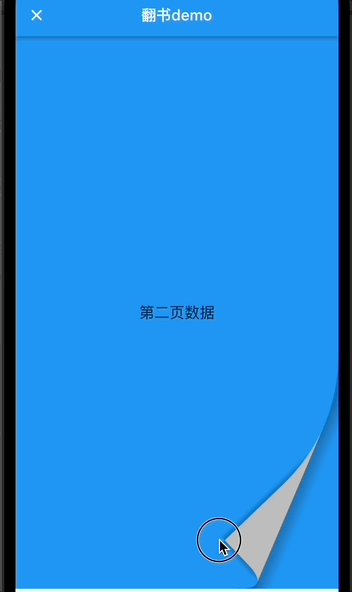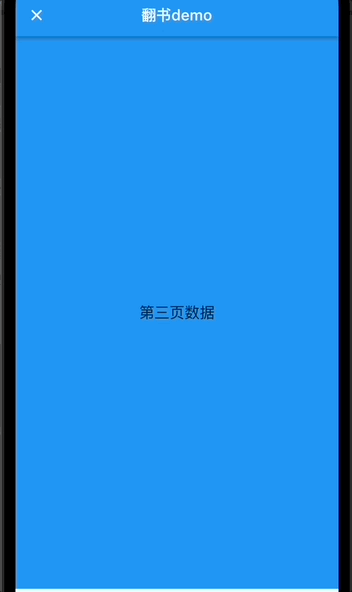
返回上一页
上面只有翻页,没有返回上一页,其实返回上一页也很简单,上面我们实现了回弹动画,这里只需要修改当前a点坐标为为书籍左侧外面,之后调用回弹动画,当前页面-1即可。非常简单。
ElevatedButton(
onPressed: () {
setState(() {
// 表示从页面左侧外面开始回弹
currentA = Point(-100, size.height - 100);
currentIndex--;
// 回弹动画
isNext = false;
});
// _p.value = PaperPoint(currentA, size);
_controller.forward(
from: 0,
);
},
child: Text("上一页"))
下面再看下最终效果:
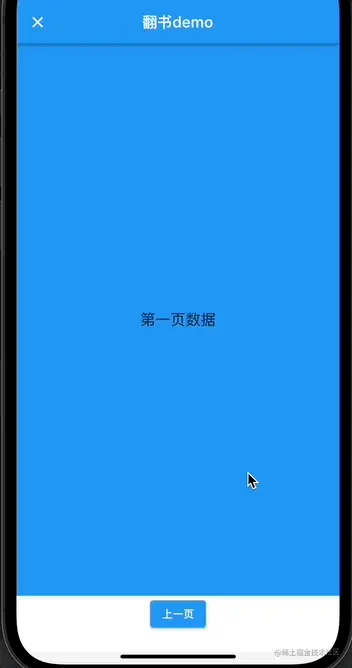
这里示例只是简单的填充了一个Text文本,更多内容也是可以的,毕竟裁剪的是个Widget。
总结
翻页示例可以说是手势和绘制的典型结合,实现过程中也是踩了许多的坑,网上找了很多资料,并且实现原理上也用到了一些初中数学知识,总的来说,过程还是比较曲折的,本篇文章主要讲了我在实现的过程中的一个详细过程及思路,代码目前先不传了,毕竟现在还是有些小问题,后续有时间再优化吧,后续有时间也许会将他优化下,做成一个开源组件,ok,那本篇文章到这里就结束了,希望对你有所帮助~










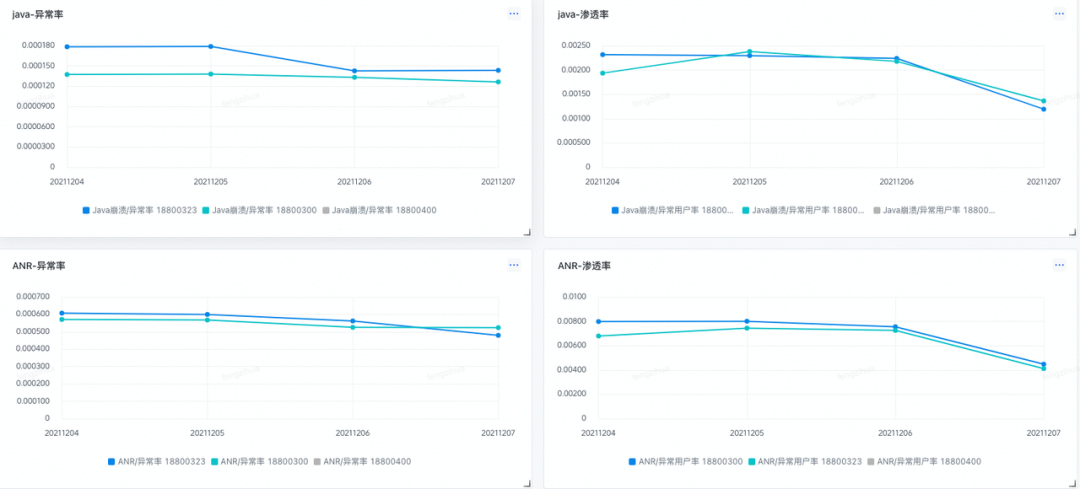
























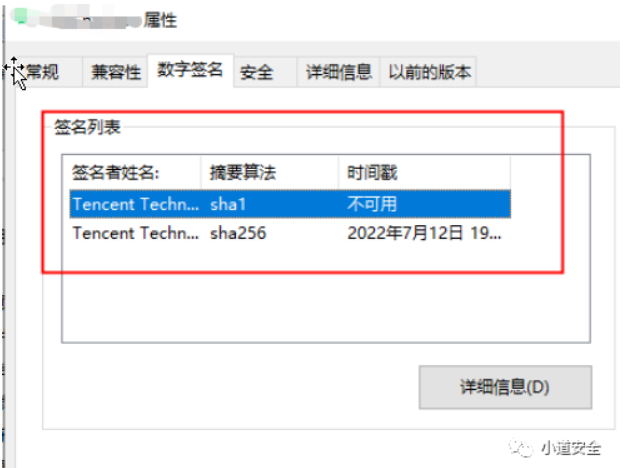
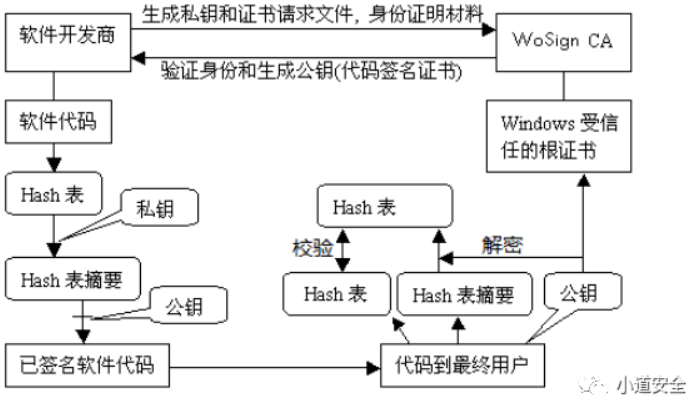
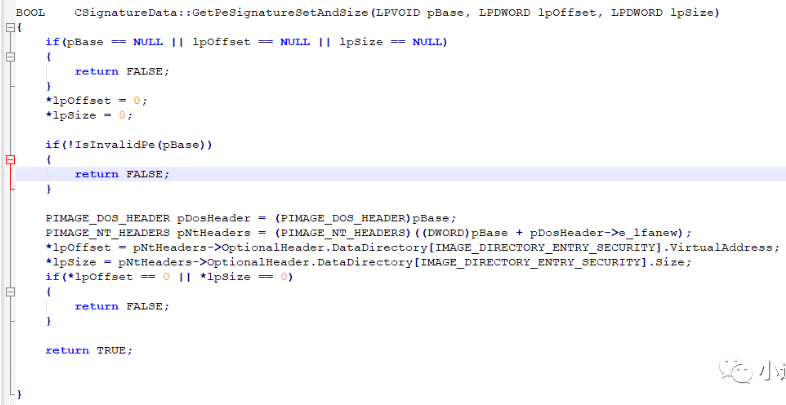
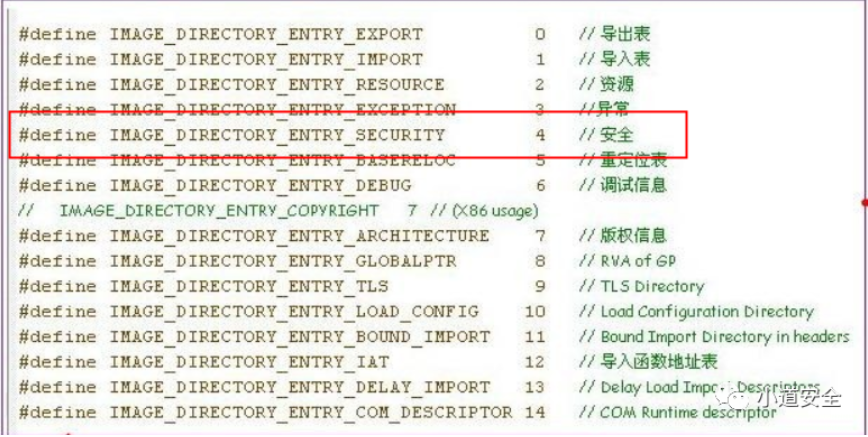
































 2. 内网开发的小伙伴 可以下载之后进行本地安装 下载地址
2. 内网开发的小伙伴 可以下载之后进行本地安装 下载地址

 img
img img
img