
谈一谈凑单页的那些优雅设计(上)
本文将详细介绍作者如何在业务增长的情况下重构与优化系统设计。
写在前面
凑单页存在的历史也算是比较悠久了,我从去年接手到现在也经历不少的版本变更,最开始只是简单feeds流,为提升用户体验,更好的帮助用户去凑到满意的商品,我们在重构整个凑单页的同时,还新增了榜单、限时秒杀模块,在双十一期间,加购率和转化率得到明显提升。今年618还新增了凑单进度购物栏模块,支持了实时凑单进度展示以及结算下单的能力,提升用户凑单体验。并且在凑单页完成业务迭代的同时,也一路沉淀了些通用的能力支撑其他业务快速迭代,本文我将详细介绍我是如何在业务增长的情况下重构与优化系统设计的。
针对一些段时间内不会变化的,数量比较有限的数据,为了减少下游的压力,并提高自身系统的性能,我们常常会使用多级缓存来达到该目的。最常见的就是本地缓存 + redis缓存来承接,如果本地缓存不存在,则取redis缓存的数据,并本地缓存起来,如果redis也不存在,则再从数据源获取,基本代码(获取榜单数据)如下:
return LOCAL_CACHE.get(key, () -> {
String cache = rdbCommonTairCluster.get(key);
if (StringUtils.isNotBlank(cache)) {
return JSON.parseObject(cache, new TypeReference<List<ItemShow>>(){});
}
List<ItemShow> itemShows = getRankingItemOriginal(context, rankingRequest);
rdbCommonTairCluster.set(key, JSON.toJSONString(itemShows), new SetParams().ex(CommonSwitch.rankingExpireSecond));
return itemShows;
});
逐渐的就出现了问题,线上偶现某些用户一段时间看不到榜单模块。榜单模块示意图如下:

这种问题排查起来最是棘手,需要一定的项目经验,我第一次遇到这类问题也是费了老大劲。总结一下,如果某次缓存过期,下游服务刚好返回了空结果,就会导致本次请求被缓存了空结果。那该缓存的生命周期内,榜单模块都会消失,但由于某些机器本地缓存还有旧数据,就会导致部分用户能看到,部分用户看不到的场景。
下面来看看我是如何优化的。核心主要关注:区分下游返回的结果是真的空还是假的空,本身就为空的情况下,就该缓存空集合(非大促期间或者某些榜没有数据,数据本身就为空)
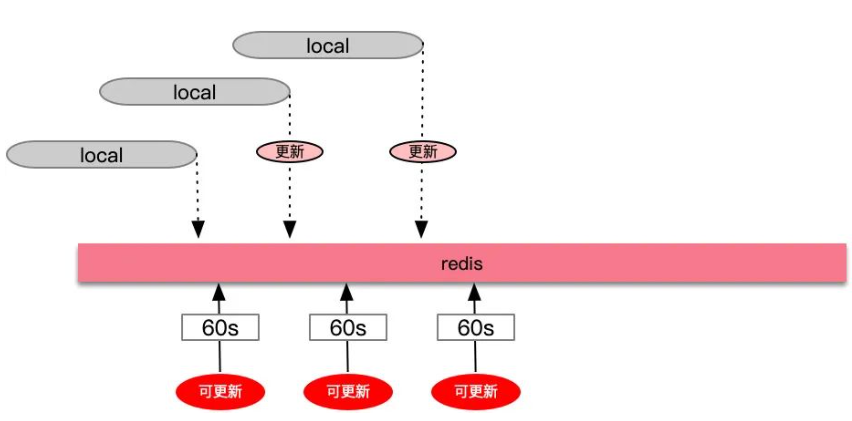
在redis中拉长value缓存的时间,同时新增一个可更新时间的缓存(比如60s过期),当判断更新时间缓存过期了,就重新读取数据源,将value值重新赋值,这里需要注意,我会对比新老数据,如果新数据为空,老数据不为空,则只是更新时间,不置换value。value随着自己的过期时间结束,改造后的代码如下:
return LOCAL_CACHE.get(key, () -> {
String updateKey = getUpdateKey(key);
String value = rdbCommonTairCluster.get(key);
List<ItemShow> cache = StringUtils.isBlank(cache) ? Collections.emptyList()
: JSON.parseObject(value, new TypeReference<List<ItemShow>>(){});
if (rdbCommonTairCluster.exists(updateKey)) {
return cache;
}
rdbCommonTairCluster.set(updateKey, currentTime, cacheUpdateSecond);
List<ItemShow> itemShows = getRankingItemOriginal(context, rankingRequest);
if (CollectionUtils.isNotEmpty(itemShows)) {
rdbCommonTairCluster.set(key, JSON.toJSONString(itemShows), new SetParams().ex(CommonSwitch.rankingExpireSecond));
}
return itemShows;
});
为了使这段代码能够复用,我将该多级缓存抽象出来一个独立对象,代码如下:
public class GatherCache<V> {
@Setter
private Cache<String, List<V>> localCache;
@Setter
private CenterCache centerCache;
public List<V> get(boolean needCache, String key, @NonNull Callable<List<V>> loader, Function<String, List<V>> parse) {
try {
// 是否需要是否缓存
return needCache ? localCache.get(key, () -> getCenter(key, loader, parse)) : loader.call();
} catch (Throwable e) {
GatherContext.error(this.getClass().getSimpleName() + " get catch exception", e);
}
return Collections.emptyList();
}
private List<V> getCenter(String key, Callable<List<V>> loader, Function<String, List<V>> parse) throws Exception {
String updateKey = getUpdateKey(key);
String value = centerCache.get(key);
boolean blankValue = StringUtils.isBlank(value);
List<V> cache = blankValue ? Collections.emptyList() : parse.apply(value);
if (centerCache.exists(updateKey)) {
return cache;
}
centerCache.set(updateKey, currentTime, cacheUpdateSecond);
List<V> newCache = loader.call();
if (CollectionUtils.isNotEmpty(newCache)) {
centerCache.set(key, JSON.toJSONString(newCache), cacheExpireSecond);
}
return newCache;
}
}
将从数据源获取数据的代码交与外部实现,使用Callable的形式,同时通过泛型约束数据源类型,这里还有一点瑕疵还没得到解决,就是通过fastJson转换String到对象时,没法使用泛型直接转,我这里就采用了外部化的处理,就是跟获取数据源方式一样,由外部来决定如何解析从redis中获取到的字符串value。调用方式如下:
List<ItemShow> itemShowList = gatherCache.get(true, rankingRequest.getKey(),
() -> getRankingItemOriginal(rankingRequest, context.getRequestContext()),
v -> JSON.parseObject(v, new TypeReference<List<ItemShow>>() {}));
同时我还采用的建造者模式,方便gatherCache类快速生成,代码如下:
@PostConstruct
public void init() {
this.gatherCache = GatherCacheBuilder.newBuilder()
.localMaximumSize(500)
.localExpireAfterWriteSeconds(30)
.build(rdbCenterCache);
}
以上的代码相对比较完美了,却忽略了一个细节点,如果多台机器的本地缓存同时失效,恰好redis的可更新时间失效了,这时就会有多个请求并发打到下游(由于凑单有本地缓存兜底,并发打到下游的个数非常有限,基本可以忽略)。但遇到问题就需要去解决,追求完美代码。我做了如下的改造:
private List<V> getCenter(String key, Callable<List<V>> loader, Function<String, List<V>> parse) throws Exception {
String updateKey = getUpdateKey(key);
String value = centerCache.get(key);
boolean blankValue = StringUtils.isBlank(value);
List<V> cache = blankValue ? Collections.emptyList() : parse.apply(value);
// 如果抢不到锁,并且value没有过期
if (!centerCache.setNx(updateKey, currentTime) && !blankValue) {
return cache;
}
centerCache.set(updateKey, currentTime, cacheUpdateSecond);
// 使用异步线程去更新value
CompletableFuture.runAsync(() -> updateCache(key, loader));
return cache;
}
private void updateCache(String key, Callable<List<V>> loader) {
List<V> newCache = loader.call();
if (CollectionUtils.isNotEmpty(newCache)) {
centerCache.set(key, JSON.toJSONString(newCache), cacheExpireSecond);
}
}
本方案使用分布式锁 + 异步线程的方式来处理更新。只会有一个请求抢到更新锁,并发情况下,其他请求在可更新时间段内还是返回老数据。由于redis封装的方法中并没有抢锁后同时设置过期时间的原子性操作,我这里用了先抢锁,再赋值过期时间的方式,在极端场景下可能会出现死锁的情况,就是刚好抢到了锁,然后机器出现异常宕机,导致过期时间没有赋值上去,就会出现永远无法更新的情况。这种情况虽然极端,但还是要解,以下是我能想到的两个方案,我选择了第二种方式:
通过使用lua脚本将两步操作合成一个原子性操作
利用value的过期时间来解该死锁问题

P.S. 一些从ThreadLocal中拿的通用信息,在使用异步线程处理的时候是拿不到的,得重新赋值
▐ 凑单核心处理流程设计
凑单本身是没有自己的数据源的,都是从其他服务读取,做各种加工后展示。这样的代码是最好写的,也是最难写的。就好比最简单的组装商品信息,一般的代码都会这么写:
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v -> {
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
itemShow.setItemId(NumberUtils.createLong(v.get("itemId")));
itemShow.setItemImg(v.get("pic"));
// 获取利益点
GuideInfoDTO guideInfoDTO = new GuideInfoDTO();
AtmosphereResult<Map<Long, List<AtmosphereFullDTO>>> atmosphereResult = guideAtmosphereClient
.extract(guideInfoDTO, "gather", "item");
List<IconText> iconTexts = parseAtmosphere(atmosphereResult);
itemShow.setItemBenefits(iconTexts);
// 预售处理
String preSalePrice = getPreSale(v);
if (Objects.nonNull(preSalePrice)) {
itemShow.setItemPrice(preSalePrice);
}
// ......
return itemShow;
}).collect(Collectors.toList());
能快速写好代码并投入使用,但代码有点杂乱无章,对代码要求比较高的开发者可能会做如下的改进
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v -> {
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
buildCommon(itemShow, v);
// 获取利益点
buildAtmosphere(itemShow, v);
// 预售处理
buildPreSale(itemShow, v);
// ......
return itemShow;
}).collect(Collectors.toList());
一般这样的代码算是比较优质的处理了,但这仅仅是针对单个业务,如果遇到多个业务需要使用该组装后,最简单但就是需要判断是来自feeds流模块的请求商品组装不需要利益点,来自前N秒杀模块的不需要处理预售价格。
// 获取推荐商品
List<Map<String, String>> summaryItemList = recommend();
List<ItemShow> itemShowList = summaryItemList.stream().map(v -> {
ItemShow itemShow = new ItemShow();
// 设置商品基本信息
buildCommon(itemShow, v);
// 获取利益点
if (!Objects.equals(soluction, FiltrateFeedsSolution.class)) {
buildAtmosphere(itemShow, v);
}
// 预售处理
if (!Objects.equals(source, "seckill")) {
buildPreSale(itemShow, v);
}
// ......
return itemShow;
}).collect(Collectors.toList());
该方案可以清晰看到整个主流程的分流结构,但会使得主流程不够整洁,降低可读性,很多人都习惯把该判断写到各自的方法里如下。(当然也有人每个模块都单独写一个主流程,以上只是为了文章易懂简化了代码,实际主流程较长,并且大部分都是需要处理的,如果每个模块都单独自己创建主流程,会带来很多重复代码,不推荐)
private void buildAtmosphere(ItemShow itemShow, Map<String, String> map) {
if (Objects.equals(soluction, FiltrateFeedsSolution.class)) {
return;
}
GuideInfoDTO guideInfoDTO = new GuideInfoDTO();
AtmosphereResult<Map<Long, List<AtmosphereFullDTO>>> atmosphereResult = guideAtmosphereClient
.extract(guideInfoDTO, "gather", "item");
List<IconText> iconTexts = parseAtmosphere(atmosphereResult);
itemShow.setItemBenefits(iconTexts);
}
纵观整个凑单的业务逻辑,不管是参数组装,商品组装,购物车组装,榜单组装,都需要信息组装的能力,并且他们都有如下的特性:
每个或每几个字段的组装都不影响其他字段,就算出现异常也不应该影响其他字段的拼装
在消费者链路下,性能的要求会比较高,能不用访问的组装逻辑就不去访问,能不调用下游,就不去调用下游
如果在组装的过程中发现有写字段是必须要的,但没有补全,则提前终止流程
每个方法的处理需要记录耗时,开发能清楚的知道耗时在哪些地方,方便找到需要优化的代码
以上的点都很小,不做或者单独做都不影响整体,凑单页含有这么多组装逻辑的情况下,如果以上逻辑全部都写一遍,将产生大量的冗余代码。但对自己代码要求比较高的人来说,这些点不加上去,心里总感觉有根刺在。慢慢的就会因为自己之前设计考虑的不全,打各种补丁,就好比想知道某个方法的耗时,就会写如下代码:
long startTime = System.currentTimeMillis();
// 主要处理
buildAtmosphere(itemShow, summaryMap);
long endTime = System.currentTimeMillis();
return endTime - startTime;
凑单各域都是做此类型的组装,有商品组装,参数组装,榜单组装,购物车组装。针对凑单业务的特性,寻遍各类设计模式,最终选择了责任链 + 命令模式。
在 GoF 的《设计模式》中,责任链模式是这么定义的:
将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
*首先,我们来看,职责链模式如何应对代码的复杂性。*
将大块代码逻辑拆分成函数,将大类拆分成小类,是应对代码复杂性的常用方法。应用职责链模式,我们把各个商品组装继续拆分出来,设计成独立的类,进一步简化了商品组装类,让类的代码不会过多,过复杂。
*其次,我们再来看,职责链模式如何让代码满足开闭原则,提高代码的扩展性。*
当我们要扩展新的组装逻辑的时候,比如,我们还需要增加价格隐藏过滤,按照非职责链模式的代码实现方式,我们需要修改主类的代码,违反开闭原则。不过,这样的修改还算比较集中,也是可以接受的。而职责链模式的实现方式更加优雅,只需要新添加一个Command 类(实际处理类采用了命令模式做一些业务定制的扩展),并且通过 addCommand() 函数将它添加到 Chain 中即可,其他代码完全不需要修改。
接下来就是使用该模式,对凑单全域进行改造升级,核心架构图如下
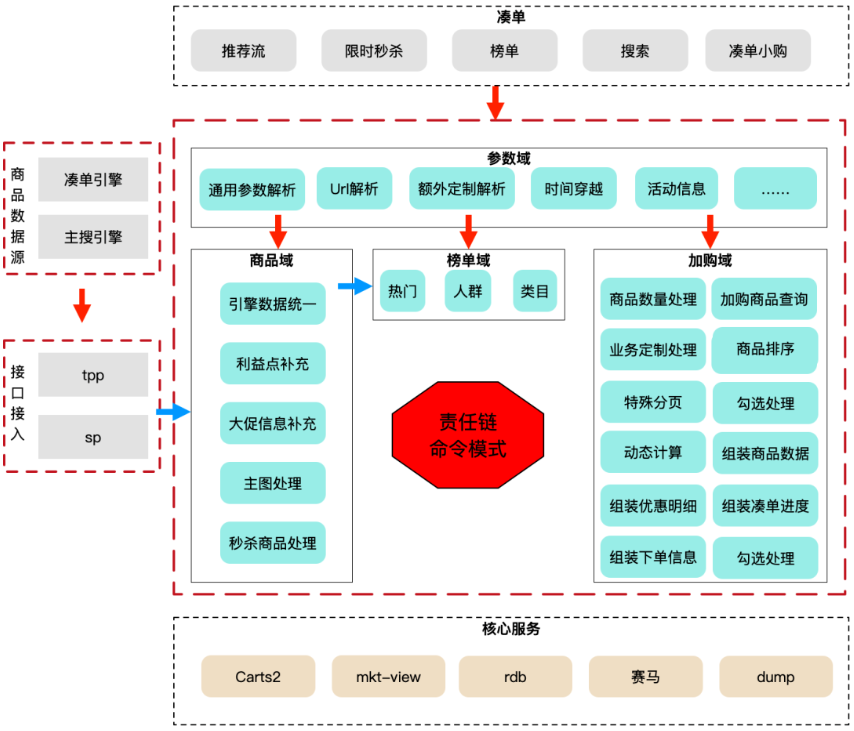
各个域需要满足如下条件:
支持单个处理和批量处理
支持提前阻断
支持前置判断是否需要处理
处理类类图如下
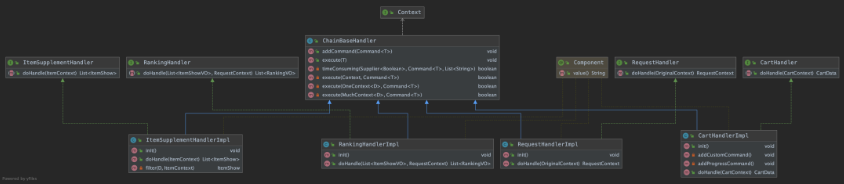
【ChainBaseHandler】:核心处理类
【CartHandler】:加购域处理类
【ItemSupplementHandler】:商品域处理类
【RankingHandler】:榜单域处理类
【RequestHanlder】:参数域处理类
我们首先来看核心处理层:
public class ChainBaseHandler<T extends Context> {
/**
* 任务执行
* @param context
*/
public void execute(T context) {
List<String> executeCommands = Lists.newArrayList();
for (Command<T> c : commands) {
try {
// 前置校验
if (!c.check(context)) {
continue;
}
// 执行
boolean isContinue = timeConsuming(() -> execute(context, c), c, executeCommands);
if (!isContinue) {
break;
}
} catch (Throwable e) {
// 打印异常信息
GatherContext.debug("exception", c.getClass().getSimpleName());
GatherContext.error(c.getClass().getSimpleName() + " catch exception", e);
}
}
// 打印个命令任务耗时
GatherContext.debug(this.getClass().getSimpleName() + "-execute", executeCommands);
}
}
中间的timeConsuming方法用来计算耗时,耗时需要前后包裹执行方法
private boolean timeConsuming(Supplier<Boolean> supplier, Command<T> c, List<String> executeCommands) {
long startTime = System.currentTimeMillis();
boolean isContinue = supplier.get();
long endTime = System.currentTimeMillis();
long timeConsuming = endTime - startTime;
executeCommands.add(c.getClass().getSimpleName() + ":" + timeConsuming);
return isContinue;
}
具体执行如下:
/**
* 执行每个命令
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(Context context, Command<T> c) {
if (context instanceof MuchContext) {
return execute((MuchContext<D>) context, c);
}
if (context instanceof OneContext) {
return execute((OneContext<D>) context, c);
}
return true;
}
/**
* 单数据执行
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(OneContext<D> oneContext, Command<T> c) {
if (Objects.isNull(oneContext.getData())) {
return false;
}
if (c instanceof CommonCommand) {
return ((CommonCommand<OneContext<D>>) c).execute(oneContext);
}
return true;
}
/**
* 批量数据执行
* @return 是否继续执行
*/
private <D extends ContextData> boolean execute(MuchContext<D> muchContext, Command<T> c) {
if (CollectionUtils.isEmpty(muchContext.getData())) {
return false;
}
if (c instanceof SingleCommand) {
muchContext.getData().forEach(data -> ((SingleCommand<MuchContext<D>, D>) c).execute(data, muchContext));
return true;
}
if (c instanceof CommonCommand) {
return ((CommonCommand<MuchContext<D>>) c).execute(muchContext);
}
return true;
入参都是统一的context,其中的data为需要拼装的数据。类图如下
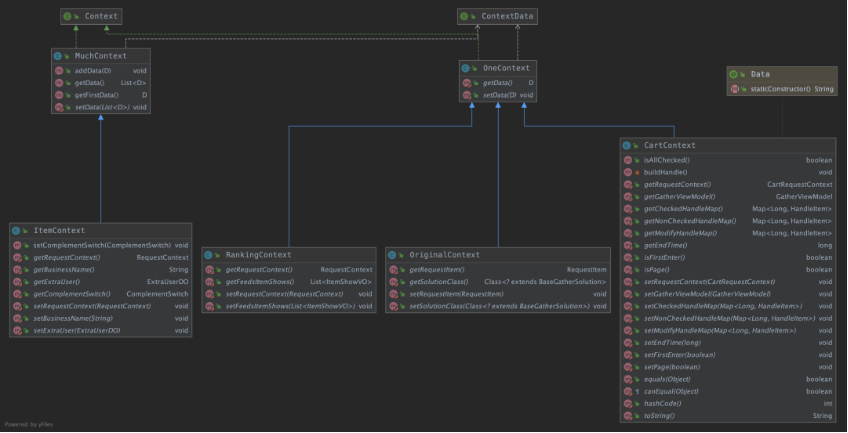
MuchContext(多值的数据拼装上下文),data是个集合
public class MuchContext<D extends ContextData> implements Context {
protected List<D> data;
public void addData(D d) {
if (CollectionUtils.isEmpty(this.data)) {
this.data = Lists.newArrayList();
}
this.data.add(d);
}
public List<D> getData() {
if (Objects.isNull(this.data)) {
this.data = Lists.newArrayList();
}
return this.data;
}
}
OneContext(单值的数据拼装上下文),data是个对象
public class OneContext <D extends ContextData> implements Context {
protected D data;
}
各域可根据自己需要实现,各个实现的context也使用了领域模型的思想,将对入参的一些操作封装在此,简化各个命令处理器的获取成本。举个例子,比如入参是一系列操作集合 List<HandleItem> handle。但实际使用是需要区分各个操作,那我们就需要在context中做好初始化,方便获取:
private void buildHandle() {
// 勾选操作集合
this.checkedHandleMap = Maps.newHashMap();
// 去勾选操作集合
this.nonCheckedHandleMap = Maps.newHashMap();
// 修改操作集合
this.modifyHandleMap = Maps.newHashMap();
Optional.ofNullable(requestContext.getExtParam())
.map(CartExtParam::getHandle)
.ifPresent(o -> o.forEach(v -> {
if (Objects.equals(v.getType(), CartHandleType.checked)) {
checkedHandleMap.put(v.getCartId(), v);
}
if (Objects.equals(v.getType(), CartHandleType.nonChecked)) {
nonCheckedHandleMap.put(v.getCartId(), v);
}
if (Objects.equals(v.getType(), CartHandleType.modify)) {
modifyHandleMap.put(v.getCartId(), v);
}
}));
}
下面来看各个命令处理器,类图如下:
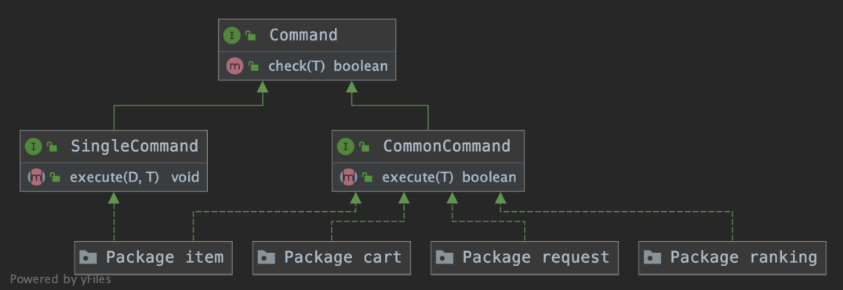
命令处理器主要分为SingleCommand和CommonCommand,CommonCommand为普通类型,即将data交与各个命令自行处理,而SingleCommand则是针对批量处理的情况下,将data集合提前拆好。两个核心区别就在于一个在框架层执行data的循环,一个是在各个命令层处理循环。主要作用在于:
SingleCommand减少重复循环代码
CommonCommand针对下游需要批量处理的可提高性能
作者:鸣翰(郑健) 大淘宝技术
