








Transform 被废弃,TransformAction 了解一下~
前言
Transform API 是 AGP1.5 就引入的特性,主要用于在 Android 构建过程中,在 Class转Dex的过程中修改 Class 字节码。利用 Transform API,我们可以拿到所有参与构建的 Class 文件,然后可以借助ASM 等字节码编辑工具进行修改,插入自定义逻辑。
国内很多团队都或多或少的用 AGP 的 Transform API 来搞点儿黑科技,比如无痕埋点,耗时统计,方法替换等。但是在AGP7.0中Transform已经被标记为废弃了,并且将在AGP8.0中移除。
而Transrom被废弃之后,它的代替品则是Transform Action,它是由Gradle提供的产物变换API。
Transform API是由AGP提供的,而Transform Action则是由Gradle提供。不光是 AGP 需要 Transform,Java 也需要,所以由 Gradle 来提供统一的 Transform API 也合情合理。
当然如果你只是想利用ASM对字节码插桩,AGP提供了对基于TransformAction的ASM插桩的封装,只需要使用AsmClassVisitorFactory即可,关于具体的使用可见:Transform 被废弃,ASM 如何适配?
而本文主要包括以下内容:
TransformAction是什么?- 如何自定义
TransformAction TransformAction在AGP中的应用
TransformAction是什么?
简单来说,TransformAction就是Gradle提供的产物转换API,可以注册两个属性间的转换Action,将依赖从一个状态切换到另一个状态
我们在项目中的依赖,可能会有多个变体,例如,一个依赖可能有以下两种变体:classes( org.gradle.usage=java-api, org.gradle.libraryelements=classes )或JAR( org.gradle.usage=java-api, org.gradle.libraryelements=jar)
它们的主要区别就在于,一个的产物是jar,一个则是classes(类目录)
当Gradle解析配置时,解析的配置上的属性将确定请求的属性,并选中匹配属性的变体。例如,当配置请求org.gradle.usage=java-api, org.gradle.libraryelements=classes时,就会选择classes目录作为输入。
但是如果依赖项没有所请求属性的变体,那么解析配置就会失败。有时我们可以将依赖项的产物转换为请求的变体。
例如,解压缩Jar的TranformAction会将 java-api,jars转换为java-api,classes变体。
这种转换可以对依赖的产物进行转换,所以称为“产物转换” 。Gradle允许注册产物转换,并且当依赖项没有所请求的变体时,Gradle将尝试查找一系列产物转换以创建变体。
TransformAction选择和执行逻辑
如上所述,当Gradle解析配置并且配置中的依赖关系不具有带有所请求属性的变体时,Gradle会尝试查找一系列TransformAction以创建变体。
每个注册的转换都是从一组属性转换为一组属性。例如,解压缩转换可以从org.gradle.usage=java-api, org.gradle.libraryelements=jars转换至org.gradle.usage=java-api, org.gradle.libraryelements=classes 。
为了找到一条这样的链,Gradle从请求的属性开始,然后将所有修改某些请求的属性的TransformAction视为通向那里的可能路径。
例如,考虑一个minified属性,它有两个值: true和false 。minified属性表示是否删除了不必要的类文件。
如果我们的依赖只有minified=false的变体,并且我们的配置中请求了minified=true的属性,如果我们注册了minify的转换,那么它就会被选中
在找到的所有变换链中,Gradle尝试选择最佳的变换链:
- 如果只有一个转换链,则选择它。
- 如果有两个变换链,并且一个是另一个的后缀,则将其选中。
- 如果存在最短的变换链,则将其选中。
- 在所有其他情况下,选择将失败并报告错误。
同时还有两个特殊情况:
- 当已经存在与请求属性匹配的依赖项变体时,
Gradle不会尝试选择产物转换。 artifactType属性是特殊的,因为它仅存在于解析的产物上,而不存在于依赖项上。因此任何只变换artifactType的TransformAction,只有在使用ArtifactView时才会考虑使用
自定义TransformAction
下面我们就以自定义一个MinifyTransform为例,来看看如何自定义TransformAction,主要用于过滤产物中不必要的文件
定义TransformAction
abstract class Minify : TransformAction<Minify.Parameters> { // (1)
interface Parameters : TransformParameters { // (2)
@get:Input
var keepClassesByArtifact: Map<String, Set<String>>
}
@get:PathSensitive(PathSensitivity.NAME_ONLY)
@get:InputArtifact
abstract val inputArtifact: Provider<FileSystemLocation>
override
fun transform(outputs: TransformOutputs) {
val fileName = inputArtifact.get().asFile.name
for (entry in parameters.keepClassesByArtifact) { // (3)
if (fileName.startsWith(entry.key)) {
val nameWithoutExtension = fileName.substring(0, fileName.length - 4)
minify(inputArtifact.get().asFile, entry.value, outputs.file("${nameWithoutExtension}-min.jar"))
return
}
}
println("Nothing to minify - using ${fileName} unchanged")
outputs.file(inputArtifact) // (4)
}
private fun minify(artifact: File, keepClasses: Set<String>, jarFile: File) {
println("Minifying ${artifact.name}")
// Implementation ...
}
}
代码很简单,主要分为以下几步:
- 实现
TransformAction接口并声明参数类型 - 实现参数接口,实现自定义参数
- 获取输入并实现
transform逻辑 - 输出变换结果,当不需要变换时直接将输入作为变换结果
其实一个TransformAction主要就是输入,输出,变换逻辑三个部分
注册TransformAction
接下来就是注册了,您需要注册TransformAction,并在必要时提供参数,以便在解析依赖项时可以选择它们
val artifactType = Attribute.of("artifactType", String::class.java)
val minified = Attribute.of("minified", Boolean::class.javaObjectType)
val keepPatterns = mapOf(
"guava" to setOf(
"com.google.common.base.Optional",
"com.google.common.base.AbstractIterator"
)
)
dependencies {
attributesSchema {
attribute(minified) // <1>
}
artifactTypes.getByName("jar") {
attributes.attribute(minified, false) // <2>
}
}
configurations.all {
afterEvaluate {
if (isCanBeResolved) {
attributes.attribute(minified, true) // <3>
}
}
}
dependencies { // (4)
implementation("com.google.guava:guava:27.1-jre")
implementation(project(":producer"))
}
dependencies {
registerTransform(Minify::class) { // <5>
from.attribute(minified, false).attribute(artifactType, "jar")
to.attribute(minified, true).attribute(artifactType, "jar")
parameters {
keepClassesByArtifact = keepPatterns
// Make sure the transform executes each time
timestamp = System.nanoTime()
}
}
}
tasks.register<Copy>("resolveRuntimeClasspath") {
from(configurations.runtimeClasspath)
into(layout.buildDirectory.dir("runtimeClasspath"))
}
注册TransformAction也分为以下几步:
- 添加
minified属性 - 将所有JAR文件的
minified属性设置为false - 在所有可解析的配置上设置请求的属性为
minified=true - 添加将要转换的依赖项
- 注册
Transformaction,设置from与to的属性,并且传递自定义参数
运行TransformAction
在定义与注册了TransformAction之后,下一步就是运行了
上面我们自定义了resolveRuntimeClasspath的Task,Minify转换会在我们请求minified=true的变体时调用
当我们运行gradle resolveRuntimeClasspath时就可以得到如下输出
> Task :resolveRuntimeClasspath
Nothing to minify - using jsr305-3.0.2.jar unchanged
Minifying guava-27.1-jre.jar
Nothing to minify - using failureaccess-1.0.1.jar unchanged
Nothing to minify - using listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar unchanged
Nothing to minify - using j2objc-annotations-1.1.jar unchanged
Nothing to minify - using checker-qual-2.5.2.jar unchanged
Nothing to minify - using error_prone_annotations-2.2.0.jar unchanged
Nothing to minify - using animal-sniffer-annotations-1.17.jar unchanged
可以看出,当我们执行task的时候,gradle自动调用了TransformAction,对guava.jar进行了变换,并将结果存储在layout.buildDirectory.dir("runtimeClasspath")中
变换ArtifactType的TransformAction
上文提到,artifactType属性是特殊的,因为它仅存在于解析的产物上,而不存在于依赖项上。因此任何只变换artifactType的TransformAction,只有在使用ArtifactView时才会考虑使用
其实在AGP中,相当一部分自定义TransformAction都是属于只变换ArtifactType的,下面我们来看下如何自定义一个这样的TransformAction
class TransformActionPlugin : Plugin<Project> {
override fun apply(project: Project) {
project.run {
val artifactType = Attribute.of("artifactType", String::class.java)
dependencies.registerTransform(MyTransform::class.java) { // 1
it.from.attribute(artifactType, "jar")
it.to.attribute(artifactType, "my-custom-type")
}
val myTaskProvider = tasks.register("myTask", MyTask::class.java) {
it.inputCount.set(10)
it.outputFile.set(File("build/myTask/output/file.jar"))
}
val includedConfiguration = configurations.create("includedConfiguration") // 2
dependencies.add(includedConfiguration.name, "org.jetbrains.kotlin:kotlin-stdlib-jdk8:1.7.10")
val combinedInputs = project.files(includedConfiguration, myTaskProvider.map { it.outputFile })
val myConfiguration = configurations.create("myConfiguration")
dependencies.add(myConfiguration.name, project.files(project.provider { combinedInputs }))
tasks.register("consumerTask", ConsumerTask::class.java) { // 3
it.artifactCollection = myConfiguration.incoming.artifactView {viewConfiguration ->
viewConfiguration.attributes.attribute(artifactType, "my-custom-type")
}.artifacts
it.outputFile.set(File("build/consumerTask/output/output.txt"))
}
}
}
}
主要分为以下几步:
- 声明与注册自定义
Transform,指定输入与输出的artifactType - 创建自定义的
configuration,指定输入的依赖是什么(当然也可以直接用AGP已有的configuration) - 在使用时,通过自定义
configuration的artifactView,获取对应的产物 ConsumerTask中消费自定义TransformAction的输出产物
然后我们运行./gradlew consumerTask就可以得到以下输出
> Task :app:consumerTask
Processing ~/.gradle/caches/modules-2/files-2.1/org.jetbrains.kotlin/kotlin-stdlib-common/1.7.10/bac80c520d0a9e3f3673bc2658c6ed02ef45a76a/kotlin-stdlib-common-1.7.10.jar. File exists = true
Processing ~/AndroidProject/2022/argust/GradleTutorials/app/build/myTask/output/file.jar. File exists = true
Processing ~/.gradle/caches/modules-2/files-2.1/org.jetbrains.kotlin/kotlin-stdlib-jdk8/1.7.10/d70d7d2c56371f7aa18f32e984e3e2e998fe9081/kotlin-stdlib-jdk8-1.7.10.jar. File exists = true
Processing ~/.gradle/caches/modules-2/files-2.1/org.jetbrains/annotations/13.0/919f0dfe192fb4e063e7dacadee7f8bb9a2672a9/annotations-13.0.jar. File exists = true
Processing ~/.gradle/caches/modules-2/files-2.1/org.jetbrains.kotlin/kotlin-stdlib/1.7.10/d2abf9e77736acc4450dc4a3f707fa2c10f5099d/kotlin-stdlib-1.7.10.jar. File exists = true
Processing ~/.gradle/caches/modules-2/files-2.1/org.jetbrains.kotlin/kotlin-stdlib-jdk7/1.7.10/1ef73fee66f45d52c67e2aca12fd945dbe0659bf/kotlin-stdlib-jdk7-1.7.10.jar. File exists = true
可以看出,当运行consumerTask时,执行了 MyTransform,并将jar类型的产物转化成了my-custom-type
TransformAction在AGP中的应用
现在AGP中的Transform已经基本上都改成TransformAction了,我们一起来看几个例子
AarTransform
Android ARchive,也就是.aar后缀的资源包,gradle是如何使用它的呢?
如果有同学尝试过就知道,如果是默认使用java-libray的工程,肯定无法依赖并使用aar的,引入时会报Could not resolve ${dependencyNotation},说明在Android Gradle Plugin当中,插件对aar包的依赖进行了处理,只有通过了插件处理,才能正确使用aar内的资源。那就来看看AGP是如何在TransformAction的帮助下做到这点的
Aar转换的实现就是AarTransform,我们一起来看下源码:
// DependencyConfigurator.kt
for (transformTarget in AarTransform.getTransformTargets()) {
registerTransform(
AarTransform::class.java,
AndroidArtifacts.ArtifactType.EXPLODED_AAR,
transformTarget
) { params ->
params.targetType.setDisallowChanges(transformTarget)
params.sharedLibSupport.setDisallowChanges(sharedLibSupport)
}
}
public abstract class AarTransform implements TransformAction<AarTransform.Parameters> {
@NonNull
public static ArtifactType[] getTransformTargets() {
return new ArtifactType[] {
ArtifactType.SHARED_CLASSES,
ArtifactType.JAVA_RES,
ArtifactType.SHARED_JAVA_RES,
ArtifactType.PROCESSED_JAR,
ArtifactType.MANIFEST,
ArtifactType.ANDROID_RES,
ArtifactType.ASSETS,
ArtifactType.SHARED_ASSETS,
ArtifactType.JNI,
ArtifactType.SHARED_JNI,
// ...
};
}
@Override
public void transform(@NonNull TransformOutputs transformOutputs) {
// 具体实现
}
代码也比较简单,主要做了下面几件事:
- 在
DependencyConfigurator中注册Aar转换成各种类型资源的TransformAction - 在
AarTransform中根据类型将aar包中的文件解压到输出到各个目录
JetifyTransform
Jetifier也是在迁移到AndroidX之后的常用功能,它可以将引用依赖内的android.support.*引用都替换为对androidx的引用,从而实现对support包的兼容
下面我们来看一下JetifyTransform的代码
// com.android.build.gradle.internal.DependencyConfigurator
if (projectOptions.get(BooleanOption.ENABLE_JETIFIER)) {
registerTransform(
JetifyTransform::class.java,
AndroidArtifacts.ArtifactType.AAR,
jetifiedAarOutputType
) { params ->
params.ignoreListOption.setDisallowChanges(jetifierIgnoreList)
}
registerTransform(
JetifyTransform::class.java,
AndroidArtifacts.ArtifactType.JAR,
AndroidArtifacts.ArtifactType.PROCESSED_JAR
) { params ->
params.ignoreListOption.setDisallowChanges(jetifierIgnoreList)
}
}
// com.android.build.gradle.internal.dependency.JetifyTransform
override fun transform(transformOutputs: TransformOutputs) {
val inputFile = inputArtifact.get().asFile
val outputFile = transformOutputs.file("jetified-${inputFile.name}")
jetifierProcessor.transform2(
input = setOf(FileMapping(inputFile, outputFile)),
copyUnmodifiedLibsAlso = true,
skipLibsWithAndroidXReferences = true
)
}
- 读取并判断
ENABLE_JETIFIER属性,这就是我们在gradle.properties中配置的jetifier开关 - 为
aar和jar类型的依赖都注册JetifyTransform转换 - 在
transform中对support包的依赖进行替换,完成后会将处理过的资源重新压缩,并且会带上jetified的前缀
总结
本文主要讲解了TransformAction是什么,TransformAction自定义,以及TransformAction在AGP中的应用,可以看出,目前AGP中的产物转换已经基本上都用TransformAction来实现了
事实上,AGP对TransformAction进行了一定的封装,如果你只是想利用ASM实现字节码插桩,那么直接使用AsmClassVisitorFactory就好了。但如果想要阅读AGP的源码,了解AGP构建的过程,还是需要了解一下TransformAction的基本使用与原理的
示例代码
本文所有代码可见:github.com/RicardoJian…
作者:程序员江同学
链接:https://juejin.cn/post/7131889789787176974
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
使用 Kotlin 对 XML 文件解析、修改及创建
一 XML 基本概念
XML 全称 ExtensibleMarkupLanguage,中文称可扩展标记语言。它是一种通用的数据交换格式,具有平台无关性、语言无关性、系统无关性的优点,给数据集成与交互带来了极大的方便。XML 在不同的语言环境中解析方式都是一样的,只不过实现的语法不同而已。
XML 可用来描述数据、存储数据、传输数据/交换数据。
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。DOM 又是基于树形结构的 XML 解析方式,能很好地呈现这棵树的样貌。XML 文档节点的类型主要有:

各节点定义:
| Node | 描述 | 子节点 |
|---|---|---|
| Document | XML document 的根节点 | Element, ProcessingInstruction, DocumentType, Comment |
| DocumentType | 文档属性 | No children |
| Element | 元素 | Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference |
| Attr | 属性 | Text, EntityReference |
| ProcessingInstruction | 处理指令 | No children |
| Comment | 注释 | No children |
| Text | 文本 | No children |
| Entity | 实体类型项目 | Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference |
二 XML 解析方式
一个 XML 文档的生命周期应该包括两部分:
- 解析文档
- 操作文档数据
那么接下来介绍如何来解析 XML 以及解析之后如何使用。
根据底层原理的不同,解析 XML 文件一般分为两种形式,一种是基于树形结构来解析的称为 DOM;另一种是基于事件流的形式称为 SAX。
2.1 DOM(Document Object Model)
DOM 是用与平台和语言无关的方式表示 XML 文档的官方 W3C 标准。是基于树形结构的 XML 解析方式,它会将整个 XML 文档读入内存并构建一个 DOM 树,基于这棵树形结构对各个节点(Node)进行操作。
优点:
- 允许随机读取访问数据,因为整个 Dom 树都加载到内存中
- 允许随机的对文档结构进行增删
缺点:
- 耗时,整个 XML 文档必须一次性解析完
- 占内存,整个 Dom 树都要加载到内存中
适用于:文档较小,且需要修改文档内容
2.1.1 DOM 解析 XML
第一步:建立一个 Stuff.xml 文件
<?xml version="1.0"?>
<company>
<staff id="1001">
<firstname>Jack</firstname>
<lastname>Ma</lastname>
<nickname>Hui Chuang A Li</nickname>
<salary currency="USD">100000</salary>
</staff>
<staff id="2001">
<firstname>Pony</firstname>
<lastname>Ma</lastname>
<nickname>Pu Tong Jia Ting</nickname>
<salary currency="RMB">200000</salary>
</staff>
</company>
第二步:DOM 解析
package com.elijah.kotlinlearning
import org.w3c.dom.Element
import org.w3c.dom.Node
import org.w3c.dom.NodeList
import java.io.File
import javax.xml.parsers.DocumentBuilderFactory
fun main(args: Array<String>) {
// Instantiate the Factory
val dbf = DocumentBuilderFactory.newInstance()
try {
// parse XML file
val xlmFile = File("${projectPath}/src/res/Staff.xml")
val xmlDoc= dbf.newDocumentBuilder().parse(xlmFile)
xmlDoc.documentElement.normalize()
println("Root Element :" + xmlDoc.documentElement.nodeName)
println("--------")
// get <staff>
val staffList: NodeList = xmlDoc.getElementsByTagName("staff")
for (i in 0 until staffList.length) {
var staffNode = staffList.item(i)
if (staffNode.nodeType === Node.ELEMENT_NODE) {
val element = staffNode as Element
// get staff's attribute
val id = element.getAttribute("id")
// get text
val firstname = element.getElementsByTagName("firstname").item(0).textContent
val lastname = element.getElementsByTagName("lastname").item(0).textContent
val nickname = element.getElementsByTagName("nickname").item(0).textContent
val salaryNodeList = element.getElementsByTagName("salary")
val salary = salaryNodeList.item(0).textContent
// get salary's attribute
val currency = salaryNodeList.item(0).attributes.getNamedItem("currency").textContent
println("Current Element : ${staffNode.nodeName}")
println("Staff Id : $id")
println("First Name: $firstname")
println("Last Name: $lastname")
println("Nick Name: $nickname")
println("Salary [Currency] : ${salary.toLong()} [$currency]")
}
}
} catch (e: Throwable) {
e.printStackTrace()
}
}
第三步:解析结果输出
Root Element :company
--------
Current Element : staff
Staff Id : 1001
First Name: Jack
Last Name: Ma
Nick Name: Hui Chuang A Li
Salary [Currency] : 100000 [USD]
Current Element : staff
Staff Id : 2001
First Name: Pony
Last Name: Ma
Nick Name: Pu Tong Jia Ting
Salary [Currency] : 200000 [RMB]
2.1.2 DOM 创建、生成 XML
第一步:创建新的 XML 并填充内容
package com.elijah.kotlinlearning
import org.w3c.dom.Document
import org.w3c.dom.Element
import java.io.File
import javax.xml.parsers.DocumentBuilderFactory
import javax.xml.transform.OutputKeys
import javax.xml.transform.TransformerFactory
import javax.xml.transform.dom.DOMSource
import javax.xml.transform.stream.StreamResult
fun main(args: Array<String>) {
// Instantiate the Factory
val docFactory = DocumentBuilderFactory.newInstance()
try {
// root elements
val docBuilder = docFactory.newDocumentBuilder()
val doc = docBuilder.newDocument()
val rootElement: Element = doc.createElement("company")
doc.appendChild(rootElement)
// add xml elements: staff 1001
val staff = doc.createElement("staff")
staff.setAttribute("id", "1001")
// set staff 1001's attribute
val firstname = doc.createElement("firstname")
firstname.textContent = "Jack"
staff.appendChild(firstname)
val lastname = doc.createElement("lastname")
lastname.textContent = "Ma"
staff.appendChild(lastname)
val nickname = doc.createElement("nickname")
nickname.textContent = "Hui Chuang A Li"
staff.appendChild(nickname)
val salary: Element = doc.createElement("salary")
salary.setAttribute("currency", "USD")
salary.textContent = "100000"
staff.appendChild(salary)
rootElement.appendChild(staff)
// add xml elements: staff 1002
val staff2: Element = doc.createElement("staff")
rootElement.appendChild(staff2)
staff2.setAttribute("id", "1002")
// set staff 1002's attribute
val firstname2 = doc.createElement("firstname")
firstname2.textContent = "Pony"
staff2.appendChild(firstname2)
val lastname2 = doc.createElement("lastname")
lastname2.textContent = "Ma"
staff2.appendChild(lastname2)
val nickname2 = doc.createElement("nickname")
nickname2.textContent = "Pu Tong Jia Ting"
staff2.appendChild(nickname2)
val salary2= doc.createElement("salary")
salary2.setAttribute("currency", "RMB")
salary2.textContent = "200000"
staff2.appendChild(salary2)
rootElement.appendChild(staff2)
val newXmlFile = File("${projectPath}/src/res/", "generatedXml.xml")
// write doc to new xml file
generateXml(doc, newXmlFile)
} catch (e: Throwable) {
e.printStackTrace()
}
}
// write doc to new xml file
private fun generateXml(doc: Document, file: File) {
// Instantiate the Transformer
val transformerFactory = TransformerFactory.newInstance()
val transformer = transformerFactory.newTransformer()
// pretty print
transformer.setOutputProperty(OutputKeys.INDENT, "yes")
val source = DOMSource(doc)
val result = StreamResult(file)
transformer.transform(source, result)
}
第二步:生成 XML 文件 generatedXml.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<company>
<staff id="1001">
<firstname>Jack</firstname>
<lastname>Ma</lastname>
<nickname>Hui Chuang A Li</nickname>
<salary currency="USD">100000</salary>
</staff>
<staff id="1002">
<firstname>Pony</firstname>
<lastname>Ma</lastname>
<nickname>Pu Tong Jia Ting</nickname>
<salary currency="RMB">200000</salary>
</staff>
</company>
2.2 SAX(Simple API for XML)
SAX 处理的特点是基于事件流的。分析能够立即开始,而不是等待所有的数据被处理。而且,由于应用程序只是在读取数据时检查数据,因此不需要将数据存储在内存中。这对于大型文档来说是个巨大的优点。
优点:
- 访问能够立即进行,不需要等待所有数据被加载
- 只在读取数据时检查数据,不需要保存在内存中
- 占用内存少,不需要将整个数据都加载到内存中
- 允许注册多个 Handler,可以用来解析文档内容,DTD 约束等等
缺点:
- 需要应用程序自己负责 TAG 的处理逻辑(例如维护父/子关系等),文档越复杂程序就越复杂
- 单向导航,无法定位文档层次,很难同时访问同一文档的不同部分数据,不支持 XPath
- 不能随机访问 xml 文档,不支持原地修改 xml
适用于: 文档较大,只需要读取文档数据。
2.2.1 SAX 解析 XML
第一步:新建 ContentHandler 解析类
package com.elijah.kotlinlearning
import org.xml.sax.Attributes
import org.xml.sax.helpers.DefaultHandler
class ContentHandler: DefaultHandler(){
private var nodeName :String? = null // 当前节点名
private lateinit var firstname: StringBuilder // 属性:firstname
private lateinit var lastname: StringBuilder // 属性:lastname
private lateinit var nickname: StringBuilder // 属性:nickname
private lateinit var salary: StringBuilder // 属性:salary
// 开始解析文档
override fun startDocument() {
firstname = StringBuilder()
lastname = StringBuilder()
nickname = StringBuilder()
salary = StringBuilder()
}
// 开始解析节点
override fun startElement(
uri: String?,
localName: String?,
qName: String?,
attributes: Attributes?
) {
nodeName = localName
}
// 开始解析字符串
override fun characters(ch: CharArray?, start: Int, length: Int) {
// 判断节点名称
when (nodeName) {
"firstname" -> {
firstname.append(ch, start, length)
}
"lastname" -> {
lastname.append(ch, start, length)
}
"nickname" -> {
nickname.append(ch, start, length)
}
"salary" -> {
salary.append(ch, start, length)
}
}
}
// 结束解析节点
override fun endElement(uri: String?, localName: String?, qName: String?) {
// 打印出来解析结果
if (localName == "staff") {
println("Staff is : $nodeName")
println("First Name: ${firstname.toString()}")
println("Last Name: ${lastname.toString()}")
println("Nick Name: ${nickname.toString()}")
println("Salary [Currency] : ${salary.toString()}")
// 清空, 不妨碍下一个 staff 节点的解析
firstname.clear()
lastname.clear()
nickname.clear()
salary.clear()
}
}
// 结束解析文档
override fun endDocument() {
super.endDocument()
}
}
第二步:新建解析器对指定 XML 进行解析
package com.elijah.kotlinlearning
import org.xml.sax.InputSource
import java.io.File
import javax.xml.parsers.SAXParserFactory
fun main(args: Array<String>) {
try{
// 新建解析器工厂
val saxParserFactory = SAXParserFactory.newInstance()
// 通过解析器工厂获得解析器对象
val saxParser = saxParserFactory.newSAXParser()
// 获得 xmlReader
val xmlReader = saxParser.xmlReader
// 设置解析器中的解析类
xmlReader.contentHandler = ContentHandler()
// 设置解析内容
val inputStream = File("${projectPath}/src/res/Staff.xml").inputStream()
xmlReader.parse(InputSource(inputStream))
} catch(e: Throwable){
e.printStackTrace()
}
}作者:话唠扇贝
链接:https://juejin.cn/post/7131018900002570276
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter 语法进阶 | 抽象类和接口本质的区别
1. 接口存在的意义?
在 Dart 中 接口 定义并没有对应的关键字。可能有些人觉得 Dart 中弱化了 接口 的概念,其实不然。我们一般对接口的理解是:接口是更高级别的抽象,接口中的方法都是 抽象方法 ,没有方法体。通过接口的定义,我们可以通过定义接口来声明功能,通过实现接口来确保某类拥有这些功能。
不过你有没有仔细想过,为什么接口会存在,引入接口的概念是为了解决什么问题?可能有人会说,通过接口,可以规范一类事物的功能,可以面向接口进行操作,从而可以更加灵活地进行拓展。其实这只是接口的作用,而且这些功能 抽象类 也可以支持。所以接口一定存在什么特殊的功能,是抽象类无法做到的。
都是抽象方法的抽象类,和接口有什么本质的区别呢?在我的初入编程时,这个问题就伴随着我,但渐渐地,这个问题好像对编程没有什么影响,也就被遗忘了。网上很多文章介绍 抽象类 和 接口 的区别,只是在说些无关痛痒的形式区别,并不能让我觉得接口存在有什么必要性。
思考一件事物存在的本质意义,可以从没有这个事物会产生什么后果来分析。现在想一下,如果没有接口,一切的抽象行为仅靠 抽象类 完成会有什么局限性 或说 弊端。没有接口,就没有 实现 (implements) 的概念,其实这就等价于在问 implements 消失了,对编程有什么影响。没有实现,类之间就只能通过 继承 (extends) 来维护 is-a 的关系。所以就等价于在问 extends 有什么局限性 或说 弊端。答案呼之欲出:多继承的二义性 。
那问题来了,为什么类不能支持 多继承 ,而接口可以支持 多实现 ,继承 和 实现 有什么本质的区别呢?为什么 实现 不会带来 二义性 的问题,这是理解接口存在关键。
2. 继承 VS 实现
下面我们来探讨一下 继承 和 实现 的本质区别。如下 A 和 B 类,有一个相同的成员变量和成员方法:
class A{
String name;
A(this.name);
void run(){ print("B"); }
}
class B{
String name;
B(this.name);
void run(){ print("B"); }
}
对于继承而言 派生类 会拥有基类的成员变量与成员方法,如果支持多继承,就会出现两个问题:
- 问题一 : 基类中有同名
成员变量,无法确定成员的归属类 - 问题二: 基类中有同名
成员方法,且子类未覆写。在调用时,无法确定执行哪个。
class C extends A , B {
C(String name) : super(name); // 如果多继承,该为哪个基类的 name 成员赋值 ??
}
void main(){
C c = C("hello")
c.run(); // 如果多继承,该执行哪个基类的 run 方法 ??
}
其实仔细思考一下,一般意义上的接口之所以能够 多实现 ,就是通过限制,对这两个问题进行解决。比如 Java 中:
- 不允许在接口中定义普通的
成员变量,解决问题一。 - 在接口中只定义抽象成员方法,不进行实现。而是强制派生类进行实现,解决问题二。
abstract class A{
void run();
}
abstract class B{
void run();
}
class C implements A,B{
@override
void run() {
print("C");
}
}
到这里,我们就认识到了为什么接口不存在 多实现 的二义性问题。这就是 继承 和 实现 最本质的区别,也是 抽象类 和 接口 最重要的差异。从这里可以看出,接口就是为了解决多继承二义性的问题,而引入的概念,这就是它存在的意义。
3. Dart 中接口与实现的特殊性
Dart 中并不像 Java 那样,有明确的关键字作为 接口类 的标识。因为 Dart 中的接口概念不再是 传统意义 上的狭义接口。而是 Dart 中的任何类都可以作为接口,包括普通的类,这也是为什么 Dart 不提供关键字来表示接口的原因。
既然普通类可以作为接口,那多实现中的 二义性问题 是必须要解决的,Dart 中是如何处理的呢? 如下是 A 、B 两个普通类,其中有两个同名 run 方法:
class A{
void run(){
print("run in a");
}
}
class B{
void run(){
print("run in a");
}
void log(){
print("log in a");
}
}
当 C 类实现 A 、B 接口,必须强制覆写 所有 成员方法 ,这点解决了二义性的 问题二 :
那 问题一 中的 成员变量 的歧义如何解决呢?如下,在 A 、B 中添加同名的成员变量:
class A{
final String name;
A(this.name);
// 略同...
}
class B{
final String name;
B(this.name);
// 略同...
}
当 C 类实现 A 、B 接口,必须强制覆为 所有 成员变量提供 get 方法 ,这点解决了二义性的 问题一 :
这样,C 就可以实现两个普通类,而避免了二义性问题:
class C implements A, B {
@override
String get name => "C";
@override
void log() {}
@override
void run() {}
}
其实,这是 Dart 对 implements 关键字的功能加强,迫使派生类必须提供 所有 成员变量的 get 方法,必须覆写 所有 成员方法。这样就可以让 类 和 接口 成为两个独立的概念,一个 class 既可以是类,也可以是接口,具有双重身份。其区别在于,在 extend 关键字后,表示继承,是作为类来对待;在 implements 关键字之后,表示实现,是作为接口来对待。
4.Dart 中抽象类作为接口的小细节
我们知道,抽象类中允许定义 普通成员变量/方法 。下面举个小例子说明一下 继承 extend 和 实现 implements 的区别。对于继承来说,派生类只需要实现抽象方法即可,抽象基类 中的普通成员方法可以不覆写:
而前面说过,implements 关键字要求派生类必须覆写 接口 中的 所有 方法 。也就表示下面的 C implements A 时,也必须覆写 log 方法。从这个例子中,可以很清楚地看出 继承 和 实现 的差异性。
抽象类 和 接口 的区别,就是 继承 和 实现 的区别,在代码上的体现是 extend 和 implements 关键字功能的区别。只有理解 继承 的局限性,才能认清 接口 存在的必要性。那本文就到这了,谢谢观看 ~
作者:张风捷特烈
链接:https://juejin.cn/post/7131880904154644516
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
灵隐寺高僧汇报 “数字化寺院” 方案,走红网络! “系统可用性” 随缘、KPI 随心?
最近,一张灵隐寺高僧汇报 “数字化寺院” 方案的图片,走红网络!

许多从事IT工作的网友沸腾了,很好奇 “数字化寺院”平台的系统可用性,做到几个9 ? 灵隐寺的IT高僧 KPI 是否随缘?
下面给大家拆解下这个大屏背后的技术架构是怎样的?
对寺院的实时业务信息做到了及时分析和展示,后台可能还接入到了杭州文旅以及杭州城市大脑,是杭州城市大脑的组成部分;
灵隐寺的数字化面临非常多的问题:如何吸引游客来?如何促进游客消费?如何及时应急和预警?如何提供更佳服务?如何定位精确客群?……从知名度、转化率、安全保障、互动体验到精准营销各方面的问题都需要解决,只有这些问题都解决了,才能成功转型。
而解决这些问题的关键钥匙最终还是落在数据上,数据驱动是涉旅企业和单位转型智慧旅游的必经之路。只有打通数据孤岛,建立全域数据共享中心,从而推动企业和单位从旅游行业格局、空间格局、旅游方式、商业模式上寻找转型点,而不是靠领导拍板、经验转型。
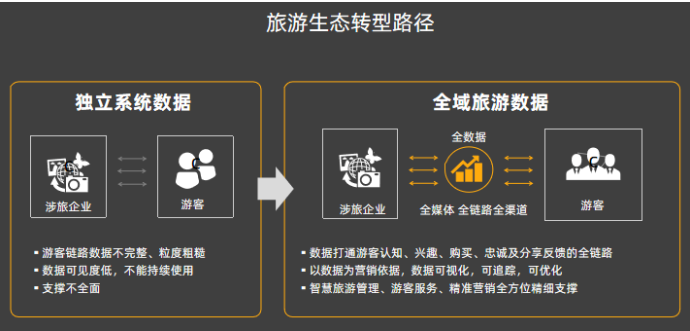
灵隐寺搭建了“灵隐寺一体化综合服务”应用场景数字大厅,深度开发了“一屏、一中心、四件事、六大管理平台”有效实现数字赋能现代寺院管理。
智慧寺院,出家人不打诳语
7月下旬,杭州灵隐寺举办了“智慧寺院”应用场景上线仪式。

“智慧寺院”上线仪式上,光泉法师表示,数字技术的飞速发展为数字赋能现代寺院智慧管理带来了新的契机,数字化不仅是佛教适应时代发展的具体路径,更是佛教自我健康传承的迫切需求。
今后,灵隐寺将不断推进应用场景优化升级,推动数字化改革成果持续输出,为推进我国宗教中国化和宗教事务治理现代化贡献智慧和力量。出家人不打诳语。智慧寺院确实有点东西。
杭州灵隐寺“智慧寺院”应用场景上线仪式成功举办,各界领导均出席了上线仪式。


省民宗委副主任、一级巡视员陈振华讲话
陈振华指出,杭州灵隐寺一直以来积极探索实践宗教活动场所数字化管理新路径,在全省争当表率、走在前列,为我省建设宗教中国化和宗教事务治理现代化先行省作出了贡献。他强调:
要勇于变革,做宗教活动场所数字化改革的探索者。
坚持数字赋能,勇于变革创新,当好宗教活动场所现代化管理的引领者,发挥好信教群众与党委政府之间的桥梁纽带作用。
要实战实效,做宗教活动场所智慧化管理的领跑者
进一步健全体制机制,重构管理体系,不断做好场景迭代升级和功能拓展,争取打造最佳应用,形成可在全省寺院推广运行的数字化管理新模式。
要守正创新,做宗教活动场所中国化建设的示范者
将“智慧寺院”应用场景与浙江省宗教中国化场所建设“151”指标体系相结合,在宗教中国化场所创建中继续做好示范,当好表率,以数字赋能牵引推动宗教中国化落实落地。

市委统战部副部长、市民宗局局长邵根松讲话
邵根松指出,杭州灵隐寺率先成立首家佛教数字赋能研究中心,在探索数字赋能现代寺院智慧管理,激发1700年江南名刹数字活力等方面倾注了大量精力,为打造具有鲜明杭州辨识度的数字化应用场景树立了榜样。

省佛教协会会长、灵隐寺方丈光泉法师致辞
光泉法师表示,数字技术的飞速发展为数字赋能现代寺院智慧管理带来了新的契机,数字化不仅是佛教适应时代发展的具体路径,更是佛教自我健康传承的迫切需求。今后,灵隐寺将不断推进应用场景优化升级,推动数字化改革成果持续输出,为推进我国宗教中国化和宗教事务治理现代化贡献智慧和力量。
来源:https://mp.weixin.qq.com/s/T5AKGcltiU5rjvOjiTs11Q
收起阅读 »Android 开发还有必要深耕吗?现状怎么样?未来前景将会怎样?
截止到今天,Android的生态发生了不少变化
以前的鼎盛时期,堪称是个公司就做App,由于当时市场上缺乏Android开发,招聘往往是低要求、高薪资,只要你面试说得上四大组件,第二天马上拎包入职,线下的Android培训也是一抓一大把,吸引了一大批人涌入Android开发行业。Android招聘市场的需求逐渐被填充,招聘要求逐步提高……
随着“互联网寒冬”的到来,大批互联网公司纷纷倒闭,大厂也纷纷裁员节流,人才供给大幅增加、需求大幅降低,造成当时的市场迅速达到饱和。培训出来的初级Android开发找不到工作,大厂被裁员的Android开发放不下薪资要求,这批人找不到工作,再加上当时自媒体的大肆渲染,Android开发可不就“凉了”吗?
毫不夸张的说,早期说得上四大组件稍微能做一点点,拿个15-20k是比较轻松的,要是你还有过完整开发经验,30k真是一点都不过分,而在“寒冬”之后,当招聘市场供给过剩时,面试官有了充分的选择权,你会四大组件,那我就有完整App独立开发经验,另一人或许有过十万级App开发经验,你说面试官会收下谁呢?岗位招聘要求也是在这时迅速拔高,整个Android市场逐渐趋于平稳,大家感觉Android开发来到了内卷期……
再来说现在:
Android凉了吗?
其实并不是Android凉了,而是技术不过硬的Android凉了
被高薪晃晕了头脑放不下身段的假高工凉了
现在的Android市场,Android初级工程师早就已经严重饱和了,供远大于求。这就导致了很多Android开发会面临被优化、被毕业、找不到工作这种情况,然后这部分人又出来说Android凉了,如此循环之下,以致于很多人都觉得Android凉了……
其核心原因只是Android开发市场由鼎盛的疯狂逐渐趋于平稳
这里也给出Android开发薪资/年限图给大家参考:
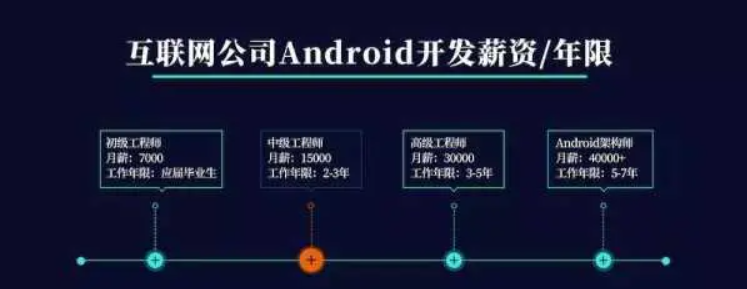
也不缺少学历突出的、能力突出的、努力突出的,这三类都可以拿到比图中同级别更可观的薪资
当然,我们并不能以薪资作为职级的标准,决定一个Android工程师到底是初级、中级、高级还是资深的,永远都不会是开发年限!
只有技术才能客观的作为衡量标准!
不管是几年经验,如果能力与工作年限不匹配,都会有被毕业的风险,如果掌握的技术达不到对应职级的标准,那别想了,毕业警告……
在很多人觉得Android凉了的时候,也不乏有Android开发跳槽进大厂拿高薪,不少在闷头提升技术水平,迄今为止还没有听过哪个Android开发大牛说“Android凉了”,当大家达到一定的高度之后,就会得知谁谁谁跳槽美团,几百万;某某某又跳进了阿里、腾讯……
不管在任何行业,任何岗位,初级技术人才总是供大于求;不管任何行业、岗位,技术过硬的也都是非常吃香的!
在初级市场”凉了“的同时,高级市场几乎是在抢人!
很多高薪、急招岗位挂上了招聘网站,往往一整年都面试不了几场,自打挂上来,就没动过了……
所以说,Android开发求职,质量才是关键!
再说到转行问题
我一直都比较佩服有大勇气转行的朋友,因为转行需要我们抛弃现有的知识技能,重新起航
佩服归佩服,身边不少之前是Android开发的朋友转行Java、Python,但他们对于目前市场还是过于乐观了,Python很火,它竞争不大吗?部分转行从0开始的,甚至连应届生都比不过~
不要轻易转行,如果要转一定要尽早转
转行有两种我认为是正常的,一种是行业消失了、没落了,继续留在业内无法施展才华。另一种是兴趣压根就不在本行,因此选一个自己感兴趣的。而现在大部分转行都是为了跟风,为了那看得见但摸不着的”风口“,而忽略了长期的发展潜力。
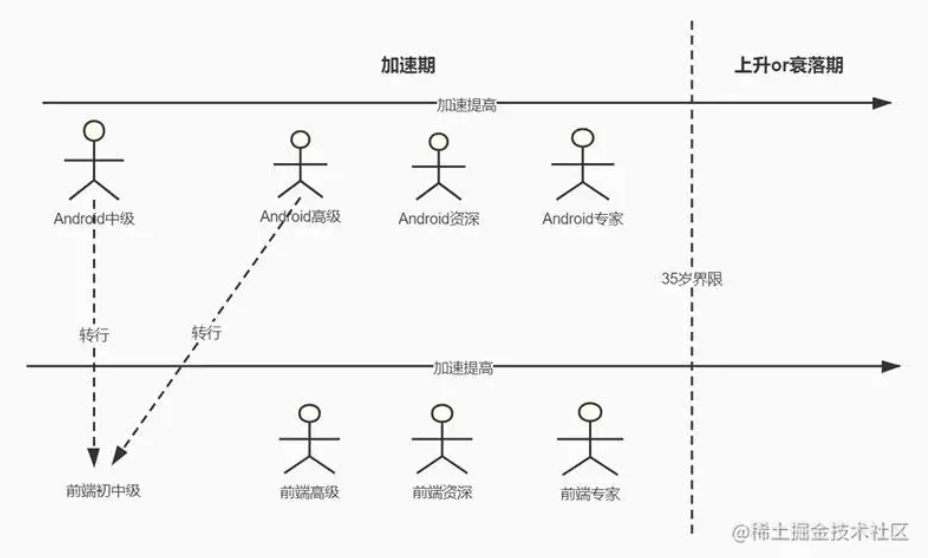
不管是学习力也好,精力也好,大部分人在35岁之前都属于加速期,加速期的一些选择,决定了35岁之后到底是上升还是衰落。
以Android开发转Python来说,一个Android高级转行Python会变为Python初级,这时从事Python的人都在加速提高,要想赶超在你之前的拥有同样学习力的人是不可能办到的,这就导致在转行前期极为被动,还要保证在35岁前成为Python专家或者Leader才有可能在35岁后不进入衰落期,当然这时你的Android基本也就荒废了,不说很难成为专家,高级也成为了一个很大的门槛。
如果你还想要在对应的技术领域走的更远,就不要轻易选择转行,如果实在想要转,那么越早越好、越快越好,你的竞争者都在加速提升技术水平,职场上,没人会停下等你的……
转行大部分都产生不了质变
我们所说的质变可以理解为在一个技术领域的大幅提升,或者是不相关领域的跨界
比如由高级开发变为专家,或者是由高级开发升到Leader,再或者跨界开始做一些技术相关的博客、培训、演讲、出书等等而被人所熟知。
凡是能帮助你在职业生涯中后期进入上升期的都可以看做是一次质变,而转行很少是质变,更多的都是倒退回到原点重新出发,形象点来说,你只是换了个不同的砖头接着搬砖而已。因此我们更应该去追求质变,而不是平行或者倒退,一次倒退或许可以承受,多次倒退就很难在职业生涯中后期再进入上升期。
其实不少转行的人都没有起到积极作用,毕竟都是从0开始,精进到专家绝不是一朝一夕可以完成的
或许到时又会有同样的问题:
前端凉了?前景怎么样?
Java凉了?前景怎么样?
大数据凉了?前景怎么样?
人工智能凉了?前景怎么样?
……
而另一类人,其实不管在哪个行业都可以混的风生水起!
如果是这种,那么想必也不需要考虑转行了。
所以根本不用想着Android凉了或是说要转行,与其焦虑不安,不如努力提升技术水平,毕竟在这时代,有硬技术的人到哪都吃香。
我们想要往高级进阶,建立属于自己的系统化知识体系才是最重要的,高工所需要掌握的技术不是通过蹭热点和玩黑科技,而是需要真正深入到核心技术的本质,知晓原理,知其然知其所以然。
可能不少人会觉得Android技术深度不深,技术栈不庞大,Android职业发展有限,这就真是个天大的误解。
先说技术上,Android的技术栈随着时间的推移变得越来越庞大,细分领域也越来越多,主要有应用开发、逆向安全、音视频、车联网、物联网、手机开发和SDK开发等等,每个细分领域都有很多技术栈组成,深度都足够精深,就拿所有细分领域通用的Android系统底层源码来说,就会叫你学起来生不如死。
还有AI、大数据、边缘计算、VR/AR,很多新的技术浪潮也都可以结合进移动开发的技术范畴……
那么现在Android怎么学?学什么?
这几年Android新技术的迭代明显加速了,有来自外部跨平台新物种的冲击,有去Java化的商业考量,也有Jetpack等官方自建平台的加速等多种原因。
作为Android开发者,我们需要密切关注的同时也不要盲目跟随,还是要认清趋势,结合项目现状学习。
Kotlin
Kotlin已经成为Android开发的官方语言,Android的新的文档和Sample代码都开始转向 Kotlin,在未来Java将加速被 Kotlin替代。
刚推出时,很多人都不愿意学习,但现在在面试中已经是经常会出现了,很多大公司也都已经拥抱新技术了。现在Kotlin是一个很明显的趋势了,不少新技术都需要结合Kotlin来使用,未来在工作中、面试中所占的比重肯定会更大。
Jetpack+Compose
Jetpack的意义在于帮我们在SDK基础上提供了一系列中间件工具,让我们可以摆脱不断造轮子抄轮子的窘境。同类的解决方案首先考虑Jetpack其次考虑第三方实现,没毛病。
Jetpack本身也会不断吸收优秀的第三方解决方案进来。所以作为开发者实时关注其最新动态就可以了。
Compose是Google I/O 2019 发布的新的声明式的UI框架。其实Google内部自2017年便开始立项,目前API已稳定,构建,预览等开发体验已经趋于完整。
而且新的设计思想绝对是趋势,已经在react和flutter等前端领域中得到验证,ios开发中同期推出的swiftUI更是证明了业界对于这种声明式UI开发趋势的共识。这必将是日后Android app极为重要的编程方式。
开源框架底层原理
现在的面试从头到尾都是比较有深度的技术问题,虽然那些问题看上去在网上都能查到相关的资料,但面试官基本都是根据你的回答持续深入,如果没有真正对技术原理和底层逻辑有一定的了解是无法通过的。
很多看似无理甚至无用的问题,比如 “Okhttp请求复用有没有了解”,其实是面试官想借此看看你对网络优化和Socket协议的理解情况和掌握程度,类似问题都是面试官想借此看看你对相关原理的理解情况和掌握程度,甚至进而引伸到你对架构,设计模式的理解。只有在熟知原理的前提下,你才能够获得面试官的青睐。
Framework
Framework作为Android的框架层,为App提供了很多API调用,但很多机制都是Framework包装好后直接给App用的,如果不懂这些机制的原理,就很难在这基础上进行优化。
像启动监控、掉帧监控、函数插桩、慢函数检测、ANR监控,都需要比较深入的了解Framework,才能知道怎么去监控、利用什么机制监控、函数插桩插到哪里、反射调用该反射哪个类哪个方法哪个属性……
性能优化
性能优化是软件工程的深水区,也是衡量一个程序员能力高低的标准。
想要搞清楚性能优化,必须对各种底层原理有着深度的了解,对各种 case非常丰富的经验;很多朋友经常遇到措手不及的问题,大多是因为对出现问题的情况和处理思路模糊不清,导致此原因就是因为没有彻底搞懂底层原理。
性能优化始终穿插在 App 整个研发生命周期中,不管是从 0 到 1 的建立阶段,还是从 1 到 N 打磨阶段,都离不开性能优化。
音视频
伴随着疫情的反复以及5G的普及,本就火爆的音视频技术是越来越热,很多大小厂在这几年也都纷纷入局。但音视频学习起来门槛比较高,没有比较系统的教程或者书籍,网上的博客文章也都是比较零散的。
招聘市场上,同级别的音视频开发要比应用开发薪资高出30%以上。
车载
在智能手机行业初兴起时,包括BAT在内许多传统互联网企业都曾布局手机产业,但是随着手机市场的基本定型,造车似乎又成了各大资本下一个追逐的方向。百度、小米先后宣布造车,阿里巴巴则与上汽集团共同投资创立了,面向汽车全行业提供智能汽车操作系统和智能网联汽车整体解决方案的斑马网络,一时间造车俨然成了资本市场的下一个风口。
而作为移动端操作系统的霸主Android,也以一种新的姿态高调侵入造车领域
关于学习
在学习的过程中,可能会选择看博客自学、看官方文档、看书、看大厂大牛整理的知识点文档、看视频,但要按学习效率来排序的话:报培训班>看视频>知识点>书籍>官方文档>博客
报班,可能很多朋友对于报班这个事情比较抵触,但不可否认,报一个培训班是可以学到很多深层次的、成体系的技术,像之前读书一样,都是捣碎了喂给你,并且培训班其实对于新技术、新趋势是相当敏锐的,可以第一时间接触,也会规避开自学的烦恼。
看视频,基本也是由别人捣碎知识点教会你,但较之培训班的话,视频的知识成体系吗?有没有过时?
大厂大牛整理的知识点文档,大厂大牛技术还是比较可靠的,这类型的知识点文档初版基本是可以放心享用,但如果只是少数人甚至是一个人进行维护的话,当整个文档的知识体系越来越广时,其中的部分知识点可能已经过时但一直没有时间更新
书籍,相比前者就更甚了,一个技术出来,先研究、再整理、修正……直到最后出版被你买到,中间经过的这段时间就是你落后于其他人的地方了,但其中的知识点基本可以肯定成体系、无重大错误。学习比较底层的,不会有很大改动的知识点还是相当不错的。
官方文档,这一块也是我思考了很久才排好,官方文档往往是第一手资源,对于有能力看懂的朋友来说,可以直接上手品尝。但其实很多开发拿到官方文档还是看的一知半解,再者说,自己看可能会有遗漏,还是没有别人一点一点将重点翻开来解读更好
博客,网络上的博客水平参差不齐,通常大家擅长的也不是同一个技术领域,往往是学习一块看A的,另一块看B的,而且网上很多博客都是抄来自己记录的,很多API已经过时了,甚至不少连代码都是完全错误的,这样的学习,可想而知……
最后
一些个人见解,也参考了不少大佬的观点,希望可以给大家带来一些帮助,如果大家有什么不同看法,也欢迎在评论区一起讨论交流
Android路漫漫,共勉!
作者:像程序一样思考
来源:juejin.cn/post/7128425172998029320
浅谈Kotlin编程-Kotlin基础语法和编码规范
前言
上一篇我们认识了Kotlin编程语言,也搭建好开发环境。本篇就进入Kotlin的基础语法介绍,与其他编程语言一样,Kotlin也有自己的一套编码规范。
文章总览
1.Kotlin基本语法
1.1 函数声明
使用关键字 fun 声明:
fun sum(a: Int, b: Int): Int { return a + b }
以上函数有俩个 int 参数:a , b;返回值为 Int 类型值。
在Kotlin中,返回值类型可以自行推断,函数体可以是表达式:这与Java是有区别的,直接用 = 相连
fun sum(a: Int, b: Int) = a + b
无返回值的函数,使用 Unit 为写法更简便可以将 Unit 省略。
fun printSum(a: Int, b: Int): Unit {
println("sum of $a and $b is ${a + b}")
}
// Unit 返回类型可以省略
1.2 程序主入口
Kotlin 程序的入口是 main函数,与 Java 是一样的。
fun main() {
println("Hello world!") // 打印字符串
}
程序在执行时,会先进入 main 函数开始执行。
1.3 变量
- 只读局部变量(常量) 使用
val定义
val a: Int = 1 // ⽴即赋值
val b = 2 // ⾃动推断出 `Int` 类型
val c: Int // 如果没有初始值类型不能省略
c = 3 // 明确赋值
- 可重新赋值变量 使用
var定义
var x = 5 // ⾃动推断出 `Int` 类型
x += 1 // x重新赋值
这与 Java 有很大区别,不用指定变量的类型,有编译器自动推断出来。
1.4 条件表达式
与 Java 中的 if 语句一样
if (a > b) {
return a
} else {
return b
}
在 Kotlin中 if 也可以⽤作表达式,更加简便
fun max(a: Int, b: Int) = if (a > b) a else b
1.5 when表达式
when 将它的参数与所有的分⽀条件顺序⽐较,直到某个分⽀满⾜条件
when (obj) {
1 -> "One"
"Hello" -> "Greeting"
is Long -> "Long"
!is String -> "Not a string"
else -> "Unknown"
}
可以类比 Java 中的 switch 语句。
1.6 空值与空检测
一个表达式或者一个变量可以为Null, 在Kotlin中可以使用 ?来结尾表示
fun parseInt(str: String): Int? { // …… }
// 函数返回值可为空,当返回值 不是 Int 类型,返回值就是Null
这一特性解决了 Java 中一老大难的问题:NullpointException 空指针报错问题,在日常开发中帮开发者提高了不少开发效率和减少了不少bug。
1.7 区间使用
使⽤ in 操作符来检测某个数字是否在指定区间内
val x = 10
val y = 9
if (x in 1..y+1) {
println("in range")
}
这个特性可以运用到 区间和数列中。
2.Kotlin编码规范
目录结构:可以类比 Java 项目,包名的规则:小写字母,公司/组织域名反写
代码源文件:以 .kt 为扩展名,命名规则首字母大写的驼峰风格,例如
HelloWorld.kt
命名规则:
- 类与对象的名称以大写字母开头并使用驼峰风格
- 包的名称总是小写且不使用下划线
文档注释:
- 多行注释
- 单行注释
代码缩进风格要统一
注解:将注解放在单独的⾏上,在它们所依附的声明之前,并使⽤相同的缩进
链式调用:对链式调⽤换⾏时,将
.字符或者?.操作符放在下⼀⾏,带有缩进
不在
.或者?.左右留空格:foo.bar().filter { it > 2 }.joinToString() , foo?.bar()
在
//之后留⼀个空格: // 这是⼀条注释
不要在⽤于指定类型参数的尖括号前后留空格:
class Map { …… }
不要在
::前后留空格:Foo::class 、String::length
不要在⽤于标记可空类型的
?前留空格:String?
总结
本文主要讲解 Kotlin 常用的基本语法,后续会针对特定的知识点展开学习,同时学习了Kotlin 编码规范,对日常规范编写代码是非常有帮助。
作者:南巷羽
链接:https://juejin.cn/post/7130094040141266957
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android—以面试角度剖析HashMap源码
前言
HashMap 这个词想必大家都挺熟悉的!但往往大多数都知其所用,而不知其原理,导致面试的处处碰壁!因此,这一篇的作用就是以面试的角度剖析HashMap!话不多说,直接开始!
温馨提示:此文有点长,建议先插眼,等有空闲时间观看
1、为什么要学HashMap?
刚刚说了本篇是以面试角度剖析HashMap,那么面试常见的问题有哪些呢?
- HashMap的原理?内部数据结构?
- HashMap中put方法的过程是怎样实现的?
- HashMap中hash函数是怎样实现的?
- HashMap是怎样扩容的呢?
- HashMap中某个Entry链太长,查找时间复杂度可能达到O(n),怎么优化?
2、剖析HashMap
2.1 HashMap初始化
虽然这一步大家很熟悉,但过程还是少补了!
HashMap hashMap = new HashMap<>(6, 1);
HashMap hashMap2 = new HashMap<>();
源码解析
这个就很简单了,初始化HashMap有两个构造器,一个无参,一个有参。(泛型就不说了吧)
那就从简先看无参的!
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
源码解析
这里我们看到:
初始化给
this.loadFactor赋值为0.75f;
而这个0.75f就是该HashMap对应的扩展因子。(扩展因子:当长度大于等于 容量长度*扩展因子时,需要对该map进行扩容)
而 map默认长度就是
DEFAULT_INITIAL_CAPACITY=1 << 4也就是默认16
结合扩展因子一起看,也就是说,当map长度大于等于 16*0.75f的时候,对应map需要扩容!(至于怎么扩容,下面会讲解)
这里看完了无参的,趁热打铁看看有参数的!
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
源码解析
这里我们看到代码瞬间多了起来,不过前面那几个if判断都是对入参进行一系列校验,核心代码在最后两句:
this.loadFactor = loadFactor这个在上面讲过,就是给扩展因子赋值,只不过由默认变成了手动this.threshold = tableSizeFor(initialCapacity);这里我们看到调用了tableSizeFor方法,并将入参一带入该方法中!
那么这个神奇的tableSizeFor方法到底做了甚么呢???
2.1.1 tableSizeFor 方法剖析
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
在进行源码解析前,先对这个方法里的两个操作符进行讲解:
>>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0。
按二进制形式把所有的数字向右移动对应的位数,低位移出(舍弃),高位的空位补零。对于正数来说和带符号右移相同,对于负数来说不同。其他结构和>>相似。
|表示的是或运算,即两个二进制数同位中,只要有一个为1则结果为1,若两个都为1其结果也为1,换句话说就是取并集。
源码解析
就以刚刚入参为6为例(cap=6):
int n = cap - 1这个时候n=5
n |= n >>> 1这个时候需要将这句代码拆成两部解析
- 继续往下走当执行
n |= n >>> 2时
- 此时不管是
n >>> 4还是n >>> 16因为是取并集结果都为0000 0111转为十进制为n=7 - 那么看看最后一句
(n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;最终结果为n=8
那我们把入参稍微调大一点,17为例(cap=17)
如图所示
我们可以得出一个结论,通过这个方法tableSizeFor计算出的值,将大于等于cap的最近的一个2的n次方的一个值,而这对应的值就是该map的初始化容量长度
OK!到这HashMap的初始化已经剖析完成了。接下来该剖析HashMap的put操作!
2.2 HashMap对应put操作
敲黑板!!核心内容来了!!!
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
源码解析
这里我们可以看到,该方法调用了两个方法:hash(xx)以及putVal(xx,xx,xx,xx,xx)。
因为hash(xx)作为putVal方法的入参,因此,我们先看hash方法是怎么工作的
2.2.1 HashMap对应Hash算法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
源码解析
这里我们可以看到 使用了^运算符,它的意思总结起来就是一句话:同为假,异为真。
比如说:
0000 0000 0001 0001
0000 0000 0001 0111
——————————
0000 0000 0000 0110
这里我们看到:相同的,运算后都为0;不同的,运算后为1
了解这个算法后,我们来看看这个方法运行:
如图所示
现在我们看到,经过一系列计算发现最终结果居然还是为 key.hashCode(),那为啥还要与 (h>>>16) 进行 ^ 异或运算呢?能不能直接return key.hashCode()呢?
答案是:当然肯定不能!!!那它为什么要这样写呢???为什么非要用^异或运算呢?
回答这个问题之前,我们先来熟悉一下:或、与、异或 这三者运算规则;
如图所示
- 或运算:(只要有1,那么就是1) 0|0=0 ,1|0=1 ,0|1=1 ,1|1=1 我们看到有三者都为1
- 与运算:(都是1时,结果才为1) 0&0=0 ,0&1=0 ,1&0=0 ,1&1=1 我们看到有三者都为0
- 异或预算:(只要一样结果就是0)0^0=0 ,0^1=1 ,1^0=1 ,1^1=0 我们看到有两者为0,两者为1
总结
从这三者运算结果看,只有异或运算 真假各占50% ,也就是说,当使用异或运算时,对应的Key更具有散列性。为什么要有散列性,下文会体现出来!
如图所示
当key比较复杂时,返回结果已经和key.hashCode有所不同了,因此对应的(h = key.hashCode()) ^ (h >>> 16)还是很有必要的
到这Hash算法差不多结束了。接下来继续下一步操作!
按理说,下一步应该剖析putVal(xx,xx,xx,xx,xx)方法源码。但仔细想了哈,还是先吧结果说出来,最后将结果带进去阅读源码应该会更好一点。
2.2.2 HashMap内部构造结构
如图所示
- HashMap内部构造为数组+链表的形式,而数组的默认长度要么是标准的16,要么就是
tableSizeFor方法返回的结果 - 当链表长度大于等于8时,将会转为红黑树结构
刚刚我们说的是,将结果带入源码解析。那我们再来分析一下这张图
试想一下,这种结构该如何保存值呢??
- 因为它是数组结构,所以第一时间得要找到能存储该值的下标,只有找到对应下标了才能更好的保存值
- 找到对应下标了,再看该下标是否存在链表结构,如果不存在则创建新的链表结构,并将对应key-value存储起来
- 如果存在对应链表结构,则判断该链表是否转化为红黑树,如果真,则按红黑树原理存储或者替换对应值
- 如果非红黑树结构,则判断对应key是否在该链表中,如果在链表中,则直接替换原有值
- 如果对应key不存在原有链表中,则先判断该链表长度是否大于等于7,如果真,则创建新的单元格按红黑树的原理存储对应元素,最终长度自增1位;(因为长度满足8位就是红黑树结构,因此要在自增前判断是否满足要求)
- 如果链表长度小于7,那么创建新的单元格直接存入该链表中,并与上一个单元格next相互关联
到这!大部分的概念理论叙述完了,接下来到了剖析源码验证环节了!!!
2.2.3 putVal方法剖析
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
int threshold;
static final int TREEIFY_THRESHOLD = 8;
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; //分析点1
if ((p = tab[i = (n - 1) & hash]) == null) //分析点2
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; //分析点3
else if (p instanceof TreeNode) //分析点 4
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); // 分析点5
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); // 分析点5-1
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break; //分析点6
p = e; //分析点7
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) //分析点8
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize(); //分析点9
afterNodeInsertion(evict);
return null;
}
源码分析
分析点1:当该map第一次进行put操作时,对应的tab数组并未初始化。因此这里需要调用
resize()方法,并给变量n赋值(分析点9会单独讲解该方法)
分析点2:这里使用了
(p = tab[i = (n - 1) & hash]) == null这句代码,从该方法前两句可以看出
- n表示该HashMap对应数组长度
- tab表示该HashMap对应数组
- hash表示该方法的第一个入参,是由上一个方法根据hash算法推算出具有散列性的值
i = (n - 1) & hash这句代码就是通过 hash算法推算的值与数组长度-1进行运算,取出对应的下标,因为hash具有散列性(平均),因此能够均匀的分配对应数组单元格
- 如果通过下标找到元素为空,那么就创建新的链表结构,并将当前key-value存入对应链表结构中
分析点3:这里使用了
p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))这句代码,结合分析点2一起看可以得出:
- p 表示通过下标找到的对应链表结构,并且非空
- k 表示该方法第二个入参,表示对应key值
- 因此该判断条件意思:如果输入的key,与链表第一个元素的key相同,那么将该单元格赋值给创建的
e节点 (分析点8还会继续讲解该变量)
分析点4:这里使用了
e = ((TreeNode结合判断条件可以看出
- p 表示通过下标找到的对应链表结构,并且非空
p instanceof TreeNode这句判断条件表示,该链表结构是否TreeNode类型(红黑树结构)- 这里红黑树就不详解了,结构组成总结起来就一句话:你比我大,那去这一边,比我小,那就去另外一边,一直往下每个节点都这样判断
- 因此这里具体意思就是:如果为红黑树结构,那就按照红黑树结构存储替换值,并且将对应节点返回赋值给上面创建的
e节点(分析点8还会继续讲解该变量)
分析点5:
- 逻辑执行此处,这说明已经不满足上述分析点,也就是说,处理的单位只会存在标注的红框里
(e = p.next) == null这句代码表示,如果往下找已经没有节点了,那么执行p.next = newNode(hash, key, value, null)创建新的单元格并将对应key-value存储起来并与p.next相互关联
分析点5-1:
- 结合分析点5一起看,上一步将创建的单元格与
p.next相关关联后 TREEIFY_THRESHOLD该变量=8binCount >= TREEIFY_THRESHOLD - 1这句代码意思是,判断当前链表是否大于等于7 ,因为自增在下文,因此这里需要减一。treeifyBin(tab, hash);这句代码意思是,满足上面判断条件,将当前链表转为红黑树结构
- 结合分析点5一起看,上一步将创建的单元格与
分析点6:
- e 在分析5 执行了
e = p.next并且不为null (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))这句意思表示在红框标注里是否通过key找到了对应的单元格,如果真则跳出循环;如果假则执行分析7
- e 在分析5 执行了
分析点7:
- 结合分析6一起看,如果当前key与当前单元格对应key不等,那么就执行
p = e;指向下一个单元格
- 结合分析6一起看,如果当前key与当前单元格对应key不等,那么就执行
分析点8:
onlyIfAbsent该变量为方法的第4个入参,value=false
能进入该逻辑,因此对应
e不为空!上述条件中,满足条件有:分析3、分析4、分析6
这三者条件都是满足对应key相同则赋值,那么这里就是替换对应相同key对应的value值
分析点9:
- 能进分析9,则说明满足
++size > threshold条件 - size表示该map中所有key-value 的总长度
- threshold 表示 达到扩容条件的目标值
resize()方法,那就是扩容了。那么这个方法到底做了甚么呢?
- 能进分析9,则说明满足
2.2.3.1 扩容 resize() 方法
讲解扩容之前先整理下,在哪些情况会调用该方法?
- 分析点1 在table=null 或者table.length=0的时候会调用该方法
- 分析点9 在满足
++size > threshold条件时,会调用该方法
因此我们得结合这两种情况来阅读该方法!
当执行分析点1逻辑时
我们可以删掉该源方法的一部分逻辑,因此
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
.....
}
else if (oldThr > 0){
//初始化HashMap时,调用了有参构造器,就会进入该逻辑
newCap = oldThr;
}
else {
//初始化HashMap时,调用无参构造器,就会进入该逻辑
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//初始化HashMap时,调用了有参构造器,就会进入该逻辑
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
.....
return newTab;
}
源码解析
这里我们可以看到,通过分析点1进入该方法时:
已知条件为:table =null , oldCap=0
默认情况下将会直接进入else 相关逻辑 ,如果用户初始化HashMap调用的有参构造器,那么就会执行代码注释标注的部分(下面所有都按初始化时,调用无参构造器讲解)
当执行
newCap = DEFAULT_INITIAL_CAPACITY对应newCap=16
当执行
(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY)对应 newThr=16*0.75f
当执行
threshold = newThr对应threshold=12
当执行
Node以及table = newTab对应table长度为newCap也就是默认16
这个就是通过分析点1进入该方法的所有逻辑!
那通过分析点9进入该方法呢?
当执行分析点9逻辑时
对应代码逻辑:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { //分析点10
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY) //分析点11
newThr = oldThr << 1; // double threshold
}
//删除上面已经讲解过的代码.....
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap]; //分析点12
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
源码解析
分析点10:这里是为了做最大限制扩容,如果扩容前的长度已经达到了
1<<30,那么此次扩容长度将会是最大值Integer.MAX_VALUE
分析点11:我们来拆分一下这段条件判断代码:
(newCap=oldCap<<1
执行
newCap=oldCap<<1时,对应 newCap=扩容前的长度<<1 ,也就是 16<<1 ,最终结果为 32
在判断逻辑里,当执行
newThr = oldThr << 1时,也就是 12<<1,最终结果为 24
分析点12:将分析11的结果创建了一个全新的数组,并在下面的循环中,将原有数组里的内容赋值给这个全新数组
到这里,整个扩容机制已经讲解完了!趁热打铁,继续下一个!
2.3 HashMap对应get操作
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
源码解析
这里我们可以看到 依然调用了两个方法
hash(xx)、getNode(xx,xx)
hash(xx)这个在put操作里讲解过,这里不再赘述
因此现在只需要讲解这个方法
getNode(xx,xx)即可
2.3.1 getNode 方法剖析
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //分析点1
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first; //分析点2
if ((e = first.next) != null) {
//分析点3
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null; //分析点4
}
源码解析
分析点1:这里仅仅是对map里面的数组进行判断,看是否为有效有值的数组,并将有效值给first赋值
分析点2:这里表示如果是在第一层节点通过key找到对应节点时,那就直接返回对应节点
分析点3:这里就和分析2相反,第一层找不到,那就只有遍历下面对应节点的下一层。如果是链表,那就按链表形式查找;如果是红黑树,那就按照红黑树形式查找;如果找到了,就将对应的节点向上一层返回
分析点4:到这里这说明上面所有方式都没有找到对应key相关的节点,因此返回null
好了!到这里HashMap相关源码已全部剖析完毕!现在来结合上文面试题总结一下!
3、总结
HashMap的原理?内部数据结构?
- HashMap底层它是有哈希表组成,当链条过长时,将会转化为红黑树结构
HashMap中put方法的过程是怎样实现的?
- 对key求hash值,然后再计算下标
- 如果没有碰撞,直接放入数组中
- 如果碰撞了,就根据key判断是否存在于链表中,存在则直接覆盖值,不存在则以链表的方式链接到后面
- 如果链表长度过长(>=8),此时链表将转为红黑树
- 如果桶满了(容量*加载因子),那么就需要调用resize方法进行扩容
HashMap中hash函数是怎样实现的?
- 高16bit不变,低16bit和高16bit做了一个异或
- 通过(n-1)&hash 得到对应的下标
HashMap是怎样扩容的呢?
- 在resize方法里,首先通过(容量*加载因子)计算出下一次扩容所需要达到的条件
- 当在putVal,如果对应长度达到了扩容的条件那么就会再次调用resize方法,通过 原长度<<1 移位操作 进行扩容
- 而对应的扩容条件也会跟随这 原扩容因子<<1 移位操作
HashMap中某个Entry链太长,查找时间复杂度可能达到O(n),怎么优化?
- 其实上面已经答了,就是将链表转化为红黑树操作!
到这里,本篇内容已经进入尾声了!相信能坚持看到这里的小伙伴,已经对hashMap有了充分的认知!
下一篇准备来个手写HashMap,来巩固HashMap知识点!!!
作者:hqk
链接:https://juejin.cn/post/7130524758059253774
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android drawFunctor 原理及应用
一. 背景
蚂蚁 NativeCanvas 项目 Android 平台中使用了基于 TextureView 环境实现 GL 渲染的技术方案,而 TextureView 需使用与 Activity Window 独立的 GraphicBuffer,RenderThread 在上屏 TextureView 内容时需要将 GraphicBuffer 封装为 EGLImage 上传为纹理再渲染,内存占用较高。为降低内存占用,经仔细调研 Android 源码,发现其中存在一种称为 drawFunctor 的技术,用来将 WebView 合成后的内容同步到 Activity Window 内上屏。经过一番探索成功实现了基于 drawFunctor 实现 GL 注入 RenderThread 的功能,本文将介绍这是如何实现的。
二. drawFunctor 原理介绍
drawFunctor 是 Android 提供的一种在 RenderThread 渲染流程中插入执行代码机制,Android 框架是通过以下三步来实现这个机制的:
- 在 UI 线程 View 绘制流程 onDraw 方法中,通过 RecordingCanvas.invoke 接口,将 functor 插入 DisplayList 中
- 在 RenderThread 渲染 frame 时执行 DisplayList,判断如果是 functor 类型的 op,则保存当前部分 gl 状态
- 在 RenderThread 中真正执行 functor 逻辑,执行完成后恢复 gl 状态并继续
目前只能通过 View.OnDraw 来注入 functor,因此对于非 attached 的 view 是无法实现注入的。Functor 对具体要执行的代码并未限制,理论上可以插入任何代码的,比如插入一些统计、性能检测之类代码。系统为了 functor 不影响当前 gl context,执行 functor 前后进行了基本的状态保存和恢复工作。
另外,如果 View 设置了使用 HardwareLayer, 则 RenderThread 会单独渲染此 View,具体做法是为 Layer 生成一块 FBO,View 的内容渲染到此 FBO 上,然后再将 FBO 以 View 在 hierachy 上的变换绘制 Activity Window Buffer 上。 对 drawFunctor 影响的是, 会切换到 View 对应的 FBO 下执行 functor, 即 functor 执行的结果是写入到 FBO 而不是 Window Buffer。
三. 利用 drawFunctor 注入 GL 渲染
根据上文介绍,通过 drawFunctor 可以在 RenderThread 中注入任何代码,那么也一定可以注入 OpenGL API 来进行渲染。我们知道 OpenGL API 需要执行 EGL Context 上,所以就有两种策略:一种是利用 RenderThread 默认的 EGL Context 环境,一种是创建与 RenderThread EGL Context share 的 EGL Context。本文重点介绍第一种,第二种方法大同小异。
Android Functor 定义
首先找到 Android 源码中 Functor 的头文件定义并引入项目:
namespace android {
class Functor {
public:
Functor() {}
virtual ~Functor() {}
virtual int operator()(int /*what*/, void * /*data*/) { return 0; }
};
}
RenderThread 执行 Functor 时将调用 operator()方法,what 表示 functor 的操作类型,常见的有同步和绘制, 而 data 是 RenderThread 执行 functor 时传入的参数,根据源码发现是 data 是 android::uirenderer::DrawGlInfo 类型指针,包含当前裁剪区域、变换矩阵、dirty 区域等等。
DrawGlInfo 头文件定义如下:
namespace android {
namespace uirenderer {
/**
* Structure used by OpenGLRenderer::callDrawGLFunction() to pass and
* receive data from OpenGL functors.
*/
struct DrawGlInfo {
// Input: current clip rect
int clipLeft;
int clipTop;
int clipRight;
int clipBottom;
// Input: current width/height of destination surface
int width;
int height;
// Input: is the render target an FBO
bool isLayer;
// Input: current transform matrix, in OpenGL format
float transform[16];
// Input: Color space.
// const SkColorSpace* color_space_ptr;
const void* color_space_ptr;
// Output: dirty region to redraw
float dirtyLeft;
float dirtyTop;
float dirtyRight;
float dirtyBottom;
/**
* Values used as the "what" parameter of the functor.
*/
enum Mode {
// Indicates that the functor is called to perform a draw
kModeDraw,
// Indicates the the functor is called only to perform
// processing and that no draw should be attempted
kModeProcess,
// Same as kModeProcess, however there is no GL context because it was
// lost or destroyed
kModeProcessNoContext,
// Invoked every time the UI thread pushes over a frame to the render thread
// *and the owning view has a dirty display list*. This is a signal to sync
// any data that needs to be shared between the UI thread and the render thread.
// During this time the UI thread is blocked.
kModeSync
};
/**
* Values used by OpenGL functors to tell the framework
* what to do next.
*/
enum Status {
// The functor is done
kStatusDone = 0x0,
// DisplayList actually issued GL drawing commands.
// This is used to signal the HardwareRenderer that the
// buffers should be flipped - otherwise, there were no
// changes to the buffer, so no need to flip. Some hardware
// has issues with stale buffer contents when no GL
// commands are issued.
kStatusDrew = 0x4
};
}; // struct DrawGlInfo
} // namespace uirenderer
} // namespace android
Functor 设计
operator()调用时传入的 what 参数为 Mode 枚举, 对于注入 GL 的场景只需处理 kModeDraw 即可,c++ 侧类设计如下:
// MyFunctor定义
namespace android {
class MyFunctor : Functor {
public:
MyFunctor();
virtual ~MyFunctor() {}
virtual void onExec(int what,
android::uirenderer::DrawGlInfo* info);
virtual std::string getFunctorName() = 0;
int operator()(int /*what*/, void * /*data*/) override;
private:
};
}
// MyFunctor实现
int MyFunctor::operator() (int what, void *data) {
if (what == android::uirenderer::DrawGlInfo::Mode::kModeDraw) {
auto info = (android::uirenderer::DrawGlInfo*)data;
onExec(what, info);
}
return android::uirenderer::DrawGlInfo::Status::kStatusDone;
}
void MyFunctor::onExec(int what, android::uirenderer::DrawGlInfo* info) {
// 渲染实现
}
因为 functor 是 Java 层调度的,而真正实现是在 c++ 的,因此需要设计 java 侧类并做 JNI 桥接:
// java MyFunctor定义
class MyFunctor {
private long nativeHandle;
public MyFunctor() {
nativeHandle = createNativeHandle();
}
public long getNativeHandle() {
return nativeHanlde;
}
private native long createNativeHandle();
}
// jni 方法:
extern "C" JNIEXPORT jlong JNICALL
Java_com_test_MyFunctor_createNativeHandle(JNIEnv *env, jobject thiz) {
auto p = new MyFunctor();
return (jlong)p;
}
在 View.onDraw () 中调度 functor
框架在 java Canvas 类上提供了 API,可以在 onDraw () 时将 functor 记录到 Canvas 的 DisplayList 中。不过由于版本迭代的原因 API 在各版本上稍有不同,经总结可采用如下代码调用,兼容各版本区别:
public class FunctorView extends View {
...
private static Method sDrawGLFunction;
private MyFunctor myFunctor = new MyFunctor();
@Override
public void onDraw(Canvas cvs) {
super.onDraw(cvs);
getDrawFunctorMethodIfNot();
invokeFunctor(cvs, myFunctor);
}
private void invokeFunctor(Canvas canvas, MyFunctor functor) {
if (functor.getNativeHandle() != 0 && sDrawGLFunction != null) {
try {
sDrawGLFunction.invoke(canvas, functor.getNativeHandle());
} catch (Throwable t) {
// log
}
}
}
public synchronized static Method getDrawFunctorMethodIfNot() {
if (sDrawGLFunction != null) {
return sDrawGLFunction;
}
hasReflect = true;
String className;
String methodName;
Class<?> paramClass = long.class;
try {
if (Build.VERSION.SDK_INT > Build.VERSION_CODES.P) {
className = "android.graphics.RecordingCanvas";
methodName = "callDrawGLFunction2";
} else if (Build.VERSION.SDK_INT > Build.VERSION_CODES.LOLLIPOP_MR1) {
className = "android.view.DisplayListCanvas";
methodName = "callDrawGLFunction2";
} else if (Build.VERSION.SDK_INT == Build.VERSION_CODES.LOLLIPOP) {
className = "android.view.HardwareCanvas";
methodName = "callDrawGLFunction";
} else if (Build.VERSION.SDK_INT == Build.VERSION_CODES.LOLLIPOP_MR1) {
className = "android.view.HardwareCanvas";
methodName = "callDrawGLFunction2";
} else {
className = "android.view.HardwareCanvas";
methodName = "callDrawGLFunction";
paramClass = int.class;
}
Class<?> canvasClazz = Class.forName(className);
sDrawGLFunction = SystemApiReflector.getInstance().
getDeclaredMethod(SystemApiReflector.KEY_GL_FUNCTOR, canvasClazz,
methodName, paramClass);
} catch (Throwable t) {
// 异常
}
if (sDrawGLFunction != null) {
sDrawGLFunction.setAccessible(true);
} else {
// (异常)
}
return sDrawGLFunction;
}
}
注意上述代码反射系统内部 API,Android 10 之后做了 Hidden API 保护,直接反射会失败,此部分可网上搜索解决方案,此处不展开。
四. 实践中遇到的问题
GL 状态保存&恢复
Android RenderThread 在执行 drawFunctor 前会保存部分 GL 状态,如下源码:
// Android 9.0 code
// 保存状态
void RenderState::interruptForFunctorInvoke() {
mCaches->setProgram(nullptr);
mCaches->textureState().resetActiveTexture();
meshState().unbindMeshBuffer();
meshState().unbindIndicesBuffer();
meshState().resetVertexPointers();
meshState().disableTexCoordsVertexArray();
debugOverdraw(false, false);
// TODO: We need a way to know whether the functor is sRGB aware (b/32072673)
if (mCaches->extensions().hasLinearBlending() &&
mCaches->extensions().hasSRGBWriteControl()) {
glDisable(GL_FRAMEBUFFER_SRGB_EXT);
}
}
// 恢复状态
void RenderState::resumeFromFunctorInvoke() {
if (mCaches->extensions().hasLinearBlending() &&
mCaches->extensions().hasSRGBWriteControl()) {
glEnable(GL_FRAMEBUFFER_SRGB_EXT);
}
glViewport(0, 0, mViewportWidth, mViewportHeight);
glBindFramebuffer(GL_FRAMEBUFFER, mFramebuffer);
debugOverdraw(false, false);
glClearColor(0.0f, 0.0f, 0.0f, 0.0f);
scissor().invalidate();
blend().invalidate();
mCaches->textureState().activateTexture(0);
mCaches->textureState().resetBoundTextures();
}
可以看出并没有保存所有 GL 状态,可以增加保存和恢复所有其他 GL 状态的逻辑,也可以针对实际 functor 中改变的状态进行保存和恢复;特别注意 functor 执行时的 GL 状态是非初始状态,例如 stencil、blend 等都可能被系统 RenderThread 修改,因此很多状态需要重置到默认。
View变换处理
当承载 functor 的 View 外部套 ScrollView、ViewPager,或者 View 执行动画时,渲染结果异常或者不正确。例如水平滚动条中 View 使用 functor 渲染,内容不会随着滚动条移动调整位置。进一步研究源码 Android 发现,此类问题原因都是 Android 在渲染 View 时加入了变换,变换采用标准 4x4 变换列矩阵描述,其值可以从 DrawGlInfo::transform 字段中获取, 因此渲染时需要处理 transform,例如将 transform 作为模型变换矩阵传入 shader。
ContextLost
Android framework 在 trimMemory 时在 RenderThread 中会销毁当前 GL Context 并创建一个新 Context, 这样会导致 functor 的 program、shader、纹理等 GL 资源都不可用,再去渲染的话可能会导致闪退、渲染异常等问题,因此这种情况必须处理。
首先,需要响应 lowMemory 事件,可以通过监听 Application 的 trimMemory 回调实现:
activity.getApplicationContext().registerComponentCallbacks(
new ComponentCallbacks2() {
@Override
public void onTrimMemory(int level) {
if (level == 15) {
// 触发functor重建
}
}
@Override
public void onConfigurationChanged(Configuration newConfig) {
}
@Override
public void onLowMemory() {
}
});然后,保存 & 恢复 functor 的 GL 资源和执行状态,例如 shader、program、fbo 等需要重新初始化,纹理、buffer、uniform 数据需要重新上传。注意由于无法事前知道 onTrimMemory 发生,上一帧内容是无法恢复的,当然知道完整的状态是可以重新渲染出来的。
鉴于存在无法提前感知的 ContextLost 情况,建议采用基于 commandbuffer 的模式来实现 functor 渲染逻辑。
五. 效果
我们用一个 OpenGL 渲染的简单 case (分辨率1080x1920),对使用 TextureView 渲染和使用 drawFunctor 渲染的方式进行了比较,结果如下:
| Simple Case | 内存 | CPU 占用 |
|---|---|---|
| 基于 TextureView | 100 M ( Graphics 38 M ) | 6% |
| 基于 GLFunctor | 84 M ( Graphics 26 M ) | 4% |
从上述结果可得出结论,使用 drawFunctor 方式在内存、CPU 占用上具有优势, 可应用于局部页面的互动渲染、视频渲染等场景。
作者:支付宝体验科技
链接:https://juejin.cn/post/7130501902545977352
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android Gradle 三方依赖管理
发展历史
Gradle 的依赖管理是一个从开始接触 Android 开发就一直伴随着我们的问题(作者是Android开发,仅以此为例),从最初的 没有统一管理 到 通过.gradle或gradle.properties管理,再到 Kotlin 出现之后使用 buildSrc 管理 以及在这基础上优化的 Composing Builds,Gradle 依赖管理一直在不断的发展、更新,而到了 Gradle 7.0,Gradle 本身又专门提供了全新的 Version Catalogs 用于依赖管理,今天我们就来说说这些方式的优劣及使用方式吧。
最原始的依赖
当我们通过 Android Studio 创建一个新项目,这个项目里面默认的依赖就是最原始的,没有经过统一管理的;如果你的项目中只有一个 module,那么这种默认的管理方式也是可以接受的,是否对它进行优化,这取决于你是否愿意投入成本去修改,谈不上什么优劣。
使用 .gradle 配置
当你的项目中 module 的数量超过一个甚至越来越多的时候,对 Gradle 依赖进行统一管理就变得重要起来,因为你不会想在升级一个三方依赖的版本后发现冲突,然后一个个打开各个 module 的 build.gradle 文件,找到你升级的那个依赖引用,重复的进行版本修改;
因此我们有了初步的优化方案:
- 在项目根目录下创建
config.gradle文件,在其中按照以下格式添加相关配置;
ext {
android = [
compileSdkVersion: 30
]
dependencies = [
"androidx-core-ktx" : "androidx.core:core-ktx:1.3.2",
"androidx-appcompat": "androidx.appcompat:appcompat:1.2.0",
"google-material" : "com.google.android.material:material:1.3.0"
]
}
- 在项目根目录下的
build.gradle文件顶部添加apply from: "config.gradle"; - 在各个
module的build.gradle中就可以通过rootProject来引用对应的依赖及参数了;
...
android {
compileSdkVersion rootProject.ext.android.compileSdkVersion
}
...
dependencies {
implementation rootProject.ext.dependencies["androidx-core-ktx"]
implementation rootProject.ext.dependencies["androidx-appcompat"]
implementation rootProject.ext.dependencies["google-material"]
}
...
使用这种方式,我们就能够将项目中的版本配置、三方依赖统一管理起来了,但是这种方式还是有缺陷的,我们无法像正常代码中一样便捷的跳转到依赖定义的地方,也不能简单的找到定义的依赖在哪些地方被使用。
使用 gradle.properties 配置
这个方式和上面的方式类似,把依赖相关数据定义到 gradle.properties 文件中:
...
androidx-core-ktx = androidx.core:core-ktx:1.3.2
androidx-appcompat = androidx.appcompat:appcompat:1.2.0
androidx-material = com.google.android.material:material:1.3.0
在各个 module 的 build.gradle 中使用;
...
dependencies {
implementation "${androidx-core-ktx}"
implementation "${androidx-appcompat}"
implementation "${google-material}"
}
这种方式相对于 .gradle 方式不需要单独创建 config.gradle 文件,但是同样的也无法快速定位到定义的地方及快速跳转到依赖使用。
使用 buildSrc 配置
在 Kotlin 的支持下,我们又有了新的方案,这个方案依赖于 IDEA 会将 buildSrc 路径作为插件编译到项目以及 Kotlin dsl 的支持,并且解决上面两个方案依赖无法快速跳转问题;
使用方式如下:
- 在项目根目录新建文件夹
buildSrc,并在该路径下新建build.gradle.kts文件,该文件使用 Kotlin 语言配置
repositories {
google()
mavenCentral()
}
plugins {
// 使用 kotlin-dsl 插件
`kotlin-dsl`
}
- 在
buildSrc中添加源码路径src/main/kotlin,并在源码路径下添加依赖配置Dependencies.kt
object Dependencies {
const val ANDROIDX_CORE_KTX = "androidx.core:core-ktx:1.3.2"
const val ANDROIDX_APPCOMPAT = "androidx.appcompat:appcompat:1.2.0"
const val GOOGLE_MATERIAL = "com.google.android.material:material:1.3.0"
}
- 在各个
module中的build.gradle.kts文件中使用依赖
...
dependencies {
implementation(Dependencies.ANDROIDX_CORE_KTX)
implementation(Dependencies.ANDROIDX_APPCOMPAT)
implementation(Dependencies.GOOGLE_MATERIAL)
}
这个方案的优点正如上面所说的,能够快速方便的定位到依赖的定义及使用,其确定就在于因为需要 Kotlin 支持,所以需要向项目中引入 Kotlin 的依赖,并且各个 module 的 build.gradle 配置文件需要转换为 build.gradle.kts 格式。
使用 Composing Builds 配置
Composing Builds 方案的本质和 buildSrc 方案是一样的,都是将对应 module 中的代码编译作为插件,在 build.gradle.kts 中可以直接引用,那为什么还要有 Composing Builds 这种方案呢?这是因为 buildSrc 方案中,如果 buildSrc 中的配置有修改,会导致整个项目都会进行重新构建,如果项目较小可能影响不大,但如果项目过大,那这个缺点显然是无法接受的,Composing Builds 方案应运而生。
使用方式:
- 在项目根目录创建
module文件夹,名称随意,这里使用plugin-version,并在文件夹中创建build.gradle.kts配置文件,内容如下:
plugins {
id("java-gradle-plugin")
id("org.jetbrains.kotlin.jvm") version "1.7.10"
}
repositories {
google()
mavenCentral()
gradlePluginPortal()
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
dependencies {
// 添加Gradle相关的API,否则无法自定义Plugin和Task
implementation(gradleApi())
implementation("org.jetbrains.kotlin:kotlin-gradle-plugin:1.7.10")
}
gradlePlugin {
plugins {
create("version") {
// 添加插件,下面是包名
id = "xx.xx.xx"
// 在源码路径创建类继承 Plugin<Project>
implementationClass = "xx.xx.xx.VersionPlugin"
}
}
}
- 创建源码目录及包路径
src/main/kotlin/xx.xx.xx,在包中新建类VersionPlugin继承org.gradle.api.Plugin
class VersionPlugin : Plugin<Project> {
override fun apply(target: Project) {
}
}
- 在项目根目录下的
settings.gradle.kts文件中添加includeBuild("plugin-version") - 最后和
buildSrc方案一样,在源码路径下新增相关依赖配置,在各个module中引用即可。
Version Catalogs 配置
从 Gradle 7.0 开始,Gradle 新增了 Version Catalogs 功能,用于在项目之间共享依赖项版本, Gradle 文档中列出的一下优点:
- 对于每个
Catelog,Gradle都会生成类型安全的访问器,可以轻松的在IDE中使用,完成添加依赖; - 每个
Catelog对生成的所有项目都可见,可以确保依赖版本同步到所有子项目; Catelog可以声明依赖关系包,这些捆绑包是通常在一起使用的依赖关系组;Catelog可以将依赖项的组、名称和实际版本分开,改用版本引用,从而可以在多个依赖项中共享版本声明。
接下来我们来学习这种方案的具体使用。
开始使用
使用 Version Catalogs 首先当然是需要项目 Gradle 版本高于 7.0,之后在项目根路径下的 settings.gradle.kts 中添加配置(因为作者项目用的是 .kts,groovy 按对应语法添加即可)
dependencyResolutionManagement {
// 版本目录配置
versionCatalogs {
// 创建一个名称为 libs 的版本目录
create("libs") {
// 声明 groovy 依赖
library("groovy-core", "org.codehaus.groovy:groovy:3.0.5")
}
}
}
在上面的配置之后,你就可以在项目中使用对应依赖了。例:build.gradle.kts
dependencies {
implementation(libs.groovy.core)
}
这里有细心的小伙伴就会发现,我们声明的是 groovy-core,使用的时候却是 libs.groovy.core,这是因为 Version Catalogs 在根据别名生成依赖时对安全访问器的映射要求,别名必须由 ascii 字符组成,后跟数字,中间分隔只支持 短划线-、下划线_、点.,因此声明别名时可以使用groovy-core、groovy_core、groovy.core,最终生成的都是 libs.groovy.core。
使用 settings.gradle.kts 配置
就如上面的示例中,我们就是在 settings.gradle.kts 中声明了 groovy-core 的依赖,并且需要的地方使用,接下来我们详细说明对依赖项声明的语法:
dependencyResolutionManagement {
// 版本目录配置
versionCatalogs {
// 创建一个名称为 libs 的版本目录
create("libs") {
// 声明 kotlin 版本
version("kotlin", "1.7.10")
// 声明 groovy 版本
version("groovy", "3.0.5")
// 声明 groovy 依赖
library("groovy-core", "org.codehaus.groovy:groovy:3.0.5")
// 声明 groovy 依赖
library("groovy-nio", "org.codehaus.groovy", "groovy-nio").version("3.05")
// 声明 groovy 依赖使用版本引用
library("groovy-json", "org.codehaus.groovy", "groovy-json").versionRef("groovy")
// 声明 groovy 依赖组
bundle("groovy", listOf("groovy-core", "groovy-json", "groovy-nio"))
// 声明 kotlin 序列化插件
plugin("kotlin-serialization", "org.jetbrains.kotlin.plugin.serialization").versionRef("kotlin")
}
}
这种方式相对统一了依赖版本,却无法做到多项目统一。
使用 libs.versions.toml 配置
还是先看示例代码:
dependencyResolutionManagement {
// 版本目录配置
versionCatalogs {
// 创建一个名称为 libs 的版本目录
create("libs") {
// 不能如此配置,会抛出异常
from(files("./gradle/libs.versions.toml"))
// 可以添加此配置
from(files("./gradle/my-libs.versions.toml"))
}
// 创建一个名称为 configLibs 的版本目录
create("configLibs") {
// 添加配置文件
from(files("./gradle/configLibs.versions.toml"))
}
}
}
在配置版本目录后,出了直接在 .kts 里面添加依赖定义,还可以通过 from 方法从 .toml 文件中加载,.toml 文件一般放在项目根路径下的 gradle 文件夹中。
这里需要注意的是,gradle 有一个默认配置名称为 libs,如果你创建的版本目录名称是 libs,那么你就无需通过 from 方法加载 libs.versions.toml 文件,因为 gradle 会默认此配置,你只需在 ./gradle 路径下创建 libs.versions.toml 文件即可,重复添加会导致编译失败;如果你已经有了一个 libs.versions.toml 你也可以在添加以下配置来修改默认配置名称:
dependencyResolutionManagement {
defaultLibrariesExtensionName.set("projectLibs")
}
如果你创建的版本目录名称不是默认配置名称,那么就需要你手动添加 from 方法加载配置;所有版本目录名称建议以 Libs 结尾,否则会有 warning,提示后续将不支持此命名。
接下来我们来看 .toml 文件的配置规则:
# 声明版本号
[versions]
kotlin = "1.7.10"
groovy = "3.0.5"
# 声明依赖
[libraries]
# groovy
groovy-core = "org.codehaus.groovy:groovy:3.0.5"
groovy-json = { module = "org.codehaus.groovy:groovy-json", version = "3.0.5" }
groovy-nio = { group = "org.codehaus.groovy", name = "groovy-nio", version.ref = "groovy" }
# 声明依赖组
[bundles]
groovy = ["groovy-core", "groovy-json", "groovy-nio"]
# 声明插件
[plugins]
kotlin-serialization = { id = "org.jetbrains.kotlin.plugin.serialization", version.ref = "kotlin" }
这种方式在统一单一项目依赖版本的同时,可以通过分享 .toml 文件来达成多项目依赖版本的统一,但是同样的,同样的文件在不同项目中不可避免是会被修改的,用着用着就不一致了。
使用插件配置
虽然从本地文件导入很方便,但是并不能解决多项目共享版本目录的问题,gradle 提供了新的解决方案,我们可以在一个独立的项目中配置好各个三方依赖,然后将其发布到 maven 等三方仓库中,各个项目再从 maven 仓库中统一获取依赖
插件配置
为了实现此功能,gradle 提供了 version-catalog 插件,再配合 maven-publish 插件,就能很方便的生产插件并发布到 maven 仓库。
新建 gradle 插件项目,修改 build.gradle.kts
plugins {
`maven-publish`
`version-catalog`
}
// 版本目录配置
catalog {
versionCatalog {
// 在这里配置各个三方依赖
from(files("./gradle/libs.versions.toml"))
version("groovy", "3.0.5")
library("groovy-json", "org.codehaus.groovy", "groovy-json").versionRef("groovy")
}
}
// 配置 publishing
publishing {
publications {
create<MavenPublication>("maven") {
from(components["versionCatalog"])
}
}
}
这里需要注意的是,插件项目的 gradle 版本必须要高于 7.0 并且低于使用该插件的项目的版本,否则将无法使用。
插件使用
配置从 maven 仓库加载版本目录
dependencyResolutionManagement {
// 版本目录配置
versionCatalogs {
// 创建一个名称为 libs 的版本目录
create("libs") {
// 从 maven 仓库获取依赖
from("io.github.wangjie0822:catalog:1.1.3")
}
}
}
重写版本
从 maven 仓库中获取版本目录一般来讲就不应该修改了,但是仅一份依赖清单怎么满足我们的开发需求呢,不说各个依赖库都在不断的持续更新,如果我们需要使用的依赖没有在版本目录里面声明呢?我们不可能为了修改一个依赖的版本或者添加一个依赖就频繁的发布Catalog插件版本,这样成本太高,这就需要我们进行个性化配置了
dependencyResolutionManagement {
// 版本目录配置
versionCatalogs {
// 创建一个名称为 libs 的版本目录
create("libs") {
// 从 maven 仓库获取依赖
from("io.github.wangjie0822:catalog:1.1.3")
// 添加仓库里面没有的依赖
library("tencent-mmkv", "com.tencent", "mmkv").version("1.2.14")
// 修改groovy版本
version("groovy", "3.0.6")
}
}
}
请注意,我们只能重写版本目录里面定义的版本号,所以在定义版本目录时尽量将所有版本号都是用版本引用控制。
使用方式
上面说了那么多的配置定义方式,下面来看看Version Catalogs的使用方式:
plugins {
// 可以直接使用定义的 version 版本号
kotlin("plugin.serialization") version libs.versions.kotlin
// 也可以直接使用定义的插件
alias(libs.plugin.kotlin.serialization)
}
android {
defaultConfig {
// 其它非依赖的字段可以在版本目录的版本中定义 通过 versions 获取
minSdk = configLibs.versions.minSdk.get().toInt()
targetSdk = configLibs.versions.targetSdk.get().toInt()
versionCode = configLibs.versions.versionCode.get().toInt()
versionName = configLibs.versions.versionName.get()
}
}
dependencies {
// 使用 groovy 依赖
implementation(libs.groovy.core)
// 使用包含 groovy-core groovy-json groovy-no 三个依赖的依赖组
implementation(libs.bundles.groovy)
// 使用 configLibs 中定义的依赖
implementation(configLibs.groovy.core)
}
上面我们已经说过这种方案的优点,可以让我们在所有项目中保持依赖版本的统一,甚至可以分享出去让其他开发者使用;同时也有着和 buildSrc、Composing Builds一样的可跳转、可追溯的优点;
但是相比于这两个方案,Version Catalogs生成的代码只有默认的注释,并且无法直接看到使用的依赖的版本号,而在 buildSrc、Composing Builds 中我们能够对依赖的功能进行详细的注释,甚至添加上对应的使用文档地址、Github 地址等,如果支持自定义注释,那这个功能就更完美了。
总结
Android 发展至今,各种新技术层出不穷,版本管理也出现了很多方案,这些方案并没有绝对的优劣,还是需要结合实际项目需求来选择的,但是新的方案还是需要学习了解的。
关于 Version Catalogs 插件项目,可以参照 WangJie0822/Catalog (github.com)
关于 Version Catalogs 的方案使用,可以参照 WangJie0822/Cashbook: 记账本 (github.com) 最新代码
如果想要了解 buildSrc 方案,可以参照 WangJie0822/Cashbook: 记账本 (github.com)
作者:王杰0822
链接:https://juejin.cn/post/7130530401763737607
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
从 React 原理来看 ahooks 是怎么解决 React 的闭包问题的?
本文是深入浅出 ahooks 源码系列文章的第三篇,该系列已整理成文档-地址。觉得还不错,给个 star 支持一下哈,Thanks。
本文来探索一下 ahooks 是怎么解决 React 的闭包问题的?。
React 的闭包问题
先来看一个例子:
import React, { useState, useEffect } from "react";
export default () => {
const [count, setCount] = useState(0);
useEffect(() => {
setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, []);
return (
<div>
count: {count}
<br />
<button onClick={() => setCount((val) => val + 1)}>增加 1</button>
</div>
);
};当我点击按钮的时候,发现 setInterval 中打印出来的值并没有发生变化,始终都是 0。这就是 React 的闭包问题。

产生的原因
为了维护 Function Component 的 state,React 用链表的方式来存储 Function Component 里面的 hooks,并为每一个 hooks 创建了一个对象。
type Hook = {
memoizedState: any,
baseState: any,
baseUpdate: Update<any, any> | null,
queue: UpdateQueue<any, any> | null,
next: Hook | null,
};这个对象的 memoizedState 属性就是用来存储组件上一次更新后的 state,next 指向下一个 hook 对象。在组件更新的过程中,hooks 函数执行的顺序是不变的,就可以根据这个链表拿到当前 hooks 对应的 Hook 对象,函数式组件就是这样拥有了state的能力。
同时制定了一系列的规则,比如不能将 hooks 写入到 if...else... 中。从而保证能够正确拿到相应 hook 的 state。
useEffect 接收了两个参数,一个回调函数和一个数组。数组里面就是 useEffect 的依赖,当为 [] 的时候,回调函数只会在组件第一次渲染的时候执行一次。如果有依赖其他项,react 会判断其依赖是否改变,如果改变了就会执行回调函数。
回到刚刚那个例子:
const [count, setCount] = useState(0);
useEffect(() => {
setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, []);它第一次执行的时候,执行 useState,count 为 0。执行 useEffect,执行其回调中的逻辑,启动定时器,每隔 1s 输出 setInterval: 0。
当我点击按钮使 count 增加 1 的时候,整个函数式组件重新渲染,这个时候前一个执行的链表已经存在了。useState 将 Hook 对象 上保存的状态置为 1, 那么此时 count 也为 1 了。但是执行 useEffect,其依赖项为空,不执行回调函数。但是之前的回调函数还是在的,它还是会每隔 1s 执行 console.log("setInterval:", count);,但这里的 count 是之前第一次执行时候的 count 值,因为在定时器的回调函数里面被引用了,形成了闭包一直被保存。
解决的方法
解决方法一:给 useEffect 设置依赖项,重新执行函数,设置新的定时器,拿到最新值。
// 解决方法一
useEffect(() => {
if (timer.current) {
clearInterval(timer.current);
}
timer.current = setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, [count]);解决方法二:使用 useRef。
useRef 返回一个可变的 ref 对象,其 .current 属性被初始化为传入的参数(initialValue)。
useRef 创建的是一个普通 Javascript 对象,而且会在每次渲染时返回同一个 ref 对象,当我们变化它的 current 属性的时候,对象的引用都是同一个,所以定时器中能够读到最新的值。
const lastCount = useRef(count);
// 解决方法二
useEffect(() => {
setInterval(() => {
console.log("setInterval:", lastCount.current);
}, 1000);
}, []);
return (
<div>
count: {count}
<br />
<button
onClick={() => {
setCount((val) => val + 1);
// +1
lastCount.current += 1;
}}
>
增加 1
</button>
</div>
);useRef => useLatest
终于回到我们 ahooks 主题,基于上述的第二种解决方案,useLatest 这个 hook 随之诞生。它返回当前最新值的 Hook,可以避免闭包问题。实现原理很简单,只有短短的十行代码,就是使用 useRef 包一层:
import { useRef } from 'react';
// 通过 useRef,保持每次获取到的都是最新的值
function useLatest<T>(value: T) {
const ref = useRef(value);
ref.current = value;
return ref;
}
export default useLatest;useEvent => useMemoizedFn
React 中另一个场景,是基于 useCallback 的。
const [count, setCount] = useState(0);
const callbackFn = useCallback(() => {
console.log(`Current count is ${count}`);
}, []);以上不管,我们的 count 的值变化成多少,执行 callbackFn 打印出来的 count 的值始终都是 0。这个是因为回调函数被 useCallback 缓存,形成闭包,从而形成闭包陷阱。
那我们怎么解决这个问题呢?官方提出了 useEvent。它解决的问题:如何同时保持函数引用不变与访问到最新状态。使用它之后,上面的例子就变成了。
const callbackFn = useEvent(() => {
console.log(`Current count is ${count}`);
});在这里我们不细看这个特性,实际上,在 ahooks 中已经实现了类似的功能,那就是 useMemoizedFn。
useMemoizedFn 是持久化 function 的 Hook,理论上,可以使用 useMemoizedFn 完全代替 useCallback。使用 useMemoizedFn,可以省略第二个参数 deps,同时保证函数地址永远不会变化。以上的问题,通过以下的方式就能轻松解决:
const memoizedFn = useMemoizedFn(() => {
console.log(`Current count is ${count}`);
});我们来看下它的源码,可以看到其还是通过 useRef 保持 function 引用地址不变,并且每次执行都可以拿到最新的 state 值。
function useMemoizedFn<T extends noop>(fn: T) {
// 通过 useRef 保持其引用地址不变,并且值能够保持值最新
const fnRef = useRef<T>(fn);
fnRef.current = useMemo(() => fn, [fn]);
// 通过 useRef 保持其引用地址不变,并且值能够保持值最新
const memoizedFn = useRef<PickFunction<T>>();
if (!memoizedFn.current) {
// 返回的持久化函数,调用该函数的时候,调用原始的函数
memoizedFn.current = function (this, ...args) {
return fnRef.current.apply(this, args);
};
}
return memoizedFn.current as T;
}总结与思考
React 自从引入 hooks,虽然解决了 class 组件的一些弊端,比如逻辑复用需要通过高阶组件层层嵌套等。但是也引入了一些问题,比如闭包问题。
这个是 React 的 Function Component State 管理导致的,有时候会让开发者产生疑惑。开发者可以通过添加依赖或者使用 useRef 的方式进行避免。
ahooks 也意识到了这个问题,通过 useLatest 保证获取到最新的值和 useMemoizedFn 持久化 function 的方式,避免类似的闭包陷阱。
值得一提的是 useMemoizedFn 是 ahooks 输出函数的标准,所有的输出函数都使用 useMemoizedFn 包一层。另外输入函数都使用 useRef 做一次记录,以保证在任何地方都能访问到最新的函数。
原文:https://segmentfault.com/a/1190000042299974
雷军:穿越人生低谷的感悟
这三年来,全球发生了巨大的变化,已经深刻地影响了我们每个人的生活和工作。
如何面对这些连续不断的巨大变化,不少人感到迷茫,甚至非常焦虑。
今天的演讲,我们就不聊小米,聊点不一样的话题:我是如何穿越人生低谷,又从中获得了哪些重要的感悟。
这次我聊三个故事,第一个故事就是,我在非常年轻的时候就遭遇了“产品失败、业务崩盘、公司差点关门”的困境。
故事要从三十年前说起。
DOS 时代 WPS 非常流行,几乎装在中国每台电脑上,金山如日中天。

同时也有很大的隐忧,微软已经带着 Windows 和 Office 进入了中国市场。我们要尽快研发出新的办公软件,才有机会正面和微软 Office 抗衡。
初生牛犊不怕虎,我们也没有细想,直接开干,还给项目取了一个气势磅礴的名字,叫“盘古”,我们希望盘古在 Windows 平台上开天辟地,能把 WPS 辉煌推到一个新的高度。

一个国内小公司,要抗衡微软,这个难度真的不是一般的大。为了这个宏伟的梦想,我们压上了几乎全部的家底,抽调了几乎所有的程序员,没日没夜,干了整整三年。到了 1995 年 4 月,盘古终于发布了。
闭关 3 年,只等大成的这一天,我们连庆功宴都提前精心准备好了。
01 生死关头

1.1 盘古受挫
但谁也没有想到,销量极为惨淡,不及预期的十分之一。
我的心态直接崩了,同事们的心情也从云端直接跌落到了谷底。
没有办法,我拼命给大家打鸡血,鼓励大家继续奋斗,就这样,我们坚持到 1995 年底 1996 年初,盘古依然没有任何起色。
更大的麻烦是,WPS 也卖不动了,收入锐减。
公司到了生死存亡的关头。
那年我 26 岁,担任北京金山的总经理,第一次面对这样的困局,有点束手无策。
每到发工资的那天,都是我最难熬的时候。我记得,最惨的时候,账上只有十几万,眼看着下个月就发不出工资。
同事们也都很绝望,不少人离开了,办公室开始有点空空荡荡的。那个时候我经常彻夜睡不着。我还记得,好多个晚上,我独自坐在沙发上,静静的看着窗外,眼睁睁地看着对面楼里的灯一盏一盏熄灭,再看着天色一点一点亮起来。这种痛苦,只有经历过的人,才真的明白。
1.2 站店的故事
金山这样的金字招牌,盘古这么好的产品,怎么可能卖不动呢?
我有点想不通,下定决心要“一杆子捅到底”,到第一线去把问题搞清楚。
我决定亲自去站店卖货。站店卖货,刚开始我信心十足。我特意选了当时中关村最大的一家软件店。虽然没有销售经验,但产品是我们自己做的,我相信我自己肯定没问题,一定可以搞定。

每个客户进店,我像见到亲人一样,直接迎上去,热情接待,细心讲解。有时候,一个客户,我能滔滔不绝的讲上半个小时。一遍又一遍,一整天讲了八个小时,讲得口干舌燥,也累得晕头转向。当晚回家,连饭都不想吃,直接躺在床上就睡着了。

我是一个程序员,每天都坐在电脑前写程序。第一次站店,就站了八个小时。辛苦的程度,大家想想就可以理解了。
如此辛苦的一天,业绩如何呢?
真的不好意思说,我一套都没有卖出去。
“一定是运气不好”,我给自己打气,毕竟是头一次干,没关系,第二天继续努力。
第二天,同样八个小时站下来,还是一套没有卖出去,我就有些懵了。
到了第三天,依然颗粒无收,尤其是看到其他店员成了一单又一单,我都有点怀疑自己了,真心觉得销售不简单。
第四天,我干脆就不卖货了。干什么呢?看看别人是如何卖货的。于是,我跟着店里最好的销售转了一整天,还真学了不少东西。
比如说,我一见到客户,就会滔滔不绝,而他,其实话并不多,先听听客户的想法,再顺着客户说。我懂技术,总是希望把技术讲明白,反而容易把问题讲复杂了,而他,总是拿着产品或者宣传页,三言两语,客户就明白了。让我最羡慕的是,他和客户交流轻松自如。对我来说,和陌生人交流,始终是个巨大的挑战。
第五天,我一边琢磨一边练,到了中午,终于开张了!
那一瞬间,我激动得就像赢得了整个世界一样。
我逐渐找到了跟客户沟通的感觉,自信心也开始恢复了。
第五天、第六天,我的业绩逐渐好起来。
第七天,我居然成为了店里的销售冠军,太不可思议了!
1.3 站店的收获
讲到这里,大家可能会觉得我在讲“一个促销员七天速成”的故事。
其实,这是“一个研发负责人在产品失败后,深入销售一线,站了七天店面”的故事。
站店,非常累,但收获巨大。
给大家举个例子。那个时候,电脑刚刚开始普及。站店那几天,每天总有几个客户,一进店就问,有没有电脑入门的软件。

我有点想不通,学电脑,买本书看不就行了,为什么还要买个软件教吗?我总是非常耐心劝他们,“确实没有这样的软件,你出门左转就是一家书店,买本书跟着学就好了”。
直到被问很多次以后,我终于恍然大悟,既然这么多人想买,做一个不就完了吗?说实话,和盘古一比,这类软件确实没啥技术含量,我们立刻开发了一个,就叫《电脑入门》,以最快的速度推向市场。结果大获成功,迅速登上了软件畅销排行榜。
这 7 天的站店卖货,我学会了:作为一个工程师,一定要做用户需要的产品,而不是做那些看起来只是高大上的产品。只要能做出用户想要的产品,销售就不是问题。有了这样的顿悟,再做产品就容易了。后来,我们陆续发布了《金山词霸》《金山毒霸》等十多款成功的软件。
回头再看盘古的问题,原因非常简单,就是因为“闭门造车”。
我非常庆幸,如果不是这次危机,我可能完全没有机会补上这么关键的一课。
这次站店经历,也成为了我日后职业生涯中最宝贵的财富。
站过店之后,再去逛店,感觉就完全不同。

我逛店就不仅仅在看商品,也在琢磨别人的店面,比如装修、动线、货架、堆头、海报等等,开始有点“内行看门道”的感觉了。从那以后,无论多忙,我一定会抽空到店里去转转。哪怕到国外出差,也会千方百计到当地最好的零售店去学习一下。我对零售行业有了一定的了解。
就这样,金山找到了活下去的路!
但我自己却陷入了新的迷茫,开始了我人生最灰暗的一段时间。
02 迷失彷徨

2.1 泡酒吧
那时候,我一直沉浸在盘古失败的情绪中,非常低落。
和微软抗衡,完全看不到赢的希望。如果只是做一家挣扎活着的公司,这绝对不是我的追求。
我彻底失去了理想,4 月底,直接交了辞职信。求伯君反复挽留我,最后决定,让我先歇半年再说。
面对这样的人生逆境,这里问大家一个问题:你们是如何解压的?
当时,我的方法就是经常和几个朋友去泡吧。那时,蹦迪特别风行,我们能疯狂蹦一晚上,都不怎么歇的。

也是这个阶段,我开始喜欢上了重金属摇滚。之前完全不能接受,但现在不一样了,沉浸在音乐中,能让自己暂时忘掉所有的烦恼。
那段时间经常泡吧,我还真的琢磨过,是不是干脆转行,在三里屯也开家酒吧。
2.2 BBS 论坛
很快,我就找到了更有趣的事,那就是 BBS。

我有了足够多的时间,整天泡在 CFIDO BBS 上。那时候,互联网还没普及,CFIDO 是爱好者自建的电话拨号连接的网络,聚集了国内一大群极客。上 BBS,可以自由自在地和远方朋友交流,这在当时,是件非常神奇的事情。这种神奇感,就特别像今天的元宇宙。
就这样,我找到了新的寄托。

那时候,在论坛发帖,要求还是蛮高的。大家都是拨号上网,上网费特别贵。如果你总是发水帖,就一定会被痛骂的。当时我有足够的时间认真准备每条帖子。
而且我有个特别强的优势,就是打字超快,多的时候一天就能写一百帖。其中最长的一个帖子,从晚上写到天亮,大约有上万字。直到今天,在网上还能搜到几篇我当年写的帖子。

就这样,我的发帖量,经常都排在全站飙信排行榜上的前几位。像我这样疯狂的人其实还不少,当时我在论坛中认识一个朋友,每天也是上百帖,他打字也很快,但他不会盲打,只会用两个手指打字,弹指如飞,号称“二指禅”,据说打坏了好几个键盘。
帖子写得多了,我就成了版主。大家别看版主官不大,事还不少,有点像今天的“群主”。首先自己要发帖,接着要拉一大帮朋友来玩,还要负责搞气氛。最难的是,大家因为观点不同经常吵架,解决网友各种纠纷就成了版主最重要的工作。
为了当好版主,我经常早上 7 点就开始上网,一直忙到凌晨,好像比上班还累。
不过,过得非常充实。有朋友认为我在逃避现实、不务正业,甚至有人为我惋惜,觉得我是在浪费生命。对于这种关心,我非常感谢,但并不是特别认可。
这半年,没有任何目的,非常纯粹的玩,玩得也特别开心。
就是在这样放松的氛围里,我的情绪也在一点点恢复。
2.3 意外收获
多年以后,我才明白了这段经历真正的价值。

2010 年我创办小米,第一步要先把论坛做好。我们非常顺利,不到一年就成了最火的手机发烧友论坛。怎么做到的?其实没啥,就是靠当年玩 BBS 当版主时学会的那几招。
很多人总觉得,看小说、上网、打游戏只会玩物丧志。
我个人的体会是,只要有一定的自制力,娱乐也是很好的学习方式。

不带任何目的,学起东西来,反而特别轻松,也特别快。
不过,玩也要玩出点名堂,不要瞎玩,瞎玩只是浪费时间。
当年在 BBS 上,我还认识了不少朋友,有的到今天,非常成功:
有一位,在一家叫润迅的寻呼机公司做程序员,叫马化腾;
还有一位,在宁波电信局做工程师,叫丁磊。
当年他们为什么有那么高的热情、那么多的时间泡论坛,我没有问过。
但我相信,这段经历,对他们后来的事业有着决定性的影响。
沉浸在论坛的这半年时间里,逐渐恢复了状态。1996 年 11 月,我结束了半年假期,正式回归了金山。

主要原因,还是放不下民族软件这份光荣与梦想。
我们下决心,要跟微软打一场“持久战”:一边在办公软件的正面战场和微软死磕,一边做各种应用软件和游戏,赚钱养家,以战养战
一家差点关门的小公司,经过二十多年的苦心经营,重新崛起了。
到今天,WPS 月活跃设备数超过了 5 亿。
我为 WPS 取得的成就感到特别自豪。
我们在网上找到了将近 20 年前的采访视频,大家一起看下。
03 错失互联网

3.1 环境变了
就在我埋头重整金山的时候,外面的世界已经天翻地覆:
大洋彼岸,网景 1995 年上市,雅虎 1996 年上市…… 互联网的第一波浪潮已经蓬勃发展。

很快,国内也开始了,1997 年网易创办,1998 年腾讯创办,中国互联网第一波浪潮汹涌而至。

而我忙着做软件,不知不觉,与这一波浪潮擦肩而过。
直到 1998 年 10 月,我才真正意识到这波浪潮已不可阻挡。我说服董事会,我们可以采用收购方式快速出击。
这些年来,网上有很多传言,有的说马化腾刚创业的时候要把 QQ 卖给我,我没买;还有的说马云刚创业的时候找我投资,我没投;这些传言整得我好像很没有眼光一样。这里,我要澄清一下,他们没有找过我,这些全是谣传。
我认真谈过的收购只有一家,就是网易。
那时网易成立一年多,公司大概五六个人,主要做个人主页托管服务,做得非常好,甚至还帮广州电信做了一套邮件系统。
我开出了 1000 万的价钱,这在当时,真的算是一个不小的数字了,但丁磊很快拒绝了。
仅仅 2 个月后,网易就融到了 1000 万美元,估值达到了 6000 多万美元,按当时的美元汇率,大约 5 亿元。
真是一个疯狂的时代,我看不懂,但大受震撼。

3.2 卓越网
收购不成,我们只能自己干。试了差不多一年,对互联网业务有了一定的认知。
当时,我以为自己完全搞明白了,“互联网就是工具。未来所有的公司都会用的,电商最有前途。”

做电商,说干就干。
2000 年 5 月,卓越网正式上线,在网上主卖图书和音像制品。
这次我信心爆棚,志在必得,力主自己掏钱干。就在这时,全球互联网泡沫破灭,进入了资本市场的寒冬。这样局面也没有动摇我们的决心,第一笔大约 2000 万的投入,全部来自于金山股东。
电商本质还是零售,我把当年站店的经验全部用上了,选品策略、定价模式、店面布置等,我们迅速用到电商上。
同时,我们在管理上也下了功夫。电商的核心就是运营,需要非常认真把每个细节做好。
每天早上一上班,我先把首页所有的 banner 广告和商品链接都检查一遍。我总是能发现一些链接错误的地方。这让我想起了,我从软件工程中学到的最重要的道理:“可能出错的地方,一定会出错”。

每天晚上,我们坚持做当天业务的复盘和总结,做完后才下班。

每个星期,我在卓越网上都要买上好多单,来测试我们的选品和物流。于是,我书架上,堆满了各种图书、电影电视剧、音乐 CD,很多连包装都没拆。那段时间,同事们特别喜欢到我办公室开会,离开的时候,到书架上带走几本。
卓越网还做了很多敢为人先的创新,开创了最早的多地仓储、最早的自建物流等,还有,北上广深 4 小时送达服务,很难想象,这些在 20 年前就已经实现了。
我们从零起步,两三年时间,就成为当时最大的 B2C 电商。
现在还有不少朋友记得,他们在卓越网上买过《大话西游》、《小王子》、《东京爱情故事》等,这些就是中国电商第一代爆品。
3.3 融资
卓越的业务非常顺利,困难只有一个:钱不够。电商平台实在太烧钱了。

全球互联网泡沫破灭后,资本市场低迷,融资非常困难。那时的 VC,基本都是外资。像我这样没有留过洋,英文又不好的本土创业者,找钱就更难了。我们至少谈了 30 家,把所有能找的 VC 基本都找了一个遍,没有一家愿意投钱。
后来,实在没有办法,才从朋友那里融了 100 万美元,金山股东不得不又追加了 100 万美元,才勉强完成融资。但仅仅一年时间,又烧光了。
卓越网创业历程,就是我们拼命找钱的过程,相当煎熬。
到了 2004 年 9 月,实在熬不下去了,我们只能忍痛把卓越网卖给了亚马逊,成了亚马逊中国。

谁也没想到,仅仅半年多之后,新一轮互联网热潮又来了,B2C 电商迎来了全面崛起的盛世。
卓越网,创办于互联网泡沫破裂之后,倒下于电商全面崛起之前。

这真的是一段刻骨铭心的经历。
3.4 痛定思痛
很多人问过我,卖掉卓越,你后不后悔?我咬着牙说,不后悔。
卖掉卓越网,对我来说,是一次重创,内心无比痛苦。
首先情感上,就像失去了自己的孩子一样,那段时间,我努力切割和卓越网的联系,强迫自己不再去卓越网办公室,不再到卓越网买东西,也尽量不见老同事了。
更痛苦的是,作为一个创业者,错失了整个互联网时代。
在那段痛苦的煎熬里,反复问自己,我们到底输在哪里?好像运气特别差。
首先,“卓越网创办于互联网泡沫破灭之后”,一上来,我们就输在起跑线上了,错过了最好的时机点。
接着,“卓越网倒下于电商全面崛起之前”,我们融资能力不足,没有资金也没有信心坚持到胜利到来的那一刻。
创业,确实需要运气,需要对大势的精准把握。这也是后来我特别强调“风口”的原因。
过了大半年时间,我才慢慢缓过来,彻底想明白了一些东西。
“互联网不仅仅是一次技术革命,更是一次观念的革命;未来互联网将融合到各行各业。”

我想通的道理,本质上就是后来大家谈的“互联网思维”和“互联网 +”。
有了这样的思考,我看很多问题的思路发生了巨大改变,我用全新的视角重新扫描了产业里的一些新机会。比如,2005 年,市场上一直传言 3G 网络即将开通。我隐约看到了一个大机会。
04 移动互联网

4.1 下一个机会
经过深入研究后,我越来越坚定:我们即将迎来移动互联网时代,而且,未来十年都将是移动互联网的十年,规模会是 PC 互联网的十倍。
想明白这些事情后,我做了一个决定:立刻行动。

我主要做了两件事:

第一、我要成为最早一批真正的用户。
要真正了解移动互联网,只有一个办法,就是自己亲自用。这是一个“笨”办法,但也是最好的办法。
十多年前,市场上主要是功能手机,无线网络是 2G。
这么小的屏幕,慢到无法忍受的网速,用这样的手机上网,是不是想想都很崩溃?

有电脑的人,绝对不愿意用手机上网。但不管多难用,我下定决心,从现在开始,所有事情都要在手机上完成,尽量不用电脑。
在这个痛苦的过程中,更深理解了:哪里有用户的痛点,哪里就有创业者的机会。

后来我做移动互联网的各种产品思路,就是这样来的。
第二、我要成为这波浪潮最早的参与者。
最快的办法,就是用天使投资的方式投资一批初创公司。几个月后,我就投资了第一家,后来陆续投了十多家。
其中,最出名的就是 UC 浏览器。

在这个过程中,我越发确信:一个全新的大时代,真的来了。

4.2 离开金山
2007 年,金山终于上市了。

接着,我离开了这家我奋斗了 16 年的公司,开始了不一样的人生。
接下来的三年里,我一边做天使投资,一边对过去经历进行系统性反思和总结。
这一系列的反思,为下一段旅程做了充分的准备。
4.3 永远相信美好的事情即将发生
今天跟大家分享的是三个我经历人生低谷的故事。

面对这些挫折、失败,我也迷茫过、动摇过、甚至放弃过。
如果没有这些挫折,没有这些挫折带来的积累,就不会有今天的我。
没有任何人会喜欢挫折、失败,但每个人不可避免一定会经历,甚至,不少人现在正在经历。
既然这些痛苦难以回避,那我们能做的,就是直面这些痛苦,在痛苦中坚持前行,让痛苦来塑造更好的我们,这就是痛苦的意义、挫折的馈赠。
而你所经历的所有挫折、失败,甚至那些看似毫无意义消磨时间的事情,都将成为你最宝贵的财富。

人生很长,无论如何,让我们保持信念:永远相信美好的事情即将发生。

05 雷军首部商业思考著作《小米创业思考》发布
今天提到的站店、泡论坛和卓越网这三段经历,都为小米的创办做了至关重要的准备。2010 年 4 月 6 号,在北京中关村一间不起眼的办公室里,我和十多个同事一起喝了碗小米粥,就创办了小米。

一转眼,小米已经 12 岁了。

小米十周年时,我们内部进行过长达半年的深入复盘总结,收获特别大。当时我就萌发了一个想法,要把这些思考和总结写下来,让更多小米同学们了解,并分享给所有关心小米的朋友们。
但这件事情比我想象得要复杂,我们下了很大功夫,花了两年时间,忙到今天才出版,这就是《小米创业思考》。

这本书包含了小米创办前后我大量的思考,以及小米创业历程、小米方法论和一些实战案例。刚在各个电商平台上架,大家如果感兴趣,现在就可以买来看看。
大家还记得小米三大铁律吗?“技术为本,性价比为纲,做最酷的产品”。

我们始终极度重视技术投入,去年我们的研发投入 132 亿元,今年预计会达到 170 亿元。
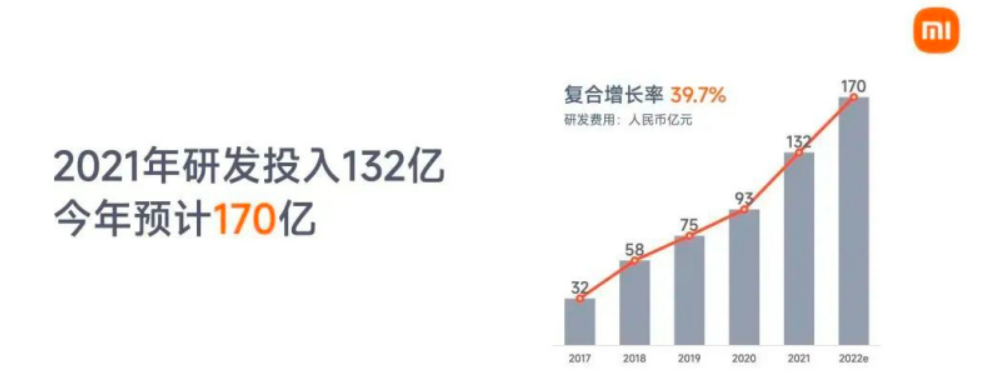
未来五年研发投入将超过 1000 亿。

正是永不止步的创新精神和不断增加的研发投入,确保了我们能一直不断研发出最酷的产品。
作者:雷军(2022年度演讲)
收起阅读 »
线程池及使用场景说明
持续创作,加速成长!这是我参与「掘金日新计划 · 6 月更文挑战」的第22天,点击查看活动详情
newFixedThreadPool(固定大小的线程池):
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
该线程池特点:
1.核心线程数和最大线程数大小一样
2.keepAliveTime为0
3.阻塞队列使用的是LinkedBlockingQuene(无界队列)
该线程池工作机制:
1.线程数少于核心线程数,新建线程执行任务
2.线程数等于核心线程数时,将任务加到阻塞队列(最大值为Integer.MAX_VALUE),可以一直加加加(可能会出现OOM)
newSingleThreadExecutor(单线程线程池)
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L,
TimeUnit.MILLISECONDS, ew LinkedBlockingQueue<Runnable>()));
}
该线程池特点:
1.核心线程数和最大线程数大小一样且都是1
2.keepAliveTime为0
3.阻塞队列是LinkedBlockingQuene
该线程池工作机制:
1.线程中没有线程时,新建线程执行任务
2有一个线程以后,将任务加到阻塞队列(最大值为Integer.MAX_VALUE),可以一直加加加
#### 该线程池特点:
1.核心线程数为0,且最大线程数为Integer.MAX_VALUE
2.阻塞队列是SynchronousQuene(同步队列)
SynchronousQuene:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量要高于LInkedBlockQuene。
锁当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端的情况下会创建过多的线程,耗尽CPU和内存资源。由于空闲60秒的线程会被终止,长时间保持空闲的CachedThreadPool不会占用任何资源。
#### 该线程池工作机制:
1.没有核心线程时,直接向SynchronousQuene中提交任务
2.执行完任务的线程有60秒处理时间
newScheduledThreadPoo
该线程池特点:
1.最大线程数为Integer.MAX_VALUE
2.阻塞队列是DelayedWorkQuene(延迟队列)
DelayedWorkQuene中封装了一个优先级队列,这个队列会对队列中的ScheduleFutureTask进行排序,两个任务的执行Time不同时,time小的先执行; 否则比较添加队列中的ScheduledFutureTask的顺序号sequenceNumber,先提交的先执行。
API
ScheduledThreadPoolExecutor添加任务提供了另外两个方法:
1.scheduleAtFixedRate():按某种速率周期执行
2.scheduleWithFixedDelay():在某个延迟后执行
两种方法的内部实现都是创建了一个ScheduledFutureTask对象封装了任务的延迟执行时间及执行周期,并调用decorateTask()方法转成RunnableScheduledFuture对象,然后添加到队列中。
该线程池工作机制:
1.调用上面两个方法添加一个任务
2.线程池中的线程从DelayQuene中取任务
3.然后执行任务
作者:北洋
链接:https://juejin.cn/post/7112061831132708878
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么要使用Kotlin 对比 Java,Kotlin简介
什么是Kotlin
打开Kotlin编程语言的官网,里面大大的写着,
A modern programming languagethat makes developers happier.
是一门让程序员写代码时更有幸福感的现代语言
- Kotlin语法糖非常多,可以写出更为简洁的代码,便于阅读。
- Kotlin提供了空安全的支持,可以的让程序更为稳定。
- Kotlin提供了协程支持,让异步任务处理起来更为方便。
- Google:Kotlin-first,优先支持kotlin,使用kotlin可以使用更多轮子
接下来对比Java举一些例子。
简洁
当定义一个网络请求的数据类时
Java
public class JPerson {
private String name;
private int age;
//getter
//setter
//hashcode
//copy
//equals
//toString
}
Kotlin
data class KPerson(val name: String,val age: Int)
这里用的是Kotlin 的data class 在class 前面加上data 修饰后,kotlin会自动为我们生成上述Java类注释掉的部分
当我们想从List中筛掉某些我们不想要的元素时
Java
List<Integer> list = new ArrayList<>();
List<Integer> result = new ArrayList<>();
for (Integer integer : list) {
if (integer > 0) { //只要值>0的
result.add(integer);
}
}
System.out.println(result);
Kotlin
val list: List<Int> = ArrayList()
println(list.filter { it > 0 })
如上代码,都能达到筛选List中 值>0 的元素的效果。
这里的filter是Kotlin提供的一个拓展函数,拓展函数顾名思义就是拓展原来类中没有的函数,当然我们也可以自定义自己的拓展函数。
当我们想写一个单例类时
Java
public class PersonInJava {
public static String name = "Jayce";
public static int age = 10;
private PersonInJava() {
}
private static PersonInJava instance;
static {
instance = new PersonInJava();
}
public static PersonInJava getInstance() {
return instance;
}
}
Kotlin
object PersonInKotlin {
val name: String = "Jayce"
val age: Int = 10
}
是的,只需要把class换成object就可以了,两者的效果一样。
还有很多很多,就不一一举例了,接下来看看空安全。
安全
空安全
var name: String = "Jayce" //name的定义是一个非空的String
name = null //将name赋值为null,IDE会报错,编译不能通过,因为name是非空的String
var name: String? = "Jayce" //String后面接"?"说明是一个可空的String
name.length //直接使用会报错,需要提前判空
//(当然,Kotlin为我们提供了很多语法糖,我们可以很方便的进行判空)
类型转换安全
fun gotoSleep(obj: Any) {
if (obj is PersonInKotlin) {//判断obj是不是PersonInKotlin
obj.sleep() // 在if的obj已经被认为是PersonInKotlin类型,所以可以直接调用他的函数,调用前不需要类型转换
}
}
携程
这里只是简单的举个例子
Kotlin的协程不是传统意义上那个可以提高并发性能的协程序
官方的对其定义是这样的
- 协程是一种并发设计模式,您可以在Android平台上使用它来简化异步执行的代码
- 程序的逻辑可以在协程中顺序地表达,而底层库会为我们解决其异步性。
当我们用Java请求网络数据时,一般是这么写的。
getPerson(new Callback<Person>() {//这里有一个回调
@Override
public void success(Person person) {
runOnUiThread(new Runnable() { //切换线程
@Override
public void run() {
updateUi(person)
}
})
}
@Override
public void failure(Exception e) {
...
}
});
有Kotlin协程后我们只需要这么写
CoroutineScope(Dispatchers.Main).launch { //启动一个协程
val person = withContext(Dispatchers.IO) {//切换IO线程
getPerson() //请求网络
}
updateUi(person)//主线程更新UI
}
他们两个都干的同一件事,最明显的区别就是,代码更为简洁了,如果在回调里面套回调的话回更加明显,用Java的传统写法就会造成人们所说的CallBack Hell。
除此之外协程还有如下优点
- 轻量
- 更少的内存泄漏
- 内置取消操作
- 集成了Jatpack
这里就不继续深入了,有兴趣的同学可以参考其他文章。
Kotlin-first
在Google I/O 2019的时候,谷歌已经宣布Kotlin-first,建议Android开发将Kotlin作为第一开发语言。
为什么呢,总结就是因为Kotlin简洁、安全、兼容Java、还有协程。
至于有没有其他原因,我也不知道。(手动狗头)
Google将为更多的投入到Kotlin中来,比如
为Kotlin提供特定的APIs (KTX, 携程, 等)
提供Kotlin的线上练习
示例代码优先支持Kotlin
Jetpack Compose,这个是用Kotlin开发的,没得选。。。。。
跨平台开发,用Kotlin实现跨平台开发。
好的Kotlin就先介绍到这里,感兴趣的同学就快学起来吧~
接下来在其他文章会对Kotlin和携程进行详细的介绍。
作者:JayceonDu
链接:https://juejin.cn/post/7130198991106637832
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
从权限系统的菜单管理看算法和数据结构
菜单管理,感觉上是个小模块,但实际做下来的感触是,要做的好用,不容易。
算法和数据结构,长期活跃在面试题中,实际业务中好像接触的不多,但如果能用好,可以解决大问题。
如上图,是我在开源世界找到的一个菜单管理的设计页面,其上可以看到,菜单管理主要管理一颗菜单树,可以增删改查、排序等功能。接下来,我们就一步一步的实现菜单管理的各个功能,这里我主要介绍后端的设计方案,不涉及前端页面的处理和展示。
type IMenu interface {
MenuList(ctx context.Context, platformId int, menuName string, status int) ([]*model.MenuListResp, response.Error)
GetMenuInfo(ctx context.Context, menuId int) (*model.MenuInfo, response.Error)
EditMenu(ctx context.Context, params *model.MenuEditParams) response.Error
DeleteMenu(ctx context.Context, platformId, menuId int) response.Error
AddMenu(ctx context.Context, params *model.MenuAddParams) response.Error
MenuExport(ctx context.Context, platformId int) ([]byte, response.Error)
MenuImport(ctx context.Context,platformId int,jsonData []byte) response.Error
MenuSort(ctx context.Context, platformId int, tree []*model.MenuTree) response.Error
}
可以看到,菜单管理模块主要分三块,一是对菜单的增删改查、二是菜单的导入导出、三是菜单的排序。 由于菜单模块天然的就是一个树状结构,所以我就想到能不能在代码中用树作为处理菜单时的数据结构,把这个模块做完后,我发现这种思路是对的,可以解决菜单树的重排问题,无需在手动填写排序字段(就是人工为菜单的顺序赋值)。
首先我们设计数据库,由于我们确认了以树处理菜单的思路,所以在表设计时,我把菜单信息和菜单树剥离,首先避免了字段过多,其次在用menu_id去获取单个菜单信息时,就完全不用遍历树了,直接从菜单信息表中拿数据,而且表分开后,代码逻辑也更清晰了。
介绍一下表中的关键字段,其它字段可忽略:
| 表名 | 字段名 | 说明 |
|---|---|---|
| menu_tree | platform_id | 这颗菜单树属于哪个业务系统 |
| menu_tree | parent_menu_id | 节点的父节点id,没有父则为0 |
| menu_tree | menu_id | 节点自己的id,就是 menu_info 表的主键 |
| menu_tree | index | 排序字段 |
| menu_info | alias | 菜单唯一标识 |
一、 添加菜单
添加菜单接口所需的信息如下:
type MenuAddParams struct {
PlatformId int `json:"platform_id" v:"required"` // 平台ID
Type int64 `json:"type" v:"required|in:1,2,3,4,5"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签
ParentMenuId int `json:"parent_menu_id"` // 上级菜单,没有则传0
// 菜单信息
Name string `json:"name" v:"required|length:3,20"` // 菜单名
...
}
添加菜单很简单,由于前端参数中已经存在父菜单id,我们只需要把这个菜单节点加到这个父菜单的子节点列表的末尾即可。
这里唯一需要注意的就是,我们需要 select MAX(index) 获取父节点的子节点列表中index最大的值,然后+1作为新节点的index,这样就可以把新节点添加到列表末尾。但要注意并发问题,比如两个人同时添加菜单,有可能会导致index一样。
解决方案就是把newIndex放到redis里,然后在添加时判断redis里的index是否>=数据库的maxIndex,理论上一定成立,不成立则说明newIndex还未写进db,流程图如下:
使用分布式锁,或者修改
select MAX(index)的事务隔离级别也可以实现。
二、菜单列表
菜单列表与其说是列表,不如说是菜单树,树状返回整个菜单结构,不分页,两个原因:一、我们要在菜单列表上做拖曳排序,需要整个菜单树结构;二、菜单数据有它本身的特点,再多也就千级别顶天了,而且我们在数据存储时就区分了菜单树表(menu_tree)和(menu_info),这时获取菜单列表只需要访问 menu_tree,菜单信息可以懒加载,需要时再通过 menu_id 主键id获取,速度很快。
接口返回结构设计如下:
{
"data": {
"children": [
{
"children": [
{
"children": [],
"menu_id": 2,
"name": "子菜单1",
"type": 1
}
],
"menu_id": 1,
"name": "菜单1",
"type": 1
}
],
"menu_id": 0,
"name": "",
"type": 0
},
"errmsg": "",
"errno": 0
}
我们用一个 menu_id 为0 的节点作为根节点,因为树需要一个唯一的根。
这里有人可能会说,不对啊,你 menu_tree 表里没有name和type,你不还是得去menu_info里获取吗?确实,实践中我确实有访问menu_info,但我感觉这两个字段其实可以冗余存储到 menu_tree中,这样优化后,就真的不用访问 menu_info了,只不过我模块已经写完了,就懒得改了,哈哈。
这个数据返给前端,他直接渲染成树即可,点击树中某个节点,前端拿到这个节点的menu_id,去GetMenuInfo获取菜单信息,前面说过,这个获取很简单,就是主键id查找。
要建立这样一个返回结构,用如下关键代码实现即可:
type MenuTree struct {
MenuId int `json:"menu_id"` // 菜单ID
Name string `json:"name"` // 菜单名
Type int64 `json:"type"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签
Children []*MenuTree `json:"children"` // 子菜单
}
func (s *sMenu) MenuTree(ctx context.Context, platformId int) (*model.MenuTree, error) {
// 构造一个根节点
root := &model.MenuTree{}
err := s.menuTreeChildren(ctx, root)
if err != nil{
return nil, err
}
return root, nil
}
func (s *sMenu) menuTreeChildren(ctx context.Context, node *model.MenuTree) (error) {
if node.MenuId != 0{
menuInfo, err := dao.MenuInfo.GetMenuInfo(
ctx,
node.MenuId,
dao.MenuInfo.Columns().Id,
dao.MenuInfo.Columns().Name,
dao.MenuInfo.Columns().Type,
)
if err != nil {
return gerror.Wrap(err, "")
}
node.Name = menuInfo.Name
node.Type = menuInfo.Type
}
// 获取子节点列表
// select * from menu_tree where platform_id = ? and parent_menu_id = ?
childs, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, tree.MenuId)
if err != nil {
return gerror.Wrap(err, "")
}
treeChilds := make([]*model.MenuTree, len(childs))
for i, e := range childs {
tree := &model.MenuTree{
MenuId: e.Id,
}
err := s.menuTreeChildren(ctx, platformId, tree)
if err != nil{
return err
}
treeChilds[i] = tree
}
node.Children = treeChilds
return nil
}
这个构造过程有没有一点点熟悉?这不就是树的dfs前序遍历算法的递归版本吗?
通过这种方式,我们把数据库中的树加载到内存中,后续的很多操作,都依赖对树的遍历实现。
三、编辑菜单、获取菜单信息
这两个操作都是只针对 menu_info 表的,用menu_id主键操作就行,没什么技术含量。
四、删除菜单
删除怎么实现呢?前面说过,后续的很多操作都是在对树进行遍历,那么删除也就很简单了,我们通过menuId确定要删除的节点,并遍历它的所有子节点,放到 treeIds 这个收集器中,当子节点遍历完毕时,把treeIds中收集的id取出来,去删除这条记录即可。
// menuIds 负责在遍历过程中收集所有的 menus_ids,treeIds 负责在遍历过程中收集 menu_tree表的主键
func (s *sMenu) deleteMenuTree(ctx context.Context, platformId, menuId int, menuIds []int, treeIds []int) ([]int, []int, error) {
// 把menuId从菜单树中删除,并递归删除它的所有子菜单
child, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, menuId)
if err != nil {
return menuIds, treeIds, err
}
menuIds = append(menuIds, menuId)
menuTree, err := dao.MenuTree.GetMenuTreeByMenuId(ctx, platformId, menuId, dao.MenuTree.Columns().Id)
if err != nil {
return menuIds, treeIds, err
}
treeIds = append(treeIds, int(menuTree.Id))
for _, e := range child {
menuIds, treeIds, err = s.deleteMenuTree(ctx, platformId, int(e.MenuId), menuIds, treeIds)
if err != nil {
return menuIds, treeIds, err
}
}
return menuIds, treeIds, nil
}
后续的删除代码就不再展示了,主键都收集完毕了,DELETE FROM ... WHERE id IN () 一条语句搞定即可。
五、菜单排序
来到本文的重点,菜单重排序,很多系统都是直接让用户填排序字段,非常容易出错,用过的人都知道,不太好用。我们直接来实现拖曳排序,而且可以任意拖曳,把节点拖到其它父节点,把节点拖到顶级菜单等,都可以实现。
首先前端同学需要实现拖曳组件,然后直接把拖曳后的整个菜单树回给我们即可,我们负责检查树的节点发生了什么变动。
前端同学也可以直接检测被拖曳的菜单id,和拖曳后的位置,把这些信息发给后端即可。不过为了让前端同学早点下班,这些活还是我们交给我们来干把。
我们现在拿到了前端发回的树结构,字段和数据跟我们通过菜单列表返回的json数据一致,只是其中有一个被拖曳的节点,不再原来的位置,它可能跟兄弟节点交换了顺序,可能变更了父节点,也可能变为顶级菜单。如何找到被拖曳的是哪个节点,并找到它拖曳后的位置和顺序呢?
在算法知识中,有一个很重要的思想,就是分治,当我们碰到比较复杂的问题时候,就一定要把它拆解为几个子问题解决,针对这个场景,我们可以拆分为以下几个问题:
- 如果被拖曳的节点变更了父节点,我们如何找到它的位置和顺序?
我们先序dfs遍历这个新的菜单树,每个节点都去数据库查询它的parent_menu_id,如果发现数据库的父节点id跟新菜单树的父节点id对不上,则可以断定这个节点是被拖曳过来的,同时也就知道了它的新位置和顺序。 - 如果被拖曳的节点未变更父节点,只是变更了顺序,我们如何找到它?
我们后序dfs遍历这个新菜单树,收集当前节点的子节点列表list1,并且从数据库中拉出当前节点的子节点列表list2,- 如果 list1.len < list2.len
说明这个节点有子节点被拖曳走了,我们不需要管这个节点,因为我们不关注被拖曳节点原先在哪儿。这个情况直接忽略即可 - 如果 list1.len > list2.len 说明有节点被拖曳进来,那我们遍历list1和list2找不同即可。
- 如果 list1.len == list2.len 也是遍历list1和list2,看看它们两是不是完全一样。
- 如果 list1.len < list2.len
- 找到被拖曳的节点以及它的新位置和顺序后,如何更新到数据库?
更新这个节点的父节点id,并要判断它的顺序- 它的新顺序就在父节点的子节点列表末尾
子节点列表(有序的)最后一个节点的index + 1即可 - 它在子节点列表的开头或者中间
它获得原节点的index,后续节点的index依次+1 - 原先就没有子节点,它是第一个
那它的index设为1即可
- 它的新顺序就在父节点的子节点列表末尾
具体的代码实现如下:
func (s *sMenu) MenuSort(ctx context.Context, platformId int, tree []*model.MenuTree) response.Error {
s.lockSortMenu(ctx, platformId)
defer s.unlockSortMenu(ctx, platformId)
err = s.dfsTreeSort(ctx, platformId, &model.MenuTree{
Children: tree,
}, 0)
if err != nil && err != StopDFS {
return nil, response.NewErrorAutoMsg(
http.StatusServiceUnavailable,
response.ServerError,
).WithErr(err)
}
return
}
var StopDFS = gerror.New("STOP")
// 这个dfsTreeSort遍历时有个隐含条件,由于我们知道被拖曳的节点只有一个,所以我们找到这个节点后,马上就可以终止遍历
func (s *sMenu) dfsTreeSort(ctx context.Context, platformId int, node *model.MenuTree, parentTreeId int) error {
if node == nil {
return nil
}
childsMenus := make([]*model.MenuTree, 0)
for i := 0; i < len(node.Children); i++ {
n := node.Children[i]
mt, err := dao.MenuTree.GetMenuTreeByMenuId(ctx, platformId, n.MenuId, dao.MenuTree.Columns().ParentTreeId)
if err != nil {
return err
}
if int(mt.PlatformId) != parentTreeId {
// 发现被移动节点
err = s.swapTreeNode(ctx, platformId, n, parentTreeId, i)
if err != nil {
return err
}
return StopDFS // 终止遍历
}
// 收集子菜单
childsMenus = append(childsMenus, n)
err = s.dfsTreeSort(ctx, platformId, n, n.MenuId)
if err != nil {
return err
}
}
// 判断子节点列表的顺序
if node.MenuId != 0 && len(childsMenus) > 0 {
oldChilds, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, node.MenuId)
if err != nil {
return err
}
if len(childsMenus) < len(oldChilds) {
// 这个情况不处理
return nil
}
for i := 0; i < len(childsMenus); i++ {
if i < len(oldChilds) && childsMenus[i].MenuId != int(oldChilds[i].MenuId) {
// 发现被移动节点
err = s.swapTreeNode(ctx, platformId, childsMenus[i], parentTreeId, i)
if err != nil {
return err
}
return StopDFS
}
}
// 前面顺序如果都一样,那必然是最后一个节点新增的
if len(childsMenus) > len(oldChilds){
L := len(childsMenus) - 1
err = s.swapTreeNode(ctx, platformId, childsMenus[L], parentTreeId, L)
if err != nil {
return err
}
return StopDFS
}
}
return nil
}
func (s *sMenu) swapTreeNode(ctx context.Context, platformId int, node *model.MenuTree, newParentMenuId int, index int) error {
tx, err := g.DB().Begin(ctx)
if err != nil {
return gerror.Wrap(err, "")
}
ctx = context.WithValue(ctx, "tx", tx)
childs, err := dao.MenuTree.GetMenuTreeChild(ctx, platformId, newParentMenuId)
if err != nil {
return err
}
var newIndex int64 = 1
if len(childs) == 0 {
// 原先没有子节点
newIndex = 1
}
if len(childs) != 0 && index > len(childs)-1 {
// 在末尾
newIndex = childs[len(childs)-1].Index + 1
}
if len(childs) != 0 {
// 在中间 或者在开头
for i := index; i < len(childs); i++ {
newIndex = childs[i].Index
for j, e := range childs[i:] {
fileds := make([]interface{}, 0)
fileds = append(fileds, dao.MenuTree.Columns().Index)
if int(e.MenuId) == node.MenuId{
// 不遍历到自己
continue
}
err = dao.MenuTree.EditMenuTree(ctx, &entity.MenuTree{
Id: e.Id,
Index: newIndex + int64(j) + 1,
}, fileds...)
if err != nil {
tx.Rollback()
return err
}
}
}
}
fileds := make([]interface{}, 0)
fileds = append(fileds, dao.MenuTree.Columns().ParentTreeId)
fileds = append(fileds, dao.MenuTree.Columns().Index)
err = dao.MenuTree.EditMenuTreeByMenuId(ctx, &entity.MenuTree{
MenuId: int64(node.MenuId),
PlatformId: int64(platformId),
ParentTreeId: int64(newParentMenuId),
Index: newIndex,
}, fileds...)
if err != nil {
tx.Rollback()
return err
}
tx.Commit()
return nil
}
在菜单排序操作时,最好也加上分布式锁,菜单排序时禁止添加菜单、导入菜单等操作。
六、菜单导入、导出
菜单导入、导出在实践中也是非常有用的,常用的场景是:测试环境添加、更新、删除菜单后,想同步到正式环境,难道要再操作一遍吗?简单的办法就是导出测试环境的菜单,再导入到正式环境即可。
1. 菜单导出
既然已经获取到了菜单列表,那么把它导出成json文件也不是什么难事,这里的矛盾是,菜单列表里返回的菜单树信息是不全的,我们需要补充信息,导出一颗完整的菜单树:
type MenuExportTree struct {
MenuInfo
Children []*MenuExportTree `json:"children"` // 子菜单
}
type MenuTree struct {
MenuId int `json:"id"` // 菜单ID
ParentMenuId int `json:"parent_id"` // 父菜单ID
Name string `json:"name"` // 菜单名
Type int64 `json:"type"` // 菜单类型 1菜单2子菜单3按钮4页签5数据标签
Children []*MenuTree `json:"lists"` // 子菜单
}
菜单列表返回的字段是不全的,我们需要拿到 menu_info 表的所有字段,这里有两种思路,一种是仿照菜单列表的写法再写一遍,但是这次建立树节点时要获取下 menu_info 表的信息;另一种做法则是调用菜单列表获取到菜单树,然后做一个树克隆的算法,在克隆的过程中,把 menu_info 的信息写进去。
这里介绍第二种做法,原树的节点(MenuTree)克隆一个新树(MenuExportTree),这里我们为了炫技复习基础,换用BFS来遍历树和克隆树。
// BFS 树克隆,原树 node ,新树 newNode
// BFS 遍历原树,在遍历过程中,建立新树节点
func (s *sMenu) bfsTreeCopy(node *model.MenuTree, newNode *model.MenuExportTree) {
p := node
if p == nil {
return
}
q := newNode
// isVisit是防止树中有回环指向,在菜单树中其实不存在回环,其实可以不要。
isVisit := make(map[*model.MenuTree]int)
queueP := list.New() // P 原树队列
queueQ := list.New() // Q 新树队列
queueP.PushBack(p)
queueQ.PushBack(q)
for queueP.Len() != 0 {
size := queueP.Len()
for i := 0; i < size; i++ {
e := queueP.Front()
eq := queueQ.Front()
p = e.Value.(*model.MenuTree)
q = eq.Value.(*model.MenuExportTree)
if _, ok := isVisit[p]; !ok {
q.MenuId = p.MenuId
q.Children = make([]*model.MenuExportTree, 0)
if q.MenuId != 0 {
// 获取 menu_info 表数据
menuInfo, _ := dao.MenuInfo.GetMenuInfo(
context.Background(),
q.MenuId,
dao.MenuInfo.Columns().Status,
dao.MenuInfo.Columns().Icon,
dao.MenuInfo.Columns().CreateTime,
)
q.MenuInfo = menuInfo
}
isVisit[p] = 1
}
for _, child := range p.Children {
queueP.PushBack(child)
t := &model.MenuExportTree{}
q.Children = append(q.Children, t)
queueQ.PushBack(t) // 推一个空的新节点到queueQ,下次循环会为其赋值
}
queueP.Remove(e)
queueQ.Remove(eq)
}
}
}
BFS 比较擅长处理需要针对每层节点进行操作的情况, DFS则可以在遍历时方便的获取到父节点的id,大部分时候我们选择一种遍历算法使用即可。
2. 菜单导入
导入则比较简单了,这里的导入是指我们用导入数据覆盖原数据,比较简单。如果要支持导入部分树节点,则可能比较麻烦,不能用 menu_id 数据库主键作为菜单唯一标识了,因为不同环境的主键不同。需要为菜单生成唯一标识,比如 menu_key 之类的字段,然后用它作为导入时定位菜单的依据。
所以不如简单点,导入就是用导入的数据覆盖原来数据,步骤就是,删除原来的菜单树,然后建立一颗新的菜单树。
// 根据 MenuExportTree 建立一个新的菜单树写入数据库中
func (s *sMenu) dfsTreeImport(ctx context.Context, tx *gdb.TX, root *model.MenuExportTree, parentMenuId int, index int) error {
if root == nil {
return nil
}
menuId := 0
// 前序遍历,写入 menu_info 表
if len(root.Name) != 0 {
menuInfo := &entity.MenuInfo{
PlatformId: int64(root.PlatformId),
Name: root.Name,
Type: root.Type,
Icon: root.Icon,
IsOutlink: root.IsOutLink,
RouteUrl: root.RouteData,
Status: root.Status,
ShowTime: root.Showtime,
BackendApi: root.BackendApi,
DataLabels: gjson.New(root.DataLabels.Data),
}
err := dao.MenuInfo.AddMenuInfoReturnId(ctx, menuInfo)
if err != nil {
_ = tx.Rollback()
return gerror.Wrap(err, "")
}
menuId = int(menuInfo.Id)
}
for i := 0; i < len(root.Children); i++ {
n := root.Children[i]
err := s.dfsTreeImport(ctx, tx, n, menuId, i+1)
if err != nil {
_ = tx.Rollback()
return err
}
}
// 当遍历完这个节点的子节点后,把这个节点写入 menu_tree
if len(root.Name) != 0 {
tree := &entity.MenuTree{
PlatformId: int64(root.PlatformId),
ParentTreeId: int64(parentMenuId),
MenuId: int64(menuId),
Index: int64(index),
}
err := dao.MenuTree.AddMenuTree(ctx, tree)
if err != nil {
_ = tx.Rollback()
return err
}
}
return nil
}
七、参考文献
- LeetCode
- gitee.com/fe.zookeepe… (图源)
- 代码风格(GoFrameV2)
作者:FengY_HYY
链接:https://juejin.cn/post/7129759332299702285
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android代码检查之自定义Lint
概述
Lint 是 Android studio 提供的一款静态代码检查工具,它可以帮助我们检查 Android 项目源文件是否有潜在的 bug,以及在正确性、安全性、性能、易用性、无障碍性和国际化方面是否需要优化改进。Lint 的好处不言而喻,它能够在编码阶段就帮我们提前发现代码中的“坏味道”,显著降低线上问题出现的概率;同时也能有效促进团队的开发规范的统一。
关于执行 lint 检查的几种方式不多做赘述,接下来着重来看下如何实现自定义 Lint 规则并应用到实际项目中。
自定义 Lint 接入方案
自定义 Lint 规则最终都会打成 JAR 包,只需将该输出 JAR 提供给其他组件使用即可。目前有两种方式可供选择:
全局方案
把此 jar 拷贝到 ~/.android/lint/ 目录中即可。缺点显而易见:针对所有工程生效,会影响同一台机器其他工程的 Lint 检查。即便触发工程时拷贝过去,执行完删除,但其他进程或线程使用 ./gradlew lint 仍可能会受到影响。
AAR 壳方案
另一种实现方式是将 jar 置于一个 aar 中,如果某个工程想要接入执行自定义的 lint 规则,只需依赖这个发布后的 aar 即可,如此一来,新增的 lint 规则就可将影响范围控制在单个项目内了。另外,该方案也是 Google 目前推荐的方式,aar 内容也支持 lint.jar 条目:
AAR 文件的文件扩展名为 .aar,Maven 工件类型应该也是 aar。此文件本身是一个 zip 文件。唯一的必需条目是 /AndroidManifest.xml。AAR 文件可能包含以下一个或多个可选条目:
xx.aar
|-/classes.jar
|-/res/
|-/R.txt
|-/public.txt
|-/assets/
|-/libs/name.jar
|-/jni/abi_name/name.so(其中 abi_name 是 Android 支持的 ABI 之一)
|-/proguard.txt
|-/lint.jar
|-/api.jar
|-/prefab/(用于导出原生库)
具体可参考 Android 官方对于 aar 的介绍:developer.android.com/studio/proj…
编写自定义 Lint 规则
接下来主要从以下几个方面来介绍自定义 Lint 的开发流程。
1. 创建 java-library & 配置 lint 依赖
自定义的 lint 规则最终输出格式为 jar 包,所以我们只需要创建一个 java-library 即可,build.gradle 配置如下:
lint-rules/build.gradle
plugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm'
}
dependencies {
// 官方提供的Lint相关API,并不稳定,每次AGP升级都可能会更改,且并不是向下兼容的
compileOnly "com.android.tools.lint:lint-api:${rootProject.ext.lintVersion}"
// 目前Android中内置的lint检测规则
compileOnly "com.android.tools.lint:lint-checks:${rootProject.ext.lintVersion}"
compileOnly "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlinVersion"
testImplementation "junit:junit:4.13.2"
testImplementation "com.android.tools.lint:lint:$lintVersion"
testImplementation "com.android.tools.lint:lint-tests:$lintVersion"
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
jar {
manifest {
// Only use the "-v2" key here if your checks have been updated to the
// new 3.0 APIs (including UAST)
attributes('Lint-Registry-V2': 'com.dorck.lint.rules.old.MyCustomIssueRegistry')
}
}
configurations {
lintJarOutput
}
dependencies {
lintJarOutput files(jar)
}
defaultTasks 'assemble'
配置期间如果发现如下问题:
需要将 java 闭包中的
sourceCompatibility 和 targetCompatibility 改为 1.8。
此外,如果你创建 module 时选择的是 kotlin 语言,还可能会遇到以下这个坑:
只需要将 kotlin 标准库依赖方式改为 compileOnly 即可:
compileOnly "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlinVersion"
2. 编写 lint-rules
平时经常使用 kotlin 开发项目的同学应该都遇到过这种情况:一旦我们希望类 A 实现一个接口 B,那么通过 AS 快捷键 option+ enter 选择 implement members 后就会为我们的类 A 自动实现 B 中接口,并加了一堆 TODO 方法:
目前编码环境并不会提示任何错误,然而,如果我们粗心忘记去掉上面接口实现中的 TODO 方法,一旦我们其他类调用到这个类 SomethingNew,程序就立马抛出一个 NotImplementedError 异常。显然,如果前置静态代码检查阶段没有拦住这个问题进而跑到了线上,那么就只能祈祷别人不会去调用了,否则故障在所难免了。好了,既然需求过来了,我就来尝试通过自定义 Lint 帮助团队其他成员在编码阶段就发现问题并强制处理。
首先,在上一步中,我们在 lint-rules/build.gradle 中指定了自定义的 MyCustomIssueRegistry,现在里面空空如也,我们需要先创建一个 Detector 用于检测 Standard.kt 中的 TODO() 方法:
@Suppress("UnstableApiUsage")
class KotlinTodoDetector : Detector(), Detector.UastScanner {
override fun getApplicableMethodNames(): List<String> {
return listOf("TODO")
}
override fun visitMethodCall(context: JavaContext, node: UCallExpression, method: PsiMethod) {
println("KotlinTodoDetector >>> matched TODO in [${method.parent.containingFile.toString()}]")
if (context.evaluator.isMemberInClass(method, "kotlin.StandardKt__StandardKt")) {
val deleteFix = fix().name("Delete this TODO method")
.replace().all().with("").build()
context.report(
ISSUE,
context.getLocation(node),
"You must fix `TODO()` first.", deleteFix)
}
}
companion object {
private const val ISSUE_ID = "KotlinTodo"
val ISSUE = Issue.create(
ISSUE_ID,
"Detecting `TODO()` method from kotlin/Standard.kt.",
"""
You have unimplemented method or undo work marked by `TODO()`,
please implement it or remove dangerous TODO.
""",
category = Category.CORRECTNESS,
priority = 9,
severity = Severity.ERROR,
implementation = Implementation(KotlinTodoDetector::class.java, Scope.JAVA_FILE_SCOPE),
)
}
}
此处我们需要检测的对象是 Java 源文件,这里只需要继承自 Detector 并实现 Detector.UastScanner 接口即可。当然,我们也可以选择按组合方式实现更多其他 Scanner,这取决于我们希望扫描的文件范围。目前支持的扫描范围有:
- UastScanner:扫描 Java 或者 kotlin 源文件
- ClassScanner:扫描字节码或编译的类文件
- BinaryResourceScanner:扫描二进制资源文件(res/raw/bitmap等)
- ResourceFolderScanner:扫描资源文件夹
- XmlScanner:扫描 xml 格式文件
- GradleScanner:扫描 Gradle 格式文件
- OtherFileScanner:其他类型文件
检测 Java 源文件,可以通过 getApplicableMethodNames 指定扫描的方法名,其他还有类名、文件名、属性名等等,并通过 visitMethodCall 接受检测到的方法。这里我们只需要检测 Kotlin 标准库中的 Standard.kt 中的 TODO 方法,匹配到后通过 context.report 来报告具体问题,这里需要指定一个 Issue 对象来描述问题具体信息,相关字段如下:
- id : 唯一值,应该能简短描述当前问题。利用 Java 注解或者 XML 属性进行屏蔽时,使用的就是这个 id。
- summary : 简短的总结,通常5-6个字符,描述问题而不是修复措施。
- explanation : 完整的问题解释和修复建议。
- category : 问题类别。常见的有:CORRECTNESS、SECURITY、COMPLIANCE、USABILITY、LINT等等。
- priority : 优先级。1-10 的数字,10 为最重要/最严重。
- severity : 严重级别:Fatal, Error, Warning, Informational, Ignore。
- Implementation : 为 Issue 和 Detector 提供映射关系,Detector 就是当前 Detector。声明扫描检测的范围Scope,Scope 用来描述 Detector 需要分析时需要考虑的文件集,包括:Resource文件或目录、Java文件、Class文件等。
此外,我们还可以设置出现该 issue 上报时的默认解决方案 fix,这里我们创建了一个 deleteFix 实现开发者快速移除报错位置的 TODO 代码。
最后,只需要自定义一个 Registry 声明自己需要检测的 Issues 即可:
@Suppress("UnstableApiUsage")
class MyCustomIssueRegistry : IssueRegistry() {
init {
println("MyCustomIssueRegistry, run...")
}
override val issues: List<Issue>
get() = listOf(
JcenterDetector.ISSUE,
KotlinTodoDetector.ISSUE,
)
override val minApi: Int
get() = 8 // works with Studio 4.1 or later; see com.android.tools.lint.detector.api.Api / ApiKt
override val api: Int
get() = CURRENT_API
override val vendor: Vendor
get() = Vendor(
vendorName = "Dorck",
contact = "xxx@gmail.com"
)
}
更多关于 AST 相关类及语法介绍可参考官方指导文档或者 Lint 源码,此处不多做介绍,这里很难一言以蔽之。
3. Lint 发布&接入
文章开头部分已经介绍了 Lint 的相关接入方案,出于灵活性和可用性角度考虑自然选择 aar 壳的方式。经过这几年 lint 的发展,实现起来也很简单:只需要创建一个 Android-Library module,然后稍微配置下 gradle 即可:
lint-aar:
plugins {
id 'com.android.library'
id 'org.jetbrains.kotlin.android'
}
dependencies {
lintPublish project(':checks')
// other dependencies
}
就是这么简单,此处的 lintPublish 配置允许我们引用另一个 module,它会获取该组件输出的 jar 并将其打包为 lint.jar 然后放到自身的 AAR 中。
最后,我们在 app 模块中依赖一下 lint-aar 这个组件,并编写以下测试代码:
interface SimpleInterface {
fun initialize()
fun doSomething()
}
class SomethingNew : SimpleInterface {
override fun initialize() {
TODO("Not yet implemented")
}
override fun doSomething() {
TODO("Not yet implemented")
}
}
接下来执行一下 ./gradlew :app:lint 即可看到控制台输出以下内容:
我们也可以点击 Lint 输出的测试报告链接去查看详细信息:
Note:AGP 7.0 开始,执行
./gradlew :app:lint只会作用于默认变体 lint 任务上,而不是诸如此前的执行所有变体 lint 任务。例如:我们此前执行
./gradlew :app:lint可能会导致debugLint、releaseLint、releaseChinaLint等诸多变体 lint 任务的执行,严重拖慢了编译速度,所以一般要指定特定变体的 lint 任务来执行:./gradlew :app:lintDebug。而7.0开始将无需如此麻烦,尽管放心使用./gradlew :app:lint即可。
最后,在 Android studio 中我们也可以看到编译器给我们的代码警告了:
并且我们上面设置的 deleteFix 也生效了,即点击 Delete this TODO method 就可以轻松移除 TODO() 方法,快速解决问题。
4. 编写测试代码
TTD(Test-Driven Development)是一个不错的习惯,很多时候作为开发人员大多时候无需关心最新编写的 lint 组件发布状态,因为不断发布和集成到示例代码中测试是一个比较糟糕的体验,严重消耗我们的精力。如此一来,我们就不得不了解下 lint 规则编码时的单测流程了,我相信能够显著提升你的开发效率。
首先,我们需要依赖 Lint 的单测组件:
testImplementation "com.android.tools.lint:lint-tests:$lintVersion"
接着,在 lint-rules 模块中创建单测文件用于验证我们之前的 KotlinTodo 规则:
最后来看下 KotlinTodoDetectorTest 如何实现的:
package com.dorck.lint.examples
import com.android.tools.lint.checks.infrastructure.TestFiles.kotlin
import com.android.tools.lint.checks.infrastructure.TestLintTask.lint
import com.dorck.lint.rules.old.issues.KotlinTodoDetector
import org.junit.Test
@Suppress("UnstableApiUsage")
class KotlinTodoDetectorTest {
@Test
fun sampleTest() {
lint().files(
kotlin(
"""
package test.pkg
class SimpleInterfaceImpl : SimpleInterface {
override fun doSomething(){
TODO("Not yet implemented")
}
}
interface SimpleInterface {
fun doSomething()
}
""".trimIndent()
))
.issues(KotlinTodoDetector.ISSUE)
.run()
.expect(
"""
src/test/pkg/SimpleInterfaceImpl.kt:5: Error: You must fix TODO() first. [KotlinTodo]
TODO("Not yet implemented")
~~~~~~~~~~~~~~~~~~~~~~~~~~~
1 errors, 0 warnings
""".trimIndent()
)
.expectFixDiffs(
"""
Fix for src/test/pkg/SimpleInterfaceImpl.kt line 5: Delete this TODO method:
@@ -5 +5
- TODO("Not yet implemented")
""".trimIndent()
)
}
}
其实也很简单,只需要模拟创建一个 Java/kotlin/Gradle/xml 等格式的源文件,然后在 java() 或 koltin() 方法参数里面写上测试代码,并指定要验证的 Issue 以及期待的反馈内容。当然,expect() 中期待的输出检查结果我们是无法知晓的,我们只需要先设置为空字符串,然后先跑一下测试用例,预期肯定会失败,如此,我们只需要将终端输出的实际错误信息 copy 到 expect() 中即可:
最后,重新 run 一下单测,就会发现能够正常通过测试了。更多关于 Lint 单元测试的用法可以参考:Lint unit testing
5. 忽略某些规则检查
某些情况下,我们希望忽略某些 Lint 规则的检查或者更改 Lint 规则的严重级别,那么,我们可以选择增加一个 Lint 配置文件,用于解决上述问题。我们可以手动在项目 app/根目录下创建一个名为 lint.xml 的文件:
<?xml version="1.0" encoding="UTF-8"?>
<lint>
<!-- list of issues to configure -->
<issue id="DefaultLocale" severity="ignore"/>
<issue id="DeprecatedProvider" severity="ignore"/>
<issue id="ObsoleteLayoutParam">
<!-- The <ignore> tag has two possible attributes: path and regexp (see below) -->
<ignore path="res/layout-xlarge/activation.xml" />
<!-- You can use globbing patterns in the path strings -->
<ignore path="**/layout-x*/onclick.xml" />
<ignore path="res/**/activation.xml" />
</issue>
<issue id="MissingTranslation" severity="ignore"/>
<issue id="KotlinTodo" severity="ignore"/>
</lint>
在 lint.xml 中我们可以选择更改某条规则的严重级别,使原本不受重视的规则更加引人注意或者放宽其他规则的级别。当然,我们也可以指定某条规则在特定匹配路径下被忽略,这将取决于我们自己设定的 regex 匹配规则。
Note:如果我们创建了 lint.xml (文件名强约定),并且
build.gradle的lintOptions中没有自定义设定 lint 配置文件的名称和路径,则 AGP自动在临近目录中寻找名为lint.xml的配置文件。
此外,我们也可以通过在 build.gradle >> lintOptions DSL 中设置开启或者关闭某些特定规则,当然也可以配置报告的输出格式以及路径:
lintOptions {
textReport false
lintConfig file('default-lint.xml') // At `app/default-lint.xml`
disable 'KotlinTodo', 'MissingTranslation'
xmlOutput file("lint-report.xml")
}
更多关于 LintOptions DSl 的配置可查看官方文档:LintOptions-dsl
Note:如果你项目中使用了 lint plugin,那么可以参考 lint DSL的相关释义:AGP-lint-dsl
其他的设置 lint 配置的方式还有手动在 Android studio 的工具栏 Analyze > Inspect Code > Specify Inspection Scope 中或者通过 Lint 命令行工具来配置,这两种方式就不具体介绍了,感兴趣的朋友可以去看下官方文档的介绍。
版本迭代过程
AGP 4.0开始,Android studio 支持了独立的 com.android.lint 插件,进一步降低了自定义 lint 的成本。借助此插件,在上述 lint-rules/build.gradle 中通过在 manifest 中注册自定义 Registry 改为通过服务表单注册(当然,以前的方式目前还是可以用的)。以下是基于官方最新推荐的方式来配置和注册自定义规则的:
plugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm'
id 'com.android.lint'
}
dependencies {
// 官方提供的Lint相关API,并不稳定,每次AGP升级都可能会更改,且并不是向下兼容的
compileOnly "com.android.tools.lint:lint-api:${rootProject.ext.lintVersion}"
// 目前Android中内置的lint检测规则
compileOnly "com.android.tools.lint:lint-checks:${rootProject.ext.lintVersion}"
compileOnly "org.jetbrains.kotlin:kotlin-stdlib-jdk7:$kotlinVersion"
testImplementation "junit:junit:4.13.2"
testImplementation "com.android.tools.lint:lint:$lintVersion"
testImplementation "com.android.tools.lint:lint-tests:$lintVersion"
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
可以看到,以此插件方式,我们需要关注的额外配置更少了,很大程度上降低了接入成本。
下面再来谈谈 AGP-7.0 开始的改动。其一变动是上面谈及过的执行 ./gradlew lint 只会作用于默认变体的 Lint 任务上,而不是以前的所有变体任务。
另外一项是在 7.0 中,lint 最终将能够跨模块增量运行,这意味着如果我们只更改一个模块中的代码,lint 只需在该模块下游的模块上重新运行分析检测。对于具有许多模块的大型项目,这应该是一项重大的改进。
开发技巧
1. 借助 Psi 工具查看 AST 语法树
Lint 检查的实质是对代码的 AST(Abstract Syntax Tree,即抽象语法树)数据进行检查分析,故而会用到大量 AST 与 lombok.ast 开源库相关知识。阅读源码是一种不错的分析语法树方式,不过我们可以借助 AS 的一些插件帮我们快速便捷解析类的节点树并加以解读。
利用 PsiViewer 就可以查看类的 AST 构造,如此一来我就可以另辟蹊径找到特定的属性来匹配特定代码了。值得注意的是,上面的 AST viewer 插件对 kotlin 代码支持不是很好,如果有需要,建议先将 kotlin 反编译为 java 再分析。
2. 参考 Android 内置 Lint 规则
我发现官方近期对于 Lint 的技术推进很上心,各路文档和 FAQ 陆续补齐了。关于内置规则,Android官方团队也对每条做了详细说明和用法指导,详细参考:googlesamples.github.io/android-cus…
作者:道可诉
链接:https://juejin.cn/post/7130410607534145544
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我用vue3和egg开发了一个早报学习平台,带领群友走向技术大佬
项目功能介绍
该项目的出发点是获取最新最值得推荐的文章以及面经,供群友们学习使用。带领前端阳光的群友们一起成为技术大佬。
当点击掘金的时候,就会获取掘金当前推荐的前端文章
当点击牛客网的时候,就会获取到最新的前端面经
点击【查看】就会跳到文章详情页
勾选后点击确认,就会把文章标题拼接到右边的输入框中,然后点击发送,就会将信息发送到学习群里供大家阅读。
项目源码已经放到github,欢迎fork,欢迎star。
项目启动:分别进入server和client项目,执行npm i安装相关依赖,然后启动即可。
技术栈介绍
本项目采用的是前后端分离方案
前端使用:vue3 + ts + antd
后端使用:egg.js + puppeter
前端实现
创建项目
使用vue-cli 创建vue3的项目。
按需引入antd组件
借助babel-plugin-import实现按需引入
npm install babel-plugin-import --dev然后创建配置.babelrc文件就可以了。
{
"plugins": [
["import", { "libraryName": "ant-design-vue", "libraryDirectory": "es", "style": "css" }] // `style: true` 会加载 less 文件
]
}我们可以把需要引入的组件统一写在一个文件里
antd.ts
import {
Button,
Row,
Col,
Input,
Form,
Checkbox,
Card,
Spin,
Modal,
} from "ant-design-vue";
const FormItem = Form.Item;
export default [
Button,
Row,
Col,
Input,
Form,
FormItem,
Checkbox,
Card,
Spin,
Modal,
];然后在入口文件里面use应用它们 main.js
import { createApp } from "vue";
import App from "./App.vue";
import antdCompArr from "@/antd";
const app = createApp(App);
antdCompArr.forEach((comp) => {
app.use(comp);
});
app.mount("#app");首页
其实就一个页面,所以,直接写在App.vue了
布局比较简单,直接亮html
<template>
<div class="pape-wrap">
<a-row :gutter="16">
<a-col :span="16">
<a-card
v-for="group in paperList"
:key="group.name"
class="box-card"
shadow="always"
>
<div class="clearfix">
<span>{{ group.name }}span>
div>
<div class="channels">
<a-button
:style="{ 'margin-top': '10px', 'margin-left': '10px' }"
size="large"
v-for="item in group.list"
:key="item.href"
class="btn-channel"
@click="onClick(item)"
>
{{ item.name }}
a-button>
div>
a-card>
a-col>
<a-col :span="8">
<a-form>
<a-form-item
:laba-col="{ span: 24 }"
label="支持markdown输入"
label-align="left"
>
<a-textarea
v-model:value="content"
placeholder="暂支持mardown语法"
show-count
/>
a-form-item>
<a-form-item>
<a-button @click="handleSendMsg"> 发消息 a-button>
a-form-item>
a-form>
a-col>
a-row>
<a-modal
v-model:visible="visible"
custom-class="post-modal"
title="文章列表"
@ok="handleComfirm"
>
<a-spin tip="Loading..." :spinning="isLoading">
<div class="post-list">
<div :style="{ borderBottom: '1px solid #E9E9E9' }">
<a-checkbox
v-model="checkAll"
:indeterminate="indeterminate"
@change="handleCheckAll"
>全选a-checkbox
>
div>
<br />
<a-checkbox-group v-model:value="checkedList">
<a-checkbox
:value="item.value"
v-for="item in checkoptions"
:key="item.value"
>
{{ item.label }}
<a
class="a-button--text"
style="font-size: 14px"
target="_blank"
:href="item.value"
@click.stop
>
查看a
>
a-checkbox>
a-checkbox-group>
div>
a-spin>
<span>
<a-button @click="handleComfirm">确认a-button>
span>
a-modal>
div>
template>主要就是遍历了paperList,而paperList的值是前端写死的。在constant文件里
export const channels = [
{
name: "前端",
list: [
{
name: "掘金",
bizType: "juejin",
url: "https://juejin.cn/frontend",
},
{
name: "segmentfault",
bizType: "segmentfault",
url: "https://segmentfault.com/channel/frontend",
},
{
name: "Chrome V8 源码",
bizType: "zhihu",
url: "https://zhuanlan.zhihu.com/v8core",
},
{
name: "github-Sunny-Lucky前端",
bizType: "githubIssues",
url: "https://github.com/Sunny-lucking/blog/issues",
},
],
},
{
name: "Node",
list: [
{
name: "掘金-后端",
bizType: "juejin",
url: "https://juejin.cn/frontend/Node.js",
},
],
},
{
name: "面经",
list: [
{
name: "牛客网",
bizType: "newcoder",
url: "https://www.nowcoder.com/discuss/experience?tagId=644",
},
],
},
];
点击按钮的时候,出现弹窗,然后向后端发起请求,获取相应的文章。
点击方法如下:
const onClick = async (item: any) => {
visible.value = true;
currentChannel.value = item.url;
if (cache[currentChannel.value]?.list.length > 0) {
const list = cache[currentChannel.value].list;
state.checkedList = cache[currentChannel.value].checkedList || [];
state.postList = list;
return list;
}
isLoading.value = true;
state.postList = [];
const { data } = await getPostList({
link: item.url,
bizType: item.bizType,
});
if (data.success) {
isLoading.value = false;
const list = data.data || [];
state.postList = list;
cache[currentChannel.value] = {};
cache[currentChannel.value].list = list;
} else {
message.error("加载失败!");
}
};获得文章渲染之后,勾选所选项之后,点击确认,会将所勾选的内容拼接到content里
const updateContent = () => {
const date = moment().format("YYYY/MM/DD");
// eslint-disable-next-line no-useless-escape
const header = `前端早报-${date},欢迎大家阅读。\n>`;
const tail = `本服务由**前端阳光**提供技术支持`;
const body = state.preList
.map((item, index) => `#### ${index + 1}. ${item}`)
.join("\n");
state.content = `${header}***\n${body}\n***\n${tail}`;
};
const handleComfirm = () => {
visible.value = false;
const selectedPosts = state.postList.filter((item: any) =>
state.checkedList.includes(item.href as never)
);
const selectedList = selectedPosts.map((item, index) => {
return `[${item.title.trim()}](${item.href})`;
});
state.preList = [...new Set([...state.preList, ...selectedList])];
updateContent();
};然后点击发送,就可以将拼接的内容发送给后端了,后端拿到后再转发给企业微信群
const handleSendMsg = async () => {
const params = {
content: state.content,
};
await sendMsg(params);
message.success("发送成功!");
};前端的内容就讲到这里,大家可以直接去看源码:github.com/Sunny-lucki…
后端实现
创建项目
后端是使用egg框架实现的
快速生成项目
npm init egg可以直接看看morningController的业务逻辑,其实主要实现了两个方法,一个是获取文章列表页返回给前端,一个是发送消息。
export default class MorningPaper extends Controller {
public async index() {
const link = this.ctx.query.link;
const bizType = this.ctx.query.bizType;
let html = '';
if (!link) {
this.fail({
msg: '入参校验不通过',
});
return;
}
const htmlResult = await this.service.puppeteer.page.getHtml(link);
if (htmlResult.status === false) {
this.fail({
msg: '爬取html失败,请稍后重试或者调整超时时间',
});
return;
}
html = htmlResult.data as string;
const links = this.service.morningPaper.index.formatHtmlByBizType(bizType, html) || [];
this.success({
data: links.filter(item => !item.title.match('招聘')),
});
return;
}
/**
* 推送微信机器人消息
*/
async sendMsg2Weixin() {
const content = this.ctx.query.content;
if (!content) {
this.fail({
resultObj: {
msg: '入参数据异常',
},
});
return;
}
const token = this.service.morningPaper.index.getBizTypeBoken();
const status = await this.service.sendMsg.weixin.index(token, content);
if (status) {
this.success({
resultObj: {
msg: '发送成功',
},
});
return;
}
this.fail({
resultObj: {
msg: '发送失败',
},
});
return;
}
}文章的获取
先看看文章是怎么获取的。
首先是调用了puppeter.page的getHtml方法
该方法是利用puppeter生成一个模拟的浏览器,然后模拟浏览器去浏览页面的逻辑。
public async getHtml(link) {
const browser = await puppeteer.launch(this.launch);
const page: any = await browser.newPage();
await page.setViewport(this.viewport);
await page.setUserAgent(this.userAgent);
await page.goto(link);
await waitTillHTMLRendered(page);
const html = await page.evaluate(() => {
return document?.querySelector('html')?.outerHTML;
});
await browser.close();
return {
status: true,
data: html,
};
}这里需要注意的是,需要await waitTillHTMLRendered(page);,它的作用是检查页面是否已经加载完毕。
因为,进入页面,page.evaluate的返回可能是页面还在加载列表当中,所以需要waitTillHTMLRendered判断当前页面的列表是否加载完毕。
看看这个方法的实现:每隔一秒钟就判断页面的长度是否发生了变化,如果三秒内没有发生变化,默认页面已经加载完毕
const waitTillHTMLRendered = async (page, timeout = 30000) => {
const checkDurationMsecs = 1000;
const maxChecks = timeout / checkDurationMsecs;
let lastHTMLSize = 0;
let checkCounts = 1;
let countStableSizeIterations = 0;
const minStableSizeIterations = 3;
while (checkCounts++ <= maxChecks) {
const html = await page.content();
const currentHTMLSize = html.length;
// eslint-disable-next-line no-loop-func
const bodyHTMLSize = await page.evaluate(() => document.body.innerHTML.length);
console.log('last: ', lastHTMLSize, ' <> curr: ', currentHTMLSize, ' body html size: ', bodyHTMLSize);
if (lastHTMLSize !== 0 && currentHTMLSize === lastHTMLSize) { countStableSizeIterations++; } else { countStableSizeIterations = 0; } // reset the counter
if (countStableSizeIterations >= minStableSizeIterations) {
console.log('Page rendered fully..');
break;
}
lastHTMLSize = currentHTMLSize;
await page.waitForTimeout(checkDurationMsecs);
}
};分析html,获取文章列表
上述的行为只会获取了那个页面的整个html,接下来需要分析html,然后获取文章列表。
html的分析其实 是用到了cheerio,cheerio的用法和jQuery一样,只不过它是在node端使用的。
已获取掘金文章列表为例子:可以看到是非常简单地就获取到了文章列表,接下来只要返回给前端就可以了。
getHtmlContent($): Link[] {
const articles: Link[] = [];
$('.entry-list .entry').each((index, ele) => {
const title = $(ele).find('a.title').text()
.trim();
const href = $(ele).find('a.title').attr('href');
if (title && href) {
articles.push({
title,
href: this.DOMAIN + href,
index,
});
}
});
return articles;
}发送信息到企业微信群
这个业务逻辑主要有两步,
首先要获取我们企业微信群的机器人的token,
接下来就将token 拼接成下面这样一个url
`https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=${token}`然后利用egg 的curl方法发送信息就可以了
export default class Index extends BaseService {
public async index(token, content): Promise<boolean> {
const url = `https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=${token}`;
const data = {
msgtype: 'markdown',
markdown: {
content,
},
};
const result: any = await this.app.curl(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
data,
});
if (result.status !== 200) {
return false;
}
return true;
}
}后端的实现大抵如此,大家可以看看源码实现:github.com/Sunny-lucki…
总结
至此,一个伟大的工程就打造完毕。
群员在我的带领下,技术突飞猛进。。。
撒花撒花。。
作者:阳光是sunny
来源:juejin.cn/post/7129692007584235551
远离那些过度激情的人
有些人很有激情,甚至过度,这样的人不是很好,反正我会远离他们。
我有一任领导,叫我去他办公室,他说:“我们的新项目是千载难逢的机会,我想交给你来做。你来安排人员,公司的人由你调配,资金任你使用,该加班就加班,项目完成了每人一万块钱加班费,我保证会有,不然我就没法树立威信了,给你十万。这都是小数,因为我们项目一上线就是上亿。做好了我们飞黄腾达,投入全部身心吧,少年”。
我是相信的,真的很用心,都按要求做的尽善尽美。结果未能如愿,这套系统只是意淫,不是刚需。反而耗费不少人力财力,对下无法和弟兄们交代承诺,对上还需要背负领导决策的失误,导致我万劫不复。
我还见过一个技术大牛,经朋友介绍,受到某煤老板赏识,成立科技公司,要求建立一支强劲的技术团队。老板对大牛说,我只负责业务方面,你来负责技术方面,你可以海阔天空,你可以提任何需求,你可以有独立的管理体系,我们各自半壁江山,我们要做的是一生的事业,这个平台将会价值4600亿,两年之后,你将会是2000亿身价。大牛感动涕零。
大牛调动毕生各种资源,招揽亲朋好友,遍访业内名士,众人纷纷辞职来投,终于凑齐了一支队伍,准备干一场轰轰烈烈的事业。这时,老板说,其实我们的平台并不明朗,还是不干了吧。
有激情是好事,但是只有一时激情很容易出现很多问题。
第一:过于夸大目标,忽视现实情况。动辄就是全球市场,上亿资产。心太远则舍近求远。他们的着眼点是未来,他们一般骂行业内知名的竞品都是大傻X,只有他是集大成者。忽略脚下,忽略困难,结果往往一步踏空,直坠悬崖。
第二:短暂激情,轻许诺言。当想做的时候,这件事是他的全部,他会许给你全世界,但是过几天激情退去了,原来的承诺化为乌有,让人失望。更甚者,撂摊子走人,让你不知所措。哀莫大于心死。
第三:太激情,容不下反对的声音。他激情四射,要求所有人都得激情四射。凡是他想的事情,如果你说半个不字,你便有滔天大罪。但凡有其他想法的,他们不是反思和安抚,反而直接将你清出团队。
所以,当有激情的朋友找我时,我一般让他等两天再来。当领导很有激情的给我许下承诺的时候,我会微微一笑。
做好事情是对得起自己,和有激情的人无关。
我觉得自己是平凡人,但不是个平庸的人。
平凡人就是不可能一步登天,无论多么好的平台都不可能。
平庸人就是没有追求,随波逐流,整天混日子。
来源:juejin.cn/post/7129666593918812197
收起阅读 »分库分表后路由策略设计
概述
分库分表后设计到的第一个问题就是,如何选择路由key,应该如何对key进行路由。路由key应该在每个表中都存在而且唯一。路由策略应尽量保证数据能均匀进行分布。
如果是对大数据量进行归档类的业务可以选择时间作为路由key。比如按数据的创建时间作为路由key,每个月或者每个季度创建一个表。按时间作为分库分表后的路由策略可以做到数据归档,历史数据访问流量较小,流量都会打到最新的数据库表中。
也可以设计其与业务相关的路由key。这样可以保证每个数据库的资源都能很好的承担流量。
支持场景
外卖订单平台分库分表后需要支持的场景,用户的角度,需要实时查看所点外卖订单的状态,跟踪订单信息。商家需要查询订单信息,通过订单分析菜品的质量,进行商业决策。
用户Consumer = C端 商家Business = B端
用户下单后订单可能会落到不同的表中,查询的时候可能需要查询多张表。
路由策略
如果创建订单时随机插入到某一张表中,或者不知道插入到那张表中,查询订单的时候都需要查询所有的表才能确保查询的准确信。
如果在插入订单的时候有一定的规则,根据这个规则插入到数据库中,查询的时候也执行相应的规则到对应的表中进行查询。这样就能减少数据操作的复杂性。可以通过设计路由策略来实现,用户和商家查询数据的时候都遵循相同的路由策略。
用户端路由key
根据上一小节的路由策略分析,现在需要选定一个路由key。用户端让同一个用户id的数据保存到某固定的表中,所以可以选用用户id最为路由key。
在单库的情况下,用户下单,生成一个订单,把用户id作为路由key,对user_id取hash值然后对表的数量进行取模,得到对应需要路由的表,然后写入数据。
多库多表的情况下需要先找到对应的库然后再找到对应的表。多库多表的路由策略:用户下达->生成订单->路由策略:根据用户id的hash值对数据库的数量进行取模找到对应的数据库->根据用户id的hash值除以对表的数量,然后在对表的数量进行取模即可找到对应的表。
路由策略设计的要点是根据具体的业务业务场景设计,跟用户信息关联度比较大的作为路由key进行hash值取模
商家路由key
单独为商家B端设计了一套表(C端和B端是独立的)。
用户的角度以user_id作为路由key,商户的角度以商家id作为路由key。商家是如何通过路由key路由数据的呢。游湖在下单的时候把队友的订单号发送到MQ里,商家可以去消费这个MQ,然后根据订单号获取订单信息,然后再把订单信息插入到商户的数据库表当中。商户的路由策略和用户的路由策略是一样的。
用户端和商户端的完整数据流程图:
作者:人间凑个数
链接:https://juejin.cn/post/7128726681954549768
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
自定义过滤器和拦截器实现ThreadLocal线程封闭
线程封闭
线程封闭一般通过以下三个方法:
- Ad-hoc线程封闭:程序控制实现,最糟糕,忽略
- 堆栈封闭:局部变量,无并发问题
- ThreadLocal线程封闭:特别好的封闭方法
方法2是最常用的,变量定义在接口内,本文主要讲解方法三,SpringBoot项目通过自定义过滤器和拦截器实现ThreadLocal线程封闭。实现Filter接口自定义过滤器和继承HandlerInterceptorAdapter自定义拦截器。
ThreadLocal线程封闭实现步骤
封装ThredLocal的方法
/**
* <p>自定义RequestHolder</p></p>
*
* @Author zjq
* @Date 2021/12
*/
public class RequestHolder {
private final static ThreadLocal<Long> requestHolder = new ThreadLocal<>();
public static void set(Long id) {
requestHolder.set(id);
}
public static Long get() {
return requestHolder.get();
}
public static void remove() {
requestHolder.remove();
}
}
自定义过滤器
自定义定义拦截器继承Filter接口,实现ThredLocal.add()方法
/**
* <p>自定义过滤器</p>
*
* @Author zjq
* @Date 2021/12/7
*/
@Slf4j
public class HttpFilter implements Filter {
/**
* 为Filter初始化 提供支持
*
* @param filterConfig
* @throws ServletException
*/
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
/**
* 拦截到要执行的请求时,doFilter就会执行。这里我们可以写对请求和响应的预处理。
* FilterChain把请求和响应传递给下一个 Filter处理
*
* @param servletRequest
* @param servletResponse
* @param filterChain
* @throws IOException
* @throws ServletException
*/
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
//把普通servlet强转成httpServlet
HttpServletRequest httpServletRequest = (HttpServletRequest) servletRequest;
Long threadId = Thread.currentThread().getId();
log.info("do filter,threadId:{} servletPath:{}", threadId, httpServletRequest.getServletPath());
//把当前线程id放入requestHolder
RequestHolder.set(threadId);
//放行
filterChain.doFilter(httpServletRequest, servletResponse);
}
/**
* Filter 实例销毁前的准备工作
*/
@Override
public void destroy() {
}
}
自定义拦截器
自定义拦截器在线程使用完毕后移除ThredLocal中内容,避免内存溢出
/**
* <p>自定义拦截器</p>
*
* @Author zjq
* @Date 2021/12/7
*/
@Slf4j
public class HttpInterceptor extends HandlerInterceptorAdapter {
/**
* 拦截处理程序的执行。在 HandlerMapping 确定合适的处理程序对象之后,在 HandlerAdapter 调用处理程序之前调用。
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
log.info("preHandle执行。。。");
return true;
}
/**
* 请求处理完成后(渲染视图后)的回调。将在处理程序执行的任何结果上调用,从而允许进行适当的资源清理。
* @param request
* @param response
* @param handler
* @param ex
* @throws Exception
*/
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
RequestHolder.remove();
log.info("afterCompletion执行。。。");
return;
}
}
Application类启动类中配置自定义过滤器和拦截器
/**
*
* @author zjq
*/
@SpringBootApplication
public class Application extends WebMvcConfigurationSupport {
public static void main(String[] args) {
SpringApplication.run(ConcurrencyApplication.class, args);
}
/**
* 自定义过滤器
* @return
*/
@Bean
public FilterRegistrationBean filterRegistrationBean(){
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean();
filterRegistrationBean.setFilter(new HttpFilter());
//设置自定义过滤器拦截的url
filterRegistrationBean.addUrlPatterns("/threadLocal/*");
return filterRegistrationBean;
}
/**
* 定义自定义拦截器原先需要继承WebMvcConfigurerAdapter
* SpringBoot2.0后WebMvcConfigurerAdapter被定义成过时了,推荐使用继承WebMvcConfigurationSupport
* @param registry
*/
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new HttpInterceptor()).addPathPatterns("/**");
}
}
定义调用接口
/**
* ThreadLocal测试controller
* @author zjq
*/
@Controller
@RequestMapping("/threadLocal")
public class ThreadLocalController {
@RequestMapping("/test")
@ResponseBody
public Long test() {
return RequestHolder.get();
}
}
请求访问验证
访问调用接口,控制台输出如下:
作者:共饮一杯无
链接:https://juejin.cn/post/7128195148076302350
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【flutter进阶】Widget源码详解-如何实现自由组合,动态刷新,布局绘制?
看到结局的问题:如何区分StatelessWidget 和 StatefulWidget 的使用场景,不禁开始自问,对于StatefulWidget ,StatelessWidget,以及flutter中Widget的众多子类我真的足够了解吗?
对于自己经常要打交道的东西,如果只是一知半解则不利于进步。
下面就从源码的角度来学习下flutter基础的几个Widget 都起到了什么作用。
先给个简单总结:
- 其中StatelessWidget 和 StatefulWidget 起到了组织组合子组件的作用。
- RenderObjectWidget 起到渲染作用。包含绘制偏移和测量信息。
- ProxyWidget 可以携带信息,以供其他组件使用。
一、探索StatelessWidget的组件构建
在使用StatelessWidget的时候,通常只需要实现一个build方法。就拿我们常用的Container组件举例,他就是StatelessWidget 的子类。他的build方法返回的就是各种组件的组合嵌套。
他的各种成员属性也只是用来配置子组件的组合方式而已。
1. StatelessWidget 的build调用时机,以及widget树遍历流程
Container组件是StatelessWidget的经典子类。
我们通过断点调试看看Container 组件build方法的调用堆栈
在ComponentElement 的performRebuild 方法调用的时候,触发了build方法,从stateless中获取了build返回的Widget,而又在performRebuild 调用了updateChild方法,对所有的子孙Element进行build遍历。
ComponentElement是Widget对应元素StatelessElement和StatefulElement的父类。
我们拉到最初的调用栈。Element栈调用的起点在于attachRootWidget方法。
还记得我们flutter app开发的起点吗?就是runApp(App())方法,开启了整个flutter app。
attachRootWidget方法正是我们在调用runApp的时候执行的。
在其中,执行了RenderObjectToWidgetAdapter组件的初始化,将renderView 和 rootWidget作为入参。并且调用attachToRenderTree返回元素树顶点的Element。
三颗树的顶点
其中renderView是RenderObject树的顶点,_renderViewElement是Element树的顶点。匿名的RenderObjectToWidgetAdapter则是Widget树的顶点,但是他没有被引用。Widget树的维护依赖于Element树,rootWidget就是我们的runApp组件节点,被作为参数挂载到RenderObjectToWidgetAdapter根组件中,被后续的Element挂载循环使用。
Element中也存放了_parent变量,所以我们通过Element对象可以轻松的追溯到祖先节点。
我们从上面的分析可以得出ComponentElement 的 performRebuild方法是element.build传承关键方法 ,mount方法也能由此挂载出所有子树(其他类型的Element实现方案略有不同)
在ComponentElement中。也由performRebuild构建出一层层的子孙节点。代码如下,注意红色方框的代码。
第一个红框中是build()方法的执行。意味着每次performRebuild被调用的时候,子组件都会被build出来,由此可知widget是唯一的,每次更新都会有新的Widget生成。
在updateChild的过程中,如果子element还未生成,就会调用widget.createElement()方法获得element 。
我们再看StatelessWidget 的源码,实现了createElement方法返回了自定义的StatelessElement。
生成的子Element 都会在ComponentElement中被持有,以便后续更新
由此可知,ComponentElement维系了祖孙关系,其子类Element对应的 StatelessWidget,StatefulWidget,ParentDataWidget 和 InheritedWidget都天然拥有子孙关系能力。
如下所示,StatefulElement 是 ComponentElement 的子类。
2. StatelessWidget 和Element在渲染中的更新
widget的创建都是在element树遍历的过程中执行的。
widget树依赖于element树,在Element创建的时候widget实例将会被持有。
StatelessWidget在布局和渲染流程中依赖Element维系,树关系被Element挖掘。
在Element performeRebuild重新构建的时候,有一个是否更新Element的判定机制,以优化性能。
不管是更新update还是挂载mount,每次子widget都会先build()出来。再进行新旧比较。Widget都是一次性的,如果有状态需要保存是由其他方式实现的。
我们再看updateChild方法。上面一小节提到在子element为空的时候,会在其中createElement。而在子Element不为空的时候,会根据新旧Widget 的不同,进行不同的操作。
其中通过新旧widget的equals判定。决定是否复用之前的element。如果复用了element,根据canUpdate方法的返回值,来执行child.update方法。所以我们可以得出这样一个结论。
widget 的 canUpdate 实现,将很大程度上决定 Element 的复用。减少重新绘制,对State重新赋值,甚至状态丢失的资源浪费。
3. 探索key的作用
canUpdate的默认实现中以Widget的类型和key作为关键字进行判断。如果有对key定义,那么Key的一致性就会对widget的更新显得尤为关键。
这也是我们在做性能优化的时候需要注意的。可以利用Key的配置,来控制组件是否需要更新。
static bool canUpdate(Widget oldWidget, Widget newWidget) {
return oldWidget.runtimeType == newWidget.runtimeType
&& oldWidget.key == newWidget.key;
}
复制代码Key的几种子类基本上都是根据需求,对== 操作符做不同的实现。以更好的自定义 canUpdate 的结果。
其中GlobalKey比较特殊。作为全局的唯一秘钥。提供了对应 widget 的 BuildContext 和 widget 的访问方式。并针对 StatefulWidget。还提供了 State 的访问。
以便用户对状态进行全局的更新。比如我们需要在外部使用 BuildContext 进行初始化的时候,可以进行这样调用
4. 小结
通过以上对StatelessWidget和ComponentElement 的分析,可以得出以下的判断。
StatelessWidget 基于 ComponentElement。主要功能就是提供了组合各种widget的能力,并维持了祖孙的build传承。
当然在探索当中也发现了一些技术债务,由于我们已经知道了statelesswidget的使用场景,对于具体的源码细节先按下不表,在此只记录
- 生命周期_lifecycleState 起到什么作用
- _dirty 标记和 markNeedsBuild 的用法和原理是什么
- BuildOwner 的作用是什么
二、探索StatefulWidget的动态刷新机制
StatefulWidget 和 StateflessWidget 有很多共同之处。最主要的原因就是他们创建的元素都是ComponentElement的子类,其提供了widget子孙build传承的能力。
可知StatefulWidget和StateflessWidget一样,也是一个有能力组合各种widget的组件。
1. State生命周期分析
StatefulWidget 定义了createState方法。提供了状态刷新能力。
再次从StatefullElement的build方法入手。直接调用了state.build(this)。代理了state的构建行为。
在performRebuild方法中也进行了state.didChangeDependencies生命周期回调。
在State中,除了生命周期方法外, 最重要的就是build方法了。作用和StatelessWidget的build方法一致。都是提供了组合widget的能力。
initState则给用户提供了初始化state状态的机会。断点调试看看调用栈如何。
调试中直观看到,在firstBuld的时候,state的initState被调用。并在之后调用了didChangeDependencies生命周期方法,和build方法。
代码中也对方法做了限制,不可以返回Future类型。
所以我们可以在initState中放心做一些初始化工作,没有异步参与,工作将会在build之前完成。
2. setState方法刷新页面方式分析
对于setState方法。除开生命周期的判断之外,关键代码只有一句,就是调用了element 的markNeedsBuild()
该方法将对应的element标记为dirty。并且调用owner``!.scheduleBuildFor(``this``);将其加入到 BuildOwner的脏列表(_dirtyElements)中。
将会在下次帧刷新的时候调用BuildOwner.owner.buildScope 重新构建该列表中的元素。
3. 小结
StatelessWidget给使用者提供了一个便捷的布局刷新入口,我们可以利用setState刷新布局。该方法会将对应Element标记为待刷新元素,在下次帧刷新的时候重建布局。状态的改动将会被重建的布局重新获取。
三、探索SingleChildRenderObjectWidget
SingleChildRenderObjectWidget对应的元素类是SingleChildRenderObjectElement。
我们作为开发者,布局过程中SingleChildRenderObjectWidget 的子类使用频率非常频繁,布局的约束,偏移和渲染都是由RenderObjectWidget 实现的,SingleChildRenderObjectWidget继承了RenderObjectWidget的渲染能力,并提供了单子传承的能力。布局的过程中该对象的子类不可或缺,flutter框架中也有不少对应的实现类。
Flutter 框架中实现的SingleChildRenderObjectWidget有以下几种。
- SizedBox
- LimitedBox
- ShaderMask
- RotatedBox
- SizedOverflowBox
- Padding
- ...
1. 探索SingleChildRenderObjectElement中对于子widget的挂载和更新
SingleChildRenderObjectElement`的`mount` 和 `update`方法都很简单,都是直接调用了`updateChild`方法,传进去的子widget直接是`widget.child
这个方法和ComponentElement基本上一样,都是利用canUpdate的结果进行更新或者是创建子Element。
1. 以Padding为例了解RenderObjectWidget 的布局和绘制实现。
名词解释
RenderObject:渲染对象,flutter对象布局的约束,绘制,位移全是由该对象实现,RenderObject树的祖孙中传递着约束,以做到布局大小的传承影响。
RenderObject的创建
RenderObjectWidget 会在mount挂载的时候,创建RenderObject,直接调用widge.createRenderObject。我们的约束,绘制,位移全是由RenderObject传递和实现的。
RenderPadding的布局实现
以Padding为例。createRenderObject创建了RenderPadding实例,widget的成员原封不动交给了该实例。
约束(BoxConstraint)是Flutter确定布局大小的方案,各种RenderObject对于约束的传递都有自己的实现。
下方是RenderPadding的performLayout代码。红框标记起来的代码中就展示了Padding的约束传承逻辑。
其父布局传给自己约束基础上减去Padding再传递给子RenderObject。
观察performLayout方法可以发现,该方法完成了约束的传递,计算了偏移量Offset,并确定了自己的大小。
确定大小约束之后,就会在paint中绘制自己和子孙。RenderPadding没有自定义绘制,直接使用了父类RenderShiftedBox的实现。RenderShiftedBox 提供了offset偏移。在绘制子renderObject的时候,为其施加绘制偏移量。有些需要计算子布局偏移的widget,如Padding,Align等,都对RenderShiftedBox进行了实现。
可以看到子布局的offset存在他的parentData中。PaddingRender使用的parentData是BoxParentData,内部提供了offset变量以供父布局使用。
/// Parent data used by [RenderBox] and its subclasses.
class BoxParentData extends ParentData {
/// The offset at which to paint the child in the parent's coordinate system.
Offset offset = Offset.zero;
@override
String toString() => 'offset=$offset';
}
所有的RenderBox都持有BoxParentData对象,用于存储位移信息,在setUpPrentData的时候进行的初始化。红框中的代码展示了这一细节。
到此,就能了解RenderObject是如何被约束BoxConstraint,如何被布局layout,以及如何被绘制paint。
1. RenderObjectElement的传承方式
RenderObjectElement 的父子传承在两个子类中实现,在第1小结中已经提到SingleChildRenderObjectWidget 和ComponentElement十分类似,只是直接把widget.child拿来传承,而不再提供build方法以供子组件组合。
MultiChildRenderObjectElement 也类似,只不过作为多子组件,三棵树分叉的主要因子,维护的是children 列表。
在mount 和 update 的时候,子孙组件会像点了爆竹一样被逐一构建和更新。
1. 小结
每个SingleChildRenderObjectWidget组件都实现了各自的布局和绘制方案,也各自处理了约束并传递下去。
比如ColordBox作为绘制组件,借助了RenderColord,绘制了自身颜色,约束则取得是父约束的最小值。Align作为定位组件,借助了RenderPositionedBox,布局的时候计算了对应的偏移量offset,在绘制子布局的时候使用,约束则在传递的时候转了松约束。
诸如此类,所有组件都利用了对应的RenderObject满足了各自布局和渲染的所有需求。我们自己当然也可以自定义对应的RenderObject实现自己的布局。
MultiChildRenderObjectWidget 和 SingleChildRenderObjectWidget类似,只是维护一个子widget变成了多个子widget。
他的RenderObject基本上都是ContainerRenderObjectMixin和RenderBox的子类,内部维护了头尾两个子节点,并利用存储在parentData中的双相链表维护所有的子RenderObject。
四、谈谈ProxyWidget
最后稍微提一下ProxyWidget。ProxyElement也上ComponentElement的子类。和StatefulWidget 以及StatelessWidget是兄弟关系。也有子孙维系的能力,只不过他的build方法是固定的,返回的就是child。
1. InheritedWidget
我们获取 Theme,MediaQuery数据的时候,都是使用了InheritedWidget
MediaQuery.of(context).size.width;
Theme.of(context).appBarTheme;
通过context 也就是Element实例,获取祖先节点的数据。实现数据共享的效果。
Element中维护了祖先的所有InheritedElement映射,就可以在需要的时候直接通过子孙Element获取。
2. ParentDataWidget
ParentDataWidget提供了子组件向父组件传递渲染信息的能力。
Flexible,Positioned 等组件都是ParentDataWidget 的子类。
需要注意的是:ParentDataWidget只用于渲染信息的传递
在Element.attachRenderObject的时候会调用updateParentData,然后会辗转调用到对应的ParentDataWidget.applyParentData。可以看出只有子组件是RenderObjectWidget子类的时候才会应用对应的ParentDataWidget传递信息。
由此可知,只有在子节点渲染的时候,才会应用RenderObject的数据传递赋值。
子节点的ParentData对象由父布局创建代码如下,创建时机在子节点插入的时候执行。
最后
作为开发者,很多时候完成一个任务只会建立在使用的层面。对于为什么这么使用往往不甚了解。
如果我们能更多的学习他的原理。那么如果在开发中碰到问题,我们能够更加得心应手得去解决。
flutter布局渲染的原理以前总是一层雾蒙在我地眼前。但现在,终于有一片薄雾散去,内部轮廓在我面前变得清晰。
坚持学习,见识真实的世界。
小试
我们最后尝试一下一个简单地布局,分析其三棵树结构。嵌套结构如下。其中builder是StatelessWidget。Column是 MultiChildRenderObjectWidget其他都是SingleChildRenderObjectWidget。
void main() {
runApp(Builder(builder: (context) {
return Column(
mainAxisSize: MainAxisSize.max,
crossAxisAlignment: CrossAxisAlignment.stretch,
children: [
Center(
child: SizedBox(
width: 100,
height: 100,
child: ColoredBox(color: Colors.blue),
),
),
Expanded(
child: ColoredBox(color: Colors.red),
),
],
);
}));
}
展示出来的样式如下。
分析得出的三棵树如下,源头从RenderView而起,然后构建出RenderObjectToWidgetAdapter,再构建出RootRenderObjectElement。由此从根开始三棵树的循环,直到叶子节点。
RenderObject和Widget并非一一对应,只有RenderObjjectWidget才有,但是RenderObject能自动找出自己的组件RenderObjject 自动插入到其child中,所以也能自动成树。
至此,我们的Widget初步了解完结。
作者:guuguo
链接:https://juejin.cn/post/7129770397838344206
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter中如何独立绘制每一个像素点?
Flutter中如何独立绘制每一个像素点?
前提
前一阵我参照教程:GAMEBOY 仿真器 做了一个game boy模拟器,经过漫长的调试,终于成功的在电脑上运行了起来,但作为一个移动端开发者,我最终还是想要在手机上运行,在经过一番研究后,我卡在了第一个难点:在Flutter中如何单独绘制每一个像素点呢?
Gamyboy的显示器尺寸是160 * 144,素点的格式是RGB,模拟器大概每隔16ms生成一帧画面,当模拟器运行时,我就能源源不断的拿到每一帧的像素数据(这里的像素数据可以看做是一个int32数组,长度为160 * 144),我要做的就是找到一种方法,将每一帧的像素数据绘制到屏幕上。一番搜素后,终于在How do I Render Individual Pixels in Flutter?上找到了答案
绘制像素点
想要直接绘制原始的像素点,需要用到Canvas的一个方法:
/// Draws the given [Image] into the canvas with its top-left corner at the
/// given [Offset]. The image is composited into the canvas using the given [Paint].
void drawImage(Image image, Offset offset, Paint paint)
从方法签名中可以看出,canvas绘制的是一个Image对象,它持有原始的像素数据,所以我们需要先将像素数据转换成Image对象,可以使用decodeImageFromPixels方法
/// Convert an array of pixel values into an [Image] object.
///
/// The `pixels` parameter is the pixel data in the encoding described by
/// `format`.
/// ...
void decodeImageFromPixels(
Uint8List pixels,
int width,
int height,
PixelFormat format,
ImageDecoderCallback callback, {
int? rowBytes,
int? targetWidth,
int? targetHeight,
bool allowUpscaling = true,
})
pixels是一个一维数组,每一个元素是一个字节width和height代表图片的宽和高format用来设置像素点的格式,比如:PixelFormat.rgba8888表示一个像素点由四个字节组成,分别表示红,绿,蓝,透明度等信息callback为图片解码完成后的回调函数,函数参数为最终生成的Image对象
/// Callback signature for [decodeImageFromList].
typedef ImageDecoderCallback = void Function(Image result);
至此,整个流程已经走通,共分为三步:
- 生成像素数据
- 调用
decodeImageFromPixels方法将像素数据转换为Image对象 - 调用
Canvas的drawImage方法绘制像素数据
读到这里,有些朋友可能会有疑惑,我从哪里去获取Canvas对象呢? 如何做到实时更新每一帧画面呢?接下来,我将用一个案例将整个流程串起来
演示案例
作为演示,这里用生成的雪花噪点数据来代替模拟器生成的像素数据,完整的案例请看:github.com/hcoderLee/f…
首先我们需要一个不断生成像素数据的类
import 'dart:ui' as ui;
class Emulator {
/// 每一帧生成的像素所对应的Image对象
ui.Image? _image;
ui.Image? get image => _image;
bool _isRunning = false;
Timer? _timer;
/// 用于生成雪花噪点数据
int xorshift32(int x) {
x ^= x << 13;
x ^= x >> 17;
x ^= x << 5;
return x;
}
int seed = 0xDEADBEEF;
/// 生成原始像素数据,并转换为Image对象
Future<ui.Image> makeImage() {
final c = Completer<ui.Image>();
final pixels = Int32List(lcdWidth * lcdHeight);
for (int i = 0; i < pixels.length; i++) {
seed = pixels[i] = xorshift32(seed);
}
void decodeCallback(ui.Image image) {
c.complete(image);
}
// 将像素数据转换为Image对象
ui.decodeImageFromPixels(
pixels.buffer.asUint8List(),
lcdWidth,
lcdHeight,
ui.PixelFormat.rgba8888,
decodeCallback,
);
return c.future;
}
/// 不断的生成每一帧的画面
void run() {
if (_isRunning) {
return;
}
_isRunning = true;
_timer?.cancel();
/// 每隔16ms(更新一帧的时间)更新一次画面
_timer = Timer.periodic(const Duration(milliseconds: 16), (timer) async {
final newImage = await makeImage();
_image?.dispose();
_image = newImage;
});
}
void dispose() {
_timer?.cancel();
_timer = null;
_image?.dispose();
}
}
当有了Image对象后,需要调用Canvas的drawImage方法来绘制,这里使用CustomPaint组件来获取Canvas对象:
CustomPaint(
painter: _LCD(
emulator: _emulator,
timer: _timer,
),
);
class _LCD extends CustomPainter {
final Emulator emulator;
_LCD({
required this.emulator,
required _Timer timer,
}) : super(repaint: timer);
@override
void paint(ui.Canvas canvas, ui.Size size) {
final image = emulator.image;
if (image != null) {
canvas.drawImage(image, Offset.zero, Paint());
}
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return true;
}
}
CustomPaint组件有一个重要的参数: painter, 它是一个CustomPainter对象,我们可以自定义一个类去继承CustomPainter, 实现paint方法,获取到Canvas对象,至此,我们可以利用canvas去绘制任何我们想要的东西
这里我们定义了_LCD去继承CustomPainter,它持有Emulator对象,从而获取要绘制的Image对象,这里有两个地方需要重点关注一下:
shouldRepaint方法表示如果上层组件发生重建,生成了新的CustomPaint对象,是否需要重新调用paint方法绘制内容,因为我的需求是每一帧都要绘制新的画面,所以这里直接返回true(表示需要重新调用paint方法),真实的业务场景需要根据具体情况去判断是否返回true
构造函数中有一个
_Timer对象,并调用了super(repaint: timer),那么这个_Timer对象是用来做什么的呢?
查看CustomPainter的文档,有这么一段说明:
/// The painter will repaint whenever `repaint` notifies its listeners.
repaint会通知CustomPainter去重新绘制画面,我们再查看repaint的类型是Listenable,这里我们自定义一个_Timer类,用来在每一帧更新的时候去通知CustomPainter重绘
class _Timer extends ChangeNotifier {
final TickerProvider _vsync;
late final Ticker _ticker;
_Timer(this._vsync) {
_ticker = _vsync.createTicker(_onTick);
_ticker.start();
}
void _onTick(Duration elapsed) {
notifyListeners();
}
@override
void dispose() {
_ticker.stop();
_ticker.dispose();
super.dispose();
}
}
这里我们继承了ChangeNotifier,因此间接继承了Listenable
在构造函数里创建了一个Ticker对象,用来获取每一帧更新的时机,_onTick方法会在每一帧更新的时候调用,并通知CustomPaint去重绘。实际上,Flutter的动画也是使用Ticker对象,在每一帧更新的时候触发组件重绘
为了创建Ticker对象,需要用到TickerProvider对象,它提供了创建Ticker对象的方法(createTicker),并确保onTick回调函数只在组件处在前台活跃状态的时候才触发。为了获得TickerProvider对象,最常用的做法是创建一个StatefullWidget,并给State添加SingleTickerProviderStateMixin mixin,如果大家写过动画相关的代码,对这一套应该不陌生:
class _GameView extends StatefulWidget {
const _GameView({Key? key}) : super(key: key);
@override
State<_GameView> createState() => _GameViewState();
}
class _GameViewState extends State<_GameView>
with SingleTickerProviderStateMixin {
late final Emulator _emulator;
/// 在每一帧更新的时候去通知_LCD重绘
late final _Timer _timer;
@override
void initState() {
super.initState();
_emulator = Emulator();
// 运行模拟器,不断的产生每一帧的像素数据
_emulator.run();
_timer = _Timer(this);
}
@override
Widget build(BuildContext context) {
return SizedBox(
width: lcdWidth.toDouble(),
height: lcdHeight.toDouble(),
child: CustomPaint(
painter: _LCD(
emulator: _emulator,
timer: _timer,
),
),
);
}
@override
void dispose() {
_emulator.dispose();
_timer.dispose();
super.dispose();
}
}
至此,我们已经完成了所有的步骤,看一下运行效果:
总结
本文讲述了Flutter中如何实时绘制自己生成的像素数据,有以下几个步骤:
- 生成像素数据
- 调用
decodeImageFromPixels方法将像素数据转换为Image对象 - 调用
Canvas的drawImage方法绘制像素数据 - 使用
Ticker对象获取每一帧更新的时机,并通知CustomPainter去重绘
如果有错误,还请大家帮忙指正, 希望能够对大家有所帮助
作者:RobertLee10396
链接:https://juejin.cn/post/7129170601238855694
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
React 官网为什么那么快?
当我们打开 React 官网时,会发现从浏览器上输入url 到页面首屏完全展示这一过程所花的时间极短,而且在页面中点击链接切换路由的操作非常顺滑,几乎页面可以达到“秒切”的效果,根本不会有卡顿等待的情况发生,于是带着“react官网到底是怎么做的”疑问开始了本次探索,发现其主要用了以下的优化手段
静态站点生成 SSG
下面是react官方中文文档首页的截图,大家注意下方的红色区域,后面会作为推断的一个理由
当我们打开控制台之后,点击network并选择 DOC文档请求,就会发现有一个请求路径为https://zh-hans.reactjs.org/ 的GET请求,响应结果为一个 html文档,里面刚好能找到对应上图中红色区域文字的文本,这也就佐证了这个html文档所对应的页面就是react官网首页,而这种渲染页面的方式只有两种,一种是服务端渲染 SSR,还有一种是静态站点生成 SSG
很多人总是分不清客户端渲染CSR、服务端渲染SSR还有静态站点生成SSG,下面我们简单介绍一下它们各自的特点,看完之后相信你就能清晰的感受到它们的区别所在了
页面的渲染流程
在开始之前,我们先来回顾一下页面最基本的渲染流程是怎么样的?
- 浏览器通过请求得到一个
HTML文本 - 渲染进程解析
HTML文本,构建DOM树 - 浏览器解析
HTML的同时,如果遇到内联样式或者样本样式,则下载并构建样式规则(stytle rules)。若遇到Javascript脚本,则会下载并执行脚本 DOM树和样式规则构建完成之后,渲染进程将两者合并成渲染树(render tree)- 渲染进程开始对渲染树进行布局,生成布局树(
layout tree) - 渲染进程对布局树进行绘制,生成绘制记录
- 渲染进程对布局树进行分层,分别栅格化每一层并得到合成帧
- 渲染进程将合成帧发送给
GPU进程将图像绘制到页面中
可以看到,页面的渲染其实就是浏览器将HTML文本转化为页面帧的过程,下面我们再来看看刚刚提到的技术:
客户端渲染 CSR
如今我们大部分 WEB 应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,页面中的大部分DOM元素都是通过Javascript插入的。也就是说,在执行 JavaScript 脚本之前,HTML 页面已经开始解析并且构建 DOM 树了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面成为希望成为的样子,这种渲染方式叫动态渲染,也就是平时我们所称的客户端渲染 CSR(client side render)
下面代码为浏览器请求 react 编写的单页面应用网页时响应回的HTML文档,其实它只是一个空壳,里面并没有具体的文本内容,需要执行 JavaScript 脚本之后才会渲染我们真正想要的页面
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon" href="/favicon.ico" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<meta name="theme-color" content="#000000" />
<meta name="description" content="Web site created using create-react-app" />
<link rel="apple-touch-icon" href="/logo192.png" />
<link rel="manifest" href="/manifest.json" />
<title>Jira任务管理系统</title>
<script
type="text/javascript">!function (n) { if ("/" === n.search[1]) { var a = n.search.slice(1).split("&").map((function (n) { return n.replace(/~and~/g, "&") })).join("?"); window.history.replaceState(null, null, n.pathname.slice(0, -1) + a + n.hash) } }(window.location)</script>
<link href="/static/css/2.4ddacf8e.chunk.css" rel="stylesheet">
<link href="/static/css/main.cecc54dc.chunk.css" rel="stylesheet">
</head>
<body><noscript>You need to enable JavaScript to run this app.</noscript>
<div id="root"></div>
<script>!function (e) { function r(r) { for (var n, a, i = r[0], c = r[1], f = r[2], s = 0, p = []; s < i.length; s++)a = i[s], Object.prototype.hasOwnProperty.call(o, a) && o[a] && p.push(o[a][0]), o[a] = 0; for (n in c) Object.prototype.hasOwnProperty.call(c, n) && (e[n] = c[n]); for (l && l(r); p.length;)p.shift()(); return u.push.apply(u, f || []), t() } function t() { for (var e, r = 0; r < u.length; r++) { for (var t = u[r], n = !0, i = 1; i < t.length; i++) { var c = t[i]; 0 !== o[c] && (n = !1) } n && (u.splice(r--, 1), e = a(a.s = t[0])) } return e } var n = {}, o = { 1: 0 }, u = []; function a(r) { if (n[r]) return n[r].exports; var t = n[r] = { i: r, l: !1, exports: {} }; return e[r].call(t.exports, t, t.exports, a), t.l = !0, t.exports } a.e = function (e) { var r = [], t = o[e]; if (0 !== t) if (t) r.push(t[2]); else { var n = new Promise((function (r, n) { t = o[e] = [r, n] })); r.push(t[2] = n); var u, i = document.createElement("script"); i.charset = "utf-8", i.timeout = 120, a.nc && i.setAttribute("nonce", a.nc), i.src = function (e) { return a.p + "static/js/" + ({}[e] || e) + "." + { 3: "20af26c9", 4: "b947f395", 5: "ced9b269", 6: "5785ecf8" }[e] + ".chunk.js" }(e); var c = new Error; u = function (r) { i.onerror = i.onload = null, clearTimeout(f); var t = o[e]; if (0 !== t) { if (t) { var n = r && ("load" === r.type ? "missing" : r.type), u = r && r.target && r.target.src; c.message = "Loading chunk " + e + " failed.\n(" + n + ": " + u + ")", c.name = "ChunkLoadError", c.type = n, c.request = u, t[1](c) } o[e] = void 0 } }; var f = setTimeout((function () { u({ type: "timeout", target: i }) }), 12e4); i.onerror = i.onload = u, document.head.appendChild(i) } return Promise.all(r) }, a.m = e, a.c = n, a.d = function (e, r, t) { a.o(e, r) || Object.defineProperty(e, r, { enumerable: !0, get: t }) }, a.r = function (e) { "undefined" != typeof Symbol && Symbol.toStringTag && Object.defineProperty(e, Symbol.toStringTag, { value: "Module" }), Object.defineProperty(e, "__esModule", { value: !0 }) }, a.t = function (e, r) { if (1 & r && (e = a(e)), 8 & r) return e; if (4 & r && "object" == typeof e && e && e.__esModule) return e; var t = Object.create(null); if (a.r(t), Object.defineProperty(t, "default", { enumerable: !0, value: e }), 2 & r && "string" != typeof e) for (var n in e) a.d(t, n, function (r) { return e[r] }.bind(null, n)); return t }, a.n = function (e) { var r = e && e.__esModule ? function () { return e.default } : function () { return e }; return a.d(r, "a", r), r }, a.o = function (e, r) { return Object.prototype.hasOwnProperty.call(e, r) }, a.p = "/", a.oe = function (e) { throw console.error(e), e }; var i = this.webpackJsonpjira = this.webpackJsonpjira || [], c = i.push.bind(i); i.push = r, i = i.slice(); for (var f = 0; f < i.length; f++)r(i[f]); var l = c; t() }([])</script>
<script src="/static/js/2.2b45c055.chunk.js"></script>
<script src="/static/js/main.3224dcfd.chunk.js"></script>
</body>
</html>
复制代码服务端渲染 SSR
顾名思义,服务端渲染就是在浏览器请求页面 URL 的时候,服务端将我们需要的 HTML 文本组装好,并返回给浏览器,这个 HTML 文本被浏览器解析之后,不需要经过 JavaScript 脚本的下载过程,即可直接构建出我们所希望的 DOM 树并展示到页面中。这个服务端组装HTML的过程就叫做服务端渲染 SSR
下面是服务端渲染时返回的 HTML 文档,由于代码量实在是太多,所以只保留了具有象征意义的部分代码,但不难发现,服务端渲染返回的HTML文档中具有页面的核心文本
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<link rel="preload" href="https://unpkg.com/docsearch.js@2.4.1/dist/cdn/docsearch.min.js" as="script" />
<meta name="generator" content="Gatsby 2.24.63" />
<style data-href="/styles.dc271aeba0722d3e3461.css">
/*! normalize.css v8.0.1 | MIT License | github.com/necolas/normalize.css */
html {
line-height: 1.15;
-webkit-text-size-adjust: 100%
}
/* ....many CSS style */
</style>
</head>
<body>
<script>
(function () {
/*
BE CAREFUL!
This code is not compiled by our transforms
so it needs to stay compatible with older browsers.
*/
var activeSurveyBanner = null;
var socialBanner = null;
var snoozeStartDate = null;
var today = new Date();
function addTimes(date, days) {
var time = new Date(date);
time.setDate(time.getDate() + days);
return time;
}
// ...many js code
})();
</script>
<div id="___gatsby">
<!-- ...many html dom -->
<div class="css-1vcfx3l">
<h3 class="css-1qu2cfp">一次学习,跨平台编写</h3>
<div>
<p>无论你现在使用什么技术栈,在无需重写现有代码的前提下,通过引入 React 来开发新功能。</p>
<p>React 还可以使用 Node 进行服务器渲染,或使用 <a href="https://reactnative.dev/" target="_blank"
rel="nofollow noopener noreferrer">React Native</a> 开发原生移动应用。</p>
</div>
</div>
<!-- ...many html dom -->
</div>
</body>
</html>
复制代码静态站点生成 SSG
这也就是React官网所用到的技术,与SSR的相同之处就是对应的服务端同样是将已经组合好的HTML文档直接返回给客户端,所以客户端依旧不需要下载Javascript文件就能渲染出整个页面,那不同之处又有哪些呢?
使用了SSG技术搭建出的网站,每个页面对应的HTML文档在项目build打包构建时就已经生成好了,用户请求的时候服务端不需要再发送其它请求和进行二次组装,直接将该HTML文档响应给客户端即可,客户端与服务端之间的通信也就变得更加简单
但读到这里很容易会发现它有几个致命的弱点:
HTML文档既然是在项目打包时就已经生成好了,那么所有用户看到的都只能是同一个页面,就像是一个静态网站一样,这也是这项技术的关键字眼——静态- 每次更改内容时都需要构建和部署应用程序,所以其具有很强的局限性,不适合制作内容经常会变换的网站
但每项技术的出现都有其对应的使用场景,我们不能因为某项技术的某个缺点就否定它,也不能因为某项技术的某个优点就滥用它!
该技术还是有部分应用场景的,如果您想要搭建一个充满静态内容的网站,比如个人博客、项目使用文档等Web应用程序,使用SSG再适合不过了,使用过后我相信你一定能感受到这项技术的强大之处!
问题解答
现在我们就可以回答为什么react官网要使用SSG这项技术去做了?
因为相对于客户端渲染,服务端渲染和静态网点生成在浏览器请求URL之后得到的是一个带有数据的HTML文本,并不是一个HTML空壳。浏览器只需要解析HTML,直接构建DOM树就可以了。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript 脚本,越是复杂的应用,需要加载的 JavaScript脚本就越多、越大,这会导致应用的首屏加载时间非常长,从而降低了体验感
至于SSR与SSG的选取,我们要从应用场景出发,到底是用户每次请求都在服务端重新组装一个HTML文档?还是在项目构建的时候就生成一个唯一的HTML文档呢?
React团队成员在开发官网的时候肯定早就想到了这个问题,既然是官网,那肯定没有权限之分,所有进入到该网站的人看到的内容应该是一样的才对,那每次请求都在服务端组装一个一模一样的HTML有什么意义呢? 为什么不提前在服务端渲染好,然后发给每个人,这样N次渲染就变成了1次渲染,大大减少了客户端与服务端通信的时间,进而提升了用户体验
总结
无论是哪种渲染方式,一开始都是要请求一个 HTML 文本,但是区别就在于这个文本是否已经被服务端组装好了
- 客户端渲染还需要去下载和执行额外的
Javascript脚本之后才能得到我们想要的页面效果,所以速度会比服务端渲染慢很多 - 服务端渲染得到的
HTML文档就已经组合好了对应的文本,浏览器请求到之后直接解析渲染出来即可,不需要再去下载和执行额外的Javasript脚本,所以速度会比客户端渲染快很多 - 对于一些内容不经常变化的网站,我们甚至可以在服务端渲染的基础上予以改进,将每次请求服务端都渲染一次
HTML文档改成总共就只渲染一次,这就是静态站点生成技术
下图是客户端渲染和服务端渲染的流程图:
一些预加载/预处理资源的方式
研究完首屏渲染之后,我们再来研究一下路由跳转后内容的切换。经常看 react 文档的朋友可能早就发现了,其路由跳转无比丝滑,感觉就像是一个静态页面一样,完全没有发送网络请求的痕迹,比如我现在处在hook 简介这一个板块,当我点击 hook 规则 目录之后
发现页面瞬间秒切了过去,内容也瞬间展现在了出来,没有一丝卡顿,用户体验直接爆炸,这到底是怎么做到的呢?
下面我们就来一点一点分析它的每个优化手段
preload
在当前页面中,你可以指定可能或很快就需要的资源在其页面生命周期的早期——浏览器的主渲染机制介入前就进行预加载,这可以让对应的资源更早的得到加载并使用,也更不易阻塞页面的初步渲染,进而提升性能
关键字 preload 作为元素 <link> 的属性 rel的值,表示用户十分有可能需要在当前浏览中加载目标资源,所以浏览器必须预先获取和缓存对应资源 。下面我们来看一个示例:
<link as="script" rel="preload" href="/webpack-runtime-732352b70a6d0733ac95.js">
复制代码这样做的好处就是让在当前页面中可能被访问到的资源提前加载但并不阻塞页面的初步渲染,进而提升性能
下面是 react文档中对 preload关键字的使用,告诉浏览器等等可能需要这个资源,希望能够尽早下载下来
可以预加载的资源有很多,现在浏览器支持的主要有:
- audio:音频文件,通常用于 audio 标签
- document: 旨在由 frame 或嵌入的 HTML 文档
- embed:要嵌入到 embed 元素中的资源
- fetch:要通过 fetch 或 XHR 请求访问的资源,例如 ArrayBuffer 或 JSON 文件
- font: 字体文件
- image: 图像文件
- object:要嵌入到 object 元素中的资源
- script: JavaScript 文件
- style: CSS 样式表
- track: WebVTT 文件
- worker:一个 JavaScript 网络工作者或共享工作者
- video:视频文件,通常用于 video 标签
注意:使用
preload作为link标签rel属性的属性值的话一定要记得在标签上添加as属性,其属性值就是要预加载的内容类型
preconnect
元素属性的关键字preconnect是提示浏览器用户可能需要来自目标域名的资源,因此浏览器可以通过抢先启动与该域名的连接来改善用户体验 —— MDN
下面来看一个用法示例:
<link rel="preconnect" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
简单来说就是提前告诉浏览器,在后面的js代码中可能会去请求这个域名下对应的资源,你可以先去把网络连接建立好,到时候发送对应请求时也就更加快速
dns-prefetch
DNS-prefetch (DNS 预获取) 是尝试在请求资源之前解析域名。这可能是后面要加载的文件,也可能是用户尝试打开的链接目标 —— MDN
那我们为什么要进行域名预解析呢?这里面其实涉及了一些网络请求的东西,下面简单介绍一下:
当浏览器从(第三方)服务器请求资源时,必须先将该跨域域名解析为 IP 地址,然后浏览器才能发出请求。此过程称为 DNS 解析。DNS 缓存可以帮助减少此延迟,而 DNS 解析可以导致请求增加明显的延迟。对于打开了与许多第三方的连接的网站,此延迟可能会大大降低加载性能。预解析域名就是为了在真正发请求的时候减少延迟,从而在一定程度上提高性能
用法示例:
<link rel="dns-prefetch" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
通俗点来说,dns-prefetch 的作用就是告诉浏览器在给第三方服务器发送请求之前去把指定域名的解析工作给做了,这个优化方法一般会和上面的preconnect一起使用,这些都是性能优化的一些手段,我们也可以在自己项目中合适的地方来使用
prefetch
关键字 prefetch 作为元素 的属性 rel 的值,是为了提示浏览器,用户未来的浏览有可能需要加载目标资源,所以浏览器会事先获取和缓存对应资源,优化用户体验 ——MDN
上面的解释已经很通俗易懂了,就是告诉浏览器用户未来可能需要这些资源,这样浏览器可以提前获取这些资源,等到用户真正需要使用这些资源的时候一般都已经加载好了,内容展示就会十分的流畅
用法示例:
<link rel="prefetch" href="/page-data/docs/getting-started.html/page-data.json" crossorigin="anonymous" as="fetch">
复制代码可以看到 react文档在项目中大量使用到了 prefetch来优化项目
那么我们在什么情况下使用 prefetch才比较合适呢?
像 react文档一样,当你的页面中具有可能跳转到其他页面的路由链接时,就可以使用prefetch 预请求对应页面的资源了
但如果一个页面中这样的路由链接很多呢?那岂不是要大量的发送网络请求,虽然现在流量很便宜,但你也不能那么玩啊!(doge)
React 当然考虑到了这个问题,因为在它的文档中包含有大量的路由链接,不可能全部都发一遍请求,这样反而不利于性能优化,那react是怎么做的呢?
通过监听 Link元素,当其出现到可见区域时动态插入带有prefetch属性值的link标签到HTML文档中,从而去预加载对应路由页面的一些资源,这样当用户点击路由链接跳转过去时由于资源已经请求好所以页面加载会特别快
举个例子,还没有点击下图中划红线的目录时,由于其子目录没有暴露到视图窗口中,所以页面中并没有对应的标签,而当点击了该目录后,其子目录就会展示在视图窗口中,react会自动将暴露出来的路由所对应的数据通过prefetch提前请求过来,这样当用户点击某个子目录的时候,由于已经有了对应的数据,直接获取内容进行展示即可。用这样的方法,我们感受到的速度能不快吗?
下面是我们在network查看到的结果
补充
react官网其实并不完全是由react这个框架进行开发的,能做上述所说的那么多性能优化其实得益于Gatsby这个库
Gatsby是一个性能很好,开发很自由的,基于React和GraphQL来构建网站的库。一般用于构建静态网站,比如博客、企业官网等,或者说静态内容相对比较多的网站
它在打包的时候就生成了所有页面对应的 HTML文件以及数据文件等,这样当你访问某个页面时,服务端可以直接返回HTML ,另外一方面当页面中有使用 Link 时,会提前加载这个页面所对应的数据,这样点击跳转后页面加载速度就会很快。所以上文中所说的优化手段,其实是 Gatsby帮助实现的,有兴趣的朋友可以去它的官网了解更多相关知识
- 至于这个监听
Link元素是怎么实现的呢?
具体实现是使用 Intersection Observer ,相关介绍见 IntersectionObserver API 使用教程 - 阮一峰的网络日志 ,有写到图片懒加载和无限滚动也可以使用这个 API 去实现,只不过现在有个别浏览器还没有支持,所以在兼容性上存在一些阻拦,导致这个 Api现在还没有被普及
参考
本篇文章参考了以下几篇文章并结合上了自己的理解,下面文章个人觉得质量真的很高,大家也可以去看看。另外大家在文章中如果发现问题可以在评论区中指出,大家共同进步~
作者:Running53
链接:https://juejin.cn/post/7128369638794231839
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
互联网打工人9大美德
打工人的美德:
贞洁:单纯不想上班
勤奋:每天都不想上班
慷慨:邀请同事一起摆烂
温和:被领导骂完继续上班
节制:一天只有23小时不想上班
宽容:等发完工资再离职
自信:公司没了我马上倒闭
勇敢:不干了,你把我开了吧
认真:摸鱼一目十行

来源:网络
Java转Android:第8天 Service帮你背诵古诗词
一、我讲
今天,我主要讲一下android里面的服务Service,以及它的使用方法。
1.1 服务 Service
Service其实是Android的四大组件之一。
安卓有四大组件,前面我们说的Activity和BroadCastReceiver,其实都属于四大组件。你看,我没有一上来就讲让你先记住四大组件,而是慢慢渗透,因为没有例子的应用,记那些没有意义。
在Android中,能看到的属于Activity,看不到的属于Service。
Service的运行不依赖于任何用户界面,即使程序被切换到后台,或者用户打开了另一个应用程序,Service仍然能够保持正常运行。
1.2 Service的使用
创建
可选中包名,右键点击菜单,输入你的服务的名称进行创建。
其实,你这步操作,影响了两处代码。
第一,新建了一个继承Service的类。
public class MyService extends Service {
@Override
public void onCreate() {
super.onCreate();
}
@Override
public int onStartCommand(final Intent intent, int flags, int startId) {
// 巴拉巴拉
return super.onStartCommand(intent, flags, startId);
}
@Override
public void onDestroy() {
super.onDestroy();
}
}
当服务每次启动时,都会执行onStartCommand方法,所以我们终点会把逻辑写到这里面。
第二,在AndroidManifest.xml中做了注册。
<?xml version="1.0" encoding="utf-8"?>
<manifest>
<application>
……
<service
android:name=".MyService"
android:enabled="true"
android:exported="true"></service>
</application>
</manifest>
启动和停止
服务的启动和停止,一般通过Intent在Activity中进行。
Intent intent = new Intent(this, MyService.class);
startService(intent);
stopService(intent);
通过Intent构建要提供哪一个服务,然后调用startService启动服务,stopService停止服务。
二、你做
我们要搞一个这样的功能:
启动服务后,在服务里面循环播放古诗,退出程序也不打断,看其他应用也不打断。这样,能播放一整天,你看抖音时也弹。这导致你,无奈地就学会了一首诗。
虽然,我们说服务没有界面,但是启动它要界面,我们写在MainActivity中,它的布局是activity_main.xml,就两个按钮,一个启动,一个关闭。
<?xml version="1.0" encoding="utf-8"?>
<ConstraintLayout tools:context=".MainActivity">
<Button
android:id="@+id/button1"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="启动服务"
android:onClick="start" />
<Button
android:id="@+id/button2"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="关闭服务"
android:onClick="stop" />
</ConstraintLayout>
又看到了熟悉的onClick=""这个我们之前讲过。
对应下面的逻辑控制代码,里面有服务的启动和停止。
public class MainActivity extends Activity {
Intent intent;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
intent = new Intent(this, MyService.class);
}
public void start(View view) {
startService(intent);
}
public void stop(View view) {
stopService(intent);
}
}
最后,也是重点,就是我们的服务实现逻辑。
先定义一个字符串数组texts用于存储每一句诗词。
然后在onStartCommand里,启动一个线程。
线程里有一个循环,每休眠3秒钟,就往外发送一条消息。
这条消息由Handler发送和接收,接收到后切换诗句,然后通过Toast弹出来。
public class MyService extends Service {
String[] texts = new String[]{"窗前明月光","疑是地上霜","举头望明月","低头思故乡"};
int index = 0;
boolean isRun = true;
……
@Override
public int onStartCommand(final Intent intent, int flags, int startId) {
new Thread(){
@Override
public void run() {
while (isRun){
if (index+1 > texts.length){
index = 0;
}
handler.sendEmptyMessage(index);
sleep(3000);
index++;
}
}
}.start();
return super.onStartCommand(intent, flags, startId);
}
Handler handler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Toast.makeText(MyService.this, ""+texts[msg.what], Toast.LENGTH_SHORT).show();
}
};
@Override
public void onDestroy() {
super.onDestroy();
isRun = false;
}
}
需要注意,isRun是控制是否还循环,如果为false了,while循环就不执行了,线程结束。
另外,Service也是有生命周期的,这个生命周期和Activity的生命周期类似,当 onDestroy() 销毁时,需要做一些收尾工作。
好了,最后点击运行,启动服务,去看看效果吧。
作者:TF男孩
链接:https://juejin.cn/post/7129276744950874149
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
发布Android库至Maven Central详解
最近,使用compose编写了一个类QQ的image picker。完成android library的编写,在此记录下发布这个Library到maven central的流程以及碰到的问题。
maven:mvnrepository.com/artifact/io…
github:github.com/huhx/compos…
Sonatype 账号
MavenCentral 和 Sonatype 的关系
| 库平台 | 运营商 | 管理后台 |
|---|---|---|
| MavenCentral | Sonatype | s01.oss.sonatype.org |
因此我们要发布Library到Maven Central的话,首先需要Sonatype的账号以及权限。
申请 Sonatype 账号
申请账号地址: issues.sonatype.org/secure/Sign…
登录账号创建issue
创建issue地址:issues.sonatype.org/secure/View…
点击 Create 按钮, 然后会弹出 Create Issue的窗口:
点击Configure Fields, 选择 Custom 选项
grouId的话最好使用: io.github.github_name, 要不然使用其他的还需要在 DNS 配置中配置一个TXT记录来验证域名所有权
填写完所有的信息点击创建,一个新的issue就创建成功了,以下就是我创建的issue,附上链接:issues.sonatype.org/browse/OSSR…
值得注意的是sonatype要求我们创建一个github仓库来验证我们的github账号。创建完仓库之后,我们回复热心的工作人员,接下来就是等他们的处理结果了。大概30分钟就能好吧
收到这样的回复,代表一切ready了你可以上传package到maven central。
编写gradle脚本上传Lib
这篇文章里面,我是使用的android library做例子的。如果你想要发布java的Library,可以参考:docs.gradle.org/current/use…
In module project, build.gradle file
// add maven-publish and signing gradle plugin
plugins {
id 'maven-publish'
id 'signing'
}
// add publish script
publishing {
publications {
release(MavenPublication) {
pom {
name = 'Image Picker Compose'
description = 'An Image Picker Library for Jetpack Compose'
url = 'https://github.com/huhx/compose_image_picker'
licenses {
license {
name = 'The Apache License, Version 2.0'
url = 'http://www.apache.org/licenses/LICENSE-2.0.txt'
}
}
developers {
developer {
id = 'huhx'
name = 'hongxiang'
email = 'gohuhx@gmail.com'
}
}
scm {
connection = 'https://github.com/huhx/compose_image_picker.git'
developerConnection = 'https://github.com/huhx/compose_image_picker.git'
url = 'https://github.com/huhx/compose_image_picker'
}
}
groupId "io.github.huhx"
artifactId "compose-image-picker"
version "1.0.2"
afterEvaluate {
from components.release
}
}
}
repositories {
maven {
url "https://s01.oss.sonatype.org/service/local/staging/deploy/maven2/"
credentials {
username ossrhUsername // ossrhUsername is your sonatype username
password ossrhPassword // ossrhUsername is your sonatype password
}
}
}
}
// signing, this need key, secret, we put it into gradle.properties
signing {
sign publishing.publications.release
}
ossrhUsername 和 ossrhPassword 是我们在第一步注册的sonatype账号。用户名和密码是敏感信息,我们放在gradle.properties并且不会提交到github。因此在 gradle.properties文件中,我们添加了以下内容:
# signing information
signing.keyId=key
signing.password=password
signing.secretKeyRingFile=file path
# sonatype account
ossrhUsername=username
ossrhPassword=password
其中包含了签名的三个重要信息,这个我们会在下面详细讲解
创建gpg密钥
我使用的是mac,这里就拿mac来说明如何创建gpg密钥。以下是shell脚本
# 安佳 gpg
> brew install gpg
# 创建gpg key,过程中会提示你输入密码。
# 记住这里要输入的密码就是上述提到你需要配置的signing.password
> gpg --full-gen-key
# 切换目录到~/.gnupg/openpgp-revocs.d, 你会发现有一个 .rev文件。
# 这个文件名称的末尾8位字符就是上述提到你需要配置的signing.keyId
> cd ~/.gnupg/openpgp-revocs.d && ls
# 创建secretKeyRingFile, 以下命令会创建一个文件secret.gpg
# 然后~/.gnupg/secret.gpg就是上述提到你需要配置的signing.secretKeyRingFile
> cd ~/.gnupg/ && gpg --export-secret-keys -o secret.gpg
把signing相关的信息成功填写到gradle.properties之后,我们就可以借助maven-publish插件发布我们的andoird包到maven的中心仓库了
maven publish的gradle task
# 这个是发布到我们的本地,你可以在~/.m2/repository/的目录找到你发布的包
> ./gradlew clean publishToMavenLocal
# 这个是发布到maven的中心仓库,你可以在https://s01.oss.sonatype.org/#stagingRepositories找到
> ./gradlew clean publish
我们执行./gradlew clean publish命令之后,访问地址:s01.oss.sonatype.org/#stagingRep…
可以看到我们的android包已经在nexus repository了,接下来你要做的两步就是Close and Release。
Maven检验以及发布
第一步:点击Close按钮,它会触发对发布包的检验。我在这个过程中碰到一个signature validation失败的问题。
# 失败原因:No public key in hkp://keyserver.ubuntu.com:11371,是因为同步key可能会花些时间。这里我们可以手动发布我们的key到相应的服务器上
> gpg --keyserver hkp://keyserver.ubuntu.com:11371 --send-keys signing.keyId
第二步:确保你填入的信息是满足要求之后,Release按钮就会被激活。点击Release,接下来就是等待时间了,不出意外的话。30分钟你可以在nexus repository manager找到,但是在mvnrepository.com/找到的话得花更长的时间。
作者:gohuhx
链接:https://juejin.cn/post/7128578180662689823
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android系统编译优化:使用Ninja加快编译
背景
Android系统模块代码的编译实在是太耗时了,即使寥寥几行代码的修改,也能让一台具有足够性能的编译服务器工作十几分钟以上(模块单编),只为编出一些几兆大小的jar和dex。
这里探究的是系统完成过一次整编后进行的模块单编,即m、mm、mmm等命令。
除此之外,一些不会更新源码、编译配置等文件的内容的操作,如touch、git操作等,会被Android系统编译工具识别为有差异,从而在编译时重新生成编译配置,重新编译并没有更新的源码、重新生成没有差异的中间文件等一系列严重耗时操作。
本文介绍关于编译过程中的几个阶段,以及这些阶段的耗时点/耗时原因,并最后给出一个覆盖一定应用场景的基于ninja的加快编译的方法(实际上是裁剪掉冗余的编译工作)。
环境
编译服务器硬件及Android信息:
- Ubuntu 18.04.4 LTS
- Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (28核56超线程)
- MemTotal: 65856428 kB (62.8GiB)
- AOSP Android 10.0
- 仅修改某个Java文件内部的boolean初始化值(true改false)
- 不修改其他任何内容,包括源码、mk、bp的情况下,使用m单编模块(在清理后,使用对比的ninja进行单编)
- 使用time计时
- 此前整个系统已经整编过一次
- 编译时不修改任何编译配置文件如Android.mk
之所以做一个代码修改量微乎其微的case,是因为要分析编译性能瓶颈,代码变更量越小的情况下,瓶颈就越明显,越有利于分析。
关键编译阶段和耗时分析
由于Makefile结构复杂、不易调试、难以扩展,因此Android决定将它替换掉。Android在7.0时引入了Soong,它将Android从Makefile的编译架构带入到了ninja的时代。
Soong包含两大模块,其中Kati负责解析Makefile并转换为.ninja,第二个模块Ninja则基于生成的.ninja完成编译。
Kati是对GNU Make的clone,并将编译后端实现切换到ninja。Kati本身不进行编译,仅生成.ninja文件提供给Ninja进行编译。
Makefile/Android.mk -> Kati -> Ninja
Android.bp -> Blueprint -> Soong -> Ninja
因此在执行编译之前(即Ninja真正开动时),还有一些生成.ninja的步骤。关键编译阶段如下:
- Soong的自举(Bootstrap),将Soong本身编译出来
- 系统代码首次编译会比较耗时,其中一个原因是Soong要全新编译它自己
- 遍历源码树,收集所有编译配置文件(Makefile/Android.mk/Android.bp)
- 遍历、验证非常耗时,多么强劲配置的机器都将受限于单线程效率和磁盘IO效率
- 由于Android系统各模块之间的依赖、引入,因此即使是单编模块,Soong(Kati)也不得不确认目标模块以外的路径是否需要重新跟随编译。
- 验证编译配置文件的合法性、有效性、时效性、是否应该加入编译,生成.ninja
- 如果没有任何更改,.ninja不需要重新生成
- 最终生成的.ninja文件很大(In my case,1GB以上),有很明显的IO性能效率问题,显然在查询效率方面也很低下
- 最后一步,真正执行编译,调用ninja进入多线程编译
- 由于Android加入了大量的代码编译期工作,如API权限控制检查、API列表生成等工作(比如,生成系统API保护名单、插桩工作等等),因此编译过程实际上不是完全投入到编译中
- 编译过程穿插“泛打包工作”,如生成odex、art、res资源打包。虽然不同的“泛打包”可以多线程并行进行,但是每个打包本身只能单线程进行
下面将基于模块单编(因开发环境系统全新编译场景频率较低,不予考虑),对这四个关键阶段进行性能分析。
阶段一:Soong bootstrap
在系统已经整编过一次的情况下,Soong已经完成了编译,因此其预热过程占整个编译时间的比例会比较小。
在“环境”下,修改一行Framework代码触发差异进行编译。并且使用下面的命令进行编译。
time m services framework -j57
编译实际耗时22m37s:
build completed successfully (22:37 (mm:ss)) ####
real 22m37.504s
user 110m25.656s
sys 12m28.056s
对应的分阶段耗时如下图。
- 可以看到,包括Soong bootstrap流程在内的预热耗时占比非常低,耗时约为11.6s,总耗时约为1357s,预热耗时占比为
0.8%。
- Kati和ninja,也就是上述编译关键流程的第2步和第3步,分别占了接近60%(820秒,13分钟半)和约35%(521秒,8分钟半)的耗时,合计占比接近95%的耗时。
注:这个耗时是仅小幅度修改Java代码后测试的耗时。如果修改编译配置文件如Android.mk,会有更大的耗时。
小结:看来在完成一次整编后的模块单编,包括Soong bootstrap、执行编译准备脚本、vendorsetup脚本的耗时占比很低,可以完全排除存在性能瓶颈的可能。
阶段二:Kati遍历、mk搜集与ninja生成
从上图可以看到,Kati耗时占比很大,它的任务是遍历源码树,收集所有的编译配置文件,经过验证和筛选后,将它们解析并转化为.ninja。
从性能角度来看,它的主要特点如下:
- 它要遍历源码树,收集所有mk文件(In my case,有983个mk文件)
- 解析mk文件(In my case,framework/base/Android.mk耗费了~6800ms)
- 生成并写入对应的.ninja
- 单线程
直观展示如下,它是一个单线程的、IO速度敏感、CPU不敏感的过程:
Kati串行地处理文件,此时对CPU利用率很低,对IO的压力也不高。
小结:可以确定它的性能瓶颈来源于IO速度,单纯为编译实例分配更多的CPU资源也无益于提升Kati的速度。
阶段三:Ninja编译
SoongClone了一份GNU Make,并将其改造为Kati。即使我们没有修改任何mk文件,前面Kati仍然会花费数分钟到数十分钟的工作耗时,只为了生成一份能够被Ninja或.ninja的生成工具能够识别的文件。接下来是调用Ninja真正开始编译工作。
从性能角度来看,它的主要特点如下:
- 根据目标target及依赖,读取前面生成的.ninja配置,进行编译
- 比较独立,不与前面的组件,如blueprint、kati等耦合,只要
.ninja文件中能找到target和build rule就能完成编译 - 多线程
直观展示如下,Ninja将会根据传入的并行任务数参数启动对应数量的线程进行编译。Ninja编译阶段会真正的启动多线程。但做不到一直多线程编译,因为部分阶段如部分编译目标(比如生成一个API文档)、泛打包阶段等本身无法多线程并行执行。
可以看到此时CPU利用率应该是可以明显上升的。但是耗时较大的阶段仅启用了几个线程,后面的阶段和最后的图形很细(时间占比很小)的阶段才用起来更多的线程。
其中,一些阶段(图中时间占比较长的几条记录)没能跑满资源的原因是这些编译目标本身不支持并行,且本次编译命令指定的目标已经全部“安排”了,不需要调动更多资源启动其他编译目标的工作。当编译整个系统时就能够跑满了。
最后一个阶段(图中最后的几列很细的记录)虽然跑满了所有线程资源,但是运行时间很短。这是因为本case进行编译分析的过程中,仅修改了一行代码来触发编译。因编译工作量很小,所以这几列很细。
小结:我们看到,Ninja编译启动比较快,这表明Ninja对.ninja文件的读取解析并不敏感。整个过程也没有看到显著的耗时点。且最后面编译量很小,表明Ninja能够确保增量编译、未更新不编译。
编译优化
本节完成点题——Android系统编译优化:使用Ninja加快编译。
根据前面分析的小结,可以总结性能瓶颈:
- Kati遍历、生成太慢,受限于IO速率
- Kati吞吐量太低,单线程
- 不论有无更新均重新解析Makefile
利用Ninja进行编译优化的思路是,大多数场景,可以舍弃Kati的工作,仅执行Ninja的工作,以节省掉60%以上的时间。其核心思路,也是制约条件,即在不影响编译正确性的前提下,舍弃不必要的Kati编译工作。
- 使用
Ninja直接基于.ninja文件进行编译来改善耗时:
结合前面的分析,容易想到,如果目标被构建前,能够确保mk文件没有更新也不需要重新生成一长串的最终编译目标(即.ninja),那么make命令带来的Soong bootstrap、Kati等工作完全是重复的冗余的——这个性质Soong和Kati自己识别不出来,它们会重复工作一次。
既重新生成.ninja是冗余的,那么直接命令编译系统根据指定的.ninja进行编译显然会节省大量的工作耗时。ninja命令is the key:
使用源码中自带的ninja:
./prebuilts/build-tools/linux-x86/bin/ninja --version
1.8.2.git
对比最上面列出的make命令的编译,这里用ninja编译同样的目标:
time ./prebuilts/build-tools/linux-x86/bin/ninja -j 57 -v -f out/combined-full_xxxxxx.ninja services framework
ninja自己识别出来CPU平台后,默认使用-j58。这里为了对比上面的m命令,使用-j57编译
-f参数指定.ninja文件。它是编译配置文件,在Android中由Kati生成。这里文件名用'x'替换修改
编译结果,对比上面的m,有三倍的提升:
real 7m57.835s
user 97m12.564s
sys 8m31.756s
编译耗时为8分半,仅make的三分之一。As we can see,当能够确保编译配置没有更新,变更仅存在于源码范围时,使用Ninja直接编译,跳过Kati可以取得很显著的提升。
直接使用ninja:
./prebuilts/build-tools/linux-x86/bin/ninja -j $MAKE_JOBS -v -f out/combined-*.ninja <targets...>
对比汇总
这里找了一个其他项目的编译Demo,该Demo的特点是本身代码较简单,编译配置也较简单,整体编译工作较少,通过make编译的大部分耗时来自soong、make等工具自身的消耗,而真正执行编译的ninja耗时占比极其低。由于ninja本身跳过了soong,因此可以跳过这一无用的繁琐的耗时。可以看到下面,ninja编译iperf仅花费10秒。这个时间如果给soong来编译,预热都不够。
$ -> f_ninja_msf iperf
Run ninja with out/combined-full_xxxxxx.ninja to build iperf.
====== ====== ======
Ninja: ./prebuilts/build-tools/linux-x86/bin/ninja@1.8.2.git
Ninja: build with out/combined-full_xxxxxx.ninja
Ninja: build targets iperf
Ninja: j72
====== ====== ======
time /usr/bin/time ./prebuilts/build-tools/linux-x86/bin/ninja -j 72 -f out/combined-full_xxxxxx.ninja iperf
[24/24] Install: out/target/product/xxxxxx/system/bin/iperf
53.62user 11.09system 0:10.17elapsed 636%CPU (0avgtext+0avgdata 5696772maxresident)
4793472inputs+5992outputs (4713major+897026minor)pagefaults 0swaps
real 0m10.174s
user 0m53.624s
sys 0m11.096s
下面给出soong编译的恐怖耗时:
$ -> rm out/target/product/xxxxxx/system/bin/iperf
$ -> time m iperf -j72
...
[100% 993/993] Install: out/target/product/xxxxxx/system/bin/iperf
#### build completed successfully (14:45 (mm:ss)) ####
real 14m45.164s
user 23m40.616s
sys 11m46.248s
As we can see,m和ninja一个是10+ minutes,一个是10+ seconds,比例是88.5倍。
作者:飞起来_飞过来
链接:https://juejin.cn/post/7129437133089013767
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 标准库随处可见的 contract 到底是什么?
Kotlin 的标准库提供了不少方便的实用工具函数,比如 with, let, apply 之流,这些工具函数有一个共同特征:都调用了 contract() 函数。
@kotlin.internal.InlineOnly
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return receiver.block()
}
@kotlin.internal.InlineOnly
public inline fun repeat(times: Int, action: (Int) -> Unit) {
contract { callsInPlace(action) }
for (index in 0 until times) {
action(index)
}
}
contract?协议?它到底是起什么作用?
函数协议
contract 其实就是一个顶层函数,所以可以称之为函数协议,因为它就是用于函数约定的协议。
@ContractsDsl
@ExperimentalContracts
@InlineOnly
@SinceKotlin("1.3")
@Suppress("UNUSED_PARAMETER")
public inline fun contract(builder: ContractBuilder.() -> Unit) { }
用法上,它有两点要求:
- 仅用于顶层方法
- 协议描述须置于方法开头,且至少包含一个「效应」(Effect)
可以看到,contract 的函数体为空,居然没有实现,真是一个神奇的存在。这么一来,此方法的关键点就只在于它的参数了。
ContractBuilder
contract的参数是一个将 ContractBuilder 作为接受者的lambda,而 ContractBuilder 是一个接口:
@ContractsDsl
@ExperimentalContracts
@SinceKotlin("1.3")
public interface ContractBuilder {
@ContractsDsl public fun returns(): Returns
@ContractsDsl public fun returns(value: Any?): Returns
@ContractsDsl public fun returnsNotNull(): ReturnsNotNull
@ContractsDsl public fun <R> callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN): CallsInPlace
}
其四个方法分别对应了四种协议类型,它们的功能如下:
returns:表明所在方法正常返回无异常returns(value: Any?):表明所在方法正常执行,并返回 value(其值只能是 true、false 或者 null)returnsNotNull():表明所在方法正常执行,且返回任意非 null 值callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN):声明 lambada 只在所在方法内执行,所在方法执行完毕后,不会再被其他方法调用;可通过 kind 指定调用次数
前面已经说了,contract 的实现为空,所以作为接受着的 ContractBuilder 类型,根本没有实现类 —— 因为没有地方调用,就不需要啊。它的存在,只是为了声明所谓的协议代编译器使用。
InvocationKind
InvocationKind 是一个枚举类型,用于给 callsInPlace 协议方法指定执行次数的说明:
@ContractsDsl
@ExperimentalContracts
@SinceKotlin("1.3")
public enum class InvocationKind {
// 函数参数执行一次或者不执行
@ContractsDsl AT_MOST_ONCE,
// 函数参数至少执行一次
@ContractsDsl AT_LEAST_ONCE,
// 函数参数执行一次
@ContractsDsl EXACTLY_ONCE,
// 函数参数执行次数未知
@ContractsDsl UNKNOWN
}
InvocationKind.UNKNOWN,次数未知,其实就是指任意次数。标准工具函数中,repeat 就指定的此类型,因为其「重复」次数由参数传入,确实未知;而除它外,其余像 let、with 这些,都是用的InvocationKind.EXACTLY_ONCE,即单次执行。
Effect
Effect 接口类型,表示一个方法的执行协议约定,其不同子接口,对应不同的协议类型,前面提到的 Returns、ReturnsNotNull、CallsInPlace 均为它的子类型。
public interface Effect
public interface ConditionalEffect : Effect
public interface SimpleEffect : Effect {
public infix fun implies(booleanExpression: Boolean): ConditionalEffect
}
public interface Returns : SimpleEffect
public interface ReturnsNotNull : SimpleEffect
public interface CallsInPlace : Effect
简单明了,全员接口!来看一个官方使用,以便理解下这些接口的意义和使用:
public inline fun Array<*>?.isNullOrEmpty(): Boolean {
contract {
returns(false) implies (this@isNullOrEmpty != null)
}
return this == null || this.isEmpty()
}
这里涉及到两个 Effect:Returns 和 ConditionalEffect。此方法的功能为:判断数组为 null 或者是无元素空数组。它的 contract 约定是这样的:
- 调用
returns(value: Any?)获得Returns协议(当然也就是SimpleEffect协议),其传入值是 false - 第1步的
Returns调用implies方法,条件是「本对象非空」,得到了一个ConditionalEffect - 于是,最终协议的意思是:函数返回 false 意味着 接受者对象非空
isNullOrEmpty() 的功能性代码给出了返回值为 true 的条件。虽然反过来说,不满足该条件,返回值就是 false,但还是通过 contract 协议里首先说明了这一点。
协议的意义
讲到这里,contract 协议涉及到的基本类型及其使用已经清楚了。回过头来,前面说到,contract() 的实现为空,即函数体为空,没有实际逻辑。这说明,这个调用是没有实际执行效果的,纯粹是为编译器服务。
不妨模仿着 let 写一个带自定义 contract 测试一下这个结论:
// 类比于ContractBuilder
interface Bonjour {
// 协议方法
fun <R> parler(f: Function<R>) {
println("parler something")
}
}
// 顶层协议声明工具,类比于contract
inline fun bonjour(b: Bonjour.() -> Unit) {}
// 模仿let
fun<T, R> T.letForTest(block: (T) -> R): R {
println("test before")
bonjour {
println("test in bonjour")
parler<String> {
""
}
}
println("test after")
return block(this)
}
fun main(args: Array<String>) {
"abc".letForTest {
println("main: $it called")
}
}
letForTest() 是类似于 let 的工具方法(其本身功能逻辑不重要)。执行结果:
test before
test after
main: abc called
如预期,bonjour 协议以及 Bonjour 协议构造器中的所有日志都未打印,都未执行。
这再一次印证,contract 协议仅为编译器提供信息。那协议对编码来说到底有什么意义呢?来看看下面的场景:
fun getString(): String? {
TODO()
}
fun String?.isAvailable(): Boolean {
return this != null && this.length > 0
}
getString() 方法返回一个 String 类型,但是有可能为 null。isAvailable 是 String? 类型的扩展,用以判断是否一个字符串非空且长度大于 0。使用如下:
val target = getString()
if (target.isAvailable()) {
val result: String = target
}
按代码的设计初衷,上述调用没问题,target.isAvailable() 为 true,证明 target 是非空且长度大于 0 的字符串,然后内部将它赋给 String 类型 —— 相当于 String? 转换成 String。
可惜,上述代码,编译器不认得,报错了:
Type mismatch.
Required:
String
Found:
String?
编译器果然没你我聪明啊!要解决这个问题,自然就得今天的主角上场了:
fun String?.isAvailable(): Boolean {
contract {
returns(true) implies (this@isAvailable != null)
}
return this != null && this.length > 0
}
使用 contract 协议指定了一个 ConditionalEffect,描述意思为:如果函数返回true,意味着 Receiver 类型非空。然后,编译器终于懂了,前面的错误提示消失。
这就是协议的意义所在:让编译器看不懂的代码更加明确清晰。
小结
函数协议可以说是写工具类函数的利器,可以解决很多因为编译器不够智能而带来的尴尬问题。不过需要明白的是,函数协议还是实验性质的,还没有正式发布为 stable 功能,所以是有可能被 Kotlin 官方 去掉的。
作者:王可大虾
链接:https://juejin.cn/post/7128258776376803359
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
来,跟我一起撸Kotlin runBlocking/launch/join/async/delay 原理&使用
之前一些列的文章重点在于分析协程本质原理,了解了协程的内核再来看其它衍生的知识就比较容易了。
接下来这边文章着重分析协程框架提供的一些重要的函数原理,通过本篇文章,你将了解到:
- runBlocking 使用与原理
- launch 使用与原理
- join 使用与原理
- async/await 使用与原理
- delay 使用与原理
1. runBlocking 使用与原理
默认分发器的runBlocking
使用
老规矩,先上Demo:
fun testBlock() {
println("before runBlocking thread:${Thread.currentThread()}")
//①
runBlocking {
println("I'm runBlocking start thread:${Thread.currentThread()}")
Thread.sleep(2000)
println("I'm runBlocking end")
}
//②
println("after runBlocking:${Thread.currentThread()}")
}
runBlocking 开启了一个新的协程,它的特点是:
协程执行结束后才会执行runBlocking 后的代码。
也就是① 执行结束后 ② 才会执行。
可以看出,协程运行在当前线程,因此若是在协程里执行了耗时函数,那么协程之后的代码只能等待,基于这个特性,runBlocking 经常用于一些测试的场景。
runBlocking 可以定义返回值,比如返回一个字符串:
fun testBlock2() {
var name = runBlocking {
"fish"
}
println("name $name")
}
原理
#Builders.kt
public fun <T> runBlocking(context: CoroutineContext = EmptyCoroutineContext, block: suspend CoroutineScope.() -> T): T {
//当前线程
val currentThread = Thread.currentThread()
//先看有没有拦截器
val contextInterceptor = context[ContinuationInterceptor]
val eventLoop: EventLoop?
val newContext: CoroutineContext
//----------①
if (contextInterceptor == null) {
//不特别指定的话没有拦截器,使用loop构建Context
eventLoop = ThreadLocalEventLoop.eventLoop
newContext = GlobalScope.newCoroutineContext(context + eventLoop)
} else {
eventLoop = (contextInterceptor as? EventLoop)?.takeIf { it.shouldBeProcessedFromContext() }
?: ThreadLocalEventLoop.currentOrNull()
newContext = GlobalScope.newCoroutineContext(context)
}
//BlockingCoroutine 顾名思义,阻塞的协程
val coroutine = BlockingCoroutine<T>(newContext, currentThread, eventLoop)
//开启
coroutine.start(CoroutineStart.DEFAULT, coroutine, block)
//等待协程执行完成----------②
return coroutine.joinBlocking()
}
重点看①②。
先说①,因为我们没有指定分发器,因此会使用loop,实际创建的是BlockingEventLoop,它继承自EventLoopImplBase,最终继承自CoroutineDispatcher(注意此处是个重点)。
根据我们之前分析的协程知识可知,协程启动后会构造DispatchedContinuation,然后依靠dispatcher将runnable 分发执行,而这个dispatcher 即是BlockingEventLoop。
#EventLoop.common.kt
//重写dispatch函数
public final override fun dispatch(context: CoroutineContext, block: Runnable) = enqueue(block)
public fun enqueue(task: Runnable) {
//将task 加入队列,task = DispatchedContinuation
if (enqueueImpl(task)) {
unpark()
} else {
DefaultExecutor.enqueue(task)
}
}
BlockingEventLoop 的父类EventLoopImplBase 里有个成员变量:_queue,它是个队列,用来存储提交的任务。
再看②:
协程任务已经提交到队列里,就看啥时候取出来执行了。
#Builders.kt
fun joinBlocking(): T {
try {
try {
while (true) {
//当前线程已经中断了,直接退出
if (Thread.interrupted()) throw InterruptedException().also { cancelCoroutine(it) }
//如果eventLoop!= null,则从队列里取出task并执行
val parkNanos = eventLoop?.processNextEvent() ?: Long.MAX_VALUE
//协程执行结束,跳出循环
if (isCompleted) break
//挂起线程,parkNanos 指的是挂起时间
parkNanos(this, parkNanos)
//当线程被唤醒后,继续while循环
}
} finally { // paranoia
}
}
//返回结果
return state as T
}
#EventLoop.common.kt
override fun processNextEvent(): Long {
//延迟队列
val delayed = _delayed.value
//延迟队列处理,这里在分析delay时再解释
//从队列里取出task
val task = dequeue()
if (task != null) {
//执行task
task.run()
return 0
}
return nextTime
}
上面代码的任务有两个:
- 尝试从队列里取出Task。
- 若是没有则挂起线程。
结合①②两点,再来过一下场景:
- 先创建协程,包装为DispatchedContinuation,作为task。
- 分发task,将task加入到队列里。
- 从队列里取出task执行,实际执行的即是协程体。
- 当3执行完毕后,runBlocking()函数也就退出了。
其中虚线箭头表示执行先后顺序。
由此可见,runBlocking()函数需要等待协程执行完毕后才退出。
指定分发器的runBlocking
上个Demo在使用runBlocking 时没有指定其分发器,若是指定了又是怎么样的流程呢?
fun testBlock3() {
println("before runBlocking thread:${Thread.currentThread()}")
//①
runBlocking(Dispatchers.IO) {
println("I'm runBlocking start thread:${Thread.currentThread()}")
Thread.sleep(2000)
println("I'm runBlocking end")
}
//②
println("after runBlocking:${Thread.currentThread()}")
}
指定在子线程里进行分发。
此处与默认分发器最大的差别在于:
默认分发器加入队列、取出队列都是同一个线程,而指定分发器后task不会加入到队列里,task的调度执行完全由指定的分发器完成。
也就是说,coroutine.joinBlocking()后,当前线程一定会被挂起。等到协程执行完毕后再唤醒当前被挂起的线程。
唤醒之处在于:
#Builders.kt
override fun afterCompletion(state: Any?) {
// wake up blocked thread
if (Thread.currentThread() != blockedThread)
//blockedThread 即为调用coroutine.joinBlocking()后阻塞的线程
//Thread.currentThread() 为线程池的线程
//唤醒线程
unpark(blockedThread)
}
红色部分比紫色部分先执行,因此红色部分执行的线程会阻塞,等待紫色部分执行完毕后将它唤醒,最后runBlocking()函数执行结束了。
不管是否指定分发器,runBlocking() 都会阻塞等待协程执行完毕。
2. launch 使用与原理
想必大家刚接触协程的时候使用最多的还是launch启动协程吧。
看个Demo:
fun testLaunch() {
var job = GlobalScope.launch {
println("hello job1 start")//①
Thread.sleep(2000)
println("hello job1 end")//②
}
println("continue...")//③
}
非常简单,启动一个线程,打印结果如下:
③一定比①②先打印,同时也说明launch()函数并不阻塞当前线程。
关于协程原理,在之前的文章都有深入分析,此处不再赘述,以图示之:
3. join 使用与原理
虽然launch()函数不阻塞线程,但是我们就想要知道协程执行完毕没,进而根据结果确定是否继续往下执行,这时候该Job.join()出场了。
先看该函数的定义:
#Job.kt
public suspend fun join()
是个suspend 修饰的函数,suspend 是咱们的老朋友了,说明协程执行到该函数会挂起(当前线程不阻塞,另有他用)。
继续看其实现:
#JobSupport.kt
public final override suspend fun join() {
//快速判断状态,不耗时
if (!joinInternal()) { // fast-path no wait
coroutineContext.ensureActive()
return // do not suspend
}
//挂起的地方
return joinSuspend() // slow-path wait
}
//suspendCancellableCoroutine 典型的挂起操作
//cont 是封装后的协程
private suspend fun joinSuspend() = suspendCancellableCoroutine<Unit> { cont ->
//执行完这就挂起
//disposeOnCancellation 是将cont 记录在当前协程的state里,构造为node
cont.disposeOnCancellation(invokeOnCompletion(handler = ResumeOnCompletion(cont).asHandler))
}
其中suspendCancellableCoroutine 是挂起的核心所在,关于挂起的详细分析请移步:讲真,Kotlin 协程的挂起没那么神秘(原理篇)
joinSuspend()函数有2个作用:
- 将当前协程体存储到Job的state里(作为node)。
- 将当前协程挂起。
什么时候恢复呢?当然是协程执行完成后。
#JobSupport.kt
private class ResumeOnCompletion(
private val continuation: Continuation<Unit>
) : JobNode() {
//continuation 为协程的包装体,它里面有我们真正的协程体
//之后重新进行分发
override fun invoke(cause: Throwable?) = continuation.resume(Unit)
}
当协程执行完毕,会例行检查当前的state是否有挂着需要执行的node,刚好我们在joinSuspend()里放了node,于是找到该node,进而找到之前的协程体再次进行分发。根据协程状态机的知识可知,这是第二次执行协程体,因此肯定会执行job.join()之后的代码,于是乎看起来的效果就是:
job.join() 等待协程执行完毕后才会往下执行。
语言比较苍白,来个图:
注:此处省略了协程挂起等相关知识,如果对此有疑惑请阅读之前的文章。
4. async/await 使用与原理
launch 有2点不足之处:协程执行没有返回值。
这点我们从它的定义很容易获悉:
然而,在有些场景我们需要返回值,此时轮到async/await 出场了。
fun testAsync() {
runBlocking {
//启动协程
var job = GlobalScope.async {
println("job1 start")
Thread.sleep(10000)
//返回值
"fish"
}
//等待协程执行结束,并返回协程结果
var result = job.await()
println("result:$result")
}
}
运行结果:
接着来看实现原理。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
//构造DeferredCoroutine
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
//coroutine == DeferredCoroutine
coroutine.start(start, coroutine, block)
return coroutine
}
与launch 启动方式不同的是,async 的协程定义了返回值,是个泛型。并且async里使用的是DeferredCoroutine,顾名思义:延迟给结果的协程。
后面的流程都是一样的,不再细说。
再来看Job.await(),它与Job.join()类似:
- 先判断是否需要挂起,若是协程已经结束/被取消,当然就无需等待直接返回。
- 先将当前协程体包装到state里作为node存放,然后挂起协程。
- 等待async里的协程执行完毕,再重新调度执行await()之后的代码。
- 此时协程的值已经返回。
这里需要重点关注一下返回值是怎么传递过来的。
将testAsync()反编译:
public final Object invokeSuspend(@NotNull Object $result) {
//result 为协程执行结果
Object var6 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
Object var10000;
switch(this.label) {
case 0:
//第一次执行这
ResultKt.throwOnFailure($result);
Deferred job = BuildersKt.async$default((CoroutineScope) GlobalScope.INSTANCE, (CoroutineContext)null, (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object var1) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure(var1);
String var2 = "job1 start";
boolean var3 = false;
System.out.println(var2);
Thread.sleep(10000L);
return "fish";
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
}
}), 3, (Object)null);
this.label = 1;
//挂起
var10000 = job.await(this);
if (var10000 == var6) {
return var6;
}
break;
case 1:
//第二次执行这
ResultKt.throwOnFailure($result);
//result 就是demo里的"fish"
var10000 = $result;
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
String result = (String)var10000;
String var4 = "result:" + result;
boolean var5 = false;
System.out.println(var4);
return Unit.INSTANCE;
}
很明显,外层的协程(runBlocking)体会执行2次。
第1次:调用invokeSuspend(xx),此时参数xx=Unit,后遇到await 被挂起。
第2次:子协程执行结束并返回结果"fish",恢复外部协程时再次调用invokeSuspend(xx),此时参数xx="fish",并将参数保存下来,因此result 就有了值。
值得注意的是:
async 方式启动的协程,若是协程发生了异常,不会像launch 那样直接抛出,而是需要等待调用await()时抛出。
5. delay 使用与原理
线程可以被阻塞,协程可以被挂起,挂起后的协程等待时机成熟可以被恢复。
fun testDelay() {
GlobalScope.launch {
println("before getName")
var name = getUserName()
println("after getName name:$name")
}
}
suspend fun getUserName():String {
return withContext(Dispatchers.IO) {
//模拟网络获取
Thread.sleep(2000)
"fish"
}
}
获取用户名字是在子线程获取的,它是个挂起函数,当协程执行到此时挂起,等待获取名字之后再恢复运行。
有时候我们仅仅只是想要协程挂起一段时间,并不需要去做其它操作,这个时候我们可以选择使用delay(xx)函数:
fun testDelay2() {
GlobalScope.launch {
println("before delay")
//协程挂起5s
delay(5000)
println("after delay")
}
}
再来看看其原理。
#Delay.kt
public suspend fun delay(timeMillis: Long) {
//没必要延时
if (timeMillis <= 0) return // don't delay
return suspendCancellableCoroutine sc@ { cont: CancellableContinuation<Unit> ->
//封装协程为cont,便于之后恢复
if (timeMillis < Long.MAX_VALUE) {
//核心实现
cont.context.delay.scheduleResumeAfterDelay(timeMillis, cont)
}
}
}
主要看context.delay 实现:
#DefaultExecutor.kt
internal actual val DefaultDelay: Delay = kotlinx.coroutines.DefaultExecutor
//单例
internal actual object DefaultExecutor : EventLoopImplBase(), Runnable {
const val THREAD_NAME = "kotlinx.coroutines.DefaultExecutor"
//...
private fun createThreadSync(): Thread {
return DefaultExecutor._thread ?: Thread(this, DefaultExecutor.THREAD_NAME).apply {
DefaultExecutor._thread = this
isDaemon = true
start()
}
}
//...
override fun run() {
//循环检测队列是否有内容需要处理
//决定是否要挂起线程
}
//...
}
DefaultExecutor 是个单例,它里边开启了线程,并且检测队列里任务的情况来决定是否需要挂起线程等待。
先看队列的出入队情况。
放入队列
我们注意到DefaultExecutor 继承自EventLoopImplBase(),在最开始分析runBlocking()时有提到过它里面有成员变量_queue 存储队列元素,实际上它还有另一个成员变量_delayed:
#EventLoop.common.kt
internal abstract class EventLoopImplBase: EventLoopImplPlatform(), Delay {
//存放正常task
private val _queue = atomic<Any?>(null)
//存放延迟task
private val _delayed = atomic<EventLoopImplBase.DelayedTaskQueue?>(null)
}
private inner class DelayedResumeTask(
nanoTime: Long,
private val cont: CancellableContinuation<Unit>
) : EventLoopImplBase.DelayedTask(nanoTime) {
//协程恢复
override fun run() { with(cont) { resumeUndispatched(Unit) } }
override fun toString(): String = super.toString() + cont.toString()
}
delay.scheduleResumeAfterDelay 本质是创建task:DelayedResumeTask,并将该task加入到延迟队列_delayed里。
从队列取出
DefaultExecutor 一开始就会调用processNextEvent()函数检测队列是否有数据,如果没有则将线程挂起一段时间(由processNextEvent()返回值确定)。
那么重点转移到processNextEvent()上。
##EventLoop.common.kt
override fun processNextEvent(): Long {
if (processUnconfinedEvent()) return 0
val delayed = _delayed.value
if (delayed != null && !delayed.isEmpty) {
//调用delay 后会放入
//查看延迟队列是否有任务
val now = nanoTime()
while (true) {
//一直取任务,直到取不到(时间未到)
delayed.removeFirstIf {
//延迟任务时间是否已经到了
if (it.timeToExecute(now)) {
//将延迟任务从延迟队列取出,并加入到正常队列里
enqueueImpl(it)
} else
false
} ?: break // quit loop when nothing more to remove or enqueueImpl returns false on "isComplete"
}
}
// 从正常队列里取出
val task = dequeue()
if (task != null) {
//执行
task.run()
return 0
}
//返回线程需要挂起的时间
return nextTime
}
而执行任务最终就是执行DelayedResumeTask.run()函数,该函数里会对协程进行恢复。
至此,delay 流程就比较清晰了:
- 构造task 加入到延迟队列里,此时协程挂起。
- 有个单独的线程会检测是否需要取出task并执行,没到时间的话就要挂起等待。
- 时间到了从延迟队列里取出并放入正常的队列,并从正常队列里取出执行。
- task 执行的过程就是协程恢复的过程。
老规矩,上图:
图上虚线紫色框部分表明delay 执行到此就结束了,协程挂起(不阻塞当前线程),剩下的就交给单例的DefaultExecutor 调度,等待延迟的时间结束后通知协程恢复即可。
关于协程一些常用的函数分析到此就结束了,下篇开始我们一起探索协程通信(Channel/Flow 等)相关知识。
由于篇幅原因,省略了一些源码的分析,若你对此有疑惑,可评论或私信小鱼人。
作者:小鱼人爱编程
链接:https://juejin.cn/post/7128961903220490270
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
润了!大龄码农从北京到荷兰的躺平生活
今天在知乎刷到了一篇大龄码农从北京到荷兰的日记,看完后着实令人羡慕不已,国外不仅生活环境和工作强度,都要比国内轻松很多,以下为原文。
作者:小李在荷兰 | 编辑:对白的算法屋
一. 背景介绍
光阴似箭,今年已经41岁的老码农一枚。在家乡生活了19年,然后到北京学习工作了19年。一直希望去北美发展,由于种种原因最终还是没有去成。出国前在朋友的公司干了一年多,本来想着趁没到40岁再拼一把,结果很遗憾,失败离场。一晃眼已经要到孩子上学的年龄,所以决定快刀斩乱麻果断出国。
二. 工作机会
在前同事(我的前Manager)的推荐下,成功通过荷兰http://Booking.com的面试。
拿到offer签完合同后,Booking会非常贴心地安排几个专员协助后续的流程,包括:搬家,签证,机票,接机,抵达荷兰后入住的酒店,租房中介服务,银行账户,市政厅档案提交等等一些列大大小的事务,整个流程专业且流畅。
三. 搬家
决定使用Booking提供的员工搬家服务后,对接国际搬家服务的公司和我联系并上门初步估算需要搬运的家具等讲占据的空间,Booking最多提供一个集装箱的空间帮助入职员工搬家。搬家相关的一切事务由搬家公司负责,从时间规划,空间大小估算,上门打包,装车,报关等。老实说当时我很忐忑,这么多东西得搬到什么时候啊!但是令我很吃惊的是,专业公司就是不一样,只用了2个小时(6个人),差不多就把我北京的家搬空了。一句话概括:这次搬家是我有史以来感觉到最满意的搬家服务。
另外,Booking还支持将车运到荷兰,以及支持宠物搬家(有限报销)。
四. 签证
Booking提供HSM工作签证,签证会有专业的移民公司跟进。公司协助:递交给大使馆的签证材料清单,提交给荷兰市政厅的材料清单,获得 30% ruling材料清单。签证材料其实是比较麻烦的,其中最麻烦的是出生证明,但是这个方面每个人的情况不同,此处不表。另外,所有材料都需要经过公证(含翻译),然后中国大使馆,荷兰大使馆双认证。我本人怕麻烦,花钱找的中介办理的,一家三口的签证材料也花了不少钱。
当年9月份,在北京亮马河的荷兰大使馆提交完材料后,整个人都轻松了,出国前最麻烦的一个阶段终于结束。

提交完签证去了蓝色港湾走一走
五. 出发前的准备
打点好北京的房子、车子
去银行取了前期在荷兰生活用的现金(人生头一次拥有那么多欧元现钞)
办理小孩用的国际疫苗本,给小孩办理幼儿园的退学手续(仅仅上了一个礼拜)
注销不用的手机卡
将自己很多重要的文件档案扫描备用
吃了好多好多小龙虾
带着孩子在北京周边尽情地玩耍
和好友,同事们道别
和荷兰的租房中介公司沟通,此时他们已经开始进入协助租房的流程了
开始了解荷兰的幼儿园和小学情况,Booking有相应的服务协助家属融入荷兰社会
与此同时,Booking开始为入职做准备工作
六. 出发
按照预定好的出发日期,家人将我们一家三口送到了机场。本来一切都很平静,家属之前也去过荷兰。只是登机前,女儿问了我一句:爸爸我们要去荷兰了嘛?我们还回北京吗?瞬间有点要飙泪的感觉。

七. 抵达
10个小时后,我们一家人顺利抵达了荷兰阿姆斯特丹斯基浦机场。天气很好,心情愉悦。
海关一听到是Booking的员工,直接就盖戳了,家属也没有问问题。出关后,去公司指定的柜台等待接机的司机到来,然后带着行李前往酒店。

八. 入住酒店
阿姆斯特丹很小,我们很快就抵达了酒店。
Booking很贴心地根据我们的人数给提供了两室一厅的公寓酒店,可以自己做饭。我们去超市买了水果牛奶面包和三文鱼,吃完就早早休息倒时差了。




九. 开始工作
正式入职后,第一个月公司将新入职员工分配到了Bootcamp,进行入职培训。
当时第一个月基本每天就是早上来喝喝咖啡,参加一下入职培训和各种手续:包括完善员工资料、工作技能培训、公司文化培训、保险知识、租房买房知识、税务问题等。与此同时,需要去和中介公司去看房(下面会提到),争取早日租到房搬离酒店公寓。用当时他们(我当时接触过的几个Manager)的话来说就是:这个阶段你最重要的任务是全家安顿下来。
入职培训差不多结束时,我被现在所在组的TL领了过去,换了办公室,正式开始工作。
说一下WLB的问题,我所在公司这方面非常好,大部分同事都是早上9点-10点陆陆续续到公司,吃早饭接水接咖啡开会,中午12:00-1:00去食堂吃午饭,下午4:30-5:30就走了。我被TL找过两次非正式谈话,说我工作太卖力了,5点就走吧。其实我不是想做奋斗逼,只是有时进入状态了实在不想放下手中的活。试过几次呆到8点多,然后被保安轰走:先生,我要下班了。
疫情前,每天下班感觉都特别好:
下了班就不用管了,所以一下班就特别轻松,没有OnCall因为有SRE,没有人会给你发消息(特别极端的情况会,但是目前还没有遇到过)。
每天都特别有仪式感,特别是下班出门:把桌上的水果皮扔了,把喝咖啡的杯子放回去,把笔记本放入包中,带上围巾,带上耳机,穿上外套,背上背包,根据GoogleMap计算好的时间听着音乐准时走到公交车站...

收起阅读 »
Elasticsearch 为什么会产生文档版本冲突?如何避免?
1、Elasticsearch 版本冲突复现
先让大家直观的看到 Elasticsearch 文档版本冲突。
1.1 场景1:create 场景
DELETE my-index-000001
# 执行创建并写入
PUT my-index-000001/_create/1
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
# 再次执行会报版本冲突错误。
# 报错信息:[1]: version conflict, document already exists (current version [1])
PUT my-index-000001/_create/1
{
"@timestamp": "2099-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "kimchy"
}
}
1.2 场景2:批量更新场景模拟
模拟脚本1:循环写入数据 index.sh。

模拟脚本2:循环update_by_query 批量更新数据 update.sh。
由于:写入脚本 index.sh 比更新脚本 update.sh (执行一次,休眠1秒)执行要快,所以更新获取的版本较写入的最新版本要低,会导致版本冲突如下图所示:
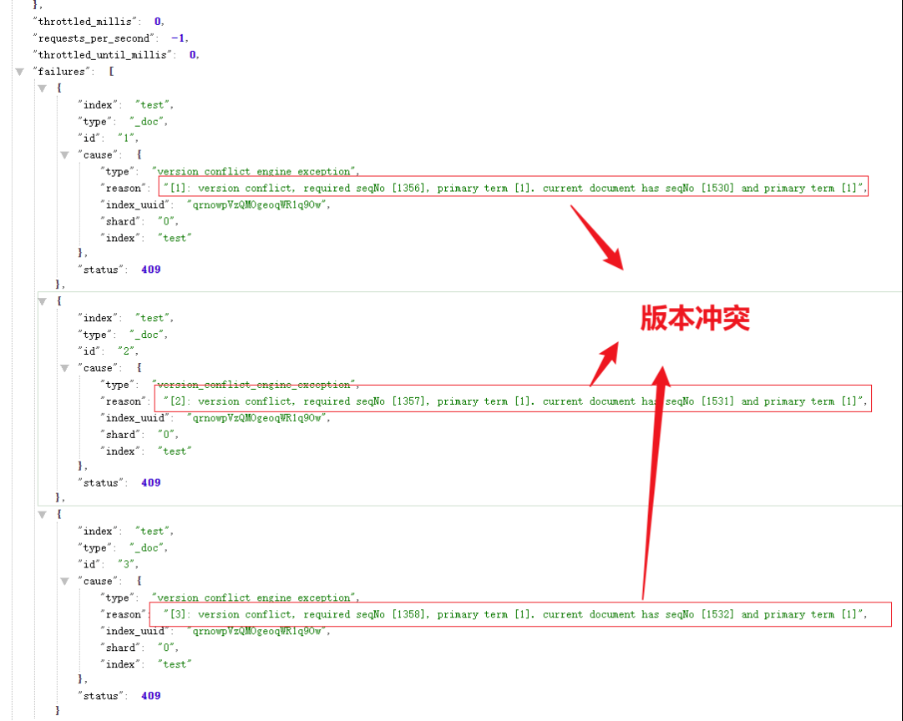
1.3 场景3:批量删除场景模拟
写入脚本 index.sh 不变。
删除脚本 delete.sh 如下:
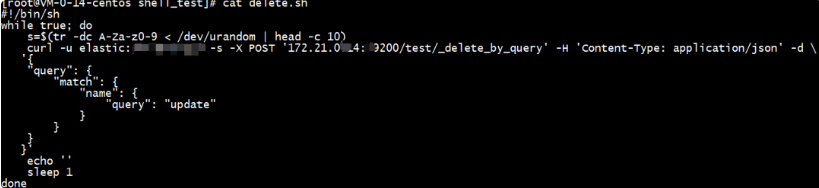
和更新原因一致,由于:写入脚本 index.sh 比删除脚本 delete.sh (执行一次,休眠1秒)执行要快,所以删除获取的版本较写入的最新版本要低,会导致版本冲突如下图所示:
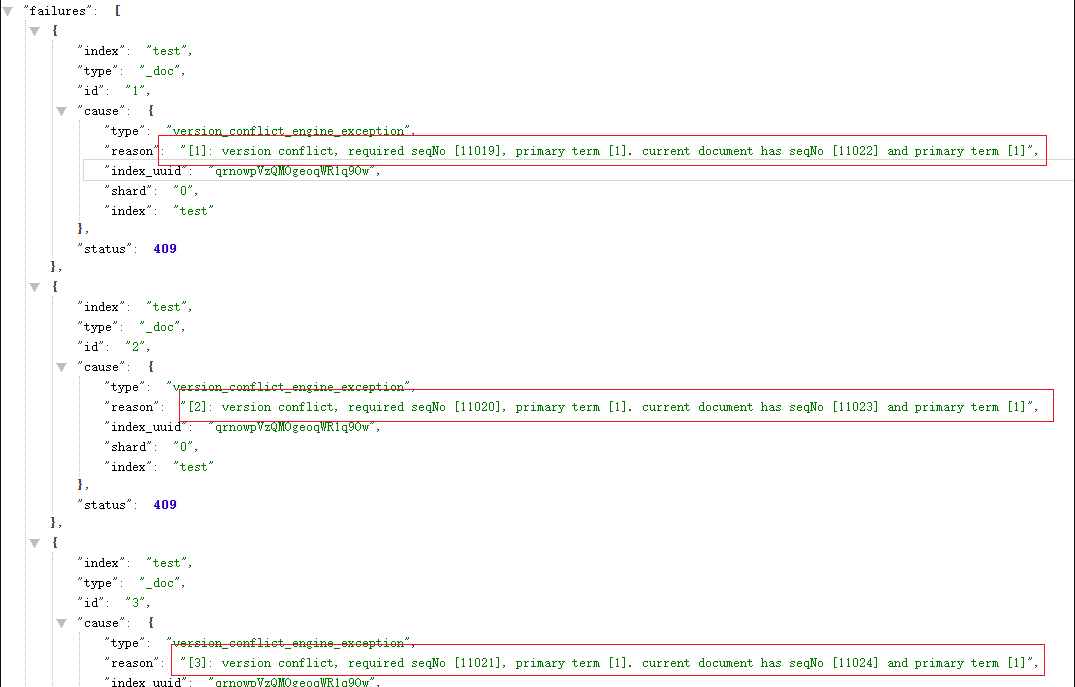
2、Elasticsearch 文档版本定义
执行:
GET test/_doc/1召回结果如下:
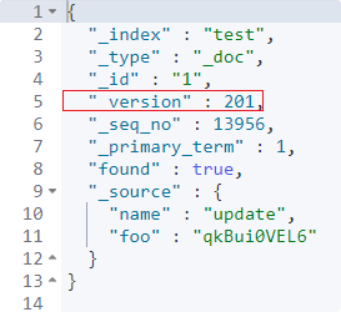
这里的 version 代表文档的版本。
当我们在 Elasticsearch 中创建一个新文档时,它会为该文档分配一个_version: 1。
当我们对该文档进行任何后续更新(更新 update、索引 index 或删除 delete)时,_version都会增加 1。
一句话:Elasticsearch 使用_version来鉴别文档是否已更改。
3、Elasticsearch 文档版本产生背景
试想一下,如果没有文档版本?当有并发访问会怎么办?
前置条件:Elasticsearch 从写入到被检索的时间间隔是由刷新频率 refresh_interval 设定的,该值可以更新,但默认最快是 1 秒。
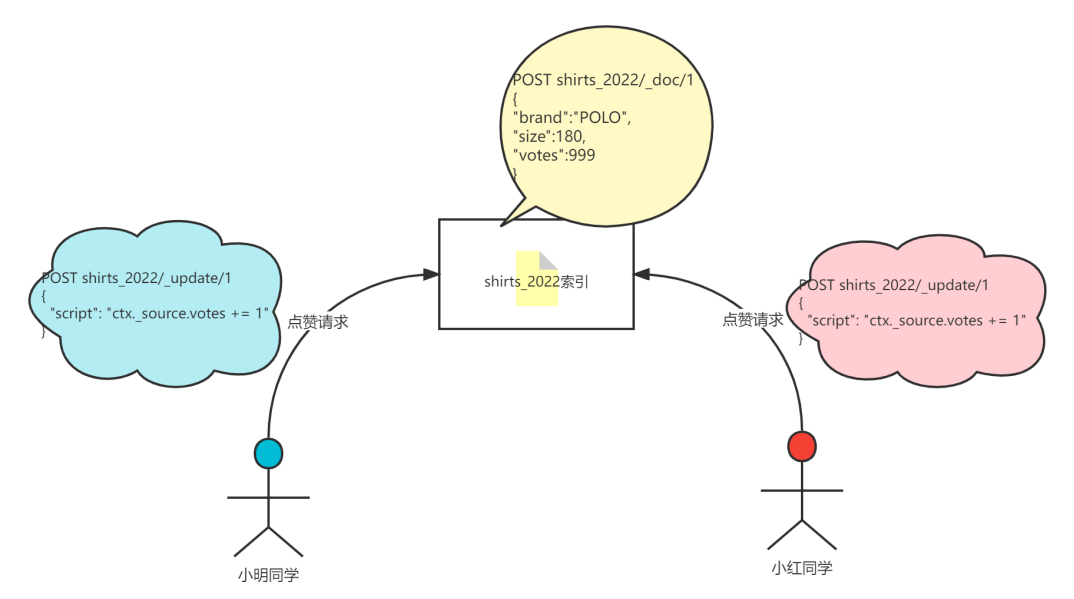
如上图所示,假设我们有一个人们用来评价 T 恤设计的网站。网站很简单,仅列出了T恤设计,允许用户给T恤投票。如果顺序投票,没有并发请求,直接发起update更新没有问题。
但是,在999累计投票数后,碰巧小明同学和小红同学两位同时(并发)发起投票请求,这时候,如果没有版本控制,将导致最终结果不是预期的1001,而是1000。
所以,为了处理上述场景以及比上述更复杂的并发场景,Elasticsearch 亟需一个内置的文档版本控制系统。这就是 _version 的产生背景。
https://www.elastic.co/cn/blog/elasticsearch-versioning-support
4、常见的并发控制策略
并发控制可以简记为:“防止两个或多个用户同时编辑同一记录而导致最终结果和预期不一致”。
常见的并发控制策略:悲观锁、乐观锁。
4.1 悲观锁
悲观锁,又名:悲观并发控制,英文全称:"Pessimistic Concurrency Control",缩写“PCC”,是一种并发控制的方法。
悲观锁本质:在修改数据之前先锁定,再修改。
悲观锁优点:采用先锁定后修改的保守策略,为数据处理的安全提供了保证。
悲观锁缺点:加锁会有额外的开销,还会增加产生死锁的机会。
悲观锁应用场景:比较适合写入操作比较频繁的场景。
4.2 乐观锁
乐观锁,又名:乐观并发控制,英文全称:“Optimistic Concurrency Control”,缩写OCC”,也是一种并发控制的方法。
乐观锁本质:假设多用户并发的事务在处理时不会彼此互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据。在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其他事务有更新的话,正在提交的事务会进行回滚。
乐观锁优点:“胆子足够大,足够乐观”,直到提交的时候才去锁定,不会产生任何锁和死锁。
乐观锁缺点:并发写入会有问题,需要有冲突避免策略补救。
乐观锁应用场景:数据竞争(data race)不大、冲突较少的场景、比较适合读取操作比较频繁的场景,确保比其他并发控制方法(如悲观锁)更高的吞吐量。
这里要强调的是,Elasticsearch 采用的乐观锁的机制来处理并发问题。
Elasticsearch 乐观锁本质是:没有给数据加锁,而是基于 version 文档版本实现。每次更新或删除数据的时候,都需要对比版本号。
5、Elasticsearch 文档版本冲突的本质
一句话,Elasticsearch 文档冲突的本质——老版本覆盖掉了新版本。
6、如何解决或者避免 Elasticsearch 文档版本冲突?
6.1 external 外部控制版本号
“external”——我的理解就是“简政放权”,交由外部的数据库或者更确切的说,是写入的数据库或其他第三方库来做控制。
版本号可以设置为外部值(例如,如果在数据库中维护)。要启用此功能,version_type应设置为 external。
使用外部版本类型 external 时,系统会检查传递给索引请求的版本号是否大于当前存储文档的版本。
如果为真,也就是新版本大于已有版本,则文档将被索引并使用新的版本号。
如果提供的值小于或等于存储文档的版本号,则会发生版本冲突,索引操作将失败。
好处:不论何时,ES 中只有最新版本的数据,借助 external 相对有效的解决版本冲突问题。
实战一把:
如果没有 external,执行如下命令:
PUT my-index-000001/_doc/1?version=2
{
"user": {
"id": "elkbee"
}
}报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "action_request_validation_exception",
"reason" : "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"
}
],
.......省略2行......
"status" : 400
}啥意思呢?内部版本控制(internal)不能用于乐观锁,也就是直接使用 version 是不可以的。需要使用:if_seq_no 和 if_primary_term,它俩的用法,后文会有专门解读。
如果用 external,执行如下命令:
PUT my-index-000001/_doc/1?version=2&version_type=external
{
"user": {
"id": "elkbee"
}
}执行结果如下:
{
"_index" : "my-index-000001",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}相比于之间没有加 external,加上 external 后,可以实现基于version的文档更新操作。
external_gt 和 external_gte的用法见官方文档,本文不展开,原理同 external。
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs-index_.html#index-versioning
6.2 通过if_seq_no 和 if_primary_term 唯一标识避免冲突
索引操作(Index,动词)是有条件的,并且只有在对文档的最后修改分配了由 if_seq_no 和 if_primary_term 参数指定的序列号和 primary term specified(翻译起来拗口,索性用英文)才执行。
如果检测到不匹配,该操作将产生一个 VersionConflictException 409 的状态码。
Step1:写入数据
DELETE products_001
PUT products_001/_doc/1567
{
"product" : "r2d2",
"details" : "A resourceful astromech droid"
}
# 查看ifseqno 和 ifprimaryterm
GET products_001/_doc/1567返回:
{
"_index" : "products_001",
"_type" : "_doc",
"_id" : "1567",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"product" : "r2d2",
"details" : "A resourceful astromech droid"
}
}Step2:以这种方式更新,前提是先拿到 if_seq_no 和 if_primary_term
# 模拟数据打tag 过程
PUT products_001/_doc/1567?if_seq_no=0&if_primary_term=1
{
"product": "r2d2",
"details": "A resourceful astromech droid",
"tags": [ "droid" ]
}
# 再获取数据
GET products_001/_doc/1567返回:
{
"_index" : "products_001",
"_type" : "_doc",
"_id" : "1567",
"_version" : 2,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"product" : "r2d2",
"details" : "A resourceful astromech droid",
"tags" : [
"droid"
]
}
}step2 更新数据的时候,是在 step1 的获取已写入文档的 if_seq_no=0 和 if_primary_term=1 基础上完成的。
这样能有效避免冲突。
6.3 批量更新和批量删除忽略冲突实现
如下是在开篇的基础上加了:conflicts=proceed。
conflicts 默认值是终止,而 proceed 代表继续。
POST test/_update_by_query?conflicts=proceed
{
"query": {
"match": {
"name": "update"
}
},
"script": {
"source": "ctx._source['foo'] = '123ss'",
"lang": "painless"
}
}conflicts=proceed 的本质——告诉进程忽略冲突并继续更新其他文档。
开篇不会报 409 错误了,但依然会有版本冲突。但,某些企业级场景是可以用的。

同理,delete_by_query 参数及返回结果均和 update_by_query 一致。

扩展:单个更新 update (区别于批量更新:update_by_query)有 retry_on_conflict 参数,可以设置冲突后重试次数。
7、关于频繁更新带来的性能问题
正如文章开篇演示的,并发更新或者并发删除可能会导致版本冲突。
除了并发性和正确性之外,请注意,非常频繁地更新文档可能会导致性能下降。
如果更新了尚未写入段(segment)的文档,将会导致刷新操作。而刷新频率越小(企业级咨询我见过设置小于1s的,不推荐),势必会导致写入低效。
更多探讨推荐阅读:
https://discuss.elastic.co/t/handling-conflicts/135240/2
8、小结
从实际问题抽象出模拟脚本,让大家看到文档版本冲突是如何产生的。而后,定义了版本冲突并指出了其产生的背景。
接着,详细讲解了解决冲突的两种机制:乐观锁、悲观锁。探讨、验证了解决文档版本冲突的几种方案。
你有没有遇到过本文提及的问题,如何解决的呢?欢迎留言交流。
参考
[2] https://learnku.com/articles/43867
[3] https://www.elastic.co/guide/en/elasticsearch/reference/current/optimistic-concurrency-control.html
[5] https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs-index_.html#index-versioning
来源:mp.weixin.qq.com/s/9XzOogqfz4tavXqDt1pxgA
收起阅读 »封装一个有趣的 Loading 组件
前言
在上一篇普通的加载千篇一律,有趣的 loading 万里挑一 中,我们介绍了使用Path类的PathMetrics属性来控制绘制点在路径上运动来实现比较有趣的loading效果。有评论说因为是黑色背景,所以看着好看。黑色背景确实显得高端一点,但是并不是其他配色也不行,本篇我们来封装一个可以自定义配置前景色和背景色的Loading组件。
组件定义
loading组件共定义4个入口参数:
- 前景色:绘制图形的前景色;
- 背景色:绘制图形的背景色;
- 图形尺寸:绘制图形的尺寸;
- 加载文字:可选,如果有文字就显示,没有就不显示。
得到的Loading组件类如下所示:
class LoadingAnimations extends StatefulWidget {
final Color bgColor;
final Color foregroundColor;
String? loadingText;
final double size;
LoadingAnimations(
{required this.foregroundColor,
required this.bgColor,
this.loadingText,
this.size = 100.0,
Key? key})
: super(key: key);
@override
_LoadingAnimationsState createState() => _LoadingAnimationsState();
}
圆形Loading
我们先来实现一个圆形的loading,效果如下所示。 这里绘制了两组沿着一个大圆运动的轴对称的实心圆,半径依次减小,圆心间距随着动画时间逐步拉大。实际上实现的核心还是基于
Path的PathMetrics。具体实现代码如下:
_drawCircleLoadingAnimaion(
Canvas canvas, Size size, Offset center, Paint paint) {
final radius = boxSize / 2;
final ballCount = 6;
final ballRadius = boxSize / 15;
var circlePath = Path()
..addOval(Rect.fromCircle(center: center, radius: radius));
var circleMetrics = circlePath.computeMetrics();
for (var pathMetric in circleMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}
}
其中路径比例为lengthRatio,通过animationValue乘以一个系数使得实心圆的间距越来越大 ,同时通过Offset(size.width - tangent.position.dx, size.height - tangent.position.dy)绘制了一组对对称的实心圆,这样整体就有一个圆形的效果了,动起来也会更有趣一点。
椭圆运动Loading
椭圆和圆形没什么区别,这里我们搞个渐变的效果看看,利用之前介绍过的Paint的shader可以实现渐变色绘制效果。
实现代码如下所示。
final ballCount = 6;
final ballRadius = boxSize / 15;
var ovalPath = Path()
..addOval(Rect.fromCenter(
center: center, width: boxSize, height: boxSize / 1.5));
paint.shader = LinearGradient(
begin: Alignment.topLeft,
end: Alignment.bottomRight,
colors: [this.foregroundColor, this.bgColor],
).createShader(Offset.zero & size);
var ovalMetrics = ovalPath.computeMetrics();
for (var pathMetric in ovalMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}
当然,如果渐变色的颜色更丰富一点会更有趣些。
贝塞尔曲线Loading
通过贝塞尔曲线构建一条Path,让一组圆形沿着贝塞尔曲线运动的Loading效果也很有趣。
原理和圆形的一样,首先是构建贝塞尔曲线Path,代码如下。
var bezierPath = Path()
..moveTo(size.width / 2 - boxSize / 2, center.dy)
..quadraticBezierTo(size.width / 2 - boxSize / 4, center.dy - boxSize / 4,
size.width / 2, center.dy)
..quadraticBezierTo(size.width / 2 + boxSize / 4, center.dy + boxSize / 4,
size.width / 2 + boxSize / 2, center.dy)
..quadraticBezierTo(size.width / 2 + boxSize / 4, center.dy - boxSize / 4,
size.width / 2, center.dy)
..quadraticBezierTo(size.width / 2 - boxSize / 4, center.dy + boxSize / 4,
size.width / 2 - boxSize / 2, center.dy);
这里实际是构建了两条贝塞尔曲线,先从左边到右边,然后再折回来。之后就是运动的实心圆了,这个只是数量上多了,ballCount为30,这样效果看着就有一种拖影的效果。
var ovalMetrics = bezierPath.computeMetrics();
for (var pathMetric in ovalMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}
这里还可以改变运动方向,实现一些其他的效果,例如下面的效果,第二组圆球的绘制位置实际上是第一组圆球的x、y坐标的互换。
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(Offset(tangent.position.dy, tangent.position.dx),
ballRadius / (1 + i), paint);
组件使用
我们来看如何使用我们定义的这个组件,使用代码如下,我们用Future延迟模拟了一个加载效果,在加载过程中使用loading指示加载过程,加载完成后显示图片。
class _LoadingDemoState extends State<LoadingDemo> {
var loaded = false;
@override
void initState() {
super.initState();
Future.delayed(Duration(seconds: 5), () {
setState(() {
loaded = true;
});
});
}
@override
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: Colors.white,
appBar: AppBar(
title: Text('Loading 使用'),
),
body: Center(
child: loaded
? Image.asset(
'images/beauty.jpeg',
width: 100.0,
)
: LoadingAnimations(
foregroundColor: Colors.blue,
bgColor: Colors.white,
size: 100.0,
),
),
);
}
最终运行的效果如下,源码已提交至:绘图相关源码,文件名为loading_animations.dart。
总结
本篇介绍了Loading组件的封装方法,核心要点还是利用Path和动画控制绘制元素的运动轨迹来实现更有趣的效果。在实际应用过程中,也可以根据交互设计的需要,做一些其他有趣的加载动效,提高等待过程的趣味性。
作者:岛上码农
链接:https://juejin.cn/post/7129071400509243423
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于mmap不为人知的秘密
mmap初入
我们常说的mmap,其实是一种内存映射文件的方法,mmap将一个文件或者其它对象映射进内存。但是更加确切的来说,其实是linux中的线性区提供的可以和基于磁盘文件系统的普通文件的某一个部分相关联的操作。线性区其实是由进程中连续的一块虚拟文件区域,由struct vm_area_struct结构体表示,我们的mmap操作,其实就是最本质的,就是通过其进行的内存操作。
按照归类的思想,其实mmap主要用到的分为两类(还有其他标识不讨论)
- 共享的:即对该线性区中的页(注意是以页为单位)的任何写操作,都会修改磁盘上的文件,并且如果一个进程对进行了mmap的页进行了写操作,那么对于其他进程(同样也通过mmap进行了映射),同样也是可见的
- 私有的:对于私有映射页的任何写操作,都会使linux内核停止映射该文件的页(注意,假如有进程a,b同时映射了该页,a对页进行了修改,此时这个页就相当于复制出来了一份,a以后的操作就在复制的该页进行操作,b还是引用原来的页,原来的页就可以继续参与内存映射,而复制出来的页,就被停止映射了),因此,在私有情况下,写操作是不会改变磁盘上的文件,同时所做的修改对于其他进程来说,就是不可见的。
我们看一下图片
共享模式下
私有模式下
mmap分析
概念我们有了,我们看一下代码mmap定义
#if defined(__USE_FILE_OFFSET64)
void* mmap(void* __addr, size_t __size, int __prot, int __flags, int __fd, off_t __offset) __RENAME(mmap64);
#else
void* mmap(void* __addr, size_t __size, int __prot, int __flags, int __fd, off_t __offset);
#endif
#if __ANDROID_API__ >= 21
/**
* mmap64() is a variant of mmap() that takes a 64-bit offset even on LP32.
*
* See https://android.googlesource.com/platform/bionic/+/master/docs/32-bit-abi.md
*
* mmap64 wasn't really around until L, but we added an inline for it since it
* allows a lot more code to compile with _FILE_OFFSET_BITS=64.
*/
void* mmap64(void* __addr, size_t __size, int __prot, int __flags, int __fd, off64_t __offset) __INTRODUCED_IN(21);
#endif
mmap分为好多个版本,但是其他的也是根据不同的Android版本或者abi进行部分的区分,我们来看一下具体含义:
- addr:参数addr指定文件应被映射到进程空间的起始地址,一般被指定一个空指针,此时选择起始地址的任务留给内核来完成。当然,我们也可以设定一个自己的地址,但是如果flag中设定起来MAP_FIXED标志,且内核也没办法从我们指定的线性地址开始分配新线性区的话,就会产生调用失败
- size:映射到调用进程地址空间的字节数,它从被映射文件开头offset个字节开始算起
- prot:指定对线性区的一组权限,比如读权限(PROT_READ),写权限(PROT_WRITE),执行权限(PROT_EXEC)
- flags:一组标志,比如我们上面说的共享模式(MAP_SHARED)或者私有模式(MAP_PRIVATE)等
- fd:文件描述符,要映射的文件
- offset:要映射的文件的偏移量(比如我想要从文件的某部分开始映射)
使用例子
下面是demo例子
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/fcntl.h>
#include <errno.h>
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#define TRUE 1
#define FALSE -1
#define FILE_SIZE 100
#define MMAP_FILE_PATH "./mmap.txt"
int main(int argc, char **argv)
{
int fd = -1;
//char buff[100] = {0};
void *result;
int lseek_result = -1;
int file_length = -1;
// 1. open the file
fd = open(MMAP_FILE_PATH, O_RDWR|O_CREAT, S_IRUSR|S_IWUSR|S_IRGRP|S_IWGRP|S_IROTH|S_IWOTH);
if (-1 == fd) {
printf("open failed\n");
printf("%s\n", strerror(errno));
return FALSE;
}
//2. call mmap 这里可以尝试一下其他的flag,比如MAP_PRIVATE
result = mmap(0, 100(这里是demo文件长度), \
PROT_READ|PROT_WRITE, \
MAP_SHARED, \
fd, 0);
if (result == (void *)-1) {
printf("mmap failed\n");
printf("%s\n", strerror(errno));
return FALSE;
}
//3. release the file descriptor
close(fd);
//4. write something to mmap addr,
strncpy(result, "test balabala...", file_length);
//5. call munmap
munmap(0, file_length);
return 0;
}
深入了解mmap
不得不说,mmap的函数实现非常复杂,首先会调用到do_mmap_pgoff进行平台无关的代码分支,然后会调用到do_mmap里面,这个函数非常长!!!
我们挑几个关键的步骤:
- 先检查要映射的文件是否定义了mmap文件操作,(如果是目录就不存在mmap文件操作了)如果没有的话就直接调用失败
- 检查一系列的一致性检查,同时根据mmap的参数与打开文件的权限标志进行对比:比如检查当前文件是否有文件锁,如果是以MAP_SHARED模式打开进行写入的话,也要检查文件是否有可写的权限,正所谓权限要一致
- 设置线性区的vm_flag字段,因为我们mmap返回的地址肯定也是要给到当前进程的,这个线性区的权限所以也要设置,比如VM_READ,VM_WRITE等标识,表明了这块内存的权限
- 增加文件的引用计数,因为我们进程mmap用到了该文件对吧,所以计数器也要加一,这样系统才会知道当前文件被多少个进程引用了
- 对文件进行映射操作,并且初始化该线性区的页,注意这个时候并没有对页进行操作,因为有可能申请了这个页而没有操作,所以这个时候是以no_page标识的,这里不得不感慨linux的写时复制思想用到了各处!只有真正访问的时候,就会产生一个缺页异常,由内核调度请求完成对该页的填充
unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, vm_flags_t vm_flags,
unsigned long pgoff, unsigned long *populate)
{
struct mm_struct *mm = current->mm; //获取该进程的memory descriptor
int pkey = 0;
*populate = 0;
//函数对传入的参数进行一系列检查, 假如任一参数出错,都会返回一个errno
if (!len)
return -EINVAL;
/*
* Does the application expect PROT_READ to imply PROT_EXEC?
*
* (the exception is when the underlying filesystem is noexec
* mounted, in which case we dont add PROT_EXEC.)
*/
if ((prot & PROT_READ) && (current->personality & READ_IMPLIES_EXEC))
if (!(file && path_noexec(&file->f_path)))
prot |= PROT_EXEC;
//假如没有设置MAP_FIXED标志,且addr小于mmap_min_addr, 因为可以修改addr, 所以就需要将addr设为mmap_min_addr的页对齐后的地址
if (!(flags & MAP_FIXED))
addr = round_hint_to_min(addr);
/* Careful about overflows.. */
len = PAGE_ALIGN(len); //进行Page大小的对齐
if (!len)
return -ENOMEM;
/* offset overflow? */
if ((pgoff + (len >> PAGE_SHIFT)) < pgoff)
return -EOVERFLOW;
/* Too many mappings? */
if (mm->map_count > sysctl_max_map_count) //判断该进程的地址空间的虚拟区间数量是否超过了限制
return -ENOMEM;
//get_unmapped_area从当前进程的用户空间获取一个未被映射区间的起始地址
addr = get_unmapped_area(file, addr, len, pgoff, flags);
if (offset_in_page(addr)) //检查addr是否有效
return addr;
if (prot == PROT_EXEC) {
pkey = execute_only_pkey(mm);
if (pkey < 0)
pkey = 0;
}
/* Do simple checking here so the lower-level routines won't have
* to. we assume access permissions have been handled by the open
* of the memory object, so we don't do any here.
*/
vm_flags |= calc_vm_prot_bits(prot, pkey) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC;
//假如flags设置MAP_LOCKED,即类似于mlock()将申请的地址空间锁定在内存中, 检查是否可以进行lock
if (flags & MAP_LOCKED)
if (!can_do_mlock())
return -EPERM;
if (mlock_future_check(mm, vm_flags, len))
return -EAGAIN;
if (file) { // file指针不为nullptr, 即从文件到虚拟空间的映射
struct inode *inode = file_inode(file); //获取文件的inode
switch (flags & MAP_TYPE) { //根据标志指定的map种类,把为文件设置的访问权考虑进去
case MAP_SHARED:
if ((prot&PROT_WRITE) && !(file->f_mode&FMODE_WRITE))
return -EACCES;
/*
* Make sure we don't allow writing to an append-only
* file..
*/
if (IS_APPEND(inode) && (file->f_mode & FMODE_WRITE))
return -EACCES;
/*
* Make sure there are no mandatory locks on the file.
*/
if (locks_verify_locked(file))
return -EAGAIN;
vm_flags |= VM_SHARED | VM_MAYSHARE;
if (!(file->f_mode & FMODE_WRITE))
vm_flags &= ~(VM_MAYWRITE | VM_SHARED);
/* fall through */
case MAP_PRIVATE:
if (!(file->f_mode & FMODE_READ))
return -EACCES;
if (path_noexec(&file->f_path)) {
if (vm_flags & VM_EXEC)
return -EPERM;
vm_flags &= ~VM_MAYEXEC;
}
if (!file->f_op->mmap)
return -ENODEV;
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
break;
default:
return -EINVAL;
}
} else {
switch (flags & MAP_TYPE) {
case MAP_SHARED:
if (vm_flags & (VM_GROWSDOWN|VM_GROWSUP))
return -EINVAL;
/*
* Ignore pgoff.
*/
pgoff = 0;
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
/*
* Set pgoff according to addr for anon_vma.
*/
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
/*
* Set 'VM_NORESERVE' if we should not account for the
* memory use of this mapping.
*/
if (flags & MAP_NORESERVE) {
/* We honor MAP_NORESERVE if allowed to overcommit */
if (sysctl_overcommit_memory != OVERCOMMIT_NEVER)
vm_flags |= VM_NORESERVE;
/* hugetlb applies strict overcommit unless MAP_NORESERVE */
if (file && is_file_hugepages(file))
vm_flags |= VM_NORESERVE;
}
//一顿检查和配置,调用核心的代码mmap_region
addr = mmap_region(file, addr, len, vm_flags, pgoff);
if (!IS_ERR_VALUE(addr) &&
((vm_flags & VM_LOCKED) ||
(flags & (MAP_POPULATE | MAP_NONBLOCK)) == MAP_POPULATE))
*populate = len;
return addr;
}
do_mmap() 根据用户传入的参数做了一系列的检查,然后根据参数初始化 vm_area_struct 的标志 vm_flags,vma->vm_file = get_file(file) 建立文件与vma的映射, mmap_region() 负责创建虚拟内存区域:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, vm_flags_t vm_flags, unsigned long pgoff)
{
struct mm_struct *mm = current->mm; //获取该进程的memory descriptor
struct vm_area_struct *vma, *prev;
int error;
struct rb_node **rb_link, *rb_parent;
unsigned long charged = 0;
/* 检查申请的虚拟内存空间是否超过了限制 */
if (!may_expand_vm(mm, vm_flags, len >> PAGE_SHIFT)) {
unsigned long nr_pages;
/*
* MAP_FIXED may remove pages of mappings that intersects with
* requested mapping. Account for the pages it would unmap.
*/
nr_pages = count_vma_pages_range(mm, addr, addr + len);
if (!may_expand_vm(mm, vm_flags,
(len >> PAGE_SHIFT) - nr_pages))
return -ENOMEM;
}
/* 检查[addr, addr+len)的区间是否存在映射空间,假如存在重合的映射空间需要munmap */
while (find_vma_links(mm, addr, addr + len, &prev, &rb_link,
&rb_parent)) {
if (do_munmap(mm, addr, len))
return -ENOMEM;
}
/*
* Private writable mapping: check memory availability
*/
if (accountable_mapping(file, vm_flags)) {
charged = len >> PAGE_SHIFT;
if (security_vm_enough_memory_mm(mm, charged))
return -ENOMEM;
vm_flags |= VM_ACCOUNT;
}
//检查是否可以合并[addr, addr+len)区间内的虚拟地址空间vma
vma = vma_merge(mm, prev, addr, addr + len, vm_flags,
NULL, file, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma) //假如合并成功,即使用合并后的vma, 并跳转至out
goto out;
//如果不能和已有的虚拟内存区域合并,通过Memory Descriptor来申请一个vma
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL);
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
//初始化vma
vma->vm_mm = mm;
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_flags = vm_flags;
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff;
INIT_LIST_HEAD(&vma->anon_vma_chain);
if (file) { //假如指定了文件映射
if (vm_flags & VM_DENYWRITE) { //映射的文件不允许写入,调用deny_write_accsess(file)排斥常规的文件操作
error = deny_write_access(file);
if (error)
goto free_vma;
}
if (vm_flags & VM_SHARED) { //映射的文件允许其他进程可见, 标记文件为可写
error = mapping_map_writable(file->f_mapping);
if (error)
goto allow_write_and_free_vma;
}
//递增File的引用次数,返回File赋给vma
vma->vm_file = get_file(file);
error = file->f_op->mmap(file, vma); //调用文件系统指定的mmap函数
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma); //假如标志为VM_SHARED,但没有指定映射文件,需要调用shmem_zero_setup(),实际映射的文件是dev/zero
if (error)
goto free_vma;
}
//将申请的新vma加入mm中的vma链表
vma_link(mm, vma, prev, rb_link, rb_parent);
/* Once vma denies write, undo our temporary denial count */
if (file) {
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
}
file = vma->vm_file;
out:
perf_event_mmap(vma);
//更新进程的虚拟地址空间mm
vm_stat_account(mm, vm_flags, len >> PAGE_SHIFT);
if (vm_flags & VM_LOCKED) {
if (!((vm_flags & VM_SPECIAL) || is_vm_hugetlb_page(vma) ||
vma == get_gate_vma(current->mm)))
mm->locked_vm += (len >> PAGE_SHIFT);
else
vma->vm_flags &= VM_LOCKED_CLEAR_MASK;
}
if (file)
uprobe_mmap(vma);
/*
* New (or expanded) vma always get soft dirty status.
* Otherwise user-space soft-dirty page tracker won't
* be able to distinguish situation when vma area unmapped,
* then new mapped in-place (which must be aimed as
* a completely new data area).
*/
vma->vm_flags |= VM_SOFTDIRTY;
vma_set_page_prot(vma);
return addr;
unmap_and_free_vma:
vma->vm_file = NULL;
fput(file);
/* Undo any partial mapping done by a device driver. */
unmap_region(mm, vma, prev, vma->vm_start, vma->vm_end);
charged = 0;
if (vm_flags & VM_SHARED)
mapping_unmap_writable(file->f_mapping);
allow_write_and_free_vma:
if (vm_flags & VM_DENYWRITE)
allow_write_access(file);
free_vma:
kmem_cache_free(vm_area_cachep, vma);
unacct_error:
if (charged)
vm_unacct_memory(charged);
return error;
}
munmap
当进程准备清除一个mmap映射时,就可以调用munmap函数
int munmap(void* __addr, size_t __size);
如demo例子所示,第一个函数是要删除的线性地址的第一个单元的地址,第二个函数是线性区的长度,由于这个函数比较简单,就是系统调用do_munmap函数,这里就不详细分析啦!
数据写回磁盘
经过上面的mmap操作,我们也知道了mmap的使用了,不知道大家有没有留意一个细节,就是上面图中我们内存写入的下一步是页高速缓存,这个时候真正的数据保存,其实还是没有真正写入到磁盘里面的,真正写入其实是靠系统调用写入,即msync函数
int msync(void* __addr, size_t __size, int __flags);
mmap的数据写入依靠着这个系统调用保证,即当前进程被异常销毁了,也可以通过这个系统级别的调用,把属于内存映射的脏页数据写回去磁盘。参数1跟2需要写回去的头地址跟大小,我们重点看一下最后一个参数flags,它有以下几个参数选择:
- MS_SYNC:要求系统挂起调用进程,直到I/O操作完成
- MS_ASYNC:可以系统调用立即返回,不用挂起调用进程(大多数使用到mmap库选择)
- MS_INVALLDATE:要求系统调用从进程地址空间删除mmap映射的所有页
这个函数主要功能是进行脏页标记,并进行真正的磁盘写入,大概的路径就是通过调用flush_tlb_page把缓冲器标记为脏页标识,同时获取文件对应的索引节点i_sem信号量,进行写入时的上锁,然后刷新到磁盘!
这里可以看到,mmap依靠系统调用,把数据刷新回到磁盘!虽然这个刷新动作是由linux系统进行刷入的,保证了进程出问题的时候,也能够在系统级别刷入数据,比如MMKV的设计就采用了这点,但是这个也不是百分百可靠的,因为这个刷入操作是没有备份操作的/异常容灾处理,如果系统异常或者断电的情况,就会出现错误数据或者没有完全刷入磁盘的数据,造成数据异常,我们也可以看到mmkv介绍
mmap不足
mmap最大的不足,就是被映射的线性区只能是按照页的整数倍进行计算,如果说我们要映射的内存少于这个数,也是按照一个页进行映射的,当然,一个页长度会根据不同架构而不同,比如常见的4kb等,同时也要时刻注意映射区的生命周期,不然无脑映射也很容易造成oom
扩展
当然,说到mmap,肯定也离不开对mmkv的介绍,虽然mmkv很优秀,但是也不能无脑就使用,这方面可以参考朱凯大佬发布的文章Android 的键值对存储有没有最优解?,这里就不再赘述,按照自己所需的使用,当然,jetpack的DataStore也是很香啊!有机会的话也出一篇解析文!
作者:Pika
链接:https://juejin.cn/post/7128675991819386893
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Kotlin协程-协程的暂停与恢复 & suspendCancellableCoroutine的使用
前言
之前在网上看到有人问协程能不能像线程一样 wait(暂停) 和 notify(恢复) 。
应用场景是开启一个线程然后执行一段逻辑,得到了某一个数据,然后需要拿到这个数据去处理一些别的事情,需要把线程先暂停,然后等逻辑处理完成之后再把线程 notify。
首先我们不说有没有其他的方式实现,我当然知道有其他多种其他实现的方式。单说这一种逻辑来看,我们使用协程能不能达到同样的效果?
那么问题来了,协程能像线程那样暂停与恢复吗?
协程默认是不能暂停与恢复的,不管是协程内部还是返回的Job对象,都不能暂停与恢复,最多只能delay延时一下,无法精准控制暂停与恢复。
但是我们可以通过 suspendCancellableCoroutine 来间接的实现这个功能。
那问题又来了,suspendCancellableCoroutine 是个什么东西?怎么用?
一、suspendCancellableCoroutine的用法
很多人不了解这个类,不知道它是干嘛的,其实我们点击去看源码就知道,源码已经给出了很清晰的注释,并且还附带了使用场景
简单的说就是把Java/Kotlin 的一些回调方法,兼容改造成 suspend 的函数,让它可以运行在协程中。
以一个非常经典的例子,网络请求我们可以通过 Retrofit+suspend 的方式,也可以直接使用 OkHttp 的方式,我们很早之前都是自己封装 OkHttpUtils 的,然后以回调的方式返回正确结果和异常处理。
我们就可以通过 suspendCancellableCoroutine 把 OkHttpUtils 的回调方式进行封装,像普通的 suspend 方法一样使用了。
fun suspendSth() {
viewModelScope.launch {
val school = mRepository.getSchool() //一个是使用Retrofit + suspend
try {
val industry = getIndustry() //一个是OkHttpUtils回调的方式
} catch (e: Exception) {
e.printStackTrace() //捕获OkHttpUtils返回的异常信息
}
}
}
private suspend fun getIndustry(): String? {
return suspendCancellableCoroutine { cancellableContinuation ->
OkhttpUtil.okHttpGet("http://www.baidu.com/api/industry", object : CallBackUtil.CallBackString() {
override fun onFailure(call: Call, e: Exception) {
cancellableContinuation.resumeWithException(e)
}
override fun onResponse(call: Call, response: String?) {
cancellableContinuation.resume(response)
}
})
}
}
感觉使用起来真是方便呢,那除了 suspendCancellableCoroutine 有没有其他的方式转换回调?有,suspendCoroutine,那它们之间的区别是什么?
suspendCancellableCoroutine 和 suspendCoroutine 区别
SuspendCancellableCoroutine 返回一个 CancellableContinuation, 它可以用 resume、resumeWithException 来处理回调和抛出 CancellationException 异常。
它与 suspendCoroutine的唯一区别就是 SuspendCancellableCoroutine 可以通过 cancel() 方法手动取消协程的执行,而 suspendCoroutine 没有该方法。
所以尽可能使用 suspendCancellableCoroutine 而不是 suspendCoroutine ,因为协程的取消是可控的。
那我们不使用回调直接用行不行?当然可以,例如:
fun suspendSth() {
viewModelScope.launch {
val school = mRepository.getSchool()
if (school is OkResult.Success) {
val lastSchool = handleSchoolData(school.data)
YYLogUtils.w("处理过后的School:" + lastSchool)
}
}
}
private suspend fun handleSchoolData(data: List<SchoolBean>?): SchoolBean? {
return suspendCancellableCoroutine {
YYLogUtils.w("通过开启一个线程延时5秒再返回")
thread {
Thread.sleep(5000)
it?.resume(mSchoolList?.last(), null)
}
}
}
那怎么能达到协程的暂停与恢复那种效果呢?我们把参数接收一下,变成成员变量不就行了吗?想什么时候resume就什么时候resume。
二、实现协程的暂停与恢复
我们定义一个方法开启一个协程,内部使用一个 suspendCancellableCoroutine 函数包裹我们的逻辑(暂停),再定义另一个方法内部使用 suspendCancellableCoroutine 的 resume 来返回给协程(恢复)。
fun suspendSth() {
viewModelScope.launch {
val school = mRepository.getSchool() //网络获取数据
if (school is OkResult.Success) {
val lastSchool = handleSchoolData(school.data)
//下面的不会执行的,除非 suspendCancellableCoroutine 的 resume 来恢复协程,才会继续走下去
YYLogUtils.w("处理过后的School:" + lastSchool)
}
}
}
private var mCancellableContinuation: CancellableContinuation<SchoolBean?>? = null
private var mSchoolList: List<SchoolBean>? = null
private suspend fun handleSchoolData(data: List<SchoolBean>?): SchoolBean? {
mSchoolList = data
return suspendCancellableCoroutine {
mCancellableContinuation = it
YYLogUtils.w("开启线程睡眠5秒再说")
thread {
Thread.sleep(5000)
YYLogUtils.w("就是不返回,哎,就是玩...")
}
}
}
//我想什么时候返回就什么时候返回
fun resumeCoroutine() {
YYLogUtils.w("点击恢复协程-返回数据")
if (mCancellableContinuation?.isCancelled == true) {
return
}
mCancellableContinuation?.resume(mSchoolList?.last(), null)
}
使用: 点击开启协程暂停了,再点击下面的按钮即恢复协程
fun testflow() {
mViewModel.suspendSth()
}
fun resumeScope() {
mViewModel.resumeCoroutine()
}
效果是点击开启协程之后我等了20秒恢复了协程,打印如下:
总结
协程虽然默认是不支持暂停与恢复,但是我们可以通过 suspendCancellableCoroutine 来间接的实现。
虽然如此,但实例开发上我还是不太推荐这么用,这样的场景我们有多种实现方式。可以用其他很好的方法实现,比如用一个协程不就好了吗串行执行,或者并发协程然后使用协程的通信来传递,或者用线程+队列也能做等等。真的一定要暂停住协程吗?不是不能实现,只是感觉不是太优雅。
(注:不好意思,这里有点主观意识了,大家不一定就要参考,毕竟它也只是一种场景需求实现的方式而已,只要性能没问题,所有的方案都是可行,大家按需选择即可)
当然关于 suspendCancellableCoroutine 谷歌的本意是让回调也能兼容协程,这也是它最大的应用场景。
本期内容如讲的不到位或错漏的地方,希望同学们可以指出交流。
如果感觉本文对你有一点点点的启发,还望你能点赞支持一下,你的支持是我最大的动力。
Ok,这一期就此完结。
作者:newki
链接:https://juejin.cn/post/7128555351725015054
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
ConstraintLayout 中的 Barrier 和 Chains
1. Barrier
是一个准则,可以说是对其的规则,这样说还不够名义,我们可以列表一些比较常见的场景; 官网 Barrier。
- 具体看图
“第二行的label”和“第二行value”是一个整体,他们距离上面是
100dp ,但是有可能“第二行value”的值为空或者是空,也需要“第二行label”距离上面的距离是 100dp ,由于我们知道“第二行value”的高度高于第一个,所以采用的是“第二行label”跟“第二行value”对其,“第二行value”距离上边 100dp 的距离,但是由于“第二行value”有可能为空,所以当“第二行value”为空的时候就会出现下面的效果:
我们发现达不到预期,现在能想到的办法有,首先在代码控制的时候随便把“第二行label”的
marginTop 也添加进去;还有就是换布局,将“第二行label”和“第二行value”放到一个布局中,比如 LinearLayout ,这样上边的 marginTop 由 LinearLayout 控制;这样的话即便“第二行value”消失了也会保持上边的效果。
除了上边的方法还能使用其他的嘛,比如我们不使用代码控制,我们不使用其他的布局,因为我们知道布局嵌套太多性能也会相应的下降,所以在编写的时候能减少嵌套的情况下尽可能的减少,当然也不能为了减少嵌套让代码变得格外的复杂。
为了满足上面的需求, Barrier 出现了,它能做到隐藏的也能依靠它,并且与它的距离保持不变对于隐藏的“第二行value”来说,虽然消失了,但保留了 marginTop 的数值。下面看看布局:
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<TextView
android:id="@+id/textView4"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="头部"
android:textSize="36sp"
app:layout_constraintBottom_toTopOf="@id/barrier3"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toTopOf="parent" />
<androidx.constraintlayout.widget.Barrier
android:id="@+id/barrier3"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:barrierDirection="top"
android:layout_marginTop="100dp"
app:constraint_referenced_ids="textView2,textView3" />
<TextView
android:id="@+id/textView2"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginStart="4dp"
android:text="第二行label"
android:textSize="36sp"
app:layout_constraintBottom_toBottomOf="@+id/textView3"
app:layout_constraintStart_toStartOf="@+id/textView4"
app:layout_constraintTop_toTopOf="@+id/textView3"
app:layout_constraintVertical_bias="0.538" />
<TextView
android:id="@+id/textView3"
android:layout_width="wrap_content"
android:layout_height="100dp"
android:layout_marginStart="12dp"
android:layout_marginTop="100dp"
android:text="第二行value"
android:textSize="36sp"
app:layout_constraintStart_toEndOf="@+id/textView2"
app:layout_constraintTop_toBottomOf="@+id/barrier3" />
</androidx.constraintlayout.widget.ConstraintLayout>
这样即便将“第二行value”消失,那么总体的布局仍然达到预期,并且也没有添加很多布局内容。在代码中:
<androidx.constraintlayout.widget.Barrier
android:id="@+id/barrier3"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:barrierDirection="top"
android:layout_marginTop="100dp"
app:constraint_referenced_ids="textView2,textView3" />
这里主要有两个属性 app:barrierDirection 和 app:constraint_referenced_ids :
- app:barrierDirection 是代表位置,也就是在包含内容的哪一个位置,我这里写的是
top,是在顶部,还有其他的属性top,bottom,left,right,start和end这几个属性,看意思就很明白了。 - app:constraint_referenced_ids 上面说的内容就是包含在这里面的,这里面填写的是
id的名称,如果有多个,那么使用逗号隔开;这里面的到Barrier的距离不会改变,即便隐藏了也不会变。
这里可能会有疑惑,为啥我写的 id 为 textView4 的也依赖于 Barrier ,这是因为本身 Barrier 只是规则不是实体,它的存在只能依附于实体,不能单独存在于具体的位置,如果我们只有“第二行value”依赖于它,但是本身“第二行value”没有上依赖,也相当于没有依赖,这样只会导致“第二行label”和“第二行value”都消失,如果 textView4 依赖于 Barrier ,由于 textView4 的位置是确定的,所以 Barrier 的位置也就确定了。
- 类似表格的效果。看布局效果:
我要做成上面的样子。也就是右边永远与左边最长的保持距离。下面是我的代码:
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<TextView
android:id="@+id/textView4"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginStart="8dp"
android:text="头部"
android:textSize="36sp"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toTopOf="parent" />
<TextView
android:id="@+id/textView2"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginStart="4dp"
android:text="第二行"
android:textSize="36sp"
app:layout_constraintBottom_toBottomOf="@+id/textView3"
app:layout_constraintStart_toStartOf="@+id/textView4"
app:layout_constraintTop_toTopOf="@+id/textView3" />
<TextView
android:id="@+id/textView3"
android:layout_width="wrap_content"
android:layout_height="50dp"
android:layout_marginStart="20dp"
android:layout_marginTop="10dp"
android:text="第二行value"
android:textSize="36sp"
app:layout_constraintStart_toEndOf="@+id/barrier4"
app:layout_constraintTop_toBottomOf="@+id/textView4" />
<TextView
android:id="@+id/textView5"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginStart="4dp"
android:text="第三次测试"
android:textSize="36sp"
app:layout_constraintBottom_toBottomOf="@+id/textView6"
app:layout_constraintStart_toStartOf="@+id/textView4"
app:layout_constraintTop_toTopOf="@+id/textView6" />
<TextView
android:id="@+id/textView6"
android:layout_width="wrap_content"
android:layout_height="50dp"
android:layout_marginStart="20dp"
android:layout_marginTop="10dp"
android:text="第三行value"
android:textSize="36sp"
app:layout_constraintStart_toEndOf="@+id/barrier4"
app:layout_constraintTop_toBottomOf="@+id/textView3" />
<androidx.constraintlayout.widget.Barrier
android:id="@+id/barrier4"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:barrierDirection="end"
app:constraint_referenced_ids="textView2,textView5"
tools:layout_editor_absoluteX="411dp" />
</androidx.constraintlayout.widget.ConstraintLayout>
添加好了,记得让右边的约束指向 Barrier 。这里的 Barrier ,我们看到包含 textView2 和 textView5 ,这个时候就能做到谁长听谁的,如果此时 textView2 变长了,那么就会将就 textView2 。
2. Chains
我们特别喜欢使用线性布局,因为我们发现 UI 图上的效果使用线性布局都可以使用,当然也有可能跟大部分人的思维方式有关系。比如我们非常喜欢的,水平居中,每部分的空间分布等等都非常的顺手。既然线性布局这么好用,那为啥还有约束布局呢,因为线性布局很容易写出嵌套很深的布局,但约束布局不会,甚至大部分情况都可以不需要嵌套就能实现,那是不是代表线性布局有的约束布局也有,答案是肯定的。
使用普通的约束关系就很容易实现水平居中等常用效果,其他的如水平方向平均分布空间,使用一般的约束是实现不了的,于是就要使用 Chains ,这个就很容易实现下面的效果:
其实上一篇中我已经把官网的教程贴上去了,这里主要写双向约束怎么做,一旦双向约束形成,那么就自然进入到
Chains 模式。
1)在视图模式中操作
如果直接操作,那么只能单向约束,如果要形成这样的约束,需要选择相关的的节点,比如我这里就是同时选择 A 和 B ,然后点击鼠标右键,就可以看到 Chains → Create Horizontal Chain 。
选择图中的选项即可完成从 A 指向 B ,修改的示意图为:
我们发现已经实现了水平方向的排列效果了。至于怎么实现上面的效果,主要是改变 layout_constraintVertical_chainStyle 和 layout_constraintHorizontal_chainStyle 属性。至于权重则是属性 layout_constraintHorizontal_weight 。
layout_constraintHorizontal_chainStyle 属性说明:
- spread 默认选项,效果就是上面的那种,也就是平均分配剩余空间;
- spread_inside 两边的紧挨着非
Chains的视图,中间的平均分配;
- packed 所有的都在中间
注意了,
layout_constraintHorizontal_weight 这个属性只有在 A 身上设置才可以,也就是首节点上设置才可行,同时 layout_constraintHorizontal_weight 是代表水平方向,只能在水平方向才发生作用,如果水平的设置了垂直则不生效。
layout_constraintHorizontal_weight 这个属性只有在当前视图的宽或者高是 0dp 。至于这个的取值跟线性布局相同。
2)代码的方式 跟上面的差别就是在做双向绑定,用代码就很容易实现双向绑定,可平时添加约束相同。
作者:吴敬悦
链接:https://juejin.cn/post/6994385157306351653
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
❤️Android 12 高斯模糊-RenderEffect❤️
Android 12 高斯模糊
新功能:更易用的模糊、彩色滤镜等特效 。
新的 API 让你能更轻松地将常见图形效果应用到视图和渲染结构上。
使用 RenderEffect 将模糊、色彩滤镜等效果应用于 RenderNode 或 View。
使用新的 Window.setBackgroundBlurRadius() API 为窗口背景创建雾面玻璃效果,
使用 blurBehindRadius 来模糊窗口后面的所有内容。
咱们一个一个玩。
🔥 RenderEffect
💥 实现效果
private void setBlur(){
View.setRenderEffect(RenderEffect.createBlurEffect(3, 3, Shader.TileMode.REPEAT));
...
}
使用特别简单,走你。
🌀 X 轴的模糊效果图
咱再看看代码
private void setBlur(){
agb.iv1.setRenderEffect(RenderEffect.createBlurEffect(3, 0, Shader.TileMode.CLAMP));
agb.iv2.setRenderEffect(RenderEffect.createBlurEffect(8, 0, Shader.TileMode.REPEAT));
agb.iv3.setRenderEffect(RenderEffect.createBlurEffect(18, 0 ,Shader.TileMode.MIRROR));
agb.iv4.setRenderEffect(RenderEffect.createBlurEffect(36, 0,Shader.TileMode.DECAL));
}
RenderEffect.createBlurEffect()的四个参数:
radiusX 沿 X 轴的模糊半径
radiusY 沿 Y 轴的模糊半径
inputEffect 模糊一次(传入 RenderEffect)
edgeTreatment 用于如何模糊模糊内核边缘附近的内容
下面两种仅看效果图。就不做代码设置了。
🌀 Y 轴的模糊效果图
🌀 XY同时模糊效果图
第四个参数对边缘模糊,效果图如下:
Shader.TileMode 提供了四个选项恕我没看出来。。
这里还有一堆方法等你玩。
注意:注意如此完美的画面只能在 Android 12(SDK31)及以上的设备上使用,其他版本的设备使用会导致崩溃,谨记谨记。
效果有了,下面咱们一起看看源码。
💥 源码
🌀 View.setRenderEffect()
public void setRenderEffect(@Nullable RenderEffect renderEffect) {
...
}
这个方法就是:renderEffect 应用于 View。 传入 null清除之前配置的RenderEffect 。这里咱们先看传入的 RenderEffect。
🌀 RenderEffect.createBlurEffect()
public static RenderEffect createBlurEffect(
float radiusX,
float radiusY,
@NonNull RenderEffect inputEffect,
@NonNull TileMode edgeTreatment
) {
long nativeInputEffect = inputEffect != null ? inputEffect.mNativeRenderEffect : 0;
return new RenderEffect(
nativeCreateBlurEffect(
radiusX,
radiusY,
nativeInputEffect,
edgeTreatment.nativeInt
)
);
}
两个 createBlurEffect() 方法,分别为三参(模糊一次)和四参(模糊两次)。inputEffect 先进行了一次模糊。
看效果图:
模糊程度一样,但是实现方式不同:
private void setBlur() {
RenderEffect radiusXRenderEffect = RenderEffect.createBlurEffect(10, 0, Shader.TileMode.MIRROR);
RenderEffect radiusYRenderEffect = RenderEffect.createBlurEffect(0, 10, Shader.TileMode.MIRROR);
agb.iv1.setRenderEffect(RenderEffect.createBlurEffect(10, 10, Shader.TileMode.CLAMP));
agb.iv2.setRenderEffect(RenderEffect.createBlurEffect(10, 10, Shader.TileMode.REPEAT));
//自身radiusY 为 0 ,传入的radiusYRenderEffect设置的radiusY为10;
agb.iv3.setRenderEffect(RenderEffect.createBlurEffect(10, 0, radiusYRenderEffect, Shader.TileMode.MIRROR));
//自身radiusX 为 0 ,传入的radiusXRenderEffect设置的radiusX为10;
agb.iv4.setRenderEffect(RenderEffect.createBlurEffect(0, 10, radiusXRenderEffect, Shader.TileMode.DECAL));
}
这个方法返回一个 new RenderEffect(nativeCreateBlurEffect(...)。
那咱们去看看 nativeCreateBlurEffect()
🌀 nativeCreateBlurEffect()
frameworks/base/libs/hwui/jni/RenderEffect.cpp
static const JNINativeMethod gRenderEffectMethods[] = {
...
{"nativeCreateBlurEffect", "(FFJI)J", (void*)createBlurEffect},
...
};
static jlong createBlurEffect(JNIEnv* env , jobject, jfloat radiusX,
jfloat radiusY, jlong inputFilterHandle, jint edgeTreatment) {
auto* inputImageFilter = reinterpret_cast<SkImageFilter*>(inputFilterHandle);
sk_sp<SkImageFilter> blurFilter =
SkImageFilters::Blur(
Blur::convertRadiusToSigma(radiusX),
Blur::convertRadiusToSigma(radiusY),
static_cast<SkTileMode>(edgeTreatment),
sk_ref_sp(inputImageFilter),
nullptr);
return reinterpret_cast<jlong>(blurFilter.release());
}
这里有两个函数来处理我们传过来的模糊的值,咱进去看看。
🌀 convertRadiusToSigma(convertSigmaToRadius)
//该常数近似于在SkBlurMask::Blur()(1/sqrt(3)中,在软件路径的"高质量"模式下进行的缩放。
static const float BLUR_SIGMA_SCALE = 0.57735f;
float Blur::convertRadiusToSigma(float radius) {
return radius > 0 ? BLUR_SIGMA_SCALE * radius + 0.5f : 0.0f;
}
float Blur::convertSigmaToRadius(float sigma) {
return sigma > 0.5f ? (sigma - 0.5f) / BLUR_SIGMA_SCALE : 0.0f;
}
🌀 sk_ref_sp(inputImageFilter)
external/skia/include/core/SkRefCnt.h
/*
* 返回包装提供的 ptr 的 sk_sp 并对其调用 ref (如果不为空)
*/
template <typename T> sk_sp<T> sk_ref_sp(T* obj) {
//sk_sp<SkImageFilter> :
return sk_sp<T>(SkSafeRef(obj));
}
//SkSafeRef:检查参数是否为非空,如果是,则调用 obj->ref() 并返回 obj。
template <typename T> static inline T* SkSafeRef(T* obj) {
if (obj) {
obj->ref();
}
return obj;
}
再往下走
🌀 SkImageFilters::Blur()
#define SK_Scalar1 1.0f
#define SK_ScalarNearlyZero (SK_Scalar1 / (1 << 12))
sk_sp<SkImageFilter> SkImageFilters::Blur(
SkScalar sigmaX, SkScalar sigmaY, SkTileMode tileMode, sk_sp<SkImageFilter> input,
const CropRect& cropRect) {
if (sigmaX < SK_ScalarNearlyZero && sigmaY < SK_ScalarNearlyZero && !cropRect) {
return input;
}
return sk_sp<SkImageFilter>(
new SkBlurImageFilter(sigmaX, sigmaY, tileMode, input, cropRect));
}
附上最后的倔强
constexpr sk_sp() : fPtr(nullptr) {}
constexpr sk_sp(std::nullptr_t) : fPtr(nullptr) {}
/**
* Shares the underlying object by calling ref(), so that both the argument and the newly
* created sk_sp both have a reference to it.
*/
sk_sp(const sk_sp<T>& that) : fPtr(SkSafeRef(that.get())) {}
template <typename U,
typename = typename std::enable_if<std::is_convertible<U*, T*>::value>::type>
sk_sp(const sk_sp<U>& that) : fPtr(SkSafeRef(that.get())) {}
/**
* Move the underlying object from the argument to the newly created sk_sp. Afterwards only
* the new sk_sp will have a reference to the object, and the argument will point to null.
* No call to ref() or unref() will be made.
*/
sk_sp(sk_sp<T>&& that) : fPtr(that.release()) {}
template <typename U,
typename = typename std::enable_if<std::is_convertible<U*, T*>::value>::type>
sk_sp(sk_sp<U>&& that) : fPtr(that.release()) {}
/**
* Adopt the bare pointer into the newly created sk_sp.
* No call to ref() or unref() will be made.
*/
explicit sk_sp(T* obj) : fPtr(obj) {}
createBlurEffect() 得到 long 类型的 native 分配的的非零地址, 传入 new RenderEffect()
🌀 new RenderEffect()
/* 构造方法:仅从静态工厂方法构造 */
private RenderEffect(long nativeRenderEffect) {
mNativeRenderEffect = nativeRenderEffect;
RenderEffectHolder.RENDER_EFFECT_REGISTRY.registerNativeAllocation(
this, mNativeRenderEffect);
}
继续
/**
* @param classLoader ClassLoader 类加载器。
* @param freeFunction 类型为 nativePtr 的本机函数的地址,用于释放这种本机分配
* @return 由系统内存分配器分配的本机内存的 NativeAllocationRegistry。此版本更适合较小的对象(通常小于几百 KB)。
*/
private static class RenderEffectHolder {
public static final NativeAllocationRegistry RENDER_EFFECT_REGISTRY =
NativeAllocationRegistry.createMalloced(
RenderEffect.class.getClassLoader(), nativeGetFinalizer());
}
🌀 NativeAllocationRegistry.createMalloced()
libcore/luni/src/main/java/libcore/util/NativeAllocationRegistry.java
@SystemApi(client = MODULE_LIBRARIES)
public static NativeAllocationRegistry createMalloced(
@NonNull ClassLoader classLoader, long freeFunction, long size) {
return new NativeAllocationRegistry(classLoader, freeFunction, size, true);
}
🌀 NativeAllocationRegistry()
libcore/luni/src/main/java/libcore/util/NativeAllocationRegistry.java
private NativeAllocationRegistry(ClassLoader classLoader, long freeFunction, long size,
boolean mallocAllocation) {
if (size < 0) {
throw new IllegalArgumentException("Invalid native allocation size: " + size);
}
this.classLoader = classLoader;
this.freeFunction = freeFunction;
this.size = mallocAllocation ? (size | IS_MALLOCED) : (size & ~IS_MALLOCED);
}
既然拿到 NativeAllocationRegistry 那就继续调用其
registerNativeAllocation() 方法。
🌀 registerNativeAllocation ()
@SystemApi(client = MODULE_LIBRARIES)
@libcore.api.IntraCoreApi
public @NonNull Runnable registerNativeAllocation(@NonNull Object referent, long nativePtr) {
//当 referent 或nativePtr 为空
...
CleanerThunk thunk;
CleanerRunner result;
try {
thunk = new CleanerThunk();
Cleaner cleaner = Cleaner.create(referent, thunk);
result = new CleanerRunner(cleaner);
registerNativeAllocation(this.size);
} catch (VirtualMachineError vme /* probably OutOfMemoryError */) {
applyFreeFunction(freeFunction, nativePtr);
throw vme;
}
// Enable the cleaner only after we can no longer throw anything, including OOME.
thunk.setNativePtr(nativePtr);
// Ensure that cleaner doesn't get invoked before we enable it.
Reference.reachabilityFence(referent);
return result;
}
向 ART 注册新的 NativePtr 和关联的 Java 对象(也就是咱们设置的模糊类)。
返回的 Runnable 可用于在引用变得无法访问之前释放本机分配。如果运行时或使用 runnable 已经释放了本机分配,则 runnable 将不起作用。
RenderEffect 算是搞完了,咱们回到View.setRenderEffect()
🌀 View.setRenderEffect()
public void setRenderEffect(@Nullable RenderEffect renderEffect) {
if (mRenderNode.setRenderEffect(renderEffect)) {
//视图属性更改(alpha、translationXY 等)的快速失效。
invalidateViewProperty(true, true);
}
}
这里有个 mRenderNode.setRenderEffect(renderEffect)。咱们近距离观望一番。
🌀 mRenderNode 的创建
咱们先找找他是在什么地方创建的。
public View(Context context) {
...
//在View的构造方法中创建
mRenderNode = RenderNode.create(getClass().getName(), new ViewAnimationHostBridge(this));
...
}
🌀 RenderNode.create()
/** @hide */
public static RenderNode create(String name, @Nullable AnimationHost animationHost) {
return new RenderNode(name, animationHost);
}
private RenderNode(String name, AnimationHost animationHost) {
mNativeRenderNode = nCreate(name);
//注册 Native Allocation。
NoImagePreloadHolder.sRegistry.registerNativeAllocation(this, mNativeRenderNode);
mAnimationHost = animationHost;
}
再往下感觉也看不到啥了 跟上面类似,看.cpp动态分配类的地址还是有点懵。让我缓缓~以后补充。
作者:Android帅次
链接:https://juejin.cn/post/7020322106353123365
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
不要把公司当成家,被通知裁员时会变得不幸...

公司对于员工来说,究竟是个什么地方?
不要把公司当家,公司只是你出卖劳动力,换取报酬的地方。
人在社会上混,不要讲感情,也不要被别人洗脑,去傻乎乎地讲感情,跟你讲感情的老板,基本上都是没更多钱给你的老板。
老板开公司就是来盈利的,不是为了什么社会责任感,也不是为了造福社会,更不是为了降低社会失业率开的。
老板只会去找一些能够适合他公司发展,能够帮他赚钱的员工过来上班。
员工对于公司来说,只是一个可有可无的螺丝钉,随时都可以替代,你有时会觉得自己在公司好像挺忙,为公司做了很大贡献,在公司不可或缺。但是都是你的错觉,要么就是老板或者公司强加给你的意识,实际上公司除了老板,哪个员工走了,公司都可以照样转。
员工跟老板的本质,就是员工出卖自己的劳动力和时间,然后跟老板换取报酬,大家都是交易而已。
如果哪天员工觉得他可以在别的公司拿到更高的薪水,他就会选择跳槽。老板觉得员工不能给公司带来与其薪水相匹配的利益,老板就会让这个员工卷铺盖走人。
对于一个员工来说,最好的老板不是每天讲情怀,讲社会责任感,也不是每天对他态度很和蔼,笑眯眯地关心他的生活过得好不好。老板的素质再高也没有什么鸟用,一个合格的老板,就是能够按时发工资。
并且这个老板有本事能够让公司越做越大,让他在公司里面打工的员工,能拿到的薪水越来越多,并且能够提升的空间也越来越大。哪怕这个老板每天板着个脸,不近人情,也是一个很好的老板。
对于一个老板来说,最好的员工就是拿最低的薪水干最多的事情,能够为他带来最大的利益,这就是一个好的员工。
所以老板不会看你是什么211、双一流、清北毕业的,也不会看你考了多少证书,这些东西虽然有时候是个敲门砖,只是因为能够为老板寻找合适的人节省时间,但是真正入职之后,老板还是要看你是否能够为他创造相应的价值。
对于绝大部分员工来说,老板跟他的关系的重要性,远远超过了他跟他所谓的亲戚朋友,同事同学等等之间的关系。
因为那些人虽然看起来有血缘关系,还沾亲带故的,但是这些人跟他都没有利益上的往来,但是老板却是他的衣食父母。
说白了,老板就是相当于是他的客户,他提供劳动,并出卖自己的时间,老板是购买他劳动和时间的人,跟他是有经济利益关系的。
很多时候,员工应该多琢磨自己跟老板之间的关系,而不要去琢磨跟自己没有经济利益往来的一些人的关系。哪怕这些人跟你很熟,还是亲戚。
所以不要把公司当家,放任自己在里面任性、软弱、懒惰,那对公司不是损失。因为它可以随时换人,而自己损失的时间和机会永远回不来了。
要把公司当成球队或船,抓住在里面的一切机会锻炼自己增加技能,让自己强大,强大到离开它也不会怕,它离开你需要掂量掂量...。
-
小编我:趁着中午吃饭,“偷拍”公司同事工位,第一张是我的...,有财神那张是财务的,嘿嘿。









作者:思齐大神
来源丨蚂蚁大喇叭
收起阅读 »多行文本下的文字渐隐消失术
本文将探讨一下,在多行文本情形下的一些有意思的文字动效。
多行文本,相对于单行文本,场景会复杂一些,但是在实际业务中,多行文本也是非常之多的,但是其效果处理比起单行文本会更困难。
单行与多行文本的渐隐
首先,我们来看这样一个例子,我们要实现这样一个单行文本的渐隐:

使用 mask,可以轻松实现这样的效果,只需要:
<p>Lorem ipsum dolor sit amet consectetur.</p>
p {
mask: linear-gradient(90deg, #fff, transparent);
}
但是,如果,场景变成了多行呢?我们需要将多行文本最后一行,实现渐隐消失,并且适配不同的多行场景:

这个就会稍微复杂一点点,但是也是有多种方式可以实现的。
首先我们来看一下使用 background 的方式。
使用 background 实现
这里会运用到一个技巧,就是 display: inline 内联元素的 background 展现形式与 display: block 块级元素(或者 inline-block、flex、grid)不一致。
简单看个例子:
<p>Lorem .....</p>
<a>Lorem .....</a>
这里需要注意,<p> 元素是块级元素,而 <a> 是内联元素。
我们给它们统一添加上一个从绿色到蓝色的渐变背景色:
p, a {
background: linear-gradient(90deg, blue, green);
}
看看效果:

什么意思呢?区别很明显,块级元素的背景整体是一个渐变整体,而内联元素的每一行都是会有不一样的效果,整体连起来串联成一个整体。
基于这个特性,我们可以构造这样一种布局:
<p><a>Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam</a></p>
p {
position: relative;
width: 400px;
}
a {
background: linear-gradient(90deg, transparent, transparent 70%, #fff);
background-repeat: no-repeat;
cursor: pointer;
color: transparent;
&::before {
content: "Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam";
position: absolute;
top: 0;
left: 0;
color: #000;
z-index: -1;
}
}
这里需要解释一下:
为了利用到实际的内联元素的
background的特性,我们需要将实际的文本包裹在内联元素<a>内实际的文本,利用了
opacity: 0进行隐藏,实际展示的文本使用了<a>元素的伪元素,并且将它的层级设置为-1,目的是让父元素的背景可以盖过它<a> 元素的渐变为从透明到白色,利用它去遮住下面的实际用伪元素展示的文字,实现文字的渐隐
这样,我们就能得到这样一种效果:

这里,<a> 元素的渐变为从透明到白色,利用后面的白色逐渐遮住文字。
如果我将渐变改为从黑色到白色(为了方便理解,渐变的黑色和白色都带上了一些透明),你能很快的明白这是怎么回事:
a {
background: linear-gradient(90deg, rgba(0,0,0, .8), rgba(0,0,0, .9) 70%, rgba(255, 255, 255, .9));
}

完整的代码,你可以戳这里:CodePen Demo -- Text fades away[1]
当然,这个方案有很多问题,譬如利用了 z-index: -1,如果父容器设置了背景色,则会失效,同时不容易准确定位最后一行。因此,更好的方式是使用 mask 来解决。
使用 mask 实现
那么,如果使用 mask 的话,问题,就会变得简单一些,我们只需要在一个 mask 中,实现两块 mask 区域,一块用于准确控制最后一行,一块用于控制剩余部分的透明。
也不需要特殊构造 HTML:
<p>Lorem ipsum dolor sit amet ....</p>
p {
width: 300px;
padding: 10px;
line-height: 36px;
mask:
linear-gradient(270deg, transparent, transparent 30%, #000),
linear-gradient(270deg, #000, #000);
mask-size: 100% 46px, 100% calc(100% - 46px);
mask-position: bottom, top;
mask-repeat: no-repeat;
}
效果如下:

核心在于整个 mask 相关的代码,正如上面而言的,mask 将整个区域分成了两块进行控制:
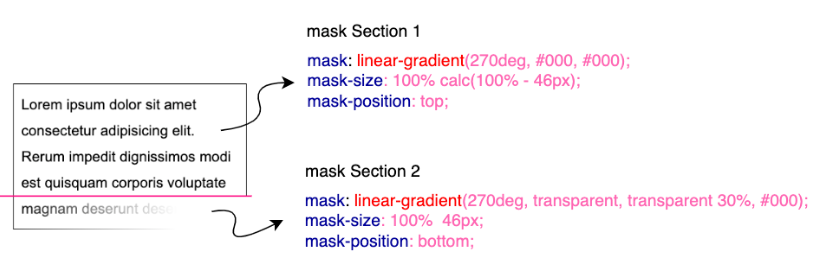
在下部分这块,我们利用 mask 做了从右向左的渐隐效果。并且利用了 mask-position 定位,以及 calc 的计算,无论文本都多少行,都是适用的!需要说明的是,这里的 46px 的意思是单行文本的行高加上 padding-bottom 的距离。可以适配任意行数的文本:

完整的代码,你可以戳这里:CodePen Demo -- Text fades away 2[2]
添加动画效果
好,看完静态的,我们再来实现一种**动态的文字渐隐消失。
整体的效果是当鼠标 Hover 到文字的时候,整个文本逐行逐渐消失。像是这样:
这里的核心在于,需要去适配不同的行数,不同的宽度,而且文字是一行一行的进行消失。
这里核心还是会运用上内联元素 background 的特性。在 妙用 background 实现花式文字效果[3] 这篇文章中,我们介绍了这样一种技巧。
实现整段文字的渐现,从一种颜色到另外一种颜色:
<div>Button</div>
<p><a>Lorem ipsum dolor sit amet consectetur adipisicing elit. Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam, molestiae laboriosam sit repellendus sed sapiente quidem quod accusantium vero.</a></p>
a {
background:
linear-gradient(90deg, #999, #999),
linear-gradient(90deg, #fc0, #fc0);
background-size: 100% 100%, 0 100px;
background-repeat: no-repeat;
background-position: 100% 100%, 0 100%;
color: transparent;
background-clip: text;
}
.button:hover ~ p a {
transition: .8s all linear;
background-size: 0 100px, 100% 100%;
}
这里需要解释一下,虽然设置了 color: transparent,但是文字默认还是有颜色的,默认的文字颜色,是由第一层渐变赋予的 background: linear-gradient(90deg, #999, #999), linear-gradient(90deg, #fc0, #fc0),也就是这一层:linear-gradient(90deg, #999, #999)。
当 hover 触发时,linear-gradient(90deg, #999, #999) 这一层渐变逐渐消失,而另外一层 linear-gradient(90deg, #fc0, #fc0)` 逐渐出现,借此实现上述效果。
CodePen -- background-clip 文字渐现效果[4]
好,我们可以借鉴这个技巧,去实现文字的渐隐消失。一层为实际的文本,而另外一层是进行动画的遮罩,进行动画的这一层,本身的文字设置为 color: transparent,这样,我们就只能看到背景颜色的变化。
大致的代码如下:
<p>
<a>Mollitia nostrum placeat consequatur deserunt.</a>
<a>Mollitia nostrum placeat consequatur deserunt.</a>
</p>
p {
width: 500px;
}
.word {
position: absolute;
top: 0;
left: 0;
color: transparent;
color: #000;
}
.pesudo {
position: relative;
background: linear-gradient(90deg, transparent, #fff 20%, #fff);
background-size: 0 100%;
background-repeat: no-repeat;
background-position: 100% 100%;
transition: all 3s linear;
color: transparent;
}
p:hover .pesudo,
p:active .pesudo{
background-size: 500% 100%;
}
其中,.word 为实际在底部,展示的文字层,而 pesudo 为叠在上方的背景层,hover 的时候,触发上方元素的背景变化,逐渐遮挡住下方的文字,并且,能适用于不同长度的文本。
当然,上述方案会有一点瑕疵,我们无法让不同长度的文本整体的动画时间一致。当文案数量相差不大时,整体可以接受,文案相差数量较大时,需要分别设定下 transition-duration 的时长。
完整的 DEMO,你可以戳:CodePen -- Text fades away Animation[5]
最后
好了,本文到此结束,希望对你有帮助 :)
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
参考资料
[1]CodePen Demo -- Text fades away: https://codepen.io/Chokcoco/pen/xxWPZmz
[2]CodePen Demo -- Text fades away 2: https://codepen.io/Chokcoco/pen/MWVvoyW
[3]妙用 background 实现花式文字效果: https://github.com/chokcoco/iCSS/issues/138
[4]CodePen -- background-clip 文字渐现效果: https://codepen.io/Chokcoco/pen/XWgpyqz
[5]CodePen -- Text fades away Animation: https://codepen.io/Chokcoco/pen/wvmqqWa
[6]Github -- iCSS: https://github.com/chokcoco/iCSS
来源:mp.weixin.qq.com/s/qADnUx3G2tKyMT7iv6qFwg
Flutter 中使用Chip 小部件
概述
典型的chip是一个圆角的小盒子。它有一个文本标签,并以一种有意义且紧凑的方式显示信息。chip可以在同一区域同时显示多个交互元素。一些流行的chip用例是:
- 发布标签(您可以在许多 WordPress ,VuePress,知乎,掘金,公众号或 GitHub等大型平台上看到它们)。
- 可删除的内容列表(一系列电子邮件联系人、最喜欢的音乐类型列表等)。
在 Flutter 中,您可以使用以下构造函数来实现 Chip 小部件:
Chip({
Key? key,
Widget? avatar,
required Widget label,
TextStyle? labelStyle,
EdgeInsetsGeometry? labelPadding,
Widget? deleteIcon,
VoidCallback? onDeleted,
Color? deleteIconColor,
bool useDeleteButtonTooltip = true,
String? deleteButtonTooltipMessage,
BorderSide? side,
OutlinedBorder? shape,
Clip clipBehavior = Clip.none,
FocusNode? focusNode,
bool autofocus = false,
Color? backgroundColor,
EdgeInsetsGeometry? padding,
VisualDensity? visualDensity,
MaterialTapTargetSize? materialTapTargetSize,
double? elevation,
Color? shadowColor
})
只有label属性是必需的,其他是可选的。一些常用的有:
- avatar:在标签前显示一个图标或小图像。
- backgroundColor : chip的背景颜色。
- padding:chip内容周围的填充。
- deleteIcon:让用户删除chip的小部件。
- onDeleted:点击deleteIcon时调用的函数。
您可以在官方文档中找到有关其他属性的更多详细信息。但是,对于大多数应用程序,我们不需要超过一半。
简单示例
这个小例子向您展示了一种同时显示多个chip的简单使用的方法。我们将使用Wrap小部件作为chip列表的父级。当当前行的可用空间用完时,筹码会自动下行。由于Wrap 小部件的间距属性,我们还可以方便地设置chip之间的距离。
截屏:
代码:
Scaffold(
appBar: AppBar(
title: const Text('大前端之旅'),
),
body: Padding(
padding: const EdgeInsets.symmetric(vertical: 30, horizontal: 10),
child: Wrap(
// space between chips
spacing: 10,
// list of chips
children: const [
Chip(
label: Text('Working'),
avatar: Icon(
Icons.work,
color: Colors.red,
),
backgroundColor: Colors.amberAccent,
padding: EdgeInsets.symmetric(vertical: 5, horizontal: 10),
),
Chip(
label: Text('Music'),
avatar: Icon(Icons.headphones),
backgroundColor: Colors.lightBlueAccent,
padding: EdgeInsets.symmetric(vertical: 5, horizontal: 10),
),
Chip(
label: Text('Gaming'),
avatar: Icon(
Icons.gamepad,
color: Colors.white,
),
backgroundColor: Colors.pinkAccent,
padding: EdgeInsets.symmetric(vertical: 5, horizontal: 10),
),
Chip(
label: Text('Cooking & Eating'),
avatar: Icon(
Icons.restaurant,
color: Colors.pink,
),
backgroundColor: Colors.greenAccent,
padding: EdgeInsets.symmetric(vertical: 5, horizontal: 10),
)
]),
),
);
在这个例子中,chip只呈现信息。在下一个示例中,chip是可交互的。
复杂示例:动态添加和移除筹码
应用预览
我们要构建的应用程序包含一个浮动操作按钮。按下此按钮时,将显示一个对话框,让我们添加一个新chip。可以通过点击与其关联的删除图标来删除每个chip。
以下是应用程序的工作方式:
完整代码
main.dart中的最终代码和解释:
// main.dart
import 'package:flutter/material.dart';
void main() {
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
debugShowCheckedModeBanner: false,
title: '大前端之旅',
theme: ThemeData(
primarySwatch: Colors.green,
),
home: const HomePage(),
);
}
}
// Data model for a chip
class ChipData {
// an id is useful when deleting chip
final String id;
final String name;
ChipData({required this.id, required this.name});
}
class HomePage extends StatefulWidget {
const HomePage({Key? key}) : super(key: key);
@override
_HomePageState createState() => _HomePageState();
}
class _HomePageState extends State<HomePage> {
// list of chips
final List<ChipData> _allChips = [];
// Text controller (that will be used for the TextField shown in the dialog)
final TextEditingController _textController = TextEditingController();
// This function will be triggered when the floating actiong button gets pressed
void _addNewChip() async {
await showDialog(
context: context,
builder: (_) {
return AlertDialog(
title: const Text('添加'),
content: TextField(
controller: _textController,
),
actions: [
ElevatedButton(
onPressed: () {
setState(() {
_allChips.add(ChipData(
id: DateTime.now().toString(),
name: _textController.text));
});
// reset the TextField
_textController.text = '';
// Close the dialog
Navigator.of(context).pop();
},
child: const Text('提交'))
],
);
});
}
// This function will be called when a delete icon associated with a chip is tapped
void _deleteChip(String id) {
setState(() {
_allChips.removeWhere((element) => element.id == id);
});
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('大前端之旅'),
),
body: Padding(
padding: const EdgeInsets.all(15),
child: Wrap(
spacing: 10,
children: _allChips
.map((chip) => Chip(
key: ValueKey(chip.id),
label: Text(chip.name),
backgroundColor: Colors.amber.shade200,
padding:
const EdgeInsets.symmetric(vertical: 7, horizontal: 10),
deleteIconColor: Colors.red,
onDeleted: () => _deleteChip(chip.id),
))
.toList(),
),
),
floatingActionButton: FloatingActionButton(
onPressed: _addNewChip,
child: const Icon(Icons.add),
),
);
}
}
结论
我们已经探索了 Chip 小部件的许多方面,并经历了不止一个使用该小部件的示例。
大家喜欢的话,点赞支持一下坚果
作者:大前端之旅
链接:https://juejin.cn/post/7060011580502573087
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
DeepLink在转转的实践
1. DeepLink 简介
DeepLink:“深度链接”技术,这个名词初看比较抽象,不过在我们身边却有不少应用,比如以下场景:
- 刷抖音看到转转的广告,点击视频下方的下载链接,如果没有安装转转则下载转转,并在打开转转后跳转到相应活动页面
- 在微信看到朋友分享的转转商品,点击后如果没有安装转转则下载转转,并在打开转转跳转到相应商品的详情页
- 看到转转发送的订单提醒短信,点击链接后如果没有安装转转则下载转转, 并在打开转转跳转到相应订单详情页
DeepLink 使用户能够在目标 APP 之外,比如广告(抖音)/社交媒体(微信)/短信中通过点击链接,直接跳转到目标 APP 特定的页面(对于已经安装了 APP 会直接进行跳转,未安装 APP 会引导下载,下载安装完成之后跳转)。DeepLink 技术可以实现场景的快速还原,缩短用户使用路径,更重要的是能够用于 APP 拉新推广场景,降低用户流失率。
随着短视频的风靡,通过短视频投放广告获客的方式也流行起来, 本文主要介绍在新媒体拉新推广场景中 DeepLink 的应用以及服务端的搭建。
2 .应用场景
我在刷抖音时刷到一个转转回收的广告视频,而家里刚好有闲置的手机,我就抱着试一试的态度点击视频下方的下载链接下载转转,看看能不能在这个平台上处理掉手中的闲置,当下载安装成功之后打开跳转到了回收页面,我可能会眉头一挑,嗯~这个体验还挺好,然后测了下闲置手机值多少钱,回收价又刚好满足我的心理预期,而且还能为碳中和贡献一份自己的力量,何乐而不为之。
以上是比较常见的一种场景,通过在抖音、快手或者其他渠道来投放广告来吸引一些有需求的用户来到转转,并通过 DeepLink 技术在下载完成打开转转后直接跳转到用户感兴趣的页面。
对于上述场景安卓和 IOS 的实现是有所区别的,包括下载策略以及 APP 内部跳转到用户感兴趣页面的策略。
2.1 IOS 应用场景
由于 IOS 下载APP只能通过 AppStore,所以 DeepLink 服务针对 IOS 会重定向到一个 H5 中间页,在 H5 中间页将服务端返回的 DeepLink 跳转链接复制到剪切板中,并拉起 AppStore 引导用户下载转转 APP,安装打开后 IOS 从剪切板中获取跳转链接进行跳转,到达用户感兴趣的页面。
2.2 安卓应用场景
安卓可以直接通过 DeepLink 服务下载转转 APP,而 DeepLink 跳转链接以 APK Signature Scheme v2 方式打入 apk 包中,安装打开后解析跳转链接跳转到用户感兴趣的页面。
APK Signature Scheme v2 是 Android 7.0 引入的一项新的应用签名方案 ,它能提供更快的应用安装时间和更多针对未授权 APK 文件更改的保护。
下图是新的签名方案和旧的签名方案的一个对比:
APK Signing Block 结构
| 偏移 | 字节数 | 描述 |
|---|---|---|
| @+0 | 8 | 这个 Block 的长度(本字段的长度不计算在内) |
| @+8 | n | 一组 ID-value |
| @-24 | 8 | 这个 Block 的长度(和第一个字段一样值) |
| @-16 | 16 | 魔数 “APK Sig Block 42” |
APK Signing Block 中的 ID-value 是可扩展的,由于 APK Signing Block 的数据块不会参与签名校验,也就是说我们可以自定义一组 ID-value,用于存储额外的信息,我们通过自定义ID-value将跳转信息打入APK包中。
3. DeepLink 服务
在 IOS DeepLink 方案中服务端只是负责重定向到一个 H5 中间页,因此不再赘述,下面我们主要介绍下安卓的 DeepLink 方案。
3.1 投放链接设计
投放链接是投放到各个渠道的下载链接,需要考虑以下几点:
各个渠道链接规则不一样,保证我们链接规则能够覆盖所有渠道
通过我们的调研有些渠道只支持 Get 请求,有些渠道不允许带参数,有些渠道必须以.apk 进行结尾
投放方便,链接投放出去之后不需要再改动
由于投放链接是给到一些自媒体创作者,在给出链接之后能够保证从始至终都能下到最新的APP
充分利用 CDN
转转 APP、找靓机 APP 的包百兆左右,为了保证服务的稳定性同样为了节约带宽,尽量发挥 CDN 的作用把绝大多数请求让 CDN 服务器来进行处理返回
3.1.1 兼容版本1.0
考虑到兼容各个渠道,某些渠道必须以 apk 结尾、某些渠道不支持Get请求带参数,采用什么方式?
既然不能带参数,那我们的参数信息可以直接拼到path中,参数以某种规则组装,服务端解析,需要的信息包括 APP 类型、渠道信息、DeepLink 链接信息、版本号等,简要设计出的投放链接 1.0 大致如下:
apk.zhuanstatic.com/deeplink/**…
- appType: APP 类型,目前支持转转和找靓机,可扩展,如 zhuanzhuan
- channel:渠道类型,根据每个投放渠道单独设置渠道 id,如 douyin666
- version:APP 版本号,如 9.0.0
- deepLink:deepLink 信息,目前传输 deepLinkId,deepLinkId 和端内跳转链接的映射关系由后台维护,服务端通过映射关系拿到跳转链接打入 apk 包中,如 huishou
3.1.2 升级版本2.0
1.0的版本号是直接写到 path 中的,这会造成很多隐患
- 可以通过修改版本号恶意下载 APP 的任意版本
- 保证用户一直下到最新的包需要版本更新之后更新所有投放链接
这显然是不合理的,针对以上两点我们必然需要删掉 version,替代方案可以让服务端在处理下载请求的时候通过其他方式拿到版本信息,修正后的投放链接 2.0 如下:
apk.zhuanstatic.com/deeplink/**…
3.1.3 最终版本3.0
2.0中没有了版本信息进而导致相同的渠道投放链接是一致的,只要 CDN 中有老版本APP的缓存,下载的是缓存的老版本APP,无法获取最新APP
因此我们考虑中间做一次重定向,通过一个不接入 CDN 的固定链接去重定向到一个接入 CDN 的带版本号的链接,这样问题就迎刃而解了,因此投放链接 3.0 应运而生:
apk.zhuanzhuan.com/deeplink/**…
apk.zhuanstatic.com/deeplink/**…
apk.zhuanzhuan.com 不走 CDN,只是将链接中的版本号补全并重定向到走 CDN 的 apk.zhuanstatic.com ,这样在投放链接不变的情况下能保证用户下载到最新的包。
3.2 打包&下载
投放链接设计好之后,通过投放链接可以解析到一些参数信息,比如:
apk.zhuanstatic.com/deeplink/zh…
我们知道用户下载的是douyin666渠道转转9.0.0版本的包,并且APP打开后需要跳转回收的页面。
下载渠道包服务端逻辑主要分为两大块,第一部分是拿到相应版本的原始包,然后通过 APK Signature Scheme v2 方式将渠道号和 DeepLink 跳转链接打入原始包中获得渠道包,将渠道包提供给用户进行下载。
为了能应对 APP 升级和渠道投放带来的流量,尤其是 CDN 中还没有缓存的时候,避免大量请求将我们服务打垮,所以需要引入本地缓存,如何引入?
首先我们分析下服务端的主要逻辑找出不可变的数据,第一原始包肯定是不变的,第二在原始包相同的情况下如果 channel 和 deepLink 跳转链接是一致的,那我们打包出来的渠道包也相应是不可变的,因此我们可以针对这两部分来进行缓存。
接下来我们分析缓存选型以及缓存策略,本地缓存的组件有好多可选的,比如 Caffeine Cache、Guava Cache 等,网上关于他们的测评如下:
可以看到在读场景下,caffeine cache 是当之无愧的王者,而且我们的场景基本是接近 100%的读,所以我们优先选择了 Caffeine Cache。
以下是两个本地缓存策略介绍:
3.2.1 一级缓存(渠道包)
/**
* 缓存高频渠道包文件
*/
private static final Cache<String, byte[]> channelFinalAppCache = CacheBuilder
.newBuilder()
.expireAfterAccess(1, TimeUnit.DAYS)
.maximumSize(15)
.build();
渠道包的缓存 key 是 appType+version+channel+deepLink,由于 channel 和 deepLink 组合的众多,通过分析之前的下载数据缓存最高频的 15 个渠道包就基本满足 90%以上的请求而且不至于占用太多的内存,而为了获取最高频的 15 个渠道,我们通过大数据平台以 T+1 的方式将渠道数据更新到数据库中,DeepLink服务通过定时任务读取数据库中的渠道数据刷新缓存。
3.2.2 二级缓存(原始包)
/**
* 缓存原始包文件
*/
private static final Cache<String, byte[]> channelAppCache = CacheBuilder
.newBuilder()
.expireAfterAccess(2, TimeUnit.DAYS)
.maximumSize(10)
.build();
原始包的缓存 key 是 appType+version,由于我们只下载最新版本的包, APP 类型暂时只有转转和找靓机,所有我们设置最大数量 10 是足够的,在我们应用启动的时候会对这个缓存进行初始化,以避免第一次用户下载速度过慢,并在之后监听APP的发版信息,新版本更新后刷新缓存。
4. 总结
DeepLink 服务支撑了新媒体投放以及 APP 内置更新的下载能力,为了保证服务稳定性和性能,除上述缓存策略外,还有其他策略来协同,比如 APP 发新版本时会进行 CDN 预热,将下载量高的渠道包缓存到 CDN 中,以使大部分流量能够在 CDN 服务器被消化,即使有突发流量打过来也会有限流规则过滤流量以保证服务的稳定性。
作者:转转技术团队
链接:https://juejin.cn/post/7127531093544140831
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Retrofit解密:接口请求是如何适配suspend协程?
最初的retrofit请求
我们先看下原来如何通过retrofit发起一个网络请求的,这里我们直接以官网的例子举例:
动态代理创建请求服务
interface GitHubService {
//创建get请求方法
@GET("users/{user}/repos")
fun listRepos(@Path("user") user: String?): Call<Response>
}
//动态代理创建GitHubService
fun createService(): GitHubService {
val retrofit = Retrofit.Builder()
.baseUrl("https://api.github.com/")
.build()
return retrofit.create(GitHubService::class.java)
}
retrofit.create底层是通过动态代理创建的GitHubService的一个子实现类;
创建的这个
GitHubService一般作为单例进行使用,这里只是简单举例没有实现单例;
发起网络请求
fun main() {
//异步执行网络请求
createService().listRepos("").enqueue(object : Callback<Response> {
override fun onResponse(call: Call<Response>, response: retrofit2.Response<Response>) {
//主线程网络请求成功回调
}
override fun onFailure(call: Call<Response>, t: Throwable) {
//主线程网络请求失败回调
}
})
}
这种调用enqueue()异步方法并执行callback的方式是不是感觉很麻烦,如果有下一个请求依赖上一个请求的执行结果,那就将会形成回调地狱这种可怕场景。
而协程suspend本就有着以同步代码编写执行异步操作的能力,所以天然是解决回调地狱好帮手。接下来我们看下如何使用协程suspend。
借助suspend发起网络请求
suspend声明接口方法
interface GitHubService {
@GET("users/{user}/repos")
suspend fun listRepos(@Path("user") user: String?): Response<String>
}
可以看到就是在listRepos方法声明前加了个suspend关键字就完了。
创建协程执行网络请求
fun main() {
//1.创建协程作用域,需要保证协程的调度器是分发到主线程执行
val scope = MainScope()
scope.launch(CoroutineExceptionHandler { _, _ ->
//2.捕捉请求异常
}) {
//3.异步执行网络请求
val result = createService().listRepos("")
val content = result.body()?
}
}
首先创建一个协程作用域,需要保证协程调度器类型为
Dispatchers.Main,这样整个协程的代码块都会默认在主线程中执行,我们就可以直接在里面执行UI相关操作
创建一个
CoroutineExceptionHandler捕捉协程执行过程中出现的异常,这个捕捉异常的粒度比较大,是捕捉整个协程块的异常,可以考虑使用try-catch专门捕获网络请求执行的异常:
//异步执行网络请求
try {
val result = createService().listRepos("")
} catch (e: Exception) {
//可以考虑执行重连等逻辑或者释放资源
}
直接调用
listRepos()方法即可,不需要传入任何回调,并直接返回方法结果。这样我们就实现了以同步的代码实现了异步网络请求。
接下来我们就看下如何retrofit源码是如何实现这一效果的。
retrofit如何适配suspend
直接定位到HttpServiceMethod.parseAnnotations()方法:
static <ResponseT, ReturnT> HttpServiceMethod<ResponseT, ReturnT> parseAnnotations(
Retrofit retrofit, Method method, RequestFactory requestFactory) {
//1.判断是否为suspend挂起方法
boolean isKotlinSuspendFunction = requestFactory.isKotlinSuspendFunction;
//省略一堆和当前分析主题不想关的代码
if (!isKotlinSuspendFunction) {
return new CallAdapted<>(requestFactory, callFactory, responseConverter, callAdapter);
} else if (continuationWantsResponse) {
//挂起执行
return (HttpServiceMethod<ResponseT, ReturnT>) new SuspendForResponse<>();
} else {
//挂起执行
return (HttpServiceMethod<ResponseT, ReturnT>) new SuspendForBody<>();
}
}
1.判断是否为suspend挂起方法
看下requestFactory.isKotlinSuspendFunction赋值的地方,经过一番查找(省略...),最终方法在RequestFactory的parseParameter间接赋值:
private @Nullable ParameterHandler<?> parseParameter() {
//...
//1.是否是方法最后一个参数
if (allowContinuation) {
try {
if (Utils.getRawType(parameterType) == Continuation.class) {
//2.标识为suspend挂起方法
isKotlinSuspendFunction = true;
return null;
}
} catch (NoClassDefFoundError ignored) {
}
}
}
如果一个方法被声明为suspend,该方法翻译成java代码就会给该方法添加一个Continuation类型的参数,并且放到方法参数的最后一个位置,比如:
private suspend fun test66(name: String) {
}
会被翻译成:
private final Object test66(String name, Continuation $completion) {
return Unit.INSTANCE;
}
所以上面的代码就可以判断出请求的接口方法是否被suspend声明,是isKotlinSuspendFunction将会被置为true。
2.挂起则创建SuspendForResponse或SuspendForBody
这个地方我们以SuspendForBody进行分析,最终会执行到其adapt()方法:
@Override
protected Object adapt(Call<ResponseT> call, Object[] args) {
call = callAdapter.adapt(call);
//1.获取参数
Continuation<ResponseT> continuation = (Continuation<ResponseT>) args[args.length - 1];
try {
return isNullable
? KotlinExtensions.awaitNullable(call, continuation)
//2.调用真正的挂起方法
: KotlinExtensions.await(call, continuation);
} catch (Exception e) {
return KotlinExtensions.suspendAndThrow(e, continuation);
}
}
获取调用的suspend声明的接口方法中获取最后一个
Continuation类型参数
调用
await方法,由于这是一个kotlin定义的接收者为Call的挂起方法,如果在java中调用,首先第一个参数要传入接收者,也就是call,其实await()是一个挂起方法,翻译成java还会增加一个Continuation类型参数,所以调用await()还要传入第一步获取的Continuation类型参数。
3.核心调用await()方法探究
await()就是retrofit适配suspend实现同步代码写异步请求的关键,也是消除回调地狱的关键:
suspend fun <T : Any> Call<T>.await(): T {
return suspendCancellableCoroutine { continuation ->
continuation.invokeOnCancellation {
cancel()
}
enqueue(object : Callback<T> {
override fun onResponse(call: Call<T>, response: Response<T>) {
if (response.isSuccessful) {
val body = response.body()
if (body == null) {
//关键
continuation.resumeWithException(KotlinNullPointerException())
} else {
//关键
continuation.resume(body)
}
} else {
//关键
continuation.resumeWithException(HttpException(response))
}
}
override fun onFailure(call: Call<T>, t: Throwable) {
//关键
continuation.resumeWithException(t)
}
})
}
}
使用到了协程的一个非常关键的方法suspendCancellableCoroutine{},该方法就是用来捕获传入的Continuation并决定什么恢复挂起的协程执行的,比如官方的delay()方法也是借助该方法实现的。
所以当我们执行调用enqueue()方法时在网络请求没有响应(成功或失败)前,协程一直处于挂起的状态,之后收到网络响应后,才会调用resume()或resumeWithException()恢复挂起协程的执行,这样我们就实现了同步代码实现异步请求的操作,而不需要任何的callback嵌套地狱。
总结
本篇文章详细分析retrofit如何适配suspend协程的,并且不用编写任何的callback回调,直接以同步代码编写实现异步请求的操作。
作者:长安皈故里
链接:https://juejin.cn/post/7127799209918464013
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【Android】一键登录 - 三大运营商
业务背景:
在条件允许的情况下(无 SIM 卡的手机,无法触发一键登录),通过运行商提供的服务,进行【一键登录】。简化用户的登录操作,提高 App 的登录注册率以及使用率。
本方案采用的是阿里云中【一键登录】方案。
效果图:
前提知识:
- 整个流程如图所
(图源自网络[掘金大佬-NanBox],侵删)
- 该方案下,不允许使用完全自定义的授权页。但是可以通过属性配置,进行一定的修改。可修改的属性如下图所示
Android 接入流程:
1.浅析 Demo
通常第一步都是下载官方 Demo 后,进行一番调试,盘点功能列表,是否符合自身需求。
链接:pan.baidu.com/s/1RX5yGp06… 提取码:qbx0
接下来,简单分析 Demo 项目架构,帮助大家尽快上手这个项目。
首先,我们要知道这个 Demo,是包括【一键登录】和【本机号码校验】两个功能。根据自己的需求分析对应的代码即可。这次我们只使用到前者,所以后者内容不在这里讲述。
主要看到下列三个模块:
Config - 就是上面预告知识中说到的配置项,主要是授权页的一些配置项
OneKeyLoginActivity - 登录页面
MessageActivity - 模拟【其他登录方式】页面
那具体的实现,就可以直接看对应模块的内容即可。可以在原 Demo,进行调试。
2.接入思路分析
基于判断是否支持【一键登录】的时机 提供两种接入思路
第一种:启动登录功能前判断
判断的方式可以通过
mPhoneNumberAuthHelper.checkEnvAvailable(PhoneNumberAuthHelper.SERVICE_TYPE_LOGIN)
复制代码是否支持【一键登录】。该流程未经检验,大家可以执行验证。
第二种:直接唤起【一键登录】,失败后再唤起【其他登录方式】
Demo 也是第二种方式。这种方式需要用到一个壳 Activity 。但这个壳主要的作用是初始化SDK,以及做逻辑判断和处理(即并无实际内容展示)。
这里引发一个思考:
既然用不到 Activity 的内容,那能不能换种方式呢呢?对于单例,我思考后,一开始觉得是没问题的,但是等写完后,发现我写成了一个 OneKeyLoginHelper 的单例,发现相应逻辑处理需要传入 activity 或者 fragment 的引用。那么我们知道单例中是不能持有这样的引用的(这里可以考虑使用弱引用),这会导致内容泄漏。不知道是否还有其他的方法?
3.代码接入流程
//STEP 1.初始化监听器(这里根据业务自己做处理)
//STEP 2.初始化SDK实例
//STEP 3.设置SDK秘钥
//STEP 4.唤起一键登录页
4.避坑
接着,讲一下接入过程中,遇到的一些问题。帮大家避免无效劳动,可以有更多的时间学(hua )习(shui)。
问题描述: 因为选择了第二种思路,那么会有个壳 Activity 的问题。这个壳,我们不处理的话,是不透明的,这样当我们进到这个壳的时候,再跳转到别的页面就会有个空白页。
解决方案: 将壳的主题改为透明色,经过实验,下述代码可以实现。(壳Activity 需要继承 AppCompatActivity)
<style name="Theme.Transparent" parent="@style/Theme.AppCompat.DayNight.NoActionBar">
<item name="android:windowBackground">@android:color/transparent</item>
<item name="android:windowNoTitle">true</item>
<item name="android:windowIsFloating">true</item>
<item name="android:windowIsTranslucent">true</item>
<item name="android:windowContentOverlay">@null</item>
<item name="android:backgroundDimEnabled">false</item>
</style>
问题描述: 发现从【授权页】跳到【其他方式登录】的时候,授权页会逐渐变透明,会看到下一层页面的内容。如动图中,粉红色的箭头所示。
解决方案: 可以直接忽略,这个是 SDK 本身的问题。因为阿里那边给的回复是:(是否有最新解决方案,会及时更新,或者可以以你们当时咨询的为准)
作者:Quincy_Ye
链接:https://juejin.cn/post/7127836566084386852
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
记录 Kotlin 实践的一些好建议
目录
- 注释
- 函数式接口
- 高阶函数
- 扩展函数
注释
Java:
/**
* @see AdVideoUserInfoContainerData#type
*/
public Builder type(int type) {
userInfoData.type = type;
return this;
}
/** 事件配置, 对应于 {@link FeedAdLottieRepoInfo#name 属性} */
public String lottieConfig;
Kotlin:
/**
* 由[CountDownType.type] mapTo [CountDownType]
* 避免了使用 when(type) 写 else 了
*/
private fun type2Enum(type: () -> String): CountDownType {
return CountDownType.values().firstOrNull {
it.type == type()
} ?: CountDownType.CIRCLE
}
Kotlin 可以使用内联标记来引用类、方法、属性等,这比 Java 中的 @see、@link 更加易用。
文档:kotlinlang.org/docs/kotlin…
函数式接口
非函数式接口:
internal interface ICountDownCallback {
/**
* 倒计时完成时回调
*/
fun finish()
}
internal fun setCountDownCallback(callback: ICountDownCallback) {
// ignore
}
internal fun show() {
setCountDownCallback(object : ICountDownCallback {
override fun finish() {
TODO("Not yet implemented")
}
})
}
函数式接口:
internal fun interface ICountDownCallback {
/**
* 倒计时完成时回调
*/
fun finish()
}
internal fun setCountDownCallback(callback: ICountDownCallback) {
// ignore
}
internal fun show() {
setCountDownCallback {
TODO("Not yet implemented")
}
}
函数式接口也被称为单一抽象方法(SAM)接口,使用函数式接口可以使代码更加简洁,富有表现力。
对于 Java 的接口,比如 View.OnClickListener,它在使用的时候可以直接转 lambda 使用的,只有是 kotlin 的单一抽象方法,需要加 fun 关键字标示它为函数式接口。
文档:kotlinlang.org/docs/fun-in…
高阶函数
如果对象的初始化比较麻烦,可以使用高阶函数,让代码更加流畅:
// 定义
open fun attachToViewGroup(
viewGroup: ViewGroup,
index: Int = -1,
lp: () -> MarginLayoutParams = {
MarginLayoutParams(
LayoutParams.WRAP_CONTENT,
LayoutParams.WRAP_CONTENT
)
}
) {
(this.parent as? ViewGroup)?.removeView(this)
viewGroup.addView(this, lp.invoke())
}
// 使用
override fun attachToViewGroup(viewGroup: ViewGroup, index: Int, lp: () -> MarginLayoutParams) {
super.attachToViewGroup(viewGroup, index) {
MarginLayoutParams(
ViewGroup.LayoutParams.WRAP_CONTENT,
ViewGroup.LayoutParams.WRAP_CONTENT
).apply {
leftMargin = 14.px(context)
topMargin = 44.px(context)
}
}
}
如果参数的获取比较复杂,代码比较长,有不少判断逻辑,也可以使用高阶函数:
// 定义
fun getCountDownViewByType(context: Context, type: () -> String = { "0" }) {
// ignore
}
// 使用
countDownView = CountDownType.getCountDownViewByType(this) {
rewardVideoCmdData.cmdPolicyData?.countDownType ?: ""
}
如果方法的返回值是一个状态值,然后根据状态值去做相关逻辑处理。这种情况下,其实我们想要的是一个行为,比如代码中充斥着大量的数据解析、校验等逻辑,我们也可以是使用高阶函数重构:
// 重构之前
/**
* 校验数据有效(校验标题和按钮有一个不为空,就可以展示 Dialog)
*/
fun checkValid(): Boolean {
return !dialogTitle.isNullOrEmpty() || !buttonList.isNullOrEmpty()
}
private fun bindData() {
rewardData = RewardDialogData(arguments?.getString(EXTRA_REWARD_DATA) ?: "")
// 弹窗数据不合法,就不需要展示 dialog 了
if (rewardData == null || !rewardData!!.checkValid()) {
dismiss()
return
}
// 更新字体颜色等
updateSkin()
}
// 重构之后
/**
* 数据校验失败,执行 [fail] 函数
*/
internal inline fun RewardDialogData?.checkFailed(fail: () -> Unit) {
this?.let {
if (dialogTitle.isNullOrEmpty() && buttonList.isNullOrEmpty()) {
fail()
}
} ?: fail()
}
private fun bindData() {
rewardData = RewardDialogData(arguments?.getString(EXTRA_REWARD_DATA) ?: "")
// 弹窗数据不合法,就不需要展示 dialog 了
rewardData?.checkFailed {
dismiss()
return
}
// 更新字体颜色等
updateSkin()
}
kotlin 标准库里面也是有非常多的高阶函数的,比如作用域函数(let、apply、run等等),除此之外,还有一些集合类的标准库函数:
// filter
fun showCharge() {
adMonitorUrl?.filter {
!it.showUrl.isNullOrEmpty()
}?.forEach {
ParallelCharge.charge(it.showUrl)
}
}
// forEachIndexed
list.forEachIndexed { index, i ->
// ignore
}
文档:kotlinlang.org/docs/lambda…
扩展函数
// 比较不流畅的写法
val topImgUrl = rewardData?.topImg
if (topImgUrl.isNullOrBlank()) {
topImg.visibility = View.GONE
} else {
topImg.hierarchy?.useGlobalColorFilter = false
topImg.visibility = View.VISIBLE
topImg.setImageURI(topImgUrl)
}
// 使用局部返回标签
topImg.apply {
if (topImgUrl.isNullOrEmpty()) {
visibility = View.GONE
return@apply
}
hierarchy?.useGlobalColorFilter = false
setImageURI(topImgUrl)
visibility = View.VISIBLE
}
/**
* 校验 View 可见性
*
* @return [predicate] false: GONE;true: VISIBLE
*/
internal inline fun <reified T : View> T.checkVisible(predicate: () -> Boolean): T? {
return if (predicate()) {
visibility = View.VISIBLE
this
} else {
visibility = View.GONE
null
}
}
// 使用扩展函数
topImg.checkVisible {
!topImgUrl.isNullOrEmpty()
}?.run {
hierarchy?.useGlobalColorFilter = false
setImageURI(topImgUrl)
}作者:Omooo
链接:https://juejin.cn/post/7029673754309427207
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
我们需要从单体转到微服务吗?
微服务或许你没有真正实践过,但一定听说过,虽然已经到了 2022 年,这个词依然很热,可以通过搜索 google 指数看得到。
起源
“微服务”一词源于 2011 年 5 月在威尼斯附近的一次软件架构师研讨会上进行的架构风格的讨论。2012 年 5 月 讨论小组决定将这种架构风格命名为“微服务”。Fred George 同年在一次技术大会上进行自己的微服务实践分享,并说微服务是一种细粒度的 SOA ,但最终将其发扬光大的是 Martin Fowler 2014 年写的博文《 Microservices 》,原文链接如下:
martinfowler.com/articles/microservices.html。
自此以后,微服务就家喻户晓了,Microservices 的 Google 指数也是在 2014 年后就一路飙升。
和微服务相对应的是单体架构,先来看看单体架构是怎样的。
单体架构
大多数人做软件开发应该都是从单体架构开始的,以 .NET 程序员来说,从最早的 WebForm、到后来的 MVC、再到现在的前后端分离,后端使用 .NET 的 WebAPI ,都是整个项目的代码放到一个解决方案中,发布要么直接整个目录进行替换,或者更新有变更的 dll 文件。
包括到现在,这种单体架构的模该还占着很大的比重,凡是存在,必有道理,单体架构有着他的可取之处:
开发方便,.NET 程序员只需只需使用宇宙最强 IDE VS 就可以。
调试方便,在开发阶段,所有的项目都在一个解决方案下,项目之间是可以直接引用,断点可以到达你想要的任何地方。
运行方便,编码完成,只需一个 F5 搞定。
部署方便,无论是之前部署 IIS ,还是现在的容器部署,都只涉及到一个发布目录。
不过,随着产品的功能越来越复杂,代码也会变得越来越复杂,团队的人数也会越来越多,这时单体架构就会带来一些问题:
因为代码库非常的臃肿,从编译、构建、运行到测试这个时间会越来越长。
技术栈几乎是受限的,比如一个 .NET 的工程,基本就是 C# 来开发了,不太可能混杂其他的语言。
不方便横向扩展,只能整套程序进行扩,满足所有模块的需求,对资源的利用率非常差。
不够敏捷,团队成员越来越多多时,都在同一个代码上进行修改、提交、合并,容易引发冲突和其他问题。
一个很小的改动点,容易引发全身问题,导致系统崩溃,因为影响点多,测试成本也会很高。
缺乏可靠性,我们就碰到过因为一个序列化的问题导致 CPU 占用很高,结果整个系统瘫痪了。
微服务架构
上面提到的单体架构存在的问题,采用微服务架构可以很好地解决。微服务的核心是为了解耦,构建成一个松耦合的分布式系统。
一个庞大的单体系统拆分成若干个小的服务,每个服务可以由一个小的团队来维护,团队会更加敏捷,构建发布的时间更短,代码也容易维护。
不同的微服务团队可以采用不同的技术栈,比如工作流引擎使用 .NET ,规则引擎可以使用 Java ,一些全新的模块更容易采用新的技术,人员流动和补充上也更加灵活。
每个服务通常采用独立的数据库,代码或者数据库层面的问题不会导致整个系统的崩溃。
扩展方便,这个很重要,如果监控发现流程引擎的压力很大,可以只针对这个服务进行横向扩展,服务器资源可以得到更好的利用。
上面说的都是好处,但没有任何一种技术是银弹,微服务解决问题的同时,也会带来更多的问题。
1、开发调试变得困难了,需要通过日志的方式或者借助一些远程调试工具。
2、单体架构中,模块之间的调用都是进程内,添加类库的引用后,就是本地方法的调用,微服务各自独立部署,就会涉及到进程间的通信。
3、线上问题往往需要多个服务团队一起来协作解决,会存在互相甩锅的问题。
4、在分布式系统中,事务、数据一致性、联合查询等相比较单体更加复杂。
5、持续集成、部署、运维的复杂度也显著提升。
6、随着服务越来越多,客户端怎样去找这些服务呢?
7、进程内的访问不存在网络的问题,拆分后的服务可能在同个机器的不同进程,更多的时候是不同机器的不同进程,网络问题导致服务不稳定怎么办?
为了解决这些问题,各种中间件和框架就应运而生,又会带来更多的学习成本。
在 .NET 技术栈中,会用到下面这些中间件:
服务注册与发现:Consul。
网关:Ocelot。
熔断降级:Polly。
服务链路追踪:SkyWalking 或 Twitter 的 Zipkin。
配置中心:Apllo。
鉴权中心:IdentityServer4。
在 Java 中也有 Spring Cloud 和 Spring Cloud Alibaba 这种全家桶套件可以使用。
要不要转微服务呢?
从单体到微服务是一个权衡和取舍的问题,切记不要跟风。以我的经验来看,可以分为两类:
做企业级系统。
做互联网系统。
做企业级应用大多都是项目交付型的,客户关系维系的好,后面可以做二期、三期,当然也有一锤子买卖的。这其中一个关键点是要快,单从快速来看,采用单体架构,开发、调试、部署都是最快的。
从客户角度来说,只要能满足业务,是单体还是微服务其实不太关心。
做互联网应用,也就是我们常说的 SaaS,也分为两种情况:
1、将现有的私有化部署的系统(单体架构)改造成支持 SaaS 的模式。
这种我也不建议一上来就大刀阔斧地进行微服务改造,可以在代码的结构上做一些调整,比如按照领域去拆分目录,不同领域之间的调用可以再进行一层抽象,目的是为了未来向微服务架构转化。
当团队的技术栈变得丰富了,比如原先只有 .NET ,现在有些模块采用的是 Java ,这时已然是朝着微服务架构发展了,只是粒度比较大而已,相应的一些中间件也需要引入,比如服务网关、服务发现、服务间通信等。
2、从零开始做一个 SaaS 系统。
互联网系统和企业级系统有很大的差别,如果说企业级系统更多关注功能性需求,那么互联网系统除了功能性需求,还需要关注非功能性需求,比如:横向扩展、限流降级、日志追踪、预警、灰度发布等。
即便因为时间关系,一开始是单体架构,我觉得也应该是微服务架构的单体,随着持续迭代和发展,根据实际情况逐步进行拆分。
如果时间上比较充裕,可以一开始就按照微服务架构进行分离,但粒度不要太小。
总结
解决常说的的三高问题(高并发、高性能、高可用),一个核心的思路就是拆,分而治之,所以说微服务肯定是能解决掉我们的很多问题,也是发展方向。
实践微服务需要根据当前的实际情况,如果单体运行的很好,也没什么问题,也不要为了炫技进行微服务改造。
如果决定要实践微服务,先做好单体架构的设计,让代码遵循面向对象的设计原则,否则即便形式上变成了微服务,也不能尝到微服务的甜头。
作者:不止dotNET
收起阅读 »牛逼,一款 996 代码分析工具
程序员是一个创作型的职业,频繁的加班并不能增加产出,而国内 996 的公司文化,真的一言难尽。但是如果你进到一家公司,你能从哪些观察来判断这家公司的工作强度的(加班文化)?是看大家走得早不早吗?有一定的参考意义,但是如果走得晚呢,可能是大家不敢提前走而在公司耗时间。
今天要推荐一个代码分析工具 code996,它可以统计 Git 项目的 commit 时间分布,进而推导出这个项目的编码工作强度。这算是一种对项目更了解的方式,杜绝 996 从了解数据开始。
我们先来看 code996 分析出来的结果示例,以下是分析项目的基本情况:

通过图表查看 commit 提交分布:

对比项目工作时间类型:
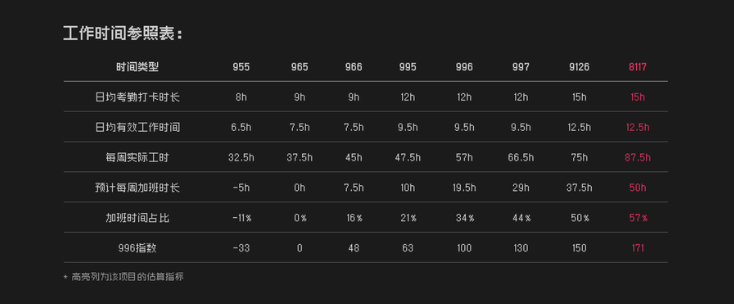
如果你对 code996 是如何工作的,以下是作者的说明:

因为代码是公司的很重要的资产,泄露是肯定不行的,为了解决大家的后顾之忧,该项目是完全安全的。

code996 除了能够分析项目的实际工作强度,也能用来分析我们代码编写的情况,对自身了解自己代码编写效率的时段、最近的工作强度等都是非常好的一个输入。
更多项目详情请查看如下链接。
开源项目地址:https://github.com/hellodigua/code996
开源项目作者:hellodigua
收起阅读 »七夕,程序员到底该送什么礼物给女朋友?参与讨论有奖励哦
据统计,程序员只有30%是有女朋友的,还有15%是有男朋友的,而已经结婚的占50%。
我想,你总不至于是剩下的5%吧!
马上情人节了,想好送什么礼物没?
获奖名单:
柳天明、美国队长、Jiayun、李全喜、conanma
请以上获奖同学8月13日24:00前私信我邮寄信息!
马上就要情人节了又到了着急买什么送给对象的时候了!
作为一名程序员,如何快乐简单不掉头发的为各种节日安排好女朋友的礼物可能是个难题。
当网络上在讨论程序员的时候,脸谱化的礼物往往就是 鼠标/键盘/降噪耳机,但我知道,每一个程序员,除了程序人生之外,都有自己的精彩而美丽的生活。对你的女朋友来说,也是同样。
先看看各路大牛脑洞大开:
- 高德地图实现“爱心”轨迹
(来源:juejin.cn/post/7126576400441540621)
- 浪漫邂逅小动画
(源码:https://github.com/alexwjj/qixi)
情诗表白墙
(来源:juejin.cn/post/7127210046840111117,预览)
- 无法拒绝的表白
(源码:https://github.com/andyngojs/crush-love)
- 浪漫专属chrome插件
(作者:蜡笔小心_)
- 代码+谜语系列



所有的相遇,都是命中注定:
致橡树(舒婷):

不得不说,这些礼物都很有特色,
但是,别人需要的是这些吗?
别人需要的是口红,是包包,是各种首饰,
你整那些,就好比看到她打扫卫生辛苦了,
自己吃个冰镇瓜、自己打把游戏、自己找朋友K歌,
把自己的享受作为对她的奖励,这合理吗?
5%的群体正在向你招手欢迎!
各位情场得意的码农届高质量群体请分享下,你在七夕送了或得到了什么礼物?
我们这些直男最擅长复制粘贴和clone了。
参与回复的5人有机会获得imgeek准备的小礼物~
获奖名单:
柳天明、美国队长、Jiayun、李全喜、conanma
请以上获奖同学8月13日24:00前私信我邮寄信息!
一天高中的女同桌突然问我是不是程序猿
背景
昨天一个我高中的女同桌突然发微信问我“你是不是程序猿 我有问题求助”,
先是激动后是茫然再是冷静,毕业多年不见联系,突然发个信息求助,感觉大脑有点反应不过来... 再说我一个搞Android的也不咋会python啊(不是说Java不能实现,大家懂的,人生苦短,我用python),即使如此,
为了大家的面子,为了程序猿们的脸,不就简单的小Python嘛,必须答应!
梳理需求
现有excel表格记录着 有效图片的名字,如:
要从一个文件夹里把excel表格里记录名字的图片筛选出来;
需求也不是很难,代码思路就有了:
- 读取Excel表格第一列的信息并放入A集合
- 遍历文件夹下所有的文件,判断文件名字是否存在A集合
- 存在A集合则拷贝到目标文件夹
实现(Python 2.7)
读取Excel表格
加载Excel表格的方法有很多种,例如pandas、xlrd、openpyxl,我这里选择openpyxl库,
先安装库
pip install openpyxl
代码如下:
from openpyxl import load_workbook
def handler_excel(filename=r'C:/Users/xxx/Desktop/haha.xlsx'):
# 根据文件路径加载一个excel表格,这里包含所有的sheet
excel = load_workbook(filename)
# 根据sheet名称加载对应的table
table = excel.get_sheet_by_name('Sheet1')
imgnames = []
# 读取所有列
for column in table.columns:
for cell in column:
imgnames.append(cell.value+".png")
# 选择图片
pickImg(imgnames)
遍历文件夹读取文件名,找到target并拷贝
使用os.listdir 方法遍历文件,这里注意windows环境下拿到的unicode编码,需要GBK重新解码
def pickImg(pickImageNames):
# 遍历所有图片集的文件名
for image in os.listdir(
r"C:\Users\xxx\Desktop\work\img"):
# 使用gbk解码,不然中文乱码
u_file = image.decode('gbk')
print(u_file)
if u_file in pickImageNames:
oldname = r"C:\Users\xxx\Desktop\work\img/" + image
newname = r"C:\Users\xxx\Desktop\work\target/" + image
# 文件拷贝
shutil.copyfile(oldname, newname)
简单搞定!没有砸程序猿的招牌,豪横的把成果发给女同桌,结果:
换来有机会请你吃饭,微信都不带回的,哎 ,xdm,小丑竟是我自己!

作者:李诺曹
链接:https://juejin.cn/post/7019167108185456677
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Kotlin协程之Dispatchers原理
Kotlin协程不是什么空中阁楼,Kotlin源代码会被编译成class字节码文件,最终会运行到虚拟机中。所以从本质上讲,Kotlin和Java是类似的,都是可以编译产生class的语言,但最终还是会受到虚拟机的限制,它们的代码最终会在虚拟机上的某个线程上被执行。
之前我们分析了launch的原理,但当时我们没有去分析协程创建出来后是如何与线程产生关联的,怎么被分发到具体的线程上执行的,本篇文章就带大家分析一下。
前置知识
要想搞懂Dispatchers,我们先来看一下Dispatchers、CoroutineDispatcher、ContinuationInterceptor、CoroutineContext之间的关系
public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
@JvmStatic
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
@JvmStatic
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
@JvmStatic
public val IO: CoroutineDispatcher = DefaultIoScheduler
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
}
public interface ContinuationInterceptor : CoroutineContext.Element {}
public interface Element : CoroutineContext {}
Dispatchers中存放的是协程调度器(它本身是一个单例),有我们平时常用的IO、Default、Main等。这些协程调度器都是CoroutineDispatcher的子类,这些协程调度器其实都是CoroutineContext。
demo
我们先来看一个关于launch的demo:
fun main() {
val coroutineScope = CoroutineScope(Job())
coroutineScope.launch {
println("Thread : ${Thread.currentThread().name}")
}
Thread.sleep(5000L)
}
在生成CoroutineScope时,demo中没有传入相关的协程调度器,也就是Dispatchers。那这个launch会运行到哪个线程之上?
运行试一下:
Thread : DefaultDispatcher-worker-1
居然运行到了DefaultDispatcher-worker-1线程上,这看起来明显是Dispatchers.Default协程调度器里面的线程。我明明没传Dispatchers相关的context,居然会运行到子线程上。说明运行到default线程是launch默认的。
它是怎么与default线程产生关联的?打开源码一探究竟:
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
//代码1
val newContext = newCoroutineContext(context)
//代码2
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
//代码3
coroutine.start(start, coroutine, block)
return coroutine
}
- 将传入的CoroutineContext构造出新的context
- 启动模式,判断是否为懒加载,如果是懒加载则构建懒加载协程对象,否则就是标准的
- 启动协程
我们重点关注代码1,这是与CoroutineContext相关的。
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
//从父协程那里继承过来的context+这次的context
val combined = coroutineContext.foldCopiesForChildCoroutine() + context
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
//combined可以简单的把它看成是一个map,它是CoroutineContext类型的
//如果当前context不等于Dispatchers.Default,而且从map里面取ContinuationInterceptor(用于拦截之后分发线程的)值为空,说明没有传入协程应该在哪个线程上运行的相关参数
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug
}
调用launch的时候,我们没有传入context,默认参数是EmptyCoroutineContext。这里的combined,它其实是CoroutineContext类型的,可以简单的看成是map(其实不是,只是类似)。通过combined[ContinuationInterceptor]可以将传入的线程调度相关的参数给取出来,这里如果取出来为空,是给该context添加了一个Dispatchers.Default,然后把新的context返回出去了。所以launch默认情况下,会走到default线程去执行。
补充一点:CoroutineContext能够通过+连接是因为它内部有个public operator fun plus函数。能够通过combined[ContinuationInterceptor]这种方式访问元素是因为有个public operator fun get函数。
public interface CoroutineContext {
/**
* Returns the element with the given [key] from this context or `null`.
*/
public operator fun <E : Element> get(key: Key<E>): E?
/**
* Returns a context containing elements from this context and elements from other [context].
* The elements from this context with the same key as in the other one are dropped.
*/
public operator fun plus(context: CoroutineContext): CoroutineContext {
......
}
}
startCoroutineCancellable
上面我们分析了launch默认情况下,context中会增加Dispatchers.Default的这个协程调度器,到时launch的Lambda会在default线程上执行,其中具体流程是怎么样的,我们分析一下。
在之前的文章 Kotlin协程之launch原理 中我们分析过,launch默认情况下会最终执行到startCoroutineCancellable函数。
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
//构建ContinuationImpl
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
public actual fun <T> (suspend () -> T).createCoroutineUnintercepted(
completion: Continuation<T>
): Continuation<Unit> {
val probeCompletion = probeCoroutineCreated(completion)
return if (this is BaseContinuationImpl)
//走这里
create(probeCompletion)
else
createCoroutineFromSuspendFunction(probeCompletion) {
(this as Function1<Continuation<T>, Any?>).invoke(it)
}
}
在Kotlin协程之launch原理 文章中,咱们分析过create(probeCompletion)这里创建出来的是launch的那个Lambda,编译器会产生一个匿名内部类,它继承自SuspendLambda,而SuspendLambda是继承自ContinuationImpl。所以 createCoroutineUnintercepted(completion)一开始构建出来的是一个ContinuationImpl,接下来需要去看它的intercepted()函数。
internal abstract class ContinuationImpl(
completion: Continuation<Any?>?,
private val _context: CoroutineContext?
) : BaseContinuationImpl(completion) {
constructor(completion: Continuation<Any?>?) : this(completion, completion?.context)
public override val context: CoroutineContext
get() = _context!!
@Transient
private var intercepted: Continuation<Any?>? = null
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
}
第一次走到intercepted()函数时,intercepted肯定是为null的,还没初始化。此时会通过context[ContinuationInterceptor]取出Dispatcher对象,然后调用该Dispatcher对象的interceptContinuation()函数。这个Dispatcher对象在demo这里其实就是Dispatchers.Default。
public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
}
可以看到,Dispatchers.Default是一个CoroutineDispatcher对象,interceptContinuation()函数就在CoroutineDispatcher中。
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
}
public fun <T> (suspend () -> T).startCoroutineCancellable(completion: Continuation<T>): Unit = runSafely(completion) {
createCoroutineUnintercepted(completion).intercepted().resumeCancellableWith(Result.success(Unit))
}
这个方法非常简单,就是新建并且返回了一个DispatchedContinuation对象,将this和continuation给传入进去。这里的this是Dispatchers.Default。
所以,最终我们发现走完startCoroutineCancellable的前2步之后,也就是走完intercepted()之后,创建的是DispatchedContinuation对象,最后是调用的DispatchedContinuation的resumeCancellableWith函数。最后这步比较关键,这是真正将协程的具体执行逻辑放到线程上执行的部分。
internal class DispatchedContinuation<in T>(
//这里传入的dispatcher在demo中是Dispatchers.Default
@JvmField val dispatcher: CoroutineDispatcher,
@JvmField val continuation: Continuation<T>
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
inline fun resumeCancellableWith(
result: Result<T>,
noinline onCancellation: ((cause: Throwable) -> Unit)?
) {
val state = result.toState(onCancellation)
//代码1
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_CANCELLABLE
//代码2
dispatcher.dispatch(context, this)
} else {
//代码3
executeUnconfined(state, MODE_CANCELLABLE) {
if (!resumeCancelled(state)) {
resumeUndispatchedWith(result)
}
}
}
}
}
internal abstract class DispatchedTask<in T>(
@JvmField public var resumeMode: Int
) : SchedulerTask() {
......
}
internal actual typealias SchedulerTask = Task
internal abstract class Task(
@JvmField var submissionTime: Long,
@JvmField var taskContext: TaskContext
) : Runnable {
......
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
}
从DispatchedContinuation的继承结构来看,它既是一个Continuation(通过委托给传入的continuation参数),也是一个Runnable。
- 首先看代码1:这个dispatcher在demo中其实是Dispatchers.Default ,然后调用它的isDispatchNeeded(),这个函数定义在CoroutineDispatcher中,默认就是返回true,只有Dispatchers.Unconfined返回false
- 代码2:调用Dispatchers.Default的dispatch函数,将context和自己(DispatchedContinuation,也就是Runnable)传过去了
- 代码3:对应Dispatchers.Unconfined的情况,它的isDispatchNeeded()返回false
现在我们要分析代码2之后的执行逻辑,也就是将context和Runnable传入到dispatch函数之后是怎么执行的。按道理,看到Runnable,那可能这个与线程执行相关,应该离我们想要的答案不远了。回到Dispatchers,我们发现Dispatchers.Default是DefaultScheduler类型的,那我们就去DefaultScheduler中或者其父类中去找dispatch函数。
public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
}
internal object DefaultScheduler : SchedulerCoroutineDispatcher(
CORE_POOL_SIZE, MAX_POOL_SIZE,
IDLE_WORKER_KEEP_ALIVE_NS, DEFAULT_SCHEDULER_NAME
) {
......
}
internal open class SchedulerCoroutineDispatcher(
private val corePoolSize: Int = CORE_POOL_SIZE,
private val maxPoolSize: Int = MAX_POOL_SIZE,
private val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
private val schedulerName: String = "CoroutineScheduler",
) : ExecutorCoroutineDispatcher() {
private var coroutineScheduler = createScheduler()
private fun createScheduler() =
CoroutineScheduler(corePoolSize, maxPoolSize, idleWorkerKeepAliveNs, schedulerName)
override fun dispatch(context: CoroutineContext, block: Runnable): Unit = coroutineScheduler.dispatch(block)
}
最后发现dispatch函数在其父类SchedulerCoroutineDispatcher中,在这里构建了一个CoroutineScheduler,直接调用了CoroutineScheduler对象的dispatch,然后将Runnable(也就是上面的DispatchedContinuation对象)传入。
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int,
@JvmField val maxPoolSize: Int,
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
) : Executor, Closeable {
override fun execute(command: Runnable) = dispatch(command)
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
trackTask() // this is needed for virtual time support
//代码1:构建Task,Task实现了Runnable接口
val task = createTask(block, taskContext)
//代码2:取当前线程转为Worker对象,Worker是一个继承自Thread的类
val currentWorker = currentWorker()
//代码3:尝试将Task提交到本地队列并根据结果执行相应的操作
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
if (notAdded != null) {
//代码4:notAdded不为null,则再将notAdded(Task)添加到全局队列中
if (!addToGlobalQueue(notAdded)) {
throw RejectedExecutionException("$schedulerName was terminated")
}
}
val skipUnpark = tailDispatch && currentWorker != null
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) {
if (skipUnpark) return
//代码5: 创建Worker并开始执行该线程
signalCpuWork()
} else {
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark)
}
}
private fun currentWorker(): Worker? = (Thread.currentThread() as? Worker)?.takeIf { it.scheduler == this }
internal inner class Worker private constructor() : Thread() {
.....
}
}
观察发现,原来CoroutineScheduler类实现了java.util.concurrent.Executor接口,同时实现了它的execute方法,这个方法也会调用dispatch()。
- 代码1:首先是通过Runnable构建了一个Task,这个Task其实也是实现了Runnable接口,只是把传入的Runnable包装了一下
- 代码2:将当前线程取出来转换成Worker,当然第一次时,这个转换不会成功,这个Worker是继承自Thread的一个类
- 代码3:将task提交到本地队列中,这个本地队列待会儿会在Worker这个线程执行时取出Task,并执行Task
- 代码4:如果task提交到本地队列的过程中没有成功,那么会添加到全局队列中,待会儿也会被Worker取出来Task并执行
- 代码5:创建Worker线程,并开始执行
开始执行Worker线程之后,我们需要看一下这个线程的run方法执行的是啥,也就是它的具体执行逻辑。
internal inner class Worker private constructor() : Thread() {
override fun run() = runWorker()
private fun runWorker() {
var rescanned = false
while (!isTerminated && state != WorkerState.TERMINATED) {
//代码1
val task = findTask(mayHaveLocalTasks)
if (task != null) {
rescanned = false
minDelayUntilStealableTaskNs = 0L
//代码2
executeTask(task)
continue
} else {
mayHaveLocalTasks = false
}
if (minDelayUntilStealableTaskNs != 0L) {
if (!rescanned) {
rescanned = true
} else {
rescanned = false
tryReleaseCpu(WorkerState.PARKING)
interrupted()
LockSupport.parkNanos(minDelayUntilStealableTaskNs)
minDelayUntilStealableTaskNs = 0L
}
continue
}
tryPark()
}
tryReleaseCpu(WorkerState.TERMINATED)
}
fun findTask(scanLocalQueue: Boolean): Task? {
if (tryAcquireCpuPermit()) return findAnyTask(scanLocalQueue)
// If we can't acquire a CPU permit -- attempt to find blocking task
val task = if (scanLocalQueue) {
localQueue.poll() ?: globalBlockingQueue.removeFirstOrNull()
} else {
globalBlockingQueue.removeFirstOrNull()
}
return task ?: trySteal(blockingOnly = true)
}
private fun executeTask(task: Task) {
val taskMode = task.mode
idleReset(taskMode)
beforeTask(taskMode)
runSafely(task)
afterTask(taskMode)
}
fun runSafely(task: Task) {
try {
task.run()
} catch (e: Throwable) {
val thread = Thread.currentThread()
thread.uncaughtExceptionHandler.uncaughtException(thread, e)
} finally {
unTrackTask()
}
}
}
run方法直接调用的runWorker(),在里面是一个while循环,不断从队列中取Task来执行。
- 代码1:从本地队列或者全局队列中取出Task
- 代码2:执行这个task,最终其实就是调用这个Runnable的run方法。
也就是说,在Worker这个线程中,执行了这个Runnable的run方法。还记得这个Runnable是谁么?它就是上面我们看过的DispatchedContinuation,这里的run方法执行的就是协程任务,那这块具体的run方法的实现逻辑,我们应该到DispatchedContinuation中去找。
internal class DispatchedContinuation<in T>(
@JvmField val dispatcher: CoroutineDispatcher,
@JvmField val continuation: Continuation<T>
) : DispatchedTask<T>(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation<T> by continuation {
......
}
internal abstract class DispatchedTask<in T>(
@JvmField public var resumeMode: Int
) : SchedulerTask() {
public final override fun run() {
assert { resumeMode != MODE_UNINITIALIZED } // should have been set before dispatching
val taskContext = this.taskContext
var fatalException: Throwable? = null
try {
val delegate = delegate as DispatchedContinuation<T>
val continuation = delegate.continuation
withContinuationContext(continuation, delegate.countOrElement) {
val context = continuation.context
val state = takeState() // NOTE: Must take state in any case, even if cancelled
val exception = getExceptionalResult(state)
/*
* Check whether continuation was originally resumed with an exception.
* If so, it dominates cancellation, otherwise the original exception
* will be silently lost.
*/
val job = if (exception == null && resumeMode.isCancellableMode) context[Job] else null
//非空,且未处于active状态
if (job != null && !job.isActive) {
//开始之前,协程已经被取消,将具体的Exception传出去
val cause = job.getCancellationException()
cancelCompletedResult(state, cause)
continuation.resumeWithStackTrace(cause)
} else {
//有异常,传递异常
if (exception != null) {
continuation.resumeWithException(exception)
} else {
//代码1
continuation.resume(getSuccessfulResult(state))
}
}
}
} catch (e: Throwable) {
// This instead of runCatching to have nicer stacktrace and debug experience
fatalException = e
} finally {
val result = runCatching { taskContext.afterTask() }
handleFatalException(fatalException, result.exceptionOrNull())
}
}
}
我们主要看一下代码1处,调用了resume开启协程。前面没有异常,才开始启动协程,这里才是真正的开始启动协程,开始执行launch传入的Lambda表达式。这个时候,协程的逻辑是在Worker这个线程上执行的了,切到某个线程上执行的逻辑已经完成了。
ps: rusume会走到BaseContinuationImpl的rusumeWith,然后走到launch传入的Lambda匿名内部类的invokeSuspend方法,开始执行状态机逻辑。前面的文章 Kotlin协程createCoroutine和startCoroutine原理 我们分析过这里,这里就只是简单提一下。
到这里,Dispatchers的执行流程就算完了,前后都串起来了。
小结
Dispatchers是协程框架中与线程交互的关键。底层会有不同的线程池,Dispatchers.Default、IO,协程任务来了的时候会封装成一个个的Runnable,丢到线程中执行,这些Runnable的run方法中执行的其实就是continuation.resume,也就是launch的Lambda生成的SuspendLambda匿名内部类,也就是开启协程状态机,开始协程的真正执行。
作者:潇风寒月
链接:https://juejin.cn/post/7127492385923137549
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter 使用 json_serializable 解析 JSON 支持泛型
一般情况下,服务端接口都会有一套数据结构规范,比如
{
"items": [],
"success": true,
"msg": ""
}
不同的接口,items 中返回的数据结构一般都是不一样的,这时使用泛型,可以简化代码
本文将以 wanAndroid 提供的开放 API 为例,介绍如何通过泛型类接解析 JSON 数据,简化代码。另外,对 wanAndroid 提供开放 API 的行为表示感谢。
本文解析 JSON 使用的方案,是官方推荐的 json_serializable,至于为什么选择 json_serializable,可以参考我之前写的一篇文章:Flutter 使用 json_serializable 解析 JSON 最佳方案
下面开始进入正文
使用 json_serializable 支持泛型
json_serializable 在大概两年前发布的 v3.5.0 版本开始支持泛型,只需要在 @JsonSerializable() 注解中设置 genericArgumentFactories 为 true,同时需要对 fromJson 和 toJson 方法进行调整,即可支持泛型解析,如下所示:
@JsonSerializable(genericArgumentFactories: true)
class Response<T> {
int status;
T value;
factory Response.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$ResponseFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$ResponseToJson<T>(this, toJsonT);
}
和正常实体类相比,fromJson 方法多了一个函数参数 T Function(dynamic json) fromJsonT;toJson 方法也多了一个函数参数:Object? Function(T value) toJsonT
分析数据结构
下面使用 wanAndroid 开放 API 接口数据,进行代码实践,我们先看一下服务端接口返回的数据结构
一般接口返回数据结构如下:
{
"data": [
{
"desc": "一起来做个App吧",
"id": 10,
"imagePath": "https://www.wanandroid.com/blogimgs/50c115c2-cf6c-4802-aa7b-a4334de444cd.png",
"isVisible": 1,
"order": 1,
"title": "一起来做个App吧",
"type": 1,
"url": "https://www.wanandroid.com/blog/show/2"
}
],
"errorCode": 0,
"errorMsg": ""
}
带分页信息的列表接口,返回数据结构如下:
{
"data": {
"curPage": 1,
"datas": [
{
"id": 23300,
"link": "https://juejin.cn/post/7114142706557075487",
"niceDate": "2022-06-28 15:30",
"niceShareDate": "2022-06-28 15:30",
"publishTime": 1656401449000,
"realSuperChapterId": 493,
"shareDate": 1656401449000,
"shareUser": "灰尘",
"superChapterId": 494,
"superChapterName": "广场Tab",
"title": "Flutter 使用 json_serializable 解析 JSON 最佳方案"
}
],
"offset": 0,
"over": false,
"pageCount": 3,
"size": 20,
"total": 46
},
"errorCode": 0,
"errorMsg": ""
}
通过上面的接口示例,我们可以发现,返回的数据结构有以下两种情况:
在一般情况下 data 是一个数组
{
"data": [],
"errorCode": 0,
"errorMsg": ""
}
在分页相关接口,data 是一个对象
{
"data": {},
"errorCode": 0,
"errorMsg": ""
}
复杂方案
如果想定义一个模型类,同时处理上述两种情况,可以把整个 data 都定义为泛型,代码如下:
import 'package:json_annotation/json_annotation.dart';
part 'base_response.g.dart';
@JsonSerializable(genericArgumentFactories: true)
class BaseResponse<T> {
T data;
int errorCode;
String errorMsg;
BaseResponse({
required this.data,
required this.errorCode,
required this.errorMsg,
});
factory BaseResponse.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$BaseResponseFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$BaseResponseToJson<T>(this, toJsonT);
}
@JsonSerializable(genericArgumentFactories: true)
class ListData<T> {
int? curPage;
List<T> datas;
int? offset;
bool? over;
int? pageCount;
int? size;
int? total;
ListData({
this.curPage,
required this.datas,
this.offset,
this.over,
this.pageCount,
this.size,
this.total,
});
factory ListData.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$ListDataFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$ListDataToJson<T>(this, toJsonT);
}
测试代码如下:
void main() {
test("json", () {
String str =
'{"data": [{"category": "设计","icon": "","id": 31,"link": "https://tool.gifhome.com/compress/","name": "gif压缩","order": 4444,"visible": 1}],"errorCode": 0,"errorMsg": ""}';
Map<String, dynamic> json = jsonDecode(str);
BaseResponse<List<CategoryModel>> result =
BaseResponse.fromJson(json, (json) {
return (json as List<dynamic>)
.map((e) => CategoryModel.fromJson(e as Map<String, dynamic>))
.toList();
});
List<CategoryModel> list = result.data;
CategoryModel model = list[0];
print(model.toJson());
expect("category:设计", "category:${model.category}");
});
test("json list", () {
String str =
'{"data": {"curPage": 1,"datas": [{"id": 23300,"link": "https://juejin.cn/post/7114142706557075487","niceDate": "2022-06-28 15:30","niceShareDate": "2022-06-28 15:30","publishTime": 1656401449000,"realSuperChapterId": 493,"shareDate": 1656401449000,"shareUser": "灰尘","superChapterId": 494,"superChapterName": "广场Tab","title": "Flutter 使用 json_serializable 解析 JSON 最佳方案"}],"offset": 0,"over": false,"pageCount": 3,"size": 20,"total": 46},"errorCode": 0,"errorMsg": ""}';
Map<String, dynamic> json = jsonDecode(str);
BaseResponse<ListData<ArticleModel>> result =
BaseResponse.fromJson(json, (json) {
return ListData.fromJson(json, (json) => ArticleModel.fromJson(json));
});
ListData<ArticleModel> listData = result.data;
List<ArticleModel> datas = listData.datas;
ArticleModel model = datas[0];
print(model.toJson());
expect("id:23300", "id:${model.id}");
});
}
虽然一个 BaseResponse 解决了两种数据结构,但使用时的代码会有些复杂,很容易出错。
一般接口:
BaseResponse<List<CategoryModel>> result =
BaseResponse.fromJson(json, (json) {
return (json as List<dynamic>)
.map((e) => CategoryModel.fromJson(e as Map<String, dynamic>))
.toList();
});
分页接口:
BaseResponse<ListData<ArticleModel>> result =
BaseResponse.fromJson(json, (json) {
return ListData.fromJson(json, (json) => ArticleModel.fromJson(json));
});
简化方案
可以对一般接口和列表分页接口进行单独处理,
处理一般接口的泛型类,命名为 BaseCommonResponse,代码如下:
import 'package:json_annotation/json_annotation.dart';
part 'base_common_response.g.dart';
@JsonSerializable(genericArgumentFactories: true)
class BaseCommonResponse<T> {
List<T> data;
int errorCode;
String errorMsg;
BaseCommonResponse({
required this.data,
required this.errorCode,
required this.errorMsg,
});
factory BaseCommonResponse.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$BaseCommonResponseFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$BaseCommonResponseToJson<T>(this, toJsonT);
}
处理分页列表接口的泛型类,命令为 BaseListResponse
import 'package:json_annotation/json_annotation.dart';
part 'base_list_response.g.dart';
@JsonSerializable(genericArgumentFactories: true)
class BaseListResponse<T> {
ListData<T> data;
int errorCode;
String errorMsg;
BaseListResponse({
required this.data,
required this.errorCode,
required this.errorMsg,
});
factory BaseListResponse.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$BaseListResponseFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$BaseListResponseToJson<T>(this, toJsonT);
}
@JsonSerializable(genericArgumentFactories: true)
class ListData<T> {
int? curPage;
List<T> datas;
int? offset;
bool? over;
int? pageCount;
int? size;
int? total;
ListData({
this.curPage,
required this.datas,
this.offset,
this.over,
this.pageCount,
this.size,
this.total,
});
factory ListData.fromJson(
Map<String, dynamic> json,
T Function(dynamic json) fromJsonT,
) =>
_$ListDataFromJson<T>(json, fromJsonT);
Map<String, dynamic> toJson(Object? Function(T value) toJsonT) =>
_$ListDataToJson<T>(this, toJsonT);
}
测试代码如下:
void main() {
test("json", () {
String str =
'{"data": [{"category": "设计","icon": "","id": 31,"link": "https://tool.gifhome.com/compress/","name": "gif压缩","order": 4444,"visible": 1}],"errorCode": 0,"errorMsg": ""}';
Map<String, dynamic> json = jsonDecode(str);
BaseCommonResponse<CategoryModel> result = BaseCommonResponse.fromJson(
json, (json) => CategoryModel.fromJson(json));
List<CategoryModel> list = result.data;
CategoryModel model = list[0];
print(model.toJson());
expect("category:设计", "category:${model.category}");
});
test("json list", () {
String str =
'{"data": {"curPage": 1,"datas": [{"id": 23300,"link": "https://juejin.cn/post/7114142706557075487","niceDate": "2022-06-28 15:30","niceShareDate": "2022-06-28 15:30","publishTime": 1656401449000,"realSuperChapterId": 493,"shareDate": 1656401449000,"shareUser": "灰尘","superChapterId": 494,"superChapterName": "广场Tab","title": "Flutter 使用 json_serializable 解析 JSON 最佳方案"}],"offset": 0,"over": false,"pageCount": 3,"size": 20,"total": 46},"errorCode": 0,"errorMsg": ""}';
Map<String, dynamic> json = jsonDecode(str);
BaseListResponse<ArticleModel> result =
BaseListResponse.fromJson(json, (json) => ArticleModel.fromJson(json));
ListData<ArticleModel> listData = result.data;
List<ArticleModel> datas = listData.datas;
ArticleModel model = datas[0];
print(model.toJson());
expect("id:23300", "id:${model.id}");
});
}
这时使用时的代码,就比较简单了,代码如下:
一般接口,使用 BaseCommonResponse
BaseCommonResponse<CategoryModel> result = BaseCommonResponse.fromJson(
json, (json) => CategoryModel.fromJson(json));
列表分页接口,使用 BaseListResponse
BaseListResponse<ArticleModel> result = BaseListResponse.fromJson(
json, (json) => ArticleModel.fromJson(json));
以上就是我在 Flutter 中解析 JSON 数据时处理泛型的实践经验,如果对你有所帮助,欢迎一键三连,👍👍👍
如果大家有相关问题,欢迎评论留言。
作者:灰尘大哥
链接:https://juejin.cn/post/7127206962915180574
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
研发同学应该如何负责好一个项目
引言
时间回到6年前,我在京东第一次独立负责项目的前端开发。当时的我可谓雄心壮志,希望表现和证明自己,结果第一次上线就造成了生产事故。
后来半年里,我几乎把所有可能的错误都犯了个遍:老板让我搞一个技术方案,我闷头搞了两周也没有给出任何结论;本来安排好的开发计划,被各种插进来的需求搞得手忙脚乱;参加需求评审没有充分的准备全程提不出问题……那段时间我很苦恼,明明很累很辛苦,但依然拿不到想要的结果。
一晃6年,自己已经从一个小白成长为技术Leader。当我站在更高的视角,我发现身边很多同学不停地重复犯着自己当年类似的错误。经过一段时间的观察与思考,我得出的结论是:他们在工作中缺少方法论的沉淀和指导。
“方法论”这个看似虚无缥缈的东西,却犹如指引行动的灯塔,连接着我们的价值观与行动。对于很多研发同学来说,“ 如何负责好一个项目” 是一门只可意会不可言传的玄学,其实不然。
我将我个人经历以及对身边同事的观察,做了一些总结,希望能够给大家带来一些启发,更好地在项目推进过程中指导我们的行动。
一 负责人的定位
这里的负责人不是指的项目经理,而是研发侧牵头和统一对外的那个人,往往是虚线Lead一个项目。
初阶的负责人通常只是做一些需求拆解、任务分配、问题收集和反馈这样一些基础的工作。因为缺乏方法论的指引和对业务的理解,过程中毫无章法、顾此失彼,表现就是像一个救火队长,永远都被事情推着走,很忙很累却拿不到结果。
在我看来,优秀的负责人是这样的:把自己负责的项目当作是一次创业,自己是这个初创团队的CTO,职责是带领这些同学打胜仗(打胜仗是指在产品和技术方案上少走弯路、做出来的东西真的有人用、帮助团队提高效率降低成本、帮助业务带来更多收入和利润)。
难点在于,上面这个表述虽然有了画面感,但具体应该怎么做呢?
二 技术负责人的三大能力
我常和团队的同学讲:技术人的三大支柱是专业技术、项目管理和业务理解。对于负责人而言,则一定是这三项均衡发展。
1、专业技术能力
负责人不见得技术很强,但有深度、有广度、有影响力会走更远。深度很容易理解,广度是指什么呢?

技术负责人需要有广度。广度一方面是 “跨领域” 的部分;比如:大多数情况负责人由后端同学担任,那么最好对前端、质量、算法也了解些,至少跟在讨论方案的时候要有得聊;另一方面是抬高自身视野:在方案评估和决策的时候,能不能看到公司内部其他团队的方案或者行业内部的方案;在做一个决策之前,都了解了哪些方案、不同方案间的对比维度和选择逻辑是什么,现成方案不满足需求时如何处理等。

技术负责人需要有影响力。影响力会让你有足够的自信去把控技术方案:如果自己提出的方案频频被挑战,或者面对别人方案的时候提不出问题和建议,则是削弱技术影响力的行为。在项目中,技术影响力主要体现在三个方面:
(1)内容和技术方案输出的专业性。我见过很多同学在沟通技术方案时都是“口述”,这样的方式既低效又不专业;
(2)工作中要有技术沉淀的意识。比如:效率和质量的提升、稳定性建设等;力争量化结果,拿数据说话;
(3)对技术的场景转化能力。专业性不在于用了哪些高大上的技术,而是用合适的工具解决实际问题,同时能反向推导这一类技术其他的适用场景。
2、项目管理能力
研发项目管理是个很专业的事,我对此的理解是:在有限资源限定的条件下,协同好上下游(包括运营、产品、设计、研发、质量),综合运用专业技能、方法和工具达成项目目标。整个研发项目管理的内容很多,通过观察,我总结出一些负责人在工作中常见问题及注意事项:
(1) 要不卑不亢,对结果负责。既不是高高在上的存在,又不是老好人,在项目中团结好大家,倾听并尊重每一位成员的意见和建议。
负责人在这个过程中要保持空杯心态。初入职场的小白,可能会非常谦虚,但是工作几年之后,专业技能逐步提升,可能还取得了一些小成就,人就会越来越自信。如果不能始终保持“空杯心态”,这种自信就会逐步演变为自满,往往表现为:工作中把别人的建议当成是批评、不喜欢听反对的声音。这样一来,团队里的声音就少了,缺少了交流碰撞,负责人就会成为团队的瓶颈。
(2) 要有敏锐的问题意识以及全局观。可以识别出项目过程中存在的问题和风险、看问题的视角要更高、也要更客观。当遇到问题,不是简单指责哪一方的问题,而是把事情经过还原,弄明白真实原因是什么。
是流程问题、依赖的问题、还是个人能力和态度的问题?在问题归因上干系人是否也这么认为、在解决问题的同时,思考这类问题今后如何规避。当项目遇到风险,不是简单的报备有风险存在,而是如何管理这个风险、过程中做什么努力。
研发面对的绝大多数都是项目延期风险,作为负责人不能单一维度的思考问题。 “上线要delay了通过加班赶工” 这种事情没有任何技术含量,即使刚入职场的实习生都知道。问题和风险不分家,作为负责人不要只看表面因,要多思考过渡原因、根本因是什么,在项目中对症下药。
(3) 要懂“外交”,要学会沟通。自己搞不定的事情,要学会向上沟通和对等沟通,跟什么样的人,说什么样的话。
对等沟通不是职级的对等,而是角色的对等,比如:负责前端的同学在沟通跟测试相关的问题时,最高效的方式是找测试中负责的同学,而不是负责执行的那个同学。
受限于客观条件,项目团队的人员配比不见得是合理的。比如:有的项目或阶段重前端、有的阶段重质量,当某一方相对弱势,除了申请追加资源外,要有补位意识,或者通过技术手段寻找出路。当有一方长期弱势,严重拖累项目进度,要及时识别出来并上升给管理者。
3、业务理解能力
作为负责人,就是要想办法让业务能更好,能让技术的价值有更大的体现。对业务有深刻理解,才知道业务更需要什么,也会更有使命感去推进。
需要特别说明的一点是,理解需求并不意味着理解业务,需求是业务经过产品消化后的产物,可能已经经过演绎,或者是其中某个拆解环节,因此需求并不是业务本身**。当然了解的需求越多,可以让你更清楚业务的全貌。

要理解业务,先要理解用户:他们在干什么、为何而来、到何处去、获得何种收益;然后,了解这里面的商业模式:流量如何来的、内容如何来的、生态情况怎么样、如何商业化的;再站在宏观角度去了解:行业情况怎么样、竞争对手怎么样;最后回到产品和技术:这个业务什么产品在承载、主要对技术的依赖和诉求又是什么。
以上信息了解过后,接下来最好还能够有一些洞察和思考,比如:现在业务发展遇到了什么瓶颈?打算如何破局?基本上把这些摸清楚了,你对这个业务就有个比较清楚的脉络了。
负责人要达到这种程度是需要下苦功夫的,搞清楚上面的问题,接下来要指导自己的行动,比如:要在过程中识别真伪需求、并控制好节奏,要判断哪些功能是一定要做的、哪些是现在这个阶段没必要做但将来可以做的、哪些是完全没必要做的。这里面第二个情况最难识别的。
有了前面这些认知,负责人要做好技术上的规划。优秀的负责人会抬高视野,从思考眼前的事,变成思考未来的事,预判业务未来发展对技术的挑战在哪里。
规划不是空想,是基于对业务理解,预测业务未来发展对技术的挑战,比如:可以通过一系列技术储备,做一些业务方原以为技术不能干、干不好的那些能够直接促进业务发展的事情;还可以发掘业务痛点或机会,然后用技术力量去改善。这里的技术可以是有很大厚度的,比如算法与机器学习、区块链,也可以是不需要技术厚度,但是需要产品设计和链接的,哪怕是简单的技术解决了业务问题。
作为负责人,要有经营意识:通过对数据的洞察寻找问题的答案。在项目中资源永远都是有限的,重要的不是做了多少功能,而是做的东西有多少人用。所以要学会用数据说话,大到交易规模、小到UV/PV等行为埋点,要定期的看,用它来指导你的行为。
一个需求评审前,你是否了解过这个功能的用户量是什么规模?上线后你是否有分析过是否符合最初的假设?这次产品功能上线给业务带来的实际结果是什么?当真实情况和假设间存在偏差,你是否有跟产品了解过背后的原因?当这种问题频频出现,你是否会质疑当前的产品路线和建设节奏有问题?有了这些思考和行动,才会保证项目往正确的方向推进。
三 总结
大家做业务,都有很大的业务压力,但对于技术人的要求,是除了完成技术实现外最大化的体现业务价值,这就需要我们做事情之前有充分的思考,在做事的过程中有正确的章法。
在负责一个项目的时候,要想清楚3个问题:
· 业务的目标是什么;
· 技术团队的策略是什么;
· 我们在里面的价值是什么。
如果3个问题都想明白了,前后的衔接也对了,这事情才靠谱。
回顾自己这7年的成长历程,我总结出技术人的成长诀窍,那便是:不混日子,有自驱;不求安逸,爱折腾
最后,希望大家还是能像最初的时候一样,能多折腾,保留这种折腾劲,甚至是孩子气,如果你还有的话。
来源:李志阳-京东云
原文:mp.weixin.qq.com/s/83qFIDTNCAGxzRzmcm4m_Q
收起阅读 »

