









 澳媒报道截图
澳媒报道截图



















































你好呀,我是歪歪。
我上周遇到了一个莫名其妙的搞心态的问题,浪费了我好几个小时。
气死我了,拿这几个小时来敲(摸)代(摸)码(鱼)不香吗?
主要是最后问题的解决方式也让我特别的无语,越想越气,写篇文章吐槽一下。
先说结论,也就是标题:
在本地以 Debug 模式启动项目的时候,千万不要在方法上打断点!千万不要!
首先什么是方法断点呢?
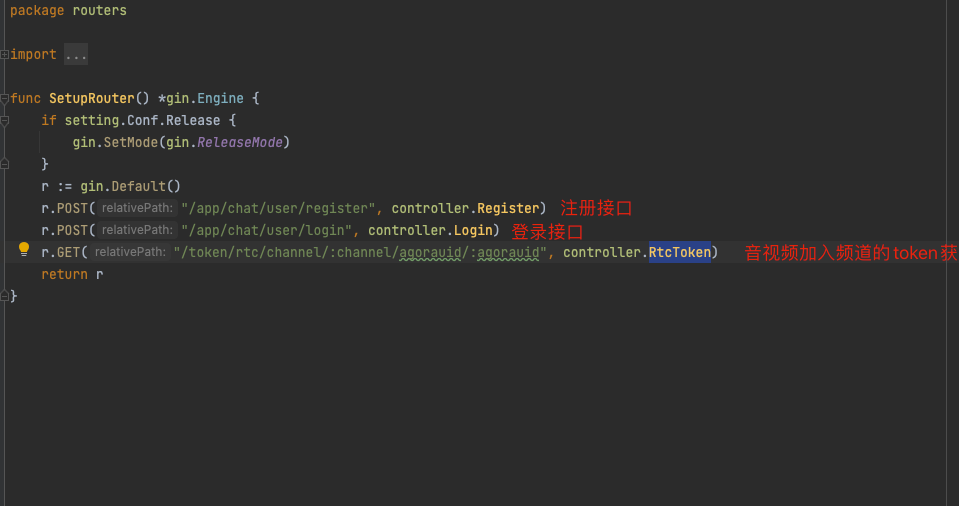
比如这样的,打在方法名这一行的断点:
你点击 IDEA 里面的下面这个图标,View Breakpoints,它会给你弹出一个框。
这个弹框里面展示的就是当前项目里面所有的断点,其中有一个复选框,Java Method Breakpoints,就是当前项目里面所有的“方法断点”:
那么这个玩意到底有什么坑呢?
当项目以 Debug 模式启动的时候,非常非常非常严重的拖慢启动速度。
给你看两个截图。
下面这个是我本地的一个非常简单的项目,没有方法断点的时候,只要 1.753 秒就启动完成了:
但是当我加上一个方法断点的时候,启动时间直接来到了 35.035 秒:
从 1.7 秒直接飙升到 35 秒,启动时间涨幅 2000%。
你说遭不遭得住?
遭不住,对不对。
那么我是怎么踩到这个坑的呢?
一个同事说他项目里面遇到一个匪夷所思的 BUG,想让我帮忙一起看看。
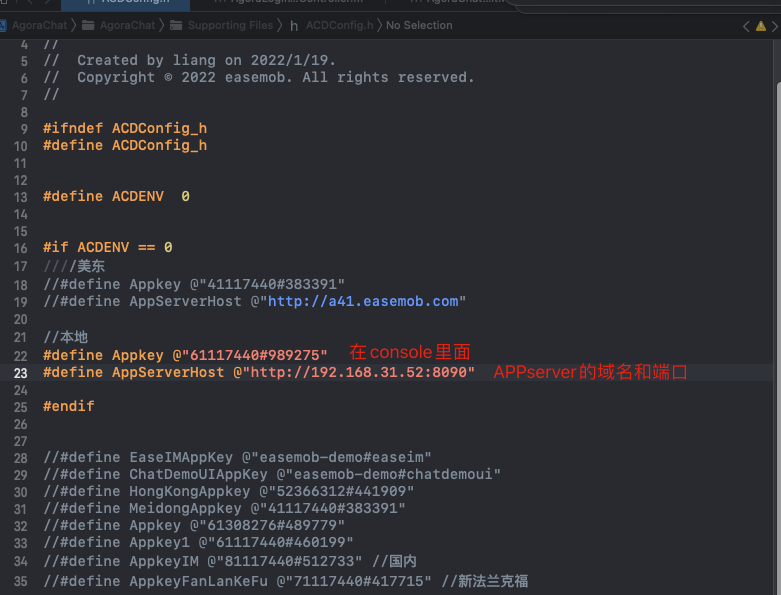
于是我先把项目拉了下来,然后简单的看了一下代码,准备把项目先在本地跑起来调试一下。
然而半个小时过去了,项目还没起来。我问他:这个项目本地启动时间怎么这么长呢?
他答:正常来说半分钟应该就启动起来了呀。
接着他还给我演示了一下,在他那边确实 30 多秒就启动成功了。
很明显,一样的代码,一个地方启动慢,一个地方启动快,首先怀疑环境问题。
于是我准备按照下面的流程走一次。
检查设置 -> 清空缓存 -> 换workspace -> 重启 -> 换电脑 -> 辞职
我检查了所有的配置、启动项、网络连接什么的,确保和他本地的环境是一模一样的。
这一套操作下来,差不多一小时过去了,并没有找到什么头绪。
但是那个时候我一点都不慌,我还有终极绝招:重启。
毕竟我的电脑已经好几个月没有关闭过了,重启一下也挺好的。
果然,重启了电脑之后,还是没有任何改变。
正在焦头烂额之际,同事过来问我啥进度了。
我能怎么说?
我只能说:从时间上来说应该解决了,但是实际上我连项目都还没启动成功。
听到这话,他坐在我的工位,准备帮我看一下。
半分钟之后,一个神奇的场景出现了,他在我的电脑上直接就把项目启动起来了。
一盘问,他并没有以 Debug 的模式启动,而是直接运行的。
用脚趾头想也知道,肯定是 Debug 模式在搞事情。
然后基于面向浏览器编程的原则,我现在有了几个关键词:IDEA debug 启动缓慢。
然后发现有很多人遇到了类似的问题,解决方法就是启动的时候取消项目里面的“方法断点”。
但是,遗憾的是,没有大多数文章都是说这样做就好了。但是并没有告诉我为什么这样做就好了。
我很想知道为什么会有这个坑,因为我用方法断点用的还是很多的,关键是以前在使用的过程中完全没有注意到还有这个坑。
“方法断点”还是非常实用的,比如我随便个例子。
之前写事务相关的文章的时候,提到过这样的一个方法:
java.sql.Connection#setAutoCommit
setAutoCommit 这个方法有好几个实现类,我也不知道具体会走哪一个:
所以,调试的时候可以在下面这个接口打上一个断点:
然后重启程序,IDEA 会自动帮你判断走那个实现类的:
但是需要特别说明的是,不是所有的方法断点都会导致启动缓慢的问题。至少在我本地看起来是这样的。
当我把方法断点加在 Mapper 的接口里面的时候,能稳定复现这个问题:
当把方法断点加在项目的其他方法上的时候,不是必现的,偶尔才会出现这个问题。
另外,其实当你以 Debug 模式启动且带有方法断点的时候,IDEA 是会弹出这个提醒,告诉你方法断点会导致 Debug 缓慢的问题:
但是,真男人,从不看提醒。反正我是直接就忽略了,根本没有关心弹窗的内容。
至于为什么会在 Mapper 的接口上打方法断点?
都怪我手贱,行了吧。
到底为什么
在找答案的过程中,我发现了这个 idea 的官方社区的链接:
这个贴子,是 JetBrains Team 发布的,关于 Debug 功能可能会导致的性能缓慢的问题。
在这个帖子中,第一个性能点,就是 Method breakpoints。
官方是怎么解释这个问题的呢?
我给你翻译一波。
Method breakpoints will slow down debugger a lot because of the JVM design, they are expensive to evaluate.
他们说由于 JVM 的设计,方法断点会大大降低调试器的速度,因为这玩意的 “evaluate” 成本很高。
evaluate,四级单词,好好记一下,考试会考:
大概就是说你要用方法断点的功能,在启动过程中,就涉及到一个关于该断点进行“评估”的成本。成本就是启动缓慢。
怎么解决这个“评估”带来的成本呢?
官方给出的方案很简单粗暴:
不要使用方法断点,不就没有成本了?
所以,Remove,完事:
Remove method breakpoints and consider using the regular line breakpoints.
删除方法断点并考虑使用常规的 line breakpoints。
官方还是很贴心的,怕你不知道怎么 Remove 还专门补充了一句:
To verify that you don't have any method breakpoints open .idea/workspace.xml file in the project root directory (or .iws file if you are using the old project format) and look for any breakpoints inside the method_breakpoints node.
可以通过下面这个方法去验证你是否打开了方法断点。
就是去 .idea/workspace.xml 文件中,找到 method_breakpoints 这个 Node,如果有就 Remove 一下。
然后我看了一下我项目里面对应的文件,没有找到 method_breakpoints 关键字,但是找到了下面这个。
应该是文档发生了变化,问题不大,反正是一个意思,
其实官方给出的这个方法,虽然逼格稍微高一点,但还是我前面给的这个操作更简单:
针对“到底为什么”这个问题。
在这里,官方给的回答,特别的模糊:because of the JVM design。
别问,问就是由于 JVM 设计如此。
我觉得这不是我想要的答案,但是好在我在这个帖子下面找到了一个“好事之人”写的回复:
这个好事之人叫做 Gabi 老铁,我看到他回复的第一句话 “I made some research”,我就知道,这波稳了,找对地方了,答案肯定就藏在他附上的这个链接里面。
Gabi 老铁说:哥子们,我研究了一下这个方法断点为啥会慢的原因,研究报告在这里:
他甚至还来了一个概要:To make the long story short,长话短时。
他真的很贴心,我哭死。
他首先指出了问题的根本原因:
it seems that the root issue is that Method Breakpoints are implemented by using JDPA's Method Entry & Method Exit feature.
根本问题在于方法断点是通过使用 JDPA 的 Method Entry & Method Exit 特性实现的。
有同学就要问了,JDPA,是啥?
是个宝贝:
JPDA,全称 Java Platform Debugger Architecture。
IDEA 里面的各种 Debug 功能,就是基于这个玩意来实现的。
不懂也没关系,这个东西面试又不考,在这里知道有这个技术就行。
接着,他用了四个 any 来完成了跳句四押:
This implementation requires the JVM to fire an event each time any thread enters any method and when any thread exits any method.
这个实现,要求 JVM,每次,在任何(any)线程进入任何(any)方法时,以及在任何(any)线程退出任何(any)方法时触发事件。
好家伙,这不就是个 AOP 吗?
这么一说,我就明白为什么方法断点的性能这么差了。要触发这么多进入方法和退出方法的事件,可不得耗费这么多时间吗?
具体的细节,他在前面说的研究报告里面都写清楚了,如果你对细节感兴趣的话,可以咨询阅读一下他的那篇报告。
话说他这个报告的名字也起的挺唬人的:Method Breakpoints are Evil。
我带你看两个关键的地方。
第一个是关于 Method Entry & Method Exit 的:
- IDE 将断点添加到其内部方法断点 list 中
- IDE 告诉前端启用 Method Entry & Method Exit 事件
- 前端(调试器)通过代理将请求传递给 VM
- 在每个 Method Entry & Method Exit 事件中,通过整个链将通知转发到 IDE
- IDE 检查其方法断点 list 是否包含当前的这个方法。
- 如果发现包含,说明这个方法上有一个方法断点,则 IDE 将向 VM 发送一个 SetBreakpoint 请求,打上断点。否则,VM 的线程将被释放,不会发生任何事情
这里是表明,前面我说的那个类似 AOP 的稍微具体一点的操作。
核心意思就一句话:触发的事件太多,导致性能下降厉害。
第二个关键的地方是这样的:
文章的最后给出了五个结论:
- 方法断点 IDE 的特性,不是 JPDA 的特性
- 方法断点是真的邪恶,evil 的一比
- 方法断点将极大的影响调试程序
- 只有在真正需要时才使用它们
- 如果必须使用方法作为断点,请考虑关闭方法退出事件
前面四个点没啥说的了。
最后一个点:考虑关闭方法退出事件。
这个点验证起来非常简单,在方法断点上右键可以看到这个选项,Method Entry & Method Exit 默认都是勾选上了:
所以我在本地随便用一个项目验证了一下。
打开 Method Exit 事件,启动耗时:113.244 秒。
关闭 Method Exit 事件,启动耗时:46.754 秒。
你别说,还真有用。
现在我大概是知道为什么方法断点这么慢了。
这真不是 BUG,而是 feature。
而关于方法断点的这个问题,我顺便在社区搜索了一下,最早我追溯到了 2008 年:
这个老哥说他调试 Web 程序的速度慢到无法使用的程度。他的项目只启用了一行断点,没有方法断点。
请求大佬帮他看看。
然后大佬帮他一顿分析也没找到原因。
他自己也特别的纳闷,说:
我啥也没动,太奇怪了。这玩意有时可以,有时不行。
像不像一句经典台词:
但是问题最后还是解决了。怎么解决的呢?
他自己说:
确实是有个方法断点,他也不知道怎么打上这个断点的,可能和我一样,是手抖了吧。
意外收获
在前面出现的官方帖子的最下面,有这样的两个链接:
它指向了这个地方:
我把这部分链接都打开看了一遍,经过鉴定,这可真是好东西啊。
这是官方在手摸手教学,教你如何使用 Debug 模式。
我之前看过的一些调试小技巧相关的文章,原来就是翻译自官方这里啊。
我在这里举两个例子,算是一个导读,强烈推荐那些在 Debug 程序的时候,只知道不停的下一步、跳过当前断点等这样的基本操作的同学去仔细阅读,动手实操一把。
首先是这个:
针对 Java 的 Streams 流的调试。
官方给了一个调试的代码示例,我做了一点点微调,你粘过去就能跑:
class PrimeFinder {
public static void main(String[] args) {
IntStream.iterate(1, n -> n + 1)
.limit(100)
.filter(PrimeTest::isPrime)
.filter(value -> value > 50)
.forEach(System.out::println);
}
}
class PrimeTest {
static boolean isPrime(int candidate) {
return candidate == 91 ||
IntStream.rangeClosed(2, (int) Math.sqrt(candidate))
.noneMatch(n -> (candidate % n == 0));
}
}
复制代码代码逻辑很简单,就是找 100 以内的,大于 50 的素数。
很明显,在 isPrime 方法里面对 91 这个非素数做了特殊处理,导致程序最终会输出 91,也就是出 BUG 了。
虽然这个 BUG 一目了然,但是不要笑,要忍住,要假装不知道为什么。
现在我们要通过调试的方式找到 BUG。
断点打在这个位置:
以 Debug 的模式运行的时候,有这样的一个图标:
点击之后会有这样的一个弹窗出来:
上面框起来的是对应着程序的每一个方法调用顺序,以及调用完成之后的输出是什么。
下面框起来的这个 “Flat Mode” 点击之后是这样的:
最右边,也就是经过 filter 之后输出的结果。
里面就包含了 91 这个数:
点击这个 “91”,发现在经过第一个 filter 之后,91 这个数据还在。
说明这个地方出问题了。
而这个地方就是前面提到的对 “91” 做了特殊处理的 isPrime 方法。
这样就能有针对性的去分析这个方法,缩小问题排除范围。
这个功能怎么说呢,反正我的评论是:
总之,以上就是 IDEA 对于 Streams 流进行调试的一个简单示例。
接着再演示一个并发相关的:
官方给了这样的一个示例:
public class ConcurrencyTest {
static final List a = Collections.synchronizedList(new ArrayList());
public static void main(String[] args) {
Thread t = new Thread(() -> addIfAbsent(17));
t.start();
addIfAbsent(17);
t.join();
System.out.println(a);
}
private static void addIfAbsent(int x) {
if (!a.contains(x)) {
a.add(x);
}
}
}
复制代码代码里面搞一个线程安全的 list 集合,然后主线程和一个异步线程分别往这个 list 里面塞同一个数据。
按照 addIfAbsent 方法的意思,如果要添加的元素在 list 里面存在了,则不添加。
你说这个程序是线程安全的吗?
肯定不是。
你想想,先判断,再添加,经典的非原子性操作。
但是这个程序你拿去直接跑,又不太容易跑出线程不安全的场景:
怎么办?
Debug 就来帮你干这个事儿了。
在这里打一个断点,然后右键断点,选择 “Thread”:
这样程序跑起来的时候主线程和异步线程都会在这个地方停下来:
可以通过 “Frames” 中的下拉框分别选择 Debug 主线程还是异步线程。
由于两个线程都执行到了 add 方法,所以最终的输出是这样的:
这不就出现线程不安全了吗?
即使你知道这个地方是线程不安全的,但是如果没有 Debug 来帮忙调试,要通过程序输出来验证还是比较困难的。
毕竟多线程问题,大多数情况下都不是每次都能必现的问题。
定位到问题之后,官方也给出了正确的代码片段:
好了,说好了是导读,这都是基本操作。还是那句话,如果感兴趣,自己去翻一下,跟着案例操作一下。
就算你看到有人把 Debug 源码,玩出花来了,也无外乎不过是这样的几个基础操作的组合而已。
回首往事
让我们再次回到官方的“关于 Debug 功能可能会导致的性能缓慢的问题”这个帖子里面:
当我看到方框里面框起来的 “Collections classes” 和 “toString()” 方法的时候,眼泪都快下来了。
我最早开始写文章的时候,曾经被这个玩意坑惨了。
三年前,2019 年,我写了这篇文章《这道Java基础题真的有坑!我也没想到还有续集。》
当时 Debug 调试 ArrayList 的时候遇到一个问题,我一度以为我被质子干扰了:
一句话汇总就是在单线程的情况下,程序直接运行的结果和 Debug 输出的结果是不一样的。
当时我是百思不得其解。
直到 8 个月后,写《JDK的BUG导致的内存溢出!反正我是没想到还能有续集》这篇文章的时候才偶然间找到问题的答案。
根本原因就是在 Debug 模式下,IDEA 会自动触发集合类的 toString 方法。而在某些集合类的 toString 方法里面,会有诸如修改头节点的逻辑,导致程序运行结果和预期的不匹配。
也就是对应这句话:
翻译过来就是:老铁请注意,如果 toString 方法中的代码更改了程序的状态,则在 debug 状态下运行时,这些方法也可以更改应用程序的运行结果。
最后的解决方案就是关闭 IDEA 的这两个配置:
同时,我也在官方文档中找到了这个两个配置的解释:
主要是为了在 Debug 的过程中用更加友好的形式显示集合类。
啥意思?
给你看个例子。
这是没有勾选前面说的配置的时候,map 集合在 Debug 模式下的样子:
这是勾选之后,map 集合在 Debug 模式下的样子:
很明显,勾选了之后的样子,更加友好。





