基于AI模型的文本、图片、语音、视频消息的审核能力:提供多种违规模型的不同消息类型的审核服务
基于AI模型的文本、图片、语音、视频消息的审核能力:提供多种违规模型的不同消息类型的审核服务
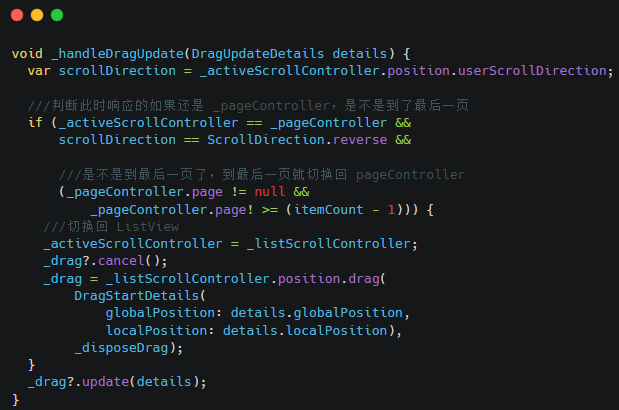
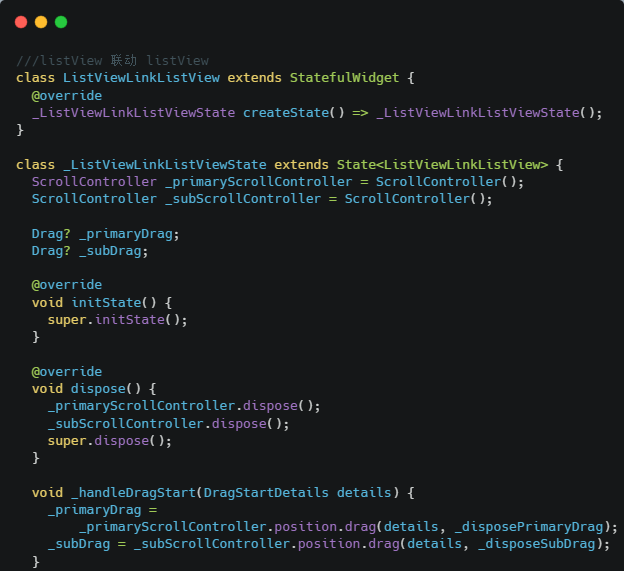
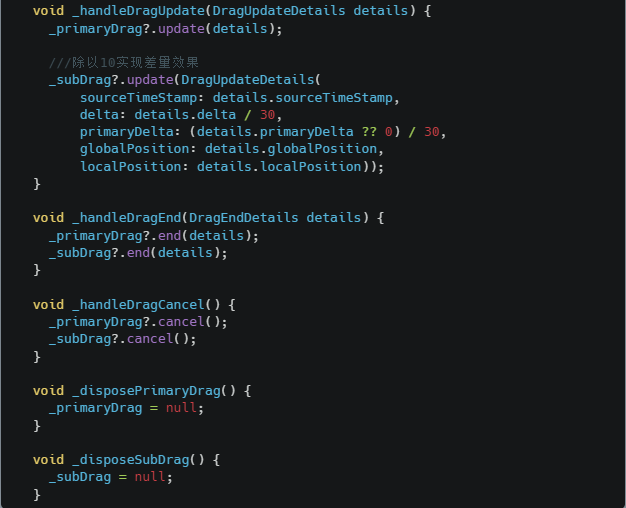
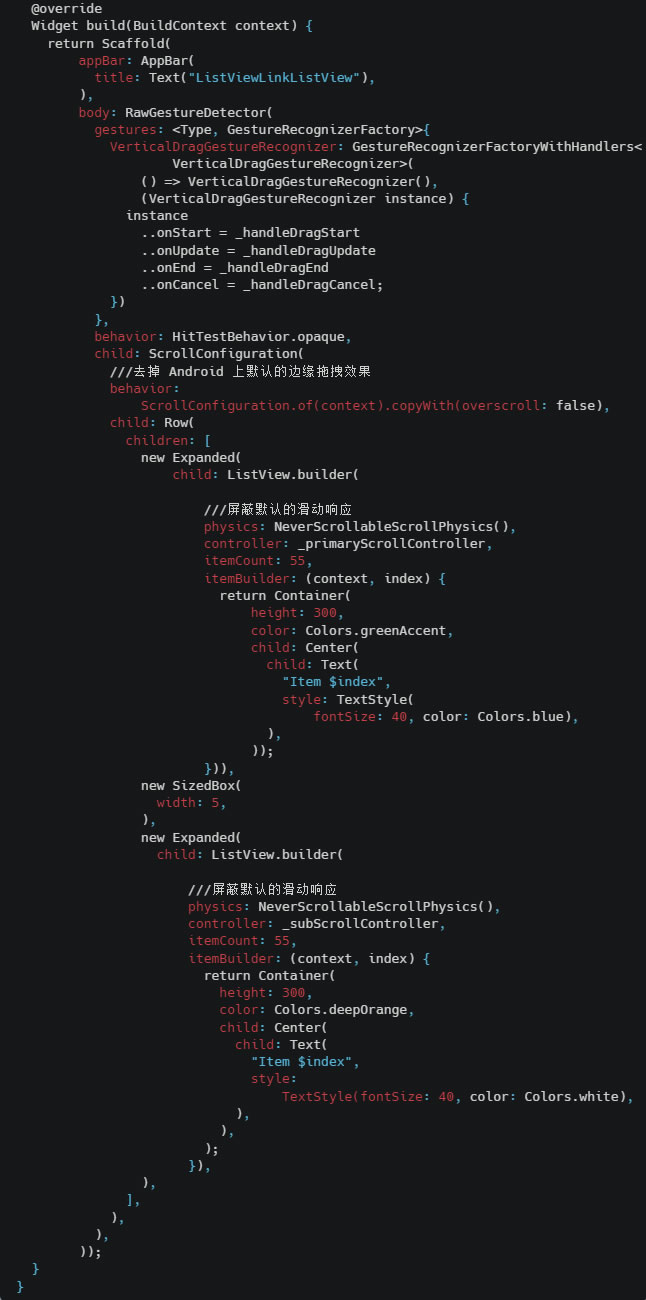
 消息子区:子区是群组成员的子集,是支持多人沟通的即时通讯系统,提供子区创建删除、成员管理等能力。
消息子区:子区是群组成员的子集,是支持多人沟通的即时通讯系统,提供子区创建删除、成员管理等能力。










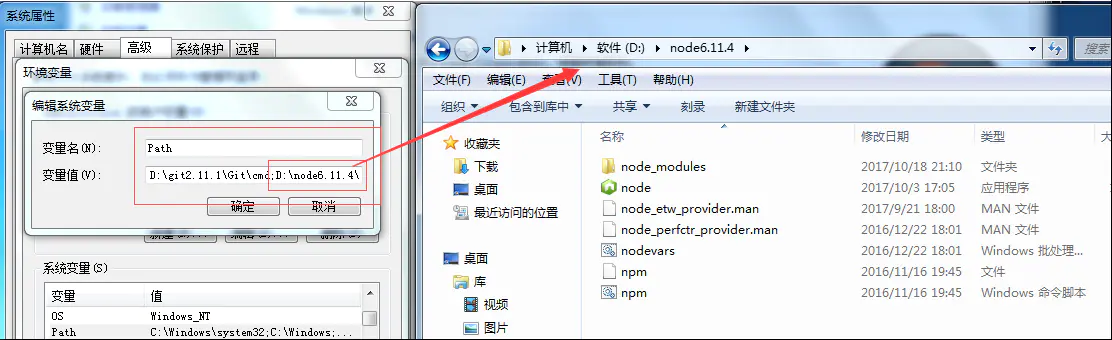

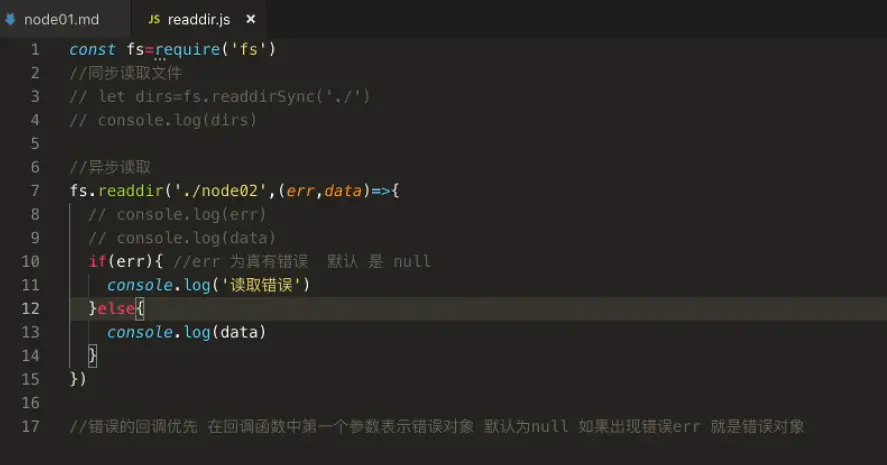
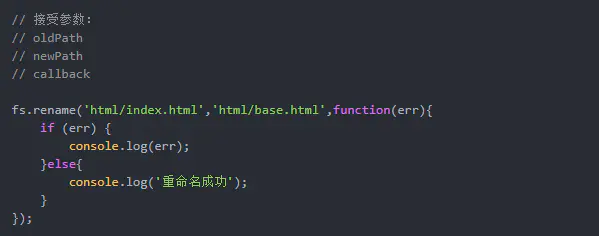
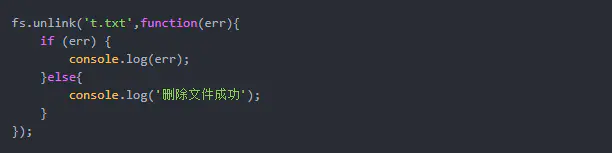










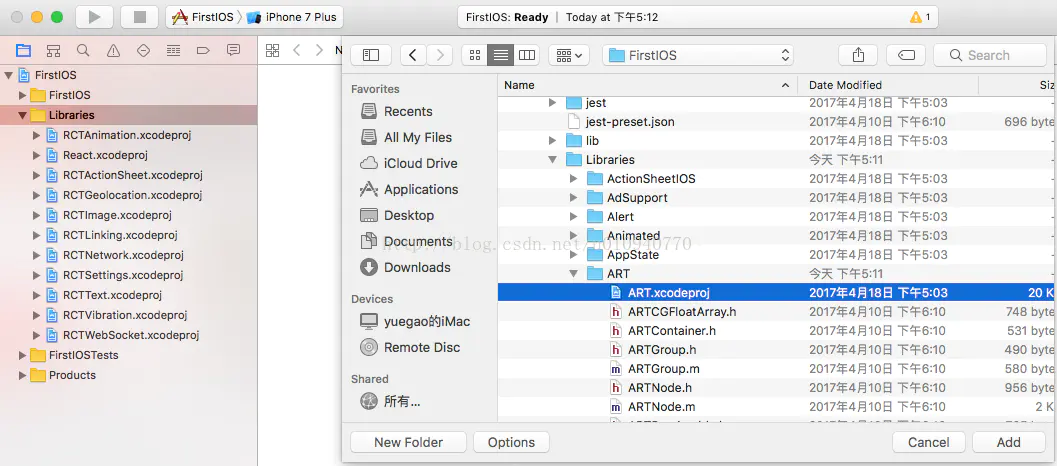
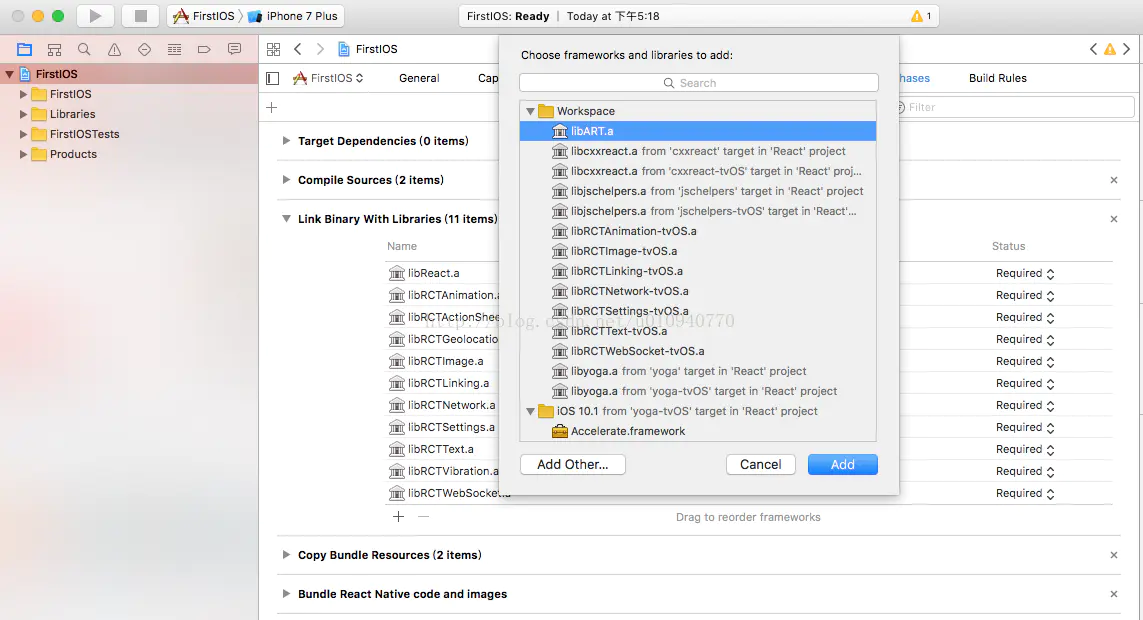



背景
缓存是用来做性能优化的好东西,但是,如果用不好缓存,就会产生一系列问题:
- 为什么我的页面显示的还是老版本
- 为什么我的网页白屏
- 请刷新下网页
- ...
以上问题大家或多或少都遇到过,归根结底是使用缓存的姿势不对,今天,我们就来一起了解下浏览器是如何进行缓存的,以及我们要怎样科学的使用缓存
浏览器的缓存机制
1. 什么是浏览器缓存?
简单说,浏览器把 http 请求的资源保存到本地,供下次使用的行为,就是浏览器缓存
这里先记一个点:http 响应头,决定了浏览器会对资源采取什么样的缓存策略
2. 浏览器是读取缓存还是请求数据?
- 用户第一次请求资源
- 整个完整流程
3. 缓存过程分类——强缓存 / 协商缓存
根据是否请求服务,我们把缓存过程分为强缓存和协商缓存,也可以理解为必然经过的过程称为强缓存,如果强缓存没有,那在和服务器协商一下
强缓存
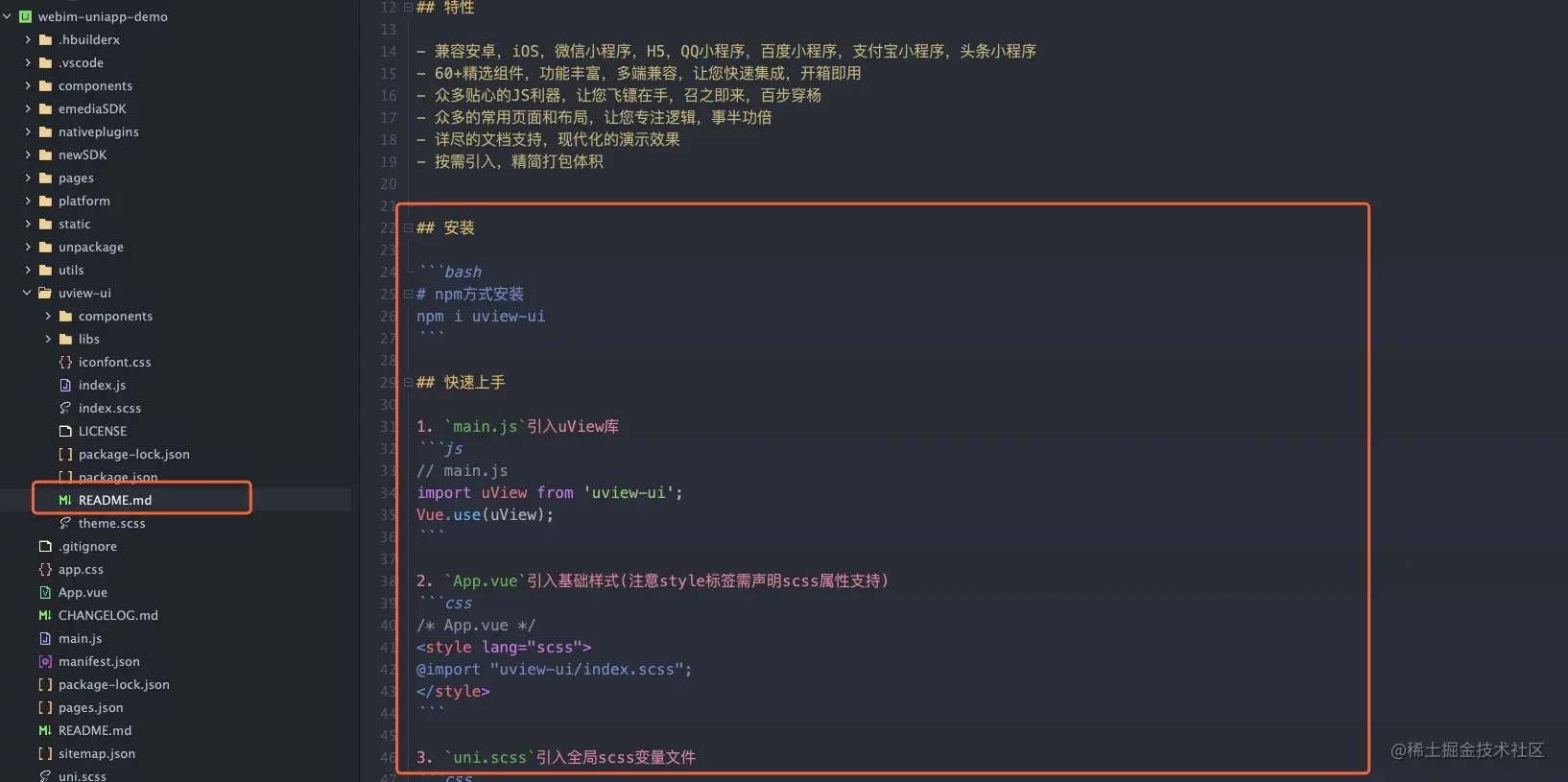
强缓存看的是响应头的 Expires 和 Cache-Control 字段
- Expires 是老规范,它表示的是一个绝对有效时间,在该时间之前则命中缓存,如果超过则缓存失效,并且,由于它是跟本地时间(可以随意修改)做比较,会导致缓存混乱
- Cache-Control 是新规范,优先级要高于Expires,也是目前主要使用的缓存策略,字段是max-age,表示的是一个相对时间,例如 Cache-Control: max-age=3600,代表着资源的有效期是 3600 秒。
其他配置
no-cache:需要进行协商缓存,发送请求到服务器确认是否使用缓存。
no-store:禁止使用缓存,每一次都要重新请求数据。
public:可以被所有的用户缓存,包括终端用户和 CDN 等中间代理服务器。
private:只能被终端用户的浏览器缓存,不允许 CDN 等中继缓存服务器对其缓存。
协商缓存
当强缓存没有命中的时候,浏览器会发送一个请求到服务器,服务器根据 header 中的部分信息来判断是否命中缓存。如果命中,则返回 304 ,告诉浏览器资源未更新,可使用本地的缓存。
协商缓存看的是 header 中的 Last-Modified / If-Modified-Since 和 Etag / If-None-Match
缓存生效,返回304,缓存失效,返回200和请求结果
Etag 优先级 Last-Modified 高
- Last-Modified / If-Modified-Since
浏览器第一次请求一个资源的时候,服务器返回的 header 中会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。
当浏览器再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的
Last-Modify。服务器收到 If-Modify-Since
后,根据资源的最后修改时间判断是否命中缓存,命中返回304使用本缓存,否则返回200和请求最新资源。
- Etag / If-None-Match
etag 是更为严谨的校验,一般情况下使用时间检验已经足够,但我们想象一个场景,如果我们在短暂时间内修改了服务端资源,然后又迅速的改回去,理论上这种情况本地缓存还是可以继续使用的,这就是 etag 诞生的场景。
使用 etag 时服务端会对资源进行一次类似 hash 的操作获得一个标识(内容不变标识不变),并返回给客户端。
再次请求时客户端会在 If-None-Match 带上 etag 的值给服务端进行对比验证,如果命中返回304使用缓存,否则重新请求资源。
注:由于 e-atg 服务端计算会有额外开销,所以性能较差
扩展:DNS缓存与CDN缓存
DNS 缓存
我们在网上所有的通信行为都需要IP来进行连接,DNS解析是指通过域名获取相应IP地址的过程。
基本上有DNS的地方就有缓存,查询顺序如下:
一般我们日常会接触到的就是有时内网域名访问需要修改本地host映射关系,或者某些科学上网的情况,可以通过修改本地host来正常访问网址
CDN 缓存
CDN 缓存从减轻根服务的分发压力和缩短物理的传输距离(跨地域访问)上2个层面对资源访问进行优化。
CDN节点解决了跨运营商和跨地域访问的问题,访问延时大大降低。
大部分请求在CDN边缘节点完成,CDN起到了分流作用,减轻了源服务器的负载。
一般CDN服务都由运营商提供,我们只需要了解如何验证CDN是否生效即可
查看域名是否配置了CDN缓存
ping {{ 域名 }} 会看到转向了其他地址(alikunlun)
例如: ping customer.kukahome.com
查看我们的页面资源是否命中CDN缓存
通过查看相应头有 X-cache:HIT 字段,则命中CDN缓存,注意这里名称并不固定,但一般都会有HIT标识,如果是MISS 或None之类的,则没有命中缓存
前端针对缓存部署优化方案
构建演进
构建方面优化的核心思想是如何更优,更快速的加载资源,以及如何保证资源的新鲜度
这个优化过程也分为几个阶段,有些其实已经不适用现在的场景,但也可以了解下
早期的图标合并雪碧图(sprite),多脚本文件整理到一个文件:目的是通过减少碎片化的请求数量来加速资源加载(相关知识点是浏览器一般最多只支持6个并发请求,同一时间请求数量需要控制在合理范围)
- 现在雪碧图已基本被 iconfont 代替,js 加载更多采用分模块异步加载,而不是一味合并
随着 web 应用的推广和浏览器缓存技术的普及,前端缓存问题也随着而来,最常见的就是服务端资源变了,但是客户端资源始终无法更新,这个阶段工程师们想了很多方案。
- 打包时在静态资源路径上加上 “?v=version” 或者使用时间戳来给资源文件命名
- 跟 modified 缓存有点像,由于时间戳并不能识别出文件内容是否变动,所以有了后来的 hash 方案,理论上 hash 出来的文件只要内容不变,文件名就不变,大大提高了缓存的使用寿命,也是现代常用打包工具的默认配置
然后,重点来了,以上我们对 html 文件里链接的资源做了一系列优化,但是 html
本身也是一种静态资源,并且,客户在访问页面时是不会带上所谓的时间戳或者版本号的,导致了很多时候虽然服务端资源更新了,但是客户端还是用老的
html 文本发起请求,这个时候就会导致各种各样的问题了,包括但不限于白屏,展现的旧版本页面等等
- 为了解决这个问题,目前主流的解决方案是不对 html 进行缓存(一般单页应用html文件较小,大的是 js),只对 js,css 等静态文件进行本地缓存
那么,如何让浏览器不缓存 html 呢,目前都是通过设置 Cache-Control实现, 有前端方案和后端方案,风险提示,前端方案很不靠谱,后端很多默认配置会覆盖前端方案,可以做了解,生产中请使用后端配置。
通过 html 标签设置 cache-control
<meta http-equiv="Pragma" content="no-cache" /> // 旧协议
<meta http-equiv="Expires" content="0" /> // 旧协议
<meta http-equiv="Cache-Control" content="no-cache" /> // 目前主流
部署配置
目前主流的前端部署方式都是使用 nginx,我们来看看 nginx 如何禁用 html 的缓存
location / {
root **;
# 配置页面不缓存html和htm结尾的文件
if ($request_filename ~* .*.(?:htm|html)$)
{
add_header Cache-Control "private, no-store, no-cache, must-revalidate, proxy-revalidate";
}
index index.html index.htm;
}
- Private 会影响到CDN缓存命中率,但本身CDN缓存也会存在版本问题,量不大的情况下也可以禁掉
- No-cache 可以使用缓存,但是使用前必须到服务端验证,可以是 no-cache,也可以是 max-age=0
- No-store 完全禁用缓存
- Must-revalidate 与 no-cache 类似,强制到服务端验证,作用于一些特殊场景,例如发送了校验请求,但发送失败了之类
- Proxy-revalidate 与上面类似,要求代理缓存服务验证有效性
以上配置可以跟据项目需要灵活配置,考虑到浏览器对缓存协议支持会有些许差异,只是想简单粗暴禁用 html 缓存全上也没有关系,并不会有特别大影响,除非特殊场景需要调优时需要关注。
资源压缩
都讲到这了,前端构建优化还有一个常用的就是 Gzip 资源压缩,可以极大减小资源包体积,前端一般构建工具都有插件支持,需要注意的是也需要 nginx 做配置才能生效
http {
gzip_static on;
gzip_proxied any;
}
如果生效了,响应头里可以看到 content-encoding: gzip