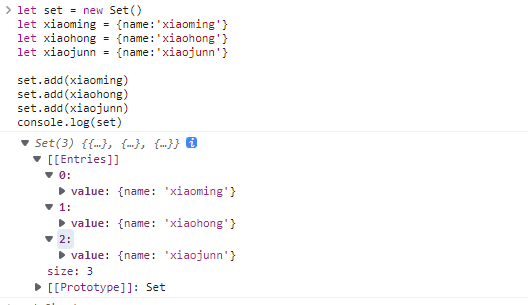
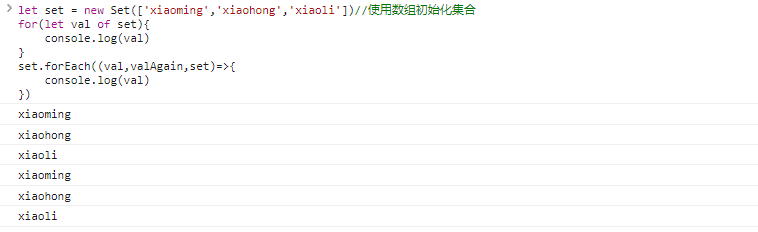
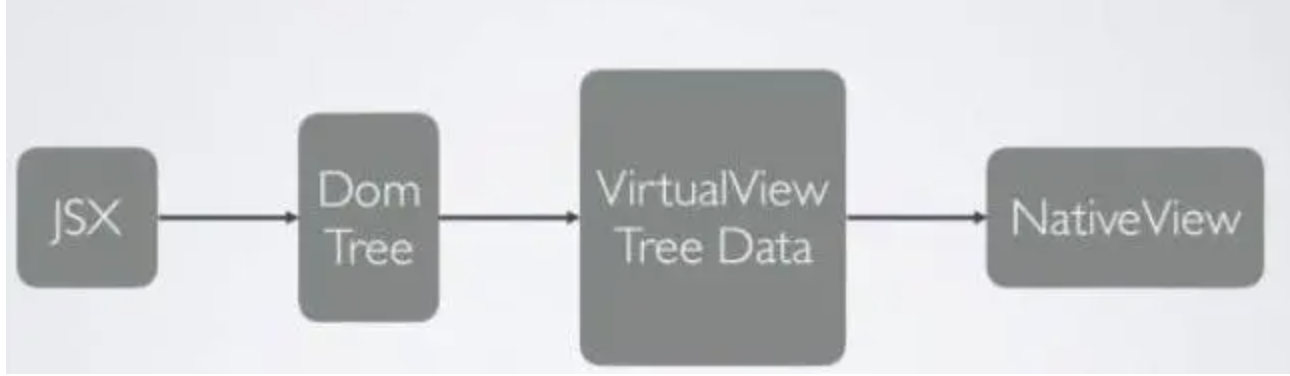
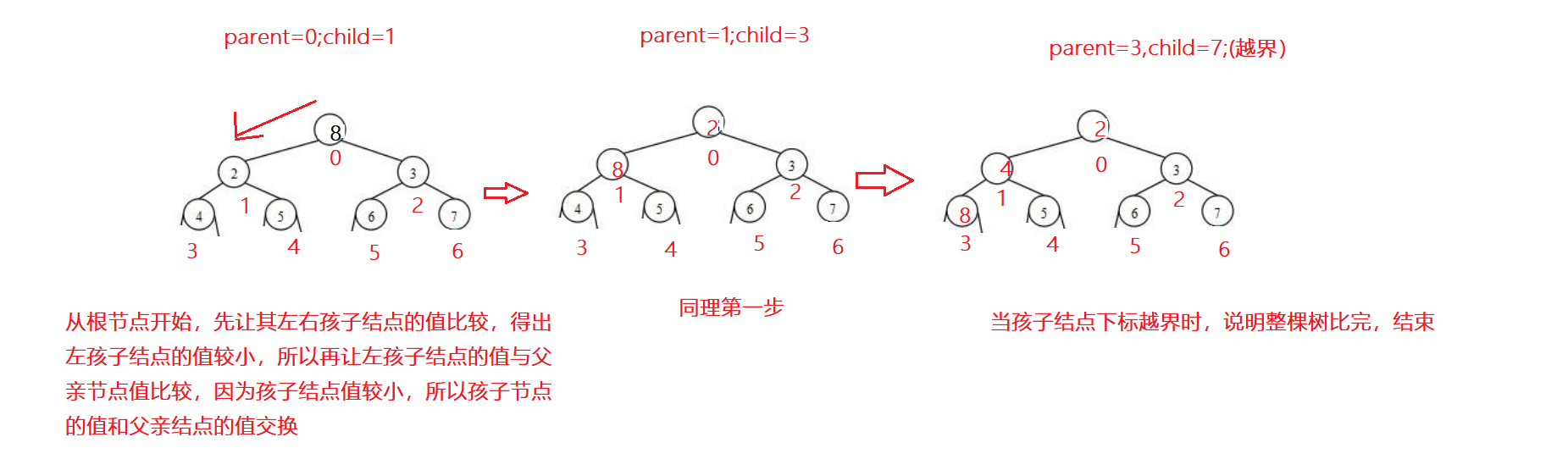
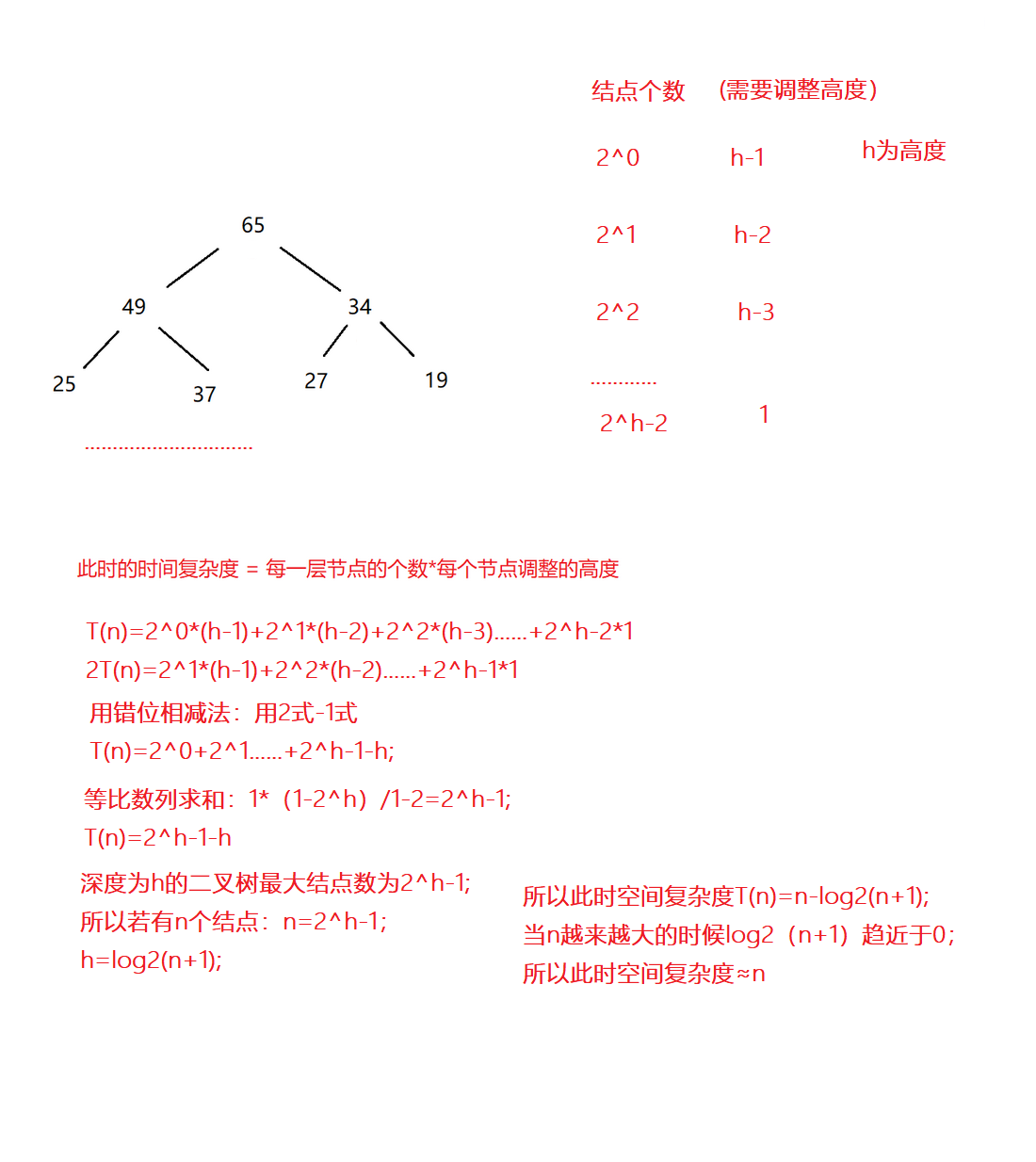
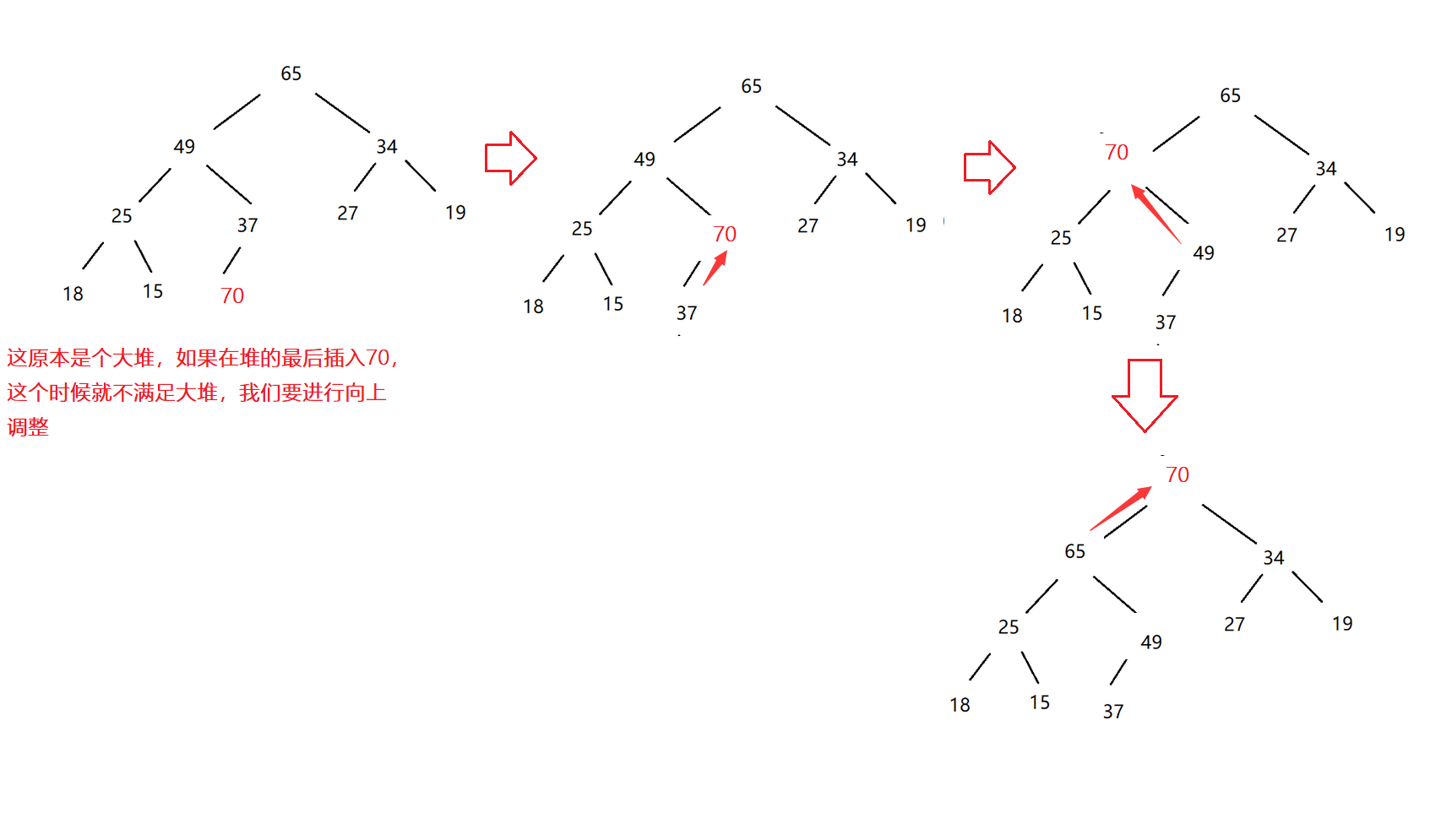
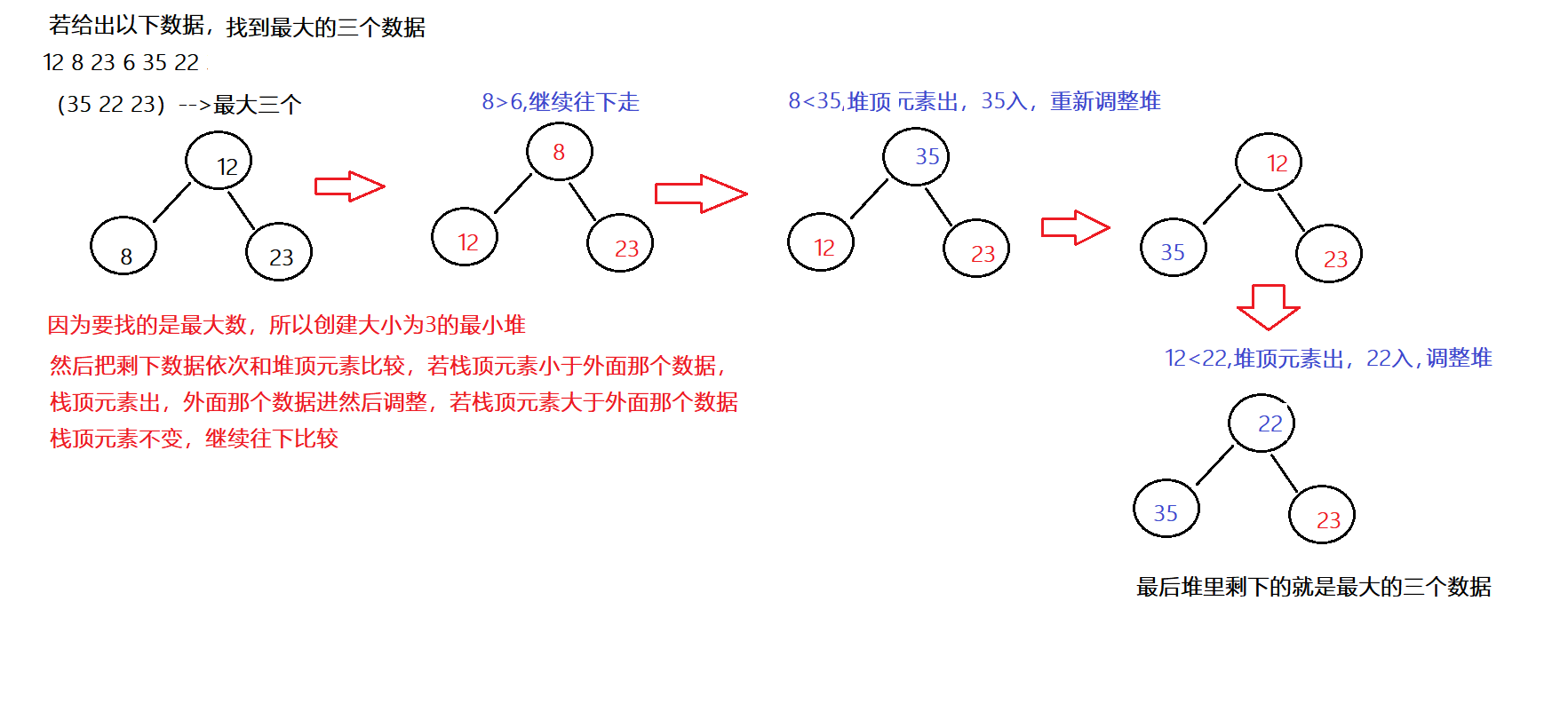
Kotlin是基于JVM的一个语言,也是很时髦的语言。Java语言这几年的发展,借鉴了Kotlin的很多特性。Google把Kotlin作为Android的优先使用语言之后,更是应者影从。本文整理了在Kotlin学习和使用中总结整理出来的几个有意思的知识点,和大家学习和交流。
Coroutines ARE light-weight
fun main() = runBlocking {
repeat(100_000) { // launch a lot of coroutines
launch {
delay(5000L)
print(".")
}
}
}
以上代码在学习Kotlin协程的时候应该都见过了,是为了说明协程很轻量。原因也很简单,在一般的操作系统中,用户线程和内核线程是一对一的关系,操作用户线程的就是操作内核线程,每一个内核线程,都有专门的内核数据结构来管理,在Linux里面使用数据结构task_struct来管理的,这是一个很复杂的数据结构,内核线程的挂起和执行,都会涉及到变量和寄存器数据的保存和恢复,甚至内核线程本身的调度就需要消耗CPU的时间。但是协程完全是用户空间里面的事情,说的简单点,就是几个任务的执行队列的管理,当然协程也是运行中线程之上的。
有个疑问产生了?那为什么现在操作系统用户线程和内核线程是一对一的关系呢?
因为在早期的Java版本中,在单核CPU的时代,用户线程和内核线程的关系是多对一。在多核时代,也有多对多的模型。即多路复用多个用户级线程到同样数量或者更少数量的内核线程。在Solaris早几年的版本也是支持类似的多对多的模型,大家想过没有,为什么现在几乎所有的操作系统都使用一对一的模型了呢?
以下是一家之言,和大家探讨。OS本身越来越复杂,参与方也越来越多。之前线程这块分两层,内核层和用户线程库。用户线程库为程序员提供创建和管理线程的API。随着互联网的发展,有一些需求产生了,如高并发支持,OS这一层比较笨重的,很难快速满足越来越快的需求的变化。这个时候,一些语言,在设计之初就考虑来解决这些新产生的问题,一些时髦的语言,也非常快速的来响应这些需求。所以就有了在线程库之上,在语言的层面来解决这些问题,所以协程产生了,并且越来越多的语言支持了这些特性。
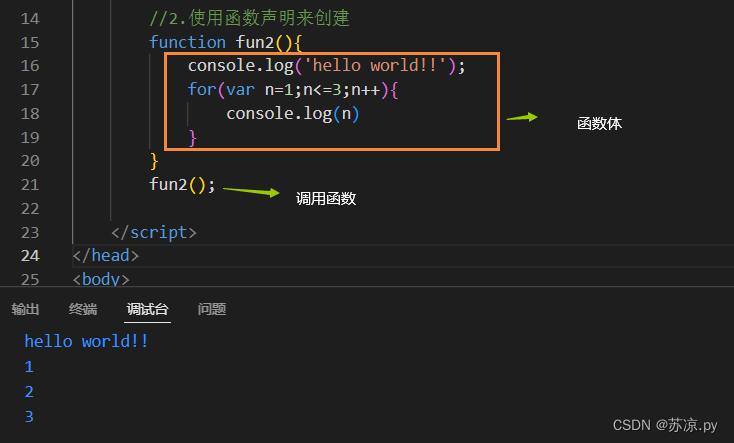
哈哈,为什么线程库为什么没有演进来支持协程呢?原因也很简单,线程库基本被定位成管理内核线程的接口,而且线程库的作者的主要精力也不在这个方向。线程库做好自己的事情(管理内核线程),然后把其他的交给别人。这也是自然形成的分工和分层。
想想这几年的Android应用开发的发展,AndroidX里的东西越来越多,演进也越来越快。这是因为Android系统的体量限制,不可能跑地很快,一年一次算得上是OS升级的极限了。所以必须把需要跑得快的东西剥离出来。这个道理和协程的发展也有异曲同工之处。
Lambda表达式捕获变量
Lambda表达式应该是一个历史比较悠久的东西了,由于函数式编程风行,Lambda表达式也是被非常广泛地使用。Java对Lambda的支持比较后知后觉,应该是在Java8才开始支持的吧,不过在JDK7的时候,JVM字节码引入了InvokeDynamic,后续应该会成为各个基于JVM语言解析Lambda表达式的统一的标准方法。后面会有单独一段来讨论这个InvokeDynamic。
Lambda本质上是一个函数,一块可以被执行的代码段。在函数式编程环境下,Lambda表达式可以被传递,保存和返回。在类似的C/C++的语言环境中,函数指针应该可以非常方便和高效的来实现Lambda,但是在Java和Kotlin这样的语言中,没有函数指针这样的东西,所以用对象来存储Lambda,这当然是在没有InvokeDynamic之前(Java7)。
说到Lambda表达式,大家还记不记得在Java中,如果Lambda要引入外部的一些变量时,这个变量一定要被声明为final。
public Runnable test() {
int i = 1000;
Runnable r = () -> System.out.println(i);
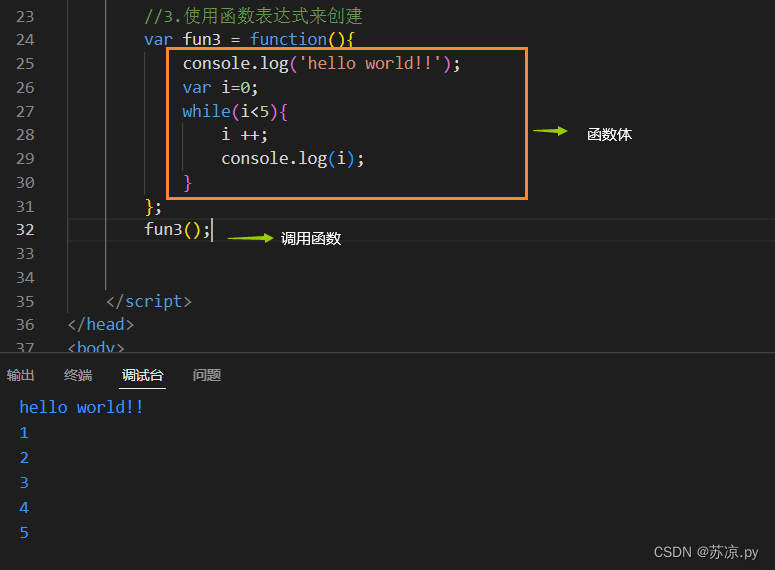
return r;
}
上面这段代码,变量i为实际上的final,编译器会把这个i变量自动加上final。
如下的代码端编译就会出错了,因为变量i不是final的。
public Runnable test() {
int i = 1000;
i++;
// Variable used in lambda expression should be final or effectively final
Runnable r = () -> System.out.println(i);
return r;
}
会什么会有这个限制呢?呵呵,你看上面test函数,如果调用test函数,然后把返回的对象保存下来后再执行,这个时候i这个变量已经在内存中销毁掉了,这个lambda也就没法执行了。因为i这个变量是栈变量,生命周期只在test函数执行期间存在。那么为什么声明称final就没事情了呢,因为在这种情况下,变量是final的,lambda可以把这个变量Copy过来。换句话说,lambda执行的是这个变量的Copy,而不是原始值。
讲到这里,如果你熟悉Kotlin的话,你知道Kotlin没有这个限制,引用的变量不是非得被声明为final啊。难道Kotlin就没有Java遇到的问题吗?
Kotlin一样会遇到同样的问题,只是Kotlin的编译器比较聪明能干啊,它把Lambda引用到的变量都变成final了啊。哈哈,可能你发现了,如果变量本身不是final的,强制变成final这就不会有问题吗?
fun test(): () -> Unit {
var i = 0
i++
return {
println("i = $i")
}
}
以上的代码是可以正常编译被执行的。原因就是编译器干了一些事情,它把i变成堆变量(IntRef)了,并且声明了一个final的栈变量来指向堆变量。
public static final Function0 test() {
final IntRef i = new IntRef();
i.element = 0;
int var10001 = i.element++;
return (Function0)(new Function0() {
// $FF: synthetic method
// $FF: bridge method
public Object invoke() {
this.invoke();
return Unit.INSTANCE;
}
public final void invoke() {
String var1 = "i = " + i.element;
System.out.println(var1);
}
});
}
呵呵,其实吧,这是违背函数式编程的原则的。函数只需要依赖函数的输入,如果引用外部变量,会导致函数输出的不确定性。可能会导致一些偶现的很难解决的bug。
尤其如果在函数里面修改这些变量的话,如在final的List对象里面进行add/remove,这样还会有并发的安全隐患。
Invokedynamic避免为Lambda创建匿名对象
先稍微介绍一下字节码InvokeDynamic指令,需要更详细可以查看官方文档。这个指令最开始是在JDK7引入的,为了支持运行在JVM上面的动态类型语言。
先看如下代码,一个简单的Lambda表达式。
public Consumer<Integer> test() {
Consumer<Integer> r = (Integer i) -> {
StringBuilder sb = new StringBuilder();
sb.append("hello world").append(i);
System.out.println(sb.toString());
};
return r;
}
查看编译之后的字节码如下:
public java.util.function.Consumer<java.lang.Integer> test();
descriptor: ()Ljava/util/function/Consumer;
flags: (0x0001) ACC_PUBLIC
Code:
stack=1, locals=2, args_size=1
0: invokedynamic #2, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
5: astore_1
6: aload_1
7: areturn
LineNumberTable:
line 7: 0
line 12: 6
Signature: #20 // ()Ljava/util/function/Consumer<Ljava/lang/Integer;>;
可以看到,具体Lambda表达式被invokedynamic取代,可以将实现Lambda表达式的这部分的字节码生成推迟的运行时。这样避免了匿名对象的创建,而且没有额外的开销,因为原本也是从Java字节码进行函数对象的创建。而且如果这个Lambda没有被使用到的话,这个过程也不会被创建。如果这个Lambda被调用多次的话,只会在第一次进行这样的转换,其后所有的Lambda调用直接调用之前的链接的实现。
Kotlin因为需要兼容Java6,没法使用invokedynamic,所以编译器会为每个Lambda生成一个.class文件。这些文件通常为XXX$1的形式出现。生成大量的类文件是对性能有负面影响的,因为每个类文件在使用之前都要进行加载和验证,这会影响应用的启动时间,尤其是Lambda被大量使用之后。不过虽然Kotlin现在不支持,但是应该会在不久的将来就支持了。
可以在一些合适的场景下,使用inline来避免匿名对象的创建,Kotlin内置的很多方法都是inline的。也要注意,如果inline关键字使用不当,也会造成字节码膨胀,并影响性能。
Callback转协程
现在很多库函数都使用回调来进行异步处理,但是回调会有一些问题。主要有两方面吧
- 错误处理比较麻烦。
- 在一些循环中处理回调也会是麻烦的事情。
所以如果我们在工程中遇到回调API的话,一般的做法会把这些回调转换成协程,这样就可以用协程进行统一处理了。
回调大致分两类:
- 一次性事件回调,用suspendCancellableCoroutine处理。
- 多次事件回调,用callbackFlow处理。
我们先来看下用suspendCancellableCoroutine,以下是模板代码,使用这段模板代码可以方便的把任意回调方便地转换成协程。
suspend fun awaitCallback(): T = suspendCancellableCoroutine { continuation ->
val callback = object : Callback { // Implementation of some callback interface
override fun onCompleted(value: T) {
// Resume coroutine with a value provided by the callback
continuation.resume(value)
}
override fun onApiError(cause: Throwable) {
// Resume coroutine with an exception provided by the callback
continuation.resumeWithException(cause)
}
}
// Register callback with an API
api.register(callback)
// Remove callback on cancellation
continuation.invokeOnCancellation { api.unregister(callback) }
// At this point the coroutine is suspended by suspendCancellableCoroutine until callback fires
}
接下来,我们来看看suspendCancellableCoroutine这个函数到底干了什么,在注释里面有相关的代码的解释。
public suspend inline fun <T> suspendCancellableCoroutine(
crossinline block: (CancellableContinuation<T>) -> Unit
): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
// 从最开始调用suspend函数的地方获取Continuation对象,并对把对象转换成CancellableContinuation对象。
val cancellable = CancellableContinuationImpl(uCont.intercepted(), resumeMode = MODE_CANCELLABLE)
cancellable.initCancellability()
// 调用block进行回调的注册
block(cancellable)
// 这个函数有个逻辑,如果回调已经结束,直接返回,调用者不进行挂起
// 如果回调还没有结束,返回COROUTINE_SUSPENDED,调用者挂起。
cancellable.getResult()
}
这里有一个关键的函数suspendCoroutineUninterceptedOrReturn,第一次看到这个函数的时候,就感到困惑,uCont这个变量是从哪里来的,这个地方光看代码是看不出从哪里来的。原因是这个uCont变量最终是编译器来处理的。每个suspend函数在编译的时候都会在参数列表最后增加一个Continuation的变量,在调用suspendCoroutineUninterceptedOrReturn的时候,会把调用者的Continuation的对象赋值给uCont。
所有这个函数给了我们一个机会,手动来处理suspend关键字给我们增加的那个参数对象。为什么我们要手动来处理呢,因为我们要把Continuation的对象转换成CancellableContinuation对象,这样我们就可以在被取消的时候来把回调给取消掉了。
如果要完全看懂以上代码,需要知道suspend关键字后面的逻辑,后面会有专门一节来说明。
关于多次事件的回调处理callbackFlow,基本逻辑与关键知识点和上面说的一致,所以这里不对callbackFlow进行说明了。
在suspend关键字后面
Kotlin协程是一个用户空间(相对于内核空间)实现的异步编程的框架。suspend关键字的处理是其中比较关键的一部分,要理解Kotlin的协程如何实现挂起和恢复,就必须要了解suspend关键字的后面的故事。
在讲suspend之前,我们先来了解一下Continuation-passing style(CPS)。
先来一道开胃菜,已知直角三角形的两条直角边长度分别为a和b,求斜边的长度 ?
define (a, b) {
return sqrt(a * a + b * b)
}
用勾股定理,可以用上面的代码可以轻松解决。上面的写法是典型的命令式编程,通过命令的组合方式解决问题。
现在我们来看看CPS的方案的代码应该如何来写?
define (a, b, continuation: (x, y) -> sqrt(x + y)) {
return continuation(a * a, b * b)
}
这里的CPS写法,把勾股定理分成两部分,第一部分计算直角边的平方和,第二部分进行开方操作。开方作为函数的参数传入,当第一部分计算完成之后,进行第二部分的操作。
哈哈,这不就是Callback的吗?没错CPS的本质就是Callback,或者说CPS就是通过Callback来实现的。当然如果仅仅把CPS理解Callback也是不完全准确。CPS要求每个函数,都需要指定这个函数执行完成之后的接下来的操作,所以这个名词应该是continuation,而不是callback,一般情况下,代码里面不会返回callback的执行结果,因为callback的语义上不是继续要干的事情,Continuation才是继续要干的事情,然后把最终的结果返回。
Kotlin编译器就是把suspend函数变成CPS的函数,来实现函数的挂起和恢复的。我们先来看最简单的例子,这个函数没有参数,也没有返回。先打印hello,1s之后再打印world。
suspend fun test() {
println("hello")
delay(1000L)
println("world")
}
对于这个函数,编译器做了两个主要的事情:
- 通过状态机的机制,把这个函数逻辑上分为两个函数,第一个函数是第一次被调用的,另一个函数是在这个函数从挂起状态恢复的时候调用,也就是在delay 1s之后执行的。
- 给suspend函数的参数添加continuation的参数,并在函数体里面对这个参数进行处理。
下面来看下,这个函数再被编译器处理之后的代码,代码以伪代码的形式给出。
fun test(con: Continuation): Any? {
class MyContinuation(
continuation: Continuation<*>): ContinuationImpl(continuation) {
var result: Any? = null
var label = 0
override fun invokeSuspend(res: Any?): Any? {
this.result = res
return test(this);
}
}
val continuation = con as? MyContinuation
?: MyContinuation(con)
if (continuation.label == 0) {
println("hello")
continuation.label = 1
if (delay(1000, continuation) == COROUTINE_SUSPENDED) {
return COROUTINE_SUSPENDED
}
}
if (continuation.label == 1) {
println("world")
return Unit
}
error("error")
}
每一个suspend函数,都有一个continuation参数传入,自己也有一个continuation,包含传入的continuation,自己的continuation对象的类是自己独有的,一般会是一个匿名内部类,这里为了好理解,我把这个匿名的内部来变成普通的类,便于说明问题。在第一次调用这个函数的时候,会实例化自己的continuation对象。实例化的逻辑是
val continuation = con as? MyContinuation
?: MyContinuation(con)
这里有个特别关键的MyContinuation对象的变量label,初始化为0,所以函数第一次执行的是代码里面label等于0的分支,通过这样状态机的机制,把函数从逻辑上可以分成多个函数。
再来看下上面函数体里面的COROUTINE_SUSPENDED,当delay函数返回COROUTINE_SUSPENDED,这个函数也返回COROUTINE_SUSPENDED,同样,如果有函数调用这个函数的时候,也返回COROUTINE_SUSPENDED。这个标识就是用来指示函数进入了挂起状态,等着被回调了。所以函数挂起的实质是,这个函数在当前的label分支下返回了。
如果suspend函数没有返回COROUTINE_SUSPENDED呢,那就接着执行,执行函数下一个状态的逻辑。所以函数在进入当前的状态的时候,就要马上把下个状态设置好。
continuation.label = 1。如果当前函数进入挂起状态,就会把当前的continuation对象传入到调用的函数中,当函数需要恢复的时候,会调用continuation的invokeSuspend的方法,就会重新执行这个函数,这里就是一个Callback了。当然会进入label等于1的分支。所以函数恢复的实质是,这个函数在新Label状态下被重新调用了。
注意了suspend函数不一定返回COROUTINE_SUSPENDED的,也可能返回具体的值。如以下的函数:
suspend fun test(): String {
return "hello"
}
这个函数就没必要进入挂起了,没有返回COROUTINE_SUSPENDED,在这种情况下,函数会执行下一个label分支。
这也是为什么每个suspend函数在编译器处理之后的函数返回值是Any?。这其实是一个union的结构体,只是现在Kotlin还不支持union这样的概念,不过Kotlin变化这么快,之后没准也会支持。
这里的MyContinuation继承了ContinuationImpl,所以看起来MyContinuation实现的比较简单,因为很多的复杂的逻辑都封装在ContinuationImpl中了。下面我们尝试用一个更复杂的例子,然后自己实现ContinuationImpl,更完整来看下背后的逻辑。
在下面的例子中,suspend会更复杂,有参数,有返回。
suspend fun test(token: String) {
println("hello")
val userId = getUserId(token) // suspending
println("userId: $userId")
val userName = getUserName(userId) // suspending
println("id: $userId, name: $userName")
println("world")
}
编译器处理过的代码大致如下:
fun test(
token: String,
con: Continuation
): Any? {
val continuation = con as? MyContinuation
?: MyContinuation(con)
var result: Result<Any>? = continuation.result
var userId: String? = continuation.userId
val userName: String
if (continuation.label == 0) {
println("hello")
continuation.label = 1
val res = getUserId(token, continuation)
if (res == COROUTINE_SUSPENDED) {
return COROUTINE_SUSPENDED
}
result = Result.success(res)
}
if (continuation.label == 1) {
userId = result.getOrThrow() as String
println("userId: $userId")
continuation.label = 2
continuation.userId = userId
val res = getUserName(userId, continuation)
if (res == COROUTINE_SUSPENDED) {
return COROUTINE_SUSPENDED
}
result = Result.success(res)
}
if (continuation.label == 2) {
userName = result.getOrThrow() as String
println("id: $userId, name: $userName")
println("world")
return Unit
}
error("error")
}
MyContinuation的代码如下:
class MyContinuation(
val completion: Continuation<Unit>,
val token: String
) : Continuation<String> {
override val context: CoroutineContext
get() = completion.context
var label = 0
var result: Result<Any>? = null
var userId: String? = null
override fun resumeWith(result: Result<String>) {
this.result = result
val res = try {
val r = test(token, this)
if (r == COROUTINE_SUSPENDED) return
Result.success(r as Unit)
} catch (e: Throwable) {
Result.failure(e)
}
completion.resumeWith(res)
}
}
还记得函数调用,一般都是通过Stack来处理,局部变量和函数的返回之后继续执行的地址都存在stack frame中,这里Continuation的作用就相当于这个Stack了。
还有一个小小的知识点,suspend函数可以调用suspend,所以总有一个最初始suspend函数的吧,不会不就没止境了啊。最初始的那个suspend函数一定是从Callback转换而来的,这里具体可以查看上一节关于Callback转suspend函数的介绍。
以上较多参考了Coroutines under the hood这篇文章,并加入了一些自己的思考,很多都是自己的理解,肯定有错误和不足之处,也请指正。
Corountine Job.join()的一个大坑
这问题起源于我的另外一篇文章,应用程序启动优化新思路 - Kotlin协程,文章讲的是应用启动时,通过Kotlin协程的方案,简化多任务并行初始化的代码逻辑。其实这类问题具有普遍性,我现在举另外一个例子来说明。
做过Android系统开发的工程师一定知道,编译整个Android系统是耗时的,因为里面有至少有数百个模块,模块和模块之间也可能存在依赖关系。这里一般系统都是支持多线程并行编译的,那如何来使用多线程来组织这些模块的编译呢?
考虑一个最简单的例子,现在有5个build tasks,依赖关系如下:
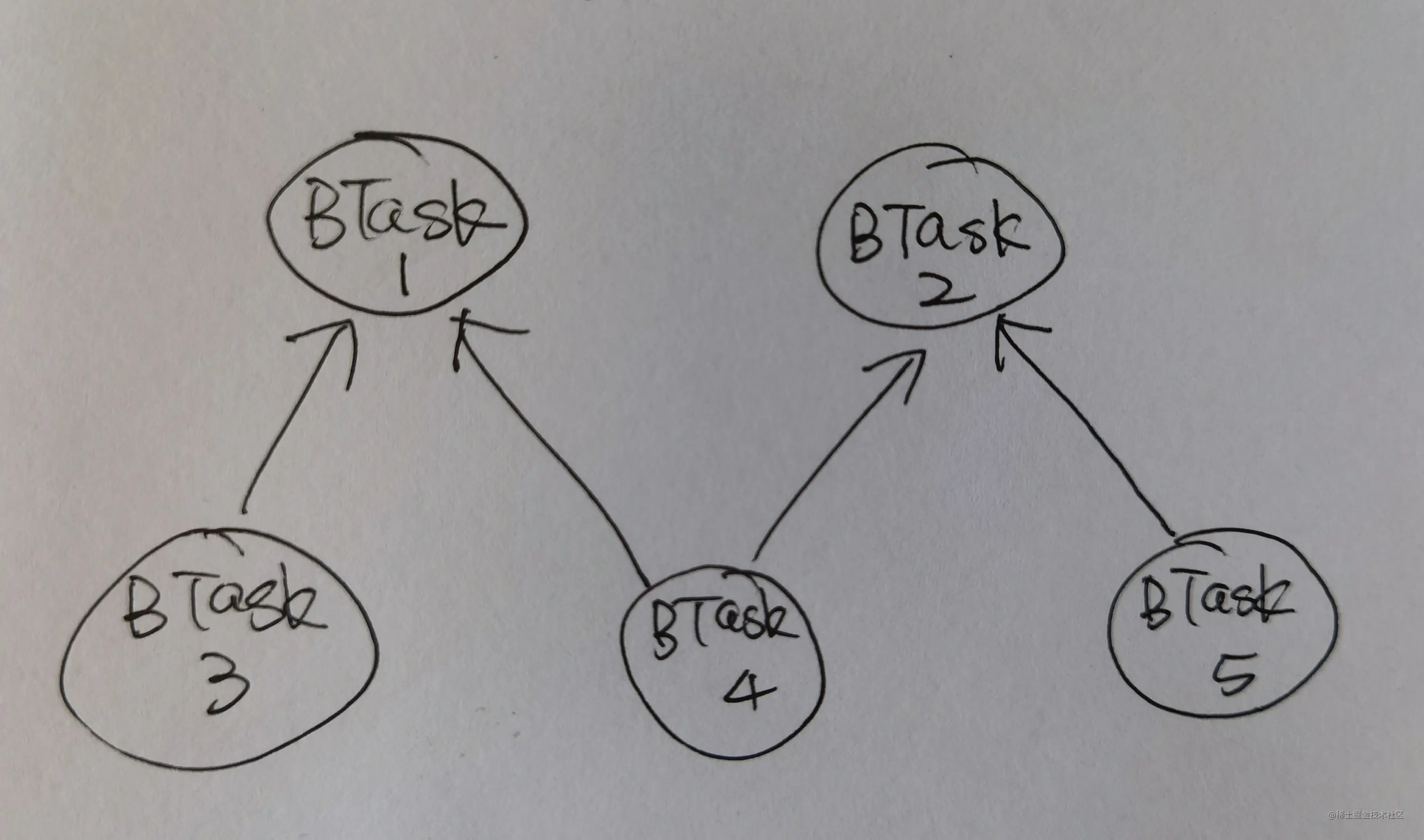
这个图是一个典型的有向无环图,按照拓扑排序的顺利来执行即可,下面考虑使用协程来多任务并行。首先,任务1和任务2没有被依赖,可以被启动,这里可以并行的执行。
suspend fun build() = coroutineScope {
// 调度协程
val job1 = launch(Dispatchers.Default) {
// start build task 1.
}
val job2 = launch(Dispatchers.Default) {
// start build task 2.
}
}
接下来有些难办,任务3,任务4,任务5都是有依赖的,但是我们没法知道任务1和任务2什么时候可以执行完成,所以我们使用了Kotlin协程系统的Join来进行等待。但是这里要注意,我们不能在调度协程里面进行对Job的Join操作。如以下的代码就会存在问题:
suspend fun build() = coroutineScope {
val job1 = launch(Dispatchers.Default) {
// start build task 1.
}
val job2 = launch(Dispatchers.Default) {
// start build task 2.
}
job1.join()
val job3 = launch(Dispatchers.Default) {
// start build task 3.
}
}
如果Task1很耗时,Task3需要等Task1完成之后执行,但是Task2很快就执行完了,可以安排Task5进行执行,如果在调度协程中进行Join,就会一直处于等待Task1执行完成,所以Join的等待不能在调度协程中,那怎么办呢? 我们可以在Task任务协程中进行等待,就可以解决这个问题了。如下面的代码。
suspend fun build() = coroutineScope {
val job1 = launch(Dispatchers.Default) {
// start build task 1.
}
val job2 = launch(Dispatchers.Default) {
// start build task 2.
}
val job3 = launch(Dispatchers.Default) {
job1.join()
// start build task 3.
}
val job4 = launch(Dispatchers.Default) {
job1.join()
job2.join()
// start build task 4.
}
val job5 = launch(Dispatchers.Default) {
job2.join()
// start build task 5.
}
}
以上代码运行良好,我们在测试的时候,所有的逻辑都按照我们所预想的方式执行。但是有一天,我们发现,有非常低的概率发生,这些任务会无法结束,也就是以上的build方法没办法返回,这是一个概率极低的事件,但是确实存在,哈哈,我们掉坑里去了。所以我们就去看了Join的源码,想看看到底发生了什么事情?首先,如果你看懂了上面关于Suspend的那节的话,你会清楚的知道Join是如何进行挂起的,重新恢复必然会走Continuation的resume方法。
以上是我们的大致的想法,然后我们来看一下Join函数到底干了什么?
public final override suspend fun join() {
if (!joinInternal()) { // fast-path no wait
coroutineContext.ensureActive()
return // do not suspend
}
return joinSuspend() // slow-path wait
}
上面Join函数两个分支,第一个分支的意思是,依赖的Job已经结束了,不需要等待了,可以执行返回了。第二个意思是依赖的任务还没有结束,我们需要等待。毫无疑问,我们出问题的代码是走的是第二个分支,那我们来看看第二个分支到底做了些什么?
private suspend fun joinSuspend() = suspendCancellableCoroutine<Unit> { cont ->
// We have to invoke join() handler only on cancellation, on completion we will be resumed regularly without handlers
cont.disposeOnCancellation(invokeOnCompletion(handler = ResumeOnCompletion(cont).asHandler))
}
哈哈,这不就是我们之前讨论的Callback转Suspend函数的代码吗?代码里面cont变量就是代表调用Join函数编译器加入的最后一个参数。我们可以看到,cont变量给了一个叫ResumeOnCompletion的类,那我们接着来看ResumeOnCompletion这个类的实现的吧。
private class ResumeOnCompletion(
private val continuation: Continuation<Unit>
) : JobNode() {
override fun invoke(cause: Throwable?) = continuation.resume(Unit)
}
我们找到了那个关键的代码了,continuation.resume(Unit),这个是Join函数返回最关键的代码了,所以我在这里这个函数上面下了断点,当函数执行到这里的时候,所有的调用栈清晰可见。原来是被依赖的Job里面有个list,里面放着所有这个Job的Join函数的ResumeOnCompletion,然后在Job结束的时候,会遍历这个list,然后执行resume函数,然后Join函数就会返回了。这里的返回只是感觉上的返回,如果你看了上面关于suspend的介绍的话,就会知道所谓的返回就是在新状态下从新执行了那个函数了。那这个ResumeOnCompletion是如何放到这个list的呢? 就是通过上面的invokeOnCompletion方法。如果需要更加细致的了解,可以自己调试一下这个代码。
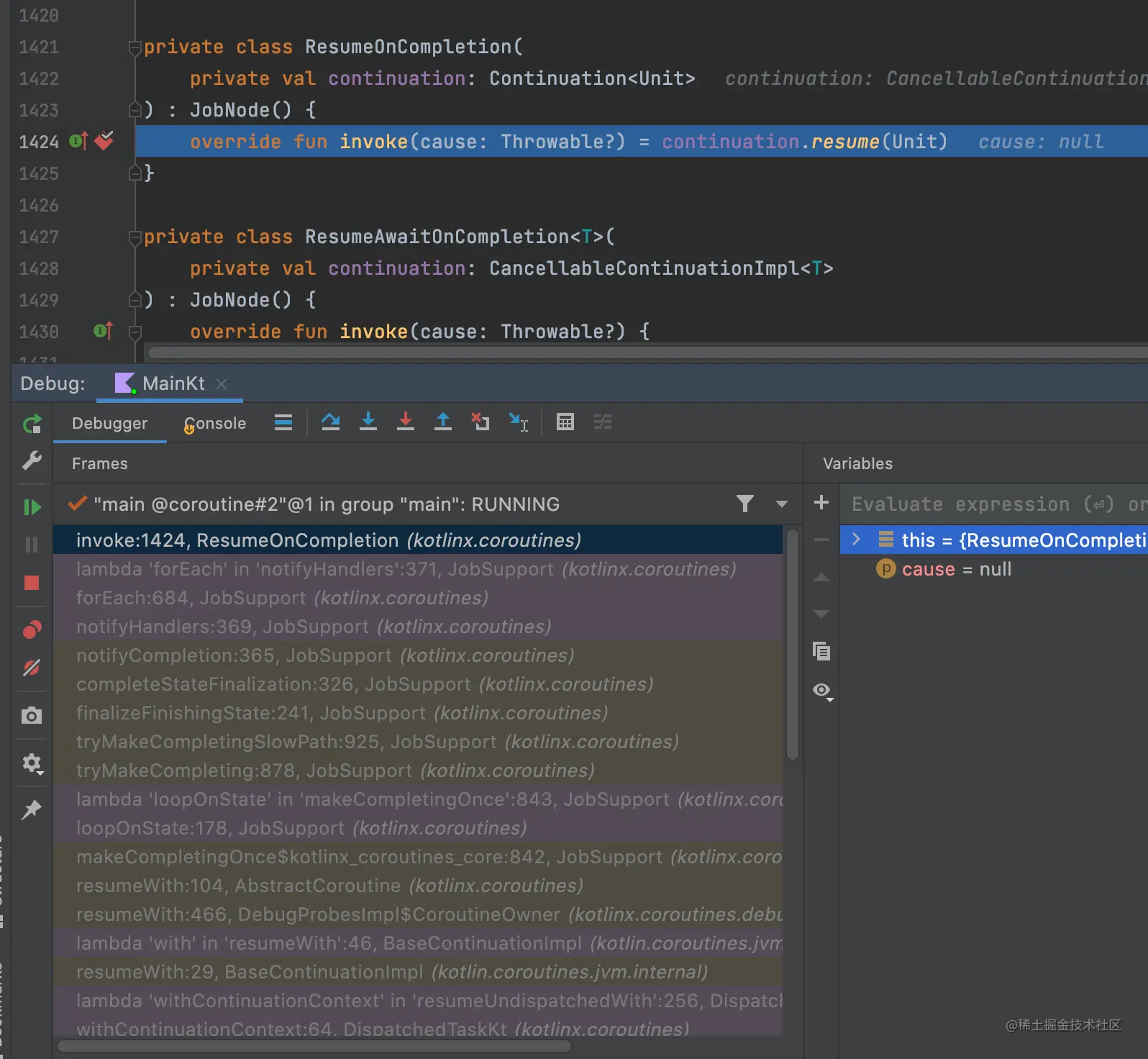
说到这里,不知道大家是否意识到之前代码的问题所在了?
问题出现在,因为Join的代码有可能运行在另外的线程,所以当判断所依赖的任务没有结束,需要等待的时候,把自己的放到list的过程中,还没有放在list里面的那一刹那,Job刚好结束,然后通知list里面的任务可以重新开始了,但是那个任务刚好没有被放到list里面,所以一旦错过,就成了永远了。
所以吧,Kotlin的官方代码里面,所有的Join函数的执行,都是在launch这个Job的协程中执行的。一个协程,不同的时候,可能会运行在不同的线程上,但是一个协程本身是顺序执行的。
好吧,正确的代码如下:
suspend fun build() = coroutineScope {
val context = coroutineContext
val job1 = launch(Dispatchers.Default) {
// start build task 1.
}
val job2 = launch(Dispatchers.Default) {
// start build task 2.
}
val job3 = launch(Dispatchers.Default) {
withContext(context) {
job1.join()
}
// start build task 3.
}
val job4 = launch(Dispatchers.Default) {
withContext(context) {
job1.join()
job2.join()
}
// start build task 4.
}
val job5 = launch(Dispatchers.Default) {
withContext(context) {
job2.join()
}
// start build task 5.
}
}
以上的代码经过长时间的测试和验证,证明是可靠的。另外,如果想知道这个问题更详细的背景,请参看 应用程序启动优化新思路 - Kotlin协程
CoroutineContext vs CoroutineScope
这一节聊下在Kotlin协程中一些基本概念,这些知识点本身不难,但是对于初学者来说,比较容易搞混。下面尝试来试着说明。
首先,先来看一下CoroutineContext,这个比较好理解,就是协程的context。什么叫context,中文一般翻译成上下文,表示一些基本信息。对于Android Application的context,包含包名,版本信息,应用安装路径,应用的工作目录和缓存目录等等基本信息,是描述应用的一些基本信息的。同理协程的context当然就是协程的基本信息。CoroutineContext包含4类信息,如下:
coroutineContext[Job],Job的作用是管理协程的生命周期,和父子协程的关系,可以通过获取。
coroutineContext[ContinuationInterceptor],协程工作线程的管理。
coroutineContext[CoroutineExceptionHandler],错误处理。
coroutineContext[CoroutineName],协程的名字,一般用作调试。
CoroutineScope这个概念,最开始看的时候和CoroutineContext有点分不清楚。其实你看CoroutineScope的接口代码,里面就包含且仅包含CoroutineContext,本质上,他们其实是一个东西。为什么要设计CoroutineScope呢?虽然这两个本质上是同一个东西,但是他们有不同的设计目的。Context是管理来协程的基本信息,而Scope是用来管理协程的启动。
一般的协程通过launch来启动,launch设计成CoroutineScope的扩展函数,非常有意思的设计是,launch的最后一个参数,新协程的执行体也是一个CoroutineScope的扩展函数。launch函数的第一个参数是一个Context,launch会把第一个参数的Context和本身的Context合成一个新的Context,这个新的Context会用来生成新协程的Context,注意这里不是作为新协程的Context。为什么呢,因为新协程为生成一个Job,这个Job和这个Context合成之后,才是作为新协程的Context。
这里两个知识点要注意,所有的Context都是Immutable的,如果要修改一个Context,就会新生成一个新的Context。另外,launch的第一个参数,一般没有指定Job的,一旦指定Job的话,会破会两个协程的父子关系。除非你很确定你要这么做。
所有这些概念的东西,本质上不难,但是对于初学者来说,会感到一头雾水,要深入了解这些概念,需要先去了解一下设计者的设计思路,这样才可以做到事半功倍。
结尾
以上希望可以给大家一些帮助。另外文章免不了一些疏忽和错误,不吝指正。