功耗优化是应用体验优化的一个重要课题,高功耗会引发用户的电量焦虑,也会导致糟糕的发热体验,从而降低了用户的使用意愿。而功耗又是涉及整机的长时间多场景的综合性复杂指标,影响因素很多。不论是功耗的量化拆解,还是异常问题的监控,以及主动的功耗优化对于开发人员来说都是很有挑战性的。
本文结合抖音的功耗优化实践中产出了一些实验结论,优化思路,从功耗的基础知识,功耗组成,功耗分析,功耗优化等几个方面,对 Android 应用的功耗优化做一个总结沉淀。
功耗基础知识介绍
首先我们回顾一下功耗的概念,这里比较容易和能耗搞混。解释一下为什么手机上用mA(电流值)来表征功耗水平,用 mAh(物理意义上是电荷值)来表征能耗水平。我们先来看几个物理公式。
P = I × U, E = P × T
能耗(E):即能量损耗,指计算机系统一段时间内总的能量消耗,单位是焦耳(J)
功耗(P):即功率损耗,指单位时间内的能量消耗,反映消耗能量的速率,单位是瓦特(W)
电流(I):指手机电池放电的电流值,手机常用 mA 为单位
电压(U):指手机电池放电的电压值,标准放电电压 3.7V,充电截止电压 4.35V,放电截止电压 2.75V(以典型值举例,不同设备的电池电压数值有差异)
电池容量 :常用单位 mAh,从单位意义上看是电荷数,实际表征的是电池以典型电压放电的时长。
如下面的功耗测试图所示,手机通常以恒定的典型电压工作,为了计算方便,就把电压恒定为 3.7V,那么 P = I × 3.7, E = I × 3.7 × T,即用 mA 表征功耗,mAh 表征能耗。
总结:对同一机型,我们用电池容量(mAh)变化的来表征一段时间总能耗,用平均电流(mA)来表征功耗水平;如 4000mAh 电池的手机刷抖音 1 小时耗电 11%,耗电量(能耗)440mAh,平均电流 440mA
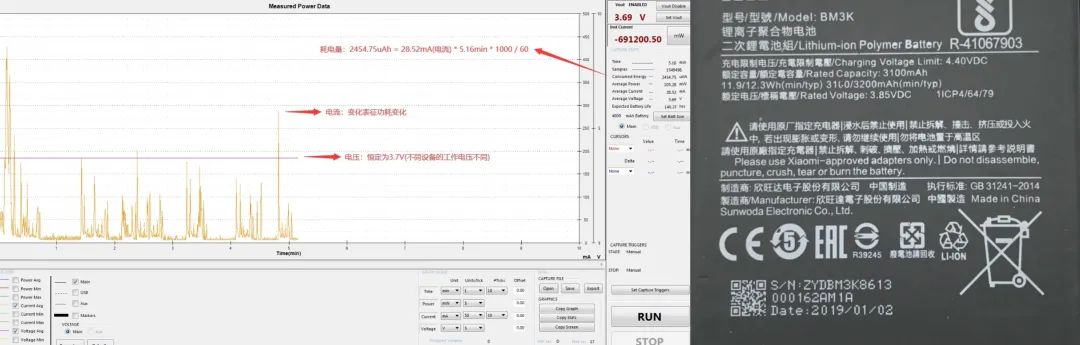 图 1. 功耗测试图
图 1. 功耗测试图
为什么要做功耗优化
从摘要里我们已经了解到高功耗会引发用户的电量焦虑,也会导致糟糕的发热体验,从而降低了用户的使用意愿。优化功耗除了可以我们带来更好的用户体验,提升用户使用时长外,降低应用耗电还具有很明显的社会价值,用一个当前比较火的词,就是可以为碳中和事业贡献一份力量。
如何来做功耗优化
不同于 Crash、ANR 等常见的 APM 指标,功耗是一个综合性的课题,分析起来很容易让人无从下手。用户反馈了耗电问题,可能是 CPU 出现高负载,又或者是后台频繁的网络访问,也可能是动画泄漏导致高功耗。或者我们自己的业务没什么变化,单纯就是环境因素影响,导致用户觉得耗电,比如低温导致的锂电池放电衰减。
我们的思路是从器件出发,应用的耗电最终都可以分解为手机器件的耗电,所以我们先对抖音做器件耗电的拆解,看主要耗电的是哪些器件,再看如何减少器件的使用,这样就做到有的放矢。
下面我们先从功耗组成,功耗分析,以及功耗优化等方面来讲述如何开展功耗优化。
功耗组成
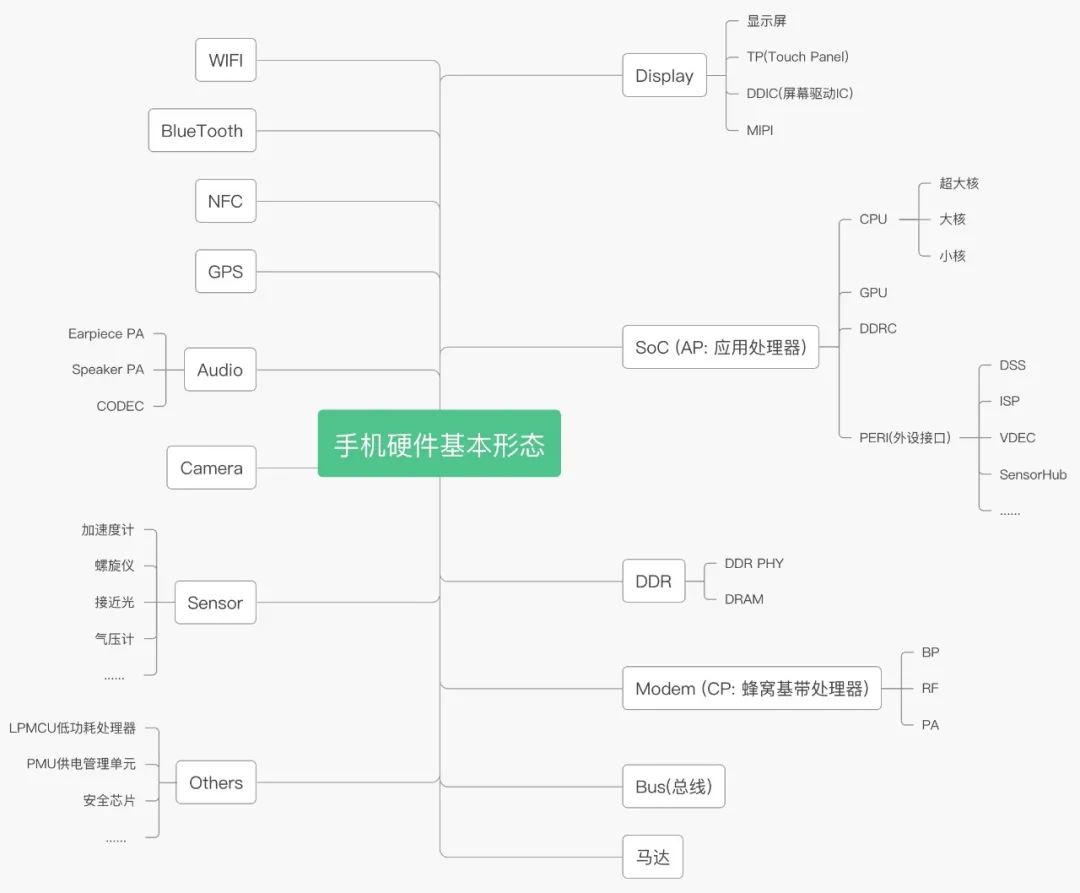
这里列举了手机硬件的基本形态,每个模块又是由复杂的器件构成。如我们常说的耗电大头 SoC 里就包含 CPU 的超大核,大核,小核,GPU,DDRC(内存接口),以及外设区的各种小 IP 核等。所以整机的功耗最终就可以拆解为各个器件的功耗,而应用的功耗就是计算其使用的器件产生的功耗。
以抖音的 Feed 流场景为例,亮度固定 120nit、7 格音量、WiFi 网络下,我们对抖音做了器件级的功耗拆解。可以看到抖音的 feed 功耗主要集中在 SOC(CPU,GPU,DDR),Display,Audio,WIFI 等四个模块。
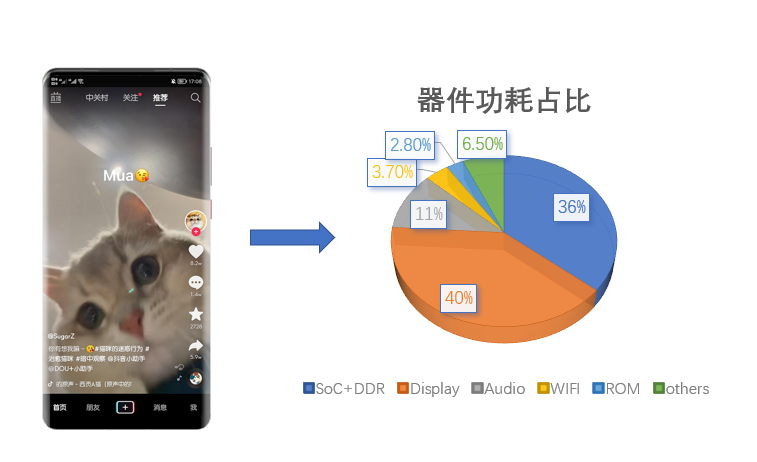
器件功耗计算
那这些器件功耗是如何被拆解出来的呢?原理是:先对器件进行耗电因子拆解,建立器件功耗模型,得到一个器件耗电的计算公式。通过运行时统计器件的使用数据,代入功耗模型,就可以计算出器件的功耗。应用的功耗则是从器件的总功耗里按应用使用的比较进行分配,这样就得到了应用的器件耗电。由于影响器件功耗的耗电因子众多,这里复杂的就是如何对耗电因子进行拆解以及建模。有了精准的建模,后面就是厂商适配校准参数的过程了。
谷歌提供了一套通用的器件耗电模型和配置方案,OEM 厂商可以按通用方案对自己的产品进行参数校准和配置。如下图里 AOSP 里的耗电配置里,以 Wifi 的耗电计算为例。https://source.android.com/devices/tech/power/values
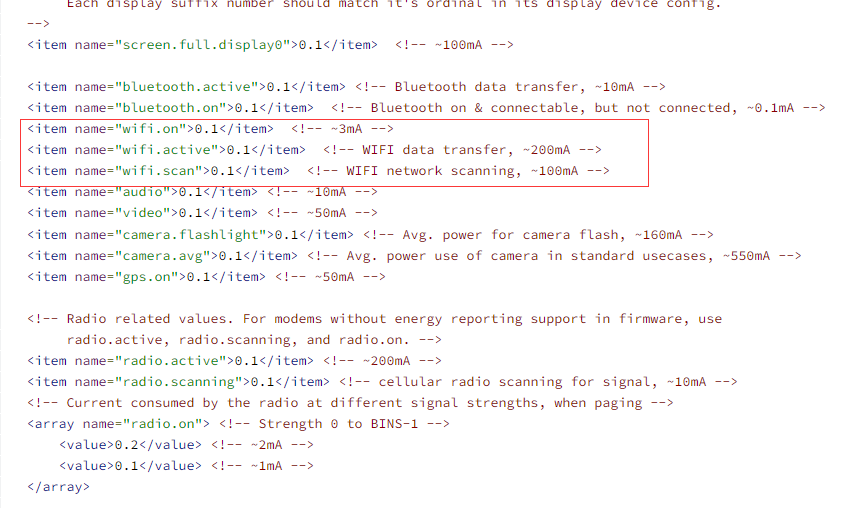

谷歌提供的建模方案是对 WIFI 分状态计算耗电,WIFI 不同状态下的耗电差异非常明显。这里分为了 wifi.on(对应 wifi 打开的基准电流), wifi.active(对应 wifi 传输数据时的基准电流), wifi.scan(对应 wifi 单次扫描的基准耗电), wifi 数据传输的耗电(controller.rx,controller.tx, controller.idle)。根据 wifi 收发数据的那计算 wifi 的耗电,通过统计这几个状态的时长或次数,乘以对应的电流,就得到 wifi 器件的耗电了。
由于谷歌是按照通用性来设计的器件耗电模型,通常只能大致计算出器件的耗电水平,具体到某个产品上可能误差很大。各 OEM 厂商通常有基于自身硬件的耗电统计方案,可以对耗电做更加精细准确的计算。这里还用 wifi 举例:如 OEM 厂商可以分别按照 2.4G,5GWIFI 单独建模,并引入天线信号的变化对应的基准电流变化,以及统计 wifi 芯片所工作的频点时长,按频点细化模型等等,OEM 厂商可以设计出更符合自己设备的精准功耗模型,计算出更精准的 wifi 耗电。这就要根据具体产品的硬件方案来确定了。
功耗分析
通过上面的功耗组成的介绍,我们可以看到功耗影响因素是多种多样。在做应用功耗分析时,我们既要有方法准确评估应用的耗电水平,又要有方法来分解出耗电的组成,以找到优化点。下面就分为功耗评估和功耗归因分析这两部分来介绍。
功耗评估
如前文功耗基础知识里所说,我们使用电流值来评估应用的功耗水平。在线下场景,我们通过控制测试条件(如固定测试机型版本,清理后台,固定亮度,音量,稳定的网络信号条件等)来测得可信的准确电流值来评估应用的前后台功耗。在线上场景,由于应用退后台时,用户使用场景的复杂性(指用户运行的前台应用不同),我们只采集前台整机电流来做线上版本监控,使用其他指标,如后台 CPU 使用率来监控后台功耗。下面我们介绍一些常用功耗评估的手段。
PowerMonitor
目前业界最通用的整机耗电评估方式是通过 PowerMonitor 外接电量计的方式,高频率高精度采集电流进行评估。常用需要精细化确认耗电情况,尤其是后台静置,灭屏等状态下的电流输出,厂商的准入测试等。常用的 Mosoon 公司的 PowerMonitorAAA10F,电流量程在 1uA ~ 6A 之间,电流精度 50uA,采样周期 200us (5KHZ)。
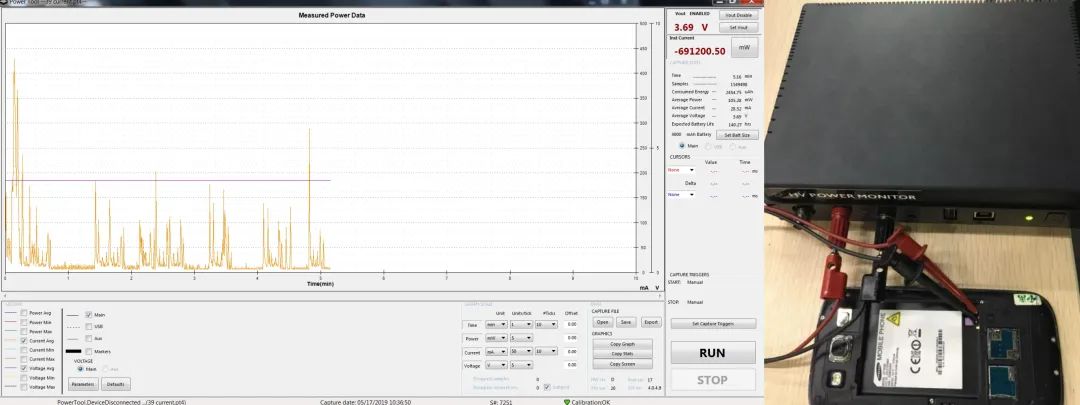
电池电量计
PowerMonitor 虽然测量结果最准确。但是需要拆机比较麻烦。我们还可以通过谷歌 BatteryManager 提供的接口直接读取电池电量计的统计结果来获得电流值。
电池电量计负责估计电池容量。其基本功能为监测电压,充电/放电电流和电池温度,并估计电池荷电状态(SOC)及电池的完全充电容量(FCC)。有两种典型的电量计:电压型电量计和电流型电量计,目前手机上使用的电量计主要是电流型电量计。
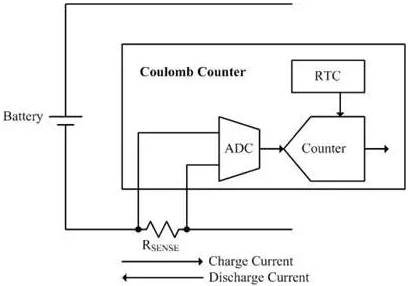
Android 提供了 BMS 的接口,通过属性提供了电池电量计的统计结果
BATTERY_PROPERTY_CHARGE_COUNTER 剩余电池容量,单位为微安时
BATTERY_PROPERTY_CURRENT_NOW 瞬时电池电流,单位为微安
BATTERY_PROPERTY_CURRENT_AVERAGE 平均电池电流,单位为微安
BATTERY_PROPERTY_CAPACITY 剩余电池容量,显示为整数百分比
BATTERY_PROPERTY_ENERGY_COUNTER 剩余能量,单位为纳瓦时
import android.os.BatteryManager;
import android.content.Context;
BatteryManager mBatteryManager = (BatteryManager)Context.getSystemService(Context.BATTERY_SERVICE);
Long energy = mBatteryManager.getLongProperty(BatteryManager.BATTERY_PROPERTY_ENERGY_COUNTER);
Slog.i(TAG, "Remaining energy = " + energy + "nWh");
以下面的 Nexus9 为例,该机型使用了 MAX17050 电流型电量计,解析度 156.25uA,更新周期 175.8ms。

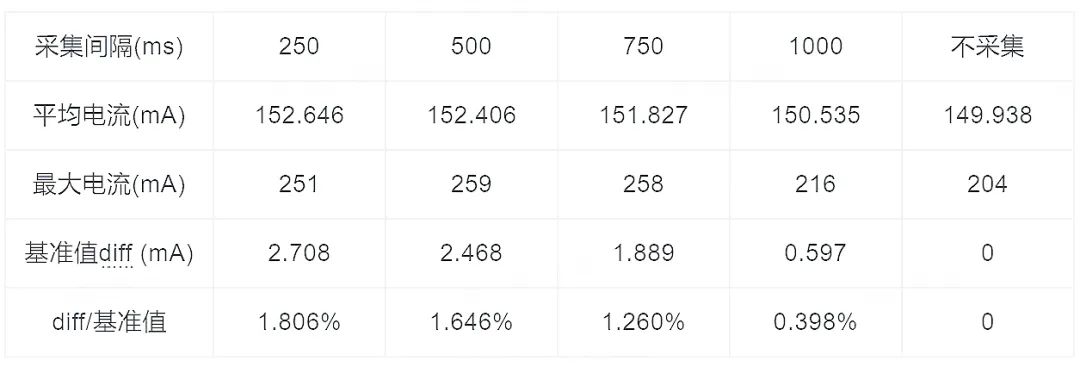
从实践结果上看,由于不同的手机使用的电量计不同,导致直接读取出来的电流值单位也不同,需要做数据转化。为了简化电池数据的获取,我们开发了 Thor SDK,只保留电流、电压、电量等指标的采集过程,针对不同机型做了数据归一处理,用户可以不用关心内部实现,只需要提供需要采样的数据类型、采样周期就可以定时返回所需要的功耗相关的数据,我们用 Thor 对比 PowerMonitor 进行了数据一致性的校验,误差<5mA,满足线上监控需求。
此外我们做了 Thor 采集功能本身的功耗影响,可以看到 1s 采集 1 次的情况下,平均电流上涨了 0.59mA,所以说这种方案的功耗影响非常低,适合线上采集电流值。
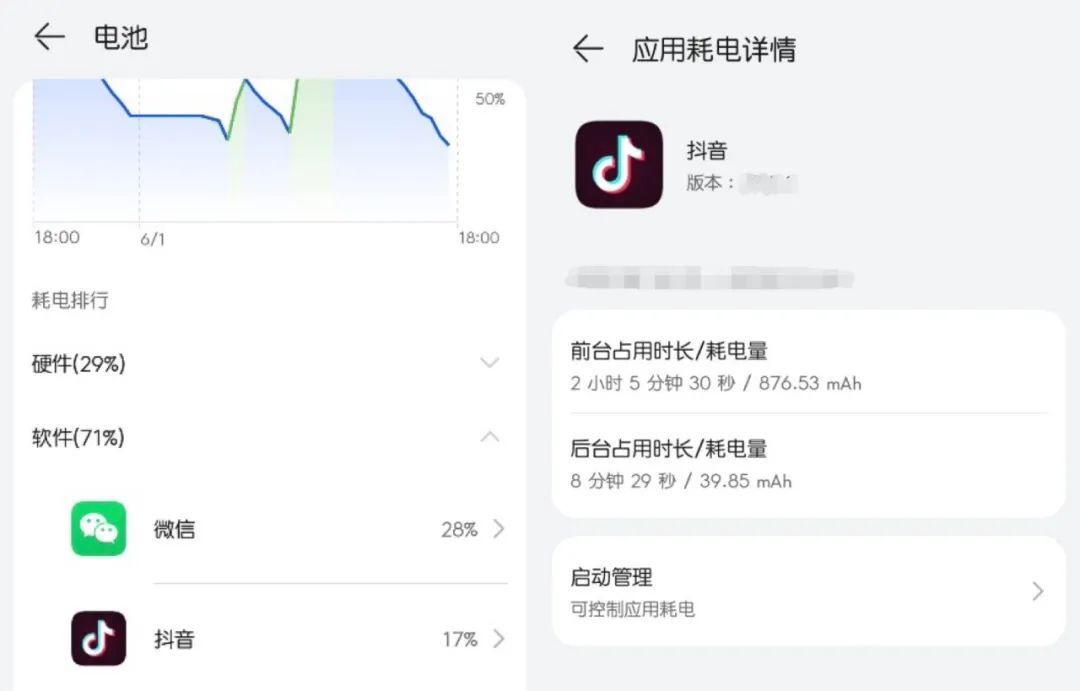
厂商自带耗电排行
耗电排行
厂商提供的耗电排行也可以用来查看一段时间内的应用耗电情况。如下面华为的耗电排行里,对硬件和软件耗电进行了分拆,并给出了应用的具体耗电量。其他厂商 OV 也是支持具体的耗电量,小米则是提供耗电占比,并不会提供具体耗电量。
入口:设置->电池->耗电排行
功耗归因
从功耗评估我们可以判断应用的整体耗电情况,但具体到某个 case 高耗电的原因是什么,就要具体问题选择不同的工具来进行分析了。目前可以直接归因到业务代码的主要是 CPU 相关的工具,这也是我们目前分析问题的主要方向,后续我们也会建设流量归因等能力,下面我列举了常用的分析工具。
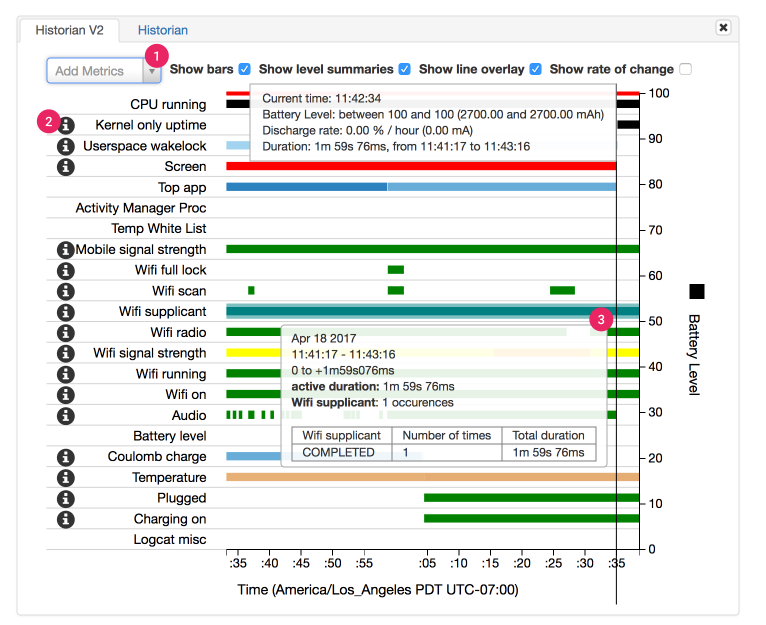
Battery Historian
谷歌官方提供的分析工具,需要先进行功耗测试,再通过 adb 抓取 bugreport.zip,再通过网页工具打开,可提供粗粒度的功耗归因。
本质上是对 systemserver 里的各种服务统计信息+手机状态+内核统计信息(kernel 唤醒)的展示,应用耗电的估算依赖厂商配置的 power_profile.xml。比较适合对整机耗电问题做耗电归因,如归因到某应用耗电较高。
对于单个应用,由于对 wakelock,alarm,gps,job,syncservice,后台服务运行时长等统计的比较详细,比较适合做后台耗电的归因。对于网络异常,CPU 异常,只能看到消耗较多,无法归因到具体业务。https://developer.android.com/topic/performance/power/setup-battery-historian?hl=zh-cn
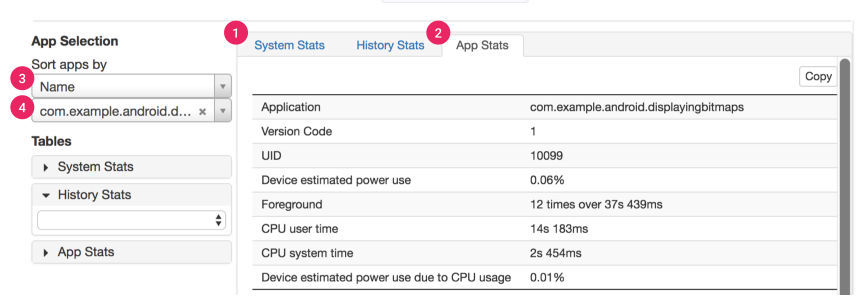
AS Profiler
相比于 BatteryHistorian 需要先手动测试,再 adb 抓取的操作繁琐,AS 自带的 Profiler 提供了 Energy 的可视化展示。使用 debug 版本的应用,可以直观的看到功耗的消耗情况,方便了线下测试。需要注意的是这里展示的功耗值是通过 GPS+网络+CPU 计算的拟合值,并不是真实功耗值,只表征功耗水平。
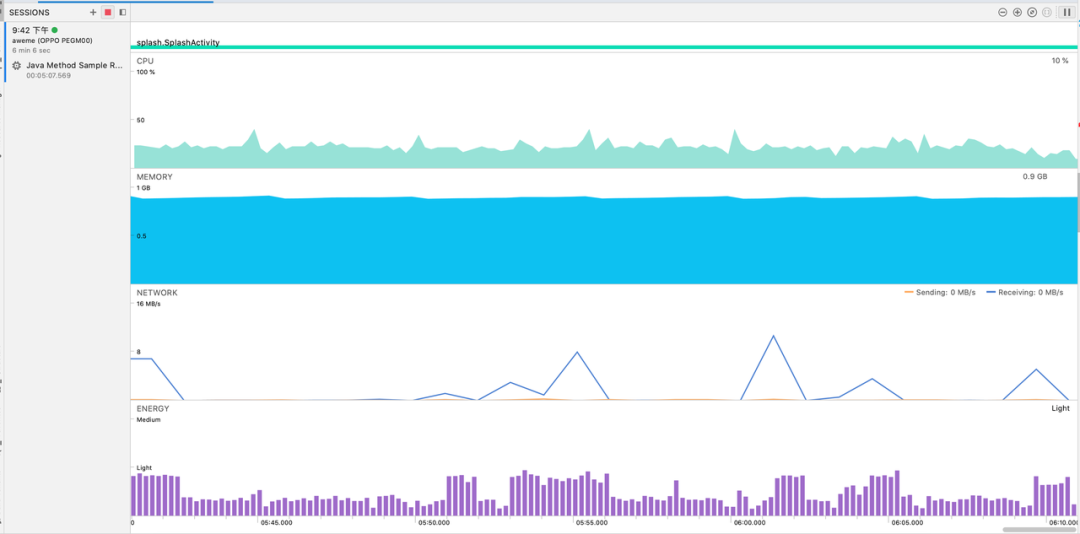
Profiler 同步展示了 CPU 使用率,网络耗电,内存信息。支持 CPU 和线程级别的跟踪。通过主动录制 Trace,可以分析各线程的 CPU 使用情况,以及耗时函数。对于容易复现的 CPU 高负载问题或者固定场景的耗时问题,这种方式可以很容易看到根因。但 trace 的展示方式并不适合偶现的 CPU 高负载,信息量特别多反而让人难以抓住重点。
网络耗电可以很方便抓取到上行下行的网络请求,可以展示网络请求的 api 细节,并且划分到线程上。对于频繁的网络访问,很容易找到问题点。但目前只支持通过 HttpURLConnection 和 OkHttp 的网络请求,使用其他的网络库,Profiler 追踪不到。
可以看到官方出品的工具,功能比较完善,但只支持 debug 版本的 app 分析,如果要分析 release 版本的 app,需要使用 root 手机。总体而言,Profiler 比较适合于线下固定某个业务场景的分析。https://developer.android.com/studio/profile/energy-profiler
线程池监控
使用上面的工具监控单个线程的 CPU 异常是可以的。但是对于线程池,Handler,AsyncTask 等异步任务不太容易归因具体的业务,尤其是网络库的线程池,由于执行的网络请求逻辑是一样的,只靠抓线程堆栈是不能归因到具体业务的。需要统计提交任务的源头代码才能抓到真正问题点。
我们可以通过多种机制,如改造线程池,java hook 等,对提交任务方进行了详细记录和聚合,可以帮忙我们分析线程池里的耗时任务。
线上 CPU 异常精准监控
除了线下的 CPU 分析,我们在进行线上 CPU 异常监控的建设时,我们考虑到单纯使用 CPU 使用率阈值不能精准的判断进程是否处于 CPU 异常。比如不同的 CPU 型号本身的性能不同,在某些低端 CPU 上的使用率就是比较高。又比如系统有不同的温控策略,省电策略,会对手机进行限频,对任务进行 CPU 核心迁移。在这种情况下,应用也会有更高的 CPU 使用率。
因此我们基于不同的变量因素(如 CPU 型号,进程/线程的 CPU 时长在不同核,不同频点的分布,充电,电量,内存,网络状态等),将 CPU 的使用阈值进行精细判定,针对不同场景、不同设备、不同业务制定精细化的 CPU 异常阈值,从而实现了高精度的 CPU 异常抓取。
此外还有业界的一些归因框架,在这里不展开介绍了。
功耗优化实践
上面介绍了功耗的组成,以及如何分析我们应用的耗电。这里我们对功耗优化做一个整体性介绍。我们把优化思路从器件角度展开,列举我们有哪些优化的思路和措施,可以减少器件的使用情况,进而降低功耗。此外对于一些用户可感知的有损业务的降级,我们通过低功耗模式来做,在低电量时通过更激进的降级手段,缓解用户的电量焦虑,带来用户的使用时长的提升。
下图列举了各器件上的优化思路,有一些优化思路会对多个器件都有收益,在这里没有特别详细的区分,就划分在主要影响的器件上,如减少刷新区域,对 GPU,CPU,DDR 都有收益,主要收益在 GPU 绘制上,在下图里就列举在 GPU 上了。
同时我们列举了厂商侧的一些优化方案,应用通常无需关注,比如降低屏幕刷新率,TP 扫描频率,整机低分辨率等,这种可以通过厂商合作的方式进行更细致的调优,如分场景动态调整屏幕刷新率,在搜索列表场景使用 90HZ 高刷,在短视频场景结合帧率对齐进行刷新率降低为 30HZ,以获得更平衡的功耗和性能体验。
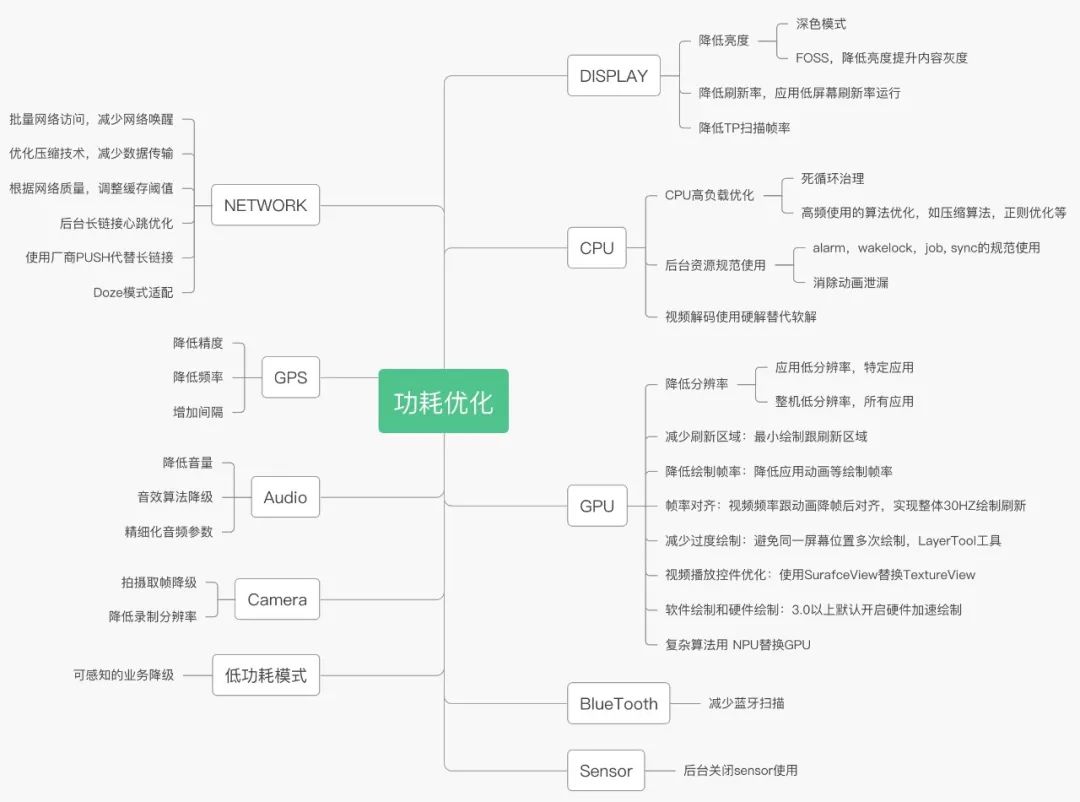
DISPLAY
显示功耗的优化主要围绕对屏幕,GPU,CPU,视频解码器,TP 等器件降级使用或者减少处理,尽量使用硬件处理等实现的。对于屏幕而言主要是降低亮度,刷新率,TP 扫描频率等。
屏幕亮度
屏幕亮度是屏幕功耗的最大来源,亮度和功耗几乎是正比的关系,参见下图:
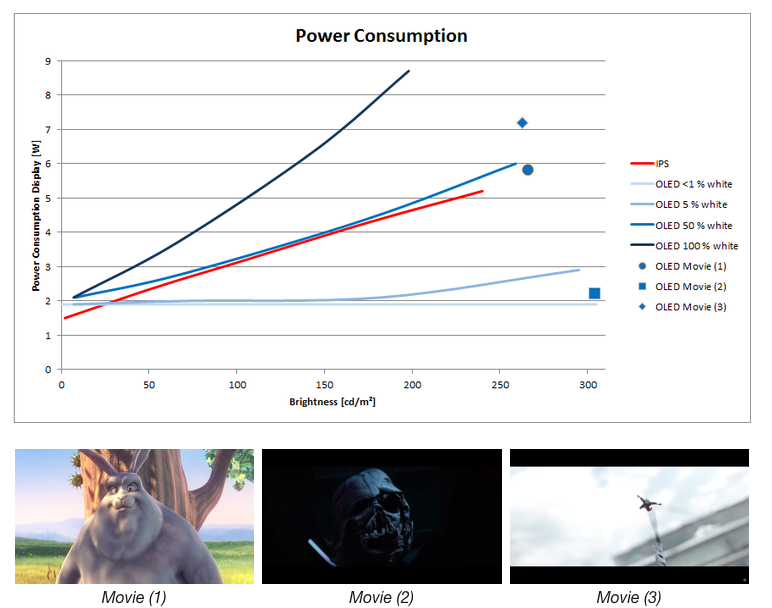
可以看出无论是 IPS 屏幕还是 OLED 屏幕,随着屏幕亮度增加,功耗几乎是线性增加。针对 OLED 屏幕则是白色内容的功耗更高,深色内容则功耗相对更低。应用通用的降低亮度的方式有进入应用后主动降低亮度,或者使用深色的 UI 模式,来达到屏幕亮度降低的效果。厂商会通过 FOSS 或者 CABC 的方案,降低屏幕亮度。
深色模式
利用 AMOLED 屏幕本身的原理,黑色功耗最低,所以可以尽量采用较暗的主题颜色等,最终获取较低的功耗,可以保持用户使用时间更长。
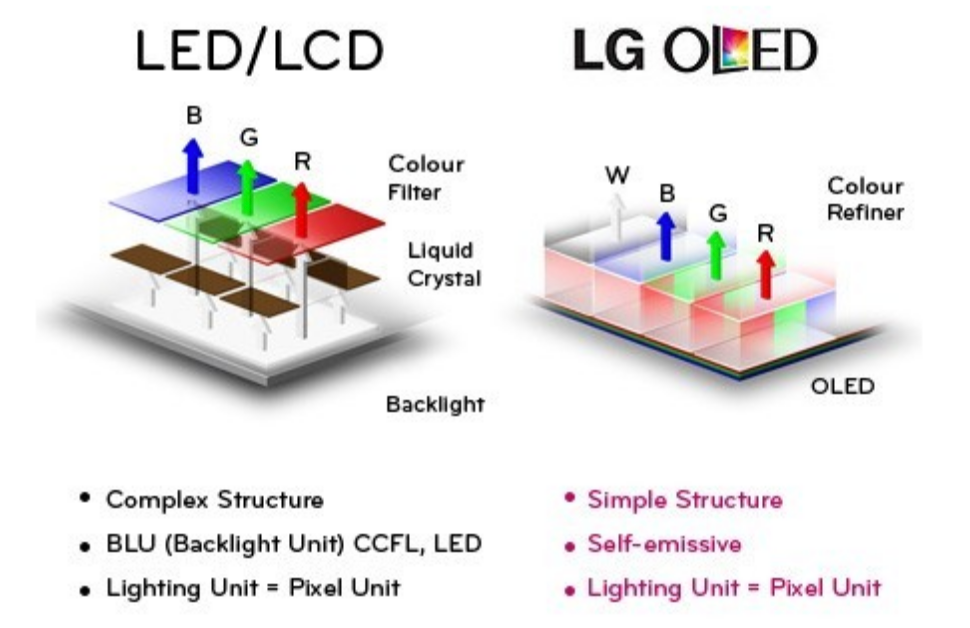
为什么说 AMOLED 屏幕显示黑色界面会消耗更少的电量呢?这要从它与传统的 LCD 屏幕之间的发光原理区别上来说。
LCD 背光显示屏,主要是靠背光层,发光层由大量 LED 灯泡组成,显示白光,通过液晶层偏振控制,显示出 RGB 颜色。在这种情况下,黑色与其它颜色的像素并没有什么不同,虽然看起来并没有光亮,但是依然还是处于发光的状态。
AMOLED 屏幕根本就没有背光一说。相反,每个小的亚像素只是发出微弱的 RGB 光,如果屏幕需要显示黑色,只需要通过调整电压使得液晶分子排列旋转从而遮蔽住背光就可以实现黑色的效果,不会额外点亮任何颜色。
下面引用测试应用为 Reddit Sync 的不同场景下彩色和黑色模式功耗对比。(参考链接:https://m.zol.com.cn/article/4895723.html#p4)
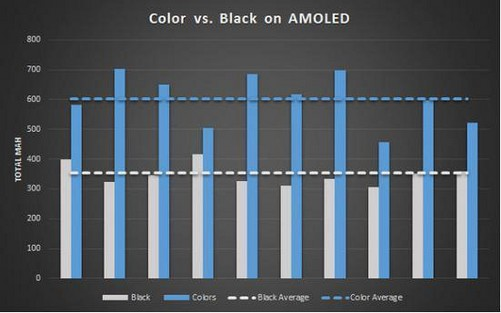
从上面的图表我们可以很清楚的看到,在黑色背景的情况下,AMOLED 屏幕在能耗上的确要比普通颜色背景少了很多,在 Reddit Sync 的测试中,平均耗电量要降低 40%左右。
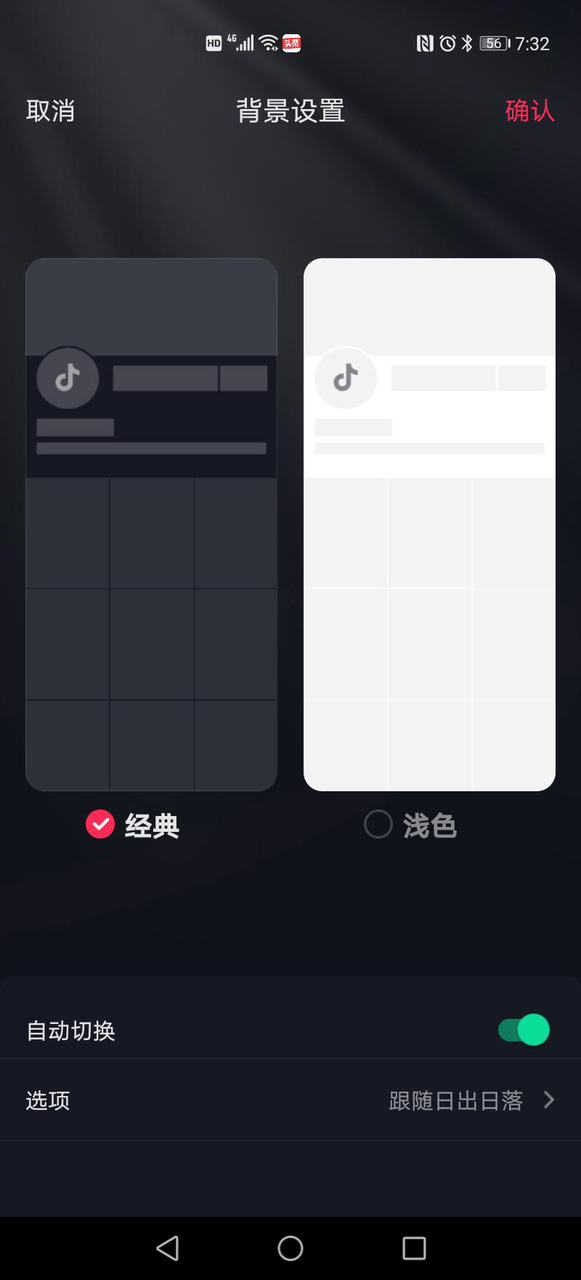
应用可以设计自己的深色模式主题,同步手机系统深色模式开关的切换。目前抖音背景设置有两种模式如下图,可以看到经典模式就是深色模式,正好对应于深色主题,这个也可以和手机平台的深色模式也结合起来。
FOSS
FOSS (Fidelity Optimized Signal Scaling,保真优化信号缩放)是芯片厂商提供的一种对 AMOLED 屏幕调节的低功耗方案。LCD 屏幕上对应的是 CABC (Content Adaptive Brightness Control,内容适应背光控制)。一方面降低屏幕亮度,一方面调节显示内容灰度值,从而使显示效果差异不大,由于降低了屏幕亮度,所以获取的功耗收益较大。一般大约是 0.2 小时左右,即平均可延长手机使用时间 0.2 小时左右。
已知的情况是厂商的 FOSS 方案在某些参数情况下会导致个别场景出现变色或闪烁问题。如果遇到未确认闪烁问题,在内部定位无法确认原因时,可以跟厂商咨询进行排除。
降低刷新率
目前市面上部分手机支持 60HZ,90HZ,120HZ,144HZ 等,高的刷新率带来了流畅度提高,用户的体验更好,但是功耗更高。通常来讲在系统应用界面比如桌面,设置,刷新率会跟当前系统设置保持一致,而在具体应用中,刷新率会根据不同场景做调整。比如抖音,即使在高刷屏幕上,平台系统一般选择让抖音运行在 60HZ 刷新率,从而相对功耗较低。
针对不同的刷新率,PhoneArena 就做了一个比较有参考性的数据来验证这个观点。他们选取了两个品牌四款产品,都是高刷新率的机型,在同一条件下进行 60Hz 刷新率和 120Hz 刷新率的测试,结果 120HZ 刷新率下手机续航相比 60HZ 下的确缩短了至少 10%,即便是支持 90Hz 的一加 8 也是比 60HZ 刷新率要差。
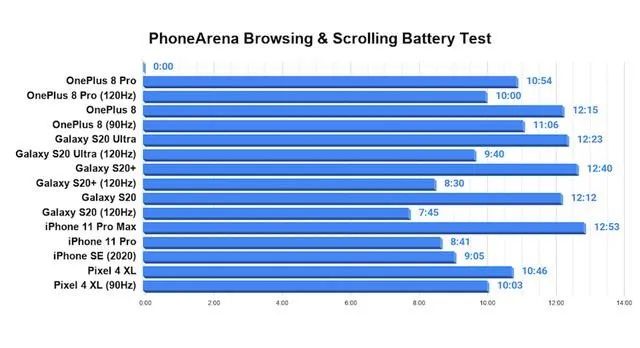 图片来源:https://www.sohu.com/a/394532665_115511
图片来源:https://www.sohu.com/a/394532665_115511
降低 TP 扫描频率
通常游戏中为了提高点击响应速度会提高 TP 扫描频率,其他场景都采用默认的扫描频率。抖音一般使用默认的 TP 扫描帧率。
GPU
GPU 的优化思路主要在减少不必要的绘制或者降低绘制面积,这体现在更低的分辨率,更低的帧率,更少的绘制图层等方面。此外视频应用使用 SurfaceView 替换 TextureView 也有显著的功耗收益。对于复杂的运算,我们可以选择更高能效比的器件来进行,比如使用硬件绘制代替软件绘制,使用 NPU 代替 GPU 执行复杂算法,对整体功耗都有明显降低。
降低分辨率
应用低分辨率
通常该模式下游戏和特定应用一般以较低分辨率运行。缩小了 GPU 绘制区域和传输区域大小,降低了 GPU 和 CPU 以及传输 DDR 的功耗。功耗收益在游戏场景下比较大,线下测试特定平台下1080p->720p约20mA左右,1440p->720p约40mA左右。
其原理如下,应用图层在低分辨率下绘制,通过 HWC 通道放大到屏幕分辨率并跟其余图层合成后送显。
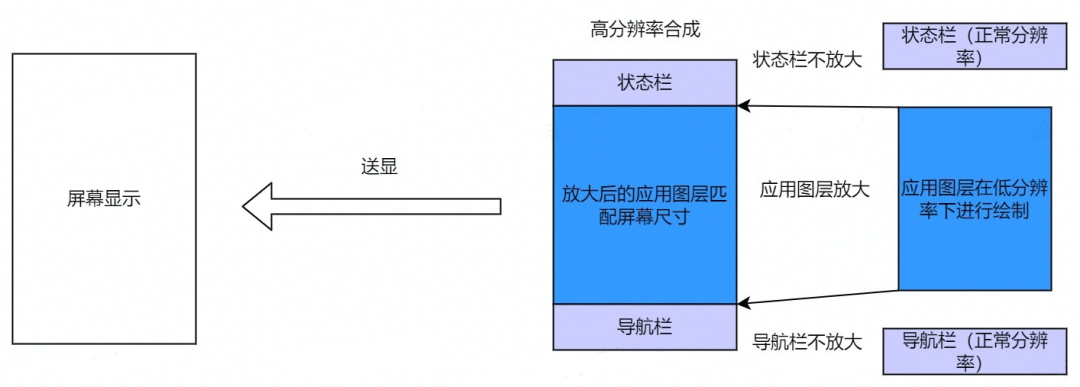
该功能通常平台侧设置,非游戏应用无需关注,游戏应用可以自己选择设置低分辨率。
部分游戏比如腾讯系游戏(如 QQ 飞车、王者荣耀和和平精英等)内部也有不同分辨率的设置,默认以低分辨率运行,从而可以实现较低功耗。
整机低分辨率
所有应用都运行在低分辨率下。同样也缩小了 GPU 绘制区域和传输区域大小,降低了 GPU 和 CPU 以及传输 DDR 的功耗。功耗收益跟应用低分辨率相同,普通应用在该模式下也有功耗收益。用户从系统设置菜单中切换,应用本身通常无需关注。
其原理如下,所有图层都在低分辨率下绘制,并在低分辨率下进行合成。合成后经过 scaler 一次性放大到屏幕分辨率,然后进行送显。其中 scaler 是放缩硬件,由芯片平台提供。
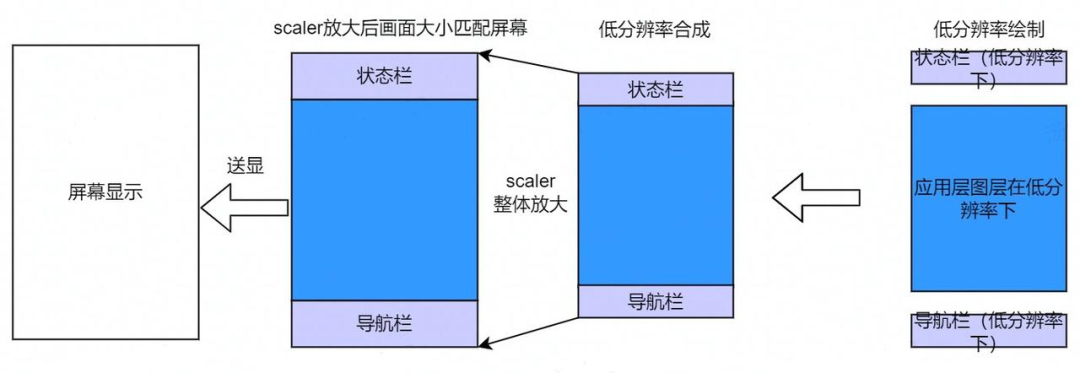
减少刷新区域
应用布局动画位置相近,布局出来一个较小的区域,绘制区域最小,刷新区域最小, 从而功耗最低。不同场景,收益不同。
如下图两种情况,可以看到左侧图,有 3 个动画区域(红色框住区域),最终形成的 Dirty 区域为大的红框区域,整个面积较大。而对比中间图,动画两个红色区域,经过运算后形成的 Dirty 大红框区域就较小,GPU 的绘制区域跟刷新的传输区域都较小,从而相对而言,功耗较低。从最右侧功耗数据图中可以看出收益较大。
可以在开发者选项中打开:设置 -> 开发者选项 -> 显示GPU视图更新,当刷新范围与动画范围明显不一致时便是动画布局不合理。这种情况需要具体到代码层面分析写法的问题并修改。
降低绘制频率
通常在游戏或应用动画中使用,可以降低 GPU 绘制频率和后面的刷新频率。通过降低动画绘制频率,可以降低 GPU,CPU 及 DDR 功耗。
不同帧率功耗情况对比如下,可以看到低帧率下相比高帧率,功耗明显低了很多。
在抖音应用中,低绘制帧率可以通过在抖音内部主动降低动画等帧率实现。在抖音推荐界面音乐转盘动画和音符动画中降低帧率,可以显著的降低功耗。此外也可以通过厂商侧提供 soft vsync 实现 30HZ 绘制,这部分抖音与厂商合作,SurfaceFlinger 控制 APP vsync,降帧时 SurfaceFlinger vsync 输出降为 30fps,在特定条件下主动降低帧率,以延长使用时长。
帧率对齐
在抖音推荐页面中,通过视频和降低频率后的动画达到同步,可以实现整个界面以30HZ 绘制和刷新。否则,如果视频30hz和动画30帧正好交错,最终形成的绘制/刷新频率还是60帧,没有达到最优。我们通过调节各种动画的绘制流程,将动画整体绘制对齐,整体帧率明显降低。
减少过度绘制
过度绘制(Overdraw)描述的是屏幕上的某个像素在同一帧的时间内被绘制了多次。在多层次重叠的 UI 结构里面,如果不可见的 UI 也在做绘制的操作,会导致某些像素区域被绘制了多次,同时也会浪费大量的 CPU 以及 GPU 资源。
可以通过如下来调试过度绘制:打开手机,设置 -> 开发者选项 -> 调试 GPU 过度绘制 -> 显示 GPU 过度绘制。过度绘制的存在会导致界面显示时浪费不必要的资源去渲染看不见的背景,或者对某些像素区域多次绘制,就会导致界面加载或者滑动时的不流畅、掉帧,对于用户体验来说就是 App 特别的卡顿。为了提升用户体验,提升应用的流畅性,优化过度绘制的工作还是很有必要做的。
抖音的 feed 页的过度绘制非常的严重,抖音存在 5 层过度绘制。下图左侧是优化前的过渡绘制情况,右侧是优化后的过度绘制情况,可以看出优化后明显改善。

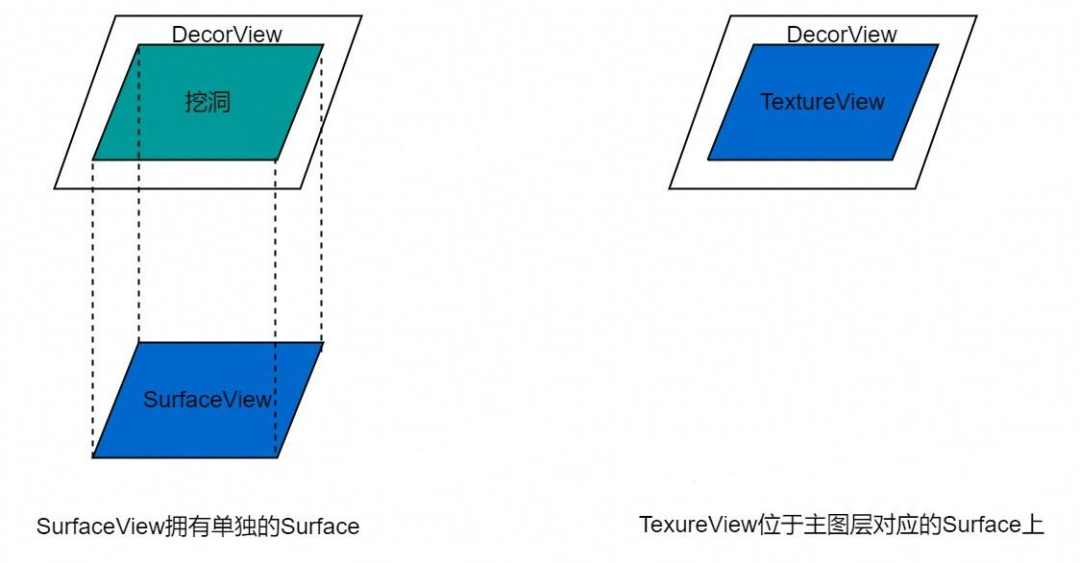
使用 SurfaceView 视频播放
TextureView 和 SurfaceView 是两个最常用的播放视频控件。TextureView 控件位于主图层上,解码器将视频帧传递到 TextureView 对象还需要 GPU 做一次绘制才能在屏幕上显示,所以其功耗更高,消耗内存更大,CPU 占用率也更高。
控件位置差异如下,可以看出 SurfaceView 拥有独立的 Surface 位于单独的图层上,而 TextureView 位于主图层上。
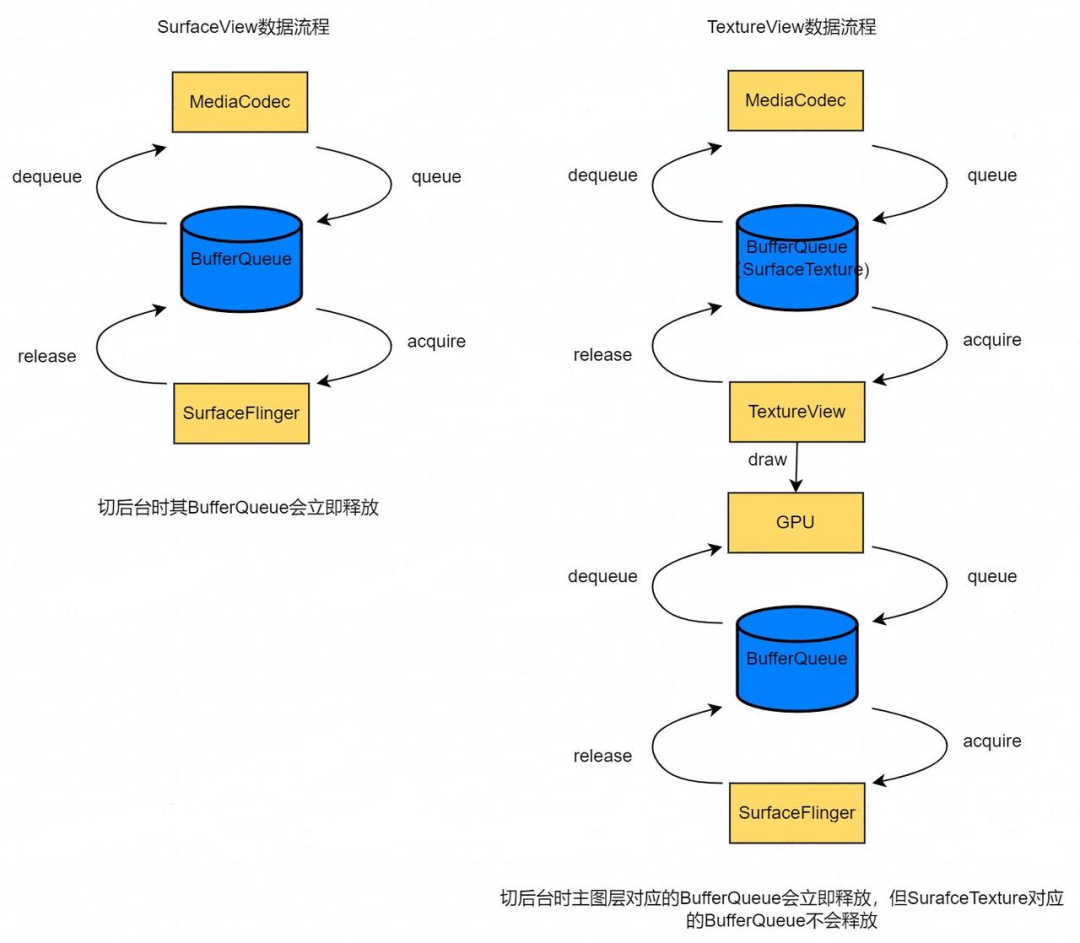
BufferQueue 是 Android 图形架构的核心,其一侧是生产者,另一侧是消费者。从这方面看,SurfaceView 和 TextureView 的差异如下。容易看出,SurfaceView 流程更短,内存使用更少,也没有 GPU 绘制,功耗更省。
下面是一些 SurfaceView 替换 TextureView 后的收益数据:
硬件绘制和软件绘制
硬件绘制是指通过 GPU 绘制,Android 从 3.0 开始支持硬件加速绘制,它在 UI 显示和绘制效率方面远高于软件绘制,但是 GPU 功耗相对较高。目前是系统默认的绘制方式。
软件绘制是指通过 CPU 实现绘制,Android 上面使用 Skia 图形库来进行绘制。两者差异参见下图。

目前默认是开硬件加速的,可以通过设置 Activity,Application,窗口,View 等方式来指定软件绘制。如果应用需要单独指定某些场景的软件绘制方式,需要对性能、功耗等做好评估。参考链接:https://developer.android.com/guide/topics/graphics/hardware-accel
复杂算法用 NPU 代替 GPU
现在的较新的 SoC 平台都带有专门进行 AI 运算的 NPU 芯片,使用 NPU 代替 GPU 运行一些复杂算法,可以有效的节省 GPU 功耗。如视频的超分算法,可以给用户带来很好的体验。但是超分开启对 GPU 的耗电影响很大,在某些平台测试整机功耗可以高出 100mA,选择用 NPU 替换 GPU 是一种优化方式。
CPU
CPU 的优化是功耗优化里最常见的,我们遇到的大部分的 CPU 异常都是出现了死循环。这里使用上面介绍过的功耗归因工具,都可以很容易的发现死循环问题。此外高频的耗时函数,效果和死循环类似,很容易让 CPU 大核跑到高频点,带来 CPU 功耗增加。另外一个典型的 CPU 问题,就是动画泄漏,泄漏动画大概能带来 20mA 的功耗增加。
由于 CPU 工作耗电很高,手机平台大多会增加各种低功耗的 DSP 来分担 CPU 的工作,减少耗电,如常见视频解码,使用硬解会有更好的功耗表现。
CPU 高负载优化
死循环治理
死循环是我们遇到的最明显的 CPU 异常,通常表现为某一个线程占满了一个大核。线程使用率达到了 100%,手机会很容易发热,卡顿。
这里举一个实际修复的死循环例子,在一段循环打包日志的代码逻辑里,所有 log打包完了,才会break跳出循环。当db query出现了异常,异常处理分支并没有做break,导致出现了死循环。
// 方法逻辑有裁剪,仅贴出主要逻辑
private JSONArray packMiscLog() {
do {
......
try {
cursor = mDb.query(......);
int n = cursor.getCount();
......
if (start_id >= max_id) {
break;
}
} catch (Exception e) {
} finally {
safeCloseCursor(cursor);
}
} while (true);
return ret;
}
对于死循环治理,我们通过实际解决的问题,总结了几种常见的死循环套路。
// 边界条件未满足,无法break
while (true) {
...
if (shouldExit()) {
break
}
}
// 异常处理不妥当,导致死循环
while (true) {
try {
do someting;
break;
} catch (e) {
}
}
// 消息处理不当,导致Handler线程死循环
void handleMessage(Message msg) {
//do something
handler.sendEmptyMessage(MSG)
}
高频耗时函数治理
除了死循环问题,我们遇到的另外一种常见的就是高频的耗时函数。通过线上监控 CPU 异常,我们也找到很多可优化的点。如 md5 压缩算法的耗时,正则表达式的不合理使用,使用 cmd 执行系统命令的耗时等。这种就 case by case 的修复,就有很不错的收益。
后台资源规范使用
Alarm,Wakelock,JobScheduler 的规范使用
最常见的后台 CPU 耗电就是对后台资源的不合理使用。Alarm 的频繁唤醒,wakelock 的长时间不释放,JobScheduler 的频繁执行,都会使 CPU 保持唤醒状态,造成后台耗电。这种行为很容易让系统判断应用为后台异常耗电,通常会被系统清理,或者发出高耗电提醒。
我们可以通过 dumpsys alarm & dumpsys power & dumpsys jobscheduler 查看相关的统计信息,也可以通过 BH 的后台统计来分析自身的使用情况。
参考绿盟的功耗标准,灭屏 Alarm 触发小于过 12 次/h,即 5min 一次,5min 一次在数据业务下可以保证长链接存活,厂商的后台功耗优化也通常会强制对齐 Alarm 为 5min 触发一次。
后台的 Partial Wakelock 通常会被重点限制,非可感知的场景(音乐,导航,运动)等会被厂商强制释放 wakelock。按照绿盟的标准,灭屏下每小时累计持锁小于 5min,从实际经验上看,持 Partial 锁超过 1min 就会被标为 Long 的 wakelock,如果是应用在后台无可感知业务并且频繁持锁,导致系统无法休眠的,系统会触发 forcestop 清理。

某些定时任务可以使用 JobScheduler 来替代 Alarm,Job 的好处是可以组合多种触发条件,选择一个最恰当的时刻让系统调度自己的后台任务。这里建议使用充电+网络可用状态下处理自己的后台任务,对功耗体验是最好的。如果是非充电场景下,设置条件频繁触发 job,同样会带来耗电问题。值得一提的是 Job 执行完要及时结束。因为 JobScheduler 在执行时会持有一个job/开头的 wakelock,最长执行时间 10min,如果一直在执行状态不结束,就会导致系统无法休眠。
视频硬解替换软解
硬解通常是用手机平台自带的硬件解码器来做解码从而实现视频播放,基于专用芯片的硬解码速度快、功耗低;软解码方面,通常使用 FFMPEG 内置的 H.264 和 H.265 的软件解码库来做解码。
下表是三星手机和苹果手机分别在软硬解情况下的功耗,可以看出硬解功耗比软解功耗显著降低,目前抖音默认使用硬解。
 图片来源:http://www.noobyard.com/article/p-eedllxrr-qz.html
图片来源:http://www.noobyard.com/article/p-eedllxrr-qz.html
NETWORK
网络耗电是应用耗电的一个重要部分,一个数据包的收发,会同步拉动 CPU 和 Modem/WIFI 两大系统。由于 LTE 的 CDRX 特性(即没有数据包接收,维持一定时间的激活态,再进入睡眠,依赖运营商配置,通常为 10s),所以批量进行网络访问,减少频繁的网络唤醒对网络功耗很有帮忙。此外优化压缩算法,减少数据传输量也从基础上减少了网络耗电。
此外弱信号条件下的网络请求会提高天线的功率,也会触发频繁的搜网,带来更高的网络功耗。根据网络质量进行网络请求调度,提前预缓存网络资源,可以减少网络耗电。
长链接心跳优化
对于应用的后台 PUSH 来说,使用厂商稳定的 push 链路替代自己的长链接可以减少功耗。如果不能替换,也可以优化长链接保活的心跳,根据不同的网络条件动态的调整心跳。根据经验,数据业务下通常是 5min,WIFI 网络下通常可以达到 20min 或更久。
抖音对于长链接进行了的心跳优化,进入后台的长链接心跳时间间隔 [4min, 28min],初始心跳 4min。采用动态心跳试探策略,每次步进 2min,确定最大心跳间隔。
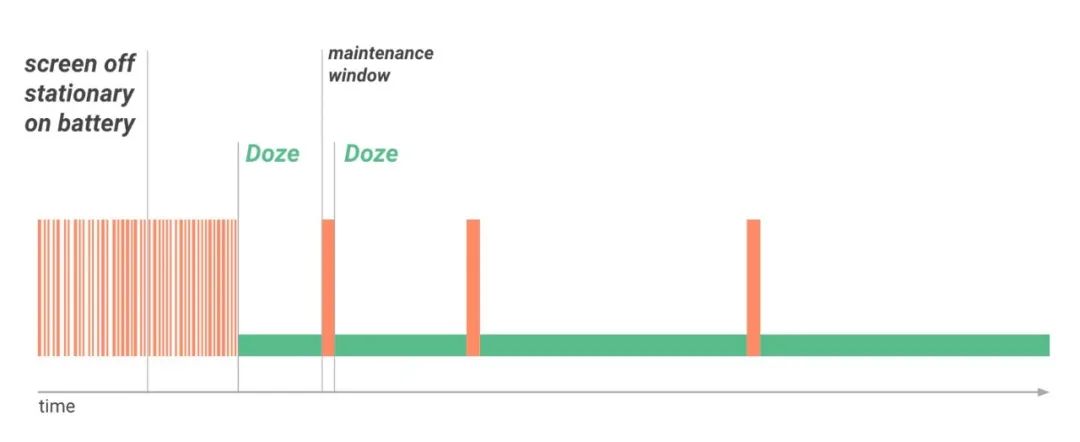
Doze 模式适配
由于系统对后台应用有多种网络限制策略,最常见的是 Doze 模式,手机灭屏一段时间后会进入 doze,限制非白名单应用访问网络,并在窗口期解除限制,窗口期为每 10min 放开 30s。所以在后台进行网络访问前要特别注意进行网络可用的判断,选择窗口期进行网络访问,避免因为被限网而浪费了 CPU 资源。
这里举一个 Doze 未适配的后台耗电例子,用户反馈抖音自上次手机充满电(24h)后,没有在前台使用过,耗电占比 31%,分析日志发现 I 在 Doze 限制网络期间,会触发轮询判断网络是否及时恢复,此逻辑在后台未适配 Doze 的窗口期模式,导致了后台频繁尝试网络请求带来的 CPU 耗电。
AUDIO
降低音量
音频的耗电最终体现在 Codec 和 SmartPA(连接喇叭的功率放大器)两部分。减少 Audio 耗电最明显的就是减少音频的音量,这直接反应到喇叭的响度上。
用 0-15 级的音量进行测试,可以看到音量对功耗的影响巨大,尤其是超过 10 之后,整体增幅非常巨大。每一级几乎与功耗成百分比上涨。
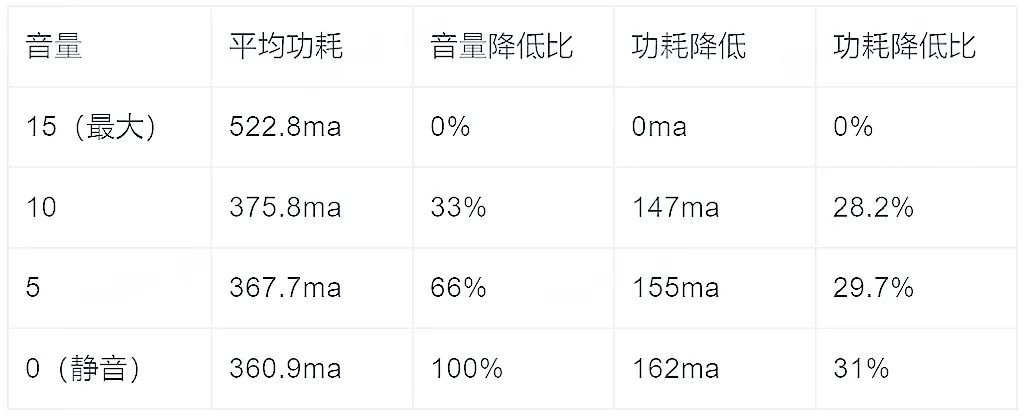
10-15 :1:30ma
5-10:1:1.62ma
0-5:1:1.36ma
调整音频参数
由于用户对音量的感受很明显,直接全局降低音量会带来不好的体验。厂商通常会针对不同的场景,设计不同的音频参数,如电影场景,游戏场景,导航场景,动态调节音频的高低频配置参数,兼顾了效果和功耗。
从这个角度出发,可以选择和厂商合作,根据播放视频的内容,精细化调整音频参数,如电影剪辑类型视频就使用电影场景的参数,游戏视频就切换为游戏场景的配置参数,从而达到用户无感调节音量节省功耗的目的。
CAMERA
Camera 是功耗大户,尤其是高分辨率高帧率的录制会带来快速的功耗消耗和温升。经过线下测算,开播场景,Camera 功耗 200mA+,占整机的 25%以上。
优化Camera功耗的思路主要是从业务降级的角度上进行,如降低录制的分辨率,降低录制帧率等。之前抖音直播和生产端都是使用30帧,但最终只使用15帧,在开播端主动下调采集帧率,按需设置帧率为15帧,功耗显著降低了120ma。
SENSOR
sensor 的典型功耗值很低,如我们常用到的 accelerometer(加速度计)的典型功耗只有 180uA。但 sensor 的开启会导致 cpu 的唤醒与负载增加,尤其是在应用退到后台,sensor 的滥用会显著增加待机功耗。可以在低电量时关闭不必要的 sensor,减少耗电。
GPS
精确度,频率,间隔是影响 GPS 耗电的三个主要因素。其中精度影响定位的工作模式,频率和间隔是影响工作时长,我们可以通过优化这三者来减少 GPS 的耗电
降低精度
Android 原生定位提供 GPS 定位和网络定位两种模式。GPS 定位支持离线定位,依靠卫星,没有网络也能定位,精度高,但功耗大,因需要开启移动设备中的 GPS 定位模块,会消耗较多电量。
Network 定位(网络定位),定位速度快,只要具备网络或者基站要求,在任何地方都可实现瞬间定位,室内同样满足;功耗小,耗电量小;但定位精度差,容易受干扰,在基站或者 WiFi 数量少、信号弱的地方定位质量较差,或者无法定位;必须连接网络才能实现定位。
我们可以在满足定位要求的情况下,主动使用低精度的网络定位,减少定位耗电,抖音在进入低功耗模式时,进行了 GPS 降级为网络定位,并且扩大了定位间隔。
降低频率&提高间隔
这里除了业务上主动控制频率与间隔外,还推荐使用厂商的定位服务。为了优化定位耗电,海外 gms 以及国内厂商都提供了位置服务 SDK,本质上是通过系统服务统一管理位置请求,根据电量,信号,请求方的延迟精度要求,进行动态调整,达到功耗与定位需求的平衡。提供了诸如被动位置更新,获取最近一次定位的位置信息,批量后台位置请求等低功耗定位能力。
https://developer.android.com/guide/topics/location/battery https://developer.huawei.com/consumer/cn/doc/development/HMSCore-References/location-description-0000001088559417
低功耗模式
上述的优化措施,有些在常规模式下已经实施。但有一部分是有损用户体验的,我们选择在低电量场景下去做,降低功耗,减少用户的电量焦虑,获得用户在低电量下更多使用时长。
在低功耗模式预研中,我们列举了很多可做的措施,通过 AB 实验,我们去掉了业务负向的降级手段,比如亮度降低,音量降低等。此外在功能触发的策略上,我们通过对比了低电量弹窗提醒,设置里增加开关+Toast 提醒,以及低电量自动进入,最终选择了对用户体验最好的 30%电量无打扰自动进入的触发方式。
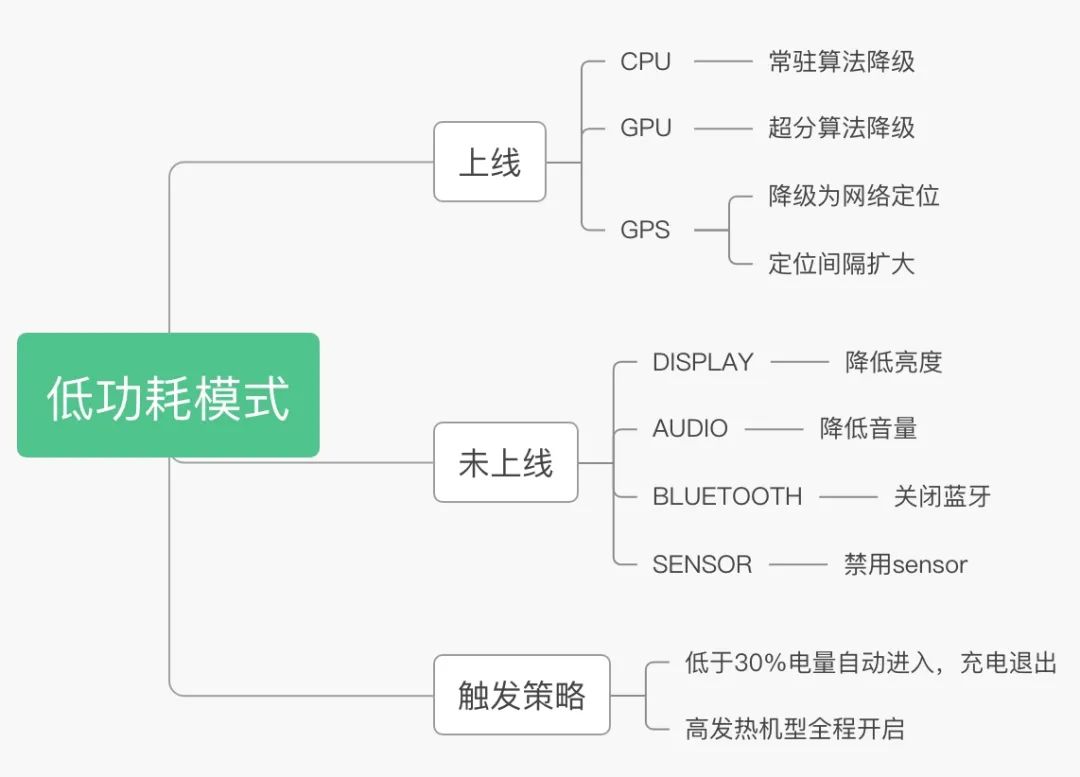
经过实验发现,一些高发热机型,通过低功耗模式全程开启,也可以拿到业务收益。说明部分有损的降级,用户在易发热的情况下也是接受的,可以置换出业务收益,目前低功耗模式线下测试功耗收益稳定在 20mA 以上。
总结
功耗优化是一个复杂的综合课题,既包含了利用工具对功耗做拆解评估,对异常的监控治理,也包含了主动挖掘优化点进行优化。上面列举的优化思路,我们也只是做了部分,还有部分待开展,包括功耗归因的工具建设上,我们也还有很多可以优化的点。我们会持续发力,产出更多的方案,在满足使用需求的前提下,消耗更少的物理资源,给抖音用户带来更好的功耗体验。
作者: 字节跳动技术团队
来源:https://blog.csdn.net/ByteDanceTech/article/details/125109383
收起阅读 »





















































 http://www.51dn.top/wp-content/uploads/2022/04/QQ截图20220407104051-624x315.jpg 624w, http://www.51dn.top/wp-content/uploads/2022/04/QQ截图20220407104051.jpg 671w" sizes="(max-width: 500px) 100vw, 500px" style="vertical-align: baseline; border-radius: 3px; box-shadow: rgba(0, 0, 0, 0.2) 0px 1px 4px;">
http://www.51dn.top/wp-content/uploads/2022/04/QQ截图20220407104051-624x315.jpg 624w, http://www.51dn.top/wp-content/uploads/2022/04/QQ截图20220407104051.jpg 671w" sizes="(max-width: 500px) 100vw, 500px" style="vertical-align: baseline; border-radius: 3px; box-shadow: rgba(0, 0, 0, 0.2) 0px 1px 4px;">