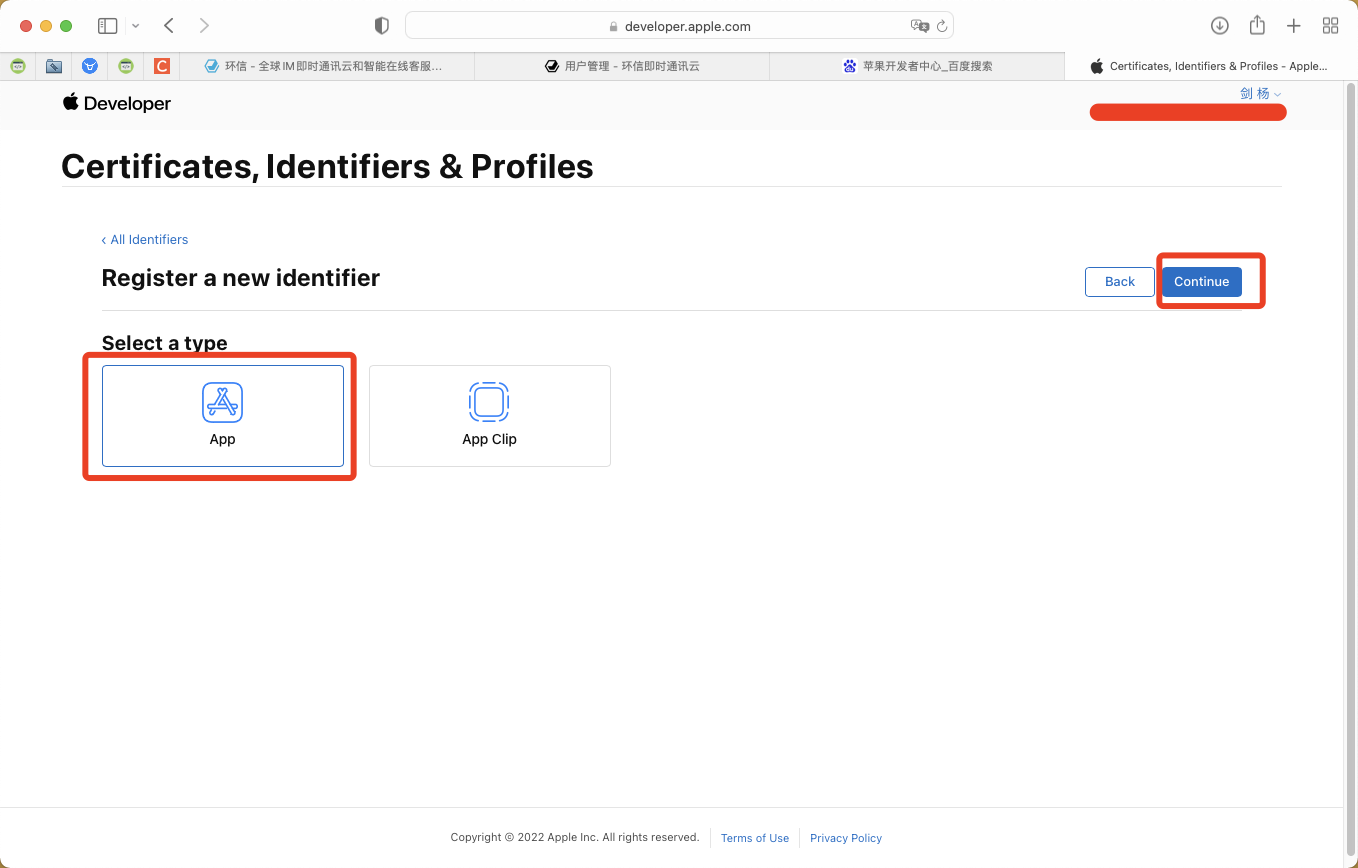
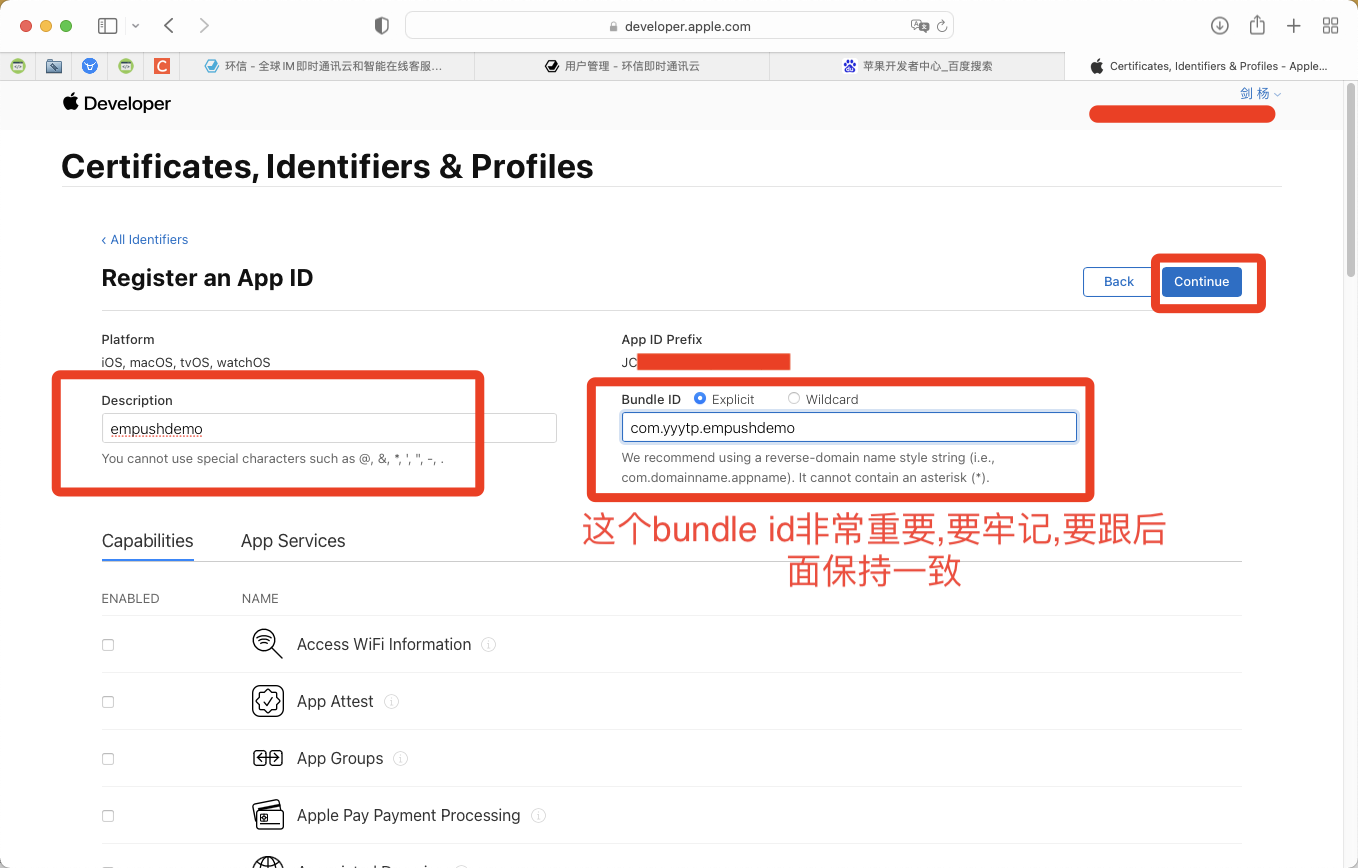
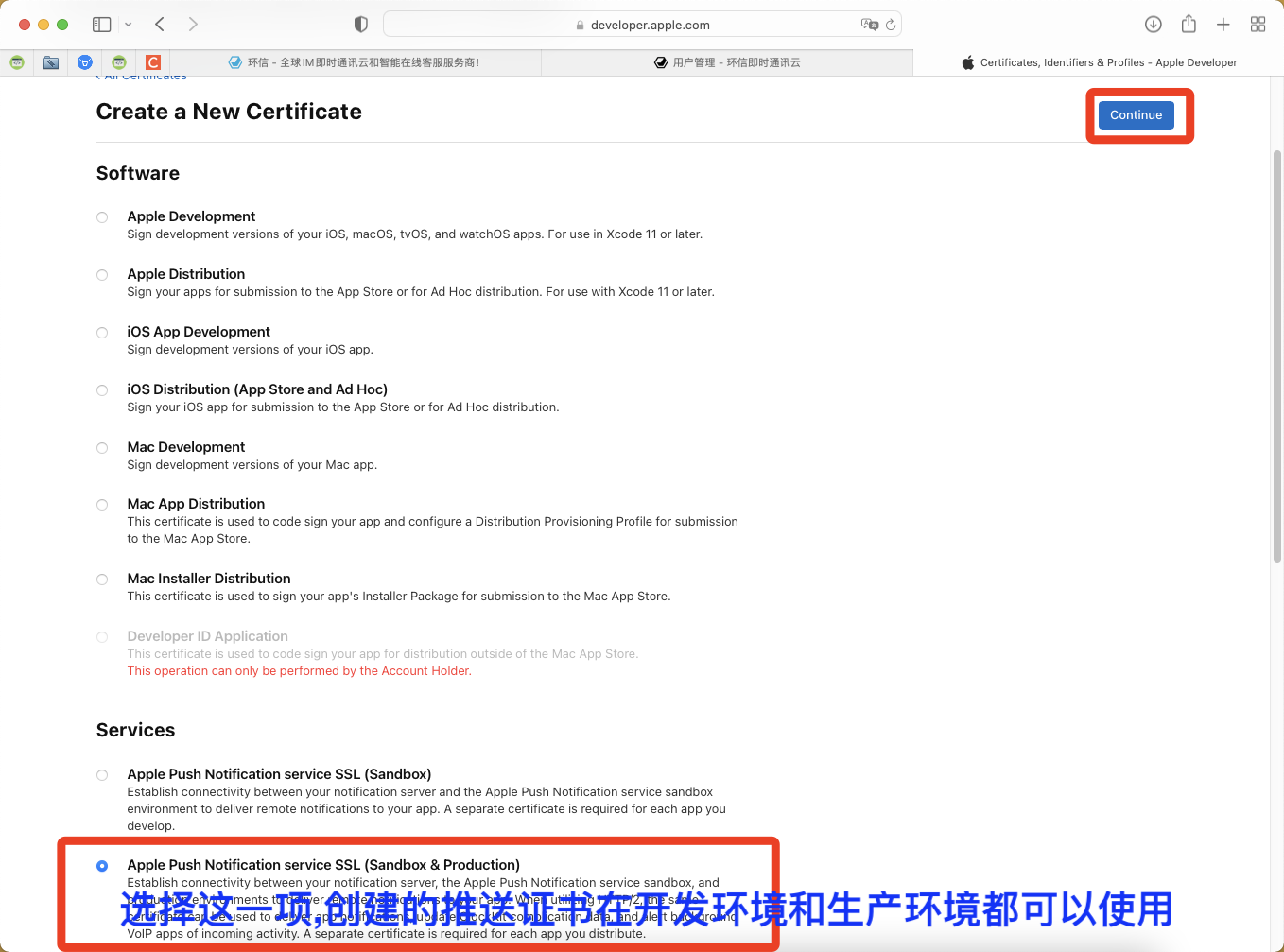
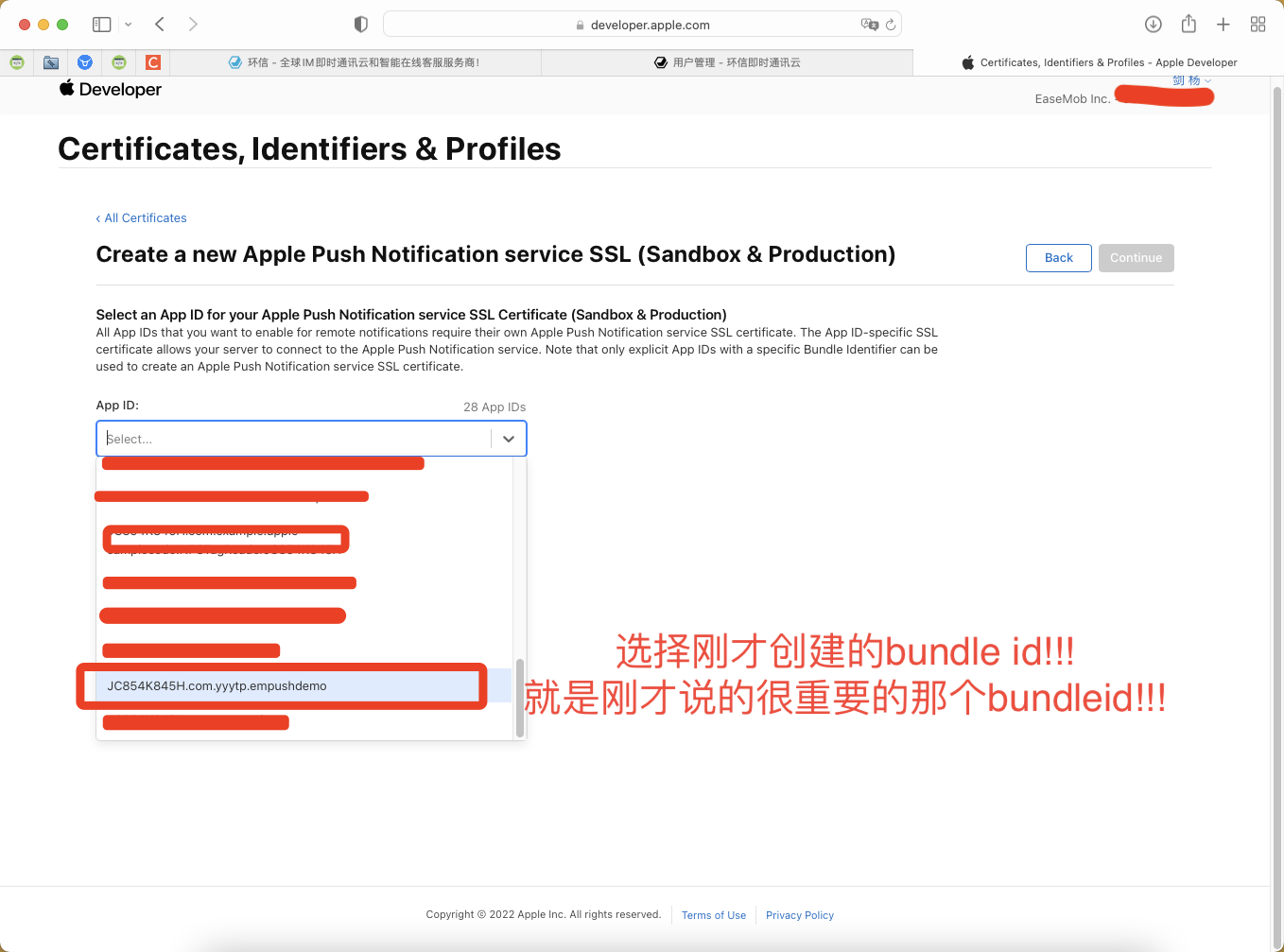
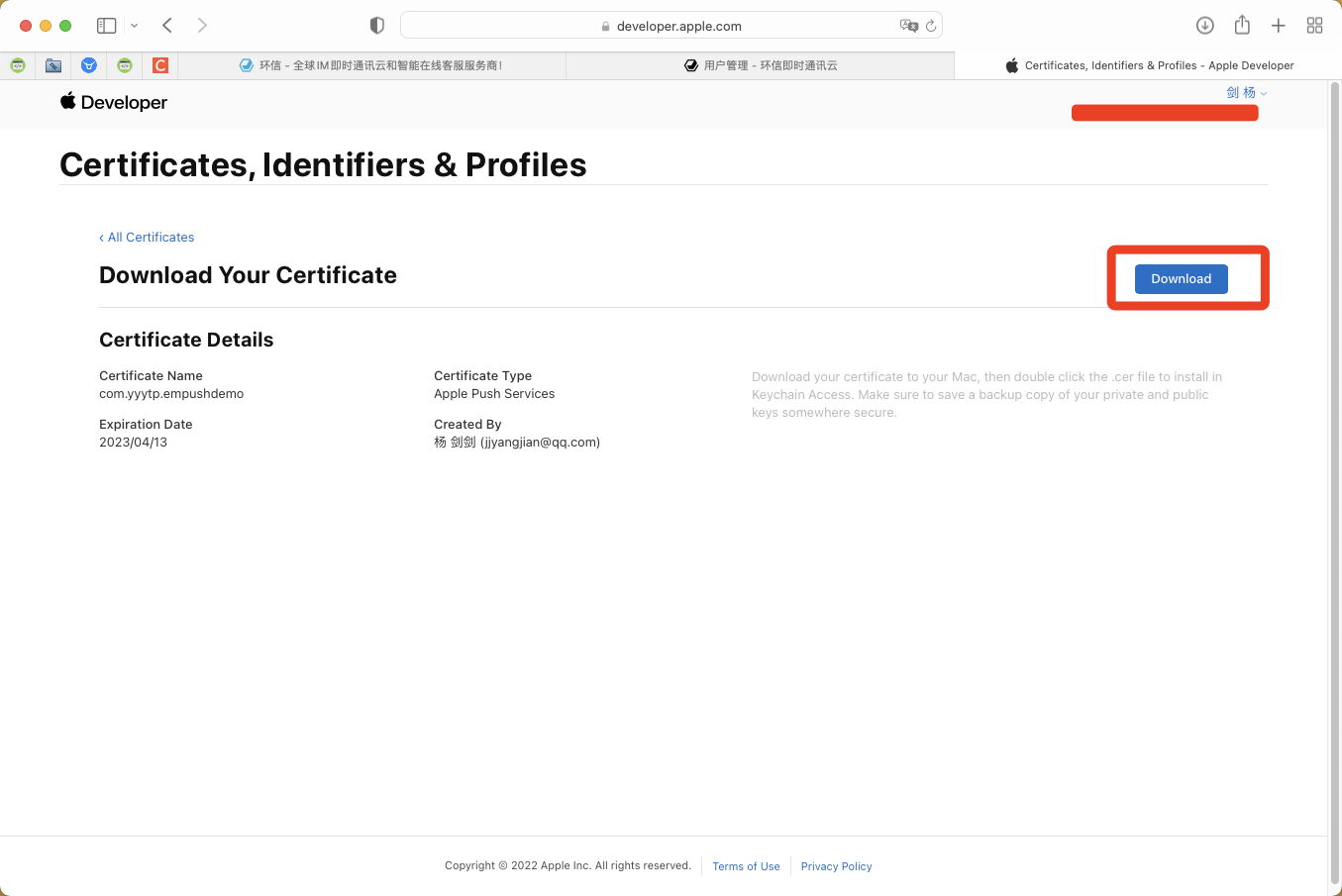
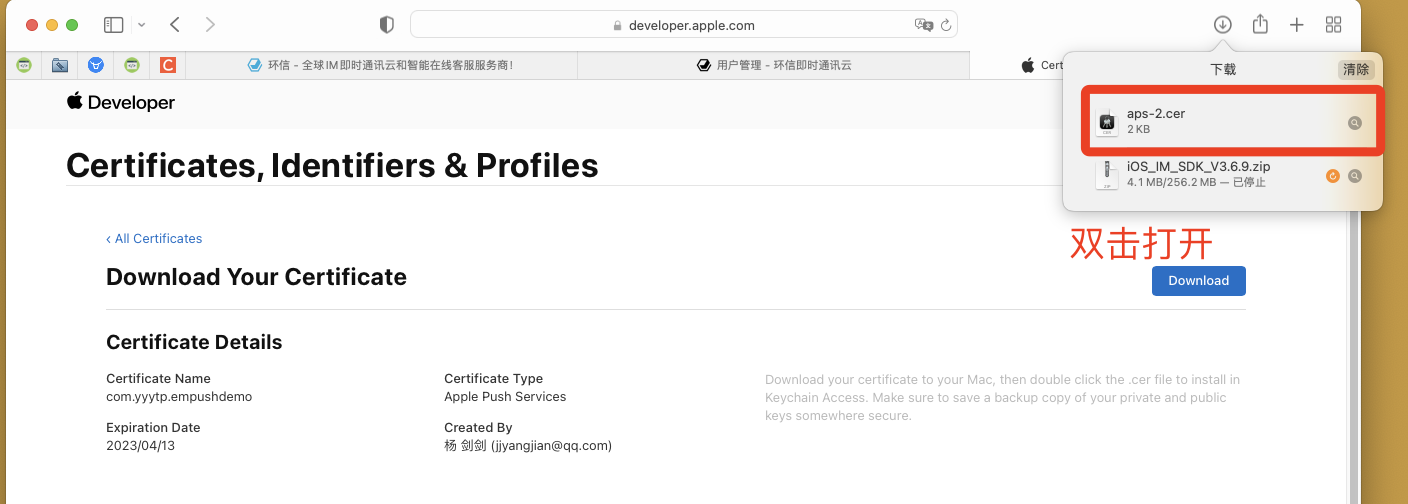
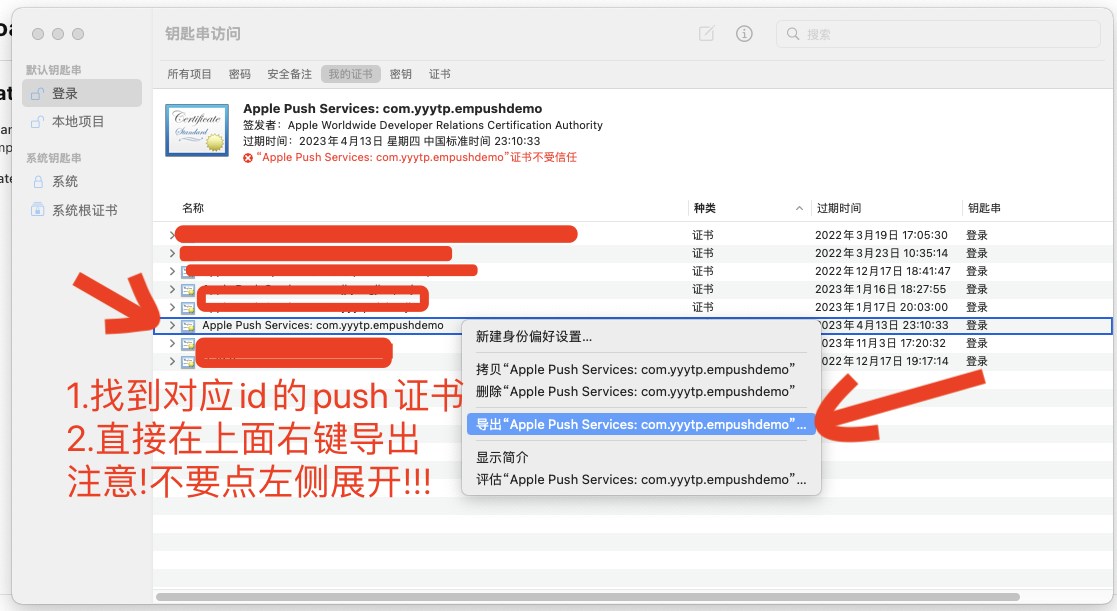
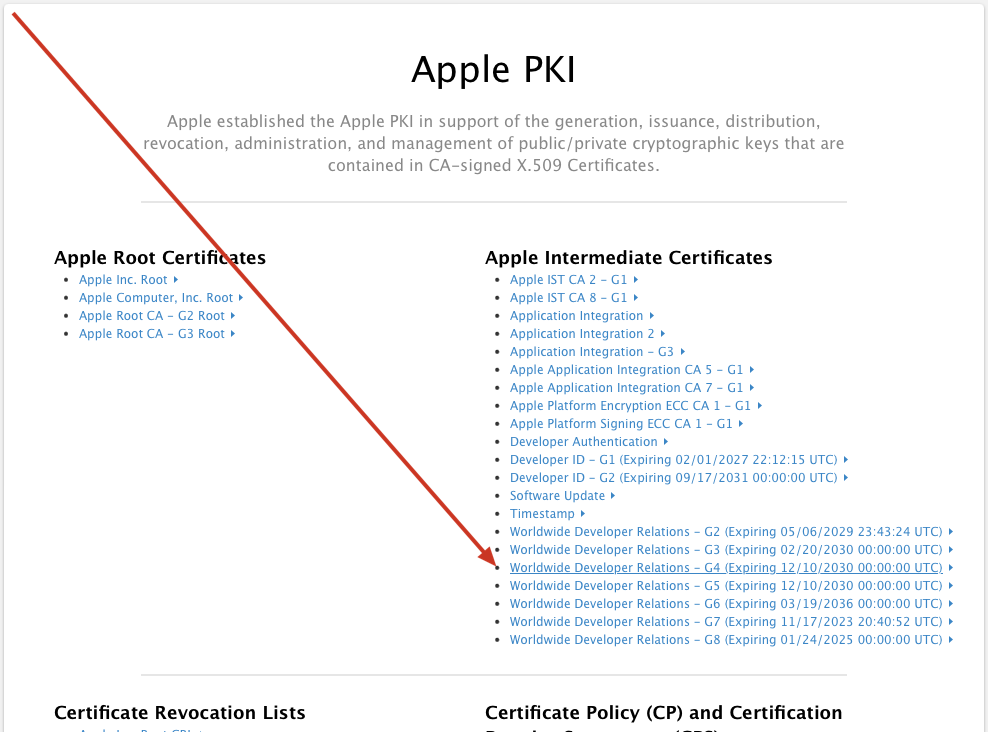
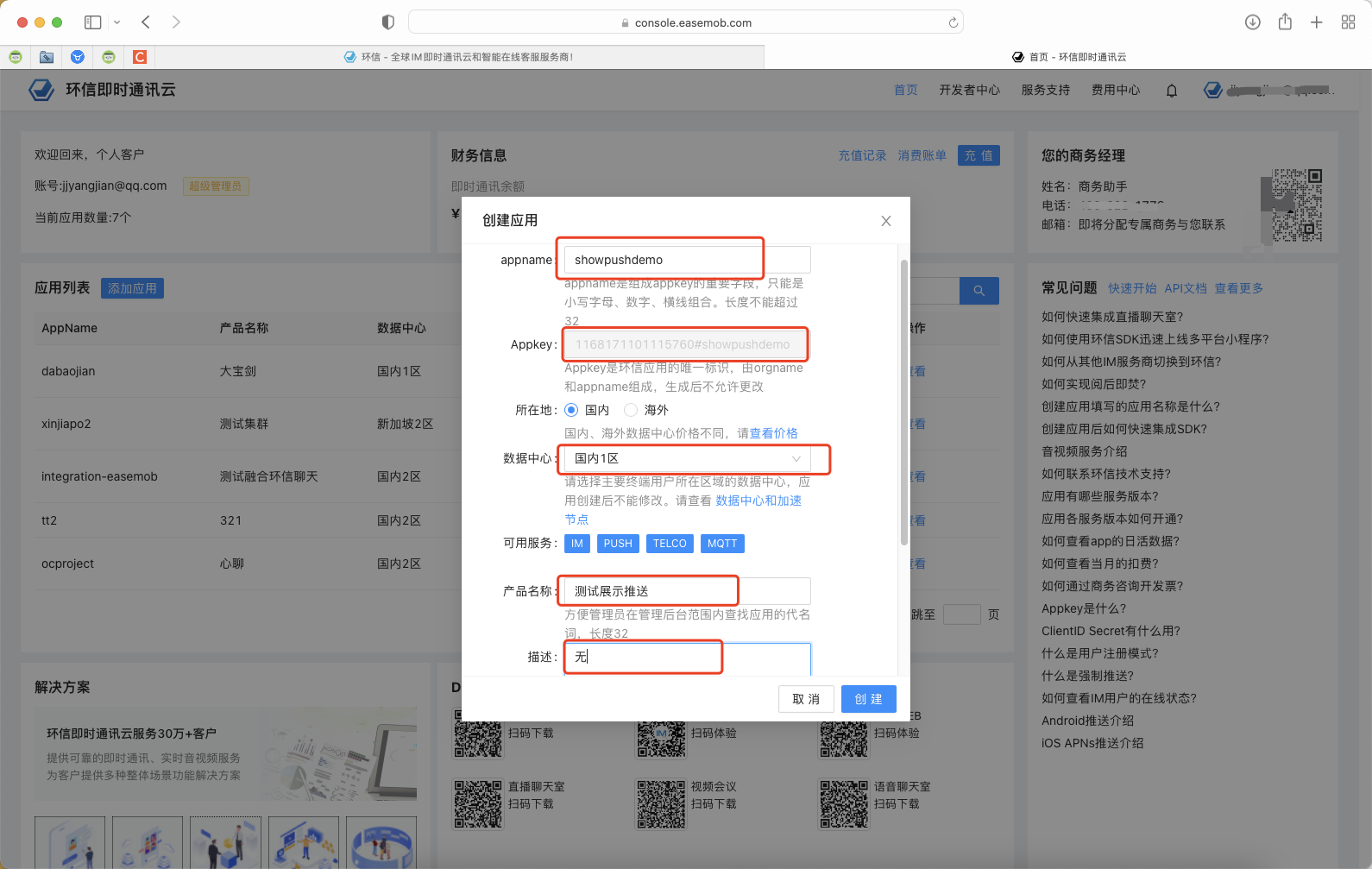
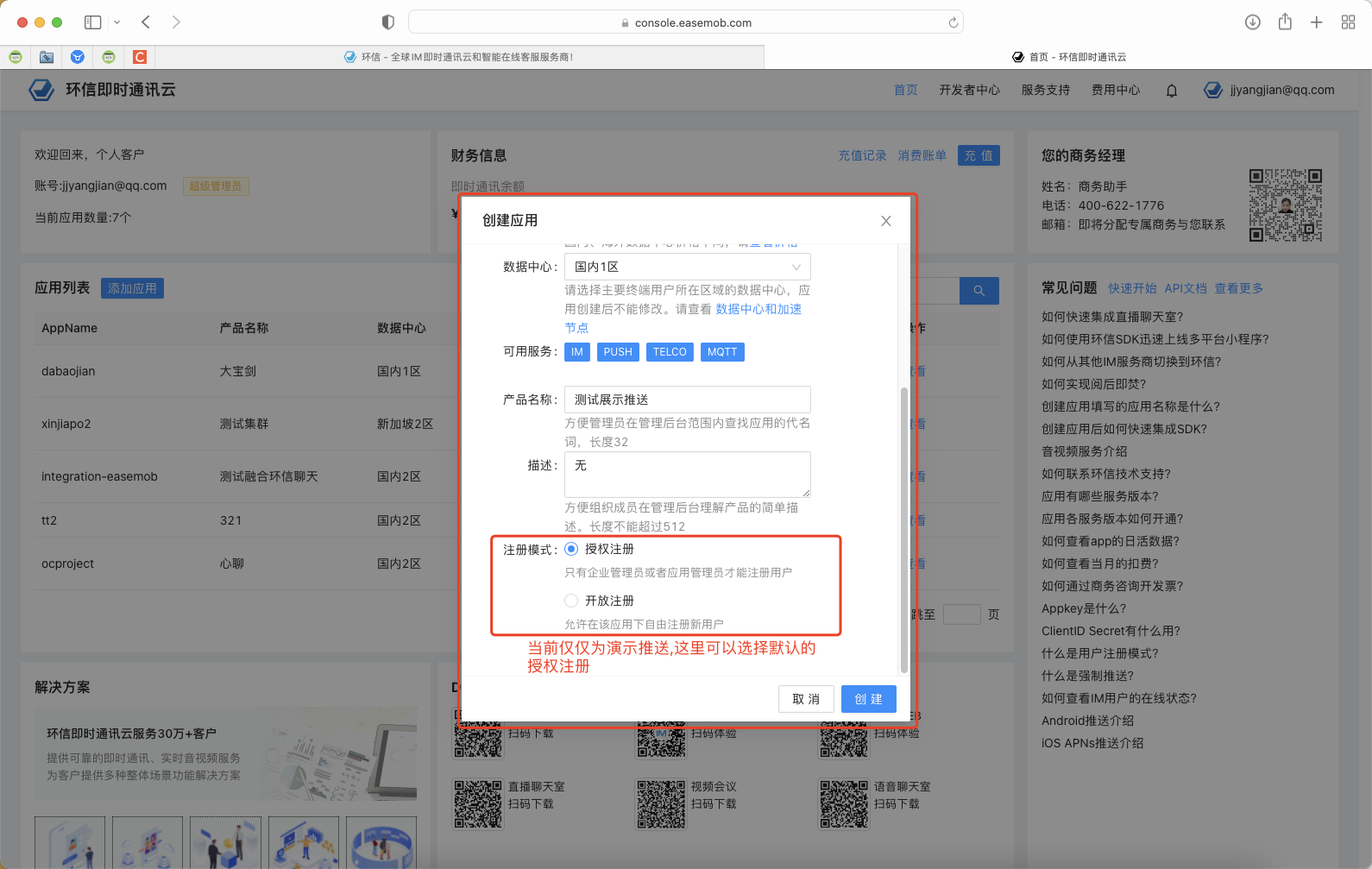
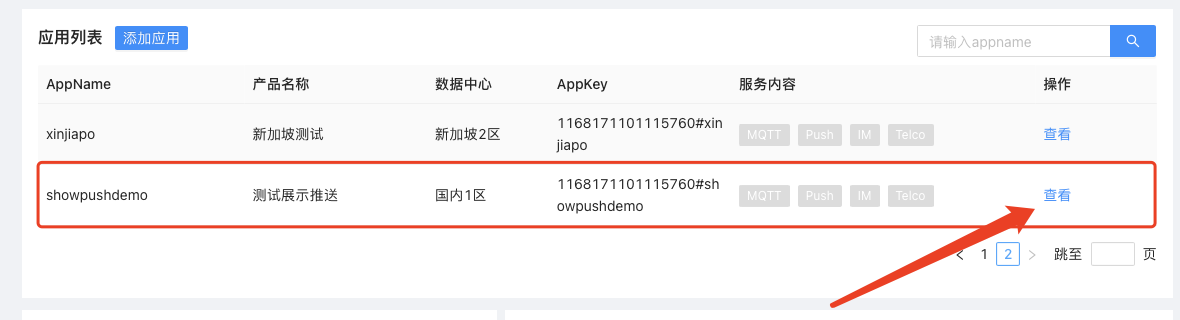
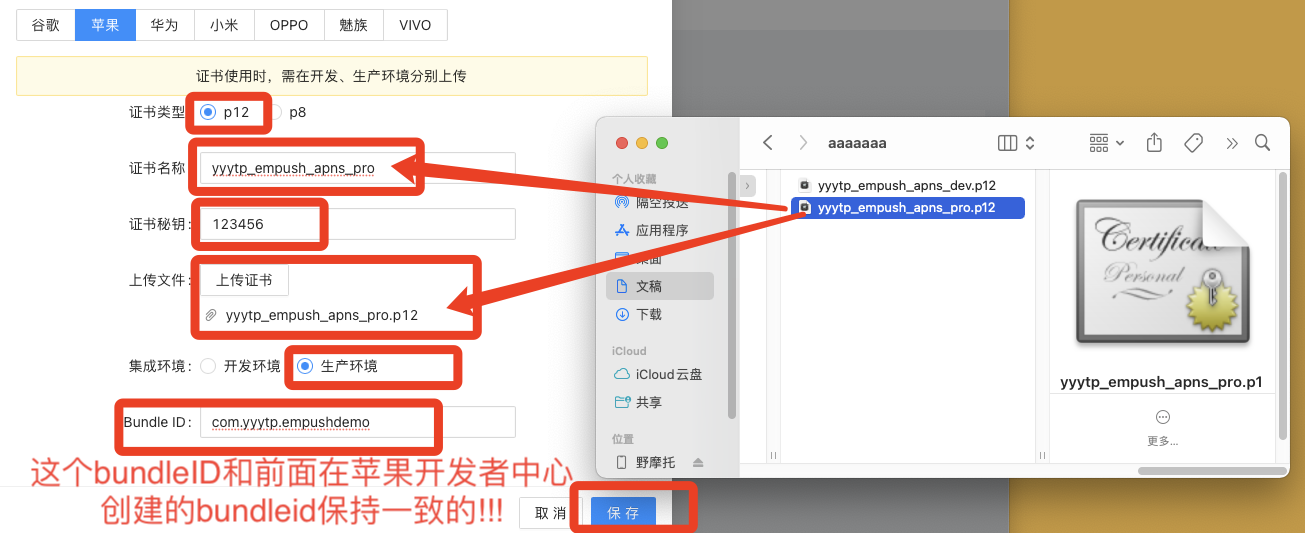
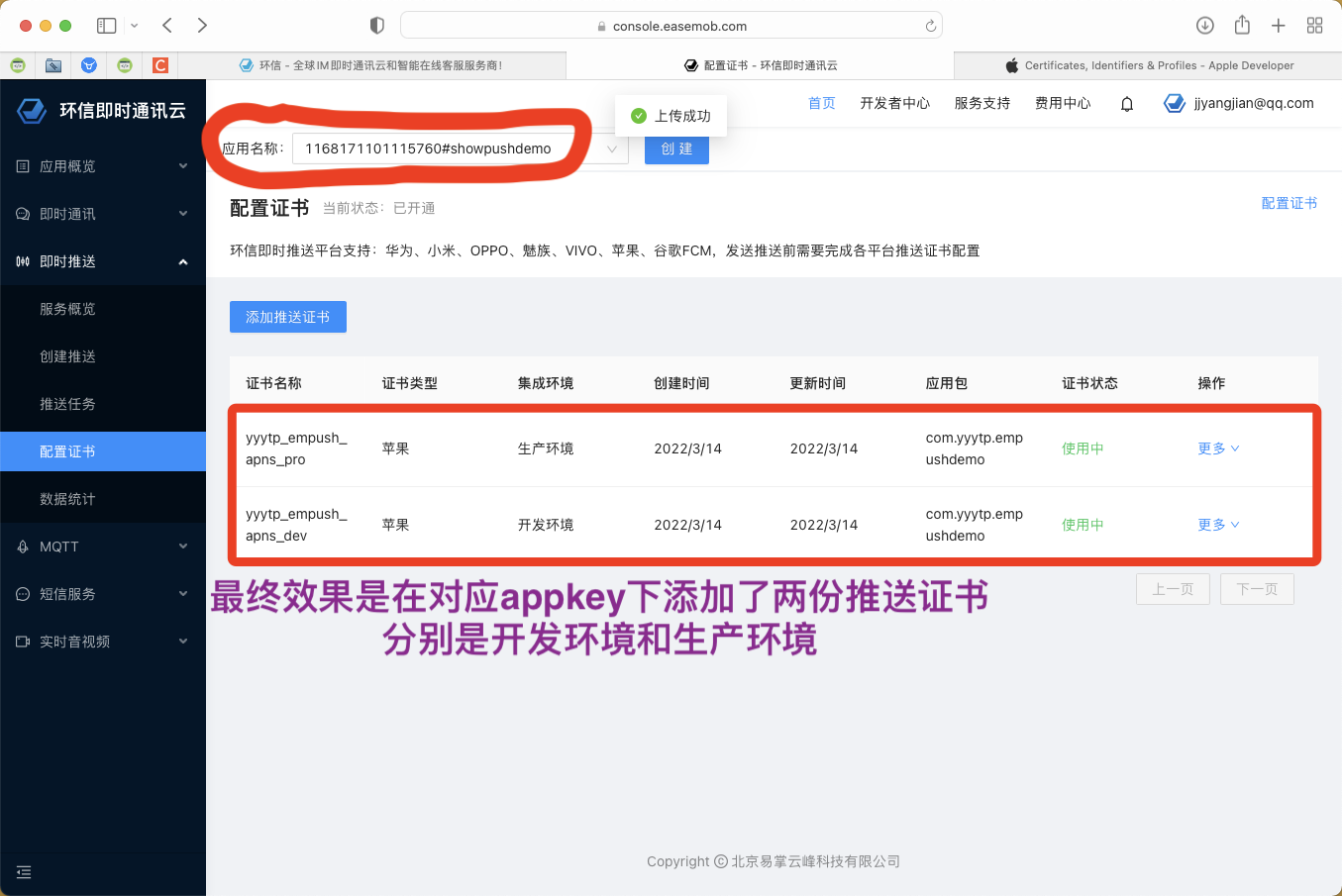
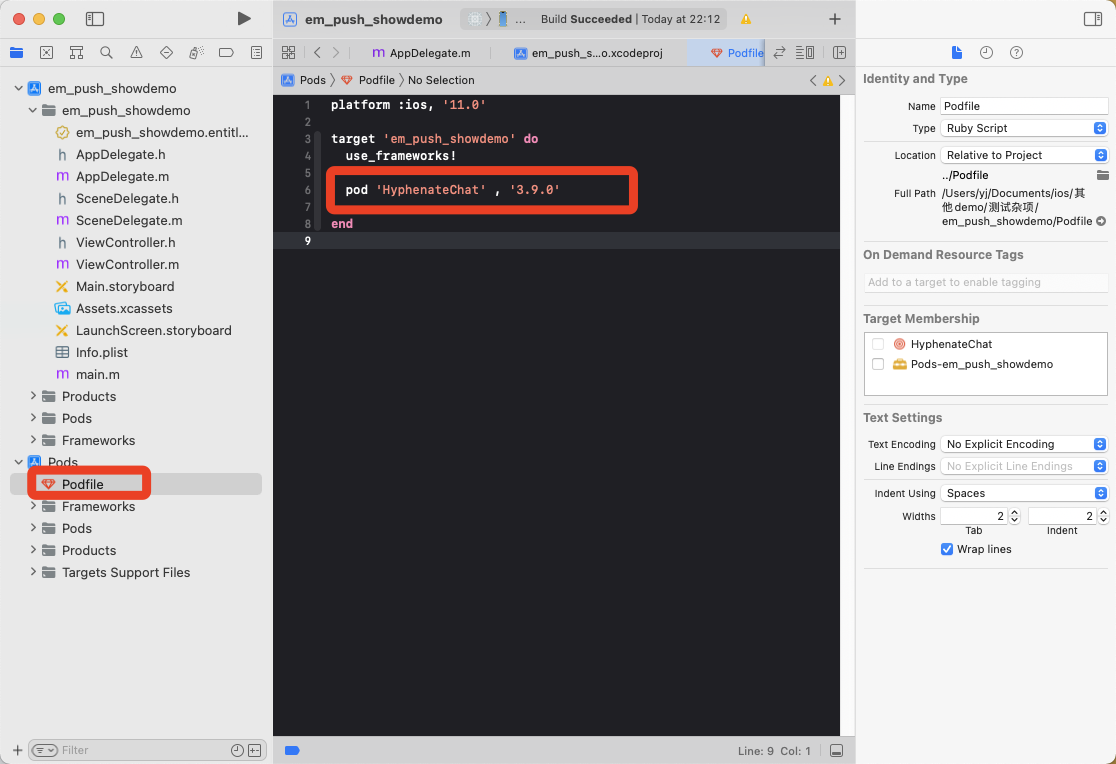
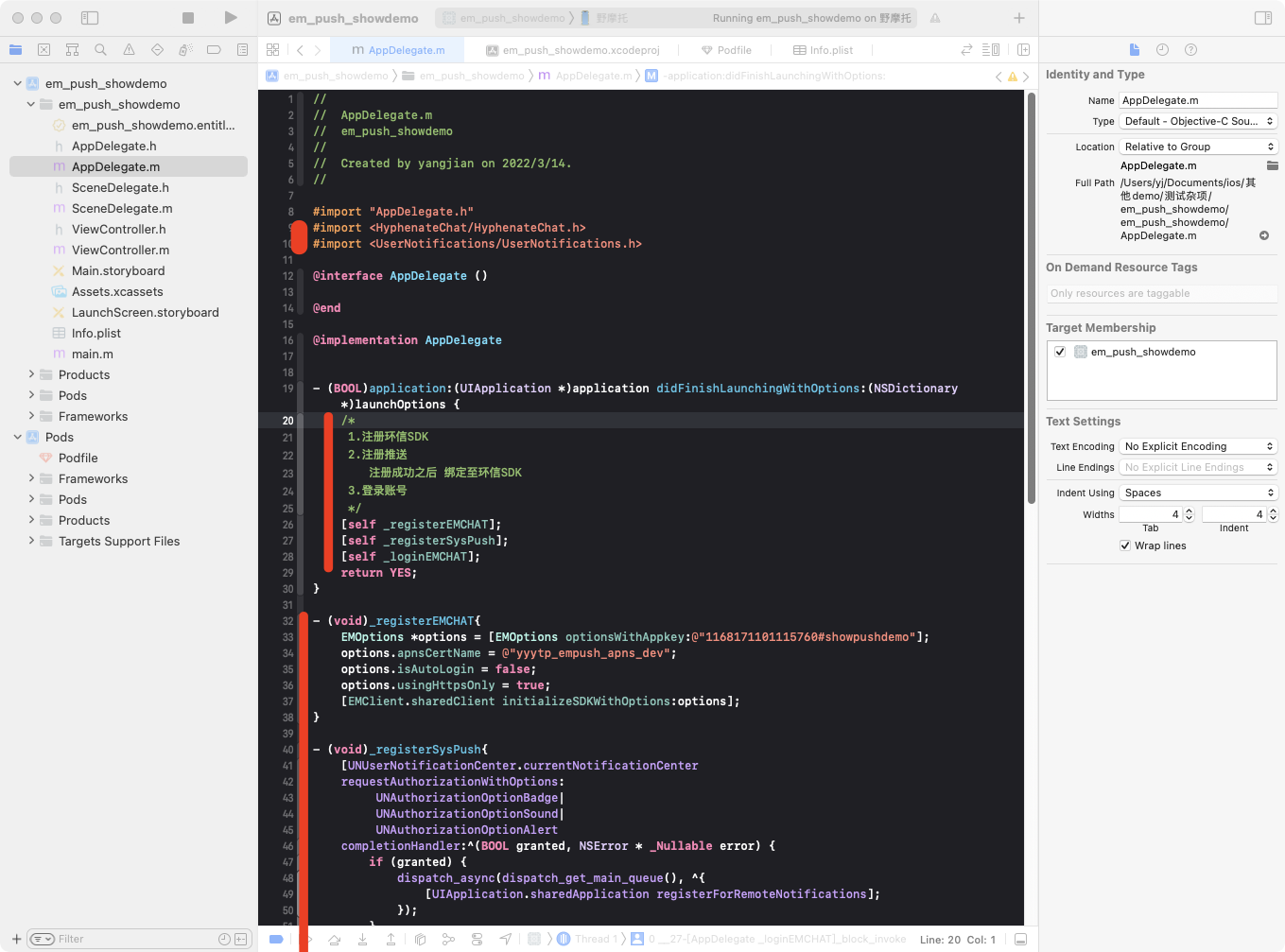
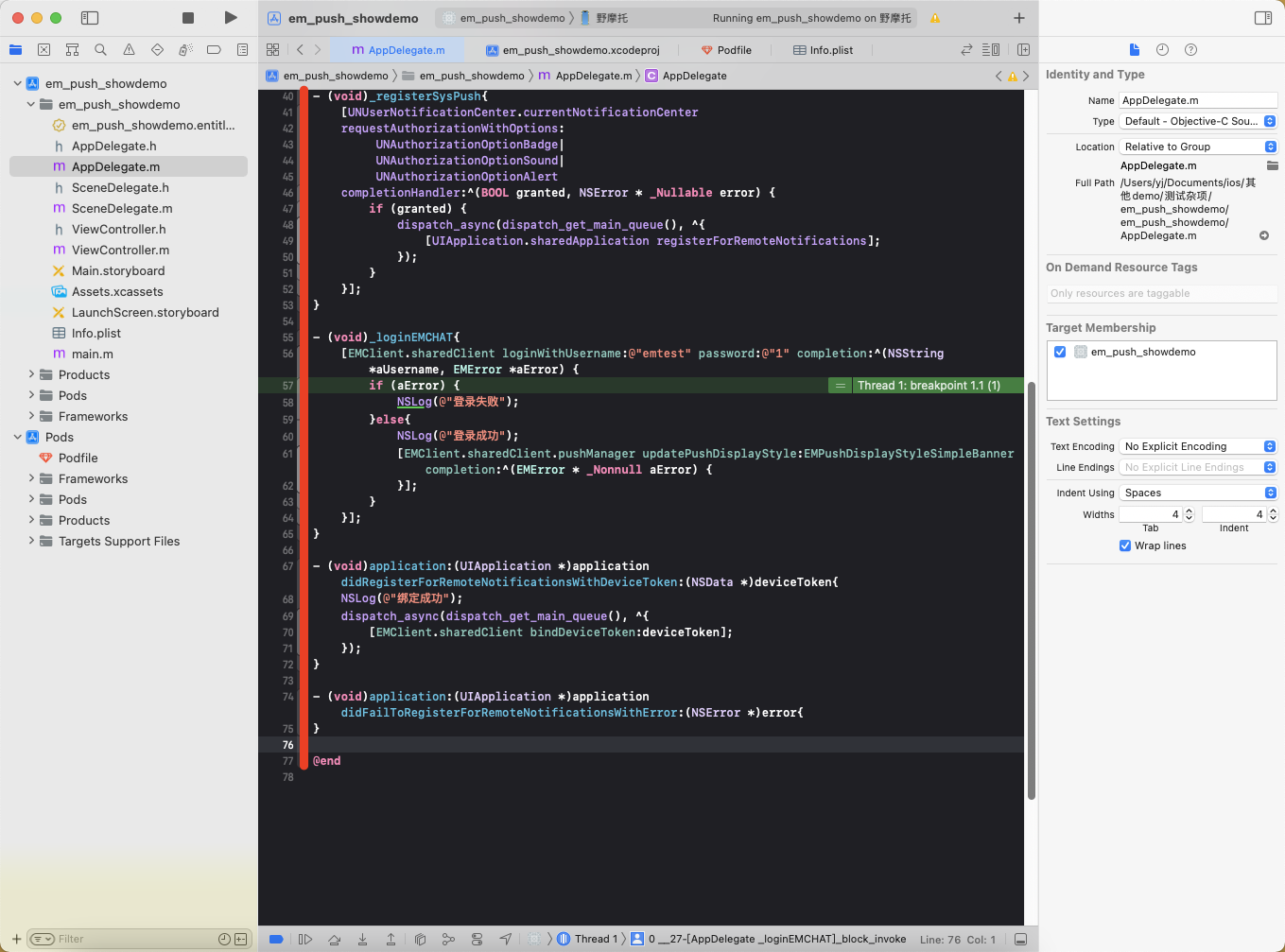
一. 项目开始
1. 新建flutter项目时首先明确native端用的语言 java还是kotlin , objectC 还是swift ,否则选错了后期换挺麻烦的
2. 选择自己的路由管理和状态管理包,决定项目架构
以我而言 第一个项目用的 fluro 和 provider 一个路由管理一个状态管理,项目目录新建store和route文件夹,分别存放provider的model文件和fluro的配置文件,到了第二个项目,发现了Getx,一个集合了依赖注入,路由管理,状态管理的包,用起来! 项目目录结构有了很大的变化,整体条理整洁
第一个 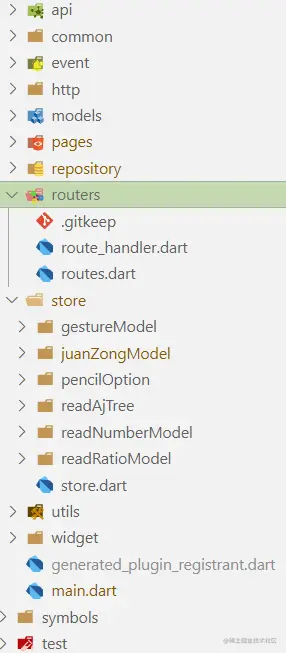
第二个 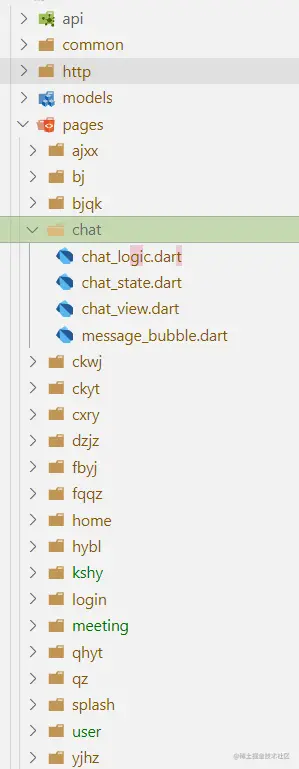
3. 常用包配置,比如 Getx 需要把外层MaterialApp换成GetMaterialApp, flutter_screenutil 需要初始化设计图比例,provider全局导入,Dio 封装,拦截器,网络提示等等
二. 全局配置
1. 复用样式
1. 由于flutter 某些小widget复用性很高,而App 需要统一样式 ,样式颜色之类的预设文件放在command文件夹内
colours.dart ,可以预设静态class,存储常用主题色

styles.dart,可以预设 字体样式 分割线样式 各种固定值间隔

2. 建议全局管理后端接口,整洁还便于维护,舒服
3. models 文件夹
models 文件夹,可能在web端并不常用,但是在dart里我觉得很需要,后端返回的Json 字符串,一定要通过model类 格式化为一个类,可以极大地减少拼写错误或者类型错误, . 语法也比 [''] 用起来舒服的多推荐一个网站 quickType 输入json对象,一键输出model类!
4. 是否强制横竖屏?
需要在main.dart里配置好
SystemChrome.setPreferredOrientations(
[DeviceOrientation.landscapeLeft, DeviceOrientation.landscapeRight]);
5. 是否需要修改顶部 底部状态栏布局以及样式?
用 SystemUiOverlayStyle 和 SystemChrome.setSystemUIOverlayStyle(systemUiOverlayStyle); 来配置
6. 设置字体不跟随系统
参考地址
class MyApp extends StatefulWidget {
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State with WidgetsBindingObserver {
@override
Widget build(BuildContext context) {
return MaterialApp(
debugShowCheckedModeBanner: false,
home: Container(color: Colors.white),
builder: (context, widget) {
return MediaQuery(
data: MediaQuery.of(context).copyWith(textScaleFactor: 1.0),
child: widget,
);
},
);
}
}
7. 国际化配置
使用部分widget会显示英文,比如IOS风格的dialog,显示中文这需要设置一下了,
首先需要一个包支持,
flutter_localizations:
sdk: flutter
引入包,然后在main.dart MetrialApp 的配置项中加入
localizationsDelegates: [
GlobalMaterialLocalizations.delegate,
GlobalWidgetsLocalizations.delegate,
const FallbackCupertinoLocalisationsDelegate()
],
supportedLocales: [
const Locale('zh', 'CH'),
const Locale('en', 'US'),
],
8. 使用CupertinoAlertDialog报错:The getter 'alertDialogLabel' was called on null
解决方法:
在main.dart中 加入如下类,然后在MetrialApp 的 localizationsDelegates 中实例化 见第 7 条
class FallbackCupertinoLocalisationsDelegate
extends LocalizationsDelegate {
const FallbackCupertinoLocalisationsDelegate();
@override
bool isSupported(Locale locale) => true;
@override
Future load(Locale locale) =>
DefaultCupertinoLocalizations.load(locale);
@override
bool shouldReload(FallbackCupertinoLocalisationsDelegate old) => false;
}
9. ImageCache
最近版本的flutter更新,限制了catchedImage的上限, 100张 1000mb ,而业务需求却需要缓存更多,设置一下了这需要
class ChangeCatchImage extends WidgetsFlutterBinding {
@override
createImageCache() *{*
Global.myImageCatche = ImageCache()
..maximumSize = 1000
..maximumSizeBytes = 1000 << 20;
return Global.myImageCatche;
}
}
然后在main.dart runApp那里实例化一下ChangeCatchImage() 就可以了
三. 业务模块
常见的业务模块代码分析,比如登录页,闪屏页,首页,退出登录等
1. 首先安利一下Getx
一个文件夹就是一个业务模块,独自管理数据,通过依赖注入数据共享,
非常舒服
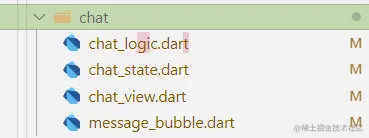
包括 logic 逻辑控制层 state 数据管理层 view 视图组件层 ,当前业务的复用widget写在文件夹下
2. 登录模块
作为app的入口门户,炫酷美观是少不了的,这就需要关注性能优化,而输入的地方,验证的逻辑要有安全设计
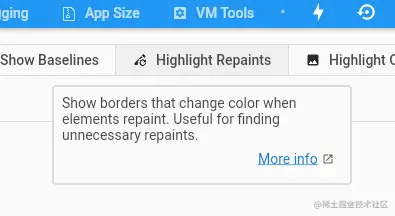
- 首先关于动画性能优化,最关键的一点是精准的更新需要变化的组件,我们可以通过devtool的工具查看更新范围
- 其次时安全设计,简单的来看,限制登录次数,禁止简易密码,加密传输,验证token等,进阶版的比如,防止参数注入,过滤敏感字符等
- 登录之前的账户验证,密码验证,必填项等,然后登录请求,需要加loading,按钮禁用,就不需要防抖了
- 登录之后保存到本地用户基本信息(可能存在安全问题,暂未深究),然后下次登陆默认检测是否存在基本信息,并验证过期时间,和token,之后隐式登录到首页
3. splash闪屏模块
app登陆首页的准备页面,可以嵌入广告,或者定制软件宣传动画,提示三秒后跳过
如何优雅的加入app闪屏页?
其实就是在main.dart里把初始化页面设置为splash页面,之后通过跳转逻辑
判断去首页还是登录注册页面
比如这里我用了Getx 就简单配置一下
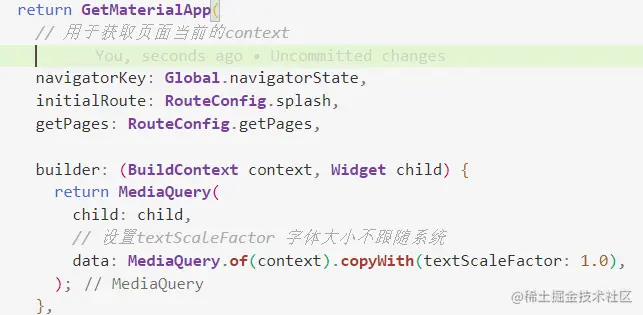
4. 操作引导模块
第一次使用app,或者重大更新之后往往会有操作引导
我的项目里用到了两种类型的操作引导
成果图
第一种

第二种

二者都是基于overlayEntry()和Overlay.of(context).insert(overlayEntry)实现的
第二种用了一个包 操作引导 flutter_intro: ^2.2.1,绑定Widget的GlobalKey,来获取Element信息,拿到位置大小,确保框选的位置正确,外层遮罩与第一种一样都是用overlayEntry()创建的

创建之后,展示出来
Overlay.of(context).insert(your_overlayEntry)
在某个按钮处切换下一个 比如点击我知道了,下一页之类的
onPressed: () {
overlayEntryTap.remove();
Overlay.of(context).insert(overlayEntryScale);
},
关于第二个实现涉及的flutter_intro包,粘一下我的代码,详细的可以参照pub食用
final intro = Intro(
// 一共有几步,这里就会创建2个GlobalKey,一会用到
stepCount: 2,
// 点击遮罩下一个
maskClosable: true,
// 高亮区域与 widget 的内边距
padding: EdgeInsets.all(0),
// 高亮区域的圆角半径
borderRadius: BorderRadius.all(Radius.circular(4)),
// use defaultTheme
widgetBuilder: StepWidgetBuilder.useDefaultTheme(
texts: ["点击添加收藏", "下拉添加书签"],
buttonTextBuilder: (currPage, totalPage) {
return currPage < totalPage - 1
? '我知道了 ${currPage + 3}/${totalPage + 2}'
: '完成 ${currPage + 3}/${totalPage + 2}';
},
),
);
......
// 这里用到key来绑定任意Widget
Positioned(
key: intro.keys[1],
top: 0,
right: 20,
...
)
......
5. CustomPaint 绘图画板模块
成果图
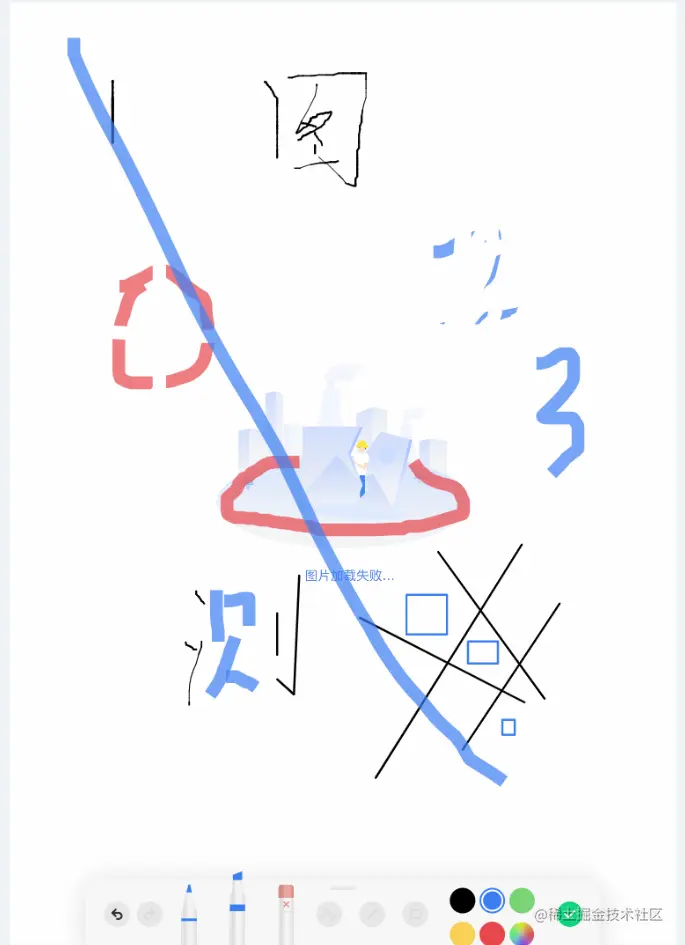
当初选择flutter就是因为,有大量的绘制需求,看中了自带skia,绘制效率高且流畅而且具备平台一致性
结果坑也不少
首先来讲一下 猪脚 CustomPaint
顾名思义,这是一个个性化绘制组件,他的工作就是给你创建一个画布,你想怎么画怎么画,我们直接看怎么用
首先格式化写法

class myPainter extends CustomPainter {
@override
void paint(Canvas canvas, Size size) {
final Paint paint = Paint();
canvas.drawCircle(Offset(50, 50), 5, paint);
}
@override
bool shouldRepaint(CustomPainter oldDelegate) => false;
第一个paint()函数,自带了画布对象 canvas,和画布尺寸 size,这样我们就可以使用Canvas的内置绘制函数了!
而绘制函数,都需要接收一个Paint 画笔对象

这个画笔对象,就是用来设置画笔颜色,粗细,样式,接头样式等等
Paint paint = Paint();
//设置画笔
paint ..style = PaintingStyle.stroke
..color = Colors.red
..strokeWidth = 10;
第二个函数shouldRepaint() 顾名思义判断是否需要重绘,如果返回false就是不需要重绘,只执行一次paine(),返回true就是总是重绘,依据实际需求设置
如果需要绘制类似于 根据数值不断变高的柱状图动画
代码如下(搬走就能用哦)
class BarChartPainter extends CustomPainter {
final List datas;
final List datasrc;
final List xAxis;
final double max;
final Animation animation;
BarChartPainter(
{@required this.xAxis,
@required this.datas,
this.max,
this.datasrc,
this.animation})
: super(repaint: animation);
@override
void paint(Canvas canvas, Size size) {
_darwBars(canvas, size);
_drawAxis(canvas, size);
}
@override
bool shouldRepaint(BarChartPainter oldDelegate) => true;
void _drawAxis(Canvas canvas, Size size) {
final double sw = size.width;
final double sh = size.height;
final Paint paint = Paint()
..color = Colors.grey
..style = PaintingStyle.stroke
..strokeWidth = 1
..strokeCap = StrokeCap.round;
final Path path = Path()
..moveTo(40, sh)
..lineTo(sw - 20, sh);
canvas.drawPath(path, paint);
}
void _darwBars(Canvas canvas, Size size) {
final sh = size.height;
final paint = Paint()..style = PaintingStyle.fill;
final double _barWidth = size.width / 20;
final double _barGap = size.width / 25 * 2 + 18;
final double textFontSize = 14.0;
for (int i = 0; i < datas.length; i++) {
final double data = datas[i] * ((size.height - 15) / max);
final top = sh - data;
final double left = i * _barWidth + (i * _barGap) + _barGap;
final rect = RRect.fromLTRBAndCorners(
left, top, left + _barWidth, top + data,
topLeft: Radius.circular(5), topRight: Radius.circular(3));
final offset = Offset(
left + _barWidth / 2 - textFontSize / 2 - 8,
top - textFontSize - 5,
);
paint.color = Color(0xFF59C8FD);
canvas.drawRRect(rect, paint);
TextPainter(
text: TextSpan(
text: datas[i] == 0.0 ? '' : datas[i].toStringAsFixed(0) + " %",
style: TextStyle(
fontSize: textFontSize,
color: paint.color,
),
),
textAlign: TextAlign.center,
textDirection: TextDirection.ltr,
)
..layout(
minWidth: 0,
maxWidth: textFontSize * data.toString().length,
)
..paint(canvas, offset);
final xData = xAxis[i];
final xOffset = Offset(left, sh + 6);
TextPainter(
textAlign: TextAlign.center,
text: TextSpan(
text: '$xData' != ''
? '$xData'.substring(0, 4) + '-' + '$xData'.substring(4, 6)
: '',
style: TextStyle(
fontSize: 12,
color: Colors.black,
),
),
textDirection: TextDirection.ltr,
)
..layout(
minWidth: 0,
maxWidth: size.width,
)
..paint(canvas, xOffset);
}
}
}
好了,customPainter,大体就这么用,下面回归话题,绘制画板
其实整体任务相当复杂,这里刨析一处,其他的融会贯通
拿最经典的铅笔画图来说
其实单纯的实现铅笔画图,甚至带笔锋,类似于签名,都很简单,网上教程一堆
大体思路就是 加一个GestureDetector ,主要用 onPanUpdate事件实时触发绘制动作,用canvas绘制出来
绘制简单,但是性能优化复杂
这里直接给出我测试的最优解
先把新的坐标点与之前的点连成线,可以一次多连接几个,也就是类似于节流的处理手法,
比如等panUpate触发了五次回调,先都把这五个点连接成线,第六次再统一绘制一条线(要是还有啥好办法,希望不吝赐教!)
详细的以后单独整理出来一个项目
6. websocket 即时通讯模块
成果图
只做了最基本的文字 图片 文件功能
简单把各项功能实现说一下,以后会详细整理,并加入音视频
关于websocket
首先肯定是连接websocket,用到一个包 web_socket_channel
然后初始化websocket
initWebsocket(){
Global.channel = IOWebSocketChannel.connect(
WebsocketUrl,
pingInterval: Duration(milliseconds: 10000),
);
Global.channel.stream.listen(
(mes) => onMessage(mes),
onError: (error) => {onError(error)},
onDone: () => {onDone()},
cancelOnError: true
);
}
处理消息
进入页面加载聊天消息,长列表还是得用ListView.build(),消息多的时候体验好很多
每次监听到新消息,加入到数组中,并更新视图,这一步不同的状态管理方法不同.
加入消息这里就有难点了
首先分四种情况 a. 自己发的并且在ListView底部,b. 自己发的但是不在ListView底部, c. 别人发的消息并且在底部,d. 别人发的不在底部.
a 和 b,c: 只要是自己发得就滚动到底部,在底部时就滚动的慢点,有种消息上拉的感觉
scrollController.jumpTo(scrollController.position.maxScrollExtent);
Scrollable.ensureVisible(
state.messageList[index].key.currentContext,
duration: Duration(milliseconds: 100),
curve: Curves.easeInOut,
alignmentPolicy: ScrollPositionAlignmentPolicy.keepVisibleAtEnd);
d : 这种情况,做了个类似于微信的提示
但是点击定位到消息有坑了,因为用的listView.build,当你在翻阅上边的消息,下面的消息并没有加载,因此获取不到currentContext,因为元素并没有渲染,也就定位错乱了,目前最理想的解决办法就是,往上翻的时候,之下的记录全部渲染,往下滑时再依次清.
文件和图片
用到了几个包 file_picker, open_file, path_provider
file_picker ,用来选择文件和图片,可以配置单选多选,需要在安卓的配置文件里加权限
open_file , 类似于微信点击文件,先下载,然后调用本地默认程序打开文件
path_provider,提供系统可用路径,用于创建文件目录
具体使用如下
final dirPath = await getExternalStorageDirectory();
Directory file = Directory(dirPath.path + "/" + "temFile");
try {
bool exists = await file.exists();
if (!exists) {
await file.create();
}
} catch (e) {
print(e);
}
Permission.storage.request().then((value) async {
if (value.isGranted) {
File _tempFile = File(file.path + '/' + wjmc);
if (!await _tempFile.exists()) {
try {
cState.path = file.path + '/' + wjmc;
cState.downloading.value = nbbh;
var response = await dio.get(fileUrl);
Stream resp = response.data.stream;
final Uint8List bytes =
await consolidateHttpClientResponseBytes(resp);
final List _filelist = List.from(bytes);
final filePath = File(cState.path);
await filePath.writeAsBytes(_filelist,
mode: FileMode.append, flush: true);
} catch (e) {
print(e);
}
}
cState.downloading.value = '';
open(cState.path);
}
});
Future consolidateHttpClientResponseBytes(Stream response) {
final Completer completer = Completer.sync();
final List> chunks = >[];
int contentLength = 0;
response.listen((chunk) {
chunks.add(chunk);
contentLength += chunk.length;
}, onDone: () {
final Uint8List bytes = Uint8List(contentLength);
int offset = 0;
for (List chunk in chunks) {
bytes.setRange(offset, offset + chunk.length, chunk);
offset += chunk.length;
}
completer.complete(bytes);
}, onError: completer.completeError, cancelOnError: true);
return completer.future;
}
void open(path) {
showCupertinoDialog(
context: Get.context,
builder: (context) {
return Material(
color: Colors.transparent,
child: CupertinoAlertDialog(
title: Padding(
padding: EdgeInsets.only(bottom: 10),
child: Text("提示"),
),
content: Padding(
padding: EdgeInsets.only(left: 5),
child: Text("是否打开文件?"),
),
actions: [
CupertinoButton(
child: Text(
"取消",
style: TextStyle(color: Colours.gray_88),
),
onPressed: () {
Get.back();
},
),
CupertinoButton(
child: Text("确定"),
onPressed: () async {
Get.back();
await OpenFile.open(
cState.path,
);
}),
]),
);
},
);
}
音视频用的小鱼易连,但是木有Flutter SDK ,只能基于安卓的去封装,以后有机会再讲讲.

































 可能这个系统确实太赶了,所以没做好?不过这个谁知道呢?作为一名技术博主就不瞎猜了。
可能这个系统确实太赶了,所以没做好?不过这个谁知道呢?作为一名技术博主就不瞎猜了。