








v-for中diff算法
当没有key时
获取新旧数组长度,取最短的数组(Math.min())进行比较,如果用长的数组进行比较,会发生越界错误
以短数组进行for循环,从新旧数组各组一个值进行patch,如果内容一样就不进行更新,如果内容不一样,Vue源码会进行更深层次的比较,如果类型都不一样的话,直接创建一个新类型,如果类型一样,值不同,就只更新值,效率会更高,当for循环完毕,新旧数组长度会进行比较,如果旧的长度大有新的长度,就会执行unmountChildren,删除多余的节点,如果新的长度大于旧的长度,就会执行mountChildren,创建新的节点
当有key时
第一步,从头部开始遍历
通过isSameVNodeType进行比较
如果type 和 key 都一样,继续遍历,如果不同,跳出循环,进入第二步
第二步,从尾部开始遍历
和第一步操作一致
如果不同,跳出循环进入第三步
第三步,果旧节点遍历完,依然有新的节点,就是添加节点操作,用一个null和新节点进行patch,n1为空值时,是添加
如果新节点遍历完了,旧节点还有就进入第四步
第四步,新节点遍历完毕,旧节点还有,就进行删除操作
第五步,如果是一个无序的节点,vue会从旧的节点里找到新的节点里相同的值并创建一个新的数组,根据key建立一个索引,找到了就放入新数组里,比较完之后,有多余的旧节点就删除,有没有比较过的新节点就添加
作者:啊哈呀呀呀呀
来源:juejin.cn/post/7100858461520560135
IP属地获取,前端获取用户位置信息
尝试获取用户的位置信息
写在前面
想要像一些平台那样显示用户的位置信息,例如某省市那样。那么这是如何做到的, 据说这个位置信息的准确性在通信网络运营商那里?先不管,先实践尝试下能不能获取。
尝试一:navigator.geolocation
尝试了使用 navigator.geolocation,但未能成功拿到信息。
getGeolocation(){
if ('geolocation' in navigator) {
/* 地理位置服务可用 */
console.log('地理位置服务可用')
navigator.geolocation.getCurrentPosition(function (position) {
console.dir('回调成功')
console.dir(position) // 没有输出
console.dir(position.coords.latitude, position.coords.longitude)
}, function (error) {
console.error(error)
})
} else {
/* 地理位置服务不可用 */
console.error('地理位置服务可用')
}
}尝试二:sohu 的接口
尝试使用 pv.sohu.com/cityjson?ie… 获取用户位置信息, 成功获取到信息,信息样本如下:
{"cip": "14.11.11.11", "cid": "440000", "cname": "广东省"}
// 需要做跨域处理
getIpAndAddressSohu(){
// config 是配置对象,可按需设置,例如 responseType,headers 中设置 token 等
const config = {
headers: {
Accept: 'application/json',
'Content-Type': 'application/json;charset=UTF-8',
},
}
axios.get('/apiSohu/cityjson?ie=utf-8', config).then(res => {
console.log(res.data) // var returnCitySN = {"cip": "14.23.44.50", "cid": "440000", "cname": "广东省"};
const info = res.data.substring(19, res.data.length - 1)
console.log(info) // {"cip": "14.23.44.50", "cid": "440000", "cname": "广东省"}
this.ip = JSON.parse(info).cip
this.address = JSON.parse(info).cname
})
}调试的时候,做了跨域处理。
proxy: {
'/apiSohu': {
target: 'http://pv.sohu.com/', // localhost=>target
changeOrigin: true,
pathRewrite: {
'/apiSohu': '/'
}
},
}下面是一张获取到位置信息的效果图:
尝试三:百度地图的接口
需要先引入百度地图依赖,有一个参数 ak 需要注意,这需要像管理方申请。例如下方这样
<script src="https://api.map.baidu.com/api?v=2.0&ak=3ufnnh6aD5CST"></script>
getLocation() { /*获取当前位置(浏览器定位)*/
const $this = this;
var geolocation = new BMap.Geolocation();//返回用户当前的位置
geolocation.getCurrentPosition(function (r) {
if (this.getStatus() == BMAP_STATUS_SUCCESS) {
$this.city = r.address.city;
console.log(r.address) // {city: '广州市', city_code: 0, district: '', province: '广东省', street: '', …}
}
});
}
function getLocationBaiduIp(){/*获取用户当前位置(ip定位)*/
function myFun(result){
const cityName = result.name;
console.log(result) // {center: O, level: 12, name: '广州市', code: 257}
}
var myCity = new BMap.LocalCity();
myCity.get(myFun);
}
成功用户的省市位置,以及经纬度坐标,但会先弹窗征求用户意见。
写在后面
尝试结果不太理想,sohu 的接口内部是咋实现的,这似乎没有弹起像下面那样的征询用户意见的提示。
而在 navigator.geolocation 和 BMap.Geolocation() 中是弹起了的。
用别人的接口总归是没多大意思,也不知道不用征求用户意见是咋实现的。
经实测 sohu 的接口和 new BMap.Geolocation() 都可以拿到用户的位置信息(省市、经纬度等)。
作者:灵扁扁
来源:https://juejin.cn/post/7100916925504421918
收起阅读 »一种兼容、更小、易用的WEB字体API
如何使用 Google Fonts CSS API 有效地使用WEB字体?
多年来,WEB字体技术发生了很多变化,过去在WEB中使用特殊字体的常用做法是图片或者Flash,这种借助图片或者Flash的实现方式不够灵活。随着 WEB 字体的出现,特别是 Google Fonts CSS API 的普及,让在WEB中使用特殊字体变得简单、快速、灵活,当然更多的还是面向英文字体,对于做外贸或者英文网站的开发者来说是福音。
Google Fonts CSS API 在不断发展,以跟上WEB字体技术的变化。它从最初的价值主张——允许浏览器在所有使用API的网站上缓存常用字体,从而使网页加载更快,到现在已经有了很大的进步。现在不再是这样了,但API仍然提供了额外的优化方案,使网站加载迅速,字体工作性能更佳。
使用Google Fonts CSS API ,网站可以请求它需要的字体数据来保持它的CSS加载时间到最少,确保网站访问者可以尽可能快地加载内容。该API将以最佳的字体响应每个请求的web浏览器。
所有这一切都是通过在代码中包含一行 HTML 来实现的。
如何使用 Google Fonts CSS API
Google Fonts CSS API 文档很好地总结了它:
你不需要做任何编程;所要做的就是在 HTML 文档中添加一个特殊的样式表链接,然后在 CSS 样式中引用该字体。
需要做的最低限度是在 HTML 中包含一行,如下所示:
<link href="https://fonts.googleapis.com/css2?family=Roboto+Mono&display=swap" rel="stylesheet" />
复制代码
当从 API 请求字体时,可以指定想要的一个或多个系列,以及(可选)它们的权重、样式、子集和其他选项。然后 API 将通过以下两种方式之一处理请求:
如果请求使用 API 已有文件的通用参数,它会立即将 CSS 返回给用户,将定向到这些文件。
如果请求的字体带有 API 当前未缓存的参数,它将即时对字体进行子集化,使用 HarfBuzz 快速完成,并返回指向它们的 CSS。
字体文件可以很大,但不一定要很大
WEB 字体可以很大,在 WOFF2 中,仅一个 Noto Sans Japanese 的大小就几乎是 3.4MB ,将其下载给每一位用户将拖累页面加载时间。当每一毫秒都很重要并且每个字节都很宝贵时,需要确保只加载用户需要的数据。
Google Fonts CSS API 可以创建非常小的字体文件(称为子集),实时生成,只为用户提供网站所需的文本和样式。可以使用 text 参数请求特定字符,而不是提供整个字体。
<link href="https://fonts.googleapis.com/css2?family=Roboto+Mono&display=swap&text=RobtMn" rel="stylesheet" />
复制代码
CSS API 还自动为用户提供额外的WEB字体优化,无需设置任何 API 参数。该 API 将为用户提供已启用 unicode-range 的 CSS 文件(如果 Web 浏览器支持),因此只为网站需要的特定字符加载字体。
unicode-range CSS 描述符是一种现在可用于应对大字体下载的工具,这个 CSS 属性设置 @font-face 声明包含的 Unicode 字符范围。如果在页面上呈现这些字符之一,则下载该字体。这适用于所有类型的语言,因此可以采用包含拉丁文、希腊文或西里尔文字符的字体并制作更小的子集。在前面的图表中,可以看到如果必须加载所有这三个字符集,则将超过 600 个字形。
这也为 Web 启用了中文、日文和韩文 (CJK) 字体提供支持。在上图中,可以看到 CJK 字体覆盖的字符数是拉丁字符字体的 15-20 倍。 CJK 字体通常非常大,并且这些语言中的许多字符不像其他字体那样频繁使用。
使用 CSS API 和 unicode-range 可以减少大约 90% 的文件传输。使用 unicode-range 描述符,可以单独定义每个部分,并且只有在内容包含这些字符范围中的一个字符时才会下载每个切片。
例如只想在 Noto Sans JP 中设置单词 こんにちは ,则可以按照如下方式使用:
自托管自己的 WOFF2 文件
使用 CSS API 检索 WOFF2
使用 CSS API 并将
text=参数设置为こんにちは
在此示例中,可以看到通过使用 CSS API,已经比自托管 WOFF2 字体节省了 97.5%,这要归功于 API 内置支持将大字体分隔到 unicode-range 中功能。通过更进一步并准确指定要显示的文本,可以进一步将字体大小减小到仅 CSS API 字体的 95.3% ,相当于比自托管字体小 99.9%。
Google Fonts CSS API 将自动以用户浏览器支持的最小和最兼容格式提供字体。如果用户使用的是支持 WOFF2 的浏览器,API 将提供 WOFF2 中的字体,但如果他们使用的是旧版浏览器,API 将以该浏览器支持的格式提供字体。为了减少每个用户的文件大小,API 还会在不需要时从字体中删除数据。例如,将为浏览器不需要的用户删除提示数据。
使用 Google Fonts CSS API 让WEB字体面向未来
Google 字体团队还为新的 W3C 标准做出了贡献,这些标准继续创新网络字体技术,例如 WOFF2。当前的一个项目是增量字体传输,它允许用户在屏幕上使用字体文件时加载非常小的部分,并按需流式传输其余部分,超过了 unicode-range 的性能。当使用 WEB 字体API时,当用户在浏览器中可用时,就可以获得这些底层字体传输技术的优化改进。
这就是字体 API 的美妙之处:用户可以从每项新技术改进中受益,而无需对网站进行任何更改。新的WEB字体格式?没问题,新的浏览器或操作系统支持?它已经处理好了。因此,可以自由地专注于用户和内容,而不是陷入WEB字体维护的困境。
可变字体支持内置
可变字体是可以在多个轴之间存储一系列设计变化的字体文件,新版本的 Google Fonts CSS API 包括对它们的支持。添加一个额外的变化轴可以使字体具有新的灵活性,但它几乎可以使字体文件的大小增加一倍。
当 CSS API 请求更具体时,Google Fonts CSS API 可以仅提供网站所需的可变字体部分,以减少用户的下载大小。这使得可以为 WEB 使用可变字体,而不会导致页面加载时间过长。可以通过在轴上指定单个值或指定范围来执行此操作,甚至可以在一个请求中指定多个轴和多个字体系列, API 可以灵活地满足需求。
总结
Google Fonts CSS API 可帮助WEB提供以下字体:
更兼容
体积更小
加载快速
易于使用
有关 Google 字体的更多信息,请访问 fonts.google.com。
作者:天行无忌
来源:juejin.cn/post/7100927964224700424
跟我学flutter:细细品Widget(五)Element
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
跟我学flutter:细细品Widget(二)StatelessWidget&StatefulWidget
跟我学flutter:细细品Widget(三)ProxyWidget,InheritedWidget
跟我学flutter:细细品Widget(四)Widget 渲染过程 与 RenderObjectWidget
跟我学flutter:细细品Widget(五)Element
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
之前的文章都有简述Element,这篇将着重去讲Element
Widget是描述一个UI元素的配置数据,Element才真正代表屏幕显示元素
分类
如上图所示Element分为两类
ComponentElement : 组合类Element。这类Element主要用来组合其他更基础的Element,得到功能更加复杂的Element。开发时常用到的StatelessWidget和StatefulWidget相对应的Element:StatelessElement和StatefulElement,即属于ComponentElement。
RenderObjectElement : 渲染类Element,对应Renderer Widget,是框架最核心的Element。RenderObjectElement主要包括LeafRenderObjectElement(叶子无节点),SingleChildRenderObjectElement(单child),和MultiChildRenderObjectElement(多child)。
Element生命周期
Element有4种状态:initial,active,inactive,defunct。其对应的意义如下:
- initial:初始状态,Element刚创建时就是该状态。
- active:激活状态。此时Element的Parent已经通过mount将该Element插入Element Tree的指定的插槽处(Slot),Element此时随时可能显示在屏幕上。
- inactive:未激活状态。当Widget Tree发生变化,Element对应的Widget发生变化,同时由于新旧Widget的Key或者的RunTimeType不匹配等原因导致该Element也被移除,因此该Element的状态变为未激活状态,被从屏幕上移除。并将该Element从Element Tree中移除,如果该Element有对应的RenderObject,还会将对应的RenderObject从Render Tree移除。但是,此Element还是有被复用的机会,例如通过GlobalKey进行复用。
- defunct:失效状态。如果一个处于未激活状态的Element在当前帧动画结束时还是未被复用,此时会调用该Element的unmount函数,将Element的状态改为defunct,并对其中的资源进行清理。
Element4种状态间的转换关系如下图所示:
ComponentElement
State和StatefulElement是一一对应的,只有在初始化StatefulElement时,才会初始化对应的State并将其绑定到StatefulElement上
核心流程
一个Element的核心操作流程有,创建、更新、销毁三种,下面将分别介绍这三个流程。
创建
ComponentElement的创建起源与父Widget调用inflateWidget,然后通过mount将该Element挂载至Element Tree,并递归创建子节点。
更新
由父Element执行更新子节点的操作(updateChild),由于新旧Widget的类型和Key均未发生变化,因此触发了Element的更新操作,并通过performRebuild将更新操作传递下去。其核心函数updateChild之后会详细介绍。
销毁
由父Element或更上级的节点执行更新子节点的操作(updateChild),由于新旧Widget的类型或者Key发生变化,或者新Widget被移除,因此导致该Element被转为未激活状态,并被加入未激活列表,并在下一帧被失效。
核心函数
- inflateWidget
Element inflateWidget(Widget newWidget, dynamic newSlot) {
final Key key = newWidget.key;
//复用GlobalKey对应的Element
if (key is GlobalKey) {
final Element newChild = _retakeInactiveElement(key, newWidget);
if (newChild != null) {
newChild._activateWithParent(this, newSlot);
final Element updatedChild = updateChild(newChild, newWidget, newSlot);
return updatedChild;
}
}
//创建Element,并挂载至Element Tree
final Element newChild = newWidget.createElement();
newChild.mount(this, newSlot);
return newChild;
}
复制代码- 判断新Widget是否有GlobalKey,如果有GlobalKey,则从Inactive Elements列表中找到对应的Element并进行复用。(可能从树的另一个位置嫁接或重新激活)
- 无可复用Element,则根据新Widget创建对应的Element,并将其挂载至Element Tree。
- mount
void mount(Element parent, dynamic newSlot) {
//更新_parent等属性,将元素加入Element Tree
_parent = parent;
_slot = newSlot;
_depth = _parent != null ? _parent.depth + 1 : 1;
_active = true;
if (parent != null) // Only assign ownership if the parent is non-null
_owner = parent.owner;
//注册GlobalKey
final Key key = widget.key;
if (key is GlobalKey) {
key._register(this);
}
_updateInheritance();
}
复制代码- 将给Element加入Element Tree,更新_parent,_slot等树相关的属性。
- 如果新Widget有GlobalKey,将该Element注册进GlobalKey中,其作用下文会详细分析。
- ComponentElement的mount函数会调用_firstBuild函数,触发子Widget的创建和更新。
- performRebuild
@override
void performRebuild() {
//调用build函数,生成子Widget
Widget built;
built = build();
//根据新的子Widget更新子Element
_child = updateChild(_child, built, slot);
}
复制代码- 调用build函数,生成子Widget。
- 根据新的子Widget更新子Element。
- update
@mustCallSuper
void update(covariant Widget newWidget) {
_widget = newWidget;
}
复制代码- 将对应的Widget更新为新的Widget。
- 在ComponentElement的各种子类中,还会调用rebuild函数触发对子Widget的重建。
- updateChild
@protected
Element updateChild(Element child, Widget newWidget, dynamic newSlot) {
if (newWidget == null) {
//新的Child Widget为null,则返回null;如果旧Child Widget,使其未激活
if (child != null)
deactivateChild(child);
return null;
}
Element newChild;
if (child != null) {
//新的Child Widget不为null,旧的Child Widget也不为null
bool hasSameSuperclass = true;
if (hasSameSuperclass && child.widget == newWidget) {
if (child.slot != newSlot)
updateSlotForChild(child, newSlot);
newChild = child;
} else if (hasSameSuperclass && Widget.canUpdate(child.widget, newWidget)){
//Key和RuntimeType相同,使用update更新
if (child.slot != newSlot)
updateSlotForChild(child, newSlot);
child.update(newWidget);
newChild = child;
} else {
//Key或RuntimeType不相同,使旧的Child Widget未激活,并对新的Child Widget使用inflateWidget
deactivateChild(child);
newChild = inflateWidget(newWidget, newSlot);
}
} else {
//新的Child Widget不为null,旧的Child Widget为null,对新的Child Widget使用inflateWidget
newChild = inflateWidget(newWidget, newSlot);
}
return newChild;
}
复制代码根据新的子Widget,更新旧的子Element,或者得到新的子Element。
逻辑如下(伪代码):
if(newWidget == null){
if(Child == null){
return null;
}else{
移除旧的子Element,返回null
}
}else{
if(Child == null){
返回新Element
}else{
如果Widget能更新,更新旧的子Element,并返回之;否则创建新的子Element并返回。
}
}
复制代码该逻辑概括如下:
- 如果newWidget为null,则返回null,同时如果有旧的子Element则移除之。
- 如果newWidget不为null,旧Child为null,则创建新的子Element,并返回之。
- 如果newWidget不为null,旧Child不为null,新旧子Widget的Key和RuntimeType等都相同,则调用update方法更新子Element并返回之。
- 如果newWidget不为null,旧Child不为null,新旧子Widget的Key和RuntimeType等不完全相同,则说明Widget Tree有变动,此时移除旧的子Element,并创建新的子Element,并返回之。
RenderObjectElement
RenderObjectElement同核心元素Widget及RenderObject之间的关系如下图所示:
如图:
RenderObjectElement持有Parent Element,但是不一定持有Child Element,有可能无Child Element,有可能持有一个Child Element(Child),有可能持有多个Child Element(Children)。
RenderObjectElement持有对应的Widget和RenderObject,将Widget、RenderObject串联起来,实现了Widget、Element、RenderObject之间的绑定。
核心流程
如ComponentElement一样,RenderObjectElement的核心操作流程有,创建、更新、销毁三种,接下来会详细介绍这三种流程。
- 创建
-
RenderObjectElement的创建流程和ComponentElement的创建流程基本一致,其最大的区别是ComponentElement在mount后,会调用build来创建子Widget,而RenderObjectElement则是create和attach其RenderObject。
- 更新
RenderObjectElement的更新流程和ComponentElement的更新流程也基本一致,其最大的区别是ComponentElement的update函数会调用build函数,重新触发子Widget的构建,而RenderObjectElement则是调用updateRenderObject对绑定的RenderObject进行更新。
- 销毁
RenderObjectElement的销毁流程和ComponentElement的销毁流程也基本一致。也是由父Element或更上级的节点执行更新子节点的操作(updateChild),导致该Element被停用,并被加入未激活列表,并在下一帧被失效。其不一样的地方是在unmount Element的时候,会调用didUnmountRenderObject失效对应的RenderObject。
核心函数
- inflateWidget
该函数和ComponentElement的inflateWidget函数完全一致,此处不再复述。
- mount
void mount(Element parent, dynamic newSlot) {
super.mount(parent, newSlot);
_renderObject = widget.createRenderObject(this);
attachRenderObject(newSlot);
_dirty = false;
}
复制代码该函数的调用时机和ComponentElement的一致,当Element第一次被插入Element Tree的时候,该方法被调用。其主要职责也和ComponentElement的一致,此处只列举不一样的职责,职责如下:
- 调用createRenderObject创建RenderObject,并使用attachRenderObject将RenderObject关联到Element上。
- SingleChildRenderObjectElement会调用updateChild更新子节点,MultiChildRenderObjectElement会调用每个子节点的inflateWidget重建所有子Widget。
- performRebuild
@override
void performRebuild() {
//更新renderObject
widget.updateRenderObject(this, renderObject);
_dirty = false;
}
复制代码performRebuild的主要职责如下:
调用updateRenderObject更新对应的RenderObject。
- update
@override
void update(covariant RenderObjectWidget newWidget) {
super.update(newWidget);
widget.updateRenderObject(this, renderObject);
_dirty = false;
}
复制代码update的主要职责如下:
- 将对应的Widget更新为新的Widget。
- 调用updateRenderObject更新对应的RenderObject。
- updateChild
@protected
List updateChildren(List oldChildren, List newWidgets, { Set forgottenChildren }) {
int newChildrenTop = 0;
int oldChildrenTop = 0;
int newChildrenBottom = newWidgets.length - 1;
int oldChildrenBottom = oldChildren.length - 1;
final List newChildren = oldChildren.length == newWidgets.length ?
oldChildren : List(newWidgets.length);
Element previousChild;
// 从顶部向下更新子Element
// Update the top of the list.
while ((oldChildrenTop <= oldChildrenBottom) && (newChildrenTop <= newChildrenBottom)) {
final Element oldChild = replaceWithNullIfForgotten(oldChildren[oldChildrenTop]);
final Widget newWidget = newWidgets[newChildrenTop];
if (oldChild == null || !Widget.canUpdate(oldChild.widget, newWidget))
break;
final Element newChild = updateChild(oldChild, newWidget, IndexedSlot(newChildrenTop, previousChild));
newChildren[newChildrenTop] = newChild;
previousChild = newChild;
newChildrenTop += 1;
oldChildrenTop += 1;
}
// 从底部向上扫描子Element
// Scan the bottom of the list.
while ((oldChildrenTop <= oldChildrenBottom) && (newChildrenTop <= newChildrenBottom)) {
final Element oldChild = replaceWithNullIfForgotten(oldChildren[oldChildrenBottom]);
final Widget newWidget = newWidgets[newChildrenBottom];
if (oldChild == null || !Widget.canUpdate(oldChild.widget, newWidget))
break;
oldChildrenBottom -= 1;
newChildrenBottom -= 1;
}
// 扫描旧的子Element列表里面中间的子Element,保存Widget有Key的Element到oldKeyChildren,其他的失效
// Scan the old children in the middle of the list.
final bool haveOldChildren = oldChildrenTop <= oldChildrenBottom;
Map oldKeyedChildren;
if (haveOldChildren) {
oldKeyedChildren = {};
while (oldChildrenTop <= oldChildrenBottom) {
final Element oldChild = replaceWithNullIfForgotten(oldChildren[oldChildrenTop]);
if (oldChild != null) {
if (oldChild.widget.key != null)
oldKeyedChildren[oldChild.widget.key] = oldChild;
else
deactivateChild(oldChild);
}
oldChildrenTop += 1;
}
}
// 根据Widget的Key更新oldKeyChildren中的Element。
// Update the middle of the list.
while (newChildrenTop <= newChildrenBottom) {
Element oldChild;
final Widget newWidget = newWidgets[newChildrenTop];
if (haveOldChildren) {
final Key key = newWidget.key;
if (key != null) {
oldChild = oldKeyedChildren[key];
if (oldChild != null) {
if (Widget.canUpdate(oldChild.widget, newWidget)) {
// we found a match!
// remove it from oldKeyedChildren so we don't unsync it later
oldKeyedChildren.remove(key);
} else {
// Not a match, let's pretend we didn't see it for now.
oldChild = null;
}
}
}
}
final Element newChild = updateChild(oldChild, newWidget, IndexedSlot(newChildrenTop, previousChild));
newChildren[newChildrenTop] = newChild;
previousChild = newChild;
newChildrenTop += 1;
}
newChildrenBottom = newWidgets.length - 1;
oldChildrenBottom = oldChildren.length - 1;
// 从下到上更新底部的Element。.
while ((oldChildrenTop <= oldChildrenBottom) && (newChildrenTop <= newChildrenBottom)) {
final Element oldChild = oldChildren[oldChildrenTop];
final Widget newWidget = newWidgets[newChildrenTop];
final Element newChild = updateChild(oldChild, newWidget, IndexedSlot(newChildrenTop, previousChild));
newChildren[newChildrenTop] = newChild;
previousChild = newChild;
newChildrenTop += 1;
oldChildrenTop += 1;
}
// 清除旧子Element列表中其他所有剩余Element
// Clean up any of the remaining middle nodes from the old list.
if (haveOldChildren && oldKeyedChildren.isNotEmpty) {
for (final Element oldChild in oldKeyedChildren.values) {
if (forgottenChildren == null || !forgottenChildren.contains(oldChild))
deactivateChild(oldChild);
}
}
return newChildren;
}
复制代码 该函数的主要职责如下:
- 复用能复用的子节点,并调用updateChild对子节点进行更新。
- 对不能更新的子节点,调用deactivateChild对该子节点进行失效。
其步骤如下:
- 从顶部向下更新子Element。
- 从底部向上扫描子Element。
- 扫描旧的子Element列表里面中间的子Element,保存Widget有Key的Element到oldKeyChildren,其他的失效。
- 对于新的子Element列表,如果其对应的Widget的Key和oldKeyChildren中的Key相同,更新oldKeyChildren中的Element。
- 从下到上更新底部的Element。
- 清除旧子Element列表中其他所有剩余Element。
收起阅读 »
跟我学flutter:细细品Widget(四)Widget 渲染过程 与 RenderObjectWidget
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
跟我学flutter:细细品Widget(二)StatelessWidget&StatefulWidget
跟我学flutter:细细品Widget(三)ProxyWidget,InheritedWidget
跟我学flutter:细细品Widget(四)Widget 渲染过程 与 RenderObjectWidget
跟我学flutter:细细品Widget(五)Element
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
StatelessWidget 和 StatefulWidget 只是用来组装控件的容器,并不负责组件最后的布局和绘制。在 Flutter 中,布局和绘制工作实际上是在 Widget 的另一个子类 RenderObjectWidget 内完成的。
RenderObjectWidget为RenderObjectElement提供配置信息。
RenderObjectElement包装了RenderObject,RenderObject为应用程序提供真正的渲染。
源码
abstract class RenderObjectWidget extends Widget {
const RenderObjectWidget({ Key? key }) : super(key: key);
@override
@factory
RenderObjectElement createElement();
@protected
@factory
RenderObject createRenderObject(BuildContext context);
@protected
void updateRenderObject(BuildContext context, covariant RenderObject renderObject) { }
@protected
void didUnmountRenderObject(covariant RenderObject renderObject) { }
}
- createElement 需要返回一个继承RenderObjectElement的类
- createRenderObject 创建 Render Widget 对应的 Render Object,同样子类需要重写该方法。该方法在对应的 Element 被挂载到树上时调用(Element.mount),即在 Element 挂载过程中同步构建了「Render Tree」
- updateRenderObject 在 Widget 更新后,修改对应的 Render Object。该方法在首次 build 以及需要更新 Widget 时都会调用;
- didUnmountRenderObject 「Render Object」从「Render Tree」上移除时调用该方法。
RenderObjectElement 源码
abstract class RenderObjectElement extends Element {
RenderObject _renderObject;
@override
void mount(Element parent, dynamic newSlot) {
super.mount(parent, newSlot);
_renderObject = widget.createRenderObject(this);
attachRenderObject(newSlot);
_dirty = false;
}
@override
void update(covariant RenderObjectWidget newWidget) {
super.update(newWidget);
widget.updateRenderObject(this, renderObject);
_dirty = false;
}
...
}
- mount: RenderObject 对象的创建,以及与渲染树的插入工作,插入到渲染树后的 Element 就可以显示到屏幕中了。
- update: 如果 Widget 的配置数据发生了改变,那么持有该 Widget 的 Element 节点也会被标记为 dirty。在下一个周期的绘制时,Flutter 就会触发 Element 树的更新,并使用最新的 Widget 数据更新自身以及关联的 RenderObject 对象,接下来便会进入 Layout 和 Paint 的流程。而真正的绘制和布局过程,则完全交由 RenderObject 完成。
RenderObject 主要处理一些固定的操作,如:布局、绘制和 Hit testing。 与ComponentElement一样RenderObjectElement也是抽象类,不同的是ComponentElement不会直接创建RenderObject,而是间接通过创建其他Element创建RenderObject。
RenderObjectElement主要有三个系统的子类,分别处理renderObject作为child时的不同情况。
- LeafRenderObjectElement:叶子渲染对象对应的元素,处理没有children的renderObject。
- SingleChildRenderObjectElement:处理只有单个child的renderObject。
- MultiChildRenderObjectElement: 处理有多个children的渲染对象
有时RenderObject的child模型更复杂一些,比如多维数组的形式,则可能需要基于RenderObjectElement实现一个新的子类。
RenderObjectElement 充当widget与renderObject之间的中介者。需要进行方法覆盖,以便它们返回元素期望的特定类型,例如:
class FooElement extends RenderObjectElement {
@override
Foo get widget => super.widget;
@override
RenderFoo get renderObject => super.renderObject;
}
widget返回Foo,renderObject 返回RenderFoo
系统常用组件与RenderObjectElement:
| 常用组件 | Widget(父级) | Element |
|---|---|---|
| Flex/Wrap/Flow/Stack | MultiChildRenderObjectWidget | MultiChildRenderObjectElement |
| RawImage(Imaget)/ErrorWidget | LeafRenderObjectWidget | LeafRenderObjectElement |
| Offstage/SizedBox/Align/Padding | SingleChildRenderObjectWidget | SingleChildRenderObjectElement |
RenderObject源码
abstract class RenderObject extends AbstractNode with DiagnosticableTreeMixin implements HitTestTarget {
...
void layout(Constraints constraints, { bool parentUsesSize = false }) {...}
void paint(PaintingContext context, Offset offset) { }
}
布局和绘制完成后,接下来的事情就交给 Skia 了。在 VSync 信号同步时直接从渲染树合成 Bitmap,然后提交给 GPU。
跟我学flutter:细细品Widget(三)ProxyWidget,InheritedWidget
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
跟我学flutter:细细品Widget(二)StatelessWidget&StatefulWidget
跟我学flutter:细细品Widget(三)ProxyWidget,InheritedWidget
跟我学flutter:细细品Widget(四)Widget 渲染过程 与 RenderObjectWidget
跟我学flutter:细细品Widget(五)Element
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
ProxyWidget作为抽象基类本身没有任何功能,但他有两个实现类ParentDataWidget & InheritedElement
源码
abstract class ProxyWidget extends Widget {
const ProxyWidget({ Key? key, required this.child }) : super(key: key);
final Widget child;
}
InheritedWidget
InheritedWidget 用于在树上向下传递数据。
通过BuildContext.dependOnInheritedWidgetOfExactType可以获取最近的「Inherited Widget」,需要注意的是通过这种方式获取「Inherited Widget」时,当「Inherited Widget」状态有变化时,会导致该引用方 rebuild。
通常,为了使用方便会「Inherited Widget」会提供静态方法of,在该方法中调用BuildContext.dependOnInheritedWidgetOfExactType。of方法可以直接返回「Inherited Widget」,也可以是具体的数据。
有时,「Inherited Widget」是作为另一个类的实现细节而存在的,其本身是私有的(外部不可见),此时of方法就会放到对外公开的类上。最典型的例子就是Theme,其本身是StatelessWidget类型,但其内部创建了一个「Inherited Widget」:_InheritedTheme,of方法就定义在上Theme上:
static ThemeData of(BuildContext context) {
final _InheritedTheme? inheritedTheme = context.dependOnInheritedWidgetOfExactType<_InheritedTheme>();
final MaterialLocalizations? localizations = Localizations.of(context, MaterialLocalizations);
final ScriptCategory category = localizations?.scriptCategory ?? ScriptCategory.englishLike;
final ThemeData theme = inheritedTheme?.theme.data ?? _kFallbackTheme;
return ThemeData.localize(theme, theme.typography.geometryThemeFor(category));
}
该of方法返回的是ThemeData类型的具体数据,并在其内部首先调用了BuildContext.dependOnInheritedWidgetOfExactType。
我们经常使用的「Inherited Widget」莫过于MediaQuery,同样提供了of方法:
static MediaQueryData of(BuildContext context) {
assert(context != null);
assert(debugCheckHasMediaQuery(context));
return context.dependOnInheritedWidgetOfExactType()!.data;
}
源码
abstract class InheritedWidget extends ProxyWidget {
const InheritedWidget({ Key? key, required Widget child })
: super(key: key, child: child);
@override
InheritedElement createElement() => InheritedElement(this);
@protected
bool updateShouldNotify(covariant InheritedWidget oldWidget);
}
createElement
「Inherited Widget」对应的 Element 为InheritedElement,一般情况下InheritedElement子类不用重写该方法;
updateShouldNotify
「Inherited Widget」rebuilt 时判断是否需要 rebuilt 那些依赖它的 Widget;
如下是MediaQuery.updateShouldNotify的实现,在新老Widget.data 不相等时才 rebuilt 那依赖的 Widget。
@override
bool updateShouldNotify(MediaQuery oldWidget) => data != oldWidget.data;
依赖了 InheritedWidget 在数据变动的情况下 didChangeDependencies 会被调用,
依赖的意思是 使用 return context.dependOnInheritedWidgetOfExactType()
如果使用context.getElementForInheritedWidgetOfExactType().widget的话,只会用其中的数据,而不会重新rebuild
@override
InheritedElement getElementForInheritedWidgetOfExactType() {
final InheritedElement ancestor = _inheritedWidgets == null ? null : _inheritedWidgets[T];
return ancestor;
}
@override
InheritedWidget dependOnInheritedWidgetOfExactType({ Object aspect }) {
assert(_debugCheckStateIsActiveForAncestorLookup());
final InheritedElement ancestor = _inheritedWidgets == null ? null : _inheritedWidgets[T];
//多出的部分
if (ancestor != null) {
return dependOnInheritedElement(ancestor, aspect: aspect) as T;
}
_hadUnsatisfiedDependencies = true;
return null;
}
我们可以看到,dependOnInheritedWidgetOfExactType() 比 getElementForInheritedWidgetOfExactType()多调了dependOnInheritedElement方法,dependOnInheritedElement源码如下:
@override
InheritedWidget dependOnInheritedElement(InheritedElement ancestor, { Object aspect }) {
assert(ancestor != null);
_dependencies ??= HashSet();
_dependencies.add(ancestor);
ancestor.updateDependencies(this, aspect);
return ancestor.widget;
}
可以看到dependOnInheritedElement方法中主要是注册了依赖关系!看到这里也就清晰了,调用dependOnInheritedWidgetOfExactType() 和 getElementForInheritedWidgetOfExactType()的区别就是前者会注册依赖关系,而后者不会,所以在调用dependOnInheritedWidgetOfExactType()时,InheritedWidget和依赖它的子孙组件关系便完成了注册,之后当InheritedWidget发生变化时,就会更新依赖它的子孙组件,也就是会调这些子孙组件的didChangeDependencies()方法和build()方法。而当调用的是 getElementForInheritedWidgetOfExactType()时,由于没有注册依赖关系,所以之后当InheritedWidget发生变化时,就不会更新相应的子孙Widget。
收起阅读 »
什么是请求参数、表单参数、url参数、header参数、Cookie参数?一文讲懂
最近在工作中对 http 的请求参数解析有了进一步的认识,写个小短文记录一下。
回顾下自己的情况,大概就是:有点点网络及编程基础,只需要加深一点点对 HTTP 协议的理解就能弄明白了。
先分享一个小故事:我至今仍清晰地记得大三实习时的第一个工作任务,我需要调用其他部门提供的 api 去完成某项业务。
那个 api 文档只告诉了我请求参数需要传什么,没有提及用什么方式传,比如这样:
其实如果有经验的话,直接在请求体或 url 里填参数试一下就知道了;另一个是新人有时候不太敢问问题,其实只要向同事确认一下就好的。
然而由于当时我掌握的编程知识有限,只会用表单提交数据。所以当我下载完同事安利的 api 调用调试工具 postman 后,我就在网上查怎么用 postman 发送表单数据,结果折腾了好久 api 还是没能调通。
当天晚上我向老同学求助,他问我上课是不是又睡过去了?
我说你怎么知道?
他说当然咯,你上课睡觉不学习又不是一天两天的事情......
后来他告诉我得好好学一下 http 协议,看看可以在协议的哪些位置放请求参数。
一个简单的 http 服务器还原
那么,在正式讲解之前,我们先简单搭建一个 http 服务器,阿菌沿用经典的 python 版云你好服务器进行讲解。
云你好服务器的代码很简单,服务器首先会获取 name 用户名这个参数,如果用户传了这个参数,就返回 Hello xxx,xxx 指的是 name 用户名;如果用户没有传这个参数则返回 Hello World:
# 云你好服务源码
from flask import Flask
from flask import request
app = Flask(__name__)
# 云你好服务 API 接口
@app.get("/api/hello")
def hello():
# 看用户是否传递了参数 name
name = request.args.get("name", "")
# 如果传了参数就向目标对象打招呼,输出 Hello XXX,否则输出 Hello World
return f"Hello {name}" if name else "Hello World"
# 启动云你好服务
if __name__ == '__main__':
app.run()为了快速开发(大伙可以下载一个 python 把这个代码跑一下,用自己的语言实现一个类似的服务器也是可以的),阿菌这里使用了 flask 框架构建后端服务。
在具体获取参数的时候,我选择了在 request.args 中获取参数。这里提前剧透一下:在 flask 框架中,request.args 指的是从 url 中获取参数(不过这是我们后面讲解的内容,大家有个印象就好)
抓包查看 http 报文
有了 http 服务器后,我们开始深入讲解 http 协议,em...个人觉得只在学校上课看教材学计算机网络好像还欠缺了点啥,比较推荐大家下载一个像 Wireshark 这样的网络抓包软件,动手拆解网络包,深入学习各种网络协议。抓取网络包的示例视频
为了搞清楚什么是请求参数、表单参数、url 参数、Header 参数、Cookie 参数,我们先发一个 http 请求,然后抓取这个请求的网络包,看看一份 http 报文会携带哪些信息。
呼应开头,用户阿菌是个只会发表单数据的萌新,他使用 postman 向云你好 api 发送了一个 post 请求:
剧情发展正常,我们没能得到 Hello 阿菌(服务器会到 url 中获取参数,咱们用表单形式提交,所以获取不到)
由于咱们对请求体这个概念比较模糊,接下来我们重新发一个一模一样的请求,并且通过 Wireshark 抓包看一下:
可以看到强大的 Wireshark 帮助我们把请求抓取了下来,并把整个网络包的链路层协议,IP层协议,传输层协议,应用层协议全都解析好了。
由于咱们小码农一般都忙于解决应用层问题,所以我们把目光聚焦于高亮的 Hypertext Transfer Protocol 超文本传输协议,也就是大名鼎鼎的 HTTP 协议。
首先我们查看一下 HTTP 报文的完整内容:
可以看到,http 协议大概是这么组成的:
第一行是请求的方式,比如 GET / POST / DELETE / PUT
请求方式后面跟的是请求的路径,一般把这个叫 URI(统一资源标识符)
补充:URL 是统一资源定位符,见名知义,因为要定位,所以要指定协议甚至是位置,比如这样:
http://localhost:5000/api/hello
请求路径后面跟的是 HTTP 的版本,比如这里是
HTTP/1.1
完整的第一行如下:
POST /api/hello HTTP/1.1第二行的 User-Agent 则用于告诉对方发起请求的客户端是啥,比如咱们用 Postman 发起的请求,Postman 就会自动把这个参数设置为它自己:
User-Agent: PostmanRuntime/7.28.4第三行的 Accept 用于告诉对方我们希望收到什么类型的数据,这里默认是能接受所有类型的数据:
Accept: */*第四行就非常值得留意,Postman-Token 是 Postman 自己传的参数,这个我们放到下面讲!
Postman-Token: ddd72e1a-0d63-4bad-a18e-22e38a5de3fc第五行是请求的主机,网络上的一个服务一般用 ip 加端口作为唯一标识:
Host: 127.0.0.1:5000第六行指定的是咱们请求发起方可以理解的压缩方式:
Accept-Encoding: gzip, deflate, br第七行告诉对方处理完当前请求后不要关闭连接:
Connection: keep-alive第八行告诉对方咱们请求体的内容格式,这个是本文的侧重点啦!比如我们这里指定的是一般浏览器的原生表单格式:
Content-Type: application/x-www-form-urlencoded
好了,下面大家要留意了,第九行的 Content-Length 给出的是请求体的大小。
而请求体,会放在紧跟着的一个空行之后。比如本请求的请求体内容是以 key=value 形式填充的,也就是我们表单参数的内容了:
Content-Length: 23
name=%E9%98%BF%E8%8F%8C
看到这里我们先简单小结一下,想要告诉服务器我们发送的是表单数据,一共需要两步:
将
Content-Type设置为application/x-www-form-urlencoded在请求体中按照
key=value的形式填写请求参数
什么是协议?进一步了解 http
好了,接下来我们进一步讲解,大家试想一下,网络应用,其实就是端到端的交互,最常见的就是服务端和客户端交互模型:客户端发一些参数数据给服务端,通过这些参数数据告诉服务端它想得到什么或想干什么,服务端根据客户端传递的参数数据作出处理。
传输层协议通过 ip 和端口号帮我们定位到了具体的服务应用,具体怎么交互是由我们程序员自己定义的。
大概在 30 年前,英国计算机科学家蒂姆·伯纳斯-李定义了原始超级文本传输协议(HTTP),后续我们的 web 应用大都延续采用了他定义的这套标准,当然这套标准也在不断地进行迭代。
许多文献资料会把 http 协议描述得比较晦涩,加上协议这个词听起来有点高大上,初学者入门学习的时候往往感觉不太友好。
其实协议说白了就是一种格式,就好比我们写书信,约定要先顶格写个敬爱的 xxx,然后写个你好,然后换一个段落再写正文,可能最后还得加上日期署名等等。
我们只要按照格式写信,老师就能一眼看出来我们在写信;只要我们按协议格式发请求数据,服务器就能一眼看出来我们想要得到什么或想干什么。
当然,老师是因为老早就学过书信格式,所以他才能看懂书信格式;服务端程序也一样,我们要预先编写好 http 协议的解析逻辑,然后我们的服务器才能根据解析逻辑去获取一个 http 请求中的各种东西。
当然这个解析 http 协议的逻辑不是谁都能写出来的,就算能写出来,也未必写得好,所以我们会使用厉害的人封装好的脚手架,比如 java 里的 spring 全套、Go 语言里的 Gin 等等。
回到我们开头给出的示例:
from flask import Flask
from flask import request
app = Flask(__name__)
# 云你好服务 API 接口
@app.get("/api/hello")
def hello():
# 看用户是否传递了参数 name
name = request.args.get("name", "")
# 如果传了参数就向目标对象打招呼,输出 Hello XXX,否则输出 Hello World
return f"Hello {name}" if name else "Hello World"
# 启动云你好服务
if __name__ == '__main__':
app.run()阿菌的示例使用了 python 里的 flask 框架,在处理逻辑中使用了 request.args 获取请求参数,而 args 封装的就是框架从 url 中获取参数的逻辑。比如我们发送请求的 url 为:
http://127.0.0.1:5000/api/hello?name=ajun框架会帮助我们从 url 中的 ? 后面开始截取,然后把 name=ajun 这些参数存放到 args 里。
切换一下,假设我们是云你好服务提供者,我们希望用户通过表单参数的形式使用云你好服务,我们只要把获取 name 参数的方式改成从表单参数里获取就可以了,flask 在 request.form 里封装了表单参数(关于框架是怎么在数行 http 请求中封装参数的,大家可以看自己使用的框架的具体逻辑,估计区别不大,只是存在一些语言特性上的差异):
@app.post("/api/hello")
def hello():
# 看用户是否传递了参数 name
name = request.form.get("name", "")
# 如果传了参数就向目标对象打招呼,输出 Hello XXX,否则输出 Hello World
return f"Hello {name}" if name else "Hello World"思考:我们可以在 http 协议中传递什么参数?
最后,我们解释本文的标题,其实想要明白各种参数之间的区别,我们可以换一个角度思考:
咱们可以在一份 http 报文的哪些位置传递参数?
接下来回顾一下一个 http 请求的内容:
POST /api/hello HTTP/1.1
User-Agent: PostmanRuntime/7.28.4
Accept: */*
Postman-Token: fbf75035-a647-46dc-adc0-333751a9399e
Host: 127.0.0.1:5000
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded
Content-Length: 23
name=%E9%98%BF%E8%8F%8C
大家看,咱们的 http 报文,也就是基于传输层之上的应用层报文,大概就长上面这样。
我们考虑两种情况,第一种情况,我们基于别人已经开发好的脚手架开发 http 服务器。
由于框架会基于 http 协议进行解析,所以框架会帮助我们解析好请求 url,各种 Header 头(比如:Cookie 等),以及具体的响应内容都帮我们封装解析好了(比如按照 key=value 的方式去读取请求体)。
那当我们开发服务端的时候,就可以指定从 url、header、响应体中获取参数了,比如:
url 参数:指的就是 url 中 ? 后面携带的 key value 形式参数
header 参数:指的就是各个 header 头,我们甚至可以自定义 header,比如 Postman-Token 就是 postman 这个软件自己携带的,我们服务端如果需要的话是可以指定获取这个参数的
Cookie 参数:其实就是名字为 Cookie 的请求头
表单参数:指的就是 Content-Type 为 application/x-www-form-urlencoded 下请求体的内容,如果我们的表单需要传文件,还会有其他的 Content-Type
json 参数:指的就是 Content-Type 为 application/json 下请求体的内容(当然服务端可以不根据 Content-Type 直接解析请求体,但按照协议的规范工程项目或许会更好维护)
综上所述,请求参数就是对上面各种类型的参数的一个总称了。
大家会发现,不管什么 url 参数、header 参数、Cookie 参数、表单参数,其实就是换着法儿,按照一定的格式把数据放到应用层报文中。关键在于我们的服务端程序和客户端程序按照一种什么样的约定去传递和获取这些参数。这就是协议吧~
还有另一种情况,当然这只是开玩笑了,比如以后哪位大佬或者哪家企业定义了一种新的数据传输标准,推广至全球,比如叫 hppt 协议,这样是完全可以自己给各种形式参数下定义取名字的。这可能就是为啥我们说一流的企业、大佬制定标准,接下来的围绕标准研发技术,进而是基于技术卖产品,最后是围绕产品提供服务了。
一旦标准制定了,整个行业都围绕这个标准转了,而且感觉影响会越来越深远......
作者:胡涂阿菌
来源:juejin.cn/post/7100400494081736711
Base64编码解码原理
Base64编码与解码
原理涉及的算法
1、短除法
短除法运算方法是先用一个除数除以能被它除尽的一个质数,以此类推,除到商是质数为止。通过短除法,十进制数可以不断除以2得到多个余数。最后,将余数从下到上进行排列组合,得到二进制数。
实例:以字符n对应的ascII编码110为例。
110 / 2 = 55...0
55 / 2 = 27...1
27 / 2 = 13...1
13 / 2 = 6...1
6 / 2 = 3...0
3 / 2 = 1...1
1 / 2 = 0...1
将余数从下到上进行排列组合,得到字符n对应的ascII编码110转二进制为1101110,因为一字节对应8位(bit), 所以需要向前补0补足8位,得到01101110。其余字符同理可得。
2、按权展开求和
按权展开求和, 8位二进制数从右到左,次数是0到7依次递增, 基数*底数次数,从左到右依次累加,相加结果为对应十进制数。我们已二进制数01101110转10进制为例:
(01101110)2=0∗20+1∗21+1∗22+1∗23+0∗24+1∗25+1∗26+0∗27(01101110)_2 = 0 * 2^0 + 1 * 2 ^ 1 + 1 * 2^2 + 1 * 2^3 + 0 * 2^4 + 1 * 2^5 + 1 * 2^6 + 0 * 2^7(01101110)2=0∗20+1∗21+1∗22+1∗23+0∗24+1∗25+1∗26+0∗27
3、位概念
二进制数系统中,每个0或1就是一个位(bit,比特),也叫存储单元,位是数据存储的最小单位。其中 8bit 就称为一个字节(Byte)。
4、移位运算符
移位运算符在程序设计中,是位操作运算符的一种。移位运算符可以在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:<<(左移)、>>(带符号右移)和>>>(无符号右移)。在base64的编码和解码过程中操作的是正数,所以仅使用<<(左移)、>>(带符号右移)两种运算符。
左移运算:是将一个二进制位的操作数按指定移动的位数向左移动,移出位被丢弃,右边移出的空位一律补0。【左移相当于一个数乘以2的次方】
右移运算:是将一个二进制位的操作数按指定移动的位数向右移动,移出位被丢弃,左边移出的空位一律补0,或者补符号位,这由不同的机器而定。在使用补码作为机器数的机器中,正数的符号位为0,负数的符号位为1。【右移相当于一个数除以2的次方】
// 左移
01101000 << 2 -> 101000(左侧移出位被丢弃) -> 10100000(右侧空位一律补0)
// 右移
01101000 >> 2 -> 011010(右侧移出位被丢弃) -> 00011010(左侧空位一律补0)
5、与运算、或运算
与运算、或运算都是计算机中一种基本的逻辑运算方式。
与运算:符号表示为&。运算规则:两位同时为“1”,结果才为“1”,否则为0
或运算:符号表示为|。运算规则:两位只要有一位为“1”,结果就为“1”,否则为0
什么是base64编码
2^6=64\
\
Base64编码是将字符串以每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节(6比特有效字节,最左边两个永远为0,其实也是8比特的字节)子序列,再将得到的子序列查找Base64的编码索引表,得到对应的字符拼接成新的字符串的一种编码方式。
每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节的拆分过程如下图所示:
为什么base64编码后的大小是原来的4/3倍
因为6和8的最大公倍数是24,所以3个8比特的字节刚好可以拆分成4个6比特的字节,3 x 8 = 6 x 4。计算机中,因为一个字节需要8个存储单元存储,所以我们要把6个比特往前面补两位0,补足8个比特。如下图所示:
补足后所需的存储单元为32个,是原来所需的24个的4/3倍。这也就是base64编码后的大小是原来的4/3倍的原因。
为什么命名为base64呢?
因为6位(bit)的二进制数有2的6次方个,也就是二进制数(00000000-00111111)之间的代表0-63的64个二进制数。
不是说一个字节是用8位二进制表示的吗,为什么不是2的8次方?
因为我们得到的8位二进制数的前两位永远是0,真正的有效位只有6位,所以我们所能够得到的二进制数只有2的6次方个。
Base64字符是哪64个?
Base64的编码索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符来代表(00000000-00111111)这64个二进制数。即
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'编码原理
要把3个字节拆分成4个字节可以怎么做?
流程图
思路
分析映射关系:abc → xyzi。我们从高位到低位添加索引来分析这个过程
x: (前面补两个0)a的前六位 => 00a7a6a5a4a3a2
y: (前面补两个0)a的后两位 + b的前四位 => 00a1a0b7b6b5b4
z: (前面补两个0)b的后四位 + c的前两位 => 00b3b2b1b0c7c6
i: (前面补两个0)c的后六位 => 00c5c4c3c2c1c0
通过上述的映射关系,得到实现思路:
将字符对应的AscII编码转为8位二进制数
将每三个8位二进制数进行以下操作
将第一个数右移位2位,得到第一个6位有效位二进制数
将第一个数 & 0x3之后左移位4位,得到第二个6位有效位二进制数的第一个和第二个有效位,将第二个数 & 0xf0之后右移位4位,得到第二个6位有效位二进制数的后四位有效位,两者取且得到第二个6位有效位二进制
将第二个数 & 0xf之后左移位2位,得到第三个6位有效位二进制数的前四位有效位,将第三个数 & 0xC0之后右移位6位,得到第三个6位有效位二进制数的后两位有效位,两者取且得到第三个6位有效位二进制
将第三个数 & 0x3f,得到第四个6位有效位二进制数
将获得的6位有效位二进制数转十进制,查找对呀base64字符
代码实现
以hao字符串为例,观察base64编码的过程,将上面转换通过代码逻辑分析实现
// 输入字符串
let str = 'hao'
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4, out
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(0) & 0xff // 104 01101000
char2 = str.charCodeAt(1) & 0xff // 97 01100001
char3 = str.charCodeAt(2) & 0xff // 111 01101111
// 输出6位有效字节二进制数
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6 // 5 000101
out4 = char3 & 0x3f // 47 101111
out = base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv算法剖析
out1: char1 >> 2
01101000 -> 00011010
复制代码out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4
// 且运算
01101000 01100001
00000011 11110000
-------- --------
00000000 01100000
// 移位运算后得
00000000 00000110
// 或运算
00000000
00000110
--------
00000110
复制代码
第三个字符第四个字符同理
整理上述代码,扩展至多字符字符串
// 输入字符串
let str = 'haohaohao'
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 获取字符串长度
let len = str.length
// 当前字符索引
let index = 0
// 输出字符串
let out = ''
while(index < len) {
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(index++) & 0xff // 104 01101000
char2 = str.charCodeAt(index++) & 0xff // 97 01100001
char3 = str.charCodeAt(index++) & 0xff // 111 01101111
// 输出6位有效字节二进制数
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6 // 5 000101
out4 = char3 & 0x3f // 47 101111
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv
}
原字符串长度不是3的整倍数的情况,需要特殊处理
...
char1 = str.charCodeAt(index++) & 0xff // 104 01101000
if (index == len) {
out2 = (char1 & 0x3) << 4
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + '=='
return out
}
char2 = str.charCodeAt(index++) & 0xff // 97 01100001
if (index == len) {
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + '='
return out
}
...
全部代码
function base64Encode(str) {
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 获取字符串长度
let len = str.length
// 当前字符索引
let index = 0
// 输出字符串
let out = ''
while(index < len) {
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(index++) & 0xff
out1 = char1 >> 2
if (index == len) {
out2 = (char1 & 0x3) << 4
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + '=='
return out
}
char2 = str.charCodeAt(index++) & 0xff
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4
if (index == len) {
out3 = (char2 & 0xf) << 2
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + '='
return out
}
char3 = str.charCodeAt(index++) & 0xff
// 输出6位有效字节二进制数
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6
out4 = char3 & 0x3f
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4]
}
return out
}
base64Encode('haohao') // aGFvaGFv
base64Encode('haoha') // aGFvaGE=
base64Encode('haoh') // aGFvaA==解码原理
逆向推导,由每4个6位有效位的二进制数合并成3个8位二进制数,根据ascII编码映射到对应字符后拼接字符串
思路
分析映射关系 xyzi -> abc
a: x后六位 + y第三、四位 => x5x4x3x2x1x0y5y4
b: y后四位 + z第三、四、五、六位 => y3y2y1y0z5z4z3z2
c: z后两位 + i后六位 => z1z0i5i4i3i2i1i0
将字符对应的base64字符集的索引转为6位有效位二进制数
将每四个6位有效位二进制数进行以下操作
第一个二进制数左移位2位,得到新二进制数的前6位,第二个二进制数 & 0x30之后右移位4位,取或集得到第一个新二进制数
第二个二进制数 & 0xf之后左移位4位,第三个二进制数 & 0x3c之后右移位2位,取或集得到第二个新二进制数
第二个二进制数 & 0x3之后左移位6位,与第四个二进制数取或集得到第二个新二进制数
根据ascII编码映射到对应字符后拼接字符串
代码实现
// base64字符串
let str = 'aGFv'
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
// 获取索引值
let char1 = base64CharsArr.findIndex(char => char==str[0]) & 0xff // 26 011010
let char2 = base64CharsArr.findIndex(char => char==str[1]) & 0xff // 6 000110
let char3 = base64CharsArr.findIndex(char => char==str[2]) & 0xff // 5 000101
let char4 = base64CharsArr.findIndex(char => char==str[3]) & 0xff // 47 101111
let out1, out2, out3, out
// 位运算
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
遇到有用'='补过位的情况时
function base64decode(str) {
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
let char1 = base64CharsArr.findIndex(char => char==str[0])
let char2 = base64CharsArr.findIndex(char => char==str[1])
let out1, out2, out3, out
if (char1 == -1 || char2 == -1) return out
char1 = char1 & 0xff
char2 = char2 & 0xff
let char3 = base64CharsArr.findIndex(char => char==str[2])
// 第三位不在base64对照表中时,只拼接第一个字符串
if (char3 == -1) {
out1 = char1 << 2 | (char2 & 0x30) >> 4
out = String.fromCharCode(out1)
return out
}
let char4 = base64CharsArr.findIndex(char => char==str[3])
// 第三位不在base64对照表中时,只拼接第一个和第二个字符串
if (char4 == -1) {
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out = String.fromCharCode(out1) + String.fromCharCode(out2)
return out
}
// 位运算
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
return out
}解码整个字符串,整理代码后
function base64decode(str) {
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
let i = 0
let len = str.length
let out = ''
while(i < len) {
let char1 = base64CharsArr.findIndex(char => char==str[i])
i++
let char2 = base64CharsArr.findIndex(char => char==str[i])
i++
let out1, out2, out3
if (char1 == -1 || char2 == -1) return out
char1 = char1 & 0xff
char2 = char2 & 0xff
let char3 = base64CharsArr.findIndex(char => char==str[i])
i++
// 第三位不在base64对照表中时,只拼接第一个字符串
out1 = char1 << 2 | (char2 & 0x30) >> 4
if (char3 == -1) {
out = out + String.fromCharCode(out1)
return out
}
let char4 = base64CharsArr.findIndex(char => char==str[i])
i++
// 第三位不在base64对照表中时,只拼接第一个和第二个字符串
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
if (char4 == -1) {
out = out + String.fromCharCode(out1) + String.fromCharCode(out2)
return out
}
// 位运算
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = out + String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
}
return out
}
base64decode('aGFvaGFv') // haohao
base64decode('aGFvaGE=') // haoha
base64decode('aGFvaA==') // haoh上述解码核心是字符与base64字符集索引的映射,网上看到过使用AscII编码索引映射base64字符索引的方法
let base64DecodeChars = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1]
//
let char1 = 'hao'.charCodeAt(0) // h -> 104
base64DecodeChars[char1] // 33 -> base64编码表中的h
由此可见,base64DecodeChars对照accII编码表的索引存放的是base64编码表的对应字符的索引。
jdk1.8之前的方式
Base64编码与解码时,会使用到JDK里sun.misc包套件下的BASE64Encoder类和BASE64Decoder类
sun.misc包所提供的Base64编码解码功能效率不高,因此在1.8之后的jdk版本已经被删除了
// 编码器
final BASE64Encoder encoder = new BASE64Encoder();
// 解码器
final BASE64Decoder decoder = new BASE64Decoder();
final String text = "字串文字";
final byte[] textByte = text.getBytes("UTF-8");
//编码
final String encodedText = encoder.encode(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(decoder.decodeBuffer(encodedText), "UTF-8"));
Apache Commons Codec包的方式
Apache Commons Codec 有提供Base64的编码与解码功能,会使用到 org.apache.commons.codec.binary 套件下的Base64类别,用法如下
1、引入依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
2、代码实现
final Base64 base64 = new Base64();
final String text = "字串文字";
final byte[] textByte = text.getBytes("UTF-8");
//编码
final String encodedText = base64.encodeToString(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(base64.decode(encodedText), "UTF-8"));
jdk1.8之后的方式
与sun.misc包和Apache Commons Codec所提供的Base64编解码器方式来比较,Java 8提供的Base64拥有更好的效能。实际测试编码与解码速度,Java 8提供的Base64,要比
sun.misc套件提供的还要快至少11倍,比Apache Commons Codec提供的还要快至少3倍。
// 解码器
final Base64.Decoder decoder = Base64.getDecoder();
// 编码器
final Base64.Encoder encoder = Base64.getEncoder();
final String text = "字串文字";
final byte[] textByte = text.getBytes(StandardCharsets.UTF_8);
//编码
final String encodedText = encoder.encodeToString(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(decoder.decode(encodedText), StandardCharsets.UTF_8));
总结
Base64 是一种数据编码方式,可做简单加密使用,可以t通过改变base64编码映射顺序来形成自己独特的加密算法进行加密解密。
编码表
Base64编码表
AscII码编码表

作者:loginfo
来源:juejin.cn/post/7100421228644532255
Python-可变和不可变类型
1. 不可变类型
不可变类型,内存中的数据不允许被修改(一旦被定义,内存中分配了小格子,就不能再修改内容了):
数字类型
int,bool,float,complex,long(2,x)字符串
str元组
tuple
2. 可变类型
可变类型,内存中的数据可以被修改(可以通过变量名调用方法来修改列表和字典内部的内容,而内存地址不发生变化):
列表
list字典
dict(注:字典中的key只能使用不可变类型的数据)
注:给变量赋新值的时候,只是改变了变量的引用地址,不是修改之前的内容
可变类型的数据变化,是通过方法来实现的
如果给一个可变类型的变量,复制了一个新的数据,引用会修改(变量从之前的数据上撕下来,贴到新赋值的数据上)
3. 代码演示
# 新建列表
a = [1, 2, 3]
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 追加元素
a.append(999)
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 移除元素
a.remove(2)
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 清空列表
a.clear()
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 将空列表赋值给变量a
a = []
print("列表a的地址:", id(a)) # 通过输出可以看出地址发生了变化
print("*"*50)
# 新建字典
d = {"name": "xiaoming"}
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 追加键值对
d["age"] = 18
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 删除键值对
d.pop("age")
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 清空所有键值对
d.clear()
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 对d赋值空字典
d = {}
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)4. 运行结果
可变类型(列表和字典)的数据变化,是通过方法(比如append,remove,pop等)来实现的,不会改变地址。而重新赋值后地址会改变。具体运行结果如下图所示:
作者:ZacheryZHANG
来源:juejin.cn/post/7100423532655411213
推荐一款超棒的SpringCloud 脚手架项目
之前接个私活,在网上找了好久没有找到合适的框架,不是版本低没人维护了,在不就是组件相互依赖较高。所以我自己搭建一个全新spingCloud框架,里面所有组件可插拔的,集成多个组件供大家选择,喜欢哪个用哪个
一、系统架构图
二、快速启动
1.本地启动nacos: http://127.0.0.1:8848
sh startup.sh -m standalone2.本地启动sentinel: http://127.0.0.1:9000
nohup java -Dauth.enabled=false -Dserver.port=9000 -jar sentinel-dashboard-1.8.1.jar &3.本地启动zipkin: http://127.0.0.1:9411/
nohup java -jar zipkin-server-2.23.2-exec.jar &三、项目概述
springboot+springcloud
注册中心:nacos
网关:gateway
RPC:feign
以下是可插拔功能组件
流控熔断降级:sentinel
全链路跟踪:sleth+zipkin
分布式事务:seata
封装功能模块:全局异常处理、日志输出打印持久化、多数据源、鉴权授权模块、zk(分布式锁和订阅者模式)
maven:实现多环境打包、直推镜像到docker私服。
这个项目整合了springcloud体系中的各种组件。以及集成配置说明。同时将自己平时使用的功能性的封装以及工具包都最为模块整合进来。可以避免某些技术点长时间不使用后的遗忘。
另一方面现在springboot springcloud 已经springcloud-alibaba的版本迭代速度越来越快。
为了保证我们的封装和集成方式在新版本中依然正常运行,需要用该项目进行最新版本的适配实验。这样可以更快的在项目中集合工程中的功能模块。
四、项目预览
五、新建业务工程模块说明
由于springboot遵循 约定大于配置的原则。所以本工程中所有的额类都在的包路径都在com.cloud.base下。
如果新建的业务项目有规定使用指定的基础包路径则需要在启动类增加包扫描注解将com.cloud.base下的所有类加入到扫描范围下。
@ComponentScan(basePackages = "com.cloud.base")如果可以继续使用com.cloud.base 则约定将启动类放在该路径下即可。
六、模块划分
父工程:
cloud-base - 版本依赖管理 <groupId>com.cloud</groupId>
|
|--common - 通用工具类和包 <groupId>com.cloud.common</groupId>
| |
| |--core-common 通用包 该包包含了SpringMVC的依赖,会与WebFlux的服务有冲突
| |
| |--core-exception 自定义异常和请求统一返回类
|
|--dependency - 三方功能依赖集合 无任何实现 <groupId>com.cloud.dependency</groupId>
| |
| |--dependency-alibaba-cloud 关于alibaba-cloud的依赖集合
| |
| |--dependency-mybatis-tk 关于ORM mybatis+tk.mybatis+pagehelper的依赖集合
| |
| |--dependency-mybatis-plus 关于ORM mybatis+mybatis—plus+pagehelper的依赖集合
| |
| |--dependency-seata 关于分布式事务seata的依赖集合
| |
| |--dependency-sentinel 关于流控组件sentinel的依赖集合
| |
| |--dependency-sentinel-gateway 关于网关集成流控组件sentinel的依赖集合(仅仅gateway网关使用该依赖)
| |
| |--dependency-sleuth-zipkin 关于链路跟踪sleuth-zipkin的依赖集合
|
|--modules - 自定义自实现的功能组件模块 <groupId>com.cloud.modules</groupId>
| |
| |--modules-logger 日志功能封装
| |
| |--modules-multi-datasource 多数据功能封装
| |
| |--modules-lh-security 分布式安全授权鉴权框架封装
| |
| |--modules-youji-task 酉鸡-分布式定时任务管理模块
| |
|
|
|
| 以下是独立部署的应用 以下服务启动后配合前端工程使用 (cloud-base-angular-admin)
|
|--cloud-gateway 应用网关
|
|--authorize-center 集成了modules-lh-security 的授权中心,提供统一授权和鉴权
|
|--code-generator 代码生成工具
|
|--user-center 用户中心 提供用户管理和权限管理的相关服务
|
|--youji-manage-server 集成了modules-youji-task 的定时任务管理服务端
七、版本使用说明
<springboot.version>2.4.2</springboot.version>
<springcloud.version>2020.0.3</springcloud.version>
<springcloud-alibaba.version>2021.1</springcloud-alibaba.version>
八、多环境打包说明
在需要独立打包的模块resources资源目录下增加不同环境的配置文件
application-dev.yml
application-test.yml
application-prod.yml
修改application.yml
spring:
profiles:
active: @profileActive@
在需要独立打包的模块下的pom文件中添加一下打包配置。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${springboot.version}</version>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<delimiters>
<delimiter>@</delimiter>
</delimiters>
<useDefaultDelimiters>false</useDefaultDelimiters>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
<profiles>
<profile>
<id>dev</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<profileActive>dev</profileActive>
</properties>
</profile>
<profile>
<id>test</id>
<properties>
<profileActive>test</profileActive>
</properties>
</profile>
<profile>
<id>prod</id>
<properties>
<profileActive>prod</profileActive>
</properties>
</profile>
</profiles>
mvn打包命令
# 打开发环境
mvn clean package -P dev -Dmaven.test.skip=ture
# 打测试环境
mvn clean package -P test -Dmaven.test.skip=ture
# 打生产环境
mvn clean package -P prod -Dmaven.test.skip=ture
九、构建Docker镜像
整合dockerfile插件,可直接将jar包构建为docker image 并推送到远程仓库
增加插件依赖
<!-- docker image build -->
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.4.10</version>
<executions>
<execution>
<id>default</id>
<goals>
<!--如果package时不想用docker打包,就注释掉这个goal-->
<!-- <goal>build</goal>-->
<goal>push</goal>
</goals>
</execution>
</executions>
<configuration>
<repository>49.232.166.94:8099/example/${project.artifactId}</repository>
<tag>${profileActive}-${project.version}</tag>
<username>admin</username>
<password>Harbor12345</password>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
在pom.xml同级目录下增加Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/lh0811/lh0811-docer:lh-jdk1.8-0.0.1
MAINTAINER lh0811
ADD ./target/${JAR_FILE} /opt/app.jar
RUN chmod +x /opt/app.jar
CMD java -jar /opt/app.jar
十、源码获取
作者:我先失陪了
来源:https://juejin.cn/post/7100457917115007013
JavaScript中的事件委托
事件委托基本概念
事件委托,就是一个元素的响应事件的函数委托给另一个元素
一般我们都是把函数绑定给当前元素的父元素或更外层元素,当事件响应到需要绑定的元素的时候,会通过事件冒泡机制(或事件捕获)去触发外层元素的绑定事件,在外层元素上去执行函数
在了解事件委托之前,我们可以先了解事件流,事件冒泡以及事件捕获
事件流:捕获阶段,目标阶段,冒泡阶段
DOM事件流有3个阶段:捕获阶段,目标阶段,冒泡阶段;
三个阶段的顺序为:捕获阶段——目标阶段——冒泡阶段
事件冒泡
事件的触发响应会从最底层目标一层层地向外到最外层(根节点)
比如说我现在有一个盒子f,里面有个子元素s
<div class="f">
<div class="s"></div>
</div>添加事件
var f = document.querySelector('.f')
var s = document.querySelector('.s')
f.addEventListener('click',()=>{
console.log('fffff');
})
s.addEventListener('click',()=>{
console.log('sssss');
})当我点击子元素的时候
冒泡顺序 s -> f
事件捕获
事件响应从最外层的Window开始,逐级向内层前进,直到具体事件目标元素。在捕获阶段,不会处理响应元素注册的冒泡事件
继续使用上一个例子,只需要将addEventListener第三个参数改为true即可
添加事件
var f = document.querySelector('.f')
var s = document.querySelector('.s')
f.addEventListener('click',()=>{
console.log('fffff');
},true)
s.addEventListener('click',()=>{
console.log('sssss');
},true)点击子元素
捕获顺序 f -> s
这里我们可以思考一下,如果同时绑定了冒泡和捕获事件的话,会有怎样的执行顺序呢?
例子不变,稍微改一下js代码
var f = document.querySelector('.f')
var s = document.querySelector('.s')
f.addEventListener('click',()=>{
console.log('f捕获');
},true)
s.addEventListener('click',()=>{
console.log('s捕获');
},true)
f.addEventListener('click',()=>{
console.log('f冒泡');
})
s.addEventListener('click',()=>{
console.log('s冒泡');
})此时点击子元素
执行顺序: f捕获->s捕获->s冒泡—>f冒泡
得出结论:当我们同时绑定捕获和冒泡事件的时候,会先从外层开始捕获到目标元素,然后由目标元素冒泡到外层
回到事件委托
了解了事件捕获和事件冒泡,再来看事件委托就很好理解了
强调一遍,事件委托把函数绑定给当前元素的父元素或更外层元素,当事件响应到需要绑定的元素的时候,会通过事件冒泡机制(或事件捕获)去触发外层元素的绑定事件,在外层元素上去执行函数
新开一个例子
<ul class="list">
<li class="item"></li>
<li class="item"></li>
<li class="item"></li>
<li class="item"></li>
<li class="item"></li>
</ul>现在我们有一个列表,当我们点击列表中的某一项时可以触发对应事件,如果我们给列表的每一项都添加事件,对于内存消耗是非常大的,效率上需要消耗很多性能
这个时候我们就可以把这个点击事件绑定到他的父层,也就是 ul 上,然后在执行事件的时候再去匹配判断目标元素;
var list = document.querySelector('.list')
// 利用冒泡机制实现
list.addEventListener('click',(e)=>{
e.target.style.backgroundColor='blue'
})
// 利用捕获机制实现
list.addEventListener('click',(e)=>{
e.target.style.backgroundColor='red'
},true)当我点击其中一个子元素的时候
总结
事件委托就是根据事件冒泡或事件捕获的机制来实现的
事件冒泡就是事件的触发响应会从最底层目标一层层地向外到最外层(根节点)
事件捕获就是事件响应从最外层的Window开始,逐级向内层前进,直到具体事件目标元素。在捕获阶段,不会处理响应元素注册的冒泡事件
补充:
对于目标元素,捕获和冒泡的执行顺序是由绑定事件的执行顺序决定的作者:张宏都
来源:https://juejin.cn/post/7100468737647575048
axios 请求拦截器&响应拦截器
一、 拦截器介绍
一般在使用axios时,会用到拦截器的功能,一般分为两种:请求拦截器、响应拦截器。
请求拦截器
在请求发送前进行必要操作处理,例如添加统一cookie、请求体加验证、设置请求头等,相当于是对每个接口里相同操作的一个封装;响应拦截器
同理,响应拦截器也是如此功能,只是在请求得到响应之后,对响应体的一些处理,通常是数据统一处理等,也常来判断登录失效等。
二、 Axios实例
创建axios实例
// 引入axios
import axios from 'axios'
// 创建实例
let instance = axios.create({
baseURL: 'xxxxxxxxxx',
timeout: 15000 // 毫秒
})baseURL设置:
let baseURL;
if(process.env.NODE_ENV === 'development') {
baseURL = 'xxx本地环境xxx';
} else if(process.env.NODE_ENV === 'production') {
baseURL = 'xxx生产环境xxx';
}
// 实例
let instance = axios.create({
baseURL: baseURL,
...
})修改实例配置的三种方式
// 第一种:局限性比较大
axios.defaults.timeout = 1000;
axios.defaults.baseURL = 'xxxxx';
// 第二种:实例配置
let instance = axios.create({
baseURL: 'xxxxx',
timeout: 1000, // 超时,401
})
// 创建完后修改
instance.defaults.timeout = 3000
// 第三种:发起请求时修改配置、
instance.get('/xxx',{
timeout: 5000
})这三种修改配置方法的优先级如下:请求配置 > 实例配置 > 全局配置
三、 配置拦截器
// 请求拦截器
instance.interceptors.request.use(req=>{}, err=>{});
// 响应拦截器
instance.interceptors.reponse.use(req=>{}, err=>{});请求拦截器
// use(两个参数)
axios.interceptors.request.use(req => {
// 在发送请求前要做的事儿
...
return req
}, err => {
// 在请求错误时要做的事儿
...
// 该返回的数据则是axios.catch(err)中接收的数据
return Promise.reject(err)
})响应拦截器
// use(两个参数)
axios.interceptors.reponse.use(res => {
// 请求成功对响应数据做处理
...
// 该返回的数据则是axios.then(res)中接收的数据
return res
}, err => {
// 在请求错误时要做的事儿
...
// 该返回的数据则是axios.catch(err)中接收的数据
return Promise.reject(err)
})常见错误码处理(error)
axios请求错误时,可在catch里进行错误处理。
axios.get().then().catch(err => {
// 错误处理
})四、 axios请求拦截器的案例
// 设置请求拦截器
axios.interceptors.request.use(
config => {
// console.log(config) // 该处可以将config打印出来看一下,该部分将发送给后端(server端)
config.headers.Authorization = store.state.token
return config // 对config处理完后返回,下一步将向后端发送请求
},
error => { // 当发生错误时,执行该部分代码
// console.log(error) // 调试用
return Promise.reject(error)
}
)
// 定义响应拦截器 -->token值无效时,清空token,并强制跳转登录页
axios.interceptors.response.use(function (response) {
// 响应状态码为 2xx 时触发成功的回调,形参中的 response 是“成功的结果”
return response
}, function (error) {
// console.log(error)
// 响应状态码不是 2xx 时触发失败的回调,形参中的 error 是“失败的结果”
if (error.response.status === 401) {
// 无效的 token
// 把 Vuex 中的 token 重置为空,并跳转到登录页面
// 1.清空token
store.commit('updateToken', '')
// 2.跳转登录页
router.push('/login')
}
return Promise.reject(error)
})作者:我彦祖不会秃
来源:https://juejin.cn/post/7100470316857557006
说说你对事件循环的理解
一、事件循环是什么
首先,JavaScript是一门单线程的语言,意味着同一时间内只能做一件事,但是这并不意味着单线程就是阻塞,而实现单线程非阻塞的方法就是事件循环
在JavaScript中,所有的任务都可以分为
同步任务:立即执行的任务,同步任务一般会直接进入到主线程中执行
异步任务:异步执行的任务,比如ajax网络请求,setTimeout定时函数等
同步任务与异步任务的运行流程图如下:
从上面我们可以看到,同步任务进入主线程,即主执行栈,异步任务进入任务队列,主线程内的任务执行完毕为空,会去任务队列读取对应的任务,推入主线程执行。上述过程的不断重复就事件循环
二、宏任务与微任务
如果将任务划分为同步任务和异步任务并不是那么的准确,举个例子:
console.log(1)
setTimeout(()=>{
console.log(2)
}, 0)
new Promise((resolve, reject)=>{
console.log('new Promise')
resolve()
}).then(()=>{
console.log('then')
})
console.log(3)
最终结果: 1=>'new Promise'=> 3 => 'then' => 2
微任务
一个需要异步执行的函数,执行时机是在主函数执行结束之后、当前宏任务结束之前
常见的微任务有:
Promise.then
MutaionObserver
Object.observe(已废弃;Proxy 对象替代)
process.nextTick(Node.js)
宏任务
宏任务的时间粒度比较大,执行的时间间隔是不能精确控制的,对一些高实时性的需求就不太符合
常见的宏任务有:
script (可以理解为外层同步代码)
setTimeout/setInterval
UI rendering/UI事件
postMessage、MessageChannel
setImmediate、I/O(Node.js)
这时候,事件循环,宏任务,微任务的关系如图所示
执行一个宏任务,如果遇到微任务就将它放到微任务的事件队列中
当前宏任务执行完成后,会查看微任务的事件队列,然后将里面的所有微任务依次执行完
回到上面的题目
console.log(1)
setTimeout(()=>{
console.log(2)
}, 0)
new Promise((resolve, reject)=>{
console.log('new Promise')
resolve()
}).then(()=>{
console.log('then')
})
console.log(3)
最终结果: 1=>'new Promise'=> 3 => 'then' => 2
// 遇到 console.log(1) ,直接打印 1
// 遇到定时器,属于新的宏任务,留着后面执行
// 遇到 new Promise,这个是直接执行的,打印 'new Promise'
// .then 属于微任务,放入微任务队列,后面再执行
// 遇到 console.log(3) 直接打印 3
// 好了本轮宏任务执行完毕,现在去微任务列表查看是否有微任务,发现 .then 的回调,执行它,打印 'then'
// 当一次宏任务执行完,再去执行新的宏任务,这里就剩一个定时器的宏任务了,执行它,打印 2
三、async与await
async 是异步的意思,await则可以理解为 async wait。所以可以理解async就是用来声明一个异步方法,而 await是用来等待异步方法执行
async
async函数返回一个promise对象,下面两种方法是等效的
function f() {
return Promise.resolve('TEST');
}
// asyncF is equivalent to f!
async function asyncF() {
return 'TEST';
}
await
正常情况下,await命令后面是一个 Promise对象,返回该对象的结果。如果不是 Promise对象,就直接返回对应的值
async function f(){
// 等同于
// return 123
return await 123
}
f().then(v => console.log(v)) // 123
不管await后面跟着的是什么,await都会阻塞后面的代码
async function fn1 (){
console.log(1)
await fn2()
console.log(2) // 阻塞
}
async function fn2 (){
console.log('fn2')
}
fn1()
console.log(3)
上面的例子中,await 会阻塞下面的代码(即加入微任务队列),先执行 async外面的同步代码,同步代码执行完,再回到 async 函数中,再执行之前阻塞的代码
所以上述输出结果为:1,fn2,3,2
四、流程分析
通过对上面的了解,我们对JavaScript对各种场景的执行顺序有了大致的了解
这里直接上代码:
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function () {
console.log('settimeout')
})
async1()
new Promise(function (resolve) {
console.log('promise1')
resolve()
}).then(function () {
console.log('promise2')
})
console.log('script end')
分析过程:
执行整段代码,遇到 console.log('script start') 直接打印结果,输出 script start
遇到定时器了,它是宏任务,先放着不执行
遇到 async1(),执行 async1 函数,先打印 async1 start,下面遇到await怎么办?先执行 async2,打印 async2,然后阻塞下面代码(即加入微任务列表),跳出去执行同步代码
跳到 new Promise 这里,直接执行,打印 promise1,下面遇到 .then(),它是微任务,放到微任务列表等待执行
最后一行直接打印 script end,现在同步代码执行完了,开始执行微任务,即 await下面的代码,打印 async1 end
继续执行下一个微任务,即执行 then 的回调,打印 promise2
上一个宏任务所有事都做完了,开始下一个宏任务,就是定时器,打印 settimeout
所以最后的结果是:script start、async1 start、async2、promise1、script end、async1 end、promise2、settimeout
作者:用户8249803991033
来源:https://juejin.cn/post/7100468871752056868
雷军:我的程序人生路
如果程序人生的话,这条路太漫长
我并非天生喜欢写程序,上高中时也没有想过程序员的生活。
我学电脑非常偶然,小时好友上大学时选择了计算机系,为了和这个朋友有更多的共同语言,我也选择了计算机系,开始步入程序人生的道路。
当我学会一些后,发现自己特别喜欢写程序。我是八七年上的武汉大学计算机系,大一下学期才有专业课。当我有资格上机的时候,发现电脑世界太美妙,就一头扎进去。
当时用的是 Motorola 68000 (相当 于 Intel 8088), 540K 的内存,运行的 UNIX 操作系统,八个人一起用。
大二学PC,又过了一学期,开始出现在老师的实验室,帮忙干活,当时就写了现在很多人用的 RI (RAMinit, 清内存的小工具, 看来我还是最早一批写 Shareware 的人)。
又过了一个学期,开始和校外的公司接触。大二暑假,也就是1989年8月,和一个朋友组建了 Yellow Rose 软件小组,写了我第一个商品软件 BITLOK 0.99。后来自己创业办过公司,也写过一些其他的软件。
大学毕业后,分到研究所,不太适应那里的气氛,就在1992年初加入金山软件,开始了职业程序员的生涯。后来成了金山软件研发部门的主管,但我一直都是一线的程序员。
程序员活在自己想象的王国里
我刚接触电脑就发现电脑的妙处,电脑远没有人那么复杂。如果你的程序写得好,你就可以和电脑处好关系,就可以指挥电脑干你想干的事。
这个时候你是十足的主宰。每每你坐在电脑面前,你就是在你的王国里巡行,这样的日子简直就是天堂般的日子。
电脑里的世界很大,编程人是活在自己想象的王国里。你可以想象到电脑里细微到每一个字节、每一个比特的东西。
我爱编程这个工作,可以肯定我会干上一辈子
不少人认为程序员最多干到三十五岁就可以收山换环境了,脑子也差不多该歇歇了,体力也不支了。并认为写程序是年轻人的事情,到了一定岁数,估计没什么人再当程序员了。
当我刚有一点本事的时候,我也和大家一样觉得编程辛苦,也想三十岁后干别的。当我年长一点后就发现了自己的无知。
一个人大学毕业就二十一二岁,有点水平的时候可能二十五,接着就是过日子诸多事情。一切搞掂的时候,也许就是三十五岁。如果这样的话,我们就不用选择程序人生的道路。
电脑进入中国时间并不短,但真正大规模开始用,还是八五年 PC 开始的,因此国内真正写电脑程序的人最长也就写了十几年(不知道是否还有这样的人)。
由于电脑应用在国内时间比较短,国内开发的主力是三十五岁以下的年轻人为主。但这不表示程序员如同红粉佳人般的容易衰老。美国主力工程师以三十四十多岁的人为主。
开始的时候,我们觉得我们没有什么不能做的(现在还能听到这样的豪言壮语),而且更要命的是好象我们特别聪明,特别适合开发软件,比老外强得多。
当我们真正接触那些杰出的开发人员的时候,发现他们太厉害了,都有十多年的开发经验。虽然也有很多年轻人做了很多好东西,但决大多数的产品出自这些有丰富开发经验的程序员的手。
刚毕业的时候,编程不仅仅是爱好,而且也成了一辈子的工作。整天不知道写些什么东西,觉得特别没劲,找不到感觉,特别灰心。
后来,才明白,只有全身心地投入,程序才会有感觉。
写程序的活特别费脑子,也特别累,但我喜欢,可以肯定我会干上一辈子,虽然我没有打算一生只干这一件事。用一生来编程序是一件既容易又困难的事。
如果碌碌无为,为交差写点程序,这样的日子太好混了。但如果想全身心地写程序,写十年就不是一件容易的事。
现在我不少朋友都洗手了,有时我也想“用什么电脑呀,Windows 外的世界不是也很大吗?”。
面对电脑的时候,立刻顿悟:写程序还是自己最擅长的事,也是最喜欢的事。
高级程序员不是追求的目标
有的人学习编程技术,是把高级程序员做为追求的目标,甚至是终身的奋斗目标。后来参与了真正的商品化软件开发后,反而困惑了,茫然了。
一个人只要有韧性和灵性,有机会接触并学习电脑的编程技术,就会成为一个不错的程序员。刚开始写程序,这时候学得多的人写的好,到了后来,大家都上了一个层次,谁写的好只取决于这个人是否细心、有韧性、有灵性。掌握多一点或少一点,很快就能补上。
成为一个高级程序员并不是件困难的事。
当我上学的时候,高级程序员也曾是我的目标,我希望我的技术能得到别人的承认。后来发现无论多么高级的程序员都没用,关键是你是否能够出想法出产品,你的劳动是否能被社会承认,能为社会创造财富。成为高级程序员绝对不是追求的目标。
编程不仅仅是技术,还是艺术
有人认为编程是一种熟练工种,也有人把编程说成是艺术创作。这两种意见争论比较激烈。
我们换个工种来看,石匠应该是熟练工种,属于工人,更和艺术似乎沾不上边。但正是这些石匠,给我们留下多少文物古迹,如乐山大佛、莫高窟等等。应该说这些石匠给我们留下了无穷的文化财产。
现代软件工业已具相当规模,很多软件的完成需要的是大兵团作战。一名普通程序员接受编写某一模块的任务后,往往只是写代码,发挥的余地很小。
在大项目中,很多程序员只能了解到和自己所编模块相关的很局部的细节,另外还受到开发环境的限制,真的很难体会到自己在从事”艺术”创造,更多的时候是感到自己在从事重体力劳动。
有的时候还担心自己苦苦参与的这个项目究竟有没有意义,是不是在同类产品中有竞争力,会不会开发出来以后就因为硬件的发展,操作系统的换代而过时……
我认为编程的工作和石匠比较相似,有技术活,更多的是体力活。不管怎么说,写出一个好软件不是一件容易的事。
这两种想法都有片面性,编程应该说两种属性都有。编程不仅仅是技术,也还是艺术。编程是技术活,才有可能大规模进行,才会有软件工程和软件工厂。也正是编程是艺术,才会有如此多的好产品,让大家如痴如醉。
著名程序编程指北点评表示,雷总是中国最早的一批程序员,极具极客精神。他把写程序当作一生的追求,完全没有去考虑程序员是吃青春饭的问题,全身心的投入到代码王国。
在他眼里编程不仅仅是谋生的一个技能,更是一种艺术。这也许就是极客程序员和普通程序员的区别吧。
希望诸君共勉,未来能在核心工业软件摆脱美国制裁上贡献属于自己的一行代码!
来源:雷军的博客 blog.sina.com.cn/leijun
收起阅读 »“寻忆·超龄少年团”APICloud AVM组件心愿征集正式启动!
随着APICloud移动低代码开发能力的持续演进,基于APICloud Studio3的可视化开发工具呼之欲出,在平台产品能力跨越式升级中,丰富的可视化开发组件将帮助用户进一步提升应用构建效率,并能够自动生成专业级源代码。
值此六一与端午双节来临之际,APICloud特别推出“寻忆·超龄少年团”AVM组件心愿征集活动,通过环环相扣的活动任务,帮助开发者进一步熟悉可视化开发工具,丰富AVM组件生态,同时更有现金、实物、积分等丰厚奖励。

活动时间
即日起至6月30日
活动入口
https://www.apicloud.com/activity2205
(请PC端访问)
活动玩法
玩法一:AVM组件心愿悬赏
活动期间内,按照组件规范,提交上架AVM组件,即可赢取奖金,所有提交上架组件均需符合最新版APICloud平台AVM组件开发规范,不符合开发规范的组件将会被拒绝上架。【我要报名开发AVM组件】
玩法二:童年寻忆·龙舟争夺战
活动期间通过寻忆任务获得记忆卡片,通过开启童年记忆卡累积的龙舟划行距离进行排行评奖(彩蛋奖每个账号仅可获得1次)。
寻忆任务:
每个成功上架的AVM组件可获得5张记忆卡片;
每日签到可获得5张记忆卡片;
参加YonMaster认证考试并且通过,可获得25张记忆卡片;
更新登录新版APICloud Studio 3,且体验拖拽式工具,可获得10张记忆卡片。
童年记忆卡:
典藏记忆卡可使龙舟划行300米,附赠300积分;
普通记忆卡可使龙舟划行100米,附赠100积分;
寻到相同记忆卡,龙舟向前划行50米,附赠50积分;
积分逢66或6,可使龙舟滑行66或6米。
活动奖品
AVM组件心愿悬赏
普通组件:每个200元;
心愿组件:每个400元,上架数量达到10个,每个600元,最高可得30000元;
伙伴组件:结合伙伴模块开发AVM组件可参与平分奖金,以及另外加奖。
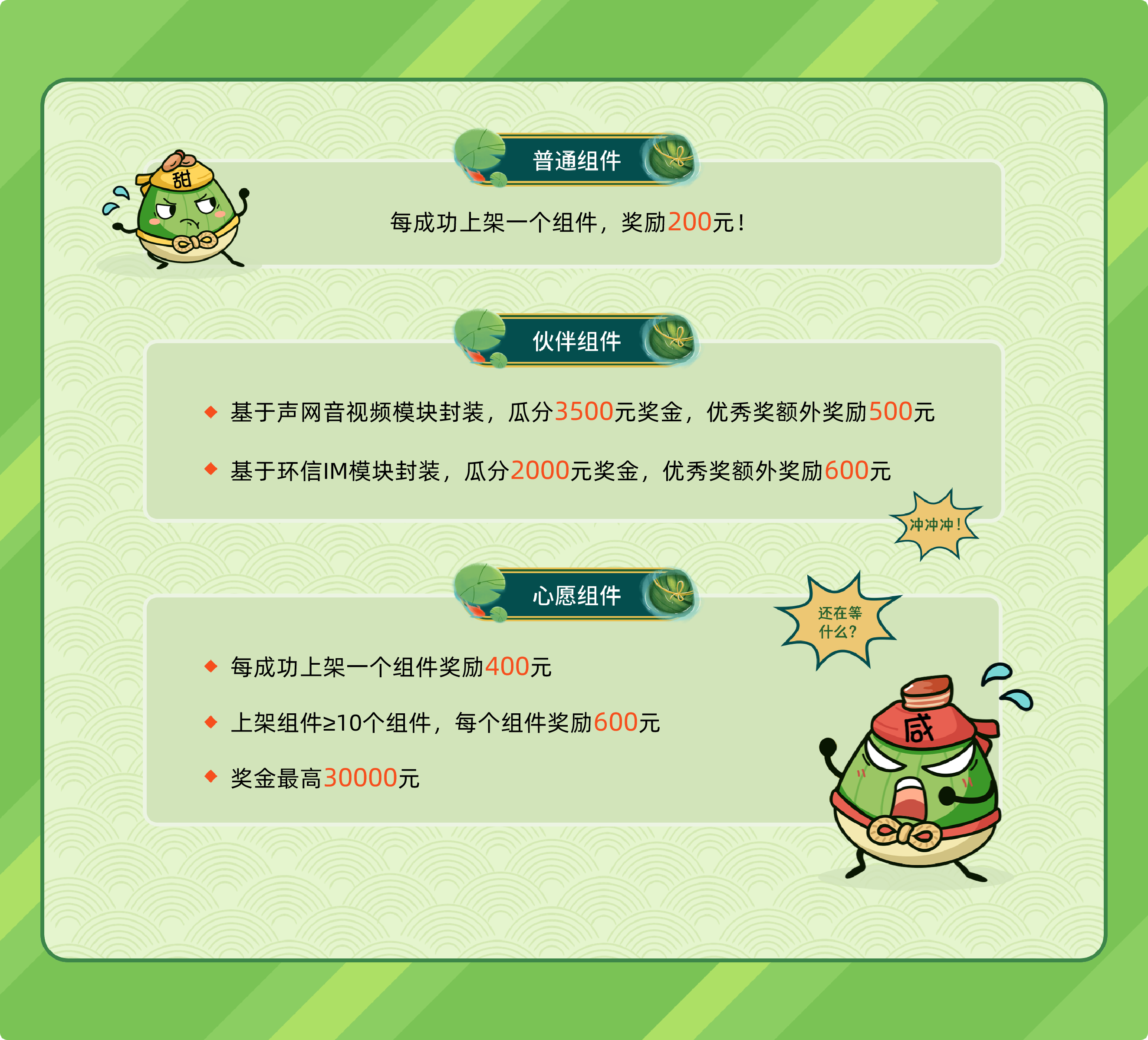
第一名:Switch游戏主机一台;
第二名至第五名:小霸王游戏机一台;
第六名至第十名:零食大礼包一袋;
第十一名至第三十名:10000APICloud积分(可转换成Y币,兑换实物礼品)。

发奖说明
积分奖励将自动发放到账户当中,请关注积分明细;
实物与现金奖励(含税)请开发者在7月10日前扫码联系活动落地页微信客服,提交收货信息进行兑奖;
未及时兑奖将视为放弃领奖,奖品预计在2022年7月30日前完成发放。
软件开发生命周期(SDLC)完全指南:6个典型阶段+6个常用开发模型
本文和您讨论了SDLC的6个典型阶段、以及6个常用开发模型,并给出如何根据不同的项目特征,选择这些开发方法的建议。
译者 | 陈峻
审校 | 孙淑娟
软件开发生命周期(Software Development Life Cycle,SDLC)包含了软件从开始到发布的不同阶段。它定义了一种用于提高待开发软件质量和效率的过程。因此,SDLC旨在通过最少的资源,交付出高质量的软件。为了避免产生严重项目失败后果,软件开发的生命周期通常可以被划分为如下六个阶段:
需求收集
设计
软件开发
测试和质量保证
部署
维护
值得注意的是,这些阶段并非是静态的,它们可以进一步地被分解成多个子类别,以适应独特的开发需求与流程。

图 1 软件开发生命周期
需求收集
这是整个周期中其他阶段的基础。在此阶段,所有利益相关者(包括客户、产品负责人等)都会去收集与待开发软件相关的信息。对此,项目经理和相关方会频繁召开会议。尽管此过程可能比较耗时,但是我们不可急于求成,毕竟大家需要对将要开发的产品有个清晰的了解。
利益相关方需要将收集到的所有信息,记录到软件需求规范(Software Requirement Specification,SRS)文档中。在完成了需求收集后,开发团队需要进行可行性研究,以确定项目是否能够被完成。
设计
此阶段旨在模拟软件应用的工作方式,并设计出软件蓝图。负责软件高级设计的开发人员将组成设计团队,并通过由上个阶段产生的SRS文档,来指导设计过程,并最终完成满足要求的体系结构。此处的高级设计是指包括用户界面、用户流程、通信设计等方面在内的基础要素。
软件开发
在此阶段,具有不同专业知识(例如前端和后端)的开发人员或工程师,会通过处理设计的需求,来构建和实现软件。这既能够由一个人,也可以由一个大型团队来执行,具体取决于项目的规模。
后端开发人员负责构建数据库结构和其他必要组件。最后,由前端开发人员根据设计去构建用户界面,并按需与后端进行对接。
在配套文档方面,用户指南会被创建,源代码中也应适当地留下相应的注释。也就是说,为了保证良好的代码质量,适当的开发指南和政策也是必不可少的。
测试
专门的测试人员协同开发团队在此阶段开展测试工作。测试既可以与开发同时进行,也可以在开发阶段结束时再开展。通常,开发人员在开发软件时就会进行单元测试,以便检查每个源代码单元是否能够按照预期工作。同时,此阶段也包括如下其他测试:
系统测试--通过测试系统,以验证其是否满足所有指定的需求。
集成测试--将各个模块组合到一起进行测试。测试团队通过单击按钮,并执行滚动和滑动操作,来与软件交互。当然,他们并不需要了解后端的工作原理。
用户验收测试--是在启动软件之前,邀请潜在用户或客户进行的最终测试。此类测试可以验证目标软件,是否能够根据需求的规范,处理各种真实的场景。
测试对于软件开发生命周期是至关重要的。倘若无法以正确的方式开展,则会让软件项目团队反复在开发和测试阶段之间徘徊,进而影响到成本和时间。
部署
完成测试后,我们就需要通过部署软件,来方便用户使用了。在此阶段,部署团队需要通过遵循若干流程,来确保部署流程的成功。无论是简单的流程,还是复杂的部署,都会涉及到创建诸如安装指南、系统用户指南等相关部署文档。
维护
作为开发周期的最后阶段,维护涉及到报告并修复在测试期间未能发现的错误。在修复方式上,我们既能够采取立即纠正错误的方式,也可以将其作为常规性的软件更新。
此外,软件项目团队还会在此阶段从用户处收集反馈,以协助软件的改进,并提高用户的软件使用体验。
SDLC方法
虽然SDLC通常都会遵从上述步骤,但是它们在实现方式上略有不同。下面,我将介绍排名靠前的6种SDLC方法:
瀑布
敏捷
精益
迭代
螺旋
DevOps方法
瀑布方法
图 2 瀑布方法
作为最古老、也是最直接的SDLC方法,瀑布方法遵循的是线性执行顺序。如上图所示,从需求收集到维护,逐步依次推进,且不存在任何逆转或倒退的步骤。也就是说,只有当上一步完成后,才能继续下一步。
由于在设计阶段之后,该方法不存在任何变化或调整的余地,因此,我们需要在需求收集阶段,收集到有关项目的所有信息,即制作软件蓝图。可见,对于经验不足的开发团队而言,如果能够保证软件的需求从项目开始就精确且稳定的话,便可以采用瀑布方法。也就是说,瀑布模型的成功,在很大程度上取决于需求收集阶段的输出是否清晰。当然,它也比较适合那些耗时较长的项目。
瀑布的优势
需求在初始阶段就能够被精心设计。
具有容易理解的线性结构。
易于管理。
瀑布的缺点
既不灵活,又不支持变更。
任何阶段一旦出现延迟,都会导致项目无法推进。
由于较为死板,因此项目总体时间较长。
并不鼓励在初始阶段之后,利益相关者进行积极地沟通。
敏捷方法
图 3 敏捷方法生命周期
敏捷(Agile)即为快速轻松的移动能力。以沟通和灵活性为中心的敏捷原则与方法,提倡以更短的周期和增量式地进行部署与发布。
在敏捷开发的生命周期中,每个阶段都有一个“仪式(ceremony)”,以便从开发团队和参与项目的其他利益相关者处获取反馈。其中包括:冲刺(sprint)计划、每日scrum、冲刺评审、以及冲刺回顾。
总地说来,敏捷开发是在各个“冲刺”中进行的,每个冲刺通常持续大约2到4周。每个冲刺的目标不一定是构建MVP(最小可行产品,Minimum Viable Product),而是构建可供客户使用的软件的一小部分。其交付出来的可能只是某个功能,而非具有完全功能的产品。也就是说,交付成果可能只是一个将来能够被慢慢增加的功能性服务,而不一定是MVP。
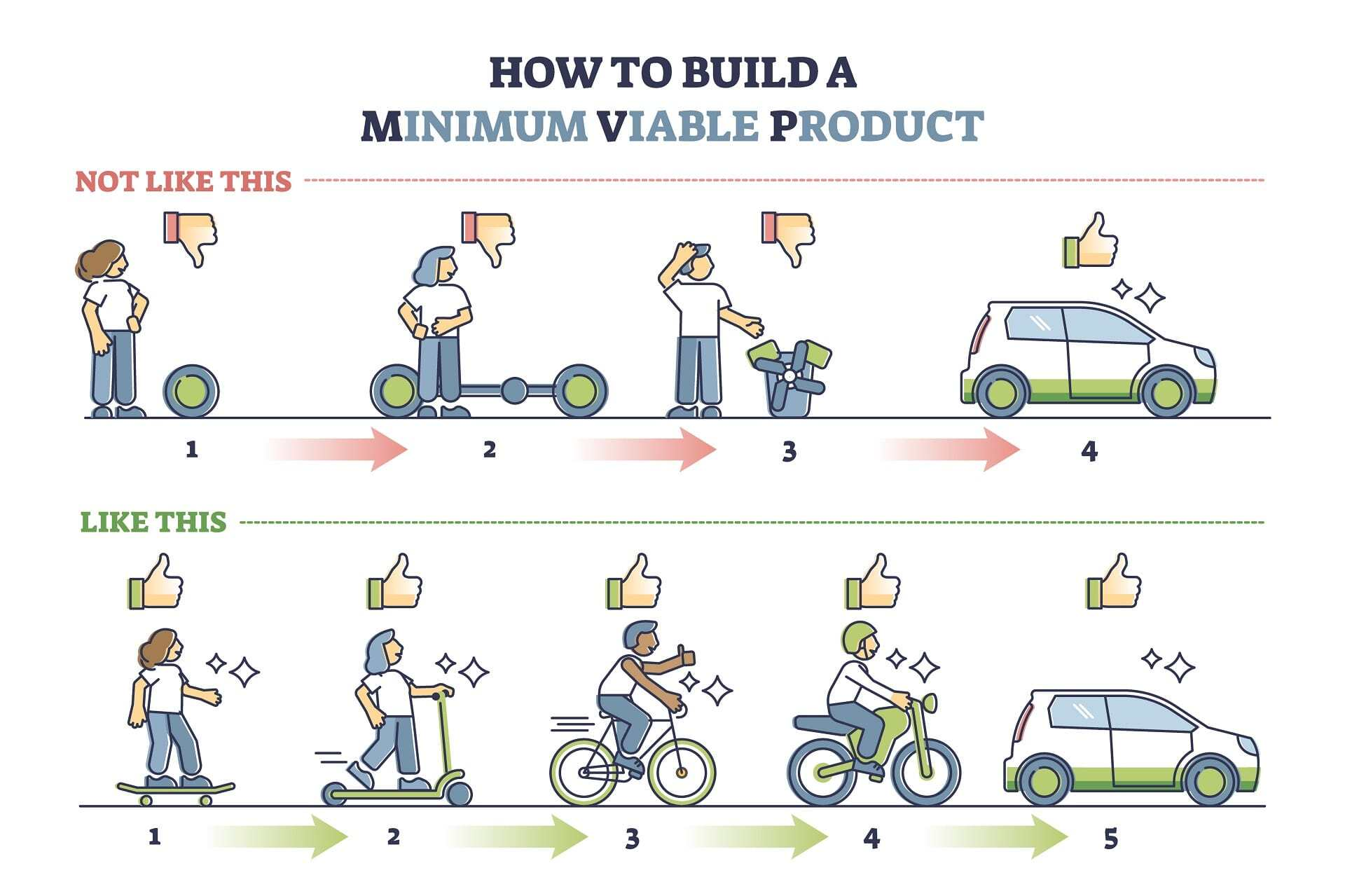
图 4 构建最小可行产品的示例
在每个冲刺结束后的冲刺审查阶段,如果利益相关者对开发的功能感到满意的话,方可开展下一轮冲刺。虽然新的功能是在冲刺中被开发的,但是整个项目期间的冲刺数量并不受限。它往往取决于项目和团队的规模。因此,敏捷方法最适用于那些从一开始就无法明确所有要求的项目。
敏捷的优势
适合不断变化的需求。
鼓励利益相关者之间的反馈和持续沟通。
由于采用了增量式方法,因此更易于管理各种潜在风险。
敏捷的缺点
最少量的文档。
需要具有高技能的资源。
如果沟通低效,则可能拖慢项目的速度。
如果过度依赖客户的互动,则可能会导致项目走向错误的方向。
精益方法
软件开发领域的精益方法源于精益制造的原则。这种方法旨在减少生产过程中的浪费和成本,从而实现利润的最大化。该方法虽与敏捷开发类似,但是侧重于效率、快速交付、以及迭代式开发。而区别在于,敏捷方法更专注于持续沟通和协作,以体现价值;而精益方法更专注于消除浪费,以创造客户价值。
精益方法的七个核心概念:
消除浪费--鼓励开发团队尽可能多地消除浪费。这种方法在某种程度上并不鼓励多任务处理。这意味着它只需要完成“份内”的处理工作,并通过节省构建所谓“锦上添花”的功能,来节省时间。同时在所有开发阶段都避免了不必要的文档和会议。
鼓励学习--通过鼓励创建一个有利于所有相关成员学习的环境,来促进团队对软件开发过程予以反馈。
推迟决定--在做出决定之前,应仔细考虑各种事实。
尽快交付--由于交付是基于时间的,因此它会专注于满足交付期限的增量式交付,而非大礼包式的发布。
团队授权--它避开了针对团队的微观管理,而是鼓励大家积极地参与到决策过程中,让彼此感到参与了重要的项目。它不但为团队成员提供了指导方向,而且为失败留出了足够的空间。
构建质量--由于在开发周期的所有阶段都关注客户价值,因此它会定期进行有关质量保证的各项测试。
整体优化--通过关注整个项目,而不是单独的项目模块,来有效地将组织战略与项目方案相结合。
精益方法的优势
由于团队参与到了决策之中,因此创造力得到了激发。
能够尽早地消除浪费,降低成本,并加快交付的速度。
精益方法的缺点
对于纪律性较差的团队而言,它不一定是最佳选择。
项目目标和重点可能会受到诸多灵活性的影响。
迭代方法
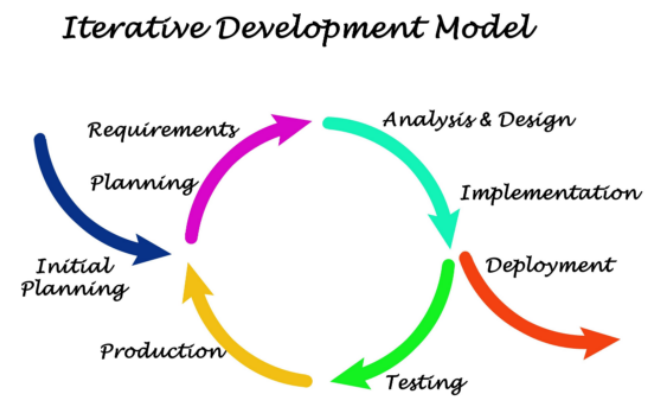
图 5 迭代开发模型
开发界引入迭代方法作为瀑布模型的替代方案。它通过添加迭代式重复性开发周期,来克隆瀑布方法的所有步骤。由于最终产品的各个部分在完成后,才在每次迭代结束时发布的,因此这种方法也属于增量式。具体而言,迭代方法的初始阶段是计划,而最后一个阶段是部署。介于两者之间的是:计划、设计、实施、测试和评估的循环过程。
迭代方法虽与敏捷方法类似,但是它涉及的客户参与度较少,并且具有预定义的增量范围。
迭代的优点
在早期阶段,它能够生成产品的可运行版本。
其变更的成本更低。
由于产品被分成较小的部分,因此更易于管理。
迭代的缺点
可能需要更多的资源。
有必要全面了解各项需求。
不适合小型项目。
螺旋方法
作为一种具有风险意识的软件开发方法,螺旋方法侧重于降低软件开发过程中的各项风险。它属于一种迭代的开发方法,在循环中不断推进。由于结合了瀑布模型和原型设计,因此螺旋方法是最灵活的SDLC方法,并具有如下四个主要阶段:
第一阶段--定义项目目标并收集需求。
第二阶段--该方法的核心是进行全面的风险分析和计划,消减已发现的风险。产品原型会在本阶段交付出来。
第三阶段--执行开发和测试。
第四阶段--涉及评估已开发的内容,并计划开展下一次迭代。
螺旋方法主要适用于高度定制化的软件开发。此外,用户对于原型的反馈可以在迭代后期(在开发阶段)扩展各项功能。
螺旋方法的优势
由于引入了广泛的风险分析,因此尽可能地避免了风险。
它适用于较大型的项目。
可以在迭代后期添加其他功能。
螺旋方法的缺点
它更关注成本收益。
它比其他SDLC方法更复杂。
它需要专家进行风险分析。
由于严重依赖风险分析,因此倘若风险分析不到位,则可能会使整个项目变得十分脆弱。
DevOps方法
图 6 DevOps方法
在传统的软件开发方法中,开发人员和运维人员之间几乎没有协作。特别是在运营过程中,开发人员往往被视为“构建者”的角色。这就造成了沟通和协作上的差距,以及在反馈过程中出现混淆。而软件开发的DevOps方法恰好弥合了两者之间的沟通鸿沟。其目标是通过将开发和运营团队有效地结合起来,以快速地开发出更可靠的优质软件。值得一提的是,DevOps也是一种将手动开发转换为自动化软件开发的方法。通常,DevOps方法会被划分为如下5个阶段:
持续开发--此阶段涉及到软件应用的规划和开发。
持续集成—此阶段会将新的功能性代码与现有的代码相集成。
持续测试--开发团队和QA测试人员会使用maven和TestNG等自动化工具开展测试,以确保在新的功能中扫清缺陷。自动化测试为各种测试用例的执行节省了大量时间。
持续部署--此阶段会使用类似puppet的配置管理工具、以及容器化工具,将代码部署到生产环境(即服务器上)。它们还将协助安排服务器上的更新,并保持配置的一致性。
持续监控—运营团队会在此阶段通过使用Nagios、Relix和Splunk等工具,主动监控用户活动中的错误、异常、不当的软件行为、以及软件的性能。所有在此阶段被发现的问题都会被传递给开发团队,以便在持续开发阶段进行修复,进而提高软件的质量。
DevOps的优势
促进了合作。
通过持续开发和部署,更快地向市场交付软件。
最大化地利用Relix。
DevOps的缺点
当各个团队使用不同的环境时,将无法保证软件的安全。
涉及到人工输入的过程时,可能会减慢整体运营的速度。
小结
综上所述,软件开发生命周期中的每一个阶段都是非常重要的。我们只有正确地执行了每个步骤,才能最大限度地利用现有资源,并交付出高质量、可靠的软件。
事实上,软件开发并没有所谓的“最佳”方法,它们往往各有利弊。因此在选择具体方法之前,您需要了解待选方法对手头项目的实用性。当然,为了尽可能地采用最适合现有流程的方法,许多公司会同时使用两种不同方法的组合,通过取长补短来实现有效的融合,并相辅相成地完成软件的交付任务。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:The Complete Guide to SDLC,作者:Mario Olomu
收起阅读 »百度程序员Android开发小技巧
本期技术加油站给大家带来百度一线的同学在日常工作中Android 开发的小技巧:Android有序管理功能引导;一行代码给View增加按下态;一行代码扩大 Andriod 点击区域,希望能为大家的技术提升助力!
01Android有序管理功能引导
随着移动互联网的发展,APP的迭代进入了深水区,产品迭代越来越精细化。很多新需求都会添加功能引导,提高用户对新功能的感知。但是,如果每个功能引导都不考虑其它的功能引导View冲突,就会出现多个引导同时出现的情况,非常影响用户体验,降低引导效果。因此,有序管理功能引导View就显得非常重要。
首先,我们需要根据自身的业务场景,梳理不同的引导类型。为了精准区分每一种引导,使用枚举定义。
enum class GuideType {
GuideTypeA,
...
GuideTypeN
}
1.
2.
3.
4.
5.
其次,将这些引导注册到引导管理器GuideManager中,注册方法需要传入引导的类型,显示引导回调,引导是否正在显示回调,引导是否已经显示回调等参数。注册引导实际上就是将引导的根据优先级保存在一个集合中,便于在需要显示引导时,判断此时是否能够显示该引导。
object GuideManager {
private val guideMap = mutableMapOf<Int, GuideModel>()
fun registerGuide(guideType: GuideType,
show: () -> Unit,
isShowing: () -> Boolean,
hasShown: () -> Boolean,
setHasShown: () -> Unit) {
guideMap[guideType.ordinal] = GuideModel(show, isShowing, hasShown, setHasShown)
}
...
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
接下来,业务方调用GuideManager.show(guideType)触发引导的显示。
如果要显示的引导没有注册,则不会显示;
如果要显示的引导正在显示或已经显示,则不会重复显示;
如果当前注册的引导集合中有引导正在显示,则不会显示;
调用show回调,设置已经显示过;
object GuideManager {
...
fun show(guideType: GuideType) {
val guideModel = guideMap[guideType.ordinal] ?: return
if (guideModel.isShowing.invoke() || guideModel.hasShown.invoke()) {
return
}
guideMap.forEach {
if (entry.value.isShowing().invoke()) {
return
}
}
guideModel.run {
show().invoke()
setHasShown().invoke()
}
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
最后,需要处理单例中已注册引导的释放逻辑,将guideMap集合清空。
object GuideManager {
...
fun release() {
guideMap.clear()
}
}
1.
2.
3.
4.
5.
6.
以上实现是简易版的引导管理器,使用时还可以结合具体业务场景,添加更多的引导拦截策略,例如当前业务场景处于某个状态时,所有引导都不展示,则可以在GuideManager.show(guideType)中添加个性化处理逻辑。
02一行代码给View增加按下态
在Android开发中,经常会遇到UE要求添加按下态效果。常规的写法是使用selector,分别设置按下态和默认态的资源,代码示例如下:
<?xml version="1.0" encoding="utf-8"?>
<selector xmlns:android="http://schemas.android.com/apk/res/android">
<item android:drawable="@drawable/XX_pressed" android:state_selected="true"/>
<item android:drawable="@drawable/XX_pressed" android:state_pressed="true"/>
<item android:drawable="@drawable/XX_normal"/>
</selector>
1.
2.
3.
4.
5.
6.
UE提供的按下态效果,有的时候仅需改变透明度。这种效果也可以用上述方法实现,但缺点也很明显,需要增加额外的按下态资源,影响包体积。这个时候我们可以使用alpha属性,代码如下:
<?xml version="1.0" encoding="utf-8"?>
<selector xmlns:android="http://schemas.android.com/apk/res/android">
<item android:drawable="@drawable/XX" android:alpha="XX" android:state_selected="true"/>
<item android:drawable="@drawable/XX" android:alpha="XX" android:state_pressed="true"/>
<item android:drawable="@drawable/XX"/>
</selector>
1.
2.
3.
4.
5.
6.
这种写法,不需要额外增加按下态资源,但也有一些缺点:该属性Android 6.0以下不生效。
我们可以利用Android的事件分发机制,封装一个工具类,从而达到一行代码实现按下态。代码如下:
@JvmOverloads
fun View.addPressedState(pressedAlpha: Float = 0.2f) = run {
setOnTouchListener { v, event ->
when (event.action) {
MotionEvent.ACTION_DOWN -> v.alpha = pressedAlpha
MotionEvent.ACTION_CANCEL, MotionEvent.ACTION_UP -> v.alpha = 1.0f
}
// 注意这里要return false
false
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
用户对屏幕的操作,可以简单划分为以下几个最基础的事件:
Android的View是树形结构的,View可能会重叠在一起,当点击的地方有多个View可以响应点击事件时,为了确定该让哪个View处理这次点击事件,就需要事件分发机制来帮忙。事件收集之后最先传递给 Activity,然后依次向下传递,大致如下:Activity -> PhoneWindow -> DecorView -> ViewGroup -> … -> View。如果没有任何View消费掉事件,那么这个事件会按照反方向回传,最终传回给Activity,如果最后 Activity 也没有处理,本次事件才会被抛弃。这是一个非常典型的责任链模式。整个过程,有三个非常重要的方法:
以上三个方法均有一个布尔类型的返回值,通过返回 true 和 false 来控制事件传递的流程。这三个方法的调用关系,可以用下面的伪代码描述:
public boolean dispatchTouchEvent(MotionEvent ev) {
boolean consume = false;
if (onInterceptTouchEvent(ev)) {
consume = onTouchEvent(ev);
} else {
consume = child.dispatchTouchEvent(ev);
}
return consume;
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
对于一个View来说,它可以注册很多事件监听器,例如单击事件、长按事件、触摸事件,并且View自身也有onTouchEvent方法,这些与事件相关的方法由View的dispatchTouchEvent方法管理,事件的调度顺序是onTouchListener -> onTouchEvent -> onLongClickListener -> onClickListener。所以我们可以通过为View添加onTouchListener来处理View的按下、抬起效果。需要注意的是,如果onTouchListener中的onTouch返回true,不会再继续执行onTouchEvent,后面的事件都不会响应,所以我们需要在工具类中return false。
03一行代码扩大 Andriod 点击区域
在Android 开发中,经常会遇到扩大某些按钮点击区域的场景,如某个页面关闭按钮比较小,为防止误触或点不到,需要扩大其点击区域。
常见的扩大点击区域的思路有三个:
1. 修改布局。如增加按钮的内padding,或者外面嵌套一层Layout,并在外层Layout设置监听。
2. 自定义事件处理。如在父布局中监听点击事件,并设置各组件的响应点击区域,在对应点击区域里时就转发到对应组件的点击。
3. 使用 Android 官方提供的TouchDelegate 设置点击事件。
其中第一种方式弊端很明显,会增加业务复杂度,降低渲染性能;或者当布局位置不够时,增加padding或添加外层布局就行不通了。
第二种方式可以从根本上扩大点击区域,但是问题依旧明显:编码的复杂度太高,每次扩大点击区域都意味着需要根据实际需求去“重复造轮子”:写一堆获取位置、判定等代码。
第三种方式是Android官方提供的一个解决方案,能够比较优雅地解决这个问题,如下描述:
Helper class to handle situations where you want a view to have a larger touch area than its actual view bounds. The view whose touch area is changed is called the delegate view. This class should be used by an ancestor of the delegate. To use a TouchDelegate, first create an instance that specifies the bounds that should be mapped to the delegate and the delegate view itself.
当然,如果使用 Android 的TouchDelegate,很多时候还不能满足我们需求,比如我们想在一个父(祖先)View 中给多个子 View 扩大点击区域,如在一个互动Bar上有点赞、收藏、评论等按钮。这时可以在自定义TouchDelegate时维护一个View Map,该Map 中保存子View和对应需要扩大的区域,然后在点击转发逻辑里动态计算该点击事件属于哪个子View区域,并进行转发。关键代码如下:
// 已省略无关代码
public class MyTouchDelegate extends TouchDelegate {
/** 需要扩大点击区域的子 View 和其点击区域的集合 */
private Map<View, ExpandBounds> mDelegateViewExpandMap = new HashMap<>();
@Override
public boolean onTouchEvent(MotionEvent event) {
// ……
// 遍历拿到对应的view和扩大区域,其它逻辑跟原始逻辑类似
for (Map.Entry<View, ExpandBounds> entry : mDelegateViewExpandMap.entrySet()) {
View child = entry.getKey();
ExpandBounds childBounds = entry.getValue()
}
// ……
}
public void addExpandChild(View delegateView, int left, int top, int right, int bottom) {
MyTouchDelegate.ExpandBounds expandBounds = new MyouchDelegate.ExpandBounds(new Rect(), left, top, right, bottom);
this.mDelegateViewExpandMap.put(delegateView, expandBounds);
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
更进一步的,可以写个工具类,或者Kotlin扩展方法,输入需要扩大点击区域的View、祖先View、以及对应的扩大大小,从而达到一行代码扩大一个View的点击区域的目的。
public static void expandTouchArea(View ancestor, View child, int left, int top, int right, int bottom) {
if (child != null && ancestor != null) {
MyTouchDelegate touchDelegate;
if (ancestor.getTouchDelegate() instanceof MyTouchDelegate) {
touchDelegate = (MyTouchDelegate)ancestor.getTouchDelegate();
touchDelegate.addExpandChild(child, left, top, right, bottom);
} else {
touchDelegate = new MyTouchDelegate(child, left, top, right, bottom);
ancestor.setTouchDelegate(touchDelegate);
}
}
}
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
注意: TouchDelegate在Android8.0及其以前有个bug,如果需要兼容低版本需要留意下,在通过delegate触发子View点击事件之后,父View自己监听的点击事件就永远无法被触发了,原因在于TouchDelegate中对点击事件转发的处理中(onTouchEvent)对MotionEvent.ACTION_DOWN)有问题,不在点击范围内时,未对mDelegateTargeted变量重置为false,导致父view再也收不到点击事件,无法处理click等操作,相关Android源码如下:
// …… 已省略无关代码
public boolean onTouchEvent(MotionEvent event) {
// ……
boolean sendToDelegate = false;
boolean handled = false;
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
Rect bounds = mBounds;
if (bounds.contains(x, y)) {
mDelegateTargeted = true;
sendToDelegate = true;
} // if的判断为false时未重置 mDelegateTargeted 的值为false
break;
// ……
if (sendToDelegate) {
// 转发代理view
handled = delegateView.dispatchTouchEvent(event);
}
return handled;
// ……
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
如果需要兼容低版本,则可以继承自TouchDelegate,覆写 onTouchEvent方法,在事件不在代理范围内时,重置mDelegateTargeted 和sendToDelegate值为false,如下:
……
if (bounds.contains(x, y)) {
mDelegateTargeted = true;
sendToDelegate = true;
} else {
mDelegateTargeted = false;
sendToDelegate = false;
}
// 或者如9.0之后源码的写法
mDelegateTargeted = mBounds.contains(x, y);
sendToDelegate = mDelegateTargeted;
……
-----------------------------------
©著作权归作者所有:来自51CTO博客作者百度Geek说的原创作品,请联系作者获取转载授权,否则将追究法律责任
百度程序员Android开发小技巧
https://blog.51cto.com/u_15082365/5305270
gitee开源必须审核?搬起石头砸自己的脚?非必要不开源?

有网友表示很能理解,因为对开源不能一刀切,需要借鉴目前先进的管控经验。对代码库进行网格化管理,责任层层压实:
未通过审核的代码显示为红码,通过的为绿码;
存在红码的仓库被划为封控区,所有member和提交过pull request的作为密接要封控14天并对参与的其他代码库进行入库统一消杀;
所有star和issue作者都作为时空伴随者,随后7天内每次commit都要重新审核,一旦发现红码立即转运;
密接拥有的代码库中其他参与者作为次密接进行定期观察;
非必要不开源,非必要不编程;
尽快摸清底数,控制增量;发现一行代码,处理一行代码,争取早日做到开源面清零。
有网友表示,:
开源不是可口可乐,全世界不能一个味。
谨防恶意开源
非必要不开源
搬起石头砸自己的脚
能用gitee,你就偷着乐吧
推动中国开源建设
以上观点来源:www.zhihu.com/question/533388365/answer/2492004178http://www.zhihu.com/question/533388365/answer/2491722941
http://www.zhihu.com/question/533388365/answer/2491840969
http://www.zhihu.com/question/533388365
B站崩的那晚,连夜谋划了这场稳定性保障SRE升级之战
本文分享主题是B站SRE在稳定性方面的运营实践。
随着B站近几年的快速发展,业务规模越来越大,迭代速度越来越快,系统运行复杂度也越来越高。线上每天都会发生各种各样的故障,且发生的场景越来越刁钻。为了应对这种情况,保障业务在任何时刻都能将稳定性维持在一个高基线之上,B站专门成立了SRE体系团队,在提升业务稳定性领域进行了全方位、体系化的积极探索,从理论性支撑和能力化建设进行着手,从故障应急响应、事件运营、容灾演练、意识形态等多方面进行稳定性运营体系的构筑。
本次分享主题是B站SRE在稳定性方面的运营实践,分享内容分为以下几个部分:
案例剖析
从应急响应看稳定性运营
核心运营要素有哪些
两个运营载体:OnCall与事件运营中心
挑战与收益
一、案例剖析
多年来业界同仁针对稳定性这一话题进行了大量的探索和实践,业界不乏针对稳定性保障相关的讨论和研究。在围绕稳定性的实践上,大家也经常听到诸如混沌工程、全链路压测、大促活动保障和智能监控等话题的分享。B站在这些方面也做了很多建设工作,今天我将从应急响应的角度切入,和大家分享B站在稳定性运营方面所做的工作。
我们先来看两个案例,案例以真实事件为依托,相关敏感内容进行了改写。
案例一

1)背景
一个手机厂商的发布会在某天晚上12点举办,B站承接了该品牌的线上发布会直播。公司的运营同学提前就配置好了12点的直播活动页面以及准点的应用内Push消息。在12点到来之后,直播活动页推送生效,大量用户收到应用内推送消息,点击进入直播活动页面。
2)故障始末
12点01分,直播活动页内嵌的播放器无法支持部分用户正常加载播放。
12点03分,研发同学李四收到了异常的报警,开始介入处理。
12点04分,客服同学收到了大量有关发布会无法正常播放的用户反馈,常规处理方法无法解决用户问题。
影响持续到12点15分,研发同学李四还在排查问题的具体原因,没有执行相对应的止损预案(该种问题有对应预案),问题持续在线上造成影响。
直到12点16分,老板朋友找到了老板反馈今晚B站的某品牌手机直播发布会页面视频无法正常播放,此时老板开始从上往下询问,研发leader知道了这件事,开始联系SRE同学介入问题处理,并及时执行了相关的切换预案,直播活动页面播放恢复正常。
3)问题
在这个案例中,暴露了以下一些问题:
故障的相关告警虽然及时,但是并没有通知到足够多对的人。
该故障的告警,在短时间没有处理响应后,并未进行有效的结构性升级(管理升级,及时让更高level的人参与进来,知晓故障影响,协调处理资源)和职能性升级(技术升级,让更专业和更对口的人来参与响应处理,如team leader、SRE等)。
一线同学往往容易沉迷于查找问题根因,不能及时有效地对故障部位进行预案执行。
案例二

1)背景
一个平淡无奇的周末晚上,23点30分,监控系统触发大量告警,几乎全业务线、各架构层都在触发告警。
2)故障始末
23点40分,企业微信拉了有十几个群,原有的业务沟通群、基础服务OnCall群,都在不停地转发告警,询问情况。整个技术线一片恐慌,起初以为是监控系统炸了。此时相关故障的SRE同学已经被拉到某一个语音会议中。
注意,此时公司的多个BU业务线同学都炸锅了,到处咨询发生了什么,业务怎么突然就不炸了。又过了几分钟,资深的SRE同学又拉了一个大群,把相关业务对接人都拉进群里,开始整体说明故障情况。此时,该同学也比较纠结如何通报和说明这个问题,因为此时没有一个明确故障定位,语言很难拿捏,各个高level的老板也都在问(已上热搜)。并且,负责恢复入口服务的一线同学把故障预案执行了个遍,发现无济于事。后续在GSLB调度层,执行了整个跨机房的流量有损切换才让服务逐渐恢复正常。
凌晨之后,原有机房的问题定位出来了,补丁迅速打上,异常的问题彻底修复了。后续,在对此事件进行复盘时,发现困难重重。因为故障处理过程中,涉及到大量的服务、组件和业务方,并且大家当时拉了一堆群,同样的消息被发送到了很多群。参与处理故障的同学在语音、电话和企微群都有进行过沟通和处理进展发布,整个事件的细节整理起来非常耗费人力和精力,准确性也很难保障。
3)问题
在上面这个案例中,我们可以看到整个故障从发生、处置到结束后复盘,都存在以下问题:
当一个影响面比较大的故障产生时,大家没有统一的故障进展同步方式,依托原始的人工拉群,人工找相关人员电话联系,导致了故障最新的进展情况只能够在小范围传播扩散,无法统一对外公布,并且在传播过程中,很容易消息失真;
在故障处理过程中,缺少主要协调人(故障指挥官)。像这种大型故障,需要有一个人能够去协调各层人员分工、消息收敛、服务业务情况等,这个人需要能够掌控整个故障的所有消息和全貌进展;
在故障处理过程中,缺乏故障上下文的信息关联,大家难以知晓故障发生的具体位置,只是感知到自己的业务受损了,自己的服务可能有异常,这导致整个故障的定位时间被拉长;
在故障恢复之后,我们对这个故障进行复盘时,发现故障处理过程中的信息太过零散,复盘成本很高。
案例剖析
通过对上述两个案例的分析我们能够发现,在故障发生前、处理中和结束后,各个阶段都会有很多因素导致我们的故障不能被快速解决,业务不能快速恢复。
这里我们从故障的前、中、后三个阶段总结可能存在的一些问题。
1)事前
告警信息量大,信息太过杂乱;
平台系统繁多,变更信息无处收敛;
客服反馈的信息,需要靠人工去关联,并反馈到技术线;
和公司舆情相关的信息,技术线很难感知到。
2)事中
一线同学过于关注技术,沉迷问题解决;
当一个故障影响面扩大之后,涉及多个团队的协同非常困难,最新的进展消息无法及时有效地传递到相关人员手中;
当参与一个故障处理的人员多了之后,多个人员之间缺乏协调,导致职责不清晰,产生事情漏做、重复做的问题;
故障处理过程中,会有一些不请自来,凑热闹的同学。
3)事后
当我们开展复盘时,发现故障处理时又是群、又是电话、又是口头聊,又是操作各种平台和工具,做了很多事情,产生了很多信息,梳理时间线很繁琐,还会遗漏,写好一份完整的复盘报告非常麻烦;
拉一大堆人进行复盘的时候,因为缺少结构化的复盘流程,经常是想到什么问什么。当某场复盘会,大家状态好的时候,能挖掘的点很多。如果状态不好或者大家意识上轻视时,复盘的效果就较差;
复盘后产出的改进事项,未及时统一地记录跟进,到底有没有完成,什么时间应该完成,完成的情况是否符合预期都不得而知;
对于已经修复的问题,是否需要演练验收确保真正修复。
以上三个阶段中可能发生的各种各样的问题,最终只会导致一个结果:服务故障时间增长,服务的SLA降低。
二、从应急响应看稳定性运营
针对上述问题,如何进行有效改善?这是本部分要重点分享的内容,从应急响应看稳定性运营。


应急响应的概念较早来源于《信息安全应急相应计划规范GB/T24363-2009》中提到的安全相关的应急响应,整体定义是“组织为了应对突发/重大信息安全事件的发生所作的准备,以及在事件发生后所采取的措施”。从这个概念我们延伸到稳定性上就产生了新的定义,“一个组织为了应对各种意外事件的发生所作的准备以及在事件发生后所采取的措施和行为”。这些措施和行为,通常用来减小和阻止事件带来的负面影响及不良后果。
三、核心运营要素有哪些

做好应急响应工作的核心目标是提升业务的稳定性。在这个过程中,我们核心关注4大要素。核心点是事件,围绕事件有三块抓手,分别是人、流程和工具/平台。
人作为应急响应过程中参与和执行的主体,对其应急的意识和心态有很高要求。特别是在一些重大的故障处理过程中,不能因为压力大或紧张导致错误判断。
流程将应急响应的流程标准化,期望响应人能够按照既定阶段的既定章程进行有效的推进和处理。
工具/平台支撑人和流程的高效合规运行,并将应急响应的过程、阶段进行度量,进而分析和运营,推进人和流程的改进。
事件
1)生命周期划分
要对故障进行有效运营,就需要先明确故障的生命周期。通过划分故障的生命周期,我们可以针对不同的周期阶段进行精准聚焦,更有目的性地开展稳定性提升工作。
针对故障生命周期的划分有很多种方式,按故障的状态阶段划分,可以分为事前、事中和事后。

按故障的流程顺序划分,可以分为故障防御、故障发生、故障响应、故障定位和故障恢复、复盘改进等阶段。
这里我围绕故障的时间阶段,从故障不同阶段的形态变化做拆分,将故障拆分为四个阶段。
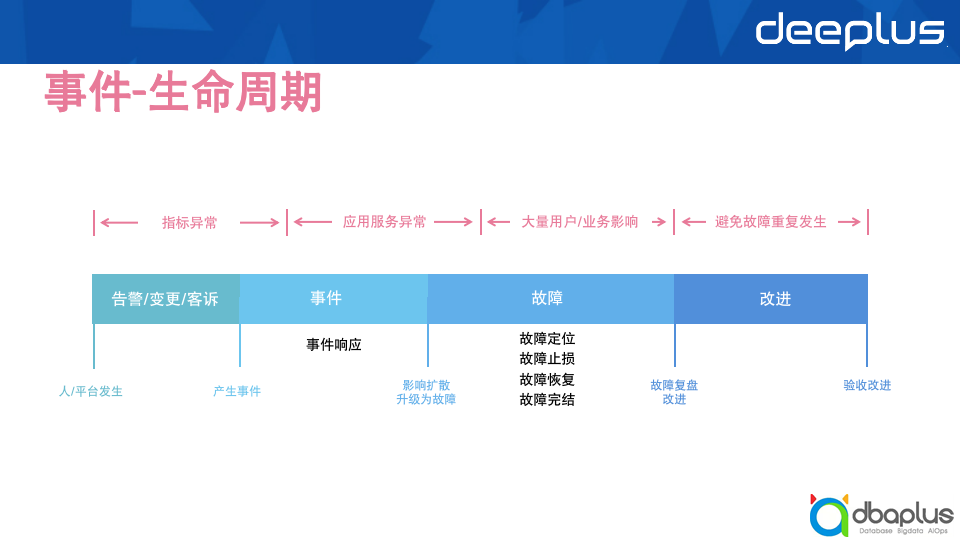
告警/变更/客诉
当故障还未被确认时,它可能是一个告警、变更或客诉。
事件
当这个告警、变更、客诉被上报后,会产生一个事件,我们需要有人去响应这个事件,此时一个真正的事件就形成了。
故障
当事件的影响范围逐渐扩散,这时往往有大量的用户、业务受到影响,我们需要将事件升级成故障,触发故障的应急协同,进行一系列的定位、止损等工作。
改进
故障最终会被恢复,接下来我们要对故障进行复盘,产生相关改进项,在改进项被完成之后,还需要进行相关的验收工作。
2)阶段度量
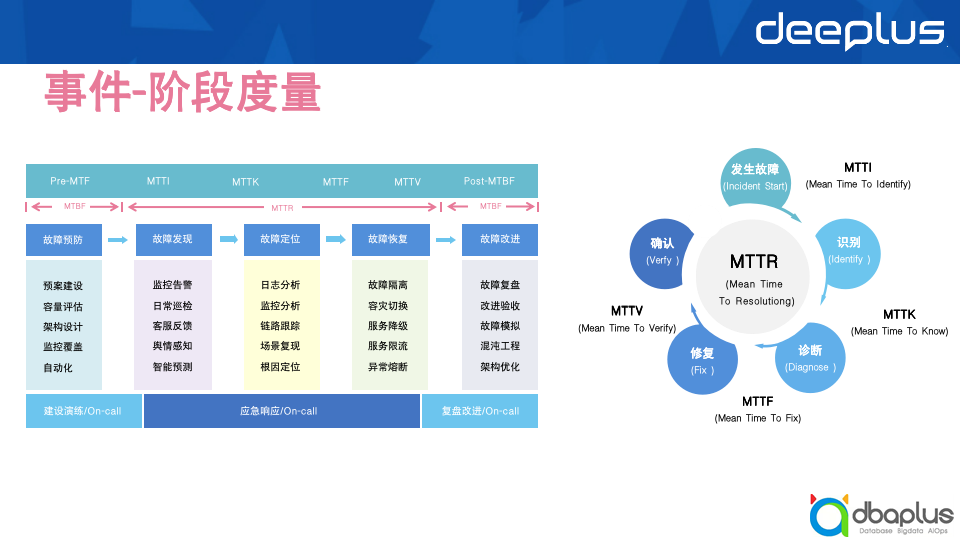
从更科学的角度看,我们知道在运营工作中,度量是很关键的一点。管理学大师彼得·德鲁克曾经说过:“你如果无法度量它,就无法管理它”。有效的度量指标定义,可以帮助我们更好更快地开展运营工作、评估价值成果。上文中我们提到的3个阶段是比较笼统的阶段,接下来我将介绍更加具体和可执行的量化拆分方法。
如上图所示,从故障预防依次到故障发现,故障定位,故障恢复,最后到故障改进,整体有两个大的阶段:MTBF(平均无故障时间)和MTTR(平均故障恢复时间)。我们进行业务稳定性运营的核心目标就是降低MTTR,增加MTBF。根据Google的定义,我们将MTTR进一步拆分为以下4个阶段:
MTTI:平均故障发现时间,指的是故障发生到我们发现的时间。
MTTK:平均故障定位时间,指的是我们发现故障到定位出原因的时间。
MTTF:平均故障修复时间,指的是我们采取恢复措施到故障彻底恢复的时间。
MTTV:平均故障修复验证时间,指的是故障恢复之后通过监控、用户验证真实恢复的时间。
3)关键节点
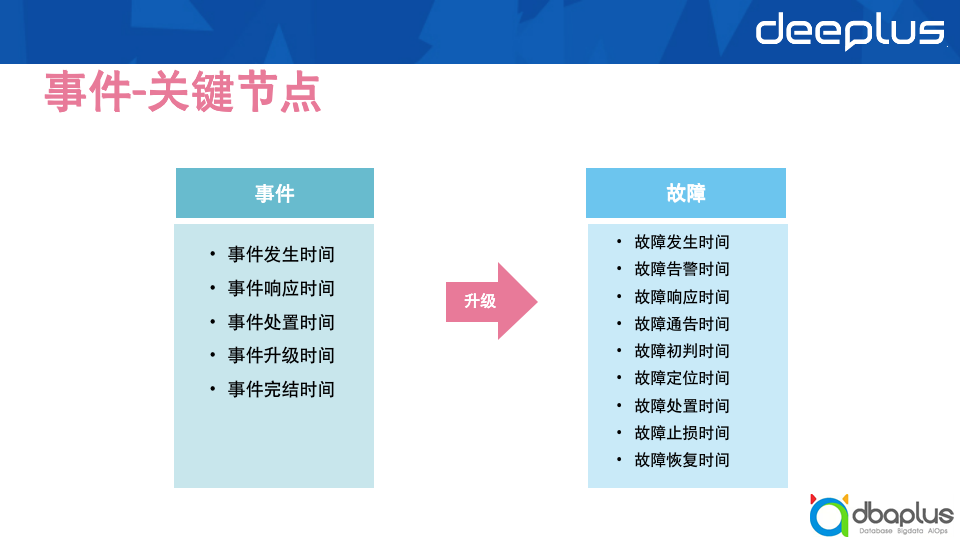
基于阶段度量的指标,我们能够得到一系列的关键时间节点。在不同的阶段形态,事件和故障会存在一些差异。故障因为形态更丰富,所存在的时间节点更多。上图中定下来的时间,均是围绕MTTR进行计算的。主要是为了通过度量事件、故障的处理过程,发现过程中存在的问题点,并对问题点进行精准优化,避免不知道如何切入去提升MTTR的问题,也方便我们对SRE的工作进行侧面考核。
人

人作为事件的一个主体,负责参与事件的响应、升级、处置和消息传播。

人通过上文中我们讲到的OnCall参与到应急响应中。我们在内部通过一套OnCall排班系统进行这方面的管理。这套系统明确了内部的业务、职能和人员团队,确保人员知道什么时间去值什么业务的班。下面的工具/平台部分会展开介绍。对参与人的要求,主要有以下几点:
具备良好的响应意识和处理心态。
具备熟练地响应执行的经验。
满足以上特征,才能做到故障来临时响应不慌乱,有条不紊地开展响应工作。
流程
那么针对人的要求如何实现?人员如何参与到应急响应的环节中去?人员的意识如何培养呢?

首先,我们内部制定了应急响应白皮书,明确了以下内容:
响应流程;
基于事件大小,所要参与的角色和角色对应的职责;
周边各个子系统SOP制定的标准规范;
针对应急过程中的对外通告内容模板;
故障过程的升级策略。
之后,我们会周期性地在部门内部、各BU进行应急响应宣讲,确保公司参与OnCall的同学能够学习和掌握。另外,我们也会将其作为一门必修课加入新同学的入职培训中。最后就是故障演练,通过实操,让没有参与过故障处理的新同学能够实际性地参与应急响应的过程,避免手生。
平台
平台作为支撑人与流程进行高效、稳定执行的载体,我将在下一部分进行具体描述。
四、两个运营载体:OnCall与事件运营中心
这部分我将向大家分享B站在应急响应方面落地的两个运营性平台。
OnCall系统
OnCall系统,即值班系统。值班系统在日常运转过程中的作用往往被低估,SRE、工程效率做这部分建设时,很容易基于二维的方式对人和事进行基于日历的值班管理,并通过网页、OpenAPI等方式对外提供数据服务。
下面我们通过几个例子来说明OnCall的必要性。
在日常工作中,当我们使用公司某个平台功能时,可能会习惯性找熟悉的同学,不管他这一天是不是oncall。这可能给那位同学带来困扰,他可能上周才值完班,这周要专心于研发或者项目的推进,你随时找他可能打断他的工作节奏。还有一种情况是新同学不知道该去找谁,我们内部之前经常有这种情况,一个新来的同学接手一套系统之后,有问题不知道该找谁,经常要转好几手,才能找到对的人,这一过程很痛苦。

以上内容总结起来就是总找一个人,总找不到人,除此之外,还会出现平台找不到人的情况。这些问题的根源是什么呢?无非就是who、when、what和how的问题,不能在正确的时间为正确的事找到正确的人。
那么OnCall系统的重要性和必要性都体现在哪些方面呢?
有问题找不到人
随着公司业务规模的扩大和领域的细分,一些新的同学和新业务方往往会出现一个问题。不知道是哪些人负责,需要咨询很多人才能找到具体解决问题的人。这一问题不仅限于故障,更存在于日常琐事中。特别是SRE同学的日常,经常会被研发同学咨询找人拉群,戏称拉群工程师。
下班不下岗
当人们遇到问题时,经常会下意识找熟悉的人。这就导致一些能力强、服务意识好的同学,总是在被人找。不论他今天值不值班,他将无时无刻都要面临被人打扰的问题。除了被人找之外,内部的监控系统、流程系统,也会给不值班的同学发送监控告警和流程审批信息。这也将SRE同学有50%的时间用于工程这一愿景变成泡影。
1)设计
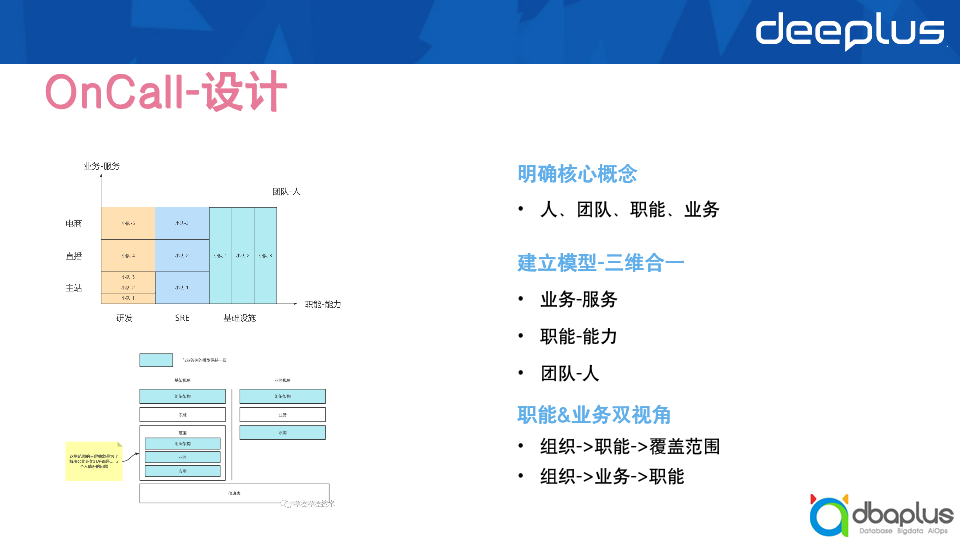
① 明确关联逻辑
针对上述两种情况,我们对公司的业务、服务、职能和组织架构进行了分析建模,明确了人、团队、职能和业务之间的关联关系。
② 建立三维合一模型
我们构建起了一套三维合一的模型。由组织-业务、职能-人员、组织-职能的关联关系,产生交汇点。值班人员会通过值班小队的方式,落在这些交汇点上,并且基于业务和基础架构的异同点,通过业务视角和职能视角分别对外提供服务。
以我们公司内部主站业务为例,我们会有专门的SRE小队进行日常的值班响应,这个小队只负责主站业务的值班响应。通过这样的对应关系,当人或平台有需求的时候,都可以通过业务和职能关联到对应实践的值班小队,最终定位到具体的人,这样也帮助我们将人藏了起来,更有利于后续SRE轮岗机制的推进落地。
③ 双视角提供服务
通过双视角的设计,区分了职能型和业务型的不同值班方式和关注点。原因在于B站的业务层级组织模式是按照“组织->业务->应用”这三级进行组织的,所有的应用归属到业务,业务归属到具体的组织架构。
职能视角
前端采用树型展示,组成结构为组织->职能->覆盖范围(组织->业务->服务),值班表具体挂载在覆盖范围下,覆盖范围可以只有一级组织也可以精确到组织下面的业务或业务下面的服务。
业务视角
前端采用树型展示,组织结构为组织->业务->职能,值班表具体挂载在职能下面。
在日常工作中,基础架构相关的服务,比如SRE、DBA、微服务、监控、计算平台等强职能型服务会通过职能视角对外提供值班信息。当业务人员有具体问题时,可以通过职能树快速定位到具体的值班人员。而对于业务服务来讲,日常的工作模式是围绕业务开展的,因此会通过业务进行展开,提供该业务下相关职能的对应值班信息。
这两个视角的底层数据是相通的,强职能相关服务提供方只需要维护好职能视角的值班信息,业务视角下的关联会自动生成。
2)功能展示
基于以上设计,我们内部做了一套OnCall排班的系统。

这套系统是管理业务、职能和人的系统。我们基于上文中提到的几个核心概念,在这些概念间建立了关系,分别是两条线,一条是职能-团队和人,另外一条是职能-业务和服务。
系统提供了排班班组的管理,支持基于日历的排班,同时支持班组设置主备oncall角色。在排班的细节上,我们支持基于时段进行自动排班计划生成,也支持在一个职能里多个班组混合排班。另外,也支持对已经排好班的班组,进行覆盖排班和换班,这个主要应对oncall同学突然有事请假的情况。在oncall通知方面,我们支持了企业微信、电话等通知方式,并且支持虚拟号码的方式,保护员工号码不对外泄露。同时也避免了因为熟悉导致的频繁被打扰的情况。
在周边生态方面,这套OnCall系统完全依赖周边系统的接入。我们目前对接了内部的告警系统、流程系统,确保告警和流程能够只通知oncall人,而不形成骚扰。在企业微信的服务号中,也进行了H5的页面嵌入,在用户通过企业微信反馈问题、找人时,知道当下该找谁。在各个接入的平台,也内嵌了OnCall的卡片页面,明确告诉用户本平台当前是谁值班。通过这套OnCall系统的落地,我们明确了人、团队、职能和业务的概念,并将这些概念进行了关系建立和对应。人员通过排班班组统一对外为某个业务提供某项职能的值班响应。通过前端的可视化,提供了日历的值班展示效果,可以直观看到某个业务所需要的某块职能在某个时间点是由哪个班组在服务,周边的各个系统也都对接OnCall系统,实现了人员响应的统一管理,解决了某些人员认人不认事,不通过正规流程处理的问题。
事件运营中心

事件运营中心这套系统是我们基于ITIL、SRE、信息安全应急计划的事件管理体系,为了满足公司对重大事件/故障的数字化管理,实现信息在线、数据在线和协同在线,使组织能够具备体系化提升业务连续性能力所做的产品平台。这个平台的定位是一站式的SRE事件运营中心,数字化运营业务连续性的目标是提升MTBF,降低MTTR,提高SLA。
1)架构设计
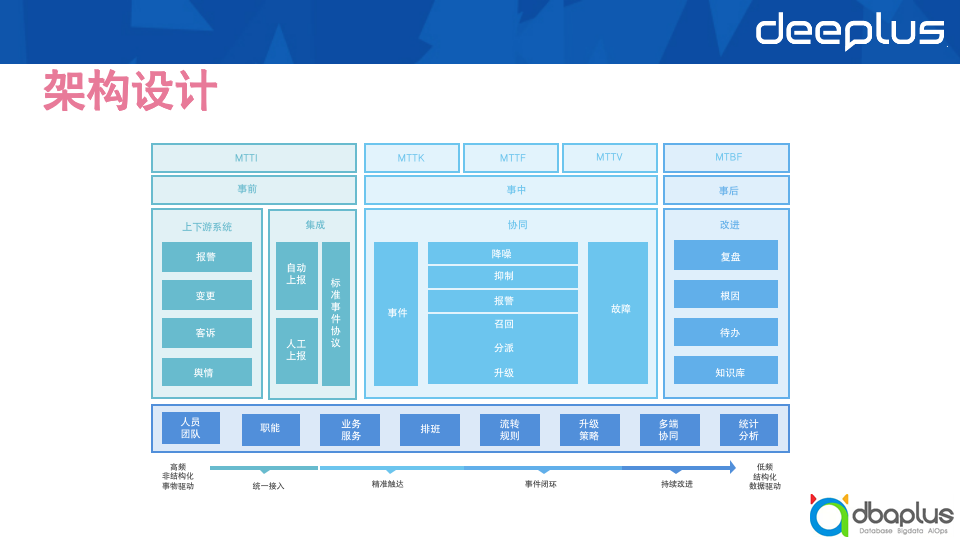
上图是我们平台的模块架构图,整体上还是围绕上文提到的事件的事前、事中和事后三个阶段拆分,覆盖了一个事件产生、响应、复盘、改进的全生命周期。
事前
我们对事件进行了4大类型的拆分,分别是告警、变更、客诉和舆情,然后通过设计标准的事件上报协议,以集成的方式将我们内部的各个系统打通,将事件信息统一收集到一起。在收集的过程中,进行二次处理,实现事件的结构化转储。
事中
我们会对接入的4大类型信息进行事件转化,然后通过预定义的规则对事件进行降噪,抑制、报警、召回、分派和升级等相关操作。在这个过程中,如果一个事件被判定影响到业务,我们会将它升级成一个故障,然后触发故障的应急响应流程。这里就进入到对故障响应处理过程中的一个阶段,在这个阶段我们会产生各种角色,例如故障指挥官、故障通讯人员、故障恢复人员等,相关人员明确认领角色,参与故障的止损。止损过程中,通过平台一键拉群创建应急响应指挥部,通过平台的进展同步进行相关群和业务人员的通告,通过记录簿实现故障信息的信息传递和记录。
事后
在故障结束之后,就进入到我们整体的改进环节。平台可以基于故障一键创建复盘报告,自动关联故障处理过程中的专家数据。平台提供预制的故障复盘问答模板,以确认各阶段是否按照预期的目标进行。复盘产生的待办列表,平台会进行定期的状态提醒和处理进度跟进。最终的这些都会以知识的形式,沉淀在我们的知识库。帮助日常On-Call问答和公司内部员工的培训学习。整体这样一套平台流程下来,就实现了将一些日常高频的非结构性事务驱动,通过统一接入、精准触达、事件闭环和持续改进等环节,转化为低频的结构化数据驱动方式。
2)场景覆盖
下面我们介绍平台在各个场景的覆盖。
① 集约化
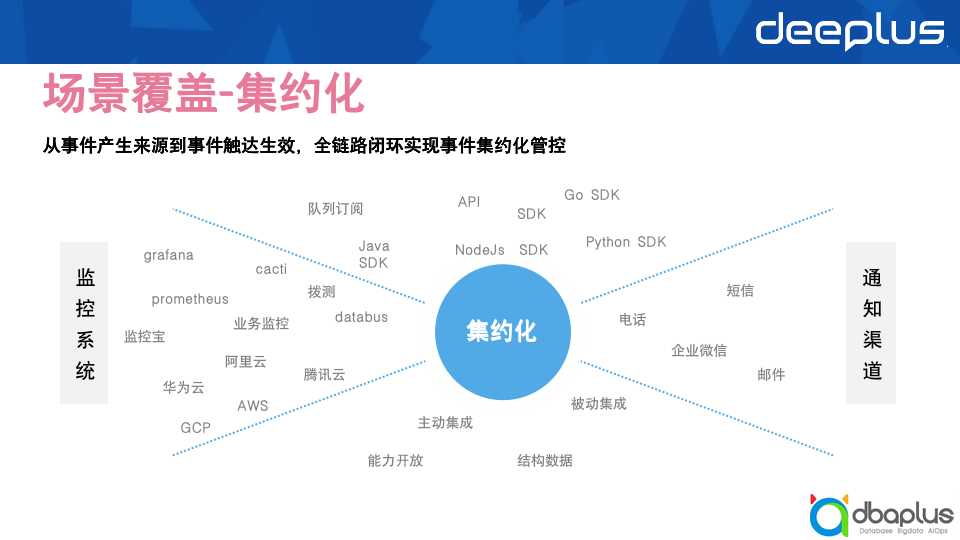
对事件产生的上游来源进行集约化管理,通过队列订阅、API和SDK的方式,将内部的监控,Prometheus、监控宝等各个云平台的监控都通过前面的4大类型定义收归到一起,然后统一进行通知触达。
② 标准事件类型

为了实现各个渠道消息的结构化规约,我们设计了标准的事件模型,通过这个事件模型,我们将周边各个系统/工具/平台进行收集,并且实现了事件的关联操作。模型主要分为4部分:
base是一些事件的基础信息字段;
who是指这一事件来自哪里,有哪些相关方;
when是指事件发生或产生影响的时间;
where是指事件来源于哪个业务、影响了哪些业务;
what是指这个事件的具体内容,它的操作对象是什么等等。
③ 降噪聚类
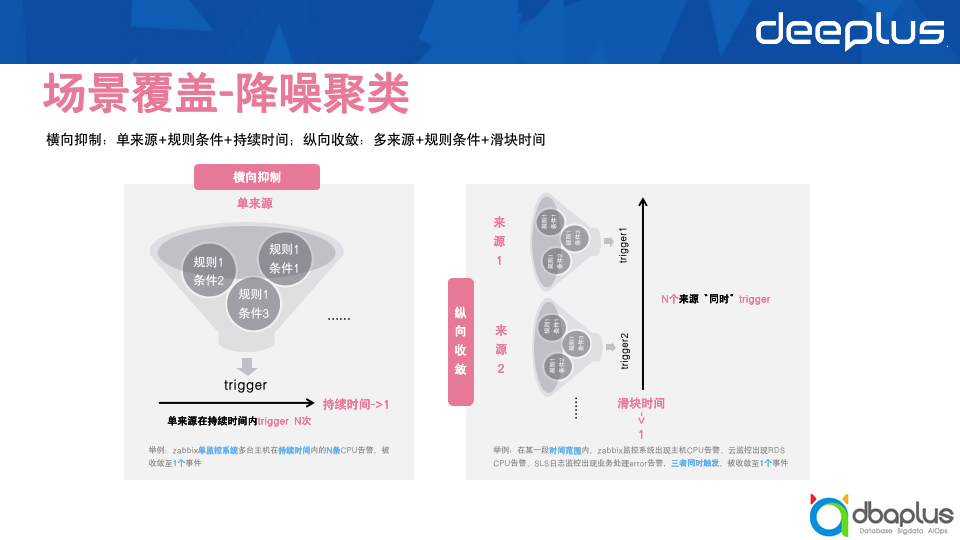
由于我们对事件的上报结构进行了标准化,并且预埋了关联字段,通过这些关联字段,我们就建立起了事件的关联关系,从而可以做事件的降噪聚类。
降噪聚类在执行上,主要分为两部分。
横向抑制
我们支持对单个来源的事件、告警,通过定义的规则进行收敛,比如Prometheus报警出一个服务在某个持续时间内持续报了N条一样的告警信息,平台会收敛到一个事件中去。
纵向抑制
这对上文中提到的底层系统故障十分有效,可以将底层故障导致的上层业务告警都统一收到一个事件中,避免大量告警使大家造成混淆。
④ 协同在线

在协同在线的场景下,我们通过一个面板将人、业务、组件和系统信息进行了汇总,通过一个事件详情页,将整个事件当下的处理人、关联业务和服务组件、当下的一些信息统一展示在一起。在协同能力上,我们提供了一键创建应急响应群的功能,建群时会自动关联该故障相关oncall同学,对故障感兴趣的同学也可以通过面板加入响应群。在故障页面,清晰看到故障当前的指挥官是谁,当下的处理人是哪些同学。彻底解决了之前靠人工拉语音、打电话、面对面交流的原始协作方式。
平台的各方面能力实现了事件全生命周期的闭环管理。监控告警、故障发现、应急响应、故障定位、故障恢复、故障复盘和故障改进,全阶段都通过平台能力去承载。
故障响应时,支持了故障的全局应急通告,提供了多种通告渠道,信息实时同步不延误,避免人工同步,漏同步、同步内容缺漏等问题;
故障跟踪阶段,平台可以实时展示最新的故障进展;故障影响面、当下处置情况,各阶段时间等等;
故障结束的复盘阶段,通过定义好的结构化、阶段化的复盘过程,确保复盘过程中,该问的问题不遗漏,该确认的点都确认到;
故障改进阶段,通过对改进项的平台化录入,关联相关责任方、验收方,确保改进的有效执行和落实。
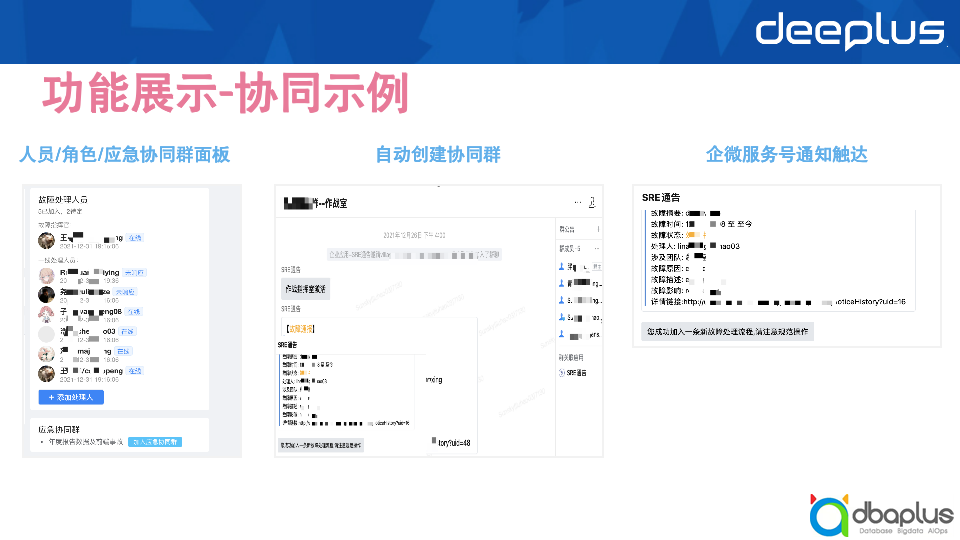
上图中是协同相关的一些示例,当一个故障被创建出来时,会自动关联该故障涉及到的业务、组件、基础设施的oncall同学,这些同学可能是SRE、研发等,平台会记录他们是否有响应这些问题,并且当下所负责的角色是什么。因为角色决定了在该事件中所担负的事项和责任;下方一键拉群,可以将相关人员,自动拉入到一个群内,方便大家进行沟通协同,并且事件、故障的相关最新进展也会定期在群内同步;涉及到事件的参与人员,事件运营中心的服务号也会定期推送最新进展,确保不会丢失消息。
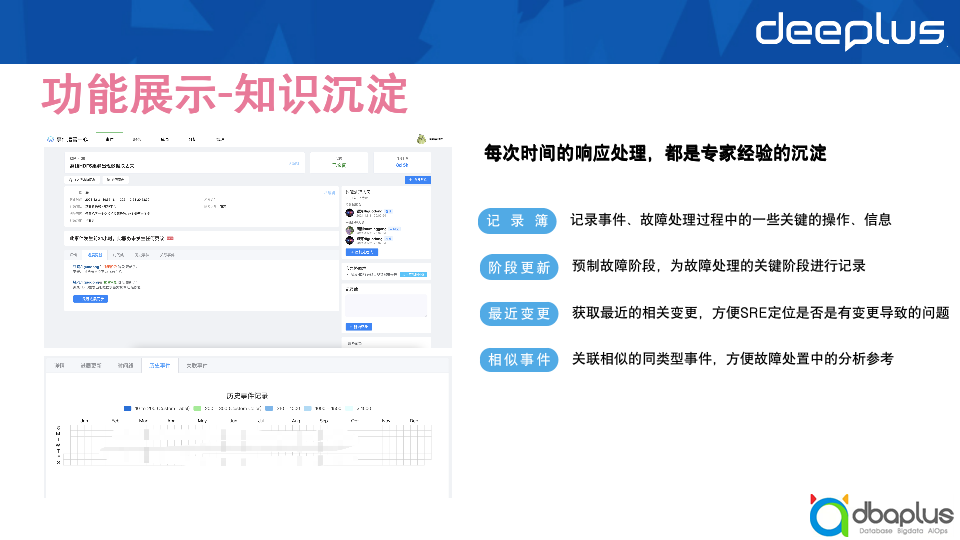
上图是我们内部的故障协同的详情页面,提供了记录簿、故障阶段更新、最近变更信息和相似事件,确保每次的响应处理,都能形成一个专家经验的沉淀,帮助后续新来的同学进行故障响应过程的学习。
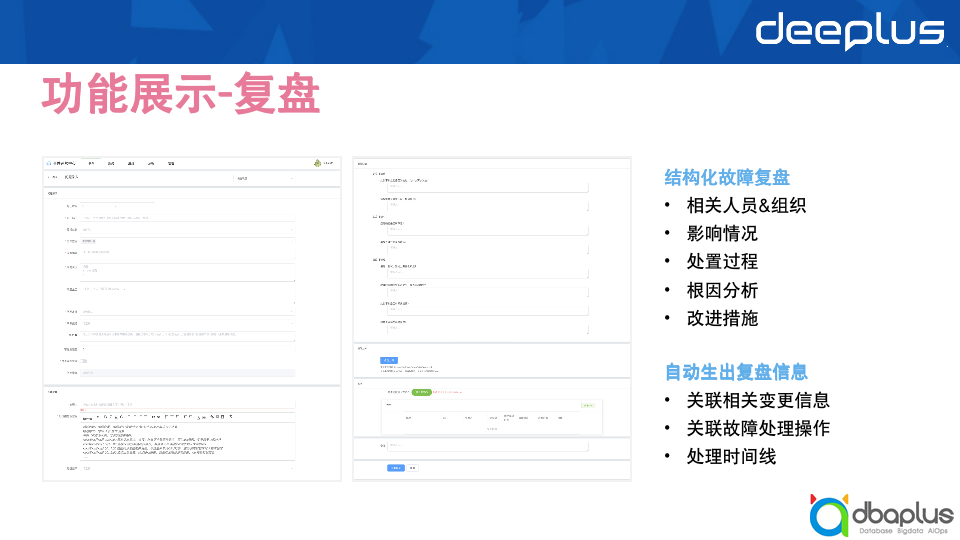
复盘方面,我们定义了结构化的故障复盘模板,像相关人员、组织、影响情况、处置过程、根因分析(在根因分析里面,我们设置了6问,确保对问题能够有深度地挖掘),改进措施等。在复盘效率方面,我们关联了相关的变更信息、故障处理时的一些变更操作,以及处理时间线,帮助复盘同学快速生成故障的相关信息,减少人工录入负担。
五、挑战与收益
挑战
在业务稳定性运营体系的建设过程中,团队也踩了很多坑,面临着诸多技术之外的挑战。鉴于业界对于技术相关的分享比较丰富,这里就针对体系逻辑和人员方面的挑战进行分享。
元信息统一
稳定性是个大话题,我们在落地整体体系时会发现,设计的上下游系统太多了。每个系统里面都会有人、业务、职能的使用需求。在初期,我们内部在服务、业务和人的关联这块没有形成统一的数据基准,导致我们在应急协同的诸多特性上难以落地,诸如故障的有效通知、群内的有效传递、故障画像的拓扑关联计算缺少映射关系等等。
在这种情况下,我们重新梳理了服务树和OnCall系统,通过服务树将组织、业务和服务的映射关系维护好,通过OnCall系统将组织、职能、业务和人的映射关系维护好,来确保找人的时候能找到人,找服务的时候能找到服务。
工作模式改变
新的应急响应流程,将故障过往对人的依赖转移到靠系统来自行驱动,这导致现有人员的工作模式产生了很大变化。传统故障处理时,响应人员手动拉群、语音或现场找人,现在变成了优先在系统内升级已有事件或录入故障信息,然后通过系统自动进行人员关联和邀请。群内的随意沟通,变成了在平台进行阶段性进展同步。原有的故障升级逻辑变成了平台定时通知,这给故障处理人员带了一定的压迫感。整体形式上更加严肃和标准,在落地初期给大家带来了一定的不适应感。针对这种情况,我们一方面通过在系统的文案描述上进行改善,交互逻辑上进行优化,尽可能在推行新标准的同时,适应旧的使用习惯。例如,常规应急协同群会先于平台的故障通告建立,这就会与平台创建的故障协同群发生冲突。此时,我们通过增加现有群关联来实现已有故障协同群和故障的关联。另外一方面,我们通过定期持续的宣讲,给大家介绍新的应急响应流程和平台使用方法,帮助大家适应新的应急响应模式。
收益
以上就是B站在业务稳定性运营方面所做的相关工作。通过体系化建设,已经在组织、流程和平台层面实现强效联动,具备了数字化运营业务稳定性的能力,建立了科学有效的稳定性评估提升量化标准,让稳定性提升有数据可依托。将故障应急响应流程从由人工驱动升级到由平台系统驱动,应急响应人员可以更专心处理故障,大幅提升故障恢复时间。后续我们将会持续探索更科学有效的管理运营方法,期望通过引入AI的能力,提升故障辅助定位能力、提早发现故障隐患,联动预案平台实现更多场景的故障自愈。
责任编辑:张燕妮来源: dbaplus社群
收起阅读 »居家办公5分钟抓拍一次人脸,不足89次算旷工,你服不服?
职场怪事儿天天有,最近感觉特别多。
看到一个新闻,有个美股上市号称“成人教育第一股”的企业,要求朝阳全区的员工实行居家办公。
这要求本来没什么毛病,相应号召嘛,但是美其名曰为了让员工在家努力搬砖,整了一个骚活,要求员工连夜安装电脑监控软件,必须每5分钟自动截屏抓拍人脸,每天截屏不够89次的算旷工。


凭心而论,居家办公有没有摸鱼的情况?
那必然是有的。
别说居家办公了,让大家老老实实坐在办公室,只要心里有摸鱼大神坐镇,办法就总比困难多。
有机会摸鱼,没机会创造机会也要摸鱼。
当年牛老师为了摸鱼恨不得长2个屁股,这样可以双倍带薪拉屎,双倍的快乐。
但对于一家合格的企业而言,摸鱼其实不重要。
老板只要不是脑瘫,都知道员工摸鱼是拦不住的,一个人要是从根源上不想摸鱼只想工作,这种人反而才是有问题的。
一般来说不是竞争对手的间谍,不会这么敬业。
现代企业管理本来就更看重最终结果,随着分工细化和专业度加强,泰勒科学管理折腾流水线工人那套已经落伍了,员工到底是一边抠着脚一边写PPT的,还是妆容整齐西装笔挺的敲键盘的,都无所谓,只要按时按量的把事情做好就行。
KPI(或者OKR)+DDL,唯结果说话就好了。
重要的是结果,而不是优雅不优雅。
结果,这家成人教育企业偏要来个微观管理,5分钟人脸抓拍一下瞅你一眼,比在办公室厕所装计时器还要骚,勾起了中学班主任扒教室后门窗户所制造的恐怖支配回忆。
2
看到这里,你以为我要开骂了?
不,你思考一个问题。
能把公司做到上市,而且还是培训机构,人家老板傻吗?
人家见识过的世间冷暖人情世故会少吗?
他情商能低吗?
他真不行,早完球了。
他不知道这样对工作效率和工作结果并无卵用么,他不知道这样会激发员工反感起到反效果么?
当然是知道的。
我曾反复说过一个道理,公司老板可能是傻X,但一定不是傻瓜。
你要思考的不是他干了啥。
而是。
他为什么这么干。
这么干的目的是不是符合他的利益。
我一直不建议从智力角度去评估企业决策,不论当年他们是踩到风口了,还是大力出奇迹了,领导层都把企业做的很大,这样的领导不会智商下线的。
既然领导不傻,那为什么会有这种刷脸神仙操作呢?
很简单,降本增效。
你没看错。
看似傻X,但其实背后有理论支持。
只不过这个理论会让你很不舒服,建议提前做一下心理建设。
社会毒打要来了。
3
降本是这段时间企业的主流思潮,体现在员工成本方面,一方面是想方设法的把之前承诺的奖励、绩效、年终奖给扣下,就如同这家公司用高频刷脸的方式找借口把全部绩效给扣除。
另一方面,就是从员工数量上入手,砍掉没用的员工,有用的员工也顺手砍一刀,把成本拿捏的死死的。
间隔5分钟人脸抓拍,正常员工都受不了,上厕所都要考虑打个时间差,而且这明显的侵犯了员工居家办公的隐私,万一家里就有个喜欢光着屁股到处跑的牛老师呢。
于是,正常员工会觉得,周扒皮好歹每天也只装鸡叫折腾员工一次,你这是高强度极限施压的折腾堪称加特林型扒皮,走了算了。
主动离职,领导脸都要笑烂了。
我查了这家企业的财报,上市公司嘛,白纸黑字的都要写出来,2020财年亏4.31亿元,2021年净利润2.124亿元,实现了首次扭亏为盈。
那怎么迅速扭亏为盈的呢?
在收入方面,学生人数并没有太大增加,2021年新生招生人数为434228人,2020年是434240人,差距只有12个人,那就只有提高学费了嘛。
另一方面,就是使劲压成本,2021财年Q4的财报算是点透了,第四季度成本8940万元,同比下降8.6%,主要是“与成本相关的薪酬费用下降”。
看来今年是打算再创辉煌了,继续把薪酬费用给压下来,从变相扣钱和软性裁员开始。
这套路还有后手,如果觉得成本压缩还不够,就可以把打卡间隔继续降低,4分钟,3分钟,20秒……
大不了全员纸尿布嘛。
这都让我看到了美联储调息的影子,我愿称之为。
调整刷脸基准利率实现量化紧缩手段。
那降本增效里面的另外一个重要环节,增效,也能通过高频刷脸打卡一石二鸟的完成。
站在领导的角度,企业本来就不需要正常员工。
正常员工最大的缺点就是太正常了,没有007的觉悟,少了“以厂为家”的大无畏奉献精神,还总能一眼看穿我努力包装成激励计划的大饼。
企业想要留下的,是那种膀胱功能超群,一坐下来工作就老僧入定一般,并且底线画的非常低只要能拿到工资就行的员工。
这一波服从性测试,“硬”币驱除“软”币,能让团队精炼化、钢印化、农奴化。
在各种骚操作下还能留下来的员工,已经异化成莫得感情的工作机器了,这都不是狼性精神,而是钢铁哥斯拉的气魄,工作效率自然是杠杠的。
到时候让他们扛起离职员工的工作量,一个人做两份活,必然也是毫无怨言的,毕竟5分钟一次刷脸打卡他们都能忍,还有什么不能接受的呢。
4
从降本增效的角度就可以理解,为什么这家成人教育第一股,在被爆出连夜安装电脑监控软件之后,非常淡定了。
记者去采访,对方工作人员说,公司内部正在沟通,沟通后再做回复。
这种拖延式回复就说明,企业根本没把这个当回事儿,遇到负面信息潜意识的否认和辟谣都懒得搞了,就这么做了,你能咬我。
大不了后面不咸不淡说几句道歉的场面话嘛。
本来就是故意恶心员工的手段,让雇员群体里的正常人赶快走,最好全都走,所以从企业的立场来说根本不怕挨骂,也不在乎员工怎么想,更别说社会舆论怎么看了。
甚至巴不得媒体多多报道,让他们尽快实现降本增效的最终效果。
虽然5分钟一次刷脸打卡是典型的过程管理,但是实际取得的成效是典型的结果导向,你说这样的领导,能用傻来形容么?只能说面厚心黑的坏而已。
可惜,在企业管理者的评价体系里面来说,坏,可不是个贬义词。
有时候坏人,反而更得利。
商业江湖,有时候就是这么魔幻。
作者zuo:半佛仙人
来源:36kr.com/p/dp1736519119879426
如何美化你的图表,关于SVG渐变你需要了解的一切!
渐变在网页设计中几乎随处可见,渐变的背景、文字、按钮、图表等等,相比于纯色,渐变的颜色显得更加灵动自然。
今天我们要探讨的,就是SVG中的渐变绘制。
更多SVG系列文章:SVG基础知识、SVG动画、SVG中的Transform变换。
概述
或许你有使用css绘制渐变图形的经验,如果要绘制一个渐变的矩形,我们可以这样写:
<div></div>
.bg{
height: 100px;
width: 200px;
//给元素设置渐变背景
background: linear-gradient(#fb3,#58a);
}
使用SVG绘图,颜色是通过设置元素的fill(填充颜色)和stroke(边框颜色)属性来实现。
<rect height="100" width="150" stroke="#45B649" stroke-width="2" fill="#DCE35B"></rect> 对于渐变颜色的设置,我们不能像在css中那样,直接写fill="linear-gradient(color1, color2)",而要使用专门的渐变标签:<linearGradient>(线性渐变) 和 <radialGradient>(径向渐变)。
线性渐变
基础使用
先来看一个最简单的例子,如何绘制一个线性渐变的矩形:
<svg>
<defs>
<linearGradient id="gradient-test">
<stop offset="0%" stop-color="#DCE35B" />
<stop offset="100%" stop-color="#45B649" />
</linearGradient>
</defs>
<rect height="100" width="150" fill="url(#gradient-test)"></rect>
</svg>
通常,我们将渐变标签<linearGradient>定义在<defs>元素中,<linearGradient>的id属性作为其唯一标识,方便后面需要使用的地方对其进行引用。
<linearGradient>中的<stop>标签定义渐变色的色标,它的offset 和 stop-color属性分别定义色标的位置和颜色值,它还有一个属性stop-opacity,设定stop-color颜色的透明度。
如果将色标的位置拉近:
<linearGradient id="gradient-1">
<stop offset="30%" stop-color="#DCE35B" />
<stop offset="70%" stop-color="#45B649" />
</linearGradient>
矩形左边的 30% 区域被填充为 #DCE35B 实色,而右边 30% 区域被填充为 #45B649 实色。真正的渐变只出现在矩形中间 40% 的区域。
如果两个颜色都设为50%,就得到了两块均分矩形的实色。在这基础上,我们可以生成各种颜色的条纹图案。
渐变的方向和范围
在没有设置渐变方向的时候,渐变的默认方向是从左向右。
如果要设定渐变方向,要用到<linearGradient>的x1,y1,x2,y2这几个属性。
<linearGradient id="gradient-1" x1="0" y1="0" x2="0" y2="1">
<stop offset="0%" stop-color="#DCE35B" />
<stop offset="100%" stop-color="#45B649" />
</linearGradient>
我们知道,在平面上,方向一般由向量来表示。而渐变的方向由(x1,y1)(起点)和(x2,y2)(点)两个点定义的向量来表示。
在一般的应用场景中,x1,y1,x2,y2的取值范围是[0,1](或者用百分数[0%, 100%])。
对于矩形而言,不管矩形的长宽比例是多少,它的左上角对应的都是(0,0),右下角则对应(1,1)。
x1="0" y1="0" x2="0" y2="1"表示从(0,0)到(0,1),即渐变方向从矩形上边框垂直向下到下边框。
x1="0" y1="0.3" x2="0" y2="0.7"的情形如下:
可以看出,x1,y1,x2,y2不仅决定渐变的方向,还决定了渐变的范围,超出渐变范围的部分由起始或结束色标的颜色进行纯色填充。
案例1:渐变文字
<svg width="600" height="270">
<defs>
<linearGradient id="background"> <!--背景渐变色-->
<stop offset="0%" stop-color="#232526" />
<stop offset="100%" stop-color="#414345" />
</linearGradient>
<linearGradient id="text-color" x1="0" y1="0" x2="0" y2="100%"> <!--文字渐变色-->
<stop offset="0%" stop-color="#DCE35B" />
<stop offset="100%" stop-color="#45B649" />
</linearGradient>
</defs>
<rect x="0" y="0" height="100%" width="100%" fill="url(#background)"></rect>
<text y="28%" x="28%">试问闲情都几许?</text>
<text y="44%" x="28%">一川烟草</text>
<text y="60%" x="28%">满城风絮</text>
<text y="76%" x="28%">梅子黄时雨</text>
</svg>
<style>
text{
font-size: 32px;
letter-spacing:5px;
fill:url(#text-color); //文字的填充使用渐变色
}
</style>
文字的填充,我们用了垂直方向的渐变色,对于每一行文字,都是从黄色渐变到绿色。
如果要将这几行文字作为一个整体来设置渐变色,像下面这样,应该怎样设置呢?
这就要用到gradientUnits属性了。
gradientUnits属性定义渐变元素(<linearGradient>、<radialGradient>)要参考的坐标系。 它有两个取值:objectBoundingBox 和 userSpaceOnUse。
默认值是objectBoundingBox,它定义渐变元素的参考坐标系为引用该渐变的SVG元素,渐变的起止、范围、方向都是基于引用该渐变的SVG元素(之前的<rect>,这里的<text>)自身,比如这里的每一个<text>元素的左上角都是渐变色的(0,0)位置,右下角都是(100%,100%)。
userSpaceOnUse则以当前的SVG元素视窗区域(viewport) 为渐变元素的参考坐标系。也就是SVG元素的左上角为渐变色的(0,0)位置,右下角为(100%,100%)。
<svg height="200" width="300">
<defs>
<!-- 定义两个渐变,除了gradientUnits,其他配置完全相同 -->
<linearGradient id="gradient-1" x1="0" y1="0" x2="100%" y2="100%" gradientUnits="objectBoundingBox">
<stop offset="0%" stop-color="#C6FFDD" />
<stop offset="100%" stop-color="#f7797d" />
</linearGradient>
<linearGradient id="gradient-2" x1="0" y1="0" x2="100%" y2="100%" gradientUnits="userSpaceOnUse">
<stop offset="0%" stop-color="#C6FFDD" />
<stop offset="100%" stop-color="#f7797d" />
</linearGradient>
</defs>
<rect x="0" y="0" ></rect>
<rect x="150" y="0" ></rect>
<rect x="0" y="100" ></rect>
<rect x="150" y="100" ></rect>
</svg>
rect{
height: 100px;
width: 150px;
fill: url(#gradient-1); //四个矩形都填充渐变色,下面左图为gradient-1,右图为gradient-2。
}
gradientUnits:userSpaceOnUse 适用于画布中有多个图形,但每个图形都是整体渐变中的一部分这样的场景。值得注意的是,当gradientUnits="userSpaceOnUse"时,x1,y1,x2,y2的取值只有用%百分数这样的相对单位才表示比例,如果取值为x2="1",那就真的是1px,这一点与gradientUnits="objectBoundingBox"是不同的。
案例2:渐变的环形进度条
在上一篇文章中,我们实现了可交互的环形进度条:
这里我们将其改造成渐变的环形进度条。
使用渐变色作为描边stroke的颜色,中间使用一个白色透明度渐变的圆,增加立体感。
<!--改动部分的代码-->
<svg height="240" width="240" viewBox="0 0 100 100">
<defs>
<linearGradient id="circle">
<stop offset="0%" stop-color="#A5FECB" />
<stop offset="50%" stop-color="#20BDFF" />
<stop offset="100%" stop-color="#5433FF" />
</linearGradient>
<linearGradient id="center">
<stop offset="0%" stop-color="rgba(255,255,255,0.25)" />
<stop offset="100%" stop-color="rgba(255,255,255,0.08)" />
</linearGradient>
</defs>
<!--灰色的背景圆环-->
<circle cx="50" cy="50" r="40" stroke-width="12" stroke="#eee" fill="none"></circle>
<!--渐变的动态圆环-->
<circle
cx="50" cy="50" r="40"
transform="rotate(-90 50 50)"
stroke-width="12"
stroke="url(#circle)"
fill="none"
stroke-linecap="round"
stroke-dasharray="251"></circle>
<!--白色透明度渐变的圆,增加立体感-->
<circle cx="50" cy="50" r="40" fill="url(#center)"></circle>
</svg>
径向渐变
基础使用
径向渐变是色彩从中心点向四周辐射的渐变。
<svg height="300" width="200">
<defs>
<radialGradient id="test">
<stop offset="0%" stop-color="#e1eec3" />
<stop offset="100%" stop-color="#f05053" />
</radialGradient>
</defs>
<rect fill="url(#test)" x="10" y="10" width="150" height="150"></rect>
</svg>
和线性渐变的结构类似,我们将径向渐变标签<radialGradient>定义在<defs>元素中,其id属性作为其唯一标识,以便后面需要使用的地方对其进行引用。
<radialGradient>中的<stop>标签定义渐变色的色标,它的offset 和 stop-color属性分别定义色标的位置和颜色值。
渐变的范围
径向渐变的范围由<radialGradient>的cx,cy,r三个属性共同决定,它们的默认值均是50%,是相对值,相对的是引用该渐变的SVG元素。
cx和cy定义径向渐变范围的圆心,(50%, 50%)意味着是引用该渐变的SVG元素的中心。r设定渐变范围的半径,当r=50%时,说明渐变范围的半径在x和y方向的分别是引用该渐变的SVG元素width和height的50%。
//当rect高度减小时,渐变在y方向的半径也减小。
<rect fill="url(#test)" x="10" y="10" width="150" height="100"></rect>
在cx,cy,r都取默认值的情况下,径向渐变的范围刚好覆盖引用该渐变的SVG元素。实际开发中,我们常常需要调整渐变范围。
渐变起点的移动
在默认情况下,渐变起点都是在渐变范围的中心,如果想要不那么对称的渐变,就需要改变渐变起点的位置。
<radialGradient>的fx和fy就是用来设置渐变色起始位置的。fx和fy的值也是相对值,相对的也是引用该渐变的SVG元素。
我们可以设定渐变的范围(cx,cy,r),也可以设定渐变的起点位置(fx,fy)。但是如果渐变的起点位置在渐变的范围之外,会出现一些我们不想要的效果。
测试代码如下,可直接运行:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
body{
display: flex;
justify-content: center;
}
.control{
margin-top:20px;
}
</style>
</head>
<body>
<svg height="300" width="200">
<defs>
<radialGradient id="test">
<stop offset="0%" stop-color="#e1eec3" />
<stop offset="100%" stop-color="#f05053" />
</radialGradient>
</defs>
<rect fill="url(#test)" x="10" y="10" width="150" height="150"></rect>
</svg>
<div>
<div>cx:<input value="50" type="range" min="0" max="100" id="cx" /></div>
<div>cy:<input value="50" type="range" min="0" max="100" id="cy" /></div>
<div>r:<input value="50" type="range" min="0" max="100" id="r" /></div>
<div>fx:<input value="50" type="range" min="0" max="100" id="fx" /></div>
<div>fy:<input value="50" type="range" min="0" max="100" id="fy" /></div>
</div>
<script>
const rg = document.getElementById('test')
document.querySelectorAll('input').forEach((elem) => {
elem.addEventListener('change', (ev) => {
rg.setAttribute(ev.target.id, ev.target.value+'%')
})
})
</script>
</body>
</html>
综合案例:透明的泡泡
最后我们用线性渐变和径向渐变画一个泡泡。
分析:
背景是一个用线性渐变填充的矩形。
泡泡分为三个部分:由径向渐变填充的一个圆形和两个椭圆。
这里的径向渐变主要是颜色透明度的渐变。设定颜色透明度,我们可以直接指定stop-color的值为rgba,也可以通过stop-opacity来设定stop-color颜色的透明度。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
.bubble{
animation: move 5s linear infinite;
animation-direction:alternate;
}
//泡泡的运动
@keyframes move {
0%{
transform: translate(0,0);
}
50%{
transform: translate(250px,220px);
}
100%{
transform: translate(520px,50px);
}
}
</style>
</head>
<body>
<svg height="400" width="700">
<defs>
<!--背景的线性渐变-->
<linearGradient id="background">
<stop offset="0%" stop-color="#DCE35B" />
<stop offset="100%" stop-color="#45B649" />
</linearGradient>
<!--光斑的径向渐变,通过fx、fy设置不对称的渐变-->
<radialGradient id="spot" fx="50%" fy="30%">
<stop offset="10%" stop-color="white" stop-opacity=".7"></stop>
<stop offset="70%" stop-color="white" stop-opacity="0"></stop>
</radialGradient>
<!--泡泡本体的径向渐变-->
<radialGradient id="bubble">
<stop offset="0%" stop-color="rgba(255,255,255,0)" ></stop>
<stop offset="80%" stop-color="rgba(255,255,255,0.1)" ></stop>
<stop offset="100%" stop-color="rgba(255,255,255,0.42)"></stop>
</radialGradient>
</defs>
<rect fill="url(#background)" width="100%" height="100%"></rect>
<g>
<circle cx="100" cy="100" r="70" fill="url(#bubble)"></circle>
<ellipse rx="50" ry="20" cx="80" cy="60" fill="url(#spot)" transform="rotate(-25, 80, 60)" ></ellipse>
<ellipse rx="20" ry="10" cx="140" cy="130" fill="url(#spot)" transform="rotate(125, 140, 130)" ></ellipse>
</g>
</svg>
</body>
</html>
以上渐变配色均来自网站: uigradients.com/
作者:Alaso
来源:juejin.cn/post/7098637240825282591
API 工程化分享
概要
本文是学习B站毛剑老师的《API 工程化分享》学习笔记,分享了 gRPC 中的 Proto 管理方式,Proto 分仓源码方式,Proto 独立同步方式,Proto git submodules 方式,Proto 项目布局,Proto Errors,服务端和客户端的 Proto Errors,Proto 文档等等
目录
Proto IDL Management
IDL Project Layout
IDL Errors
IDL Docs
Proto IDL Management
Proto IDL
Proto 管理方式
Proto 分仓源码方式
Proto 独立同步方式
Proto git submodules 方式
Proto IDL
gRPC 从协议缓冲区使用接口定义语言 (IDL)。协议缓冲区 IDL 是一种与平台无关的自定义语言,具有开放规范。 开发人员会创作 .proto 文件,用于描述服务及其输入和输出。 然后,这些 .proto 文件可用于为客户端和服务器生成特定于语言或平台的存根,使多个不同的平台可进行通信。 通过共享 .proto 文件,团队可生成代码来使用彼此的服务,而无需采用代码依赖项。
Proto 管理方式
煎鱼的一篇文章:真是头疼,Proto 代码到底放哪里?
文章中经过多轮讨论对 Proto 的存储方式和对应带来的优缺点,一共有如下几种方案:
代码仓库
独立仓库
集中仓库
镜像仓库
镜像仓库
在我自己的微服务仓库里面,有一个 Proto 目录,就是放我自己的 Proto,然后在我提交我的微服务代码到主干或者某个分支的时候,它可能触发一个 mirror 叫做自动同步,会镜像到这个集中的仓库,它会帮你复制过去,相当于说我不需要把我的源码的 Proto 开放给你,同时还会自动复制一份到集中的仓库
在煎鱼的文章里面的集中仓库还是分了仓库的,B站大仓是一个统一的仓库。为什么呢?因为比方像谷歌云它整个对外的 API 会在一个仓库,不然你让用户怎么找?到底要去哪个 GitHub 下去找?有这么多 project 怎么找?根本找不到,应该建统一的一个仓库,一个项目就搞定了
我们最早衍生这个想法是因为无意中看到了 Google APIs 这个仓库。大仓可以解决很多问题,包括高度代码共享,其实对于 API 文件也是一样的,集中在一个 Repo 里面,很方便去检索,去查阅,甚至看文档,都很方便
我们不像其他公司喜欢弄一个 UI 的后台,我们喜欢 Git,它很方便做扩展,包括 CICD 的流程,包括 coding style 的 check,包括兼容性的检测,包括 code review 等等,你都可以基于 git 的扩展,gitlab 的扩展,GitHub 的一些 actions,做很多很多的工作
Proto 分仓源码方式
过去为了统一检索和规范 API,我们内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。它只是一个申明文件。
API 仓库,方便跨部门协作;
版本管理,基于 git 控制;
规范化检查,API lint;
API design review,变更 diff;
权限管理,目录 OWNERS;
集中式仓库最大的风险是什么呢?是谁都可以更改
大仓的核心是放弃了读权限的管理,针对写操作是有微观管理的,就是你可以看到我的 API 声明,但是你实际上调用不了,但是对于迁入 check in,提到主干,你可以在不同层级加上 owner 文件,它里面会描述谁可以合并代码,或者谁负责 review,两个角色,那就可以方便利用 gitlab 的 hook 功能,然后用 owner 文件做一些细粒度的权限管理,针对目录级别的权限管理
最终你的同事不能随便迁入,就是说把文件的写权限,merge 权限关闭掉,只允许通过 merge request 的评论区去回复一些指令,比方说 lgtm(looks good to me),表示 review 通过,然后你可以回复一个 approve,表示这个代码可以被成功 check in,这样来做一些细粒度的权限检验
怎么迁入呢?我们的想法是在某一个微服务的 Proto 目录下,把自己的 Proto 文件管理起来,然后自动同步进去,就相当于要写一个插件,可以自动复制到 API 仓库里面去。做完这件事情之后,我们又分了 api.go,api.java,git submodule,就是把这些代码使用 Google protobuf,protoc 这个编译工具生成客户端的调用代码,然后推到另一个仓库,也就是把所有客户端调用代码推到一个源码仓库里面去
Proto 独立同步方式
移动端采用自定义工具方式,在同步代码阶段,自动更新最新的 proto 仓库到 worksapce 中,之后依赖 bazel 进行构建整个仓库
业务代码中不依赖 target 产物,比如 objective-c 的 .h/.a 文件,或者 Go 的 .go 文件(钻石依赖、proto 未更新问题)
源码依赖会引入很多问题
依赖信息丢失
proto 未更新
钻石依赖
依赖信息丢失
在你的工程里面依赖了其他服务,依赖信息变成了源码依赖,你根本不知道依赖了哪个服务,以前是 protobuf 的依赖关系,现在变成了源码依赖,服务依赖信息丢失了。未来我要去做一些全局层面的代码盘点,比方说我要看这个服务被谁依赖了,你已经搞不清楚了,因为它变成了源码依赖
proto 未更新
如果我的 proto 文件更新了,你如何保证这个人重新生成了 .h/.a 文件,因为对它来说这个依赖信息已经丢失,为什么每次都要去做这个动作呢?它不会去生成 .h/.a 文件
钻石依赖
当我的 A 服务依赖 B 服务的时候,通过源码依赖,但是我的 A 服务还依赖 C 服务,C 服务是通过集中仓库 bapis 去依赖的,同时 B 和 C 之间又有一个依赖关系,那么这个时候就可能出现对于 C 代码来说可能会注册两次,protobuf 有一个约束就是说重名文件加上包名是不允许重复的,否则启动的时候就会 panic,有可能会出现钻石依赖
A 依赖 B
A 依赖 C
A 和 B 是源码依赖
A 和 C 是 proto 依赖
B 和 C 之间又有依赖
那么它的版本有可能是对不齐的,就是有风险的,这就是为什么 google basic 构建工具把 proto 依赖的名字管理起来,它并没有生成 .go 文件再 checkin 到仓库里面,它不是源码依赖,它每一次都要编译,每次都要生成 .go 文件的原因,就是为了版本对齐
Proto git submodules 方式
经过多次讨论,有几个核心认知:
proto one source of truth,不使用镜像方式同步,使用 git submodules 方式以仓库中目录形式来承载;
本地构建工具 protoc 依赖 go module 下的相对路径即可;
基于分支创建新的 proto,submodules 切换分支生成 stub 代码,同理 client 使用联调切换同一个分支;
维护 Makefile,使用 protoc + go build 统一处理;
声明式依赖方式,指定 protoc 版本和 proto 文件依赖(基于 BAZEL.BUILD 或者 Yaml 文件)
proto one source of truth
如果只在一个仓库里面,如果只有一个副本,那么这个副本就是唯一的真相并且是高度可信任的,那如果你是把这个 proto 文件拷来拷去,最终就会变得源头更新,拷贝的文件没办法保证一定会更新
镜像方式同步
实际上维护了本地微服务的目录里面有一个 protobuf 的定义,镜像同步到集中的仓库里面,实际上是有两个副本的
使用 git submodules 方式以仓库中目录形式来承载
子模块允许您将 Git 存储库保留为另一个 Git 存储库的子目录。这使您可以将另一个存储库克隆到您的项目中并保持您的提交分开。
图中 gateway 这个目录就是以本地目录的形式,但是它是通过 git submodules 方式给承载进来的
如果公司内代码都在一起,api 的定义都在一起,那么大仓绝对是最优解,其次才是 git submodules,这也是 Google 的建议
我们倾向于最终 proto 的管理是集中在一个仓库里面,并且只有一份,不会做任何的 copy,通过 submodules 引入到自己的微服务里面,也就是说你的微服务里面都会通过 submodules 把集中 API 的 git 拷贝到本地项目里面,但是它是通过 submodeles 的方式来承载的,然后你再通过一系列 shell 的工具让你的整个编译过程变得更简单
IDL Project Layout
Proto Project Layout
在统一仓库中管理 proto,以仓库为名
根目录:
目录结构和 package 对齐;
复杂业务的功能目录区分;
公共业务功能:api、rpc、type;
目录结构和 package 对齐
我们看一下 googleapis 大量的 api 是如何管理的?
第一个就是在 googleapis 这个项目的 github 里面,它的第一级目录叫 google,就是公司名称,第二个目录是它的业务域,业务的名称
目录结构和 protobuf 的包名是完全对齐的,方便检索
复杂业务的功能目录区分
v9 目录下分为公共、枚举、错误、资源、服务等等
公共业务功能:api、rpc、type
在 googleapis 的根目录下还有类似 api、rpc、type 等公共业务功能
IDL Errors
Proto Errors
Proto Errors:Server
Proto Errors:Client
Proto Errors
使用一小组标准错误配合大量资源
错误传播
用简单的协议无关错误模型,这使我们能够在不同的 API,API 协议(如 gRPC 或 HTTP)以及错误上下文(例如,异步,批处理或工作流错误)中获得一致的体验。
使用一小组标准错误配合大量资源
服务器没有定义不同类型的“找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息。
我们以前自己的业务代码关于404,关于某种资源找不到的错误码,定义了上百上千个,请问为什么大家在设计 HTTP restful 或者 grpc 接口的时候不用人家标准的状态码呢?人家有标准的404,或者 not found 的状态码,用状态码去映射一下通用的错误信息不好吗?你不可能调用一个接口,返回几十种具体的错误码,你根本对于调用者来说是无法使用的。当我的接口返回超过3个自定义的错误码,你就是面向错误编程了,你不断根据错误码做不同的处理,非常难搞,而且你每一个接口都要去定义
这里的核心思路就是使用标准的 HTTP 状态码,比方说500是内部错误,503是网关错误,504是超时,404是找不到,401是参数错误,这些都是通用的,非常标准的一些状态码,或者叫错误码,先用它们,因为不是所有的错误都需要我们叫业务上 hint,进一步处理,也就是说我调你的服务报错了,我大概率是啥都不做的,因为我无法纠正服务端产生的一个错误,除非它是带一些业务逻辑需要我做一些跳转或者做一些特殊的逻辑,这种不应该特别多,我觉得两个三个已经非常多了
所以说你会发现大部分去调用别人接口的时候,你只需要用一个通用的标准的状态码去映射,它会大大降低客户端的逻辑复杂性,同时也不限制说你包含一些可操作的 hint 的一些信息,也就是说你可以包含一些指示你接下来要去怎么做的一些信息,就是它不冲突
错误传播
如果您的 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到您的客户端。
举个例子,你现在要跟移动端说我有一个接口,那么这个接口会返回哪些错误码,你始终讲不清楚,你为什么讲不清楚呢?因为我们整个微服务的调用链是 A 调 B,B 调 C,C 调 D,D 的错误码会一层层透传到 A,那么 A 的错误码可能会是 ABCD 错误码的并集,你觉得你能描述出来它返回了哪些错误码吗?根本描述不出来
所以对于一个服务之间的依赖关系不应该盲目地将下游服务产生的这些错误码无脑透传到客户端,并且曾经跟海外很多公司,像 Uber,Twitter,Netflix,跟他们很多的华人的朋友交流,他们都不建议大家用这种全局的错误码,比方 A 部门用 01 开头,B 部门用 02 开头,类似这样的方式去搞所谓的君子契约,或者叫松散的没有约束的脆弱的这种约定
在翻译错误时,我们建议执行以下操作:
隐藏实现详细信息和机密信息
调整负责该错误的一方。例如,从另一个服务接收 INVALID_ARGUMENT 错误的服务器应该将 INTERNAL 传播给它自己的调用者。
比如你返回的错误码是4,代表商品已下架,我对这个错误很感兴趣,但是错误码4 在我的项目里面已经被用了,我就把它翻译为我还没使用的错误码6,这样每次翻译的时候就可以对上一层你的调用者,你就可以交代清楚你会返回错误码,因为都是你定义的,而且是你翻译的,你感兴趣的才翻译,你不感兴趣的通通返回 500 错误,就是内部错误,或者说 unknown,就是未知错误,这样你每个 API 都能讲清楚自己会返回哪些错误码
在 grpc 传输过程中,它会要求你要实现一个 grpc states 的一个接口的方法,所以在 Kraots 的 v2 这个工程里面,我们先用前面定义的 message Error 这个错误模型,在传输到 grpc 的过程中会转换成 grpc 的 error_details.proto 文件里面的 ErrorInfo,那么在传输到 client 的时候,就是调用者请求服务,service 再返回给 client 的时候再把它转换回来
也就是说两个服务使用一个框架就能够对齐,因为你是基于 message Error 这样的错误模型,这样在跨语言的时候同理,经过 ErrorInfo 使用同样的模型,这样就解决了跨语言的问题,通过模型的一致性
Proto Errors:Server
errors.proto 定义了 Business Domain Error 原型,使用最基础的 Protobuf Enum,将生成的源码放在 biz 大目录下,例如 biz/errors
biz 目录中核心维护 Domain,可以直接依赖 errors enum 类型定义;
data 依赖并实现了 biz 的 Reporisty/ACL,也可以直接使用 errors enum 类型定义;
TODO:Kratos errors 需要支持 cause 保存,支持 Unwrap();
在某一个微服务工程里面,errors.proto 文件实际上是放在 API 的目录定义,之前讲的 API 目录定义实际上是你的服务里面的 API 目录,刚刚讲了一个 submodules,现在你可以理解为这个 API 目录是另外一个仓库的 submodules,最终你是把这些信息提交到那个 submodules,然后通过 reference 这个 submodules 获取到最新的版本,其实你可以把它打成一个本地目录,就是说我的定义声明是在这个地方
这个 errors.proto 文件其实就列举了各种错误码,或者叫错误的字符串,我们其实更建议大家用字符串,更灵活,因为一个数字没有写文档前你根本不知道它是干啥的,如果我用字符串的话,我可以 user_not_found 告诉你是用户找不到,但是我告诉你它是3548,你根本不知道它是什么含义,如果我没写文档的话
所以我们建议使用 Protobuf Enum 来定义错误的内容信息,定义是在这个地方,但是生成的代码,按照 DDD 的战术设计,属于 Domain,因为业务设计是属于领域的一个东西,Domain 里面 exception 它最终的源码会在哪?会在 biz 的大目录下,biz 是 business 的缩写,就是在业务的目录下,举个例子,你可以放在 biz 的 errors 目录下
有了这个认知之后我们会做三个事情
首先你的 biz 目录维护的是领域逻辑,你的领域逻辑可以直接依赖 biz.errors 这个目录,因为你会抛一些业务错误出去
第二,我们的 data 有点像 DDD 的 infrastructure,就是所谓的基础设施,它依赖并实现了 biz 的 repository 和 acl,repository 就是我们所谓的仓库,acl 是防腐层
因为我们之前讲过它的整个依赖倒置的玩法,就是让我们的 data 去依赖 biz,最终让我们的 biz 零依赖,它不依赖任何人,也不依赖基础设施,它把 repository 和 acl 的接口定义放在 biz 自己目录下,然后让 data 依赖并实现它
也就是说最终我这个 data 目录也可以依赖 biz 的 errors,我可能通过查 mysql,结果这个东西查不到,会返回一个 sql no rows,但肯定不会返回这个错误,那我就可以用依赖 biz 的这个 errors number,比如说 user_not_found,我把它包一个 error 抛出去,所以它可以依赖 biz 的 errors
目前 Kratos 还不支持根因保存,根因保存是什么呢?刚刚说了你可能是 mysql 报了一个内部的错误,这个内部错误你实际上在最上层的传输框架,就是 HTTP 和 grpc 的 middleware 里面,你可能会把日志打出来,就要把堆栈信息打出来,那么根因保存就是告诉你最底层发生的错误是什么
不支持 Unwrap 就是不支持递归找根因,如果支持根因以后呢,就可以让 Kratos errors 这个 package 可以把根因传进去,这样子既能搞定我们 go 的 wrap errors,同时又支持我们的状态码和 reason,大类错误和小类错误,大类错误就是状态码,小类错误就是我刚刚说的用 enum 定义的具体信息,比方说这个商品被下架,这种就不太好去映射一个具体的错误码,你可能是返回一个500,再带上一个 reason,可能是这样的一个做法
Proto Errors:Client
从 Client 消费端只能看到 api.proto 和 error.proto 文件,相应的生成的代码,就是调用测的 api 以及 errors enum 定义
使用 Kratos errors.As() 拿到具体类型,然后通过 Reason 字段进行判定;
使用 Kratos errors.Reason() helper 方法(内部依赖 errors.As)快速判定;
拿到这两个文件之后你可以生成相应代码,然后调用 api
举个例子,图中的代码是调用服务端 grpc 的某一个方法,那么我可能返回一个错误,我们可以用 Kratos 提供的一个 Reason 的 short car,一个快捷的方法,然后把 error 传进去,实际上在内部他会调用标准库的 error.As,把它强制转换成 Kratos 的 errors 类型,然后拿到里面的 Reason 的字段,然后再跟这个枚举值判定,这样你就可以判定它是不是具体的一个业务错误
第二种写法你可以拿到原始的我们 Kratos 的 Error 模型,就是以下这个模型
new 出来之后用标准库的 errors.As 转换出来,转换出来之后再用 switch 获取它里面的 reason 字段,然后可以写一些业务逻辑
这样你的 client 代码跨语言,跨传输,跨协议,无论是 grpc,http,同样是用一样的方式去解决
IDL Docs
Proto Docs
Proto Docs
基于 openapi 插件 + IDL Protobuf 注释(IDL 即定义,IDL 即代码,IDL 即文档),最终可以在 Makefile 中使用 make api 生成 openapi.yaml,可以在 gitlab/vscode 插件直接查看
API Metadata 元信息用于微服务治理、调试、测试等;
因为我们可以在 IDL 文件上面写上大量的注释,那么当讲到这个地方,你就明白了 IDL 有什么样的好处?
IDL 文件它既定义,同时又是代码,也就是说你既做了声明,然后使用 protoc 可以去生成代码,并且是跨语言的代码,同时 IDL 本身既文档,也就是说它才真正满足了 one source of truth,就是唯一的事实标准
最终你可以在 Makefile 中定义一个 api 指令,然后生成一个 openapi.yaml,以前是 swagger json,现在叫 openapi,用 yaml 声明
生成 yaml 文件以后,现在 gitlab 直接支持 openapi.yaml 文件,所以你可以直接打开 gitlab 去点开它,就能看到这样炫酷的 UI,然后 VSCode 也有一个插件,你可以直接去查看
还有一个很关键的点,我们现在的 IDL 既是定义,又是代码,又是文档,其实 IDL 还有一个核心作用,这个定义表示它是一个元信息,是一个元数据,最终这个 API 的 mate data 元信息它可以用于大量的微服务治理
因为你要治理的时候你比方说对每个服务的某个接口进行路由,进行熔断进行限流,这些元信息是哪来的?我们知道以前 dubbo 2.x,3.x 之前都是把这些元信息注册到注册中心的,导致整个数据中心的存储爆炸,那么元信息在哪?
我们想一想为什么 protobuf 是定义一个文件,然后序列化之后它比 json 要小?因为它不是自描述的,它的定义和序列化是分开的,就是原始的 payload 是没有任何的定义信息的,所以它可以高度的compressed,可被压缩,或者说叫更紧凑
所以说同样的道理,IDL 的定义和它的元信息,和生成代码是分开的话,意味着你只要有 one source of truth 这份唯一的 pb 文件,基于这个 pb 文件,你就有办法把它做成一个 api 的 metadata 的服务,你就可以用于做微服务的治理
你可以选一个服务,然后看它有些什么接口,然后你可以通过一个管控面去做熔断、限流等功能,然后你还可以基于这个元信息去调试,你做个炫酷的 UI 可以让它有一些参数,甚至你可以写一些扩展,比方说这个字段叫 etc,建议它是什么样的值,那么你在渲染 UI 的时候可以把默认值填进去,那你就很方便做一些调试,甚至包含测试,你基于这个 api 去生成大量的 test case
参考
API 工程化分享 http://www.bilibili.com/video/BV17m…
接口定义语言 docs.microsoft.com/zh-cn/dotne…
真是头疼,Proto 代码到底放哪里? mp.weixin.qq.com/s/cBXZjg_R8…
git submodules git-scm.com/book/en/v2/…
kratos github.com/go-kratos/k…
error_details.proto github.com/googleapis/…
pkg/errors github.com/pkg/errors
Modifying gRPC Services over Time
作者:郑子铭_
来源:juejin.cn/post/7097866377460973599
H5如何实现唤起APP
前言
写过hybrid的同学,想必都会遇到这样的需求,如果用户安装了自己的APP,就打开APP或跳转到APP内某个页面,如果没安装则引导用户到对应页面或应用商店下载。这里就涉及到了H5与Native之间的交互,为什么H5能够唤起APP并且跳转到对应的页面?
就算你没写过想必也体验过,最常见的就是抖音里面的一些广告,如果你点击了广告,他判断你手机装了对应APP,那他就会去打开那个APP,如果没安装,他会帮你跳转到应用商店去下载,这个还算人性化一点的,有些直接后台给你去下载,你完全无感知。
哈哈,是不是觉得这种技术很神奇,今天我们就一起来看看它是如何实现的~
如果这篇文章有帮助到你,❤️关注+点赞❤️鼓励一下作者,文章公众号首发,关注 前端南玖 第一时间获取最新文章~
唤端体验
实现之前我们先简单体验一下什么是唤端
从上图中,我们可以看到在浏览器中我们点击打开知乎,系统会提示我们是否在知乎中打开,当我们点击打开时,知乎就被打开了,这就是一个简单的唤端体验。
有了这项技术我们就可以实现H5唤起APP应用了,现阶段的引流方式大都得益于这种技术,比如广告投放、用户拉新、引流等。
唤端技术
体验过后,我们就来聊一聊它的实现技术是怎样的,唤端技术我们也称之为deep link技术。当然,不同平台的实现方式有些不同,一般常见的有这几种,分别是:
URL Scheme(通用)
Universal Link (iOS)
App Link、Chrome Intents(android)
URL Scheme(通用)
这种方式是一种比较通用的技术,各平台的兼容性也很好,它一般由协议名、路径、参数组成。这个一般是由Native开发的同学提供,我们前端同学再拿到这个scheme之后,就可以用来打开APP或APP内的某个页面了。
URL Scheme 组成
[scheme:][//authority][path][?query][#fragment]常用APP的 URL Scheme
打开方式
常用的有以下这几种方式
直接通过window.location.href跳转
window.location.href = 'zhihu://'通过iframe跳转
const iframe = document.createElement('iframe')
iframe.style.display = 'none'
iframe.src = 'zhihu://'
document.body.appendChild(iframe)直接使用a标签进行跳转
通过js bridge来打开
window.miduBridge.call('openAppByRouter', {url: 'zhihu://'})判断是否成功唤起
当用户唤起APP失败时,我们希望可以引导用户去进行下载。那么我们怎么才能知道当前APP是否成功唤起呢?
我们可以监听当前页面的visibilitychange事件,如果页面隐藏,则表示唤端成功,否则唤端失败,跳转到应用商店。
OK,我们尝试来实现一下:
首先我手机上并没有安装腾讯微博,所以也就无法唤起,我们让他跳到应用商店对应的应用下载页,这里就用淘宝的下载页来代替一下~
<template>
<div class="open_app">
<div class="open_app_title">前端南玖唤端测试Demo</div>
<div class="open_btn" @click="open">打开腾讯微博</div>
</div>
</template>
<script>
let timer
export default {
name: 'openApp',
methods: {
watchVisibility() {
window.addEventListener('visibilitychange', () => {
// 监听页面visibility
if(document.hidden) {
// 如果页面隐藏了,则表示唤起成功,这时候需要清除下载定时器
clearTimeout(timer)
}
})
},
open() {
timer = setTimeout(() => {
// 没找到腾讯微博的下载页,这里暂时以淘宝下载页代替
window.location.href = 'http://apps.apple.com/cn/app/id387682726'
}, 3000)
window.location.href = 'TencentWeibo://'
}
}
}
</script>
<style lang="less">
.open_app_title {
font-size: (20/@rem);
}
.open_btn{
margin-top:(20/@rem);
padding:(10/@rem) 0;
border-radius: (8/@rem);
background: salmon;
color: #fff;
font-size: (16/@rem);
}
</style>适用性
URL Scheme 这种方式兼容性好,无论安卓或者 iOS 都能支持,是目前最常用的方式。从上图我们能够看出它也有一些比较明显的缺点:
无法准确判断是否唤起成功,因为本质上这种方式就是打开一个链接,并且还不是普通的 http 链接,所以如果用户没有安装对应的 APP,那么尝试跳转后在浏览器中会没有任何反应,通过定时器来引导用户跳到应用商店,但这个定时器的时间又没有准确值,不同手机的唤端时间也不同,我们只能大概的估计一下它的时间来实现,一般设为3000ms左右比较合适;
从上图中我们可以看到会有一个弹窗提示你是否在对应 APP中打开,这就可能会导致用户流失;
有 URL Scheme 劫持风险,比如有一个 app 也向系统注册了
zhihu://这个 scheme ,唤起流量可能就会被劫持到这个 app 里;容易被屏蔽,app 很轻松就可以拦截掉通过 URL Scheme 发起的跳转,比如微信内经常能看到一些被屏蔽的现象。
Universal Link (iOS)
Universal Link 是在iOS 9中新增的功能,使用它可以直接通过https协议的链接来打开 APP。 它相比前一种URL Scheme的优点在于它是使用https协议,所以如果没有唤端成功,那么就会直接打开这个网页,不再需要判断是否唤起成功了。并且使用 Universal Link,不会再弹出是否打开的弹出,对用户来说,唤端的效率更高了。
原理
在 APP 中注册自己要支持的域名;
在自己域名的根目录下配置一个
apple-app-site-association文件即可。(具体的配置前端同学不用关注,只需与iOS同学确认好支持的域名即可)
打开方式
openByUniversal () {
// 打开知乎问题页
window.location.href = 'https://oia.zhihu.com/questions/64966868'
// oia.zhihu.com
},适用性
相对 URL Scheme,universal links 有一个较大优点是它唤端时没有弹窗提示是否打开,提升用户体验,可以减少一部分用户流失;
无需关心用户是否安装对应的APP,对于没有安装的用户,点击链接就会直接打开对应的页面,因为它也是http协议的路径,这样也能一定程度解决 URL Scheme 无法准确判断唤端失败的问题;
只能够在iOS上使用
只能由用户主动触发
App Link、Chrome Intents(Android)
App Link
在2015年的Google I/O大会上,Android M宣布了一个新特性:App Links让用户在点击一个普通web链接的时候可以打开指定APP的指定页面,前提是这个APP已经安装并且经过了验证,否则会显示一个打开确认选项的弹出框,只支持Android M以上系统。
App Links的最大的作用,就是可以避免从页面唤醒App时出现的选择浏览器选项框;
前提是必须注册相应的Scheme,就可以实现直接打开关联的App。
App links在国内的支持还不够,部分安卓浏览器并不支持跳转至App,而是直接在浏览器上打开对应页面。
系统询问是否打开对应App时,假如用户选择“取消”并且选中了“记住此操作”,那么用户以后就无法再跳转App。
Chrome Intents
Chrome Intent 是 Android 设备上 Chrome 浏览器中 URI 方案的深层链接替代品。
如果 APP 已安装,则通过配置的 URI SCHEME 打开 APP。
如果 APP 未安装,配置了 fallback url 的跳转 fallback url,没有配置的则跳转应用市场。
这两种方案在国内的应用都比较少。
方案对比
| URL Scheme | Universal Link | App Link | |
|---|---|---|---|
| <ios9 | 支持 | 不支持 | 不支持 |
| >=ios9 | 支持 | 支持 | 不支持 |
| <android6 | 支持 | 不支持 | 不支持 |
| >=android6 | 支持 | 不支持 | 支持 |
| 是否需要HTTPS | 不需要 | 需要 | 需要 |
| 是否需要客户端 | 需要 | 需要 | 需要 |
| 无对应APP时的现象 | 报错/无反应 | 跳到对应的页面 | 跳到对应的页面 |
URI Scheme
URI Scheme的兼容性是最高,但使用体验相对较差:
当要被唤起的APP没有安装时,这个链接就会出错,页面无反应。
当注册有多个scheme相同的时候,没有办法区分。
不支持从其他app中的UIWebView中跳转到目标APP, 所以ios和android都出现了自己的独有解决方案。
Universal Link
已经安装APP,直接唤起APP;APP没有安装,就会跳去对应的web link。
universal Link 是从服务器上查询是哪个APP需要被打开,所以不会存在冲突问题
universal Link 支持从其他app中的UIWebView中跳转到目标app
缺点在于会记住用户的选择:在用户点击了Universal link之后,iOS会去检测用户最近一次是选择了直接打开app还是打开网站。一旦用户点击了这个选项,他就会通过safiri打开你的网站。并且在之后的操作中,默认一直延续这个选择,除非用户从你的webpage上通过点击Smart App Banner上的OPEN按钮来打开。
App link
优点与 universal Link 类似
缺点在于国内的支持相对较差,在有的浏览器或者手机ROM中并不能链接至APP,而是在浏览器中打开了对应的链接。
在询问是否用APP打开对应的链接时,如果选择了“取消”并且“记住选择”被勾上,那么下次你再次想链接至APP时就不会有任何反应
作者:南玖
来源:https://juejin.cn/post/7097784616961966094
金三银四必备,全面总结 Kotlin 面试知识点
「Offer 驾到,掘友接招!我正在参与2022春招系列活动-经验复盘,点击查看 活动详情 即算参赛
你的支持对我意义重大!
🔥 Hi,我是旭锐。本文已收录到 GitHub · Android-NoteBook 中。这里有 Android 进阶成长路线笔记 & 博客,有志同道合的朋友,欢迎跟着我一起成长。(联系方式 & 入群方式在 GitHub)
前言
- 在 Android 面试中很重视基础知识的考察,其中语言基础主要包括 Java、Kotlin、C/C++ 三种编程语言。在小彭面试的经验中,发现很多同学的 Kotlin 语言能力只是停留在一些非常入门的语法使用上;
- 在这篇文章里,我将为你浓缩总结 Kotlin 中最常用的知识点和原理。希望通过这篇文章能够帮助你扫除支持盲区,对于一些语法背后的原理也有所涉猎。
1. 为什么要使用 Kotlin?
面试官问这个问题一方面可能是先想引入 Kotlin 这个话题,另一方面是想考察你的认知能力,是不是真的有思考过 Kotlin 的优势 / 价值,还是随波逐流别人用我也跟着用。你可以这么回答:
在 Android 生态中主要有 C++、Java、Kotlin 三种语言 ,它们的关系不是替换而是互补。其中,C++ 的语境是算法和高性能,Java 的语境是平台无关和内存管理,而 Kotlin 则融合了多种语言中的优秀特性,带来了一种更现代化的编程方式。 例如简化异步编程的协程(coroutines),提高代码质量的可空性(nullability),lambda 表达式等。
2. 语法糖的味道
== 和 equal() 相同,=== 比较内存地址
顶级成员(函数 & 属性)的原理: Kotlin 顶级成员的本质是 Java 静态成员,编译后会自动生成
文件名Kt的类,可以使用@Jvm:fileName注解修改自动生成的类名。
默认参数的原理: Kotlin 默认参数的本质是将默认值 固化 到调用位置,所以在 Java 中无法直接调用带默认参数的函数,需要在 Kotlin 函数上增加
@JvmOverloads注解,指示编译器生成重载方法(@JvmOverloads会为默认参数提供重载方法)。
解构声明的原理: Kotlin 解构声明可以把一个对象的属性分解为一组变量,所以解构声明的本质是局部变量。
举例:
val (name, price) = Book("Kotlin入门", 66.6f)
println(name)
println(price)
-------------------------------------------
Kotlin 类需要声明`operator fun componentN()`方法来实现解构功能,否则是不具备解构声明的功能的,例如:
class Book(var name: String, var price: Float) {
operator fun component1(): String { // 解构的第一个变量
return name
}
operator fun component2(): Float { // 解构的第二个变量
return price
}
}
Sequences 序列的原理: Sequences 提升性能的关键在于多个操作共享同一个 Iterator 迭代器,只需要一次循环就可以完成数据操作。Sequences 又是懒惰的,需要遇到终端操作才会开始工作。
扩展函数的原理: 扩展函数的语义是在不修改类 / 不继承类的情况下,向一个类添加新函数或者新属性。本质是静态函数,静态函数的第一个参数是接收者类型,调用扩展时不会创建适配对象或者任何运行时的额外消耗。在 Java 中,我们只需要像调用普通静态方法那样调用扩展即可。相关资料:Kotlin | 扩展函数(终于知道为什么 with 用 this,let 用 it)
let、apply、with 的区别和应用场景: let、with、apply 都是标准库函数,它们的主要区别在 lambda 参数类型定义不同。apply、with 的 lambda 参数是 T 的扩展函数,因此在 lambda 内使用 this 引用接收者对象,而 let 的 lambda 参数是参数为 T 的高阶函数,因此 lambda 内使用 it 引用唯一参数。
委托机制的原理: Kotlin 委托的语法关键字是 by,其本质上是面向编译器的语法糖,三种委托(类委托、对象委托和局部变量委托)在编译时都会转化为 “无糖语法”。例如类委托:编译器会实现基础接口的所有方法,并直接委托给基础对象来处理。例如对象委托和局部变量委托:在编译时会生成辅助属性(prop$degelate),而属性 / 变量的 getter() 和 setter() 方法只是简单地委托给辅助属性的 getValue() 和 setValue() 处理。相关资料:Kotlin | 委托机制 & 原理 & 应用
中缀函数: 声明 infix 关键字的函数是中缀函数,调用中缀函数时可以省略圆点以及圆括号等程序符号,让语句更自然。
中缀函数的要求:
- 1、成员函数或扩展函数
- 2、函数只有一个参数
- 3、不能使用可变参数或默认参数
举例:
infix fun String.吃(fruit: String): String {
return "${this}吃${fruit}"
}
调用: "小明" 吃 "苹果"
3. 类型系统
数值类型: Kotlin 将基本数据类型和引用型统一为:Byte、Short、Int、Long、Float、Double、Char 和 Boolean。需要注意的是,类型的统一并不意味着 Kotlin 所有的数值类型都是引用类型,大多数情况下,它们在编译后会变成基本数据类型,类型参数会被编译为引用类型。
隐式转换: Kotlin 不存在隐式类型转换,即时是低级类型也需要显式转换为高级类型:
//隐式转换,编译器会报错
val anInt: Int = 5
val ccLong: Long = anInt
//需要去显式的转换,下面这个才是正确的
val ddLong: Long = anInt.toLong()
平台类型: 当可空性注解不存在时,Java 类型会被转换为 Kotlin 的平台类型。平台类型本质上是 Kotlin 编译器无法确定其可空信息,既可以把它当作可空类型,也可以把它当作非空类型。
如果所有来自 Java 的值都被看成非空是不合理的,反之把 Java 值都当作可空的,由会引出大量 Null 检查。综合考量,平台类型是 Kotlin 为开发者选择的折中的设计方案。
类型转换: 较小类型并不是较大类型的子类型,较小的类型不能隐式转换为较大的类型。
val b: Byte = 1 // OK
val i: Int = b // 编译错误
val i: Int = b.toInt() // OK
只读集合和可变集合: 只读集合只可读,而可变集合可以增删该差(例如 List 只读,MutableList 可变)。需要注意,只读集合引用指向的集合不一定是不可变的,因为你使用的变量可能是众多指向同一个集合的其中一个。
Array 和 IntArray 的区别: Array 相当于引用类型数组 Integer[],IntArray 相当于数值类型数组 int[]。
Unit: Any 的子类,作为函数返回值时表示没有返回值,可以省略,与 Java void 类似。
Nothing: 表示表达式或者函数永远不会返回,Nothing? 唯一允许的值是 null。
Java Void: void 的包装类,与 void 类似表示一个函数没有有效的返回值,返回值只能是 null。
4. 面向对象
类修饰符: Kotlin 类 / 方法默认是 final 的,如果想让继承类 / 重写方法,需要在基类 / 基方法添加 open 修饰符。
final:不允许继承或重写
open:允许继承或重写
abstract:抽象类 / 抽象方法
访问修饰符: Java 默认的访问修饰符是 protected,Kotlin 默认的访问修饰符是 public。
public:所有地方可见
internal:模块中可见,一个模块就是一组编译的 Kotlin 文件
protected:子类中可见(与 Java 不同,相同包不可见,Kotlin 没有 default 包可见)
private:类中可见
构造函数:
- 默认构造函数: class 默认有一个无参主构造函数,如果显式声明了构造函数,则默认的无参主构造函数失效;
- 主构造函数: 声明在 class 关键字后,其中 constructor 关键词可以省略;
- 次级构造函数: 如果声明了次级构造函数,则默认的无参主构造函数会失效。如果存在主构造函数,次级构造函数需要直接或间接委托给主构造函数。
init 函数执行顺序: 主构造函数 > init > 次级构造函数
内部类: Kotlin 默认为静态内部类,如果想访问类中的成员方法和属性,需要添加 inner 关键字称为非静态内部类;Java 默认为非静态内部类。
data 关键字原理: data 关键字用于定义数据类型,编译器会自动从主构造函数中提取属性并生成一系列函数:equals()/hashCode()、toString()、componentN()、copy()。
sealed 关键字原理: 密封类用来表示受限的类继承结构,密封类可以有子类,但是所有子类都必须内嵌在该密封类中。
object 与 companion object 的区别 object 有两层语义:静态匿名内部类 + 单例对象 companion object 是伴生对象,一个类只能有一个,代表了类的静态成员(函数 / 属性)
单例: Kotlin 可以使用 Java 相似的方法实现单例,也可以采用 Kotlin 特有的语法。相关资料:Kotlin下的5种单例模式
- object
// Kotlin实现
object SingletonDemo
- by lazy(mode = LazyThreadSafetyMode.SYNCHRONIZED)
class SingletonDemo private constructor() {
companion object {
val instance: SingletonDemo by lazy(mode = LazyThreadSafetyMode.SYNCHRONIZED) {
SingletonDemo()
}
}
}
5. lambda 表达式
lambda 表达式本质上是「可以作为值传递的代码块」。在老版本 Java 中,传递代码块需要使用匿名内部类实现,而使用 lambda 表达式甚至连函数声明都不需要,可以直接传递代码块作为函数值。
it: 当 lambda 表达式只有一个参数,可以用 it 关键字来引用唯一的实参。
lambda 表达式的种类
- 1、普通 Lambda 表达式:例如 ()->R
- 2、带接收者对象的 Lambda 表达式:例如 T.()->R
lambda 表达式访问局部变量的原理: 在 Java 中,匿名内部类访问的局部变量必须是 final 修饰的,否则需要使用数组或对象做一层包装。在 Kotlin 中,lambda 表达式可以直接访问非 final 的局部变量,其原理是提供了一层包装类,修改局部变量本质上是修改包装类中的属性。
class Ref<T>(var value:T)
复制代码
lambda 表达式编译优化: 在循环中使用 Java 8 与 Kotlin 中的 lambda 表达式时,会存在编译时优化,编译器会将 lambda 优化为一个 static 变量,除非 lambda 表达式中访问了外部的变量或函数。
inline 内联函数的原理:
内联 lambda 表达式参数(主要优点): 内联函数的参数如果是 lambda 表达式,则该参数默认也是 inline 的。lambda 表达式也会被固化的函数调用位置,从而减少了为 lambda 表达式创建匿名内部类对象的开销。当 lambda 表达式被经常调用时,可以减少内存开销。
减少入栈出栈过程(次要优点): 内联函数的函数体被固化到函数调用位置,执行过程中减少了栈帧创建、入栈和出栈过程。需要注意:如果函数体太大就不适合使用内联函数了,因为会大幅度增加字节码大小。
@PublishApi 注解: 编译器要求内联函数必须是 public 类型,使用 @PublishApi 注解可以实现 internal 等访问修饰的同时又实现内联
noinline 非内联: 如果在内联函数内部,lambda 表达式参数被其它非内联函数调用,会报编译时错误。这是因为 lambda 表达式已经被拉平而无法传递给其他非内联函数。可以给参数加上 noinline 关键字表示禁止内联。
inline fun test(noinline inlined: () -> Unit) {
otherNoinlineMethod(inlined)
}
复制代码
非局部返回(Non-local returns): 一个不带标签的 return 语句只能用在 fun 声明的函数中使用,因此在 lambda 表达式中的 return 必须带标签,指明需要 return 的是哪一级的函数:
fun song(f: (String) -> Unit) {
// do something
}
fun behavior() {
song {
println("song $it")
return //报错: 'return' is not allowed here
return@song // 局部返回
return@behavior // 非局部返回
}
}
唯一的例外是在内联函数中的 lambda 表达式参数,可以直接使用不带标签的 return,返回的是调用内联函数的外部函数,而不是内联函数本身,默认就是非局部返回。
inline fun song(f: (String) -> Unit) {
// do something
}
fun behavior() {
song {
println("song $it")
return // 非局部返回
return@song // 局部返回
return@behavior // 非局部返回
}
}
crossinline 非局部返回: 禁止内联函数的 lambda 表达式参数使用非局部返回
实化类型参数 reified: 因为泛型擦除的影响,运行期间不清楚类型实参的类型,Kotlin 中使用 带实化类型参数的内联函数 可以突破这种限制。实化类型参数在插入到调用位置时会使用类型实参的确切类型代替,因此可以确定实参类型。
在这个函数里,我们传入一个List,企图从中过滤出 T 类型的元素:
Java:
<T> List<T> filter(List list) {
List<T> result = new ArrayList<>();
for (Object e : list) {
if (e instanceof T) { // compiler error
result.add(e);
}
}
return result;
}
---------------------------------------------------
Kotlin:
fun <T> filter(list: List<*>): List<T> {
val result = ArrayList<T>()
for (e in list) {
if (e is T) { // cannot check for instance of erased type: T
result.add(e)
}
}
return result
}
调用:
val list = listOf("", 1, false)
val strList = filter<String>(list)
---------------------------------------------------
内联后:
val result = ArrayList<String>()
for (e in list) {
if (e is String) {
result.add(e)
}
}
5. DSL 领域特定语言
DSL 是专门用于解决某个问题的语言,虽然没有通用语言那么全面,但在解决特定问题时更加高效。案例:Compose 的 UI 代码也是采用了 DSL,使得 Compose 拥有了不输于 XML 的编码效率。实现 DSL 需要可以利用的 Kotlin 语法特性,相关资料:Kotlin DSL 实战:像 Compose 一样写代码
高阶函数: 使得 lambda 参数脱离圆括号,减少一个参数;
扩展函数: 传递 Receiver,减少一个参数;
Context Receivers: 传递多个 Receiver,在扩展函数的基础上减少多个参数;
中缀函数: 让语法更简洁自然;
@DSLMarker: 用于限制 lambda 中不带标签的 this 只能访问到最近的 Receiver 类型,当调用更外层的 Receiver 时必须显式指定 this@XXX。
context(View)
val Float.dp
get() = this * this@View.resources.displayMetrics.density
class SomeView : View {
val someDimension = 4f.dp
}
6. 总结
少部分比较聪明的小伙伴就会问了,你这怎么没有涉及协程、Flow 这些知识点?那是因为这些知识点比较多,小彭决定单独放在一篇文章里。一篇文章拆成两篇用,它不香吗?
作者:彭旭锐
链接:https://juejin.cn/post/7076744947440812062
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
效率翻倍!大型Flutter项目快速实现JSON转Model实战
一、前言
在原生应用开发中,我们通常会使用YYModel、SwiftyJSON、GSON等库实现JSON解析,并使用JSONConverter等类似工具实现JSON自动转模型,极大的提高工作效率。
但在Flutter开发中,却并没有类似的解析库给我们使用,因为这样的库需要使用运行时反射,这在 Flutter 中是禁用的。运行时反射会干扰 Dart 的 tree shaking,使用_tree shaking_,可以在 release 版中“去除”未使用的代码,这可以显著优化应用程序的大小。由于反射会默认应用到所有代码,因此_tree shaking_ 会很难工作,因为在启用反射时很难知道哪些代码未被使用,因此冗余代码很难剥离,所以 Flutter 中禁用了 Dart 的反射功能,而正因如此也就无法实现动态转化 Model 的功能。
二、json_serializable
虽然不能在Flutter中使用运行时反射,但官方提供了类似易于使用的API,它是基于代码生成库实现,json_serializable package,它是一个自动化的源代码生成器,可以生成JSON序列化模板,由于序列化代码无需手写和维护,将运行时产生JSON序列化异常的风险降至最低,使用方法如下:
1. 在项目中添加json_serializable
要包含json_serializable到我们的项目中,需要一个常规和两个开发依赖项。简而言之,开发依赖项是不包含在我们的应用程序源代码中的依赖项。
通过此链接可以查看这些所需依赖项的最新版本 。
在您的项目根文件夹中运行 flutter packages get (或者在编辑器中点击 “Packages Get”) 以在项目中使用这些新的依赖项.
2. 以json_serializable的方式创建model类
让我们看看如何将我们的User类转换为一个json_serializable。为了简单起见,我们使用前面示例中的简化JSON model。
user.dart
import 'package:json_annotation/json_annotation.dart';
// user.g.dart 将在我们运行生成命令后自动生成
part 'user.g.dart';
///这个标注是告诉生成器,这个类是需要生成Model类的
@JsonSerializable()
class User {
String name;
String email;
User(this.name, this.email);
factory User.fromJson(Map json) => _$UserFromJson(json);
Map toJson() => _$UserToJson(this);
}
有了这个设置,源码生成器将生成用于序列化name和email字段的JSON代码。
如果需要,自定义命名策略也很容易。例如,如果我们正在使用的API返回带有_snake_case_的对象,但我们想在我们的模型中使用_lowerCamelCase_, 那么我们可以使用@JsonKey标注:
@JsonKey(name: 'registration_date_millis')
final int registrationDateMillis;
3. 运行代码生成程序
- 一次性生成
通过在我们的项目根目录下运行flutter packages pub run build_runner build,我们可以在需要时为我们的Model生成JSON序列化代码。 这触发了一次性构建,它通过我们的源文件,挑选相关的并为它们生成必要的序列化代码。
- 持续生成
虽然这非常方便,但如果我们不需要每次在model类中进行更改时都要手动运行构建命令的话会更好。
使用_watcher_可以使我们的源代码生成的过程更加方便。它会监视我们项目中文件的变化,并在需要时自动构建必要的文件。我们可以通过flutter packages pub run build_runner watch在项目根目录下运行来启动_watcher_。
只需启动一次观察器,然后并让它在后台运行,这是安全的
4. 使用json_serializable模型
要通过json_serializable方式反序列化JSON字符串,我们不需要对先前的代码进行任何更改。
Map userMap = JSON.decode(json);
var user = new User.fromJson(userMap);
序列化也一样。调用API与之前相同。
String json = JSON.encode(user);
有了json_serializable,我们只需要编写User类文件 。源代码生成器创建一个名为user.g.dart的文件,它具有所有必需的序列化逻辑。 现在,我们不必编写自动化测试来确保序列化的正常工作 - 这个库会确保序列化工作正常。
三、 JSONConverter
如上面所写,即便使用了json_serializable,仍然需要手动编写模型类文件并逐一编写对应的模型属性,生产工作中一个项目可能会有几百个API, 如果全部手写依旧浪费大量摸鱼的时间,这里我们可以使用JSONConverter, 它可根据后台返回的JSON自动生成模型文件,配合json_serializable,可以非常方便的实现接口对接,模型文件一键生成,极大节省程序员的体力。
另外JSONConverter除了支持Flutter,还支持其他语言和第三方库,功能可能说非常丰富了。
四、总结
生产项目中推荐使用json_serializable + JSONConverter 完成服务端返回的JSON数据解析工作,效率翻倍!!
作者:vvkeep
链接:https://juejin.cn/post/7098890613839364127
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
ListView界面在Flutter 3.0错乱
一、 入坑
一直以来有一个口口相传的秘诀,就是Flutter版本等到*.*.3版本再升级。
大版本升级一定要慎重的。不然不知道哪个界面中就会出现未知的异常。
Flutter3.0发布了,但是选择不升级,忍了一个星期后,突然发现Flutter开始支持APPLE Silicon M1了。心动了,控制不住自己了,升吧。
然后出现了,我的小怪兽。
上拉和下拉进行刷新界面的时候,出现了诡异的现象。
二、现象
第一反应是Flutter3.0的锅,而已经无法回退版本了,只能选择一往无前。
用一休的大脑:
- 第三方库不兼容了,赶紧升级下版本。
RefreshIndicator有新改动吗。ListView有改动吗?Column配合Expanded界面混乱了。ListView的Item用错了。- Debug模式也有这个问题吗。
。。。。。。
前前后后修改,编译,运行,修改,编译,运行。。。(还好我的M1 Max效率还是比较高的)
三、分析
询问度娘,google,gitHub。。。查看所有可能的答案。如果真的是ListView有问题,那应该早就有人碰到了。怎么说3.0出来已经一个星期了。
Nope Nope Nope
行吧。请教同事,拉来所有同事问问,出谋划策。
No Way
排查了所有组件的可能性,把所有代码都删干净了,仅仅就一个ListView了,还是存在一样的问题。
那这个锅就是你了ListView了,出来的怪兽。不要躲了。
四、解决
为了确定是Flutter 3.0的锅,然后甩给Flutter,搞一个Demo吧。风风火火。。。
Demo竟然没有没有没有问题。Flutter表示这个锅它不背啊。
啊啊啊啊 流失了一天宝贵时光,此处省去1万字...
终于在比较了所有代码后,发现了它,那个引起问题的代码。
五、原因
是的。
<item name="android:fitsSystemWindows">true</item>
就是它,删除后,出现了,出现了。
那么舒服的感觉,我很喜欢。
六、后记
一定要记得*.*.3版本再升级,不能TiMi时间浪费在编译上了。
作者:_阿南_
链接:https://juejin.cn/post/7098909224612134942
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
跟我学企业级flutter项目:flutter模块化,单工程架构模式构思与实践
前言
在原生Android开发的时候,我们经常会用到ARouter,来设计我们项目的整体架构。因为ARouter会帮助我们实现模块化的思想,那么在Flutter中如何去构建模块化的架构呢?再深入一点,如何去运行一个单一模块,不去跑整体项目呢?本篇文章将会带你学习Flutter版本下的单工程架构模式。
应用场景
两模块业务有较大的隔离性,业务有迁移不同项目的可能性
开始
展示效果
那我们在开始前,看下我项目的展示效果:
整体项目运行
单工程模式下运行
架构分析
本项目有三个独立工程
- 家长端工程
- 教师端工程
- 公用lib工程
一个应用飞阅应用中包含三个独立工程,三个独立工程可单独通过壳来运行
如何构建单工程架构
Flutter具有天然的模块化思想,是可以不借助其他工具来实现单工程构建。
事前准备
- Android stuido
步骤1
构建一个Flutter plugin
这个plugin就是你的单工程,构建好的插件如图所示
你需要构建几个plugin呢?简单分析一下,我们公司有两个业务端,需要合并在一个项目里做,那么至少需要两个plugin,但是由于有公用的页面,这时候需要提取出一个公用的模块。那么由此分析,我公司需要三个plugin,那么就需要按照如上步骤在建立两个plugin
步骤二
建立好的plugin进行关联
- 公用工程yaml
name: commonlib
description: 阅卷公用lib
dependencies:
flutter:
sdk: flutter
flutter_localizations:
sdk: flutter
#####本地库
flutter_base_lib:
path: ../flutter_baselib/flutter_base_lib
#####本UI地库
flutter_base_ui:
path: ../flutter_baselib/flutter_base_ui
- 老师工程yaml
name: teacher
description: 老师端
dependencies:
flutter:
sdk: flutter
commonlib:
path: ../commonlib
- 家长工程yaml
name: client
description: 学生&家长工程
dependencies:
flutter:
sdk: flutter
commonlib:
path: ../commonlib
- 总工程yaml
dependencies:
flutter:
sdk: flutter
flutter_localizations:
sdk: flutter
teacher:
path: ./teacher
client:
path: ./client
commonlib:
path: ./commonlib
步骤三
业务拆封
- 将登录与注册等业务拆分到commonlib
- 老师端独有业务拆分
- 家长端独有业务拆分
- 路由拆分
- 启动代码重新构建
部分示例代码:
家长端路由代码
class ClientRouterPage{
static Widget? getRouter(RouteSettings settings){
//判断家长权限
if(UserStore().getIdentityType() == CommonlibConfig.ruleParent){
String? routerName = settings.name;
//跳转家长业务页面
switch (routerName) {
case RouterName.home:
return HomePage();
case RouterName.bind_student:
return BindStudentPage();
}
}
}
主工程全部代码(只有一个类,只有如下代码)
class MyCommentConfiger extends ICommentConfiger{
@override
Widget getRouter(RouteSettings settings) {
//通过登录用户类型来跳转不同业务
//老师跳转
var teachertRouter = RouterPage.getRouter(settings);
if(teachertRouter!=null){
return teachertRouter;
}
//家长跳转
var clientRouter = ClientRouterPage.getRouter(settings);
if(clientRouter!=null){
return clientRouter;
}
//commonlib跳转
return LibRouterPage.getRouter(settings);
}
}
//启动运行
void main() {
Application.init(
init: AppInit(MyCommentConfiger()),
syncinitFin: () {
runApp(App());
});
}
家长端壳工程全部代码
class ClientCommentConfiger extends ICommentConfiger{
@override
Widget getRouter(RouteSettings settings) {
var router = ClientRouterPage.getRouter(settings);
if(router!=null){
return router;
}
//commonlib跳转
return LibRouterPage.getRouter(settings);
}
}
//启动运行
void main() {
Application.init(
init: AppInit(ClientCommentConfiger()),
syncinitFin: () {
runApp(App());
});
}
如上就是单工程架构模式的全部内容
说明:单工程架构模式,主要适用于业务有一定的隔离性,如果你的项目有一块业务极其的独立,那么你可以采用这种模式。该块业务也可以快速移植到其他项目上。
跟我学flutter:细细品Widget(二)StatelessWidget&StatefulWidget
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
跟我学flutter:细细品Widget(二)StatelessWidget&StatefulWidget
跟我学flutter:细细品Widget(三)ProxyWidget,InheritedWidget
跟我学flutter:细细品Widget(四)Widget 渲染过程 与 RenderObjectWidget
跟我学flutter:细细品Widget(五)Element
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
StatelessWidget和StatefulWidget是Flutter开发必不可少的。两者的区别在于state。有状态的widget需要继承StatefulWidget无状态的需要继承StatelessWidget。
StatelessWidget
无状态Widget
源码
abstract class StatelessWidget extends Widget {
const StatelessWidget({ Key? key }) : super(key: key);
@override
StatelessElement createElement() => StatelessElement(this);
@protected
Widget build(BuildContext context);
}
createElement
StatelessWidget的对应Element 为StatelessElement
build
用于构建widget
build 在很多种情况下会被调用
- Widget第一次被加载(Widget 第一次被加入到 Widget Tree 中 ,更准确地说是其对应的 Element 被加入到 Element Tree 时,即 Element 被挂载(mount)时)
- Parent Widget 修改了其配置信息;
- 该 Widget 依赖的Inherited Widget发生变化时。
当Parent Widget或 依赖的Inherited Widget频繁变化时,build方法也会频繁被调用。因此,提升build方法的性能就显得十分重要,Flutter 官方给出了几点建议:
1.减少不必要的中间节点,即减少 UI 的层级,*如:对于「Single Child Widget」,没必要通过组合「Row」、「Column」、「Padding」、「SizedBox」等复杂的 Widget 达到某种布局的目标,或许通过简单的「Align」、「CustomSingleChildLayout」即可实现。又或者,为了实现某种复杂精细的 UI 效果,不一定要通过组合多个「Container」,再附加「Decoration」来实现,通过 「CustomPaint」自定义或许是更好的选择;
2.尽可能使用const Widget,*为 Widget 提供const构造方法;
3.可以将「Stateless Widget」重构成「Stateful Widget」,*以便可以使用「Stateful Widget」中一些特定的优化手法,如:缓存「sub trees」的公共部分,并在改变树结构时使用GlobalKey;
4.尽量减小 rebuilt 范围,*如:某个 Widget 因使用了「Inherited Widget」,导致频繁 rebuilt,可以将真正依赖「Inherited Widget」的部分提取出来,封装成更小的独立 Widget,并尽量将该独立 Widget 推向树的叶子节点,以便减小 rebuilt 时受影响的范围。
StatefulWidget
有状态 Widget
StatefulWidget本身是不可变,状态在State中。
源码
abstract class StatefulWidget extends Widget {
const StatefulWidget({ Key? key }) : super(key: key);
@override
StatefulElement createElement() => StatefulElement(this);
@protected
@factory
State createState();
}
createElement
StatefulElement的对应Element 为StatefulElement
createState
实际上是「Stateful Widget」对应的「Stateful Element」被添加到 Element Tree 时,伴随「Stateful Element」的初始化,createState方法被调用。从后文可知一个 Widget 实例可以对应多个 Element 实例 (也就是同一份配置信息 (Widget) 可以在 Element Tree 上不同位置配置多个 Element 节点),因此,createState方法在「Stateful Widget」生命周期内可能会被调用多次。
另外,需要注意的是配有GlobalKey的 Widget 对应的 Element 在整个 Element Tree 中只有一个实例。
State
生命周期:
- 在对应的(Stateful Element)被挂载 (mount) 到树上时,通过StatefulElement.constructor –> StatefulWidget.createState创建 State 实例
State._emelent就是对应的Element 实例,State与Element绑定关系一经确定,在整个生命周期内不会再变了 (Element 对应的 Widget 可能会变,但对应的 State 永远不会变),期间,Element可以在树上移动,但上述关系不会变
StatefulElement 在挂载过程中接着会调用State.initState,子类可以重写该方法执行相关的初始化操作 (此时可以引用context、widget属性);
同样在挂载过程中会调用State.didChangeDependencies,该方法在 State 依赖的对象 (如:「Inherited Widget」) 状态发生变化时也会被调用,*子类很少需要重写该方法,*除非有非常耗时不宜在build中进行的操作,因为在依赖有变化时build方法也会被调用;
State 初始化已完成,其build方法此后可能会被多次调用,在状态变化时 State 可通过setState方法来触发其子树的重建;
此时,「element tree」、「renderobject tree」、「layer tree」已构建完成,完整的 UI 应该已呈现出来。此后因为变化,「element tree」中「parent element」可能会对树上该位置的节点用新配置 (Widget) 进行重建,当新老配置 (oldWidget、newWidget)具有相同的「runtimeType」&&「key」时,framework 会用 newWidget 替换 oldWidget,并触发一系列的更新操作 (在子树上递归进行)。同时,State.didUpdateWidget方法被调用,子类重写该方法去响应 Widget 的变化;
在 UI 更新过程中,任何节点都有被移除的可能,State 也会随之移除,(如上一步中「runtimeType」||「key」不相等时)。此时会调用State.deactivate方法,由于被移除的节点可能会被重新插入树中某个新的位置上,故子类重写该方法以清理与节点位置相关的信息 (如:该 State 对其他 element 的引用)、同时,不应在该方法中做资源清理;
重新插入操作必须在当前帧动画结束之前
- 当节点被重新插入树中时,State.build方法被再次调用;
- 对于在当前帧动画结束时尚未被重新插入的节点,State.dispose方法被执行,State 生命周期随之结束,此后再调用State.setState方法将报错。子类重写该方法以释放任何占用的资源。
源码
void setState(VoidCallback fn) {
assert(fn != null);
assert(() {
if (_debugLifecycleState == _StateLifecycle.defunct) {
throw FlutterError.fromParts([
ErrorSummary('setState() called after dispose(): $this'),
ErrorDescription(
'This error happens if you call setState() on a State object for a widget that '
'no longer appears in the widget tree (e.g., whose parent widget no longer '
'includes the widget in its build). This error can occur when code calls '
'setState() from a timer or an animation callback.',
),
ErrorHint(
'The preferred solution is '
'to cancel the timer or stop listening to the animation in the dispose() '
'callback. Another solution is to check the "mounted" property of this '
'object before calling setState() to ensure the object is still in the '
'tree.',
),
ErrorHint(
'This error might indicate a memory leak if setState() is being called '
'because another object is retaining a reference to this State object '
'after it has been removed from the tree. To avoid memory leaks, '
'consider breaking the reference to this object during dispose().',
),
]);
}
if (_debugLifecycleState == _StateLifecycle.created && !mounted) {
throw FlutterError.fromParts([
ErrorSummary('setState() called in constructor: $this'),
ErrorHint(
'This happens when you call setState() on a State object for a widget that '
"hasn't been inserted into the widget tree yet. It is not necessary to call "
'setState() in the constructor, since the state is already assumed to be dirty '
'when it is initially created.',
),
]);
}
return true;
}());
final Object? result = fn() as dynamic;
assert(() {
if (result is Future) {
throw FlutterError.fromParts([
ErrorSummary('setState() callback argument returned a Future.'),
ErrorDescription(
'The setState() method on $this was called with a closure or method that '
'returned a Future. Maybe it is marked as "async".',
),
ErrorHint(
'Instead of performing asynchronous work inside a call to setState(), first '
'execute the work (without updating the widget state), and then synchronously '
'update the state inside a call to setState().',
),
]);
}
// We ignore other types of return values so that you can do things like:
// setState(() => x = 3);
return true;
}());
_element!.markNeedsBuild();
}
分析:
- _debugLifecycleState == _StateLifecycle.defunct 在State.dispose后不能调用setState
- _debugLifecycleState == _StateLifecycle.created && !mounted 在 State 的构造方法中不能调用setState
- if (result is Future) setState方法的回调函数 (fn) 不能是异步的 (返回值为Future)
通过setState方法之所以能更新 UI,是在其内部调用_element.markNeedsBuild()
若State.build方法依赖了自身状态会变化的对象,如:ChangeNotifier、Stream或其他可以被订阅的对象,需要确保在initState、didUpdateWidget、dispose
等 3 方法间有正确的订阅 (subscribe) 与取消订阅 (unsubscribe) 的操作:
1.在initState中执行 subscribe;
2.如果关联的「Stateful Widget」与订阅有关,在didUpdateWidget中先取消旧的订阅,再执行新的订阅;
3.在dispose中执行 unsubscribe。
在State.initState方法中不能调用BuildContext.dependOnInheritedWidgetOfExactType,但State.didChangeDependencies会随之执行,在该方法中可以调用。
收起阅读 »
跟我学企业级flutter项目:如何将你的项目简单并且快速屏幕自适应
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
你的flutter在小屏幕手机上出现文字丢失了么? 你的flutter应用在小屏幕手机上排版出错了么? 你的flutter应用在大屏幕手机上布局错乱了么? 你在用flutter_screenutil做屏幕自适应么? 今天我来给大家介绍一款简单不侵入代码的自适应。 如果你有如下需求:
- 旧的flutter想快速屏幕适应各种手机
- 页面代码中不想增加关于适配屏幕的代码
kg_density
kg_density 是一个极简的屏幕适配方案,可以快速的帮助已经开发好的项目适配屏幕
开始集成
dependencies:
kg_density: ^0.0.1
以下机型来自 iphone5s
登录适配之前
登录适配之后
图表页面适配之前
图表页面适配之后
其他页面适配之前
其他页面适配之后
使用方法:
- 创建 FlutterBinding
class MyFlutterBinding extends WidgetsFlutterBinding with KgFlutterBinding {
static WidgetsBinding ensureInitialized() {
if (WidgetsBinding.instance == null) MyFlutterBinding();
return WidgetsBinding.instance!;
}
}
- MaterialApp 配置
MaterialApp(
///定义主题
theme: ThemeData(),
builder: KgDensity.initSize(),
);
- 启动前的配置
void main() {
///初始化
KgDensity.initKgDensity(375);
MyFlutterBinding.ensureInitialized();
///运行
runApp(App());
}
注意说明:
- KgDensity.initSize(builder: ??)
为了方便其他builder配置,代码中专门增加其他builder
使用方法
builder: KgDensity.initSize(builder: EasyLoading.init()),
- KgDensity.initKgDensity(375)
数字配置的是按照设计稿件的最窄边来配置的
若不使用KgDensity 进行适配,请不要init
- 正确获取size
MediaQuery.of(context).size
请不要使用 window.physicalSize,MediaQueryData.fromWindow(window)
收起阅读 »算法图解-读书笔记
前言
首先要说明的是: 这本书的定义是一本算法入门书,更多的是以简单地描述和示例介绍常见的数据结构和算法以及其应用场景,所以如果你在算法上有了一定造诣或者想深入学习算法,这本书很可能不太适合你。
但如果你对算法感兴趣,但是不知从何学起或者感觉晦涩难懂,这本书绝对是一本很好的入门书,它以简单易懂的描述和示例,配以插画,向我们讲解了常见的算法及其应用场景。
本文是我基于自己的认知总结本书比较重点的部分,并不一定准确,更不一定适合所有人,所以如果你对本书的内容感兴趣,推荐阅读本书,本书总计180+页,而且配以大量示例和插画讲解,相信你很快就可以读完。
第一章:算法简介
算法是一组完成任务的指令。任何代码片段都可以视为算法。
二分查找
二分查找是一种用来在有序列表中快速查找指定元素的算法,每次判断待查找区间的中间元素和目标元素的关系,如果相同,则找到了目标元素,如果不同,则根据大小关系缩短了一半的查找区间。
相比于从头到尾扫描有序列表,一一对比的方式,二分查找无疑要快很多。
大O表示法
大O表示法是一种特殊的表示法,指出了算法的运行时间或者需要的内存空间,也就是时间复杂度和空间复杂度。
比如冒泡排序,
export default function bubbleSort(original:number[]) {
const len = original.length
for (let i = 0; i < len - 1; i++) {
for (let j = 1; j < len - i; j++) {
if (original[j - 1] > original[j]) {
[original[j - 1], original[j]] = [original[j], original[j - 1]]
}
}
}
}需要两层循环,每次循环的长度为 n(虽然并不完全等于n),那它的时间复杂度就是 O(n²)。同时因为需要创建常数量的额外变量(len,i,j),所以它的空间复杂度是 O(1)。
第二章:选择排序
内存的工作原理
当我们去逛商场或者超市又不想随身携带着背包或者手提袋时,就需要将它们存入寄存柜,寄存柜有很多柜子,每个柜子可以放一个东西,你有两个东西寄存,就需要两个柜子,也就是计算机内存的工作原理。计算机就像是很多柜子的集合,每个柜子都有地址。
数组和链表
有时我们需要在内存中存储一系列元素,应使用数组还是链表呢?
想要搞清楚这个问题,就需要知道数组和链表的区别。
数组是一组元素的集合,其中的元素都是相邻的,创建数组的时候需要指定其长度(这里不包括JavaScript中的数组)。可以理解为数组是一个大柜子,里边有固定数量的小柜子。
而链表中的元素则可以存储在任意位置,无需相邻,也不需要在创建的时候指定长度。
对应到电影院选座问题,
数组需要在初始就确定几个人看电影,并且必须是邻座。而一旦选定,此时如果再加一人,就需要重新选座,因为之前申请的位置坐不下现在的人数。而且如果没有当前数量的相邻座位,那么这场电影就没办法看了。
而链表则不要求指定数量和相邻性,所以如果是两个人,则只要还有大于等于两个空座,就可以申请座位,同样,如果此时再加一个人,只要还有大于等于一个空座,同样可以申请座位。\
数组因为可以通过索引获取元素,所以其读取元素的时间复杂度为O(1),但是因为其连续性,在中间插入或者删除元素涉及到其他元素的移动,所以插入和删除的时间复杂度为O(n)。
链表因为只存储了链表的头节点,获取元素需要从头节点开始向后查找,所以读取元素的时间复杂度为O(1),因为其删除和插入元素只需要改变前一个元素的next指针,所以其插入和删除的时间复杂度为O(1)。
选择排序
选择排序就是每次找出待排序区间的最值,放到已排序区间的末尾,比较简单,这里不做赘述了。
第三章:递归
个人理解,递归就是以相同的逻辑重复处理更深层的数据,直到满足退出条件或者处理完所有数据。
其中退出条件又称为基线条件,其他情况则属于递归条件,即需要继续递归处理剩余数据。
栈
这里主要讲的是调用栈,因为递归函数是不断调用自身,所以就导致调用栈也来越大,因为每次函数调用都会占用内存,当调用栈很高,就会导致内存占用很大的问题。解决这个问题通常有两种方法:
将递归改写为循环
使用尾递归
第四章:快速排序
快速排序使用的是分而治之的策略。
分而治之
简单理解,分治就是将大规模的问题,拆解为小规模的问题,直到规模小到很容易处理,然后对小规模问题进行处理后,再将处理结果合并,得到大规模问题的处理结果。
关于快排这里也不做赘述,感兴趣的可以看我之前的文章,需要注意的是,递归的方式更容易理解,但是会存在上述递归调用栈及多个子数组占用内存过高的问题。
第五章:散列表
散列表类似于JavaScript中的array、object和map,只不过作为上层语言,JavaScript帮我们做了很多工作,不需要我们自己实现散列函数,而散列函数,简单理解就是传入数据,会返回一个数字,而这个数字可以作为数组的索引下标,我们就可以根据得到的索引将数据存入索引位置。一个好的散列函数应该保证每次传入相同的数据,都返回相同的索引,并且计算的索引应该均匀分布。
常见的散列表的应用有电话簿,域名到IP的映射表,用户到收货地址的映射表等等。
冲突
散列表还有一个比较重要的问题是解决冲突,比如传入字符串"abc",散列函数返回1,然后我们将"abc"存储在索引1的位置,而传入"def",散列函数同样返回1,此时索引1的位置已经存储了"abc",此时怎么办呢?
一种常见的解决方案是在每个索引的位置存储一个链表,这样就可以在一个索引位置,存储多个元素。
第六章:广度优先搜索
图
如果我们要从A去往B,而A去往B的路线可能很多条,这些路线就可以抽象成图,图中每个地点是图中的节点,地点与地点之间的连接线称为边。而如果我们要找出从A去往B的最近路径,需要两个步骤:
使用图来建立问题模型
使用广度优先搜索求解最短路径
广度优先搜索
所谓广度优先搜索,顾名思义,就是搜索过程中以广度优先,而不是深度,对于两点之间最短路径的问题,就是首先从出发点,走一步,看看是否有到达B点的路径,如果没有,就从第一步走到的所有点在走一步,看看有没有到达B点的路径,依此类推,直到到达B点。
实际算法中,广度优先搜索通常需要借助队列实现,即不停的把下一次能到达的点加入队列,并每次取出队首元素判断是否是B点,如果不是,再把它的下一个地点加入队列。
第七章:狄克斯特拉算法
在上一章我们可以使用广度优先搜索计算图的最短路径,但是如果图的每一条边都有相应的权重,也就是加权图,那么广度优先搜索求得的只是边数最少的路径,但是不一定是加权图中的最短路径,这个时候,想要求得最短路径,就需要狄克斯特拉算法。
狄克斯特拉算法的策略是:
每次都寻找下一个开销最小的节点
更新该节点的邻居节点的开销
重复这个过程,直到对图中每个节点都这样做
计算最终路径
但是要注意的是狄克斯特拉算法只适合权重为正的情况下使用,如果图中有负权边,要使用贝尔曼-福德算法。
第八章:贪婪算法
所谓贪婪算法,就是每一步都采用最优解,当所有的局部解都是最优解,最终所有局部最优解组合得到的全局解就是近似的全局最优解。
要注意的是,贪婪算法得到的并不一定是最优解,但是是近似最优解的结果。
可能你会有疑问,为什么不使用可以准确得到最优解的算法呢?这是因为有些问题很难求出准确的最优解,比如书中的城市路线问题。
如果只有2个城市,则会有2条路线
3个城市会有6条路线
4个城市会有24条路线
5个城市会有120条路线
6个城市会有720条路线
你会发现随着城市的增加,路线总数是城市数量的阶乘,当城市数量增加到一定程度,要枚举所有路线几乎是不可能的,这个时候就需要用贪婪算法求得一个近似的最优解。
第九章:动态规划
动态规划的主要思路是将一个大问题拆成相同的小问题,通过不断求解小问题,最后得出大问题的结果。
解题过程通常分为两步,状态定义和转移方程。
所谓状态定义,即抽象出一个状态模型,来表示某个状态下的结果值。
所谓转移方程,即推导出状态定义中的状态模型可以由什么计算得出。
以LeetCode 746. 使用最小花费爬楼梯为例: 因为最小花费只和台阶层数有关,所以可以定义 dp[i] 表示第i层台阶所需花费,这就是状态定义。
又因为第i层台阶可能从i-2上来,也可能从i-1上来,所以第i层台阶的最小花费等于前面两层台阶中花费更小的那个加上本层台阶的花费,即dp[i] = Math.min(dp[i-1],dp[i-2])+cost[i],这就是转移方程。
完整解题代码如下:
var minCostClimbingStairs = function(cost) {
const dp = [cost[0],cost[1]]
for(let i = 2;i<cost.length;i++){
dp[i] = Math.min(dp[i-1],dp[i-2])+cost[i]
}
return Math.min(dp.at(-1),dp.at(-2))
}这里我讲解的方式和本书中画网格求解的方式并不一致,但是道理相同,一个是思考推导,一个是画网格推导。
第十章:K最近邻算法
K最近邻算法通常用来实现推荐系统,预测数值等。它的主要思想就是通过特征抽离,将节点绘制在坐标系中,当我们预测某个节点的数值或喜好时,通过对它相邻K个节点的数值和喜好的数据进行汇总求平均值,大概率就是它的数值和喜好。
比如常见的视频网站,社交网站,都会要求我们选择自己感兴趣的方面,或者在我们使用过程中记录我们的喜好,然后基于这些数据抽离我们的特征,然后根据相同特征的用户最近的观影记录或者话题记录,向我们推荐相同的电影和话题,也就是常见的猜你喜欢。还有机器学习的训练过程,也是提供大量数据给程序,让它进行特征抽离和记录,从而完善它的特征数据库,所以就有了机器越来越聪明的表现。
第十一章:接下来如何做
本章列举了本书没有单独拿出来讲但是依然很重要的数据结构和算法。
树
这里没有介绍树的基本概念,而是直接基于前面章节的二分查找引申出二叉查找树,这种树的性质是对于任意一个节点,它的左子树中的节点值都小于它,它的右子树的节点值都大于它。从而如果把整个树压平,就是一个升序的结果。然后还提到了B树,红黑树,堆和伸展树。
傅里叶变换
一个对傅里叶变换的比喻是:给她一杯冰沙,它能告诉你其中包含哪些成分。类似于给定一首歌曲,傅里叶变换能够将其中的各种频率分离出来。
常见的应用场景有音频、图片压缩。以音频为例,因为可以将歌曲分解为不同的频率,然后可以通过强调关系的部分,减弱或者隐藏不关心的部分,实现各种音效,也可以通过删除一些不重要的部分,实现压缩。
并行算法
因为笔记本和台式机都有多核处理器,那为了提高算法的速度,我们可以让它在多个内核中并行执行,这就是并行算法。
MapReduce
分布式算法是一种特殊的并行算法,并行算法通常是指在一台计算机上的多个内核中运行,而如果我们的算法复杂到需要数百个内核呢?这个时候就需要在多台计算机上运行,这就是分布式算法,MapReduce就是一种流行的分布式算法。
映射函数
映射函数接受一个数组,对其中的每个元素执行同样的操作。
归并函数
归并是指将多项合并于一项的操作,这可能不太好理解,但是你可以回想下归并排序和递归快排在回溯过程中合并结果数组的过程。
布隆过滤器 和 HyperLogLog
布隆过滤器 是一种概率型数据结构,它提供的答案有可能不对,但很可能是正确的。
比如Google负责搜集网页,但是它只需要搜集新出现的网页,因此需要判断该网页是否搜集过。固然我们可以使用一个散列表存储网页是否已经搜集过,查找和插入的时间复杂度都是O(1),一切看起来很不错,但是因为网页会有数以万亿个,所以这个散列表会非常大,需要极大的存储空间,而这个时候,布隆过滤器就是一个不错的选择,它只需要占用很少的存储空间,提供的结果又很可能准确,对于网页是否搜集过的问题,可能出现误报的情况,即给出答案这个网页已搜集过,但是没有搜集,但是如果给出的答案是没有搜集,就一定没有搜集。\
HyperLogLog 是一种类似于布隆过滤器的算法,比如Google要计算用户执行的不同搜索的数量,要回答这个问题,就需要耗费大量的空间存储日志,HyperLogLog可以近似的计算集合中不同的元素数,与布隆过滤器一样,它不能给出准确的答案,但是近似准确答案,但是占用空间小很多。
以上两者,都适用于不要求答案绝对准确,但是数据量很大的场景。
哈希算法
这里介绍的就是哈希算法,常见的就是对文件进行哈希计算,判断两个文件是否相同,比如大文件上传中就可以通过计算文件的哈希值与已上传文件的散列表或者布隆过滤器比对,如果上传过,则直接上传成功,实现秒传。
还有一种应用场景就是密码的加密,通常用户输入的密码并不会进行明文传输,而是通过哈希算法进行加密,这样即使传输报文并黑客拦截,他也并不能知道用户的密码。书中还引申了局部敏感的散列函数,对称加密,非对称加密。
线性规划
线性规划用于在给定约束条件下最大限度的改善指定的指标。
比如你的公司生产两种产品,衬衫和手提袋。衬衫每件利润2元,需要消耗1米布料和5粒扣子;手提袋每个利润3元,需要消耗2米布料和2粒扣子。现在有11米布料和20粒扣子,为了最大限度提高利润,该生产多少衬衫好手提袋呢?
以上就是个人对 《算法图解》 这本书的读书总结,如果能给你带来一点帮助,那就再好不过了。
保持学习,不断进步!一起加油鸭!💪
作者:前端_奔跑的蜗牛
来源:https://juejin.cn/post/7097881646858240007
Dart 语言的7个很酷的特点
正文
今天的文章简短地揭示了 Dart 语言所提供的很酷的特性。更多时候,这些选项对于简单的应用程序是不必要的,但是当你想要通过简单、清晰和简洁来改进你的代码时,这些选项是一个救命稻草。
考虑到这一点,我们走吧。
Cascade 级联
Cascades (.., ?..) 允许你对同一个对象进行一系列操作。这通常节省了创建临时变量的步骤,并允许您编写更多流畅的代码。
var paint = Paint();
paint.color = Colors.black;
paint.strokeCap = StrokeCap.round;
paint.strokeWidth = 5.0;
//above block of code when optimized
var paint = Paint()
..color = Colors.black
..strokeCap = StrokeCap.round
..strokeWidth = 5.0;
Abstract 抽象类
使用 abstract 修饰符定义一个 _abstract 抽象类(无法实例化的类)。抽象类对于定义接口非常有用,通常带有一些实现。
// This class is declared abstract and thus
// can't be instantiated.
abstract class AbstractContainer {
// Define constructors, fields, methods...
void updateChildren(); // Abstract method.
}
Factory constructors 工厂建造者
在实现不总是创建类的新实例的构造函数时使用 factory 关键字。
class Logger {
String name;
Logger(this.name);
factory Logger.fromJson(Map<String, Object> json) {
return Logger(json['name'].toString());
}
}
Named 命名构造函数
使用命名构造函数为一个类实现多个构造函数或者提供额外的清晰度:
class Points {
final double x;
final double y;
//unnamed constructor
Points(this.x, this.y);
// Named constructor
Points.origin(double x,double y)
: x = x,
y = y;
// Named constructor
Points.destination(double x,double y)
: x = x,
y = y;
}
Mixins 混合物
Mixin 是在多个类层次结构中重用类代码的一种方法。
要实现 implement mixin,创建一个声明没有构造函数的类。除非您希望 mixin 可以作为常规类使用,否则请使用 mixin 关键字而不是类。
若要使用 mixin,请使用后跟一个或多个 mixin 名称的 with 关键字。
若要限制可以使用 mixin 的类型,请使用 on 关键字指定所需的超类。
class Musician {}
//creating a mixin
mixin Feedback {
void boo() {
print('boooing');
}
void clap() {
print('clapping');
}
}
//only classes that extend or implement the Musician class
//can use the mixin Song
mixin Song on Musician {
void play() {
print('-------playing------');
}
void stop() {
print('....stopping.....');
}
}
//To use a mixin, use the with keyword followed by one or more mixin names
class PerformSong extends Musician with Feedback, Song {
//Because PerformSong extends Musician,
//PerformSong can mix in Song
void awesomeSong() {
play();
clap();
}
void badSong() {
play();
boo();
}
}
void main() {
PerformSong().awesomeSong();
PerformSong().stop();
PerformSong().badSong();
}
Typedefs
类型别名ー是指代类型的一种简明方式。通常用于创建在项目中经常使用的自定义类型。
typedef IntList = List<int>;
List<int> i1=[1,2,3]; // normal way.
IntList i2 = [1, 2, 3]; // Same thing but shorter and clearer.
//type alias can have type parameters
typedef ListMapper<X> = Map<X, List<X>>;
Map<String, List<String>> m1 = {}; // normal way.
ListMapper<String> m2 = {}; // Same thing but shorter and clearer.
Extension 扩展方法
在 Dart 2.7 中引入的扩展方法是一种向现有库和代码中添加功能的方法。
//extension to convert a string to a number
extension NumberParsing on String {
int customParseInt() {
return int.parse(this);
}
double customParseDouble() {
return double.parse(this);
}
}
void main() {
//various ways to use the extension
var d = '21'.customParseDouble();
print(d);
var i = NumberParsing('20').customParseInt();
print(i);
}
可选的位置参数
通过将位置参数包装在方括号中,可以使位置参数成为可选参数。可选的位置参数在函数的参数列表中总是最后一个。除非您提供另一个默认值,否则它们的默认值为 null。
String joinWithCommas(int a, [int? b, int? c, int? d, int e = 100]) {
var total = '$a';
if (b != null) total = '$total,$b';
if (c != null) total = '$total,$c';
if (d != null) total = '$total,$d';
total = '$total,$e';
return total;
}
void main() {
var result = joinWithCommas(1, 2);
print(result);
}
unawaited_futures
当您想要启动一个 Future 时,建议的方法是使用 unawaited
否则你不加 async 就不会执行了
import 'dart:async';
Future doSomething() {
return Future.delayed(Duration(seconds: 5));
}
void main() async {
//the function is fired and awaited till completion
await doSomething();
// Explicitly-ignored
//The function is fired and forgotten
unawaited(doSomething());
}
end.
作者:会煮咖啡的猫
链接:https://juejin.cn/post/7095177614024769566
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
贝塞尔曲线动起来会是什么样?
彩虹系列
通过动画控制绘制的结束点,就可以让贝塞尔曲线动起来。例如下面的动图展示的效果,看起来像搭了一个滑滑梯一样。实际上就是用7条贝塞尔曲线实现的,我们使用了 Animation 对象的值来控制绘制的结束点,从而实现了对应的动画效果。
具体源码如下,其中控制绘制结束点就是在动画过程中修改循环的次数,即t <= (100 * animationValue).toInt();这句代码,其中 animationValue 是动画控制器当前值,范围时从0-1。
class AnimationBezierPainter extends CustomPainter {
AnimationBezierPainter({required this.animationValue});
final double animationValue;
@override
void paint(Canvas canvas, Size size) {
final lineWidth = 6.0;
paint.strokeWidth = lineWidth;
paint.style = PaintingStyle.stroke;
final colors = [
Color(0xFFE05100),
Color(0xFFF0A060),
Color(0xFFE0E000),
Color(0xFF10F020),
Color(0xFF2080F5),
Color(0xFF104FF0),
Color(0xFFA040E5),
];
final lineNumber = 7;
for (var i = 0; i < lineNumber; ++i) {
paint.color = colors[i % colors.length];
_drawAnimatedLines(canvas, paint, size, size.height / 4 + i * lineWidth);
}
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return true;
}
_drawRainbowLines(Canvas canvas, Paint paint, Size size, yPos) {
var yGap = 60.0;
var p0 = Offset(0, yPos - yGap / 2);
var p1 = Offset(size.width * 2 / 3, yPos - yGap);
var p2 = Offset(size.width / 3, yPos + yGap);
var p3 = Offset(size.width, yPos + yGap * 1.5);
var path = Path();
path.moveTo(p0.dx, p0.dy);
for (var t = 1; t <= (100 * animationValue).toInt(); t += 1) {
var curvePoint =
BezierUtil.get3OrderBezierPoint(p0, p1, p2, p3, t / 100.0);
path.lineTo(curvePoint.dx, curvePoint.dy);
}
canvas.drawPath(path, paint);
}
}
我们修改曲线的控制点还可以实现下面的效果,大家有兴趣可以自己尝试一下。
弹簧动画
用多个贝塞尔曲线首尾相接,在垂直方向叠起来就能画出一条弹簧了,然后我们更改弹簧的间距和高度(曲线的数量)就能做出弹簧压下去和弹起来的动画效果了。
这部分的代码如下所示:
@override
void paint(Canvas canvas, Size size) {
var paint = Paint()..color = Colors.black54;
final lineWidth = 2.0;
paint.strokeWidth = lineWidth;
paint.style = PaintingStyle.stroke;
final lineNumber = 20;
// 弹簧效果
final yGap = 2.0 + 16.0 * animationValue;
for (var i = 0; i < (lineNumber * animationValue).toInt(); ++i) {
_drawSpiralLines(
canvas, paint, size, size.width / 2, size.height - i * yGap, yGap);
}
}
_drawSpiralLines(Canvas canvas, Paint paint, Size size, double xPos,
double yPos, double yGap) {
final xWidth = 160.0;
var p0 = Offset(xPos, yPos);
var p1 = Offset(xPos + xWidth / 2 + xWidth / 4, yPos - yGap);
var p2 = Offset(xPos + xWidth / 2 - xWidth / 4, yPos - 3 * yGap);
var p3 = Offset(xPos, yPos - yGap);
var path = Path();
path.moveTo(p0.dx, p0.dy);
for (var t = 1; t <= 100; t += 1) {
var curvePoint =
BezierUtil.get3OrderBezierPoint(p0, p1, p2, p3, t / 100.0);
path.lineTo(curvePoint.dx, curvePoint.dy);
}
canvas.drawPath(path, paint);
}
复杂立体感动画
通过多条贝塞尔图形组成的曲线往往会有立体的效果,而立体的效果动起来的时候就会感觉是3D 动画一样,实际上通过贝塞尔曲线是能够绘制出一些3D 效果的动画的,比如下面这个效果,就感觉像在三维空间飞行一样(如果配上背景图移动会更逼真)。这里实际使用了4组贝塞尔曲线来实现,当然实际还可以画一些有趣的图形,比如说画一条鱼。这个源码比较长,就不贴了,有兴趣的可以自行去下载源码(注:本篇之后的 Flutter版本升级到了2.10.3):绘图相关源码。
总结
可以看到,通过动画控制贝赛尔曲线动起来的效果还是挺有趣的。而且,我们还可以根据之前动画相关的篇章做一些更有趣的效果出来。这种玩法可以用在一些特殊的加载动画或是做一些比较酷炫的特效上面,增添 App 的趣味性。
作者:岛上码农
链接:https://juejin.cn/post/7095735501793001479
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
美团面试官问我一个字符的String.length()是多少,我说是1,面试官说你回去好好学一下吧
public class testT {
public static void main(String [] args){
String A = "hi你是乔戈里";
System.out.println(A.length());
}
}以上结果输出为7。
小萌边说边在IDEA中的win环境下选中String.length()函数,使用ctrl+B快捷键进入到String.length()的定义。
/**
* Returns the length of this string.
* The length is equal to the number of Unicode
* code units in the string.
*
* @return the length of the sequence of characters represented by this
* object.
*/
public int length() {
return value.length;
}接着使用google翻译对这段英文进行了翻译,得到了大体意思:返回字符串的长度,这一长度等于字符串中的 Unicode 代码单元的数目。
小萌:乔戈里,那这又是啥意思呢?乔哥:前几天我写的一篇文章:面试官问你编码相关的面试题,把这篇甩给他就完事!)里面对于Java的字符使用的编码有介绍:
Java中 有内码和外码这一区分简单来说
- 内码:char或String在内存里使用的编码方式。
- 外码:除了内码都可以认为是“外码”。(包括class文件的编码)
而java内码:unicode(utf-16)中使用的是utf-16.所以上面的那句话再进一步解释就是:返回字符串的长度,这一长度等于字符串中的UTF-16的代码单元的数目。
代码单元指一种转换格式(UTF)中最小的一个分隔,称为一个代码单元(Code Unit),因此,一种转换格式只会包含整数个单元。UTF-X 中的数字 X 就是各自代码单元的位数。
UTF-16 的 16 指的就是最小为 16 位一个单元,也即两字节为一个单元,UTF-16 可以包含一个单元和两个单元,对应即是两个字节和四个字节。我们操作 UTF-16 时就是以它的一个单元为基本单位的。
你还记得你前几天被面试官说菜的时候学到的Unicode知识吗,在面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜这里面提到,UTF-16编码一个字符对于U+0000-U+FFFF范围内的字符采用2字节进行编码,而对于字符的码点大于U+FFFF的字符采用四字节进行编码,前者是两字节也就是一个代码单元,后者一个字符是四字节也就是两个代码单元!
而上面我的例子中的那个字符的Unicode值就是“U+1D11E”,这个Unicode的值明显大于U+FFFF,所以对于这个字符UTF-16需要使用四个字节进行编码,也就是使用两个代码单元!
所以你才看到我的上面那个示例结果表示一个字符的String.length()长度是2!
来看个例子!
public class testStringLength {
public static void main(String [] args){
String B = "𝄞"; // 这个就是那个音符字符,只不过由于当前的网页没支持这种编码,所以没显示。
String C = "\uD834\uDD1E";// 这个就是音符字符的UTF-16编码
System.out.println(C);
System.out.println(B.length());
System.out.println(B.codePointCount(0,B.length()));
// 想获取这个Java文件自己进行演示的,可以在我的公众号【程序员乔戈里】后台回复 6666 获取
}
}可以看到通过codePointCount()函数得知这个音乐字符是一个字符!
几个问题:0.codePointCount是什么意思呢?1.之前不是说音符字符是“U+1D11E”,为什么UTF-16是"uD834uDD1E",这俩之间如何转换?2.前面说了UTF-16的代码单元,UTF-32和UTF-8的代码单元是多少呢?
一个一个解答:
第0个问题:
codePointCount其实就是代码点数的意思,也就是一个字符就对应一个代码点数。
比如刚才音符字符(没办法打出来),它的代码点是U+1D11E,但它的代理单元是U+D834和U+DD1E,如果令字符串str = "u1D11E",机器识别的不是音符字符,而是一个代码点”/u1D11“和字符”E“,所以会得到它的代码点数是2,代码单元数也是2。
但如果令字符str = "uD834uDD1E",那么机器会识别它是2个代码单元代理,但是是1个代码点(那个音符字符),故而,length的结果是代码单元数量2,而codePointCount()的结果是代码点数量1.
第1个问题
上图是对应的转换规则:
- 首先 U+1D11E-U+10000 = U+0D11E
- 接着将U+0D11E转换为二进制:0000 1101 0001 0001 1110,前10位是0000 1101 00 后10位是01 0001 1110
- 接着套用模板:110110yyyyyyyyyy 110111xxxxxxxxxx
- U+0D11E的二进制依次从左到右填入进模板:110110 0000 1101 00 110111 01 0001 1110
- 然后将得到的二进制转换为16进制:d834dd1e,也就是你看到的utf-16编码了
第2个问题
- 同理,UTF-32 以 32 位一个单元,它只包含这一种单元就够了,它的一单元自然也就是四字节了。
- UTF-8 的 8 指的就是最小为 8 位一个单元,也即一字节为一个单元,UTF-8 可以包含一个单元,二个单元,三个单元及四个单元,对应即是一,二,三及四字节。
参考
作者:程序员乔戈里
来源:juejin.cn/post/6844904036873814023 收起阅读 »
不做跟风党,LiveData,StateFlow,SharedFlow 使用场景对比
Android 常用的分层架构
Android 中加载 UI 数据不是一件轻松的事,开发者经常需要处理各种边界情况。如各种生命周期和因为「配置更改」导致的 Activity 的销毁与重建。
「配置更改」的场景有很多:屏幕旋转,切换至多窗口模式,调整窗口大小,浅色模式与暗黑模式的切换,更改默认语言,更改字体大小等等
因此普遍处理方式是使用分层的架构。这样开发者就可以编写独立于 UI 的代码,而无需过多考虑生命周期,配置更改等场景。 例如,我们可以在表现层(Presentation Layer)的基础上添加一个领域层(Domain Layer) 来保存业务逻辑,使用数据层(Data Layer)对上层屏蔽数据来源(数据可能来自远程服务,可能是本地数据库)。
表现层可以分成具有不同职责的组件:
View:处理生命周期回调,用户事件和页面跳转,Android 中主要是 Activity 和 Fragment
Presenter 或 ViewModel:向 View 提供数据,并不了解 View 所处的生命周期,通常生命周期比 View 长
Presenter 和 ViewModel 向 View 提供数据的机制是不同的,简单来说:
Presenter 通过持有 View 的引用并直接调用操作 View,以此向 View 提供数据
ViewModel 通过将可观察的数据暴露给观察者来向 View 提供数据
官方提供的可观察的数据 组件是 LiveData。Kotlin 1.4.0 正式版发布之后,开发者有了新的选择:StateFlow 和 SharedFlow。
最近网上流传出「LiveData 被弃用,应该使用 Flow 替代 LiveData」的声音。
LiveData 真的有那么不堪吗?Flow 真的适合你使用吗?
不人云亦云,只求接近真相。我们今天来讨论一下这两种组件。
ViewModel + LiveData
为了实现高效地加载 UI 数据,获得最佳的用户体验,应实现以下目标:
目标1:已经加载的数据无需在「配置更改」的场景下再次加载
目标2:避免在非活跃状态(不是
STARTED或RESUMED)下加载数据和刷新 UI目标3:「配置更改」时不会中断的工作
Google 官方在 2017 年发布了架构组件库:使用 ViewModel + LiveData 帮助开发者实现上述目标。
相信很多人在官方文档中见过这个图,ViewModel 比 Activity/Fragment 的生命周期更长,不受「配置更改」导致 Activity/Fragment 重建的影响。刚好满足了目标 1 和目标 3。
LiveData 是可生命周期感知的。 新值仅在生命周期处于 STARTED 或 RESUMED 状态时才会分配给观察者,并且观察者会自动取消注册,避免了内存泄漏。 LiveData 对实现目标 1 和 目标 2 很有用:它缓存其持有的数据的最新值,并将该值自动分派给新的观察者。
LiveData 的特性
既然有声音说「LiveData 要被弃用了」,那么我们先对 LiveData 进行一个全面的了解。聊聊它能做什么,不能做什么,以及使用过程中有哪些要注意的地方。
LiveData 是 Android Jetpack Lifecycle 组件中的内容。属于官方库的一部分,Kotlin/Java 均可使用。
一句话概括 LiveData:LiveData 是可感知生命周期的,可观察的,数据持有者。
它的能力和作用很简单:更新 UI。
它有一些可以被认为是优点的特性:
观察者的回调永远发生在主线程
仅持有单个且最新的数据
自动取消订阅
提供「可读可写」和「仅可读」两个版本收缩权限
配合
DataBinding实现「双向绑定」
观察者的回调永远发生在主线程
这个很好理解,LiveData 被用来更新 UI,因此 Observer 的 onChanged() 方法在主线程回调。
背后的原理也很简单,LiveData 的 setValue() 发生在主线程(非主线程调用会抛异常,postValue() 内部会切换到主线程调用 setValue())。之后遍历所有观察者的 onChanged() 方法。
仅持有单个且最新的数据
作为数据持有者(data holder),LiveData 仅持有 单个 且 最新 的数据。
单个且最新,意味着 LiveData 每次持有一个数据,并且新数据会覆盖上一个。
这个设计很好理解,数据决定了 UI 的展示,绘制 UI 时肯定要使用最新的数据,「过时的数据」应该被忽略。
配合
Lifecycle,观察者只会在活跃状态下(STARTED到RESUMED)接收到LiveData持有的最新的数据。在非活跃状态下绘制 UI 没有意义,是一种资源的浪费。
自动取消订阅
这是 LiveData 可感知生命周期的重要表现,自动取消订阅意味着开发者无需手动写那些取消订阅的模板代码,降低了内存泄漏的可能性。
背后原理是在生命周期处于 DESTROYED 时,移除观察者。
提供「可读可写」和「仅可读」两个版本
public abstract class LiveData<T> {
@MainThread
protected void setValue(T value) {
// ...
}
protected void postValue(T value) {
// ...
}
@Nullable
public T getValue() {
// ...
}
}
public class MutableLiveData<T> extends LiveData<T> {
@Override
public void postValue(T value) {
super.postValue(value);
}
@Override
public void setValue(T value) {
super.setValue(value);
}
}抽象类
LiveData的setValue()和postValue()是 protected,而其实现类MutableLiveData均为 public。
LiveData 提供了 mutable(MutableLiveData) 和 immutable(LiveData) 两个类,前者「可读可写」,后者「仅可读」。通过权限的细化,让使用者各取所需,避免由于权限泛滥导致的数据异常。
class SharedViewModel : ViewModel() {
private val _user : MutableLiveData<User> = MutableLiveData()
val user : LiveData<User> = _user
fun setUser(user: User) {
_user.posetValue(user)
}
}配合 DataBinding 实现「双向绑定」
LiveData 配合 DataBinding 可以实现 更新数据自动驱动 UI 变化,如果使用「双向绑定」还能实现 UI 变化影响数据的变化。
以下也是 LiveData 的特性,但我不会将其归类为「设计缺陷」或「LiveData 的缺点」。作为开发者应了解这些特性并在使用过程中正确处理它们。
value 是 nullable 的
在 fragment 订阅时需要传入正确的
lifecycleOwner当
LiveData持有的数据是「事件」时,可能会遇到「粘性事件」LiveData是不防抖的LiveData的transformation工作在主线程
value 是 nullable 的
@Nullable
public T getValue() {
Object data = mData;
if (data != NOT_SET) {
return (T) data;
}
return null;
}LiveData#getValue() 是可空的,使用时应该注意判空。
使用正确的 lifecycleOwner
fragment 调用 LiveData#observe() 方法时传入 this 和 viewLifecycleOwner 是不一样的。
原因之前写过,此处不再赘述。感兴趣的小伙伴可以移步查看。
AS 在 lint 检查时会避免开发者犯此类错误。
粘性事件
官方在 [译] 在 SnackBar,Navigation 和其他事件中使用 LiveData(SingleLiveEvent 案例) 一文中描述了一种「数据只会消费一次」的场景。如展示 Snackbar,页面跳转事件或弹出 Dialog。
由于 LiveData 会在观察者活跃时将最新的数据通知给观察者,则会产生「粘性事件」的情况。
如点击 button 弹出一个 Snackbar,在屏幕旋转时,lifecycleOwner 重建,新的观察者会再次调用 Livedata#observe(),因此 Snackbar 会再次弹出。
解决办法是:将事件作为状态的一部分,在事件被消费后,不再通知观察者。这里推荐两种解决方案:
默认不防抖
setValue()/postValue() 传入相同的值多次调用,观察者的 onChanged() 会被多次调用。
严格讲这不算一个问题,看具体的业务场景,处理也很容易,官方在 Transformations 中提供了 distinctUntilChanged() 方法,配合官方提供的扩展函数,如下使用即可:
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
viewModel.headerText.distinctUntilChanged().observe(viewLifecycleOwner) {
header.text = it
}
}transformation 工作在主线程
有些时候我们从 repository 层拿到的数据需要进行处理,例如从数据库获得 User List,我们想根据 id 获取某个 User。
此时我们可以借助 MediatorLiveData 和 Transformatoins 来实现:
class MainViewModel {
val viewModelResult = Transformations.map(repository.getDataForUser()) { data ->
convertDataToMainUIModel(data)
}
}map 和 switchMap 内部均是使用 MediatorLiveData#addSource() 方法实现的,而该方法会在主线程调用,使用不当会有性能问题。
@MainThread
public <S> void addSource(@NonNull LiveData<S> source, @NonNull Observer<? super S> onChanged) {
Source<S> e = new Source<>(source, onChanged);
Source<?> existing = mSources.putIfAbsent(source, e);
if (existing != null && existing.mObserver != onChanged) {
throw new IllegalArgumentException(
"This source was already added with the different observer");
}
if (existing != null) {
return;
}
if (hasActiveObservers()) {
e.plug();
}
}我们可以借助 Kotlin 协程和 RxJava 实现异步任务,最后在主线程上返回 LiveData。如 androidx.lifecycle:lifecycle-livedata-ktx 提供了这样的写法
val result: LiveData<Result> = liveData {
val data = someSuspendingFunction() // 协程中处理
emit(data)
}LiveData 小结
LiveData作为一个 可感知生命周期的,可观察的,数据持有者,被设计用来更新 UILiveData很轻,功能十分克制,克制到需要配合ViewModel使用才能显示其价值由于
LiveData专注单一功能,因此它的一些方法使用上是有局限性的,即通过设计来强制开发者按正确的方式编码(如观察者仅在主线程回调,避免了开发者在子线程更新 UI 的错误操作)由于
LiveData专注单一功能,如果想在表现层之外使用它,MediatorLiveData的操作数据的能力有限,仅有的map和switchMap发生在主线程。可以在switchMap中使用协程或RxJava处理异步任务,最后在主线程返回LiveData。如果项目中使用了RxJava的 AutoDispose,甚至可以不使用LiveData,关于Kotlin协程的Flow,我们后文介绍。笔者不喜欢将
LiveData改造成 bus 使用,让组件做其分内的事(此条属于个人观点)
Flow
Flow 是 Kotlin 语言提供的功能,属于 Kotlin 协程的一部分,仅 Kotlin 使用。
Kotlin 协程被用来处理异步任务,而 Flow 则是处理异步数据流。
那么 suspend 方法和 Flow 的区别是什么?各自的使用场景是哪些?
一次性调用(One-shot Call)与数据流(data stream)
假如我们的 app 的某一屏里显示以下元素,其中红框部分实时性不高,不必很频繁的刷新,转发和点赞属于实时性很高的数据,需要定时刷新。
对于实时性不高的数据,我们可以使用 Kotlin 协程处理(此处数据的请求是异步任务):
suspend fun loadData(): Data
uiScope.launch {
val data = loadData()
updateUI(data)
}而对于实时性较高的数据,挂起函数就无能为力了。有的小伙伴可能会说:「返回个 List 不就行了嘛」。其实无论返回什么类型,这种操作都是 One-shot Call,一次性的请求,有了结果就结束。
示例中的点赞和转发,需要一个 数据是异步计算的,能够 按顺序 提供 多个值 的结构,在 Kotlin 协程中我们有 Flow。
fun dataStream(): Flow<Data>
uiScope.launch {
dataStream().collect { data ->
updateUI(data)
}
}当点赞或转发数发生变化时,
updateUI()会被执行,UI 根据最新的数据更新
Flow 的三驾马车
FLow 中有三个重要的概念:
生产者(Producer)
消费者(Consumer)
中介(Intermediaries)
生产者提供数据流中的数据,得益于 Kotlin 协程,Flow 可以 异步地生产数据。
消费者消费数据流内的数据,上面的示例中,updateUI() 方法是消费者。
中介可以对数据流中的数据进行更改,甚至可以更改数据流本身,我们可以借助官方视频中的动画来理解:
在 Android 中,数据层的 DataSource/Repository 是 UI 数据的生产者;而 view/ViewModel 是消费者;换一个角度,在表现层中,view 是用户输入事件的生产者(例如按钮的点击),其它层是消费者。
「冷流」与「热流」
你可能见过这样的描述:「流是冷的」
简单来说,冷流指数据流只有在有消费者消费时才会生产数据。
val dataFlow = flow {
// 代码块只有在有消费者 collect 后才会被调用
val data = dataSource.fetchData()
emit(data)
}
...
dataFlow.collect { ... }有一种特殊的 Flow,如 StateFlow/SharedFlow ,它们是热流。这些流可以在没有活跃消费者的情况下存活,换句话说,数据在流之外生成然后传递到流。
BroadcastChannel` 未来会在 Kotlin 1.6.0 中弃用,在 Kotlin 1.7.0 中删除。它的替代者是 `StateFlow` 和 `SharedFlowStateFlow
StateFlow 也提供「可读可写」和「仅可读」两个版本。
SateFlow` 实现了 `SharedFlow`,`MutableStateFlow` 实现 `MutableSharedFlowStateFlow 与 LiveData 十分像,或者说它们的定位类似。
StateFlow 与 LiveData 有一些相同点:
提供「可读可写」和「仅可读」两个版本(
StateFlow,MutableStateFlow)它的值是唯一的
它允许被多个观察者共用 (因此是共享的数据流)
它永远只会把最新的值重现给订阅者,这与活跃观察者的数量是无关的
支持
DataBinding
它们也有些不同点:
必须配置初始值
value 空安全
防抖
MutableStateFlow 构造方法强制赋值一个非空的数据,而且 value 也是非空的。这意味着 StateFlow 永远有值
StateFlow 的
emit()和tryEmit()方法内部实现是一样的,都是调用setValue()
StateFlow 默认是防抖的,在更新数据时,会判断当前值与新值是否相同,如果相同则不更新数据。
SharedFlow
与 SateFlow 一样,SharedFlow 也有两个版本:SharedFlow 与 MutableSharedFlow。
那么它们有什么不同?
MutableSharedFlow没有起始值SharedFlow可以保留历史数据MutableSharedFlow发射值需要调用emit()/tryEmit()方法,没有setValue()方法
与 MutableStateFlow 不同,MutableSharedFlow 构造器中是不能传入默认值的,这意味着 MutableSharedFlow 没有默认值。
val mySharedFlow = MutableSharedFlow<Int>()
val myStateFlow = MutableStateFlow<Int>(0)
...
mySharedFlow.emit(1)
myStateFlow.emit(1)SateFlow 与 SharedFlow 还有一个区别是 SateFlow 只保留最新值,即新的订阅者只会获得最新的和之后的数据。
而 SharedFlow 根据配置可以保留历史数据,新的订阅者可以获取之前发射过的一系列数据。
后文会介绍背后的原理
它们被用来应对不同的场景:UI 数据是状态还是事件。
状态(State)与事件(Event)
状态可以是的 UI 组件的可见性,它始终具有一个值(显示/隐藏)
而事件只有在满足一个或多个前提条件时才会触发,不需要也不应该有默认值
为了更好地理解 SateFlow 和 SharedFlow 的使用场景,我们来看下面的示例:
用户点击登录按钮
调用服务端验证登录合法性
登录成功后跳转首页
我们先将步骤 3 视为 状态 来处理:
使用状态管理还有与 LiveData 一样的「粘性事件」问题,如果在 ViewNavigationState 中我们的操作是弹出 snackbar,而且已经弹出一次。在旋转屏幕后,snackbar 会再次弹出。
如果我们将步骤 3 作为 事件 处理:
使用 SharedFlow 不会有「粘性事件」的问题,MutableSharedFlow 构造函数里有一个 replay 的参数,它代表着可以对新订阅者重新发送多个之前已发出的值,默认值为 0。
SharedFlow 在其 replayCache 中保留特定数量的最新值。每个新订阅者首先从 replayCache 中取值,然后获取新发射的值。replayCache 的最大容量是在创建 SharedFlow 时通过 replay 参数指定的。replayCache 可以使用 MutableSharedFlow.resetReplayCache 方法重置。
当 replay 为 0 时,replayCache size 为 0,新的订阅者获取不到之前的数据,因此不存在「粘性事件」的问题。
StateFlow 的 replayCache 始终有当前最新的数据:
至此, StateFlow 与 SharedFlow 的使用场景就很清晰了:
状态(State)用 StateFlow ;事件(Event)用 SharedFlow
StateFlow,SharedFlow 与 LiveData 的使用对比
上图分别展示了
LiveData,StateFlow,SharedFlow在ViewModel中的使用。其中
LiveDataViewModel中使用EventLiveData处理「粘性事件」
FlowViewModel中使用SharedFlow处理「粘性事件」emit()` 方法是挂起函数,也可以使用 `tryEmit()
注意:Flow 的 collect 方法不能写在同一个
lifecycleScope中
flowWithLifecycle是lifecycle-runtime-ktx:2.4.0-alpha01后提供的扩展方法
Flow 在 fragment 中的使用要比 LiveData 繁琐很多,我们可以封装一个扩展方法来简化:
关于 repeatOnLifecycle 的设计问题,可以移步 设计 repeatOnLifecycle API 背后的故事。
使用 collect 方法时要注意一个问题。
这种写法是错误的!
viewModel.headerText.collect 在协程被取消前会一直挂起,这样后面的代码便不会执行。
Flow 与 RxJava
Flow 和 RxJava 的定位很接近,限于篇幅原因,此处不展开讲,本节只罗列一下它们的对应关系:
Flow= (cold)Flowable/Observable/SingleChannel=SubjectsStateFlow=BehaviorSubjects(永远有值)SharedFlow=PublishSubjects(无初始值)suspend function=Single/Maybe/Completable
参考文档与推荐资源
LiveData with Coroutines and Flow — Part II: Launching coroutines with Architecture Components
LiveData beyond the ViewModel — Reactive patterns using Transformations and MediatorLiveData
The Benefits of StateFlow and SharedFlow over LiveData - Andrey Liashuk
DevFest South Africa - Migrating from LiveData to Coroutines and Flow - Jossi Wolf
总结
LiveData的主要职责是更新 UI,要充分了解其特性,合理使用Flow可分为生产者,消费者,中介三个角色冷流和热流最大的区别是前者依赖消费者
collect存在,而热流一直存在,直到被取消StateFlow与LiveData定位相似,前者必须配置初始值,value 空安全并且默认防抖StateFlow与SharedFlow的使用场景不同,前者适用于「状态」,后者适用于「事件」
回到文章开头的话题,LiveData 并没有那么不堪,由于其作用单一,功能简单,简单便意味着不易出错。所以在表现层中ViewModel 向 view 暴露 LiveData 是一个不错的选择。而在 Repository 或 DataSource 中,我们可以利用 LiveData + 协程来处理数据的转换。当然,我们也可以使用功能更强大的 Flow。
LiveData,StateFLow,SharedFlow,它们都有着各自的使用场景。并且如果使用不当,都会或多或少地遇到一些所谓的「坑」。因此在使用某个组件时,要充分了解其设计缘由以及相关特性,否则就会掉进陷阱,收到不符合预期的行为。
关于我
人总是喜欢做能够获得正反馈(成就感)的事情,如果感觉本文内容对你有帮助的话,麻烦点亮一下👍,这对我很重要哦~
我是 Flywith24,人只有通过和别人的讨论,才能知道我们自己的经验是否是真实的,加我微信交流,让我们共同进步。
作者:Flywith24
来源:https://juejin.cn/post/7007602776502960165
基于react/vue开发一个专属于程序员的朋友圈应用
前言
今天本来想开源自己写的CMS应用的,但是由于五一期间笔者的mac电脑突然崩溃了,所有数据无法恢复,导致部分代码丢失,但庆幸的是cms的打包文件已上传服务器,感兴趣的朋友可以在文末链接中访问查看。
今天要写的H5朋友圈也是基于笔者开发的cms搭建的,我将仿照微信朋友圈,带大家一起开发一个能发布动态(包括图片上传)的朋友圈应用。有关服务端部分笔者在本文中不会细讲,后续会在cms2.0中详细介绍。
你将收获
使用umi快速创建一个H5移动端应用
基于react-lazy-load实现图片/内容懒加载
使用css3基于图片数量动态改变布局
利用FP创建一个朋友圈form
使用rc-viewer查看/旋转/缩放朋友圈图片
基于axios + formdata实现文件上传功能
ZXCMS介绍
应用效果预览
朋友圈列表
查看朋友圈图片
发布动态
正文
在开始文章之前,笔者想先粗略总结一下开发H5移动端应用需要考虑的点。对于任何移动端应用来说,我们都要考虑如下问题:
首屏加载时间
适配问题
页面流畅度
动画性能
交互友好
提供用户反馈 这些不仅仅是前端工程师需要考虑的问题,也是产品经理和交互设计师考虑的范畴。当然还有很多实际的考虑点需要根据自身需求去优化,以上几点大致解决方案如下:
提高首屏加载时间 可以采用资源懒加载+gzip+静态资源CDN来优化,并且提供加载动画来降低用户焦虑。
适配问题 移动端适配问题可以通过js动态设置视口宽度/比率或者采用css媒介查询来处理,这块市面上已经有非常成熟的方案
页面流畅度 我们可以在body上设置-webkit-overflow-scrolling:touch;来提高滚动流畅度,并且可以在a/img标签上使用 -webkit-touch-callout: none来禁止长按产生菜单栏。
动画性能 为了提高动画性能, 我们可以将需要变化的属性采用transform或者使用absolute定位代替,transform不会导致页面重绘。
提供用户反馈 提供友好的用户反馈我们可以通过合理设置toast,modal等来控制
以上介绍的只是移动端优化的凤毛麟角,有关前端页面性能优化的方案还有很多,笔者在之前的文章中也详细介绍过,下面我们进入正文。
1. 使用umi快速创建一个应用
笔者将采用umi作为项目的前端集成解决方案,其提供了非常多了功能,使用起来也非常方便,并且对于antd和antd-mobile自动做了按需导入,所以熟悉react的朋友可以尝试一下,本文的方案对于vue选手来说也是适用的,因为任何场景下,方法和思维模式都是跨语言跨框架的。
目前umi已经升级到3.0,本文所使用的是2.0,不过差异不是很大,大家可以放心使用3.0. 具体使用步骤如下
// umi2.0
// 新建项目目录
mkdir friendcircle
// 创建umi项目
cd friendcircle
yarn create umi
// 安装依赖
yarn
yarn add antd-moblie
这样一个umi项目就创建好了。
2. 基于react-lazy-load实现图片/内容懒加载
在项目创建好之后,我们先分析我们需要用到那些技术点:
笔者在设计时研究了很多懒加载实现方式,目前采用react-lazy-load来实现,好处是支持加载事件通知,比如我们需要做埋点或者广告上报等功能时非常方便。当然大家也可以自己通过observer API去实现,具体实现方案笔者在几个非常有意思的javascript知识点总结文章中有所介绍。 具体使用方式:
<LazyLoad key={item.uid} overflow height={280} onContentVisible={onContentVisible}>
// 需要懒加载的组件
<ComponentA />
</LazyLoad>
react-lazy-load使用方式非常简单,大家不懂的可以在官网学习了解。
3. 使用css3基于图片数量动态改变布局
目前在朋友圈列表页有个核心的需求就是我们需要在用户传入不同数量的图片时,要有不同的布局,就像微信朋友圈一样,主要作用就是为了让用户尽可能多的看到图片,提高用户体验,如下图所示例子:
我们用js实现起来很方便,但是对性能及其不友好,而且对于用户发布的每一条动态的图片都需要用js重新计算一遍,作为一个有追求的程序员是不可能让这种情况发生的,所以我们用css3来实现,其实有关这种实现方式笔者在之前的css3高级技巧的文章中有详细介绍,我们这里用到了子节点选择器,具体实现如下:
.imgItem {
margin-right: 6px;
margin-bottom: 10px;
&:nth-last-child(1):first-child {
margin-right: 0;
width: 100%;
}
&:nth-last-child(2):first-child,
&:nth-last-child(3):first-child,
&:nth-last-child(4):first-child,
&:first-child:nth-last-child(n+2) ~ div {
width:calc(50% - 6px);
height: 200px;
overflow: hidden;
}
&:first-child:nth-last-child(n+5),
&:first-child:nth-last-child(n+5) ~ div {
width: calc(33.33333% - 6px);
height: 150px;
overflow: hidden;
}
}
以上代码中我们对于一张图片,2-4张图片,5张以上的图片分别设置了不同的尺寸,这样就可以实现我们的需求了,还有一个要注意的是,当用户上传不同尺寸的图片时,有可能出现高低不一致的情况,这个时候为了显示一致,我们可以使用img样式中的object-fit属性,有点类似于background-size,我们可以把img便签看作一个容器,里面的内容如何填充这个容器,完全用object-fit来设置,具体属性如下:
fill 被替换的内容正好填充元素的内容框。整个对象将完全填充此框。如果对象的宽高比与内容框不相匹配,那么该对象将被拉伸以适应内容框
contain 被替换的内容将被缩放,以在填充元素的内容框时保持其宽高比。 整个对象在填充盒子的同时保留其长宽比,因此如果宽高比与框的宽高比不匹配,该对象将被添加“黑边”
cover 被替换的内容在保持其宽高比的同时填充元素的整个内容框。如果对象的宽高比与内容框不相匹配,该对象将被剪裁以适应内容框
scale-down 内容的尺寸与 none 或 contain 中的一个相同,取决于它们两个之间谁得到的对象尺寸会更小一些
none 被替换的内容将保持其原有的尺寸
所以为了让图片保持一致,我们这么设置img标签的样式:
img {
width: 100%;
height: 100%;
object-fit: cover;
}
4. 利用FP创建一个朋友圈form
FP是笔者开源的一个表单配置平台,主要用来定制和分析各种表单模型,界面如下:
通过该平台可以定制各种表单模版并分析表单数据。这里朋友圈功能我们只需要配置一个简单的朋友圈发布功能即可,如下:
由于笔者电脑数据丢失导致代码部分损失,感兴趣可以了解一下。
5. 使用rc-viewer查看/旋转/缩放朋友圈图片
对于朋友圈另一个重要的功能就是能查看每一条动态的图片,类似于微信朋友圈的图片查看器,这里笔者采用第三方开源库rc-viewer来实现,具体代码如下:
<RcViewer options={{title: 0, navbar: 0, toolbar: 0}} ref={imgViewRef}>
<div className={styles.imgBox}>
{
item.imgUrls.map((item, i) => {
return <div className={styles.imgItem} key={i}>
<img src={item} alt=""/>
</div>
})
}
</div>
</RcViewer>
由上代码可知我们只需要在RcViewer组件里写我们需要的查看的图片结构就行了,其提供了很多配置选项可是使用,这里笔者在option中配置了title,navbar,toolbar均为0,意思是不显示这些功能,因为移动端只需要有基本的查看,缩放,切换图片功能即可,尽可能轻量化。效果如下:
当我们点击动态中的某一张图片时,我们可以看到它的大图,并通过手势进行切换。
6. 基于axios + formdata实现文件上传功能
实现文件上传,除了采用antd的upload组件,我们也可以结合http请求库和formdata来实现,为了支持多图上传并保证时机,我们采用async await函数,具体代码如下:
const onSubmit = async () => {
// ... something code
const formData = new FormData()
for(let i=0; i< files.length; i++) {
formData.delete('file')
formData.append('file', files[i].file)
try{
const res = await req({
method: 'post',
url: '/files/upload/tx',
data: formData,
headers: {
'Content-Type': 'multipart/form-data'
}
});
// ... something co
}catch(err) {
Toast.fail('上传失败', 2);
}
}
其中req是笔者基于axios封装的http请求库,支持简单的请求/响应拦截,感兴趣的朋友可以参考笔者源码。
7. ZXCMS介绍
ZXCMS是笔者开发的一个商业版CMS,可以快速搭建自己的社区,博客等,并且集成了表单定制平台,配置中心,数据分发中心等功能,后期会扩展H5可视化搭建平台和PC端建站平台,成为一个更加只能强大的开源系统。设计架构如下:
具体界面如下:
一个笔者配置的社区平台:
文章详情页:
社区支持评论,搜索文章等功能。以下介绍后台管理系统:
简单介绍一下,后期笔者会专门出文章介绍具体实现方式和源码设计。
8. 源码地址
由于笔者电脑数据丢失,只能找到部分源码,所以大家可以参考以下地址:
开源不易,欢迎支持~
作者:徐小夕
来源:https://juejin.cn/post/6844904150417801224
如何利用performance进行性能优化
Performance 可以记录站点在运行过程中的性能数据,有了这些性能数据,就可以回放整个页面的执行过程,这样就方便我们来定位和诊断每个时间段内页面的运行情况,从而有效的找出页面的性能瓶颈。
配置 Performance
各种配置及说明如图所示:
Performance 不仅可以录制加载阶段的性能数据,还可以录制交互阶段,不过交互阶段的录制需要手动停止录制过程。
观察下图的报告页,我们可以将它分为三个主要的部分,分别为概览面板、性能指标面板和详情面板。
在概览面板中,Performance 就会将几个关键指标,诸如页面帧速 (FPS)、CPU 资源消耗、网络请求流量、V8 内存使用量 (堆内存) 等,按照时间顺序做成图表的形式展现出来,可以参看上图。
如果 FPS 图表上出现了红色块,那么就表示红色块附近渲染出一帧所需时间过久,帧的渲染时间过久,就有可能导致页面卡顿。
如果 CPU 图形占用面积太大,表示 CPU 使用率就越高,那么就有可能因为某个 JavaScript 占用太多的主线程时间,从而影响其他任务的执行。
除了以上指标以外,概览面板还展示加载过程中的几个关键时间节点,如 FP、LCP、DOMContentLoaded、Onload 等事件产生的时间点。
Main 指标
在性能面板中,记录了非常多的性能指标项,比如 Main 指标记录渲染主线程的任务执行过程,Compositor 指标记录了合成线程的任务执行过程,GPU 指标记录了 GPU 进程主线程的任务执行过程。有了这些详细的性能数据,就可以帮助我们轻松地定位到页面的性能问题。
简而言之,我们通过概览面板来定位问题的时间节点,然后再使用性能面板分析该时间节点内的性能数据。具体地讲,比如概览面板中的 FPS 图表中出现了红色块,那么我们点击该红色块,性能面板就定位到该红色块的时间节点内了。
因为浏览器的渲染机制过于复杂,所以渲染模块在执行渲染的过程中会被划分为很多子阶段,输入的 HTML 数据经过这些子阶段,最后输出屏幕上的像素,我们把这样的一个处理流程叫做渲染流水线。一条完整的渲染流水线包括了解析 HTML 文件生成 DOM、解析 CSS 生成 CSSOM、执行 JavaScript、样式计算、构造布局树、准备绘制列表、光栅化、合成、显示等一系列操作。
渲染流水线主要是在渲染进程中执行的,在执行渲染流水线的过程中,渲染进程又需要网络进程、浏览器进程、GPU 等进程配合,才能完成如此复杂的任务。另外在渲染进程内部,又有很多线程来相互配合。具体的工作方式你可以参考下图:
观察上图,一段段横条代表执行一个个任务,长度越长,花费的时间越多;竖向代表该任务的执行记录。我们知道主线程上跑了特别多的任务,诸如渲染流水线的大部分流程,JavaScript 执行、V8 的垃圾回收、定时器设置的回调任务等等,因此 Main 指标的内容非常多,而且非常重要,所以我们在使用 Perofrmance 的时候,大部分时间都是在分析 Main 指标。
任务 vs 过程
渲染进程中维护了消息队列,如果通过 SetTimeout 设置的回调函数,通过鼠标点击的消息事件,都会以任务的形式添加消息队列中,然后任务调度器会按照一定规则从消息队列中取出合适的任务,并让其在渲染主线程上执行。
Main 指标就记录渲染主线上所执行的全部任务,以及每个任务的详细执行过程。
观察上图,图上方有很多一段一段灰色横条,每个灰色横条就对应了一个任务,灰色长条的长度对应了任务的执行时长。通常,渲染主线程上的任务都是比较复杂的,如果只单纯记录任务执行的时长,那么依然很难定位问题,因此,还需要将任务执行过程中的一些关键的细节记录下来,这些细节就是任务的过程,灰线下面的横条就是一个个过程,同样这些横条的长度就代表这些过程执行的时长。
直观地理解,你可以把任务看成是一个 Task 函数,在执行 Task 函数的过程中,它会调用一系列的子函数,这些子函数就是我们所提到的过程。为了让你更好地理解,我们来分析下面这个任务的图形:
观察上面这个任务记录的图形,你可以把该图形看成是下面 Task 函数的执行过程:
function A(){
A1()
A2()
}
function Task(){
A()
B()
}
Task()
分析页面加载过程
结合 Main 指标来分析页面的加载过程。先来分析一个简单的页面,代码如下所示:
<html>
<head>
<title>Main</title>
<style>
area {
border: 2px ridge;
}
box {
background-color: rgba(106, 24, 238, 0.26);
height: 5em;
margin: 1em;
width: 5em;
}
</style>
</head>
<body>
<div class="area">
<div class="box rAF"></div>
</div>
<br>
<script>
function setNewArea() {
let el = document.createElement('div')
el.setAttribute('class', 'area')
el.innerHTML = '<div class="box rAF"></div>'
document.body.append(el)
}
setNewArea()
</script>
</body>
</html>
可以看出,它只是包含了一段 CSS 样式和一段 JavaScript 内嵌代码,其中在 JavaScript 中还执行了 DOM 操作了,我们就结合这段代码来分析页面的加载流程。
首先生成报告页,再观察报告页中的 Main 指标,由于阅读实际指标比较费劲,所以先手动绘制了一些关键的任务和其执行过程,如下图所示:
通过上面的图形我们可以看出,加载过程主要分为三个阶段,它们分别是:
导航阶段,该阶段主要是从网络进程接收 HTML 响应头和 HTML 响应体。
解析 HTML 数据阶段,该阶段主要是将接收到的 HTML 数据转换为 DOM 和 CSSOM。
生成可显示的位图阶段,该阶段主要是利用 DOM 和 CSSOM,经过计算布局、生成层树 (LayerTree)、生成绘制列表 (Paint)、完成合成等操作,生成最终的图片。
那么接下来,我就按照这三个步骤来介绍如何解读 Main 指标上的数据。
导航阶段
当你点击了 Performance 上的重新录制按钮之后,浏览器进程会通知网络进程去请求对应的 URL 资源;一旦网络进程从服务器接收到 URL 的响应头,便立即判断该响应头中的 content-type 字段是否属于 text/html 类型;如果是,那么浏览器进程会让当前的页面执行退出前的清理操作,比如执行 JavaScript 中的 beforunload 事件,清理操作执行结束之后就准备显示新页面了,这包括了解析、布局、合成、显示等一系列操作。
当你点击重新加载按钮后,当前的页面会执行上图中的这个任务:
该任务的第一个子过程就是 Send request,该过程表示网络请求已被发送。然后该任务进入了等待状态。
接着由网络进程负责下载资源,当接收到响应头的时候,该任务便执行 Receive Respone 过程,该过程表示接收到 HTTP 的响应头了。
接着执行 DOM 事件:pagehide、visibilitychange 和 unload 等事件,如果你注册了这些事件的回调函数,那么这些回调函数会依次在该任务中被调用。
这些事件被处理完成之后,那么接下来就接收 HTML 数据了,这体现在了 Recive Data 过程,Recive Data 过程表示请求的数据已被接收,如果 HTML 数据过多,会存在多个 Receive Data 过程。
等到所有的数据都接收完成之后,渲染进程会触发另外一个任务,该任务主要执行 Finish load 过程,该过程表示网络请求已经完成。
解析 HTML 数据阶段
这个阶段的主要任务就是通过解析 HTML 数据、解析 CSS 数据、执行 JavaScript 来生成 DOM 和 CSSOM。那么继续来分析这个阶段的图形,看看它到底是怎么执行的?可以观看下图:
观察上图这个图形,可以看出,其中一个主要的过程是 HTMLParser,顾名思义,这个过程是用来解析 HTML 文件,解析的就是上个阶段接收到的 HTML 数据。
在 ParserHTML 的过程中,如果解析到了 script 标签,那么便进入了脚本执行过程,也就是图中的 Evalute Script。
要执行一段脚本我们需要首先编译该脚本,于是在 Evalute Script 过程中,先进入了脚本编译过程,也就是图中的 Complie Script。脚本编译好之后,就进入程序执行过程,执行全局代码时,V8 会先构造一个 anonymous 过程,在执行 anonymous 过程中,会调用 setNewArea 过程,setNewArea 过程中又调用了 createElement,由于之后调用了 document.append 方法,该方法会触发 DOM 内容的修改,所以又强制执行了 ParserHTML 过程生成的新的 DOM。
DOM 生成完成之后,会触发相关的 DOM 事件,比如典型的 DOMContentLoaded,还有 readyStateChanged。
生成可显示位图阶段
生成了 DOM 和 CSSOM 之后,就进入了第三个阶段:生成页面上的位图。通常这需要经历布局 (Layout)、分层、绘制、合成等一系列操作,同样,将第三个阶段的流程也放大了,如下图所示:
结合上图,我们可以发现,在生成完了 DOM 和 CSSOM 之后,渲染主线程首先执行了一些 DOM 事件,诸如 readyStateChange、load、pageshow。具体地讲,如果你使用 JavaScript 监听了这些事件,那么这些监听的函数会被渲染主线程依次调用。
接下来就正式进入显示流程了,大致过程如下所示。
首先执行布局,这个过程对应图中的 Layout。
然后更新层树 (LayerTree),这个过程对应图中的 Update LayerTree。
有了层树之后,就需要为层树中的每一层准备绘制列表了,这个过程就称为 Paint。
准备每层的绘制列表之后,就需要利用绘制列表来生成相应图层的位图了,这个过程对应图中的 Composite Layers。
走到了 Composite Layers 这步,主线程的任务就完成了,接下来主线程会将合成的任务完全教给合成线程来执行,下面是具体的过程,你也可以对照着 Composite、Raster 和 GPU 这三个指标来分析,参考下图:
首先主线程执行到 Composite Layers 过程之后,便会将绘制列表等信息提交给合成线程,合成线程的执行记录你可以通过 Compositor 指标来查看。
合成线程维护了一个 Raster 线程池,线程池中的每个线程称为 Rasterize,用来执行光栅化操作,对应的任务就是 Rasterize Paint。
当然光栅化操作并不是在 Rasterize 线程中直接执行的,而是在 GPU 进程中执行的,因此 Rasterize 线程需要和 GPU 线程保持通信。
然后 GPU 生成图像,最终这些图层会被提交给浏览器进程,浏览器进程将其合成并最终显示在页面上。
本文解答了个人一个长期困扰的问题:在某些情况下,比如网速比较慢或者页面内容很多的时候,页面是一点一点的显示出来的,原本以为是网络数据是加载一点就渲染一点,其实不是的,数据在导航阶段就已经全部获取回来了。之所以会慢慢渲染出来,是因为浏览器的显示频率是60hz,也就是16.67ms就刷新下浏览器,但是在16.67ms内,渲染流水线可能只进行到一半,但是这个时候也要把渲染一半的画面显示出来,所以就会看到页面是一点一点的绘制出来的。
作者:小p
来源:juejin.cn/post/7095647383488299044
收起阅读 »
“𠈌”计划4月优秀环友表彰及5月获选标准
环信4月发起“𠈌”计划,以传递“人人为我,我为人人”的开发者互助精神为目标,将程序员自由开放和共享精神发扬光大。每月结束后由社区综合评选出当月积极帮助他人或参与环信社区建设的优秀开发者,送上优秀环友墙并发放环信大礼包,下面我们康康首批优秀环友们吧~
社区/社群优秀环友
环信官方群聚集了数千名开发者,这里有2名活跃的老朋友 @麦田稻草人 @孤狼☞小九 ,陪伴是最长情的告白,他们多年坚守在环信群里帮群友解答问题,是环信编外员工?很多群友傻傻分不清。他们与环信的故事从那一年开始。。
麦田稻草人
从第一次修改环信的头像问题,到现在已经接触环信六年多了,见识过环信的贴心服务,也见证过超级大群的热闹,也算是见证了环信论坛的搭建历程,见证过环信从国内到国外再到国内的过程。一点点熟悉环信,从简单修改到后面修改sdk,感慨良多
孤狼☞小九
不知不觉间,已经接触环信七年多了,见识过环信的贴心服务,也见识过环信QQ群友的互帮互助,也算是参与到环信论坛的搭建与完善.见证过环信功能的一步步完善,也见证过环信的从国内出圈到国外再回归到国内的过程.一点点一步步的熟悉了环信,从刚开始集成时的茫然不知,到后面的各种自定义消息.所遇帮助颇多,感触良多
开源项目贡献者
环信开源项目频道(https://www.imgeek.org/code/)主要展示开发者们基于环信IM的奇思妙想,做出的众多优秀开源项目。为广大开发者提供便捷易用的开源作品,帮助赶工期的煎熬党们开发效率起飞。
感谢以下5名开发者,对环信开源项目卓越的贡献。希望更多开发者加入到开源项目贡献天团,环信有数百名产品经理天团帮你出谋划策哦。
@GraysonGao、@Friday、@魏头儿、@我爱捏猫肚、@穿裤衩闯天下(lzan13)
环信内容共建者
IMGeek社区不仅承载帮助使用环信SDK的开发者解决问题,也希望通过精选优质的技术文章帮助更多技术从业者积累知识不断进步。你可能经常看到这些人的身影,
@柳天明、@zuyu、@费城、@马师傅、@王二蛋和他的张大花、@雨淋湿了天空、@上帝之眼
他们推荐了数百条精选文章,连载了一系列个人原创文章,感谢他们的贡献~希望更多开发者5月份加入到内容共建队伍😀~
恭喜以上14名开发者首批入选优秀环友墙,请联系微信环信冬冬(vx:huanxin-hh)领取4月礼包及纪念徽章。

“𠈌”计划5月礼包发放标准:
1、社区/社群活跃用户 --2-5人符合5月领取礼包条件的开发者本帖回复,然后坐等福利小助手联系你~
2、IMGeek发文章2篇原创或5篇转载 不限人数
3、反馈IM SDK bug并技术确认 不限人数

关于Kotlin的一些小事
一、碎碎念
说实话,原本是没有这个系列的,或者说是没想过去建立这个系列。
虽然,但是,所以就有了(别问为什么?)
val var 声明变量
- 被 val 修饰的变量:被 final 修饰,且只会为其提供 getter() 而不会提供 setter() 方法。
- 因为被 final 修饰的值,只能被赋值一次;所以不会有 setter()。
- 是否添加了"?":声明变量的时候会根据是否有"?",将变量添加 NotNull 或者 Nullable 注解。
- 被 var 修饰的变量:普通定义变量的方式,且会同时提供 setter()、getter() 方法。
- 是否添加了"?":如果没有?,则setter()方法的入参会被标记位NotNull;如果有?,则setter()方法的入参会被标记为Nullable。
?. 操作符
- 对于声明为 var 的变量,在调用方法时会需要加上 ?. 操作符来进行判空处理,避免空指针。实现空安全。
- 实现原理:通过在方法内部构造一个局部变量,然后赋值为该数据,紧接着通过判断局部变量是否为空?如果为空,则进行预设的处理;如果不为空,则直接进行方法调用。
声明变量的方式,能否全部声明为可空来避免空指针?为什么?
- 猜测:这里涉及到一个 java 和 Kt 互调的问题。
- 假设1:【Java 调 Kotlin 方法,在于调用】java 用一个可能为空的数据作为方法参数去调用 kt 方法,如果此时入参为空,但 kt 方法将方法参数配置为不可空的数据类型,那么此时就会直接报空指针异常。
- 因为 kt 会对那些入参不可空的对象先进行空指针判断再执行方法操作。
- 假设2:【Kotlin 调 Java 方法,在于接收】kt 用一个不可空的变量来接收 java 方法调用得到的返回值,如果此时 java 方法返回一个空,那么此时就会直接报空指针异常。
- 假设1:【Java 调 Kotlin 方法,在于调用】java 用一个可能为空的数据作为方法参数去调用 kt 方法,如果此时入参为空,但 kt 方法将方法参数配置为不可空的数据类型,那么此时就会直接报空指针异常。
单例的实现方式
- 后面新建文章再说
data class
- data class,编译之后变成 public final class;声明的所有参数会作为构造函数的入参。
- ① 声明为 val 的参数,只会被提供 getter() 方法;而声明为 var 的参数,会被同时提供 setter()/gettter() 方法。
- ② 带了 ? 标记的参数,即标明为可空的参数,在构造函数中会被检测是否为空并抛出异常。
by lazy 和 lateinit var
- 【作用对象不同】
- lateinit 只能用在 var 声明变量且数据类型不能为空。
- by lazy {} 只能用在 val 声明变量。
- 【初始化数据的时机不同】
- 使用 lateinit 标记的变量,认定了开发者自己在使用该变量之前一定会先为其赋值,所以在访问的时候,会先进行判空处理。如果为空则直接crash。
- 这也证实了 lateinit 只能对数据类型不为空的变量进行修饰。
- 通过 by lazy 声明的变量,会为该变量提供私有的 getter() 方法并通过该方法来访问变量,而真正保存数据的位置,是类中一个声明为 final 的数据类型为 Lazy 的私有代理对象,将其作为访问入口,通过 Lazy 的 value 属性来获取数据。Lazy.getValue() 会通过执行初始化函数 initializer 来进行初始化。
- 详见:链接,下面会接着说。
- 使用 lateinit 标记的变量,认定了开发者自己在使用该变量之前一定会先为其赋值,所以在访问的时候,会先进行判空处理。如果为空则直接crash。
- 其他方面:看一下对比
by lazy - val
by lazy{} 的使用
- by lazy{} 入参:需要传入一个初始化数据的函数 initializer: () -> T。
- by lazy{} 返回值:会通过 initializer 函数作为方法参数,构造并返回一个 SynchronizedLazyImpl:Lazy 对象。
如何获取数据?
- 可见,访问 by lazy 的变量,会通过其 getter() 方法来获取数据。
- 而此时可以看到 getter() 方法是通过访问数据类型为 Lazy 的代理对象的 getValue() 方法获取数据;由上述可知,此时得到的代理对象是一个 SynchronizedLazyImpl:Lazy 对象。
- 立下一个 Flag:后续再对所有 Lazy 实现类新建文章看看?
SynchronizedLazyImpl:Lazy
- 【关于数据 _value:Any? 】
- 初始值为一个单例对象 internal object UNINITIALIZED_VALUE,表示当前未初始化。
- 因此 _value 的数据类型为 Any。
- 【getVaule() 方法】
- ① 首先会判断当前保存的数据 _value是否为这个单例对象 UNINITIALIZED_VALUE?如果不是,则直接通过 as 强装为返回值类型并返回。如果数据未初始化,那么
- ② 进入一个同步块 synchronized(lock),在同步块中,再次判断 _value是否为这个单例对象 UNINITIALIZED_VALUE?这里的流程就类似于 double check lock。如果已经初始化,则同样通过 as 强装为返回值类型并返回。如果数据未初始化,那么
- ③ 执行初始化函数 initializer 获取数据并赋值给 _value,从而保证下次获取数据时直接返回该数据。此时,还会将初始化函数 initializer 置空。然后返回数据。
- 【关于 initializer 函数】
- 由上述可见,我们传递给 lazy 的 Lambda ,会被编译成为一个静态内部类。
- 静态内部类:继承了 FunctionN,且是一个单例类。invoke() 方法的方法体就是我们在 lambda 中的操作,并且返回值为最后一句。
- 因此可以知道,在执行初始化函数的时候,实际上就是执行我们传递给 lazy{} 的 lambda 中的执行指令。
- 【关于线程安全】
- SynchronizedLazyImpl 接受一个锁对象 lock:Any?=null ,这个锁对象可以是任意类型的对象,当然也可以为空,那么默认使用的就是当前实例对象作为锁对象来进行加锁。
- 在执行初始化函数 initializer 为数据赋值的时候,正是通过加锁来保证线程安全。
lateinit var 对比 by lazy
- 关于线程安全
- by lazy {} 的初始化默认是线程安全的,默认是 SynchronizedLazyImpl:Lazy 实现。并且能保证初始化函数 initializer 只会被调用一次,在数据未初始化时进行调用 且 调用完毕后会置空。
- lateint 默认是不保证线程安全的。
- 关于内存泄漏
- 由上述可知,传递给 lazy 的 Lambda ,会被编译成为一个静态内部类。
- 在使用 by lazy{} 的时候,如果在 lambda 里面使用了类中的成员变量,那么这个引用会一直被持有,直到该初始化函数执行,即该变量被初始化了才会释放(因为初始化函数执行完毕之后会被置空,断开引用链)。
- 而这里就很可能会导致内存泄漏。
二、各种函数?
- Flag 立下来:
- T.let
- T.run
- T.also
- T.apply
- with
- run
- 扩展函数
- 高阶函数
- inline noinline crossinline
作者:冰美式上瘾患者
链接:https://juejin.cn/post/7085965272510627877
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Dart中的extends, with, implements, on关键字详解
Dart中类的类型
Dart是支持基于mixin继承机制的面向对象语言,所有对象都是一个类的实例,而除了 Null以外的所有的类都继承自Object类。 基于mixin的继承意味着尽管每个类(top class Object? 除外)都只有一个超类,一个类的代码可以在其它多个类继承中重复使用。
以上这段是官方文档的说明,在实际使用中,由于mixin的加入,使得Dart中类的使用和其它语言有所不同。Dart中类的类型有三种,分别是:
class:声明一个类,提供具体的成员变量和方法实现。abstract class:声明一个抽象类,抽象类将无法被实例化。抽象类常用于声明接口方法、有时也会有具体的方法实现。mixin:声明一个Mixin类,与抽象类一样无法被实例化,是一种在多重继承中复用某个类中代码的方法模式,可以声明接口方法或有具体的方法实现。
- 每一个类都隐式地定义了一个接口并实现了该接口,这个接口包含所有这个类的成员变量以及这个类所实现的其它接口。
- 如果想让抽象类同时可被实例化,可以为其定义
工厂构造函数。具体内容可以参考:抽象类的实例化
mixin关键字在Dart 2.1中才被引用支持。早期版本中的代码通常使用abstract class代替
从上述内容可以看出,mixin是后面才被引入的,与abstract class有些通用的地方,可以理解为abstract class的升级版。它相对于abstract class说,可以同时引入多个Mixin,并且可以通过on关键字来限制使用范围。
类相关关键字的使用
而对上述这些类型的使用,又有extends, with, implements, on这几个关键字:
extends:继承,和其它语言的继承没什么区别。with:使用Mixin模式混入一个或者多个Mixin类。implements:实现一个或多个接口并实现每个接口定义的API。on:限制Mixin的使用范围。
针对这几个关键字的使用,我做了一张表进行总结:
样例说明
针对上面的内容,我举几个例子,可以复制代码到DartPad中进行验证:
类混入类或者抽象类(class with class)
class Animal {
String name = "Animal";
}
abstract class Flyer {
String name = "Flyer";
void fly() => print('$name can fly!');
}
abstract class Eater extends Animal {
void eat() => print('I can Eat!');
}
// 同时混入class和abstract class
abstract class Bird with Animal, Flyer {}
class Bird1 with Animal, Flyer {}
// 只支持无任何继承和混入的类,Eater继承自Animal,所以它不支持被混入。
// 报错:The class 'Eater' can't be used as a mixin because it extends a class other than 'Object'.
// class Bird with Eater {
// }
main() {
Bird1().fly(); // Flyer can fly!
}
类继承抽象类并混入Mixin
class Animal {
String name = "Animal";
}
mixin Flyer {
String name = "Flyer";
void fly() => print('$name can fly!');
}
abstract class Eater extends Animal {
@override
String get name => "Eater";
void eat() => print('$name can Eat!');
}
// 类继承抽象类并混入Mixin
class Bird extends Eater with Flyer { }
main() {
// 因为with(混入)的优先级比extends(继承)更高,所以打印出来的是Flyer而不是Eater
Bird().fly(); // Flyer can fly!
Bird().eat(); // Flyer can Eat!
}
类继承抽象类并混入Mixin的同时实现接口
class Biology {
void breathe() => print('I can breathe');
}
class Animal {
String name = "Animal";
}
// 这里设置实现了Biology接口,但是mixin与abstract class一样并不要求实现接口,声明与实现均可。
// on关键字限制混入Flyer的类必须继承自Animal或它的子类
mixin Flyer on Animal implements Biology {
@override
String get name => "Flyer";
void fly() => print('$name can fly!');
}
abstract class Eater extends Animal {
@override
String get name => "Eater";
void eat() => print('$name can Eat!');
}
// 类继承抽象类并混入Mixin的同时实现接口
// 注意关键字的使用顺序,依次是extends -> with -> implements
class Bird extends Eater with Flyer implements Biology {
// 后面使用了`implements Biology`,所以子类必须要实现这个类的接口
@override
void breathe() => print('Bird can breathe!');
}
main() {
// 因为with(混入)的优先级比extends(继承)更高,所以打印出来的是Flyer而不是Eater
Bird().fly(); // Flyer can fly!
Bird().eat(); // Flyer can Eat!
Bird().breathe(); // Bird can breathe!
}
混入mixin的顺序问题
abstract class Biology {
void breathe() => print('I can breathe');
}
mixin Animal on Biology {
String name = "Animal";
@override
void breathe() {
print('$name can breathe!');
super.breathe();
}
}
mixin Flyer on Animal {
@override
String get name => "Flyer";
void fly() => print('$name can fly!');
}
/// mixin的顺序问题:
/// with后面的Flyer必须在Animal后面,否则会报错:
/// 'Flyer' can't be mixed onto 'Biology' because 'Biology' doesn't implement 'Animal'.
class Bird extends Biology with Animal, Flyer {
@override
void breathe() {
print('Bird can breathe!');
super.breathe();
}
}
main() {
Bird().breathe();
/*
* 上述代码执行,依次输出:
* Bird can breathe!
* Flyer can breathe!
* I can breathe
* */
}
这里的顺序问题和运行出来的结果会让人有点费解,但是可以这样理解:Mixin语法糖, 本质还是类继承. 继承可以复用代码, 但多继承会导致代码混乱。 Java为了解决多继承的问题, 用了interface, 只有函数声明而没有实现(后面加的default也算语法糖了)。以A with B, C, D为例,实际是A extends D extends C extends B, 所以上面的Animal必须在Flyer前面,否则就变成了Animal extends Flyer,会出现儿子给爹当爹的混乱问题。
mixin的底层本质只是猜测,并没有查看语言底层源码进行验证.
总结
从上述样例可以看出,三种类结构可以同时存在,关键字的使用有前后顺序:extends -> mixins -> implements。
另外需要注意的是相同方法的优先级问题,这个有两种情况:
- 同时被
extends,with,implements时,混入(with)的优先级比继承(extends)要高,而implements只提供接口,不会被调用。 with多个Mixin时,则会调用距离with关键字最远Mixin中的方法。
当然,如果当前使用类重写了该方法,就会优先调用当前类中的方法。
参考资料
- Dart官方文档
- Dart之Mixin详解
- Flutter 基础 | Dart 语法 mixin:对
mixin的使用场景进行了很好的说明
作者:星的天空
链接:https://juejin.cn/post/7094642592880525320
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter Modular使用教程
什么是Flutter Modular?
随着应用项目发展和变得越来越复杂,保持代码和项目结构可维护和可复用越来越难。Modular提供了一堆适配Flutter的解决方案来解决这些问题,比如依赖注入,路由系统和“一次性单例”系统(也就是说,当注入模块超出范围时,模块化自动配置注入模块)。
Modular的依赖注入为任何状态管理系统提供了开箱即用的支持,管理你应用的内存。
Modular也支持动态路由和相对路由,像在Web一样。
Modular结构
Modular结构由分离和独立的模块组成,这些模块将代表应用程序的特性。
每个模块都位于自己的目录中,并控制自己的依赖关系、路由、页面、小部件和业务逻辑。因此,您可以很容易地从项目中分离出一个模块,并在任何需要的地方使用它。
Modular支柱
这是Modular关注的几个方面:
- 自动内存管理
- 依赖注入
- 动态和相对路由
- 代码模块化
在项目中使用Modular
安装
打开你项目的pubspec.yaml并且添加flutter_modular作为依赖:
dependencies:
flutter_modular: any
在一个新项目中使用
为了在新项目中使用Modular,你必须做一些初始化步骤:
用
MaterialApp创建你的main widget并且调用MaterialApp().modular()方法。
// app_widget.dart
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
class AppWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
initialRoute: "/",
).modular();
}
}
创建继承自
Module的你项目的main module文件:
// app_module.dart
class AppModule extends Module {
// Provide a list of dependencies to inject into your project
@override
final Listbinds = [];
// Provide all the routes for your module
@override
final Listroutes = [];
}
在
main.dart文件中,将main module包裹在ModularApp中以使Modular初始化它:
// main.dart
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
import 'app/app_module.dart';
void main() => runApp(ModularApp(module: AppModule(), child: AppWidget()));
完成!你的应用已经设置完成并且准备好和Modular一起工作!
创建child modules
你可以在你的项目中创建任意多module:
class HomeModule extends Module {
@override
final List binds = [
Bind.singleton((i) => HomeBloc()),
];
@override
final List routes = [
ChildRoute('/', child: (_, args) => HomeWidget()),
ChildRoute('/list', child: (_, args) => ListWidget()),
];
}
你可以通过module参数将子模块传递给你main module中的一个Route。
class AppModule extends Module {
@override
final List routes = [
ModuleRoute('/home', module: HomeModule()),
];
}
我们建议你讲代码分散到不同模块中,例如一个AuthModule,并将与此模块相关的所有路由放入其中。通过这样做,维护和与其他项目分享你的代码将变得更加容易。
**注意:**使用ModuleRoute对象创建复杂的路由。
添加路由
模块路由是通过覆盖routes属性来提供的。
// app_module.dart
class AppModule extends Module {
// Provide a list of dependencies to inject into your project
@override
final List binds = [];
// Provide all the routes for your module
@override
final List routes = [
// Simple route using the ChildRoute
ChildRoute('/', child: (_, __) => HomePage()),
ChildRoute('/login', child: (_, __) => LoginPage()),
];
}
**注意:**使用
ChildRoute对象来创建简单路由。
动态路由
你可以使用动态路由系统来提供参数给你的Route:
// 使用 :参数名 语法来为你的路由提供参数。
// 路由参数可以通过' args '获得,也可以在' params '属性中访问,
// 使用方括号符号 (['参数名']).
@override
final List routes = [
ChildRoute(
'/product/:id',
child: (_, args) => Product(id: args.params['id']),
),
];
当调用给定路由时,参数将是模式匹配的。例如:
// In this case, `args.params['id']` will have the value `1`.
Modular.to.pushNamed('/product/1');
你也可以在多个界面中使用它。例如:
@override
final List routes = [
// We are sending an ID to the DetailPage
ChildRoute(
'/product/:id/detail',
child: (_, args) => DetailPage(id: args.params['id']),
),
// We are sending an ID to the RatingPage
ChildRoute(
'/product/:id/rating',
child: (_, args) => RatingPage(id: args.params['id']),
),
];
与第一个实例相同,我们只需要调用这个路由。例如:
// In this case, modular will open the page DetailPage with the id of the product equals 1
Modular.to.navigate('/product/1/detail');
// We can use the pushNamed too
// The same here, but with RatingPage
Modular.to.navigate('/product/1/rating');
然而,这种表示法只对简单的文字有效。
发送对象
如果你想传递一个复杂对象给你的路由,通过arguments参数传递给它::
Modular.to.navigate('/product', arguments: ProductModel());
并且,它将通过args.data属性提供而不是args.params:
@override
final List routes = [
ChildRoute(
'/product',
child: (_, args) => Product(model: args.data),
),
];
你可以直接通过binds来找回这些参数:
@override
final List binds = [
Bind.singleton((i) => MyController(data: i.args.data)),
];
路由泛型类型
你可以从导航返回一个值,就像.pop。为了实现这个,将你期望返回的参数作为类型参数传递给Route:
@override
final List routes = [
// This router expects to receive a `String` when popped.
ChildRoute('/event', child: (_, __) => EventPage()),
]
现在,使用.pop就像你使用Navigator.pop:
// Push route
String name = await Modular.to.pushNamed('/event');
// And pass the value when popping
Modular.to.pop('banana');
路由守卫
路由守卫是一种类似中间件的对象,允许你从其它路由控制给定路由的访问权限。你通过让一个类implements RouteGuard可以实现一个路由守卫.
例如,下面的类只允许来自/admin的路由的重定向:
class MyGuard implements RouteGuard {
@override
Future canActivate(String url, ModularRoute route) {
if (url != '/admin'){
// Return `true` to allow access
return Future.value(true);
} else {
// Return `false` to disallow access
return Future.value(false);
}
}
}
要在路由中使用你的RouteGuard,通过guards参数传递:
@override
final List routes = [
final ModuleRoute('/', module: HomeModule()),
final ModuleRoute(
'/admin',
module: AdminModule(),
guards: [MyGuard()],
),
];
如果你设置到module route上,RouteGuard将全局生效。
如果RouteGuard验证失败,添加guardedRoute属性来添加路由选择路由:
@override
final List routes = [
ChildRoute(
'/home',
child: (context, args) => HomePage(),
guards: [AuthGuard()],
guardedRoute: '/login',
),
ChildRoute(
'/login',
child: (context, args) => LoginPage(),
),
];
什么时候和如何使用navigate或pushNamed
你可以在你的应用中使用任何一个,但是需要理解每一个。
pushNamed
无论何时使用,这个方法都将想要的路由放在当前路由的上面,并且您可以使用AppBar上的后退按钮返回到上一个页面。 它就像一个模态,它更适合移动应用程序。
假设你需要深入你的路线,例如:
// Initial route
Modular.to.pushNamed('/home');
// User route
Modular.to.pushNamed('/home/user');
// User profile route
Modular.to.pushNamed('/home/user/profile');
最后,您可以看到返回到前一页的back按钮,这加强了模态页面在前一页上面的想法。
navigate
它删除堆栈中先前的所有路由,并将新路由放到堆栈中。因此,在本例中,您不会在AppBar中看到后退按钮。这更适合于Web应用程序。
假设您需要为移动应用程序创建一个注销功能。这样,您需要从堆栈中清除所有路由。
// Initial route
Modular.to.pushNamed('/home');
// User route
Modular.to.pushNamed('/home/user');
// User profile route
Modular.to.pushNamed('/home/user/profile');
// Then you need to go again to the Login page, only use the navigation to clean all the stack.
Modular.to.navigate('/login');
Relative Navigation
要在页面之间导航,请使用Modular.to.navigate。
Modular.to.navigate('/login');
你可以使用相对导航来导航,就像在web程序一样:
// Modules Home → Product
Modular.to.navigate('/home/product/list');
Modular.to.navigate('/home/product/detail/3');
// Relative Navigation inside /home/product/list
Modular.to.navigate('detail/3'); // it's the same as /home/product/detail/3
Modular.to.navigate('../config'); // it's the same as /home/config
您仍然可以使用旧的Navigator API来堆叠页面。
Navigator.pushNamed(context, '/login');
或者,您可以使用Modular.to.pushhnamed,你不需要提供BuildContext:
Modular.to.pushNamed('/login');
Flutter Web URL routes (Deeplink-like)
路由系统可以识别URL中的内容,并导航到应用程序的特定部分。动态路由也适用于此。例如,下面的URL将打开带有参数的Product视图。args.params['id']设置为1。
https://flutter-website.com/#/product/1
它也可以处理查询参数或片段:
https://flutter-website.com/#/product?id=1
路由过渡动画
通过设置Route的转换参数,提供一个TransitionType,您可以选择在页面转换中使用的动画类型。
ModuleRoute('/product',
module: AdminModule(),
transition: TransitionType.fadeIn,
), //use for change transition
如果你在一个Module中指定了一个过渡动画,那么该Module中的所有路由都将继承这个过渡动画。
自定义过渡动画路由
你也可以通过将路由器的transition和customTransition参数分别设置为TransitionType.custom和你的CustomTransition来使用自定义的过渡动画:
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
CustomTransition get myCustomTransition => CustomTransition(
transitionDuration: Duration(milliseconds: 500),
transitionBuilder: (context, animation, secondaryAnimation, child){
return RotationTransition(turns: animation,
child: SlideTransition(
position: Tween(
begin: const Offset(-1.0, 0.0),
end: Offset.zero,
).animate(animation),
child: ScaleTransition(
scale: Tween(
begin: 0.0,
end: 1.0,
).animate(CurvedAnimation(
parent: animation,
curve: Interval(
0.00,
0.50,
curve: Curves.linear,
),
),
),
child: child,
),
),
)
;
},
);
依赖注入
可以通过重写Module的binds的getter将任何类注入到Module中。典型的注入例子有BLoCs、ChangeNotifier实例或(MobX)。
一个Bind对象负责配置对象注入。我们有4个Bind工厂类型和一个AsyncBind。
class AppModule extends Module {
// Provide a list of dependencies to inject into your project
@override
List get binds => [
Bind((i) => AppBloc()),
Bind.factory((i) => AppBloc()),
Bind.instance(myObject),
Bind.singleton((i) => AppBloc()),
Bind.lazySingleton((i) => AppBloc()),
AsyncBind((i) => SharedPreferences.getInstance())
];
...
}
Factory
每当调用类时实例化它。
@override
List get binds => [
Bind.factory((i) => AppBloc()),
];
Instance
使用已经实例化的对象。
@override
List get binds => [
Bind.instance((i) => AppBloc()),
];
Singleton
创建一个类的全局实例。
@override
List get binds => [
Bind.singleton((i) => AppBloc()),
];
LazySingleton
只在第一次调用类时创建一个全局实例。
@override
List get binds => [
Bind.lazySingleton((i) => AppBloc()),
];
AsyncBind
若干类的一些方法返回一个Future。要注入那些特定方法返回的实例,你应该使用AsyncBind而不是普通的同步绑定。使用Modular.isModuleReady等待所有AsyncBinds解析,以便放开Module供使用。
重要:如果有其他异步绑定的相互依赖,那么
AsyncBind的顺序很重要。例如,如果有两个AsyncBind,其中A依赖于B,AsyncBindB必须在A之前声明。注意这种类型的顺序!
import 'package:flutter_modular/flutter_modular.dart' show Disposable;
// In Modular, `Disposable` classes are automatically disposed when out of the module scope.
class AppBloc extends Disposable {
final controller = StreamController();
@override
void dispose() {
controller.close();
}
}
isModuleReady
如果你想确保所有的AsyncBinds都在Module加载到内存之前被解析,isModuleReady是一个方法。使用它的一种方法是使用RouteGuard,将一个AsyncBind添加到你的AppModule中,并将一个RouteGuard添加到你的ModuleRoute中。
class AppModule extends Module {
@override
List get binds => [
AsyncBind((i)=> SharedPreferences.getInstance()),
];
@override
List get routes => [
ModuleRoute(Modular.initialRoute, module: HomeModule(), guards: [HomeGuard()]),
];
}
然后,像下面这样创建一个RouteGuard。这样,在进入HomeModule之前,模块化会评估你所有的异步依赖项。
import 'package:flutter_modular/flutter_modular.dart';
class HomeGuard extends RouteGuard {
@override
Future canActivate(String path, ModularRoute router) async {
await Modular.isModuleReady();
return true;
}
}
在视图中检索注入的依赖项
让我们假设下面的BLoC已经定义并注入到我们的模块中(就像前面的例子一样):
import 'package:flutter_modular/flutter_modular.dart' show Disposable;
// In Modular, `Disposable` classes are automatically disposed when out of the module scope.
class AppBloc extends Disposable {
final controller = StreamController();
@override
void dispose() {
controller.close();
}
}
注意:Modular自动调用这些
Binds类型的销毁方法:Sink/Stream, ChangeNotifier和[Store/Triple]
有几种方法可以检索注入的AppBloc。
class HomePage extends StatelessWidget {
@override
Widget build(BuildContext context) {
// You can use the object Inject to retrieve..
final appBloc = Modular.get();
//or for no-ready AsyncBinds
final share = Modular.getAsync();
}
}
使用Modular小部件检索实例
ModularState
在本例中,我们将使用下面的MyWidget作为页面,因为这个页面需要是StatefulWidget。
让我们来了解一下ModularState的用法。当我们定义类_MyWidgetState扩展ModularState时,我们正在为这个小部件(在本例中是HomeStore)将Modular与我们的Store链接起来。当我们进入这个页面时,HomeStore将被创建,store/controller变量将被提供给我们,以便在MyWidget中使用。
在此之后,我们可以使用存储/控制器而没有任何问题。在我们关闭页面后,模块化将自动处理HomeStore。
class MyWidget extends StatefulWidget {
@override
_MyWidgetState createState() => _MyWidgetState();
}
class _MyWidgetState extends ModularState {
store.myVariableInsideStore = 'Hello!';
controller.myVariableInsideStore = 'Hello!';
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text("Modular"),
),
body: Center(child: Text("${store.counter}"),),
);
}
}
WidgetModule
WidgetModule具有与Module相同的结构。如果你想要一个带有Modular页面的TabBar,这是非常有用的。
class TabModule extends WidgetModule {
@override
List binds => [
Bind((i) => TabBloc(repository: i())),
Bind((i) => TabRepository()),
];
final Widget view = TabPage();
}
Mock导航系统
我们认为,在使用Modular.to和Modular.link时,提供一种native方式来mock导航系统会很有趣。要做到这一点,您只需实现IModularNavigator并将您的实现传递给Modular.navigatorDelegate。
使用 Mockito示例:
main() {
var navigatorMock = MyNavigatorMock();
// Modular.to and Modular.link will be called MyNavigatorMock implements!
Modular.navigatorDelegate = navigatorMock;
test('test navigator mock', () async {
when(navigatorMock.pushNamed('/test')).thenAnswer((_) async => {});
Modular.to.pushNamed('/test');
verify(navigatorMock.pushNamed('/test')).called(1);
});
}
class MyNavigatorMock extends Mock implements IModularNavigator {
@override
Future pushNamed(String? routeName, {Object? arguments, bool? forRoot = false}) =>
(super.noSuchMethod(Invocation.method(#pushNamed, [routeName], {#arguments: arguments, #forRoot: forRoot}), returnValue: Future.value(null)) as Future);
}
本例使用手动实现,但您也可以使用 代码生成器来创建模拟。
RouterOutlet
每个ModularRoute都可以有一个ModularRoute列表,这样它就可以显示在父ModularRoute中。反映这些内部路由的小部件叫做RouterOutlet。每个页面只能有一个RouterOutlet,而且它只能浏览该页面的子页面。
class StartModule extends Module {
@override
List get binds => [];
@override
List get routes => [
ChildRoute(
'/start',
child: (context, args) => StartPage(),
children: [
ChildRoute('/home', child: (_, __) => HomePage()),
ChildRoute('/product', child: (_, __) => ProductPage()),
ChildRoute('/config', child: (_, __) => ConfigPage()),
],
),
];
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: RouterOutlet(),
bottomNavigationBar: BottomNavigationBar(
onTap: (id) {
if (id == 0) {
Modular.to.navigate('/start/home');
} else if (id == 1) {
Modular.to.navigate('/start/product');
} else if (id == 2) {
Modular.to.navigate('/start/config');
}
},
currentIndex: currentIndex,
items: const [
BottomNavigationBarItem(
icon: Icon(Icons.home),
label: 'Home',
),
BottomNavigationBarItem(
icon: Icon(Icons.control_camera),
label: 'product',
),
BottomNavigationBarItem(
icon: Icon(Icons.settings),
label: 'Config',
),
],
),
);
}作者:牛奶燕麦
链接:https://juejin.cn/post/6998910339882418189
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
jetpack compose实战——基本框架搭建
前言
- 项目地址:github.com/Peakmain/Co…
- 网上现在有不少jetpack compose的文章和教程,但是实战项目不多。
- 项目接口基于玩Android,这里也非常感谢大佬提供的免费接口
建议
先学习kotlin语言,最好有Android App开发经验
项目结构
新建项目New Project->选择 Empty Compose Activity
项目结构
新建项目New Project->选择 Empty Compose Activity
填写必要信息,完成项目创建
Compose和Android View的区别
| Android View | compose |
|---|---|
| Button | Button |
| TextView | Text |
| EditText | TextField |
| ImageView | Image |
| LinearLayout(horizontally) | Row |
| LinearLayout(vertically) | Column |
| FrameLayout | Box |
| RecyclerView | LazyColumn |
| RecyclerView(horizontally) | LazyRow |
| Snackbar | Snackbar |
一些基础知识
Scaffold
@Composable
fun Scaffold(
modifier: Modifier = Modifier,
scaffoldState: ScaffoldState = rememberScaffoldState(),
topBar: @Composable () -> Unit = {},
bottomBar: @Composable () -> Unit = {},
snackbarHost: @Composable (SnackbarHostState) -> Unit = { SnackbarHost(it) },
floatingActionButton: @Composable () -> Unit = {},
floatingActionButtonPosition: FabPosition = FabPosition.End,
isFloatingActionButtonDocked: Boolean = false,
drawerContent: @Composable (ColumnScope.() -> Unit)? = null,
drawerGesturesEnabled: Boolean = true,
drawerShape: Shape = MaterialTheme.shapes.large,
drawerElevation: Dp = DrawerDefaults.Elevation,
drawerBackgroundColor: Color = MaterialTheme.colors.surface,
drawerContentColor: Color = contentColorFor(drawerBackgroundColor),
drawerScrimColor: Color = DrawerDefaults.scrimColor,
backgroundColor: Color = MaterialTheme.colors.background,
contentColor: Color = contentColorFor(backgroundColor),
content: @Composable (PaddingValues) -> Unit
)
Scaffold主要用于快速搭建一个项目的结构,包含:
- topBar:通常是TopAppBar
- bottomBar 通常是一个 BottomNavigation,里面每个item是BottomNavigationItem
- floatingActionButton 悬浮按钮
- floatingActionButtonPosition 悬浮按钮位置
- isFloatingActionButtonDocked 悬浮按钮是否贴到 bottomBar 上
- drawerContent 侧滑菜单
- content:内容区域
状态
状态和组合
由于 Compose 是声明式工具集,因此更新它的唯一方法是通过新参数调用同一可组合项。这些参数是界面状态的表现形式。每当状态更新时,都会发生重组。因此,TextField 不会像在基于 XML 的命令式视图中那样自动更新。可组合项必须明确获知新状态,才能相应地进行更新
@Composable
fun HelloContent() {
Column(modifier = Modifier.padding(16.dp)) {
Text(
text = "Hello!",
modifier = Modifier.padding(bottom = 8.dp),
style = MaterialTheme.typography.h5
)
OutlinedTextField(
value = "",
onValueChange = { },
label = { Text("Name") }
)
}
}
- OutlinedTextField与 TextField 只是样式不同
- 如果运行此代码,您将不会看到任何反应。这是因为,TextField 不会自行更新,但会在其 value 参数更改时更新。
Compose中的状态
- Composable中可以使用remember来记住单个对象。
- 系统会在初始化由 remember计算的值存储在Composable中,并在重组的时候返回存储的值
- remember既可以存储可变对象,也可以存储不可变对象。
注意:remember 会将对象存储在组合中,当调用 remember 的可组合项从组合中移除后,它会忘记该对象。
mutableStateOf 会创建可观察的 MutableState,后者是与 Compose 运行时集成的可观察类型。
interface MutableState<T> : State<T> {
override var value: T
}
value 如有任何更改,系统会安排重组读取 value 的所有可组合函数。
在可组合项中声明 MutableState 对象的方法有三种:
- val mutableState = remember { mutableStateOf(default) }
- var value by remember { mutableStateOf(default) }
- val (value, setValue) = remember { mutableStateOf(default) }
这些声明是等效的,以语法糖的形式针对状态的不同用法提供。您选择的声明应该能够在您编写的可组合项中生成可读性最高的代码。
所以上面代码的解决办法
@Composable
fun HelloContent() {
Column(modifier = Modifier.padding(16.dp)) {
var name by remember { mutableStateOf("") }//👈🏻定义状态
if (name.isNotEmpty()) {
Text(
text = "Hello, $name!",
modifier = Modifier.padding(bottom = 8.dp),
style = MaterialTheme.typography.h5
)
}
OutlinedTextField(
value = name,//👈🏻要显示的当前值
onValueChange = { name = it },//👈🏻请求更改值的事件,其中 T 是建议的新值
label = { Text("Name") }
)
}
}
小技巧:Compose的代码模板
在搭建基本框架之前,我们先来定义一个模板,方便大家开发(我的是Mac电脑)
- 1、Android Studio-> Preferences->Editor->File and Code Templates
- 2、点击➕号
- 3、使用,右击选择New->kotlin compose
基本框架搭建
效果图
- 1、新建项目,修改MainActivity
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
ComposeProjectTheme {
// A surface container using the 'background' color from the theme
Surface(color = MaterialTheme.colors.background) {
MainFrame()
}
}
}
}
}
- 2、MainFrame
@Composable
fun MainFrame() {
val navigationItems = listOf(
NavigationItem("首页", Icons.Default.Home),
NavigationItem("项目", Icons.Default.Article),
NavigationItem("分类", Icons.Default.Category),
NavigationItem("我的", Icons.Default.Person)
)
var currentNavigationIndex by remember {
mutableStateOf(0)
}
Scaffold(
bottomBar = {
BottomNavigation(backgroundColor = MaterialTheme.colors.surface) {
navigationItems.forEachIndexed { index, navigationItem ->
BottomNavigationItem(
selected = currentNavigationIndex == index,
onClick = { currentNavigationIndex = index },
icon = {
Icon(imageVector = navigationItem.icon, contentDescription = null)
},
label = {
Text(text = navigationItem.title)
},
selectedContentColor = Color_149EE7,
unselectedContentColor = Color_999999
)
}
}
},
) {
when (currentNavigationIndex) {
0 -> HomeFragment()
1 -> ProjectFragment()
2 -> TypeFragment()
else -> MineFragment()
}
}
}
代码其实很简单,主要通过Scaffold来搭建一个项目结构,用remember+ mutableStateOf来记住状态。内容区域通过选中的index来展示不同的Fragment
- 3、这里运用到Google的一个图标库
- 图标地址:fonts.google.com/icons
- 集成依赖
implementation "androidx.compose.material:material-icons-extended:$compose_version"
总结
到这里呢,基本框架已经搭完了,其实还是比较简单的。有不动的呢,可以多看看Google官方文档:developer.android.google.cn/jetpack/com…
作者:peakmain
链接:https://juejin.cn/post/7093341380549804045
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
重复setContentView后fitsSystemWindows失效
项目中有个沉浸式的activity,在调用setContentView切换布局的时候fitsSystemWindows失效了,效果如图:
Activity代码:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
immerse()
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
private fun immerse() {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
val decorView = window.decorView
decorView.systemUiVisibility =
View.SYSTEM_UI_FLAG_LAYOUT_STABLE or View.SYSTEM_UI_FLAG_LAYOUT_FULLSCREEN or View.SYSTEM_UI_FLAG_LIGHT_STATUS_BAR
window.addFlags(WindowManager.LayoutParams.FLAG_DRAWS_SYSTEM_BAR_BACKGROUNDS)
window.clearFlags(WindowManager.LayoutParams.FLAG_TRANSLUCENT_STATUS)
window.statusBarColor = Color.TRANSPARENT
}
}
fun reload(view: View) {
setContentView(R.layout.activity_main)
}
}
布局代码:
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
android:fitsSystemWindows="true"
android:gravity="center_horizontal"
android:orientation="vertical"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<ImageView
android:scaleType="centerCrop"
android:id="@+id/imageView"
android:layout_width="match_parent"
android:layout_height="400dp"
android:src="@drawable/avatar"
app:layout_constraintTop_toTopOf="parent" />
<Button
android:layout_marginTop="20dp"
android:onClick="reload"
android:gravity="center"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="reload"
android:textAllCaps="false"/>
</LinearLayout>
首先看下fitsSystemWindows起到的作用
<!-- Boolean internal attribute to adjust view layout based on
system windows such as the status bar.
If true, adjusts the padding of this view to leave space for the system windows.
Will only take effect if this view is in a non-embedded activity. -->
<attr name="fitsSystemWindows" format="boolean" />
这个属性用于根据系统窗口(如状态栏)来调整视图的布局。如果为true,则调整此视图的padding来为系统窗口留出空间,也就是说视图布局的内容不会扩展到任务栏中
正常情况下,什么时候会触发fitsSystemWindows的padding调整?
ViewRootImpl首次绘制的时候会调用dispatchApplyInsets方法,将WindowInset(窗口内容的插入,包括状态栏,导航栏,键盘等,可以理解为这些它们所占窗口的大小)分发给decorView,最终会分发到到上述布局中的根布局LinearLayout的fitSystemWindowsInt方法完成padding的设置,LinearLayout没有重写此方法,最终调用的还是View的fitSystemWindowsInt
ViewRootImpl
private void performTraversals() {
......
//首次绘制判断,host为decorView
if (mFirst) {
......
dispatchApplyInsets(host);
}
......
//其他条件触发,这个标记位在下文会用到
if (...... || mApplyInsetsRequested){
dispatchApplyInsets(host)
}
......
}
public void dispatchApplyInsets(View host) {
......
WindowInsets insets = getWindowInsets(true);
host.dispatchApplyWindowInsets(insets);
......
}
View
private boolean fitSystemWindowsInt(Rect insets) {
//判断fitSystemWindows是否为true
if ((mViewFlags & FITS_SYSTEM_WINDOWS) == FITS_SYSTEM_WINDOWS) {
Rect localInsets = sThreadLocal.get();
boolean res = computeFitSystemWindows(insets, localInsets);
applyInsets(localInsets);
return res;
}
return false;
}
private void applyInsets(Rect insets) {
mUserPaddingStart = UNDEFINED_PADDING;
mUserPaddingEnd = UNDEFINED_PADDING;
mUserPaddingLeftInitial = insets.left;
mUserPaddingRightInitial = insets.right;
internalSetPadding(insets.left, insets.top, insets.right, insets.bottom);
}
protected void internalSetPadding(int left, int top, int right, int bottom) {
......
//设置padding
......
//如果padding改变了,重新布局
if (changed) {
requestLayout();
invalidateOutline();
}
}
为什么重新setContentView之后没有为新的视图设置padding?
当我们调用setContentView重新设置布局时,activity对应的window已经被添加到WindowManager中了,ViewRootImpl不会重新创建,但是布局是重新加载并实例化视图了。此时ViewRootImpl的首次绘制判断不成立,不会将WindowInset分发给新加载的布局,因此新的视图没有设置顶部的padding,绘制的时候也就跑到了状态栏中去了
ActivityThread
public void handleResumeActivity(ActivityClientRecord r, boolean finalStateRequest,
boolean isForward, String reason) {
......
if (r.window == null && !a.mFinished && willBeVisible) {
......
if (!a.mWindowAdded) {
a.mWindowAdded = true;
//ViewRootImpl创建的起点
wm.addView(decor, l);
}
......
}
......
}
应该怎样让ViewRootImpl重新分发WindowInset?
从上文中ViewRootImpl调用dispatchApplyInsets的地方可以看到,mApplyInsetsRequested也能影响是否调用该方法,可以从这个标志位入手。分析代码发现,调用View的requestFitSystemWindows或requestApplyInsets方法可以向上调用到ViewRootImpl的同名方法中,在这个方法中会将mApplyInsetsRequested设为true,并调用scheduleTraversals触发界面绘制。
View
@Deprecated
public void requestFitSystemWindows() {
//最终会调用到ViewRootImpl中去
if (mParent != null) {
mParent.requestFitSystemWindows();
}
}
public void requestApplyInsets() {
requestFitSystemWindows();
}
ViewRootImpl
public void requestFitSystemWindows() {
checkThread();
mApplyInsetsRequested = true;
scheduleTraversals();
}
demo中的reload方法修改为如下可以解决此问题
fun reload(view: View) {
val root = layoutInflater.inflate(R.layout.activity_main, null)
setContentView(root)
//使用此方法做版本兼容,最终还是会调用到 View.requestFitSystemWindows()
ViewCompat.requestApplyInsets(root)
}作者:今天想吃什么
链接:https://juejin.cn/post/7091260989504815112
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter启动页白屏处理
前言
在上篇实现了一个Nike的加载页,但有一些遗留问题,其中之一就是启动时的白屏处理。如下:
启动页
几乎所有App都会设计一个启动页,Flutter项目如果不做处理的话,在点开时都会有这个白色的闪屏。其实这个启动页在项目文件就可以进行更改。
安卓
1.打开AndroidManifes.xml文件,可以看到启动屏数据源指向了drawable中的launch_background。
2.打开drawable/launch_background文件,就会发现现在的启动页背景是白色。
3.若要设置图片样式的启动页,则需要将下面注释的内容放开。
4. 默认情况下是没有launch_image的,将启动页图片的名字设置为launch_image,然后放到drawable文件下,启动页就设置好啦。
iOS
打开下面文件,将LaunchImag.png、LaunchImag@2x.png、LaunchImag@3x.png替换为我们自己的图片即可。
虚假の示例
这里以之前完成的启动图为例来试一下效果。
1.首先随便掏出个画图软件做一张启动页图片:
2.然后将上面所说项目中的图片替换为我们自己的图片看下效果:
。。。
这是什么鬼,难道图片尺寸必须跟屏幕保持一致才可以吗... 非也,其实用这种方式设置启动图并非上策,因为不同尺寸的屏幕间很难做适配,特别是示例中需要启动页中的logo与启动页消失后的logo大小保持一致的情况,所以需要尝试其他方法:
真正の示例
1.以iOS为例,使用Xcode打开项目,在Asset中我们看到了刚才拖入的图片。
2.点击LaunchScreen,这是iOSApp启动时展示的屏幕窗口,可以看到我们拖入的图片展示在一个imageView中。
3.那如果把LaunchImage的约束重新设置一下呢
4.再来看一下效果,这次似乎像那么回事儿了,但还是能发现logo大小不一样的情况(虽然这是我随手做的一张启动页图片,但既然我们的需求是根据代码,让启动页在所有屏幕上的显示效果都一样的话就不该止步于此)。
5.终极解决方案:设置背景底色,为盛放logo的imageView设置约束(在上一篇文章中,我们设置logo的初始大小为屏幕宽度的1/3,位置为屏幕的中心),那么我们为imageView设置同样的约束,然后就有了⬇️
6.最后看一下效果:
完美 🎉🎉🎉
结语
最后说一些题外话吧,其实看过苹果的App设计规范就会了解到,其实启动页被设计的初衷就是起一个过渡的作用,让用户在使用感受上不回觉得太过突兀,比如iOS系统自带的天气app,启动页只是一张简单的渐变图片,是不建议添加产品Logo或者其他一些花里胡哨的广告的,否则审核有可能会因此被拒,大家随手打开几个App感受下就不难发现,会这样做的产品少之又少,在不知不觉中就被消费了体验,也许是已经习惯了。不过毕竟咱也不是产品,在下随口说说,诸君随意听听就好 ~
作者:晚夜
链接:https://juejin.cn/post/7092371526111985694
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Today,我们不聊技术,聊聊前端发展
今天是2022年04月26日,一年已经过去三分之一。
掘金里面有很多的技术文章,每一位前端工程师都在这里展现自己的技术水平。有很多时候,我看见很多的技术文章,里面大致上的内容其实都是差不多的,总的来说,其实普通的前端工程师是用不到去学习这么多的技术点的。就比如Node.js 。 一般的公司也不会用JavaScript语言来写后端,所以大部分的前端甚至都不需要去了解它,反而更应该了解多一点Ajax与网络请求协议。数据的问题交给后端去处理就好了,前端有自己要做的活。
我个人认为,技术框架的源码这种东西,如果能不学习,就不要去深入的学习了。很多人其实是没有达到进大厂的门槛的,大部分的前端其实都达不到,而一些中小型的公司,一般也不会去问一个技术架构的源码及核心问题(绝大部分),因为中小型公司需要的是能干活的人,而大部分的项目业务,其实还没有说你不懂源码就做不了的程度。总的来说就是只要你能干活,你懂什么是你自己的事儿,我就给这么多钱,这些项目你能干就来,你做不了我就辞退你。
其实大部分的前端,只要有请求到后端的接口,然后能把后端接口的数据处理好,并渲染到页面上就可以了。然后一些不懂的问题,一些复杂的功能模块,其实你一百度,基本上都能解决问题,如果你百度都不能解决的问题,那不是百度解决不了,而是你的项目本身就是有问题的。这里面说的是绝大部分的情况,当然也有一些奇怪的例子,这种只是占少部分。
其实我们前端的活总体来说都不难,就好比开车,其实绝大部分人都会开车,但是要想要把车技提升上去,那就需要去学习了,如果说你只是为了通勤,那么很多时候,你都不需要去提升你的车技。你只需要懂得怎么启动,怎么刹车等一些基本的操作就行了(实在不行就百度)。
前端往后的生态
其实前端往后也不会有什么太大的变化,基本上就定型了。像网上说的什么新技术啊,新方向什么的,其实很多都会不了了之,因为在没有发生技术变革的年代,我们想要去改变一些东西是很难的。我们很多人其实都是需要去等待,等待那个奇点的到来。没有很大的改变,其实都只能这样子。就好比我知道的,在网络请求中,其实有很大部分资源都浪费在了一些协议上,而这些协议的束缚,导致了我们的网络传输会消耗掉三分之一的性能,这种问题是历史遗留问题,虽然现在已经有很多方法能够解决掉这个性能消耗问题,但是解决这个问题需要互联网的企业把旧机器换成新机器,而新机器的成本又高于网络传输消耗的成本,所以我们普通人只能这样去无端的消耗掉这些资源,又或者等待那个奇点的到来。
说到设备又不得不提现如今的大部分互联网用户,在现在的互联网,其实绝大部分用户的设备性能已经是非常高了,而我们缺还有的人说在项目做一些性能优化问题,其实有时候,这种优化是无意义的,还不如不去做这种优化。当然这种场景也是区分项目的体验人的年龄段,如果项目主要服务于年轻人,其实年轻人的设备性能说不定比我们自己的设备都好,你的优化起不到太大的作用。如果项目主要服务于老年人,其实这个时候需要思考的不是设备性能优化的问题,反而更需要注重项目体验上的问题,就是怎么简单怎么来,别让老人觉得用你的东西太麻烦。
我所期待的前端世界
随着电子产品的更新换代,设备的性能越来越好,用户的CUP跑得越来越快,我们可以在我们的前端项目中放更多的新颖东西,比如把项目变革为3D场景,让用户在体验产品时,如同进入一个真实的虚拟世界(希望这一天不会超过50年)web3D值得期待。还有就是网页端游戏,现在绝大部分游戏都是部署在用户的设备中,而每个人的设备存放1个G,那一百个人, 就会有100个G的文件是存在重复,如果一款游戏,能把他部署在服务器上面,而用户只需要进入到网页中就可以体验,那真的是非常令人期待。
END
其实这些都是我瞎写的,没有什么值得看的地方,各位看官就当做是一个笑话,如果觉得有意思,麻烦点个赞。谢谢
作者:无我上青云
链接:https://juejin.cn/post/7090725867441258503
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为了看Flutter到底有没有人用我竟然
Flutter这个东西出来这么久了,到底市场占有率怎么样呢?为了让大家了解这一真实数据,也为了让大家了解当前Flutter在各大App中的使用情况,我今天下载了几百个App,占了手机将近80G空间,就为了得出一个结论——Flutter,到底有没有人用。
首先,我在vivo应用市场中,下载了4月11日软件排行榜中的所有App,总计230个,再加上平时用的比较多的一些App,总共270个App,作为我们的统计基数。
检测方法,我使用LibChecker来查看App是否有使用Flutter相关的so。
除了使用LibChecker之外,还有其它方案也可以,例如使用shell指令——zipinfo。
Apk本质上也是一种压缩包,所以,通过zipinfo指令并进行grep,就可以很方便的获取了,同时,如果配合一下爬虫来爬取应X宝的Apk下载地址,就可以成为一个全自动化的脚本分析工具,这里没这么强的需求,所以就不详细做了。
App列表
我们来看下,我都下载了多少App。
这些App基本上已经覆盖了应用商店各个排行榜里的Top软件,所以应该还是比较具有代表性和说服力的。
下面我们就用LibChecker来看下,这些App里面到底有多少使用了Flutter。
统计结果
已经使用Flutter的App共52个,占全体样本的19.2%,作为参考,统计了下RN相关的App,共有45个,占全体样本的16.6%,可以说,Flutter已经超过RN成为跨平台方案的首选。
在52个使用Flutter的App中:
腾讯系:QQ邮箱、微信、QQ同步助手、蓝盾、腾讯课堂、QQ浏览器、微视、企业微信、腾讯会议
百度系:百度网盘、百度输入法
阿里系:优酷视频、哈啰出行、淘特、酷狗直播、阿里1688、学习强国、钉钉、淘宝、闲鱼
其它大厂:链家、转转、智联招聘、拍拍贷、哔哩哔哩漫画、网易有道词典、爱奇艺、考拉海购、携程旅行、微博、Soul、艺龙旅行、唯品会、飞猪旅行
从上面的数据来看,各大厂都对Flutter有使用,头条系未列出的原因是,目前好像只有头条系大规模使用了Flutter的动态化加载方案,所以原始包内找不到Flutter相关的so,所以未检出(猜测是这样,具体可以请头条系的朋友指出,根据上次头条的分享,内部有90+App在使用Flutter)。
不过这里要注意的 ,这里并不是选取的大家常用的一些APP来做测试的,而是直接选取的排行榜,如果直接用常用APP来测试,那比例可能更高,大概统计了下,估计在60%左右。
不过大厂里面,京东没有使用Flutter我还是比较意外的,看了下京东的几个App,目前还是以RN为主作为跨平台的方案。这跟其它很多大厂一样,它们不仅使用了Flutter,RN也还可以检出,这也从侧面说明了,各个厂商,对跨平台的方案探索,从未停止。
所以,总结一下,目前使用Flutter的团队的几个特定:
创业公司:快速试错、快速开发,像Blued、夸克这也的
大厂:大厂的话题永远是效率,如何利用跨平台技术来提高开发效率,是它们引入Flutter的根本原因
创新型业务:例如B漫、淘特、Soul这类没有太多历史包袱的新业务App,可以利用Flutter进行极为高效的开发
所以,整体在知乎上吵「Flutter被抛弃了」、「Flutter要崛起了」,有什么意义呢?所有的争论都抵不过数据来的真实。
嘴上说着不要,身体倒是很诚实。
希望这份数据能给你一些帮助。
作者:xuyisheng
来源:juejin.cn/post/7088864824284676110
前端单点登录实现
通过token校验登录信息
前端单点存储方式
共享本地存储数据token值,token存储方式用的是localStorage 或 sessionStorage,由于这两种都会受到同源策略限制。
跨域存储
想要实现跨域存储,先找到一种可跨域通信的机制,就是 iframe postMessage,它可以安全的实现跨域通信,不受同源策略限制(后端要修改配置允许iframe打开其他域的地址)。
cross-storage.js(开源库)
原理是用 postMessage 可跨域特性,来实现跨域存储。因为多个不同域下的页面无法共享本地存储数据,我们需要找个“中转页面”来统一处理其它页面的存储数据
前端后端通讯
多平台入口页=》某平台中转页=》平台首页
平台中转页
主要将其他平台的token 转成当前平台的信任token值
/** 单点登录获取票据 */
export async function getTicket(token) {
return request('/getTicket', {
method: 'GET',
headers: { 'Content-Type': 'application/x-www-form-urlencoded', 'x-access-token': token },
});
}
/**免登录 */
export async function singleLogin(data) {
return request('/singleLogin', {
method: 'POST',
headers: { 'Content-Type': 'application/x-www-form-urlencoded', 'x-access-token': token },
data
});
}
export default (props: any) => {
const _singleLogin = async () => {
try {
//根据本地token 获取票据 getTicket 通过localStorage.getItem("token")
const { code, data } = await getTicket(token);
//免登录成功后跳转页面
const link = '/home';
if (code !== 200 || !data) {
window.location.href = link;
return;
}
//免登接口 获取登录token值
const res: any = await singleLogin({
ticket: data,
source: '',//平台来源
});
if (res?.code === 200) {
localStorage.setItem('tokneKey', res?.data.tokneKey);
localStorage.setItem('tokenValue', res?.data.tokenValue);
} else {
console.log(res?.msg);
localStorage.removeItem('tokneKey');
localStorage.removeItem('tokenValue');
}
window.location.href = link;
} catch (e) {
window.location.href = link;
}
};
useEffect(() => {
_singleLogin();
});
return (
<div style={{ width: '100%', height: '100%', justifyContent: 'center', alignItems: 'center', display: 'flex' }}>
<Spin spinning={loading}></Spin>
</div>
);
};
作者:NeverSettle_
来源:https://juejin.cn/post/7021407926837313544
关于防抖函数的思考
防抖概念
本质:是优化高频率执行代码的一种手段。
防抖: n 秒后在执行该事件,若在 n 秒内被重复触发,则重新计时。
好处:能够保证用户在频繁触发某些事件的时候,不会频繁的执行回调,只会被执行一次。
一个经典的比喻:
想象每天上班大厦底下的电梯。把电梯完成一次运送,类比为一次函数的执行和响应。
电梯第一个人进来后,等待15秒。如果过程中又有人进来,15秒等待重新计时,直到15秒后开始运送,这就是防抖策略(debounce)。
用于测试的HTML结构
实现效果:鼠标在盒子上移动时,盒子中央打印出数字。
//未实现防抖时的测试代码
const container = document.querySelector('#container')
let count = 0
function move(e) {
container.innerHTML = count++
console.log(this)
console.log(e)
}
container.addEventListener('mousemove', move)未实现防抖时对应的页面效果如下:
//实现防抖后的测试代码
const container = document.querySelector('#container')
let count = 0
function move(e) {
container.innerHTML = count++
console.log(this)
console.log(e)
}
const test = debounce(move, 500, true)
container.addEventListener('mousemove', test)
const btn = document.querySelector('button')
btn.onclick = function () {
test.cancel()
}实现防抖后对应的页面效果如下:
接下来记录我一步步思考完善的过程。
v1.0 简单实现一个防抖(非立即执行版本)
function debounce(func, delay) {
let timeout
return function () {
if (timeout) clearTimeout(timeout)
timeout = setTimeout(func, delay)
}
}问题探讨:发现打印出来的this是window,打印出来的e是undefined。实际想要得到的是div#container和mouseEvent。出现这种情况的原因:在container的鼠标移动事件调用debounce函数时,在传递给形参func的实参move里打印了this与e。注意move是在定时器setTimeout里,定时器里的this在非严格模式下指向的是window对象,而window对象里的e自然是undefined。解决办法是在return的function里保存this与arguments,通过apply改变func的this指向同时把保存的参数传递给func。
v2.0 解决了this指向和event对象的问题。
function debounce(func, delay) {
let timeout
return function () {
const context = this,
args = arguments
if (timeout) clearTimeout(timeout)
timeout = setTimeout(function () {
func.apply(context, args)
}, delay)
}
}问题探讨:发现第一次不能立即执行,需要等到delay秒以后才会执行第一次。
v3.0 立即执行版本
function debounce(func, delay) {
let timeout
return function () {
const context = this,
args = arguments,
callNow = !timeout
if (timeout) clearTimeout(timeout)
timeout = setTimeout(function () {
timeout = null
}, delay)
if (callNow) func.apply(context, args)
}
}Q:为什么利用callNow = !timeout来判断?而不是用callNow = true,然后在定时器内将callNow设置为false?
首先解答为什么不能用布尔值来判断。因为定时器是异步任务,在delay时间段内,callNow始终为true,这就会导致func在delay时间段内会一直触发,直到时间到达delay,callNow变成false才会停止执行func。
再回到为什么可以利用callNow = !timeout来判断的问题上。在首次触发mousemove事件时,'let timeout'执行,此时timeout为undefined;callNow对timeout取反为true;因为此时timeout为undefined,跳过清除定时器操作;把定时器赋值给timeout,注意此时timeout保存的值是1(第一个定时器的id),但是定时器是异步任务,里面的'timeout = null'尚未执行;接下来判断callNow为true,执行func函数,达到了立即执行的效果。在delay秒内第二次移动鼠标,此时timeout保存的值为1,callNow取反为false;清除上一个id为1的定时器;timeout保存值2(id为2的定时器),判断callNow为false,不执行func;反之如果等到delay秒后第二次移动鼠标,此时异步任务已执行,timeout变为null,callNow取反为true,就会执行func。注意点:这里利用了闭包,timeout是可以被访问的。
问题探讨:可以通过传入一个参数来判断实际业务需求是要立即执行还是非立即执行。
v4.0 立即执行与非立即执行结合版本(immediate为true时立即执行,反之非立即执行)
function debounce(func, delay, immediate) {
let timeout
return function () {
const context = this,
args = arguments
if (timeout) clearTimeout(timeout)
if (immediate) {
const callNow = !timeout
timeout = setTimeout(function () {
timeout = null
}, delay)
if (callNow) func.apply(context, args)
} else {
timeout = setTimeout(function () {
func.apply(context, args)
}, delay)
}
}
}问题探讨:继续完善,如果需要获得func函数的返回值该怎么办呢?那就需要把func的执行结果保存为一个result变量return出来。由此又引出了一个问题,setTimeout是一个异步任务,return时获得的是undefined,只有在立即执行的情况下会获得返回值(immediate为true时)。
v5.0 包含返回值的版本
function debounce(func, delay, immediate) {
let result, timeout
return function () {
const context = this,
args = arguments
if (timeout) clearTimeout(timeout)
if (immediate) {
const callNow = !timeout
timeout = setTimeout(function () {
timeout = null
}, delay)
if (callNow) result = func.apply(context, args)
} else {
timeout = setTimeout(function () {
func.apply(context, args)
}, delay)
}
return result
}
}问题探讨:当delay设置时间过长时(比如30秒甚至更长),我只有等到delay时间过后才能再次触发,如果可以把取消防抖绑定在一个按钮上,点击之后可以立即执行代码。需要考虑的问题是:可以把这个功能做成是debounce的一个cancel方法,因为函数也是一个对象。具体实现思路应该是把原先return出来的函数用一个变量debounced保存,然后再定义debounced.cancel,赋值为一个函数。
v6.0 包含取消功能的版本
function debounce(func, delay, immediate) {
let timeout, result
const debounced = function () {
const context = this,
args = arguments
if (timeout) clearTimeout(timeout)
if (immediate) {
const callNow = !timeout
timeout = setTimeout(function () {
timeout = null
}, delay)
if (callNow) result = func.apply(context, args)
} else {
timeout = setTimeout(function () {
func.apply(context, args)
}, delay)
}
return result
}
debounced.cancel = function () {
if (timeout) clearTimeout(timeout)
//需要注意,这里的目的并不是为了避免内存泄漏!而是为了让取消后鼠标再次移入盒子能立即执行代码。如果不置空,取消过后再移入,是不会立即执行打印数字的操作的。
timeout = null
}
return debounced
}v7.0 ES6箭头函数版本(省略了this指向与参数对象的版本)
function debounce(func, delay, immediate) {
let timeout, result
//注意下面的函数声明不能改成箭头函数,否则this会指向window
const debounced = function () {
if (timeout) clearTimeout(timeout)
if (immediate) {
const callNow = !timeout
timeout = setTimeout(() => {
timeout = null
}, delay)
if (callNow) result = func.apply(this, arguments)
} else {
timeout = setTimeout(() => {
func.apply(this, arguments)
}, delay)
}
return result
}
debounced.cancel = () => {
if (timeout) clearTimeout(timeout)
timeout = null
}
return debounced
}作者:GreyJiangy
来源:https://juejin.cn/post/7093466427805401118
跟我学flutter:细细品Widget(一)Widget&Element初识
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
跟我学flutter:细细品Widget(一)Widget&Element初识
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
Everything's a widget!
Widget
Flutter 中 Widget是一个“描述一个UI元素的配置信息”,Widget就是接受元素,而不是真是绘制的显示元素。 类比原生的Android开发,Widget更像是负责UI配置的xml文件,而非负责绘制组件的View。 当一个Widget状态发生变化时,Widget就会重新调用build()函数来返回控件的描述,过程中Flutter框架会与之前的Widget进行比较,确保实现渲染树中最小的变动来保证性能和稳定性。换句话说,当Widget发生改变时,渲染树只会更新其中的一小部分而非全部重新渲染。
源码
@immutable
abstract class Widget extends DiagnosticableTree {
const Widget({ this.key });
final Key? key;
@protected
@factory
Element createElement();
@override
String toStringShort() {
final String type = objectRuntimeType(this, 'Widget');
return key == null ? type : '$type-$key';
}
@override
void debugFillProperties(DiagnosticPropertiesBuilder properties) {
super.debugFillProperties(properties);
properties.defaultDiagnosticsTreeStyle = DiagnosticsTreeStyle.dense;
}
@override
@nonVirtual
bool operator ==(Object other) => super == other;
@override
@nonVirtual
int get hashCode => super.hashCode;
static bool canUpdate(Widget oldWidget, Widget newWidget) {
return oldWidget.runtimeType == newWidget.runtimeType
&& oldWidget.key == newWidget.key;
}
...
}
图:
@immutable
@immutable widget中的属性时不可变的,如果有可变的你需要放在state中。
如果属性发生变更flutter则会重新构建Widget树,一旦 Widget 自己的属性变了自己就会被替换。
如你在开发过程中会有如下提示:This class (or a class that this class inherits from) is marked as '@immutable', but one or more of its instance fields aren't final:
key
主要用于控制当 Widget 更新时,对应的 Element 如何处理 (是更新还是新建)。若某 Widget 是其「Parent Widget」唯一的子节点时,一般不用设置 key
LocalKey
LocalKey是diff算法的核心所在,用做Element和Widget的比较。常用子类有以下几个:
ValueKey:以一个数据为作为key,比如数字、字符等。 ObjectKey:以Object对象作为Key。 UniqueKey:可以保证key的唯一性,如果使用这个类型的key,那么Element对象将不会被复用。 PageStorageKey:用于存储页面滚动位置的key。
GlobalKey
每个globalkey都是一个在整个应用内唯一的key。globalkey相对而言是比较昂贵的,如果你并不需要globalkey的某些特性,那么可以考虑使用Key、ValueKey、ObjectKey或UniqueKey。 他有两个用途:
- 允许widget在应用程序中的任何位置更改其parent而不丢失其状态。应用场景:在两个不同的屏幕上显示相同的widget,并保持状态相同。
- 可以获取对应Widget的state对象:
createElement
一个 widget 可以对应多个Element
canUpdate
控制一个widget如何替换树中另一个widget。如果两个widget的runtimeType与key相同,则表示新的widget将替换旧的widget,并调用Element.update更新Element;否则旧的element将从树中移出,新的element插入树中。
Widget在重新build的时候,是增量更新的,而不是全部更新 runtimeType就是这个widget的类型
Widget类大家族
简述(后面文章将展开讲解):
- StatelessWidget:无状态Widget
- StatefulWidget:有状态Widget,值得注意的是StatefulWidget是不可变的,变化的状态在。
- ProxyWidget:其有2个比较重要的子类, ParentDataWidget和InheritedWidget
- RenderObjectWidget:持有RenderObject对象的Widget,RenderObject是完成界面的布局、测量与绘制,像Padding,Table,Align都是它的子类
Widget的创建可以做到复用,通过const修饰,否则setState后,Widget重新被创建了(Element不会重建)
Element
通过Widget Tree,会生成一系列Element Tree,其主要功能如下:
- 维护这棵Element Tree,根据Widget Tree的变化来更新Element Tree,包括:节点的插入、更新、删除、移动等
- Element 是 Widget 和 RenderObject 的粘合剂,根据 Element 树生成 Render 树(渲染树)
Element类大家族
两大类:
简述(后面文章将展开讲解):
ComponentElement
组合类Element。这类Element主要用来组合其他更基础的Element,得到功能更加复杂的Element。开发时常用到的StatelessWidget和StatefulWidget相对应的Element:StatelessElement和StatefulElement,即属于ComponentElement。
RenderObjectElement
渲染类Element,对应Renderer Widget,是框架最核心的Element。RenderObjectElement主要包括LeafRenderObjectElement,SingleChildRenderObjectElement,和MultiChildRenderObjectElement。其中,LeafRenderObjectElement对应的Widget是LeafRenderObjectWidget,没有子节点;SingleChildRenderObjectElement对应的Widget是SingleChildRenderObjectWidget,有一个子节点;MultiChildRenderObjectElement对应的Widget是MultiChildRenderObjecWidget,有多个子节点。
Element生命周期
Element有4种状态:initial,active,inactive,defunct。其对应的意义如下:
- initial:初始状态,Element刚创建时就是该状态。
- active:激活状态。此时Element的Parent已经通过mount将该Element插入Element Tree的指定的插槽处(Slot),Element此时随时可能显示在屏幕上。
- inactive:未激活状态。当Widget Tree发生变化,Element对应的Widget发生变化,同时由于新旧Widget的Key或者的RunTimeType不匹配等原因导致该Element也被移除,因此该Element的状态变为未激活状态,被从屏幕上移除。并将该Element从Element Tree中移除,如果该Element有对应的RenderObject,还会将对应的RenderObject从Render Tree移除。但是,此Element还是有被复用的机会,例如通过GlobalKey进行复用。
- defunct:失效状态。如果一个处于未激活状态的Element在当前帧动画结束时还是未被复用,此时会调用该Element的unmount函数,将Element的状态改为defunct,并对其中的资源进行清理。
Element4种状态间的转换关系如下图所示:
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
跟我学flutter:在国内如何发布自己的Plugin 或者 Package
跟我学flutter:Flutter雷达图表(一)如何使用kg_charts
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
本节主要讲如何使用kg_charts中的雷达图表,来绘制一个雷达图,下一章节则会对如何绘制一个可点击雷达图表进行详细说明。 最近我在开发有关雷达图表的的业务,但的确在线上找不到可以快速集成的雷达图表,找到一篇文章(Flutter雷达图package)但不是很好定制化我们的业务,但其中的代码有比较好的借鉴。然后我借鉴了部分代码,进行了kg_charts的开发。
集成方式
dependencies:
kg_charts: ^0.0.1
展示效果
1、圆形雷达图表
2、方形雷达图表
3、方形可点击雷达图表(点击效果为气泡)
4、方形多绘制区域图表(自定义展示文字)
4、方形多绘制区域图表(无自定义展示文字)
参数说明
| 参数 | 类型 | 是否必要 | 说明 |
|---|---|---|---|
| radarMap | RadarMapModel | 是 | 包含 图例,雷达点,雷达数据,半径 ,雷达种类(圆形,方形),文字最大宽度,内部画几条线(LineModel中包含绘制线颜色,文字大小等) |
| textStyle | style | 否 | 外部绘制文字颜色与大小 |
| isNeedDrawLegend | bool | 否 | 默认为true |
| lineText | fun | 否 | 内部线上画的文字,根据数据动态生成,如果为空则不展示 |
| dilogText | fun | 否 | 点击出现的dialog,根据数据动态生成,如果为空则不展示 |
| outLineText | fun | 否 | 外部线上画的文字,根据数据动态生成,如果为空则不展示 |
详细使用说明
图片说明
代码使用说明
1、图例
legend: [
LegendModel('10/10',const Color(0XFF0EBD8D)),
LegendModel('10/11',const Color(0XFFEAA035)),
]
2、维度数据 如上代码所示,假设目前有两个日期维度,(业务假设是两天的考试)制定两个维度。
data: [
MapDataModel([100,90,90,90,10,20]),
MapDataModel([90,90,90,90,10,20]),
],
两个维度需要配置两套数据
维度和数据必须对应,两个维度必须是两套数据
3、数据组
indicator: [
IndicatorModel("English",100),
IndicatorModel("Physics",100),
IndicatorModel("Chemistry",100),
IndicatorModel("Biology",100),
IndicatorModel("Politics",100),
IndicatorModel("History",100),
]
数据的长短必须与数据的参数一致,比如说是六个科目,那么每套数据必须是6个数据,这个数据设置一个最大数据值,而且数据组中的值不能比该数据大。
4、RadarMapModel中其他基本参数
radius: 130,
shape: Shape.square,
maxWidth: 70,
line: LineModel(4),
radius 半径 shape 圆形的图还是方形的图 maxWidth 展示外环文字最大宽度 line 内环有几个环(还可配置内环文字大小和颜色)
5、其他基本配置
textStyle: const TextStyle(color: Colors.black,fontSize: 14),
isNeedDrawLegend: true,
lineText: (p,length) => "${(p*100~/length)}%",
dilogText: (IndicatorModel indicatorModel,List legendModels,List mapDataModels) {
StringBuffer text = StringBuffer("");
for(int i=0;i "${data*100~/max}%",
textStyle : 外环文字颜色,大小 isNeedDrawLegend:是否需要图例 lineText : 线上标注的文字(动态) 如上代码所示是转换为% dilogText:点击后弹出的浮动框(动态) 如上代码所示把日期都输出 outLineText:区域外环是否展示文字(动态) 如上代码所示是转换为%
整体代码展示
RadarWidget(
radarMap: RadarMapModel(
legend: [
LegendModel('10/10',const Color(0XFF0EBD8D)),
LegendModel('10/11',const Color(0XFFEAA035)),
],
indicator: [
IndicatorModel("English",100),
IndicatorModel("Physics",100),
IndicatorModel("Chemistry",100),
IndicatorModel("Biology",100),
IndicatorModel("Politics",100),
IndicatorModel("History",100),
],
data: [
// MapDataModel([48,32.04,1.00,94.5,19,60,50,30,19,60,50]),
// MapDataModel([42.59,34.04,1.10,68,99,30,19,60,50,19,30]),
MapDataModel([100,90,90,90,10,20]),
MapDataModel([90,90,90,90,10,20]),
],
radius: 130,
duration: 2000,
shape: Shape.square,
maxWidth: 70,
line: LineModel(4),
),
textStyle: const TextStyle(color: Colors.black,fontSize: 14),
isNeedDrawLegend: true,
lineText: (p,length) => "${(p*100~/length)}%",
dilogText: (IndicatorModel indicatorModel,List legendModels,List mapDataModels) {
StringBuffer text = StringBuffer("");
for(int i=0;i "${data*100~/max}%",
), 


{kind=link}
{kind=link}