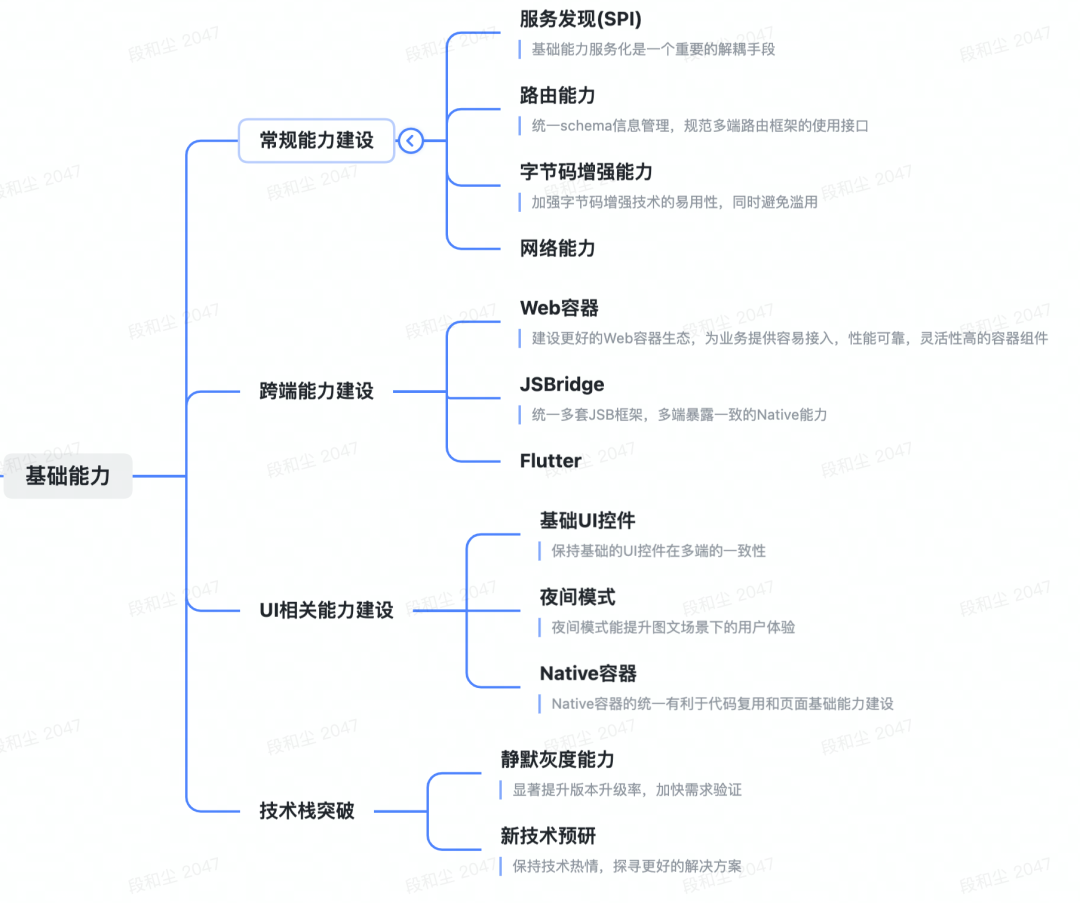
前面我们已经介绍了 Flutter 的入口方法 —— main,入口方法做了初始化、根节点生成并绑定等工作。这一节我们就详细介绍 Flutter 的初始化。
混入 mixin
混入是一个很实用的语法特性,可以让一个类在不成为某一个目标类的父类的情况下,目标类可以使用混入类的方法和属性。混入的关键字是 with 、 mixin、on,mixin 用来声明混入类,with 用来使用混入类,on 用来限制混入的层级。
最简单的使用如下:
首先: 声明混入类
mixin CustomerBinding {
String name = 'CustomerBinding';
void printName() {
print(name);
}
}
然后:目标类添加混入类
class TestClass with CustomerBinding {
}
我们使用 with 关键字为 TestClass 添加了混入类,那么 TestClass 中就有了 name 字段 和 printName 方法。
最后:使用目标类
void main(List<String> args) {
TestClass().printName();
}
即使 TestClass 没有明确的声明 printName,也可以被调用到,原因就是 TestClass 的混入类中有该方法。
上面的过程就是混入的基本使用,大家可能会问到的问题是:
首先 看混入类和普通类的区别,混入类是不可以直接构造的,这意味着它的这一方面的功能要弱化一点点 🤏🏻。
其次 Dart 也是单继承的,就是一个类只能有一个直接的父类,而混入是可以多混入的,所以可以把不同的功能模块线性的混入到目标类中。
这就是为啥搞出来一个混入。
- 既然一个类既可以混入又可以继承,那么继承和混入的优先级谁高呢?
结论是混入高于继承,我们先看例子。
void main(List<String> args) {
var testClass = TestClass();
// 第三处
testClass.printName();
}
class TestClass extends Parent with CustomerBinding {}
class Parent {
// 第二处
void printName() {
print('Parent');
}
}
mixin CustomerBinding {
// 第一处
void printName() {
print('CustomerBinding');
}
}
第一处 和 第二处分别在混入类和父类中定义了 同名方法
第三处是使用该方法,控制台打印的是 CustomerBinding
出现这种现象的原因是:混入的实现是依靠生成中间类的方式。上面的继承关系如下:
每混入一个类都会生成一个中间类,比如上面的例子,就根据 CustomerBinding 生成一个中间类,这个类继承自 Parent,而 TestClass 是继承自中间类。
所以 testClass 调用的就是中间类的方法,而中间类的方法就是 CustomerBinding 中的方法,所以打印了 CustomerBinding。
结论:混入是线性的,后面的会覆盖前面的同名方法。
看这个例子:
void main(List<String> args) {
var testClass = TestClass();
testClass.printName();
}
class TestClass extends Parent with CustomerBinding, CustomerBinding2 {}
class Parent {
void printName() {
print('Parent');
}
}
mixin CustomerBinding {
void printName() {
print('CustomerBinding');
}
}
mixin CustomerBinding2 {
void printName() {
print('CustomerBinding2');
}
}
上面的代码会打印 CustomerBinding2 ,因为 CustomerBinding2 在混入的最后面。上面形成的体系图如下:
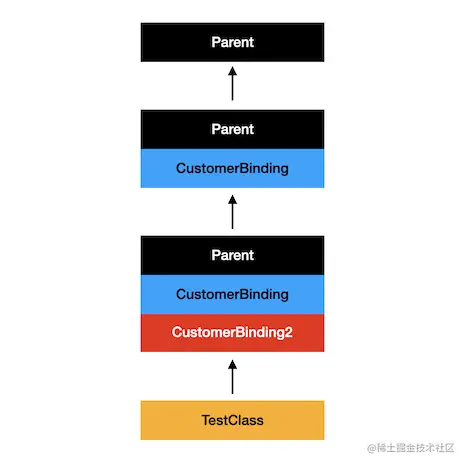
TextClass 直接调用的就是距离它最近的父类,也就是 CustomerBinding2 中的方法,所以打印了 CustomerBinding2。
- 既然可以多混入,那么混入可以有层级吗?就是同名不方法不覆盖,在原有逻辑的基础上实现自己的逻辑。
结论是可以的,实现的方式就是混入限定 on
既然要调到前排混入类的逻辑,首先要知道有前排的存在。 比如子类调用父类的方法,可以用 super,前提是子类要 extends 父类。
而混入类是不知道是否有混入类存在的,这个时候就需要 on 来限定了。
看下面的例子:
void main(List<String> args) {
var testClass = TestClass();
testClass.printName();
}
class TestClass extends Parent with CustomerBinding, CustomerBinding2 {}
class Parent {
void printName() {
print('Parent');
}
}
mixin CustomerBinding on Parent{ //第一处
void printName() {
super.printName();
print('CustomerBinding');
}
}
mixin CustomerBinding2 on Parent{ //第二处
void printName() {
super.printName();
print('CustomerBinding2');
}
}
和前面的例子相比,第一处和第二处多了 on Parent,表示 CustomerBinding 和 CustomerBinding 只能用在 Parent 的子类上,所以它俩内部的 printName 就可以调用到 super。
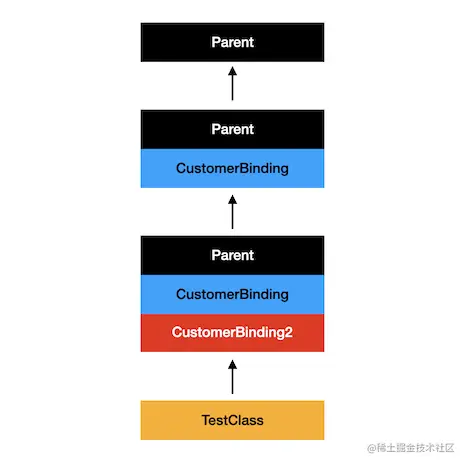
而且根据上面的线性规则,每次调用 super 都是向前一个混入的类调用,所以最后把三个打印语句都执行了。
小结
上面介绍了混入类、混入类的规则、大家可能会问到的混入类的问题,混入在 Flutter 中经常遇到,比如我们写动画的 TickerProviderStateMixin、初始化的 Binding 等等,大家也可以在自己的项目用混入来封装公有逻辑,比如 Loading 等。
混入类的规则如下:
- 混入高于继承
- 混入是线性的,后面的会覆盖前面的同名方法
super 会保证混入的执行顺序为从前往后
知道了混入,下面我们来看 Flutter 是怎么用混入来实现初始化的。
Binding 初始化
前面我们讲了混入,下面我们就看看初始化中怎么使用混入的。
class WidgetsFlutterBinding extends BindingBase with GestureBinding, SchedulerBinding, ServicesBinding, PaintingBinding, SemanticsBinding, RendererBinding, WidgetsBinding {
static WidgetsBinding ensureInitialized() {
if (WidgetsBinding.instance == null)
WidgetsFlutterBinding();//第一处
return WidgetsBinding.instance!;
}
}
这是初始化的代码,这个地方可以看 Flutter 必知必会系列 —— runApp 做了啥 这一篇的介绍。
我们这一节的任务就是看看 WidgetsFlutterBinding() 构造方法干了啥。
WidgetsFlutterBinding 继承自 BindingBase,并混入了 7 个类。
WidgetsFlutterBinding 没有构造方法,第一处直接调用到了父类 BindingBase 的构造方法中。如下:
BindingBase() {
//...省略代码
initInstances();//第一处
initServiceExtensions();//第二处
}
省略一些无关的代码,就剩下了第一处和第二处的代码。从名字就可以,看出来这俩方法是用来初始化的。
initInstances 用来初始化实例对象,initServiceExtensions 用来注册服务。
这里介绍一下 注册服务 是咋回事。
注册服务
Flutter 是运行在 Dart VM 上的,Flutter 应用和 Dart VM 是可以互相调用的,比如 Flutter 可以调用 Dart VM 的各种服务来获取,内存信息、类信息、调用方法等等,Dart VM 同样可以调用到 Flutter 层注册好的方法。
Flutter 和 Dart VM 的调用需要遵循 JSON 协议,详细的可以看这里 Json 协议
上面列出的方法,都是 Flutter 对 Dart VM 的调用。
Dart VM 对 Flutter 的调用也是一样的,只要注册过,名字可以匹对上就可以调用。
Flutter 的注册是 registerServiceExtension 方法。
void registerServiceExtension({
required String name,
required ServiceExtensionCallback callback,
}) {
final String methodName = 'ext.flutter.$name';
developer.registerExtension(methodName, (String method, Map<String, String> parameters) async {
// 代码省略
late Map<String, dynamic> result;
try {
result = await callback(parameters);
} catch (exception, stack) {
}
result['type'] = '_extensionType';
result['method'] = method;
return developer.ServiceExtensionResponse.result(json.encode(result));
});
}
registerServiceExtension 就是注册方法,接受的入参就是服务名字 和 回调。
服务名字:就是 Flutter 和 Dart Vm 能够认识的服务标示,方法名字就是 VM 可以调用到的名字。
回调:就是 VM 调用服务名字时,Flutter 做出的反应。
这里注意一点,我们传递的名字会被 包装成 ext.flutter.$名字 的形式。
注册会调用 developer 的 registerExtension 方法。developer 是一个开发者包,里面有一个比较基础的 API。
最后这个 registerExtension 会将名字和回调注册到 VM 中,这是一个 native 的方法。
external _registerExtension(String method, ServiceExtensionHandler handler);
大家感兴趣,可以从 native 看看。这里我们只需要知道 flutter 调用注册,就是为 VM 注册了一个执行 Flutter 方法的回调。
下面我们以注册的退出应用服务来验证注册过程。
registerSignalServiceExtension(
name: 'exit',
callback: _exitApplication,
);
Future<void> _exitApplication() async {
exit(0);
}
这个服务的效果是:只要 VM 调用 exit 方法,应用就退出去。
Dart VM 和 Flutter 的通信遵循 socket 的协议,只要连接上虚拟机运行的 URL 就可以了。
首先 Flutter 的 pubspec.yaml 文件中添加 vm_service 依赖
其次 Flutter 应用主动连接 vm 虚拟机
// 连接虚拟机的服务
Service.getInfo().then((value) {
String url = value.serverUri.toString();
Uri uri = Uri.parse(url);
Uri socketUri = convertToWebSocketUrl(serviceProtocolUrl: uri);
vmServiceConnectUri(socketUri.toString()).then((value) {
});
});
Service.getInfo 是获取虚拟机服务的 url,这是 Flutter 提供的 API ,这种方式更加方便。FlutterEngine 也提供了获取 url 的方法,但是需要通过插件来传递,使用不方便。
convertToWebSocketUrl 就是对 url 进行了转换,结果就是 WebSocket 可以识别的 url。
vmServiceConnectUri 就是 Flutter 与 vmService 进行了连接
最后 我们调用一下:
Service.getInfo().then((value) {
String url = value.serverUri.toString();
Uri uri = Uri.parse(url);
Uri socketUri = convertToWebSocketUrl(serviceProtocolUrl: uri);
vmServiceConnectUri(socketUri.toString()).then((service) {
service.callServiceExtension('ext.flutter.exit',
isolateId: Service.getIsolateID(Is.Isolate.current),
args: {'enabled': true}); //第一处
});
});
第一处的代码执行之后 应用就退出去了,可以看一下效果。
Flutter DevTools 就是调用 Flutter 注册的服务来实现调试效果的,大家可以看这里:Flutter DevTools 的调试工具
上面就是 注册服务的过程和作用,下面我们来看 BaseBiding 注册了哪些服务:
void initServiceExtensions() {
if (!kReleaseMode) {
if (!kIsWeb) {
registerSignalServiceExtension(
name: 'exit',
callback: _exitApplication,
);
}
// These service extensions are used in profile mode applications.
registerStringServiceExtension(
name: 'connectedVmServiceUri',
getter: () async => connectedVmServiceUri ?? '',
setter: (String uri) async {
connectedVmServiceUri = uri;
},
);
registerStringServiceExtension(
name: 'activeDevToolsServerAddress',
getter: () async => activeDevToolsServerAddress ?? '',
setter: (String serverAddress) async {
activeDevToolsServerAddress = serverAddress;
},
);
}
}
exit 是退出应用,上面我们已经看过了。
connectedVmServiceUri 是设置虚拟机的URL
activeDevToolsServerAddress 设置是否可以连接 DevTools
小结
Binding 的构造方法会调用 initInstances 和initServiceExtensions 两个方法,其中 initInstances 用于初始化实例,initServiceExtensions 用于注册虚拟机可以调用的方法。
所以 Binding 的构造方法 起到了模版方法的功能,定义好了初始化的流程。
根据上面介绍到的规则,大家知道 WidgetsFlutterBinding 初始化执行的顺序吗?
就是从前向后的执行,因为每一个 Binding 都调用了 super
BaseBinding 的构造方法起到了模版方法的功能,定义好了初始化的流程。下面我们看各个 Binding 初始化了啥。
GestureBinding 初始化
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
_instance = this; //第一处
window.onPointerDataPacket = _handlePointerDataPacket;//第二处
}
static GestureBinding? get instance => _instance;
static GestureBinding? _instance;//第一处
第一处就是对 \_instance 进行了赋值,因为 initInstances 是在构造方法中调用的,并且构造方法值调用一次,所以 \_instance 只会初始化一次,这也是 Flutter 中另外一种单例的实现方式。
第二处就是对 window 的 onPointerDataPacket 进行赋值。onPointerDataPacket 是一个方法回调,就是屏幕的手势会调用到这里。
所以 GestureBinding 的 _handlePointerDataPacket 是 Flutter 手势系统的起点。
如果我们自己对 onPointerDataPacket 进行重新复制,那么就会走到我们自定义的手势流程。
比如:
@override
void initState() {
super.initState();
ui.window.onPointerDataPacket = (PointerDataPacket packet) {
};
}
这样不管怎么点击、滑动屏幕,都是没有任何反应的。
这个有什么用呢?拦截手势增加自定义操作。
比如 屏幕上有一个浮窗,点击浮窗以外的其他区域,关闭浮窗,就可以在这个里面做。定义的点击埋点也可以在这里做。
_handlePointerDataPacket 的具体流程,我们后面在详细介绍。
各个子 Binding 初始化
SchedulerBinding 初始化
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
_instance = this; //第一处
if (!kReleaseMode) { //第二处
addTimingsCallback((List<FrameTiming> timings) {
timings.forEach(_profileFramePostEvent);
});
}
}
第一处的代码是不是很熟悉,同样实例化单例对象。
第二处的代码就是增加了一个回调,这个回调就是一个帧绘制的监听,类似于我们的性能监控,只不过监控的是帧的信息,包含了以下信息:
postEvent('Flutter.Frame', <String, dynamic>{
'number': frameTiming.frameNumber,
'startTime': frameTiming.timestampInMicroseconds(FramePhase.buildStart),
'elapsed': frameTiming.totalSpan.inMicroseconds,
'build': frameTiming.buildDuration.inMicroseconds,
'raster': frameTiming.rasterDuration.inMicroseconds,
'vsyncOverhead': frameTiming.vsyncOverhead.inMicroseconds,
});
initServiceExtensions 注册服务
@override
void initServiceExtensions() {
super.initServiceExtensions();
if (!kReleaseMode) {
registerNumericServiceExtension(
name: 'timeDilation',
getter: () async => timeDilation,
setter: (double value) async {
timeDilation = value;
},
);
}
}
注册了 timeDilation 服务,timeDilation 就是来设置动画慢放倍数的。Android Studio 和 DevTools 都有这个调试功能。
ServicesBinding 初始化
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
//第一处
_instance = this;
//第二处
_defaultBinaryMessenger = createBinaryMessenger();
_restorationManager = createRestorationManager();
//第三处
_initKeyboard();
initLicenses();
//第四处
SystemChannels.system.setMessageHandler((dynamic message) => handleSystemMessage(message as Object));
SystemChannels.lifecycle.setMessageHandler(_handleLifecycleMessage);
SystemChannels.platform.setMethodCallHandler(_handlePlatformMessage);
readInitialLifecycleStateFromNativeWindow();
}
第一处 就是实例化单例对象,和之前的一样
第二处 就是处理 channel 通信和数据恢复,可以在这一层做 channel 调用的拦截
第三处 就是初始化了键盘之类的内容
第四处 就是做了系统自带的 channel 的回调,system 是内存紧张的回调,lifecycle 是生命周期的回调,platform 是剪切板、系统声音等的回调
initServiceExtensions 初始化注册服务
@override
void initServiceExtensions() {
super.initServiceExtensions();
registerStringServiceExtension(
name: 'evict',
getter: () async => '',
setter: (String value) async {
evict(value);
},
);
}
void evict(String asset) {
rootBundle.evict(asset);
}
调试工具调用 ext.flutter.evict 就会从缓存中清除指定路径的资源。
PaintingBinding
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
_instance = this; //第一处
_imageCache = createImageCache(); //第二处
shaderWarmUp?.execute();//第三处
}
第一处 依然是初始化实例
第二处 声明了一个图片缓存,Flutter 自带了图片缓存,缓存的算法是 LRU ,缓存的大小是 100 MB,图片张数是 1000张。
第三处 是让 Skia 着色器执行一下,随便画了一个小图片,避免发起绘制任务的时候 Skia 初始化等待的时间。
RendererBinding
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
_instance = this; //第一处
_pipelineOwner = PipelineOwner( //第二处
onNeedVisualUpdate: ensureVisualUpdate,
onSemanticsOwnerCreated: _handleSemanticsOwnerCreated,
onSemanticsOwnerDisposed: _handleSemanticsOwnerDisposed,
);
window
..onMetricsChanged = handleMetricsChanged
..onTextScaleFactorChanged = handleTextScaleFactorChanged
..onPlatformBrightnessChanged = handlePlatformBrightnessChanged
..onSemanticsEnabledChanged = _handleSemanticsEnabledChanged
..onSemanticsAction = _handleSemanticsAction; //第三处
initRenderView(); //第四处
_handleSemanticsEnabledChanged();
addPersistentFrameCallback(_handlePersistentFrameCallback); //第五处
}
第一处 依然是初始化实例
第二处 初始化了渲染绘制的 PipelineOwner,PipelineOwner 会管理绘制过程,比如布局、合成涂层、绘制等等
第三处 为 window 中与绘制相关的属性赋值,onMetricsChanged 是窗口尺寸变化的回调,onTextScaleFactorChanged 是系统文字变化的回调,onPlatformBrightnessChanged 是深色模式与否变化的回调
第四处 是根节点 RenderObject 的初始化
第五处 是添加帧阶段的回调,发起布局任务
initServiceExtensions 初始化注册服务
initServiceExtensions 中注册的服务都是和绘制、RenderObject相关的,代码较多,就不一一列举了。
debugPaint 就是 RenderObject 的边框
debugDumpRenderTree 就是打印出 RenderObject 的树信息等等
WidgetsBinding
initInstances 初始化实例
@override
void initInstances() {
super.initInstances();
_instance = this;//第一处
_buildOwner = BuildOwner(); //第二处
buildOwner!.onBuildScheduled = _handleBuildScheduled;
window.onLocaleChanged = handleLocaleChanged;
window.onAccessibilityFeaturesChanged = handleAccessibilityFeaturesChanged; //第三处
SystemChannels.navigation.setMethodCallHandler(_handleNavigationInvocation); //第四处
}
第一处 依然是初始化实例
第二处 是初始化 BuildOwner,BuildOwner 用于管理 Element,维护了 '脏' Element 的列表
第三处 是为 window 的属性赋值
第四处 是系统的物理返回键添加 channel 回调
initServiceExtensions 初始化注册服务
initServiceExtensions 中注册的服务都是和 Widget 相关的,代码较多,就不一一列举了。
debugDumpApp 就是打印 Widget 树的信息
showPerformanceOverlay 就是页面中添加帧性能的浮窗等等
小结
不知道到大家注意到一点没有,从 GestureBinding 开始到 WidgetsBinding 结束,它们的 initInstances 和 initServiceExtensions 都调用了 super。
所以按着我们之前介绍的混入规则,虽然 WidgetsBinding 在最后面,但是调用的顺序也是在最后面,这样保证了初始化的正确性。
总结
这一篇介绍了混入的使用和规则,并借此延伸到了 Flutter 的初始化。WidgetsFlutterBinding 的继承体系看着唬人,其实就是从前向后的依次调用,后面我们就从第一个 GestureBinding 开始看起。












 。
。
















 ~
~