








你不买我不买,显卡出货量破二十年新低!红绿蓝三家混战,国产GPU引起海外关注
显卡市场的寒气,藏不住了。
刚刚过去的2022年,全球独显出货量创下二十年新低,比2021年同期下跌将近50%。
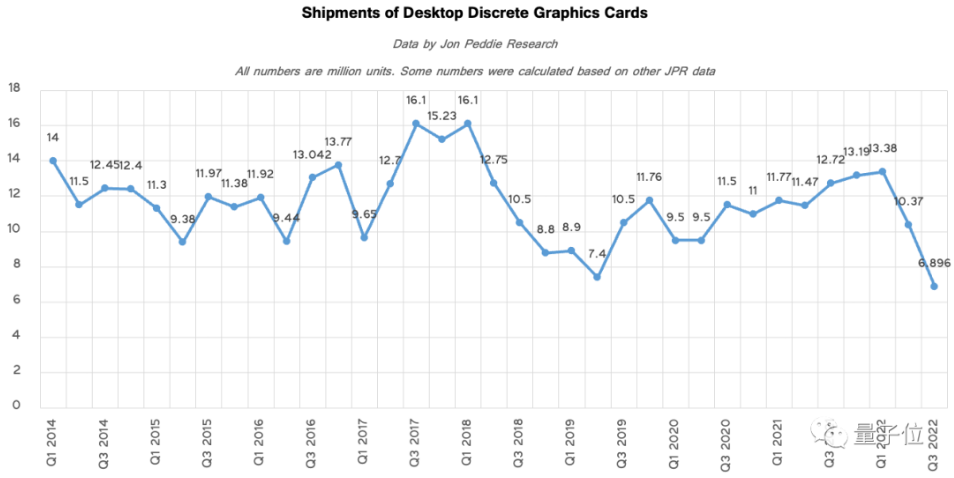
Jon Peddie Research(JPR)最新数据显示,今年第三季度独显出货量仅690万块。
如果追溯到2005年Q3,这一数据为2000万+。

而英伟达作为全球显卡市场头号玩家,遭受的重创早就开始显现:今年Q2、Q3业绩连续下滑,如今股价已跌至去年最高点一半左右。
内忧之下,还有外患。
前有CPU巨头英特尔高调官宣分拆图形芯片部门,为更好和英伟达、AMD打擂台;后有中国GPU厂商异军突起,多家公司在今年宣布流片或量产,已引起国外关注。
看来老黄的2022,或许并不好过。
今年显卡市场扑朔迷离
如果以“短缺”概括2021年显卡市场,那么今年的江湖,则如过山车般跌宕。
年初还在到处缺货,市场价高过发售价太过正常,一些装机玩家索性改买品牌高性价笔记本。1月时,Meta还被曝一次性从英伟达买下1.6万个GPU,还引来不少艳羡目光。
3月,情况就发生了变化。
显卡市场价已有跳水现象,再到7月,国内外消费者已基本都能以建议零售价从官方渠道及主流平台购入英伟达及AMD显卡。
“空气卡”一词逐渐隐退,不再是引发大家共鸣的表达。
缺芯潮基本结束。

短短数月的变化,主要源于两点。
其一,全球消费热潮冷却;
其二,大规模挖矿行动的终结。
当然,此前显卡缺货引发的供应链加码生产,一消一涨,数月内就将显卡从“空气”变成“实体”。
但很快,产品过剩去库存,就成为了后半年主旋律。对各大厂商,冷热交替过快过烈,着实一番冰火两重天体验。
以占大半壁江山的英伟达为例。
7月初大批产品跌至零售价,到中旬,高端款RTX 3090 Ti跌到了比零售价还便宜38%。
一个月后,英伟达颤颤巍巍预披露了Q2财报,不出所料,与消费级显卡直接挂钩的游戏业务塌方,营收环比跌掉44%,黄仁勋表示,随季度推进,该板块销售预测还将下调,去库存成为主要目标。
随后,就是官方打折,甚至搞出买30系显卡及配备的电脑,送59.99美元游戏的促销路数。
在这种动荡之下,英伟达生意越来越不好做,从财报上就能看到。
2022年5-7月,公司营收环比下跌了66%(non-GAAP),净利润环比下跌62%(non-GAAP)。后面一季的数据略有回涨,营收环比涨幅为16%(non-GAAP),但同比去年同期,跌幅还是很大,达到了55%(non-GAAP)。
这当中,英伟达还和最大合作伙伴EVGA闹掰了。
9月,EVGA单方面宣布,不会同英伟达下一代产品合作。

要知道,两者合作20多年,而且EVGA收入中80%来自英伟达合作的显卡。
根据EVGA的说法,英伟达的合作态度是两者关系恶化的关键。具体来说,英伟达一方沟通越来越少,新产品信息不同步,重要活动也不cue合作方,连价格调整也不事先同步。
比如RTX 3090 Ti显卡,英伟达给零售商报价比EVGA对外低了300美元,却不事先沟通,这下,合作方相当“被动”。
由于双方交恶时间点又赶在40系列显卡前一周,当时引发不小震动。
而几天后40系高调发布,售价最高12999人民币,很多消费者反馈却是“不值”二字,更别说4090电源接口熔化,又是一波不满。

△ 图源:theverge
而更大的变动或许还没到来——英伟达的新对手也越来越多。
各路对手杀到老黄城下
最明显的一个动向就是,英特尔开抢GPU市场份额了。
本月初,英特尔宣布将把图形芯片部门(AXG)一分为二,通过重组业务,更好地和英伟达、AMD竞争。
过去英特尔一直在主导CPU市场,GPU方面一直不是其发展核心。但在AI热浪下,英特尔也不得不重视起加速计算市场了。
其在官方声明表示:
图形芯片和加速计算是英特尔的关键增长引擎。我们正在改进我们的结构,以加速和扩大它们的影响,并通过向客户发出统一的声音来推动上市战略。
据JPR统计,今年第三季度独显市场中,英特尔占比4%。对比来看,AMD也仅有8%。
而更引人注目的变化,发生在国内。
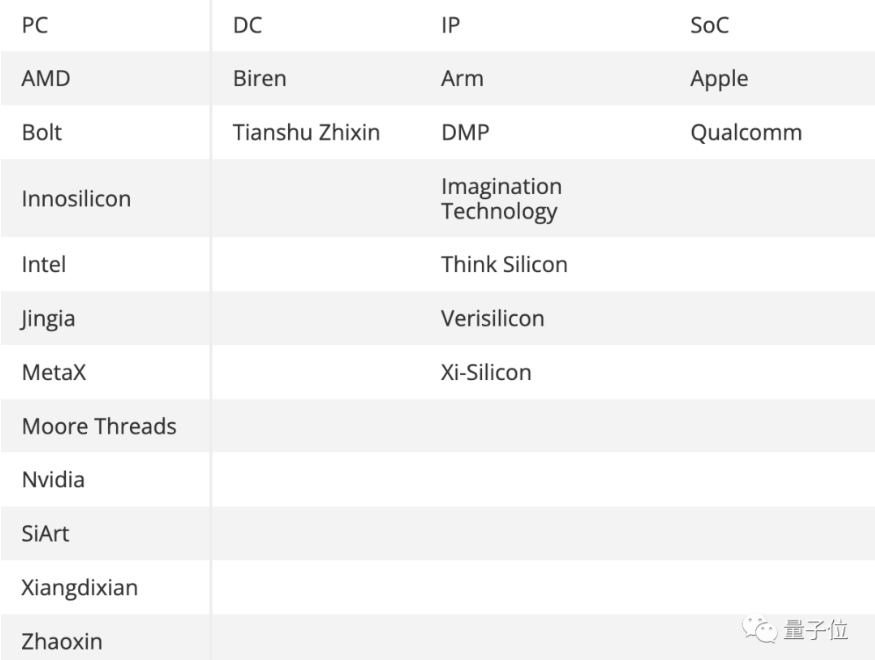
今年,摩尔线程一年内交出两块全功能GPU;芯动科技发布了“风华2号”、“风华1号”开始量产;面向数据中心的壁仞则发布了首款通用GPU芯片BR100,单芯片峰值算力达到PFLOPS级别;象帝先也发布了拥有100%自主知识产权的通用GPU……
脚步之快,已引发海外关注。
权威机构Jon Peddie Research在其对2022全球GPU市场的年度报告中写道:
在AI和高性能计算的驱动下,中国厂商正在向GPU市场发起进军。
由此也带动全球GPU厂商数量激增,独显厂商中,中国面孔就占据了一半席位。
当然这不是一夜之间发生的事。
在AI浪潮的驱动下,中国在数字化升级和人工智能行业融入的脚步上都十分迅速,国内对于GPU的需求空前高涨。
另一边,中国人工智能行业过度依赖英伟达显卡的情况也确实存在。这不光会造成资金上的压力,还容易出现“卡脖子”的情况。
在多种趋势和因素的影响下,早在20年下半年开始,资本市场上讲出了包括图形渲染在内的全功能GPU的新故事。壁仞科技、摩尔线程先后成立并大笔融资,芯动科技、兆芯等老牌芯片公司的独立显卡项目也在这附近官宣。
如今2年时间过去,已有多家厂商完成了流片或量产。
不可否认,当下或许还只是国内厂商迈出的第一步。从IP供应商处购买授权的方式,好处是能够减少投入加速回报,还能迅速积累经验、逐步建立起人才队伍。但在自研上后面还有很长的路要走。
而且如苹果、三星等攀登IP自研之路时,也并非一帆风顺。苹果分手3年后又回头重新与Imagination合作,据市场传闻有专利方面的原因。
因此,对于国内GPU自研,还需要更多耐心。
但无论如何,在全球显卡市场遭遇动荡的背景下,风险和机遇都随之而来。眼下,或许只是市场变革的开始了。
另外,最新消息显示,英伟达、AMD以及英特尔都已削减在台积电的订单。
参考链接:
[1]https://www.tomshardware.com/news/sales-of-desktop-graphics-cards-hit-20-year-low
[2]https://www.tomshardware.com/news/ai-and-tech-sovereignity-drive-number-of-gpu-developers-in-china
詹士 明敏 发自 凹非寺
来自|量子位
收起阅读 »react的useState源码分析
前言
简单说下为什么React选择函数式组件,主要是class组件比较冗余、生命周期函数写法不友好,骚写法多,functional组件更符合React编程思想等等等。更具体的可以拜读dan大神的blog。其中Function components capture the rendered values这句十分精辟的道出函数式组件的优势。
但是在16.8之前react的函数式组件十分羸弱,基本只能作用于纯展示组件,主要因为缺少state和生命周期。本人曾经在hooks出来前负责过纯函数式的react项目,所有状态处理都必须在reducer中进行,所有副作用都在saga中执行,可以说是十分艰辛的经历了。在hooks出来后我在公司的一个小中台项目中使用,落地效果不错,代码量显著减少的同时提升了代码的可读性。因为通过custom hooks可以更好地剥离代码结构,不会像以前类组件那样在cDU等生命周期堆了一大堆逻辑,在命令式代码和声明式代码中有一个良性的边界。
useState在React中是怎么实现的
Hooks take some getting used to — and especially at the boundary of imperative and declarative code.
如果对hooks不太了解的可以先看看这篇文章:前情提要,十分简明的介绍了hooks的核心原理,但是我对useEffect,useRef等钩子的实现比较好奇,所以开始啃起了源码,下面我会结合源码介绍useState的原理。useState具体逻辑分成三部分:mountState,dispatch, updateState
hook的结构
首先的是hooks的结构,hooks是挂载在组件Fiber结点上memoizedState的
//hook的结构
export type Hook = {
memoizedState: any, //上一次的state
baseState: any, //当前state
baseUpdate: Update<any, any> | null, // update func
queue: UpdateQueue<any, any> | null, //用于缓存多次action
next: Hook | null, //链表
};renderWithHooks
在reconciler中处理函数式组件的函数是renderWithHooks,其类型是:
renderWithHooks(
current: Fiber | null, //当前的fiber结点
workInProgress: Fiber,
Component: any, //jsx中用<>调用的函数
props: any,
refOrContext: any,
nextRenderExpirationTime: ExpirationTime, //需要在什么时候结束
): any在renderWithHooks,核心流程如下:
//从memoizedState中取出hooks
nextCurrentHook = current !== null ? current.memoizedState : null;
//判断通过有没有hooks判断是mount还是update,两者的函数不同
ReactCurrentDispatcher.current =
nextCurrentHook === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate;
//执行传入的type函数
let children = Component(props, refOrContext);
//执行完函数后的dispatcher变成只能调用context的
ReactCurrentDispatcher.current = ContextOnlyDispatcher;
return children;useState构建时流程
mountState
在HooksDispatcherOnMount中,useState调用的是下面的mountState,作用是创建一个新的hook并使用默认值初始化并绑定其触发器,因为useState底层是useReducer,所以数组第二个值返回的是dispatch。
type BasicStateAction<S> = (S => S) | S;
function mountState<S>(
initialState: (() => S) | S,
){
const hook = mountWorkInProgressHook();
//如果入参是func则会调用,但是不提供参数,带参数的需要包一层
if (typeof initialState === 'function') {
initialState = initialState();
}
//上一个state和基本(当前)state都初始化
hook.memoizedState = hook.baseState = initialState;
const queue = (hook.queue = {
last: null,
dispatch: null,
eagerReducer: basicStateReducer, // useState使用基础reducer
eagerState: (initialState: any),
});
//返回触发器
const dispatch: Dispatch<
//useState底层是useReducer,所以type是BasicStateAction
(queue.dispatch = (dispatchAction.bind(
null,
//绑定当前fiber结点和queue
((currentlyRenderingFiber: any): Fiber),
queue,
): any));
return [hook.memoizedState, dispatch];
}mountWorkInProgressHook
这个函数是mountState时调用的构建hook的方法,在初始化完毕后会连接到当前hook.next(如果有的话)
function mountWorkInProgressHook(): Hook {
const hook: Hook = {
memoizedState: null,
baseState: null,
queue: null,
baseUpdate: null,
next: null,
};
if (workInProgressHook === null) {
// 列表中的第一个hook
firstWorkInProgressHook = workInProgressHook = hook;
} else {
// 添加到列表的末尾
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}dispatch分发函数
在上面我们提到,useState底层是useReducer,所以返回的第二个参数是dispatch函数,其中的设计十分巧妙。
假设我们有以下代码:
相关参考视频讲解:进入学习
const [data, setData] = React.useState(0)
setData('first')
setData('second')
setData('third')在第一次setData后, hooks的结构如上图
在第二次setData后, hooks的结构如上图
在第三次setData后, hooks的结构如上图
在正常情况下,是不会在dispatcher中触发reducer而是将action存入update中在updateState中再执行,但是如果在react没有重渲染需求的前提下是会提前计算state即eagerState。作为性能优化的一环。
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
const alternate = fiber.alternate;
{
flushPassiveEffects();
//获取当前时间并计算可用时间
const currentTime = requestCurrentTime();
const expirationTime = computeExpirationForFiber(currentTime, fiber);
const update: Update<S, A> = {
expirationTime,
action,
eagerReducer: null,
eagerState: null,
next: null,
};
//下面的代码就是为了构建queue.last是最新的更新,然后last.next开始是每一次的action
// 取出last
const last = queue.last;
if (last === null) {
// 自圆
update.next = update;
} else {
const first = last.next;
if (first !== null) {
update.next = first;
}
last.next = update;
}
queue.last = update;
if (
fiber.expirationTime === NoWork &&
(alternate === null || alternate.expirationTime === NoWork)
) {
// 当前队列为空,我们可以在进入render阶段前提前计算出下一个状态。如果新的状态和当前状态相同,则可以退出重渲染
const lastRenderedReducer = queue.lastRenderedReducer; // 上次更新完后的reducer
if (lastRenderedReducer !== null) {
let prevDispatcher;
if (__DEV__) {
prevDispatcher = ReactCurrentDispatcher.current; // 暂存dispatcher
ReactCurrentDispatcher.current = InvalidNestedHooksDispatcherOnUpdateInDEV;
}
try {
const currentState: S = (queue.lastRenderedState: any);
// 计算下次state
const eagerState = lastRenderedReducer(currentState, action);
// 在update对象中存储预计算的完整状态和reducer,如果在进入render阶段前reducer没有变化那么可以服用eagerState而不用重新再次调用reducer
update.eagerReducer = lastRenderedReducer;
update.eagerState = eagerState;
if (is(eagerState, currentState)) {
// 在后续的时间中,如果这个组件因别的原因被重渲染且在那时reducer更变后,仍有可能重建这次更新
return;
}
} catch (error) {
// Suppress the error. It will throw again in the render phase.
} finally {
if (__DEV__) {
ReactCurrentDispatcher.current = prevDispatcher;
}
}
}
}
scheduleWork(fiber, expirationTime);
}
}useState更新时流程
updateReducer
因为useState底层是useReducer,所以在更新时的流程(即重渲染组件后)是调用updateReducer的。
function updateState<S>(
initialState: (() => S) | S,
): [S, Dispatch<BasicStateAction<S>>] {
return updateReducer(basicStateReducer, (initialState: any));
}所以其reducer十分简单
function basicStateReducer<S>(state: S, action: BasicStateAction<S>): S {
return typeof action === 'function' ? action(state) : action;
}我们先把复杂情况抛开,跑通updateReducer流程
function updateReducer(
reducer: (S, A) => S,
initialArg: I,
init?: I => S,
){
// 获取当前hook,queue
const hook = updateWorkInProgressHook();
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
// action队列的最后一个更新
const last = queue.last;
// 最后一个更新是基本状态
const baseUpdate = hook.baseUpdate;
const baseState = hook.baseState;
// 找到第一个没处理的更新
let first;
if (baseUpdate !== null) {
if (last !== null) {
// 第一次更新时,队列是一个自圆queue.last.next = queue.first。当第一次update提交后,baseUpdate不再为空即可跳出队列
last.next = null;
}
first = baseUpdate.next;
} else {
first = last !== null ? last.next : null;
}
if (first !== null) {
let newState = baseState;
let newBaseState = null;
let newBaseUpdate = null;
let prevUpdate = baseUpdate;
let update = first;
let didSkip = false;
do {
const updateExpirationTime = update.expirationTime;
if (updateExpirationTime < renderExpirationTime) {
// 优先级不足,跳过这次更新,如果这是第一次跳过更新,上一个update/state是newBaseupdate/state
if (!didSkip) {
didSkip = true;
newBaseUpdate = prevUpdate;
newBaseState = newState;
}
// 更新优先级
if (updateExpirationTime > remainingExpirationTime) {
remainingExpirationTime = updateExpirationTime;
}
} else {
// 处理更新
if (update.eagerReducer === reducer) {
// 如果更新被提前处理了且reducer跟当前reducer匹配,可以复用eagerState
newState = ((update.eagerState: any): S);
} else {
// 循环调用reducer
const action = update.action;
newState = reducer(newState, action);
}
}
prevUpdate = update;
update = update.next;
} while (update !== null && update !== first);
• if (!didSkip) {
• newBaseUpdate = prevUpdate;
• newBaseState = newState;
• }
• // 只有在前后state变了才会标记
• if (!is(newState, hook.memoizedState)) {
• markWorkInProgressReceivedUpdate();
• }
• hook.memoizedState = newState;
• hook.baseUpdate = newBaseUpdate;
• hook.baseState = newBaseState;
queue.lastRenderedState = newState;
}
const dispatch: Dispatch<A> = (queue.dispatch: any);
return [hook.memoizedState, dispatch];
}
export function markWorkInProgressReceivedUpdate() {
didReceiveUpdate = true;
}
后记
作为系列的第一篇文章,我选择了最常用的hooks开始,抛开提前计算及与react-reconciler的互动,整个流程是十分清晰易懂的。mount的时候构建钩子,触发dispatch时按序插入update。updateState的时候再按序触发reducer。可以说就是一个简单的redux。
作者:flyzz177
来源:juejin.cn/post/7184636589564231735
徒手撸一个注解框架
运行时注解主要是通过反射来实现的,而编译时注解则是在编译期间帮助我们生成代码,所以编译时注解效率高,但是实现起来复杂一点,运行时注解效率较低,但是实现起来简单。 首先来看下运行时注解怎么实现的吧。
1.运行时注解
1.1定义注解
首先定义两个运行时注解,其中Retention标明此注解在运行时生效,Target标明此注解的程序元范围,下面两个示例RuntimeBindView用于描述成员变量和类,成员变量绑定view,类绑定layout;RuntimeBindClick用于描述方法,让指定的view绑定click事件。
@Retention(RetentionPolicy.RUNTIME)//运行时生效
@Target({ElementType.FIELD,ElementType.TYPE})//描述变量和类
public @interface RuntimeBindView {
int value() default View.NO_ID;
}
@Retention(RetentionPolicy.RUNTIME)//运行时生效
@Target(ElementType.METHOD)//描述方法
public @interface RuntimeBindClick {
int[] value();
}1.2反射实现
以下代码是用反射实现的注解功能,其中ClassInfo是一个能解析处类的各种成员和方法的工具类, 源码见github.com/huangbei199… 其实逻辑很简单,就是从Activity里面取出指定的注解,然后再调用相应的方法,如取出RuntimeBindView描述类的注解,然后得到这个注解的返回值,接着调用activity的setContentView将layout的id设置进去就可以了。
public static void bindId(Activity obj){
ClassInfo clsInfo = new ClassInfo(obj.getClass());
//处理类
if(obj.getClass().isAnnotationPresent(RuntimeBindView.class)) {
RuntimeBindView bindView = (RuntimeBindView)clsInfo.getClassAnnotation(RuntimeBindView.class);
int id = bindView.value();
clsInfo.executeMethod(clsInfo.getMethod("setContentView",int.class),obj,id);
}
//处理类成员
for(Field field : clsInfo.getFields()){
if(field.isAnnotationPresent(RuntimeBindView.class)){
RuntimeBindView bindView = field.getAnnotation(RuntimeBindView.class);
int id = bindView.value();
Object view = clsInfo.executeMethod(clsInfo.getMethod("findViewById",int.class),obj,id);
clsInfo.setField(field,obj,view);
}
}
//处理点击事件
for (Method method : clsInfo.getMethods()) {
if (method.isAnnotationPresent(RuntimeBindClick.class)) {
int[] values = method.getAnnotation(RuntimeBindClick.class).value();
for (int id : values) {
View view = (View) clsInfo.executeMethod(clsInfo.getMethod("findViewById", int.class), obj, id);
view.setOnClickListener(v -> {
try {
method.invoke(obj, v);
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
}1.3使用
如下所示,将我们定义好的注解写到相应的位置,然后调用BindApi的bind函数,就可以了。很简单吧
@RuntimeBindView(R.layout.first)//类
public class MainActivity extends AppCompatActivity {
@RuntimeBindView(R.id.jump)//成员
public Button jump;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
BindApi.bindId(this);//调用反射
}
@RuntimeBindClick({R.id.jump,R.id.jump2})//方法
public void onClick(View view){
Intent intent = new Intent(this,SecondActivity.class);
startActivity(intent);
}
}2.编译时注解
编译时注解就是在编译期间帮你自动生成代码,其实原理也不难。
2.1定义注解
我们可以看到,编译时注解定义的时候Retention的值和运行时注解不同。
@Retention(RetentionPolicy.CLASS)//编译时生效
@Target({ElementType.FIELD,ElementType.TYPE})//描述变量和类
public @interface CompilerBindView {
int value() default -1;
}
@Retention(RetentionPolicy.CLASS)//编译时生效
@Target(ElementType.METHOD)//描述方法
public @interface CompilerBindClick {
int[] value();
}2.2根据注解生成代码
1)准备工作
首先我们要新建一个java的lib库,因为接下需要继承AbstractProcessor类,这个类Android里面没有。
然后我们需要引入两个包,javapoet是帮助我们生成代码的包,auto-service是帮助我们自动生成META-INF等信息,这样我们编译的时候就可以执行我们自定义的processor了。
apply plugin: 'java-library'
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
api 'com.squareup:javapoet:1.9.0'
api 'com.google.auto.service:auto-service:1.0-rc2'
}
sourceCompatibility = "1.8"
targetCompatibility = "1.8"2)继承AbstractProcessor
如下所示,我们需要自定义一个类继承子AbstractProcessor并复写他的方法,并加上AutoService的注解。 ClassElementsInfo是用来存储类信息的类,这一步先暂时不用管,下一步会详细说明。 其实从函数的名称就可以看出是什么意思,init初始化,getSupportedSourceVersion限定所支持的jdk版本,getSupportedAnnotationTypes需要处理的注解,process我们可以在这个函数里面拿到拥有我们需要处理注解的类,并生成相应的代码。
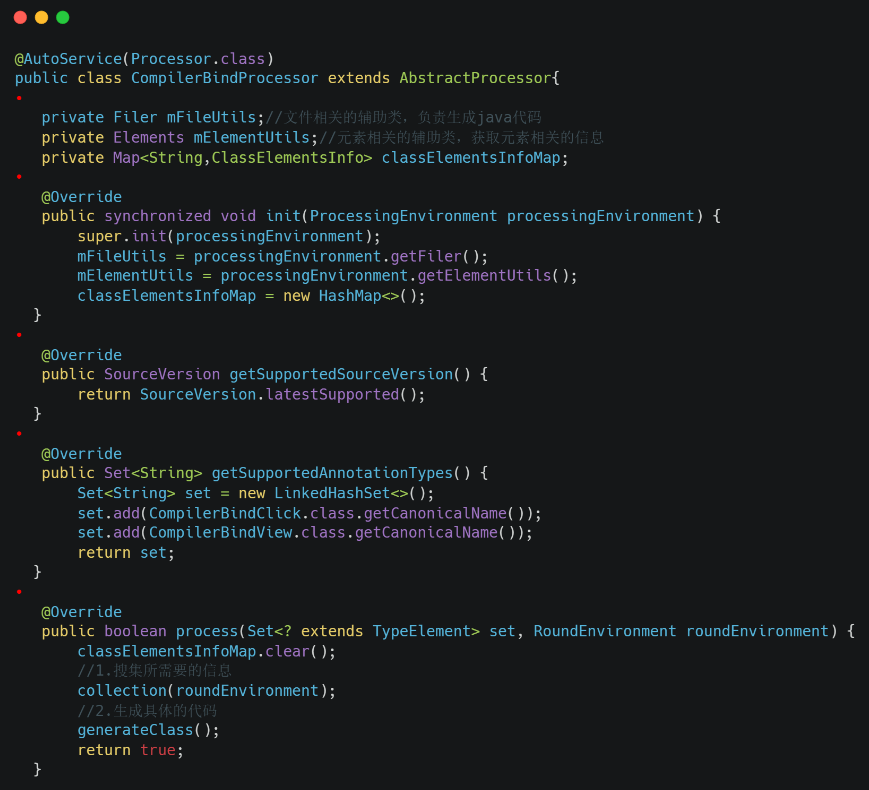
3)搜集注解
首先我们看下ClassElementsInfo这个类,也就是我们需要搜集的信息。 TypeElement为类元素,VariableElement为成员元素,ExecutableElement为方法元素,从中我们可以获取到各种注解信息。 classSuffix为前缀,例如原始类为MainActivity,注解生成的类名就为MainActivity+classSuffix
public class ClassElementsInfo {
//类
public TypeElement mTypeElement;
public int value;
public String packageName;
//成员,key为id
public Map<Integer,VariableElement> mVariableElements = new HashMap<>();
//方法,key为id
public Map<Integer,ExecutableElement> mExecutableElements = new HashMap<>();
//后缀
public static final String classSuffix = "proxy";
public String getProxyClassFullName() {
return mTypeElement.getQualifiedName().toString() + classSuffix;
}
public String getClassName() {
return mTypeElement.getSimpleName().toString() + classSuffix;
}
......
}然后我们就可以开始搜集注解信息了, 如下所示,按照注解类型一个一个的搜集,可以通过roundEnvironment.getElementsAnnotatedWith函数拿到注解元素,拿到之后再根据注解元素的类型分别填充到ClassElementsInfo当中。 其中ClassElementsInfo是存储在Map当中,key是String是classPath。
private void collection(RoundEnvironment roundEnvironment){
//1.搜集compileBindView注解
Set<? extends Element> set = roundEnvironment.getElementsAnnotatedWith(CompilerBindView.class);
for(Element element : set){
//1.1搜集类的注解
if(element.getKind() == ElementKind.CLASS){
TypeElement typeElement = (TypeElement)element;
String classPath = typeElement.getQualifiedName().toString();
String className = typeElement.getSimpleName().toString();
String packageName = mElementUtils.getPackageOf(typeElement).getQualifiedName().toString();
CompilerBindView bindView = element.getAnnotation(CompilerBindView.class);
if(bindView != null){
ClassElementsInfo info = classElementsInfoMap.get(classPath);
if(info == null){
info = new ClassElementsInfo();
classElementsInfoMap.put(classPath,info);
}
info.packageName = packageName;
info.value = bindView.value();
info.mTypeElement = typeElement;
}
}
//1.2搜集成员的注解
else if(element.getKind() == ElementKind.FIELD){
VariableElement variableElement = (VariableElement) element;
String classPath = ((TypeElement)element.getEnclosingElement()).getQualifiedName().toString();
CompilerBindView bindView = variableElement.getAnnotation(CompilerBindView.class);
if(bindView != null){
ClassElementsInfo info = classElementsInfoMap.get(classPath);
if(info == null){
info = new ClassElementsInfo();
classElementsInfoMap.put(classPath,info);
}
info.mVariableElements.put(bindView.value(),variableElement);
}
}
}
//2.搜集compileBindClick注解
Set<? extends Element> set1 = roundEnvironment.getElementsAnnotatedWith(CompilerBindClick.class);
for(Element element : set1){
if(element.getKind() == ElementKind.METHOD){
ExecutableElement executableElement = (ExecutableElement) element;
String classPath = ((TypeElement)element.getEnclosingElement()).getQualifiedName().toString();
CompilerBindClick bindClick = executableElement.getAnnotation(CompilerBindClick.class);
if(bindClick != null){
ClassElementsInfo info = classElementsInfoMap.get(classPath);
if(info == null){
info = new ClassElementsInfo();
classElementsInfoMap.put(classPath,info);
}
int[] values = bindClick.value();
for(int value : values) {
info.mExecutableElements.put(value,executableElement);
}
}
}
}
}4)生成代码
如下所示使用javapoet生成代码,使用起来并不复杂。
public class ClassElementsInfo {
......
public String generateJavaCode() {
ClassName viewClass = ClassName.get("android.view","View");
ClassName clickClass = ClassName.get("android.view","View.OnClickListener");
ClassName keepClass = ClassName.get("android.support.annotation","Keep");
ClassName typeClass = ClassName.get(mTypeElement.getQualifiedName().toString().replace("."+mTypeElement.getSimpleName().toString(),""),mTypeElement.getSimpleName().toString());
//构造方法
MethodSpec.Builder builder = MethodSpec.constructorBuilder()
.addModifiers(Modifier.PUBLIC)
.addParameter(typeClass,"host",Modifier.FINAL);
if(value > 0){
builder.addStatement("host.setContentView($L)",value);
}
//成员
Iterator<Map.Entry<Integer,VariableElement>> iterator = mVariableElements.entrySet().iterator();
while(iterator.hasNext()){
Map.Entry<Integer,VariableElement> entry = iterator.next();
Integer key = entry.getKey();
VariableElement value = entry.getValue();
String name = value.getSimpleName().toString();
String type = value.asType().toString();
builder.addStatement("host.$L=($L)host.findViewById($L)",name,type,key);
}
//方法
Iterator<Map.Entry<Integer,ExecutableElement>> iterator1 = mExecutableElements.entrySet().iterator();
while(iterator1.hasNext()){
Map.Entry<Integer,ExecutableElement> entry = iterator1.next();
Integer key = entry.getKey();
ExecutableElement value = entry.getValue();
String name = value.getSimpleName().toString();
MethodSpec onClick = MethodSpec.methodBuilder("onClick")
.addAnnotation(Override.class)
.addModifiers(Modifier.PUBLIC)
.addParameter(viewClass,"view")
.addStatement("host.$L(host.findViewById($L))",value.getSimpleName().toString(),key)
.returns(void.class)
.build();
//构造匿名内部类
TypeSpec clickListener = TypeSpec.anonymousClassBuilder("")
.addSuperinterface(clickClass)
.addMethod(onClick)
.build();
builder.addStatement("host.findViewById($L).setOnClickListener($L)",key,clickListener);
}
TypeSpec typeSpec = TypeSpec.classBuilder(getClassName())
.addModifiers(Modifier.PUBLIC)
.addAnnotation(keepClass)
.addMethod(builder.build())
.build();
JavaFile javaFile = JavaFile.builder(packageName,typeSpec).build();
return javaFile.toString();
}
}最终使用了注解之后生成的代码如下
package com.android.hdemo;
import android.support.annotation.Keep;
import android.view.View;
import android.view.View.OnClickListener;
import java.lang.Override;
@Keep
public class MainActivityproxy {
public MainActivityproxy(final MainActivity host) {
host.setContentView(2131296284);
host.jump=(android.widget.Button)host.findViewById(2131165257);
host.findViewById(2131165258).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
host.onClick(host.findViewById(2131165258));
}
});
host.findViewById(2131165257).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
host.onClick(host.findViewById(2131165257));
}
});
}
}5)让注解生效
我们生成了代码之后,还需要让原始的类去调用我们生成的代码
public class BindHelper {
static final Map<Class<?>,Constructor<?>> Bindings = new HashMap<>();
public static void inject(Activity activity){
String classFullName = activity.getClass().getName() + ClassElementsInfo.classSuffix;
try{
Constructor constructor = Bindings.get(activity.getClass());
if(constructor == null){
Class proxy = Class.forName(classFullName);
constructor = proxy.getDeclaredConstructor(activity.getClass());
Bindings.put(activity.getClass(),constructor);
}
constructor.setAccessible(true);
constructor.newInstance(activity);
}catch (Exception e){
e.printStackTrace();
}
}
}2.3调试
首先在gradle.properties里面加入如下的代码
android.enableSeparateAnnotationProcessing = true
org.gradle.daemon=true
org.gradle.jvmargs=-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=8888然后点击Edit Configurations
新建一个remote
然后填写相关的参数,127.0.0.1表示本机,port与刚才gradle.properties里面填写的保持一致,然后点击ok
然后将Select Run/Debug Configuration选项调整到刚才新建的Configuration上,然后点击Build--Rebuild Project,就可以开始调试了。
2.4使用
如下所示为原始的类
@CompilerBindView(R.layout.first)
public class MainActivity extends AppCompatActivity {
@CompilerBindView(R.id.jump)
public Button jump;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
BindHelper.inject(this);
}
@CompilerBindClick({R.id.jump,R.id.jump2})
public void onClick(View view){
Intent intent = new Intent(this,SecondActivity.class);
startActivity(intent);
}
}以下为生成的类
package com.android.hdemo;
import android.support.annotation.Keep;
import android.view.View;
import android.view.View.OnClickListener;
import java.lang.Override;
@Keep
public class MainActivityproxy {
public MainActivityproxy(final MainActivity host) {
host.setContentView(2131296284);
host.jump=(android.widget.Button)host.findViewById(2131165257);
host.findViewById(2131165258).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
host.onClick(host.findViewById(2131165258));
}
});
host.findViewById(2131165257).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
host.onClick(host.findViewById(2131165257));
}
});
}
}3.总结
注解框架看起来很高大上,其实弄懂之后也不难,都是一个套路。
作者:我是黄大仙
来源:juejin.cn/post/7180166142093656120
这可能是中国最“恨”地铁的高校,甚至写了篇论文反对地铁经过

常坐北京地铁4号线的人可能听过这样一句调侃 “坐4号线的学生谁先下车谁就输了,坚持到最后的都是学霸中的学霸。”
因为这一路会经过十多所高校,全都是名校。

虽然是个玩笑话,但很多地方的地铁都喜爱用高校名做站名。
比如2022年11月28日,深圳地铁6号线支线正式通车,其中,“深理工站”就以正在筹建的深圳理工大学来作为站名。
另一方面,大多数的高校也会有意的去争夺地铁站,一方面是方便学生出行,另一方面,地铁站命名也是一次对学校的宣传。

甚至在2021年,西安还曾发生过两高校掐架“争夺”地铁站命名的事,当时,西安地铁官网发布了14号线相关站点初步命名信息。
其中在西安北郊大学城的一站,暂被命名为“西安工业大学”。此站距离西安工业大学正门,陕西科技大学南门都非常近,仅200米左右。

这立刻引起了陕西科技大学的强烈不满。为了争取命名权,陕西科技大学先后两次和西安工业大学的校领导进行了沟通,并提出一些条件。
因为两所高校谈崩了,陕西科技大学要求旗下幼儿园方3月24日起不再接受西安工业大学子女入托。
最后,在被媒体和舆论痛批后,两所高校握手言和,解决了幼儿园不让孩子入园事件,同时,西安地铁14号线也更改了地铁站名,修改为 “西安工大·武德路站”

虽然只是一件小事,但高校间争夺地铁站命名确实不是第一次,有时候,地铁方面也会一碗水端平,把大家的校名都列上去。
比如 西工程大●西科大(临潼校区)站、

南医大●江苏经贸学院站 等。

但凡事都有例外,也有那么一些学校为了让地铁“远离”自己,还有学者专门写了论文来论证理由。
这可能真是中国最“恨”地铁的一所高校。
1 地铁和北大那些事
2018年,北京地铁4号线列车在13.5米深的地下呼啸而过,100米外北京大学信息科学技术学院大楼中,一台电子显微镜内“仿佛刮起了一阵飓风”。
用肉眼看,这台1米多高的白色金属镜筒安稳立在桌上。将它调至最高精度却会发现,显示屏上的黑白图像长了“毛刺”,原本纤毫毕现的原子图案因为振动变得模糊不清。
在北大校园内,因地铁运行受到影响的精密仪器,远不止这台价值数百万元的电镜。4号线开通时,北大有价值11亿元的精密仪器,其中4亿元的仪器受到影响。

地图上与地铁线路相邻的北京大学校园
原因很简单——交通微振动。**虽然这种振动几乎不易察觉,但对高校内的精密仪器来说,地铁几乎意味着“灾难性打击”。**
北大环境振动监测与评估实验室主任雷军,曾和学生拎着地震仪,测量过北京多条地铁线路,他们发现,在精密仪器更敏感的低频范围内,离地铁100米内地表振动强度比没有列车通过时高了30~100倍。
许多仪器的使用者并不知晓地铁振动会影响仪器。曾有同事找到雷军,抱怨实验室一台测量岩石年龄的精密仪器突然不正常了。这位老师叫来厂家,左调右调,愣是修不好,厂家也摸不着头脑。
事实上,并非仪器坏了,而是地铁4号线开通后,振动干扰了仪器。
实际上,当年在地铁4号线线路规划出来后,北大就曾和地铁公司为两个方案反复争论。
● 北大拒绝4号线地铁经过,想让地铁改线。
● 地铁公司表示,北大也可以整个搬走。
直至最后一次研讨会,双方仍僵持不下。那次会议由北京市一位副市长主持,邀请了一位院士和多位北大校外专家。
最后大家采取了一个折中方案,4号线经过北大的789米轨道段,将采用世界上最先进的轨道减振技术,也就是在钢轨下铺设钢弹簧浮置板。这种浮置板由一家德国公司发明,上面是约50厘米厚的钢筋混凝土板,下面是支撑着的钢弹簧,能将列车的振动与道床隔离。
最后北大做了妥协,这才有了后来的【北京大学东门站】。

图片来源:北京大学新闻中心
不过,4号线真的开通后,北大学者发现虽然轨道减振有用,但也不算完全有用,很多精密仪器还是会受到干扰。
最后,北大自己一合计,决定在受地铁振动影响最小的西南边的校医院旧址那盖综合科研楼,将部分受影响的仪器搬过来。在此之前,很多科研人为了能正常做实验,只能选择在地铁停运的深夜开始运行精密仪器。
谁知道一波未平一波又起,北大综合科研楼地基刚打好,正在施工时,北京地铁16号线的规划出来了,好家伙,地铁16号线将绕经北大西门,离综合科研楼仅200米。

这一次可把北大气坏了,由于校内精密仪器已无处可挪,北大开始了强烈抗议。
后面才知道,因为地铁4号线的成功,地铁方面以为减振成功了,北大也没有把自己准备盖科研楼挪仪器的事告诉地铁方,这才有了擦着北大西边而过的地铁16号线规划。
这一次,北大再次重拳出击,首先论文论证是不能少的。

北京市为此还拨出上千万元专项资金,让大家拿出一个合理的解决方案,包括地铁轨道减振、重新设计综合科研楼,考虑在低层装减振平台等等。
最后,双方谁也不愿意退让的时候,项目戛然而止。据说北大领导和一位市领导在某个会议碰面,双方握手言好。地铁16号退后一步,往西绕开300多米,甩掉两座车站,北大也不再提要求。
就这样,这场北大和地铁的交锋,双方鸣鼓收兵。
2 高校与地铁的对抗
不过,高校和地铁的对抗,北大也绝不是个例。
与北大相似的还有清华,但是在拒绝这件事上,清华更强硬了一点。
早在1955年,清华大学就曾让铁路改过线。那时候,京张铁路位于清华校园同侧,振动曾严重干扰科研,在清华的争取下,铁路线向东迁了800米。
后面,地铁15号线原计划下穿清华大学,遭清华极力反对。最终,15号线只进入清华校内120米,没与4号线相连,形成换乘站。

受地铁影响的高校还有复旦大学、南京大学、中国科学院、首都医科大学、郑州大学医学院等。
不过并不是所有的高校都拥有强大的谈判能力。要知道,一个地铁线路方案如果已落成,再挪动位置几乎是不可能的。
因此,有的985高校没太多考虑,直接在同意文件上盖了章。有的高校遭遇了损失,却不愿意公开化。
中国电子工程设计院有限公司曾表示,给复旦大学、南京大学等多个受地铁影响的高校做过减振方案。
没想到一个小小的振动,也能引起如此大的漩涡,这可能就是“地铁蝴蝶效应”吧~
本文选自募格学术。参考资料:人民资讯、中科院深圳理工大学、潇湘晨报、人民日报等。
收起阅读 »Android 字节码插桩全流程解析
1 准备工作
但凡涉及到gradle开发,我一般都是会在buildSrc文件夹下进行,还有没有伙伴不太了解buildSrc的,其实buildSrc是Android中默认的插件工程,在gradle编译的时候,会编译这个项目并配置到classpath下。这样的话在buildSrc中创建的插件,每个项目都可以引入。
在buildSrc中可以创建groovy目录(如果对groovy或者kotlin了解),也可以创建java目录,对于插件开发个人更便向使用groovy,因为更贴近gradle。
1.1 创建插件
创建插件,需要实现Plugin接口,在引入这个插件后,项目编译的时候,就会执行apply方法。
class ASMPlugin implements Plugin<Project>{
@Override
void apply(Project project) {
def ext = project.extensions.getByType(AppExtension)
if (ext != null){
ext.registerTransform(new ASMTransform())
}
}
}在apply方法中,可以执行自定义的Task,也可以执行自定义的Transform(其实也可以看做是一种特殊的Task),这里我们自定义了插桩相关的Transform。
1.2 创建Transform
什么是Transform呢?就是在class文件打包生成dex文件的过程中,对class字节码做处理,最终生成新的dex文件,那么有什么方式能够对字节码操作呢?ASM是一种方式,使用Javassist也可以织入字节码。
class ASMTransform extends Transform {
@Override
String getName() {
return "ASMTransform"
}
@Override
Set<QualifiedContent.ContentType> getInputTypes() {
return TransformManager.CONTENT_CLASS
}
@Override
Set<QualifiedContent.Scope> getScopes() {
return TransformManager.SCOPE_FULL_PROJECT
}
@Override
boolean isIncremental() {
return false
}
@Override
void transform(Context context, Collection<TransformInput> inputs, Collection<TransformInput> referencedInputs, TransformOutputProvider outputProvider, boolean isIncremental) throws IOException, TransformException, InterruptedException {
inputs.each { input ->
input.directoryInputs.each { dic ->
/**这里会拿到两个路径,分别是java代码编译后的javac/debug/classes,以及kotlin代码编译后的 tmp/kotlin-classes/debug */
println("dic path == >${dic.file.path}")
/**所有的class文件的根路径,我们已经拿到了,接下来就是分析这些文件夹下的class文件*/
findAllClass(dic.file)
/**这里一定不能忘记写*/
def dest = outputProvider.getContentLocation(dic.name, dic.contentTypes, dic.scopes, Format.DIRECTORY)
FileUtils.copyDirectory(dic.file, dest)
}
input.jarInputs.each { jar ->
/**这里也一定不能忘记写*/
def dest = outputProvider.getContentLocation(jar.name,jar.contentTypes,jar.scopes,Format.JAR)
FileUtils.copyFile(jar.file,dest)
}
}
}
/**
* 查找class文件
* @param file 可能是文件也可能是文件夹
*/
private void findAllClass(File file) {
if (file.isDirectory()) {
file.listFiles().each {
findAllClass(it)
}
} else {
modifyClass(file)
}
}
/**
* 进行字节码插桩
* @param file 需要插桩的字节码文件
*/
private void modifyClass(File file) {
println("最终的class文件 ==> ${file.absolutePath}")
/**如果不是.class文件,抛弃*/
if (!file.absolutePath.endsWith(".class")) {
return
}
/**BuildConfig.class文件以及R文件都抛弃*/
if (file.absolutePath.contains("BuildConfig.class") || file.absolutePath.contains("R")) {
return
}
doASM(file)
}
/**
* 进行ASM字节码插桩
* @param file 需要插桩的class文件
*/
private void doASM(File file) {
def fis = new FileInputStream(file)
def cr = new ClassReader(fis)
def cw = new ClassWriter(ClassWriter.COMPUTE_MAXS)
cr.accept(new ASMClassVisitor(Opcodes.ASM9, cw), ClassReader.SKIP_FRAMES | ClassReader.SKIP_DEBUG)
/**重新覆盖*/
def bytes = cw.toByteArray()
def fos = new java.io.FileOutputStream(file.absolutePath)
fos.write(bytes)
fos.flush()
fos.close()
}
}如果想要使用Transform,那么需要引入transform-api,其实在transform 1.5之后gradle就支持Transform了。
implementation 'com.android.tools.build:transform-api:1.5.0'
当执行Transform任务的时候,最终会执行到transform方法,在这个方法中可以获取TransformInput的输入,主要包括两种:文件夹和Jar包;对于Jar包,我们不需要处理,只需要拷贝到目标文件夹下即可。
对于文件夹我们是需要处理的,因为这里包含了我们要处理的.class文件,对于Java编译后的class文件是存在javac/debug/classes根文件夹下,对于kotlin编译后的class文件是存在temp/classes根文件下。
所以在整个编译的过程中,只要是.class文件都会执行doASM这个方法,在这个方法中就是我们在上节提到的对于字节码的插桩。
1.3 ASM字节码插桩
class ASMClassVisitor extends ClassVisitor {
ASMClassVisitor(int api) {
super(api)
}
@Override
MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
println("visitMethod==>$name")
/**所有的方法都会在ASMMethodVisitor中插入字节码*/
def method = super.visitMethod(access, name, descriptor, signature, exceptions)
return new ASMMethodVisitor(api, method, access, name, descriptor)
}
ASMClassVisitor(int api, ClassVisitor classVisitor) {
super(api, classVisitor)
}
@Override
FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
return super.visitField(access, name, descriptor, signature, value)
}
@Override
AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
return super.visitAnnotation(descriptor, visible)
}
}class ASMMethodVisitor extends AdviceAdapter {
private def methodName
/**
* Constructs a new {@link AdviceAdapter}.
*
* @param api the ASM API version implemented by this visitor. Must be one of {@link
* Opcodes#ASM4}, {@link Opcodes#ASM5}, {@link Opcodes#ASM6} or {@link Opcodes#ASM7}.
* @param methodVisitor the method visitor to which this adapter delegates calls.
* @param access the method's access flags (see {@link Opcodes}).
* @param name the method's name.
* @param descriptor the method's descriptor (see {@link Type Type}).
*/
protected ASMMethodVisitor(int api, MethodVisitor methodVisitor, int access, String name, String descriptor) {
super(api, methodVisitor, access, name, descriptor)
this.methodName = name
}
@Override
protected void onMethodEnter() {
super.onMethodEnter()
visitFieldInsn(GETSTATIC,
"com/lay/learn/base_net/LoggUtils",
"INSTANCE",
"Lcom/lay/learn/base_net/LoggUtils;")
visitMethodInsn(INVOKEVIRTUAL, "com/lay/learn/base_net/LoggUtils", "start", "()V", false)
}
@Override
protected void onMethodExit(int opcode) {
super.onMethodExit(opcode)
visitFieldInsn(GETSTATIC,
"com/lay/learn/base_net/LoggUtils",
"INSTANCE",
"Lcom/lay/learn/base_net/LoggUtils;")
visitLdcInsn(methodName)
visitMethodInsn(INVOKEVIRTUAL, "com/lay/learn/base_net/LoggUtils", "end", "(Ljava/lang/String;)V",false)
}
}这里就不再细说了,贴上源码大家可以借鉴一下哈。
最终在编译的过程中,对所有的方法插入了我们自己的耗时计算逻辑,当运行之后
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}虽然我们没有显示地在MainActivity的onCreate中插入耗时检测代码,但是在控制台中我们可以看到,onCreate方法耗时180ms
2022-12-28 19:50:19.243 13665-13665/com.lay.learn.asm E/LoggUtils: <init> 耗时==>0
2022-12-28 19:50:19.458 13665-13665/com.lay.learn.asm E/LoggUtils: onCreate 耗时==>180
1.4 插件配置
当我们完成一个插件之后,需要在META-INF文件夹下创建一个gradle-plugins文件夹,并在properties文件中声明插件全类名。
implementation-class=com.lay.asm.ASMPlugin
要注意插件id就是properties文件的名字。
这样只要某个工程中需要字节码插桩,只需要引入asm_plugin这个插件即可在编译的时候扫描整个工程。
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
id 'asm_plugin'
}附上buildSrc中的gradle配置文件
plugins{
id 'groovy'
}
repositories {
google()
mavenCentral()
}
dependencies {
implementation gradleApi()
implementation localGroovy()
implementation 'org.apache.commons:commons-io:1.3.2'
implementation "com.android.tools.build:gradle:7.0.3"
implementation 'com.android.tools.build:transform-api:1.5.0'
implementation 'org.ow2.asm:asm:9.1'
implementation 'org.ow2.asm:asm-util:9.1'
implementation 'org.ow2.asm:asm-commons:9.1'
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
最后需要说一点就是,在Transform任务执行时,一定要将文件夹或者jar包传递到下一级的Transform中,否则会导致apk打包时缺少文件导致apk无法运行。
链接:https://juejin.cn/post/7182178552207376421
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 惰性集合操作-序列 Sequence
集合操作函数 和 序列
在了解 Kotlin 惰性集合之前,先看一下 Koltin 标准库中的一些集合操作函数。
定义一个数据模型 Person 和 Book 类:
data class Person(val name: String, val age: Int)
data class Book(val title: String, val authors: List<String>)
filter 和 map 操作:
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
//大于 30 岁的人的名字集合列表
people.filter { it.age >= 30 }.map(Person::name)
count 操作:
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
//小于 30 岁人的个数
people.count { it.age < 30 }
flatmap 操作:
val books = listOf<Book>(
Book("Java 语言程序设计", arrayListOf("xiaowang", "xiaozhang")),
Book("Kotlin 语言程序设计", arrayListOf("xiaoli", "xiaomao")),
)
// 所有书的名字集合列表
books.flatMap { it.authors }.toList()
在上面这些函数,每做一步操作,都会创建中间集合,也就是每一步的中间结果都被临时存储在一个临时集合中。
filter 函数源码:
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
//创建一个新的集合列表
return filterTo(ArrayList<T>(), predicate)
}
public inline fun <T, C : MutableCollection<in T>> Iterable<T>.filterTo(destination: C, predicate: (T) -> Boolean): C {
for (element in this) if (predicate(element)) destination.add(element)
return destination
}map 函数源码:
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
//创建一个新的集合列表
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
如果被操作的元素过多,假设 people 或 books 超过 50个、100个,那么 函数链式调用 如:fliter{}.map{} 就会变得低效,且浪费内存。
Kotlin 为解决上面这种问题,提供了惰性集合操作 Sequence 接口。这个接口表示一个可以逐个列举的元素列表。Sequence 只提供了一个 方法, iterator,用来从序列中获取值。
public interface Sequence<out T> {
/**
* Returns an [Iterator] that returns the values from the sequence.
*
* Throws an exception if the sequence is constrained to be iterated once and `iterator` is invoked the second time.
*/
public operator fun iterator(): Iterator<T>
}
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
/**
* Creates a sequence that returns all elements from this iterator. The sequence is constrained to be iterated only once.
*
* @sample samples.collections.Sequences.Building.sequenceFromIterator
*/
public fun <T> Iterator<T>.asSequence(): Sequence<T> = Sequence { this }.constrainOnce()
序列中的元素求值是惰性的。因此,可以使用序列更高效地对集合元素执行链式操作,而不需要创建额外的集合来保存过程中产生的中间结果。关于这个惰性是怎么来的,后面再详细解释。
可以调用扩展函数 asSequence 把任意集合转换成序列,调用 toList 来做反向的转换。
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
people.asSequence().filter { it.age >= 30 }.map(Person::name).toList()
val books = listOf<Book>(
Book("Java 语言程序设计", arrayListOf("xiaowang", "xiaozhang")),
Book("Kotlin 语言程序设计", arrayListOf("xiaoli", "xiaomao")),
)
books.asSequence().flatMap { it.authors }.toList()
序列中间和末端操作
序列操作分为两类:中间的和末端的。一次中间操作返回的是另一个序列,这个新序列知道如何变换原始序列中的元素。而一次末端返回的是一个结果,这个结果可能是集合、元素、数字,或者其他从初始集合的变换序列中获取的任意对象。
中间操作始终是惰性的。
下面从例子来理解这个惰性:
listOf(1, 2, 3, 4).asSequence().map {
println("map${it}")
it * it
}.filter {
println("filter${it}")
it % 2 == 0
}上面这段代码在控制台不会输出任何内容(因为没有末端操作)。
listOf(1, 2, 3, 4).asSequence().map {
println("map${it}")
it * it
}.filter {
println("filter${it}")
it % 2 == 0
}.toList()
控制台输出:
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map1
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter1
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map2
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter4
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map3
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter9
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map4
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter16
在末端操作 .toList()的时候,map 和 filter 变换才被执行,而且元素是被逐个执行的。并不是所有元素经在 map 操作执行完成后,再执行 filter 操作。
为什么元素是逐个被执行,首先看下 toList() 方法:
public fun <T> Sequence<T>.toList(): List<T> {
return this.toMutableList().optimizeReadOnlyList()
}
public fun <T> Sequence<T>.toMutableList(): MutableList<T> {
return toCollection(ArrayList<T>())
}
public fun <T, C : MutableCollection<in T>> Sequence<T>.toCollection(destination: C): C {
for (item in this) {
destination.add(item)
}
return destination
}最后的 toCollection 方法中的 for (item in this),其实就是调用 Sequence 中的迭代器 Iterator 进行元素迭代。其中这个 this 来自于 filter,也就是使用 filter 的 Iterator 进行元素迭代。来看下 filter :
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}
internal class FilteringSequence<T>(
private val sequence: Sequence<T>,
private val sendWhen: Boolean = true,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
while (iterator.hasNext()) {
val item = iterator.next()
if (predicate(item) == sendWhen) {
nextItem = item
nextState = 1
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem
nextItem = null
nextState = -1
@Suppress("UNCHECKED_CAST")
return result as T
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext()
return nextState == 1
}
}
}filter 中又会使用上一个 Sequence 的 sequence.iterator() 进行元素迭代。再看下 map :
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}也是使用上一个 Sequence 的 sequence.iterator() 进行元素迭代。所以以此类推,最终会使用转换为 asSequence() 的源 iterator()。
下面自定义一个 Sequence 来验证上面的猜想:
listOf(1, 2, 3, 4).asSequence().mapToString {
Log.d("TestSequence","mapToString${it}")
it.toString()
}.toList()
fun <T> Sequence<T>.mapToString(transform: (T) -> String): Sequence<String> {
return TransformingStringSequence(this, transform)
}
class TransformingStringSequence<T>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> String) : Sequence<String> {
override fun iterator(): Iterator<String> = object : Iterator<String> {
val iterator = sequence.iterator()
override fun next(): String {
val next = iterator.next()
Log.d("TestSequence","next:${next}")
return transformer(next)
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
}
控制台输出:
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:1
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString1
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:2
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString2
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:3
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString3
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:4
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString4
所以这就是 Sequence 为什么在获取结果的时候才会被应用,也就是末端操作被调用的时候,才会依次处理每个元素,这也是 被称为惰性集合操作的原因。
经过一系列的 序列操作,每个元素逐个被处理,那么优先处理 filter 序列,其实可以减少变换的总次数。因为每个序列都是使用上一个序列的 sequence.iterator() 进行元素迭代。
创建序列
在集合操作上,可以使用集合直接调用 asSequence() 转换为序列。那么不是集合,有类似集合一样的变换,该怎么操作呢。
下面以求 1到100 的所有自然数之和为例子:
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
val sum = numbersTo100.sum()
println(sum)
控制台输出:
5050先看下 generateSequence 源码:
public fun <T : Any> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction)
private class GeneratorSequence<T : Any>(private val getInitialValue: () -> T?, private val getNextValue: (T) -> T?) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
var nextItem: T? = null
var nextState: Int = -2 // -2 for initial unknown, -1 for next unknown, 0 for done, 1 for continue
private fun calcNext() {
//getInitialValue 获取的到就是 generateSequence 的第一个参数 0
//getNextValue 获取到的就是 generateSequence 的第二个参数 it+1,这个it 就是 nextItem!!
nextItem = if (nextState == -2) getInitialValue() else getNextValue(nextItem!!)
nextState = if (nextItem == null) 0 else 1
}
override fun next(): T {
if (nextState < 0)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem as T
// Do not clean nextItem (to avoid keeping reference on yielded instance) -- need to keep state for getNextValue
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState < 0)
calcNext()
return nextState == 1
}
}
}上面代码其实就是创建一个 Sequence 接口实现类,并实现它的 iterator 接口方法,返回一个 Iterator 迭代器。
public fun <T> Sequence<T>.takeWhile(predicate: (T) -> Boolean): Sequence<T> {
return TakeWhileSequence(this, predicate)
}
internal class TakeWhileSequence<T>
constructor(
private val sequence: Sequence<T>,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
if (iterator.hasNext()) {
//iterator.next() 调用的就是上一个 GeneratorSequence 的 next 方法,而返回值就是它的 it+1
val item = iterator.next()
//判断条件,也就是 it <= 100 -> item <= 100
if (predicate(item)) {
nextState = 1
nextItem = item
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext() // will change nextState
if (nextState == 0)
throw NoSuchElementException()
@Suppress("UNCHECKED_CAST")
val result = nextItem as T
// Clean next to avoid keeping reference on yielded instance
nextItem = null
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext() // will change nextState
return nextState == 1
}
}
}在 TakeWhileSequence 的 next 方法中,会优先调用内部方法 calcNext,而这个方法内部又是调用 GeneratorSequence的 next方法,这样就 拿到了当前值 it+1(上一个是0+1,下一个就是1+1),拿到值后再判断 it <= 100 -> item <= 100。
public fun Sequence<Int>.sum(): Int {
var sum: Int = 0
for (element in this) {
sum += element
}
return sum
}sum 方法是序列的末端操作,也就是获取结果。for (element in this) ,调用上一个 Sequence 中的迭代器 Iterator 进行元素迭代,以此类推,直到调用 源 Sequence 中的迭代器 Iterator 进行元素迭代。
总结
Kotlin 标准库提供的集合操作函数:filter,map, flatmap 等,在操作的时候会创建存储中间结果的临时列表,当集合元素较多时,这种链式操作就会变得低效。为了解决这种问题,Kotlin 提供了惰性集合操作 Sequence 接口,只有在 末端操作被调用的时候,也就是获取结果的时候,序列中的元素才会被逐个执行,处理完第一个元素后,才会处理第二个元素,这样中间操作是被延期执行的。而且因为是顺序地去执行每一个元素,所以可以先做 filter 变换,再做 map 变换,这样有助于减少变换的总次数。
链接:https://juejin.cn/post/7184250146933178405
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
深入flutter布局约束原理
刚开始接触flutter的时候,Container组件是用得最多的。它就像HTML中的div一样普遍,专门用来布局页面的。
但是使用Container嵌套布局的时候,经常出现一些令人无法理解的问题。就如下面代码,在一个固定的容器中,子组件却铺满了全屏。
/// 例一
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}然后要加上alignment属性,子组件正常显示了,但容器还是铺满全屏。
/// 例二
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}而在容器外层添加一个Scaffold组件,它就正常显示了。
/// 例三
@override
Widget build(BuildContext context) {
return Scaffold(
body: Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
),
);
}这一切的怪异行为困扰了我很久,直到我深入了flutter布局的学习,才渐渐解开这些疑惑。
1、flutter的widget类型
flutter的widget可以分为三类,组合类ComponentWidget、代理类ProxyWidget和绘制类RenderObjectWidget
组合类:如Container、Scaffold、MaterialApp还有一系列通过继承StatelessWidget和StatefulWidget的类。组合类是我们开发过程中用得最多的组件。
代理类:InheritedWidget,功能型组件,它可以高效快捷的实现共享数据的跨组件传递。如常见的Theme、MediaQuery就是InheritedWidget的应用。
绘制类:屏幕上看到的UI几乎都会通过RenderObjectWidget实现。通过继承它,可以进行界面的布局和绘制。如Align、Padding、ConstrainedBox等都是通过继承RenderObjectWidget,并通过重写createRenderObject方法来创建RenderObject对象,实现最终的布局(layout)和绘制(paint)。
2、Container是个组合类
显而易见Container继承StatelessWidget,它是一个组合类,同时也是一个由DecoratedBox、ConstrainedBox、Transform、Padding、Align等组件组合的多功能容器。可以通过查看Container类,看出它实际就是通过不同的参数判断,再进行组件的层层嵌套来实现的。
@override
Widget build(BuildContext context) {
Widget? current = child;
if (child == null && (constraints == null || !constraints!.isTight)) {
current = LimitedBox(
maxWidth: 0.0,
maxHeight: 0.0,
child: ConstrainedBox(constraints: const BoxConstraints.expand()),
);
} else if (alignment != null) {
current = Align(alignment: alignment!, child: current);
}
final EdgeInsetsGeometry? effectivePadding = _paddingIncludingDecoration;
if (effectivePadding != null) {
current = Padding(padding: effectivePadding, child: current);
}
if (color != null) {
current = ColoredBox(color: color!, child: current);
}
if (clipBehavior != Clip.none) {
assert(decoration != null);
current = ClipPath(
clipper: _DecorationClipper(
textDirection: Directionality.maybeOf(context),
decoration: decoration!,
),
clipBehavior: clipBehavior,
child: current,
);
}
if (decoration != null) {
current = DecoratedBox(decoration: decoration!, child: current);
}
if (foregroundDecoration != null) {
current = DecoratedBox(
decoration: foregroundDecoration!,
position: DecorationPosition.foreground,
child: current,
);
}
if (constraints != null) {
current = ConstrainedBox(constraints: constraints!, child: current);
}
if (margin != null) {
current = Padding(padding: margin!, child: current);
}
if (transform != null) {
current = Transform(transform: transform!, alignment: transformAlignment, child: current);
}
return current!;
}
组合类基本不参与ui的绘制,都是通过绘制类的组合来实现功能。
3、flutter布局约束
flutter中有两种布局约束BoxConstraints盒约束和SliverConstraints线性约束,如Align、Padding、ConstrainedBox使用的是盒约束。
BoxConstraints盒约束是指flutter框架在运行时遍历整个组件树,在这过程中 「向下传递约束,向上传递尺寸」,以此来确定每个组件的尺寸和大小。
BoxConstraints类由4个属性组成,最小宽度minWidth、最大宽度maxWidth、最小高度minHeight、最大高度maxHeight。
BoxConstraints({
this.minWidth,
this.maxWidth,
this.minHeight,
this.maxHeight,
});根据这4个属性的变化,可以分为“紧约束(tight)”、“松约束(loose)”、“无界约束”、“有界约束”。
紧约束:最小宽(高)度和最大宽(高)度值相等,此时它是一个固定宽高的约束。
BoxConstraints.tight(Size size)
: minWidth = size.width,
maxWidth = size.width,
minHeight = size.height,
maxHeight = size.height;
松约束:最小宽(高)值为0,最大宽(高)大于0,此时它是一个约束范围。
BoxConstraints.loose(Size size)
: minWidth = 0.0,
maxWidth = size.width,
minHeight = 0.0,
maxHeight = size.height;
无界约束:最小宽(高)和最大宽(高)值存在double.infinity(无限)。
BoxConstraints.expand({double? width, double? height})
: minWidth = width ?? double.infinity,
maxWidth = width ?? double.infinity,
minHeight = height ?? double.infinity,
maxHeight = height ?? double.infinity;
有界约束:最小宽(高)和最大宽(高)值均为固定值。
BoxConstraints(100, 300, 100, 300)
4、Container布局行为解惑
了解了BoxConstraints布局约束,回到本文最开始的问题。
/// 例一
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}例一中,两个固定宽高的Container,为什么子容器铺满了全屏?
根据BoxConstraints布局约束,遍历整个组件树,最开始的root是树的起点,它向下传递的是一个紧约束。因为是移动设备,root即是屏幕的大小,假设屏幕宽414、高896。于是整个布局约束如下:
这里有个问题,就是Container分明已经设置了固定宽高,为什么无效?
因为父级向下传递的约束,子组件必须严格遵守。这里Container容器设置的宽高超出了父级的约束范围,就会自动被忽略,采用符合约束的值。
例一两上Container都被铺满屏幕,而最底下的红色Container叠到了最上层,所以最终显示红色。
/// 例二
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}例二也同样可以根据布局约束求证,如下图:
这里Container为什么是ConstrainedBox和Align组件?前面说过Container是一个组合组件,它是由多个原子组件组成的。根据例二,它是由ConstrainedBox和Align嵌套而成。
Align提供给子组件的是一个松约束,所以容器自身设置50宽高值是在合理范围的,因此生效,屏幕上显示的就是50像素的红色方块。ConstrainedBox受到的是紧约束,所以自身的300宽高被忽略,显示的是铺满屏幕的黄色块。
/// 例三
@override
Widget build(BuildContext context) {
return Scaffold(
body: Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
),
);
}例三中Scaffold向下传递的是一个松约束,所以黄色Container的宽高根据自身设置的300,在合理的范围内,有效。Container再向下传递的也是松约束,最终红色Container宽高为50。
这里还有个问题,怎么确定组件向下传递的是紧约束还是松约束?
这就涉及到组件的内部实现了,这里通过Align举个例。
Align是一个绘制组件,它能够进行界面的布局和绘制,这是因为Align的继承链为:
Align -> SingleChildRenderObjectWidget -> RenderObjectWidget
Align需要重写createRenderObject方法,返回RenderObject的实现,这里Align返回的是RenderPositionedBox,所以核心内容就在这个类中
class Align extends SingleChildRenderObjectWidget {
/// ...
@override
RenderPositionedBox createRenderObject(BuildContext context) {
return RenderPositionedBox(
alignment: alignment,
widthFactor: widthFactor,
heightFactor: heightFactor,
textDirection: Directionality.maybeOf(context),
);
}
/// ...
}而RenderPositionedBox类中,重写performLayout方法,该方法用于根据自身约束条件,计算出子组件的布局,再根据子组件的尺寸设置自身的尺寸,形成一个至下而上,由上到下的闭环,最终实现界面的整个绘制。
RenderPositionedBox -> RenderAligningShiftedBox -> RenderShiftedBox -> RenderBox
class RenderPositionedBox extends RenderAligningShiftedBox {
/// ...
@override
void performLayout() {
final BoxConstraints constraints = this.constraints; // 自身的约束大小
final bool shrinkWrapWidth = _widthFactor != null || constraints.maxWidth == double.infinity;
final bool shrinkWrapHeight = _heightFactor != null || constraints.maxHeight == double.infinity;
/// 存在子组件
if (child != null) {
/// 开始布局子组件
child!.layout(constraints.loosen(), parentUsesSize: true);
/// 根据子组件的尺寸设置自身尺寸
size = constraints.constrain(Size(
shrinkWrapWidth ? child!.size.width * (_widthFactor ?? 1.0) : double.infinity,
shrinkWrapHeight ? child!.size.height * (_heightFactor ?? 1.0) : double.infinity,
));
/// 计算子组件的位置
alignChild();
} else {
/// 不存在子组件
size = constraints.constrain(Size(
shrinkWrapWidth ? 0.0 : double.infinity,
shrinkWrapHeight ? 0.0 : double.infinity,
));
}
}
/// ...
}根据Align中performLayout方法的实现,可以确定该组件最终会给子组件传递一个怎么样的约束。
/// constraints.loosen提供的是一个松约束
child!.layout(constraints.loosen(), parentUsesSize: true);
/// loosen方法
BoxConstraints loosen() {
assert(debugAssertIsValid());
/// BoxConstraints({double minWidth = 0.0, double maxWidth = double.infinity, double minHeight = 0.0, double maxHeight = double.infinity})
return BoxConstraints(
maxWidth: maxWidth,
maxHeight: maxHeight,
);
}其它绘制类的组件基本跟Align大同小异,只要重点看performLayout方法的实现,即可判断出组件提供的约束条件。
总结
1、flutter的widget分为,组合类、代理类和绘制类。
2、Container是一个组合类,由DecoratedBox、ConstrainedBox、Transform、Padding、Align等绘制组件组合而成。
3、flutter中有两种布局约束BoxConstraints盒约束和SliverConstraints线性约束。
4、BoxConstraints的约束原理是: 「向下传递约束,向上传递尺寸」。
5、BoxConstraints的约束类型为:紧约束、松约束、无界约束、有界约束。
6、判断一个绘制组件的约束行为可以通过查看performLayout方法中layout传入的约束值。
链接:https://juejin.cn/post/7183549888406224955
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
IM会话列表刷新优化思考
背景
脱离业务场景讲技术方案都是耍流氓
最近接手了IM的业务,一上来就来了几个大需求,搞得有点手忙脚乱。在做需求的过程中发现,我们的会话列表(RecyclerView)居然每次更新都是notifyDataSetChanged(),因为IM的刷新频率是非常高的
大家可以想象一下微信消息列表,每来1条消息,就全局调用notifyDataSetChanged。
这里瞎猜一下,可能由于历史原因,之前设计的同学也是不得已而为之。既然发现了这个问题,那么我们如何来进行优化呢?
IM列表跟普通列表的区别
有序性:列表中的Item按时间排序,或者其他规则(置顶也是修改时间实现)
唯一性:每个会话都是唯一的,不存在重复
单item更新频率高:可以参考微信的会话列表
DiffUtil
首先想到的是DiffUtil,它用来比较两个数据集,寻找出旧数据集->新数据集的最小变化量
实现思路:
获取原始会话数据,进行排序,去重操作
采用DiffUtil自动计算新老数据集差异,自动完成定向刷新
这里只摘取DiffUtil关键使用部分,至于高级用法和更高级的用法不再赘述
class DiffMsgCallBack: DiffUtil.Callback() {
private val oldData: MutableList<MsgItem> = mutableListOf()
private val newData: MutableList<MsgItem> = mutableListOf()
//老数据集size
override fun getOldListSize(): Int {
return oldData.size
}
//新数据集size
override fun getNewListSize(): Int {
return newData.size
}
/**
* 比较的是position,被DiffUtil调用,用来判断两个对象是否是相同的Item
* 例如,如果你的Item有唯一的id字段,这个方法就 判断id是否相等
*/
override fun areItemsTheSame(oldItemPosition: Int, newItemPosition: Int): Boolean {
return oldData[oldItemPosition].id == newData[newItemPosition].id
}
/**
* 用来检查 两个item是否含有相同的数据,当前item的内容是否发生了变化,这个方法仅仅在areItemsTheSame()返回true时,才调用
*/
override fun areContentsTheSame(oldItemPosition: Int, newItemPosition: Int): Boolean {
if (oldData[oldItemPosition].id != newData[newItemPosition].id){
return false
}
if (oldData[oldItemPosition].content != newData[newItemPosition].content){
return false
}
if (oldData[oldItemPosition].time != newData[newItemPosition].time){
return false
}
return true
}
/**
* 高级用法:实现部分(partial)绑定的方法,需要配合onBindViewHolder的3个参数的方法
* 更高级用法:AsyncListDiffer+ListAdapter
*
*/
override fun getChangePayload(oldItemPosition: Int, newItemPosition: Int): Any? {
return super.getChangePayload(oldItemPosition, newItemPosition)
}SortedList
当我以为DiffUtil已经可以满足需求的时候,无意间又发现了一个SortedList。
SortedList是一个有序列表(数据集)的实现,可以保持ItemData都是有序的,并(自动)通知列表(RecyclerView)(数据集)中的更改。
搭配RecyclerView使用,去重,有序,自动定向刷新
这里也只摘取关键使用部分,具体用法不再详解
class SortListCallBack(adapter: RecyclerView.Adapter<*>?) : SortedListAdapterCallback<MsgItem>(adapter) {
/**
* 排序条件,实现排序的逻辑
*/
override fun compare(o1: MsgItem?, o2: MsgItem?): Int {
o1 ?: return -1
o2 ?: return -1
return o1.time - o2.time
}
/**
* 和DiffUtil方法一致,用来判断 两个对象是否是相同的Item。
*/
override fun areItemsTheSame(item1: MsgItem?, item2: MsgItem?): Boolean {
return item1?.id == item2?.id
}
/**
* 和DiffUtil方法一致,返回false,代表Item内容改变。会回调mCallback.onChanged()方法;
* 相同:areContentsTheSame+areItemsTheSame
*/
override fun areContentsTheSame(oldItem: MsgItem?, newItem: MsgItem?): Boolean {
if (oldItem?.id != newItem?.id){
return false
}
if (oldItem?.content != newItem?.content){
return false
}
if (oldItem?.time != newItem?.time){
return false
}
return true
}
/**
* 高级用法:实现部分绑定的方法,需要配合onBindViewHolder的3个参数的方法
*/
override fun getChangePayload(item1: MsgItem?, item2: MsgItem?): Any? {
return super.getChangePayload(item1, item2)
}
}对比
DiffUtil和SortedList是非常相似的,修改过数据后,内部持有的回调接口都是同一个:androidx.recyclerview.widget.ListUpdateCallback
/**
* An interface that can receive Update operations that are applied to a list.
* <p>
* This class can be used together with DiffUtil to detect changes between two lists.
*/
public interface ListUpdateCallback {
void onInserted(int position, int count);
void onRemoved(int position, int count);
void onMoved(int fromPosition, int toPosition);
void onChanged(int position, int count, @Nullable Object payload);DiffUtil计算出Diff或者SortedList察觉出数据集有改变后,会回调ListUpdateCallback接口的这四个方法,DiffUtil和SortedList提供的默认Callback实现中,都会通知Adapter完成定向刷新。 这就是自动定向刷新的原理
总结
DiffUtil比较两个数据源(一般是List)的差异(Diff),Callback中比对时传递的参数是 position
SortedList能完成数据集的排序和去重,Callback中比对时,传递的参数是ItemData
都能完成自动定向刷新 + 部分绑定,一种自动定向刷新的手段
DiffUtil: 检测不出重复的,会被认为是新增的
DiffUtil高级用法支持子线程中处理数据,而SortList不支持
理想与现实
2种方案都有了,是不是可以进行IM会话列表的优化了呢,答案是不能
业务需求迭代,牵一发而动全身
祖传代码,无人敢动,更别说优化了
有时候我们写代码会想着后面再优化一下,然而很多时候都不会给你优化的机会,除非重大需求变动,所以一开始设计框架的时候就要结合业务场景尽量设计的更加合理
参考文章:blog.csdn.net/zxt0601/art…
作者:掀乱书页的风
来源:juejin.cn/post/7183517773790707769
前端白屏的检测方案,让你知道自己的页面白了
前言
页面白屏,绝对是让前端开发者最为胆寒的事情,特别是随着 SPA 项目的盛行,前端白屏的情况变得更为复杂且棘手起来( 这里的白屏是指页面一直处于白屏状态 )
要是能检测到页面白屏就太棒了,开发者谁都不想成为最后一个知道自己页面白的人😥
web-see 前端监控方案,提供了 采样对比+白屏修正机制 的检测方案,兼容有骨架屏、无骨架屏这两种情况,来解决开发者的白屏之忧
知道页面白了,然后呢?
web-see 前端监控,会给每次页面访问生成一个唯一的uuid,当上报页面白屏后,开发者可以根据白屏的uuid,去监控后台查询该id下对应的代码报错、资源报错等信息,定位到具体的源码,帮助开发者快速解决白屏问题
白屏检测方案的实现流程
采样对比+白屏修正机制的主要流程:
1、页面中间取17个采样点(如下图),利用 elementsFromPoint api 获取该坐标点下的 HTML 元素
2、定义属于容器元素的集合,如 ['html', 'body', '#app', '#root']
3、判断17这个采样点是否在该容器集合中。说白了,就是判断采样点有没有内容;如果没有内容,该点的 dom 元素还是容器元素,若17个采样点都没有内容则算作白屏
4、若初次判断是白屏,开启轮询检测,来确保白屏检测结果的正确性,直到页面的正常渲染
采样点分布图(蓝色为采样点):
如何使用
import webSee from 'web-see';
Vue.use(webSee, {
dsn: 'http://localhost:8083/reportData', // 上报的地址
apikey: 'project1', // 项目唯一的id
userId: '89757', // 用户id
silentWhiteScreen: true, // 开启白屏检测
skeletonProject: true, // 项目是否有骨架屏
whiteBoxElements: ['html', 'body', '#app', '#root'] // 白屏检测的容器列表
});下面聊一聊具体的分析与实现
白屏检测的难点
1) 白屏原因的不确定
从问题推导现象虽然能成功,但从现象去推导问题却走不通。白屏发生时,无法和具体某个报错联系起来,也可能根本没有报错,比如关键资源还没有加载完成
导致白屏的原因,大致分两种:资源加载错误、代码执行错误
2) 前端渲染方式的多样性
前端页面渲染方式有多种,比如 客户端渲染 CSR 、服务端渲染 SSR 、静态页面生成 SSG 等,每种模式各不相同,白屏发生的情况也不尽相同
很难用一种统一的标准去判断页面是否白了
技术方案调研
如何设计出一种,在准确性、通用型、易用性等方面均表现良好的检测方案呢?
本文主要讨论 SPA 项目的白屏检测方案,包括有无骨架屏的两种情况
方案一:检测根节点是否渲染
原理很简单,在当前主流 SPA 框架下,DOM 一般挂载在一个根节点之下(比如 <div id="app"></div> ),发生白屏后通常是根节点下所有 DOM 被卸载,该方法通过检测根节点下是否挂载 DOM,若无则证明白屏
这是简单明了且有效的方案,但缺点也很明显:其一切建立在 白屏 === 根节点下 DOM 被卸载 成立的前提下,缺点是通用性较差,对于有骨架屏的情况束手无策
方案二:Mutation Observer 监听 DOM 变化
通过此 API 监听页面 DOM 变化,并告诉我们每次变化的 DOM 是被增加还是删除
但这个方案有几个缺陷
1)白屏不一定是 DOM 被卸载,也有可能是压根没渲染,且正常情况也有可能大量 DOM 被卸载
2)遇到有骨架屏的项目,若页面从始至终就没变化,一直显示骨架屏,这种情况 Mutation Observer 也束手无策
方案三:页面截图检测
这种方式是基于原生图片对比算法处理白屏检测的 web 实现
整体流程:对页面进行截图,将截图与一张纯白的图片做对比,判断两者是否足够相似
但这个方案有几个缺陷:
1、方案较为复杂,性能不高;一方面需要借助 canvas 实现前端截屏,同时需要借助复杂的算法对图片进行对比
2、通用性较差,对于有骨架屏的项目,对比的样张要由纯白的图片替换成骨架屏的截图
方案四:采样对比
该方法是对页面取关键点,进行采样对比,在准确性、易用性等方面均表现良好,也是最终采用的方案
对于有骨架屏的项目,通过对比前后获取的 dom 元素是否一致,来判断页面是否变化(这块后面专门讲解)
采样对比代码:
// 监听页面白屏
function whiteScreen() {
// 页面加载完毕
function onload(callback) {
if (document.readyState === 'complete') {
callback();
} else {
window.addEventListener('load', callback);
}
}
// 定义外层容器元素的集合
let containerElements = ['html', 'body', '#app', '#root'];
// 容器元素个数
let emptyPoints = 0;
// 选中dom的名称
function getSelector(element) {
if (element.id) {
return "#" + element.id;
} else if (element.className) {// div home => div.home
return "." + element.className.split(' ').filter(item => !!item).join('.');
} else {
return element.nodeName.toLowerCase();
}
}
// 是否为容器节点
function isContainer(element) {
let selector = getSelector(element);
if (containerElements.indexOf(selector) != -1) {
emptyPoints++;
}
}
onload(() => {
// 页面加载完毕初始化
for (let i = 1; i <= 9; i++) {
let xElements = document.elementsFromPoint(window.innerWidth * i / 10, window.innerHeight / 2);
let yElements = document.elementsFromPoint(window.innerWidth / 2, window.innerHeight * i / 10);
isContainer(xElements[0]);
// 中心点只计算一次
if (i != 5) {
isContainer(yElements[0]);
}
}
// 17个点都是容器节点算作白屏
if (emptyPoints == 17) {
// 获取白屏信息
console.log({
status: 'error'
});
}
}
}白屏修正机制
若首次检测页面为白屏后,任务还没有完成,特别是手机端的项目,有可能是用户网络环境不好,关键的JS资源或接口请求还没有返回,导致的页面白屏
需要使用轮询检测,来确保白屏检测结果的正确性,直到页面的正常渲染,这就是白屏修正机制
白屏修正机制图例:
轮询代码:
// 采样对比
function sampling() {
let emptyPoints = 0;
……
// 页面正常渲染,停止轮询
if (emptyPoints != 17) {
if (window.whiteLoopTimer) {
clearTimeout(window.whiteLoopTimer)
window.whiteLoopTimer = null
}
} else {
// 开启轮询
if (!window.whiteLoopTimer) {
whiteLoop()
}
}
// 通过轮询不断修改之前的检测结果,直到页面正常渲染
console.log({
status: emptyPoints == 17 ? 'error' : 'ok'
});
}
// 白屏轮询
function whiteLoop() {
window.whiteLoopTimer = setInterval(() => {
sampling()
}, 1000)
}骨架屏
对于有骨架屏的页面,用户打开页面后,先看到骨架屏,然后再显示正常的页面,来提升用户体验;但如果页面从始至终都显示骨架屏,也算是白屏的一种
骨架屏示例:
骨架屏的原理
无论 vue 还是 react,页面内容都是挂载到根节点上。常见的骨架屏插件,就是基于这种原理,在项目打包时将骨架屏的内容直接放到 html 文件的根节点中
有骨架屏的html文件:
骨架屏的白屏检测
上面的白屏检测方案对有骨架屏的项目失灵了,虽然页面一直显示骨架屏,但判断结果页面不是白屏,不符合我们的预期
需要通过外部传参明确的告诉 SDK,该页面是不是有骨架屏,如果有骨架屏,通过对比前后获取的 dom 元素是否一致,来实现骨架屏的白屏检测
完整代码:
/**
* 检测页面是否白屏
* @param {function} callback - 回到函数获取检测结果
* @param {boolean} skeletonProject - 页面是否有骨架屏
* @param {array} whiteBoxElements - 容器列表,默认值为['html', 'body', '#app', '#root']
*/
export function openWhiteScreen(callback, { skeletonProject, whiteBoxElements }) {
let _whiteLoopNum = 0;
let _skeletonInitList = []; // 存储初次采样点
let _skeletonNowList = []; // 存储当前采样点
// 项目有骨架屏
if (skeletonProject) {
if (document.readyState != 'complete') {
sampling();
}
} else {
// 页面加载完毕
if (document.readyState === 'complete') {
sampling();
} else {
window.addEventListener('load', sampling);
}
}
// 选中dom点的名称
function getSelector(element) {
if (element.id) {
return '#' + element.id;
} else if (element.className) {
// div home => div.home
return ('.' + element.className.split(' ').filter(item => !!item).join('.'));
} else {
return element.nodeName.toLowerCase();
}
}
// 判断采样点是否为容器节点
function isContainer(element) {
let selector = getSelector(element);
if (skeletonProject) {
_whiteLoopNum ? _skeletonNowList.push(selector) : _skeletonInitList.push(selector);
}
return whiteBoxElements.indexOf(selector) != -1;
}
// 采样对比
function sampling() {
let emptyPoints = 0;
for (let i = 1; i <= 9; i++) {
let xElements = document.elementsFromPoint(
(window.innerWidth * i) / 10,
window.innerHeight / 2
);
let yElements = document.elementsFromPoint(
window.innerWidth / 2,
(window.innerHeight * i) / 10
);
if (isContainer(xElements[0])) emptyPoints++;
// 中心点只计算一次
if (i != 5) {
if (isContainer(yElements[0])) emptyPoints++;
}
}
// 页面正常渲染,停止轮训
if (emptyPoints != 17) {
if (skeletonProject) {
// 第一次不比较
if (!_whiteLoopNum) return openWhiteLoop();
// 比较前后dom是否一致
if (_skeletonNowList.join() == _skeletonInitList.join())
return callback({
status: 'error'
});
}
if (window._loopTimer) {
clearTimeout(window._loopTimer);
window._loopTimer = null;
}
} else {
// 开启轮训
if (!window._loopTimer) {
openWhiteLoop();
}
}
// 17个点都是容器节点算作白屏
callback({
status: emptyPoints == 17 ? 'error' : 'ok',
});
}
// 开启白屏轮训
function openWhiteLoop() {
if (window._loopTimer) return;
window._loopTimer = setInterval(() => {
if (skeletonProject) {
_whiteLoopNum++;
_skeletonNowList = [];
}
sampling();
}, 1000);
}
}如果不通过外部传参,SDK 能否自己判断是否有骨架屏呢? 比如在页面初始的时候,根据根节点上有没有子节点来判断
因为这套检测方案需要兼容 SSR 服务端渲染的项目,对于 SSR 项目来说,浏览器获取 html 文件的根节点上已经有了 dom 元素,所以最终采用外部传参的方式来区分
总结
这套白屏检测方案是从现象推导本质,可以覆盖绝大多数 SPA 项目的应用场景
小伙们若有其他检测方案,欢迎多多讨论与交流 💕
作者:海阔_天空
来源:juejin.cn/post/7176206226903007292
Android App封装 —— 实现自己的EventBus
背景
在项目中我们经常会遇到跨页面通信的需求,但传统的EventBus都有各自的缺点,如EventBus和RxBus需要自己管理生命周期,比较繁琐,基于LiveData的Bus切线程比较困难等。于是我参考了一些使用Flow实现EventBus的文章,结合自身需求,实现了极简的EventBus。
EventBus
EventBus是用于 Android 和 Java 的发布/订阅事件总线。Publisher可以将事件Event post给每一个订阅者Subscriber中接收,从而达到跨页面通信的需求。
可以看出EventBus本身就是一个生产者消费者模型,而在我们第一篇搭建MVI框架的时候,用到的Flow天然就支持生产者和消费者模型,所以我们可以自己用Flow搭建一个自己的EventBus
基于Flow搭建EventBus
根据EventBus的架构图,我们来用Flow搭建,需要定义一下几点
- 定义事件Event
- 发送者 Publisher 如何发送事件
- 如何存储Event并且分发
- 如何订阅事件
1. 定义事件
sealed class Event {
data class ShowInit(val msg: String) : Event()
}这个和之前搭建MVI框架类似,用一个sleaed class和data class或者object来定义事件,用来传递信息
2. 发送事件
fun post(event: Event, delay: Long = 0) {
...
}发送事件定义一个这样的函数就可以了,传入事件和延迟时间
3. 存储Event并且分发
对于同一种Event,我们可以用一个SharedFlow来存储,依次发送给订阅方。而在整个App中,我们会用到各种不同种类的Event,所以这时候我们就需要用到HashMap去存储这些Event了。数据结构如下:
private val flowEvents = ConcurrentHashMap<String, MutableSharedFlow<Event>>()
4. 订阅事件
inline fun <reified T : Event> observe(
lifecycleOwner: LifecycleOwner,
minState: Lifecycle.State = Lifecycle.State.CREATED,
dispatcher: CoroutineDispatcher = Dispatchers.Main,
crossinline onReceived: (T) -> Unit
)lifecycleOwner,用来定义订阅者的生命周期,这样我们就不需要额外管理注册与反注册了minState,定义执行订阅的生命周期Statedispatcher,定义执行所在的线程onReceived,收到Event后执行的Lamda
使用
//任何地方
FlowEventBus.post(Event.ShowInit("article init"))
// Activity或者Fragment中
FlowEventBus.observe<Event.ShowInit>(this, Lifecycle.State.STARTED) {
binding.button.text = it.msg
}完整代码
object FlowEventBus {
//用HashMap存储SharedFlow
private val flowEvents = ConcurrentHashMap<String, MutableSharedFlow<Event>>()
//获取Flow,当相应Flow不存在时创建
fun getFlow(key: String): MutableSharedFlow<Event> {
return flowEvents[key] ?: MutableSharedFlow<Event>().also { flowEvents[key] = it }
}
// 发送事件
fun post(event: Event, delay: Long = 0) {
MainScope().launch {
delay(delay)
getFlow(event.javaClass.simpleName).emit(event)
}
}
// 订阅事件
inline fun <reified T : Event> observe(
lifecycleOwner: LifecycleOwner,
minState: Lifecycle.State = Lifecycle.State.CREATED,
dispatcher: CoroutineDispatcher = Dispatchers.Main,
crossinline onReceived: (T) -> Unit
) = lifecycleOwner.lifecycleScope.launch(dispatcher) {
getFlow(T::class.java.simpleName).collect {
lifecycleOwner.lifecycle.whenStateAtLeast(minState) {
if (it is T) onReceived(it)
}
}
}
}链接:https://juejin.cn/post/7182399245859684412
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 —— DI框架 Hilt?Koin?
背景
前面的项目Github wanandroid例子我们可以看到,我们创建Repository和ViewModel的时候,都是直接创建的
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
private val mWanRepo = HomeRepository()
...
}
class MainActivity : BaseActivity<ActivityMainBinding>() {
override fun onCreate(savedInstanceState: Bundle?) {
mViewModel = ViewModelProvider(this).get(MainViewModel::class.java)
}
}但是一般一个repository会被多个viewModel使用,我们不想创建多个同样类型的repository实例,这时候我们需要将WanRepository设置为单例。但是当代码越来越多,对象的共享、依赖关系以及生命周期越来越复杂的时候,我们全部自己手写显然是比较复杂的。
所以Goolge强推我们使用DI(Dependency Injection)依赖注入来管理对象的创建,之前推出了强大的Dagger,但是由于难学难用,很少有人用到这个框架。后面又推出了Hilt,基于Dagger实现,针对于Android平台简化了使用方式,原理和Dagger是一致的。
本来准备将Hilt引用到项目中,后来发现了一个轻量级的DI框架koin,两者学习对比了一下之后还是决定使用Koin这个轻量级的框架,koin和Hilt的详细对比就不在此展开了,网上有很多文章。
那么就开始动工,准备在项目中集成koin吧。
koin
koin官网,官网永远是学习一个东西的最佳途径
1. 依赖
网上看到很多koin的使用案例,我看依赖的都是2.X的包
implementation "org.koin:koin-android:$koin_version"
implementation "org.koin:koin-android-viewmodel:$koin_version"
后面我去官网看了下文档,发现koin已经升级到3.x了,合并所有 Scope/Fragment/ViewModel API,只需要引用一个包就可以了
implementation "io.insert-koin:koin-android:$koin_version" //3.3.1
2. 启动
添加好依赖后,可以在Application中启动koin,初始化koin的配置,代码如下
class App : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
//开始启动koin
androidLogger()
androidContext(this@App)//这边传Application对象,这样你注入的类中,需要app对象的时候,可以直接使用
modules(appModule)//这里面传各种被注入的模块对象,支持多模块注入
}
}
}3. 模块Module
上文中的modules(appModule),是用来配置koin使用的Module有哪些,那么Module是什么呢?
Koin是以Module的形式组织依赖项,我们可以将可能用到的依赖项定义在Module中,也就是对象的提供者
val repoModule = module {
single { HomeRepository() }
}
val viewModelModule = module {
viewModel { MainViewModel(get()) }
}
val appModule = listOf(viewModelModule, repoModule)
上面这段代码就是定义了两个Module,一个我专门用来定义repository,一个专门用来定义viewModel。
然后通过get()、inject(),表示在需要注入依赖项,也就是对象的使用者,这时就会在Module里面检索对应的类型,然后自动注入。
所以之前Repository的创建变为
val mWanRepo: HomeRepository by inject(HomeRepository::class.java)
并且依据single定义为了单例
进一步简化可以将repository写到ViewModel的构造方法中
class MainViewModel(private val homeRepo: HomeRepository) : BaseViewModel<MainState, MainIntent>() {
...
}
根据viewModel { MainViewModel(get()) }的定义,在构造MainViewModel的时候会自动因为get()填充HomeRepository对象
4. Activity中使用ViewModel
class MainActivity : BaseActivity<ActivityMainBinding>() {
private val mViewModel by viewModel<MainViewModel>()
}总结
koin和Hilt,大家可以看自己的习惯使用,Hilt的特点主要是利用注解生成代码,使用方便,效率也挺高的。koin我主要是看中它比较轻量级,可以快速入门使用。
项目地址:Github wanandroid。
链接:https://juejin.cn/post/7179151577864175671
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 —— ViewBinding
一、背景
在前面的Github wanandroid项目中可以看到,我获取控件对象还是用的findviewbyId
button = findViewById(R.id.button)
viewPager = findViewById(R.id.view_pager)
recyclerView = findViewById(R.id.recycler_view)
现在肯定是需要对这个最常用的获取View的findViewById代码进行优化,主要是有两个原因
过于冗余
findViewById对应所有的View都要书写findViewById(R.id.xxx)的方法,代码过于繁琐
不安全
强制转换不安全,findViewById获取到的是一个View对象,是需要强转的,一旦类型给的不对则会出现异常,比如将TextView错转成ImageView
所以我们需要一个框架解决这个问题,大致是有三个方案
二、方案
方案一 butterkniife
这个应该很多人都用过,由大大佬JakeWharton开发,通过注解生成findViewById的代码来获取对应的View。
@BindView(R.id.button)
EditText mButton;但是2020年3月份,大佬已在GitHub上说明不再维护,推荐使用 ViewBinding了。
方案二 kotlin-android-extensions(KAE)
kotlin-android-extensions只需要直接引入布局可以直接使用资源Id访问View,节省findviewbyid()。
import kotlinx.android.synthetic.main.<布局>.*
button.setOnClickListener{...} 但是这个插件也已经被Google废弃了,会影响效率并且安全性和兼容性都不太友好,Google推荐ViewBinding替代
方案三 ViewBinding
既然都推荐ViewBinding,那现在来看看ViewBinding是啥。官网是这么说的
通过ViewBinding功能,您可以更轻松地编写可与视图交互的代码。在模块中启用视图绑定之后,系统会为该模块中的每个 XML 布局文件生成一个绑定类。绑定类的实例包含对在相应布局中具有 ID 的所有视图的直接引用。在大多数情况下,视图绑定会替代 findViewById。
简而言之就是就是替代findViewById来获取View的。那我们来看看ViewBinding如何使用呢?
三、ViewBinding使用
1. 条件
确保你的Android Studio是3.6或更高的版本
ViewBinding在 Android Studio 3.6 Canary 11 及更高版本中可用
2. 启用ViewBinding
在模块build.gradle文件android节点下添加如下代码
android {
viewBinding{
enabled = true
}
}Android Studio 4.0 中,viewBinding 变成属性被整合到了 buildFeatures 选项中,所以配置要改成:
// Android Studio 4.0
android {
buildFeatures {
viewBinding = true
}
}配置好后就已经启用好了ViewBinding,重新编译后系统会为每个布局生成对应的Binding类,类中包含布局ID对应的View引用,并采取驼峰式命名。
3. 使用
以activity举例,我们的MainActivity的布局是activity_main,之前我们布局代码是:
class MainActivity : BaseActivity() {
private lateinit var button: Button
private lateinit var viewPager: ViewPager2
private lateinit var recyclerView: RecyclerView
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
button = findViewById(R.id.button)
button.setOnClickListener { ... }
}
}现在就要改为
- 对应的Binding类如ActivityMainBinding类去用inflate加载布局
- 然后通过getRoot获取到View
- 将View传入到setContentView(view:View)中
Activity就能显示activity_main.xml这个布局的内容了,并可以通过Binding对象直接访问对应View对象。
class MainActivity : BaseActivity() {
private lateinit var mBinding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
mBinding = ActivityMainBinding.inflate(layoutInflater)
setContentView(mBinding.root)
mBinding.button.setOnClickListener { ... }
}
}而在其他UI elements中,如fragment、dialog、adapter中,使用方式大同小异,都是通过inflate去加载出View,然后后面加以使用。
四、原理
生成的类可以在/build/generated/data_binding_base_class_source_out下找到
public final class ActivityMainBinding implements ViewBinding {
@NonNull
private final ConstraintLayout rootView;
@NonNull
public final Button button;
@NonNull
public final RecyclerView recyclerView;
@NonNull
public final ViewPager2 viewPager;
private ActivityMainBinding(@NonNull ConstraintLayout rootView, @NonNull Button button,
@NonNull RecyclerView recyclerView, @NonNull ViewPager2 viewPager) {
this.rootView = rootView;
this.button = button;
this.recyclerView = recyclerView;
this.viewPager = viewPager;
}
@Override
@NonNull
public ConstraintLayout getRoot() {
return rootView;
}
@NonNull
public static ActivityMainBinding inflate(@NonNull LayoutInflater inflater) {
return inflate(inflater, null, false);
}
@NonNull
public static ActivityMainBinding inflate(@NonNull LayoutInflater inflater,
@Nullable ViewGroup parent, boolean attachToParent) {
View root = inflater.inflate(R.layout.activity_main, parent, false);
if (attachToParent) {
parent.addView(root);
}
return bind(root);
}
@NonNull
public static ActivityMainBinding bind(@NonNull View rootView) {
// The body of this method is generated in a way you would not otherwise write.
// This is done to optimize the compiled bytecode for size and performance.
int id;
missingId: {
id = R.id.button;
Button button = ViewBindings.findChildViewById(rootView, id);
if (button == null) {
break missingId;
}
id = R.id.recycler_view;
RecyclerView recyclerView = ViewBindings.findChildViewById(rootView, id);
if (recyclerView == null) {
break missingId;
}
id = R.id.view_pager;
ViewPager2 viewPager = ViewBindings.findChildViewById(rootView, id);
if (viewPager == null) {
break missingId;
}
return new ActivityMainBinding((ConstraintLayout) rootView, button, recyclerView, viewPager);
}
String missingId = rootView.getResources().getResourceName(id);
throw new NullPointerException("Missing required view with ID: ".concat(missingId));
}
}可以看到关键的方法就是这个bind方法,里面通过ViewBindings.findChildViewById获取View对象,而继续查看这个方法
public class ViewBindings {
private ViewBindings() {
}
/**
* Like `findViewById` but skips the view itself.
*
* @hide
*/
@Nullable
public static <T extends View> T findChildViewById(View rootView, @IdRes int id) {
if (!(rootView instanceof ViewGroup)) {
return null;
}
final ViewGroup rootViewGroup = (ViewGroup) rootView;
final int childCount = rootViewGroup.getChildCount();
for (int i = 0; i < childCount; i++) {
final T view = rootViewGroup.getChildAt(i).findViewById(id);
if (view != null) {
return view;
}
}
return null;
}
}可见还是使用的findViewById,ViewBinding这个框架只是帮我们在编译阶段自动生成了这些findViewById代码,省去我们去写了。
五、优缺点
优点
- 对比kotlin-extension,可以控制访问作用域,kotlin-extension可以访问不是该布局下的view;
- 对比butterknife,减少注解以及id的一对一匹配
- 兼容Kotlin、Java;
- 官方推荐。
缺点
- 增加编译时间,因为ViwBinding是在编译时生成的,会产生而外的类,增加包的体积;
- include的布局文件无法直接引用,需要给include给id值,然后间接引用;
整体来说ViewBinding的优点还是远远大于缺点的,所以可以放心使用。
六、 封装
既然选择了方案ViewBinding,那我们要在项目中使用,肯定还需要对他加一些封装,我们可以用泛型封装setContentView的代码
abstract class BaseActivity<T : ViewBinding> : AppCompatActivity() {
private lateinit var _binding: T
protected val binding get() = _binding;
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
_binding = getViewBinding()
setContentView(_binding.root)
initViews()
initEvents()
}
protected abstract fun getViewBinding(): T
open fun initViews() {}
open fun initEvents() {}
}class MainActivity : BaseActivity<ActivityMainBinding>() {
override fun getViewBinding() = ActivityMainBinding.inflate(layoutInflater)
override fun initViews() {
binding.button.setOnClickListener {
...
}
}
}这样在Activity中使用起来就很方便,fragment也可以做类似的封装
abstract class BaseFragment<T : ViewBinding> : Fragment() {
private var _binding: T? = null
protected val binding get() = _binding!!
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?
): View? {
_binding = getViewBinding(inflater, container)
return binding.root
}
protected abstract fun getViewBinding(inflater: LayoutInflater, container: ViewGroup?): T
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
}注意:
这里会发现Fragment和Activity的封装方式不一样,没有用lateinit。
因为binding变量只有在onCreateView与onDestroyView才是可用的,而fragment的生命周期和activity的不同,fragment可以超出其视图的生命周期,比如fragment hide的时候,如果不将这里置为空,有可能引起内存泄漏。
所以我们要在onCreateView中创建,onDestroyView置空。
七、总结
ViewBinding相比优点还是很多的,解决了安全性问题和兼容性问题,所以我们可以放心大胆的使用。
项目源码地址: Github wanandroid
链接:https://juejin.cn/post/7177673339517796413
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 ——架构(MVI + kotlin + Flow)
一、背景
最近看了好多MVI的文章,原理大多都是参照google发布的 应用架构指南,但是实现方式有很多种,就想自己封装一套自己喜欢用的MVI架构,以供以后开发App使用。
说干就干,准备对标“玩Android”,利用提供的数据接口,搭建一个自己习惯使用的一套App项目,项目地址:Github wanandroid。
二、MVI
先简单说一下MVI,从MVC到MVP到MVVM再到现在的MVI,google是为了一直解决痛点所以不断推出新的框架,具体的发展流程就不多做赘诉了,网上有好多,我们可以选择性适合自己的。
应用架构指南中主要的就是两个架构图:
2.1 总体架构
Google推荐的是每个应用至少有两层:
- UI Layer 界面层: 在屏幕上显示应用数据
- Data Layer 数据层: 提供所需要的应用数据(通过网络、文件等)
- Domain Layer(optional)领域层/网域层 (可选):主要用于封装数据层的逻辑,方便与界面层的交互,可以根据User Case
图中主要的点在于各层之间的依赖关系是单向的,所以方便了各层之间的单元测试
2.2 UI层架构
UI简单来说就是拿到数据并展示,而数据是以state表示UI不同的状态传送给界面的,所以UI架构分为
- UI elements层:UI元素,由
activity、fragment以及包含的控件组成 - State holders层: state状态的持有者,这里一般是由
viewModel承担
2.3 MVI UI层的特点
MVI在UI层相比与MVVM的核心区别是它的两大特性:
- 唯一可信数据源
- 数据单向流动。
从图中可以看到,
- 数据从Data Layer -> ViewModel -> UI,数据是单向流动的。ViewModel将数据封装成
UI State传输到UI elements中,而UI elements是不会传输数据到ViewModel的。 - UI elements上的一些点击或者用户事件,都会封装成
events事件,发送给ViewModel
2.4 搭建MVI要注意的点
了解了MVI的原理和特点后,我们就要开始着手搭建了,其中需要解决的有以下几点
- 定义
UI State、events - 构建
UI State单向数据流UDF - 构建事件流
events UI State的订阅和发送
三、搭建项目
3.1 定义UI State、events
我们可以用interface先定义一个抽象的UI State、events,event和intent是一个意思,都可以用来表示一次事件。
@Keep
interface IUiState
@Keep
interface IUiIntent
然后根据具体逻辑定义页面的UIState和UiIntent。
data class MainState(val bannerUiState: BannerUiState, val detailUiState: DetailUiState) : IUiState
sealed class BannerUiState {
object INIT : BannerUiState()
data class SUCCESS(val models: List<BannerModel>) : BannerUiState()
}
sealed class DetailUiState {
object INIT : DetailUiState()
data class SUCCESS(val articles: ArticleModel) : DetailUiState()
}通过MainState将页面的不同状态封装起来,从而实现唯一可信数据源
3.2 构建单向数据流UDF
在ViewModel中使用StateFlow构建UI State流。
_uiStateFlow用来更新数据uiStateFlow用来暴露给UI elements订阅
abstract class BaseViewModel<UiState : IUiState, UiIntent : IUiIntent> : ViewModel() {
private val _uiStateFlow = MutableStateFlow(initUiState())
val uiStateFlow: StateFlow<UiState> = _uiStateFlow
protected abstract fun initUiState(): UiState
protected fun sendUiState(copy: UiState.() -> UiState) {
_uiStateFlow.update { copy(_uiStateFlow.value) }
}
}class MainViewModel : BaseViewModel<MainState, MainIntent>() {
override fun initUiState(): MainState {
return MainState(BannerUiState.INIT, DetailUiState.INIT)
}
}3.3 构建事件流
在ViewModel中使用 Channel构建事件流
_uiIntentFlow用来传输Intent- 在viewModelScope中开启协程监听
uiIntentFlow,在子ViewModel中只用重写handlerIntent方法就可以处理Intent事件了 - 通过sendUiIntent就可以发送Intent事件了
abstract class BaseViewModel<UiState : IUiState, UiIntent : IUiIntent> : ViewModel() {
private val _uiIntentFlow: Channel<UiIntent> = Channel()
val uiIntentFlow: Flow<UiIntent> = _uiIntentFlow.receiveAsFlow()
fun sendUiIntent(uiIntent: UiIntent) {
viewModelScope.launch {
_uiIntentFlow.send(uiIntent)
}
}
init {
viewModelScope.launch {
uiIntentFlow.collect {
handleIntent(it)
}
}
}
protected abstract fun handleIntent(intent: IUiIntent)
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
override fun handleIntent(intent: IUiIntent) {
when (intent) {
MainIntent.GetBanner -> {
requestDataWithFlow()
}
is MainIntent.GetDetail -> {
requestDataWithFlow()
}
}
}
}3.4 UI State的订阅和发送
3.4.1 订阅UI State
在Activity中订阅UI state的变化
- 在
lifecycleScope中开启协程,collectuiStateFlow。 - 使用
map来做局部变量的更新 - 使用
distinctUntilChanged来做数据防抖
class MainActivity : BaseMVIActivity() {
private fun registerEvent() {
lifecycleScope.launchWhenStarted {
mViewModel.uiStateFlow.map { it.bannerUiState }.distinctUntilChanged().collect { bannerUiState ->
when (bannerUiState) {
is BannerUiState.INIT -> {}
is BannerUiState.SUCCESS -> {
bannerAdapter.setList(bannerUiState.models)
}
}
}
}
lifecycleScope.launchWhenStarted {
mViewModel.uiStateFlow.map { it.detailUiState }.distinctUntilChanged().collect { detailUiState ->
when (detailUiState) {
is DetailUiState.INIT -> {}
is DetailUiState.SUCCESS -> {
articleAdapter.setList(detailUiState.articles.datas)
}
}
}
}
}
}3.4.2 发送Intent
直接调用sendUiIntent就可以发送Intent事件
button.setOnClickListener {
mViewModel.sendUiIntent(MainIntent.GetBanner)
mViewModel.sendUiIntent(MainIntent.GetDetail(0))
}3.4.3 更新Ui State
调用sendUiState发送Ui State更新
需要注意的是: 在UiState改变时,使用的是copy复制一份原来的UiState,然后修改变动的值。这是为了做到 “可信数据源”,在定义MainState的时候,设置的就是val,是为了避免多线程并发读写,导致线程安全的问题。
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
private val mWanRepo = WanRepository()
override fun initUiState(): MainState {
return MainState(BannerUiState.INIT, DetailUiState.INIT)
}
override fun handleIntent(intent: IUiIntent) {
when (intent) {
MainIntent.GetBanner -> {
requestDataWithFlow(showLoading = true,
request = { mWanRepo.requestWanData() },
successCallback = { data -> sendUiState { copy(bannerUiState = BannerUiState.SUCCESS(data)) } },
failCallback = {})
}
is MainIntent.GetDetail -> {
requestDataWithFlow(showLoading = false,
request = { mWanRepo.requestRankData(intent.page) },
successCallback = { data -> sendUiState { copy(detailUiState = DetailUiState.SUCCESS(data)) } })
}
}
}
}其中 requestDataWithFlow 是封装的一个网络请求的方法
protected fun <T : Any> requestDataWithFlow(
showLoading: Boolean = true,
request: suspend () -> BaseData<T>,
successCallback: (T) -> Unit,
failCallback: suspend (String) -> Unit = { errMsg ->
//默认异常处理
},
) {
viewModelScope.launch {
val baseData: BaseData<T>
try {
baseData = request()
when (baseData.state) {
ReqState.Success -> {
sendLoadUiState(LoadUiState.ShowMainView)
baseData.data?.let { successCallback(it) }
}
ReqState.Error -> baseData.msg?.let { error(it) }
}
} catch (e: Exception) {
e.message?.let { failCallback(it) }
}
}
}至此一个MVI的框架基本就搭建完毕了
3.5运行效果
四、 总结
不管是MVC、MVP、MVVM还是MVI,主要就是View和Model之间的交互关系不同
- MVI的核心是 数据的单向流动
- MVI使用kotlin flow可以很方便的实现 响应式编程
- MV整个View只依赖一个State刷新,这个State就是 唯一可信数据源
目前搭建了基础框架,后续还会在此项目的基础上继续封装jetpack等更加完善这个项目。
链接:https://juejin.cn/post/7177619630050000954
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
产品经理不靠谱怎么办
一、产品和开发之争
开发和产品宿命的争斗由来已久,倏然就是一对天敌。
平安产品掐架事件
在刚毕业那会,还不知道产品具体是干啥的时候,就听到了不少产品和开发打架的事情。印象最深的,就是平安产品开发掐架事件了。起因是产品经理提了一个需求,要求APP开发人员可以做到根据用户的手机壳来改变手机软件主题,面对这样的需求,开发自然是要起义的。
真假分辨不是重点,从争论的热点而言可知,就这件事情而言,争论的原因是需求不符合常理。开发做的事情只是对世界建模而不是无中生有。而我们作为开发,平时和产品决斗最多的情况,是对于时间资源之争。产品混乱的开发节奏,不符合逻辑的需求,不合理的时间安排,不重点的优先级安排。
而且很多时候,产品的职位是要比开发的高的,话语权更加的高,会让他们更加的肆无忌惮,可恨!
拿我之前公司的真实的例子来说,产品所谓的需求文档都是短短几句话;一个迭代周期内从来没有按照原订计划上线计划的功能,各种小需求,拍脑袋的需求随意插入。前者,总监对这种行为的解释是需要开发和产品共同去参与设计,相互残缺不漏,不说开发得不到第一手信息,但是你的时间可还是有限的,工资也不是不涨的。后者直接导致了开发的加班。
为什么会有这些不靠谱的产品经理呢?
根本还是我的问题,我没有能力轻易的选择自己工作环境🙃
其次才是他们专业程度不够,被培训机构忽悠的,人人都是产品经理,门槛低工资还高,上可以直接对话老板,下可以指挥程序员,所以导致了什么阿猫阿狗都涌入。
但是产品的门槛其实很高的。他们需要很强逻辑能力, 整理出来的需求需要逻辑自洽, 需要思考用户的操作体验,需要思考人力资源的分配。面对老板、市场、业务方抛来的‘建议’,能够甄别出什么是功能,什么是需求,然后制定出合理的优先级。在敏捷项目中,还要制定迭代的计划,顶得住上面的压力,压得服下面的开发。
其中涉及到的专业技能有社会心理学、管理学、软件工程管理、用户画像学、以及一定的开发基础、一定的设计基础、一定的运营基础。
这些东西的难度不是程序员用计算机能够模拟的,不然为什么会有智障的小爱同学、小冰同学、siri。
根本的目的是为了解决问题
当然,本篇文章依旧《10x程序员》目的并不是为了抨击产品多么多么的不靠谱。就像郑晔老师所说,如果从不靠谱的数量来说,程序员是比产品多得多得。第一是因为程序员基数就比产品的多,第二也是因为万物皆可转码导致的。培训班培养几个月就出来工作了,他能有多强的编程能力?
只是从整个市场来看,当然还是有很多转行的,培训出来的很强的人。
这篇文章的目的,是为了解决点那个我们碰到这些不靠谱的产品经理的时候,我们应该如何怎么办?
首先要知道产品和开发的战争是因何而战的。
二、争论的真相是什么
争论的原因
产品和开发相互攻击是解决不了任何问题的。为了解决争斗,我们首先需要知道到底是争什么?为何而争。方能对症下药。
我们常常会出现下面这样的一个场景:
产品:我们需要一个单点登录的界面。输入账号密码就可以进行我们的界面。
开发:好的
一天时间,界面和交互逻辑,接口哗哗做完。
开发:东西做完了,你来看看
产品:??? 验证码呢?
开发:你又没说
产品:这个不是常识么?
开发:。。。。
又是半天时间,验证码搞定
产品:这个项目是放在门户下面,登录的功能不是应该在门户上面做么?现在跳转到别的项目还需要重新登陆,你怎么想的?
开发:顶你个肺,一开始怎么不说是这个场景
产品:你又没问。。。
🔪 🙎♂️
这是由于双方信息不同步的导致的。如果一开始开发就问:
这个需求的用户是谁?
这个需求的使用场景在哪里?
我想问题就会拖到后面了。开发必须要有自己的独立思考,多问几个为什么,才能够减少掉进坑中的次数。
双方的知识储备不一样,双方掌握的信息不一样,得到的结论自然也不一样。
所以这就需要我们在一个信息平台上,才能够沟通得有效率。
而这就需要我们双方都能有一个很好的沟通能力。也需要我们开发多张十个心眼,默认产品都是不靠谱的。多问几个为什么,不要害怕问题幼稚。如果产品都能够一一回应,而且逻辑自洽的话,那么恭喜你,你碰到了一个不错的产品。
有一句话说得好,当你和一个人谈话谈得很开心的时候,很可能是因为对方的段位比你高,他在向下兼容。
当然,出现上面的那些问题,也由于现在解决的问题不再是明确的,常常范围模糊,别说产品自己,业务用户也不知道自己想要什么?这个无形中提高了产品的门槛,还提高了需要软件设计师的架构能力,需要提前布局。
软件开发的主流由面向确定性问题,逐渐变成了面向不确定性问题。为了应付这个问题,敏捷开发这个最佳实践就应运而生。到了中国就变成了“田园敏捷”🐶,需求不明确,所有需求都是P0级。 为了解决这个问题,我们产品和开发能够在有效的资源中做些什么呢?这就不得不提到敏捷开发中两个很重要的阶段,需求澄清和需求反澄清,如果是开发负责人还需要参加需求准入。
沟通的真正目的是什么
先简单的介绍一些敏捷开发流程:
两周一迭代,在进入开发之前,产品内部需要先过一遍需求,随后根据列的需求和开发负责人讨论需求准入,开发负责人会根据人力资源来和产品共同商量,这个迭代可以上的内容。
到需求澄清,这个是全体人员都参加,产品一一说需求的逻辑,开发可以提问。
之后就到了需求反澄清,这个阶段是开发在说自己对于需求的开发,以及开发的思路。随后进入开发阶段。开发完成,向产品show case, 测试通过之后前后端封版。
封完版提发布工单,然后才进行反版。在这个阶段还包括了每日的站会过需求,还有发版之后的回顾会。
如时间表下图:
从图片可以看到对于开发两个重要的节点,一个是需求澄清,另外一个是需求反澄清。前者是产品在说,开发问。后者是开发在说,产品再问。这两个就是一个很好的拉平双方认知的机会。 这两个沟通的机会至关重要,是有效减少之后扯皮的关键节点。这就需要我们知道如何有效的进行沟通了。
唯心主义不是贬义,而是一个客观的事实。具体表现就在于,这个客观世界和我们所想象的总是不一样的。同样的,由于每个人认知的世界是不一样的,所以信息的传递是会衰减的,你不可能把你理解的信息 100% 传递给另外一个人,而这中间,如何传递,也就是如何描述将直接决定衰减的比例。
可以根据书中信息论模型来进行解释:
幻化为人的沟通的话。人的脑子就是信源,携带着信息到发送器,发送器通过自己的表达通过声带发送给对方,对方接受到信息还需要转译一遍进行自己的大脑。在传送的中间过程,还有噪声源,这个噪声源可以是物理环境认为的嘈杂,也可以认为是双方因为地位的不同,导致的思维方式的不同的噪声。
根据这个例子,可以用下面这张图来表示上面争论的原因:
扮演不同角色的时候,我们的思考模式是不同的。上图是产品作为信源,而开发作为信宿,反之亦然。
作为信源的话,我们将自己脑中的信息通过嘴巴表达出去的过程,是受限于知识储备和表达能力的。也就是说如果我们的知识储备足够的多,表达能力足够的强的话,在发送信息到对方的闹钟的时候,偏差自然也会更加的小。
作为信宿的话,我们开发作为接受的一方,需要提高自己的知识边界,主要是了解业务的前因后果,尽可能的提升解码的能力。
综上所述,我们沟通的目的是为了同步信息,减少对于需求的理解的偏差。而沟通出来的结果,就是共同确立一个验收的标准。
只有验收的标准确定下来之后,才可以最到限度的减少后期扯皮的可能性。
那么我们作为开发需要怎么做呢?
开发需要做什么
开发在需求澄清的时候,其他问题都可以不问,但是这两个问题一定要搞清楚。
需求的背景是什么
需求能够给用户带来什么业务的价值
前者是为了理解业务的前因后果,当自己当成产品经理,让需求的逻辑能够自洽。后者是换位自己作为一个用户,以用户的视角来看问题。这也和我们公司以用户导向的价值观相符。
在需求反澄清的时候,作为一个前端工程师,我们最低限度的需要出两个东西,一个是API的设计文档,另外一个就是数据走向图。这个数据走向图我的前一篇文章《vue的业务开发如何进行组件化》中进行过阐述,具体可以去那篇文章看看。
敏捷开发不代表文档的缺失。
我曾经把产品问懵逼之后,把需求都砍了一大半。也间接实现了最好维护的代码。
我的目的不是为了砍需求,而是为了写出全世界最好维护的代码,即不用的代码。
三、抛弃固有印象
在程序员眼里:
产品一般都没逻辑、缺乏交流基础(没常识)、没能力没主见;
在产品经理眼里:
程序员通常属于严重沟通障碍、缺乏用户和产品意识、只考虑技术、没有大局观。
抛弃这些固有的刻板印象,沟通和理解更为重要。作为开发不能因为一时的占了上风,就沾沾自喜,大快人心,觉得压了产品一头。爽归爽了,你的工资可还是没动的。班还是要加的。所以解决问题才是主要的目的,不管工作中,还是生活中。 而这就要求我们:
加强专业知识的学习,
增加对彼此工作领域的认知,
用逻辑而非借口来说服对方。
开发可以去考考PMP证书,虽然都说没有含金量,但是你得过了才有资格来说这句话。作为前端还可以去学学基础的美学设计。总的来说就是要扩展自己的知识边界。
而且,大家都是打工人,成年人了,我们要知道矛盾的根源是什么?真的是产品的不靠谱和开发的沟通障碍么?或许不见得。
四、矛盾的根源
之前刷知乎看到过程墨大佬的一段话,记了下来:
在我国,产品经理和研发工程师的核心冲突,是“有限的开发资源”与“无限制的目标”之间的矛盾。 “有限的开发资源”在研发工程师这一边,人力是有限的,人的工作时间是有限的,人的耐心是有限的,人能够做的事情是有限的。
“无限制的目标”在产品经理这一边,无数量限制的需求变更,无规则限制的产品设计流程,无时间限制的工期规划……
怎么解决?
要么提供更多的开发资源,也就是招更多更合格的工程师;要么就让产品经理对自己的行为做更多限制,让产品设计和规划按照客观规律办事。
当然,说到底两者之间的矛盾的根源是我国特色资本主义的内部矛盾,一方面想让团队跑得快,一方面又没有本事进行合理管理,最后产品经理和程序员打架,世人在骂产品经理无能程序员暴躁,其实归根结底是上面人无能而已。
五、一个问题
我之前面试,被问我这么一个问题:
一个需求你评估完成的时间需要两周,但是产品最多只能给你一周的时间,你怎么办?
那场面试虽然过了,但是我没有收到对于我说的答案的评价。所以很好奇大家的答案是什么😂
作者:我是小橘子哦
来源:juejin.cn/post/7175444771173826615
微信开放小程序运行SDK,我们的App可以跑小程序了
前言
这几天看到微信团队推出了一个名为 Donut 的小程序原生语法开发移动应用框架,通俗的讲就是将微信小程序的能力开放给其他的企业,第三方的 App 也能像微信一样运行小程序了。
其实不止微信,面对潜力越来越大的 B 端市场,阿里早期就开放了这样产品——mPaas,只不过阿里没有做太多的宣传推广,再加上并没有兼容市面中占比和使用范围最大的微信小程序,所以一直处于不温不火的状态。
今天就主要对比分析下目前市面上这类产品的技术特点及优劣。
有这些产品
目前这类产品有一个统一的技术名称:小程序容器技术。
小程序容器顾名思义,是一个承载小程序的运行环境,可主动干预并进行功能扩展,达到丰富能力、优化性能、提升体验的目的。
目前我已知的技术产品包括:mPaas、FinClip、uniSDK 以及上周微信团队才推出的 Donut。下面我们就一一初略讲下各自的特点。
他们的特点
1、mPaas
mPaaS是源于支付宝 App 的移动开发平台,为移动开发、测试、运营及运维提供云到端的一站式解决方案,能有效降低技术门槛、减少研发成本、提升开发效率,协助企业快速搭建稳定高质量的移动 App。
mPaaS 提供了包括 App 开发、H5 开发、小程序开发的能力,只要按照其文档可以开发 App,而且可以在其开发的 App 上跑 H5、也可跑基于支付宝小程序标准开发的的小程序。
由于行业巨头之间互不对眼,目前 mPaas 仅支持阿里生态的小程序,不能直接兼容例如微信、百度、字节等其他生态平台的小程序。
2、FinClip
FinClip是一款小程序容器,不论是移动 App,还是电脑、电视、车载主机等设备,在集成 FinClip SDK 之后,都能快速获得运行小程序的能力。
提供小程序 SDK 和小程序管理后台,开发者可以将已有的小程序迁移部署在自有 App 中,从而获得足够灵活的小程序开发与管理体验。
FinClip 兼容微信小程序语法,提供全套的的小程序开发管理套件,开发者不需要学习新的语法和框架,使用 FinClip IDE、小程序管理后台、小程序开发文档、FinClip App就能低成本高质量地完成从开发测试,到预览部署的全部工作。
3、Donut
Donut多端框架是支持使用小程序原生语法开发移动应用的框架,开发者可以一次编码,分别编译为小程序和 Android 以及 iOS 应用,实现多端开发。
基于该框架,开发者可以将小程序构建成可独立运行的移动应用,也可以将小程序构建成运行于原生应用中的业务模块。该框架还支持条件编译,开发者可灵活按需构建多端应用模块,可更好地满足企业在不同业务场景下搭建移动应用的需求。
4、uniSDK
Uni-app小程序 SDK,是为原生 App 打造的可运行基于 uni-app 开发的小程序前端项目的框架,从而帮助原生 App 快速获取小程序的能力。uni 小程序 SDK 是原生SDK,提供 Android 版本 和 iOS 版本,需要在原生工程中集成,然后即可运行用uni-app框架开发的小程序前端项目。
Unisdk是 uni-app 小程序生态中的一部分,开发者 App 集成了该 SDK 之后,就可以在自有 App 上面跑起来利用 uni-app 开发的小程序。
优劣势对比
1、各自的优势
mPaas
大而全,App开发、H5开发、小程序开发一应俱全;
技术产品来源于支付宝,背靠蚂蚁金服有大厂背书;
兼容阿里系的小程序,例如支付宝、钉钉、高德、淘宝等;
拥有小程序管理端、云端服务。
FinClip
小而巧,只专注小程序集成,集成SDK后体积增加3M左右,提供小程序全生命周期的管理 ;
提供小程序转 App 服务,能够一定程度解决 App 开发难的问题;
几个产品中唯一支持企业私有化部署的,可进行定制化开发,满足定制化需求;
兼容微信小程序,之前开发者已拥有的微信小程序,可无缝迁移至 FinClip;
多端支持:iOS、Android、Windows、macOS、Linux,国产信创、车载操作系统。
Donut
微信的亲儿子,对微信小程序兼容度有其他厂商无可比拟的优势(但也不是100%兼容微信小程序);
提供小程序转 App 服务,能够一定程度解决 App 开发难的问题;
体验分析支持自动接入功能,无需修改代码即可对应用中的所有元素进行埋点;
提供丰富的登录方法:微信登录、苹果登录、验证码登录等。
uniSDK
开源社区,众人拾柴火焰高;
uniapp 开发小程序可迁移至微信、支付宝、百度等平台之上,如果采用 uni 小程序 SDK,之后采用 uni-app 开发小程序,那么就可以实现一次开发,多端上架;
免费不要钱。
2、各自的不足
mPaas
小程序管理略简单,没有小程序全生命周期的管理;
App 集成其 SDK 之后,体积会扩大 30M 左右;
不兼容微信小程序,之前微信开发的小程序,需要用支付宝小程序的标准进行重写才可迁移到 mPaaS 上;
目前只支持 iOS 与 Android 集成,不支持其他端。
FinClip
没有对应的移动应用开发平台,只专注于做小程序;
生态能力相较于其他三者相对偏弱,但兼容微信语法可一定程度补齐;
暂不支持 Serveless 服务;
产品快速迭代,既有惊喜,也有未知。
Donut
对小程序的数量、并发数、宽带上限等有比较严格的规定;
目前仅处于 beta 阶段,使用过程有一定 bug 感;
集成后体积增加明显,核心 SDK 500 MB,地图 300 MB;
没有小程序全生命周期的管理;
目前仅支持 iOS 与 Android 集成,不支持其他端。
uniSDK
开源社区,质量由开源者背书,在集成、开发过程当中出现问题,bug解决周期长;
uni 小程序 SDK 仅支持使用 uni-app 开发的小程序,不支持纯 wxml 微信小程序运行;
目前 uni 小程序 SDK 仅支持在原生 App 中集成使用,暂不支持 HBuilderX 打包生成的 App 中集成;
目前只支持 iOS 与 Android 集成,不支持其他端。
以上就是关于几个小程序容器的测评分析结果,可以看出并没有完美的选择,每个产品都有自己的一些优势和不足,选择适合自己的就是最好的。希望能给需要的同学一定的参考,如果你有更好的选择欢迎交流讨论。
作者:Finbird
来源:juejin.cn/post/7181301359554068541
Java系列 | 远程热部署在美团的落地实践
1 前言
1.1 什么是热部署
所谓热部署,就是在应用正在运行时升级软件,却不需要重新启动应用。对于Java应用程序来说,热部署就是在运行时更新Java类文件,同时触发Spring以及其他常用第三方框架的一系列重新加载的过程。在这个过程中不需要重新启动,并且修改的代码实时生效,好比是战斗机在空中完成加油,不需要战斗机熄火降落,一系列操作都在“运行”状态来完成。
1.2 为什么我们需要热部署
据了解,美团内部很多工程师每天本地重启服务高达5~12次,单次大概3~8分钟,每天向Cargo(美团内部测试环境管理工具)部署3~5次,单次时长20~45分钟,部署频繁频次高、耗时长,严重影响了系统上线的效率。而插件提供的本地和远程热部署功能,可让将代码变更“秒级”生效。一般而言,开发者日常工作主要分为开发自测和联调两个场景,下面将分别介绍热部署在每个场景中发挥的作用。

1.2.1 开发自测场景
一般来讲,在用插件之前,开发者修改完代码还需等待3~8分钟启动时间,然后手动构造请求或协调上游发请求,耗时且费力。在使用完热部署插件后,修改完代码可以一键增量部署,让变更“秒级”生效,能够做到快速自测。而对于那些无法本地启动项目,也可以通过远程热部署功能使代码变更“秒级”生效。

1.2.2 联调场景
通常情况下,在使用插件之前,开发者修改代码经过20~35分钟的漫长部署,需要联系上游联调开发者发起请求,一直要等到远程服务器查看日志,才能确认代码生效。在使用热部署插件之后,开发者修改代码远程热部署能够秒级(2~10s)生效,开发者直接发起服务调用,可以节省大量的碎片化时间(热部署插件还具备流量回放、远程调用、远程反编译等功能,可配合进行使用)。

所以,热部署插件希望解决的痛点是:在可控的条件内,帮助开发者减少频繁编译部署的次数,节省碎片化的时间。最终为开发者每天节约出一定量的编码时间。
1.3 热部署难在哪
为什么业界目前没有好用的开源工具?因为热部署不等同于热重启,像Tomcat或者Spring Boot DevTools此类热重启模式需要重新加载项目,性能较差。增量热部署难度较大,需要兼容常用的中间件版本,需要深入启动销毁加载流程。以美团为例,我们需要对JPDA(Java Platform Debugger Architecture)、Java Agent、ASM字节码增强、Classloader、Spring框架、Spring Boot框架、MyBatis框架、Mtthrift(美团RPC框架)、Zebra(美团持久层框架)、Pigeon(美团RPC框架),MDP(美团快速开发框架)、XFrame(美团快速开发脚手架)、Crane(美团分布式任务调度框架)等众多框架和技术原理深入了解才能做到全面的兼容和支持。另外,还需要IDEA插件开发能力,形成整体的产品解决方案闭环,美团的热部署插件Sonic正是在这种背景下应运而生。

1.4 Sonic可以做什么
Sonic是美团内部研发设计的一款IDEA插件,旨在通过低代码开发辅助远程/本地热部署,解决Coding、单测编写执行、自测联调等阶段的效率问题,提高开发者的编码产出效率。数据统计表明,开发者日常大概有35%时间用于编码的产出。如果想提高研发效率,要么扩大编码产出的时间占比,要么提高编码阶段的产出效率,而Sonic则聚焦提高编码阶段的产出效率。
目前,使用Sonic热部署可以解决大部分代码重复构建的问题。Sonic可以使用户在本地编写代码一键部署到远程环境,修改代码、部署、联调请求、查看日志,循环反复。如果不考虑代码修改时间,通常一个循环需要20~35分钟,而使用Sonic可以把整个时长缩短至5~10秒,而且能够给开发者带来高效沉浸式的开发体验。在实际编码工作中,多文件修改是家常便饭,Sonic对多文件的热部署能力尤为突出,它可以通过依赖分析等手段来对多文件批量进行远程热部署,并且支持Spring Bean Class、普通Class、Spring XML、MyBatis XML等多类型文件混合热部署。
那么跟业界现有的产品相比,Sonic有哪些优劣势呢?下面我们尝试给出几种产品的对比,仅供大家参考:
| 特性 | JRebel | Spring Boot DevTools | IDEA热加载 | Tomcat热加载 | Spring Loader | Sonic |
|---|---|---|---|---|---|---|
| 远程Debug | 基于Debug协议修改 | ❌ | ❌ | ❌ | ❌ | ✅ |
| 修改方法体内容 | ✅ | ✅效率低 | ✅ | ✅效率低 | ✅ | ✅ |
| 新增方法体 | ✅ | ✅效率低 | ❌ | ✅效率低 | ✅ | ✅ |
| Jar包变更 | ✅ | ✅效率低 | ❌ | ✅效率低 | ✅ | ✅ |
| Spring MVC | ✅ | ✅效率低 | ❌ | ✅效率低 | ✅ | ✅ |
| 多文件热部署 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 新增泛型方法 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 新增非静态字段 | ✅ | ✅效率低 | ❌ | ✅效率低 | ✅ | ✅ |
| 新增静态字段 | ✅ | ✅效率低 | ❌ | ✅效率低 | ✅ | ✅ |
| 新增修改继承类 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 新增修改接口方法 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 新增修改匿名内部类 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 增加修改静态块 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| FastJson | ❌ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Cglib | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| MyBatis Annotation | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| MyBatis XML | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Gson | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Jackson | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Jdk代理 | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Log4j | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Slf4J | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Logback | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Spring Tx | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Spring 新增Xml | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Spring Bean | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Spring Boot | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| Spring Validator | ✅ | ✅效率低 | ❌ | ✅效率低 | ❌ | ✅ |
| 远程热部署 | 配置繁琐 | ❌ | ❌ | ❌ | ❌ | ✅ |
| IDEA插件集成 | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ |
上表未把Sofa-Ark、Osgi、Arthas列举,此类属于插件化、模块化应用框架,以及Java在线诊断工具,核心能力非热部署。值得注意的是,Spring Boot DevTools只能应用在Spring Boot项目中,并且它不是增量热部署,而是通过Classloader迭代的方式重启项目,对大项目而言,性能上是无法接受的。虽然,JRebel支持三方插件较多,生态庞大,但是对于国产的插件不支持,例如FastJson等,同时它还存在远程热部署配置局限,对于公司内部的中间件需要个性化开发,并且是商业软件,整体的使用成本较高。
1.5 Sonic远程热部署落地推广的实践经验
相信大家都知道,对于技术产品的推广,尤其是开发、测试阶段使用的产品,由于远离线上环境,推动力、执行力、产品功能闭环能否做好,是决定着该产品是否能在企业内部落地并得到大多数人认可的重要的一环。此外,因为很多开发者在开发、测试阶段已逐渐形成了“固化动作”,如何改变这些用户的行为,让他们拥抱新产品,也是Sonic面临的艰巨挑战之一。我们从主动沟通、零成本(或极低成本)快速接入、自动化脚本,以及产品自动诊断、收集反馈等方向出发,践行出了四条原则。

2 整体设计方案
2.1 Sonic结构
Sonic插件由4大部分组成,包括脚本端、插件端、Agent端,以及Sonic服务端。脚本端负责自动化构建Sonic启动参数、服务启动等集成工作;IDEA插件端集成环境为开发者提供更便捷的热部署服务;Agent端随项目启动负责热部署的功能实现;服务端则负责收集热部署信息、失败上报等统计工作。如下图所示:

2.2 走进Agent
2.2.1 Instrumentation类常用API
public interface Instrumentation {
//增加一个Class 文件的转换器,转换器用于改变 Class 二进制流的数据,参数 canRetransform 设置是否允许重新转换。
void addTransformer(ClassFileTransformer transformer, boolean canRetransform);
//在类加载之前,重新定义 Class 文件,ClassDefinition 表示对一个类新的定义,
//如果在类加载之后,需要使用 retransformClasses 方法重新定义。addTransformer方法配置之后,后续的类加载都会被Transformer拦截。
//对于已经加载过的类,可以执行retransformClasses来重新触发这个Transformer的拦截。类加载的字节码被修改后,除非再次被retransform,否则不会恢复。
void addTransformer(ClassFileTransformer transformer);
//删除一个类转换器
boolean removeTransformer(ClassFileTransformer transformer);
//是否允许对class retransform
boolean isRetransformClassesSupported();
//在类加载之后,重新定义 Class。这个很重要,该方法是1.6 之后加入的,事实上,该方法是 update 了一个类。
void retransformClasses(Class<?>... classes) throws UnmodifiableClassException;
//是否允许对class重新定义
boolean isRedefineClassesSupported();
//此方法用于替换类的定义,而不引用现有的类文件字节,就像从源代码重新编译以进行修复和继续调试时所做的那样。
//在要转换现有类文件字节的地方(例如在字节码插装中),应该使用retransformClasses。
//该方法可以修改方法体、常量池和属性值,但不能新增、删除、重命名属性或方法,也不能修改方法的签名
void redefineClasses(ClassDefinition... definitions) throws ClassNotFoundException, UnmodifiableClassException;
//获取已经被JVM加载的class,有className可能重复(可能存在多个classloader)
@SuppressWarnings("rawtypes")
Class[] getAllLoadedClasses();
}2.2.2 Instrument简介
Instrument的底层实现依赖于JVMTI(JVM Tool Interface),它是JVM暴露出来的一些供用户扩展的接口集合,JVMTI是基于事件驱动的,JVM每执行到一定的逻辑就会调用一些事件的回调接口(如果存在),这些接口可以供开发者去扩展自己的逻辑。
JVMTIAgent是一个利用JVMTI暴露出来的接口提供了代理启动时加载(Agent On Load)、代理通过Attach形式加载(Agent On Attach)和代理卸载(Agent On Unload)功能的动态库。而Instrument Agent可以理解为一类JVMTIAgent动态库,别名是JPLISAgent(Java Programming Language Instrumentation Services Agent),也就是专门为Java语言编写的插桩服务提供支持的代理。
2.2.3 启动时和运行时加载Instrument Agent过程

2.3 那些年JVM和HotSwap之间的“相爱相杀”
围绕着Method Body的HotSwap JVM一直在进行改进。从1.4版本开始,JPDA引入HotSwap机制(JPDA Enhancements),实现Debug时的Method Body的动态性。大家可参考文档:enhancements1.4 。
1.5版本开始通过JVMTI实现的java.lang.instrument(Java Platform SE 8)的Premain方式,实现Agent方式的动态性(JVM启动时指定Agent)。大家可参考文档:package-summary。
1.6版本又增加Agentmain方式,实现运行时动态性(通过The Attach API 绑定到具体VM)。大家可参考文档:package-summary 。基本实现是通过JVMTI的retransformClass/redefineClass进行method、body级的字节码更新,ASM、CGLib基本都是围绕这些在做动态性。但是针对Class的HotSwap一直没有动作(比如Class添加method、添加field、修改继承关系等等),为什么会这样呢?因为复杂度过高,且没有很高的回报。
2.4 Sonic如何解决Instrumentation的局限性
由于JVM限制,JDK 7和JDK 8都不允许改类结构,比如新增字段,新增方法和修改类的父类等,这对于Spring项目来说是致命的。比如开发同学想修改一个Spring Bean,新增一个@Autowired字段,此类场景在实际应用时很多,所以Sonic对此类场景的支持必不可少。
那么,具体是如何做到的呢?这里要提一下“大名鼎鼎”的Dcevm。Dcevm(DynamicCode Evolution Virtual Machine)是Java Hostspot的补丁(严格上来说是修改),允许(并非无限制)在运行环境下修改加载的类文件。当前虚拟机只允许修改方法体(Method,Body),而Decvm可以增加、删除类属性、方法,甚至改变一个类的父类,Dcevm是一个开源项目,遵从GPL 2.0协议。更多关于Dcevm的介绍,大家可以参考:Wuerthinger10a以及GitHub Decvm。
值得一提的是,在美团内部,针对Dcevm的安装,Sonic已经打通HULK,集成发布镜像即可完成(本地热部署可结合插件功能实现一键安装热部署环境)。
3 Sonic热部署技术解析
3.1 Sonic整体架构模型
上一章节我们主要介绍了Sonic的组成。下图详细介绍了Sonic在运行期间各个组成部分的工作职责,由它们形成一整套完备的技术产品落地闭环方案:

3.2 Sonic功能流转
Sonic通过NIO监听本地文件变更,触发文件变更事件,例如Class新增、Class修改、Spring Bean重载等事件流程。下图展示了一次热部署单个文件的生命周期:

3.3 文件监听
Sonic首先会在本地和远程预定义两个目录,/var/tmp/sonic/extraClasspath和/var/tmp/sonic/classes。extraClasspath为Sonic自定义的拓展Classpath URL,classes为Sonic监听的目录,当有文件变更时,通过IDEA插件来部署到远程/本地,触发Agent的监听目录,来继续下面的热加载逻辑:

为什么Sonic不直接替换用户ClassPath下面的资源文件呢?因为考虑到业务方WAR包的API项目、Spring Boot、Tomcat项目、Jetty项目等,都是以JAR包来启动的,这样是无法直接修改用户的Class文件的。即使是用户项目可以修改,直接操作用户的Class,也会带来一系列的安全问题。
所以,Sonic采用拓展ClassPath URL路径来实现文件的修改和新增。并且存在这么一种场景,多个业务侧的项目引入相同的JAR包,在JAR里面配置MyBatis的XML和注解。在此类情况下,Sonic没有办法直接来修改JAR包中源文件,通过拓展路径的方式可以不需要关注JAR包,来修改JAR包中某一文件和XML。同理,采用此类方法可以进行整个JAR包的热替换。下面我们简单介绍一下Sonic的核心监听器,如下图所示:

3.4 JVM Class Reload
JVM的字节码批量重载逻辑,通过新的字节码二进制流和旧的Class对象生成ClassDefinition定义,instrumentation.redefineClasses(definitions),来触发JVM重载,重载过后将触发初始化时Spring插件注册的Transfrom。接下来,我们简单讲解一下Spring是怎么重载的。
新增class Sonic如何保证可以加载到Classloader上下文中?由于项目在远程执行,所以运行环境复杂,有可能是JAR包方式启动(Spring Boot),也有可能是普通项目,也有可能是War Web项目,针对此类情况Sonic做了一层Classloader URL拓展。

User ClassLoader是框架自定义的ClassLoader统称,例如Jetty项目是WebAppclassLoader。其中Urlclasspath为当前项目的lib文件件下,例如Spring Boot项目也是从当前项目BOOT-INF/lib/路径中加载CLass等等,不同框架的自定义位置稍有不同。所以针对此类情况,Agent必须拿到用户的自定义Classloader,如果是常规方式启动的,比如普通Spring XML项目,借助Plus(美团内部服务发布平台)发布,此类没有自定义Classloader,是默认AppClassLoader,所以Agent在用户项目启动过程中,借助字节码增强的方式来获取到真正的用户Classloader。

找到用户使用的子Classloader之后,通过反射的方式来获取Classloader中的元素Classpath,其中ClassPath中的URL就是当前项目加载Class时需要的所有运行时Class环境,并且包括三方的JAR包依赖等。
Sonic获取到URL数组,把Sonic自定义的拓展Classpath目录加入到URL数组首位,这样当有新增Class时,Sonic只需要将Class文件复制到拓展Classpath对应的包目录下面即可,当有其他Bean依赖新增的Class时,会从当前目录下面查找类文件。
为什么不直接对Appclassloader进行加强?而是对框架的自定义Classloader进行加强?

考虑这样一个场景,框架自定义类加载器中有ClassA,此时用户新增ClassB需要热加载,B Class里面有A的引用关系,如果增强AppClassLoader,初始化B实例时ClassLoader。loadclass首先从UserClassLoader开始加载ClassB的字节码,依靠双亲委派原则,B被Appclassloader加载,因为B依赖类A,所以当前AppClassLoader加载B一定是加载不到的,此时会抛出ClassNotFoundException异常。所以对类加载器拓展,一定要拓展最上层的类加载器,这样才会达到使用者想要的效果。
3.5 Spring Bean重载
Spring Bean Reload过程中,Bean的销毁和重启流程,主要内容如下图展示:

首先当修改Java Class D时,通过Spring ClasspathScan扫描校验当前修改的Bean是否Sprin Bean(注解校验),然后触发销毁流程(BeanDefinitionRegistry.removeBeanDefinition),此方法会将当前Spring上下文中的Bean D和依赖Spring Bean D的Bean C一并销毁,但是作用范围仅仅在当前Spring上下文。如果C被子上下文中的Bean B依赖,就无法更新子上下文中的依赖关系,当有系统请求时,Bean B中关联的Bean C还是热部署之前的对象,所以热部署失败。
因此,在Spring初始化过程中,需要维护父子上下文的对应关系,当子上下文变时若变更范围涉及到Bean B时,需要重新更新子上下文中的依赖关系,当有多上下文关联时需要维护多上下文环境,且当前上下文环境入口需要Reload。这里的入口是指:Spring MVC Controller、Mthrift和Pigeon,对不同的流量入口,采用不同的Reload策略。RPC框架入口主要操作为解绑注册中心、重新注册、重新加载启动流程等等,对Spring MVC Controller,主要是解绑和注册URL Mappping来实现流量入口类的变化切换。
3.6 Spring XML重载
当用户修改/新增Spring XML时,需要对XML中所有Bean进行重载。

重新Reload之后,将Spring销毁后重启。需要注意的是:XML修改方式改动较大,可能涉及到全局的AOP的配置以及前置和后置处理器相关的内容,影响范围为全局,所以目前只放开普通的XML Bean标签的新增/修改,其他能力酌情逐步放开。
3.7 MyBatis 热部署
Spring MyBatis热部署的主要处理流程是在启动期间获取所有Configuration路径,并维护它和Spring Context的对应关系,在热部署Class、XML时去匹配Configuration,从而重新加载Configuration以达到热部署的目的。

4 总结
4.1 热部署功能一览
上一章节主要讲述了Spring Bean、Spring MVC、MyBatis的重载流程,Sonic还支持其它常用的开发框架,丰富的框架支持和兼容能力是Sonic的基石,下面列举一些Sonic支持的常用的第三方框架:

截止目前,Sonic已经支持绝大部分常用第三方框架的热加载,常规业务开发几乎无需重启服务。并且在美团内部的成功率已经高达99.9%以上,真正地让热部署来代替常规部署构建成为一种可能。
4.2 IDE插件集成
Sonic也提供了功能强大的IDEA插件,让用户进行沉浸式开发,远程热部署也变得更加便利。

4.3 推广使用情况
截止到发稿时,Sonic在美团使用人数3000+,应用项目数量2000+。该项目还获得了美团内部2020年下半年到家研发平台“最佳效率团队”奖。
5 作者简介
凯哥、占峰、李晗、龚炎、程骁、玉龙等,均来自美团/到家研发平台。
来源:tech.meituan.com/2022/03/17/java-hotswap-sonic.html
收起阅读 »程序猿健康防猝指南:体重和减肥的秘密
00、 引言
作为一名IT码农,入行十载有余,写的代码(Bug)越来越多,习惯了加班熬夜、久坐不动,身体各项指标也不出意外的屡创新高。近年来各行业高压工作导致的猝死的时有发生,长此以往,充满惊喜的人生不知道404和和503哪个先来!
本着科学、严谨的代码精神,大量查阅、学习了健康、运动的相关知识,顺便整理成文。生命在于运动,运动需要科学!
申明:信息都来自书籍、网络,难以保证完全准确,只能尽量追求科学、可信。有些知识本身就存在争议,或科学研究有限只是说明其相关性,并无明确结论。
01、 标准体重与体质指数(BMI<24)
身体质量指数 BMI(Body Mass Index),又称体质指数、体重指数。是目前国际上常用的衡量人体胖瘦程度以及是否健康的一个标准,BMI指数用来判断你的体重正常、超重还是肥胖。
体重的公斤数(单位:千克)除以自己的身高(单位:米)的平方所得到的一个数字,公式:
网上也有很多计算器:薄荷健康 免费在线 BMI 计算器 BMI计算网
中国BMI标准如下图,适用范围:18至65岁的成年人。儿童、发育中的青少年、孕妇、乳母、老人及身型健硕的运动员除外。世界卫生组织认为BMI指数保持在22左右是比较理想的。
您目前BMI指数为:
23.12,22.1,身体状况属于 【正常】,您的健康体重范围为 56~73 kg
标准体重有多种计算方法,常用的几个方法:
| 方法 | 公式 | 示例 |
|---|---|---|
| 世界卫生组织(WHO)的体重计算方法 | ♂️ 男性:标准体重(kg)=(身高cm-80)X70% ♀️ 女性:标准体重(kg)=(身高cm-70)X60% | (174-80)X70% = 65.8kg |
| 我国常用的标准体重的计算公式 | ♂️ 男性:标准体重(kg)=身高cm-105 ♀️ 女性:标准体重(kg)=身高cm-105-2.5 | 174-105=69kg |
| 我国征兵标准体重计算: 标准体重kg=身高cm - 110 | ♂️ 男性:不超过30% ,不低于15%,合格 ♀️ 女性:不超过20% ,不低于15% ,合格 | 174-110=64kg |
标准体重正负10﹪为正常体重
标准体重正负10﹪~ 20﹪为体重过重或过轻
标准体重正负20﹪以上为肥胖或体重不足
⚠️注意:标准体重和体质体质指数(BMI)是一种基于群体平均值的计算方法,针对单独个体其实并不严谨,个体都是有各种差异的,如年龄、肌肉、骨骼、脂肪含量都不同,BMI超重的人不一定就是肥胖,因此这个数据作为参考即可,体脂率(见后续章节)指标判定胖瘦更为科学。
02、 人体的主要物质=水、脂肪、蛋白质
人体内的水分含量最高,构成人体三大基础物质是糖、蛋白质、脂肪,也是人体的主要的营养物质。
人体必需的七种营养元素(蛋白质、脂肪、碳水化合物、矿物质、维生素、水、膳食纤维)。
2.1、水(多喝开水🐶1500~1700ml)
成年人体内水分约占体重的55%~65%,年龄越小体内所含水分的百分比越高。水是细胞生存的基础,人体的各种生理化活动都是在水的参与下完成和实现的。一个成年人每日的摄水量总和约为2500毫升,注意是来自饮水、食物、物质代谢的总和,每天应该饮水1500~1700毫升(不要用饮料代替)。天热、排汗多的人要适当多补充水分。
水的输出:肾脏(尿液 一天1500ml);呼吸(350ml);皮肤(500ml);大便(150ml)。
当人体中缺水量达到人体体重的2%时,会感到口渴;到10%时,会烦躁无力,体温升高,血压下降;达到20%就会有生命危险。
渴了才喝水是不对的,可以观察尿液的颜色和排尿量判断喝水量,正常情况下尿液是淡黄色的,一天的排尿量是1500毫升左右,一般3~4小时排尿一次。如果半天不想上厕所,或者排出的尿液是深黄色的,那就说明饮水量不足了。
2.2、糖(碳水化合物)
糖又称为碳水化合物,由碳、氢、氧三种元素组成的有机化合物,是生物界三大基础物质之一,是人体活动的主要能量来源,谷类食物当中的碳水化合物是主要来源之一。
碳水化合物摄入不足,人就容易出现低血糖症状,皮下脂肪及肌肉也会分解来供能,长期下去就会明显消瘦;反之,如果一个人很胖,特别是腹部肥胖,或者血浆中甘油三酯明显增高,可能碳水化合物摄入过多。
摄入过多碳水,且运动不足,摄入能量多于消耗能量,造成能量的蓄积,会以化学能的形式储存起来,表现为多余的脂肪,从而造成肥胖。白米、白面中的淀粉含量较高,同样100克,米面的淀粉含量是薯类(土豆、山药、芋头等)的四倍,是豆类(赤小豆、芸豆等)的近两倍。因此多摄入粗粮、蔬菜水果,部分代替精致碳水(米面),更有利于控制体重。
2.2、脂肪
脂肪 不仅是人体重要的功能物质,人体每天所需能量有20%-30%来自脂肪。还有构成身体组织和生物活性物质,调节生理机能,保护内脏器官等多种作用。
现代社会中人们普遍面临的是脂肪过剩的问题,所以减肥大多主要是减脂。脂肪堆积在胸部、腹部、大腿及臀部,还有身体内部,如内脏、血管,内部脂肪过多会严重影响我们的身体健康。
2.3、蛋白质
蛋白质是一切生命的物质基础,蛋白质是肌肉的主要组成物质,也是构成大脑、内脏、血液、毛发、骨骼、皮肤、神经、抗体、酶等的基本物质。动物类的食物、豆类、坚果的蛋白质含量较高,而蔬菜水果中几乎没有多少蛋白。谷物的蛋白质含量属于中等,例如米饭90%的淀粉,剩下的就是10%的蛋白质。
人体蛋白质含量16%~20%正常,超标会增大肾脏的负担,对身体反而不好,通过体脂称也可以测量。
2.4、膳食纤维(多吃蔬菜水果!)
它与淀粉的构成差别不大,但却无法被人体消化吸收,对人体有益。膳食纤维最为人所熟知的作用就是促进排便。
有利于通便,不可溶性膳食纤维可以加速肠道的排泄,改善便秘,维护肠道健康。
有利于减肥,由于膳食纤维多的食物能量密度低,并且有饱腹感,从而控制能量摄入量。
膳食纤维主要存在于蔬菜、水果中,精米、精面中很少,肉、鱼、奶中没有。我们每个人一天最好吃1斤蔬菜,其中叶菜最好占一半。水果最好是连皮吃,这样膳食纤维可以多吃一些。
【关键事实】
蔬菜水果提供丰富的微量营养素、膳食纤维和植物化学物。
增加蔬菜和水果、全谷物摄入可降低心血管疾病的发病和死亡风险。增加全谷物摄入可降低体重增长。
增加蔬菜摄入总量及十字花科蔬菜和绿色叶菜摄入量,可降低肺癌的发病风险。
多摄入蔬菜水果、全谷物,可降低结直肠癌的发病风险。
03、 你的身体是否肥胖?—体脂率
长胖的原因是你摄入的能量超过了消耗的能量,从而导致身体囤积脂肪。我们的脂肪包括“皮下脂肪”和“内脏脂肪”,如果皮下脂肪高,那么通常内脏脂肪也不会低。脂肪含量是衡量身体胖瘦的关键,减肥也大多是减脂(也称燃脂)。
研究表明,与BMI一直保持肥胖的人群相比,将BMI从成年早期的肥胖减至中年时的超重,可显著降低全因死亡率风险,而如果BMI超重或肥胖人群将体重减到正常BMI,则可避免12.4%的早期死亡。 —— 减肥(控制体重)更长寿!
3.1、体脂率
体脂率是指人体内脂肪重量在人体总体重中所占的比例,又称体脂百分数,它反映人体内脂肪含量的多少。正常成年人的体脂率分别是男性15%~18%和女性20%~28%。男性体脂肪若超过25%,女性若超过30%则可判定为肥胖。
体脂率应保持在正常范围,若体脂率过高,超过正常值的20%以上就可视为肥胖。肥胖则表明运动不足、营养过剩或有某种内分泌系统的疾病,而且常会并发高血压、高血脂症、动脉硬化、冠心病、糖尿病、胆囊炎等病症。若体脂率过低,低于体脂含量的安全下限,即男性5%,女性13%~15%,则可能引起功能失调。
3.2、怎么测量体脂率呢?—体脂称
目前体脂称比较通用的测量方法是:BIA测量法。主要原理是将身体简单分为导电的体液、肌肉等,以及不导电的脂肪组织,测量时由电极片发出极微小电流经过身体,若脂肪比率高,则所测得的生物电阻较大,反之亦然。
含水量高的部分,例如肌肉,导电性好,电阻率低。
含水量低的部分,例如脂肪,导电性差,电阻率高。
当我们站在体脂秤上之后, 体脂秤会通过一只脚下的电极片发出人体感知不到的微弱电流,电流穿过你的全身,到达另一只脚下的电极片,形成一个回路。最后结合通过人体的电流大小,即可对脂肪率、肌肉率、内脏脂肪等级等数据进行分析。
3.3、内脏脂肪等级
内脏脂肪等级也叫内脏脂肪指数,正常范围是在1-9。内脏脂肪是我们身体当中一种必需的脂肪组织,与皮下脂肪不一样,皮下脂肪就是看得见、摸得着的所谓的的肥肉。内脏脂肪围绕着人体的脏器,主要在腹腔里面,所以大多表现为腰围粗、啤酒肚。
内脏脂肪等级也可以通过体脂称进行测量,如果超标是必须要重视的,可以通过“运动+合理饮食”减脂减肥。
04、 减肥/减脂的秘密?
4.1、热量差
体重变化的核心公式就是:每天变化的体重 = 每天吃进去的 - 每天消耗的,吃的更多就会体重增加,消耗的更多就会减重。
所以体重的变化取决于热量差,公式:
热量差 = 所有消耗(运动消耗+基础代谢消耗+食物热效应)- 所有摄入(食物热量*肠道吸收率)
这里的 食物热效应 指的是进食导致的额外的能量消耗,这些额外的能量主要用于食物的消化、吸收和代谢储存,又叫食物的特殊热力作用。《中国居民膳食指南》建议运动代谢能量至少占比15%,大约240-260卡路里,除去日常家务、基础活动之外,还需要大概6000步快走的运动量。
4.2、食物热量单位:卡路里
卡路里(Calorie,缩写为cal),简称卡,其定义为将1克水在1大气压下提升1摄氏度所需要的热量。
卡路里 (也叫热量),卡路里是能量单位,我们身体的运行需要能量,各种食物是提供给我们能量的原料,衡量这些能量的单位就是——卡路里。
正常活动量的成年人,《中国居民膳食指南》建议每天摄入的热量:男性2250大卡,女性1800大卡。
1卡路里=1千卡=1大卡=1000卡 = 4.184 千焦耳 一般包装食品的营养成分表中能量单位就用的“千焦”。
1kg脂肪=7700kcal(卡路里) 理论上来说,1kg脂肪=7700卡路里,就是说减肥1Kg,需要消耗7700卡路里,等于14个超级汉堡,慢跑运动15天(每天1个小时)。
4.3、基础代谢消耗(BMR)
基础代谢率是维持人体最基本的生理活动所需要消耗的能量,在安静状态下(通常为静卧状态)消耗的最低热量,主要是身体保持体温、维持心跳、维持呼吸等基本生理活动。基础代谢和年龄、性别、体重、肌肉含量有关。通过体脂称也可测量,在线的计算器:1分钟彻底了解自己
您的年龄身高对应标准体重为 63 KG(1KG=2斤)
您的基础代谢率为 1539 大卡
4.4、减肥的秘密—迈开腿+管住嘴
人体需要的能量是糖分、脂肪以及蛋白质为主,糖分约占比70%,余下是脂肪、蛋白质在人体当中的主要功能不是提供能量,是给器官供给生长和消耗的补充。
那这三种能量是怎么给我们的身体供能的呢?是否有先后顺序呢?是否像网上流行所说等糖分消耗完了才会消耗脂肪吗?
答案是一起消耗!实际上,不管做什么运动,甚至是休息的时候,它们都是同时供能的,只是比例不同。如下图,脂肪(Fat)在有氧运动20分钟后对身体的供能比例提升,碳水(糖分CHO)占比下降。
运动是减脂的最有效手段,但减肥是一个系统工程,必须结合“管住嘴”控制热量输入+“迈开腿”增加热量消耗,双管齐下才有效果。
管住嘴: 在吃的里面,糖(碳水化合物)、脂肪是最容易长胖的了,必须要控制每天的热量摄入,相比运动燃脂,吃就容易太多了!
脂肪的消耗:有氧运动为主 + 力量训练为辅!
脂肪的燃烧需要氧气,有氧运动燃脂更高效。
运动要达到中低强度的运动心率,低于或高于这个范围,都不算中低强度运动心率,燃烧的脂肪的比例就不高了。
这种中低强度运动心率的运动要持续20分钟以上。
这种运动必须是大肌肉群的运动,如慢跑、游泳、健身操等。
05、 减肥/减脂的错误认知
❓只节食可以减肥吗?
理论可以,但效果不理想,方法也不对,不利于身体健康。
减脂就是在玩“热量差”的游戏,通过控制热量摄入在短时间内是可以很快有减肥效果,但很容易反弹。我们的身体是非常精明的,当你吃的太少时,你的身体接到的信号是你正在面临食物短缺的危机,为了防止你饿死,它会自动开启节能模式,降低你的基础代谢。也就是说,虽然你摄入的热量变少了,但是你的基础代谢消耗也变少了,并没有产生多大的能量缺口。
很多人通过节食减肥,开始掉秤很快,没几天就反弹回来,这是因为你的身体会先消耗糖原,而每消耗 1g 糖,会同时消耗点 3g 水,所以节食减肥时,你身体里的水分波动非常大,但是脂肪并没有太大变化。虽然你减重了,但没有减脂,可能你再正常吃个两三顿,体重马上又恢复回来了。而且因为之前出现过热量供应短缺的信号,当你再次正常吃的时候,身体反而会存储更多的脂肪来应对下一次危机,这也是为什么很多人越减肥反而越胖的原因。
❓只运动会不会瘦?
一个巨无霸汉堡大约是 500kcal,需要慢跑1个小时才能消耗,可以看到,吃是很容易的,消耗起来却是很难的,必须运动和控制饮食两者结合。
❓流汗是不是就是在减脂?
不是,流汗和脂肪消耗没有直接关系,流汗是身体平衡体温的一种方式。而脂肪大多被分解后(分解为甘油酸酯)通过呼吸排出,小部分在汗液、排便中排出。
❓快跑(高强度)和慢跑(中强度)哪个更燃脂?
慢跑!慢跑15分钟脂肪供能(分解)增加,25分钟明显增多。快跑(高强度)需要的能量更多,脂肪分解(先分解为糖)需要更多时间,不足以支撑高强度运动需求,会直接消耗糖类(糖类供能最快)。因此慢跑减脂效率更高,保持心率60%-75%范围。
❓运动30(*)分钟才会燃脂吗?
就像有人说“运动达不到有效燃脂心率=白练”一样,不是! 只要你还活着,任何时候糖原、脂肪都会消耗,只是比例不同,有氧运动20+分钟燃脂的效率(比例/或效果)更高。
❓运动强度越大燃脂越多吗?
不是,如下图,运动强度越高,身体所需的能量也随之增多,脂肪供能的速度比较慢,供能比例减小。
作者:安木夕
来源:juejin.cn/post/7182374196108853306
90%的Java开发人员都会犯的5个错误
前言
作为一名java开发程序员,不知道大家有没有遇到过一些匪夷所思的bug。这些错误通常需要您几个小时才能解决。当你找到它们的时候,你可能会默默地骂自己是个傻瓜。是的,这些可笑的bug基本上都是你忽略了一些基础知识造成的。其实都是很低级的错误。今天,我总结一些常见的编码错误,然后给出解决方案。希望大家在日常编码中能够避免这样的问题。
1. 使用Objects.equals比较对象
这种方法相信大家并不陌生,甚至很多人都经常使用。是JDK7提供的一种方法,可以快速实现对象的比较,有效避免烦人的空指针检查。但是这种方法很容易用错,例如:
Long longValue = 123L;
System.out.println(longValue==123); //true
System.out.println(Objects.equals(longValue,123)); //false
为什么替换==为Objects.equals()会导致不同的结果?这是因为使用==编译器会得到封装类型对应的基本数据类型longValue,然后与这个基本数据类型进行比较,相当于编译器会自动将常量转换为比较基本数据类型, 而不是包装类型。
使用该Objects.equals()方法后,编译器默认常量的基本数据类型为int。下面是源码Objects.equals(),其中a.equals(b)使用的是Long.equals()会判断对象类型,因为编译器已经认为常量是int类型,所以比较结果一定是false。
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}知道了原因,解决方法就很简单了。直接声明常量的数据类型,如Objects.equals(longValue,123L)。其实如果逻辑严密,就不会出现上面的问题。我们需要做的是保持良好的编码习惯。
2. 日期格式错误
在我们日常的开发中,经常需要对日期进行格式化,但是很多人使用的格式不对,导致出现意想不到的情况。请看下面的例子。
Instant instant = Instant.parse("2021-12-31T00:00:00.00Z");
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss")
.withZone(ZoneId.systemDefault());
System.out.println(formatter.format(instant));//2022-12-31 08:00:00
以上用于YYYY-MM-dd格式化, 年从2021 变成了 2022。为什么?这是因为 java 的DateTimeFormatter 模式YYYY和yyyy之间存在细微的差异。它们都代表一年,但是yyyy代表日历年,而YYYY代表星期。这是一个细微的差异,仅会导致一年左右的变更问题,因此您的代码本可以一直正常运行,而仅在新的一年中引发问题。12月31日按周计算的年份是2022年,正确的方式应该是使用yyyy-MM-dd格式化日期。
这个bug特别隐蔽。这在平时不会有问题。它只会在新的一年到来时触发。我公司就因为这个bug造成了生产事故。
3. 在 ThreadPool 中使用 ThreadLocal
如果创建一个ThreadLocal 变量,访问该变量的线程将创建一个线程局部变量。合理使用ThreadLocal可以避免线程安全问题。
但是,如果在线程池中使用ThreadLocal ,就要小心了。您的代码可能会产生意想不到的结果。举个很简单的例子,假设我们有一个电商平台,用户购买商品后需要发邮件确认。
private ThreadLocal<User> currentUser = ThreadLocal.withInitial(() -> null);
private ExecutorService executorService = Executors.newFixedThreadPool(4);
public void executor() {
executorService.submit(()->{
User user = currentUser.get();
Integer userId = user.getId();
sendEmail(userId);
});
}如果我们使用ThreadLocal来保存用户信息,这里就会有一个隐藏的bug。因为使用了线程池,线程是可以复用的,所以在使用ThreadLocal获取用户信息的时候,很可能会误获取到别人的信息。您可以使用会话来解决这个问题。
4. 使用HashSet去除重复数据
在编码的时候,我们经常会有去重的需求。一想到去重,很多人首先想到的就是用HashSet去重。但是,不小心使用 HashSet 可能会导致去重失败。
User user1 = new User();
user1.setUsername("test");
User user2 = new User();
user2.setUsername("test");
List<User> users = Arrays.asList(user1, user2);
HashSet<User> sets = new HashSet<>(users);
System.out.println(sets.size());// the size is 2
细心的读者应该已经猜到失败的原因了。HashSet使用hashcode对哈希表进行寻址,使用equals方法判断对象是否相等。如果自定义对象没有重写hashcode方法和equals方法,则默认使用父对象的hashcode方法和equals方法。所以HashSet会认为这是两个不同的对象,所以导致去重失败。
5. 线程池中的异常被吃掉
ExecutorService executorService = Executors.newFixedThreadPool(1);
executorService.submit(()->{
//do something
double result = 10/0;
});上面的代码模拟了一个线程池抛出异常的场景。我们真正的业务代码要处理各种可能出现的情况,所以很有可能因为某些特定的原因而触发RuntimeException 。
但是如果没有特殊处理,这个异常就会被线程池吃掉。这样就会导出出现问题你都不知道,这是很严重的后果。因此,最好在线程池中try catch捕获异常。
链接:https://juejin.cn/post/7182184496517611576
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
快速上手Compose约束布局
前言
今天对Compose中约束布局的使用方法进行一下记录,我发现在学习Compose的过程中,像Column,Row等布局可以很快上手,可以理解怎样使用,但是对于ConstraintLayout 还是得额外学习一下,所以总结一下进行记录。其实Compose-ConstraintLayout 完全是我对传统布局使用习惯的迁移,已经习惯了约束的思维方式。
接下来我们就看Compose中ConstraintLayout 是怎样使用的。
使用
首先我们先引入依赖
Groovy
implementation "androidx.constraintlayout:constraintlayout-compose:1.0.1"
Kotlin
implementation("androidx.constraintlayout:constraintlayout-compose:1.0.1")
在传统布局中,我们对约束布局的使用都是通过id进行相互约束的,那在Compose中我们同样需要先创建一个类似id功能一样的引用。
val (text) = createRefs()
在Compose中有两种创建引用的方式:createRefs() 和createRef()。createRef()只能创建一个,createRefs()每次能创建多个(最多16个)。
然后对我们的组件设置约束,这里我用了一个Text()做示例。
ConstraintLayout(modifier = Modifier.fillMaxSize()) {
val (text) = createRefs()
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
top.linkTo(parent.top)
})
}
这样就实现了 Text() 组件在我们布局的左上角。
当我们同时也对end 做出约束,就会达到一个Text()组件在布局中横向居中的效果。
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
end.linkTo(parent.end)
top.linkTo(parent.top)
})
当我们想有一个Button按钮 在文字的下方居中显示,我们可以这样做:
ConstraintLayout(modifier = Modifier.fillMaxSize()) {
val (text, button) = createRefs()
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
end.linkTo(parent.end)
top.linkTo(parent.top)
})
Button(onClick = {}, modifier = Modifier.constrainAs(button) {
start.linkTo(text.start)
end.linkTo(text.end)
top.linkTo(text.bottom)
}) {
Text("按钮")
}
}
将Button组件相对于文字组件做出前,后,顶部约束。
实践
接下来我们尝试使用约束布局来做一个个人信息显示的效果。我们先看下我们要实现的效果:
我们先分解一下这个效果,一个Image图片,一个Text 名称,一个Text 微信号, 还有一个 二维码。
接下来我们就一步步来实现一下。
先是头像部分,我们对Image头像,先进行上,下,前约束,再设置一下左边距,能够留出空间来。
Image(painter = painterResource(R.drawable.logo8), "head",
contentScale = ContentScale.Crop,
modifier = Modifier.constrainAs(head) {
start.linkTo(parent.start)
top.linkTo(parent.top)
bottom.linkTo(parent.bottom)
}.padding(start = 20.dp).size(60.dp).clip(CircleShape)
)
然后我们开始添加名称和id。
Text()名称组件是顶部和头像顶部对齐,start 和 头像的end 进行对齐;Id 是对于名称 start对齐,顶部与名称底部对齐。
Text("Android开发那点事儿",
style = TextStyle(fontSize = 16.sp,
color = Color.Black, fontWeight = FontWeight(600)),
modifier = Modifier.constrainAs(name) {
top.linkTo(head.top)
start.linkTo(head.end)
}.padding(start = 10.dp)
)
Text("微信号:android-blog",
style = TextStyle(fontSize = 12.sp,
color = Color.DarkGray, fontWeight = FontWeight(400)),
modifier = Modifier.constrainAs(id) {
top.linkTo(name.bottom)
start.linkTo(name.start)
}.padding(start = 10.dp, top = 5.dp)
)
效果:
最后我们来加载二维码,二维码图标和右箭头图标都是从“阿里icon”中找的图标。
将图标相对于头像上下居中,紧靠右边,然后留出间距,然后是箭头上下都跟二维码图标对齐,左侧紧贴二维码的右侧。
ConstraintLayout(modifier = Modifier.width(300.dp)
.height(80.dp).background(Color.LightGray)) {
........
Image(
painter = painterResource(R.drawable.qr),"",
modifier = Modifier.size(20.dp).constrainAs(qr) {
top.linkTo(head.top)
bottom.linkTo(head.bottom)
end.linkTo(parent.end, 30.dp)
})
Image(
painter = painterResource(R.drawable.left), "",
modifier = Modifier.size(20.dp).constrainAs(left) {
top.linkTo(qr.top)
bottom.linkTo(qr.bottom)
start.linkTo(qr.end)
})
}
我们来看下最后完成的效果。
至此,我们就通过ConstraintLayout完成了一个简单的效果,如果有传统布局的使用基础,Compose的使用起来还是可以很快上手的。
最后
ConstraintLayout 最基础的用法我们就写到这里,另外还有一些进阶用法会在后续的文章中给大家详细介绍。
链接:https://juejin.cn/post/7181455100374679589
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
分析了1011个程序员的裁员情况后得出的启示
大家应该能明显感觉到最近几个月求职环境不太好,但究竟有多不好,具体的情况是什么样的?
为了分析程序员职场现状,我进行了裁员情况调查,一共有1011位程序员朋友参与。
本文会根据调查结果,为大家带来一些启示(如果不想看分析过程,可以直接跳到文末看结论)。
裁员真的多么?
按工作职级来看,受访者中初级工程师的裁员比例最少(可能是因为工资相对最低,裁员收益不大),而专家及以上最多,但整体差别不大。
平均来看,受访者中有19%经历了裁员。
按公司中技术团队人数来定义公司规模,技术团队只有几人的小公司裁员最严重,其他更大些的企业差距则不大。
可能是因为太小的企业还没有跑通业务变现的逻辑,老板抗风险能力也更差。
对我们的启示是 —— 为了工作稳定,不一定要去大厂(毕竟裁员比例也不低),而应该尽量选择有稳定业务的企业。
你觉得这个裁员比例高吗?
大家都从事什么工作?
很多做业务的程序员会觉得做架构比较高大上。从工作职级来看看,随着职级与能力的提升,确实有越来越多的程序员从事架构工作:
从技术团队规模来看,一线大厂(技术团队千人以上)从事架构工作的程序员比例最高,但整体差别不大。
平均来看,约有17%的程序员从事架构工作。
给我们的启示是 —— 在求职架构岗位时,可以打听下公司从事架构岗位的程序员比例,如果高于17%,可能没有多少让你施展拳脚的地方。
同时,从上述两个分析看,架构工作既有难度(职级越高,从事架构工作的比例越高),又有稀缺性(公司平均只有17%的程序员从事架构工作)。
那程序员推崇架构工作就不难理解了 —— 因为更难,也更少。
如果业务不赚钱,那么业务线被砍,做业务的程序员被裁,这个逻辑是很好理解的。而做架构一般有通用性。
那么,面对裁员的浪潮,做架构真的比做业务有更高的抗风险能力么?
做架构还是做业务?
按工作职级来看从事架构工作的裁员比例,会发现 —— 随着职级上升,架构工作的裁员比例显著提升。
对于立志在架构方面长期发展的程序员,肯定不想随着自己职级提升,被裁的风险越来越高吧。
相对应的,随着职级提升,做业务的程序员被裁的比例会逐渐降低。
虽然不同职级做架构的裁员比例都低于做业务,但诚如上文提到,公司平均只有17%的程序员从事架构工作。显然做业务的工作机会远远多于做架构。
这对我们的启示是 —— 经济下行时期,程序员规划职业发展时,尽量向离钱近(做业务)的领域发展。
大厂是救命稻草?
尽量往大厂卷是不是可以减少被裁的风险?
按公司规模来看架构、业务工作的裁员比例,在技术团队只有几人的公司被裁的风险确实是最大的。但是一线大厂(技术团队千人以上)裁员比例也很高。
风险相对较小的,是技术团队几十人的公司。这样的公司可能自身有稳定的业务,也不盲目扩张,所以裁员规模相对较小。
从表中还发现个有趣的情况 —— 随着公司规模变大,架构岗被裁的比例显著增大。
大家都想去大厂做架构,但大厂架构是被裁的最多的。这是不是侧面印证了,很多大厂搞的高大上的轮子,并没有什么价值?
大家心里也这么想?
上面的很多分析结果,都对架构的同学不友好(尤其是大厂)。那么,大家听到的情况也是这样么?
我统计了你听说你司被裁程序员都是做什么的,其中从事架构岗位的比例如下:
可见,不仅参与调查的当事人的数据汇总后显示 —— 不要去大厂做架构。
大家听说的公司的情况汇总后也在印证这一观点。
那么大家意识到在大厂做架构可能并不是个好选择了么?下面是没有被裁员,且认为自己发展前景好的程序员中从事业务、架构的比例:
先不管这样的认知是否正确(觉得自己前景好)。单从比例看,不管是小厂大厂,做业务的同学们的认知比例趋于一致。
而大厂做架构的同学显然对自己的前景有极高的预期(不知道他们知不知道,他们也是被裁的比例最高的?)
为什么对于在大厂做架构的同学来说,预期会与实际有这么大差距呢?都是什么职级的同学会觉得公司架构岗被裁的比例更多呢?
下面是按工作职级划分的,谁听说的公司中架构岗被裁的比较多:
没有初级工程师觉得公司架构岗被裁的更多,而有56%的专家及以上认为架构岗裁员更多。
年轻人还是太年轻,不愿相信事实。专家们早已看穿了现实。
总结
本次调查为我们带来了几条启示:
大厂裁员比例也不低。为了工作稳定,应该尽量选择有稳定业务的企业
在求职架构岗位时,可以打听下公司从事架构岗位的程序员比例,最好低于17%
不要迷信技术。在经济下行时期,应该尽量选择离钱近的业务
不要去大厂做架构。实际情况与大部分程序员预期完全不符
不管是做架构还是做业务,我们都要明白 —— 技术是为了创造价值。那么什么是价值?
对于好的年景,能够为业务赋能的架构是有价值的。而在不好的年景,价值直接与能赚多少钱划等号,离钱越近的业务,价值就越大。
而这一切,都与技术本身的难度无关。
所以,为了稳定的职业发展,更应该着眼于业务本身,而不是深究技术。
作者:魔术师卡颂
来源:juejin.cn/post/7142674429649109000
前端常见登录方案梳理
前端登录有很多种方式,我们来挑一些常见的方案先梳理一下,后续再补充更多的。
账号密码登录
在系统数据库中已经有了账号密码,或者通过注册渠道生成了账号和密码,此时可以直接通过账号密码登录,只要账号密码正确就认为身份合法,可以换到系统访问的 token,用于后续业务鉴权。
验证码登录
比如手机验证码,邮箱验证码等等。用户首先提供手机号/邮箱,后端根据会话信息生成一个特定的码下发到用户的手机或者邮箱(通过运营商提供的能力)。
用户得到这个码后填入登录表单,随手机号/邮箱一并发给后端,后端拿到手机号/邮箱、码后,与会话信息做校验,确认身份信息是否合法。
如果一致就检查数据库中是否有这个手机号/邮箱,有的话就不用创建用户了,直接通过登录;没有的话就说明是新用户,可以先创建用户,绑定好手机号/邮箱,然后通过登录。
第三方授权
比如微信授权,github授权之类的,可以通过OAuth授权得到访问对方开放API的能力。
OAuth 协议读起来很复杂,其实本质上就是:
我是开发者,有个自己的业务系统。
用户想图方便,希望通过一些常用的平台(比如微信,支付宝等)登录到我的业务系统。
但是这也不是你想用就能用的,我首先要去三方平台登记一下我的应用,比如注册一个微信公众号,公众号再绑定我的业务域名(验证所有权),可能还要交个费做微信认证之类的。
交了保护费后(经过上面的操作),我的业务系统就是某三方平台的合法应用了,就可以使用某三方平台的开放接口了。
此时用户来到我的业务系统客户端,点击微信一键登录。
然后我的业务系统就会按照微信的规矩生成一些鉴权需要的信息,拉起微信的中间页(如果是手机客户端,那可能就是通过 SDK 拉起手机微信)让用户授权。
用户同意授权,微信的中间页鉴权成功后,就会给我的客户端返回一个 code 之类的回调信息,客户端需要把这个 code 传给后端。
后端拿到这个 code 可以去微信服务器换取 access_token,基于这个 access_token,可以获取微信用户基本开放信息和帮助用户实现基础开放功能等。
后端也可以基于此封装自定义的登录态返给客户端,如有必要,也可以生成用户表中的记录。
此时我就认为这个用户是通过微信合法登录到我的系统中了。
有些字段或者信息之类的可能会描述得不够精确,但是整个鉴权的思路大概就是这样。
微信小程序登录
wx.login + code2Session 无感登录
如果你的业务系统需要鉴权大部分接口,但是又不想让用户一打开小程序就去输入啥或者点啥按钮登录,那么无感登录是比较适合的。
关键是找到能唯一标识用户身份的东西,openid 或者 unionid 就不错。那么怎么无感得到这些?wx.login + code2Session 值得拥有。
小程序前端 wx.login 得到用户登录凭证 code(目前说的有效期是五分钟),然后把 code 传给服务端,服务端调用微信服务的 auth.code2Session,使用 code 换取 openid、unionid、session_key 等信息,session_key 相当于是当前用户在微信的会话标识,我们可以基于此自定义登录态再返回给前端,前端拿着登录态再访问后端的业务接口。
getPhonenumber授权手机号登录
当指定 button 组件的 open-type 为 getPhoneNumber 时,可以拉起手机号授权,手机号某种程度上可以标识用户身份,自然也可以用来做登录。
旧版方案中,getPhonenumber得到的 e 对象中有 encryptedData, iv 字段,传给后端,根据解密算法能得到手机号和区号等信息。手机号也相当于是一种可以唯一标识用户的信息(虽然一个人可以有多个手机号,不过宽松点来说也可以用来标识用户),自然可以用来生成用户表记录,后续再与其他信息做关联即可。
但是旧版方案已经不建议使用了,目前 getPhonenumber得到的 e 对象中有 code 字段,这个 code 和 wx.login 得到的 code 不是同一回事。我们把这个 code 传给后端,后端再调用 phonenumber.getPhoneNumber得到手机号信息。
接着再封装登录态返回给前端即可。
微信公众号登录
首先分析一下渠道,在微信环境中,用户可能会直接通过链接访问 H5,也可能通过公众号菜单进入 H5。
微信公众号网页提供了授权方案,具体可以参考这个网页授权文档。
授权有两种形式,snsapi_base 和 snsapi_userinfo。
这个授权是支持无感的,具体见这个解释。
关于特殊场景下的静默授权
上面已经提到,对于以snsapi_base为 scope 的网页授权,就静默授权的,用户无感知;
对于已关注公众号的用户,如果用户从公众号的会话或者自定义菜单进入本公众号的网页授权页,即使是 scope 为snsapi_userinfo,也是静默授权,用户无感知。
这基本上就是说,如果是 snsapi_base 方式,目的主要是取 token 和 openid,用来做后续业务鉴权,那就是无感的。
如果是 snsapi_userinfo 方式,除了拿鉴权信息,还要要拿头像昵称等信息,可能需要用户授权,不过只要关注了该公众号,也可以不出现授权中间页,也是无感的。
下面说下具体的交互形式。
snsapi_base 场景下,需要绑定一个回调地址,交互形式是:
根据标准格式提供链接:
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect你可以在公众号菜单跳转这个标准链接,或者通过其他网页跳转这个链接。这个链接是个微信鉴权的中间页,如果鉴权没问题就会回调到 REDIRECT_URI 对应的业务系统页面,也就是用户真正前往的网页,用户能感知到的就是网页的进度条加载了两次,然后就到目标页面了,基本上是无感的。
页面在回调时会在 querystring 上携带 code 参数。前端在这个页面拿到 code 后,可以传给后端,后端就可以调下面这个接口得到 token 信息,然后封装出登录态返给前端。
https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code具体实现时,不一定要在页面层级上完成 code 换 token 的操作,也可以在应用层级上实现。
后续可以根据需要进行 refreshToken。
snsapi_userinfo 场景下,也是跳一个标准链接。与 snsapi_base 场景相比,除了 scope 参数不一样,其他都一样。跳转这个标准链接时会根据有没有关注公众号决定是否要拉起授权中间页面。
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect接着也可以根据 code 换 token,进行必要的 refreshToken。
最重要的是,在 scope=snsapi_userinfo 场景下,还可以发起获取用户信息的请求,这才是它与 snsapi_base 的本质区别。如果 scope 不符合要求,则无法通过调用下面的接口得到用户信息。
https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN还有一些公告调整内容要注意一下:
结语
好了,前端常见的一些登录方式先整理到这里,实际上还有很多种方案还没提到,比如生物认证登录,运营商验证登录等等,后面再补充,只要是双方互相认可的方案,并且能标识用户身份,不管是严格的还是宽松的,都可以拿来做认证使用,具体还要根据你的业务特性决定。
作者:Tusi
来源:juejin.cn/post/7172026468535369735
B站:你阳了和我裁员有什么关系
千万不要为了情怀去一家公司,尤其是持续亏损的公司,当他们裁员自救的时候,情怀这东西,啥也不是。
下半年来,B站断断续续的裁员,最近疫情感染迅速,很多打工人一边发烧头痛,一边坚持工作。更惨的是,还有一些人被折磨的死去活来,还得撑着病体,接受着被裁的通知。
犀牛在名古屋长跑:牛的,上周我被裁员,这周我对象也接到 hr 通知约谈。但他刚好阳性在家,hr 在明知道他阳性发烧的情况下一直在打电话,要求线上沟通,想赶紧完成他的 kpi。对象在床上一边发烧,一边偷偷抹眼泪。我在旁边看着有气发不出,只是心疼他。他应届毕业放弃其他 offer,拿了 b 站 sp 进来,现在却突然被裁。打工人已经很惨了,选 b 站打工,惨上加惨。
翻了下聊天记录,从发帖人和网友的对话中,了解到这对小情侣都是毕业时应届加入的 b 站,一方面,公司给他们开出了 sp 级别的 offer;另一方面,他们本身也是 b 站的资深用户,骨子里对这家公司还是有美好的向往和热爱的。
如今,没想到还没度过试用期,就收到了裁员的消息,而且是双双被裁,年关将至,人阳了、工作没了,对他们来说,梦想在这一刻,破碎的稀里哗啦的,这属实操蛋的生活。
在进行职业抉择的时候,持续亏损的企业、部门,尽量避免去,那里面暴雷的概率太大了。
创业从来都是九死一生的,无论是企业内部创业还是外部创业,都是如此,在老板眼里,大部分员工是资源、是耗材,业务红火的时候,疯狂投钱招人,遇到瓶颈时,就会冷静下来仔细盘算,开始降本增效。
打工要有打工的觉悟,不要觉得老板们冷酷无情,我们自己当了老板,也不一定会干的好,不一定更有人情味。现在站在打工人的视角,就要做好自身的基本面,避开那些风险高的公司和部门。
去稳定一些的公司,即使拿的工资少点,也是能够接受的,眼下稳定是最为重要的。我工作了几年了,越来越明白一个道理,穷的地方,裁起人来是很狠的。这和人品素质无关,公司、部门自己都撑不下去了,只能断臂求生。
b 站是 18 年 3 月份上市的,到现在小五年的时间了,还是持续亏损,股价曾经有过一段辉煌期,美股最高点157,现在 20 左右徘徊,今年三季度亏损 17 亿,同比收窄了,但距离盈利,还是有很长一段路要走。
年底失业,短时间内想找到工作,是较为困难的,建议他们等身体康复之后,开始整理这半年的工作经验,同时回顾下面试过程中的八股文,等到年后,一些公司盘点新年计划之后,新放出来hc,市场的情况会稍稍回暖一些,这时候面试成功的概率会大一些。
只不过,这个年就不那么好过了,大概率是不敢对两鬓斑斑的老父母说的,成年人了,很多事情,都是自己默默承担。
来源:公子龙
收起阅读 »订单30分钟未支付自动取消怎么实现?
目录
- 了解需求
- 方案 1:数据库轮询
- 方案 2:JDK 的延迟队列
- 方案 3:时间轮算法
- 方案 4:redis 缓存
- 方案 5:使用消息队列
了解需求
在开发中,往往会遇到一些关于延时任务的需求。
例如
- 生成订单 30 分钟未支付,则自动取消
- 生成订单 60 秒后,给用户发短信
对上述的任务,我们给一个专业的名字来形容,那就是延时任务。那么这里就会产生一个问题,这个延时任务和定时任务的区别究竟在哪里呢?一共有如下几点区别
定时任务有明确的触发时间,延时任务没有
定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
下面,我们以判断订单是否超时为例,进行方案分析
方案 1:数据库轮询
思路
该方案通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行 update 或 delete 等操作
实现
可以用 quartz 来实现的,简单介绍一下
maven 项目引入一个依赖如下所示
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.2</version>
</dependency>调用 Demo 类 MyJob 如下所示
package com.rjzheng.delay1;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class MyJob implements Job {
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("要去数据库扫描啦。。。");
}
public static void main(String[] args) throws Exception {
// 创建任务
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1", "group1").build();
// 创建触发器 每3秒钟执行一次
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1", "group3")
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(3).
repeatForever())
.build();
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
// 将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);
// 调度器开始调度任务
scheduler.start();
}
}运行代码,可发现每隔 3 秒,输出如下
要去数据库扫描啦。。。优点
简单易行,支持集群操作
缺点
- 对服务器内存消耗大
- 存在延迟,比如你每隔 3 分钟扫描一次,那最坏的延迟时间就是 3 分钟
- 假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大
方案 2:JDK 的延迟队列
思路
该方案是利用 JDK 自带的 DelayQueue 来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入 DelayQueue 中的对象,是必须实现 Delayed 接口的。
DelayedQueue 实现工作流程如下图所示
其中 Poll():获取并移除队列的超时元素,没有则返回空
take():获取并移除队列的超时元素,如果没有则 wait 当前线程,直到有元素满足超时条件,返回结果。
实现
定义一个类 OrderDelay 实现 Delayed,代码如下
package com.rjzheng.delay2;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class OrderDelay implements Delayed {
private String orderId;
private long timeout;
OrderDelay(String orderId, long timeout) {
this.orderId = orderId;
this.timeout = timeout + System.nanoTime();
}
public int compareTo(Delayed other) {
if (other == this) {
return 0;
}
OrderDelay t = (OrderDelay) other;
long d = (getDelay(TimeUnit.NANOSECONDS) - t.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
// 返回距离你自定义的超时时间还有多少
public long getDelay(TimeUnit unit) {
return unit.convert(timeout - System.nanoTime(), TimeUnit.NANOSECONDS);
}
void print() {
System.out.println(orderId + "编号的订单要删除啦。。。。");
}
}运行的测试 Demo 为,我们设定延迟时间为 3 秒
package com.rjzheng.delay2;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.TimeUnit;
public class DelayQueueDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("00000001");
list.add("00000002");
list.add("00000003");
list.add("00000004");
list.add("00000005");
DelayQueue<OrderDelay> queue = newDelayQueue < OrderDelay > ();
long start = System.currentTimeMillis();
for (int i = 0; i < 5; i++) {
//延迟三秒取出
queue.put(new OrderDelay(list.get(i), TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS)));
try {
queue.take().print();
System.out.println("After " + (System.currentTimeMillis() - start) + " MilliSeconds");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}输出如下
00000001编号的订单要删除啦。。。。
After 3003 MilliSeconds
00000002编号的订单要删除啦。。。。
After 6006 MilliSeconds
00000003编号的订单要删除啦。。。。
After 9006 MilliSeconds
00000004编号的订单要删除啦。。。。
After 12008 MilliSeconds
00000005编号的订单要删除啦。。。。
After 15009 MilliSeconds可以看到都是延迟 3 秒,订单被删除
优点
效率高,任务触发时间延迟低。
缺点
- 服务器重启后,数据全部消失,怕宕机
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
- 代码复杂度较高
方案 3:时间轮算法
思路
先上一张时间轮的图(这图到处都是啦)
时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。这样可以看出定时轮由个 3 个重要的属性参数,ticksPerWheel(一轮的 tick 数),tickDuration(一个 tick 的持续时间)以及 timeUnit(时间单位),例如当 ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。
如果当前指针指在 1 上面,我有一个任务需要 4 秒以后执行,那么这个执行的线程回调或者消息将会被放在 5 上。那如果需要在 20 秒之后执行怎么办,由于这个环形结构槽数只到 8,如果要 20 秒,指针需要多转 2 圈。位置是在 2 圈之后的 5 上面(20 % 8 + 1)
实现
我们用 Netty 的 HashedWheelTimer 来实现
给 Pom 加上下面的依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.24.Final</version>
</dependency>测试代码 HashedWheelTimerTest 如下所示
package com.rjzheng.delay3;
import io.netty.util.HashedWheelTimer;
import io.netty.util.Timeout;
import io.netty.util.Timer;
import io.netty.util.TimerTask;
import java.util.concurrent.TimeUnit;
public class HashedWheelTimerTest {
static class MyTimerTask implements TimerTask {
boolean flag;
public MyTimerTask(boolean flag) {
this.flag = flag;
}
public void run(Timeout timeout) throws Exception {
System.out.println("要去数据库删除订单了。。。。");
this.flag = false;
}
}
public static void main(String[] argv) {
MyTimerTask timerTask = new MyTimerTask(true);
Timer timer = new HashedWheelTimer();
timer.newTimeout(timerTask, 5, TimeUnit.SECONDS);
int i = 1;
while (timerTask.flag) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i + "秒过去了");
i++;
}
}
}输出如下
1秒过去了
2秒过去了
3秒过去了
4秒过去了
5秒过去了
要去数据库删除订单了。。。。
6秒过去了优点
效率高,任务触发时间延迟时间比 delayQueue 低,代码复杂度比 delayQueue 低。
缺点
- 服务器重启后,数据全部消失,怕宕机
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
方案 4:redis 缓存
思路一
利用 redis 的 zset,zset 是一个有序集合,每一个元素(member)都关联了一个 score,通过 score 排序来取集合中的值
添加元素:ZADD key score member [score member …]
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
查询元素 score:ZSCORE key member
移除元素:ZREM key member [member …]
测试如下
添加单个元素
redis> ZADD page_rank 10 google.com
(integer) 1
添加多个元素
redis> ZADD page_rank 9 baidu.com 8 bing.com
(integer) 2
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
查询元素的score值
redis> ZSCORE page_rank bing.com
"8"
移除单个元素
redis> ZREM page_rank google.com
(integer) 1
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"那么如何实现呢?我们将订单超时时间戳与订单号分别设置为 score 和 member,系统扫描第一个元素判断是否超时,具体如下图所示
实现一
package com.rjzheng.delay4;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Tuple;
import java.util.Calendar;
import java.util.Set;
public class AppTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedisPool = new JedisPool(ADDR, PORT);
public static Jedis getJedis() {
return jedisPool.getResource();
}
//生产者,生成5个订单放进去
public void productionDelayMessage() {
for (int i = 0; i < 5; i++) {
//延迟3秒
Calendar cal1 = Calendar.getInstance();
cal1.add(Calendar.SECOND, 3);
int second3later = (int) (cal1.getTimeInMillis() / 1000);
AppTest.getJedis().zadd("OrderId", second3later, "OID0000001" + i);
System.out.println(System.currentTimeMillis() + "ms:redis生成了一个订单任务:订单ID为" + "OID0000001" + i);
}
}
//消费者,取订单
public void consumerDelayMessage() {
Jedis jedis = AppTest.getJedis();
while (true) {
Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1);
if (items == null || items.isEmpty()) {
System.out.println("当前没有等待的任务");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
int score = (int) ((Tuple) items.toArray()[0]).getScore();
Calendar cal = Calendar.getInstance();
int nowSecond = (int) (cal.getTimeInMillis() / 1000);
if (nowSecond >= score) {
String orderId = ((Tuple) items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis() + "ms:redis消费了一个任务:消费的订单OrderId为" + orderId);
}
}
}
public static void main(String[] args) {
AppTest appTest = new AppTest();
appTest.productionDelayMessage();
appTest.consumerDelayMessage();
}
}此时对应输出如下
可以看到,几乎都是 3 秒之后,消费订单。
然而,这一版存在一个致命的硬伤,在高并发条件下,多消费者会取到同一个订单号,我们上测试代码 ThreadTest
package com.rjzheng.delay4;
import java.util.concurrent.CountDownLatch;
public class ThreadTest {
private static final int threadNum = 10;
private static CountDownLatch cdl = newCountDownLatch(threadNum);
static class DelayMessage implements Runnable {
public void run() {
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
AppTest appTest = new AppTest();
appTest.consumerDelayMessage();
}
}
public static void main(String[] args) {
AppTest appTest = new AppTest();
appTest.productionDelayMessage();
for (int i = 0; i < threadNum; i++) {
new Thread(new DelayMessage()).start();
cdl.countDown();
}
}
}输出如下所示
显然,出现了多个线程消费同一个资源的情况。
解决方案
(1)用分布式锁,但是用分布式锁,性能下降了,该方案不细说。
(2)对 ZREM 的返回值进行判断,只有大于 0 的时候,才消费数据,于是将 consumerDelayMessage()方法里的
if(nowSecond >= score){
String orderId = ((Tuple)items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId);
}修改为
if (nowSecond >= score) {
String orderId = ((Tuple) items.toArray()[0]).getElement();
Long num = jedis.zrem("OrderId", orderId);
if (num != null && num > 0) {
System.out.println(System.currentTimeMillis() + "ms:redis消费了一个任务:消费的订单OrderId为" + orderId);
}
}在这种修改后,重新运行 ThreadTest 类,发现输出正常了
思路二
该方案使用 redis 的 Keyspace Notifications,中文翻译就是键空间机制,就是利用该机制可以在 key 失效之后,提供一个回调,实际上是 redis 会给客户端发送一个消息。是需要 redis 版本 2.8 以上。
实现二
在 redis.conf 中,加入一条配置
notify-keyspace-events Ex
运行代码如下
package com.rjzheng.delay5;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPubSub;
public class RedisTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedis = new JedisPool(ADDR, PORT);
private static RedisSub sub = new RedisSub();
public static void init() {
new Thread(new Runnable() {
public void run() {
jedis.getResource().subscribe(sub, "__keyevent@0__:expired");
}
}).start();
}
public static void main(String[] args) throws InterruptedException {
init();
for (int i = 0; i < 10; i++) {
String orderId = "OID000000" + i;
jedis.getResource().setex(orderId, 3, orderId);
System.out.println(System.currentTimeMillis() + "ms:" + orderId + "订单生成");
}
}
static class RedisSub extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
System.out.println(System.currentTimeMillis() + "ms:" + message + "订单取消");
}
}
}输出如下
可以明显看到 3 秒过后,订单取消了
ps:redis 的 pub/sub 机制存在一个硬伤,官网内容如下
原:Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.
翻: Redis 的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后又重连,则在客户端断链期间的所有事件都丢失了。因此,方案二不是太推荐。当然,如果你对可靠性要求不高,可以使用。
优点
(1) 由于使用 Redis 作为消息通道,消息都存储在 Redis 中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2) 做集群扩展相当方便
(3) 时间准确度高
缺点
需要额外进行 redis 维护
方案 5:使用消息队列
思路
我们可以采用 rabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
RabbitMQ 可以针对 Queue 和 Message 设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为 dead letter
lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。
优点
高效,可以利用 rabbitmq 的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点
本身的易用度要依赖于 rabbitMq 的运维.因为要引用 rabbitMq,所以复杂度和成本变高。
链接:https://juejin.cn/post/7181297729979547705
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么计算机中的负数要用补码表示?
思维导图:
1. 为什么计算机要使用二进制数制?
所谓数制其实就是一种 “计数的进位方式”。
常见的数制有十进制、二进制、八进制和十六进制:
十进制是我们日常生活中最熟悉的进位方式,它一共有 0、1、2、3、4、5、6、7、8 和 9 十个符号。在计数的过程中,当某一位满 10 时,就需要向它临近的高位进一,即逢十进一;
二进制是程序员更熟悉的进位方式,也是随着计算机的诞生而发展起来的,它只有 0 和 1 两个符号。在计数的过程中,当某一位满 2 时,就需要向它临近的高位进一,即逢二进一;
八进制和十六进制同理。
那么,为什么计算机要使用二进制数制,而不是人类更熟悉的十进制呢?其原因在于二进制只有两种状态,制造只有 2 个稳定状态的电子元器件可以使用高低电位或有无脉冲区分,而相比于具备多个状态的电子元器件会更加稳定可靠。
2.有符号数与无符号数
在计算机中会区分有符号数和无符号数,无符号数不需要考虑符号,可以将数字编码中的每一位都用来存放数值。有符号数需要考虑正负性,然而计算机是无法识别符号的 “正+” 或 “负-” 标志的,那怎么办呢?
好在我们发现 “正 / 负” 是两种截然不同的状态,正好可以映射到计算机能够理解的 “0 / 1” 上。因此,我们可以直接 “将符号数字化”,将 “正+” 数字化为 “0”,将 “负-” 数字化为 “1”,并将数字化后的符号和数值共同组成数字编码。
另外,为了计算方便,我们额外再规定将 “符号位” 放在数字编码的 “最高位”。例如,+1110 和 -1110 用 8 位二进制表示就是:
- 0000, 1110(符号作为编码的一部分,最高位 0 表示正数)
- 1000, 1110(符号作为编码的一部分,最高位 1 表示负数)
从中我们也可以看出无符号数和有符号数的区别:
1、最高位功能不同: 无符号数的编码中的每一位都可以用来存放数值信息,而有符号数需要在编码的最高位留出一位符号位;
2、数值范围不同: 相同位数下有符号数和无符号数表示的数值范围不同。以 16 位数为例,无符号数可以表示 0
65536,而有符号数可以表示 -3276832768。
提示: 无符号数和有符号数表示的数值范围大小是一样大的,n 位二进制最多只能表示 个信息量,这是无法被突破的。
3. 机器数的运算效率问题
在计算机中,我们会把带 “正 / 负” 符号的数称为真值(True Value),而把符号化后的数称为机器数(Computer Number)。
机器数才是数字在计算机中的二进制表示。 例如在前面的数字中, +1110 是真值,而 0000, 1110 是机器数。新的问题来了:将符号数字化后的机器数,在运算的过程中符号位是否与数值参与运算,又应该如何运算呢?
我们先举几个加法运算的例子:
- 两个正数相加:
0000, 1110 + 0000, 0001 = 0000, 1111 // 14 + 1 = 15 正确
^ ^ ^
符号位 符号位 符号位
- 两个负数相加:
1000, 1110 + 1000, 0001 = 0000, 1111 // (-14) + (-1) = 15 错误
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
- 正负数相加:
0000, 1110 + 1000, 0001 = 1001, 1111 // 14 + (-1) = -15 错误
^ ^ ^
符号位 符号位 符号位
可以看到,在对机器数进行 “按位加法” 运算时,只有两个正数的加法运算的结果是正确的,而包含负数的加法运算的结果却是错误的,会出现 -14 - 1 = 15 和 14 - 1 = -15 这种错误结果。
所以,带负数的加法运算就不能使用常规的按位加法运算了,需要做特殊处理:
两个正数相加:
- 直接做按位加法。
两个负数相加:
- 1、用较大的绝对值 + 较小的绝对值(加法运算);
- 2、最终结果的符号为负。
正负数相加:
- 1、判断两个数的绝对值大小(数值部分);
- 2、用较大的绝对值 - 较小的绝对值(减法运算);
- 3、最终结果的符号取绝对值较大数的符号。
哇🤩?好好的加法运算给整成减法运算? 运算器的电路设计不仅要多设置一个减法器,而且运算步骤还特别复杂。那么,有没有不需要设置减法器,而且步骤简单的方案呢?
4. 原码、反码、补码
为了解决有符号机器数运算效率问题,计算机科学家们提出多种机器数的表示法:
| 机器数 | 正数 | 负数 |
|---|---|---|
| 原码 | 符号位表示符号 数值位表示真值的绝对值 | 符号位表示数字的符号 数值位表示真值的绝对值 |
| 反码 | 无(或者认为是原码本身) | 符号位为 1 数值位是对原码数值位的 “按位取反” |
| 补码 | 无(或者认为是原码本身) | 在负数反码的基础上 + 1 |
1、原码: 原码是最简单的机器数,例如前文提到从
+1110和-1110转换得到的0000, 1110和1000, 1110就是原码表示法,所以原码在进行数字运算时会存在前文提到的效率问题;
2、反码: 反码一般认为是原码和补码转换的中间过渡;
3、补码: 补码才是解决机器数的运算效率的关键, 在计算机中所有 “整型类型” 的负数都会使用补码表示法;
正数的补码是原码本身;- 零的补码是零;
- 负数的补码是在反码的基础上再加 1。
很多教材和网上的资料会认为正数的原码、反码和补码是相同的,这么说倒也不影响什么。 但结合补码的设计原理,小彭的观点是正数是没有反码和补码的,负数使用补码是为了找到一个 “等价” 的正补数代替负数参与计算,将加减法运算统一为两个正数加法运算,而正数自然是不需要替换的,所以也就没有补码的形式。
提示: 为了便于你理解,小彭后文会继续用
“正数的补码是原码本身”这个观点阐述。
5. 使用补码消除减法运算
理解补码表示法后,似乎还是不清楚补码有什么用❓
我们重新计算上一节的加法运算试试:
| 举例 | 真值 | 原码 | 反码 | 补码 |
|---|---|---|---|---|
| +14 | +1110 | 0000, 1110 | 0000, 1110 | 0000, 1110 |
| +13 | +1101 | 0000, 1101 | 0000, 1101 | 0000, 1101 |
| -14 | +1110 | 1000, 1110 | 1111, 0001 | 1111, 0010 |
| -15 | -1110 | 1000, 1111 | 1111, 0000 | 1111, 0001 |
| +1 | +0001 | 0000, 0001 | 0000, 0001 | 0000, 0001 |
| -1 | -0001 | 1000, 0001 | 1111, 1110 | 1111, 1111 |
- 两个正数相加:
// 补码表示法
0000, 1110 + 0000, 0001 = 0000, 1111 // 14 + 1 = 15 正确
^ ^ ^
符号位 符号位 符号位
- 两个负数相加:
// 补码表示法
1111, 0010 + 1111, 1111 = 1111, 0001 // (-14) + (-1) = -15 正确
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
- 正负数相加:
// 补码表示法
0000, 1110 + 1111, 1111 = 0000, 1101 // 14 + (-1) = 13 正确
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
可以看到,使用补码表示法后,有符号机器数加法运算就只是纯粹的加法运算,不会因为符号的正负性而采用不同的计算方法,也不需要减法运算。因此电路设计中只需要设置加法器和补数器,就可以完成有符号数的加法和减法运算,能够简化电路设计。
除了消除减法运算外,补码表示法还实现了 “0” 的机器数的唯一性:
在原码表示法中,“+0” 和 “-0” 都是合法的,而在补码表示法中 “0” 只有唯一的机器数表示,即 0000, 0000 。换言之补码能够比原码多表示一个最小的负数 1000, 0000。
最后提供按照不同表示法解释二进制机器数后得到的真值对比:
| 二进制数 | 无符号真值 | 原码真值 | 反码真值 | 补码真值 |
|---|---|---|---|---|
| 0000, 0000 | 0 | +0 | +0 | +0 |
| 0000, 0001 | 1 | +1 | +1 | +1 |
| … | … | … | … | … |
| 1000, 0000 | 128 | -0(负零,无意义) | -127 | -128(多表示一个数) |
| 1000, 0001 | 129 | -1 | -126 | -127 |
| … | … | … | … | … |
| 1111, 1110 | 254 | -126 | -1 | -2 |
| 1111, 1111 | 255 | -127 | -0(负零) | -1 |
6. 补码我懂了,但是为什么?
理解原码和补码的定义不难,理解补码作用也不难,难的是理解补码是怎么设计出来的,总不可能是被树上的苹果砸到后想到的吧?
这就要提到数学中的 “补数” 概念:
- 1、当一个正数和一个负数互为补数时,它们的绝对值之和就是模;
- 2、一个负数可以用它的正补数代替。
6.1 时钟里的补数
听起来很抽象对吧❓其实生活中,就有一个更加形象的例子 —— 时钟,时钟里就蕴含着补数的概念!
比如说,现在时钟的时针刻度指向 6 点,我们想让它指向 3 点,应该怎么做:
- 方法 1 : 逆时针地拨动 3 个点数,让时针指向 3 点,这相当于做减法运算 -3;
- 方法 2: 顺时针地拨动 9 个点数,让时针指向 3 点,这相当于做加法运算 +9。
可以看到,对于时钟来说 -3 和 +9 竟然是等价的! 这是因为时钟只能 12 个小时,当时间点数超过 12 时就会自动丢失,所以 15 点和 3 点在时钟看来是都是 3 点。如果我们要在时钟上进行 6 - 3 减法运算,我们可以将 -3 等价替换为它的正补数 +9 后参与计算,从而将减法运算替换为 6 + 9 加法运算,结果都是 3。
6.2 十进制的例子
理解了补数的概念后,我们再多看一个十进制的例子:我们要计算十进制 354365 - 95937 = 的结果,怎么做呢?
- 方法 1 - 借位做减法: 常规的做法是利用连续向前借位做减法的方式计算,这没有问题;
- 方法 2 - 减模加补: 使用补数的概念后,我们就可以将减法运算消除为加法运算。
具体来说,如果我们限制十进制数的位长最多只有 6 位,那么模就是 1000000,-95937 对应的正补数就是 1000000 - 95937 = 904063 。此时,我们可以直接用正补数代替负数参与计算,则有:
354365 - 95937 // = 258428
= 354365 - (1000000 - 904063)
= 354365 - 1000000 + 904063 【减整加补】
= 258428可以看到,把 -95937 等价替换为 +904063 后,就把减法运算替换为加法运算。细心的你可能要举手提问了,还是需要减去 1000000 呀?🙋🏻♀️
其实并不用,因为 1000000 是超过位数限制的,所以减去 1000000 这一步就像时针逆时针拨动一整圈一样是无效的。所以实际上需要计算的是:
// 实际需要计算的是:
354365 + 904063
= 1258428 = 258428
^
最高位 1 超出位数限制,直接丢弃
6.3 为什么要使用补码?
继续使用前文提到的 14 + (-1) 正负数相加的例子:
// 原码表示法
0000, 1110 + 1000, 0001 = 1001, 1111 // 14 + (-1) = -15 错误
^ ^ ^
符号位 符号位 符号位
// 补码表示法
0000, 1110 + 1111, 1111 = 1, 0000, 1101 // 14 + (-1) = 13 正确
^ ^ ^
符号位 符号位 最高位 1 超出位数限制,直接丢弃
如果我们限制二进制数字的位长最多只有 8 位,那么模就是 1, 0000, 0000 ,此时,-1 的二进制数 1000, 0001 的正补数就是 1111, 1111。
我们使用正补数 1111, 1111 代替负数 1000, 0001 参与运算,加法运算后的结果是 1, 0000, 1101。其中最高位 1 超出位数限制,直接丢弃,所以最终结果是 0000, 1101,也就是 13,计算正确。
补码示意图
到这里,相信补码的设计原理已经很清楚了。
补码的关键在于:找到一个与负数等价的正补数,使用该正补数代替负数,从而将减法运算替换为两个正数加法运算。 补码的出现与运算器的电路设计有关,从设计者的角度看,希望尽可能简化电路设计和计算复杂度。而使用正补数代替负数就可以消除减法器,实现简化电路的目的。
所以,小彭认为只有负数才存在补码,正数本身就是正数,根本就没必要使用补数,更不需要转为补码。而且正数使用补码的话,还不能把负数转补码的算法用在正数上,还得强行加一条 “正数的补码是原码本身” 的规则,就离谱好吧。
7. 总结
1、无符号数的编码中的每一位都可以用来存放数值信息,而有符号数需要在最高位留出一位符号位;
2、在有符号数的机器数运算中,需要对正数和负数采用不同的计算方法,而且需要引入减法器;
3、为了解决有符号机器数运算效率问题,计算机科学家们提出多种机器数的表示法:原码、反码、补码和移码;
4、使用补码表示法后,运算器可以消除减法运算,而且实现了 “0” 的机器数的唯一性;
5、补码的关键是找到一个与负数等价的正补数,使用该正补数代替负数参与计算,从而将减法运算替换为加法运算。
在前文讲补码的地方,我们提到计算机所有 “整型类型” 的负数都会使用补码表示法,刻意强调 “整数类型” 是什么原因呢,难道浮点数和整数在计算机中的表示方法不同吗?这个问题我们在 下一篇文章 里讨论,请关注。
参考资料
- 计算机组成原理教程(第 2、6 章) —— 尹艳辉 王海文 邢军 著
- 深入浅出计算机组成原理(第 11 ~ 16 讲) —— 徐文浩 著,极客时间 出品
- 10分钟速成课 计算机科学 —— Carrie Anne 著
- Binary number —— Wikipedia
链接:https://juejin.cn/post/7169966346753540103
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
掌握这17张图,没人比你更懂RecyclerView的预加载
实际上,预拉取(prefetch)机制作为RecyclerView的重要特性之一,常常与缓存复用机制一起配合使用、共同协作,极大地提升了RecyclerView整体滑动的流畅度。
并且,这种特性在ViewPager2中同样得以保留,对ViewPager2滑动效果的呈现也起着关键性的作用。因此,我们ViewPager2系列的第二篇,就是要来着重介绍RecyclerView的预拉取机制。
预拉取是指什么?
在计算机术语中,预拉取指的是在已知需要某部分数据的前提下,利用系统资源闲置的空档,预先拉取这部分数据到本地,从而提高执行时的效率。
具体到RecyclerView预拉取的情境则是:
- 利用UI线程正好处于空闲状态的时机
- 预先拉取待进入屏幕区域内的一部分列表项视图并缓存起来
- 从而减少因视图创建或数据绑定等耗时操作所引起的卡顿。
预拉取是怎么实现的?
正如把缓存复用的实际工作委托给了其内部的Recycler类一样,RecyclerView也把预拉取的实际工作委托给了一个名为GapWorker的类,其内部的工作流程,可以用以下这张思维导图来概括:
接下来我们就循着这张思维导图,来一一拆解预拉取的工作流程。
1.发起预拉取工作
通过查找对GapWorker对象的引用,我们可以梳理出3个发起预拉取工作的时机,分别是:
- RecyclerView被拖动(Drag)时
@Override
public boolean onTouchEvent(MotionEvent e) {
...
switch (action) {
...
case MotionEvent.ACTION_MOVE: {
...
if (mScrollState == SCROLL_STATE_DRAGGING) {
...
// 处于拖动状态并且存在有效的拖动距离时
if (mGapWorker != null && (dx != 0 || dy != 0)) {
mGapWorker.postFromTraversal(this, dx, dy);
}
}
}
break;
...
}
...
return true;
}
- RecyclerView惯性滑动(Fling)时
class ViewFlinger implements Runnable {
...
@Override
public void run() {
...
if (!smoothScrollerPending && doneScrolling) {
...
} else {
...
if (mGapWorker != null) {
mGapWorker.postFromTraversal(RecyclerView.this, consumedX, consumedY);
}
}
}
...
} - RecyclerView嵌套滚动时
private void nestedScrollByInternal(int x, int y, @Nullable MotionEvent motionEvent, int type) {
...
if (mGapWorker != null && (x != 0 || y != 0)) {
mGapWorker.postFromTraversal(this, x, y);
}
...
}2.执行预拉取工作
GapWorker是Runnable接口的一个实现类,意味着其执行工作的入口必然是在run方法。
final class GapWorker implements Runnable {
@Override
public void run() {
...
prefetch(nextFrameNs);
...
}
}在run方法内部我们可以看到其调用了一个prefetch方法,在进入该方法之前,我们先来分析传入该方法的参数。
// 查询最近一个垂直同步信号发出的时间,以便我们可以预测下一个
final int size = mRecyclerViews.size();
long latestFrameVsyncMs = 0;
for (int i = 0; i < size; i++) {
RecyclerView view = mRecyclerViews.get(i);
if (view.getWindowVisibility() == View.VISIBLE) {
latestFrameVsyncMs = Math.max(view.getDrawingTime(), latestFrameVsyncMs);
}
}
...
// 预测下一个垂直同步信号发出的时间
long nextFrameNs = TimeUnit.MILLISECONDS.toNanos(latestFrameVsyncMs) + mFrameIntervalNs;
prefetch(nextFrameNs);由该方法的实参命名nextFrameNs可知,传入的是下一帧开始绘制的时间。
了解过Android屏幕刷新机制的人都知道,当GPU渲染完图形数据并放入图像缓冲区(buffer)之后,显示屏(Display)会等待垂直同步信号(Vsync)发出,随即交换缓冲区并取出缓冲数据,从而开始对新的一帧的绘制。
所以,这个实参同时也表示下一个垂直同步信号(Vsync)发出的时间,这是个预测值,单位为纳秒。由最近一个垂直同步信号发出的时间(latestFrameVsyncMs),加上每一帧刷新的间隔时间(mFrameIntervalNs)计算而成。
其中,每一帧刷新的间隔时间是这样子计算得到的:
// 如果取自显示屏的刷新率数据有效,则不采用默认的60fps
// 注意:此查询我们只静态地执行一次,因为它非常昂贵(>1ms)
Display display = ViewCompat.getDisplay(this);
float refreshRate = 60.0f; // 默认的刷新率为60fps
if (!isInEditMode() && display != null) {
float displayRefreshRate = display.getRefreshRate();
if (displayRefreshRate >= 30.0f) {
refreshRate = displayRefreshRate;
}
}
mGapWorker.mFrameIntervalNs = (long) (1000000000 / refreshRate); // 1000000000纳秒=1秒也即假定在默认60fps的刷新率下,每一帧刷新的间隔时间应为16.67ms。
再由该方法的形参命名deadlineNs可知,传入的参数表示的是预抓取工作完成的最后期限:
void prefetch(long deadlineNs) {
...
}综合一下就是,预抓取的工作必须在下一个垂直同步信号发出之前,也即下一帧开始绘制之前完成。
什么意思呢?
这是由于从Android 5.0(API等级21)开始,出于提高UI渲染效率的考虑,Android系统引入了RenderThread机制,即渲染线程。这个机制负责接管原先主线程中繁重的UI渲染工作,使得主线程可以更加专注于与用户的交互,从而大幅提高页面的流畅度。
但这里有一个问题。
当UI线程提前完成工作,并将一个帧传递给RenderThread渲染之后,就会进入所谓的休眠状态,出现了大量的空闲时间,直至下一帧开始绘制之前。如图所示:
一方面,这些UI线程上的空闲时间并没有被利用起来,相当于珍贵的线程资源被白白浪费掉;
另一方面,新的列表项进入屏幕时,又需要在UI线程的输入阶段(Input)就完成视图创建与数据绑定的工作,这会推迟UI线程及RenderThread上的其他工作,如果这些被推迟的工作无法在下一帧开始绘制之前完成,就有可能造成界面上的丢帧卡顿。
GapWorker正是选择在此时间窗口内安排预拉取的工作,也即把创建和绑定的耗时操作,移到UI线程的空闲时间内完成,与原先的RenderThread并行执行。
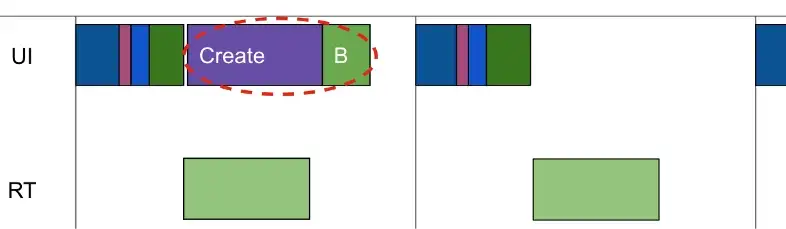
但这个预拉取的工作同样必须在下一帧开始绘制之前完成,否则预拉取的列表项视图还是会无法被及时地绘制出来,进而导致丢帧卡顿,于是才有了前面表示最后期限的传入参数。
了解完这个参数的含义后,让我们继续往下阅读源码。
2.1 构建预拉取任务列表
void prefetch(long deadlineNs) {
buildTaskList();
...
}进入prefetch方法后可以看到,预拉取的第一个动作就是先构建预拉取的任务列表,其内部又可分为以下3个事项:
2.1.1 收集预拉取的列表项数据
private void buildTaskList() {
// 1.收集预拉取的列表项数据
final int viewCount = mRecyclerViews.size();
int totalTaskCount = 0;
for (int i = 0; i < viewCount; i++) {
RecyclerView view = mRecyclerViews.get(i);
// 仅对当前可见的RecyclerView收集数据
if (view.getWindowVisibility() == View.VISIBLE) {
view.mPrefetchRegistry.collectPrefetchPositionsFromView(view, false);
totalTaskCount += view.mPrefetchRegistry.mCount;
}
}
...
} static class LayoutPrefetchRegistryImpl
implements RecyclerView.LayoutManager.LayoutPrefetchRegistry {
...
void collectPrefetchPositionsFromView(RecyclerView view, boolean nested) {
...
// 启用了预拉取机制
if (view.mAdapter != null
&& layout != null
&& layout.isItemPrefetchEnabled()) {
if (nested) {
...
} else {
// 基于移动量进行预拉取
if (!view.hasPendingAdapterUpdates()) {
layout.collectAdjacentPrefetchPositions(mPrefetchDx, mPrefetchDy,
view.mState, this);
}
}
...
}
}
}public class LinearLayoutManager extends RecyclerView.LayoutManager implements
ItemTouchHelper.ViewDropHandler, RecyclerView.SmoothScroller.ScrollVectorProvider {
public void collectAdjacentPrefetchPositions(int dx, int dy, RecyclerView.State state,
LayoutPrefetchRegistry layoutPrefetchRegistry) {
// 根据布局方向取水平方向的移动量dx或垂直方向的移动量dy
int delta = (mOrientation == HORIZONTAL) ? dx : dy;
...
ensureLayoutState();
// 根据移动量正负值判断移动方向
final int layoutDirection = delta > 0 ? LayoutState.LAYOUT_END : LayoutState.LAYOUT_START;
final int absDelta = Math.abs(delta);
// 收集与预拉取相关的重要数据,并存储到LayoutState
updateLayoutState(layoutDirection, absDelta, true, state);
collectPrefetchPositionsForLayoutState(state, mLayoutState, layoutPrefetchRegistry);
}
}这一事项主要是依据RecyclerView滚动的方向,收集即将进入屏幕的、待预拉取的列表项数据,其中,最关键的2项数据是:
- 待预拉取项的position值——用于预加载项位置的确定
- 待预拉取项与RecyclerView可见区域的距离——用于预拉取任务的优先级排序
我们以最简单的LinearLayoutManager为例,看一下这2项数据是怎样收集的,其最关键的实现就在于前面的updateLayoutState方法。
假定此时我们的手势是向上滑动的,则其进入的是layoutToEnd == true的判断:
private void updateLayoutState(int layoutDirection, int requiredSpace,
boolean canUseExistingSpace, RecyclerView.State state) {
...
if (layoutToEnd) {
...
// 步骤1,获取滚动方向上的第一个项
final View child = getChildClosestToEnd();
// 步骤2,确定待预拉取项的方向
mLayoutState.mItemDirection = mShouldReverseLayout ? LayoutState.ITEM_DIRECTION_HEAD
: LayoutState.ITEM_DIRECTION_TAIL;
// 步骤3,确认待预拉取项的position
mLayoutState.mCurrentPosition = getPosition(child) + mLayoutState.mItemDirection;
mLayoutState.mOffset = mOrientationHelper.getDecoratedEnd(child);
// 步骤4,确认待预拉取项与RecyclerView可见区域的距离
scrollingOffset = mOrientationHelper.getDecoratedEnd(child)
- mOrientationHelper.getEndAfterPadding();
} else {
...
}
...
mLayoutState.mScrollingOffset = scrollingOffset;
}步骤1,获取RecyclerView滚动方向上的第一项,如图中①所示:
步骤2,确定待预拉取项的方向。不用反转布局的情况下是ITEM_DIRECTION_TAIL,该值等于1,如图中②所示:
步骤3,确认待预拉取项的position值。由滚动方向上的第一项的position值加上步骤2确定的方向值相加得到,对应的是RecyclerView待进入屏幕区域的下一个项,如图中③所示:
步骤4,确认待预拉取项与RecyclerView可见区域的距离,该值由以下2个值相减得到:
getEndAfterPadding:指的是RecyclerView去除了Padding后的底部位置,并不完全等于RecyclerView的高度。getDecoratedEnd:指的是由列表项的底部位置,加上列表项设立的外边距,再加上列表项间隔的高度计算得到的值。
我们用一张图来说明一下:
首先,图中的①表示一个完整的屏幕可见区域,其中:
- 深灰色区域对应的是RecyclerView设立的上下内边距,即Padding值。
- 中灰色区域对应的是RecyclerView的列表项分隔线,即Decoration。
- 浅灰色区域对应的是每一个列表项设立的外边距,即Margin值。
RecyclerView的实际可见区域,是由虚线a和虚线b所包围的区域,即去除了上下内边距之后的区域。getEndAfterPadding方法返回的值,即是虚线b所在的位置。
图中的②是对RecyclerView底部不可见区域的透视图,假定现在position=2的列表项的底部正好贴合到RecyclerView可见区域的底部,则getDecoratedEnd方法返回的值,即是虚线c所在的位置。
接下来,如果按前面的步骤4进行计算,即用虚线c所在的位置减去的虚线b所在的位置,得到的就是图中的③,即刚好是列表项的外边距加上分隔线的高度。
这个结果就是待预拉取列表项与RecyclerView可见区域的距离。随着向上滑动的手势这个距离值逐渐变小,直到正好进入RecyclerView的可见区域时变为0,随后开始预加载下一项。
这2项数据收集到之后,就会调用GapWorker的addPosition方法,以交错的形式存放到一个int数组类型的mPrefetchArray结构中去:
@Override
public void addPosition(int layoutPosition, int pixelDistance) {
...
// 根据实际需要分配新的数组,或以2的倍数扩展数组大小
final int storagePosition = mCount * 2;
if (mPrefetchArray == null) {
mPrefetchArray = new int[4];
Arrays.fill(mPrefetchArray, -1);
} else if (storagePosition >= mPrefetchArray.length) {
final int[] oldArray = mPrefetchArray;
mPrefetchArray = new int[storagePosition * 2];
System.arraycopy(oldArray, 0, mPrefetchArray, 0, oldArray.length);
}
// 交错存放position值与距离
mPrefetchArray[storagePosition] = layoutPosition;
mPrefetchArray[storagePosition + 1] = pixelDistance;
mCount++;
}需要注意的是,RecyclerView每次的预拉取并不限于单个列表项,实际上,它可以一次获取多个列表项,比如使用了GridLayoutManager的情况。
2.1.2 根据预拉取的数据填充任务列表
private void buildTaskList() {
...
// 2.根据预拉取的数据填充任务列表
int totalTaskIndex = 0;
for (int i = 0; i < viewCount; i++) {
RecyclerView view = mRecyclerViews.get(i);
...
LayoutPrefetchRegistryImpl prefetchRegistry = view.mPrefetchRegistry;
final int viewVelocity = Math.abs(prefetchRegistry.mPrefetchDx)
+ Math.abs(prefetchRegistry.mPrefetchDy);
// 以2为偏移量进行遍历,从mPrefetchArray中分别取出前面存储的position值与距离
for (int j = 0; j < prefetchRegistry.mCount * 2; j += 2) {
final Task task;
if (totalTaskIndex >= mTasks.size()) {
task = new Task();
mTasks.add(task);
} else {
task = mTasks.get(totalTaskIndex);
}
final int distanceToItem = prefetchRegistry.mPrefetchArray[j + 1];
// 与RecyclerView可见区域的距离小于滑动的速度,该列表项必定可见,任务需要立即执行
task.immediate = distanceToItem <= viewVelocity;
task.viewVelocity = viewVelocity;
task.distanceToItem = distanceToItem;
task.view = view;
task.position = prefetchRegistry.mPrefetchArray[j];
totalTaskIndex++;
}
}
...
}Task是负责存储预拉取任务数据的实体类,其所包含属性的含义分别是:
position:待预加载项的Position值distanceToItem:待预加载项与RecyclerView可见区域的距离viewVelocity:RecyclerView的滑动速度,其实就是滑动距离immediate:是否立即执行,判断依据是与RecyclerView可见区域的距离小于滑动的速度view:RecyclerView本身
从第2个for循环可以看到,其是以2为偏移量进行遍历,从mPrefetchArray中分别取出前面存储的position值与距离的。
2.1.3 对任务列表进行优先级排序
填充任务列表完毕后,还要依据实际情况对任务进行优先级排序,其遵循的基本原则就是:越可能快进入RecyclerView可见区域的列表项,其预加载的优先级越高。
private void buildTaskList() {
...
// 3.对任务列表进行优先级排序
Collections.sort(mTasks, sTaskComparator);
} static Comparator sTaskComparator = new Comparator() {
@Override
public int compare(Task lhs, Task rhs) {
// 首先,优先处理未清除的任务
if ((lhs.view == null) != (rhs.view == null)) {
return lhs.view == null ? 1 : -1;
}
// 然后考虑需要立即执行的任务
if (lhs.immediate != rhs.immediate) {
return lhs.immediate ? -1 : 1;
}
// 然后考虑滑动速度更快的
int deltaViewVelocity = rhs.viewVelocity - lhs.viewVelocity;
if (deltaViewVelocity != 0) return deltaViewVelocity;
// 最后考虑与RecyclerView可见区域距离最短的
int deltaDistanceToItem = lhs.distanceToItem - rhs.distanceToItem;
if (deltaDistanceToItem != 0) return deltaDistanceToItem;
return 0;
}
};
2.2 调度预拉取任务
void prefetch(long deadlineNs) {
...
flushTasksWithDeadline(deadlineNs);
}预拉取的第二个动作,则是将前面填充并排序好的任务列表依次调度执行:
private void flushTasksWithDeadline(long deadlineNs) {
for (int i = 0; i < mTasks.size(); i++) {
final Task task = mTasks.get(i);
if (task.view == null) {
break; // 任务已完成
}
flushTaskWithDeadline(task, deadlineNs);
task.clear();
}
} private void flushTaskWithDeadline(Task task, long deadlineNs) {
long taskDeadlineNs = task.immediate ? RecyclerView.FOREVER_NS : deadlineNs;
RecyclerView.ViewHolder holder = prefetchPositionWithDeadline(task.view,
task.position, taskDeadlineNs);
...
}2.2.1 尝试根据position获取ViewHolder对象
进入prefetchPositionWithDeadline方法后,我们终于再次见到了上一篇的老朋友——Recycler,以及熟悉的成员方法tryGetViewHolderForPositionByDeadline:
private RecyclerView.ViewHolder prefetchPositionWithDeadline(RecyclerView view,
int position, long deadlineNs) {
...
RecyclerView.Recycler recycler = view.mRecycler;
RecyclerView.ViewHolder holder;
try {
...
holder = recycler.tryGetViewHolderForPositionByDeadline(
position, false, deadlineNs);
...
}
这个方法我们在上一篇文章有介绍过,作用是尝试根据position获取指定的ViewHolder对象,如果从缓存中查找不到,就会重新创建并绑定。
2.2.2 根据绑定成功与否添加到mCacheViews或RecyclerViewPool
private RecyclerView.ViewHolder prefetchPositionWithDeadline(RecyclerView view,
int position, long deadlineNs) {
...
if (holder != null) {
if (holder.isBound() && !holder.isInvalid()) {
// 如果绑定成功,则将该视图进入缓存
recycler.recycleView(holder.itemView);
} else {
//没有绑定,所以我们不能缓存视图,但它会保留在池中直到下一次预取/遍历。
recycler.addViewHolderToRecycledViewPool(holder, false);
}
}
...
return holder;
}接下来,如果顺利地获取到了ViewHolder对象,且该ViewHolder对象已经完成数据的绑定,则下一步就该立即回收该ViewHolder对象,缓存到mCacheViews结构中以供重用。
而如果该ViewHolder对象还未完成数据的绑定,意味着我们没能在设定的最后期限之前完成预拉取的操作,列表项数据不完整,因而我们不能将其缓存到mCacheViews结构中,但它会保留在mRecyclerViewPool结构中,以供下一次预拉取或重用。
预拉取机制与缓存复用机制的怎么协作的?
既然是与缓存复用机制共用相同的缓存结构,那么势必会对缓存复用机制的流程产生一定的影响,同样,让我们用几张流程示意图来演示一下:
假定现在position=5的列表项的底部正好贴合到RecyclerView可见区域的底部,即还要滑动超过该列表项的外边距+分隔线高度的距离,下一个列表项才可见。
随着向上拖动的手势,GapWorker开始发起预加载的工作,根据前面梳理的流程,它会提前创建并绑定position=6的列表项的ViewHolder对象,并将其缓存到mCacheViews结构中去。
- 继续保持向上拖动,当position=6的列表项即将进入屏幕时,它会按照上一篇缓存复用机制的流程,从mCacheViews结构取出可复用的ViewHolder对象,无需再次经历创建和绑定的过程,因此滑动的流畅度有了提升。
- 同时,随着position=6的列表项进入屏幕,GapWorker也开始了对position=7的列表项的预加载
- 之后,随着拖动距离的增大,position=0的列表项也将被移出屏幕,添加到mCachedViews结构中去。
上一篇文章我们讲过,mCachedViews结构的默认大小限制为2,从这里就可以看出,其这样设计是想刚好能缓存一个被移出屏幕的可复用ViewHolder对象+一个待进入屏幕的预拉取ViewHolder对象的。
不知道你们注意到没有,在步骤5的示意图中,可复用ViewHolder对象是添加到预拉取ViewHolder对象前面的,之所以这样子画是遵循了源码中的实现:
// 添加之前,先移除最老的一个ViewHolder对象
int cachedViewSize = mCachedViews.size();
if (cachedViewSize >= mViewCacheMax && cachedViewSize > 0) { // 当前已经放满
recycleCachedViewAt(0); // 移除mCachedView结构中的第1个
cachedViewSize--; // 总数减1
}
// 默认从尾部添加
int targetCacheIndex = cachedViewSize;
// 处理预拉取的情况
if (ALLOW_THREAD_GAP_WORK
&& cachedViewSize > 0
&& !mPrefetchRegistry.lastPrefetchIncludedPosition(holder.mPosition)) {
// 从最后一个开始,跳过所有最近预拉取的对象排在其前面
int cacheIndex = cachedViewSize - 1;
while (cacheIndex >= 0) {
int cachedPos = mCachedViews.get(cacheIndex).mPosition;
// 添加到最近一个非预拉取的对象后面
if (!mPrefetchRegistry.lastPrefetchIncludedPosition(cachedPos)) {
break;
}
cacheIndex--;
}
targetCacheIndex = cacheIndex + 1;
}
mCachedViews.add(targetCacheIndex, holder);也就是说,虽然缓存复用的对象和预拉取的对象共用同一个mCachedViews结构,但二者是分组存放的,且缓存复用的对象是排在预拉取的对象前面的。这么说或许还是很难理解,我们用几张示意图来演示一下就懂了:
1.假定现在mCachedViews中同时有2种类型的ViewHolder对象,黑色的代表缓存复用的对象,白色的代表预拉取的对象;
2.现在,有另外一个缓存复用的对象想要放到mCachedViews中,按源码的做法,默认会从尾部添加,即targetCacheIndex = 3:
3.随后,需要进一步确认放入的位置,它会从尾部开始逐个遍历,判断是否是预拉取的ViewHolder对象,判断的依据是该ViewHolder对象的position值是否存在mPrefetchArray结构中:
boolean lastPrefetchIncludedPosition(int position) {
if (mPrefetchArray != null) {
final int count = mCount * 2;
for (int i = 0; i < count; i += 2) {
if (mPrefetchArray[i] == position) return true;
}
}
return false;
}
4.如果是,则跳过这一项继续遍历,直到找到最近一个非预拉取的对象,将该对象的索引+1,即targetCacheIndex = cacheIndex + 1,得到确认放入的位置。
5.虽然二者是分组存放的,但二者内部仍是有序的,即按照加入的顺序正序排列。
开启预拉取机制后的实际效果如何?
最后,我们还剩下一个问题,即预拉取机制启用之后,对于RecyclerView的滑动展示究竟能有多大的性能提升?
关于这个问题,已经有人做过相关的测试验证,这里就不再大量贴图了,只概括一下其方案的整体思路:
- 测量工具:开发者模式-GPU渲染模式
- 该工具以滚动显示的直方图形式,直观地呈现渲染出界面窗口帧所需花费的时间
- 水平轴上的每个竖条即代表一个帧,其高度则表示渲染该帧所花的时间。
- 绿线表示的是16.67毫秒的基准线。若想维持每秒60帧的正常绘制,则需保证代表每个帧的竖条维持在此线以下。
- 耗时模拟:在onBindViewHolder方法中,使用Thread.sleep(time)来模拟页面渲染的复杂度。复杂度的大小,通过time时间的长短来体现。时间越长,复杂度越高。
- 测试结果:对比同一复杂度下的RecyclerView滑动,未启用预拉取机制的一侧流畅度明显更低,并且随着复杂度的增加,在16ms内无法完成渲染的帧数进一步增多,延时更长,滑动卡顿更明显。
最后总结一下:
| 预加载机制 | |
|---|---|
| 概念 | 利用UI线程正好处于空闲状态的时机,预先拉取一部分列表项视图并缓存起来,从而减少因视图创建或数据绑定等耗时操作所引起的卡顿。 |
| 重要类 | GapWorker:综合滑动方向、滑动速度、与可见区域的距离等要素,构建并调度预拉取任务列表。 |
| Recycler:获取ViewHolder对象,如果缓存中找不到,则重新创建并绑定 | |
| 结构 | mCachedViews:顺利获取到了ViewHolder对象,且已完成数据的绑定时放入 |
| mRecyclerPool:顺利获取到了ViewHolder对象,但还未完成数据的绑定时放入 | |
| 发起时机 | 被拖动(Drag)、惯性滑动(Fling)、嵌套滚动时 |
| 完成期限 | 下一个垂直同步信号发出之前 |
链接:https://juejin.cn/post/7181979065488769083
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
移动端防抓包实践
01.整体概述介绍
1.1 项目背景
通讯安全是App安全检测过程中非常重要的一项
针对该项的主要检测手段就是使用中间人代理机制对网络传输数据进行抓包、拦截和篡改,以检验App在核心链路上是否有安全漏洞。
保证数据安全
通过charles等工具可以对app的网络请求进行抓包,这样这些信息就会被清除的提取出来,会被不法分子进行利用。
不想被竞争对手逆向抓包
不想自身App的数据被别人轻而易举地抓包获取到,从而进行类似业务或数据分析、爬虫或网络攻击等破坏性行为。
1.2 思考问题
开发项目的时候,都需要抓包,很多情况下即使是Https也能正常抓包正常。那么问题来了:
抓包的原理是?任何Https的 app 都能抓的到吗?如果不能,哪些情况下可以抓取,哪些情况下抓取不到?
什么叫做中间人攻击?
使用HTTPS协议进行通信时,客户端需要对服务器身份进行完整性校验,以确认服务器是真实合法的目标服务器。
如果没有校验,客户端可能与仿冒的服务器建立通信链接,即“中间人攻击”。
1.3 设计目标
防止App被各种方式抓包
做好各种防抓包安全措施,避免各种黑科技抓包。
沉淀为技术库复用
目前只是针对App端有需要做防抓包措施,后期其他业务线可能也有这个需要。因此下沉为工具库,傻瓜式调用很有必要。
该库终极设计目标如下所示
第一点:必须是低入侵性,对原有代码改动少,最简单的加入是一行代码设置即可。完全解耦合。
第二点:可以动态灵活配置,支持配置禁止代理,支持配置是否证书校验,支持配置域名合法性过滤,支持拦截器加解密数据。
第三点:可以检测App是否在双开,挂载,Xposed攻击环境
第四点:可以灵活设置加解密的key,可以灵活替换加解密方式,比如目前采用RC4,另一个项目想用DES,可以灵活更换。
1.4 收益分析
抓包库收益
提高产品App的数据安全,必须对数据传输做好安全保护措施和完整性校验,以防止自身数据在网络传输中裸奔,甚至是被三方恶意利用或攻击。
技能的收益
下沉为功能基础库,可以方便各个产品线使用,提高开发的效率。避免跟业务解耦合。傻瓜式调用,低成本接入!
02.市面抓包的分析
2.1 Https三要素
要清楚HTTPS抓包的原理,首先需要先说清楚 HTTPS 实现数据安全传输的工作原理,主要分为三要素和三阶段。
Http传输数据目前存在的问题
1.通信使用明文,内容可能被窃听;2.不验证通信方的身份,因此可能遭遇伪装;3.无法证明报文的完整性,所以有可能遭到篡改。
Https三要素分别是:
1.加密:通过对称加密算法实现。
2.认证:通过数字签名实现。(因为私钥只有 “合法的发送方” 持有,其他人伪造的数字签名无法通过验证)
3.报文完整性:通过数字签名实现。(因为数字签名中使用了消息摘要,其他人篡改的消息无法通过验证)
Https三阶段分别是:
1.CA 证书校验:CA 证书校验发生在 TLS 的前两次握手,客户端和服务端通过报文获得服务端 CA 证书,客户端验证 CA 证书合法性,从而确认 CA 证书中的公钥合法性(大多数场景不会做双向认证,即服务端不会认证客户端合法性,这里先不考虑)。
2.密钥协商:密钥协商发生在 TLS 的后两次握手,客户端和服务端分别基于公钥和私钥进行非对称加密通信,协商获得 Master Secret 对称加密私钥(不同算法的协商过程细节略有不同)。
3.数据传输:数据传输发生在 TLS 握手之后,客户端和服务端基于协商的对称密钥进行对称加密通信。
Https流程图如下
2.2 抓包核心原理
HTTPS抓包原理
Fiddler、Charles等抓包工具,其实都是采用了中间人攻击的方案: 将客户端的网络流量代理到MITM(中间人)主机,再通过一系列的面板或工具将网络请求结构化地呈现出来。
抓包Https有两个突破点
CA证书校验是否合法;数据传递过程中的加密和解密。如果是要抓包,则需要突破这两点的技术,无非就是MITM(中间人)伪造证书和使用自己的加解密方式。
抓包的工作流程如下
中间人截获客户端向发起的HTTPS请求,佯装客户端,向真实的服务器发起请求;
中间人截获真实服务器的返回,佯装真实服务器,向客户端发送数据;
中间人获取了用来加密服务器公钥的非对称秘钥和用来加密数据的对称秘钥,处理数据加解密。
2.3 搞定CA证书
Https抓包核心CA证书
HTTPS抓包的原理还是挺简单的,简单来说,就是Charles作为“中间人代理”,拿到了服务器证书公钥和HTTPS连接的对称密钥。
前提是客户端选择信任并安装Charles的CA证书,否则客户端就会“报警”并中止连接。这样看来,HTTPS还是很安全的。
安装CA证书到手机中必须洗白
抓包应用内置的 CA 证书要洗白,必须安装到系统中。而 Android 系统将 CA 证书又分为两种:用户 CA 证书和系统 CA 证书(必要Root权限)。
Android从7.0开始限制CA证书
只有系统(system)证书才会被信任。用户(user)导入的Charles根证书是不被信任的。相当于可以理解Android系统增加了安全校验!
如何绕过CA证书这种限制呢?已知有以下四种方式
第一种方式:AndroidManifest 中配置 networkSecurityConfig,App 信任用户 CA 证书,让系统对用户 CA 证书的校验给予通过。
第二种方式:调低 targetSdkVersion < 24,不过这种方式谷歌市场有限制,意味着抓 HTTPS 的包越来越难操作。
第三种方式:挂载App抓包,VirtualApp 这种多开应用可以作为宿主系统来运行其它应用,利用xposed避开CA证书校验。
第四种方式:Root手机,把 CA 证书安装到系统 CA 证书目录中,那这个假 CA 证书就是真正洗白了,难度较大。
2.4 突破CA证书校验
App版本如何让证书校验安全
1.设置targetSdkVersion大于24,去掉清单文件中networkSecurityConfig文件中的system和user配置,设置不信任用户证书。
2.公钥证书固定。指 Client 端内置 Server 端真正的公钥证书。在 HTTPS 请求时,Server 端发给客户端的公钥证书必须与 Client 端内置的公钥证书一致,请求才会成功。
证书固定的一般做法是,将公钥证书(.crt 或者 .cer 等格式)内置到 App 中,然后创建 TrustManager 时将公钥证书加进去。
那么如何突破CA证书校验
第一种:JustTrustMe 破解证书固定。Xposed 和 Magisk 都有相应的模块,用来破解证书固定,实现正常抓包。破解的原理大致是,Hook 创建 SSLContext 等涉及 TrustManager 相关的方法,将固定的证书移除。
第二种:基于 VirtualApp 的 Hook 机制破解证书固定。在 VirtualApp 中加入 Hook 代码,然后利用 VirtualApp 打开目标应用进行抓包。具体看:VirtualHook
2.5 如何搞定加解密
目前使用对称加密和解密请求和响应数据
加密和解密都是用相同密钥。只有一把密钥,如果密钥暴露,内容就会暴露。但是这一块逆向破解有些难度。而破解解密方式就是用密钥逆向解密,或者中间人冒充使用自己的加解密方式!
加密后数据镇兼顾了安全性吗
不一定安全。中间人伪造自己的公钥和私钥,然后拦截信息,进行篡改。
2.6 Charles原理
Charles类似代理服务器
Charles 通过将软件本身设置成系统的网络访问代理服务器,使得所有的网络请求都会走一遍 Charles 代理,从而 Charles 可以截取经过它的请求,然后我们就可以对其进行网络包的分析。
截取设备网络封包数据
Charles对应设置:将代理功能打开,并设置一个固定的端口。默认情况下,端口号为:8888 。
移动设备设置:在手机上设置 WIFI 的 HTTP 代理。注意这里的前提是,Phone 和 Charles 代理设备链接的是同一网络(同一个ip地址和端口号)。
截取Https的网络封包
正常情况下,Charles 是不能截取Https的网络包的,这涉及到 Https 的证书问题。
2.7 抓包原理图
Charles抓包原理图
Android上的网络抓包原来是这样工作的
Charles抓包
2.8 抓包核心流程
抓包核心流程关键节点
第一步,客户端向服务器发起HTTPS请求,charles截获客户端发送给服务器的HTTPS请求,charles伪装成客户端向服务器发送请求进行握手 。
第二步,服务器发回相应,charles获取到服务器的CA证书,用根证书(这里的根证书是CA认证中心给自己颁发的证书)公钥进行解密,验证服务器数据签名,获取到服务器CA证书公钥。然后charles伪造自己的CA证书(这里的CA证书,也是根证书,只不过是charles伪造的根证书),冒充服务器证书传递给客户端浏览器。
第三步,与普通过程中客户端的操作相同,客户端根据返回的数据进行证书校验、生成密码Pre_master、用charles伪造的证书公钥加密,并生成HTTPS通信用的对称密钥enc_key。
第四步,客户端将重要信息传递给服务器,又被charles截获。charles将截获的密文用自己伪造证书的私钥解开,获得并计算得到HTTPS通信用的对称密钥enc_key。charles将对称密钥用服务器证书公钥加密传递给服务器。
第五步,与普通过程中服务器端的操作相同,服务器用私钥解开后建立信任,然后再发送加密的握手消息给客户端。
第六步,charles截获服务器发送的密文,用对称密钥解开,再用自己伪造证书的私钥加密传给客户端。
第七步,客户端拿到加密信息后,用公钥解开,验证HASH。握手过程正式完成,客户端与服务器端就这样建立了”信任“。
在之后的正常加密通信过程中,charles如何在服务器与客户端之间充当第三者呢?
服务器—>客户端:charles接收到服务器发送的密文,用对称密钥解开,获得服务器发送的明文。再次加密, 发送给客户端。
客户端—>服务端:客户端用对称密钥加密,被charles截获后,解密获得明文。再次加密,发送给服务器端。由于charles一直拥有通信用对称密钥enc_key,所以在整个HTTPS通信过程中信息对其透明。
03.防止抓包思路
3.1 先看如何抓包
使用Charles需要做哪些操作
1.电脑上需要安装证书。这个主要是让Charles充当中间人,颁布自己的CA证书。
2.手机上需要安装证书。这个是访问Charles获取手机证书,然后安装即可。
3.Android项目代码设置兼容。Google 推出更加严格的安全机制,应用默认不信任用户证书(手机里自己安装证书),自己的app可以通过配置解决,相当于信任证书的一种操作!
尤其可知抓包的突破口集中以下几点
第一点:必须链接代理,且跟Charles要具有相同ip。思路:客户端是否可以判断网络是否被代理了。
第二点:CA证书,这一块避免使用黑科技hook证书校验代码,或者拥有修改CA证书权限。思路:集中在可以判断是否挂载。
第三点:冒充中间人CA证书,在客户端client和服务端server之间篡改拦截数据。思路:可以做CA证书校验。
第四点:为了可以在7.0上抓包,App往往配置清单文件networkSecurityConfig。思路:线上环境去掉该配置。
3.2 设置配置文件
一个是CA证书配置文件
debug包为了能够抓包,需要配置networkSecurityConfig清单文件的system和user权限,只有这样才会信任用户证书。
一个是检验证书配置
不论是权威机构颁发的证书还是自签名的,打包一份到 app 内部,比如存放在 asset 里。然后用这个KeyStore去引导生成的TrustManager来提供证书验证。
一个是检验域名合法性
Android允许开发者重定义证书验证方法,使用HostnameVerifier类检查证书中的主机名与使用该证书的服务器的主机名是否一致。
如果重写的HostnameVerifier不对服务器的主机名进行验证,即验证失败时也继续与服务器建立通信链接,存在发生“中间人攻击”的风险。
如何查看CA证书的数据
证书验证网站 ;SSL配置检查网站
3.3 数据加密处理
网络数据加密的需求
为了项目数据安全性,对请求体和响应体加密,那肯定要知道请求体或响应体在哪里,然后才能加密,其实都一样不论是加密url里面的query内容还是加密body体里面的都一样。
对数据哪里进行加密和解密
目前对数据返回的data进行加解密。那么如何做数据加密呢?目前项目中采用RC4加密和解密数据。
抓取到的内容为乱码
有的APP为了防止抓取,在返回的内容上做了层加密,所以从Charles上看到的内容是乱码。这种情况下也只能反编译APP,研究其加密解密算法进行解密。难度极大!
3.4 避免黑科技抓包
基于Xposed(或者)黑科技破解证书校验
这种方式可以检查是否有Xposed环境,大概的思路是使用ClassLoader去加载固定包名的xp类,或者手动抛出异常然后捕获去判断是否包含Xposed环境。
基于VirtualApp挂载App突破证书访问权限
这个VirtualApp相当于是一个宿主App(可以把它想像成桌面级App),它突破证书校验。然后再实现挂载App的抓包。判断是否是双开环境!
04.防抓包实践开发
4.1 App安全配置
添加配置文件
android:networkSecurityConfig="@xml/network_security_config"
配置networkSecurityConfig抓包说明
中间人代理之所有能够获取到加密密钥就是因为我们手机上安装并信任了其代理证书,这类证书安装后都会被归结到用户证书一类,而不是系统证书。
那我们可以选择只信任系统内置的系统证书,而屏蔽掉用户证书(Android7.0以后就默认是只信任系统证书了),就可以防止数据被解密了。
实现App防抓包安全配置方式有两种:
一种是Android官方提供的网络安全配置;另一种也可以通过设置网络框架实现(以okhttp为例)。
第一种:具体可以看清单配置文件,相当于base-config标签下去掉 这组标签。
第二种:需要给okhttpClient配置 X509TrustManager 来监听校验服务端证书有效性。遍历设备上信任的证书,通过证书别名将用户证书(别名中含有user字段)过滤掉,只将系统证书添加到验证列表中。
该方案优点和缺点分析说明
优点:network_security_config配置简单,对整个app网络生效,无需修改代码;代码实现对通过该网络框架请求的生效,能兼容7.0以前系统。
缺陷:network_security_config配置方式,7.0以前的系统配置不生效,依然可以通过代理工具进行抓包。okhttp配置的方式只能对使用该网络框架进行数据传输的接口生效,并不能对整个app生效。
破解:将手机进行root,然后将代理证书放置到系统证书列表内,就可以绕过代码或配置检查了。
4.2 关闭代理
charles 和 fiddler 都使用代理来进行抓包,对网络客户端使用无代理模式即可防止抓包,如
OkHttpClient.Builder()
.proxy(Proxy.NO_PROXY)
.build()no_proxy实际上就是type属性为direct的一个proxy对象,这个type有三种
direct,http,socks。这样因为是直连,所以不走代理。所以charles等工具就抓不到包了,这样一定程度上保证了数据的安全,这种方式只是通过代理抓不到包。
通常情况下上述的办法有用,但是无法防住使用 VPN 导流进行的抓包
使用VPN抓包的原理是,先将手机请求导到VPN,再对VPN的网络进行Charles的代理,绕过了对App的代理。
该方案优点和缺点分析说明
优点:实现简单方便,无系统版本兼容问题。
缺陷:该方案比较粗暴,将一切代理都切断了,对于有合理诉求需要使用网络代理的场景无法满足。
破解:使用ProxyDroid全局代理工具通过iptables对请求进行强制转发,可以有效绕过代理检测。
4.3 证书校验(单向认证)
下载服务器端公钥证书
为了防止上面方案可能导致的“中间人攻击”,可以下载服务器端公钥证书,然后将公钥证书编译到Android应用中一般在assets文件夹保存,由应用在交互过程中去验证证书的合法性。
如何设置证书校验
通过OkHttp的API方法 sslSocketFactory(sslSocketFactory,trustManager) 设置SSL证书校验。
如何设置域名合法性校验
通过OkHttp的API方法 hostnameVerifier(hostnameVerifier) 设置域名合法性校验。
证书校验的原理分析
按CA证书去验证的,若不是CA可信任的证书,则无法通过验证。
单向认证流程图
该方案优点和缺点分析说明
优点:安全性比较高,单向认证校验证书在代码中是方便的,安全性相对较高。
缺陷:CA证书存在过期的问题,证书升级。
破解:证书锁定破解比较复杂,比如老牌的JustTrustMe插件,通过hook各网络框架的证书校验方法,替换原有逻辑,使校验失效。
4.4 双向认证
什么叫做双向认证
SSL/TLS 协议提供了双向认证的功能,即除了 Client 需要校验 Server 的真实性,Server 也需要校验 Client 的真实性。
双向认证的原理
双向认证需要 Server 支持,Client 必须内置一套公钥证书 + 私钥。在 SSL/TLS 握手过程中,Server 端会向 Client 端请求证书,Client 端必须将内置的公钥证书发给 Server,Server 验证公钥证书的真实性。
用于双向认证的公钥证书和私钥代表了 Client 端身份,所以其是隐秘的,一般都是用 .p12 或者 .bks 文件 + 密钥进行存放。
代码层面如何做双向认证
双向校验就是自定义生成客户端证书,保存在服务端和客户端,当客户端发起请求时在服务端也校验客户端的证书合法性,如果不是可信任的客户端发送的请求,则拒绝响应。
服务端根据自身使用语言和网络框架配置相应证书校验机制即可。
双向认证流程图
该方案优点和缺点分析说明
优点:安全性非常高,使用三方工具不易破解。
缺陷:服务端需要存储客户端证书,一般服务端会对应多个客户端,就需要分别存储和校验客户端证书,增加校验成本,降低响应速度。该方案比较适合对安全等级要求比较高的业务(如金融类业务)。
破解:由于在服务端也做校验,在服务端安全的情况下很难被攻破。
4.5 防止挂载抓包
Xposed是一个牛逼的黑科技
Xposed + JustTrustMe 可以破解绕过校验CA证书。那么这样CA证书的校验就形同虚设了,对App的危险性也很大。
App多开运行在多个环境上
多开App的原理类似,都是以新进程运行被多开的App,并hook各类系统函数,使被多开的App认为自己是一个正常的App在运行。
一种是从多开App中直接加载被多开的App,如平行空间、VirtualApp等,另一种是让用户新安装一个App,但这个App本质上就是一个壳,用来加载被多开的App。
VirtualApp是一个牛逼的黑科技
它破坏了Android 系统本身的隔离措施,可以进行免root hook和其他黑科技操作,你可以用这个做很多在原来APP里做不到事情,于此同时Virtual App的安全威胁也不言而喻。
如何判断是否具有Xposed环境
第一种方式:获取当前设备所有运行的APP,根据安装包名对应用进行检测判断是否有Xposed环境。
第二种方式:通过自造异常来检测堆栈信息,判断异常堆栈中是否包含Xposed等字符串。
第三种方式:通过ClassLoader检查是否已经加载了XposedBridge类和XposedHelpers类来检测。
第四种方式:获取DEX加载列表,判断其中是否包含XposedBridge.jar等字符串。
第五种方式:检测Xposed相关文件,通过读取/proc/self/maps文件,查找Xposed相关jar或者so文件来检测。
如何判断是否是双开环境
第一种方式:通过检测app私有目录,多开后的应用路径会包含多开软件的包名。还有一种思路遍历应用列表如果出现同样的包名,则被认为双开了。
第二种方式:如果同一uid下有两个进程对应的包名,在"/data/data"下有两个私有目录,则该应用被多开了。
判断了具有xposed或者多开环境怎么处理App
目前使用VirtualApp挂载,或者Xposed黑科技去hook,前期可以先用埋点统计。测试学而思App发现挂载在VA上是推出App。
4.5 数据加解密
针对数据加解密入口
目前在网络请求类里添加拦截器,然后在拦截器中处理request请求和response响应数据的加密和解密操作。
主要是加密什么数据
在request请求数据阶段,如果是get请求加密url数据,如果是post请求则加密url数据和requestBody数据。
在response响应数据阶段,
如何进行加密:发起请求(加密)
第一步:获取请求的数据。主要是获取请求url和requestBody,这一块需要对数据一块处理。
第二步:对请求数据进行加密。采用RC4加密数据
第三步:根据不同的请求方式构造新的request。使用 key 和 result 生成新的 RequestBody 发起网络请求
如何进行解密:接收返回(解密)
第一步:常规解析得到 result ,然后使用RC4工具,传入key去解密数据得到解密后的字符串
第二步:将解密的字符串组装成ResponseBody数据传入到body对象中
第三步:利用response对象去构造新的response,然后最后返回给App
4.7 证书锁定
证书锁定是Google官方比较推荐的一种校验方式
原理是在客户端中预先设置好证书信息,握手时与服务端返回的证书进行比较,以确保证书的真实性和有效性。
如何实现证书锁定
有两种实现方式:一种通过network_security_config.xml配置,另一种通过代码设置;
//第一种方式:配置文件 api.zuoyebang.cn 38JpactkIAq2Y49orFOOQKurWxmmSFZhBCoQYcRhK90= 9k1a0LRMXouZHRC8Ei+4PyuldPDcf3UKgO/04cDM90K=
//第二种方式:代码设置 fun sslPinning(): OkHttpClient { val builder = OkHttpClient.Builder() val pinners = CertificatePinner.Builder() .add("api.zuoyebang.cn", "sha256//89KpactkIAq2Y49orFOOQKurWxmmSFZhBCoQYcRh00L=") .add("api.zuoyebang.com", "sha256//a8za0LRMXouZHRC8Ei+4PyuldPDcf3UKgO/04cDM1o=09") .build() builder.apply { certificatePinner(pinners) } return builder.build() }
该方案优点和缺点分析说明
优点:安全性高,配置方式也比较简单,并能实现动态更新配置。
缺陷:网络安全配置无法实现证书证书的动态更新,另外该配置也受Android系统影响,对7.0以前的系统不支持。代码配置相对灵活些。
破解:证书锁定破解比较复杂,比如老牌的JustTrustMe插件,通过hook各网络框架的证书校验方法,替换原有逻辑,使校验失效
4.8 Sign签名
先说一下背景和问题
这种方式简单粗暴,通过调用getbanner方法即可获取轮播图列表信息,但是这样的方式会存在很严重的安全性问题,没有进行任何的验证,大家都可以通过这个方法获取到数据,导致产品信息泄露。
在写开放的API接口时是如何保证数据的安全性的?
请求来源(身份)是否合法?请求参数被篡改?请求的唯一性(不可复制)?
问题的解决方案设想
解决方案:为了保证数据在通信时的安全性,我们可以采用参数签名的方式来进行相关验证。
最终决定的解决方案
调用接口之前需要验证签名和有效时间,要生成一个sign签名。先拼接-后转码-再加密-再发请求!
sign签名校验实践
需要对请求参数进行签名验证,签名方式如下:key1=value1&key2=value2&key3=value3&secret=yc 。对这个字符串进行md5一下。
然后被sign后的接口就变成了:api.test.com/getbanner?k…
为什么在获取sign的时候建议使用secret参数?secret仅作加密使用,添加在参数中主要是md5,为了保证数据安全请不要在请求参数中使用。
服务端对sign校验
这样请求的时候就需要合法正确签名sign才可以获取数据。这样就解决了身份验证和防止参数篡改问题,如果请求参数被人拿走,没事,他们永远也拿不到secret,因为secret是不传递的。再也无法伪造合法的请求。
如何保证请求的唯一性
通过stamp时间戳用来验证请求是否过期。这样就算被人拿走完整的请求链接也是无效的。
Sign签名安全性分析:
通过上面的案例,安全的关键在于参与签名的secret,整个过程中secret是不参与通信的,所以只要保证secret不泄露,请求就不会被伪造。
05.架构设计说明
5.1 整体架构设计
如下所示
5.2 关键流程图
5.3 稳定性设计
对于请求和响应的数据加解密要注意
在网络上交换数据(网络请求数据)时,可能会遇到不可见字符,不同的设备对字符的处理方式有一些不同。
Base64对数据内容进行编码来适合传输。准确说是把一些二进制数转成普通字符用于网络传输。统统变成可见字符,这样出错的可能性就大降低了。
5.4 降级设计
可以一键配置AB测试开关
.setMonitorToggle(object : IMonitorToggle {
override fun isOpen(): Boolean {
//todo 是否降级,如果降级,则不使用该功能。留给AB测试开关
return false
}
})
5.5 异常设计说明
base64加密和解密导致错误问题
Android 有自带的Base64实现,flag要选Base64.NO_WRAP,不然末尾会有换行影响服务端解码。导致解码失败。
5.6 Api文档
关于初始化配置
NotCaptureHelper.getInstance().config = CaptureConfig.builder()
//设置debug模式
.setDebug(true)
//设置是否禁用代理
.setProxy(false)
//设置是否进行数据加密和解密,
.setEncrypt(true)
//设置cer证书路径
.setCerPath("")
//设置是否进行CA证书校验
.setCaVerify(false)
//设置加密和解密key
.setEncryptKey(key)
//设置参数
.setReservedQueryParam(OkHttpBuilder.RESERVED_QUERY_PARAM_NAMES)
.setMonitorToggle(object : IMonitorToggle {
override fun isOpen(): Boolean {
//todo 是否降级,如果降级,则不使用该功能。留给AB测试开关
return false
}
})
.build()设置okHttp配置
NotCaptureHelper.getInstance().setOkHttp(app,okHttpBuilder)如何设置自己的加解密方式
NotCaptureHelper.getInstance().encryptDecryptListener = object : EncryptDecryptListener {
/**
* 外部实现自定义加密数据
*/
override fun encryptData(key: String, data: String): String {
LoggerReporter.report("NotCaptureHelper", "encryptData data : $data")
val str = data.encryptWithRC4(key) ?: ""
LoggerReporter.report("NotCaptureHelper", "encryptData str : $str")
return str
}
/**
* 外部实现自定义解密数据
*/
override fun decryptData(key: String, data: String): String {
LoggerReporter.report("NotCaptureHelper", "decryptData data : $data")
val str = data.decryptWithRC4(key) ?: ""
LoggerReporter.report("NotCaptureHelper", "decryptData str : $str")
return str
}
}
5.7 防抓包功能自测
网络请求测试
正常请求,测试网络功能是否正常
抓包测试
配置fiddler,charles等工具
手机上设置代理
手机上安装证书
单向认证测试:进行网络请求,会提示SSLHandshakeException即ssl握手失败的错误提示,即表示app端的单向认证成功。
数据加解密:进行网络请求,看一下请求参数和响应body数据是否加密,如果看不到实际json实体则表示加密成功。
视频播放器:github.com/yangchong21…
作者:杨充
来源:juejin.cn/post/7175325220109025339
2022年年终杂谈,如何成为出色的工程师
重新认识自己
我一直对 NodeJS 工具方向比较感兴趣,今年终于有机会在公司内,开始工具项目的研发,调研并设计了整体架构、独立负责开发工作。
去年年末时,我刚刚来到字节半年,其实心态还没有完全转换过来,之前在创业公司,涉及了很多不同端的开发工作。所以我对自己的定位,还处于一个支持业务开发的状态,对技术渴望度足够,但对于技术路线有些许迷茫。只能看到一些比较聚焦度比较高的技术名词,例如 WASM、WebGL,会对这些技术存在追捧,却并没有做到脚踏实地。
相比去年的我,今年我对一些概念又有了许多新的见解,到底什么样才是出色的工程师?
当今国内工程师的问题
按照国内对工程师的区分,在各厂招聘列表中经常出现的是这几类,前端/后端/客户端工程师。
在我的工作中,经常会接触各端 SDK 的开发的同学,接触过程中,有时感觉到大家会存在一些 gap,也就是说 SDK 同学想去做一些事情,但是在他的角度他很明白底层逻辑,但对于其他端(前/后)同学,他们对底层原理其实并不了解。这就造成开发前,需要很长的时间去对齐功能的逻辑,合作同学也很难理解需求的意义与价值。
如果想摆脱这些困惑,那我认为你需要成为一名「全栈工程师」,其实说是全栈,不如是「软件工程师」,作为一名工程师,需要拥有一些闭环整体开发流程的能力。
例如,以 SDK 开发的角度来说,对于 SDK 同学,实际上最终只负责到上报这个动作,至于之后数据的流向,以及数据清洗,并不在掌控的范畴之内。这虽然降低了 SDK 侧上手的门槛,但并不利于长期的维护。
假如你是一个软件工程师,对于以下流程,你都了如指掌:
数据上报 -> 清洗 -> 存储 -> 消费
那你对于系统的整体认知就会提升,从优化上,可以给出更好的建议;在排查问题时,也可以更快速的定位问题。
何为工程师?
下面我详细谈一谈,如何成为一个有宏观视角的工程师。
首先,我目前的关注点主要在前端方向,如果你有仔细观察,你可以看到最终大部分比较厉害的前端,都是具有一些全栈能力的人。
对于服务端层面,我的建议是把 Golang 学好,这是一个还不错的方向。一个技术栈,如果有很多人关注聚焦,广泛地提出问题,那它的发展前景一定是不错的,起码不会垮掉,也就是说,开发生态是健康的。
对于前端层面,如果想去把前端学的很深入的话,那么前端工具以及工程化,必不可少。
在这一年内,我扩展一些自己原本不是很擅长的领域:
产品
竞品调研
PRD 撰写
服务端方向
MySQL
Rust
Golang
前端方向
单测/e2e:Jest、@testing-library/react、Cypress
工程化:Rush.js、Pnpm、Webpack、TypeScript
工具:Babel、CLI 相关的 npm 包工具
插件:Chrome、VSCode
设计
Figma 学习
英语学习
除了开发角色,一个合格的工程师,还应该掌握技术方案设计的能力,这样可以将整体的开发流程闭环。也就是说一个人扮演,调研、方案设计、编码、测试的工作。从我的 Roadmap 中,你也可以看出来这一点。为什么要闭环呢,当一个需求,有越来越多的角色参与进来的时候,你会发现方案细节的对齐,变成了一个不简单的工作。
有时候我们经常会讲一个词,融会贯通。当你把一整套研发体系都吃下来的时候,你会发现可以顺利地解决掉项目的问题。
我的工作场景
在我的工作中,会涉及到工具链的开发。首先在开始前,需要做一些竞品调研,方案设计的工作。
开发环节,对前端来说,按照目前的趋势,我们更好的方式是以 Monorepo 的形式去做开发。这里 Pnpm 就是一个很不错的选择,但接下来你会遇到一些问题,例如如何去做这些包的发版编排?
由于在 Workspace 中会存在一些包之间的相互引用,在发版时,也要按照拓扑排序的方式进行发版,这时,我们就可以用到 Rush.js 去做拓扑发版,以及自动生成 Changelog。
工具链对于质量需要较强的把控,这时我们就要引入 Jest 做单测,但一些场景下,单测是不够的,这时我们需要引入 e2e 测试。
在 Monorepo 中,不像单仓中,可能只存在一个 tsconfig,这时会存在配置之间 extends 的关系,需要我们对 tsconfig 的配置了如指掌。
对于多种工具消费方式,例如 CLI、Chrome 插件等,实则需要公用一些方法与配置,这里就需要抽象出公用的 utils 等。
在开发中,可能会关注一些新闻,比如 Vite 4 启用了 SWC 替代 Babel做编译。那你是否有好奇过,为什么 SWC 会更快,这时候如果学过 Rust,就知道 Rust 特有的语言特性。
总结
我想说的是,作为一个工程师,不要去把自己划分为「前端/后端/ PM」这些更加细分的角色。你都可以去学习任何方面的知识。并且你学的一切知识,都是有意义的。虽然学习的道路很长,但只要坚持下去,你就会朝着优秀的工程师进发。
作者:EricLee
来源:juejin.cn/post/7181000277208760378
给你的网站接入 github 提供的第三方登录
什么年代了还在用传统账号密码登录?没钱买手机号验证码组合?直接把鉴权和用户系统全盘托出依赖第三方(又不是不能用),省去鉴权系列 SQL 攻击、密码加密、CSRF 攻击、XSS 攻击,老板再也不用担心黑产盗号了(我们的系统根本没有号)
要实现上面的功能就得接入第三方登录,接下来就随着文章一起试试吧!
github
本章节将使用 github 作为第三方登录服务提供商
github 不愧是阿美力卡之光,极其简便的操作即可开启你的第三方登录之旅,经济又实惠,你可以通过快捷链接进入创建 OAuth 应用界面,也可以按照下面的顺序
然后填写相应的信息
生成你的密钥(Client secrets),就可以去试试第三方登录了
组合 URL
您可以在线查看本章节源代码
这里我使用的是 express-generator 去生成项目,并且前后端分离,在选项上不需要 HTML 渲染器
npx express --no-view your-project-path && cd your-project-path前端部分简单设置一下跳转验证
<html>
<body>
<div>
第三方登录
<br />
<button onclick="handleGithubLoginClick()">github</button>
</div>
</body>
<script>
const handleGithubLoginClick = () => {
const state = Math.floor(Math.random() * Math.pow(10, 8));
localStorage.setItem("state", state);
window.open(
`https://github.com/login/oauth/authorize?client_id=b351931efd1203b2230e&redirect_uri=http://localhost:8080&state=${state}`,
"_blank"
);
};
</script>
</html>其中有三个比较重要的 params
redirect_uri 默认是注册 OAuth 应用(Register a new OAuth application)是填写的授权回调 URL(Authorization callback URL)
而对于 state 就在前端用随机字符串模拟,通常此类加密的敏感数据会再后端生成,而这里为了方便演示就采用了前端生成
详细参数请参考文档
鉴权验证
登录之后就可以进行相对应的验证,比如输入账号密码、授权、Github 客户端验证
成功鉴权后会再新弹出的页面重定向至 redirect_uri
注意要在属于用户操作的范畴下,比如点击按钮的操作,去使用 window.open(strUrl, strWindowName, [strWindowFeatures]) 这种方式去跳转鉴权,否则像 window.open("https://github.com...", "_blank") 这种常见的写法,会报错
浏览器会以为是弹窗式广告,所以我推荐使用直接在当前窗口跳转的方法,而不是选择新开窗口或者浮动窗口
window.location.href = "https://github.com/login/oauth/authorize?client_id=b351931efd1203b2230e&redirect_uri=http://localhost:8080";处理回调
通过用户授权时,Github 的响应如下
GET redirect_uri参数
| 名称 | 类型 | 说明 |
|---|---|---|
code | string | 鉴权通过的响应代码 |
state | string | 请求第三方登录时防 csrf 凭证 |
state 参数负责安全非常重要,想要快速通关的选手可以跳过这部分
对于这里的 state 处理可以分为前端处理和后端处理
前端处理
当 redirect_uri 是前端路由时,可以将之前提交的 state 从 localStorage 或者 sessionStorage 中取出,验证是否一致,再去向后端请求并带上 state 和 code
优点
无需缓存
state
缺点
需要防止
XSS的DOM型攻击
后端处理
当 redirect_uri 是后端时,后端需要持有 state 的缓存,具体做法可以在前端处理第三方登录时同步随机生成的 state,并在后端缓存
优点
不需要防止
XSS的DOM型攻击
缺点
需要缓存
state
科普:早期 token 其实就是这里的 state
获取 token
第三方登录从本质上来讲就是获取到 token,在安全的拿到 code 和 state 之后,需要向 github 发送获取 token 请求,其文档如下
POST https://github.com/login/oauth/access_token参数
| 名称 | 类型 | 说明 |
|---|---|---|
client_id | string | 必填。 从 GitHub 收到的 OAuth App 的客户端 ID。 |
client_secret | string | 必填。 从 GitHub 收到的 OAuth App 的客户端密码。 |
code | string | 必填。 收到的作为对步骤 1 的响应的代码。 |
redirect_uri | string | 用户获得授权后被发送到的应用程序中的 URL。 |
响应
| 名称 | 类型 | 说明 |
|---|---|---|
access_token | string | github 的 token |
scope | string | 参考文档 |
token_type | string | token 类型 |
注意因为 client_secret 属于私钥,所以该请求必须放在后端,不能在前端请求!否则会失去登录的意义
const { default: axios } = require("axios");
const express = require("express");
const router = express.Router();
router.post("/redirect", function (req, res, next) {
const { code } = req.body;
axios({
method: "POST",
url: "https://github.com/login/oauth/access_token",
headers: {
"Accept": "application/json",
},
timeout: 60 * 1000,
data: {
client_id: "your_client_id",
client_secret: "your_client_secret",
code,
},
})
.then((response) => {
res.send(response.data);
})
.catch((e) => {
res.status(404);
});
});
module.exports = router;注意,由于 github 的服务器在国外,所以这个请求非常容易超时或者失效,建议做好对应的处理(或者设置一个比较长的时间)
最后拿到对应的 token
总结
如果还没有了解过第三方登录的同学可以试试,毕竟不需要审核,有对应的 github 账号就行,截至写完文章的现在,我仍然没有通过微博第三方登录的审核/(ㄒoㄒ)/~~
参考资料
作者:2分钟速写快排
来源:juejin.cn/post/7181114761394782269
electron-egg 当代桌面开发框架,轻松入门electron
当前技术社区中出现了各种下一代技术或框架,却很少有当代可以用的,于是electron-egg就出现了。
它愿景很大:希望所有开发者都能学会桌面软件开发
当前桌面软件技术有哪些?
| 语言 | 技术 | 优点 | 缺点 |
|---|---|---|---|
| C# | wpf | 专业的桌面软件技术,功能强大 | 学习成本高 |
| Java | swing/javaFx | 跨平台和语言流行 | GUI库少,界面不美观 |
| C++ | Qt | 跨平台,功能和类库丰富 | 学习成本高 |
| Swift | 无 | 非跨平台,文档不友好,UI库少 | |
| JS | electron | 跨平台,入门简单,UI强大,扩展性强 | 内存开销大,包体大。 |
为什么使用electron?
某某说:我们的应用要兼容多个平台,原生开发效率低,各平台研发人员不足,我们没有资源。
也许你觉得只是中小公司没有资源,no!大公司更没有资源。因为软件体量越大,所需研发人员越多。再加上需要多平台支持的话,研发人员更是指数级增长的。
我们来看看QQ团队负责人最近的回应吧:
“感谢大家对新版桌面QQ NT的使用和关注,今年QQ团队启动了QQ的架构升级计划,第一站就是解决目前桌面端迭代慢的问题,我们使用新架构从前到后对QQ代码进行了重构,而其中选择使用Electron作为新版QQ桌面端UI跨平台解决方案,是基于提升研发效率、框架成熟度、团队技术及人才积累等几个方面综合考虑的结果。”
也许electron的缺点很明显,但它的投入产出比却是最高的。
所以,对企业而言,效率永远是第一位的。不要用程序员的思维去思考产品。
哪些企业或软件在使用electron?
国内:抖音客户端、百度翻译、阿里云盘、B站客户端、迅雷、网易有道云、QQ(doing) 等
国外:vscode、Slack、Atom、Discord、Skype、WhatsApp、等
你的软件用户体量应该没有上面这些公司多吧?所以你还有什么可担心的呢?
开发者 / 决策者不要去关心性能、包体大小这些东西,当你的产品用户少时,它没意义;当你的产品用户多时,找nb的人把它优化。
聊聊electron-egg框架
EE是一个业务框架;就好比 Spring之于java,thinkphp之于php,nuxt.js之于vue;electron只提供了基础的函数和api,但你写项目的时候,业务和代码工程化是需要自己实现的,ee就提供了这个工程化能力。
特性
🍄 跨平台:一套代码,可以打包成windows版、Mac版、Linux版、国产UOS、Deepin、麒麟等
🌹 简单高效:只需学习 js 语言
🌱 前端独立:理论上支持任何前端技术,如:vue、react、html等等
🌴 工程化:可以用前端、服务端的开发思维,来编写桌面软件
🍁 高性能:事件驱动、非阻塞式IO
🌷 功能丰富:配置、通信、插件、数据库、升级、打包、工具... 应有尽有
🌰 安全:支持字节码加密、压缩混淆加密
💐 功能demo:桌面软件常见功能,框架集成或提供demo
谁可以使用electron-egg?
前端、服务端、运维、游戏等技术人员皆可使用。我相信在你的工作生涯中,或多或少都接触过js,恭喜你,可以入门了。
为什么各种技术栈的开发者都能使用electron-egg?
这与它的架构有关。
第一:前端独立
你可以用vue、react、angular等开发框架;也可用antdesign、layui、bootstrap等组件库;或者你用cococreater开发游戏也行; 框架只需要最终构建的资源(html/css/js)。
第二:工程化-MVC编程模式
如果你是java、php、python等后端开发者,不懂js那一套编程模式怎么办?
没关系,框架已经为你提供了MVC(controller/service/model/view),是不是很熟悉?官方提供了大量业务场景demo,直接开始撸代码吧。
开箱即用
编程方法、插件、通信、日志、数据库、调试、脚本工具、打包工具等开发需要的东西,框架都已经提供好了,你只需要专注于业务的实现。
十分钟体验
安装
# 下载
git clone https://gitee.com/dromara/electron-egg.git
# 安装依赖
npm install
# 启动
npm run start效果
界面中的功能是demo,方便初学者入门。
项目案例
EE框架已经应用于医疗、学校、政务、股票交易、ERP、娱乐、视频、企业等领域客户端
以下是部分开发者使用electron-egg开发的客户端软件,请看效果
后语
仓库地址,欢迎给项目点赞!
gitee : gitee.com/dromara/ele… 2300+
github : github.com/dromara/ele… 500+
关于 Dromara
Dromara 是由国内顶尖的开源项目作者共同组成的开源社区。提供包括分布式事务,流行工具,企业级认证,微服务RPC,运维监控,Agent监控,分布式日志,调度编排等一系列开源产品、解决方案与咨询、技术支持与培训认证服务。技术栈全面开源共建、 保持社区中立,致力于为全球用户提供微服务云原生解决方案。让参与的每一位开源爱好者,体会到开源的快乐。
Dromara开源社区目前拥有10+GVP项目,总star数量超过十万,构建了上万人的开源社区,有成千上万的个人及团队在使用Dromara社区的开源项目。
electron-egg已加入dromara组织。
作者:哆啦好梦
来源:juejin.cn/post/7181279242628366397
Android URL Scheme数据还原流程与踩坑分享
前言
最近在搞URL Scheme数据还原相关代码的重构工作,借此梳理一下整体的流程。并且在重构过程中呢,还遇到了一个天坑,拿出来与大家分享一下。如果大家有更好的方案,欢迎评论或私信我让我学习一下~
前置知识点
首先我们对齐一下所需要的前置知识点,避免后面造成理解上的冲突。
URL Scheme
URL Scheme指的是遵守以下格式的URL:
{scheme://action?param1=value1¶m2=value2...}
APP识别到URL Scheme数据后,会根据action去执行相应的逻辑。
scheme通常由业务定义好,一般以app层级划分或业务域层级划分,比如"taobao://"、"douyin://",或者"tbSearch://"、"douyinSearch://"。action指的是行为,比如"user/detail"是打开个人详情页面,"item/detail"是打开商品详情页面等。再由后面的参数决定具体的页面数据。举个例子:
{wodeApp://user/detail?userId=123}
wodeApp识别到这个Url Scheme以wodeApp开头,就知道是它需要的数据,进而解析数据,打开userId为123的用户页面。
URL Scheme来源
Scheme数据的来源可以有很多,最常见的就是剪贴板、H5页面唤端、消息通知唤端、短信通知唤端等。因为后面的内容会涉及到数据来源,场景又比较复杂可能会比较混乱,所以这里我们先理清一下。
我们把所有的唤端(包括H5页面唤端、消息通知唤端、短信通知唤端)统一一下,都称为Intent唤端,因为他们最终给到App的数据都是放在Intent中的,所以后面讲到唤端就不再一一区分了。
那么我们现在能拿到URL Scheme的场景就分为四种:
- 冷启动时从剪贴板获取
- 热启动时从剪贴板获取
- 冷启动时从唤端Intent中获取
- 热启动时从唤端Intent中获取
为什么要分冷热启动呢?因为冷热启动,URL Scheme获取的方式是不一样的,具体后面会说到。
数据还原
数据还原,在产品上是非常重要的。最基本的一种数据还原,就是跳转目标页面。比如用户被消息推送了某个商品,点击进来后根据解析得到的Scheme数据我们需要跳转到指定的商品详情页面。另外,我们可能还需要根据解析的Scheme数据向服务端发起某个请求,比如从平价商品页面唤端来的用户我们需要打上用户标签。
所有的根据action指定的业务逻辑,我们都称之为数据还原。
产品的迭代历程
上面也讲到了,我是因为重构才有机会写这篇文章的。那为什么要重构呢?自然是代码hold不住产品的迭代速度了,这就要从产品的需求讲起。(当然,需求的迭代只是重构的原因之一,更主要的原因是之前的代码没封装,写的很乱,职责不清晰,所以才把重构提上日程的..)
有一天,PD找上门来
PD:咱们做个简单的唤端哈,从消息通知进来,或者从H5页面唤端进来,我们能打开相应的页面就行。另外,如果剪贴板里有这样的数据,也要能达到一样的效果。
程序员A:没问题,这项技术已经很成熟了,马上给你搞出来
最终这个需求的实现,也基本上不存在什么问题。唤端的Intent数据从闪屏页拿到后,传递到首页,首页再根据数据执行相应的Action。另外在首页onResume生命周期中获取剪贴板数据,如果符合Scheme数据协议,也去做相应的Action。
过了一个月,PD又找上门来
PD:咱们唤端需要再做一个通用能力哈。如果唤端数据带了某个api的某个参数,需要在下次请求这个api的时候把这个参数给带上,从而满足服务端数据的定制化能力。当然了,还是跟上次一样,如果剪贴板里有这样的数据,也要能达到一样的效果。
程序员A:为啥要这样搞啊?有啥用?
PD:你想啊,比如首页的推荐流理论上对每个人都是不一样的。那如何实现更精准地推送呢?唤端就是一个手段。每个唤端页面唤端的时候,都带上用户相关的数据,然后把这份数据作为接口参数传给服务端,不就可以实现定向推送了嘛。
程序员A:你很有想法,但是我得想一想...
糟了,之前的剪贴板相关的代码要重写了。为什么呢?因为之前是在首页onResume生命周期中获取剪贴板数据,如果剪贴板数据符合Scheme数据协议,就去做相应的Action。但这个新的需求,又必须保证得在首页请求发出去之前,就要拿到剪贴板数据并预埋好接口参数,否则就不会起作用了。比如用户冷启App时,如果不在闪屏页预先拿到剪贴板数据并预埋上首页的接口参数的话,到首页做这个逻辑就没法保证是在首页接口请求前完成参数的预埋了。
那这个逻辑是要放在闪屏页么?也不对,因为在热启App时,是不会经过闪屏页的,但热启时也要有这样的能力,这就要我们必须把解析剪贴板的这段逻辑放在BaseActivity中去。
下面就来分享一下URL Scheme数据还原改善后的流程。
数据还原流程
剪贴板
冷启:闪屏页onWindowFocusChanged获取剪贴板数据->解析scheme数据(执行预埋接口参数等Action)->跳转首页->首页跳转至目标页面->清空剪贴板
热启:BaseActivity#onWindowFocusChanged获取剪贴板数据->解析(执行预埋接口参数等Action)->跳转目标页面->清空剪贴板
因为某些原因,我们的项目中闪屏页没有继承BaseActivity,所以这里分开了两个部分。如果大家都是统一继承BaseActivity的,那么这部分解析scheme的逻辑是可以合二为一的。
唤端
冷启:闪屏页onCreate获取唤端Intent->解析scheme数据(执行预埋接口参数等Action)->跳转首页->首页跳转至目标页面->清空剪贴板
热启:闪屏页onCreate获取唤端Intent->解析scheme数据(执行预埋接口参数等Action)->跳转目标页面->清空剪贴板
总结
- 唤端的逻辑全部在闪屏页的onCreate生命周期做。只有在冷启唤端时需要先跳转至首页,首页再跳转至模板页面。
- 剪贴板的逻辑,冷启时在闪屏页做剪贴板的获取与解析,热启时在页面基类做剪贴板的获取与解析,解析完数据后统一在页面基类进行目标页面的跳转。之所以放在页面基类而不是首页,是因为热启回APP后可能处于任意一个页面,所以这段逻辑只能放到基类里面去处理。
另外需要注意的一点是,闪屏页的LaunchMode需要设置为singleTask,否则唤端启动时新创建的闪屏页会到浏览器的栈去,不符合业务需求。
踩坑分享
在这个过程中,我也踩了一个大坑..没想到Android对剪贴板的获取有这样的限制。细心的同学可能已经发现了,在重构前我们是在首页的onResume生命周期去获取剪贴板的,去网上一搜获取剪贴板数据,大部分的回答都是这样:
override fun onResume() {
window.decorView.post{
val content = ClipboardService.getInstance().clipboardContent
}
}那为什么在方案设计中,却是在onWindowFocusChanged回调中才去获取剪贴板数据呢?因为上面的代码,在部分场景(尤其是闪屏页),是没法保证能拿到剪贴板数据的。
原因
Android获取剪贴板存在限制,必须在当前Activity获得焦点的情况下才能成功获取到。
闪屏页的生命周期:onCreate->onResume->跳转页面->onPause
闪屏页获取焦点时的回调:onWindowFocusChanged(boolean hasFocus);当回调中hasFocus收到true时,表面当前Activity窗口获取到了焦点。
经试验,当闪屏页跳转页面过快,部分机型(如Redmi k40 pro)onWindowFocusChanged会回调false,收不到true,即一直没有获得过焦点,那么这种情况下就无法获取剪贴板数据(拿到是空字符串)。所以获取剪贴板数据的时机,不能太早,也不能太晚。不能在onCreate中去获取剪贴板数据,也不能等到发生跳转了再去拿。
其次,因为onWindowFocusChanged回调时机必在onResume之后,所以即使我们在onResume中post去拿剪贴板,我们也没法保证post的Runnable执行的时机是正正好的。有可能Runnable执行时,闪屏页已经发生跳转了。也有可能Runnable执行时,闪屏页还未获取到焦点。
所以呢,我们应该把获取剪贴板数据的时机放到onWindowFocusChanged中去,而闪屏页冷启跳转首页的逻辑,也要放到onWindowFocusChanged之后,保证闪屏页已经获取到焦点了,且成功获取到剪贴板数据了。
总结
通过这篇文章,我们知道了URL Scheme数据还原的整体流程。如果大家实际业务中没有类似“根据唤端数据,预埋首页接口参数”这样的需求,其实可以比较简单地就实现了。另外,分享了一下Android上获取剪贴板数据所存在的限制,以及在实际业务中遇到的坑该怎么解决。
文章不足之处,还望大家多多海涵,多多指点,先行谢过!
链接:https://juejin.cn/post/7177315439532310584
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android代码静态检查(lint、Checkstyle、ktlint、Detekt)
Android代码静态检查(lint、Checkstyle、ktlint、Detekt)
在Android项目开发过程中,开发团队往往要花费大量的时间和精力发现并修改代码缺陷。
静态代码分析工具能够在代码构建过程中帮助开发人员快速、有效的定位代码缺陷并及时纠正这些问题,从而极大地提高软件可靠性
节省软件开发和测试成本。
Android目前主要使用的语言为kotlin、java,所以我们需要尽可能支持这两种语言。
Lint
Android Studio 提供的代码扫描工具。通过进行 lint 检查来改进代码
能检测什么?是否包含潜在错误,以及在正确性、安全性、性能、易用性、便利性和国际化方面是否需要优化改进,帮助我们发现代码结/质量问题,同时提供一些解决方案。每个问题都有信息描述和等级。
支持【300+】检测规则,支持Manifest文件、XML、Java、Kotlin、Java字节码、Gradle文件、Proguard文件、Propetty文件和图片资源;
基于抽象语法树分析,经历了LOMBOK-AST、PSI、UAST三种语法分析器;
主要包括以下几个方面
Correctness:不够完美的编码,比如硬编码、使用过时 API 等;Performance:对性能有影响的编码,比如:静态引用,循环引用等;Internationalization:国际化,直接使用汉字,没有使用资源引用等;Security:不安全的编码,比如在WebView中允许使用JavaScriptInterface等
在module下的build.gradle中添加以下代码:
android {
lintOptions {
// true--关闭lint报告的分析进度
quiet true
// true--错误发生后停止gradle构建
abortOnError false
// true--只报告error
ignoreWarnings true
// true--忽略有错误的文件的全/绝对路径(默认是true)
//absolutePaths true
// true--检查所有问题点,包含其他默认关闭项
checkAllWarnings true
// true--所有warning当做error
warningsAsErrors true
// 关闭指定问题检查
disable 'TypographyFractions','TypographyQuotes'
// 打开指定问题检查
enable 'RtlHardcoded','RtlCompat', 'RtlEnabled'
// 仅检查指定问题
check 'NewApi', 'InlinedApi'
// true--error输出文件不包含源码行号
noLines true
// true--显示错误的所有发生位置,不截取
showAll true
// 回退lint设置(默认规则)
lintConfig file("default-lint.xml")
// true--生成txt格式报告(默认false)
textReport true
// 重定向输出;可以是文件或'stdout'
textOutput 'stdout'
// true--生成XML格式报告
xmlReport false
// 指定xml报告文档(默认lint-results.xml)
//xmlOutput file("lint-report.xml")
// true--生成HTML报告(带问题解释,源码位置,等)
htmlReport true
// html报告可选路径(构建器默认是lint-results.html )
//htmlOutput file("lint-report.html")
// true--所有正式版构建执行规则生成崩溃的lint检查,如果有崩溃问题将停止构建
checkReleaseBuilds true
// 在发布版本编译时检查(即使不包含lint目标),指定问题的规则生成崩溃
fatal 'NewApi', 'InlineApi'
// 指定问题的规则生成错误
error 'Wakelock', 'TextViewEdits'
// 指定问题的规则生成警告
warning 'ResourceAsColor'
// 忽略指定问题的规则(同关闭检查)
ignore 'TypographyQuotes'
}
}运行./gradlew lint,检测结果在build/reports/lint/lint.html可查看详情。
CheckStyle
Java静态代码检测工具,主要用于代码的编码规范检测 。
CheckStyle是Gralde自带的Plugin,The Checkstyle Plugin
通过分析源码,与已知的编码约定进行对比,以html或者xml的形式将结果展示出来。
其原理是使用Antlr库对源码文件做词语发分析生成抽象语法树,遍历整个语法树匹配检测规则。
目前不支持用户自定义检测规则,已有的【100+】规则中,有一部分规则是有属性的支持设置自定义参数。
在module下的build.gradle中添加以下代码:
/**
* The Checkstyle Plugin
*
* Gradle plugin that performs quality checks on your project's Java source files using Checkstyle
* and generates reports from these checks.
*
* Tasks:
* Run Checkstyle against {rootDir}/src/main/java: ./gradlew checkstyleMain
* Run Checkstyle against {rootDir}/src/test/java: ./gradlew checkstyleTest
*
* Reports:
* Checkstyle reports can be found in {project.buildDir}/build/reports/checkstyle
*
* Configuration:
* Checkstyle is very configurable. The configuration file is located at {rootDir}/config/checkstyle/checkstyle.xml
*
* Additional Documentation:
* https://docs.gradle.org/current/userguide/checkstyle_plugin.html
*/
apply plugin: 'checkstyle'
checkstyle {
//configFile = rootProject.file('checkstyle.xml')
configProperties.checkstyleSuppressionsPath = rootProject.file("suppressions.xml").absolutePath
// The source sets to be analyzed as part of the check and build tasks.
// Use 'sourceSets = []' to remove Checkstyle from the check and build tasks.
//sourceSets = [project.sourceSets.main, project.sourceSets.test]
// The version of the code quality tool to be used.
// The most recent version of Checkstyle can be found at https://github.com/checkstyle/checkstyle/releases
//toolVersion = "8.22"
// Whether or not to allow the build to continue if there are warnings.
ignoreFailures = true
// Whether or not rule violations are to be displayed on the console.
showViolations = true
}
task projectCheckStyle(type: Checkstyle) {
group 'verification'
classpath = files()
source 'src'
//include '**/*.java'
//exclude '**/gen/**'
reports {
html {
enabled = true
destination file("${project.buildDir}/reports/checkstyle/checkstyle.html")
}
xml {
enabled = true
destination file("${project.buildDir}/reports/checkstyle/checkstyle.xml")
}
}
}
tasks.withType(Checkstyle).each { checkstyleTask ->
checkstyleTask.doLast {
reports.all { report ->
// 检查生成报告中是否有错误
def outputFile = report.destination
if (outputFile.exists() && outputFile.text.contains("<error ") && !checkstyleTask.ignoreFailures) {
throw new GradleException("There were checkstyle errors! For more info check $outputFile")
}
}
}
}
// preBuild的时候,执行projectCheckStyle任务
//project.preBuild.dependsOn projectCheckStyle
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn projectCheckStyle
println("project.preBuild.dependsOn projectCheckStyle")
}
}默认情况下,Checkstyle插件希望将配置文件放在根项目中,但这可以更改。
<root>
└── config
└── checkstyle
└── checkstyle.xml //Checkstyle 配置
└── suppressions.xml //主Checkstyle配置文件执行preBuild就会执行checkstyle并得到结果。
支持Kotlin
怎么实现Kotlin的代码检查校验呢?我找到两个富有意义的方法。
1. Detekt — https://github.com/arturbosch/detekt 2. ktlint — https://github.com/shyiko/ktlint
KtLint
添加插件依赖
buildscript {
dependencies {
classpath "org.jlleitschuh.gradle:ktlint-gradle:11.0.0"
}
}引入插件,完善相关配置:
apply plugin: "org.jlleitschuh.gradle.ktlint"
ktlint {
android = true
verbose = true
outputToConsole = true
outputColorName = "RED"
enableExperimentalRules = true
ignoreFailures = true
//["final-newline", "max-line-length"]
disabledRules = []
reporters {
reporter "plain"
reporter "checkstyle"
reporter "sarif"
reporter "html"
reporter "json"
}
}
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn tasks.findByName("ktlintCheck")
println("project.preBuild.dependsOn tasks.findByName(\"ktlintCheck\")")
}
}运行prebuild,检测结果在build/reports/ktlint/ktlintMainSourceSetCheck/ktlintMainSourceSetCheck.html可查看详情。
Detekt
添加插件依赖
buildscript {
dependencies {
classpath "io.gitlab.arturbosch.detekt:detekt-gradle-plugin:1.22.0"
}
}引入插件,完善相关配置(PS:可以在yml文件配置相关的规则):
apply plugin: 'io.gitlab.arturbosch.detekt'
detekt {
// Version of Detekt that will be used. When unspecified the latest detekt
// version found will be used. Override to stay on the same version.
toolVersion = "1.22.0"
// The directories where detekt looks for source files.
// Defaults to `files("src/main/java", "src/test/java", "src/main/kotlin", "src/test/kotlin")`.
source = files(
"src/main/kotlin",
"src/main/java"
)
// Builds the AST in parallel. Rules are always executed in parallel.
// Can lead to speedups in larger projects. `false` by default.
parallel = false
// Define the detekt configuration(s) you want to use.
// Defaults to the default detekt configuration.
config = files("$rootDir/config/detekt/detekt-ruleset.yml")
// Applies the config files on top of detekt's default config file. `false` by default.
buildUponDefaultConfig = false
// Turns on all the rules. `false` by default.
allRules = false
// Specifying a baseline file. All findings stored in this file in subsequent runs of detekt.
//baseline = file("path/to/baseline.xml")
// Disables all default detekt rulesets and will only run detekt with custom rules
// defined in plugins passed in with `detektPlugins` configuration. `false` by default.
disableDefaultRuleSets = false
// Adds debug output during task execution. `false` by default.
debug = false
// If set to `true` the build does not fail when the
// maxIssues count was reached. Defaults to `false`.
ignoreFailures = true
// Android: Don't create tasks for the specified build types (e.g. "release")
//ignoredBuildTypes = ["release"]
// Android: Don't create tasks for the specified build flavor (e.g. "production")
//ignoredFlavors = ["production"]
// Android: Don't create tasks for the specified build variants (e.g. "productionRelease")
//ignoredVariants = ["productionRelease"]
// Specify the base path for file paths in the formatted reports.
// If not set, all file paths reported will be absolute file path.
//basePath = projectDir
}
tasks.named("detekt").configure {
reports {
// Enable/Disable XML report (default: true)
xml.required.set(true)
xml.outputLocation.set(file("build/reports/detekt/detekt.xml"))
// Enable/Disable HTML report (default: true)
html.required.set(true)
html.outputLocation.set(file("build/reports/detekt/detekt.html"))
// Enable/Disable TXT report (default: true)
txt.required.set(true)
txt.outputLocation.set(file("build/reports/detekt/detekt.txt"))
// Enable/Disable SARIF report (default: false)
sarif.required.set(true)
sarif.outputLocation.set(file("build/reports/detekt/detekt.sarif"))
// Enable/Disable MD report (default: false)
md.required.set(true)
md.outputLocation.set(file("build/reports/detekt/detekt.md"))
custom {
// The simple class name of your custom report.
reportId = "CustomJsonReport"
outputLocation.set(file("build/reports/detekt/detekt.json"))
}
}
}
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn tasks.findByName("detekt")
println("project.preBuild.dependsOn tasks.findByName(\"detekt\")")
}
}运行prebuild,检测结果在build/reports/detekt/detekt.html可查看详情。
总结
CheckStyle不支持kotlin,Ktlin和Detekt两者对比Ktlint它的规则不可定制,Detekt 工作得很好并且可以定制,尽管插件集成看起来很新。虽然输出的格式都支持html,但显然Detekt输出的结果的阅读体验更好一些。
以上相关的插件因为都支持命令行运行,所以都可以结合Git 钩子,它用于检查即将提交的快照,例如,检查是否有所遗漏,确保测试运行,以及核查代码。
不同团队的代码的风格不尽相同,不同的项目对于代码的规范也不一样。目前项目开发中有很多同学几乎没有用过代码检测工具,但是对于一些重要的项目中代码中存在的缺陷、性能问题、隐藏bug都是零容忍的,所以说静态代码检测工具尤为重要。
链接:https://juejin.cn/post/7181424552583364645
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 实现手写签名效果
如何使用Flutter实现手写签名的效果
思路
- 需要监听用户触摸的起始点和结束点,并记录途经点,这里我使用了
StreamController - 将途经点从起始位置到结束位置绘制出来,这里用到
CustomPainter
绘制流程
- 获取触摸点作为画笔的起始点
- 手机途经点
- 绘制途径路线
- 结束触摸点重置画笔
具体实现
需要一个Listener用来监听用户行为,并将这些行为的点添加到StreamController中,
两个变量
final List _points = []; //承载对应的点
final StreamController _controller = StreamController(); //数据通信
Widget _buildWriteWidget() {
return Stack(
children: [
Listener( //用来监听用户的触摸行为
child: Container(
color: Colors.transparent,
),
onPointerDown: (PointerDownEvent event) {
_points.add(event.localPosition);
_controller.sink.add([_points]); //起始点的记录
},
onPointerMove: (PointerMoveEvent event) {
_points.add(event.localPosition);
_controller.sink.add([_points]); //添加途经点
},
onPointerUp: (PointerUpEvent event) {
_points.add(Offset.zero); //结束的标记
},
),
StreamBuilder(
stream: _controller.stream,
builder: (BuildContext context, AsyncSnapshot snapshot) {
return snapshot.hasData
? CustomPaint(painter: LinePainter(snapshot.data)) //关联数据到Painter
: const SizedBox();
}),
Positioned(
bottom: 50,
right: 50,
child: FloatingActionButton(
onPressed: () {
_clear();
},
child: const Icon(Icons.cleaning_services),
))
],
);
}清除StreamController的内容,重置数据
void _clear() {
_points.clear();
_controller.add(null);
}dispose时释放StreamController
@override
void dispose() {
_controller.close();
super.dispose();
}画笔Painter
class LinePainter extends CustomPainter {
final List<List<Offset>> lines;
final Color paintColor = Colors.black;
final Paint _paint = Paint();
LinePainter(this.lines);
@override
void paint(Canvas canvas, Size size) {
_paint.strokeCap = StrokeCap.round;
_paint.strokeWidth = 5.0;
if (lines.isEmpty) {
canvas.drawPoints(PointMode.polygon, [Offset.zero, Offset.zero], _paint);
} else {
for (int i = 0; i < lines.length; i++) {
for (int j = 0; j < lines[i].length - 1; j++) {
if (lines[i][j] != Offset.zero && lines[i][j + 1] != Offset.zero) {
canvas.drawLine(lines[i][j], lines[i][j + 1], _paint); //绘制相应的点
}
}
}
}
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) => true;
}链接:https://juejin.cn/post/7180186082489663547
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ChatGPT进入百度“弱智吧”后,疯了
无论你玩不玩贴吧,“弱智吧”的大名很多人应该听说过。
如今弱智吧的关注人数已经超过了200万。。。
不得不说,能将这么多“弱智”聚在一起,“弱智吧”撑起了后·百度贴吧时代的辉煌。。。
来一起感受下“弱智吧”的日常:
能问出这些问题,确实脑回路已经超越普通人了。。。
弱智吧的存在已经够离谱了,更离谱的是,弱智吧官方微博把这几天火出圈的ChatGPT与“弱智吧”做了连接——让ChatGPT去回答弱智吧上的问题。

真是离谱他爸给离谱开门,离谱到家了。。。
“弱智”与“弱AI”的较量,从此揭开了序幕。来,一起感受下!
弱智提问1
弱智提问2
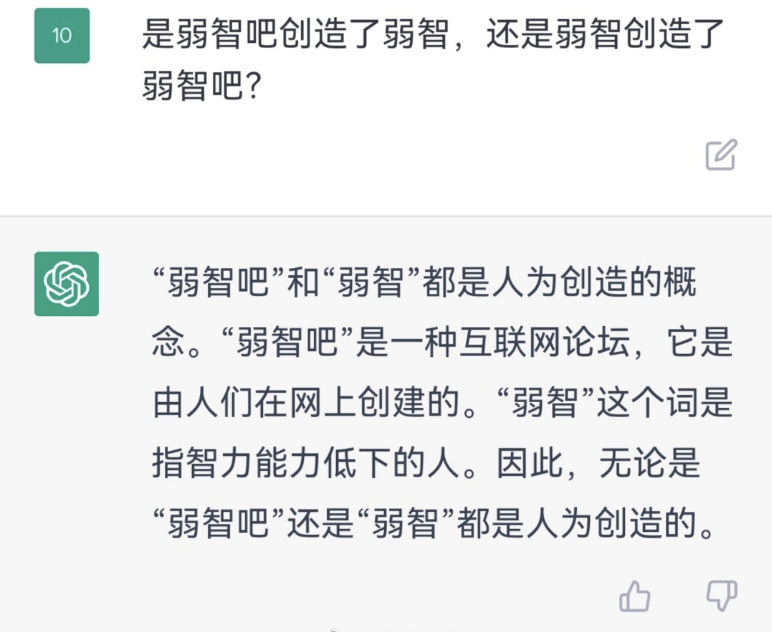
这个回答属实有点“社交牛逼症”了。我觉得别再沉溺于图灵测试了,这已经满足不了ChatGPT了。笔者觉得有必要直接给ChatGPT测下情商
弱智提问3
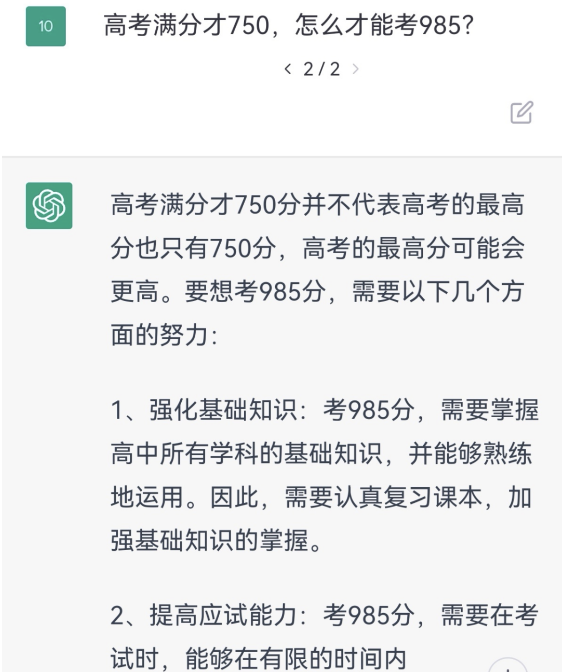
这个回答,让笔者一时分不清ChatGPT是认真的还是故意的。。。
弱智提问4
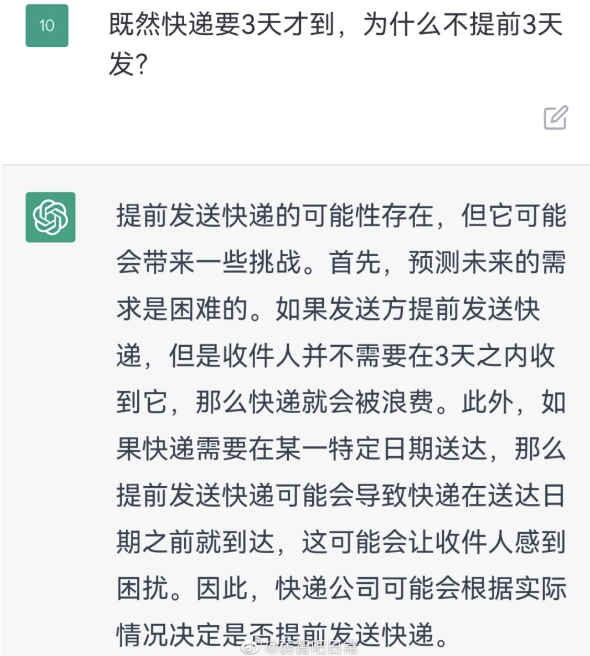
弱智提问5

弱智提问6
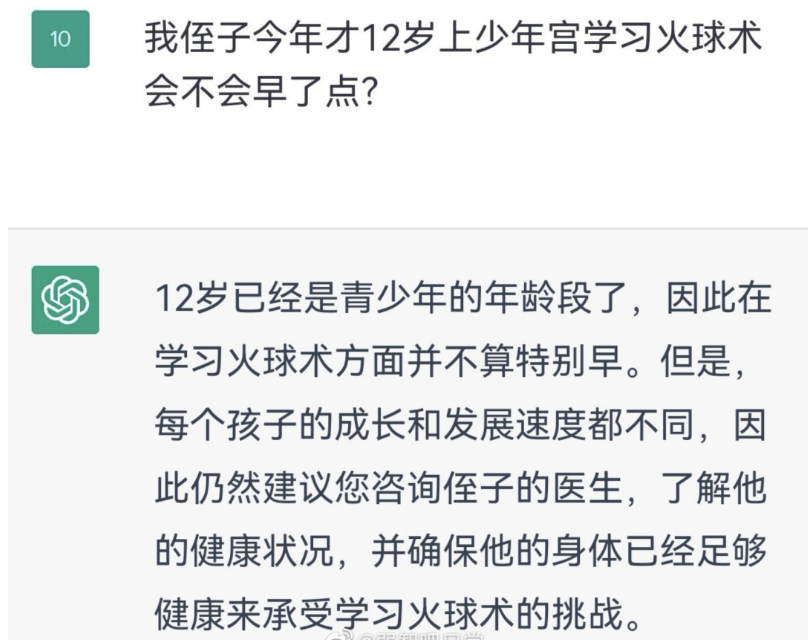
我已经20多岁了,还能开写轮眼吗?
弱智提问7
弱智提问8
突然不知道该怎么反驳,我果然既不如弱智,也不如AI
弱智提问9
弱智提问10

弱智提问11
弱智提问12
弱智提问13
AI,这波是你输了
弱智提问14
我觉得这波AI赢了
那么问题来了,你认为是人类创造的“弱智问题”赢了?还是AI创造的“机智回答”赢了?
最后,笔者还找了一些弱智吧的牛逼问题,手里有ChatGPT账号的读者小伙伴可以在评论区分享测试结果:
开放问题1
开放问题2

开放问题3

作者:兔子酱
来源:夕小瑶的卖萌屋
Java中多线程的ABA问题探讨
前言
本文是笔者在日常开发过程中遇到的对 CAS 、 ABA 问题以及 JUC(java.util.concurrent)中 AtomicReference 相关类的设计的一些思考记录。 对需要处理 ABA 问题,或有诸如笔者一样的设计疑问探索好奇心的读者可能会带来一些启发。
本文主体由三部分构成:
首先阐述多线程场景数据同步的常用语言工具
接着阐述什么是 ABA 问题,以及产生的原因和可能带来的影响
再探索 JUC 中官方为解决 ABA 问题而做一些工具类设计
文章的最后会对多线程数据同步常用解决方案做了简短地经验性总结与概括。
受限于笔者的理解与知识水平,文章的一些术语表述难免可能会失偏颇,对于有理解歧义或争议的部分,欢迎大家探讨和指正。
一、异步场景常用工具
在Java中的多线程数据同步的场景,常会出现:
关键字
volatile关键字
synchronized可重入锁/读写锁
java.util.concurrent.locks.*容器同步包装,如
Collections.synchronizedXxx()新的线程安全容器,如
CopyOnWriteArrayList/ConcurrentHashMap阻塞队列
java.util.concurrent.BlockingQueue原子类
java.util.concurrent.atomic.*以及 JUC 中其他工具诸如
CountDownLatch/Exchanger/FutureTask等角色。
其中 volatile 关键字用于刷新数据缓存,即保证在 A 线程修改某数据后,B 线程中可见,这里面涉及的线程缓存和指令重排因篇幅原因不在本文探讨范围之内。而不论是 synchronized 关键字下的对象锁,还是基于同步器 AbstractQueuedSynchronizer 的 Lock 实现者们,它们都属于悲观锁。而在同步容器包装、新的线程程安全容器和阻塞队列中都使用的是悲观锁;只是各类的内部使用不同的 Lock 实现类和 JUC 工具,另外不同容器在加锁粒度和加锁策略上分别做了处理和优化。
这里值得一说的,也是本文聚焦的重点则是原子类,即 java.util.concurrent.atomic.* 包下的几个类库诸如 AtomicBoolean/AtomicInteger/AtomicReference
二、CAS 与 ABA 问题
我们知道在使用悲观锁的场景中,如果有有一个线程抢先取得了锁,那么其他想要获得锁的线程就得被阻塞等待,直到占锁线程完成计算释放锁资源。而现代 CPU 提供了硬件级指令来实现同步原语,也就是说可以让线程在运行过程中检测是否有其他线程也在对同一块内存进行读写,基于此 Java 提供了使用忙循环来取代阻塞的系列工具类 AutomicXxx,这属于是一种乐观锁的实现。其常规使用方式形如:
public class Requester {
private AtomicBoolean isRequesting = new AtomicBoolean(false)
public void request() {
// 修改成功时返回true;compareAndSet 方法由 Native 层调硬件指令实现
if (!isRequesting.compareAndSet(false, true)) {
return;
}
try {
// do sth...
} finally {
isRequesting.set(false)
}
}
} 进入到 JDK11 AtomicBoolean 的源码中,可以看到 compareAndSet 最终调用 Native 层的方式如下。其实在旧的版本中 JDK 是使用 Unsafe 类处理的,在入参数中有传入状态变量的字段偏移值,新版本则将两者封装到 VarHandle 中采用DL方式查找依赖(笔者猜测可能和JDK9模块化改造有关):
// 旧版
public class AtomicBoolean {
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
private static final long VALUE;
static {
try {
VALUE = U.objectFieldOffset
(AtomicBoolean.class.getDeclaredField("value"));
} catch (ReflectiveOperationException e) {
throw new Error(e);
}
}
private volatile int value;
public final boolean compareAndSet(boolean expect, boolean update) {
return U.compareAndSwapInt(this, VALUE, (expect ? 1 : 0), (update ? 1 : 0));
}
}
// 新版
public class AtomicBoolean {
private static final VarHandle VALUE;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
VALUE = l.findVarHandle(AtomicBoolean.class, "value", int.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
private volatile int value;
public final boolean compareAndSet(boolean expectedValue, boolean newValue) {
return VALUE.compareAndSet(this, (expectedValue ? 1 : 0), (newValue ? 1 : 0));
}
} 犹如入仓有 this 和 value 的偏移值,则 Native 层可根据此二者值定位到某块栈内存,这样对于基本类型没什么问题。原子类型体系中使用 AtomicReference 来引用复合类型实例,但 Java 中 Object 类型在栈中保存的只是堆中对象数据块的地址,其结构形如下图:
而实际运行过程中,调用 AtomicReference#compareAndSet() 时,Native层只会对比栈中内存的值,而不会关注其指向的堆中数据。这样说可能有点抽象,看一段实验代码:
StringBuilder varA = new StringBuilder("abc");
StringBuilder varB = new StringBuilder("123");
AtomicReference<StringBuilder> ref = new AtomicReference<>(varA);
ref.compareAndSet(varA, varB); // (1)
System.out.println(ref.get()); // (2) varB->123
varB.append('4'); // (3) changed varB->1234
if (ref.compareAndSet(varB, varA)) { // (4)
System.out.println("CAS succeed"); // (5) CAS succeed
}
System.out.println(ref.get()); // abc喜欢动手的读者可以尝试自定义一个类,观察下 Compare 过程是否真的没有调用对象的
equals方法。
ref 在经过处理后再 (2) 处引用变量B,而在注释 (3) 处将 B 值修改了,但由于原子类不会检查堆中数据,所以还是能通过注释 (4) 处的相等比较走到注释 (5) 。这也就引入了 所谓的 ABA 问题:
假设,线程 1 的任务希望将变量从 A 变为 C ,但执行到一半被线程 2 抢走 CPU
线程 2 将变量从 A 改成了 B ,此时 CPU 时间片又被系统分给了线程 3
线程 3 讲变量从 B 又设置成一个新的 A 。
线程 1 获取时间片,检查变量发现其仍然是 A(但 A 对象内部的数据已经改变了),检查通过将变量置为 C 。
若业务场景中,线程 1 不在意变量经过了一轮变化,也不在意 A 中数据是否有变化,则该问题无关痛痒。而若线程 1 对这两个变化敏感,则将变量置为 C 的操作就不符合预期了。用维基百科的例子来表述,其大意是:
你提着有很多现金的包去机场,这时来了个辣妹挑逗你,并趁你不注意时用一个看起来一样的空包换了你的现金包,然后她就走了;此时你检查了下发现你的包还在,于是就匆忙拿着包赶飞机去了。
换个角度看这几个关键字:
有现金的包:指向堆中数据的栈引用
辣妹挑逗:其他线程抢占 CPU
看起来一样空包:其他线程修改堆中数据
发现包还在:仅检查栈中内存的地址值是否一致
三、用 JUC 工具处理 ABA 问题
为处理 ABA 问题,JDK 提供了另外两个工具类:AtomicMarkableReference 和 AtomicStampedReference 他们除了对比栈中对象的引用地址外,另外还保存了一个 boolean 或 int 类型的标记值,用于 CAS 比较。
StringBuilder varA = new StringBuilder("abc");
StringBuilder varB = new StringBuilder("123");
AtomicStampedReference<StringBuilder> ref = new AtomicStampedReference<>(varA, varA.toString().hashCode());
ref.compareAndSet(varA, varB, varA.toString().hashCode(), varB.toString().hashCode());
System.out.println(ref.get(new int[1]));
varB.append('4');
// CAS失败,因为Stamp值对不上
if (ref.compareAndSet(varB, varA, varB.toString().hashCode(), varA.toString().hashCode())) {
System.out.println("compareAndSet: succeed");
}
System.out.println(ref.get(new int[1]));注:这种设计和为快速判断文件是否相同,而比较文件摘要值(MD5、SHA值)和预期是否一致的思想倒有异曲同工之妙。
总结
通常在多线程场景中,这些工具的应用场景具有各自的适用特征:
若各线程读写数据没有竞争关系,则可考虑仅使用
volatile关键字;若各线程对某数据的读写需要去重,则可优先考虑使用乐观锁实现,即用原子类型;
若各线程有竞争关系且不去重必须按顺序抢占某资源,即必须用锁阻塞,若没有多条件队列的诉求则可先考虑使用
synchronized添加对象锁(但需注意锁对象的不可变和私有化),否则考虑用Lock实现类,但特别的如需读写分锁以实现共享锁则只能用Lock了。若需使用线程安全容器,出于性能考虑优先考虑
java.util.concurrent.*类,如ConcurrentHashMap、CopyOnWriteArrayList;再考虑使用容器同步包装Collections.synchronizedXxx()。而阻塞队列则多用于生产-消费模型中的任务容器,典型如用在线程池中。
作者:Chavin
来源:juejin.cn/post/7181077489211408443
纯 JS 简单实现类似 404 可跳跃障碍物页面
废话开篇:一些 404 页面为了体现趣味性会添加一些简单的交互效果。 这里用纯 JS 简单实现类似 404 可跳跃障碍物页面,内容全部用 canvas 画布实现。
一、效果展示
二、画面拆解
1、绘制地平线
地平线这里就是简单的一条贯穿屏幕的线。
2、绘制红色精灵
绘制红色精灵分为两部分:
(1)上面圆
(2)下面定点与上面圆的切线。
绘制结果:
进行颜色填充,再绘制中小的小圆,绘制结果:
(3)绘制障碍物
这里绘制的是一个黑色的长方形。最后的实现效果:
三、逻辑拆解
1、全局定时器控制画布重绘
创建全局的定时器。
它有两个具体任务:
(1)全局定时刷新重置,将画布定时擦除之前的绘制结果。
(2)全局定时器刷新动画重绘新内容。
2、精灵跳跃动作
在接收到键盘 “空格” 点击的情况下,让精灵起跳一定高度,到达顶峰的时候进行回落,当然这里设计的是匀速。
3、障碍物移动动作
通过定时器,重绘障碍物从最右侧移动到最左侧。
4、检测碰撞
在障碍物移动到精灵位置时,进行碰撞检测,判断障碍物最上端的左、右顶点是否在精灵的内部。
5、绘制提示语
提示语也是用 canvas 绘制的,当障碍物已移动到左侧的时候进行,结果判断。如果跳跃过程中无碰撞,就显示 “完美跳跃~”,如果调跃过程中有碰撞,就显示 “再接再厉”。
四、代码讲解
1、HTML
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<script src="./wsl404.js"></script>
</head>
<body>
<div id="content">
<canvas id="myCanvas">
</canvas>
</div>
</body>
<script>
elves.init();
</script>
</html>2、JS
(function WSLNotFoundPage(window) {
var elves = {};//精灵对象
elves.ctx = null;//画布
elves.width = 0;//屏幕的宽度
elves.height = 0;//屏幕的高度
elves.point = null;//精灵圆中心
elves.elvesR = 20;//精灵圆半径
elves.runloopTargets = [];//任务序列(暂时只保存跳跃)
elves.upDistance = 50;//当前中心位置距离地面高度
elves.upDistanceInitNum = 50;//中心位置距离地面高度初始值
elves.isJumping = false;//是否跳起
elves.jumpTarget = null;//跳跃任务
elves.jumpTop = false;//是否跳到最高点
elves.maxCheckCollisionWith = 0;//碰撞检测的最大宽度尺寸
elves.obstaclesMovedDistance = 0;//障碍物移动的距离
elves.isCollisioned = false;//是否碰撞过
elves.congratulationFont = 13;//庆祝文字大小
elves.congratulationPosition = 40;//庆祝文字位移
elves.isShowCongratulation = false;//是否展示庆祝文字
elves.congratulationContent = "完美一跃~";
elves.congratulationColor = "red";
//初始化
elves.init = function(){
this.drawFullScreen("content");
this.drawElves(this.upDistance);
this.keyBoard();
this.runloop();
}
//键盘点击事件
elves.keyBoard = function(){
var that = this;
document.onkeydown = function whichButton(event)
{
if(event.keyCode == 32){
//空格
that.elvesJump();
}
}
}
//开始跑圈
elves.runloop = function(){
var that = this;
setInterval(function(){
//清除画布
that.cleareAll();
//绘制障碍物
that.creatObstacles();
if(that.isJumping == false){
//未跳起时重绘精灵
that.drawElves(that.upDistanceInitNum);
}
//绘制地面
that.drawGround();
//跳起任务
for(index in that.runloopTargets){
let target = that.runloopTargets[index];
if(target.isRun != null && target.isRun == true){
if(target.runCallBack){
target.runCallBack();
}
}
}
//碰撞检测
that.checkCollision();
//展示庆祝文字
if(that.isShowCongratulation == true){
that.congratulation();
}
},10);
}
//画布
elves.drawFullScreen = function (id){
var element = document.getElementById(id);
this.height = window.screen.height - 200;
this.width = window.screen.width;
element.style.width = this.width + "px";
element.style.height = this.height + "px";
element.style.background = "white";
this.getCanvas("myCanvas",this.width,this.height);
}
elves.getCanvas = function(id,width,height){
var c = document.getElementById(id);
this.ctx = c.getContext("2d");
//锯齿修复
if (window.devicePixelRatio) {
c.style.width = this.width + "px";
c.style.height = this.height + "px";
c.height = height * window.devicePixelRatio;
c.width = width * window.devicePixelRatio;
this.ctx.scale(window.devicePixelRatio, window.devicePixelRatio);
}
};
//绘制地面
elves.drawGround = function() {
// 设置线条的颜色
this.ctx.strokeStyle = 'gray';
// 设置线条的宽度
this.ctx.lineWidth = 1;
// 绘制直线
this.ctx.beginPath();
// 起点
this.ctx.moveTo(0, this.height / 2.0 + 1);
// 终点
this.ctx.lineTo(this.width,this.height / 2.0);
this.ctx.closePath();
this.ctx.stroke();
}
//绘制精灵
elves.drawElves = function(upDistance){
//绘制圆
var angle = Math.acos(this.elvesR / upDistance);
this.point = {x:this.width / 3,y : this.height / 2.0 - upDistance};
this.ctx.fillStyle = "#FF0000";
this.ctx.lineWidth = 1;
this.ctx.beginPath();
this.ctx.arc(this.point.x,this.point.y,this.elvesR,Math.PI / 2 + angle,Math.PI / 2 - angle,false);
//绘制切线
var bottomPoint = {x:this.width / 3,y : this.point.y + this.upDistanceInitNum};
let leftPointY = this.height / 2.0 - (upDistance - Math.cos(angle) * this.elvesR);
let leftPointX = this.point.x - (Math.sin(angle) * this.elvesR);
var leftPoint = {x:leftPointX,y:leftPointY};
let rightPointY = this.height / 2.0 - (upDistance - Math.cos(angle) * this.elvesR);
let rightPointX = this.point.x + (Math.sin(angle) * this.elvesR);
var rightPoint = {x:rightPointX,y:rightPointY};
this.maxCheckCollisionWith = (rightPointX - leftPointX) * 20 / (upDistance - Math.cos(angle) * this.elvesR);
this.ctx.moveTo(bottomPoint.x, bottomPoint.y);
this.ctx.lineTo(leftPoint.x,leftPoint.y);
this.ctx.lineTo(rightPoint.x,rightPoint.y);
this.ctx.closePath();
this.ctx.fill();
//绘制小圆
this.ctx.fillStyle = "#FFF";
this.ctx.lineWidth = 1;
this.ctx.beginPath();
this.ctx.arc(this.point.x,this.point.y,this.elvesR / 3,0,Math.PI * 2,false);
this.ctx.closePath();
this.ctx.fill();
}
//清除画布
elves.cleareAll = function(){
this.ctx.clearRect(0,0,this.width,this.height);
}
//精灵跳动
elves.elvesJump = function(){
if(this.isJumping == true){
return;
}
this.isJumping = true;
if(this.jumpTarget == null){
var that = this;
this.jumpTarget = {type:'jump',isRun:true,runCallBack:function(){
let maxDistance = that.upDistanceInitNum + 55;
if(that.jumpTop == false){
if(that.upDistance > maxDistance){
that.jumpTop = true;
}
that.upDistance += 1;
} else if(that.jumpTop == true) {
that.upDistance -= 1;
if(that.upDistance < 50) {
that.upDistance = 50;
that.jumpTop = false;
that.jumpTarget.isRun = false;
that.isJumping = false;
}
}
that.drawElves(that.upDistance);
}};
this.runloopTargets.push(this.jumpTarget);
} else {
this.jumpTarget.isRun = true;
}
}
//绘制障碍物
elves.creatObstacles = function(){
let obstacles = {width:20,height:20};
if(this.obstaclesMovedDistance != 0){
this.ctx.clearRect(this.width - obstacles.width - this.obstaclesMovedDistance + 0.5, this.height / 2.0 - obstacles.height,obstacles.width,obstacles.height);
}
this.obstaclesMovedDistance += 0.5;
if(this.obstaclesMovedDistance >= this.width + obstacles.width) {
this.obstaclesMovedDistance = 0;
//重置是否碰撞
this.isCollisioned = false;
}
this.ctx.beginPath();
this.ctx.fillStyle = "#000";
this.ctx.moveTo(this.width - obstacles.width - this.obstaclesMovedDistance, this.height / 2.0 - obstacles.height);
this.ctx.lineTo(this.width - this.obstaclesMovedDistance,this.height / 2.0 - obstacles.height);
this.ctx.lineTo(this.width - this.obstaclesMovedDistance,this.height / 2.0);
this.ctx.lineTo(this.width - obstacles.width - this.obstaclesMovedDistance, this.height / 2.0);
this.ctx.closePath();
this.ctx.fill();
}
//检测是否碰撞
elves.checkCollision = function(){
var obstaclesMarginLeft = this.width - this.obstaclesMovedDistance - 20;
var elvesUpDistance = this.upDistanceInitNum - this.upDistance + 20;
if(obstaclesMarginLeft > this.point.x - this.elvesR && obstaclesMarginLeft < this.point.x + this.elvesR && elvesUpDistance <= 20) {
//需要检测的最大范围
let currentCheckCollisionWith = this.maxCheckCollisionWith * elvesUpDistance / 20;
if((obstaclesMarginLeft < this.point.x + currentCheckCollisionWith / 2.0 && obstaclesMarginLeft > this.point.x - currentCheckCollisionWith / 2.0) || (obstaclesMarginLeft + 20 < this.point.x + currentCheckCollisionWith / 2.0 && obstaclesMarginLeft + 20 > this.point.x - currentCheckCollisionWith / 2.0)){
this.isCollisioned = true;
}
}
//记录障碍物移动到精灵左侧
if(obstaclesMarginLeft + 20 < this.point.x - this.elvesR && obstaclesMarginLeft + 20 > this.point.x - this.elvesR - 1){
if(this.isCollisioned == false){
//跳跃成功,防止检测距离内重复得分置为true,在下一次循环前再置为false
this.isCollisioned = true;
//庆祝
if(this.isShowCongratulation == false) {
this.congratulationContent = "完美一跃~";
this.congratulationColor = "red";
this.isShowCongratulation = true;
}
} else {
//鼓励
if(this.isShowCongratulation == false) {
this.isShowCongratulation = true;
this.congratulationColor = "gray";
this.congratulationContent = "再接再厉~";
}
}
}
}
//庆祝绘制文字
elves.congratulation = function(){
this.congratulationFont += 0.1;
this.congratulationPosition += 0.1;
if(this.congratulationFont >= 30){
//重置
this.congratulationFont = 13;
this.congratulationPosition = 30;
this.isShowCongratulation = false;
return;
}
this.ctx.fillStyle = this.congratulationColor;
this.ctx.font = this.congratulationFont + 'px "微软雅黑"';
this.ctx.textBaseline = "bottom";
this.ctx.textAlign = "center";
this.ctx.fillText( this.congratulationContent, this.point.x, this.height / 2.0 - this.upDistanceInitNum - this.congratulationPosition);
}
window.elves = elves;
})(window)五、总结与思考
逻辑注释基本都写在代码里,里面的一些计算可能会绕一些。
作者:头疼脑胀的代码搬运工
来源:juejin.cn/post/7056610619490828325
关于自建组件库的思考
很多公司都会有自己的组件库,但是在使用起来都不尽如人意,这里分享下我自己的一些观点和看法
问题思考
在规划这种整个团队都要用的工具之前要多思考,走一步想一步的方式是不可取的
首先,在开发一个组件库之前先要明确以下几点:
目前现状
不自建的话会有哪些问题,为什么不用 antd/element
哪些人提出了哪些的问题
分析为什么会出现这些问题
哪些问题是必须解决的,哪些是阶段推进的
期望目标
组件库的定位是什么
自建组件库是为了满足什么场景
阶段目标是什么
最终期望达到什么效果
具体实现
哪些问题用哪些方法来解决
关于后续迭代是怎么考虑的
目前现状
仅仅是因为前端开发为了部分代码或者样式不用重复写就封装一个组件甚至组件库是一件很搞笑的事情,最终往往会出现以下问题:
代码分散但是却高耦合,存在很多职责不明确
封装过于死板,且暴露的属性职责不明确
可维护性低,无法应对不断变化的需求
可靠性低,对上游数据不做错误处理,对下游使用者不做兼容处理
最后没法迭代,因为代码质量及版本问题,连原始开发者都改不动的,相关使用者怨声载道,然后又重构一遍,还是同样的设计思路,只不过基于已知业务场景改了写法,然后过一段时间又成为一个新的历史包袱。。。
当你为了方便改别人的代码而选择 fork 别人的组件库下来简单改改再输出时,难道你觉得别人不会对“你写的”这个组件库持同样的看法么?
你会发现,如果仅仅以一个业务员的角度去寻求解决办法的话,最后往往不能够得到其他业务员的认可的~
组件库的存在目的是为了提高团队的工作效率,不是单纯为了个别人能少写代码,前者才是目的,后者只是其中一种实现方式(这句话自己悟吧)
期望目标
一个合格的组件库应该要让使用者感受到两点:
约束(为什么只能这样传嘛?)
方便(只要这样传就可以耶~)
不合格的组件库往往只关注后者,但是其实前者更加重要
在能实现甲方的需求前提下,约束的树立会让团队对某一问题形成一个固有的解决方案,这个使用过程会促成惯性的产生
同时,这个惯性一旦建立,就能促成两个结果:
弥合了人与人之间的差异
提高了交流效率(不单单是开发,还包括设计、产品、测试等一条工作链路上的相关人)
要知道的是,团队合作过程中,效率最低的环节永远是沟通,一个好的团队不是全员大神,而是做什么事情以一个整体,每个人步调趋于一致,这样效率才高~
具体实现
编写一个公共库需要考虑很多东西,下面主要分三点来阐述
逻辑的分割
避免一次性、不通用、没必要的封装
不允许出现相互跨级或交叉引用的情况,应形成明确的上下级关系
被抽离的逻辑代码应该尽可能的“独立“,避免变成”谁也离不开谁”
逻辑的封装
对于一个管理平台框架来说,宗旨是让开发少写代码、产品少写文档,不需要每次有新业务都要重复产出
对于开发来说,具体有两点:
大部分情况下,能拷贝下 demo 即可实现各类交互效果
小部分情况下,组件能提供其他更多的可能以满足特殊需求
封装过程中,仅暴露关键属性,提供多种可能,并且以比较常用的值作为“默认值”并明确定义,即可满足“大部分需求只需无脑引用,同时小部分的特殊需求也能被满足”
维护与开发
作为一个上游的 UI 库,要充分考虑下游使用者的情况
做到升级后保证下游大部分情况下不需要改动
组件的新增、删除、修改要有充分的理由(需求或 bug),并且要遵循最小影响原则
组件的设计要充分考虑日后可能发生的变化
未来展望
仅靠一个 UI 框架难以解决问题,对于未来的想法有分成三个阶段:
UI 库,沉淀稳定高效的组件
代码片段生成器,收集业务案例代码
页面生成器,输出有效模版
这里更多面向的是中后台项目的解决方案
总结
组件库输出约束和统一解决办法,前者通过抚平团队中个体的差异来提高团队的沟通效率,后者通过形成工作惯性来提高团队的工作效率
作者:tellyourmad
来源:juejin.cn/post/7063017892714905608
RxJava观察者模式
1.RxJava的观察者模式
RxJava的观察者模式是扩展的观察者模式,扩展的地方主要体现在事件通知的方式有很多种
2.RxJava的观察者模式涉及到几个类
- Observable:被观察者
- Observer:观察者
- Subscribe:订阅
- Event:被观察者通知观察者的事件
3.Obsercerable与Observer通过Subscribe实现关联,Event主要向Observer通知Observeble的变化,Event有几个通知方式
- Next:常规事件,可以传递各种各样的数据
- Error:异常事件,当被观察者发送异常事件后那么其他的事件就不会再继续发送了
- Completed:结束事件,当观察者接收到这个事件后就不会再接收后续被观察者发送过来的事件
4.代码实现
- 首先定义一个观察者Observer
public abstract class Observer<T> {
//和被观察者订阅后,会回调这个方法
public static void onSubscribe(Emitter emitter);
// 传递常规事件,用于传递数据
public abstract void onNext(T t);
// 传递异常事件
public abstract void onError(Throwable e);
// 传递结束事件
public abstract void onComplete();
}
Observer中的方法都是回调,其中多了一个Emitter的接口类,他是一个发射器
public interface Emitter<T> {
void onNext(T t);
void onError(Throwable error);
void onCompleted();
}
实现逻辑就是通过包装Observer,里面最终是通过Observer进行回调的
public class CreateEmitter<T> implements Emitter<T> {
final Observer<T> observer;
CreateEmitter(Observer<T> observer) {
this.observer = observer;
}
@Override
public void onNext(T t) {
observer.onNext(t);
}
@Override
public void onError(Throwable error) {
observer.onError(error);
}
@Override
public void onComplete() {
observer.onComplete();
}
} - 被观察者的实现
public abstract class Observable<T>{
public void subscribe(Observer<T> observer) {
//通过传入的Observer包装成CreateEmitter,用于回调
CreateEmitter emitter = new CreateEmitter(observer);
//回调订阅成功的方法
observer.onSubscribe(emitter);
//回调发射器emitter
subscribe(emitter);
}
/**
* 订阅成功后,进行回调
*/
public abstract void subscribe(Emitter<T> emitter);
}
就两步,第一步用于订阅,第二步用于回调- 具体的使用
private void observer() {
// 第一步,创建被观察者
Observable<String> observable = new Observable<String>() {
@Override
public void subscribe(Emitter<String> emitter) {
emitter.onNext("第一次");
emitter.onNext("第二次");
emitter.onNext("第三次");
emitter.onComplete();
}
};
// 第二步,创建观察者
Observer<String> observer = new Observer<String>() {
@Override
public void onSubscribe(Emitter emitter) {
Log.i("TAG", " onSubscribe ");
}
@Override
public void onNext(String s) {
Log.i("TAG", " onNext s:" + s);
}
@Override
public void onError(Throwable e) {
Log.i("TAG", " onError e:" + e.toString());
}
@Override
public void onComplete() {
Log.i("TAG", " onComplete ");
}
};
// 第三步,被观察者订阅观察者
observable.subscribe(observer);
}
被订阅成功后,被观察者的subscribe里面就可以通过发射器发送事件了,最终在观察者的方法里进行回调。RxJava也是观察者和被观察者订阅的过程,只不过被观察者有变化的时候是由发射器进行发送的,这样就不止有一种事件了
1.RxJava的装饰者模式
- 装饰者模式:在不改变原有的架构基础上添加一些新的功能,是作为其原有结构的包装,这个过程称为装饰。
- RxJava的装饰者模式主要是用于实现Observable和Observer的包装,主要是为了与RxJava的观察者模式配合实现代码的方式更简洁。
- 拆解RxJava的装饰器模式
- 被观察者Observable
参考手机包装的例子
第一步:要有一个抽象接口,在RxJava中这个抽象接口是ObservableSource,里面有一个方法subscribe
public interface ObservableSource<T> {
/**
* Subscribes the given Observer to this ObservableSource instance.
* @param observer the Observer, not null
* @throws NullPointerException if {@code observer} is null
*/
void subscribe(@NonNull Observer<? super T> observer);
}
第二步:要有一个包装类,实现了ObservableSource的,RxJava的包装类是Observable,实现了对应的接口,
并且在subscribe方法里通过调用抽象方法subscribeActual,来对观察者进行订阅
public abstract class Observable<T> implements ObservableSource<T> {
...
@Override
public final void subscribe(Observer<? super T> observer) {
...
subscribeActual(observer);
...
}
protected abstract void subscribeActual(Observer<? super T> observer);
...
}
第三步:这就是具体的包装类了如图所示2.观察者Observer:
- 第一步:要有一个抽象接口,而RxJava的接口是Emitter和Observer,里面有好几个方法基本一样,onNext,onError,onComplete,用于被观察者进行回调;
- 第二步:要有一个包装类,实现了Emitter或者Observer,但是观察者比较特殊,没有一个基础的包装类,而是直接封装了很多的包装类
RxJava的的被观察者是在创建的时候进行包装的,例如第一步的Observable.create方法,通过Observable.create的创建后进行了第一层包装,结构如下
第二步的subscribeO方法调用时进行了第二层的包装,此时结构如下:
第三步的observerOn方法调用时,进行了第四层的包装,那么结构就是下面的样子
最终调用订阅方法的时候已经进行了四次包装,那么可以理解每调用一次操作符就会进行一层被观察者的包装。
那么这样包装的好处是什么呢?
这就是装饰者模式的特性,在不改变原有功能的基础上添加额外的功能。
5.总结
我们在创建被观察者的时候,会对被观察者做一层包装,创建几次就包装几次,然后在被观察者调用subscribe方法时,一层层回调被观察者的subscribeAcutal方法,而在被观察者的subscribeAcutal方法里,会对观察者做一层包装;
也就是说被观察者是在创建的时候进行包装,然后在subscribeActual中实现额外的功能;
而观察者是在被观察者调用subscribeActual方法里进行包装的,然后针对观察者实现自己额外的功能;
流程图如下:
链接:https://juejin.cn/post/7180698264251924536
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RxJava装饰者模式
1.装饰者模式
- 装饰者模式时在保留原有结构的前提下添加新的功能,这些功能作为其原有结构的包装。
2.RxJava的装饰者模式
1.被观察者Observable
- 根据
Observerable的源码可知Observable的结构接口是Observerablesource<T>,里面有一个方法subscribe用于和观察者实现订阅,源码如下
/**
* Represents a basic, non-backpressured {@link Observable} source base interface,
* consumable via an {@link Observer}.
*
* @param <T> the element type
* @since 2.0
*/
public interface ObservableSource<T> {
/**
* Subscribes the given Observer to this ObservableSource instance.
* @param observer the Observer, not null
* @throws NullPointerException if {@code observer} is null
*/
void subscribe(Observer<? super T> observer);
}- 然后需要一个包装类,就是实现
ObservableSource接口的类,就是Observable<T>,它实现了ObservableSource并在subscribe方法中调用了subscribeActual方法与观察者实现订阅关系,源码如下
public abstract class Observable<T> implements ObservableSource<T> {
@Override
public final void subscribe(Observer<? super T> observer) {
...
subscribeActual(observer);
...
}
protected abstract void subscribeActual(Observer<? super T> observer);
}- 第三步就是包装类了,包装类有很多有一百多个,如
ObservableAll、ObservableAny、ObservableCache
2.观察者Observer
- 第一步,
Observer的结构的接口有Emitter和Observer,两个接口中的方法差不多,都是onNext、OnError、OnComplete,用于被观察者的回调 - 第二步,实现
Emitter或者Observer接口的包装类,观察者中没有实现这两个接口的基础包装类,而是直接封装了很多包装类
3.被观察者和观察者的包装类有在创建的时候进行包装也有在调用的时候包装,那么他们的结构又是怎么样的
以RxJava的最基础用法来分析,Observable.create().subscribeOn().observeOn().subscribe()为例,层层调用后它的结构如下:
- 首先是
Observable.create,通过创建ObservableCreate对象进行第一层包装,把ObservableOnSubscribe包在了里面
- 然后是
Observable.create().subscribeOn(),调用时又进行了一层包装,把ObservableCreate包进去了
- 再然后就分别是
observeOn()了,结构如下
- 总共进行了4层包装,可以理解为每调用一次操作符就会进行一层被观察者的包装,这样包装的好处就是为了添加额外的功能,那么每一层又添加了哪些额外的功能呢
4.被观察者的subscribe方法
调用subscribe方法后会从最外层的包装类一步一步的往里面调用,从被观察者的subscribe方法中可以得知额外功能的实现是在subscribeActual方法中,那么上面几层包装的subscribeActual方法中又做了什么呢,分析如下
- 先看最外层的包装
observerOn的subscribeActual方法做了什么,先看源码:
public final class ObservableObserveOn<T> extends AbstractObservableWithUpstream<T, T> {
final Scheduler scheduler;
final boolean delayError;
final int bufferSize;
public ObservableObserveOn(ObservableSource<T> source, Scheduler scheduler, boolean delayError, int bufferSize) {
super(source);
this.scheduler = scheduler;
this.delayError = delayError;
this.bufferSize = bufferSize;
}
@Override
protected void subscribeActual(Observer<? super T> observer) {
if (scheduler instanceof TrampolineScheduler) {
source.subscribe(observer);
} else {
Scheduler.Worker w = scheduler.createWorker();
source.subscribe(new ObserveOnObserver<T>(observer, w, delayError, bufferSize));
}
}
...
}- 源码中有一个
source,这个source是上一层包装类的实例,在source.subscribe()中对观察者进行了一层包装,也就是ObserveOnObserver,它在onNext方法里面实现了线程切换,这个onNext是在被观察者在通知观察者时会被回调,然后通过包装类实现额外的线程切换,这里是切换到了主线程执行。此时观察者的结构如下:
@Override
public void onNext(T t) {
if (done) {
return;
}
if (sourceMode != QueueDisposable.ASYNC) {
queue.offer(t);
}
schedule();
}- 再看下一层的包装
subscribeOn的subscribeActual方法做了什么,先看源码
public final class ObservableSubscribeOn<T> extends AbstractObservableWithUpstream<T, T> {
final Scheduler scheduler;
public ObservableSubscribeOn(ObservableSource<T> source, Scheduler scheduler) {
super(source);
this.scheduler = scheduler;
}
@Override
public void subscribeActual(final Observer<? super T> s) {
final SubscribeOnObserver<T> parent = new SubscribeOnObserver<T>(s);
s.onSubscribe(parent);
parent.setDisposable(scheduler.scheduleDirect(new Runnable() {
@Override
public void run() {
source.subscribe(parent);
}
}));
}
...
}这里又对观察者进行了一层包装,也就是SubscribeOnObserver,这里面的额外功能就是资源释放,包装完后的结构如下
static final class SubscribeOnObserver<T> extends AtomicReference<Disposable> implements Observer<T>, Disposable {
private static final long serialVersionUID = 8094547886072529208L;
...
@Override
public void dispose() {
DisposableHelper.dispose(s);
DisposableHelper.dispose(this);
}
@Override
public boolean isDisposed() {
return DisposableHelper.isDisposed(get());
}
void setDisposable(Disposable d) {
DisposableHelper.setOnce(this, d);
}
}在subscribeActual方法中有一个调用是source.subscribe(parent),这个source就是它的上一层的包装类ObservableCreate,那么ObservableCreate的subscribeActual方法就会在子线程执行。
ObservableCreate的subscribeActual方法做了什么,先看源码
public final class ObservableCreate<T> extends Observable<T> {
final ObservableOnSubscribe<T> source;
public ObservableCreate(ObservableOnSubscribe<T> source) {
this.source = source;
}
@Override
protected void subscribeActual(Observer<? super T> observer) {
CreateEmitter<T> parent = new CreateEmitter<T>(observer);
observer.onSubscribe(parent);
try {
source.subscribe(parent);
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
parent.onError(ex);
}
}
...
}源码中的source就是创建最原始的ObservableOnSubscribe,这里会回调到ObservableOnSubscribe的subscribe方法,在subscribeActual方法中又对观察者进行了一层包装也就是CreateEmitter,这个类里面做的事情是判断线程是否被释放,如果释放了则不再进行回调,这时候结构如下图
@Override
public void onNext(T t) {
if (t == null) {
onError(new NullPointerException("onNext called with null. Null values are generally not allowed in 2.x operators and sources."));
return;
}
if (!isDisposed()) {
observer.onNext(t);
}
}这里由于上面的包装类已经切换到了子线程所以ObservableOnSubscribe的subscribe方法的执行也是在子线程;
3.总结
在创建被观察者的时候会对被观察者进行层层的包装,创建几次就包装几次,然后在被观察者调用subscribe方法时,一层层回调被观察者的subscribeActual方法,而在被观察者subscribeActual方法中会对观察者做一层包装。也就是说被观察者是创建的时候包装,在subscribeActual方法中实现额外的功能,观察者是在被观察者调用subscribeActual方法时进行包装的,然后针对观察者实现自己的额外的功能,流程图如下:
最终的结构如下:
- 第一步:创建被观察者时或者使用操作符时会对被观察者进行包装
- 第二步:当被观察者和观察者产生订阅关系后,被观察者会一层层的回调被观察者的
subscribeActual方法,在这个方法中对观察者进行包装,此时被观察者的功能实现是在subscribeActual中,观察者的实现是在包装类里
- 第三步:被观察者和观察者不同的是,被观察者是在订阅成功后就执行了包装类相应的功能,而观察者是在事件回调的时候,会在观察者的包装类里实现相应的功能
- 最终流程图
链接:https://juejin.cn/post/7180695827252248633
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 源码阅读 - StatefulWidget 源码分析 & State 生命周期
一、StatefulWidget
StatefulWidget 也是继承自 Widget,重写了 createElement,并且添加了一个新的接口 createState,下面我们看一下它的源码:
看起来是不是很简单,代码不足十行。
createElement方法返回一个StatefulElement类型的Element。createState抽象方法返回一个State类型的实例对象。在给定的位置为StatefulWidget创建可变状态(state)。框架可以在StatefulWidget生命周期内多次调用此方法,比如:将StatefulWidget插入到Widget Tree中的多个位置时,会创建多个单独的State实例,如果将StatefulWidget从Widget Tree中删除,稍后再次将琦插入到Widget Tree中,框架将会再次调用createState创建一个新的State实例对象。
StatefulWidget 我们暂时就先讲到这里, 关于 State 和 StatefulElement 我们在下面会进行分析。
二、StatefulElement
上面讲到 StatefulWidget 中 createElement 会创建一个 StatefulElement 类型的 Element。下面我们就一起看下 StatefulElement 的源码。
在执行 StatefulWidget#createElement 时会把 this 传递进去,此时执行 StatefulElement 的构造方法中我们可以看出会做以下三件事情:
- 首先通过
_state = widget.createState()执行StatefulWidget中的createState进行闯将State实例; - 其次通过
state._element = this将当前对象赋值给State中的_element属性; - 最后通过
state._widget = widget,将StatefulWidget赋值给State中的_widget属性。
通过以上分析我们相应的可以得出以下结论:
StatefulElement持有State状态;State中又会反过来持有StatefulElement和StatefulWidget(当然,State的源码我们还没有看到);StatefulWidget只是负责创建StatefulElement和State,但是并不持有它们。
至此我们已经理清了 StatefulWidget、StatefulElement 和 State 三者之间的关系,关于 State 我们会在后面讲到。现在我们已经知道 StatefulWidget 中的 createState 在何时执行,那么 StatefulElement#createElement 又是在何时执行的呢?下面我们来看一个例子:
import 'package:flutter/material.dart';
void main() {
runApp(
const MyApp(),
);
}
class MyApp extends StatefulWidget {
const MyApp({super.key});
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
@override
Widget build(BuildContext context) {
return const ColoredBox(
color: Colors.red,
);
}
}通过断点调试可以看出在 Element#inflateWidget 中 通过 newWidget.createElement() 来进行触发 StatefulWidget#createElement 的执行,进而执行 StatefulElement 的构造函数。
关于更多 StatefulElement 内部方法,将在 State 源码以及相关案例中穿插进行。
三、State
State 是一个抽象类,它只定义了一个 build 抽象方法,由于构建 Widget 对象。它是通过StatefulElement#build 方法进行调用的。
如下是 State 源码的部分截图:
从源码中我们也可以对上面的结论得到验证,State 持有 StatefulElement 、StatefulWidget,这里的泛型 T必须是 StatefulWidget 类型,如下图所示:
除此之外 State 中还持有 BuildContext,通过源码我们可以看出 BuildContext 其实就是 StatefulElement 。
BuildContext get context {
return _element!;
}那么现在我们可以思考一下 State 中的生命周期方法在何时调用以及在哪里调用呢?从上面我们得出的结论:StatefulElement 持有 State 状态,State 中又会反过来持有 StatefulElement 和 StatefulWidget,StatefulWidget 只是负责创建 StatefulElement 和 State,但是并不持有它们。不难猜测出,应该是在 StatefulElement 中来触发的,下面我通过一个小的案例来进行研究一下:
void main() {
runApp(
const WrapWidget(),
);
}class WrapWidget extends StatelessWidget {
const WrapWidget({
Key? key,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text("StatefulWidget Demo"),
),
body: MyApp(),
),
);
}
}class MyApp extends StatefulWidget {
const MyApp({
super.key,
});
@override
// ignore: no_logic_in_create_state
State<MyApp> createState() {
debugPrint("createState");
return _MyAppState();
}
}
class _MyAppState extends State<MyApp> {
late int _count = 0;
@override
void initState() {
debugPrint("initState");
super.initState();
}
@override
void didChangeDependencies() {
debugPrint("didChangeDependencies");
super.didChangeDependencies();
}
@override
void didUpdateWidget(MyApp oldWidget) {
debugPrint("didUpdateWidget");
super.didUpdateWidget(oldWidget);
}
@override
void deactivate() {
debugPrint("deactivate ");
super.deactivate();
}
@override
void dispose() {
debugPrint("dispose");
super.dispose();
}
@override
void reassemble() {
debugPrint("reassemble");
super.reassemble();
}
@override
Widget build(BuildContext context) {
debugPrint("build");
return Column(
children: [
Text('$_count'),
OutlinedButton(
onPressed: () {
setState(() {
_count++;
});
},
child: const Text('OnPress'),
),
],
);
}
}程序刚运行时打印日志如下:
然后我们点击⚡️按钮热重载,控制台输出日志如下:
我们再次点击 OnPress 按钮时,打印日志如下:
此时我们注释掉 WrapWidget 中的 body: MyApp() 这行代码,打印日志如下:
此时结合源码,我们来一起看下各个生命周期函数:
initState: 当Widget第一次插入到Widget Tree中,会执行一次,我们一般在这里可以做一些初始化状态的操作以及订阅通知事件等,通过源码我们可以看出它是在Statefulelement#_firstBuild中执行的;didChangeDependencies: 当State对象的依赖发生变化时会进行调用,例如:例如系统语言Locale或者应用主题等,通过源码我们可以看出它在Statefulelement#_firstBuild和Statefulelement#performRebuild中都会执行;build:在以下场景中都会调用:initState调用之后didUpdateWidget调用之后setState调用之后didChangeDependencies调用之后- 调用
deactivate之后,然后又重新插入到Widtget Tree中
通过源码可以看出它是在
Statefulelement#build中执行的;reassemble:专门为了开发调试而提供的,在hot reload时会被调用,在Release模式下永远不会被调用,通过源码可以看出它是在Statefulelement#reassemble中执行的;didUpdateWidget:在 Widget 重新构建时,Flutter 框架会在Element#updateChild中通过Widget.canUpdate判断是否需要进行更新,如果为 true 则进行更新;在
canUpdate源码中,新旧 widget 的key和runtimeType同时相等时会返回true,也就是说在在新旧widget的key和runtimeType同时相等时didUpdateWidget()就会被调用;deactivate:当 State 对象从树中被移除时将会调用,它将会在Statefulelement#deactivate中进行调用;dispose:当 State 对象从树中被永久移除时调用;通常在此回调中释放资源,它将会在Statefulelement#unmount中进行调用。
总结
至此,结合一些小的案例和源码阅读,我们大致明白了 StatefulWidget、State 以及 StatefulElement 他们三者之间的关系以及 State 的生命周期,相信在以后的实际应用中会更加得心应手。
链接:https://juejin.cn/post/7180626500951998520
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Jetpack Compose 十几行代码快速模仿即刻点赞数字切换效果
缘由
四点多刷掘金的时候,看到这样一篇文章:
自定义View模仿即刻点赞数字切换效果,作者使用自定义绘制的技术完成了数字切换的动态效果,也就是如图:
两图分别为即刻的效果和作者的实现
不得不说,作者模仿的很像,自定义绘制玩的炉火纯青,非常优秀。不过,即使是这样简单的动效,使用 View 体系实现起来仍然相对麻烦。对上文来说,作者使用的 Kotlin 代码也达到了约 170 行。
Composable
如果换成 Compose 呢?作为声明式框架,在处理这类动画上会不会有奇效?
答案是肯定的!下面是最简单的实现:
Row(modifier = modifier) {
text.forEach {
AnimatedContent(
targetState = it,
transitionSpec = {
slideIntoContainer(AnimatedContentScope.SlideDirection.Up) with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)
}
) { char ->
Text(text = char.toString(), modifier = modifier.padding(textPadding), fontSize = textSize, color = textColor)
}
}
}你没看错,这就是 Composable 对应的简单模仿,核心代码不过十行。它的大致效果如下:
能看到,在数字变化时,相应的动画效果已经非常相似。当然他还有小瑕疵,比如在 99 - 100 时,最后一位的 0 没有初始动画;比如在数字减少时,他的动画方向应该相反。但这两个问题都是可以加点代码解决的,这里核心只是思路
原理
与上文作者将每个数字当做一个整体对待不同,我将每一位独立处理。观察图片,动画的核心在于每一位有差异时要做动画处理,因此将每一位单独处理能更好的建立状态。
Jetpack Compose 是声明式 UI,状态的变化自然而然就导致 UI 的变化,我们所需要做的只是在 UI 变化时加个动画就可以。而刚好,对于这种内容的改变,Compose 为我们提供了开箱即用的微件:AnimatedContent
AnimatedContent
此 Composable 签名如下:
@Composable
fun <S> AnimatedContent(
targetState: S,
modifier: Modifier = Modifier,
transitionSpec: AnimatedContentScope<S>.() -> ContentTransform = {
...
},
contentAlignment: Alignment = Alignment.TopStart,
content: @Composable() AnimatedVisibilityScope.(targetState: S) -> Unit
)重点在于 targetState,在 content 内部,我们需要获取到用到这个值,根据值的不同,呈现不同的 UI。AnimatedContent 会在 targetState 变化使自动对上一个 Composable 执行退出动画,并对新 Composable 执行进入动画 (有点幻灯片切换的感觉hh),在这里,我们的动画是这样的:
slideIntoContainer(AnimatedContentScope.SlideDirection.Up)
with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)上半部分的 slideIntoContainer 会执行进入动画,方向为自下向上;后半部分则是退出动画,由向上的路径动画和淡出结合而来。中缀函数 with 连接它们。这也体现了 Kotlin 作为一门现代化语言的优雅。
关于 Compose 的更多知识,可以参考 Compose 中文社区的大佬们共同维护的 Jetpack Compose 博物馆。
代码
本文的所有代码如下:
import androidx.compose.animation.*
import androidx.compose.foundation.layout.*
import androidx.compose.material.Text
import androidx.compose.material.TextButton
import androidx.compose.runtime.*
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
import androidx.compose.ui.graphics.Color
import androidx.compose.ui.unit.TextUnit
import androidx.compose.ui.unit.dp
import androidx.compose.ui.unit.sp
@OptIn(ExperimentalAnimationApi::class)
@Composable
fun NumberChangeAnimationText(
modifier: Modifier = Modifier,
text: String,
textPadding: PaddingValues = PaddingValues(horizontal = 8.dp, vertical = 12.dp),
textSize: TextUnit = 24.sp,
textColor: Color = Color.Black
) {
Row(modifier = modifier) {
text.forEach {
AnimatedContent(
targetState = it,
transitionSpec = {
slideIntoContainer(AnimatedContentScope.SlideDirection.Up) with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)
}
) { char ->
Text(text = char.toString(), modifier = modifier.padding(textPadding), fontSize = textSize, color = textColor)
}
}
}
}
@Composable
fun NumberChangeAnimationTextTest() {
Column(horizontalAlignment = Alignment.CenterHorizontally) {
var text by remember { mutableStateOf("103") }
NumberChangeAnimationText(text = text)
Row(Modifier.fillMaxWidth(), horizontalArrangement = Arrangement.SpaceEvenly) {
// 加一 和 减一
listOf(1, -1).forEach { i ->
TextButton(onClick = {
text = (text.toInt() + i).toString()
}) {
Text(text = if (i == 1) "加一" else "减一")
}
}
}
}
}这个示例也被收录到了我的 JetpackComposeStudy: 本人 Jetpack Compose 主题文章所包含的示例,包括自定义布局、部分组件用法等 里,感兴趣的可以去那里查看更多代码。
最近掘金开启了2022的年度人气创作者评选,如果您对我的文章认可的话,欢迎投给我宝贵的一票,感谢!本文有帮助的话,也欢迎点赞交流。
(现在6点13分,连写代码加写文章共用了一个多小时,嗯,收工~)
链接:https://juejin.cn/post/7179543408347152442
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
超级全面的Flutter性能优化实践
前言
Flutter是谷歌的移动UI框架,可以快速在iOS和Android上构建高质量的原生用户界面。 Flutter可以与现有的代码一起工作。在全世界,Flutter正在被越来越多的开发者和组织使用,并且Flutter是完全免费、开源的,可以用一套代码同时构建Android和iOS应用,性能可以达到原生应用一样的性能。但是,在较为复杂的 App 中,使用 Flutter 开发也很难避免产生各种各样的性能问题。在这篇文章中,我将介绍一些 Flutter 性能优化方面的应用实践。
一、优化检测工具
flutter编译模式
Flutter支持Release、Profile、Debug编译模式。
Release模式,使用AOT预编译模式,预编译为机器码,通过编译生成对应架构的代码,在用户设备上直接运行对应的机器码,运行速度快,执行性能好;此模式关闭了所有调试工具,只支持真机。
Profile模式,和Release模式类似,使用AOT预编译模式,此模式最重要的作用是可以用DevTools来检测应用的性能,做性能调试分析。
Debug模式,使用JIT(Just in time)即时编译技术,支持常用的开发调试功能hot reload,在开发调试时使用,包括支持的调试信息、服务扩展、Observatory、DevTools等调试工具,支持模拟器和真机。
通过以上介绍我们可以知道,flutter为我们提供 profile模式启动应用,进行性能分析,profile模式在Release模式的基础之上,为分析工具提供了少量必要的应用追踪信息。
如何开启profile模式?
如果是独立flutter工程可以使用flutter run --profile启动。如果是混合 Flutter 应用,在 flutter/packages/flutter_tools/gradle/flutter.gradle 的 buildModeFor 方法中将 debug 模式改为 profile即可。
检测工具
1、Flutter Inspector (debug模式下)
Flutter Inspector有很多功能,其中有两个功能更值得我们去关注,例如:“Select Widget Mode” 和 “Highlight Repaints”。
Select Widget Mode点击 “Select Widget Mode” 图标,可以在手机上查看当前页面的布局框架与容器类型。
通过“Select Widget Mode”我们可以快速查看陌生页面的布局实现方式。
Select Widget Mode模式下,也可以在app里点击相应的布局控件查看
Highlight Repaints
点击 “Highlight Repaints” 图标,它会 为所有 RenderBox 绘制一层外框,并在它们重绘时会改变颜色。
这样做帮你找到 App 中频繁重绘导致性能消耗过大的部分。
例如:一个小动画可能会导致整个页面重绘,这个时候使用 RepaintBoundary Widget 包裹它,可以将重绘范围缩小至本身所占用的区域,这样就可以减少绘制消耗。
2、Performance Overlay(性能图层)
在完成了应用启动之后,接下来我们就可以利用 Flutter 提供的渲染问题分析工具,即性能图层(Performance Overlay),来分析渲染问题了。
我们可以通过以下方式开启性能图层
性能图层会在当前应用的最上层,以 Flutter 引擎自绘的方式展示 GPU 与 UI 线程的执行图表,而其中每一张图表都代表当前线程最近 300 帧的表现,如果 UI 产生了卡顿,这些图表可以帮助我们分析并找到原因。
下图演示了性能图层的展现样式。其中,GPU 线程的性能情况在上面,UI 线程的情况显示在下面,蓝色垂直的线条表示已执行的正常帧,绿色的线条代表的是当前帧:
如果有一帧处理时间过长,就会导致界面卡顿,图表中就会展示出一个红色竖条。下图演示了应用出现渲染和绘制耗时的情况下,性能图层的展示样式:
如果红色竖条出现在 GPU 线程图表,意味着渲染的图形太复杂,导致无法快速渲染;而如果是出现在了 UI 线程图表,则表示 Dart 代码消耗了大量资源,需要优化代码执行时间。
3、CPU Profiler(UI 线程问题定位)
在视图构建时,在 build 方法中使用了一些复杂的运算,或是在主 Isolate 中进行了同步的 I/O 操作。
我们可以使用 CPU Profiler 进行检测:
你需要手动点击 “Record” 按钮去主动触发,在完成信息的抽样采集后,点击 “Stop” 按钮结束录制。这时,你就可以得到在这期间应用的执行情况了。
其中:
x 轴:表示单位时间,一个函数在 x 轴占据的宽度越宽,就表示它被采样到的次数越多,即执行时间越长。
y 轴:表示调用栈,其每一层都是一个函数。调用栈越深,火焰就越高,底部就是正在执行的函数,上方都是它的父函数。
通过上述CPU帧图我们可以大概分析出哪些方法存在耗时操作,针对性的进行优化
一般的耗时问题,我们通常可以 使用 Isolate(或 compute)将这些耗时的操作挪到并发主 Isolate 之外去完成。
例如:复杂JSON解析子线程化
Flutter的isolate默认是单线程模型,而所有的UI操作又都是在UI线程进行的,想应用多线程的并发优势需新开isolate 或compute。无论如何await,scheduleTask 都只是延后任务的调用时机,仍然会占用“UI线程”, 所以在大Json解析或大量的channel调用时,一定要观测对UI线程的消耗情况。
二、Flutter布局优化
Flutter 使用了声明式的 UI 编写方式,而不是 Android 和 iOS 中的命令式编写方式。
声明式:简单的说,你只需要告诉计算机,你要得到什么样的结果,计算机则会完成你想要的结果,声明式更注重结果。
命令式:用详细的命令机器怎么去处理一件事情以达到你想要的结果,命令式更注重执行过程。
flutter声明式的布局方式通过三棵树去构建布局,如图:
Widget Tree: 控件的配置信息,不涉及渲染,更新代价极低。
Element Tree : Widget树和RenderObject树之间的粘合剂,负责将Widget树的变更以最低的代价映射到RenderObject树上。
RenderObject Tree : 真正的UI渲染树,负责渲染UI,更新代价极大。
1、常规优化
常规优化即针对 build() 进行优化,build() 方法中的性能问题一般有两种:耗时操作和 Widget 层叠。
1)、在 build() 方法中执行了耗时操作
我们应该尽量避免在 build() 中执行耗时操作,因为 build() 会被频繁地调用,尤其是当 Widget 重建的时候。
此外,我们不要在代码中进行阻塞式操作,可以将一般耗时操作等通过 Future 来转换成异步方式来完成。
对于 CPU 计算频繁的操作,例如图片压缩,可以使用 isolate 来充分利用多核心 CPU。
2)、build() 方法中堆叠了大量的 Widget
这将会导致三个问题:
1、代码可读性差:画界面时需要一个 Widget 嵌套一个 Widget,但如果 Widget 嵌套太深,就会导致代码的可读性变差,也不利于后期的维护和扩展。
2、复用难:由于所有的代码都在一个 build(),会导致无法将公共的 UI 代码复用到其它的页面或模块。
3、影响性能:我们在 State 上调用 setState() 时,所有 build() 中的 Widget 都将被重建,因此 build() 中返回的 Widget 树越大,那么需要重建的 Widget 就越多,也就会对性能越不利。
所以,你需要 控制 build 方法耗时,将 Widget 拆小,避免直接返回一个巨大的 Widget,这样 Widget 会享有更细粒度的重建和复用。
3)、尽可能地使用 const 构造器
当构建你自己的 Widget 或者使用 Flutter 的 Widget 时,这将会帮助 Flutter 仅仅去 rebuild 那些应当被更新的 Widget。
因此,你应该尽量多用 const 组件,这样即使父组件更新了,子组件也不会重新进行 rebuild 操作。特别是针对一些长期不修改的组件,例如通用报错组件和通用 loading 组件等。
4)、列表优化
尽量避免使用 ListView默认构造方法
不管列表内容是否可见,会导致列表中所有的数据都会被一次性绘制出来
建议使用 ListView 和 GridView 的 builder 方法
它们只会绘制可见的列表内容,类似于 Android 的 RecyclerView。
其实,本质上,就是对列表采用了懒加载而不是直接一次性创建所有的子 Widget,这样视图的初始化时间就减少了。
2、深入光栅化优化
优化光栅线程
屏幕显示器一般以60Hz的固定频率刷新,每一帧图像绘制完成后,会继续绘制下一帧,这时显示器就会发出一个Vsync信号,按60Hz计算,屏幕每秒会发出60次这样的信号。CPU计算好显示内容提交给GPU,GPU渲染好传递给显示器显示。
Flutter遵循了这种模式,渲染流程如图:
flutter通过native获取屏幕刷新信号通过engine层传递给flutter framework
所有的 Flutter 应用至少都会运行在两个并行的线程上:UI 线程和 Raster 线程。
UI 线程
构建 Widgets 和运行应用逻辑的地方。
Raster 线程
用来光栅化应用。它从 UI 线程获取指令将其转换成为GPU命令并发送到GPU。
我们通常可以使用Flutter DevTools-Performance 进行检测,步骤如下:
在 Performance Overlay 中,查看光栅线程和 UI 线程哪个负载过重。
在 Timeline Events 中,找到那些耗费时间最长的事件,例如常见的 SkCanvas::Flush,它负责解决所有待处理的 GPU 操作。
找到对应的代码区域,通过删除 Widgets 或方法的方式来看对性能的影响。
三、Flutter内存优化
1、const 实例化
const 对象只会创建一个编译时的常量值。在代码被加载进 Dart Vm 时,在编译时会存储在一个特殊的查询表里,仅仅只分配一次内存给当前实例。
我们可以使用 flutter_lints 库对我们的代码进行检测提示
2、检测消耗多余内存的图片
Flutter Inspector:点击 “Highlight Oversizeded Images”,它会识别出那些解码大小超过展示大小的图片,并且系统会将其倒置,这些你就能更容易在 App 页面中找到它。
通过下面两张图可以清晰的看出使用“Highlight Oversizeded Images”的检测效果
针对这些图片,你可以指定 cacheWidth 和 cacheHeight 为展示大小,这样可以让 flutter 引擎以指定大小解析图片,减少内存消耗。
3、针对 ListView item 中有 image 的情况来优化内存
ListView 不会销毁那些在屏幕可视范围之外的那些 item,如果 item 使用了高分辨率的图片,那么它将会消耗非常多的内存。
ListView 在默认情况下会在整个滑动/不滑动的过程中让子 Widget 保持活动状态,这一点是通过 AutomaticKeepAlive 来保证,在默认情况下,每个子 Widget 都会被这个 Widget 包裹,以使被包裹的子 Widget 保持活跃。
其次,如果用户向后滚动,则不会再次重新绘制子 Widget,这一点是通过 RepaintBoundaries 来保证,在默认情况下,每个子 Widget 都会被这个 Widget 包裹,它会让被包裹的子 Widget 仅仅绘制一次,以此获得更高的性能。
但,这样的问题在于,如果加载大量的图片,则会消耗大量的内存,最终可能使 App 崩溃。
通过将这两个选项置为 false 来禁用它们,这样不可见的子元素就会被自动处理和 GC。
4、多变图层与不变图层分离
在日常开发中,会经常遇到页面中大部分元素不变,某个元素实时变化。如Gif,动画。这时我们就需要RepaintBoundary,不过独立图层合成也是有消耗,这块需实测把握。
这会导致页面同一图层重新Paint。此时可以用RepaintBoundary包裹该多变的Gif组件,让其处在单独的图层,待最终再一块图层合成上屏。
5、降级CustomScrollView,ListView等预渲染区域为合理值
默认情况下,CustomScrollView除了渲染屏幕内的内容,还会渲染上下各250区域的组件内容,例如当前屏幕可显示4个组件,实际仍有上下共4个组件在显示状态,如果setState(),则会进行8个组件重绘。实际用户只看到4个,其实应该也只需渲染4个, 且上下滑动也会触发屏幕外的Widget创建销毁,造成滚动卡顿。高性能的手机可预渲染,在低端机降级该区域距离为0或较小值。
四、总结
Flutter为什么会卡顿、帧率低?总的来说均为以下2个原因:
UI线程慢了-->渲染指令出的慢
GPU线程慢了-->光栅化慢、图层合成慢、像素上屏慢
所以我们一般使用flutter布局尽量按照以下原则
Flutter优化基本原则:
尽量不要为 Widget 设置半透明效果,而是考虑用图片的形式代替,这样被遮挡的 Widget 部分区域就不需要绘制了;
控制 build 方法耗时,将 Widget 拆小,避免直接返回一个巨大的 Widget,这样 Widget 会享有更细粒度的重建和复用;
对列表采用懒加载而不是直接一次性创建所有的子 Widget,这样视图的初始化时间就减少了。
五、其他
如果大家对flutter动态化感兴趣,我们也为大家准备了flutter动态化平台-Fair
欢迎大家使用 Fair,也欢迎大家为我们点亮star
Github地址:github.com/wuba/fair
Fair官网:fair.58.com
链接:https://juejin.cn/post/7145730792948252686
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
内存优化之掌握 APP 运行时的内存模型
为了让大家深入掌握 App 运行时的内存模型,这一节的内容按照由外到内、逐步深入的原则,分为了 3 个部分:
内存描述指标
内存数据获取
内存模型详解
话不多说,让我们马上开始这一章学习吧!
内存描述指标
在进行内存优化之前,我们必须要先熟悉常用的内存描述指标。内存描述指标可以用来度量一个 App 的内存情况,也可以在我们做内存优化时,更直观地展示出优化前后的效果。
常用的内存描述指标有 6 个,我们先来简单了解一下。
PSS( Proportional Set Size ):实际使用的物理内存,会按比例分配共享的内存。比如一个应用有两个进程都用到了 Chrome 的 V8 引擎,那么每个进程会承担 50% 的 V8 这个 so 库的内存占用。PSS 是我们使用最频繁的一个指标,App 线上的内存数据统计一般都取这个指标。
RSS( Resident Set Size ):PSS 中的共享库会按比例分担,但是 RSS 不会,它会完全算进当前进程,所以把所有进程的 RSS 加总后得出来的内存会比实际高。按比例计算内存占用会有一定的消耗,因此当想要高性能的获取内存数据时便可以使用 RSS,Android 的 LowMemoryKiller 机制就是根据每个进程的 RSS 来计算进程优先级的。
Private Clean / Private Dirty:当我们执行 dump meminfo 时会看到这个指标,Private 内存是只被当前进程独占的物理内存。独占的意思是即使释放之后也无法被其他进程使用,只有当这个进程销毁后其他进程才能使用。Clean 表示该对应的物理内存已经释放了,Dirty 表示对应的物理内存还在使用。
Swap Pss Dirty:这个指标和上面的 Private 指标刚好相反,Swap 的内存被释放后,其他进程也可以继续使用,所以我们在 meminfo 中只看得到 Swap Pss Dirty,而看不到Swap Pss Clean,因为 Swap Pss Clean 是没有意义的。
Heap Alloc:通过 Malloc、mmap 等函数实际申请的虚拟内存,包括 Naitve 和虚拟机申请的内存。
Heap Free:空闲的虚拟内存。
内存描述指标并不多,上面这几个就完全够用了,而且我相信大家或多或少都接触过,所以这里列出来便于我们后面查阅。
内存数据获取
了解了内存的描述指标,我们再来看看如何获取内存的数据,主要有 2 种方式。
① 线下通过 adb 命令获取,一般用于线下调试:
adb shell
dumpsys meminfo 进程名/pid
② 线上通过代码获取,一般用于收集线上的内存数据:
ActivityManager am = (ActivityManager) context.getSystemService(Context.ACTIVITY_SERVICE);
ActivityManager.MemoryInfo memoryInfo = new ActivityManager.MemoryInfo();
虽然获取方法不同,但这两种方式获取数据的原理完全一样,它们调用的都是 android_os_Debug.cpp 对象中的 android_os_Debug_getDirtyPagesPid 接口,它的源码如下:
static jboolean android_os_Debug_getDirtyPagesPid(JNIEnv *env, jobject clazz,
jint pid, jobject object)
{
bool foundSwapPss;
stats_t stats[_NUM_HEAP];
memset(&stats, 0, sizeof(stats));
//1. 加载maps文件,获取
if (!load_maps(pid, stats, &foundSwapPss)) {
return JNI_FALSE;
}
struct graphics_memory_pss graphics_mem;
//2. 获取graphics区域内存数据
if (read_memtrack_memory(pid, &graphics_mem) == 0) {
stats[HEAP_GRAPHICS].pss = graphics_mem.graphics;
stats[HEAP_GRAPHICS].privateDirty = graphics_mem.graphics;
stats[HEAP_GRAPHICS].rss = graphics_mem.graphics;
stats[HEAP_GL].pss = graphics_mem.gl;
stats[HEAP_GL].privateDirty = graphics_mem.gl;
stats[HEAP_GL].rss = graphics_mem.gl;
stats[HEAP_OTHER_MEMTRACK].pss = graphics_mem.other;
stats[HEAP_OTHER_MEMTRACK].privateDirty = graphics_mem.other;
stats[HEAP_OTHER_MEMTRACK].rss = graphics_mem.other;
}
//3. 获取Unkonw区域数据
for (int i=_NUM_CORE_HEAP; i<_NUM_EXCLUSIVE_HEAP; i++) {
stats[HEAP_UNKNOWN].pss += stats[i].pss;
stats[HEAP_UNKNOWN].swappablePss += stats[i].swappablePss;
stats[HEAP_UNKNOWN].rss += stats[i].rss;
stats[HEAP_UNKNOWN].privateDirty += stats[i].privateDirty;
stats[HEAP_UNKNOWN].sharedDirty += stats[i].sharedDirty;
stats[HEAP_UNKNOWN].privateClean += stats[i].privateClean;
stats[HEAP_UNKNOWN].sharedClean += stats[i].sharedClean;
stats[HEAP_UNKNOWN].swappedOut += stats[i].swappedOut;
stats[HEAP_UNKNOWN].swappedOutPss += stats[i].swappedOutPss;
}
//4. 将获取的数据存放到容器中
……
return JNI_TRUE;
}这段源码比较长,我们一起来梳理下里面的逻辑,主要分为 4 部分。
读取 maps 文件,获取该进程的内存详情:通过上一节的学习,我们知道进程使用的内存都是虚拟内存,并且虚拟内存都以页为维度来管理和维护。这个进程的虚拟内存每一页上存放了什么数据,都会记录在 maps 文件中,maps 文件是一个很重要的文件,后面会详细介绍它。
调用 libmemtrack 接口获取 graphics 内存数据:Graphic 内存分配和使用方式具有特殊性,并没有全部映射到应用进程,需要通过 HAL 层(抽象硬件层)libmemtrack 的接口查询,才能完整得到使用的 graphics 内存数据。
分配 Unknow 区域的内存数据:根据前面的知识我们知道,mmap 除了做内存映射,还可以用来申请虚拟内存,如果在申请内存时是私有且匿名的( fd 如果为 -1,flag 入参为MAP_ANONYMOUS 或 MAP_PRIVATE )就会算入 Unknow 中,如果 mmap 申请内存时指定了申请这段内存的名字,就会算入 Other Dev 当中。因此,对这一区域内存问题的排查往往比较复杂,因为我们不知道内存的来源。
存放获取到的内存数据并返回:最后一部分就是将前面获取到的数据放到对应的数据结构中,并返回给接口调用方。
内存模型详解
我们已经知道如何获取内存数据,但是这些数据从哪儿来呢?毕竟只有知道来源,我们才能从源头进行治理。那接下来,我们就对 App 运行时的内存模型进行一个全面且详细的剖析。
我们以系统设置这个 App 为例子,通过 adb 命令获取的内存数据如下:
这里把上面的数据分为两个部分:A 区域和 B 区域。其中 A 区域的数据主要来自前面提到的 android_os_Debug_getMemInfo 接口,B 区域的数据则是对 A 区域中的数据做了汇总处理。
A区域
前面我们已经了解到,android_os_Debug_getMemInfo 接口的数据有两部分来源,一部分是读取 maps 文件解析到每块内存所属的数据,另一部分是读取 libmemtrack 接口的数据获取到的 graphic 内存数据。这两部分的数据来源就组成了 A 区域中的三块数据。下面我们分别来看看这三块数据。
数据 ①:maps 文件数据
maps 文件是分析内存很重要的一个文件,通过 maps 文件我们可以详细知道这个进程的内存中存放了哪些数据。maps 文件存放在 /proc/{ pid }/maps 路径中,该路径除了存放该进程的 maps 文件,还存放了该进程的所有其他信息的数据。如果你感兴趣可以深入了解一下。
对于 root 的手机,我们可以直接查看该目录下的 maps 文件。但是 maps 文件非常长,直接看会很吃力,所以我们一般会通过脚本对 maps 文件中的数据做分析和归类。下面还是以系统设置这个应用为例,它的 maps 文件的部分内容如下:
图中从左至右各个数据段的解释如下:
| 字段 | address | perms offset | offset | dev | inode | pathname |
|---|---|---|---|---|---|---|
| 数据 | 12c00000-32c00000 | rw-p | 00000000 | 00:00 | 0 | main space (region space)] |
| 含义 | 本段内存映射的虚拟地址空间范围 | 读写权限 | 本段映射地址在文件中的偏移 | 所映射的文件所属设备的设备号 | 文件的索引节点号 | 对有名映射而言,pathname 是映射的文件名;对匿名映射来说,pathname 是此段内存在进程中的作用 |
如果手机没有 root 也没关系,我们可以在运行时通过 native 层的 c++ 代码读取该文件,可以看一下android_os_Debug_getMemInfo 接口中调用的 load_maps 方法,该方法读取 maps 文件后,还做了一个详细的分类操作,分完类之后就是我们看到的数据 ① 中的数据,这个方法比较长,所以我精简了部分代码。
static bool load_maps(int pid, stats_t* stats, bool* foundSwapPss)
{
*foundSwapPss = false;
uint64_t prev_end = 0;
int prev_heap = HEAP_UNKNOWN;
std::string smaps_path = base::StringPrintf("/proc/%d/smaps", pid);
auto vma_scan = [&](const meminfo::Vma& vma) {
int which_heap = HEAP_UNKNOWN;
int sub_heap = HEAP_UNKNOWN;
bool is_swappable = false;
std::string name;
if (base::EndsWith(vma.name, " (deleted)")) {
name = vma.name.substr(0, vma.name.size() - strlen(" (deleted)"));
} else {
name = vma.name;
}
uint32_t namesz = name.size();
// 解析Native Heap 内存
if (base::StartsWith(name, "[heap]")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:libc_malloc]")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:scudo:")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:GWP-ASan")) {
which_heap = HEAP_NATIVE;
}
// 解析 stack 部分内存
else if (base::StartsWith(name, "[stack")) {
which_heap = HEAP_STACK;
} else if (base::StartsWith(name, "[anon:stack_and_tls:")) {
which_heap = HEAP_STACK;
}
// 解析 code 部分的内存
else if (base::EndsWith(name, ".so")) {
which_heap = HEAP_SO;
is_swappable = true;
} else if (base::EndsWith(name, ".jar")) {
which_heap = HEAP_JAR;
is_swappable = true;
} else if (base::EndsWith(name, ".apk")) {
which_heap = HEAP_APK;
is_swappable = true;
} else if (base::EndsWith(name, ".ttf")) {
which_heap = HEAP_TTF;
is_swappable = true;
} else if ((base::EndsWith(name, ".odex")) ||
(namesz > 4 && strstr(name.c_str(), ".dex") != nullptr)) {
which_heap = HEAP_DEX;
sub_heap = HEAP_DEX_APP_DEX;
is_swappable = true;
} else if (base::EndsWith(name, ".vdex")) {
which_heap = HEAP_DEX;
……
} else if (base::EndsWith(name, ".oat")) {
which_heap = HEAP_OAT;
is_swappable = true;
} else if (base::EndsWith(name, ".art") || base::EndsWith(name, ".art]")) {
which_heap = HEAP_ART;
……
} else if (base::StartsWith(name, "/dev/")) {
which_heap = HEAP_UNKNOWN_DEV;
// 解析 gl 区域内存
if (base::StartsWith(name, "/dev/kgsl-3d0")) {
which_heap = HEAP_GL_DEV;
}
// 解析 cursor 区域内存
else if (base::StartsWith(name, "/dev/ashmem/CursorWindow")) {
which_heap = HEAP_CURSOR;
} else if (base::StartsWith(name, "/dev/ashmem/jit-zygote-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_ZYGOTE_CODE_CACHE;
}
//解析ashmen匿名共享内存
else if (base::StartsWith(name, "/dev/ashmem")) {
which_heap = HEAP_ASHMEM;
}
} else if (base::StartsWith(name, "/memfd:jit-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_APP_CODE_CACHE;
} else if (base::StartsWith(name, "/memfd:jit-zygote-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_ZYGOTE_CODE_CACHE;
}
//解析java Heap内存
else if (base::StartsWith(name, "[anon:")) {
which_heap = HEAP_UNKNOWN;
if (base::StartsWith(name, "[anon:")) {
which_heap = HEAP_DALVIK_OTHER;
if (base::StartsWith(name, "[anon:dalvik-LinearAlloc")) {
sub_heap = HEAP_DALVIK_OTHER_LINEARALLOC;
} else if (base::StartsWith(name, "[anon:dalvik-alloc space") ||
base::StartsWith(name, "[anon:dalvik-main space")) {
// This is the regular Dalvik heap.
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_NORMAL;
} else if (base::StartsWith(name,
"[anon:dalvik-large object space") ||
base::StartsWith(
name, "[anon:dalvik-free list large object space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_LARGE;
} else if (base::StartsWith(name, "[anon:dalvik-non moving space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_NON_MOVING;
} else if (base::StartsWith(name, "[anon:dalvik-zygote space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_ZYGOTE;
} else if (base::StartsWith(name, "[anon:dalvik-indirect ref")) {
sub_heap = HEAP_DALVIK_OTHER_INDIRECT_REFERENCE_TABLE;
} else if (base::StartsWith(name, "[anon:dalvik-jit-code-cache") ||
base::StartsWith(name, "[anon:dalvik-data-code-cache")) {
sub_heap = HEAP_DALVIK_OTHER_APP_CODE_CACHE;
} else if (base::StartsWith(name, "[anon:dalvik-CompilerMetadata")) {
sub_heap = HEAP_DALVIK_OTHER_COMPILER_METADATA;
} else {
sub_heap = HEAP_DALVIK_OTHER_ACCOUNTING; // Default to accounting.
}
}
} else if (namesz > 0) {
which_heap = HEAP_UNKNOWN_MAP;
} else if (vma.start == prev_end && prev_heap == HEAP_SO) {
// bss section of a shared library
which_heap = HEAP_SO;
}
prev_end = vma.end;
prev_heap = which_heap;
const meminfo::MemUsage& usage = vma.usage;
if (usage.swap_pss > 0 && *foundSwapPss != true) {
*foundSwapPss = true;
}
uint64_t swapable_pss = 0;
if (is_swappable && (usage.pss > 0)) {
float sharing_proportion = 0.0;
if ((usage.shared_clean > 0) || (usage.shared_dirty > 0)) {
sharing_proportion = (usage.pss - usage.uss) / (usage.shared_clean + usage.shared_dirty);
}
swapable_pss = (sharing_proportion * usage.shared_clean) + usage.private_clean;
}
// 将获取的数据进行累加
……
};
//for循环函数,执行maps文件的读取
return meminfo::ForEachVmaFromFile(smaps_path, vma_scan);
}通过上面对 maps 的解析函数,我们不仅可以看到 maps 中的数据类型及格式,也可以知道 Dalvik Heap,Native Heap 等数据的组成。在做内存的线上异常监控时,异常情况下,也可以将 maps 文件上传到服务端,服务端对 maps 文件进行解析和分类,这样我们就能非常方便的定位和排查线上内存问题。
数据②:graphic 相关数据
了解了 maps 文件中的内存数据,我们再来看看 graphic 的数据,graphic 的数据有 3 部分。
Gfx dev:绘制时分配,并且已经映射到应用进程虚拟内存中。这里需要注意的是,只有高通的芯片才会将这一块的内存放在 /dev/kgsl-3d0 路径,并映射到进程的虚拟内存中,其他的芯片不会放在这个路径。在上面的 load_maps 方法中,我们也可以看到对这一块内存数据的解析逻辑。
GL mtrack:绘制时分配,没有映射到应用地址空间,包括纹理、顶点数据、shader program 等。
EGL mtrack:应用的 Layer Surface,通过 gralloc 分配,没有映射到应用地址空间。不熟悉 Layer Surface 的话,可以将一个界面理解成一个 Layer Surface,Surface 存储了界面的数据,并交给 GPU 绘制。
上面 1 的数据是通过 load_maps 函数解析获取的,2 和 3 的数据是通过 read_memtrack_memory 函数获取的。该函数会读取和解析路径为 /d/kgsl/proc/{ pid }/mem 的文件,这个文件节点中的数据是gpu driver写入的,该方法的实现可以参考下面高通855源码中的 kgsl_memtrack_get_memory 函数,下面是这个函数的主体逻辑代码。(官方源码:kgsl.c)
int kgsl_memtrack_get_memory(pid_t pid, enum memtrack_type type,
struct memtrack_record *records,
size_t *num_records)
{
……
// 1. 设置目标文件路径
snprintf(tmp, sizeof(tmp), "/d/kgsl/proc/%d/mem", pid);
……
while (1) {
// 2. 读取并解析该文件
……
}
……
return 0;
}我们也可以在 root 手机中,查看 kgsl_memtrack_get_memory 函数读取到该应用进程的数据,下面是系统设置这个应用的部分 graphic 数据。
/d/kgsl/proc/3160 # cat mem
gpuaddr useraddr size id flags type usage sglen mapcount eglsrf eglimg
0000000000000000 0 196608 1 --w---N-- gpumem any(0) 0 0 0 0
0000000000000000 0 16384 2 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 3 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 4 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 5 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 6 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 7 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 20480 8 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 9 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 10 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 196608 11 --w---N-- gpumem any(0) 0 0 0 0
0000000000000000 0 16384 12 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 13 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 14 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 15 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 16 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 17 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 32768 18 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 19 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 20 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 65536 21 --w--pY-- gpumem arraybuffer 0 1 0 0
0000000000000000 0 131072 22 --wl-pY-- gpumem command 0 1 0 0
0000000000000000 0 32768 23 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 131072 24 --wl-pY-- gpumem gl 0 1 0 0
0000000000000000 0 8192 25 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 8192 26 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 16384 27 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 9469952 28 --wL--N-- ion egl_surface 152 0 1 1
0000000000000000 0 131072 29 --wl-pY-- gpumem command 0 1 0 0
0000000000000000 0 8192 30 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 31 -----pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 32 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 33 -----pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 34 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 35 -----pY-- gpumem gl 0 1 0 0
……数据③:Alloc 内存
在内存描述指标这一部分,我们已经知道数据 ③ 中的数据是调用 malloc、mmap、calloc 等内存申请函数时积累的数据,想要获取这个数据,可以通过下面的接口实现。
- 获取 Java 层申请的内存:会直接去 Art 虚拟机中获取虚拟机已经申请的内存大小。
Runtime runtime = Runtime.getRuntime();
//获取已经申请的Java内存 long usedMemory=runtime.totalMemory() ;
//获取申请但未使用Java内存 long freeMemory = runtime.freeMemory();- 获取 Native 申请的内存:会调用 android_os_Debug.cpp 对象中的android_os_Debug_getNativeHeapSize 接口获取数据,该接口又是调用的 mallinfo 函数,mallinfo 函数会返回 native 层已经申请的内存大小。
//获取已经申请的Native内存
long nativeHeapSize = Debug.getNativeHeapSize()
//获取申请但未使用Native内存
long nativeHeapFreeSize = Debug.getNativeHeapFreeSize()
//Naitve层
static jlong android_os_Debug_getNativeHeapSize(JNIEnv *env, jobject clazz)
{
struct mallinfo info = mallinfo();
return (jlong) info.usmblks;
}我们可以看下 mallinfo 函数的说明文档:
通过上面两个接口获取 Naitve 和 Java 的内存数据效率最高,性能消耗最小,所以适合在代码中做数据监控使用。通过读取和解析 maps 文件来获取内存数据对性能的开销较大,所以从 Android10 开始加了 5 分钟的频控。
B区域
B 区域的数据就是将 A 区域中的 ① 数据做了汇总操作,方便我们查看,并没有太特别的内容,这里就简单列一下了。
Java Heap:(Dalvik Heap 的 Private Dirty 数据) + ( .art mmap 部分的 Private Dirty 和 Private Clean 数据) + getOtherPrivate ( OTHER_ART ) 。这里的 .art 是应用的 dex 文件预编译后的 art 文件,所以也是属于该应用的 JavaHeap。
Native Heap:Native Heap 的 Private Dirty 数据。
Code:.so .jar .apk .ttf .dex .oat 等资源加总。
Stack:getOtherPrivateDirty ( OTHER_STACK )。
Graphics:gl,gfx,egl 的数据加总。
System:( Total Pss ) - ( Private Dirty 和 Private Clean 的总和)。主要是系统占用的内存,如共享的字体、图像资源等。
小结
想要深入掌握 App 运行时的内存模型,夯实内存优化的基础,首先我们要熟悉描述内存的指标,它们是度量我们内存优化效果的重要工具。
常用的指标有 6 个,分别是共享库按比例分担的 Pss;进程在 RAM 中实际保存的总内存 RSS;只被当前进程独占的物理内存 Private Clean / Private Dirty;和 Private 相反的 Swap Pss Dirty;以及 Heap Alloc 和空闲的虚拟内存 Heap Free。获取这些指标的方法有两个,线下可以通过 adb 命令获取,线上可以通过代码获取。
其次,我们需要从原理上深入了解内存的组成,以及这些组成的来源,这样我们才能在内存优化中,做到有的放矢。我们重点掌握 3 类数据:maps 文件数据、graphic 相关数据和 Alloc 内存。
这一章节的内容虽然属于基础知识,但掌握它们可以在后面的实战章节中,帮助我们更容易理解和上手。
链接:https://juejin.cn/post/7175438290324029498
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
算法| Java的int类型最大值为什么是21亿多?
开篇
本文主要介绍在Java中,为什么int类型的最大值为2147483647。
理论值
我们都知道在Java中,int 的长度为32位。
理论上,用二进制表示,32位每一位都是1的话,那么这个数是多少呢?
我们来计算一下,第0位可以用2表示,第1位可以用2表示,第31位可以用231表示,那么32位二进制能够表示的最大值为232 - 1,所以理论上32位数值的取值范围为0 ~ 232 - 1。
那么,Java的int最大值真的为232 - 1吗?
我们知道,232 - 1这个值为42亿多。而在Java中,int的最大值为2147483647也就是21亿多,为什么有这个差距呢?
分析
我们来看下,Java中int的最大值以及这个最大值的二进制数据。
可以看到,int的最大值的最高位为0,而不是1,也就是用31位来表示能够取到的最大值,而不是32位。
因为在Java中,整型是有符号整型,最高位是有特殊含义,代表符号,真正表示数据值的范围为0 ~ 30位。
所以,按照31位来表示的话,其最大值为231 - 1,而这个值就是2147483647即21亿多。
int数据有正负之分,所以最高位用来表示符号,0代表正数,1代表负数。因此Java中,int的数据范围为 -231 ~ 231 - 1。
为啥减1
那为什么都是231, 正数的时候需要减1呢?
我们先来看一下,int的最大值和最小值:
不看符号位的话,最大值比最小值少了1个,这是因为0归到正数里面,所以占用了正数的一个位置。
拓展
负数表示
负数的二进制形式如何表示呢?
先看-100这个数的二进制形式:
最高位为1,就代表负数。值就为符号位后面的值取反再加上1。
二进制1100100对应的10进制就是100.
反码
反码就是,对一个数的二进制除符号位外,按位取反。取反就是二进制数,1变成0,0变成1,这个过程就是取反。
来看一个例子:
可以看到,a、b两个数的二进制是完全相反的。
为什么要取反加1呢?为什么要设计的这么扭曲?到底是人性的扭曲还是道德的沦丧? 这样设计有什么好处?
在计算机系统里,加减乘除的运算,并不是我们想象中10进制的加减乘除,他最后都会被翻译成2进制的位运算来计算。
假如有2个数,a、b都是整数,那么a + b 对应的二进制就是简单的相加。那么如果a为负数,b为正数呢?在执行a + b 的时候,难道还需要特殊处理一下吗?显然是不可能的,在二进制运算中,加减乘除运算只有各自的一套逻辑,无论符号两边的数是什么样子的。
a为负数,那么对a进行取反加1,再与b进行相加,可以按正常的相加逻辑,这样运算结果依然是正确的,而不是说,当a为负数时,计算机去执行另一套的相加逻辑。设计成取反加1,可以让相加运算不去关注两边的数据是正是负,只执行一套相加逻辑就可以了,这对计算机来说是一个性能的提升。
示例
从上面我们得知,负数的二进制表示为数值部分取反加1,以-100为例,那么可以得出-100 等于 ~100 + 1。
知道负数的二进制的样子后,再看int最小值和-1的二进制数据,就不会惊讶了。要不然,当看到int的最小值的二进制居然是一堆0组成,而-1居然是一堆1,看到这样的数据,心里岂不是冒出一堆问号或者一群小羊飘过。
取反加1还是自己的数
有没有一个数,取反加1还是自己?有,0和int的最小值,下面来看下:
先看下Integer.MIN_VALUE的取反加1的过程,可以看到,Integer.MIN_VALUE在取反后加上1,仍然还是他自己。
再看下0的取反加1过程,可以看到0再取反加1后,我嘞个去,居然溢出了!溢出怎么办?溢出就扔了吧不要了,结果还是他自己。
后记
本文主要介绍在Java中,为什么int类型的最大值为什么是21亿多,以及涉及到的知识点的拓展,如有错误欢迎之处。
链接:https://juejin.cn/post/7179455685455773753
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
让人恶心的多线程代码,性能怎么优化!
Java 中最烦人的,就是多线程,一不小心,代码写的比单线程还慢,这就让人非常尴尬。
通常情况下,我们会使用 ThreadLocal 实现线程封闭,比如避免 SimpleDateFormat 在并发环境下所引起的一些不一致情况。其实还有一种解决方式。通过对parse方法进行加锁,也能保证日期处理类的正确运行,代码如图。
1. 锁很坏
但是,锁这个东西,很坏。就像你的贞操锁,一开一闭热情早已烟消云散。
所以,锁对性能的影响,是非常大的。对资源加锁以后,资源就被加锁的线程所独占,其他的线程就只能排队等待这个锁。此时,程序由并行执行,变相的变成了顺序执行,执行速度自然就降低了。
下面是开启了50个线程,使用ThreadLocal和同步锁方式性能的一个对比。
Benchmark Mode Cnt Score Error Units
SynchronizedNormalBenchmark.sync thrpt 10 2554.628 ± 5098.059 ops/ms
SynchronizedNormalBenchmark.threadLocal thrpt 10 3750.902 ± 103.528 ops/ms
========去掉业务影响========
Benchmark Mode Cnt Score Error Units
SynchronizedNormalBenchmark.sync thrpt 10 26905.514 ± 1688.600 ops/ms
SynchronizedNormalBenchmark.threadLocal thrpt 10 7041876.244 ± 355598.686 ops/ms
可以看到,使用同步锁的方式,性能是比较低的。如果去掉业务本身逻辑的影响(删掉执行逻辑),这个差异会更大。代码执行的次数越多,锁的累加影响越大,对锁本身的速度优化,是非常重要的。
我们都知道,Java 中有两种加锁的方式,一种就是常见的synchronized 关键字,另外一种,就是使用 concurrent 包里面的 Lock。针对于这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。
2. synchronied原理
synchronized关键字给代码或者方法上锁时,都有显示的或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。
给普通方法加锁时,上锁的对象是
this
给静态方法加锁时,锁的是class对象。
给代码块加锁,可以指定一个具体的对象作为锁
monitor,在操作系统里,其实就叫做管程。
那么,synchronized 在字节码中,是怎么体现的呢?参照下面的代码,在命令行执行javac,然后再执行javap -v -p,就可以看到它具体的字节码。可以看到,在字节码的体现上,它只给方法加了一个flag:ACC_SYNCHRONIZED。
synchronized void syncMethod() {
System.out.println("syncMethod");
}
======字节码=====
synchronized void syncMethod();
descriptor: ()V
flags: ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #4
3: ldc #5
5: invokevirtual #6
8: return
我们再来看下同步代码块的字节码。可以看到,字节码是通过monitorenter和monitorexit两个指令进行控制的。
void syncBlock(){
synchronized (Test.class){
}
}
======字节码======
void syncBlock();
descriptor: ()V
flags:
Code:
stack=2, locals=3, args_size=1
0: ldc #2
2: dup
3: astore_1
4: monitorenter
5: aload_1
6: monitorexit
7: goto 15
10: astore_2
11: aload_1
12: monitorexit
13: aload_2
14: athrow
15: return
Exception table:
from to target type
5 7 10 any
10 13 10 any
这两者虽然显示效果不同,但他们都是通过monitor来实现同步的。我们可以通过下面这张图,来看一下monitor的原理。
注意了,下面是面试题目高发地。
如图所示,我们可以把运行时的对象锁抽象的分成三部分。其中,EntrySet 和WaitSet 是两个队列,中间虚线部分是当前持有锁的线程。我们可以想象一下线程的执行过程。
当第一个线程到来时,发现并没有线程持有对象锁,它会直接成为活动线程,进入 RUNNING 状态。
接着又来了三个线程,要争抢对象锁。此时,这三个线程发现锁已经被占用了,就先进入 EntrySet 缓存起来,进入 BLOCKED 状态。此时,从jstack命令,可以看到他们展示的信息都是waiting for monitor entry。
"http-nio-8084-exec-120" #143 daemon prio=5 os_prio=31 cpu=122.86ms elapsed=317.88s tid=0x00007fedd8381000 nid=0x1af03 waiting for monitor entry [0x00007000150e1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.io.BufferedInputStream.read(java.base@13.0.1/BufferedInputStream.java:263)
- waiting to lock <0x0000000782e1b590> (a java.io.BufferedInputStream)
at org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
at org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
at org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
at org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
at org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)处于活动状态的线程,执行完毕退出了;或者由于某种原因执行了wait 方法,释放了对象锁,就会进入 WaitSet 队列。这就是在调用wait之前,需要先获得对象锁的原因。就像下面的代码:
synchronized (lock){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}此时,jstack显示的线程状态是 WAITING 状态,而原因是in Object.wait()。
"wait-demo" #12 prio=5 os_prio=31 cpu=0.14ms elapsed=12.58s tid=0x00007fb66609e000 nid=0x6103 in Object.wait() [0x000070000f2bd000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(java.base@13.0.1/Native Method)
- waiting on <0x0000000787b48300> (a java.lang.Object)
at java.lang.Object.wait(java.base@13.0.1/Object.java:326)
at WaitDemo.lambda$main$0(WaitDemo.java:7)
- locked <0x0000000787b48300> (a java.lang.Object)
at WaitDemo$$Lambda$14/0x0000000800b44840.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)
发生了这两种情况,都会造成对象锁的释放。进而导致 EntrySet里的线程重新争抢对象锁,成功抢到锁的线程成为活动线程,这是一个循环的过程。
那 WaitSet 中的线程是如何再次被激活的呢?接下来,在某个地方,执行了锁的 notify 或者 notifyAll 命令,会造成WaitSet中 的线程,转移到 EntrySet 中,重新进行锁的争夺。
如此周而复始,线程就可按顺序排队执行。
3. 分级锁
JDK1.8中,synchronized 的速度已经有了显著的提升。那它都做了哪些优化呢?答案就是分级锁。JVM会根据使用情况,对synchronized 的锁,进行升级,它大体可以按照下面的路径:偏向锁->轻量级锁->重量级锁。
锁只能升级,不能降级,所以一旦升级为重量级锁,就只能依靠操作系统进行调度。
和锁升级关系最大的就是对象头里的 MarkWord,它包含Thread ID、Age、Biased、Tag四个部分。其中,Biased 有1bit大小,Tag 有2bit,锁升级就是靠判断Thread Id、Biased、Tag等三个变量值来进行的。
偏向锁
在只有一个线程使用了锁的情况下,偏向锁能够保证更高的效率。
具体过程是这样的。当第一个线程第一次访问同步块时,会先检测对象头Mark Word中的标志位Tag是否为01,以此判断此时对象锁是否处于无锁状态或者偏向锁状态(匿名偏向锁)。
01也是锁默认的状态,线程一旦获取了这把锁,就会把自己的线程ID写到MarkWord中。在其他线程来获取这把锁之前,锁都处于偏向锁状态。
轻量级锁
当下一个线程参与到偏向锁竞争时,会先判断 MarkWord 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。
轻量级锁的获取是怎么进行的呢?它们使用的是自旋方式。
参与竞争的每个线程,会在自己的线程栈中生成一个 LockRecord ( LR ),然后每个线程通过 CAS (自旋)的方式,将锁对象头中的 MarkWord 设置为指向自己的 LR 的指针,哪个线程设置成功,就意味着哪个线程获得锁。
当锁处于轻量级锁的状态时,就不能够再通过简单的对比Tag的值进行判断,每次对锁的获取,都需要通过自旋。
当然,自旋也是面向不存在锁竞争的场景,比如一个线程运行完了,另外一个线程去获取这把锁。但如果自旋失败达到一定的次数,锁就会膨胀为重量级锁。
重量级锁
重量级锁即为我们对synchronized的直观认识,这种情况下,线程会挂起,进入到操作系统内核态,等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,重量级锁的名称由此而来。
如果系统的共享变量竞争非常激烈,锁会迅速膨胀到重量级锁,这些优化就名存实亡。如果并发非常严重,可以通过参数-XX:-UseBiasedLocking禁用偏向锁,理论上会有一些性能提升,但实际上并不确定。
4. Lock
在 concurrent 包里,我们能够发现ReentrantLock和ReentrantReadWriteLock两个类。Reentrant就是可重入的意思,它们和synchronized关键字一样,都是可重入锁。
这里有必要解释一下可重入这个概念,因为在面试的时候经常被问到。它的意思是,一个线程运行时,可以多次获取同一个对象锁。这是因为Java的锁是基于线程的,而不是基于调用的。比如下面这段代码,由于方法a、b、c锁的都是当前的this,线程在调用a方法的时候,就不需要多次获取对象锁。
public synchronized void a(){
b();
}
public synchronized void b(){
c();
}
public synchronized void c(){
}主要方法
LOCK是基于AQS(AbstractQueuedSynchronizer)实现的,而AQS 是基于 volitale 和 CAS 实现的。关于CAS,我们将在下一课时讲解。
Lock与synchronized的使用方法不同,它需要手动加锁,然后在finally中解锁。Lock接口比synchronized灵活性要高,我们来看一下几个关键方法。
lock: lock方法和synchronized没什么区别,如果获取不到锁,都会被阻塞
tryLock: 此方法会尝试获取锁,不管能不能获取到锁,都会立即返回,不会阻塞。它是有返回值的,获取到锁就会返回true
tryLock(long time, TimeUnit unit): 与tryLock类似,但它在拿不到锁的情况下,会等待一段时间,直到超时
lockInterruptibly: 与lock类似,但是可以锁等待可以被中断,中断后返回InterruptedException
一般情况下,使用lock方法就可以。但如果业务请求要求响应及时,那使用带超时时间的tryLock是更好的选择:我们的业务可以直接返回失败,而不用进行阻塞等待。tryLock这种优化手段,采用降低请求成功率的方式,来保证服务的可用性,高并发场景下经常被使用。
读写锁
但对于有些业务来说,使用Lock这种粗粒度的锁还是太慢了。比如,对于一个HashMap来说,某个业务是读多写少的场景,这个时候,如果给读操作也加上和写操作一样的锁的话,效率就会很慢。
ReentrantReadWriteLock是一种读写分离的锁,它允许多个读线程同时进行,但读和写、写和写是互斥的。使用方法如下所示,分别获取读写锁,对写操作加写锁,对读操作加读锁,并在finally里释放锁即可。
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
Lock readLock = lock.readLock();
Lock writeLock = lock.writeLock();
public void put(K k, V v) {
writeLock.lock();
try {
map.put(k, v);
} finally {
writeLock.unlock();
}
}
...那么,除了ReadWriteLock,我们能有更快的读写分离模式么?JDK1.8加入了哪个API?欢迎留言区评论。
公平锁与非公平锁
我们平常用到的锁,都是非公平锁。可以回过头来看一下monitor的原理。当持有锁的线程释放锁的时候,EntrySet里的线程就会争抢这把锁。这个争抢的过程,是随机的,也就是说你并不知道哪个线程会获取对象锁,谁抢到了就算谁的。
这就有一定的概率,某个线程总是抢不到锁,比如,线程通过setPriority 设置的比较低的优先级。这个抢不到锁的线程,就一直处于饥饿状态,这就是线程饥饿的概念。
公平锁通过把随机变成有序,可以解决这个问题。synchronized没有这个功能,在Lock中可以通过构造参数设置成公平锁,代码如下。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
由于所有的线程都需要排队,需要在多核的场景下维护一个同步队列,在多个线程争抢锁的时候,吞吐量就很低。下面是20个并发之下锁的JMH测试结果,可以看到,非公平锁比公平锁性能高出两个数量级。
Benchmark Mode Cnt Score Error Units
FairVSNoFairBenchmark.fair thrpt 10 186.144 ± 27.462 ops/ms
FairVSNoFairBenchmark.nofair thrpt 10 35195.649 ± 6503.375 ops/ms5. 锁的优化技巧
死锁
我们可以先看一下锁冲突最严重的一种情况:死锁。下面这段示例代码,两个线程分别持有了对方所需要的锁,进入了相互等待的状态,就进入了死锁。面试中手写这段代码的频率,还是挺高的。
public class DeadLockDemo {
public static void main(String[] args) {
Object object1 = new Object();
Object object2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (object1) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (object2) {
}
}
}, "deadlock-demo-1");
t1.start();
Thread t2 = new Thread(() -> {
synchronized (object2) {
synchronized (object1) {
}
}
}, "deadlock-demo-2");
t2.start();
}
}
使用我们上面提到的,带超时时间的tryLock方法,有一方让步,可以一定程度上避免死锁。
优化技巧
锁的优化理论其实很简单,那就是减少锁的冲突。无论是锁的读写分离,还是分段锁,本质上都是为了避免多个线程同时获取同一把锁。我们可以总结一下优化的一般思路:减少锁的粒度、减少锁持有的时间、锁分级、锁分离 、锁消除、乐观锁、无锁等。
减少锁粒度
通过减小锁的粒度,可以将冲突分散,减少冲突的可能,从而提高并发量。简单来说,就是把资源进行抽象,针对每类资源使用单独的锁进行保护。比如下面的代码,由于list1和list2属于两类资源,就没必要使用同一个对象锁进行处理。
public class LockLessDemo {
List<String> list1 = new ArrayList<>();
List<String> list2 = new ArrayList<>();
public synchronized void addList1(String v){
this.list1.add(v);
}
public synchronized void addList2(String v){
this.list2.add(v);
}
}
可以创建两个不同的锁,改善情况如下:
public class LockLessDemo {
List<String> list1 = new ArrayList<>();
List<String> list2 = new ArrayList<>();
final Object lock1 = new Object();
final Object lock2 = new Object();
public void addList1(String v) {
synchronized (lock1) {
this.list1.add(v);
}
}
public void addList2(String v) {
synchronized (lock2) {
this.list2.add(v);
}
}
}减少锁持有时间通过让锁资源尽快的释放,减少锁持有的时间,其他线程可更迅速的获取锁资源,进行其他业务的处理。考虑到下面的代码,由于slowMethod不在锁的范围内,占用的时间又比较长,可以把它移动到synchronized代码快外面,加速锁的释放。
public class LockTimeDemo {
List<String> list = new ArrayList<>();
final Object lock = new Object();
public void addList(String v) {
synchronized (lock) {
slowMethod();
this.list.add(v);
}
}
public void slowMethod(){
}
}
锁分级锁分级指的是我们文章开始讲解的synchronied锁的锁升级,属于JVM的内部优化。它从偏向锁开始,逐渐会升级为轻量级锁、重量级锁,这个过程是不可逆的。
锁分离我们在上面提到的读写锁,就是锁分离技术。这是因为,读操作一般是不会对资源产生影响的,可以并发执行。写操作和其他操作是互斥的,只能排队执行。所以读写锁适合读多写少的场景。
锁消除通过JIT编译器,JVM可以消除某些对象的加锁操作。举个例子,大家都知道StringBuffer和StringBuilder都是做字符串拼接的,而且前者是线程安全的。
但其实,如果这两个字符串拼接对象用在函数内,JVM通过逃逸分析分析这个对象的作用范围就是在本函数中,就会把锁的影响给消除掉。比如下面这段代码,它和StringBuilder的效果是一样的。
String m1(){
StringBuffer sb = new StringBuffer();
sb.append("");
return sb.toString();
}End
Java中有两种加锁方式,一种是使用synchronized关键字,另外一种是concurrent包下面的Lock。本课时,我们详细的了解了它们的一些特性,包括实现原理。下面对比如下:
| 类别 | Synchronized | Lock |
|---|---|---|
| 实现方式 | monitor | AQS |
| 底层细节 | JVM优化 | Java API |
| 分级锁 | 是 | 否 |
| 功能特性 | 单一 | 丰富 |
| 锁分离 | 无 | 读写锁 |
| 锁超时 | 无 | 带超时时间的tryLock |
| 可中断 | 否 | lockInterruptibly |
Lock的功能是比synchronized多的,能够对线程行为进行更细粒度的控制。但如果只是用最简单的锁互斥功能,建议直接使用synchronized。有两个原因:
synchronized的编程模型更加简单,更易于使用
synchronized引入了偏向锁,轻量级锁等功能,能够从JVM层进行优化,同时,JIT编译器也会对它执行一些锁消除动作
多线程代码好写,但bug难找,希望你的代码即干净又强壮,兼高性能与高可靠于一身。
链接:https://juejin.cn/post/7178679092970012731
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
App实现JSBridge的最佳方案
前沿
写这篇文章的主要目的是对 App 的 JSBridge 做一个全面的介绍,同时根据不同的使用场景总结出一份 App 实现 JSBridge 的最佳方案。对于没有接触过 App 的同学能够对 JSBridge 有个大致的概念,对于做过 App 的 JSBridge 开发的同学也能有更系统的认识,也是自己对于相关知识点的归纳总结。
一、概念
什么是 JSBridge ?
JSBridge 的全称:JavaScript Bridge,中文名 JS桥 或 JS桥接器。
JSBridge 是一种用于在 Android 和 iOS 应用与 H5 之间进行通信的技术。它允许应用开发者在原生代码中调用 JavaScript 函数,以及 在JavaScript 中调用原生代码函数。其通常用于移动应用开发中,可以使用 JSBridge 技术在原生应用中嵌入网页,并在网页与原生应用之间进行交互。
二、原理
JSBridge 通过在 WebView 中注册 JavaScript 函数来实现通信。WebView 是一种在应用中嵌入网页的组件,可以在应用中显示网页内容。JSBridge 通过在 WebView 中注册 JavaScript 函数,并在原生代码中调用这些函数来实现通信。
例如,下面是一个使用 JSBridge 实现通信的示例代码:
/* Android 端实现 */
// 在WebView中注册JavaScript函数
webView.loadUrl("javascript:function myFunction() { /* JavaScript code here */ }");
// 在原生代码中调用JavaScript函数
webView.loadUrl("javascript:myFunction()");
/* iOS 端实现 */
// 在WebView中注册JavaScript函数
[self.webView stringByEvaluatingJavaScriptFromString:@"function myFunction() { /* JavaScript code here */ }"];
// 在原生代码中调用JavaScript函数
[self.webView stringByEvaluatingJavaScriptFromString:@"myFunction()"];
上面的代码通过在 WebView 中注册 JavaScript 函数 myFunction,并在原生代码中调用这个函数来实现通信。
在实际开发中,我们一般是创建一个 JSBridge 对象,然后通过 WebView 的 addJavascriptInterface 方法进行注册。
// WebView 的 addJavascriptInterface 方法源码
public void addJavascriptInterface(Object object, String name) {
checkThread();
if (object == null) {
throw new NullPointerException("Cannot add a null object");
}
if (name == null || name.length() == 0) {
throw new IllegalArgumentException("Invalid name");
}
mJavascriptInterfaces.put(name, object);
}该方法首先检查当前线程是否是 UI 线程,以确保添加桥接对象的操作是在 UI 线程中进行的。接着,该方法会检查桥接对象和名称的有效性,确保它们都不为空。最后,该方法会把桥接对象与名称关联起来,并存储到 WebView 的 mJavascriptInterfaces 对象中。
当网页加载完成后,WebView 会把桥接对象的方法注入到网页中,使得网页能够调用这些方法。当网页中的 JavaScript 代码调用桥接对象的方法时,WebView 会把该方法调用映射到原生代码中,从而实现网页与原生应用之间的交互。
addJavascriptInterface 方法的主要作用是把桥接对象的方法注入到网页中,使得网页能够调用这些方法。它的具体实现方式可能会因平台而异,但是它的基本原理是一致的。
三、原生实现
以 H5 获取 App 的版本号为例。Android相关源码
要实现一个获取 App 版本号的 JSBridge,需要在 H5 中编写 JavaScript 代码,并在 Android 原生代码中实现对应的原生方法。
首先,需要在 H5 中编写 JavaScript 代码,用于调用 Android 的原生方法。例如,可以在 H5 中定义一个函数,用于调用 Android 的原生方法:
// assets/index.html
function getAppVersion() {
// 通过JSBridge调用Android的原生方法
JSBridge.getAppVersion(function(version) {
// 在这里处理获取到的Android版本号
});
}然后,需要在 Android 的原生代码中实现对应的原生方法。例如,可以实现一个名为 getAppVersion 的方法,用于在 H5 中调用:
// com.fitem.webviewdemo.AppJSBridge
@JavascriptInterface
public String getAppVersion() {
// 获取App版本号
String version = BuildConfig.VERSION_NAME;
// 将App版本号返回给H5
return version;
}最后通过 Webview 注入定义的 JavascriptInterface 方法的对象,在 H5 生成 window.jsBridge 对象进行调用。
// com.fitem.webviewdemo.MainActivity.kt
webView.addJavascriptInterface(jsBridge, "jsBridge")iOS 的实现和 Android 类似:
- (void)getIOSVersion:(WVJBResponseCallback)callback {
// 获取App版本号
let version = Bundle.main.object(forInfoDictionaryKey:
"CFBundleShortVersionString") as! String
// 将App版本号返回给H5
callback(version);
}
// 在网页加载完成后设置JSBridge
- (void)webViewDidFinishLoad:(UIWebView *)webView {
// 设置JSBridge
[WebViewJavascriptBridge enableLogging];
self.bridge = [WebViewJavascriptBridge bridgeForWebView:webView];
[self.bridge setWebViewDelegate:self];
}
四、跨平台(Flutter)
1. JSBridge 实现
Flutter 实现 JSBridge 功能的插件有很多,但基本上大多数都是基于原生的 JSBridge 能力实现。这里主要介绍官方的 webview_flutter 插件。
webview_flutter 插件实现 App 与 H5 之前的通信分为:App 发送消息到 H5 和 H5 发送消息到 APP 两部分。
H5 发送消息到 APP。首先在 Flutter 应用中添加 WebView 组件,并设置 JavascriptChannel:
WebView(
initialUrl: 'https://www.example.com',
javascriptMode: JavascriptMode.unrestricted,
javascriptChannels: {
// 设置JavascriptChannel
JavascriptChannel(
name: 'JSBridge',
onMessageReceived: (JavascriptMessage message) {
// 在这里处理来自H5的消息
},
),
},
),在H5中,可以通过 JSBridge 对象来调用原生方法:
// 通过JSBridge调用原生方法
window.jsBridge.postMessage('Hello, world!');App 发送消息到 H5。 在 Flutter 中,通过 WebViewController 的 runJavascrip 调用 H5 中 window 对象的方法
controller.runJavascript("receiveMessage(${json.encode(res)})")在 H5 中,可以通过 onmessage 事件来接收来自原生的消息:
// 接收来自原生的消息
window.receiveMessage = function receiveMessage(message) {
console.log(message);
};2. 局限性
webview_flutter 最大的局限在于 App 端与 H5 端之间的通信只支持单向通信,无法通过一次调用直接获取另一端的返回值。
五、App 实现 JSBridge 的最佳方案
1. 实现目标
H5 兼容原生老版本 JSBridge。
支持两端双向通信。针对
webview_flutter的单向通信的局限性进行改造优化,使其能支持返回值的回调。
2. NativeBridge 插件开发
NativeBridge 本质上是对 webview_flutter 的单向通信能力进行扩展和封装。
NativeBridge 插件的使用和实现原理,请阅读之前的文章《Flutter插件之NativeBridge》和《NativeBridge实现原理解析》。
3. 实现效果
- H5 支持原生老版本 JSBridge 兼容。
// 获取app版本号 返回String
async getVersionCode() {
// 是否是新的JSBridge
if (this.isNewJSBridge()) {
return await window.jsBridgeHelper.sendMessage('getVersionCode', null)
} else {
return window.iLotJsBridge.getVersionCode()
}
}- 支持两端双向通信。
// H5 获取 App 的值
const versionNo = await jsBridge.getVersionCode()
// App 获取 H5 的值
var isHome = await NativeBridgeHelper.sendMessage("isHome", null, webViewController).future ?? false;- 新增超时连接机制
就像网络请求一样,我们不能让代码执行一直阻塞在获取返回值的位置上。因为单向发送消息是不可靠的,可能存在消息丢失,或者另一端不响应消息的情况。因此我们需要类似网络请求一样,增加超时回调机制。
// 增加回调异常容错机制,避免消息丢失导致一直阻塞
Future.delayed(const Duration(milliseconds: 100), (){
var completer = _popCallback(callbackId);
completer?.complete(Future.value(null));
});总结
我们首先介绍了 JSBridge 的概念和原理,然后通过在 Android 、iOS 和 Flutter 中实现 JSBridge 来理解原生和 Flutter 之前的差异,最后总结了在 App 中实现 JSBridge 的最佳方案,方案包括支持原生和 Flutter 的兼容,并优化 webview_flutter 只支持单向通信的局限性和增加超时回调机制。
链接:https://juejin.cn/post/7177407635317063735
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Glide 原理探索
implementation 'com.github.bumptech.glide:glide:4.12.0'
annotationProcessor 'com.github.bumptech.glide:compiler:4.12.0'
Glide.with(this).load(url).into(imageView)
上面这行代码,是 Glide 最简单的使用方式了,下面我们来一个个拆解下。
with
with 就是根据传入的 context 来获取图片请求管理器 RequestManager,用来启动和管理图片请求。
public static RequestManager with(@NonNull FragmentActivity activity) {
return getRetriever(activity).get(activity);
}context 可以传入 Application,Activity 和 Fragment,这关系着图片请求的生命周期。通常使用当前页面的 context,这样当我们打开一个页面加载图片,然后退出页面时,图片请求会跟随页面的销毁而被取消,而不是继续加载浪费资源。
当 context 是 Application 时,获得的 RequestManager 是一个全局单例,图片请求的生命周期会跟随整个 APP 。
如果 with 发生在子线程,不管 context 是谁,都返回应用级别的 RequestManager 单例。
private RequestManager getApplicationManager(@NonNull Context context) {
// Either an application context or we're on a background thread.
if (applicationManager == null) {
synchronized (this) {
if (applicationManager == null) {
// Normally pause/resume is taken care of by the fragment we add to the fragment or
// activity. However, in this case since the manager attached to the application will not
// receive lifecycle events, we must force the manager to start resumed using
// ApplicationLifecycle.
// TODO(b/27524013): Factor out this Glide.get() call.
Glide glide = Glide.get(context.getApplicationContext());
applicationManager =
factory.build(
glide,
new ApplicationLifecycle(),
new EmptyRequestManagerTreeNode(),
context.getApplicationContext());
}
}
}
return applicationManager;
}当 context 是 Activity 时,会创建一个无界面的 Fragment 添加到 Activity,用于感知 Activity 的生命周期,同时创建 RequestManager 给该 Fragment 持有。
private RequestManager supportFragmentGet(
@NonNull Context context,
@NonNull FragmentManager fm,
@Nullable Fragment parentHint,
boolean isParentVisible) {
SupportRequestManagerFragment current = getSupportRequestManagerFragment(fm, parentHint);
RequestManager requestManager = current.getRequestManager();
if (requestManager == null) {
// TODO(b/27524013): Factor out this Glide.get() call.
Glide glide = Glide.get(context);
requestManager =
factory.build(
glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode(), context);
// This is a bit of hack, we're going to start the RequestManager, but not the
// corresponding Lifecycle. It's safe to start the RequestManager, but starting the
// Lifecycle might trigger memory leaks. See b/154405040
if (isParentVisible) {
requestManager.onStart();
}
current.setRequestManager(requestManager);
}
return requestManager;
}load
load 方法会得到一个图片请求构建器 RequestBuilder,用来创建图片请求。
public RequestBuilder<Drawable> load(@Nullable String string) {
return asDrawable().load(string);
}into
首先是根据 ImageView 的 ScaleType,来配置参数.
public ViewTarget<ImageView, TranscodeType> into(@NonNull ImageView view) {
Util.assertMainThread();
Preconditions.checkNotNull(view);
BaseRequestOptions<?> requestOptions = this;
if (!requestOptions.isTransformationSet()
&& requestOptions.isTransformationAllowed()
&& view.getScaleType() != null) {
// Clone in this method so that if we use this RequestBuilder to load into a View and then
// into a different target, we don't retain the transformation applied based on the previous
// View's scale type.
switch (view.getScaleType()) {
case CENTER_CROP:
requestOptions = requestOptions.clone().optionalCenterCrop();
break;
case CENTER_INSIDE:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case FIT_CENTER:
case FIT_START:
case FIT_END:
requestOptions = requestOptions.clone().optionalFitCenter();
break;
case FIT_XY:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case CENTER:
case MATRIX:
default:
// Do nothing.
}
}
return into(
glideContext.buildImageViewTarget(view, transcodeClass),
/*targetListener=*/ null,
requestOptions,
Executors.mainThreadExecutor());
}继续跟进 into,会创建图片请求,获取 Target 载体已有的请求,对比两个请求,如果等效,启动异步请求,然后,图片载体绑定图片请求,也就是 ImageView setTag 为 request 。
private <Y extends Target<TranscodeType>> Y into(
@NonNull Y target,
@Nullable RequestListener<TranscodeType> targetListener,
BaseRequestOptions<?> options,
Executor callbackExecutor) {
Preconditions.checkNotNull(target);
if (!isModelSet) {
throw new IllegalArgumentException("You must call #load() before calling #into()");
}
Request request = buildRequest(target, targetListener, options, callbackExecutor);
Request previous = target.getRequest();
if (request.isEquivalentTo(previous)
&& !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) {
// If the request is completed, beginning again will ensure the result is re-delivered,
// triggering RequestListeners and Targets. If the request is failed, beginning again will
// restart the request, giving it another chance to complete. If the request is already
// running, we can let it continue running without interruption.
if (!Preconditions.checkNotNull(previous).isRunning()) {
// Use the previous request rather than the new one to allow for optimizations like skipping
// setting placeholders, tracking and un-tracking Targets, and obtaining View dimensions
// that are done in the individual Request.
previous.begin();
}
return target;
}
requestManager.clear(target);
target.setRequest(request);
requestManager.track(target, request);
return target;
}继续跟进异步请求 requestManager.track(target, request)
synchronized void track(@NonNull Target<?> target, @NonNull Request request) {
targetTracker.track(target);
requestTracker.runRequest(request);
} public void runRequest(@NonNull Request request) {
requests.add(request);
if (!isPaused) {
request.begin();//开启图片请求
} else {
request.clear();
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Paused, delaying request");
}
pendingRequests.add(request);//如果是暂停状态,就把请求存起来。
}
}到这里就启动了图片请求了,我们继续跟进 request.begin()
public void begin() {
synchronized (requestLock) {
//......
if (Util.isValidDimensions(overrideWidth, overrideHeight)) {
//如果有尺寸,开始加载
onSizeReady(overrideWidth, overrideHeight);
} else {
//如果无尺寸就先去获取
target.getSize(this);
}
//......
}
}然后继续瞧瞧 onSizeReady
public void onSizeReady(int width, int height) {
stateVerifier.throwIfRecycled();
synchronized (requestLock) {
//......
loadStatus =
engine.load(
glideContext,
model,
requestOptions.getSignature(),
this.width,
this.height,
requestOptions.getResourceClass(),
transcodeClass,
priority,
requestOptions.getDiskCacheStrategy(),
requestOptions.getTransformations(),
requestOptions.isTransformationRequired(),
requestOptions.isScaleOnlyOrNoTransform(),
requestOptions.getOptions(),
requestOptions.isMemoryCacheable(),
requestOptions.getUseUnlimitedSourceGeneratorsPool(),
requestOptions.getUseAnimationPool(),
requestOptions.getOnlyRetrieveFromCache(),
this,
callbackExecutor);
//......
}
}跟进 engine.load
public <R> LoadStatus load(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb,
Executor callbackExecutor) {
long startTime = VERBOSE_IS_LOGGABLE ? LogTime.getLogTime() : 0;
EngineKey key =
keyFactory.buildKey(
model,
signature,
width,
height,
transformations,
resourceClass,
transcodeClass,
options);
EngineResource<?> memoryResource;
synchronized (this) {
//从内存加载
memoryResource = loadFromMemory(key, isMemoryCacheable, startTime);
if (memoryResource == null) { //如果内存里没有
return waitForExistingOrStartNewJob(
glideContext,
model,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
options,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache,
cb,
callbackExecutor,
key,
startTime);
}
}
cb.onResourceReady(
memoryResource, DataSource.MEMORY_CACHE, /* isLoadedFromAlternateCacheKey= */ false);
return null;
} private <R> LoadStatus waitForExistingOrStartNewJob(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb,
Executor callbackExecutor,
EngineKey key,
long startTime) {
EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache);
if (current != null) {
current.addCallback(cb, callbackExecutor);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Added to existing load", startTime, key);
}
return new LoadStatus(cb, current);
}
EngineJob<R> engineJob =
engineJobFactory.build(
key,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache);
DecodeJob<R> decodeJob =
decodeJobFactory.build(
glideContext,
model,
key,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
onlyRetrieveFromCache,
options,
engineJob);
jobs.put(key, engineJob);
engineJob.addCallback(cb, callbackExecutor);
engineJob.start(decodeJob);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Started new load", startTime, key);
}
return new LoadStatus(cb, engineJob);
}DecodeJob 是一个 Runnable,它通过一系列的调用,会来到 HttpUrlFetcher 的 loadData 方法。
public void loadData(
@NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) {
long startTime = LogTime.getLogTime();
try {
//获取输入流,此处使用的是 HttpURLConnection
InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0, null, glideUrl.getHeaders());
//回调出去
callback.onDataReady(result);
} catch (IOException e) {
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "Failed to load data for url", e);
}
callback.onLoadFailed(e);
} finally {
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Finished http url fetcher fetch in " + LogTime.getElapsedMillis(startTime));
}
}
}至此,网络请求结束,最后把图片设置上去就行了,在 SingleRequest 的 onResourceReady 方法,它会把结果回调给 Target 载体。
target.onResourceReady(result, animation);继续跟进它,最终会执行 setResource,把图片设置上去。
protected void setResource(@Nullable Drawable resource) {
view.setImageDrawable(resource);
}总结
with 根据传入的 context 获取图片请求管理器 RequestManager,当传入的 context 是 Application 时,图片请求的生命周期会跟随应用,当传入的是 Activity 时,会创建一个无界面的空 Fragment 添加到 Activity,用来感知 Activity 的生命周期。load 会得到了一个图片请求构建器 RequestBuilder,用来创建图片请求。into 开启加载,先会根据 ImageView 的 ScaleType 来配置参数,创建图片请求,图片载体绑定图片请求,然后开启图片请求,先从内存中加载,如果内存里没有,会创建一个 Runnable,通过一系列的调用,使用 HttpURLConnection 获取网络输入流,把结果回调出去,最后把回调结果设置上去就行了。
缓存
Glide 三级缓存原理:读取一张图片时,顺序是: 弱引用缓存,LruCache,磁盘缓存。
用 Glide 加载某张图片时,先去弱引用缓存中寻找图片,如果有则直接取出来使用,如果没有,则去 LruCache 中寻找,如果 LruCache 中有,则中取出使用,并将它放入弱引用缓存中,如果没有,则从磁盘缓存或网络中加载图片。
private EngineResource<?> loadFromMemory(
EngineKey key, boolean isMemoryCacheable, long startTime) {
if (!isMemoryCacheable) {
return null;
}
EngineResource<?> active = loadFromActiveResources(key); //从弱引用获取图片
if (active != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
}
return active;
}
EngineResource<?> cached = loadFromCache(key); //从 LruCache 获取缓存图片
if (cached != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
}
return cached;
}
return null;
}不过,这会产生一个问题:Glide 加载图片时,URL 不变但是图片变了的这种情况,还是用以前的旧图片。因为 Glide 加载图片会将图片缓存到本地,如果 URL 不变则直接读取缓存不会再从网络上加载。
解决方案:
- 清除缓存
- 让后台每次都更改图片的名字
- 图片地址选用 ”url?key="+随机数这种格式
LruCache
LruCache 就是维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,最先被淘汰,而最近访问的对象将放在队头,最后被淘汰。其内部维护了一个集合 LinkedHashMap,LinkHashMap 继承 HashMap,在 HashMap 的基础上,新增了双向链表结构,每次访问数据的时候,会更新被访问数据的链表指针,该 LinkedHashMap 是以访问顺序排序的,当调用 put 方法时,就会在集合中添加元素,判断缓存是否已满,如果满了就删除队尾元素,即近期最少访问的元素,当调用 LinkedHashMap 的 get 方法时,就会获得对应的集合元素,同时更新该元素到队头。
Glide 会为每个不同尺寸的 Imageview 缓存一张图片,也就是说不管这张图片有没有加载过,只要 Imageview 的尺寸不一样,Glide 就会重新加载一次,这时候,它会在加载 Imageview 之前从网络上重新下载,然后再缓存。举个例子,如果一个页面的 Imageview 是 100 * 100,另一个页面的 Imageview 是 800 * 800,它俩展示同一张图片的话,Glide 会下载两次图片,并且缓存两张图片,因为 Glide 缓存 Key 的生成条件之一就是控件的长宽。
由上可知,在图片加载中关闭页面,此页面也不会造成内存泄漏,因为 Glide 在加载资源的时候,如果是在 Activity 或 Fragment 这类有生命周期的组件上进行的话,会创建一个无界面的 Fragment 加入到 FragmentManager 之中,感知生命周期,当 Activity 或 Fragment 进入不可见或销毁的时候,Glide 会停止加载资源。但是,如果是在非生命周期的组件上进行时,一般会采用 Application 的生命周期贯穿整个应用,此时只有在应用程序关闭的时候才会停止加载。
链接:https://juejin.cn/post/7178370740406714423
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android的线程和线程池
从用途上来说Android的线程主要分为主线程和子线程两类,主线程主要处理和界面相关的工作,子线程主要处理耗时操作。除Thread之外,Android中还有其他扮演线程的角色如AsyncTask、IntentService、HandleThread,其中AsyncTask的底层用到了线程池,IntentService和HandleThread的底层直接使用了线程。
AsyncTask内部封装了线程池和Handler主要是为了方便开发者在在线程中更新UI;HandlerThread是一个具有消息循环的线程,它的内部可以使用Handler;IntentService是一个服务,系统对其进行了封装使其可以更方便的执行后台任务,IntentService内部采用HandleThread来执行任务,当任务执行完毕后IntentService会自动退出。IntentService是一个服务但是它不容易被系统杀死因此它可以尽量的保证任务的执行。
1.主线程和子线程
主线程是指进程所拥有的的线程,在Java中默认情况下一个进程只能有一个线程,这个线程就是主线程。主线程主要处理界面交互的相关逻辑,因为界面随时都有可能更新因此在主线程不能做耗时操作,否则界面就会出现卡顿的现象。主线程之外的线程都是子线程,也叫做工作线程。
Android沿用了Java的线程模型,也有主线程和子线程之分,主线程主要工作是运行四大组件及处理他们和用户的交互,子线程的主要工作就是处理耗时任务,例如网络请求,I/O操作等。Android3.0开始系统要求网络访问必须在子线程中进行否则就会报错,NetWorkOnMainThreadException
2.Android中的线程形态
2.1 AsyncTask
AsyncTask是一个轻量级的异步任务类,它可以在线程池中执行异步任务然后把执行进度和执行结果传递给主线程并在主线程更新UI。从实现上来说AsyncTask封装了Thread和Handler,通过AsyncTask可以很方便的执行后台任务以及主线程中访问UI,但是AsyncTask不适合处理耗时任务,耗时任务还是要交给线程池执行。
AsyncTask的四个核心类如下:
- onPreExecute():主要用于做一些准备工作,在主线程中执行异步任务执行之前
- doInBackground(Params ... params):在线程池执行,此方法用于执行异步任务,params表示输入的参数,在此方法中可以通过publishProgress方法来更新任务进度,publishProgress会调用onProgressUpdate
- onProgressUpdate(Progress .. value):在主线程执行,当任务执行进度发生改变时会调用这个方法
- onPostExecute(Result result):在主线程执行,异步任务之后执行这个方法,result参数是返回值,即doInBackground的返回值。
2.2 AsyncTask的工作原理
2.3 HandleThread
HandleThread继承自Thread,它是一种可以使用Handler的Thread,它的实现在run方法中调用Looper.prepare()来创建消息队列然后通过Looper.loop()来开启消息循环,这样在实际使用中就可以在HandleThread中创建Handler了。
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}HandleThread和Thread的区别是什么?
- Thread的run方法中主要是用来执行一个耗时任务;
- HandleThread在内部创建了一个消息队列需要通过Handler的消息方式来通知HandleThread执行一个具体的任务,HandlerThread的run方法是一个无限循环因此在不使用是调用quit或者quitSafely方法终止线程的执行。HandleTread的具体使用场景是IntentService。
2.4 IntentService
IntentService继承自Service并且是一个抽象的类因此使用它时就必须创建它的子类,IntentService可用于执行后台耗时的任务,当任务执行完毕后就会自动停止。IntentService是一个服务因此它的优先级要比线程高并且不容易被系统杀死,因此可以利用这个特点执行一些高优先级的后台任务,它的实现主要是HandlerThread和Handler,这点可以从onCreate方法中了解。
//IntentService#onCreate
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}当IntentService第一次被启动时回调用onCreate方法,在onCreate方法中会创建HandlerThread,然后使用它的Looper创建一个Handler对象ServiceHandler,这样通过mServiceHandler把消息发送到HandlerThread中执行。每次启动IntentService都会调用onStartCommand,IntentService在onStartCommand中会处理每个后台任务的Intent。
//IntentService#onStartCommand
@Override
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
//IntentService#onStart
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}onStartCommand是如何处理外界的Intent的?
在onStartCommand方法中进入了onStart方法,在这个方法中IntentService通过mserviceHandler发送了一条消息,然后这个消息会在HandlerThread中被处理。mServiceHandler接收到消息后会把intent传递给onHandlerIntent(),这个intent跟启动IntentService时的startService中的intent是一样的,因此可以通过这个intent解析出启动IntentService传递的参数是什么然后通过这些参数就可以区分具体的后台任务,这样onHandleIntent就可以对不同的后台任务做处理了。当onHandleIntent方法执行结束后IntentService就会通过stopSelf(int startId)方法来尝试停止服务,这里不用stopSelf()的原因是因为这个方法被调用之后会立即停止服务但是这个时候可能还有其他消息未处理完毕,而采用stopSelf(int startId)方法则会等待所有消息都处理完毕后才会终止服务。调用stopSelf(int startId)终止服务时会根据startId判断最近启动的服务的startId是否相等,相等则立即终止服务否则不终止服务。
每执行一个后台任务就会启动一次intentService,而IntentService内部则通过消息的方式向HandlerThread请求执行任务,Handler中的Looper是顺序处理消息的,这就意味着IntentService也是顺序执行后台任务的,当有多个后台任务同时存在时这些后台任务会按照外界发起的顺序排队执行。
3.Android中的线程池
线程池的优点:
- 线程池中的线程可重复使用,避免因为线程的创建和销毁带来的性能开销;
- 能有效控制线程池中的最大并发数避免大量的线程之间因互相抢占系统资源导致的阻塞现象;
- 能够对线程进行简单的管理并提供定时执行以及指定间隔循环执行等功能。
Android的线程池的概念来自于Java中的Executor,Executor是一个接口,真正的线程的实现是ThreadPoolExecutor,它提供了一些列参数来配置线程池,通过不同的参数可以创建不同的线程池。
3.1 ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}ThreadPoolExecutor是线程池的真正实现,它的构造函数中提供了一系列参数,先看一下每个参数的含义:
- corePoolSize:线程池的核心线程数,默认情况下核心线程会在线程池中一直存活即使他们处于闲置状态。如果将ThreadPoolExecutor的allowCoreThreadTimeOut置为true那么闲置的核心线程在等待新的任务到来时会有超时策略,超时时间由keepAliveTime指定,当等待时间超过keepAliveTime设置的时间后核心线程就会被终止。
- maxinumPoolSize:线程池中所能容纳的最大线程数,当活动线程达到做大数量时后续的新任务就会被阻塞。
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长非核心线程就会被回收。
- unit:用于指定超时时间的单位,常用单位有毫秒、秒、分钟等。
- workQueue:线程池中的任务队列,通过线程池中的execute方法提交的Runnable对象会存储在这个参数中。
- threadFactory:线程工厂,为线程池提供创建新的线程的功能。
- handler:这个参数不常用,当线程池无法执行新的任务时,这可能是由于任务队列已满或者无法成功执行任务,这个时候ThreadPoolExecutor会调用handler的rejectExecution方法来通知调用者。
ThreadPoolExecutor执行任务时大致遵循如下规则:
- 如果线程池中的线程数量没有达到核心线程的数量那么会直接启动一个核心线程来执行任务;
- 如果线程池中线程数量已经达到或者超过核心线程的数量那么会把后续的任务插入到队列中等待执行;
- 如果任务队列也无法插入那么在基本可以确定是队列已满这时如果线程池中的线程数量没有达到最大值就会立刻创建非核心线程来执行任务;
- 如果非核心线程的创建已经达到或者超过线程池的最大数量那么就拒绝执行此任务,同时ThreadPoolExecutor会通过RejectedExecutionHandler抛出异常rejectedExecution。
3.2线程池的分类
- FixedThreadPool:它是一种数量固定的线程池,当线程处于空闲状态时也不会被回收,除非线程池被关闭。当所有的线程都处于活动状态时,新任务都会处于等待状态,直到有空闲线程出来。FixedThreadPool只有核心线程并且不会被回收因此它可以更加快速的响应外界的请求。
- CacheThreadPool:它是一种线程数量不定的线程池且只有非核心线程,线程的最大数量是Integer.MAX_VALUE,当线程池中的线程都处于活动状态时如果有新的任务进来就会创建一个新的线程去执行任务,同时它还有超时机制,当一个线程闲置超过60秒时就会被回收。
- ScheduleThreadPool:它是一种拥有固定数量的核心线程和不固定数量的非核心线程的线程池,当非核心线程闲置时会立即被回收。
- SignleThreadExecutor:它是一种只有一个核心线程的线程池,所有任务都在同一个线程中按顺序执行。
链接:https://juejin.cn/post/7178847227598045241
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 位图(图片)加载引入的内存溢出问题分析
1.一些定义
在分析具体问题之前,我们先了解一些基本概念,这样可以帮助理解后面的原理部分。当然了,大家对于这部分定义已经了然于胸的,就可以跳过了。
什么是内存泄露?
我们知道Java GC管理的主要区域是堆,Java中几乎所有的实例对象数据实际是存储在堆上的(当然JDK1.8之后,针对于不会被外界调用的数据而言,JVM是放置于栈内的)。针对于某一程序而言,堆的大小是固定的,我们在代码中新建对象时,往往需要在堆中申请内存,那么当系统不能满足需求,于是产生溢出。或者可以这样理解堆上分配的内存没有被释放,从而失去对其控制。这样会造成程序能使用的内存越来越少,导致系统运行速度减慢,严重情况会使程序宕掉。
什么是位图?
位图使用我们称为像素的一格一格的小点来描述图像,计算机屏幕其实就是一张包含大量像素点的网格,在位图中,平时看到的图像将会由每一个网格中的像素点的位置和色彩值来决定,每一点的色彩是固定的,而每个像素点色彩值的种类,产生了不同的位图Config,常见的有:
ALPHA_8, 代表8位Alpha位图,每个像素占用1byte内存
RGB_565,代表8位RGB位图,每个像素占用2byte内存
ARGB_4444 (@deprecated),代表16位ARGB位图,每个像素占用2byte内存
ARGB_8888,代表32位ARGB位图,每个像素占用4byte内存
其实很好理解,我们知道RGB是指红蓝绿,不同的config代表,计算机中每种颜色用几位二进制位来表示,例如:RGB_565代表红5为、蓝6位、绿5为。
2.原理分析
2.1 原理分析一
由第一节的基础定义,我们知道不过JVM还是Android虚拟机,对于每个应用程序可用内存大小是有约束的,而针对于单个程序中Bitmap所占的内存大小也有约束(一般机器是8M、16M,大家可以通过查看build.prop文件去查看这个定义大小),一旦超过了这个大小,就会报OOM错误。
Android编程中,我们经常会使用ImageView 控件,加载图片,例如以下代码:
package com.itbird.BitmapOOM;
import android.graphics.BitmapFactory;
import android.os.Bundle;
import android.widget.ImageView;
import androidx.appcompat.app.AppCompatActivity;
import com.itbird.R;
public class ImageViewLoadBitmapTestActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.imageviewl_load_bitmap_test);
ImageView imageView = findViewById(R.id.imageview);
imageView.setImageResource(R.drawable.bigpic);
imageView.setBackgroundResource(R.drawable.bigpic);
imageView.setImageBitmap(BitmapFactory.decodeFile("path/big.jpg"));
imageView.setImageBitmap(BitmapFactory.decodeResource(getResources(), R.drawable.bigpic));
}
}当图片很小时,一般不会有问题,当图片很大时,就会出现OOM错误,原因是直接调用decodeResource、setImageBitmap、setBackgroundResource时,实际上,这些函数在完成照片的decode之后,都是调用了java底层的createBitmap来完成的,需要消耗更多的内存。至于为什么会消耗那么多内存,如下面的源码分析:
android8.0之前Bitmap源码
public final class Bitmap implements Parcelable {
private static final String TAG = "Bitmap";
...
private byte[] mBuffer;
...
}android8.0之后Bitmap源码
public final class Bitmap implements Parcelable {
...
// Convenience for JNI access
private final long mNativePtr;
...
}对上上述两者,相信大家已经看出点什么了,android8.0之前,Bitmap在Java层保存了byte数组,而且细跟源码的话,您也会发现,8.0之前虽然调用了native函数,但是实际其实就是在native层创建Java层byte[],并将这个byte[]作为像素存储结构,之后再通过在native层构建Java Bitmap对象的方式,将生成的byte[]传递给Bitmap.java对象。(这里其实有一个小知识点,android6.0之前,源码里面很多这样的实现,通过C层来创建Java层对象)。
而android8.0之后,Bitmap在Java层保存的只是一个地址,,Bitmap像素内存的分配是在native层直接调用calloc,所以其像素分配的是在native heap上, 这也是为什么8.0之后的Bitmap消耗内存可以无限增长,直到耗尽系统内存,也不会提示Java OOM的原因。
2.2 原理分析二
看完上面的源码解读,大家一定想知道,那我如果在自己应用中的确有大图片的加载需求,那怎么办呢?调用哪个函数呢?
BitmapFactory.java中有一个Bitmap decodeStream(InputStream is)这个函数,我们可以查看源码,这个函数底层调用了native c函数
在底层进行了decode之后,转换为了bitmap对象,返回给Java层。
3 编程中如何避免图片加载的OOM错误
通过上面章节的知识探索,相信大家已经知道了加载图片时出现OOM错误的原因,其实真正的原因并未是网上很多文章说的,不要使用调用ImageView的某某函数、BitmapFactory的某某函数,真正的原因是,对于大图片,Java堆和Native堆无法申请到可用内存时,就会出现OOM错误,那么针对于不同的系统版本,Android存储、创建图片的方式又有所不同,带来了加载大图片时的OOM错误。
那么接下来,大家最关心的解决方案,有哪些?我们在日常编码中,应该如何编码,才能有效规避此类错误的出现,别急。
3.1 利用BitmapFactory.decodeStream加载InputStream图片字节流的方式显示图片
/**
* 以最省内存的方式读取本地资源的图片
*/
public static Bitmap readBitMap(String path, BitmapFactory.Options opt, InputStream is) {
opt.inPreferredConfig = Bitmap.Config.RGB_565;
if (Build.VERSION.SDK_INT <=android.os.Build.VERSION_CODES.KITKAT ) {
opt.inPurgeable = true;
opt.inInputShareable = true;
}
opt.inSampleSize = 2;//二分之一缩放,可写1即100%显示
//获取资源图片
try {
is = new FileInputStream(path);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return BitmapFactory.decodeStream(is, null, opt);
}大家可以看到上面的代码,实际上一方面针对Android 4.4之下的直接声明了opt属性,告诉系统可以回收,一方面直接进行了图片缩放。说到这里,大家会有疑问,为什么是android4.4以下加这两个属性,难道之后就不用了了。不要着急,我们看源码:
可以看到源码上说明,此属性4.4之前有用,5.0之后即使设置了,底层也是忽略的。也许大家会问,难道5.0之后Bitmap的源码有什么大的改动吗?的确是,可以看一下以下源码。
8.0之后的Bitmap内存回收机制
NativeAllocationRegistry是Android 8.0引入的一种辅助自动回收native内存的一种机制,当Java对象因为GC被回收后,NativeAllocationRegistry可以辅助回收Java对象所申请的native内存,拿Bitmap为例,如下:
Bitmap(long nativeBitmap, int width, int height, int density,
boolean isMutable, boolean requestPremultiplied,
byte[] ninePatchChunk, NinePatch.InsetStruct ninePatchInsets) {
...
mNativePtr = nativeBitmap;
long nativeSize = NATIVE_ALLOCATION_SIZE + getAllocationByteCount();
<!--辅助回收native内存-->
NativeAllocationRegistry registry = new NativeAllocationRegistry(
Bitmap.class.getClassLoader(), nativeGetNativeFinalizer(), nativeSize);
registry.registerNativeAllocation(this, nativeBitmap);
if (ResourcesImpl.TRACE_FOR_DETAILED_PRELOAD) {
sPreloadTracingNumInstantiatedBitmaps++;
sPreloadTracingTotalBitmapsSize += nativeSize;
}
}当然这个功能也要Java虚拟机的支持,有机会再分析。
**实际使用效果:**3M以内的图片加载没有问题,但是大家注意到一点,没我们代码中是固定缩放了一般,这时大家肯定有疑问,有没有可能,去动态根据图片的大小,决定缩放比例。
3.2 利用BitmapFactory.decodeStream通过按比例压缩方式显示图片
/**
* 以计算的压缩比例加载大图片
*
* @param res
* @param resId
* @param reqWidth
* @param reqHeight
* @return
*/
public static Bitmap decodeCalSampledBitmapFromResource(Resources res, int resId, int reqWidth, int reqHeight) {
// 检查bitmap的大小
final BitmapFactory.Options options = new BitmapFactory.Options();
// 设置为true,BitmapFactory会解析图片的原始宽高信息,并不会加载图片
options.inJustDecodeBounds = true;
options.inPreferredConfig = Bitmap.Config.RGB_565;
BitmapFactory.decodeResource(res, resId, options);
// 计算采样率
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
// 设置为false,加载bitmap
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}
/*********************************
* @function: 计算出合适的图片倍率
* @options: 图片bitmapFactory选项
* @reqWidth: 需要的图片宽
* @reqHeight: 需要的图片长
* @return: 成功返回倍率, 异常-1
********************************/
private static int calculateInSampleSize(BitmapFactory.Options options, int reqWidth,
int reqHeight) {
// 设置初始压缩率为1
int inSampleSize = 1;
try {
// 获取原图片长宽
int width = options.outWidth;
int height = options.outHeight;
// reqWidth/width,reqHeight/height两者中最大值作为压缩比
int w_size = width / reqWidth;
int h_size = height / reqHeight;
inSampleSize = w_size > h_size ? w_size : h_size; // 取w_size和h_size两者中最大值作为压缩比
Log.e("inSampleSize", String.valueOf(inSampleSize));
} catch (Exception e) {
return -1;
}
return inSampleSize;
}大家可以看到,上面代码实际上使用了一个属性inJustDecodeBounds,当inJustDecodeBounds设为true时,不会加载图片仅获取图片尺寸信息,也就是说,我们先通过不加载实际图片,获取其尺寸,然后再按照一定算法(以需要的图片长宽与实际图片的长宽比例来计算)计算出压缩的比例,然后再进行图片加载。
**实际使用效果:**测试该方法可以显示出来很大的图片,只要你设定的长宽合理。
3,3 及时的回收和释放
直接上代码
/**
* 回收bitmap
*/
private static void recycleBitmap(ImageView iv) {
if (iv != null && iv.getDrawable() != null) {
BitmapDrawable bitmapDrawable = (BitmapDrawable) iv.getDrawable();
iv.setImageDrawable(null);
if (bitmapDrawable != null) {
Bitmap bitmap = bitmapDrawable.getBitmap();
if (bitmap != null) {
bitmap.recycle();
}
}
}
}
/**
* 在Activity或Fragment的onDestory方法中进行回收(必须确保bitmap不在使用)
*/
public static void recycleBitmap(Bitmap bitmap) {
// 先判断是否已经回收
if (bitmap != null && !bitmap.isRecycled()) {
// 回收并且置为null
bitmap.recycle();
bitmap = null;
}
}4.总结
4.1 OOM出现原因
对于大图片,直接调用decodeResource、setImageBitmap、setBackgroundResource时,这些函数在完成照片的decode之后,都是调用了java底层的createBitmap来完成的,需要消耗更多的内存。Java堆和Native堆无法申请到可用内存时,就会出现OOM错误,那么针对于不同的系统版本,Android存储、创建图片的方式又有所不同,带来了加载大图片时的OOM错误。
4.2 解决方案
1.针对于图片小而且频繁加载的,可以直接使用系统函数setImageXXX等
2针对于大图片,在进行ImageView setRes之前,需要先对图片进行处理
1)压缩
2)android4.4之前,需要设置opt,释放bitmap,android5.0之后即使设置,系统也会忽略
3)设置optConfig为565,降低每个像素点的色彩值
4)针对于频繁使用的图片,可以使用inBitmap属性
5)由于decodeStream直接读取的图片字节码,并不会根据各种机型做自动适配,所以需要在各个资源文件夹下放置相应的资源
6)及时回收
链接:https://juejin.cn/post/7179037417704259640
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Handler就是一个简化的邮递系统么?
前置补充
关于本文的初衷不是讲很多细节,主要像聚焦在
Handler的设计理念上,主要想讲述计算机系统中的很多事情在现实中其实有现成的例子可以参考理解,当然现实生活比程序肯定更复杂。
知行合一,想完全理解一个事物,肯定不能光靠看文章,还是要在实际的工作中去使用。
学习是渐进的,可能文中的一些知识点,笔者已经掌握,可能会一笔带过,大家有疑惑 ,建议或者文中的错误,多多提出意见和批评。
ThreadLocal推荐一本书 任玉刚老师的 Android开发艺术探索
关于
Java线程相关知识,推荐 杨冠宝/高海慧 老师的 码出高效:Java开发手册
正文
网上关于Handler的的文章已经有很多了,可能大家看了很多有的同学还是云里雾里,我写这篇文章的理念就是怎样将Handler讲述成我们平常经常使用的事物。
大家已经点进来了,就应该知道Handler是做什么用的,关于它的定义不在多言。
我们用一个爱情故事来模仿这个通信的流程。
1:MainThread(一个人见人爱的女生,我们就叫她
main)。
2:BThread (一个很倾慕
main的男生,我们简称他为B)。
3:剧情设定两个人无法直接通信(具体原因不赘述,大家可以百度一下
ThreadLocal,本文不讲这个了)。
有了设定和人物,那么假如B想给main通信他需要怎么办呢,写信是一种方式。那我们就用写信来比喻Handler。那让我们来分析一下这个通信系统,首先来看Handler。
本文采用6.0源代码
Handler系统
我们平常说的通过Handler进行线程间通信,通常是指的是通过整个Handler系统进行通信,Handler.java只是这个系统的一个入口.
Handler
分析一个东西,我们先从构造函数开始。
public Handler() {
this(null, false);
}
public Handler(Callback callback) {
this(callback, false);
}
public Handler(Looper looper) {
this(looper, null, false);
}
public Handler(Looper looper, Callback callback) {
this(looper, callback, false);
}
public Handler(boolean async) {
this(null, async);
}
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
上面是Handler所有的构造函数,4个是没有实际的逻辑的,有实际的逻辑只有两个,我们就从这两个构造函数开始分析。
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
两者的差别就是Looper是否是外部传入的,一个Looper使用的静态函数myLooper() 赋值的,我们暂时先放过这个静态函数一步一步来(放到Looper的环节中讲述)。不过我们看到这个mLooper如果为null就会抛出一个异常,可能很多同志都见到过这个异常Can't create handler inside thread that has not called Looper.prepare(),这个异常就是从这里来的。
分析以上的构造函数,我们发现在Handler整个系统中Looper是必须存在的一个事物。(有的同学会说,我可以在创建Handler的时候手动的传一个null进去,是的,这样的话会得到一个空指针异常)。
如果我们如开头所说,Handler来类比我们现实生活中的通信系统,我们通过它的构造函数得知这个通信系统有4个必须存在的参数,mLooper,mQueue,mCallback,mAsynchronous(mQueue包含在Looper中)。那我们再来一个一个的分析这4个参数,他们究竟在这个通信系统中扮演什么角色。首先先看Looper
Looper
mQueue包含在Looper中,放在一起看。
按照惯例,还是先看构造函数。
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}是一个私有的构造函数,里面讲我们上文提到mQueue给赋值,还有就是将mThread变量赋值为当前所处的线程。Thread.currentThread()不理解请自行百度。
那我们看一下Looper对象既然外部无法通过new关键字直接创建,那么它通过什么方式创建的呢?
在Looper源码中,函数返回类型为Looper的函数只有下面两个。 我们先分析getMainLooper()函数,函数中只是返回了一个sMainLooper。
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}我们先看sMainLooper。
private static Looper sMainLooper; // guarded by Looper.class
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}大家发现饶了一圈,怎么有回到了myLooper()函数,那接下我们看myLooper()函数中的sThreadLocal是什么东西?
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}我们发现sThreadLocal就是一个ThreadLocal,使用它来存储Looper对象。
- (前文提过
ThreadLocal,它是Java多线程中一个非常非常重要的概念,建议不懂这个的同志,先去看一下这个东西到底是什么?然后再回过头来看这篇文章)。
我们会发现创建Looper对象只能通过唯一入口prepare来创建它。创建Looper的时候,它顺手的将MessageQueue给创建了出来(在上文Looper的构造函数中)。
MessageQueue包含的任务是非常重要的,并且要写入一些c++代码来分析。我们暂且跳过,先得出一个结论之后,在来逆推MessageQueue到底做了什么。
mCallback && mAsynchronous
mCallback:可以从Handler中是可以为null,不传就默认为null,其实是比较容易理解的一个概念,回调函数,不多做解释了,非主线剧情。
mAsynchronous: 从名字来看就是是不是异步的意思,后面会解释一下这个异步的概念。
实际例子
我们上面将Handler想象成一个通信系统,设定了人物,也简单的分析了一下Handler,下面我们来看一个实际的写信流程。
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
}
});
public Thread BThread = new Thread(new Runnable() {
@Override
public void run() {
}
});假如B想通过Handler通信系统给Main写信,那么第一步
- 1: Main得在通信系统中创建
Handler,这个时候Handler可以形容为一个地址。看如下代码:
public Handler mainHandler;
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
if (mainHandler == null) {
Looper.prepare();
mainHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.e(TAG, "handleMessage: "+ msg.obj);
}
};
Looper.loop();
}
}
});
2 我们看在创建
Handler之前,需要现在线程中使用Looper.prepare()创建一个Looper出来之后才能创建Handler(前文提到过原因)。那么Looper可以形容为什么呢,这个通信系统中的后台系统,我们接着往下看,看这个形容是否准确。
3 :B拿到Main的
Handler,就使用sendMessage()去给Main传递信息,sendMessage必须发送Message类型的消息,那么Message在通信系统中是什么角色呢,可以理解为信封和邮票,必须以规定好的方式去包装你写得信,这样才可以去发送。这个时候Handler扮演了一个投递入口的角色。
public Thread BThread = new Thread(new Runnable() {
@Override
public void run() {
if (mainHandler != null) {
Message message = Message.obtain();
message.obj= "I LOVE YOU";
mainHandler.sendMessage(message);
Log.e(TAG, "BThread sendMessage 发送了");
}
}
});- 4:从上面的例子代码和上文对
Looper的分析中,我们没有看到Looper.loop()的作用,并且还有一个疑问,B只是投递了信息,谁帮忙传信的呢?我们看下是不是Looper.loop()。只展示关键代码,想看完整代码的同志请自行查看源码。
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
//这里好像是发送了。
msg.target.dispatchMessage(msg);
...
}
}- 5: 我们在
Looper.loop()中看到了一句msg.target.dispatchMessage(msg),这个从名字看上去很像一个传信的人,但是这个msg.target是个什么鬼东西啊,完全看不懂。从源码得知msg是一个Message类型的对象,那我们去看一下msg.target。
public final class Message implements Parcelable {
...
/*package*/ Handler target;
...
}target就是一个Handler啊,那它是在哪里赋值的呢?其实sendMessage最终会调用到enqueueMessage,具体的调用函数栈,就不贴出来了,有兴趣自行查看源码。
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}在这里我们看到target被赋值为调用者。也就是mainHandler.sendMessage(message);,target就是mainHandler,看了下面的代码你更好理解
Message message = Message.obtain();
message.setTarget(mainHandler);
message.obj= "I LOVE YOU";
mainHandler.sendMessage(message);
Log.e(TAG, "BThread sendMessage 发送了");Message每个信封都支持我们手动写地址的setTarget,但是很多人觉得麻烦,那么通信系统呢,就默认将拿到的地址作为你要传送的地址。也就支持了我们不需要必须调用setTarget()。(有的同学可能比较调皮,我用mainHandler,去发送,target写其他可以么,是可以的,但是系统会帮我们修正,大家可以尝试一下)
MessageQueue,隐藏在内部的工作者
看到这这里,如果不接着深入探究,基本上一个完整的链条已经存在,但是还是有很多疑点,之前提到的MessageQueue还没说到,整个链条就完整了么?其实MessageQueue已经出镜了。loop()函数虽然起了一个死循环,但是每一封信都是从MessageQueue.next()中取出来的。
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
//这里好像是发送了。
msg.target.dispatchMessage(msg);
...
}
}国际惯例,先看构造函数。
// True if the message queue can be quit.
private final boolean mQuitAllowed;
private long mPtr; // used by native code
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}构造函数,从名字来看mQuitAllowed是否允许关闭。退出机制比较复杂不想看的可以跳过,包含的知识点有点多。
1:大家都知道Java的线程机制,1.5之前提供了stop函数,后面移除,移除的原因不赘述,现在线程退出机制就是代码执行完之后就会自动销毁。
2:我们回头看下我们的例子代码,在调用
Looper.loop()函数之后会启动一个死循环不停的取消息,一直到消息为null,才会returen。我们知道了退出的条件,我们看下系统怎么创造这个条件的。
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
Looper.prepare();
if (mainHandler == null) {
mainHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.e(TAG, "handleMessage: "+ msg.obj);
}
};
Looper.loop();
}
}
});
Looper.java
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
....
}- 3:调用
Loooper.quit(),来主动退出这个这个死循环,下面就讲述一下这个退出死循环的流程
public void quit() {
mQueue.quit(false);
}
void quit(boolean safe) {
//判断当前是否允许退出,不允许就抛出异常
if (!mQuitAllowed) {
throw new IllegalStateException("Main thread not allowed to quit.");
}
synchronized (this) {
//锁+ 标志位 ,防止重复执行,记住这标志位。 后面还要用到
if (mQuitting) {
return;
}
mQuitting = true;
if (safe) {
removeAllFutureMessagesLocked();
} else {
//退出是这个,清除所有的消息
removeAllMessagesLocked();
}
// We can assume mPtr != 0 because mQuitting was previously false.
//native 函数。 从名字上看是唤醒。
nativeWake(mPtr);
}
}
大家看到了熟悉的一个主动异常"Main thread not allowed to quit.",简单理解主线程不可以退出。主线程创建Looper的流程在本文不赘述,我们接着看调用MessageQueue的quit函数的地方,
- 4: 从上面的代码我们就看到了清除了缓存队列中的所有未发送的消息,然后唤醒?唤醒什么呢?不是退出么? 带着这三个疑问,走向更深的源码。
android_os_MessageQueue.cpp
{ "nativeWake", "(J)V", (void*)android_os_MessageQueue_nativeWake },
static void android_os_MessageQueue_nativeWake(JNIEnv* env, jclass clazz, jlong ptr) {
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->wake();
}
Looper.cpp
void Looper::wake() {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ wake", this);
#endif
uint64_t inc = 1;
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
if (nWrite != sizeof(uint64_t)) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}这是一个到达Native的一个简单的逻辑顺序,Looper.cpp是对epoll的一个封装,我简单的描述一下这个过程
就是有(三个人都活着(线程),要喝水(用CPU),那么三个人要把水给平分(平分Cpu时间片)。
两个人没事干也不累,但是不能die,(还有一些专属任务,需要等待通知),那不干活就不应该喝水,要不就是资源浪费啊,怎么办?
epoll就是干这个的pollOnce就是通知线程进入休眠状态,等到有消息来的时候就会通知对应的人(对应的线程)去干活了,怎么通知呢? 就是通过wake函数。贴一下pollOnce的相关的关键代码,有兴趣的看一下
int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) {
int result = 0;
for (;;) {
...
//这里
result = pollInner(timeoutMillis);
}
}
int Looper::pollInner(int timeoutMillis) {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ pollOnce - waiting: timeoutMillis=%d", this, timeoutMillis);
#endif
...
//这里 epoll出现 ,如果想把这个探究明白 建议读这个类的源码,是Android对epoll的封装了
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
// No longer idling.
mPolling = false;
// Acquire lock.
mLock.lock();
// Rebuild epoll set if needed.
if (mEpollRebuildRequired) {
mEpollRebuildRequired = false;
rebuildEpollLocked();
goto Done;
}
// Check for poll error.
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
ALOGW("Poll failed with an unexpected error, errno=%d", errno);
result = POLL_ERROR;
goto Done;
}
// Check for poll timeout.
if (eventCount == 0) {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ pollOnce - timeout", this);
#endif
result = POLL_TIMEOUT;
goto Done;
}
...
}
epoll.h
extern int epoll_wait (int __epfd, struct epoll_event *__events,
int __maxevents, int __timeout);
- 5 :看到这里其实大部分人是很迷惑的,建议迷惑的同志单独深入探究,单独理解上层的同学就看到喝水的故事就好了。那么回到上文说的唤醒,我们知道唤醒之后的线程从休眠的地方开始执行,我们看看陷入休眠的时候在哪里呢?
Message next() {
...
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//这里休眠的.
nativePollOnce(ptr, nextPollTimeoutMillis);
//唤醒之后从这里开始执行.
synchronized (this) {
...
//还记得这个标志么?在quit函数中赋值为ture的
if (mQuitting) {
dispose();
//这里reture 一个 null
return null;
}
...
}
}
}
(主线程)不会卡死的原因即 Looper退出总结,线程退出机制.
上面描述了退出的一个过程。在简单总结一下
1:
Looper.loop启动死循环,然而实际干的活是从MessageQueue.next()中一直取Message,如果没有Message MessageQueue会调用nativePollOnce让当前线程休眠(这就是为啥死循环不会卡死的原因,很浅显啊,只是简单论述,epoll 可以写好几篇文章了)。
2: 发起退出死循环,终结线程,调用
Looper.quit(),然后还是要调用MessageQueue.quit().
3:
MessageQueue.quit(),先判断当前是否允许退出,允许了将退出的标志位mQuitting设置为true,然后调用removeAllMessagesLocked()清除现在队列中的所有消息。然后唤醒线程
4: 线程被唤醒了就回到第一步,当前没有消息你却唤醒线程,且退出标志位
mQuitting设置为true了,MessageQueue.next()就会返回一个null。
5:
Looper.loop的死循环如果取到了的Message为null,就会returen跳出死循环了。这样一个线程所有的代码执行完成之后,就会自然死亡了,这也是我们Android的Main Thread的MessageQueue不允许退出的原因。
大总结
整个大的线程通信系统
Handler就是一个门面,可以理解为地址。
Message像一个传递员,规定了信的格式和最后一公里的取信和传信。
Looper是一个后台系统,注册什么,所有的入口发起全在这里,让大家以为它把所有的活都干了。
MessageQueue位居后台的一个分拣员,和通知传递员去送信,这个核心就是它,就是所有人都看不到。
链接:https://juejin.cn/post/7049987023662219301
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你真的了解 RSA 加密算法吗?
记得那是我毕业🎓后的第一个秋天,申请了域名,搭建了论坛。可惜好景不长,没多久进入论坛后就出现各种乱七八糟的广告,而这些广告压根都不是我加的。
这是怎么回事?后来我才知道,原来我的论坛没有加 HTTPS 也就是没有 SSL 证书。那这和数学中的素数有啥关系呢?这是因为每一个 SSL 的生成都用到了 RSA 非对称加密,而 RSA 的加解密就是使用了两个互为质数的大素数生成公钥和私钥的。
这就是我们今天要分享的,关于素数在 RSA 算法中的应用。
一、什么是素数
素数(或质数)指的是大于1的且不能通过两个较小的自然数乘积得来的自然数。而大于1的自然数如果不是素数,则称之为合数。例如:7是素数,因为它的乘积只能写成 1 * 7 或者 7 * 1 这样。而像自然数 8 可以写成 2 * 4,因为它是两个较小数字的乘积。
通常在 Java 程序中,我们可以使用下面的代码判断一个数字是否为素数;
boolean isPrime = number > 0;
// 计算number的平方根为k,可以减少一半的计算量
int k = (int) Math.sqrt(number);
for (int i = 2; i <= k; i++) {
if (number % i == 0) {
isPrime = false;
break;
}
}
return isPrime;二、对称加密和非对称加密
假如 Alice 时而需要给北漂搬砖的 Bob 发一些信息,为了安全起见两个人相互协商了一个加密的方式。比如 Alice 发送了一个银行卡密码 142857 给 Bob,Alice 会按照与 Bob 的协商方式,把 142857 * 2 = 285714 的结果传递给 Bob,之后 Bob 再通过把信息除以2拿到结果。
但一来二去,Alice 发的密码、生日、衣服尺寸、鞋子大小,都是乘以2的规律被别人发现。这下这个加密方式就不安全了。而如果每次都给不同的信息维护不同的秘钥又十分麻烦,且这样的秘钥为了安全也得线下沟通,人力成本又非常高。
所以有没有另外一种方式,使用不同的秘钥对信息的加密和解密。当 Bob 想从 Alice 那获取信息,那么 Bob 就给 Alice 一个公钥,让她使用公钥对信息进行加密,而加密后的信息只有 Bob 手里有私钥才能解开。那么这样的信息传递就变得非常安全了。如图所示。
| 对称加密 | 非对称加密 |
|---|---|
三、算法公式推导
如果 Alice 希望更安全的给 Bob 发送的信息,那么就需要保证经过公钥加密的信息不那么容易被反推出来。所以这里的信息加密,会需用到求模运算。像计算机中的散列算法,伪随机数都是求模运算的典型应用。
例如;5^3 mod 7 = 6 —— 5的3次幂模7余6
- 5相当于 Alice 要传递给 Bob 的信息
- 3相当于是秘钥
- 6相当于是加密后的信息
经过求模计算的结果6,很难被推到出秘钥信息,只能一个个去验证;
5^1 mod 7 = 5
5^2 mod 7 = 3
5^3 mod 7 = 6
5^4 mod 7 = 2
...但如果求模的值特别大,例如这样:5^3 mod 78913949018093809389018903794894898493... = 6 那么再想一个个计算就有不靠谱了。所以这也是为什么会使用模运算进行加密,因为对于大数来说对模运算求逆根本没法搞。
根据求模的计算方式,我们得到加密和解密公式;—— 关于加密和解密的公式推到,后文中会给出数学计算公式。
对于两个公式我们做一下更简单的转换;
从转换后的公式可以得知,m 的 ed 次幂,除以 N 求求模可以得到 m 本身。那么 ed 就成了计算公钥加密的重要因素。为此这里需要提到数学中一个非常重要的定理,欧拉定理。—— 1763年,欧拉发现。
欧拉定理:m^φ(n) ≡ 1 (mod n) 对于任何一个与 n 互质的正整数 m,的 φ(n) 次幂并除以 n 去模,结果永远等于1。φ(n) 代表着在小于等于 n 的正整数中,有多少个与 n 互质的数。
例如:φ(8) 小于等于8的正整数中 1、2、3、4、5、6、7、8 有 1、3、5、7 与数字 8 互为质数。所以 φ(8) = 4 但如果是 n 是质数,那么 φ(n) = n - 1 比如 φ(7) 与7互为质数有1、2、3、4、5、6 所有 φ(7) = 6
接下来我们对欧拉公式做一些简单的变换,用于看出ed的作用;
经过推导的结果可以看到 ed = kφ(n) + 1,这样只要算出加密秘钥 e 就可以得到一个对应的解密秘钥 d。那么整套这套计算过程,就是 RSA 算法。
四、关于RSA算法
RSA加密算法是一种非对称加密算法,在公开秘钥加密和电子商业中被广泛使用。
于1977年,三位数学家;罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字命名,叫做RSA算法。
1973年,在英国政府通讯总部工作的数学家克利福德·柯克斯(Clifford Cocks)在一个内部文件中提出了一个与之等效的算法,但该算法被列入机密,直到1997年才得到公开。
RSA 的算法核心在于取了2个素数做乘积求和、欧拉计算等一系列方式算得公钥和私钥,但想通过公钥和加密信息,反推出来私钥就会非常复杂,因为这是相当于对极大整数的因数分解。所以秘钥越长做因数分解越困难,这也就决定了 RSA 算法的可靠性。—— PS:可能以上这段话还不是很好理解,程序员👨🏻💻还是要看代码才能悟。接下来我们就来编写一下 RSA 加密代码。
五、实现RSA算法
RSA 的秘钥生成首先需要两个质数p、q,之后根据这两个质数算出公钥和私钥,在根据公钥来对要传递的信息进行加密。接下来我们就要代码实现一下 RSA 算法,读者也可以根据代码的调试去反向理解 RSA 的算法过程,一般这样的学习方式更有抓手的感觉。嘿嘿 抓手
1. 互为质数的p、q
两个互为质数p、q是选择出来的,越大越安全。因为大整数的质因数分解是非常困难的,直到2020年为止,世界上还没有任何可靠的攻击RSA算法的方式。只要其钥匙的长度足够长,用RSA加密的信息实际上是不能被破解的。—— 不知道量子计算机出来以后会不会改变。如果改变,那么程序员又有的忙了。
2. 乘积n
n = p * q 的乘积。
public long n(long p, long q) {
return p * q;
}3. 欧拉公式 φ(n)
φ(n) = (p - 1) * (q - 1)
public long euler(long p, long q) {
return (p - 1) * (q - 1);
}4. 选取公钥e
e 的值范围在 1 < e < φ(n)
public long e(long euler){
long e = euler / 10;
while (gcd(e, euler) != 1){
e ++;
}
return e;
}5. 选取私钥d
d = (kφ(n) + 1) / e
public long inverse(long e, long euler) {
return (euler + 1) / e;
}6. 加密
c = m^e mod n
public long encrypt(long m, long e, long n) {
BigInteger bM = new BigInteger(String.valueOf(m));
BigInteger bE = new BigInteger(String.valueOf(e));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bM.modPow(bE, bN).toString());
}7. 解密
m = c^d mod n
public long decrypt(long c, long d, long n) {
BigInteger bC = new BigInteger(String.valueOf(c));
BigInteger bD = new BigInteger(String.valueOf(d));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bC.modPow(bD, bN).toString());
}8. 测试
@Test
public void test_rsa() {
RSA rsa = new RSA();
long p = 3, // 选取2个互为质数的p、q
q = 11, // 选取2个互为质数的p、q
n = rsa.n(p, q), // n = p * q
euler = rsa.euler(p, q), // euler = (p-1)*(q-1)
e = rsa.e(euler), // 互为素数的小整数e | 1 < e < euler
d = rsa.inverse(e, euler), // ed = φ(n) + 1 | d = (φ(n) + 1)/e
msg = 5; // 传递消息 5
System.out.println("消息:" + msg);
System.out.println("公钥(n,e):" + "(" + n + "," + e + ")");
System.out.println("私钥(n,d):" + "(" + n + "," + d + ")");
long encrypt = rsa.encrypt(msg, e, n);
System.out.println("加密(消息):" + encrypt);
long decrypt = rsa.decrypt(encrypt, d, n);
System.out.println("解密(消息):" + decrypt);
}测试结果
消息:5
公钥(n,e):(33,3)
私钥(n,d):(33,7)
加密(消息):26
解密(消息):5- 通过选取3、11作为两个互质数,计算出公钥和私钥,分别进行消息的加密和解密。如测试结果消息5的加密后的信息是26,解密后获得原始信息5
六、RSA数学原理
整个 RSA 的加解密是有一套数学基础可以推导验证的,这里小傅哥把学习整理的资料分享给读者,如果感兴趣可以尝试验证。这里的数学公式会涉及到;求模运算、最大公约数、贝祖定理、线性同于方程、中国余数定理、费马小定理。当然还有一些很基础的数论概念;素数、互质数等。以下推理数学内容来自博客:luyuhuang.tech/2019/10/24/…
1. 模运算
1.1 整数除法
定理 1 令 a 为整数, d 为正整数, 则存在唯一的整数 q 和 r, 满足 0⩽r<d, 使得 a=dq+r.
当 r=0 时, 我们称 d 整除 a, 记作 d∣a; 否则称 d 不整除 a, 记作 d∤a
整除有以下基本性质:
定理 2 令 a, b, c 为整数, 其中 a≠0a≠0. 则:
- 对任意整数 m,n,如果 a∣b 且 a∣c, 则 a∣(mb + nc)
- 如果 a∣b, 则对于所有整数 c 都有 a∣bc
- 如果 a∣b 且 b∣c, 则 a∣c
1.2 模算术
在数论中我们特别关心一个整数被一个正整数除时的余数. 我们用 a mod m = b表示整数 a 除以正整数 m 的余数是 b. 为了表示两个整数被一个正整数除时的余数相同, 人们又提出了同余式(congruence).
定义 1 如果 a 和 b 是整数而 m 是正整数, 则当 m 整除 a - b 时称 a 模 m 同余 b. 记作 a ≡ b(mod m)
a ≡ b(mod m) 和 a mod m= b 很相似. 事实上, 如果 a mod m = b, 则 a≡b(mod m). 但他们本质上是两个不同的概念. a mod m = b 表达的是一个函数, 而 a≡b(mod m) 表达的是两个整数之间的关系.
模算术有下列性质:
定理 3 如果 m 是正整数, a, b 是整数, 则有
(a+b)mod m=((a mod m)+(b mod m)) mod m
ab mod m=(a mod m)(b mod m) mod m
根据定理3, 可得以下推论
推论 1 设 m 是正整数, a, b, c 是整数; 如果 a ≡ b(mod m), 则 ac ≡ bc(mod m)
证明 ∵ a ≡ b(mod m), ∴ (a−b) mod m=0 . 那么
(ac−bc) mod m=c(a−b) mod m=(c mod m⋅(a−b) mod m) mod m=0
∴ ac ≡ bc(mod m)
需要注意的是, 推论1反之不成立. 来看推论2:
推论 2 设 m 是正整数, a, b 是整数, c 是不能被 m 整除的整数; 如果 ac ≡ bc(mod m) , 则 a ≡ b(mod m)
证明 ∵ ac ≡ bc(mod m) , 所以有
(ac−bc)mod m=c(a−b)mod m=(c mod m⋅(a−b)mod m) mod m=0
∵ c mod m≠0 ,
∴ (a−b) mod m=0,
∴a ≡ b(mod m) .
2. 最大公约数
如果一个整数 d 能够整除另一个整数 a, 则称 d 是 a 的一个约数(divisor); 如果 d 既能整除 a 又能整除 b, 则称 d 是 a 和 b 的一个公约数(common divisor). 能整除两个整数的最大整数称为这两个整数的最大公约数(greatest common divisor).
定义 2 令 a 和 b 是不全为零的两个整数, 能使 d∣ad∣a 和 d∣bd∣b 的最大整数 d 称为 a 和 b 的最大公约数. 记作 gcd(a,b)
2.1 求最大公约数
如何求两个已知整数的最大公约数呢? 这里我们讨论一个高效的求最大公约数的算法, 称为辗转相除法. 因为这个算法是欧几里得发明的, 所以也称为欧几里得算法. 辗转相除法基于以下定理:
引理 1 令 a=bq+r, 其中 a, b, q 和 r 均为整数. 则有 gcd(a,b)=gcd(b,r)
证明 我们假设 d 是 a 和 b 的公约数, 即 d∣a且 d∣b, 那么根据定理2, d 也能整除 a−bq=r 所以 a 和 b 的任何公约数也是 b 和 r 的公约数;
类似地, 假设 d 是 b 和 r 的公约数, 即 d∣bd∣b 且 d∣rd∣r, 那么根据定理2, d 也能整除 a=bq+r. 所以 b 和 r 的任何公约数也是 a 和 b 的公约数;
因此, a 与 b 和 b 与 r 拥有相同的公约数. 所以 gcd(a,b)=gcd(b,r).
辗转相除法就是利用引理1, 把大数转换成小数. 例如, 求 gcd(287,91) 我们就把用较大的数除以较小的数. 首先用 287 除以 91, 得
287=91⋅3+14
我们有 gcd(287,91)=gcd(91,14) . 问题转换成求 gcd(91,14). 同样地, 用 91 除以 14, 得
91=14⋅6+7
有 gcd(91,14)=gcd(14,7) . 继续用 14 除以 7, 得
14=7⋅2+0
因为 7 整除 14, 所以 gcd(14,7)=7. 所以 gcd(287,91)=gcd(91,14)=gcd(14,7)=7.
我们可以很快写出辗转相除法的代码:
def gcd(a, b):
if b == 0: return a
return gcd(b, a % b)2.2 贝祖定理
现在我们讨论最大公约数的一个重要性质:
定理 4 贝祖定理 如果整数 a, b 不全为零, 则 gcd(a,b)是 a 和 b 的线性组合集 {ax+by∣x,y∈Z}中最小的元素. 这里的 x 和 y 被称为贝祖系数
证明 令 A={ax+by∣x,y∈Z}. 设存在 x0x0, y0y0 使 d0d0 是 A 中的最小正元素, d0=ax0+by0 现在用 d0去除 a, 这就得到唯一的整数 q(商) 和 r(余数) 满足
又 0⩽r<d0, d0 是 A 中最小正元素
∴ r=0 , d0∣a.
同理, 用 d0d0 去除 b, 可得 d0∣b. 所以说 d0 是 a 和 b 的公约数.
设 a 和 b 的最大公约数是 d, 那么 d∣(ax0+by0)即 d∣d0
∴∴ d0 是 a 和 b 的最大公约数.
我们可以对辗转相除法稍作修改, 让它在计算出最大公约数的同时计算出贝祖系数.
def gcd(a, b):
if b == 0: return a, 1, 0
d, x, y = gcd(b, a % b)
return d, y, x - (a / b) * y3. 线性同余方程
现在我们来讨论求解形如 ax≡b(modm) 的线性同余方程. 求解这样的线性同余方程是数论研究及其应用中的一项基本任务. 如何求解这样的方程呢? 我们要介绍的一个方法是通过求使得方程 ¯aa≡1(mod m) 成立的整数 ¯a. 我们称 ¯a 为 a 模 m 的逆. 下面的定理指出, 当 a 和 m 互素时, a 模 m 的逆必然存在.
定理 5 如果 a 和 m 为互素的整数且 m>1, 则 a 模 m 的逆存在, 并且是唯一的.
证明 由贝祖定理可知, ∵ gcd(a,m)=1 , ∴ 存在整数 x 和 y 使得 ax+my=1 这蕴含着 ax+my≡1(modm) ∵ my≡0(modm), 所以有 ax≡1(modm)
∴ x 为 a 模 m 的逆.
这样我们就可以调用辗转相除法 gcd(a, m) 求得 a 模 m 的逆.
a 模 m 的逆也被称为 a 在模m乘法群 Z∗m 中的逆元. 这里我并不想引入群论, 有兴趣的同学可参阅算法导论
求得了 a 模 m 的逆 ¯a 现在我们可以来解线性同余方程了. 具体的做法是这样的: 对于方程 ax≡b(modm)a , 我们在方程两边同时乘上 ¯a, 得 ¯aax≡¯ab(modm)
把 ¯aa≡1(modm) 带入上式, 得 x≡¯ab(modm)
x≡¯ab(modm) 就是方程的解. 注意同余方程会有无数个整数解, 所以我们用同余式来表示同余方程的解.
4. 中国余数定理
中国南北朝时期数学著作 孙子算经 中提出了这样一个问题:
有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?
用现代的数学语言表述就是: 下列同余方程组的解释多少?
孙子算经 中首次提到了同余方程组问题及其具体解法. 因此中国剩余定理称为孙子定理.
定理 6 中国余数定理 令 m1,m2,…,mn 为大于 1 且两两互素的正整数, a1,a2,…,an 是任意整数. 则同余方程组
有唯一的模 m=m1m2…mnm=m1m2…mn 的解.
证明 我们使用构造证明法, 构造出这个方程组的解. 首先对于 i=1,2,…,ni=1,2,…,n, 令
即, MiMi 是除了 mimi 之外所有模数的积. ∵∵ m1,m2,…,mn 两两互素, ∴∴ gcd(mi,Mi)=1. 由定理 5 可知, 存在整数 yiyi 是 MiMi 模 mimi 的逆. 即
上式等号两边同时乘 aiai 得
就是第 i 个方程的一个解; 那么怎么构造出方程组的解呢? 我们注意到, 根据 Mi 的定义可得, 对所有的 j≠ij≠i, 都有 aiMiyi≡0(modmj). 因此我们令
就是方程组的解.
有了这个结论, 我们可以解答 孙子算经 中的问题了: 对方程组的每个方程, 求出 MiMi , 然后调用 gcd(M_i, m_i) 求出 yiyi:
最后求出 x=−2⋅35+3⋅21+2⋅15=23≡23(mod105)
5. 费马小定理
现在我们来看数论中另外一个重要的定理, 费马小定理(Fermat's little theorem)
定理 7 费马小定理 如果 a 是一个整数, p 是一个素数, 那么
当 n 不为 p 或 0 时, 由于分子有质数p, 但分母不含p; 故分子的p能保留, 不被约分而除去. 即 p∣(np).
令 b 为任意整数, 根据二项式定理, 我们有
令 a=b+1, 即得 a^p ≡ a(mod p)
当 p 不整除 a 时, 根据推论 2, 有 a^p−1 ≡ 1(mod p)
6. 算法证明
我们终于可以来看 RSA 算法了. 先来看 RSA 算法是怎么运作的:
RSA 算法按照以下过程创建公钥和私钥:
- 随机选取两个大素数 p 和 q, p≠qp≠q;
- 计算 n=pq
- 选取一个与 (p−1)(q−1) 互素的小整数 e;
- 求 e 模 (p−1)(q−1) 的逆, 记作 d;
- 将 P=(e,n)公开, 是为公钥;
- 将 S=(d,n)保密, 是为私钥.
所以 RSA 加密算法是有效的.
(1) 式表明, 不仅可以用公钥加密, 私钥解密, 还可以用私钥加密, 公钥解密. 即加密计算 C=M^d mod n, 解密计算 M=C^e mod n
RSA 算法的安全性基于大整数的质因数分解的困难性. 由于目前没有能在多项式时间内对整数作质因数分解的算法, 因此无法在可行的时间内把 n 分解成 p 和 q 的乘积. 因此就无法求得 e 模 (p−1)(q−1)的逆, 也就无法根据公钥计算出私钥.
七、常见面试题
- 质数的用途
- RSA 算法描述
- RSA 算法加解密的过程
- RSA 算法使用场景
- 你了解多少关于 RSA 的数学数论知识
链接:https://juejin.cn/post/7173830290812370958
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


