








Android 控件自动贴边实现
最近接到个需求,需要在用户与App交互时,把SDK中之前实现过的悬浮控件贴边隐藏,结束交互后延迟一段时间再自动显示。本篇文章介绍一下实现的思路。
判断交互
用户与App交互、结束交互可以通过监听触摸事件来实现。建议使用的Activity的dispatchTouchEvent,Activity下的所有触摸事件分发时都会回调此方法,代码如下:
class AutoEdgeHideActivity : BaseGestureDetectorActivity() {
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
// 手指按下,开始本次交互
// 在此实现隐藏逻辑
}
MotionEvent.ACTION_UP -> {
// 手指抬起,结束本次交互
// 在此实现延迟显示功能
}
}
return super.dispatchTouchEvent(ev)
}
}隐藏与显示
想要实现的效果是当用户与App交互时,悬浮控件平移贴边,但保留一部分显示。结束交互延迟一段时间后,悬浮控件平移回原来的位置。
此处通过ValueAnimator来实现,计算好控件的起始和结束位置,然后改变控件的x坐标,代码如下:
private fun xCoordinateAnimator(view: View, startX: Float, endX: Float) {
val animator = ValueAnimator.ofFloat(startX, endX)
animator.addUpdateListener {
// 不断更改控件的X坐标
view.x = it.animatedValue as Float
}
// 设置插值器,速度由快变慢
animator.interpolator = DecelerateInterpolator()
// 设置动画的持续时间
animator.duration = 500
animator.start()
}示例
整合之后做了个示例Demo,完整代码如下:
class AutoEdgeHideActivity : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutAutoEdgeHideActivityBinding
private var widthPixels: Int = 0
private val autoShowInterval = 2
private var interacting = false
private var hidden = false
private var lastPositionX: Float = 0f
private val handler = Handler(Looper.myLooper() ?: Looper.getMainLooper())
private val autoShowRunnable = Runnable { autoShow() }
@SuppressLint("SetTextI18n")
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_auto_edge_hide_activity)
widthPixels = resources.displayMetrics.widthPixels
binding.includeTitle.tvTitle.text = "AutoEdgeHideExample"
binding.vFloatView.setOnClickListener {
if (hidden) {
// 当前为隐藏状态,先显示
// 把之前的延迟线程先取消
handler.removeCallbacks(autoShowRunnable)
autoShow()
Toast.makeText(this, "手动显示控件", Toast.LENGTH_SHORT).show()
} else {
// 相应正常的事件
Toast.makeText(this, "点击了浮标控件", Toast.LENGTH_SHORT).show()
}
}
}
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
if (!checkIsTouchFloatView(ev, binding.vFloatView)) {
// 起始ACTION_DOWN事件在浮标控件外,自动隐藏浮标控件,标记正在交互
interacting = true
handler.removeCallbacks(autoShowRunnable)
autoHide()
}
}
MotionEvent.ACTION_UP -> {
if (interacting) {
// 交互结束,一定时间后自动显示,时间可以自由配置
interacting = false
handler.postDelayed(autoShowRunnable, autoShowInterval * 1000L)
}
}
}
return super.dispatchTouchEvent(ev)
}
/**
* 检查是否触摸浮标控件
*/
private fun checkIsTouchFloatView(ev: MotionEvent, view: View): Boolean {
val screenLocation = IntArray(2)
view.getLocationOnScreen(screenLocation)
val viewX = screenLocation[0]
val viewY = screenLocation[1]
return (ev.x >= viewX && ev.x <= (viewX + view.width)) && (ev.y >= viewY && ev.y <= (viewY + view.height))
}
private fun autoShow() {
if (hidden) {
hidden = false
binding.vFloatView.let {
xCoordinateAnimator(it, it.x, lastPositionX)
}
}
}
private fun autoHide() {
if (!hidden) {
hidden = true
binding.vFloatView.let {
// 记录一下显示状态下的x坐标
lastPositionX = it.x
// 隐藏时的x坐标,留一点控件的边缘显示(示例中默认控件在屏幕右侧)
val endX = widthPixels - it.width * 0.23f
xCoordinateAnimator(it, lastPositionX, endX)
}
}
}
private fun xCoordinateAnimator(view: View, startX: Float, endX: Float) {
val animator = ValueAnimator.ofFloat(startX, endX)
animator.addUpdateListener {
view.x = it.animatedValue as Float
}
animator.interpolator = DecelerateInterpolator()
animator.duration = 500
animator.start()
}
}效果如图:
链接:https://juejin.cn/post/7170191911284637727
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
终于理解~Android 模块化里的资源冲突
⚽ 前言
作为 Android 开发者,我们常常需要去管理非常多不同的资源文件,编译时这些资源文件会被统一地收集和整合到同一个包下面。根据官方的《Configure your build》文档介绍的构建过程可以总结这个过程:
- 编译器会将源码文件转换成包含了二进制字节码、能运行在 Android 设备上的 DEX 文件,而其他文件则被转换成编译后资源。
- APK 打包工具则会将 DEX 文件和编译后资源组合成独立的 APK 文件。
但如果资源的命名发生了碰撞、冲突,会对编译产生什么影响?
事实证明这个影响是不确定的,尤其是涉及到构建外部 Library。
本文将探究一些不同的资源冲突案例,并逐个说明怎样才能安全地命名资源。
🇦🇷 App module 内资源冲突
先来看个最简单的资源冲突的案例:同一个资源文件中出现两个命名、类型一样的资源定义,比如:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
<string name="hello_world">Hello World!</string>
</resources>试图去编译的话,会导致显而易见的错误提示:
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> /.../strings.xml: Error: Found item String/hello_world more than one time
类似的,另一种常见冲突是在多个文件里定义冲突的资源:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>
<!--other_strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>我们会收到类似的编译错误,而这次的错误将列出所有发生冲突的具体文件位置。
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> [string/hello_world] /.../other_strings.xml
[string/hello_world] /.../strings.xml: Error: Duplicate resourcesAndroid 平台上资源的运作方式变得愈加清晰。我们需要为 App module 指定在类型、名称、设备配置等限定组合下的唯一资源。也就是说,当 App module 引用 string/hello_world 资源的时候,有且仅有一个值被解析出来。开发者们必须解决发生的资源冲突,可以选择删除那些内容重复的资源、重命名仍然需要的资源、亦或移动到其他限定条件下的资源文件。
更多关于资源和限定的信息可以参考官方的《App resources overview》 文档。
🇩🇪 Library 和 App module 的资源冲突
下面这个案例,我们将研究 Library module 定义了一个和 App module 重复的资源而引发的冲突。
<!--app/../strings.xml-->
<resources>
<string name="hello">Hello from the App!</string>
</resources>
<!--library/../strings.xml-->
<resources>
<string name="hello">Hello from the Library!</string>
</resources>当你编译上面的代码的时候,发现竟然通过了。从我们上个章节的发现来看,我们可以推测 Android 肯定采用了一个规则,去确保在这种场景下仍能够找到一个独有的 string/hello 资源值。
根据官方的《Create an Android library》文档:
编译工具会将来自 Library module 的资源和独立的 App module 资源进行合并。如果双方均具备一个资源 ID 的话,将采用 App 的资源。
这样的话,将会对模块化的 App 开发造成什么影响?比如我们在 Library 中定义了这么一个 TextView 布局:
<!--library/../text_view.xml-->
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello"
xmlns:android="http://schemas.android.com/apk/res/android" />AS 中该布局的预览是这样的。
现在我们决定将这个 TextView 导入到 App module 的布局中:
<!--app/../activity_main.xml-->
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center"
tools:context=".MainActivity"
>
<include layout="@layout/text_view" />
</LinearLayout>无论是 AS 中预览还是实际运行,我们可以看到下面的一个显示结果:
不仅是通过布局访问 string/hello 的 App module 会拿到 “Hello from the App!”,Library 本身拿到的也是如此。基于这个原因,我们需要警惕不要无意覆盖 Lbrary 中的资源定义。
🇧🇷 Library 之间的资源冲突
再一个案例,我们将讨论下当多个 Library 里定义了冲突的资源,会发生什么。
首先来看下如下的布局,如果这样写的话会产生什么结果?
<!--library1/../strings.xml-->
<resources>
<string name="hello">Hello from Library 1!</string>
</resources>
<!--library2/../strings.xml-->
<resources>
<string name="hello">Hello from Library 2!</string>
</resources>
<!--app/../activity_main.xml-->
<TextView
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello" />string/hello 将会被显示成什么?
事实上这取决于 App build.gradle 文件里依赖这些 Library 的顺序。再次到官方的《Create an Android library》文档里找答案:
如果多个 AAR 库之间发生了冲突,依赖列表里第一个列出(在依赖关系块的顶部)的资源将会被使用。
假使 App module 有这样的依赖列表:
dependencies {
implementation project(":library1")
implementation project(":library2")
...
}最后 string/hello 的值将会被编译成 Hello from Library 1!。
那么如果这两个 implementation 代码调换顺序,比如 implementation project(":library2") 在前、 implementation project(":library1") 在后,资源值则会被编译成 Hello from Library 2!。
从这种微妙的变化可以非常直观地看到,依赖顺序可以轻易地改变 App 的资源展示结果。
🇪🇸 自定义 Attributes 的资源冲突
目前为止讨论的示例都是针对 string 资源的使用,然而需要特别留意的是自定义 attributes 这种有趣的资源类型。
看下如下的 attr 定义:
<!--app/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>大家可能都认为上面的写法能通过编译、不会报错,而事实上这种写法必将导致下面的编译错误:
Execution failed for task ':app:mergeDebugResources'.
> /.../attrs.xml: Error: Found item Attr/freeText more than one time但如果 2 个 Library 也采用了这样的自定义 attr 写法:
<!--library1/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>
<!--library2/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>事实上它却能够通过编译。
然而,如果我们进一步将 Library2 的 attr 做些调整,比如改为 <attr name="freeText" format="boolean"/>。再次编译,它竟然又失败了,而且出现了更多令人费解的错误:
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> A failure occurred while executing com.android.build.gradle.internal.tasks.Workers$ActionFacade
> Android resource compilation failed
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: duplicate value for resource 'attr/freeText' with config ''.
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: resource previously defined here.
/.../app/build/intermediates/incremental/mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile.上面错误的一个重点是: mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile。
到底是怎么回事呢?
事实上 values.xml 的编译指的是为 App module 生成 R 类。编译期间,AAPT 会尝试在 R 类里为每个资源属性生成独一无二的值。而对于 styleable 类型里的每个自定义 attr,都会在 R 类里生成 2 个的属性值。
第一个是 styleable 命名空间属性值(位于 R.styleable 包下),第二个是全局的 attr 属性值(位于 R.attr 包下)。对于这个探讨的特殊案例,我们则遇到了全局属性值的冲突,并且由于此冲突造成存在 3 个属性值:
R.styleable.CustomStyleable_freeText:来自 Library1,用于解析string格式的、名称为freeText的 attrR.styleable.CustomStyleable2_freeText:来自 Library2,用于解析boolean格式的、名称为freeText的 attrR.attr.freeText:无法被成功解析,源自我们给它赋予了来自 2 个 Library 的数值,而它们的格式不同,造成了冲突
前面能通过编译的示例是因为 Library 间同名的 R.attr.freeText 格式也相同,最终为 App module 编译到的是独一无二的数值。需要注意:每个 module 具备自己的 R 类,我们不能总是指望属性的数值在 Library 间保持一致。
再次看下官方的《Create an Android library》文档的建议:
当你构建依赖其他 Library 的 App module 时,Library module 们将会被编译成 AAR 文件再添加到 App module 中。所以,每个 Library 都会具备自己的
R类,用 Library 的包名进行命名。所有包都会创建从 App module 和 Library module 生成的R类,包括 App module 的包和 Library moudle 的包。
📝 结语
所以我们能从上面的这些探讨得到什么启发?
是资源编译过程的复杂和微妙吗?
确实是的。但是作为开发者,我们能为自己和团队做的是:解释清楚定义的资源想要做什么,也就是说可以加上名称前缀。我们最喜欢的官方文档《Create an Android library》也提到了这宝贵的一点:
通用的资源 ID 应当避免发生资源冲突,可以考虑使用前缀或其他一致的、对 module 来说独一无二的命名方案(抑或是整个项目都是独一无二的命名)。
根据这个建议,比较好的做法是在我们的项目和团队中建立一个模式:在 module 中的所有资源前加上它的 module 名称,例如library_help_text。
这将带来两个好处:
大大降低了名称冲突的概率。
明确资源覆盖的意图。
比如也在 App module 中创建
library_help_text的话,则表明开发者是有意地覆盖 Library module 中的某些定义。有的时候我们的确会想去覆盖一些其他资源,而这样的编码方式可以明确地告诉自己和团队,在编译的时候会发生预期的覆盖。
抛开内部开发不谈,至少是所有公开的资源都应该加上前缀,尤其是作为一个供应商或者开源项目去发布我们的 library。
可以往的经验来看,Google 自己的 library 也没有对所有的资源进行恰当地前缀命名。这将导致意外的副作用:依赖我们发行的 library 可能会因为命名冲突引发 App 编译失败。
Not a great look!
例如,我们可以看到 Material Design library 会给它们的颜色资源统一地添加 mtrl 的前缀。可是 styleable 下嵌套的 attribute resources 却没有使用 material 之类的前缀。
所以你会看到:假使一个 module 依赖了 Material library,同时依赖的另一个 library 中包含了与 Material library 一样名称的 attribute,那么在为这个 moudle 生成 R 类的时候,会发生冲突的可能。
链接:https://juejin.cn/post/7170562275374268447
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从0到1搭建前端监控平台,面试必备的亮点项目
前言
常常会苦恼,平常做的项目很普通,没啥亮点;面试中也经常会被问到:做过哪些亮点项目吗?
前端监控就是一个很有亮点的项目,各个大厂都有自己的内部实现,没有监控的项目好比是在裸奔
文章分成以下六部分来介绍:
自研监控平台解决了哪些痛点,实现了什么亮点功能?
相比sentry等监控方案,自研监控的优势有哪些?
前端监控的设计方案、监控的目的
数据的采集方式:错误信息、性能数据、用户行为、加载资源、个性化指标等
设计开发一个完整的监控SDK
监控后台错误还原演示示例
痛点
某⼀天用户:xx商品无法下单!
⼜⼀天运营:xx广告在手机端打开不了!
大家反馈的bug,怎么都复现不出来,尴尬的要死!😢
如何记录项目的错误,并将错误还原出来,这是监控平台要解决的痛点之一
错误还原
web-see 监控提供三种错误还原方式:定位源码、播放录屏、记录用户行为
定位源码
项目出错,要是能定位到源码就好了,可线上的项目都是打包后的代码,也不能把 .map 文件放到线上
监控平台通过 source-map 可以实现该功能
最终效果:
播放录屏
多数场景下,定位到具体的源码,就可以定位bug,但如果是用户做了异常操作,或者是在某些复杂操作下才出现的bug,仅仅通过定位源码,还是不能还原错误
要是能把用户的操作都录制下来,然后通过回放来还原错误就好了
监控平台通过 rrweb 可以实现该功能
最终效果:
回放的录屏中,记录了用户的所有操作,红色的线代表了鼠标的移动轨迹
前端录屏确实是件很酷的事情,但是不能走极端,如果把用户的所有操作都录制下来,是没有意义的
我们更关注的是,页面报错的时候用户做了哪些操作,所以监控平台只把报错前10s的视频保存下来(单次录屏时长也可以自定义)
记录用户行为
通过 定位源码 + 播放录屏 这套组合,还原错误应该够用了,同时监控平台也提供了 记录用户行为 这种方式
假如用户做了很多操作,操作的间隔超过了单次录屏时长,录制的视频可能是不完整的,此时可以借助用户行为来分析用户的操作,帮助复现bug
最终效果:
用户行为列表记录了:鼠标点击、接口调用、资源加载、页面路由变化、代码报错等信息
通过 定位源码、播放录屏、记录用户行为 这三板斧,解决了复现bug的痛点
自研监控的优势
为什么不直接用sentry私有化部署,而选择自研前端监控?
这是优先要思考的问题,sentry作为前端监控的行业标杆,有很多可以借鉴的地方
相比sentry,自研监控平台的优势在于:
1、可以将公司的SDK统一成一个,包括但不限于:监控SDK、埋点SDK、录屏SDK、广告SDK等
2、提供了更多的错误还原方式,同时错误信息可以和埋点信息联动,便可拿到更细致的用户行为栈,更快的排查线上错误
3、监控自定义的个性化指标:如 long task、memory页面内存、首屏加载时间等。过多的长任务会造成页面丢帧、卡顿;过大的内存可能会造成低端机器的卡死、崩溃
4、统计资源缓存率,来判断项目的缓存策略是否合理,提升缓存率可以减少服务器压力,也可以提升页面的打开速度
设计思路
一个完整的前端监控平台包括三个部分:数据采集与上报、数据分析和存储、数据展示
监控目的
异常分析
按照 5W1H 法则来分析前端异常,需要知道以下信息
What,发⽣了什么错误:JS错误、异步错误、资源加载、接口错误等
When,出现的时间段,如时间戳
Who,影响了多少用户,包括报错事件数、IP
Where,出现的页面是哪些,包括页面、对应的设备信息
Why,错误的原因是为什么,包括错误堆栈、⾏列、SourceMap、异常录屏
How,如何定位还原问题,如何异常报警,避免类似的错误发生
错误数据采集
错误信息是最基础也是最重要的数据,错误信息主要分为下面几类:
JS 代码运行错误、语法错误等
异步错误等
静态资源加载错误
接口请求报错
错误捕获方式
1)try/catch
只能捕获代码常规的运行错误,语法错误和异步错误不能捕获到
示例:
// 示例1:常规运行时错误,可以捕获 ✅
try {
let a = undefined;
if (a.length) {
console.log('111');
}
} catch (e) {
console.log('捕获到异常:', e);
}
// 示例2:语法错误,不能捕获 ❌
try {
const notdefined,
} catch(e) {
console.log('捕获不到异常:', 'Uncaught SyntaxError');
}
// 示例3:异步错误,不能捕获 ❌
try {
setTimeout(() => {
console.log(notdefined);
}, 0)
} catch(e) {
console.log('捕获不到异常:', 'Uncaught ReferenceError');
}
复制代码2) window.onerror
window.onerror 可以捕获常规错误、异步错误,但不能捕获资源错误
/**
* @param { string } message 错误信息
* @param { string } source 发生错误的脚本URL
* @param { number } lineno 发生错误的行号
* @param { number } colno 发生错误的列号
* @param { object } error Error对象
*/
window.onerror = function(message, source, lineno, colno, error) {
console.log('捕获到的错误信息是:', message, source, lineno, colno, error )
}
复制代码示例:
window.onerror = function(message, source, lineno, colno, error) {
console.log("捕获到的错误信息是:", message, source, lineno, colno, error);
};
// 示例1:常规运行时错误,可以捕获 ✅
console.log(notdefined);
// 示例2:语法错误,不能捕获 ❌
const notdefined;
// 示例3:异步错误,可以捕获 ✅
setTimeout(() => {
console.log(notdefined);
}, 0);
// 示例4:资源错误,不能捕获 ❌
let script = document.createElement("script");
script.type = "text/javascript";
script.src = "https://www.test.com/index.js";
document.body.appendChild(script);
复制代码3) window.addEventListener
当静态资源加载失败时,会触发 error 事件, 此时 window.onerror 不能捕获到
示例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<script>
window.addEventListener('error', (error) => {
console.log('捕获到异常:', error);
}, true)
</script>
<!-- 图片、script、css加载错误,都能被捕获 ✅ -->
<img src="https://test.cn/×××.png">
<script src="https://test.cn/×××.js"></script>
<link href="https://test.cn/×××.css" rel="stylesheet" />
<script>
// new Image错误,不能捕获 ❌
// new Image运用的比较少,可以自己单独处理
new Image().src = 'https://test.cn/×××.png'
</script>
</html>
复制代码4)Promise错误
Promise中抛出的错误,无法被 window.onerror、try/catch、 error 事件捕获到,可通过 unhandledrejection 事件来处理
示例:
try {
new Promise((resolve, reject) => {
JSON.parse("");
resolve();
});
} catch (err) {
// try/catch 不能捕获Promise中错误 ❌
console.error("in try catch", err);
}
// error事件 不能捕获Promise中错误 ❌
window.addEventListener(
"error",
error => {
console.log("捕获到异常:", error);
},
true
);
// window.onerror 不能捕获Promise中错误 ❌
window.onerror = function(message, source, lineno, colno, error) {
console.log("捕获到异常:", { message, source, lineno, colno, error });
};
// unhandledrejection 可以捕获Promise中的错误 ✅
window.addEventListener("unhandledrejection", function(e) {
console.log("捕获到异常", e);
// preventDefault阻止传播,不会在控制台打印
e.preventDefault();
});
复制代码Vue 错误
Vue项目中,window.onerror 和 error 事件不能捕获到常规的代码错误
异常代码:
export default {
created() {
let a = null;
if(a.length > 1) {
// ...
}
}
};
复制代码main.js中添加捕获代码:
window.addEventListener('error', (error) => {
console.log('error', error);
});
window.onerror = function (msg, url, line, col, error) {
console.log('onerror', msg, url, line, col, error);
};
复制代码控制台会报错,但是 window.onerror 和 error 不能捕获到
vue 通过 Vue.config.errorHander 来捕获异常:
Vue.config.errorHandler = (err, vm, info) => {
console.log('进来啦~', err);
}
复制代码控制台打印:
errorHandler源码分析
在src/core/util目录下,有一个error.js文件
function globalHandleError (err, vm, info) {
// 获取全局配置,判断是否设置处理函数,默认undefined
// 配置config.errorHandler方法
if (config.errorHandler) {
try {
// 执行 errorHandler
return config.errorHandler.call(null, err, vm, info)
} catch (e) {
// 如果开发者在errorHandler函数中,手动抛出同样错误信息throw err,判断err信息是否相等,避免log两次
if (e !== err) {
logError(e, null, 'config.errorHandler')
}
}
}
// 没有配置,常规输出
logError(err, vm, info)
}
function logError (err, vm, info) {
if (process.env.NODE_ENV !== 'production') {
warn(`Error in ${info}: "${err.toString()}"`, vm)
}
/* istanbul ignore else */
if ((inBrowser || inWeex) && typeof console !== 'undefined') {
console.error(err)
} else {
throw err
}
}
复制代码通过源码明白了,vue 使用 try/catch 来捕获常规代码的报错,被捕获的错误会通过 console.error 输出而避免应用崩溃
可以在 Vue.config.errorHandler 中将捕获的错误上报
Vue.config.errorHandler = function (err, vm, info) {
// handleError方法用来处理错误并上报
handleError(err);
}
复制代码React 错误
从 react16 开始,官方提供了 ErrorBoundary 错误边界的功能,被该组件包裹的子组件,render 函数报错时会触发离当前组件最近父组件的ErrorBoundary
生产环境,一旦被 ErrorBoundary 捕获的错误,也不会触发全局的 window.onerror 和 error 事件
父组件代码:
import React from 'react';
import Child from './Child.js';
// window.onerror 不能捕获render函数的错误 ❌
window.onerror = function (err, msg, c, l) {
console.log('err', err, msg);
};
// error 不能render函数的错误 ❌
window.addEventListener( 'error', (error) => {
console.log('捕获到异常:', error);
},true
);
class ErrorBoundary extends React.Component {
constructor(props) {
super(props);
this.state = { hasError: false };
}
static getDerivedStateFromError(error) {
// 更新 state 使下一次渲染能够显示降级后的 UI
return { hasError: true };
}
componentDidCatch(error, errorInfo) {
// componentDidCatch 可以捕获render函数的错误
console.log(error, errorInfo)
// 同样可以将错误日志上报给服务器
reportError(error, errorInfo);
}
render() {
if (this.state.hasError) {
// 自定义降级后的 UI 并渲染
return <h1>Something went wrong.</h1>;
}
return this.props.children;
}
}
function Parent() {
return (
<div>
父组件
<ErrorBoundary>
<Child />
</ErrorBoundary>
</div>
);
}
export default Parent;
复制代码子组件代码:
// 子组件 渲染出错
function Child() {
let list = {};
return (
<div>
子组件
{list.map((item, key) => (
<span key={key}>{item}</span>
))}
</div>
);
}
export default Child;
复制代码同vue项目的处理类似,react项目中,可以在 componentDidCatch 中将捕获的错误上报
componentDidCatch(error, errorInfo) {
// handleError方法用来处理错误并上报
handleError(err);
}
复制代码跨域问题
如果当前页面中,引入了其他域名的JS资源,如果资源出现错误,error 事件只会监测到一个 script error 的异常。
示例:
window.addEventListener("error", error => {
console.log("捕获到异常:", error);
}, true );
// 当前页面加载其他域的资源,如https://www.test.com/index.js
<script src="https://www.test.com/index.js"></script>
// 加载的https://www.test.com/index.js的代码
function fn() {
JSON.parse("");
}
fn();
复制代码报错信息:
只能捕获到 script error 的原因:
是由于浏览器基于安全考虑,故意隐藏了其它域JS文件抛出的具体错误信息,这样可以有效避免敏感信息无意中被第三方(不受控制的)脚本捕获到,因此,浏览器只允许同域下的脚本捕获具体的错误信息
解决方法:
前端script加crossorigin,后端配置 Access-Control-Allow-Origin
<script src="https://www.test.com/index.js" crossorigin></script>
复制代码添加 crossorigin 后可以捕获到完整的报错信息:
如果不能修改服务端的请求头,可以考虑通过使用 try/catch 绕过,将错误抛出
<!doctype html>
<html>
<body>
<script src="https://www.test.com/index.js"></script>
<script>
window.addEventListener("error", error => {
console.log("捕获到异常:", error);
}, true );
try {
// 调用https://www.test.com/index.js中定义的fn方法
fn();
} catch (e) {
throw e;
}
</script>
</body>
</html>
复制代码接口错误
接口监控的实现原理:针对浏览器内置的 XMLHttpRequest、fetch 对象,利用 AOP 切片编程重写该方法,实现对请求的接口拦截,从而获取接口报错的情况并上报
1)拦截XMLHttpRequest请求示例:
function xhrReplace() {
if (!("XMLHttpRequest" in window)) {
return;
}
const originalXhrProto = XMLHttpRequest.prototype;
// 重写XMLHttpRequest 原型上的open方法
replaceAop(originalXhrProto, "open", originalOpen => {
return function(...args) {
// 获取请求的信息
this._xhr = {
method: typeof args[0] === "string" ? args[0].toUpperCase() : args[0],
url: args[1],
startTime: new Date().getTime(),
type: "xhr"
};
// 执行原始的open方法
originalOpen.apply(this, args);
};
});
// 重写XMLHttpRequest 原型上的send方法
replaceAop(originalXhrProto, "send", originalSend => {
return function(...args) {
// 当请求结束时触发,无论请求成功还是失败都会触发
this.addEventListener("loadend", () => {
const { responseType, response, status } = this;
const endTime = new Date().getTime();
this._xhr.reqData = args[0];
this._xhr.status = status;
if (["", "json", "text"].indexOf(responseType) !== -1) {
this._xhr.responseText =
typeof response === "object" ? JSON.stringify(response) : response;
}
// 获取接口的请求时长
this._xhr.elapsedTime = endTime - this._xhr.startTime;
// 上报xhr接口数据
reportData(this._xhr);
});
// 执行原始的send方法
originalSend.apply(this, args);
};
});
}
/**
* 重写指定的方法
* @param { object } source 重写的对象
* @param { string } name 重写的属性
* @param { function } fn 拦截的函数
*/
function replaceAop(source, name, fn) {
if (source === undefined) return;
if (name in source) {
var original = source[name];
var wrapped = fn(original);
if (typeof wrapped === "function") {
source[name] = wrapped;
}
}
}
复制代码2)拦截fetch请求示例:
function fetchReplace() {
if (!("fetch" in window)) {
return;
}
// 重写fetch方法
replaceAop(window, "fetch", originalFetch => {
return function(url, config) {
const sTime = new Date().getTime();
const method = (config && config.method) || "GET";
let handlerData = {
type: "fetch",
method,
reqData: config && config.body,
url
};
return originalFetch.apply(window, [url, config]).then(
res => {
// res.clone克隆,防止被标记已消费
const tempRes = res.clone();
const eTime = new Date().getTime();
handlerData = {
...handlerData,
elapsedTime: eTime - sTime,
status: tempRes.status
};
tempRes.text().then(data => {
handlerData.responseText = data;
// 上报fetch接口数据
reportData(handlerData);
});
// 返回原始的结果,外部继续使用then接收
return res;
},
err => {
const eTime = new Date().getTime();
handlerData = {
...handlerData,
elapsedTime: eTime - sTime,
status: 0
};
// 上报fetch接口数据
reportData(handlerData);
throw err;
}
);
};
});
}
复制代码性能数据采集
谈到性能数据采集,就会提及加载过程模型图:
以Spa页面来说,页面的加载过程大致是这样的:
包括dns查询、建立tcp连接、发送http请求、返回html文档、html文档解析等阶段
最初,可以通过 window.performance.timing 来获取加载过程模型中各个阶段的耗时数据
// window.performance.timing 各字段说明
{
navigationStart, // 同一个浏览器上下文中,上一个文档结束时的时间戳。如果没有上一个文档,这个值会和 fetchStart 相同。
unloadEventStart, // 上一个文档 unload 事件触发时的时间戳。如果没有上一个文档,为 0。
unloadEventEnd, // 上一个文档 unload 事件结束时的时间戳。如果没有上一个文档,为 0。
redirectStart, // 表示第一个 http 重定向开始时的时间戳。如果没有重定向或者有一个非同源的重定向,为 0。
redirectEnd, // 表示最后一个 http 重定向结束时的时间戳。如果没有重定向或者有一个非同源的重定向,为 0。
fetchStart, // 表示浏览器准备好使用 http 请求来获取文档的时间戳。这个时间点会在检查任何缓存之前。
domainLookupStart, // 域名查询开始的时间戳。如果使用了持久连接或者本地有缓存,这个值会和 fetchStart 相同。
domainLookupEnd, // 域名查询结束的时间戳。如果使用了持久连接或者本地有缓存,这个值会和 fetchStart 相同。
connectStart, // http 请求向服务器发送连接请求时的时间戳。如果使用了持久连接,这个值会和 fetchStart 相同。
connectEnd, // 浏览器和服务器之前建立连接的时间戳,所有握手和认证过程全部结束。如果使用了持久连接,这个值会和 fetchStart 相同。
secureConnectionStart, // 浏览器与服务器开始安全链接的握手时的时间戳。如果当前网页不要求安全连接,返回 0。
requestStart, // 浏览器向服务器发起 http 请求(或者读取本地缓存)时的时间戳,即获取 html 文档。
responseStart, // 浏览器从服务器接收到第一个字节时的时间戳。
responseEnd, // 浏览器从服务器接受到最后一个字节时的时间戳。
domLoading, // dom 结构开始解析的时间戳,document.readyState 的值为 loading。
domInteractive, // dom 结构解析结束,开始加载内嵌资源的时间戳,document.readyState 的状态为 interactive。
domContentLoadedEventStart, // DOMContentLoaded 事件触发时的时间戳,所有需要执行的脚本执行完毕。
domContentLoadedEventEnd, // DOMContentLoaded 事件结束时的时间戳
domComplete, // dom 文档完成解析的时间戳, document.readyState 的值为 complete。
loadEventStart, // load 事件触发的时间。
loadEventEnd // load 时间结束时的时间。
}
复制代码后来 window.performance.timing 被废弃,通过 PerformanceObserver 来获取。旧的 api,返回的是一个 UNIX 类型的绝对时间,和用户的系统时间相关,分析的时候需要再次计算。而新的 api,返回的是一个相对时间,可以直接用来分析
现在 chrome 开发团队提供了 web-vitals 库,方便来计算各性能数据
用户行为数据采集
用户行为包括:页面路由变化、鼠标点击、资源加载、接口调用、代码报错等行为
设计思路
1、通过Breadcrumb类来创建用户行为的对象,来存储和管理所有的用户行为
2、通过重写或添加相应的事件,完成用户行为数据的采集
用户行为代码示例:
// 创建用户行为类
class Breadcrumb {
// maxBreadcrumbs控制上报用户行为的最大条数
maxBreadcrumbs = 20;
// stack 存储用户行为
stack = [];
constructor() {}
// 添加用户行为栈
push(data) {
if (this.stack.length >= this.maxBreadcrumbs) {
// 超出则删除第一条
this.stack.shift();
}
this.stack.push(data);
// 按照时间排序
this.stack.sort((a, b) => a.time - b.time);
}
}
let breadcrumb = new Breadcrumb();
// 添加一条页面跳转的行为,从home页面跳转到about页面
breadcrumb.push({
type: "Route",
form: '/home',
to: '/about'
url: "http://localhost:3000/index.html",
time: "1668759320435"
});
// 添加一条用户点击行为
breadcrumb.push({
type: "Click",
dom: "<button id='btn'>按钮</button>",
time: "1668759620485"
});
// 添加一条调用接口行为
breadcrumb.push({
type: "Xhr",
url: "http://10.105.10.12/monitor/open/pushData",
time: "1668760485550"
});
// 上报用户行为
reportData({
uuid: "a6481683-6d2e-4bd8-bba1-64819d8cce8c",
stack: breadcrumb.getStack()
});
复制代码页面跳转
通过监听路由的变化来判断页面跳转,路由有history、hash两种模式,history模式可以监听popstate事件,hash模式通过重写 pushState和 replaceState事件
vue项目中不能通过 hashchange 事件来监听路由变化,vue-router 底层调用的是 history.pushState 和 history.replaceState,不会触发 hashchange
vue-router源码:
function pushState (url, replace) {
saveScrollPosition();
var history = window.history;
try {
if (replace) {
history.replaceState({ key: _key }, '', url);
} else {
_key = genKey();
history.pushState({ key: _key }, '', url);
}
} catch (e) {
window.location[replace ? 'replace' : 'assign'](url);
}
}
...
// this.$router.push时触发
function pushHash (path) {
if (supportsPushState) {
pushState(getUrl(path));
} else {
window.location.hash = path;
}
}
复制代码通过重写 pushState、replaceState 事件来监听路由变化
// lastHref 前一个页面的路由
let lastHref = document.location.href;
function historyReplace() {
function historyReplaceFn(originalHistoryFn) {
return function(...args) {
const url = args.length > 2 ? args[2] : undefined;
if (url) {
const from = lastHref;
const to = String(url);
lastHref = to;
// 上报路由变化
reportData("routeChange", {
from,
to
});
}
return originalHistoryFn.apply(this, args);
};
}
// 重写pushState事件
replaceAop(window.history, "pushState", historyReplaceFn);
// 重写replaceState事件
replaceAop(window.history, "replaceState", historyReplaceFn);
}
function replaceAop(source, name, fn) {
if (source === undefined) return;
if (name in source) {
var original = source[name];
var wrapped = fn(original);
if (typeof wrapped === "function") {
source[name] = wrapped;
}
}
}
复制代码用户点击
给 document 对象添加click事件,并上报
function domReplace() {
document.addEventListener("click",({ target }) => {
const tagName = target.tagName.toLowerCase();
if (tagName === "body") {
return null;
}
let classNames = target.classList.value;
classNames = classNames !== "" ? `` : "";
const id = target.id ? ` id="${target.id}"` : "";
const innerText = target.innerText;
// 获取包含id、class、innerTextde字符串的标签
let dom = `<${tagName}${id}${
classNames !== "" ? classNames : ""
}>${innerText}</${tagName}>`;
// 上报
reportData({
type: 'Click',
dom
});
},
true
);
}
复制代码资源加载
获取页面中加载的资源信息,比如它们的 url 是什么、加载了多久、是否来自缓存等
可以通过 performance.getEntriesByType('resource') 获取,包括静态资源和动态资源,同时可以结合 initiatorType 字段来判断资源类型,对资源进行过滤
其中 PerformanceResourceTiming 来分析资源加载的详细数据
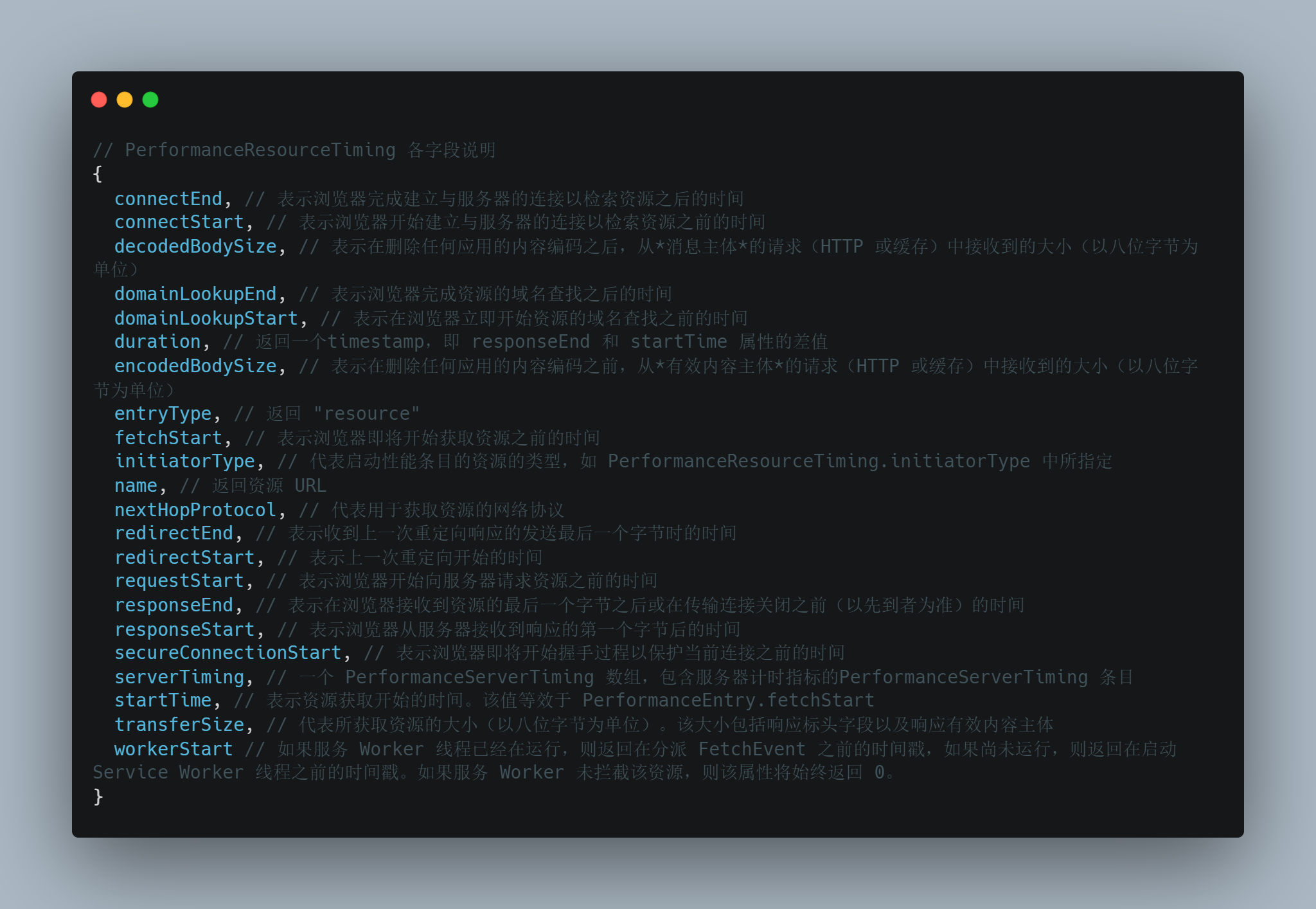
获取资源加载时长为 duration 字段,即 responseEnd 与 startTime 的差值
获取加载资源列表:
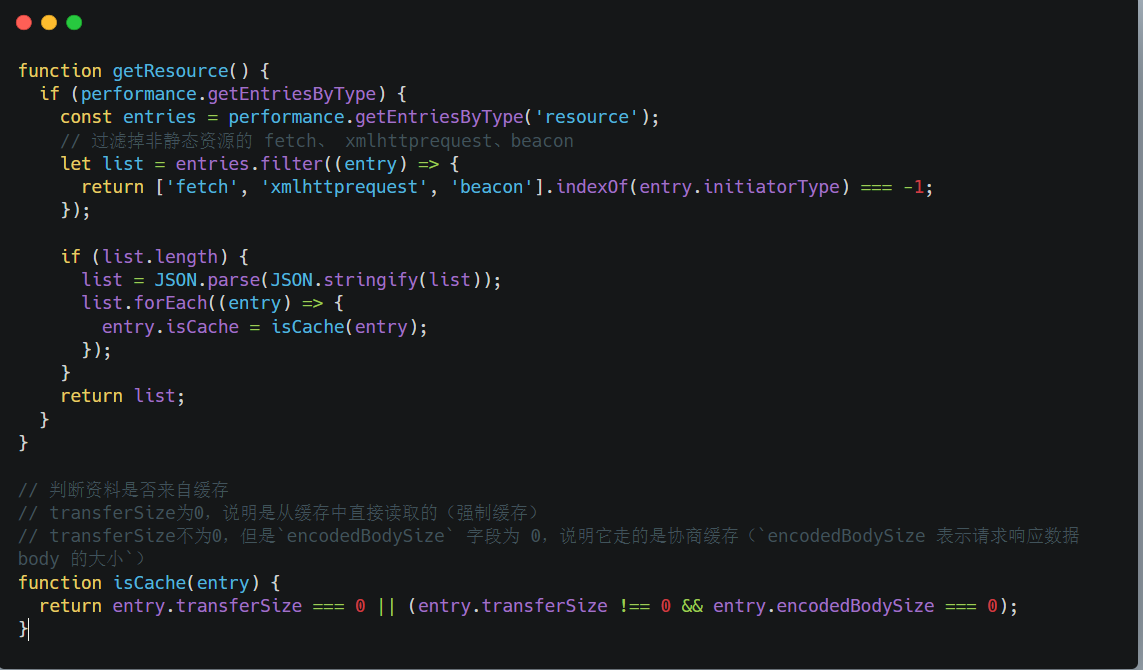
一个真实的页面中,资源加载大多数是逐步进行的,有些资源本身就做了延迟加载,有些是需要用户发生交互后才会去请求一些资源
如果我们只关注首页资源,可以在 window.onload 事件中去收集
如果要收集所有的资源,需要通过定时器反复地去收集,并且在一轮收集结束后,通过调用 clearResourceTimings 将 performance entries 里的信息清空,避免在下一轮收集时取到重复的资源
个性化指标
long task
执行时间超过50ms的任务,被称为 long task 长任务
获取页面的长任务列表:
const entryHandler = list => {
for (const long of list.getEntries()) {
// 获取长任务详情
console.log(long);
}
};
let observer = new PerformanceObserver(entryHandler);
observer.observe({ entryTypes: ["longtask"] });
复制代码memory页面内存
performance.memory 可以显示此刻内存占用情况,它是一个动态值,其中:
jsHeapSizeLimit 该属性代表的含义是:内存大小的限制。
totalJSHeapSize 表示总内存的大小。
usedJSHeapSize 表示可使用的内存的大小。
通常,usedJSHeapSize 不能大于 totalJSHeapSize,如果大于,有可能出现了内存泄漏
// load事件中获取此时页面的内存大小
window.addEventListener("load", () => {
console.log("memory", performance.memory);
});
复制代码首屏加载时间
首屏加载时间和首页加载时间不一样,首屏指的是屏幕内的dom渲染完成的时间
比如首页很长需要好几屏展示,这种情况下屏幕以外的元素不考虑在内
计算首屏加载时间流程
1)利用MutationObserver监听document对象,每当dom变化时触发该事件
2)判断监听的dom是否在首屏内,如果在首屏内,将该dom放到指定的数组中,记录下当前dom变化的时间点
3)在MutationObserver的callback函数中,通过防抖函数,监听document.readyState状态的变化
4)当document.readyState === 'complete',停止定时器和 取消对document的监听
5)遍历存放dom的数组,找出最后变化节点的时间,用该时间点减去performance.timing.navigationStart 得出首屏的加载时间
监控SDK
监控SDK的作用:数据采集与上报
整体架构
整体架构使用 发布-订阅 设计模式,这样设计的好处是便于后续扩展与维护,如果想添加新的hook或事件,在该回调中添加对应的函数即可
SDK 入口
src/index.js
对外导出init事件,配置了vue、react项目的不同引入方式
vue项目在Vue.config.errorHandler中上报错误,react项目在ErrorBoundary中上报错误
事件发布与订阅
通过添加监听事件来捕获错误,利用 AOP 切片编程,重写接口请求、路由监听等功能,从而获取对应的数据
src/load.js
用户行为收集
core/breadcrumb.js
创建用户行为类,stack用来存储用户行为,当长度超过限制时,最早的一条数据会被覆盖掉,在上报错误时,对应的用户行为会添加到该错误信息中
数据上报方式
支持图片打点上报和fetch请求上报两种方式
图片打点上报的优势:
1)支持跨域,一般而言,上报域名都不是当前域名,上报的接口请求会构成跨域
2)体积小且不需要插入dom中
3)不需要等待服务器返回数据
图片打点缺点是:url受浏览器长度限制
core/transportData.js
数据上报时机
优先使用 requestIdleCallback,利用浏览器空闲时间上报,其次使用微任务上报
监控SDK,参考了 sentry、 monitor、 mitojs
项目后台demo
主要用来演示错误还原功能,方式包括:定位源码、播放录屏、记录用户行为
后台demo功能介绍:
1、使用 express 开启静态服务器,模拟线上环境,用于实现定位源码的功能
2、server.js 中实现了 reportData(错误上报)、getmap(获取 map 文件)、getRecordScreenId(获取录屏信息)、 getErrorList(获取错误列表)的接口
3、用户可点击 'js 报错'、'异步报错'、'promise 错误' 按钮,上报对应的代码错误,后台实现错误还原功能
4、点击 'xhr 请求报错'、'fetch 请求报错' 按钮,上报接口报错信息
5、点击 '加载资源报错' 按钮,上报对应的资源报错信息
通过这些异步的捕获,了解监控平台的整体流程
安装与使用
npm官网搜索 web-see
仓库地址
监控SDK: web-see
监控后台: web-see-demo
总结
目前市面上的前端监控方案可谓是百花齐放,但底层原理都是相通的。从基础的理论知识到实现一个可用的监控平台,收获还是挺多的
有兴趣的小伙伴可以结合git仓库的源码玩一玩,再结合本文一起阅读,帮助加深理解
作者:海阔_天空
来源:juejin.cn/post/7172072612430872584
Flutter App开发黑白化UI实现方案ColorFiltered
一、相信大家对App黑白化并不陌生,经常可以看到大厂的App在一定的时候会呈现黑白样式如下:
这种效果在原生开发上大家肯定或多或少都了解过,原理都是在根布局绘制的时候将画笔饱和度设置成0;具体实现大家可以搜一搜这里就不贴了。
二、下面就来说说在Flutter这一侧需要怎么实现
- 原理和原生还是一样都是将饱和度设置成0,不过在Flutter这实现起来会比在原生更加的简单。
- Flutter直接为我们提供了ColorFiltered组件(以Color作为源的混合模式Widget)。
- 只需要将ColorFiltered做为根组件(包裹MaterialApp)即可改变整个应用的颜色模式。
实现的最终代码如下
class SaturationWidget extends StatelessWidget {
final Widget child;
///value [0,1]
final double saturation;
const SaturationWidget({
required this.child,
this.saturation = 0,
Key? key,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return ColorFiltered(
colorFilter: ColorFilter.matrix(_saturation(saturation)),
child: child,
);
}
///Default matrix
List<double> get _matrix => [
1, 0, 0, 0, 0, //R
0, 1, 0, 0, 0, //G
0, 0, 1, 0, 0, //B
0, 0, 0, 1, 0, //A
];
///Generate a matrix of specified saturation
///[sat] A value of 0 maps the color to gray-scale. 1 is identity.
List<double> _saturation(double sat) {
final m = _matrix;
final double invSat = 1 - sat;
final double R = 0.213 * invSat;
final double G = 0.715 * invSat;
final double B = 0.072 * invSat;
m[0] = R + sat;
m[1] = G;
m[2] = B;
m[5] = R;
m[6] = G + sat;
m[7] = B;
m[10] = R;
m[11] = G;
m[12] = B + sat;
return m;
}
}- 通过4x5的R、G、B、A、颜色矩阵来生成一个colorFilter
- 最终通过饱和度的值来计算颜色矩阵(饱和度计算算法从Android原生copy过来的)这样就轻松实现了整个App的黑白化(不过iOS的webview是不支持的)
三、最后来看下实现的效果
链接:https://juejin.cn/post/7172022347262590984
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin协程之一文看懂Channel管道
概述
Channel 类似于 Java 的 BlockingQueue 阻塞队列,不同之处在于 Channel 提供了挂起的 send() 和 receive() 方法。另外,通道 Channel 可以被关闭表明不再有数据会进入 Channel, 而接收端可以通过 for 循环取出数据。
Channel 也是生产-消费者模式,这个设计模式在协程中很常见。
基本使用
val channel = Channel<Int>()
// 发送
launch {
repeat(10) {
channel.send(it)
delay(200)
}
// 关闭
channel.close()
}
// 接收
launch {
for (i in channel) {
println("receive: $i")
}
// 关闭后
println("closed")
}produce 和 actor
produce 和 actor 是 Kotlin 提供的构造生产者与消费者的便捷方法。
其中 produce 方法用来启动一个生产者协程,并返回一个 ReceiveChannel 在其他协程中接收数据:
// produce 生产协程
val receiveChannel = CoroutineScope(Dispatchers.IO).produce {
repeat(10) {
send(it)
delay(200)
}
}
// 接收者 1
launch {
for (i in receiveChannel) {
println("receive-1: $i")
}
}
// 接收者 2
launch {
for (i in receiveChannel) {
println("receive-2: $i")
}
}输出:
2022-11-29 10:48:03.045 I/System.out: receive-1: 0
2022-11-29 10:48:03.250 I/System.out: receive-1: 1
2022-11-29 10:48:03.451 I/System.out: receive-2: 2
2022-11-29 10:48:03.654 I/System.out: receive-1: 3
2022-11-29 10:48:03.856 I/System.out: receive-2: 4
2022-11-29 10:48:04.059 I/System.out: receive-1: 5
2022-11-29 10:48:04.262 I/System.out: receive-2: 6
2022-11-29 10:48:04.466 I/System.out: receive-1: 7
2022-11-29 10:48:04.669 I/System.out: receive-2: 8
2022-11-29 10:48:04.871 I/System.out: receive-1: 9
反之也可以用 actor 来启动一个消费协程:
// actor 消费协程
val sendChannel = CoroutineScope(Dispatchers.IO).actor<Int> {
while (true) {
println("receive: ${receive()}")
}
}
// 发送者 1
launch {
repeat(10) {
sendChannel.send(it)
delay(200)
}
}
// 发送者 2
launch {
repeat(10) {
sendChannel.send(it * it)
delay(200)
}
}可以看出 produce 创建的是一个单生产者——多消费者的模型,而 actor 创建的是一个单消费者--多生产者的模型。
不过这些相关的 API 要不就是 ExperimentalCoroutinesApi 实验性标记的,要不就是 ObsoleteCoroutinesApi 废弃标记的,个人感觉暂时没必要使用它们。
Channel 是公平的
发送和接收操作是公平的,它们遵守先进先出原则。官方也给了一个例子:
data class Ball(var hits: Int)
fun main() = runBlocking {
val table = Channel<Ball>() // 一个共享的 table(桌子)
launch { player("ping", table) }
launch { player("pong", table) }
table.send(Ball(0)) // 率先打出第一个球
delay(1000) // 延迟 1 秒钟
coroutineContext.cancelChildren() // 游戏结束,取消它们
}
suspend fun player(name: String, table: Channel<Ball>) {
for (ball in table) { // 在循环中接收球
ball.hits++
println("$name $ball")
delay(300) // 等待一段时间
table.send(ball) // 将球发送回去
}
}由于 ping 协程首先被启动,所以它首先接收到了球,接着即使 ping 协程在将球发送后会立即开始接收,但是球还是被 pong 协程接收了,因为它一直在等待着接收球:
ping Ball(hits=1)
pong Ball(hits=2)
ping Ball(hits=3)
pong Ball(hits=4)带缓冲的 Channel
前面已经说过 Channel 实际上是一个队列,那它当然也存在一个缓存区以及缓存满后的策略(处理背压之类的问题),在创建 Channel 时可以指定两个相关的参数:
public fun <E> Channel(
capacity: Int = RENDEZVOUS,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E>这里的 Channel() 其实并不是构造函数,而是一个顶层函数,它内部会根据不同的入参来创建不同类型的 Channel 实例。其参数含义如下:
- capacity: Channel 缓存区的容量,默认为
RENDEZVOUS = 0 - onBufferOverflow: 缓冲区满后发送端的处理策略,默认挂起。当消费者处理数据比生产者生产数据慢时,新生产的数据会存入缓存区,当缓存区满后,生产者再调用 send() 方法会挂起,等待消费者处理数据。
看个小栗子:
// 创建缓存区大小为 4 的 Channel
val channel = Channel<Int>(4)
// 发送
launch {
repeat(10) {
channel.send(it)
println("send: $it")
delay(200)
}
}
// 接收
launch {
val channel = viewModel.channel
for (i in channel) {
println("receive: $i")
delay(1000)
}
}输出结果:
2022-11-28 17:16:47.905 I/System.out: send: 0
2022-11-28 17:16:47.907 I/System.out: receive: 0
2022-11-28 17:16:48.107 I/System.out: send: 1
2022-11-28 17:16:48.310 I/System.out: send: 2
2022-11-28 17:16:48.512 I/System.out: send: 3
2022-11-28 17:16:48.715 I/System.out: send: 4
2022-11-28 17:16:48.910 I/System.out: receive: 1
2022-11-28 17:16:48.916 I/System.out: send: 5 // 缓存区满了, receive 后才能继续发送
2022-11-28 17:16:49.913 I/System.out: receive: 2
2022-11-28 17:16:49.914 I/System.out: send: 6
2022-11-28 17:16:50.917 I/System.out: receive: 3
2022-11-28 17:16:50.917 I/System.out: send: 7
2022-11-28 17:16:51.920 I/System.out: receive: 4
2022-11-28 17:16:51.920 I/System.out: send: 8
2022-11-28 17:16:52.923 I/System.out: receive: 5
2022-11-28 17:16:52.923 I/System.out: send: 9
2022-11-28 17:16:53.925 I/System.out: receive: 6
2022-11-28 17:16:54.928 I/System.out: receive: 7
2022-11-28 17:16:55.932 I/System.out: receive: 8
2022-11-28 17:16:56.935 I/System.out: receive: 9Channel 构造类型
这一节来简单看看 Channel 构造的几种类型,为防止内容过于枯燥,就不深入剖析一些源码细节了。
Channel 构造
public fun <E> Channel(
capacity: Int = RENDEZVOUS,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E> =
when (capacity) {
RENDEZVOUS -> {
if (onBufferOverflow == BufferOverflow.SUSPEND)
RendezvousChannel(onUndeliveredElement)
else
ArrayChannel(1, onBufferOverflow, onUndeliveredElement)
}
CONFLATED -> {
require(onBufferOverflow == BufferOverflow.SUSPEND) {
"CONFLATED capacity cannot be used with non-default onBufferOverflow"
}
ConflatedChannel(onUndeliveredElement)
}
UNLIMITED -> LinkedListChannel(onUndeliveredElement) // ignores onBufferOverflow: it has buffer, but it never overflows
BUFFERED -> ArrayChannel( // uses default capacity with SUSPEND
if (onBufferOverflow == BufferOverflow.SUSPEND) CHANNEL_DEFAULT_CAPACITY else 1,
onBufferOverflow, onUndeliveredElement
)
else -> {
if (capacity == 1 && onBufferOverflow == BufferOverflow.DROP_OLDEST)
ConflatedChannel(onUndeliveredElement)
else
ArrayChannel(capacity, onBufferOverflow, onUndeliveredElement)
}
}前面我们说了 Channel() 并不是构造函数,而是一个顶层函数,它内部会根据不同的入参来创建不同类型的 Channel 实例。我们看看入参可取的值:
public const val UNLIMITED: Int = Int.MAX_VALUE
public const val RENDEZVOUS: Int = 0
public const val CONFLATED: Int = -1
public const val BUFFERED: Int = -2
public enum class BufferOverflow {
SUSPEND, DROP_OLDEST, DROP_LATEST
}其实光看这个构造的过程,以及两个入参的取值,我们基本上就能知道生成的这个 Channel 实例的表现了。
比如说 UNLIMITED 表示缓存区无限大的管道,它所创建的 Channel 叫 LinkedListChannel; 而 BUFFERED 或指定 capacity 大小的入参,创建的则是 ArrayChannel 实例,这也正是命名为 LinkedList(链表) 和 Array(数组) 的数据结构一个区别,前者可以视为无限大,后者有固定的容量大小。
比如说 SUSPEND 表示缓存区满后挂起, DROP_OLDEST 表示缓存区满后会删除缓存区里最旧的那个元素且把当前 send 的数据存入缓存区, DROP_LATEST 表示缓存区满后会删除缓存区里最新的那个元素且把当前 send 的数据存入缓存区。
Channel 类型
上面创建的这四种 Channel 都有一个共同的基类——AbstractChannel,简单看看他们的继承关系:
在 AbstractSendChannel 中有个重要的成员变量:
protected val queue = LockFreeLinkedListHead()它是一个循环双向链表,形成了一个队列 queue 结构,send() 数据时存入链表尾部,receive() 数据时就从链表头第一个节点取。至于具体的挂起,恢复等流程,感兴趣的可以自己看看源码。
值得一提的是, queue 中的节点类型可以大体分为三种:
- Send
- Receive
- Closed: 当调用
Channel.close()方法时,会往 queue 队列中加入 Closed 节点,这样当send or receive时就知道 Channel 已经关闭了。
另外,对于 ArrayChannel 管道,它有一个成员变量:
private var buffer: Array<Any?> = arrayOfNulls<Any?>(min(capacity, 8)).apply { fill(EMPTY) }这是一个数组类型,用来实现指定 capacity 的缓存区。但是它的初始大小不是 capacity, 主要是用来防止一些不必要的内存分配。
总结
Channel 类似于 BlockingQueue 阻塞队列,其不同之处是默认把阻塞行为换成了挂起,这也是协程的一大特性。它的思想是生产-消费模式(观察者模式)。
简单比较一下四种 Channel 类型:
- RendezvousChannel: 翻译成约会类型,缓存区大小为0,且指定为 SUSPEND 挂起策略。发送者和接收者一对一出现,接收者没出现,则发送者 send 会被挂起;发送者没出现,则接收者 receive 会被挂起。
- ConflatedChannel: 混合类型。发送者不会挂起,它只有一个 value 值,会被新的值覆盖掉;如果没有数据,则接收者会被挂起。
- LinkedListChannel: 不限缓存区大小的类型。发送者不会挂起,能一直往队列里存数据;队列无数据时接收者会被挂起。
- ArrayChannel: 指定缓存区大小的类型。当缓存区满时,发送者根据 BufferOverflow 策略来处理(是否挂起);当缓存区空时,接收者会被挂起。
链接:https://juejin.cn/post/7171272840426029063
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何启动协程
1.launch启动协程
fun main() = runBlocking {
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello")
Thread.sleep(2000L)
}
//输出结果
//Hello
//World!上面是两段代码,这两段代码都是通过launch启动了一个协程并且输出结果也是一样的。
第一段代码中的runBlocking是协程的另一种启动方式,这里先看第二段代码中的launch的启动方式;
- GlobalScope.launch
GlobalScope.launch是一个扩展函数,接收者是CoroutineScope,意思就是协程作用域,这里的launch等价于CoroutineScope的成员方法,如果要调用launch来启动一个协程就必须先拿到CoroutineScope对象。GlobalScope.launch源码如下
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}里面有三个参数:
- context: 意思是上下文,默认是
EmptyCoroutineContext,有默认值就可以不传,但是也可以传递Kotlin提供的Dispatchers来指定协程运行在哪一个线程中; - start:
CoroutineStart代表了协程的启动模式,不传则默认使用DEFAULT(根据上下文立即调度协程执行),除DEFAULT外还有其他类型:
- LAZY:延迟启动协程,只在需要时才启动。
- ATOMIC:以一种不可取消的方式,根据其上下文安排执行的协程;
- UNDISPATCHED:立即执行协程,直到它在当前线程中的第一个挂起点;
- block:
suspend是挂起的意思,CoroutineScope.()是一个扩展函数,Unit是一个函数类似于Java的void,那么suspend CoroutineScope.() -> Unit就可以这么理解了:首先,它是一个挂起函数,然后它还是CoroutineScope类的成员或者扩展函数,参数为空,返回值类型为Unit。
- delay(): delay()方法从字面理解就是延迟的意思,在上面的代码中延迟了1秒再执行World,从源码可以看出来它跟其他方法不一样,多了一个
suspend关键字
// 挂起
// ↓
public suspend fun delay(timeMillis: Long) {
if (timeMillis <= 0) return // don't delay
return suspendCancellableCoroutine sc@ { cont: CancellableContinuation<Unit> ->
// if timeMillis == Long.MAX_VALUE then just wait forever like awaitCancellation, don't schedule.
if (timeMillis < Long.MAX_VALUE) {
cont.context.delay.scheduleResumeAfterDelay(timeMillis, cont)
}
}
}suspend的意思就是挂起,被它修饰的函数就是挂起函数, 这也就意味着delay()方法具有挂起和恢复的能力;
- Thread.sleep(2000L)
这个是休眠2秒,那么这里为什么要有这个呢?要解答这疑问其实不难,将Thread.sleep(2000L)删除后在运行代码可以发现只打印了Hello然后程序就结束了,World!并没有被打印出来。
为什么? 将上面的代码转换成线程实现如下:
fun main() {
thread(isDaemon = true) {
Thread.sleep(1000L)
println("Hello World!")
}
}如果不添加isDaemon = true结果输出正常,如果加了那么就没有结果输出。isDaemon的加入后其实是创建了一个【守护线程】,这就意味着主线程结束的时候它会跟着被销毁,所以对于将Thread.sleep删除后导致GlobalScope创建的协程不能正常运行的主要原因就是通过launch创建的协程还没开始执行程序就结束了。那么Thread.sleep(2000L)的作用就是为了不让主线程退出。
另外这里还有一点需要注意:程序的执行过程并不是按照顺序执行的。
fun main() {
GlobalScope.launch { // 1
println("Launch started!") // 2
delay(1000L) // 3
println("World!") // 4
}
println("Hello") // 5
Thread.sleep(2000L) // 6
println("Process end!") // 7
}
/*
输出结果:
Hello
Launch started!
World!
Process end!
*/上面的代码执行顺序是1、5、6、2、3、4、7,这个其实好理解,首先执行1,然后再执行5,执行6的时候等待2秒,在这个等待过程中协程创建完毕了开始执行2、3、4都可以执行了,当2、3、4执行完毕后等待6执行完毕,最后执行7,程序结束。
2.runBlocking启动协程
fun main() {
runBlocking { // 1
println("launch started!") // 2
delay(1000L) // 3
println("World!") // 4
}
println("Hello") // 5
Thread.sleep(2000L) // 6
println("Process end!") // 7
}上面这段代码只是将GlobalScope.launch改成了runBlocking,但是执行顺序却完全不一样,它的执行顺讯为代码顺序1~7,这是因为runBlocking是带有阻塞属性的,它会阻塞当前线程的执行。这是它跟launch的最大差异。
runBlocking与lanuch的另外一个差异是GlobalScope,从代码中可以看出runBlocking并不需要这个,这点可以从源码中分析
public actual fun <T> runBlocking(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T): T {
...
}顶层函数:类似于Java中的静态函数,在Java中常用与工具类,例如StringUtils.lastElement();
runBlocking是一个顶层函数,因此可以直接使用它;在它的第二个参数block中有一个返回值类型:T,它刚好跟runBlocking的返回值类型是一样的,因此可以推测出runBlocking是可以有返回值的
fun main() {
val result = test(1)
println("result:$result")
}
fun test(num: Int) = runBlocking {
return@runBlocking num.toString()
}
//输出结果:
//result:1但是,Kotlin在文档中注明了这个函数不应该从协程中使用。它的设计目的是将常规的阻塞代码与以挂起风格编写的库连接起来,以便在主函数和测试中使用。 因此在正式环境中这种方式最好不用。
3.async启动协程
在 Kotlin 当中,可以使用 async{} 创建协程,并且还能通过它返回的句柄拿到协程的执行结果。
fun main() = runBlocking {
val deferred = async {
1 + 1
}
println("result:${deferred.await()}")
}
//输出结果:
//result:2上面的代码启动了两个协程,启动方式是runBlocking和async,因为async的调用需要一个作用域,而runBlocking恰好满足这个条件,GlobalScope.launch也可以满足这个条件但是GlobalScope也不建议在生产环境中使用,因为GlobalScope 创建的协程没有父协程,GlobalScope 通常也不与任何生命周期组件绑定。除非手动管理,否则很难满足我们实际开发中的需求。
上面的代码多了一个deferred.await()它就是获取最终结果的关键。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}async和launch一样也是一个扩展函数,也有三个参数,和launch的区别在于两点:
- block的函数类型:
launch返回的是Unit类型,async返回的是泛型T - 返回值不同:
launch返回的是Job,async返回的是Deffered<T>,而async可以返回执行结果的关键就在这里。
启动协程的三种方式都讲完了,这里存在一个疑问,launch和async都有返回值,为什么async可以获取执行结果,launch却不行?
这主要跟launch的返回值有关,launch的返回值Job代表的是协程的句柄,而句柄并不能返回协程的执行结果。
句柄: 句柄指的是中间媒介,通过这个中间媒介可以控制、操作某样东西。举个例子,door handle 是指门把手,通过门把手可以去控制门,但 door handle 并非 door 本身,只是一个中间媒介。又比如 knife handle 是刀柄,通过刀柄可以使用刀。
协程的三中启动方式区别如下:
- launch:无法获取执行结果,返回类型Job,不会阻塞;
- async:可获取执行结果,返回类型Deferred,调用await()会阻塞不调用则不会但也无法获取执行结果;
- runBlocking:可获取执行结果,阻塞当前线程的执行,多用于Demo、测试,官方推荐只用于连接线程与协程。
链接:https://juejin.cn/post/7171981069720223751
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android-多套环境的维护
记录一下项目中多套环境维护的一种思路。
一、多套环境要注意的问题
1、方便使用灵活配置
2、配置安全不会被覆写
3、扩展灵活
4、安装包可动态切换环境,方便测试人员使用
二、解决思路
1、Android中的Properties文件是只读的,打包后不可修改,所以用Properties文件维护所有的配置。
2、在一个安装包内动态切换环境,方便测试人员切换使用,这一点用MMKV来动态存储。为了防止打包时可能出现的错误,这一点也需要Properties文件来控制。
三、Properties文件的封装
package com.abc.kotlinstudio
import android.content.Context
import java.io.IOException
import java.util.*
object PropertiesUtil {
private var pros: Properties? = null
fun init(c: Context) {
pros = Properties()
try {
val input = c.assets.open("appConfig.properties")
pros?.load(input)
} catch (e: IOException) {
e.printStackTrace()
}
}
private fun getProperty(key: String, default: String): String {
return pros?.getProperty(key, default) ?: default
}
/**
* 判断是否是国内版本
*/
fun isCN(): Boolean {
return getProperty("isCN", "true").toBoolean()
}
/**
* 判断是否是正式环境
*/
fun isRelease(): Boolean {
return getProperty("isRelease", "false").toBoolean()
}
/**
* 获取版本的环境 dev test release
* 如果isRelease为true就读Properties文件,为false就读MMKV存储的值
*/
fun getEnvironment(): Int = if (isRelease()) {
when (getProperty("environment", "test")) {
"dev" -> {
GlobalUrlConfig.EnvironmentConfig.DEV.value
}
"test" -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
"release" -> {
GlobalUrlConfig.EnvironmentConfig.RELEASE.value
}
else -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
}
} else {
when (CacheUtil.getEnvironment(getProperty("environment", "test"))) {
"dev" -> {
GlobalUrlConfig.EnvironmentConfig.DEV.value
}
"test" -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
"release" -> {
GlobalUrlConfig.EnvironmentConfig.RELEASE.value
}
else -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
}
}
/**
* 获取国内外环境
*/
fun getCN(): Int = if (isRelease()) {
when (getProperty("isCN", "true")) {
"true" -> {
GlobalUrlConfig.CNConfig.CN.value
}
"false" -> {
GlobalUrlConfig.CNConfig.I18N.value
}
else -> {
GlobalUrlConfig.CNConfig.CN.value
}
}
} else {
when (CacheUtil.getCN(getProperty("isCN", "true"))) {
"true" -> {
GlobalUrlConfig.CNConfig.CN.value
}
"false" -> {
GlobalUrlConfig.CNConfig.I18N.value
}
else -> {
GlobalUrlConfig.CNConfig.CN.value
}
}
}
}注意二点,打包时如果Properties文件isRelease为true则所有配置都读Properties文件,如果为false就读MMKV存储的值;如果MMKV没有存储值,默认值也是读Properties文件。
内容比较简单:
isCN = true //是否国内环境
isRelease = false //是否release,比如日志的打印也可以用这个变量控制
#dev test release //三种环境
environment = dev //环境切换
四、MMKV封装
package com.abc.kotlinstudio
import android.os.Parcelable
import com.tencent.mmkv.MMKV
import java.util.*
object CacheUtil {
private var userId: Long = 0
//公共存储区的ID
private const val STORAGE_PUBLIC_ID = "STORAGE_PUBLIC_ID"
//------------------------公共区的键------------------
//用户登录的Token
const val KEY_PUBLIC_TOKEN = "KEY_PUBLIC_TOKEN"
//------------------------私有区的键------------------
//用户是否第一次登录
const val KEY_USER_IS_FIRST = "KEY_USER_IS_FIRST"
/**
* 设置用户的ID,根据用户ID做私有化分区存储
*/
fun setUserId(userId: Long) {
this.userId = userId
}
/**
* 获取MMKV对象
* @param isStoragePublic true 公共存储空间 false 用户私有空间
*/
fun getMMKV(isStoragePublic: Boolean): MMKV = if (isStoragePublic) {
MMKV.mmkvWithID(STORAGE_PUBLIC_ID)
} else {
MMKV.mmkvWithID("$userId")
}
/**
* 设置登录后token
*/
fun setToken(token: String) {
put(KEY_PUBLIC_TOKEN, token, true)
}
/**
* 获取登录后token
*/
fun getToken(): String = getString(KEY_PUBLIC_TOKEN)
/**
* 设置MMKV存储的环境
*/
fun putEnvironment(value: String) {
put("environment", value, true)
}
/**
* 获取MMKV存储的环境
*/
fun getEnvironment(defaultValue: String): String {
return getString("environment", true, defaultValue)
}
/**
* 设置MMKV存储的国内外环境
*/
fun putCN(value: String) {
put("isCN", value, true)
}
/**
* 获取MMKV存储的国内外环境
*/
fun getCN(defaultValue: String): String {
return getString("isCN", true, defaultValue)
}
//------------------------------------------基础方法区-----------------------------------------------
/**
* 基础数据类型的存储
* @param key 存储的key
* @param value 存储的值
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun put(key: String, value: Any?, isStoragePublic: Boolean): Boolean {
val mmkv = getMMKV(isStoragePublic)
return when (value) {
is String -> mmkv.encode(key, value)
is Float -> mmkv.encode(key, value)
is Boolean -> mmkv.encode(key, value)
is Int -> mmkv.encode(key, value)
is Long -> mmkv.encode(key, value)
is Double -> mmkv.encode(key, value)
is ByteArray -> mmkv.encode(key, value)
else -> false
}
}
/**
* 这里使用安卓自带的Parcelable序列化,它比java支持的Serializer序列化性能好些
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun <T : Parcelable> put(key: String, t: T?, isStoragePublic: Boolean): Boolean {
if (t == null) {
return false
}
return getMMKV(isStoragePublic).encode(key, t)
}
/**
* 存Set集合的数据
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun put(key: String, sets: Set<String>?, isStoragePublic: Boolean): Boolean {
if (sets == null) {
return false
}
return getMMKV(isStoragePublic).encode(key, sets)
}
/**
* 取数据,因为私有存储区用的多,所以这里给了默认参数为私有区域,如果公共区域取要记得改成true.下同
*/
fun getInt(key: String, isStoragePublic: Boolean = false, defaultValue: Int = 0): Int {
return getMMKV(isStoragePublic).decodeInt(key, defaultValue)
}
fun getDouble(
key: String,
isStoragePublic: Boolean = false,
defaultValue: Double = 0.00
): Double {
return getMMKV(isStoragePublic).decodeDouble(key, defaultValue)
}
fun getLong(key: String, isStoragePublic: Boolean = false, defaultValue: Long = 0L): Long {
return getMMKV(isStoragePublic).decodeLong(key, defaultValue)
}
fun getBoolean(
key: String,
isStoragePublic: Boolean = false,
defaultValue: Boolean = false
): Boolean {
return getMMKV(isStoragePublic).decodeBool(key, defaultValue)
}
fun getFloat(key: String, isStoragePublic: Boolean = false, defaultValue: Float = 0F): Float {
return getMMKV(isStoragePublic).decodeFloat(key, defaultValue)
}
fun getByteArray(key: String, isStoragePublic: Boolean = false): ByteArray? {
return getMMKV(isStoragePublic).decodeBytes(key)
}
fun getString(
key: String,
isStoragePublic: Boolean = false,
defaultValue: String = ""
): String {
return getMMKV(isStoragePublic).decodeString(key, defaultValue) ?: defaultValue
}
/**
* getParcelable<Class>("")
*/
inline fun <reified T : Parcelable> getParcelable(
key: String,
isStoragePublic: Boolean = false
): T? {
return getMMKV(isStoragePublic).decodeParcelable(key, T::class.java)
}
fun getStringSet(key: String, isStoragePublic: Boolean = false): Set<String>? {
return getMMKV(isStoragePublic).decodeStringSet(key, Collections.emptySet())
}
fun removeKey(key: String, isStoragePublic: Boolean = false) {
getMMKV(isStoragePublic).removeValueForKey(key)
}
fun clearAll(isStoragePublic: Boolean = false) {
getMMKV(isStoragePublic).clearAll()
}
}五、URL的配置
假设有国内外以及host、h5_host环境 :
object GlobalUrlConfig {
private val BASE_HOST_CN_DEV = "https://cn.dev.abc.com"
private val BASE_HOST_CN_TEST = "https://cn.test.abc.com"
private val BASE_HOST_CN_RELEASE = "https://cn.release.abc.com"
private val BASE_HOST_I18N_DEV = "https://i18n.dev.abc.com"
private val BASE_HOST_I18N_TEST = "https://i18n.test.abc.com"
private val BASE_HOST_I18N_RELEASE = "https://i18n.release.abc.com"
private val BASE_HOST_H5_CN_DEV = "https://cn.dev.h5.abc.com"
private val BASE_HOST_H5_CN_TEST = "https://cn.test.h5.abc.com"
private val BASE_HOST_H5_CN_RELEASE = "https://cn.release.h5.abc.com"
private val BASE_HOST_H5_I18N_DEV = "https://i18n.dev.h5.abc.com"
private val BASE_HOST_H5_I18N_TEST = "https://i18n.test.h5.abc.com"
private val BASE_HOST_H5_I18N_RELEASE = "https://i18n.release.h5.abc.com"
private val baseHostList: List<List<String>> = listOf(
listOf(
BASE_HOST_CN_DEV,
BASE_HOST_CN_TEST,
BASE_HOST_CN_RELEASE
), listOf(
BASE_HOST_I18N_DEV,
BASE_HOST_I18N_TEST,
BASE_HOST_I18N_RELEASE
)
)
private val baseHostH5List: List<List<String>> = listOf(
listOf(
BASE_HOST_H5_CN_DEV,
BASE_HOST_H5_CN_TEST,
BASE_HOST_H5_CN_RELEASE
), listOf(
BASE_HOST_H5_I18N_DEV,
BASE_HOST_H5_I18N_TEST,
BASE_HOST_H5_I18N_RELEASE
)
)
//base
var BASE_HOST: String =
baseHostList[PropertiesUtil.getCN()][PropertiesUtil.getEnvironment()]
//base_h5
var BASE_H5_HOST: String =
baseHostH5List[PropertiesUtil.getCN()][PropertiesUtil.getEnvironment()]
enum class CNConfig(var value: Int) {
CN(0), I18N(1)
}
enum class EnvironmentConfig(var value: Int) {
DEV(0), TEST(1), RELEASE(2)
}六、测试人员可在打好的App动态切换
可以弹Dialog动态切换环境,下面为测试代码:
//初始化
PropertiesUtil.init(this)
MMKV.initialize(this)
CacheUtil.setUserId(1000L)
val btSetCn = findViewById<AppCompatButton>(R.id.bt_set_cn)
val btSeti18n = findViewById<AppCompatButton>(R.id.bt_set_i8n)
val btSetDev = findViewById<AppCompatButton>(R.id.bt_set_dev)
val btSetTest = findViewById<AppCompatButton>(R.id.bt_set_test)
val btSetRelease = findViewById<AppCompatButton>(R.id.bt_set_release)
//App内找个地方弹一个Dialog动态修改下面的参数即可。
btSetCn.setOnClickListener {
CacheUtil.putCN("true")
//重启App(AndroidUtilCode工具类里面的方法)
AppUtils.relaunchApp(true)
}
btSeti18n.setOnClickListener {
CacheUtil.putCN("false")
AppUtils.relaunchApp(true)
}
btSetDev.setOnClickListener {
CacheUtil.putEnvironment("dev")
AppUtils.relaunchApp(true)
}
btSetTest.setOnClickListener {
CacheUtil.putEnvironment("test")
AppUtils.relaunchApp(true)
}
btSetRelease.setOnClickListener {
CacheUtil.putEnvironment("release")
AppUtils.relaunchApp(true)
}总结
一般会有4套环境: 开发环境,测试环境,预发布环境,正式环境。如果再区分国内外则乘以2。除了base的主机一般还会引入其他主机,比如h5的主机,这样会导致整个环境复杂多变。
刚开始是给测试打多渠道包,测试抱怨切环境,频繁卸载安装App很麻烦,于是做了这个优化。上线时记得把Properties文件isRelease设置为true,则发布的包就不会有问题,这个一般都不会忘记,风险很小。相比存文件或者其他形式安全很多。
写的比较匆忙,代码略粗糙,主要体现思路。以上!
链接:https://juejin.cn/post/7168497103516205069
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线程池封装及拒绝策略
前文提到线程的使用以及线程间通信方式,通常情况下我们通过new Thread或者new Runnable创建线程,这种情况下,需要开发者手动管理线程的创建和回收,线程对象没有复用,大量的线程对象创建与销毁会引起频繁GC,那么事否有机制自动进行线程的创建,管理和回收呢?线程池可以实现该能力。
线程池的优点:
- 线程池中线程重用,避免线程创建和销毁带来的性能开销
- 能有效控制线程数量,避免大量线程抢占资源造成阻塞
- 对线程进行简单管理,提供定时执行预计指定间隔执行等策略
线程池的封装实现
在java.util.concurrent包中提供了一系列的工具类以方便开发者创建和使用线程池,这些类的继承关系及说明如下:
| 类名 | 说明 | 备注 |
|---|---|---|
| Executor | Executor接口提供了一种任务提交后的执行机制,包括线程的创建与运行,线程调度等,通常不直接使用该类 | / |
| ExecutorService | ExecutorService接口,提供了创建,管理,终止Future执行的方法,用于跟踪一个或多个异步任务的进度,通常不直接使用该类 | / |
| ScheduledExecutorService | ExecutorService的实现接口,提供延时,周期性执行Future的能力,同时具备ExecutorService的基础能力,通常不直接使用该类 | / |
| AbstractExecutorService | AbstractExecutorService是个虚类,对ExecutorService中方法进行了默认实现,其提供了newTaskFor函数,用于获取RunnableFuture对象,该对象实现了submit,invokeAny和invokeAll方法,通常不直接使用该类 | / |
| ThreadPoolExecutor | 通过创建该类对象就可以构建一个线程池,通过调用execute方法可以向该线程池提交任务。通常情况下,开发者通过自定义参数,构造该类对象就来获得一个符合业务需求的线程池 | / |
| ScheduledThreadPoolExecutor | 通过创建该类对象就可以构建一个可以周期性执行任务的线程池,通过调用schedule,scheduleWithFixedDelay等方法可以向该线程池提交任务并在指定时间节点运行。通常情况下,开发者通过构造该类对象就来获得一个符合业务需求的可周期性执行任务的线程池 | / |
由上表可知,对于开发者而言,通常情况下我们可以通过构造ThreadPoolExecutor对象来获取一个线程池对象,通过其定义的execute方法来向该线程池提交任务并执行,那么怎么创建线程池呢?让我们一起看下
ThreadPoolExecutor
ThreadPoolExecutor完整参数的构造函数如下所示:
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:
* {@code corePoolSize < 0}
* {@code keepAliveTime < 0}
* {@code maximumPoolSize <= 0}
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} 从上述代码可以看出,在构建ThreadPoolExecutor时,主要涉及以下参数:
- corePoolSize:核心线程个数,一般情况下可以使用 处理器个数/2 作为核心线程数的取值,可以通过Runtime.getRuntime().availableProcessors()来获取处理器个数
- maximumPoolSize:最大线程个数,该线程池支持同时存在的最大线程数量
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长,非核心线程就会被回收,我们也可以通过allowCoreThreadTimeOut(true)来设置核心线程闲置时,在超时时间到达后回收
- unit:keepAliveTime的时间单位
- workQueue:线程池中的任务队列,当核心线程数满或最大线程数满时,通过线程池的execute方法提交的Runnable对象存储在这个参数中,遵循先进先出原则
- threadFactory:创建线程的工厂 ,用于批量创建线程,统一在创建线程时进行一些初始化设置,如是否守护线程、线程的优先级等。不指定时,默认使用Executors.defaultThreadFactory() 来创建线程,线程具有相同的NORM_PRIORITY优先级并且是非守护线程
- handler:任务拒绝处理策略,当线程数量等于最大线程数且等待队列已满时,就会采用拒绝处理策略处理新提交的任务,不指定时,默认的处理策略是AbortPolicy,即抛弃该任务
综上,我们可以看出创建一个线程池最少需要明确核心线程数,最大线程数,超时时间及单位,等待队列这五个参数,下面我们创建一个核心线程数为1,最大线程数为3,5s超时回收,等待队列最多能存放5个任务的线程池,代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));随后我们使用for循环向该executor中提交任务,代码如下:
public static void main(String[] args) {
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));
for (int i=0;i<10;i++) {
int finalI = i;
System.out.println("put runnable "+ finalI +"to executor");
// 向线程池提交任务
executor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");
}
});
}
}输出如下:
从输出可以看到,当提交一个任务到线程池时,其执行流程如下:
线程池拒绝策略
线程池拒绝策略有四类,定义在ThreadPoolExecutor中,分别是:
- AbortPolicy:默认拒绝策略,丢弃提交的任务并抛出RejectedExecutionException,在该异常输出信息中,可以看到当前线程池状态
- DiscardPolicy:丢弃新来的任务,但是不抛出异常
- DiscardOldestPolicy:丢弃队列头部的旧任务,然后尝试重新执行,如果再次失败,重复该过程
- CallerRunsPolicy:由调用线程处理该任务
当然,如果上述拒绝策略不能满足需求,我们也可以自定义异常,实现RejectedExecutionHandler接口,即可创建自己的线程池拒绝策略,下面是使用自定义拒绝策略的示例代码:
public static void main(String[] args) {
RejectedExecutionHandler handler = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("runnable " + r +" in executor "+executor+" is refused");
}
};
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5),handler);
for (int i=0;i<10;i++) {
int finalI = i;
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");
}
};
System.out.println("put runnable "+ runnable+" index:"+finalI +" to executor:"+executor);
executor.execute(runnable);
}
}输出如下:
任务队列
对于线程池而言,任务队列需要是BlockingQueue的实现类,BlockingQueue接口的实现类类图如下:
下面我们针对常用队列做简单了解:
ArrayBlockingQueue:ArrayBlockingQueue是基于数组的阻塞队列,在其内部维护一个定长数组,所以使用ArrayBlockingQueue时必须指定任务队列长度,因为不论对数据的写入或者读取都使用的是同一个锁对象,所以没有实现读写分离,同时在创建时我们可以指定锁内部是否采用公平锁,默认实现是非公平锁。
非公平锁与公平锁
公平锁:多个任务阻塞在同一锁时,等待时长长的优先获取锁
非公平锁:多个任务阻塞在同一锁时,锁可获取时,一起抢锁,谁先抢到谁先执行
LinkedBlockingQueue:LinkedBlockingQueue是基于链表的阻塞队列,在创建时可不指定任务队列长度,默认值是Integer.MAX_VALUE,在LinkedBlockingQueue中读锁和写锁实现了分支,相对ArrayBlockingQueue而言,效率提升明显。
SynchronousQueue:SynchronousQueue是一个不存储元素的阻塞队列,也就是说当需要插入元素时,必须等待上一个元素被移出,否则不能插入,其适用于任务多但是执行比较快的场景。
PriorityBlockingQueue:PriorityBlockingQueue是一个支持指定优先即的阻塞队列,默认初始化长度为11,最大长度为Integer.MAX_VALUE - 8,可以通过让装入队列的对象实现Comparable接口,定义对象排序规则来指定队列中元素优先级,优先级高的元素会被优先取出。
DelayQueue:DelayQueue是一个带有延迟时间的阻塞队列,队列中的元素,只有等待延时时间到了才可以被取出,由于其内部用PriorityBlockingQueue维护数据,故其长度与PriorityBlockingQueue一致。一般用于定时调度类任务。
下表从一些角度对上述队列进行了比较:
| 队列名称 | 底层数据结构 | 默认长度 | 最大长度 | 是否读写分离 | 适用场景 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组 | 0 | 开发者指定大小 | 否 | 任务数量较少时使用 |
| LinkedBlockingQueue | 链表 | Integer.MAX_VALUE | Integer.MAX_VALUE | 是 | 大量任务时使用 |
| SynchronousQueue | 公平锁-队列/非公平锁-栈 | 0 | / | 否 | 任务多但是执行速度快的场景 |
| PriorityBlockingQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 有任务需要优先处理的场景 |
| DelayQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 定时调度类场景 |
链接:https://juejin.cn/post/7171813123286892557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单封装一个易拓展的Dialog
Dialog,每个项目中多多少少都会用到,肯定也会有自己的一套封装逻辑,无论如何封装,都是奔着简单复用的思想,有的是深层次的封装,也就是把相关的UI效果直接封装好,暴露可以修改的属性和方法,让调用者根据实际业务,调用修改即可,当然也有简单的封装,只封装基本的功能,其UI和实际的动作,交给调用者,两种封装方式,各有利弊,前者调用者不用自己创建UI和实现相关动作,只需要简单的调用即可,但是不易于扩展,效果比较局限,想要拓展其他的效果,就不得不自己动手实现;后者扩展性强,因为只提供基本的调用方式,也就是说,你想要什么效果都行,毕竟是所有的UI和动作都是你自己来实现,优点是它,其缺点也是它。
前者的封装司空见惯,大多数的公司也都是采取的这样的封装,毕竟调用者实现起来也是很方便,这里就不详细说了,具体我们谈一下后者的封装,后者的封装虽然调用者需要自己来实现,但是扩展性是很强的。
今天的内容大致如下:
1、效果及代码具体调用。
2、如何封装一个Dialog。
3、开源地址。
4、总结及注意事项。
一、效果及代码具体调用
通过Kotlin的扩展函数,参数以类做为扩展,封装之后,调用非常的便捷,只需要传递你要的视图即可,我们先看下具体的案例,代码如下:
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//传递dialog视图
set {
//Dialog操作,获取View及绑定数据
}
}通过以上的代码,我们就实现了一个Dialog的弹出,addLayout方法传递视图,set扩展函数进行获取View和绑定数据,这样的一个简单的封装,我们就实现了Dialog的扩展操作,针对不同的Dialog样式,传递不同的xml视图即可。
1、快速使用
为了方便大家使用,目前已经上传到了远程maven,大家可以进行依赖使用,或者下载源码依赖也可以。
根项目build.gradle
allprojects {
repositories {
……
maven { url "https://gitee.com/AbnerAndroid/almighty/raw/master" }
}
}在需要的Module下引入依赖
dependencies {
……
implementation "com.vip:dialog:1.0.0"
}2、代码案例
源码下载之后,运行项目,就可以看到给大家提供的相关Demo,当然了,由于做到了可扩展,大家想实现什么样的效果都是可以的,毕竟视图都是自己传递的。
由于所有的案例都是调用开头的代码,就不一一列举了,简单的列举几个。
普通的提示框
普通的提示框,可以按照下面的代码逻辑进行调用。
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//添加弹出的视图
set {//逻辑处理,获取view,绑定数据
setDialogCancelable(false)//点击空白不消失
val btnConfirm = findView<TextView>(R.id.dialog_button_confirm)//获取View
btnConfirm.setOnClickListener {
toast("确定")
dismiss()
}
}
}方法一览
| 方法名 | 参数类型 | 概述 |
|---|---|---|
| addLayout | int | xml视图 |
| set | 无参 | 逻辑处理 |
| style | 无参 | dialog设置样式 |
| setDialogCancelable | Boolean | 点击空白是否消失,默认true消失,false为不消失 |
| findView | int | 控件id,泛型为控件 |
| dismiss | 无参 | 隐藏dialog |
| getDialogView | 无参 | 获取当前View视图 |
DataBinding形式的提示框
DataBinding形式和普通的区别在于,不用再获取View视图,由普通的set扩展函数改为bind扩展函数,泛型为Binding,记得把xml视图进行convert to data binding layout。
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//添加弹出的视图
bind<LayoutDialogCustomBinding> {//逻辑处理,获取view,绑定数据
it.dialogButtonConfirm.setOnClickListener {
toast("确定")
dismiss()
}
}
}方法一览
除了普通的方法调用之外,还可以调用下面的方法。
| 方法名 | 参数类型 | 概述 |
|---|---|---|
| bind | 无参 | 和set一样进行逻辑处理,泛型为ViewDataBinding |
| getDataBinding | 无参 | 获取当前的DataBinding,用于更新视图 |
| setPendingBindings | int | 传递的BR,用于xml和Data数据进行绑定 |
具体的案例大家直接可以看源码,源码中提供了很多常见的效果,都是可以自定义实现的,具体的就不罗列了,本身没有多少难度。
确认框
输入框
底部列表
菊花加载
二、如何封装一个Dialog
这样的一个简单的Dialog如何进行封装呢?在封装之前,我们首先要明确封装思路,1、视图由调用者传递,2、逻辑操作由调用者处理,3、样式也由调用者进行设置,也就是说,我们只封装基本的dialog使用,也就是一个壳,具体的内容,统统交给调用者进行处理,有了这三个思路我们就可以进行着手封装了。
1、封装BaseDialog
封装Base的原因,在于统一管理子类,在于简化子类的代码逻辑,便于提供公共的方法让子类实现或调用,BaseDialog这里继承的是DialogFragment,最大的原因就是,容易通过生命周期回调来管理弹窗,还有对于复杂样式的弹窗,使用DialogFragment会更加方便和高效。
和之前封装Activity一样,做为一个抽象父类,子类要实现的无非就是,视图的传递和逻辑的处理,我们就可以在父类中进行定义抽象方法,Dialog一般有自己定义的样式,我们也可以定义一个初始化样式的方法。
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
abstract fun initData()
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化样式
*/
abstract fun initStyle()
/**
* AUTHOR:AbnerMing
* INTRODUCE:传递的视图
*/
abstract fun getLayoutId(): Int除了必要实现的方法之外,我们还可以把一些公用的方法,定义到Base里,如获取View的方法,获取控件的方法等,这么做的目的,便于子类自定义实现一些效果以及减少findViewById的调用次数。
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取View视图
*/
fun <V> findView(id: Int): View {
var view = mViewSparseArray[id]
if (view == null) {
view = mView?.findViewById(id)
mViewSparseArray.put(id, view)
}
return view
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取当前View视图
*/
fun getDialogView(): View {
return mView!!
}以上只是列举了几个实现的方法,完整的代码,大家可以看源码中的BaseDialog类。
2、拓展ViewDataBinding形式Dialog
正常的普通Dialog就可以继承BaseDialog,基本就可以满足需要的,若是要和ViewDataBinding进行结合,那么就需要拓展需求了,具体的拓展也很简单,一是绑定View,二是绑定数据,完整的代码,大家可以看源码中BaseBindingDialog类。
绑定View
通过DataBindingUtil的bind方法,得到ViewDataBinding。
mBinding = DataBindingUtil.bind(getDialogView())
复制代码绑定数据
完成xml视图和数据的绑定。
mBinding.setVariable(variableId, t)
mBinding.executePendingBindings()3、封装工具类,拓展相关功能
为了更加方便的让调用者使用,封装拓展函数是很有必要的,要不然,调用者每次都得要继承上边的两个父类,这样的代码就会增加很多,还会创建很多的类,我们需要单独的创建一个工具类,来实例化我们需要简化的功能逻辑。
提供添加xml视图的方法
很简单的一个普通方法,没什么好说的,把传递的xml,赋值给重写的getLayoutId方法即可。
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置layout
* @param mLayoutId xml布局
*/
fun addLayout(mLayoutId: Int): VipDialog {
this.mLayoutId = mLayoutId
return this
}提供普通使用和DataBinding形式使用方法
普通和DataBinding方法,这里用到了接口回调,接口的实现则在initVMData方法里,两个方法本身功能是一样的,无非就是一个是普通,一个是返回ViewDataBinding。
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun <VB : ViewDataBinding> bind(block: (bind: VB) -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke(getDataBinding())
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun set(block: () -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke()
}
})
return this
}提供设置样式的方法
样式的设置也就是使用了接口回调。
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置样式
*/
fun style(style: () -> Unit): VipDialog {
setStyleCallBackListener(object : OnStyleCallBackListener {
override fun styleCallback() {
style.invoke()
}
})
return this
}提供获取ViewDataBinding的方法
这个方法的提供是便于拿到ViewDataBinding,有效的更新视图数据。
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取ViewDataBinding
*/
fun <VB : ViewDataBinding> getDataBinding(): VB {
return mBinding as VB
}我们看下整体的代码,如下:
/**
*AUTHOR:AbnerMing
*DATE:2022/11/22
*INTRODUCE:实例化功能
*/
class VipDialog : BaseBindingDialog<ViewDataBinding>() {
companion object {
fun init(): VipDialog {
return VipDialog()
}
}
private var mLayoutId = 0
override fun initVMData() {
mOnDialogDataCallbackListener?.dataCallback()
}
override fun initStyle() {
mOnStyleCallBackListener?.styleCallback()
}
override fun getLayoutId(): Int {
return mLayoutId
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取ViewDataBinding
*/
fun <VB : ViewDataBinding> getDataBinding(): VB {
return mBinding as VB
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置layout
* @param mLayoutId xml布局
*/
fun addLayout(mLayoutId: Int): VipDialog {
this.mLayoutId = mLayoutId
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun <VB : ViewDataBinding> bind(block: (bind: VB) -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke(getDataBinding())
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun set(block: () -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke()
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置样式
*/
fun style(style: () -> Unit): VipDialog {
setStyleCallBackListener(object : OnStyleCallBackListener {
override fun styleCallback() {
style.invoke()
}
})
return this
}
private var mOnDialogDataCallbackListener: OnDialogDataCallbackListener? = null
private fun setDataCallBackListener(mOnDialogDataCallbackListener: OnDialogDataCallbackListener) {
this.mOnDialogDataCallbackListener = mOnDialogDataCallbackListener
}
private var mOnStyleCallBackListener: OnStyleCallBackListener? = null
private fun setStyleCallBackListener(mOnStyleCallBackListener: OnStyleCallBackListener) {
this.mOnStyleCallBackListener = mOnStyleCallBackListener
}
}4、封装拓展函数,简化调用
dialog的弹出可能有很多场景,比如Activity里,比如Fragment里,比如一个工具类中,我们可以根据已知的场景,来定义我们的调用方式,目前,我定义了两种,在Activity或者Fragment里可以直接进行调用,也就是开头的调用方式,当然了,大家也可以自己拓展。
/**
* AUTHOR:AbnerMing
* INTRODUCE:Activity显示Dialog
*/
fun AppCompatActivity.showVipDialog(vipDialog: VipDialog.() -> Unit): VipDialog {
val dialog = VipDialog.init()
dialog.apply(vipDialog)
setActivityDialog(this.supportFragmentManager, dialog)
return dialog
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:Fragment显示Dialog
*/
fun Fragment.showVipDialog(vipDialog: VipDialog.() -> Unit): VipDialog {
val dialog = VipDialog.init()
dialog.apply(vipDialog)
setActivityDialog(this.childFragmentManager, dialog)
return dialog
}通过以上几步,我们就可以实现开头的简单调用,具体的大家可以查看相关源码。
三、开源地址
四、总结及注意事项
在开头已经阐述,这种方式易于拓展,但是代码量相对比较多,毕竟所有的UI和逻辑都必须独自来处理,在项目中的解决方式为,如果很多的弹框效果一样,建议再封装一层,抽取公共的工具类。
还有一个需要注意的,本身扩展函数showVipDialog返回的就是调用的类,也就是一个Dialog,大家可以直接获取变量,在其他的地方做更新Dialog或者销毁的操作。
val dialog=showVipDialog {
……
}链接:https://juejin.cn/post/7171983903228428318
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 玩转彩虹, 吃定彩虹
闲暇时,又听到了这首歌. 抑郁质性格的人难免会惆怅,美好的东西转瞬即逝.不过谁叫咱们是程序员呢~ 这就安排上.整上一个想看就看的彩虹!
玩转彩虹
彩虹,是气象中的一种光学现象,当太阳光照射到半空中的水滴,光线被折射及反射,在天空上形成拱形的七彩光谱,由外圈至内圈呈红、橙、黄、绿、蓝、靛蓝、蓝紫七种颜色. 相信小伙伴们在大雨过后的不经意间都见过吧! 接下来,我们就自己手动绘制一下.一般这种, 我们都会分析一下绘制的步骤.
分析步骤
彩虹实际上就是7道拱桥型状的颜色堆积,绘制彩虹第一步我们不如先绘制一道拱桥形状的颜色块.也就是说, 本质上我们绘制一个半圆环即可解决问题.
绘制半圆环
在Flutter中, 半圆环都绘制有很多方法. 比如canvas中,有drawOval(rect,paint) 的方法,这种方法可以绘制出一整个圆环, 我们可以对它作切割即可. 不过这种方法不便利的是它控制不了圆环的进度, 有没有一种方法可以让我们自己去控制圆环绘制的进度呢? 答案就是Path, 好多伙伴们应该都对Path 有过或多或少都了解, 它不仅可以画直线、三角形、圆锥,更可以画优美的贝塞尔曲线. 这里我们调用它的acrTo(Rect rect, double startAngle, double sweepAngle, bool forceMoveTo) 方法, 它的参数:
- rect: 给定一个矩形范围,在矩形范围中绘制弧形. 也就是我们如果是正方形的话,实际上绘制的便是一个圆形,如果是长方形的话最终产物就是椭圆形.
- startAngle: 起始的角度
- sweepAngle: 扫过的角度
实际上这里的坐标系和笛卡尔坐标系是一样的, 所以是从x轴开始算的, 也就是顺时针方向分别是0 -> pi/2 -> pi -> 3/2pi-> 2pi. 我们假设startAngle是0的话, sweepAngle为1/3pi, 那么最终的圆弧如图左示.
- forceMoveTo: false的时候,添加一个线段开始于当前点,结束于弧的起点.true时为原点.
理论知识了解完毕以后,我们通过如下代码进行绘制试一下:
{
Path path = Path();
path.moveTo(-width, 0.0);
path.arcTo(
Rect.fromCenter(center: Offset.zero, width: width, height: width),
-pi,
pi,
true,
);
}结果如图:
第一道圆弧已经出来了, 说明理论上这样做可行.
多道圆弧
一道圆弧既然可以了, 我们首先记录下彩虹的颜色
final List<Color> colors = const [
Color(0xFF8B00FF),
Color(0xFF0000FF),
Color(0xFF00FFFF),
Color(0xFF00FF00),
Color(0xFFFFFF00),
Color(0xFFFF7F00),
Color(0xFFFF0000),
];记录好颜色后, 我们首先回顾一下. 刚刚一道圆弧是怎么绘制的呢? 通过path的arcTo()方法,起始在负x轴, 终止于x轴.也就是说我们重复的绘制上七道, 只需要半径不一样即可绘制出相互连接的颜色体.
for (var color in colors) {
_paint.color = color;
// 绘制圆弧
drawArc();
canvas.drawPath(path, _paint);
// width 为每到圆弧的半径
width += widthStep;
}嗯~ 没错, 结果确实和意料的一样
但是,总觉得有些不完美. 彩虹似乎都是有光晕的吧~
添加光晕
好, 光晕说来这不就来了.实际上我们可以通过画笔绘制周围部分作模糊当作光晕的形成, 恰恰Paint的mastFilter 也提供了这个方法.
{
_paint.maskFilter = const MaskFilter.blur(BlurStyle.solid, 6);
}我们先简要分析一下MaskFilter.blur() 提供了参数有哪些用处吧~实际上也就是style和sigma.style控制最终绘制出来的效果.sigma控制效果的大小.这里我们使用BlurStyle.solid就可以绘制出光晕的效果
光晕也有了, 但是我感觉不够个性. 我希望它可以像扇子一样展开收起. 我们来看看怎么实现.
动画
实际上控制它的展开收起也就是在path中sweepAngle.我们最小扫过是0弧度,最大是pi.
我们控制了弧度变化也就控制了彩虹的展示大小.直接安排上repeat()动画
{
AnimationController _controller = AnimationController(
vsync: this,
// 这里需要把最大值改成pi, 这样才会完全展开
upperBound: pi,
duration: const Duration(seconds: 2),
);
_controller.repeat(reverse: true);
}链接:https://juejin.cn/post/7169872546936913934
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何使用 uni-app 30分钟快速开发即时通讯应用|开发者活动

“一套代码,多端运行”是很多开发团队的梦想,基于 uni-app 跨平台框架支持 iOS、Android、Web以及各种小程序并支持平台间互通,快速实现搭建多端即时通讯功能,降低开发难度,提升开发效率。
12月13日 晚 19:00,环信线上公开课《使用 uniapp 30分钟快速开发即时通讯应用》为题,讲解多端 uni-app 基础框架知识及搭建即时通讯功能项目实战技巧,掌握开发步骤及思路,大大增强代码复用率,提升效率。来直播间 get 环信 IM 的正确打开方式!
一、时间地点
活动时间:12 月 13 日(星期二)19:00-20:00
活动地点:线上直播
二、演讲大纲
- uni-app 跨平台框架介绍
- 使用uni-app 生成 Android&iOS 应用
- 如何搭建自己的即时通讯应用
- IM实战篇-uni-app 经典问题答疑
三、活动报名
报名链接:https://mudu.tv/live/watch/meddae1l

工程师的自我修养:了解技术的前世今生
“真正的教育,不传授任何的知识和技能 ”
——耶鲁大学校长 理查德莱文
1.一次飞速的转岗
2017年,因为我接手一个Go语言新项目,作为研发的leader,需要建设临时的团队完成这件事。拉到的其中一个人是公司对口的外包资源的总接口人,这位接口人其实原本管管外包,做个管理者即可,但是他跟我说特别想要做技术,就跟我一起干点事情。同时因为职务之便,也可以帮我甄别最适合的外包研发补充到队伍中。
作为leader,我则过着深圳北京2地周期往返的生活,这为后续我没办法很好的管理人的部分,埋下了伏笔。
这位外包leader很快为我物色了一位Java研发,他挺看好他的潜力,然而不到一周,这位研发就离开了队伍,理由是希望继续做深java这个语言,不想轻易换语言,赶上我不在现场,事出突然,我甚至没见过一面就这么离开了。
不可否认一门具体的编程语言的技术深度挺重要的,但是如果我在现场,或许有机会聊聊关于一些我曾经在Java,Ruby,python,nodejs间反复横跳,哪要救火就补哪的经历对我的帮助有哪些,即便留不住他,但或许我的观点对他未来的路有些帮助。
2.对领导者的失望
时间回到2015年,在另一家公司就职的我,听了高管在与研发的演讲中大概这么说:“大家不要看重编程语言啊,那只是一种具体的工具”。在台下的我深以为然。
没过多久,我短暂带过的一个研发离职了,临走时跟我说:你看这个高管说的话就是不重视技术,我还是走吧。听他这么说完,我直接愣了,虽然想要反驳,但是心想我年纪跟他一般,实在不配做教育他的那个人,毕竟不是他领导还是算了吧,毕竟离职已成定局。
现在的我不会那么腼腆,肯定会给他讲讲我背后的逻辑和观点。
那么我的观点是什么呢?我为何更认可高管。
3.第一次认知冲击
时间再回到2012年,工作了2年多的我入职这家公司。领导在面试我的最后,问的问题是我难以想象的题目:UTF8描述了什么,他的来历是怎样的,为何会有UTF8编码?
我直接放弃作答。领导说了至今让我受益终身的话,大概是这样的:了解技术本身的机制肯定是重要的,了解他背后产生的逻辑则更重要。面试就结束了,让我等消息
其实我现在再想想当初,领导或许只是想通过面试给我上一堂课吧(因为这问题问的“前不着村,后不着店”),但是却能一直不断影响我,我在进入任何一个技术领域后都将这种思维作为指导。
进入云计算领域学完技术后,就把背后的发展历史搞清楚。
从Java转Ruby就看看Ruby作者的一些思考,而不只是ruby语言的高级特性相关知识
等等,用这样的方式学习,我不会局限于工作安排所需我掌握的这些知识和技能,而是主动自学背后逻辑和发展演进历史。
4.高维度思考
那么领导想要我悟什么呢?相比知识和技能,更重要的是掌握产生这些东西的背后的思维逻辑是什么。不断积累这些思维,我才能逐渐的独立思考,创新。
看看第一个离职的研发:研发在意的Java是一种知识和工具,而Java的作者除此之外还掌握了思维,我希望研发掌握的应该包含2者
看看第二个离职的研发:高管期望大家不只是执着于工具,而是更高阶的思维,以创造新的商业模式,服务等等。而寻找技术和场景之间缺少的东西,跨越技术到商业成功的鸿沟,正是技术人员则无旁贷的事情,不积累是不行的。
去了解你所涉足的技术的前世今生,甚至细节到一个小小的功能特性,那么或许看透事物本质的你可以看到未来
来源:mp.weixin.qq.com/s/YBovCZ8OdELi17w_HFnvqg
收起阅读 »这样封装列表 hooks,一天可以开发 20 个页面
前言
在做移动端的需求时,我们经常会开发一些列表页,这些列表页大多数有着相似的功能:分页获取列表、上拉加载、下拉刷新···
在 Vue 出来 compositionAPI之前,我们想要复用这样的逻辑还是比较麻烦的,好在现在 Vue2.7+都支持 compositionAPI语法了,这篇文章我将 手把手带你用 compositionAPI封装一个名为 useList的 hooks来实现列表页的逻辑复用。
基础版
需求分析
一个列表,最基本的需求应该包括: 发起请求,获取到列表的数组,然后将该数组渲染成相应的 DOM 节点。要实现这个功能,我们需要以下变量:
list : 数组变量,用来存放后端返回的数据,并在
template模板中使用v-for来遍历渲染成我们想要的样子。listReq: 发起 http 请求的函数,一般是
axios的实例
代码实现
有了上面的分析,我们可以很轻松地在 setup中写出如下代码:
import { ref } from 'vue'
import axios from 'axios' // 简单示例,就不给出封装axios的代码了
const list = ref([])
const listReq = () => {
axios.get('/url/to/getList').then((res) => {
list.value = res.list
})
}
listReq()这样,我们就完成了一个基本的列表需求的逻辑部分。大部分的列表需求都是类似的逻辑,既然如此,Don't Repeat Yourself!(不要重复写你的代码!),我们来把它封装成通用的方法:
首先,既然是通用的,会在多个地方使用,那么数据肯定不能乱了,我们要在每次使用
useList的时候都拿到独属于自己的那一份数据。是不是感觉很熟悉?对的,就是以前的data为什么是一个函数那个问题!所以我们的useList是需要导出一个函数,我们从这个函数中获取数据与方法。让这个函数导出一个对象/数组,这样调用的时候解构就可以拿到我们需要的变量和方法了
// useList.js 中
const useList = () => {
// 待补充的函数体
return {}
}
export default useList然后,不同的地方调用的接口肯定不一样,我们想一次封装,不再维护,那么咱们干脆在使用的时候,把调用接口的方法传进来就可以了
// useList.js 中
import { ref } from 'vue'
const useList = (listReq) => {
if (!listReq) {
return new Error('请传入接口调用方法!')
}
const list = ref([])
const getList = () => {
listReq().then((res) => (list.value = res.list))
}
return {
list,
getList,
}
}
export default useList这样,我们就完成了一个简单的列表 hooks,使用的时候直接:
// setup中
import useList from '@/utils'
const { list, getList } = useList(axios.get('url/to/get/list'))
getList()等等!列表好像不涉及到 DOM操作,那咱们再偷点懒,直接在 useList内部就调用了吧!
// useList.js中
import { ref } from 'vue'
const useList = (listReq) => {
if (!listReq) {
return new Error('请传入接口调用方法!')
}
const list = ref([])
const getList = () => {
listReq().then((res) => (list.value = res.list))
}
getList() // 直接初始化,省去在外面初始化的步骤
return {
list,
getList,
}
}
export default useList这时有老哥要说了,那我要是一个页面有多个列表怎么办?嘿嘿,别忘了,解构的时候是可以重命名的
// setup中
const { list: goodsList, getList: getGoodsList } = useList(
axios.get('/url/get/goods')
)
const { list: recommendList, getList: getRecommendList } = useList(
axios.get('/url/get/goods')
)这样,我们就同时在一个页面里面,获取到了商品列表以及推荐列表所需要的变量与方法啦
带分页版
如果数据量比较大的话,所有的数据全部拿出来渲染显然不合理,所以我们一般要进行分页处理,我们来分析一下这个需求:
需求分析
要分页,那咱们肯定要告诉后端当前请求的是第几页、每页多少条,可能有些地方还需要展示总共有多少条,为了方便管理,咱们把这些分页数据统一放到
pageInfo对象中分页了,那咱们肯定还有加载下一页的需求,需要一个
loadmore函数分页了,那咱们肯定还会有刷新的需求,需要一个
initList函数
代码实现
需求分析好了,代码实现起来就简单了,废话少说,上代码!
// useList.js中
import { ref } from 'vue'
const useList = (listReq) => {
if (!listReq) {
return new Error('请传入接口调用方法!')
}
const list = ref([])
// 新增pageInfo对象保存分页数据
const pageInfo = ref({
pageNum: 1,
pageSize: 10,
total: 0,
})
const getList = () => {
// 分页数据作为参数传递给接口调用函数即可
// 将请求这个Promise返回出去,以便链式then
return listReq(pageInfo.value).then((res) => {
list.value = res.list
// 更新总数量
pageInfo.value.total = res.total
// 返回出去,交给then默认的Promise,以便后续使用
return res
})
}
// 新增加载下一页的函数
const loadmore = () => {
// 下一页,那咱们把当前页自增一下就行了
pageInfo.value.pageNum += 1
// 如果已经是最后一页了(本次获取到空数组)
getList().then((res) => {
if (!res.list.length) {
uni.showToast({
title: '没有更多了',
icon: 'none',
})
}
})
}
// 新增初始化
const initList = () => {
// 初始化一般是要把所有的查询条件都初始化,这里只有分页,咱就回到第一页就行
pageInfo.value.pageNum = 1
getList()
}
getList()
return {
list,
getList,
loadmore,
initList,
}
}
export default useList完工!跑起来试试,Perfec......等等,好像不太对...
加载更多,应该是把两次请求的数据合并到一起渲染出来才对,这怎么直接替换掉了?
回头看看代码,原来是咱们漏了拼接的逻辑,补上,补上
// useList.js中
// ...省略其余代码
const getList = () => {
// 分页数据作为参数传递给接口调用函数即可
return listReq(pageInfo.value).then((res) => {
// 当前页不为1则是加载更多,需要拼接数据
if (pageInfo.value.pageNum === 1) {
list.value = res.list
} else {
list.value = [...list.value, ...res.list]
}
pageInfo.value.total = res.total
return res
})
}
// ...省略其余代码带 hooks 版
上面的分页版,我们给出了 加载更多和 初始化列表功能,但是还是要手动调用。仔细想想,咱们刷新列表,一般都是在页面顶部下拉的时候刷新的;而加载更多,一般都是在滚动到底部的时候加载的。既然都是一样的触发时机,那咱们继续封装吧!
需求分析
uni-app 中提供了
onPullDownRefresh和onReachBottom钩子,在其中处理相关逻辑即可有些列表可能不是在页面中,而是在
scroll-view中,还是需要手动处理,因此上面的函数咱们依然需要导出
代码实现
钩子函数(hooks)接受一个回调函数作为参数,咱们直接把上面的函数传入即可
需要注意的是,uni-app 中,下拉刷新的动画需要手动关闭,咱们还需要改造一下 listReq函数
// useList中
import { onPullDownRefresh, onReachBottom } from '@dcloudio/uni-app'
// ...省略其余代码
onPullDownRefresh(initList)
onReachBottom(loadmore)
const getList = () => {
// 分页数据作为参数传递给接口调用函数即可
return listReq(pageInfo.value)
.then((res) => {
// ...省略其余代码
})
.finally((info) => {
// 不管成功还是失败,关闭下拉刷新的动画
uni.stopPullDownRefresh()
// 在最后再把前面返回的消息return出去,以便后续处理
return info
})
}
// ...省略其余代码
带参数
其实在实际开发中,我们在发起请求时可能还需要其他的参数,上面我们都是固定的只有分页的参数,可以稍加改造
需求分析
可能大家第一反应是多一个参数,或者用 展开运算符 (...)再定义一个形参就行了。这么做肯定是没问题的,不过在这里的话不够优雅~
我们这里是要增加一个传给后端的参数,一般都是一起以 JSON 对象的形式传过去,既然如此,那咱们把所有的参数都用一个对象接受,发起请求的时候和分页参数对象合并为一个对象,代码的可读性会更高,使用者在使用时也可以自由地定义 key-value 键值对
代码实现
// useList中
const useList = (listReq, data) => {
// ...省略其余代码
// 判断第二个参数是否是对象,以免后面使用展开运算符时报错
if (data && Object.prototype.toString.call(data) !== '[object Object]') {
return new Error('额外参数请使用对象传入')
}
const getList = () => {
const params = {
...pageInfo.value,
...data,
}
return listReq(params).then((res) => {
// ...省略其余代码
})
}
// ...省略其余代码
}
// ...省略其余代码带默认配置版
有些时候我们的列表是在页面中间,不需要触底加载更多;有时候我们可能需要在不同的地方调用相同的接口,但是需要获取的数据量不一样....
为了适应各种各样的需求,我们可以稍加改造,添加一个带有默认值的配置对象,
// useList.js中
const defaultConfig = {
pageSize: 10, // 每页数量,其实也可以在data里面覆盖
needLoadMore: true, // 是否需要下拉加载
data: {}, // 这个就是给接口用的额外参数了
// 还可以根据自己项目需求添加其他配置
}
// 添加一个有默认值的参数,依然满足大部分列表页传入接口即可使用的需求
const useList = (listReq, config = defaultConfig) => {
// 解构的时候赋上初始值,这样即使配置参数只传了一个参数,也不影响其他的配置
const {
pageSize = defaultConfig.pageSize,
needLoadMore = defaultConfig.needLoadMore,
data = defaultConfig.data,
} = config
// 应用相应的配置
if (needLoadMore) {
onReachBottom(loadmore)
}
const pageInfo = ref({
pageNum: 1,
pageSize,
total: 0,
})
// ...省略其余代码
}
// ...省略其余代码这样一来,咱们就实现了一个满足大部分移动端列表页的逻辑复用 hooks
web 端的几乎只有加载更多(翻页)的时候逻辑不太一样,不需要拼接数据,在封装的时候可以把分页器的处理逻辑一起封装进来
总结
在这篇文章中,咱们从需求分析开始,到代码关键逻辑分析,再到实现后的 bug 修复,再到功能扩展,基本完整地复现了编码的思考过程,希望能给大家带来一些收获~
同时,欢迎大家在评论区和谐讨论~
作者:八宝粥要加纯牛奶
来源:juejin.cn/post/7165467345648320520
你需要了解的android注入技术
背景
在android系统中,进程之间是相互隔离的,两个进程之间是没办法直接跨进程访问其他进程的空间信息的。那么在android平台中要对某个app进程进行内存操作,并获取目标进程的地址空间内信息或者修改目标进程的地址空间内的私有信息,就需要涉及到注入技术。
通过注入技术可以将指定so模块或代码注入到目标进程中,只要注入成功后,就可以进行访问和篡改目标进程空间内的信息,包括数据和代码。
Android的注入技术的应用场景主要是进行一些非法的操作和实现如游戏辅助功能软件、恶意功能软件。
zygote注入
zygote是一个在android系统中是非常重要的一个进程,因为在android中绝大部分的应用程序进程都是由它孵化(fork)出来的,fork是一种进程复用技术。也就是说在android系统中普通应用APP进程的父亲都是zygote进程。
zygote注入目的就是将指定的so模块注入到指定的APP进程中,这个注入过程不是直接向指定进程进程注入so模块,而是先将so模块注入到zygote进程。
在so模块注入到zygote进程后,在点击操作android系统中启动的应用程序APP进程,启动的App进程中包括需要注入到指定进程的so模块,太都是由zygote进程fork生成,因而在新创建的进程中都会包含已注入zygote进程的so模块。
这种的注入是通过间接注入方式完成的,也是一种相对安全的注入so模块方式。目前xposed框架就是基于zygote注入。
1.通过注入器将要注入的so模块注入到zygote进程;
2.手动启动要注入so模块的APP进程,由于APP进程是通过zygote进程fork出来的,所以启动的APP进程都包含zygote进程中所有模块;
3.注入的so模块劫持被注入APP进程的控制权,执行注入so模块的代码;
4.注入so模块归还APP进程的控制权,被注入进程正常运行。
(注入器主要是基于ptrace注入shellcode方式的进程注入)
通过ptrace进行附加到zygote进程。
调用mmap申请目标进程空间,用于保存注入的shellcode汇编代码。
执行注入shellcode代码(shellcode代码是注入目标进程中并执行的汇编代码)。
调用munmap函数释放申请的内存。
通过ptrace进行剥离zygote进程。
下面是关键的zygote代码注入实现
ptrace注入
ptrace注入实现上分类:
通过利用ptrace函数将shellcode注入远程进程的内存空间中,然后通过执行shellcode加载远程进程so模块。
通过直接远程调用dlopen、dlsym、dlclose等函数加载被注入so模块,并执行指定的代码。
ptrace直接调用函数注入流程:
通过利用ptrace进行附加到要注入的进程;
保存寄存环境;
远程调用mmap函数分配内存空间;
向远程进程内存空间写入加载模块名称和函数名称;
远程调用dlopen函数打开注入模块;
远程调用dlsym函数或需要调用的函数地址;
远程调用被注入模块的函数;
恢复寄存器环境;
利用ptrace从远程进程剥离。
关键的ptrace直接调用系统函数实现
shellcode注入就是通过将dlopen/dlsym库函数的操作放在shellcode代码中,注入函数只是通过对远程APP进程进行内存空间申请,接着修改shellcode 代码中有关dlopen、dlsymdlclose等函数使用到的参数信息,然后将shellcode代码注入到远程APP进程申请的空间中,最后通过修改PC寄存器的方式来执行shellcode 的代码。
关键 的ptrace注入shellcode代码实现
修改ELF文件注入
在android平台Native层的可执行文件SO文件,它是属于ELF文件格式,通过修改ELF文件格式可以实现对so文件的注入。
通过修改ELF二进制的可执行文件,并在ELF文件中添加自己的代码,使得可执行文件在运行时会先执行自定义添加的代码,最后在执行ELF文件的原始逻辑。
修改二进制ELF文件需要关注两个重要的结构体:
其中ELF Header 它是ELF文件中唯一的,一个固定位置的文件结构,它保存着Program Header Table和Section Header Table的位置和大小信息。
修改ELF文件实现so文件注入实现原理为:通过修改 Program Header Table中的依赖库信息,添加自定义的so文件信息,APP进程运行加载被该修改过的ELF文件,它也同时会加载并运行自定义的so文件。
Program Header Table表项结构
程序头表项中的类型选项有如下
当程序头表项结构中的类型为PT_DYNAMIC也就是动态链接信息的时候,它是由程序头表项的偏移(p_offset)和p_filesz(大小)指定的数据块指向.dynamic段。这个.dynamic段包含程序链接和加载时的依赖库信息。
关键ELF文件修改代码实现
作者:小道安全
来源:juejin.cn/post/7077940770941960223
关于无感刷新Token,我是这样子做的
什么是JWT
JWT是全称是JSON WEB TOKEN,是一个开放标准,用于将各方数据信息作为JSON格式进行对象传递,可以对数据进行可选的数字加密,可使用RSA或ECDSA进行公钥/私钥签名。
使用场景
JWT最常见的使用场景就是缓存当前用户登录信息,当用户登录成功之后,拿到JWT,之后用户的每一个请求在请求头携带上Author ization字段来辨别区分请求的用户信息。且不需要额外的资源开销。
相比传统session的区别
比起传统的session认证方案,为了让服务器能识别是哪一个用户发过来的请求,都需要在服务器上保存一份用户的登录信息(通常保存在内存中),再与浏览器的cookie打交道。
安全方面 由于是使用
cookie来识别用户信息的,如果cookie被拦截,用户会很容易受到跨站请求伪造的攻击。负载均衡 当服务器A保存了用户A的数据之后,在下一次用户A服务器A时由于服务器A访问量较大,被转发到服务器B,此时服务器B没有用户A的数据,会导致
session失效。内存开销 随着时间推移,用户的增长,服务器需要保存的用户登录信息也就越来越多的,会导致服务器开销越来越大。
为什么说JWT不需要额外的开销
JWT为三个部分组成,分别是Header,Payload,Signature,使用.符号分隔。
// 像这样子
xxxxx.yyyyy.zzzzz标头 header
标头是一个JSON对象,由两个部分组成,分别是令牌是类型(JWT)和签名算法(SHA256,RSA)
{
"alg": "HS256",
"typ": "JWT"
}负荷 payload
负荷部分也是一个JSON对象,用于存放需要传递的数据,例如用户的信息
{
"username": "_island",
"age": 18
}此外,JWT规定了7个可选官方字段(建议)
| 属性 | 说明 |
|---|---|
| iss | JWT签发人 |
| exp | JWT过期时间 |
| sub | JWT面向用户 |
| aud | JWT接收方 |
| nbf | JWT生效时间 |
| iat | JWT签发时间 |
| jti | JWT编号 |
签章 signature
这一部分,是由前面两个部分的签名,防止数据被篡改。 在服务器中指定一个密钥,使用标头中指定的签名算法,按照下面的公式生成这签名数据
HMACSHA256(
base64UrlEncode(header) + "." +
base64UrlEncode(payload),
secret)在拿到签名数据之后,把这三个部分的数据拼接起来,每个部分中间使用.来分隔。这样子我们就生成出一个了JWT数据了,接下来返回给客户端储存起来。而且客户端在发起请求时,携带这个JWT在请求头中的Authorization字段,服务器通过解密的方式即可识别出对应的用户信息。
JWT优势和弊端
优势
数据体积小,传输速度快
无需额外资源开销来存放数据
支持跨域验证使用
弊端
生成出来的
Token无法撤销,即使重置账号密码之前的Token也是可以使用的(需等待JWT过期)无法确认用户已经签发了多少个
JWT不支持
refreshToken
关于refreshToken
refreshToken是Oauth2认证中的一个概念,和accessToken一起生成出来的。
当用户携带的这个accessToken过期时,用户就需要在重新获取新的accessToken,而refreshToken就用来重新获取新的accessToken的凭证。
为什么要有refreshToken
当你第一次接触的时候,你有没有一个这样子的疑惑,为什么需要refreshToken这个东西,而不是服务器端给一个期限较长甚至永久性的accessToken呢?
抱着这个疑惑我在网上搜寻了一番,
其实这个accessToken的使用期限有点像我们生活中的入住酒店,当我们在入住酒店时,会出示我.们的身份证明来登记获取房卡,此时房卡相当于accessToken,可以访问对应的房间,当你的房卡过期之后就无法再开启房门了,此时就需要再到前台更新一下房卡,才能正常进入,这个过程也就相当于refreshToken。
accessToken使用率相比refreshToken频繁很多,如果按上面所说如果accessToken给定一个较长的有效时间,就会出现不可控的权限泄露风险。
使用refreshToken可以提高安全性
用户在访问网站时,
accessToken被盗取了,此时攻击者就可以拿这个accessToke访问权限以内的功能了。如果accessToken设置一个短暂的有效期2小时,攻击者能使用被盗取的accessToken的时间最多也就2个小时,除非再通过refreshToken刷新accessToken才能正常访问。设置
accessToken有效期是永久的,用户在更改密码之后,之前的accessToken也是有效的
总体来说有了refreshToken可以降低accessToken被盗的风险
关于JWT无感刷新TOKEN方案(结合axios)
业务需求
在用户登录应用后,服务器会返回一组数据,其中就包含了accessToken和refreshToken,每个accessToken都有一个固定的有效期,如果携带一个过期的token向服务器请求时,服务器会返回401的状态码来告诉用户此token过期了,此时就需要用到登录时返回的refreshToken调用刷新Token的接口(Refresh)来更新下新的token再发送请求即可。
话不多说,先上代码
工具
axios作为最热门的http请求库之一,我们本篇文章就借助它的错误响应拦截器来实现token无感刷新功能。
具体实现
本次基于axios-bz代码片段封装响应拦截器 可直接配置到你的项目中使用 ✈️ ✈️
利用interceptors.response,在业务代码获取到接口数据之前进行状态码401判断当前携带的accessToken是否失效。 下面是关于interceptors.response中异常阶段处理内容。当响应码为401时,响应拦截器会走中第二个回调函数onRejected
下面代码分段可能会让大家阅读起来不是很顺畅,我直接把整份代码贴在下面,且每一段代码之间都添加了对应的注释
// 最大重发次数
const MAX_ERROR_COUNT = 5;
// 当前重发次数
let currentCount = 0;
// 缓存请求队列
const queue: ((t: string) => any)[] = [];
// 当前是否刷新状态
let isRefresh = false;
export default async (error: AxiosError<ResponseDataType>) => {
const statusCode = error.response?.status;
const clearAuth = () => {
console.log('身份过期,请重新登录');
window.location.replace('/login');
// 清空数据
sessionStorage.clear();
return Promise.reject(error);
};
// 为了节省多余的代码,这里仅展示处理状态码为401的情况
if (statusCode === 401) {
// accessToken失效
// 判断本地是否有缓存有refreshToken
const refreshToken = sessionStorage.get('refresh') ?? null;
if (!refreshToken) {
clearAuth();
}
// 提取请求的配置
const { config } = error;
// 判断是否refresh失败且状态码401,再次进入错误拦截器
if (config.url?.includes('refresh')) {
clearAuth();
}
// 判断当前是否为刷新状态中(防止多个请求导致多次调refresh接口)
if (isRefresh) {
// 设置当前状态为刷新中
isRefresh = true;
// 如果重发次数超过,直接退出登录
if (currentCount > MAX_ERROR_COUNT) {
clearAuth();
}
// 增加重试次数
currentCount += 1;
try {
const {
data: { access },
} = await UserAuthApi.refreshToken(refreshToken);
// 请求成功,缓存新的accessToken
sessionStorage.set('token', access);
// 重置重发次数
currentCount = 0;
// 遍历队列,重新发起请求
queue.forEach((cb) => cb(access));
// 返回请求数据
return ApiInstance.request(error.config);
} catch {
// 刷新token失败,直接退出登录
console.log('请重新登录');
sessionStorage.clear();
window.location.replace('/login');
return Promise.reject(error);
} finally {
// 重置状态
isRefresh = false;
}
} else {
// 当前正在尝试刷新token,先返回一个promise阻塞请求并推进请求列表中
return new Promise((resolve) => {
// 缓存网络请求,等token刷新后直接执行
queue.push((newToken: string) => {
Reflect.set(config.headers!, 'authorization', newToken);
// @ts-ignore
resolve(ApiInstance.request<ResponseDataType<any>>(config));
});
});
}
}
return Promise.reject(error);
};抽离代码
把上面关于调用刷新token的代码抽离成一个refreshToken函数,单独处理这一情况,这样子做有利于提高代码的可读性和维护性,且让看上去代码不是很臃肿
// refreshToken.ts
export default async function refreshToken(error: AxiosError<ResponseDataType>) {
/*
将上面 if (statusCode === 401) 中的代码贴进来即可,这里就不重复啦
代码仓库地址: https://github.com/QC2168/axios-bz/blob/main/Interceptors/hooks/refreshToken.ts
*/
}经过上面的逻辑抽离,现在看下拦截器中的代码就很简洁了,后续如果要调整相关逻辑直接在refreshToken.ts文件中调整即可。
import refreshToken from './refreshToken.ts'
export default async (error: AxiosError<ResponseDataType>) => {
const statusCode = error.response?.status;
// 为了节省多余的代码,这里仅展示处理状态码为401的情况
if (statusCode === 401) {
refreshToken()
}
return Promise.reject(error);
};作者:_island
来源:juejin.cn/post/7170278285274775560
收起阅读 »开发一个APP多少钱?
开发一个APP多少钱?
开发一个APP要多少钱?相信不光是客户有这个疑问,就算是一般的程序员也想知道答案。很多程序员想在业余时间接外包挣外快,但是他们常常不知道该如何定价,如何有说服力的要价。这是因为没有一套好的计算APP开发成本的方法。由于国内没有公开的数据,而且大家对于报价都喜欢藏着掖着,这里我们就整理了国外一些软件外包平台的资料,帮助大家对Flutter APP开发成本有一个直观而立体的认识。(注意,这里是以美元单位计算,请不要直接转换为RMB,应当根据消费力水平来衡量)
跨平台项目正在慢慢取代原生应用程序的开发。跨平台的方法更省时,也更节省成本。最近,原生应用程序的主要优势是其性能。但随着新的跨平台框架给开发者带来更多的力量,这不再是它们的强项。
Flutter就是其中之一。这个框架在2017年发布,并成为跨平台社区中最受推崇的框架之一。Statista称,Flutter是2021年十大最受欢迎的框架之一,并在最受欢迎的跨平台框架中排名第一。对于这样一项新技术来说,这是一个相当不错的结果。它的高需求使我们可以定义软件建设的大致成本。
Flutter应用程序的开发成本根据项目定义的工作范围而变化:
简单的 Flutter 应用程序:
$40,000 - $60,000中等复杂度应用程序:
$60,000 – $120,000高度复杂的 Flutter 应用程序:
$120,000 – $200,000+
有一些决定性的因素来回答Flutter应用开发的成本是多少。
在这篇文章中,我们将讨论不同行业的Flutter应用开发成本,找出如何计算精确的价格,以及如何利用这个框架削减项目开支。
Flutter应用的平均开发成本
应用程序的开发成本是一个复杂的数字,取决于各种因素 ——功能的复杂性,开发人员的位置,支持的平台,等等。如果不进行研究和了解所有的要求,就不可能得出项目的价格。
不过,你还是可以看看按项目复杂程度分类的估算:
一个具有简单功能的软件,如带有锻炼建议、膳食计划、个人档案和体重日记的健身应用,其成本从26,000美元到34,800美元
一个中等复杂度的软件,如带有语音通话、消息通信,Flutter应用的开发成本将从34,950美元到48,850美元不等
开发一个像 Instagram 这样具有复杂功能的应用程序的成本将从41,500美元到55,000美元不等
影响价格的因素
为了明确 Flutter 应用开发成本的所有组成部分,我们将挑选出每个因素并分析其对价格的影响。
原生应用开发 vs. Flutter
当我们估算一个原生项目时,我们要考虑到两个平台的开发时间。Flutter是一个跨平台的框架,可以让开发者为Android和iOS编写同一个代码库。这一特点使开发时间减半,使Flutter应用程序的开发成本比原生的低。
Flutter 的非凡之处在于它优化了代码并且没有性能问题。Flutter在所有设备上都能提供稳定的接近 60 FPS,如果设备支持,甚至可以提供120 FPS。
然而,Flutter也有一些缺点。如果你的项目需要Wear OS版本或智能电视应用,就会面临一些麻烦。从技术上讲,你可以为这些平台建立一个Flutter应用程序。但是,Flutter的很多开发功能并不被Wear OS所支持。在安卓电视的情况下,必须从头开始建立控制逻辑。原因是安卓电视只读取遥控器的输入,而Flutter则适用于触摸屏和鼠标移动。这一事实会减慢开发进程,给开发者带来麻烦,并增加Flutter应用的开发成本。
这就是为什么如果你的目标是特定的平台,最好去做原生开发。
功能的复杂性
功能是应用程序的主要组成部分。也是影响Flutter应用程序开发成本的主要因素。简单的功能(如登录)需要最少的工作量,而视频通话的集成可能需要长达 2-3 周的开发时间。
让我们想象一下,要建立一个类似 Instagram 的应用程序。照片上传功能需要大约13小时的开发时间。以每小时50美元的平均费率计算,这将花费650美元。然而,要建立用于照片编辑的过滤器,开发团队将不得不花费30至120小时,这取决于它们的类型和数量。一家软件开发公司将为这个功能收取1500-6000美元。
Flutter应用开发中最昂贵的功能
| 功能 | 描述 | 大约时间(小时) | 大约成本($50/h) |
|---|---|---|---|
| 导航 | 位置地图开发 | 194 | $9,700 |
| 聊天 | 视频、音频、文字聊天 | 188 | $9,400 |
| 支付集成 | 与 PayPal 集成,添加信用卡支付 | 70 | $3,500 |
开发商的位置和所选择的雇用方式
影响总成本的另一个方面是你在雇用项目专家时选择的就业方式:
自由职业者
由于有机会减少开发费用,这种选择被广泛采用。然而,就Flutter应用的开发而言,无法保证自由职业者的能力和质量。此外,在支持、维护和更新服务方面,这样的专家也没有优势,因为他们可能会转到另一个项目,从而无法建立长期的合作伙伴关系。
内部团队
在这种情况下,你要负责项目开发管理,以及搜索和检查潜在雇主的经验和知识。此外,内部团队的聚集需要一排额外的费用,如购买硬件,租用办公室,病假,工资,等等。因此,这些条件大大增加了总成本。
外包公司
项目外包指的是已经组建的专家团队,具有成熟深入的资质,接手所有的创作过程。这种选择是一种节省开发投资和避免影响产品质量的好方法。除了这个事实之外,这里还有一些你将通过外包获得的好处。
成本的灵活性。全球市场提供了很多准备以合理价格提供服务的外包软件开发公司。中欧已经成为实现这一目标的顶级地区,许多企业已经从来自该地的优秀开发人员的一流表现中受益。
可扩展性。可以根据您的要求调整开发流程:此类公司的团队包括所有类型的开发人员,将在需要他们的能力时参与创建过程。此外,如果有必要的话,这也是加快项目完成的绝佳方式。外包提供了多种合作模式。 从专门的团队到工作人员的增援
更快的产品交付。有了外包,就不需要在招聘上花费时间。你可以调整项目创建速度,例如,让更多的专家参与进来。因此,进入市场的时间缩短了,支出也减少了。只为已完成的工作付费。
庞大的人才库。IT外包包括大量具有丰富专业知识和经验的技术专家。外包商为企业提供灵活的招聘机会。你可以在全球范围大量的的软件架构师中选择。
可应用的技术非常多样化。根据你的项目要求,你可以从这些公司中选择一个具有相关专业知识的专家。
除了雇佣选择,开发团队的位置可能会对Flutter应用程序的开发成本产生很大的影响。在不同地区,开发人员有不同的价格。在美国,开发人员的平均费率是60美元/小时,而在爱沙尼亚,只有37美元/小时。
在下面的表格中,可以找到开发人员的每小时费率,并将它们进行比较。
Flutter开发人员在不同地区的费率:
| 地区 | 每小时费率 ($) |
|---|---|
| 北美 | $75 - $120 |
| 拉丁美洲 | $30 - $50 |
| 西欧 | $70 - $90 |
| 爱沙尼亚 | $30 - $50 |
| 印度 | $25 - $40 |
| 澳大利亚 | $41 - $70 |
| 非洲 | $20 - $49 |
如何计算 Flutter 应用开发成本
正如前面提到的,功能对Flutter应用开发成本的影响最大。Flutter 适用于不包含原生功能的项目。但是当涉及到地图、流媒体、AR和后台进程时,开发人员必须为iOS和Android单独构建这些功能,然后再与Flutter结合。
让我们回到例子上。如果是原生开发,你将需要大约60-130个小时在你的应用程序中实现AR过滤器。Flutter开发将需要约80-150小时,因为AR是一个原生功能。考虑到50美元/小时的费率,我们应该把它乘以开发时间。这个公式可以用来计算出最终的Flutter应用开发成本。
除了这个公式外,还有一件事在初始阶段很重要。
发现阶段
一个糟糕的发现阶段可能导致整个项目的崩溃。但为什么这个阶段如此重要?在发现阶段,业务分析人员和项目经理与你举行会议,找出可能的风险,并提出消除这些风险的解决方案
粗略估算
粗略估算的精确度从75%到25%不等。这个评估包括在客户和软件团队合作的初级阶段。它也有助于双方决定是否成为合作伙伴。粗略估算的主要目的是计算完成项目所需的最短和最长时间以及大致的总成本,以便客户知道在开发流程中需要多少投资。此外,这个估算包括整个创建过程,分为几个阶段。这个文件不应该被认为是有固定条款和条件的文件。它是为客户准备的,只是为了通知他们。
一个粗略的估算包括:
主要部分包含准备工作。它们在不同的项目中都是一样的,包括产品描述、数据库设置、REST架构。该部分所指出的项目不一定一次就能完成。有些工作是在整个项目中完成的。
开发与加密过程有关。这部分包括要实现的功能、屏幕和特性。开发部分包括 "业务逻辑 "和 "UI/UX "要求,以及某部分工作的小时数。
为了更有效地实现功能,需要整合框架和库,并相应减少开发时间和相应的花费。
非开发工作主要与技术写作有关。专家们准备详细的代码文档和准备有关产品创建的其他数据。
建议部分包含了各种改进建议。
当所有的问题都解决后,会进入发现阶段并创建一个项目规范。客户必须积极参与,因为会根据客户提供的数据来建立项目规范。在下一个阶段,客户应当创建他们的应用程序草稿图。这是一个用户界面元素在屏幕上的位置示意图。
然后,开发人员和业务分析师会对客户的Flutter应用开发成本进行详细的估算。有了准确的预算、项目要求和草稿图,就可以签署合同并开始开发阶段。
如你所见,发现阶段是任何项目的关键部分。没有这个阶段,你就无法知道开发所需的价格和时间,因为会有太多的变数。如果在任何阶段出了问题,整个项目的计划就会出问题。这就是为什么客户必须与软件开发公司合作,使他们能够建立客户需要的项目。
额外费用
就像任何其他产品一样,客户的应用程序需要维护和更新,以便在市场上保持成功。这导致了影响Flutter应用程序开发成本的额外费用。
服务器
如果要处理和存储用户产生的数据,就必须考虑到服务器的问题。脆弱的服务器会导致用户方面的低性能和高响应时间。此外,不可靠的服务器和脆弱的保护系统会导致你的用户的个人数据泄露。为了减少风险,团队只信任可靠的供应商,如亚马逊EC2。根据AWS价格计算器,一台8核CPU和32G内存的工作服务器将花费大约1650美元/年。在计算整个Flutter应用程序的开发成本时,请牢记这笔费用。
UI/UX设计
移动应用的导航、排版和配色是UI/UX设计师应该注意的主要问题。他们还应该向你提供你的应用程序的原型。根据你的应用程序的复杂性,设计可能需要40到90多个小时。这一行的费用将使Flutter应用的开发成本提高到2000-4500美元
发布到应用商店
当你已经有了一个成品,你必须在某个地方发布它。Google Play和App Store是应用程序分发的主要平台。然而,这些平台在应用发布前会收取费用:
Google Play 帐号一次收取25美元,可以永久使用
而Apple Store 收取99美元的年费,只要你的APP还想待在应用商店,每年都得花费这笔钱
除此之外,这两个平台对每次产生的应用内购买行为都有30%的分成。如果你通过订阅模式发布你的应用,那你只能得到70%收益。然而,最近Google Play和App Store已经软化了他们的政策。目前,他们对每一个购买了十二个月订阅的账户只收取15%的分成。
应用维护和更新
应用商店排行榜的应用能保持其地位是有原因的。他们通过不断的升级和全新的功能吸引客户。即使你的应用是完美的,但没有更新将导致停滞,用户可能卸载你的应用程序。在完美的构想里,你应该雇用一家开发应用程序的公司。他们从一开始就为你的项目工作。注意,应用程序的维护费用在应用程序的生命周期内会上升。公司通常将Flutter应用开发成本的15-20%纳入应用维护的预算。然而,你的应用程序拥有稳定受众的时间越长,需要投入的更新资金就越多。在一定时间内,你花在更新上的钱比花在实际开发上的钱多,这并不奇怪。尽管如此,但是你的应用产生的收入多于损失,所以这是一项值得的投资。不幸的是,随着新的功能发布可能出现新的错误和漏洞。你不能对这个问题视而不见,因为它使用户体验变差,并为欺诈者提供了新的漏洞。有一些软件开发公司会提供发布后的支持,包括开发新功能、测试和修复错误。
按类型划分的开发成本
由于你已经知道影响价格的主要和次要因素,现在是时候对不同应用程序的Flutter开发成本进行概述了。这里估算了来自不同行业和不同复杂程度的几个现有应用程序的开发成本。
分别是:
交通运输
流媒体
社交媒体
Flutter 应用程序开发成本:交通运输
示例:BlaBlaCar
功能实现的大概时间:438 小时
大概费用:21,900 美元
运输应用程序需要用户档案、司机和乘客的角色、支付网关和GPS支持。请注意,如果你使用Flutter来构建地理定位等本地功能,整个项目的开发时间可能会增加。
请注意,下面的估算不包括代码文档、框架集成、项目管理等方面的时间。
下面是一个类似BlaBlaCar的应用程序的基本功能的粗略估计,基于Flutter的交通应用开发成本:
| 功能 | 开发时间(小时) | 大概费用(美元) |
|---|---|---|
| 注册 | 28 | $1400 |
| 登录(通过电邮和 Facebook) | 22 | $1350 |
| 推送通知 | 20 | $1000 |
| 用户资料 | 77 | $3850 |
| 支付系统 | 40 | $2000 |
| 乘车预订 | 80 | $4000 |
| 乘车支付+优惠券 | 42 | $2100 |
| 地理定位 | 26 | $1300 |
| 司机端 | 103 | $5150 |
Flutter应用程序开发成本:流媒体
例子: Twitch, Periscope, YouTube Live
功能实现的大概时间: 600小时
大概的成本: $30,000
流媒体应用程序是一个复杂的软件。它要求开发团队使用流媒体协议(这不是Flutter的强项),开发与观众沟通的文本聊天,推送通知,使用智能手机的摄像头,等等。其中一些有捐赠系统,与第三方的多种集成,甚至还有付费的表情符号。以下是一个类似Twitch的应用程序的基本功能的粗略估计。
基于Flutter的流媒体应用开发成本:
| 功能 | 开发时间(小时) | 大概费用(美元) |
|---|---|---|
| 注册 | 20 | $1000 |
| 登录(通过电邮和 Facebook) | 23 | $1150 |
| 个人资料 | 43 | $2150 |
| 搜索系统 | 36 | $1800 |
| 流媒体协议 | 20 | $1000 |
| 播放器集成 | 33 | $1650 |
| 流管理(启动/关闭,设置比特率) | 120 | $6000 |
| 聊天 | 146 | $7300 |
| 捐赠系统 | 35 | $1750 |
| 支付网关 | 64 | $3200 |
| 频道管理 | 40 | $2000 |
| 推送通知 | 20 | $1000 |
Flutter应用程序开发成本:消息通信
例子: Facebook Messenger, WhatsApp, Telegram
功能实现的大概时间: 589小时
估计成本: $29,450
消息通信工具的功能乍一看很简单,但详细的分析证明情况恰恰相反。整合各种状态的聊天(打字,在线/离线,阅读),文件传输,语音信息需要大量的时间。如果再加上语音通话和群组聊天,事情会变得更加复杂。
让我们单独列出每个功能及其成本,基于Flutter的消息通信应用开发成本:
| 功能 | 开发时间(小时) | 大概费用(美元) |
|---|---|---|
| 注册 | 45 | $2250 |
| 登录 | 27 | $1350 |
| 聊天 | 156 | $7800 |
| 发送媒体文件 | 40 | $2000 |
| 语音消息 | 35 | $1750 |
| 群聊 | 57 | $2850 |
| 语音电话 | 100 | $5000 |
| 通知 | 15 | $750 |
| 设置 | 76 | $3800 |
| 搜索 | 38 | $1900 |
作者:编程之路从0到1
来源:juejin.cn/post/7170168967690977293
Android性能优化方法论
作为一名开发,性能优化是永远绕不过去的话题,在日常的开发中,我们可肯定都会接触过。Android 的性能优化其实是非常成熟的了,成熟的套路,成熟的方法论,成熟的开源框架等等。
对于接触性能优化经验较少的开发者来说,可能很少有机会能去总结或者学到这些成熟的套路,方法论,或者框架。所以作为一位多年长期做性能优化的开发者,在这篇文章中对性能优化的方法论做一些总结,以供大家借鉴。
性能优化的本质
首先,我先介绍一下性能优化的本质。我对其本质的认知是这样的:性能优化的本质是合理且充分的使用硬件资源,让程序的表现更好,并且程序表现更好的目的则是为了获取更多来自客户的留存,使用时长,口碑、利润等收益。
所以基于本质来思考,性能优化最重要的两件事情:
合理且充分的使用硬件资源
让程序表现更好,并取得收益
下面讲一下这两件事情。
合理且充分的使用硬件资源
充分表示能将硬件的资源充分发挥出来,但充分不一定是合理的,比如我们一下子打了几百个线程,cpu 被充分发挥了,但是并不合理,所以合理表示所发挥出来的硬件资源能给程序表现有正向的作用。
硬件资源包括:CPU,内存,硬盘,电量,流量(不属于硬件资源,不过也归于需要合理使用的资源之一)等等。
下面举几个合理且充分的使用硬件资源的例子:
CPU 资源的使用率高,但并不是过载的状态,并且 cpu 资源主要为当前场景所使用,而不是被全业务所分散消耗。比如我们优化页面打开速度,速度和 cpu 有很大的关系,那么我们首先要确保 cpu 被充分发挥出来了,我们可以使用多线程、页面打开前提前预加载等策略,来发挥手机的 cpu。但是在打开页面的时候,我们要合理的确保 cpu 资源主要被打开页面相关的逻辑所使用,比如组件创建,数据获取,页面渲染等等,至于其他和当前打开页面场景联系较少的逻辑,比如周期任务,监控,或者一些预加载等等都可以关闭或者延迟,以此减少非相关任务对 cpu 的消耗,
内存资源缓使用充分,并且又能将 OOM 等异常控制在合理范围内。比如我们做内存优化,内存优化并不是越少越好,相反内存占用多可能让程序更快,但是内存占用也不能太高,所以我们可以根据不同档次机型的 OOM 率,将内存的占用控制在充分使用并且合理的状态,低端机上,通过功能降级等优化,减少内存的使用,高端机上,则可以适当提升内存的占用,让程序表现的更好。
……
让程序表现更好,并取得收益
我们有很多直接的指标来度量我性能优化取得的收益,比如做内存优化可以用 pss,java 内存占用,native 内存占用等等;做速度优化,可以用启动速度,页面打开速度;做卡顿优化,这用帧率等等。掌握这些指标很重要,我们需要知道如何能正确并且低开销的监控这些指标数据。
除了上面的直接指标外,我们还需要了解性能优化的最终体现指标,用户留存率,使用时长,转换率,好评率等指标。有时候,这些指标才是最终度量我们性能优化成果的数据,比如我们做内存优化,pss 降低了 100 M,但仅仅只是内存占用少了 100M 并没有太大的收益,如果这个 100M 体现在对应用的存活时间,转化率的提升上,那这 100 M 的优化就是值得的,我们再向上报告我们产出时,也更容易获得认可。
如何做好性能优化
讲完了性能优化的本质,我再讲讲如何做好性能优化。我主要从下面这三个方面来讲解
知识储备
思考的角度和方式
形成完整的闭环
知识储备
想要做好性能优化,特别是原创性、或者完善并且体系的、或者效果很好的优化,不是我们从网上看一些文章然后模仿一下就能进行,需要我们有比较扎实的知识储备,然后基于这些知识储备,通过深入思考,去分析我们的应用,寻找优化点。我依然举一些例子,来说明硬件层面,系统层面和软件层面的知识对我们做好性能优化的帮助。
硬件层面
在硬件层面,我们需要处理器的体系结构,存储器的层次结构有一定的了解。如果我们如果不知道 cpu 由几个核组成,哪些是大核,哪些是小核,我们就不会想到将核心线程绑定大核来提升性能的优化方案;如果我们不了解存储结构中寄存器,高速缓存,主存的设计,我们就没法针对这一特效来提升性能,比如将核心数据尽量放在高速缓存中就能提升不少速度相关的性能。
系统层面
对操作系统的熟悉和了解,也是帮助我们做好性能优化不可缺少的知识。我在这里列一下系统层面需要掌握的知识,但不是全的,Linux的知识包括进行管理和调度,内存管理,虚拟内存,锁,IPC通信等。Android系统的知识包括虚拟机,核心服务如ams,wms等等,渲染,以及一些核心流程,如启动,打开activity,安装等等。
如果我们不了解Linux系统的进程调度系统,我们就没法充分利用进程优先来帮助我们提升性能;如果我们不熟悉 Android 的虚拟机,那么围绕这虚拟机一些相关的优化,比如 oom 优化,或者是 gc 优化等等都无法很好的开展。
软件层面
软件层面就是我们自己所开发的 App,在性能优化中,我们需要对自己所开发的应用尽可能得熟悉。比如我们需要知道自己所开发的 App 有哪些线程,都是干嘛的,这些线程的 cpu 消耗情况,内存占用多少,都是哪些业务占用的,缓存命中率多少等等。我们需要知道自己所开发的 App 有哪些业务,这些使用都是干嘛的,使用率多少,对资源的消耗情况等等。
除了上面提到的三个层面的知识,想要深入做好性能优化,还需要掌握更多的知识,比如汇编,编译器、编程语言、逆向等等知识。比如用c++ 写代码就比用java写代码运行更快,我们可以通过将一些业务替换成 c++ 来提高性能;比如编译期间的内联,无用代码消除等优化能减少包体积;逆向在性能优化上的用处也非常大,通过逆向我们可以修改系统的逻辑,让程序表现的更好。
可以看到,想要做好性能优化,需要庞大的知识储备,所以性能优化是很能体现开发者技术深度和广度的,这也是面试时,一定会问性能优化相关的知识的原因。这是知识储备不是一下就能形成的,需要我们慢慢的进行学习和积累。
思考的角度及方式
讲完了知识储备,再讲讲思考的角度和方式。需要注意它和知识储备没有先后关系,并不是说要有了足够的技术知识后才能开始考虑如何思考。思考的角度和方式体现在我们开发的所有生命周期中,即使是新入门的开发,也可以锻炼自己从不同的角度和方式去进行思考。下面就聊一聊我在做性能优化的过程中,在思考的角度和方式上的一些认知。为了让大家能更形象的理解,我就都以启动优化来讲解。
思考角度
我这里主要通过应用层,系统词,硬件层这三个角度来介绍我对启动速度优化的思考。
应用层
做启动速度优化时,如果从应用层来考虑,我会基于业务的维度考虑所加载的业务的使用率,必要性等等,然后制定优先级,在启动的时候只加载首屏使用,或者使用率高的业务。所以接着我就可以设计启动框架用来管理任务,启动框架要设计好优先级,并且能对这些初始化的任务有使用率或者其他性能方面的统计,比如这些任务初始化后,被使用率的概率是多少,又或者初始化之后,对业务的表现提升提现在哪,帮助有多大。
从应用层的思考主要是基于对业务的管控或者对业务进行优化来提升性能。
系统层
以及系统层来考虑启动优化也有很多点,比如线程和线程优先级维度,在启动过程中,如何控制好线程数量,如何提高主线程的优先级,如何减少启动过程中不相关的线程,比如 gc 线程等等。
硬件层
从硬件层来考虑启动优化,我们可以从 cpu 的利用率,高速缓存cache的命中率等维度来考虑优化。
除了上面提到的这几个角度,我们还可以有更多角度。比如跳出本设备之外来思考,是否可以用其他的设备帮助我们加速启动。google play 就有类似的优化,gp会上传一些其他机器已经编译好的机器码,然后相同的设备下载这个应用时,也会带着这些编译好的机器码一起下载。还有很常用的服务端渲染技术,也是让服务端线渲染好界面,然后直接暂时静态模块来提升页面打开速度;又或者站在用户的角度去思考,想一想到底什么样的优化对用户感知上是有好处的,比如有时候我们再做启动或者页面打开速度优化,会给用户一个假的静态页面让用户感知已经打开了,然后再去绑定真实的数据。
做性能优化时,考虑的角度多一些,全面一些,能帮助我们想出更多的优化方案。
思考方式
除了锻炼我们站在不同的角度思考问题,我们还可以锻炼自己思考问题的方式,这里介绍自上而下和自下而上两种思考方式。
自上而下
我们做启动优化,自上而下的优化思路可能是直接从启动出发,然后分析启动过程中的链路,然后寻找耗时函数,将耗时函数放子线程或者懒加载处理,但是这种方式会导致优化做的不全面。比如将耗时的任务都放在子线程,我们再高端机上速度确实变快了,但是在低端机上,可能会降低了启动速度,因为低端机的 cpu 很差,线程一多,导致 cpu 满载,主线程反而获取不到运行时间。其次,如果从上层来看,一个函数执行耗时久可能并不是这个函数的问题,也可能是因为该函数长时间没有获取到 cpu 时间。
自上而下的思考很容易让我们忽略本质,导致优化的效果不明显或者不完整。
自下而上
自下而上思考就是从底层开始思考,还是以启动优化为例子,自下而上的思考就不是直接分析启动链路,寻找慢函数,而是直接想着如何在启动过程中合理且充分的使用 cpu 资源,这个时候我们的方案就很多了,比如我们可能会想到不同的机型 cpu 能力是不一样的,所以我们会针对高端机和低端机来分别优化,高端机上,我们想办法让cpu利用率更高,低端机上想办法避免 cpu 的超载,同时配合慢函数,线程,锁等知识进行优化,就能制定一套体系并且完整的启动优化方案。
完整的闭环
上面讲的都是如何进行优化,优化很重要,但并不是全部,在实际的性能优化中,我们需要做的有监控,优化,防劣化,数据收益收集等等,这些部分都做好才能形成一个完整的闭环。我一一讲一下这几个部分:
监控:完整的监控应用中各项性能的指标,仅仅有指标监控是不够的,我们还需要尽量做归因的监控。比如内存监控,我们不仅仅要监控我们应用的内存指标,还可以还要能监控到各个业务的内存使用占比,大集合,大图片,大对象等等归因项。并且我们的监控同样要基于性能考虑去设计。完整的监控能让我们更高效的发现和解决异常。
优化:优化就是前面提到的,合理且充分的使用硬件资源,让程序的表现更好。
防劣化:防劣化也是有很多事情可以做的,包括建立完善的线下性能测试,线上监控的报警等。比如内存,我们可以在线下每天通过monkey跑内存泄露并提前治理,这就是防劣化。
数据收益收集。学会用好A/B测试,学会关注核心价值的指标。比如我们做内存优化,一味的追求降低应用内存的占用并不是最优,内存占用的多,可能会让我们的程序运行更快,用户体验更好,所以我们需要结合崩溃率,留存等等这种体验核心价值的指标,来确定内存到底要不要继续进行优化或者优化到多少。
小结
上面就是我在多年的性能优化经验中总结出来的认知及方法论。只有了解了这些方法论,我们才能在进行性能优化时,如鱼得水,游刃有余。
这篇文章也没有介绍具体的优化方案,因为性能优化的方案通过一篇文章是介绍不完的,大家有兴趣可以看看我写的掘金小册《Android 性能优化》,可以体系的学一学如何进行优化,上面讲解的方法论,也都会在这本小册中体现出来。
作者:helson赵子健
来源:juejin.cn/post/7169486107866824717
万维网之父:Web3 根本不是 Web,我们应该忽略它
万维网之父、英国计算机科学家 Tim Berners-Lee 在 2022 年 Web 峰会上表示,区块链并不是构建下一代互联网的可行解决方案,我们应该忽略它。
他有自己的 Web 去中心化项目,叫作 Solid。
Berners-Lee 在里斯本举行的 Web 峰会上说,“在讨论新技术的影响时,你必须理解我们正在讨论的术语的真正含义,而不仅仅是停留在流行词的层面,这一点很重要。”
“事实上,Web3 被以太坊那班人用在了区块链上,这是一件可耻的事。事实上,Web3 根本就不是 Web。”
在科技行业,Web3 是一个模糊的术语,被用来描述一个假设的未来互联网版本,它比现在更加去中心化,不被亚马逊、微软和谷歌等少数巨头玩家所主导。
它涉及到一些新的技术,包括区块链、加密货币和非同质化的的代币。
虽然 Berners-Lee 的目标是将个人数据从大型科技公司的控制中解放出来,但他不相信支撑比特币等加密货币的分布式账本技术区块链会是解决方案。
他说,“区块链协议可能对某些事情有用,但对 Solid 来说不是。”Solid 是 Berners-Lee 领导的一个 Web 去中心化项目。“它们太慢、太贵、太公开。个人数据存储必须快速、廉价和私密。”
他说,“忽略所谓的 Web3,那些构建在区块链之上的随机的 Web3,我们不会把它用在 Solid 上。”
Berners-Lee 说,人们经常把 Web3 和“Web 3.0”混为一谈,而“Web 3.0”是他提出的重塑互联网的提议。他的初创公司 Inrupt 旨在让用户控制自己的数据,包括如何访问和存储数据。据 TechCrunch 报道,该公司在去年 12 月获得了一轮 3000 万美元的融资。
Berners-Lee 表示,个人数据被谷歌和 Facebook 等少数大型科技平台独自占有,它们利用这些数据“将我们锁定在它们的平台上”。
他说,“其结果就是一场大数据竞赛,赢家是控制最多数据的公司,其他的都是输家。”
他的初创公司旨在通过三种方式解决这个问题:
全球“单点登录”功能,可以让任何人从任何地方登录。
允许用户与其他人共享数据的登录 ID。
一个“通用 API”或应用程序编程接口,允许应用程序从任何来源提取数据。
Berners-Lee 并不是唯一一个对 Web3 持怀疑态度的知名科技人士。一些硅谷领袖也对 Web3 提出了异议,比如推特联合创始人 Jack Dorsey 和特斯拉首席执行官 Elon Musk。
批评人士表示,Web3 容易出现与加密货币相同的问题,比如欺诈和安全缺陷。
原文链接:https://www.cnbc.com/2022/11/04/web-inventor-tim-berners-lee-wants-us-to-ignore-web3.html
作者 | Ryan Browne
译者 | 明知山
策划 | Tina
收起阅读 »按时上班有全勤奖,按时下班叫什么奖?
网友评论:
@快溜儿的还我昵称:老板有话对你奖
@放学去后山:节约用电奖
@小镜子375:领导不鼓励下班
@钱灿灿秋啾啾:福报都不接吗?
来源于网络
Spring Boot 分离配置文件的 N 种方式
今天聊一个小伙伴在星球上的提问:
问题不难,解决方案也有很多,因此我决定撸一篇文章和大家仔细说说这个问题。
1. 配置文件位置
首先小伙伴们要明白,Spring Boot 默认加载的配置文件是 application.properties 或者 application.yaml,默认的加载位置一共有五个,五个位置可以分为两类:
从 classpath 下加载,这个又细分为两种:
直接读取 classpath 下的配置文件,对应到 Spring Boot 项目中,就是 resources 目录下的配置。
读取 classpath:/config/ 目录下的文件,对应到 Spring Boot 项目中就是 resources/config 目录下的配置。
这两种情况如下图:
从项目所在的当前目录下加载,这个又细分为三种情况:
从项目当前目录下加载配置文件。
从项目当前目录下的 config 文件夹中加载配置文件。
从项目当前目录下的 config 文件夹的子文件夹中加载(孙子文件夹不可以)。
这三种情况如下图:
config 目录下的配置文件可以被加载,config/a 目录下的配置文件也可以被加载,但是 config/a/b 目录下的配置文件不会被加载,因为不是直接子文件夹。
配置文件可以放在这么多不同的位置,如果同一个属性在多个配置文件中都写了,那么后面加载的配置会覆盖掉前面的。例如在 classpath:application.yaml 中设置项目端口号是 8080,在 项目当前目录/config/a/application.yaml 中设置项目端口是 8081,那么最终的项目端口号就是 8081。
这是默认的文件位置。
如果你不想让自己的配置文件叫 application.properties 或者 application.yaml,那么也可以自定义配置文件名称,只需要在项目启动的时候指定配置文件名即可,例如我想设置我的配置文件名为 app.yaml,那么我们可以在启动 jar 包的时候按照如下方式配置,此时系统会自动去上面提到的五个位置查找对应的配置文件:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.name=app如果项目已经打成 jar 包启动了,那么前面所说的目录中,后三个中的项目当前目录就是指 jar 包所在的目录。
如果你不想去这五个位置查找,那么也可以在启动 jar 包的时候明确指定配置文件的位置和名称,如下:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.location=optional:classpath:/app.yaml注意,我在 classpath 前面加上了 optional: 表示如果这个配置文件不存在,则按照默认的方式启动,而不会报错说找不到这个配置文件。如果不加这个前缀,那么当系统找不到指定的配置文件时,就会抛出 ConfigDataLocationNotFoundException 异常,进而导致应用启动失败。
如果配置文件和 jar 包在相同的目录结构下,如下图:
那么启动脚本如下:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.location=optional:javaboy/app.yaml如果 spring.config.location 的配置,只是指定了目录,那么必须以 / 结尾,例如上面这个启动脚本,也可以按照如下方式启动:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.location=optional:javaboy/ --spring.config.name=app通过 spring.config.location 属性锁定配置文件的位置,通过 spring.config.name 属性锁定配置文件的文件名。
2. 额外位置
前面我们关于配置文件位置的设置,都是覆盖掉已有的配置,如果不想覆盖掉 Spring Boot 默认的配置文件查找策略,又想加入自己的,那么可以按照如下方式指定配置文件位置:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.additional-location=optional:javaboy/app.yaml如果这个额外指定的配置文件和已有的配置文件有冲突,那么还是以后来者为准。
3. 位置通配符
有一种情况,假设我有 redis 和 mysql 的配置,我想将之放在两个不同的文件夹中以便于管理,像下面这样:
那么在项目启动时,可以通过通配符 * 批量扫描相应的文件夹:
java -jar boot_config_file-0.0.1-SNAPSHOT.jar --spring.config.location=optional:config/*/使用通配符批量扫描 mysql 和 redis 目录时,默认的加载顺序是按照文件夹的字母排序,即先加载 mysql 目录后加载 redis 目录。
需要注意的是,通配符只能用在外部目录中,不可以用在 classpath 中的目录上。另外,包含了通配符的目录,只能有一个通配符
*,不可以有多个,并且还必须是以*/结尾,即一个目录的最后部分可以不确定。
4. 导入外部配置
从 Spring Boot2.4 开始,我们也可以使用 spring.config.import 方法来导入配置文件,相比于 additional-location 配置,这个 import 导入更加灵活,可以导入任意名称的配置文件。
spring.config.import=optional:file:./dev.properties甚至,这个 spring.config.import 还可以导入无扩展名的配置文件,例如我有一个配置文件,是 properties 格式的,但是这个这个配置文件没有扩展名,现在我想将之作为 properties 格式的配置文件导入,方式如下:
spring.config.import=optional:file:/Users/sang/dev[.properties]好啦,看完上面的内容,文章一开始的问题答案就不用我多说了吧~
作者:江南一点雨
来源:juejin.cn/post/7168285587374342180
Android依赖冲突解决
一、背景
工程中引用不同的库(库A和B),当不同的库又同时依赖了某个库的不同版本(如A依赖C的1.1版本,B依赖C2.2版本),这时就出现了依赖冲突。
二、问题解决步骤
查看依赖树
运行android studio的中如下task任务即可生成依赖关系,查看冲突是由哪哪些库引入的(即找到库A和库B)。
排除依赖
使用 exclude group:'group_name',module:'module_name'
//剔除rxpermissions这依赖中所有com.android.support相关的依赖,避免和我们自己的冲突
implementation 'com.github.tbruyelle:rxpermissions:0.10.2', {
exclude group: 'com.android.support'
}注意:下图中红框处表示依赖的版本由1.0.0被提升到了1.1.0。如果对1.0.0的库中的group或module进行exclude时,当库的版本被提升时,exclude将会失效,解决办法时工程中修改库的依赖版本为被提升后的版本。
使用强制版本
冲突的库包含了多个版本,这时可直接使用强制版本。在项目的主module的build.gradle的dependencies节点里添加configurations.all {},{}中的前缀是 resolutionStrategy.force ,后面是指定各module强制依赖的包,如下图所示,强制依赖com.android.tools:sdklib包的30.0.0:
作者:Android_Developer
来源:juejin.cn/post/7042951122872434696
每个前端都应该掌握的7个代码优化的小技巧
本文将介绍7种JavaScript的优化技巧,这些技巧可以帮助你更好的写出简洁优雅的代码。
1. 字符串的自动匹配(Array.includes)
在写代码时我们经常会遇到这样的需求,我们需要检查某个字符串是否是符合我们的规定的字符串之一。最常见的方法就是使用||和===去进行判断匹配。但是如果大量的使用这种判断方式,定然会使得我们的代码变得十分臃肿,写起来也是十分累。其实我们可以使用Array.includes来帮我们自动去匹配。
代码示例:
// 未优化前的写法
const isConform = (letter) => {
if (
letter === "a" ||
letter === "b" ||
letter === "c" ||
letter === "d" ||
letter === "e"
) {
return true;
}
return false;
};
// 优化后的写法
const isConform = (letter) =>
["a", "b", "c", "d", "e"].includes(letter);
2.for-of和for-in自动遍历
for-of和for-in,可以帮助我们自动遍历Array和object中的每一个元素,不需要我们手动跟更改索引来遍历元素。
注:我们更加推荐对象(object)使用for-in遍历,而数组(Array)使用for-of遍历
for-of
const arr = ['a',' b', 'c'];
// 未优化前的写法
for (let i = 0; i < arr.length; i++) {
const element = arr[i];
console.log(element);
}
// 优化后的写法
for (const element of arr) {
console.log(element);
}
// expected output: "a"
// expected output: "b"
// expected output: "c"
for-in
const obj = {
a: 1,
b: 2,
c: 3,
};
// 未优化前的写法
const keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
const key = keys[i];
const value = obj[key];
// ...
}
// 优化后的写法
for (const key in obj) {
const value = obj[key];
// ...
}
3.false判断
如果你想要判断一个变量是否为null、undefined、0、false、NaN、'',你就可以使用逻辑非(!)取反,来帮助我们来判断,而不用每一个值都用===来判断
// 未优化前的写法
const isFalsey = (value) => {
if (
value === null ||
value === undefined ||
value === 0 ||
value === false ||
value === NaN ||
value === ""
) {
return true;
}
return false;
};
// 优化后的写法
const isFalsey = (value) => !value;
4.三元运算符代替(if/else)
在我们编写代码的时候肯定遇见过if/else选择结构,而三元运算符可以算是if/else的一种语法糖,能够更加简洁的表示if/else。
// 未优化前的写法
let info;
if (value < minValue) {
info = "Value is最小值";
} else if (value > maxValue) {
info = "Value is最大值";
} else {
info = "Value 在最大与最小之间";
}
//优化后的写法
const info =
value < minValue
? "Value is最小值"
: value > maxValue ? "Value is最大值" : "在最大与最小之间";
5.函数调用的选择
三元运算符还可以帮我们判断当前情况下该应该调用哪一个函数,
function f1() {
// ...
}
function f2() {
// ...
}
// 未优化前的写法
if (condition) {
f1();
} else {
f2();
}
// 优化后的写法
(condition ? f1 : f2)();
6.用对象代替switch/case选择结构
switch case通常是有一个case值对应一个返回值,这样的结构就类似于我们的对象,也是一个键对应一个值。我们就可以用我们的对象代替我们的switch/case选择结构,使代码更加简洁
const dayNumber = new Date().getDay();
// 未优化前的写法
let day;
switch (dayNumber) {
case 0:
day = "Sunday";
break;
case 1:
day = "Monday";
break;
case 2:
day = "Tuesday";
break;
case 3:
day = "Wednesday";
break;
case 4:
day = "Thursday";
break;
case 5:
day = "Friday";
break;
case 6:
day = "Saturday";
}
// 优化后的写法
const days = {
0: "Sunday",
1: "Monday",
2: "Tuesday",
3: "Wednesday",
4: "Thursday",
5: "Friday",
6: "Saturday",
};
const day = days[dayNumber];
7. 逻辑或(||)的运用
如果我们要获取一个不确定是否存在的值时,我们经常会运用if判断先去判断值是否存在,再进行获取。如果不存在我们就会返回另一个值。我们可以运用逻辑或(||)的特性,去优化我们的代码
// 未优化前的写法
let name;
if (user?.name) {
name = user.name;
} else {
name = "Anonymous";
}
// 优化后的写法
const name = user?.name || "Anonymous";
作者:zayyo
来源:juejin.cn/post/7169420903888584711
听说你学过架构设计?来,弄个短链系统
01 引言
1)背景
这是本人在面试“字节抖音”部门的一道系统设计题,岗位是“后端高级开发工程师”,二面的时候问到的。一开始,面试官笑眯眯地让我做个自我介绍,然后聊了聊项目。
当完美无瑕(吞吞吐吐)地聊完项目,并写了一道算法题之后。
面试官就开始发问了:小伙子,简历里面写到了熟悉架构设计是吧,那你知道程序设计的‘三高’指什么吗?
我心想,那不是由于程序员的系统不靠谱,领导不当人,天天加班改 BUG,导致年纪轻轻都高血脂、高血压和高血糖嘛!
但是,既然是面试,那领导肯定不愿意听这,于是我回答:程序三高,就是系统设计时需要考虑的高并发、高性能和高可用:
高并发就是在系统开发的过程中,需要保证系统可以同时并行处理很多请求;
高性能是指程序需要尽可能地占用更少的内存和 CPU,并且处理请求的速度要快;
高可用通常描述系统在一段时间内不可服务的时候很短,比如全年停机不超过 31.5 秒,俗称 6 个 9,即保证可用的时间为 99.9999%。
于是,面试官微微点头,心想小伙子还行,既然这难不住你,那我可得出大招了,就来道系统设计题吧!
2)需求说明
众所周知,当业务场景需要给用户发送网络地址或者二维码时,由于地址的长度比较长,通常为了占用更少的资源和提升用户体验。例如,谷歌搜索“计算机”词条地址如下:
https://www.google.com/search?q=%E8%AE%A1%E7%AE%97%E6%9C%BA&ei=KNZ5Y7y4MpiW-AaI4LSACw&ved=0ahUKEwi87MGgnbz7AhUYC94KHQgwDbAQ4dUDCBA&uact=5&oq=%E8%AE%A1%E7%AE%97%E6%9C%BA&gs_lcp=Cgxnd3Mtd2l6LXNlcnAQAzIECAAQQzIFCAAQgAQyBQgAEIAEMgUIABCABDIFCC4QgAQyBQgAEIAEMgUIABCABDIFCAAQgAQyBQgAEIAEMgUIABCABDoKCAAQRxDWBBCwAzoLCC4QgAQQxwEQ0QM6FggAEOoCELQCEIoDELcDENQDEOUCGAE6BwguENQCEENKBAhBGABKBAhGGABQpBZYzSVglydoA3ABeACAAZ0DiAGdD5IBCTAuNy4xLjAuMZgBAKABAbABCsgBCsABAdoBBAgBGAc&sclient=gws-wiz-serp很明显,如果将这一长串网址发给用户,是十分不“体面”的。而且,遇到一些有字数限制的系统里面,比如微博发帖子就有字数限制,肯定无法发送这样的长链接地址。一般的短信链接中,大多也都是短链接地址:
所以,为了提升用户体验,以及日常业务的需要。我们需要设计一个短链接生成系统,除了业务功能实现以外,我们还得为全国的网络地址服务。在这么大的用户量下,数据该如何存储,高并发如何处理呢?
02 三种链接生成方法
1)需求分析
我心想,这面试官看着“慈眉善目”还笑眯眯的,但出的题目可不简单,这种类型的系统需要考虑的点太多了,绝对不能掉以轻心。
于是,我分别从链接生成、网址访问、缓存优化和高可用四个方面开始着手设计。
首先,生成短链地址,可以考虑用 UUID 或者自增 ID。对于每一个长链接转短链地址时,都必须生成一个全局唯一的短链值,不然就会发生冲突。所以,短链接的特点是:
数据存储量很大,全国的网址每天至少都是百万个短链接地址需要生成;
并发量也不小,遇到同时来访问系统,按一天 3600 秒来算,平均每秒至少上千个请求数;
短链接不可重复,否则会引起数据访问冲突。
2)雪花算法
首先,生成短链接,可以用雪花算法+哈希的方式来实现。
雪花算法是在分布式场景下,根据时间戳、不同的机器 ID 以及序列号生成的唯一数。它的优点在于简单方便,随取随用。
通过雪花算法取到的唯一数,再用哈希映射,将数字转为一个随机的字符串,如果短链字符串比较长,可以直接取前 6 位。但是,由于哈希映射的结果可能会发生冲突,所以对哈希算法的要求比较高。
2)62 进制数生成短链接
除了雪花算法,还可以用 62 进制数(A-Za-z0-9)来生成短链接地址。首先得到一个自增 ID,再将此值转换为 62 进制(a-zA-Z0-9)的字符串,一个亿的数字转换后也就五六位(1亿 -> zAL6e)。
将短链接服务器域名,与这个字符串进行拼接,就能得到短链接的 URL,比如:t.cn/zAL6e。
而生成自增 ID 需要考虑性能影响和并发安全性,所以我们可以通过 Redis 的 incr 命令来做一个发号器,它是一个原子操作,因此我们不必担心数字的安全性。而 Redis 是内存操作,所以效率也挺高。
3)随机数+布隆过滤器
除了自增 ID 以外,我们还可以生成随机数再转 62 进制的方法来生成短链接。但是,由于随机数可能重复,因此我们需要用布隆过滤器来去重。
布隆过滤器是一个巧妙设计的数据结构,它的原理是将一个值多次哈希,映射到不同的 bit 位上并记录下来。当新的值使用时,通过同样的哈希函数,比对各个 bit 位上是否有值:如果这些 bit 位上都没有值,说明这个数是唯一的;否则,就可能不是唯一的。
当然,这可能会产生误判,布隆过滤器一定可以发现重复的值,但 也可能将不重复的值判断为重复值,误判率大概为 0.05%,是可以接受的范围,而且布隆过滤器的效率极高。
因此,通过布隆过滤器,我们能判断生成的随机数是否重复:如果重复,就重新生成一个;如果不重复,就存入布隆过滤器和数据库,从而保证每次取到的随机数都是唯一的。
4)将短链接存到数据库
存库时,可能会因为库存量和技术栈,选用不同的数据库。但由于公司部门用 MySQL 比较多,且当前题目未提及技术选型,所以我们还是选用 MySQL 作为持久化数据库。
每当生成一个短链接后,需要在 MySQL 存储短链接到长链接的映射关系并加上唯一索引,即 zAL6e -> 真实URL。
03 重定向过程
浏览器访问短链接服务时,根据短链地址取到原始 URL,然后进行网址重定向。我们通常有两种重定向方式:
一种是返回给浏览器 301 响应码永久重定向,让其后续直接访问真实的 URL 地址;
一种是 302 临时重定向,让浏览器当前这次访问真实 URL,但后续请求时还是根据短链地址访问。
虽然用 301 浏览器只需一次请求,后续可以直接从浏览器获取长链接,这种方法可以提升访问速度,但是它没法统计短链接的访问次数。
所以根据业务需要,我们一般选用 302 重定向。
04 缓存设计
由于短链接是分发到多个用户手里的,可能在短时间内会多次访问,所以从 MySQL 写入/获取到长链接后可以放入 redis 缓存。
1)加入缓存
并且,短链接和长链接的对应关系一般不会频繁修改,所以数据库和缓存的一致性通过简单的旁路缓存模式来保证:
读(Read)数据时,若缓存未命中,则先读 DB,从 DB 中取出数据,放入缓存,同时返回响应;
写(Write)数据时,先更新 DB,再删除缓存。
当用户需要生成短链接时,先到这个映射表中看一下有没有对应的短链接地址。有就直接返回,并将这个 key-value 的过期时间增加一小时;没有就重新生成,并且将对应关系存入这个映射表中。
缓存的淘汰策略可以选用:
LRU:Least Recently Used,最近最少使用算法,最近经常被读写的短链地址作为热点数据可以一直存在于缓存,淘汰那些很久没有访问过的短链 key;
LFU:Least Frequently Userd,最近最不频繁使用算法,最近访问频率高的短链地址作为热点数据,淘汰那些访问频率较低的短链 key。
2)缓存穿透
但是,使用缓存也防止不了一些异常情况,比如“缓存穿透”。所谓缓存穿透,就是查询一个缓存和数据库中都不存在的短链接,如果并发量很大,就会导致所有在缓存中不存在的请求都打到 MySQL 服务器上,导致服务器处理不了这么多请求而阻塞,甚至崩溃。
所以,为了防止不法分子通过类似“缓存穿透”的方式来攻击服务器,我们可以采用两种方法来应对:
对不存在的短链地址加缓存,key 为短链接地址,value 值为空,过期时间可以设置得短一点;
采用布隆过滤器将已有的短链接多次哈希后存起来,当有短链接请求时,先通过布隆过滤器判断一下该地址是否存在数据库中;如果不在,则说明数据库中不存在该地址,就直接返回。
05 高可用设计
由于缓存和数据库持久化依赖于 Redis 和 MySQL,因此 MySQL 和 Redis 的高可用性必须要保证。
1)MySQL 高可用
MySQL 数据库采用主从复制,进行读写分离。Master 节点进行写操作,Slave 节点用作读操作,并且可以用 Keepalived 来实现高可用。
Keepalived 的原理是采用虚拟 IP,检测入口的多个节点,选用一台热备服务器作为主服务器,并分配给它一个虚拟 IP,外部请求都通过这个虚拟 IP 来访问数据库。
同时,Keepalived 会实时检测多个节点的可用状态,当发现一台服务器宕机或出现故障时,会从集群中将这台服务器踢除。如果这台服务器是主服务器,keepalived 会触发选举操作,从服务器集群中再选出一个服务器充当 master 并分配给它相同的虚拟 IP,以此完成故障转移。
并且,在 Keepalived 的支持下,这些操作都不需要人工参与,只需修复故障机器即可。
2)Redis 高可用
由于在大数据高并发的场景下,写请求全部落在 Redis 的 master 节点上,压力太大。如果一味地采用增加内存和 CPU 这种纵向扩容的方式,那么一台机器所面临的磁盘 IO,网络等压力逐渐增大,也会影响性能。
所以 Redis 采用集群模式,实现数据分片。并且,加入了哨兵机制来保证集群的高可用。它的基本原理是哨兵节点监控集群中所有的主从节点,当主节点宕机或者发生故障以后,哨兵节点会标记它为主观下线;当足够多的哨兵节点将 Redis 主节点标记为主观下线,就将其状态改为客观下线。
此时,哨兵节点们通过选举机制选出一个领头哨兵,对 Redis 主节点进行故障转移操作,以保障 Redis 集群的高可用,这整个流程都不需要人工干预。
3)系统容错
服务在上线之前,需要做好充分的业务量评估,以及性能测试。做好限流、熔断和服务降级的逻辑,比如:采用令牌桶算法实现限流,hystrix 框架来做熔断,并且将常用配置放到可以热更新的配置中心,方便对其实时更改。
当业务量过大时,将同步任务改为异步任务处理。通过这些服务治理方案,让系统更加稳定。
06 后记
当我答完最后一个字的时候,面试官看着我,眼神中充满了“欣赏”与疑惑。我想,他应该是被我这番表现给镇住了,此次面试应该是十拿九稳。
但是,出奇地,面试官没有对刚才的架构设计提出评价,只看了看我说:“那今天的面试就到这里,你有什么想要问的吗?”
这下,轮到我震惊了,那到底过不过呢?倒是给句话呀,于是我问道:“通过这次面试,您觉得我有哪些方面需要提升呢?”
“算法和项目需要再多练练,但是我发现了你一个优点。”面试官笑了笑接着说,“八股文背的倒是挺不错的!”
悬着的心总算放下,我心想:“哦,那稳了~”
作者:xin猿意码
来源:juejin.cn/post/7168090412370886686
女程序员做了个梦。。。
昨晚梦见男朋友和别的女人在逛街,梦里我的第一反应是查源代码…结果调试半天查不出来为什么显示的是那个女人不是我,最后含泪把那个女人给注释掉了,再一运行就是我男朋友自己逛街了…醒来囧字脸呆了很久…囧rz
看看神级评论
亡羊补牢型
把那个女人的指针指向你即可;
谁让你把男朋友设成 public 的;
心真软,就该把他的接口屏蔽掉;
protected 逛街(youOnly);
设计问题,应该采用单例模式;
没做回归测试;
标准做法是做个断言;
注释掉了,逛街的参数就不用改了吗?
“最后含泪把那个女人注释掉了,再一运行就是我男朋友自己逛街了。”很明显是变量名作用域的问题,改个名字就行了;
还可以有个多线程的算法,把你的优先级设成 99,一个 idle 线程的优先级设成 50,把那个女人的优先级设成 49。酱紫就永远调度不到啦。
破罐破摔型
加个断点看看那个女人是谁;
那也没关系,那就老调用那个女人…你 BF 放在那里不动…养着…
上绝招,用 goto,做个死循环,让他们逛死;
善心点,别 goto 了,加个 exit 结束进程吧,冤冤相报何时了啊。
来源:http://www.douban.com/group/topic/14168111/
收起阅读 »我为什么不愿意主动思考?
写在前面
最近一直在想一个问题;我为什么不愿意主动思考?
引发这个思考的是最近在开发中遇到的一个问题,问题并不难在这里就不多赘述了。遇到这个问题后,我的第一反应就是百度,百度无果后我请教了身边的同事、交流群里的大佬,还是没有解决(提供了一些思路)。没办法,我只能自己思考、尝试,后来发现是某一项隐藏较深的配置有问题。解决这个问题后,我在想:为什么遇到问题的第一时间,我不愿意主动去思考,而是要在一系列的尝试无果后才愿意直面问题呢?是因为领导逼的紧,没有时间?还是能力有限毫无思路?都不是,是我自己本身不愿意去思考。
三重大脑
美国神经生物学家Paul Maclean曾提出一个叫”三重大脑“的理论。按照进化的顺序,把大脑分为三重:爬行动物时期的大脑,爬行脑,控制身体行为、识别危险,快速反应;哺乳动物时期的大脑,情绪脑,与情绪相关,根据相关情绪做出反应;灵长动物时期的大脑,理论脑,关于自尊、自信、自我认知、逻辑、思考等。从进化的时间和生存的重要性来看,爬行脑和情绪脑对人体的控制明显大于逻辑脑。这不难想象,当安全都存在问题时,谁还能静下心来思考,同样的,处于极度愤怒、悲伤的情绪中也没办法思考。因此,思考或者说情绪脑,优先级并不高。同时,思考这种行为相对消耗能量更高(大脑的神经元每天要消耗75%的肝脏血液,消耗占全身总消耗量20%的氧气),本身就被我们的身体排斥。那么,我们大脑不排斥什么,或者说喜欢什么?答案是即时满足。从进化角度来看,我们的祖先过的是茹毛饮血、饔飧不济的生活,对他们来说最重要的是当下,而不是将来,这是人类刻在骨子里的天性,也是我们大脑喜欢即时满足的原因。而思考这种延迟满足的行为是同时被身体和天性所排斥的,所以我们不喜欢思考。那么,我们该如何控制这种天性,如何彻底控制我们的大脑,让逻辑脑当大哥呢?
用进废退
和肌肉一样,当我们不断使用逻辑脑进行思考时,他的话语权会不断扩大,相应的爬行脑和情绪脑带来的不良影响会不断减小,此消彼长,最终形成思考的习惯。
间歇满足
自我控制很难,我们可以适当放松。当我们在进行思考、学习等行为时,大脑渴望即时满足的天性会不断出来作祟,再加上数字时代的今天,诱惑与满足无处不在,稍不注意就会前功尽弃,时时刻刻对抗天性这不现实。我们可以适当、短暂的满足它,如番茄工作法等。这种间歇性的满足是在我们的控制之中的,长此以往,能有效提升我们的自控能力。开始可能很难,坚持下去会越来越轻松。
思考正反馈
通过思考解决某个问题时,我们同样会得到满足,这种来之不易的满足,大脑会更喜欢。 这样的正反馈,可以让我们在提升自己的同时,保持一个长期的、积极的主动思考的状态。
耳濡目染
大脑获取信息的方式有两种,主动思考、被动接受。环境对人的影响是无可估量的,古有孟母三迁,今有高校保安。当我们无力改变当下的自己时,我们可以试着改变环境,再通过环境改变自己,好的环境能让我们在不知不觉中成长。
自我认知
主动思考往往源于自我认知。为什么别人的技术比我好?薪水比我高?是因为智商吗?可能会有一定影响,但占比非常低,更多的源于其自身的主动思考、学习所带来的差距。自我认知让我们发现这份差距,主动思考让我们知道如何弥补这份差距。
作者:侃如
来源:juejin.cn/post/7166658322995609636
这一篇让你搞定 Flutter 的数据表格
前言
目前,越来越多的管理层(所谓的领导)都希望在手机端查看各种各样的数据报表,以达到随时随地关注经营业绩(监督干活)的目的。这就要求移动端能够提供数据表来满足这类诉求,本篇我们就来介绍 Flutter 的数据表格的使用。通过本篇你会了解到:
- Flutter 自带的
DataTable的使用; - 第三方强大的数据表
SfDataGrid的使用。
组成DataTable的基本元素
DataTable 是 Flutter 自带的数据表组件,支持定义表头和行数据来实现数据表格,同时支持列排序、选中行等操作,对于基础的数据表格展示基本能够满足,DataTable类的定义如下。
DataTable({
Key? key,
required this.columns,
this.sortColumnIndex,
this.sortAscending = true,
this.onSelectAll,
this.decoration,
this.dataRowColor,
this.dataRowHeight,
this.dataTextStyle,
this.headingRowColor,
this.headingRowHeight,
this.headingTextStyle,
this.horizontalMargin,
this.columnSpacing,
this.showCheckboxColumn = true,
this.showBottomBorder = false,
this.dividerThickness,
required this.rows,
this.checkboxHorizontalMargin,
this.border,
}) 常用的属性说明如下:
columns:是一个DataColumn数组,用于定义表头。rows:是一个DataRow数组,用于定义每一行要显示的数据。sortColumnIndex:要排序的列,可以通过该值设定当前使用那一列进行排序。指定的列会有一个向上或向下的箭头指示当前的排序方式。sortAscending:排序的方式,默认为升序排序。onSelectAll:全选回调事件,如果全选携带的参数为true,否则为false。
DataColumn 是数据列组件,包括了如下4个属性:
label:可以是任意组件,通常我们使用的是Text组件,也可以使用其他组件。tooltip:列的描述文字,用于列宽受限时展示完整的列内容。numeric:是否是数字列,如果是数字列会采用右对齐方式呈现。onSort:排序事件回调,携带两个参数指示当前实用第几列排序,排序方式是升序还是降序。我们可以通过这个方法来响应排序操作对要展示的行数据进行排序。
DataRow是数据行组件,包括如下5个属性:
cells:DataCell数组,用于定义每一列对应的元素。selected:行的选中状态,默认为不选中。onSelectChanged:行选中状态改变时的回调函数。onLongPress:长按行的回调,我们可以用来做长按删除、上移、下移类的操作。color:MaterialStateProperty<Color?>类,可以用来定义不同状态下的行的颜色。
DataCell是数据单元格组件,用于定义要显示的单元格内容以及响应单元格的交互(包括点击、长按、双击等)。
由此我们就得到了一个完整的 DataTable 所需要的元素。
DataTable 示例
首先说一下,Flutter 提供的 DataTable 如果超出屏幕范围默认是不支持滚动的,因此如果要支持滚动,就需要用 SingleChildScrollView 包裹,然后定义滚动的方向来实现横向或纵向滚动。如果要同时支持横向和纵向滚动,就需要使用两个SingleChildScrollView来包裹。下面的示例代码就是实用了两个SingleChildScrollView实现了列表的横向和纵向滚动。
class _DataTableDemoState extends State<DataTableDemo> {
var _sortAscending = true;
int? _sortColumn;
final dataModels = <DataModel>[
DataModel(nation: '中国', population: 14.1, continent: '亚洲'),
DataModel(nation: '美国', population: 2.42, continent: '北美洲'),
DataModel(nation: '俄罗斯', population: 1.43, continent: '欧洲'),
DataModel(nation: '巴西', population: 2.14, continent: '南美洲'),
DataModel(nation: '印度', population: 13.9, continent: '亚洲'),
DataModel(nation: '德国', population: 0.83, continent: '欧洲'),
DataModel(nation: '埃及', population: 1.04, continent: '非洲'),
DataModel(nation: '澳大利亚', population: 0.26, continent: '大洋洲'),
DataModel(nation: '印度', population: 13.9, continent: '亚洲'),
DataModel(nation: '德国', population: 0.83, continent: '欧洲'),
DataModel(nation: '埃及', population: 1.04, continent: '非洲'),
DataModel(nation: '澳大利亚', population: 0.26, continent: '大洋洲'),
];
Function(int, bool)? _sortCallback;
@override
void initState() {
super.initState();
_sortCallback = (int column, bool isAscending) {
setState(() {
_sortColumn = column;
_sortAscending = isAscending;
});
};
}
@override
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: Colors.white,
appBar: AppBar(
title: const Text('DataTable'),
backgroundColor: Colors.red[400]!,
),
body: SingleChildScrollView(
scrollDirection: Axis.vertical,
child: SingleChildScrollView(
scrollDirection: Axis.horizontal,
child: DataTable(
horizontalMargin: 10.0,
showBottomBorder: true,
sortAscending: _sortAscending,
sortColumnIndex: _sortColumn,
showCheckboxColumn: true,
headingTextStyle: const TextStyle(
fontWeight: FontWeight.bold,
color: Colors.black,
),
columns: [
const DataColumn(label: Text('国家')),
DataColumn(
label: const Text('人口(亿)'),
numeric: true,
onSort: _sortCallback,
),
DataColumn(
label: const Text('大洲'),
onSort: _sortCallback,
),
const DataColumn(label: Text('说明')),
],
rows: sortDataModels(),
),
),
),
);
}
List<DataRow> sortDataModels() {
dataModels.sort((dataModel1, dataModel2) {
bool isAscending = _sortAscending;
var result = 0;
if (_sortColumn == 0) {
result = dataModel1.nation.compareTo(dataModel2.nation);
}
if (_sortColumn == 1) {
result = dataModel1.population.compareTo(dataModel2.population);
}
if (_sortColumn == 2) {
result = dataModel1.continent.compareTo(dataModel2.continent);
}
if (isAscending) {
return result;
}
return -result;
});
return dataModels
.map((dataModel) => DataRow(
onSelectChanged: (selected) {},
cells: [
DataCell(
Text(dataModel.nation),
),
DataCell(
Text('${dataModel.population}'),
),
DataCell(
Text(dataModel.continent),
),
const DataCell(
Text('这是详细介绍'),
),
],
))
.toList();
}
}上述代码的实现效果如下图所示。
可以看到,使用 DataTable 能够满足我们基本的数据表格的需求,但是我们如果希望表头固定或者列固定,实现起来就有点麻烦了。复杂表格的场景,推荐大家一个好用的第三方库:SfDataGrid。
SfDataGrid
SfDataGrid 同时支持移动端、Web 端和桌面端,基本上和前端 Web 表格功能有的它都有,比如固定某些列或某些行、自动滚动、编辑单元格、设置行高和列宽、排序、单击选择单行或多行、自定义样式、合并单元格、调整列宽、上拉加载或分页浏览、导出到 Excel 文件等等。可以说,用 SfDataGrid 可以满足绝大多数数据表格的场景,更重要的是,官方提供了详细的文档(点此查看使用文档)和示例代码,可以让我们轻松上手。下面是实用 SfDataGrid实现的一个示例效果(移动端列宽调整需要使用长按功能)。
总结
本篇介绍了 Flutter 中的数据表格组件 DataTable 的使用,并介绍了一个很强大的数据表格库 SfDataGrid。如果是简单的数据表格可以使用 Flutter 自带的 DataTable,如果涉及到复杂的样式和交互效果,建议实用 SfDataGrid 来搞定。
链接:https://juejin.cn/post/7168430613891842055
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
温故知新--MV*系列架构模型
下文仅代表个人理解,可能会有偏差或错误,欢迎评论或私信讨论。
MVC
从软件架构模型角度
MVC 是比较“古老”的架构模型,后面的 MV* 都是基于它进行拓展。MVC 出现的意义是为了提高程序的可维护性与拓展性。在 View 层与 Model 层中添加了 Controller 层作为中转层。
从实现角度
在 Android 中关于 MVC 的实现比较简单粗暴,View 层就是 xml 布局文件,Controller 层就是 Activity/Fragment。但由于 xml 布局文件功能性比较差,与 UI 有关的操作主要靠 Activity/Fragment。所以, Activity/Fragment 同时承载了 View 层与 Controller 层的任务。
优缺点
- 优点:
- 通过分层思想划分不同职责,提高了程序的拓展性与可维护性
- 缺点:
- 在 Android 中由于 xml 文件功能性太低,导致 Activity/Fragment 承载了 View 与 Controller 职责,导致其复杂度太高,降低了程序可维护性。
- 三层间是互相持有,耦合度太高。
MVP
从软件架构模型角度
MVP 是从 MVC 派生出来的。Presenter 层相较于 MVC 的 Controller 层除了中转外,还承载了数据处理任务(将从 Model 层中获取的数据处理成 View 层需要的格式)。
从实现角度
在 Android 中 MVP 模型是通过接口实现的,通过定义 View 层与 Presenter 层接口,提高程序拓展性。将页面逻辑处理至 Presenter 层,降低了 Activity/Fragment 的复杂度,提高程序的可维护性。
优缺点
- 优点:
- 将页面逻辑抽离到 Presenter 层,降低了 Activity/Fragment 内部的复杂度,使其替代 xml 布局文件承担了 View 层任务。
- 通过面向接口开发,提高了代码拓展性。
- 缺点:
- View 层接口中的方法定义粒度无法保证,太细导致逻辑分散,出现"改不全"问题,太粗导致代码维护性退化。
- View 层接口仅支持单一实现,例如 Activity 和 Fragment 需要单独实现,导致无法实现跨页面通信。
- View 层与 Presenter 层相互持有,增加了耦合度,同时由于 Presenter 层持有 View 层(Activity/Fragment) 也会存在内存泄露的风险。
- Presenter 层生命周期与 Activity 一致,无法处理屏幕旋转等场景。
MVVM
关于 MVVM 架构的理解分歧还是蛮大的,主要有两种:
- MVVM 指的是 DataBinding
- MVVM 指的是 View(Activity/Fragment) + ViewModel(Jetpack组件) + Model
其实这两种理解都是对的,只是站在的角度不同。
从软件架构模型角度
MVVM 的核心就是数据绑定,借助数据绑定将 View 层与 Model 层进行解耦。ViewModel 层的作用是一个数据中转站,负责暴露 Model 层数据。所以 MVVM 也是一种数据驱动模式。
从实现角度
MVVM 在 Android 中的实现可借助 Jetpack 组件库。但要注意区分 ViewModel 层并不是指 ViewModel 组件,怎么理解这句话呢?
如果按照严格的软件架构模型实现,那么这里的 ViewModel 层需要依靠 ViewMode + DataBinding 实现。但目前 DataBinding 在大多数的项目中落地情况不是很好,所以大部分项目是通过 ViewModel + LiveData 来实现。
优缺点
- 优点:
- 借助 Jetpack 组件库可以实现生命周期感应,并且 ViewModel 生命周期长于 Activity,可处理屏幕旋转等场景。
- 通过监听/绑定方式,将 View 层与 ViewModel 层进行解耦。
- 缺点:
- 通过数据驱动的方式,并且 LiveData 仅支持单一数据类型,导致在复杂页面时 LiveData 的维护成本增加。
MVI
从软件架构模型角度
关于 MVI 目前没有明确的定义。主流的解释是“基于响应式编程实现的事件(状态)驱动模式”。这里与 MVVM 的主要区别就在于,MVVM 是数据驱动,而 MVI 是事件(状态)驱动。
从实现角度
实现 MVI 模型可以通过 View + Presenter + Model 或者 View + JetPack(ViewModel + LiveData/Flow) + Model 方式都实现。关键在于 Model 层与 View 层之间的传递的状态。
怎么理解数据驱动与事件(状态)驱动呢?(以 JetPack 实现为例)
- 数据驱动:ViewModel 持有的是数据,View 通过监听数据变化触发页面逻辑。
- 事件(状态)驱动:ViewModel 持有的是页面状态,View 通过监听状态触发页面变换。
关于具体的实现,这里推荐两个示例:
- 通过 MVP 实现 MVI(这是一篇海外博客)
- 通过 Jetpack 实现 MVI (这是 Airbnb 开源的框架)
Google 推荐框架模式
目前通过官方最新架构指南中可以发现,官方推荐通过 Jetpack 来实现 MVI 模型。
- UI Layer: 用于处理页面逻辑。内部包含了 Activity/Fragment(UI Element)、ViewModel(State Holder)
- Domain Layer: 用于处理 DataLayer 获取的数据,提高代码的复用性。
- Data Layer: 用于处理业务逻辑。内部包含了数据处理(Repositories)、数据存储(Data Sources)
链接:https://juejin.cn/post/7167288478487543816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 官方项目是怎么做模块化的?快来学习下
本篇文章将会以 Now in Android 项目为例,讲解 Android 官方 App 模块化相关知识及策略。
概述
模块化是将单一模块代码结构拆分为高内聚内耦合的多模块的一种编码实践。
模块化的好处
模块化有以下好处:
- 可扩展性:在高耦合的单一代码库中,牵一发而动全身。模块化项目当采用关注点分离原则。这会赋予了贡献者更多的自主权,同时也强制执行架构模式。
- 支持并行工作:模块化有助于减少代码冲突,为大型团队中的开发人员提供更高效的并行工作。
- 所有权:一个模块可以有一个专门的 owner,负责维护代码和测试、修复错误和审查更改。
- 封装:独立的代码更容易阅读、理解、测试和维护。
- 减少构建时间:利用 Gradle 的并行和增量构建可以减少构建时间。
- 动态交付:模块化是 Play 功能交付 的一项要求,它允许有条件地交付应用程序的某些功能或按需下载。
- 可重用性:模块化为代码共享和构建多个应用程序、跨不同平台、从同一基础提供了机会。
模块化的误区
模块化也可能会被滥用,需要注意以下问题:
- 太多模块:每个模块都有其成本,如 Gradle 配置的复杂性增加。这可能会导致 Gradle 同步及编译时间的增加,并产生持续的维护成本。此外,与单模块相比,添加更多模块会增加项目 Gradle 设置的复杂性。这可以通过使用约定插件来缓解,将可重用和可组合的构建配置提取到类型安全的 Kotlin 代码中。在 Now in Android 应用程序中,可以在 build-logic文件夹 中找到这些约定插件。
- 没有足够的模块:相反,如果你的模块很少、很大并且紧密耦合,最终会产生另外的大模块。这将失去模块化的一些好处。如果您的模块臃肿且没有单一的、明确定义的职责,您应该考虑将其进一步拆分。
- 太复杂了:模块化并没有灵丹妙药 -- 一种方案解决所有项目的模块化问题。事实上,模块化你的项目并不总是有意义的。这主要取决于代码库的大小和相对复杂性。如果您的项目预计不会超过某个阈值,则可扩展性和构建时间收益将不适用。
模块化策略
需要注意的是没有单一的模块化方案,可以确保其对所有项目都适用。但是,可以遵循一般准则,可以尽可能的享受其好处并规避其缺点。
这里提到的模块,是指 Android 项目中的 module,通常会包含 Gradle 构建脚本、源代码、资源等,模块可以独立构建和测试。如下:
一般来说,模块内的代码应该争取做到低耦合、高内聚。
- 低耦合:模块应尽可能相互独立,以便对一个模块的更改对其他模块的影响为零或最小。他们不应该了解其他模块的内部工作原理。
- 高内聚:一个模块应该包含一组充当系统的代码。它应该有明确的职责并保持在某些领域知识的范围内。例如,Now in Android 项目中的core-network模块负责发出网络请求、处理来自远程数据源的响应以及向其他模块提供数据。
Now in Android 项目中的模块类型
注:模块依赖图(如下)可以在模块化初期用于可视化各个模块之间的依赖关系。
Now in Android 项目中有以下几种类型的模块:
- app 模块: 包含绑定其余代码库的应用程序级和脚手架类,
app例如和应用程序级受控导航。一个很好的例子是通过导航设置和底部导航栏设置。该模块依赖于所有模块和必需的模块。 feature-模块: 功能特定的模块,其范围可以处理应用程序中的单一职责。这些模块可以在需要时被任何应用程序重用,包括测试或其他风格的应用程序,同时仍然保持分离和隔离。如果一个类只有一个feature模块需要,它应该保留在该模块中。如果不是,则应将其提取到适当的core模块中。一个feature模块不应依赖于其他功能模块。他们只依赖于core他们需要的模块。core-模块:包含辅助代码和特定依赖项的公共库模块,需要在应用程序中的其他模块之间共享。这些模块可以依赖于其他核心模块,但它们不应依赖于功能模块或应用程序模块。- 其他模块 - 例如和模块
sync、benchmark、test以及app-nia-catalog用于快速显示我们的设计系统的目录应用程序。
项目中的主要模块
基于以上模块化方案,Now in Android 应用程序包含以下模块:
| 模块名 | 职责 | 关键类及核心示例 |
|---|---|---|
app | 将应用程序正常运行所需的所有内容整合在一起。这包括 UI 脚手架和导航。 | NiaApp, MainActivity 应用级控制导航通过 NiaNavHost, NiaTopLevelNavigation |
feature-1, feature-2 ... | 与特定功能或用户相关的功能。通常包含从其他模块读取数据的 UI 组件和 ViewModel。如:feature-author在 AuthorScreen 上显示有关作者的信息。feature-foryou它在“For You” tab 页显示用户的新闻提要和首次运行期间的入职。 | AuthorScreen AuthorViewModel |
core-data | 保存多个特性模块中的数据。 | TopicsRepository AuthorsRepository |
core-ui | 不同功能使用的 UI 组件、可组合项和资源,例如图标。 | NiaIcons NewsResourceCardExpanded |
core-common | 模块之间共享的公共类。 | NiaDispatchers Result |
core-network | 发出网络请求并处理对应的结果。 | RetrofitNiANetworkApi |
core-testing | 测试依赖项、存储库和实用程序类。 | NiaTestRunner TestDispatcherRule |
core-datastore | 使用 DataStore 存储持久数据。 | NiaPreferences UserPreferencesSerializer |
core-database | 使用 Room 的本地数据库存储。 | NiADatabase DatabaseMigrations Dao classes |
core-model | 整个应用程序中使用的模型类。 | Author Episode NewsResource |
core-navigation | 导航依赖项和共享导航类。 | NiaNavigationDestination |
Now in Android 的模块化
Now in Android 项目中的模块化方案是在综合考虑项目的 Roadmap、即将开展的工作和新功能的情况下定义的。Now in Android 项目的目标是提供一个接近生产环境的大型 App 的模块化方案,并且要让方案看起来并没有过度模块化,希望是在两者之间找到一种平衡。
这种方法与 Android 社区进行了讨论,并根据他们的反馈进行了改进。这里并没有一个绝对的正确答案。归根结底,模块化 App 有很多方法和方法,没有唯一的灵丹妙药。这就需要在模块化之前考虑清楚目标、要解决的问题已经对后续工作的影响,这些特定的情况会决定模块化的具体方案。可以绘制出模块依赖关系图,以便帮助更好地分析和规划。
这个项目就是一个示例,并不是一个需要固守不可改变固定结构,相反而是可以根据需求就行变化的。根据 Now in Android 这是我们发现最适合我们项目的一般准则,并提供了一个示例,可以在此基础上进一步修改、扩展和构建。如果您的数据层很小,则可以将其保存在单个模块中。但是一旦存储库和数据源的数量开始增长,可能值得考虑将它们拆分为单独的模块。
最后,官方对其他方式的模块化方案也是持开发态度,有更好的方案及建议也可以反馈出来。
总结
以上内容是根据 Modularization learning journey 翻译整理而得。整体上是提供了一个示例,对一些初学者有一个可以参考学习的工程,对社区中模块化开发起到的积极的作用。说实话,这部分技术在国内并不是什么新技术了。
下面讲一个我个人对这个模块化方案的理解,以下是个人观点,请批判性看待。
首先是好的点提供了通用的 Gradle 配置,简化了各个模块的配置步骤,各种方式预计会在之后的一些项目中流行开来。
不足的点就是没有明确模块化的整体策略,是应采取按照功能还是按照特性分,类似讨论还有我们平时的类文件是按照功能来分还是特性来分,如下是按照特性区分:
# DO,建议方式
- Project
- feature1
- ui
- domain
- data
- feature2
- ui
- domain
- data
- feature3
按照功能区分的方式大致如下:
# DO NOT,不建议方式
- Project
- ui
- feature1
- feature2
- feature3
- domain
- feature1
- feature2
- feature3
- data
我个人是倾向去按照特性的方式区分,而示例中看上去是偏后者,或者是一个混合体,比如有的模块是添加 feature 前缀的,但是 core-model 模块又是在统一的一个模块中集中管理。个人建议的方式应该是将各个模块中各自使用的模型放到自己的模块中,否则项目在后续进行组件化时将会遇到频繁发版的问题。当然,这种方式在模块化的阶段并没有什么大问题。
模块化之后就是组件化,组件化之后就是壳工程,每个技术阶段对应到团队发展的阶段,有机会的话后面可以展开聊聊。
链接:https://juejin.cn/post/7128069998978793509
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
货拉拉客户端通用日志组件 - Glog
Glog 是货拉拉移动端监控系统中的日志存储组件,Glog 意即 General log - 通用日志。为了满足我们对日志格式的多种需求,我们在存储方式、归档方式上做了一些探索和实践,使得 Glog 的通用性和性能优于常见的日志方案。Glog 已经在货拉拉全线 App 中稳定运行了 1 年多,现在将其开源,我们希望 Glog 的开源能够为移动开发者提供一种更加通用的日志方案,同时希望 Glog 能够从社区中汲取养分,不断得到优化和完善。GitHub 地址:https://github.com/huolalatech/hll-wp-glog
背景简介
移动端日志系统通常来说,主要的目标是辅助开发同学排查线上问题,这些问题包括但不限于
- 客诉渠道反馈的 App 使用问题;
- Crash 系统上报的崩溃问题;
- 其他线上冒烟问题。
为了能够尽快定位问题,我们希望能够快速、详细的还原问题现场,这就需要在代码中 App 运行的关键节点埋入日志,将出现问题时的运行状态快速上报。这对日志系统提出了两个关键的要求,信息完整性以及实时性。
在移动端,公司之前存在一套简单的日志系统,收集的日志信息比较有限,我们通过 App 的常见使用流程来看其覆盖的关键节点
另外,之前的日志系统只能通过下发任务回捞,实时性较差,还存在 I/O 性能等问题。
为了解决这些问题,我们开发了新的移动端日志系统,覆盖了上面 App 使用流程的全节点信息
另一方面,为了提升日志的实时性,我们增加了实时日志,通过短轮询来进行定时上报,此外还补充了监控日志来支撑 App 的横向数据对比、评估 App 的性能指标,最终的方案如下
系统主要组成包括
- Android/iOS 上层日志采集 SDK
- 跨平台的储存组件 Glog
- 负责日志存储过滤的日志后端
- 负责日志展示的日志前端
新的监控系统包括实时性要求较高的实时日志,信息较完整的离线日志以及为大盘数据服务的监控日志
- 实时日志,快速上传,信息精简,能够接近实时的查看,快速定位、排查用户反馈的问题;
- 离线日志,通过后台任务触发上传,按天归档,作为实时日志的兜底,要求信息完整详尽;
- 监控日志,支持采样,作为监控大盘的信息源,实时性要求最高,日志只包括监控信息。
为了适配不同日志的存储格式,我们希望存储组件能够在格式上尽量通用,最好做到格式无关;另一方面我们也希望其性能、可靠和安全方面能够对齐一线水平,在调研了市面上流行的日志组件后,我们发现并没有现成方案满足我们的需求,因此我们自研了自己的日志存储组件 Glog。
方案概览
应用上层对不同类型的日志序列化(推荐 Protobuf)之后,将二进制数据存储到 Glog,对于上传频次较高的实时日志和监控日志,采用重命名缓存的方式快速归档;对于信息较全而上传频次不高的离线日志,我们采用 mmap 偏移映射的方式归档,相较标准 I/O 复制归档的方式,提升了性能。在可靠性和安全性方面我们也借鉴了当前的流行方案,例如 mmap I/O 提升性能和可靠性、流式的加密和压缩防止 CPU 突发峰值,另外我们在日志中加入了同步标记支持读取容错。
存储方式
为了适应不同的日志格式,Glog 存储二进制数据,上层依据自己的需要,将数据序列化后交给 Glog
具体的文件格式:使用 2 个字节描述每条日志长度,在每条日志末尾加入一个同步标志,用于文件损坏时的读取容错。

归档方式
回顾一下常见的日志组件中 mmap 的使用方式,首先 mmap I/O 需要映射一片大小为 page size (通常为 4KB) 整数倍大小的缓存,随着数据的写入将这片空间耗尽后,我们无法持续扩展这片空间的大小(由于它占用的是 App 的运行内存空间),因此需要将其中的数据归档,常见的方式是将其中内容 flush 追加到另一个归档文件当中,之后再清空 mmap 缓存,这个 flush 的过程一般使用标准 I/O
而我们的实时、监控日志为了快速上传保证数据实时性,采用间隔较短的轮询来触发 flush 并上传,这将导致 flush 频率变得很高;而通常的 flush 方式采用标准 I/O 来复制数据,性能相对较低,后续的日志写入需要等待 flush 完成,这将影响我们的写入性能,因此我们考虑两种方案来提升 flush 速度以优化写入性能
- mmap 偏移映射,通过 mmap 映射归档文件的末尾,之后通过内存拷贝将 mmap 缓存追加到归档文件末尾。这种方式将文件复制变成内存复制,性能较好。
- 文件重命名,对于可以快速上传并删除的日志,我们可以在需要时将 mmap 缓存重命名成归档文件,之后重建缓存。这种方式直接去除了复制的环节,但是在日志量较大时,可能产生很多零碎的归档文件。
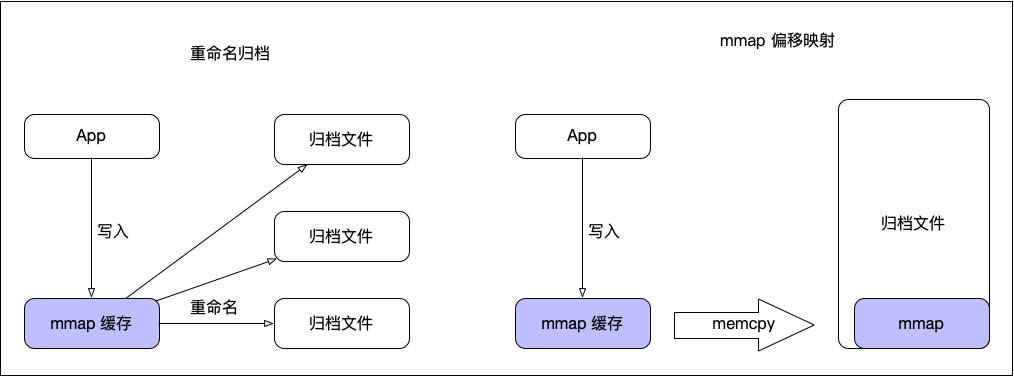
这两种方案可以在我们的不同日志场景应用,对于实时、监控日志来说,对性能要求最高,选用第 2 种方案,这个方案带来的零碎归档文件问题,由于上传和删除较快,在这里并不会堆积,另一方面,考虑到实时、监控日志上传周期较短,零碎的归档文件也便于控制上传的数据量;而离线日志选用第 1 种方案,可以将每天的日志归档在一个文件中,相对常见的标准 I/O 也有性能上的优势。
加密方式
Glog 使用了 ECDH + AES CFB-128,对每条日志进行单独加密。具体来说通过 ECDH 协商加密秘钥,之后 AES CFB-128 进行对称加密。
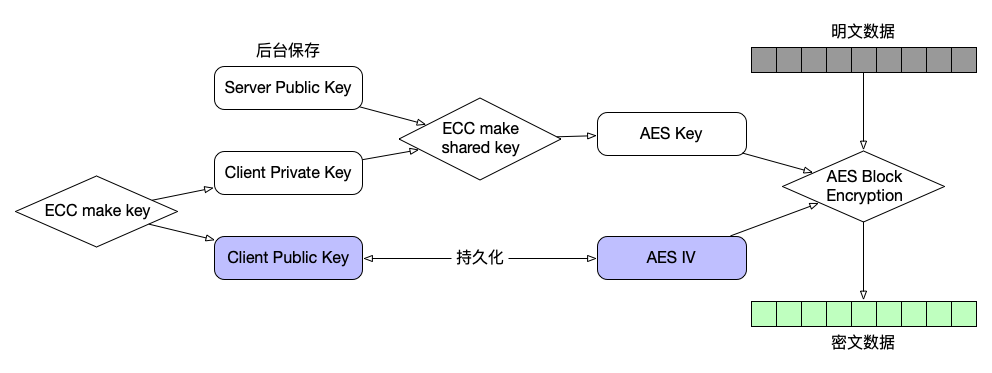
选择 CFB-128 是因为 AES 通用性和安全性较好,加解密只需执行相同块加密算法,对 IV 随机性要求低,ECC 相对 RSA 在加密强度相同的前提下,秘钥更短。
| Security(In Bits) | RSA Key Length Required(In Bits) | ECC Key Length Required(In Bits) |
|---|---|---|
| 80 | 1024 | 160-223 |
| 112 | 2048 | 224-255 |
| 128 | 3072 | 256-383 |
| 192 | 7680 | 384-511 |
| 256 | 15360 | 512+ |
压缩方式
考虑到解压缩的便捷性和通用性,Glog 使用了常见的 Deflate 无损压缩算法,对日志进行流式压缩,即以每条日志为压缩单元,在每次写入时进行同步压缩。这样避免了归档时对整个 mmap 缓存做压缩带来的 CPU 波峰,具体的原理下面做一些解释。
Deflate 算法是 LZ77 与哈夫曼编码的组合
LZ77
LZ77 将数据(短语)通过前向缓冲区,然后移动到滑动窗口中成为字典的一部分,之后从字典中搜索能与前向缓冲区匹配的最长短语,如果能够命中,则成为短语标记作为结果保存起来,不能命中则作为字符标记保存。
解压时,如果是字符标记则直接拷贝到滑动窗口中,如果是短语标记则在滑动窗口中查找相应的偏移量,之后将滑动窗口中相应长度的短语拷贝到结果中。
短语标记包括了
- 滑动窗口中的偏移量
- 匹配命中的字符长度
- 匹配结束后前向缓冲区的第一个字符
下面展示了对字符 LABLALALABLA 进行 LZ77 压缩和解压缩的过程,
接下来霍夫曼编码对 LZ77 的处理结果(包括前面提到的偏移量、长度、字符),按照出现频率越高,占用空间越少的方式进行编码存储。
在简要说明原理之后,我们知道影响压缩率的几个因素:滑动窗口(字典)大小,输入的数据(短语)长度、以及短语中字符的重复率。字典越大、短语越长,越容易从字典中找到匹配短语进而变成短语标记,那么流式压缩以每条日志作为压缩单元,输入数据长度变短,我们如何保证压缩率呢?
这里我们能做的是尽量保证字典的大小,不频繁重置字典,具体做法是只在 mmap 缓存归档时重置字典,对于归档前 mmap 缓存的数据,复用字典来保证压缩率。
消息队列
mmap 相对标准 I/O 在性能上有较大优势,主要是由于其减少了内核空间与用户空间的拷贝、以及 write lseek 系统调用带来的上下文切换开销
但在系统资源不足时 mmap 仍有可能出现性能问题,举个例子,我们知道 mmap 与标准 I/O 一样也需要通过 Page Cache 回写到磁盘
Page Cache 的生命周期:
当用户通过标准 I/O 从用户缓冲区向内核空间拷贝数据时,如果内核缓冲区中没有这个 Page,将发生缺页中断分配一个 Page,之后拷贝数据,结束后这个 Page Cache 变成一个脏页,然后该脏页同步到磁盘中,同步结束后,这个 Page Cache 变成 Clean Page 保存在系统中。
Android 中可以通过 showmap 命令观察 mmap 写入了 Page Cache
当系统内存不足时,系统将回收 Page Cache 来释放内存,引起频繁的磁盘回写,mmap 性能也会受到影响。
另一方面由于实时日志、监控日志需要高频归档,而归档会阻塞后续的写入。因此我们在 Glog 底层加入了消息队列来处理写入和归档等操作,进一步提升性能,避免卡顿。
性能对比
| 手机型号 | 日志 SDK | 1w 条日志耗时 | 10w 条日志耗时 |
|---|---|---|---|
| Samsung Galaxy S10+ Android 11 | glog | 21 ms | 182 ms |
| glog+pb | 54 ms | 335 ms | |
| xlog | 207 ms | 1961 ms | |
| logan | 250 ms | 6469 ms | |
| Huawei Honor Magic 2 Android 10 | glog | 38 ms | 286 ms |
| glog+pb | 84 ms | 505 ms | |
| xlog | 263 ms | 2165 ms | |
| logan | 242 ms | 3643 ms | |
| Xiaomi 10 Android 11 | glog | 27 ms | 244 ms |
| xlog | 198 ms | 1863 ms | |
| logan | 210 ms | 4238 ms | |
| Huawei Mate 40 pro HarmonyOS 2.0.0 | glog | 30 ms | 257 ms |
| xlog | 275 ms | 2484 ms | |
| logan | 260 ms | 4020 ms | |
| OPPO R11 Android 8.1.0 | glog | 63 ms | 324 ms |
| glog+pb | 234 ms | 1611 ms | |
| xlog | 464 ms | 3625 ms | |
| logan | 430 ms | 5355 ms | |
| iPhone 12 128G iOS 14.8 | glog | 7 ms | 29 ms |
| xlog | 152 ms | 1079 ms | |
| logan | 162 ms | 12821 ms | |
| iPhone 8 64G iOS 13.7 | glog | 12 ms | 50 ms |
| xlog | 242 ms | 2106 ms | |
| logan | 251 ms | 38312 ms |
Glog 使用异步模式、按天归档
通过对比数据来看,Glog 异步模式由于使用了消息队列,即使累加上 Protobuf 的序列化时间,写入性能相对来说依然有较大优势。
遇到的问题
- 使用 mmap 偏移映射方式拷贝数据时,需要通过 mmap 映射文件末尾,其偏移量也需要是 page size 的整数倍,而归档文件和复制数据大小通常情况下都不是 page size 的整数倍,需要做额外的计算;
- 如果只对归档文件总体积作为阈值来清理,在重命名归档这种情况下零碎文件较多,可能在收集文件列表的过程中导致 JNI 本地引用超限,需要限制文件总个数、及时回收 JNI 本地引用;
- 在跨天写入日志的情况下,mmap 缓存中的数据可能无法及时归档,造成部分日志误写入次日的归档文件当中,需要在归档轮询中增加时间窗口的判定;
- 为了便于上层上传日志,在底层需要添加日志解析模块。
总结
通过上面的介绍,可以看到 Glog 相较其他流行方案的主要区别是:
- 存储的是格式无关的二进制数据,具有更好的定制性;
- 底层实现的消息队列,性能更优使用也更方便;
- 新的归档方式一方面提升性能,另一方面也便于高频读取。
当然这些手段也带来了一些妥协,比如由于存储的是二进制数据,使用 Glog 需要额外添加序列化代码;异步模式下,消息队列中的任务在 Crash 或断电时可能丢失,这些问题在我们的使用场景基本可以忽略。
为了实现货拉拉的业务需求,我们参考流行的日志方案,站在巨人的肩膀上,在移动端存储组件高性能、可靠、安全的基本要求之外,提供了更多的特性和额外的优化。在开源之后,也希望能够反哺社区,为移动开发者提供一种更为通用的日志方案。
以 Glog 为存储模块的日志系统,目前已经接入了公司的全线 app,实时日志的单日日志量达到数十亿条,稳定运行在百万级别的 App 上。为线上用户反馈问题解决、App 崩溃排查提供了有力的帮助,除此之外,还为风控系统、监控大盘提供了数据支撑。
链接:https://juejin.cn/post/7168662263337861133
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【杰哥带你玩转Android自动化】AccessibilityService基础
0x1、引言
Hi,我是杰哥,忙了好一阵子,终于有点时间来继续填坑啦~
间隔太久没更新,读者估计都忘记这个专栏了,所以在开始本节前,再重复下这段话:
所有Android自动化框架和工具中 操作Android设备的功能实现 都基于 adb 和 无障碍服务AccessibilityService。
前面所学的 adb 更倾向于 PC端控制Android设备自动化,无论有线连接还是无线连接,你都需要一台PC 来跑脚本。它的 不方便 还体现在:你写了一个很屌的脚本,跟亲朋好友Share,他们还得 安装配置一波运行环境 才能用。
而本节要学的 无障碍服务AccessibilityService 则更倾向于 APP控制Android设备自动化,把编写好的脚本打包成 Android APK安装包,直接把apk发给别人,安装了启动下无障碍服务,直接能用,相比之下方便得不是一星半点。当然,编写脚本需要一点 一点基本的Android开发经验。
AccessibilityService,别看名字长,其实一点都不难,本节学习路线如下:
- 简单了解下AccessibilityService是什么东西;
- AccessibilityService的基本使用,先跑起来再说;
- 掌握一些常用伎俩;
- 动手写个超简单的案例:自动登录Windows/Mac微信
没有前戏,我直接开始~
0x2、AccessibilityService简介
Android官方文档中有个专题 → 【打造无障碍应用】 其中包含了对 无障碍相关 的一系列解读,在Android开发者的公号里也有两篇讲解的文章:
感兴趣的可移步至相关文章进行阅读,这里不展开讲,我们更关注的是 无障碍服务的使用。点开官方文档:《创建自己的无障碍服务》,这样介绍到:
无障碍服务是一种应用,可提供界面增强功能,来协助残障用户或可能暂时无法与设备进行全面互动的用户完成操作。例如,正在开车、照顾孩子或参加喧闹聚会的用户可能需要其他或替代的界面反馈方式。Android 提供了标准的无障碍服务(包括 TalkBack),开发者也可以创建和分发自己的服务。
简而言之就是:优化残障人士使用Android设备和应用程序的体验
读者看完这段话,估计是一脸懵逼,落地一下就是:利用这个服务自动控制其它APP的各种操作,如点击、滑动、输入等。然后文档下面有一个 注意:
只能是为了!!!
2333,在国内是不存在的,它的应用场景五花八门,凡是和 自动点 有关的都离不开它,如:灰产微商工具、开屏广告跳过、自动点击器、红包助手、自动秒杀工具、一键XX、第三方应用监听等等。em...读者暂且把它理解成一个可以拿来帮助我们自动点点点的工具就好,接着说下怎么用。
0x3、AccessibilityService基本使用
AccessibilityService无障碍服务 说到底,还是一个 服务,那妥妥滴继承 Service,并具有它的生命周期和一些特性。
用户手动到设置里启动无障碍服务,系统绑定服务后,会回调 onServiceConnected(),而当用户在设置中手动关闭、杀死进程、或开发者调用 disableSelf() 时,服务会被关闭销毁。
关于它的基本用法非常简单,四步走~
① 自定义AccessibilityService
继承 AccessibilityService,重写 onInterrupt() 和 onAccessibilityEvent() 方法,示例代码如下:
import android.accessibilityservice.AccessibilityService
import android.util.Log
import android.view.accessibility.AccessibilityEvent
class JumpAdAccessibilityService: AccessibilityService() {
val TAG = javaClass.simpleName
override fun onAccessibilityEvent(event: AccessibilityEvent?) {
Log.d(TAG, "onAccessibilityEvent:$event")
}
override fun onInterrupt() {
Log.d(TAG, "onInterrupt")
}
}上述两个方法是 必须重写 的:
onInterrupt()→ 服务中断时回调;onAccessibilityEvent()→ 接收到系统发送AccessibilityEvent时回调,如:顶部Notification,界面更新,内容变化等,我们可以筛选特定的事件类型,执行不同的响应。比如:顶部出现WX加好友的Notification Event,跳转到加好友页自动通过。
具体的Event类型可参见文尾附录,另外两个 可选 的重写方法:
onServiceConnected()→ 当系统成功连接无障碍服务时回调,可在此调用 setServiceInfo() 对服务进行配置调整onUnbind()→ 系统将要关闭无障碍服务时回调,可在此进行一些关闭流程,如取消分配的音频管理器
② Service注册
上面说了AccessbilityService本质还是Service,所以需要在 AndroidManifest.xml 中进行注册:
<service
android:name=".JumpAdAccessibilityService"
android:exported="false"
android:label="跳过广告哈哈哈哈"
android:permission="android.permission.BIND_ACCESSIBILITY_SERVICE">
<intent-filter>
<action android:name="android.accessibilityservice.AccessibilityService" />
</intent-filter>
</service>
Tips:设置 android:permission="android.permission.BIND_ACCESSIBILITY_SERVICE" 是为了确保只有系统可以绑定此服务。而 android:label 是设置在无障碍服务那里文案,其它照抄。
③ 监听相关配置
就是监听什么类型的Event,监听什么app等的配置,配置方法有两种,二选一 即可~
动态配置
重写 onServiceConnected(),配置代码示例如下:
override fun onServiceConnected() {
val serviceInfo = AccessibilityServiceInfo().apply {
eventTypes = AccessibilityEvent.TYPES_ALL_MASK
feedbackType = AccessibilityServiceInfo.FEEDBACK_GENERIC
flags = AccessibilityServiceInfo.DEFAULT
packageNames = arrayOf("com.tencent.mm") //监听的应用包名,支持多个
notificationTimeout = 10
}
setServiceInfo(serviceInfo)
}属性与可选值详解可见文尾附录,接着说另一种配置方式~
静态配置
Android 4.0 后,可以在AndroidManifest.xml中添加一个引用配置文件的<meta-data>元素:
<service android:name=".JumpAdAccessibilityService"
...
<meta-data
android:name="android.accessibilityservice"
android:resource="@xml/accessible_service_config_jump_ad" />
可以看到resource属性会引用了一个xml文件,我们来创建这个文件:
在 res 文件夹下 新建xml文件夹 (有的话不用建),然后 新建一个配置xml文件 (名字自己定),如:
内容如下:
<?xml version="1.0" encoding="utf-8"?>
<accessibility-service xmlns:android="http://schemas.android.com/apk/res/android"
android:accessibilityEventTypes="typeAllMask"
android:accessibilityFeedbackType="feedbackGeneric"
android:accessibilityFlags="flagDefault"
android:canRetrieveWindowContent="true"
android:description="@string/accessibility_desc"
android:notificationTimeout="100"
android:packageNames="com.tencent.mm"
android:settingsActivity="cn.coderpig.jumpad.MainActivity" />
属性与可选值详解可见文尾附录,说下两种配置方式的优缺点:
静态配置可配置属性更多,适合参数不需要动态改变的场景,动态配置属性有限,但灵活性较高,可按需修改参数,可以搭配使用。
④ 启用无障碍服务
二选一配置完毕后,运行APP,然后依次打开手机 (不同手机系统会有些许差异):设置 → 无障碍 → 找到我们的APP → 显示关闭说明无障碍服务没起来,点开:
开关打开后,会弹出授权窗口,点击允许:
上面我们设置监听的包名是com.tencent.mm,打开微信,也可以看到控制台陆续输出一些日志信息:
可以,虽然没具体干点啥,但服务算是支棱起来了!!!
0x3、一些常用伎俩
无障碍服务的常用伎俩有这四个:判断无障碍服务是否开启、结点查找、结点交互、全局交互。接着一一讲解:
① 判断无障碍服务是否打开
这个没啥好讲的,直接上工具代码:
fun Context.isAccessibilitySettingsOn(clazz: Class<out AccessibilityService?>): Boolean {
var accessibilityEnabled = false // 判断设备的无障碍功能是否可用
try {
accessibilityEnabled = Settings.Secure.getInt(
applicationContext.contentResolver,
Settings.Secure.ACCESSIBILITY_ENABLED
) == 1
} catch (e: Settings.SettingNotFoundException) {
e.printStackTrace()
}
val mStringColonSplitter = SimpleStringSplitter(':')
if (accessibilityEnabled) {
// 获取启用的无障碍服务
val settingValue: String? = Settings.Secure.getString(
applicationContext.contentResolver,
Settings.Secure.ENABLED_ACCESSIBILITY_SERVICES
)
if (settingValue != null) {
// 遍历判断是否包含我们的服务
mStringColonSplitter.setString(settingValue)
while (mStringColonSplitter.hasNext()) {
val accessibilityService = mStringColonSplitter.next()
if (accessibilityService.equals(
"${packageName}/${clazz.canonicalName}",
ignoreCase = true
)
) return true
}
}
}
return false
}每次打开我们的APP都调用下这个方法判断无障碍服务是否打开,没有弹窗或者给提示,引导用户去 无障碍设置页设置下,跳转代码如下:
startActivity(Intent(Settings.ACTION_ACCESSIBILITY_SETTINGS))设置完返回APP,再获取一次服务状态,所以建议在 onResume() 中调用,并做一些对应的UI更新操作。
② 节点查找
比如我要点击某个按钮,我需要先查找到节点,然后再触发点击交互,所以得先定位到节点。下述两个方法可以 获取当前页面节点信息AccessibilityNodeInfo:
AccessibilityEvent.getSource()AccessibilityService.getRootInActiveWindow()
但要注意两个节点个数不一定相等,而获取到 AccessibilityNodeInfo 实例后可以通过下述方法定位结点(可能匹配到多个,所以返回类型是List<AccessibilityNodeInfo>):
AccessibilityNodeInfo.findAccessibilityNodeInfosByText()→ 通过Text查找;AccessibilityNodeInfo.findAccessibilityNodeInfosByViewId()→ 通过节点ID查找
根据文本匹配就不用说了,注意它是contain()包含匹配,不是equals()的方式就好,这里主要说下如何获取 节点ID,需要用到一些工具,前三个是最常见的工具,从旧到新依次是:
1、HierarchyView
老牌分析工具,早期Android SDK有快捷方式,新版找不到了,得自己点击:android-sdk目录下的tools\monitor.bat 启动 Android Device Monitor:
然后点击生成节点数,会dump出节点树,点击相应节点获取所需数据:
直接生成当前页面节点树,方便易用,而且不止布局分析,还有方法调用跟踪、文件管理器等,百宝箱啊,不过小卡,用的时候鼠标一直显示Loading。
2、UI Automator Viewer
比HierarchyView更纯粹,只有生成当前页面节点树的功能,新版同样找不到快捷方式了,得点击
android-sdk目录下的 tools\bin\uiautomatorviewer.bat 启动:
用法也同样简单,而且支持保存节点树,不卡~
3、LayoutInspector
AS 3.0后取消了老旧的DDMS后提供的界面更友好的全新工具,依次点击:Tools → Layout Inspector 打开:
然后选择要监听的进程:
选择完可能会一直转加载不出来,因为默认勾选了 Enable Live Layout Inspector 它会实时加载布局内容,关掉它。
依次点击:File → Settings → Experimental → 找到Layout Inspector → 取消勾选
确定后,此时入口变成了这个:
选择要查看的进程,OK,有多个Windows还可以自行选择:
这里笔者试了几次没load出微信的布局,不知道电脑太辣鸡还是手机问题:
试了一个简单页面倒可以:
还有一点,选进程只能选可debug的进程,所以想调所有进程的话,要么虚拟机,要么Root了的真机,2333,虽然高档,但是用起来没前两个顺手。
4、其它工具
除上面三个之外其它都是一些小众工具了,如 autojs,划出左侧面板 → 打开悬浮框 → 点击悬浮图标展开扇形菜单 → 点击蓝色的 → 选择布局范围分析 → 点击需要获得结点信息的区域。具体步骤如下图所示:
开发者助手等工具获取方式也是类型。这里顺带安利一波笔者在《学亿点有备无患的"姿势"》 写的工具代码 → 获取当前页面所有控件信息,直接调用下方法:
解析好的节点树直接dump出来,获取id就是这么so easy~
③ 节点交互
除了根据ID或文本定位到节点的方法外,还可以调用下述方法进行循环迭代:
- getParent() → 获取父节点;
- getChild() → 获取子节点;
- getChildCount() → 获取节点的子节点数;
获取节点后,可以调用 performAction() 方法对节点执行一个动作,如点击、长按、滑动等,直接上工具代码:
// 点击
fun AccessibilityNodeInfo.click() = performAction(AccessibilityNodeInfo.ACTION_CLICK)
// 长按
fun AccessibilityNodeInfo.longClick() =
performAction(AccessibilityNodeInfo.ACTION_LONG_CLICK)
// 向下滑动一下
fun AccessibilityNodeInfo.scrollForward() =
performAction(AccessibilityNodeInfo.ACTION_SCROLL_FORWARD)
// 向上滑动一下
fun AccessibilityNodeInfo.scrollBackward() =
performAction(AccessibilityNodeInfo.ACTION_SCROLL_BACKWARD)
// 填充文本
fun AccessibilityNodeInfo.input(content: String) = performAction(
AccessibilityNodeInfo.ACTION_SET_TEXT, Bundle().apply {
putCharSequence(AccessibilityNodeInfo.ACTION_ARGUMENT_SET_TEXT_CHARSEQUENCE, content)
}
)④ 全局交互
除了控件触发事件外,AccessibilityService提供了一个 performGlobalAction() 来执行一些通用交互,示例如下:
performGlobalAction(GLOBAL_ACTION_BACK) // 返回键
performGlobalAction(GLOBAL_ACTION_HOME) // Home键关于AccessibilityService常用伎俩就这些,接着写个超简单的例子来练练手~
0x4、超简单案例:自动登录Windows/Mac微信
登录过微信的PC,下次登录需要在手机上点击确定登录:
我有强迫症,每次下班都会退掉PC的微信,上班再重新登,每次都要点一下,不得不说有点蠢。
完全可以用本节学的姿势写一个自动登录的小jio本啊,简单,也好演示脚本开发的基本流程~
① 判断无障碍服务是否开启
直接在《AccessibilityService基本使用》的代码基础上进行开发,先撸出一个骚气的设置页:
接着是控件初始化,事件设置的一些简单逻辑:
运行下看看效果:
② 看下需要监听什么类型的Event
先把无障碍配置文件里的 android:accessibilityEventTypes 设置为 typeAllMask,即监听所有类型的Event。接着直接把 onAccessibilityEvent() 的参数 event 打印出来:
运行后,开启无障碍服务,接着点击登录/或者扫二维码,微信弹出登录页面,可以看到下述日志:
即打开登录页会触发 TYPE_WINDOW_STATE_CHANGED 类型的 Event,且页面为 ExtDeviceWXLoginUI。
行吧,那就只关注这类型的Event,把 android:accessibilityFeedbackType 设置为 typeWindowStateChanged,改下 onAccessibilityEvent() 里的处理逻辑:
③ 找到登录按钮并触发点击
懒得用工具扣,直接用adb的脚本打印出节点树,直接就定位要找的节点了:
行吧,可以根据文本查找,也可以根据id查找,前者是contain()的方式匹配,包含登录文本的节点都会被选中:
而这里的id是唯一的,所以直接根据id进行查找,找到后触发点击:
运行下看看效果:
脚本检测到登录页面,自动点击登录按钮,迅雷不及掩耳之势页面就关了~
0x5、小结
本节过了一下 AccessibilityService无障碍服务 的基础姿势,并写了一个超简单的微信自动登录案例演示脚本编写的大概过程,相信读者学完可以动手尝试编写一些简单的脚本。而在实际开发中还会遇到一些问题,如:获取到控件,但无法点击,在后续实战环节中会一一涉猎,剧透下,下一节会带着大家来开发一个:微信僵尸好友检测工具,敬请期待~
参考文献
- 官方文档:《创建自己的无障碍服务》
- AccessibilityService使用入门
- (AccessibilityService) Android 辅助功能笔记
- 辅助功能 AccessibilityService笔记(2)
附录:属性、参数、可选值详解
Tips:下述内容可能过时,或者有部分不准确,建议以官方文档和源码为准
android:accessibilityEventTypes → AccessibilityServiceInfo.eventTypes
服务监听的事件类型,可选值有这些,支持多个,属性值用|分隔,代码设置值用or分隔
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 所有类型的事件 | typeAllMask | xxx |
| 一个应用产生一个通知事件 | typeAnnouncement | TYPE_ANNOUNCEMENT |
| 辅助用户读取当前屏幕事件 | typeAssistReadingContext | TYPE_ASSIST_READING_CONTEXT |
| view中上下文点击事件 | typeContextClicked | TYPE_VIEW_CONTEXT_CLICKED |
| 监测到的手势事件完成 | typeGestureDetectionEnd | TYPE_GESTURE_DETECTION_END |
| 开始手势监测事件 | typeGestureDetectionStart | TYPE_GESTURE_DETECTION_START |
| Notification变化事件 | typeNotificationStateChanged | TYPE_NOTIFICATION_STATE_CHANGED |
| 触摸浏览事件完成 | typeTouchExplorationGestureEnd | TYPE_TOUCH_EXPLORATION_GESTURE_END |
| 触摸浏览事件开始 | typeTouchExplorationGestureStart | TYPE_TOUCH_EXPLORATION_GESTURE_START |
| 用户触屏事件结束 | typeTouchInteractionEnd | TYPE_TOUCH_INTERACTION_END |
| 触摸屏幕事件开始 | typeTouchInteractionStart | TYPE_TOUCH_INTERACTION_START |
| 无障碍焦点事件清除 | typeViewAccessibilityFocusCleared | TYPE_VIEW_ACCESSIBILITY_FOCUS_CLEARED |
| 获得无障碍的焦点事件 | typeViewAccessibilityFocused | TYPE_VIEW_ACCESSIBILITY_FOCUSED |
| View被点击 | typeViewClicked | TYPE_VIEW_CLICKED |
| View被长按 | typeViewLongClicked | TYPE_VIEW_LONG_CLICKED |
| View被选中 | typeViewSelected | TYPE_VIEW_SELECTED |
| View获得焦点 | typeViewFocused | TYPE_VIEW_FOCUSED |
| 一个View进入悬停 | typeViewHoverEnter | TYPE_VIEW_HOVER_ENTER |
| 一个View退出悬停 | typeViewHoverExit | TYPE_VIEW_HOVER_EXIT |
| View滚动 | typeViewScrolled | TYPE_VIEW_SCROLLED |
| View文本变化 | typeViewTextChanged | TYPE_VIEW_TEXT_CHANGED |
| View文字选中发生改变事件 | typeViewTextSelectionChanged | TYPE_VIEW_TEXT_SELECTION_CHANGED |
| 窗口的内容发生变化,或子树根布局发生变化 | typeWindowContentChanged | TYPE_WINDOW_CONTENT_CHANGE |
| 新的弹出层导致的窗口变化(dialog、menu、popupwindow) | typeWindowStateChanged | TYPE_WINDOW_STATE_CHANGED |
| 屏幕上的窗口变化事件,需要API 21+ | typeWindowsChanged | TYPE_WINDOWS_CHANGED |
| UIanimator中在一个视图文本中进行遍历会产生这个事件,多个粒度遍历文本。一般用于语音阅读context | typeViewTextTraversedAtMovementGranularity | TYPE_VIEW_TEXT_TRAVERSED_AT_MOVEMENT_GRANULARITY |
android:accessibilityFeedbackType → AccessibilityServiceInfo.feedbackType
操作相关按钮后,服务给用户的反馈类型,可选值如下:
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 取消所有的反馈方式,一般用这个 | feedbackAllMask | FEEDBACK_ALL_MASK |
| 可听见的(非语音反馈) | feedbackAudible | FEEDBACK_AUDIBLE |
| 通用反馈 | feedbackGeneric | FEEDBACK_GENERIC |
| 触觉反馈(震动) | feedbackHaptic | FEEDBACK_HAPTIC |
| 语音反馈 | feedbackSpoken | FEEDBACK_SPOKEN |
| 视觉反馈 | feedbackVisual | FEEDBACK_VISUAL |
| 盲文反馈 | 不支持 | FEEDBACK_BRAILLE |
android:accessibilityFlags → AccessibilityServiceInfo.flags
辅助功能附加的标志,可选值有这些,支持多个,属性值用|分隔,代码设置值用or分隔:
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 默认配置 | flagDefault | DEFAULT |
| 为WebView中呈现的内容提供更好的辅助功能支持 | flagRequestEnhancedWebAccessibility | FLAG_REQUEST_ENHANCED_WEB_ACCESSIBILITY |
| 使用该flag表示可获取到view的ID | flagReportViewIds | FLAG_REPORT_VIEW_IDS |
| 获取到一些被表示为辅助功能无权获取到的view | flagIncludeNotImportantViews | FLAG_INCLUDE_NOT_IMPORTANT_VIEWS |
| 监听系统的物理按键 | flagRequestFilterKeyEvents | FLAG_REQUEST_FILTER_KEY_EVENTS |
| 监听系统的指纹手势 API 26+ | flagRequestFingerprintGestures | FLAG_REQUEST_FINGERPRINT_GESTURES |
| 系统进入触控探索模式,出现一个鼠标在用户的界面 | flagRequestTouchExplorationMode | FLAG_REQUEST_TOUCH_EXPLORATION_MODE |
| 如果辅助功能可用,提供一个辅助功能按钮在系统的导航栏 API 26+ | flagRequestAccessibilityButton | FLAG_REQUEST_ACCESSIBILITY_BUTTON |
| 要访问所有交互式窗口内容的系统,这个标志没有被设置时,服务不会收到TYPE_WINDOWS_CHANGE事件 | flagRetrieveInteractiveWindows | FLAG_RETRIEVE_INTERACTIVE_WINDOWS |
| 系统内所有的音频通道,使用由STREAM_ACCESSIBILTY音量控制USAGE_ASSISTANCE_ACCESSIBILITY | flagEnableAccessibilityVolume | FLAG_ENABLE_ACCESSIBILITY_VOLUME |
android:canRetrieveWindowContent
服务是否能取回活动窗口内容的属性,与flagRetrieveInteractiveWindows搭配使用,无法在运行时更改此配置。
android:notificationTimeout → AccessibilityServiceInfo.notificationTimeout
同一类型的两个辅助功能事件发送到服务的最短间隔(毫秒,两个辅助功能事件之间的最小周期)
android:packageNames → AccessibilityServiceInfo.packageNames
监听的应用包名,多个用逗号(,)隔开,两种方式设置监听所有应用的事件:
- 不设置此属性;
- 赋值null → android:packageNames="@null"
网上一堆说空字符串的,都是没经过验证的,用空字符串你啥都捕获不到!!!
android:settingsActivity → AccessibilityServiceInfo.settingsActivityName
允许修改辅助功能的activity类名,就是你自己的无障碍服务的设置页。
android:description
该服务的简单说明,会显示在无障碍服务说明页:
android:canPerformGestures
是否可以执行手势,API 24新增
链接:https://juejin.cn/post/7169033859894345765
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin Flow啊,你将流向何方?
前言
前边一系列的协程文章铺垫了很久,终于要分析Flow了。如果说协程是Kotlin的精华,那么Flow就是协程的精髓。
通过本篇文章,你将了解到:
- 什么是流?
- 为什么引进Flow?
- Fow常见的操作
- 为什么说Flow是冷流?
1. 什么是流
自然界的流水,从高到低,从上游到下游流动。
而对于计算机世界的流:
数据的传递过程构成了数据流,简称流
比如想要查找1~1000内的偶数,可以这么写:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000) {
if (i % 2 == 0)
list.add(i)
i++
}此处对数据的处理即为找出其中的偶数。
若想要在偶数中找到>500的数,则继续筛选:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000) {
if (i > 500 && i % 2 == 0)
list.add(i)
i++
}可以看出,原始数据是1~1000,我们对它进行了一些操作:过滤偶数、过滤>500的数。当然还可以进行其它操作,如映射、变换等。
提取上述过程三要素:
- 原始数据
- 对数据的一系列操作
- 最终的数据
把这一系列的过程当做流:
从流的方向来观察,我们称原始数据为上流,对数据进行一系列处理后,最终的数据为下流。
从流的属性来观察,我们认为生产者在上流生产数据,消费者在下流消费数据。
2. 为什么引进Flow?
由前面的文章我们知道,Java8提供了StreamAPI,专用来操作流,而Kotlin也提供了Sequence来处理流。
那为什么还要引进Flow呢?
在Kotlin的世界里当然不会想再依赖Java的StreamAPI了,主要来对比Kotlin里的各种方案选择。
先看应用场景的演变。
a、集合获取多个值
想要获取多个值,很显而易见的想到了集合。
fun testList() {
//构造集合
fun list(): List<Int> = listOf(1, 2, 3)
list().forEach {
//获取多个值
println("value = $it")
}
}以上函数功能涉及两个对象:生产者和消费者。
生产者:负责将1、2、3构造为集合。
消费者:负责从集合里将1、2、3取出。
若此时想要控制生产者的速度,比如先将1放到集合里,过1秒后再讲2放进集合,在此种场景下该函数显得不那么灵活了。
b、Sequence控制生成速度
Sequence可以生产数据,先看看它是怎么控制生产速度的。
fun testSequence() {
fun sequence():Sequence<Int> = sequence {
for (i in 1..3) {
Thread.sleep(1000)
yield(i)
}
}
sequence().forEach {
println("value = $it")
}
}通过阻塞线程控制了生产者的速度。
你可能会说:在协程体里为啥要用Thread.sleep()阻塞线程呢,用delay()不香吗?
看起来很香,我们来看看实际效果:
直接报编译错误了,提示是:受限制的挂起函数只能调用自己协程作用域内的成员和其它挂起函数。
而sequence的作用域是SequenceScope,查看其定义发现:
究其原因,SequenceScope 被RestrictsSuspension 修饰限制了。
c、集合配合协程使用
sequence 因为协程作用域的限制,不能异步生产数据,而使用集合却没此限制。
suspend fun testListDelay() {
suspend fun list():List<Int> {
delay(1000)
return listOf(1, 2, 3)
}
list().forEach {
println("value = $it")
}
}但也暴露了一个缺陷,只能一次性的返回集合元素。
综上所述:
不管是集合还是Sequence,都不能完全覆盖流的需求,此时Flow闪亮登场了
3. Fow常见的操作
最简单的Flow使用
suspend fun testFlow1() {
//生产者
var flow = flow {
//发射数据
emit(5)
}
//消费者
flow.collect {
println("value=$it")
}
}通过flow函数构造一个flow对象,然后通过调用flow.collect收集数据。
flow函数的闭包为生产者的生产逻辑,collect函数的闭包为消费者的消费逻辑。
当然,还有更简单的写法:
suspend fun testFlow2() {
//生产者
flow {
//发射数据
emit(5)
}.collect {
//消费者
println("value=$it")
}
}执行流程:
Flow操作符
上面只提到了flow数据的发送以及接收,并没有提及对flow数据的操作。
flow提供了许多操作符方便我们对数据进行处理(对流进行加工)。
我们以寻找1~1000内大于500的偶数为例:
suspend fun testFlow3() {
//生产者
var flow = flow {
for (i in 1..1000) {
emit(i)
}
}.filter { it > 500 && it % 2 == 0 }
//消费者
flow.collect {
println("value=$it")
}
}filter函数的作用根据一定的规则过滤数据,一般称这种函数为flow的操作符。
当然还可以对flow进行映射、变换、异常处理等。
suspend fun testFlow3() {
//生产者
var flow = flow {
for (i in 1..1000) {
emit(i)
}
}.filter { it > 500 && it % 2 == 0 }
.map { it - 500 }
.catch {
//异常处理
}
//消费者
flow.collect {
println("value=$it")
}
}中间操作符
前面说过流的三要素:原始数据、对数据的操作、最终数据,对应到Flow上也是一样的。
flow的闭包里我们看做是原始数据,而filter、map、catch等看做是对数据的操作,collect闭包里看做是最终的数据。
filter、map等操作符属于中间操作符,它们负责对数据进行处理。
中间操作符仅仅只是预先定义一些对流的操作方式,并不会主动触发动作执行
末端操作符
末端操作符也叫做终端操作符,调用末端操作符后,Flow将从上流发出数据,经过一些列中间操作符处理后,最后流到下流形成最终数据。
如上面的collect操作符就是其中一种末端操作符。
怎么区分中间操作符和末端操作符呢?
和Sequence操作符类似,可以通过返回值判断。
先看看中间操作符filter:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform { value ->
if (predicate(value)) return@transform emit(value)
}
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow { // Note: unsafe flow is used here, because unsafeTransform is only for internal use
collect { value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
}
}可以看出,filter操作符仅仅只是构造了Flow对象,并重写了collect函数。
再看末端操作符collect:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})返回值为Unit,并且通过调用collect最终调用了emit,触发了流。
Flow相比Sequence、Collection的优势
Sequence对于协程的支持不够好,不能调用其作用域外的suspend函数,而Collection生产数据不够灵活,来看看Flow是如何解决这些问题的。
suspend fun testFlow4() {
//生产者
var flow = flow {
for (i in 1..1000) {
delay(1000)
emit(i)
}
}.flowOn(Dispatchers.IO)//切换到io线程执行
//消费者
flow.collect {
delay(1000)
println("value=$it")
}
}如上,flow的生产者、消费者闭包里都支持调用协程的suspend函数,同时也支持切换线程执行。
再者,flow可以将集合里的值一个个发出,可调整其流速。
当然,flow还提供了许多操作符帮助我们实现各种各样的功能,此处限于篇幅就不再深入。
万变不离其宗,知道了原理,一切迎刃而解。
4. 为什么说Flow是冷流?
flow 的流动
在sequence的分析里有提到过sequence是冷流,那么什么是冷流呢?
没有消费者,生产者不会生产数据
没有观察者,被观察者不会发送数据
suspend fun testFlow5() {
//生产者
var flow = flow {
println("111")
for (i in 1..1000) {
emit(i)
}
}.filter {
println("222")
it > 500 && it % 2 == 0
}.map {
println("333")
it - 500
}.catch {
println("444")
//异常处理
}如上代码,只要生产者没有消费者,该函数运行后不会有任何打印语句输出。
这个时候将消费者加上,就会触发流的流动。
还是以最简单的flow demo为例,看看其调用流程:
图上1~6步骤即为最简单的flow调用流程。
可以看出,只有调用了末端操作符(如collect)之后才会触发flow的流动,因此flow是冷流。
flow 的原理
suspend fun testFlow1() {
//生产者
var flow = flow {
//发射数据
emit(5)
}
//消费者
flow.collect {
println("value=$it")
}
}以上代码涉及到三个关键函数(flow、emit、collect),两个闭包(flow闭包、collect闭包。
从上面的调用图可知,以上五者的调用关系:
flow-->collect-->flow闭包-->emit-->collect闭包
接下来逐一分析在代码里的关系。
先看生产者动作(flow函数)
flow函数实现:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
传入的参数类型为:FlowCollector的扩展函数,而FlowCollector是接口,它有唯一的函数:emit(xx)。因此在flow函数的闭包里可以调用emit(xx)函数,flow闭包作为SafeFlow的成员变量block。
flow 函数返回SafeFlow,SafeFlow继承自AbstractFlow,并实现了collect函数:
#Flow.kt
public final override suspend fun collect(SafeCollector: FlowCollector<T>) {
//构造SafeCollector
//collector 作为SafeCollector的成员变量
val safeCollector = SafeCollector(collector, coroutineContext)
try {
//抽象函数,子类实现
collectSafely(safeCollector)
} finally {
safeCollector.releaseIntercepted()
}
}collect的闭包作为SafeCollector的成员变量collector,后面会用到。
由此可见:flow函数仅仅只是构造了flow对象并返回。
再看消费者动作(collect)
当消费者调用flow.collect函数时:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})此时调用的collect即为flow里定义的collect函数,并构造了匿名对象FlowCollector,实现了emit函数,而emit函数的真正实现为action,也就是外层传入的collect的闭包。
上面分析到的collect源码里调用了collectSafely:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}此处的block即为在构造flow对象时传入的闭包。
此时,消费者通过collect函数已经调用到生产者的闭包里
还剩下最后一个问题:生产者的闭包是如何流转到消费者的闭包里呢?
最后看发射动作(emit)
在生产者的闭包里调用了emit函数:
override suspend fun emit(value: T) {
//挂起函数
return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->
try {
//uCont为当前协程续体
emit(uCont, value)
} catch (e: Throwable) {
// Save the fact that exception from emit (or even check context) has been thrown
lastEmissionContext = DownstreamExceptionElement(e)
throw e
}
}
}
private fun emit(uCont: Continuation<Unit>, value: T): Any? {
val currentContext = uCont.context
currentContext.ensureActive()
// This check is triggered once per flow on happy path.
val previousContext = lastEmissionContext
if (previousContext !== currentContext) {
checkContext(currentContext, previousContext, value)
}
completion = uCont
//collector.emit 最终调用collect的闭包
return emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
}如此一来,生产者的闭包里调用emit函数后,将会调用到collect的闭包里,此时数据从flow的上游流转到下游。
总结以上步骤,其实本质还是对象调用。
中间操作符的原理
以filter为例:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform { value ->
//判断过滤条件是否满足,若是则发送数据
if (predicate(value)) return@transform emit(value)
}
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow { // Note: unsafe flow is used here, because unsafeTransform is only for internal use
//调用当前对象collect
collect { value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
}
}
internal inline fun <T> unsafeFlow(@BuilderInference crossinline block: suspend FlowCollector<T>.() -> Unit): Flow<T> {
//构造flow,重写collect
return object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
collector.block()
}
}
}filter操作符构造了新的flow对象,该对象重写了collect函数。
当调用flow.collect时,先调用到filter对象的collect,进而调用到原始flow的collect,接着调用到原始flow对象的闭包,在闭包里调用的emit即为filter的闭包,若filter闭包里条件满足则调动emit函数,最后调用到collect的闭包。
理解中间操作符的要点:
- 中间操作符返回新的flow对象,重写了collect函数
- collect函数会调用当前flow(调用filter的flow对象)的collect
- collect函数做其它的处理
与sequence类似,使用了装饰者模式。
以上以filter为例阐述了原理,其它中间操作符的原理类似,此处就不再细说。
下篇将分析Flow的背压与线程切换,相信分析的逻辑会让大家耳目一新,敬请期待~
本文基于Kotlin 1.5.3,文中完整Demo请点击
链接:https://juejin.cn/post/7168511169781563428
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter富文本性能优化 — 渲染
文本的排版与绘制
在经过之前文章的学习后,我们可以知道RichText主要是通过构建InlineSpan树来实现图文混排的功能。对InlineSpan树的结构我们也已经很清晰,在树中,除了TextSpan,还存在着PlaceholderSpan类型的节点,而WidgetSpan又是继承于PlaceholderSpan的,PlaceholderSpan会在文字排版的时候作为占位符参与排版,WidgetSpan就可以在排版完之后得到位置信息,然后绘制在正确的地方。
RichText继承的是MultiChildRenderObjectWidget,对应的RenderObject就是负责文本的排版和渲染的RenderParagraph。RenderParagraph负责文本的Layout和Paint,但RenderParagraph并不会直接的绘制文本,它最终都是调用TextPainter对象,再由TextPainter去触发Engine层中的排版和渲染。
那么文本具体的排版和绘制过程是怎么样的呢? ——知道它的原理实现过程,才能更好的优化它
我们已经知道PlaceholderSpan会在文字排版的时候作为占位符参与排版,那么editable.dart中的_layoutChildren方法就是用来收集PlaceholderSpan的信息,用于后续的文本排版。
///如果没有PlaceholderSpan(WidgetSpan),这个方法不会做任何事
List<PlaceholderDimensions> _layoutChildren(BoxConstraints constraints, {bool dry = false}) {
if (childCount == 0) {
_textPainter.setPlaceholderDimensions(<PlaceholderDimensions>[]);
return <PlaceholderDimensions>[];
}
RenderBox? child = firstChild;
final List<PlaceholderDimensions> placeholderDimensions = List<PlaceholderDimensions>.filled(childCount, PlaceholderDimensions.empty);
int childIndex = 0;
//将宽度设置为PlaceholderSpan所在段落的最大宽度,若不做限制,会溢出。
BoxConstraints boxConstraints = BoxConstraints(maxWidth: constraints.maxWidth);
...
//遍历InlineSpan树下PlaceholderSpan的所有子节点,收集它的尺寸信息(PlaceholderDimensions)
placeholderDimensions[childIndex] = PlaceholderDimensions(
size: childSize,
alignment: _placeholderSpans[childIndex].alignment,
baseline: _placeholderSpans[childIndex].baseline,
baselineOffset: baselineOffset,
);
child = childAfter(child);
childIndex += 1;
}
return placeholderDimensions;
}通过paragraph.dart下的_layoutTextWithConstraints方法,将收集的PlaceholderSpan信息更新到TextPainter。
void _layoutTextWithConstraints(BoxConstraints constraints) {
//设置每个占位符(PlaceholderSpan)的尺寸,传入的PlaceholderDimensions必须与PlaceholderSpan的数量对应。
_textPainter.setPlaceholderDimensions(_placeholderDimensions);
//用于计算需要绘制的文本的位置
_layoutText(minWidth: constraints.minWidth, maxWidth: constraints.maxWidth);
}当PlaceholderSpan信息更新到TextPainter后,我们在看到layout方法,
void layout({ double minWidth = 0.0, double maxWidth = double.infinity }) {
...
//_rebuildParagraphForPaint用于判断是否需要重建文本段落。
//_paragraph为空则意味着样式发生改变,文本需要重新布局。
if (_rebuildParagraphForPaint || _paragraph == null) {
//重建文本段落
_createParagraph();
}
...
//TextBox会在Paint时被绘制。
_inlinePlaceholderBoxes = _paragraph!.getBoxesForPlaceholders();
}在layout中调用的_createParagraph,主要来添加TextSpan和计算PlaceholderDimensions。
void _createParagraph() {
...
//遍历InlineSpan树,如果是TextSpan就将其添加到builder中。
//如果是PlaceholderSpan(WidgetSpan和自定义span),就计算PlaceholderDimensions。
final ui.ParagraphBuilder builder = ui.ParagraphBuilder(_createParagraphStyle());
text.build(builder, textScaleFactor: textScaleFactor, dimensions: _placeholderDimensions);
_inlinePlaceholderScales = builder.placeholderScales;
_paragraph = builder.build();
_rebuildParagraphForPaint = false;
}在计算完PlaceholderDimensions后,需要将它更新到对应的节点。
void _setParentData() {
RenderBox? child = firstChild;
int childIndex = 0;
//循环遍历布局的子节点,给每一个子节点的占位符设置parentData的偏移量
while (child != null && childIndex < _textPainter.inlinePlaceholderBoxes!.length) {
final TextParentData textParentData = child.parentData! as TextParentData;
//主要计算offset和scale
textParentData.offset = Offset(
_textPainter.inlinePlaceholderBoxes![childIndex].left,
_textPainter.inlinePlaceholderBoxes![childIndex].top,
);
textParentData.scale = _textPainter.inlinePlaceholderScales![childIndex];
child = childAfter(child);
childIndex += 1;
}
}在layout被调用后(计算好需要绘制的区域后),将进行paint,paint主要为两个部分:文本的绘制和占位符的绘制。·
void _paintContents(PaintingContext context, Offset offset) {
//断言,如果最后绘制的宽高与最大宽高的约束不相同,则抛出一个异常。(断言只在debug模式下运行有效,如果在release模式运行,断言不会执行)
debugAssertLayoutUpToDate();
//绘制的偏移
final Offset effectiveOffset = offset + _paintOffset;
if (selection != null && !_floatingCursorOn) {
//计算插入的文本的偏移量
_updateSelectionExtentsVisibility(effectiveOffset);
}
final RenderBox? foregroundChild = _foregroundRenderObject;
final RenderBox? backgroundChild = _backgroundRenderObject;
//绘制child的RenderObject
if (backgroundChild != null) {
context.paintChild(backgroundChild, offset);
}
//绘制layout布局好的文本
//调用canvas.drawParagraph()将文本绘制到指定的区域中
_textPainter.paint(context.canvas, effectiveOffset);
RenderBox? child = firstChild;
int childIndex = 0;
//循环遍历InlineSpan树,其中每一个TextBox都对应一个PlaceholderSpan
while (child != null && childIndex < _textPainter.inlinePlaceholderBoxes!.length) {
//parentData的偏移量
final TextParentData textParentData = child.parentData! as TextParentData;
final double scale = textParentData.scale!;
//绘制占位的child
//在pushTransform中,用了TransformLayer包裹了一层,用于对排版进行变换,主要是包含offset和scale
context.pushTransform中,用了(
needsCompositing,
effectiveOffset + textParentData.offset,
Matrix4.diagonal3Values(scale, scale, scale),
(PaintingContext context, Offset offset) {·
context.paintChild(
child!,
offset,
);
},
);
child = childAfter(child);
childIndex += 1;
}
if (foregroundChild != null) {
//绘制RenderObject
context.paintChild(foregroundChild, offset);
}
}在了解Flutter文本的排版和绘制后,我们会发现,在文本的排版和绘制过程中,有着许多位置计算和构建文本段落的逻辑,这是非常耗时的过程,为了程序的高性能,我们是不可能每一帧都去重新排版渲染的。当然,我们能想到,Flutter官方肯定也能想到,所以Flutter在更新文本时,会通过比较文本信息,更具文本信息的更新状态来判断下一帧是否要进行文本的重新排版渲染。
enum RenderComparison {
//更新后的InlineSpan树与更新前完全一样
identical,
//更新后的InlineSpan树与更新前一样(布局一样),只是像一些点击事件发生改变
metadata,
//更新后的InlineSpan树与更新前存在TextSpan的样式变化,但是树的结构没有变化,布局没有改变
paint,
//更新后的InlineSpan树与更新前发生了布局变化,例如文本大小改变,或插入了图片...
layout,
}四种状态的变化情况是越来越大的,identical与metadata的状态是不会对RenderObject渲染对象进行改变的,paint是需要重新绘制文本,layout是需要重新排版文本。了解了Flutter对文本更新状态的定义,再让我们了解下,Flutter是如何判断文本更新的状态的。
@override
RenderComparison compareTo(InlineSpan other) {
...
//判断Text或子child数量是否发生变化,若发生变化则需要重新排版
if (textSpan.text != text ||
children?.length != textSpan.children?.length ||
(style == null) != (textSpan.style == null)) {
//返回文本更新状态
return RenderComparison.layout;
}
RenderComparison result = recognizer == textSpan.recognizer ?
RenderComparison.identical :
RenderComparison.metadata;
//比较textSpan.style
if (style != null) {
//style!.compareTo()用于比较样式,若只是color这些属性的修改,只需要重新绘制即可
//若是字体大小这样属性发生变化,则需要重新进行排版
final RenderComparison candidate = style!.compareTo(textSpan.style!);
if (candidate.index > result.index) {
result = candidate;
}
if (result == RenderComparison.layout) {
return result;
}
}
//递归比较子child节点
if (children != null) {
for (int index = 0; index < children!.length; index += 1) {
final RenderComparison candidate = children![index].compareTo(textSpan.children![index]);
if (candidate.index > result.index) {
result = candidate;
}
if (result == RenderComparison.layout) {
return result;
}
}
}
return result;
}文本渲染优化探索
结论 —— 按段落(块)渲染文本。
文本渲染最头疼的问题就在于长文本(超十万字)的渲染,这样的长文本在渲染时往往会占用很大的内存,滚动卡顿,给用户带来极差的体验。如果你对长文本渲染没有概念,那么可以和我一起看下这个测试例子(所有测试代码均在Profile模式下运行):
代码实现如下:模拟将长文本渲染进一个Text的操作。
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text("长文本渲染 — 测试"),
),
body: Center(
child: ListView(
children: <Widget>[
//创建一个Iterable,通过序列来动态生成元素
Text(Iterable.generate(100000, (i) => "Hello Flutter $i").join('\n'))
],
),
),
);
}我们可以在效果图中看到,在快速滑动时,页面有明显卡顿。通过计算得到帧率在15帧左右。这在现在动不动就屏幕刷新率为144的手机中,体验十分糟糕。
优化:对于渲染时,在一个Text组件中渲染10万条文本,不如生成10万个Text组件,每个组件渲染一行文本。不要以我们的思维去理解Flutter,认为Flutter做某件事会很累。Flutter渲染一个和渲染10万个Text,在性能上没有太多的差距。
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text("Flutter 长文本渲染测试"),
),
body: Center(
child: ListView(
children: <Widget>[
// 三个点...是dart的语法糖,用于拼接集合(List、Map...),可以将其拼接到一个ListView(Column、Row)上面
...Iterable.generate(100000, (i) => Text("Hello Taxze $i"))
],
),
),
);
}这样优化后,帧率基本保持在60帧。
但是,这不是较好的优化方式,属于暴力解法。如果你只需要显示文本的话,你可以使用ListView.build用来逐行动态加载文本,同时给列表指定itemExtent或prototypeItem会有更高的性能,所以当我们知道列表项的高度都相同时,强烈建议指定itemExtent或prototypeItem。使用prototypeItem是在我们知道列表组件高度相同,但不确定列表组件的具体高度时使用。
body: Center(
child: ListView.builder(
prototypeItem: const Text(''),
itemCount: 100000,
itemBuilder: (BuildContext context, int index) {
return Text("Hello Taxze $index");
},
),
)当需要像富文本这样,需要图文混排或编辑文本的功能时,那渲染的基本框架像下面这样比较好:
SingleChildScrollView(
child: Column(
children: <Widget>[
...Iterable.generate(100000, (i) => Text("Hello Taxze $i"))
],
),
)当然,真实的业务需求中肯定不是这么简单的,一般需要我们自己魔改SingleChildScrollView,例如在SingleChildScrollView添加一些其他的参数。
富文本块结构定义
知道了文本渲染优化的一些点,那么我们再看向富文本。想要高性能的渲染富文本,那么我们同样不能将所有文本放在一个Editable下渲染。我们需要定义富文本的块状规则,将同一块样式的文本渲染在一个RichText中,将该RichText定义为一个TextLine,一个文本段落。若有图片等WidgetSpan,则将其插入在段落中。遇到单段落文本为长文本时,选择将其分行、分多个RichText渲染。段落规则定义的实现逻辑我们可以参考Quill:
//Quill文档中的一行富文本。输入一个新样式的文本时,会渲染新的一行,且完全占用该行。
class Line extends Container<Leaf?> {
//判断该行是否嵌入其他元素,例如图片
bool get hasEmbed {
return children.any((child) => child is Embed);
}
//判断是否为最后一行·
Line? get nextLine {
if (!isLast) {
return next is Block ? (next as Block).first as Line? : next as Line?;
}
if (parent is! Block) {
return null;
}
if (parent!.isLast) {
return null;
}
...
}
@override
void insert(int index, Object data, Style? style) {
final text = data as String;
//判断是否换行符,如果没有,则不需要更新段落块
final lineBreak = text.indexOf('\n');
if (lineBreak < 0) {
_insertSafe(index, text, style);
return;
}
// 如果输入一个文本超过了一行的宽度,则自动换行且继承该行样式。这样就能把TextLine变为Block
final nextLine = _getNextLine(index);
// 设置新的格式且重新布局
_format(style);
// 继续插入剩下的文本
final remain = text.substring(lineBreak + 1);
nextLine.insert(0, remain, style);
}
...
}具体的段落规则(插入、删除、嵌入Widget到段落、删除Widget),都需要根据自己的业务来定义。Quill的实现方式只是单做一个参考。
尾述
在这篇文章中,我们分析了Flutter文本的排版与绘制原理,且对文本的渲染进行优化分析。最后的目的都是将这些知识、优化的点结合到富文本中。在对富文本块状规则的定义时,需要结合真实的业务逻辑,避免段落规则的计算部分过于复杂,否则容易造成UI绘制时间过长。希望这篇文章能对你有所帮助,有问题欢迎在评论区留言讨论~
链接:https://juejin.cn/post/7168248386545451016
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【造轮子】自定义一个随意拖拽可吸边的悬浮View
1、效果
2、前言
在开发中,随意拖拽可吸边的悬浮View还是比较常见的,这种功能网上也有各种各样的轮子,其实写起来并不复杂,看完本文,你也可以手写一个,而且不到400行代码就能实现一个通用的随意拖拽可吸边的悬浮View组件。
3、功能拆解
4、功能实现
4.1、基础实现
4.1.1、自定义view类
先定义一个FloatView类,继承自FrameLayout,实现构造方法。
创建一个ShapeableImageView,并添加到这个FloatView中。
class FloatView : FrameLayout {
constructor(context: Context) : this(context, null)
constructor(context: Context, attributeSet: AttributeSet?) : this(context, attributeSet, 0)
constructor(context: Context, attributeSet: AttributeSet?, defStyle: Int) : super(context, attributeSet, defStyle) {
initView()
}
private fun initView() {
val lp = LayoutParams(LayoutParams.WRAP_CONTENT, LayoutParams.WRAP_CONTENT)
layoutParams = lp
val imageView = ShapeableImageView(context)
imageView.setImageResource(R.mipmap.ic_avatar)
addView(imageView)
}
}4.1.2、添加到window
在页面的点击事件中,通过DecorView把这个FloatView添加到window中
mBinding.btnAddFloat.setOnClickListener {
val contentView = this.window.decorView as FrameLayout
contentView.addView(FloatView(this))
}来看下效果:
默认在左上角,盖住了标题栏,也延伸到了状态栏,不是很美观。
从这个视图层级关系中可以看出,我们是把FloatView添加到DecorView的根布局(rootView)里面了,实际下面还有一层contentView,contentView是不包含状态栏、导航栏和ActionBar的。
我们改一下添加的层级(content):
val contentView = this.window.decorView.findViewById(android.R.id.content) as FrameLayout
contentView.addView(FloatView(this))再看下效果:
此时,是默认显示在状态栏下面了,但还是盖住了标题栏。
这是因为标题栏是在activity的layout中加的toolbar,不是默认的ActionBar,app主题是Theme.Material3.DayNight.NoActionBar,所以显示效果其实是正确的。
手动加上ActionBar看看效果:
这就验证了我们之前的论点了。
不管我们添加的根布局是rootView还是contentView,实际上可能都有需求不要盖住原有页面上的某些元素,这时候可以通过margin或者x/y坐标位置来限制view显示的位置。
4.1.3、视图层级关系
4.2、拖拽
4.2.1、View.OnTouchListener
实现View.OnTouchListener接口,重写onTouch方法,在onTouch方法中根据拖动的坐标实时修改view的位置。
override fun onTouch(v: View, event: MotionEvent): Boolean {
val x = event.x
val y = event.y
when (event.action) {
MotionEvent.ACTION_DOWN -> {
mDownX = event.x
mDownY = event.y
}
MotionEvent.ACTION_MOVE -> {
offsetTopAndBottom((y - mDownY).toInt())
offsetLeftAndRight((x - mDownX).toInt())
}
MotionEvent.ACTION_UP -> {
}
}
return true
}- MotionEvent.ACTION_DOWN 手指按下
- MotionEvent.ACTION_MOVE 手指滑动
- MotionEvent.ACTION_UP 手指抬起
效果:
ok,这就实现随意拖拽了。
4.2.2、动态修改view坐标
上面我们修改view坐标用的是offsetTopAndBottom和offsetLeftAndRight,分别是垂直方向和水平方向的偏移,当然也还有别的方式可以修改坐标
- view.layout()
- view.setX/view.setY
- view.setTranslationX/view.setTranslationY
- layoutParams.topMargin...
- offsetTopAndBottom/offsetLeftAndRight
4.2.3、view坐标系
上面我们获取坐标用的是event.x,实际上还有event.rawX,他们的区别是什么,view在视图上的坐标又是怎么定义的?
搞清楚了这些,在做偏移计算时,就能达到事半功倍的效果,省去不必要的调试工作。
一图胜千言:
4.3、吸边
吸边的场景基本可以分为两种:
- 上下吸边
- 左右吸边
要么左右吸,要么上下吸,上下左右同时吸一般是违背交互逻辑的(四象限),用户也会觉得很奇怪。
吸边的效果其实就是当手指抬起(MotionEvent.ACTION_UP)的时候,根据滑动的距离,以及初始的位置,来决定view最终的位置。
比如默认在顶部,向下滑动的距离不足半屏,那就还是吸附在顶部,超过半屏,则自动吸附在底部,左右同理。
4.3.1、上下吸边
计算公式:
1.上半屏:
1.1.滑动距离<半屏=吸顶
1.2.滑动距离>半屏=吸底
2.下半屏:
2.1.滑动距离<半屏=吸底
2.2.滑动距离>半屏=吸顶先看下效果:
可以看到基础效果我们已经实现了,但是顶部盖住了ToolBar,底部也被NavigationBar遮住了,我们再优化一下,把ToolBar和NavigationBar的高度也计算进去。
看下优化后的效果:
这样看起来就好很多了。
上图效果最终代码:
private fun adsorbTopAndBottom(event: MotionEvent) {
if (isOriginalFromTop()) {
// 上半屏
val centerY = mViewHeight / 2 + abs(event.rawY - mFirstY)
if (centerY < getScreenHeight() / 2) {
//滑动距离<半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
} else {
//滑动距离>半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
}
} else {
// 下半屏
val centerY = mViewHeight / 2 + abs(event.rawY - mFirstY)
if (centerY < getScreenHeight() / 2) {
//滑动距离<半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
} else {
//滑动距离>半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
}
}
}4.3.2、左右吸边
计算公式:
1.左半屏:
1.1.滑动距离<半屏=吸左
1.2.滑动距离>半屏=吸右
2.右半屏:
2.1.滑动距离<半屏=吸右
2.2.滑动距离>半屏=吸左看下效果:
左右吸边的效果相对上下吸边来说要简单些,因为不用计算ToolBar和NavigationBar,计算逻辑与上下吸边相通,只不过参数是从屏幕高度变为屏幕宽度,Y轴变为X轴。
代码:
private fun adsorbLeftAndRight(event: MotionEvent) {
if (isOriginalFromLeft()) {
// 左半屏
val centerX = mViewWidth / 2 + abs(event.rawX - mFirstX)
if (centerX < getScreenWidth() / 2) {
//滑动距离<半屏=吸左
val leftX = 0f
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(leftX).start()
} else {
//滑动距离<半屏=吸右
val rightX = getScreenWidth() - mViewWidth
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(rightX.toFloat()).start()
}
} else {
// 右半屏
val centerX = mViewWidth / 2 + abs(event.rawX - mFirstX)
if (centerX < getScreenWidth() / 2) {
//滑动距离<半屏=吸右
val rightX = getScreenWidth() - mViewWidth
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(rightX.toFloat()).start()
} else {
//滑动距离<半屏=吸左
val leftX = 0f
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(leftX).start()
}
}
}
Author:yechaoa
5、进阶封装
为什么要封装一下呢,因为现在的计算逻辑、参数配置都是在FloatView这一个类里,定制化太强反而不具备通用性,可以进行一个简单的抽取封装,向外暴露一些配置和接口,这样在其他的业务场景下也可以复用,避免重复造轮子。
5.1、View封装
5.1.1、BaseFloatView
把FloatView改成BaseFloatView,然后把一些定制化的能力交给子view去实现。
这里列举了3个方法:
/**
* 获取子view
*/
protected abstract fun getChildView(): View
/**
* 是否可以拖拽
*/
protected abstract fun getIsCanDrag(): Boolean
/**
* 吸边的方式
*/
protected abstract fun getAdsorbType(): Int5.1.2、子view
class AvatarFloatView(context: Context) : BaseFloatView(context) {
override fun getChildView(): View {
val imageView = ShapeableImageView(context)
imageView.setImageResource(R.mipmap.ic_avatar)
return imageView
}
override fun getIsCanDrag(): Boolean {
return true
}
override fun getAdsorbType(): Int {
return ADSORB_VERTICAL
}
}这样稍微抽一下,代码看起来就简洁很多了,只需要配置一下就可以拥有随意拖拽的能力了。
5.1.3、吸边距离可配
目前吸边的逻辑是判断拖拽距离是否超过半屏,来决定吸哪边,为了更好的通用性,可以把这个距离参数变为可配置的,比如不一定要以半屏为界限,也可以是屏幕的30%。
先定义一个距离系数的变量,默认为屏幕的一半,取值范围0-1
private var mDragDistance = 0.5 // 默认吸边需要的拖拽距离为屏幕的一半然后定义一个设置这个距离系数的方法
/**
* 设置吸边需要的拖拽距离,默认半屏修改吸边方向,取值0-1
*/
fun setDragDistance(distance: Double) {
mDragDistance = distance
}再定义获取实际需要拖拽距离的方法
/**
* 获取上下吸边时需要拖拽的距离
*/
private fun getAdsorbHeight(): Double {
return getScreenHeight() * mDragDistance
}
/**
* 获取左右吸边时需要拖拽的距离
*/
private fun getAdsorbWidth(): Double {
return getScreenWidth() * mDragDistance
}最后修改判断的地方
if (centerY < getAdsorbHeight()) {
//滑动距离<半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
} else {
//滑动距离>半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
}由if (centerY < getScreenHeight() / 2)改为if (centerY < getAdsorbHeight())
这样,在调用的时候就可以根据需要,来配置拖拽吸边的界限了。
比如屏幕的30%:
mFloatView?.setDragDistance(0.3)5.2、调用封装
5.2.1、管理类
新建一个FloatManager的管理类,它来负责FloatView的显示隐藏,以及回收逻辑。
设计模式还是使用单例,我们需要在这个单例类里持有Activity,因为需要通过Activity的window获取decorView然后把FloatView添加进去,但是Activity与单例的生命周期是不对等的,这就很容易造成内存泄露。
怎么解?也好办,管理一下activity的生命周期就好了。
在之前分析LifecycleScope源码的文章中有提到关于Activity生命周期的管理,得益于lifecycle的强大,这个问题解起来也变得更简单。
private fun addLifecycle(activity: ComponentActivity?) {
activity?.lifecycle?.addObserver(mLifecycleEventObserver)
}
private var mLifecycleEventObserver = LifecycleEventObserver { _, event ->
if (event == Lifecycle.Event.ON_DESTROY) {
hide()
}
}
fun hide() {
if (::mContentView.isInitialized && mFloatView != null && mContentView.contains(mFloatView!!)) {
mContentView.removeView(mFloatView)
}
mFloatView?.release()
mFloatView = null
mActivity?.lifecycle?.removeObserver(mLifecycleEventObserver)
mActivity = null
}- 添加生命周期的监听
- 在ON_DESTROY的时候处理回收逻辑
5.2.2、FloatManager完整代码
@SuppressLint("StaticFieldLeak")
object FloatManager {
private lateinit var mContentView: FrameLayout
private var mActivity: ComponentActivity? = null
private var mFloatView: BaseFloatView? = null
fun with(activity: ComponentActivity): FloatManager {
mContentView = activity.window.decorView.findViewById(android.R.id.content) as FrameLayout
mActivity = activity
addLifecycle(mActivity)
return this
}
fun add(floatView: BaseFloatView): FloatManager {
if (::mContentView.isInitialized && mContentView.contains(floatView)) {
mContentView.removeView(floatView)
}
mFloatView = floatView
return this
}
fun setClick(listener: BaseFloatView.OnFloatClickListener): FloatManager {
mFloatView?.setOnFloatClickListener(listener)
return this
}
fun show() {
checkParams()
mContentView.addView(mFloatView)
}
private fun checkParams() {
if (mActivity == null) {
throw NullPointerException("You must set the 'Activity' params before the show()")
}
if (mFloatView == null) {
throw NullPointerException("You must set the 'FloatView' params before the show()")
}
}
private fun addLifecycle(activity: ComponentActivity?) {
activity?.lifecycle?.addObserver(mLifecycleEventObserver)
}
private var mLifecycleEventObserver = LifecycleEventObserver { _, event ->
if (event == Lifecycle.Event.ON_DESTROY) {
hide()
}
}
fun hide() {
if (::mContentView.isInitialized && mFloatView != null && mContentView.contains(mFloatView!!)) {
mContentView.removeView(mFloatView)
}
mFloatView?.release()
mFloatView = null
mActivity?.lifecycle?.removeObserver(mLifecycleEventObserver)
mActivity = null
}
}5.2.3、调用方式
- 显示
FloatManager.with(this).add(AvatarFloatView(this)).show()- 隐藏
FloatManager.hide()- 带点击事件
FloatManager.with(this).add(AvatarFloatView(this))
.setClick(object : BaseFloatView.OnFloatClickListener {
override fun onClick(view: View) {
Toast.makeText(this@FloatViewActivity, "click", Toast.LENGTH_SHORT).show()
}
})
.show()6、Github
链接:https://juejin.cn/post/7126475397645991972
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin常用的by lazy你真的了解吗
前言
在使用Kotlin语言进行开发时,我相信很多开发者都信手拈来地使用by或者by lazy来简化你的属性初始化,但是by lazy涉及的知识点真的了解吗 假如让你实现这个功能,你会如何设计。
正文
话不多说,我们从简单的属性委托by来说起。
委托属性
什么是委托属性呢,比较官方的说法就是假如你想实现一个比较复杂的属性,它们处理起来比把值保存在支持字段中更复杂,但是却不想在每个访问器都重复这样的逻辑,于是把获取这个属性实例的工作交给了一个辅助对象,这个辅助对象就是委托。
比如可以把这个属性的值保存在数据库中,一个Map中等,而不是直接调用其访问器。
看完这个委托属性的定义,假如你不熟悉Kotlin也可以理解,就是我这个类的实例由另一个辅助类对象来提供,但是这时你可能会疑惑,上面定义中说的支持字段和访问器是什么呢,这里顺便给不熟悉Kotlin的同学普及一波。
Java的属性
当你定义一个Java类时,在定义字段时并不是所有字段都是属性,比如下面代码:
//Java类
public class Phone {
//3个字段
private String name;
private int price;
private int color;
//name字段访问器
private String getName() {
return name;
}
private void setName(String name){
this.name = name;
}
//price字段访问器
private int getPrice() {
return price;
}
private void setPrice(int price){
this.price = price;
}
}上面我在Phone类中定义了3个字段,但是只有name和price是Phone的属性,因为这2个字段有对应的get和set,也只有符合有getter和setter的字段才叫做属性。
这也能看出Java类的属性值是保存在字段中的,当然你也可以定义setXX函数和getXX函数,既然XX属性没有地方保存,XX也是类的属性。
Kotlin的属性
而对于Kotlin的类来说,属性定义就非常简单了,比如下面类:
class People(){
val name: String? = null
var age: Int? = null
}在Kotlin的类中只要使用val/var定义的字段,它就是类的属性,然后会自带getter和setter方法(val属性相当于Java的final变量,是没有set方法的),比如下面:
val people = People()
//调用name属性的getter方法
people.name
//调用age属性的setter方法
people.age = 12这时就有了疑问,为什么上面代码定义name时我在后面给他赋值了即null值,和Java一样不赋值可以吗 还有个疑问就是在Java中是把属性的值保存在字段中,那Kotlin呢,比如name这个属性的值就保存给它自己吗
带着问题,我们继续分析。
Kotlin属性访问器
前面我们可知Java中的属性是保存在字段中,或者不要字段,其实Kotlin也可以,这个就是给属性定义自定义setter方法和getter方法,如下代码:
class People(){
val name: String? = null
var age: Int = 0
//定义了isAbove18这个属性
var isAbove18: Boolean = false
get() = age > 18
}比如这里自定义了get访问器,当再访问这个属性时,便会调用其get方法,然后进行返回值。
Kotlin属性支持字段field
这时一想那Kotlin的属性值保存在哪里呢,Kotlin会使用一个field的支持字段来保存属性。如下代码:
class People{
val name: String? = null
var age: Int = 0
//返回field的值
get() = field
//设置field的值
set(value){
Log.i("People", "旧值是$field 新值是$value ")
field = value
}
var isAbove18: Boolean = false
get() = age > 18
}可以发现每个属性都会有个支持字段field来保存属性的值。
好了,为了介绍为什么Kotlin要有委托属性这个机制,假如我在一个类中,需要定义一个属性,这时获取属性的值如果使用get方法来获取,会在多个类都要写一遍,十分不符合代码设计,所以委托属性至关重要。
委托属性的实现
在前面说委托属性的概念时就说了,这个属性的值需要由一个新类来代理处理,这就是委托属性,那我们也可以大概猜出委托属性的底层逻辑,大致如下面代码:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//email属性进行委托,把它委托给ProduceEmail类
var email: String by ProduceEmail()
}假如People的email属性需要委托,上面代码编译器会编译成如下:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//委托类的实例
private val productEmail = ProduceEmail()
//委托属性
var email: String
//访问器从委托类实例获取值
get() = productEmail.getValue()
//设置值把值设置进委托类实例
set(value) = productEmail.setValue(value)
}当然上面代码是编译不过的,只是说一下委托的实现大致原理。那假如想使ProduceEmail类真的具有这个功能,需要如何实现呢。
by约定
其实我们经常使用 by 关键字它是一种约定,是对啥的约定呢 是对委托类的方法的约定,关于啥是约定,一句话说明白就是简化函数调用,具体可以查看我之前的文章:
# Kotlin invoke约定,让Kotlin代码更简洁
那这里的by约定简化了啥函数调用呢 其实也就是属性的get方法和set方法,当然委托类需要定义相应的函数,也就是下面这2个函数:
//by约定能正常使用的方法
class ProduceEmail(){
private val emails = arrayListOf("111@qq.com")
//对应于被委托属性的get函数
operator fun getValue(people: People, property: KProperty<*>): String {
Log.i("zyh", "getValue: 操作的属性名是 ${property.name}")
return emails.last()
}
//对于被委托属性的get函数
operator fun setValue(people: People, property: KProperty<*>, s: String) {
emails.add(s)
}
}定义完上面委托类,便可以进行委托属性了:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//委托属性
var email: String by ProduceEmail()
}然后看一下调用地方:
val people = People()
Log.i("zyh", "onCreate: ${people.email}")
people.email = "222@qq.com"
Log.i("zyh", "onCreate: ${people.email}")打印如下:
会发现每次调用email属性的访问器方法时,都会调用委托类的方法。
关于委托类中的方法,当你使用by关键字时,IDE会自动提醒,提醒如下:
比如getValue方法中的参数,第一个就是接收者了,你这个要委托的属性是哪个类的,第二个就是属性了,关于KProperty不熟悉的同学可以查看文章:
# Kotlin反射全解析3 -- 大展身手的KProperty
它就代表这属性,可以调用其中的一些方法来获取属性的信息。
而且方法必须使用operator关键字修饰,这是重载操作符的必须步骤,想使用约定,就必须这样干。
by lazy的实现
由前面明白了by的原理,我们接着来看一下我们经常使用的by lazy是个啥,直接看代码:
//这里使用by lazy惰性初始化一个实例
val instance: DataStoreManager by lazy(mode = LazyThreadSafetyMode.SYNCHRONIZED) {
DataStoreManager(store) }比如上面代码,使用惰性初始化初始了一个实例,我们来看一下这个by的实现:
//by代码
@kotlin.internal.InlineOnly
public inline operator fun <T> Lazy<T>.getValue(thisRef: Any?, property: KProperty<*>): T = value哦,会发现它是Lazy类的一个扩展函数,按照前面我们对by的理解,它就是把被委托的属性的get函数和getValue进行配对,所以可以想象在Lazy< T >类中,这个value便是返回的值,我们来看一下:
//惰性初始化类
public interface Lazy<out T> {
//懒加载的值,一旦被赋值,将不会被改变
public val value: T
//表示是否已经初始化
public fun isInitialized(): Boolean
}到这里我们注意一下 by lazy的lazy,这个就是一个高阶函数,来创建Lazy实例的,lazy源码:
//lazy源码
public actual fun <T> lazy(mode: LazyThreadSafetyMode, initializer: () -> T): Lazy<T> =
when (mode) {
LazyThreadSafetyMode.SYNCHRONIZED -> SynchronizedLazyImpl(initializer)
LazyThreadSafetyMode.PUBLICATION -> SafePublicationLazyImpl(initializer)
LazyThreadSafetyMode.NONE -> UnsafeLazyImpl(initializer)
}这里会发现第一个参数便是线程同步的模式,第二个参数是初始化器,我们就直接看一下最常见的SYNCHRONIZED的模式代码:
//线程安全模式下的单例
private class SynchronizedLazyImpl<out T>(initializer: () -> T, lock: Any? = null) : Lazy<T>, Serializable {
private var initializer: (() -> T)? = initializer
//用来保存值,当已经被初始化时则不是默认值
@Volatile private var _value: Any? = UNINITIALIZED_VALUE
//锁
private val lock = lock ?: this
override val value: T
//见分析1
get() {
//第一次判空,当实例存在则直接返回
val _v1 = _value
if (_v1 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST")
return _v1 as T
}
//使用锁进行同步
return synchronized(lock) {
//第二次判空
val _v2 = _value
if (_v2 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST") (_v2 as T)
} else {
//真正初始化
val typedValue = initializer!!()
_value = typedValue
initializer = null
typedValue
}
}
}
//是否已经完成
override fun isInitialized(): Boolean = _value !== UNINITIALIZED_VALUE
override fun toString(): String = if (isInitialized()) value.toString() else "Lazy value not initialized yet."
private fun writeReplace(): Any = InitializedLazyImpl(value)
}分析1:这个单例实现是不是有点眼熟,没错它就是双重校验锁实现的单例,假如你对双重校验锁的实现单例方式还不是很明白可以查看文章:
这里实现懒加载单例的模式就是双重校验锁,2次判空以及volatile关键字都是有作用的,这里不再赘述。
总结
先搞明白by的原理,再理解by lazy就非常好理解了,虽然这些关键字我们经常使用,不过看一下其源码实现还是很舒爽的,尤其是Kotlin的高阶函数的一些SDK写法还是很值的学习。
链接:https://juejin.cn/post/7057675598671380493
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
优雅的数据统计图表
前言
一直想花时间复刻学习一下Apple产品的原生UI和动画,超级丝滑。
今天,目标是健康的心率数据统计图表。
健康及Android实现效果预览
- Apple健康的图表交互效果:
丝滑,有数据条滑动、滑动查看数据标注两种模式;数据标注位置自适应;两端超出边界会有自动回滚的效果。
- 本文用Android复刻的图表交互效果:
暂时着眼于核心的实现思路,细节有长足的优化空间(如自动回滚的运动曲线、快速滑动、刻度线变化等,但他们对于Demo来说不是重点)😥。
1. 页面内容分析
在开始前,我们不妨先仔细观察一下这个页面所涵盖的信息,再将其转换为我们的业务需求,提前整理好思路再开始上手写。
1.1 图表静态布局
我们把图表打散,它本质上由以下三个组件构成:
- 数据条
- 单个数据条:表示单元时间内的心率分布情况,这里我们将它简化为单元时间内的心率变化范围(最小~最大)
- 数据存储:每个数据条需要涵盖的信息有三点:时间、最小值、最大值,我们使用一个ArrayList将他们放在一起,对于那些空缺的数据,我们可以根据时间来填充数值(设为0),以此实现在图表上的留白。
- 坐标轴 Axis
- 横向:横向坐标轴、背景线及其刻度(0,50,100)几乎是静态的,只有刻度会变化,这里我们暂时忽略这一点。
- 纵向:纵向背景线按照特定的间隔分布,滑动过程中也会跟着变化,与数据条是相对静止的。因此,我们尝试把他们和数据条捆绑在一起来实现。
- 数据标注 IndicatorLabel
- 默认形态:它固定在左上角,取当前可见数据的时间范围、心率变化范围进行展示
- 指示形态:当用户长触摸/点击图表数据条时,它就会展现在其上方;在左右边界会有位置的自适应调整。
- 默认形态和指示形态是非此即彼的,我们可以设置一个boolean值,isShowIndicator来控制他们,true的时候展示指示形态,false就为默认形态,以此简化我们的后续处理逻辑。
1.2 图表动态效果
图表滑动与边界效果
- 滑动变化:图表左右滑动来调整,滑动过程中,上方的 默认形态数据标注的值会发生变化,纵向背景线、刻度值会跟着移动;
- 自动回滚:
- 每次滑动结束后,都会有一个轻微的自动回滚,来保证窗口内呈现的完整的24个数据条。
- 在滑动窗口超出两侧边界后,会进行自动回滚,回到原来的边界。
触摸/点击产生的数据标注
- 用户点击/触摸会触发 指示形态的数据标注,进入此状态后,手指按住屏幕左右滑动可以实现滑动数据标注的效果
- 在进入上述状态后,如果手指快速滑动,则可以恢复标注的默认形态并滑动图表。
2. 页面实现
在使用自定义View实现页面前,结合上述对布局的分析,思考一下我们的工作流程:
- 画一个图表的框架草图,标注出重要的尺寸,确保这些尺寸能够让我们计算出每一个点的坐标;
- 准备一个数据类来容纳每个时间点的数据,用ArrayList打包起来,作为我们的数据源;
- 横向背景线、y轴刻度都是全程静态的,优先绘制它;
- 将纵向背景线、x轴刻度与数据条绑定起来绘制;结合ArrayList中每一个item的索引来计算坐标、使用item的数值计算数据条的y轴位置;
- 实现数据标注的绘制函数,它可以通过指定一个item的索引来展示出对应点的具体信息;
- 通过重写onTouchEvent来实现点击/触摸触发数据标注的效果,实现图表的滑动效果。
脑子里粗略思考一遍每一步的可能难度,发现我们主要面临三个难题😥:
- 使用怎样的布局可以让我们轻松地通过item的索引来计算坐标?
- 该怎么用最简洁优雅的方式让我们的数据条动起来?
- 同样是滑动,有时候用户需要数据条左右滑动,有时候却需要数据条不动,数据标注动,这该怎么区分呢?
为保证阅读体验,实现部分不会列出所有代码并阐述所有细节,代码可以在最下方Ctrl C+V获取。
2.1 图表的基础结构
我们按照拟定的工作流程一步步来:
2.1.1画一个图表的框架草图。
提前拆解思考过图表以后,我们可以快速画出以下结构图:
对于数据条宽度(lineWidth),及数据条间隙宽度(lineSpace)的选取,假设我们最大可视数据条为n个,为了实现规整的页面,需要保证以下等式成立:
其中chartWidth我们在上方结构图中标出的——存放数据条的chart的宽度;
这么做的原因很简单:假设现在n为24,那么这个chart的宽度就是 24* lineWidth +23* lineSpace + 最左侧空白宽度 + 最右侧空白宽度;如上等式保证了左右侧空白宽度都为 0.5 * lineSpace。
2.1.2 准备一个数据类
目前的需求是,存放时间,一个最小值一个最大值,所以创建一个简单的DataClass即可。
data class HeartRateChartEntry(
val time: Date = Date(), val minValue:Int = 66, val maxValue:Int = 88
)
复制代码然后我们创建一些随机数据,用ArrayList存储。
2.1.3 绘制横向背景线、y轴刻度
他们是静态的,直接用绘制出来的结构图计算chart、文本的起讫点坐标直接画就好。
- startX = (getWidth() - chartWidth)/2。当然,你也可以自己定义chart的起点,我建议这个起点的x坐标与lineWidth+lineSpace成正比
- endX = startX + chartWidth
- endY = startY = totalHeight - bottomTextHeight
我们要绘制k条线,就首先计算线之间的距离unitDistance = chartHeight/(k-1),每次绘制让unitDistance*i - startY就可以获取到当前横线的纵坐标了。
(0..mHorizontalLineSliceAmount).forEach{ i ->
//获取当前要写上去的刻度
currentLabel = .....
//计算当前Y
currentY = startY - i * mVerticalUnitDistance
//画线
canvas.drawLine(startX, currentY, endX, currentY, mAxisPaint)
//画text
canvas?.drawText("${currentLabel}", endX + mTextSize/3, currentY+mTextSize/3, mTextLabePaint)
//再画上最左侧的边界线
canvas.drawLine(startX, startY, startX, startY-mChartHeight, mAxisPaint)
}2.1.4绘制数据条与纵向背景线
好,遇到了我们预料的难题,用什么方式绘制数据条,可以让他符合我们的滑动需求呢?
被否定的方案:
假设我们通过onTouchEvent计算手指滑动的距离,用滑动的距离来计算我们需要绘制的数据索引;但这种方式虽然符合我们静态页面的需求,但没法实现顺畅的动画效果,滑动过程中只会不停地闪烁。
究其原因是他实际上没有改变数据条绘制时的横坐标,我们再去根据onTouchEvent的滑动距离来微调他们吗?但这仍然无法避免边缘数据条的闪烁。
更好的方案:窗口
想象我们正对着坐在窗口前,我们把这个窗口假设为一个viewPort,在这个窗口,我们能够看到横向切换的风景,是因为窗口和背景之间的相对移动。
如果我们将其设想为我们的chart和数据条,可不可以把chart理解为窗口,数据条是浮在其表面的风景,然后我们只需要移动数据条,就可以切换风景(数据条滑动的视觉效果),这可以保证不会出现割裂感,毕竟所有东西都已经绘制了,只是位置调整了。
想法看来可以一试,上手前,我们还是先画图理一下思路。
- 我们需要从右往左绘制数据条以展现时间格式
- 初始起点不如设定为chart的最右端
- 如果要向右滑动,是不是把绘图的起始点往右边移就可以了?
看来这个思路没错,我们用viewStartX作为起始点,从右向左画数据条(for循环配合数据下标计算x轴坐标),然后去onTouchEvent的ActionMove里计算滑动的距离,动态调整viewStartX就搞定了。
不过有一点要想一想,如果我们每次都滑动都重新绘制了所有的数据条,如果数据量一大,必定会造成性能问题呀!
不过他很好解决,我们只需要计算当前窗口展示的最左和最右的数据条索引,分别为leftRangeIndex, rightRangeIndex,我们在遍历画数据条的过程中设置为只执行(leftRangeIndex-3, rightRangeIndex+3)范围即可,这就实现了每次只画窗口内+窗口边缘的数据条了。
最后,我们需要在绘制完数据条以后,截取一个窗口下来,放回到我们的chart里,我们可以通过canvas.saveLayer()和canvas.restoreToCount()配对使用来实现。
以下是绘制数据条的核心代码,看个思路就好
- 用saveLayer()来确定一个窗口范围
val windowLayer = canvas?.saveLayer(
left = chartLeftMargin, //chart左边界的x坐标
top = 0F,
right = chartRightBorner, //chart右边界的x坐标
bottom = widthBottom //chart下边界的y坐标
)- 遍历我们存储数据的ArrayList,使用viewStartX和索引来计算每个数据条的横坐标,绘制出来
(0 until mValueArray.size).forEach { it ->
//如果不在我们预期的绘制范围内,那就溜溜球,不画了
if (it > drawRangeRight || it < drawRangeLeft) {
return@forEach
}
//计算坐标x,数据条的y轴起讫点
currentX = mViewStartX - (it) * (mLineWidth + mLineSpace) - chartRightMargin
startY = baseY - mChartHeight / mYAxisRange.second * mValueArray[it].maxValue
endY = baseY - mChartHeight / mYAxisRange.second * mValueArray[it].minValue
if (mValueArray[it].maxValue != 0) {
canvas?.drawLine(currentX, startY, currentX, endY, mLinePaint)
}
在我们既定的特定时间点,绘制纵向背景线和刻度(代码略了,完整版在最下方)
最后,把这个窗口再存储到我们的view里去就完成了
cavas?.restoreToCount(windowLayer!!)2.1.5 数据标注的绘制函数
前文有提到,我们的图表一共有两种数据标注的形式,一是默认形态,二是指示形态,他们是非此即彼的,我们只需要设置一个boolean变量,isShowIndicator,然后在onTouchEvent中动态设置这个变量,就可以实现他们的切换了。
同时,我们在onTouchEvent中维护一个变量indexOnClicked,它用来表示当前被点击的那个数据条的索引,并绘制指示形态的数据标注。
这里的绘制流程不赘述了。
2.2 图表的触摸事件
还是一样,理清思路再上手写代码。
我们希望:
图表能够判定用户的长触摸、快速滑动行为
- 我们的图表需要能够判断以下两个状态值
- 正在数据条滑动状态—isScrolling:表示用户通过快速的手指滑动 来切换 数据条(也就是改变viewStartX的坐标)
- 正在长触摸状态-isLongTouch: 用户的手指一直停留在我们的屏幕上,这是因为他想要查看数据标注,这个状态下的切换不会切换数据条,而是切换数据标注的下标。
- 我们的图表需要能够判断以下两个状态值
图表能够计算每次滑动的距离,动态调整viewStartX与要绘制的数组左右边界
onTouchEvent事件链
为了实现以上需求,我们需要研究一下onTouchEvent(event: MotionEvent?)
对于触摸事件,我们处理以下回调:
- ACTION_DOWN
- 手指按下:无论是点击还是滑动,ACTION_DOWN都是他们的初始动作
- ACTION_MOVE
- 手指滑动:在ACTION_DOWN触发后,如果手指滑动,MOVE就会被触发若干次,以表示手指在图表上的滑动
- ACTION_UP
- 手指抬起:一定是点击事件的结束步,可能是滑动事件的结束步(也可能是ACTION_CANCEL)
- ACTION_CANCEL
- 手势放弃:可能是滑动事件的结束步(也可能是ACTION_UP)
我们先处理该怎么让图表判断是快速滑动:
- 我们维护一个当前时间currentTime
- 每次ACTION_DOWN手指按下的时候,我们就记录那一时刻的时间;
- 在遇到ACTION_MOVE的时候,我们就首先获取当前时间,减去记录的currentTime来获取时间间隔
- 如果这个间隔小于某个时间阈值TIMEDURATION,我们把它认定为是一次快速滑动
- 但是,我们添加限制条件,这一次move的距离必须大于某个阈值,否则视为一次轻微move(手滑产生的,不是用户的内心想法)
- 对于后续的滑动事件来说(上图中的n号ACTION_MOVE),他们时间可能已经超过了阈值,但他们也需要执行这个滑动任务;还记得我们提到的状态变量isScrolling吗,我们在1号ACTION_MOVE中将isScrolling设置为true,后续的n号滑动事件中,只要发现当前是isScrolling==true 是正在滑动状态,它就可以大胆开始执行滑动事件了。
据上,我们有了以下代码:
override fun onTouchEvent(event:MotionEvent?):Boolean{
//获取当前触摸点的横坐标
mCurrentX = event!!.x
when (event.action) {
MotionEvent.ACTION_DOWN -> {
//记录一下触摸的点,用来记录滑动距离
mLastX = mCurrentX
//记录现在的时间,用来判断快速滑动
currentMS = System.currentTimeMillis()
}
MotionEvent.ACTION_MOVE -> {
//获得滑动的距离
mMoveX = mLastX - mCurrentX
//记录一下触摸的点
mLastX = mCurrentX
//如果 move time <Xms and moveX > Xpx, 这是快速滑动
if (((System.currentTimeMillis() - currentMS) < TOUCHMOVEDURATION && (abs(mMoveX) > mLineWidth)) || isScrolling) {
isScrolling = true
//更新viewStartX,实现数据条切换,记得给mViewStartX的setter加invalidate()
mViewStartX -= mMoveX
//更新左右边界
updateCurrentDrawRange()
}
}
}接着,我们来处理该怎么让图表判断是长触摸-isLongTouch:
- 怎样的事件流是长触摸呢?
- 长触摸,就是用户的手放上去以后,没有抬起,只有轻微滑动
- 我们将这个阈值设置为判断快速滑动的时间阈值为TIMEDURATION
- 如果我们在执行ACTION_DOWN后,TIMEDURATION时间内,除了轻微滑动外,没有任何其他ACTION事件触发,那就认定为是长触摸
- 用代码来实现:
- 我们在每次ACTION_DOWN后,都开启一个子线程,在TIMEDURATION后,如果他没有被取消运行,那就将isLongTouch设置为true
- 这样我们就开启了长触摸模式,可以在ACTION_MOVE中增加判断,配合isLongTouch来展示我们的数据标注切换。
- 同样,我们在ACTION_UP和 ACTION_MOVE显著移动的事件中,取消这个子线程。
这里,我用kotlin协程来实现的这个判断长触摸的子线程
开启协程的函数:
fun startIndicatorTimer() {
showIndicatorJob = mScope.launch(Dispatchers.Default) {
//用了hasTimer来辅助外面判断有没有子线程在运行
hasTimer = true
//延时任务进行
delay(TOUCHMOVEDURATION + 10.toLong())
withContext(Dispatchers.Main) {
//长触摸了,那正在滑动状态就必须是false啦
isScrolling = false
//长触摸:轮到我了
isLongTouch = true
//找到当前被触摸的数据条索引
setCurrentIndexOnClicked()
//展示指示形态的数据标签
isShowIndicator = true
//子线程运行完毕,把标记设置为false
hasTimer = false
}
}
}关闭协程的函数:
fun turnOffIndicatorTimer() {
if (hasTimer) {
showIndicatorJob.cancel()
hasTimer = false
}
}触摸事件里的核心代码
//节选
when(event.action){
MotionEvent.ACTION_DOWN->{
//记录坐标,记录时间
mLastX = mCurrentX
currentMS = System.currentTimeMillis()
//开始子线程的任务
startIndicatorTimer()
}
MotionEvent.ACTION_MOVE->{
mMoveX = mLastX - mCurrentX
mLastX = mCurrentX
if(是快速滑动){
//关闭这个长触摸判断线程
turnOffIndicatorTimer()
}
//是长触摸状态,那我们激活isShowIndicator
else if(isLongTouch){
isShowIndicator = true
}
else if(不是轻微滑动){
//关闭长触摸判断事件
turnOffIndicatorTimer()
}
}
}自动回滚
- 我们需要每次滑动结束后去判断,让窗口内呈现完成的N个数据条
- 基于我们的结构,这很容易实现,只需要让我们的viewStartX(绘画初始点)的坐标变为(lineWidth+lineSpace)的整数即可
mViewStartX - (mViewStartX - mInitialStartX).mod(mLineSpace+mLineWidth)
- 我们要在滑动超出边界后,让窗口自动回滚到边界值
- 这同样同意实现,我们通过viewStartX来判断是否出界,然后让viewStartX回到设定的边界值就好了
但我们不能采用直接给viewStartX赋值的方法,而是通过ObjectAnimator来实现顺滑的切换,我们将这个逻辑写在方法drawBackToBorder()中,并把它添加到ACTION_CANCEL和ACTION_UP的回调中,因为只有他们俩可能是触摸事件流的结尾。
别放了给viewStartX的Setter方法添加invalidate(),否则动画不会触发。😈
fun drawBackToBorder(){
var endValue:Float = 0F
endValue =
//out of right borderline
if(mViewStartX < mInitialStartX){
mInitialStartX
//out of left borderline
} else if(mViewStartX > mInitialStartX + (mValueArray.size-24)*(mLineWidth+mLineSpace)){
mInitialStartX + (mValueArray.size-24)*(mLineWidth+mLineSpace)
//does not reach the bound, need reposition to exact place.
} else {
mViewStartX - (mViewStartX - mInitialStartX).mod(mLineSpace+mLineWidth)
}
val anim = ObjectAnimator.ofFloat(mViewStartX, endValue)
anim.interpolator = DecelerateInterpolator()
anim.addUpdateListener {
mViewStartX = it.animatedValue as Float
}
anim.start()
}写在最后
写博客核心是希望能复盘的同时锻炼自己讲清楚思路的能力,相比于贴代码,画图+文字阐述是更我喜欢的做的事。
感谢看到这里,如果有任何疑问,欢迎留言和我交流。😋
3. 附-代码
代码涵盖两个文件:
- HeartRateEntry.kt 数据类
- IsenseChart.kt 自定义view文件,没有添加外部参数StyleValue
YunmaoLeo/AppleHealthChart (github.com)
链接:https://juejin.cn/post/7077960004745199646
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android自定义View的交互,往往都是从星星开始
前言
在前面的学习中,我们基本了解了一些 Canvas 的绘制,那么这一章我们一起复习一下图片的绘制几种方式,和事件的简单交互方式。
我们从易到难,作为基础的进阶控件,我们从最简单的交互开始,那就自定义一个星星评分的控件吧。
一个 App 必不可少的评论系统打分的控件,可以展示评分,可以点击评分,可以滑动评分。它的实现总体上可以分为以下的步骤:
- 强制测量大小为我们指定的大小
- 先绘制Drawable未评分的图片
- 在绘制Bitmap已评分的图片
- 在onTouch中点击和移动的事件中动态计算当前的评分,进而刷新布局
- 回调的处理与属性的抽取
思路我们已经有了,下面一步一步的来实现吧。
话不多说,Let's go
1、测量与图片的绘制
我们需要绘制几个星星,那么我们必须要设置的几个属性:
当前的评分值,总共有几个星星,每一个星星的间距和大小,选中和未选中的Drawable图片:
private int mStarDistance = 0;
private int mStarCount = 5;
private int mStarSize = 20; //每一个星星的宽度和高度是一致的
private float mScoreNum = 0.0F; //当前的评分值
private Drawable mStarScoredDrawable; //已经评分的星星图片
private Drawable mStarUnscoredDrawable; //还未评分的星星图片
private void init(Context context, AttributeSet attrs) {
mScoreNum = 2.1f;
mStarSize = context.getResources().getDimensionPixelSize(R.dimen.d_20dp);
mStarDistance = context.getResources().getDimensionPixelSize(R.dimen.d_5dp);
mStarScoredDrawable = context.getResources().getDrawable(R.drawable.iv_normal_star_yellow);
mStarUnscoredDrawable = context.getResources().getDrawable(R.drawable.iv_normal_star_gray);
}
测量布局的时候,我们就不能根据xml设置的 match_parent 或 wrap_content 来设置宽高,我们需要根据星星的大小与间距来动态的计算,所以不管xml中如何设置,我们都强制性的使用我们自己的测量。
星星的数量 * 星星的宽度再加上中间的间距 * 数量-1,就是我们的控件宽度,控件高度则是星星的高度。
具体的确定测量我们再上一篇已经详细的复习过了,这里直接贴代码:
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
setMeasuredDimension(mStarSize * mStarCount + mStarDistance * (mStarCount - 1), mStarSize);
}这样就可以得到对应的测量宽高 (加一个背景方便看效果):
如何绘制星星?直接绘制Drawable即可,默认的Drawable的绘制为:
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
for (int i = 0; i < mStarCount; i++) {
mStarUnscoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarUnscoredDrawable.draw(canvas);
}
}如果有5个星星图片,那么就为每一个星星定好位置:
那么已经选中的图片也需要使用这种方法绘制吗?
计算当前的评分,然后计算计算需要绘制多少星星,那么就是这样做:
int score = (int) Math.ceil(mScoreNum);
for (int i = 0; i < score; i++) {
mStarScoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarScoredDrawable.draw(canvas);
}可是这么做不符合我们的要求啊 ,我们是需要是可以显示评分为2.5之类值,那么我们怎么能绘制半颗星呢?Drawable.draw(canvas) 的方式满足不了,那我们可以使用 BitmapShader 的方式来绘制。
初始化一个 BitmapShader 设置给 Paint 画笔,通过画笔就可以画出对应的形状。
比如此时的场景,我们如果想只画0.5个星星,那么我们就可以
paint = new Paint();
paint.setAntiAlias(true);
paint.setShader(new BitmapShader(drawableToBitmap(mStarScoredDrawable), BitmapShader.TileMode.CLAMP, BitmapShader.TileMode.CLAMP));
@Override
protected void onDraw(Canvas canvas) {
for (int i = 0; i < mStarCount; i++) {
mStarUnscoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarUnscoredDrawable.draw(canvas);
}
canvas.drawRect(0, 0, mStarSize * mScoreNum, mStarSize, paint);
}那么如果是大于一个星星之后的小数点就可以用公式计算
if (mScoreNum > 1) {
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
if (mScoreNum - (int) (mScoreNum) == 0) {
//如果评分是3.0之类的整数,那么直接按正常的rect绘制
for (int i = 1; i < mScoreNum; i++) {
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
}
} else {
//如果是小数例如3.5,先绘制之前的3个,再绘制后面的0.5
for (int i = 1; i < mScoreNum - 1; i++) {
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
}
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize * (Math.round((mScoreNum - (int) (mScoreNum)) * 10) * 1.0f / 10), mStarSize, paint);
}
} else {
canvas.drawRect(0, 0, mStarSize * mScoreNum, mStarSize, paint);
}效果:
关于 BitmapShader 的其他用法,可以翻看我之前的自定义圆角圆形View,和自定义圆角容器的文章,里面都有用到过,主要是方便一些图片的裁剪和缩放等。
2、事件的交互与计算
这里并没有涉及到什么事件嵌套,拦截之类的复杂处理,只需要处理自身的 onTouch 即可。而我们需要处理的就是按下的时候和移动的时候评分值的变化。
在onDraw方法中,我们使用 mScoreNum 变量来绘制的已评分的 Bitmap 绘制。所以这里我们只需要在 onTouch 中计算出对应的 mScoreNum 值,让其重绘即可。
@Override
public boolean onTouchEvent(MotionEvent event) {
//x轴的宽度做一下最大最小的限制
int x = (int) event.getX();
if (x < 0) {
x = 0;
}
if (x > mMeasuredWidth) {
x = mMeasuredWidth;
}
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
case MotionEvent.ACTION_MOVE: {
mScoreNum = x * 1.0f / (mMeasuredWidth * 1.0f / mStarCount);
invalidate();
break;
}
case MotionEvent.ACTION_UP: {
break;
}
}
return super.onTouchEvent(event);
}计算出一颗星的长度,然后计算当前x轴的长度,就可以计算出当前有几颗星,我们默认处理的是 float 类型。就可以根据计算出的 mScoreNum 值来得到对应的动画效果:
3. 回调处理与自定义属性抽取
到此效果的实现算是结束了,但是我们还有一些收尾工作没做,如何监听进度的回调,如何控制整数与浮点数的显示,是否支持触摸等等。然后对其做一些自定义属性的抽取,就可以在应用中比较广泛的使用了。
自定义属性:
private int mStarDistance = 5;
private int mStarCount = 5;
private int mStarSize = 20; //每一个星星的宽度和高度是一致的
private float mScoreNum = 0.0F; //当前的评分值
private Drawable mStarScoredDrawable; //已经评分的星星图片
private Drawable mStarUnscoredDrawable; //还未评分的星星图片
private boolean isOnlyIntegerScore = false; //默认显示小数类型
private boolean isCanTouch = true; //默认支持控件的点击
private OnStarChangeListener onStarChangeListener;自定义属性的赋值与初始化操作:
private void init(Context context, AttributeSet attrs) {
setClickable(true);
TypedArray mTypedArray = context.obtainStyledAttributes(attrs, R.styleable.StarScoreView);
this.mStarDistance = mTypedArray.getDimensionPixelSize(R.styleable.StarScoreView_starDistance, 0);
this.mStarSize = mTypedArray.getDimensionPixelSize(R.styleable.StarScoreView_starSize, 20);
this.mStarCount = mTypedArray.getInteger(R.styleable.StarScoreView_starCount, 5);
this.mStarUnscoredDrawable = mTypedArray.getDrawable(R.styleable.StarScoreView_starUnscoredDrawable);
this.mStarScoredDrawable = mTypedArray.getDrawable(R.styleable.StarScoreView_starScoredDrawable);
this.isOnlyIntegerScore = mTypedArray.getBoolean(R.styleable.StarScoreView_starIsTouchEnable, true);
this.isOnlyIntegerScore = mTypedArray.getBoolean(R.styleable.StarScoreView_starIsOnlyIntegerScore, false);
mTypedArray.recycle();
paint = new Paint();
paint.setAntiAlias(true);
paint.setShader(new BitmapShader(drawableToBitmap(mStarScoredDrawable), BitmapShader.TileMode.CLAMP, BitmapShader.TileMode.CLAMP));
}自定义属性的定义xml文件:
<!-- 评分星星控件 -->
<declare-styleable name="StarScoreView">
<!--星星间距-->
<attr name="starDistance" format="dimension" />
<!--星星大小-->
<attr name="starSize" format="dimension" />
<!--星星个数-->
<attr name="starCount" format="integer" />
<!--星星已评分图片-->
<attr name="starScoredDrawable" format="reference" />
<!--星星未评分图片-->
<attr name="starUnscoredDrawable" format="reference" />
<!--是否可以点击-->
<attr name="starIsTouchEnable" format="boolean" />
<!--是否显示整数-->
<attr name="starIsOnlyIntegerScore" format="boolean" />
</declare-styleable>在OnTouch的时候就可以判断是否能触摸
@Override
public boolean onTouchEvent(MotionEvent event) {
if (isCanTouch) {
//x轴的宽度做一下最大最小的限制
int x = (int) event.getX();
if (x < 0) {
x = 0;
}
if (x > mMeasuredWidth) {
x = mMeasuredWidth;
}
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
case MotionEvent.ACTION_MOVE: {
setStarMark(x * 1.0f / (getMeasuredWidth() * 1.0f / mStarCount));
break;
}
case MotionEvent.ACTION_UP: {
break;
}
}
return super.onTouchEvent(event);
} else {
//如果设置不能点击,直接不触发事件
return false;
}
}而 setStarMark 则是设置入口的方法,内部判断是否支持小数点和设置对于的监听,并调用重绘。
public void setStarMark(float mark) {
if (isOnlyIntegerScore) {
mScoreNum = (int) Math.ceil(mark);
} else {
mScoreNum = Math.round(mark * 10) * 1.0f / 10;
}
if (this.onStarChangeListener != null) {
this.onStarChangeListener.onStarChange(mScoreNum); //调用监听接口
}
invalidate();
}一个简单的图片绘制和事件触摸的控件就完成啦,使用起来也是超级方便。
<com.guadou.kt_demo.demo.demo18_customview.star.StarScoreView
android:id="@+id/star_view"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:layout_marginTop="@dimen/d_40dp"
android:background="#f1f1f1"
app:starCount="5"
app:starDistance="@dimen/d_5dp"
app:starIsOnlyIntegerScore="false"
app:starIsTouchEnable="true"
app:starScoredDrawable="@drawable/iv_normal_star_yellow"
app:starSize="@dimen/d_35dp"
app:starUnscoredDrawable="@drawable/iv_normal_star_gray" />Activity中可以设置评分和设置监听:
override fun init() {
val starView = findViewById<StarScoreView>(R.id.star_view)
starView.setOnStarChangeListener {
YYLogUtils.w("当前选中的Star:$it")
}
findViewById<View>(R.id.set_progress).click {
starView.setStarMark(3.5f)
}
}效果:
后记
整个流程走下来是不是很简单呢,此控件不止用于星星类型的评分,任何图片资源都可以使用,现在我们思路打开扩展一下,相似的场景和效果我们可以实现一些图片进度,触摸进度条,圆环的SeekBar,等等类似的控制都是相似的思路。
这一期的比较简单,我并没有上传到 Maven ,如果有需求可以去我的项目里面拿,如果有需求的话也可以自行修改,如果大家有兴趣可以查看源码点击【传送门】。你也可以关注我的这个Kotlin项目,我有时间都会持续更新。
关于事件交互的自定义View后面有时间会再出稍微复杂一点的,帮助大家巩固与复习。我心里的路线是先学绘制再学交互(因为交互的基础就是绘制),然后再学ViewGroup的嵌套、拦截、分发、排版等等,从易到难争取让大家复习个通透,当然如果有人看的话,我会继续更新。
惯例,我如有讲解不到位或错漏的地方,希望同学们可以指出交流。
如果感觉本文对你有一点点的启发,还望你能点赞支持一下,你的支持是我最大的动力。
Ok,这一期就此完结。
链接:https://juejin.cn/post/7167256092051767326
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ConstraintLayout解决的一种布局问题
期望实现的效果
这个效果看上去很简单,但是等到要实现的时候,发现用常规的布局在左侧文字较长的时候,右侧文字标签的控件会控件被左侧文字挤压导致标签控件显示不了(LinearLayout、RelativeLayout都存在一样的问题)
(修改:评论给出了一种用LinearLayout实现的一种方式更便捷,那么这篇文章就当做提供另外一种方案吧- -)
使用ConstraintLayout就能解决这个问题,先贴个代码:
<androidx.constraintlayout.widget.ConstraintLayout
android:layout_width="match_parent"
android:layout_height="wrap_content">
<TextView
android:layout_width="0dp"
android:layout_height="wrap_content"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintRight_toLeftOf="@+id/tv2"
android:ellipsize="end"
android:maxLines="1"
android:id="@+id/tv1"
android:textSize="20dp"
app:layout_constraintHorizontal_chainStyle="packed"
app:layout_constraintHorizontal_bias="0"
app:layout_constraintWidth_default="wrap"
android:text="王小明"
/>
<TextView
app:layout_constraintBottom_toBottomOf="@+id/tv1"
app:layout_constraintRight_toRightOf="parent"
android:background="@drawable/co_border_blue"
app:layout_constraintLeft_toRightOf="@+id/tv1"
app:layout_constraintTop_toTopOf="@id/tv1"
android:id="@+id/tv2"
android:text="父亲"
android:paddingLeft="5dp"
android:paddingRight="5dp"
android:visibility="visible"
android:textSize="15dp"
android:textColor="#59baf5"
android:layout_width="wrap_content"
android:layout_height="wrap_content" />
</androidx.constraintlayout.widget.ConstraintLayout>
核心思路
第一步先把两个文本的对齐方式约束起来
左侧文本需要在右侧文本右侧,右侧文本需要在左侧文本左侧,右侧文本还需要和父布局右对齐
关键代码
<TextView
android:layout_width="0dp"
android:layout_height="wrap_content"
app:layout_constraintRight_toLeftOf="@+id/tv2"
android:id="@+id/tv1"
...
/>
这里tv1设置layout_width="0dp",即match_constraint,如果自适应则按照目前的约束方式两个文本整体会居中
<TextView
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintLeft_toRightOf="@+id/tv1"
android:id="@+id/tv2"
android:text="父亲"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
...
/>
这个时候的效果:
虽然第二种场景下满足了,但是第一种场景下是不符合期望的,这个时候需要考虑再进一步约束:
1)左侧文字需要做到自适应
2)左侧文字自适应后需要对齐到最左侧
3)自适应后左右侧文字需要连接在一起
所以进一步引入了【链条样式】
关键代码:
<TextView
android:id="@+id/tv1"
app:layout_constraintHorizontal_chainStyle="packed"
app:layout_constraintHorizontal_bias="0"
app:layout_constraintWidth_default="wrap"
android:text="王小明"
/>
app:layout_constraintHorizontal_chainStyle="packed" 使链条上的元素都打包到一起
app:layout_constraintHorizontal_bias="0" 使左侧控件最左侧对齐
app:layout_constraintWidth_default="wrap" 使左侧文字自适应大小并且不超过约束限制,默认是“spread”,会占用所有符合约束的控件
这样就完成了目标的效果
链接:https://juejin.cn/post/7041808829113171998
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我代码就加了一行log日志,结果引发了P1的线上事故
线上事故回顾
前段时间新增一个特别简单的功能,晚上上线前review代码时想到公司拼搏进取的价值观临时加一行log日志,觉得就一行简单的日志基本上没啥问题,结果刚上完线后一堆报警,赶紧回滚了代码,找到问题删除了添加日志的代码,重新上线完毕。
情景还原
定义了一个
CountryDTO
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public Boolean isChinaName() {
return this.country.equals("中国");
}
}
定义测试类
FastJonTest
public class FastJonTest {
@Test
public void testSerialize() {
CountryDTO countryDTO = new CountryDTO();
String str = JSON.toJSONString(countryDTO);
System.out.println(str);
}
}运行时报空指针错误:
通过报错信息可以看出来是 序列化的过程中执行了 isChinaName()方法,这时候this.country变量为空, 那么问题来了:
- 序列化为什么会执行
isChinaName()呢? - 引申一下,序列化过程中会执行那些方法呢?
源码分析
通过debug观察调用链路的堆栈信息
调用链中的ASMSerializer_1_CountryDTO.write是FastJson使用asm技术动态生成了一个类ASMSerializer_1_CountryDTO,
asm技术其中一项使用场景就是通过到动态生成类用来代替
java反射,从而避免重复执行时的反射开销
JavaBeanSerizlier序列化原理
通过下图看出序列化的过程中,主要是调用JavaBeanSerializer类的write()方法。
而JavaBeanSerializer 主要是通过 getObjectWriter()方法获取,通过对getObjectWriter()执行过程的调试,找到比较关键的com.alibaba.fastjson.serializer.SerializeConfig#createJavaBeanSerializer方法,进而找到 com.alibaba.fastjson.util.TypeUtils#computeGetters
public static List<FieldInfo> computeGetters(Class<?> clazz, //
JSONType jsonType, //
Map<String,String> aliasMap, //
Map<String,Field> fieldCacheMap, //
boolean sorted, //
PropertyNamingStrategy propertyNamingStrategy //
){
//省略部分代码....
Method[] methods = clazz.getMethods();
for(Method method : methods){
//省略部分代码...
if(method.getReturnType().equals(Void.TYPE)){
continue;
}
if(method.getParameterTypes().length != 0){
continue;
}
//省略部分代码...
JSONField annotation = TypeUtils.getAnnotation(method, JSONField.class);
//省略部分代码...
if(annotation != null){
if(!annotation.serialize()){
continue;
}
if(annotation.name().length() != 0){
//省略部分代码...
}
}
if(methodName.startsWith("get")){
//省略部分代码...
}
if(methodName.startsWith("is")){
//省略部分代码...
}
}
}从代码中大致分为三种情况:
@JSONField(.serialize = false, name = "xxx")注解getXxx(): get开头的方法isXxx():is开头的方法
序列化流程图
示例代码
/**
* case1: @JSONField(serialize = false)
* case2: getXxx()返回值为void
* case3: isXxx()返回值不等于布尔类型
* case4: @JSONType(ignores = "xxx")
*/
@JSONType(ignores = "otherName")
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
/**
* case1: @JSONField(serialize = false)
*/
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
/**
* case2: getXxx()返回值为void
*/
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
/**
* case3: isXxx()返回值不等于布尔类型
*/
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}运行结果为:
isChinaName()执行!!
getEnglishName()执行!!
{"chinaName":true,"englishName":"lucy"}代码规范
可以看出来序列化的规则还是很多的,比如有时需要关注返回值,有时需要关注参数个数,有时需要关注@JSONType注解,有时需要关注@JSONField注解;当一个事物的判别方式有多种的时候,由于团队人员掌握知识点的程度不一样,这个方差很容易导致代码问题,所以尽量有一种推荐方案。
这里推荐使用@JSONField(serialize = false)来显式的标注方法不参与序列化,下面是使用推荐方案后的代码,是不是一眼就能看出来哪些方法不需要参与序列化了。
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
@JSONField(serialize = false)
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
@JSONField(serialize = false)
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}三个频率高的序列化的情况
以上流程基本遵循 发现问题 --> 原理分析 --> 解决问题 --> 升华(编程规范)。
- 围绕业务上:解决问题 -> 如何选择一种好的额解决方案 -> 好的解决方式如何扩展n个系统应用;
- 围绕技术上:解决单个问题,顺着单个问题掌握这条线上的原理。
链接:https://juejin.cn/post/7156439842958606349
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
安卓APP全局黑白化实现方案
在清明节时各大APP都会进行黑白化处理,当时在接到这个需求的时候感觉好麻烦,是不是又要搞一套皮肤?
然而在一系列搜索之后,找到了两位大神(鸿洋、U2tzJTNE)的实现方案,其实相当的简单!
让我们一起站在巨人的肩膀上来分析一下原理,并思考会不会有更简便的实现?
一、原理
两位大神的置灰方案是相同的,都能看到一段同样的代码:
Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
// 设置饱和度为0
mColorMatrix.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
他们都用了Android提供的ColorMatrix(颜色矩阵),将其饱和度设置为0,这样使用Paint绘制出来的都是没有饱和度的灰白样式!
然而两位在何时使用Paint绘制时选择了不同方案。
1.1 鸿洋:重写draw方法
鸿洋老师分析,如果我们把每个Activity的根布局饱和度设置为0是不是就可以了?
那根布局是谁?
鸿洋老师分析我们的布局最后setContentView最后都会设置到一个R.id.content的FrameLayout当中。
我们去自定义一个GrayFrameLayout,在draw的时候使用这个饱和度为0的画笔,被这个FrameLayout包裹的布局都会变成黑白。
// 转载自鸿洋
// https://blog.csdn.net/lmj623565791/article/details/105319752
public class GrayFrameLayout extends FrameLayout {
private Paint mPaint = new Paint();
public GrayFrameLayout(Context context, AttributeSet attrs) {
super(context, attrs);
ColorMatrix cm = new ColorMatrix();
cm.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(cm));
}
@Override
protected void dispatchDraw(Canvas canvas) {
canvas.saveLayer(null, mPaint, Canvas.ALL_SAVE_FLAG);
super.dispatchDraw(canvas);
canvas.restore();
}
@Override
public void draw(Canvas canvas) {
canvas.saveLayer(null, mPaint, Canvas.ALL_SAVE_FLAG);
super.draw(canvas);
canvas.restore();
}
}然后我们用GrayFrameLayout去替换这个R.id.content的FrameLayout,是不是就可以做到将页面黑白化了?
替换FrameLayout的方法可以去【鸿洋】这篇文章下查看。
1.2 U2tzJTNE:监听DecorView的添加
U2tzJTNE大佬使用了另一种巧妙的方案。
他先创建了一个具有数据变化感知能力的ObservableArrayList(当内容发生变化有回调)。
之后使用反射将WindowManagerGlobal内的mViews容器(ArrayList,该容器会存放所有的DecorView),替换为ObservableArrayList,这样就可以监听到每个DecorView的创建,并且拿到View本身。
拿到DecorView,那就可以为所欲为了!
大佬使用了setLayerType(View.LAYER_TYPE_HARDWARE, mPaint),对布局进行了重绘。至于为什么要用LAYER_TYPE_HARDWARE?因为默认的View.LAYER_TYPE_NONE会把Paint强制设置为null。
// 转载自U2tzJTNE
// https://juejin.cn/post/6892277675012915207
public static void enable(boolean enable) {
try {
//灰色调Paint
final Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
mColorMatrix.setSaturation(enable ? 0 : 1);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
//反射获取windowManagerGlobal
@SuppressLint("PrivateApi")
Class<?> windowManagerGlobal = Class.forName("android.view.WindowManagerGlobal");
@SuppressLint("DiscouragedPrivateApi")
java.lang.reflect.Method getInstanceMethod = windowManagerGlobal.getDeclaredMethod("getInstance");
getInstanceMethod.setAccessible(true);
Object windowManagerGlobalInstance = getInstanceMethod.invoke(windowManagerGlobal);
//反射获取mViews
Field mViewsField = windowManagerGlobal.getDeclaredField("mViews");
mViewsField.setAccessible(true);
Object mViewsObject = mViewsField.get(windowManagerGlobalInstance);
//创建具有数据感知能力的ObservableArrayList
ObservableArrayList<View> observerArrayList = new ObservableArrayList<>();
observerArrayList.addOnListChangedListener(new ObservableArrayList.OnListChangeListener() {
@Override
public void onChange(ArrayList list, int index, int count) {
}
@Override
public void onAdd(ArrayList list, int start, int count) {
// 拿到DecorView触发重绘
View view = (View) list.get(start);
if (view != null) {
view.setLayerType(View.LAYER_TYPE_HARDWARE, mPaint);
}
}
@Override
public void onRemove(ArrayList list, int start, int count) {
}
});
//将原有的数据添加到新创建的list
observerArrayList.addAll((ArrayList<View>) mViewsObject);
//替换掉原有的mViews
mViewsField.set(windowManagerGlobalInstance, observerArrayList);
} catch (Exception e) {
e.printStackTrace();
}
}只需要在Application里面调用该方法即可。
1.3 方案分析
两位大佬的方案都非常的棒,咱们理性的来对比一下。
鸿洋老师: 使用自定义FrameLayout的方案需要一个BaseActivity统一设置,稍显麻烦,代码侵入性较强。
U2tzJTNE大佬: 方案更加简单、动态,一行代码设置甚至可以做到在当前页从彩色变黑白,但是使用了反射,有一点点性能消耗。
二、简易方案(直接复制)
既然研究明白了大佬的方案,那有没有又不需要反射,设置又简单的方法呢?
能不能使用原生方式获取DecorView的实例呢?
突然灵光一闪,Application里面不是有registerActivityLifecycleCallbacks这个注册监听方法吗?监听里面的onActivityCreated不是可以获取到当前的Activity吗?那DecorView不就拿到了!
搞起!上代码!
public class StudyApp extends Application {
@Override
public void onCreate() {
super.onCreate();
Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
mColorMatrix.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
// 当Activity创建,我们拿到DecorView,使用Paint进行重绘
View decorView = activity.getWindow().getDecorView();
decorView.setLayerType(View.LAYER_TYPE_HARDWARE, mPaint);
}
....
});
}
}这样看起来是不是更简单了!使用了APP原生的方法实现了黑白化!当然也有缺点,因为在Activity级别设置,无法做到在当前页面即时变为黑白。
三、注意事项
这三种方案因为都使用了颜色矩阵,所以坑都是一样的,请注意。
3.1 启动图windowBackground无法变色
在我们可以设置渲染的时候windowBackground已经展示完毕了。
解决方案:只能在当前的包里修改,或者不去理会。
3.2 SurfaceView无法变色
因为我们使用了setLayerType进行重绘,而SurfaceView是有独立的Window,脱离布局内的Window,运行在其他线程,不影响主线程的绘制,所以当前方案无法使SurfaceView变色。
解决方案:
1、使用TextureView。
2、看下这个SurfaceView是否可以设置滤镜,正常都是一些三方或者自制的播放器。
3.3 多进程变色
我们可能会在APP内置小程序,小程序基本是运行在单独的进程中,但是如果我们的黑白配置在运行过程中发生变化,其他进程是无法感知的。
解决方案:使用MMKV存储黑白配置,并设置多进程共享,在开启小程序之前都判断一下黑白展示。
总结
最后咱们再总结一下黑白化方案。
使用了ColorMatrix设置饱和度为0,设置到Paint中,让根布局拿着这个Paint去进行重绘。
这样APP全局黑白化的介绍就结束了,希望大家读完这篇文章,会对APP黑白化有一个更深入的了解。如果我的文章能给大家带来一点点的福利,那在下就足够开心了。
下次再见!
链接:https://juejin.cn/post/7167300200921301028
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android启动优化之多线程依赖线程池
背景
开发中会存在多个任务之间互相依赖,运行非常慢的情况,譬如Android在主线程中初始化多个SDK导致App启动慢的情况,搜索一下发现业界的通用做法是构造任务的有向无环图,拓扑排序生成有序的任务列表,然后用线程池执行任务列表(通俗的说就是先找到没有依赖的任务执行,执行完了以后再找到剩下的没有依赖的任务执行,如此反复直到执行完所有任务),但是这个做法无法解决有的任务需要点击对话框授权的情况,基于这个情况打算再造一个轮子出来。
问题
造轮子之前先梳理了一下对这个轮子的要求,发现除了有向无环图外还是有很多细节要解决的。
-依赖任务多线程启动
-支持交互性任务,先拦截任务,交互完成以后再继续执行
-可视化有向无环图
-可视化任务执行情况
-支持多线程、主线程、主进程、第一个任务、最后一个任务等配置属性
方案
开源
TaskGraph: github.com/JonaNorman/…
线程池只能执行没有依赖关系的任务,TaskGraph开源库用有向无环图实现多线程依赖线程池,用拦截器实现交互式任务
图中添加了A任务,B任务依赖A任务执行完再执行,其中A任务需要点击对话框才能执行。
TaskGraph taskGraph = new TaskGraph();
taskGraph.addTask(new Task("A",new Runnable() {//添加A任务
@Override
public void run() {
}
}).addTaskInterceptor(new Task.TaskInterceptor() {
@Override
public void onIntercept(Task.TaskInterceptorChain interceptorChain) {//拦截A任务,在A任务之前可以插入对话框
AlertDialog.Builder builder = new AlertDialog.Builder(TaskGraphModule.getTopActivity());
builder.setPositiveButton("ok", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
interceptorChain.proceed();//继续
}
});
builder.setNegativeButton("cancel", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
interceptorChain.cancel();//取消
}
});
builder.show();
}
}));
taskGraph.addTask(new Task("B",new Runnable() {
@Override
public void run() {//添加B任务,B任务依赖A任务先完成
}
}).dependsOn("A").setMainThread(true));
taskGraph.execute();可视化有向图
搜索TASK_GRAPH_LOG: graphviz:会输出有向图日志,复制到 graphviz-visual-editor 可视化查看
可视化任务执行情况
python systrace.py -o trace.html -a packagename sched
复制代码packagename要替换成运行的app的包名 chrome浏览器打开chrome://tracing/,load 按钮加载trace.html
原理
依赖任务多线程启动
正常的线程池只能执行没有依赖关系的任务,怎么才能让线程池支持运行相互依赖的任务呢?
先找到所有没有进来箭头的节点执行,在该图中也就是A,执行完后删除这个节点和边,
变成了下图
继续以上步骤,找到B运行后删除B,变成下图这样
继续以上步骤,找到C D E同时运行,最终所有任务执行完毕。
把上面的步骤翻译成术语
- 有箭头的图叫有向图
- 节点有多少个进来的箭头叫入度
- 没有进来箭头的节点叫入度为0的节点
- 箭头没有形成环的图叫有向无环图
- 依次找到所有入度为0的节点叫拓扑排序
这里有个问题,多线程怎么执行拓扑排序的节点,有两种做法
- 拓扑排序的节点列表作为runnable提交到线程池,依赖的任务线程等待其他任务完成在执行
- 先把入度为0的所有节点提交到线程池,有一个执行完,就触发寻找剩下入度为0的节点继续执行
两种方案我选了方案2,个人感觉方案2找到的节点执行顺序是最优的,并且不需要线程等待,代码简单而且不需要空占有线程池的线程数量
主要思想:
Grpah图有多个node节点,每个Node节点有一个Vertex顶点,多个入边edge,多个出边edge,
拓扑排序就是找所有node节点入度为0的边移除然后继续找直到找完所有节点,核心代码地址
支持交互性任务
有些任务需要交互输入,完成以后再继续执行,为了实现该功能,可以用拦截器的方式来实现。
拦截器的原理就是调用到拦截器时候会用锁等待,如果执行了proceed方法会唤醒锁然后执行下个拦截器,如果执行了cancel会唤醒锁终止所有任务标记cancel状态,每个拦截器必须调用其中一个方法,要不然会一直等待
核心代码如下:代码地址
private void nextIntercept() {
synchronized (sync) {
currentInterceptor = taskInterceptorQueue.poll();//获取下一个拦截器
if (currentInterceptor == null) {
return;
}
currentInterceptor.onIntercept(this);//处罚拦截器
}
while (!graphController.isFinished()) {
synchronized (sync) {
if (cancel) {//调用cancel方法会把cancel赋值为true
throw new TaskCancelException();
} else if (currentInterceptor == proceedInterceptor) {//如果调用了proceed会proceedInterceptor赋值为currentInterceptor
nextIntercept();//执行下一个拦截器
break;
} else {
try {
sync.wait();//等待执行proceed或者cancel方法
} catch (InterruptedException e) {
}
}
}
}
}可视化有向无环图
多个依赖任务添加进去以后如果不能可视化成图就会对影响对任务的把控程度,graphviz是一个图的可视化项目,只要把图的情况写成文本输入就会生成对应图。
digraph pic {
A->B;
B->C;
}可视化任务执行情况
多个任务执行实时运行情况,有助于我们优化任务依赖,主要就是在每个任务执行开始调用Trace.beginSection(name),执行完调用Trace.endSection(),然后用命令
python systrace.py -o trace.html -a packagename sched
生成trace.html,然后用chrome浏览器打开chrome://tracing/点击load按钮加载trace.html就可以查看每个任务的执行情况
支持多线程、主线程、主进程、第一个任务、最后一个任务等配置属性
任务具有多个属性,多线程、主线程、主进程等属性,该实现只要加对应判断就行,第一个任务和最后一个任务则需要遍历所有任务,添加对应依赖关系。
收获
依赖任务多线程调度本身不是很难,在该开源项目中我收获了很多,包括如何实现有向无环图,如何在多线程中实现任务拦截继发,如何使用graphviz实现可视化图,如何用systemtrace可视化任务执行,希望看完文章的同学也可以从中学到什么,谢谢大家的浏览,如果觉得可以,欢迎大家多多star这个开源项目。
链接:https://juejin.cn/post/7168092996133453861
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Lucene源码系列:正排索引文件构建
背景
Lucene中根据term字典和倒排可以快速查找到相关文档的id,那怎么获取文档中的字段内容呢,这就是我们今天要讲的正排数据。
Lucene中对于某个文档的各个字段,可以通过配置来控制是否要存储进正排索引文件中,只有存储到正排索引文件中,查询的时候,有需要才能返回相应的字段。
如果理解了之前介绍过的词向量的索引文件构建,可以发现其实正排索引文件和词向量索引文件构建非常类似。
最终生成的正排索引文件有3个:
- fdt:按chunk存储doc的开启了store的字段
- fdx:chunk的索引文件,记录的是每个chunk的起始docID,以及每个chunk的起始位置,方便根据docID快速定位到chunk。
- fdm:正排索引文件的元信息,用来读取正排索引文件使用的。
前置知识
- 在对字段数据的存储时,对不同的数据类型,有不同的压缩算法,详见《单值编码压缩算法》。
- 构建chunk索引文件的时候会用到工具类FieldsIndexWriter,具体我们已经在《词向量索引文件构建》中详细介绍过了。
索引文件格式
fdm
fdm是正排索引文件的元信息,用来读取的时候使用。
字段详解
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldsIndexMeta
- codec版本
- segment id(也是Segment_N文件中的N)
- segment后缀名(一般为空)
ChunkSize
用来判断是否满足一个chunk的一种条件,如果chunk的大小超过了ChunkSize的限制,则可以构建一个chunk
NumDocs
doc总数
BlockShift
DirectMonotonicWriter需要的参数,DirectMonotonicWriter压缩存储会生成多个block,BlockShift决定了block的大小。
TotalChunks + 1
chunk总数 + 1,在生成fdx索引文件中ChunkStartDocIDs和ChunkOffsets两个字段时,使用DirectMonotonicWriter写入的值的总数。
fdxDocStartFP
fdx索引文件中ChunkStartDocIDs的起始位置
DocBlockMetas
fdx索引文件中ChunkStartDocIDs使用DirectMonotonicWriter编码存储,会生成多个block,这些block的元信息。
tvxOffsetStartFP
fdx中ChunkOffsets的起始位置
OffsetBlockMetas
fdx索引文件中ChunkOffsets使用DirectMonotonicWriter编码存储,会生成多个block,这些block的元信息。
SPEndPoint
fdx文件的结束位置,后面是fdx的footer信息。
MaxPointer
fdt文件的结束位置,后面fdt的footer信息。
NumChunks
chunk总数
NumDirtyChunks
dirtyChunk总数
NumDirtyDocs
dirtyChunk中的doc总数
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
fdt
fdt中按chunk存储各个doc所有的字段数据。
字段详解
Header
文件头部信息,主要是包括:
文件头魔数(同一lucene版本所有文件相同)
该文件使用的codec名称
根据压缩模式的不同有两种:
- Lucene90StoredFieldsFastData
- Lucene90StoredFieldsHighData
codec版本
segment id(也是Segment_N文件中的N)
segment后缀名(一般为空)
chunk
- DocBase:Chunk中Doc的起始编号,Chunk中所有doc的真实编号需要加上这个DocBase
- NumDocsCode:是NumDocs和IsDirty,IsSlice的int组合体
- NumDocs:chunk中的doc总数
- IsDirty:chunk是否是dirtyChunk
- IsSlice:chunk是否被分成多个slice
- DocNumFields:chunk中每个文档的字段个数。
- DocDataLengths:chunk中每个doc占用的存储空间大小。
- Doc:doc中每个store字段的信息
- Field:store的字段
- FieldNumAndTypeCode:FieldNumber和type的long组合体
- FieldNumber:字段的编号
- type:字段的类型
- FieldValue:根据不同的数值类型,有不同的存储方式
- 二进制/string:先存length,再存数据
- byte/short/int:zint存储
- long:tlong存储
- float:zfloat存储
- double:zdouble存储
- FieldNumAndTypeCode:FieldNumber和type的long组合体
- Field:store的字段
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
fdx
fdt中所有chunk的索引信息,可以快速根据docID定位到chunk的位置。
字段详解
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldsIndexIdx
- codec版本
- segment id(也是Segment_N文件中的N)
- segment后缀名(一般为空)
ChunkStartDocIDs
所有chunk的起始docID,使用DirectMonotonicWriter编码存储,会生成多个block。
ChunkOffsets
所有chunk在fdt索引文件中的起始位置,使用DirectMonotonicWriter编码存储,会生成多个block。
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
构建源码
本文源码解析基于lucene-core-9.1.0。
- StoredFieldsConsumer负责调度正排索引文件的构建主要有:启动一个doc的处理,处理doc中的field,结束一个doc的处理,结束正排索引的构建。
- Lucene90CompressingStoredFieldsWriter负责持久化生成正排索引文件
构建涉及到的StoredFieldsConsumer和Lucene90CompressingStoredFieldsWriter逻辑其实非常简单,下面我们一起来看下。
StoredFieldsConsumer
class StoredFieldsConsumer {
final Codec codec;
// 索引文件的目录
final Directory directory;
final SegmentInfo info;
// 实现类是 Lucene90CompressingStoredFieldsWriter,负责正排索引文件的持久化
StoredFieldsWriter writer;
Accountable accountable = Accountable.NULL_ACCOUNTABLE;
// 前一个处理的docID
private int lastDoc;
StoredFieldsConsumer(Codec codec, Directory directory, SegmentInfo info) {
this.codec = codec;
this.directory = directory;
this.info = info;
this.lastDoc = -1;
}
// 创建 Lucene90CompressingStoredFieldsWriter
protected void initStoredFieldsWriter() throws IOException {
if (writer == null) {
this.writer = codec.storedFieldsFormat().fieldsWriter(directory, info, IOContext.DEFAULT);
accountable = writer;
}
}
// 开始处理一个doc
void startDocument(int docID) throws IOException {
assert lastDoc < docID;
initStoredFieldsWriter();
while (++lastDoc < docID) { // 确保doc是连续的
writer.startDocument();
writer.finishDocument();
}
// Lucene90CompressingStoredFieldsWriter中开始处理doc
writer.startDocument();
}
// 每个需要构建的正排字段都会被处理
void writeField(FieldInfo info, IndexableField field) throws IOException {
writer.writeField(info, field);
}
// 结束doc的处理
void finishDocument() throws IOException {
writer.finishDocument();
}
// 结束正排的构建
void finish(int maxDoc) throws IOException {
while (lastDoc < maxDoc - 1) {
startDocument(lastDoc);
finishDocument();
++lastDoc;
}
}
// 持久化正排索引文件
void flush(SegmentWriteState state, Sorter.DocMap sortMap) throws IOException {
try {
writer.finish(state.segmentInfo.maxDoc());
} finally {
IOUtils.close(writer);
}
}
void abort() {
IOUtils.closeWhileHandlingException(writer);
}
}Lucene90CompressingStoredFieldsWriter
成员变量
// 数据文件
public static final String FIELDS_EXTENSION = "fdt";
// 索引文件
public static final String INDEX_EXTENSION = "fdx";
// 元信息文件
public static final String META_EXTENSION = "fdm";
/** Codec name for the index. */
public static final String INDEX_CODEC_NAME = "Lucene90FieldsIndex";
// 不同数据类型编码
static final int STRING = 0x00;
static final int BYTE_ARR = 0x01;
static final int NUMERIC_INT = 0x02;
static final int NUMERIC_FLOAT = 0x03;
static final int NUMERIC_LONG = 0x04;
static final int NUMERIC_DOUBLE = 0x05;
// 数据类型编码的bit数量
static final int TYPE_BITS = PackedInts.bitsRequired(NUMERIC_DOUBLE);
// 提取类型的掩码
static final int TYPE_MASK = (int) PackedInts.maxValue(TYPE_BITS);
static final int VERSION_START = 1;
static final int VERSION_CURRENT = VERSION_START;
static final int META_VERSION_START = 0;
private final String segment;
// 索引生成工具
private FieldsIndexWriter indexWriter;
private IndexOutput metaStream, fieldsStream;
private Compressor compressor;
private final CompressionMode compressionMode;
// chunk的大小
private final int chunkSize;
// 每个chunk最多可以存储多少个doc
private final int maxDocsPerChunk;
// 缓存所有的字段的值
private final ByteBuffersDataOutput bufferedDocs;
// 下标是当前chunk中的docID的偏移量,值是对应doc的字段个数
private int[] numStoredFields;
// 下标是当前chunk中的docID的偏移量,值是对应doc的所有需要store的数据在bufferedDocs中的结束位置
private int[] endOffsets;
// chunk中的起始docID
private int docBase;
// chunk中的doc个数
private int numBufferedDocs;
// chunk总数
private long numChunks;
// dirtyChunk总数,未满足生成chunk的条件时,强制生成的chunk是dirtyChunk
private long numDirtyChunks;
// dirtyDoc总数,dirtyChunk中的doc是dirtyDoc
private long numDirtyDocs;
// 在处理一个doc的时候,统计已经处理的field个数
private int numStoredFieldsInDoc;
核心方法
开始处理一个doc
当前实现中是空操作。
@Override
public void startDocument() throws IOException {}
处理一个field
处理一个field,就是读取field的值,根据值的类型按对应的值的存储方式存入bufferedDocs缓存中。
public void writeField(FieldInfo info, IndexableField field) throws IOException {
++numStoredFieldsInDoc;
int bits = 0;
final BytesRef bytes;
final String string;
Number number = field.numericValue();
if (number != null) { // 如果是数值类型
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
// byte,short,int都标记为int
bits = NUMERIC_INT;
} else if (number instanceof Long) {
// long
bits = NUMERIC_LONG;
} else if (number instanceof Float) {
// float
bits = NUMERIC_FLOAT;
} else if (number instanceof Double) {
// double
bits = NUMERIC_DOUBLE;
} else {
throw new IllegalArgumentException("cannot store numeric type " + number.getClass());
}
string = null;
bytes = null;
} else {
bytes = field.binaryValue();
if (bytes != null) { // 是二进制
bits = BYTE_ARR;
string = null;
} else { // 是字符串
bits = STRING;
string = field.stringValue();
if (string == null) {
throw new IllegalArgumentException(
"field "
+ field.name()
+ " is stored but does not have binaryValue, stringValue nor numericValue");
}
}
}
// 字段的编号和类型组合体
final long infoAndBits = (((long) info.number) << TYPE_BITS) | bits;
bufferedDocs.writeVLong(infoAndBits);
if (bytes != null) {
bufferedDocs.writeVInt(bytes.length);
bufferedDocs.writeBytes(bytes.bytes, bytes.offset, bytes.length);
} else if (string != null) {
bufferedDocs.writeString(string);
} else {
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
bufferedDocs.writeZInt(number.intValue());
} else if (number instanceof Long) {
writeTLong(bufferedDocs, number.longValue());
} else if (number instanceof Float) {
writeZFloat(bufferedDocs, number.floatValue());
} else if (number instanceof Double) {
writeZDouble(bufferedDocs, number.doubleValue());
} else {
throw new AssertionError("Cannot get here");
}
}
}结束处理一个doc
结束doc的处理,需要做4件事:
- 如果numBufferedDocs空间不足了,需要扩容
- 记录doc对应的field个数
- 记录doc数据在bufferedDocs中的结束位置
- 判断如果满足一个chunk的生成,则生成chunk
public void finishDocument() throws IOException {
if (numBufferedDocs == this.numStoredFields.length) {
final int newLength = ArrayUtil.oversize(numBufferedDocs + 1, 4);
this.numStoredFields = ArrayUtil.growExact(this.numStoredFields, newLength);
endOffsets = ArrayUtil.growExact(endOffsets, newLength);
}
// 记录doc对应的field个数
this.numStoredFields[numBufferedDocs] = numStoredFieldsInDoc;
numStoredFieldsInDoc = 0;
// 记录当前doc在bufferedDocs中的结束位置
endOffsets[numBufferedDocs] = Math.toIntExact(bufferedDocs.size());
++numBufferedDocs;
if (triggerFlush()) {
flush(false);
}
}生成一个chunk
生成一个chunk的条件:
- bufferDocs缓存超出了chunkSize
- chunk中收集的doc数量超出了maxDocsPerChunk
- 强制生成
// 生成一个chunk的条件
// 1.bufferDocs缓存超出了chunkSize
// 2.chunk中收集的doc数量超出了maxDocsPerChunk
private boolean triggerFlush() {
return bufferedDocs.size() >= chunkSize || numBufferedDocs >= maxDocsPerChunk;
}
private void flush(boolean force) throws IOException {
// chunk数+1
numChunks++;
if (force) { // 如果是强制构建chunk,可能是不满足chunk条件的,这种chunk被定义为dirtyChunk
numDirtyChunks++;
numDirtyDocs += numBufferedDocs;
}
// 生成chunk的索引
indexWriter.writeIndex(numBufferedDocs, fieldsStream.getFilePointer());
// 把各个doc在bufferedDocs中的endOffsets转成length
final int[] lengths = endOffsets;
for (int i = numBufferedDocs - 1; i > 0; --i) {
lengths[i] = endOffsets[i] - endOffsets[i - 1];
}
// 如果当前chunk的大小超出了2倍chunkSize,则需要分片
final boolean sliced = bufferedDocs.size() >= 2 * chunkSize;
final boolean dirtyChunk = force;
writeHeader(docBase, numBufferedDocs, numStoredFields, lengths, sliced, dirtyChunk);
// 下面是压缩处理
byte[] content = bufferedDocs.toArrayCopy();
bufferedDocs.reset();
if (sliced) {
// big chunk, slice it
for (int compressed = 0; compressed < content.length; compressed += chunkSize) {
compressor.compress(
content, compressed, Math.min(chunkSize, content.length - compressed), fieldsStream);
}
} else {
compressor.compress(content, 0, content.length, fieldsStream);
}
// 更新下一个chunk的起始docID
docBase += numBufferedDocs;
// 重置doc数统计
numBufferedDocs = 0;
bufferedDocs.reset();
}
private static void saveInts(int[] values, int length, DataOutput out) throws IOException {
if (length == 1) {
out.writeVInt(values[0]);
} else {
StoredFieldsInts.writeInts(values, 0, length, out);
}
}
private void writeHeader(
int docBase,
int numBufferedDocs,
int[] numStoredFields,
int[] lengths,
boolean sliced,
boolean dirtyChunk)
throws IOException {
final int slicedBit = sliced ? 1 : 0;
final int dirtyBit = dirtyChunk ? 2 : 0;
// save docBase and numBufferedDocs
fieldsStream.writeVInt(docBase);
fieldsStream.writeVInt((numBufferedDocs << 2) | dirtyBit | slicedBit);
// save numStoredFields
saveInts(numStoredFields, numBufferedDocs, fieldsStream);
// save lengths
saveInts(lengths, numBufferedDocs, fieldsStream);
}结束构建
结束构建的时候最重要的就是生成fdx索引文件。
public void finish(int numDocs) throws IOException {
if (numBufferedDocs > 0) { // 如果还有未处理的doc,强制生成一个chunk
flush(true);
} else {
assert bufferedDocs.size() == 0;
}
if (docBase != numDocs) {
throw new RuntimeException(
"Wrote " + docBase + " docs, finish called with numDocs=" + numDocs);
}
// 构建fdx文件
indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
// 记录一些元信息
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}
}链接:https://juejin.cn/post/7166898028941410312
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android中的硬件加速那么好用?为啥没被普及?
浅谈
前几天有个朋友问我:Android中硬件加速那么好用,为啥没被普及?,嗯?其实我也想知道。。。
手机开发中最重要的两个点:
- 1.用户点击的流畅性
- 2.界面效果的展示
早期的Android系统这两个事件都是在主线程上执行,导致用户点击的时候,界面绘制停滞或者界面绘制的时候,用户点击半天不响应,体验性很差。
于是在4.0以后,以 “run fast, smooth, and responsively” 为核心目标对 UI 进行了优化,应用开启了硬件加速对UI进行绘制。
1.硬件加速
在之前文章中我们分析过,Android 屏幕的绘制流程分为两部分:
1.生产者:app侧将View渲染到一个buffer中,供SurfaceFlinger消费2.消费者:SurfaceFlinger测将多个buffer合并后放入buffer中,供屏幕显示
其中 第二步一直都是在GPU中实现的,而我们所说的硬件加速就是第一步中的view渲染流程。
早期view的渲染是在主线程中进行的,而硬件加速则使用一个新的线程RenderThread以及硬件GPU进行渲染,
2.CPU / GPU结构对比
- CPU (Central Processing Unit): 中央处理器,计算机设备核心器件,适用于一些复杂的计算。
- GPU (Graphic Processing Unit): 图形处理器,通常所说“显卡”的核心部件就是GPU,主要用于处理图形运算。
CPU和GPU结构对比:
- 黄色代表控制器(Control):用于协调控制整个CPU的运行,包括取指令等操作。
- 绿色的ALU(Arithmetic Logic Unit):算数逻辑单元,主要用于进行数学,逻辑计算。
- 橙色的Cache和DRAM分别为缓存和RAM,用于存储信息。
1.结构上看:CPU的ALU较少,而了解过OpenGl的同学应该知道View的渲染过程中是有大量的浮点数计算的,而浮点数转换为整数计算,可能会消耗大量的ALU单元,这对于CPU是比较难接受的。
2.CPU是串行的,一个CPU同一时间只能做一件事情,(多线程其实也是将CPU时间片分割而已),而GPU内部使用的是几千个小的GPU内核,每个GPU内核处理单元都是并行的,
这就非常符合图形的渲染过程。
GPU是显卡的核心部分,在破解密码方面也非常出色,再知道为啥哪些挖矿的使用的是显卡而不是CPU了吧,一个道理。
硬件加速底层原理:
通过将计算机不擅长的图形计算指令使用特殊的api转换为GPU的专用指令,由GPU完成。这里可能是传统的OpenGL或其他开放语言。
3.OpenGL
Android端一般使用OpenGL ES来实现硬件加速。
这里简单介绍下OpenGL和OpenGL ES。
- OpenGL(Open Graphics Library):开放式图形库,是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API)。这个接口由近350个不同的函数调用组成,
用来绘制从简单的图形比特到复杂的三维景象。 - OpenGL ES(OpenGL for Embedded Systems):是 OpenGL 三维图形 API 的子集,针对手机、PDA和游戏主机等嵌入式设备而设计
如果一个设备支持GPU硬件加速渲染(有可能不支持,看GPU厂商是不是适配了OpenGL 等接口),
那么当Android应用程序调用Open GL接口来绘制UI时,Android应用程序的 UI 就是通过GPU进行渲染的。
4.Android图形系统整体架构
在介绍Android图像系统架构前,我们先来了解几个概念:如果把UI的绘制过程当成一幅画的制作过程:
那么:
1.画笔:
- Skia:CPU用来绘制2D图形
- Open GL /ES:GPU绘制2D和3D图形。
2.画纸:
Surface:所有的绘制和渲染都是在这张画纸上进行,每个窗口都是一个DecorView的容器,同时每个窗口都关联一个Surface
3.画板:
Graphic Buffer :Graphic Buffer是谷歌在4.1以后针对双缓冲的jank问题提出的第三个缓冲,CPU/GPU渲染的内容都将写到这个buffer上。
4.合成
SurfaceFlinger:将所有的Surface合并叠加后显示到一个buffer里面。
简单理解过程:我们使用画笔(Skia、Open GL ES)将内容画到画纸(Surface)中,这个过程可能使用OpenGl ES也可能使用Skia,
使用OpenGl ES表示使用了硬件加速绘制,使用Skia,表示使用的是纯软件绘制。
下面是Android 图形系统的整体架构:
Image Stream Producers:图像数据流生产者,图像或视频数据最终绘制到Surface中。
WindowManager :前面一篇文章《WindowManager体系(上)》笔者说过,每个Surface都有一个Window和他一一对应,而WindowManager则用来管理窗口的各个方面:
动画,位置,旋转,层序,生命周期等。
SurfaceFlinger:用来对渲染后的Surface进行合并,并传递给硬件抽象层处理。
HWC : Hardware Composer,SurfaceFlinger 会委派一些合成的工作给 Hardware Composer 以此减轻 GPU 的负载。这样会比单纯通过 GPU 来合成消耗更少的电量。
Gralloc(Graphics memory allocator):前面讲解的Graphic Buffer分配的内存。
5.软硬件绘制过程源码解析
前面讲解了那么多理论知识,下面从源码角度来分析下硬件加速和软件绘制过程。
“read the fking source”
在前面文章《》中分析过。View最终是在ViewRootImpl的performDraw方法最新渲染的,
而performDraw内部调用的是draw方法。
定位到draw方法:
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {//1
...
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);//2
}else {
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {//3
return;
}
}
}
}注释1:如果mThreadedRenderer不为null且isEnabled为true,则调用注释2处的mThreadedRenderer.draw,这个就是硬件绘制的入口
如果其他情况,则调用注释3处的drawSoftware,这里就是软件绘制的入口,再正式对软硬件绘制进行深入之前我们看下mAttachInfo.mThreadedRenderer是在哪里赋值的?
源码全局搜索下:我们发现ViewRootImpl的enableHardwareAcceleration方法中有创建mThreadedRenderer的操作。
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
// Try to enable hardware acceleration if requested
...
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
//这里如果attrs.flags设置了WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,则表示该Window支持硬件加速绘制
if (hardwareAccelerated) {
// Persistent processes (including the system) should not do
// accelerated rendering on low-end devices. In that case,
// sRendererDisabled will be set. In addition, the system process
// itself should never do accelerated rendering. In that case, both
// sRendererDisabled and sSystemRendererDisabled are set. When
// sSystemRendererDisabled is set, PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED
// can be used by code on the system process to escape that and enable
// HW accelerated drawing. (This is basically for the lock screen.)
//Persistent的应用进程以及系统进程不能使用硬件加速
final boolean fakeHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FAKE_HARDWARE_ACCELERATED) != 0;
final boolean forceHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED) != 0;
if (fakeHwAccelerated) {
mAttachInfo.mHardwareAccelerationRequested = true;
} else if (!ThreadedRenderer.sRendererDisabled
|| (ThreadedRenderer.sSystemRendererDisabled && forceHwAccelerated)) {
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mThreadedRenderer.destroy();
}
...
//这里创建了mAttachInfo.mThreadedRenderer
mAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent,
attrs.getTitle().toString());
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
}
}
}这里源码告诉我们:
- 1.硬件加速是通过attrs.flags 设置WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED标识来启动的、
- 2、因为硬件加速是一个耗内存的操作,只是硬件加速渲染环境初始化这一操作,就要花掉8M的内存,
所以一般永久性的进程或者系统进程不要使用硬件加速标志,防止出现内存泄露。
再看哪里调用enableHardwareAcceleration方法?
通过源码查找我们注意到ViewRootImpl的setView方法中:
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
//注释1
if (view instanceof RootViewSurfaceTaker) {
mSurfaceHolderCallback =
((RootViewSurfaceTaker)view).willYouTakeTheSurface();
if (mSurfaceHolderCallback != null) {
mSurfaceHolder = new TakenSurfaceHolder();
mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);
mSurfaceHolder.addCallback(mSurfaceHolderCallback);
}
}
...
// If the application owns the surface, don't enable hardware acceleration
if (mSurfaceHolder == null) {//注释2
enableHardwareAcceleration(attrs);
}
}注释1处:表示当前view实现了RootViewSurfaceTaker接口,且view的willYouTakeTheSurface返回的mSurfaceHolderCallback不为null,
则表示应用想自己接管所有的渲染操作,这样创建出来的Activity窗口就类似于一个SurfaceView一样,完全由应用程序自己来控制它的渲染
基本上我们是不会将一个Activity窗口当作一个SurfaceView来使用的,
因此在ViewRootImpl类的成员变量mSurfaceHolder将保持为null值,
这样就会导致ViewRootImpl类的成员函数enableHardwareAcceleration被调用为判断是否需要为当前创建的Activity窗口启用硬件加速渲染。
好了我们回到ViewRootImpl的draw方法:
1.先来看软件绘制
软件绘制调用的是drawSoftware方法。
进入
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
...
canvas = mSurface.lockCanvas(dirty);//1
mView.draw(canvas);//2
surface.unlockCanvasAndPost(canvas);//3
}软件绘制基本就分三步走:
- 步骤1:lockCanvas:每个Window都关联了一个Surface,当有需要绘制UI时,就调用lockCanvas获取一个Canvas对象,这个Canvas封装了Skia提供的2D图形绘制api、
并且向SurfaceFlinger Dequeue了一块Graphic buffer,绘制的内容都会输出到这个buffer中,供SurfaceFlinger合成使用。
步骤2:draw:调用了View的draw方法,这个就会调用到我们自定义组件中View的onDraw方法,传入1中创建的Canvas对象,使用Skia api对图像进行绘制。
步骤3:unlockCanvasAndPost:绘制完成后,通知SurfaceFlinger绘制完成,可以进行buffer的交换,显示到屏幕上了,本质是给SurfaceFlinger queue 一个Graphic buffer、
关于什么是Queue和Dequeue看下图:
软件绘制条形简图:
2.硬件加速分析:
硬件加速分为两个步骤:
- 1.构建阶段
- 2.绘制阶段
构建阶段:
这个阶段用于遍历所有的视图,将需要绘制的Canvas API调用及其参数记录下来,保存在一个Display List,这个阶段发生在CPU主线程上。
Display List本质上是一个缓存区,它里面记录了即将要执行的绘制命令序列,这些命令最终会在绘制阶段被OpenGL转换为GPU渲染指令。
视图构建阶段会将每个View抽象为一个RenderNode,每个View的绘制操作抽象为一系列的DrawOp,
比如:
View的drawLine操作会被抽象为一个DrawLineOp,drawBitmap操作会被抽象成DrawBitmapOp,每个子View的绘制被抽象成DrawRenderNodeOp,每个DrawOp都有对应的OpenGL绘制指令,同时内部也握有需要绘制的数据元。
使用Display List的好处:
- 1、在绘制窗口的下一帧时,如果某个视图UI没有发生变化,则不需要执行与他相关的Canvas API操作,即不用重复执行View的onDraw操作,
而是直接使用上一帧的Display List即可 - 2.如果绘制窗口下一帧时,视图发生了变化,但是只是一些简单属性变化,如位置和透明度等,则只需要修改上次构建的Display List的相关属性即可,也不必重复构建
Display List模型图:
接下来我们从源码角度来看下:
前面我们分析了硬件加速入口是在ThreadedRenderer的draw方法:
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this)进入这个方法看看:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2通知RenderThread线程绘制
}ThreadedRenderer主要作用就是在主线程CPU中视图的构建,然后通知RenderThread使用OpenGL进行视图的渲染(注释2处)。
注释1处:updateRootDisplayList看名称应该就是用于视图构建,进去看看
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
//1.构建参数view(DecorView)视图的Display List
updateViewTreeDisplayList(view);
//2
//mRootNodeNeedsUpdate true表示需要更新视图
//mRootNode.isValid() 表示已经构建了Display List
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
//获取DisplayListCanvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);//3
try {
//ReorderBarrie表示会按照Z轴坐标值重新排列子View的渲染顺序
canvas.insertReorderBarrier();
//构建并缓存所有的DrawOp
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
canvas.restoreToCount(saveCount);
} finally {
//将所有的DrawOp填充到根RootNode中,作为新的Display List
mRootNode.end(canvas);
}
}
}注释1:updateViewTreeDisplayList对View树Display List进行构建
private void updateViewTreeDisplayList(View view) {
view.mPrivateFlags |= View.PFLAG_DRAWN;
view.mRecreateDisplayList = (view.mPrivateFlags & View.PFLAG_INVALIDATED)
== View.PFLAG_INVALIDATED;
view.mPrivateFlags &= ~View.PFLAG_INVALIDATED;
view.updateDisplayListIfDirty();
view.mRecreateDisplayList = false;
}看View的updateDisplayListIfDirty方法。
/**
* Gets the RenderNode for the view, and updates its DisplayList (if needed and supported)
* @hide
*/
@NonNull
public RenderNode updateDisplayListIfDirty() {
//获取当前mRenderNode
final RenderNode renderNode = mRenderNode;
//2.判断是否需要进行重新构建
if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0
|| !renderNode.isValid()
|| (mRecreateDisplayList)) {
if (renderNode.isValid()
&& !mRecreateDisplayList) {
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
//这里用于当前View是ViewGroup,且自身不需要重构,对其子View的DisplayList进行构建
dispatchGetDisplayList();
return renderNode; // no work needed
}
...
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
//软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
...
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
//View是ViewGroup,需要绘制子View
dispatchDraw(canvas);
...
} else {
draw(canvas);
}
}
} finally {
//将绘制好后的数据填充到renderNode中去
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
}updateDisplayListIfDirty主要作用:
- 1.获取当前View的RenderNode。
- 2.如果需要或者支持则更新当前DisplayList
判断是否需要进行重新构建的条件如下:
- 1.mPrivateFlags 设置了 PFLAG_DRAWING_CACHE_VALID,表明当前缓存已经失效,需要重新构建
- 2.!renderNode.isValid():表明当前Display List的数据不合法,需要重新构建
- 3.mRecreateDisplayList的值等于true,一些其他原因需要重新构建
mRenderNode在View的构造方法中初始化:
public View(Context context) {
...
mRenderNode = RenderNode.create(getClass().getName(), this);
}构建过程如下:
- 1.使用renderNode.start获得一个与当前View关联的DisplayListCanvas。
- 2.使用draw(canvas),将当前View以及子View绘制到当前DisplayListCanvas
- 3.使用renderNode.end(canvas),将已经绘制在 DisplayListCanvas 的 Display List Data 填充到当前 View 关联的 Render Node 中
通过上面几个步骤就将View树对应的DisplayList构建好了。而且这个构建过程会递归构建子View的Display List
我们从绘制流程火焰图中也可以看到大概流程:
红色框中部分:是绘制的DecorView的时候,一直递归updateDisplayListIfDirty方法进行Display List的构建
其他颜色框部分是子View Display List的构建
绘制阶段
这个阶段会调用OpenGL接口将构建好视图进行绘制渲染,将渲染好的内容保存到Graphic buffer中,并提交给SurfaceFlinger。
回到ThreadedRenderer的draw方法:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2
}在注释1中创建好视图对应的Display List后,在注释2处调用nSyncAndDrawFrame方法通知RenderThread线程进行绘制
nSyncAndDrawFrame是一个native方法,在讲解nSyncAndDrawFrame方法前我们先来看ThreadedRenderer构造函数中做了哪些事。
ThreadedRenderer(Context context, boolean translucent, String name) {
//这个方法在native层创建RootRenderNode对象并返回对象的地址
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
//这个方法在native层创建一个RenderProxy
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
}nCreateRootRenderNode和nCreateProxy方法在android_view_ThreadedRenderer.cpp中实现:
static jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) {
RootRenderNode* node = new RootRenderNode(env);
node->incStrong(0);
node->setName("RootRenderNode");
return reinterpret_cast(node);
}
static jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz,
jboolean translucent, jlong rootRenderNodePtr) {
RootRenderNode* rootRenderNode = reinterpret_cast(rootRenderNodePtr);
ContextFactoryImpl factory(rootRenderNode);
return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);
}
RenderProxy构造方法:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())//1
, mContext(nullptr) {
...
} 注意到mRenderThread使用的是RenderThread::getInstance()单例线程,也就说整个绘制过程只有一个RenderThread线程。
接着看RenderThread::getInstance()创建线程的方法:
RenderThread::RenderThread() : Thread(true)
...
Properties::load();
mFrameCallbackTask = new DispatchFrameCallbacks(this);
mLooper = new Looper(false);
run("RenderThread");
}居然也是使用的Looper,是不是和我们的主线程的消息机制一样呢?哈哈
调用run方法会执行RenderThread的threadLoop方法。
bool RenderThread::threadLoop() {
...
int timeoutMillis = -1;
for (;;) {
int result = mLooper->pollOnce(timeoutMillis);
...
nsecs_t nextWakeup;
{
...
while (RenderTask* task = nextTask(&nextWakeup)) {
workQueue.push_back(task);
}
for (auto task : workQueue) {
task->run();
// task may have deleted itself, do not reference it again
}
}
if (nextWakeup == LLONG_MAX) {
timeoutMillis = -1;
} else {
nsecs_t timeoutNanos = nextWakeup - systemTime(SYSTEM_TIME_MONOTONIC);
timeoutMillis = nanoseconds_to_milliseconds(timeoutNanos);
if (timeoutMillis < 0) {
timeoutMillis = 0;
}
}
if (mPendingRegistrationFrameCallbacks.size() && !mFrameCallbackTaskPending) {
...
requestVsync();
}
if (!mFrameCallbackTaskPending && !mVsyncRequested && mFrameCallbacks.size()) {
...
requestVsync();
}
}
return false;
}石锤了就是应用程序主线程的消息机制模型,
- 空闲的时候,Render Thread就睡眠在成员变量mLooper指向的一个Looper对象的成员函数pollOnce中。
- 当其它线程需要调度Render Thread,就会向它的任务队列增加一个任务,然后唤醒Render Thread进行处理。Render Thread通过成员函数nextTask获得需要处理的任务,并且调用它的成员函数run进行处理。
这里做个小结:
ThreadedRenderer构造方法中
- 1.初始化mRootNode指向native层的一个RootRenderNode
- 2.初始化mNativeProxy指向native层的RenderProxy
- 3.在native层创建RenderProxy时,同时也会创建RenderThread线程,这个线程机制和我们主线程消息机制一直,轮询等待获取绘制任务。
好了回头看nSyncAndDrawFrame的native方法
nSyncAndDrawFrame同样也在android_view_ThreadedRenderer.cpp中实现:
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) {
LOG_ALWAYS_FATAL_IF(frameInfoSize != UI_THREAD_FRAME_INFO_SIZE,
"Mismatched size expectations, given %d expected %d",
frameInfoSize, UI_THREAD_FRAME_INFO_SIZE);
RenderProxy* proxy = reinterpret_cast(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
return proxy->syncAndDrawFrame();
} 这个方法返回值是proxy->syncAndDrawFrame(),进入RenderProxy的syncAndDrawFrame方法:
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}这里的 mDrawFrameTask.drawFrame其实就是向RenderThread的TaskQueue添加一个drawFrame渲染任务,通知RenderThread渲染UI视图。
如下图:
mDrawFrameTask是DrawFrameTask中的函数
int DrawFrameTask::drawFrame() {
...
postAndWait();
return mSyncResult;
}
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue(this);
mSignal.wait(mLock);//锁住等待锁释放
}
void RenderThread::queue(RenderTask* task) {
AutoMutex _lock(mLock);
mQueue.queue(task);
if (mNextWakeup && task->mRunAt < mNextWakeup) {
mNextWakeup = 0;
mLooper->wake();
}
}看到这就知道了drawFrame其实就是往RenderThread线程的任务队列mQueue中按时间顺序加入一个绘制task,并调用mLooper->wake()唤醒RenderThread线程处理。
说到底还是主线程消息机制那套东西。
注意DrawFrameTask在postAndWait的mRenderThread->queue(this)中是将this传入任务队列,所以此任务就是this自己。后面执行绘制任务就使用到了OpenGL对构建好的DisplayList进行渲染。
经过上面的分析,整个硬件绘制流程就有个清晰模型了
点到为止,后面代码大家可以自行找到源码阅读。
绘制阶段这块可能比较复杂些,因为基本上都是native层的东西,有的消化下。
硬件加速和纯软件绘制对比
| 渲染场景 | 纯软件绘制 | 硬件加速 | 加速效果分析 |
|---|---|---|---|
| 页面初始化 | 绘制所有View | 创建所有DisplayList | GPU分担了复杂计算任务 |
| 在一个复杂页面调用背景透明TextView的setText(),且调用后其尺寸位置不变 | 重绘脏区所有View | TextView及每一级父View重建DisplayList | 重叠的兄弟节点不需CPU重绘,GPU会自行处理 |
| TextView逐帧播放Alpha / Translation / Scale动画 | 每帧都要重绘脏区所有View | 除第一帧同场景2,之后每帧只更新TextView对应RenderNode的属性 | 刷新一帧性能极大提高,动画流畅度提高 |
| 修改TextView透明度 | 重绘脏区所有View | 直接调用RenderNode.setAlpha()更新 | 只触发DecorView.updateDisplayListIfDirty,不再往下遍历,CPU执行时间可忽略不计 |
呈现模式分析工具
Android 4.1(API 级别 16)或更高版本的设备上,
执行以下步骤开启工具:
- 1.启动开发者选项;
- 2.在“监控”部分,找到“GPU呈现模式分析”(不同厂商命名有所区别);
- 3.点击“GPU呈现模式分析”,弹出页面中,选择“在屏幕上显示为条形图”即可。
这时,GPU 呈现模式工具已经开启了,接下来,我们可以打开我们要测试的APP来进行观察测试了。
视觉呈现
GPU 渲染模式分析工具以图表(以颜色编码的直方图)的形式显示各个阶段及其相对时间。
Android 10 上显示的彩色部分:
注意点:
- 1.一个应用对应一个图形
- 2.沿水平轴的每个竖条代表一个帧,每个竖条的高度表示渲染该帧所花的时间(以毫秒为单位)。
- 3.中间绿色的线是16.6ms的分割线,高于绿色线表示出现了掉帧
- 4.通过加宽竖条降低透明度来反应比较耗时的帧
- 5.每个竖条都有与渲染管道中某个阶段对应的彩色区段。区段数因设备的 API 级别不同而异。
颜色块含义
Android 6.0 及更高版本的设备时分析器输出中某个竖条的每个区段含义:
4.0(API 级别 14)和 5.0(API 级别 21)之间的 Android 版本具有蓝色、紫色、红色和橙色区段。低于 4.0 的 Android 版本只有蓝色、红色和橙色区段。下表显示的是 Android 4.0 和 5.0 中的竖条区段。
GPU 呈现模式工具,很直观的为我们展示了 APP 运行时每一帧的耗时详情。我们只需要关注代表每一帧的柱状图的颜色详情,就可以分析出卡顿的原因了。
好了,现在来回答标题帧的内容,既然硬件优化这么好用,为啥没被普及?
理由如下:
- 1.稳定性,开启硬件加速后,有小概率出现画面崩溃,所以在一些视频播放器会给个开关让用户手动开关。
- 2.功耗:GPU的功耗远远大于CPU,所以使用场景比较少,一般在游戏端开启硬件加速辅助游戏运行。
- 3.内存消耗:使用OpenGL接口初始化就需要8M作用的内存。
- 4.兼容性:不兼容某些接口和api。
这就是所谓的双刃剑吧!用得好还好,用不好就鸽蛋了。。
链接:https://juejin.cn/post/7166935241108488222
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
实现一个简易Retrofit
前言
作为Android开发,大名鼎鼎的Retrofit网络请求库肯定都用过,而且在Kotlin更新协程后,Retrofit也第一时间更新了协程方式、Flow方式等编码模式,这篇文章我们利用前面的学习知识,尝试着实现一个建议版本的Retrofit,然后看看如何利用挂起函数,来以同步的方式实现异步的代码。
正文
Retrofit涉及的知识点还是蛮多的,包括自定义注解、动态代理、反射等知识点,我们就来复习一下,最后再看如何使用协程来把我们不喜欢的Callback给消灭掉。
定义注解
和Retrofit一样,我们定义俩个注解:
/**
* [Field]注解用在API接口定义的方法的参数上
* */
@Target(AnnotationTarget.VALUE_PARAMETER)
@Retention(AnnotationRetention.RUNTIME)
annotation class Field(val value: String)/**
* [GET]注解用于标记该方法的调用是HTTP的GET方式
* */
@Target(AnnotationTarget.FUNCTION)
@Retention(AnnotationRetention.RUNTIME)
annotation class GET(val value: String)这里我们定义俩个注解,Field用来给方法参数设置,GET用来给方法设置,表明它是一个HTTP的GET方法。
定义ApiService
和Retrofit一样,来定义一个接口文档,里面定义我们需要使用的接口:
/**
* [ApiService]类定义了整个项目需要调用的接口
* */
interface ApiService{
/**
* [reposAsync]用于异步获取仓库信息
*
* @param language 要查询的语言,http真实调用的是[Field]中的lang
* @param since 要查询的周期
*
* @return
* */
@GET("/repo")
fun reposAsync(
@Field("lang") language: String,
@Field("since") since: String
): KtCall<RepoList>
/**
* [reposSync]用于同步调用
* @see [reposSync]
* */
@GET("/repo")
fun reposSync(
@Field("lang") language: String,
@Field("since") since: String
): RepoList
}这里我们查询GitHub上某种语言近期的热门项目,其中reposAsync表示异步调用,返回值类型是KtCall<RepoList>,而reposSync表示同步调用,这里涉及的RepoList就是返回值的数据类型:
data class RepoList(
var count: Int?,
var items: List<Repo>?,
var msg: String?
)
data class Repo(
var added_stars: String?,
var avatars: List<String>?,
var desc: String?,
var forks: String?,
var lang: String?,
var repo: String?,
var repo_link: String?,
var stars: String?
)而KtCall则是用来承载异步调用的回调简单处理:
/**
* 该类用于异步请求承载,主要是用来把[OkHttp]中返回的请求值给转换
* 一下
*
* @param call [OkHttp]框架中的[Call],用来进行网络请求
* @param gson [Gson]的实例,用来反序列化
* @param type [Type]类型实例,用来反序列化
* */
class KtCall<T: Any>(
private val call: Call,
private val gson: Gson,
private val type: Type
){
fun call(callback: CallBack<T>): Call{
call.enqueue(object : okhttp3.Callback{
override fun onFailure(call: Call, e: IOException) {
callback.onFail(e)
}
override fun onResponse(call: Call, response: Response) {
try {
val data = gson.fromJson<T>(response.body?.string(),type)
callback.onSuccess(data)
}catch (e: java.lang.Exception){
callback.onFail(e)
}
}
})
return call
}
}在这里定义了一个泛型类,用来处理T类型的数据,异步调用还是调用OkHttp的Call的enqueue方法,在其中对OkHttp的Callback进行封装和处理,转变为我们定义的Callback类型:
/**
* 业务使用的接口,表示返回的数据
* */
interface CallBack<T: Any>{
fun onSuccess(data: T)
fun onFail(throwable:Throwable)
}这里我们暂时只简单抽象为成功和失败。
单例Http工具类
再接着,我们模仿Retrofit,来使用动态代理等技术来进行处理:
/**
* 单例类
*
* */
object KtHttp{
private val okHttpClient = OkHttpClient
.Builder()
.addInterceptor(HttpLoggingInterceptor().apply {
level = HttpLoggingInterceptor.Level.BASIC
})
.build()
private val gson = Gson()
val baseUrl = "https://trendings.herokuapp.com"
/**
* 利用Java的动态代理,传递[T]类型[Class]对象,可以返回[T]的
* 对象。
* 其中在lambda中,一共有3个参数,当调用[T]对象的方法时,会动态
* 代理到该lambda中执行。[method]就是对象中的方法,[args]是该
* 方法的参数。
* */
fun <T: Any> create(service: Class<T>): T {
return Proxy.newProxyInstance(
service.classLoader,
arrayOf(service)
){ _,method,args ->
val annotations = method.annotations
for (annotation in annotations){
if (annotation is GET){
val url = baseUrl + annotation.value
return@newProxyInstance invoke<T>(url, method, args!!)
}
}
return@newProxyInstance null
} as T
}
/**
* 调用[OkHttp]功能进行网络请求,这里根据方法的返回值类型选择不同的策略。
* @param path 这个是HTTP请求的url
* @param method 定义在[ApiService]中的方法,在里面实现中,假如方法的返回值类型是[KtCall]带
* 泛型参数的类型,则认为需要进行异步调用,进行封装,让调用者传入[CallBack]。假如返回类型是普通的
* 类型,则直接进行同步调用。
* @param args 方法的参数。
* */
private fun <T: Any> invoke(path: String, method: Method, args: Array<Any>): Any?{
if (method.parameterAnnotations.size != args.size) return null
var url = path
val paramAnnotations = method.parameterAnnotations
for (i in paramAnnotations.indices){
for (paramAnnotation in paramAnnotations[i]){
if (paramAnnotation is Field){
val key = paramAnnotation.value
val value = args[i].toString()
if (!url.contains("?")){
url += "?$key=$value"
}else{
url += "&$key=$value"
}
}
}
}
val request = Request.Builder()
.url(url)
.build()
val call = okHttpClient.newCall(request)
//泛型判断
return if (isKtCallReturn(method)){
val genericReturnType = getTypeArgument(method)
KtCall<T>(call, gson, genericReturnType)
} else {
val response = okHttpClient.newCall(request).execute()
val genericReturnType = method.genericReturnType
val json = response.body?.string()
Log.i("zyh", "invoke: json = $json")
//这里这个调用,必须要传入泛型参数
gson.fromJson<Any?>(json, genericReturnType)
}
}
/**
* 判断方法返回类型是否是[KtCall]类型。这里调用了[Gson]中的方法。
*/
private fun isKtCallReturn(method: Method) =
getRawType(method.genericReturnType) == KtCall::class.java
/**
* 获取[Method]的返回值类型中的泛型参数
* */
private fun getTypeArgument(method: Method) =
(method.genericReturnType as ParameterizedType).actualTypeArguments[0]
}上面的代码主要分为俩个部分,第一部分使用Java的动态代理类Porxy,可以通过create方法创建一个接口对象。调用该接口对象的方法,会被代理到lambda中进行处理,在lambda中我们对有GET修饰的方法进行额外处理。
第二部分就是方法的拼接和调用处理,先是针对Field注解修饰的方法参数,给拼接到url中,然后就是重点地方,判断方法的返回值类型,是否是KtCall类型,如果是的话,就认为是异步调用,否则就是同步调用。
对于异步调用,我们封装为一个KtCall的对象,而对于同步调用,我们可以直接利用Gson来解析出我们希望的数据。
Android客户端测试
这样我们就完成了一个简易的既有同步又有异步调用的网络请求封装库,我们写个页面调用一下如下:
//同步调用
private fun sync(){
thread {
val apiService: ApiService = KtHttp.create(ApiService::class.java)
val data = apiService.reposSync(language = "Kotlin", since = "weekly")
runOnUiThread {
findViewById<TextView>(R.id.result).text = data.toString()
Toast.makeText(this, "$data", Toast.LENGTH_SHORT).show()
}
}
}//异步调用
private fun async(){
KtHttp.create(ApiService::class.java).reposAsync(language = "Java", since = "weekly").call(object : CallBack<RepoList>{
override fun onSuccess(data: RepoList) {
runOnUiThread {
findViewById<TextView>(R.id.result).text = data.toString()
Toast.makeText(this@MainActivity, "$data", Toast.LENGTH_SHORT).show()
}
}
override fun onFail(throwable: Throwable) {
runOnUiThread {
findViewById<TextView>(R.id.result).text = throwable.toString()
Toast.makeText(this@MainActivity, "$throwable", Toast.LENGTH_SHORT).show()
}
}
})
}经过测试,这里代码可以正常执行。
协程小试牛刀
在前面我们说过挂起函数可以用同步的代码来写出异步的效果,就比如这里的异步回调,我们可以使用协程来进行简单改造。
首先,想把Callback类型的方式改成挂起函数方式的,有2种方法。第一种是不改变原来代码库的方式,在Callback上面套一层,也是本篇文章所介绍的方法。第二种是修改原来代码块的源码,利用协程的底层API,这个方法等后面再说。
其实在原来Callback上套一层非常简单,我们只需要利用协程库为我们提供的2个顶层函数即可:
/**
* 把原来的[CallBack]形式的代码,改成协程样式的,即消除回调,使用挂起函数来完成,以同步的方式来
* 完成异步的代码调用。
*
* 这里的[suspendCancellableCoroutine] 翻译过来就是挂起可取消的协程,因为我们需要结果,所以
* 需要在合适的时机恢复,而恢复就是通过[Continuation]的[resumeWith]方法来完成。
* */
suspend fun <T: Any> KtCall<T>.await() : T =
suspendCancellableCoroutine { continuation ->
//开始网络请求
val c = call(object : CallBack<T>{
override fun onSuccess(data: T) {
//这里扩展函数也是奇葩,容易重名
continuation.resume(data)
}
override fun onFail(throwable: Throwable) {
continuation.resumeWithException(throwable)
}
})
//当收到cancel信号时
continuation.invokeOnCancellation {
c.cancel()
}
}这里我们推荐使用suspendCancelableCoroutine高阶函数,听名字翻译就是挂起可取消的协程,我们给KtCall扩展一个挂起方法await,在该方法中,我们使用continuation对象来处理恢复的值,同时还可以响应取消,来取消OkHttp的调用。
这里注意的就是resume使用的是扩展函数,与之类似的还有一个suspendCoroutine方法,这个方法无法响应取消,我们不建议使用。
在定义完上面代码后,我们在Android使用一下:
findViewById<TextView>(R.id.coroutineCall).setOnClickListener {
lifecycleScope.launch {
val data = KtHttp.create(ApiService::class.java).reposAsync(language = "Kotlin", since = "weekly").await()
findViewById<TextView>(R.id.result).text = data.toString()
}
}可以发现在这种情况下,我们就可以使用同步的方式写出了异步代码,由于挂起函数的特性,下面那行UI操作会等到挂起函数恢复后才会执行。
总结
本篇文章主要是介绍了一些常用知识点,也让我们对Retrofit的各种方法返回类型兼容性有了一定了解,最后我们使用了在不改变原来代码库的情况下,利用封装一层的方式,来实现以同步的代码写异步的形式。
本篇文章代码地址: github.com/horizon1234…
链接:https://juejin.cn/post/7166799125559083016
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
LeakCanary 浅析
前言
平时我们都有用到LeakCanary来分析内存泄露的情况,这里可以来看看LeakCanary是如何实现的,它的内部又有哪些比较有意思的操作。
LeakCanary的使用
官方文档:square.github.io/leakcanary/…
引用方式
dependencies {
// debugImplementation because LeakCanary should only run in debug builds.
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.10'
}可以看到LeakCanary的新版本中依赖非常简单,甚至不需要你做什么就可以直接使用。
LeakCanary原理
LeakCanary的封装主要是利用ContentProvider,LeakCanary检测内存泄漏主要是监听Activity和Fragment、view的生命周期,配合弱引用和ReferenceQueue。
源码浅析
初始化
首先debugImplementation只是在Debug的包会依赖,在正式包不会把LeakCanary的内容打进包中。
LeakCanary的初始化是使用了ContentProvider,ContentProvider的onCreate会在Application的onCreate之前,它把ContentProvider写在自己的AndroidMainifest中,打包时会进行合并,所以这整个过程都不需要接入端做初始化操作。
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.squareup.leakcanary.objectwatcher" >
<uses-sdk android:minSdkVersion="14" />
<application>
<provider
android:name="leakcanary.internal.MainProcessAppWatcherInstaller"
android:authorities="${applicationId}.leakcanary-installer"
android:enabled="@bool/leak_canary_watcher_auto_install"
android:exported="false" />
</application>
</manifest>这是它在AndroidManifest所定义的,打包的时候会合并所有的AndroidManifest
这就是它自动初始化的操作,也比较明显了,不用过多解释。
使用
先看看它要监测什么,因为LeakCanary 2.x的代码都是kotlin写的,所以这里得分析kotlin,如果不熟悉kt的朋友,我只能说尽量讲慢一些,因为我想看旧版本的能不能用java来分析,但是简单看了下源码上是有一定的差别,所以还是要分析2.x。
fun appDefaultWatchers(
application: Application,
reachabilityWatcher: ReachabilityWatcher = objectWatcher
): List<InstallableWatcher> {
return listOf(
ActivityWatcher(application, reachabilityWatcher),
FragmentAndViewModelWatcher(application, reachabilityWatcher),
RootViewWatcher(reachabilityWatcher),
ServiceWatcher(reachabilityWatcher)
)
}从这里看到他主要分析Activity、Fragment和Fragment的View、RootView、Service。
看Activity的监听ActivityWatcher
监听Activity调用Destroy时会调用reachabilityWatcher的expectWeaklyReachable方法。
这里可以看看旧版本的做法(正好以前有记录)
private final Application.ActivityLifecycleCallbacks lifecycleCallbacks =
new ActivityLifecycleCallbacksAdapter() {
@Override public void onActivityDestroyed(Activity activity) {
refWatcher.watch(activity);
}
};旧版本是调用refWatcher的watch,虽然代码不同,但是思想一样,再看看旧版本的Fragment
private final FragmentManager.FragmentLifecycleCallbacks fragmentLifecycleCallbacks =
new FragmentManager.FragmentLifecycleCallbacks() {
@Override public void onFragmentViewDestroyed(FragmentManager fm, Fragment fragment) {
View view = fragment.getView();
if (view != null) {
refWatcher.watch(view);
}
}
@Override
public void onFragmentDestroyed(FragmentManager fm, Fragment fragment) {
refWatcher.watch(fragment);
}
};这里监听了Fragment和Fragment的View,所以相比于新版本,旧版本只监听Activity、Fragment和Fragment的View
再回到新版本,分析完Activity的监听之后看看Fragment的
最终Destroy之后也是调用到reachabilityWatcher的expectWeaklyReachable。然后看看RootViewWatcher的操作
private val listener = OnRootViewAddedListener { rootView ->
val trackDetached = when(rootView.windowType) {
PHONE_WINDOW -> {
when (rootView.phoneWindow?.callback?.wrappedCallback) {
is Activity -> false
is Dialog -> {
......
}
else -> true
}
}
POPUP_WINDOW -> false
TOOLTIP, TOAST, UNKNOWN -> true
}
if (trackDetached) {
rootView.addOnAttachStateChangeListener(object : OnAttachStateChangeListener {
val watchDetachedView = Runnable {
reachabilityWatcher.expectWeaklyReachable(
rootView, "${rootView::class.java.name} received View#onDetachedFromWindow() callback"
)
}
......
})
}
}最终也是调用到reachabilityWatcher的expectWeaklyReachabl。最后再看看Service的。
这边因为只是做浅析,不是源码详细分析,所以我这边就不去一个个分析是如何调用到销毁的这个方法的,我们通过上面的方法得到一个结论,Activity、Fragment和Fragment的View、RootView、Service,他们几个,在销毁时都会调用到reachabilityWatcher的expectWeaklyReachabl。所以这些地方就是检测对象是否泄漏的入口。
然后我们来看看expectWeaklyReachable方法
@Synchronized override fun expectWeaklyReachable(
watchedObject: Any,
description: String
) {
// 先从queue中移除一次已回收对象
removeWeaklyReachableObjects()
// 生成随机数当成key
val key = UUID.randomUUID().toString()
val watchUptimeMillis = clock.uptimeMillis()
// 创建弱引用关联ReferenceQueue
val reference =
KeyedWeakReference(watchedObject, key, description, watchUptimeMillis, queue)
......
// 把reference和key 添加到一个Map中
watchedObjects[key] = reference
// 下一步
checkRetainedExecutor.execute {
moveToRetained(key)
}
}你们运气真好,我正好以前也有记录旧版本的refWatcher的watch方法
public void watch(Object watchedReference, String referenceName) {
......
// 生成随机数当成key
String key = UUID.randomUUID().toString();
// 把key 添加到一个Set中
this.retainedKeys.add(key);
// 创建弱引用关联ReferenceQueue
KeyedWeakReference reference = new KeyedWeakReference(watchedReference, key, referenceName, this.queue);
// 下一步
this.ensureGoneAsync(watchStartNanoTime, reference);
}通过对比发现,模板的流程是一样的,但是细节不一样,以前是用Set,现在是用Map,这就是我觉得不能拿旧版本代码来分析的原因。
文章写到这里,突然想到一个很有意思的东西,你要是面试时,面试官看过新版本的代码,你看的是旧版本的代码,结果如果问到一些比较深入的细节,你答出来的和他所理解的不同,那就尴尬了,所以面试时得先说清楚你是看过旧版本的代码
看到用一个弱引用生成一个key和对象绑定起来。然后调用ensureGoneAsync方法
private void ensureGoneAsync(final long watchStartNanoTime, final KeyedWeakReference reference) {
this.watchExecutor.execute(new Retryable() {
public Result run() {
return RefWatcher.this.ensureGone(reference, watchStartNanoTime);
}
});
}execute里面会调用到waitForIdle方法。
我们再回到新版本的代码中
checkRetainedExecutor.execute其实是会执行到这里(kt里面的是写得简单,但是不熟的话可以先别管怎么执行的,只要先知道反正执行到这个地方就行)
这里是做了一个延时发送消息的操作,延时5秒,具体代码在这里
写到这里我感觉有点慌了,因为如果不熟kt的朋友可能真会看困,其实如果看不懂这个代码的话没关系,只要我圈出来的地方,我觉是大概能看懂的,然后流程我会说,我的意思是没必要深入去看每一行是什么意思,我们的目的是找出大概的流程(用游戏的说法,我们是走主线任务,不是要全收集)
延迟5秒后会调回到前面的moveToRetained(key)。那不好意思各位,我又要拿旧版本来对比了,因为细节不同。
private void waitForIdle(final Retryable retryable, final int failedAttempts) {
// 使用IdleHandler来实现在闲时才去执行后面的流程
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override public boolean queueIdle() {
postToBackgroundWithDelay(retryable, failedAttempts);
return false;
}
});
}使用IdleHandler来完成闲时触发,我不记得很早之前的版本是不是也用的IdleHandler,这里使用IdleHandler只能说有好有坏吧,好处是闲时触发确实是一个很好的操作,不好的地方是如果一直有异步消息,就一直不会触发后面的流程。
private void postToBackgroundWithDelay(final Retryable retryable, final int failedAttempts) {
long exponentialBackoffFactor = (long) Math.min(Math.pow(2, failedAttempts), maxBackoffFactor);
long delayMillis = initialDelayMillis * exponentialBackoffFactor;
// 根据上下文去计算,这里是5秒
backgroundHandler.postDelayed(new Runnable() {
@Override public void run() {
Retryable.Result result = retryable.run();
if (result == RETRY) {
postWaitForIdle(retryable, failedAttempts + 1);
}
}
}, delayMillis);
}看到旧版本是先用IdelHanlder,在闲时触发的情况下再去延时5秒,而新版本是直接延时5秒,不使用IdelHandler,我没看过这块具体的文档描述,我猜是为了防止饿死,如果用IdelHanlder的话可能会出现一直不触发的情况。
返回看新版本的moveToRetained
@Synchronized private fun moveToRetained(key: String) {
// 从ReferenceQueue中拿出对象移除
removeWeaklyReachableObjects()
// 经过上一步之后判断Map中还有没有这个key,有的话进入下一步操作
val retainedRef = watchedObjects[key]
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis()
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}
private fun removeWeaklyReachableObjects() {
// 从ReferenceQueue中拿出对象,然后从Map中移除
var ref: KeyedWeakReference?
do {
ref = queue.poll() as KeyedWeakReference?
if (ref != null) {
watchedObjects.remove(ref.key)
}
} while (ref != null)
}moveToRetained主要是从ReferenceQueue中找出弱引用对象,然后移除Map中相应的弱引用对象。弱引用+ReferenceQueue的使用,应该不用多说吧,如果弱引用持有的对象被回收,弱引用会添加到ReferenceQueue中。所以watchedObjects代表的是应该将要被回收的对象,queue表示已经被回收的对象,这步操作就是从queue中找出已经回收的对象,然后从watchedObjects移除相应的对象,剩下的的就是应该被回收却没被回收的对象。如果对象被正常回收,那这整个流程就走完了,如果没被回收,会执行到onObjectRetained(),之后就是Dump操作了,之后的就是内存分析、弹出通知那堆操作了,去分析内存的泄漏这些,因为内容比较多,这篇先大概就先到这里。
总结
浅析,就是只做了简单分析LeakCanary的整个工作过程和工作原理。
原理就是用弱引用和ReferenceQueue去判断应该被回收的对象是否已经被回收。大致的工作流程是:监听Activity、Fragment和Fragment的View、RootView、Service对象的销毁,然后将这些对象放入“应该被回收”的容器中,然后5秒后通过弱引用和ReferenceQueue去判断对象是否已被回收,如果被回收则从容器中删除对应的对象,否则进行内存分析。
至于是如何判断不同对象的销毁和如何分析内存情况找出泄漏的引用链,这其中也是细节满满,但是我个人LeakCanary应该是看过两三次源码了,从一开始手动初始化,到旧版本java的实现方式,到现在用kt去实现,能发现它的核心思想其实是一样的,只不过在不断的优化一些细节和不断的扩展可以监测的对象。
2.10版本的源码我也是第一次看,我是一面看一面写这篇文章,如果有哪里流程是我看错的,希望大佬们能及时提出,我也会及时更正。
链接:https://juejin.cn/post/7167026728596946980
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
分享Kotlin协程在Android中的使用
前言
之前我们学了几个关于协程的基础知识,本文将继续分享Kotlin协程的知识点~挂起,同时介绍协程在Android开发中的使用。
正文
挂起
suspend关键字
说到挂起,那么就会离不开suspend关键字,它是Kotlin中的一个关键字,它的中文意思是暂停或者挂起。
以下是通过suspend修饰的方法:
suspend fun suspendFun(){
withContext(Dispatchers.IO){
//do db operate
}
}通过suspend关键字来修饰方法,限制这个方法只能在协程里边调用,否则编译不通过。
suspend方法其实本身没有挂起的作用,只是在方法体力便执行真正挂起的逻辑,也相当于提个醒。如果使用suspend修饰的方法里边没有挂起的操作,那么就失去了它的意义,也就是无需使用。
虽然我们无法正常去调用它,但是可以通过反射去调用:
suspend fun hello() = suspendCoroutine<Int> { coroutine ->
Log.i(myTag,"hello")
coroutine.resumeWith(kotlin.Result.success(0))
}
//通过反射来调用:
fun helloTest(){
val helloRef = ::hello
helloRef.call()
}
//抛异常:java.lang.IllegalArgumentException: Callable expects 1 arguments, but 0 were provided.fun helloTest(){
val helloRef = ::hello
helloRef.call(object : Continuation<Int>{
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: kotlin.Result<Int>) {
Log.i(myTag,"result : ${result.isSuccess} value:${result.getOrNull()}")
}
})
}
//输出:hello挂起与恢复
看一个方法:
public suspend inline fun <T> suspendCancellableCoroutine(
crossinline block: (CancellableContinuation<T>) -> Unit
): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
val cancellable = CancellableContinuationImpl(uCont.intercepted(), resumeMode = MODE_CANCELLABLE)
block(cancellable)
cancellable.getResult()
}这是Kotlin协程提供的api,里边虽然只有短短的三句代码,但是实现甚是复杂而且关键。
继续跟进看看getResult()方法:
internal fun getResult(): Any? {
installParentCancellationHandler()
if (trySuspend()) return COROUTINE_SUSPENDED//返回此对象表示挂起
val state = this.state
if (state is CompletedExceptionally) throw recoverStackTrace(state.cause, this)
if (resumeMode == MODE_CANCELLABLE) {//检查
val job = context[Job]
if (job != null && !job.isActive) {
val cause = job.getCancellationException()
cancelResult(state, cause)
throw recoverStackTrace(cause, this)
}
}
return getSuccessfulResult(state)//返回结果
}最后写一段代码,然后转为Java看个究竟:
fun demo2(){
GlobalScope.launch {
val user = requestUser()
println(user)
val state = requestState()
println(state)
}
}编译后生成的代码大致流程如下:
public final Object invokeSuspend(Object result) {
...
Object cs = IntrinsicsKt.getCOROUTINE_SUSPENDED();//上面所说的那个Any:CoroutineSingletons.COROUTINE_SUSPENDED
switch (this.label) {
case 0:
this.label = 1;
user = requestUser(this);
if(user == cs){
return user
}
break;
case 1:
this.label = 2;
user = result;
println(user);
state = requestState(this);
if(state == cs){
return state
}
break;
case 2:
state = result;
println(state)
break;
}
}当协程挂起后,然后恢复时,最终会调用invokeSuspend方法,而协程的block代码会封装在invokeSuspend方法中,使用状态来控制逻辑的实现,并且保证顺序执行。
通过以上我们也可以看出:
- 本质上也是一个回调,Continuation
- 根据状态进行流转,每遇到一个挂起点,就会进行一次状态的转移。
协程在Android中的使用
举个例子,使用两个UseCase来模拟挂起的操作,一个是网络操作,另一个是数据库的操作,然后操作ui,我们分别看一下代码上面的区别。
没有使用协程:
//伪代码
mNetworkUseCase.run(object: Callback {
onSuccess(user: User) {
mDbUseCase.insertUser(user, object: Callback{
onSuccess() {
MainExcutor.excute({
tvUserName.text = user.name
})
}
})
}
})我们可以看到,用回调的情况下,只要对数据操作稍微复杂点,回调到主线程进行ui操作时,很容易就嵌套了很多层,导致了代码难以看清楚。那么如果使用协程的话,这种代码就可以得到很大的改善。
使用协程:
private fun requestDataUseGlobalScope(){
GlobalScope.launch(Dispatchers.Main){
//模拟从网络获取用户信息
val user = mNetWorkUseCase.requireUser()
//模拟将用户插入到数据库
mDbUseCase.insertUser(user)
//显示用户名
mTvUserName.text = user.name
}
}对以上函数作说明:
- 通过GlobalScope开启一个顶层协程,并制定调度器为Main,也就是该协程域是在主线程中运行的。
- 从网络获取用户信息,这是一个挂起操作
- 将用户信息插入到数据库,这也是一个挂起操作
- 将用户名字显示,这个操作是在主线程中。
由此在这个协程体中就可以一步一步往下执行,最终达到我们想要的结果。
如果我们需要启动的线程越来越多,可以通过以下方式:
private fun requestDataUseGlobalScope1(){
GlobalScope.launch(Dispatchers.Main){
//do something
}
}
private fun requestDataUseGlobalScope2(){
GlobalScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseGlobalScope3(){
GlobalScope.launch(Dispatchers.Main){
//do something
}
}但是平时使用,我们需要注意的就是要在适当的时机cancel掉,所以这时我们需要对每个协程进行引用:
private var mJob1: Job? = null
private var mJob2: Job? = null
private var mJob3: Job? = null
private fun requestDataUseGlobalScope1(){
mJob1 = GlobalScope.launch(Dispatchers.Main){
//do something
}
}
private fun requestDataUseGlobalScope2(){
mJob2 = GlobalScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseGlobalScope3(){
mJob3 = GlobalScope.launch(Dispatchers.Main){
//do something
}
}如果是在Activity中,那么可以在onDestroy中cancel掉
override fun onDestroy() {
super.onDestroy()
mJob1?.cancel()
mJob2?.cancel()
mJob3?.cancel()
}可能你发现了一个问题:如果启动的协程不止是三个,而是更多呢?
没错,如果我们只使用GlobalScope,虽然能够达到我们的要求,但是每次我们都需要去引用他,不仅麻烦,还有一点是它开启的顶层协程,如果有遗漏了,则可能出现内存泄漏。所以我们可以使用kotlin协程提供的一个方法MainScope()来代替它:
private val mMainScope = MainScope()
private fun requestDataUseMainScope1(){
mMainScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseMainScope2(){
mMainScope.launch {
//do something
}
}
private fun requestDataUseMainScope3(){
mMainScope.launch {
//do something
}
}可以看到用法基本一样,但有一点很方便当我们需要cancel掉所有的协程时,只需在onDestroy方法cancel掉mMainScope就可以了:
override fun onDestroy() {
super.onDestroy()
mMainScope.cancel()
}MainScope()方法:
@Suppress("FunctionName")
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)使用的是一个SupervisorJob(制定的协程域是单向传递的,父传给子)和Main调度器的组合。
在平常开发中,可以的话使用类似于MainScope来启动协程。
结语
本文的分享到这里就结束了,希望能够给你带来帮助。关于Kotlin协程的挂起知识远不止这些,而且也不容易理清,还是会继续去学习它到底用哪些技术点,深入探究原理究竟是如何。
链接:https://juejin.cn/post/7130427677432872968
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
愿内卷早日结束!
上个周末幸得空闲时间和爱人去图书馆学习看书,整理了一下思绪,回忆了一下这两年自己的心态变化,成长经历,学习状态,时间管理等,于是乎我发现自己变懒了,趁着今天反思一下自己,也希望能给大家有一些警示所用吧。
状态
随着年龄的增长和周遭事物的快速变化以及自己肩上的担子越来越重,我发现自己很难再进入长时间的学习状态。这种学习状态也是我们经常说的心流,即长时间心无旁骛的专心看书,没有频繁的 CPU 线程切换,也不用保存上一秒的内存状态。
由于年龄的不断增大,我发现自己的记忆和理解能力确实在衰退,这种衰退的现象可能起源于不经常用脑导致的脑细胞组织衰减所致,脑细胞衰减就导致思考能力变弱,思考能力变弱就会导致越来越不愿意动脑,这是一种负面循环,很可能会使老年痴呆提前到来。人最重要的是大脑,而我们对大脑的开发和利用却少的可怜。
不知道大家有没有经历过这样一种情况,每天都很多人找你,你看似很匆忙,但是晚上回想一下自己一天的经过却发现做的事情大多数重复性且可替代性很强的工作,而当你一天很快进入工作状态却没人打断你,你勤加动脑你会发现自己能解决很多难题,会有很多创造性的 idea 出现,会觉得自己非常有成就感,这就是一种心流状态。
上面是两种不同情况之间的差距,真实情况其实是第一种:每天有无数个毫无意义的会议和很多人来找你,你自己很难进入心流状态。每天担心自己的绩效在这个季度会不会垫底,会不会存在被优化的风险,导致自己一天天的忧心忡忡,拒绝思考,喜欢做简单且可替代性强的工作来争取绩效,从而产生工作中的内卷 ...... 陷入负面循环。
还有就是手机对我们的控制和吃瓜心态的优先级正在变的越来越高,不摸鱼也不会吃瓜,不吃瓜也不会摸鱼,这也是一种循环,你想摸鱼你才会吃瓜,你吃瓜的时候你肯定正在摸鱼,这就是一种热点效应,中国老百姓就是喜欢看热闹,无非就是形式变了,把现实中聚在一起看热闹搬到了网上变成大家围观吃瓜。所以为啥每次微博只要一崩肯定就是 xx 明星又出轨了这种生活作风性质的烂批事儿,你除了向他键盘伤害之外,还能跟广大的网友有啥关系?你爱看无非就是人性罢了,而进入心流状态是一种逆人性的事情,但很可怕的是这种逆人性的事情在变得越来越少。
编码是需要创造和思考的,而程序员的美好愿景不就是 debug the world 吗?我们不能陷入毫无意义只想划水吃瓜的猎奇怪圈中,我们需要及时跳出来,也许终究一生我们都只是柴米油盐酱醋茶的普通人,但是我们写过的代码,带过的人,都会是这个行业中浓墨重彩的一比,就像 GitHub 尘封在北极中的代码是一样的。
在平时的工作和生活中,要让自己多多进入心流,减少外界事物对自己的干扰,进入心流状态,让自己静下心来,思考问题的深度就会加深,会让自己沉浸在一种状态下,一种持续精进的状态中。
怪圈
最近经常听到一些读者不经意间的讨论,cxuan 最近更文的频率慢了很多,我承认确实是这样的。那么为什么会这样呢?其实这些话我很早讲,但是奈何没有找到一个合适的时机,所以趁着今天,我也想说明一下。
其实我陷入了一种怪圈,一种我想写出更优秀的作品,但是写出这种作品需要以大量的基础知识作为铺垫,所以我就想要吸收更多的知识,看更多的书,读更多的文章,汲取大量的营养,但是谁也没法保证在吸收这么多知识后就一定能写出优质的文章,有可能我写的越来越屎。但是有一点确定的是,在吸收大量知识的同时,我是无法持续更文的,但是不写文章就会变的焦虑,导致越来越没信心吸收更多的知识。最终导致文章也断更了,知识也没学到多少。
就比如我是 Java 程序员,也许我写关于 Java 类型的文章会好很多,但是我偏偏想要写操作系统、C/C++ 、计算机网络、汇编等方面的文章,这就需要吸收大量的只是并揉碎了给大家讲出来,不过这需要大量的时间和精力。也许单纯的写 Java 方向的文章会好很多,但是谁叫我愿意呢?理论上我必须承受这些知识带给我的压力,我必须要挤出来更多的时间来接纳,但是实际情况是我躺平了。
躺平的原因有很多种,但是我只接受一种:我变懒了。
我一直以为工作不忙就会有更多的时间做自己的事情,但实际情况是工作不忙就会有更多的时间划水摸鱼,到点打卡下班。再加上结婚之后暂无要孩子的打算,于是自己心态变了。这是很可怕的一件事情,屠龙少年,终成恶龙。
再加上我现在又有健身的兴趣,但是我为满足我的兴趣和工作以及学习的总时间并没有变多,所以我的兴趣就会挤占其他项目的时间,导致我最近的时间管理这块变得很糟糕。
希望我自己能及时调整心态,合理平衡兴趣、工作和学习的时间,慢慢找回之前的状态。人若无名便可专心练剑,时刻让自己保持一种空杯心态。
寒潮
今年对互联网行业最大的一个冲击就是裁员潮和 HC 的锁紧,随着互联网脚步放缓,很多毕业生毕业找不到工作,很多培训班也爆雷。但是由于计算机这几年鼓吹的太狠,所以毕业季有很多毕业生同时抢一个 offer,因此越来越内卷,所以现在的互联网环境可以说是半死不活了。但是这种环境下,对真正优秀的毕业生来说还是影响不太大,还是有一些岗位在招人,不过对于大多数同学来讲,能上岸就抓紧上岸,先活着再生活。考研的人数也是一年比一年多,现在大学生都不好意思跟人说自己是大学生了,因为遍地都是研究生,甚至博士都已经见怪不怪了。
就拿石家庄某个高效来说,二本学校招聘教师 120 个岗位无一例外全是博士学历起,令人卷到只想骂人。
我还依稀记得一年前互联网在高位的时候,应届毕业生年薪 package 50w 已经不算什么大新闻了,再看看与现在的对比,令人唏嘘,无非是在风口浪尖罢了,并不是真正的能力。
那么如何破局呢?其实谁都无法给出准确的答案,我们能做的只是丈量好脚下的步数,不过还是有一些建议可以采取的。
精进基础知识
再过多强调基础知识都不为过,但很多人依然认识不到其重要性,很多同学都以为开发就是会写代码就完事儿了,玩玩框架做做增删改查就是全部工作内容,只不过现实是不给你转身的机会的,你看看现在的就业环境是只会增删改查就能找到一份称心如意的工作吗?就拿面试来说,两年前面试还是卷一些框架用法、了解基本原理即可,再看看这两年面试直接卷深层次的内容和应用实现,底层原理等。
基础知识是一通百通的,比如你了解计算机网络的分层设计之后就知道网络协议的每一层打包的目的是什么,Socket 为什么是端口通信的大门?ping 的实现原理,为什么要发 ECHO_REQUEST 包?为什么有的电脑插入网线不用配置 IP 就能直接上网?点击http://www.google.com背后的实现过程是怎样的?操作系统为什么要分为三大抽象?
再好比你在搞并发编程,你就得知道为什么读写要遵循 MESI 协议?Java 实现的各种并发工具类其实都是操作系统读写的几种模型罢了,以及线程和进程的本质区别是啥,管程是啥?等等,要学的内容太多了。可以说这个行业你不得不随时都准备学习,可以说是把终身学习理念贯彻最彻底的行业。
掌握核心技术
今年很多大厂对内都进行了人员优化,比如前段时间虾皮裁员毁约闹的挺大的,只不过裁掉和优化的都是边缘部门和边缘开发同学,也就是不赚钱没有盈利前景的那些部门。核心岗位的核心开发还是公司的支柱,所以这里建议大家还是要向公司的核心业务、核心部门靠拢,这才是一家互联网公司的全部核心。也就是说要让自己具有核心竞争力和不可替代性,也要有随时离开的本领。
一言以蔽之,多看书,多实践,向公司核心技术和核心业务靠拢,覆巢之下无完卵,大家加油。
作者:程序员cxuan
链接:mp.weixin.qq.com/s/X7iBi6WARIjhJ80mOAqvBw
[YYEVA]一个极致的特效框架
今年在公司内开发了一个mp4的特效框架,用于支撑各种礼物特效的玩法,是继SVGA特效框架的另外一个极致的特效框架。这里介绍的是YYEVA框架生成原理
为何要选用MP4资源作为特效框架?
这里一张图告诉你透明MP4特效的优势
可以看到透明mp4框架支持软解硬解,H264/265压缩,支持特效元素替换,支持透明通道。
为何称为极致?
YYEVA-Android 稳定版本是1.0.11版本,支持了业界中独有功能,例如文字左右对齐,元素图片缩放方式,支持嵌入背景图片,循环播放。
YYEVA-Android 已经出了2.0.0-beta版本,为大家带来业界领先的功能。
1.这个版本支持了框架多进程,将解码器放到子进程远程。
支持多进程解码,让主进程内存压力减少,让主进程更专注于渲染效果。 开发中主要遇到是,进程间的渲染的生命周期的回调,主进程中如何剥离出独立解码器等问题。
这里有个小插曲,尝试过是否能够单独使用子进程进行主进程传递的Surface渲染以及解码,答案是无法做到的,因为主进程创建Surface的egl环境无法和子进程共通,所以只能独立出解码器。或者使用Service创建Dialog依附新的windows来来创建egl环境和surface来做独立渲染。
2.支持高清滤镜,未来支持更多的高清滤镜功能。
支持高清滤镜,小尺寸资源,缩放效果不再纯粹的线性缩放,可以带有高清的滤镜计算来优化,各种屏幕上的表现。当然高清滤镜需要耗费一些性能,由开发接入sdk来自行判断使用策略。
现在分别支持 lagrange和hermite两种不同的滤镜算法,这两种算法已经在手Y中得到很好的实践,还有更加强大的高清滤镜正在试验中。
如果有更好的滤镜算法,也可以提供我们嵌入优化。
3.将opengles从2.0升级到3.1,并加入多种opengles的特性来优化整个gpu的缓存读取
使用了vbo,ebo,vao等opengles缓存技术来优化整个gpu运行缓存。优化特效渲染的压力,让特效渲染更好更快。 将原来Java层I妈个View中进行图片变换效果,完全转移到opengles来完成,进一步提高了整个绘制效率。还有将整个点击触摸系统反馈系统缩放计算置于Native中。
4.将硬解解码器下放到native层,未来正式版将兼容ffmpeg软解。
将原来1.0版本视频解码模块,音频解码和音频播放逻辑,转移到Native层实现,更好的功能代码统一性。 未来我们将加入ffmpeg软解/硬解,能够更好支持解码嵌入技术。
YYEVA未来将会提供更多业界领先的能力,发布更多重磅功能,欢迎大家点赞收藏一波
作者:Cang_Wang
来源:juejin.cn/post/7166071141226774565
看完这篇,你也可以搞定有趣的动态曲线绘制
前言
接下来我们来了解一下 Path 类的一些特性。Path 类用于描述绘制路径,可以实现绘制线段、曲线、自定义形状等功能。本篇我们介绍 Path 的一个描述类 PathMetric 的应用。通过本篇你会了解以下两方面的内容:
PathMetric类简介。PathMetric的应用。
PathMetric 简介
PathMetric 是一个用于测量 Path 和抽取子路径(sub-paths) 的工具,通过 Path 类的 computeMetrics方法可以返回一组PathMetric 类。为什么是一组,而不是一个呢?这是因为 Path 可能包含多个不连续的子路径,比如通过 moveTo 可以重新开启新的一段路径。
通过 PathMetric 可以获取到 Path 的长度,路径是否闭合,以及某一段路径是否是 Path的子路径。PathMetrics 是一个迭代器,因此在不获取其中的 PathMetric 对象时,并不会实际进行 Path 的相关计算,这样可以提高效率。另外需要注意的是,通过 computeMetrics 方法计算得到的是一个当前Path 对象的快照,如果在之后更改了 Path 对象,并不会进行更新。
我们来看一下 PathMetric 的一些属性和方法。
length:Path对象其中一段(独立的)的长度;isClosed:判断Path对象是否闭合;contourIndex:当前对象在PathMetrics中的次序;getTangentForOffset:这个方法通过距离起点的长度的偏移量(即从0 到length中的某个位置)返回一个Tangent对象,通过这个对象可以获取到Path某一段路径途中的任意一点的位置以及角度。以下面的图形为例,从点(0, 0)到点(2, 2)的线段总长度为2.82,如果我们通过getTangentForOffset获取距离起始点1.41 的位置的Tangent对象,就会得到该位置的坐标是(1, 1),角度是45度(实际以弧度的方式计算)。
extractPath:通过距离 Path 起点的开始距离和结束距离获取这段路劲的子路径,如下图所示。
PathMetric 应用
我们来通过 PathMetric 实现下面动图的效果。
这张图最开始绘制的是一条贝塞尔曲线,是通过 Path 自带的贝塞尔曲线绘制的,代码如下所示。
Path path = Path();
final curveHeight = 60.0;
final stepWidth = size.width / 4;
path.moveTo(0, size.height / 2);
path.quadraticBezierTo(size.width / 2 - stepWidth,
size.height / 2 - curveHeight, size.width / 2, size.height / 2);
path.quadraticBezierTo(size.width / 2 + stepWidth,
size.height / 2 + curveHeight, size.width, size.height / 2);
quadraticBezierTo这个方法就是从 Path 当前的终点到参数3,4(参数名为 x2,y2)绘制一条贝塞尔曲线,控制点为参数1,2(参数名为 x1,y1)。
动画过程中曲线上的红色圆点就是通过 PathMetric 得到的,动画对象 Animation 的值从0-1变化,我们通过这个值乘以曲线的长度就能得到getTangentForOffset方法所需的偏移量,然后就可以确定动画过程中绘制圆点的位置了,代码如下所示。
for (var pathMetric in metrics) {
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * animationValue);
paint.style = PaintingStyle.fill;
canvas.drawCircle(tangent!.position, 4.0, paint);
}接下来是动画过程中的我们看到红色曲线会逐步覆盖蓝色曲线,这就是用 extractPath获取子路径完成的,在动画过程,我们控制 extractPath的结束位置,就可以逐步完成原有曲线的覆盖了,实现代码只有两行,如下所示。
var subPath =
pathMetric.extractPath(0.0, pathMetric.length * animationValue);
canvas.drawPath(subPath, paint);
最后是底下的填充,填充我们使用了渐变色,这个利用了之前我们讲过的Paint 对象的 shader 属性实现,具体可以参考之前的文章。填充其实就是一段闭合的 Path,只是在动画过程中控制右边绘制的边界就可以了,然后上面跟随曲线的部分还是基于子路径完成的。填充部分实现代码如下。
var fillPath = Path();
fillPath.moveTo(0, size.height);
fillPath.lineTo(0, size.height / 2);
fillPath.addPath(subPath, Offset(0, 0));
fillPath.lineTo(tangent.position.dx, size.height);
fillPath.lineTo(0, size.height);
paint.shader = LinearGradient(
begin: Alignment.topCenter,
end: Alignment.bottomCenter,
colors: [Colors.red[400]!, Colors.blue[50]!],
).createShader(Rect.fromLTRB(
0,
size.height / 2 - curveHeight,
size.width,
size.height,
));
canvas.drawPath(fillPath, paint);完整代码已经提交至:绘图相关代码,文件名为:path_metrics_demo.dart。
总结
本篇介绍了 Flutter 路径Path 的工具类 PathMetric的介绍和应用,通过 PathMetric 我们可以定位到 Path 的指定位长度的位置的信息,也可以通过起始点从 Path 中抽取子路径。有了这些基础,就可以实现很多场景的应用,比如曲线上布局标识或填充,标记指定位置的点等等。
链接:https://juejin.cn/post/7122790277315559437
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
10 个有用的 Kotlin flow 操作符
Kotlin 拥有函数式编程的能力,运用得当,可以简化代码,层次清晰,利于阅读,用过都说好。
然而操作符数量众多,根据使用场景选择合适的操作符是一个很大的难题,网上搜索了许久只是学习了一个操作符,还要再去验证它,实在浪费时间,开发效率低下。
一种方式是转至命令式开发,将过程按步骤实现,即可完成需求;另一种方式便是一次学习多个操作符,在下次选择操作符时,增加更多选择。
本篇文章当然关注的是后者,列举一些比较常用 Kotlin 操作符,为提高效率助力,文中有图有代码有讲解,文末有参考资料和一个交互式学习的网站。
让我们开始吧。
1. reduce
reduce 操作符可以将所有数据累加(加减乘除)得到一个结果
listOf(1, 2, 3).reduce { a, b ->
a + b
}
输出:6如果 flow 中没有数据,将抛出异常。如不希望抛异常,可使用 reduceOrNull 方法。
reduce 操作符不能变换数据类型。比如,Int 集合的结果不能转换成 String 结果。
2. fold
fold 和 reduce 很类似,但是 fold 可以变换数据类型
有时候,我们不需要一个结果值,而是需要继续操 flow,可使用 runningFold 。
flowOf(1, 2, 3).runningFold("a") { a, b ->
a + b
}.collect {
println(it)
}
输出:
a
a1
a12
a123同样的,reduce 也有类似的方法 runningReduce
flowOf(1, 2, 3).runningReduce { a, b ->
a + b
}.collect {
println(it)
}
输出:
1
3
63. debounce
debounce 需要传递一个毫秒值参数,功能是:只有达到指定时间后才发出数据,最后一个数据一定会发出。
例如,定义 1000 毫秒,也就是 1 秒,被观察者发出数据,1秒后,观察者收到数据,如果 1 秒内多次发出数据,则重置计算时间。
flow {
emit(1)
delay(590)
emit(2)
delay(590)
emit(3)
delay(1010)
emit(4)
delay(1010)
}.debounce(
1000
).collect {
println(it)
}
输出结果:
3
4rebounce 的应用场景是限流功能
4. sample
sample 和 debounce 很像,功能是:在规定时间内,只发送一个数据
flow {
repeat(4) {
emit(it)
delay(50)
}
}.sample(100).collect {
println(it)
}
输出结果:
1
3sample 的应用场景是截流功能
debounce 和 sample 的限流和截流功能已有网友实现,点击这里
5. flatmapMerge
简单的说就是获得两个 flow 的乘积或全排列,合并并且平铺,发出一个 flow。
描述的仍然不好理解,一看代码便能理解了
flowOf(1, 3).flatMapMerge {
flowOf("$it a", "$it b")
}.collect {
println(it)
}
输出结果:
1 a
1 b
3 a
3 bflatmapMerge 还有一个特性,在下一个操作符里提及。
6. flatmapConcat
先看代码。
flowOf(1, 3).flatMapConcat {
flowOf("a", "b", "c")
}.collect {
println(it)
}功能和 flatmapMerge 一致,不同的是 flatmapMerge 可以设置并发量,可以理解为 flatmapMerge 是线程安全的,而 flatmapConcat 不是线程安全的。
本质上,在 flatmapMerge 的并发参数设置为 1 时,和 flatmapConcat 基本一致,而并发参数大于 1 时,采用 channel 的方式发出数据,具体内容请参阅源码。
7. buffer
介绍 buffer 的时候,先要看这样一段代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.collect { println("2 $it") }
输出结果:
1 A
2 A
1 B
2 B
1 C
2 C
1 D
2 D注意输出的内容。
加上 buffer 的代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.buffer()
.collect { println("2 $it") }
输出结果:
1 A
1 B
1 C
1 D
2 A
2 B
2 C
2 D输出内容有所不同,buffer 操作符可以改变收发顺序,像有一个容器作为缓冲似的,在容器满了或结束时,下游开始接到数据,onEach 添加延迟,效果更明显。
8. combine
合并两个 flow,长的一方会持续接受到短的一方的最后一个数据,直到结束
flowOf(1, 3).combine(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b3
c39. zip
也是合并两个 flow,结果长度与短的 flow 一致,很像木桶原理。
flowOf(1, 3).zip(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b310. distinctUntilChanged
就像方法名写的那样,和前一个数据不同,才能收到,和前一个数据想通,会被过滤掉。
flowOf(1, 1, 2, 2, 3, 1).distinctUntilChanged().collect {
println(it)
}
输出结果:
1
2
3
1最后
以上就是今天要介绍的操作符,希望对大家有所帮助。
参考文章:Android — 9 Useful Kotlin Flow Operators You Need to Know
Kotlin 交互式操作符网站:交互式操作符网站
链接:https://juejin.cn/post/7135013334059122719
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GET 和 POST 有什么区别?
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,在日常开发的 RESTful 接口中,都能看到它们的身影。而它们之间的区别,也是一道常见且经典的面试题,所以我们本文就来详细的聊聊。
HTTP 协议定义的方法类型总共有以下 10 种:
PS:目前大部分的网站使用的都是 HTTP 1.1 的协议。
但在日常开发中,使用频率最高的就属 GET 请求和 POST 请求了,尤其是在中、小型公司,基本只会使用这两种请求来实现一个项目。
1.相同点和最本质的区别
1.1 相同点
GET 请求和 POST 请求底层都是基于 TCP/IP 协议实现的,使用二者中的任意一个,都可以实现客户端和服务器端的双向交互。
1.2 最本质的区别
GET 和 POST 最本质的区别是“约定和规范”上的区别,在规范中,定义 GET 请求是用来获取资源的,也就是进行查询操作的,而 POST 请求是用来传输实体对象的,因此会使用 POST 来进行添加、修改和删除等操作。
当然如果严格按照规范来说,删除操作应该使用 DELETE 请求才对,但在实际开发中,使用 POST 来进行删除的用法更常见一些。
按照约定来说,GET 和 POST 的参数传递也是不同的,GET 请求是将参数拼加到 URL 上进行参数传递的,而 POST 是将请参数写入到请求正文中传递的,如下图所示:
2.非本质区别
2.1 缓存不同
GET 请求一般会被缓存,比如常见的 CSS、JS、HTML 请求等都会被缓存;而 POST 请求默认是不进行缓存的。
2.2 参数长度限制不同
GET 请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,通常为 2k,当然浏览器厂商不同、版本不同这个限制的大小值可能也不同,但相同的是它们都会对 URL 的大小进行限制;而 POST 请求参数是存放在请求正文(request body)中的,所以没有大小限制。
2.3 回退和刷新不同
GET 请求可以直接进行回退和刷新,不会对用户和程序产生任何影响;而 POST 请求如果直接回滚和刷新将会把数据再次提交,如下图所示:
2.4 历史记录不同
GET 请求的参数会保存在历史记录中,而 POST 请求的参数不会保留到历史记录中。
2.5 书签不同
GET 请求的地址可被收藏为书签,而 POST 请求的地址不能被收藏为书签。
总结
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,它们的底层都是基于 TCP/IP 实现的。它们的区别主要体现在 5 个方面:缓存不同、参数长度限制不同、回退和刷新不同、历史记录不同、能否保存为书签不同,但它们最大的区别是规范和约定上的不同,规范中定义 GET 是用来获取信息的,而 POST 是用来传递实体的,并且 GET 请求的参数要放在 URL 上,而 POST 请求的参数要放在请求正文中。
链接:https://juejin.cn/post/7127443645073981476
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


