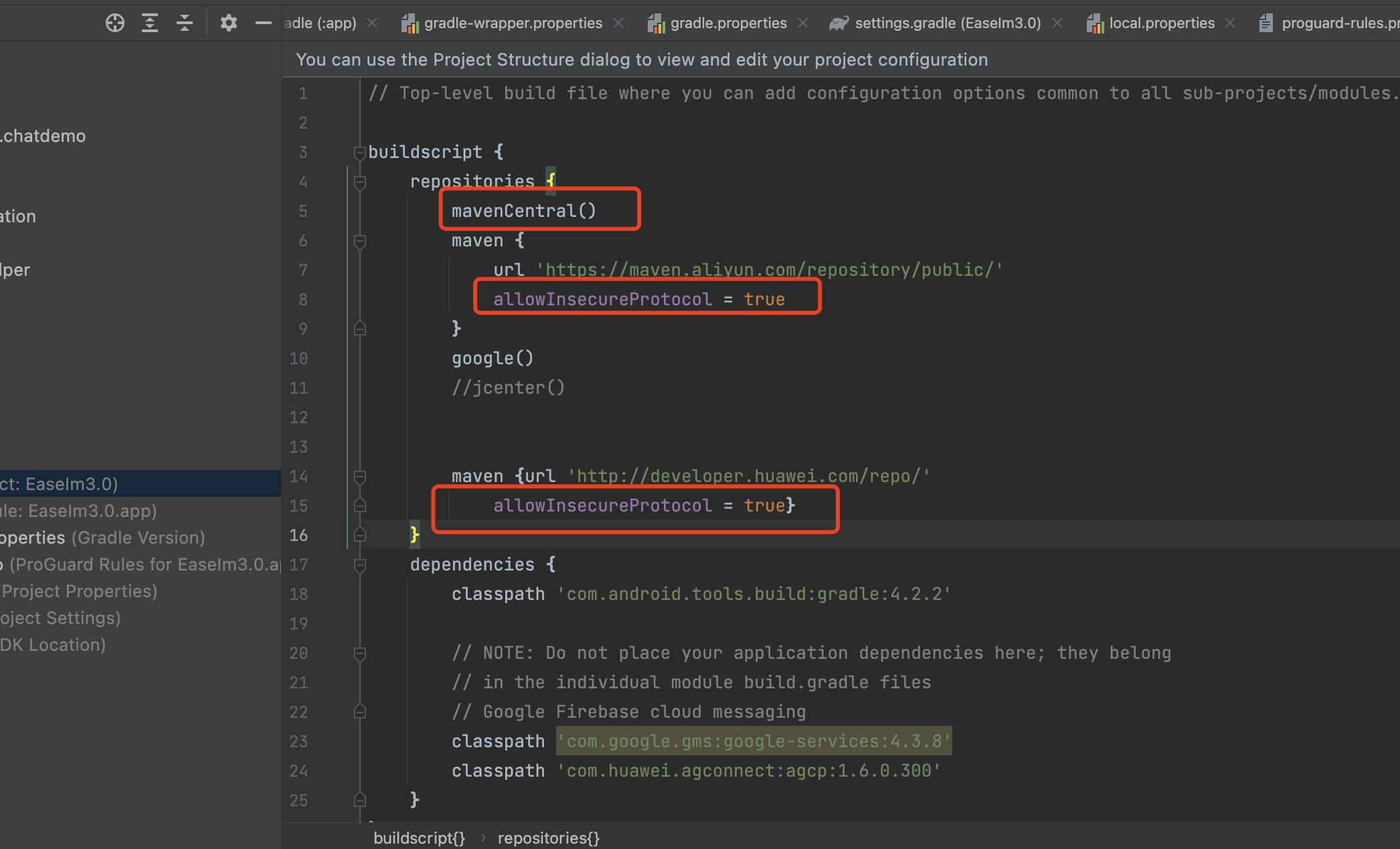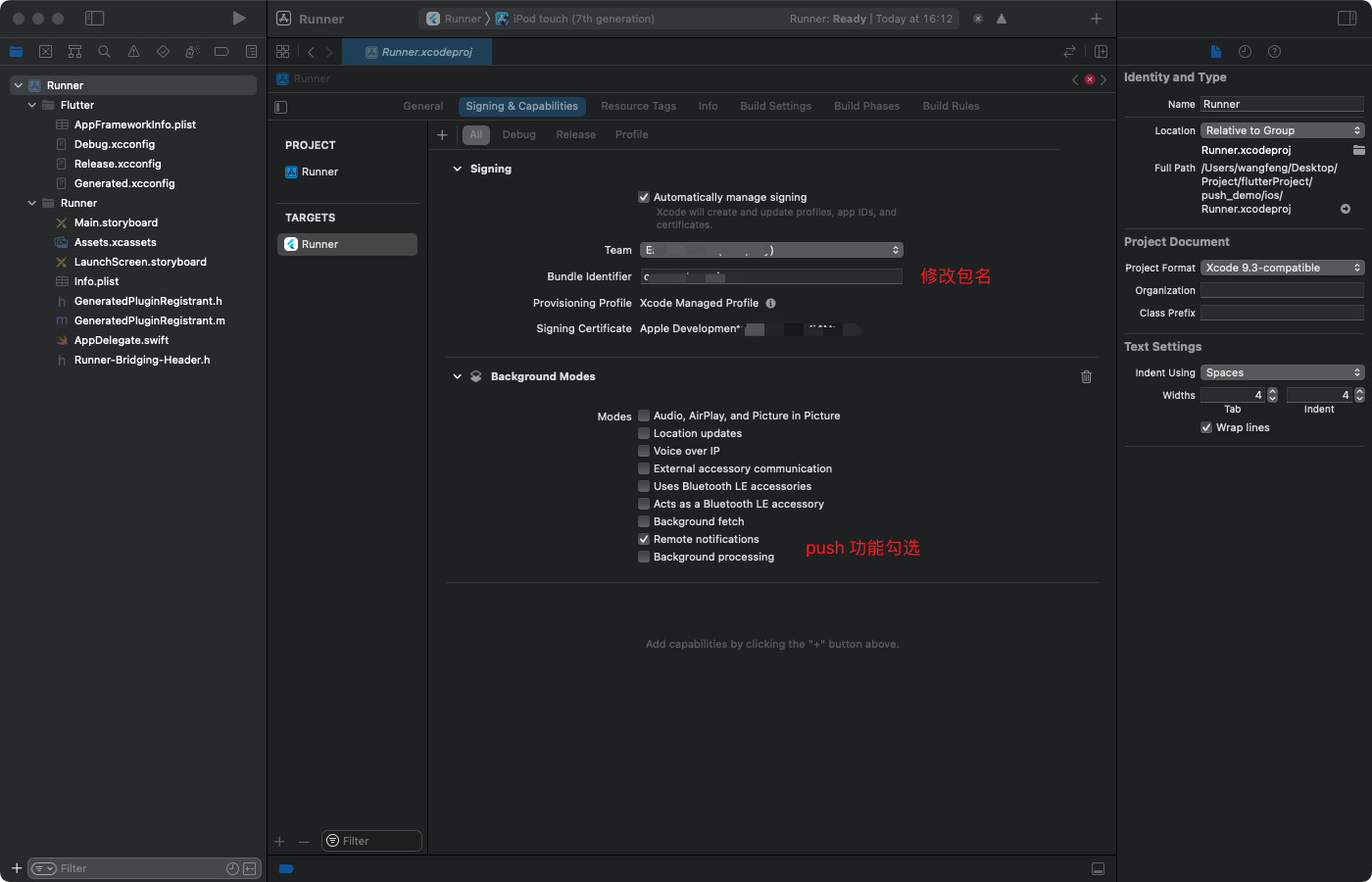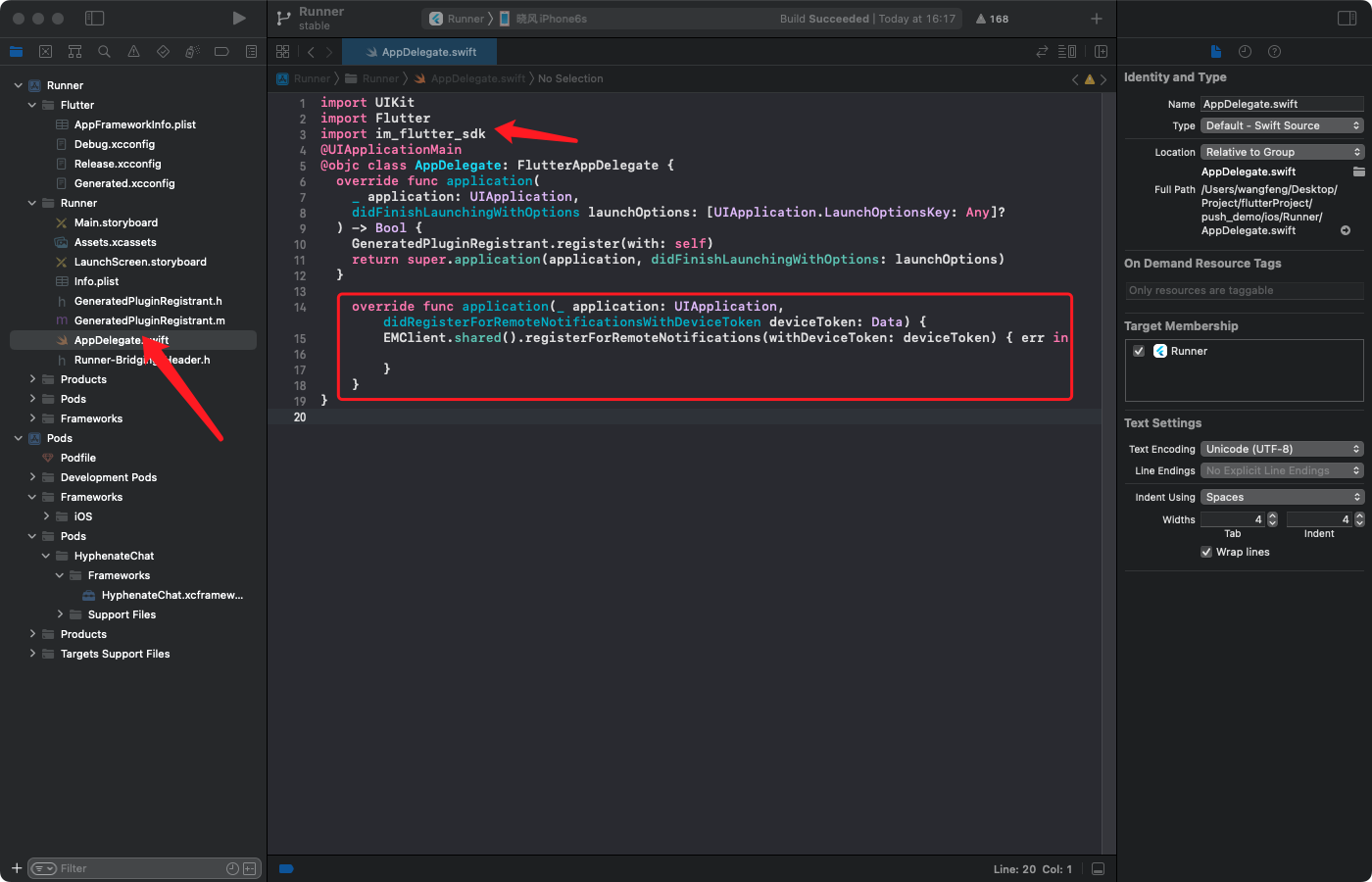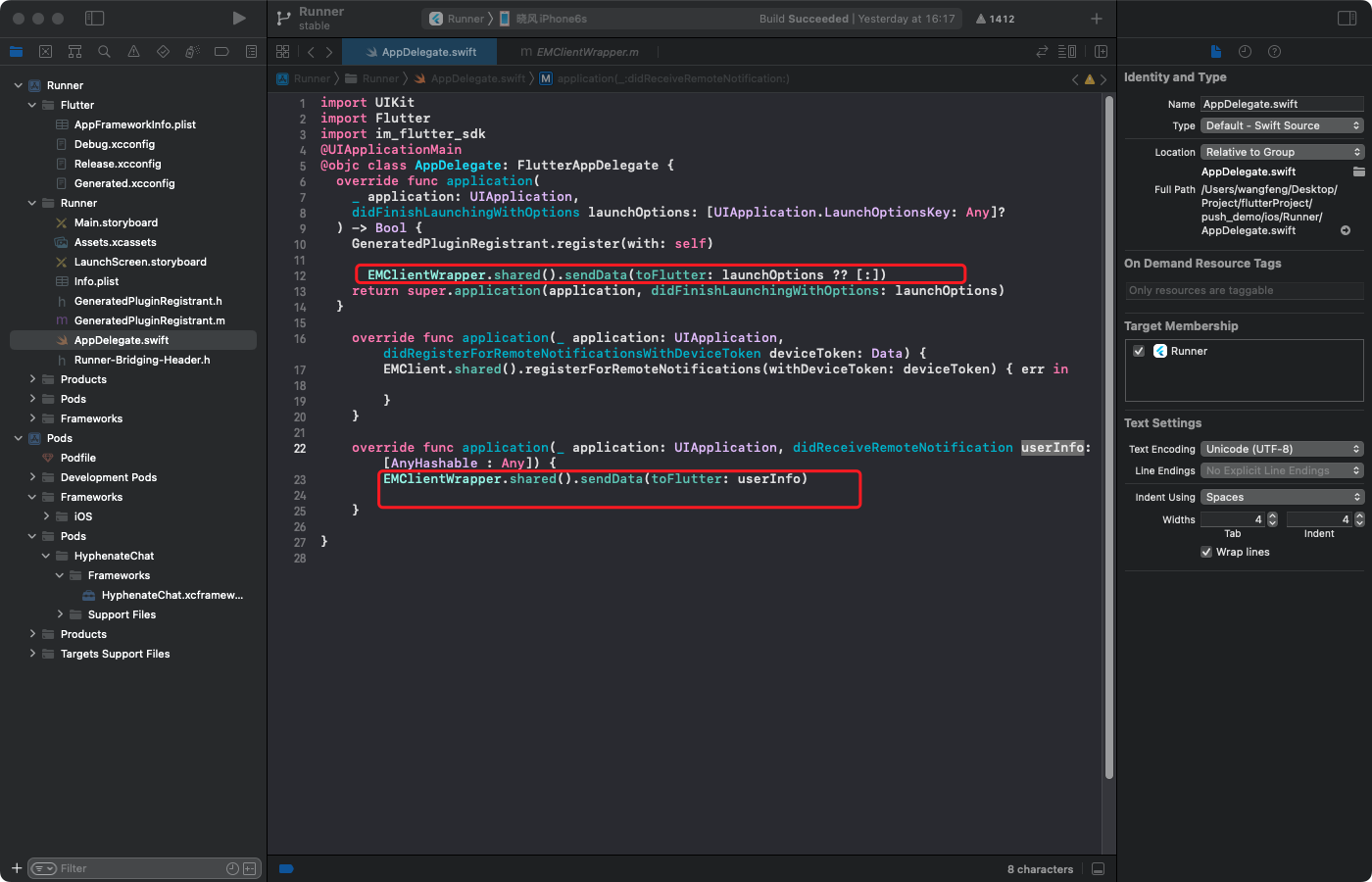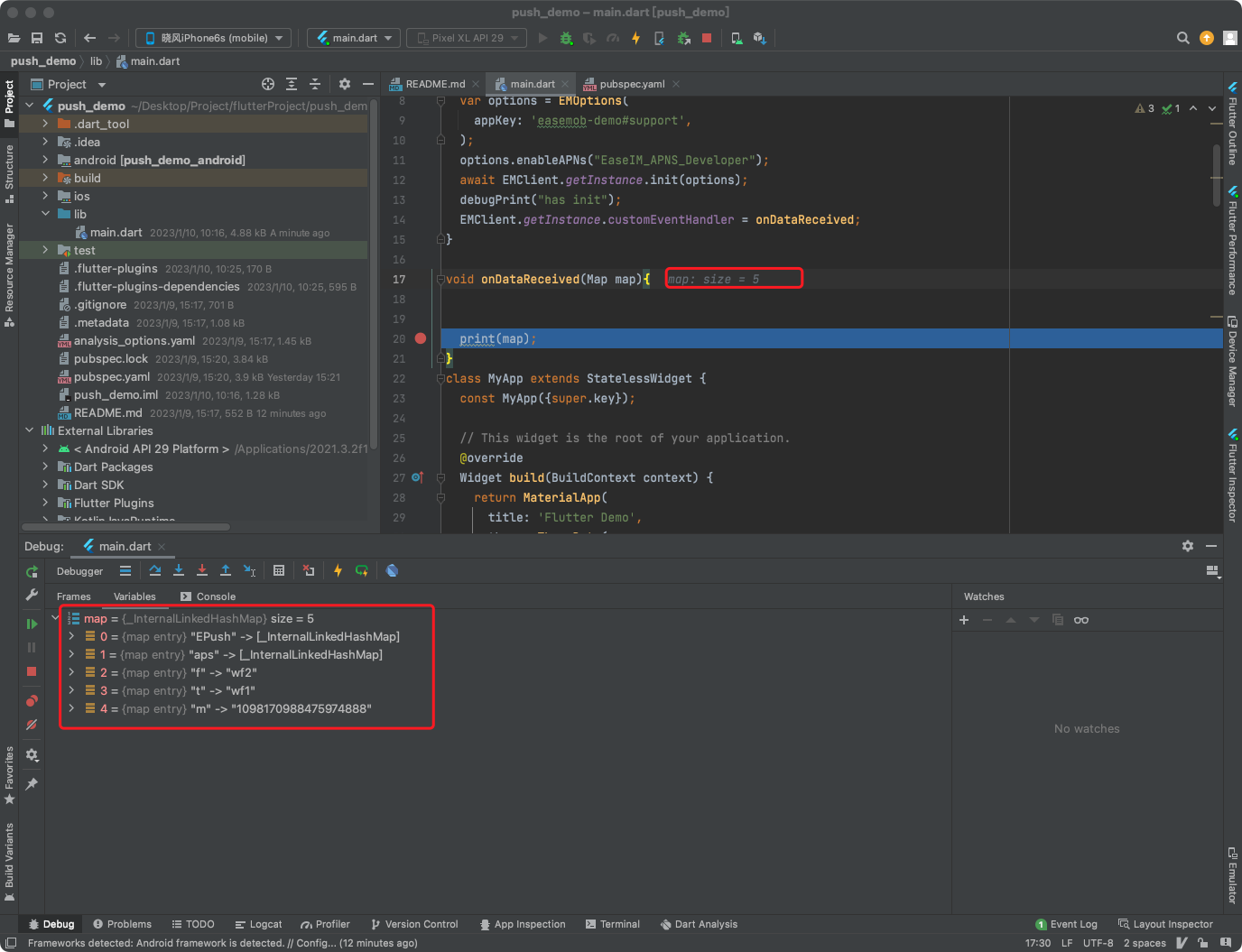
一、背景简介
1、遇到的问题
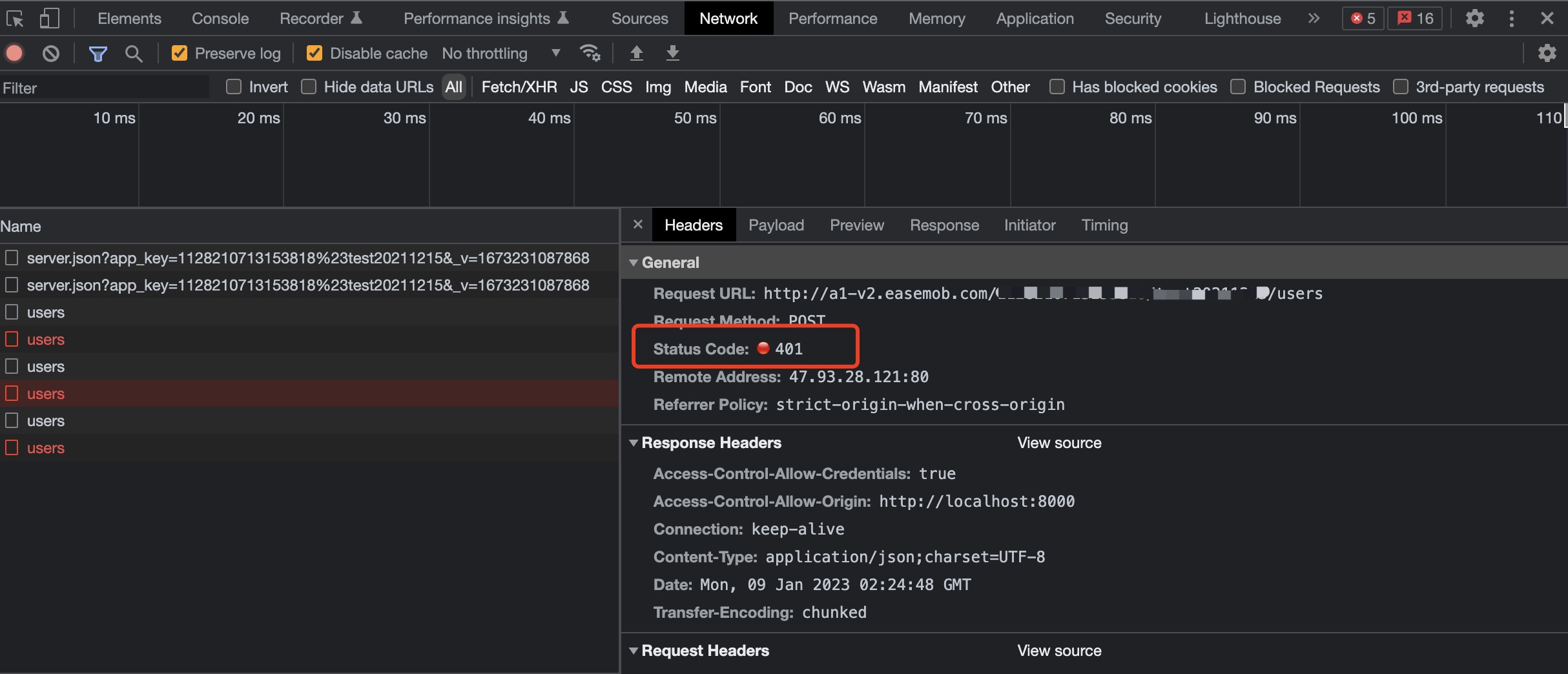
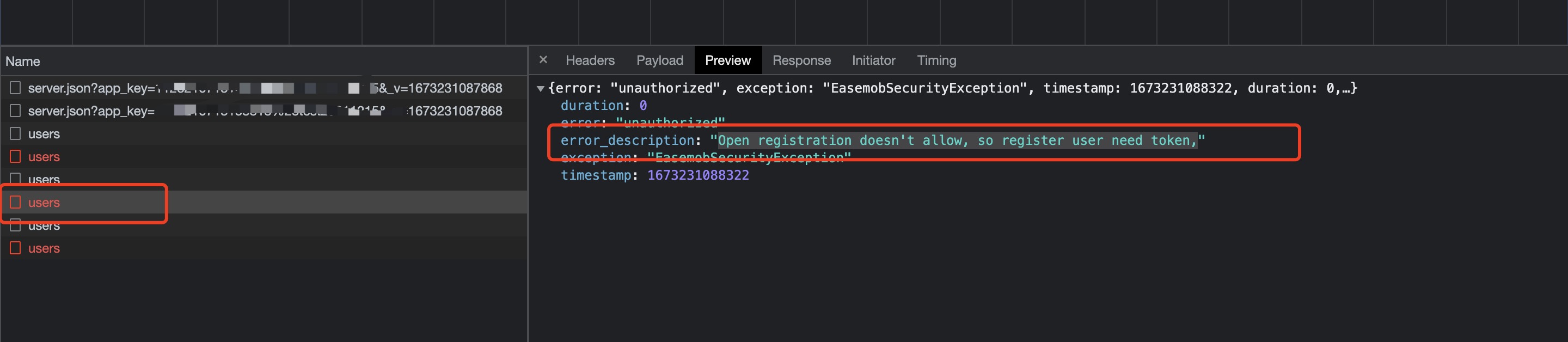
2020年,货拉拉运营部门和客户端开发对齐了https网络通信协议中的SSL网络证书校验方案;但是由于Android客户端的证书配置不规范,导致在客户端内置的SSL网络证书到期前十几天被发现证书校验异常,Android客户端面临全网访问异常的问题
2、本文内容
本文主要介绍解决货拉拉Android客户端SSL证书到期的解决方案及Android端SSL证书相关知识
二、SSL证书简介
1、SSL证书诞生背景
1994年,Netscape公司首先使用了SSL协议,SSL协议全称为:安全套接层协议(Secure Sockets Layer),它指定了在应用程序协议(如HTTP、Telnet、FTP)和TCP/IP之间提供数据安全性分层的机制,它是在传输通信协议(TCP/IP)上实现的一种安全协议,采用公开密钥技术,它为TCP/IP连接提供数据加密、服务器认证、消息完整性以及可选的客户端认证。由于SSL协议很好地解决了互联网明文传输的不安全问题,很快得到了业界的支持,并已经成为国际标准
HyperText Transfer Protocol over Secure Socket Layer。在HTTPS中,使用传输层安全性(TLS)或安全套接字层(SSL)对通信协议进行加密。也就是HTTP+SSL(TLS)=HTTPS
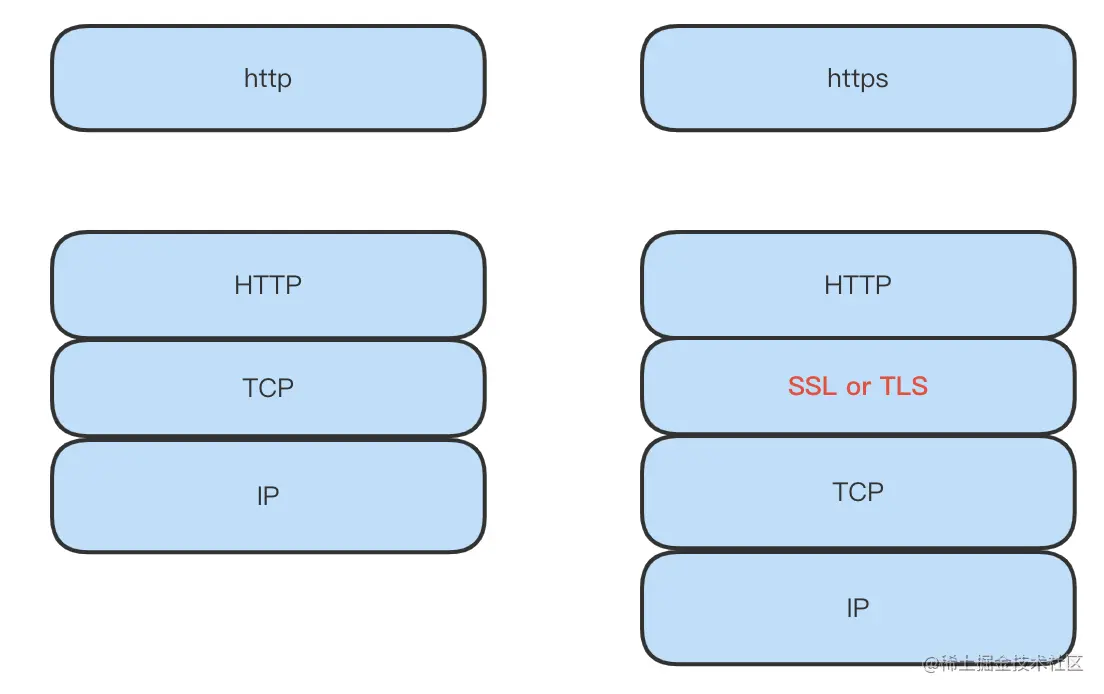
2、SSL证书简介
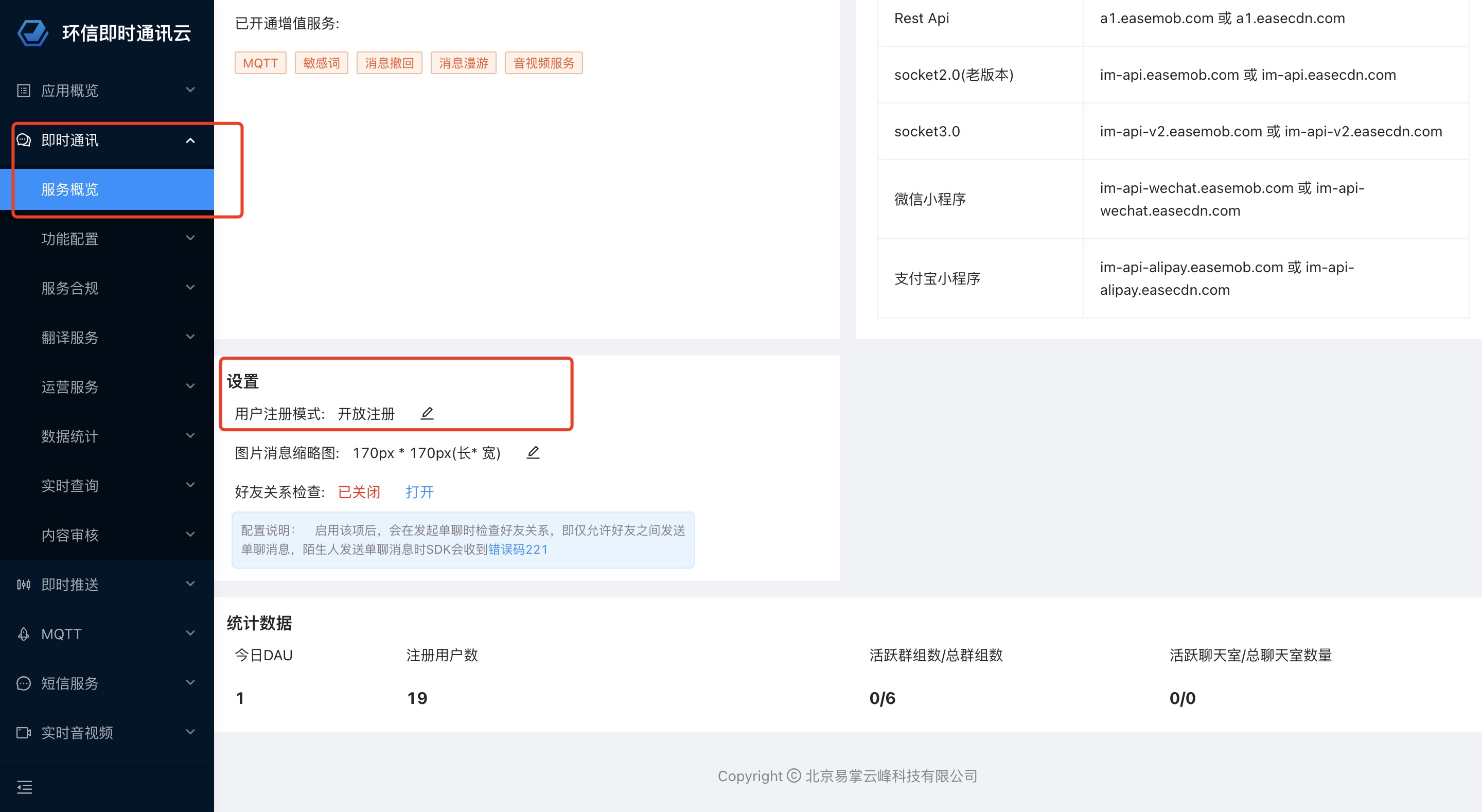
按类型划分,SSL证书包括CA证书、用户证书两种
(1)CA证书(Certification Authority证书颁发机构)
证书的签发机构(CA)颁发的电子证书,包含根证书和中间证书两种
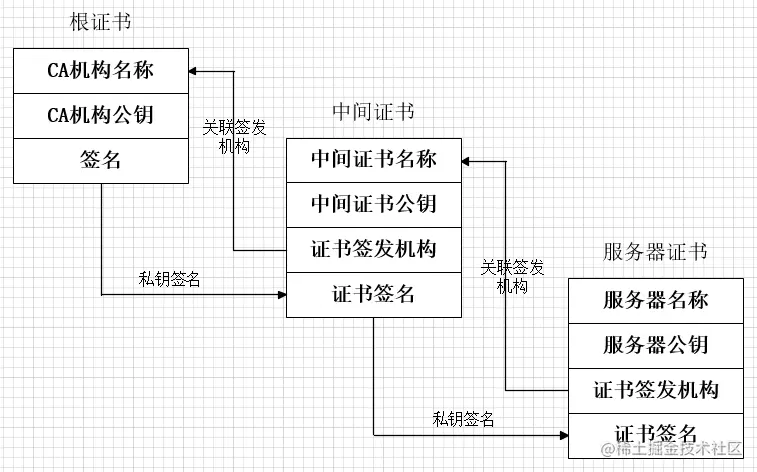
[i]根证书
属于根证书颁发机构(CA)的公钥证书,是在公开密钥基础建设中,信任链的起点
一般客户端会内置
[ii]中间证书
因为根证书太宝贵了,直接颁发风险太大了。因此,为了保护根证书,CAs通常会颁发所谓的中间证书。CA使用它的私钥对中间证书签名,使它受到信任。然后CA使用中间证书的私钥签署和颁发终端用户SSL证书。这个过程可以执行多次,其中一个中间根对另一个中间根进行签名
(2)用户证书
用户证书是由CA中间证书签发给用户的证书,包含服务器证书、客户端证书
[i]服务器证书
组成Web服务器的SSL安全功能的唯一的数字标识。 通过CA签发,并为用户提供验证您Web站点身份的手段。
服务器证书包含详细的身份验证信息,如服务器内容附属的组织、颁发证书的组织以及称为公开密钥的唯一的身份验证文件
[ii]客户端证书
在双向https验证中,就必须有客户端证书,生成方式同服务器证书一样;
单向证书则不用生成
3、SSL证书链
SSL证书链是从用户证书、生成用户证书的CA中间证书、生成CA中间证书的CA中间证书...一直到CA根证书;其中根证书只能有一个,但是CA中间证书可以有多个
(1)以baidu的证书为例
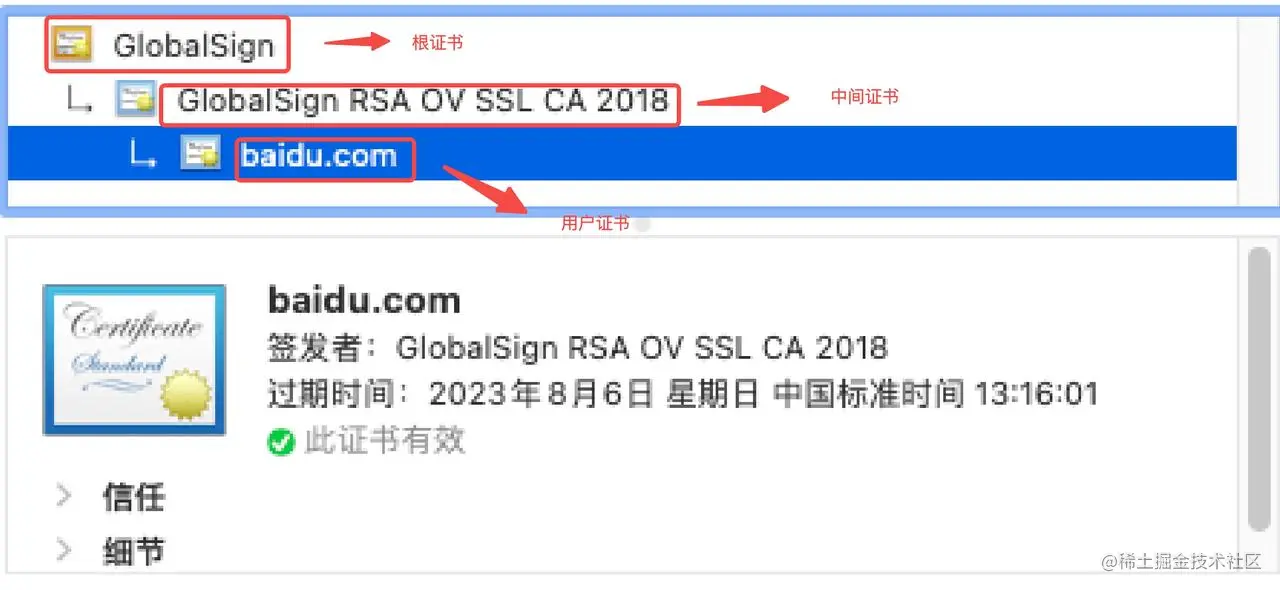
(2)证书链
客户端(比如浏览器或者Android手机)验证我们SSL证书的有效性的时候,会一层层的去寻找颁发者的证书,直到自签名的根证书,然后通过相应的公钥再反过来验证下一级的数字签名的正确性
任何数字证书都必须要有根证书做支持,有了根证书的支持才说明这个数字证书是有效的是被信任的
4、SSL证书文件的后缀
证书的后缀主要有.key、.csr、.crt、.pem等
(1).key文件:密钥文件,SSL证书的私钥就包含在其中
(2).csr文件:这个文件里面包含着证书的公钥和其他一些公司信息,通过请求签名之后就可以直接生出证书
(3).crt文件:该文件中也包含了证书的公钥、签名信息以及根据不同类型证书携带不同的认证信息,如IP等(该文件在有些机构、系统中也可能表现为.cert后缀)
(4).pem文件:该文件相对比较少见,里面包含着证书的私钥以及部分证书信息
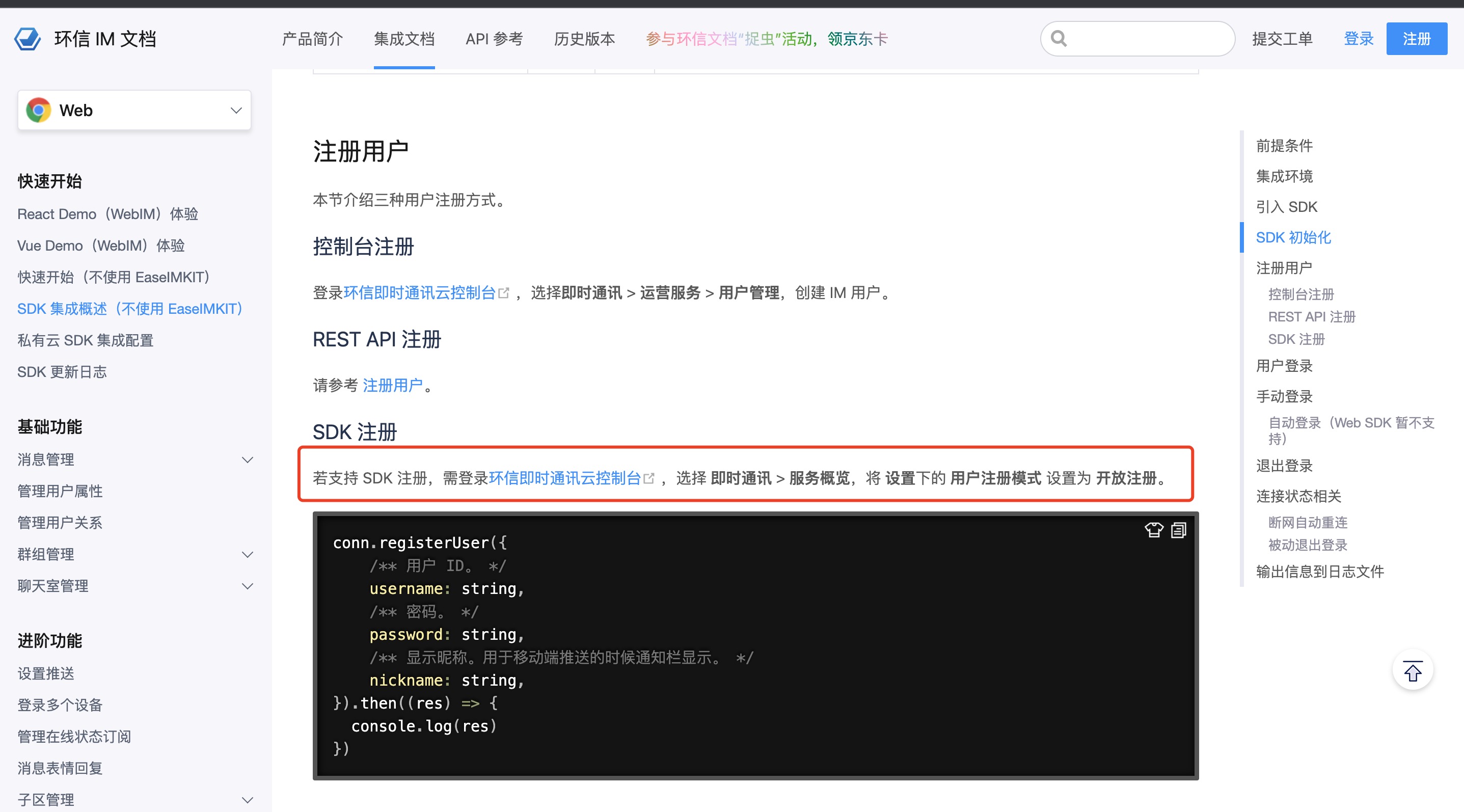
5、SSL用户证书类型
SSL用户证书主要分为(1)DV SSL证书 (2)OV SSL证书 (3)EV SSL证书
(1)DV SSL证书(域名验证型):只需验证域名所有权,无需人工验证申请单位真实身份,几分钟就可颁发的SSL证书。价格一般在百元至千元左右,适用于个人或者小型网站
(2)OV SSL证书(企业验证型):需要验证域名所有权以及企业身份信息,证明申请单位是一个合法存在的真实实体,一般在1~5个工作日颁发。价格一般在百元至几千元左右,适用于企业型用户申请
(3)EV SSL证书(扩展验证型):除了需要验证域名所有权以及企业身份信息之外,还需要提交一下扩展型验证,通常CA机构还会进行电话回访,一般在2~7个工作日颁发证书。价格一般在千元至万元左右,适用于在线交易网站、企业型网站
6、SSL证书结构

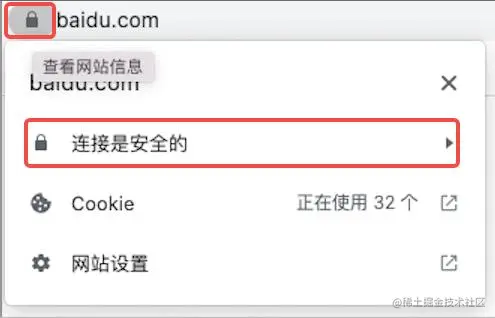
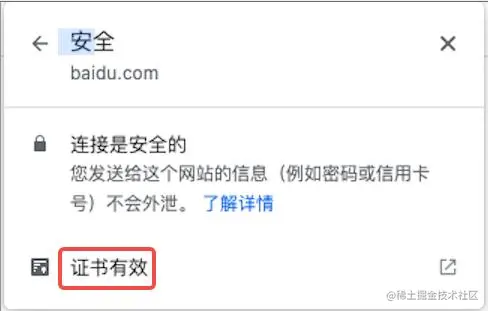
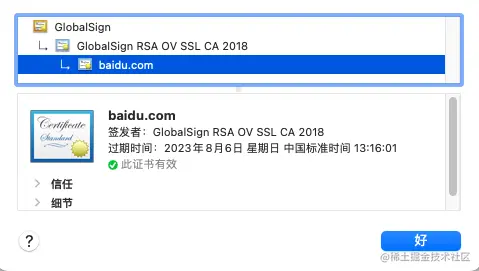
7、SSL证书查看
以Chorme上的baidu为例:
第1步
第2步
第3步
三、客户端SSL证书校验流程
1、客户端SSL证书校验主要是在网络连接的SSL/TLS握手环节校验
SSL/TLS握手(用非对称加密的手段传递密钥,然后用密钥进行对称加密传递数据)
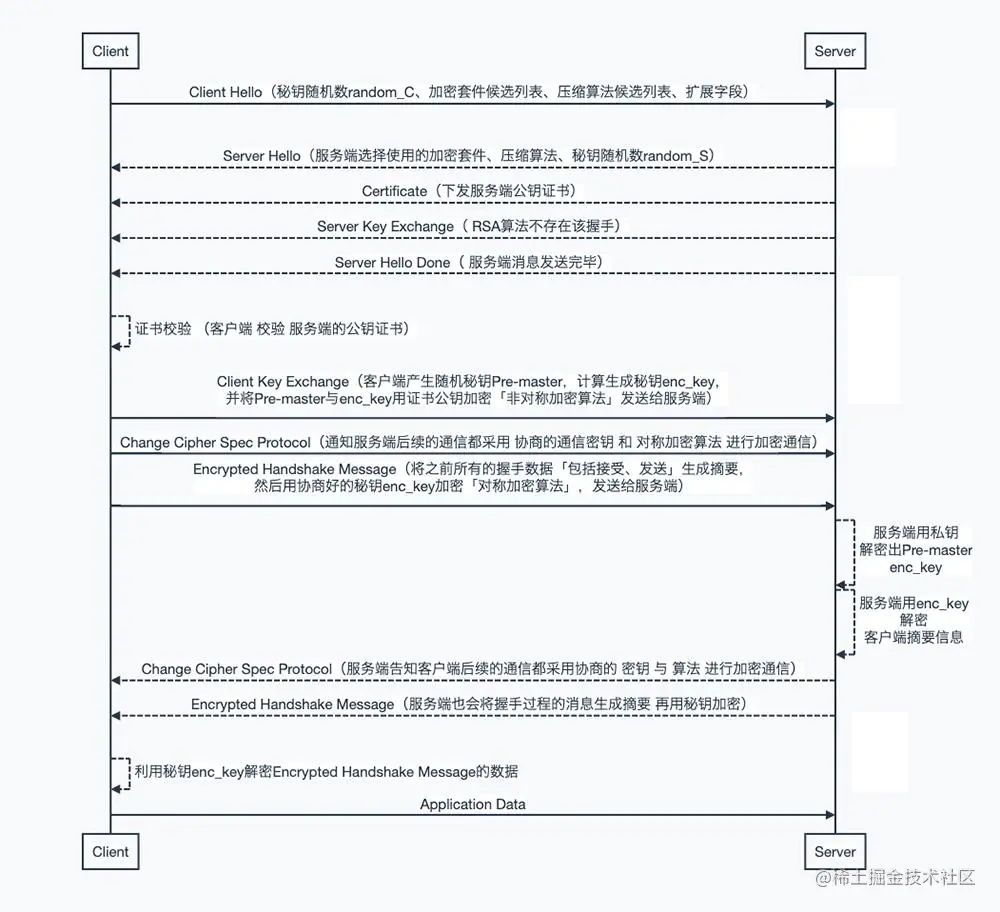
校验流程主要在上述过程的第三步和第六步
第三步:Certificate
Server——>Client 服务端下发公钥证书
第六步:证书合法性校验
Client 对 Server下发的公钥证书进行合法性校验
2、客户端证书校验过程
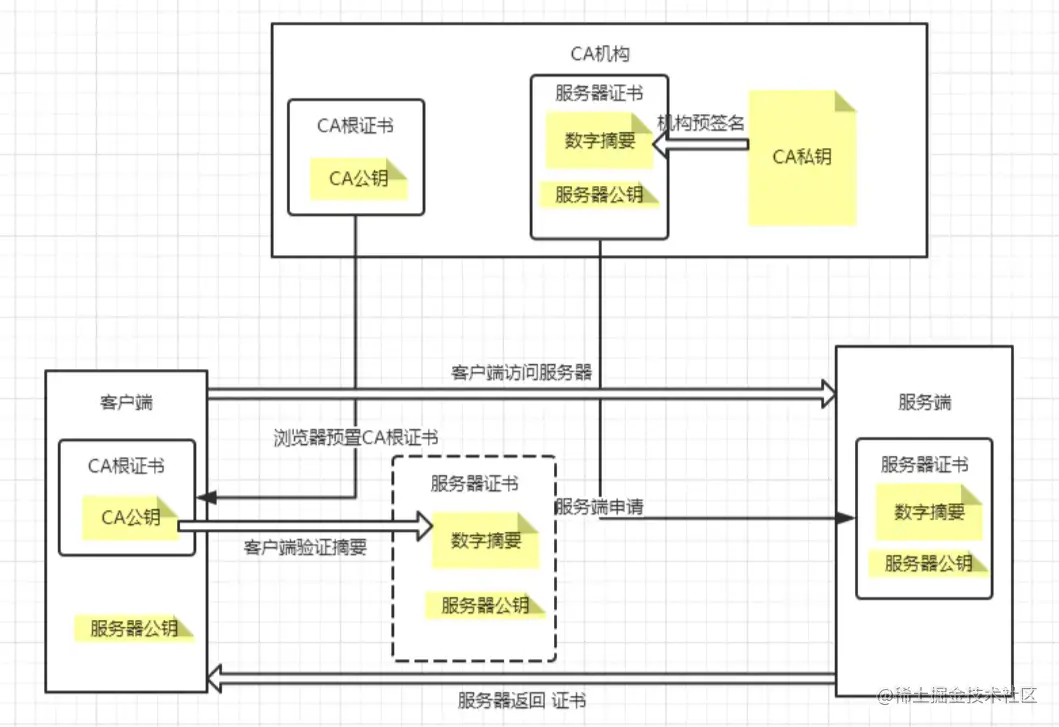
(1)校验证书是否是受信任的CA根证书颁发机构颁发
客户端通过服务器证书 中签发机构信息,获取到中间证书公钥;利用中间证书公钥进行服务器证书的签名验证
a、中间证书公钥解密 服务器签名,得到证书摘要信息;
b、摘要算法计算 服务器证书 摘要信息;
c、然后对比两个摘要信息。
客户端通过中间证书中签发机构信息,客户端本地查找到根证书公钥;利用根证书公钥进行中间证书的签名验证
(2)客户端校验服务端证书公钥及摘要信息
客户端获取到服务端的公钥:Https请求 TLS握手过程中,服务器公钥会下发到请求的客户端。
客户端用存储在本地的CA机构的公钥,对服务端公钥中对应的摘要信息进行解密,获取到服务端公钥的摘要信息A;
客户端根据对服务端公钥进行摘要计算,得到摘要信息B;
对比摘要信息A与B,相同则证书验证通过
(3)校验证书是否在上级证书的吊销列表
若证书的申请主体出现:私钥丢失、申请证书无效等情况,CA机构需要废弃该证书
(详细策略见《四、Android端证书吊销校验策略》)
(4)校验证书是否过期
校验证书的有效期是否已经过期:主要判断证书中Validity period字段是否过期(ps:Android系统默认不校验证书有效期,但浏览器和ios系统默认会校验证书有效期)
(5)校验证书域名是否一致
校验证书域名是否一致:核查 证书域名*是否与当前的*访问域名 匹配。
比如:我们请求的域名 http://www.huolala.cn 是否与证书文件中DNS标签下所列的域名相匹配;

四、Android端证书吊销校验策略
1、证书吊销校验主要存在两类机制:CRL 与 OCSP
(1)证书吊销列表校验:CRL(Certificate Revocation List)
证书吊销列表:是一个单独的文件,该文件包含了 CA机构 已经吊销的证书序列号与吊销日期;
证书中一般会包含一个 URL 地址 CRL Distribution Point,通知使用者去哪里下载对应的 CRL 以校验证书是否吊销。
该吊销方式的优点是不需要频繁更新,但是不能及时吊销证书,这期间可能已经造成了极大损失
(2)证书状态在线查询:OCSP(Online Certificate Status Protocol)
证书状态在线查询协议:一个实时查询证书是否吊销的方式。
请求者发送证书的信息并请求查询,服务器返回正常、吊销或未知中的任何一个状态。
证书中一般也会包含一个 OCSP 的 URL 地址,要求查询服务器具有良好的性能。
部分 CA 或大部分的自签 CA (根证书)都是未提供 CRL 或 OCSP 地址的,对于吊销证书会是一件非常麻烦的事情
2、Android系统默认使用CRL方式来校验证书是否被吊销
核心实现类是CertBlocklistImpl(维护了本地黑名单列表),部分源码逻辑如下:
(1)TrustManagerImpl(证书校验核心类)
第1步循环校验信任证书
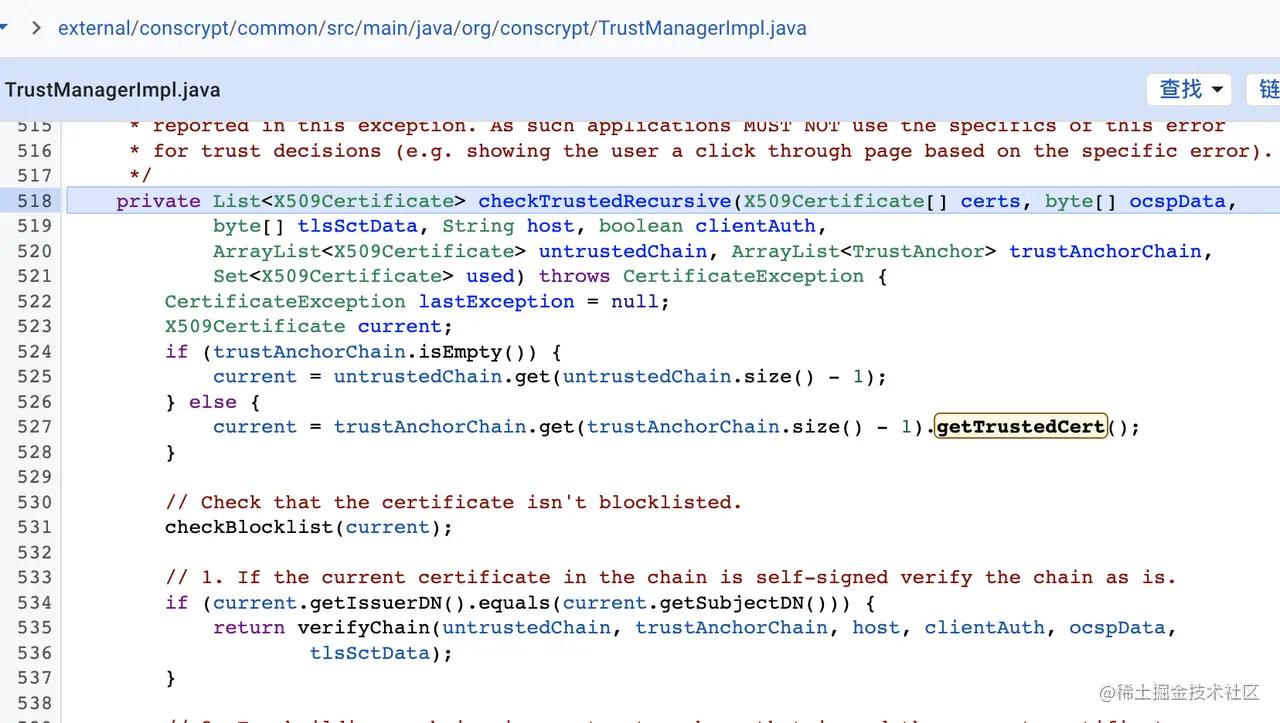
第2步检查该证书是否在黑名单列表里面
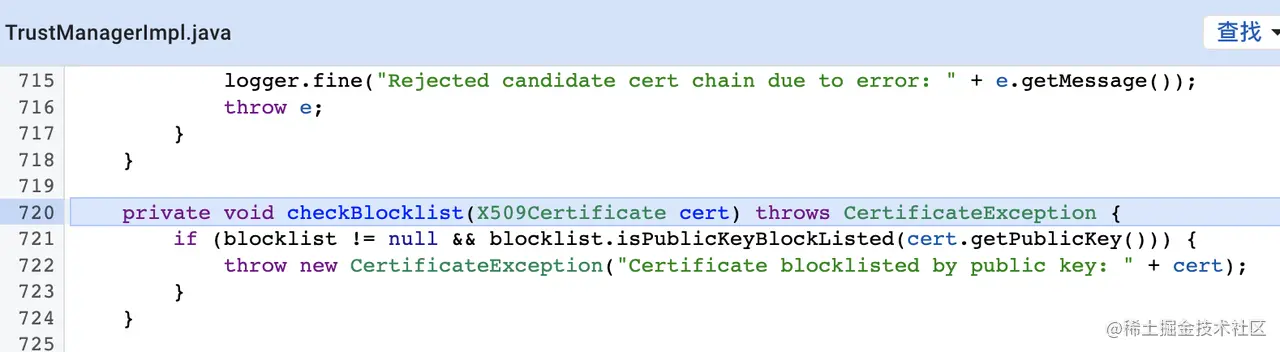
(2)CertBlocklistImpl(证书黑名单列表维护类)
黑名单校验逻辑:主要检查是否在黑名单列表里面
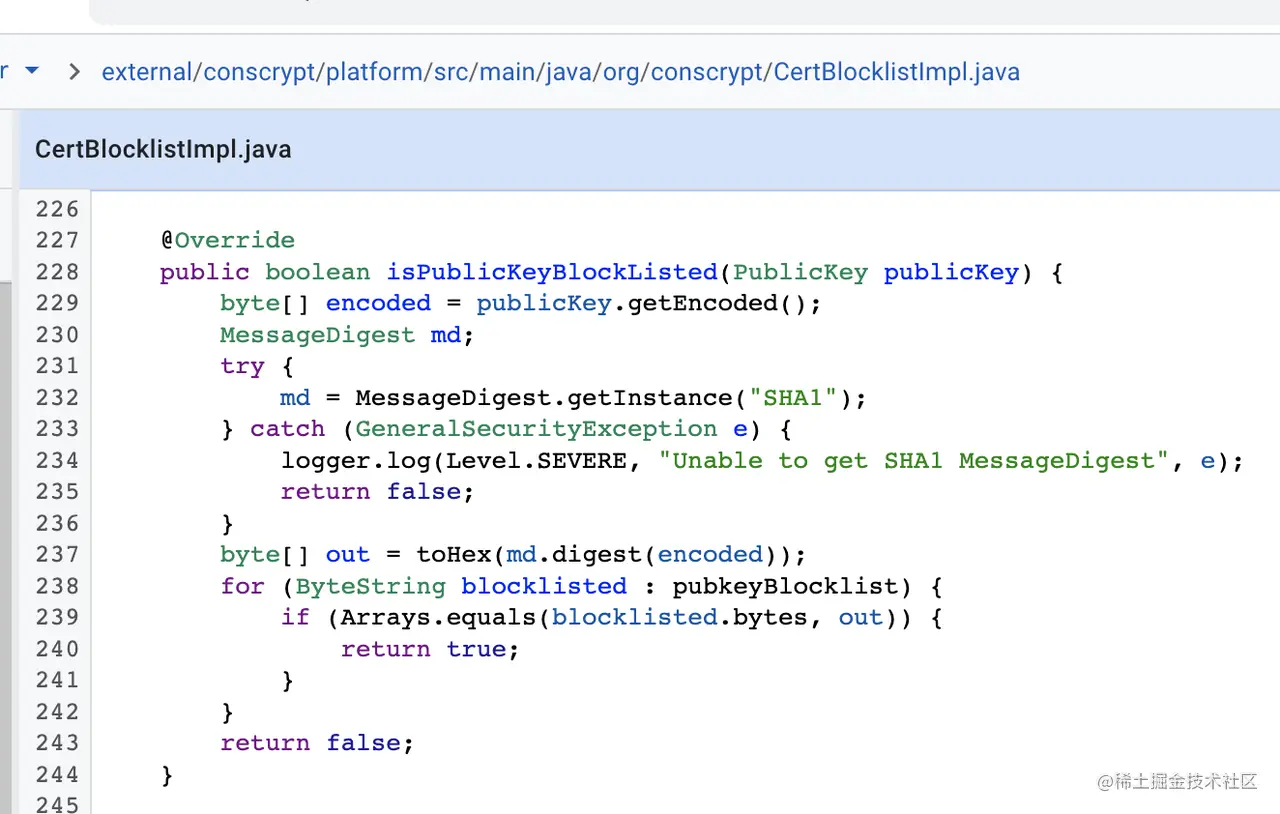
黑名单本地存储位置

可以看到黑名单文件储存在环境变量“ANDROID_DATA”/misc/keychain/pubkey_blacklist.txt;
可以通过adb shell--export--echo $ANDROID_DATA,拿到环境变量位置,一般在/data目录下
3、Android端自定义证书吊销校验逻辑
核心类在TrustManagerFactory、CertPathTrustManagerParameters、PKIXRevocationChecker
(1)TrustManagerFactory工厂模式的证书管理类
有两种init方式
[i]init(KeyStore ks) 默认使用
传递私钥,一般传递系统默认或者传空
以okhttp为例(默认传空)

[ii]init(ManagerFactoryParameters spec) 自定义方式
下面介绍下通过自定义方式来实现OCSP方式校验证书是否吊销
4、基于PKIXRevocationChecker方式自定义OCSP方式
(1)自定义TrustManagerFactory.init(ManagerFactoryParameters spec)
init方法传入基于CertPath的TrustManagerCertPathTrustManagerParameters,包装策略PKIXRevocationChecker

(2)PKIXRevocationChecker(用于检查PKIX算法的证书撤销状态)
默认使用OCSP方式校验,可以自定义使用OCSP策略还是CLR策略
参考谷歌开发者文档:developers.google.cn/j2objc/java…

五、Android端证书校验方式
主要有四种校验方式:
客户端单向认证服务端---证书锁定
客户端单向认证服务端---公钥锁定
客户端服务端双向认证
客户端信任所有证书
1、客户端单向认证服务端---证书锁定
(1)校验过程
校验服务端证书的subject信息和publickey信息是否与客户端内置证书一致,如果不一致会报错:
“java.security.cert.CertPathValidatorException: Trust anchor for certification path not found”
(2)实现方式
[i]network-security-config配置方式
(生效范围:app全局,包含webview请求)
(只支持android7.0及以上)
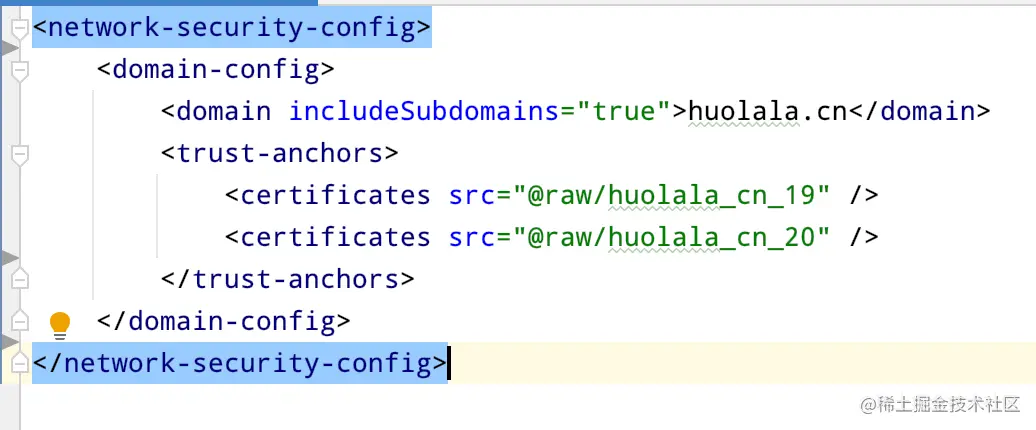
[ii]代码配置方式(生效范围:配置了该SSLParams的实例)
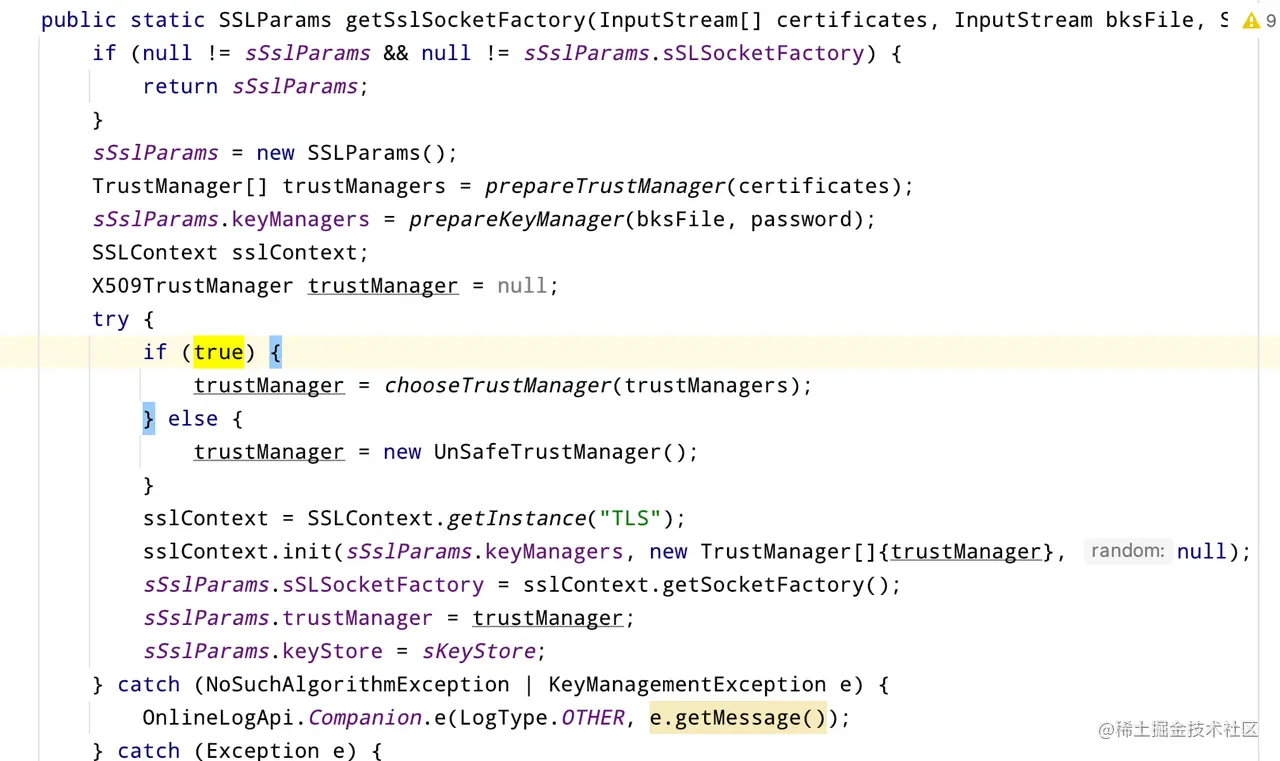
(3)优点
校验了subject信息和publickey信息,防信息篡改的安全等级高一点
(4)缺点
[i]因为一般网络证书的有效期是1-2年,所以面临过期之后可能校验异常的问题(ps:本次货拉拉客户端遇到的就是这种内置的网络证书快到期的case)
[ii]内置在app里面,证书容易泄漏
2、客户端单向认证服务端---公钥锁定
(1)校验过程
校验服务端证书的公钥信息是否与客户端内置证书的一致
(2)实现方式
[i]network-security-config配置方式
(生效范围:app全局,包含webview请求)
(只支持android7.0及以上)

[ii]代码配置方式(生效范围:配置了该参数的实例)

(3)优点
只要服务端的公钥保持不变,更换证书也能通过校验
(4)缺点
只校验了公钥,防信息篡改的安全等级低一点
3、客户端和服务端双向认证
(1)实现方式
自定义的SSLSocketFactory实现客户端和服务端双向认证
public class SSLHelper {
/** * 存储客户端自己的密钥 */ private final static String CLIENT_PRI_KEY = "client.bks";
/** * 存储服务器的公钥 */ private final static String TRUSTSTORE_PUB_KEY = "publickey.bks";
/** * 读取密码 */ private final static String CLIENT_BKS_PASSWORD = "123321";
/** * 读取密码 */ private final static String PUCBLICKEY_BKS_PASSWORD = "123321";
private final static String KEYSTORE_TYPE = "BKS";
private final static String PROTOCOL_TYPE = "TLS";
private final static String CERTIFICATE_STANDARD = "X509";
public static SSLSocketFactory getSSLCertifcation(Context context) {
SSLSocketFactory sslSocketFactory = null;
try {
// 服务器端需要验证的客户端证书,其实就是客户端的keystore
KeyStore keyStore = KeyStore.getInstance(KEYSTORE_TYPE);
// 客户端信任的服务器端证书
KeyStore trustStore = KeyStore.getInstance(KEYSTORE_TYPE);
//读取证书
InputStream ksIn = context.getAssets().open(CLIENT_PRI_KEY);
InputStream tsIn = context.getAssets().open(TRUSTSTORE_PUB_KEY);
//加载证书
keyStore.load(ksIn, CLIENT_BKS_PASSWORD.toCharArray());
trustStore.load(tsIn, PUCBLICKEY_BKS_PASSWORD.toCharArray());
//关闭流
ksIn.close();
tsIn.close();
//初始化SSLContext
SSLContext sslContext = SSLContext.getInstance(PROTOCOL_TYPE);
TrustManagerFactory trustManagerFactory = TrustManagerFactory.getInstance(CERTIFICATE_STANDARD);
KeyManagerFactory keyManagerFactory = KeyManagerFactory.getInstance(CERTIFICATE_STANDARD);
trustManagerFactory.init(trustStore);
keyManagerFactory.init(keyStore, CLIENT_BKS_PASSWORD.toCharArray());
sslContext.init(keyManagerFactory.getKeyManagers(), trustManagerFactory.getTrustManagers(), null);
sslSocketFactory = sslContext.getSocketFactory();
} catch (KeyStoreException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (CertificateException e) {
e.printStackTrace();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (UnrecoverableKeyException e) {
e.printStackTrace();
} catch (KeyManagementException e) {
e.printStackTrace();
}
return sslSocketFactory;
}
}(2)优点
双向校验更安全
(3)缺点
需要服务端支持,TLS/SSL握手耗时增长
4、客户端信任所有证书
不检验任何证书,下面列两种常见的实现方式
(1)OkHttp版本

(2)HttpURLConnection版本

六、Android端一种源码调试的方式
背景:由于证书校验相关源码不在Android.jar中,为了方便调试证书校验的流程,这里简单介绍一种非android.jar包中的Android源码调试的方式
1、下载源码
android官方提供了各个模块的git仓库地址
(2)以SSL证书调试为例
我们只需要conscrypt部分的源码:android.googlesource.com/platform/ex…
注意点:选择的分支要和被调试的手机版本一致(因为不同系统版本下源码有点区别)
如果测试及时Android10.0系统,我们可以选择android10-release分支
2、源码导入
新建一个module 把刚才的系统源码复制进来,不需要依赖,只需要在setting.gradle中include,这样做隔离性好,方便移除
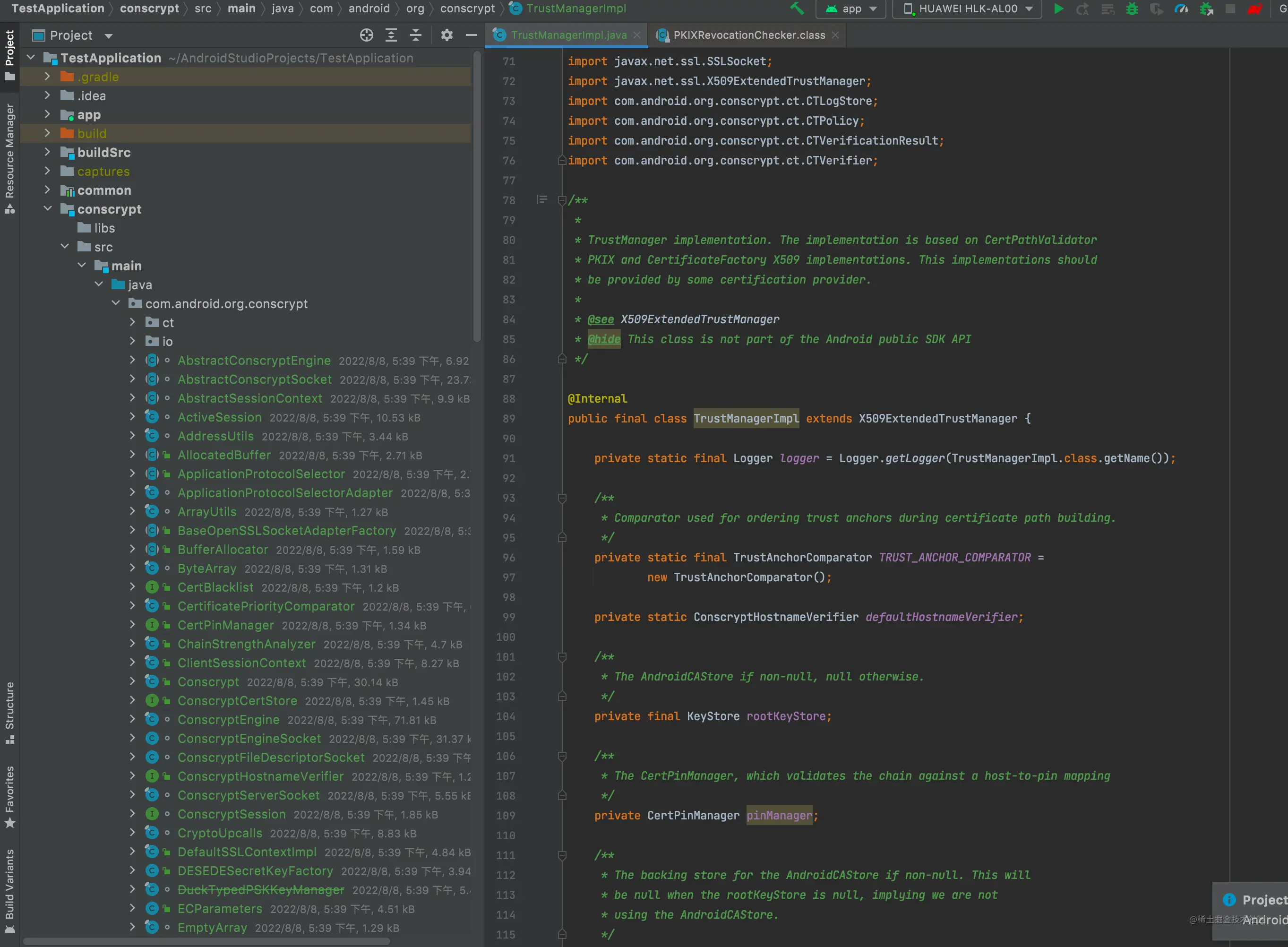
3、源码编译
导入源码之后,可能会有部分编译问题,可以解决的可以先解决,如果解决不了可以先注释;
需要注意点:
(1)不能修改行号,否则调试的时候走不到
(2)不能新增代码,新增的代码不会执行
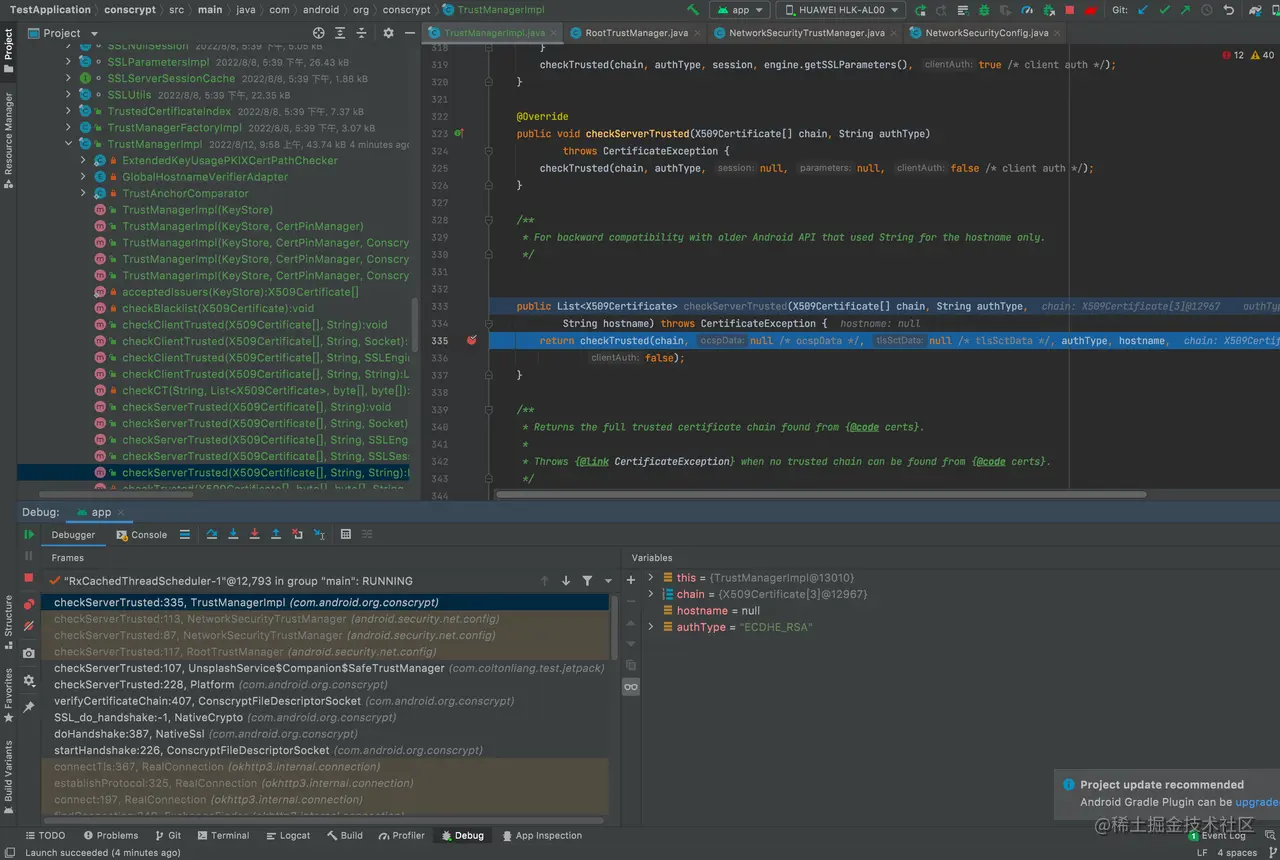
4、断点调试
打好断点就可以发车了
可以看到app发起网络请求之后会走到TrustManagerImpl里面的checkServerTrusted校验服务端证书
七、Android端证书校验源码解析
1、证书校验主要分3步
(1)握手过程中验证证书
验证证书合法性,判断是否由合法的CA签发,由上面的Android系统根证书库来判断
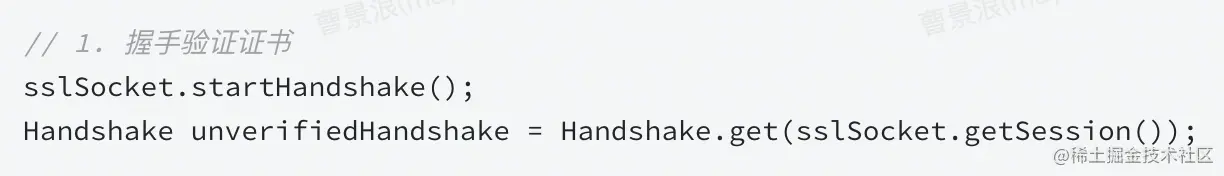
(2)验证域名
判断服务端证书是否为特定域名签发,验证网站身份,这里如果出错就会抛出
SSLPeerUnverifiedException的异常
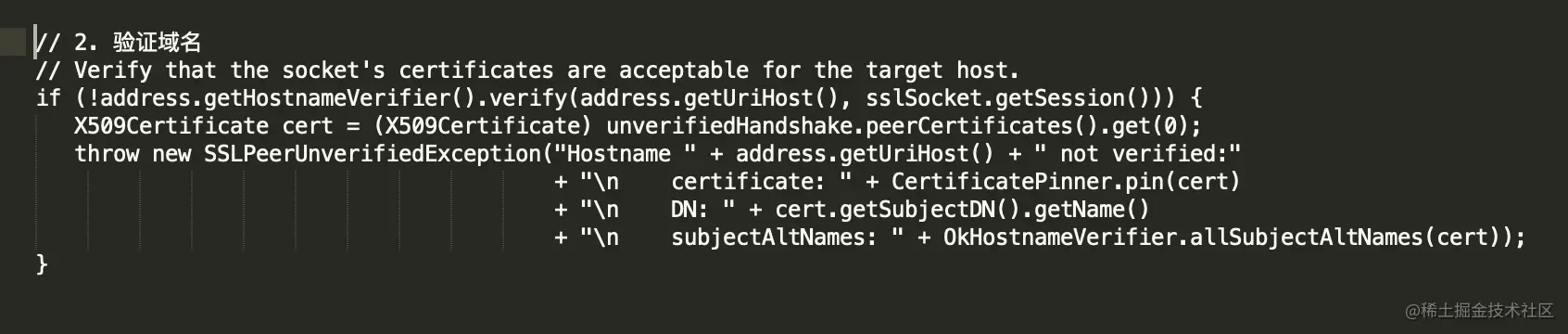
(3)验证证书绑定
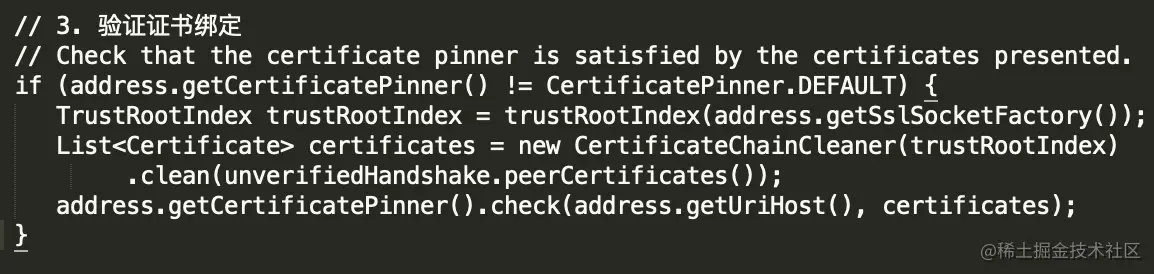
2、Android根证书相关源码
Android会内置常用的根证书,系统根证书存放在/system/etc/security/cacerts 目录下,文件均为 PEM 格式的 X509 证书格式,包含明文base64编码公钥,证书信息,哈希等
Android系统的根证书管理类
位于/frameworks/base/core/java/android/security/net/config 目录下
以下是根证书管理类的类关系图
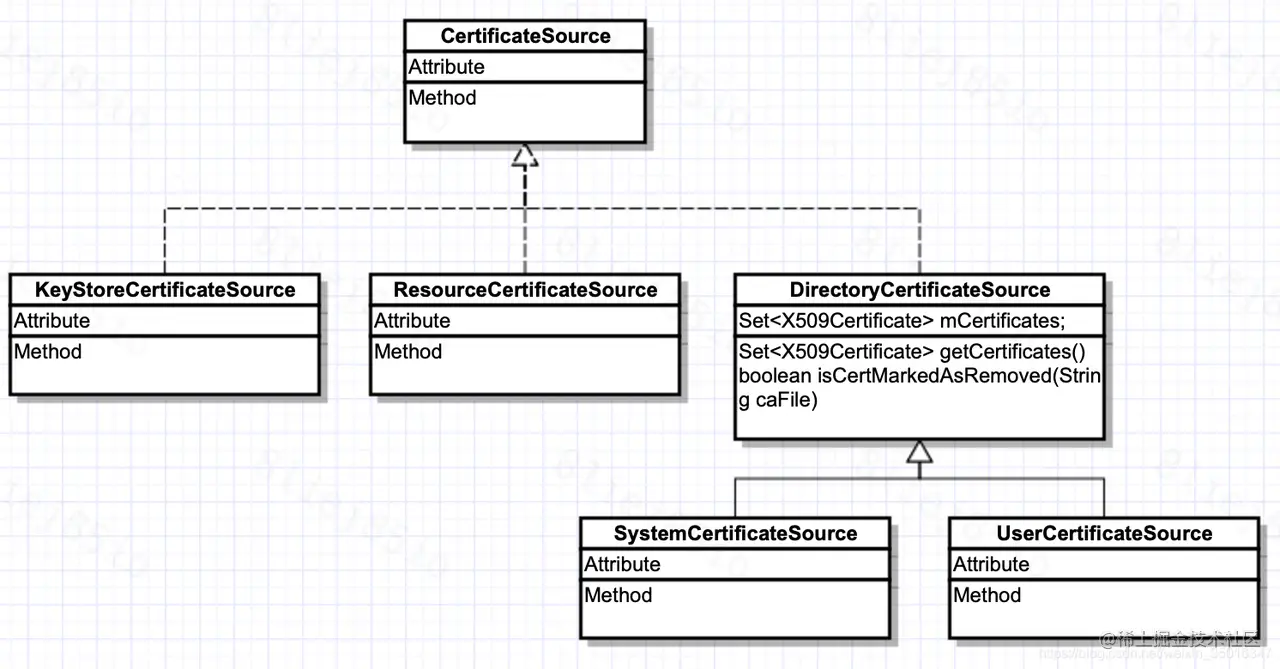
(1)CertificateSource
接口类,定义了对根证书可执行的获取和查询操作

有三个实现类,分别是KeyStoreCertificateSource、ResourceCertificateSource、DirectoryCertificateSource
(2)KeyStoreCertificateSource
从 KeyStore 中获取证书

(3)ResourceCertificateSource
基于 ResourceId 从资源目录读取文件并构造证书
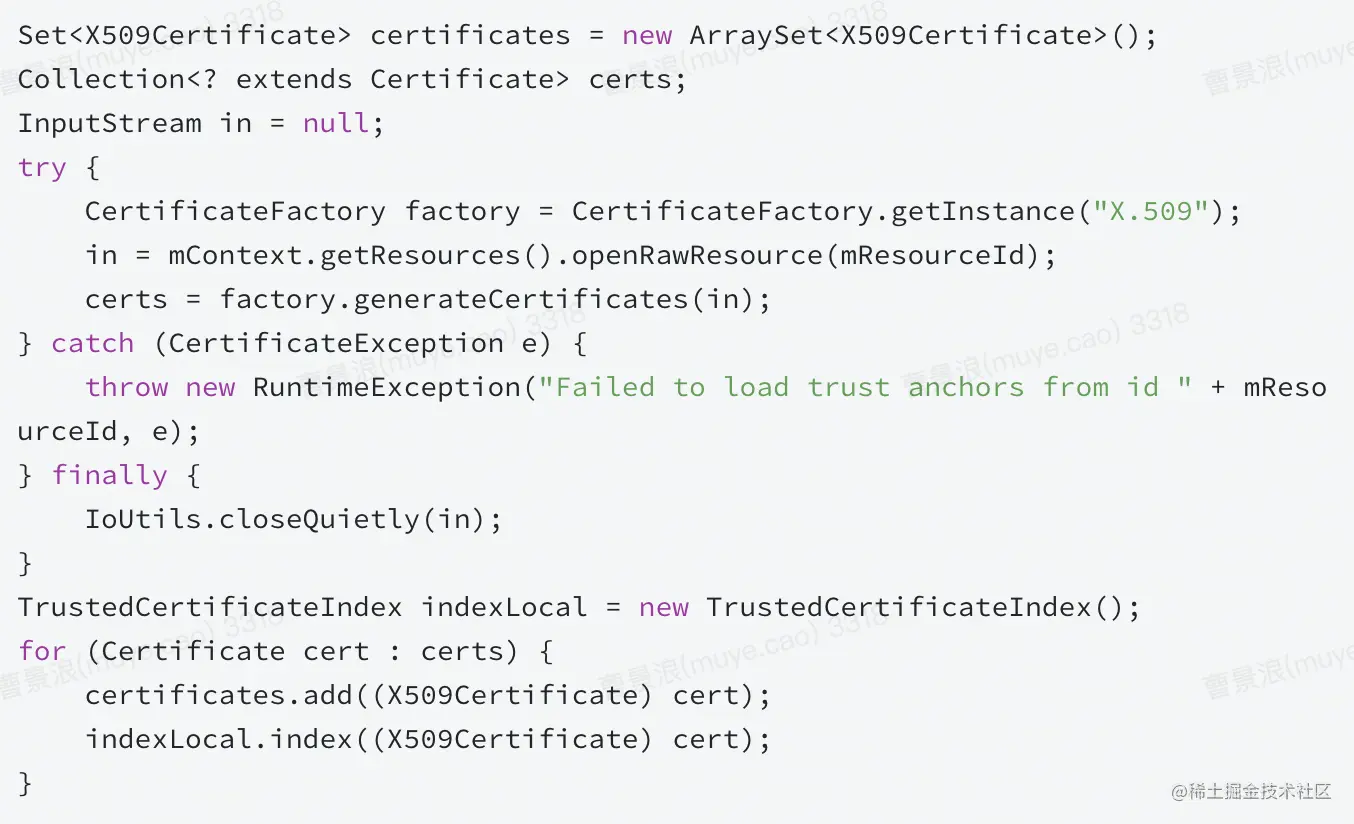
(4)DirectoryCertificateSource(抽象类)
遍历指定的目录 mDir 读取证书;还提供了一个抽象方法 isCertMarkedAsRemoved() 用于判断证书是否被移除

SystemCertificateSource 和 UserCertificateSource 继承了DirectoryCertificateSource并且分别定义了系统和用户根证书库的路径,并实现抽象方法
[i]SystemCertificateSource
定义了系统证书查询路径,并且还指定了被移除的证书文件的目录
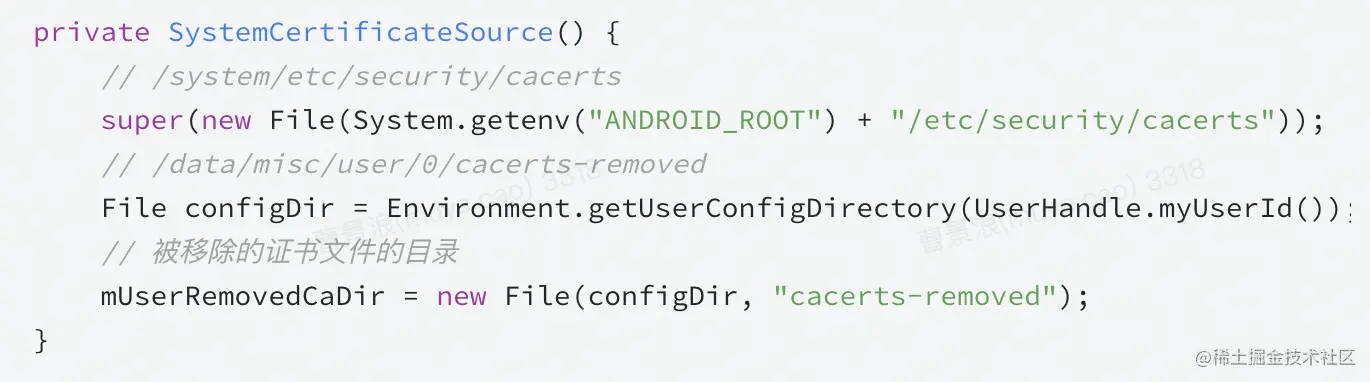
判断证书是否移除就是直接判断证书文件是否存在于指定的目录

[ii]UserCertificateSource
定义了用户证书指定查询路径,证书是否移除永远为false
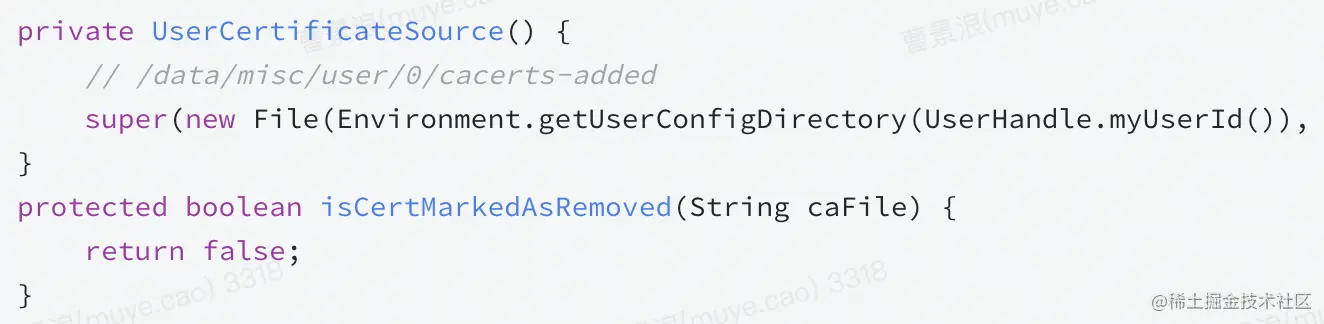
3、Android证书校验源码
(以证书锁定方式的单向校验服务端证书为例)
核心类TrustManagerImpl、TrustedCertificateIndex、X500Principal
(1)第一步checkServerTrusted()
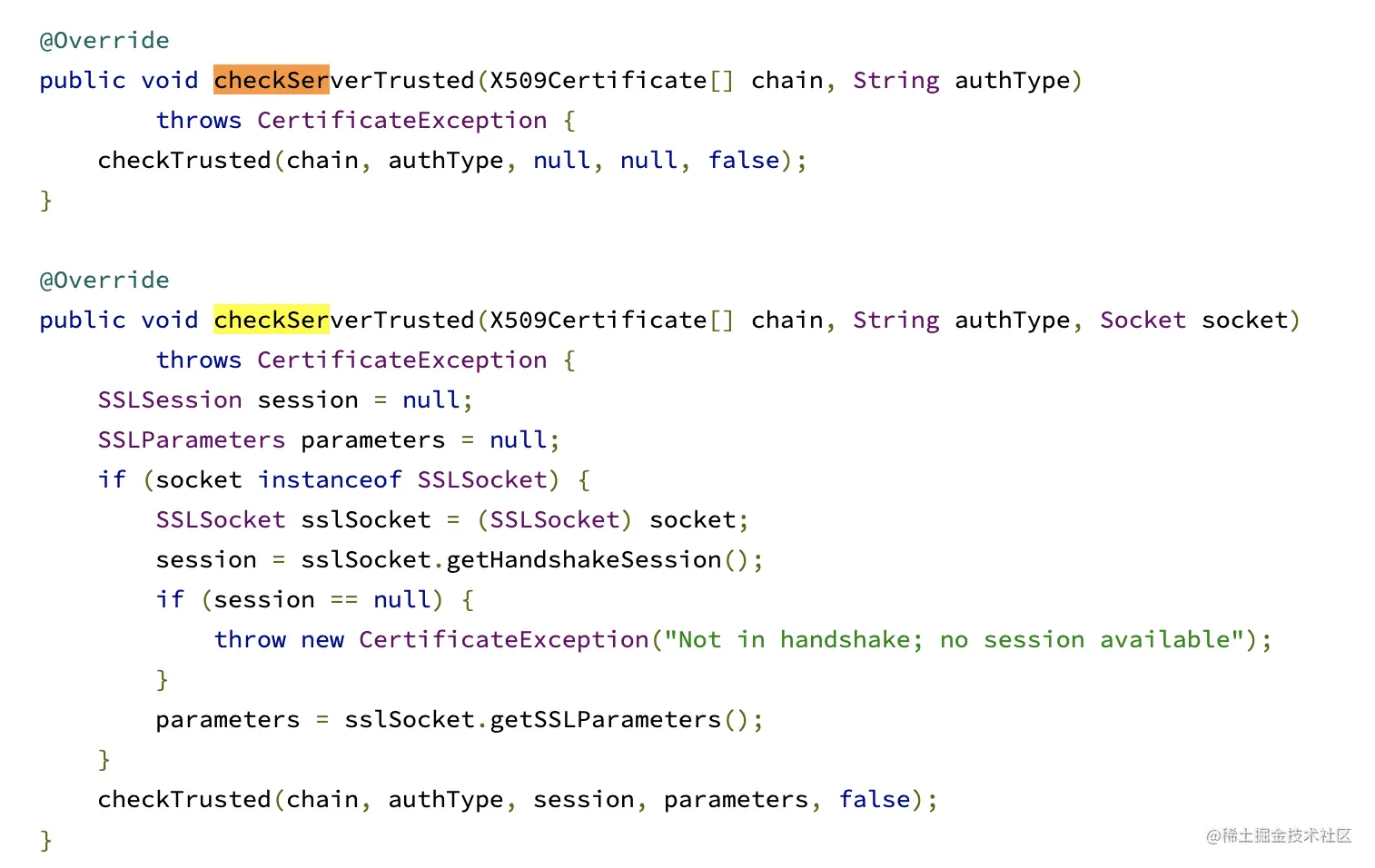
(2)第二步checkTrusted()

(3)第三步TrustedCertificateIndex类匹配证书issuer和signature信息
private final Map<X500Principal, List> subjectToTrustAnchors
= new HashMap<X500Principal, List>();
可以看到获取TrustAnchor是通过HashMap的key X500Principal匹配获取的,

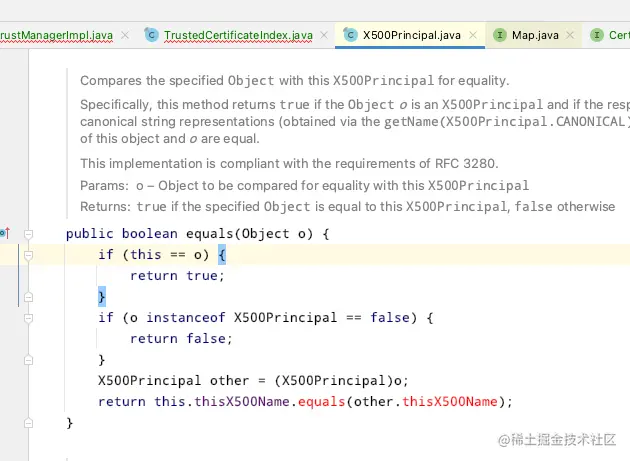
(4)X500Principal
private transient X500Name thisX500Name;
查看X500Principal的源码可以看到它覆写了equals()方法,对比的是属性中的thisX500Name
调试下来发现我们客户端证书的 thisX500Name 的值为
“CN=*. huolala.cn , OU=IT, O=深圳货拉拉科技有限公司, L=深圳市, ST=广东省, C=CN”
(ps:后面会提到,货拉拉客户端证书异常主要因为新证书缺少了OU字段)
(5)subject和issue信息
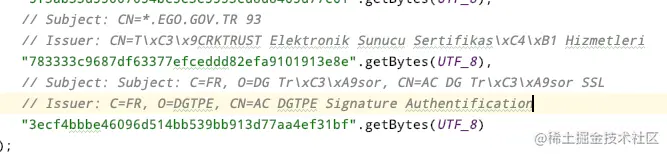
八、货拉拉SSL证书踩坑流程
1、背景简介
2020年7月份的时候,货拉拉出现了因为网络证书过期导致的异常,所以运维的同事拉了客户端的同事一起对齐了方案,使用上述《客户端单向认证服务端---公钥锁定》的方式
由于历史原因:
货拉拉用户端使用了上述(三、1(2)客户端单向认证服务端---证书锁定,代码配置方式)
货拉拉司机端使用了上述(三、1(1)客户端单向认证服务端---证书锁定,network-security-config配置方式)
2021年7月份的时候,运维同事更新了服务端的证书,因为更换过程中没有出现异常,所以运维的同事以为android端都是按照之前约定的《客户端单向认证服务端---公钥锁定》方式
(但实际原因是用户和司机端提前内置了2022-8-19过期的证书)
2、线上出现异常
2022-8-1的时候,运维同事开始操作更新服务端2023年的证书,在更新了H5部分域名的证书之后,司机Android端出现部分网页白屏的问题
排查之后发现服务端更新了证书导致客户端证书校验证书非法导致异常
2022-8-2的时候开始排查用户端的逻辑,发现是《客户端单向认证服务端---证书锁定,代码配置方式》,测试之后发现
(1)删除app内置2022年的证书,只保留2020年的证书之后,native请求异常,无法进入app
(2)手动调整手机设备时间,发现native请求正常,webview白屏和图片加载失败
意味着在服务端更换的证书2022-8-19到期之后,客户端将面临全网访问异常的问题
3、第一次尝试解决
测试的时候发现,android端在证书过期时仍然可以访问服务端(客户端和服务端都保持一致的2022年的证书);
所以想的第1个解决方案是服务端仍然使用2022-8-19的证书,直到大部分用户升级上来之后再更换新证书;
但是ios和web发现如果服务端使用过期证书的情况,系统底层会拦截这个过期证书直接报错;
所以无法兼容所有客户端
4、第二次尝试解决
在查看源码TrustManagerImpl类源码的时候发现,TrustManagerImpl的服务端检验只是校验了publickey(公钥),所以如果2022年的旧证书和2023年的新证书如果公钥一致的话,可能可以校验通过;
所以想的第2个解决方案是服务端使用的新证书保持和2022-8-19的证书的公钥一致就可以;
但是测试的时候发现native请求还是会报错
“java.security.cert.CertPathValidatorException: Trust anchor for certification path not found”
5、第三次尝试解决
开发发现按照证书链的校验过程,如下:
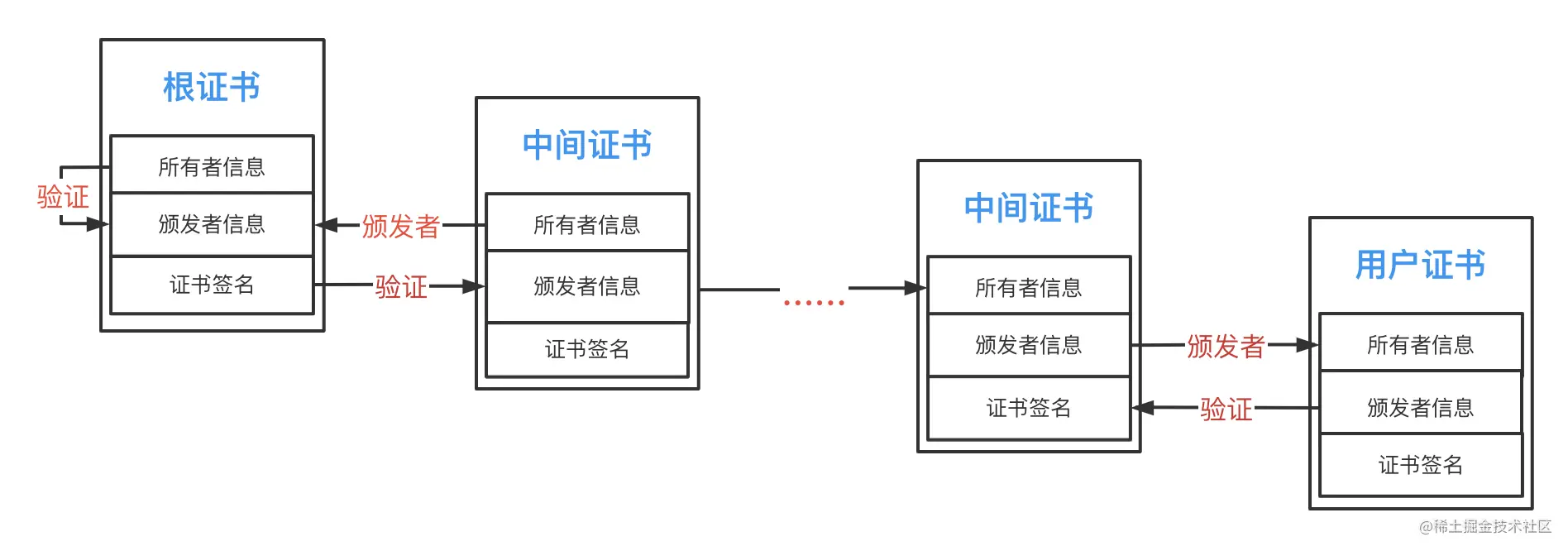
如果有中间证书,那么这个中间证书机构颁发的任何服务器证书都可以都校验通过;
所以想出的第3个解决方案是服务器证书内置中间证书组成证书链;
但是排查之后发现服务器证书和客户端内置的证书里面都已经包含了中间证书,所以依然行不通
(ps:如果客户端内置的证书里面删除用户证书信息,只保留中间证书信息,那么只要是这家中间证书颁发的所有的服务器证书都是可以校验通过的,而且一般中间证书的有效期是10年,这也可以作为一个备选项,不过缺点是不安全)
6、第四次尝试解决
(1)测试同学在网上找到一篇《那些年踩过HTTPS的坑(二)——APP证书链mp.weixin.qq.com/s/yv_XcMLvr…
所以想到的解决方案是重新申请一个带OU字段的新服务器证书
(2)但是运维同事咨询了两家之前的中间商之后对方的回复都是新的证书已经不再提供OU字段,理由是


(3)最后历经一言难尽的各种插曲最后找UniTrust颁发了带OU字段的新证书
(ps:还在使用证书锁定方式校验的可以留意下证书里面的OU字段,后续证书都不会再提供)
九、Android端证书校验的解决方案
1、认证方式
按照安全等级划分,从高到低依次为:
(1)客户端和服务端双向认证,参考上述《五、Android端证书校验方式-3、客户端和服务端双向认证》
(2)客户端单向认证服务端---证书锁定,参考上述《五、Android端证书校验方式-1、客户端单向认证服务端---证书锁定》
(3)客户端单向认证服务端---公钥锁定,参考上述《五、Android端证书校验方式-2、客户端单向认证服务端---公钥锁定》
可以根据各自的安全需求选择合适的认证方式
2、校验方式
(1)证书校验
具体方式参考《五、Android端证书校验方式-1、客户端单向认证服务端---证书锁定》;
为了增强安全性,app可以内置加密后的证书,将解密信息存放在加固后的c++端,增强安全性
(2)公钥校验
具体方式参考《五、Android端证书校验方式-2、客户端单向认证服务端---公钥锁定》;
为了增强安全性,app可以内置加密后的公钥,将解密信息存放在加固后的c++端,增强安全性
3、配置降级
为了在出现异常情况时不影响app访问,可以添加动态配置和动态降级能力
(1)动态配置
动态下发公钥和证书信息,需要留意下发的时机要尽量早一点,避免证书异常时走不到下发的请求
(2)动态降级
动态降级证书校验功能,在客户端证书或者服务端证书出现异常时,支持动态关闭所有的证书校验的功能
十、总结
最后,总结一下整体的思路:
1、SSL证书分为CA证书和用户证书
2、客户端SSL证书校验是在网络连接的SSL/TLS握手环节进行校验
3、SSL证书的认证方式分为(1)单向认证(2)双向认证
4、SSL证书的校验方式分为(1)证书校验(2)公钥校验
5、SSL证书的校验流程主要是校验证书是否是由受信任的CA机构签发的合法证书
6、SSL证书的吊销校验策略分为(1)CRL本地校验证书吊销列表(2)OCSP证书状态在线查询
7、纵观本次踩坑之旅,也暴露出一个比较深刻的问题:大部分的客户端开发的认知还是停留在app上层,缺少对底层技术的认识和探索,导致一个很小的配置问题差点酿成大的事故;这也为想在客户端领域进一步提升提供了一个思路:多学习客户端的底层技术,包含网络底层实现、安全、系统底层源码等等
8、最后,解决技术类问题最核心的点还是学习和熟悉源代码;解决证书配置问题的过程中,走了不少弯路,本质上是最开始没有彻底掌握证书校验相关的系统源代码的逻辑,客观上是由于缺少非android.jar源码的调试手段导致阅读源码遗漏了部分校验逻辑,所以本次特意补上(六、Android端一种源码调试的方式),希望后续遇到系统级的疑难杂症可以用的上
参考:
http://www.cnblogs.com/xiaxveliang…
blog.csdn.net/weixin_3501…
作者:货拉拉技术
来源:https://juejin.cn/post/7186837003026038843
收起阅读 »