








Flutter 组件分析之AspectRatio
引言
AspectRatio 可以根据具体的长宽比约束 child 的布局范围, 从而影响 child 的大小. 通常在视频、图像中会经常使用, 今天我们来分析一下它的实现原理.
AspectRatio
AspectRatio 的参数只有 key、aspectRatio、child. 它会根据 aspectRatio 去重计算约束 child 的布局范围.
我们举一个例子:
Center(
child: AspectRatio(
aspectRatio: 1.0,
child: Image.network('xx'),
),
)以图片长宽比3:2为例子
当 aspectRatio 为1.0时:
由于图片的比例大于 1.0, aspectRatio 取 1.0 时, 以屏宽为基准, 1:1为比例, 构建了一个正方形的布局约束范围. 当图片比大于 1.0 时, 图片以屏宽为图片宽, 而图片高要小于约束高. 因此实际布局中, 图片在约束中央.
当 aspectRatio 为0.2时:
由于图片的比例大于 1.0, aspectRatio 取 0.2 时, 屏幕宽高大于0.2. 以屏高为基准, 1:5为比例, 构建了一个矩形的布局约束范围. 当图片比大于 1.0 时, 图片以屏幕高的1/5为图片宽. 因此实际布局中, 图片会比正常小.
当 aspectRatio 为5.0时:
由于图片的比例大于 1.0, aspectRatio 取 5.0 时, 屏幕宽高小于5.0. 以屏宽为基准, 5:1为比例, 构建了一个矩形的布局约束范围. 当图片比大于 1.0 时, 图片以屏幕高为图片的高. 因此实际布局中, 图片会比正常小.
这一系列的原因都来自于内部的算法, 让我们一起进入源码中学习一下~
RenderAspectRatio
RenderAspectRatio 是 AspectRatio 的 RenderObject . 里面也封装了关于布局的计算规则, AspectRatio 的计算核心在于 _applyAspectRatio.
constraints.isTight
如果尺寸刚刚好合适的话, 会返回满足约束的最小大小
非constraints.isTight
这种情况下, width 会拥有默认赋值. 首先会等于约束的最大宽度. 如果宽度是有限的, 那么高度会根据 _aspectRatio 赋值. 反之, 高度会取约束限制的最大高, 同时将宽根据高度重赋值.在赋值完基础度宽高后, 会通过四个判断获取最后的尺寸.
四个判断如下:
- width > constraints.maxWidth
当宽度大于约束最大宽时, 会重新把宽赋值为约束的最大宽, 并重计算高 - height > constraints.maxHeight
当高度大于约束最大高时, 会重新把高赋值为约束的最大高, 并重计算宽 - width < constraints.minWidth
当宽小于约束的最小值时, 会把宽赋值为约束度最小值, 并重计算高 - height < constraints.minHeight
当高小于约束的最小值时, 会把高赋值为约束度最小值, 并重计算宽
在经过这一系列计算后, 宽高将会根据 aspectRatio 重计算直至符合 aspectRatio 并且能放进约束中.
链接:https://juejin.cn/post/7177559990805217340
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 小技巧之快速理解手势逻辑
GestureDetector
不管你用 InkWell 、InkResponse 、TextButton 还是 ElevatedButton , 它们针对手势的处理逻辑都是来自于 GestureDetector ,也就是理解 Flutter 的手势处理逻辑入门,核心可以从分析 GestureDetector 开始。
其实更严格意义上讲,手势事件是来自
Listener,GestureDetector是针对Listener进行了封装,只是为了避免复杂的源码分析,这里就不做展开,你可以简单理解为:并不是所有的控件都会响应手势,只有带有Listener的才会响应,这主要体现在触摸事件的递归响应上。
在 GestureDetector 里关于事件的响应逻辑主要来自于各种 GestureRecognizer (手势识别)的实现逻辑,不同的手势识别逻辑会响应不同手势结果,相互竞争,最后在 GestureArenaManager (竞技场) 决定出一个胜利者。
简单来说,在竞技场里手势基本遵循两个逻辑:
- 每个 Recognizer 都可以随时选择失败退出,当竞技场只有它一个的时候它就赢了
- 每个 Recognizer 都可以随时宣布自己获得胜利,这时其他 Recognizer 也将不再响应
那么如下图所示,在 GestureDetector 里主要有这 8 种 GestureRecognizer 在处理不同的场景,他们会根据用户使用 GestureDetector 时的参数搭配来参与到事件竞技场里。
举个例子,当你使用了 GestureDetector 并配置了 onTap 、onLongPress 和 onDoubleTap ,它们是如何分别响应手势事件的?
这里的核心逻辑就在于 deadline (时间) 的处理,不管是 onLongPress 还是 onDoubleTap 都是靠 deadline 来判断胜负。
例如,当用户只是普通点击时,如下代码所示,因为默认 LongPressGestureRecognizer 的 deadline 是 500 毫秒,所以在定时器达到 500ms 响应之前,就会因为 PointerUpEvent 导致长按定时器停止,无法触发响应长按事件。
反之如果没有 PointerUpEvent 产生,那么 500 ms 之后 LongPressGestureRecognizer 就会响应,直接宣布胜利(accepted)。
默认情况下
GestureDetector是不支持修改 deadline ,只有直接使用LongPressGestureRecognizer时才可以修改 deadline 的时长。
类似的逻辑在 DoubleTapGestureRecognizer 下也有,DoubleTap 的 deadline 是 300 毫秒,当用户首次点击时会注册一个定时器,如果 300 毫秒以内用户没有产生新的点击,那么 DoubleTapGestureRecognizer 就会宣布“失败“退出竞技,反之如果在 300 毫秒内有新的点击,则直接宣布“获胜”,响应 DoubleTap 回调。
那这时候有人就要问了:“在 DoubleTap 过程中,为什么不会触发 onTap” ? 这就需要说到 TapGestureRecognizer 的触发逻辑。
继续前面 GestureDetector 并配置了 onTap 、onLongPress 和 onDoubleTap 的例子,在用户只做普通点击的时候,前面说过:
LongPressGestureRecognizer的定时器 deadline 还没到 500 毫秒会因为 Up 事件而导致失败退出DoubleTapGestureRecognizer会因为定时器超过 deadline 300 毫秒,没有下一个点击而宣布退出
那么在 Long 和 Double 都失败的情况下,此时 GestureArenaManager (竞技场) 里的成员就只有 TapGestureRecognizer ,这时候竞技场会 close ,会触发竞技场的 sweep 逻辑,直接让最后剩下来的 Recognizer “胜利”,响应 onTap 事件。
所以
TapGestureRecognizer靠的是胜者为王。
所以基于这个例子,配合一开始说的两个逻辑,就可以直观的理解 Flutter 手势竞技场里的响应逻辑和关键 deadline 的作用。
多个 GestureDetector
那么前面都是只有一个 GestureDetector 的场景,如果有两个呢?如下代码所示,在嵌套两个 GestureDetector 下,它们的响应逻辑会是怎么样的?
当区域内有两个 GestureDetector 的时候,用户在普通点击时,因为 deadline 影响,依旧会是在竞技场 close 时才响应 onTap , 但是不同在于此时竞技场里还会有多个 Recognizer 存在,这时候只有排在列表的第一个的 Recognizer 可以赢得事件,也就是上门代码里的红色 200x200 小方块。
因为对于多个 GestureDetector 的情况, Recognizer 在竞技场列表(List<GestureArenaMember)里的顺序和 HitTest 时的递归调用有关系,简单说就是:递归调用会就让我们自下而上的得到一个 HitTestResult 列表,代码里最后的 child 会在最上面。
同时对于单个
GestureDetector而言,TapGestureRecognizer会是_recognizers的第一个,所以first会是响应了TapGestureRecognizer,详细逻辑可以看 《面深入触摸和滑动原理》 。
所以简单理解:
- 两个
GestureDetector在竞技场里的member列表排序时,作为 child 的红色GestureDetector因为 HitTest 递归会被排前面 GestureDetector内部TapGestureRecognizer会在其内部_recognizers排第一
所以 member.first 最终响应了 TapGestureRecognizer ,回到上面两个定律,如果结合多个 GestureDetector 的场景,就应该是:
- 每个 Recognizer 都可以随时选择失败退出,当竞技场只有它一个的时候它就赢了;如果不止一个,那么在竞技场
close时,member.first会获得响应 - 每个 Recognizer 都可以随时宣布自己获得胜利,这是其他 Recognizer 也将不再响应
进阶补充
前面简单介绍了 Flutter 的手势响应的基础逻辑,这里再额外补充两个知识点。
首先,当用户在长按的时候, GestureDetector 何时会发出 onTapDown 事件?
这其实就涉及了另外一个 deadline 参数,当用户在长按的时候,Recognizer 还会触发另外一个定时器,然后通过执行 didExceedDeadline 来发出 onTapDown 事件。
那么问题又来了,既然长按会触发 onTapDown 事件,如果点击区域内有两个 TapGestureRecognizer ,长按的时候因为定时器都触发了 didExceedDeadline ,那是不是两个都会收到 onTapDown 事件 ?
答案是:会的!因为定时器都触发了 didExceedDeadline,从而都发出了 onTapDown 事件,所以两个 onTapDown 回调都会执行,但是后续竞争只会有一个控件能响应 onLongPress 。
另外,如果不是长按导致的 Down 事件, 是不会导致两个
GestureDetector都触发回调onTapDown回调。
第二个补充的是 Listener , 如果你还想深入去看 GestureDetector 的实现,你就会发现 GestureDetector 对 Listener 的封装也许和你想象不大一样, 因为 Listener 的封装只用到了 PointerDown ,并没有用到 onPointerUp ,那 GestureDetector 是怎么响应 Up 和 Move 事件?
这就需要说到前面介绍 《面深入触摸和滑动原理》 里的源码分析,但是为了简单,我们这里只说结论:
因为只有响应了
PointerDown事件,对应的GestureRecognizer才能被添加到GestureBinding的PointerRouter事件路由和GestureArenaManager事件竞技中,而后续的 Up 和 Move 事件主要是通过GestureBinding来处理。
更简单的说,就是只有响应了 PointerDown 事件,控件的 Recognizer 才能响应后续统一处理的其他手势事件,而其他事件不需要在 Listener 这里获取回调。
链接:https://juejin.cn/post/7177283291542880293
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
职场羊,不要再抱怨公司,看看领导怎么说
最近很多人羊了,抱怨公司,无力工作,甚至嗅觉还失灵了。
在此,我想替领导们问问:
为什么是你羊?不是别人羊?
你羊的底层逻辑是什么?能解决什么问题?
你羊的抓手在哪里?怎么羊的?为什么羊?
如何证明你比别人羊的好?
你这个职级,不是羊了就可以的,我是希望你羊了之后,能够拼一把。
你的羊是否沉淀了一套可复用的康复论?
你的羊是否形成了毒株的差异性进化?
你的羊是否形成了流感传播的核心竞争力?
我希望看到你对羊的思考,而不仅仅是休息+应付。
提醒你一下,目前你的羊是有些单薄的,和同级相比,温度是不够的。
要到年底了,我希望你能加把劲,你看隔壁组的谁谁谁,39度羊都是在办公室打地铺的。
成长,一定是伴随着温度的。
今天最高的温度,就是明天最低的要求。
只有39度的时候,才是你成长最快的时候。
我希望看到你的沉淀,下班前写个总结给我,我向上汇报用。
加油!
收起阅读 »不就是代码缩进吗?别打起来啊
免战申明
本文不讨论两种缩进方式的优劣,只提供一种能够同时兼容大家关于缩进代码风格的解决方案
字符缩进,2还是4?
很久之前,组内开发时发现大家的tab.size不一样,有的伙伴表示都能接受,有的伙伴习惯使用2字符缩进,有的伙伴习惯4字符缩进,导致开发起来很痛苦,一直在寻找兼容大家代码风格的办法,今天终于研究出一种解决方案(不一定适用所有人)。
工具准备
vscode
prettierrc插件
解决方案
首先设置"editor.tabSize"为自己习惯的tabSize
设置tab按下时不插入空格"editor.insertSpaces": false
项目根目录下创建.prettierrc(可添加到.gitignore),设置"useTabs": true
{
"printWidth": 180,
"semi": true,
"singleQuote": true,
//使用tab进行格式化
"useTabs": true
}设置展示效果"editor.renderWhitespace": "selection"
最终效果
可以看到,编辑器内设置不同的代码缩进,展示效果不同,但最终提交的代码风格一致。 (小缺陷:对于强制要求使用空格代替tab的情况不适用)
作者:断律绎殇
来源:juejin.cn/post/7095001798120833061
细节决定成败:探究Mybatis中javaType和ofType的区别
一. 背景描述
今天,壹哥给学生讲解了Mybatis框架,学习了基础的ORM框架操作及多对一的查询。在练习的时候,小张同学突然举手求助,说在做预习作业使用一对多查询时,遇到了ReflectionException 异常 。
二. 情景再现
1. 实体类
为了给大家讲清楚这个异常的产生原因,壹哥先列出今天案例中涉及到的两张表:书籍表和书籍类型表。这两张表中存在着简单的多对一关系,实体类如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Book {
private Integer id;
private String name;
private String author;
private String bookDesc;
private String createTime;
private BookType type;
private String imgPath;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class BookType {
private Integer id;
private String name;
}2.BookMapper.xml映射文件
上课时,壹哥讲解的关联查询是通过查询书籍信息,并同时对书籍类型查询。即在查询Book对象时i,同时查询出BookType对象。BookMapper.xml映射文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.qf.day7.dao.BookDAO">
<resultMap id="booksMap" type="com.qf.day7.entity.Books">
<id property="id" column="id"></id>
<result property="name" column="name"></result>
<result property="author" column="author"></result>
<result property="bookDesc" column="book_desc"></result>
<result property="createTime" column="create_time"></result>
<result property="imgPath" column="img_path"></result>
<!-- 单个对象的关联,javaType是指实体类的类型-->
<association property="type" javaType="com.qf.day7.entity.BookType">
<id property="id" column="type_id"></id>
<result property="name" column="type_name"></result>
</association>
</resultMap>
<select id="findAll" resultMap="booksMap">
SELECT
b.id,
b.`name`,
b.author,
b.book_desc,
b.create_time,
b.img_path,
t.id type_id,
t.`name` type_name
FROM
books AS b
INNER JOIN book_type AS t ON b.type_id = t.id
</select>
</mapper>3. 核心配置
核心配置文件如下:mybatisCfg.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.qf.day7.entity"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!-- 事务管理器-->
<transactionManager type="JDBC"></transactionManager>
<!-- 使用mybatis自带连接池-->
<dataSource type="POOLED">
<!-- jdbc四要素-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://localhost:3306/books?useUnicode=true&characterEncoding=utf-8&useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/BookMapper.xml"></mapper>
<mapper resource="mapper/BookTypeMapper.xml"></mapper>
</mappers>
</configuration>4. 测试代码
接着我们对上面的配置进行测试。
public class BookDAOTest {
private SqlSessionFactory factory;
@Before
public void setUp() throws Exception {
final InputStream inputStream = Resources.getResourceAsStream("mybatisCfg.xml");
factory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void findAll() {
final SqlSession session = factory.openSession();
final BookDAO bookDAO = session.getMapper(BookDAO.class);
final List<Book> list = bookDAO.findAll();
list.stream().forEach(System.out::println);
session.close();
}
}学生按照我讲的内容,测试没有问题。在后续的预习练习中,要求实现在BookType中添加List属性books,在查询BookType对象同时将该类型的Book对象集合查出。小张同学有了如下实现思路。
5. 修改实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Book {
private Integer id;
private String name;
private String author;
private String bookDesc;
private String createTime;
private String imgPath;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class BookType {
private Integer id;
private String name;
private List<Book> books;
}6. 添加映射文件BookTypeMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.qf.day7.dao.BookTypeDAO">
<resultMap id="bookTypeMap" type="com.qf.day7.entity.BookType">
<id column="id" property="id"></id>
<result column="name" property="name"></result>
<collection property="books" javaType="com.qf.day7.entity.Book">
<id property="id" column="book_id"></id>
<result property="name" column="book_name"></result>
<result property="author" column="author"></result>
<result property="bookDesc" column="book_desc"></result>
<result property="createTime" column="create_time"></result>
<result property="imgPath" column="img_path"></result>
</collection>
</resultMap>
<select id="findById" resultMap="bookTypeMap">
SELECT
b.id book_id,
b.`name` book_name,
b.author,
b.book_desc,
b.create_time,
b.img_path,
t.id,
t.`name`
FROM
books AS b
INNER JOIN book_type AS t ON b.type_id = t.id
where t.id = #{typeId}
</select>
</mapper>7. 编写测试类
public class BookTypeDAOTest {
private SqlSessionFactory factory;
@Before
public void setUp() throws Exception {
final InputStream inputStream = Resources.getResourceAsStream("mybatisCfg.xml");
factory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void findById() {
final SqlSession session = factory.openSession();
final BookTypeDAO bookTypeDAO = session.getMapper(BookTypeDAO.class);
BookType bookType = bookTypeDAO.findById(1);
for (Book book : bookType.getBooks()) {
System.out.println(book.getName());
}
session.close();
}然后就出现了一开始提到的异常:
org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.reflection.ReflectionException: Could not set property 'books' of 'class com.qf.day7.entity.BookType' with value 'Book(id=1, name=Java从入门到精通, author=千锋, bookDesc=很不错的Java书籍, createTime=2022-05-27, type=null, imgPath=174cc662fccc4a38b73ece6880d8c07e)' Cause: java.lang.IllegalArgumentException: argument type mismatch
### The error may exist in mapper/BookTypeMapper.xml
### The error may involve com.qf.day7.dao.BookTypeDAO.findById
### The error occurred while handling results
### SQL: SELECT b.id book_id, b.`name` book_name, b.author, b.book_desc, b.create_time, b.img_path, t.id, t.`name` FROM books AS b INNER JOIN book_type AS t ON b.type_id = t.id where t.id = ?
### Cause: org.apache.ibatis.reflection.ReflectionException: Could not set property 'books' of 'class com.qf.day7.entity.BookType' with value 'Book(id=1, name=Java从入门到精通, author=千锋, bookDesc=很不错的Java书籍, createTime=2022-05-27, type=null, imgPath=174cc662fccc4a38b73ece6880d8c07e)' Cause: java.lang.IllegalArgumentException: argument type mismatch三. 异常分析
上面的 异常提示 , 是 说在 BookType类中的books属性设置有问题 。 我们来仔细查看一下代码,发现是因为直接 复制了之前的关系配置, 在配置文件中 使用javaType 节点 , 但正确的 应该 是 使用ofType。如下图所示:
四. 解析
那么为什么有的关系配置要使用javaType,而有的地方又要使用ofType呢?
这我们就不得不说说Mybatis的底层原理了!在关联映射中,如果是单个的JavaBean对象,那么可以使用javaType;而如果是集合类型,则需要写ofType。以下是Mybatis的官方文档原文:
五. 结尾
虽然上面的代码中只是因为一个单词的不同,却造成了不小的错误。我们的程序是严格的,小问题就可能会耽误你很久的时间。就比如我们的小张同学,在求助壹哥之前已经找bug找了一个小时......最后壹哥一眼就给他看出了问题所在,他都无语凝噎了.....
现在你明白javaType和ofType用法上的区别了吗?如果你还有其他什么问题,可以在评论区留言或私信哦!关注Java架构栈,干货天天都不断。
链接:https://juejin.cn/post/7176860138367057981
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我尝试以最简单的方式帮你梳理 Lifecycle
前言
我们都知道 Activity 与 Fragment 都是有生命周期的,例如:onCreate()、onStop() 这些回调方法就代表着其生命周期状态。我们开发者所做的一些操作都应该合理的控制在生命周期内,比如:当我们在某个 Activity 中注册了广播接收器,那么在其 onDestory() 前要记得注销掉,避免出现内存泄漏。
生命周期的存在,帮助我们更加方便地管理这些任务。但是,在日常开发中光凭 Activity 与 Fragment 可不够,我们通常还会使用一些组件来帮助我们实现需求,而这些组件就不像 Activity 与 Fragment 一样可以很方便地感知到生命周期了。
假设当前有这么一个需求:
开发一个简易的视频播放器组件以供项目使用,要求在进入页面后注册播放器并加载资源,一旦播放器所处的页面不可见或者不位于前台时就暂停播放,等到页面可见或者又恢复到前台时再继续播放,最后在页面销毁时则注销掉播放器。
试想一下:如果现在让你来实现该需求?你会怎么去实现呢?
实现这样的需求,我们的播放器组件就需要获取到所处页面的生命周期状态,在 onCreate() 中进行注册,onResume() 开始播放,onStop() 暂停播放,onDestroy() 注销播放器。
最简单的方法:提供方法,暴露给使用方,供其自己调用控制。
class VideoPlayerComponent(private val context: Context) {
/**
* 注册,加载资源
*/
fun register() {
loadResource(context)
}
/**
* 注销,释放资源
*/
fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
fun stopPlay() {
stopPlayVideo()
}
}然后,我们的使用方MainActivity自己,主动在其相对应的生命周期状态进行控制调用相对应的方法。
class MainActivity : AppCompatActivity() {
private lateinit var videoPlayerComponent: VideoPlayerComponent
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
videoPlayerComponent = VideoPlayerComponent(this)
videoPlayerComponent.register(this)
}
override fun onResume() {
super.onResume()
videoPlayerComponent.startPlay()
}
override fun onPause() {
super.onPause()
videoPlayerComponent.stopPlay()
}
override fun onDestroy() {
videoPlayerComponent.unRegister()
super.onDestroy()
}
}虽然实现了需求,但显然这不是最优雅的实现方式。一旦使用方忘记在 onDestroy() 进行注销播放器,就容易造成内存泄漏,而忘记注销显然是一件很容易发生的事情😂 。
回想初衷,之所以将方法暴露给使用方来调用,就是因为我们的组件自身无法感知到使用者的生命周期。所以,一旦我们的组件自身可以感知到使用者的生命周期状态的话,我们就不需要将这些方法暴露出去了。
那么问题来了,组件如何才能感知到生命周期呢?
答:Lifecycle !
直接上案例,借助 Lifecycle 我们改进一下我们的播放器组件👇
class VideoPlayerComponent(private val context: Context) : DefaultLifecycleObserver {
override fun onCreate(owner: LifecycleOwner) {
super.onCreate(owner)
register(context)
}
override fun onResume(owner: LifecycleOwner) {
super.onResume(owner)
startPlay()
}
override fun onPause(owner: LifecycleOwner) {
super.onPause(owner)
stopPlay()
}
override fun onDestroy(owner: LifecycleOwner) {
super.onDestroy(owner)
unRegister()
}
/**
* 注册,加载资源
*/
private fun register(context: Context) {
loadResource(context)
}
/**
* 注销,释放资源
*/
private fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
private fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
private fun stopPlay() {
stopPlayVideo()
}
}改进完成后,我们的调用方MainActivity只需要一行代码即可。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
lifecycle.addObserver(VideoPlayerComponent(this))
}
}这样是不是就优雅多了。
那这 Lifecycle 又是怎么感知到生命周期的呢?让我们这就带着问题,出发探一探它的实现方式与源码!
如果让你来做,你会怎么做
在查看源码前,让我们试着思考一下,如果让你来实现 Jetpack Lifecycle 这样的功能,你会怎么做呢?该从何入手呢?
我们的目的是不通过回调方法即可获取到生命周期,这其实就是解耦,实现解耦的一种很好方法就是利用观察者模式。
利用观察者模式,我们就可以这么设计👇
被观察者对象就是生命周期,而观察者对象则是需要知晓生命周期的对象,例如:我们的三方组件。
接着我们就具体探探源码,看一看Google是如何实现的吧。
Google 实现方式
Lifecycle
一个代表着Android生命周期的抽象类,也就是我们的抽象被观察者对象。
public abstract class Lifecycle {
public abstract void addObserver(@NonNull LifecycleObserver observer);
public abstract void removeObserver(@NonNull LifecycleObserver observer);
public enum Event {
ON_CREATE,
ON_START,
ON_RESUME,
ON_PAUSE,
ON_STOP,
ON_DESTROY,
ON_ANY;
}
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
}
}内包含 State 与 Event 分别者代表生命周期的状态与事件,同时定义了抽象方法 addObserver(LifecycleObserver) 与removeObserver(LifecycleObserver) 方法用于添加与删除生命周期观察者。
Event 很好理解,就像是 Activity | Fragment 的 onCreate()、onDestroy()等回调方法,它代表着生命周期的事件。
那这 State 又是什么呢?何为状态?他们之间又是什么关系呢?
Event 与 State 之间的关系
关于 Event 与 State 之间的关系,Google官方给出了这么一张两者关系图👇
乍一看,可能第一感觉不是那么直观,我整理了一下👇
INITIALIZED:在ON_CREATE事件触发前。CREATED:在ON_CREATE事件触发后以及ON_START事件触发前;或者在ON_STOP事件触发后以及ON_DESTROY事件触发前。STARTED:在ON_START事件触发后以及ON_RESUME事件触发前;或者在ON_PAUSE事件触发后以及ON_STOP事件触发前。RESUMED:在ON_RESUME事件触发后以及ON_PAUSE事件触发前。DESTROYED:在ON_DESTROY事件触发之后。
Event 代表生命周期发生变化那个瞬间点,而 State 则表示生命周期的一个阶段。这两者结合的好处就是让我们可以更加直观的感受生命周期,从而可以根据当前所处的生命周期状态来做出更加合理操作行为。
例如,在LiveData的生命周期绑定观察者源码中,就会判断当前观察者对象的生命周期状态,如果当前是DESTROYED状态,则直接移除当前观察者对象。同时,根据观察者对象当前的生命周期状态是否 >= STARTED来判断当前观察者对象是否是活跃的。
class LifecycleBoundObserver extends ObserverWrapper implements LifecycleEventObserver {
......
@Override
boolean shouldBeActive() {
//根据观察者对象当前的生命周期状态是否 >= STARTED 来判断当前观察者对象是否是活跃的。
return mOwner.getLifecycle().getCurrentState().isAtLeast(STARTED);
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
//根据当前观察者对象的生命周期状态,如果是DESTROYED,直接移除当前观察者
Lifecycle.State currentState = mOwner.getLifecycle().getCurrentState();
if (currentState == DESTROYED) {
removeObserver(mObserver);
return;
}
......
}
......
}其实 Event 与 State 这两者之间的联系,在我们生活中也是处处可见,例如:自动洗车。
想必现在你对 Event 与 State 之间的关系有了更好的理解了吧。
LifecycleObserver
生命周期观察者,也就是我们的抽象观察者对象。
public interface LifecycleObserver {
}所以,我们想成为观察生命周期的观察者的话,就需要具体实现该接口,也就是成为具体观察者对象。
换句话说,就是如果你想成为观察者对象来观察生命周期的话,那就必须实现 LifecycleObserver 接口。
例如Google官方提供的 DefaultLifecycleObserver、 LifecycleEventObserver 。
LifecycleOwner
正如其名字一样,生命周期的持有者,所以像我们的 Activity | Fragment 都是生命周期的持有者。
大白话很好理解,但代码应该如何实现呢?
抽象概念 + 具体实现
抽象概念:定义 LifecycleOwner 接口。
public interface LifecycleOwner {
@NonNull
Lifecycle getLifecycle();
}具体实现:Fragment 实现 LifecycleOwner 接口。
public class Fragment implements ComponentCallbacks, OnCreateContextMenuListener, LifecycleOwner,
ViewModelStoreOwner, HasDefaultViewModelProviderFactory, SavedStateRegistryOwner,
ActivityResultCaller {
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}具体实现:Activity 实现 LifecycleOwner 接口。
public class ComponentActivity extends androidx.core.app.ComponentActivity implements
ContextAware,
LifecycleOwner,
ViewModelStoreOwner,
HasDefaultViewModelProviderFactory,
SavedStateRegistryOwner,
OnBackPressedDispatcherOwner,
ActivityResultRegistryOwner,
ActivityResultCaller {
@NonNull
@Override
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}这样,Activity | Fragment 就都是生命周期持有者了。
疑问?在上方 Activity | Fragment 的类中,getLifecycle() 方法中都是返回 mLifecycleRegistry,那这个 mLifecycleRegistry 又是什么玩意呢?
LifecycleRegistry
是
Lifecycle的一个具体实现类。
LifecycleRegistry 负责管理生命周期观察者对象,并将最新的生命周期事件与状态及时通知给对应的生命周期观察者对象。
添加与删除观察者对象的具体实现方法。
//用户保存生命周期观察者对象
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap = new FastSafeIterableMap<>();
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
enforceMainThreadIfNeeded("addObserver");
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
//将生命周期观察者对象包装成带生命周期状态的观察者对象
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
... 省略代码 ...
}
@Override
public void removeObserver(@NonNull LifecycleObserver observer) {
mObserverMap.remove(observer);
}可以从上述代码中发现,LifecycleRegistry 还对生命周期观察者对象进行了包装,使其带有生命周期状态。
static class ObserverWithState {
//生命周期状态
State mState;
//生命周期观察者对象
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
//这里确保observer为LifecycleEventObserver类型
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
//并初始化了状态
mState = initialState;
}
//分发事件
void dispatchEvent(LifecycleOwner owner, Event event) {
//根据 Event 得出当前最新的 State 状态
State newState = event.getTargetState();
mState = min(mState, newState);
//触发观察者对象的 onStateChanged() 方法
mLifecycleObserver.onStateChanged(owner, event);
//更新状态
mState = newState;
}
}将最新的生命周期事件通知给对应的观察者对象。
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
... 省略代码 ...
ObserverWithState observer = mObserverMap.entrySet().getValue();
observer.dispatchEvent(lifecycleOwner, event);
... 省略代码 ...
mLifecycleObserver.onStateChanged(owner, event);
}那 handleLifecycleEvent() 方法在什么时候被调用呢?
相信看到下方这个代码,你就明白了。
public class FragmentActivity extends ComponentActivity {
......
final LifecycleRegistry mFragmentLifecycleRegistry = new LifecycleRegistry(this);
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_CREATE);
}
@Override
protected void onDestroy() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_DESTROY);
}
@Override
protected void onPause() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_PAUSE);
}
@Override
protected void onStop() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_STOP);
}
......
}在 Activity | Fragment 的 onCreate()、onStart()、onPause()等生命周期方法中,调用LifecycleRegistry 的 handleLifecycleEvent() 方法,从而将生命周期事件通知给观察者对象。
总结
Lifecycle 通过观察者设计模式,将生命周期感知对象与生命周期提供者充分解耦,不再需要通过回调方法来感知生命周期的状态,使代码变得更加的精简。
虽然不通过 Lifecycle,我们的组件也是可以获取到生命周期的,但是 Lifecycle 的意义就是提供了统一的调用接口,让我们的组件可以更加方便的感知到生命周期,方便广达开发者。而且,Google以此推出了更多的生命周期感知型组件,例如:ViewModel、LiveData。正是这些组件,让我们的开发变得越来越简单。
链接:https://juejin.cn/post/7176901382702628924
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose 为什么可以跨平台?
前言
Compose 不止能用于 Android 应用开发,借助其分层的架构设计以及 Kotlin 的跨平台优势,也是一个极具潜力的 Kotlin 跨平台框架。本文让我们从 Compose Runtime 的视角出发,看看 Compose 实现跨平台开发的基本原理。
Compose Architecture Layers
Compose 作为一个框架,在架构上从下到上分成多层:
- Compose Compiler:Kotlin 编译器插件,负责对 Composable 函数的静态检查以及代码生成等。
- Compose Runtime:负责 Composable 函数的状态管理,以及执行后的渲染树生成和更新
- Compose UI: 基于渲染树进行 UI 的布局、绘制等 UI 渲染工作
- Compose Foundation: 提供用于布局的基础 Composable 组件,例如
Column,Row等。 - Compose Material:提供上层的面向 Material 设计风格的 Composable 组件。
各层的职责明确,其中 Compose Compiler 和 Runtime 是支撑整个声明式 UI 运转的基石。
Compose Compiler
我们先看一下 Compose Compiler 的作用:
左边的源码是一个非常简单的 Composable 函数,定义了个一大带有状态的 Button,点击按钮,Button 中显示的 count 数增加。
源码经 Compose Compiler 编译后变成右边这样,生成了很多代码。首先函数签名上多了几个参数,特别是多了 %composer 参数。然后函数体中插入了很多对 %composer 的调用,例如 startRestartGroup/endRestartGroup,startReplaceGroup/endReplaceGroup 等。这些生成代码用来完成 Compose Runtime 这一层的工作。接下来我们分析一下 Runtime 具体在做什么
Group & SlotTable
Composable 函数虽然没有返回值,但是执行过程中需要生成服务于 UI 渲染的产物,我们称之为 Composition。参数 %composer 就是 Composition 的维护者,用来创建和更新 Composition。Composition 中包含两棵树,一棵状态树和一棵渲染树。
关于两棵树:如果你了解 React,可以将这两棵树的关系类比成 React 中的 VIrtual DOM Tree 与 Real DOM Tree。Compose 中的这棵 “Virtual DOM” 用来记录 UI 显示所需要的状态信息, 所以我们称之为状态树。
状态树上的节点单元是 Group,编译器生成的 startXXXGroup 本质上就是在创建 Group 单元, startXXXGroup 与 endXXXGroup 之间产生的数据状态都归属当前 Group;产生的 Group 就成为子 Group,因此随着 Composable 的执行,基于 Group 的树型结构就被构建出来了。
关于 Group:Group 都是一些功能单元,比如 RestartGroup 是一个可重组的最小单元,ReplaceableGroup 是可以被动态插入的最小单元等,以 Group 为单位组织状态,可以更灵活的更新状态树。代码中什么位置插入什么样的 startXXXGroup 完全由 Compose Compiler 智能的帮我们生成,我们在写代码时不必付出这方面的思考。
状态树实际是使用一个被称作 Slot Table 的线性数据结构实现的,可以把他理解为一个数组,存储着状态树深度遍历的结果,数组的各个区间存储着对应 UI 节点上的状态。
Comopsable 首次执行时,产生的 Group 以及所瞎的状态会以此填充到 Slot Table 中,填充时会附带一个编译时给予代码位置生成的不重复的 key,所以 Slot Table 中的记录也被称作基于代码位置的存储(Positional Memoization)。当重组发生时, Composable 会再次遍历 SlotTable,并在 startXXXGroup 中根据 key 访问当前代码所需的状态,比如 count 就可以通过 remember 在重组中获取最近的值。
Applier & Node Tree
Slot Table 中的状态不能直接用来渲染,UI 的渲染依赖 Composition 中的另一棵树 - 渲染树。Slot Table 通过 Applier 转换成渲染树。渲染树是真真正的树形结构体 Node Tree。
Applier 是一个接口,从接口定义不难看出,它用于对一棵 Node 类型节点树进行增删改等维护工作。以一个 UI 的插入为例,我们在 Compoable 中的一段 if 语句就可以实现一个 UI 片段的插入。if 代码块在编译期会生成一个 ReplaceGroup,当重组中命中 if 条件执行到 startReplaceGroup 时,发现 Slot Table 中缺少 Group 对应 key 的信息,因此可以识别出是一个插入操作,然后插入新的 Group 以及所辖的 Node 信息,并通过 Applier 转换成 Node Tree 中新插入的节点。
SlotTable 中插入新元素后,后续元素会通过 Gap Buffer 机制进行后移,而不是直接删除。这样可以保证后续元素在 Node Tree 中的对应节点的保留,实现 Node Tree 的增量更新,实现局部刷新,提升性能。
Compose Phases
我们结合前面的介绍,整体看一下 Compose 从源码到上屏的全过程:
Composable 源码经 Compiler 处理后插入了用于更新 Composition 的代码。这部分工作由 Compose Compiler 完成。
当 Compose 框架接收到系统侧发送的帧信号后,从顶层开始执行 Composable 函数,执行过程中依次更新 Composition 中的状态树和渲染树,这个过程即所谓的“组合”。这部分工作由 Compose Runtime 完成。
Compose 在 Android 平台的容器是 AndroidComposeView,当接收到系统发送的 disptachDraw 时,便开始驱动 Composition 的渲染树以及进行 Measure,Lyaout,Drawing 完成 UI 的渲染。这部分工作由 Compose UI 负责完成。
Comopse 渲染一帧的三个阶段 : Composition -> Layout -> Drawing。
传统视图开发中,渲染树(View Tree)的维护需要我们在代码逻辑中完成;Compose 渲染树的维护则交给了框架,所以多了 Composition 这一阶段。这也是 Compose 相对于自定义 View 代码更简单的根本原因。
把这整个过程从中间一分为二来看,Compose Compiler 与 Compose Runtime 负责驱动一棵节点树的更新,这部分与平台无关,节点树也可以是任意类型的节点树甚至是一颗渲染无关的树。不同平台的渲染机制不同,所以 Compose UI 与平台相关。 我们只要在 Compoe UI 这一层,针对不同平台实现自己的 Node Tree 和对应的 Applier,就可以在 Compose Runtime 的驱动下实现 UI 的声明式开发。
Compose for Android View
基于这一结论,我们做一个实验:使用 Compose Runtime 驱动 Android 原生 View 的渲染。
我们首先定义一个基于 View 类型节点的 Applier :ViewApplier
class ViewApplier(val view: FrameLayout) : AbstractApplier<View>(view) {
override fun onClear() {
(view as? ViewGroup)?.removeAllViews()
}
override fun insertBottomUp(index: Int, instance: View) {
(current as? ViewGroup)?.addView(instance, index)
}
override fun insertTopDown(index: Int, instance: View) {
}
override fun move(from: Int, to: Int, count: Int) {
// NOT Supported
TODO()
}
override fun remove(index: Int, count: Int) {
(view as? ViewGroup)?.removeViews(index, count)
}
}然后,我们创建两个 Android View 对应的 Composable,TextView 和 LinearLayout:
@Composable
fun TextView(
text: String,
onClick: () -> Unit = {}
) {
val context = localContext.current
ComposeNode<TextView, ViewApplier>(
factory = {
TextView(context)
},
update = {
set(text) {
this.text = text
}
set(onClick) {
setOnClickListener { onClick() }
}
},
)
}
@Composable
fun LinearLayout(children: @Composable () -> Unit) {
val context = localContext.current
ComposeNode<LinearLayout, ViewApplier>(
factory = {
LinearLayout(context).apply {
orientation = LinearLayout.VERTICAL
layoutParams = ViewGroup.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT,
ViewGroup.LayoutParams.MATCH_PARENT,
)
}
},
update = {},
content = children,
)
}
ComposeNode 是 Compose Runtime 提供的 API,用来像 Slot Table 添加一个 Node 信息。Slot Tabl 通过 Applier 创建基于 View 的节点树时,会通过 Node 的 factory 创建对应的 View 节点。
有了上述实验,我们就可以使用 Compose 构建 Android View 了,同时可以通过 Compose 的 SnapshotState 驱动 View 的更新:
@Composable
fun AndroidViewApp() {
var count by remember { mutableStateOf(1) }
LinearLayout {
TextView(
text = "This is the Android TextView!!",
)
repeat(count) {
TextView(
text = "Android View!!TextView:$it $count",
onClick = {
count++
}
)
}
}
}执行效果如下:
同样,我们也可以基于 Compose Runtime 为任意平台打造基于 Compose 的声明式 UI 框架。
Compose for Desktop & Web
JetBrains 在 Compose 多平台应用方面进行了很多尝试,并做出了很多成果。JetBrains 基于谷歌 Jetpack Compose 的 fork 相继发布了 Compose for Desktop 以及 Compose for Web。
Compose Desktop 与 Android 同样基于 LayoutNode 的渲染树,通过 Skia 引擎完成跨平台渲染。所以它们在渲染效果以及开发体验上都保持高度一致。Compose Desktop 依靠 Kotlin/JVM 编译成字节码产物,并使用 Jpackage 和 Jlink 打包成不同桌面系统的( Linux/Mac/Windows)的安装包,可以在脱离 JVM 的环境下直接运行。
Compose Web 使用了基于 W3C 标准的 DomNode 作为渲染树节点,在 Compose Runtime 驱动下生成 DOM Tree 。Compose Web 通过 Kotlin/JS 编译成 JavaScript 最终在浏览器中运行和渲染。Compose Web 中预制了更贴近 HTML 风格的 Composable API,所以 UI 代码上与 Android/Desktop 无法直接复用。
通过 compose-jb 官方的例子,感受一下 Desktop & Web 的不同
上面使用 Compose 在各个平台实现的页面效果,Desktop 和 Android 的渲染效果完全一致,Web 与前两者在现实效果上不同,他们的代码分别如下所示:
Compose Desktop 与 Jetpack Compose 在代码上没有区别,而 Compose Web 使用 Div,Ul 这样与 HTML 标签同名的 Composable,而且使用 style { ...} 这样面向 CSS 的 DSL 替代 Modifier,开发体验更符合前端的习惯。虽然 UI 部分的代码在不同平台有差异,但是在逻辑部分,可以实现完全复用,各平台的 Comopse UI 都使用 component.models.subscribeAsState() 监听状态变化。
Compose for Multiplatform
JetBrains 将 Android,Desktop,Web 三个平台的 Compose 整合成统一 Group Id 的 Kotlin Multiplatform 库,便诞生了 Comopse Multiplatform。
Compose Mutiplatform 作为一个 KM 库,让一个 KMP (Kotlin Multiplatform Project) 中可共享的代码从 Data 层上升到 UI 层以及 UI 相关的 Logic 层。
使用 IntelliJ IDEA 可以创建一个 Compose Multiplatform 工程模版,在结构上与一个普通的 KMP 无异。
android/desktop/web 文件夹是各个平台的工程文件,基于 gradle 编译成目标平台的产物。
common 文件夹是 KMP 的核心。commonMain 中是完全共享的 Kt 代码,通过 expect/actual 关键字实现平台差异化开发。
我们先在 gradle 中依赖 Comopse Multiplatform 库,之后就可以在 commonMain 中开发共享基于 Compose 的 UI 代码了。Comopse Multiplatform 的各个组件将 Jetpack Compose 对应组件的 Group Id 中的 androidx 前缀替换为 org.jertbrains 前缀:
androidx.compose.runtime -> org.jetbrains.compose.runtime
androidx.compose.material -> org.jetbrains.compose.material
androidx.compose.foundation -> org.jetbrains.compose.foundation最后
最后,我们来思考一下 Compose for Multiplatform 与 Compose Multiplatform 这两个词的区别?在我看来,Compose Multiplatform 会让家将焦点放在 Multiplatform 上面,自然会拿来与 Flutter 等同类框架作对比。但是通过本文的介绍,大家已经知道了 Compose 并非一个专门为跨平台打造的框架,现阶段它并不追求渲染效果和开发体验完全一致,它的出现更像是 Kotlin 带来的增值服务。
而 Compose for Multiplatfom 的焦点则更应该放在 Compose 上,它表示 Compose 可以服务于更多平台,依托强大的 Compiler 和 Runtime 层,我们可以为更多平台打造声明式框架。扩大 Kotlin 的应用场景和 Kotlin 开发者的能力边界。希望今后再提到 Compose 跨平台式,大家可以多从 Compose for Multiplatform 的角度去看待他的意义和价值。
链接:https://juejin.cn/post/7176437908935540797
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Suspend函数与回调的互相转换
前言
我们再来一期关于kotlin协程的故事,我们都知道在Coroutine没有出来之前,我们对于异步结果的处理都是采用回调的方式进行,一方面回调层次过多的话,容易导致“回调地狱”,另一方法也比较难以维护。当然,我们并不是否定了回调本身,回调本身同时也是具备很多优点的,比如符合代码阅读逻辑,同时回调本身也是比较可控的。这一期呢,我们就是来聊一下,如何把回调的写法变成suspend函数,同时如何把suspend函数变成回调,从而让我们更加了解kotlin协程背后的故事
回调变成suspend函数
来一个回调
我们以一个回调函数作为例子,当我们normalCallBack在一个子线程中做一些处理,比如耗时函数,做完就会通过MyCallBack回调onCallBack,这里返回了一个Int类型,如下:
var myCallBack:MyCallBack?= null
interface MyCallBack{
fun onCallBack(result: Int)
}
fun normalCallBack(){
thread {
// 比如做一些事情
myCallBack?.onCallBack(1)
}
}转化为suspend函数
此时我们可以通过suspendCoroutine函数,内部其实是通过创建了一个SafeContinuation并放到了我们suspend函数本身(block本身)启动了一个协程,我们之前在聊一聊Kotlin协程"低级"api 这篇文章介绍过
public suspend inline fun <T> suspendCoroutine(crossinline block: (Continuation<T>) -> Unit): T {
contract { callsInPlace(block, InvocationKind.EXACTLY_ONCE) }
return suspendCoroutineUninterceptedOrReturn { c: Continuation<T> ->
val safe = SafeContinuation(c.intercepted())
block(safe)
safe.getOrThrow()
}
}这时候我们就可以直接写为,从而将回调消除,变成了一个suspend函数。
suspend fun mySuspend() = suspendCoroutine<Int> {
thread {
// 比如做一些事情
it.resume(1)
}
}当然,如果我们想要支持一下外部取消,比如当前页面销毁时,发起的网络请求自然也就不需要再请求了,就可以通过suspendCancellableCoroutine创建,里面的Continuation对象就从SafeContinuation(见上文)变成了CancellableContinuation,变成了CancellableContinuation有一个invokeOnCancellation方便,支持在协程体被销毁时的逻辑。
public suspend inline fun <T> suspendCancellableCoroutine(
crossinline block: (CancellableContinuation<T>) -> Unit
): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
val cancellable = CancellableContinuationImpl(uCont.intercepted(), resumeMode = MODE_CANCELLABLE)
/*
* For non-atomic cancellation we setup parent-child relationship immediately
* in case when `block` blocks the current thread (e.g. Rx2 with trampoline scheduler), but
* properly supports cancellation.
*/
cancellable.initCancellability()
block(cancellable)
cancellable.getResult()
}此时我们就可以写出以下代码
suspend fun mySuspend2() = suspendCancellableCoroutine<Int> {
thread {
// 比如做一些事情
it.resume(1)
}
it.invokeOnCancellation {
// 取消逻辑
}
}suspend函数变成回调
见到了回调如何变成suspend函数,那么我们反过来呢?有没有办法?当然有啦!当时suspend函数中有很多种区分,我们一一区分一下
直接返回的suspend函数
suspend fun myNoSuspendFunc():Int{
return 1
}调用suspendCoroutine后直接resume的suspend函数
suspend fun myNoSuspendFunc() = suspendCoroutine<Int> {
continuation ->
continuation.resume(1)
}调用suspendCoroutine后异步执行的suspend函数(这里异步可以是单线程也可以是多线程,跟线程本身无关,只要是异步就会触发挂起)
suspend fun myRealSuspendFunc() = suspendCoroutine<Int> {
thread {
Thread.sleep(300)
it.resume(2)
}那么我们来想一下,这里真正发起挂起的函数是哪个?通过代码其实我们可以猜到,真正挂起的函数只有最后一个myRealSuspendFunc,其他都不是真正的挂起,这里的挂起是什么意思呢?我们从协程的状态就可以知道,当前处于CoroutineSingletons.COROUTINE_SUSPENDED时,就是挂起状态。我们回归一下,一个suspend函数有哪几种情况
这里的1,2,3就分别对应着上文demo中的例子
- 直接返回结果,不需要进入状态机判断,因为本身就没有启动协程
- 进入了协程,但是不需要进行SUSPEND状态就已经有了结果,所以直接返回了结果
- 进入了SUSPEND状态,之后才能获取结果
这里我们就不贴出来源码了,感兴趣可自己看Coroutine的实现,这里我们要明确一个概念,一个Suspend函数的运行机制,其实并不依靠了协程本身。
对应代码表现就是,这个函数的返回结果可能就是直接返回结果本身,另一种就是通过回调本身通知外部(这里我们还会以例子说明)
suspend函数转换为回调
这里有两种情况,我们分别以kotlin代码跟java代码表示:
kotlin代码
由于kotlin可以直接通过suspend的扩展函数startCoroutine启动一个协程,
fun myRealSuspendCallBack(){
::myRealSuspendFunc.startCoroutine(object :Continuation<Int>{
当前环境
override val context: CoroutineContext
get() = Dispatchers.IO
结果
override fun resumeWith(result: Result<Int>) {
if(result.isSuccess){
myCallBack?.onCallBack(result.getOrDefault(0))
}
}
})
}其中Result就是一个内联类,属于kotlin编译器添加的装饰类,在这里我们无论是1,2,3的情况,都可以在resumeWith 中获取到结果,在这里通过callback回调即可
@JvmInline
public value class Result<out T> @PublishedApi internal constructor(
@PublishedApi
internal val value: Any?
) : Serializable {Java代码
这里我们更正一个误区,就是suspend函数只能在kotlin中使用/Coroutine协程只能在kotlin中使用,这个其实是错误的,java代码也能够调起协程,只不过麻烦了一点,至少官方是没有禁止的。
比如我们需要调用startCoroutine,可直接调用
ContinuationKt.startCoroutine();当然,我们也能够直接调用suspend函数
Object result = CallBack.INSTANCE.myRealSuspendFunc(new Continuation<Integer>() {
@NonNull
@Override
public CoroutineContext getContext() {
这里启动的环境其实协程没有用到,读者们可以思考一下为什么!这里就当一个谜题啦!可以在评论区说出你的想法(我会在评论区解答)
return (CoroutineContext) Dispatchers.getIO();
//return EmptyCoroutineContext.INSTANCE;
}
@Override
public void resumeWith(@NonNull Object o) {
情况3
Log.e("hello","resumeWith result is "+ o +" is main "+ (Looper.myLooper() == Looper.getMainLooper()));
// 回调处理即可
myCallBack?.onCallBack(result)
}
});
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
情况1,2
Log.e("hello","func result is "+ result);
// 回调处理即可
myCallBack?.onCallBack(result)
}这里我们需要注意的是,这里java代码比kotlin多了一个判断,同时resumeWith的参数不再是Result,而是一个Object
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
}这里脱去了kotlin给我们添加的各种外壳,其实这就是真正的对于suspend结果的处理(只不过kotlin帮我们包了一层)
我们上文说过,suspend函数对应的三种情况,这里的1,2都是直接返回结果的,因为没有走到SUSPEND状态(IntrinsicsKt.getCOROUTINE_SUSPENDED())这里需要读者好好阅读上文,因此
result != IntrinsicsKt.getCOROUTINE_SUSPENDED(),就会直接走到这里,我们就直接拿到了结果
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
}如果属于情况3,那么这里的result就不再是一个结果,而是当前协程的状态标记罢了,此时当协程完成执行的时候(调用resume的时候),就会回调到resumeWith,这里的Object类型o才是经过SUSPEND状态的结果!
总结
经过我们suspend跟回调的互相状态,能够明白了suspend背后的逻辑与挂起的细节,希望能帮到你!最后本篇还留下了一个小谜题,可以发挥你的理解在评论区说出你的想法!笔者之后会在评论区解答!
链接:https://juejin.cn/post/7175752374458253373
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 线上卡顿监控
1. 卡顿与ANR的关系
卡顿是UI没有及时的按照用户的预期进行反馈,没有及时地渲染出来,从而看起来不连续、不一致。产生卡顿的原因太多了,很难一一列举,但ANR是Google人为规定的概念,产生ANR的原因最多只有4个。分别是:
- Service Timeout:比如前台服务在20s内未执行完成,后台服务Timeout时间是前台服务的10倍,200s;
- BroadcastQueue Timeout:比如前台广播在10s内未执行完成,后台60s
- ContentProvider Timeout:内容提供者,在publish过超时10s;
- InputDispatching Timeout: 输入事件分发超时5s,包括按键和触摸事件。
假如我在一个button的onClick事件中,有一个耗时操作,这个耗时操作的时间是10秒,但这个耗时操作并不会引发ANR,它只是一次卡顿。
一方面,两者息息相关,长时间的UI卡顿是导致ANR的最常见的原因;但另一方面,从原理上来看,两者既不充分也不必要,是两个纬度的概念。
市面上的一些卡顿监控工具,经常被用来监控ANR(卡顿阈值设置为5秒),这其实很不严谨:首先,5秒只是发生ANR的其中一种原因(Touch事件5秒未被及时消费)的阈值,而其他原因发生ANR的阈值并不是5秒;另外,就算是主线程卡顿了5秒,如果用户没有输入任何的Touch事件,同样不会发生ANR,更何况还有后台ANR等情况。真正意义上的ANR监控方案应该是类似matrix里面那样监控signal信号才算。
2. 卡顿原理
主线程从ActivityThread的main方法开始,准备好主线程的looper,启动loop循环。在loop循环内,无消息则利用epoll机制阻塞,有消息则处理消息。因为主线程一直在loop循环中,所以要想在主线程执行什么逻辑,则必须发个消息给主线程的looper然后由这个loop循环触发,由它来分发消息,然后交给msg的target(Handler)处理。举个例子:ActivityThread.H。
public static void loop() {
......
for (;;) {
Message msg = queue.next(); // might block
......
msg.target.dispatchMessage(msg);
}
}loop循环中可能导致卡顿的地方有2个:
- queue.next() :有消息就返回,无消息则使用epoll机制阻塞(nativePollOnce里面),不会使主线程卡顿。
- dispatchMessage耗时太久:也就是Handler处理消息,app卡顿的话大多数情况下可以认为是这里处理消息太耗时了
3. 卡顿监控
- 方案1:WatchDog,往主线程发消息,然后延迟看该消息是否被处理,从而得出主线程是否卡顿的依据。
- 方案2:利用loop循环时的消息分发前后的日志打印(matrix使用了这个)
3.1 WatchDog
开启一个子线程,死循环往主线程发消息,发完消息后等待5秒,判断该消息是否被执行,没被执行则主线程发生ANR,此时去获取主线程堆栈。
- 优点:简单,稳定,结果论,可以监控到各种类型的卡顿
- 缺点:轮询不优雅,不环保,有不确定性,随机漏报
轮询的时间间隔越小,对性能的负面影响就越大,而时间间隔选择的越大,漏报的可能性也就越大。
- UI线程要不断处理我们发送的Message,必然会影响性能和功耗
- 随机漏报:ANRWatchDog默认的轮询时间间隔为5秒,当主线程卡顿了2秒之后,ANRWatchDog的那个子线程才开始往主线程发送消息,并且主线程在3秒之后不卡顿了,此时主线程已经卡顿了5秒了,子线程发送的那个消息也随之得到执行,等子线程睡5秒起床的时候发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
假设将间隔时间改为
改进:
- 监控到发生ANR时,除了获取主线程堆栈,再获取一下CPU、内存占用等信息
- 还可结合ProcessLifecycleOwner,app在前台才开启检测,在后台停止检测
另外有些方案的思路,如果我们不断缩小轮询的时间间隔,用更短的轮询时间,连续几个周期消息都没被处理才视为一次卡顿。则更容易监控到卡顿,但对性能损耗大一些。即使是缩小轮询时间间隔,也不一定能监控到。假设每2秒轮询一次,如果连续三次没被处理,则认为发生了卡顿。在02秒之间主线程开始发生卡顿,在第2秒时开始往主线程发消息,这样在到达次数,也就是8秒时结束,但主线程的卡顿在68秒之间就刚好结束了,此时子线程在第8秒时醒来发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
3.2 Looper Printer
替换主线程Looper的Printer,监控dispatchMessage的执行时间(大部分主线程的操作最终都会执行到这个dispatchMessage中)。这种方案在微信上有较大规模使用,总体来说性能不是很差,matrix目前的EvilMethodTracer和AnrTracer就是用这个来实现的。
- 优点:不会随机漏报,无需轮询,一劳永逸
- 缺点:某些类型的卡顿无法被监控到,但有相应解决方案
queue.next()可能会阻塞,这种情况下监控不到。
//Looper.java
for (;;) {
//这里可能会block,Printer无法监控到next里面发生的卡顿
Message msg = queue.next(); // might block
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
}
//MessageQueue.java
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
//......
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
//IdleHandler的queueIdle,如果Looper是主线程,那么这里明显是在主线程执行的,虽然现在主线程空闲,但也不能做耗时操作
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
//......
}- 主线程空闲时会阻塞next(),具体是阻塞在nativePollOnce(),这种情况下无需监控
- Touch事件大部分是从nativePollOnce直接到了InputEventReceiver,然后到ViewRootImpl进行分发
- IdleHandler的queueIdle()回调方法也无法监控到
- 还有一类相对少见的问题是SyncBarrier(同步屏障)的泄漏同样无法被监控到
第一种情况我们不用管,接下来看一下后面3种情况下如何监控卡顿。
3.2.1 监控TouchEvent卡顿
首先,Touch是怎么传递到Activity的?给一个view设置一个OnTouchListener,然后看一些Touch的调用栈。
com.xfhy.watchsignaldemo.MainActivity.onCreate$lambda-0(MainActivity.kt:31)
com.xfhy.watchsignaldemo.MainActivity.$r8$lambda$f2Bz7skgRCh8TKh1SZX03s91UhA(Unknown Source:0)
com.xfhy.watchsignaldemo.MainActivity$$ExternalSyntheticLambda0.onTouch(Unknown Source:0)
android.view.View.dispatchTouchEvent(View.java:13695)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
com.android.internal.policy.DecorView.superDispatchTouchEvent(DecorView.java:741)
com.android.internal.policy.PhoneWindow.superDispatchTouchEvent(PhoneWindow.java:2013)
android.app.Activity.dispatchTouchEvent(Activity.java:4180)
androidx.appcompat.view.WindowCallbackWrapper.dispatchTouchEvent(WindowCallbackWrapper.java:70)
com.android.internal.policy.DecorView.dispatchTouchEvent(DecorView.java:687)
android.view.View.dispatchPointerEvent(View.java:13962)
android.view.ViewRootImpl$ViewPostImeInputStage.processPointerEvent(ViewRootImpl.java:6420)
android.view.ViewRootImpl$ViewPostImeInputStage.onProcess(ViewRootImpl.java:6215)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl$InputStage.onDeliverToNext(ViewRootImpl.java:5657)
android.view.ViewRootImpl$InputStage.forward(ViewRootImpl.java:5623)
android.view.ViewRootImpl$AsyncInputStage.forward(ViewRootImpl.java:5781)
android.view.ViewRootImpl$InputStage.apply(ViewRootImpl.java:5631)
android.view.ViewRootImpl$AsyncInputStage.apply(ViewRootImpl.java:5838)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl$InputStage.onDeliverToNext(ViewRootImpl.java:5657)
android.view.ViewRootImpl$InputStage.forward(ViewRootImpl.java:5623)
android.view.ViewRootImpl$InputStage.apply(ViewRootImpl.java:5631)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl.deliverInputEvent(ViewRootImpl.java:8701)
android.view.ViewRootImpl.doProcessInputEvents(ViewRootImpl.java:8621)
android.view.ViewRootImpl.enqueueInputEvent(ViewRootImpl.java:8574)
android.view.ViewRootImpl$WindowInputEventReceiver.onInputEvent(ViewRootImpl.java:8959)
android.view.InputEventReceiver.dispatchInputEvent(InputEventReceiver.java:239)
android.os.MessageQueue.nativePollOnce(Native Method)
android.os.MessageQueue.next(MessageQueue.java:363)
android.os.Looper.loop(Looper.java:176)
android.app.ActivityThread.main(ActivityThread.java:8668)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1109)
当有触摸事件时,nativePollOnce()会收到消息,然后会从native层直接调用InputEventReceiver.dispatchInputEvent()。
public abstract class InputEventReceiver {
public InputEventReceiver(InputChannel inputChannel, Looper looper) {
if (inputChannel == null) {
throw new IllegalArgumentException("inputChannel must not be null");
}
if (looper == null) {
throw new IllegalArgumentException("looper must not be null");
}
mInputChannel = inputChannel;
mMessageQueue = looper.getQueue();
//在这里进行的注册,native层会将该实例记录下来,每当有事件到达时就会派发到这个实例上来
mReceiverPtr = nativeInit(new WeakReference<InputEventReceiver>(this),
inputChannel, mMessageQueue);
mCloseGuard.open("dispose");
}
// Called from native code.
@SuppressWarnings("unused")
@UnsupportedAppUsage
private void dispatchInputEvent(int seq, InputEvent event) {
mSeqMap.put(event.getSequenceNumber(), seq);
onInputEvent(event);
}
}InputReader(读取、拦截、转换输入事件)和InputDispatcher(分发事件)都是运行在system_server系统进程中,而我们的应用程序运行在自己的应用进程中,这里涉及到跨进程通信,这里的跨进程通信用的非binder方式,而是用的socket。
InputDispatcher会与我们的应用进程建立连接,它是socket的服务端;我们应用进程的native层会有一个socket的客户端,客户端收到消息后,会通知我们应用进程里ViewRootImpl创建的WindowInputEventReceiver(继承自InputEventReceiver)来接收这个输入事件。事件传递也就走通了,后面就是上层的View树事件分发了。
这里为啥用socket而不用binder?Socket可以实现异步的通知,且只需要两个线程参与(Pipe两端各一个),假设系统有N个应用程序,跟输入处理相关的线程数目是N+1(1是Input Dispatcher线程)。然而,如果用Binder实现的话,为了实现异步接收,每个应用程序需要两个线程,一个Binder线程,一个后台处理线程(不能在Binder线程里处理输入,因为这样太耗时,将会阻塞住发射端的调用线程)。在发射端,同样需要两个线程,一个发送线程,一个接收线程来接收应用的完成通知,所以,N个应用程序需要2(N+1)个线程。相比之下,Socket还是高效多了。
//frameworks/native/services/inputflinger/InputDispatcher.cpp
void InputDispatcher::startDispatchCycleLocked(nsecs_t currentTime,
const sp<Connection>& connection) {
......
status = connection->inputPublisher.publishKeyEvent(dispatchEntry->seq,
keyEntry->deviceId, keyEntry->source,
dispatchEntry->resolvedAction, dispatchEntry->resolvedFlags,
keyEntry->keyCode, keyEntry->scanCode,
keyEntry->metaState, keyEntry->repeatCount, keyEntry->downTime,
keyEntry->eventTime);
......
}
//frameworks/native/libs/input/InputTransport.cpp
status_t InputPublisher::publishKeyEvent(
uint32_t seq,
int32_t deviceId,
int32_t source,
int32_t action,
int32_t flags,
int32_t keyCode,
int32_t scanCode,
int32_t metaState,
int32_t repeatCount,
nsecs_t downTime,
nsecs_t eventTime) {
......
InputMessage msg;
......
msg.body.key.keyCode = keyCode;
......
return mChannel->sendMessage(&msg);
}
//frameworks/native/libs/input/InputTransport.cpp
//调用 socket 的 send 接口来发送消息
status_t InputChannel::sendMessage(const InputMessage* msg) {
size_t msgLength = msg->size();
ssize_t nWrite;
do {
nWrite = ::send(mFd, msg, msgLength, MSG_DONTWAIT | MSG_NOSIGNAL);
} while (nWrite == -1 && errno == EINTR);
......
}
有了上面的知识铺垫,现在回到我们的主问题上来,如何监控TouchEvent卡顿。既然它们是用socket来进行通信的,那么我们可以通过PLT Hook,去Hook这对socket的发送(send)和接收(recv)方法,从而监控Touch事件。当调用到了recvfrom时(send和recv最终会调用sendto和recvfrom,这2个函数的具体定义在socket.h源码),说明我们的应用接收到了Touch事件,当调用到了sendto时,说明这个Touch事件已经被成功消费掉了,当两者的时间相差过大时即说明产生了一次Touch事件的卡顿。
PLT Hook是什么,它是一种native hook,另外还有一种native hook方式是inline hook。PLT hook的优点是稳定性可控,可线上使用,但它只能hook通过PLT表跳转的函数调用,这在一定程度上限制了它的使用场景。
对PLT Hook的具体原理感兴趣的同学可以看一下下面2篇文章:
目前市面上比较流行的PLT Hook开源库主要有2个,一个是爱奇艺开源的xhook,一个是字节跳动开源的bhook。我这里使用xhook来举例,InputDispatcher.cpp最终会被编译成libinput.so(具体Android.mk信息看这里)。那我们就直接hook这个libinput.so的sendto和recvfrom函数。
理论知识有了,直接开干:
ssize_t (*original_sendto)(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t my_sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen) {
//应用端已消费touch事件
if (getCurrentTime() - lastTime > 5000) {
__android_log_print(ANDROID_LOG_DEBUG, "xfhy_touch", "Touch有点卡顿");
//todo xfhy 在这里调用java去dump主线程堆栈
}
long ret = original_sendto(sockfd, buf, len, flags, dest_addr, addrlen);
return ret;
}
ssize_t (*original_recvfrom)(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t my_recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen) {
//收到touch事件
lastTime = getCurrentTime();
long ret = original_recvfrom(sockfd, buf, len, flags, src_addr, addrlen);
return ret;
}
void Java_com_xfhy_touch_TouchTest_start(JNIEnv *env, jclass clazz) {
xhook_register(".*libinput\\.so$", "__sendto_chk",(void *) my_sendto, (void **) (&original_sendto));
xhook_register(".*libinput\\.so$", "sendto",(void *) my_sendto, (void **) (&original_sendto));
xhook_register(".*libinput\\.so$", "recvfrom",(void *) my_recvfrom, (void **) (&original_recvfrom));
}上面这个是我写的demo,完整代码看这里,这个demo肯定是不够完善的。但方案是可行的。完善的方案请看matrix的Touch相关源码。
3.2.2 监控IdleHandler卡顿
IdleHandler任务最终会被存储到MessageQueue的mIdleHandlers (一个ArrayList)中,在主线程空闲时,也就是MessageQueue的next方法暂时没有message可以取出来用时,会从mIdleHandlers 中取出IdleHandler任务进行执行。那我们可以把这个mIdleHandlers 替换成自己的,重写add方法,添加进来的 IdleHandler 给它包装一下,包装的那个类在执行 queueIdle 时进行计时,这样添加进来的每个IdleHandler在执行的时候我们都能拿到其 queueIdle 的执行时间 。如果超时我们就进行记录或者上报。
fun startDetection() {
val messageQueue = mHandler.looper.queue
val messageQueueJavaClass = messageQueue.javaClass
val mIdleHandlersField = messageQueueJavaClass.getDeclaredField("mIdleHandlers")
mIdleHandlersField.isAccessible = true
//虽然mIdleHandlers在Android Q以上被标记为UnsupportedAppUsage,但居然可以成功设置. 只有在反射访问mIdleHandlers时,才会触发系统的限制
mIdleHandlersField.set(messageQueue, MyArrayList())
}
class MyArrayList : ArrayList<IdleHandler>() {
private val handlerThread by lazy {
HandlerThread("").apply {
start()
}
}
private val threadHandler by lazy {
Handler(handlerThread.looper)
}
override fun add(element: IdleHandler): Boolean {
return super.add(MyIdleHandler(element, threadHandler))
}
}
class MyIdleHandler(private val originIdleHandler: IdleHandler, private val threadHandler: Handler) : IdleHandler {
override fun queueIdle(): Boolean {
log("开始执行idleHandler")
//1. 延迟发送Runnable,Runnable收集主线程堆栈信息
val runnable = {
log("idleHandler卡顿 \n ${getMainThreadStackTrace()}")
}
threadHandler.postDelayed(runnable, 2000)
val result = originIdleHandler.queueIdle()
//2. idleHandler如果及时完成,那么就移除Runnable。如果上面的Runnable得到执行,说明主线程的idleHandler已经执行了2秒还没执行完,可以收集信息,对照着检查一下代码了
threadHandler.removeCallbacks(runnable)
return result
}
}反射完成之后,我们简单添加一个IdleHandler,然后在里面sleep(10000)测试一下,得到结果如下:
2022-10-17 07:33:50.282 28825-28825/com.xfhy.allinone D/xfhy_tag: 开始执行idleHandler
2022-10-17 07:33:52.286 28825-29203/com.xfhy.allinone D/xfhy_tag: idleHandler卡顿
java.lang.Thread.sleep(Native Method)
java.lang.Thread.sleep(Thread.java:443)
java.lang.Thread.sleep(Thread.java:359)
com.xfhy.allinone.actual.idlehandler.WatchIdleHandlerActivity$startTimeConsuming$1.queueIdle(WatchIdleHandlerActivity.kt:47)
com.xfhy.allinone.actual.idlehandler.MyIdleHandler.queueIdle(WatchIdleHandlerActivity.kt:62)
android.os.MessageQueue.next(MessageQueue.java:465)
android.os.Looper.loop(Looper.java:176)
android.app.ActivityThread.main(ActivityThread.java:8668)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1109)
从日志堆栈里面很清晰地看到具体是哪里发生了卡顿。
3.2.3 监控SyncBarrier泄漏
什么是SyncBarrier泄漏?在说这个之前,我们得知道什么是SyncBarrier,它翻译过来叫同步屏障,听起来很牛逼,但实际上就是一个Message,只不过这个Message没有target。没有target,那这个Message拿来有什么用?当MessageQueue中存在SyncBarrier的时候,同步消息就得不到执行,而只会去执行异步消息。我们平时用的Message一般是同步的,异步的Message主要是配合SyncBarrier使用。当需要执行一些高优先级的事情的时候,比如View绘制啥的,就需要往主线程MessageQueue插个SyncBarrier,然后ViewRootlmpl 将mTraversalRunnable 交给 Choreographer ,Choreographer 等到下一个VSYNC信号到来时,及时地去执行mTraversalRunnable ,交给Choreographer 之后的部分逻辑优先级是很高的,比如执行mTraversalRunnable 的时候,这种逻辑是放到异步消息里面的。回到ViewRootImpl之后将SyncBarrier移除。
关于同步屏障和
Choreographer的详细逻辑可以看我之前的文章:Handler同步屏障、Choreographer原理及应用
@UnsupportedAppUsage
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
//插入同步屏障,mTraversalRunnable的优先级很高,我需要及时地去执行它
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
//mTraversalRunnable里面会执行doTraversal
mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
void unscheduleTraversals() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
mChoreographer.removeCallbacks(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
performTraversals();
}
}再来说说什么是同步屏障泄露:我们看到在一开始的时候scheduleTraversals里面插入了一个同步屏障,这时只能执行异步消息了,不能执行同步消息。假设出现了某种状况,让这个同步屏障无法被移除,那么消息队列中就一直执行不到同步消息,可能导致主线程假死,你想想,主线程里面同步消息都执行不了了,那岂不是要完蛋。那什么情况下会导致出现上面的异常情况?
- scheduleTraversals线程不安全,万一不小心post了多个同步屏障,但只移除了最后一个,那有的同步屏障没被移除的话,同步消息无法执行
- scheduleTraversals中post了同步屏障之后,假设某些操作不小心把异步消息给移除了,导致没有移除该同步屏障,也会造成同样的悲剧
问题找到了,怎么解决?有什么好办法能监控到这种情况吗(虽然这种情况比较少见)?微信的同学给出了一种方案,我简单描述下:
- 开个子线程,轮询检查主线程的MessageQueue里面的message,检查是否有同步屏障消息的when已经过去了很久了,但还没得到移除
- 此时可以合理怀疑该同步屏障消息可能已泄露,但还不能确定(有可能是主线程卡顿,导致没有及时移除)
- 这个时候,往主线程发一个同步消息和一个异步消息(可以间隔地多发几次,增加可信度),如果同步消息没有得到执行,但异步消息得到执行了,这说明什么?说明主线程有处理消息的能力,不卡顿,且主线程的MessageQueue中有一个同步屏障一直没得到移除,所以同步消息才没得到执行,而异步消息得到执行了。
- 此时,可以激进一点,把这个泄露的同步泄露消息给移除掉。
下面是此方案的核心代码,完整源码在这里
override fun run() {
while (!isInterrupted) {
val messageHead = mMessagesField.get(mainThreadMessageQueue) as? Message
messageHead?.let { message ->
//该消息为同步屏障 && 该消息3秒没得到执行,先怀疑该同步屏障发生了泄露
if (message.target == null && message.`when` - SystemClock.uptimeMillis() < -3000) {
//查看MessageQueue#postSyncBarrier(long when)源码得知,同步屏障message的arg1会携带token,
// 该token类似于同步屏障的序号,每个同步屏障的token是不同的,可以根据该token唯一标识一个同步屏障
val token = message.arg1
startCheckLeaking(token)
}
}
sleep(2000)
}
}
private fun startCheckLeaking(token: Int) {
var checkCount = 0
barrierCount = 0
while (checkCount < 5) {
checkCount++
//1. 判断该token对应的同步屏障是否还存在,不存在就退出循环
if (isSyncBarrierNotExist(token)) {
break
}
//2. 存在的话,发1条异步消息给主线程Handler,再发1条同步消息给主线程Handler,
// 看一下同步消息是否得到了处理,如果同步消息发了几次都没处理,而异步消息则发了几次都被处理了,说明SyncBarrier泄露了
if (detectSyncBarrierOnce()) {
//发生了SyncBarrier泄露
//3. 如果有泄露,那么就移除该泄露了的同步屏障(反射调用MessageQueue的removeSyncBarrier(int token))
removeSyncBarrier(token)
break
}
SystemClock.sleep(1000)
}
}
private fun detectSyncBarrierOnce(): Boolean {
val handler = object : Handler(Looper.getMainLooper()) {
override fun handleMessage(msg: Message) {
super.handleMessage(msg)
when (msg.arg1) {
-1 -> {
//异步消息
barrierCount++
}
0 -> {
//同步消息 说明主线程的同步消息是能做事的啊,就没有SyncBarrier一说了
barrierCount = 0
}
else -> {}
}
}
}
val asyncMessage = Message.obtain()
asyncMessage.isAsynchronous = true
asyncMessage.arg1 = -1
val syncMessage = Message.obtain()
syncMessage.arg1 = 0
handler.sendMessage(asyncMessage)
handler.sendMessage(syncMessage)
//超过3次,主线程的同步消息还没被处理,而异步消息缺得到了处理,说明确实是发生了SyncBarrier泄露
return barrierCount > 3
}4. 小结
文中详细介绍了卡顿与ANR的关系,以及卡顿原理和卡顿监控,详细捋下来可对卡顿有更深的理解。对于Looper Printer方案来说,是比较完善的,而且微信也在使用此方案,该踩的坑也踩完了。
链接:https://juejin.cn/post/7177194449322606647
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
日常思考,目前Kotlin协程能完全取代Rxjava吗
前言
自从jetbrains公司提出Kotlin协程用来解决异步线程问题,并且衍生出来了Flow作为响应式框架,引来了大量Android开发者的青睐;而目前比较稳定的响应式库当属Rxjava,这样以来目的就很明显了,旨在用Kotlin协程来逐步替代掉Rxjava;
仔细思考下,真的可以完全替代掉Rxjava么,它的复杂性和多样化的操作符,而协程的许多API仍然是实验性的,目前为止,随着kt不断地进行版本迭代,越来越趋于稳定,对此我不能妄下断言;当然Rxjava无疑也是一个非常优秀的框架,值得我们不断深入思考,但是随着协程的出现,就个人而言我会更喜欢使用协程来作为满足日常开发的异步解决方案。
协程的本质和
Rxjava是截然不同的,所以直接拿它们进行对比是比较棘手的;换一种思路,本文我们从日常开发中的异步问题出发,分别观察协程与Rxjava是如何提供相应的解决方案,依次来进行比对,探讨下Kotlin协程是否真的足以取代Rxjava这个话题吧
流类型的比较
现在我们来看下Rxjava提供的流类型有哪些,我们可以使用的基本流类型操作符如下图所示
它们的基本实现在下文会提及到,这里我们简单来讨论下在协程中是怎么定义这些流操作符的
Single<T>其实就是一个返回不可空值的suspend函数
Maybe<T>恰好相反,是一个返回可空的supspend函数
Completable不会发送事件,所以在协程中就是一个不返回任何东西的简单挂起函数
对于
Observable和Flowable,两者都可以发射多个事件,不同在于前者是没有背压管理的,后者才有,而他们在协程中我们可以直接使用Flow来完成,在异步数据流中按顺序发出值,所以只需要一个返回当前Data数据类型的Flow<T>
值得注意的是,该函数本身是不需要
supsend修饰符的,由于Flow是冷流,在进行收集\订阅之前是不会发射数据,只要在collect的时候才需要协程作用域中执行。为什么说Flow足以替代Observable和Flowable原因在与它处理背压(backpressure)的方式。这自然而然来源于协程中的设计与理念,不需要一些巧妙设计的解决方案来处理显示背压,Flow中所有Api基本上都带有suspend修复符,它也成为了解决背压的关键先生。其目的就是在不阻塞线程的情况下暂停调用者的执行,因此,当Flow<T>在同一个协程中发射和收集的时候,如果收集器跟不上数据流,它可以简单地暂停元素的发射,直到它准备好接收更多。
流类型比较的基本实现
好的小伙伴们,上文我们简单用协程写出Rxjava的几个基本流类型,现在让我们用几个详细的实例来看看他们的不同之处吧
Completable ---- 异步任务完成没有结果,可能会抛出错误
在Rxjava中,我们使用Completable.create去创建,里面的CompletableEmitter中有onComplete表示完成的方法和一个onError传递异常的方法,如下代码所示
//completable in Rxjava
fun completableRequest(): Completable {
return Completable.create { emitter->
try {
emitter.onComplete()
}catch (e:Exception) {
emitter.onError(e)
}
}
}
fun main() {
completableRequest()
.subscribe {
println("I,am done")
println()
}
}在协程当中,我们对应的就是调用一个不返回任何内容的挂起函数(returns Unit),就类似于我们调用一个普通函数一样
fun completableCoroutine() = runBlocking {
try {
delay(500L)
println("I am done")
} catch (e: Exception) {
println("Got an exception")
}
}
注意不要在生产环境代码使用
runBlocking,你应该有一个合适的CoroutineScope,由于是测试代码本文都将使用runBlocking来辅助说明测试场景
Single ---- 必须返回或抛出错误的异步任务
在 RxJava 中,我们使用一个Single ,它里面有一个onSuccess传递返回值的方法和一个onError传递异常的方法。
```kotlin
/**
* Single in RxJava
*/
fun main() {
singleResult()
.subscribe(
{ result -> println(result) },
{ println("Got an exception") }
)
}
fun singleResult(): Single<String> {
return Single.create { emitter ->
try {
// process a request
emitter.onSuccess("Some result")
} catch (e: Exception) {
emitter.onError(e)
}
}
```而在协程中,我们调用一个返回非空值的挂起函数:
/**
* Single equivalent in coroutines
*/
fun main() = runBlocking {
try {
val result = getResult()
println(result)
} catch (e: Exception) {
println("Got an exception")
}
}
suspend fun getResult(): String {
// process a request
delay(100)
return "Some result"
}Maybe --- 可能返回结果或抛出错误的异步任务
在 RxJava 中,我们使用一个Maybe. 它里面有一个onSuccess传递返回值的方法onComplete,一个在没有值的情况下发出完成信号的方法,以及一个onError传递异常的方法。
/**
* Maybe in RxJava
*/
fun main() {
maybeResult()
.subscribe(
{ result -> println(result) },
{ println("Got an exception") },
{ println("Completed without a value!") }
)
}
fun maybeResult(): Maybe<String> {
return Maybe.create { emitter ->
try {
// process a request
if (Random.nextBoolean()) {
emitter.onSuccess("Some value")
} else {
emitter.onComplete()
}
} catch (e: Exception) {
emitter.onError(e)
}
}
}在协程中,我们调用一个返回可空值得挂起函数
/**
* Maybe equivalent in coroutines
*/
fun main() = runBlocking {
try {
val result = getNullableResult()
if (result != null) {
println(result)
} else {
println("Completed without a value!")
}
} catch (e: Exception) {
println("Got an exception")
}
}
suspend fun getNullableResult(): String? {
// process a request
delay(100)
return if (Random.nextBoolean()) {
"Some value"
} else {
null
}
}0..N事件的异步流
由于在Rxjava中,Flowable和Observable都是属于0..N事件的异步流,但是Observable几乎没有做相应的背压管理,所以这里我们主要以Flowable为例子,onNext发出下一个流值的方法,一个onComplete表示流完成的方法,以及一个onError传递异常的方法。
/**
* Flowable in RxJava
*/
fun main() {
flowableValues()
.subscribe(
{ value -> println(value) },
{ println("Got an exception") },
{ println("I'm done") }
)
}
fun flowableValues(): Flowable<Int> {
val flowableEmitter = { emitter: FlowableEmitter<Int> ->
try {
for (i in 1..10) {
emitter.onNext(i)
}
} catch (e: Exception) {
emitter.onError(e)
} finally {
emitter.onComplete()
}
}
return Flowable.create(flowableEmitter, BackpressureStrategy.BUFFER)
}在协程中,我们只是创建一个Flow就可以完成这个方法
/**
* Flow in Kotlin
*/
fun main() = runBlocking {
try {
eventFlow().collect { value ->
println(value)
}
println("I'm done")
} catch (e: Exception) {
println("Got an exception")
}
}
fun eventFlow() = flow {
for (i in 1..10) {
emit(i)
}
}
在惯用的
Kotlin中,创建上述流程的方法之一是:fun eventFlow() = (1..10).asFlow()
如上面这些代码所见,我们基本可以使用协程涵盖Rxjava所有的主要基本用法,此外,协程的设计允许我们使用所有标准的Kotlin功能编写典型的顺序代码 ,它还消除了对onComplete或onError回调的需要。我们可以像在普通代码中那样捕获错误或设置协程异常处理程序。并且,考虑到当挂起函数完成时,协程继续按顺序执行,我们可以在下一行继续编写我们的“完成逻辑”。
值得注意的是,当我们进行调用collect收集的时候也是如此,在收集完所有元素后才会执行下一行代码
eventFlow().collect { value ->
println(value)
}
println("I'm done")
Flow收集完所有元素后,才会调用打印I'm done
操作符的比较
总所周知,Rxjava的主要优势在于它拥有非常多的操作符,基本上可以应对日常开发中出现的各种情况,由于它种类特别繁多又比较难记忆,这里我只简单举些常见的操作符进行比较
COMPLETABLE,SINGLE, MAYBE
这里需要强调的是,在Rxjava中Completable,Single和Maybe都有许多相同的操作符,然而在协程中任何类型的操作符其实都是多余的,我们以Single中的map()简单操作符为例来看下:
/**
* Maps Single<String> to
* Single<User> synchronously
*/
fun main() {
getUsername()
.map { username ->
User(username)
}
.subscribe(
{ user -> println(user) },
{ println("Got an exception") }
)
}map作为Rxjava中最常用的操作符,获取一个值并将其转换为另一个值,但是在协程中我们不需要.map()操作符就可以实现这种操作
fun main() = runBlocking {
try {
val username = getUsername() // suspend fun
val user = User(username)
println(user)
} catch (e: Exception) {
println("Got an exception")
}
}使用suspend挂起函数可以挂起当前函数,当执行完毕后在按顺序执行接下来的代码
Flow操作符与Rxjava操作符
现在让我们看看Flow中有哪些操作符,它们与Rxjava相比有什么不同,由于篇幅原因,这里我简单比较下日常开发中最常用的操作符
map()
对于map操作符,Flow中也具有相同的操作符
/**
* Maps Flow<String> to Flow<User>
*/
fun main() = runBlocking {
usernameFlow()
.map { username ->
User(username)
}
.collect { user ->
println(user)
}
}Flow中的map操作符 相当于Rxjava做了一定的简化处理,这是它的一个主要优势,可以看下它的源码
fun <T, R> Flow<T>.map(transform: suspend (T) -> R): Flow<R> = flow {
collect { value -> emit(transform(value)) }
}是不是非常简单,只是重新创建一个新的flow,它从从上游收集值transform并在当前函数应用后发出这些值;事实上大多数Flow的操作符都是这样工作的,不需要遵循严格的协议;对于大多数应用场景,标准Flow操作符就已经足够了,当然编写自定义操作符也是非常简单容易的;相对于Rxjava,如果想要编写自定义操作符,你必须非常了解Rxjava的
flatmap()
另外,在Rxjava中我们经常使用的操作符还有flatmap(),同时还有很多种变体,例如.flatMapSingle(),flatMapObservable(),flatMapIterable()等,简单来说,在Rxjava中我们如果需要对一个值进行同步转换,就使用map,进行异步转换的时候就需要使用flatMap();对此,Flow进行同步或者异步转换的时候不需要不同的操作符,仅仅使用map就足够了,由于它们都有supsend挂起函数进行修饰,不用担心同步性
可以看下在Rxjava中的示例
fun compareFlatMap() {
getUsernames() //Flowable<String>
.flatMapSingle { username ->
getUserFromNetwork(username) // Single<User>
}
.subscribe(
{ user -> println(user) },
{ println("Got an exception") }
)
}好的,我们使用Flow来转换下上述的这一段代码,只需要使用map就可以以任何方式进行转换值,如下代码所示:
runBlocking {
flow {
emit(User("Jacky"))
}.map {
getUserFromName(it) //suspend
}.collect {
println(it)
}
}
suspend fun getUserFromName(user: User): String {
return user.userName
}实际上使用Flow中的map操作符,就可以将上游流发出的值转换为新流,然后将所有流扁平化为一个,这和flatMap的功能几乎可以达到同样的效果
filter()
对于filter操作符,我们在Rxjava中并没有直接的方法进行异步过滤,这需要我们自己编写代码来进行过滤判断,如下所示
fun getUsernames(): Flowable<String> {
val flowableEmitter = { emitter: FlowableEmitter<String> ->
emitter.onNext("Jacky")
}
return Flowable.create(flowableEmitter, BackpressureStrategy.BUFFER)
}
fun isCorrectUserName(userName: String): Single<Boolean> {
return Single.create { emitter ->
runCatching {
//名字判断....
if (userName.isNotEmpty()) {
emitter.onSuccess(true)
} else {
emitter.onSuccess(false)
}
}.onFailure {
emitter.onError(it)
}
}
}
fun compareFilter() {
getUsernames()//Flowable<String>
.flatMapSingle { userName ->
isCorrectUserName(userName)
.flatMap { isCorrect ->
if (isCorrect) {
Single.just(userName)
} else {
Single.never()
}
}
}.subscribe {
println(it)
}
}乍一看,是不是感觉有点麻烦,事实上这确实需要我们使用些小手段才能达到目的;而在Flow中,我们能够轻松地根据同步和异步调用过滤流
runBlocking {
userNameFlow().filter { user ->
isCorrectName(user.userName)
}.collect { user->
println(user)
}
}
suspend fun isCorrectName(userName: String): Boolean {
return userName.isNotEmpty()
}
结语
由于篇幅原因,Rxjava和协程都是一个非常庞大的思考话题,它们之间的不同比较可以永远进行下去;事实上,在Kotlin协程被广泛使用之前,Rxjava作为项目中主要的异步解决方案,以至于到现在工作上还有很多项目用着Rxjava, 所以即使切换到Kotlin协程之后,还有相当长一段时间还在用着Rxjava;这并不代表Rxjava不够好,而是协程让代码变得更易读,更易于使用;
暂时先告一段落了,事实上证明协程确实能够满足我们日常开发的主要需求,下次将会对Rxjava中的背压和之前所讨论的Flow背压问题进行比较探讨,还有非常多的东西要学,共勉!!!!
链接:https://juejin.cn/post/7175803413232844855
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
某大龄单身程序员自曝:追求美团女员工,却被她欺骗利用,天天免费加班写代码!
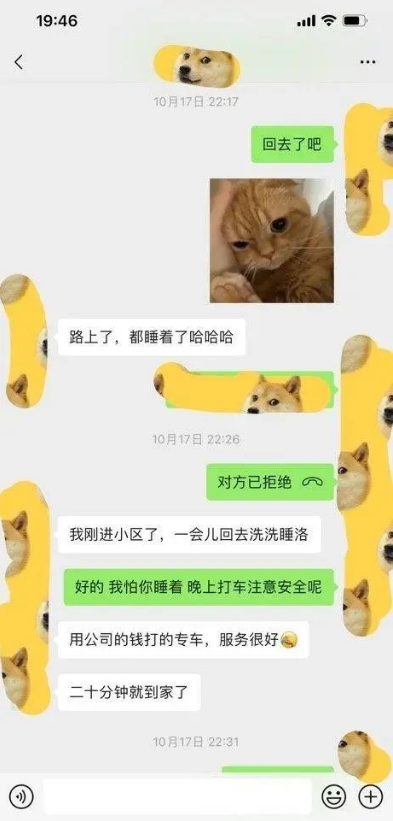
一位程序员最近非常生气,因为他喜欢上一位美团的妹子,却被妹子骗去写代码做苦力,成了妥妥的工具人。

该程序员一怒之下,把妹子和自己的聊天记录曝光了出来:

另外,搜索公众号后端架构师后台回复“架构整洁”,获取一份惊喜礼包。
楼主说,自己已经在美团官网举报了,该女生就等待阳光职场通报吧。其实这几个月早就发现她有很多不对劲的地方,但希望她能良心发现,跟自己坦诚一下,然而并没有。

有人评价,这就是传说中的职场妲己?

有人嘲笑楼主被女生当成了工具人。
有人说,这种人不是一个,只是有的靠外面的备胎养,有的压榨下面的人。美团管理层很狂妄傲慢,一直坚持pua。

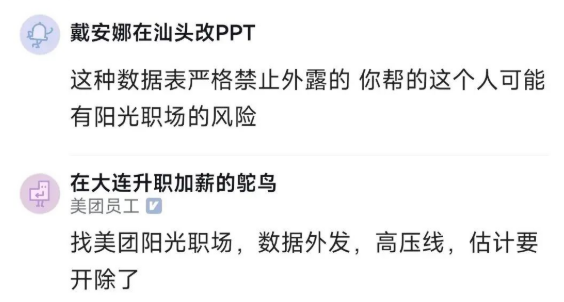
有人说,这种数据表严禁外露,这个女生可能有阳光职场的风险,估计要被开除了。
也有人说,这是私德问题,公司不管。看开点,愿意帮就帮,不愿意就算了。

有人说,工作是工作,感情是感情,楼主可以帮一部分,但不能帮全部。

还有人说,这就是一个舔狗舔而不得的故事,楼主追不到女生就恼羞成怒了,明显表白不成想报复,还用掐头去尾的聊天记录。其实帮她之前就该知道,帮不帮都不能影响她和自己的关系。

站在楼主的角度,我们完全能理解他为什么这么生气。在他的复杂情绪里,既有没追上妹子的失望沮丧,也有被妹子欺骗利用的愤怒。无论是谁,被别人当成工具人都会火冒三丈吧?
在现实生活中,的确有一些心术不正的人喜欢利用别人的感情,让别人成为自己职业生涯的跳板和垫脚石,无论男女,坏人不分性别。
所以,即使你对某人动了心,也一定要警惕别有用心的感情陷阱。一旦发现自己有成为工具人的苗头,赶紧保持冷静,好好看清目前的局势。不要变成恋爱脑,像王宝钏一样,为了等待一个不值得的人,挖着野菜苦守寒窑十八年,成了一个笑话。
来自:行者
收起阅读 »面试官:你如何实现大文件上传
提到大文件上传,在脑海里最先想到的应该就是将图片保存在自己的服务器(如七牛云服务器),保存在数据库,不仅可以当做地址使用,还可以当做资源使用;或者将图片转换成base64,转换成buffer流,但是在javascript这门语言中不存在,但是这些只适用于一些小图片,对于大文件还是束手无策。
一、问题分析
如果将大文件一次性上传,会发生什么?想必都遇到过在一个大文件上传、转发等操作时,由于要上传大量的数据,导致整个上传过程耗时漫长,更有甚者,上传失败,让你重新上传!这个时候,我已经咬牙切齿了。先不说上传时间长久,毕竟上传大文件也没那么容易,要传输更多的报文,丢包也是常有的事,而且在这个时间段万不可以做什么其他会中断上传的操作;其次,前后端交互肯定是有时间限制的,肯定不允许无限制时间上传,大文件又更容易超时而失败....
一、解决方案
既然大文件上传不适合一次性上传,那么将文件分片散上传是不是就能减少性能消耗了。
没错,就是分片上传。分片上传就是将大文件分成一个个小文件(切片),将切片进行上传,等到后端接收到所有切片,再将切片合并成大文件。通过将大文件拆分成多个小文件进行上传,确实就是解决了大文件上传的问题。因为请求时可以并发执行的,这样的话每个请求时间就会缩短,如果某个请求发送失败,也不需要全部重新发送。
二、具体实现
1、前端
(1)读取文件
准备HTML结构,包括:读取本地文件(input类型为file)、上传文件按钮、上传进度。
<input type="file" id="input">
<button id="upload">上传</button>
<!-- 上传进度 -->
<div style="width: 300px" id="progress"></div>JS实现文件读取:
监听input的change事件,当选取了本地文件后,打印事件源可得到文件的一些信息:
let input = document.getElementById('input')
let upload = document.getElementById('upload')
let files = {}//创建一个文件对象
let chunkList = []//存放切片的数组
// 读取文件
input.addEventListener('change', (e) => {
files = e.target.files[0]
console.log(files);
//创建切片
//上传切片
})观察控制台,打印读取的文件信息如下:
(2)创建切片
文件的信息包括文件的名字,文件的大小,文件的类型等信息,接下来可以根据文件的大小来进行切片,例如将文件按照1MB或者2MB等大小进行切片操作:
// 创建切片
function createChunk(file, size = 2 * 1024 * 1024) {//两个形参:file是大文件,size是切片的大小
const chunkList = []
let cur = 0
while (cur < file.size) {
chunkList.push({
file: file.slice(cur, cur + size)//使用slice()进行切片
})
cur += size
}
return chunkList
}切片的核心思想是:创建一个空的切片列表数组chunkList,将大文件按照每个切片2MB进行切片操作,这里使用的是数组的Array.prototype.slice()方法,那么每个切片都应该在2MB大小左右,如上文件的大小是8359021,那么可得到4个切片,分别是[0,2MB]、[2MB,4MB]、[4MB,6MB]、[6MB,8MB]。调用createChunk函数,会返回一个切片列表数组,实际上,有几个切片就相当于有几个请求。
调用创建切片函数:
//注意调用位置,不是在全局,而是在读取文件的回调里调用
chunkList = createChunk(files)
console.log(chunkList);观察控制台打印的结果:
(3)上传切片
上传切片的个关键的操作:
第一、数据处理。需要将切片的数据进行维护成一个包括该文件,文件名,切片名的对象,所以采用FormData对象来进行整理数据。FormData 对象用以将数据编译成键值对,可用于发送带键数据,通过调用它的append()方法来添加字段,FormData.append()方法会将字段类型为数字类型的转换成字符串(字段类型可以是 Blob、File或者字符串:如果它的字段类型不是 Blob 也不是 File,则会被转换成字符串类。
第二、并发请求。每一个切片都分别作为一个请求,只有当这4个切片都传输给后端了,即四个请求都成功发起,才上传成功,使用Promise.all()保证所有的切片都已经传输给后端。
//数据处理
async function uploadFile(list) {
const requestList = list.map(({file,fileName,index,chunkName}) => {
const formData = new FormData() // 创建表单类型数据
formData.append('file', file)//该文件
formData.append('fileName', fileName)//文件名
formData.append('chunkName', chunkName)//切片名
return {formData,index}
})
.map(({formData,index}) =>axiosRequest({
method: 'post',
url: 'http://localhost:3000/upload',//请求接口,要与后端一一一对应
data: formData
})
.then(res => {
console.log(res);
//显示每个切片上传进度
let p = document.createElement('p')
p.innerHTML = `${list[index].chunkName}--${res.data.message}`
document.getElementById('progress').appendChild(p)
})
)
await Promise.all(requestList)//保证所有的切片都已经传输完毕
}
//请求函数
function axiosRequest({method = "post",url,data}) {
return new Promise((resolve, reject) => {
const config = {//设置请求头
headers: 'Content-Type:application/x-www-form-urlencoded',
}
//默认是post请求,可更改
axios[method](url,data,config).then((res) => {
resolve(res)
})
})
}
// 文件上传
upload.addEventListener('click', () => {
const uploadList = chunkList.map(({file}, index) => ({
file,
size: file.size,
percent: 0,
chunkName: `${files.name}-${index}`,
fileName: files.name,
index
}))
//发请求,调用函数
uploadFile(uploadList)
})2、后端
(1)接收切片
主要工作:
第一:需要引入multiparty中间件,来解析前端传来的FormData对象数据;
第二:通过path.resolve()在根目录创建一个文件夹--qiepian,该文件夹将存放另一个文件夹(存放所有的切片)和合并后的文件;
第三:处理跨域问题。通过setHeader()方法设置所有的请求头和所有的请求源都允许;
第四:解析数据成功后,拿到文件相关信息,并且在qiepian文件夹创建一个新的文件夹${fileName}-chunks,用来存放接收到的所有切片;
第五:通过fse.move(filePath,fileName)将切片移入${fileName}-chunks文件夹,最后向前端返回上传成功的信息。
//app.js
const http = require('http')
const multiparty = require('multiparty')// 中间件,处理FormData对象的中间件
const path = require('path')
const fse = require('fs-extra')//文件处理模块
const server = http.createServer()
const UPLOAD_DIR = path.resolve(__dirname, '.', 'qiepian')// 读取根目录,创建一个文件夹qiepian存放切片
server.on('request', async (req, res) => {
// 处理跨域问题,允许所有的请求头和请求源
res.setHeader('Access-Control-Allow-Origin', '*')
res.setHeader('Access-Control-Allow-Headers', '*')
if (req.url === '/upload') { //前端访问的地址正确
const multipart = new multiparty.Form() // 解析FormData对象
multipart.parse(req, async (err, fields, files) => {
if (err) { //解析失败
return
}
console.log('fields=', fields);
console.log('files=', files);
const [file] = files.file
const [fileName] = fields.fileName
const [chunkName] = fields.chunkName
const chunkDir = path.resolve(UPLOAD_DIR, `${fileName}-chunks`)//在qiepian文件夹创建一个新的文件夹,存放接收到的所有切片
if (!fse.existsSync(chunkDir)) { //文件夹不存在,新建该文件夹
await fse.mkdirs(chunkDir)
}
// 把切片移动进chunkDir
await fse.move(file.path, `${chunkDir}/${chunkName}`)
res.end(JSON.stringify({ //向前端输出
code: 0,
message: '切片上传成功'
}))
})
}
})
server.listen(3000, () => {
console.log('服务已启动');
})通过node app.js启动后端服务,可在控制台打印fields和files:
(2)合并切片
第一:前端得到后端返回的上传成功信息后,通知后端合并切片:
// 通知后端去做切片合并
function merge(size, fileName) {
axiosRequest({
method: 'post',
url: 'http://localhost:3000/merge',//后端合并请求
data: JSON.stringify({
size,
fileName
}),
})
}
//调用函数,当所有切片上传成功之后,通知后端合并
await Promise.all(requestList)
merge(files.size, files.name)第二:后端接收到合并的数据,创建新的路由进行合并,合并的关键在于:前端通过POST请求向后端传递的合并数据是通过JSON.stringify()将数据转换成字符串,所以后端合并之前,需要进行以下操作:
解析POST请求传递的参数,自定义函数
resolvePost,目的是将每个切片请求传递的数据进行拼接,拼接后的数据仍然是字符串,然后通过JSON.parse()将字符串格式的数据转换为JSON对象;接下来该去合并了,拿到上个步骤解析成功后的数据进行解构,通过
path.resolve获取每个切片所在的路径;自定义合并函数
mergeFileChunk,只要传入切片路径,切片名字和切片大小,就真的将所有的切片进行合并。在此之前需要将每个切片转换成流stream对象的形式进行合并,自定义函数pipeStream,目的是将切片转换成流对象,在这个函数里面创建可读流,读取所有的切片,监听end事件,所有的切片读取完毕后,销毁其对应的路径,保证每个切片只被读取一次,不重复读取,最后将汇聚所有切片的可读流汇入可写流;最后,切片被读取成流对象,可读流被汇入可写流,那么在指定的位置通过
createWriteStream创建可写流,同样使用Promise.all()的方法,保证所有切片都被读取,最后调用合并函数进行合并。
if (req.url === '/merge') { // 该去合并切片了
const data = await resolvePost(req)
const {
fileName,
size
} = data
const filePath = path.resolve(UPLOAD_DIR, fileName)//获取切片路径
await mergeFileChunk(filePath, fileName, size)
res.end(JSON.stringify({
code: 0,
message: '文件合并成功'
}))
}
// 合并
async function mergeFileChunk(filePath, fileName, size) {
const chunkDir = path.resolve(UPLOAD_DIR, `${fileName}-chunks`)
let chunkPaths = await fse.readdir(chunkDir)
chunkPaths.sort((a, b) => a.split('-')[1] - b.split('-')[1])
const arr = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
// 在指定的位置创建可写流
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
})
await Promise.all(arr)//保证所有的切片都被读取
}
// 将切片转换成流进行合并
function pipeStream(path, writeStream) {
return new Promise(resolve => {
// 创建可读流,读取所有切片
const readStream = fse.createReadStream(path)
readStream.on('end', () => {
fse.unlinkSync(path)// 读取完毕后,删除已经读取过的切片路径
resolve()
})
readStream.pipe(writeStream)//将可读流流入可写流
})
}
// 解析POST请求传递的参数
function resolvePost(req) {
// 解析参数
return new Promise(resolve => {
let chunk = ''
req.on('data', data => { //req接收到了前端的数据
chunk += data //将接收到的所有参数进行拼接
})
req.on('end', () => {
resolve(JSON.parse(chunk))//将字符串转为JSON对象
})
})
}还未合并前,文件夹如下图所示:
合并后,文件夹新增了合并后的文件:
作者:来碗盐焗星球
来源:juejin.cn/post/7177045936298786872
你还在躺平摆烂?别人已经达到精神离职境界
Z近几个月,在年轻群体中,出现一个新鲜的热词—精神离职,从前的躺平、摆烂流行词已经过时,新的流行词不知不觉间已经取代了旧的。
什么是精神离职?从哪里来?褒的贬的?
员工为什么要精神离职?
精神离职通常在哪个群体?
精神离职的表现有哪些?
应不应该精神离职?
是做低级的精神离职,还是高级的精神离职?
员工精神离职,老板怎么应对?
还有人精神离职,Z后当了CEO,甚至当了老板,这是真的吗?
精神离职一词延伸出许多疑惑,我将分几期来谈论这个话题。

一、什么是精神离职?
Quiet Quitting翻译为安静地放弃,即精神离职,顾名思义,通俗易懂地讲,就是精神离了职,身体还在职。这个词是从欧美年轻群体传过来,在国外TK短视频火起来,Z近慢慢在中国开始受人关注。
精神离职是一种出勤不出力、人在心不在、有力不愿使、事不关己高高挂起的状态。也是一种拿多少钱办多少事、不内卷、不加班、不承担额外责任的工作心态。
精神离职的人只是把工作当成以出卖劳动和时间换取生存的手段,只是把工作当成一个需要扮演的角色。是一种自我保护,一种对现状的妥协。他们不屑于996和狼性文化,内卷也卷不动他们。
精神离职人的表现有哪些?到底什么造成这一现象?
二、精神离职人的表现
1、不违规违纪,相当隐蔽。是平静海底的暗流。
2、上下班特别规律。
3、公司不论怎么变,都岿然不动。
4、不管遇到什么事,不生气,特别平静。不抱怨,觉得一切都很正常,不正常的也是正常的。
5、一切照章办事,如机器人一般。
三、员工为什么要精神离职?
1、外部就业环境、经济环境、工作环境。
2、工作不能自由选择。
3、工作痛苦、无聊、无力、孤立。
4、感觉工作没有意义,没有价值。没有认同感和成就感。
5、企业不考虑员工感受,不听取员工意见与建议。
6、工作中受到打击,没有信心。
7、怀才不遇,没有伯乐。
8、员工心态不好,没有责任感、没有目标追求。
你精神离职了吗?又是哪一种原因的精神离职?
工作痛苦的时候,是选择精神离职,还是身体离职?应不应该精神离职?怎么样才是对自己好的精神离职?怎么样才是高级的精神离职?员工精神离职老板怎么应对?下一期继续。

工作痛苦怎么办?精神离职还是身体离职?
是不是有很多人都觉得工作很痛苦,很无聊,没有意义,没有价值感,没有成就感?甚至让人压抑崩溃?据统计,大部分人每天都有离职的念头。但因为各种原因,一直纠结该不该离职。
那我们工作痛苦时,到底应不应该离职?是选择精神离职还是身体离职?
选择精神离职
1、如果你喜欢你的行业和工作,但因为其它原因而痛苦,可以选择精神离职。
2、如果你的工作你所在公司很有前途,你也很有前途,工资很高,很有希望,可以选择精神离职。
3、如果你非常需要这份工作来养家糊口,经济压力很大,又暂时找不到其他合适的工作,你可以选择精神离职。
4、如果你能从这份工作中学到知识,得到成长,为未来铺路,你可以选择精神离职。
选择身体离职
1、活太多,工资太低,养不活自己。
2、学不到任何东西,未来没有希望。
3、被老板PUA,被人欺负,没有丝毫的受尊重感,每天都活得很憋屈。
4、整个环境让人压抑抑郁。同事素质普遍低下。
5、加班太多,身体被搞垮。
6、加班很多,还没加班费。
7、行业、公司没有前景。
8、特别讨厌这份工作,觉得像活在地Y。
9、每天上班都很疲惫,工作让你觉得活着没意义。
10、有其它好的工作机会。
如果你的工作痛苦,你会选择精神离职还是身体离职?

精神离职=躺平摆烂?
你是低级的精神离职,还是高级的精神离职?
精神离职就是躺平摆烂吗?他们有区别吗?其实精神离职大于摆烂,小于内卷。
精神离职又分为高级的精神离职和低级的精神离职。看看你是哪一种?
低级的精神离职
1、上班时不开心,无聊,麻木,让干啥干啥,就一个机器人。
2、不在乎一切,不受尊重,被骂也无所谓,不想生气不想吵架。
3、没有梦想,没有目标,没有追求,混一天是一天,就是混工资求生存的。
4、不想沟通,不想交际,没有想法,没有建议。
5、没有责任感,事不关己高高挂起,我只做我该做的事,其它事情和我无关。
6、下班刷视频追剧玩网络游戏,继续躺平,娱乐至上。
7、每天浑浑噩噩,虚度人生。
高级的精神离职
1、上班虽然佛系,让干什么干什么,但心里有目标和想法。
2、暗地里为自己努力,让自己渐渐变强大。不加班是觉得加班没用,不如回家提升自己。
3、下班搞副业,或者学习,提升各种能力,给自己更多的机会。哪天副业上来了,就变成主业了。
4、反抗方式放在创造力上,文学、艺术、音乐、运动、写作等是工作痛苦的解Y。
5、把更多的时间放在提升自己,或者维持健康,陪伴家人身上。
你是低级的精神离职还是高级的精神离职?都是精神离职,不如让自己成为高级的。
员工精神离职,老板怎么应对?怎么防止员工精神离职?
精神离职这个词近期突然火了起来,很多人都选择了精神离职,让自己身心舒坦一些。
那么员工精神离职,对企业有什么影响,老板应该怎么应对?
其实大部分精神离职,都是一种负面的,影响企业发展的因素,不能不重视。如果不及时纠正、引导、化解,一定如离岸流一般,拖累企业,让企业走向艰难的境地。
我们先来了解一下精神离职的人,以便对症下药。
精神离职人的特征:
1、精神离职的人不在意尊严荣誉,不在意自己的感受,没有目的追求,没有责任感,看不到努力的意义。不愿和公司沟通,选择一种被动攻击。
2、精神离职的人不再反思、选择,不再有目标、梦想等。
3、精神离职的人在工作中没有获得知识和成长,没有价值感、归属感、认同感、成就感,找不到自己在社会中的位置。
4、精神离职的人经常感觉无力,无意义,孤立,痛苦、无聊等。
5、精神离职的人觉得工作不能自由选择。
6、精神离职的人工作中受到打击,没有信心。企业不考虑员工感受,不听取员工意见与建议。
7、精神离职的人怀才不遇,感觉没有伯乐。
总结为两大点,一是对公司不满,二是对自己不满。
一般对公司不满时,有三种表现,一是直接身体离职,二是抱怨或提建议,三是沉默冷战,即精神离职。
精神离职其实是比较可怕的。因为它是一股暗流,你不知道的时候,它已经发展壮大,你可能没有机会挽救。
所以作为老板,要防止精神离职,或者在有苗头时掐灭。如果已经成形,便采取应对方法。
老板应对员工精神离职的方法:
1、管理者要从自负的控制者转变为谦逊的学习者。不要抑制员工的反馈与建议,不要不听负面的声音。
2、管理者要以互助学习模式来面对和解决工作问题。
3、公司要有公正的企业文化氛围, 有原则和规则的文化,能让员工获得信息沟通的安全感。缺少员工认同和员工互动的文化,不能称为企业文化。
4、征求员工意见,关注员工合理的需求。
5、多听合理的建议,解决企业的一些实际问题。
6、多采取激励方法,激励员工工作热情。
7、关心员工工作、生活和休息,注意假期安排,比如主动积极安排年休假等。
8、多肯定认可鼓励员工,肯定员工个人价值。
9、多增强团体信任感。
精神离职是一种安静社交,安静工作,因为感觉没有希望,所以沉默,愿我们都能在工作中找到真正的自己,快乐的自己。
来源:baijiahao.baidu.com/s?id=1749641382911734394
收起阅读 »研究良久,终于发现了他代码写的快且bug少的原因
前言
读者诸君,今日我们适当放松一下,不钻研枯燥的知识和源码,分享一套高效的摸鱼绝活。
我有一位程序员朋友,当时在一个团队中开发Android应用,历经多次考核后发现:
在组内以及与iOS团队的对比中:
他的任务量略多
但他的bug数量和严重度均低
但他加班的时间又少于其他人
不禁令人产生好奇,他是如何做到代码别的又快,质量又高的
经过多次研究我终于发现了奥秘。
为了行文方便我用"老L"来代指这位朋友。
最常见的客户端bug
"老L,听说昨晚上线,你又坐那摸鱼看测试薅别人,有什么秘诀吗?"
老L:"秘诀?倒也谈不上,你这么说,我倒是有个问题,你觉得平日里最常见的bug有哪些?"
"emm,编码上不健壮的地方,例如NPE,IndexOutOfBoundsException,UI上的可就海了去了,文本长度不一导致显示不下,间距问题,乱七八糟的一大堆"
老L:"哈哈,都是些看起来很幼稚、愚蠢的问题吧?是不是测试挂嘴边的那句:' 你就不能跑一跑吗,你又不瞎,跑两下不就看到了,这么明显!!!' "
我突然来了兴致,"你是说我们有必要上 TDD(test-driven-develop),按照DevOps思想,在CI(Continuous Integration)的时候,顺带跑自动化测试用例发现问题?"
老L突然打断了我:"不要拽你那些词了,记住了,事情是要人干的,机器只能替代可重复劳动,现在还不能替代人的主观能动性,拽词并不能解决问题。我们已经找到了第一个问题的答案,现在换个角度"
平日里最常见的bug有哪些?
编码不健壮, 例如NPE,IndexOutOfBoundsException
UI细节问题, 例如文本长度不一导致显示不下,间距,等
为什么很浅显的问题没有被发现
老L:"那么问题来了,为什么这些浅显的问题,在交测前没有被发现呢?"
我陷入了思考...
是开发们都很懒吗?也不至于啊!
是时间很紧来不及吗?确实节奏紧张,但也不至于不给调试就拿去测了!
"emm, 可能是迭代的节奏的太频繁,压力较大,并没有整块的时间用来自测联调"
老L接过话茬,"假定你说的是正确的,那么就有两种可能。"
"第一种,自测与联调要比开发还要耗费心思的一件事情。但实际上,你我都知道,这一点并站不住脚!"
"而第二种,就是在开发阶段无法及时测试,拖到开发完,简单测测甚至被催促着就交差了"
仔细的思考后
业务逐步展开,无法在任意时间自由地进行有效的集成测试
后端节奏并不比前端快多少,在前端的开发阶段,难以借助后端接口测试,也许接口也有问题
"确实,这是一个挺麻烦的问题,听你一说,我感觉除了多给几天,开发完集中自测一波才行" 我如是说到。
"NO NO NO",老L又打断了我:"你想的过多了,你想借助一个可靠的、已经完备的后端系统来进行自测。对于你的需求来说,这个要求过高了,你这是准备干QA的活"
"我帮你列举一下情况"
一些数据处理的算法,这种没有办法,老老实实写单元测试,在开发阶段就可以做好,保障可靠性
UI呢,我们现在写的代码,基本都做到了UI与逻辑分层,只要能模拟数据,就能跑起来看页面
业务层,后端逻辑我们无法控制,但 Web-API 调用的情况可以分析下并做一下测试,而对于返回数据的JSON结构校验、约束性校验也可以考虑做一下测试
总而言之,我们只需要先排除掉浅显的错误。而这些浅显的错误,属于情况2、3
老L接着说道:"你先歇歇吧,我来说,你再插嘴这文章就太长了!"
接下来就可以实现矛盾转移:"如何模拟数据进行测试",准确的说,问题分成两个子问题:
如何生成模拟数据
如何从接缝中塞入数据,让系统得以使用
可能存在的接缝
先看问题2:"如何从接缝中塞入数据,让系统得以使用"
脑暴一下,可以得出结论:
应用内部
替换调用web-api的业务模块,使用假数据调用业务链,一般替换Presenter、Controller实例
替换Model层,不调用web-api,返回假数据或用假数据调用回调链
侵入网络层实现,不进行实际网络层交互,直接使用假数据
遵循切面,向缓存等机制模块中植入假数据
应用外部
使用代理,返回假数据
假数据服务器
简单分析:
"假数据服务器",并且使用逻辑编造假数据的代价太大,过。"使用代理,返回假数据",可以用于特定问题的调试,不适用广泛情况,过。
"替换调用web-api的业务模块",成本过大,过。"替换Model层",对项目的依赖注入管理具有较大挑战,备选,可能带来很多冗余代码。
"侵入网络层实现",优选。
"向缓存等机制模块中植入假数据",操作真实的缓存较复杂,但可以考虑增加一个 Mock缓存实现模块,基于SPI等机制,可以解决冗余代码问题,备选。
得出结论:
方案1:"侵入网络层实现",优选
方案2:"替换Model层",(项目的依赖注入做得很好时)作为备选,可能带来冗余代码
方案3:"向缓存等机制模块中植入假数据",增加一个 Mock缓存实现模块,备选。(基于SPI等机制,可以解决冗余代码问题)
再仔细分析: 方案1和方案3可以合并,形成一个完整的方案,但未必需要限定在缓存机制中
OK 我们先搁置一下这个问题,看前一个问题。
创造假数据
简单脑暴一下,无非三种:
人工介入,手动编写 -- 成本过大
可能在前期准备好,基本是纯文本
可能使用一个交互工具,在需要数据时介入,通过图形化操作和输入产生数据
人工介入,逻辑编码
基于反射等自省机制,并完全随机或者基于限制生成数据
"第一种代价过大,暂且抛弃"
"第二种可以采用,但是人力成本不容忽视! 一个可以说服我使用它的理由是:"可以精心设计单测数据,针对性的发现问题"
"第三种很轻松,例如使用Mockito,但生成合适的数据需要花费一定的精力"
我们来扒一扒第三种方式,其核心思想为:
获取类信息,得到属性集
遍历属性填充 >
基础类型、箱体类型,枚举,确定取值范围,使用Random取值,赋值
2. 普通类、泛型类,创建实例,回归步骤1
3. 集合、数组等,创建实例,回归步骤1,收集填充
不难得出结论,这一方法虽然很强大,但 创建高度定制化的数据 是一件有挑战的事情。
举个例子,模拟字符串时,一般会使用语料集作为枚举,进行取值。要得到“地址”、“邮箱”等特定风格的数据,需要结合框架做配置,客观上存在较高地学习、使用门槛。
你也知道,前几年我图好玩,写了个 mock库 。
必须强调的一点:“我并不认为我写的库比Mockito等库强大,仅仅是在我们开发人员够用的基础上,做到尽可能简单!”
你也知道,Google 在Androidx(前身为support)中提供了一套注解包: annotations。但Google并未提供bean validation 实现 ,我之前也基于此做过一套JSR303实现,有一次突发灵感,这套注解的含义同样适用于 声明假数据取值范围 !!!
所以,我能使用它便捷的生成合适的假数据,在开发阶段及时的进行 “伪集成”
此刻,我再也忍不住要发言了:“且慢,老L,你这个做法有一定的侵入性吧。而且,如果数据类在不同业务下复用的话,是否存在问题呢?”
老L顿了顿,“确实,google的annotations是源码级注解,并不是运行时,我为了保持简单,使用了运行时反射而非代码生成。所以确实存在一定的代码侵入性”。
但是,我们可以基于此建立一套简单的MOCK-API,这样就不存在代码侵入了。
另外,也可以增加一套Annotation-Processor 实现方案,这样就可以适当沿用项目中的注解约束了,但我个人认为华而不实。
看你的第二个问题,Mocker一开始确实存在这个问题,有一次从Spring的JSR380中得到灵感,我优化了注解规则,这个问题已经被解决了。得空你可以顺着这个图看看:
或者去看看代码和使用说明:github.com/leobert-lan…
再次审视如何处理接缝
此时我已经有点云里雾里,虽然听起来很牛,如何用起来呢?我还是很茫然,简直人麻了!不得不再次请教。
老L笑着说:“你问的是一个实践方案的问题,而这类问题没有银弹.不同的项目、不同的习惯都有最适宜的方法,我只能分享一下我的想法和做法,仅做参考”
在之前的项目中,我自己建了一个Mock-API,利用我的Mocker库,写一个假数据接口就是分分钟的事情。
测试机挂上charles代理,有需要的接口直接进行mapping,所以在客户端代码中,你看不到我做了啥。
当然,这个做法是在软件外部。
如果要在软件内部做,我个人认为这也是一个华而不实的事情。不过不得不承认是一件好玩的事情,那就提一些思路。
基于Retrofit的CallAdapter
public interface CallAdapter<R, T> {
Type responseType();
T adapt(Call<R> call);
abstract class Factory {
public abstract @Nullable
CallAdapter<?, ?> get(Type returnType, Annotation[] annotations,
Retrofit retrofit);
protected static Type getParameterUpperBound(int index,
ParameterizedType type) {
return Utils.getParameterUpperBound(index, type);
}
protected static Class<?> getRawType(Type type) {
return Utils.getRawType(type);
}
}
}很明显,我们可以追加注解,用以区分是否需要考虑mock;
可选:对于有可能需要mock的接口,可以继续追加切面,实现在软件外部控制使用 mock数据 或 真实数据
而Retrofit已经使用反射确定了方法的 return Type ,在Mocker中也有适应的API直接生成假数据
基于Retrofit的Interceptor
相比于上一种,拦截器已经在Retrofit处理流程中靠后,此时在 Chain 中能够得到的内容已经属于Okhttp库的范畴。
所以需要一定的前置措施用于确定 "return Type"、"是否需要Mock" 等信息。可以借助Tag机制:
@Documented
@Target(PARAMETER)
@Retention(RUNTIME)
public @interface Tag {
}
@GET("/")
Call<ResponseBody> foo(@Tag String tag);最终从 Request#tag(type: Class<out T>): T? 方式获取,并接入mock,并生成 Response
其他针对Okhttp的封装
思路基本类似,不再展开。
写在最后
听完老L的思路,我若有所思,若有所悟。他的方案似乎很有效,而且直觉告诉我,这些方案中还有很多留白空间,例如:
借用SPI等技术思路,可以轻易的解决 "Mock 模块集成与移除" 的问题
提前外部控制是否Mock的接缝,可以在加一个工具APP、或者Socket+网页端工具 用以实现控制
但我似乎遗漏了问题的开始
是否原意做 用于约束假数据生成规则的基础建设工作呢??? 例如维护注解
事情终究是人干的,人原意做,办法总比困难多。
最后一个小问题:
作者:leobert-lan
来源:juejin.cn/post/7175772997582585917
跟报阳的朋友沟通的微信礼节
这篇文章适用于你和得病的朋友、熟人、同学和同事的沟通场景。
如果你本人发烧了,不妨把这篇转出去。
他们看了就算不能对你好一点儿,也能少说一点气人的话来激怒你。

图片来自:作者提供
1. 别人报阳千万别点赞
遇到朋友报发烧、报抗原两杠、红码截图。
普通熟人、朋友,可以用“辛苦了”“保重啊”来评论,也可以用“拥抱”“咖啡”等表情。
如果是对你比较重要的人,建议你小窗发消息问候。
不建议只点一个赞,什么都不说。
即使是日常的损友也不要这么做。
2. 问候的三种方式
对方是病人,病人情绪不会太好,病痛会让他们比较易怒,问候宜简短、不要长篇大论。
我的同事欧小宅老师(今天刚退烧)总结说,问候有三种方式:
“你还好吗?”
“祝早日康复!”
“能帮你做点什么?”
你可能会觉得这些问候太书面、太客套,但是请明白一点,大多数别出心裁、自来熟的问候都会砸锅,我们探望病人问候病人的时候形成了这三种问候,是有原因的,因为它们不会出错。
3. 想帮忙该怎么说
如果对方是你比较亲近、比较重要的朋友,你可以把“能帮你做点什么”具体化。
“你的药够吗?如果缺药,我匀点给你。”
“我买了一箱黄桃罐头,可以分你四个,要不要?”
注意,后半句一定要有。
如果你只是简单地问:“你囤药了吗?”对方会摸不准你要做什么。
这句话是看不出“我要你给我药”还是“我有药可以分享给你的”。
明确地表达自己的意图,是跟病人高效沟通的关键。
4. 如何请病人坚持工作
如果你因为工作的缘故仍然要跟一个病人对接,请务必先行问候对方,再谈工作。
工作谈完之后,一定要说“好好休息”之类安慰和勉励的话。
尽快结束工作,比什么安慰都好。

图片来自:作者提供
5. 刨根问底很无聊
“你阳了吗?”
“阳了吗?阳了吗?阳了吗?”
“怎么不理我,我好心问候你,你到底阳了没有啊?”

图片来自:作者提供
“烧起来之后反正都要吃感冒药,不去测还更不容易感染别人。”
这种追问,是没有把对方当病人,而是把对方当风险源和管理对象。
小区门口的大白们都撤了,但有些人心中的防护服还没有脱下来——这种盘根问底,就是他代入了某种角色的表现。
6. 发烧的人没法特么关心世界
有的人其实是想问候病人的,但是一开口就是极其宏大的命题,比如:
“发烧是不是很疼啊?”(废话,你烧到39.5试试看。)
“你身边病倒的人多吗?”(朋友圈有两百多人,你要每个人的电话号码是吗?)
“北京那边形势怎么样?”(我两眼冒金星,你觉得我关心吗?)

图片来自:作者提供
你是出考研政治大题的吗?
开放式问题是问候病人的大忌。
7. 过来人如何给支持
昨天我的一位朋友张老师作为过来人给我分享了一个要诀。
“退热贴已经不好买了,如果买不到,可以把面膜放在冰箱里,烧厉害的时候替代退热贴。”
这种就是非常宝贵的信息,病人只能接受这样明确的信息。
如果你给一个已经病倒的人分享医生嘚嘚嘚讲如何防护的短视频,或者用药大名单之类的PDF,完全没意义了。
此外,每个人的体质不同,疼痛是一种主观感受,作为过来人,不要说“不疼”“没事儿”之类的话,只要告诉病人“我理解你的感受”就够了。
8. 遇到含糊的问题怎么办
刚才说的是如何问候病人。
如果你的领导含含糊糊地问你“你囤药了吗?”应该怎么回答?
建议你实话实说。
“布洛芬还有一盒,不多了。”
如果他是要给你药,你可以决定要不要,如果他是跟你要药,这会儿就会去找别人了。
9. 讨药的注意事项
中国不缺布洛芬或者对乙酰氨基酚,如果开足马力,一年能够30亿人轮番发烧吃的。
退烧药不会吃很多,大多数拍照发朋友圈的囤药者,未来都会剩很多药放在家里过期。
如果你断了药,就直接请那些发囤药照的朋友帮忙就好了。
鉴于发烧的人很多,可能跑腿快递也很难叫到,所以如果缺药,优先在邻居群里求。
如果要发朋友圈求助某类药品,最好是写上自己所在的位置,这样能得到最快的支援。
记得说谢谢,等一切都过去了,一定要坐下来吃个饭。

图片来自:作者提供
有些关系,是给出来的,有些关系,是要出来的。
10. 为什么要这样强调礼貌
这三年的经验就是,全靠自己做自了汉是不行的。
人需要互相扶持。
你今天安慰一个正在发烧的朋友,向他提供帮助,明天你病倒,而且危险的时候,他作为一个刚刚康复有抗体的人,可能就能送打不上车的你去医院(你不会相信等那三个数派车能轮到你吧)。
有一批错峰发病、互相关心的朋友,是我们健康平安的保险阀。
p.s
普通家庭肯定是一阳全阳的,没有双卫怎么保证不传染?
双卫了也照样……
专家都会告诉你说,把病人单独搁一个屋里,没病的在外面。我跟说,你真这样会没朋友的。
媳妇在屋里疼得哞哞哭,自己爬起来吃药倒水,你在外面看世界杯?转阴之日也就是你离异之时了。自己权衡一下,这就是个烧三天的病。
有时候就要冒着风险做该做的事。
活学活用,是生活的奥义。
作者:能老师
来源:mp.weixin.qq.com/s/PMj6gLj32AUNOXPvptYscA
大公司病了,这也太形象了吧!!!
作家采铜说过一个很有意思的比喻,他说,我们真的生活在一个肤浅的时代……希望今天的文章能够给你们带来收获,欢迎分享和点亮在看。



......................................................

......................................................

......................................................

外国的神父呆了不久
留下几个 P 就走了,
一个 P 叫 BPR,
一个 P 叫 ERP。
......................................................
监院也没闲着,
他认为问题的关键在于
人才没有充分利用、
寺庙文化没有建设好,
于是就成立了
人力资源部和寺庙工会等等

......................................................

......................................................

......................................................

......................................................

最后决定,
成立专门的挑水部负责后勤
和专门的烧香部负责市场前台。
同时,为了更好地开展工作,
寺庙提拔了十几名和尚
分别担任副主持、主持助理,
并在每个部门任命了
部门小主持、副小主持、小主持助理。
......................................................
老问题终于得到缓解了,
可新的问题跟着又来了。

后台挑水的和尚也抱怨人手不足、
水的需求量太大而且没个准儿,
不好伺候。

为了便于沟通、协调,
每个部门都设立了对口的联系和尚。
协调虽然有了,但效果却不理想,
仔细一研究,
原来是由于水的需求量不准、
水井数量不足等原因造成的。
于是各部门又召开了几次会,
决定加强前台念经和尚对饮用水的预测
和念经和尚对挑水和尚满意度测评等,
让前后台签署协议、相互打分,
健全考核机制。

同时成立香火钱管理部、
香火钱出账部、
打井策略研究部、
打井建设部、
打井维护部等等。
由于各个系统出来的数总
不准确、都不一致,
于是又成立了技术开发中心,
负责各个系统的维护、
二次开发。
......................................................
由于部门太多、办公场地不足,
寺院专门成立了综合部
来解决这一问题

......................................................

同时,
为了精简机构、提高效率,
寺院还成立了精简机构办公室、
机构改革研究部等部门。
......................................................
一切似乎都合情合理,
但香火钱和喝水的问题
还是迟迟不能解决。
问题在哪呢?
有的和尚提出来每月应该开一次分析会,
于是经营分析部就应运而生了。

寺院空前地热闹起来,
有的和尚在拼命挑水、
有的和尚在拼命念经、
有的和尚在拼命协调、
有的和尚在拼命分析……
忙来忙去,水还是不够喝,
香火钱还是不够用。
什么原因呢?
这个和尚说流程不顺、
那个和尚说任务分解不合理,
这个和尚说部门职责不清、
那个和尚说考核力度不够。
只有三个人最清楚问题之关键所在,
那三个人就是最早的那三个和尚。

......................................................

......................................................

三个人忍无可忍,斗胆向上汇报,
要求增加挑水的人手,
越过数个层级之后,
主持和监院总算收到了这个请求。
经过各个部门季度会议的总结和分析,
经过了数次激烈的探讨,
总算可以从其他部门抽调过来
一些和尚进行支援,
但这些跨部门过来的和尚
根本挑不动水,
还对挑水的这几个和尚指手画脚,
挑水的和尚再次请求,
自己担任挑水的和尚团队负责人。

......................................................
又过了一年,寺院黄了,
大部分和尚都死了

......................................................


大企业管理特色:
总部愈来愈庞大,基层愈来愈忙碌,
成本愈来愈高,客户愈来愈不满。
来源:芝麻观点
收起阅读 »拒绝躺平,来自底层前端的2022总结
一.求学之路
首先说一下自己的背景:由于家庭原因高中辍学,后面报了一个成人专科,浑浑噩噩在学校呆了3年,没有学到什么有用的东西(浪了3年)。我在17年的时候通过自学前端的知识找到了人生的第一份前端开发的工作,当时真的是培训班盛行,那些培训班打着面试的旗号让你进去培训班,出来打工还债。我也是差点就被带进去了。后来还是抵住了诱惑,通过自己学习前端找到了工作。
第一家公司没有明确的分开前后端,项目也是没有前后端分离的,当时他们主要使用的语言是C# + .net 开发。我当时没有接触过C#(只会一些基本的语法)。那时候我也是心非常的慌,害怕好不容易找到的工作就这样丢了,于是每天晚上回去都会去自学C#的基础。幸运的是遇到一个非常好的同事与领导带着我去做项目,我也是顺利的转正了。公司的主要业务是做客户端系统,业务很复杂,通过在公司一年多的磨练,我从一个什么都不会的小白,变成了一个什么都会一点(前端,后端,sql,运维)的萌新了。
当时公司的前端主要框架是JQuery,当时我还不知道Vue,React这种数据驱动的框架,公司也没有其他真正的前端来教我(没错,我是那个公司的唯一一个前端)。后面通过自学,学习了Vue的框架,想在公司中推广这种架构。对于我这个人微言轻的小萌新来说,显然是失败的,大概就是公司不想冒风险,毕竟公司需要求稳。
没办法,当时的我觉得在这里已经没有办法能提高了,毕竟是没有人带,但是那边的老板非常看重我,也是希望我留下,在经过一系列的思想斗争后,还是离开了在这里的呆了一年半的公司,从广州跑去了深圳。
在深圳,再一次被社会毒打。由于是专科的学历,而且不是全日制,找工作处处碰壁,经过一个月的艰苦找工作之路,拿到了两个offer,一个是主要是做邮箱后台的,使用的技术栈是Vue,薪资8K;另外是一个新成立的部门,主要的业务是小程序与后台,但是所有东西都是从零开始搭,薪资6K。当时我希望学习的更多的东西,所以我选择了后者。现在看来,我的选择是正确的,在这个公司,我自学的node,帮助公司搭起架构,学会了服务器运维,同时也学会了Vue。
在那时,我是深刻地意识到,没有学历真的寸步难行。别人轻易拿到的东西,我们需要拼尽全力才能拿到。同时我见识到了成人本科的摆烂行为。我不想混一个本科,既然要拿本科,那自己也要学习到对得起学历的知识。所以我选择了自考。我没有报班,坚持自己的学习计划:每天6点起来学习,下班回去复习,周末没事就去图书馆学习。
这是部分自考的书籍
或许我不是一个特别聪明的人,书上的很多概念有很多很多,因为我是自学的,没有人给我总结重点,所以我认为整本书都是重点,自己去手抄每一个知识点加深记忆,通过三年时间的学习,我写满了二十几个笔记簿(下面只是部分)。没有人教我,那我就去网上自学,刷题。(不得不说通信原理自学是真的很难(傅里叶变换,傅里叶级数...),网上教学也很笼统,只能自己硬啃,我挂了两次!!)
在自考路上的同时,我也不忘深入地学习前端的知识。所以想起当时的自己总是很忙,工作,自考,提升技术,没有时间去做其他的事情。
通过三年(2019-2022)的自学。我终于拿到了学位证。或许这就是给自己努力的回报吧~!
(最差的英语一遍过了!!)
(仅仅过关的学位考试)
(校园随拍)
(校园随拍)
(毕业设计)
(毕业设计)
(毕业设计)
(学历信息)
(学位证)
要说最高兴的不是我拿到了学位证,是我在自考的过程中真正地学习到了知识。我报的是网络工程专业,在自考之前,除了数据结构和程序设计,其他专业课与基础课基本我都没有学习过。通过自考这个渠道,我学习了高数,线代,网络原理,通信原理,多路复用,信号传输原理,如何搭建网络,如何设计一个属于自己的网络协议等很多很多的知识,这种学习到自己喜欢的专业知识是非常让人兴奋的。
还有就是,这是我第一次通过学习得到了老师的肯定——毕业论文的导师愿意帮我写推荐信,可把我高兴得泪目了。
很显然,经过社会毒打四年多的我拿到这一个本科学历绝对不是终点,我希望再次进入学校学习(其实就是我不想去做公司的那些重复无聊的表单设计前端工作)。于是在我面前有3条路可走:1.躺平,2.考研,3.留学。
18岁时我没得选,现在我再一次站在了人生的十字路口中。这次我选择的是后者,考研和留学(希望这次我不会选错吧)。
经过几年的工作,也有一些积蓄去支撑我到国外留学,那就先试试留学吧,不行就去考研。于是我就一步一步按着学校的流程准备资料。
留学最大的难度就是英语,我自认为自己最差的就是英语了,总是学不会。但我不会向困难屈服的,觉得自己英语不好,那就从背单词开始,每天背一点,一直坚持了几年(期间换了一个APP),也总算把初中高中的词汇量补回来了。可以开始下一步的学习了
于是现在我除了工作,就是学英语。我是这样想的,即使我留学申请都没过,但雅思过了,多少也能提升一点竞争力,让社会资源多倾向自己多一点(这就是我几个月没更文的原因😢)。
(凌乱的书桌)
(雅思开始迫在眉睫,压力山大)
二.是什么驱动着我去学习
我觉得,当我们有一个目标,而且这个目标的吸引力足够大的时候,人们就会将逼迫着自己去努力,去拿到自己想要的东西。就比如高考,有的人希望自己能考一个好的学校,于是他很努力地想要达到自己想要的结果,有人却无所谓,没有了驱动力,通常情况是不会得到好的结果。
对我而言,我的目标就是,我不希望被其他人歧视自己是非全日制的学生,还有一点小小的梦想——能稍微改变一下这个社会对于非全日制但是却有足够能力的人的看法。人就是这么与无力,这样一个目标就足以让我们奋斗一生。
对我而言,遇到社会的不公已经是习以为常,甚至已经麻木了。没办法,一步错步步错,没有得到社会资源的倾斜也是自己不够努力的结果。前面我也说了,我是一个要强的人,这种社会的毒打对我而言就是一种动力,只会让我更加努力,让那些看不起我们的人后悔或是另眼相看。
说一个我亲身经历的例子,19年的时候我入职了一个node开发的岗位,入职的时候HR看到我的bi业证是业余大专的时候,他给我发了信息说:你这个大专不是全日制的啊?我说对,后面她也没说什么,只是说好吧。
估计那时候HR已经有不想要的意思了,我甚至都可能撑不过试用期。但是经过三个月的工作,我完美地完成了公司的工作,还优化了公司的后端基础工程,在转正答辩的时候得到所有领导的同意转正。那个HR从此路转粉甚至还加了我的私人微信。
可能是我运气比较好的原因吧,如果我遇到的是一些规定严格的公司,我估计一点机会都不会有。毕竟全日制的学历的学生出现差错的概率比非全日制学历的学生小得多,没有哪一个人愿意冒着风险去请一个人有可能踩雷的员工。对吧?
三.2022的成长
毫无意外,2022也是忙碌的一年,除了准备学位考试,同时还对外输出了文章,参加了两次掘金更文活动。
自学了go基础,用go语言将自己的博客后端服务重构了
做了一个读书笔记的网站
做了一个自用的cli工具,源码
为了了解非关系型数据库,自己手写了一个类似非关系型的数据存储项目,源码
除此之外,在公司中,我给公司创建了公共UI库,通用请求队列库,异常捕捉系统,低代码项目等前端基础工程~
四.保持自己的危机感
第一次听到危机意识这个词,是我在第一个公司的时候,带我的一个同事跟我说的。
其实无论是否躺平,我们都需要保持自己的危机意识,不能说在一个公司里面很闲,工作很轻松,就觉得可以放松下去了。万一遇到一些突发情况(例如:被毕业之类的),自己的处境就会很被动了。
当然过度的紧张也会适得其反。如果有🐟可摸,我一般都会抽出一半的时间去学习,让自己保持学习的状态。
我在这个公司已经工作一年半了。怎么说呢,一开始这个公司说是弄SCRM的,结果入职后天天搞小程序和管理系统,而且都是一些基础的表单UI,对我而言,我在没有什么可以学习的。
其实我也不是第一次遇到这种情况了,毕竟除了第一个公司,后面的公司我都是靠自学一个人走过来的。遇到这种情况,首先我做的是在空闲的时间输出一些便于开发公共库,在公司的期间,我也开了一个关于微前端的内部分享会,同时我也写了一遍关于微前端框架的文章从0到1实现一个微前端框架。
(分享会的PPT)
为了应对长期的活动页面需求(基本上一周需要上线一个小程序活动页),于是我在摸鱼的时候给小程序做了一个低代码生成活动页的模块,很愉快地将需求甩给了其他人😄,给自己挣到了摸鱼的时间!!
(低代码后台)
我是什么时候萌生跑路的意思的,其实也都是一些人际关系的问题,还有就是工作对于我而言了,我希望向难度挑战。
先说一下人际关系吧,就是在一次需求评审过程中,我第一次听到资源这个词。没错,他们那些项目经理把我们当成是资源供他们调度,后面听说他们之间还有一个资源群,这让我更加反感了。
怎么说呢,对我来说就是不把人当人,我们只是他们的一个棋子的意思吧,所以我很反感这种,所以我受不了,决定到过年前就跑路了。这几年也没怎么真正休息过,正好趁着这次机会休息一下吧~
(聊天记录)
五.明年目标
前面我也说过,做人还是得有目标,才会有动力去做事情,每年给自己定一些小目标。
首先持续输出技术文章这个肯定是要做的,希望明年能到LV5
如果有哪个学校肯收留我了,那我就去读书了(这回我肯定拼尽全力地学习了)!!如果没有收留,那就开始着手准备考研的事情。
第三个就是英语,希望雅思6.5。这个是属于挑战自己最不擅长的事情了,希望能做到~!
如果进去学校了,我会开始研究物联网相关的知识。
作者:Ichmag
来源:juejin.cn/post/7174340400151265294
一个33岁老程序员的感悟
一、在中国你千万不要以为学习技术就可以换来稳定的生活和高的薪水待遇,你更不要认为那些从事市场开发,跑腿的人,没有前途。
不清楚你是不是知道,咱们中国有相当大的一部分软件公司,他们的软件开发团队都小的可怜,甚至只有1-3个人,连一个项目小组都算不上,而这样的团队却要承担一个软件公司所有的软件开发任务,在软件上线和开发的关键阶段需要团队的成员没日没夜的加班,还需要为测试出的BUG和不能按时提交的软件模块功能而心怀忐忑,有的时候如果你不幸加入现场开发的团队你则需要背井离乡告别你的女友,进行封闭开发,你平时除了编码之外就是吃饭和睡觉(有钱的公司甚至请个保姆为你做饭,以让你节省出更多的时间来投入到工作中,让你一直在那种累了就休息,不累就立即工作的状态)
更可怕的是,会让你接触的人际关系非常单一,除了有限的技术人员之外你几乎见不到做其他行业工作和职位的人,你的朋友圈子小且单一,甚至破坏你原有的爱情(想象一下,你在外地做现场开发2个月以上,却从没跟女友见过一面的话,你的女友是不是会对你呲牙裂嘴)。
也许你拿到了所谓的白领的工资,但你却从此失去享受生活的自由,如果你想做技术人员尤其是开发人员,我想你很快就会理解,你多么想在一个地方长期待一段时间,认识一些朋友,多一些生活时间的愿望。
比之于我们的生活和人际关系及工作,那些从事售前和市场开发的朋友,却有比我们多的多的工作之外的时间,甚至他们工作的时间有的时候是和生活的时间是可以兼顾的,他们可以通过市场开发,认识各个行业的人士,可以认识各种各样的朋友,他们比我们坦率说更有发财和发展的机会,只要他们跟我们一样勤奋。(有一种勤奋的普通人,如果给他换个地方,他马上会成为一个勤奋且出众的人。)
二、在学习技术的时候千万不要认为如果做到技术最强,就可以成为100%受尊重的人。
有一次一个人在面试项目经理的时候说了这么一段话:我只用最听话的人,按照我的要求做只要是听话就要,如果不听话不管他技术再好也不要。随后这个人得到了试用机会,如果没意外的话,他一定会是下一个项目经理的继任者。
朋友们你知道吗?不管你技术有多强,你也不可能自由的腾出时间象别人那样研究一下LINUX源码,甚至写一个LINUX样的杰作来表现你的才能。需要做的就是按照要求写代码,写代码的含义就是都规定好,你按照规定写,你很快就会发现你昨天写的代码,跟今天写的代码有很多类似,等你写过一段时间的代码,你将领略:复制,拷贝,粘贴那样的技术对你来说是何等重要。(如果你没有做过1年以上的真正意义上的开发不要反驳我)。
如果你幸运的能够听到市场人员的谈话,或是领导们的谈话,你会隐约觉得他们都在把技术人员当作编码的机器来看,你的价值并没有你想象的那么重要。而在你所在的团队内部,你可能正在为一个技术问题的讨论再跟同事搞内耗,因为他不服你,你也不服他,你们都认为自己的对,其实你们两个都对,而争论的目的就是为了在关键场合证明一下自己比对方技术好,比对方强。(在一个项目开发中,没有人愿意长期听别人的,总想换个位置领导别人。)
三、你更不要认为,如果我技术够好,我就自己创业,自己有创业的资本,因为自己是搞技术的。
如果你那样认为,真的是大错特错了,你可以做个调查在非技术人群中,没有几个人知道C#与JAVA的,更谈不上来欣赏你的技术是好还是不好。一句话,技术仅仅是一个工具,善于运用这个工具为别人干活的人,却往往不太擅长用这个工具来为自己创业,因为这是两个概念,训练的技能也是完全不同的。
创业最开始的时候,你的人际关系,你处理人际关系的能力,你对社会潜规则的认识,还有你明白不明白别人的心,你会不会说让人喜欢的话,还有你对自己所提供的服务的策划和推销等等,也许有一万,一百万个值得我们重视的问题,但你会发现技术却很少有可能包含在这一万或一百万之内,如果你创业到了一个快成功的阶段,你会这样告诉自己:我干吗要亲自做技术,我聘一个人不就行了,这时候你才真正会理解技术的作用,和你以前做技术人员的作用。
小结
基于上面的讨论,我奉劝那些学习技术的朋友,千万不要拿科举考试样的心态去学习技术,对技术的学习几近的痴迷,想掌握所有所有的技术,以让自己成为技术领域的权威和专家,以在必要的时候或是心里不畅快的时候到网上对着菜鸟说自己是前辈。
技术仅仅是一个工具,是你在人生一个阶段生存的工具,你可以一辈子喜欢他,但最好不要一辈子靠它生存。
掌握技术的唯一目的就是拿它找工作(如果你不想把技术当作你第二生命的话),就是干活。所以你在学习的时候千万不要去做那些所谓的技术习题或是研究那些帽泡算法,最大数算法了,什么叫干活?
就是做一个东西让别人用,别人用了,可以提高他们的工作效率,想象吧,你做1万道技术习题有什么用?只会让人觉得酸腐,还是在学习的时候,多培养些自己务实的态度吧,比如研究一下当地市场目前有哪些软件公司用人,自己离他们的要求到底有多远,自己具体应该怎么做才可以达到他们的要求。等你分析完这些,你就会发现,找工作成功,技术的贡献率其实并没有你原来想象的那么高。
不管你是学习技术为了找工作还是创业,你都要对技术本身有个清醒的认识,在中国不会出现Bill Gates,因为,中国目前还不是十分的尊重技术人才,还仅仅的停留在把软件技术人才当作人才机器来用的尴尬境地。(如果你不理解,一种可能是你目前仅仅从事过技术工作,你的朋友圈子里技术类的朋友占了大多数,一种可能是你还没有工作,但喜欢读比尔·盖茨的传记)。
总结
“千万不要一辈子靠技术生存”,这是一句比较现实的话。很多人觉得自己现在20多岁,月入2~3W或者更多了,很OK呀。
理解这句话的前提是,你不满足于现在的收入(如果是工作年限比较短的,你可以看看这个行业做的比较好的人的收入,你能否满足),对自己的未来或者行业有感到担忧,那么你才能很好的理解这句话。
这也是为什么能理解这句话的人,大多是到了35岁左右的。诚然,对于一个工作7、8年或者不到的程序员,这个阶段技术是必须的,要深、要有一个今天被开,我可以保证明天找到工作的技术能力; 如果你足够幸运,能有在某一个领域做到专家级的、后面的小辈无法替代你,那"千万不要一辈子靠技术生存"这句话当然也就不适合你了,大牛,请受吾一拜。 但是,对于大多数人,都无法做到在一个领域无可替代(机遇与天赋),那么就要想办法保证在上了年纪、上有老下有下的时候不被公司裁掉、收入不减、生活质量不降。
如果在这个阶段你还在研究这个功能怎么实现、这个算法是多么的精妙,我觉得你不是太单纯,就是在借技术之名在逃避现实。 说一句庸俗的话,我满脑子想得都是怎么搞钱,怎么让家人生活的更好,做技术的在35岁之前没达到这一点(且不论财务自由),你觉得35岁以后还有机会吗?或者说扪心自问一下,你所做的事情有多少是你能做,别人不能做的,有多少技术含量自己心里应该也有点数。 所以,技术只是现阶段谋生的一项技能。
每个人的技术都是有天花板的,你的技术到了天花板的时候,你的收入能否满足你,这个是需要考虑的。当然,你家里有矿或者北京二环内有几套房,那你完全可以把技术当爱好。
作者:小伙子有前途
来源:juejin.cn/post/7175009448854257725
我最喜欢高效学习前端的两种方式
先说结论:
看经典书
看官方文档
为什么是经典书籍
我买过很多本计算机、前端、JavaScript方面的书,在这方面也踩过一些坑,分享下我的经验。
在最早我也买过亚马逊的kindle,kindle的使用体验还不错,能达到和纸书差不多的阅读体验,而且很便携,但由于上面想看的书很多都没有,又懒得去折腾,所以后来就卖了。
之后就转到了纸书上,京东经常搞100减50的活动,买了很多的书,这些书有的只翻了几页,有的翻来覆去看了几遍。
翻了几页的也有两种情况,一种是内容质量太差,完全照抄文档,而且还是过时的文档,你们都知道,前端的技术更新是比较快的,框架等更新也很快,所以等书出版了,技术可能就已经翻篇了。
另一种就是过于专业的,比较复杂难懂,比如编译原理,深入了解计算机系统 算法(第4版)等这种计算机传世经典之作。
纸书其实也有缺点,它真的是太沉了,如果要是出差的话想要带几本书的话,都得去考虑考虑,带多了是真的重。
还有就是在搬家的时候,真的就是噩梦,我家里有将近100本的纸书,每次搬家真的就是累死了。
所以最近一两年我都很少买纸书了,如果有需要我都会尽量选择电子版。
电子版书走到哪里都能看,不会有纸书那么多限制,唯一缺点可能就是没有纸书那股味道。
还有就是电子书平台的问题,一个平台的书可能不全,比如我就有微信图书和京东这两个,这也和听歌看剧一样,想看个东西,还得去多个平台,如果要是能够统一的话就好了。
还有就是盗版的pdf,这个我也看过,有一些已经买不到的书,没办法只能去网上寻找资源了。建议大家如果能支持正版,还是支持正版,如果作者赚不到钱,慢慢就没有人愿意创作优质内容,久而久之形成了恶性循环。
看经典书学习前端,是非常好的方式之一,因为书是一整套系统的内容,它不同于网上的碎片化文章。同时好书也是经过成千上万人验证后的,我们只需选择对的就可以了。
我推荐几本我读过的比较好的前端方面的书
javascript高级程序设计
你不知道的javascript 上 中 下卷
狼书 卷1 卷2
关于计算机原理方面的书
编码:隐匿在计算机软硬件背后的语言
算法图解
图解http
大话数据结构
上面的书都是我买过,看过的,可能还有我不知道的,欢迎在评论中留言
这些书都有一些共同的特征,就是能经过时间的检验,不会过时,可以重复的去阅读,学习。
为什么是官方API文档
除了经典书之外,就是各种语言、框架的官方文档,这里一定注意是“官方文档”,因为百度里面搜索的结果里,有很多镜像的文档网站,官方第一时间发布的更新,他们有时并不能及时同步,所以接受信息就比人慢一步。所以一定要看“官方文档”。
比如要查询javascript、css的内容,就去mdn上查看。要去看nodejs就去nodejs的官网,要去看react、vue框架就去官网。尽量别去那些第三方网站。
作者:小帅的编程笔记
来源:juejin.cn/post/7060102025232515086
做一个具有高可用性的网络库(下)
网速检测
如果可以获取到当前手机的网速,就可以做很多额外的操作。 比如在图片场景中,可以基于当前的实时网速进行图片的质量的变换,在网速快的场景下,加载高质量的图片,在网速慢的场景下,加载低质量的图片。 我们如何去计算一个比较准确的网速呢,比如下面列举的几个场景
当前app没有发起网络请求,但是存在其他进程在使用网络,占用网速
当前app发起了一个网络请求,计算当前网络请求的速度
当前app并发多个网络请求,导致每个网络请求的速度都比较慢
可能还会存在一些其他的场景,那么在这么复杂的场景,我们通过两种不同的计算方式进行合并计算
基于当前网络接口的response读取的速度,进行网速的动态计算
基于流量和时间计算出网速
通过计算出来的两者,取最大值的网速作为当前的网速值。
基于当前接口动态计算
基于前面网络请求的全流程监控,我们可以在全局添加所有网络接口的监听,在ResponseBody这个周期内,基于response的byte数和时间,可以计算每一个网络body读取速度。之所以要选取body读取的时间来计算网速,主要是为了防止把网络建连的耗时影响了最终的网速计算。 不过接口网速的动态计算需要针对不同场景去做不同的计算。
当前只有一个网络请求 在当前只有一个网络请求的场景下, 当前body计算出来请求速度就是当前的网速。
当前同时存在多个网络请求发起时 每一个请求都会瓜分网速,所以在这个场景下,每个网络请求的网速都有其对应的网速占比。比如当前有6个网络请求,每个网络请求的网速近似为1/6。
当然,为了防止网速的短时间的波动,每个网络请求对于当前的网速的影响是有固定的占比的, 比如我们可以设置的占比为5%。
currentSpeed = (requestSpeed * concurrentRequestCount - preSpeed) * ratePercent + preSpeed其中
requestSpeed:表示为当前网络请求计算出来的网速。
concurrentRequestCount:表示当前网络请求的总数
preSpeed:表示先前计算出来的网速
ratePercent:表示当前计算出来网速对于真正的网速影响占比
为了防止body过小导致的计算出来网速不对的场景,我们选取当前body大小超过20K的请求参与进行计算。
基于流量动态计算
基于流量的计算,可以参照TrafficState进行计算。可以参照facebook的network-connection-class 。可以通过每秒获取系统当前进程的流量变化,网速 = 流量总量 / 计算时间。 它内部也有一个计算公式:
public void addMeasurement(double measurement) {
double keepConstant = 1 - mDecayConstant;
if (mCount > mCutover) {
mValue = Math.exp(keepConstant * Math.log(mValue) + mDecayConstant * Math.log(measurement));
} else if (mCount > 0) {
double retained = keepConstant * mCount / (mCount + 1.0);
double newcomer = 1.0 - retained;
mValue = Math.exp(retained * Math.log(mValue) + newcomer * Math.log(measurement));
} else {
mValue = measurement;
}
mCount++;
}自定义注解处理
假如我们现在有一个需求,在我们的网络库中有一套内置的接口加密算法,现在我们期望针对某几个网络请求做单独的配置,我们有什么样的解决方案呢? 比较容易能够想到的方案是添加给网络添加一个全局拦截器,在拦截器中进行接口加密,然后在拦截器中对符合要求的请求URL的进行加密。但是这个拦截器可能是一个网络库内部的拦截器,在这里面去过滤不同的url可能不太合适。 那么,有什么方式可以让这个配置通用并且简洁呢? 其中一种方式是通过接口配置的地方,添加一个Header,然后在网络库内部拦截器中获取Header中有没有这个key,但是这个这个使用起来并且没有那么方便。首先业务方并不知道header里面key的值是什么,其次在添加到header之后,内部还需要在拦截器中把这个header的key给移除掉。
最后我们决定对于网络库给单接口提供的能力都通过注解来提供。 就拿接口加密为例子,我们期望加密的配置方式如下所示
@Encryption
@POST("xxUrl)
fun testRequest(@Field("xxUrl") nickname: String)这个注解是如何能够透传到网络库中的内部拦截器呢。首先需要把在Interface中配置的注解获取出来。CallAdapter.Factory可以拿到网络请求中配置的注解。
override fun get(returnType: Type, annotations: Array<Annotation>, retrofit: Retrofit): CallAdapter<*, *>? {}我们可以在这里讲注解和同一个url的request的关联起来。 然后在拦截器中获取是否有对应的注解。
override fun intercept(chain: Interceptor.Chain): Response {
val request = chain.request()
if (!NetAnnotationUtil.isAnntationExsit(request, Encryption::class)) {
return chain.proceed(request)
}
//do encrypt we want
...
}调试工具
对于网络能力,我们经常会去针对网络接口进行调试。最简单的方式是通过charles抓包。 通过charles抓包我们可以做到哪些调试呢?
查看请求参数、查看网络返回值
mock网络数据 看着上面2个能力似乎已经满足我们了日常调试了,但是它还是有一些缺陷的:
必须要借助PC
在App关闭了可抓包能力之后,就不能再抓包了
无法针对于post请求参数区分
所以,我们需要有一个强大的网络调试能力,既满足了charles的能力, 也可以不借助PC,并且不论apk是否开启了抓包能力也能够允许抓包。 可以添加一个专门Debug网络拦截器,在拦截器中实现这个能力。
把网络的debug文件配置在本地Sdcard下(也可以配置在远端统一的地址中)
通过拦截器,进行url、参数匹配,如果命中,将本地json返回。否则,正常走网络请求。
data class GlobalDebugConfig(
@SeerializedName("printToConsole") var printData: Boolean = false,
@SeerializedName("printToPage") var printData: Boolean = false
)
data class NetDebugInfo(
@SerializedName("filter") var debugFilterInfo: NetDebugFilterInfo?,
@SerializedName("response") var responseString: Any?,
@SerializedName("code") var httpCode: Int,
@SerializedName("message") var httpMessage: String? = null,
@SeerializedName("printToConsole") var printData: Boolean = true,
@SeerializedName("printToPage") var printData: Boolean = true)
data class NetDebugFilterInfo(
@SerializedName("host") var host: String? = null,
@SerializedName("path") var path: String? = null,
@SerializedName("parameter") var paramMap: Map<String, String>? = null)首先日志输出有个全局配置和单个接口的配置,单接口配置优于全局配置。
printToConsole表示输出到控制台
printToPage表示将接口记录到本地中,可以在本地页面查看请求数据
其次filterInfo就是我们针对接口请求的匹配规则。
host表示域名
path表示接口请求地址
parameter表示请求参数的值,如果是post请求,会自动匹配post请求的body参数。如果是get请求,会自动匹配get请求的query参数。
val host = netDebugInfo.debugFilterInfo?.host
if (!TextUtils.isEmpty(host) && UriUtils.getHost(request.url().toString()) != host) {
return chain.proceed(request)
}
val filterPath = netDebugInfo.debugFilterInfo?.path
if (!TextUtils.isEmpty(filterPath) && path != filterPath) {
return chain.proceed(request)
}
val filterRequestFilterInfo = netDebugInfo.debugFilterInfo?.paramMap
if (!filterRequestFilterInfo.isNullOrEmpty() && !checkParam(filterRequestFilterInfo, request)) {
return chain.proceed(request)
}
val resultResponseJsonObj = netDebugInfo.responseString
if (resultResponseJsonObj == null) {
return chain.proceed(request)
}
return Response.Builder()
.code(200)
.message("ok")
.protocol(Protocol.HTTP_2)
.request(request)
.body(NetResponseHelper.createResponseBody(GsonUtil.toJson(resultResponseJsonObj)))
.build()对于配置文件,最好能够共同维护mock数据。 本地可以提供mock数据展示列表。
组件化上网络库的能力支持
在组件化中,各个组件都需要使用网络请求。 但是在一个App内,都会有一套统一的网络请求的Header,例如AppInfo,UA,Cookie等参数。。在组件化中,针对这几个参数的配置有下面几个比较容易想到的解决方案:
在各个组件单独配置这几个Header
每个组件都需要但单独配置Header,会存在很多重复代码
通用信息很大概率在各个组件中获取不到
由主工程实现代理发起网络请求 这种实现方式也有下面几个缺陷
主工程需要关注所有组件,随着集成的组件越来越多,主工程需要初始化网络代理接口会越来越多
由于主工程并不知道组件什么时候会启动,只能App启动就初始化网络代理,导致组件初始化提前
所有直接和间接依赖的模块都需要由主工程来实现代理,很容易遗漏
通用信息拦截器自动注入
正因为上面两个实现方式或多或少都有问题,所以需要从网络库这一层来解决这个问题。 我们可以在网络层通过服务发现的能力,给外部提供一个通用网络信息拦截器注解, 一般由主工程实现, 完成默认信息的Header修改。创建网络Client实例时,自动查找app中被通用网络信息拦截器注解标注的拦截器。
线程池、连接池复用
各个组件都会有自己的网络Client实例,导致在同一个进程中,创建出来网络Client实例过多,同时线程池、连接池并没有复用。所以在网络库中,各个组件创建的网络Client默认会共享网络连接池和线程池,有特殊需要的模块,可以强制使用独立线程池和连接池。
作者:谢谢谢_xie
来源:juejin.cn/post/7074493841956405278
做一个具有高可用性的网络库(上)
在android中,网络模块是一个不可或缺的模块,相信很多公司都会有自建的网络库。目前市面上主流的网络请求框架都是基于okHttp做的延伸和扩展,并且android底层的网络库实现也使用OkHttp了,可见okHttp应用的广泛性。
Retrofit本身就是对于OkHttp库的封装,它的优点很很多,比如注解来实现的,配置简单,使用方便等。那为什么我们要做二次封装呢?最根本的原因还是我们现有的业务过于复杂,我们期望有更多的自定义的能力,有更好用的使用方式等。就好比下面这些自定义的能力
屏蔽底层的网络库实现
网络层统一处理code码和线程回调问题
网络请求绑定生命周期
网络层的全局监控
网络的调试能力
网络层对于组件化的通用能力支持
这些目前能力目前如果直接使用Retrofit,基本都是满足不了的。 本文是基于Retrofit + OkHttp提供的基础能力上,做的网络库的二次封装。主要介绍下如何在retrofit和Okhhtp的基础上,提供上述几个通用的能力。 本文需要有部分okHttp和retrofit源码的了解。 有兴趣的可以先查看官方文档,传送门:
屏蔽底层的网络库实现
虽然Retrofit是一个非常强大的封装框架,但是它并没有完全把网路库底层的实现的屏蔽掉。 默认的内部网络请求使用的okHttp,在我们创建Retrofit实例的时候,如果需要配置拦截器,就会直接依赖到底层的OkHttp,导致上层业务直接访问到了网络库的底层实现。这个对于后续的网络库底层的替换会是一个不小的成本。 因此,我们希望能够封装一层网络层,让业务的使用仅仅依赖到网络库的封装层,而不会使用到网络库的底层实现。 首先,我们需要先知道业务层当前使用到了哪些网络库底层的API, 其实最主要的还是拦截器这一层的封装。 拦截器这一层,主要涉及到几个类:
Request
Response
Chain和Intercept 我们可以针对这几个类进行封装,定义对象接口,IRequest、IResponse、IChain和INetIntercept,这套接口不带任何具体实现。 然后在真正需要访问到具体的实例的时候,转化成具体的Request和Response等。我们可以看看在自己定义了一套拦截器之后,如何添加到之前OkHttp的流程中。 先看看IChain和INetIntercept的定义。
interface IChain {
fun getRequestInfo(): IRequest
@Throws(IOException::class)
fun proceed(request: IRequest): IResponse?
}
interface INetInterceptor {
@Throws(IOException::class)
fun intercept(chain: IChain): IResponse?
}在构造Retrofit的实例时,内部会尝试创建OkHttpClient,在此时把外部传入的INetInterceptor合并组装成一个OkHttp的拦截器,添加到OkHttpClient中。
fun swicherToIntercept(list: MutableList<INetInterceptor>): Interceptor {
return object: Interceptor {
override fun intercept(chain: Interceptor.Chain): Response? {
val netRequest = IRequest(chain.request())
val realChain = IRealChain(0, netRequest, list as MutableList<IInterceptor>, chain, this)
val response: Response?
return (realChain.proceed(netRequest) as? IResponse)?.response
}
}
}整体修改后的拦截器的调用链如下所示:
上面举的只是在构建拦截器中的隔离,如果你们项目还有访问到其他内部的OkHttp的能力,也可以参照上面的封装流程,定义接口,在需要使用的地方转换为具体实现。
Retrofit的Call自定义
对于Retrofit,我们在接口中定义的方法就是每一个请求的配置,每一个请求都会被包装成Call。我们想要的请求做一些通用的逻辑处理和自定义,就比如在请求前做一些逻辑处理,请求后做一些逻辑处理,最后才返回给上层,就需要hook这个请求流程,可以做Retrofit的二次动态代理。 如果希望做一些更精细化的处理,hook能力就满足不了了。这种时候,可以选择使用自定义Call对象。如果整个Call对象都是我们提供的,我们当然可以在里面实现任何我们期望的逻辑。接下来简单介绍下如何自定义Retrofit的Call对象。
定义Call类型
class TestCall<T>(internal var call: Call<T>) {}自定义CallAdapter
自定义CallAdapter时,需要使用我们前面自定义的返回值类型,并将call对象转化为我们我们自定义的返回值类型。
class NetCallAdapter<R>(repsoneType: Type): CallAdapter<R, TestCall<R>> {
override fun adapt(call: Call<R>): TestCall<R> {
return TestCall(call)
}
override fun responseType(): Type {
return responseType
}
}首先需要在class的继承关系上,显式的标明CallAdapter的第二个泛型参数是我们自定义的Call类型。
在adapt适配方法中,通过原始的call,转化为我们期望的TestCall。
自定义Factory
class NetCallAdapterFactory: CallAdapter.Factory() {
override fun get(returnType: Type, annotations: Array<Annotation>, retrofit: Retrofit): CallAdapter<*, *>? {
val rawType = getRawType(returnType)
if (rawType == TestCall::class.java && returnType is ParameterizedType) {
val callReturnType = getParameterUpperBound(0, returnType)
return NetCallAdapter<ParameterizedType>(callReturnType)
}
return null
}
}在自定义的Factory中,根据从接口定义中获取到的网络返回值,匹配TestCall类型,如果匹配上,就返回我们定义的CallAdapter。
注册Factory
val builder = Retrofit.Builder()
.baseUrl(retrofitBuilder.baseUrl!!)
.client(client)
.addCallAdapterFactory(NetCallAdapterFactory())网络层统一处理code码和线程回调问题
code码统一处理
相信每一个产品都会定义业务错误码,每一个业务都可能有自己的一套错误码,有一些错误码可能是全局的,比如说登录过期、被封禁等,这种错误码可能跟特定的接口无关,而是一个全局的业务错误码,在收到这些错误码时,会有统一的逻辑处理。 我们可以先定义code码解析的接口
interface ICodehandler {
fun handle(context: Context?, code: Int, message: String?, isBackGround: Boolean): Boolean
}code码处理器的注册。
code码处理器的注册方式有两种,一种是全局的code码处理器。 在创建Retrofit实例的传入。
NetWorkClientBuilder()
.addNetCodeHandler(SocialCodeHandler())
.build()另一种是在具体的网络请求时,传入错误码处理器,
TestInterface.inst.testCall().backGround(true)
.withInterceptor(new CodeRespHandler() {
@Override
public boolean handle(int code, @Nullable String message) {
....
}
})
.enqueue(null)code码处理的调用
因为Call是我们自定义的,我们可以在网络成功的返回时,优先执行错误码处理器,如果命中业务错误码,那么对外返回失败。否则正常返回成功。
线程回调
OkHttp的callback线程回调默认是在子线程,retrofit的回调线程取决于创建实例时的配置,可以配置callbackExecutor,这个是对整个实例生效的,在这个实例内,所有的网络返回都会通过callbackExecutor。我们希望能够针对每一个接口单独配置回调的线程,所以同样基于自定义call的前提下,我们自定义Callback和UiCallback。
Callback: 表示当前回调线程无需主线程
UICallback: 表示当前回调线程需要在主线程
通用业务传入的接口类型就标识了当前回调的线程.
网络请求绑定生命周期
大部分网络请求都是异步发起的。所以可能会导致下面两个问题:
内存泄漏问题
空指针问题
先看一个比较常见的内存泄漏的场景
class XXXFragment {
var unBinder: Unbinder? = null
@BindView(R.id.xxxx)
val view: AView;
@Override
public void onDestroyView() {
unBinder?.unbind();
}
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View? {
val view= super.onCreateView(inflater, container, savedInstanceState)
unBinder = ButterKnife.bind(this, view)
loadDataOfPay(1, 20)
return view
}
private void testFun() {
TestInterface.getInst().getTestFun()
.enqueue(new UICallback<TestResponse>() {
@Override
public void onSuccessful(TestResponse test) {
view.xxxx = test.xxx
}
@Override
public void onFailure(@NotNull NetException e) {
....
}
});
}
}在上面的例子中,在testFun方法中编译后会创建匿名内部类,并且显式的调用了外部Fragment的View,一旦这个网络请求阻塞了,或者晚于这个Fragment的销毁时机回调,就会导致这个Fragment出现内存泄漏,直至这个请求正常结束返回。
更严重的是,这个被操作的view是通过ButterKnife绑定的,在Fragment走到onDestory之后就进行了解绑,会将这个View的值设置为null,导致在这个callback的回调时候,可能出现view为null的情况,导致空指针。 对于空指针的问题,我们可以看到有很多网络请求的回调都可能会出现类似下面的代码段。
TestInterface.getInst().getTestFun()
.enqueue(new UICallback<TestResponse>() {
@Override
public void onSuccessful(TestResponse test) {
if(!isFinishing() && view != null) {
view.xxxx = test.xxx
}
}}); 在匿名内部类回调时,通过判断页面是否已经销毁,以及view是否为空,再进行对应的UI操作。 我们通过动态代理来解决了这个空指针和内存泄漏的问题。 详细的方案可以阅读下这个文章匿名内部类导致内存泄漏的解决方案 因为我们把Activity、Fragment抽象为UIContext。在网络接口调用时,传入对应的UIContext,会将网络请求的Callabck通过动态代理,将Callback和UIContext进行关联,在页面销毁时,不进行回调。
自动Cancel无用请求
很多的业务场景中,在页面一进去就会触发很多网络请求,这个请求可能有一部分处于网络库的请求等待队列中,一部分处于进行中。当我们退出了这个页面之后,这些网络请求其实都已经没有了存在的意义。 所以我们可以在页面销毁时,取消还未发起和进行中的网络请求。 我们可以通过上面提过的UIContext,将网络请求跟页面进行关联。监听页面的生命周期,在页面关闭时,cancel掉对应的网络请求。
页面关联
在网络请求发起前,把当前的网络请求关联上对应的页面。
class TestCall {
fun enqueue(uiCallBack: Callback, uiContext: UIContext?) {
LifeCycleRequestManager.registerCall(this, uiContext)
....
}
}
internal object LifeCycleRequestManager {
init {
registerApplicationLifecycle()
}
private val registerCallMap = ConcurrentHashMap<Int, MutableList<BaseNetCall>>()
}ConcurrentHashMap的key为页面的HashCode,value的请求list。每一个页面都会关联一个请求List。
cancel请求
通过Application监听Activity、Fragment的生命周期。在页面销毁时,调用cancel取消对应的网络请求。
private fun registerActivityLifecycle(app: Application) {
app.registerActivityLifecycleCallbacks(object : Application.ActivityLifecycleCallbacks {
override fun onActivityDestroyed(activity: Activity?) {
registerCallMap.remove(activity.hashCode())
}})
}这个是针对Activity的生命周期的监听。对于Fragment的生命周期的监听其实和Activity类似。
private fun registerActivityLifecycle(app: Application) {
app.registerActivityLifecycleCallbacks(object : Application.ActivityLifecycleCallbacks {
override fun onActivityCreated(activity: Activity?, savedInstanceState: Bundle?) {
(activity as? FragmentActivity)?.supportFragmentManager
?.registerFragmentLifecycleCallbacks(fragmentLifecycleCallbacks, true)
}})
}网络监听
网络模使用的场景非常多,当前出现问题的概率也更好,网络相关的问题非常多,比如网络异常、DNS解析失败、连接超时等。所以一套完善网络流程监控是非常有必要的,可以帮助我们在很多问题中快速分析出问题,提高我们的排查问题的效率
网络流程监控
根据OkHttp官方的EventListener提供的回调:OkHttpEvent事件,我们定义了以下几个一个网络请求中可能 触发的Action事件。
enum class NetEventType {
EN_QUEUE, //入队
NET_START, //网络请求真正开始执行
DNS_START, //开始DNS解析
DNS_END, //DNS解析结束
CONNECT_START, //开始建立连接
TLS_START, // TLS握手开始
TLS_END, //TLS握手结束
CONNECT_END, //建立连接结束
RETRY, //尝试重新连接
REUSE, //连接重用,从连接池中获取到连接
CONNECTION_ACQUIRE, //获取到链接(可能不走连接建立,直接从连接池中获取)
CONNECT_FAILED, // 连接失败
REQUEST_HEADER_START, // request写Header开始
REQUEST_HEADER_END, // request写Header结束
REQUEST_BODY_START, // request写Body开始
REQUEST_BODY_END, // request写Body结束
RESPONSE_HEADER_START, // response写Header开始
RESPONSE_HEADER_END, // response写Header结束
RESPONSE_BODY_START, // response写Body开始
RESPONSE_BODY_END, // response写Body结束
FOLLOW_UP, // 是否发生重定向
CALL_END, //请求正常结束
CONNECTION_RELEASE, // 连接释放
CALL_FAILED, // 请求失败
NET_END, // 网络请求结束(包括正常结束和失败)
}可以看到,除了okHttp原有的几个Event,还额外多了一个ENQUEUE事件。这个时机最主要的作用是计算出请求从调用到真正发起接口请求的等待时间。 当我们调用了RealCall.enqueue方法时,实际上这个接口请求并不是都会立即执行,OkHttp对于同一个时刻的请求数有限制。
同一个Dispatcher,同一时刻并发数不能超过64
同一个Host,同一时刻并发数不能超过5
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);
executorService().execute(call);
} else {
readyAsyncCalls.add(call);
}
}所以一旦超过对应的阈值,当次请求就会被添加到readyAsyncCalls中,等待被执行。
根据这几个Action,我们可以将统计的时间分为下面几个阶段
enum class NetRecordItemType {
WAIT, // 等待时间,入队到真正开始执行耗时
DNS, // DNS耗时
TLS, // TLS耗时
RequestHeader, // request写入Header耗时
RequestBody, // request写入Body耗时
Request, // request写入header和body总耗时
NetworkLatency, // 网络请求延时
ResponseHeader, // response写入Header耗时
ResponseBody, // response写入Body耗时
Response, // response写入header和body总耗时
Connect, // 连接建立总耗时
RequestAndResponse, // 数据传输耗时
CallTime, // 单次网络请求总耗时(包含排队时间)
UNKNOWN
}唯一ID
我们不仅仅想对整个网络的大盘进行监控,我们还希望能够精细化到每一个独立的网络请求进行监控。针对单个网络请求进行的监控的难点是我们如何去标志出来每一个网络请求,因为EventListener回调只会返回对应的call。
public abstract class EventListener {
public void callStart(Call call) {}
public void callEnd(Call call) {}
}而这个Call没有办法与单个监控的请求进行关联。 并且在网络请求发起的阶段就需要标识出来,所以需要在Request创建的最前头就生成这个唯一ID。通过阅读源码,我们发现可以生成唯一id最早时机是在OkHttp的RealCall创建的最前头。
RealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
final EventListener.Factory eventListenerFactory = client.eventListenerFactory();
this.client = client;
this.originalRequest = originalRequest;
this.forWebSocket = forWebSocket;
this.retryAndFollowUpInterceptor = new RetryAndFollowUpInterceptor(client, forWebSocket);
this.eventListener = eventListenerFactory.create(this);
}其中,eventListenerFactory是由外部传递到Okhttp中的。
public Builder eventListenerFactory(EventListener.Factory eventListenerFactory) {
if (eventListenerFactory == null) {
throw new NullPointerException("eventListenerFactory == null");
}
this.eventListenerFactory = eventListenerFactory;
return this;
}因此,我们可以在EventListener.Factory中生成标记request的唯一Id。
internal class CallEventFactory(var configuration: CallEventConfiguration?) : EventListener.Factory {
companion object {
private val nextCallId = AtomicLong(1L)
}
override fun create(call: Call): EventListener {
val callId = nextCallId.getAndIncrement()
}
}那生成的callId如何与request进行关联呢?最直接的是给Request添加一个Header的key。Request本身没有提供Api去修改Header。 所以这个时候就需要通过反射来设置, 先获取当前的Header,然后给header新增这个CallId,最后通过反射设置到request的header字段上。
fun appendToHeader(request: Request?, key: String?, value: String?) {
key ?: return
request ?: return
value ?: return
val headerBuilder = request.headers().newBuilder().add(key, value)
ReflectUtils.setFieldValue(Request::class.java, request, NetCallAdapter.HEADER_NAME, headerBuilder.build())
}需要注意的是,因为使用了反射,所以需要在proguard文件中keep住request。 当然这个key最好能够不带到服务端,所以需要新增一个拦截器,添加到所有拦截器最后,这个这个唯一id的key就不会被添加到真正的请求上了。
class NetLastInterceptor: Interceptor {
companion object {
const val TAG = "NetLastInterceptor"
}
override fun intercept(chain: Interceptor.Chain): Response {
val request = chain.request()
val requestBuilder = request
.newBuilder()
.removeHeader(NetConstants.CALL_ID)
return chain.proceed(requestBuilder.build())
}
}监控
在生成完唯一Id之后,我们再来看看如何外部是如何添加期望的网络监控的。
基于Client的监控
networkClient = NetWorkClientBuilder()
.addLifecycleListener("*", object : INetLifecycleListener {
override fun onLifecycle(info: INetLifecycleInfo) { }})
.registerEventListener("xxxUrl", NetEventType.CALL_END, object : INetEventListener {
override fun onEvent(event: NetEventType, request: NetRequest) { }})
.build()基于单个请求的监控
TestInterface.inst.testFun()
.addLifeCycleListener(object : INetLifecycleListener {
override fun onLifecycle(info: INetLifecycleInfo) {} })
.registerEventListener(mutableListOf(NetEventType.CALL_END, NetEventType.NET_START), object : INetEventListener {
override fun onEvent(event: NetEventType, request: NetRequest) {} })
.enqueue(null)在创建EventListener时,按照下面的规则添加。
添加网络库系统的内部监听
添加OkHttpClient初始化配置的监听
添加单个请求配置的监听
基于单个请求的网络监控,需要提前把这个Request和网络监听的listener的关联关系存起来,因为EventListener的设置是针对整个OkHttpClient的生效的,所以需要在EventListener处理的过程中,获取当前的Request设置进去的listener。
作者:谢谢谢_xie
来源:juejin.cn/post/7074493841956405278
JS封装覆盖水印
废话开篇:简单实现一个覆盖水印的小功能,水印一般都是添加在图片上,然后直接加载处理过的图片url即可,这里并没有修改图片,而是直接的在待添加水印的 dom 上添加一个 canvas 蒙版。
一、效果
处理之前
DIV
IMG
处理之后
DIV
IMG
这里添加 “水印”(其实并不是真正的水印) 到 DIV 的时候按钮点击事件并不会因为有蒙版遮挡而无法点击
二、JS 代码
class WaterMark{
//水印文字
waterTexts = []
//需要添加水印的dom集合
needAddWaterTextElementIds = null
//保存添加水印的dom
saveNeedAddWaterMarkElement = []
//初始化
constructor(waterTexts,needAddWaterTextElementIds){
if(waterTexts && waterTexts.length != 0){
this.waterTexts = waterTexts
} else {
this.waterTexts = ['水印文字哈哈哈哈','2022-12-08']
}
this.needAddWaterTextElementIds = needAddWaterTextElementIds
}
//开始添加水印
startWaterMark(){
const self = this
if(this.needAddWaterTextElementIds){
this.needAddWaterTextElementIds.forEach((id)=>{
let el = document.getElementById(id)
self.saveNeedAddWaterMarkElement.push(el)
})
} else {
this.saveNeedAddWaterMarkElement = Array.from(document.getElementsByTagName('img'))
}
this.saveNeedAddWaterMarkElement.forEach((el)=>{
self.startWaterMarkToElement(el)
})
}
//添加水印到到dom对象
startWaterMarkToElement(el){
let nodeName = el.nodeName
if(['IMG','img'].indexOf(nodeName) != -1){
//图片,需要加载完成进行操作
this.addWaterMarkToImg(el)
} else {
//普通,直接添加
this.addWaterMarkToNormalEle(el)
}
}
//给图片添加水印
async addWaterMarkToImg(img){
if(!img.complete){
await new Promise((resolve)=>{
img.onload = resolve
})
}
this.addWaterMarkToNormalEle(img)
}
//给普通dom对象添加水印
addWaterMarkToNormalEle(el){
const self = this
let canvas = document.createElement('canvas')
canvas.width = el.width ? el.width : el.clientWidth
canvas.height = el.height ? el.height : el.clientHeight
let ctx = canvas.getContext('2d')
let maxSize = Math.max(canvas.height, canvas.width)
let font = (maxSize / 25)
ctx.font = font + 'px "微软雅黑"'
ctx.fillStyle = "rgba(195,195,195,1)"
ctx.textAlign = "left"
ctx.textBaseline = "top"
ctx.save()
let angle = -Math.PI / 10.0
//进行平移,计算平移的参数
let translateX = (canvas.height) * Math.tan(Math.abs(angle))
let translateY = (canvas.width - translateX) * Math.tan(Math.abs(angle))
ctx.translate(-translateX / 2.0, translateY / 2.0)
ctx.rotate(angle)
//起始坐标
let x = 0
let y = 0
//一组文字之间间隔
let sepY = (font / 2.0)
while(y < canvas.height){
//当前行的y值
let rowCurrentMaxY = 0
while(x < canvas.width){
let totleMaxX = 0
let currentY = 0
//绘制水印
this.waterTexts.forEach((text,index)=>{
currentY += (index * (sepY + font))
let rect = self.drawWater(ctx,text,x,y + currentY)
let currentMaxX = (rect.x + rect.width)
totleMaxX = (currentMaxX > totleMaxX) ? currentMaxX: totleMaxX
rowCurrentMaxY = currentY
})
x = totleMaxX + 20
}
//重置x,y值
x = 0
y += (rowCurrentMaxY + (sepY + font + (canvas.height / 5)))
}
ctx.restore()
//添加canvas
this.addCanvas(canvas,el)
}
//绘制水印
drawWater(ctx,text,x,y){
//绘制文字
ctx.fillText(text,x,y)
//计算尺度
let textRect = ctx.measureText(text)
let width = textRect.width
let height = textRect.height
return {x,y,width,height}
}
//添加canvas到当前标签的父标签上
addCanvas(canvas,el){
//创建div(canvas需要依赖一个div进行位置设置)
let warterMarDiv = document.createElement('div')
//关联水印dom对象
el.warterMark = warterMarDiv
//添加样式
this.resetCanvasPosition(el)
//添加水印
warterMarDiv.appendChild(canvas)
//添加到父标签
el.parentElement.insertBefore(warterMarDiv,el)
}
//重新计算位置
resetCanvasPosition(el){
if(el.warterMark){
//设置父标签的定位
el.parentElement.style.cssText = `position: relative;`
//设施水印载体的定位
el.warterMark.style.cssText = 'position: absolute;top: 0px;left: 0px;pointer-events:none'
}
}
}用法
<div>
<!-- 待加水印的IMG -->
<img style="width: 100px;height: auto" src="" alt="">
</div>
let waterMark = new WaterMark()
waterMark.startWaterMark();ctx.save() 与 ctx.restore() 其实在这里的作用不是很大,但还是添加上了,目的是保存添加水印前的上下文,跟结束绘制后恢复水印前的上下文,这样,这些斜体字只在这两行代码之间生效,下面如果再绘制其他,那么,将不受影响。
防止蒙版水印遮挡底层按钮或其他事件,需要添加 pointer-events:none 属性到蒙版标签上。
添加水印的标签外需要添加一个 父标签 ,这个 父标签 的作用就是添加约束 蒙版canvas 的位置,这里想通过 MutationObserver 观察 body 的变化来进行更新 蒙版canvas 的位置,这个尝试失败了,因为复杂的布局只要变动会都在这个回调里触发。因此,直接在添加水印的标签外需要添加一个 父标签 ,用这个 父标签 来自动约束 蒙版canvas 的位置。
MutationObserver 逻辑如下,在监听回调里可以及时修改布局或者其他操作(暂时放弃)。
var MutationObserver = window.MutationObserver || window.webkitMutationObserver || window.MozMutationObserver;
var mutationObserver = new MutationObserver(function (mutations) {
//修改水印位置
})
mutationObserver.observe(document.getElementsByTagName('body')[0], {
childList: true, // 子节点的变动(新增、删除或者更改)
attributes: true, // 属性的变动
characterData: true, // 节点内容或节点文本的变动
subtree: true // 是否将观察器应用于该节点的所有后代节点
})图片的大小只有在加载完成之后才能确定,所以,对于 IMG 的操作,需要观察它的 complete 事件。
三、总结与思考
用 canvas ctx.drawImage(img, 0, 0) 进行绘制,再将 canvas.toDataURL('image/png') 生成的 url 加载到之前的图片上,也是一种方式,但是,有时候会因为图片的原因导致最后的合成图片的 base64 数据是空,所以,直接增加一个蒙版,本身只是为了显示,并不是要生成真正的合成图片。实现了简单的伪水印,没有特别复杂的代码,代码拙劣,大神勿笑。
作者:头疼脑胀的代码搬运工
来源:juejin.cn/post/7174695149195231293
百度 Android 直播秒开体验优化
导读
网络直播功能作为一项互联网基本能力已经越来越重要,手机中的直播功能也越来越完善,电商直播、新闻直播、娱乐直播等多种直播类型为用户提供了丰富的直播内容。随着直播的普及,为用户提供极速、流畅的直播观看体验也越来越重要。
全文6657字,预计阅读时间17分钟。
01 背景
百度 APP 作为百度的航母级应用为用户提供了完善的移动端服务,直播也作为其中一个必要功能为用户提供内容。随着直播间架构、业务能力逐渐成熟,直播间播放指标优化也越来越重要。用户点击直播资源时,可以快速的看到直播画面是其中一个核心体验,起播速度也就成了直播间优化中的一个关键指标。
02 现状
由于包体积等原因,百度 APP 的 Android 版中直播功能使用插件方式接入,在用户真正使用直播功能时才会将直播模块加载。为解决用户点击直播功能时需要等待插件下载、安装、加载等阶段及兼容插件下载失败的情况,直播团队将播放、IM 等核心能力抽到了一个独立的体积较小的一级插件并内置在百度 APP 中,直播间的挂件、礼物、关注、点赞等业务能力在另外一个体积较大的二级插件中。特殊的插件逻辑和复杂的业务场景使得 Android 版整体起播时长指标表现的不尽人意。
2022 年 Q1 直播间整体起播时长指标 80 分位在 3s 左右,其中二跳(直播间内上下滑)场景在 1s 左右,插件拆分上线后通过观察起播数据发现随着版本收敛,一跳进入直播间携带流地址(页面启动后会使用该地址预起播,与直播列表加载同步执行)场景起播时有明显的增长,从发版本初期 1.5s 左右,随版本收敛两周内会逐步增长到 2.5s+。也就是线上在直播间外点击直播资源进直播间时有很大一部分用户在点击后还需要等待 3s 甚至更长时间才能真正看到直播画面。这个时长对用户使用直播功能有非常大的负向影响,起播时长指标急需优化。
03 目标
△起播链路
起播过程简单描述就是用户点击直播资源,打开直播页面,请求起播地址,调用内核起播,内核起播完成,内核通知业务,业务起播完成打点。从对内核起播时长监控来看,直播资源的在内核中起播耗时大约为 600-700ms,考虑链路中其他阶段损耗以及二跳(直播间内上下滑)场景可以在滑动时提前起播,整体起播时长目标定位为1.5 秒;考虑到有些进入直播间的位置已经有了起播流地址,可以在某些场景省去 “请求起播地址” 这一个阶段,在这种直播间外已经获取到起播地址场景,起播时长目标定为 1.1 秒。
04 难点
特殊的插件逻辑和复杂的业务场景使得 Android 版每一次进入直播的起播链路都不会完全一样。只有一级插件且二级插件还未就绪时在一级插件中请求直播数据并起播,一二级插件都已加载时使用二级插件请求直播数据并处理起播,进直播间携带流地址时为实现秒开在 Activity 启动后就创建播放器使用直播间外携带的流地址起播。除了这几种链路,还有一些其他情况。复杂的起播链路就导致了,虽然在起播过程中主要节点间都有时间戳打点,也有天级别相邻两个节点耗时 80 分位报表,但线上不同场景上报的起播链路无法穷举,使用现有报表无法分析直播大盘起播链路中真正耗时位置。需要建立新的监控方案,找到耗时点,才能设计针对性方案将各个耗时位置进行优化。
05 解决方案
5.1 设计新报表,定位耗时点
△一跳有起播地址时起播链路简图
由于现有报表无法满足起播链路耗时阶段定位,需要设计新的监控方案。观察在打开直播间时有流地址场景的流程图(上图),进入直播间后就会同步创建直播间列表及创建播放器预起播,当直播间列表创建完毕且播放器收到首帧通知时起播流程结束。虽然用户点击到页面 Activity 的 onCreate 中可能有多个节点(一级插件安装、加载等),页面 onCreate 调用播放器预起播中可能多个节点,内核完成到直播业务收到通知中有多个节点,导致整个起播链路无法穷举。但是我们可以发现,从用户点击到 onCreate 这个路径是肯定会有的,onCreate 到创建播放器路径也是肯定有的。这样就说明虽然两个关键节点间的节点数量和链路无法确定,但是两个关键节点的先后顺序是一定的,也是必定会有的。由此,我们可以设计一个自定义链路起点和自定义链路终点的查询报表,通过终点和起点时间戳求差得到两个任意节点间耗时,将线上这两个节点所有差值求 80 分位,就可以得到线上起播耗时中这两个节点间耗时。将起播链路中所有核心关键节点计算耗时,就可以找到整个起播链路中有异常耗时的分段。
按照上面的思路开发新报表后,上面的链路各阶段耗时也就比较清晰了,见下图,这样我们就可以针对不同阶段逐个击破。
△关键节点间耗时
5.2 一跳使用一级插件起播
使用新报表统计的重点节点间耗时观察到,直播间列表创建(模版组件创建)到真正调用起播(业务视图就绪)中间耗时较长,且这个耗时随着版本收敛会逐步增加,两周内大约增加 1000ms,首先我们解决这两个节点间耗时增加问题。
经过起播链路观察和分析后,发现随版本收敛,这部分起播链路有较大变化,主要是因为随版本收敛,在二级插件中触发 “业务调用起播” 这个节点的占比增加。版本收敛期,进入直播间时大概率二级插件还未下载就绪或未安装,此时一级插件中可以很快的进行列表创建并创建业务视图,一级插件中在 RecyclerView 的 item attach 到视图树时就会触发起播,这个链路主要是等待内核完成首帧数据的拉取和解析。当二级插件逐渐收敛,进入直播间后一级插件就不再创建业务视图,而是有二级插件创建业务视图。由于二级插件中业务组件较多逐个加载需要耗时还有一级到二级中逐层调用或事件分发也存在一定耗时,这样二级插件起播场景就大大增加了直播间列表创建(模版组件创建)到真正调用起播(业务视图就绪)中间耗时。
5.2.1 一跳全部使用一级插件起播
基于上面的问题分析,我们修改了一跳场景起播逻辑,一跳全部使用一级插件起播。一级插件和二级插件创建的播放器父容器 id 是相同的,这样在一级插件中初始化播放器父容器后,当内核首帧回调时起播过程就可以结束了。二级插件中在初始化播放器父容器时也会通过 id 判断是否已经添加到视图树,只有在未添加的情况(二跳场景或一跳时出现异常)才会在二级中进行兜底处理。在一级插件中处理时速度可以更快,一级优先二级兜底逻辑保证了进入直播间后一定可以顺利初始化视图。
5.2.2 提前请求接口
使用由一起插件处理起播优化了二级插件链路层级较多问题,还有一个耗时点就是进直播间时只传入了房间 room_id 未携带流地址场景,此时需要通过接口请求获取起播数据后才能创建播放器和起播。为优化这部分耗时,我们设计了一个直播间数据请求管理器,提供了缓存数据和超时清理逻辑。在页面 onCreate 时就会触发管理器进行接口请求,直播间模版创建完成后会通过管理器获取已经请求到的直播数据,如果管理器接口请求还未结束,则会复用进行中请求,待请求结束后立刻返回数据。这样在进直播间未携带流数据时我们可以充分利用图中这 300ms 时间做更多必要的逻辑。
5.3 播放器Activity外预起播
通过进直播间播放器预创建、预起播、一跳使用一级插件起播等方案来优化进入直播间业务链路耗时后,业务链路耗时逐渐低于内核部分耗时,播放器内核耗时逐渐成为一跳起播耗时优化瓶颈。除了在内核内部探索优化方案,继续优化业务整个起播链路也是一个重要方向。通过节点间耗时可以发现,用户点击到 Activity 页面 onCrete 中间也是有 300ms 左右耗时的。当无法将这部分耗时缩到更短时,我们可以尝试在这段时间并行处理一些事情,减少页面启动后的部分逻辑。
一级插件在百度 APP 中内置后,设计并上线了插件预加载功能,上线后用户通过点击直播资源进入直播间的场景中,有 99%+ 占比都是直播一级插件已加载情况,一级插件加载这里就没有了更多可以的操作空间。但将预起播时机提前到用户点击处,可以将内核数据加载和直播间启动更大程度并行,这样来降低内核耗时对整个起播耗时影响。
△播放器在直播间外起播示意图
如上图,新增一个提前起播模块,在用户点击后与页面启动并行创建播放器起播并缓存,页面启动后创建播放器时会先从提前起播模块的缓存中尝试取已起播播放器,如果未获取到则走正常播放器创建起播逻辑,如果获取到缓存的播放器且播放器未发生错误,则只需要等待内核首帧即可。
播放器提前起播后首帧事件大概率在 Activity 启动后到达,但仍有几率会早于直播业务中设置首帧监听前到达,所以在直播间中使用复用内核的播放器时需要判断是否起播成功,如果已经起播成功需要马上分发已起播成功事件(含义区别于首帧事件,防止与首帧事件混淆)。
提前起播模块中还设计了超时回收逻辑,如果提前起播失败或 5s (暂定)内没有被业务复用(Activity 启动异常或其他业务异常),则主动回收缓存的播放器,防止直播间没有复用成功时提前创建的播放器占用较多内存及避免泄漏;超时时间是根据线上大盘起播时间决定,使用一个较大盘起播时间 80 分位稍高的值,防止起播还未完成时被回收,但也不能设置较长,防止不会被复用时内存占用较多。
通过提前起播功能,实验期命中提前起播逻辑较不进行提前起播逻辑,整体起播耗时 80 分位优化均值:450ms+。
5.4直播间任务打散
△内核首帧分发耗时
业务链路和内核链路耗时都有一定优化后,我们继续拆解重点节点间耗时。内核内部标记首帧通知到直播业务真正收到首帧通知之间耗时较长,如上图,线上内核首帧分发耗时 80 分位均值超过 1s,该分段对整体起播耗时优化影响较大。内核首帧是在子线程进行标记,通知业务时会通过主线程 Handler 分发消息,通过系统的消息分发机制将事件转到主线程。
通过排查内核标记首帧时间点到业务收到首帧通知事件时间点之间所有主线程任务,发现在首帧分发任务开始排队时,主线程任务队列中已有较多其他任务,其他事件处理时间较长,导致首帧分发排队时间较久,分发任务整体耗时也就较长。直播业务复杂度较高,如果内核首帧分发任务排队时直播间其他任务已在队列中或正在执行,首帧分发任务需要等直播任务执行完成后才能执行。
通过将直播间启动过程中所有主线程任务进行筛查,发现二级插件的中业务功能较多,整体加载任务执行时间较长,为验证线上也是由于二级业务任务阻塞了首帧分发任务,我们设计了一个二级组件加载需要等待内核首帧后才能进行的实验,通过实验组与对照组数据对比,在命中实验时首帧分发耗时和起播整体耗时全部都有明显下降,整体耗时有 500ms 左右优化。
通过实验验证及本地对起播阶段业务逻辑分析,定位到直播间各业务组件及对应视图的预加载数量较多且耗时比较明显,这个功能是二级插件为充分利用直播间接口数据返回前时间,二级插件加载后会与接口请求并行提前创建业务视图,提起初始化组件及视图为接口完成后组件渲染节省时间。如果不预创建,接口数据回来后初始化业务组件也会主动创建后设置数据。但将所有预创建任务全部串行执行耗时较长,会阻塞主线程,页面一帧中执行太多任务,也会造成页面明显卡顿。
发现这个阻塞问题后,我们设计了将预创建视图任务进行拆分打散,将一起执行的大任务拆分成多个小任务,每个组件的初始化都作为一个单独任务在主线程任务队列中进行排队等待执行。避免了一个大任务耗时特别长的问题。该功能上线后,整个二级插件中的组件加载大任务耗时降低了 40%+。
5.5 内核子线程分发首帧
由于主线程消息队列中任务是排队执行的,将阻塞首帧分发事件的大任务拆分成较多小任务后,还是无法解决首帧事件开始排队时这些小任务已经在主线程任务队列中排队问题。除了降低直播业务影响,还可以通过加快内核任务分发速度,使首帧分发耗时降低。需要设计一个在不影响内核稳定性与业务逻辑情况下内核首帧事件如何避免主线程排队或快速排队后被执行的方案。
为解决上面的问题, 我们推动内核,单独增加了一个子线程通知业务首帧事件能力。业务收到子线程中首帧回调后通过 Handler 的 postAtFrontOfQueue() 方法将一个新任务插到主线程任务队列最前面,这样主线程处理完当前任务后就可以马上处理我们新建的这个任务,在这个新任务中可以马上处理播放器上屏逻辑。无需等待播放内核原本的主线程消息。
主线程任务前插无法打断新任务排队时主线程中已经开始执行的任务,需要正在执行任务结束后才会被执行。为优化这个场景,内核通过子线程通知首帧后,播放器中需要记录这个状态,在一级插件及二级插件中的直播间业务任务执行开始前后,增加判断播放器中是否已经收到首帧逻辑,如果已经收到,就可以先处理上屏后再继续当前任务。
通过直播内核首帧消息在主线程任务队列前插和业务关键节点增加是否可上屏判断,就可以较快处理首帧通知,降低首帧分发对起播时长影响。
5.6 起播与完载指标平衡
直播间起播优化过程中,完载时长指标(完载时长:用户点击到直播间核心功能全部出现的时间,其中经历页面启动,直播间列表创建,二级插件下载、安装、加载,直播间接口数据请求,初始化直播间功能组件视图及渲染数据,核心业务组件显示等阶段)的优化也在持续进行。直播间二级插件是在使用二级插件中的功能时才会触发下载安装及加载逻辑,完载链路中也注意到了用户点击到页面 onCreate 这段耗时,见下图。
△页面启动耗时示意图
为优化直播间完载指标,直播团队考虑如果将插件加载与页面启动并行,那么完载耗时也会有一定的优化。直播团队继续设计了二级插件预加载方案,将二级插件加载位置提前到了用户点击的时候(该功能上线在 5.4、5.5 章节对应功能前)。该功能上线后试验组与对照组数据显示,实验组完载耗时较对照组确实有 300ms+ 优化。但起播耗时却出现了异常,实验组的起播耗时明显比对照组增长了 500ms+,且随版本收敛这个起播劣化还在增加。我们马上很快发现了这个异常,并通过数据分析确定了这个数据是正确的。完载的优化时如何引起起播变化的?
经过数据分析,我们发现起播受影响的主要位置还是内核首帧消息分发到主线程这个分段引起,也就是二级插件加载越早,内核首帧分发与二级组件加载时的耗时任务冲突可能性越大。确认问题原因后,我们做了 5.4、5.5 章节的功能来降低二级组件加载任务对起播影响。由于二级插件中的耗时任务完全拆分打散来缓解二级插件预下载带来的起播劣化方案复杂度较高,对直播间逻辑侵入太大,二级插件提前加载没有完全上线,完载的优化我们设计了其他方案来实现目标。
虽然不能在进入直播间时直接加载二级插件,但我们可以在进入直播间前尽量将二级插件下载下来,使用时直接加载即可,这个耗时相对下载耗时是非常小的。我们优化了插件预下载模块,在直播间外展示直播资源时触发该模块预下载插件。该模块会通过对当前设备网络、带宽、下载频次等条件综合判断,在合适的时机将匹配的二级插件进行下载,插件提前下载后对完载指标有较大优化。除了插件预下载,直播间内通过 5.4 章节直播间二级组件初始化拆分,也将全部组件初始化对主线程阻塞进行了优化,这样接口数据请求成功后可以优先处理影响完载统计的组件,其他组件可以在完载结束后再进行初始化,这个方案也对直播完载指标有明显优化。
除了以上两个优化方案,直播团队还在其他多个方向对完载指标进行了优化,同时也处理了完载时长与起播时长的指标平衡,没有因为一个指标优化而对其他指标造成劣化影响。最终实现了起播、完载指标全部达到目标。
06 收益
△2022 Android 端起播耗时走势
经过以上多个优化方案逐步迭代,目前 Android 端最新版本数据,大盘起播时间已经由 3s+ 降到 1.3s 左右;一跳带流地址时起播时长由 2.5s+ 左右降低到 1s 以内;二跳起播时长由 1s+ 降低到 700ms 以内,成功完成了预定目标。
07 展望
起播时长作为直播功能一个核心指标,还需要不断打磨和优化。除了业务架构上的优化,还有优化拉流协议、优化缓冲配置、自适应网速起播、优化 gop 配置、边缘节点加速等多个方向可以探索。百度直播团队也会持续深耕直播技术,为用户带来越来越好的直播体验。
作者:任雪龙
来源:百度Geek说 juejin.cn/post/7174596046641692709
本轮疫情期间的金庸梗大全

文/萧十一
事情是这样的。就在几天前,关于“神雕大侠”的梗火了。












- 有请 全冠清 出来走两步[得意]
郭襄也阳过,她住襄阳……
大家多开窗通风,因为风清扬(阳)
刘兰芳:今天我给大家讲的是满门忠烈《🐏家将》!
好像明白了为何昨天突然郭襄上了微博热搜第一了
想要不🐑去南阳(难阳)
前端实现电子签名(web、移动端)通用
前言
在现在的时代发展中,从以前的手写签名,逐渐衍生出了电子签名。电子签名和纸质手写签名一样具有法律效应。电子签名目前主要还是在需要个人确认的产品环节和司法类相关的产品上较多。
举个常用的例子,大家都用过钉钉,钉钉上面就有电子签名,相信大家这肯定是知道的。
那作为前端的我们如何实现电子签名呢?其实在html5中已经出现了一个重要级别的辅助标签,是啥呢?那就是canvas。
什么是canvas
Canvas(画布)是在HTML5中新增的标签用于在网页实时生成图像,并且可以操作图像内容,基本上它是一个可以用JavaScript操作的位图(bitmap)。Canvas 对象表示一个 HTML 画布元素 -。它没有自己的行为,但是定义了一个 API 支持脚本化客户端绘图操作。
大白话就是canvas是一个可以在上面通过javaScript画图的标签,通过其提供的context(上下文)及Api进行绘制,在这个过程中canvas充当画布的角色。
<canvas></canvas>如何使用
canvas给我们提供了很多的Api,供我们使用,我们只需要在body标签中创建一个canvas标签,在script标签中拿到canvas这个标签的节点,并创建context(上下文)就可以使用了。
...
<body>
<canvas></canvas>
</body>
<script>
// 获取canvas 实例
const canvas = document.querySelector('canvas')
canvas.getContext('2d')
</script>
...步入正题。
实现电子签名
知道几何的朋友都很清楚,线有点绘成,面由线绘成。
多点成线,多线成面。
所以我们实际只需要拿到当前触摸的坐标点,进行成线处理就可以了。
在body中添加canvas标签
在这里我们不仅需要在在body中添加canvas标签,我们还需要添加两个按钮,分别是取消和保存(后面我们会用到)。
<body>
<canvas></canvas>
<div>
<button>取消</button>
<button>保存</button>
</div>
</body>添加文件
我这里全程使用js进行样式设置及添加。
// 配置内容
const config = {
width: 400, // 宽度
height: 200, // 高度
lineWidth: 5, // 线宽
strokeStyle: 'red', // 线条颜色
lineCap: 'round', // 设置线条两端圆角
lineJoin: 'round', // 线条交汇处圆角
}获取canvas实例
这里我们使用querySelector获取canvas的dom实例,并设置样式和创建上下文。
// 获取canvas 实例
const canvas = document.querySelector('canvas')
// 设置宽高
canvas.width = config.width
canvas.height = config.height
// 设置一个边框,方便我们查看及使用
canvas.style.border = '1px solid #000'
// 创建上下文
const ctx = canvas.getContext('2d')基础设置
我们将canvas的填充色为透明,并绘制填充一个矩形,作为我们的画布,如果不设置这个填充背景色,在我们初识渲染的时候是一个黑色背景,这也是它的一个默认色。
// 设置填充背景色
ctx.fillStyle = 'transparent'
// 绘制填充矩形
ctx.fillRect(
0, // x 轴起始绘制位置
0, // y 轴起始绘制位置
config.width, // 宽度
config.height // 高度
);
上次绘制路径保存
这里我们需要声明一个对象,用来记录我们上一次绘制的路径结束坐标点及偏移量。
保存上次坐标点这个我不用说大家都懂;
为啥需要保存偏移量呢,因为鼠标和画布上的距离是存在一定的偏移距离,在我们绘制的过程中需要减去这个偏移量,才是我们实际的绘制坐标。
但我发现
chrome中不需要减去这个偏移量,拿到的就是实际的坐标,之前在微信小程序中使用就需要减去偏移量,需要在小程序中使用的朋友需要注意这一点哦。
// 保存上次绘制的 坐标及偏移量
const client = {
offsetX: 0, // 偏移量
offsetY: 0,
endX: 0, // 坐标
endY: 0
}设备兼容
我们需要它不仅可以在web端使用,还需要在移动端使用,我们需要给它做设备兼容处理。我们通过调用navigator.userAgent获取当前设备信息,进行正则匹配判断。
// 判断是否为移动端
const mobileStatus = (/Mobile|Android|iPhone/i.test(navigator.userAgent))
初始化
这里我们在监听鼠标按下(mousedown)(web端)/触摸开始(touchstart)的时候进行初始化,事件监听采用addEventListener。
// 创建鼠标/手势按下监听器
window.addEventListener(mobileStatus ? "touchstart" : "mousedown", init)
三元判断说明: 这里当
mobileStatus为true时则表示为移动端,反之则为web端,后续使用到的三元依旧是这个意思。
声明初始化方法
我们添加一个init方法作为监听鼠标按下/触摸开始的回调方法。
这里我们需要获取到当前鼠标按下/触摸开始的偏移量和坐标,进行起始点绘制。
Tips:
web端可以直接通过event中取到,而移动端则需要在event.changedTouches[0]中取到。
这里我们在初始化后再监听鼠标的移动。
// 初始化
const init = event => {
// 获取偏移量及坐标
const { offsetX, offsetY, pageX, pageY } = mobileStatus ? event.changedTouches[0] : event
// 修改上次的偏移量及坐标
client.offsetX = offsetX
client.offsetY = offsetY
client.endX = pageX
client.endY = pageY
// 清除以上一次 beginPath 之后的所有路径,进行绘制
ctx.beginPath()
// 根据配置文件设置进行相应配置
ctx.lineWidth = config.lineWidth
ctx.strokeStyle = config.strokeStyle
ctx.lineCap = config.lineCap
ctx.lineJoin = config.lineJoin
// 设置画线起始点位
ctx.moveTo(client.endX, client.endY)
// 监听 鼠标移动或手势移动
window.addEventListener(mobileStatus ? "touchmove" : "mousemove", draw)
}绘制
这里我们添加绘制draw方法,作为监听鼠标移动/触摸移动的回调方法。
// 绘制
const draw = event => {
// 获取当前坐标点位
const { pageX, pageY } = mobileStatus ? event.changedTouches[0] : event
// 修改最后一次绘制的坐标点
client.endX = pageX
client.endY = pageY
// 根据坐标点位移动添加线条
ctx.lineTo(pageX , pageY )
// 绘制
ctx.stroke()
}结束绘制
添加了监听鼠标移动/触摸移动我们一定要记得取消监听并结束绘制,不然的话它会一直监听并绘制的。
这里我们创建一个cloaseDraw方法作为鼠标弹起/结束触摸的回调方法来结束绘制并移除鼠标移动/触摸移动的监听。
canvas结束绘制则需要调用closePath()让其结束绘制
// 结束绘制
const cloaseDraw = () => {
// 结束绘制
ctx.closePath()
// 移除鼠标移动或手势移动监听器
window.removeEventListener("mousemove", draw)
}添加结束回调监听器
// 创建鼠标/手势 弹起/离开 监听器
window.addEventListener(mobileStatus ? "touchend" :"mouseup", cloaseDraw)
ok,现在我们的电子签名功能还差一丢丢可以实现完了,现在已经可以正常的签名了。
我们来看一下效果:
取消功能/清空画布
我们在刚开始创建的那两个按钮开始排上用场了。
这里我们创建一个cancel的方法作为取消并清空画布使用
// 取消-清空画布
const cancel = () => {
// 清空当前画布上的所有绘制内容
ctx.clearRect(0, 0, config.width, config.height)
}然后我们将这个方法和取消按钮进行绑定
<button onclick="cancel()">取消</button>保存功能
这里我们创建一个save的方法作为保存画布上的内容使用。
将画布上的内容保存为图片/文件的方法有很多,比较常见的是blob和toDataURL这两种方案,但toDataURL这哥们没blob强,适配也不咋滴。所以我们这里采用a标签 ➕ blob方案实现图片的保存下载。
// 保存-将画布内容保存为图片
const save = () => {
// 将canvas上的内容转成blob流
canvas.toBlob(blob => {
// 获取当前时间并转成字符串,用来当做文件名
const date = Date.now().toString()
// 创建一个 a 标签
const a = document.createElement('a')
// 设置 a 标签的下载文件名
a.download = `${date}.png`
// 设置 a 标签的跳转路径为 文件流地址
a.href = URL.createObjectURL(blob)
// 手动触发 a 标签的点击事件
a.click()
// 移除 a 标签
a.remove()
})
}然后我们将这个方法和保存按钮进行绑定
<button onclick="save()">保存</button>我们将刚刚绘制的内容进行保存,点击保存按钮,就会进行下载保存
完整代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
* {
margin: 0;
padding: 0;
}
</style>
</head>
<body>
<canvas></canvas>
<div>
<button onclick="cancel()">取消</button>
<button onclick="save()">保存</button>
</div>
</body>
<script>
// 配置内容
const config = {
width: 400, // 宽度
height: 200, // 高度
lineWidth: 5, // 线宽
strokeStyle: 'red', // 线条颜色
lineCap: 'round', // 设置线条两端圆角
lineJoin: 'round', // 线条交汇处圆角
}
// 获取canvas 实例
const canvas = document.querySelector('canvas')
// 设置宽高
canvas.width = config.width
canvas.height = config.height
// 设置一个边框
canvas.style.border = '1px solid #000'
// 创建上下文
const ctx = canvas.getContext('2d')
// 设置填充背景色
ctx.fillStyle = 'transparent'
// 绘制填充矩形
ctx.fillRect(
0, // x 轴起始绘制位置
0, // y 轴起始绘制位置
config.width, // 宽度
config.height // 高度
);
// 保存上次绘制的 坐标及偏移量
const client = {
offsetX: 0, // 偏移量
offsetY: 0,
endX: 0, // 坐标
endY: 0
}
// 判断是否为移动端
const mobileStatus = (/Mobile|Android|iPhone/i.test(navigator.userAgent))
// 初始化
const init = event => {
// 获取偏移量及坐标
const { offsetX, offsetY, pageX, pageY } = mobileStatus ? event.changedTouches[0] : event
// 修改上次的偏移量及坐标
client.offsetX = offsetX
client.offsetY = offsetY
client.endX = pageX
client.endY = pageY
// 清除以上一次 beginPath 之后的所有路径,进行绘制
ctx.beginPath()
// 根据配置文件设置相应配置
ctx.lineWidth = config.lineWidth
ctx.strokeStyle = config.strokeStyle
ctx.lineCap = config.lineCap
ctx.lineJoin = config.lineJoin
// 设置画线起始点位
ctx.moveTo(client.endX, client.endY)
// 监听 鼠标移动或手势移动
window.addEventListener(mobileStatus ? "touchmove" : "mousemove", draw)
}
// 绘制
const draw = event => {
// 获取当前坐标点位
const { pageX, pageY } = mobileStatus ? event.changedTouches[0] : event
// 修改最后一次绘制的坐标点
client.endX = pageX
client.endY = pageY
// 根据坐标点位移动添加线条
ctx.lineTo(pageX , pageY )
// 绘制
ctx.stroke()
}
// 结束绘制
const cloaseDraw = () => {
// 结束绘制
ctx.closePath()
// 移除鼠标移动或手势移动监听器
window.removeEventListener("mousemove", draw)
}
// 创建鼠标/手势按下监听器
window.addEventListener(mobileStatus ? "touchstart" : "mousedown", init)
// 创建鼠标/手势 弹起/离开 监听器
window.addEventListener(mobileStatus ? "touchend" :"mouseup", cloaseDraw)
// 取消-清空画布
const cancel = () => {
// 清空当前画布上的所有绘制内容
ctx.clearRect(0, 0, config.width, config.height)
}
// 保存-将画布内容保存为图片
const save = () => {
// 将canvas上的内容转成blob流
canvas.toBlob(blob => {
// 获取当前时间并转成字符串,用来当做文件名
const date = Date.now().toString()
// 创建一个 a 标签
const a = document.createElement('a')
// 设置 a 标签的下载文件名
a.download = `${date}.png`
// 设置 a 标签的跳转路径为 文件流地址
a.href = URL.createObjectURL(blob)
// 手动触发 a 标签的点击事件
a.click()
// 移除 a 标签
a.remove()
})
}
</script>
</html>各内核和浏览器支持情况
Mozilla 程序从 Gecko 1.8 (Firefox 1.5 (en-US)) 开始支持 <canvas>。它首先是由 Apple 引入的,用于 OS X Dashboard 和 Safari。Internet Explorer 从 IE9 开始支持<canvas> ,更旧版本的 IE 中,页面可以通过引入 Google 的 Explorer Canvas 项目中的脚本来获得<canvas>支持。Google Chrome 和 Opera 9+ 也支持 <canvas>。
小程序中提示
在小程序中我们如果需呀实现的话,也是同样的原理哦,只是我们需要将创建实例和上下文的Api进行修改,因为小程序中是没有dom,既然没有dom,哪来的操作dom这个操作呢。
如果是
uni-app则需要使用uni.createCanvasContext进行上下文创建如果是原生微信小程序则使用
wx.createCanvasContext进行创建(2.9.0)之后的库不支持
作者:桃小瑞
来源:juejin.cn/post/7174251833773752350
你真的了解 RSA 加密算法吗?
沉淀、分享、成长,让自己和他人都能有所收获!😄
记得那是我毕业🎓后的第一个秋天,申请了域名,搭建了论坛。可惜好景不长,没多久进入论坛后就出现各种乱七八糟的广告,而这些广告压根都不是我加的。
这是怎么回事?后来我才知道,原来我的论坛没有加 HTTPS 也就是没有 SSL 证书。那这和数学中的素数有啥关系呢?这是因为每一个 SSL 的生成都用到了 RSA 非对称加密,而 RSA 的加解密就是使用了两个互为质数的大素数生成公钥和私钥的。
这就是我们今天要分享的,关于素数在 RSA 算法中的应用。
一、什么是素数
素数(或质数)指的是大于1的且不能通过两个较小的自然数乘积得来的自然数。而大于1的自然数如果不是素数,则称之为合数。例如:7是素数,因为它的乘积只能写成 1 * 7 或者 7 * 1 这样。而像自然数 8 可以写成 2 * 4,因为它是两个较小数字的乘积。
通常在 Java 程序中,我们可以使用下面的代码判断一个数字是否为素数;
boolean isPrime = number > 0;
// 计算number的平方根为k,可以减少一半的计算量
int k = (int) Math.sqrt(number);
for (int i = 2; i <= k; i++) {
if (number % i == 0) {
isPrime = false;
break;
}
}
return isPrime;二、对称加密和非对称加密
假如 Alice 时而需要给北漂搬砖的 Bob 发一些信息,为了安全起见两个人相互协商了一个加密的方式。比如 Alice 发送了一个银行卡密码 142857 给 Bob,Alice 会按照与 Bob 的协商方式,把 142857 * 2 = 285714 的结果传递给 Bob,之后 Bob 再通过把信息除以2拿到结果。
但一来二去,Alice 发的密码、生日、衣服尺寸、鞋子大小,都是乘以2的规律被别人发现。这下这个加密方式就不安全了。而如果每次都给不同的信息维护不同的秘钥又十分麻烦,且这样的秘钥为了安全也得线下沟通,人力成本又非常高。
所以有没有另外一种方式,使用不同的秘钥对信息的加密和解密。当 Bob 想从 Alice 那获取信息,那么 Bob 就给 Alice 一个公钥,让她使用公钥对信息进行加密,而加密后的信息只有 Bob 手里有私钥才能解开。那么这样的信息传递就变得非常安全了。如图所示。
| 对称加密 | 非对称加密 |
|---|---|
三、算法公式推导
如果 Alice 希望更安全的给 Bob 发送的信息,那么就需要保证经过公钥加密的信息不那么容易被反推出来。所以这里的信息加密,会需用到求模运算。像计算机中的散列算法,伪随机数都是求模运算的典型应用。
例如;5^3 mod 7 = 6 —— 5的3次幂模7余6
5相当于 Alice 要传递给 Bob 的信息
3相当于是秘钥
6相当于是加密后的信息
经过求模计算的结果6,很难被推到出秘钥信息,只能一个个去验证;
5^1 mod 7 = 5
5^2 mod 7 = 3
5^3 mod 7 = 6
5^4 mod 7 = 2
...但如果求模的值特别大,例如这样:5^3 mod 78913949018093809389018903794894898493... = 6 那么再想一个个计算就有不靠谱了。所以这也是为什么会使用模运算进行加密,因为对于大数来说对模运算求逆根本没法搞。
根据求模的计算方式,我们得到加密和解密公式;—— 关于加密和解密的公式推到,后文中会给出数学计算公式。
对于两个公式我们做一下更简单的转换;
从转换后的公式可以得知,m 的 ed 次幂,除以 N 求求模可以得到 m 本身。那么 ed 就成了计算公钥加密的重要因素。为此这里需要提到数学中一个非常重要的定理,欧拉定理。—— 1763年,欧拉发现。
欧拉定理:m^φ(n) ≡ 1 (mod n) 对于任何一个与 n 互质的正整数 m,的 φ(n) 次幂并除以 n 去模,结果永远等于1。φ(n) 代表着在小于等于 n 的正整数中,有多少个与 n 互质的数。
例如:φ(8) 小于等于8的正整数中 1、2、3、4、5、6、7、8 有 1、3、5、7 与数字 8 互为质数。所以 φ(8) = 4 但如果是 n 是质数,那么 φ(n) = n - 1 比如 φ(7) 与7互为质数有1、2、3、4、5、6 所有 φ(7) = 6
接下来我们对欧拉公式做一些简单的变换,用于看出ed的作用;
经过推导的结果可以看到 ed = kφ(n) + 1,这样只要算出加密秘钥 e 就可以得到一个对应的解密秘钥 d。那么整套这套计算过程,就是 RSA 算法。
四、关于RSA算法
RSA加密算法是一种非对称加密算法,在公开秘钥加密和电子商业中被广泛使用。
于1977年,三位数学家;罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字命名,叫做RSA算法。
1973年,在英国政府通讯总部工作的数学家克利福德·柯克斯(Clifford Cocks)在一个内部文件中提出了一个与之等效的算法,但该算法被列入机密,直到1997年才得到公开。
RSA 的算法核心在于取了2个素数做乘积求和、欧拉计算等一系列方式算得公钥和私钥,但想通过公钥和加密信息,反推出来私钥就会非常复杂,因为这是相当于对极大整数的因数分解。所以秘钥越长做因数分解越困难,这也就决定了 RSA 算法的可靠性。—— PS:可能以上这段话还不是很好理解,程序员👨🏻💻还是要看代码才能悟。接下来我们就来编写一下 RSA 加密代码。
五、实现RSA算法
RSA 的秘钥生成首先需要两个质数p、q,之后根据这两个质数算出公钥和私钥,在根据公钥来对要传递的信息进行加密。接下来我们就要代码实现一下 RSA 算法,读者也可以根据代码的调试去反向理解 RSA 的算法过程,一般这样的学习方式更有抓手的感觉。嘿嘿 抓手
1. 互为质数的p、q
两个互为质数p、q是选择出来的,越大越安全。因为大整数的质因数分解是非常困难的,直到2020年为止,世界上还没有任何可靠的攻击RSA算法的方式。只要其钥匙的长度足够长,用RSA加密的信息实际上是不能被破解的。—— 不知道量子计算机出来以后会不会改变。如果改变,那么程序员又有的忙了。
2. 乘积n
n = p * q 的乘积。
public long n(long p, long q) {
return p * q;
}3. 欧拉公式 φ(n)
φ(n) = (p - 1) * (q - 1)
public long euler(long p, long q) {
return (p - 1) * (q - 1);
}4. 选取公钥e
e 的值范围在 1 < e < φ(n)
public long e(long euler){
long e = euler / 10;
while (gcd(e, euler) != 1){
e ++;
}
return e;
}5. 选取私钥d
d = (kφ(n) + 1) / e
public long inverse(long e, long euler) {
return (euler + 1) / e;
}6. 加密
c = m^e mod n
public long encrypt(long m, long e, long n) {
BigInteger bM = new BigInteger(String.valueOf(m));
BigInteger bE = new BigInteger(String.valueOf(e));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bM.modPow(bE, bN).toString());
}7. 解密
m = c^d mod n
public long decrypt(long c, long d, long n) {
BigInteger bC = new BigInteger(String.valueOf(c));
BigInteger bD = new BigInteger(String.valueOf(d));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bC.modPow(bD, bN).toString());
}8. 测试
@Test
public void test_rsa() {
RSA rsa = new RSA();
long p = 3, // 选取2个互为质数的p、q
q = 11, // 选取2个互为质数的p、q
n = rsa.n(p, q), // n = p * q
euler = rsa.euler(p, q), // euler = (p-1)*(q-1)
e = rsa.e(euler), // 互为素数的小整数e | 1 < e < euler
d = rsa.inverse(e, euler), // ed = φ(n) + 1 | d = (φ(n) + 1)/e
msg = 5; // 传递消息 5
System.out.println("消息:" + msg);
System.out.println("公钥(n,e):" + "(" + n + "," + e + ")");
System.out.println("私钥(n,d):" + "(" + n + "," + d + ")");
long encrypt = rsa.encrypt(msg, e, n);
System.out.println("加密(消息):" + encrypt);
long decrypt = rsa.decrypt(encrypt, d, n);
System.out.println("解密(消息):" + decrypt);
}测试结果
消息:5
公钥(n,e):(33,3)
私钥(n,d):(33,7)
加密(消息):26
解密(消息):5通过选取3、11作为两个互质数,计算出公钥和私钥,分别进行消息的加密和解密。如测试结果消息5的加密后的信息是26,解密后获得原始信息5
六、RSA数学原理
整个 RSA 的加解密是有一套数学基础可以推导验证的,这里小傅哥把学习整理的资料分享给读者,如果感兴趣可以尝试验证。这里的数学公式会涉及到;求模运算、最大公约数、贝祖定理、线性同于方程、中国余数定理、费马小定理。当然还有一些很基础的数论概念;素数、互质数等。以下推理数学内容来自博客:luyuhuang.tech/2019/10/24/…
1. 模运算
1.1 整数除法
定理 1 令 a 为整数, d 为正整数, 则存在唯一的整数 q 和 r, 满足 0⩽r<d, 使得 a=dq+r.
当 r=0 时, 我们称 d 整除 a, 记作 d∣a; 否则称 d 不整除 a, 记作 d∤a
整除有以下基本性质:
定理 2 令 a, b, c 为整数, 其中 a≠0a≠0. 则:
对任意整数 m,n,如果 a∣b 且 a∣c, 则 a∣(mb + nc)
如果 a∣b, 则对于所有整数 c 都有 a∣bc
如果 a∣b 且 b∣c, 则 a∣c
1.2 模算术
在数论中我们特别关心一个整数被一个正整数除时的余数. 我们用 a mod m = b表示整数 a 除以正整数 m 的余数是 b. 为了表示两个整数被一个正整数除时的余数相同, 人们又提出了同余式(congruence).
定义 1 如果 a 和 b 是整数而 m 是正整数, 则当 m 整除 a - b 时称 a 模 m 同余 b. 记作 a ≡ b(mod m)
a ≡ b(mod m) 和 a mod m= b 很相似. 事实上, 如果 a mod m = b, 则 a≡b(mod m). 但他们本质上是两个不同的概念. a mod m = b 表达的是一个函数, 而 a≡b(mod m) 表达的是两个整数之间的关系.
模算术有下列性质:
定理 3 如果 m 是正整数, a, b 是整数, 则有
(a+b)mod m=((a mod m)+(b mod m)) mod m
ab mod m=(a mod m)(b mod m) mod m
根据定理3, 可得以下推论
推论 1 设 m 是正整数, a, b, c 是整数; 如果 a ≡ b(mod m), 则 ac ≡ bc(mod m)
证明 ∵ a ≡ b(mod m), ∴ (a−b) mod m=0 . 那么
(ac−bc) mod m=c(a−b) mod m=(c mod m⋅(a−b) mod m) mod m=0
∴ ac ≡ bc(mod m)
需要注意的是, 推论1反之不成立. 来看推论2:
推论 2 设 m 是正整数, a, b 是整数, c 是不能被 m 整除的整数; 如果 ac ≡ bc(mod m) , 则 a ≡ b(mod m)
证明 ∵ ac ≡ bc(mod m) , 所以有
(ac−bc)mod m=c(a−b)mod m=(c mod m⋅(a−b)mod m) mod m=0
∵ c mod m≠0 ,
∴ (a−b) mod m=0,
∴a ≡ b(mod m) .
2. 最大公约数
如果一个整数 d 能够整除另一个整数 a, 则称 d 是 a 的一个约数(divisor); 如果 d 既能整除 a 又能整除 b, 则称 d 是 a 和 b 的一个公约数(common divisor). 能整除两个整数的最大整数称为这两个整数的最大公约数(greatest common divisor).
定义 2 令 a 和 b 是不全为零的两个整数, 能使 d∣ad∣a 和 d∣bd∣b 的最大整数 d 称为 a 和 b 的最大公约数. 记作 gcd(a,b)
2.1 求最大公约数
如何求两个已知整数的最大公约数呢? 这里我们讨论一个高效的求最大公约数的算法, 称为辗转相除法. 因为这个算法是欧几里得发明的, 所以也称为欧几里得算法. 辗转相除法基于以下定理:
引理 1 令 a=bq+r, 其中 a, b, q 和 r 均为整数. 则有 gcd(a,b)=gcd(b,r)
证明 我们假设 d 是 a 和 b 的公约数, 即 d∣a且 d∣b, 那么根据定理2, d 也能整除 a−bq=r 所以 a 和 b 的任何公约数也是 b 和 r 的公约数;
类似地, 假设 d 是 b 和 r 的公约数, 即 d∣bd∣b 且 d∣rd∣r, 那么根据定理2, d 也能整除 a=bq+r. 所以 b 和 r 的任何公约数也是 a 和 b 的公约数;
因此, a 与 b 和 b 与 r 拥有相同的公约数. 所以 gcd(a,b)=gcd(b,r).
辗转相除法就是利用引理1, 把大数转换成小数. 例如, 求 gcd(287,91) 我们就把用较大的数除以较小的数. 首先用 287 除以 91, 得
287=91⋅3+14
我们有 gcd(287,91)=gcd(91,14) . 问题转换成求 gcd(91,14). 同样地, 用 91 除以 14, 得
91=14⋅6+7
有 gcd(91,14)=gcd(14,7) . 继续用 14 除以 7, 得
14=7⋅2+0
因为 7 整除 14, 所以 gcd(14,7)=7. 所以 gcd(287,91)=gcd(91,14)=gcd(14,7)=7.
我们可以很快写出辗转相除法的代码:
def gcd(a, b):
if b == 0: return a
return gcd(b, a % b)2.2 贝祖定理
现在我们讨论最大公约数的一个重要性质:
定理 4 贝祖定理 如果整数 a, b 不全为零, 则 gcd(a,b)是 a 和 b 的线性组合集 {ax+by∣x,y∈Z}中最小的元素. 这里的 x 和 y 被称为贝祖系数
证明 令 A={ax+by∣x,y∈Z}. 设存在 x0x0, y0y0 使 d0d0 是 A 中的最小正元素, d0=ax0+by0 现在用 d0去除 a, 这就得到唯一的整数 q(商) 和 r(余数) 满足
又 0⩽r<d0, d0 是 A 中最小正元素
∴ r=0 , d0∣a.
同理, 用 d0d0 去除 b, 可得 d0∣b. 所以说 d0 是 a 和 b 的公约数.
设 a 和 b 的最大公约数是 d, 那么 d∣(ax0+by0)即 d∣d0
∴∴ d0 是 a 和 b 的最大公约数.
我们可以对辗转相除法稍作修改, 让它在计算出最大公约数的同时计算出贝祖系数.
def gcd(a, b):
if b == 0: return a, 1, 0
d, x, y = gcd(b, a % b)
return d, y, x - (a / b) * y3. 线性同余方程
现在我们来讨论求解形如 ax≡b(modm) 的线性同余方程. 求解这样的线性同余方程是数论研究及其应用中的一项基本任务. 如何求解这样的方程呢? 我们要介绍的一个方法是通过求使得方程 ¯aa≡1(mod m) 成立的整数 ¯a. 我们称 ¯a 为 a 模 m 的逆. 下面的定理指出, 当 a 和 m 互素时, a 模 m 的逆必然存在.
定理 5 如果 a 和 m 为互素的整数且 m>1, 则 a 模 m 的逆存在, 并且是唯一的.
证明 由贝祖定理可知, ∵ gcd(a,m)=1 , ∴ 存在整数 x 和 y 使得 ax+my=1 这蕴含着 ax+my≡1(modm) ∵ my≡0(modm), 所以有 ax≡1(modm)
∴ x 为 a 模 m 的逆.
这样我们就可以调用辗转相除法 gcd(a, m) 求得 a 模 m 的逆.
a 模 m 的逆也被称为 a 在模m乘法群 Z∗m 中的逆元. 这里我并不想引入群论, 有兴趣的同学可参阅算法导论
求得了 a 模 m 的逆 ¯a 现在我们可以来解线性同余方程了. 具体的做法是这样的: 对于方程 ax≡b(modm)a , 我们在方程两边同时乘上 ¯a, 得 ¯aax≡¯ab(modm)
把 ¯aa≡1(modm) 带入上式, 得 x≡¯ab(modm)
x≡¯ab(modm) 就是方程的解. 注意同余方程会有无数个整数解, 所以我们用同余式来表示同余方程的解.
4. 中国余数定理
中国南北朝时期数学著作 孙子算经 中提出了这样一个问题:
有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?
用现代的数学语言表述就是: 下列同余方程组的解释多少?
孙子算经 中首次提到了同余方程组问题及其具体解法. 因此中国剩余定理称为孙子定理.
定理 6 中国余数定理 令 m1,m2,…,mn 为大于 1 且两两互素的正整数, a1,a2,…,an 是任意整数. 则同余方程组
有唯一的模 m=m1m2…mnm=m1m2…mn 的解.
证明 我们使用构造证明法, 构造出这个方程组的解. 首先对于 i=1,2,…,ni=1,2,…,n, 令
即, MiMi 是除了 mimi 之外所有模数的积. ∵∵ m1,m2,…,mn 两两互素, ∴∴ gcd(mi,Mi)=1. 由定理 5 可知, 存在整数 yiyi 是 MiMi 模 mimi 的逆. 即
上式等号两边同时乘 aiai 得
就是第 i 个方程的一个解; 那么怎么构造出方程组的解呢? 我们注意到, 根据 Mi 的定义可得, 对所有的 j≠ij≠i, 都有 aiMiyi≡0(modmj). 因此我们令
就是方程组的解.
有了这个结论, 我们可以解答 孙子算经 中的问题了: 对方程组的每个方程, 求出 MiMi , 然后调用 gcd(M_i, m_i) 求出 yiyi:
最后求出 x=−2⋅35+3⋅21+2⋅15=23≡23(mod105)
5. 费马小定理
现在我们来看数论中另外一个重要的定理, 费马小定理(Fermat's little theorem)
定理 7 费马小定理 如果 a 是一个整数, p 是一个素数, 那么
当 n 不为 p 或 0 时, 由于分子有质数p, 但分母不含p; 故分子的p能保留, 不被约分而除去. 即 p∣(np).
令 b 为任意整数, 根据二项式定理, 我们有
令 a=b+1, 即得 a^p ≡ a(mod p)
当 p 不整除 a 时, 根据推论 2, 有 a^p−1 ≡ 1(mod p)
6. 算法证明
我们终于可以来看 RSA 算法了. 先来看 RSA 算法是怎么运作的:
RSA 算法按照以下过程创建公钥和私钥:
随机选取两个大素数 p 和 q, p≠qp≠q;
计算 n=pq
选取一个与 (p−1)(q−1) 互素的小整数 e;
求 e 模 (p−1)(q−1) 的逆, 记作 d;
将 P=(e,n)公开, 是为公钥;
将 S=(d,n)保密, 是为私钥.
所以 RSA 加密算法是有效的.
(1) 式表明, 不仅可以用公钥加密, 私钥解密, 还可以用私钥加密, 公钥解密. 即加密计算 C=M^d mod n, 解密计算 M=C^e mod n
RSA 算法的安全性基于大整数的质因数分解的困难性. 由于目前没有能在多项式时间内对整数作质因数分解的算法, 因此无法在可行的时间内把 n 分解成 p 和 q 的乘积. 因此就无法求得 e 模 (p−1)(q−1)的逆, 也就无法根据公钥计算出私钥.
七、常见面试题
质数的用途
RSA 算法描述
RSA 算法加解密的过程
RSA 算法使用场景
你了解多少关于 RSA 的数学数论知识
RSA加密算法:zh.wikipedia.org/wiki/RSA%E5…
RSA算法背后的数学原理:luyuhuang.tech/2019/10/24/…
莱昂哈德·欧拉:en.wikipedia.org/wiki/Leonha…
源码:github.com/fuzhengwei/…
作者:小傅哥
来源:juejin.cn/post/7173830290812370958
Android Jetpack:利用Palette进行图片取色
与产品MM那些事
新来一个产品MM,因为比较平,我们就叫她A妹吧。A妹来第一天就指出:页面顶部的Banner广告位的背景是白色的,太单调啦,人家不喜欢啦,需要根据广告图片的内容自动切换背景颜色,颜色要与广告图主色调一致。作为一名合格的码农我直接回绝了,我说咱们的应用主打简洁,整这花里胡哨的干嘛,劳民伤财。A妹也没放弃,与我深入交流了一夜成功说服了我。
其实要实现这个需求也不难,Google已经为我们提供了一个方便的工具————Palette。
前言
Palette即调色板这个功能其实很早就发布了,Jetpack同样将这个功能也纳入其中,想要使用这个功能,需要先依赖库
implementation 'androidx.palette:palette:1.0.0'本篇文章就来讲解一下如何使用Palette在图片中提取颜色。
创建Palette
创建Palette其实很简单,如下
var builder = Palette.from(bitmap)
var palette = builder.generate()这样,我们就通过一个Bitmap创建一个Pallete对象。
注意:直接使用Palette.generate(bitmap)也可以,但是这个方法已经不推荐使用了,网上很多老文章中依然使用这种方式。建议还是使用Palette.Builder这种方式。
generate()这个函数是同步的,当然考虑图片处理可能比较耗时,Android同时提供了异步函数
public AsyncTask<Bitmap, Void, Palette> generate(
@NonNull final PaletteAsyncListener listener) {通过一个PaletteAsyncListener来获取Palette实例,这个接口如下:
public interface PaletteAsyncListener {
/**
* Called when the {@link Palette} has been generated. {@code null} will be passed when an
* error occurred during generation.
*/
void onGenerated(@Nullable Palette palette);
}提取颜色
有了Palette实例,就可以通过Palette对象的相应函数就可以获取图片中的颜色,而且不只一种颜色,下面一一列举:
getDominantColor:获取图片中的主色调
getMutedColor:获取图片中柔和的颜色
getDarkMutedColor:获取图片中柔和的暗色
getLightMutedColor:获取图片中柔和的亮色
getVibrantColor:获取图片中有活力的颜色
getDarkVibrantColor:获取图片中有活力的暗色
getLightVibrantColor:获取图片中有活力的亮色
这些函数都需要提供一个默认颜色,如果这个颜色Swatch无效则使用这个默认颜色。光这么说不直观,我们来测试一下,代码如下:
var bitmap = BitmapFactory.decodeResource(resources, R.mipmap.a)
var builder = Palette.from(bitmap)
var palette = builder.generate()
color0.setBackgroundColor(palette.getDominantColor(Color.WHITE))
color1.setBackgroundColor(palette.getMutedColor(Color.WHITE))
color2.setBackgroundColor(palette.getDarkMutedColor(Color.WHITE))
color3.setBackgroundColor(palette.getLightMutedColor(Color.WHITE))
color4.setBackgroundColor(palette.getVibrantColor(Color.WHITE))
color5.setBackgroundColor(palette.getDarkVibrantColor(Color.WHITE))
color6.setBackgroundColor(palette.getLightVibrantColor(Color.WHITE))运行后结果如下:
这样各个颜色的差别就一目了然。除了上面的函数,还可以使用getColorForTarget这个函数,如下:
@ColorInt
public int getColorForTarget(@NonNull final Target target, @ColorInt final int defaultColor) {这个函数需要一个Target,提供了6个静态字段,如下:
/**
* A target which has the characteristics of a vibrant color which is light in luminance.
*/
public static final Target LIGHT_VIBRANT;
/**
* A target which has the characteristics of a vibrant color which is neither light or dark.
*/
public static final Target VIBRANT;
/**
* A target which has the characteristics of a vibrant color which is dark in luminance.
*/
public static final Target DARK_VIBRANT;
/**
* A target which has the characteristics of a muted color which is light in luminance.
*/
public static final Target LIGHT_MUTED;
/**
* A target which has the characteristics of a muted color which is neither light or dark.
*/
public static final Target MUTED;
/**
* A target which has the characteristics of a muted color which is dark in luminance.
*/
public static final Target DARK_MUTED;其实就是对应着上面除了主色调之外的六种颜色。
文字颜色自动适配
在上面的运行结果中可以看到,每个颜色上面的文字都很清楚的显示,而且它们并不是同一种颜色。其实这也是Palette提供的功能。
通过下面的函数,我们可以得到各种色调所对应的Swatch对象:
getDominantSwatch
getMutedSwatch
getDarkMutedSwatch
getLightMutedSwatch
getVibrantSwatch
getDarkVibrantSwatch
getLightVibrantSwatch
注意:同上面一样,也可以通过getSwatchForTarget(@NonNull final Target target)来获取
Swatch类提供了以下函数:
getPopulation(): 样本中的像素数量
getRgb(): 颜色的RBG值
getHsl(): 颜色的HSL值
getBodyTextColor(): 能都适配这个Swatch的主体文字的颜色值
getTitleTextColor(): 能都适配这个Swatch的标题文字的颜色值
所以我们通过getBodyTextColor()和getTitleTextColor()可以很容易得到在这个颜色上可以很好现实的标题和主体文本颜色。所以上面的测试代码完整如下:
var bitmap = BitmapFactory.decodeResource(resources, R.mipmap.a)
var builder = Palette.from(bitmap)
var palette = builder.generate()
color0.setBackgroundColor(palette.getDominantColor(Color.WHITE))
color0.setTextColor(palette.dominantSwatch?.bodyTextColor ?: Color.WHITE)
color1.setBackgroundColor(palette.getMutedColor(Color.WHITE))
color1.setTextColor(palette.mutedSwatch?.bodyTextColor ?: Color.WHITE)
color2.setBackgroundColor(palette.getDarkMutedColor(Color.WHITE))
color2.setTextColor(palette.darkMutedSwatch?.bodyTextColor ?: Color.WHITE)
color3.setBackgroundColor(palette.getLightMutedColor(Color.WHITE))
color3.setTextColor(palette.lightMutedSwatch?.bodyTextColor ?: Color.WHITE)
color4.setBackgroundColor(palette.getVibrantColor(Color.WHITE))
color4.setTextColor(palette.vibrantSwatch?.bodyTextColor ?: Color.WHITE)
color5.setBackgroundColor(palette.getDarkVibrantColor(Color.WHITE))
color5.setTextColor(palette.darkVibrantSwatch?.bodyTextColor ?: Color.WHITE)
color6.setBackgroundColor(palette.getLightVibrantColor(Color.WHITE))
color6.setTextColor(palette.lightVibrantSwatch?.bodyTextColor ?: Color.WHITE)这样每个颜色上的文字都可以清晰的显示。
那么这个标题和主体文本颜色有什么差别,他们又是如何的到的?我们来看看源码:
/**
* Returns an appropriate color to use for any 'title' text which is displayed over this
* {@link Swatch}'s color. This color is guaranteed to have sufficient contrast.
*/
@ColorInt
public int getTitleTextColor() {
ensureTextColorsGenerated();
return mTitleTextColor;
}
/**
* Returns an appropriate color to use for any 'body' text which is displayed over this
* {@link Swatch}'s color. This color is guaranteed to have sufficient contrast.
*/
@ColorInt
public int getBodyTextColor() {
ensureTextColorsGenerated();
return mBodyTextColor;
}可以看到都会先执行ensureTextColorsGenerated(),它的源码如下:
private void ensureTextColorsGenerated() {
if (!mGeneratedTextColors) {
// First check white, as most colors will be dark
final int lightBodyAlpha = ColorUtils.calculateMinimumAlpha(
Color.WHITE, mRgb, MIN_CONTRAST_BODY_TEXT);
final int lightTitleAlpha = ColorUtils.calculateMinimumAlpha(
Color.WHITE, mRgb, MIN_CONTRAST_TITLE_TEXT);
if (lightBodyAlpha != -1 && lightTitleAlpha != -1) {
// If we found valid light values, use them and return
mBodyTextColor = ColorUtils.setAlphaComponent(Color.WHITE, lightBodyAlpha);
mTitleTextColor = ColorUtils.setAlphaComponent(Color.WHITE, lightTitleAlpha);
mGeneratedTextColors = true;
return;
}
final int darkBodyAlpha = ColorUtils.calculateMinimumAlpha(
Color.BLACK, mRgb, MIN_CONTRAST_BODY_TEXT);
final int darkTitleAlpha = ColorUtils.calculateMinimumAlpha(
Color.BLACK, mRgb, MIN_CONTRAST_TITLE_TEXT);
if (darkBodyAlpha != -1 && darkTitleAlpha != -1) {
// If we found valid dark values, use them and return
mBodyTextColor = ColorUtils.setAlphaComponent(Color.BLACK, darkBodyAlpha);
mTitleTextColor = ColorUtils.setAlphaComponent(Color.BLACK, darkTitleAlpha);
mGeneratedTextColors = true;
return;
}
// If we reach here then we can not find title and body values which use the same
// lightness, we need to use mismatched values
mBodyTextColor = lightBodyAlpha != -1
? ColorUtils.setAlphaComponent(Color.WHITE, lightBodyAlpha)
: ColorUtils.setAlphaComponent(Color.BLACK, darkBodyAlpha);
mTitleTextColor = lightTitleAlpha != -1
? ColorUtils.setAlphaComponent(Color.WHITE, lightTitleAlpha)
: ColorUtils.setAlphaComponent(Color.BLACK, darkTitleAlpha);
mGeneratedTextColors = true;
}
}通过代码可以看到,这两种文本颜色实际上要么是白色要么是黑色,只是透明度Alpha不同。
这里面有一个关键函数,即ColorUtils.calculateMinimumAlpha():
public static int calculateMinimumAlpha(@ColorInt int foreground, @ColorInt int background,
float minContrastRatio) {
if (Color.alpha(background) != 255) {
throw new IllegalArgumentException("background can not be translucent: #"
+ Integer.toHexString(background));
}
// First lets check that a fully opaque foreground has sufficient contrast
int testForeground = setAlphaComponent(foreground, 255);
double testRatio = calculateContrast(testForeground, background);
if (testRatio < minContrastRatio) {
// Fully opaque foreground does not have sufficient contrast, return error
return -1;
}
// Binary search to find a value with the minimum value which provides sufficient contrast
int numIterations = 0;
int minAlpha = 0;
int maxAlpha = 255;
while (numIterations <= MIN_ALPHA_SEARCH_MAX_ITERATIONS &&
(maxAlpha - minAlpha) > MIN_ALPHA_SEARCH_PRECISION) {
final int testAlpha = (minAlpha + maxAlpha) / 2;
testForeground = setAlphaComponent(foreground, testAlpha);
testRatio = calculateContrast(testForeground, background);
if (testRatio < minContrastRatio) {
minAlpha = testAlpha;
} else {
maxAlpha = testAlpha;
}
numIterations++;
}
// Conservatively return the max of the range of possible alphas, which is known to pass.
return maxAlpha;
}它根据背景色和前景色计算前景色最合适的Alpha。这期间如果小于minContrastRatio则返回-1,说明这个前景色不合适。而标题和主体文本的差别就是这个minContrastRatio不同而已。
回到ensureTextColorsGenerated代码可以看到,先根据当前色调,计算出白色前景色的Alpha,如果两个Alpha都不是-1,就返回对应颜色;否则计算黑色前景色的Alpha,如果都不是-1,返回对应颜色;否则标题和主体文本一个用白色一个用黑色,返回对应颜色即可。
更多功能
上面我们创建Palette时先通过Palette.from(bitmap)的到了一个Palette.Builder对象,通过这个builder可以实现更多功能,比如:
addFilter:增加一个过滤器
setRegion:设置图片上的提取区域
maximumColorCount:调色板的最大颜色数 等等
总结
通过上面我们看到,Palette的功能很强大,但是它使用起来非常简单,可以让我们很方便的提取图片中的颜色,并且适配合适的文字颜色。同时注意因为ColorUtils是public的,所以当我们需要文字自动适配颜色的情况时,也可以通过ColorUtils的几个函数自己实现计算动态颜色的方案。
作者:BennuCTech
来源:juejin.cn/post/7077380907333582879
炸裂的点赞动画
前言
之前偶然间看到某APP点赞有个炸裂的效果,觉得有点意思,就尝试了下,轻微还原,效果图如下
封装粒子
从动画效果中我们可以看到,当动画开始的时候,会有一组粒子从四面八方散射出去,然后逐渐消失,于是可以定义一个粒子类包含以下属性
public class Particle {
public float x, y;
public float startXV;
public float startYV;
public float angle;
public float alpha;
public Bitmap bitmap;
public int width, height;
}x,y是粒子的位置信息
startXV,startYV是X方向和Y方向的速度
angle是发散出去的角度
alpha是粒子的透明度
bitmap, width, height即粒子图片信息 我们在构造函数中初始化这些信息,给定一些默认值
public Particle(Bitmap originalBitmap) {
alpha = 1;
float scale = (float) Math.random() * 0.3f + 0.7f;
width = (int) (originalBitmap.getWidth() * scale);
height = (int) (originalBitmap.getHeight() * scale);
bitmap = Bitmap.createScaledBitmap(originalBitmap, width, height, true);
startXV = new Random().nextInt(150) * (new Random().nextBoolean() ? 1 : -1);
startYV = new Random().nextInt(170) * (new Random().nextBoolean() ? 1 : -1);
int i = new Random().nextInt(360);
angle = (float) (i * Math.PI / 180);
float rotate = (float) Math.random() * 180 - 90;
Matrix matrix = new Matrix();
matrix.setRotate(rotate);
bitmap = Bitmap.createBitmap(bitmap, 0, 0, width, height, matrix, false);
originalBitmap.recycle();
}仔细看效果动画,会发现同一个图片每次出来的旋转角度会有不同,于是,在创建bitmap的时候我们随机旋转下图片。
绘制粒子
有了粒子之后,我们需要将其绘制在View上,定义一个ParticleView,重写onDraw()方法,完成绘制
public class ParticleView extends View {
Paint paint;
List<Particle> particles = new ArrayList<>();
//.....省略构造函数
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
for (Particle particle : particles) {
paint.setAlpha((int) (particle.alpha * 255));
canvas.drawBitmap(particle.bitmap, particle.x - particle.width / 2, particle.y - particle.height / 2, paint);
}
}
public void setParticles(List<Particle> particles) {
this.particles = particles;
}
}管理粒子
绘制的时候我们发现需要不断改变粒子的x,y值,才能使它动起来,所以我们需要一个ValueAnimator,然后通过监听动画执行情况,不断绘制粒子。
private void startAnimator(View emiter) {
ValueAnimator valueAnimator = ObjectAnimator.ofInt(0, 1).setDuration(1000);
valueAnimator.addUpdateListener(animation -> {
for (Particle particle : particles) {
particle.alpha = 1 - animation.getAnimatedFraction();
float time = animation.getAnimatedFraction();
time *= 10;
particle.x = startX - (float) (particle.startXV * time * Math.cos(particle.angle));
particle.y = startY - (float) (particle.startYV * time * Math.sin(particle.angle) - 9.8 * time * time / 2);
}
particleView.invalidate();
});
valueAnimator.start();
}由于我们的点赞按钮经常出现在RecyclerView的item里面,而点赞动画又是全屏的,所以不可能写在item的xml文件里面,而且我们需要做到0侵入,在不改变原来的逻辑下添加动画效果。
我们可以通过activity.findViewById(android.R.id.content)获取FrameLayout然后向他添加子View
public ParticleManager(Activity activity, int[] drawableIds) {
particles = new ArrayList<>();
for (int drawableId : drawableIds) {
particles.add(new Particle(BitmapFactory.decodeResource(activity.getResources(), drawableId)));
}
topView = activity.findViewById(android.R.id.content);
topView.getLocationInWindow(parentLocation);
}首先我们通过构造函数传入当前Activity以及我们需要的图片资源,然后将图片资源都解析成Particle对象,保存在particles中,然后获取topView以及他的位置信息。
然后需要知道动画从什么位置开始,传入一个view作为锚点
public void start(View emiter) {
int[] location = new int[2];
emiter.getLocationInWindow(location);
startX = location[0] + emiter.getWidth() / 2 - parentLocation[0];
startY = location[1] - parentLocation[1];
particleView = new ParticleView(topView.getContext());
topView.addView(particleView);
particleView.setParticles(particles);
startAnimator(emiter);
}通过传入一个emiter,计算出起始位置信息并初始化particleView中的粒子信息,最后开启动画。
使用
val ids = ArrayList<Int>()
for (index in 1..18) {
val id = resources.getIdentifier("img_like_$index", "mipmap", packageName);
ids.add(id)
}
collectImage.setOnClickListener {
ParticleManager(this, ids.toIntArray())
.start(collectImage)
}运行之后会发现基本和效果图一致,但是其实有个潜在的问题,我们只是向topView添加了view,并没有移除,虽然界面上看不到,其实只是因为我们的粒子在最后透明度都是0了,将粒子透明度最小值设置为0.1后运行会发现,动画结束之后粒子没有消失,会越堆积越多,所以我们还需要移除view。
valueAnimator.addListener(new AnimatorListenerAdapter() {
@Override
public void onAnimationStart(Animator animation, boolean isReverse) {
}
@Override
public void onAnimationEnd(Animator animation) {
topView.removeView(particleView);
topView.postInvalidate();
}
@Override
public void onAnimationCancel(Animator animation) {
topView.removeView(particleView);
topView.postInvalidate();
}
});移除的时机放在动画执行完成,所以继续使用之前的valueAnimator,监听他的完成事件,移除view,当然,如果动画取消了也需要移除。
作者:晚来天欲雪_
来源:juejin.cn/post/7086471790502871054
记一次代码评鉴
前言
近期公司组织了一次代码评鉴,在这边记录下学习到的一些规范吧
案例
案例1
参数过多,改为对象好一些
const start = (filename, version, isFirst, branch, biz) => {
// ....
}案例2
query不应该直接透传
对象解构可能导致覆盖,可以调下顺序
// ...
await axios.post('xxx', {
data: {
host: 'xxx'
...getQuery()
}
})案例3
超过三个条件的判断抽出为表达式或者函数
魔法数字用变量代替
与和非不一起使用
if (bottom < boxMaxH && topRemain < boxMax || top > 20) {
}作者:沐晓
来源:juejin.cn/post/7173595497641443364
底层程序员4年的逆袭之旅:穷屌丝到小老板
我创业了
3年前立的flag,现在做到了我当时难以想象的程度,我自己一直激励我自己,要努力,要坚持!结果如何,交给老天!
我离职了,结束了4年的前端职业生涯,比我想象的要快很多!休息了几天,来聊一聊这几年的经历,希望能够给到大家帮助(挺后悔的,因为在这个时间点离职,就意味着没有年终了,虽然已经说服了自己,但是,刚离职完,同事就和我说公司裁员了,血亏!!!!!!害想想就来气,我的N+1,4个月呢,十几万就这样飞了!好了不说了闲话了,难受!)
月哥这一路走来充满鸡血,经常写鸡汤文章,激励大家,其实也在激励我自己在努力的奋斗,没办法,学历低,履历差,我哪有时间抱怨,我只能拼搏,奋斗,因为我知道我只有这样我才可能有一些,别人看不上的机会,但是需要我这种人拼尽全力,才能获取到的!
月哥这十年
2012年上大学,因为穷,借了助学贷款,也在学校拿贫困生补助,安徽工程大学机电学院(三本计算机系)
2014年参军-2016年退伍 中国人民解放军 陆军 某特殊兵种(其实当兵的主要原因就是穷,那时候当兵可以免学费,而且还有补助,我家里农村的,两个人上大学,欠了很多钱,学费也是东拼西凑,没办法!)
2017年实习,学的java,实习岗位c#,在合肥,工资1900,干了29天被开。永远的痛啊
IT干不下去了,要生活,17年转行至游泳教练,龙格亲子游泳,干了一年,锻炼了自己很强的耐心,因为学员是0-6岁的宝宝!教他们游泳,玩水!
18年5月底,说服自己重新干回前端,感觉自己在学习上从来没有做出过什么,高考也好,去部队也好,关于学习,一切都是不用心,除了学习其他都挺好,身体不错,但是始终在浑浑噩噩在逃避学习,不敢直面自己的内心,感觉天天泡水不是我自己想要的生活,同学们也在一个一个的找到不错的工作,甚至有的人还去了中大厂,又想到泡在水里的自己,心里很不是滋味,有一种叫做"挫败感"的东西,正在如影随形地跟着我;我决定再拼最后一把,失败与否,干一把;遂报名某马培训前端,
18年6月底毕业!6年大学生涯,此时我24岁!属于大龄了!
18年8月初,第一次找工作,学完jq,找到15k,因为没学框架,心里虚,拒绝了没去,然后自学node,vue
18年9月中旬,出来面试,背完两本面试宝典!一天当场拿到两个offer,一个16k,一个17k,然后直接入职了;依稀的记得,那天下午面完试,我下了公司的楼,然后去小店买了包软中,蹲在路边抽,百感交集!10月底拿到19koffer,心虚没敢去!以前行情好,简历上不写项目都可以拿到offer,只要会吹,然后拿到了有生以来第一个学习上的第一名,某马上海前端25期,第一个找到工作的,也是工资最高的,5月中旬到9月18号找到工作,历时4个月!
入职3月就做了前端leader,优势能喝酒,能吹牛,能做事,敢承担,又是军人出身!领导比较喜欢!
19年涨薪3千至2w
19年10月出去面试,拿到某安 36w-42w offer,去了要降月base,年终8-12月,觉得不靠谱,没去!同时背调因为第一家公司的问题,背调出了问题,吃一堑长一智!
20年7月跳槽至目前这家公司,工资23K * 14 ; 试用期6个月结束:表现突出,涨薪4k,年中又涨薪2k ,21年中旬,base到29k , 职级p6+,又带了小团队!
21年出去面试,拿到(29+1)* 17 的offer,医疗行业,没去,还有其他一堆的offer!
22年出去面试,拿到 44*16 offer,链圈技术专家岗位,没去!
22年11月,离职创业!结束4年前端职业生涯,开始新的职业!
关于学习
大家都知道我比较的努力,喜欢写励志文章,因为我相信,当数量累计到一定程度的时候,就会发生质的变化,这句话也在我身上深刻的体现出来。学不会我就硬学,我智商不够体力来凑,结果????,不坚持做怎么知道结果是好是坏,于是乎我秉承大力出奇迹的思路,疯狂学习
在培训班的时候,我先预习课程,因为可以在网上买到录屏课,然后代码先敲三遍,然后第二天上课的时候等于就在复习,我的学习节奏保持领先学校的课程一周,就这样还是效果不好,我抓狂啊,我怀疑我自己,表面上每天都在继续,每天似乎都在一样的过去,但某些在内心深处涌动的东西却在不断的积累,直到后来我才知道,那是斗志,来自狼血深处的斗志,终于在一天爆发了。我在电脑上冲动地敲上了给自己看的一行字,“要么赢得风风光光,要么输得精精光光”,狂怒的表达了那种必死的心理,近乎于歇斯底里的疯。
然后学完js就是疯狂刷面试题,刚开始确实不会,也看不太懂,但是我猖狂啊,我尼玛,都这样,还能输啥,干 !我就背下来,两本面试宝典扎扎实实的背了下来,然后到天台,让同学随便出题,我来答,就这样循环往复,我背下来了,并且掌握了面试的答题套路,同时我也理解了很多知识点。
学到js其实也是一知半解,然后开始抄笔记,疯狂抄,笔记本抄完**,发现复盘的时候翻页太麻烦,还是不好记,然后想到抄到a4纸上面,这样每一页的内容就是非常多了,然后 贴墙上,天天背,后面自然就通了**!
然后就有了后来的故事,学完jq出去面试就拿到了15k,然后自学完了vue,node,拿到了16k,17k,19k,20k,29k,30多k,44k ,时间记录成长,虽然不跳槽,但是我没事喜欢出去面试,看看自己还值多少钱!
时间记录了成长,努力见证了成果!入职之后也是抓一切能够学习的机会,地铁上,摸鱼时间,早起... 反正就是学,狂学!
大家看我的学习经历就知道,我不是一个智商很高的人,刚开始学什么都很慢,就是硬怼数量,硬坚持,虽然不知道能够带了什么样的结果,但是每次收获的结果都是令自己什么吃惊的!
焦虑,迷茫
高强度的学习,肯定是充满疲惫,焦虑,同时没有取得成果之前,你自己也会很迷茫,我也是!
我不知道我这么努力,我能不能取得一些成果,但是,我确信一点就是,我如果不努力,我肯定毛机会都没有。所以我强压自己,先做,坚持持续的做,每当焦虑的时候,我就会去抄书、抄代码、看书,这些真的很有效果,阅读可以让我安静下来,抄书也能够让我安静下来,忙起来就没有时间乱想了,前期是非常痛苦的,但是后面就是很舒服了。
我专门弄了一个文件,然后就是在焦虑的时候狂抄代码,类似promise啊,各种手写,少则无脑写了10多遍,多则几十遍,那必然是都背下来了,那必然是理解了其中的逻辑!经过时间的积累,大家可以猜一猜这个文件的代码行数有多少了,有没有过20w行代码?所以焦虑一直伴随着我,直到现在,但是我不怕,焦虑了我就去学习,不管目标,就是干!
关于生活
因为以前都很穷,物质欲望没有那么高,我刚来上海的时候,那时候工资3000多,刚开始住在宿舍,但是我觉得比较贵,每个月得快1000块钱,因为每个月还得存1000多,所以觉得成本太高了,当你穷的时候,1块钱都能难倒英雄汉呀!
于是我搬家到了虹桥的华漕的民房,因为便宜,但是生活条件差了比较多,没有厕所,几平米的房间,连桌子都放不下,还得600多块,上厕所得跑到村里的公厕,冬天还能忍一忍,但是夏天不行,实在没法洗澡,身上臭的很,于是又换了旁边的二楼
然后就是热,贼热,因为二楼就是顶楼,楼板房子,住过的应该都知道,当然肯定没有空调的,连电风扇都没有!对!我为了省钱,我连电风扇都没有买,就是这个刚!但是好处是门口有水龙头,实在太热,我就出来,冲凉,然后再回去睡
终于买了电风扇,为什么呢,因为我的同学来上海找工作,然后住在我这里,当天晚上他就受不了了,他问我你怎么能住的下去的,然后我花了几十块钱,买了电风扇,于是我有的电风扇,然后他在这住了两周,就回了老家,说在上海实在是太艰苦了。先走了!
上班的话,就骑不知道多少手的n手自行车,然后有时候骑车到淞虹路,有时候骑到二号航站楼,反正都是几公里。小黄车我肯定是不舍得骑的,毕竟基本每天都骑,挺贵的!
累习惯,反正也能受得了,吃的饱就好,因为当过兵,在部队的时候经历的可能比这个艰苦多了,所以我觉得还挺好,挺幸福了!
然后就是转行到了前端,17年来的上海,18年底才终于住了有空调的房子,然后就是一室户,然后就是一室一厅,然后就是三室一厅
到现在,正在买房子,准备在上海定居了!
关于工作
我是很卷的,很努力,领导都喜欢我这种人,听话,干活快,产出高,能加班,问题少,还能喝酒!
我在这家公司,公司的领导,hr都知道我干副业,但是也没说啥,因为我干活还是很好的,产出高,bug少,第一家公司优秀员工,目前这家公司连续获得季度优秀员工!
这样做的好处就是,每次我找领导加工资,都很有话语权,第一家公司,我要求加5000,然后加了3000,第二家,转正我就要加工资,加了4000,然后年中又加了2000;我就秉承着我干的好,你就必须给我加钱,不然我没有动力干,半年不加工资,我就感觉没有工作动力了,那我就得跑路(因为我有随时跳槽的能力)。因为表现确实不错,所以每次加薪都很顺利!
我入职一家公司,我就开始准备跳槽了,因为我相信机会是留给有准备的人的,下面是我真实的简历,现在也用不到了,分享给大家看看!
我在公司的人际关系我觉得还是很不错的,包括和后端,产品测试同学,我其实9月份就提离职了,我们领导说,你不如忍一忍,拿完年终再走,毕竟也不少钱,然后hr也是这样说,你不再考虑考虑拿完年终再走!但是现在实在太忙,我也实话实说,留下来也会影响到工作,虽然我不用怎么干活,熬到年后也是可以的,但是人过留名,我不想背骂名,哈哈!然后就愉快的离职了!
要明确自己打工人的身份,我就要多挣钱,你只要给我画饼,我就要立马吃,顺着你的路走,你不得不给我钱。我们在公司就要自己的利益最大化,干好事是前提,不然你没有话语权!我只卷学习,技术越来越好,所以我干活效率高,干活快,每天又大量的时间摸鱼,那我就疯狂的学习,学源码!领导喜欢看,那我就做你喜欢的事,这样我找你加工资的时候,你就没话说的吧!职场小技巧,哈哈!
关于副业--->主业
为什么离职,因为副业做的太大了,今年暴涨,学员也突破了千人,团队的规模也越来越大,开公司,整合团队,希望把这件事做的越来越好,目前团队有13个人,4名p8+级别大佬,3位p7大佬,有5名伙伴全职all in到这块,主要分为两块,培训(0基础,面试辅导,进阶辅导,晋升辅导,管理辅导),和接外包私活!
这一年多以来,基本上很少的休息时间,因为周六日要给学员面试辅导,而且还要写文章,自己还得不断的学习,经常就是3-4点睡觉,然后7-8点起床去上班,有的时候每天只睡2个多小时,有时候凌晨我还在群里发消息,没办法,你做了这件事,就得把这件事做好!贼累,因为要同时兼顾好副业,和工作!
我老婆之前问我,你不累吗?我说怎么可能不累,但是还能坚持!
然后11月魔鬼训练营放开了报名,一下子报名了50多位同学,直接给我顶离职了,原来你用心做培训,是真的会被别人认可的!市场不会说谎!
争议,谩骂
做培训,经常被骂,被diss,说你割韭菜,就包括写文章,文末引流,被骂的太多了,但是了解下来的就会知道,我们不是卖课的,我们是做服务的,1对1辅导,你直接来吃我们这群里整理好的面试,项目经验,来1对1的给你把关,给你指导,你的提高能不快吗!
而且看这个报名的人数就知道,我们效果差的话,怎么可能这么多人来报名,而且大家都是在职的,有的年入百万也来报名学习,很多大厂的同学也来报名辅导,因为这个不是吹出来的,真正的让他们看到了来到这边能够获取到价值的
我的学员拿遍了全国所有大厂的offer,薪资比我高的有好多个,有的还是我的两倍,这是我最骄傲的事情,最远的学员,在美国,新加坡,目前也进了美国的top大厂,很开心,做培训最开心的事情莫过于学员能够超过自己,我们也是毫无保留的给他们辅导!
骂我也好,说我割韭菜也罢,我现在也不太关注这些声音,我只要能给学员带来真正的提升就好。你不参与,你根本不知道我做的好不好,教的垃圾不垃圾!
关于身体
很多人觉得我吃不消,虽然我很久没锻炼了,但是老本厚,来来来,上图!
所以,加班熬夜我顶的住,然后现在离职了,也就开始有时间锻炼了!此处需要66个赞,哈哈!关于我怎么练的,我这么扣的人怎么可能去健身房,从小就壮,干农活,十多岁就能开拖拉机下地了,穷人的孩子早当家!
大家一定要注意身体!别硬干!身体是革命的本钱,我也是日常去医院检查身体,切记,身体第一!
关于收入
说一个笑话吧!以下纯属虚构--> 收入暴涨的心态,当第一个月收入过10万的时候,兴奋啊,激动啊,后面每个月,都越来越多之后,心态也就没那么激动了,很平常了!
士兵突击里面的装甲团的团长说过一句话,一直激励着我,“想要,和得到之间还需要做到!”
关于未来
我很早就清晰的明白,拼技术,很难拼的过各位大佬,你们随便学一学都比我强很多,这是必须要承认的;就像我们培训出来的一些校招拿到sp的同学,一毕业就30k,我这种学历怎么比,没法比呀!虽然说这四年看来在工作技术上还可以,但是对比顶层还有巨大的差距,这些差距不是努力能够追上的,因为别人也在努力,只有反其道而行,利用自己的优势,把自己的优势无限的扩大,才能够有机会。我技术上干不过你,那我就把你招进来,做我的合作伙伴!这种方式能够最快弥补自己短板,然后就没有短板了!以前不敢想,现在团队招来了这么多p7,p8的大佬,我在正确的道路上坚持的做着,就是为了能够给到学员带来巨大的价值,学各位大佬的精华,补充到自己身上!我们能够做的就是,想尽一切办法快速的提升实力,找这些大佬solo,无疑是最快的方式!
我自身有很强的毅力和决心,以及很好的自律性,这些年的经历告诉我,韧性非常重要,坚持住,就算失败了,也无所谓,过程最精彩,结果就是成盒 ,so what!
嗯嗯嗯,不知道能做到什么程度,但是不变的是,要努力,要坚持,要做学员的榜样,既然选择了创业,all in 在前后端培训上面,就要好好服务学员,给他们带来价值,让他们觉得花的钱太值了,那我就扛起枪,持续的战斗下去!结果交给老天,管它个锤子!
寄语
抱怨没有用,焦虑是日常,当你抱怨时,当你焦虑中,其实你是对现状的不满,你内心肯定要往好的方面走,你还有变好的欲望,我们需要这些欲望,来当作我们的动力源泉,持续坚持下去!反向去利用,你会得到正向反馈!
当你一点焦虑都没有的时候,你也不会抱怨的时候,那么恭喜你看透了
很多人说努力没有用,我想问你真正努力过吗?这个你得和你自己对话,你才能够更加的清晰,不要假努力,结果不会说谎;你基础很好,算法很好,源码很好,项目也很有思考,你会拿到很差的offer吗? 我想大概率不会,你不一定能够进大厂,履历、学历、运气也有很大的关系,但是有的不错的涨薪还是能够做到的,和别人比太累,只和自己的昨天比。我进步了,我就很开心!大家加油,不卷,也不能躺平,别等到被裁,然后不好找工作才知道,再去后悔,那时候你会发现努力学习真的有用
千万、一定,不要放弃努力!或许段时间内看不到结束,但厚积薄发才是最佳方式背水一战,逼到绝境反而可能练出真本事!因为没的选!
好了,这是我的4年,大家看一看我是拼的学历、智商、履历还是拼的努力、坚持、韧性!我是月哥,我为自己代言!下一个四年拭目以待!
感谢大家的观看和点赞、转发;也可添加月哥微信lisawhy0706沟通交流,结尾依旧是:长风破浪会有时,直挂云帆济沧海
作者:前端要努力
来源:juejin.cn/post/7170596452266147871
这10张图拿去,别再说学不会RecyclerView的缓存复用机制了!
ViewPager2是在RecyclerView的基础上构建而成的,意味着其可以复用RecyclerView对象的绝大部分特性,比如缓存复用机制等。
作为ViewPager2系列的第一篇,本篇的主要目的是快速普及必要的前置知识,而内容的核心,正是前面所提到的RecyclerView的缓存复用机制。
RecyclerView,顾名思义,它会回收其列表项视图以供重用。
具体而言,当一个列表项被移出屏幕后,RecyclerView并不会销毁其视图,而是会缓存起来,以提供给新进入屏幕的列表项重用,这种重用可以:
避免重复创建不必要的视图
避免重复执行昂贵的findViewById
从而达到的改善性能、提升应用响应能力、降低功耗的效果。而要了解其中的工作原理,我们还得回到RecyclerView是如何构建动态列表的这一步。
RecyclerView是如何构建动态列表的?
与RecyclerView构建动态列表相关联的几个重要类中,Adapter与ViewHolder负责配合使用,共同定义RecyclerView列表项数据的展示方式,其中:
ViewHolder是一个包含列表项视图(itemView)的封装容器,同时也是RecyclerView缓存复用的主要对象。
Adapter则提供了数据<->视图 的“绑定”关系,其包含以下几个关键方法:
- onCreateViewHolder:负责创建并初始化ViewHolder及其关联的视图,但不会填充视图内容。
- onBindViewHolder:负责提取适当的数据,填充ViewHolder的视图内容。
然而,这2个方法并非每一个进入屏幕的列表项都会回调,相反,由于视图创建及findViewById执行等动作都主要集中在这2个方法,每次都要回调的话反而效率不佳。因此,我们应该通过对ViewHolder对象积极地缓存复用,来尽量减少对这2个方法的回调频次。
最优情况是——取得的缓存对象正好是原先的ViewHolder对象,这种情况下既不需要重新创建该对象,也不需要重新绑定数据,即拿即用。
次优情况是——取得的缓存对象虽然不是原先的ViewHolder对象,但由于二者的列表项类型(itemType)相同,其关联的视图可以复用,因此只需要重新绑定数据即可。
最后实在没办法了,才需要执行这2个方法的回调,即创建新的ViewHolder对象并绑定数据。
实际上,这也是RecyclerView从缓存中查找最佳匹配ViewHolder对象时所遵循的优先级顺序。而真正负责执行这项查找工作的,则是RecyclerView类中一个被称为回收者的内部类——Recycler。
Recycler是如何查找ViewHolder对象的?
/**
* ...
* When {@link Recycler#getViewForPosition(int)} is called, Recycler checks attached scrap and
* first level cache to find a matching View. If it cannot find a suitable View, Recycler will
* call the {@link #getViewForPositionAndType(Recycler, int, int)} before checking
* {@link RecycledViewPool}.
*
* 当调用getViewForPosition(int)方法时,Recycler会检查attached scrap和一级缓存(指的是mCachedViews)以找到匹配的View。
* 如果找不到合适的View,Recycler会先调用ViewCacheExtension的getViewForPositionAndType(RecyclerView.Recycler, int, int)方法,再检查RecycledViewPool对象。
* ...
*/
public abstract static class ViewCacheExtension {
...
} public final class Recycler {
...
/**
* Attempts to get the ViewHolder for the given position, either from the Recycler scrap,
* cache, the RecycledViewPool, or creating it directly.
*
* 尝试通过从Recycler scrap缓存、RecycledViewPool查找或直接创建的形式来获取指定位置的ViewHolder。
* ...
*/
@Nullable
ViewHolder tryGetViewHolderForPositionByDeadline(int position,
boolean dryRun, long deadlineNs) {
if (mState.isPreLayout()) {
// 0 尝试从mChangedScrap中获取ViewHolder对象
holder = getChangedScrapViewForPosition(position);
...
}
if (holder == null) {
// 1.1 尝试根据position从mAttachedScrap或mCachedViews中获取ViewHolder对象
holder = getScrapOrHiddenOrCachedHolderForPosition(position, dryRun);
...
}
if (holder == null) {
...
final int type = mAdapter.getItemViewType(offsetPosition);
if (mAdapter.hasStableIds()) {
// 1.2 尝试根据id从mAttachedScrap或mCachedViews中获取ViewHolder对象
holder = getScrapOrCachedViewForId(mAdapter.getItemId(offsetPosition),
type, dryRun);
...
}
if (holder == null && mViewCacheExtension != null) {
// 2 尝试从mViewCacheExtension中获取ViewHolder对象
final View view = mViewCacheExtension
.getViewForPositionAndType(this, position, type);
if (view != null) {
holder = getChildViewHolder(view);
...
}
}
if (holder == null) { // fallback to pool
// 3 尝试从mRecycledViewPool中获取ViewHolder对象
holder = getRecycledViewPool().getRecycledView(type);
...
}
if (holder == null) {
// 4.1 回调createViewHolder方法创建ViewHolder对象及其关联的视图
holder = mAdapter.createViewHolder(RecyclerView.this, type);
...
}
}
if (mState.isPreLayout() && holder.isBound()) {
...
} else if (!holder.isBound() || holder.needsUpdate() || holder.isInvalid()) {
...
// 4.1 回调bindViewHolder方法提取数据填充ViewHolder的视图内容
bound = tryBindViewHolderByDeadline(holder, offsetPosition, position, deadlineNs);
}
...
return holder;
}
...
} 结合RecyclerView类中的源码及注释可知,Recycler会依次从mChangedScrap/mAttachedScrap、mCachedViews、mViewCacheExtension、mRecyclerPool中尝试获取指定位置或ID的ViewHolder对象以供重用,如果全都获取不到则直接重新创建。这其中涉及的几层缓存结构分别是:
mChangedScrap/mAttachedScrap
mChangedScrap/mAttachedScrap主要用于临时存放仍在当前屏幕可见、但被标记为「移除」或「重用」的列表项,其均以ArrayList的形式持有着每个列表项的ViewHolder对象,大小无明确限制,但一般来讲,其最大数就是屏幕内总的可见列表项数。
final ArrayList<ViewHolder> mAttachedScrap = new ArrayList<>();
ArrayList<ViewHolder> mChangedScrap = null;
复制代码但问题来了,既然是当前屏幕可见的列表项,为什么还需要缓存呢?又是什么时候列表项会被标记为「移除」或「重用」的呢?
这2个缓存结构实际上更多是为了避免出现像局部刷新这一类的操作,导致所有的列表项都需要重绘的情形。
区别在于,mChangedScrap主要的使用场景是:
- 开启了列表项动画(itemAnimator),并且列表项动画的
canReuseUpdatedViewHolder(ViewHolder viewHolder)方法返回false的前提下; - 调用了notifyItemChanged、notifyItemRangeChanged这一类方法,通知列表项数据发生变化;
boolean canReuseUpdatedViewHolder(ViewHolder viewHolder) {
return mItemAnimator == null || mItemAnimator.canReuseUpdatedViewHolder(viewHolder,
viewHolder.getUnmodifiedPayloads());
}
public boolean canReuseUpdatedViewHolder(@NonNull ViewHolder viewHolder,
@NonNull List<Object> payloads) {
return canReuseUpdatedViewHolder(viewHolder);
}
public boolean canReuseUpdatedViewHolder(@NonNull ViewHolder viewHolder) {
return true;
}canReuseUpdatedViewHolder方法的返回值表示的不同含义如下:
- true,表示可以重用原先的ViewHolder对象
- false,表示应该创建该ViewHolder的副本,以便itemAnimator利用两者来实现动画效果(例如交叉淡入淡出效果)。
简单讲就是,mChangedScrap主要是为列表项数据发生变化时的动画效果服务的。
而mAttachedScrap应对的则是剩下的绝大部分场景,比如:
- 像notifyItemMoved、notifyItemRemoved这种列表项发生移动,但列表项数据本身没有发生变化的场景。
- 关闭了列表项动画,或者列表项动画的canReuseUpdatedViewHolder方法返回true,即允许重用原先的ViewHolder对象的场景。
下面以一个简单的notifyItemRemoved(int position)操作为例来演示:
notifyItemRemoved(int position)方法用于通知观察者,先前位于position的列表项已被移除, 其往后的列表项position都将往前移动1位。
为了简化问题、方便演示,我们的范例将会居于以下限制:
- 列表项总个数没有铺满整个屏幕——意味着不会触发mCachedViews、mRecyclerPool等结构的缓存操作
- 去除列表项动画——意味着调用notifyItemRemoved后RecyclerView只会重新布局子视图一次
recyclerView.itemAnimator = null理想情况下,调用notifyItemRemoved(int position)方法后,应只有位于position的列表项会被移除,其他的列表项,无论是位于position之前或之后,都最多只会调整position值,而不应发生视图的重新创建或数据的重新绑定,即不应该回调onCreateViewHolder与onBindViewHolder这2个方法。
为此,我们就需要将当前屏幕内的可见列表项暂时从当前屏幕剥离,临时缓存到mAttachedScrap这个结构中去。
等到RecyclerView重新开始布局显示其子视图后,再遍历mAttachedScrap找到对应position的ViewHolder对象进行复用。
mCachedViews
mCachedViews主要用于存放已被移出屏幕、但有可能很快重新进入屏幕的列表项。其同样是以ArrayList的形式持有着每个列表项的ViewHolder对象,默认大小限制为2。
final ArrayList<ViewHolder> mCachedViews = new ArrayList<ViewHolder>();
int mViewCacheMax = DEFAULT_CACHE_SIZE;
static final int DEFAULT_CACHE_SIZE = 2;比如像朋友圈这种按更新时间的先后顺序展示的Feed流,我们经常会在快速滑动中确定是否有自己感兴趣的内容,当意识到刚才滑走的内容可能比较有趣时,我们往往就会将上一条内容重新滑回来查看。
这种场景下我们追求的自然是上一条内容展示的实时性与完整性,而不应让用户产生“才滑走那么一会儿又要重新加载”的抱怨,也即同样不应发生视图的重新创建或数据的重新绑定。
我们用几张流程示意图来演示这种情况:
同样为了简化问题、方便描述,我们的范例将会居于以下限制:
- 关闭预拉取——意味着之后向上滑动时,都不会再预拉取「待进入屏幕区域」的一个列表项放入mCachedView了
recyclerView.layoutManager?.isItemPrefetchEnabled = false- 只存在一种类型的列表项,即所有列表项的itemType相同,默认都为0。
我们将图中的列表项分成了3块区域,分别是被滑出屏幕之外的区域、屏幕内的可见区域、随着滑动手势待进入屏幕的区域。
- 当position=0的列表项随着向上滑动的手势被移出屏幕后,由于mCachedViews初始容量为0,因此可直接放入;
- 当position=1的列表项同样被移出屏幕后,由于未达到mCachedViews的默认容量大小限制,因此也可继续放入;
此时改为向下滑动,position=1的列表项重新进入屏幕,Recycler就会依次从mAttachedScrap、mCachedViews查找可重用于此位置的ViewHolder对象;
mAttachedScrap不是应对这种情况的,自然找不到。而mCachedViews会遍历自身持有的ViewHolder对象,对比ViewHolder对象的position值与待复用位置的position值是否一致,是的话就会将ViewHolder对象从mCachedViews中移除并返回;
此处拿到的ViewHolder对象即可直接复用,即符合前面所述的最优情况。
- 另外,随着position=1的列表项重新进入屏幕,position=7的列表项也会被移出屏幕,该位置的列表项同样会进入mCachedViews,即RecyclerView是双向缓存的。
mViewCacheExtension
mViewCacheExtension主要用于提供额外的、可由开发人员自由控制的缓存层级,属于非常规使用的情况,因此这里暂不展开讲。
mRecyclerPool
mRecyclerPool主要用于按不同的itemType分别存放超出mCachedViews限制的、被移出屏幕的列表项,其会先以SparseArray区分不同的itemType,然后每种itemType对应的值又以ArrayList的形式持有着每个列表项的ViewHolder对象,每种itemType的ArrayList大小限制默认为5。
public static class RecycledViewPool {
private static final int DEFAULT_MAX_SCRAP = 5;
static class ScrapData {
final ArrayList<ViewHolder> mScrapHeap = new ArrayList<>();
int mMaxScrap = DEFAULT_MAX_SCRAP;
long mCreateRunningAverageNs = 0;
long mBindRunningAverageNs = 0;
}
SparseArray<ScrapData> mScrap = new SparseArray<>();
...
}由于mCachedViews默认的大小限制仅为2,因此,当滑出屏幕的列表项超过2个后,就会按照先进先出的顺序,依次将ViewHolder对象从mCachedViews移出,并按itemType放入RecycledViewPool中的不同ArrayList。
这种缓存结构主要考虑的是随着被滑出屏幕列表项的增多,以及被滑出距离的越来越远,重新进入屏幕内的可能性也随之降低。于是Recycler就在时间与空间上做了一个权衡,允许相同itemType的ViewHolder被提取复用,只需要重新绑定数据即可。
这样一来,既可以避免无限增长的ViewHolder对象缓存挤占了原本就紧张的内存空间,又可以减少回调相比较之下执行代价更加昂贵的onCreateViewHolder方法。
同样我们用几张流程示意图来演示这种情况,这些示意图将在前面的mCachedViews示意图基础上继续操作:
假设目前存在于mCachedViews中的仍是position=0及position=1这两个列表项。
当我们继续向上滑动时,position=2的列表项会尝试进入mCachedViews,由于超出了mCachedViews的容量限制,position=0的列表项会从mCachedViews中被移出,并放入RecycledViewPool中itemType为0的ArrayList,即图中的情况①;
同时,底部的一个新的列表项也将随着滑动手势进入到屏幕内,但由于此时mAttachedScrap、mCachedViews、mRecyclerPool均没有合适的ViewHolder对象可以提供给其复用,因此该列表项只能执行onCreateViewHolder与onBindViewHolder这2个方法的回调,即图中的情况②;
- 等到position=2的列表项被完全移出了屏幕后,也就顺利进入了mCachedViews中。
我们继续保持向上滑动的手势,此时,由于下一个待进入屏幕的列表项与position=0的列表项的itemType相同,因此我们可以在走到从mRecyclerPool查找合适的ViewHolder对象这一步时,根据itemType找到对应的ArrayList,再取出其中的1个ViewHolder对象进行复用,即图中的情况①。
由于itemType类型一致,其关联的视图可以复用,因此只需要重新绑定数据即可,即符合前面所述的次优情况。
- ②③ 情况与前面的一致,此处不再赘余。
最后总结一下,
| RecyclerView缓存复用机制 | |
|---|---|
| 对象 | ViewHolder(包含列表项视图(itemView)的封装容器) |
| 目的 | 减少对onCreateViewHolder、onBindViewHolder这2个方法的回调 |
| 好处 | 1.避免重复创建不必要的视图 2.避免重复执行昂贵的findViewById |
| 效果 | 改善性能、提升应用响应能力、降低功耗 |
| 核心类 | Recycler、RecyclerViewPool |
| 缓存结构 | mChangedScrap/mAttachedScrap、mCachedViews、mViewCacheExtension、mRecyclerPool |
| 缓存结构 | 容器类型 | 容量限制 | 缓存用途 | 优先级顺序(数值越小,优先级越高) |
|---|---|---|---|---|
| mChangedScrap/mAttachedScrap | ArrayList | 无,一般为屏幕内总的可见列表项数 | 临时存放仍在当前屏幕可见、但被标记为「移除」或「重用」的列表项 | 0 |
| mCachedViews | ArrayList | 默认为2 | 存放已被移出屏幕、但有可能很快重新进入屏幕的列表项 | 1 |
| mViewCacheExtension | 开发者自己定义 | 无 | 提供额外的可由开发人员自由控制的缓存层级 | 2 |
| mRecyclerPool | SparseArray<ArrayList> | 每种itemType默认为5 | 按不同的itemType分别存放超出mCachedViews限制的、被移出屏幕的列表项 | 3 |
以上的就是RecyclerView缓存复用机制的核心内容了。
链接:https://juejin.cn/post/7173816645511544840
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Gradle 依赖切换源码的实践
最近,因为开发的时候经改动依赖的库,所以,我想对 Gradle 脚本做一个调整,用来动态地将依赖替换为源码。这里以 android-mvvm-and-architecture 这个工程为例。该工程以依赖的形式引用了我的另一个工程 AndroidUtils。在之前,当我需要对 AndroidUtils 这个工程源码进行调整时,一般来说有两种解决办法。
1、一般的修改办法
一种方式是,直接修改 AndroidUtils 这个项目的源码,然后将其发布到 MavenCentral. 等它在 MavenCentral 中生效之后,再将项目中的依赖替换为最新的依赖。这种方式可行,但是修改的周期太长。
另外一种方式是,修改 Gradle 脚本,手动地将依赖替换为源码依赖。此时,需要做几处修改,
修改 1,在 settings.gradle 里面将源码作为子工程添加到项目中,
include ':utils-core', ':utils-ktx'
project(':utils-core').projectDir = new File('../AndroidUtils/utils')
project(':utils-ktx').projectDir = new File('../AndroidUtils/utils-ktx')
修改 2,将依赖替换为工程引用,
// implementation "com.github.Shouheng88:utils-core:$androidUtilsVersion"
// implementation "com.github.Shouheng88:utils-ktx:$androidUtilsVersion"
// 上面的依赖替换为下面的工程引用
implementation project(":utils-core")
implementation project(":utils-ktx")这种方式亦可行,只不过过于繁琐,需要手动修改 Gradle 的构建脚本。
2、通过 Gradle 脚本动态修改依赖
其实 Gradle 是支持动态修改项目中的依赖的。动态修改依赖在上述场景,特别是组件化的场景中非常有效。这里我参考了公司组件化的切换源码的实现方式,用了 90 行左右的代码就实现了上述需求。
2.1 配置文件和工作流程抽象
这种实现方式里比较重要的一环是对切换源码工作机制的抽象。这里我重新定义了一个 json 配置文件,
[
{
"name": "AndroidUtils",
"url": "git@github.com:Shouheng88/AndroidUtils.git",
"branch": "feature-2.8.0",
"group": "com.github.Shouheng88",
"open": true,
"children": [
{
"name": "utils-core",
"path": "AndroidUtils/utils"
},
{
"name": "utils-ktx",
"path": "AndroidUtils/utils-ktx"
}
]
}
]它内部的参数的含义分别是,
name:工程的名称,对应于 Github 的项目名,用于寻找克隆到本地的代码源码url:远程仓库的地址branch:要启用的远程仓库的分支,这里我强制自动切换分支时的本地分支和远程分支同名group:依赖的 group idopen:表示是否启用源码依赖children.name:表示子工程的 module 名称,对应于依赖中的artifact idchildren.path:表示子工程对应的相对目录
也就是说,
- 一个工程下的多个子工程的
group id必须相同 children.name必须和依赖的artifact id相同
上述配置文件的工作流程是,
def sourceSwitches = new HashMap<String, SourceSwitch>()
// Load sources configurations.
parseSourcesConfiguration(sourceSwitches)
// Checkout remote sources.
checkoutRemoteSources(sourceSwitches)
// Replace dependencies with sources.
replaceDependenciesWithSources(sourceSwitches)
- 首先,Gradle 在 setting 阶段解析上述配置文件
- 然后,根据解析的结果,将打开源码的工程通过 project 的形式引用到项目中
- 最后,根据上述配置文件,将项目中的依赖替换为工程引用
2.2 为项目动态添加子工程
如上所述,这里我们忽略掉 json 配置文件解析的环节,直接看拉取最新分支并将其作为子项目添加到项目中的逻辑。该部分代码实现如下,
/** Checkout remote sources if necessary. */
def checkoutRemoteSources(sourceSwitches) {
def settings = getSettings()
def rootAbsolutePath = settings.rootDir.absolutePath
def sourcesRootPath = new File(rootAbsolutePath).parent
def sourcesDirectory = new File(sourcesRootPath, "open_sources")
if (!sourcesDirectory.exists()) sourcesDirectory.mkdirs()
sourceSwitches.forEach { name, sourceSwitch ->
if (sourceSwitch.open) {
def sourceDirectory = new File(sourcesDirectory, name)
if (!sourceDirectory.exists()) {
logd("clone start [$name] branch [${sourceSwitch.branch}]")
"git clone -b ${sourceSwitch.branch} ${sourceSwitch.url} ".execute(null, sourcesDirectory).waitFor()
logd("clone completed [$name] branch [${sourceSwitch.branch}]")
} else {
def sb = new StringBuffer()
"git rev-parse --abbrev-ref HEAD ".execute(null, sourceDirectory).waitForProcessOutput(sb, System.err)
def currentBranch = sb.toString().trim()
if (currentBranch != sourceSwitch.branch) {
logd("checkout start current branch [${currentBranch}], checkout branch [${sourceSwitch.branch}]")
def out = new StringBuffer()
"git pull".execute(null, sourceDirectory).waitFor()
"git checkout -b ${sourceSwitch.branch} origin/${sourceSwitch.branch}"
.execute(null, sourceDirectory).waitForProcessOutput(out, System.err)
logd("checkout completed: ${out.toString().trim()}")
}
}
// After checkout sources, include them as subprojects.
sourceSwitch.children.each { child ->
settings.include(":${child.name}")
settings.project(":${child.name}").projectDir = new File(sourcesDirectory, child.path)
}
}
}
}这里,我将子项目的源码克隆到 settings.gradle 文件的父目录下的 open_sources 目录下面。这里当该目录不存在的时候,我会先创建该目录。这里需要注意的是,我在组织项目目录的时候比较喜欢将项目的子工程放到和主工程一样的位置。所以,上述克隆方式可以保证克隆到的 open_sources 仍然在当前项目的工作目录下。
然后,我对 sourceSwitches,也就是解析的 json 文件数据,进行遍历。这里会先判断指定的源码是否已经拉下来,如果存在的话就执行 checkout 操作,否则执行 clone 操作。这里在判断当前分支是否为目标分支的时候使用了 git rev-parse --abbrev-ref HEAD 这个 Git 指令。该指令用来获取当前仓库所处的分支。
最后,将源码拉下来之后通过 Settings 的 include() 方法加载指定的子工程,并使用 Settings 的 project() 方法指定该子工程的目录。这和我们在 settings.gradle 文件中添加子工程的方式是相同的,
include ':utils-core', ':utils-ktx'
project(':utils-core').projectDir = new File('../AndroidUtils/utils')
project(':utils-ktx').projectDir = new File('../AndroidUtils/utils-ktx')
2.3 使用子工程替换依赖
动态替换工程依赖使用的是 Gradle 的 ResolutionStrategy 这个功能。也许你对诸如
configurations.all {
resolutionStrategy.force 'io.reactivex.rxjava2:rxjava:2.1.6'
}这种写法并不陌生。这里的 force 和 dependencySubstitution 一样,都属于 ResolutionStrategy 提供的功能的一部分。只不过这里的区别是,我们需要对所有的子项目进行动态更改,因此需要等项目 loaded 完成之后才能执行。
下面是依赖替换的实现逻辑,
/** Replace dependencies with sources. */
def replaceDependenciesWithSources(sourceSwitches) {
def gradle = settings.gradle
gradle.projectsLoaded {
gradle.rootProject.subprojects {
configurations.all {
resolutionStrategy.dependencySubstitution {
sourceSwitches.forEach { name, sourceSwitch ->
sourceSwitch.children.each { child ->
substitute module("${sourceSwitch.artifact}:${child.name}") with project(":${child.name}")
}
}
}
}
}
}
}这里使用 Gradle 的 projectsLoaded 这个点进行 hook,将依赖替换为子工程。
此外,也可以将子工程替换为依赖,比如,
dependencySubstitution {
substitute module('org.gradle:api') using project(':api')
substitute project(':util') using module('org.gradle:util:3.0')
}2.4 注意事项
上述实现方式要求多个子工程的脚本尽可能一致。比如,在 AndroidUtils 的独立工程中,我通过 kotlin_version 这个变量指定 kotlin 的版本,但是在 android-mvvm-and-architecture 这个工程中使用的是 kotlinVersion. 所以,当切换了子工程的源码之后就会发现 kotlin_version 这个变量找不到了。因此,为了实现可以动态切换源码,是需要对 Gradle 脚本做一些调整的。
在我的实现方式中,我并没有将子工程的源码放到主工程的根目录下面,也就是将 open_sources 这个目录放到 appshell 这个目录下面。而是放到和 appshell 同一级别。
这样做的原因是,实际开发过程中,通常我们会克隆很多仓库到 open_sources 这个目录下面(或者之前开发遗留下来的克隆仓库)。有些仓库虽然我们关闭了源码依赖,但是因为在 appshell 目录下面,依然会出现在 Android Studio 的工程目录里。而按照上述方式组织目录,我切换了哪个项目等源码,哪个项目的目录会被 Android Studio 加载。其他的因为不在 appshell 目录下面,所以会被 Android Studio 忽略。这种组织方式可以尽可能减少 Android Studio 加载的文本,提升 Android Studio 响应的速率。
总结
上述是开发过程中替换依赖为源码的“无痕”修改方式。不论在组件化还是非组件化需要开发中都是一种非常实用的开发技巧。按照上述开发开发方式,我们可以既能开发 android-mvvm-and-architecture 的时候随时随地打开 AndroidUtils 进行修改,亦可对 AndroidUtil 这个工程独立编译和开发。
源代码参考 android-mvvm-and-architecture 项目(当前是 feature-3.0 分支)的 AppShell 下面的 sources.gradle 文件。
链接:https://juejin.cn/post/7174753036143689787
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
BasicLibrary架构设计旅程(一)—Android必备技能
前言
- 2022年对大部分人来说真的是不容易的一年,有不少粉丝私信问我,今年行情不好,但是现在公司又不好怎么办,我的建议就是学习。无论过去,现在,未来,投资自己一定是不会错的,只有当你足够强大,哪怕生活一地鸡毛,你也能垫起脚尖独揽星空。
- 对于Android来说,我觉得有两个能力和一个态度一定要掌握
- 阅读源码的能力
- 阅读字节码的能力
- 怀疑的态度
阅读源码的能力
- 个人技巧:我个人阅读源码喜欢自己给自己提问题,随后带着问题去读源码的流程,当遇到不确定的可以看看别的大神写的博客和视频。
为什么需要具有阅读源码的能力呢?
当我们通过百度搜索视频,博客,stackOverflow找不到我们问题解决办法的时候,可以通过阅读源码来寻找问题,并解决问题,如以下两个案例
一、AppBarLayout阴影问题
- 源码地址:github.com/Peakmain/Ba…
- 我们每次在项目添加头部的时候,一般做法都是说定义一个公用的布局,但是这其实并不友好,而且每次都需要findVIewById,为了解决上述问题,我用了Builder设计模式设计了NavigationBar,可以动态添加头部
- 其中有个默认的头部设计DefaultNavigationBar,使用的是AppBarLayout+ToolBar,AppBarLayout有个问题就是会存在阴影,我想要在不改变布局的情况下,动态设置取消阴影,在百度中得到的前篇一律的答案是,设置主题,布局中设置阴影
- 既然说布局中设置elevation有效,那么是否可以通过findViewById找到AppBarLayout然后设置elevation=0
findViewById<AppBarLayout>(R.id.navigation_header_container).elevation=0f
运行之后,发现阴影还仍然存在
- 既然布局中设置elevation有效,那它的源码怎么写的呢?
我们可以在AppBarLayout的构造函数中找到这行代码
我们可以发现最终调用的是一个非公平类的静态方法,直接将方法拷贝到我们自己的项目,之后调用该方法
static void setDefaultAppBarLayoutStateListAnimator(
@NonNull final View view, final float elevation) {
final int dur = view.getResources().getInteger(R.integer.app_bar_elevation_anim_duration);
final StateListAnimator sla = new StateListAnimator();
// Enabled and liftable, but not lifted means not elevated
sla.addState(
new int[] {android.R.attr.state_enabled, R.attr.state_liftable, -R.attr.state_lifted},
ObjectAnimator.ofFloat(view, "elevation", 0f).setDuration(dur));
// Default enabled state
sla.addState(
new int[] {android.R.attr.state_enabled},
ObjectAnimator.ofFloat(view, "elevation", elevation).setDuration(dur));
// Disabled state
sla.addState(new int[0], ObjectAnimator.ofFloat(view, "elevation", 0).setDuration(0));
view.setStateListAnimator(sla);
}
二、Glide加载图片读取设备型号问题
- 再比如App加载网络图片时候,App移动应用检测的时候说我们应用自身获取个人信息行为,描述说的是我们有图片上传行为,看了堆栈,主要问题是加载图片的时候,user-Agent有读取设备型号行为
- 关于这篇文章的源码分析,大家可以看我之前的文章:隐私政策整改之Glide框架封装
- glide加载图片默认用的是HttpUrlConnection
- 加载网络图片的时候,默认是在GlideUrl中设置了Headers.DEFAULT,它的内部会在static中添加默认的User-Agent。
小总结
- 优秀的阅读源码能力可以帮我们快速定位并解决问题。
- 优秀的阅读源码能力也可以让我们快速上手任何一个热门框架并了解其原理
阅读字节码的能力的重要性
当我们熟练掌握字节码能力,我们能够深入了解JVM,通过ASM实现一套埋点+拦截第三方频繁调用隐私方法的问题
字节码基础知识
- 由于跨平台性的设计,java的指令都是根据栈来设计的,而这个栈指的就是虚拟机栈
- JVM运行时数据区分为本地方法栈、程序计数器、堆、方法区和虚拟机栈
局部变量表
- 每个线程都会创建一个虚拟机栈,其内部保存一个个栈帧,对应一次次方法的调用
- 栈帧的内部结构是分为:局部变量表、操作数栈、动态链接(指向运行时常量池的方法引用)和返回地址
- 局部变量表内部定义了一个数字数组,主要存储方法参数和定义在方法体内的局部变量
- 局部变量表存储的基本单位是slot(槽),long和double存储的是2个槽,其他都是1个槽
- 非静态方法,默认0槽位存的是this(指的是该方法的类对象)
操作数栈
- 在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈和出栈
- 主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间
- 方法调用的开始,默认的操作数栈是空的,但是操作数栈的数组已经创建,并且大小已知
- 操作数栈并非采用访问索引的方式来进行数据访问的,而是只能通过标准的入栈和出栈操作来完成一次数据访问
一些常用的助记符
- 从局部变量表到操作数栈:iload,iload_,lload,lload_,fload,fload_,dload,dload_,aload,aload
- 操作数栈放到局部变量表:istore,istore_,lstore,lstore_,fstore,fstore_,dstore,dstor_,astore,astore_
- 把常数放到到操作数栈:bipush,sipush,ldc,ldc_w,ldc2_w,aconst_null,iconst_ml,iconst_,lconst_,fconst_,dconst_
- 取出栈顶两个数进行相加,并将结果压入操作数栈:iadd,ladd,fadd,dadd
- iinc:对局部变量表的值进行加1操作
i++和++i区别
public class Test {
public static void main(String[] args) {
int i=10;
int a=i++;
int j=10;
int b=++j;
System.out.println(i);
System.out.println(a);
System.out.println(j);
System.out.println(b);
}
}- 大家可以思考下,这个结果会是什么呢?
- 结果分别是11 10 11 11
字节码结果分析
- 查看字节码命令:javap -v Test.class
- 大家也可以使用idea自带的jclasslib工具,或者ASM Bytecode Viewer工具
0 bipush 10
2 istore_1
3 iload_1
4 iinc 1 by 1
7 istore_2
8 bipush 10
10 istore_3
11 iinc 3 by 1
14 iload_3
15 istore 4
17 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
20 iload_1
21 invokevirtual #3 <java/io/PrintStream.println : (I)V>
24 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
27 iload_2
28 invokevirtual #3 <java/io/PrintStream.println : (I)V>
31 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
34 iload_3
35 invokevirtual #3 <java/io/PrintStream.println : (I)V>
38 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
41 iload 4
43 invokevirtual #3 <java/io/PrintStream.println : (I)V>
46 return- 由于我们是非静态方法,所以局部变量表0的位置存储的是this
- bipush 10:将常量10压入操作数栈
- istore1:将操作数栈的栈顶元素放入到局部变量表1的位置
- iload1:将局部变量表1的位置放入到操作数栈
- iinc 1 by 1:局部变量表1的位置的值+1
- istore2:将操作栈的栈顶元素压入局部变量表2的位置
- 至此最上面两行代码执行完毕,下面的代码我就不再画图阐述了,我相信机智聪敏的你一定已经学会分析了
- 最后来一个小小的总结吧
- i++是先iload1,后局部变量表自增,再istore2,所以a的值还是10
- ++i是先局部变量表自增,随后iload,再istore,所以b的值已经变成了11
ASM 解决隐私方法问题
- 项目地址:github.com/Peakmain/As…
- 大家可以去看下我的源码和文章,具体细节我就不阐述了,里面涉及到了大量的opcodec的操作符,比如Opcode.ILOAD
怀疑的态度
- 无论是视频还是博客,大家对不确认的知识保持一颗怀疑的态度,因为一篇文章或者视频都有可能是不对的,包括我现在写的这篇文章。
kotlin object实现的单例类是懒汉式还是饿汉式
- 以上两个都是网上的文章截取的文章,那kotlin实现的object单例到底是饿汉式还是懒汉式的呢?
- 假设我们有以下代码
object Test {
const val TAG="test"
}通过工具看下反编译后的代码
static代码块什么时候初始化呢?
- 首先我们需要知道JVM的类加载过程:loading->link->初始化
- link又分为:验证、准备、解析
- 而static代码块()是在初始化的过程中调用的
- 虚拟机会必须保证一个类的方法在多线程下被同步加锁
- Java使用方式分为两种:主动和被动
- 主动使用才会导致static代码块的调用
单例的懒汉式和饿汉式的区别是什么呢
- 懒汉式:类加载不会导致该实例被创建,而是首次使用该对象才会被创建
- 饿汉式:类加载就会导致该实例对象被创建
public class Test {
private static Test mInstance;
static {
System.out.println("static:"+mInstance);
}
private Test() {
System.out.println("init:"+mInstance);
}
public static Test getInstance() {
if (mInstance == null) {
mInstance = new Test();
}
return mInstance;
}
public static void main(String[] args) {
Test.getInstance();
}
}- 当调用getInstance的时候,类加载过程中会进行初始化,也就是调用static代码块
- static代码块执行时,由于类没有实例化,所以获取到是null。
- 也就是说,类加载的时候并没有对该实例进行创建(懒汉式)
public class Test1 {
private static final Test1 mInstance=new Test1();
private Test1(){
System.out.println("init:"+mInstance);
}
static {
System.out.println("static:"+mInstance);
}
public static Test1 getInstance(){
return mInstance;
}
public static void main(String[] args) {
Test1.getInstance();
}
}- 类的初始化顺序是由代码的顺序来决定的,上面的代码首先对mInstance进行初始化,但是由于此时构造函数执行完成后才完成类的初始化,所以构造函数返回的是null
- static代码块执行的时候,类实例已经创建完毕
- 正如上面说的static代码块执行的时候还处于类加载中的初始化状态,所以实例是在初始化之前完成(饿汉式)
我们现在回到kotlin的object,我们将其转成Java类
public class Test2 {
public static final String TAG = "test";
private Test2() {
System.out.println("init:" + mInstance);
}
public static Test2 mInstance;
static {
Test2 test2 = new Test2();
mInstance = test2;
System.out.println("static:" + mInstance);
}
public static void main(String[] args) {
System.out.println(Test2.TAG);
}
}- 上面代码在static代码块的时候(类加载的初始化时)进行了类的实例初始化(饿汉式)
总结
- Android必备的技能,其实很多,比如JVM、高并发、binder、泛型、AMS,WMS等等
- 我个人觉得源阅读码能力和掌握字节码属于必备技能,能提高自己知识领域
- 当然如我上面所说,要保持怀疑的态度,本文说的可能也不对。
- 下一篇文章,我将介绍BasicLibrary中基于责任链设计模式搭建的Activity Results API权限封装框架,欢迎大家讨论。
链接:https://juejin.cn/post/7173266221444366372
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
居家办公竟被读取脑电波?老板们为远程监控想出奇招
朋友居家办公期间,他们老板为了远程监控工作,要求大家必须装上专门的软件和摄像头。
我还记得,Ta花了一个晚上来安装这些东西……
但万万没想到,为了关怀员工监督工作,老板们的奇招简直一山更比一山高:
连读取脑电波都想出来了。
就算你居家办公,老板甚至还能观测到你的心情。
而要实现这个神操作,只需要一个耳机就够了。

不同于普通耳机,这种耳机上还有几个专门读取人脑电波的电极。
戴上它后,既不用动手也不用说话,AI就能快速读心,帮你操控电脑。

好家伙,老板们竟然如此紧跟潮流,都把当下正红火的脑机接口搬进办公室了。
这种“读心耳机”的背后的开发者宣称:“戴上它,不仅能提高工作效率,还可以让员工更快乐。”

据IEEE Spectrum报道,关于这项新技术,有2家公司最为突出:
一个是来自以色列的InnerEye,另一个是硅谷神经技术公司Emotiv,不少老板都投资了他们。
那么,他们的耳机到底靠谱吗?
读取员工脑电波,AI快速做决策
先来看看InnerEye的头戴式耳机,它共有7个通道来读取人的脑电图。
他们的技术人员开发了一个专门的InnerEye软件,来接收、分析大脑信号,并和商业脑电扫描系统搭配使用。
AI可以整合人眼球活动信号、脑电波,以及电脑屏幕信息,快速做出决策。
举个栗子~
机场的安检员需要盯着X光扫描图流,判断行李中是否有违禁物品。
戴上InnerEye的耳机后,安检员每秒能处理3到10张图像,比纯用肉眼+手动记录快了一个量级。
至于原因嘛,一是安检员不用再敲键盘了,直接“意念控制”计算机就行;二是在人还没全完想清楚时,AI可能已经找出了违禁物品。
“这个系统的判断结果,和人类手动操作时一样准确”,InnerEye的研发副总裁Vaisman如是说道。
另外,当佩戴者闭眼或者注意力不集中时,AI还可以检测出来,并且再次显示错过的图像。
有意思的是,人类带着这个耳机处理任务时,AI还在继续根据人的大脑活动不断深度学习。
不过在这个过程中,人类虽然不一定要主动决策,但还得是懂行的(比如这里是职业安检员),并且要保持专注。
而比起InnerEye,Emotiv的耳机更加小巧。
它的外观看起来很像蓝牙运动耳机,甚至连贴头皮的电极都无影无踪了。
不过玄机正藏在左右两个耳塞里,这里面有电极,用来读取脑电波。

Emotiv公司研发了一个叫MN8的系统,也和商业脑电扫描系统搭配使用。
通过这些系统,佩戴者可以看到他们个人的注意力集中程度以及压力水平。
实际上,脑电图技术早在1912年就被科学家发明出来了,随后很快在医学领域被普及。
但过去扫描脑电图时,需要用一种叫导电膏的东西来固定电极,并保证生物信号能够稳定准确地传输。
而且为了提升空间分辨率,电极或“通道”往往越多越好,有时一个脑电帽甚至有200多个电极。

△脑电帽示意图
而现在,已经有了不需导电膏的“干式”电极,再加上AI也发展迅猛,于是出现了众多轻便的新式脑机接口设备,包括头戴式耳机。
既然操作简化、成本大幅下降,不难猜到,下一个动作应该就是商用普及了。
神经伦理专家表示担忧
虽然这种耳机的开发者很看好它的前景,甚至还说员工戴上之后可以更快乐。
但不少神经学伦理专家和学者却表示,并没看出哪里让人快乐了,而是感到害怕好吗…
比如,埃默里大学神经学和精神病学系的副教授Karen Rommelfanger说:
我认为老板对使用这种技术有很大的兴趣,但不知道雇员是否也有兴趣。
绝大多数研究脑机接口的公司,并没有为技术商用做好充分准备。
乔治敦大学的Mark Giordano教授也觉得,员工基本会对此产生抵触情绪,因为这涉嫌侵犯了他们的隐私和人权。
Giordano教授认为,这种技术对某些特定职业确实有些帮助,比如运输、建筑行业,可以用此检测工人的疲劳程度,保障他们的安全。
但对于办公室的白领而言,似乎没有明显的好处。
即便公司的初衷是提高员工福利,但可能很快就变味儿了。
如果员工的生产效率普遍提高,公司难免会跟着提高绩效标准,员工的压力反而变大了。(懂的都懂…)
但无论如何,专家们预测,就现在的发展趋势,这种读取脑电波的设备可能会很快普及。
所以,它们的诸多安全隐患,必须尽早解决。
背后的技术公司
话说回来,“读心耳机”背后的这两家公司,到底是什么来头?
其中,Emotiv成立于2011年,目前已经发布了三种型号的轻型脑电波扫描设备。
之前他们的产品主要是卖给神经科学研究人员;部分也会卖给一些开发者,这些人主要研究的是基于大脑控制的程序或游戏。
从今年起,Emotiv开始盯上了企业,他们发布了第四代MN8系统,并搞出了能读取脑电波的耳机。
Emotiv的CEO兼创始人Tan Le大胆猜测,五年后这种大脑追踪设备会变得随处可见。
至于安全隐患,Le表示Emotiv已经意识到了这些趋势,他们会严格审查合作公司,来保护员工隐私:
只有员工自己才能看到个人的注意力和压力水平,领导们只能看到团队的匿名数据汇总。
Innereye则成立于2013年,他们的官网上赫然写着公司愿景:
把人类的智慧与人工智能结合起来。

那么,戴上能读脑电波的耳机,是否可以算把人类智慧和AI的能力结合起来?
如果未来老板让你戴上能读取脑电波的东西,你会接受吗?

参考链接:
[1]https://www.iflscience.com/employers-are-investing-in-tech-that-constantly-reads-employee-brainwaves-to-optimize-performance-66426
[2]https://spectrum.ieee.org/neurotech-workplace-innereye-emotiv
来源:Alex 发自 凹非寺
收起阅读 »10年老前端,开发的一款文档编辑器(年终总结)
2022年接近尾声,鸽了近一年,是时候补一下去年的年终总结了。
2021年对我来说是一个意义重大的一年。
这一年,我们团队开发出了一款基于canvas的类word文档编辑器,并因此产品获得了公司最高荣誉——产品创新奖。
当时感慨良多,早该总结一下的,终因自己的懒惰,拖到了现在。
直到这周五晚上,在我想着罗织什么借口推迟,以便于周末能放飞自我的时候,老天终于看不下去了,我被电话告知了核酸同管阳性……
产品介绍
懒惰是可耻的,发自内心的忏悔过后,我还是要稍稍骄傲的介绍下编辑器产品:
整个编辑器都是用canvas底层API绘制的,包括了它的光标,滚动条。
除了弹窗及右键菜单的UI组件外,所有的核心功能都是手搓TS,没有用任何的插件。
包括:核心,排版,光标管理,分页,文本编辑,图片,表格,列表,表单控件,撤销还原,页面设置,页眉页脚等的所有功能,都只源于canvas提供的这几个底层的API接口:
在直角坐标系下,从一点到另一点画一个矩形,或圆,或三角。
测绘字体宽高。
从某一点绘制一个指定样式的字。
接口简单,但是经过层层封装,配合健壮的架构和性能良好的算法,就实现了各种复杂的功能。
看一下几个特色功能:
丰富的排版形式:
复杂的表格拆分:
灵活的列表:
表单控件:
独有的字符对齐:
辅助输入
痕迹对比:
此外,我们开发了c++打印插件,可以灵活的定制各种打印功能。
基础的排版也不演示了,“,。》”等标点不能在行首,一些标点不能在行尾,文字基线等排版基础省略一百八十二个字,
性能也非常不错,三百页数据秒级加载。
提供全个功能的程序接口,借助模版功能,完成各种复杂的操作功能。
心路历程
开发
这么复杂的项目我们开发了多长时间呢?
答案是一年。事实是前年底立项,去年初开始开发,团队基本只有我一人(其实项目初期还有另一个老技术人员,技术也很强,很遗憾开始合作不到两周老技术员就离开这个项目了),一直到7月份团队进了4个强有力的新成员,又经过了半年的紧锣密鼓的开发,不出意外的就意外开发完了。
真实怀念那段忙碌的日子,仿佛一坐下一抬头就要吃午饭了,一坐一抬头又晚上了,晚上还要继续在小区里一圈圈散步考虑各种难点的实现技术方案。真是既充实又酣畅淋漓。
由衷的感谢每一位团队成员的辛苦付出,尽管除了我这个半混半就得老开发,其他还都是1年到4年开发经验的伪新兵蛋子,但是每个人都表现出了惊人的开发效率和潜力。
这让我深刻理解到,任何一个牛掰的项目,都是需要团队齐心协力完成的。现在这个战斗力超强的团队,也是我值得骄傲的底气。
上线,惨遭毒打
事实证明,打江山难,守江山更难,项目开发亦是如此,尤其是在项目刚刚面向用户使用阶段。
当我们还沉浸在获得成功的喜悦中时,因为糟糕的打印速度及打印清晰度问题被用户一顿骑脸输出,打印相关体验之前从未在我们的优化计划之内。而这是用户难以忍受的。
好在持续半个月驻现场加班加点,终于得到了一定的优化。后面我们也是自研c++打印插件,打印问题算是得到彻底解决。
之后仍然有大大小小的问题层出不穷,还好渐渐趋于稳定。
当然现在还是有一些小问题,这是属于这个产品成长的必经之路。
现在,该产品在成千上万用户手中得以稳定运行,偶尔博得称赞,既感到骄傲,又感觉所有辛苦与委屈不值一提。
未来
之前跟领导沟通过开源的问题,领导也有意向开源,佩服领导的远大格局及非凡气度。但现在还不太成熟,仍需从长计议。
随着编辑器功能的完善,一些难以解决的问题也浮出水面,例如对少数民族语言的支持。开源是一个好的方式,可以让大家一同来完善它。
感慨
勇气,是你最走向成功的首要前提。当我主动申请要做这个项目时,身边大部分人给我的忠告是不要做。不尝试一下,怎么知道能不能做好呢。不给自己设限,大胆尝试。
满足来源于专注。
小团队作战更有效率。
产品与技术不分家,既要精进技术,也要有产品思维。技术是产品的工具,产品是技术的目的。如何做出用户体验良好的产品,是高级研发的高级技能。
感悟很多,一时不知道说啥了,有时间单独再细聊聊。
碎碎念
不知道是幸运还是不幸,公司秃然安排研发在线版excel了,无缝衔接了属于是,身为高质量打工人,抖M属性值点满,没有困难创造困难也要上。
同时今年也发生了一件十分悲痛的事,好朋友的身体垮了。身体是革命的本钱。最后就总结三个重点:健康,健康,还是TMD健康。
作者:张三风
来源:juejin.cn/post/7172975010724708389
MyBatis-Plus联表查询的短板,终于有一款工具补齐了
mybatis-plus作为mybatis的增强工具,它的出现极大的简化了开发中的数据库操作,但是长久以来,它的联表查询能力一直被大家所诟病。一旦遇到left join或right join的左右连接,你还是得老老实实的打开xml文件,手写上一大段的sql语句。
直到前几天,偶然碰到了这么一款叫做mybatis-plus-join的工具(后面就简称mpj了),使用了一下,不得不说真香!彻底将我从xml地狱中解放了出来,终于可以以类似mybatis-plus中QueryWrapper的方式来进行联表查询了,话不多说,我们下面开始体验。
引入依赖
首先在项目中引入引入依赖坐标,因为mpj中依赖较高版本mybatis-plus中的一些api,所以项目建议直接使用高版本。
<dependency>
<groupId>com.github.yulichang</groupId>
<artifactId>mybatis-plus-join</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>引入相关依赖后,在springboot项目中,像往常一样正常配置数据源连接信息就可以了。
数据准备
因为要实现联表查询,所以我们先来建几张表进行测试。
订单表:
用户表,包含用户姓名:
商品表,包含商品名称和单价:
在订单表中,通过用户id和商品id与其他两张表进行关联。
修改Mapper
以往在使用myatis-plus的时候,我们的Mapper层接口都是直接继承的BaseMapper,使用mpj后需要对其进行修改,改为继承MPJBaseMapper接口。
@Mapper
public interface OrderMapper extends MPJBaseMapper<Order> {
}对其余两个表的Mapper接口也进行相同的改造。此外,我们的service也可以选择继承MPJBaseService,serviceImpl选择继承MPJBaseServiceImpl,这两者为非必须继承。
查询
Mapper接口改造完成后,我们把它注入到Service中,虽然说我们要完成3张表的联表查询,但是以Order作为主表的话,那么只注入这一个对应的OrderMapper就可以,非常简单。
@Service
@AllArgsConstructor
public class OrderServiceImpl implements OrderService {
private final OrderMapper orderMapper;
}MPJLambdaWrapper
接下来,我们体验一下再也不用写sql的联表查询:
public void getOrder() {
List<OrderDto> list = orderMapper.selectJoinList(OrderDto.class,
new MPJLambdaWrapper<Order>()
.selectAll(Order.class)
.select(Product::getUnitPrice)
.selectAs(User::getName,OrderDto::getUserName)
.selectAs(Product::getName,OrderDto::getProductName)
.leftJoin(User.class, User::getId, Order::getUserId)
.leftJoin(Product.class, Product::getId, Order::getProductId)
.eq(Order::getStatus,3));
list.forEach(System.out::println);
}不看代码,我们先调用接口来看一下执行结果:
可以看到,成功查询出了关联表中的信息,下面我们一点点介绍上面代码的语义。
首先,调用mapper的selectJoinList()方法,进行关联查询,返回多条结果。后面的第一个参数OrderDto.class代表接收返回查询结果的类,作用和我们之前在xml中写的resultType类似。
这个类可以直接继承实体,再添加上需要在关联查询中返回的列即可:
@Data
@ToString(callSuper = true)
@EqualsAndHashCode(callSuper = true)
public class OrderDto extends Order {
String userName;
String productName;
Double unitPrice;
}接下来的MPJLambdaWrapper就是构建查询条件的核心了,看一下我们在上面用到的几个方法:
selectAll():查询指定实体类的全部字段select():查询指定的字段,支持可变长参数同时查询多个字段,但是在同一个select中只能查询相同表的字段,所以如果查询多张表的字段需要分开写selectAs():字段别名查询,用于数据库字段与接收结果的dto中属性名称不一致时转换leftJoin():左连接,其中第一个参数是参与联表的表对应的实体类,第二个参数是这张表联表的ON字段,第三个参数是参与联表的ON的另一个实体类属性
除此之外,还可以正常调用mybatis-plus中的各种原生方法,文档中还提到,默认主表别名是t,其他的表别名以先后调用的顺序使用t1、t2、t3以此类推。
我们用插件读取日志转化为可读的sql语句,可以看到两条左连接条件都被正确地添加到了sql中:
MPJQueryWrapper
和mybatis-plus非常类似,除了LamdaWrapper外还提供了普通QueryWrapper的写法,改造上面的代码:
public void getOrderSimple() {
List<OrderDto> list = orderMapper.selectJoinList(OrderDto.class,
new MPJQueryWrapper<Order>()
.selectAll(Order.class)
.select("t2.unit_price","t2.name as product_name")
.select("t1.name as user_name")
.leftJoin("t_user t1 on t1.id = t.user_id")
.leftJoin("t_product t2 on t2.id = t.product_id")
.eq("t.status", "3")
);
list.forEach(System.out::println);
}运行结果与之前完全相同,需要注意的是,这样写时在引用表名时不要使用数据库中的原表名,主表默认使用t,其他表使用join语句中我们为它起的别名,如果使用原表名在运行中会出现报错。
并且,在MPJQueryWrapper中,可以更灵活的支持子查询操作,如果业务比较复杂,那么使用这种方式也是不错的选择。
分页查询
mpj中也能很好的支持列表查询中的分页功能,首先我们要在项目中加入分页拦截器:
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.H2));
return interceptor;
}接下来改造上面的代码,调用selectJoinPage()方法:
public void page() {
IPage<OrderDto> orderPage = orderMapper.selectJoinPage(
new Page<OrderDto>(2,10),
OrderDto.class,
new MPJLambdaWrapper<Order>()
.selectAll(Order.class)
.select(Product::getUnitPrice)
.selectAs(User::getName, OrderDto::getUserName)
.selectAs(Product::getName, OrderDto::getProductName)
.leftJoin(User.class, User::getId, Order::getUserId)
.leftJoin(Product.class, Product::getId, Order::getProductId)
.orderByAsc(Order::getId));
orderPage.getRecords().forEach(System.out::println);
}注意在这里需要添加一个分页参数的Page对象,我们再执行上面的代码,并对日志进行解析,查看sql语句:
可以看到底层通过添加limit进行了分页,同理,MPJQueryWrapper也可以这样进行分页。
最后
经过简单的测试,个人感觉mpj这款工具在联表查询方面还是比较实用的,能更应对项目中不是非常复杂的场景下的sql查询,大大提高我们的生产效率。当然,在项目的issues中也能看到当前版本中也仍然存在一些问题,希望在后续版本迭代中能继续完善。
作者:码农参上
来源:juejin.cn/post/7173493838143553549
都2202年了,不会有人还不会发布npm包吧
背景
恰逢最近准备写一个跨框架组件库(工作量很大,前端三个小伙伴利用空闲时间在卷,待组件库完善后会分享给大家,敬请期待),需要学习发布npm包,昨天就想着利用空闲时间把之前写的去除重复请求的axios封装发布为npm包,便于代码复用,回馈社区的同时也能学以致用。
阅读本文,你将收获:
从0开始创建并发布npm的全过程
一个持续迭代且简单实用的axios请求去重工具库
工具库准备
创建一个新项目,包含package.json
{
"name": "drrq",
"type": "module",
"version": "1.0.0"
}功能实现 /src/index.js
npm i qs axios
主要思路是用请求的url和参数作为key记录请求队列,当出现重复请求时,打断后面的请求,将前面的请求结果返回时共享给后面的请求。
import qs from "qs";
import axios from "axios";
let pending = []; //用于存储每个ajax请求的取消函数和ajax标识
let task = {}; //用于存储每个ajax请求的处理函数,通过请求结果调用,以ajax标识为key
//请求开始前推入pending
const pushPending = (item) => {
pending.push(item);
};
//请求完成后取消该请求,从列表删除
const removePending = (key) => {
for (let p in pending) {
if (pending[p].key === key) {
//当前请求在列表中存在时
pending[p].cancelToken(); //执行取消操作
pending.splice(p, 1); //把这条记录从列表中移除
}
}
};
//请求前判断是否已存在该请求
const existInPending = (key) => {
return pending.some((e) => e.key === key);
};
// 创建task
const createTask = (key, resolve) => {
let callback = (response) => {
resolve(response.data);
};
if (!task[key]) task[key] = [];
task[key].push(callback);
};
// 处理task
const handleTask = (key, response) => {
for (let i = 0; task[key] && i < task[key].length; i++) {
task[key][i](response);
}
task[key] = undefined;
};
const getHeaders = { 'Content-Type': 'application/json' };
const postHeaders = { 'Content-Type': 'application/x-www-form-urlencoded' };
const fileHeaders = { 'Content-Type': 'multipart/form-data' };
const request = (method, url, params, headers, preventRepeat = true, uploadFile = false) => {
let key = url + '?' + qs.stringify(params);
return new Promise((resolve, reject) => {
const instance = axios.create({
baseURL: url,
headers,
timeout: 30 * 1000,
});
instance.interceptors.request.use(
(config) => {
if (preventRepeat) {
config.cancelToken = new axios.CancelToken((cancelToken) => {
// 判断是否存在请求中的当前请求 如果有取消当前请求
if (existInPending(key)) {
cancelToken();
} else {
pushPending({ key, cancelToken });
}
});
}
return config;
},
(err) => {
return Promise.reject(err);
}
);
instance.interceptors.response.use(
(response) => {
if (preventRepeat) {
removePending(key);
}
return response;
},
(error) => {
return Promise.reject(error);
}
);
// 请求执行前加入task
createTask(key, resolve);
instance(Object.assign({}, { method }, method === 'post' || method === 'put' ? { data: !uploadFile ? qs.stringify(params) : params } : { params }))
.then((response) => {
// 处理task
handleTask(key, response);
})
.catch(() => {});
});
};
export const get = (url, data = {}, preventRepeat = true) => {
return request('get', url, data, getHeaders, preventRepeat, false);
};
export const post = (url, data = {}, preventRepeat = true) => {
return request('post', url, data, postHeaders, preventRepeat, false);
};
export const file = (url, data = {}, preventRepeat = true) => {
return request('post', url, data, fileHeaders, preventRepeat, true);
};
export default { request, get, post, file };新增示例代码文件夹/example
示例入口index.js
import { exampleRequestGet } from './api.js';
const example = async () => {
let res = await exampleRequestGet();
console.log('请求成功 ');
};
example();api列表api.js
import { request } from './request.js';
// 示例请求Get
export const exampleRequestGet = (data) => request('get', '/xxxx', data);
// 示例请求Post
export const exampleRequestPost = (data) => request('post', '/xxxx', data);
// 示例请求Post 不去重
export const exampleRequestPost2 = (data) => request('post', '/xxxx', data, false);
// 示例请求Post 不去重
export const exampleRequestFile = (data) => request('file', '/xxxx', data, false);全局请求封装request.js
import drrq from '../src/index.js';
const baseURL = 'https://xxx';
// 处理请求数据 (拼接url,data添加token等) 请根据实际情况调整
const paramsHandler = (url, data) => {
url = baseURL + url;
data.token = 'xxxx';
return { url, data };
};
// 处理全局接口返回的全局处理相关逻辑 请根据实际情况调整
const resHandler = (res) => {
// TODO 未授权跳转登录,状态码异常报错等
return res;
};
export const request = async (method, _url, _data = {}, preventRepeat = true) => {
let { url, data } = paramsHandler(_url, _data);
let res = null;
if (method == 'get' || method == 'GET' || method == 'Get') {
res = await drrq.get(url, data, preventRepeat);
}
if (method == 'post' || method == 'POST' || method == 'Post') {
res = await drrq.post(url, data, preventRepeat);
}
if (method == 'file' || method == 'FILE' || method == 'file') {
res = await drrq.file(url, data, preventRepeat);
}
return resHandler(res);
};测试功能
代码写完后,我们需要验证功能是否正常,package.json加上
"scripts": {
"test": "node example"
},执行npm run test
功能正常,工具库准备完毕。
(eslint和prettier读者可视情况选用)
打包
一般项目的打包使用webpack,而工具库的打包则使用rollup
安装 Rollup
通过下面的命令安装 Rollup:
npm install --save-dev rollup创建配置文件
在根目录创建一个新文件 rollup.config.js
export default {
input: "src/index.js",
output: {
file: "dist/drrp.js",
format: "esm",
name: 'drrp'
}
};input —— 要打包的文件
output.file —— 输出的文件 (如果没有这个参数,则直接输出到控制台)
output.format —— Rollup 输出的文件类型
安装babel
如果要使用 es6 的语法进行开发,还需要使用 babel 将代码编译成 es5。因为rollup的模块机制是 ES6 Modules,但并不会对 es6 其他的语法进行编译。
安装模块
rollup-plugin-babel 将 rollup 和 babel 进行了完美结合。
npm install --save-dev rollup-plugin-babel@latest
npm install --save-dev @babel/core
npm install --save-dev @babel/preset-env根目录创建 .babelrc
{
"presets": [
[
"@babel/preset-env",
{
"modules": false
}
]
]
}兼容 commonjs
rollup 提供了插件 rollup-plugin-commonjs,以便于在 rollup 中引用 commonjs 规范的包。该插件的作用是将 commonjs 模块转成 es6 模块。
rollup-plugin-commonjs 通常与 rollup-plugin-node-resolve 一同使用,后者用来解析依赖的模块路径。
安装模块
npm install --save-dev rollup-plugin-commonjs rollup-plugin-node-resolve压缩 bundle
添加 UglifyJS 可以通过移除注上释、缩短变量名、重整代码来极大程度的减少 bundle 的体积大小 —— 这样在一定程度降低了代码的可读性,但是在网络通信上变得更有效率。
安装插件
用下面的命令来安装 rollup-plugin-uglify:
npm install --save-dev rollup-plugin-uglify完整配置
rollup.config.js 最终配置如下
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import babel from 'rollup-plugin-babel';
import { uglify } from 'rollup-plugin-uglify';
import json from '@rollup/plugin-json'
const paths = {
input: {
root: 'src/index.js',
},
output: {
root: 'dist/',
},
};
const fileName = `drrq.js`;
export default {
input: `${paths.input.root}`,
output: {
file: `${paths.output.root}${fileName}`,
format: 'esm',
name: 'drrq',
},
plugins: [
json(),
resolve(),
commonjs(),
babel({
exclude: 'node_modules/**',
runtimeHelpers: true,
}),
uglify(),
],
};在package.json中加上
"scripts": {
"build": "rollup -c"
},即可执行npm run build将/src/index.js打包为/dist/drrq.js
发包前的准备
准备npm账号,通过npm login或npm adduser。这里有一个坑,终端内连接不上npm源,需要在上网工具内复制终端代理命令后到终端执行才能正常连接。
准备一个简单清晰的readme.md
修改package.json
完整的package.json如下
{
"name": "drrq",
"private": false,
"version": "1.3.5",
"main": "/dist/drrq.js",
"repository": "https://gitee.com/yuanying-11/drrq.git",
"author": "it_yuanying",
"license": "MIT",
"description": "能自动取消重复请求的axios封装",
"type": "module",
"keywords": [
"取消重复请求",
],
"dependencies": {
"axios": "^1.2.0",
"qs": "^6.11.0"
},
"scripts": {
"test": "node example",
"build": "rollup -c"
},
"devDependencies": {
...
}
}name 包名称 一定不能与npm已有的包名重复,想一个简单易记的
private 是否为私有
version 版本
main 入口文件位置
repository git仓库地址
author 作者
license 协议
description 描述
keywords 关键词,便于检索
每个 npm 包都需要一个版本,以便开发人员在安全地更新包版本的同时不会破坏其余的代码。npm 使用的版本系统被叫做 SemVer,是 Semantic Versioning 的缩写。
不要过分担心理解不了相较复杂的版本名称,下面是他们对基本版本命名的总结: 给定版本号 MAJOR.MINOR.PATCH,增量规则如下:
MAJOR 版本号的变更说明新版本产生了不兼容低版本的 API 等,
MINOR 版本号的变更说明你在以向后兼容的方式添加功能,接下来
PATCH 版本号的变更说明你在新版本中做了向后兼容的 bug 修复。
表示预发布和构建元数据的附加标签可作为 MAJOR.MINOR.PATCH 格式的扩展。
最后,执行npm publish就搞定啦
本文的完整代码已开源至gitee.com/yuanying-11… ,感兴趣的读者欢迎fork和star!
另外,本文参考了juejin.cn/post/684490… 和juejin.cn/post/684490…
作者:断律绎殇
来源:juejin.cn/post/7172240485778456606
我裁完兄弟们后,辞职了,转行做了一名小职员
那天早晨,我冲进总经理的办公室,发现人力资源总监也在,我说:真巧,真好,两位都在,我要辞职!
我在马路上走着,头脑有些昏昏沉沉的。
“大爷,我有故事你听听吗?”,扫马路的大爷没理我,提起垃圾桶,走了。
“阿姨,你想听听我的经历不?”,等公交的大妈拦下一辆出租车,走了。
算了,年中总结到了,我就谈一谈我的上半身……上半生……不是,上半年吧。
一、十年职场终一梦,互联网里心不平
2022年,是我工作的第11年,这11年,我都在互联网中沉浮,而且一直是向着风口奔跑。
我一开始处于电信增值行业,我们叫SP业务。
现在的年轻人可能很难想象,以前的互动主要靠短信,就是1毛钱一条的短信。
比如某电视台有个话题,对于一个事件你是支持还是反对,如果支持发短信1,反对发送2。
这时候,发送一条短信的定价可以自己设置,比如2元1条,在运营商那里备个案就行,当时来说,这是合法的。
一般为了提高发短信的积极性,都会在最后搞一个抽奖,抽中之后送套茶壶啥的,这样,两块钱也就舍得花了。
因为自己有定价的权利,所以可玩的就有很多。
比如:
我做一个游戏嵌到手机里,想玩就发短信啊。
再比如:
我提供一个服务,每天给你发送天气预报信息,想订阅就发短信啊。
2011年,随着智能手机的兴起,短信有被网络消息取代的趋势,而且乱收费也受到了监管。
所以,一些SP企业就纷纷转型移动互联网,去做智能手机应用。
我此时毕业,因为学的就是智能手机应用开发专业,而且大学期间也自己搞了一些和iOS的APP去运作,所以很顺利地就找到工作。
这一干就是5年,搞过手机游戏,搞过订餐系统,搞过电商,搞过O2O,搞过政务……因为企业转型,一般没有目标,什么火就搞什么。
后来,我感觉干的太乱了,自己应该抓住一个行业去搞,于是在2016年就去了另一家公司,主要做在线教育平台。
所有公司都一样,一个公司干久了,职位自然会提升,因为人都熬走了,只剩下你了,另外你跟各部门都熟,工作推进起来也方便。
我也是这么一步一步走过来,从普通开发到技术组长,从技术组长到技术经理,从技术经理再到项目经理。
工作内容也是越来越杂:
普通开发时,只写客户端代码就可以。
负责技术时,因为客户端嵌入了H5页面,客户端要调服务端的接口,所以我也学会了前端和后端的开发。实际工作中,你会发现,你不了解一线的实际操作,你是心虚的,你没法避免别人糊弄你,你也无法更公正地解决争端,所谓的什么“道理都是相通的”、“能管理好煤炭企业,也能管理好体育企业”这类管理理论,只是作为管理者懒政的借口。
负责项目时,需要对产品原型、UI设计进行一个把握,需要对前期需求和后期售后进行一个兼顾,出个差,陪个酒也是常有的事情。有时候,哪里有空缺了,比如没有人设计原型,那么就要自己顶上去。
整体下来,自己基本上达到这么一种情况:做一个互联网项目,从需求到上线,如果有更专业的人,那么能干的更快更好,如果只有自己,也能磕磕碰碰地完成。
这种技能就是,要说没有本事吧,好像还能干不少事情。要说有本事呢,还真没有一样可以拿出手的绝活。
但是,这不重要。
我更关注的是,我供职的几家公司,包括身边的互联网公司,做产品也好,做平台也罢,都没有实现盈利。
此处需要解释一下,我心中的盈利是指传统的盈利,就是通过销售的方式,产生了大于成本的收入,比如这软件花5块钱做的,卖了10块钱。
我供职的公司,基本上都融过资,从百万到千万都有,都是拿着一份未来的规划,就有人投钱。
没有实现盈利,却依然可以持续地生存下去,我认为这不是一种常态。
看不到自己的作品实打实地变现,我是心虚的。
十年互联网一场梦,看着一波又一波游走在风口的企业,虽然从没有耽误过我拿薪水,但是我却是担惊受怕的:
这是泡沫吗?
会破吗?
哪一天会到来?
我这10年的积累稳不稳定?
二、裁员浪潮突袭来,转行意识在徘徊
上半年,大家还在期待着加薪,没想到等到的是裁员。
还好,我是项目负责人,因为平时工作表现还可以,所以不裁我。不但不裁我,还给我升职加薪。
但是,我也面临了一个问题:你裁谁?
我刚上任,哪里知道该裁谁,就这么推推搡搡,确定了一个名单。
裁人那天早上,我推门去找总经理,我说我要辞职了,于是就出现了开头的那一幕。
我走在街上,我觉得这是一个经过反复思考后的决定。
可能很多人觉得,疫情期间,能有一份工作不就挺好吗?
但是,我还考虑到了未来。
三十多岁的人了,只考虑眼下的工作吗?问过自己要什么吗?
1、你处的行业怎么样?
教育行业,崩盘式堕落。
2、行业不行,公司有发展也可以啊,你公司发展怎么样?
失去方向,驱逐人员。
3、公司不佳,工作内容有前途也可以,你的工作有没有挑战?
重复性工作,得心应手。
复制代码
好像只剩下钱了,但是这钱,还能挣多久,现在挣得心虚吗?
不只是我这么想,我身边好多人都这么想。
于是,戏剧性的一幕发生了。
大家开始纷纷转行了,这个转行只是小转行,指的是IT行业内的工种转行。
做前端开发的开始转行做后端开发。
做后端开发的开始转行做项目管理。
做项目管理的开始转行做产品管理。
有时候我在想,这个问题是转行就能破局的吗?
是跟整体经济形势有关呢,还是跟个人职业匹配有关呢,说不好,不好说,好像只能试试看了。
其实,我也准备转行了,从项目管理转向人工智能开发。
我从2018年开始,出于兴趣,就已经开始学习人工智能了,我认为写逻辑代码的顶峰就是无逻辑,那就是神经网络,就是人工智能。
4年的学习,也有了一些实践和应用,也该宝刀出鞘了。
三、出去面试吓一跳,行业经验很重要
我先是奔着人工智能算法工程师去投简历,但是我的简历太复杂了,啥都干过,起初我还认为这是优势。
直到碰到一个招聘主管点醒了我,她居然还是我的学姐,她说你把算法部分抽出来吧,面试啥岗位就写啥经历。
我一想也对,以前自己也当过面试官,一般除非管理岗位,大公司都比较看重专业性,你招聘一个Android开发,结果简历上80%写的是PHP,这不合适。
我把其他项目都删除了,只保留算法相关的应用案例,基本上都是应用在教育教学方面的。
后来,面试机会真的多了。
但是问题也来了,这些招聘的企业,有的是搞煤炭的,有的是搞养殖的,你与他们很难对上话。
比如他们说一个“倒线”,你听不明白,他们都觉得很奇怪,这不是行业基础知识吗?他们认为你应该明白。
再后来,我还是决定去教育行业试试,这一去不要紧,一发不可收拾,什么“教材”、“章节”、“知识点”、“题库”、“资源”、“备授课”,搞了多少年了,而且既全面又深度。
最后,我还是选择了一家做算法的教育企业,这将作为我算法职业生涯的起点。
你看,是否教育行业已经不重要了,重要的是算法这个职业,这就是除了钱之外,我们另外追求的点。
四、人到中年再重启,空杯心态学到底
这次我选择了做一名小职员,最最底层那种普通开发。
原因是你选择了算法,那么以你在算法领域的资历,当不了管理。
强行做,是会有问题的,所谓:德不配位,必有灾殃。
而我也很坦然,做管理这么多年,沉下心来,踏踏实实学习一两年,不好吗?
入职新公司这两个月,我感受到了从来没有过的舒适,没有了没完没了的会议,没有了上午说完中午就交的方案,也没有了深夜打来处理现场问题的电话,只有我深爱的算法代码。
而且,通过实际的项目,也让我对算法有了更深的见解,这两个月的收获也远远超过之前的两年。
挺好的,善于舍得就会有更多的收获。
相信我通过几年的学习,再结合之前杂七杂八的经验,最终在人工智能产业方面可以做出一定的成绩,这也是我最新的规划。
看见没有,人一旦有了新的希望,就有了动力。
我有时候就在思考一个问题,那就是换一个赛道的意义。
你在一个赛道里已经到了8分,换一个赛道再经过几年可能只到7分,换赛道究竟是逃避还是提升?
这个真的不好说。
但是有一点可以肯定,你在8分的赛道里已经没有斗志了,换一个赛道你会充满求知欲,重新赋予它新的希望,将以往的成功或者失败的经验全部用来成就它,猜测它应该不会很差吧。
五、长江后浪推前浪,后浪有话对你讲
虽然这是我的总结,但是我也希望对你多少有些影响,该唾弃的唾弃,值得借鉴的借鉴。
对于职场新人,我想对你们说几句话:
1、从基层到管理,从单一到复杂,这是在向上走,肯定是进步的,但同时也在越走越窄。
不要觉得领导傻,尤其是大领导,你觉得一圈人都在骗他,他还不知道呢,就我知道。
其实,有可能是他在骗你们一圈人。
能向上走就向上走。
古今中外,位置越高接触的信息就越多,决策也越正确,而这种正确不是你认为的正确。
我之前带过一个项目,开发人员很烂,产品逻辑很烂,我认为应该先梳理人和事,大领导确不以为然。我考虑的是怎样做好,做不好其他的都无从谈起。但是大领导考虑的是平台有没有,某个时间点没有,可能都不用做了。
但是,越往上路是越窄的。
一个开发,可能有
5000个合适的岗位。一个组长,可能有
3000个合适的岗位。一个经理,可能只有
1000个合适岗位。一个总监,可能只有
50个岗位。一个总裁,可能找不到工作。
2、搞管理并一定是你能力强,和信息差有关系,这种能力不一定能平移到其他公司。
如果你当上了管理,也不要骄傲。
这个角色可能并不是你能力强,可能就是没有人愿意干,也可能是你在这公司待得住,甚至可能仅仅就是老板看你顺眼。
不管怎样,你既然在这个职位上了,你就会去开各种会,去参与各种决策,去描绘各种规划,这可能会让你产生一种自己优秀的错觉。
这种优秀,换一个公司就会把你打回原形。
平台和能力的故事,数不胜数。
所以,如果你是个管理者,不要变成行政管理,那就变成了员工的服务员,每天就是喝茶看新闻,收收报表啊,鼓励鼓励信心啊,你以为没有你的协调就转不起来,其实那是假象,久而久之你就废了。
一定要做业务领导,指导员工的行进路线,披荆斩棘,攻坚克难,培养人才,只有这样,你才能不管去哪里都能立起一杆大旗,这种能力只和你有关。
3、民营企业,就是为了实现老板的个人想法,一个单位待得时间越久,你被定制化的就会越深。
很遗憾,这可能很打击人。
你不要谈什么行业规范,谈什么职业操守,起码在民营企业,真的就是为了实现老板的个人想法。
他出钱,你干活,除了立马应验的坑,否则你不要去阻拦他、打断他、抵制他。
第一,他会不高兴。第二,你的判断未必对。
一个企业,老板是第一责任人,员工是第一背锅人。
你想要在他这里发展,就要多和他站在统一战线上,但是站久了,也会让你忘了世界上还有别人。
有些事,是相同的。但是,有些事是千差万别的。
同一个行为,这个老板可能高度赞扬你,另一个老板就会极度批判你,对错很随机,这就是定制化人才。
就像高速路的收费员,她干了15年,结果来了ETC,她失业了,她说:我只会收费,你撤了,我以后还怎么活啊,我可是连续10年被评为优秀员工的。
你都按照领导说的做了,最终却导致你无路可走,这就是被深度定制。
要防止被定制,就要多抬头看看,放眼行业,多思考你在行业中处于什么水平,而不是你在单位中处于什么地位。
一个人的职业生涯,总会受到行业的影响,行业又会受时代影响,各种影响下,我们太渺小了。好好把握机会,不要虚度时光,你努力过,以后不会后悔。有时候鸡汤也挺好,起码让你充实,让这一天积极地度过,这是会提高成功概率的。
作者:TF男孩
来源:juejin.cn/post/7110237776984932389
比 JSON.stringify 快两倍的fast-json-stringify
前言
相信大家对JSON.stringify并不陌生,通常在很多场景下都会用到这个API,最常见的就是HTTP请求中的数据传输, 因为HTTP 协议是一个文本协议,传输的格式都是字符串,但我们在代码中常常操作的是 JSON 格式的数据,所以我们需要在返回响应数据前将 JSON 数据序列化为字符串。但大家是否考虑过使用JSON.stringify可能会带来性能风险🤔,或者说有没有一种更快的stringify方法。
JSON.stringify的性能瓶颈
由于 JavaScript 是动态语言,它的变量类型只有在运行时才能确定,所以 JSON.stringify 在执行过程中要进行大量的类型判断,对不同类型的键值做不同的处理。由于不能做静态分析,执行过程中的类型判断这一步就不可避免,而且还需要一层一层的递归,循环引用的话还有爆栈的风险。
我们知道,JSON.string的底层有两个非常重要的步骤:
类型判断
递归遍历
既然是这样,我们可以先来对比一下JSON.stringify与普通遍历的性能,看看类型判断这一步到底是不是影响JSON.stringify性能的主要原因。
JSON.stringify 与遍历对比
const obj1 = {}, obj2 = {}
for(let i = 0; i < 1000000; i++) {
obj1[i] = i
obj2[i] = i
}
function fn1 () {
console.time('jsonStringify')
const res = JSON.stringify(obj1) === JSON.stringify(obj2)
console.timeEnd('jsonStringify')
}
function fn2 () {
console.time("for");
const res = Object.keys(obj1).every((key) => {
if (obj2[key] || obj2[key] === 0) {
return true;
} else {
return false;
}
});
console.timeEnd("for");
}
fn1()
fn2()从结果来看,两者的性能差距在4倍左右,那就证明JSON.string的类型判断这一步还是非常耗性能的。如果JSON.stringify能够跳过类型判断这一步是否对类型判断有帮助呢?
定制化更快的JSON.stringify
基于上面的猜想,我们可以来尝试实现一下:
现在我们有下面这个对象
const obj = {
name: '南玖',
hobby: 'fe',
age: 18,
chinese: true
}上面这个对象经过JSON.stringify处理后是这样的:
JSON.stringify(obj)
// {"name":"南玖","hobby":"fe","age":18,"chinese":true}现在假如我们已经提前知道了这个对象的结构
键名不变
键值类型不变
这样的话我们就可以定制一个更快的JSON.stringify方法
function myStringify(obj) {
return `{"name":"${obj.name}","hobby":"${obj.hobby}","age":${obj.age},"chinese":${obj.chinese}}`
}
console.log(myStringify(obj) === JSON.stringify(obj)) // true这样也能够得到JSON.stringify一样的效果,前提是你已经知道了这个对象的结构。
事实上,这是许多JSON.stringify加速库的通用手段:
需要先确定对象的结构信息
再根据结构信息,为该种结构的对象创建“定制化”的
stringify方法内部实现依然是这种字符串拼接
更快的fast-json-stringify
fast-json-stringify 需要JSON Schema Draft 7输入来生成快速
stringify函数。
这也就是说fast-json-stringify这个库是用来给我们生成一个定制化的stringily函数,从而来提升stringify的性能。
这个库的GitHub简介上写着比 JSON.stringify() 快 2 倍,其实它的优化思路跟我们上面那种方法是一致的,也是一种定制化stringify方法。
语法
const fastJson = require('fast-json-stringify')
const stringify = fastJson(mySchema, {
schema: { ... },
ajv: { ... },
rounding: 'ceil'
})schema: $ref 属性引用的外部模式。ajv: ajv v8 实例对那些需要ajv.rounding: 设置当integer类型不是整数时如何舍入。largeArrayMechanism:设置应该用于处理大型(默认情况下20000或更多项目)数组的机制
scheme
这其实就是我们上面所说的定制化对象结构,比如还是这个对象:
const obj = {
name: '南玖',
hobby: 'fe',
age: 18,
chinese: true
}它的JSON scheme是这样的:
{
type: "object",
properties: {
name: {type: "string"},
hobby: {type: "string"},
age: {type: "integer"},
chinese: {type: 'boolean'}
},
required: ["name", "hobby", "age", "chinese"]
}AnyOf 和 OneOf
当然除了这种简单的类型定义,JSON Schema 还支持一些条件运算,比如字段类型可能是字符串或者数字,可以用 oneOf 关键字:
"oneOf": [
{
"type": "string"
},
{
"type": "number"
}
]fast-json-stringify支持JSON 模式定义的anyOf和oneOf关键字。两者都必须是一组有效的 JSON 模式。不同的模式将按照指定的顺序进行测试。stringify在找到匹配项之前必须尝试的模式越多,速度就越慢。
anyOf和oneOf使用ajv作为 JSON 模式验证器来查找与数据匹配的模式。这对性能有影响——只有在万不得已时才使用它。
关于 JSON Schema 的完整定义,可以参考 Ajv 的文档,Ajv 是一个流行的 JSON Schema验证工具,性能表现也非常出众。
当我们可以提前确定一个对象的结构时,可以将其定义为一个 Schema,这就相当于提前告诉 stringify 函数,需序列化的对象的数据结构,这样它就可以不必再在运行时去做类型判断,这就是这个库提升性能的关键所在。
简单使用
const fastJson = require('fast-json-stringify')
const stringify = fastJson({
title: 'myObj',
type: 'object',
properties: {
name: {
type: 'string'
},
hobby: {
type: 'string'
},
age: {
description: 'Age in years',
type: 'integer'
},
chinese: {
type: 'boolean'
}
}
})
console.log(stringify({
name: '南玖',
hobby: 'fe',
age: 18,
chinese: true
}))生成 stringify 函数
fast-json-stringify是跟我们传入的scheme来定制化生成一个stringily函数,上面我们了解了怎么为我们对象定义一个scheme结构,接下来我们再来了解一下如何生成stringify。
这里有一些工具方法还是值得了解一下的:
const asFunctions = `
function $asAny (i) {
return JSON.stringify(i)
}
function $asNull () {
return 'null'
}
function $asInteger (i) {
if (isLong && isLong(i)) {
return i.toString()
} else if (typeof i === 'bigint') {
return i.toString()
} else if (Number.isInteger(i)) {
return $asNumber(i)
} else {
return $asNumber(parseInteger(i))
}
}
function $asNumber (i) {
const num = Number(i)
if (isNaN(num)) {
return 'null'
} else {
return '' + num
}
}
function $asBoolean (bool) {
return bool && 'true' || 'false'
}
// 省略了一些其他类型......从上面我们可以看到,如果你使用的是 any 类型,它内部依然还是用的 JSON.stringify。 所以我们在用TS进行开发时应避免使用 any 类型,因为如果是基于 TS interface 生成JSON Schema 的话,使用 any 也会影响到 JSON 序列化的性能。
然后就会根据 scheme 定义的具体内容生成 stringify 函数的具体代码。而生成的方式也比较简单:通过遍历 scheme,根据不同数据类型调用上面不同的工具函数来进行字符串拼接。感兴趣的同学可以在GitHub上查看源码
总结
事实上fast-json-stringify只是通过静态的结构信息将优化与分析前置了,通过开发者定义的scheme内容可以提前知道对象的数据结构,然后会生成一个stringify函数供开发者调用,该函数内部其实就是做了字符串的拼接。
开发者定义 Object 的
JSON schemestringify 库根据 scheme 生成对应的模版方法,模版方法里会对属性与值进行字符串拼接
最后开发者调用生成的stringify 方法
作者:前端南玖
来源:juejin.cn/post/7173482852695146510
为 Kotlin 的函数添加作用域限制(以 Compose 为例)
前言
不知道各位是否已经开始了解 Jetpack Compose?
如果已经开始了解并且上手写过。那么,不知道你们有没有发现,在 Compose 中对于作用域(Scopes)的应用特别多。比如, weight 修饰符只能用在 RowScope 或者 ColumnScope 作用域中。又比如,item 组件只能用在 LazyListScope 作用域中。
如果你还没有了解过 Compose 的话,那你也应该知道,kotlin 标准库中有 5 个作用域函数:let() apply() also() with() run() ,这 5 个函数会以不同的方式持有和返回上下文对象,即调用这些函数时,在它们的 lambda 参数中写的代码将处于特定的作用域。
不知道你们有没有思考过,这些作用域限制是怎么实现的呢?如果我们想自定义一个 Composable 函数,只支持在特定的作用域中使用,应该怎么写呢?
本文将为你解开这个疑惑。
作用域
不过在正式开始之前我们还是先大概补充一点有关 kotlin 中作用域的基本知识。
什么是作用域
其实对于咱们程序员来说,不管学的是什么语言,对于作用域应该都是有一个了解的。
举个简单的例子:
val valueFile = "file"
fun a() {
val valueA = "a"
println(valueFile)
println(valueA)
println(valueB)
}
fun b() {
val valueB = "b"
println(valueFile)
println(valueA)
println(valueB)
}这段代码不用运行都知道肯定会报错,因为在函数 a 中无法访问 valueB ;在函数 b 中无法访问 valueA 。但是这两个函数都可以成功访问 valueFile 。
这是因为 valueFile 的作用域是整个 .kt 文件,也就是说,只要是在这个文件中的代码,都可以访问到它。
而 valueA 和 valueB 的作用域则分别是在函数 a 和 b 中,显然只能在各自的作用域中使用。
同理,如果我们想要调用类的方法或者函数也需要考虑作用域:
class Test {
val valueTest = "test"
fun a(): String {
val valueA = "a"
println(valueTest)
println(valueA)
return "returnA"
}
fun b() {
println(valueA)
println(valueTest)
println(a())
}
}
fun main() {
println(valueTest)
println(valueA)
println(a())
}这里举的例子可能不太恰当,但是这里是为了说明这个情况,不要过多纠结哦~
显然,上面这个代码,在 main 函数中是无法访问到变量 valueTest 和 valueA 的,并且也无法调用函数 a() ;而在 Test 类中的函数 a() 显然可以访问到 valueTest 和 valueA ,并且函数 b() 也可以调用函数 a(),可以访问变量 valueTest 但是无法访问变量 valueA 。
这是因为函数 a() 和 b() 以及变量 valueTest 位于同一个作用域中,即类 Test 的作用域。
而变量 valueA 位于函数 a() 的作用域内,由于 a() 又位于 Test 的作用域内,所以实际上这里的 valueA 的作用域称为嵌套作用域,即同时位于 a() 和 Test 的作用域内。
因为本节只是为了引出我们今天要介绍的内容,所以有关作用域的知识就简单介绍这么多,更多有关作用域的知识可以阅读参考资料 1 。
kotlin 标准库中的作用域函数
在前言中我们说过,kotlin标准库中有5个称之为作用域函数的东西:with、run、let、also、apply 。
它们有什么作用呢?
先看一段我们经常会遇到的代码形式:
val person = Person()
person.fullName = "equationl"
person.lastName = "l"
person.firstName = "equation"
person.age = 24
person.gender = "man"在某些情况下,我们可能会需要多次重复的写一堆 person,可读性很差,写起来也很繁琐。
此时我们就可以使用作用域函数,例如使用 with 改写:
with(person) {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}此时,我们就可以省略掉 person ,直接访问或修改它的属性值,这是因为 with 的第一个参数接收的是需要作为第二个参数的 lambda 上下文对象,即此时,第二个参数 lambda 匿名函数所在的作用域为第一个参数传入的对象,此时 IDE 的提示也指出了此时 with 的匿名函数中的作用域为 Person :
所以在这个匿名函数中能直接访问或修改 Person 的属性。
同理,我们也可以使用 run 函数改写:
person.run {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}可以看出,run 与 with 非常相似,只是 run 是以扩展函数的形式接收上下文对象,它的参数只有一个 lambda 匿名函数。
后面还有 let :
person.let {
it.fullName = "equationl"
it.lastName = "l"
it.firstName = "equation"
it.age = 24
it.gender = "man"
}它与 run 的区别在于,匿名函数中的上下文对象不再是隐式接收器(this),而是作为一个参数(it)存在。
使用 also() 则是:
person.also {
it.fullName = "equationl"
it.lastName = "l"
it.firstName = "equation"
it.age = 24
it.gender = "man"
}和 let 一样,它也是扩展函数,并且上下文也作为参数传入匿名函数,但是不同于 let ,它会返回上下文对象,这样可以方便的进行链式调用,如:
val personString = person
.also {
it.age = 25
}
.toString()最后是 apply :
person.apply {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}与 also 一样,它是扩展函数,也会返回上下文对象,但是它的上下文将作为隐式接收者,而不是匿名函数的一个参数。
下面是它们 5 个函数的对比图和表格:
| 函数 | 上下文形式 | 返回值 | 是否是扩展函数 |
|---|---|---|---|
| with | 隐式接收者(this) | lambda函数(Unit) | 否 |
| run | 隐式接收者(this) | lambda函数(Unit) | 是 |
| let | 匿名函数的参数(it) | lambda函数(Unit) | 是 |
| also | 匿名函数的参数(it) | 上下文对象 | 是 |
| apply | 隐式接收者(this) | 上下文对象 | 是 |
Compose 中的作用域限制
在前言中我们说过,在 Compose 对作用域限制的应用非常多。
例如 Modifier 修饰符,从这个 Compose 修饰符列表 中,我们也能看到很多修饰符的作用域都做了限制:
这里需要对修饰符做限制的原因非常简单:
In the Android View system, there is no type safety. Developers usually find themselves trying out different layout params to discover which ones are considered and their meaning in the context of a particular parent.
在传统的 xml view 体系中就是没有对布局的参数做限制,这就导致所有的参数都可以用在任意布局中,这会导致一些问题。轻则参数无效,写了一堆无用参数;严重的可能会干扰到布局的正常使用。
当然,Modifier 修饰符限制只是 Compose 中其中一个应用,在 Compose 中还有很多作用域限制的例子,例如:
在上图中 item 只能在 LazyListScope 作用域使用,drawRect 只能在 DrawScope 作用域使用。
当然,正如我们前面说的,作用域中不只有函数和方法,还可以访问类的属性,例如,在 DrawScope 作用域提供了一个名为 size 的属性,可以通过它来拿到当前的画布大小:
那么,这些是怎么实现的呢?
自定义我们的作用域限制函数
原理
在开始实现我们自己的作用域函数之前,我们需要先了解一下原理。
这里我们以 Compose 的 Canvas 为例来看看。
首先是 Canvas 的定义:
可以看到这里 Canvas 接收了两个参数:modifier 和 onDraw 的 lambda ,且这个 lambda 的 Receiver(接收者) 为 DrawScope ,也就是说,onDraw 这个匿名函数的作用域被限制在了 DrawScope 内,这也意味着可以在匿名函数内部使用 DrawScope 作用域内的属性、方法等。
再来看看这个 DrawScope 是何方神圣:
可以看到这是一个接口,里面定义了一些属性变量(如我们上面说的 size) 和一些方法(如我们上面说的 drawRect )。
然后再实现这个接口,编写具体实现代码:
实现
所以总结来说,如果我们想实现自己的作用域限制大致分为三步:
- 编写作为作用域的接口
- 实现这个接口
- 在暴露的方法中将 lambda 参数接收者使用上面定义的接口
下面我们举个例子。
假如我们要在 Compose 中实现一个遮罩引导层,用于引导新用户操作,类似这样:
但是我们希望引导层上的提示可以多样化,例如可以支持文字提示、图片提示、甚至播放视频或动图提示,但是我们不希望这些提示 item 在遮罩层以外的地方被调用,因为它们依赖于遮罩层的某些参数,如果在外部调用会出错。
这时候,使用作用域限制就非常合适。
首先,我们编写一个接口:
interface ShowcaseScreenScope {
val isShowOnce: Boolean
@Composable
fun ShowcaseTextItem()
}在这个接口中我们定义了一个属性变量 isShowOnce 用于表示这个引导层是否只显示一次、定义一个方法 ShowcaseTextItem 表示在引导层上显示一串文字,同理我们还可以定义 ShowcaseImageItem 表示显示图片。
然后实现这个接口:
private class ShowcaseScopeImpl: ShowcaseScreenScope {
override val isShowOnce: Boolean
get() = TODO("在这里编写是否只显示一次的逻辑")
@Composable
override fun ShowcaseTextItem() {
// 在这里写你的实现代码
Text(text = "我是说明文字")
}
}在接口实现中,根据我们的需求编写相应的实现逻辑代码。
最后,写一个提供给外部调用的 Composable:
@Composable
fun ShowcaseScreen(content: @Composable ShowcaseScreenScope.() -> Unit) {
// 在这里实现其他逻辑(例如显示遮罩)后调用 content
// ……
ShowcaseScopeImpl().content()
}在这个 composable 中,我们可以先处理完其他逻辑,例如显示遮罩层 UI 或显示动画后再调用 ShowcaseScopeImpl().content() 将我们传递的子 Item 组合上去。
最后,使用时只需要调用:
ShowcaseScreen {
if (!isShowOnce) {
ShowcaseTextItem()
}
}当然,这个 ShowcaseTextItem() 和 isShowOnce 位于 ShowcaseScreenScope 作用域内,在外面是不能调用的:
总结
本文简要介绍了 Kotlin 中的作用域概念和标准库中的作用域函数,并引申到 Compsoe 中关于作用域的应用,最终分析实现原理并讲解如何自定义一个我们自己的 Compose 作用域函数。
本文写的可能比较浅显,很多知识点都是点到为止,没有过多讲解,推荐读者阅读完后,可以看看文末的参考链接中其他大佬写的文章。
链接:https://juejin.cn/post/7173913850230603812
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
检测Android应用使用敏感信息(mac地址、IMEI等)的方法
今天在提交app时,遇到授权前隐私不过的问题,所有的初始化都后置到授权后了,还是被报有获取mac地址和android_id的行为,这很是奇怪,自己也是无处下手,毕竟log里面是没有的,应用商店也没有提供堆栈。
经过一番查找,找到一套自测的工具,这里自己也记录并分享一下,手把手的来一步步操作,就可以自测了,废话不多说,下面按步骤来写了(无需ROOT):
- 下载虚拟系统:VirtualXposed 0.22.0版本这个反正我用有问题,就用了0.20.3了~
- 压缩包里面有
VirtualXposed_for_GameGuardian_0.20.3.apk和VirtualXposed_0.20.3.apk - 将两个apk都安装到手机里面,桌面会看到VirtualXposed图标。
- 自行编译PrivacyCheck检测隐私打点工具或者可以用我编译好的 测试包privacy_check.apk
- 安装要检测的应用,我们这里随便拿个app来测试,就拿掘金来练手吧~ 现在桌面是这样的:
- 打开
VirtualXposed,如果是全面屏记得恢复成普通导航,因为需要菜单功能。做安卓的应该知道菜单怎么调用,小米手机:长按任务键进入设置~~ - 点击添加应用:勾选
PrivacyCheck和稀土掘金,点击下面的安装按钮。 - 弹框选择:
VIRTUALXPOSED,等待安装结束,点击完成! 界面如下: - 点击
Xposed Installer,也就是最右面那个app。安装完成的样子: - 在
Xposed Installerapp里面,左上角点击侧滑栏,点击模块,勾选PrivacyCheck,如图: - 返回到
VirtualXposed界面,进入菜单,最下面有一个重启项,点击重启~ 很快就可以了~ - 返回到这个界面:
- 点击
PrivacyCheckapp,启动完成后,看到就一行字,无需关心,此时切换应用回:VirtualXposed界面。(不要返回,直接应用间切换就好了,保持PrivacyCheck没有杀死。 - 打开终端(mac),输入:
adb logcat | grep PrivacyCheck,回车,会看到这样一行:E PrivacyCheck: 加载app 包名:com.test.privacycheck。 - 打开要测试的app,这里是打开掘金app,不要点击同意,观察log输出:
E PrivacyCheck: 加载app 包名:com.daimajia.gold,只输出了一行,看上去很不错,没有任何问题。 - 参考步骤5,打开其他测试app,比如我之前有问题的app,观察下log:
可以很清楚的看到错误堆栈,看到我这里是因为调用页面start的统计造成的,一下就想起来自己统计根页面时路径导致的,很容易就解决了~~
最后问题改动很简单,但查找的过程还比较麻烦,同时也学到了这种排查隐私的方法,希望也能帮到需要的人~~
链接:https://juejin.cn/post/7106522434261483528
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 一种点赞动画的实现
最近有个需求,需要仿照公司的H5实现一个游戏助手,其中一个点赞的按钮有动画效果,如下图:
分析一下这个动画,点击按钮后,拇指首先有个缩放的效果,然后有5个拇指朝不同的方向移动,其中部分有放大的效果。
点击后的缩放效果
本文通过ScaleAnimation 实现缩放效果,代码如下:
private fun playThumbUpScaleAnimator() {
// x、y轴方向都从1倍放大到2倍,以控件的中心为原点进行缩放
ScaleAnimation(1f, 2f, 1f, 2f, Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).run {
// 先取消控件当前的动画效果(重复点击时)
view.clearAnimation()
// 设置动画的持续时间
duration = 300
// 开始播放动画
view.startAnimation(this)
}
}拇指的散开效果
有5个拇指分别往不同的方向移动,本文通过动态添加View,并对View设置动画来实现。可以看到在移动的同时还有缩放的效果,所以需要同时播放几个动画。
本文通过ValueAnimator和AnimatorSet来实现该效果,代码如图:
// 此数组控制动画的效果
// 第一个参数控制X轴移动距离
// 第二个参数控制Y轴移动距离
// 第三个参数控制缩放的倍数(基于原大小)
val animatorConfig: ArrayList<ArrayList<Float>> = arrayListOf(
arrayListOf(-160f, 150f, 1f),
arrayListOf(80f, 130f, 1.1f),
arrayListOf(-120f, -170f, 1.3f),
arrayListOf(80f, -130f, 1f),
arrayListOf(-20f, -80f, 0.8f))
private fun playDiffusionAnimator() {
for (index in 0 until 5) {
binding.root.run {
if (this is ViewGroup) {
// 创建控件
val ivThumbUp = AppCompatImageView(context)
ivThumbUp.setImageResource(R.drawable.icon_thumb_up)
// 设置与原控件一样的大小
ivThumbUp.layoutParams = FrameLayout.LayoutParams(DensityUtil.dp2Px(25), DensityUtil.dp2Px(25))
// 先设置为全透明
ivThumbUp.alpha = 0f
addView(ivThumbUp)
// 设置与原控件一样的位置
ivThumbUp.x = binding.ivThumbUp.x
ivThumbUp.y = binding.ivThumbUp.y
AnimatorSet().apply {
// 设置动画集开始播放前的延迟
startDelay = 330L + index * 50L
// 设置动画监听
addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(animation: Animator) {
// 开始播放时把控件设置为不透明
ivThumbUp.alpha = 1f
}
override fun onAnimationEnd(animation: Animator) {
// 播放结束后再次设置为透明,并从根布局中移除
ivThumbUp.alpha = 0f
ivThumbUp.clearAnimation()
ivThumbUp.post { removeView(ivThumbUp) }
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationRepeat(animation: Animator) {}
})
// 设置三个动画同时播放
playTogether(
// 缩放动画
ValueAnimator.ofFloat(1f, animatorConfig[index][2]).apply {
duration = 700
// 设置插值器,速度一开始快,快结束时减慢
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
(values.animatedValue as Float).let { value ->
ivThumbUp.scaleX = value
ivThumbUp.scaleY = value
}
}
},
// X轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.x, ivThumbUp.x + animatorConfig[index][0]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.x = values.animatedValue as Float
}
},
// Y轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.y, ivThumbUp.y + animatorConfig[index][1]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.y = values.animatedValue as Float
}
})
}.start()
}
}
}
}示例
整合之后做了个示例Demo,完整代码如下:
class AnimatorSetExampleActivity : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutAnimatorsetExampleActivityBinding
private val animatorConfig: ArrayList<java.util.ArrayList<Float>> = arrayListOf(
arrayListOf(-160f, 150f, 1f),
arrayListOf(80f, 130f, 1.1f),
arrayListOf(-120f, -170f, 1.3f),
arrayListOf(80f, -130f, 1f),
arrayListOf(-20f, -80f, 0.8f))
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_animatorset_example_activity)
binding.ivThumbUp.setOnClickListener {
playThumbUpScaleAnimator()
playDiffusionAnimator()
}
}
private fun playThumbUpScaleAnimator() {
// x,y轴方向都从1倍放大到2倍,以控件的中心为原点进行缩放
ScaleAnimation(1f, 2f, 1f, 2f, Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).run {
// 先取消控件当前的动画效果(重复点击时)
binding.ivThumbUp.clearAnimation()
// 设置动画的持续时间
duration = 300
// 开始播放动画
binding.ivThumbUp.startAnimation(this)
}
}
private fun playDiffusionAnimator() {
for (index in 0 until 5) {
binding.root.run {
if (this is ViewGroup) {
// 创建控件
val ivThumbUp = AppCompatImageView(context)
ivThumbUp.setImageResource(R.drawable.icon_thumb_up)
// 设置与原控件一样的大小
ivThumbUp.layoutParams = FrameLayout.LayoutParams(DensityUtil.dp2Px(25), DensityUtil.dp2Px(25))
// 先设置为全透明
ivThumbUp.alpha = 0f
addView(ivThumbUp)
// 设置与原控件一样的位置
ivThumbUp.x = binding.ivThumbUp.x
ivThumbUp.y = binding.ivThumbUp.y
AnimatorSet().apply {
// 设置动画集开始播放前的延迟
startDelay = 330L + index * 50L
// 设置动画监听
addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(animation: Animator) {
// 开始播放时把控件设置为不透明
ivThumbUp.alpha = 1f
}
override fun onAnimationEnd(animation: Animator) {
// 播放结束后再次设置为透明,并从根布局中移除
ivThumbUp.alpha = 0f
ivThumbUp.clearAnimation()
ivThumbUp.post { removeView(ivThumbUp) }
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationRepeat(animation: Animator) {}
})
// 设置三个动画同时播放
playTogether(
// 缩放动画
ValueAnimator.ofFloat(1f, animatorConfig[index][2]).apply {
duration = 700
// 设置插值器,速度一开始快,快结束时减缓
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
(values.animatedValue as Float).let { value ->
ivThumbUp.scaleX = value
ivThumbUp.scaleY = value
}
}
},
// Y轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.x, ivThumbUp.x + animatorConfig[index][0]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.x = values.animatedValue as Float
}
},
// X轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.y, ivThumbUp.y + animatorConfig[index][1]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.y = values.animatedValue as Float
}
})
}.start()
}
}
}
}
}效果如图:
个人感觉还原度还是可以的哈哈。
链接:https://juejin.cn/post/7172867784278769677
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
反思:Google 为何把 SurfaceView 设计的这么难用?
启程
如果你有过 SurfaceView 的使用经历,那么你一定和我一样,曾经被它所引发出 层出不穷的异状 折磨的 怀疑人生—— 毕竟,作为一个有理想的开发者,在深入了解 SurfaceView 之前,你很难想通这样一个问题:
为什么
SurfaceView设计的这么难用?
- 不支持
transform动画;
- 不支持半透明混合;
- 移动,大小改变,隐藏/显示操作引发的各种问题;
另一方面,即使你对 SurfaceView 使用不多,图形系统 的这朵乌云依然笼罩在每一位 Android 开发者的头顶,来看 Google 对其的 描述:
最终我尝试走近这片迷雾,并一点点去思考下列问题的答案:
SurfaceView的设计初衷是为了解决什么问题?
- 实际开发中,
SurfaceView这么 难用 的根本原因是什么?
- 实际开发中,
- 为了解决这些问题,
Google的工程师进行了哪些 尝试 ?
- 为了解决这些问题,
接下来,读者可带着这些问题,跟随笔者一起,再次回顾 SurfaceView 设计和实现的精彩历程。
一、世界观
在了解 SurfaceView 的设计初衷之前,读者首先需要对 Android 现有的图形架构有一个基本的了解。
Android 系统采用一种称为 Surface 的图形架构,简而言之,每一个 Activity 都关联有至少一个 Window(窗口),每一个 Window 都对应有一个 Surface。
Surface 这里直译过来叫做 绘图表面 ,顾名思义,其可在内存中生成一个图形缓冲区队列,用于描述 UI,经与系统服务的WindowServiceManager 通信后、通过 SurfaceFlinger 服务持续合成并送显到显示屏。
读者可通过下图,在印象上对整个流程建立一个简单的轮廓:
由此可见,通常情况下,一个 Activity 的 UI 渲染本质是 系统提供一块内存,并创建一个图形缓冲区进行维护;这块内存就是 Surface,最终页面所有 View 的 UI 状态数据,都会被填充到同一个 Surface 中。
截至目前一切正常,但需要指出的是,现有图形系统的架构设计中还藏了一个线程相关的 隐患 。
二、设计起源
1.线程问题
问题点在于:我们还需保证 Surface 内部 Buffer 缓冲区的 线程安全。
这样的描述,对于读者似乎太过飘渺,但从结论来说,最终,一条 Android开发者 耳熟能详 的规则因此而诞生:
主线程不能执行耗时操作。
我们知道, UI 的所有操作,一定会涉及到视图(View 树) 内部大量状态的维护,而 Surface 内部的缓冲区也会不断地被读写,并交给系统渲染。因此,如果 UI 相关的操作,放在不同的线程中执行,而多线程对这一块内存区域的读写,势必会引发内部状态的混乱。
为了避免这个问题,设计者就需要通过某种手段保证线程同步(比如加锁),而这种同步所带来的巨大开销,对于开发者而言,是不可接受的。
因此,最合理的方案就是保证所有UI相关操作都在同一个线程,而这个线程也被称作 主线程 或 UI 线程。
现在,我们将UI操作限制到主线程去执行,以解决了本小节开始时提到的线程问题,但开发者仍需小心—— 众所周知,主线程除了执行UI相关的操作之外,还负责接收各种各样的 输入事件(比如触摸、按键等),因此,为了保证用户的输入事件能够及时得到响应,我们就要保证 UI 操作的 稳定高效,尽可能避免耗时的 UI 操作。
2.动机
挑战随之而来。
当渲染的缓冲数据来自外部的其它系统服务或API时——比如系统媒体解码器的音视频数据,或者 Camera API 的相机数据等,这时 UI 渲染的效率要求会变得非常高。
开发者有了新的诉求:能否有这样一种特殊的视图,它拥有独立的 Surface ,这样就可以脱离现有 Activity 宿主的限制,在一个独立的线程中进行绘制。
由于该视图不会占用主线程资源,一方面可以实现复杂而高效的 UI 渲染,另一方面可以及时响应用户其它输入事件。
因此,SurfaceView 应运而生:与常规视图控件不同,SurfaceView 拥有独立的 Surface,如果我们将一个 Surface 理解为一个层级 (Layer),最终 SurfaceFlinger 会将前后两者的2个 Layer 进行 合成 和 渲染 :
现在,我们引用官方文档的描述,再次重申适用 SurfaceView 的场景:
在需要渲染到单独的
Surface(例如,使用Camera API或OpenGL ES上下文进行渲染)时,使用SurfaceView进行渲染很有帮助。使用SurfaceView进行渲染时,SurfaceFlinger会直接将缓冲区合成到屏幕上。
如果没有
SurfaceView,您需要将缓冲区合成到屏幕外的Surface,然后该Surface会合成到屏幕上,而使用SurfaceView进行渲染可以省去额外的工作。
3.具体思路
根据当前的设想,我们针对 SurfaceView 设计思路进行细化。
首先,我们需对现有的视图树结构进行改造。为了便于使用,我们允许开发者将 SurfaceView 直接加入到现有的视图树中(即作为控件,它受限于宿主 View Hierachy的结构关系),但在系统服务端中,对于 SurfaceFlinger 而言,SurfaceView 又是完全与宿主完全分离开的:
在上图中,我们可以看到,在 z 轴上,SurfaceView 默认是低于 DecorView 的,也就是说,SurfaceView 通常总是处于当前页面的最下方。
这似乎有些违反直觉,但仔细考虑 SurfaceView 的应用场景,无论是 Camera 相机应用、音视频播放页,亦或者是渲染游戏画面等,SurfaceView 承载的画面似乎总应该在页面的最下面。
实际设计中也是如此,用来描述 SurfaceView 的 Layer 或者 LayerBuffer 的 z 轴位置默认是低于宿主窗口的。与此同时,为了便于最底层的视图可见, SurfaceView 在宿主 Activity 的窗口上设置了一块透明区域(挖了一个洞)。
最终,SurfaceFlinger 把所有的 Layer 通过用统一流程来绘制和合成对应的 UI。
在整个过程中,我们需更进一步深入研究几个细节:
SurfaceView与宿主视图树结构的关系,以及 挖洞 过程的实现;SurfaceView与系统服务的通信创建Surface的实现;SurfaceView具体绘制流程的实现。
三、施工
1. 视图树与挖洞
一句话总结 SurfaceView 与视图树的关系: 在视图树内部,但又没完全在内部 。
首先,SurfaceView 的设计依然遵循 Android 的 View 体系,继承了 View,这意味着使用时,它可以声明在 xml 布局文件中:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View { }
出于安全性的考量,
SurfaceView相关源码并未直接开放出来,开发者只能看到自动生成的一个接口类,源码可以借助梯子在 这里 查阅。
LayoutInflater 布局填充阶段,按既有的布局填充流程,将 SurfaceView 构造并加入到视图树的某个结点;接下来,根布局会通过深度遍历依次执行 onAttachedToWindow() 处理视图挂载窗口的事件:
// /frameworks/base/core/java/android/view/SurfaceView.java
@Override
protected void onAttachedToWindow() {
// ...
mParent.requestTransparentRegion(SurfaceView.this); // 1.
ViewTreeObserver observer = getViewTreeObserver();
observer.addOnPreDrawListener(mDrawListener); // 2.
}
@UnsupportedAppUsage
private final ViewTreeObserver.OnPreDrawListener mDrawListener = new ViewTreeObserver.OnPreDrawListener() {
@Override
public boolean onPreDraw() {
updateSurface(); // 3.
return true;
}
};
protected void updateSurface() {
// ...
mSurfaceSession = new SurfaceSession();
mSurfaceControl = new SurfaceControl.Builder(mSurfaceSession); // 4
//...
}步骤 1 中,SurfaceView 会向父视图依次向上请求创造一份透明区域,根视图统计到最终的信息后,通过 Binder 通知 WindowManagerService 将对应区域设置为透明。
步骤 2、3、4 是在同一个方法的调用栈中,由此可见,SurfaceView 向系统请求透明区域后,会立即创建一个与绘图表面的连接 SurfaceSession ,并创建一个对应的控制器 SurfaceControl,便于对这个独立的绘图表面进行直接通信。
由此可见,Android 自有的视图树体系中,SurfaceView 作为一个普通的 View 被挂载上去之后,通过 Binder 通信,WindowManagerService 将其所在区域设置为透明(挖洞);并建立了与独立绘图表面的连接,后续便可与其直接通信。
2. 子图层类型
在阐述绘制流程之前,读者需简单了解 子图层类型 的概念。
上文说到,SurfaceView 的绝大多数使用场景中,其 z 轴的位置通常是在页面的 最下方 。但在实际开发中,随着业务场景复杂度的上升,仍然有部分场景是无法被满足的,比如:在页面的最上方播放一条全屏的视频广告。
因此,SurfaceView 的设计中引入了一个 子图层类型 的概念,用于定义这个独立的 Surface 相比较当前页面窗口 (即Activity) 的位置:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
// SurfaceView 的子图层类型
int mSubLayer = APPLICATION_MEDIA_SUBLAYER;
// SurfaceView 是否展示在当前窗口的最上方
// 该方法在挖洞和绘制流程中都有使用,最终影响到用户的视觉效果
private boolean isAboveParent() {
return mSubLayer >= 0;
}
}
// /frameworks/base/core/java/android/view/WindowManagerPolicyConstants.java
public interface WindowManagerPolicyConstants {
// ...
int APPLICATION_MEDIA_SUBLAYER = -2;
int APPLICATION_MEDIA_OVERLAY_SUBLAYER = -1;
int APPLICATION_PANEL_SUBLAYER = 1;
int APPLICATION_SUB_PANEL_SUBLAYER = 2;
int APPLICATION_ABOVE_SUB_PANEL_SUBLAYER = 3;
// ...
}如代码所示,mSubLayer 默认值为 -2,这表示 SurfaceView 默认总是在 Activity 的下方,想要让 SurfaceView 展示在 Activity 上方,可以调用 setZOrderOnTop(true) 以修改 mSubLayer 的值:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
public void setZOrderOnTop(boolean onTop) {
if (onTop) {
mSubLayer = APPLICATION_PANEL_SUBLAYER;
} else {
mSubLayer = APPLICATION_MEDIA_SUBLAYER;
}
}
public void setZOrderMediaOverlay(boolean isMediaOverlay) {
mSubLayer = isMediaOverlay ? APPLICATION_MEDIA_OVERLAY_SUBLAYER : APPLICATION_MEDIA_SUBLAYER;
}
}现在,无论是将 SurfaceView 放在页面的上方还是下方,都轻而易举。
但这仍然无法满足所有诉求,比如针对具有 alpha 通道的透明视频进行渲染时,产品希望其所在的图层位置能够更灵活(在两个 View 之间),但由于 SurfaceView 自身设计的原因,其并无法与视图树融合,这也正是 SurfaceView 饱受诟病的主要原因之一。
通过辩证的观点来看, SurfaceView 的这种设计虽然满足不了严苛的业务诉求,但在绝大多数场景下,独立绘图表面 这种设计都能够保证足够的渲染性能,同时不影响主线程输入事件的处理,绝对是一个优秀的设计。
3.子图层类型-插曲
值得一提的是,在 SurfaceView 的设计中,设计者还考虑到了音视频渲染时,字幕相关业务的场景,因此额外提供了一个 setZOrderMediaOverlay() 方法:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
public void setZOrderMediaOverlay(boolean isMediaOverlay) {
mSubLayer = isMediaOverlay ? APPLICATION_MEDIA_OVERLAY_SUBLAYER : APPLICATION_MEDIA_SUBLAYER;
}
}该方法的设计说明了2点:
首先,由于 APPLICATION_MEDIA_SUBLAYER 和 APPLICATION_MEDIA_OVERLAY_SUBLAYER 都小于0,因此,无论如何,字幕始终被渲染在页面的下方。又因为视频理应渲染在字幕的下方,所以 不推荐 开发者在使用 SurfaceView 渲染视频时调用 setZOrderOnTop(true),将视频放在页面视图的顶层。
其次,同时具有 setZOrderOnTop() 和 setZOrderMediaOverlay() 方法,显然是提供给两个不同 SurfaceView 分别使用的,以定义不同的渲染层级,因此同一个页面存在多个 SurfaceView 是正常的,开发者完全可以根据业务场景,合理运用。
4. 令人头大的黑屏问题
在使用 SurfaceView 的过程中,笔者最终也遇到了 默认黑屏 的问题:
由于视频本身的加载和编解码的耗时,用户总是会先看到 SurfaceView 的黑色背景一闪而过,然后视频才开始播放的情况,对于产品而言,这种交互体验是 不可容忍 的。
通过上文读者知道,SurfaceView 拥有独立的绘制表面,因此常规对付 View 的一些手段——比如 setVisibility() 、setAlpha() 、setBackgroundColor() 并不能解决上述问题;因此,想真正解决它,就必须先弄清楚 SurfaceView 底层的绘制流程。
SurfaceView 虽然特殊,但其作为视图树的一个结点,其依然参与到了视图树常规绘制流程,这里我们直接看 SurfaceView 的 draw() 方法:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
//...
@Override
public void draw(Canvas canvas) {
if (mDrawFinished && !isAboveParent()) { // 1.
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == 0) {
clearSurfaceViewPort(canvas);
}
}
super.draw(canvas);
}
private void clearSurfaceViewPort(Canvas canvas) {
// ...
canvas.drawColor(0, PorterDuff.Mode.CLEAR); // 2.
}
}由此可见,当满足 !isAboveParent() 的条件——即 SurfaceView 的子图层类型位于宿主视图的下方时,SurfaceView 默认会将绘图表面的颜色指定为黑色。
显然,该问题最简单的解决方式就是对源码进行hook或者反射,遗憾的是,上文我们也提到了,出于安全性的考量,SurfaceView 的源码是没有公开暴露的。
设计者其实也想到了这个问题,因此额外提供了一个 SurfaceHolder 的 API 接口,通过该接口,开发者可以直接拿到独立绘图表面的 Canvas 对象,以及对这个画布进行绘制操作:
// /frameworks/base/core/java/android/view/SurfaceHolder.java
public interface SurfaceHolder {
// ...
public Canvas lockCanvas();
public void unlockCanvasAndPost(Canvas canvas);
//...
}遗憾的是,即使拿到 Canvas,开发者仍然会受到限制:
// /frameworks/base/core/java/com/android/internal/view/BaseSurfaceHolder.java
public abstract class BaseSurfaceHolder implements SurfaceHolder {
private final Canvas internalLockCanvas(Rect dirty, boolean hardware) {
if (mType == SURFACE_TYPE_PUSH_BUFFERS) {
throw new BadSurfaceTypeException("Surface type is SURFACE_TYPE_PUSH_BUFFERS");
}
// ...
}
}这里的代码,笔者引用 罗升阳 的 这篇文章 中的一段来解释:
注意,只有在一个
SurfaceView的绘图表面的类型不是SURFACE_TYPE_PUSH_BUFFERS的时候,我们才可以自由地在上面绘制UI。我们使用SurfaceView来显示摄像头预览或者播放视频时,一般就是会将它的绘图表面的类型设置为SURFACE_TYPE_PUSH_BUFFERS。在这种情况下,SurfaceView的绘图表面所使用的图形缓冲区是完全由摄像头服务或者视频播放服务来提供的,因此,我们就不可以随意地去访问该图形缓冲区,而是要由摄像头服务或者视频播放服务来访问,因为该图形缓冲区有可能是在专门的硬件里面分配的。
由此可见,SurfaceView 黑屏问题的原因是综合且复杂的,无论是通过 setZOrderOnTop() 等方法设置为背景透明(但是会在页面层级的最上方),亦或者调整布局参数,都会有大大小小的一些问题。
小结
综合来看,SurfaceView 这些饱受争议的问题,从设计的角度来看,都是有其自身考量的。
而为了解决这些问题,官方后续提供了 TextureView 以替换 SurfaceView,TextureView 的原理是和 View 一样绘制到当前 Activity 的窗口上,因此不存在 SurfaceView 的这些问题。
换个角度来看,由于 TextureView 渲染依赖于主线程,因此也会导致了新的问题出现。除了性能比较 SurfaceView 会有明显下降外,还会有经常掉帧的问题,有机会笔者会另起一篇进行分享。
参考 & 感谢
细心的读者应该能够发现,关于 参考&感谢 一节,笔者着墨越来越多,原因无他,笔者 从不认为 一篇文章就能够讲一个知识体系讲解的面面俱到,本文亦如是。
因此,读者应该有选择性查看其它优质内容的权利,甚至是为其增加一些简洁的介绍(因为标题大多都很相似),而不是文章末尾甩一堆
https开头的链接不知所云。
这也是对这些内容创作者的尊重,如果你喜欢本文,也同样希望你能够喜欢下面这些文章。
1. Android源码-frameworks-SurfaceView
阅读源码永远是学习最有效的方式,如果你想更进一步深入了解 SurfaceView,选它就对了。
遗憾的是,在笔者学习的过程中,官方文档并未给予到很大的帮助,相当一部分原因是因为文档中的内容太 规范 了,保持内容 精炼 且 准确 的同时,也增加了读者的理解成本。
但无论如何,作为权威的官方文档,仍适合作为复习资料,反复阅读。
3. Android视图SurfaceView的实现原理分析 @罗升阳
神作, 我认为它是 最适合 进阶学习和研究 SurfaceView 源码的文章。
4. Android 5.0(Lollipop)中的SurfaceTexture,TextureView, SurfaceView和GLSurfaceView @ariesjzj
在笔者摸索学习,困惑于标题中这些概念的阶段,本文以浅显易懂的方式对它们进行了简单的总结,推荐。
链接:https://juejin.cn/post/7140191497982312455
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
超有用的Android开发技巧:拦截界面View创建
LayoutInflater.Factory2是个啥?
Activity内界面的创建是由LayoutInflater负责,LayoutInflater最终会交给内部的一个类型为LayoutInflater.Factory2的factory2成员变量进行创建。
这个属性值可以外部自定义传入,默认的实现类为AppCompatDelegateImpl:
然后在AppCompatActivity的初始化构造方法中向LayoutInflater注入AppCompatDelegateImpl:
常见的ImageView、TextView被替换成AppcompatImageView、AppCompatTextView等就是借助AppCompatDelegateImpl进行实现的。
这里有个实现的小细节,在initDelegate()方法中,调用了addOnContextAvailableListener()方法传入一个监听事件实现的factory2注入,这个addOnContextAvailableListener()方法有什么魅力呢?
addOnContextAvailableListener()是干啥用的?
咱们先看下这个方法是干啥用的:
最终是将这个监听对象加入到了ContextAwareHelper类的内部mListeners集合中,咱们接下里看下这个监听对象集合最终是在哪里被调用的。
可以看到,这个集合最终在ComponetActivity的onCreate()方法中调用,请注意,这个调用时机还是在父类的super.onCreate()方法前进行调用的。
所以我们可以得出结论,addOnContextAvailableListener()添加的监听器将在父类onCreate()方法前进行调用。
这个用处的场景还是比较多的,比如我们设置Activity的主题就必须在父类的onCreate()方法前调用,借助这个监听,可以轻松实现。
代码实战
请注意,这个
factory2的设置必须在Activity的onCreate()方法前调用,所以我们可以直接借助addOnContextAvailableListener()进行实现,也可以重写onCreate()方法在指定位置实现。当然了,前者更加的灵活,这里我们还是以后者进行举例。
override fun onCreate(savedInstanceState: Bundle?) {
LayoutInflaterCompat.setFactory2(layoutInflater, object : LayoutInflater.Factory2 {
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet
): View? {
return if (name == "要替换的系统View名称") {
CustumeView()
} else delegate.createView(parent, name, context, attrs)
}
})
}请注意,这里也有一个实现的小细节,如果当某个系统View不属于我们要替换的View,请继续委托给AppCompatDelegateImpl进行处理,这样就保证了实现系统组件特有功能的前提下,又能完成我们的View替换工作。
统一所有界面View的替换工作
如果要替换View的界面非常多,一个Activity一个Activity替换过去太麻烦 ,这个时候就可以使用我们经常使用到的Application的registerActivityLifecycleCallbacks()监听所有Activity的创建流程,其中我们用到的方法就是onActivityPreCreated():
registerActivityLifecycleCallbacks(object : Application.ActivityLifecycleCallbacks {
override fun onActivityPreCreated(activity: Activity, savedInstanceState: Bundle?) {
LayoutInflaterCompat.setFactory2(activity.layoutInflater, object : LayoutInflater.Factory2 {
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet
): View? {
return if (name == "要替换的系统View名称") {
CustumeView()
} else (activity as? AppCompatActivity)?.delegate?.createView(parent, name, context, attrs) ?: null
}
override fun onCreateView(name: String, context: Context, attrs: AttributeSet): View? {
TODO("Not yet implemented")
}
})
}
}不过这个Application.ActivityLifecycleCallbacks接口要重写好多无用的方法,太麻烦了,之前写过一篇关于接口优化相关的文章吗,详情可以参考:接口使用额外重写的无关方法太多?优化它
总结
之前看过很多换肤、埋点统计上报等相关文章,多多少少都介绍了向AppCompatActivity中注入factory2拦截系统View创建的思想,我们设置还可以借助此实现界面黑白化的效果,非常的好用,每个开发者都应该去了解掌握的知识点。
链接:https://juejin.cn/post/7137305357415612452
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
synchronized实现原理
synchronized作为java语言中的并发关键词,其在代码中出现的频率相当高频,大多数开发者在涉及到并发场景时,一般都会下意识得选取synchronized。
synchronized在代码中主要有三类用法,根据其用法不同,所获取的锁对象也不同,如下所示:
- 修饰代码块:这种用法通常叫做同步代码块,获取的锁对象是在synchronized中显式指定的
- 修饰实例方法:这种用法通常叫做同步方法,获取的锁对象是当前的类对象
- 修饰静态方法:这种用法通常叫做静态同步方法,获取的锁对象是当前类的类对象
下面我们一起来测试下三种方式下,对象锁的归属及锁升级过程,SynchronizedTestClass类代码如下:
import org.openjdk.jol.info.ClassLayout;
public class SynchronizedTestClass {
private Object mLock = new Object();
public void testSynchronizedBlock(){
System.out.println("before get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(mLock).toPrintable());
synchronized (mLock) {
System.out.println("testSynchronizedBlock start:"+Thread.currentThread().getName());
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(mLock).toPrintable());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedBlock end:"+Thread.currentThread().getName());
}
}
public synchronized void testSynchronizedMethod() {
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(this).toPrintable());
System.out.println("testSynchronizedMethod start:"+Thread.currentThread().getName());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedMethod end:"+Thread.currentThread().getName());
}
public static synchronized void testSynchronizedStaticMethod() {
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(SynchronizedTestClass.class).toPrintable());
System.out.println("testSynchronizedStaticMethod start:"+Thread.currentThread().getName());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedStaticMethod end:"+Thread.currentThread().getName());
}
}同步代码块
在main函数编写如下代码,调用SynchronizedTestClass类中包含同步代码块的测试方法,如下所示:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}运行结果如下:
从上图可以看出在线程2获取锁前,mLock处于无锁状态,等线程2获取锁后,mLock对象升级为轻量级锁,等线程1获取锁后升级为重量级锁,有同学要问了,你在多线程与锁中不是说了synchronized锁升级有四个吗?你是不是写BUG了,当然没有啊,现在我们来看看偏向锁去哪儿了?
偏向锁
对于不同版本的JDK而言,其针对偏向锁的开关和配置均有所不同,我们可以通过执行java -XX:+PrintFlagsFinal -version | grep BiasedLocking来获取偏向锁相关配置,执行命令输出如下:
从上图可以看出在JDK 1.8上,偏向锁默认开启,具有4秒延时,那么我们修改main内容,延时5秒开始执行,看看现象如何,代码如下:
public static void main(String[] args) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}输出如下:
从上图可以看出在延迟5s执行后,mLock锁变成了无锁可偏向状态,结合上面两个示例,我们可以看出,在轻量级锁和偏向锁阶段均有可能直接升级成重量级锁,是否升级依赖于当时的锁竞争关系,据此我们可以得到synchronized锁升级的常见过程,如下图所示:
可以看出,我们遇到的两种情况分别对应升级路线1和升级路线4。
同步方法
使用线程池调用SynchronizedTestClass类中的同步方法,代码如下:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
}运行结果如下:
可以看出,在调用同步方法时,直接升级为重量级锁,同一时刻,有且仅有一个线程在同步方法中执行,其他函数在同步方法入口处阻塞等待。
静态同步方法
使用线程池调用SynchronizedTestClass类中的静态同步方法,代码如下
public static void main(String[] args) {
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
}运行结果如下:
可以看出,在调用静态同步方法时,直接升级为重量级锁,同一时刻,有且仅有一个线程在静态同步方法中执行,其他函数在同步方法入口处阻塞等待。
前面我们看的是多个线程竞争同一个锁对象,那么假设我们有三个线程分别执行这三个函数,又会怎样呢?代码如下:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}运行结果:
可以看到,3个线程各自运行,互不影响,这也进一步印证了前文所说的锁对象以及MarkWord中标记锁状态的概念。
synchronized实现原理
上面已经学习了synchronized的常见用法,关联的锁对象以及锁升级的过程,接下来我们来看下synchronized实现原理,仍然以上面的SynchronizedTestClass为例,查看其生成的字节码来了解synchronized关键字的实现。
同步代码块
testSynchronizedBlock其所对应的字节码如下图所示:
从上图代码和字节码对应关系可以看出,在同步代码块中获取锁时使用monitorenter指令,释放锁时使用monitorexit指令,且会有两个monitorexit,确保在当前线程异常时,锁正常释放,避免其他线程等待死锁。
所以synchronized的同步机制是依赖monitorenter和monitorexit指令实现的,而这两个指令操作的就是mLock对象的monitor锁,monitorenter尝试获取mLock的monitor锁,如果获取成功,则monitor中的计数器+1,同时记录相关线程信息,如果获取失败,则当前线程阻塞。
Monitor锁就是存储在MarkWord中的指向重量级锁的指针所指向的对象,每个对象在构造时都会创建一个Monitor锁,用于监视当前对象的锁状态以及持锁线程信息,
同步方法
testSynchronizedMethod其所对应的字节码如下图所示:
可以看到同步方法依赖在函数声明时添加ACC_SYNCHRONIZED标记实现,在函数被ACC_SYNCHRONIZED修饰时,调用该函数会申请对象的Monitor锁,申请成功则进入函数,申请失败则阻塞当前线程。
静态同步方法
testSynchronizedStaticMethod其所对应的字节码如下图所示:
和同步方法相同,同步静态方法也是在函数声明部分添加了ACC_SYNCHRONIZED标记,也同步方法不同的是,此时申请的是该类的类对象的Monitor锁。
扩展
上文中针对synchronized的java使用以及字节码做了说明,我们可以看出synchronized是依赖显式的monitorenter,monitorexit指令和ACC_SYNCHRONIZED实现,但是字节码并不是最靠近机器的一层,相对字节码,汇编又是怎么处理synchronized相关的字节码指令的呢?
我们可以通过获取java代码的汇编代码来查看,查看Java类的汇编代码需要依赖hsdis工具,该工具可以从chriswhocodes.com/hsdis/下载(科学上网),下载完成后,在Intellij Idea中配置Main类的编译参数如下图所示:
其中vm options详细参数如下:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=compileonly,*SynchronizedTestClass.testSynchronizedBlock -XX:CompileCommand=compileonly,*SynchronizedTestClass.testSynchronizedMethod -XX:+LogCompilation -XX:LogFile=/Volumes/Storage/hotspot.log
其中“compileOnly,”后面跟的是你要抓取的函数名称,格式为:*类名.函数名,LogFile=后指向的是存储汇编代码的文件。
环境变量配置如下:
LIBRARY_PATH=/Volumes/Storage/hsdis
这里的写法是:hsdis存储路径+/hsdis
随后再次运行Main.main即可看到相关汇编代码输出在运行窗口,通过分析运行窗口输出的内容,我们可以看到如下截图:
可以看出在运行时调用SynchronizedTestClass::testSynchronizedMethod时,进入synchronized需要执行lock cmpxchg以确保多线程安全,故synchronized的汇编实现为lock cmpxchg指令。
链接:https://juejin.cn/post/7174054610301091877
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
花里胡哨的文字特效,你学会了吗?
前言
我们的 App 大部分时候的文字都是一种颜色,实际上,文字的颜色也可以多姿多彩。我们今天就来介绍一个能够轻松实现文字渐变色的组件 —— ShaderMask。ShaderMask 能够构建一个着色器(shader),然后覆盖(mask)到它的子组件上,从而改变子组件的颜色。
ShaderMask 实现渐变色文字
ShaderMask 的构造函数定义如下。
const ShaderMask({
Key? key,
required this.shaderCallback,
this.blendMode = BlendMode.modulate,
Widget? child,
})其中关键的参数是 shaderCallback回调方法,通过 回调方法可以构建一个着色器来为子组件着色,典型的做法是使用 Gradient 的子类(如 LinearGradient 和 RadialGradial)来创建着色器。blendMode 参数则用于设置着色的方式。
因此,我们可以利用LinearGradient来实现渐变色文字,示例代码如下,其中 blendMode 选择为 BlendMode.srcIn 是忽略子组件原有的颜色,使用着色器来对子组件着色。
ShaderMask(
shaderCallback: (rect) {
return LinearGradient(
begin: Alignment.centerLeft,
end: Alignment.centerRight,
colors: [
Colors.blue,
Colors.green[300]!,
Colors.orange[400]!,
Colors.red,
],
).createShader(rect);
},
blendMode: BlendMode.srcIn,
child: const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
),实现效果如下图。
实际上,不仅仅能够对文字着色,还可以对图片着色,比如我们使用一个 Row 组件在文字前面增加一个Image 组件,可以实现下面的效果。
让渐变色动起来
静态的渐变色着色还不够,Gradient 还有个 transform 来实现三维空间变换的渐变效果,我们可以利用这个参数和动画组件实现动画效果,比如下面这样。
这里其实就是使用了动画控制 transform 实现横向平移。由于 transform 是一个 GradientTransform 类,实现这样的效果需要定义一个GradientTransform子类,如下所示。
@immutable
class SweepTransform extends GradientTransform {
const SweepTransform(this.dx, this.dy);
final double dx;
final double dy;
@override
Matrix4 transform(Rect bounds, {TextDirection? textDirection}) {
return Matrix4.identity()..translate(dx, dy);
}
@override
bool operator ==(Object other) {
if (identical(this, other)) {
return true;
}
if (other.runtimeType != runtimeType) {
return false;
}
return other is SweepTransform && other.dx == dx && other.dy == dy;
}
@override
int get hashCode => dx.hashCode & dy.hashCode;
}然后通过 Animation 动画对象的值控制渐变色平移的距离就可以实现渐变色横向扫过的效果了,代码如下所示。
ShaderMask(
shaderCallback: (rect) {
return LinearGradient(
begin: Alignment.centerLeft,
end: Alignment.centerRight,
colors: [
Colors.blue,
Colors.green[300]!,
Colors.orange[400]!,
Colors.red,
],
transform: SweepTransform(
(_animation.value - 0.5) * rect.width, 0.0),
).createShader(rect);
},
blendMode: BlendMode.srcIn,
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.asset(
'images/logo.png',
scale: 2,
),
const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
],
),
),图片填充
除了使用渐变色之外,我们还可以利用 ImageShader 使用图片填充文字,实现一些其他的文字特效,比如用火焰图片作为背景,让文字看起来像燃烧了一样。
实现的代码如下,其中动效是通过 ImageShader 的构造函数的第4个参数的矩阵matrix4运算实现的,相当于是让填充图片移动来实现火焰往上升的效果。
ShaderMask(
shaderCallback: (rect) {
return ImageShader(
fillImage,
TileMode.decal,
TileMode.decal,
(Matrix4.identity()
..translate(-20.0 * _animation.value,
-150.0 * _animation.value))
.storage);
},
blendMode: BlendMode.srcIn,
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.asset(
'images/logo.png',
scale: 2,
),
const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
],
),
)总结
本篇介绍了 ShaderMask 组件的应用,通过 ShaderMask 组件我们可以对子组件进行着色,从而改变子组件原来的颜色,实现如渐变色填充、图片填充等效果。本篇完整源码已提交至:实用组件相关源码。
链接:https://juejin.cn/post/7172513057044692999
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从阅读仿真页看贝塞尔曲线
前言
一直觉得阅读器里面的仿真页很有意思,最近在看阅读器相关代码的时候发现仿真页是基于贝塞尔曲线去实现的,所以就有了此篇文章。
仿真页一般有两种实现方式:
- 将内容绘制在Bitmap上,基于Canvas去处理仿真页
- OpenGl es
本篇文章我会向大家介绍如何使用Canvas绘制贝塞尔曲线,以及详细的像大家介绍仿真页的实现思路。
后续有机会的话,希望可以再向大家介绍方案二(OpenGL es 学习中...)。
一、贝塞尔曲线介绍
贝塞尔曲线是应用于二维图形应用程序的数学曲线,最初是用在汽车设计的。我们在绘图工具上也常常见到曲线,比如钢笔工具。
为了绘制出更加平滑的曲线,在 Android 中我们也可以使用 Path 去绘制贝塞尔曲线,比如这类曲线图或者描述声波的图:
我们先简单的了解一下基础知识,可以在这个网站先体验一把如何控制贝塞尔曲线:
http://www.jasondavies.com/animated-be…
一阶到四阶都有。
1. 一阶贝塞尔曲线
给定点 P0 和 P1,一阶贝塞尔曲线是两点之间的直线,这条线的公式如下:
图片表示如下:
2. 二阶贝塞尔曲线
从二阶开始,就变得复杂起来,对于给定的 P0、P1 和 P2,都对应的曲线:
图片表示如下:
二阶的公式是如何得出来的?我们可以假设 P0 到 P1 点是 P3,P1 - P2 的点是P4,二阶贝塞尔也只是 P3 - P4 之间的动态点,则有:
P3 = (1-t) P0 + tP1
P4 = (1-t) P1 + tP2
二阶贝塞尔曲线 B(t) = (1-t)P3 + tP4 = (1-t)((1-t)P0 + tP1) + t((1-t)P1 + tP2) = (1-t)(1-t)P0 + 2t(1-t)P1 + ttP2
与最终的公式对应。
3. 三阶贝塞尔曲线
三阶贝塞尔曲线由四个点控制,对于给定的 P0、P1、P2 和 P3,有对应的曲线:
对应的图片:
同样的,三阶贝塞尔可以由二阶贝塞尔得出,从上面的知识我们可以得处,下图中的点 R0 和 R1 的路径其实是二阶的贝塞尔曲线:
对于给定的点 B,有如下的公式,将二阶贝塞尔曲线带入:
R0 = (1-t)(1-t)P0 + 2t(1-t)P1 + ttP2
R1 = (1-t)(1-t)P1 + 2t(1-t)P2 + ttP3
B(t) = (1-t)R0 + tR1 = (1-t)((1-t)(1-t)P0 + 2t(1-t)P1 + ttP2) + t((1-t)(1-t)P1 + 2t(1-t)P2 + ttP3)
最终的结果就是三阶贝塞尔曲线的最终公式。
4. 多阶贝塞尔曲线
多阶贝塞尔曲线我们就不细讲了,可以知道的是,每一阶都可以由它的上一阶贝塞尔曲线推导而出。就像我们之前由一阶推导二阶,由二阶推导出三阶。
二、Android对应的API
Android提供了 Path 供我们去绘制贝塞尔曲线。一阶贝塞尔是一条直线,所以不用处理了。
看一下 Path 对应的 API:
- Path#quadTo(float x1, float y1, float x2, float y2):二阶
- Path#cubicTo(float x1, float y1, float x2, float y2,float x3, float y3):三阶
对于一段贝塞尔曲线来说,由三部分组成:
- 一个开始点
- 一到多个控制点
- 一个结束点
使用的方法也很简单,先挪到开始点,然后将控制点和结束点统统加进来:
class BezierView @JvmOverloads constructor(
context: Context,
attributeSet: AttributeSet? = null,
defStyle: Int = 0
) : View(context, attributeSet, defStyle) {
private val path = Path()
private val paint = Paint()
override fun onDraw(canvas: Canvas?) {
super.onDraw(canvas)
paint.style = Paint.Style.STROKE
paint.strokeWidth = 3f
path.moveTo(0f, 200f)
path.quadTo(200f, 0f, 400f, 200f)
paint.color = Color.BLUE
canvas?.drawPath(path, paint)
path.rewind()
path.moveTo(0f, 600f)
path.cubicTo(100f, 400f, 200f, 800f, 300f, 600f)
paint.color = Color.RED
canvas?.drawPath(path, paint);
}
}最后的结果:
上面是二阶贝塞尔,下面是三阶贝塞尔,可以发现,控制点越多,就能设计出越复杂的曲线。如果想使用二阶贝塞尔实现三阶的效果,就得使用两个二阶贝塞尔曲线。
三、简单案例
既然刚刚画了两个曲线,我们可以利用这个方式简单模拟一个动态声波的曲线,像这样:
这个动画只需要在刚刚的代码的基础上稍微改动一点:
class BezierView @JvmOverloads constructor(
context: Context,
attributeSet: AttributeSet? = null,
defStyle: Int = 0
) : View(context, attributeSet, defStyle) {
private val path = Path()
private val paint = Paint()
private var width = 0f
private var height = 0f
private var quadY = 0f
private var cubicY = 0f
private var per = 1.0f
private var quadHeight = 100f
private var cubicHeight = 200f
private var bezierAnim: ValueAnimator? = null
init {
paint.style = Paint.Style.STROKE
paint.strokeWidth = 3f
paint.isDither = true
paint.isAntiAlias = true
}
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
width = w.toFloat()
height = h.toFloat()
quadY = height / 4
cubicY = height - height / 4
}
fun startBezierAnim() {
bezierAnim?.cancel()
bezierAnim = ValueAnimator.ofFloat(1.0f, 0f, 1.0f).apply {
addUpdateListener {
val value = it.animatedValue as Float
per = value
invalidate()
}
addListener(object :AnimatorListener{
override fun onAnimationStart(animation: Animator?) {
}
override fun onAnimationEnd(animation: Animator?) {
}
override fun onAnimationCancel(animation: Animator?) {
}
override fun onAnimationRepeat(animation: Animator?) {
val random = Random(System.currentTimeMillis())
val one = random.nextInt(400).toFloat()
val two = random.nextInt(800).toFloat()
quadHeight = one
cubicHeight = two
}
})
duration = 300
repeatCount = -1
start()
}
}
override fun onDraw(canvas: Canvas?) {
super.onDraw(canvas)
var quadStart = 0f
path.reset()
path.moveTo(quadStart, quadY)
while (quadStart <= width){
path.quadTo(quadStart + 75f, quadY - quadHeight * per, quadStart + 150f, quadY)
path.quadTo(quadStart + 225f, quadY + quadHeight * per, quadStart + 300f, quadY)
quadStart += 300f
}
paint.color = Color.BLUE
canvas?.drawPath(path, paint)
path.reset()
var cubicStart = 0f
path.moveTo(cubicStart, cubicY)
while (cubicStart <= width){
path.cubicTo(cubicStart + 100f, cubicY - cubicHeight * per, cubicStart + 200f, cubicY + cubicHeight * per, cubicStart + 300f, cubicY)
cubicStart += 300f
}
paint.color = Color.RED
canvas?.drawPath(path, paint);
}
}上面基于二阶贝塞尔曲线,下面基于三阶贝塞尔曲线,加了一层属性动画。
四、仿真页的拆分
我们在本篇文章不会涉及到仿真页的代码,主要做一下仿真页的拆分。
下面的这套方案也是总结自何明桂大佬的方案。
从图中的仿真页中我们可以看出,上下一共两页,我们需要处理:
- 第一页的内容
- 第一页的背面
- 第二页露出来的内容
这三部分中,除了 GE 和 FH 是两段曲线,其他都是直线,直线是比较好计算的,先看两段曲线。
通过观察发现,这里的 GE 和 FH 都是对称的,只有一个平滑的弯,用一个控制点就能应付,所以选择二阶贝塞尔曲线就够了。GE 这段二阶段贝塞尔曲线,对应的控制点是 C,FH 对应的控制点是 D。
1. 第一页正面
再看图片,路径 A - F - H - B - G - E - A 之外的就是第一页正面,将内容页和这个路径的 Path 取反即可。
具体的过程:
- 已知 A 是触摸点,B 是内容页的底角点,可以求出中点 M 的坐标
- AB 和 CD 相互垂直,所以可得 CD 的斜率,从 M 点坐标推出 CD 两点坐标
- E 是 AC 中点,F 是 AD 中点,那么 E 和 F 的点位置很容易推导出来
2. 第二页内容
第二页的重点 KLB 这个三角形,M 是 AB 的中点,J 是 AM 的中点,N 是 JM 的重点,通过斜率很容易推导出与边界相交的KL 两点,之后从内容页上裁出 KLB 这个Path,第二页的内容绘制在这个 Path 即可。
3. 第一页的背面
背面这一块儿绘制的区域是三角形 AOP,AC、AD 和 KL 都已知,求出相交的 KL 点即可。
但是我们还得将第一页底部的内容做一个旋转和偏移,再加上一层蒙层,就可以得到我们想要的背面内容。
总结
可以看出,学会了贝塞尔曲线以后,仿真页其实并不算特别复杂,但是整个数学计算还是很麻烦的。
下篇文章再和大家讨论具体的代码,如果觉得本文有什么问题,评论区见!
参考文章:
链接:https://juejin.cn/post/7173850844977168392
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么?还在傻傻地手写Parcelable实现?
什么?还在傻傻地手写Parcelable实现?
缘起
序列化已经是Android司空见惯的东西了,场景太多了。就拿Intent来说吧,extra能放的数据,除了基本类型外,就是序列化的数据了,有两种:
Serializable:Java世界自带的序列化工具,大道至简,是一个无方法接口Parcelable:Android的官配序列化工具
这二者在性能、用法乃至适用场景上均有不同,网上的讨论已经很多了,这里不再赘述。
下面来看看官配正品怎么用的。
Android的Parcelable
首先看看官方示例:
public class MyParcelable implements Parcelable {
private int mData;
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel out, int flags) {
out.writeInt(mData);
}
public static final Parcelable.Creator<MyParcelable> CREATOR
= new Parcelable.Creator<MyParcelable>() {
public MyParcelable createFromParcel(Parcel in) {
return new MyParcelable(in);
}
public MyParcelable[] newArray(int size) {
return new MyParcelable[size];
}
};
private MyParcelable(Parcel in) {
mData = in.readInt();
}
}可以总结,实现Parcelable的数据类,有两个要点:
- 必须有一个 非空的、静态的且名为"CREATOR" 的对象,该对象实现
Parcelable.Creator接口 - 实现方法
describeContents,描述内容;
实现方法writeToParcel,将类数据打入parcel内
示例中,实际的数据只有一个简单的整型。
实验:Intent中的Parcelable传递
这里通过一个案例来说明一下Parcelable的使用。
首先,定义一个数据类User,它包含一个String和一个Int:
class User() : Parcelable {
var name: String? = ""
var updatedTime: Long = 0L
constructor(parcel: Parcel) : this() {
name = parcel.readString()
updatedTime = parcel.readLong()
}
constructor(name: String?, time: Long) : this() {
this.name = name
updatedTime = time
}
override fun writeToParcel(parcel: Parcel, flags: Int) {
Log.d("p-test", "write to")
parcel.writeString(name)
parcel.writeLong(updatedTime)
}
override fun describeContents(): Int {
return 0
}
companion object CREATOR : Parcelable.Creator<User> {
override fun createFromParcel(parcel: Parcel): User {
Log.d("p-test", "createFromParcel")
return User(parcel)
}
override fun newArray(size: Int): Array<User?> {
return arrayOfNulls(size)
}
}
override fun toString(): String = "$name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}启动方带上User数据:
Log.d("p-test", "navigate to receiver")
context.startActivity(Intent(context, ReceiverActivity::class.java).apply {
putExtra("user", User("Dale", System.currentTimeMillis())) // 调用Intent.putExtra(String name, @Nullable Parcelable value)
})接收方读取并显示User数据:
Log.d("p-test", "onCreate")
val desc: User? = intent?.getParcelableExtra("user")
// 省略展示:desc?.toString()来看看日志:
2022-05-18 11:45:28.280 26148-26148 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 11:45:28.282 26148-26148 p-test com.jacee.example.parcelabletest D write to
2022-05-18 11:45:28.342 26148-26148 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 11:45:28.343 26148-26148 p-test com.jacee.example.parcelabletest D createFromParcel其过程为:
- 启动
- User类调用
writeToParcel,将数据写入Parcel - 接收
CREATOR调用createFromParcel,从Parcel中读取数据,并构造相应的User数据类对象
界面上,User正确展示:
由此,Parcelable的数据类算是正确实现了。
看起来,虽然没有很难,但是,是真心有点儿烦啊,尤其是相较于Java的Serializable来说。有没有简化之法呢?当然有啊,要知道,现在可是Kotlin时代了!
kotlin-parcelize插件
隆重介绍kotlin-parcelize插件:它提供了一个 Parcelable 的实现生成器。有了此生成器,就不必再写如前的复杂代码了。
怎么使用呢?
首先,需要在gradle里面添加此插件:
plugins {
id 'kotlin-parcelize'
}然后,在需要 Parcelable 的数据类上添加 @kotlinx.parcelize.Parcelize 注解就行了。
来吧,改造前面的例子:
import kotlinx.parcelize.Parcelize
@Parcelize
data class User(
val name: String?,
val updatedTime: Long
): Parcelable {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}哇,简化如斯,真能实现?还是来看看上述代码对应的字节码吧:
@Metadata(
mv = {1, 6, 0},
k = 1,
d1 = {"\u0000:\n\u0002\u0018\u0002\n\u0002\u0018\u0002\n\u0000\n\u0002\u0010\u000e\n\u0000\n\u0002\u0010\t\n\u0002\b\t\n\u0002\u0010\b\n\u0000\n\u0002\u0010\u000b\n\u0000\n\u0002\u0010\u0000\n\u0002\b\u0003\n\u0002\u0010\u0002\n\u0000\n\u0002\u0018\u0002\n\u0002\b\u0002\b\u0087\b\u0018\u00002\u00020\u0001B\u0017\u0012\b\u0010\u0002\u001a\u0004\u0018\u00010\u0003\u0012\u0006\u0010\u0004\u001a\u00020\u0005¢\u0006\u0002\u0010\u0006J\u000b\u0010\u000b\u001a\u0004\u0018\u00010\u0003HÆ\u0003J\t\u0010\f\u001a\u00020\u0005HÆ\u0003J\u001f\u0010\r\u001a\u00020\u00002\n\b\u0002\u0010\u0002\u001a\u0004\u0018\u00010\u00032\b\b\u0002\u0010\u0004\u001a\u00020\u0005HÆ\u0001J\t\u0010\u000e\u001a\u00020\u000fHÖ\u0001J\u0013\u0010\u0010\u001a\u00020\u00112\b\u0010\u0012\u001a\u0004\u0018\u00010\u0013HÖ\u0003J\t\u0010\u0014\u001a\u00020\u000fHÖ\u0001J\b\u0010\u0015\u001a\u00020\u0003H\u0016J\u0019\u0010\u0016\u001a\u00020\u00172\u0006\u0010\u0018\u001a\u00020\u00192\u0006\u0010\u001a\u001a\u00020\u000fHÖ\u0001R\u0013\u0010\u0002\u001a\u0004\u0018\u00010\u0003¢\u0006\b\n\u0000\u001a\u0004\b\u0007\u0010\bR\u0011\u0010\u0004\u001a\u00020\u0005¢\u0006\b\n\u0000\u001a\u0004\b\t\u0010\n¨\u0006\u001b"},
d2 = {"Lcom/jacee/example/parcelabletest/data/User;", "Landroid/os/Parcelable;", "name", "", "updatedTime", "", "(Ljava/lang/String;J)V", "getName", "()Ljava/lang/String;", "getUpdatedTime", "()J", "component1", "component2", "copy", "describeContents", "", "equals", "", "other", "", "hashCode", "toString", "writeToParcel", "", "parcel", "Landroid/os/Parcel;", "flags", "parcelable-test_debug"}
)
@Parcelize
public final class User implements Parcelable {
@Nullable
private final String name;
private final long updatedTime;
public static final android.os.Parcelable.Creator CREATOR = new User.Creator();
@NotNull
public String toString() {
return "new: " + this.name + " - [" + DateFormat.getInstance().format(new Date(this.updatedTime)) + ']';
}
@Nullable
public final String getName() {
return this.name;
}
public final long getUpdatedTime() {
return this.updatedTime;
}
public User(@Nullable String name, long updatedTime) {
this.name = name;
this.updatedTime = updatedTime;
}
@Nullable
public final String component1() {
return this.name;
}
public final long component2() {
return this.updatedTime;
}
@NotNull
public final User copy(@Nullable String name, long updatedTime) {
return new User(name, updatedTime);
}
// $FF: synthetic method
public static User copy$default(User var0, String var1, long var2, int var4, Object var5) {
if ((var4 & 1) != 0) {
var1 = var0.name;
}
if ((var4 & 2) != 0) {
var2 = var0.updatedTime;
}
return var0.copy(var1, var2);
}
public int hashCode() {
String var10000 = this.name;
return (var10000 != null ? var10000.hashCode() : 0) * 31 + Long.hashCode(this.updatedTime);
}
public boolean equals(@Nullable Object var1) {
if (this != var1) {
if (var1 instanceof User) {
User var2 = (User)var1;
if (Intrinsics.areEqual(this.name, var2.name) && this.updatedTime == var2.updatedTime) {
return true;
}
}
return false;
} else {
return true;
}
}
public int describeContents() {
return 0;
}
public void writeToParcel(@NotNull Parcel parcel, int flags) {
Intrinsics.checkNotNullParameter(parcel, "parcel");
parcel.writeString(this.name);
parcel.writeLong(this.updatedTime);
}
@Metadata(
mv = {1, 6, 0},
k = 3
)
public static class Creator implements android.os.Parcelable.Creator {
@NotNull
public final User[] newArray(int size) {
return new User[size];
}
// $FF: synthetic method
// $FF: bridge method
public Object[] newArray(int var1) {
return this.newArray(var1);
}
@NotNull
public final User createFromParcel(@NotNull Parcel in) {
Intrinsics.checkNotNullParameter(in, "in");
return new User(in.readString(), in.readLong());
}
// $FF: synthetic method
// $FF: bridge method
public Object createFromParcel(Parcel var1) {
return this.createFromParcel(var1);
}
}
}嗯,十分眼熟 —— 这不就是 完美且完整地实现了Parcelable 吗?当然是能正确工作的!
2022-05-18 13:13:30.197 27258-27258 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 13:13:30.237 27258-27258 p-test com.jacee.example.parcelabletest D onCreate复杂的序列化逻辑
如果需要添加更复杂的序列化逻辑,就需要额外通过伴随对象实现,该对象需要实现接口 Parceler:
interface Parceler<T> {
/**
* Writes the [T] instance state to the [parcel].
*/
fun T.write(parcel: Parcel, flags: Int)
/**
* Reads the [T] instance state from the [parcel], constructs the new [T] instance and returns it.
*/
fun create(parcel: Parcel): T
/**
* Returns a new [Array]<T> with the given array [size].
*/
fun newArray(size: Int): Array<T> {
throw NotImplementedError("Generated by Android Extensions automatically")
}
}看样子,Parceler 和原生 Parcelable.Creator 十分像啊,不过多了一个 write 函数 —— 其实就是对应了Parcelable.writeToParcel方法。
简单打印点日志模拟所谓的“复杂的序列化逻辑”:
@Parcelize
data class User(
val name: String?,
val updatedTime: Long
): Parcelable {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
private companion object : Parceler<User> {
override fun create(parcel: Parcel): User {
Log.d("p-test", "new: create")
return User(parcel.readString(), parcel.readLong())
}
override fun User.write(parcel: Parcel, flags: Int) {
Log.d("p-test", "new: write to")
parcel.writeString("【${name}】")
parcel.writeLong(updatedTime)
}
}
}来看看:
2022-05-18 13:24:49.365 29603-29603 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 13:24:49.366 29603-29603 p-test com.jacee.example.parcelabletest D new: write to
2022-05-18 13:24:49.450 29603-29603 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 13:24:49.450 29603-29603 p-test com.jacee.example.parcelabletest D new: create果然调用了,其中,接收方拿到的name,确实就是write函数改造过的(加了“【】”):
映射序列化
假如数据类不能直接支持序列化,那就可以通过自定义一个Parceler,实现映射序列化。
怎么理解呢?假如有一个数据类A,是一个普通实现,不支持序列化(或者有其他原因,总之是不支持),但是呢,我们又有需求是将它序列化后使用,这时候就可以实现 Parceler<A> 类,然后用包裹A的类B来实现序列化 —— 即,通过Parceler,将普通的A包裹成了序列化的B。
// 目标数据类A
data class User(
val name: String?,
val updatedTime: Long
) {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}
// 实现的Parceler<A>
object UserParceler: Parceler<User> {
override fun create(parcel: Parcel): User {
Log.d("djx_test", "1 new: create")
return User(parcel.readString(), parcel.readLong())
}
override fun User.write(parcel: Parcel, flags: Int) {
Log.d("djx_test", "1 new: write to")
parcel.writeString("【${name}】")
parcel.writeLong(updatedTime)
}
}
// 映射类B
@Parcelize
@TypeParceler<User, UserParceler>
class Target(val value: User): Parcelable // 这个类来实现Parcelable如上就是 A -> B 的序列化映射,同样没问题:
2022-05-18 14:08:26.091 30639-30639 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 14:08:26.094 30639-30639 p-test com.jacee.example.parcelabletest D 1 new: write to
2022-05-18 14:08:26.148 30639-30639 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 14:08:26.148 30639-30639 p-test com.jacee.example.parcelabletest D 1 new: create上面的映射类B,还可以这么写:
@Parcelize
class Target(@TypeParceler<User, UserParceler> val value: User): Parcelable
// 或
@Parcelize
class Target(val value: @WriteWith<UserParceler> User): Parcelable总结
说了这么多,其实总结一下就是:
插件kotlin-parcelize接管了套路化、模版化的工作,帮我们自动生成了序列化的实现,它并没有改变 Parcelable 的实现方式。
用它就对了!
链接:https://juejin.cn/post/7098969859777789966
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
聊一聊Kotlin协程"低级"api
聊一聊kotlin协程“低级”api
Kotlin协程已经出来很久了,相信大家都有不同程度的用上了,由于最近处理的需求有遇到协程相关,因此今天来聊一Kotlin协程的“低级”api,首先低级api并不是它真的很“低级”,而是kotlin协程库中的基础api,我们一般开发用的,其实都是通过低级api进行封装的高级函数,本章会通过低级api的组合,实现一个自定义的async await 函数(下文也会介绍kotlin 高级api的async await),涉及的低级api有startCoroutine ,ContinuationInterceptor 等
startCoroutine
我们知道,一个suspend关键字修饰的函数,只能在协程体中执行,伴随着suspend 关键字,kotlin coroutine common库(平台无关)也提供出来一个api,用于直接通过suspend 修饰的函数直接启动一个协程,它就是startCoroutine
@SinceKotlin("1.3")
@Suppress("UNCHECKED_CAST")
public fun <R, T> (suspend R.() -> T).startCoroutine(
作为Receiver
receiver: R,
当前协程结束时的回调
completion: Continuation<T>
) {
createCoroutineUnintercepted(receiver, completion).intercepted().resume(Unit)
}可以看到,它的Receiver是(suspend R.() -> T),即是一个suspend修饰的函数,那么这个有什么作用呢?我们知道,在普通函数中无法调起suspend函数(因为普通函数没有隐含的Continuation对象,这里我们不在这章讲,可以参考kotlin协程的资料)
但是普通函数是可以调起一个以suspend函数作为Receiver的函数(本质也是一个普通函数)
其中startCoroutine就是其中一个,本质就是我们直接从外部提供了一个Continuation,同时调用了resume方法,去进入到了协程的世界
startCoroutine实现
createCoroutineUnintercepted(completion).intercepted().resume(Unit)这个原理我们就不细讲下去原理,之前也有写过相关的文章。通过这种调用,我们其实就可以实现在普通的函数环境,开启一个协程环境(即带有了Continuation),进而调用其他的suspend函数。
ContinuationInterceptor
我们都知道拦截器的概念,那么kotlin协程也有,就是ContinuationInterceptor,它提供以AOP的方式,让外部在resume(协程恢复)前后进行自定义的拦截操作,比如高级api中的Diapatcher就是。当然什么是resume协程恢复呢,可能读者有点懵,我们还是以上图中出现的mySuspendFunc举例子
mySuspendFunc是一个suspned函数
::mySuspendFunc.startCoroutine(object : Continuation<Unit> {
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
}
})它其实等价于
val continuation = ::mySuspendFunc.createCoroutine(object :Continuation<Unit>{
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
Log.e("hello","当前协程执行完成的回调")
}
})
continuation.resume(Unit)startCoroutine方法就相当于创建了一个Continuation对象,并调用了resume。创建Continuation可通过createCoroutine方法,返回一个Continuation,如果我们不调用resume方法,那么它其实什么也不会执行,只有调用了resume等执行方法之后,才会执行到后续的协程体(这个也是协程内部实现,感兴趣可以看看之前文章)
而我们的拦截器,就相当于在continuation.resume前后,可以添加自己的逻辑。我们可以通过继承ContinuationInterceptor,实现自己的拦截器逻辑,其中需要复写的方法是interceptContinuation方法,用于返回一个自己定义的Continuation对象,而我们可以在这个Continuation的resumeWith方法里面(当调用了resume之后,会执行到resumeWith方法),进行前后打印/其他自定义操作(比如切换线程)
class ClassInterceptor() :ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>):Continuation<T> by continuation{
override fun resumeWith(result: Result<T>) {
Log.e("hello","MyContinuation start ${result.getOrThrow()}")
continuation.resumeWith(result)
Log.e("hello","MyContinuation end ")
}
}其中的key是ContinuationInterceptor,协程内部会在每次协程恢复的时候,通过coroutineContext取出key为ContinuationInterceptor的拦截器,进行拦截调用,当然这也是kotlin协程内部实现,这里简单提一下。
实战
kotlin协程api中的 async await
我们来看一下kotlon Coroutine 的高级api async await用法
CoroutineScope(Dispatchers.Main).launch {
val block = async(Dispatchers.IO) {
// 阻塞的事项
}
// 处理其他主线程的事务
// 此时必须需要async的结果时,则可通过await()进行获取
val result = block.await()
}我们可以通过async方法,在其他线程中处理其他阻塞事务,当主线程必须要用async的结果的时候,就可以通过await等待,这里如果结果返回了,则直接获取值,否则就等待async执行完成。这是Coroutine提供给我们的高级api,能够将任务简单分层而不需要过多的回调处理。
通过startCoroutine与ContinuationInterceptor实现自定义的 async await
我们可以参考其他语言的async,或者Dart的异步方法调用,都有类似这种方式进行线程调用
async {
val result = await {
suspend 函数
}
消费result
}await在async作用域里面,同时获取到result后再进行消费,async可以直接在普通函数调用,而不需要在协程体内,下面我们来实现一下这个做法。
首先我们想要限定await函数只能在async的作用域才能使用,那么首先我们就要定义出来一个Receiver,我们可以在Receiver里面定义出自己想要暴露的方法
interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = EmptyCoroutineContext,
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
注意这个类,resumeWith 只会跟startCoroutine的这个协程绑定关系,跟await的协程没有关系
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}上面我们定义出来一个async函数,同时定义出来了一个AsyncStub的类,它有两个用处,第一个是为了充当Receiver,用于规范后续的await函数只能在这个Receiver作用域中调用,第二个作用是startCoroutine函数必须要传入一个参数completion,是为了收到当前协程结束的回调resumeWith中可以得到当前协程体结束回调的信息
await方法里面
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
// 自定义的Receiver函数
myFunc()
Thread{
切换线程执行await中的方法
it.resumeWith(Result.success(block()))
}.start()
}在await中,其实是一个扩展函数,我们可以调用任何在AsyncScope中定义的方法,同时这里我们模拟了一下线程切换的操作(Dispatcher的实现,这里不采用Dispatcher就是想让大家知道其实Dispatcher.IO也是这样实现的),在子线程中调用it.resumeWith(Result.success(block())),用于返回所需要的信息
通过上面定的方法,我们可以实现
async {
val result = await {
suspend 函数
}
消费result
}这种调用方式,但是这里引来了一个问题,因为我们在await函数中实际将操作切换到了子线程,我们想要将消费result的动作切换至主线程怎么办呢?又或者是加入我们希望获取结果前做一些调整怎么办呢?别急,我们这里预留了一个CoroutineContext函数,我们可以在外部传入一个CoroutineContext
public interface ContinuationInterceptor : CoroutineContext.Element
而CoroutineContext.Element又是继承于CoroutineContext
CoroutineContext.Element:CoroutineContext而我们的拦截器,正是CoroutineContext的子类,我们把上文的ClassInterceptor修改一下
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(自定义内容))
}
Log.e("hello", "MyContinuation end ")
}
}同时把async默认参数CoroutineContext实现一下即可
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}此后我们就可以直接通过,完美实现了一个类js协程的调用,同时具备了自动切换线程的能力
async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}结果
E start
E MyContinuation start kotlin.Unit
E MyContinuation end
E end
E 执行阻塞函数 test 1923
E MyContinuation start 自定义内容数值
E MyContinuation end
E result is 自定义内容的数值 true
E AsyncStub resumeWith 2 kotlin.Unit最后,这里需要注意的是,为什么拦截器回调了两次,因为我们async的时候开启了一个协程,同时await的时候也开启了一个,因此是两个。AsyncStub只回调了一次,是因为AsyncStub被当作complete参数传入了async开启的协程block.startCoroutine,因此只是async中的协程结束才会被回调。
本章代码
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(6 as T))
}
Log.e("hello", "MyContinuation end ")
}
}interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
myFunc()
Thread{
it.resumeWith(Result.success(block()))
}.start()
}模拟阻塞
fun test(): Int {
Thread.sleep(5000)
Log.e("hello", "执行阻塞函数 test ${Thread.currentThread().id}")
return 5
}async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}最后
我们通过协程的低级api,实现了一个与官方库不同版本的async await,同时也希望通过对低级api的设计,也能对Coroutine官方库的高级api的实现有一定的了解。
链接:https://juejin.cn/post/7172813333148958728
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter — 仅用三个步骤就能帮你把文本变得炫酷!
前言:
前天,一位不愿意透露姓名的朋友找到我,问我怎么样才能把文本变得炫酷一些,他想用图片嵌入到自己的名字里去,用来当作朋友圈的背景。我直接回了一句,你PS下不就好了。他回我一句:想要这样效果的人比较多,全部都PS的话怕不是电脑要干冒烟...能不能用代码自动生成下(请你喝奶茶🍹)。作为一个乐于助人的人,看到朋友有困难,而且实现起来也不复杂,那我必须要帮忙啊~
注:本文是一篇整活文,让大家看的开心最重要~文章只对核心代码做分析,完整代码在这里
话不多说,直接上图:
填入文本中的可以是手动上传的图片,也可以是彩色小块。
功能实现步骤分析:
1.数据的获取 — 获取输入的文本数据、获取输入的图片数据。
2.将输入的文本生成为图片
3.解析文本图片,替换像素为图片
简单三步骤,实现朴素到炫酷的转换~
1.数据的获取 — 获取输入的文本数据、获取输入的图片数据。
定义需要存放的数据
//用于获取输入的文本
TextEditingController textEditingController = TextEditingController();
//存放输入的图片
List<File> imagesPath = [];输入框
Container(
margin: const EdgeInsets.all(25.0),
child: TextField(
controller: textEditingController,
decoration: const InputDecoration(
hintText: "请输入文字",
border: OutlineInputBorder(
borderRadius: BorderRadius.all(Radius.circular(16.0)))),
),
),九宫格图片封装
@override
Widget build(BuildContext context) {
var maxWidth = MediaQuery.of(context).size.width;
//计算不同数量时,图片的大小
var _ninePictureW = (maxWidth - _space * 2 - 2 * _itemSpace - lRSpace);
...
return Offstage(
offstage: imgData!.length == -1,
child: SizedBox(
width: _bgWidth,
height: _bgHeight,
child: GridView.builder(
gridDelegate: SliverGridDelegateWithFixedCrossAxisCount(
// 可以直接指定每行(列)显示多少个Item
crossAxisCount: _crossAxisCount, // 一行的Widget数量
crossAxisSpacing: _itemSpace, // 水平间距
mainAxisSpacing: _itemSpace, // 垂直间距
childAspectRatio: _childAspectRatio, // 子Widget宽高比例
),
// 禁用滚动事件
physics: const NeverScrollableScrollPhysics(),
// GridView内边距
padding: const EdgeInsets.only(left: _space, right: _space),
itemCount:
imgData!.length < 9 ? imgData!.length + 1 : imgData!.length,
itemBuilder: (context, index) {
if (imgData!.isEmpty) {
return _addPhoto(context);
} else if (index < imgData!.length) {
return _itemCell(context, index);
} else if (index == imgData!.length) {
return _addPhoto(context);
}
return SizedBox();
}),
),
);
}添加图片
使用A佬的
wechat_assets_picker,要的就是效率~Future<void> selectAssets() async {
//获取图片
final List<AssetEntity>? result = await AssetPicker.pickAssets(
context,
);
List<File> images = [];
//循环取出File
if (result != null) {
for (int i = 0; i < result.length; i++) {
AssetEntity asset = result[i];
File? file = await asset.file;
if (file != null) {
images.add(file);
}
}
}
//更新状态,修改存放File的数组
setState(() {
imagesPath = images;
});
}
2.将输入的文本生成为图片
构建输入的文本布局
RepaintBoundary(
key: repaintKey,
child: Container(
color: Colors.white,
width: MediaQuery.of(context).size.width,
height: 300,
//image是解析图片的数据
child: image != null
? PhotoLayout(
n: 1080,
m: 900,
image: image!,
fileImages: widget.images)
:
//将输入的文本布局
Center(
child: Text(
widget.photoText,
style: const TextStyle(
fontSize: 100, fontWeight: FontWeight.bold),
),
),
)),通过
RepaintBoundary将生成的布局生成Uint8List数据/// 获取截取图片的数据,并解码
Future<img.Image?> getImageData() async {
//生成图片数据
BuildContext buildContext = repaintKey.currentContext!;
Uint8List imageBytes;
RenderRepaintBoundary boundary =
buildContext.findRenderObject() as RenderRepaintBoundary;
double dpr = ui.window.devicePixelRatio;
ui.Image image = await boundary.toImage(pixelRatio: dpr);
// image.width
ByteData? byteData = await image.toByteData(format: ui.ImageByteFormat.png);
imageBytes = byteData!.buffer.asUint8List();
var tempDir = await getTemporaryDirectory();
//生成file文件格式
var file =
await File('${tempDir.path}/image_${DateTime.now().millisecond}.png')
.create();
//转成file文件
file.writeAsBytesSync(imageBytes);
//存放生成的图片到本地
// final result = await ImageGallerySaver.saveFile(file.path);
return img.decodeImage(imageBytes);
}
3.解析文本图片,替换像素为图片
判断文本像素,在对应像素位置生成图片
Widget buildPixel(int x, int y) {
int index = x * n + y;
//根据给定的x和y坐标,获取像素的颜色编码
Color color = Color(image.getPixel(y, x));
//判断是不是白色的像素点,如果是,则用SizedBox替代
if (color == Colors.white) {
return const SizedBox.shrink();
}
else {
//如果不是,则代表是文本所在的像素,替换为输入的图片
return Image.file(
fileImages![index % fileImages!.length],
fit: BoxFit.cover,
);
}
}构建最终生成的图片
@override
Widget build(BuildContext context) {
List<Widget> children = [];
//按点去渲染图片的像素位置,每次加10是因为,图像的像素点很多,如果每一个点都替换为图片,第一是效果不好,第二是渲染的时间很久。
for (int i = 0; i < n; i = i+10) {
List<Widget> columnChildren = [];
for (int x = 0; x < m; x = x+10) {
columnChildren.add(
Expanded(
child: buildPixel(x, i),
),
);
}
children.add(Expanded(
child: Column(
crossAxisAlignment: CrossAxisAlignment.stretch,
children: columnChildren,
)));
}
//CrossAxisAlignment.stretch:子控件完全填充交叉轴方向的空间
return Row(
crossAxisAlignment: CrossAxisAlignment.stretch,
children: children,
);
}
这样就实现了文本替换为图片的功能啦~
链接:https://juejin.cn/post/7173112836569169927
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


