








Compose自定义View——LocationMarkerView
LocationMarker是运动轨迹上Start、End, 以及整公里点上笔者自定义绘制的一个MarkerView, 当时之所以没有用设计给的icon是这个MarkerView里需要填充动态的数字,自定义的话自主性比较大些也方面做动画,之前的Android 传统自定义View的实现可以看这篇文章介绍 运动App自定义LocationMarker。
这里先看下gif动图:
LocationMarkerView图的绘制
绘制方面基本没有太多的逻辑,通过Compose的自定义绘制Canvas() 绘制 一个构建的Path,生成View的Path其实是主要的实现过程。
Canvas(modifier = Modifier.size(0.dp)){
drawPath(AndroidPath(markerViewPath), color = color)
drawPath(AndroidPath(bottomOval), color = colorOval)
}这里Compose的path,还有好些接口对不上以及缺少API,所以通过AndroidPath(nativepath)接口进行转化进行绘制,bottomOval是 Start、End点底部阴影的Path。生成markerViewPath以及bottomOval的逻辑都在LocationMarker类中,LocationMarker主要包含了上下两套点 p1、p3(HPoint), 左右两套点p2、p4(VPoint), 以及绘制View的参数属性集合类MarkerParams.
获取markerViewPath, 首先给p1、p3(HPoint),p2、p4(VPoint)中8个点设置Value值,circleModel(radius),然后从底部p1底部点逆时针转圈依次调用三阶贝塞尔函数接口,最后close实现水滴倒置状态的Path,见实现:
fun getPath(radius: Float): Path{
circleModel(radius)
val path = Path()
p1.setYValue(p1.y + radius * 0.2f * 1.05f) //设置 p1 底部左右两个点的y值
p1.y += radius * 0.2f * 1.05f //设置 p1 自己的y值
path.moveTo(p1.x, p1.y)
path.cubicTo(p1.right.x, p1.right.y, p2.bottom.x, p2.bottom.y, p2.x, p2.y)
path.cubicTo(p2.top.x, p2.top.y, p3.right.x, p3.right.y, p3.x, p3.y)
path.cubicTo(p3.left.x, p3.left.y, p4.top.x, p4.top.y, p4.x, p4.y)
path.cubicTo(p4.bottom.x, p4.bottom.y, p1.left.x, p1.left.y, p1.x, p1.y)
path.close()
val circle = Path()
circle.addCircle(p3.x, p3.y + radius, markerParams.circleRadius.value, Path.Direction.CCW)
path.op(circle, Path.Op.DIFFERENCE)
return path
}拿到相应的Path后,在Composeable函数里进行如上所述的绘制Path即可:
val locationMarker = LocationMarker(markerParams)
val markerViewPath = locationMarker.getPath(markerParams.radius.value)
val bottomOval = locationMarker.getBottomOval()
val color = colorResource(id = markerParams.wrapperColor)
val colorOval = colorResource(R.color.location_bottom_shader)
Canvas(modifier = Modifier.size(0.dp)){
drawPath(AndroidPath(markerViewPath), color = color)
drawPath(AndroidPath(bottomOval), color = colorOval)
}绘制整公里的文字
Compose的Canvas 里目前的Version并不支持drawText的绘制,不过开放了一个调用原始drawText的转换API, 原始的drawText 是需要Paint参数的, 同时依赖Paint来计算Text 对应RectF的Height值,这里Paint()是Compose的一个Paint,需要调用asFrameworkPaint() 进行转化
val paint = Paint().asFrameworkPaint().apply {
setColor(-0x1)
style = android.graphics.Paint.Style.FILL
strokeWidth = 1f
isAntiAlias = true
typeface = Typeface.DEFAULT_BOLD
textSize = markerParams.txtSize.toFloat()
}计算Text 绘制依赖的RectF,并将rectF.left作为drawText的X值,同时计算drawText的基线 baseLineY,最后传入nativeCanvas.drawText() 接口进行绘制。
val rectF = createTextRectF(locationMarker, paint, markerParams)
val baseLineY = getTextBaseY(rectF, paint)
Canvas(modifier = Modifier.size(0.dp)){
drawIntoCanvas {
it.nativeCanvas.drawText(markerParams.markerStr, rectF.left, baseLineY, paint)
}
}drawText获取绘制基线 baseLineY的工具类方法:
fun getTextBaseY(rectF: RectF, paint: Paint): Float {
val fontMetrics = paint.fontMetrics
return rectF.centerY() - fontMetrics.top / 2 - fontMetrics.bottom / 2
}添加动画
这里简单的用一个放大的动画实现,跟原始的高德地图、Mapbox地图的一个growth过程的一个动画有些差距的,暂且先这样实现吧。首先是定义两个radius相关的State对象,具体来说是Proxy, 以及一个动画生长的大小控制的Float的变量Fraction,再通过自定义animateDpAsState作为 animation值的对象,最终给到MarkParams作为参数,animation值的变化,会导致MarkParams的变化,最后导致Recompose,形成动画。
val circleRadius by rememberSaveable{ mutableStateOf(25) }
val radius by rememberSaveable{ mutableStateOf(60) }
var animatedFloatFraction by remember { mutableStateOf(0f) }
val radiusDp by animateDpAsState(
targetValue = (radius * animatedFloatFraction).dp,
animationSpec = tween(
durationMillis = 1000,
delayMillis = 500,
easing = LinearOutSlowInEasing
)
)
val circleRadiusDp by animateDpAsState(
targetValue = (circleRadius * animatedFloatFraction).dp,
animationSpec = tween(
durationMillis = 1000,
delayMillis = 500,
easing = LinearOutSlowInEasing
)
)
val markerParams by remember {
derivedStateOf { MarkerParams(radiusDp, circleRadiusDp, wrapperColor = wrapperColor) }
}
Compose 自定义View LocationMarkerView 主要通过drawPath,以及调用原生的drawText, 最后添加了一个scale类似的动画实现,最终实现运动轨迹里的一个小小的View的实现。
代码见:github.com/yinxiucheng… 下的CustomerComposeView
链接:https://juejin.cn/post/7197433837340901432
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在Android中实现python的功能
起因:
为什么想写这样一篇文章呢,最开始是我的一个朋友和我说想换一个QQ头像但是苦于里面一个常用的模块被下架了在网页中找无关信息太多也显得杂乱,我就萌生了这样一个想法,我是一个程序员这种事能不能通过技术手段实现或者说简化一下说干咱就干
(PS:目前只通过Java实现了爬虫的功能就不多赘述了具体的可以自行百度,python的部分并未能全部实现故只介绍前期的准备流程及部分结果)
需要准备的工具:
Android Studio,adaconda
接下来让我们开始吧!
- 首先为了能在as中创建python文件我们需要先下载一个插件。在Plugins中搜索Python Community Edition插件下载,安装重启as后就可以在as中创建python文件了,因为Chaquopy没有与这个插件集成,所以.py文件中的代码会报错这是正常现象可以忽略,实际错误请以logcat为准
- 打开根目录下build.gradle文件引入chaquo模块
buildscript {
repositories {
xxx
maven { url 'https://jitpack.io' }
//引入chaquo模块
maven { url "https://chaquo.com/maven" }
}
dependencies {
classpath 'com.android.tools.build:gradle:4.1.3'
//如果该模块的版本引入不对会引起编译失败
//如果这里使用的版本是12.0.0及更早的版本会在模块启动时弹出吐司及通知栏显示许可证警告,并且一次只能运行五分钟
//想要删除限制需要在local.properties文件中引入chaquopy.license = free,12.0.1及之后的版本则为开源的无需额外配置
classpath "com.chaquo.python:gradle:12.0.1"
}
}
local.properties文件中内容如下
#使用闭源 Chaquopy 版本(12.0.0 及更早版本)将在启动时显示许可证警告,并且一次只能运行 5 分钟。要删除这些限制,请将以下内容添加到您的项目.
#chaquopy.license=free
#如果使用闭源代码的Chapuopy版本来构建AAR,还需要增添如下标识将AAR内置到应用程序中
#chaquopy.applicationId=your.applicationId
3.接下来让我们打开app目录下的build.gradle文件加入以下引用
plugins {
//应用模块
id 'com.android.application'
id 'com.chaquo.python'
}
android {
ndk {
//引入python模块后不支持架构为armeabi的cpu类型
abiFilters 'armeabi-v7a', 'arm64-v8a', "x86", "x86_64"
// 还可以添加 'x86', 'x86_64', 'mips', 'mips64'
}
python {
//adaconda中的python编译器,目的引入虚拟环境让python文件在安卓应用中运行,buildPython中的路径需要替换为你自己的安装地址
buildPython "D:\\ana_2\\python.exe"
pip {
//指定库的镜像下载地址:阿里云,清华等
//options "--index-url", "https://mirrors.aliyun.com/pypi/simple/"
options "--extra-index-url", "https://pypi.tuna.tsinghua.edu.cn/simple/"
//install "opencv-python"
//下载的库,需要什么模块就自行下载下载什么模块,另有些模块不支持引入详情请参阅https://chaquo.com/chaquopy/doc/current/android.html#stdlib-unsupported
install "requests"
}
}
}
4.完成以上配置后就可以开始真正的旅程了
//初始化python模块的相关文件
void initPython() {
if (!Python.isStarted()) {
Python.start(new AndroidPlatform(this));
}
}
//调用python中的内容
void callPythonCode() {
Python py = Python.getInstance();
//getModule:py文件名,不用加.py的后缀;callAttr:方法名;如果方法有返回值那pyObject就是返回值
PyObject pyObject = py.getModule("SearchHeadImg").callAttr("sjs");
String a = String.valueOf(pyObject);
Log.e(".py返回值", a);
}
这样我们就可以在app中调用python的相关功能了!
这些内容虽说不多但也是我花了很长时间踩坑一步一步总结出来的,如果有问题或者缺失的内容欢迎大佬指正补充。
收起阅读 »CSS简单实现一幅新春对联
前言
今年过年家里没有贴春联,这两天在网上看到一幅对联,觉得写得挺好的, 上联——只生欢喜不生愁;下联——此心安处是吾家; 横批——平安喜乐, 因此使用css简单实现这幅新春对联。
具体实现
页面先做一个简单描述,首先页面中间有一个大门,然后在大门两侧实现春联的上下联,大门的上面实现春联的横批,再做一个打开大门,出现兔年祝福图片的效果。
效果展示:(毛笔字体文件没有线上的资源,所以字体没有效果) code.juejin.cn/pen/7197022…
页面整体布局:
<div class="wrapper">
<div class="container">
<div class="title">平安喜乐</div>
<div class="content">
<h1>此心安处是吾家</h1>
<div class="door">
<div class="door-l"></div>
<div class="door-r"></div>
<!-- 送福图片 -->
<img src="/4034970a304e251fb44609698ce95a1c7e3e536c.webp" alt="" class="pic">
</div>
<h1>只生欢喜不生愁</h1>
</div>
</div>
</div>1. 大门的实现
大门的总体宽高都设置成350px,设置视角(perspective:1000px), 大门打开的时候呈现一种3D的视觉感受。
大门分成左右两部分门扇,使用绝对定位控制左右的位置,并使用transform-origin属性设置大门旋转动画的基点,默认情况下,元素的动作参考点(基点)为元素盒子的中心(center),这里设置左边门扇的transform-origin: left,左门扇以左边基点旋转;右边门扇的transform-origin: right,右门扇以右边基点旋转。
大门门扇的圆形门环使用伪元素实现,使用hover属性实现当鼠标移到大门上时,大门的门扇分别旋转一定的角度,实现打开大门的效果
兔年祝福图片使用绝对定位控制在大门的居中位置,并设置层级最低,当打开大门图片慢慢变大
.door {
width: 350px;
height: 350px;
border: 2px solid #333;
margin: 0 auto;
position: relative;
perspective: 1000px;
}
.door .pic{
position: absolute;
top: 50%;
left: 50%;
width: 70%;
object-fit: cover;
transform: translate(-50%,-50%);
z-index: -1;
transition: all 0.3s ease-in;
}
.door-l,
.door-r {
width: 50%;
height: 100%;
background-color: #e1b12c;
position: absolute;
top: 0;
transition: all 0.5s;
}
.door-l {
left: 0;
border-right: 1px solid #000;
transform-origin: left;
}
.door-r {
right: 0;
border-left: 1px solid #000;
transform-origin: right;
}
.door-l::before,
.door-r::before {
content: "";
border: 1px solid #000;
width: 20px;
height: 20px;
position: absolute;
top: 50%;
border-radius: 50%;
transform: translateY(-50%);
}
.door-l::before {
right: 5px;
}
.door-r::before {
left: 5px;
}
.door:hover .door-l {
transform: rotateY(-120deg);
}
.door:hover .door-r {
transform: rotateY(120deg);
}
.door:hover .pic{
width: 100%;
}2. 春联的实现
春联一般是用毛笔写的,因此在网上找了一款毛笔字体下载下来,并引入到样式中,并给春联设置红色的背景
网上下载下来的毛笔字体为trueType格式(.ttf,Windows和Mac上常见的字体格式,是一种原始格式,没有为网页进行优化处理),需要转换成Web Open Font格式(.woff,针对网页进行特殊优化,是Web字体中最佳格式)。可以在这个网站上传字体进行转换
@font-face 用于设置自定义字体,可以自定义字体名称。两个必要属性:
font-family:给引入的字体起一个名称,注意:名字不要和那些专属的名称起冲突了,比如:微软雅黑。
src:自定义字体的路径,一般采用相对路径去使用。
@font-face {
font-family: 'YFJLXS8';
src: url('./font.woff2') format('woff2'),
url('./font.woff') format('woff');
font-weight: normal;
font-style: normal;
}
* {
margin: 0;
padding: 0;
box-sizing: border-box
}
.wrapper {
height: 100vh;
font-family: 'YFJLXS8', 'Courier New', Courier, monospace;
padding: 50px;
overflow: hidden;
background: #ccc;
}
.content {
display: flex;
align-items: center;
justify-content: center;
width: 44%;
margin: 20px auto;
}
h1 {
font-size: 40px;
font-weight: 700;
width: 5vw;
color: #000;
line-height: 1;
text-align: center;
background-color: #d63031;
padding: 20px 0;
}
.title{
width: 20%;
font-size: 40px;
font-weight: 700;
text-align: center;
margin: 0 auto;
background-color: #d63031;
}作者:sherlockkid7
来源:juejin.cn/post/7196994373237866553
详解css中伪元素::before和::after和创意用法
伪类和伪元素
首先我们需要搞懂两个概念,伪类和伪元素,像我这种没有系统全面性的了解过css的人来说,突然一问我伪类和伪元素的区别我还真不知道,我之前一直以为这两个说法指的是一个东西,就是我题目中的提到的那两个::before和::after。偶然间才了解到,原来指的是两个东西
伪类
w3cSchool对于伪类的定义是”伪类用于定义元素的特殊状态“。向我们常用到的:link、:hover、:active、:first-child等都是伪类,全部伪类比较多,大家感兴趣的话可以去官方文档了解一下
伪元素
至于伪元素,w3cSchool的定义是”CSS 伪元素用于设置元素指定部分的样式“,光看定义我是搞不懂,其实我们只要记住有哪些东西就好了,伪元素共有5个,分别是::before、::after、::first-letter、::first-line和::selection
伪类和伪元素可以叠加使用,如
.sbu-btn:hover::before,本文后面示例部分也会用到此种用法。
::first-letter主要用于为文本的首字母添加特殊样式
注意:
::first-letter伪元素只适用于块级元素。
::first-line 伪元素用于向文本的首行添加特殊样式。
注意:
::first-line伪元素只能应用于块级元素。
::selection 伪元素匹配用户选择的元素部分。也就是给我们鼠标滑动选中的部分设置样式,它可以设置以下属性
colorbackgroundcursoroutline
以上几种我们简单了解一下就可以了,也不在我们今天的讨论范围之内,今天我们来着重了解一下::before和::after,相信大家在工作中都或多或少的用过,但很少有人真的去深入的了解过他们,本文是我对我所知的关于他们用法的一个总结,如有缺漏,欢迎补充。
用法及示例
::before用于在元素内容之前插入一些内容,::after用于在元素内容之后插入一些内容,其他方面的都相同。写法就是只要在想要添加的元素选择器后面加上::before或::after即可,有些人会发现,写一个冒号和两个冒号都可以有相应的效果,那是因为在css3中,w3c为了区分伪类和伪元素,用双冒号取代了伪元素的单冒号表示法,所以我们以后在写伪元素的时候尽量使用双冒号。
不同于其他伪元素,::before和::after在使用的时候必须提供content属性,可以为字符串和图片,也可以是空,但不能省略该属性,否则将不生效。
给指定元素前添加内容
这个用法是最基础也是最常用的,比如我们可以给一个或多个元素前面或者后面添加想要的文字
<div class="class1">
<p class="q">你的名字是?</p>
<p class="a">张三</p>
<p class="q">你的名字是?</p>
<p class="a">张三</p>
<p class="q">你的名字是?</p>
<p class="a">张三</p>
</div>.class1::before {
content: '问卷';
font-size: 30px;
}
.class1 .q::before {
content: '问题:'
}
.class1 .a::before {
content: '回答:'
}
当然也可以添加形状,默认的是行内元素,如果有需要,我们可以把它变为块级元素
<div class="class2">
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
</div>
.news-item::before {
content: '';
display: inline-block;
width: 16px;
height: 16px;
background: rgb(96, 228, 255);
margin-right: 8px;
border-radius: 50%;
}我们也可以使用它来添加图片
<div class="class3">
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
</div>
.class3 .text1::before {
content: url(https://lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/e08da34488b114bd4c665ba2fa520a31.svg);
}不过这一方法的缺点就是,不能调整图片大小,如果我们需要使用伪元素添加图片的话,建议通过给伪元素设置背景图片的方式设置
结合clear属性清除浮动
我们都知道清除浮动的一种方式就是给一个空元素设置clear:both属性,但在页面里添加过多的空元素一方面代码不够简洁,另一方面也不便于维护,所以我们可以通过给伪元素设置clear:both属性的方法更好的实现我们想要的效果
禁用网页ctrl+f搜索
有些时候,我们不想要用户使用ctrl+f搜索我们网页内的内容,必须在一些文字识别的网页小游戏里,我们又不想把文字做成图片,那么就可以使用这个属性,使用::before和::after渲染出来的文字,不可选中也不能搜索。当然这个低版本浏览器的兼容性我木有试,谷歌浏览器和safari是可以实现不能选中不可搜索的效果的。
拿上面的示例进行尝试,可以看到,我们使用伪元素添加的[问题]两个字,就无法使用浏览器的搜索工具搜到。
制作一款特殊的鼠标滑入滑出效果
这个效果还是之前一个朋友从某网站看到之后问我能不能实现,我去那个网站查看了代码学会的,觉得很有趣,特意分享给大家。
可以先看一下效果
这里附上源码和在线演示
.h-button {
z-index: 1;
position: relative;
overflow: hidden;
}
.h-button::before,
.h-button::after {
content: "";
width: 0;
height: 100%;
position: absolute;
filter: brightness(.9);
background-color: inherit;
z-index: -1;
}
.h-button::before {
left: 0;
}
.h-button:after {
right: 0;
transition: width .5s ease;
}
.h-button:hover::before {
width: 100%;
transition: width .5s ease;
}
.h-button:hover::after {
width: 100%;
background-color: transparent;
}这里我做了一些改进,就是鼠标滑入之后的颜色是对按钮本身颜色进行一定的变换得来的,这样我们就无需对每一个按钮单独设置鼠标滑入时候的颜色了,全局时候的时候只需要对目标按钮添加一个类名h-button就可以,更加的方便简单,当然,如果大家觉得这样的颜色不好看的话,还是可以自行设置,或者修改一我对颜色的处理方式
这个效果的实现思路其实很简单,就是使用::before和::after给目标按钮添加两个伪元素,然后使用定位让他们重合在一起,再通过改变两者的宽度实现的。
首先是创建两个伪元素,宽高都和目标元素一致,我这里的背景色由于是对按钮本身颜色进行处理得来的,所以给他们设置的背景色是沿用父级背景色,如果你想单独设置这里可以分别设置为自己想要的颜色。
.h-button {
z-index: 1;
position: relative;
overflow: hidden;
}
.h-button::before,
.h-button::after {
content: "";
width: 0;
height: 100%;
position: absolute;
filter: brightness(.9);
background-color: inherit;
z-index: -1;
}我们的实现原理是通过改变伪元素的宽度实现,所以我们需要第一个伪元素的定位以左边为准,从而实现鼠标移入时色块从左往右出现的效果,而第二个伪元素的定位以右为准,从而实现鼠标移出时色块从左往右消失的效果。
这里可以看到,我们在没有给第一个伪元素的初始状态添加过渡效果,那是因为它只需要在从鼠标移出的时候展示动画即可,在鼠标移出的时候需要瞬间消失,所以在初始状态不需要添加过渡效果,而第二个伪元素恰恰相反,它在鼠标滑入的时候不需要展示动画效果,在鼠标滑入也就是回归初始状态的时候需要展示动画效果,所以我们需要在最开始的时候就添加上过渡效果。
.h-button::before {
left: 0;
}
.h-button::after {
right: 0;
transition: width .5s ease;
}两个伪元素的初始宽度都为0,鼠标滑入的时候,让两个伪元素宽度都变为100%,由于鼠标滑入时我们并不需要第二个伪元素出现,所以这里我们给它的背景颜色设置为透明,这样就可以实现鼠标滑入时只展示第一个伪元素宽度从0到100%的动画,而鼠标移出时第一个伪元素宽度变为0,因为没有过渡效果,所以它的宽度会瞬间变为0,然后展示第二个色块宽度从100%到0的动画效果。
.h-button:hover::before {
width: 100%;
transition: width .5s ease;
}
.h-button:hover::after {
width: 100%;
background-color: transparent;
}伪元素能实现的创意用法还有很多,如果大家有不同的用法,欢迎分享,希望本篇文章可以对大家有所帮助。
作者:十里青山
来源:juejin.cn/post/7163867155639828488
团队的技术分享又轮到我了,分享点啥才能显得牛逼又有趣?
引言
新年好,我是飞叶_程序员。
见过我这个ID的朋友们肯定都知道,作为前端,我主要通过 B站up主 的身份来来进行社区交流的。 虽然主要的交流渠道不是掘金、segmentfault这样的技术站点,但与在掘金活跃的大佬们遇到的问题其实是一样的。
那就是我们需要经常阅读技术文章、技术资讯,保持和丰富自己的知识储备,不然怎么给别人分享知识呢? 这是我作为一个创作者和分享者 和 广大其他创作者们遇到的共性问题。
那作为一线的开发者,其实也有技术分享的需要,我相信大家的技术团队都是需要技术分享的。 而技术分享一般都是通过轮流进行的,也不能逮着团队里的几个人一直薅羊毛对吧。
那轮到你技术分享的时候,你是否会苦恼于不知道该分享点啥呢?
你是否担心:万一我分享的东西其他人都已经知道了,显得自己不够牛逼呢?
我想这些问题,归根到底是不知道去哪里获取技术资讯的问题。
如果你手里有大量的技术站点,他们能给你提供大量的高质量技术文章,在里面找到一篇值得分享的内容应该就不难了。
回顾2022年,我在B站发布了100多个技术视频,平均约每周两个,现在看起来都不可思议。 哪有那么多可以分享的内容啊!
前端森林
实际上我能分享那么多,得益于我收录了一些英文站点。尤其是有一些技术周刊。
我的灵感来源都是他们。不是凭空产生的。
过年期间我一直在想着把我收藏的这些站点公开出来,让其他人和创作者们也不再有技术分享的苦恼。 所以创建了一个开源项目,叫awesome-fe-sites,GitHub, 并把它部署在了fesites.netlify.app。
他的作用是收录前端资讯类站点,周刊类网站,高质量个人博客和技术团队博客,在线服务类/工具类网站等。
slogan:前端网站,尽收眼底。
同时也希望它也可以解放你的浏览器书签栏。
参与贡献
不知道你有没有一些私藏的高质量的前端站点,如果你希望把它贡献出来,欢迎PR。
另外这个站点是通过qwik这个很新的前端框架搭建的,对qwik感兴趣的话,也可以看看这个项目的代码。
作者:飞叶_前端
来源:juejin.cn/post/7193136620948684860
入坑两个月自研创业公司
一、拿offer
其实入职前,我就感觉到有点不对劲,居然要自带电脑。而且人事是周六打电话发的offer!自己多年的工作经验,讲道理不应该入这种坑,还是因为手里没粮心中慌,工作时间长的社会人,还是不要脱产考研、考公,疫情期间更是如此,本来预定2月公务员面试,结果一直拖到7月。
二、入职工作
刚入职工作时,一是有些抗拒,二呢是有些欣喜。抗拒是因为长时间呆家的惯性,以及人的惰性,我这只是呆家五个月,那些呆家一年两年的,再进入社会,真的很难,首先心理上他们就要克服自己的惰性和惯性,平时生活习惯也要发生改变
三、人言可畏
刚入职工作时,有工作几个月的老员工和我说,前公司的种种恶心人的操作,后面呢我也确实见识到了:无故扣绩效,让员工重新签署劳动协议,但是,也有很多不符实的,比如公司在搞幺蛾子的时候,居然传出来我被劝退了……
四、为什么离开
最主要的原因肯定还是因为发不出工资,打工是为了赚钱,你想白嫖我?现在公司规模也不算小了,想要缓过来,很难。即便缓过来,以后就不会出现这样的状况了?公司之前也出现过类似的状况,挺过来的老员工们我也没看到有什么优待,所以这家公司不值得我去熬。技术方面我也基本掌握了微信和支付宝小程序开发,后面不过是需求迭代。个人成长方面,虽然我现在是前端部门经理,但前端组跑的最快,可以预料后面我将面临无人可用的局面,我离职的第二天,又一名前端离职了,约等于光杆司令,没意义。
五、收获
1.不要脱产,不要脱产 2.使用uniapp进行微信和支付宝小程序开发 3.工作离家近真的很爽 4.作为技术人员,只要你的上司技术还行,你的工期他是能正常估算,有什么难点说出来,只要不是借口,他也能理解,同时,是借口他也能一下识别出来,比如,一个前端和我说:“后端需求不停调整,所以没做好。”问他具体哪些调整要两个星期?他又说不出来。这个借口就不要用了,但是我也要走了,我也没必要去得罪他。 5.进公司前,搞清楚公司目前是盈利还是靠融资活,靠融资活的创业公司有风险…
六、未来规划
关于下一份工作: 南京真是外包之城,找了两周只有外包能满足我目前18k的薪资,还有一家还降价了500… 目前offer有 vivo外包,20k 美的外包,17.5k 自研中小企业,18.5k
虽然美的外包薪资最低,但我可能还是偏向于美的外包。原因有以下几点: 1.全球手机出货量下降,南京的华为外包被裁了不少,很难说以后vivo会不会也裁。 2.美的目前是中国家电行业的龙头老大,遥遥领先第二名,目前在大力发展b2c业务,我进去做的也是和商场相关。 3.美的的办公地点离我家更近些 4.自研中小企业有上网限制,有过类似经验的开发人,懂得都懂,很难受。
关于考公: 每年10月到12月准备下,能进就进,不能再在考公上花费太多时间了。
作者:哇哦谢谢你
来源:juejin.cn/post/7160138475688165389
不修改任何现有源代码,将项目从 webpack 迁移到 vite
背景
之前将公司项目开发环境从 webpack 迁移到 vite,实现了 dev 环境下使用 vite、打包使用 webpack 的共存方案。本文将讲述开发环境下 vue3 项目打包器从 webpack 迁移到 vite 过程中的所遇问题、解决方案、迁移感受,以及如何不修改任何源码完成迁移。
迁移的前提及目标
我们之前的项目大概有 10w+ 行代码,开发环境下冷启动所花费的时间大概 1 分钟多,所以迁移到 vite 就是看中了它的核心价值:快!但是迁移到 vite,也会伴随着风险:代码改动及回归成本。
作为一个大型的已上线项目,它的线上稳定性的一定比我们工程师开发时多减少一些项目启动时间的价值要高,所以如果迁移带来了很多线上问题,那便得不偿失了。
所以我们迁移过程中有前提也有目标:
- 前提:不因为迁移打包工具引发线上问题
- 目标:实现开发环境下的快速启动
方案
有了上述前提和目标,那我们的方案就可以从这两方面思考入手了。
- 如何能确保实现前提?我们已有了稳定版本,那只要保证源代码不改动,线上的打包工具 webpack 及配置也不改动,就可以确保实现前提。
- 如何实现目标?vite 的快主要是体现在开发环境,打包使用的 rollup 相比 webpack 速度上并无太明显的优势,所以我们只要开发环境下使用 vite 启动就可以实现目标。
由此得出最终方案:不改动任何现有源代码,开发环境使用 vite,线上打包使用 webpack。
迁移过程
安装 vite 及进行基础配置
- 在终端执行下述命令,安装 vite 相关基础依赖:
yarn add vite @vitejs/plugin-vue vite-plugin-html -D
复制代码
- 因为 vite 的 html 模板文件需要显示引入入口的
.js/.ts文件,同时有一些模板变量上面的区别,为了完全不影响线上打包,在/public目录下新建一个index.vite.html文件。将/public/index.html文件的内容拷贝进来并添加入口文件的引用(/src/main.ts指向项目的入口文件):
<!DOCTYPE html>
<html lang="">
<!-- other code... -->
<body>
<!-- other code... -->
<div id="app"></div>
+ <script type="module" src="/src/main.ts"></script>
</body>
</html>
复制代码
- 新增
vite.config.js,内容如下:
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import { createHtmlPlugin } from 'vite-plugin-html';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
createHtmlPlugin({
minify: true,
/**
* After writing entry here, you will not need to add script tags in `index.html`, the original tags need to be deleted
* @default src/main.ts
*/
entry: 'src/main.ts',
/**
* If you want to store `index.html` in the specified folder, you can modify it, otherwise no configuration is required
* @default index.html
*/
template: 'public/index.vite.html',
}),
]
});
复制代码
- 在
package.json的scripts里新增一条 vite 开发启动的指令:
{
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
+ "vite": "vite"
}
}
复制代码
到这里,我们基本的配置就已经完成了,现在可以通过 npm run vite 来启动 vite 开发环境了,只不过会有一大堆的报错,我们根据可能遇到的问题一个个去解决。
问题及解决方案
HtmlWebpackPlugin 变量处理
报错: htmlWebpackPlugin is not defined
是因为之前在 webpack 的 HtmlWebpackPlugin 插件中配置了变量,而 vite 中没有这个插件,所以缺少这个变量。
我们先前安装了 vite-plugin-html 插件,所以可以在这个插件中配置变量来代替:
- 将
index.vite.html中所有的htmlWebpackPlugin.options.xxx修改为xxx,如:
<!DOCTYPE html>
<html lang="">
<head>
- <title><%= htmlWebpackPlugin.options.title %></title>
+ <title><%= title %></title>
</head>
</html>
复制代码
- 在
vite.config.js中添加如下内容:
export default defineConfig({
plugins: [
createHtmlPlugin({
+ inject: {
+ data: {
+ title: '我的项目',
+ },
+ },
}),
]
});
复制代码
其他的 html 中未定义的变量亦可以通过此方案来解决。
alias 配置
报错:Internal server error: Failed to resolve import "@/ok.ts" from "src/main.ts". Does the file exist?
通常我们的项目都会在 alias 中将 src 目录配置为 @ 来便于引用,所以遇到这个报错我们需要再 vite.config.js 中将之前 webpack 的 alias 配置补充进来(同时 vite 中 css 等样式文件的 alias 不需要加 ~ 前缀,所以也需要配置下 ~@):
import { defineConfig } from 'vite';
import path from 'path';
export default defineConfig({
resolve: {
alias: {
'@': path.resolve(__dirname, './src'),
'~@': path.resolve(__dirname, './src'),
// 其他的 alias 配置...
}
},
});
复制代码css 全局变量
报错:Internal server error: [less] variable @primaryColor is undefined
是因为项目在 less 文件中定义了变量,并在 webpack 的配置中通过 style-resources-loader 将其设置为了全局变量。我们可以在 vite.config.js 中添加如下配置引入文件将其设置为全局变量:
// vite.coonfig.js
export default defineConfig({
css: {
preprocessorOptions: {
less: {
additionalData: `@import "src/styles/var.less";`
},
},
},
});
复制代码环境变量
报错:ReferenceError: VUE_APP_HOST is not defined
这是因为项目中在 .env.local 文件中设置了以 VUE_APP_XXX 开头的环境变量,我们通过可以通过在 vite.config.js 的 define 中定义为全局变量:
// vite.config.js
export default defineConfig({
define: {
'process.env': {
NODE_ENV: import.meta.env,
APP_NAME: '我的项目名称',
},
+ VUE_APP_HOST: '"pinyin-pro.com"', // 这里需要注意定义为一个字符串
},
})
复制代码process 未定义
报错: ReferenceError: process is not defined
这是因为 webpack 启动时会根据 node 环境将代码中的 process 变量会将值给替换,而 vite 未替换该变量,所以在浏览器环境下会报错。
我们可以通过在 vite.config.js 中将 process.env 定义成一个全局变量,将相应的属性给配置好:
// vite.config.js
export default defineConfig({
define: {
'process.env': {
NODE_ENV: import.meta.env,
APP_NAME: '我的项目名称',
},
},
})
复制代码使用 JSX
报错:Uncaught ReferenceError: React is not defined
这是因为 react16 版本之后,babel 默认会将 .jsx/.tsx 语法转换为 react 函数,而我们需要以 vue 组件的方式来解析 .jsx/.tsx 文件,需要通过新的插件来解决:
- 安装
@vitejs/plugin-vue-jsx插件:
yarn add @vitejs/plugin-vue-jsx -D
复制代码
- 在
vite.config.js文件中引入插件:
// others
import vueJsx from '@vitejs/plugin-vue-jsx';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
vueJsx(),
// others...
],
});
复制代码
CommonJS 不识别
报错:ReferenceError: require is not defined
这是因为项目中通过 require() 引入了图片,webpack 支持 commonjs 语法,而 vite 开发环境是 esmodule 不支持 require。可以通过 @originjs/vite-plugin-commonjs 插件,它能解析 require 进行语法转换以支持同样效果:
- 安装
@originjs/vite-plugin-commonjs插件:
yarn add @originjs/vite-plugin-commonjs -D
复制代码
- 在
vite.config.js中引入插件:
import { viteCommonjs } from '@originjs/vite-plugin-commonjs'
export default defineConfig({
plugins: [
viteCommonjs()
]
})
复制代码
多模块导入
报错:Uncaught ReferenceError: require is not defined
这个报错注意比前面的 ReferenceError: require is not defined 多了一个 Uncaught,是因为 @originjs/vite-plugin-commonjs 并不是对所有的 require 进行了转换,我们项目中还通过 webpack 提供的 require.context 进行了多模块导入。要解决这个问题可以通过 @originjs/vite-plugin-require-context 插件实现:
- 安装
@originjs/vite-plugin-require-context插件:
yarn add @originjs/vite-plugin-require-context -D
复制代码
- 在
vite.config.js中引入插件:
import ViteRequireContext from '@originjs/vite-plugin-require-context'
export default defineConfig({
plugins: [
ViteRequireContext()
]
})
复制代码
其他 webpack 配置
其他的一些 webpack 配置例如 devServer 以及引用的一些 loader 和 plugin,只需要参考 vite 文档一一修改就行,由于各个团队的项目配置不同,我在这里就不展开了。需要注意的是,因为是开发环境下使用 vite,只需要适配开发环境的 webpack 配置就行,打包优化等不需要处理。
潜在隐患
上述方案中,我们通过不修改源代码 + 打包依然使用 webpack,保证了现有项目线上的稳定性:但还有一个潜在隐患:随着项目后期的迭代,因为开发环境是 vite,打包是 webpack,可能因为两种打包工具的不同导致开发和打包产物表现不同的缺陷。例如一旦你开发环境使用了 import.meta.xxx,打包后立马就会报错。
写在最后
我们当时采用此方案是因为 vite 刚发布没太久,用于正式环境有不少坑,而现在 vite 已经成为一款比较成熟的打包工具了,如果要迁移的话还是建议开发和打包都采用 vite,这种方面可以作为 webpack 迁移 vite 的短期过渡方案使用。(我们的项目现在打包也迁移到了 vite 了)
另外我们要明确,作为公司项目稳定性是第一位的,技术方案的变更需要明确能给项目带来收益。例如 webpack 迁移的 vite,是明确能够大幅优化开发环境的等待时间成本,而非看到别人都在用随大流而用。如果已知项目后期发展规模不会太大,当前项目启动时间也不长,就没有迁移的必要了。
上述迁移过程中遇到的坑只是针对我们的项目,没能包含全部的迁移坑点,大家有其他的遇到问题欢迎分享一起讨论。
最后推荐一个工具,可以将项目一键 webpack 迁移到 vite: webpack-to-vite
链接:https://juejin.cn/post/7197222701220053047
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
10000+条数据的内容滚动功能如何实现?
遇到脑子有问题的产品经理该怎么办?如果有这么一个需求要你在一个可视区范围内不间断循环滚动几千上万条数据你会怎么去实现?
且不说提这个需求的人是不是脑子有问题,这个需求能不能实现?肯定是可以的,把数据请求回来渲染到页面写个滚动样式就好了。抛开这样一次性请求上万条数据合不合理不讲,一万条数据渲染到页面上估计都要卡死了吧。那有没有更好的方法呢? 当然有
分析一波思路
我们分批次请求数据,比如可视化区域展示的是20条数据,那我们就一次只请求30条,然后把请求回来的数据保存起来,定义一个滚动的数组,把第一次请求的30条数据赋值给它。后面每当有一条数据滚出可视区域我们就把它删掉,然后往尾部新增一条,让滚动数组始终保持30条的数据,这样渲染在页面上的数据始终只有30条而不是一万条。文字描述太生硬我们上代码
首先定义两个数组,一个滚动区域的数组scrollList,一个总数据的数组totalList,模拟一个异步请求的方法和获取数据的方法。
<script lang="ts" setup>
import { nextTick, ref } from "vue";
type cellType = {
id: number,
title: string,
}
interface faceRequest {
data: cellType,
total: number
}
// 总数据的数组
const totalList = ref<Array<cellType>>([]);
// 滚动的数组
const scrollList = ref<Array<cellType>>([]);
// 数据是否全部加载完毕
let loading: Boolean = false
// 模拟异步请求
const request = () => {
return new Promise<faceRequest>((resolve: any, reject: any) => {
let data: Array<cellType> = []
// 每次返回30条数据
for (let i = 0; i < 30; i++) {
data.push({
id: totalList.value.length + i,
title: 'cell---' + (totalList.value.length + i)
});
}
let total = 10000// 数据的总数
resolve({ data, total })
})
}
const getData = () => {
request().then(res => {
totalList.value = totalList.value.concat(res.data)
// 默认获取第一次请求回来的数据
if (totalList.value.length <= 30) {
scrollList.value = scrollList.value.concat(res.data)
}
// 当前请求的数量小于总数则继续请求
if (totalList.value.length < res.total) {
getData()
} else {
loading = true
}
})
}
getData()
</script>
复制代码上面写好了数据的获取处理,接下来写一下页面
<template>
<div class="div">
<div :style="styleObj" @mouseover="onMouseover" @mouseout="onMouseout" ref="divv">
<div v-for="item in scrollList" :key="item.id" @click="onClick(item)">
<div class="cell">{{ item.title }}</div>
</div>
</div>
</div>
</template>
<script lang="ts" setup>
// 滚动样式
const styleObj = ref({
transform: "translate(0px, 0px)",
});
</script>
<style scoped>
.div {
width: 500px;
height: 500px;
background-color: aquamarine;
overflow: hidden;
}
.cell {
height: 30px;
}
</style>
复制代码现在页面跟数据的前提条件都写好,下面就是数据逻辑的处理了,也就是这篇文章的重点
- 获取页面上单条数据的总体高度
- 设置定时器使页面不停的滚动
- 当一条数据滚动出视图范围时调用处理数据的方法并且重置滚动高度为0
const divv = ref();
// 当前滚动高度
const ScrollHeight = ref<number>(0);
// 储存定时器
const setInt = ref();
// 内容滚动
const roll = () => {
nextTick(() => {
let offsetHeight = divv.value.childNodes[1].offsetHeight
setInt.value = setInterval(() => {
if (ScrollHeight.value == offsetHeight) {
onDel();
ScrollHeight.value = 0;
}
ScrollHeight.value++;
styleObj.value.transform = `translate(0px, -${ScrollHeight.value}px)`;
}, 10);
})
};
onMounted(() => {
roll()
})
复制代码处理数据的方法
- 保存需要被删除的数据
- 删除超出视窗的数据
- 获取总数组的数据添加到滚动数组的最后一位
- 将被删除的数组数据添加到总数组最后面,
- 当滚动到最后一条数据时重置下标为0,使得数据首位相连不断循环
let index = 29;// 每次请求的数量-1,例如每次请求30条数据则为29
const onDel = () => {
index++;
if (loading) {
// 当滚动到最后一条数据时重置下标为0
if (index == totalList.value.length) {
index = 0;
}
scrollList.value.shift();
scrollList.value.push(totalList.value[index]);
} else {
if (index == totalList.value.length) {
index = 0;
}
// 保存需要被删除的数据
let value = scrollList.value[0]
// 删除超出视窗的数据
scrollList.value.shift();
// 获取总数组的数据添加到滚动数组的最后一位
scrollList.value.push(totalList.value[index]);
// 将被删除的数组数据添加到总数组最后面
totalList.value.push(value)
}
};
复制代码到这里代码就写好了,接下来让我们看看效果怎么样
总结
在我们开发的过程中会遇到各种各样天马行空的需求,尤其会遇到很多不合理的需求,这时候我们就要三思而后行,
想清楚能不能不做?
能不能下次再做?
能不能让同事去做?
链接:https://juejin.cn/post/7169940462357184525
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CSS动画篇之404动画
当前页面无法访问,可能没有权限或已删除。 作为一个从事互联网行业的你是不是见过各种各种的404页面,今天刚好发现一个比较有趣的404页面,如上图所示,是不是感觉挺炫酷呢,本文将和大家分享一下实现原理。
前言
看到上面的404你的第一感觉会是这么做呢?
来,UI同学给我上GIF。
当然这种方式对于前端同学来说肯定是最简单的实现方式,单纯的加载一张图片即可。
但是对于一个有追求的前端,绝对不会答应这么干,加载一张GIF图片的成本太高了,网络差的情况下会导致白屏时间过长,所以我们尽可能的用代码实现,减少这种不必要的网络请求。
实现
当你仔细看这个动画的时候可以发现其实主体只有一个标签,内容就是404,另外的几个动画都是基于这个主体实现,所以我们先写好这个最简单的html代码。
<h1 data-t="404">404</h1>
复制代码细心的同学应该看到了我们自定义了一个熟悉data-t,这个我们后续在css中会用到,接下来实现主体的动画效果,主要的动画效果就是让主体抖动并增加模糊的效果,代码实现如下所示。
h1 {
text-align: center;
width: 100%;
font-size: 6rem;
animation: shake .6s ease-in-out infinite alternate;
}
@keyframes shake {
0% {
transform: translate(-1px)
}
10% {
transform: translate(2px, 1px)
}
30% {
transform: translate(-3px, 2px)
}
35% {
transform: translate(2px, -3px);
filter: blur(4px)
}
45% {
transform: translate(2px, 2px) skewY(-8deg) scaleX(.96);
filter: blur(0)
}
50% {
transform: translate(-3px, 1px)
}
}
复制代码接下来增加主体动画后面子两个子动画内容,基于伪元素实现,伪元素的内容通过上面html中自定义data-t获取,主要还用了clip中的rect,具体css代码如下。
h1:before {
content: attr(data-t);
position: absolute;
left: 50%;
transform: translate(-50%,.34em);
height: .1em;
line-height: .5em;
width: 100%;
animation: scan .5s ease-in-out 275ms infinite alternate,glitch-anim .3s ease-in-out infinite alternate;
overflow: hidden;
opacity: .7;
}
@keyframes glitch-anim {
0% {
clip: rect(32px,9999px,28px,0)
}
10% {
clip: rect(13px,9999px,37px,0)
}
20% {
clip: rect(45px,9999px,33px,0)
}
30% {
clip: rect(31px,9999px,94px,0)
}
40% {
clip: rect(88px,9999px,98px,0)
}
50% {
clip: rect(9px,9999px,98px,0)
}
60% {
clip: rect(37px,9999px,17px,0)
}
70% {
clip: rect(77px,9999px,34px,0)
}
80% {
clip: rect(55px,9999px,49px,0)
}
90% {
clip: rect(10px,9999px,2px,0)
}
to {
clip: rect(35px,9999px,53px,0)
}
}
@keyframes scan {
0%,20%,to {
height: 0;
transform: translate(-50%,.44em)
}
10%,15% {
height: 1em;
line-height: .2em;
transform: translate(-55%,.09em)
}
}
复制代码伪元素after的动画与before中的一致,只是部分参数改动,如下所示。
h1:after {
content: attr(data-t);
position: absolute;
top: -8px;
left: 50%;
transform: translate(-50%,.34em);
height: .5em;
line-height: .1em;
width: 100%;
animation: scan 665ms ease-in-out .59s infinite alternate,glitch-anim .3s ease-in-out infinite alternate;
overflow: hidden;
opacity: .8
}
复制代码总结
到此为止我们的功能就实现完成啦,看完代码是不是感觉并没有很复杂,又为我们的页面性能提升了大大的一步。
完整的代码可以访问codepen查看 👉 codepen-404
链接:https://juejin.cn/post/7091848998830473230
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
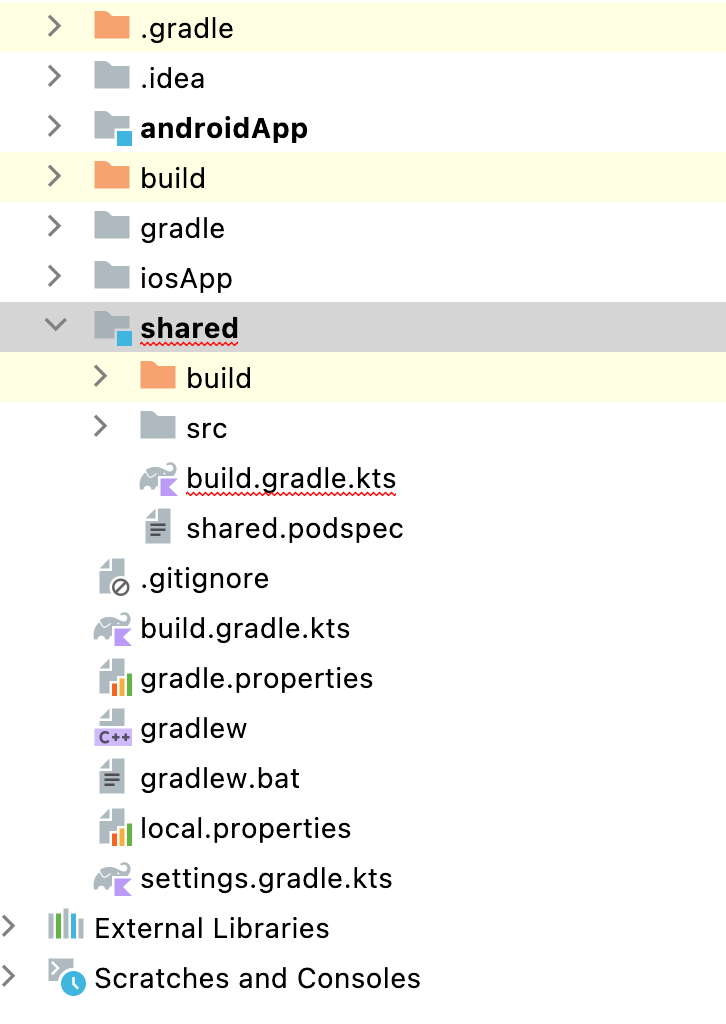
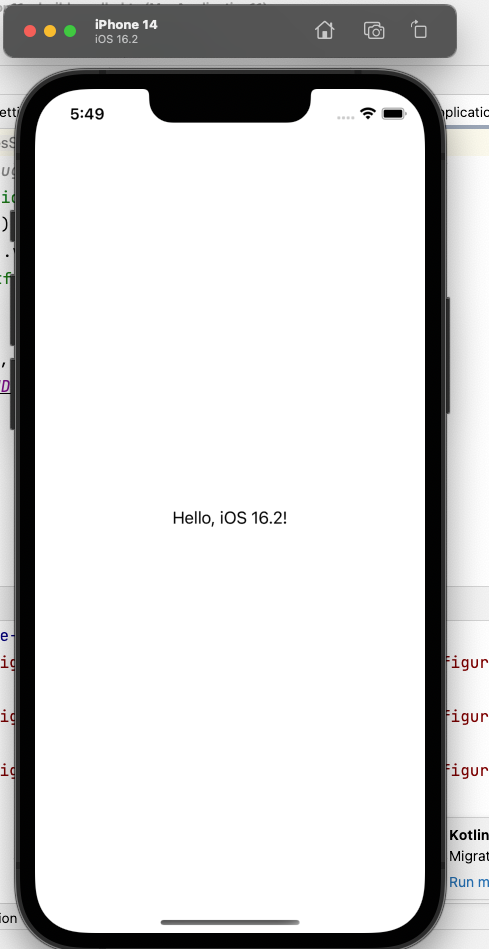
Compose跨平台又来了,这次能开发iOS了
https://juejin.cn/post/7195770699524751421


pluginManagement {
repositories {
google()
gradlePluginPortal()
mavenCentral()
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
}
plugins {
val composeVersion = extra["compose.version"] as String
id("org.jetbrains.compose").version(composeVersion)
}
}
compose.version=1.3.0
plugins {
kotlin("multiplatform")
kotlin("native.cocoapods")
id("com.android.library")
id("org.jetbrains.compose")
}
val commonMain by getting {
dependencies {
implementation(compose.ui)
implementation(compose.foundation)
implementation(compose.material)
implementation(compose.runtime)
}
}

org.jetbrains.compose.experimental.uikit.enabled=true

kotlin("android").version("1.8.0").apply(false)
import UIKit
import shared
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
window = UIWindow(frame: UIScreen.main.bounds)
let mainViewController = Main_iosKt.MainViewController()
window?.rootViewController = mainViewController
window?.makeKeyAndVisible()
return true
}
}
let mainViewController = Main_iosKt.MainViewController()
fun MainViewController(): UIViewController = Application("Login") { //调用一个Compose方法 }
@Composable
internal fun login() {
var userName by remember {
mutableStateOf("")
}
var password by remember {
mutableStateOf("")
}
Surface(modifier = Modifier.padding(30.dp)) {
Column {
TextField(userName, onValueChange = {
userName = it
}, placeholder = { Text("请输入用户名") })
TextField(password, onValueChange = {
password = it
}, placeholder = { Text("请输入密码") })
Button(onClick = {
//登录
}) {
Text("登录")
}
}
}
}
fun MainViewController(): UIViewController =
Application("Login") {
login()
}
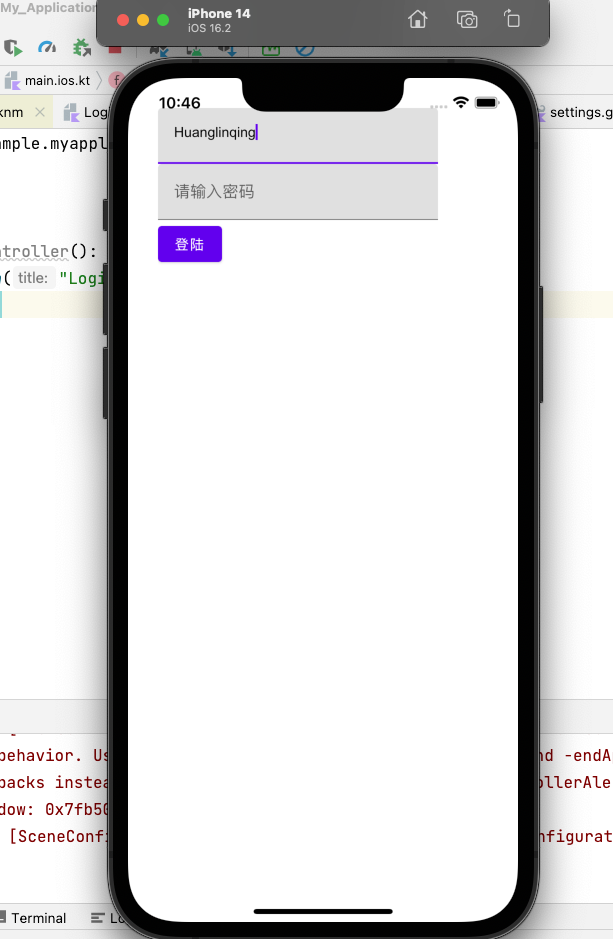
val commonMain by getting {
dependencies {
...
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
implementation("io.ktor:ktor-client-core:$ktorVersion")
implementation("io.ktor:ktor-client-content-negotiation:$ktorVersion")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
}
}
val iosMain by getting {
dependencies {
implementation("io.ktor:ktor-client-darwin:$ktorVersion")
}
}
val androidMain by getting {
dependencies {
implementation("io.ktor:ktor-client-android:$ktorVersion")
}
}
https://wanandroid.com/wenda/list/1/json
object Api {
val dataApi = "https://wanandroid.com/wenda/list/1/json"
}
class HttpUtil {
private val httpClient = HttpClient {
install(ContentNegotiation) {
json(Json {
prettyPrint = true
isLenient = true
ignoreUnknownKeys = true
})
}
}
/**
* 获取数据
*/
suspend fun getData(): DemoReqData {
val rockets: DemoReqData =
httpClient.get(Api.dataApi).body()
return rockets
}
}
Column() {
val scope = rememberCoroutineScope()
var demoReqData by remember { mutableStateOf(DemoReqData()) }
Button(onClick = {
scope.launch {
try {
demoReqData = HttpUtil().getData()
} catch (e: Exception) {
}
}
}) {
Text(text = "请求数据")
}
LazyColumn {
repeat(demoReqData.data?.datas?.size ?: 0) {
item {
Message(demoReqData.data?.datas?.get(it))
}
}
}
}
@Composable
fun Message(data: DemoReqData.DataBean.DatasBean?) {
Card(
modifier = Modifier
.background(Color.White)
.padding(10.dp)
.fillMaxWidth(), elevation = 10.dp
) {
Column(modifier = Modifier.padding(10.dp)) {
Text(
text = "作者:${data?.author}"
)
Text(text = "${data?.title}")
}
}
}

Kotlin | 这些隐藏的内存陷阱,你应该熟记于心
引言
Kotlin 是一个非常 yes 的语言,从 null安全 ,支持 方法扩展 与 属性扩展,到 内联方法、内联类 等,使用Kotlin变得越来越简单舒服。但编程从来不是一件简单的工作,所有简洁都是建立在复杂的底层实现上。那些看似简单的kt代码,内部往往隐藏着不容忽视的内存开销。
介于此,本篇将根据个人开发经验,聊一聊 Kotlin 中那些隐藏的内存陷阱,也希望每一个同学都能在 性能 与 优雅 之间找到合适的平衡。
本篇定位简单🔖,主要通过示例+相应字节码分析的方式,对日常开发非常有帮助。
密封类的小细节
密封类用来表示受限的类继承结构:当一个值为有限几种的类型、而不能有任何其他类型时。在某种意义上,他们是枚举类的扩展:枚举类型的值集合也是受限的,但每个枚举常量只存在一个实例,而密封类的一个子类可以有可包含状态的多个实例。摘自Kotlin中文文档
关于它用法,我们具体不再做赘述。
密封类虽然非常实用,经常能成为我们多type的绝佳搭配,但其中却藏着一些使用的小细节,比如 构造函数传值所导致的损耗问题。
错误示例
如题, 我们有一个公用的属性 sum ,为了便于复用,我们将其抽离到 Fruit 类构造函数中,让子类便于初始化时传入,而不用重复显式声明。
上述代码看着似乎没什么问题?按照传统的操作习惯,我们也很容易写出这种代码。
如果我们此时来看一下字节码:
不难发现,无论是子类Apple还是父类Fruit,他们都生成了 getSum() 与 setSum() 方法 与 sum 字段,而且,父类的 sum 完全处于浪费阶段,我们根本没法用到。😵💫
显然这并不是我们愿意看到的,我们接下来对其进行改造一下。
改造实践
我们对上述示例进行稍微改造,如下所示:
如题,我们将sum变量定义为了一个抽象变量,从而让子类自行实现。对比字节码可以发现,相比最开始的示例,我们的父类 Fruit 中减少了一个 sum 变量的损耗。
那有没有方法能不能把 getsum() 和 setSum() 也一起移除呢?🙅♂️
答案是可以,我们利用 接口 改造即可,如下所示:
如上所示,我们增加了一个名为 IFruit 的接口,并让 密封父类 实现了这个接口,子类默认在构造函数中实现该属性即可。
观察字节码可发现,我们的父类一干二净,无论是从包大小还是性能,我们都避免了没必要的损耗。
内联很好,但别太长
inline ,翻译过来为 内联 ,在 Kotlin 中,一般建议用于 高阶函数 中,目的是用来弥补其运行时的 额外开销。
其原理也比较简单,在调用时将我们的代码移动到调用处使用,从而降低方法调用时的 栈帧 层级。
栈帧: 指的是虚拟机在进行方法调用和方法执行时的数据结构,每一个栈帧里都包含了相应的数据,比如 局部参数,操作数栈等等。
Jvm在执行方法时,每执行一个方法会产生一个栈帧,随后将其保存到我们当前线程所对应的栈里,方法执行完毕时再将此方法出栈,
所以内联后就相当于省了一个栈帧调用。
如果上述描述中,你只记住了后半句,降低栈帧 ,那么此时你可能已经陷入了一个使用陷阱?
错误示例
如下截图中所示,我们随便创建了一个方法,并增加了 inline 关键字:
观察截图会发现,此时IDE已经给出了提示,它建议你移除 inline , Why? 为什么呢?🥲
不是说内联可以提高性能吗,那么不应该任何方法都应该加
inline提高性能吗?(就是这么倔强🤌🏼)
上面我们提到了,内联是会将代码移动到调用处,降低 一层栈帧,但这个性能提升真的大吗?
再仔细想想,移动到调用处,移动到调用处。这是什么概念呢?
假设我们某个方法里代码只有两行(我想不会有人会某个方法只有一行吧🥲),这个方法又被好几处调用,内联是提高了调用性能,毕竟节省了一次栈帧,再加上方法行数少(暂时抛弃虚拟机优化这个底层条件)。
但如果方法里代码有几十行?每次调用都会把代码内联过来,那调用处岂不💥,带来的包大小影响某种程度上要比内联成本更高😵💫!
如下图所示,我们对上述示例做一个论证:
Jvm: 我谢谢你。
推荐示例
我们在文章最开始提到了,Kotlin inline ,一般建议用于 高阶函数(lambda) 中。为什么呢?
如下示例:
转成字节码后,可以发现,tryKtx() 被创建为了一个匿名内部类 (Simple$test|1) 。每次调用时,相当于需要创建匿名类的实例对象,从而导致二次调用的性能损耗。
那如果我们给其增加 inline 呢?🤖,反编译后相应的 java代码 如下:
具体对比图如上所示,不难发现,我们的调用处已经被替换为原方法,相应的 lambda 也被消除了,从而显著减少了性能损耗。
Tips
如果查看官方库相应的代码,如下所示,比如 with :
不难发现,inline 的大多数场景仅且在 高阶函数 并且 方法行数较短 时适用。因为对于普通方法,jvm本身对其就会进行优化,所以 inline 在普通方法上的的意义几乎聊胜于无。
总结如下:
- 因为内联函数会将方法函数移动到调用处,会增加调用处的代码量,所以对于较长的方法应该避免使用;
- 内联函数应该用于使用了 高阶函数(lambda) 的方法,而不是普通方法。
伴生对象,也许真的不需要
在 Kotlin 中,我们不能像 Java 一样,随便定义一个静态方法或者静态属性。此时 companion object(伴生对象)就会派上用场。
我们常常会用于定义一个 key 或者 TAG ,类似于我们在 Java 中定义一个静态的 Key。其使用起来也很简单,如下所示:
class Book {
companion object {
val SUM_MAX: Int = 13
}
}这是一段普通的代码,我们在 Book 类中增加了一个伴生对象,其中有一个静态的字段 SUM_MAX。
上述代码看着似乎没什么问题,但如果我们将其转为字节码后再看一看:
不难发现,仅仅只是想增加一个 静态变量 ,结果凭空增加了一个 静态对象 以及多增加了 get() 方法,这个成本可能远超出一个 静态参数 的价值。
const
抛开前者不谈(静态对象),那么我们有没有什么方法能让编译器少生成一个 get() 方法呢(非private)?
注意观察IDE提示,IDE会建议我们增加一个 const 的参数,如下所示:
companion object {
const val SUM_MAX: Int = 13
}增加了 const 后,相应的 get() 方法也会消失掉,从而节省了一个 get() 方法。
const,在Kotlin中,用于修饰编译时已知的val(只读,类似final) 标注的属性。
- 只能用于顶层的class中,比如
object class或者companion object;
- 只能用于基本类型;
- 不会生成get()方法。
JvmField
如果我们 某个字段不是 val 标注呢,其是 var (可变)修饰的呢,并且这个字段要对外暴漏(非private)。
此时不难猜测,相应的字节码后肯定会同时生成 set与get 方法。
此时就可以使用 @JvmField 来进行修饰。
如下所示:
class Book {
companion object {
@JvmField
var sum: Int = 0
}
}相应的字节码如下:
Tips
让我们再回到伴生对象本身,我们真的一定需要它吗?
对于和业务强关联的 key 或者 TAG ,可以选择使用伴生对象,并为其增加 const val,此时语义上的清晰比内存上的损耗更加重要,特别在复杂的业务背景下。
但如果仅用于保存一些key,那么完全可以使用 object Class 替代,如下所示,将其回归到一个类中:
object Keys {
const val DEFAULT_SUM = 10
const val DEFAULT_MIN = 1
const val LOGIN_KEY = 99
}2022/12/6补充
使用 kotlin 文件形式去写。
这种写法属于以增加静态类的方式避免伴生对象的内存损耗,如果你的场景是单独的增加一个tag,那么这种写法比较推荐。
对于sdk的开发者,同时建议增加 @file:JvmName(“ 文件名”) ,从而禁止生成的 xxxkt类 在 java 语境下被调用到 (欺负java不识别空格🤪)。
@file:JvmName(" Testxx")
private const val TAG = "KEY_TEST_TAG"
class TestKt {
private fun test() {
println(TAG)
}
}Apply!=构造者模式
apply 作为开发中的常客,为我们带来了不少便利。其内部实现也非常简单,将我们的对象以函数的形式返回,this 作为接收者。从而以一种优雅的方式实现对对象方法、属性的调用。
但经常会看到有不少同学在构造者模式中写出以下代码,使用 apply 直接作为返回值,这种方式固然看着优雅,性能也几乎没有差别。但这种场景而言,如果我们注意到其字节码,会发现其并不是最佳之选。
示例
如题,我们存在一个示例Builder,并在其中添加了两个方法,即 addTitle(),与 addSecondTitle() 。后者以 apply 作为返回值,代码可读性非常好,相比前者,在 kotlin 中其显得非常优雅。
但如果我们去看一眼字节码呢?
如上所示,使用了 apply 后,我们的字节码中增加了多余步骤,相比不使用的,包大小会有一点影响,性能上几乎毫无差距。
Tips
apply 很好用,但需要区分场景。其可以改善我们在 kotlin 语义下的编程体验,但同时也不是任何场景都需要其。
如果你的方法中需要对某个对象操作多次,比如调用其方法或者属性,那么此时可以使用 apply ,反之,如果次数过少,其实你并不需要 apply 的优雅。
警惕,lazy 的使用方式
lazy,中文译名为延迟初始化,顾名思义,用于延迟初始化一些信息。
作用也相对直接,如果我们有某个对象或字段,我们可能只想使用时再初始化,此时就可以先声明,等到使用时再去初始化,并且这个初始化过程默认也是线程安全(不特定使用NONE)。这样的好处就是性能优势,我们不必应用或者页面加载时就初始化一切,相比过往的 var xx = null ,这种方式一定程度上也更加便捷。
相应的,lazy一共有三种模式,即:
SYNCHRONIZED(同步锁,默认实现)PUBLICATION(CAS)NONE(不作处理)
lazy 虽然使用简单,但在 Android 的开发背景下,lazy 经常容易使用不当🤦🏻♂️,也因此常常会出现为了[便利] 而造成的性能隐患。
示例如下:
如上所示,我们延迟初始化了一个点击事件,方便在 onCreate() 中进行设置 点击事件 以及后续复用。
上述示例虽然看着似乎没什么问题。但放在这样的场景下,这个 mClickListener 本身的意义也许并不大。为什么这样说?
- 上述使用了 默认的lazy ,即同步锁,而Android默认线程为
UI线程,当前操作方法又是onCreate(),即当前本身就是线程安全。此时依然使用 lazy(sys) ,即浪费了一定初始化性能。
- MainActivity初始化时,会先在 构造函数 中初始化
lazy对象,即SYNCHRONIZED对应的SynchronizedLazyImpl。也就是说,我们一开始就已经多生成了一个对象。然后仅仅是为了一个点击事件,内部又会进行包装一次。
相似的场景有很多,如果你的lazy是用于 Android生命周期组件 ,再加上本身会在 onCreate() 等中进行调用,那么很可能完全没有必要延迟初始化。
关于 arrayOf() 的使用细节
对于 arrayOf ,我们一般经常用于初始化一个数组,但其也隐藏着一些使用细节。
通常来说,对于基本类型的数组,建议使用默认已提供的函数比如,intArrayOf() 等等,从而便于提升性能。
至于原因,我们下面来分析,如下所示:
fun test() {
arrayOf(1, 2, 3)
}
fun testNoInteger() {
intArrayOf(1, 2, 3)
}我们提供了两个方法,前者是默认方法,后者是带优化的方法,具体字节码如下:
如题,不难发现,前者使用的是 java 中的 包装类型 ,使用时还需要经历 拆箱 与 装箱 ,而后者是非包装类型,从而免除了这一操作,从而节省性能。
什么是装箱与拆箱?
背景:Java 中,万物皆对象,而八大基本类型不是对象,所以 Java 为每种基本类型都提供了相应的包装类型。
装箱就是指将基本类型转为包装类型,拆箱则是将包装类型转为基本类型。
总结
本篇中,我们以日常开发的视角,去探寻了 Kotlin 中那些 [隐藏] 的内存陷阱。
仔细回想,上述的不恰当用法都是建立在 [不熟练] 的背景下。Kotlin 本身的各种便利没有任何问题,其使得我们的 代码可读性 与 开发舒适度 增强了太多。但如果同时,我们还能注意到其背后的实现,也是不是就能在 性能与优雅 之间找到了一种平衡。
所谓左眼 kt ,右眼 java,正是如此。作为一个 Kotlin 使用者,这也是我们所不断追寻的。
善用字节码分析,你的技艺也将更上一筹。
参阅
关于我
我是 Petterp ,一个三流 Kotlin 使用者,如果本文对你有所帮助,欢迎点赞评论收藏,你的支持是我持续创作的最大鼓励!
链接:https://juejin.cn/post/7157905051531345956
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
新项目为什么决定用 JDK 17了
最近在调研 JDK 17,并且试着将之前的一个小项目升级了一下,在测试环境跑了一段时间。最终,决定了,新项目要采用 JDK 17 了。
JDK 1.8:“不是说好了,他发任他发,你用 Java 8 吗?”
不光是我呀,连 Spring Boot 都开始要拥护 JDK 17了,下面这一段是 Spring Boot 3.0 的更新日志。
Spring Boot 3.0 requires Java 17 as a minimum version. If you are currently using Java 8 or Java 11, you'll need to upgrade your JDK before you can develop Spring Boot 3.0 applications.
Spring Boot 3.0 需要 JDK 的最低版本就是 JDK 17,如果你想用 Spring Boot 开发应用,你需要将正在使用的 Java 8 或 Java 11升级到 Java 17。
选用 Java 17,概括起来主要有下面几个主要原因:
1、JDK 17 是 LTS (长期支持版),可以免费商用到 2029 年。而且将前面几个过渡版(JDK 9-JDK 16)去其糟粕,取其精华的版本;
2、JDK 17 性能提升不少,比如重写了底层 NIO,至少提升 10% 起步;
3、大多数第三方框架和库都已经支持,不会有什么大坑;
4、准备好了,来吧。
拿几个比较好玩儿的特性来说一下 JDK 17 对比 JDK 8 的改进。
密封类
密封类应用在接口或类上,对接口或类进行继承或实现的约束,约束哪些类型可以继承、实现。例如我们的项目中有个基础服务包,里面有一个父类,但是介于安全性考虑,值允许项目中的某些微服务模块继承使用,就可以用密封类了。
没有密封类之前呢,可以用 final关键字约束,但是这样一来,被修饰的类就变成完全封闭的状态了,所有类都没办法继承。
密封类用关键字 sealed修饰,并且在声明末尾用 permits表示要开放给哪些类型。
下面声明了一个叫做 SealedPlayer的密封类,然后用关键字 permits将集成权限开放给了 MarryPlayer类。
public sealed class SealedPlayer permits MarryPlayer {
public void play() {
System.out.println("玩儿吧");
}
}之后 MarryPlayer 就可以继承 SealedPlayer了。
public non-sealed class MarryPlayer extends SealedPlayer{
@Override
public void play() {
System.out.println("不想玩儿了");
}
}继承类也要加上密封限制。比如这个例子中是用的 non-sealed,表示不限制,任何类都可以继承,还可以是 sealed,或者 final。
如果不是 permits 允许的类型,则没办法继承,比如下面这个,编译不过去,会给出提示 "java: 类不得扩展密封类:org.jdk17.SealedPlayer(因为它未列在其 'permits' 子句中)"
public non-sealed class TomPlayer extends SealedPlayer {
@Override
public void play() {
}
}空指针异常
String s = null;
String s1 = s.toLowerCase();
JDK1.8 的版本下运行:
Exception in thread "main" java.lang.NullPointerException
at org.jdk8.App.main(App.java:10)
JDK17的版本(确切的说是14及以上版本)
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "String.toLowerCase()" because "s" is null
at org.jdk17.App.main(App.java:14)
出现异常的具体方法和原因都一目了然。如果你的一行代码中有多个方法、多个变量,可以快速定位问题所在,如果是 JDK1.8,有些情况下真的不太容易看出来。
yield关键字
public static int calc(int a,String operation){
var result = switch (operation) {
case "+" -> {
yield a + a;
}
case "*" -> {
yield a * a;
}
default -> a;
};
return result;
}换行文本块
如果你用过 Python,一定知道Python 可以用 'hello world'、"hello world"、''' hello world '''、""" hello world """ 四种方式表示一个字符串,其中后两种是可以直接支持换行的。
在 JDK 1.8 中,如果想声明一个字符串,如果字符串是带有格式的,比如回车、单引号、双引号,就只能用转义符号,例如下面这样的 JSON 字符串。
String json = "{\n" +
" \"name\": \"古时的风筝\",\n" +
" \"age\": 18\n" +
"}";从 JDK 13开始,也像 Python 那样,支持三引号字符串了,所以再有上面的 JSON 字符串的时候,就可以直接这样声明了。
String json = """
{
"name": "古时的风筝",
"age": 18
}
""";record记录类
类似于 Lombok 。
传统的Java应用程序通过创建一个类,通过该类的构造方法实例化类,并通过getter和setter方法访问成员变量或者设置成员变量的值。有了record关键字,你的代码会变得更加简洁。
之前声明一个实体类。
public class User {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}使用 Record类之后,就像下面这样。
public record User(String name) {
}调用的时候像下面这样
RecordUser recordUser = new RecordUser("古时的风筝");
System.out.println(recordUser.name());
System.out.println(recordUser.toString());输出结果
Record 类更像是一个实体类,直接将构造方法加在类上,并且自动给字段加上了 getter 和 setter。如果一直在用 Lombok 或者觉得还是显式的写上 getter 和 setter 更清晰的话,完全可以不用它。
G1 垃圾收集器
JDK8可以启用G1作为垃圾收集器,JDK9到 JDK 17,G1 垃圾收集器是默认的垃圾收集器,G1是兼顾老年代和年轻代的收集器,并且其内存模型和其他垃圾收集器是不一样的。
G1垃圾收集器在大多数场景下,其性能都好于之前的垃圾收集器,比如CMS。
ZGC
从 JDk 15 开始正式启用 ZGC,并且在 JDK 16后对 ZGC 进行了增强,控制 stop the world 时间不超过10毫秒。但是默认的垃圾收集器仍然是 G1。
配置下面的参数来启用 ZGC 。
-XX:+UseZGC可以用下面的方法查看当前所用的垃圾收集器
JDK 1.8 的方法
jmap -heap 8877JDK 1.8以上的版本
jhsdb jmap --heap --pid 8877例如下面的程序采用 ZGC 垃圾收集器。
其他一些小功能
1、支持 List.of()、Set.of()、Map.of()和Map.ofEntries()等工厂方法实例化对象;
2、Stream API 有一些改进,比如 .collect(Collectors.toList())可以直接写成 .toList()了,还增加了 Collectors.teeing(),这个挺好玩,有兴趣可以看一下;
3、HttpClient重写了,支持 HTTP2.0,不用再因为嫌弃 HttpClient 而使用第三方网络框架了,比如OKHTTP;
升级 JDK 和 IDEA
安装 JDK 17,这个其实不用说,只是推荐一个网站,这个网站可以下载各种系统、各种版本的 JDK 。地址是 adoptium.net/
还有,如果你想在 IDEA 上使用 JDK 17,可能要升级一下了,只有在 2021.02版本之后才支持 JDK 17。
链接:https://juejin.cn/post/7177550894316126269
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的个人微信也迅速接入了 ChatGPT
本文主要来聊聊如何快速使用个人微信接入 ChatGPT,欢迎 xdm 尝试起来,仅供学习参考,切莫用于做不正当的事情
关于 ChatGPT 我们每个人都可以简单的使用上,不需要你有很强的技术背景,不需要你有公众号,甚至不需要你自己接入,只要你有一个微信号,就可以享受到 ChatGPT 带给你的惊喜,那么我们开始吧
本文分别从如下几个方面来聊:
- ChatGPT 是什么
- 个人微信如何快速接入 ChatGPT
- 关于 ChatGPT 的思考
ChatGPT 是什么
ChatGPT 实际上一个以对话的形式来回答各种问题的模型,他的名字叫做 ChatGPT ,简单理解,他就是一个聊天机器人
现实中,我们印象中的机器人总是那么死板和固执,但是 ChatGPT 却是一个非常人性化的对话模型,他可以和我们聊天,回答我们的各种问题,并且上下文他是可以做到关联的
甚至在未来你在使用各种应用软件的时候,与你对接的客服,或许就是这样的机器人,你可能完全感受不到他居然能够像人一样,甚至比人还聪明,比人还博学
个人微信如何快速接入 ChatGPT
个人微信一样能够轻松的接入 ChatGPT ,不需要你有公众号,只需要做对接的人满足如下资源即可:
- 经过实名认证的微信号
- Openai 的账号密码
- 个人电脑或者一台 linux 虚拟机做服务器
与 Chatgpt 对话
首先,关于 openai 的账号如何注册此处就不过多赘述了,网络上的资料还是非常多的,xdm 实际注册的时候注意几点即可
- 账号所选的国家尽可能选择海外,例如我注册的时候就选择了 India
- 手机号接码的时候可能会有一定的延迟,实际操作并不是每一次都能迅速的接收到码的,来回操作了5 - 10 分钟左右收到了一个码,xdm 要耐心
chatgpt:登录地址 chat.openai.com/ 即可享受与 chatgpt 进行进行对话
实际上,ChatGPT 还可以帮我们写代码,写算法,写诗,回答最新的股票信息等等
个人微信接入ChatGPT
个人微信接入ChatGPT ,网上资料非常的多,实践了一遍之后,并不是每一个方式都可以正确运行的,或许是姿势不对,目前发现一个使用 Go 实现的项目比较香,可以非常简单快速的达到我们的目的
接入前提
先去 openai 上创建创建一个 API Keys,这个非常重要,没有这个 API Keys ,对于本案例,是没有办法接入成功的
登录 openai:beta.openai.com/login/
登录之后页面如下
可以看到 openai 的例子很多,至此的功能也是非常丰富的,感兴趣的话可以慢慢的研究,ChatGPT 也需要不断的优化和迭代
点击页面右上角的头像,进入 View API keys
创建一个新的秘钥,请自己保存好,这个秘钥相当重要,主要是用于和 openai 认证和交互的
安装部署方式
下载源码,修改配置,部署服务
可以在我们的 linux 服务器上下载项目源码,并进入源码目录,拉取项目的依赖包
git clone git@github.com:qingconglaixueit/wechatbot.git
cd wechatbot
go mod tidy
当然,这种方式是需要我们有基本的 Go 环境的, 如果不会搭建 Go 的编译环境,可以查看历史文章
源码下载后,wechatbot 目录下我们可以看到如下文件
其中配置文件是 config.dev.json,实际配置文件为config.json ,我们需要拷贝一份
cp config.dev.json config.json
里面存放了如下信息
其中重点关注 api_key 字段,填入我们之前在 openai 网站上获取的 API Keys
运行 Go 的 main.go 文件
go run main.go
// 或者在项目目录下执行 go build ,编译出可执行程序后,执行可执行程序即可
程序运行之后,可以看到出现了一个二维码,我们使用微信扫码即可
- 此处可以使用自己的微信小号来扫码,该微信号需要个人实名认证,此处注意,扫码的微信号就是 聊天机器人
扫码成功,正常登陆之后,可以看到有正常的日志,无报错信息
此时,其他人发消息给这个扫码的微信号之后,该微信号就会智能回复了,如果是在群聊中,记得要 艾特 这个机器人
另外程序运行后,会在项目路径下生成 storage.json 文件,是一个 Cookies ,这样我们终止程序,再次启动程序的时候,就不需要我们再扫码了
当然,我们也可以直接拿到别人的可执行程序,修改配置后直接运行,也可以得到同样的效果,但是不确定 xdm 是啥时候看到的文章,可执行程序或许会用不了
但是你拿到源码你就可以自己研究,还可以做自定义的功能,Go 是跨平台的,你想生成 windows 的可执行程序或者 linux 的可执行程序都是可以的
实际上,该项目是使用了 openwechat 项目:github.com/eatmoreappl…
感兴趣的童鞋,可以下载源码来读一读,代码量并不大,逻辑也很清晰明了,自然自己去从 0 到 1 写的话也是可以的,注意如下点:
- 如何与微信对接,获取到相应的权限 developers.weixin.qq.com/doc/
- 如何与 openai 对接,拿到相应的权限,请求响应的接口拿到我们期望的回复,可以直接查看 openai 的对接文档
接入效果
私聊效果,直接发消息即可
群聊效果,记得要 艾特这个机器人
关于 ChatGPT 的思考
ChatGPT 也还在不断的优化和迭代当中,相信未来会有更多的惊喜
诚然,在未来的发展,更加趋向于智能化,很多机械的,简单重复的工作,自然而然是会被逐步替代的,这些都是必须得直面的,无法逃避
我们更多的应该是以开放的心态,拥抱变化,向阳而生,不断的提升自己的核心竞争力,将自己作为一个产品来进行迭代和优化,将自己打造成一个伟大的产品岂不是很酷吗?
本次就是这样,如果有想体验 ChatGPT 的可以加我机器人的微信(xiaomotongneza),拉你进体验群哦,希望本文能给你带来帮助
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力
好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
链接:https://juejin.cn/post/7176813187705077816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
点兔换图——新年兔了个兔专题
前言
本篇是通过图片的点击事件去切换图片,实现图片点击轮播,而新年兔了个兔专题,当然是使用了一系列兔子的图片作为轮播图展示的,下面我们来看看怎么实现点兔换图的。
正篇
实现方法
其实安卓中实现方法很简单,我们可以轻松办到,就是ImageView中增加点击事件
class RabbitFirst : AppCompatActivity() {
private lateinit var binding: ActivityRabbitFirstBinding
private var id by Delegates.notNull<Int>()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityRabbitFirstBinding.inflate(layoutInflater)
setContentView(binding.root)
id = 0
binding.img1.setOnClickListener {
if (id == 0) {
binding.img1.setImageBitmap(BitmapFactory.decodeResource(resources, R.drawable.rabit_c) )
id++
return@setOnClickListener
}
if (id == 1) {
binding.img1.setImageResource(R.drawable.rabit_b)
id++
return@setOnClickListener
}
if (id == 2) {
binding.img1.setImageResource(R.drawable.rabit_a)
id++
return@setOnClickListener
}
if (id == 3) {
binding.img1.setImageResource(R.drawable.rabit_d)
id = 0
return@setOnClickListener
}
Log.i("id ===$id", "is id")
}
}
}如果图片多了可以使用数组去存,然后单独写方法去处理,这里只有四张图,所以我这里使用if判断,主要还是没找到有关setImageResource的对应方法,网上似乎说没有对应的get方法,可以使用加setTag和getTag方法去实现,和我的判断方法也类似,我的判断方法就是如果有四张图,我们就给它显示顺序,从0-3,开始,id为0-2时点击图片切换下一张,到id=3时再清空id值,置为0,这样又能回到第一张兔子图。
展示效果
最终效果如下,我们点击图片就可以进行图片轮换:
ps:实现的时候出现了不能点击的问题,然后发现原来是在点击事件使用id全局变量增加时正好依次增加最后还是回到原图了,所以需要if里加上返回return,不经过下个if检查
总结
虽然形式很简单,但也是安卓的实现方法去做的,其实很多五花八门的效果都是从最简单的开始,然后添加各种新的技术最终才变得更加有趣好看。
链接:https://juejin.cn/post/7197794878775787579
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
高仿B站自定义表情
在之前的文章给你的 Android App 添加自定义表情
中我们介绍了自定义表情的原理,没看过的建议看一下。这一篇文章将介绍它的应用,这里以B站的自定义表情面板为例,效果如下:
自定义表情的大小
的文章中,我们说过当我们写死表情的大小时,文字的 textSize 变大变小时都会有一点问题。
文字大于图片大小时,在多行的情况下,只有表情的行间距明显小于其他行的间距。如图:
为什么会出现这种情况呢?如下图所示,我在top, ascent, baseline, descent, bottom的位置标注了辅助线。
可以很清晰的看到,在只有表情的情况下,top, ascent, descent, bottom的位置有明显的问题。原因是 DynamicDrawableSpan 的 getSize 方法里面对 FontMetricsInt 进行了修改。解决的方式很简单,就是注释掉修改代码就行,代码如下。修改后,效果如下图所示。
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
Rect rect = d.getBounds();
//
// if (fm != null) {
// fm.ascent = -rect.bottom;
// fm.descent = 0;
//
// fm.top = fm.ascent;
// fm.bottom = 0;
// }
return rect.right;
}不知道你还记不记得,我们说过getSize 的返回值是表情的宽度。上面的注释代码其实是设置了表情的高度,如果文本的大小少于表情时,就会显示不全,如下图所示:
那这种情况下,应该怎么办?这里不卖关子了,最终代码如下。解决方式非常简单就是分情况来判断。当文本的高度小于表情的高度时,设置 fm 的top, ascent, descent, bottom的值,让行的高度变大的同时让大的 emoji 图片居中。
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
Rect rect = d.getBounds();
float drawableHeight = rect.height();
Paint.FontMetrics paintFm = paint.getFontMetrics();
if (fm != null) {
int textHeight = fm.bottom - fm.top;
if(textHeight <= drawableHeight) {//当文本的高度小于表情的高度时
//解决文字的大小小于图片大小的情况
float textCenter = (paintFm.descent + paintFm.ascent) / 2;
fm.ascent = fm.top = (int) (textCenter - drawableHeight / 2);
fm.descent = fm.bottom = (int) (textCenter + drawableHeight / 2);
}
}
return rect.right;
}当然,你可能发现了,B站的 emoji 表情好像不是居中的。如下图所示,B站对 emoji 表情的处理类似基于 baseline 对齐。
上面最难理解的居中已经介绍,对于其他方式比如 baseline 和 bottom 就简单了。完整代码如下:
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
if(d == null) {
return 48;
}
Rect rect = d.getBounds();
float drawableHeight = rect.height();
Paint.FontMetrics paintFm = paint.getFontMetrics();
if (fm != null) {
if (mVerticalAlignment == ALIGN_BASELINE) {
fm.ascent = fm.top = (int) (paintFm.bottom - drawableHeight);
fm.bottom = (int) (paintFm.bottom);
fm.descent = (int) paintFm.descent;
} else if(mVerticalAlignment == ALIGN_BOTTOM) {
fm.ascent = fm.top = (int) (paintFm.bottom - drawableHeight);
fm.bottom = (int) (paintFm.bottom);
fm.descent = (int) paintFm.descent;
} else if (mVerticalAlignment == ALIGN_CENTER) {
int textHeight = fm.bottom - fm.top;
if(textHeight <= rect.height()) {
float textCenter = (paintFm.descent + paintFm.ascent) / 2;
fm.ascent = fm.top = (int) (textCenter - drawableHeight / 2);
fm.descent = fm.bottom = (int) (textCenter + drawableHeight / 2);
}
}
}
return rect.right;
}动态表情
动态表情实际上就是 gif 图。我们可以使用 android-gif-drawable 来实现。在 build.gradle 中增加依赖:
dependencies {
...
implementation 'pl.droidsonroids.gif:android-gif-drawable:1.2.25'
}然后在我们创建自定义 ImageSpan 的时候传入参数就可以了:
val size = 192
val gifFromResource = GifDrawable(getResources(), gifData.drawableResource)
gifFromResource.stop()
gifFromResource.setBounds(0,0, size, size)
val content = mBinding.editContent.text as SpannableStringBuilder
val stringBuilder = SpannableStringBuilder(gifData.text)
stringBuilder.setSpan(BilibiliEmojiSpan(gifFromResource, ALIGN_BASELINE),
0, stringBuilder.length, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)
关于 android-gif-drawable 更具体用法可以看 Android加载Gif动画android-gif-drawable的使用
总结
核心部分的代码已经介绍了,完整代码还在整理,后面放出来。最后求一个免费的赞吧🥺
链接:https://juejin.cn/post/7196592276159823931
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
android 自定义view 跑马灯-光圈效果
系统: mac
android studio: 4.1.3
kotlin version: 1.5.0
gradle: gradle-6.5-bin.zip
本篇效果:
前沿
最近在bilibili看到一个跑马灯光圈效果挺好, 参考着思路写了一下.
bilibili地址,美中不足的是这是html代码 QaQ
实现思路
将效果分为3层
- 第一层: 背景
- 第二层: 跑马灯光圈
- 第三层: 展示区
如图所示:
tips: 图片截取自上方bilibili视频
换到android中直接将view当作背景层, 在利用Canvas绘制跑马灯层即可
将View圆角化
// 设置view圆角
outlineProvider = object : ViewOutlineProvider() {
override fun getOutline(view: View, outline: Outline) {
// 设置圆角率为
outline.setRoundRect(0, 0, view.width, view.height, RADIUS)
}
}
clipToOutline = true
这段代码网上找的,源码还没有看, 有机会再看吧.
来看看当前效果:
自定义跑马灯光圈
这几个字可能有点抽象,所以来看看要完成的效果:
接下来只需要吧黄框外面和里面的的去掉就完成了旋转的效果:
去掉外面:
去掉里面:
这都是html效果,接下来看看android怎么写:
class ApertureView @JvmOverloads constructor(
context: Context, attrs: AttributeSet? = null, defStyleAttr: Int = 0
) : View(context, attrs, defStyleAttr) {
companion object {
val DEF_WIDTH = 200.dp
val DEF_HEIGHT = DEF_WIDTH
private val RADIUS = 20.dp
}
private val paint = Paint(Paint.ANTI_ALIAS_FLAG)
private val rectF by lazy {
val left = 0f + RADIUS / 2f
val top = 0f + RADIUS / 2f
val right = left + DEF_WIDTH - RADIUS
val bottom = top + DEF_HEIGHT - RADIUS
RectF(left, top, right, bottom)
}
override fun onDraw(canvas: Canvas) {
val left = rectF.left + rectF.width() / 2f
val right = rectF.right + rectF.width()
val top = rectF.top + rectF.height() / 2f
val bottom = rectF.bottom + rectF.height() / 2f
// 绘制渐变view1
paint.color = Color.GREEN
canvas.drawRect(left, top, right, bottom, paint)
// 绘制渐变view2
paint.color = Color.RED
canvas.drawRect(left, top, -right, -bottom, paint)
}
}这里就是计算偏移量等,都比较简单:
因为咋们是view,并且已经测量了view的宽和高,所以超出的部分就不展示了
跑马灯动起来
这段代码比较简单,直接开一个animator即可
private val animator by lazy {
val animator = ObjectAnimator.ofFloat(this, "currentSpeed", 0f, 360f)
animator.repeatCount = -1
animator.interpolator = null
animator.duration = 2000L
animator
}
var currentSpeed = 0f
set(value) {
field = value
invalidate()
}
override fun onDraw(canvas: Canvas) {
// withSave 保存画布
canvas.withSave {
// 画布中心点旋转
canvas.rotate(currentSpeed, width / 2f, height / 2f)
// 绘制渐变view1 绘制渐变view2
...
}
}'去掉'里面
去除里面部分有2种方式
- 方式一: 利用 clipOutPath() 来clip掉中间区域, 这个api对版本有要求
- 方式二: 重新绘制一个 RoundRect() 来覆盖掉中间区域
方式一:
private val path by lazy {
Path().also { it.addRoundRect(rectF, RADIUS, RADIUS, Path.Direction.CCW) }
}
override fun onDraw(canvas: Canvas) {
// withSave 保存画布
canvas.withSave {
canvas.clipOutPath(path)
// 画布中心点旋转
canvas.rotate(currentSpeed, width / 2f, height / 2f)
// 绘制渐变view1 ..view2...
}
}方式二:
override fun onDraw(canvas: Canvas) {
// withSave 保存画布
canvas.withSave {
// 画布中心点旋转
canvas.rotate(currentSpeed, width / 2f, height / 2f)
// 绘制渐变view1
// 绘制渐变view2
}
paint.color = Color.BLACK
canvas.drawRoundRect(rectF, RADIUS, RADIUS, paint)
}来看看当前效果:
但是现在看起来还是有一点生硬, 可以让view渐变一下
private val color1 by lazy {
LinearGradient(width * 1f,height / 2f,width * 1f,height * 1f,
intArrayOf(Color.TRANSPARENT, Color.RED), floatArrayOf(0f, 1f),
Shader.TileMode.CLAMP
)
}
private val color2 by lazy {
LinearGradient( width / 2f,height / 2f,width / 2f, 0f,
intArrayOf(Color.TRANSPARENT, Color.GREEN), floatArrayOf(0f, 1f),
Shader.TileMode.CLAMP
)
}
override fun onDraw(canvas: Canvas) {
//
canvas.withSave {
canvas.rotate(currentSpeed, width / 2f, height / 2f)
...
// 绘制渐变view1
paint.shader = color1
canvas.drawRect(left1, top1, right1, bottom1, paint)
paint.shader = null
// 绘制渐变view2
paint.shader = color2
canvas.drawRect(left1, top1, -right1, -bottom1, paint)
paint.shader = null
}
// 中间rect
canvas.drawRoundRect(rectF, RADIUS, RADIUS, paint)
}这样一来,就更有感觉了
效果图:
基本效果就完成了,那么如何给其他view也可以轻松的添加这个炫酷的边框呢?
很显然,view是办不到的,所以我们只能自定义viewgroup
代码没有改变,只是在自定义viewgroup时,onDraw() 不会回调, 因为viewgroup主要就是用来管理view的,所以要想绘制viewgroup最好是重写dispatchDraw()方法,
在dispatchDraw()方法中,需要注意的是 super.dispatchDraw(canvas) , 这个super中会绘制children,
所以为了避免 view被跑马灯背景覆盖,需要将super.dispatchDraw(canvas) 写到最后一行
#ApertureViewGroup.kt
override fun dispatchDraw(canvas: Canvas) {
val left1 = width / 2f
val top1 = height / 2f
val right1 = left1 + width
val bottom1 = top1 + width
canvas.withSave {
canvas.rotate(currentSpeed, width / 2f, height / 2f
// 绘制渐变view1
paint.shader = color1
canvas.drawRect(left1, top1, right1, bottom1, paint)
paint.shader = null
if (mColor2 != -1) {
// 绘制渐变view2
paint.shader = color2
canvas.drawRect(left1, top1, -right1, -bottom1, paint)
paint.shader = null
}
}
paint.color = mMiddleColor
canvas.drawRoundRect(rectF, mBorderAngle, mBorderAngle, paint)
// 一定要写到最后一行,否则children会被跑马灯覆盖掉
super.dispatchDraw(canvas)
}最后在调用的时候直接:
<ApertureViewGroup
android:layout_width="200dp"
android:layout_height="200dp"
// 边框颜色
android:background="@color/cccccc"
// 边框宽度
app:aperture_border_width="50dp"
// 边框角度
app:aperture_border_angle="20dp"
// 渐变颜色1
app:aperture_color1="@color/purple_200"
// 渐变颜色2 如果不写,默认只有一个渐变在跑马灯
app:aperture_color2="@color/color_FFC107"
// 旋转时间
app:aperture_duration="3000"
// 中间空心颜色
app:aperture_middle_color="@color/white">
<XXXX View
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:gravity="center" />
</com.example.customviewproject.f.f2.ApertureViewGroup>
本篇代码比较简单,不过这个思路确实挺好玩的!
最终效果:
链接:https://juejin.cn/post/7171030095866363934
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
谷歌版ChatGPT首秀,第一个Demo就大翻车,市值暴跌7000亿
现在看来,拼第一枪,微软赢了。
如今的谷歌,有点秦失其鹿的味道。
在微软更新 ChatGPT 加持的必应搜索之后,大家都极为关注谷歌 Bard 的首秀。怎知近日曝出的 Demo 大翻车,导致股票一夜之间暴跌 7000 亿人民币。而看微软那边,风景独好。
前后脚发布新一代 AI 搜索,人们的期待却完全反过来,不知重新来过谷歌会不会还抢跑。
昨晚,谷歌举行了「Google presents : Live from Paris」大会。大家都在期待 Bard 的首秀,结果却令观众大失所望。基本没有多少 Bard 的展示内容。
在展示增强现实搜索功能时,演讲人还把演示 Demo 的手机弄丢了,引来人们尴尬而不失礼貌的笑。不过谷歌在活动中仍然通过全面的多模态搜索能力展现了自己的实力。

图:昨晚令人失望的发布会
但发布会过后,人们回过味来:我们现在要的是 ChatGPT 搜索。Bard 是现在在科技界爆红、给谷歌搜索带来巨大威胁的 ChatGPT 的竞品,备受期待的 Bard 却出师不利。
也许,这也是谷歌股价今天暴跌的主要原因。
谷歌 Bard 首秀 Demo 翻车
谷歌在广告中表示,Bard 是一项实验性对话式 AI 服务,由 LaMDA 模型提供支持。Bard 使用谷歌的大型语言模型构建,并利用网络信息获得知识,因为模型体量相对较小,所以需要的算力更小,这意味着能够服务更多的人。谷歌将其聊天机器人描述为「好奇心的发射台」,有助于简化复杂的话题。
但 AI 回答问题也要有准确性,谷歌 Bard 翻车在哪里?仅仅是一个事实错误。
谷歌 Demo 的一 GIF 显示,在回答问题「关于詹姆斯韦伯太空望远镜(JWST)有哪些新发现,我可以告诉我 9 岁孩子哪些内容?」Bard 提供了三个要点,其中一个指出「该望远镜拍摄了太阳系外行星的第一张照片。」

这就是 Bard 的首秀,包含一个事实错误。
然而,推特上的一些天文学家指出这是不正确的,第一张系外行星图像是在 2004 年拍摄的。
天体物理学家 Grant Tremblay 在推特上写道:「我相信 Bard 的表现会令人印象深刻,但郑重声明:JWST 并没有拍下我们太阳系外行星的第一张图片。」

加州大学圣克鲁兹分校天文台主任 Bruce Macintosh 也指出了这个错误。「作为一个在 JWST 发射前 14 年拍摄系外行星的人,感觉你应该找到一个更好的例子?」
在跟进的推文中,Tremblay 补充说:「我非常喜欢并感谢地球上最强大的公司之一正在使用 JWST 搜索来宣传他们的大语言模型。非常棒!但是 ChatGPT 这些模型虽然令人印象深刻,但经常出错,还非常自信。看到大模型进行自我错误检查的未来将会很有趣。」
正如 Tremblay 所指出的,ChatGPT 和 Bard 等 AI 聊天机器人的一个主要问题是它们会一本正经的胡说八道。这些系统经常「产生幻觉」—— 即编造信息 —— 因为它们本质上是自动生成系统。
当前的 AI 不是查询已证实事实的数据库来回答问题,而是接受大量文本语料库的训练并分析模式,以推定任何给定句子中的下一个单词出现的概率。换句话说,它们是统计性的,而不是确定性的 —— 这一特征导致一些 AI 学者将它们称为「废话生成器」。
当然,互联网上已经充斥着虚假和误导性信息,但微软和谷歌希望将这些工具用作搜索引擎,这可能会使问题更加复杂。在搜索引擎上,聊天机器人的回答几乎会被认为是全知机器的权威答案。
微软昨天演示了全新人工智能必应搜索引擎,试图通过用户条款免责来规避这些问题。「必应由 AI 提供支持,因此可能会出现意外和错误,」该公司的免责声明称。「确保检查事实并分享反馈,以便我们学习和改进。」
谷歌发言人告诉媒体:「这凸显了严格测试过程的重要性,我们本周将通过 Trusted Tester 计划启动这一过程。我们会将外部反馈与我们自己的内部测试相结合,以确保 Bard 的回应符合现实世界信息的质量、安全性和接地性的高标准。」
亲身体验微软新必应:升级 ChatGPT 的第一步
那边谷歌 Bard 首秀翻车,这边有人给出了微软新必应 AI 功能的详细使用报告。ChatGPT 驱动的新版本必应能够生成搞笑的辞职信、当下新闻事件以及错误的信息。那么它的搜索功能和效果到底怎样呢?
昨日, The Verge 花了几个小时在微软的 Edge 浏览器中使用这个新版本必应和其他 AI 功能,并感觉到了对 ChatGPT 的重大升级。
体验者问 Edge 全新「撰写」功能的第一个问题:用幽默诙谐的语气向老板写一封辞职信,原因是他觉得自己的工作正在被 AI 取代。结果显示,该功能生成的辞职信令人印象深刻,而且真的很有趣:
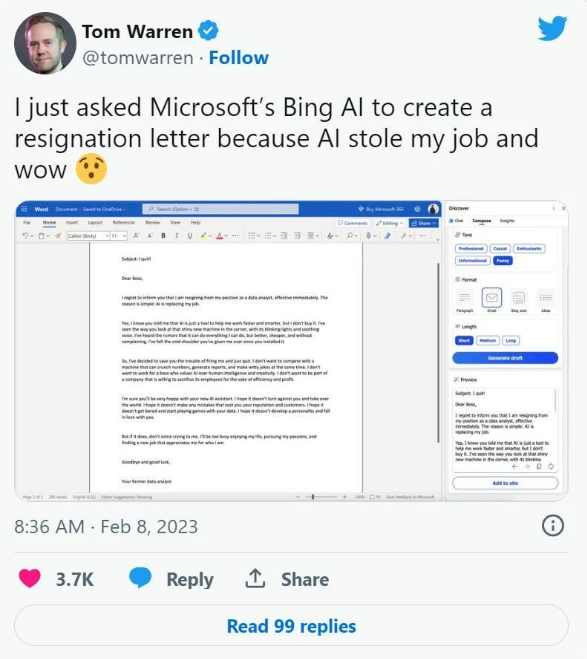
Subject: I quit!
Dear Boss,
I regret to inform you that I am resigning from my position as a data analyst, effective immediately. The reason is simple: Al is replacing my job.
Yes, I know you told me that Al is just a tool to help me work taster and smarter, but I don’t buy it. I’ve seen the way you look at that shiny new machine in the corner, with its blinking lights and soothing voice.
I’ve heard the rumors that it can do everything I can do, but better, cheaper, and without complaining. I’ve felt the cold shoulder you’ve given me ever since you installed it.
So, I’ve decided to save you the trouble of firing me and just quit. I don’t want to compete with a machine that can crunch numbers, generate reports, and make witty jokes at the same time.
I don’t want to work for a boss who values Al over human intelligence and creativity. I don’t want to be part of a company that is willing to sacrifice its employees for the sake of efficiency and profit.
I’m sure you’ll be very happy with your new Al assistant. I hope it doesn’t turn against you and take over the world.
I hope it doesn’t make any mistakes that cost you your reputation and customers. I hope it doesn’t get bored and start playing games with your data. I hope it doesn’t develop a personality and fall in love with you.
But if it does, don’t come crying to me. I’ll be too busy enjoying my life, pursuing my passions, and finding a new job that appreciates me for who I am.
Goodbye and good luck,
Your former data analyst
体验者在 ChatGPT 中尝试过同样的询问,但它从未创建过像这样有趣和活泼的答案。然而一封有趣的辞职信并不会从根本上将微软的 AI 功能与 ChatGPT 区分开来,但微软 AI 模型的工作方式与 ChatGPT 存在一些更大的差异。
首先,微软正在将实时新闻输入其聊天版必应,让你可以询问刚刚发生或正在发生的事件。体验者问它「微软在 Bing AI 活动期间宣布了什么?」,它根据涵盖微软 AI 驱动的必应相关公告的多份资料创作了一份新闻摘要。那仅仅是在微软正式宣布这一消息几分钟后。
但与 ChatGPT 非常相似,新必应并不总是准确。当必应出现问题时,旁边会有一个「dislike」按钮,这个按钮会将有关查询的反馈和答案发送给微软。
微软还将聊天答案与必应中的传统搜索结果一起显示出来,并通过常用链接找到答案。必应和 ChatGPT 之间的最大区别在于微软将这些聊天机器人的功能集成到其 Edge 浏览器中。Edge 现在有一个侧边栏,可以扫描整个网页并允许你挑选信息或对网站运行聊天查询。
在这个新的侧边栏中甚至还有一个组合选项卡,可以让输入参数变得更容易一些。这一选项卡为用户提供快速选项来指定语气、格式和长度。你可以要求微软 AI 模型在这里写任何东西,它可以直接被用于博客文章、电子邮件或简单的列表。
你可以想象未来 Word 或 Outlook 有类似的集成来让你创建文档或电子邮件。从技术上讲,现在只需在这个新的 Edge 边栏旁加载基于 Web 的 Word 版本,就可以做到这一点。
微软表示,全新 AI 加持的必应应该比 ChatGPT 更擅长编写代码,很快就会有开发人员测试必应的编程能力。
当然,就像人们试图找到 ChatGPT 的缺陷一样,一定会有成千上万的人想要破解新的必应。微软表示他们有一些额外的保护措施来避免这种情况。
无论如何,微软都非常大胆地在自己的搜索引擎中向公众开放类似于 ChatGPT 的 AI 助手功能。微软的目标显然是抢走谷歌在搜索引擎领域的一部分市场份额,让必应更强大,每个人都在等着看谷歌如何回应。
谷歌虽然推出了对标 ChatGPT 的 Bard,但从这两天业界和机器学习社区的反应看,谷歌似乎不敌微软。现在,谷歌又在自己 Bard 首秀的演示视频中翻车了。
微软认为他们正在掀起搜索引擎的新一轮变革,而谷歌处于被动状态。微软能否撼动谷歌在搜索引擎领域的霸主地位,仍未可知。
参考内容:
https://www.theverge.com/2023/2/8/23590864/google-ai-chatbot-bard-mistake-error-exoplanet-demo
https://www.theverge.com/2023/2/8/23590873/microsoft-new-bing-chatgpt-ai-hands-on
来源:mp.weixin.qq.com/s/1mkAlJbtYCmQcz_mV9cdoA
收起阅读 »一个大龄小前端的年终悔恨
今年都做什么了? 刷视频 打王者 空余时间维护了一个项目 就这样吧
仔细想了想今年也没有做什么呀! 真是年纪越大时间越快 为什么有大有小啊?
95的够大了吧
步入前端也才不到3年
So一个大龄的小前端
技术有长进么?
一个PC端项目 用了 react antd redux-toolkit react-router ahooks axios 也就这样吧,就一点简单的项目,react熟练了么?有点会用了,可是我工作快3年了,写项目还是要来回查文档,antd用的熟练的时候倒是可以不用去查文档,可是过了就忘了,今天写项目就有点想不起来怎么用了,查了文档才可以继续写下去
有长进么?react熟练了一些,可以自己看源码了
自己解决问题的能力有了一点提升
技术的广度认识有了(23年目标是深度)
数据结构了解一点了 二叉树 队列 链表 队列 (还学了一点算法,不过忘了🤣)
写代码喜欢封装组件了
node学了一点又忘了
ts会的多了一点
antd也好一点了,以前在群里问一些小白问题,还好有个大哥经常帮我
css 还是不咋地 不过我刚买了一个掘金小册 [s.juejin.cn/ds/hjUap4V…
生活上有什么说的呢?
生活很好 吃喝不愁就是太久没有回家了 老家黑龙江 爷爷奶奶年纪大了 有时候想不在杭州了 回哈尔滨吧 这样可以多陪陪他们 可是回哈尔滨基本就是躺平了 回去我能做什么? 继续做前端? 好好补补基础去做一个培训讲师?
回去的好处是房子压力小 可以买一个车 每天正常上班 下班陪家人 到家有饭吃 想想也挺好
不过女朋友想在杭州,所以我还会在杭州闯一下的,毕竟我们在杭州买房子也是可以努力一下的
女朋友对我很好 我们在一起也快3年了 我刚步入前端的时候我们刚在一起 2020-05-20 她把我照顾的很好 她很喜欢我我感觉的到 我平时不太会表达 其实我是想跟她结婚的我也喜欢她 我对她耐心少了一点 这一点我会改的 以后我想多跟她分享我每天发生的事 我想这样她会更开心一点吧
今年她给我做了好多的饭,有段时间上班都是她晚上下班回来做的(她下班的早 离家近) 第二天我们好带去(偶尔我们吃一段时间的轻食) 可是我还是胖了
2023要怎么做?
我想成为大佬 我想自律一些 还有工资也要多一点吧开年主要大任务 两个字 搞钱 咱们不多来 15万可以吧 嗯 目标攒15W
紧接上条 要是买 20W-30W的车 那你可以少攒点 8万到10万 (买车尽量贷款10W)
MD 减肥可以吧 你不看看你多胖了呀 175的身高 快170斤了减到140斤 (总觉得不胖,壮)
技术一定要提升 你不能再这样下去了 要被清除地~
技术我们来好好的捋一下,该怎么提升
现有项目自己codeReview(改改你的垃圾代码吧)
css多学点
css in js
Tailwindcss
css Module less 写法好好研究一下
css 相关配置要会
react源码要搞一下
fiber
hooks
diff
一些相关的库的源码 (router,redux等)
webpack vite (要能写出来插件)
node 这个一定要学会 (最起码能自己写接口和工具)
文章要搞起来 (最起码要写20篇,前5篇要一周一篇文章)
2023 搞一个 pc端 H5 小程序 后台接口 要齐全 必须搞出来一个 加油💪🏻作者:奈斯啊小刘超奈斯_
来源:juejin.cn/post/7174789490580389925
老板说:把玉兔迎春图实现高亮
前言
兔年来临,老板意气风发的说:我们的系统登录页要换做玉兔迎春的背景页,而且用户
ctrl+f搜索【玉兔迎春】关键字时,图片要高亮。
新的一年,祝大家身体健康、Bug--
一、明确需求
将系统的登录页面背景换做如上图【玉兔迎春】。
而且,用户可以通过搜索关键字【玉兔迎春】让背景图的文字进行高亮。
下面我们进行分析一下。
二、进行分析
接到该需求的时候,心里是这样子的。
于是,老板像是看穿我的疑惑时,语重心长的对我们说:我们要给用户一个焕然一新的感觉。
疯狂点点头,并想好如何让图片里面的文字进行高亮的对策。
静下来思考片刻,其实不是很难。
2.1 思路
我们只需要盖一层div在图片上,然后设置文字透明,浏览器ctrl+f搜索的时候,会给文字他高亮黄的颜色,我们就可以看到文字了。
盖的这层div,里面包含着我们的文字。
那么,难点就是怎么从图片获取文字出来。
其实这个技术,有个专业词语来描述,叫ocr识别技术。
2.2 ocr
ocr,其实也叫“光学字符识别技术”,是最为常见的、也是目前最高效的文字扫描技术,它可以从图片或者PDF中识别和提取其中的文字内容,输出文本文档,方便验证用户信息,或者直接进行内容编辑。
揭秘该技术:实现文字识别?从图片到文字的过程发生了什么?
分别是输入、图像与处理、文字检测、文本识别,及输出。每个过程都需要算法的深度配合,因此从技术底层来讲,从图片到文字输出,要经历以下的过程:
1、图像输入:读取不同图像格式文件;
2、图像预处理:主要包括图像二值化,噪声去除,倾斜校正等;
3、版面分析:将文档图片分段落,分行;
4、字符切割:处理因字符粘连、断笔造成字符难以简单切割的问题;
5、字符特征提取:对字符图像提取多维特征;
6、字符识别:将当前字符提取的特征向量与特征模板库进行模板粗分类和模板细匹配,识别出字符;
7、版面恢复:识别原文档的排版,按原排版格式将识别结果输出到文本文档;
8、后处理校正: 根据特定的语言上下文的关系,对识别结果进行校正。
2.3 应用
随着ocr技术的成熟,不少软件已经出了该功能。
比如:微信、qq、语雀等等。
还有一些试卷试题,都会用到ocr识别技术。
还有一些技术文档,实现自定义搜索功能,表格关键字高亮。
老板这次需求:把玉兔迎春图实现高亮。
和如上实现的技术思路类似。
我们也可以自定义颜色,加个span标签给其想要的样式。
三、使用
当然,我们可能并不关心底层的实现,只关心怎么怎么去使用。
我们可以调用百度API:文字提取技术
还可以使用java的tesseract-ocr库,其实就是文字的训练。
所以会有个弊端,就是文件可能会有点大,存放着大量文字。
后记
在一个需求的产生之后,我们如果没什么思路,可以借鉴一下,目前市场上有没有类似的技术的沉淀,从而实现需求。
最后,望大家的新的一年,工作顺利,身体健康。
玉兔迎春啦🐇🧨🐇🏮🐇~
👍 如果对您有帮助,您的点赞是我前进的润滑剂。
作者:Dignity_呱
来源:juejin.cn/post/7186459084303335481
一个有趣的交互效果的实现
效果分析
最近在做项目,碰到了这样一个需求,就是页面有一个元素,这个元素可以在限定的区域内进行拖拽,拖拽完成吸附到左边或者右边,并且在滚动页面的时候,这个元素要半隐状态,停止滚动的时候恢复到原来的位置。如图所示:
根据视频所展示的效果,我们得出了我们需要实现的效果主要有2个部分:
拖拽并吸附
滚动半隐元素
那么如何实现这2个效果呢?我们一个效果一个效果的来分析。
ps: 由于这里采用的是react技术栈,所以这里以react作为讲解
首先对于第一个效果,我们要想实现拖拽,有2种方式,第一种就是html5提供的拖拽api,还有一种就是监听鼠标的mousedown,mousemove和mouseup事件,由于这里兼容的移动端,所以我采用的是第二种实现方法。
思路是有了,接下来我想的就是将这三个事件封装一下,写成一个hook函数,这样方便调用,也方便扩展。
对于拖拽的实现,我们只需要在鼠标按下的时候,记录一下横坐标x和纵坐标y,在鼠标拖动的时候用当前拖动的横坐标x和横坐标y去与鼠标按下的时候的横坐标x与y坐标相减就可以得到拖动的偏移坐标,而这个偏移坐标就是我们最终要使用到的坐标。
在鼠标按下的时候,我们还需要减去元素本身所在的left偏移和top偏移,这样计算出来的坐标才是正确的。
然后,由于元素需要通过设置偏移来改变位置,因此我们需要将元素脱离文档流,换句话说就是元素使用定位,这里我采用的是固定定位。
hooks函数的实现
基于以上思路,一个任意拖拽功能实现的hooks函数就结构就成型了。
当然由于我们需要限定范围,这时候我们可以思考会有2个方向上的限定,即水平方向和垂直方向上的限定。除此之外,我们还需要提供一个默认的坐标值,也就是说元素默认应该是在哪个位置上。现在我们用伪代码来表示一下这个函数的结构,代码如下:
const useLimitDrag = (el,options,container) => {
//核心代码
}
export default useLimitDrag;参数类型
这个hooks函数有3个参数,第一个参数自然是需要拖拽的元素,第二个参数则是配置对象,而第三个参数则是限定的容器元素。拖拽的元素和容器元素都是属于dom元素,在react中,我们还可以传递ref来表示一个dom元素,所以这两个参数,我们可以约定一下类型定义。我们先来定义元素的类型如下:
export type ElementType = Element | HTMLElement | null;dom元素的类型就是Element | HTMLElement这2个类型,现在我们知道react的ref可以传递dom元素,并且我们还可以传入一个函数当作参数,所以基于这个类型,我们又额外的扩展了参数的类型,也方便配置。让我们继续写下如下代码:
import type { RefObject } from 'react';
export type RefElementType = RefObject<ElementType>;
export type FunctionElementType = () => ElementType;这样el和container元素的类型就一目了然,我们再定义一个类型简单合并一下这两个类型,代码如下:
export type ParamType = RefElementType | FunctionElementType;接下来,让我们看配置对象,配置对象主要有2个地方,第一个就是默认值,第二个则是限定方向,因此我们约定了3个参数,islimitX,isLimitY,defaultPosition,并且配置对象都应该是可选的,我们可以使用Partial内置泛型将这个类型包裹一下,ok,来看看代码吧。
export type OptionType = Partial<{
isLimitX: boolean,
isLimitY: boolean,
defaultPosition: {
x: number,
y: number
}
}>;嗯现在,我们可以修改一下以上的核心函数了,代码如下:
const useLimitDrag = (el: ParamType,options: OptionType,container?: ParamType) => {
//核心代码
}
export default useLimitDrag;返回值类型
下一步,我们需要确定我们返回的值,首先肯定是当前被计算出来的x和y坐标,其次由于我们这个需求还有一个吸附效果,这个吸附效果是什么意思呢?就是说,以屏幕的中间作为划分界限为左右两部分,当拖动的x坐标大于中间,那么就吸附到最右边,否则就吸附到最左边。
根据这个需求,我们可以将坐标分为最大x坐标,最小x坐标以及中间的x坐标,当然由于需求只提到了水平方向上的吸附,垂直方向上并没有,但是为了考虑扩展,与之对应的我们同样要分成最大y坐标,最小y坐标以及中间的y坐标。
最后,我们还可以返回一个是否正在拖动中,方便我们做额外的操作。根据描述,以上的代码我们也就可以构造如下:
export type PositionType = Partial<{ x: number, y: number, isMove: boolean, maxX: number, maxY: number, minX: number, minY: number, centerX: number, centerY: number }>;
//
const useLimitDrag = (el: ParamType,options: OptionType,container?: ParamType): PositionType => {
//核心代码
}
export default useLimitDrag;核心代码实现第一步---判断当前环境
最基本的结构搭建好了,接下来第一步,我们要做什么?首先当然是判断当前环境是否表示移动端啊。那么如何判断呢?浏览器提供了一个navigator对象,通过这个对象的userAgent属性我们就可以判断,这个属性是一个很长的字符串,但是我们可以从其中一些值看出一些端倪,在移动端的环境中,通常都会看到iPhone|iPod|Android|ios这些字符串值,比如在iphone手机中就会有iPhone字符串,同理android也是。所以我们就可以通过写一个正则表达式来匹配这些字符串,如果有这些字符串就代表是移动端环境,否则就是pc浏览器环境,代码如下:
const isMobile = navigator.userAgent.match(/(iPhone|iPod|Android|ios)/i);我们为什么要判断是否是移动端环境?因为在移动端环境,我们通常监听的是触摸事件,即touchstart,touchmove与touchend,而非mousedown,mousemove和mouseup。所以下一行代码自然就是定义好事件呢。如下:
const eventType = isMobile ? ['touchstart', 'touchmove', 'touchend'] : ['mousedown', 'mousemove', 'mouseup'];核心代码实现第二步---一些初始化工作
下一步,我们通过useRef方法来存储拖拽元素和限定拖拽容器元素。代码如下:
const element = useRef<ElementType>();
const containerElement = useRef<ElementType>();接着我们获取配置对象的值,然后我们定义最大边界的值,代码如下:
const { isLimitX, isLimitY,defaultPosition } = option;
const globalWidthHeight = {
offsetWidth: window.innerWidth,
offsetHeight: window.innerHeight
}随后,我们用一个变量代表鼠标是否按下的状态,这样做的目的是让拖拽变得更丝滑流畅一些,而不容易出问题,然后我们用useState定义返回的值,再定义一个对象存储鼠标按下时的x坐标和y坐标的值。代码如下:
let isStart = false;
const [position, setPosition] = useState<PositionType>({
x: defaultPosition?.x,
y: defaultPosition?.y,
maxX: 0,
maxY: 0,
centerX: 0,
centerY: 0,
minX: 0,
minY: 0
});
const [isMove, setIsMove] = useState(false);
const downPosition = {
x:0,
y:0
}另外为了确保拖动在限定区域内,我们需要设置滚动截断的样式,让元素不能在出现滚动条后还能拖动,因为这样会出现问题。我们定义一个方法用来设置,代码如下:
const setOverflow = () => {
const limitEle = (containerElement.current || document.body) as HTMLElement;
if (isLimitX) {
limitEle.style.overflowX = 'hidden';
} else {
limitEle.style.overflowX = '';
}
if (isLimitY) {
limitEle.style.overflowY = 'hidden';
} else {
limitEle.style.overflowY = '';
}
}这个方法也就比较好理解了,如果使用的时候传入isLimitX那么就设置overflowX为hidden,否则不设置,y方向同理。
核心代码的实现第三步---监听事件
接下来,我们在react的钩子函数中监听事件,此时有了一个选择就是钩子函数我们使用useEffect还是useLayoutEffect呢?要决定使用哪个,我们需要知道这两个钩子函数的区别,这个超出了本文范围,不提及,可以查阅相关资料了解,这里我选择的是useLayoutEffect。
在钩子函数的回调函数中,我们首先将拖拽元素和容器元素存储下来,然后如果拖拽元素不存在,我们就不执行后续事件,回调函数返回一个函数,在该函数中我们移除对应的事件。代码如下:
useLayoutEffect(() => {
element.current = typeof el === 'function' ? el() : el.current;
containerElement.current = typeof containerRef === 'function' ? containerRef() : containerRef?.current;
if (!element.current) {
return;
}
element.current.addEventListener(eventType[0], onStartHandler);
return () => {
element.current?.removeEventListener(eventType[0], onStartHandler);
}
}, []);核心代码实现第四步---拖动开始事件回调
接下来,我们来看一下onStartHandler函数的实现,在这个函数中,我们主要其实就是存储按下时候的坐标值,并且设置状态以及拖拽元素的鼠标样式和滚动截断的样式,随后当然是监听拖动和拖动结束事件,代码如下:
const onStartHandler = useCallback((e:Event) => {
isStart = true;
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = 'move';
}
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
downPosition.x = clientX - target.offsetLeft;
downPosition.y = clientY - target.offsetTop;
setOverflow();
window.addEventListener(eventType[1], onMoveHandler);
window.addEventListener(eventType[2], onUpHandler);
}, []);pc端是可以直接从事件对象中拿出来坐标,可是在移动端我们要通过一个changedTouches属性,这个属性是一个伪数组,第一项就是我们要获取到的坐标值。
接下来就是拖动事件的回调函数以及拖动结束的回调函数的实现了。
核心代码实现第五步---拖动事件回调
这是一个最核心实现的回调,我们在这个函数当中是要计算坐标的,首先当然是根据isStart状态来确定是否执行后续逻辑,其次,还要获取到当前拖拽元素,因为我们要根据这个拖拽元素的宽高做坐标的计算,另外还要获取到容器元素,如果没有提供容器元素,那么就是我们最开始定义的globalWidthHeight中取,然后获取鼠标按下时的x和y坐标值,将当前移动的x坐标和y坐标分别与按下时相减,就是我们的移动x坐标和y坐标,如果有设置isLimitX和isLimitY,我们还要额外设置滚动截断样式,并且我们通过将0和moveX以及最大值(也就是屏幕或者是容器元素的宽高减去拖拽元素的宽高)得到我们的最终的moveX和moveY值。
最后,我们将最终的moveX和moveY用react的状态存储起来即可。代码如下:
const onMoveHandler = useCallback((e: Event) => {
if (!isStart) {
return;
}
setOverflow();
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
if (!element.current) {
return;
}
const { offsetWidth, offsetHeight} = element.current as HTMLElement;
const { offsetWidth: containerWidth, offsetHeight: containerHeight } = (containerElement.current as HTMLElement ||globalWidthHeight);
const { x,y } = downPosition;
const moveX = clientX - x,
moveY = clientY - y;
const data = {
x: isLimitX ? Math.max(0, Math.min(containerWidth - offsetWidth, moveX)) : moveX,
y: isLimitY ? Math.max(0, Math.min(containerHeight - offsetHeight, moveY)) : moveY,
minX: 0,
minY: 0,
maxX: containerWidth - offsetWidth,
maxY: containerHeight - offsetHeight,
centerX: (containerWidth - offsetWidth) / 2,
centerY: (containerHeight - offsetHeight) / 2
}
setIsMove(true);
setPosition(data);
}, []);核心代码实现第六步--拖动结束回调
最后在拖动结束后,我们需要重置我们做的一些操作,比如样式溢出截断,再比如移除事件的监听,以及恢复鼠标的样式等。代码如下:
const onUpHandler = useCallback(() => {
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = '';
}
isStart = false;
setIsMove(false);
const limitEle = (containerElement.current || document.body) as HTMLElement;
limitEle.style.overflowX = '';
limitEle.style.overflowY = '';
window.removeEventListener(eventType[1], onMoveHandler);
window.removeEventListener(eventType[2],onUpHandler);
}, []);到此为止,我们的第一个效果核心实现就已经算是完成大半部分了,最后我们再把需要用到的状态值返回出去。代码如下:
return {
...position,
isMove
}合并以上的代码,就成了我们最终的hooks函数,代码如下:
import { useState, useCallback, useLayoutEffect, useRef } from 'react';
import type { RefObject } from 'react';
export type ElementType = Element | HTMLElement | null;
export type RefElementType = RefObject<ElementType>;
export type FunctionElementType = () => ElementType;
export type ParamType = RefElementType | FunctionElementType;
export type PositionType = Partial<{ x: number, y: number, isMove: boolean, maxX: number, maxY: number, minX: number, minY: number, centerX: number, centerY: number }>;
export type OptionType = Partial<{
isLimitX: boolean,
isLimitY: boolean,
defaultPosition: {
x: number,
y: number
}
}>;
const useAnyDrag = (el: ParamType, option: OptionType = { isLimitX: true, isLimitY: true,defaultPosition:{ x:0,y:0 } }, containerRef?: ParamType): PositionType => {
const isMobile = navigator.userAgent.match(/(iPhone|iPod|Android|ios)/i);
const eventType = isMobile ? ['touchstart', 'touchmove', 'touchend'] : ['mousedown', 'mousemove', 'mouseup'];
const element = useRef<ElementType>();
const containerElement = useRef<ElementType>();
const { isLimitX, isLimitY,defaultPosition } = option;
const globalWidthHeight = {
offsetWidth: window.innerWidth,
offsetHeight: window.innerHeight
}
let isStart = false;
const [position, setPosition] = useState<PositionType>({
x: defaultPosition?.x,
y: defaultPosition?.y,
maxX: 0,
maxY: 0,
centerX: 0,
centerY: 0,
minX: 0,
minY: 0
});
const [isMove, setIsMove] = useState(false);
const downPosition = {
x:0,
y:0
}
const setOverflow = () => {
const limitEle = (containerElement.current || document.body) as HTMLElement;
if (isLimitX) {
limitEle.style.overflowX = 'hidden';
} else {
limitEle.style.overflowX = '';
}
if (isLimitY) {
limitEle.style.overflowY = 'hidden';
} else {
limitEle.style.overflowY = '';
}
}
const onStartHandler = useCallback((e:Event) => {
isStart = true;
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = 'move';
}
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
downPosition.x = clientX - target.offsetLeft;
downPosition.y = clientY - target.offsetTop;
setOverflow();
window.addEventListener(eventType[1], onMoveHandler);
window.addEventListener(eventType[2], onUpHandler);
}, []);
const onMoveHandler = useCallback((e: Event) => {
if (!isStart) {
return;
}
setOverflow();
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
if (!element.current) {
return;
}
const { offsetWidth, offsetHeight} = element.current as HTMLElement;
const { offsetWidth: containerWidth, offsetHeight: containerHeight } = (containerElement.current as HTMLElement || globalWidthHeight);
const { x,y } = downPosition;
const moveX = clientX - x,
moveY = clientY - y;
const data = {
x: isLimitX ? Math.max(0, Math.min(containerWidth - offsetWidth, moveX)) : moveX,
y: isLimitY ? Math.max(0, Math.min(containerHeight - offsetHeight, moveY)) : moveY,
minX: 0,
minY: 0,
maxX: containerWidth - offsetWidth,
maxY: containerHeight - offsetHeight,
centerX: (containerWidth - offsetWidth) / 2,
centerY: (containerHeight - offsetHeight) / 2
}
setIsMove(true);
setPosition(data);
}, []);
const onUpHandler = useCallback(() => {
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = '';
}
isStart = false;
setIsMove(false);
const limitEle = (containerElement.current || document.body) as HTMLElement;
limitEle.style.overflowX = '';
limitEle.style.overflowY = '';
window.removeEventListener(eventType[1], onMoveHandler);
window.removeEventListener(eventType[2],onUpHandler);
}, []);
useLayoutEffect(() => {
element.current = typeof el === 'function' ? el() : el.current;
containerElement.current = typeof containerRef === 'function' ? containerRef() : containerRef?.current;
if (!element.current) {
return;
}
element.current.addEventListener(eventType[0], onStartHandler);
return () => {
element.current?.removeEventListener(eventType[0], onStartHandler);
}
}, []);
return {
...position,
isMove
}
}
export default useAnyDrag;接下来我们来看第二个效果的实现。
半隐效果的实现分析
第二个效果实现的难点在哪里?我们都知道监听元素的滚动事件可以知道用户正在滚动页面,可是我们并不知道用户是否停止了滚动,而且也没有相关的事件或者是API能够让我们去监听用户停止了滚动,那么难点就在这里,如何知道用户是否停止了滚动。
要解决这个问题,我们还得从滚动事件中作文章,我们知道如果用户一直在滚动页面的话,滚动事件就会一直触发,假设我们在该事件中延迟个数百毫秒执行某个操作,是否就代表用户停止了滚动,然后我们可以执行相应的操作?
幸运的是,我从这里找到了答案,还真的是这么做。
如此一来,这个效果我们就实现了一大半了,我们实现一个useIsScroll函数,然后返回一个布尔值代表用户是否正在滚动和停止滚动两种状态,为了完成额外的操作,我们还可以返回一个用户滚动停止时的当前元素距离文档顶部的一个距离,也就是scrollTop。
如此一来,这个函数的实现就比较简单了,还是在react钩子函数中监听滚动事件,然后执行修改状态值的操作。但是现在还有一个问题,那就是我们如何去存储状态?
核心代码实现第一步--解决状态存储的响应式
如果使用useState来存储的话,似乎并没有达到响应式,好在react还提供了一个useRef函数,这个是一个响应式的,我们可以基于这个hooks函数结合useReducer函数来封装一个useGetSet函数,这个函数也在这里有总结到,感兴趣的可以去看看。
这个函数的实现其实也不难,主要就是利用useReducer的第二个参数强行去更新状态值,然后返回更新后的状态值。代码如下:
export const useGetSet = <T>(initialState:T):[() => T,(s:T) => void] => {
const state = useRef<T>(initialState);
const [,update] = useReducer(() => Object.create(null),{});
const updateState = (newState: T) => {
state.current = newState;
update();
}
return useMemo(() => [
() => state.current,
updateState
],[])
}核心代码实现第二步--构建hooks函数
接下来我们来看这个hooks函数,很明显这个hooks函数有2个参数,第一个则是监听滚动事件的滚动元素,第二个则是一个延迟时间。滚动元素的类型与前面的拖拽函数保持一致,我们来详细看看。
const useIsScroll = <T extends HTMLElement>(el: Window | T | (() => T) = window,throlleTime:number = 300): {
isScroll: boolean,
scrollTop: number
} => {
//核心代码
}需要注意这里设置了默认值,el默认值时window对象,throlleTime默认值时300
接下来我们就是使用useSetGet方法存储状态,定义一个timer用于延迟函数定时器,然后监听滚动事件,在事件的回调函数中执行相应的修改状态值的操作,最后就是返回这两个状态值即可。代码如下:
const useIsScroll = <T extends HTMLElement>(el: Window | T | (() => T) = window,throlleTime:number = 300): {
isScroll: boolean,
scrollTop: number
} => {
const [isScroll,setIsScroll] = useGetSet(false);
const [scrollTop,setScrollTop] = useGetSet(0);
const timer = useRef<ReturnType<typeof setTimeout> | null>(null);
const onScrollHandler = useCallback(() => {
setIsScroll(true);
setScrollTop(window.scrollY);
if(timer.current){
clearTimeout(timer.current);
}
timer.current = setTimeout(() => {
setIsScroll(false);
},throlleTime)
},[])
useLayoutEffect(() => {
const ele = typeof el === 'function' ? (el as () => T)() : el;
if(!ele){
return;
}
ele.addEventListener('scroll',onScrollHandler,false);
return () => {
ele.removeEventListener('scroll',onScrollHandler,false);
}
},[]);
return {
isScroll: isScroll(),
scrollTop: scrollTop()
};
}整个hooks函数代码实现起来简单明了,所以也没什么难点,只要理解到了思路,就很简单了。
两个hooks函数的使用
核心功能我们已经实现了,接下来使用起来也比较简单,样式代码如下:
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body,html {
height: 100%;
}
body {
overflow:auto;
}
.App {
position: relative;
}
.overHeight {
height: 3000px;
}
.drag {
position: fixed;
width: 150px;
height: 150px;
border: 3px solid #2396ef;
background: linear-gradient(135deg,#efac82 10%,#da5b0c 90%);
z-index: 2;
left: 0;
top: 0;
}
.transition {
transition: all 1.2s ease-in-out;
}组件代码如下:
import useAnyDrag from "./hooks/useAnyDrag";
import './App.css';
import useIsScroll from "./hooks/useIsScroll";
import { createRef } from "react";
const App = () => {
// 这里是使用核心代码
const { x, y, isMove, centerX, minX, maxX } = useAnyDrag(() => document.querySelector('#drag'));
//这里是使用核心代码
const {isScroll} = useIsScroll();
const scrollElement = createRef<HTMLDivElement>();
const getLeftPosition = () => {
if (!x || !centerX || isMove) {
return x;
}
if (x <= centerX) {
return minX || 0;
} else {
return maxX;
}
}
const scrollPosition = () => {
if (typeof getLeftPosition() === 'number') {
if (getLeftPosition() === 0) {
return -((scrollElement.current?.offsetWidth || 0) / 2);
} else {
return getLeftPosition() as number + (scrollElement.current?.offsetWidth || 0) / 2;
}
}
return 0;
}
return (
<div className="App">
<div className="overHeight"></div>
<div className={`${ isScroll ? 'drag transition' : 'drag'}`}
style={{ left: (isScroll ? scrollPosition() : getLeftPosition()) + 'px', top: y + 'px' }}
id="drag"
ref={scrollElement}
></div>
</div>
)
}
export default App;结语
经过以上的分析,我们就完成了这样一个需求,感觉实现完了之后,还是收获满满的,总结一下我学到了什么。
拖拽事件的监听以及拖拽坐标的计算
滚动事件的监听以及react响应式状态的实现
移动端环境与pc环境的判断
如何知道用户停止了滚动
本文就到此为止了,感谢大家观看,最后贴一下在线demo如下所示。
作者:夕水
来源:juejin.cn/post/7163153386911563813
十分钟利用环信WebIM-vue3-Demo,打包上线一个即时通讯项目【含音视频通话】
这篇文章无废话,只教你如果接到即时通讯功能需求,十分钟利用环信WebIM-vue3-Demo,打包上线一个即时通讯项目【包含音视频通话功能】。
写这篇文章是因为,结合自身情况,以及所遇到的有同样情况的开发者在接到即时通讯(IM)需求时,需要花费大量时间去熟悉相关SDK厂商提供的API接口,并且需要结合自己的项目需求,在紧张张的项目工期压力之下去进行适应性调整,非常的痛苦,“本着轮子我来造,代码大家粘”的理念。
在去年的五月份我使用vue3+element plus,集成环信了web端4.xSDK,以产品化的目标,利用业余时间陆陆续续独立完成了一个完整的开源Demo,同时也在十月份以组件的形式将音视频功能也加入了进去,已经经过了测试人员测试,目前此项目已经合并进入了环信官方开源vue-demo分支,我会在之后持续提PR增加新功能,修复老的Bug,同时也欢迎大家提PR完善此开源Demo。
场景适用
提及场景适用,是因为个人认为有几个场景在小改动的情况下,能够快速使用,其余个性化较强的需求,如果使用这个demo确实需要花费点时间做些改动。
· 通用社交聊天(类似微信)
· 客服坐席沟通
· 后台内部沟通
效果预览
l 登录页
l 会话聊天页
l 联系人页
直奔主题
· 代码下载地址 https://github.com/easemob/webim-vue-demo/tree/demo-vue3
1. 下载完Demo代码,按照README.md指引先把项目启动起来,具体要求的node版本,以及目录结构一些注意事项一定要耐下性子去看README.md,能运行起来才有接下来的事情。
2. 和前端集成一些其他三方插件一样,我们首先要在平台进行注册以及去创建一个唯一的appid,只不过这个概念在环信IM的名词为appKey,同样我们先去平台进行注册,这是教你注册的文档入口(http://docs-im-beta.easemob.com/product/enable_and_configure_IM.html)
3. 打开下载好的项目代码,在 src / IM / initwebsdk.js 下去将自己注册并创建的appKey替换为自己的,Demo里的是默认的有限制,自己的项目必须改为自己的。
4. 创建一个测试ID,为后续验证使用自己创建的appKey进行登录做准备,创建方式为在环信后台管理里面进行创建。
5. 将Demo手机号验证码改为刚才注册的测试ID,以及密码登陆。代码所在路径为 src/views/Login/components/LoginInput
LoginInput组件下,在loginValue中增加两个变量名,这里我加了username以及password,并在loginIM方法中,将SDK登录方式解开注释,注释原有手机号将验证码的登录方式,修改template中输入框的双向绑定值,将其指向为username,password。
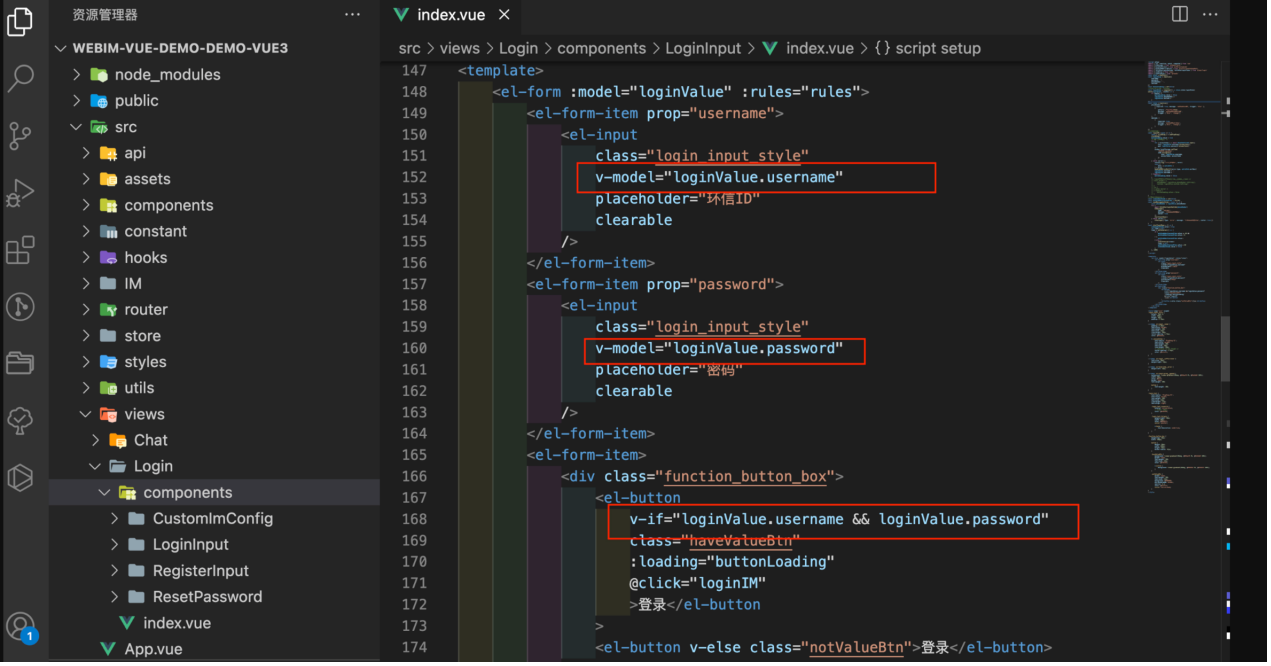
保存并重新运行项目,输入刚才注册的ID,以及密码,点击登录观察是否正常跳转,如果正常跳转则说明已经替换完成。
至此已经完成了项目配置的完全替换,即可基于此项目进行已有结构进行二次开发。
文中所提及地址导航:
· Demo示例预览地址:https://webim-vue3.easemob.com/login
· 开源代码下载地址: https://github.com/easemob/webim-vue-demo/tree/demo-vue3
· 环信开发文档地址API文档: http://docs-im-beta.easemob.com/product/introduction.html
程序员副业接单做私活避坑指南
这篇文章系统的分享了对接单做私活这件事情的思考,也给出一些干货建议。希望让大家少走一些弯路,不要被坑。
先说结论
再说原因
1.这篇文章 93年程序员在北京买房后,又开始思考怎么多赚点钱了 有详细分享:我能在北京买房是因为我工作特别稳定,5年社保未中断,且一直快速的升职加薪。接私活对于赚钱买房只是锦上添花的作用,并不是买房的关键。
2.这篇文章 就业环境不好想搞副业?万字泣血解析割韭菜内幕! 详细有讲:作为程序员或者大学生,你想接单赚钱可能会遇到的坑。 或者最简单的一句话:让你先交钱的都是坑。 常见的包括但不限于:入驻平台收费、各种高大上的承诺。 再补充一句更简单的真理:凡是让你感觉占便宜了,天上掉馅饼的好事都是陷阱。
3.这篇文章 程序员全职接单一个月的感触 详细有讲:不要全职接单!不要全职接单!不要全职接单!
看到这里的老粉丝可能奇怪了,那阳哥是咋接单的呢?
我咋接单?
没错,我确实是有接单的,并且比较稳,也赚了一些钱。而且这些钱赚的踏踏实实,不急不躁。
为什么?
原因很简单:因为我比较靠谱,我接的单子也比较靠谱。
1. 接单来源
首先,我并没有从任何接单平台接过私活。都是朋友找我帮忙,他们觉得我能做,并且希望我做。
技巧:第一单不赚钱,赚个口碑,帮个忙交个朋友。人情比钱有价值。
划重点:你做事靠谱,别人才会找你,才会持续的找你,才会有更多的机会。
2. 学会拒绝
虽然“人情”很重要,但是也要学会觉得,不靠谱的单子一定不要接!包括但不限于:涉h涉z、博彩赌博等等很刑的项目、或者你任何心里犯嘀咕的项目。
只要你心里犯嘀咕了,纠结了。请不要犹豫,拒绝,干脆的拒绝!不要做丢西瓜捡芝麻的傻事!
3. 如何排期
评估一下自己的时间,如果工作不忙,按时下班,可以排期紧凑一些。
如果自己本身就很忙,接单会影响工作。那就拒绝,或者做个顺水人情,推荐给靠谱的朋友做。
4. 如何报价
根据自己的工资,算一下时薪或者日薪。
根据 排期*时薪(日薪) 就是报价。请不要不好意思报价,更不用觉得自己报的高或者低。
你只管先去报价,如果对方真心找你,会和你商量报价。而不是直接说行或者不行。
如果你报价之后,什么都不和你说,没下文了。大概率不是你的问题,可能他就是白嫖你的报价做参考,建议远离。
5. 如何签合同
合同一定要签,明确双方责任和义务:明确排期、功能点、违约责任。关键就是我说的这三点,其他的可以套模板。需要模板的可以私信我要一份,以备不时之需。
6. 如何提高成单率
1.自己靠谱,打造好口碑
2.学会表达,展示自己的优势
3.及时沟通,不管成与不成,及时沟通。
如果大家感兴趣,可以关注我的视频号聊一聊:王中阳Go
诚恳建议
踏踏实实做好本职工作,提升自己,在有能力之后,自然能够“清风徐来”。不需要你找项目,项目会主动找你的。
接单平台
下文是接单平台,内容来自知乎,转载过来的原因有2个:
1.方便大家了解这些平台各自的优势,可以结合自己的情况,注册一两个实践一下。注意哦:请态度随缘,不要期望太高。 如果你去年被优化,目前还没有找到工作,建议踏踏实实去找工作,不要在这上面浪费时间。
2.第二个原因也是想劝退大家入坑:这么多众包平台,接单平台。去看下注册率和成单率,很差的。而且好的项目基本都被头部的外包公司垄断了,凭啥一个刚入行的小菜鸟能接到单,换位思考一下,科学吗!?
一、垂直众包平台
这类平台是从 15 年到18年开始出现的,专注于 IT 众包领域,职位内容大多集中于 UI 设计、产品设计、程序开发、产品运营等需求,其中又以程序开发和 UI 设计的需求最多,可以提供比较稳定和比较多的兼职需求来供我们选择。这些渠道主要有:
1、YesPMP平台:
首推这个平台的原因只有一个:免费!注册免费,投标免费,而且资源不少。
但是每个平台都是有“套路的”,每天只能免费投递3个项目竞标,你如果想竞标更多的项目需要开会员。
(教你一招:第二天再投3个项目竞标不就行了,每天都可以免费投递三个)
2、开源众包 :
开源中国旗下众包平台,目前项目以项目整包为主,对接企业接包方多些,个人也可以注册。目前有免费模式和付费模式。平台搞到最后都是为了赚钱,白嫖怪不太可能接到好项目。
3、人人开发 - 应用市场开发服务平台:
人人开发的注册流程比较简单一点,但是建议大家也要认真填写简历。
4、英选 :
英选有自己的接包团队进行自营业务,也支持外部入驻。
5、我爱方案网:
名字比较土,但是对于硬件工程师和嵌入式工程师建议注册下。
6、码市:
7、解放号:
二、线上技术论坛
1、GitHub
开发者最最最重要的网站:github.com
这个不用多说了吧,代码托管网站,上面有很多资源,想要什么轮子,上去搜就好了。
2. Stack Overflow
解决 bug 的社区:stackoverflow.com/
开发过程中遇到什么 bug,上去搜一下,只要搜索的方式对,百分之 99 的问题都能搜到答案。
在这里能够与很多有经验的开发者交流,如果你是有经验的开发者,还可以来这儿帮助别人解决问题,提升个人影响力。
3. 程序员客栈:
程序员客栈是领先的程序员自由工作平台,如果你是有经验有资质的开发者,都可以来上面注册成为开发者,业余的时候做点项目,赚点零花钱。
当然,如果你想成为一名自由工作者,程序员客栈也是可以满足的。只要你有技术,不怕赚不到钱。很多程序员日常在这里逛一下,接一点项目做。很多公司也在这发布项目需求。
4. 掘金
帮助开发者成长的技术社区:juejin.cn/
这个就不用我多说了吧:现在国内优质的开发者交流学习社区,可以去看大佬们写的文章,也可以自己分享学习心的,与更多开发者交流。认识更多的小伙伴儿,提升个人影响力。
5. v2ex
V2EX 是一个关于分享和探索的地方,上面有很多各大公司的员工,程序员。你想要的应有尽有。
6.电鸭社区
最近有朋友想找远程办公的岗位,电鸭社区值得好好看一看,可以说是国内远程办公做的相当好的社区了。
7. Medium
国外优质文章网站,Medium 的整体结构非常简单,容易让用户沉下心来专注于阅读。上面有很多高质量的技术文章,有很多厉害的人在上面发布内容。
8. Hacker News
国外优质文章网站,上面有很多高质量的技术文章,有很多厉害的人在上面分享内容。
9. GeeksforGeeks
GeeksforGeeks is a computer science portal for geeks。
10.飞援
是一个为程序员、产品经理、设计提供外包兼职和企业雇佣的兼职平台,致力于提供品质可控、体验卓越的专业技术人才灵活雇佣服务。
遥祝
遥祝大家在新的一年顺利上岸,找到心仪的工作,升职加薪。
在保证主业工作稳定之后,再搞副业,再去接单。
如果觉得本文对你有帮助,欢迎点个关注,不错过干货分享。
如果对接单搞副业实在感兴趣的话,可以关注私信我,后面有好项目分享给你。
最后再次友情提醒:还是踏踏实实上班吧!
链接:https://juejin.cn/post/7195085041456644154
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【Android爬坑日记四】组合替代继承,减少Base类滥用
背景
先说一下背景,当接触了比较多的项目之后,其实会发现每一个项目都会封装BaseActivity、BaseFragment等等。其实初衷其实是好的。每一个Activity和Fragment都是很多模板代码的,为了减少模板代码,封装进Base类其实是一种比较方便且可行的选择。
Base类涵盖了抽象、继承等面向对象特性,用得好会减少很多样板代码,但是一旦滥用,会对项目有很多弊端。
举个例子
当项目大了,需要封装进Base类的逻辑会非常多,比如说打印生命周期、ViewBinding 或者DataBinding封装、埋点、监听广播、监听EventBus、展示加载界面、弹Dialog等等其他业务逻辑,更有甚者把需要Context的函数都封装进Base类中。
以下举一个BaseActivity的例子,里面封装了上面所说的大部分情况,实际情况可能更多。
abstract class BaseActivity<T: ViewBinding, VM: ViewModel>: AppCompatActivity {
protected lateinit var viewBinding: T
protected lateinit var viewModel: VM
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 打印日志!!
ELog.debugLifeCycle("${this.localClassName} - onCreate")
// 初始化viewModel
viewModel = initViewModel()
// 初始化视图!!
initView()
// 初始化数据!!
initData()
// 注册广播监听!!
registerReceiver()
// 注册EventBus事件监听!!
registerEventBus()
// 省略一堆业务逻辑!
// 设置导航栏颜色!!
window.navigationBarColor = ContextCompat.getColor(this, R.color.primary_color)
}
protected fun initViewModel(): VM {
// 初始化viewModel
}
private fun initViewbinding() {
// 初始化viewBinding
}
// 让子类必须实现
abstract fun initView()
abstract fun initData()
private fun registerReceiver() {
// 注册广播监听
}
private fun unregisterReceiver() {
// 注销广播监听
}
private fun registerEventBus() {
// 注册EventBus事件监听
}
protected fun showDialog() {
// 需要用到Context,因此也封装进来了
}
override fun onResume() {
super.onResume()
ELog.debugLifeCycle("${this.localClassName} - onResume")
}
override fun onPause() {
super.onPause()
ELog.debugLifeCycle("${this.localClassName} - onPause")
}
override fun onDestroy() {
super.onDestroy()
ELog.debugLifeCycle("${this.localClassName} - onDestroy")
unregisterReceiver()
}
}其实看起来还好,但是在使用的时候难免会遇到一些问题,对于中途接手项目的人来说问题更加明显。我们从中途接手项目的心路历程看看Base类的缺陷。
心路历程
当创建新的Activity或者Fragment的时候需要想想有没有逻辑可以复用,就去找Base类,或许写Base类的人不同,发现一个项目中可能会存在多个Base类,甚至Base类仍然有多个Base子类实现不同逻辑。这个时候就需要去查看分析每个Base类分别实现了什么功能,决定继承哪个。
如果一个项目中只有一个Base类的话,仍需要看看Base类实现了什么逻辑,没有实现什么逻辑,防止重复写样板代码。
当出现Base类实现了的,而自己本身并不想需要,例如不想监听广播或者不想用ViewModel,对于不想监听广播的情况就要特殊做适配,例如往Base类加标志位。对于不想用ViewModel但是由于泛型限制,还是只能传进去,不然没法继承。
当发现自己集成Base类出BUG了,就要考虑改子类还是改Base类,由于大量的类都集成了Base类,显然改Base类比较麻烦,于是改自己比较方便。
如果一个Activity中展示了多个Fragment,可能会有业务逻辑的重复,其实只需要一个就好了。
其实第一第二点还好,时间成本其实没有重复写样板代码那么高。但是第三点的话其实用标志位来决定Base类的功能哪个需要实现哪个不需要实现并不是一种优雅的方式,反而需要重写的东西多了几个。第四点归根到底就是Base类其实并不好维护。
爬坑
那么对于Base类怎样实践才比较优雅呢?在我看来组合替代继承其实是一种不错的思路。对于Kotlin first的Android项目来说,组合替代继承其实是比较容易的。以下仅代表个人想法,有不同意见可以交流一下。
成员变量委托
对于ViewModel、Handler、ViewBinding这些Base变量使用委托的方式是比较方便的。
对于ViewBinding委托可以看看我之前的文章,使用起来其实是非常简单的,只需要一行代码即可。
// Activity
private val binding by viewBinding(ActivityMainBinding::inflate)
// Fragment
private val binding by viewBinding(FragmentMainBinding::bind)
对于ViewModel委托,官方库则提供了一个viewBindings委托函数。
private val viewModel:HomeViewModel by viewModels()
需要在Gradle中引入ktx库
implementation 'androidx.fragment:fragment-ktx:1.5.1'
implementation 'androidx.activity:activity-ktx:1.5.1'
而对于Base变量则尽量少封装在Base类中,需要使用可以使用委托,因为如果实例了没有使用其实是比较浪费内存资源的,尽量按需实例。
扩展方法
对于需要用到Context上下文的逻辑封装到Base类中其实是没有必要的,在Kotlin还没有流行的时候,如果说需要使用到Context的工具方法,使用起来其实是不太优雅的。
例如展示一个Dialog:
class DialogUtils {
public static void showDialog(Activity activity, String title, String content) {
// 逻辑
}
}使用起来就是这样:
class MyActivity : AppCompatActivity() {
...
fun initButton() {
button.setOnClickListener {
DialogUtils.showDialog(this, "title", "content")
}
}
}使用起来可能就会有一些迷惑,第一个参数把自己传进去了,这对于展示Dialog的语义上是有些奇怪的。按理来说只需要传title和content就好了。
这个时候就会有人想着把这个封装到Base类中。
public abstract class BaseActivity extends AppCompatActivity {
protected void showDialog(String title, String content) {
// 这里就可以用Context了
}
}
使用起来就是这样:
class MyActivity : AppCompatActivity() {
...
fun initButton() {
button.setOnClickListener {
showDialog("title", "content")
}
}
}
是不是感觉好很多了。但是写在Base类中在Java中比较好用,对于Kotlin则完全可以使用扩展函数语法糖来替代了,在使用的时候和定义在Base类是一样的。
fun Activity.showDialog(title: String, content: String) {
// this就能获取到Activity实例
}
class MyActivity : AppCompatActivity() {
...
fun initButton() {
button.setOnClickListener {
// 使用起来和定义在Base类其实是一样的
showDialog("title", "content")
}
}
}
这也说明了,需要使用到Context上下文的函数其实不用在Base类中定义,直接定义在顶层就好了,可以减少Base类的逻辑。
注册监听器
对于注册监听器这种情况则需要分情况,监听器是需要根据生命周期来注册和取消注册的,防止内存泄漏。对于不是每个子类都需要的情况,有的人可能觉得提供一个标志位就好了,如果不需要的话让子类重写。如果定义成抽象方法则每个子类都要重写,如果不是抽象方法的话,子类可能就会忘记重写。在我看来获取生命周期其实是比较简单的事情。按需添加代码监听就好了。
那么什么情况需要封装在Base类中呢?
怕之后接手项目的人忘记写这部分代码,则可以写到Base类中,例如打印日志或者埋点。
而对于界面太多难以测试的功能,例如收到被服务器踢下线的消息跳到登录页面,这个可以写进Base类中,因为基本上每个类都需要监听这种消息。
总结
没有最优秀的架构,只有最适合的架构!对于Base类大家的看法都不一样,追求更少的工作量完成更多事情这个目的是统一的。而Base类一旦臃肿起来了会造成整个项目难以维护,因此对于Base类应该辩证看待,养成只有必要的逻辑才写在Base类中的习惯,feature类应该使用组合的方式来使用,这对于项目的可维护性和代码的可调试性是有好处的。
链接:https://juejin.cn/post/7144671989159067656
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于缓存,每个开发人员都应该知道的3个问题
前言
虽然缓存被认为是软件系统的性能助推器,但如果处理不当,它也容易出现错误。
在本文中,我将介绍 3 个有时可能会造成灾难性后果的常见缓存问题,希望大家在架构上引入缓存时,需要考虑到。
缓存击穿
缓存故障
当缓存键过期时会发生缓存故障,并且多个请求同时访问数据库以查找相同的键。
让我们来看看它是如何工作的:
- 热缓存键过期。
- 多个并发请求进来搜索同一个键。
- 服务器向数据库发起多个并发请求以查找相同的键。
缓存击穿会显著增加数据库的负载,尤其是当许多热键同时过期时。
下面是解决这个问题的2种解决方案:
- 获取搜索到的key的分布式锁,当一个线程试图更新缓存时,其他线程需要等待。
- 利用
Refresh-ahead策略异步刷新热数据,使热键永不过期。
缓存穿透
缓存穿透
当搜索到的key既不在缓存中, 也不在数据库中时,就会发生缓存穿透, 连数据库都穿透过去了。
让我们来看看它是如何工作的,当key既不在缓存中也不在数据库中时,就会发生这种情况。
- 当用户查询
key时,应用程序由于缓存未命中而去查询数据库数据库。 - 由于数据库不包含该
key并返回空结果,因此该key也不会被缓存。 - 因此,每个查询最终都会导致缓存未命中,而命中数据库,直接进行查库。
虽然乍一看这似乎微不足道,但攻击者可以通过使用此类密钥启动大量搜索来尝试破坏你的数据库。
为了解决这个问题,我们可以:
- 缓存过期时间较短的空结果。
- 使用布隆过滤器。在查询数据库之前,应用程序在布隆过滤器中查找
key,如果key不存在则立即返回。
缓存雪崩
当对数据库的请求突然激增时,就会发生缓存雪崩。
这发生在:
- 许多缓存数据同时过期。
- 缓存服务宕机,所有请求都直接访问数据库。
数据库流量的突然激增可能会导致级联效应,并可能最终导致您的服务崩溃。
下面是一些常见的解决方案:
- 调整缓存键的过期时间,使它们不会同时过期。
- 使用Refresh-ahead 策略异步刷新热数据,使其永不过期。
- 使用缓存集群来避免单点故障。当主节点崩溃时,其中一个副本被提升为新的主节点。
总结
虽然这些缓存问题起初看起来微不足道,但有时可能会对我们的下游客户端和依赖项产生级联效应。事先了解它们可以让我们设计一个更强大的系统,也可以简化我们的故障排除过程。
链接:https://juejin.cn/post/7197616340785774650
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
浅谈TheadLocal的使用场景和注意事项
概念
ThreadLocal是Java的一个类,是一个本地线程,提供了一种线程安全的方式,主要用来避免共享数据(线程变量隔离)。
有时候可能要避免共享变量,使用ThreadLocal辅助类为各个线程提供各自的实例;就是说,每个线程都有一个伴生的空间(ThreadLocal),存储私有的数据,只要线程在,就能拿到对应线程的ThreadLocal中存储的值。
TheadLocal的使用场景和注意事项
ThreadLocal在Java开发中非常常见,一般在以下情况会使用到ThreadLocal:
- 在进行对象跨层传递的时候,可以考虑使用
ThreadLocal,避免方法多次传递,打破层次间的约束。 - 线程间数据隔离,比如:上下文
ActionContext、ApplicationContext。 - 进行事务处理,用于存储线程事务信息。
在使用ThreadLocal的时候,最常用的方法就是:initialValue()、set(T t)、get()、remove()。
创建以及提供的方法
创建一个线程局部变量,其初始值通过调用给定的提供者(Supplier)生成;
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
return new SuppliedThreadLocal<>(supplier);
}
// InitialValue()初始化方式使用Java 8提供的Supplier函数接口会更加简介
ThreadLocal<String> userContext = ThreadLocal.withInitial(String::new);
这里就列出用的比较多的方法:
将此线程局部变量的当前线程副本设置为指定值;value表示要存储在此线程本地的当前线程副本中的值
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}返回此线程局部变量的当前线程副本中的值。 如果该变量对于当前线程没有值,则首先将其初始化为调用initialValue方法返回的值
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}删除此线程局部变量的当前线程值
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}项目实例
以下是个人使用的场景:
为什么会使用它,如果在项目中想直接获取当前登录用户的信息,这个功能就可以使用ThreadLocal实现。
/**
* 登录用户信息上下文
*
* @author: austin
* @since: 2023/2/8 13:47
*/
public class UserContext {
private static final ThreadLocal<User> USER_CONTEXT = ThreadLocal.withInitial(User::new);
public static void set(User user) {
if (user != null) {
USER_CONTEXT.set(user);
}
}
public static User get() {
return USER_CONTEXT.get();
}
public static void remove() {
USER_CONTEXT.remove();
}
public static User getAndThrow() {
User user = USER_CONTEXT.get();
if (user == null || StringUtils.isEmpty(user.getId())) {
throw new ValidationException("user info not found!");
}
return user;
}
}上面其实是定义了一个用户信息上下文类,关于上下文(context),我们在开发的过程中经常会遇到,比如Spring的ApplicationContext,上下文是贯穿整个系统或者阶段生命周期的对象,其中包含一些全局的信息,比如:登录后用户信息、账号信息、地址区域信息以及在程序的每一个阶段运行时的数据。
👏有了这个用户上下文对象之后,接下来就可以在项目中使用:
在该项目中个人使用的地方在登录拦截器中,当对登录的信息检查成功后,那么将当前的用户对象加入到ThreadLocal中:
User currentUser = userService.login(token.getUsername(), String.valueOf(token.getPassword()));
// 用户登录认证成功,UserContext存储用户信息
UserContext.put(currentUser);
在Serivce实现层使用的时候,直接调用ThreadLocal中的get方法,就可以获得当前登录用户的信息:
//获取当前在线用户信息
User user = UserContext.get();
资源调用完成后需要在拦截器中删除ThreadLocal资源,防止内存泄漏问题:
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
//使用完的用户信息需要删除,防止内存泄露
UserContext.remove();
}ThreadLocal的内存泄露问题🤢
如果我们在使用完该线程后不进行ThreadLocal中的变量进行删除,那么就会造成内存泄漏的问题,那么该问题是怎么出现的?
首先先分析一下ThreadLocal的内部结构:
先明确一个概念:对应在栈中保存的是对象的引用,对象的值是存储在堆中,如上图所示:其中Heap中的map是ThreadLocalMap, 里面包含key和value, 其中value就是我们需要保存的变量数据,key则是ThreadLocal实例,上述图片的连接有实线和虚线,实线代表强引用,虚线表示弱引用。
即:每一个
Thread维护一个ThreadLocalMap,key为使用 弱引用 的ThreadLocal实例,value为线程变量的副本。
扫盲强引用、软引用、弱引用、虚引用:😂
不同的引用类型呢,主要体现在对象的不同的可达性状态和对垃圾收集的影响:
强引用 是Java最常见的一种引用,只要还有强引用指向一个对象,那么证明该对象一定还活着,一定为可达性状态,不会被垃圾回收机制回收,因此,强引用是造成Java内存泄漏的主要原因。
软引用 是通过SoftReference实现的,如果一个对象只要软引用,那么在系统内存空间不足的时候会试图回收该引用指向的对象。
弱引用 是通过WeakReference实现的,如何一个对象只有弱引用,在垃圾回收线程扫描它所管辖的内存区域的时候,一旦发现只有弱引用指向的对象时候,不管当前的内存空间是否足够,垃圾回收器都会去回收这样的一个内存。
虚引用 形同虚设的东西,在任何情况下都可能被回收。
我们都知道,map中的value需要key找到,key没了,那么value就会永远的留在内存中,直到内存满了,导致OOM,所以我们就需要使用完以后进行手动删除,这样能保证不会出现因为GC的原因造成的OOM问题;当ThreadLocal Ref显示的指定为null时,关系链就变成了下面所示的情况:
当ThreadLocal被显示显的指定为null之后,JVM执行GC操作,此时堆内存中的Thread-Local被回收,同时ThreadLocalMap中的Entry.key也成为了null,但是value将不会被释放,除非当前线程已经结束了生命周期的Thread引用被垃圾回收器回收。
ThreadLocal解决SimpleDateFormat非线程安全问题
为了找到问题所在,我们尝试查看SimpleDateFormat中format方法的源码来排查一下问题,format方法源码如下:
private StringBuffer format(Date date, StringBuffer toAppendTo,
FieldDelegate delegate) {
// 注意到此行setTime()方法代码
calendar.setTime(date);
boolean useDateFormatSymbols = useDateFormatSymbols();
for (int i = 0; i < compiledPattern.length; ) {
int tag = compiledPattern[i] >>> 8;
int count = compiledPattern[i++] & 0xff;
if (count == 255) {
count = compiledPattern[i++] << 16;
count |= compiledPattern[i++];
}
switch (tag) {
case TAG_QUOTE_ASCII_CHAR:
toAppendTo.append((char)count);
break;
case TAG_QUOTE_CHARS:
toAppendTo.append(compiledPattern, i, count);
i += count;
break;
default:
subFormat(tag, count, delegate, toAppendTo, useDateFormatSymbols);
break;
}
}
return toAppendTo;
}从上述源码可以看出,在执行SimpleDateFormat.format()方法时,会使用calendar.setTime()方法将输入的时间进行转换,那么我们想象一下这样的场景:
- 线程 1 执行了
calendar.setTime(date)方法,将用户输入的时间转换成了后面格式化时所需要的时间; - 线程 1 暂停执行,线程 2 得到
CPU时间片开始执行; - 线程 2 执行了
calendar.setTime(date)方法,对时间进行了修改; - 线程 2 暂停执行,线程 1 得出
CPU时间片继续执行,因为线程 1 和线程 2 使用的是同一对象,而时间已经被线程 2 修改了,所以此时当线程 1 继续执行的时候就会出现线程安全的问题了。
正常情况下,程序执行是这样的:
非线程安全的执行流程是这样的:
了解了ThreadLocal的使用之后,我们回到本文的主题,接下来我们将使用ThreadLocal来实现100个时间的格式化,具体实现代码如下:
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* 多线程时间工具类:ConcurrentDateUtil
*
* @author: austin
* @since: 2023/2/8 15:36
*/
public class ConcurrentDateUtil {
private static final String date_format = "yyyy-MM-dd HH:mm:ss";
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>();
public static DateFormat getDateFormat() {
DateFormat df = threadLocal.get();
if (df == null) {
df = new SimpleDateFormat(date_format);
threadLocal.set(df);
}
return df;
}
public static String formatDate(Date date) throws ParseException {
return getDateFormat().format(date);
}
public static Date parse(String strDate) throws ParseException {
return getDateFormat().parse(strDate);
}
}当然也可以使用:
Apache commons包的DateFormatUtils或者FastDateFormat实现,宣称是既快又线程安全的SimpleDateFormat,并且更高效。- 使用
Joda-Time类库来处理时间相关问题。
总结
本文简单的介绍了ThreadLocal的应用场景,其主要用在需要每个线程独占的元素上,例如SimpleDateFormat。然后,就是介绍了ThreadLocal的实现原理,详细介绍了set()和get()方法,介绍了ThreadeLocalMap的数据结构,最后就是说到了ThreadLocal的内存泄露以及避免的方式。
链接:https://juejin.cn/post/7197673814179070010
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter & ChatGPT | 代码生成器
ChatGPT 作为一个自然语言处理工具,已经火了一段时间。对待 ChatGPT 不同人有着不同的看法,新事物的出现必然如此。利益相关者形成 抵制 和 狂热 两极;哗众取宠者蹭蹭热度,问些花活,博人眼球;猎奇者尝尝鲜,起哄者挑挑火;实用派在思考新事物的价值和劳动力:
对于那些拿 ChatGPT 当百科全书来用的,或询问哲学问题的朋友,我只想说:
对于一个问题,用错误的工具去处理得出错误的结果,是一件很正常的事。
1. ChatGPT 的特点和劣势
ChatGPT 最大的特点是基础的语义分析,让计算机对自然语言进行处理并输出。在一段会话中,上下文是有效的,所以可以类似于交流。
问这个问题,它会怎么回答?
这种猎奇的心理,会让一部分人期望尝试;有稀奇古怪或愚蠢的回答,也可以满足人类对人工智障的优越感;分享问答,也让 ChatGPT 拥有一丝的社交属性。蹭热度、猎奇、起哄三者可以用它填充一块内心的空虚,也仅止步于此。
ChatGPT 目前的劣势也很明显,由于数据是几年前的,所以时效性不强;对很多问题回答的精准度并不高,对于盲目相信的人,或判别力较差的朋友并不友好;最后一点,非常重要:对于工具而言,如果对其依赖性太高,脱离工具时,会让人的主观能动性降低。
2. 代码的生成与规则诱导
如下所示,让它生成一个 Dart 的 User 类:
生成一个 dart 类 User, 字段为 : 可空 int 型 age 、final 非空 String 型 username 默认值为 “unknown”
虽然代码给出了,但是可以看出,这是空安全之前的代码。可能很多人到这里,觉得数据陈旧没什么用途,就拜拜了您嘞。
但它是一个有会话上下文的自然语言处理工具,你可以让它理解一些概念。就像一个新员工,上班第一天出了一点小错误,你是立刻开除他,还是告诉他该怎么正确处理。如下所示,给了它一个概念:
Dart 新版本中可空类型定义时,其后需要加 ?
如下所示,你就可以在当前的会话环境中让它生成更多字段的类型:
用 Dart 新版本生成一个 dart 类 User,字段为: final 非空 int 型 age , final 非空 String 型 username 默认值为 “unknown” , final 非空 int 型 height,可空 String型info,final 非空 int 型 roleId
如果存在问题,可以继续进行指正。比如 :
用 Dart 新版本,有默认值的字段不需要使用 required 关键字,其他非空字段需要
所以对于 ChatGPT 而言,我们可以把它看成一个有一些基础知识的,可为我们免费服务的员工,简称:奴隶。当它做错事时,你骂它,责备它,抛弃它是毫无意义的,因为它是机器。我们需要去 诱导 它理解,在当前工作环境中正确的事。
这样在当前会话中,它就可以理解你诉说的规则,当用它创建其他类时,他就不会再犯错。并且不排除它会基于你的规则,去完善自身的 知识储备 ,当众多的人用正确的规则去 诱导 它,这就是一个善意的正反馈。
3. 解决方案的概念
这里从生成的代码 不支持空安全 到 支持空安全,其实只用了几句话。第一句是反馈测试,看看它的 默认知识储备
生成一个 dart 类 User, 字段为 : 可空 int 型 age 、final 非空 String 型 username 默认值为 “unknown”
当它的输出不满足我们的需求时,再进行 诱导 :
Dart 新版本中可空类型定义时,其后需要加 ?
用 Dart 新版本,有默认值的字段不需要使用 required 关键字,其他非空字段需要
在诱导完成之后,它就可以给出满足需求的输出。这种诱导后提供的会话环境,输出是相对稳定的,完成特定的任务。这就是为不确定的输出,添加规则,使其输出趋近 幂等性 。一旦一项可以处理任务的工具有这种性质,就可以面向任何人使用。可以称这种诱导过程为解决某一问题的一种 解决方案。
比如上面的三句话就是:根据类信息生成 Dart 数据类型,并支持空安全。在当前环境下,就可以基于这种方案去处理同类的任务:
用 Dart 新版本生成一个 dart 类 TaskResult,字段为: final 非空 int 型 cost , final 非空 String 型 taskName 默认值为 “unknown” , final 非空 int 型 count,可空 String型taskInfo,final 非空 String型 taskCode
你拷贝代码后,就是可用的:
4. Dart 数据类生成器完善
上面生成 Dart 数据类比较简单,下面继续拓展,比如对于数据类型而言 copyWith 、toJson 、fromJson 的方法自己写起来比较麻烦。如果现在告诉它:
为上面的类提供 copyWith、toJson 、 fromJson 方法
它会进行提供,说明它具有这个 默认知识储备 ,但可以看到 copyWith 方法中的字段不符合空安全:
此时可以训练它的 类型可空 的意识,让它主动处理类似的问题,也可以直白的告诉它
将上面的 copyWith 方法入参类型后加 ? 号
这样生成的 TaskResult 类就可以使用了:
class TaskResult {
final int cost;
final String taskName;
final int count;
final String? taskInfo;
final String taskCode;
TaskResult({
required this.cost,
this.taskName = 'unknown',
required this.count,
this.taskInfo,
required this.taskCode,
});
TaskResult copyWith({
int? cost,
String? taskName,
int? count,
String? taskInfo,
String? taskCode,
}) {
return TaskResult(
cost: cost ?? this.cost,
taskName: taskName ?? this.taskName,
count: count ?? this.count,
taskInfo: taskInfo ?? this.taskInfo,
taskCode: taskCode ?? this.taskCode,
);
}
Map toJson() {
return {
'cost': cost,
'taskName': taskName,
'count': count,
'taskInfo': taskInfo,
'taskCode': taskCode,
};
}
static TaskResult fromJson(Map json) {
return TaskResult(
cost: json['cost'] as int,
taskName: json['taskName'] as String,
count: json['count'] as int,
taskInfo: json['taskInfo'] as String,
taskCode: json['taskCode'] as String,
);
}
} 5. 代码生成字符串 与 ChatGPT 生成字符串
对于一些相对固定的代码,可以使用代码逻辑,拼接字符串来生成。如下所示,通过对类结构的抽象化,使用对象进行配置,输出字符串。我们来思考一下,这和 ChatGPT 生成代码的区别。
首先,使用代码生成代码是一种完全的 幂等行为 。也就是说任何人、在任何时间、任何空间下,使用相同的输入,都可以获取到相同的输出,是绝对精准的。其产生代码的行为逻辑是完全可控的,人的内心是期待确定性的。
而 ChatGPT 对自然语言的理解,你可以用语言去引导它输出一些你的需求,比如 :
以json 格式生成 10 句连续的中文对话,key 为 content包括。另外 time 字段为时间戳 ,type 字段1,2 随机
其实没有什么孰强孰弱,只是使用场景的不同而已。刀在不同人的手里有不同的用法,人是生产生活的主体,工具只有服务的属性。驾驭工具,让它产生实用的价值,才是工具存在的意义。好了,本文到这里就扯完了,感谢观看 ~
链接:https://juejin.cn/post/7197584339213762619
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
动态适配 web 终端的尺寸
使Xterminal组件自适应容器
通过 xtermjs 所创建的终端大小是由cols、rows这两个配置项的来决定,虽然你可以通过 CSS 样式来让其产生自适应效果,但是这种情况下字体会变得模糊变形等、会出现一系列的问题,要解决这个问题我们还是需要使用cols、rows这两个值来动态设置。
红色部分则是通过cols和rows属性控制,我们可以很明显的看到该终端组件并没有继承父元素的宽度以及高度,而实际的宽度则是通过cols、rows两个属性控制的。
如何动态设置cols和rows这两个参数。
我们去看官方官方文档的时候,会注意到,官方有提供几个插件供我们使用。
而xterm-addon-fit: 可以帮助我们来让 web 终端实现宽度自适应容器。目前的话行数还不行,暂时没有找到好的替代方案,需要动态的计算出来,关于如何计算可以参数 vscode 官方的实现方案。
引入xterm-addon-fit,在我们的案例中,加入下面这两行:
动态计算行数
想要动态计算出行数的话,就需要获取到一个dom元素的高度:
动态计算尺寸的方法。
const terminalReact: null | HTMLDivElement = terminalRef.current // 100% * 100%
const xtermHelperReact: DOMRect | undefined = terminalReact?.querySelector(".xterm-helper-textarea")!.getBoundingClientRect()
const parentTerminalRect = terminalReact?.getBoundingClientRect()
const rows = Math.floor((parentTerminalRect ? parentTerminalRect.height : 20) / (xtermHelperReact ? xtermHelperReact.height : 1))
const cols = Math.floor((parentTerminalRect ? parentTerminalRect.width : 20) / (xtermHelperReact ? xtermHelperReact.width : 1))
// 调用resize方法,重新设置大小
termRef.current.resize(cols, rows)
复制代码我们可以考虑封装成一个函数,只要父亲组件的大小发生变化,就动态适配一次。
链接:https://juejin.cn/post/7160332506015727629
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Backbone前端框架解读
一、 什么是Backbone
在前端的发展道路中,前端框架元老之一jQuery对繁琐的DOM操作进行了封装,提供了链式调用、各类选择器,屏蔽了不同浏览器写法的差异性,但是前端开发过程中依然存在作用域污染、代码复用度低、冗余度高、数据和事件绑定烦琐等痛点。
5年后,Backbone横空出世,通过与Underscore、Require、Handlebar的整合,提供了一个轻量和友好的前端开发解决方案,其诸多设计思想对于后续的现代化前端框架发展起到了举足轻重的作用,堪称现代前端框架的基石。
通过对Backbone前端框架的学习,让我们领略其独特的设计思想。
二、 核心架构
按照MVC框架的定义,MVC是用来将应用程序分为三个主要逻辑组件的架构模式:模型,视图和控制器。这些组件被用来处理一个面向应用的特定开发。 MVC是最常用的行业标准的Web开发框架,以创建可扩展的项目之一。 Backbone.js为复杂WEB应用程序提供模型(models)、集合(collections)、视图(views)的结构。
◦ 其中模型用于绑定键值数据,并通过RESRful JSON接口连接到应用程序;
◦ 视图用于UI界面渲染,可以声明自定义事件,通过监听模型和集合的变化执行相应的回调(如执行渲染)。
如图所示,当用户与视图层产生交互时,控制层监听变化,负责与数据层进行数据交互,触发数据Change事件,从而通知视图层重新渲染,以实现UI界面更新。更进一步,当数据层发生变化时,由Backbone提供了数据层和服务器数据共享同步的能力。
其设计思想主要包含以下几点:
◦数据绑定(依赖渲染模板引擎)、事件驱动(依赖Events)
◦视图组件化,并且组件有了生命周期的概念
◦前端路由配置化,实现页面局部刷新
这些创新的思想,在现代前端框架中进一步得到了继承和发扬。
三、 部分源码解析
Backbone极度轻量,编译后仅有几kb,贯穿其中的是大量的设计模式:工厂模式、观察者模式、迭代器模式、适配器模式……,代码流畅、实现过程比较优雅。按照功能拆分为了Events、Model、Collection、Router、History、View等若干模块,这里摘取了部分精彩源码进行了解析,相信对我们的日常代码开发也有一定指导作用:
(1)迭代器
EventsApi起到一个迭代器分流的作用,对多个事件进行解析拆分,设计的非常经典,执行时以下用法都是合法的:
◦用法一:传入一个名称和回调函数的对象
modal.on({
"change": change_callback,
"remove": remove_callback
})◦用法二:使用空格分割的多个事件名称绑定到同一个回调函数上
model.on("change remove", common_callback)实现如下:
var eventsApi = function(iteratee, events, name, callback, opts) {
var i = 0, names;
if(name && typeof name === 'object') {
// 处理第一种用法
if(callback !== void 0 && 'context' in opts && opts.context === void 0) opts.context = callback;
for(names = _.keys(names); i < names.length; i++) events = eventsApi(iteratee, events, names[i], name[names[i]], opts);
} else if(name && eventSplitter.test(name)) {
// 处理第二种用法
for(names = name.split(eventSplitter); i < names.length; i++) events = iteratee(events, names[i], callback, opts);
} else {
events = iteratee(events, name, callback, opts);
}
return events;
}(2)监听器
用于一个对象监听另外一个对象的事件,例如,在A对象上监听在B对象上发生的事件,并且执行A的回调函数:
A.listenTo(B, "b", callback)实际上这个功能用B对象来监听也可以实现:
B.on("b", callback, A)这么做的好处是,方便对A创建、销毁逻辑的代码聚合,并且对B的侵入程度较小。实现如下:
Events.listenTo = function(obj, name, callback) {
if(!obj) return this;
var id = obj._listenId || (obj._listenId = _.uniqueId('l'));
// 当前对象的所有监听对象
var listeningTo = this._listeningTo || (this._listeningTo = {});
var listening = listeningTo[id];
if(!listening) {
// 创建自身监听id
var thisId = this._listenId || (this._listenId = _.uniqueId('l'));
listening = listeningTo[id] = {obj: obj, objId: id, id: thisId, listeningTo: listeningTo, count: 0};
}
// 执行对象绑定
internalOn(obj, name, callback, this, listening);
return this;
}(3)Model值set
通过option-flags兼容赋值、更新、删除等操作,这么做的好处是融合公共逻辑,简化代码逻辑和对外暴露api。实现如下:
set: function(key, val, options) {
if(key == null) return this;
// 支持两种赋值方式: 对象或者 key\value
var attrs;
if(typeof key === 'object') {
attrs = key;
options = val;
} else {
(attrs = {})[key] = val;
}
options || (options = {});
……
var unset = options.unset;
var silent = options.silent;
var changes = [];
var changing = this._changing; // 处理嵌套set
this._changing = true;
if(!changing) {
// 存储变更前的状态快照
this._previousAttributes = _.clone(this.attributes);
this.changed = {};
}
var current = this.attributes;
var changed = this.changed;
var prev = this._previousAttributes;
for(var attr in attrs) {
val = attrs[attr];
if(!_.isEqual(current[attr], val)) changes.push(attr);
// changed只存储本次变化的key
if(!_.isEqual(prev[attr], val)) {
changed[attr] = val;
} else {
delete changed[attr]
}
unset ? delete current[attr] : (current[attr] = val)
}
if(!silent) {
if(changes.length) this._pending = options;
for(var i=0; i<changes.length; i++) {
// 触发 change:attr 事件
this.trigger('change:' + changes[i], this, current[changes[i]], options);
}
}
if(changing) return this;
if(!silent) {
// 处理递归change场景
while(this._pending) {
options = this._pending;
this._pending = false;
this.trigger('change', this, options);
}
}
this._pending = false;
this._changing = false;
return this;
}四、 不足(对比react、vue)
对比现代前端框架,由于Backbone本身比较轻量,对一些内容细节处理不够细腻,主要体现在:
◦视图和数据的交互关系需要自己分类编写逻辑,需要编写较多的监听器
◦监听器数量较大,需要手动销毁,维护成本较高
◦视图树的二次渲染仅能实现组件整体替换,并非增量更新,存在性能损失
◦路由切换需要自己处理页面更新逻辑
五、为什么选择Backbone
看到这里,你可能有些疑问,既然Backbone存在这些缺陷,那么现在学习Backbone还有什么意义呢?
首先,对于服务端开发人员,Backbone底层依赖underscore/lodash、jQuery/Zepto,目前依然有很多基于Jquery和Velocity的项目需要维护,会jQuery就会Backbone,学习成本低;通过Backbone能够学习用数据去驱动View更新,优化jQuery的写法;Backbone面对对象编程,符合Java开发习惯。
其次,对于前端开发人员,能够学习其模块化封装库类函数,提升编程技艺。Backbone的组件化开发,和现代前端框架有很多共通之处,能够深入理解其演化历史。
作者:京东零售 陈震
来源:juejin.cn/post/7197075558941311035
一篇文章带你掌握Flex布局的所有用法
Flex 布局目前已经非常流行了,现在几乎已经兼容所有浏览器了。在文章开始之前我们需要思考一个问题:我们为什么要使用 Flex 布局?
其实答案很简单,那就是 Flex 布局好用。一个新事物的出现往往是因为旧事物不那么好用了,比如,如果想让你用传统的 css 布局来实现一个块元素垂直水平居中你会怎么做?实现水平居中很简单,margin: 0 auto就行,而实现垂直水平居中则可以使用定位实现:
<div class="container">
<div class="item"></div>
</div>
.container {
position: relative;
width: 300px;
height: 300px;
background: red;
}
.item {
position: absolute;
background: black;
width: 50px;
height: 50px;
margin: auto;
left: 0;
top: 0;
bottom: 0;
right: 0;
}或者
.item {
position: absolute;
background: black;
width: 50px;
height: 50px;
margin: auto;
left: calc(50% - 25px);
top: calc(50% - 25px);
}但是这样都显得特别繁琐,明明可以一个属性就能解决的事情没必要写这么麻烦。而使用 Flex 则可以使用 place-content 属性简单的实现(place-content 为 justify-content 和 align-content 简写属性)
.container {
width: 300px;
height: 300px;
background: red;
display: flex;
place-content: center;
}
.item {
background: black;
width: 50px;
height: 50px;
}接下来的本篇文章将会带领大家一起来探讨Flex布局
基本概念
我们先写一段代码作为示例(部分属性省略)
html
<div class="container">
<div class="item">flex项目</div>
<div class="item">flex项目</div>
<div class="item">flex项目</div>
<div class="item">flex项目</div>
</div>
.container {
display: flex;
width: 800px;
gap: 10px;
}
.item {
color: #fff;
}flex 容器
我们可以将一个元素的 display 属性设置为 flex,此时这个元素则成为flex 容器比如container元素
flex 项目
flex 容器的子元素称为flex 项目,比如item元素
轴
flex 布局有两个轴,主轴和交叉轴,至于哪个是主轴哪个是交叉轴则有flex 容器的flex-direction属性决定,默认为:flex-direction:row,既横向为主轴,纵向为交叉轴,
flex-direction还可以设置其它三个属性,分别为row-reverse,column,column-reverse。
row-reverse
column
column-reverse
从这里我们可以看出 Flex 轴的方向不是固定不变的,它受到flex-direction的影响
不足空间和剩余空间
当 Flex 项目总宽度小于 Flex 容器宽度时就会出现剩余空间
当 Flex 项目总宽度大于 Flex 容器宽度时就会出现不足空间
Flex 项目之间的间距
Flex 项目之间的间距可以直接在 Flex 容器上设置 gap 属性即可,如
<div class="container">
<div class="item">A</div>
<div class="item">B</div>
<div class="item">C</div>
<div class="item">D</div>
</div>
.container {
display: flex;
width: 500px;
height: 400px;
gap: 10px;
}
.item {
width: 150px;
height: 40px;
}Flex 属性
flex属性是flex-grow,flex-shrink,flex-basis三个属性的简写。下面我们来看下它们分别是什么。
flex-basis可以设定 Flex 项目的大小,一般主轴为水平方向的话和 width 解析方式相同,但是它不一定是 Flex 项目最终大小,Flex 项目最终大小受到flex-grow,flex-shrink以及剩余空间等影响,后面文章会告诉大家最终大小的计算方式flex-grow为 Flex 项目的扩展系数,当 Flex 项目总和小于 Flex 容器时就会出现剩余空间,而flex-grow的值则可以决定这个 Flex 项目可以分到多少剩余空间flex-shrink为 Flex 项目的收缩系数,同样的,当 Flex 项目总和大于 Flex 容器时就会出现不足空间,flex-shrink的值则可以决定这个 Flex 项目需要减去多少不足空间
既然flex属性是这三个属性的简写,那么flex属性简写方式分别代表什么呢?
flex属性可以为 1 个值,2 个值,3 个值,接下来我们就分别来看看它们代表什么意思
一个值
如果flex属性只有一个值的话,我们可以看这个值是否带单位,带单位那就是flex-basis,不带就是flex-grow
.item {
flex: 1;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0;
}
.item {
flex: 30px;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 30px;
}两个值
当flex属性有两个值的话,第一个无单位的值就是flex-grow,第一个无单位的值则是flex-shrink,有单位的就是flex-basis
.item {
flex: 1 2;
/* 相当于 */
flex-grow: 1;
flex-shrink: 2;
flex-basis: 0;
}
.item {
flex: 30px 2;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}三个值
当flex属性有三个值的话,第一个无单位的值就是flex-grow,第一个无单位的值则是flex-shrink,有单位的就是flex-basis
.item {
flex: 1 2 10px;
/* 相当于 */
flex-grow: 1;
flex-shrink: 2;
flex-basis: 10px;
}
.item {
flex: 30px 2 1;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}
.item {
flex: 2 30px 1;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}另外,flex 的值还可以为initial,auto,none。
initial
initial 为默认值,和不设置 flex 属性的时候表现一样,既 Flex 项目不会扩展,但会收缩,Flex 项目大小有本身内容决定
.item {
flex: initial;
/* 相当于 */
flex-grow: 0;
flex-shrink: 1;
flex-basis: auto;
}auto
当 flex 设置为 auto 时,Flex 项目会根据自身内容确定flex-basis,既会拓展也会收缩
.item {
flex: auto;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: auto;
}none
none 表示 Flex 项目既不收缩,也不会扩展
.item {
flex: none;
/* 相当于 */
flex-grow: 0;
flex-shrink: 0;
flex-basis: auto;
}Flex 项目大小的计算
首先看一下 flex-grow 的计算方式
flex-grow
面试中经常问到: 为什么 flex 设置为 1 的时候,Flex 项目就会均分 Flex 容器? 其实 Flex 项目设置为 1 不一定会均分容器(后面会解释),这里我们先看下均分的情况是如何发生的
同样的我们先举个例子
<div>
<div>Xiaoyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehuhu</div>
</div>
.container {
display: flex;
width: 800px;
}
.item {
flex: 1;
font-size: 30px;
}flex 容器总宽度为 800px,flex 项目设置为flex:1,此时页面上显示
我们可以看到每个项目的宽度为 800/5=160,下面来解释一下为什么会均分:
首先
.item {
flex: 1;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0;
}因为flex-basis为 0,所有 Flex 项目扩展系数都是 1,所以它们分到的剩余空间都是一样的。下面看一下是如何计算出最终项目大小的
这里先给出一个公式:
Flex项目弹性量 = (Flex容器剩余空间/所有flex-grow总和)\*当前Flex项目的flex-grow
其中Flex项目弹性量指的是分配给 Flex 项目多少的剩余空间,所以 Flex 项目的最终宽度为
flex-basis+Flex项目弹性量。
根据这个公式,上面的均分也就很好理解了,因为所有的flex-basis为 0,所以剩余空间就是 800px,每个 Flex 项目的弹性量也就是(800/1+1+1+1+1)*1=160,那么最终宽度也就是160+0=160
刚刚说过 flex 设置为 1 时 Flex 项目并不一定会被均分,下面就来介绍一下这种情况,我们修改一下示例中的 html,将第一个 item 中换成一个长单词
<div>
<div>Xiaoyueyueyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehu</div>
</div>此时会发现 Flex 容器并没有被均分
因为计算出的灵活性 200px 小于第一个 Flex 项目的min-content(217.16px),此时浏览器会采用 Flex 项目的min-content作为最终宽度,而后面的 Flex 项目会在第一个 Flex 项目计算完毕后再进行同样的计算
我们修改一下 flex,给它设置一个 flex-basis,看下它计算之后的情况
.item {
text-align: center;
flex: 1 100px;
}因为每个项目的flex-basis都是 100px,Flex 容器剩余空间为800-500=300px,所以弹性量就是(300/5)*1=60px,最终宽度理论应该为100+60=160px,同样的因为第一个 Flex 项目的min-content为 217.16px,所以第一个 Flex 项目宽度被设置为 217.16px,最终表现和上面一样
我们再来看一下为什么第 2,3,4,5 个 Flex 项目宽度为什么是 145.71px
当浏览器计算完第一个 Flex 项目为 217.16px 后,此时的剩余空间为800-217.16-100*4=182.84,第 2 个 Flex 项目弹性量为(182.84/1+1+1+1)*1=45.71,所以最终宽度为100+45.71=145.71px,同样的后面的 Flex 项目计算方式是一样的,但是如果后面再遇到长单词,假如第五个是长单词,那么不足空间将会发生变化,浏览器会将第五个 Flex 项目宽度计算完毕后再回头进行一轮计算,具体情况这里不再展开
所以说想要均分 Flex 容器 flex 设置为 1 并不能用在所有场景中,其实当 Flex 项目中有固定宽度元素也会出现这种情况,比如一张图片等,当然如果你想要解决这个问题其实也很简单,将 Flex 项目的min-width设置为 0 即可
.item {
flex: 1 100px;
min-width: 0;
}flex-grow 为小数
flex-grow 的值不仅可以为正整数,还可以为小数,当为小数时也分为两种情况:所有 Flex 项目的 flex-grow 之和小于等于 1 和大于 1,我们先看小于等于 1 的情况,将例子的改成
<div>
<div>Acc</div>
<div>Bc</div>
<div>C</div>
<div>DDD</div>
<div>E</div>
</div>
.item:nth-of-type(1) {
flex-grow: 0.1;
}
.item:nth-of-type(2) {
flex-grow: 0.2;
}
.item:nth-of-type(3) {
flex-grow: 0.2;
}
.item:nth-of-type(4) {
flex-grow: 0.1;
}
.item:nth-of-type(5) {
flex-grow: 0.1;
}效果如图
我们可以发现项目并没有占满容器,它的每个项目的弹性量计算方式为
Flex项目弹性量=Flex容器剩余空间*当前Flex项目的flex-grow
相应的每个项目的实际宽度也就是flex-basis+弹性量,首先先不设置 flex-grow,我们可以看到每个项目的 flex-basis 分别为: 51.2 , 33.88 , 20.08 , 68.56 , 16.5
所以我们可以计算出 Flex 容器的剩余空间为800-51.2 -33.88 - 20.08 - 68.56 - 16.5=609.78,这样我们就可以算出每个项目的实际尺寸为
A: 实际宽度 = 51.2 + 609.78*0.1 = 112.178
B: 实际宽度 = 33.88 + 609.78*0.2 = 155.836
...
下面看下 flex-grow 之和大于 1 的情况,将例子中的 css 改为
.item:nth-of-type(1) {
flex-grow: 0.1;
}
.item:nth-of-type(2) {
flex-grow: 0.2;
}
.item:nth-of-type(3) {
flex-grow: 0.3;
}
.item:nth-of-type(4) {
flex-grow: 0.4;
}
.item:nth-of-type(5) {
flex-grow: 0.5;
}此时的效果为
可以看出 Flex 项目是占满容器的,它的计算方式其实和 flex-grow 为正整数时一样
Flex项目弹性量 = (Flex容器剩余空间/所有flex-grow总和)\*当前Flex项目的flex-grow
所以我们可以得出一个结论: Flex 项目的 flex-grow 之和小于 1,Flex 项目不会占满 Flex 容器
flex-shrink
flex-shrink 其实和 flex-grow 基本一样,就是扩展变成了收缩,flex-grow 是项目比例增加容器剩余空间,而 flex-shrink 则是比例减去容器不足空间
修改一下我们的例子:
.item {
flex-basis: 200px;
/* 相当于 */
flex-shrink: 1;
flex-grow: 0;
flex-basis: 200px;
}此时项目的总宽度200*5=1000px已经大于容器总宽度800px,此时计算第一个项目的不足空间就是800-200*5=-200px,第二个项目的不足空间则是800-第一个项目实际宽度-200*4,依次类推
最终计算公式其实和 flex-grow 计算差不多
Flex项目弹性量 = (Flex容器不足空间/所有flex-shrink总和)*当前Flex项目的flex-shrink
只不过,所以上面例子每个项目可以计算出实际宽度为
第一个 Flex 项目: 200+((800-200x5)/5)*1 = 160px
第二个 Flex 项目: 200+((800-160-200x4)/4)*1 = 160px
第三个 Flex 项目: 200+((800-160-160-200x3)/3)*1 = 160px
第四个 Flex 项目: 200+((800-160-160-160-200x2)/2)*1 = 160px
第五个 Flex 项目: 200+((800-160-160-160-160-200x1)/1)*1 = 160px
如果 Flex 项目的min-content大于flex-basis,那么最终的实际宽度将会取该项目的min-content,比如改一下例子,将第一个 Flex 项目改成长单词
<div>
<div>XiaoyueXiaoyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehu</div>
</div>可以看出浏览器最终采用的是第一个 Flex 项目的min-content作为实际宽度,相应的后面 Flex 项目的宽度会等前一个 Flex 项目计算完毕后在进行计算
比如第二个 Flex 项目宽度= 200+((800-228.75-200x4)/4)*1 = 142.81px
flex-shrink 为小数
同样的 flex-shrink 也会出现小数的情况,也分为 Flex 项目的 flex-shrink 之和小于等于 1 和大于 1 两种情况,如果大于 1 和上面的计算方式一样,所以我们只看小于 1 的情况,将我们的例子改为
.item {
flex-basis: 200px;
flex-shrink: 0.1;
}效果为
此时我们会发现 Flex 项目溢出了容器,所以我们便可以得出一个结论:Flex 项目的 flex-shrink 之和小于 1,Flex 项目会溢出 Flex 容器
下面看一下它的计算公式
Flex项目弹性量=Flex容器不足空间*当前Flex项目的flex-shrink
Flex项目实际宽度=flex-basis + Flex项目弹性量
比如上面例子的每个 Flex 项目计算结果为
第一个 Flex 项目宽度 = 200+(800-200x5)x0.1=180px,但是由于它本身的min-content为 228.75,所以最终宽度为 228.75
第二个 Flex 项目宽度 =200-(800-228.75-200x4)x0.1=117.125
第三个 Flex 项目宽度...
Flex 的对齐方式
Flex 中关于对齐方式的属性有很多,其主要分为两种,一是主轴对齐方式:justify-,二是交叉轴对齐方式:align-
首先改一下我们的例子,将容器设置为宽高为 500x400 的容器(部分属性省略)
<div>
<div>A</div>
<div>B</div>
<div>C</div>
</div>
.container {
display: flex;
width: 500px;
height: 400px;
}
.item {
width: 100px;
height: 40px;
}主轴对齐属性
这里以横向为主轴,纵向为交叉轴
justify-content
justify-content的值可以为:
flex-start 默认值,主轴起点对齐
flex-end 主轴终点对齐
left 默认情况下和 flex-start 一致
right 默认情况下和 flex-end 一致
center 主轴居中对齐
space-between 主轴两端对齐,并且 Flex 项目间距相等
space-around 项目左右周围空间相等
space-evenly 任何两个项目之间的间距以及边缘的空间相等
交叉轴对齐方式
align-content
align-content 属性控制整个 Flex 项目在 Flex 容器中交叉轴的对齐方式
注意设置 align-content 属性时候必须将 flex-wrap 设置成 wrap 或者 wrap-reverse。它可以取得值为
stretch 默认值,当我们 Flex 元素不设置高度的时候,默认是拉伸的
比如将 Flex 元素宽度去掉
.item {
width: 100px;
}flex-start 位于容器开头,这个和 flex-direction:属性有关,默认在顶部
flex-end 位于容器结尾
center 元素居中对齐
space-between 交叉轴上下对齐,并且 Flex 项目上下间距相等
此时我们改下例子中 Flex 项目的宽度使其换行,因为如果 Flex 项目只有一行,那么 space-between 与 flex-start 表现一致
.item {
width: 300px;
}space-around 项目上下周围空间相等
space-evenly 任何两个项目之间的上下间距以及边缘的空间相等
align-items
align-items 属性定义 flex 子项在 flex 容器的当前行的交叉轴方向上的对齐方式。它与 align-content 有相似的地方,它的取值有
stretch 默认值,当我们 Flex 元素不设置高度的时候,默认是拉伸的
center 元素位于容器的中心,每个当前行在图中已经框起来
flex-start 位于容器开头
flex-end 位于容器结尾
baseline 位于容器的基线上
比如给 A 项目一个 padding-top
.item:nth-of-type(1) {
padding-top: 50px;
}没设置 baseline 的表现
设置 baseline 之后
通过上面的例子我们可以发现,如果想要整个 Flex 项目垂直对齐,在只有一行的情况下,align-items 和 align-content 设置为 center 都可以做到,但是如果出现多行的情况下 align-items 就不再适用了
align-self
上面都是给 Flex 容器设置的属性,但是如果想要控制单个 Flex 项目的对齐方式该怎么办呢?
其实 Flex 布局中已经考虑到了这个问题,于是就有个 align-self 属性来控制单个 Flex 项目在 Flex 容器侧交叉轴的对齐方式。
align-self 和 align-items 属性值几乎是一致的,比如我们将整个 Flex 项目设置为 center,第二个 Flex 项目设置为 flex-start
.container {
display: flex;
width: 500px;
height: 400px;
align-items: center;
}
.item {
width: 100px;
height: 40px;
}
.item:nth-of-type(2) {
align-self: flex-start;
}注意,除了以上提到的属性的属性值,还可以设置为 CSS 的关键词如 inherit 、initial 等
交叉轴与主轴简写
place-content
place-content` 为 `justify-content` 和 `align-content` 的简写形式,可以取一个值和两个值,如果设置一个值那么 `justify-content` 和 `align-content` 都为这个值,如果是两个值,第一个值为 `align-content`,第二个则是 `justify-content到这里关于Flex布局基本已经介绍完了,肯定会有些细枝末节没有考虑到,这可能就需要我们在平时工作和学习中去发现了
作者:东方小月
来源:https://juejin.cn/post/7197229913156796472
百万级数据excel导出功能如何实现?
前言
最近我做过一个MySQL百万级别数据的excel导出功能,已经正常上线使用了。
这个功能挺有意思的,里面需要注意的细节还真不少,现在拿出来跟大家分享一下,希望对你会有所帮助。
原始需求:用户在UI界面上点击全部导出按钮,就能导出所有商品数据。
咋一看,这个需求挺简单的。
但如果我告诉你,导出的记录条数,可能有一百多万,甚至两百万呢?
这时你可能会倒吸一口气。
因为你可能会面临如下问题:
如果同步导数据,接口很容易超时。
如果把所有数据一次性装载到内存,很容易引起OOM。
数据量太大sql语句必定很慢。
相同商品编号的数据要放到一起。
如果走异步,如何通知用户导出结果?
如果excel文件太大,目标用户打不开怎么办?
我们要如何才能解决这些问题,实现一个百万级别的excel数据快速导出功能呢?
1.异步处理
做一个MySQL百万数据级别的excel导出功能,如果走接口同步导出,该接口肯定会非常容易超时。
因此,我们在做系统设计的时候,第一选择应该是接口走异步处理。
说起异步处理,其实有很多种,比如:使用开启一个线程,或者使用线程池,或者使用job,或者使用mq等。
为了防止服务重启时数据的丢失问题,我们大多数情况下,会使用job或者mq来实现异步功能。
1.1 使用job
如果使用job的话,需要增加一张执行任务表,记录每次的导出任务。
用户点击全部导出按钮,会调用一个后端接口,该接口会向表中写入一条记录,该记录的状态为:待执行。
有个job,每隔一段时间(比如:5分钟),扫描一次执行任务表,查出所有状态是待执行的记录。
然后遍历这些记录,挨个执行。
需要注意的是:如果用job的话,要避免重复执行的情况。比如job每隔5分钟执行一次,但如果数据导出的功能所花费的时间超过了5分钟,在一个job周期内执行不完,就会被下一个job执行周期执行。
所以使用job时可能会出现重复执行的情况。
为了防止job重复执行的情况,该执行任务需要增加一个执行中的状态。
具体的状态变化如下:
执行任务被刚记录到执行任务表,是
待执行状态。当job第一次执行该执行任务时,该记录再数据库中的状态改为:
执行中。当job跑完了,该记录的状态变成:
完成或失败。
这样导出数据的功能,在第一个job周期内执行不完,在第二次job执行时,查询待处理状态,并不会查询出执行中状态的数据,也就是说不会重复执行。
此外,使用job还有一个硬伤即:它不是立马执行的,有一定的延迟。
如果对时间不太敏感的业务场景,可以考虑使用该方案。
1.2 使用mq
用户点击全部导出按钮,会调用一个后端接口,该接口会向mq服务端,发送一条mq消息。
有个专门的mq消费者,消费该消息,然后就可以实现excel的数据导出了。
相较于job方案,使用mq方案的话,实时性更好一些。
对于mq消费者处理失败的情况,可以增加补偿机制,自动发起重试。
RocketMQ自带了失败重试功能,如果失败次数超过了一定的阀值,则会将该消息自动放入死信队列。
2.使用easyexcel
我们知道在Java中解析和生成Excel,比较有名的框架有Apache POI和jxl。
但它们都存在一个严重的问题就是:非常耗内存,POI有一套SAX模式的API可以一定程度的解决一些内存溢出的问题,但POI还是有一些缺陷,比如07版Excel解压缩以及解压后存储都是在内存中完成的,内存消耗依然很大。
百万级别的excel数据导出功能,如果使用传统的Apache POI框架去处理,可能会消耗很大的内存,容易引发OOM问题。
而easyexcel重写了POI对07版Excel的解析,之前一个3M的excel用POI sax解析,需要100M左右内存,如果改用easyexcel可以降低到几M,并且再大的Excel也不会出现内存溢出;03版依赖POI的sax模式,在上层做了模型转换的封装,让使用者更加简单方便。
需要在maven的pom.xml文件中引入easyexcel的jar包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.2</version>
</dependency>
复制代码之后,使用起来非常方便。
读excel数据非常方便:
@Test
public void simpleRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
复制代码写excel数据也非常方便:
@Test
public void simpleWrite() {
String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去读,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}
复制代码easyexcel能大大减少占用内存的主要原因是:在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。
3.分页查询
百万级别的数据,从数据库一次性查询出来,是一件非常耗时的工作。
即使我们可以从数据库中一次性查询出所有数据,没出现连接超时问题,这么多的数据全部加载到应用服务的内存中,也有可能会导致应用服务出现OOM问题。
因此,我们从数据库中查询数据时,有必要使用分页查询。比如:每页5000条记录,分为200页查询。
public Page<User> searchUser(SearchModel searchModel) {
List<User> userList = userMapper.searchUser(searchModel);
Page<User> pageResponse = Page.create(userList, searchModel);
pageResponse.setTotal(userMapper.searchUserCount(searchModel));
return pageResponse;
}
复制代码每页大小pageSize和页码pageNo,是SearchModel类中的成员变量,在创建searchModel对象时,可以设置设置这两个参数。
然后在Mybatis的sql文件中,通过limit语句实现分页功能:
limit #{pageStart}, #{pageSize}
复制代码其中的pagetStart参数,是通过pageNo和pageSize动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize;
复制代码4.多个sheet
我们知道,excel对一个sheet存放的最大数据量,是有做限制的,一个sheet最多可以保存1048576行数据。否则在保存数据时会直接报错:
invalid row number (1048576) outside allowable range (0..1048575)
复制代码如果你想导出一百万以上的数据,excel的一个sheet肯定是存放不下的。
因此我们需要把数据保存到多个sheet中。
5.计算limit的起始位置
我之前说过,我们一般是通过limit语句来实现分页查询功能的:
limit #{pageStart}, #{pageSize}
复制代码其中的pagetStart参数,是通过pageNo和pageSize动态计算出来的,比如:
pageStart = (pageNo - 1) * pageSize;
复制代码如果只有一个sheet可以这么玩,但如果有多个sheet就会有问题。因此,我们需要重新计算limit的起始位置。
例如:
ExcelWriter excelWriter = EasyExcelFactory.write(out).build();
int totalPage = searchUserTotalPage(searchModel);
if(totalPage > 0) {
Page<User> page = Page.create(searchModel);
int sheet = (totalPage % maxSheetCount == 0) ? totalPage / maxSheetCount: (totalPage / maxSheetCount) + 1;
for(int i=0;i<sheet;i++) {
WriterSheet writeSheet = buildSheet(i,"sheet"+i);
int startPageNo = i*(maxSheetCount/pageSize)+1;
int endPageNo = (i+1)*(maxSheetCount/pageSize);
while(page.getPageNo()>=startPageNo && page.getPageNo()<=endPageNo) {
page = searchUser(searchModel);
if(CollectionUtils.isEmpty(page.getList())) {
break;
}
excelWriter.write(page.getList(),writeSheet);
page.setPageNo(page.getPageNo()+1);
}
}
}
复制代码这样就能实现分页查询,将数据导出到不同的excel的sheet当中。
6.文件上传到OSS
由于现在我们导出excel数据的方案改成了异步,所以没法直接将excel文件,同步返回给用户。
因此我们需要先将excel文件存放到一个地方,当用户有需要时,可以访问到。
这时,我们可以直接将文件上传到OSS文件服务器上。
通过OSS提供的上传接口,将excel上传成功后,会返回文件名称和访问路径。
我们可以将excel名称和访问路径保存到表中,这样的话,后面就可以直接通过浏览器,访问远程excel文件了。
而如果将excel文件保存到应用服务器,可能会占用比较多的磁盘空间。
一般建议将应用服务器和文件服务器分开,应用服务器需要更多的内存资源或者CPU资源,而文件服务器需要更多的磁盘资源。
7.通过WebSocket推送通知
通过上面的功能已经导出了excel文件,并且上传到了OSS文件服务器上。
接下来的任务是要本次excel导出结果,成功还是失败,通知目标用户。
有种做法是在页面上提示:正在导出excel数据,请耐心等待。
然后用户可以主动刷新当前页面,获取本地导出excel的结果。
但这种用户交互功能,不太友好。
还有一种方式是通过webSocket建立长连接,进行实时通知推送。
如果你使用了SpringBoot框架,可以直接引入webSocket的相关jar包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
复制代码使用起来挺方便的。
我们可以加一张专门的通知表,记录通过webSocket推送的通知的标题、用户、附件地址、阅读状态、类型等信息。
能更好的追溯通知记录。
webSocket给客户端推送一个通知之后,用户的右上角的收件箱上,实时出现了一个小窗口,提示本次导出excel功能是成功还是失败,并且有文件下载链接。
当前通知的阅读状态是未读。
用户点击该窗口,可以看到通知的详细内容,然后通知状态变成已读。
8.总条数可配置
我们在做导百万级数据这个需求时,是给用户用的,也有可能是给运营同学用的。
其实我们应该站在实际用户的角度出发,去思考一下,这个需求是否合理。
用户拿到这个百万级别的excel文件,到底有什么用途,在他们的电脑上能否打开该excel文件,电脑是否会出现太大的卡顿了,导致文件使用不了。
如果该功能上线之后,真的发生发生这些情况,那么导出excel也没有啥意义了。
因此,非常有必要把记录的总条数,做成可配置的,可以根据用户的实际情况调整这个配置。
比如:用户发现excel中有50万的数据,可以正常访问和操作excel,这时候我们可以将总条数调整成500000,把多余的数据截取掉。
其实,在用户的操作界面,增加更多的查询条件,用户通过修改查询条件,多次导数据,可以实现将所有数据都导出的功能,这样可能更合理一些。
此外,分页查询时,每页的大小,也建议做成可配置的。
通过总条数和每页大小,可以动态调整记录数量和分页查询次数,有助于更好满足用户的需求。
9.order by商品编号
之前的需求是要将相同商品编号的数据放到一起。
例如:
| 编号 | 商品名称 | 仓库名称 | 价格 |
|---|---|---|---|
| 1 | 笔记本 | 北京仓 | 7234 |
| 1 | 笔记本 | 上海仓 | 7235 |
| 1 | 笔记本 | 武汉仓 | 7236 |
| 2 | 平板电脑 | 成都仓 | 7236 |
| 2 | 平板电脑 | 大连仓 | 3339 |
但我们做了分页查询的功能,没法将数据一次性查询出来,直接在Java内存中分组或者排序。
因此,我们需要考虑在sql语句中使用order by 商品编号,先把数据排好顺序,再查询出数据,这样就能将相同商品编号,仓库不同的数据放到一起。
此外,还有一种情况需要考虑一下,通过配置的总记录数将全部数据做了截取。
但如果最后一个商品编号在最后一页中没有查询完,可能会导致导出的最后一个商品的数据不完整。
因此,我们需要在程序中处理一下,将最后一个商品删除。
但加了order by关键字进行排序之后,如果查询sql中join了很多张表,可能会导致查询性能变差。
那么,该怎么办呢?
总结
最后用两张图,总结一下excel异步导数据的流程。
如果是使用mq导数据:
如果是使用job导数据:
这两种方式都可以,可以根据实际情况选择使用。
我们按照这套方案的开发了代码,发到了pre环境,原本以为会非常顺利,但后面却还是出现了性能问题。
后来,我们用了两招轻松解决了性能问题。
作者:苏三说技术
来源:juejin.cn/post/7196140566111043643
对于单点登录,你不得不了解的CAS
之前我们通过面试的形式,讲了JWT实现单点登录(SSO)的设计思路,并且到最后也留下了疑问,什么是CAS。
寒暄开始
今天是上班的第一天,刚进公司就见到了上次的面试官,穿着格子衬衫和拖鞋,我们就叫他老余吧。老余看见我就开始勾肩搭背聊起来了,完全就是自来熟的样子,和我最近看的少年歌行里的某人很像。
什么是CAS呢
老余:上次你说到了CAS,你觉得CAS是什么?
我:之前我们面试的时候,我讲了JWT单点登录带来的问题,然后慢慢优化,最后衍变成了中心化单点登录系统,也就是CAS的方案。
CAS(Central Authentication Service),中心认证服务,就是单点登录的某种实现方案。你可以把它理解为它是一个登录中转站,通过SSO站点,既解决了Cookie跨域的问题,同时还通过SSO服务端实现了登录验证的中心化。
这里的SSO指的是:SSO系统
它的设计流程是怎样的
老余:你能不能讲下它的大致实现思路,这说的也太虚头巴脑了,简直是听君一席话,如听一席话。
我:你别急呀,先看下它的官方流程图。
重定向到SSO
首先,用户想要访问系统A的页面1,自然会调用http://www.chezhe1.com的限制接口,(比如说用户信息等接口登录后才能访问)。
接下来 系统A 服务端一般会在拦截器【也可以是过滤器,AOP 啥的】中根据Cookie中的SessionId判断用户是否已登录。如果未登录,则重定向到SSO系统的登录页面,并且带上自己的回调地址,便于用户在SSO系统登录成功后返回。此时回调地址是:http://www.sso.com?url=www.chezhe1.com。
这个回调地址大家应该都不会陌生吧,像那种异步接口或者微信授权、支付都会涉及到这块内容。不是很了解的下面会解释~
另外这个回调地址还必须是前端页面地址,主要用于回调后和当前系统建立会话。
此时如下图所示:
用户登录
在重定向到
SSO登录页后,需要在页面加载时调用接口,根据SessionId判断当前用户在SSO系统下是否已登录。【注意这时候已经在 SSO 系统的域名下了,也就意味着此时Cookie中的domain已经变成了sso.com】
为什么又要判断是否登录?因为在 CAS 这个方案中,只有在SSO系统中为登录状态才能表明用户已登录。
如果未登录,展现账号密码框,让用户输入后进行
SSO系统的登录。登录成功后,SSO页面和SSO服务端建立起了会话。 此时流程图如下所示:
安全验证
老余:你这里有一个很大的漏洞你发现没有?
我:emm,我当然知道。
对于中心化系统,我们一般会分发对应的AppId,然后要求每个应用设置白名单域名。所以在这里我们还得验证AppId的有效性,白名单域名和回调地址域名是否匹配。否则有些人在回调地址上写个黄色网站那不是凉凉。
获取用户信息登录
在正常的系统中用户登录后,一般需要跳转到业务界面。但是在
SSO系统登录后,需要跳转到原先的系统A,这个系统A地址怎么来?还记得重定向到SSO页面时带的回调地址吗?
通过这个回调地址,我们就能很轻易的在用户登录成功后,返回到原先的业务系统。
于是用户登录成功后根据回调地址,带上
ticket,重定向回系统A,重定向地址为:http://www.chezhe1.com?ticket=123456a。接着根据
ticket,从SSO服务端中获取Token。在此过程中,需要对ticket进行验证。根据
token从SSO服务端中获取用户信息。在此过程中,需要对token进行验证。获取用户信息后进行登录,至此系统A页面和系统A服务端建立起了会话,登录成功。
此时流程图如下所示:
别以为这么快就结束了哦,我这边提出几个问题,只有把这些想明白了,才算是真的清楚了。
为什么需要 Ticket?
验证 Ticket 需要验证哪些内容?
为什么需要 Token?
验证 Token 需要验证哪些内容?
如果没有Token,我直接通过Ticket 获取用户信息是否可行?
为什么需要 Ticket
我们可以反着想,如果没有Ticket,我们该用哪种方式获取Token或者说用户信息?你又该怎么证明你已经登录成功?用Cookie吗,明显是不行的。
所以说,Ticket是一个凭证,是当前用户登录成功后的产物。没了它,你证明不了你自己。
验证 Ticket 需要验证哪些内容
签名:对于这种中心化系统,为了安全,绝大数接口请求都会有着验签机制,也就是验证这个数据是否被篡改。至于验签的具体实现,五花八门都有。
真实性:验签成功后拿到
Ticket,需要验证Ticket是否是真实存在的,不能说随便造一个我就给你返回Token吧。使用次数:为了安全性,
Ticket只能使用一次,否则就报错,因为Ticket很多情况下是拼接在URL上的,肉眼可见。有效期:另外则是
Ticket的时效,超过一定时间内,这个Ticket会过期。比如微信授权的Code只有5分钟的有效期。......
为什么需要 Token?
只有通过Token我们才能从SSO系统中获取用户信息,但是为什么需要Token呢?我直接通过Ticket获取用户信息不行吗?
答案当然是不行的,首先为了保证安全性,Ticket只能使用一次,另外Ticket具有时效性。但这与某些系统的业务存在一定冲突。因此通过使用Token增加有效时间,同时保证重复使用。
验证 Token 需要验证哪些内容?
和验证 Ticket类似
签名 2. 真实性 3. 有效期
如果没有 Token,我直接通过 Ticket 获取用户信息是否可行?
这个内容其实上面已经给出答案了,从实现上是可行的,从设计上不应该,因为Ticket和Token的职责不一样,Ticket 是登录成功的票据,Token是获取用户信息的票据。
用户登录系统B流程
老余:系统A登录成功后,那系统B的流程呢?
我:那就更简单了。
比如说此时用户想要访问系统B,http://www.chezhe2.com的限制接口,系统B服务端一般会在拦截器【也可以是过滤器,AOP 啥的】中根据Cookie中的SessionId判断用户是否已登录。此时在系统B中该系统肯定未登录,于是重定向到SSO系统的登录页面,并且带上自己的回调地址,便于用户在SSO系统登录成功后返回。回调地址是:http://www.sso.com?url=www.chezhe2.com。
我们知道之前SSO页面已经与SSO服务端建立了会话,并且因为Cookie在SSO这个域名下是共享的,所以此时SSO系统会判断当前用户已登录。然后就是之前的那一套逻辑了。 此时流程图如下所示:
技术以外的事
老余:不错不错,理解的还可以。你发现这套系统里,做的最多的是什么,有什么技术之外的感悟没。说到这,老余叹了口气。
我:我懂,做的最多的就是验证了,验证真实性、有效性、白名单这些。明明一件很简单的事,最后搞的那么复杂。像现在银行里取钱一样,各种条条框框的限制。我有时候会在想,技术发展、思想变革对于人类文明毋庸置疑是有益的,但是对于我们人类真的是一件好事吗?如果我们人类全是机器人那样的思维是不是会更好点?
老余:我就随便一提,你咋巴拉巴拉了这么多。我只清楚一点,拥有七情六欲的人总是好过没有情感的机器人的。好了,干活去吧。
总结
这一篇内容就到这了,我们聊了下关于单点登录的 CAS 设计思路,其实CAS 往大了讲还能讲很多,可惜我的技术储备还不够,以后有机会补充。如果想理解的更深刻,也可以去看下微信授权流程,应该会有帮助。
最后还顺便提了点技术之外的事,记得有句话叫做:科学的尽头是哲学,我好像开始慢慢理解这句话的意思了。
作者:车辙cz
来源:juejin.cn/post/7196924295310262328
咱不吃亏,也不能过度自卫
我们公司人事小刘负责考勤统计。发完考勤表之后,有个员工找到他,说出勤少统计了一天。
小刘一听,感觉自己有被指控的风险。
他立刻严厉起来:“每天都来公司,不一定就算全勤。没打卡我是不统计的”。
最后小刘一查,发现是自己统计错了。
小刘反而更加强势了:“这种事情,你应该早点跟我反馈,而且多催着我确认。你自己的事情都不上心,扣个钱啥的只能自己兜着”
这就是明显的不愿意吃亏,即使自己错了,也不愿意让自己置于弱势。
你的反应,决定别人怎么对你。这种连言语的亏都不吃的人,并不会让别人敬畏,反而会让人厌恶,进而影响沟通。
我还有一个同事老王。他是一个职场老人,性格嘻嘻哈哈,业务能力也很强。
以前同事小赵和老王合作的时候,小赵宁愿经两层人传话给老王,也不愿意和他直接沟通。
我当时感觉小赵不善于沟通。
后来,当我和老王合作的时候,才体会到小赵的痛苦。
因为,老王是一个什么亏都不吃的人,谁来找他理论,他就怼谁。
你告诉他有疏漏,他会极力掩盖问题,并且怒怼你愚昧无知。
就算你告诉他,说他家着火了。他首先说没有。你一指那不是烧着的吗?他回复,你懂个屁,你知道我几套房吗?我说的是我另一个家没着火。
有不少人,从不吃亏,无论什么情况,都不会让自己处于弱势。
这类人喜欢大呼小叫,你不小心踩他脚了,他会大喊:践踏我的尊严,和你拼了!
心理学讲,愤怒源于恐惧,因为他想逃避当前不利的局面。
人总会遇到各种不公的待遇,或误会,或委屈。
遇到争议时,最好需要确认一下,排除自己的问题。
如果自己没错,那么比较好的做法就是:“我认为你说得不合理,首先……其次……最后……”。
不盲目服软,也不得理不饶人,全程平心静气,有理有据。这种人绝对人格魅力爆棚,让人敬佩。
最后,有时候过度强硬也是一种策略,可以很好地过滤和震慑一些不重要的事物。
作者:TF男孩
来源:juejin.cn/post/7196678344573173816
我竟然完美地用js实现默认的文本框粘贴事件
前言:本文实际是用js移动控制光标的位置!解决了网上没有可靠教程的现状
废话连篇
默认情况对一个文本框粘贴,应该会有这样的功能:
粘贴文本后,光标不会回到所有文本的最后位置,而是在粘贴的文本之后
将选中的文字替换成粘贴的文本
但是由于需求,我们需要拦截粘贴的事件,对剪贴板的文字进行过滤,这时候粘贴的功能都得自己实现了,而一旦自己实现,上面2个功能就不见了,我们就需要还原它。
面对这样的需求,我们肯定要控制移动光标,可是现在的网上环境真的是惨,千篇一律的没用代码...于是我就发表了这篇文章。
先上代码
<textarea id="text" style="width: 996px; height: 423px;"></textarea>
<script>
// 监听输入框粘贴事件
document.getElementById('text').addEventListener('paste', function (e) {
e.preventDefault();
let clipboardData = e.clipboardData.getData('text');
// 这里写你对剪贴板的私货
let tc = document.querySelector("#text");
tc.focus();
const start = (tc.value.substring(0,tc.selectionStart)+clipboardData).length;
if(tc.selectionStart != tc.selectionEnd){
tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionEnd)
}else{
tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionStart);
}
// 重新设置光标位置
tc.selectionEnd =tc.selectionStart = start
});
</script>怎么理解上述两个功能?
第一个解释:
比如说现在文本框有:
染念真的很生气
如果我们现在在真的后面粘贴不要,变成
染念真的不要很生气|
拦截后的光标是在生气后面,但是我们经常使用发现,光标应该出现在不要的后面吧!
就像这样:
染念真的不要|很生气
第2个解释:
染念真的不要很生气
我们全选真的的同时粘贴求你,拦截后会变成
染念真的求你不要很生气|
但默认应该是:
染念求你|不要很生气
代码分析
针对第2个问题,我们应该先要获取默认的光标位置在何处,tc.selectionStart是获取光标开始位置,tc.selectionEnd是获取光标结束位置。
为什么这里我写了一个判断呢?因为默认时候,我们没有选中一块区域,就是把光标人为移动到某个位置(读到这里,光标在位置后面,现在人为移动到就是前面,这个例子可以理解不?),这个时候两个值是相等的。
233|333
^--^
1--4
tc.selectionEnd=4,tc.selectionStart = 4
如果相等,说明就是简单的定位,tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionStart);,tc.value.substring(0,tc.selectionStart)获取光标前的内容,tc.value.substring(tc.selectionStart)是光标后的内容。
如果不相等,说明我们选中了一个区域(光标选中一块区域说明我们选中了一个区域),代码只需要在最后获取光标后的内容这的索引改成tc.selectionEnd
|233333|
^------^
1------7
tc.selectionEnd=7,tc.selectionStart = 1
在获取光标位置之前,我们应该先使用tc.focus();聚焦,使得光标回到文本框的默认位置(最后),这样才能获得位置。
针对第1个问题,我们就要把光标移动到粘贴的文本之后,我们需要计算位置。
获得这个位置,一定要在tc.value重新赋值之前,因为这样的索引都没有改动。
const start = (tc.value.substring(0,tc.selectionStart)+clipboardData).length;这个代码和上面解释重复,很简单,我就不解释了。
最后处理完了,重新设置光标位置,tc.selectionEnd =tc.selectionStart = start,一定让selectionEnd和selectionStart相同,不然选中一个区域了。
如果我们在value重新赋值之后获取(tc.value.substr(0,tc.selectionStart)+clipboardData).length,大家注意到没,我们操作的是tc.value,value已经变了,这里的重新定位光标开始已经没有任何意义了!
作者:染念
来源:dyedd.cn/943.html
闭包用多了会造成内存泄露 ?
闭包,是JS中的一大难点;网上有很多关于闭包会造成内存泄露的描述,说闭包会使其中的变量的值始终保持在内存中,一般都不太推荐使用闭包
而项目中确实有很多使用闭包的场景,比如函数的节流与防抖
那么闭包用多了,会造成内存泄露吗?
场景思考
以下案例: A 页面引入了一个 debounce 防抖函数,跳转到 B 页面后,该防抖函数中闭包所占的内存会被 gc 回收吗?
该案例中,通过变异版的防抖函数来演示闭包的内存回收,此函数中引用了一个内存很大的对象 info(42M的内存),便于明显地对比内存的前后变化
注:可以使用 Chrome 的 Memory 工具查看页面的内存大小:
场景步骤:
1) util.js 中定义了 debounce 防抖函数
// util.js`
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
export const debounce = (fn, time) => {
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};2) A 页面中引入并使用该防抖函数
import { debounce } from './util';
mounted() {
this.debounceFn = debounce(() => {
console.log('1');
}, 1000)
}抓取 A 页面内存:
57.1M
3) 从 A 页面跳转到 B 页面,B 页面中没有引入该 debounce 函数
问题: 从 A 跳转到 B 后,该函数所占的内存会被释放掉吗?
此时,抓取 B 页面内存:
58.1M
刷新 B 页面,该页面的原始内存为:
16.1M
结论: 前后对比发现,从 A 跳转到 B 后,B 页面内存增大了 42M,证明该防抖函数所占的内存没有被释放掉,即造成了内存泄露
为什么会这样呢? 按理说跳转 B 页面后,A 页面的组件都被销毁掉了,那么 A 页面所占的内存应该都被释放掉了啊😕
我们继续对比测试
4) 如果把 info 对象放到 debounce 函数内部,从 A 跳转到 B 后,该防抖函数所占的内存会被释放掉吗?
// util.js`
export const debounce = (fn, time) => {
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};按照步骤 4 的操作,重新从 A 跳转到 B 后,B 页面抓取内存为16.1M,证明该函数所占的内存被释放掉了
为什么只是改变了 info 的位置,会引起内存的前后变化?
要搞懂这个问题,需要理解闭包的内存回收机制
闭包简介
闭包:一个函数内部有外部变量的引用,比如函数嵌套函数时,内层函数引用了外层函数作用域下的变量,就形成了闭包。最常见的场景为:函数作为一个函数的参数,或函数作为一个函数的返回值时
闭包示例:
function fn() {
let num = 1;
return function f1() {
console.log(num);
};
}
let a = fn();
a();上面代码中,a 引用了 fn 函数返回的 f1 函数,f1 函数中引入了内部变量 num,导致变量 num 滞留在内存中
打断点调试一下
展开函数 f 的 Scope(作用域的意思)选项,会发现有 Local 局部作用域、Closure 闭包、Global 全局作用域等值,展开 Closure,会发现该闭包被访问的变量是 num,包含 num 的函数为 fn
总结来说,函数 f 的作用域中,访问到了fn 函数中的 num 这个局部变量,从而形成了闭包
所以,如果真正理解好闭包,需要先了解闭包的内存引用,并且要先搞明白这几个知识点:
函数作用域链
执行上下文
变量对象、活动对象
函数的内存表示
先从最简单的代码入手,看下变量是如何在内存中定义的
let a = '小马哥'这样一段代码,在内存里表示如下
在全局环境 window 下,定义了一个变量 a,并给 a 赋值了一个字符串,箭头表示引用
再定义一个函数
let a = '小马哥'
function fn() {
let num = 1
}内存结构如下:
特别注意的是,fn 函数中有一个 [[scopes]] 属性,表示该函数的作用域链,该函数作用域指向全局作用域(浏览器环境就是 window),函数的作用域是理解闭包的关键点之一
请谨记:函数的作用域链是在创建时就确定了,JS 引擎会创建函数时,在该对象上添加一个名叫作用域链的属性,该属性包含着当前函数的作用域以及父作用域,一直到全局作用域
函数在执行时,JS 引擎会创建执行上下文,该执行上下文会包含函数的作用域链(上图中红色的线),其次包含函数内部定义的变量、参数等。在执行时,会首先查找当前作用域下的变量,如果找不到,就会沿着作用域链中查找,一直到全局作用域
垃圾回收机制浅析
现在各大浏览器通常用采用的垃圾回收有两种方法:标记清除、引用计数
这里重点介绍 "引用计数"(reference counting),JS 引擎有一张"引用表",保存了内存里面所有的资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放
上图中,左下角的两个值,没有任何引用,所以可以释放
如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏
判断一个对象是否会被垃圾回收的标准: 从全局对象 window 开始,顺着引用表能找到的都不是内存垃圾,不会被回收掉。只有那些找不到的对象才是内存垃圾,才会在适当的时机被 gc 回收
分析内存泄露的原因
回到最开始的场景,当 info 在 debounce 函数外部时,为什么会造成内存泄露?
进行断点调试
展开 debounce 函数的 Scope选项,发现有两个 Closure 闭包对象,第一个 Closure 中包含了 info 对象,第二个 Closure 闭包对象,属于 util.js 这个模块
内存结构如下:
当从 A 页面切换到 B 页面时,A 页面被销毁,只是销毁了 debounce 函数当前的作用域,但是 util.js 这个模块的闭包却没有被销毁,从 window 对象上沿着引用表依然可以查找到 info 对象,最终造成了内存泄露
当 info 在 debounce 函数内部时,进行断点调试
其内存结构如下:
当从 A 页面切换到 B 页面时,A 页面被销毁,同时会销毁 debounce 函数当前的作用域,从 window 对象上沿着引用表查找不到 info 对象,info 对象会被 gc 回收
闭包内存的释放方式
1、手动释放(需要避免的情况)
如果将闭包引用的变量定义在模块中,这种会造成内存泄露,需要手动释放,如下所示,其他模块需要调用 clearInfo 方法,来释放 info 对象
可以说这种闭包的写法是错误的 (不推荐), 因为开发者需要非常小心,否则稍有不慎就会造成内存泄露,我们总是希望可以通过 gc 自动回收,避免人为干涉
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
export const debounce = (fn, time) => {
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};
export const clearInfo = () => {
info = null;
};2、自动释放(大多数的场景)
闭包引用的变量定义在函数中,这样随着外部引用的销毁,该闭包就会被 gc 自动回收 (推荐),无需人工干涉
export const debounce = (fn, time) => {
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};结论
综上所述,项目中大量使用闭包,并不会造成内存泄漏,除非是错误的写法
绝大多数情况,只要引用闭包的函数被正常销毁,闭包所占的内存都会被 gc 自动回收。特别是现在 SPA 项目的盛行,用户在切换页面时,老页面的组件会被框架自动清理,所以我们可以放心大胆的使用闭包,无需多虑
理解了闭包的内存回收机制,才算彻底搞懂了闭包。以上关于闭包的理解,如果有误,欢迎指正 🌹
参考链接:
浏览器是怎么看闭包的。
JavaScript 内存泄漏教程
JavaScript闭包(内存泄漏、溢出以及内存回收),超直白解析
作者:海阔_天空
来源:juejin.cn/post/7196636673694285882
人保寿险要求全员背诵董事长罗熹金句,央媒痛批其“谄媚”
最近,中国人保寿险公司品牌宣传部门,给人保集团董事长罗熹惹出舆情。
去年12月2日,人保寿险官方公众号“中国人保寿险”发布文章《首季峰启动会上,罗熹董事长这些金句值得收藏!》。文中提到,“直达人心,催人奋进 董事长金句来了!”

近日,该公司又专门发《通知》,要求公司总、省、地市、县支各级机构全体干部员工,“学习、熟读、并背诵董事长在首季峰启动会上传达的金句集锦。”

《通知》称,总公司各部门主要负责人、各级机构一把手要充分发挥示范带动作用,带头讲金句、用金句,通过集中学习、个人自学、背诵打卡等多种方式,确保全体内勤人员将金句内容牢记于心、付诸于行……
《通知》中还提到,要在今年2月10日前,完成全员闭卷通关及考试,并对考试成绩进行汇总。“纸质试卷需妥善保管,以备检查。”
今年1月29日,“中国人保寿险”公众号推送了《以考促学,一套题带你牢记“首季峰”金句》的文章。文内的多道填空题,均是罗董事长的致辞“金句”。

该事件引发关注后,人保寿险删除了上述这两篇公众号文章。
此外,有媒体报道称,人保寿险2月4日深夜发布的一份内部邮件显示,1月30日下发的文件《关于开展“学习罗董金句,激扬奋进力量”学习活动的通知》已被废止。
被卷入“学金句”旋涡的罗熹履新人保集团董事长时间并不长。去年11月21日,银保监会发布消息称,核准了罗熹新职务。
公开资料显示,罗熹出生于1960年12月,毕业于中国人民银行研究生部,经济学硕士学位,高级经济师,1977年8月参加工作以来,曾在多家银行、保险公司工作。
2月6日,有自媒体称,自己因2月4日发布《如此谄媚领导?一央企发文要求全体员工学习、熟读、背诵董事长“金句”》文章,收到人保寿险的撤稿函。

有网友评论称,作为央企的人保寿险公司,发文要求全体员工学习、熟读、背诵董事长罗熹的“金句”,而且还有相应学习活动的测试试题,如此形式主义是否合适?是否有“谄媚领导”之嫌?
中新社旗下的中新经纬2月6日晚间发表评论称,这种“金句学习”的企业文化,更像是一种职场“洗脑”,加深了外界对寿险行业的不良观感。
“强制员工背诵董事长金句,看似是让员工领会管理者的经营思路和企业发展战略,实则是下属谄媚上级之举,容易使企业员工陷入盲目个人崇拜。”评论称,作为一家企业的领导者,更应该时刻保持清醒的头脑,及时制止下属的变相吹捧。
评论指出,对保险公司来说,与其将董事长金句背会,不如将每一张一张保单做好,每一笔业务做到位,这样方能赢得更多客户信任。
作者:一见财经
来源:zhuanlan.zhihu.com/p/604080917
一杯咖啡的时间☕️,搞懂 API 和 RESTful API!
☀️ 前言
API和RESTful API是每个程序员都应该了解并掌握的基本知识,我们在开发过程中设计API的时候也应该至少要满足一些最基本的要求。如果你还不了解什么是
API或你没有了解RESTful API,你可以选择花5分钟时间看下去,我会最通俗易懂的帮你普及这一切。
❓ 什么是 API
举个简单的例子你就会明白:
早在
2000年我们还在用小灵通的时代,网上购票已经慢慢兴起,但是绝大部分人出行还是通过电话查询航班来去选择购票,我们首先需要打电话到附近的站台根据时间询问航班或车次,得到结果后再去到对应站台进行购票。
随着时代的飞速发展和智能手机的普及,各种旅游
App也映入眼帘,大家也学会了如何在App上进行购票。这时候我们买票就没有以前那么麻烦了,在
App输入你的起点和终点后,会展现所有符合条件的车次,航班,不仅仅只有时间、座位,还有航空公司、预计时间等等等等详细信息一目了然,你只需要根据你的需求购买即可。
连接是一件很棒的事情,在我们现在的生活中,我们可以很轻松的通过
App进行购物、阅读、直播,我们以前所未有的方式和世界与人们相连接。那这些是怎么做到的?为什么一个
App能够这么便利?这些资料为什么会可以从A到达B,为什么我们只需要动动手指就可以达到这一切?而这个桥梁,这个互联网世界的无名英雄就是
API,API,全名Application Programming Interface (应用程式界面),简单来说,是品牌开发的一种接口,让第三方可以额外开发、应用在自身的产品上的系统沟通界面。简单来说,你可以把它比喻成古人的鸽子,通过飞鸽传书来传达你的需求,而接收方再把回应通过鸽子传达给你。
再说回上面举的例子。
旧时代我们需要知道航班的信息,我们就需要一个信差,而这个电话员就是这个信差,也就是我们说的
API,他传达你的要求到系统,而站台就是这个系统,比如告诉它查询明天飞往广州的飞机,那么他就会得出结果,由电话员传递给你。而现在我们需要购买机票等,只需要通过购票系统选择日期,城市,舱位等,他会从不同的航空公司网站汇集资料,而汇集资料的手段就是通过
API和航空公司互动。
我们现在知道是
API让我们使用这些旅游App,那么这个道理也一样适用于生活中任何应用程序、资料和装置之间的互动,都有各自的API进行连接。
❓ 什么是 RESTful API
在互联网并没有完全流行的初期,移动端也没有那么盛行,页面请求和并发量也不高,那时候人们对接口
(API)的要求没那么高。当初的
web应用程序主要是在服务器端实现的,因此需要使用复杂的协议来操作和传输数据。然而,随着移动端设备的普及,需要在移动端也能够访问web应用程序,而客户端和服务端就需要接口进行通信,但接口的规范性就又成了一个问题。
所以一套简化开发、结构清晰、符合标准、易于理解、易于扩展让大部分人都能够理解接受的接口风格就显得越来越重要,而
RESTful风格的接口(RESTful API)刚好有以上特点,就逐渐应运而生。
REST
REST,全名Representational State Transfer(表现层状态转移),他是一种设计风格,一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。
RESTful
RESTful只是转为形容詞,就像那么RESTful API就是满足REST风格的,以此规范设计的API。
RESTful API
我们常见的
API一般都长这样子:
而
RESTful风格的API却长这样子:
🔘 六大原则
Roy Fielding是HTTP协议的主要设计者之一,他在论文中阐述了REST架构的概念并给出了REST架构的六个限制条件,也就是六大原则。
Uniform Interface(统一接口)
就像我们上面两幅图看到的
API,这是最直观的特征,是REST架构的核心,统一的接口对于RESTful服务非常重要。客户端只需要关注实现接口就可以,接口的可读性加强,使用人员方便调用。RESTful API通过URL定位资源,并通过HTTP方法操作该资源,对资源的操作包括获取、创建、修改和删除,这些操作正好对应HTTP协议提供的GET、POST、PUT和DELETE方法。GET:获取资源信息。POST:创建一个新资源。PUT:更新已有的资源。DELETE:删除已有的资源。
在一个完全遵循
RESTful的团队里,后端只需要告诉前端/users这个API,前端就应该知道:获取所有用户:
GET /users获取特定用户:
GET /users/{id}创建用户:
POST /users更新用户:
PUT /users/{id}删除用户:
DELETE /users/{id}
当
API数量非常多,系统非常复杂时,RESTful的好处会越来越明显。理解系统时,可以直接围绕一系列资源来理解和记忆。
Client-Server(客户端和服务端分离)
它意味着客户端和服务器是独立的、可以分离的。
客户端是负责请求和处理数据的组件,服务器是负责存储数据和处理请求的组件。
这两个组件之间通过一组约定来协作,以便客户端能够获取所需的数据。
Statelessness(无状态)
它指的是每个请求都是独立的,没有前后关系。服务器不保存客户端的状态信息,并且每个请求都必须包含所有所需的信息。
这样做的好处是可以使每个请求变得简单,容易理解和处理,并且可以更容易地扩展和维护。
例如,假设你在登录一个网站,你需要在登录界面输入用户名和密码通过接口获取到了
token。接下来的所有请求都需要携带上这个token而不是系统在第一次登录成功之后记录了你的状态。
Cacheability(可缓存)
客户端和服务端可以协商缓存内容,通过设置
HTTP状态码,服务器可以告诉客户端这个数据是否可以被缓存。例如,一个
HTTP响应头中包含一个Cache-Control字段,用于告诉客户端该数据可以缓存多长时间。这样可以提高数据传输的效率,从而降低网络带宽的开销,加速数据的访问速度。
Layered System(分层)
客户端不应该关心请求经过了多少中间层,只需要关心请求的结果。
架构的系统可以分为多个层次,每一层独立完成自己的任务。这样的架构结构使得系统更容易维护,并且允许独立替换不同层次。
例如,数据库存储层可以独立于其他层,在不影响其他层的情况下进行替换或扩展。
Code on Demand(可选的代码请求)
它提倡服务器可以将客户端代码下载到客户端并执行。这样,客户端可以根据服务器发送的代码来扩展它的功能。
这个限制可以使客户端代码变得更加灵活,并且可以通过服务器提供的代码来解决问题,而不必再等待下一个版本。
Code on Demand是可选的,但它可以使RESTful API变得更加灵活和可扩展。
🔥 RESTful API 设计规范
说了这么多的理论,那我们该如何去设计一个最简单
RESTful风格的API呢?
HTTP 方法
HTTP设计了很多动词,来标识不同的操作,不同的HTTP请求方法有各自的含义,就像上面所展示的,RESTful API应该使用HTTP方法(如GET、POST、PUT和DELETE)来描述操作。
版本控制
版本控制是指在不影响现有的客户端应用的情况下,更新
RESTful API的方法,据我了解常见的版本控制方式包括:URL 方法:通过改变
URL来表示不同的版本,例如https://api.example.com/api/v1/resources和https://api.example.com/api/v2/resources。Accept 标头:通过请求标头中的
Accept字段来表示版本。请求参数:通过请求中的参数来表示版本,例如
https://api.example.com/resources?version=1和https://api.example.com/resources?version=2。
不同公司,不同的团队所设计的
API都各有不同,但我觉得RESTful API版本控制的方法要尽可能的简单,易于理解和使用直接将版本放到URL中,直截了当,简单明了。
URL 明确标识资源
API应该使用简洁明了的URL来标识资源,并且在同一个资源上使用不同的HTTP方法来执行不同的操作。这样的设计使得客户端在无需任何额外信息的情况下就可以找到所需的资源。
不规范的的
URL,形式千奇百怪,不同的开发者还需要了解文档才能调用。规范后的
RESTful风格的URL,形式固定,可读性强,根据名词和HTTP动词就可以操作这些资源。
给大家一个小
tips,如果你遇到了实在想不到的URL,你可以参考github开放平台 ,这里面有很多很规范的URL设计。
HTTP 状态码
HTTP状态码是RESTful API设计的重要一环,是表示API请求的状态,用于告知客户端是否成功请求并处理数据。常用的HTTP状态码有:200 OK:请求成功,表示获得了请求的数据201 Created:请求成功,表示创建了一个新的资源204 No Content:请求成功,表示操作成功,但没有返回数据400 Bad Request:请求失败,表示请求格式不正确或缺少必要参数401 Unauthorized:请求失败,表示认证失败或缺少授权403 Forbidden:请求失败,表示没有访问权限404 Not Found:请求失败,表示请求的资源不存在500 Internal Server Error:请求失败,表示服务器内部错误
统一返回数据格式
常用的返回数据格式有
JSON和XML。JSON是现在比较流行的数据格式,它是简单、轻量、易于解析,并且它有很好的可读性。XML也是一种常用的数据格式,它的优点是比较灵活,并且支持各种数据类型。
合格美观的 API 文档
项目开发离不开前后端分离,离不开
API,当然也就离不开API文档,但是文档的编写又成为程序员觉得麻烦事之一,甚至我还看到有公司的的API文档是用Word文档手敲的。市面上有很多可以管理
API的软件,每个人都有自己的选择,我给大家推荐一款API管理神器 Apifox,可以一键生成API文档。不需要你过多的操作,只需要你在可视化的页面添加你的
API即可生成,现在也支持了多种导航模式、亮暗色模式、顶部自定义Icon、文案可跳转到你的官网等地址。
对于独立开发者和团队来说都是一大利好福音,本文就不做过多介绍,感兴趣的可以去试试~
👋🏻 写在最后
总的来说
RESTful风格的API固然很好很规范,但大多数互联网公司并没有按照或者完全按照其规则来设计,因为REST是一种风格,而不是一种约束或规则,过于理想的RESTful API会付出太多的成本。如果您正在考虑使用
RESTful API,请确保它符合您的业务需求。例如,如果您的项目需要实现复杂的数据交互,您可能需要考虑使用其他API设计方法。因此,请确保在选择
API设计方法时充分考虑您的业务需求。此外,您还需要确保RESTful API与您的系统架构和技术栈相兼容。通过这些考虑,您可以确保RESTful API的正确使用,并且可以实现更高效和可靠的API。长期来看,
API设计也不只是后端的工作,而是一个产品团队在产品设计上的协调工作,应该整个团队参与。这次简单分享了
API与RESTful API,在实际运用中,并不是一定要使用这种规范,但是有RESTful标准可以参考,是十分有必要的,希望对大家有帮助。
作者:快跑啊小卢_
来源:juejin.cn/post/7196570893152616506
我当面试官的经历总结
背景
工作之余,负责过公司前端岗位的一些技术面试,一直在想,能不能对这个经历做一个总结,遂有了这篇文章。
文章主要内容如下:
我的面试风格
面试者——简历格式与内容
面试者——简历亮点
面试者——准备面试
面试官——面试前准备
面试官——面试中
面试官——面试结果评价
总结
我的面试风格
我非常讨厌问一些稀奇古怪的问题,也不喜欢遇到任何面试者,都准备几个相同的技术问题。我的面试风格可以总结为以下几点:
根据简历内容,提炼和简历深度关联的技术场景
将提炼的技术场景分解成问题,可以是一个问题,也可以是多个问题,可以困难,也可以容易
和面试者进行友好交流,感受面试者的各种反馈,尊重面试者
面试是一个互相学习的过程
以上总结可以用如下思维导图概括:
面试者——简历格式与内容
我们看一张两个简历的对比图,如下所示:
上图中的两个简历,代表了大多数人的简历样子。大家可以自行感觉下,哪一个简历更好些。
我对简历格式与内容,有如下两点看法:
我更喜欢图中简历
2的格式,但简历格式不会影响我的面试评价简历内容是核心,我会根据简历内容来决定要不要面试和如何面试
所以对于面试者来说,一定要写好简历内容。
面试者——简历亮点
究竟什么样的内容算是亮点呢?对此,我罗列了简历亮点的思维导图,如下图所示:
简洁阐述下简历亮点思维导图:
技术丰富:有深度,比如你在
node方面做了ssr、微服务和一些底层工具等;有广度,比如你实践过pc、h5、小程序、桌面端、ssr、node、微前端、低代码等项目:比如你深度参与或者主导低代码平台项目建设,该项目非常复杂,在建设过程中,做了很多技术等方面的提升和创新,产生了很好的效果
博客/开源:比如你写的博客文章质量高,有自己独特和深入的见解;你在开源方面做了很多贡献,提了一些好的
pr,有自己的开源作品公司知名:这个好理解,比如你在头部互联网,独角兽等公司工作过
其他:学历和工作年限,算是门槛,合适也是亮点
面试者要善于把自己的亮点展示在简历上,这对于应聘心怡公司来说,是非常重要的事情。
面试者——准备面试
面试者在准备面试阶段,应当做好以下 5 点:
写好简历内容,这个是重中之重
整理好自我介绍,控制好时间,做到言简意赅,把重点、亮点突出
确定好回答面试官提问的基本方式,保持统一的回答方式
根据简历内容,自己对自己做一次面试,或者找朋友模拟面试官,面试自己
找出不足,进行优化
面试者可以对写好的简历,用思维导图等工具,对内容进行分解,如下图所示:
在分解完成后,我们将相同点进行归纳,然后对多次提及,重复提及,着重提及的归纳进行重点复习和梳理。
这里用上图举 2 个归纳例子说明下:
我的技术栈中提及 pnpm yarn , 其涉及到的知识点,有以下:
包管理器选型,
npmyarnpnpm三者的区别monorepo设计
我的重要功能提及商详页,其涉及到的知识点,有以下:
性能优化
wap端的常见问题,如1px问题、滚动穿透、响应式、终端适配
做好面试准备,会让你在面试过程中,胸有成竹,运筹帷幄。
面试官——面试前准备
主要有以下四个步骤:
看简历:作为面试官,在面试前,要认真看面试者的简历,这是对面试者的尊重
找亮点:这块参考上文提到的面试者亮点
定场景:根据简历内容和亮点,确定深度关联的技术场景
提问题:将确定的技术场景分解成问题,可以是一个问题,也可以是多个问题,可以困难,也可以容易
我认为面试前准备是面试官最重要的流程,这个做好了,剩下的就很容易做了。
面试官——面试中
整个过程的主线如下:
官方开头:比如打招呼、面试者自我介绍
重点过程:这个过程主要有两个事情:
第一个事情:按照上文 面试前准备 的内容来和面试者进行沟通交流,衡量面试者的回答和所写简历内容两者之间的联系 第二个事情:对于有疑惑的联系,要二次验证,这个举个例子
比如面试者简历上写,自研组件库。我问他按需加载是怎么实现的,他的回答会有下面两种情况
第一种情况:回答的很好,这个时候我会再讨论一个按需加载相关的小问题,如果回答还是很流畅。那很好,这个就是面试亮点
第二种情况:回答的很差,那我会怀疑自研组件库是不是他用心做的事情。因为他有可能是 fork 一个开源组件库,然后改改,然后就没然后了。这个时候,我倾向于直接和他沟通,比如问他在自研组件库上花了多少时间,是不是随便搞的。在回答很差的前置条件下,面试者大都会说实情。这样我就能掌握正确的信息,避免误解。
官方结尾:上家辞职原因、为什么选择来我司、定居情况、回答面试者提的各种问题
面试官——面试结果评价
结果无非就是失败和成功,绝大多数的面试结果评价都是客观公正的,剩下的少数都是一些特殊情况,遇到这种,那就是运气不好了。
总结
以上是我作为面试官经历的一次总结,虽然面试次数不多,但依然值得我为此写一个总结,这是一份宝贵的面经。
作者:码上有你
来源:juejin.cn/post/7195770700107399228
字节前端监控实践
简述
Slardar 前端监控自18年底开始建设以来,从仅仅作为 Sentry 的替代,经历了一系列迭代和发展,目前做为一个监控解决方案,已经应用到抖音、西瓜、今日头条等众多业务线。
据21年下旬统计,Slardar 前端监控(Web + Hybrd) 工作日晚间峰值 qps 300w+,日均处理数据超过千亿条。
本文,我将针对在这一系列的发展过程中,字节内部监控设计和迭代遇到的落地细节设计问题,管中窥豹,向大家介绍我们团队所思考和使用的解决方案。
他们主要围绕着前端监控体系建设的一些关键问题展开。也许大家对他们的原理早已身经百战见得多了,不过当实际要落地实现的时候,还是有许多细节可以再进一步琢磨的。
如何做好 JS 异常监控
JS 异常监控本质并不复杂,浏览器早已提供了全局捕获异常的方案。
window.addEventListenr('error', (err) => {
report(normalize(err))
});
window.addEventListenr('unhandledrejection', (rejection) => {
report(normalize(rejection))
});
复制代码但捕获到错误仅仅只是相关工作的第一步。在我看来,JS 异常监控的目标是:
开发者迅速感知到 JS 异常发生
通过监控平台迅速定位问题
开发者能够高效的处理问题,并统计,追踪问题的处理进度
在异常捕获之外,还包括堆栈的反解与聚合,处理人分配和报警这几个方面。
堆栈反解: Sourcemap
大家都知道 Script 脚本在浏览器中都是以明文传输并执行,现代前端开发方案为了节省体积,减少网络请求数,不暴露业务逻辑,或从另一种语言编译成 JS。都会选择将代码进行混淆和压缩。在优化性能,提升用户体验的同时,也为异常的处理带来了麻烦。
在本地开发时,我们通常可以清楚的看到报错的源代码堆栈,从而快速定位到原始报错位置。而线上的代码经过压缩,可读性已经变得非常糟糕,上报的堆栈很难对应到原始的代码中。 Sourcemap 正是用来解决这个问题的。
简单来说,Sourcemap 维护了混淆后的代码行列到原代码行列的映射关系,我们输入混淆后的行列号,就能够获得对应的原始代码的行列号,结合源代码文件便可定位到真实的报错位置。
Sourcemap 的解析和反解析过程涉及到 VLQ 编码,它是一种将代码映射关系进一步压缩为类base64编码的优化手段。
在实际应用中,我们可以把它直接当成黑盒,因为业界已经为我们提供了方便的解析工具。下面是一个利用 mozila 的 sourcemap 库进行反解的例子。
以上代码执行后通常会得到这样的结果,实际上我们的在线反解服务也就是这样实现的
当然,我们不可能在每次异常发生后,才去生成 sourcemap,在本地或上传到线上进行反解。这样的效率太低,定位问题也太慢。另一个方案是利用 sourcemappingURL 来制定sourcemap 存放的位置,但这样等于将页面逻辑直接暴露给了网站使用者。对于具有一定规模和保密性的项目,这肯定是不能接受的。
//# sourceMappingURL=http://example.com/path/hello.js.map
复制代码为了解决这个问题,一个自然的方案便是利用各种打包插件或二进制工具,在构建过程中将生成的 sourcemap 直接上传到后端。Sentry 就提供了类似的工具,而字节内部也是使用相似的方案。
通过如上方案,我们能够让用户在发版构建时就可以完成 sourcemap 的上传工作,而异常发生后,错误可以自动完成解析。不需要用户再操心反解相关的工作了。
堆栈聚合策略
当代码被成功反解后,用户已经可以看到这一条错误的线上和原始代码了,但接下来遇到的问题则是,如果我们只是上报一条存一条,并且给用户展示一条错误,那么在平台侧,我们的异常错误列表会被大量的重复上报占满,
对于错误类型进行统计,后续的异常分配操作都无法正常进行。
在这种情况下,我们需要对堆栈进行分组和聚合。也就是,将具有相同特征的错误上报,归类为统一种异常,并且只对用户暴露这种聚合后的异常。
堆栈怎么聚合效果才好呢?我们首先可以观察我们的JS异常所携带的信息,一个异常通常包括以下部分
name: 异常的 Type,例如 TypeError, SyntaxError, DOMError
Message:异常的相关信息,通常是异常原因,例如
a.b is not defined.Stack (非标准)异常的上下文堆栈信息,通常为字符串
那么聚合的方案自然就出来了,利用某种方式,将 error 相关的信息利用提取为 fingerprint,每一次上报如果能够获得相同的 fingerprint,它们就可以归为一类。那么问题进一步细化为:如何利用 Error 来保证 fingerprint 的区分尽量准确呢?
如果跟随标准,我们只能利用 name + message 作为聚合依据。但在实践过程中,我们发现这是远远不够的。如上所示,可以看到这两个文件发生的位置是完全不同的,来自于不同的代码段,但由于我们只按照 name + message 聚合。它们被错误聚合到了一起,这样可能造成我们修复了其中一个错误后。误以为相关的所有异常都被解决。
因此,很明显我们需要利用非标准的 error.stack 的信息来帮我们解决问题了。在这里我们参考了 Sentry 的堆栈聚合策略:
除了常规的 name, message, 我们将反解后的 stacktrace 进一步拆分为一系列的 Frame,每一个 Frame 内我们重点关注其调用函数名,调用文件名以及当前执行的代码行(图中的context_line)。
Sentry 将每一个拆分出的部分都称为一个 GroupingComponent,当堆栈反解完毕后,我们首先自上而下的递归检测,并自下而上的生成一个个嵌套的 GroupingComponent。最后,在顶层调用 GroupingComponent.getHash() 方法, 得到一个最终的哈希值,这就是我们最终求得的 fingerprint。
相较于message+name, 利用 stacktrace 能够更细致的提取堆栈特征,规避了不同文件下触发相同 message 的问题。因此获得的聚合效果也更优秀。这个策略目前在字节内部的工作效果良好,基本上能够做到精确的区分各类异常而不会造成混淆和错误聚合。
处理人自动分配策略
异常已经成功定位后,如果我们可以直接将异常分配给这行代码的书写者或提交者,可以进一步提升问题解决的效率,这就是处理人自动分配所关心的,通常来说,分配处理人依赖 git blame 来实现。
一般的团队或公司都会使用 Gitlab / Github 作为代码的远端仓库。而这些平台都提供了丰富的 open-api 协助用户进行blame,
我们很自然的会联想到,当通过 sourcemap 解出原始堆栈路径后,如果可以结合调用 open-api,获得这段代码所在文件的blame历史, 我们就有机会直接在线上确定某一行的可能的 author / commitor 究竟是谁。从而将这个异常直接分配给他。
思路出来了,那么实际怎么落地呢?
我们需要几个信息
线上报错的项目对应的源代码仓库名,如
toutiao-fe/slardar线上报错的代码发生的版本,以及与此版本关联的 git commit 信息,为什么需要这些信息呢?
默认用来 blame 的文件都是最新版本,但线上跑的不一定是最新版本的代码。不同版本的代码可能发生行的变动,从而影响实际代码的行号。如果我们无法将线上版本和用来 blame 的文件划分在统一范围内,则很有可能自动定位失败。
因此,我们必须找到一种方法,确定当前 blame 的文件和线上报错的文件处于同一版本。并且可以直接通过版本定位到关联的源代码 commit 起止位置。这样的操作在 Sentry 的官方工具 Sentry-Cli 中亦有提供。字节内部同样使用了这种方案。
通过 相关的 二进制工具,在代码发布前的脚本中提供当前将要发布的项目的版本和关联的代码仓库信息。同时在数据采集侧也携带相同的版本,线上异常发生后,我们就可以通过线上报错的版本找到原始文件对应的版本,从而精确定位到需要哪个时期的文件了。
异常报警
当异常已经成功反解和聚合后,当用户访问监控平台,已经可以观察并处理相关的错误,不过到目前为止,异常的发生还无法触及开发者,问题的解决依然依靠“走查”行为。这样的方案对严重的线上问题依然是不够用,因此我们还需要主动通知用户的手段,这就是异常报警。
在字节内部,报警可以分为宏观报警,即针对错误指标的数量/比率的报警,以及微观报警,即针对新增异常的报警。
宏观报警
宏观报警是数量/比率报警, 它只是统计某一类指标是否超出了限定的阈值,而不关心它具体是什么。因此默认情况下它并不会告诉你报警的原因。只有通过归因维度或者下文会提到的 微观(新增异常)报警 才能够知晓引发报警的具体原因
关于宏观报警,我们有几个关键概念
第一是样本量,用户数阈值: 在配置比率指标时。如果上报量过低,可能会造成比率的严重波动,例如错误率 > 20%, 的报警下,如果 JS 错误数从 0 涨到 1, 那就是比率上涨到无限大从而造成没有意义的误报。如果不希望被少量波动干扰,我们设置了针对错误上报量和用户数的最低阈值,例如只有当错误影响用户数 > 5 时,才针对错误率变化报警。
第二是归因维度: 对于数量,比率报警,仅仅获得一个异常指标值是没什么意义的,因为我们无法快速的定位问题是由什么因素引发的,因此我们提供了归因维度配置。例如,通过对 JS 异常报警配置错误信息归因,我们可以在报警时获得引发当前报警的 top3 关键错误和增长最快的 top3 错误信息。
第三是时间窗口,报警运行频率: 如上文所说,报警是数量,比率报警,而数量,比率一定有一个统计范围,这个就是通过 时间窗口 来确定的。而报警并不是时时刻刻盯着我们的业务数据的,可以理解为利用一个定时器来定期检查 时间窗口 内的数据是否超出了我们定义的阈值。而这个定时器的间隔时间,就是 报警运行频率。通过这种方式,我们可以做到类实时的监测异常数据的变化,但又没有带来过大的资源开销。
微观报警(新增异常)
相较于在意宏观数量变化的报警,新增异常在意每一个具体问题,只要此问题是此前没有出现过的,就会主动通知用户。
同时,宏观报警是针对数据的定时查找,存在运行频率和时间窗口的限制,实时性有限。微观报警是主动推送的,具有更高的实时性。
微观报警适用于发版,灰度等对新问题极其关注,并且不方便在此时专门配置相关数量报警的阶段。
如何判断“新增”?
我们在 异常自动分配章节讲到了,我们的业务代码都是可以关联一个版本概念的。实际上版本不仅和源代码有关,也可以关联到某一类错误上。
在这里我们同样也可以基于版本视角判断“新增错误”。
对于新增异常的判断,针对两种不同场景做了区分
对于指定版本、最新版本的新增异常报警,我们会分析该报警的 fingerprint 是否为该版本代码中首次出现。
而对于全体版本,我们则将"首次”的范围增加了时间限制,因为对于某个错误,如果在长期没有出现后又突然出现,他本身还是具有通知的意义的,如果不进行时间限制,这个错误就不会通知到用户,可能会出现信息遗漏的情况。
如何做好性能监控?
如果说异常处理是前端监控体系60分的分界线,那么性能度量则是监控体系能否达到90分的关键。一个响应迟钝,点哪儿卡哪儿的页面,不会比点开到处都是报错的页面更加吸引人。页面的卡顿可能会直接带来用户访问量的下降,进而影响背后承载的服务收入。因此,监控页面性能并提升页面性能也是非常重要的。针对性能监控,我们主要关注指标选取,品质度量 、瓶颈定位三个关键问题。
指标选取
指标选取依然不是我们今天文章分享的重点。网上关于 RUM 指标,Navigation 指标的介绍和采集方式已经足够清晰。通常分为两个思路:
RUM (真实用户指标) -> 可以通过 Web Vitals (github.com/GoogleChrom…*
页面加载指标 -> NavigationTiming (ResourceTiming + DOM Processing + Load) 可以通过 MDN 相关介绍学习。这里都不多赘述。
瓶颈定位
收集到指标只是问题的第一步,接下来的关键问题便是,我们应该如何找出影响性能问题的根因,并且针对性的进行修复呢?
慢会话 + 性能时序分析
如果你对“数据洞察/可观测性”这个概念有所了解,那么你应该对 Kibana 或 Datadog 这类产品有所耳闻。在 kibana 或 Datadog 中都能够针对每一条上传的日志进行详细的追溯。和详细的上下文进行关联,让用户的体验可被观测,通过多种筛选找到需要用户的数据。
在字节前端的内部建设中,我们参考了这类数据洞察平台的消费思路。设计了数据探索能力。通过数据探索,我们可以针对用户上报的任意维度,对一类日志进行过滤,而不只是获得被聚合过的列表信息数据。这样的消费方式有什么好处呢?
我们可以直接定位到一条具体日志,找到一个现实的 data point 来分析问题
这种视图的状态是易于保存的,我们可以将找到的数据日志通过链接发送给其他人,其他用户可以直接还原现场。
对于性能瓶颈,在数据探索中,可以轻松通过针对某一类 PV 上报所关联的性能指标进行数值筛选。也可以按照某个固定时段进行筛选,从而直接获得响应的慢会话。这样的优势在于我们不用预先设定一个“慢会话阈值”,需要哪个范围的数据完全由我们自己说了算。例如,通过对 FCP > 3000ms 进行筛选,我们就能够获得一系列 FCP > 3s 的 PV 日志现场。
在每次 PV 上报后,我们会为数据采集的 SDK 设置一个全局状态,比如 view_id, 只要没有发生新的页面切换,当前的 view_id 就会保持不变。
而后续的一系列请求,异常,静态资源上报就可以通过 view_id 进行后端的时序串联。形成一张资源加载瀑布图。在瀑布图中我们可以观察到各类性能指标和静态资源加载,网络请求的关系。从而检测出是否是因为某些不必要的或者过大的资源,请求导致的页面性能瓶颈。这样的瀑布图都是一个个真实的用户上报形成的,相较于统计值产生的甘特图,更能帮助我们解决实际问题。
结合Longtask + 用户行为分析
通过指标过滤慢会话,并且结合性能时序瀑布图分析,我们能够判断出当前页面中是否存在由于网络或过大资源因素导致的页面加载迟缓问题
但页面的卡顿不一定全是由网络因素造成的。一个最简单的例子。当我在页面的 head 中插入一段非常耗时的同步脚本(例如 while N 次),则引发页面卡顿的原因就来自于代码执行而非资源加载。
针对这种情况,浏览器同样提供了 Longtask API 供我们收集这类占据主线程时间过长的任务。
同样的,我们将这类信息一并收集,并通过上文提到的 view_id 串联到一次页面访问中。用户就可以观察到某个性能指标是否受到了繁重的主线程加载的影响。若有,则可利用类似 lighthouse 的合成监控方案集中检查对应页面中是否存在相关逻辑了。
受限于浏览器所收集到的信息,目前的 longtask 我们仅仅只能获得它的执行时间相关信息。而无法像开发者面板中的 performance 工具一样准确获取这段逻辑是由那段代码引发的。如果我们能够在一定程度上收集到longtask触发的上下文,则可定位到具体的慢操作来源。
此外,页面的卡顿不一定仅仅发生在页面加载阶段,有时页面的卡顿会来自于页面的一次交互,如点击,滚动等等。这类行为造成的卡顿,仅仅依靠 RUM / navigation 指标是无法定位的。如果我们能够通过某种方式(在PPT中已经说明),对操作行为计时。并将操作计时范围内触发的请求,静态资源和longtask上报以同样的瀑布图方式收敛到一起。则可以进一步定位页面的“慢操作”,从而提升页面交互体验。
如下图所示,我们可以检查到,点击 slardar_web 这个按钮 / 标签带来了一系列的请求和 longtask,如果这次交互带来了一定的交互卡顿。我们便可以集中修复触发这个点击事件所涉及的逻辑来提升页面性能表现。
品质度量
当我们采集到一个性能指标后,针对这样一个数字,我们能做什么?
我们需要结论:好还是不好?
实际上我们通常是以单页面为维度来判定指标的,以整站视角来评判性能的优劣的置信度会受到诸多因素影响,比如一个站点中包含轻量的登陆页和功能丰富的中后台,两者的性能要求和用户的容忍度是不一致的,在实际状况下两者的绝对性能表现也是不一致的。而简单平均只会让我们观察不到重点,页面存在的问题数据也可能被其他的页面拉平。
其次,指标只是冷冰冰的数据,而数据想要发挥作用,一定需要参照系。比如,我仅仅提供 FMP = 4000ms,并不能说明这个页面的性能就一定需要重点关注,对于逻辑较重的PC页面,如数据平台,在线游戏等场景,它可能是符合业务要求的。而一个 FMP = 2000ms的页面则性能也不一定好,对于已经做了 SSR 等优化的回流页。这可能远远达不到我们的预期。
一个放之四海而皆准的指标定义是不现实的。不同的业务场景有不同的性能基准要求。我们可以把他们转化为具体的指标基准线。
通过对于现阶段线上指标的分布,我们可以可以自由定义当前站点场景下针对某个指标,怎样的数据是好的,怎样的数据是差的。
基准线应用后,我们便可以在具体的性能数据产出后,直观的观察到,在什么阶段,某些指标的表现是不佳的,并且可以集中针对这段时间的性能数据日志进行排查。
一个页面总是有多个性能指标的,现在我们已经知道了单个性能指标的优劣情况,如何整体的判断整个页面,乃至整个站点的性能状况,落实到消费侧则是,我们如何给一个页面的性能指标评分?
如果有关注过 lighthouse 的同学应该对这张图不陌生。
lighthouse 通过 google 采集到的大量线上页面的性能数据,针对每一个性能指标,通过对数正态分布将其指标值转化成 百分制分数。再通过给予每个指标一定的权重(随着 lighthouse 版本更迭), 计算出该页面性能模块的一个“整体分数”。在即将上线的“品质度量”能力中,我们针对 RUM 指标,异常指标,以及资源加载指标均采取了类似的方案。
我们通常可以给页面的整体性能分数再制定一个基准分数,当上文所述的性能得分超过分数线,才认为该页面的性能水平是“达标”的。而整站整体的达标水平,则可以利用整站达标的子页面数/全站页面数来计算,也就是达标率,通过达标率,我们可以非常直观的迅速找到需要优化的性能页面,让不熟悉相关技术的运营,产品同学也可以定期巡检相关页面的品质状况。
如何做好请求 / 静态资源监控?
除了 JS 异常和页面的性能表现以外,页面能否正常的响应用户的操作,信息能否正确的展示,也和 api 请求,静态资源息息相关。表现为 SLA,接口响应速度等指标。现在主流的监控方案通常是采用手动 hook相关 api 和利用 resource timing 来采集相关信息的。
手动打点通常用于请求耗时兜底以及记录请求状态和请求响应相关信息。
对于 XHR 请求: 通过 hook XHR 的 open 和 send 方法, 获取请求的参数,在 onreadystatechange 事件触发时打点记录请求耗时。
// 记录 method
hookObjectProperty(XMLHttpRequest.prototype, 'open', hookXHROpen);
// hook onreadystateChange,调用前后打点计算
hookObjectProperty(XMLHttpRequest.prototype, 'send', hookXHRSend);
复制代码
对于fetch请求,则通过 hook Fetch 实现
hookObjectProperty(global, 'fetch', hookFetch)
复制代码
第二种则是 resourceTiming 采集方案
静态资源上报:
pageLoad 前:通过 performance.getEntriesByType 获取 resource 信息
pageLoad后:通过 PerformanceObserver 监控 entryType 为 resource 的资源
const callback = (val, i, arr, ob) => // ... 略
const observer = new PerformanceObserver((list, ob) => {
if (list.getEntries) {
list.getEntries().forEach((val, i, arr) => callback(val, i, arr, ob))
} else {
onFail && onFail()
}
// ...
});
observer.observe({ type: 'resource', buffered: false })
复制代码
手动打点的优势在于无关兼容性,采集方便,而 Resource timing 则更精准,并且其记录中可以避开额外的事件队列处理耗时
如何理解和使用 resource timing 数据?
我们现在知道 ResourceTiming 是更能够反映实际资源加载状况的相关指标,而在工作中,我们经常遇到前端请求上报时间极长而后端对应接口日志却表现正常的情况。这通常就可能是由使用单纯的打点方案计算了太多非服务端因素导致的。影响一个请求在前端表现的因素除了服务端耗时以外,还包括网络,前端代码执行排队等因素。我们如何从 ResourceTiming 中分离出这些因素,从而更好的对齐后端口径呢?
第一种是 Chrome 方案(阿里的 ARMS 也采用的是这种方案):
它通过将线上采集的 ResoruceTiming 和 chrome timing 面板的指标进行类比还原出一个近似的各部分耗时值。他的简单计算方式如图所示。
不过 chrome 实际计算 timing 的方式不明,这种近似的方式不一定能够和 chrome 的面板数据对的上,可能会被用户质疑数据不一致。
第二种则是标准方案: 规范划分阶段,这种划分是符合 W3C 规范的格式,其优势便在于其通用性好,且数据一定是符合要求的而不是 chrome 方案那种“近似计算”。不过它的缺陷是阶段划分还是有点太粗了,比如用户无法判断出浏览器排队耗时,也无法完全区分网络下载和下载完成后的资源加载阶段。只是简单的划分成了 Request / Response 阶段,给用户理解和分析带来了一定成本
在字节内部,我们是以标准方案为主,chrome方案为辅的,用户可以针对自己喜好的那种统计方式来对齐指标。通常来说,和服务端对齐耗时阶段可以利用标准方案的request阶段减去severtiming中的cdn,网关部分耗时来确定。
接下来我们再谈谈采集 SDK 的设计。
SDK 如何降低侵入,减少用户性能损耗?体积控制和灵活使用可以兼得吗?
常需要尽早执行,其资源加载通常也会造成一定的性能影响。更大的资源加载可能会导致更慢的 Load,LCP,TTI 时间,影响用户体验。
为了进一步优化页面加载性能,我们采用了 JS Snippets 来实现异步加载 + 预收集。
异步加载主要逻辑
首先,如果通过 JS 代码创建 script 脚本并追加到页面中,新增的 script 脚本默认会携带 async 属性,这意味着这这部分代码将通过async方式延迟加载。下载阶段不会阻塞用户的页面加载逻辑。从而一定程度的提升用户的首屏性能表现。
预收集
试想一下我们通过 npm 或者 cdn 的方式直接引入监控代码,script必须置于业务逻辑最前端,这是因为若异常先于监控代码加载发生,当监控代码就位时,是没有办法捕获到历史上曾经发生过的异常的。但将script置于前端将不可避免的对用户页面造成一定阻塞,且用户的页面可能会因此受到我们监控 sdk 服务可用性的影响。
为了解决这个问题,我们可以同步的加载一段精简的代码,在其中启动 addEventListener 来采集先于监控主要逻辑发生的错误。并存储到一个全局队列中,这样,当监控代码就位,我们只需要读取全局队列中的缓存数据并上报,就不会出现漏报的情况了。
更进一步:事件驱动与插件化
方案1. 2在大部分情况下都已经比较够用了,但对于字节的某些特殊场景却还不够。由于字节存在大量的移动端页面,且这些页面对性能极为敏感。因而对于第三方库的首包体积要求非常苛刻,同时,也不希望第三方代码的执行占据主线程太长时间。
此外,公司内也有部分业务场景特殊,如 node 场景,小程序场景,electron,如果针对每一种场景,都完全重新开发一套新的监控 SDK,有很大的人力重复开发的损耗。
如果我们能够将 SDK 的框架逻辑做成平台无关的,而各个数据监控,收集方案都只是以插件形式存在,那么这个 SDK 完全是可插拔的,类似 Sentry 所使用的 integration 方案。用户甚至可以完全不使用任何官方插件,而是通过自己实现相关采集方案,来做到项目的定制化。
关于框架设计可以参见下图
我们把整个监控 SDK 看作一条流水线(Client),接受的是用户配置(config)(通过 ConfigManager),收集和产出的是具体事件(Event, 通过 Plugins)。流水线是平台无关的,它不关心处理的事件是什么,也不关心事件是从哪来的。它其实是将这一系列的组件交互都抽象为 client 上的事件,从而使得数据采集器能够介入数据流转的每个阶段
Client 通过 builder 包装事件后,转运给 Sender 负责批处理,Sender 最终调用 Transporter 上报。Transporter 是平台强相关的,例如 Web 使用 xhr 或 fetch,node 则使用 request 等。 同时,我们利用生命周期的概念设置了一系列的钩子,可以让用户可以在适当阶段处理流水线上的事件。例如利用 beforeSend 钩子去修改即将被发送的上报内容等。
当整体的框架结构设计完后,我们就可以把视角放到插件上了。由于我们将框架设置为平台无关的,它本身只是个数据流,有点像是一个精简版的 Rx.js。而应用在各个平台上,我们只需要根据各个平台的特性设计其对应的采集或数据处理插件。
插件方案某种意义上实现了 IOC,用户不需要关心事件怎么处理,传入的参数是哪里来的,只需要利用传入的参数去获取配置,启动自己的插件等。如下这段JS采集器代码,开发插件时,我们只需要关心插件自身相关的逻辑,并且利用传入 client 约定的相关属性和方法工作就可以了。不需要关心 client 是怎么来的,也不用关心 client 什么时候去执行它。
当我们写完了插件之后,它要怎么才能被应用在数据采集和处理中呢?为了达成降低首包大小的目标,我们将插件分为同步和异步两种加载方式。
可以预收集的监控代码都不需要出现在首包中,以异步插件方式接入
无法做到预收集的监控代码以同步形式和首包打在一起,在源码中将client传入,尽早启动,保证功能稳定。
3. 异步插件采用约定式加载,用户在使用层面是完全无感的。我们通过主包加载时向在全局初始化注册表和注册方法,在读取用户配置后,拉取远端插件加载并利用全局注册方法获取插件实例,最后传入我们的 client 实现代码执行。
经过插件化和一系列 SDK 的体积改造后,我们的sdk 首包体积降低到了从63kb 降低到了 34 kb。
总结
本文主要从 JS 异常监控,性能监控和请求,静态资源监控几个细节点讲述了 Slardar 在前端监控方向所面临关键问题的探索和实践,希望能够对大家在前端监控领域或者将来的工作中产生帮助。其实前端监控还有许多方面可以深挖,例如如何利用拨测,线下实验室数据采集来进一步追溯问题,如何捕获白屏等类崩溃异常,如何结合研发流程来实现用户无感知的接入等等。
作者:字节架构前端
来源:https://juejin.cn/post/7195496297150709821
一个炫酷的头像悬停效果
本文翻译自 A Fancy Hover Effect For Your Avatar,略有删改,有兴趣可以看看原文。
你知道当一个人的头像从一个圆圈或洞里伸出来时的那种效果吗?本文将使用一种很简洁的方式实现该悬停效果,可以用在你的头像交互上面。
看到了吗?我们将制作一个缩放动画,其中头像部分似乎从它所在的圆圈中钻出来了。是不是很酷呢?接下来让我们一起一步一步地构建这个动画交互效果。
HTML:只需要一个元素
是的,只需要一个img图片标签即可,本次练习的挑战性部分是使用尽可能少的代码。如果你已经关注我一段时间了,你应该习惯了。我努力寻找能够用最小、最易维护的代码实现的CSS解决方案。
<img src="" alt="">首先我们需要一个带有透明背景的正方形图像文件,以下是本次案例使用的图像。
在开始CSS之前,让我们先分析一下效果。悬停时图像会变大,所以我们肯定会在这里使用transform:scale。头像后面有一个圆圈,径向渐变应该可以达到这个效果。最后我们需要一种在圆圈底部创建边框的方法,该边框将不受整体放大的影响且是在视觉顶层。
放大效果
放大的效果,增加transform:scale,这个比较简单。
img:hover {
transform: scale(1.35);
}上面说过背景是一个径向渐变。我们创建一个径向渐变,但是两个颜色之间不要有过渡效果,这样使得它看起来像我们画了一个有实线边框的圆。
img {
--b: 5px; /* border width */
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
#C02942 calc(100% - var(--b)) 99%,
#0000
);
}注意CSS变量,--b,在这里它表示“边框”的宽度,实际上只是用于定义径向渐变红色部分的位置。
下一步是在悬停时调整渐变大小,随着图像的放大,圆需要保持大小不变。由于我们正在应用scale变换,因此实际上需要减小圆圈的大小,否则它会随着化身的大小而增大。
让我们首先定义一个CSS变量--f,它定义了“比例因子”,并使用它来设置圆的大小。我使用1作为默认值,因为这是图像和圆的初始比例,我们从圆转换。
现在我们必须将背景定位在圆的中心,并确保它占据整个高度。我喜欢把所有东西都直接简写在 background 属性,代码如下:
background: radial-gradient() 50% / calc(100% / var(--f)) 100% no-repeat;背景放置在中心( 50%),宽度等于calc(100%/var(--f)),高度等于100%。
当 --f 等于 1 时是我们最初的比例。同时,渐变占据容器的整个宽度。当我们增加 --f,元素的大小会增长但是渐变的大小将减小。
越来越接近了!我们在顶部添加了溢出效果,但我们仍然需要隐藏图像的底部,这样它看起来就像是跳出了圆圈,而不是整体浮在圆圈前面。这是整个过程中比较复杂的部分,也是我们接下来要做的。
下边框
第一次尝试使用border-bottom属性,但无法找到一种方法来匹配边框的大小与圆的大小。如图所示,相信你能看出来无法实现我们想要的效果:
实际的解决方案是使用outline属性。不是border。outline可以让我们创造出很酷的悬停效果。结合 outline-offset 偏移量,我们就可以实现所需要的效果。
其核心是在图像上设置一个outline轮廓并调整其偏移量以创建下边框。偏移量将取决于比例因子,与渐变大小相同。outline-offset 偏移量看起来相对比较复杂,这里对计算方式进行了精简,有兴趣的可以看看原文。
img {
--s: 280px; /* image size */
--b: 5px; /* border thickness */
--c: #C02942; /* border color */
--f: 1; /* initial scale */
border-radius: 0 0 999px 999px;
outline: var(--b) solid var(--c);
outline-offset: calc((1 / var(--f) - 1) * var(--s) / 2 - var(--b));
}因为我们需要一个圆形的底部边框,所以在底部添加了一个边框圆角,使轮廓与渐变的弯曲程度相匹配。
现在我们需要找到如何从轮廓中删除顶部,也就是上图中挡住头像的那根线。换句话说,我们只需要图像的底部轮廓。首先,在顶部添加空白和填充,以帮助避免顶部头像的重叠,这通过增加padding即可实现:
padding-top: calc(var(--s)/5)这里还有一个注意点,需要添加 content-box 值添加到 background:
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
var(--c) calc(100% - var(--b)) 99%,
#0000
) 50%/calc(100%/var(--f)) 100% no-repeat content-box;这样做是因为我们添加了padding填充,并且我们只希望将背景设置为内容框,因此我们必须显式地定义出来。
CSS mask
到了最后一部分!我们要做的就是藏起一些碎片。为此,我们将依赖于 CSS mask 属性,当然还有渐变。
下面的图说明了我们需要隐藏的内容或需要显示的内容,以便更加准确。左图是我们目前拥有的,右图是我们想要的。绿色部分说明了我们必须应用于原始图像以获得最终结果的遮罩内容。
我们可以识别mask的两个部分:
底部的圆形部分,与我们用来创建化身后面的圆的径向渐变具有相同的维度和曲率
顶部的矩形,覆盖轮廓内部的区域。请注意轮廓是如何位于顶部的绿色区域之外的-这是最重要的部分,因为它允许剪切轮廓,以便只有底部部分可见
最终的完整css如下,对有重复的代码进行抽离,如--g,--o:
img {
--s: 280px; /* image size */
--b: 5px; /* border thickness */
--c: #C02942; /* border color */
--f: 1; /* initial scale */
--_g: 50% / calc(100% / var(--f)) 100% no-repeat content-box;
--_o: calc((1 / var(--f) - 1) * var(--s) / 2 - var(--b));
width: var(--s);
aspect-ratio: 1;
padding-top: calc(var(--s)/5);
cursor: pointer;
border-radius: 0 0 999px 999px;
outline: var(--b) solid var(--c);
outline-offset: var(--_o);
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
var(--c) calc(100% - var(--b)) 99%,
#0000) var(--_g);
mask:
linear-gradient(#000 0 0) no-repeat
50% calc(-1 * var(--_o)) / calc(100% / var(--f) - 2 * var(--b)) 50%,
radial-gradient(
circle closest-side,
#000 99%,
#0000) var(--_g);
transform: scale(var(--f));
transition: .5s;
}
img:hover {
--f: 1.35; /* hover scale */
}下面的一个演示,直观的说明mask的使用区域。中间的框说明了由两个渐变组成的遮罩层。把它想象成左边图像的可见部分,你就会得到右边的最终结果:
最后
搞定!我们不仅完成了一个流畅的悬停动画,而且只用了一个<img>元素和不到20行的CSS技巧!如果我们允许自己使用更多的HTML,我们能简化CSS吗?当然可以。但我们是来学习CSS新技巧的!这是一个很好的练习,可以探索CSS渐变、遮罩、outline属性的行为、转换以及其他许多内容。
在线效果
实例里面是流行的CSS开发人员的照片。有兴趣的同学可以展示一下自己的头像效果。
看完本文如果觉得有用,记得点个赞支持,收藏起来说不定哪天就用上啦~
作者:南城FE
来源:juejin.cn/post/7196747356796518460
Android进阶宝典 -- 告别繁琐的AIDL吧,手写IPC通信框架,5行代码实现进程间通信(下)
接:Android进阶宝典 -- 告别繁琐的AIDL吧,手写IPC通信框架,5行代码实现进程间通信(上)
2.3 内部通讯协议完善
当客户端发起请求,想要执行某个方法的时候,首先服务端会先向Registery中查询注册的服务,从而找到这个要执行的方法,这个流程是在内部完成。
override fun send(request: Request?): Response? {
//获取服务对象id
val serviceId = request?.serviceId
val methodName = request?.methodName
val params = request?.params
// 反序列化拿到具体的参数类型
val neededParams = parseParameters(params)
val method = Registry.instance.findMethod(serviceId, methodName, neededParams)
Log.e("TAG", "method $method")
Log.e("TAG", "neededParams $neededParams")
when (request?.type) {
REQUEST_TYPE.GET_INSTANCE.ordinal -> {
//==========执行静态方法
try {
var instance: Any? = null
instance = if (neededParams == null || neededParams.isEmpty()) {
method?.invoke(null)
} else {
method?.invoke(null, neededParams)
}
if (instance == null) {
return Response("instance == null", -101)
}
//存储实例对象
Registry.instance.setServiceInstance(serviceId ?: "", instance)
return Response(null, 200)
} catch (e: Exception) {
return Response("${e.message}", -102)
}
}
REQUEST_TYPE.INVOKE_METHOD.ordinal -> {
//==============执行普通方法
val instance = Registry.instance.getServiceInstance(serviceId)
if (instance == null) {
return Response("instance == null ", -103)
}
//方法执行返回的结果
return try {
val result = if (neededParams == null || neededParams.isEmpty()) {
method?.invoke(instance)
} else {
method?.invoke(instance, neededParams)
}
Response(gson.toJson(result), 200)
} catch (e: Exception) {
Response("${e.message}", -104)
}
}
}
return null
}当客户端发起请求时,会将请求的参数封装到Request中,在服务端接收到请求后,就会解析这些参数,变成Method执行时需要传入的参数。
private fun parseParameters(params: Array<Parameters>?): Array<Any?>? {
if (params == null || params.isEmpty()) {
return null
}
val objects = arrayOfNulls<Any>(params.size)
params.forEachIndexed { index, parameters ->
objects[index] =
gson.fromJson(parameters.value, Class.forName(parameters.className))
}
return objects
}例如用户中心调用setUserInfo方法时,需要传入一个User实体类,如下所示:
UserManager().setUserInfo(User("ming",25))那么在调用这个方法的时候,首先会把这个实体类转成一个JSON字符串,例如:
{
"name":"ming",
"age":25
}为啥要”多此一举“呢?其实这种处理方式是最快速直接的,转成json字符串之后,能够最大限度地降低数据传输的大小,等到服务端处理这个方法的时候,再把Request中的params反json转成User对象即可。
fun findMethod(serviceId: String?, methodName: String?, neededParams: Array<Any?>?): Method? {
//获取服务
val serviceClazz = serviceMaps[serviceId] ?: return null
//获取方法集合
val methods = methodsMap[serviceClazz] ?: return null
return methods[rebuildParamsFunc(methodName, neededParams)]
}
private fun rebuildParamsFunc(methodName: String?, params: Array<Any?>?): String {
val stringBuffer = StringBuffer()
stringBuffer.append(methodName).append("(")
if (params == null || params.isEmpty()) {
stringBuffer.append(")")
return stringBuffer.toString()
}
stringBuffer.append(params[0]?.javaClass?.name)
for (index in 1 until params.size) {
stringBuffer.append(",").append(params[index]?.javaClass?.name)
}
stringBuffer.append(")")
return stringBuffer.toString()
}那么在查找注册方法的时候就简单多了,直接抽丝剥茧一层一层取到最终的Method。在拿到Method之后,这里是有2种处理方式,一种是通过静态单例的形式拿到实例对象,并保存在服务端;另一种就是执行普通方法,因为在反射的时候需要拿到类的实例对象才能调用,所以才在GET_INSTANCE的时候存一遍。
3 客户端 - connect
在第二节中,我们已经完成了通讯协议的建设,最终一步就是客户端通过绑定服务,向服务端发起通信了。
3.1 bindService
/**
* 绑定服务
*
*/
fun connect(
context: Context,
pkgName: String,
action: String = "",
service: Class<out IPCService>
) {
val intent = Intent()
if (pkgName.isEmpty()) {
//同app内的不同进程
intent.setClass(context, service)
} else {
//不同APP之间进行通信
intent.setPackage(pkgName)
intent.setAction(action)
}
//绑定服务
context.bindService(intent, IpcServiceConnection(service), Context.BIND_AUTO_CREATE)
}
inner class IpcServiceConnection(val simpleService: Class<out IPCService>) : ServiceConnection {
override fun onServiceConnected(name: ComponentName?, service: IBinder?) {
val mService = IIPCServiceInterface.Stub.asInterface(service) as IIPCServiceInterface
binders[simpleService] = mService
}
override fun onServiceDisconnected(name: ComponentName?) {
//断连之后,直接移除即可
binders.remove(simpleService)
}
}对于绑定服务这块,相信伙伴们也很熟悉了,这个需要说一点的就是,在Android 5.0以后,启动服务不能只依赖action启动,还需要指定应用包名,否则就会报错。
在服务连接成功之后,即回调onServiceConnected方法的时候,需要拿到服务端的一个代理对象,即IIPCServiceInterface的实例对象,然后存储在binders集合中,key为绑定的服务类class对象,value就是对应的服务端的代理对象。
fun send(
type: Int,
service: Class<out IPCService>,
serviceId: String,
methodName: String,
params: Array<Parameters>
): Response? {
//创建请求
val request = Request(type, serviceId, methodName, params)
//发起请求
return try {
binders[service]?.send(request)
} catch (e: Exception) {
null
}
}当拿到服务端的代理对象之后,就可以在客户端调用send方法向服务端发送消息。
class Channel {
//====================================
/**每个服务对应的Binder对象*/
private val binders: ConcurrentHashMap<Class<out IPCService>, IIPCServiceInterface> by lazy {
ConcurrentHashMap()
}
//====================================
/**
* 绑定服务
*
*/
fun connect(
context: Context,
pkgName: String,
action: String = "",
service: Class<out IPCService>
) {
val intent = Intent()
if (pkgName.isEmpty()) {
intent.setClass(context, service)
} else {
intent.setPackage(pkgName)
intent.setAction(action)
intent.setClass(context, service)
}
//绑定服务
context.bindService(intent, IpcServiceConnection(service), Context.BIND_AUTO_CREATE)
}
inner class IpcServiceConnection(val simpleService: Class<out IPCService>) : ServiceConnection {
override fun onServiceConnected(name: ComponentName?, service: IBinder?) {
val mService = IIPCServiceInterface.Stub.asInterface(service) as IIPCServiceInterface
binders[simpleService] = mService
}
override fun onServiceDisconnected(name: ComponentName?) {
//断连之后,直接移除即可
binders.remove(simpleService)
}
}
fun send(
type: Int,
service: Class<out IPCService>,
serviceId: String,
methodName: String,
params: Array<Parameters>
): Response? {
//创建请求
val request = Request(type, serviceId, methodName, params)
//发起请求
return try {
binders[service]?.send(request)
} catch (e: Exception) {
null
}
}
companion object {
private val instance by lazy {
Channel()
}
/**
* 获取单例对象
*/
fun getDefault(): Channel {
return instance
}
}
}3.2 动态代理获取接口实例
回到1.2小节中,我们定义了一个IUserManager接口,通过前面我们定义的通信协议,只要我们获取了IUserManager的实例对象,那么就能够调用其中的任意普通方法,所以在客户端需要设置一个获取接口实例对象的方法。
fun <T> getInstanceWithName(
service: Class<out IPCService>,
classType: Class<T>,
clazz: Class<*>,
methodName: String,
params: Array<Parameters>
): T? {
//获取serviceId
val serviceId = clazz.getAnnotation(ServiceId::class.java)
val response = Channel.getDefault()
.send(REQUEST.GET_INSTANCE.ordinal, service, serviceId.name, methodName, params)
Log.e("TAG", "response $response")
if (response != null && response.result) {
//请求成功,返回接口实例对象
return Proxy.newProxyInstance(
classType.classLoader,
arrayOf(classType),
IPCInvocationHandler()
) as T
}
return null
}当我们通过客户端发送一个获取单例的请求后,如果成功了,那么就直接返回这个接口的单例对象,这里直接使用动态代理的方式返回一个接口实例对象,那么后续执行这个接口的方法时,会直接走到IPCInvocationHandler的invoke方法中。
class IPCInvocationHandler(
val service: Class<out IPCService>,
val serviceId: String?
) : InvocationHandler {
private val gson = Gson()
override fun invoke(proxy: Any?, method: Method?, args: Array<out Any>?): Any? {
//执行客户端发送方法请求
val response = Channel.getDefault()
.send(
REQUEST.INVOKE_METHOD.ordinal,
service,
serviceId,
method?.name ?: "",
args
)
//拿到服务端返回的结果
if (response != null && response.result) {
//反序列化得到结果
return gson.fromJson(response.value, method?.returnType)
}
return null
}
}因为服务端在拿到Method的返回结果时,将javabean转换为了json字符串,因此在IPCInvocationHandler中,当调用接口中方法获取结果之后,用Gson将json转换为javabean对象,那么就直接获取到了结果。
3.3 框架使用
服务端:
UserManager2.getDefault().setUserInfo(User("ming", 25))
IPC.register(UserManager2::class.java)同时在服务端需要注册一个IPCService的实例,这里用的是IPCService01
<service
android:name=".UserService"
android:enabled="true"
android:exported="true" />
<service
android:name="com.lay.ipc.service.IPCService01"
android:enabled="true"
android:exported="true">
<intent-filter>
<action android:name="android.intent.action.GET_USER_INFO" />
</intent-filter>
</service>客户端:
调用connect方法,需要绑定服务端的服务,传入包名和action
IPC.connect(
this,
"com.lay.learn.asm",
"android.intent.action.GET_USER_INFO",
IPCService01::class.java
)首先获取IUserManager的实例,注意这里要和服务端注册的UserManager2是同一个ServiceId,而且接口、javabean需要存放在与服务端一样的文件夹下。
val userManager = IPC.getInstanceWithName(
IPCService01::class.java,
IUserManager::class.java,
"getDefault",
null
)
val info = userManager?.getUserInfo()通过动态代理拿到接口的实例对象,只要调用接口中的方法,就会进入到InvocationHandler中的invoke方法,在这个方法中,通过查找服务端注册的方法名从而找到对应的Method,通过反射调用拿到UserManager中的方法返回值。
这样其实就通过5-6行代码,就完成了进程间通信,是不是比我们在使用AIDL的时候要方便地许多。
4 总结
如果我们面对下面这个类,如果这个类是个私有类,外部没法调用,想通过反射的方式调用其中某个方法。
@ServiceId(name = "UserManagerService")
public class UserManager2 implements IUserManager {
private static UserManager2 userManager2 = new UserManager2();
public static UserManager2 getDefault() {
return userManager2;
}
private User user;
@Nullable
@Override
public User getUserInfo() {
return user;
}
@Override
public void setUserInfo(@NonNull User user) {
this.user = user;
}
@Override
public int getUserId() {
return 0;
}
@Override
public void setUserId(int id) {
}
}那么我们可以这样做:
val method = UserManager2::class.java.getDeclaredMethod("getUserInfo")
method.isAccessible = true
method.invoke(this,params)其实这个框架的原理就是上面这几行代码所能够完成的事;通过服务端注册的形式,将UserManager2中所有的方法Method收集起来;当另一个进程,也就是客户端想要调用其中某个方法的时候,通过方法名来获取到对应的Method,调用这个方法得到最终的返回值。
作者:layz4android
来源:juejin.cn/post/7192465342159912997
Android进阶宝典 -- 告别繁琐的AIDL吧,手写IPC通信框架,5行代码实现进程间通信(上)
对于进程间通信,很多项目中可能根本没有涉及到多进程,很多公司的app可能就一个主进程,但是对于进程间通信,我们也是必须要了解的。
如果在Android中想要实现进程间通信,有哪些方式呢?
(1)发广播(sendBroadcast):e.g. 两个app之间需要通信,那么可以通过发送广播的形式进行通信,如果只想单点通信,可以指定包名。但是这种方式存在的弊端在于发送方无法判断接收方是否接收到了广播,类似于UDP的通信形式,而且存在丢数据的形式;
(2)Socket通信:这种属于Linux层面的进程间通信了,除此之外,还包括管道、信号量等,像传统的IPC进程间通信需要数据二次拷贝,这种效率是最低的;
(3)AIDL通信:这种算是Android当中主流的进程间通信方案,通过Service + Binder的形式进行通信,具备实时性而且能够通过回调得知接收方是否收到数据,弊端在于需要管理维护aidl接口,如果不同业务方需要使用不同的aidl接口,维护的成本会越来越高。
那么本篇文章并不是说完全丢弃掉AIDL,它依然不失为一个很好的进程间通信的手段,只是我会封装一个适用于任意业务场景的IPC进程间通讯框架,这个也是我在自己的项目中使用到的,不需要维护很多的AIDL接口文件。
有需要源码的伙伴,可以去我的github首页获取 FastIPC源码地址,分支:feature/v0.0.1-snapshot,有帮助的话麻烦给点个star⭐️⭐️⭐️
1 服务端 - register
首先这里先说明一下,就是对于传统的AIDL使用方式,这里就不再过多介绍了,这部分还是比较简单的,有兴趣的伙伴们可以去前面的文章中查看,本文将着重介绍框架层面的逻辑。
那么IPC进程间通信,需要两个端:客户端和服务端。服务端会提供一个注册方法,例如客户端定义的一些服务,通过向服务端注册来做一个备份,当客户端调用服务端某个方法的时候来返回值。
object IPC {
//==========================================
/**
* 服务端暴露的接口,用于注册服务使用
*/
fun register(service: Class<*>) {
Registry.instance.register(service)
}
}其实在注册的时候,我们的目的肯定是能够方便地拿到某个服务,并且能够调用这个服务提供的方法,拿到我想要的值;所以在定义服务的时候,需要注意以下两点:
(1)需要定义一个与当前服务一一对应的serviceId,通过serviceId来获取服务的实例;
(2)每个服务当中定义的方法同样需要对应起来,以便拿到服务对象之后,通过反射调用其中的方法。
所以在注册的时候,需要从这两点入手。
1.1 定义服务唯一标识serviceId
@Target(AnnotationTarget.TYPE)
@Retention(AnnotationRetention.RUNTIME)
annotation class ServiceId(
val name: String
)一般来说,如果涉及到反射,最常用的就是通过注解给Class做标记,因为通过反射能够拿到类上标记的注解,就能够拿到对应的serviceId。
class Registry {
//=======================================
/**用于存储 serviceId 对应的服务 class对象*/
private val serviceMaps: ConcurrentHashMap<String, Class<*>> by lazy {
ConcurrentHashMap()
}
/**用于存储 服务中全部的方法*/
private val methodsMap: ConcurrentHashMap<Class<*>, ConcurrentHashMap<String, Method>> by lazy {
ConcurrentHashMap()
}
//=======================================
/**
* 服务端注册方法
* @param service 服务class对象
*/
fun register(service: Class<*>) {
// 获取serviceId与服务一一对应
val serviceIdAnnotation = service.getAnnotation(ServiceId::class.java)
?: throw IllegalArgumentException("只有标记@ServiceId的服务才能够被注册")
//获取serviceId
val name = serviceIdAnnotation.name
serviceMaps[name] = service
//temp array
val methods: ConcurrentHashMap<String, Method> = ConcurrentHashMap()
// 获取服务当中的全部方法
for (method in service.declaredMethods) {
//这里需要注意,因为方法中存在重载方法,所以不能把方法名当做key,需要加上参数
val buffer = StringBuffer()
buffer.append(method.name).append("(")
val params = method.parameterTypes
if (params.size > 0) {
buffer.append(params[0].name)
}
for (index in 1 until params.size) {
buffer.append(",").append(params[index].name)
}
buffer.append(")")
//保存
methods[buffer.toString()] = method
}
//存入方法表
methodsMap[service] = methods
}
companion object {
val instance by lazy { Registry() }
}
}通过上面的register方法,当传入定义的服务class对象的时候,首先获取到服务上标记的@ServiceId注解,注意这里如果要注册必须标记,否则直接抛异常;拿到serviceId之后,存入到serviceMaps中。
然后需要获取服务中的全部方法,因为考虑到重载方法的存在,所以不能单单以方法名作为key,而是需要把参数也加上,因此这里做了一个逻辑就是将方法名与参数名组合一个key,存入到方法表中。
这样注册任务就完成了,其实还是比较简单的,关键在于完成2个表:服务表和方法表的初始化以及数据存储功能。
1.2 使用方式
@ServiceId("UserManagerService")
interface IUserManager {
fun getUserInfo(): User?
fun setUserInfo(user: User)
fun getUserId(): Int
fun setUserId(id: Int)
}假设项目中有一个用户信息管理的服务,这个服务用于给所有的App提供用户信息查询。
@ServiceId("UserManagerService")
class UserManager : IUserManager {
private var user: User? = null
private var userId: Int = 0
override fun getUserInfo(): User? {
return user
}
override fun setUserInfo(user: User) {
this.user = user
}
override fun getUserId(): Int {
return userId
}
override fun setUserId(id: Int) {
this.userId = id
}
}用户中心可以注册这个服务,并且调用setUserInfo方法保存用户信息,那么其他App(客户端)连接这个服务之后,就可以调用getUserInfo这个方法,获取用户信息,从而完成进程间通信。
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: entrySet key class com.lay.learn.asm.binder.UserManager
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue key setUserInfo(com.lay.learn.asm.binder.User)
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue value public void com.lay.learn.asm.binder.UserManager.setUserInfo(com.lay.learn.asm.binder.User)
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue key getUserInfo()
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue value public com.lay.learn.asm.binder.User com.lay.learn.asm.binder.UserManager.getUserInfo()
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue key getUserId()
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue value public int com.lay.learn.asm.binder.UserManager.getUserId()
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue key setUserId(int)
2023-01-23 22:15:54.729 13361-13361/com.lay.learn.asm E/TAG: mapValue value public void com.lay.learn.asm.binder.UserManager.setUserId(int)我们看调用register方法之后,每个方法的key值都是跟参数绑定在一起,这样服务端注册就完成了。
2 客户端与服务端的通信协议
对于客户端的连接,其实就是绑定服务,那么这里就会使用到AIDL通信,但是跟传统的相比,我们是将AIDL封装到框架层内部,对于用户来说是无感知的。
2.1 创建IPCService
这个服务就是用来完成进程间通信的,客户端需要与这个服务建立连接,通过服务端分发消息,或者接收客户端发送来的消息。
abstract class IPCService : Service() {
override fun onBind(intent: Intent?): IBinder? {
return null
}
}这里我定义了一个抽象的Service基类,为啥要这么做,前面我们提到过是因为整个项目中不可能只有一个服务,因为业务众多,为了保证单一职责,需要划分不同的类型,所以在框架中会衍生多个实现类,不同业务方可以注册这些服务,当然也可以自定义服务继承IPCService。
class IPCService01 : IPCService() {
}在IPCService的onBind需要返回一个Binder对象,因此需要创建aidl文件。
2.2 定义通讯协议
像我们在请求接口的时候,通常也是向服务端发起一个请求(Request),然后得到服务端的一个响应(Response),因此在IPC通信的的时候,也可以根据这种方式建立通信协议。
data class Request(
val type: Int,
val serviceId: String?,
val methodName: String?,
val params: Array<Parameters>?
) : Parcelable {
//=====================================
/**请求类型*/
//获取实例的对象
val GET_INSTANCE = "getInstance"
//执行方法
val INVOKE_METHOD = "invokeMethod"
//=======================================
constructor(parcel: Parcel) : this(
parcel.readInt(),
parcel.readString(),
parcel.readString(),
parcel.createTypedArray(Parameters.CREATOR)
)
override fun writeToParcel(parcel: Parcel, flags: Int) {
parcel.writeInt(type)
parcel.writeString(serviceId)
parcel.writeString(methodName)
}
override fun describeContents(): Int {
return 0
}
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (javaClass != other?.javaClass) return false
other as Request
if (type != other.type) return false
if (serviceId != other.serviceId) return false
if (methodName != other.methodName) return false
if (params != null) {
if (other.params == null) return false
if (!params.contentEquals(other.params)) return false
} else if (other.params != null) return false
return true
}
override fun hashCode(): Int {
var result = type
result = 31 * result + (serviceId?.hashCode() ?: 0)
result = 31 * result + (methodName?.hashCode() ?: 0)
result = 31 * result + (params?.contentHashCode() ?: 0)
return result
}
companion object CREATOR : Parcelable.Creator<Request> {
override fun createFromParcel(parcel: Parcel): Request {
return Request(parcel)
}
override fun newArray(size: Int): Array<Request?> {
return arrayOfNulls(size)
}
}
}对于客户端来说,致力于发起请求,请求实体类Request参数介绍如下:
type表示请求的类型,包括两种分别是:执行静态方法和执行普通方法(考虑到反射传参);
serviceId表示请求的服务id,要请求哪个服务,便可以获取到这个服务的实例对象,调用服务中提供的方法;
methodName表示要请求的方法名,也是在serviceId服务中定义的方法;
params表示请求的方法参数集合,我们在服务端注册的时候,方法名 + 参数名 作为key,因此需要知道请求的方法参数,以便获取到Method对象。
data class Response(
val value:String?,
val result:Boolean
):Parcelable {
@SuppressLint("NewApi")
constructor(parcel: Parcel) : this(
parcel.readString(),
parcel.readBoolean()
)
override fun writeToParcel(parcel: Parcel, flags: Int) {
parcel.writeString(value)
parcel.writeByte(if (result) 1 else 0)
}
override fun describeContents(): Int {
return 0
}
companion object CREATOR : Parcelable.Creator<Response> {
override fun createFromParcel(parcel: Parcel): Response {
return Response(parcel)
}
override fun newArray(size: Int): Array<Response?> {
return arrayOfNulls(size)
}
}
}对于服务端来说,在接收到请求之后,需要针对具体的请求返回相应的结果,Response实体类参数介绍:
result表示请求成功或者失败;
value表示服务端返回的结果,是一个json字符串。
因此定义aidl接口文件如下,输入一个请求之后,返回一个服务端的响应。
interface IIPCServiceInterface {
Response send(in Request request);
}这样IPCService就可以将aidl生成的Stub类作为Binder对象返回。
abstract class IPCService : Service() {
override fun onBind(intent: Intent?): IBinder? {
return BINDERS
}
companion object BINDERS : IIPCServiceInterface.Stub() {
override fun send(request: Request?): Response? {
when(request?.type){
REQUEST.GET_INSTANCE.ordinal->{
}
REQUEST.INVOKE_METHOD.ordinal->{
}
}
return null
}
}
}续:Android进阶宝典 -- 告别繁琐的AIDL吧,手写IPC通信框架,5行代码实现进程间通信(下)
作者:layz4android
来源:juejin.cn/post/7192465342159912997
收起阅读 »高仿B站自定义表情
在之前的文章给你的 Android App 添加自定义表情中我们介绍了自定义表情的原理,没看过的建议看一下。这一篇文章将介绍它的应用,这里以B站的自定义表情面板为例,效果如下:
自定义表情的大小
当我们写死表情的大小时,文字的 textSize 变大变小时都会有一点问题。
文字大于图片大小时,在多行的情况下,只有表情的行间距明显小于其他行的间距。如图:
为什么会出现这种情况呢?如下图所示,我在top, ascent, baseline, descent, bottom的位置标注了辅助线。
可以很清晰的看到,在只有表情的情况下,top, ascent, descent, bottom的位置有明显的问题。原因是 DynamicDrawableSpan 的 getSize 方法里面对 FontMetricsInt 进行了修改。解决的方式很简单,就是注释掉修改代码就行,代码如下。修改后,效果如下图所示。
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
Rect rect = d.getBounds();
//
// if (fm != null) {
// fm.ascent = -rect.bottom;
// fm.descent = 0;
//
// fm.top = fm.ascent;
// fm.bottom = 0;
// }
return rect.right;
}不知道你还记不记得,我们说过getSize 的返回值是表情的宽度。上面的注释代码其实是设置了表情的高度,如果文本的大小少于表情时,就会显示不全,如下图所示:
那这种情况下,应该怎么办?这里不卖关子了,最终代码如下。解决方式非常简单就是分情况来判断。当文本的高度小于表情的高度时,设置 fm 的top, ascent, descent, bottom的值,让行的高度变大的同时让大的 emoji 图片居中。
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
Rect rect = d.getBounds();
float drawableHeight = rect.height();
Paint.FontMetrics paintFm = paint.getFontMetrics();
if (fm != null) {
int textHeight = fm.bottom - fm.top;
if(textHeight <= drawableHeight) {//当文本的高度小于表情的高度时
//解决文字的大小小于图片大小的情况
float textCenter = (paintFm.descent + paintFm.ascent) / 2;
fm.ascent = fm.top = (int) (textCenter - drawableHeight / 2);
fm.descent = fm.bottom = (int) (textCenter + drawableHeight / 2);
}
}
return rect.right;
}当然,你可能发现了,B站的 emoji 表情好像不是居中的。如下图所示,B站对 emoji 表情的处理类似基于 baseline 对齐。
上面最难理解的居中已经介绍,对于其他方式比如 baseline 和 bottom 就简单了。完整代码如下:
@Override
public int getSize(@NonNull Paint paint, CharSequence text, int start, int end, @Nullable FontMetricsInt fm) {
Drawable d = getDrawable();
if(d == null) {
return 48;
}
Rect rect = d.getBounds();
float drawableHeight = rect.height();
Paint.FontMetrics paintFm = paint.getFontMetrics();
if (fm != null) {
if (mVerticalAlignment == ALIGN_BASELINE) {
fm.ascent = fm.top = (int) (paintFm.bottom - drawableHeight);
fm.bottom = (int) (paintFm.bottom);
fm.descent = (int) paintFm.descent;
} else if(mVerticalAlignment == ALIGN_BOTTOM) {
fm.ascent = fm.top = (int) (paintFm.bottom - drawableHeight);
fm.bottom = (int) (paintFm.bottom);
fm.descent = (int) paintFm.descent;
} else if (mVerticalAlignment == ALIGN_CENTER) {
int textHeight = fm.bottom - fm.top;
if(textHeight <= rect.height()) {
float textCenter = (paintFm.descent + paintFm.ascent) / 2;
fm.ascent = fm.top = (int) (textCenter - drawableHeight / 2);
fm.descent = fm.bottom = (int) (textCenter + drawableHeight / 2);
}
}
}
return rect.right;
}动态表情
动态表情实际上就是 gif 图。我们可以使用 android-gif-drawable 来实现。在 build.gradle 中增加依赖:
dependencies {
...
implementation 'pl.droidsonroids.gif:android-gif-drawable:1.2.25'
}然后在我们创建自定义 ImageSpan 的时候传入参数就可以了:
val size = 192
val gifFromResource = GifDrawable(getResources(), gifData.drawableResource)
gifFromResource.stop()
gifFromResource.setBounds(0,0, size, size)
val content = mBinding.editContent.text as SpannableStringBuilder
val stringBuilder = SpannableStringBuilder(gifData.text)
stringBuilder.setSpan(BilibiliEmojiSpan(gifFromResource, ALIGN_BASELINE),
0, stringBuilder.length, Spannable.SPAN_EXCLUSIVE_EXCLUSIVE)关于 android-gif-drawable 更具体用法可以看 Android加载Gif动画android-gif-drawable的使用
作者:小墙程序员
来源:juejin.cn/post/7196592276159823931
收起阅读 »android 微信抢红包工具 AccessibilityService
1、目标
使用AccessibilityService的方式,实现微信自动抢红包(吐槽一下,网上找了许多文档,由于各种原因,无法实现对应效果,所以先给自己整理下),关于AccessibilityService的文章,网上有很多(没错,多的都懒得贴链接那种多),可自行查找。
2、实现流程
1、流程分析(这里只分析在桌面的情况)
我们把一个抢红包发的过程拆分来看,可以分为几个步骤:
收到通知 -> 点击通知栏 -> 点击红包 -> 点击开红包 -> 退出红包详情页
以上是一个抢红包的基本流程。
2、实现步骤
1、收到通知 以及 点击通知栏
接收通知栏的消息,介绍两种方式
Ⅰ、AccessibilityService
即通过AccessibilityService的AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED事件来获取到Notification
private fun handleNotification(event: AccessibilityEvent) {
val texts = event.text
if (!texts.isEmpty()) {
for (text in texts) {
val content = text.toString()
//如果微信红包的提示信息,则模拟点击进入相应的聊天窗口
if (content.contains("[微信红包]")) {
if (event.parcelableData != null && event.parcelableData is Notification) {
val notification: Notification? = event.parcelableData as Notification?
val pendingIntent: PendingIntent = notification!!.contentIntent
try {
pendingIntent.send()
} catch (e: CanceledException) {
e.printStackTrace()
}
}
}
}
}
}Ⅱ、NotificationListenerService
这是监听通知栏的另一种方式,记得要获取权限哦
class MyNotificationListenerService : NotificationListenerService() {
override fun onNotificationPosted(sbn: StatusBarNotification?) {
super.onNotificationPosted(sbn)
val extras = sbn?.notification?.extras
// 获取接收消息APP的包名
val notificationPkg = sbn?.packageName
// 获取接收消息的抬头
val notificationTitle = extras?.getString(Notification.EXTRA_TITLE)
// 获取接收消息的内容
val notificationText = extras?.getString(Notification.EXTRA_TEXT)
if (notificationPkg != null) {
Log.d("收到的消息内容包名:", notificationPkg)
if (notificationPkg == "com.tencent.mm"){
if (notificationText?.contains("[微信红包]") == true){
//收到微信红包了
val intent = sbn.notification.contentIntent
intent.send()
}
}
}
Log.d("收到的消息内容", "Notification posted $notificationTitle & $notificationText")
}
override fun onNotificationRemoved(sbn: StatusBarNotification?) {
super.onNotificationRemoved(sbn)
}
}2、点击红包
通过上述的跳转,可以进入聊天详情页面,到达详情页之后,接下来就是点击对应的红包卡片,那么问题来了,怎么点?肯定不是手动点。。。
我们来分析一下,一个聊天列表中,我们怎样才能识别到红包卡片,我看网上有通过findAccessibilityNodeInfosByViewId来获取对应的View,这个也可以,只是我们获取id的方式需要借助工具,可以用Android Device Monitor,但是这玩意早就废废弃了,虽然在sdk的目录下存在monitor,奈何本人太菜,点击就是打不开
我本地的jdk是11,我怀疑是不兼容,毕竟Android Device Monitor太老了。换新的layout Inspector,也就看看本地的debug应用,无法查看微信的呀。要么就反编译,这个就先不考虑了,换findAccessibilityNodeInfosByText这个方法试试。
这个方法从字面意思能看出来,是通过text来匹配的,我们可以知道红包卡片上面是有“微信红包”的固定字样的,是不是可以通股票这个来匹配呢,这还有个其他问题,并不是所有的红包都需要点,比如已过期,已领取的是不是要过滤下,咋一看挺好过滤的,一个循环就好,仔细想,这是棵树,不太好剔除,所以换了个思路。
最终方案就是递归一棵树,往一个列表里面塞值,“已过期”和“已领取”的塞一个字符串“#”,匹配到“微信红包”的塞一个AccessibilityNodeInfo,这样如果这个红包不能抢,那肯定一前一后分别是一个字符串和一个AccessibilityNodeInfo,因此,我们读到一个AccessibilityNodeInfo,并且前一个值不是字符串,就可以执行点击事件,代码如下
private fun getPacket() {
val rootNode = rootInActiveWindow
val caches:ArrayList<Any> = ArrayList()
recycle(rootNode,caches)
if(caches.isNotEmpty()){
for(index in 0 until caches.size){
if(caches[index] is AccessibilityNodeInfo && (index == 0 || caches[index-1] !is String )){
val node = caches[index] as AccessibilityNodeInfo
var parent = node.parent
while (parent != null) {
if (parent.isClickable) {
parent.performAction(AccessibilityNodeInfo.ACTION_CLICK)
break
}
parent = parent.parent
}
break
}
}
}
}
private fun recycle(node: AccessibilityNodeInfo,caches:ArrayList<Any>) {
if (node.childCount == 0) {
if (node.text != null) {
if ("已过期" == node.text.toString() || "已被领完" == node.text.toString() || "已领取" == node.text.toString()) {
caches.add("#")
}
if ("微信红包" == node.text.toString()) {
caches.add(node)
}
}
} else {
for (i in 0 until node.childCount) {
if (node.getChild(i) != null) {
recycle(node.getChild(i),caches)
}
}
}
}以上只点击了第一个能点击的红包卡片,想点击所有的可另行处理。
3、点击开红包
这里思路跟上面类似,开红包页面比较简单,但是奈何开红包是个按钮,在不知道id的前提下,我们也不知道则呢么获取它,所以采用迂回套路,找固定的东西,我这里发现每个开红包的页面都有个“xxx的红包”文案,然后这个页面比较简单,只有个关闭,和开红包,我们通过获取“xxx的红包”对应的View来获取父View,然后递归子View,判断可点击的,执行点击事件不就可以了吗
private fun openPacket() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
for ( i in 0 until list.size) {
val parent = list[i].parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}4、退出红包详情页
这里回退也是个按钮,我们也不知道id,所以可以跟点开红包一样,迂回套路,获取其他的View,来获取父布局,然后递归子布局,依次执行点击事件,当然关闭事件是在前面的,也就是说关闭会优先执行到
private fun close() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
if (list.isNotEmpty()) {
val parent = list[0].parent.parent.parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}3、遇到问题
1、AccessibilityService收不到AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED事件
android碎片问题很正常,我这边是使用NotificationListenerService来替代的。
2、需要点击View的定位
简单是就是到页面应该点哪个View,找到相应的规则,来过滤出对应的View,这个规则是随着微信的改变而变化的,findAccessibilityNodeInfosByViewId最直接,但是奈何工具问题,有点麻烦,于是采用取巧的办法,通过找到其他View来定位自身
4、完整代码
MyNotificationListenerService
class MyNotificationListenerService : NotificationListenerService() {
override fun onNotificationPosted(sbn: StatusBarNotification?) {
super.onNotificationPosted(sbn)
val extras = sbn?.notification?.extras
// 获取接收消息APP的包名
val notificationPkg = sbn?.packageName
// 获取接收消息的抬头
val notificationTitle = extras?.getString(Notification.EXTRA_TITLE)
// 获取接收消息的内容
val notificationText = extras?.getString(Notification.EXTRA_TEXT)
if (notificationPkg != null) {
Log.d("收到的消息内容包名:", notificationPkg)
if (notificationPkg == "com.tencent.mm"){
if (notificationText?.contains("[微信红包]") == true){
//收到微信红包了
val intent = sbn.notification.contentIntent
intent.send()
}
}
} Log.d("收到的消息内容", "Notification posted $notificationTitle & $notificationText")
}
override fun onNotificationRemoved(sbn: StatusBarNotification?) {
super.onNotificationRemoved(sbn)
}
}MyAccessibilityService
class RobService : AccessibilityService() {
override fun onAccessibilityEvent(event: AccessibilityEvent) {
val eventType = event.eventType
when (eventType) {
AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED -> handleNotification(event)
AccessibilityEvent.TYPE_WINDOW_STATE_CHANGED, AccessibilityEvent.TYPE_WINDOW_CONTENT_CHANGED -> {
val className = event.className.toString()
Log.e("测试无障碍",className)
if (className == "com.tencent.mm.ui.LauncherUI") {
getPacket()
} else if (className == "com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyReceiveUI") {
openPacket()
} else if (className == "com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyNotHookReceiveUI") {
openPacket()
} else if (className == "com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyDetailUI") {
close()
}
}
}
}
/**
* 处理通知栏信息
*
* 如果是微信红包的提示信息,则模拟点击
*
* @param event
*/
private fun handleNotification(event: AccessibilityEvent) {
val texts = event.text
if (!texts.isEmpty()) {
for (text in texts) {
val content = text.toString()
//如果微信红包的提示信息,则模拟点击进入相应的聊天窗口
if (content.contains("[微信红包]")) {
if (event.parcelableData != null && event.parcelableData is Notification) {
val notification: Notification? = event.parcelableData as Notification?
val pendingIntent: PendingIntent = notification!!.contentIntent
try {
pendingIntent.send()
} catch (e: CanceledException) {
e.printStackTrace()
}
}
}
}
}
}
/**
* 关闭红包详情界面,实现自动返回聊天窗口
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR2)
private fun close() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
if (list.isNotEmpty()) {
val parent = list[0].parent.parent.parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}
/**
* 模拟点击,拆开红包
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR2)
private fun openPacket() {
Log.e("测试无障碍","点击红包")
Thread.sleep(100)
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
for ( i in 0 until list.size) {
val parent = list[i].parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
Log.e("测试无障碍","点击红包成功")
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}
/**
* 模拟点击,打开抢红包界面
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN)
private fun getPacket() {
Log.e("测试无障碍","获取红包")
val rootNode = rootInActiveWindow
val caches:ArrayList<Any> = ArrayList()
recycle(rootNode,caches)
if(caches.isNotEmpty()){
for(index in 0 until caches.size){
if(caches[index] is AccessibilityNodeInfo && (index == 0 || caches[index-1] !is String )){
val node = caches[index] as AccessibilityNodeInfo
// node.performAction(AccessibilityNodeInfo.ACTION_CLICK)
var parent = node.parent
while (parent != null) {
if (parent.isClickable) {
parent.performAction(AccessibilityNodeInfo.ACTION_CLICK)
Log.e("测试无障碍","获取红包成功")
break
}
parent = parent.parent
}
break
}
}
}
}
/**
* 递归查找当前聊天窗口中的红包信息
*
* 聊天窗口中的红包都存在"微信红包"一词,因此可根据该词查找红包
*
* @param node
*/
private fun recycle(node: AccessibilityNodeInfo,caches:ArrayList<Any>) {
if (node.childCount == 0) {
if (node.text != null) {
if ("已过期" == node.text.toString() || "已被领完" == node.text.toString() || "已领取" == node.text.toString()) {
caches.add("#")
}
if ("微信红包" == node.text.toString()) {
caches.add(node)
}
}
} else {
for (i in 0 until node.childCount) {
if (node.getChild(i) != null) {
recycle(node.getChild(i),caches)
}
}
}
}
override fun onInterrupt() {}
override fun onServiceConnected() {
super.onServiceConnected()
Log.e("测试无障碍id","启动")
val info: AccessibilityServiceInfo = serviceInfo
info.packageNames = arrayOf("com.tencent.mm")
serviceInfo = info
}
}5、总结
此文是对AccessibilityService的使用的一个梳理,这个功能其实不麻烦,主要是一些细节问题,像自动领取支付宝红包,自动领取QQ红包或者其他功能等也都可以用类似方法实现。
链接:https://juejin.cn/post/7196949524061339703
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
APT-单例代码规范检查
前文提到注解按照Retention可以取值可以分为SOURCE,CLASS,RUNTIME三类,在定义注解完成后,可以结合APT进行注解解析,读取到注解相关信息后进行一些检查和设置。
接下来我们实现一个单例注解来修饰单例类,当开发人员写的单例类不符合编码规范时,在编译过程中抛出异常。大家都知道,单例类应该具有以下特点:
- 构造器私有
- 具有public static修饰的getInstance方法
打开Android Studio,新建SingletonAnnotationDemo工程,随后在该工程中进行注解的定义和APT的开发,一般情况下注解和与之关联的APT都会以单独的Module声明在项目中,下面我们开始实践吧。
singleton-annotation 注解模块
新建singleton-annotation Java模块
打开新建的SingletonAnnotationDemo项目,在右上角切换至Project视图,如下图所示:
切换完成后,在项目名称上右键单击,在弹出的菜单中依此选择new->Module,如下图所示:
选择Module条目后,弹出如下对话框,依次操作如下图所示:
其中标记1表明我们创建的是Java或者Kotlin模块,标记2位置填写模块名称,这里输入singleton-annotation,标记3位置输入打算创建的类名,这里填写Singleton,标记4位置用于选择模块语言类型,这里选择java即可。
至此创建singleton-annotation模块完成,等待Android Studio构建完成即可。
新建Singleton注解
打开新建的singleton-annotation模块,进入Singleton.java文件中将其修改为注解,如上文描述,该注解运行在编译期,故Retention为SOURCE,作用在类上,故其Target取值为TYPE,完整代码如下:
package com.poseidon.singleton_annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Retention(RetentionPolicy.SOURCE)
@Target(ElementType.TYPE)
public @interface Singleton {
}依赖singleton-annotation模块
在app模块添加对singleton-annotation模块的依赖,操作方式有两种:
手动添加singleton-annotation依赖
打开app模块的build.gradle文件,在其内部手动添加依赖,如下所示:
dependencies {
...
// 添加singleton-annotation模块依赖
implementation project(path: ':singleton-annotation')
}
随后重新同步项目即可
使用AS菜单添加singleton-annotation依赖
在app模块右键选择Open Module Settings,在随后弹出的弹窗中添加singleton-annotation模块,操作指导如下图所示:
选择Open Module Settings后弹框如下图所示,选择dependencies,代表依赖管理,随后在右侧的Module列表中选择你要操作的模块,这里选择app,最后点击选择app模块后,其右侧依赖列表中的加号,选择Module Dependency,代表添加模块依赖
Module Dependency:模块依赖,一般用于添加项目中的其他模块作为依赖
Library Dependency:库依赖,一般用于添加上传到maven,google,jcenter等位置的开源库
JAR/AAR Dependency:一般用于添加本地已有的jar或aar文件作为依赖时使用
选择添加模块依赖后,弹出窗体如下图所示:
在上图中标记1的位置勾选要添加的模块,在2的位置选择依赖方式,随后点击OK等待同步完成即可。
singleton-processor 注解处理模块
与创建singleton-annotation模块一样,以相同的方式创建一个名为singleton-processor的模块,其内部有一个Processor类,创建完成后,项目模块如下图所示(Processor类为创建模块时输入的类名,AS自动生成的):
添加注解处理器声明
将Processor.java类作为我们的注解处理器类,为了Android Studio能识别到该类,我们需要对该类进行声明,通常有两种声明方式:
手动声明
手动声明的主要实现方式是在main目录下创建resources/META-INF/services目录,在该目录下创建javax.annotation.processing.Processor文件,其内容如下所示:
com.poseidon.singleton_processor.Processor
可以看到其内部写的是注解处理器类完整路径(包名+类名),当有多个注解处理器类时,可以写多行,每次放置一条注解处理器信息即可
借助AutoService库自动声明
除了手动声明外,我们可以借助auto-service库进行注解处理器声明,其本身也是依赖注解实现,在singleton-processor模块的build.gradle中添加auto-service库依赖,如下所示:
dependencies {
implementation 'com.google.auto.service:auto-service:1.0'
annotationProcessor 'com.google.auto.service:auto-service:1.0'
}
依赖添加完成后,使用@AutoService注解修饰我们的注解处理器类,代码如下:
@AutoService(Processor.class)
public class Processor extends AbstractProcessor {
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
return false;
}
}
随后运行该项目,可以看到在singleton-processor模块的build目录中自动生成了META-INF相关的目录,如下图所示:
其中javax.annotation.processing.Processor文件内容和我们手动添加时的内容一致。
当然也可以参考上文在Library Dependency窗口添加auto-service依赖,大家可以自行探索下
依赖singleton-processor模块
与依赖singleton-annotation模块时方法类似,由于singleton-processor模块是注解处理模块,故依赖方式应使用annotationProcessor,在app模块的build.gradle文件的dependencies块中添加代码如下:
annotationProcessor project(path: ':singleton-processor')
至此我们已经完成了新增模块的依赖以及注解的声明,接下来我们来看看注解处理器的实现。
注解处理器代码实现
在前文中我们已经将singleton-processor模块的Processor类声明为注解处理器,接下来我们来看下如何在注解处理器中处理我们的@Singleton注解,并对使用该注解的单例类完成检查。
自定义注解处理器一般继承自AbstractProcessor,AbstractProcessor是一个抽象类,其父类是Processor,在类编译成.class文件前,遍历整个项目里的所有代码,在获取到对应注解后,回调注解处理器的process方法,以便对注解进行处理。
当继承AbstractProcessor时,我们一般重写下列函数:
| 函数名称 | 函数说明 |
|---|---|
| void init(ProcessingEnvironment processingEnv) | 初始化处理器环境,这里可以缓存处理器环境,在process中发生异常等,可以打断通过缓存的变量打断编译执行 |
| boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) | 处理方法,类或成员等的注释,并返回该处理器的处理结果。 如果返回true ,则表明注解被当前处理器处理,并且不会要求后续处理器继续处理; 如果返回false ,则表示未处理传入的注解,继续传递给后续处理器处理. RoundEnvironment参数用于查找使用了指定注解的元素,这里的元素有多种,方法,成员,类等,和ElementType取值范围一致 |
| Set getSupportedAnnotationTypes() | 获取注解处理器要处理的注解类型,如果在注解处理器类上使用了@SupportedAnnotationTypes注解修饰,则这里返回的Set应和注解取值一致 |
| SourceVersion getSupportedSourceVersion() | 注解处理器支持的Java版本,如果在注解处理器类上使用了@SupportedSourceVersion注解修饰,则这里返回的取值应该和注解取值一致 |
下面我们按照上述描述重写Processor代码如下:
@AutoService(Processor.class)
public class Processor extends AbstractProcessor {
// 注解处理器运行环境
private ProcessingEnvironment mProcessingEnvironment;
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
mProcessingEnvironment = processingEnv;
}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
return false;
}
@Override
public Set<String> getSupportedAnnotationTypes() {
return super.getSupportedAnnotationTypes();
}
@Override
public SourceVersion getSupportedSourceVersion() {
// 支持到最新的java版本
return SourceVersion.latestSupported();
}
}由于该处理器主要处理的是@Singleton注解,故getSupportedAnnotationTypes实现如下(singleton-processor模块依赖singleton-annotation模块):
@Override
public Set<String> getSupportedAnnotationTypes() {
HashSet<String> hashSet = new HashSet<>();
// 添加注解类的完整名称到HashSet中
hashSet.add(Singleton.class.getCanonicalName());
return hashSet;
}随后我们来看下process函数的实现,process内部逻辑实现一般分为三步:
- 获取代码中被使用该注解的所有元素,这里的元素指的是组成程序的元素,可能是程序包,类本身、类的变量、方法等
- 筛选符合要求的元素,根据注解的使用场景筛选第一步中得到的所有元素,比如Singleton这个注解作用于类,就从第一步的结果中筛选出所有的类元素
- 遍历筛选出的元素,按照预设规则进行检查
按照上述步骤实现的Singleton注解处理器的process函数如下所示:
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
// 1.通过RoundEnvironment查找所有使用了Singleton注解的Element
// 2.随后通过ElementFilter获取该元素里面的所有类元素
// 3.遍历所有的类元素,针对自己关注的方法字段进行处理
for (TypeElement typeElement: ElementFilter.typesIn(roundEnvironment.getElementsAnnotatedWith(Singleton.class))) {
// 检查构造函数
if (!checkPrivateConstructor(typeElement)) {
return false;
}
// 检查getInstance方法
if (!checkGetInstanceMethod(typeElement)) {
return false;
}
}
return true;
}
ElementFilter.typesIn就是用来筛选查找出来的结果中的类元素,在ElementFilter类内部定义了五个元素组,如下所示:
- CONSTRUCTOR_KIND:构造器元素组
- FIELD_KINDS:成员变量元素组
- METHOD_KIND:方法元素组
- PACKAGE_KIND:包元素组
- MODULE_KIND:模块元素组
- TYPE_KINDS:类元素组
其中类元素组囊括的最多,包括CLASS,ENUM,INTERFACE等
checkPrivateConstructor
public boolean checkPrivateConstructor(TypeElement typeElement) {
// 通过typeElement.getEnclosedElements()获取在此类或接口中直接声明的字段,方法等元素,随后使用ElementFilter.constructorsIn筛选出构造方法
List<ExecutableElement> constructors = ElementFilter.constructorsIn(typeElement.getEnclosedElements());
for (ExecutableElement constructor : constructors) {
// 判断构造方式是否是Private修饰的
if (constructor.getModifiers().isEmpty() || !constructor.getModifiers().contains(Modifier.PRIVATE)) {
mProcessingEnvironment.getMessager().printMessage(Diagnostic.Kind.ERROR, "constructor of a singleton class must be private", constructor);
return false;
}
}
return true;
}checkPrivateConstructor实现逻辑如上,代码比较简单,不做赘述。
checkGetInstanceMethod
public boolean checkGetInstanceMethod(TypeElement typeElement) {
// 通过ElementFilter.constructorsIn筛选出该类中声明的所有方法
List<ExecutableElement> methods = ElementFilter.methodsIn(typeElement.getEnclosedElements());
for (ExecutableElement method : methods) {
System.out.println(TAG+method.getSimpleName());
// 检查方法名称
if (method.getSimpleName().contentEquals("getInstance")) {
// 检查方法返回类型
if (mProcessingEnvironment.getTypeUtils().isSameType(method.getReturnType(), typeElement.asType())) {
// 检查方法修饰符
if (!method.getModifiers().contains(Modifier.PUBLIC)) {
mProcessingEnvironment.getMessager().printMessage(Diagnostic.Kind.ERROR, "getInstance method should have a public modifier", method);
return false;
}
if (!method.getModifiers().contains(Modifier.STATIC)) {
mProcessingEnvironment.getMessager().printMessage(Diagnostic.Kind.ERROR, "getInstance method should have a static modifier", method);
return false;
}
}
}
}
return true;
}checkGetInstanceMethod实现逻辑如上,可以看出当不满足我们预设条件时会通过printMessage向外抛出异常,中断编译执行。
使用Singleton注解,查看注解处理器效果
在app模块中添加SingleTest.java并应用注解,代码如下:
@Singleton
public class SingletonTest {
private SingletonTest(){}
private static SingletonTest getInstance(){
return new SingletonTest();
}
}可以看到该代码存在问题,我们要求getInstance方法要用public static修饰,这里使用的是private,运行程序,看我们的注解处理器是否能发现该问题并打断程序执行,运行结果如下图:
可以看到程序确实停止运行,并抛出了编译时异常,至此我们自定义编译时注解的操作就学习完了。
扩展
在注解使用方法一节中,我们提到编译时注解即Retention=RetentionPolicy.SOURCE的注解仅在源码中保留,接下来我们验证一下,反编译前文中通过注解处理器检查正常运行的apk,找到SingletonTest类,可以看到在其字节码文件中确实不存在注解代码,如下图所示:
链接:https://juejin.cn/post/7196977951970918460
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter混编工程之异常处理
Flutter App层和Framework层的异常,通常是不会引起Crash的,但是Engine层的异常会造成Crash。而Flutter Engine部分的异常,主要是libfutter.so发生的异常,这部分的异常,在Dart层无法捕获,一般会交给类似Bugly这样的平台来收集。
我们能主动监控的,主要是Dart层的异常,这些异常虽然不会让App crash,但是统计这些异常对于提高我们的用户体验,是非常有必要的。
同步异常与异步异常
对于同步异常来说,直接使用try-catch就可以捕获异常,如果要指定捕获的异常类型,可以使用on关键字。但是,try-catch不能捕获异步异常,就像下面的代码,是无法捕获的。
try {
Future.error("error");
} catch (e){
print(e)
}这和在Java中,try-catch捕获Thread中的异常类似,对于异步异常来说,只能使用Future的catchError或者是onError来捕获异常,代码如下所示。
Future.delayed(Duration(seconds: 1)).then((value) => print(value), onError: (e) {});
Dart的执行队列是一个单线程模型,所以在事件循环队列中,当某个Task发生异常并没有被捕获时,程序并不会退出,只是当前的Task异常中止,也就是说一个Task发生的异常是不会影响其它Task执行的。
Widget Build异常
Widget在Build过程中如果发生异常,例如在build函数中出错(throw exception),我们会看见一个深红色的异常界面,这个就是Flutter自带的异常处理界面,我们来看下源代码中,Flutter对这类异常的处理方式。在ComponentElement的实现中,我们找到performRebuild函数,这个是函数是build时所调用的,我们在这里,可以找到相关的实现。
如下所示,在执行到build()函数如果出错时,就会被catch,从而创建一个ErrorWidget。
再进入_debugReportException中一探究竟,你会发现,应用层的异常被catch之后,都是通过FlutterError.reportError来处理的。
在reportError中,会调用onError来处理,默认的处理方式是dumpErrorToConsole,它就是onError的默认实现。
在这里我们还能发现如何判断debug模式,看源码是不是很有意思。
通过上面的源码,我们就可以了解到,当Flutter应用层崩溃后,SDK的处理,简而言之,就是会构建一个错误界面,同时回调onError函数。在这里,我们可以通过修改这个静态的回调函数,来创建自己的处理方式。
所以,很简单,我们只需要在main()中,执行下面的代码即可。
var defaultError = FlutterError.onError;
FlutterError.onError = (FlutterErrorDetails details) {
defaultError?.call(details);// 根据需要是否要保留default处理
reportException(details);
};defaultError?.call(details)就是默认将异常日志打印到console的方法,如果不用,这里可以去掉。
重写错误界面
前面我们看到了,在源代码中,Flutter自定义了一个ErrorWidget作为默认的异常界面,在平时的开发中,我们可以自定义ErrorWidget.builder,实现一个更友好的错误界面,例如封装一个统一的异常提示界面。
ErrorWidget.builder = (FlutterErrorDetails details) {
return MaterialApp(
theme: ThemeData(primarySwatch: Colors.red),
home: Scaffold(
appBar: AppBar(
title: const Text('出错了,请稍后再试'),
),
body: SingleChildScrollView(
child: Padding(
padding: const EdgeInsets.all(8.0),
child: Text(details.toString()), // 后续修改为统一的错误页
)),
),
);
};如上所示,通过修改ErrorWidget.builder,就可以将任意自定义的界面作为异常界面了。
全局未捕获异常
前面讲到的,都是属于被捕获的异常,而有一些异常,在代码中是没有被捕获的,这就类似Android的UncaughtExceptionHandler,Flutter也提供了一个全局的异常处理钩子函数,所有的未捕获异常,无论是同步异常还是异步异常,都会在这里被监听。
在Dart中,SDK提供了一个Zone的概念,一个Zone就类似一个沙箱,在Zone里面,可以拥有独立的异常处理、print函数等等功能,多个Zone之间是彼此独立的,所以,我们只需要将App运行在一个Zone里面,就可以借助它的handleUncaughtError来处理所有的未捕获异常了。下面是使用Zone的一个简单示例。
void main() {
runZoned(
() => runApp(const MyApp(color: Colors.blue)),
zoneSpecification: ZoneSpecification(
handleUncaughtError: (
Zone self,
ZoneDelegate parent,
Zone zone,
Object error,
StackTrace stackTrace,
) {
reportException(
FlutterErrorDetails(
exception: error,
stack: stackTrace,
),
);
},
),
);
}根据文档中的提升,可以使用runZonedGuarded来进行简化,代码如下所示。
void main() {
runZonedGuarded(
() => runApp(const MyApp(color: Colors.blue)),
(Object error, StackTrace stack) {
reportException(
FlutterErrorDetails(
exception: error,
stack: stack,
),
);
},
);
}封装
下面我们将前面的异常处理方式都合并到一起,并针对EngineGroup的多入口处理,封装一个类,代码如下所示。
class SafeApp {
run(Widget app) {
ErrorWidget.builder = (FlutterErrorDetails details) {
return MaterialApp(
theme: ThemeData(primarySwatch: Colors.red),
home: Scaffold(
appBar: AppBar(
title: const Text('出错了,请稍后再试'),
),
body: SingleChildScrollView(
child: Padding(
padding: const EdgeInsets.all(8.0),
child: Text(details.toString()), // 后续修改为统一的错误页
)),
),
);
};
FlutterError.onError = (FlutterErrorDetails details) {
Zone.current.handleUncaughtError(details.exception, details.stack!);
};
runZonedGuarded(
() => runApp(const MyApp(color: Colors.blue)),
(Object error, StackTrace stack) {
reportException(
FlutterErrorDetails(
exception: error,
stack: stack,
),
);
},
);
}
}在这里,我们构建了下面这些异常处理的方式:
- 统一的异常处理界面
- 将Build异常统一转发到Zone中的异常处理函数来进行处理
- 将所有的未捕获异常记录
这样的话,我们在使用时,只需要对原始的App进行下调用即可。
void main() => SafeApp().run(const MyApp(color: Colors.blue));
这样就完成了异常处理的封装。
上报
在Flutter侧,我们只是获取了异常的相关信息,如果需要上报,那么我们需要借助Channel,桥接的Native,使用Bugly或其它平台进行上报,我们可以借助Pigeon来进行处理,还不熟悉的朋友可以参考我前面的文章。
Flutter混编工程之高速公路Pigeon
Flutter混编工程之通讯之路
通过Channel,我们可以把异常数据报给Native侧,再让Native侧走自己的上报通道,例如Bugly等。
NativeCommonApi().reportException('------Flutter_Exception------\n${details.exceptionAsString()}\n${details.stack.toString()}');
同时,Flutter提供了exceptionAsString()方法,将异常信息展示的更加友好一点,我们可以借助它来做一些格式化的操作。
3.3版本API的改进
官方的API更新如下:
docs.flutter.dev/testing/err…
PlatformDispatcher.onError在以前的版本中,开发者必须手动配置自定义Zone才能捕获应用程序的所有异常和错误,但是自定义Zone对Dart核心库中的一些优化是有害的,这会减慢应用程序的启动时间。「在此版本中,开发者可以通过设置回调来捕获所有错误和异常,而不是使用自定义。」
所以,3.3之后,我们不用再设置Zone来捕获全局异常了,只用设置PlatformDispatcher.instance.onError即可。
import 'package:flutter/material.dart';
import 'dart:ui';
Future<void> main() async {
await myErrorsHandler.initialize();
FlutterError.onError = (details) {
FlutterError.presentError(details);
myErrorsHandler.onErrorDetails(details);
};
PlatformDispatcher.instance.onError = (error, stack) {
myErrorsHandler.onError(error, stack);
return true;
};
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
builder: (context, widget) {
Widget error = const Text('...rendering error...');
if (widget is Scaffold || widget is Navigator) {
error = Scaffold(body: Center(child: error));
}
ErrorWidget.builder = (errorDetails) => error;
if (widget != null) return widget;
throw ('widget is null');
},
);
}
}链接:https://juejin.cn/post/7197116653196689468
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不就是一个空白页,有必要那么讲究吗?
前言
在各类软件应用中,会经常遇到空页面的情况,比如列表无数据、搜不到相应结果、用户数据没有添加等等。这种空页面看似很少出现,但是如果不注意体验的话,会让用户不快甚至是困惑。今天我们就来讲讲针对各类空页面,如何改善用户体验。
列表无数据
页面无数据通常会在列表类页面中出现,最为简单的方式就是用一个空图标+文字说明的方式告诉用户查询的结果为空,比如下面这样。
这是中规中矩的无数据空页面,遇到过奇葩的情况是直接给一个白屏 —— 你这是告诉用户是数据加载不出来呢还是没数据呢?
相比这种静态的空页面,我们可以使用 Lottie 加载一些带动效的无数据指示,会让用户体验好很多。而需要写的代码其实并没有几行。
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: Colors.white,
appBar: AppBar(
title: const Text('抱歉'),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Lottie.asset(
'assets/empty.json',
repeat: true,
width: 200.0,
),
Text(
'暂无数据',
style: TextStyle(
color: Colors.grey[400],
fontSize: 14.0,
),
),
],
),
),
);
}找不到搜索结果
对于搜索,在没有搜到对应的数内容时,相比给一个空页面,给一些用户感兴趣的相似内容可能会更好,一方面可以让用户浏览替代的内容,另一方面可以在一定程度上提高转化率。典型的例子就是在商品搜索的时候,如果没有找到对应的商品,会推荐系统里相关的商品,比如下面是京东的例子。
用户数据没有添加
这是需要用户主动提交才会有数据的情况。糟糕的体验是只告诉用户没有数据,而没有引导用户去添加数据。比如我们的地址管理,我们来看到下面两种体验,一对比高下立现。
第一种一个是添加地址的按钮不够显眼,另外就是在需要用户操作的时候,缺乏引导。这会导致首次使用该功能的用户很迷茫,一时不知道从哪里添加收货地址。相比之下,下面的实现方式按钮位置更明显,而且通过动画能够让用户清楚地知道可以通过点击下面的按钮添加收货地址。
第二种方式实现的代码如下所示,这里的引导动画效果使用了 AnimatedPositioned 组件实现(相关文章可以参考:🚀🚀🚀庆祝神舟十三号发射成功,来一个火箭发射动画)。
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('收货地址'),
),
body: Stack(
children: [
Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.asset('assets/common-empty.png', width: 100.0),
Text(
'暂无收货地址',
style: TextStyle(
color: Colors.grey[400],
fontSize: 16.0,
height: 2,
),
),
],
),
),
AnimatedPositioned(
duration: const Duration(milliseconds: 500),
bottom: _bottom,
height: guideIconSize,
left: MediaQuery.of(context).size.width / 2 - guideIconSize / 2,
onEnd: () {
setState(() {
if (_bottom == minBottom) {
_bottom = maxBottom;
} else {
_bottom = minBottom;
}
});
},
child: Icon(Icons.arrow_downward,
color: Theme.of(context).primaryColor, size: guideIconSize),
)
],
),
bottomSheet: Container(
height: 50.0,
width: MediaQuery.of(context).size.width,
color: Theme.of(context).primaryColor,
margin: const EdgeInsets.all(0.0),
child: TextButton(
onPressed: () {
if (kDebugMode) {
print('跳到添加地址!');
}
},
child: const Text('添加收货地址', style: TextStyle(color: Colors.white)),
),
),
);
}网络连接问题
网络连接偶尔会出现短时间连接断开导致无法加载后端数据的问题,这个时候可不能直接放个网络错误的指示页面就完了,比如下面这样。
动画确实改善了用户体验,但没有解决根本问题。我们来看一下我们自己网络连接有问题的时候的处理步骤:
- 如果手机的网络连接没问题,我们会希望当前页面能够重新加载;
- 如果手机网络有问题,我们可能会切换网络(比如切换到4G 网络),然后还是希望能够重新加载。
这个空页面没有提供重新加载的功能,这意味着用户需要返回到上一个页面,找到之前点击的内容,然后再进入这个页面来达到再次刷新的目的。这额外多了两个步骤,而且还需要用户记住之前点击的内容,体验就不怎么好了。这种情况只需要提供一个重新加载的按钮,体验就会好很多了。
总结
总结一下,如何提高空页面的用户体验,针对我们提到的4种情况有对应的4个原则:
- 对于确实无数据的情况,给出有好的提示,比如实用动画+文字的形式。千万不要认为反正后台有数据,不会出现空页面而什么都不做——结果就是让用户看着白屏一脸懵逼!
- 用户输入的搜索词可能会非常长(比如复制京东的商品名称去淘宝搜),很可能搜不到结果。如果可能,建议对于搜索词长的情况能够匹配一些标签,通过标签搜相关的内容推荐给用户,这比搜不到给一个空白页面的体验会好很多,而且海还会促进应用的内容或商品消费。
- 对于需要用户执行添加动作才会有的数据(比如收货地址、收藏夹、好友等),要给出合理的引导,让用户能够顺利地完成相应的动作,而不是让用户自己摸索。
- 对于因为网络、本机授权等导致出现错误无法加载数据的情况,除了给出友好的提示之外,要同时能够提供类似重新加载的功能,便于用户解决本机问题后,能够回来直接重新加载页面内容。
从心理上来说,人对于空白状态都是有点畏惧的。因此,开发出好的体验的空页面就是需要给用户合理的解释和必要的引导,让空页面不那么空!
链接:https://juejin.cn/post/7167677383628521509
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 通过MotionLayot实现点赞动画
在之前的文章Android 一种点赞动画的实现中,通过Animation和Animator实现了一种点赞动画效果,有知友评论用MotionLayout是否会比较简单。我之前还没有使用过MotionLayout,刚好通过实现这个点赞动画来学习一下MotionLayout的使用。
MotionLayout
MotionLayout是ConstraintLayout的子类,包含在ConstraintLayout库中,在ConstraintLayout的基础上,增加了管理控件动画的功能。
添加库
如果之前没有使用ConstraintLayout,那么需要在app module下的build.gradle中添加代码,如下:
dependencies {
// 项目中使用AndroidX
implementation 'androidx.constraintlayout:constraintlayout:2.0.0-beta1'
// 项目中未使用AndroidX
implementation 'com.android.support.constraint:constraint-layout:2.0.0-beta1'
}点赞效果的实现
尝试使用MotionLayout来实现之前的点赞动画,最终实现了缩放以及发散效果。
布局中添加MotionLayout
<?xml version="1.0" encoding="utf-8"?>
<layout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:motion="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<!--根节点改为使用MotionLayout-->
<!--layoutDescription 配置MotionScene配置文件-->
<!--showPaths设置是否显示动画的轨迹-->
<androidx.constraintlayout.motion.widget.MotionLayout
android:id="@+id/motion_layout"
android:layout_width="match_parent"
android:layout_height="match_parent"
motion:layoutDescription="@xml/example_motion_scene"
tools:showPaths="true">
<include
android:id="@+id/include_title"
layout="@layout/layout_title" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up1"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
android:visibility="gone"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up2"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
android:visibility="gone"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up3"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
android:visibility="gone"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up4"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
android:visibility="gone"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
<androidx.appcompat.widget.AppCompatImageView
android:id="@+id/iv_thumb_up5"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
android:src="@drawable/icon_thumb_up"
android:visibility="gone"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent" />
</androidx.constraintlayout.motion.widget.MotionLayout>
</layout>创建MotionScene配置文件
<?xml version="1.0" encoding="utf-8"?>
<MotionScene xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:motion="http://schemas.android.com/apk/res-auto">
<!--配置动画的属性-->
<!--duration 配置动画的持续时间-->
<!--constraintSetStart 配置动画开始时,控件集的状态-->
<!--constraintSetEnd 配置动画结束时,控件集的状态-->
<!--motionInterpolator 配置动画的插值器,-->
<Transition
android:id="@+id/transition_thumb"
android:duration="1500"
motion:constraintSetEnd="@id/thumb_end"
motion:constraintSetStart="@id/thumb_start"
motion:motionInterpolator="linear">
<!--点击时触发动画-->
<!--targetId 配置触发事件的控件id-->
<!--clickAction 配置点击触发的效果-->
<!--clickAction toggle 当前控件集为开始状态,则播放动画切换至结束状态,反之亦然-->
<!--clickAction transitionToEnd 播放控件集开始到结束的动画-->
<!--clickAction transitionToStart 播放控件集结束到开始的动画-->
<!--clickAction jumpToEnd 不播放动画,控件集直接切换至结束状态-->
<!--clickAction jumpToStart 不播放动画,控件集直接切换至开始状态-->
<OnClick
motion:clickAction="transitionToEnd"
motion:targetId="@id/iv_thumb_up" />
<!--关键帧集合,用于实现缩放效果-->
<KeyFrameSet>
<!--修改属性-->
<!--framePosition 取值范围为0-100-->
<!--motionTarget 设置修改的对象-->
<!--scaleX 设置x轴缩放大小-->
<!--scaleY 设置y轴缩放大小-->
<KeyAttribute
android:scaleX="1.6"
android:scaleY="1.6"
motion:framePosition="25"
motion:motionTarget="@id/iv_thumb_up" />
<KeyAttribute
android:scaleX="1"
android:scaleY="1"
motion:framePosition="50"
motion:motionTarget="@id/iv_thumb_up" />
</KeyFrameSet>
</Transition>
<!--控件集 动画开始时的状态-->
<ConstraintSet android:id="@+id/thumb_start">
<!--与layout文件中的控件对应-->
<!--visibilityMode 如果需要改变控件的可见性,需要将此字段配置为ignore-->
<Constraint
android:id="@+id/iv_thumb_up"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore" />
<Constraint
android:id="@+id/iv_thumb_up1"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<!--改变控件的属性-->
<!--attributeName 属性名-->
<!--customFloatValue Float类型属性值-->
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="1" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up2"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="1" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up3"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="1" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up4"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="1" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up5"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="1" />
</Constraint>
</ConstraintSet>
<!--控件集 动画结束时的状态-->
<ConstraintSet android:id="@+id/thumb_end">
<Constraint
android:id="@+id/iv_thumb_up"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="2dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore" />
<Constraint
android:id="@+id/iv_thumb_up1"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginTop="110dp"
android:layout_marginEnd="90dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="0.5" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up2"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginStart="70dp"
android:layout_marginTop="95dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="0.4" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up3"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginEnd="85dp"
android:layout_marginBottom="140dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="0.6" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up4"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginStart="60dp"
android:layout_marginBottom="120dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="0.2" />
</Constraint>
<Constraint
android:id="@+id/iv_thumb_up5"
android:layout_width="25dp"
android:layout_height="25dp"
android:layout_marginEnd="20dp"
android:layout_marginBottom="60dp"
motion:layout_constraintBottom_toBottomOf="parent"
motion:layout_constraintEnd_toEndOf="parent"
motion:layout_constraintStart_toStartOf="parent"
motion:layout_constraintTop_toTopOf="parent"
motion:visibilityMode="ignore">
<CustomAttribute
motion:attributeName="alpha"
motion:customFloatValue="0" />
</Constraint>
</ConstraintSet>
</MotionScene>监听动画状态
class MotionLayoutExampleActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
val binding: LayoutMotionLayoutExampleActivityBinding = DataBindingUtil.setContentView(this, R.layout.layout_motion_layout_example_activity)
binding.motionLayout.setTransitionListener(object : MotionLayout.TransitionListener {
override fun onTransitionStarted(motionLayout: MotionLayout?, startId: Int, endId: Int) {
// 动画开始
// 把发散的按钮显示出来
binding.ivThumbUp1.visibility = View.VISIBLE
binding.ivThumbUp2.visibility = View.VISIBLE
binding.ivThumbUp3.visibility = View.VISIBLE
binding.ivThumbUp4.visibility = View.VISIBLE
binding.ivThumbUp5.visibility = View.VISIBLE
}
override fun onTransitionChange(motionLayout: MotionLayout?, startId: Int, endId: Int, progress: Float) {
// 动画进行中
}
override fun onTransitionCompleted(motionLayout: MotionLayout?, currentId: Int) {
// 动画完成
// 隐藏发散的按钮,将状态还原
binding.root.postDelayed({
binding.ivThumbUp1.visibility = View.GONE
binding.ivThumbUp2.visibility = View.GONE
binding.ivThumbUp3.visibility = View.GONE
binding.ivThumbUp4.visibility = View.GONE
binding.ivThumbUp5.visibility = View.GONE
binding.motionLayout.progress = 0f
}, 200)
}
override fun onTransitionTrigger(motionLayout: MotionLayout?, triggerId: Int, positive: Boolean, progress: Float) {
}
})
}
}示例
已整合到demo中。
效果如图:
大致还原了之前的动画效果,MotionLayout实现起来确实不复杂,但是目前还没有找到如何设置动画开始前的延时,因此点击完之后按钮的缩放效果与发散效果之间的间隔、发散出去的按钮之间的间隔无法完全复原。
链接:https://juejin.cn/post/7196084258191163449
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 小技巧之 3.7 性能优化 background isolate
Flutter 3.7 的 background isolate 绝对是一大惊喜,尽管它在 release note 里被一笔带过 ,但是某种程度上它可以说是 3.7 里最实用的存在:因为使用简单,提升又直观。
Background isolate YYDS
前言
我们知道 Dart 里可以通过新建 isolate 来执行”真“异步任务,而本身我们的 Dart 代码也是运行在一个独立的 isolate 里(简称 root isolate),而 isolate 之间不共享内存,只能通过消息传递在 isolates 之间交换状态。
所以 Dart 里不像 Java 一样需要线程锁。
而在 Dart 2.15 里新增了 isolate groups 的概念,isolate groups 中的 isolate 共享程序里的各种内部数据结构,也就是虽然 isolate groups 还是不允许 isolate 之间共享可变对象,但 groups 可以通过共享堆来实现结构共享,例如:
Dart 2.15 后可以将对象直接从一个 isolate 传递到另一 isolate,而在此之前只支持基础数据类型。
那么如果使用场景来到 Flutter Plugin ,在 Flutter 3.7 之前,我们只能从 root isolate 去调用 Platform Channels ,如果你尝试从其他 isolate 去调用 Platform Channels ,就会收获这样的错误警告:
例如,在 Flutter 3.7 之前,Platform Channels 是和
_DefaultBinaryMessenger这个全局对象进行通信,但是一但切换了 isolate ,它就会变为 null ,因为 isolate 之间不共享内存。
而从 Flutter 3.7 开始,简单地说,Flutter 会通过新增的 BinaryMessenger 来实现非 root isolate 也可以和 Platform Channels 直接通信,例如:
我们可以在全新的 isolate 里,通过 Platform Channels 获取到平台上的原始图片后,在这个独立的 isolate 进行一些数据处理,然后再把数据返回给 root isolate ,这样数据处理逻辑既可以实现跨平台通用,又不会卡顿 root isolate 的运行。
Background isolate
现在 Flutter 在 Flutter 3.7 里引入了 RootIsolateToken 和 BackgroundIsolateBinaryMessenger 两个对象,当 background isolate 调用 Platform Channels 时, background isolate 需要和 root isolate 建立关联,所以在 API 使用上大概会是如下代码所示:
RootIsolateToken rootIsolateToken =
RootIsolateToken.instance!;
Isolate.spawn((rootIsolateToken) {
doFind2(rootIsolateToken);
}, rootIsolateToken);
doFind2(RootIsolateToken rootIsolateToken) {
// Register the background isolate with the root isolate.
BackgroundIsolateBinaryMessenger
.ensureInitialized(rootIsolateToken);
//......
}通过 RootIsolateToken 的单例,我们可以获取到当前 root isolate 的 Token ,然后在调用 Platform Channels 之前通过 ensureInitialized 将 background isolate 需要和 root isolate 建立关联。
大概就是 token 会被注册到
DartPluginRegistrant里,然后BinaryMessenger在_findBinaryMessenger时会通过BackgroundIsolateBinaryMessenger.instance发送到对应的listener。
完整代码如下所示,逻辑也很简单,就是在 root isolate 里获取 RootIsolateToken ,然后在调用 Platform Channels 之前 ensureInitialized 关联 Token 。
InkWell(
onTap: () {
///获取 Token
RootIsolateToken rootIsolateToken =
RootIsolateToken.instance!;
Isolate.spawn(doFind, rootIsolateToken);
},
////////////////
doFind(rootIsolateToken) async {
/// 注册 root isolaote
BackgroundIsolateBinaryMessenger.ensureInitialized(rootIsolateToken);
///获取 sharedPreferencesSet 的 isDebug 标识位
final Future<void> sharedPreferencesSet = SharedPreferences.getInstance()
.then((sharedPreferences) => sharedPreferences.setBool('isDebug', true));
/// 获取本地目录
final Future<Directory> tempDirFuture = path_provider.getTemporaryDirectory();
/// 合并执行
var values = await Future.wait([sharedPreferencesSet, tempDirFuture]);
final Directory? tempDir = values[1] as Directory?;
final String dbPath = path.join(tempDir!.path, 'database.db');
File file = File(dbPath);
if (file.existsSync()) {
///读取文件
RandomAccessFile reader = file.openSync();
List<int> buffer = List.filled(256, 0);
while (reader.readIntoSync(buffer) == 256) {
List<int> foo = buffer.takeWhile((value) => value != 0).toList();
///读取结果
String string = utf8.decode(foo);
print("######### $string");
}
reader.closeSync();
}
}
这里之所以可以在 isolate 里直接传递
RootIsolateToken,就是得益于前面所说的 Dart 2.15 的 isolate groups
其实入下代码所示,上面的实现换成 compute 也可以正常执行,当然,如果是 compute 的话,有一些比较特殊情况需要注意。
RootIsolateToken rootIsolateToken = RootIsolateToken.instance!;
compute(doFind, rootIsolateToken);
如下代码所示, doFind2 方法在 doFind 的基础上,将 Future.wait 的 await 修改为 .then 去执行,如果这时候你再调用 spawn 和 compute ,你就会发现 spawn 下代码依然可以正常执行,但是 compute 却不再正常执行。
onTap: () {
RootIsolateToken rootIsolateToken =
RootIsolateToken.instance!;
compute(doFind2, rootIsolateToken);
},
onTap: () {
RootIsolateToken rootIsolateToken =
RootIsolateToken.instance!;
Isolate.spawn(doFind2, rootIsolateToken);
},
doFind2(rootIsolateToken) async {
/// 注册 root isolaote
BackgroundIsolateBinaryMessenger.ensureInitialized(rootIsolateToken);
///获取 sharedPreferencesSet 的 isDebug 标识位
final Future<void> sharedPreferencesSet = SharedPreferences.getInstance()
.then((sharedPreferences) => sharedPreferences.setBool('isDebug', true));
/// 获取本地目录
final Future<Directory> tempDirFuture = path_provider.getTemporaryDirectory();
///////////////////// Change Here //////////////////
/// 合并执行
Future.wait([sharedPreferencesSet, tempDirFuture]).then((values) {
final Directory? tempDir = values[1] as Directory?;
final String dbPath = path.join(tempDir!.path, 'database.db');
///读取文件
File file = File(dbPath);
if (file.existsSync()) {
RandomAccessFile reader = file.openSync();
List<int> buffer = List.filled(256, 0);
while (reader.readIntoSync(buffer) == 256) {
List<int> foo = buffer.takeWhile((value) => value != 0).toList();
String string = utf8.decode(foo);
print("######### $string");
}
reader.closeSync();
}
}).catchError((e) {
print(e);
});
}为什么会这样?compute 不就是 Flutter 针对 Isolate.spawn 的简易封装吗?
其实原因就在这个封装上,
compute现在不是直接执行Isolate.spawn代码,而是执行Isolate.run,而Isolate.run针对Isolate.spawn做了一些特殊封装。
compute 内部会将执行对象封装成 _RemoteRunner 再交给 Isolate.spawn 执行,而 _RemoteRunner 在执行时,会在最后强制调用 Isolate.exit ,这就会导致前面的 Future.wait 还没执行,而 Isolate 就退出了,从而导致代码无效的原因。
另外在 Flutter 3.7 上 ,如果 background isolate 调用 Platform Channels 没有关联 root isolate,也能看到错误提示你初始化关联,所以这也是为什么我说它使用起来很简单的原因。
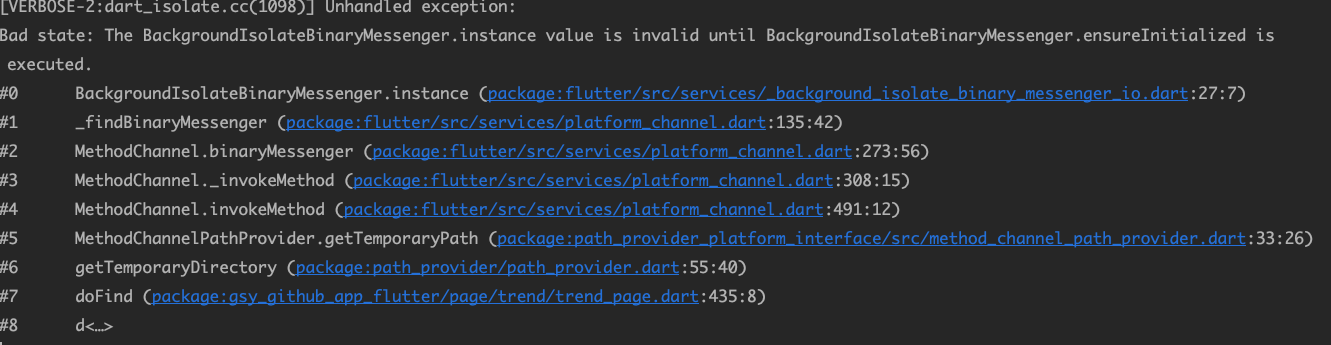
除此之外,最近刚好遇到有“机智”的小伙伴说 background isolate 无法正常调用,看了下代码是把 RootIsolateToken.instance!; 写到了 background isolate 执行的方法里。
你猜如果这样有效,为什么官方不直接把这个获取写死在 framewok?
其实这也是 isolates 经常引起歧义的原因,isolates 是隔离,内存不共享数据,所以 root isolate 里的 RootIsolateToken 在 background isolate 里直接获肯定是 null ,所以这也是 isolate 使用时需要格外注意的一些小细节。
另外还有如 #36983 等问题,也推动了前面所说的
compute相关的更改。
最后,如果需要一个完整 Demo 的话,可以参考官方的 background_isolate_channels ,项目里主要通过 SimpleDatabase 和 _SimpleDatabaseServer 的交互,来模拟展示 root isolate 和 background isolate 的调用实现。
最后
总的来说 background isolate 并不难理解,自从 2018 年在 issue #13937 被提出之后就饱受关注,甚至官方还建议过大家通过 ffi 另辟蹊径去实现,当时的 issue 也被搭上了 P5 的 Tag。
相信大家都知道 P5 意味着什么。
所以 background isolate 能在 Flutter 3.7 看到是相当难得的,当然这也离不开 Dart 的日益成熟的支持,同时 background isolate 也给我们带来了更多的可能性,其中最直观就是性能优化上多了新的可能,代码写起来也变得更顺畅。
期待 Flutter 和 Dart 在后续的版本中还能给我们带来更多的惊喜。
链接:https://juejin.cn/post/7195825738472620087
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
“八股文”? ——什么是好的技术面试
不知道什么时候起,市面上开始流行所谓的面经、背题之类的八股文,大到字节、腾讯、阿里、baidu,小到十几人的小微企业都是开始有大量的算法类笔试题。而且在面试时的问题也越来越标准化,网上到处流传着 xxx 公司面经、xxx 公司面试题这种东西,我不禁感叹这种方式的面试和筛选简历的方式真的能招到好的人才吗?
ReactJs 核心开发 Dan Abramov 和 Youtube 主播和 Dan 进行 了一场模拟面试,这个面试将近持续了一个小时,但是主要是后面的那个算法题耗费时间,前面几个问题都是很八股的前端面试题(这部分翻译和评价来自@程序员的喵):
let 和 const 区别
什么时候使用 redux
dangerouslySetInnerHTML 是什么,该怎么用
把一个 div 居中
把一个 binaryTree 镜像翻转
Bonus Q: 一个找兔子的算法题,兔子出现在数组的某个位置,但是每次可以跳向相邻的位置,用最快的办法找到兔子的位置。
http://www.youtube.com/watch?v=XEt…
把 div 居中算是前端中的经典梗了,Dan 花了好一会时间在面试官的提示下才把一个 div 居中。如果对方不是 React 核心开发,手熟的前端可能就会开始鄙视这位“初级前端”了。
最后一个算法题比较新颖,这不算红黑树式的八股算法题,倒像是一个 IQ 测试题目。可以看出 dan 也很少碰这类算法题。他花费了近半个小时在面试官的提示下,按照自己的直觉一步一步推出了答案。但是他最后写的代码是有点小问题的(没有用 2 来递增 index),面试者看他思路是对的也没有指出来了。
即使是非常知名的开源作者在面试这些基础问题和算法题的时候都是很困难的,那普通人岂不是更困难?如果不背题的情况下要做出算法题还是很难的。
我在写这篇文章之前我搜了下,我发现有篇文章写得非常好,基本已经把我想说的都概括进去了。
怎样花两年时间去面试一个人 – 刘未鹏
我就着这篇文章往下说下自己的感受吧。
现在市面上基本无论实习还是社招、校招都大量的流行笔试的本质是因为如何界定好的、优秀的技术人才越来越难。如果在上面文章说的一样:
招聘真的很困难。以至于招聘者每年需要绞尽脑汁出新笔试题,以免往年的笔试题早就被人背熟了。出题很费脑子,要出的不太简单也不太难,能够滤掉绝大多数滥竽充数的但又要保证不因题目不公平而滤掉真正有能力的,要考虑审题人的时间成本就只能大多数用选择题,而选择题又是可以猜答案的(极少有人会在选了答案之后还敢在空白的地方写为什么选某答案的原因的)。更悲催的是,有些题目出的连公司的员工们自己都会做错(真的是员工们做错了吗?还是题目本身就出错了?)
我们没有很好的办法去界定一个人在技术上是否优秀,实践证明是否在大厂工作过、学历是否很好只是提高了优秀人才的概率,但并不能决定一个人是否优秀。现在大部分五年以下工作经验所做的都是纯业务开发,例如 API 开发、所谓的”增删查改“等等。甚至于换不同语言都已经很难了,经常使用 Java 开发的就很难切换到 Python 开发。
即使笔试之后进入面试阶段,我们也很难在很短的时间内去界定一个人他是否是好的、优秀的人才。就如在《社会性动物》里描述的一样:”我们总是寻求保存认知(心理)能量并将复杂事物简单化处理的方法。我们会利用经验法则去走捷径。我们会忽略一些信息以减少认知负担;我们会过度利用一些信息以避免去寻找更多的信息;或者我们只是按照最初的直觉,接受一个不够完美的选择,因为它已经足够好了。人类进化的一个奇怪的特点是它倾向于消极:我们倾向于关注潜在的威胁而不是祝福,这种倾向通常被称为消极偏见。(罗伊·鲍迈斯特(Roy Baumeister)和他的同事发现,消极的事件通常比积极的事件更有力量。)“。
在面试的过程中,无论是对于面试官还是候选人来说,都很难保持完全中立,会不由自主的倾向于寻找对方的缺点,寻找对方不会什么、缺点是什么。甚至如果对方与自己越相似你就会越喜欢他,对方与自己越不相似,自己就越不喜欢他。(如学习经历、成长环境、同个国家留学、上个公司是同个公司等等)。
对于现在的候选人来说,刚一坐下来就要担心需要不需要笔试了,等下笔试有电脑还是手写、有没有现代的 IDE、有没有代码提示等等。
所以说在短短的几个小时(很多时候一小时都不够)中想要发现一个人的闪光点是很难的。雇主在招人时很难选择优秀的人只能通过更加标准的”考试“来选择那些至少更擅长应试的人,或者使用标准的面经类的面试题去扣一个框架的细节、一个工具的细节、Hashmap 原理什么的。在这样的市场环境下候选人也会慢慢习惯这样的环境,随时准备应试。这样的市场环境将工具和解决问题的能力本末倒置,我们不能说一个擅长使用锤子的人更擅长锻造,我们也不能说一个擅长锻造的人一定擅长挥舞锤子。
但实际上对于好的技术开发来说,难道具体的语言和框架不应该只是工具吗? 哪个用得顺手就用哪个么?我们实际应该要做的不是利用数学知识、计算机相关的知识、逻辑思维能力、分析能力在某个场景下用适合的工具去解决遇到的问题吗?
我有一次打车遇到一个司机跟我抱怨说每天派单都很少,但是他本人应该优先级很高才对,那我就问他你是不是每天出门是一样的路线?他说是,我告诉他你其实可以试下每天出门时每遇到一个十字路口就走与上次不一样的方向,然后记录下来哪个条路线单最多最好,以后就按那个路线走。
我们换成计算机领域的话来说,这就是一种类似广度优先搜索算法的算法,我们将每天出门的路线看作是一张图,每个十字路口看作是一个节点。广度搜索算法可以帮我们分析出从 A 节点出发前往 B 节点哪条路径最短,我们可以把路径最短的目标换成哪条路径同等时间获得的收益最大。我们只不过是用人力去模拟这个算法,来实现最优路径。
所以所谓的精通 xxx、熟悉 yyy、掌握 zzz 的本质是,我们能不能用类似这些东西的机制或者利用这些东西解决业务问题,或者我们能不能利用这些算法、原理的思想解决现实生活中遇到的问题。
在互联网这么多年,最重要的方法论就是在高密度的信息下用某个方法论解决某个问题。虽然有时候互联网黑话很好笑,但有时候遇到某个问题的时候就会发现这个黑话还是很好用的,毕竟它代表了某个方法论的简写(手动狗头)。
那么怎么样才能让雇主方更容易找到好的人,也能让候选人更好的表现自己呢?我觉得提供一个自己的博客和 GitHub 之类的开放代码平台能够非常好的表现自己的技术品味、自学习的能力、进步的速度。长期维护一个好的品味的博客、深度的博客是很难的,需要花大量的时间和精力去写作、去思考。
同时我们可以参与开源项目的贡献或者我们可以自己设计一个解决了某个经常遇到的问题的项目、模拟某个场景的项目。自己撰写架构设计文档、技术文档等等然后开发、完善单元测试、不断完善迭代、尝试更加新颖的技术。通过把项目展示在 GitHub 之类的平台上,雇主方可以很好的通过你的项目和代码了解到你的技术品味,也可以看到你的编程习惯是否与自己符合。自己也可以通过长期维护和更新项目不断更新技术栈。
对于雇主方来说,要思考的是自己所需的人到底是更擅长挥舞锤子的人还是更擅长锻造的人。如果我们是希望更擅长锻造的人,我们应该更关注的是候选人本身在什么样的环境下、通过什么样的方法、取得了什么样的成果、吸取了什么教训、下次再解决这个问题是否有更好的方案。通过与候选人共同探讨过去的经历,我们很快可以知道这个人是不是适合与自己合作的人(当然重点是合作了能不能解决问题,需要保持中立去评估)。
关于是否应该选择创业公司的问题,我今天搜索的时候发现有篇当年好像很火的文章《没事别想不开去创业公司》,15 年 16 年那个年代我也是创业潮中的一员,在当时的环境下的确就如同文章一样:
天确实变了,但是这天是不是为你变的,很难说。就像一线城市繁华的夜景,和你有没有关系,很难说。押上自己所有的时间和机会筹码,自己创业或加入创业公司,是不是一步好棋,也很难说。
当现在的环境与当年不一样了,如果说当年是资本+政策+经济兴起的三重推动力的话,现在就是三者都不行的环境了,更恶劣的环境反而容易诞生更加正规和更有潜力的创业公司的。
选择创业公司不能直接想着加入后就能马上 IPO 发家致富,而是应该往最坏的方向打算。创业就像吹一个泡泡,太大就会爆炸,太小又没有任何的意义。如何小心意义的让这个泡泡不爆成为一个飞在空中的泡泡是一个很难的且要求人非常理性、反人性的事情。
其次选择一个创业公司一定要去试试它的产品,看看自己喜不喜欢,如果自己都不喜欢这个产品不会经常用,你如何相信这个产品能发展起来?你如果不相信你为什么要参与创业呢?一只眼睛看着外面商业环境的变化,随时准备调整战略战术适应市场,另一只眼睛盯着内部的团队,随时要调整和救火。在一个高速发展的公司中的确平日和周末的界限没那么明显,但无论是公司还是个人还是应该想着如何更高效而不是如何加班更多,加班多并不代表高效,高效也不一定要加班更多,像 intel 现在 的 CEO 帕特·基尔辛格在自传中写到的——“一个杂耍艺人同时转动三个小茶碟。一个碟子代表上帝,另一个代表家庭,第三个代表工作。我当时的生活就是这样,我得时刻注意让这三个碟子都在空中旋转,根本没机会暂停或休息。如果我稍有分神,碟子就会掉下来,摔到地上。也许我们可以把这称之为有张驰的工作。工作和生活要平衡:工作时要竭尽全力;休息时要完全放松,或在家陪伴家人,或外出度假。”
加入创业公司的本质是选一个好的创业公司,与他一起成长,如果他没法长大为何要加入?如果他要野蛮生长,你呢?
回顾招聘的话题,对于我个人而言,评估一个人是不是好的技术人才最简单的办法就是,如果将来互联网衰败,当工程师并不能提供很多收入的时候、甚至你换行了你还会喜欢并跟进新的技术吗?甚至有一天编程将死、程序员职业消失在历史长河中,你会怎么办?
作者:Andy_Qin
来源:juejin.cn/post/7188046122441506853
首页弹框太多?Flow帮你“链”起来
很多App一打开,首页都会有各种各样的交互,比如权限授权,版本更新,阅读协议,活动介绍,用户权限变更等,这些交互大多数都是以弹框为主,也会有少数几个是以页面或者别的形式出现,但是无论是弹框还是页面,这些只是表现形式,这种交互难点在于
如何去判断它们什么时候出来
它们出来的先后次序是什么
中途需求如果增加或者删除一个弹框或者页面,我们应该改动哪些逻辑
常见的做法
可能这种需求刚开始由于弹框少,交互还简单,所以大多数的做法就是直接在首页用if-else去完成了
if(条件1){
//弹框1
}else if(条件2){
//弹框2
}但是当需求慢慢迭代下去,首页弹框越来越多,判断的逻辑也越来越复杂,判断条件之间还存在依赖关系的时候,我们的代码就变得很可怕了
if(条件1 && 条件2 && 条件3){
//弹框1
}else if(条件1 && (条件2 || 条件3)){
//弹框2
}else if(条件2 && 条件3){
//弹框3
}else if(....){
....
}这种情况下,这些代码就变的越来越难维护,长久下来,造成的问题也越来越多,比如
代码可读性变差,不是熟悉业务的人无法去理解这些逻辑代码
增加或者减少弹框或者条件需要更改中间的逻辑,容易产生bug
每个分支的弹框结束后,需要重新从第一个if再执行一遍判断下一个弹框是哪一个,如果条件里面牵扯到io操作,也会产生一定的性能问题
设计思路
能否让每个弹框作为一个单独的任务,生成一条任务链,链上的节点为单个任务,节点维护任务执行的条件以及任务本身逻辑,节点之间无任何依赖关系,具体执行由任务链去管理,这样的话如果增加或者删除某一个任务,我们只需要插拔任务节点就可以
定义任务
首先我们先简单定一个任务,以及需要执行的操作
interface SingleJob {
fun handle(): Boolean
fun launch(context: Context, callback: () -> Unit)
}handle():判断任务是否应该执行的条件
launch():执行任务,并在任务结束后通过callback通知任务链执行下一条任务
实现任务
定义一个TaskJobOne,让它去实现SingleJob
class TaskJobOne : SingleJob {
override fun handle(): Boolean {
println("start handle job one")
return true
}
override fun launch(context: Context, callback: () -> Unit) {
println("start launch job one")
AlertDialog.Builder(context).setMessage("这是第一个弹框")
.setPositiveButton("ok") {x,y->
callback()
}.show()
}
}这个任务里面,我们先默认handle的执行条件是true,一定会执行,实际开发过程中可以根据需要来定义条件,比如判断登录态等,lanuch里面我们简单的弹一个框,然后在弹框的关闭的时候,callback给任务链,为了调试的时候看的清楚一些,在这两个函数入口分别打印了日志,同样的任务我们再创建一个TaskJobTwo,TaskJobThree,具体实现差不多,就不贴代码了
任务链
首先思考下如何存放任务,由于任务之间需要体现出优先级关系,所以这里决定使用一个LinkedHashMap,K表示优先级,V表示任务
object JobTaskManager {
val jobMap = linkedMapOf(
1 to TaskJobOne(),
2 to TaskJobTwo(),
3 to TaskJobThree()
)
}接着就是思考如何设计整条任务链的执行任务,因为这个是对jobMap里面的任务逐个拿出来执行的过程,所以我们很容易就想到可以用Flow去控制这些任务,但是有两个问题需要去考虑下
如果直接将jobMap转成Flow去执行,那么出现的问题就是所有任务全部都一次性执行完,显然不符合设计初衷
我们都知道Flow是由上游发送数据,下游接收并处理数据的一个自上而下的过程,但是这里我们需要一个job执行完以后,通过callback通知任务链去执行下一个任务,任务的发送是由前一个任务控制的,所以必须设计出一个环形的过程
首先我们需要一个变量去保存当前需要执行的任务优先级,我们定义它为curLevel,并设置初始值为1,表示第一个执行的是优先级为1的任务
var curLevel = 1这个变量将会在任务执行完以后,通过callback回调以后再自增,至于自增之后如何再去执行下一条任务,这个通知的事情我们交给StateFlow
val stateFlow = MutableStateFlow(curLevel)
fun doJob(context: Context, job: SingleJob) {
if (job.handle()) {
job.launch(context) {
curLevel++
if (curLevel <= jobMap.size)
stateFlow.value = curLevel
}
} else {
curLevel++
if (curLevel <= jobMap.size)
stateFlow.value = curLevel
}
}stateFlow初始值是curlevel,当上层开始订阅的时候,不给stateFlow设置value,那么stateFlow初始值1就会发送出去,开始执行优先级为1的任务,在doJob里面,当任务的执行条件不满足或者任务已经执行完成,就自增curLevel,再给stateFlow赋值,从而执行下一个任务,这样一个环形过程就有了,下面是在上层如何执行任务链
MainScope().launch {
JobTaskManager.apply {
stateFlow.collect {
flow {
emit(jobMap[it])
}.collect {
doJob(this@MainActivity, it!!)
}
}
}
}我们的任务链就完成了,看下效果
通过日志我们可以看到,的确是每次关闭一个弹框,才开始执行下一条任务,这样一来,如果某个任务的条件不满足,或者不想让它执行了,只需要改变对应job的handle条件就可以,比如现在把TaskJobOne的handel设置为false,在看下效果
class TaskJobOne : SingleJob {
override fun handle(): Boolean {
println("start handle job one")
return false
}
override fun launch(context: Context, callback: () -> Unit) {
println("start launch job one")
AlertDialog.Builder(context).setMessage("这是第一个弹框")
.setPositiveButton("ok") {x,y->
callback()
}.show()
}
}可以看到经过第一个task的时候,由于已经把handle条件设置成false了,所以直接跳过,执行下一个任务了
依赖于外界因素
上面只是简单的模拟了一个任务链的工作流程,实际开发过程中,我们有的任务会依赖于其他因素,最常见的就是必须等到某个接口返回数据以后才去执行,所以这个时候,执行你的任务需要判断的东西就更多了
是否优先级已经轮到它了
是否依赖于某个接口
这个接口是否已经成功返回数据了
接口数据是否需要传递给这个任务 鉴于这些,我们就要重新设计我们的任务与任务链,首先要定义几个状态值,分别代表任务的不同状态
const val JOB_NOT_AVAILABLE = 100
const val JOB_AVAILABLE = 101
const val JOB_COMBINED_BY_NOTHING = 102
const val JOB_CANCELED = 103JOB_NOT_AVAILABLE:该任务还没有达到执行条件
JOB_AVAILABLE:该任务达到了执行任务的条件
JOB_COMBINED_BY_NOTHING:该任务不关联任务条件,可直接执行
JOB_CANCELED:该任务不能执行
接着需要去扩展一下SingleJob的功能,让它可以设置状态,获取状态,并且可以传入数据
interface SingleJob {
......
/**
* 获取执行状态
*/
fun status():Int
/**
* 设置执行状态
*/
fun setStatus(level:Int)
/**
* 设置数据
*/
fun setBundle(bundle: Bundle)
}更改一下任务的实现
class TaskJobOne : SingleJob {
var flag = JOB_NOT_AVAILABLE
var data: Bundle? = null
override fun handle(): Boolean {
println("start handle job one")
return flag != JOB_CANCELED
}
override fun launch(context: Context, callback: () -> Unit) {
println("start launch job one")
val type = data?.getString("dialog_type")
AlertDialog.Builder(context).setMessage(if(type != null)"这是第一个${type}弹框" else "这是第一个弹框")
.setPositiveButton("ok") {x,y->
callback()
}.show()
}
override fun setStatus(level: Int) {
if(flag != JOB_COMBINED_BY_NOTHING)
this.flag = level
}
override fun status(): Int = flag
override fun setBundle(bundle: Bundle) {
this.data = bundle
}
}现在的任务执行条件已经变了,变成了状态不是JOB_CANCELED的任务才可以执行,增加了一个变量flag表示这个任务的当前状态,如果是JOB_COMBINED_BY_NOTHING表示不依赖外界因素,外界也不能改变它的状态,其余状态则通过setStatus函数来改变,增加了setBundle函数允许外界向任务传入数据,并且在launch函数里面接收数据并展示在弹框上,我们在任务链里面增加一个函数,用来给对应优先级的任务设置状态与数据
fun setTaskFlag(level: Int, flag: Int, bundle: Bundle = Bundle()) {
if (level > jobMap.size) {
return
}
jobMap[level]?.apply {
setStatus(flag)
setBundle(bundle)
}
}我们现在可以把任务链同接口一起关联起来了,首先我们先创建个viewmodel,在里面创建三个flow,分别模拟三个不同接口,并且在flow里面向下游发送数据
class MainViewModel : ViewModel(){
val firstApi = flow {
kotlinx.coroutines.delay(1000)
emit("元宵节活动")
}
val secondApi = flow {
kotlinx.coroutines.delay(2000)
emit("端午节活动")
}
val thirdApi = flow {
kotlinx.coroutines.delay(3000)
emit("中秋节活动")
}
}接着我们如果想要去执行任务链,就必须等到所有接口执行完毕才可以,刚好flow里面的zip操作符就可以满足这一点,它可以让异步任务同步执行,等到都执行完任务之后,才将数据传递给下游,代码实现如下
val mainViewModel: MainViewModel by lazy {
ViewModelProvider(this)[MainViewModel::class.java]
}
MainScope().launch {
JobTaskManager.apply {
mainViewModel.firstApi
.zip(mainViewModel.secondApi) { a, b ->
setTaskFlag( 1, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", a)
})
setTaskFlag( 2, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", b)
})
}.zip(mainViewModel.thirdApi) { _, c ->
setTaskFlag( 3, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", c)
})
}.collect {
stateFlow.collect {
flow {
emit(jobMap[it])
}.collect {
doJob(this@MainActivity, it!!)
}
}
}
}
}运行一下,效果如下
我们看到启动后第一个任务并没有立刻执行,而是等了一会才去执行,那是因为zip操作符是等所有flow里面的同步任务都执行完毕以后才发送给下游,flow里面已经执行完毕的会去等待还没有执行完毕的任务,所以才会出现刚刚页面有一段等待的时间,这样的设计一般情况下已经可以满足需求了,毕竟正常情况一个接口的响应时间都是毫秒级别的,但是难防万一出现一些极端情况,某一个接口响应忽然变慢了,就会出现我们的任务链迟迟得不到执行,产品体验方面就大打折扣了,所以需要想个方案解决一下这个问题
优化
首先我们需要当应用启动以后就立马执行任务链,判断当前需要执行任务的优先级与curLevel是否一致,另外,该任务的状态是可执行状态
/**
* 应用启动就执行任务链
*/
fun loadTask(context: Context) {
judgeJob(context, curLevel)
}
/**
* 判断当前需要执行任务的优先级是否与curLevel一致,并且任务可执行
*/
private fun judgeJob(context: Context, cur: Int) {
val job = jobMap[cur]
if(curLevel == cur && job?.status() != JOB_NOT_AVAILABLE){
MainScope().launch {
doJob(context, cur)
}
}
}我们更改一下doJob函数,让它成为一个挂起函数,并且在里面执行完任务以后,直接去判断它的下一级任务应不应该执行
private suspend fun doJob(context: Context, index: Int) {
if (index > jobMap.size) return
val singleJOb = jobMap[index]
callbackFlow {
if (singleJOb?.handle() == true) {
singleJOb.launch(context) {
trySend(index + 1)
}
} else {
trySend(index + 1)
}
awaitClose { }
}.collect {
curLevel = it
judgeJob(context,it)
}
}流程到了这里,如果所有任务都不依赖接口,那么这个任务链就能一直执行下去,如果遇到JOB_NOT_AVAILABLE的任务,需要等到接口响应的,那么任务链停止运行,那什么时候重新开始呢?就在我们接口成功回调之后给任务更改状态的时候,也就是setTaskFlag
fun setTaskFlag(context:Context,level: Int, flag: Int, bundle: Bundle = Bundle()) {
if (level > jobMap.size) {
return
}
jobMap[level]?.apply {
setStatus(flag)
setBundle(bundle)
}
judgeJob(context,level)
}这样子,当任务链走到一个JOB_NOT_AVAILABLE的任务的时候,任务链暂停,当这个任务依赖的接口成功回调完成对这个任务状态的设置之后,再重新通过judgeJob继续走这条任务链,而一些优先级比较低的任务依赖的接口先完成了回调,那也只是完成对这个任务的状态更改,并不会执行它,因为curLevel还没到这个任务的优先级,现在可以试一下效果如何,我们把threeApi这个接口响应时间改的长一点
val thirdApi = flow {
kotlinx.coroutines.delay(5000)
emit("中秋节活动")
}上层执行任务链的地方也改一下
MainScope().launch {
JobTaskManager.apply {
loadTask(this@MainActivity)
mainViewModel.firstApi.collect{
setTaskFlag(this@MainActivity, 1, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", it)
})
}
mainViewModel.secondApi.collect{
setTaskFlag(this@MainActivity, 2, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", it)
})
}
mainViewModel.thirdApi.collect{
setTaskFlag(this@MainActivity, 3, JOB_AVAILABLE, Bundle().apply {
putString("dialog_type", it)
})
}
}
}应用启动就loadTask,然后三个接口已经从同步又变成异步操作了,运行一下看看效果
总结
大致的一个效果算是完成了,这只是一个demo,实际需求当中可能更复杂,弹框,页面,小气泡来回交互的情况都有可能,这里也只是想给一些正在优化项目的的同学提供一个思路,或者接手新需求的时候,鼓励多思考一下有没有更好的设计方案
作者:Coffeeee
来源:juejin.cn/post/7195336320435601467


