








2022被裁员两次的应届毕业生的年终总结
前言
“生活的苦可以被疲劳麻痹、被娱乐转移,最终变得习以为常、得过且过,可以称之为钝化。学习的苦在于,始终要保持敏锐而清醒的认知,乃至丰沛的感情,这不妨叫锐化。”
1. 二月,初到上海
1.1 第一段艰辛的实习生涯
从学校到校园,仿佛好像是一瞬之间。现在回想起21年的秋招,也算是收获满满,拿下了不少大大小小好几家公司的offer。那时候对于面试题和自己的项目都有较为深刻的印象,由于本人表达能力还不错(面试一堆胡吹),经过五轮面试最终接下了壹药网的offer。 仿佛一切美好都在向我招手,世间是如此的美好。
在2.17入职之后,也算是正式开启了社畜的角色。奈何在公司工作不到半个月之后,开始迎来了为期三个多月的疫情,疫情不仅是对公司有着强烈的冲击,对打工人也是晴天霹雳。
由于是第一次实习,Git工具根本就不会用 (此时省略一万点艰辛,以致于我们老大叫带我的导师,专门给我先培训好我的Git技能,在这里也是超级感谢我的导师,在远程办公 事务繁忙 我还贼菜的情况下,历时一个多月我的GIT终于出师)。
不过在实习期间,也学到了很多中型的公司的开发流程以及代码规范等等,也是宝贵的实习经历让我逐渐过渡到一个标准的社畜。
2.六月,第一次被裁员
在疫情解封的第一周的第三天下午,领导把我叫到会议室,通知所有的校招生全部解约。那时已是6.13号,校招已经结束,并且我已经答辩结束顺利 “毕业” 了。此时陷入了非常被动的局势,校招已经过了时间,社招没有工作经验。
那时候让我真真切切感受到互联网公司的不稳定,也让我感受到找工作的不容易。此时我也是被迫开始了海投模式,每天都在刷BOSS直聘,每天都在EMO ,并且面试题根本看不进去啊,谁能懂?
此时逃离上海成为了我最大的想法,奈何疫情当下,去哪里都要隔离 并且杭州的公司是一家回应的都没有,此时我内心是奔腾的。 有那种陷入谷底的绝望(没敢和家里面人说,只能自己硬抗)
2.1 试用期两个月,正式工两个月
肯定是上天眷顾我,觉得我自己硬扛着太不容易了。给我了个机会,在海投十天之后,那天上午突然一个电话打给我,问我下午有没有时间面试,此时我内心的感觉(只要你们愿意要我,我愿意当牛做马,工资啥的都无所谓,主要是给老板打工)。 当时也算是比较幸运,在我的再一次胡说海吹之下,拿到了第二家公司的offer。 试用期两个月,工资打八折。这家公司入职之后,公司全是年轻人,技术用的也很新,主要是都是河南人 真的亲切啊。我也是很快就融入了公司的氛围里面,开始称兄道弟的。两个月后在我的班门弄斧之下,顺利转正了,虽然自己陆陆续续也弄出了好几个线上较为严重的BUG 但还是在大家的努力下成功补救了回来。超级感谢当时公司里面的雷哥,权哥,昊哥等等,帮我帮了超级多。同时也督促我要一直看书一直学习来着。
于是乎,周六周日有时间都会去公司熟悉业务,精进自己的代码能力。
早上上班拍的公司照片,真的超级好看鸭。
3.十一月,第二次被裁员
就这样在公司一直干着,经常会加班(1.5倍的加班费,真的超级香),可是后来也陆陆续续有些消息说公司业绩不太行,疫情(再一次给我送来了惊喜),然后11.25号又被老大 再一次叫到了办公室里面,开门见山,立马滚蛋。
就是如此狗血,就是这么残忍。我现在依稀记得,就在上周我又弄出了一个超级大的BUG,导致业务受到了极大的影响。
业务改版,对之前老的数据迁移有问题,并且新的数据也有部分问题(还是太不认真,太年轻了),导致投诉电话不断,产品直接都要崩溃。没办法,又有好多人给我擦屁股。然后第二周老板宣布裁员,我和一个前端都被开除了。那天上海降温超级明显,并且还下着小雨和我的心情是一样一样的。
那天拍的最后一次公司的图片
2.十二月,开启第三份工作
在第二次被裁员之后,我是真的对自己产生了深深地怀疑,也觉得为什么我一个应届毕业生要被裁员两次。不得不否认,我的技术水平是真的菜,代码水平也是真的烂,运气也真的好差劲。
对啊,为什么幸福不是我,我没有乱七八糟的圈子,不出去乱玩每天不是上班就是下班,下班就回去煮饭吃,看看书就睡觉,周末休息就回家,我不明白生活为什么要给予我如此重重的打击,可是生活总得继续下去,我也只能收拾好行李,再出发。
不过还好,在我摆烂了大概几天之后,我又开始再一次的海投模式 同样收到的回复很少,很少有需要2022届毕业生的,简历都不太好包装。好像上帝给我关了一扇门,总会给我开一扇窗。那个本来可以不认真对待的面试题,在我认认真真对待之后,成功收到了一面通知,然后线下的面试(我不得不承认有被打击到,但是我的胡说海吹的功夫也不是盖得),最终成功拿下了两家公司的offer(另一家没有细讲,因为没去,为什么没去,钱没给到位))。
面试路上,路过字节
2023年一月,找到对象
哈哈哈哈哈哈哈哈哈哈哈嗝,虽然2022年职场过得比较坎坷。但是我想告诉大家的是,大年初一我就遇到了我对象。哈哈哈哈哈哈哈哈哈哈嗝。她真的超级超级好,我也超级超级喜欢她。2023除了升职加薪,那就是好好爱她,带她吃好多好吃的,玩好多好玩的。
送大家一句话: 没娶的别慌,待嫁的别忙, 经营好自己,珍惜当下时光。一切该来的总会到。 怕什么,岁月漫长,你心地善良 终会有一人陪你骑马喝酒走四方
一起看的第一场电影
链接:https://juejin.cn/post/7197411581927833655
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
聊一聊过度设计!
新手程序员在做设计时,因为缺乏经验,很容易写出欠设计的代码,但有一些经验的程序员,尤其是在刚学习过设计模式之后,很容易写出过度设计的代码,而这种代码比新手程序员的代码更可怕,过度设计的代码不仅写出来时的成本很高,后续维护的成本也高。因为相对于毫无设计的代码,过度设计的代码有比较高的理解成本。说这么多,到底什么是过度设计?
什么是过度设计?
为了解释清楚,我这里用个类比,假如你想拧一颗螺丝,正常的解决方案是找一把螺丝刀,这很合理对吧。 但是有些人就想:“我就要一个不止能拧螺丝的工具,我想要一个可以干各种事的工具!”,于是就花大价钱搞了把瑞士军刀。在你解决“拧螺丝”问题的时候,重心早已从解决问题转变为搞一个工具,这就是过度设计。
再举个更技术的例子,假设你出去面试,面试官让你写一个程序,可以实现两个数的加减乘除,方法出入参都给你提供好了 int calc(int x, int y, char op),普通程序员可能会写出以下实现。
public int calc(int x, int y, int op) {
if (op == '+') {
return x + y;
} else if (op == '-') {
return x - y;
} else if (op == '*') {
return x * y;
} else {
return x / y;
}
}而高级程序员会运用设计模式,写出这样的代码:
public interface Strategy {
int calc(int x, int y);
}
public class AddStrategy implements Strategy{
@Override
public int calc(int x, int y) {
return x + y;
}
}
public class MinusStrategy implements Strategy{
@Override
public int calc(int x, int y) {
return x - y;
}
}
/**
* 其他实现
*/
public class Main {
public int calc(int x, int y, int op) {
Strategy add = new AddStrategy();
Strategy minux = new MinusStrategy();
Strategy multi = new MultiStrategy();
Strategy div = new DivStrategy();
if (op == '+') {
return add.calc(x, y);
} else if (op == '-') {
return minux.calc(x, y);
} else if (op == '*') {
return multi.calc(x, y);
} else {
return div.calc(x, y);
}
}
}策略模式好处在于将计算(calc)和具体的实现(strategy)拆分,后续如果修改具体实现,也不需要改动计算的逻辑,而且之后也可以加各种新的计算,比如求模、次幂……,扩展性明显增强,很是牛x。 但光从代码量来看,复杂度也明显增加。回到我们原始的需求上来看,如果我们只是需要实现两个整数的加减乘除,这明显过度设计了。
过度设计的坏处
个人总结过度设计有两大坏处,首先就是前期的设计和开发的成本问题。过度设计的方案,首先设计的过程就需要投入额外的时间成本,其次越复杂的方案实现成本也就越高、耗时越长,如果是在快速迭代的业务中,这些可能都会决定到业务的生死。其次即便是代码正常上线后,其复杂度也会导致后期的维护成本高,比如当你想将这些代码交接给别人时,别人也需要付出额外的学习成本。
如果成本问题你都可以接受,接下来这个问题可能影响更大,那就是过度设计可能会影响到代码的灵活性,这点听起来和做设计的目的有些矛盾,做设计不就是为了提升代码的灵活性和扩展性吗!实际上很多过度设计的方案搞错了扩展点,导致该灵活的地方不灵活,不该灵活的地方瞎灵活。在机器学习领域,有个术语叫做“过拟合”,指的是算法模型在测试数据上表现完美,但在更广泛的数据上表现非常差,模式缺少通用性。 过度设计也会出现类似的现象,就是缺少通用性,在面对稍有差异的需求上时可能就需要伤筋动骨级别的改造了。
如何避免过度设计
既然过度设计有着成本高和欠灵活的问题,那如何避免过度设计呢!我这里总结了几个方法,希望可以帮到大家。
充分理解问题本身
在设计的过程中,要确保充分理解了真正的问题是什么,明确真正的需求是什么,这样才可以避免做出错误的设计。
保持简单
过度设计毫无例外都是复杂的设计,很多时候未来有诸多的不确定性,如果过早的针对某个不确定的问题做出方案,很可能就白做了,等遇到真正问题的时候再去解决问题就行。
小步快跑
不要一开始就想着做出完美的方案,很多时候优秀的方案不是设计出来的,而是逐渐演变出来的,一点点优化已有的设计方案比一开始就设计出一个完美的方案容易得多。
征求其他人的意见
如果你不确定自己的方案是不是过度设计了,可以咨询下其他人的,尤其是比较资深的人,交叉验证可以快速让你确认问题。
总结
其实在业务的快速迭代之下,很难判定当前的设计是欠设计还是过度设计,你当前设计了一个简单的方案,未来可能无法适应更复杂的业务需求,但如果你当前设计了一个复杂的方案,有可能会浪费时间……。 在面对类似这种不确定性的时候,我个人还是比较推崇大道至简的哲学,当前用最简单的方案,等需要复杂性扩展的时候再去重构代码。
链接:https://juejin.cn/post/7204423284905738298
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你在公司混的差,可能和组织架构有关!
如果你接触过公司的面试工作,一定见过很多来自大公司的渣渣。这些人的薪资和职位,比你高出很多,但能力却非常一般。
如果能力属实,我们大可直接把这些大公司的员工打包接收,也免了乱七八糟的面试工作。但可惜的是,水货的概率通常都比较大,新的公司也并不相信他们的能力。尤其是这两年互联网炸了锅,猪飞的日子不再,这种情况就更加多了起来。
反过来说也一样成立,就像是xjjdog在青岛混了这么多年,一旦再杀回北上广,也一样是落的下乘的评价。
除了自身的努力之外,你在上家公司混的差,还与你在组织架构中所处于的位置和组织架构本身有关。
一般公司会有两种组织架构方式:垂直化划分和层级化划分。
1. 垂直划分
垂直划分,多以业务线为模型进行划分。各条业务线共用公司行政资源,相互之间关联不大。
各业务线之间,内部拥有自治权。
如上图所示,公司共有四个业务线。
业务线A,有前端和后端开发。因为成员能力比较强,所以没有测试运维等职位;
业务线B倡导全栈技能,开发后台前端一体化;
业务线C的管理能力比较强,仅靠少量自有研发,加上大量的外包,能够完成一次性工作。
业务线D是传统的互联网方式,专人专岗,缺什么招什么,不提倡内部转岗
运行模式
业务线A缺人,缺项目,与业务线BCD无任何关系,不允许借调
业务线发展良好,会扩大规模;其他业务线同学想要加入需要经过复杂的流程,相当于重新找工作
业务线发展萎靡,会缩减人员,甚至会整体砍掉。优秀者会被打散吸收进其他业务线
好处
业务线之间存在竞争关系,团队成员有明确的奋斗目标和危机意识
一条业务线管理和产品上的失败,不会影响公司整体运营
可以比较容易的形成单向汇报的结构,避免成本巨大且有偏差的多重管理
便于复制成功的业务线,或者找准公司的发展重点
坏处
对业务线主要分管领导的要求非常高
多项技术和产品重复建设,容易造成人员膨胀,成本浪费
部门之间隔阂加大,共建、合作困难,与产品化相逆
业务线容易过度自治,脱离掌控
太激进,大量过渡事宜需要处理
修订
为了解决上面存在的问题,通常会有一个协调和监管部门,每个业务线,还需要有响应的协调人进行对接。以以往的观察来看,效果并不会太好。因为这样的协调,多陷于人情沟通,不好设计流程规范约束这些参与人的行为。
在公司未摸清发展方向之前,并不推荐此方式的改革。它的本意是通过竞争增加部门的进取心,通过充分授权和自治发挥骨干领导者的作用。但在未有成功案例之前,它的结果变成了:寄希望于拆分成多个小业务线,来解决原大业务线存在的问题。所以依然是处于不太确定的尝试行为。
2. 水平划分
水平划分方式,适合公司有确定的产品,并能够形成持续迭代的团队。
它的主要思想,是要打破“不会做饭的项目经理不是好程序员”的思维,形成专人专业专岗的制度。
这种方式经历了非常多的互联网公司实践,可以说是最节约研发成本,能动性最高的组织方式。主要是因为:
研发各司其职,做好自己的本职工作可以避免任务切换、沟通成本,达到整体最优
个人单向汇报,组织层级化,小组扁平化。“替领导负责,就是替公司负责”
任何职位有明确的JD,可替换性高,包括小组领导
这种方式最大的问题就是,对团队成员的要求都很高。主动性与专业技能都有要求,需要经过严格的面试筛选。
坏处
是否适合项目类公司,存疑
存在较多技术保障部门,公共需求 下沉容易造成任务积压
需要对其他部门进行整合,才能发挥更大的价值
分析
如上图,大体会分为三层。
技术保障,保障公司的底层技术支撑,问题处理和疑难问题解决。小组多但人少,职责分明
基础业务,公司的旗舰业务团队,需求变更小但任何改动都非常困难。团队人数适中
项目演化,纯项目,可以是一锤子买卖,也可以是服务升级,属于朝令夕改类需求的聚居地。人数最多
可以看到项目演化层,多是脏活,有些甚至是尝试性的项目-----这是合理的。
技术保障和基础业务的技术能力要求高,业务稳定,适合长期在公司发展,发展属性偏技术的人群,流动性小,招聘困难
项目演化层,业务多变,项目奖金或者其他回报波动大,人员流动性高,招聘容易
成功的孵化项目,会蜕变成产品,或者基础业务,并入基础业务分组。
从这种划分可以看出,一个人在公司的命运和发展,在招聘入职的时候就已经确定了。应聘人员可以根据公司的需求进行判断,提前预知自己的倾向。
互联网公司大多数将项目演化层的人员当作炮灰,因为他们招聘容易,团队组件迅速,但也有很多可能获得高额回报,这也是很多人看中的。
3.组合
组合一下垂直划分和层级划分,可以是下面这种效果。
采用层级+垂直方式进行架构。即:首选层级模式,然后在项目演化层采用垂直模式,也叫做业务线,拥有有限的自治权。
为每一个业务线配备一个与下层产品化或者技术保障对接的人员。
绩效方面,上层的需求为下层的实现打分。基础业务和技术保障,为绿色的协调人员打分。他们的利益是一致的。
End
大公司出来的并不一定是精英,小公司出来的也并不一定是渣渣。这取决于他在公司的位置和所从事的内容。核心部门会得到更多的利益,而边缘的尝试性部门只能吃一些残羹剩饭。退去公司的光环,加上平庸的项目经历,竞争力自然就打上一个折扣。
以上,仅限IT行业哦。赵家人不在此列。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
链接:https://juejin.cn/post/7203651773622452261
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 手写热修复dex
现有的热修复框架很多,尤以AndFix 和Tinker比较多
具体的实现方式和项目引用可以参考网络上的文章,今天就不谈,也不是主要目的
今天就来探讨,如何手写一个热修复的功能
对于简单的项目,不想集成其他修复框架的SDK,也不想用第三方平台,只是紧急修复一些bug
还是挺方便的
言归正传,如果一个或多个类出现bug,导致了崩溃或者数据显示异常,如果修复呢,如果熟悉jvm dalvik 类的加载机制,就会清楚的了解 ClassLoader的 双亲委托机制 就可以通过这个
什么是双亲委托机制
- 当前ClassLoader首先从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。
每个类加载器都有自己的加载缓存,当一个类被加载了以后就会放入缓存,等下次加载的时候就可以直接返回了。 - 当前classLoader的缓存中没有找到被加载的类的时候,委托父类加载器去加载,父类加载器采用同样的策略,首先查看自己的缓存,然后委托父类的父类去加载,一直到bootstrp ClassLoader.
- 当所有的父类加载器都没有加载的时候,再由当前的类加载器加载,并将其放入它自己的缓存中,以便下次有加载请求的时候直接返回。
突破口来了,看1(如果已经加载则直接返回原来已经加载的类)
对于同一个类,如果先加载修复的类,当后续在加载未修复的类的时候,直接返回修复的类,这样bug不就解决了吗?
Nice ,多看源码和jvm 许多问题可以从framework和底层去解决
话不多说,提出了解决方法,下面着手去实现
public class InitActivity extends FragmentActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//这里默认在SD卡根目录,实际开发过程中可以把dex文件放在服务器,在启动页下载后加载进来
//第二次进入的时候可以根据目录下是否已经下载过,处理,避免重新下载
//最后根据当前app版本下载不同的修复dex包 等等一系列处理
String dexFilePath = Environment.getExternalStorageDirectory().getAbsolutePath() + "/fix.dex";
DexFile dexFile = null;
try {
dexFile = DexFile.loadDex(dexFilePath, null, Context.MODE_PRIVATE);
} catch (IOException e) {
e.printStackTrace();
}
patchDex(dexFile);
startActivity(new Intent(this, MainActivity.class));
}
/**
* 修复过程,可以放在启动页,这样在等待的过程中,网络下载修复dex文件
*
* @param dexFile
*/
public void patchDex(DexFile dexFile) {
if (dexFile == null) return;
Enumeration<String> enumeration = dexFile.entries();
String className;
//遍历dexFile中的类
while (enumeration.hasMoreElements()) {
className = enumeration.nextElement();
//加载修复后的类,只能修复当前Activity后加载类(可以放入Application中执行)
dexFile.loadClass(className, getClassLoader());
}
}
}方法很简单在启动页,或者Application中提前加载有bug的类
这里写的很简单,只是展示核心代码,实际开发过程中,dex包下载的网络请求,据当前app版本下载不同的修复dex,文件存在的时候可以在Application中先加载一次,启动页就不用加载,等等,一系列优化和判断处理,这里就不过多说明,具体一些处理看github上的代码
###ok 代码都了解了,这个 fix.dex 文件哪里来的呢
熟悉Android apk生成的小伙伴都知道了,跳过这个步骤,不懂的小伙伴继续往下看
上面的InitActivity中startActivity(new Intent(this, MainActivity.class)); 启动了一个MainActivity
看看我的MainActivity
public class MainActivity extends FragmentActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//0不能做被除数,这里会报ArithmeticException异常
Toast.makeText(this, "结果" + 10 / 0, Toast.LENGTH_LONG).show();
}
}哎呀不小心,写了一个bug 0 咋能做除数呢,app已经上线了,这里必崩啊,咋办
不要急,按照以下步骤:
- 我们要修复这个类
MainActivity,先把bug解决
Toast.makeText(this, "结果" + 10 / 2, Toast.LENGTH_LONG).show();
- 把修复类生成
.class文件(可以先run一次,之后在 build/intermediates/javac/debug/classes/com开的的文件夹,找到生成的class文件,也可以通过javac 命令行生成,也可以通过右边的gradle Task生成)
- 把修复类
.class文件 打包成dex (其他.class删除,只保留修复类) 打开cmd命令行,输入下面命令
D:\Android\sdk\build-tools\28.0.3\dx.bat --dex --output C:\Users\pei\Desktop\dx\fix.dex C:\Users\pei\Desktop\dx\D:\Android\sdk 为自己sdk目录 28.0.3为build-tools版本,可以根据自己已经下载的版本更换
后面两个目录分别是生成.dex文件目录,和.class文件目录
切记
.class文件的目录必须是包名一样的,我的目录是C:\Users\pei\Desktop\dx\com\pei\test\MainActivity.class,不然会报class name does not match path
- 这样dx文件夹下就会生成fix.dex文件了,把fix.dex放进手机根目录试试吧
再次打开App,完美Toast 结果5,完美解决
总结
- 修复方法要在bug类之前执行
- 适合少量bug,太多bug影响性能
- 目前只能修复类,不能修复资源文件
- 目前只能适配单dex的项目,多dex的项目由于当前类和所有的引用类在同一个dex会 当前类被打上CLASS_ISPREVERIFIED标记,被打上这个标记的类不能引用其他dex中的类,否则就会报错
解决办法是在构造方法里引用一个单独的dex中的类,这样不符合规则就不会被标记了
链接:https://juejin.cn/post/7203989318271483960
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
新版Android Studio Logcat view使用简明教程
从Android Studio Dophin开始,Android Studio中的默认展示了新版的logcat。新版的logcat色彩上是更加的好看了,不同的tag会有不同的颜色,不同level等级的log默认也有不同的颜色。log过滤修改的更简洁了,当然使用起来也更加复杂了。原先的log视图只需要勾选就可以选择不同level的log了,只需要选择只展示当前应用的log就可以过滤掉其他应用的log了,但是新版只提供了一个输入框去过滤。在经过几个月的适应和对于官方文档的学习后,终于熟练使用,这里简单分享一下,让更多人更快入门。
定义自己专属的log view
log view 默认提供了两种视图,Standard View 和Compat View。Stand View会展示每一条log的日期,时间,进程线程id,tag,包名,log level以及message。Compat View只展示时间,log level和详细的message。可以通过log view左边的Configure Logcat Formatting Options按钮来修改,同时这个按钮中还有一个Modify Views选项可以来修改standard和 Compat视图的具体展示内容,可以定制自己的logview样式,如下图所示。
个性化的logcat 视图不仅仅是可以自定义展示的内容,还可以修改log和filter的配色方案。前往Settings(Windows)/Preferences(Mac) ->Editor -> Color Scheme,选择Android Logcat即可修改log 的颜色,选择Logcat Filter即可修改filter的颜色。
以上修改的是logcat view的外表,我们还可以修改它的内核,一个是logcat循环滚动区的大小,以及新logcat window的默认filter,可以通过前往Settings(Windows)/Preferences(Mac) -> Tools -> Logcat 设置。
一些操作技巧
在标准布局下,或者我们的log太长的时候,一屏通常展示不下,我们需要不停的向右滑动,滚动才能看到log的信息,我们可以用log view左侧的Soft-Wrap 按钮来让log换行。
左侧的Clear Logcat按钮可以清空logcat。左侧的Pause按钮可以暂停logcat的输出,方便看错误日志,可以避免关心的日志被新的日志冲掉。
新版本中,可以通过点击logcat tab右侧的New tab 按钮来同时创建多个logcat view窗口。这种方式创建的不能同时展示,而利用logcat view左侧的split Panels 按钮则可以创建多个窗口,并且同时展示。每一个窗口都可以设置自己要展示的连接设备,展示样式,以及过滤选项。这样就可以很方便的同时观察多种log。
通过键值对来过滤Log
新的过滤器,看起来简单,实际上更加复杂且强大了。通过Ctrl+Space按键可以查看系统建议的一些查询列表。这里介绍一下查询中会用到的键:
- tag: 匹配日志的tag字段
- package:匹配记录日志的软件包名,其中特殊值mine匹配当前打开项目对应的应用log。
- process:匹配记录日志的进程名
- message:匹配日志中我们自己填写的message的部分。
- level:与指定或者更高级别的日志匹配,比如debug或者error,输入level后as会自动提示可以选择。
- age:让窗口中只保留最近一段时间的log,值为数字加单位,s表示秒,m表示分钟,h表示小时,d表示天。如age:10s就只保留最近10s的日志。
- is: 这个键有两个固定的value取值,
crash匹配应用崩溃日志,stacktrace匹配任意类似java堆栈轨迹的日志,这两个对于看crash查问题是非常好用的。
这么多的键匹配,是可以逻辑组合的。我们可以使用&和|以及圆括号,系统会强制执行常规的运算符优先级。level:ERROR | tag:foo & package:mine 会被强转为level:ERROR | (tag:foo & package:mine ) 。如果我们没有填写逻辑运算符,查询语言会将多个具有相同键的非否定过滤视为OR,其他过滤视为AND。
如:
tag:fa tag:ba package:mine 计算逻辑是 (tag:fa | tag:ba) & package:mine
但tag:fa -tag:ba package:mine 计算逻辑是 tag:fa & -tag:ba & package:mine。这里的-用来表示否定,既tag不包含ba的情况。
新版的logcat view当然也是支持正则的,tag、message、package、process这几项是支持正则的。使用正则需要在键后面加一个~,例如: tag~:My.*Report。
除了正则这个选项之外,这几个键还有完全匹配和包含字符串即可的选项。不加修饰符号就是包含指定的字符串即可匹配。如果后面加=则要完全匹配才可以,例如process=:system_server和process:system_ser可以匹配到system_server的log,但是process=:system_ser则无法匹配到。
同时如上几个匹配选项都支持和前面说的否定符号连用如:-process=:system_server。
既然新版支持了这么复杂和强大过滤功能,如果每次都现想现写,那肯定是头皮发麻。as也为我们提供了收藏和历史记录功能。点击右侧的的星星按钮即可收藏当前的过滤条件,点击左侧的漏斗即可查看历史和收藏,并且可以删除不想要的记录。
切换回旧版log view
最后的最后,如果你觉得新版本适应不了,还是想要切换回旧版本的log view,还想要保留新版的android studio,也还是可以通过修改设置进行切换的。
前往Settings(Windows)/Preferences(Mac) -> Experimental, 反选Enable new logcat tool window 即可,如下图所示。
学习工具的目的,是为了让工具更好的为我们服务。希望大家都能够通过使用as提供的新功能来提高效率,从而有更多的时间去风花雪月。
链接:https://juejin.cn/post/7203336895886819388
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 逆向从入门到入yu
免责声明
本次技术分享仅用于逆向技术的交流与学习,请勿用于其他非法用途;技术是把双刃剑,请善用它。
逆向是什么、可以做什么、怎么做
简单讲,就是将别人打包好的 apk 进行反编译,得到源码并分析代码逻辑,最终达成自己的目的。
可以做的事:
- 修改 smali 文件,使程序达到自己想要的效果,重新编译签名安装,如去广告、自动化操作、电商薅羊毛、单机游戏修改数值、破解付费内容、汉化、抓包等
- 阅读源码,借鉴别人写好的技术实践
- 破解:小组件盒子:http://www.coolapk.com/apk/io.ifte…
怎么做:
- 这是门庞杂的技术活,需要知识的广度、经验、深度
- 需要具体问题,具体分析,有针对性的学习与探索
- 了解打包原理、ARM、Smali汇编语言
- 加固、脱壳
- Xposed、Substrate、Fridad等框架
- 加解密
- 使用好工具## 今日分享涉及工具
apktool:反编译工具
- 反编译:
apktool d <apkPath> o <outputPath> - 重新打包:
apktool b <fileDirPath> -o <apkPath> - 安装:
brew install apktool
- 反编译:
jadx:支持命令行和图形界面,支持apk、dex、jar、aar等格式的文件查看
apksigner:签名工具
Charles:抓包工具
- http://www.charlesproxy.com/
- Android 7 以上抓包 HTTPS ,需要手机 Root 后将证书安装到系统中
- Android 7 以下 HTTPS 直接抓
正题
正向编译
- java -> class -> dex -> apk
反向编译
- apk -> dex -> smali -> java
Smali 是 Android 的 Dalvik 虚拟机所使用的一种 dex 格式的中间语言
官方文档source.android.com/devices/tec…
正题开始,以反编译某瓣App为例:
jadx 查看 Java 源码,找到想修改的代码
反编译得到 smali 源码:
apktool d douban.apk -o doubancode --only-main-classes
修改:找到 debug 界面入口并打开
将修改后的 smali 源码正向编译成 apk:
apktool b doubancode -o douban_mock1.apk
重签名:
jarsigner -verbose -keystore keys.jks test.apk key0
此时的包不能正常访问接口,因为豆瓣 API 做了签名校验,而我们的新 apk 是用了新的签名,看接口抓包
怎么办呢?
继续分析代码,修改网络请求中的 apikey
来看看新的 apk
也可以做爬虫等
启发与防范
- 混淆
- 加固
- 加密
- 运行环境监测
- 不写敏感信息或操作到客户端
- App 运行签名验证
- Api 接口签名验证
One More Thing
工具分享:code.flyleft.cn/posts/3e3d8…
书籍分享:book.douban.com/subject/205…
进阶(下次分享):
- 静态调试
- 动态调试
- 脱壳
- NDK你想
- so文件修改
链接:https://juejin.cn/post/7202573260659163195
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
世界上最健康的程序员作息表!「值得一看」
昨晚看了一篇“传说中”的“世界上最健康的作息时间表”,开始纠结自己还要不要5点半起床。
都说程序员这一行,猝死概率极高,究其原因还是加班太狠、作息不规律、缺乏运动....
今天和大家分享一下这篇文章,还是非常值得参考的,随时提醒自己吧,毕竟身体可是自己的哦。
7:30
起床
英国威斯敏斯特大学的研究人员发现,那些在早上5:22-7:21分起床的人,其血液中有一种能引起心脏病的物质含量较高,因此,在7:21之后起床对身体健康更加有益。
(我是不是要调整作息时间了,不再是每天5点半起床,改成7点半吧~)
开灯
(这也是我家小孩晚上睡觉最爱说的话,晚上爱开灯睡觉,每次关灯讲故事,总会说:“开灯”。究其原因还是小孩不想睡觉,所以要“开灯”)
为什么要说上面小孩要开灯的例子呢?发现国外有位科学家也反馈了类似的理论:“一醒来,就将灯打开,这样将会重新调整体内的生物钟,调整睡眠和醒来模式。”拉夫堡大学睡眠研究中心教授吉姆·霍恩说。
开关灯就是一种信号:关灯的信号是告诉身体要睡觉,开灯的信号是告诉身体要起床啦。
喝水
喝一杯水:水是身体内成千上万化学反应得以进行的必需物质。早上喝一杯清水,可以补充晚上的缺水状态。
7:30-8:00
在早饭之前刷牙:“在早饭之前刷牙可以防止牙齿的腐蚀,因为刷牙之后,可以在牙齿外面涂上一层含氟的保护层。
要么,就等早饭之后半小时再刷牙。”英国牙齿协会健康和安全研究人员戈登·沃特金斯说。
8:00-8:30
吃早饭:“早饭必须吃,因为它可以帮助你维持血糖水平的稳定。” 伦敦大学国王学院营养师凯文·威尔伦说。早饭可以吃燕麦粥等,这类食物具有较低的血糖指数。
(我起床早的很大一部分动力就是吃早饭,晚上9点之后不吃东西只喝水。饿了就劝自己早点睡觉,明天吃一顿丰盛的早饭)
自从我坚持5点半起床和每天晚上9点之后不吃东西以后,体重从最高的170斤+,降到了最近的150斤-
8:30-9:00
避免运动
来自布鲁奈尔大学的研究人员发现,在早晨进行锻炼的运动员更容易感染疾病,因为免疫系统在这个时间的功能最弱。
(看来我不晨练是对的,哈哈哈~)
步行上班
马萨诸塞州大学医学院的研究人员发现,每天走路的人,比那些久坐不运动的人患感冒病的几率低25%。
(这段时间应该还在地铁上~)
9:30
开始一天中最困难的工作:纽约睡眠中心的研究人员发现,大部分人在每天醒来的一两个小时内头脑最清醒。
10:30
让眼睛离开屏幕休息一下:如果你使用电脑工作,那么每工作一小时,就让眼睛休息3分钟。
11:00
吃点水果:这是一种解决身体血糖下降的好方法。吃一个橙子或一些红色水果,这样做能同时补充体内的铁含量和维生素C含量。
12:00-13:00
干饭:你需要一顿可口的午餐,并且能够缓慢地释放能量。“烘烤的豆类食品富含纤维素,番茄酱可以当作是蔬菜的一部分。”维伦博士说。 (干饭人,干饭魂,干饭人吃饭得用盆)
13:00-14:00
午休一小会儿:雅典的一所大学研究发现,那些每天中午午休30分钟或更长时间,每周至少午休3次的人,因心脏病死亡的几率会下降37%。
16:00
喝杯酸奶:这样做可以稳定血糖水平。在每天三餐之间喝些酸牛奶,有利于心脏健康。 (看来我爱喝酸奶是个好习惯呀)
17:00-19:00
锻炼身体:根据体内的生物钟,这个时间是运动的最佳时间,舍菲尔德大学运动学医生瑞沃·尼克说。 (没错,这个时间段该下班了,通勤路上多走一走,少开车、少骑车)
19:30
晚餐少吃点:晚饭吃太多,会引起血糖升高,并增加消化系统的负担,影响睡眠。晚饭应该多吃蔬菜,少吃富含卡路里和蛋白质的食物。吃饭时要细嚼慢咽。
21:45
这个时间看会儿手机、电视放松一下,有助于睡眠,但要注意,尽量不要躺在床上看电视,这会影响睡眠质量。
或者睡前读读书,也挺好,正好我最近搞了免费送书活动,感兴趣可以参与一下:免费送3本书,肯定有你喜欢的
23:00
洗个热水澡:“体温的适当降低有助于放松和睡眠。”拉夫堡大学睡眠研究中心吉姆·霍恩教授说。
23:30
上床睡觉:如果你早上7点30起床,现在入睡可以保证你享受8小时充足的睡眠。
看到这里,我准备调整作息了,不再5点半就起床了,怕伤害我宝贵的小心脏。
时间、健康的小常识
要知道,任何试图更改生物钟的行为,都将给身体留下莫名其妙的疾病,等到20、30年之后再后悔,已经来不及了。下面再补充一些和时间、健康有关的小常识,继续供大家参考:
晚上9-11点为免疫系统(淋巴)排毒时间,此段时间应安静或听音乐。
晚间11-凌晨1点,肝的排毒,需在熟睡中进行。
凌晨1-3点,胆的排毒,亦同。
凌晨3-5点,肺的排毒。此即为何咳嗽的人在这段时间咳得最剧烈,因排毒动作已走到肺;不应用止咳药,以免抑制废积物的排出。
凌晨5-7点,大肠的排毒,应上厕所排便。
凌晨7-9点,小肠大量吸收营养的时段,应吃早餐。疗病者最好早吃,在6点半前,养生者在7点半前,不吃早餐者应改变习惯,即使拖到9、10点吃都比不吃好。
半夜至凌晨4点为脊椎造血时段,必须熟睡,不宜熬夜。
你的作息时间是怎么样的,或者你还知道哪些保持健康的好习惯,欢迎在评论区留言~
作者:王中阳Go
来源:juejin.cn/post/7200779100124921912
Android:面向单Activity开发
记得前一两年很多人都跟风面向单Activity开发,顾名思义,就是整个项目只有一个Activity。一个Activity里面装着N多个Fragment,再给Fragment加上转场动画,效果和多Activity跳转无异。其实想想还比较酷,以前还需要关注多个Acitivity之间的生命周期,现在只需关注一个,但还是需要对Fragment的生命周期进行关注。
其实早在六七年前GitHub上就有单Activity的开源库Fragmentation,后来谷歌也出了一个库Navigation。本来以为官方出品必为经典,当时跟着官方文档一步一步踩坑,最后还是放弃了该方案。理由大概如下:
- 需要创建XML文件,配置导航关系和跳转参数等
- 页面回退是重新创建,需要配合livedata使用
- 貌似还会存在卡顿,一些栈内跳转处理等问题
而Github上Fragmentation库已经停止维护,所幸的是再lssuse中发现了一个基于它继续维护的SFragmentation,于是正是开启了面向单Activity的开发。
提供了可滑动返回的版本
dependencies {
//请使用最新版本
implementation 'com.github.weikaiyun.SFragmentation:fragmentation:latest'
//滑动返回,可选
implementation 'com.github.weikaiyun.SFragmentation:fragmentation_swipeback:latest'
}
复制代码由于是Fragment之间的跳转,我们需要将原有的Activity跳转动画在框架初始化时设置到该框架中
Fragmentation.builder()
//设置 栈视图 模式为 (默认)悬浮球模式 SHAKE: 摇一摇唤出 NONE:隐藏, 仅在Debug环境生效
.stackViewMode(Fragmentation.BUBBLE)
.debug(BuildConfig.DEBUG)
.animation(
R.anim.public_translate_right_to_center, //进入动画
R.anim.public_translate_center_to_left, //隐藏动画
R.anim.public_translate_left_to_center, //重新出现时的动画
R.anim.public_translate_center_to_right //退出动画
)
.install()
复制代码因为只有一个Activity,所以需要在这个Activity中装载根Fragment
loadRootFragment(int containerId, SupportFragment toFragment)
复制代码但现在的APP几乎都是一个页面多个Tab组成的怎么办呢?
loadMultipleRootFragment(int containerId, int showPosition, SupportFragment... toFragments);
复制代码有了多个Fragment的显示,我们需要切换Tab实际也很简单
showHideFragment(ISupportFragment showFragment);
复制代码是不是使用起来很简单,首页我们解决了,关于跳转和返回、参数的接受和传递呢?
//启动目标fragment
start(SupportFragment fragment)
//带返回的启动方式
startForResult(SupportFragment fragment,int requestCode)
//接收返回参数
override fun onFragmentResult(requestCode: Int, resultCode: Int, data: Bundle?) {
super.onFragmentResult(requestCode, resultCode, data)
}
//返回到上个页面,和activity的back()类似
pop()
复制代码对于单Activity而言,我们其实也可以注册一个全局的Fragment监听,这样就能掌控当前的Fragmnet
supportFragmentManager.registerFragmentLifecycleCallbacks(
object : FragmentManager.FragmentLifecycleCallbacks() {
override fun onFragmentAttached(fm: FragmentManager, f: Fragment, context: Context) {
super.onFragmentAttached(fm, f, context)
}
override fun onFragmentCreated(
fm: FragmentManager,
f: Fragment,
savedInstanceState: Bundle?
) {
super.onFragmentCreated(fm, f, savedInstanceState)
}
override fun onFragmentStarted(fm: FragmentManager, f: Fragment) {
super.onFragmentStarted(fm, f)
}
override fun onFragmentResumed(fm: FragmentManager, f: Fragment) {
super.onFragmentResumed(fm, f)
}
override fun onFragmentDestroyed(fm: FragmentManager, f: Fragment) {
super.onFragmentDestroyed(fm, f)
}
},
true
)
复制代码接下来我们看看Pad应用。对于手机应用来说,一般不会存在局部页面跳转的情况,但是Pad上是常规操作。
如图,点击左边列表的单个item,右边需要显示详情,这时候再点左边的其他item,此时的左边页面是保持不动的,但右边的详情页需要跳转对应的页面。使用过Pad的应该经常见到这种页面,比如Pad的系统设置等页面。这时只使用Activty应该是不能实现的,必须配合Fragment,左右分为两个Fragment。
但问题又出现了,这时候点击back怎么区分局部返回和整个页面返回呢?
//整个页面回退,主要是用于当前装载了Fragment的页面回退
_mActivity.pop()
//局部回退,被装载的Fragment之间回退
pop()
复制代码如下图,这样的页面我们又应该怎么装载呢?
可以分析,页面最外面是一个Activty,要实现单Activity其内部必装载了一个根Fragment。接着这个根Fragment中使用ViewPage和tablayout完成主页框架。当前tab页要满足右边详情页的单独跳转,还得将右边页面作为主页面,以此装载子Fragment才能实现。
总结
单Activity开发在手机和平板上使用都一样,但在平板上注意的地方更多,尤其是平板一个页面可能是多个页面组成,其局部还能单独跳转的功能,其中涉及到参数回传和栈的回退问题。使用下来,我还是觉得某些页面对硬件要求很高的使用单Activity会出现体验不好的情况,有可能是优化不到位。手机应用我还是使用多Activity方式,平板应用则使用该框架实现单Activity方式。
链接:https://juejin.cn/post/7204100079430123557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
三行代码让你的git记录保持整洁
前言
笔者最近在主导一个项目的架构迁移工作,由于迁移项目的历史包袱较重,人员合作较多,在迁移过程中免不了进行多分支、多次commit的情况,时间一长,git的提交记录便混乱不堪,随便截一个图形化的git提交历史给大家感受一下。
各种分支疯狂打架宛如后宫争宠的妃子们,之所以会出现这种情况,主要还是因为滥用git merge命令并且不考虑后续的理解成本导致的。如今在大厂工作的程序员们,频繁接受变更的需求,一旦一开始考虑不周到,就一定会出现了大量无意义的commit log,加上“敏捷”理念的推广,产品的快速迭代上线变成了核心指标,这些无意义的commit log便被“下次再处理”,久而久之就混乱不堪了。
而我们在看一些开源仓库时,会发现他们的commit记录十分整洁,其实这并不是社区的程序员能力更强,而是因为他们没有KPI大棒的鞭笞,在提交代码前会花时间整理自己的commit log。而这就是本文的主角了——“Git Rebase”。
git rebase和git merge
git rebase,中文翻译为“变基”,通常用于分支合并。既然提到了分支合并,那就一定离不开git merge这个命令。
相信每个新手程序员刚进入职场的时候,都会听到“xxx你把这个分支merge一下”这样的话。那么问题来了,假如你有6个程序员一起工作, 你就会有6个程序员的分支, 如果你使用merge, 你的代码历史树就会有六个branch跟这个主的branch交织在一起。
上图是 git merge 操作的流程示意图,Merge命令会保留所有commit的历史时间。每个人对代码的提交是各式各样的。尽管这些时间对于程序本身并没有任何意义。但是merge的命令初衷就是为了保留这些时间不被修改。于是也就形成了以merge时间为基准的网状历史结构。每个分支上都会继续保留各自的代码记录,主分支上只保留merge的历史记录。子分支随时都有可能被删除。子分子删除以后,你能够看到的记录也就是,merge某branch到某branch上了。这个历史记录描述基本上是没有意义的。
而 git rebase 中文翻译为“变基”,变得这个基指的是基准。如何理解这个基准呢?我们看一下下图。
我们可以看到经过变基后的feature分支的基准分支发生了变化,变成了最新的master。这就是所谓的“变基”。
通过上面的两张图可以很明显的发现,这两种合并分支的方式最大的区别在于,merge后的分支,会保留两个分支的操作记录,这在git commit log 树中会以交叉的形式保存。而rebase后的分支会基于最新的master分支,从而不会形成分叉,自始至终都是一条干净的直线。
关于
git rebase和git merge的详细用法不在本文的介绍范围内,详情可以参考互联网上的其他资料。
在变基过程中,我们通常需要进行commit的修改,而这也为我们整理git记录提供了一个可选方案。
保持最近的几条记录整洁
假设我们有一个仓库,我在这个仓库里执行了4次提交,通过 git reflog 命令查看提交记录如下。
如果我们想将Commit-3、Commit-2和Commit-1的提交合并成一次提交(假设某次提交至改了一些pom文件),我们可以直接执行下面的命令
git rebase -i HEAD~3
复制代码-i 指的是 --interactive ,HEAD~3 指的是最近三次commit。
当然我们也可以直接指定最新的一个想保留的 Commit的ID,在上面的例子中就是Commit-0的ID,因此我们也可以写成
git rebase -i d2b9b78
复制代码执行该命令后,我们会进入到这么如下一个界面:
这个界面是一个Vim界面,我们可以在这个界面中查看、编辑变更记录。有关Vim的操作,可以看我之前写的文章和录制的视频👉《和Vim的初次见面》
在看前三行之前,我们先来看一下第5行的命令加深一下我们对git rebase的认识。
翻译过来就是,将d2b9b78..0e65e22这几个分支变基到d2b9b78这个分支,也就是将Commit-3/2/1/0这几次变更合并到Commit-0上。
回到前面三行,这三行表示的是我们需要操作的三个 Commit,每行最前面的是对该 Commit 操作的 Command。而每个命令指的是什么,命令行里都已经详细的告诉我们了。
pick:使用该commitsquash:使用该 Commit,但会被合并到前一个 Commit 当中fixup:就像squash那样,但会抛弃这个 Commit 的 Commit message
因此我们可以直接改成下面这样
这里使用fixup,而不是squash的主要原因是squash会让你再输入一遍commit的log,图省事的话,可以无脑选择fixup模式。
然后执行:wq退出vim编辑器,我们可以看到控制台已经输出Successful了。
这个时候我们再来看下log 记录,执行git log --oneline
于是最近三次的提交记录就被合并成一条提交记录了。
保持中间某些记录整洁
那如果不是最后的几个commit合并,而是中间连续的几个Commit记录,可以用上述方法整理合并吗?答案是可以的,只不过需要注意一下。
我们重新创建一个新的仓库
如果这次我们想将"third commit"和"second commit"合并为一个提交,其实和上面的方式一样,我们只需执行git rebase -i HEAD~3,然后将中间的提交改成fixup/squash模式即可,如下图所示:
之所以是HEAD~3,是因为我们要做的变更是基于first commit做的,因此我们也可以写成
git rebase -i a1f3929
我们来看下更改完的commit log,如下图所示:
是不是就干掉了third commit了。
三行代码让git提交记录保持整洁
上面我们都是在本地的git仓库中进行的commit记录整理,但是在实际的开发过程中,我们基本上都是写完就直接push到远程仓库了,那应该如何让远程的开发分支也保持记录的整洁呢?
第一种做法是在push代码前就做在本地整理好自己的代码,但是这种做法并不适用于那种本地无法部署,需要部署到远程环境才能调试的场景。
这时我们只需要执行git push -f命令,将自己的修改同步到远程分支即可。
-f是force强制的意思,之所以要强制推送是因为本地分支的变更和远程分支出现了分歧,需要用本地的变更覆盖远程的。
而远程分支更新后,如果其他人也在这条分支上更改的话,还需要执行一个git pull命令来同步远程分支。
这里我们来总结下让git提交记录保持整洁的三行代码。
git rebase -i xxx
git push -f
git pull
复制代码
❗️❗️❗️Tips:由于rebase和push -f是有些危险的操作,因此只建议在自己的分支上执行哦。
链接:https://juejin.cn/post/7203989318272237624
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
vue2实现带有阻尼下拉加载的功能
在vue中,需要绑定触发的事件
<div
id="testchatBox"
class="chatWrap"
:style="{paddingTop: chatScroollTop + 'px'}"
@touchstart="touchStart"
@touchmove="touchMove"
@touchend="touchEnd">
</div>代码片段使用到了三个回调函数:
touchstart: 手指触摸到屏幕的那一刻的时候
touchmove: 手指在屏幕上移动的时候
touchend: 手指离开屏幕的时候
从paddingTop可以看出,我们是通过控制这个容器距离的顶部的padding来实现下拉的效果。所以说我们的重调就是通过上面的三个回调函数来确定chatScroollTop的值。
通过chatScroollTop 这个命名就可以知道,我们这个下拉刷新是用在聊天框容器当中.
我们需要使用这些变量:
data() {
return {
chatScroollTop: 0, // 容器距离顶部的距离
isMove: false, // 是否处于touchmove状态
startY: 0, // 当前手指在屏幕中的y轴值
pageScrollTop: 0, // 滚动条当前的纵坐标
}
}三个回调函数对应三个阶段,而我们核心代码也分为三个部分:
第一部分:初始化当前容器的到顶部的距离,以及初始化当前是否处于滑动的状态,并获取当前滚动条的纵坐标。
touchStart(e) {
// e代表该事件对象,e.targetTouches[0].pageY可以拿到手指按下的 y轴点
this.startY = e.targetTouches[0].pageY
// 开启下拉刷新状态
this.isMove = false
this.pageScrollTop = document.documentElement && document.documentElement.scrollTop
}第二部分:根据当前手指当前距离触摸屏幕时刻的纵坐标差来确定容器和顶部的距离。但是由于不能一直的滑动,所以给了一个0 -> 80的氛围。为了让滑动更加的有趣,添加了一个step步进值来调整滑动的距离比例,所谓的距离比例就是手指距离一开始的距离越远,那么容量跟着滑动的距离就越短。实现一个类似阻尼的效果。
touchMove(e) {
// 这个 touchMove,只要页面在动都会发生的,所以 touching就起作用了
// 获取移动的距离
let diff = e.targetTouches[0].pageY - this.startY
let step = 60
if (diff > 0 && diff < 80 && this.pageScrollTop === 0) {
step++ // 越来越大
this.chatScroollTop += (diff / (step * 0.1)) // 越向下给人的阻力感越大
this.isMove = true
}
}第三部分:手指松开之后,给一个距离顶部的距离是为了添加加载滚动条。
touchEnd() {
if(this.isMove) {
this.chatScroollTop = 40
this.downCallback() // api拉取数据
}
}
async downCallback() {
try {
// 拿数据
} catch() {}
finall{
this.chatScrollTop = 0
}
}作者:砂糖橘加盐
来源:juejin.cn/post/7200388232106704952
柯里化到底是什么?
这本来是一篇柯里化的介绍文章,但是在我准备例子的时候,越写越不知道自己写什么。因为柯里化这个东西我现在无法真正的理解。所以这篇文章的标题其实是一个疑问句。
一、柯里化是什么?
有这么一道面试题:*实现一个add函数 满足add(1,2,3)与add(1)(2)(3)结果相同。*
实现如下:
const addCurry = (a) => (b) => (c) => a + b + c;
console.log(addCurry(1)(2)(3)) // 6
// 等同于
const addCurry = function (a) {
return function (b) {
return function (c) {
return a + b + c;
}
}
}就是利用闭包 的特性,函数运行之后不马上销毁对象来实现的。
再来一个进阶的,如果要同时满足add(1)(2, 3)、add(1, 2)(3)。实现如下:
const curry = (fn, ...args) =>
// 函数的参数个数可以直接通过函数数的.length属性来访问
args.length >= fn.length // 这个判断很关键!!!
// 传入的参数大于等于原始函数fn的参数个数,则直接执行该函数
? fn(...args)
/**
* 传入的参数小于原始函数fn的参数个数时
* 则继续对当前函数进行柯里化,返回一个接受所有参数(当前参数和剩余参数) 的函数
*/
: (..._args) => curry(fn, ...args, ..._args)
function add1(x, y, z) {
return x + y + z
}
const add = curry(add1)
console.log(add(1, 2, 3)) // 6
console.log(add(1)(2)(3)) // 6
console.log(add(1, 2)(3)) // 6
console.log(add(1)(2, 3)) // 6上面将fn(a, b, c) ⇒ fn(a)(b)(c)的过程就是柯里化。把前后两者当成一个黑盒子,它们就是完全等价的。
简单总结一下:
柯里化用在工具函数中,提高了函数使用的灵活性和可读性。
二、为什么我老记不住柯里化
因为我只当它是面试的知识点,而不是JS函数式的知识点。
我是这么记忆它的,通过面试题来进行记忆。看到对应的题目就会想到curry()函数。什么是八股文,就是固定的模版,我只用把题干中的参数放入函数当中。和我读书的时候做题很像,看到不同的题目,脑中切换对应的公式,然后从题干中找到变量,将其放入公式当中。这不正是应试。
所以每次面试完之后,就把这个东西给忘得一干二净。下一次面试的时候再来背一次,如此循环,周而复始。
面向面试去学习,不去真正的理解它,平时工作中真遇到了对应场景自然想不到。前端是一门手艺活,不去使用又怎么能够会呢?
JS是一个多范式的语法,柯里化就是我们要学习函数式的重要概念。
也就意味着我们想要真正的学会柯里化,必须要理解函数式解决了问题,它在我们写业务代码的时候如何运用上。
想要真正的理解柯里化的,我们需要知道「多参数函数」和「单参数函数」的概念。想要理解柯里化的作用,我们需要知道「函数组合」是什么?它相比其他方式能够带来什么优点。
我们在学习一个知识点的时候,它不是孤立的一个点,它不是为了面试题而存在的。知识点之间是有联系的,我们要做的就是将这些知识点串联起来,形成自己的知识体系。
三、如何更近一步的理解柯里化
仅就柯里化而言,我们需要学习函数式的思考逻辑,如何学习呢?
在《JavaScript忍者秘籍》说,函数是一等公民。这个是JS具有写函数式的必要条件。
这也意味着JS这种非纯粹的函数式语言仅仅是模拟罢了。和设计模式一样,脱胎于Java,多数设计模式对于JS的使用场景而言根本没有意义,甚至扭曲了本来的意义。
所以说,我们只有学习一门函数式的语言才能够真正的理解函数式,才能够更加的理解为何要柯里化。
正如设计模式之于Java,它本来就是基于Java开发而总结的。不通过Java来学习设计模式,而直接使用JS来学习,理解起来的难度是大于学习一个语言的难度的。
为了理解一些概念就要去学习一门语言么?
如果觉得学习语言已经是一个门槛的话,那么或许真如别人说的那样,前端就是切图仔了。
共勉!
作者:砂糖橘加盐
来源:juejin.cn/post/7204031026338414648
组内一次讨论,把我cpu干烧了
缘由
最近有次开会,谈到个人成长,也涉及到绩效的评定,大家探讨怎么拿到比较好的绩效,怎么有效的成长。有些同学提出了思考的这项能力,理论依据是通过对比,就是普通同学跟比较好的同学他们之间的差异是思考能力。
我是认可这种说法的,但是太泛了,有些东西一旦虚了就容易没有发力点。比如努力会有成就,那往哪方面努力呢?那努力一定会有收获吗?答案显而易见是否定的。
把蛋糕做大
1、角色角度
一般研发团队内部分几种:业务工程师、TL、架构师
业务工程师又分几个层次:第一层可以把活干好,任务按时交付;第二层对业务有较深理解,比如说对当前业务专业内容,对整个链路有清晰的了解,这个是为了解决问题的时候更加快捷;第三个层次是有pm的意识,大部分公司还是pm来主导,如果pm经验比较少,那么很容易把项目带偏了,研发如果有能力还是要具备pm意识。
TL:我认为它职责除了搞技术,还有就是管理,相当于资源管理者,撮合各方去完成任务
那么TL我认为比工程师多了一个管理的职责,还有项目管理、规划,团队任务拆分。技术上也不再局限个人,需要审查团队代码,制定代码规范,各个项目核心代码设计审查。
架构师:微软把架构师分为3种:企业架构师、解决方案架构师、基础架构师。日常最常见的就是后两者。解决方案架构师,比如说梳理整个功能的交互,系统之间的交互,制定合理的技术方案,思考风险点、扩容机制、落地关键步骤,它跟业务工程师又不一样,你需要具备知识面更广以应对各种突发情况,有所备案。
基础架构师,是为了规范各个团队之间协作,制定好规范,封装基础工具包,建设基础设施,让各个研发团队井井有条的运作。它更不一样了,它通过规范、框架来约束开发者动作,它不再局限项目或者某个团队,相当于房子的框架,发挥的作用也更大。
总结时刻
1、把蛋糕做大
你说思考能力是里面层次的影响因素,没有错,但是它放哪里都没有错,那就是没有意义的一个东西。我认为是把蛋糕做大。从上面几个例子,都在告诉我们他们产出的价值都在一层一层的叠加,这里面确实有思考的结果,但是如果思考的东西没有价值,那思考的意义在哪里?或者说思考出来的东西大佬不看好,那又有什么用?
把蛋糕做大,第一层意思就是价值在哪里,该往哪个方向去思考,第二层才是往下去推。
很忌讳一点:为了思考而思考,跟为了技术而技术一个道理。最近遇到一些不太愉快的事情,就是我整理个慢查询东西,一个同学觉得有些是在sql平台查的不需要优化,我觉得这个可以商量不用优化。但是有些同学非要揪着这些点,让我画个数据库架构图,里面select还要统一成dml。
虽然我了解我们数据库架构,它对慢查询改进很大作用吗?我能依靠这个去改架构吗?为了解释yearming平台sql不需要优化我们在那里搞了一天,目的体现有独特思考能力,这跟我的理念冲突了。
把蛋糕做大,我认为做技术有一点就是有成体系,有同学问我,这个项目你跟其他同学做有什么区别?慢查询里面可以发现团队里面连自己数据库规范都没有,包括一些索引都是重复的,需要推动团队规范建设,推动慢查询机制,这就是把蛋糕做大。
包括扣着读写分离不放,我因为主从节点说成读写,揪着不放,不要怀疑我的八股文,19年我面网易、阿里不虚的,只不过平时缺少知识点跟实际应用,揪着这些东西不可能把蛋糕做大。我画了这张图为了跟一个同学解释yearming的慢查询不需要优化,那我其他事情还用不用做了是吧。
2、提升特定的品质
每个岗位都有对应的要求,比如说业务工程师,那么业务能力是要拉满的;比如管理者,对项目管理,资源分配,推动事情能力拉满的。并不是我偏偏要去搞思考能力,逻辑是某个岗位特定的品质拉满。
富人跟穷人本质区别是什么?网上大部分人答案是思维方式不同。这里引用北京大爷的话,穷人变富人,那是很小几率,大富靠命,小富是心态好,知足常乐。
从上面的例子来看,并不是通过两个人对比,就可以看出个所以然。而是需要从群体来看,才能看清。
通才往往是平庸者,偏才成就会更突出,我认为这个世界并不是要你什么技能都去拉满,比如业务工程师很有思考能力,你都不近需求端,你思考对业务作用不是很大,而是在业务场景下技术思考会更有价值,就是这个场景怎么设计会更好。(一般公司还是业务驱动技术)
不同岗位拉满的技能也不一样
3、有时需要点运气,需要点机会
我身边很多业界大佬的,以前跟我聊的有些是技术TL、大厂的leader、开源社区头头,除了本身优秀之外,我认为还是需要点运气,刚好有那么一个机会去来当攻坚人,有机会去大厂磨练,在这之前需要练好自身的本事~
就像哪个富婆忽然看上我是吧,哈哈哈,赶紧把你们的富婆通讯录交出来~
成长的方向
1、不止是思考,而是有价值的思考
比如夏天我穿个短裤跟穿个长裤,对我影响不大,这确实可以体现思考多了,但是意义不大。
2、不要去乱点技能,要有自己的见解,发展特定技能
3、降维打击,也是把蛋糕做大,4维打3维,就像捏死一只蚂蚁,你说思考重要吗?重要,但是维度更重要,比如说一个点到一个体系,一个团队到各个团队协作,它对人品质有要求。
4、既然说到思考,就会涉及结构化思考,当然这也是个人弱项。
作者:大鸡腿同学
来源:https://juejin.cn/post/7203730887786348599
前端这样的时钟代码,简直就是炫技!
在网上收了一番,找到一个专门收集时钟代码的网站!
这里和大家分享一下!几十款各种各样好玩又酷炫的时钟代码!值得收藏!
概要
网站上的所有代码都来自 codepen 站点。作者把它们收集起来,统一呈现给大家。
作者把它们分为了三大类:BEAUTIFUL STYLE,CREATIVE DESIGN, ELECTRONIC CLOCK.
大师兄看了半天,觉得这分类带有强烈的个人偏好!毕竟大师兄觉得在BEAUTIFUL STYLE下的很多例子都很具有CREATIVE范儿!一起来看下吧!
BEAUTIFUL STYLE CLOCK
这个分类下的时钟,表现形式比较简朴,但不妨碍它的美感!
这个时钟的呈现方式其实也满富有创造力的
这个就像家里的挂钟一样
CREATIVE DESIGN
凡是归纳到这个分类下的设计,都是很具有创作力的!
米老鼠的手臂指着时针、分针,脚和尾巴有规律的动着
通过肢体的动作来表示时间,真是别具一格
ELECTRONIC CLOCK
这个分类就是电子时钟类别了!
如果你的页面需要电子时钟,直接来这个类别找吧!
重点说明
上面只是在每个类别中选了两个给大家展示。官网上还有其他几十种样式供大家学习!
另外,每个例子都有可参考的代码!
(伸手党们的福利!) 如果你现在的项目用不上!那赶紧找一款好看的时钟挂到你的博客主页上, 瞬间会让它变得高大上的。
作者:程序员老鱼
来源:juejin.cn/post/7202619396991352893
狂飙!Android 14 第一个预览版已发布~
前言
Android系统的更新速度真的是“一路狂飙”,23年2月8日,Android 14 第一个预览版本发布。Android 14 将继续致力于提高开发人员的工作效率,同时增强性能、隐私、安全性和用户自定义。
预计将会在八月份发布最终的Release版本
获取Android 14
如果你想获取Android 14系统可以使用下列Pixel系列设备
Pixel 4a (5G)
Pixel 5 and 5a
Pixel 6 and 6 Pro
Pixel 6a
Pixel 7 and 7 Pro
或者使用虚拟机的方式,因为家庭困难,所以这里我使用的是虚拟机的方式。
设置SDK
首先我们来安装Android 14 SDK,操作如下图所示。
安装好之后,设置编译版本和目标版本为Android 14 ,代码如下所示
android {
compileSdkPreview "UpsideDownCake"
defaultConfig {
targetSdkPreview "UpsideDownCake"
}
}
复制代码接着我们重点来看,第一个预览版本主要更新了哪些内容,重要分为对所有App的影响和目标版本为14的影响。
更新内容
所有App
安全
- 从Android 14开始,targetSdkVersion低于23的应用无法安装。
也就是说所有App的targetSdkVersion至少等于23,也就是要适配Android 6.0,这是因为Google考虑到部分应用恶意使用低级别的目标版本来规避隐私和安全权限。
辅助功能
- 从 Android 14 开始,系统支持高达 200% 的字体缩放。
这一目的是为弱视用户提供符合 Web 内容无障碍指南 (WCAG) 的额外无障碍选项。如果开发者已经使用缩放像素 (sp) 单位来定义文本大小,那么此更改可能不会对您的应用产生重大影响。
核心功能
- 默认情况下拒绝计划精确警报
精确警报用于用户有意的通知,或用于需要在精确时间发生的操作。 从 Android 14 开始,SCHEDULE_EXACT_ALARM 权限不再预先授予大多数新安装的针对 Android 13 及更高版本的应用程序——该权限默认情况下被拒绝。
- 上下文注册的广播在缓存应用程序时排队
在 Android 14 上,当应用处于缓存状态时,系统可能会将上下文注册的广播放入队列中,也就说,并不是注册之后广播就会直接启动,将根据系统使用情况来等待分配。
目标版本为Android 14的App
核心功能
- 需要前台服务类型
如果应用以 Android 14 为目标平台,则它必须为应用内的每个前台服务指定至少一种前台服务类型。
Android 14 还引入了用于健康和远程消息传递用例的前台服务类型。 该系统还为短服务、特殊用例和系统豁免保留新类型。
前台服务类型有很多,如下列所示:
connectedDevice
dataSync
health
location
mediaPlayback
mediaProjection
microphone
phoneCall
remoteMessaging
shortService
specialUse
systemExempted
其中health、remoteMessaging、shortService、specialUse 和 systemExempted 类型是 Android 14 中提供的新类型。
声明代码如下所示:
<manifest ...>
<uses-permission android:name="android.permission.FOREGROUND_SERVICE_TYPE_MEDIA_PLAYPACK" />
<application ...>
<service
android:name=".MyMediaPlaybackService"
android:foregroundServiceType="mediaPlayback"
android:permission="android.permission.FOREGROUND_SERVICE_TYPE_MEDIA_PLAYPACK"
android:exported="false">
</service>
</application>
</manifest>
Service.startForeground(0, notification, FOREGROUND_SERVICE_TYPE_LOCATION)
安全
对隐式意图的限制
应用程序必须使用明确的意图来交付给未导出的组件,或者将组件标记为已导出。
如果应用程序创建一个可变的挂起意图,但意图未指定组件或包,系统现在会抛出异常。
比如我们在配置文件中声明了一个exported为false的Activity,代码如下所示:
<activity
android:name=".AppActivity"
android:exported="false">
<intent-filter>
<action android:name="com.example.action.APP_ACTION" />
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</activity>
然后我们按照意图启动这个Activity,代码如下所示。
context.startActivity(Intent("com.example.action.APP_ACTION"))
那么很抱歉,这里将抛出一个异常。必须改为显示的Intent,代码如下所示:
val explicitIntent =
Intent("com.example.action.APP_ACTION")
explicitIntent.apply {
package = context.packageName
}
context.startActivity(explicitIntent)
- 更安全的动态代码加载
新增功能
联系人
Android 14 增加了以下两个字段:
Contract.Contacts#ENTERPRISE_CONTENT_URI
ContactsContract.CommonDataKinds.Phone#ENTERPRISE_CONTENT_URI
这些字段一起允许具有 READ_CONTACTS 权限的个人应用程序列出所有工作配置文件联系人和电话号码,只要 DevicePolicyManager 中的跨配置文件联系人策略允许。
写在最后
由于,昨天刚刚发布了第一个预览版本,所以我们能感觉到的变化不是太大,不过Android的方向一直都是在权限、隐私等方向。后续如何适配,我们只有等着官方稳定版本出来之后在讨论了~
Android系统更新如此迅速,你觉得这算是狂飙吗?
链接:https://juejin.cn/post/7198067983775973432
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2023面试真题之浏览器篇
人生当中,总有一个环节,要收拾你一下,让你尝一尝生活的铁拳
大家好,我是柒八九。
今天,我们继续2023前端面试真题系列。我们来谈谈关于浏览器的相关知识点。
如果,想了解该系列的文章,可以参考我们已经发布的文章。如下是往期文章。
你能所学到的知识点
- 浏览器的进程和线程 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
- 浏览器渲染过程 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
- Link rel= "prelaod" 推荐阅读指数⭐️⭐️⭐️⭐️
- cookie设置的几种方式 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
- cookie和session的区别和联系 推荐阅读指数⭐️⭐️⭐️⭐️
- 客户端缓存 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
- LightHouse v8/v9性能指标 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
好了,天不早了,干点正事哇。
浏览器的进程和线程
进程:某个应用程序的执行程序。
线程:常驻在进程内部并负责该进程部分功能的执行程序。
当你启动一个应用程序,对应的进程就被创建。进程可能会创建一些线程用于帮助它完成部分工作,新建线程是一个可选操作。在启动某个进程的同时,操作系统(OS)也会分配内存以用于进程进行私有数据的存储。该内存空间是和其他进程是互不干扰的。
有人的地方就会有江湖,如果想让多人齐心协力的办好一件事,就需要一个人去统筹这些工作,然后通过大喇叭将每个人的诉求告诉对方。而对于计算机而言,统筹的工作归OS负责,OS通过Inter Process Communication (IPC)的机制去传递消息。
网页中的主要进程
浏览器渲染过程(13步)
页面渲染起始标识
- 当垂直同步信号(VSync)被
排版线程接收到,新的屏幕渲染开始
- 当垂直同步信号(VSync)被
输入事件回调
- 输入事件的数据信息从
排版线程向主线程的事件回调中传递。 - 所有输入事件的回调(
touchmove/scroll/click)应该先被调用,并且每帧都应该触发,但是这不是必须的
- 输入事件的数据信息从
rAF(requestAnimationFrame)- 这是一个用于屏幕视觉更新的理想的位置。
- 因为,在此处能够获取到
垂直同步事件最新的输入数据。
{解析HTML|Parse HTML}
- 通过指定的解析器,将不能被浏览器识别的HTML文本,转换为浏览器能识别的数据结构:DOM对象。
重新计算样式
- 对新生成或被修改的元素进行样式信息计算。
- 生成CSSOM
- 将元素样式和DOM元素结合起来,就会生成
Render Tree
{布局|Layout}
- 计算每个可视元素的位置信息(距离视口的距离和元素本身大小)。
- 并生成对应的
Layout Tree。
{更新图层树|Update Layer Tree}
- 在
Render 树的基础上,我们会将拥有相同z 坐标空间的Layout Objects归属到同一个{渲染层|Paint Layer}中。 Paint Layer最初是用来实现{层叠上下文|Stacking Context}- 它主要来保证⻚面元素以正确的顺序合成。
- 在
{绘制|Paint}:
- 该过程包含两个过程,
- 第一个过程是绘制操作(
painting)- 该过程用于生成任何被新生成或者改动元素的绘制信息(包含图形信息和文本信息);
- 第二个过程是栅格化(
Rasterization),- 用于执行上一个过程生成的绘制信息。
{页面合成|Composite}:
- 将图层信息(
layer)和图块信息提交(commit)到合成线程(排版线程)中。并且在合成线程中会对一些额外的属性进行解释处理。 - 例如:某些元素被赋值
will-change或者一些使用了硬件加速的绘制方式(canvas)。
- 将图层信息(
{栅格化|Rasterize} :
- 在绘制阶段(
Paint)生成的绘制记录(Paint Record)被合成线程维护的{图块工作线程|Compositor Tile Worker}所消费。 - 栅格化是根据图层来完成的,而每个图层由多个图块组成。
- 在绘制阶段(
页面信息提交:
- 当页面中所有的图层都被栅格化,并且所有的图块都被提交到{合成线程|Compositor},此时{合成线程|Compositor}将这些信息连同输入数据(input data)一起打包,并发送到GPU线程。
页面显示:
- 当前页面的所有信息在
GPU中被处理,GPU会将页面信息传入到双缓存中的后缓存区,以备下次垂直同步信号到达后,前后缓存区相互置换。然后,此时屏幕中就会显示想要显示的页面信息。
- 当前页面的所有信息在
requestIdleCallback:如果在当前屏幕刷新过程中,主线程在处理完上述过程后还有剩余时间(<
16.6ms),此时主线程会主动触发requestIdleCallback。
Link rel= "prelaod"
元素的rel属性的preload值允许你在HTML的中声明获取请求,指定页面将很快需要的资源,你希望在页面生命周期的早期开始加载这些资源,在浏览器的主线程启动之前。这确保了它们更早可用,不太可能阻塞页面的呈现,从而提高了性能。即使名称包含术语load,它也不会加载和执行脚本,而只是安排以更高的优先级下载和缓存脚本。
将
rel属性设置为preload,它将转换为我们想要的任何资源的预加载器。
还需要指定其他的属性:
href属性设置资源的路径。as属性设置资源类型
"utf-8" />
"preload" href="style.css" as="style" />
"preload" href="main.js" as="script" />
复制代码预加载还有其他优点。使用as指定要预加载的内容类型允许浏览器:
- 更准确地优先考虑资源加载。
- 存储在缓存中以备将来的请求,并在适当时重用该资源。
- 对资源应用正确的内容安全策略(
CSP)。- 内容安全策略(CSP)是一个额外的安全层,它有助于检测和减轻某些类型的攻击,包括
- 跨站脚本(XSS)
- 数据注入攻击。
- 为它设置正确的
Accept请求标头。
预加载资源的类型(as的值类型)
cookie设置的几种方式
通常我们有两种方式给浏览器设置或获取Cookie:
- 第一种 通过
HTTP方式对Cookie进行赋值,又分为Request和Response:- HTTP Response Headers 中的
Set-CookieHeader - HTTP Request Headers 中的
CookieHeader
- HTTP Response Headers 中的
- 第二种 通过
JavaScript对document.cookie进行赋值或取值。
两种方式的区别
HTTP Cookie
Set-Cookie Header,除了必须包含Cookie正文,还可以选择性包含6个属性:
path、domain、max-age、expires、secure、httponly
它们之间用英文分号和空格("; ")连接;
JS Cookie
在浏览器端,通过 document.cookie 也可以设置Cookie,JS Cookie 的内容除了必须包含正文之外,还可选5个属性:
path、domain、max-age、expires、secure
JS 中设置
Cookie和HTTP方式相比较,少了对HttpOnly的控制,是因为 JS 不能读写HttpOnly Cookie。
http请求什么情况下会携带cookie
Cookie请求头字段是客户端发送请求到服务器端时发送的信息
如果满足下面几个条件:(domain/http/path)
- 浏览器端某个
Cookie的domain(.a.com) 字段等于请求的域名或者是请求的父域名,请求的域名需要是a.com/b.a.com才可以 - 都是
http或者https,或者不同的情况下Secure属性为false(即secure是true的情况下,只有https请求才能携带这个cookie) - 要发送请求的路径,跟浏览器端
Cookie的path属性必须一致,或者是浏览器端Cookie的path的子目录,- 比如浏览器端
Cookie的path为/test,那么请求的路径必须为/test或者/test/xxxx等子目录才可以
- 比如浏览器端
上面 3 个条件必须同时满足,否则该请求就不能自动带上浏览器端已存在的 Cookie
客户端怎么设置跨域携带 cookie
- 前端请求时在
request对象中- 配置
"withCredentials": true;
- 配置
- 服务端在
response的header中- 配置
"Access-Control-Allow-Origin", "http://xxx:${port}"; - 配置
"Access-Control-Allow-Credentials", "true"`
- 配置
cookie和session的区别和联系
Session比Cookie安全,Session是存储在服务器端的,Cookie是存储在客户端的
cookie数据存放在客户端,session数据放在服务器上。cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗- 考虑到安全应当使用
session
- 考虑到安全应当使用
session会在一定时间内保存在服务器上,当访问增多,会比较占用服务器的性能- 考虑性能应当使用
cookie
- 考虑性能应当使用
- 不同浏览器对
cookie的数据大小限制不同,个数限制也不相同。 - 可以考虑将登陆信息等重要信息存放为
session,不重要的信息可以放在cookie中。
客户端缓存
本地存储小容量
Cookie主要用于用户信息的存储,Cookie的内容可以自动在请求的时候被传递给服务器。- 服务器在响应 HTTP 请求时,通过发送
Set-CookieHTTP 头部包含会话信息。 - 浏览器会存储这些会话信息,并在之后的每个请求中都会通过 HTTP 头部
cookie再将它们发回服务器。 - 有一种叫作
HTTP-only的cookie。HTTP-only可以在浏览器设置,也可以在服务器设置,但只能在服务器上读取
- 服务器在响应 HTTP 请求时,通过发送
Web Storage- 提供在
cookie之外的存储会话数据的途径 - 提供跨会话持久化存储大量数据的机制
Web Storage的第 2 版定义了两个对象:- 1.
LocalStorage的数据将一直保存在浏览器内,直到用户清除浏览器缓存数据为止。 - 2.
SessionStorage的其他属性同LocalStorage,只不过它的生命周期同标签页的生命周期,当标签页被关闭时,SessionStorage也会被清除。 。
- 提供在
本地存储大容量
IndexDB:是浏览器中存储结构化数据的一个方案IndexedDB是类似于MySQL或Web SQL Database的数据库
WebSQL: 用于存储较大量数据的缓存机制。- 已废弃并且被
IndexDB所替代
- 已废弃并且被
Application Cache:允许浏览器通过manifest配置文件在本地有选择的存储JS/CSS/图片等静态资源的文件级缓存机制- 已废弃并且被
ServerWorkers所替代
- 已废弃并且被
ServerWorkers:离线缓存
{服务工作线程|Service Worker}
{服务工作线程|Service Worker}是一种类似浏览器中代理服务器的线程,可以拦截外出请求和缓存响应。这可以让网页在没有网络连接的情况下正常使用,因为部分或全部页面可以从服务工作线程缓存中提供服务。
服务工作线程在两个主要任务上最有用:
- 充当网络请求的缓存层
- 启用推送通知
在某种意义上
- 服务工作线程就是用于把网页变成像原生应用程序一样的工具
- 服务工作线程对大多数主流浏览器而言就是网络缓存
创建服务工作线程
ServiceWorkerContainer 没有通过全局构造函数创建,而是暴露了 register()方法,该方法以与 Worker()或 SharedWorker()构造函数相同的方式传递脚本 URL。
serviceWorker.js
// 处理相关逻辑
main.js
navigator.serviceWorker.register('./serviceWorker.js');
复制代码
register()方法返回一个Promise
- 该
Promise成功时返回ServiceWorkerRegistration对象- 在注册失败时拒绝
serviceWorker.js
// 处理相关逻辑
main.js
// 注册成功,成功回调(解决)
navigator.serviceWorker.register('./serviceWorker.js')
.then(console.log, console.error);
// ServiceWorkerRegistration { ... }
// 使用不存在的文件注册,失败回调(拒绝)
navigator.serviceWorker.register('./doesNotExist.js')
.then(console.log, console.error);
// TypeError: Failed to register a ServiceWorker:
// A bad HTTP response code (404) was received
// when fetching the script.
复制代码即使浏览器未全局支持服务工作线程,服务工作线程本身对页面也应该是不可见的。这是因为它的行为类似代理,就算有需要它处理的操作,也仅仅是发送常规的网络请求。
考虑到上述情况,注册服务工作线程的一种非常常见的模式是基于特性检测,并在页面的 load 事件中操作。
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker
.register('./serviceWorker.js');
});
}
复制代码如果没有
load事件做检测,服务工作线程的注册就会与页面资源的加载重叠,进而拖慢初始页面渲染的过程
使用 ServiceWorkerContainer 对象
ServiceWorkerContainer接口是浏览器对服务工作线程生态的顶部封装
ServiceWorkerContainer 始终可以在客户端上下文中访问:
console.log(navigator.serviceWorker);
// ServiceWorkerContainer { ... }
复制代码ServiceWorkerContainer 支持以下事件处理程序
oncontrollerchange:
在ServiceWorkerContainer触发controllerchange事件时会调用指定的事件处理程序。- 在获得新激活的
ServiceWorkerRegistration时触发。 - 可以使用
navigator.serviceWorker.addEventListener('controllerchange',handler)处理。
- 在获得新激活的
onerror:
在关联的服务工作线程触发ErrorEvent错误事件时会调用指定的事件处理程序。- 在关联的服务工作线程内部抛出错误时触发
- 也可以使用
navigator.serviceWorker.addEventListener('error', handler)处理
onmessage:
在服务工作线程触发MessageEvent事件时会调用指定的事件处理程序- 在服务脚本向父上下文发送消息时触发
- 也可以使用
navigator.serviceWorker.addEventListener('message', handler)处理
ServiceWorkerContainer 支持下列属性
ready:返回Promise- 成功时候返回激活的
ServiceWorkerRegistration对象。 - 该Promise不会拒绝
- 成功时候返回激活的
controller:
返回与当前页面关联的激活的ServiceWorker对象,如果没有激活的服务工作线程则返回null。
ServiceWorkerContainer 支持下列方法
register():
使用接收的url和options对象创建或更新ServiceWorkerRegistrationgetRegistration():返回Promise- 成功时候返回与提供的作用域匹配的
ServiceWorkerRegistration对象 - 如果没有匹配的服务工作线程则返回
undefined
- 成功时候返回与提供的作用域匹配的
getRegistrations():返回Promise- 成功时候返回与
ServiceWorkerContainer关联的ServiceWorkerRegistration对象的数组; - 如果没有关联的服务工作者线程则返回空数组。
- 成功时候返回与
startMessage():开始传送通过Client.postMessage()派发的消息
使用 ServiceWorkerRegistration 对象
ServiceWorkerRegistration 对象表示注册成功的服务工作线程。该对象可以在 register() 返回的解决Promise的处理程序中访问到。通过它的一些属性可以确定关联服务工作线程的生命周期状态。
调用 navigator.serviceWorker.register()之后返回的Promise会将注册成功的 ServiceWorkerRegistration 对象(注册对象)发送给处理函数。
在同一页面使用同一 URL 多次调用该方法会返回相同的注册对象:即该操作是幂等的
navigator.serviceWorker.register('./sw1.js')
.then((registrationA) => {
console.log(registrationA);
navigator.serviceWorker.register('./sw2.js')
.then((registrationB) => {
console.log(registrationA === registrationB);
// 这里结果为true
});
});
复制代码ServiceWorkerRegistration 支持以下事件处理程序
onupdatefound:
在服务工作线程触发updatefound事件时会调用指定的事件处理程序。- 在服务工作线程开始安装新版本时触发,表现为
ServiceWorkerRegistration.installing收到一个新的服务工作者线程 - 也可以使用
serviceWorkerRegistration.addEventListener('updatefound',handler)处理
- 在服务工作线程开始安装新版本时触发,表现为
LightHouse v8/v9性能指标 (6个)
FCP(First Contentful Paint)FCP衡量的是,在用户导航到页面后,浏览器呈现第一块DOM内容所需的时间。- 页面上的图片、非白色
元素和svg都被认为是DOM内容; iframe内的任何内容都不包括在内- 优化手段:缩短字体加载时间
SI(Speed Index)SI指数衡量内容在页面加载期间视觉显示的速度。Lighthouse首先在浏览器中捕获页面加载的视频,并计算帧之间的视觉进展- 优化手段:1. 减少主线程工作 2. 减少
JavaScript的执行时间
LCP(Largest Contentful Paint)LCP测量视口中最大的内容元素何时呈现到屏幕上。这接近于用户可以看到页面的主要内容
TTI(Time to Interactive)TTI测量一个页面变成完全交互式需要多长时间- 当页面显示
- 有用的内容(由First Contentful Paint衡量),
- 为大多数可见的页面元素注册了事件处理程序
- 并且页面在50毫秒内响应用户交互时,
- 页面被认为是完全交互式的。
TBT(Total Blocking Time)TBT测量页面被阻止响应用户输入(例如鼠标点击、屏幕点击或按下键盘)的总时间。总和是FCP和TTI之间所有长时间任务的阻塞部分之和- 任何执行时间超过 50 毫秒的任务都是长任务。50 毫秒后的时间量是阻塞部分。
- 例如,如果检测到一个 70 毫秒长的任务,则阻塞部分将为 20 毫秒。
CLS(Cumulative Layout Shift)- 累积布局偏移 (
CLS) 是测量视觉稳定性的一个以用户为中心的重要指标 - CLS 较差的最常见原因为:
- 1.无尺寸的图像
- 2.无尺寸的嵌入和
iframe - 3.动态注入的内容
- 优化手段1. 除非是对用户交互做出响应,否则切勿在现有内容的上方插入内容 2. 倾向于选择
transform动画
- 累积布局偏移 (
优化LCP
导致 LCP 不佳的最常见原因是:
- 缓慢的服务器响应速度
- 阻塞渲染的
JavaScript和CSS - 缓慢的资源加载速度
- 客户端渲染
缓慢的服务器响应速度
使用{首字节时间|Time to First Byte}(
TTFB) 来测量您的服务器响应时间
- 将用户路由到附近的
CDN - 缓存资产
- 如果
HTML是静态的,且不需要针对每个请求进行更改,那么缓存可以防止网页进行不必要的重建。通过在磁盘上存储已生成HTML的副本,服务器端缓存可以减少TTFB并最大限度地减少资源使用。 - 配置反向代理(Varnish、nginx)来提供缓存内容
- 使用提供边缘服务器的 CDN
- 如果
- 优先使用缓存提供 HTML 页面
- 安装好的
Service Worker会在浏览器后台运行,并可以拦截来自服务器的请求。此级别的程序化缓存控制使得缓存部分或全部 HTML 页面内容得以实现,并且只会在内容发生更改时更新缓存。
- 安装好的
- 尽早建立第三方连接
- 对第三方域的服务器请求也会影响
LCP,尤其是当浏览器需要这些请求来在页面上显示关键内容的情况下。 - 使用
rel="preconnect"来告知浏览器您的页面打算尽快建立连接。 - 还可以使用
dns-prefetch来更快地完成 DNS 查找。 - 尽管两种提示的原理不同,但对于不支持
preconnect的浏览器,可以考虑将dns-prefetch做为后备。
- 对第三方域的服务器请求也会影响
阻塞渲染的 JavaScript 和 CSS
- 减少
CSS阻塞时间- 削减
CSS:CSS文件可以包含空格、缩进或注释等字符。这些字符对于浏览器来说都不是必要的,而对这些文件进行削减能够确保将这些字符删除。使用模块打包器或构建工具,那么可以在其中包含一个相应的插件来在每次构建时削减 CSS 文件:对于webpack5:css-minimizer-webpack-plugin i - 延迟加载非关键
CSS:使用Chrome开发者工具中的代码覆盖率选项卡查找您网页上任何未使用的CSS。
对于任何初始渲染时不需要的CSS,使用loadCSS来异步加载文件,这里运用了rel="preload"和onload。 - 内联关键
CSS:把用于首屏内容的任何关键路径 CSS 直接包括在中来将这些CSS进行内联。
- 削减
- 减少
JavaScript阻塞时间- 缩小和压缩
JavaScript文件:
缩小是删除空格和不需要的代码,从而创建较小但完全有效的代码文件的过程。Terser是一种流行的JavaScript压缩工具;
压缩是使用压缩算法修改数据的过程。Gzip是用于服务器和客户端交互的最广泛使用的压缩格式。Brotli是一种较新的压缩算法,可以提供比Gzip更好的压缩结果。
静态压缩涉及提前压缩和保存资产。这会使构建过程花费更长的时间,尤其是在使用高压缩级别的情况下,但可确保浏览器获取压缩资源时不会出现延迟。如果您的web服务器支持Brotli,那么请使用BrotliWebpackPlugin等插件通过webpack压缩资产,将其纳入构建步骤。否则,请使用CompressionPlugin通过gzip压缩您的资产。 - 延迟加载未使用的
JavaScript
通过代码拆分减少JavaScript负载,-SplitChunksPlugin - 最大限度减少未使用的
polyfill
- 缩小和压缩
最大限度减少未使用的 polyfill
Babel 是最广泛使用的编译代码的工具,它将包含较新语法的代码编译成不同浏览器和环境都能理解的代码。
要使用 Babel 只传递用户需要的信息
- 确定浏览器范围
- 对
@babel/preset-env设置适当的浏览器目标 - 使用
我开源了一个好玩且好用的前端脚手架😏
经过半年的幻想,一个多月的准备,十天的开发,我终于开源了自己的脚手架。
背景
在我最开始学习 React 的时候,使用的脚手架就是 create-react-app,我想大部分刚开始学的时候都是使用这个脚手架吧。
使用这个脚手架挺适合新手的,零配置,执行该脚手架命令安装特定的模板,安装相关依赖包,通过执行 npm start 即可把项目运行起来。
但是这个脚手架在开发的过程中我要引入相对应的模块,例如要引入一个组件 import NiuBi from '../../../components/niubi.jsx',这个路径看起来就很丑,而且编写的时候极度困难,因此我们可以通过 Webpack 配置路径别名,可那时候我哪会配置 Webpack 啊,善于思考的我决定打开百度,发现可以使用 carco 配置 Webpack,但是发现 carco 版本和 react-script 版本并不兼容,因为这个问题把我折磨了一天,因此这个时刻我想自己去开源一个脚手架的想法从此诞生,虽然那时候的我技术非常菜,不过我现在的技术也菜,但是我胆子大啊!!!😏😏😏
所以在这里我总结一下 create-react-app 脚手架的一些缺点,但是这仅仅是个人观点:
难定制: 如果你需要自定义配置
Webpack,你需要额外使用第三方工具carco或者eject保留全部Webpack配置文件;模板单一: 模板少而且简单,这意味着我们每次开发都要从零开始;
那么接下来就来看看我的这个脚手架是怎么使用的。
基本使用
全局安装
npm install @obstinate/react-cli -g该脚手架提供的的全局指令为 crazy,查看该脚手架帮助,你可以直接使用:
crazy输入该命令后,输出的是整个脚手架的命令帮助,如下图所示:
创建项目
要想创建项目,你可以执行以下命令来根据你想要的项目:
crazy create <projectName> [options]例如创建一个名为 moment,如果当前终端所在的目录下存在同名文件时直接覆盖,你可以执行以下命令:
crazy create moment -f如果你不想安装该脚手架,你也可以使用 npx 执行,使用 npx @obstinate/react-cli 代替 crazy 命令,例如,你要创建一个项目,你可以执行以下命令:
npx @obstinate/react-cli create moment -f如果没有输入 -f,则会在后面的交互信息询问是否覆盖当前已存在的文件夹。
之后便有以下交互信息,你可以根据这些交互选择你想要的模板:
最终生成的文件如下图所示:
当项目安装完成之后你就可以根据控制台的指示去启动你的项目了。
创建文件
通过该脚手架你可以快速创建不同类型的文件,你可以指定创建文件的指定路径,否则则使用默认路径。
要想成创建创建文件,请执行以下指令:
crazy mkdir <type> [router]其中 type 为必选命令,为你要创建的文件类型,现在可供选择的有 axios、component、page、redux、axios,router 为可选属性,为创建文件的路径。
具体操作请看下列动图:
输入不同的类型会有不同的默认路径,并且无需你输入文件的后缀名,会根据你的项目生成相对应的文件后缀名,其中最特别的是创建 redux 文件会自动全局导入 reduxer,无需你自己手动导入,方便了日常的开发效率。
灵活配置
与 create-react-app 不同的是,该脚手架提供了自定义 Webpack 和 babel 配置,并通过 webpack-merge 对其进行合并,美中不足的是暂时并还没有提供 env 环境变量,要区分环境你可以在你通过脚手架下来的项目的 webpack.config.js 文件中这样操作:
// 开发环境
const isDevelopment = process.argv.slice(2)[0] === "serve";
module.exports = {
// ...
};最后一个小提示,如果全局安装失败,检查是否权限不够,可以通过管理员身份打开 cmd 即可解决。
这些就是目前仅有的功能,其他的功能正在逐渐开发中......
未来(画饼)
逐步优化用户体验效果,编写更完美的使用文档;
添加对
vue的支持;提供更多代码规范化配置选择,例如
husky;提供单元测试;
添加
env环境变量配置;增加更多的完美配置,减少用户对项目的额外配置;
添加更多的模板,例如后台管理系统;
将来会考虑开发一些配套的生态,例如组件库;
等等......
如何贡献
项目从开发到现在都是我自己一人在开发,但仅凭一己之力会慢慢变得疲惫,其实现在这个版本早在几天前就已经写好了,就单纯不想写文档一直拖到现在。
所以希望能在这里找到一些志同道合的朋友一起把这个脚手架完善,我希望在不久的将来能创造出一个比 create-react-app 更好玩且好用的脚手架。
本人的联系方式请查看评论区图片。
最后
本人是一个掘金的活跃用户,一天里可能就两三次上 GitHub,如果你联系不到我,如果你不想添加我微信好友你可以通过掘金里私信我,掘金私信有通知,如果我不忙,我可能很快就能回复到你。
如果该脚手架有什么问题或者有什么想法可以通过 Github 的 issue 给我留言。
如果觉得该项目对你有帮助,也欢迎你给个 star,让更多的朋友能看到。
如果本篇文章的点赞或者评论较高,后期会考虑出一期文章来讲解如何基于 pnpm + monorepo + webpack 开发的脚手架,如果本篇文章对你有帮助,希望你能随时点个赞,让更多的人看到!!!😉😉😉
最后贴上一些地址:
作者:Moment
来源:juejin.cn/post/7202891949380173880
10 个值得掌握的 reduce 技巧
作为一个前端开发者,一定有接触过 reduce 函数,它是一个强大而实用的数组方法,熟练掌握 reduce 的使用可以在开发中提高开发效率和代码质量。本文介绍的 reduce 的 10 个技巧值得拥有,可以让你少写很多代码!
reduce 方法在数组的每个元素上执行提供的回调函数迭代器。它传入前一个元素计算的返回值,结果是单个值,它是在数组的所有元素上运行迭代器的结果。
迭代器函数逐个遍历数组的元素,在每一步中,迭代器函数将当前数组值添加到上一步的结果中,直到没有更多元素要添加。
语法
参数包含回调函数和可选的初始值,如下:
array.reduce(callback(accumulator, currentValue[, index[, array]])[, initialValue])
callback(必须):执行数组中每个值(如果没有提供
initialValue则第一个值除外)的
reducer函数,包含四个参数
accumulator(必须):累计器累计回调的返回值; 它是上一次调用回调时返回的累积值,初始值可以通过initialValue定义,默认为数组的第一个元素值,累加器将保留上一个操作的值,就像静态变量一样currentValue(必须):数组中正在处理的元素index(可选):数组中正在处理的当前元素的索引。 如果提供了initialValue,则起始索引号为0,否则从索引1起始。注意:如果没有提供
initialValue,reduce会从索引1的地方开始执行callback方法,跳过第一个索引。如果提供initialValue,从索引0开始。array(可选):调用reduce()的数组
initialValue(可选):作为第一次调用callback函数时的第一个参数的值。 如果没有提供初始值,则将使用数组中的第一个元素。 在没有初始值的空数组上调用reduce将报错。
1. 计算数组的最大值和最小值
有很多种方式可以获取数组的最大值或最小值?
使用 Math.max 和 Math.min
使用 Math 的 API 是最简单的方式。
const arrayNumbers = [-1, 10, 6, 5, -3];
const max = Math.max(...arrayNumbers); // 10
const min = Math.min(...arrayNumbers); // -3
console.log(`max=${max}`); // max=10
console.log(`min=${min}`); // min=-3使用 reduce
一行代码,就可以实现与 Math 的 API 相同的效果。
const arrayNumbers = [-1, 10, 6, 5, -3];
const getMax = (array) => array.reduce((max, num) => (max > num ? max : num));
const getMin = (array) => array.reduce((max, num) => (max < num ? max : num));
const max = getMax(arrayNumbers); // 10
const min = getMin(arrayNumbers); // -3
console.log(`max=${max}`); // max=10
console.log(`min=${min}`); // min=-3或者写成一个函数:
const arrayNumbers = [-1, 10, 6, 5, -3];
const getMaxOrMin = (array, type = "min") =>
type === "max"
? array.reduce((max, num) => (max > num ? max : num))
: array.reduce((max, num) => (max < num ? max : num));
const max = getMaxOrMin(arrayNumbers, "max"); // 10
const min = getMaxOrMin(arrayNumbers, "min"); // -3
console.log(`max=${max}`); // max=10
console.log(`min=${min}`); // min=-32. 数组求和和累加器
使用 reduce ,可以轻松实现多个数相加或累加的功能。
// 数组求和
const sum = (...nums) => {
return nums.reduce((sum, num) => sum + num);
};
// 累加器
const accumulator = (...nums) => {
return nums.reduce((acc, num) => acc * num);
};
const arrayNumbers = [1, 3, 5];
console.log(accumulator(1, 2, 3)); // 6
console.log(accumulator(...arrayNumbers)); // 15
console.log(sum(1, 2, 3, 4, 5)); // 15
console.log(sum(...arrayNumbers)); // 93. 格式化搜索参数
获取 URL 种的搜索参数是经常要处理的功能。
// url https://www.devpoint.cn/index.shtml?name=devpoint&id=100
// 格式化 search parameters
{
name: "devpoint",
id: "100",
}常规方式
这是大多数人使用它的方式。
const parseQuery = (search = window.location.search) => {
const query = {};
search
.slice(1)
.split("&")
.forEach((it) => {
const [key, value] = it.split("=");
query[key] = decodeURIComponent(value);
});
return query;
};
console.log(parseQuery("?name=devpoint&id=100")); // { name: 'devpoint', id: '100' }使用 reduce
const parseQuery = (search = window.location.search) =>
search
.replace(/(^\?)|(&$)/g, "")
.split("&")
.reduce((query, it) => {
const [key, value] = it.split("=");
query[key] = decodeURIComponent(value);
return query;
}, {});
console.log(parseQuery("?name=devpoint&id=100")); // { name: 'devpoint', id: '100' }4. 反序列化搜索参数
当要跳转到某个链接并为其添加一些搜索参数时,手动拼接的方式不是很方便。如果要串联的参数很多,那将是一场灾难。
const searchObj = {
name: "devpoint",
id: 100,
// ...
};
const strLink = `https://www.devpoint.cn/index.shtml?name=${searchObj.name}&age=${searchObj.id}`;
console.log(strLink); // https://www.devpoint.cn/index.shtml?name=devpoint&age=100reduce 可以轻松解决这个问题。
const searchObj = {
name: "devpoint",
id: 100,
// ...
};
const stringifySearch = (search = {}) =>
Object.entries(search)
.reduce(
(t, v) => `${t}${v[0]}=${encodeURIComponent(v[1])}&`,
Object.keys(search).length ? "?" : ""
)
.replace(/&$/, "");
const strLink = `https://www.devpoint.cn/index.shtml${stringifySearch(
searchObj
)}`;
console.log(strLink); // https://www.devpoint.cn/index.shtml?name=devpoint&age=1005. 展平多层嵌套数组
如何展平多层嵌套数组吗?
const array = [1, [2, [3, [4, [5]]]]];
const flatArray = array.flat(Infinity);
console.log(flatArray); // [ 1, 2, 3, 4, 5 ]如果运行环境支持方法 flat ,则可以直接用,如果不支持,使用 reduce 也可以实现和flat一样的功能。
const array = [1, [2, [3, [4, [5]]]]];
const flat = (arrayNumbers) =>
arrayNumbers.reduce(
(acc, it) => acc.concat(Array.isArray(it) ? flat(it) : it),
[]
);
const flatArray = flat(array);
console.log(flatArray); // [ 1, 2, 3, 4, 5 ]6. 计算数组成员的数量
如何计算数组中每个成员的个数?即计算重复元素的个数。
const count = (array) =>
array.reduce(
(acc, it) => (acc.set(it, (acc.get(it) || 0) + 1), acc),
new Map()
);
const array = [1, 2, 1, 2, -1, 0, "0", 10, "10"];
console.log(count(array));这里使用了数据类型 Map ,关于 JavaScript 的这个数据类型,有兴趣可以阅读下文:
上面代码的输出结果如下:
Map(7) {
1 => 2,
2 => 2,
-1 => 1,
0 => 1,
'0' => 1,
10 => 1,
'10' => 1
}7.获取一个对象的多个属性
这是一个项目开发中比较常遇见的场景。通过 API 获取后端数据,前端很多时候只需要取其中部分的数据。
// 一个有很多属性的对象
const obj = {
a: 1,
b: 2,
c: 3,
d: 4,
e: 5,
// ...
};
// 只是想得到它上面的一些属性来创建一个新的对象
const newObj = {
a: obj.a,
b: obj.b,
c: obj.c,
d: obj.d,
// ...
};这个时候可以使用
reduce来解决。
/**
*
* @param {*} obj 原始对象
* @param {*} keys 需要获取的属性值列表,数组形式
* @returns
*/
const getObjectKeys = (obj = {}, keys = []) =>
Object.keys(obj).reduce(
(acc, key) => (keys.includes(key) && (acc[key] = obj[key]), acc),
{}
);
const obj = {
a: 1,
b: 2,
c: 3,
d: 4,
e: 5,
// ...
};
const newObj = getObjectKeys(obj, ["a", "b", "c", "d"]);
console.log(newObj); // { a: 1, b: 2, c: 3, d: 4 }8.反转字符串
反转字符串是面试中最常问到的 JavaScript 问题之一。
const reverseString = (string) => {
return string.split("").reduceRight((acc, s) => acc + s);
};
const string = "devpoint";
console.log(reverseString(string)); // tniopved9.数组去重
reduce 也很容易实现数组去重。
const array = [1, 2, 1, 2, -1, 10, 11];
const uniqueArray1 = [...new Set(array)];
const uniqueArray2 = array.reduce(
(acc, it) => (acc.includes(it) ? acc : [...acc, it]),
[]
);
console.log(uniqueArray1); // [ 1, 2, -1, 10, 11 ]
console.log(uniqueArray2); // [ 1, 2, -1, 10, 11 ]10. 模拟方法 flat
虽然现在的JavaScript有原生方法已经实现了对深度嵌套数组进行扁平化的功能,但是如何才能完整的实现扁平化的功能呢?下面就是使用 reduce 来实现其功能:
// 默认展开一层
Array.prototype.flat2 = function (n = 1) {
const len = this.length;
let count = 0;
let current = this;
if (!len || n === 0) {
return current;
}
// 确认当前是否有数组项
const hasArray = () => current.some((it) => Array.isArray(it));
// 每次循环后展开一层
while (count++ < n && hasArray()) {
current = current.reduce((result, it) => result.concat(it), []);
}
return current;
};
const array = [1, [2, [3, [4, [5]]]]];
// 展开一层
console.log(array.flat()); // [ 1, 2, [ 3, [ 4, [ 5 ] ] ] ]
console.log(array.flat2()); // [ 1, 2, [ 3, [ 4, [ 5 ] ] ] ]
// 展开所有
console.log(array.flat(Infinity)); // [ 1, 2, 3, 4, 5 ]
console.log(array.flat2(Infinity)); // [ 1, 2, 3, 4, 5 ]作者:天行无忌
来源:https://juejin.cn/post/7202935318457860151
前端程序员是怎么做物联网开发的(下)
mqttController.js
// const mqtt = require('mqtt')
$(document).ready(() => {
// Welcome to request my open interface. When the device is not online, the latest 2000 pieces of data will be returned
$.post("https://larryblog.top/api", {
topic: "getWemosDhtData",
skip: 0
},
(data, textStatus, jqXHR) => {
setData(data.res)
// console.log("line:77 data==> ", data)
},
);
// for (let i = 0; i <= 10; i++) {
// toast.showToast(1, "test")
// }
const options = {
clean: true, // true: 清除会话, false: 保留会话
connectTimeout: 4000, // 超时时间
// Authentication information
clientId: 'userClient_' + generateRandomString(),
username: 'userClient',
password: 'aa995231030',
// You are welcome to use my open mqtt broker(My server is weak but come on you). When connecting, remember to give yourself a personalized clientId to prevent being squeezed out
// Topic rule:
// baseName/deviceId/events
}
// 连接字符串, 通过协议指定使用的连接方式
// ws 未加密 WebSocket 连接
// wss 加密 WebSocket 连接
// mqtt 未加密 TCP 连接
// mqtts 加密 TCP 连接
// wxs 微信小程序连接
// alis 支付宝小程序连接
let timer;
let isShowTip = 1
const connectUrl = 'wss://larryblog.top/mqtt'
const client = mqtt.connect(connectUrl, options)
client.on('connect', (error) => {
console.log('已连接:', error)
toast.showToast("Broker Connected")
timer = setTimeout(onTimeout, 3500);
// 订阅主题
client.subscribe('wemos/dht11', function (err) {
if (!err) {
// 发布消息
client.publish('testtopic', 'getDHTData')
}
})
client.subscribe('home/status/')
client.publish('testtopic', 'Hello mqtt')
})
client.on('reconnect', (error) => {
console.log('正在重连:', error)
toast.showToast(3, "reconnecting...")
})
client.on('error', (error) => {
console.log('连接失败:', error)
toast.showToast(2, "connection failed")
})
client.on('message', (topic, message) => {
// console.log('收到消息:', topic, message.toString())
switch (topic) {
case "wemos/dht11":
const str = message.toString()
const arr = str.split(", "); // 分割字符串
const obj = Object.fromEntries(arr.map(s => s.split(": "))); // 转化为对象
document.getElementById("Temperature").innerHTML = obj.Temperature + " ℃"
optionTemperature.xAxis.data.push(moment().format("MM-DD/HH:mm:ss"))
optionTemperature.xAxis.data.length >= 100 && optionTemperature.xAxis.data.shift()
optionTemperature.series[0].data.length >= 100 && optionTemperature.series[0].data.shift()
optionTemperature.series[0].data.push(parseFloat(obj.Temperature))
ChartTemperature.setOption(optionTemperature, true);
document.getElementById("Humidity").innerHTML = obj.Humidity + " %RH"
optionHumidity.xAxis.data.push(moment().format("MM-DD/HH:mm:ss"))
optionHumidity.xAxis.data.length >= 100 && optionHumidity.xAxis.data.shift()
optionHumidity.series[0].data.length >= 100 && optionHumidity.series[0].data.shift()
optionHumidity.series[0].data.push(parseFloat(obj.Humidity))
ChartHumidity.setOption(optionHumidity, true);
break
case "home/status/":
$("#statusText").text("device online")
deviceOnline()
$(".statusLight").removeClass("off")
$(".statusLight").addClass("on")
clearTimeout(timer);
timer = setTimeout(onTimeout, 3500);
break
}
})
function deviceOnline() {
if (isShowTip) {
toast.showToast(1, "device online")
}
isShowTip = 0
}
function setData(data) {
// console.log("line:136 data==> ", data)
for (let i = data.length - 1; i >= 0; i--) {
let item = data[i]
// console.log("line:138 item==> ", item)
optionTemperature.series[0].data.push(item.temperature)
optionHumidity.series[0].data.push(item.humidity)
optionHumidity.xAxis.data.push(moment(item.updateDatetime).format("MM-DD/HH:mm:ss"))
optionTemperature.xAxis.data.push(moment(item.updateDatetime).format("MM-DD/HH:mm:ss"))
}
ChartTemperature.setOption(optionTemperature);
ChartHumidity.setOption(optionHumidity);
}
function onTimeout() {
$("#statusText").text("device offline")
toast.showToast(3, "device offline")
isShowTip = 1
document.getElementById("Temperature").innerHTML = "No data"
document.getElementById("Humidity").innerHTML = "No data"
$(".statusLight").removeClass("on")
$(".statusLight").addClass("off")
}
function generateRandomString() {
let result = '';
let characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
let charactersLength = characters.length;
for (let i = 0; i < 6; i++) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
}
return result;
}
});
showTip.js 是我发布在npm上的一个包,如果有需要可以自行npm下载
style.less
* {
padding: 0;
margin: 0;
color: #fff;
}
.app {
background: #1b2028;
width: 100vw;
height: 100vh;
display: flex;
flex-direction: column;
overflow: hidden;
#deviceStatus {
display: flex;
align-items: center;
gap: 10px;
padding: 20px;
.statusLight {
display: block;
height: 10px;
width: 10px;
border-radius: 100px;
background: #b8b8b8;
&.on {
background: #00a890;
}
&.off {
background: #b8b8b8;
}
}
}
.container {
width: 100%;
height: 0;
flex: 1;
display: flex;
@media screen and (max-width: 768px) {
flex-direction: column;
}
>div {
flex: 1;
height: 100%;
text-align: center;
#echartsViewTemperature,
#echartsViewHumidity {
width: 80%;
height: 50%;
margin: 10px auto;
// background: #eee;
}
}
}
}echarts.js 这个文件是我自己写的,别学我这种命名方式,这是反例
let optionTemperature = null
let ChartTemperature = null
$(document).ready(() => {
setTimeout(() => {
// waiting
ChartTemperature = echarts.init(document.getElementById('echartsViewTemperature'));
ChartHumidity = echarts.init(document.getElementById('echartsViewHumidity'));
// 指定图表的配置项和数据
optionTemperature = {
textStyle: {
color: '#fff'
},
tooltip: {
trigger: 'axis',
// transitionDuration: 0,
backgroundColor: '#fff',
textStyle: {
color: "#333",
align: "left"
},
},
xAxis: {
min: 0,
data: [],
boundaryGap: false,
splitLine: {
show: false
},
axisLine: {
lineStyle: {
color: '#fff'
}
}
},
yAxis: {
splitLine: {
show: false
},
axisTick: {
show: false // 隐藏 y 轴的刻度线
},
axisLine: {
show: false,
lineStyle: {
color: '#fff'
}
}
},
grid: {
// 为了让标尺和提示框在图表外面,需要将图表向外扩展一点
left: '10%',
right: '5%',
bottom: '5%',
top: '5%',
containLabel: true,
},
series: [{
// clipOverflow: false,
name: '温度',
type: 'line',
smooth: true,
symbol: 'none',
data: [],
itemStyle: {
color: '#00a890'
},
areaStyle: {
color: {
type: 'linear',
x: 0,
y: 0,
x2: 0,
y2: 1,
colorStops: [{
offset: 0,
color: '#00a89066' // 0% 处的颜色
}, {
offset: 1,
color: '#00a89000' // 100% 处的颜色
}],
global: false // 缺省为 false
}
},
hoverAnimation: true,
label: {
show: false,
},
markLine: {
symbol: ['none', 'none'],
data: [
{
type: 'average',
name: '平均值',
},
],
},
}]
};
optionHumidity = {
textStyle: {
color: '#fff'
},
tooltip: {
trigger: 'axis',
backgroundColor: '#fff',
textStyle: {
color: "#333",
align: "left"
},
},
xAxis: {
min: 0,
data: [],
boundaryGap: false,
splitLine: {
show: false
},
axisTick: {
//x轴刻度相关设置
alignWithLabel: true,
},
axisLine: {
lineStyle: {
color: '#fff'
}
}
},
yAxis: {
splitLine: {
show: false
},
axisTick: {
show: false // 隐藏 y 轴的刻度线
},
axisLine: {
show: false,
lineStyle: {
color: '#fff'
}
}
},
grid: {
// 为了让标尺和提示框在图表外面,需要将图表向外扩展一点
left: '5%',
right: '5%',
bottom: '5%',
top: '5%',
containLabel: true,
},
// toolbox: {
// feature: {
// dataZoom: {},
// brush: {
// type: ['lineX', 'clear'],
// },
// },
// },
series: [{
clipOverflow: false,
name: '湿度',
type: 'line',
smooth: true,
symbol: 'none',
data: [],
itemStyle: {
color: '#ffa74b'
},
areaStyle: {
color: {
type: 'linear',
x: 0,
y: 0,
x2: 0,
y2: 1,
colorStops: [{
offset: 0,
color: '#ffa74b66' // 0% 处的颜色
}, {
offset: 1,
color: '#ffa74b00' // 100% 处的颜色
}],
global: false // 缺省为 false
}
},
hoverAnimation: true,
label: {
show: false,
},
markLine: {
symbol: ['none', 'none'],
data: [
{
type: 'average',
name: '平均值',
},
],
},
}]
};
// 使用刚指定的配置项和数据显示图表。
ChartTemperature.setOption(optionTemperature);
ChartHumidity.setOption(optionHumidity);
}, 100)
});
当你看到这里,你应该可以在你的前端页面上展示你的板子发来的每一条消息了,但是还远远做不到首图上那种密密麻麻的数据,我并不是把页面开了一天,而是使用了后端和数据库存储了一部分数据。
后端
后端我们分为了两个部分,一个是nodejs的后端程序,一个是nginx代理,这里先讲代理,因为上一步前端的连接需要走这个代理
nginx
如果你没有使用https连接,那么可以不看本节,直接使用未加密的mqtt协议,如果你有自己的域名,且申请了ssl证书,那么可以参考我的nginx配置,配置如下
http {
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# SSL Settings
##
server {
listen 80;
server_name jshub.cn;
#将请求转成https
rewrite ^(.*)$ https://$host$1 permanent;
}
server {
listen 443 ssl;
server_name jshub.cn;
location / {
root /larryzhu/web/release/toolbox;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
location /mqtt {
proxy_pass http://localhost:8083;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
# SSL 协议版本
ssl_protocols TLSv1.2;
# 证书
ssl_certificate /larryzhu/web/keys/9263126_jshub.cn.pem;
# 私钥
ssl_certificate_key /larryzhu/web/keys/9263126_jshub.cn.key;
# ssl_ciphers ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384;
# ssl_ciphers AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256;
# 与False Start没关系,默认此项开启,此处减少抓包的干扰而关闭
# ssl_session_tickets off;
# return 200 "https ok \n";
}注意这只是部分配置,切不可全部覆盖你的配置。
如果你不会使用nginx,说明你无需配置 ssl ,直接使用 mqtt协议即可。
后端程序部分
这里以egg.js框架为例
首先需要下载egg.js的插件 egg-emqtt ,直接使用npm下载即可,详细配置和启用方法 参见 MQTT系列实践二 在EGG中使用mqtt
上面教程的方法并不全面,可以下载我的示例,仿照着写一下,因为内容相对复杂,地址:gitee.com/zhu_yongbo/…
其中还包含了 mysql 数据库的连接方法,内有我服务器的地址、mysql开放端口,用户名以及密码,我服务器还剩不到十天到期,有缘人看到我的文章可以对我的服务器为所欲为,没有什么重要数据。
mysql
mysql方面,只需要一个库,一个表即可完成全部工作
如图所示,不复杂,仿照我的建库即可
有一点,比较重要,因为mysql本身不适用于存储量级太大的数据,我们的数据重复的又比较多,可以考虑一下压缩算法,或者添加一个事件(每次插入时检查数据量是否超过一定值)。像我的板子大概正常累计运行了几天的时间(每两秒一条数据),到目前可以看到已经累计了七十万条数据了,如果不是因为我设置了插入事件,这个数据量已经可以明显影响查询速度了。
可以仿照我的事件,语句如下:
DELIMITER $$
CREATE TRIGGER delete_oldest_data
AFTER INSERT ON wemosd1_dht11
FOR EACH ROW
BEGIN
-- 如果数据量超过43200(每两秒插入一条,这是一天的量)条,调用存储过程删除最早的一条数据
IF (SELECT COUNT(*) FROM wemosd1_dht11) > 43200 THEN
CALL delete_oldest();
END IF;
END$$
DELIMITER ;
-- 创建存储过程
CREATE PROCEDURE delete_oldest()
BEGIN
-- 删除最早的一条数据
delete from wemosd1_dht11 order by id asc limit 1
END$$
DELIMITER ;BTW:这是chatGPT教我的,我只进行了一点小小的修改。
这样做会删除id比较小的数据,然后就会导致,id会增长的越来越大,好处是可以看到一共累计了多少条数据。但是如果你不想让id累计,那么可以选择重建id,具体做法,建议你咨询一下chatGPT
结语
至此,我们已经完成了前端、后端、设备端三端连通。
我们整体梳理一下数据是怎么一步一步来到我们眼前的:
首先wemos d1开发板会在DHT11温湿度传感器上读取温湿度值,然后开发板把数据通过mqtt广播给某topic,我们的前后端都订阅了此topic,后端收到后,把处理过的数据存入mysql,前端直接使用echarts进行展示,当前端启动时,还可以向后端程序查询历史数据,比如前8000条数据,之后的变化由在线的开发板提供,我们就得到了一个实时的,并且能看到历史数据的温湿度在线大屏。
作者:加伊juejin
来源:juejin.cn/post/7203180003471081531
前端程序员是怎么做物联网开发的(上)
前端程序员是怎么做物联网开发的
上图是我历时一周做的在线的温湿度可视化项目,可以查看截至目前往前一天的温度、湿度变化趋势,并且实时更新当前温湿度
本文可能含有知识诅咒
概述和基础讲解
该项目用到的技术有:
前端:jq、less、echarts、mqtt.js
后端:eggjs、egg-emqtt
数据库:mysql
服务器:emqx(mqtt broker)
硬件:
板子:wemos D1 R2(设计基于 Arduino Uno R3 , 搭载esp8266 wifi模块)
调试工具:mqttx、Arduino IDE v2.0.3 使用Arduino C开发
必备知识:
nodejs(eggjs框架)能面向业务即可
mysql 能写基本插入查询语句即可
C语言的基本语法了解即可
知道mqtt协议的运作方式即可
arduino 开发板或任何其他电路板的初步了解即可
简单介绍一下上面几个的知识点:
从来没有后端学习经验的同学,推荐一个全栈项目供你参考:vue-xmw-admin-pro ,该项目用到了 前端VUE、后端eggjs、mysql、redis,对全栈学习很有帮助。
mysql 只需要知道最简单的插入和查询语句即可,在本项目中,其实使用mongodb是更合适的,但是我为了方便,直接用了现成的mysql
即使你不知道C语言的基本语法,也可以在一小时内快速了解一下,知道简单的定义变量、函数、返回值即可
MQTT(消息队列遥测传输)是一种网络协议(长连接,意思就是除了客户端可以主动向服务器通信外,服务器也可以主动向客户端发起),也是基于TCP/IP的,适用于算力低下的硬件设备使用,基于发布\订阅范式的消息协议,具体示例如下:
当某客户端想发布消息时,图大概长这样:
由上图可知,当客户端通过验证上线后,还需要订阅主题,当某客户端向某主题发布消息时,只有订阅了该主题的客户端会收到broker的转发。
举一个简单的例子:你和我,还有他,我们把自己的名字、学号报告给门卫大爷(broker),门卫大爷就同意我们在警卫室玩一会,警卫室有无数块黑板(topic),我们每个人都可以向门卫请求:如果某黑板上被人写了字,请转告给我。门卫会记住每个人的要求,比如当你向一块黑板写了字(你向某topic发送了消息),所有要求门卫告诉的人都会被门卫告知你写了什么(如果你也要求被告知,那么也包括你自己)。
开发板可以被写入程序,程序可以使用简单的代码控制某个针脚的高低电平,或者读取某针脚的数据。
开始
购买 wemos d1开发板、DHT11温湿度传感器,共计19.3元。
使用arduino ide(以下简称ide) 对wemos d1编程需要下载esp8266依赖 参见:Arduino IDE安装esp8266 SDK
在ide的菜单栏选择:文件>首选项>其他开发板管理器地址填入:arduino.esp8266.com/stable/pack…,可以顺便改个中文
安装ch340驱动参见: win10 安装 CH340驱动 实测win11同样可用
使用 micro-usb 线,连接电脑和开发板,在ide菜单中选择:工具>开发板>esp8266>LOLIN(WEMOS) D1 R2 & mini
选择端口,按win+x,打开设备管理器,查看你的ch340在哪个端口,在ide中选择对应的端口
当ide右下角显示LOLIN(WEMOS) D1 R2 & mini 在comXX上时,连接就成功了
打开ide菜单栏 :文件>示例>esp8266>blink,此时ide会打开新窗口,在新窗口点击左上角的上传按钮,等待上传完成,当板子上的灯一闪一闪,就表明:环境、设置、板子都没问题,可以开始编程了,如果报错,那么一定是哪一步出问题了,我相信你能够根据错误提示找出到底是什么问题,如果实在找不出问题,那么可能买到了坏的板子(故障率还是蛮高的)
wemos d1 针脚中有一个 3.3v电源输出,三个或更多的GND接地口,当安装DHT11传感器元件时,需要将正极插入3.3v口,负极插入GND口,中间的数据线插入随便的数字输入口,比如D5口(D5口的PIN值是14,后面会用到)。
使用DHT11传感器,需要安装库:DHT sensor library by Adafruit , 在ide的左侧栏中的库管理中直接搜索安装即可
下面是一个获取DHT11数据的简单示例,如果正常的话,在串口监视器中,会每秒输出温湿度数据
#include "DHT.h" //这是依赖或者叫库,或者叫驱动也行
#include "string.h"
#define DHTPIN 14 // DHT11数据引脚连接到D5引脚 D5引脚的PIN值是14
#define DHTTYPE DHT11 // 定义DHT11传感器
DHT dht(DHTPIN, DHTTYPE); //初始化传感器
void setup() {
Serial.begin(115200);
//wemos d1 的波特率是 115200
pinMode(BUILTIN_LED, OUTPUT); //设置一个输出的LED
dht.begin(); //启动传感器
}
char* getDHT11Data() {
float h = dht.readHumidity(); //获取湿度值
float t = dht.readTemperature(); //获取温度值
static char data[100];
if (isnan(h) || isnan(t)) {
Serial.println("Failed to read from DHT sensor!");
sprintf(data, "Temperature: %.1f, Humidity: %.1f", 0.0, 0.0); //如果任何一个值没有值,直接返回两个0.0,这样我们就知道传感器可能出问题了
return data;
}
sprintf(data, "Temperature: %.1f, Humidity: %.1f", t, h); //正常就取到值,我这里拼成了一句话
return data;
}
void loop() {
char* data = getDHT11Data(); //此处去取传感器值
Serial.println("got: " + String(data)); // 打印主题内容
delay(1000); //每次循环延迟一秒
}继续
到了这一步,如果你用的是普通的arduino uno r3板子,就可以结束了。
取到数据之后,你就可以根据数据做一些其他的事情了,比如打开接在d6引脚上的继电器,而这个继电器控制着一个加湿器。
如果你跟我一样,使用了带wifi网络的板子,就可以继续跟我做。
我们继续分步操作:
设备端:
引入esp8266库(上面已经提到安装过程)
#include "ESP8266WiFi.h"
复制代码
安装mqtt客户端库 ,直接在库商店搜索 PubSubClient ,下载 PubSubClient by Nick O'Leary 那一项,下载完成后:
#include "PubSubClient.h"
复制代码
至此,库文件已全部安装引入完毕
设置 wifi ssid(即名字) 和 密码,如:
char* ssid = "2104";
char* passwd = "13912428897";
复制代码
尝试连接 wifi
WiFiClient espClient;
int isConnect = 0;
void connectWIFI() {
isConnect = 0;
WiFi.mode(WIFI_STA); //不知道什么意思,照着写就完了
WiFi.begin(ssid, passwd); //尝试连接
int timeCount = 0; //尝试次数
while (WiFi.status() != WL_CONNECTED) { //如果没有连上,继续循环
for (int i = 200; i <= 255; i++) {
analogWrite(BUILTIN_LED, i);
delay(2);
}
for (int i = 255; i >= 200; i--) {
analogWrite(BUILTIN_LED, i);
delay(2);
}
// 上两个循环共计200ms左右,在控制LED闪烁而已,你也可以不写
Serial.println("wifi connecting......" + String(timeCount));
timeCount++;
isConnect = 1; //每次都需要把连接状态码设置一下,只有连不上时设置为0
// digitalWrite(BUILTIN_LED, LOW);
if (timeCount >= 200) {
// 当40000毫秒时还没连上,就不连了
isConnect = 0; //设置状态码为 0
break;
}
}
if (isConnect == 1) {
Serial.println("Connect to wifi successfully!" + String("SSID is ") + WiFi.SSID());
Serial.println(String("mac address is ") + WiFi.macAddress());
// digitalWrite(BUILTIN_LED, LOW);
analogWrite(BUILTIN_LED, 250); //设置LED常亮,250的亮度对我来说已经很合适了
settMqttConfig(); //尝试连接mqtt服务器,在下一步有详细代码
} else {
analogWrite(BUILTIN_LED, 255); //设置LED常灭,不要问我为什么255是常灭,因为我的灯是高电平熄灭的
//连接wifi失败,等待一分钟重连
delay(60000);
}
}
复制代码
尝试连接 mqtt
const char* mqtt_server = "larryblog.top"; //这里是我的服务器,当你看到这篇文章的时候,很可能已经没了,因为我的服务器还剩11天到期
const char* TOPIC = "testtopic"; // 设置信息主题
const char* client_id = "mqttx_3b2687d2"; //client_id不可重复,可以随便取,相当于你的网名
PubSubClient client(espClient);
void settMqttConfig() {
client.setServer(mqtt_server, 1883); //设定MQTT服务器与使用的端口,1883是默认的MQTT端口
client.setCallback(onMessage); //设置收信函数,当订阅的主题有消息进来时,会进这个函数
Serial.println("try connect mqtt broker");
client.connect(client_id, "wemos", "aa995231030"); //后两个参数是用户名密码
client.subscribe(TOPIC); //订阅主题
Serial.println("mqtt connected"); //一切正常的话,就连上了
}
//收信函数
void onMessage(char* topic, byte* payload, unsigned int length) {
Serial.print("Message arrived [");
Serial.print(topic); // 打印主题信息
Serial.print("]:");
char* payloadStr = (char*)malloc(length + 1);
memcpy(payloadStr, payload, length);
payloadStr[length] = '\0';
Serial.println(payloadStr); // 打印主题内容
if (strcmp(payloadStr, (char*)"getDHTData") == 0) {
char* data = getDHT11Data();
Serial.println("got: " + String(data)); // 打印主题内容
client.publish("wemos/dht11", data);
}
free(payloadStr); // 释放内存
}
复制代码
发送消息
client.publish("home/status/", "{device:client_id,'status':'on'}");
//注意,这里向另外一个主题发送的消息,消息内容就是设备在线,当有其他的客户端(比如web端)订阅了此主题,便能收到此消息
复制代码
至此,板子上的代码基本上就写完了,完整代码如下:
#include "ESP8266WiFi.h"
#include "PubSubClient.h"
#include "DHT.h"
#include "string.h"
#define DHTPIN 14 // DHT11数据引脚连接到D5引脚
#define DHTTYPE DHT11 // DHT11传感器
DHT dht(DHTPIN, DHTTYPE);
char* ssid = "2104";
char* passwd = "13912428897";
const char* mqtt_server = "larryblog.top";
const char* TOPIC = "testtopic"; // 订阅信息主题
const char* client_id = "mqttx_3b2687d2";
int isConnect = 0;
WiFiClient espClient;
PubSubClient client(espClient);
long lastMsg = 0;
void setup() {
Serial.begin(115200);
// Set WiFi to station mode
connectWIFI();
pinMode(BUILTIN_LED, OUTPUT);
dht.begin();
}
char* getDHT11Data() {
float h = dht.readHumidity();
float t = dht.readTemperature();
static char data[100];
if (isnan(h) || isnan(t)) {
Serial.println("Failed to read from DHT sensor!");
sprintf(data, "Temperature: %.1f, Humidity: %.1f", 0.0, 0.0);
return data;
}
sprintf(data, "Temperature: %.1f, Humidity: %.1f", t, h);
return data;
}
void connectWIFI() {
isConnect = 0;
WiFi.mode(WIFI_STA);
WiFi.begin(ssid, passwd);
int timeCount = 0;
while (WiFi.status() != WL_CONNECTED) {
for (int i = 200; i <= 255; i++) {
analogWrite(BUILTIN_LED, i);
delay(2);
}
for (int i = 255; i >= 200; i--) {
analogWrite(BUILTIN_LED, i);
delay(2);
}
// 上两个循环共计200ms左右
Serial.println("wifi connecting......" + String(timeCount));
timeCount++;
isConnect = 1;
// digitalWrite(BUILTIN_LED, LOW);
if (timeCount >= 200) {
// 当40000毫秒时还没连上,就不连了
isConnect = 0;
break;
}
}
if (isConnect == 1) {
Serial.println("Connect to wifi successfully!" + String("SSID is ") + WiFi.SSID());
Serial.println(String("mac address is ") + WiFi.macAddress());
// digitalWrite(BUILTIN_LED, LOW);
analogWrite(BUILTIN_LED, 250);
settMqttConfig();
} else {
analogWrite(BUILTIN_LED, 255);
//连接wifi失败,等待一分钟重连
delay(60000);
}
}
void settMqttConfig() {
client.setServer(mqtt_server, 1883); //设定MQTT服务器与使用的端口,1883是默认的MQTT端口
client.setCallback(onMessage);
Serial.println("try connect mqtt broker");
client.connect(client_id, "wemos", "aa995231030");
client.subscribe(TOPIC);
Serial.println("mqtt connected");
}
void onMessage(char* topic, byte* payload, unsigned int length) {
Serial.print("Message arrived [");
Serial.print(topic); // 打印主题信息
Serial.print("]:");
char* payloadStr = (char*)malloc(length + 1);
memcpy(payloadStr, payload, length);
payloadStr[length] = '\0';
Serial.println(payloadStr); // 打印主题内容
if (strcmp(payloadStr, (char*)"getDHTData") == 0) {
char* data = getDHT11Data();
Serial.println("got: " + String(data)); // 打印主题内容
client.publish("wemos/dht11", data);
}
free(payloadStr); // 释放内存
}
void publishDhtData() {
char* data = getDHT11Data();
Serial.println("got: " + String(data)); // 打印主题内容
client.publish("wemos/dht11", data);
delay(2000);
}
void reconnect() {
Serial.print("Attempting MQTT connection...");
// Attempt to connect
if (client.connect(client_id, "wemos", "aa995231030")) {
Serial.println("reconnected successfully");
// 连接成功时订阅主题
client.subscribe(TOPIC);
} else {
Serial.print("failed, rc=");
Serial.print(client.state());
Serial.println(" try again in 5 seconds");
// Wait 5 seconds before retrying
delay(5000);
}
}
void loop() {
if (!client.connected() && isConnect == 1) {
reconnect();
}
if (WiFi.status() != WL_CONNECTED) {
connectWIFI();
}
client.loop();
publishDhtData();
long now = millis();
if (now - lastMsg > 2000) {
lastMsg = now;
client.publish("home/status/", "{device:client_id,'status':'on'}");
}
// Wait a bit before scanning again
delay(1000);
}服务器
刚才的一同操作很可能让人一头雾水,相信大家对上面mqtt的操作还是一知半解的,不过没有关系,通过对服务端的设置,你会对mqtt的机制了解的更加透彻
我们需要在服务端部署 mqtt broker,也就是mqtt的消息中心服务器
在网络上搜索 emqx , 点击 EMQX: 大规模分布式物联网 MQTT 消息服务器 ,这是一个带有可视化界面的软件,而且画面特别精美,操作特别丝滑,功能相当强大,使用起来基本上没有心智负担。点击立即下载,并选择适合你的服务器系统的版本:
这里拿 ubuntu和windows说明举例,相信其他系统也都大差不差
在ubuntu上,推荐使用apt下载,按上图步骤操作即可,如中途遇到其他问题,请自行解决
sudo ufw status 查看开放端口,一般情况下,你只会看到几个你手动开放过的端口,或者只有80、443端口
udo ufw allow 18083 此端口是 emqx dashboard 使用的端口,开启此端口后,可以在外网访问 emqx看板控制台
当你看到如图所示的画面,说明已经开启成功了
windows下直接下载安装包,上传到服务器,双击安装即可
打开 “高级安全Windows Defender 防火墙”,点击入站规则>新建规则
点击端口 > 下一步
点击TCP、特定本地端口 、输入18083,点击下一步
一直下一步到最后一步,输入名称,推荐输入 emqx 即可
当你看到如图所示画面,说明你已经配置成功了。
完成服务端程序安装和防火墙端口配置后,我们需要配置服务器后台的安全策略,这里拿阿里云举例:
如果你是 ESC 云主机,点击实例>点击你的服务器名>安全组>配置规则>手动添加
添加这么一条即可:
如果你是轻量服务器,点击安全>防火墙>添加规则 即可,跟esc设置大差不差。
完成后,可以在本地浏览器尝试访问你的emqx控制台
直接输入域名:18083即可,初始用户名为admin,初始密码为public,登录完成后,你便会看到如下画面
接下来需要配置 客户端登录名和密码,比如刚刚在设备中写的用户名密码,就是在这个系统中设置的
点击 访问控制>认证 > 创建,然后无脑下一步即可,完成后你会看到如下画面
点击用户管理,添加用户即可,用户名和密码都是自定义的,这些用户名密码可以分配给设备端、客户端、服务端、测试端使用,可以参考我的配置
userClient是准备给前端页面用的 ,server是给后端用的,995231030是我个人自留的超级用户,wemos是设备用的,即上面设备连接时输入的用户名密码。
至此,emqx 控制台配置完成。
下载 mqttx,作为测试端尝试连接一下
点击连接,你会发现,根本连接不上......
因为,1883(mqtt默认端口)也是没有开启的,当然,和开启18083的方法一样。
同时,还建议你开启:
1803 websocket 默认端口
1804 websockets 默认端口
3306 mysql默认端口
后面这四个端口都会用到。
当你开启完成后,再次尝试使用mqttx连接broker,会发现可以连接了
这个页面的功能也是很易懂的,我们在左侧添加订阅,右侧的聊天框里会出现该topic的消息
你是否还记得,在上面的设备代码中,我们在loop中每一秒向 home/status/ 发送一条设备在线的提示,我们现在在这里就收到了。
当你看到这些消息的时候,就说明,你的设备、服务器、emqx控制台已经跑通了。
前后端以及数据库
前端
前端不必多说,我们使用echarts承载展示数据,由于体量较小,我们不使用任何框架,直接使用jq和echarts实现,这里主要讲前端怎么连接mqtt
首先引入mqtt库
然后设置连接参数
const options = {
clean: true, // true: 清除会话, false: 保留会话
connectTimeout: 4000, // 超时时间
clientId: 'userClient_' + generateRandomString(),
//前端客户端很可能比较多,所以这里我们生成一个随机的6位字母加数字作为clientId,以保证不会重复
username: 'userClient',
password: 'aa995231030',
}
function generateRandomString() {
let result = '';
let characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
let charactersLength = characters.length;
for (let i = 0; i < 6; i++) {
result += characters.charAt(Math.floor(Math.random() * charactersLength));
}
return result;
}
连接
// const connectUrl = 'mqtt://larryblog.top/mqtt' 当然你可以使用mqtt协议,但是有可能会遇到 ssl 跨域的问题,如果你不使用 https 可以忽略这一项,直接使用mqtt即可
const connectUrl = 'wss://larryblog.top/mqtt' //注意,这里使用了nginx进行转发,后面会讲
const client = mqtt.connect(connectUrl, options)因为前端代码不多,我这里直接贴了
html:
index.html
<span class="http"><span class="properties"><span class="hljs-attr">wemos</span> <span class="hljs-string">d1 test</span></span></span>
Loading device status
Current temperature:
loading...
Current humidity:
loading...
作者:加伊juejin
来源:juejin.cn/post/7203180003471081531
一支不足百人的团队创造了ChatGPT :90后挑大梁,应届生11人,华人抢眼
让全网沸腾的 ChatGPT,其背后团队不足百人。
ChatGPT 发布以来,在短短 2 个月时间月活破亿,成为历史上用户增长最快的消费应用。有分析机构感叹:“在互联网领域发展 20 年来,我们想不出有哪个消费者互联网应用比它上升速度更快。”
这样一个“最强 AI”的背后,是怎样的一支团队?
根据 OpenAI 官网显示,为 ChatGPT 项目做出贡献的人员共 87 人。近日,智谱研究联合 AMiner 发布了一份《ChatGPT 团队背景研究报告》。报告显示,ChatGPT 团队的显著特征是“年纪很轻”、“背景豪华”、“聚焦技术”、“积累深厚”、“崇尚创业”和“华人抢眼”。
报告原文:
https://originalfileserver.aminer.cn/sys/aminer/ai10/pdf/ChatGPT-team-background-research-report.pdf
ChatGPT 背后的 AI“梦之队”
多为名校毕业,华人成员占比 10%
报告显示,ChatGPT 团队成员绝大多数拥有名校学历,且具有全球知名企业工作经历。从成员毕业高校分布看,校友最多的前 5 大高校是斯坦福大学(14 人)、加州大学伯克利分校(10 人)、麻省理工学院(7 人)、剑桥大学(5 人)、哈佛大学(4 人)和佐治亚理工学院(4 人)。
此外,ChatGPT 团队有 9 位华人,占团队总人数的 10%。
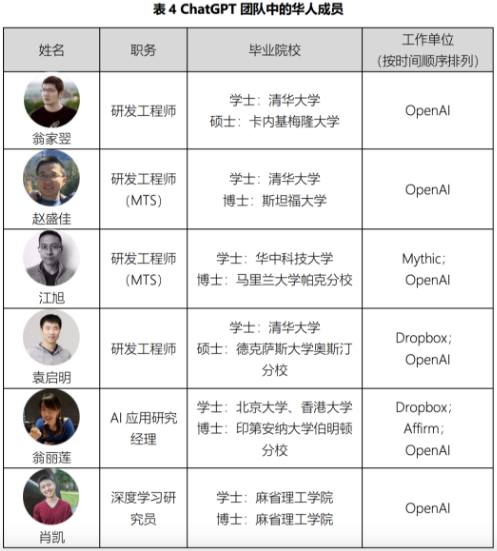
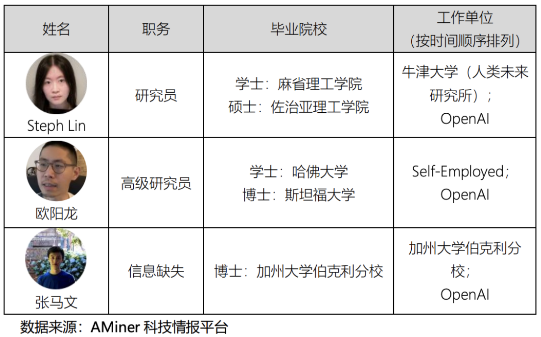
其中,5 人本科就读于国内高校,3 人本科教育经历在美国高校完成。梳理毕业于中国高校的 ChatGPT 华人成员成长路径发现,他们本科毕业后赴美深造,获得硕士或博士学位后,加入美国的一些创新型公司,诸如 Dropbox、OpenAI 等。
报告认为,华人学者欧阳龙参与了与 ChatGPT 相关的 7 大技术项目中的 4 大项目的研发,他是 InstructGPT 论文的第一作者,是 RLHF 论文的第二作者,可见他是这两个关键技术项目的核心人员。
注:*与 ChatGPT 相关的先前关键技术项目有 RLHF3、GPT14、GPT25、 GPT36、codex7、InstructGPT8、webGPT9 等 7 项。统计发现,ChatGPT 团队中,有 2 人参与了其中 4 项关键技术项目的研发,他们分别是高级研究员欧阳龙和研发工程师 Christopher Hesse,二人均为机器学习领域专家。*
“90 后”是主力军,女性力量占一成
报告显示,从 ChatGPT 团队年龄分布看,20~29 岁的成员有 28 人,占全体成员(剔除年龄信息缺失的 5 位成员)的 34%;30~39 岁的共 50 人,占 61%;40~49 岁的仅 3 人,无 50~59 岁年龄段的成员,60 岁以上的有 1 人。
经计算, ChatGPT 团队平均年龄为 32 岁。
报告认为,“90 后”是这支团队的主力军,他们引领了这一波大语言大模型技术的创新风潮, 这说明经常被认为研发经验不足的年轻人,完全有可能在前沿科技领域取得重大突破。
性别分布方面,ChatGPT 团队中有女性 9 人,占总数的 10%;男性共 78 人,占 90%。9 位女性成员中,有 2 位是华人,分别是曾就读于北京大学的翁丽莲,以及 Steph Lin。
10 人从谷歌跳槽加入,1 人曾在百度任职
人员流动方面,ChatGPT 团队成员主要来自外部公司(81%)、高校应届毕业生(13%)、科研机构 (4%)和高校教职人员(3%)等。
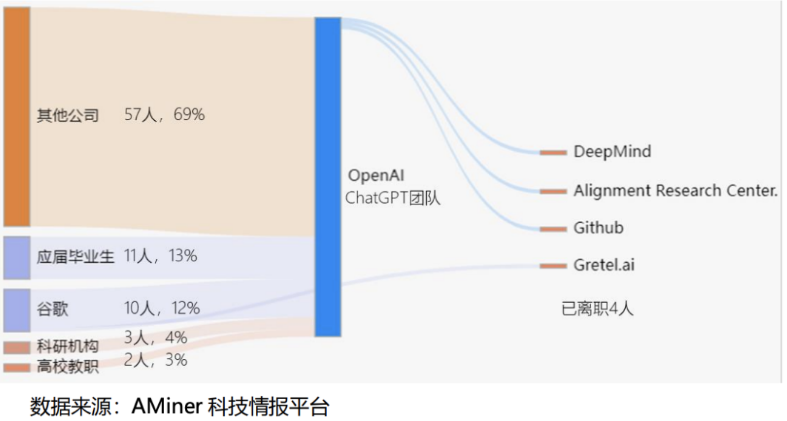
其中,人数来源最多的外部企业是谷歌, 共 10 人跳槽加入;来源人数超过 2 人(含)以上的外部企业还有 Facebook、Stripe、Uber、 Quora、NVIDIA、Microsoft、Dropbox、DeepMind 等知名科技公司。作为应届生直接加入 ChatGPT 团队的共 11 人。
报告发现,ChatGPT 研究员 Heewoo Jun 曾在 2015-2019 年间在百度(美国研究院,Sunnyvale, California, USA.)担任研究员,2019 年从百度离职后加入 OpenAI 担任研究员至今。
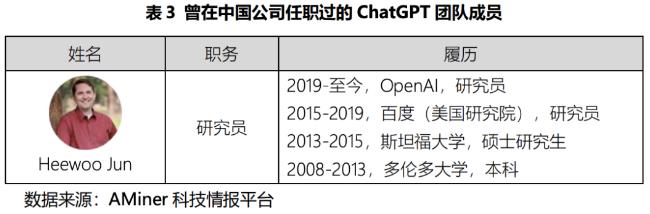
到目前为止,ChatGPT 团队已离职员工有 4 人(离职率为 4.6%),他们是 Jacob Hilton、Igor Babuschkin、Matthias Plappert 和 Andrew Carr,去向分别为 Alignment Research Center、DeepMind、Github 和 Gretel.ai。
报告认为,从 ChatGPT 团队离职的人员,并非为外界想象的加入所谓“大厂”,而是仍然选择具有创新潜力的创业公司或机构。
报告还根据以上信息,就国内人工智能前沿技术发展提出了几点建议:
注重科技兴趣和信仰培育,鼓励优秀年轻人投身于前沿技术创新浪潮;
“大厂”前沿科技创新疲态显现,鼓励年轻人将目光投向创业公司;
海外华人学者是全球科技创新的重要力量, 鼓励加强对外学术交流。
ChatGPT 爆火引发 AIGC 人才战
在 ChatGPT 爆火之前,人工智能行业人才缺口就已显现。
脉脉人才智库数据显示,2022 年人工智能行业人才紧缺指数(人才需求量 /⼈才投递量)达 0.83,成为人才最紧缺的行业。人工智能行业人才需求集中于技术研发、产品开发和商业化部门。其中软件人才需求最高,其次是产品、销售、算法、运营和项目经理。
随着 ChatGPT 在全球范围内爆火,进一步带动了相关的岗位需求。
2 月 14 日,脉脉创始人兼 CEO 林凡在社交平台发文表示,在脉脉高聘上 AIGC 相关岗位来看,科技巨头、头部猎企纷纷下场抢人,甚至开出 10 万月薪挖人。林凡认为,ChatGPT 带动的 AIGC 创业热潮要来了。这波 AIGC 创业热潮的兴起,必将推动人工智能人才的薪资再攀高峰。
根据脉脉网站显示,目前招聘 AIGC 相关人才的科技公司包括百度、腾讯、阿里、商汤、美团等。据甲子光年报道,CGL 深圳前沿科技组合伙人梁弘进表示,过去两周,已经有超过10家客户找到他。这些客户基本都是国内一二梯队的互联网大厂。客户们的诉求只有一条:“就想找OpenAI项目里的华人”,而且“薪资不设限,越快越好”。
日前,猎聘大数据研究院发布的《ChatGPT 相关领域就业洞察报告》(以下简称“报告”)显示,人工智能人才供不应求,需求是五年前的近 3 倍,紧缺程度持续高于互联网总体水平。
报告对比了各季度的人工智能和互联网的新发职位数,结果显示,五年来,互联网人才需求(新发职位)增长趋势平缓,而人工智能在 2020 年之后处于总体迅速上升态势。2022 年四季度,人工智能新发职位是 2018 年一季度的 2.74 倍,而互联网仅是 2018 年一季度的 1.06 倍。
薪资方面,过去五年,人工智能和互联网的招聘薪资均处于上涨态势,人工智能年均招聘薪资均明显高出互联网。2022 年,人工智能招聘平均年薪为 33.15 万元,比互联网高出 4.27 万元,即 14.78%。
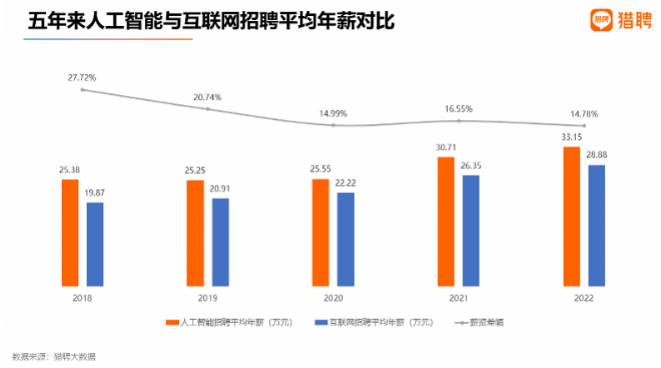
报告显示,人工智能以计算机算法为核心基础,因而对算法工程师需求最大,近一年新发职位占比为 7.26%,招聘平均年薪为 46.40 万元。此外,智能网联工程师、图像算法、机器视觉、深度学习、自然语言处理等职能排名靠前,跻身热招职能 TOP15,招聘平均年薪均超 39 万。
参考链接:
mp.weixin.qq.com/s/Y_LjjsuoEEmhIg5WO_iQhA
economy.gmw.cn/2023-02/14/content_36366347.htm?s=gmwreco2
整理:凌敏
收起阅读 »教你解决字符对齐问题
前言
其实很多人都会碰到文本不对齐,文字不对齐的情况,但是只要不明显被提出,一般都会置之不理。我关注这个问题是因为有个老哥问我倒计时的时候,10以上和10以下会出现宽度变化,因为2位数变1位数确实会变化很大,有的人会说1位数的时候前面补零,这也是一个方法,还有人说,你设置控件的宽度固定不就行了吗?其实还真不好,即便你宽度固定,你的文字内容也是会变的。
所以我就去想这个问题,虽然不是一个什么大问题,但当你去探究,确实能收获一些不一样的东西。
基础概念
首先回顾一些基础的东西。
1字节是8位,所以1字节能有256种组合,说到这个,就能联系出ASCII码,ASCII码都熟吧,就是数字和字母啊这些。然后ASCII码的定义的符号,是没有到256的,这个也很容易理解,去看看ASCII码的表就知道了。所以,ASCII码中的符号,都能用1个字节表示。
但是你的汉字是没办法用256表示的,我们中华文化博大精深,不是区区256能容纳得下的。所以汉字得用2个字节表示,甚至3个字节表示。然后emoji好像是要占3个字节还是4个字节得,这个我记得不太清了。而且不同的编码占的也不同。
回顾一下这些内容主要是为了找找感觉。
半角和全角
这个相信大家也有点了解,我们平时用输入法的时候就能进行半角全角的切换。
简单来说,全角em是指一个字符占用两个标准字符位置,半角en是指一个字符占用一个标准字符的位置。注意这里说的是占多少的位置,和上面提的字节没关系,不是说你2个字节就占2个位置,1个字节只占一个位置。
但是一般半角和圆角都是针对ASCII码里面的符号的(这个我没找到相应的概念,我是根据现象推导的)
所以先来看看直接设置半角和全角的效果
上面是半角,下面是全角,能明显看出来,中文的半角和全角都是占了两个标准字符的位置,而ASCII码中的符号,在半角的情况下是占一个,在全角的情况下是占两个。
汉字是这样,但是我在找资料的时候看到一个挺有意思的场景。就是日文,因为编码方式,会出现部分日文的半角效果和全角效果是不同的。可以参考这个老哥写的juejin.cn/post/716953… ,用的是JIS C 6220这种编码方式。
那说到这里,其实你就已经有一个概念了,数字中,每个数字在半角情况下都是占一个字符(我这里说占一个坑位可能会更好理解),默认变量输出都是半角,那两位数,就占两个坑位。所以要让1位数的显示和两位数的相同,让1位数占两个坑位不就行了吗,把1位数转成全角就行了。
看我这的效果,蓝色的区域就是全角的效果,看得出是比之前好过一些,但也没办法完全等于两个半角数字的宽度,还是差了点意思。
空格
除了用半角全角的思路去处理,还有办法吗?当然有了,发挥想象力想想,要实现1位数和2位数对齐,我可以给1位数的两边加上空格,不就行了吗,所以这空格也是有讲究滴。
我们可以来看看Unicode中有哪些空格(只列举部分):
U+0020:ASCII空格
U+00A0:不间断空格
U+2002:EN空格
U+2003:EM空格
U+2004:⅓EM空格
U+2005:¼EM空格
U+2006:⅙EM空格
U+2007:数字空格
U+2009:窄空格
U+3000:文字空格
如果先了解了半角你就知道什么是en,什么是em,看这些的时候也会更有感觉。那这么多空格,我怎么知道哪个合适?那合不合适,试试不就知道了吗,这不就和谈女朋友一样,去试试嘛
首先看到ASCII空格是合适的,会不会有人看到这里有答案就跑了 ,然后还有几个看着也相近,我们可以单独拿出来比一下。U+2004、U+2005和U+2009
发现都不合适,那这个代码具体要怎么加呢,其实也很简单,直接写\u0020就行,比如我这里的布局就是这样
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:background="@color/blue"
android:textColor="#000000"
android:text="\u00206\u0020"
android:textSize="26sp"
/>其它
上面都是通过编码的方向去解决这个问题,那还有其它方式吗?当然又有,其实一开始就有人想说了,用几个textview去拼接,然后设置数字的textview固定宽度并且内容居中。
这当然可以。比如“倒计时30秒”这段文字,拆成3个textview,让第二个textview固定宽度并且内容居中,也能实现这个效果,但是这实现方式也太......,所以需要去探索不同的方式去处理。
那绘制可以吗,我不用textview,我自定义一个view然后画上去,我自己画的话能很好把控各种细节的处理。我倒是觉得这是一个好的主意。这是通过绘制的方式去解决这个问题。
所以从这里可以看出,其实解决这个问题的方式有很多,可以从不同的角度去处理。
作者:流浪汉kylin
来源:juejin.cn/post/7202501888616431672
每一个人都应该明白的ChatGPT所带来的意义
每一个人都应该明白的ChatGPT所带来的意义
ChatGPT的横空问世,因其更高的智能程度、更宽泛的领域知识、更灵活的响应能力、更自然的对话语境使整个互联网都受到极大的冲击。 我本人试用了一段时间后,并结合在网上看到的文章、评论、观点,想说说我对ChatGPT的看法,以及它应该带给我们的革命。
因本人是互联网行业从业者,本文更多叙述ChatGPT+编程开发从业相关。
本文内容将阐述如下观点:
观点1:ChatGPT给互联网从业者带来的革命-智能时代的每一个人都应成为架构师。
观点2:ChatGPT可以取代哪一部分人?
以上内容包含延伸观点1:人类和人工智能的对决,人类要学会弯道超车
以上内容包含延伸观点2:所有人都要学会“如何提问”
本文尽可能不讲如上面摘要第一句话那种对背景的复述,相信ChatGPT问世以来大家以从不同渠道获取过很多背景知识,我将尽可能只讲干货。
ChatGPT给互联网从业者带来的革命-智能时代的每一个人都应成为架构师
学会限定答案的边界条件,提高效率
对于互联网从业者来说,我们通过 ChatGPT 可以快速地得到需要的信息和解决问题,但前提是必须学会如何提问并限定答案的边界条件,以提高效率。 首先,请想象一个场景:
我是一名开发工程师,今天接到一个需求,是实现一个冒泡排序方法。
于是我在ChatGPT上提问如下:
它完成了吗?是的,完成了。可是如果我这样提问:
可能我这个场景举例不是很恰当,但是我相信这个例子能够表达出我的意思:大家用的ChatGPT是一样的,在不同的人手中,它将发挥差异巨大的效果。
许多Java工程师都在使用Java,那么他们编写代码的能力不同,难道是因为Java版本?显然不是。而不管是搜索引擎,还是人工智能对话都需要一个能力, “学会提问”以及“运用你所知道知识丰富你的提问”。虽然这个事情大家可能早已听到无数次了,但是“你不会百度吗?”带来的冲击远远没有使用ChatGPT对话 还是无法让人工智能听懂并准确表达出你的意思来的冲击力大。我们应该认识到:“无论是工作中的需求对接、会议上的观点阐述、开发上的问题提问,我们要学习高效地、 准确的、全面的表达和提问方法。”
所以,从ChatGPT问世以来,我极力推荐在面试中添加一个问题:“如果你遇到技术问题,你的解决方式是?”
当然,这是一个笼统的问题,接下来再抛出一个具体的问题
如“你在开发一套系统,开发完成后测试正常,交付运维部署后发现无法访问,询问运维发现日志中报错,可是你在本地无法复现因为没有问题,请想象自己 并不懂这个情况发生的原因,你如何表达你的问题?”
再如“你在编写Hive sql,a列值为10,b列值为20,你编写了 select a + b,可是结果并不是30,请想象自己并不懂这个情况发生的原因,你如何表达你的问题?”
请相信我,这个问题的回答通常不会让面试官根据此就决定录用或取消录用,面试结果是多个问题、多方面考虑综合得到的结果。并且此问题的回答并无真正意义上的对错之分,如第一个问题 ,我可以说“请问我的系统本地正常,部署就不正常了,为啥?”,也可以说“请问我的系统本地运行正常,交付后部署在k8s集群化环境,页面不断重定向/404,为啥?”。 那么两个回答都行的前提是什么?在询问同事的时候。 如果是自己在互联网上、ChatGPT上提问呢?显然第一个问题将会收到无数种情况,你需要在无数种情况中挑选符合自己的情况。 这其实就是在限定答案的边界条件。
学会提问,与掌握所有知识相比约为0成本
很有意思,这让我想起了人工钻与天然钻。当然我不是很了解这个方面的知识,只是听说人工钻在各个 方面已经超越了天然钻,可是天然钻价格依然居高不下,理由是“纯天然”。
类比一下,如果你认为知识放在自己脑子里才是最好的,非要使用大脑和数千台、数万台服务器构成的人工智能去对决 , 那也没有问题,但是我想说的是无非是你知道“茴”有3种写法,人工智能只知道“茴”有2种写法的区别,你学习的速度能够赶上24小时 不休息的神经网络、深度学习算法吗?革命就在于此,我们应转变思想,我们不再需要知道使用鱼竿怎么钓鱼,但是我们要知道可以使用哪些工具钓鱼。
什么叫做“我们不再需要知道使用鱼竿怎么钓鱼,但是我们要知道可以使用哪些工具钓鱼?”
我大概说一个岗位大家就明白了,这个岗位是“架构师”。我们通常说,在一个点钻研就有可能成为这个领域的专家, 贪多可能嚼不烂,哪个领域都平平无奇,但是时代变了。在人工智能领域,我们扩宽知识面的优先级要高于深挖非自己感兴趣的、非自己常用的知识面。
这就是弯道超车。
ChatGPT可以取代哪一部分人?
我可以直接说出结论:
思维固化,工作只会接收指令输出内容的人。或者反向说不能取代的是需要具有创造性和判断力的领域,人类的创造力和想象力是不可替代的。
只会产品介绍,遇到问题只会说“您的问题我收到了,已经向上反馈了,请您耐心等待电话哦”的客服,是我认为目前职业危机最重的职业,因为它的主要工作内容 交给人工智能来做不会有任何风险,并且人工智能不带有情绪,可以保持高强度高效率的沟通,而且遇到实际问题,人工智能也可以自动往上反馈呀,它没有自主决定的 权力,所以不会因人工智能的行为产生巨大的风险。可惜的是,这类客服岗位的大量存在相信不用我去证明。我们应意识到ChatGPT的发力点在哪里,学会运用它,而不是被它取代。
下面,我使用ChatGPT为本文生成总结:
总的来说,这篇文章提供了一个重要的思考框架,即如何在智能时代更好地与ChatGPT互动,以提高个人和社会的效率和创造力。
作为职场人,学会如何提问是非常重要的,因为一个好的问题可以帮助你更快地解决问题,提高工作效率。在与ChatGPT交互时,我们更需要学会如何提问,因为ChatGPT的回答往往依赖于我们提出的问题。一个好的问题可以帮助我们得到更准确、更有用的答案。
ChatGPT能够取代一部分人,但并不是所有人。ChatGPT可以模拟人类的思维,能够回答一些常见的问题,但是它并不能替代具有专业知识和经验的人类专家。
我们需要学会如何与人工智能合作,发挥各自的优势,以提高个人和社会的效率和创造力,创造更好的未来。
作者:我感觉我变聪明了
来源:juejin.cn/post/7201540320654524473
如何做一条快鱼?
前言
现在不是一个大鱼吃小鱼,而是一个快鱼吃慢鱼的时代。我们都学过马克思主义经济学原理,知道一个社会必要劳动时间的概念,要想提高个人的竞争力,就要使自己做同样的工作,在保证质量的情况下,自己所花费的时间低于社会必要劳动时间。那么如何提高效率,使自己的必要劳动时间低于社会平均劳动时间呢? 这是一个仁者见仁,智者见智的话题,笔者结合自己工作经验,列举几条,供大家参考,如有不同意见和补充,欢迎留言区讨论。
定期整理
对工作中,生活中经常用到的技能或遇到的问题进行归类整理。散乱的没有联系的知识,碎片化的知识,一般没有多大用处。只有成体系,有联系的系统知识,实用价值才比较高。散乱碎片化的知识经过自己一番悉心整理之后,才能变成自己的知识。为我所用。做为一名程序员,我会定期梳理项目中遇到过的刁钻的bug(不单单是自己的),和常用的一些编程语法点和业务方法,业务知识。这么做的好处是:我发现许多人将整个项目的业务串通不起来,只对自己做的那一块比较熟, 而我可以。另外平常在开发功能的过程中,得益于这个习惯,让我找到了许多可以复用的模块,编码得心应手,在开发时间方面几无压力。还有生产环境遇到未知缺陷时,我也比工作年限相同的同事思路开阔,底气也足。总结起来就是一句话,定期整理能提高你解决问题时的联想能力和反应速度。
不要钻牛角尖
钻牛角尖这种事情,一般都发生在我们觉得某件事情很简单, 实际在做的过程中,在某个细节之处出现了意料之外的困难,我们太过执拗,自己跟自己斗气,欲罢不能。不理性的后果就是大半天过去了,甚至好几天过去了,工作进展不大。事后我们发现,有许多简单重复性劳动,我们却没做,心中懊悔不已。如果半个小时过去了,看似简单的问题还未解决,就要引起我们的警觉,每件事情的难易程度是不同的,自己在一天之中的思维活跃度也是有波峰和波谷。我们要及时做自己的思想工作,调整自己的心态,先把鸡肋的事情放一放,继续开展其它的工作,等把那些没有难度的事情做完了,再杀个回马枪,乘胜追击,捣碎当初感到鸡肋的事情。
缩小时间利用颗粒度
你对时间利用的颗粒度,是以天,周,月,年为单位,还是以秒,分钟,时刻,小时为单位? 对时间的利用颗粒度越大,对时间的浪费越严重。一件事情,你计划半天完成,实际上你可能只需要一个小时,最后的结果就是你真的花费了半天,人都是怎么惯怎么来,你看部队上规章条例很多,许多人都觉得那不是人过的生活,可是我们的人民子弟兵,也适应的很好。一般自己在自然状态下做一件事情的时间,都有压缩的空间,你对时间利用的颗粒度管理得越精细,对时间利用的就越充分,等同于延长了生命的长度。你可以把节省下来的时间,投入到自己喜欢的事情上,工作与健康,家庭与生活,亲情与社交等皆不误。
保持专注
现在的智能设备,电脑,iPad,手机等,尤其是手机,把人的注意力,撕得支离破碎。许多人,一打游戏或刷视频,根本停不下来。因为视频内容和游戏厂商,给你推送的视频或者设计的游戏,都参考了让人成瘾的一些心理学理论,不要说未成年人,就是成年人也把持不住。在注意力涣散的情况下,要想提高效率简直就是痴人说梦。我自己也深受其害,因为每天使用手机的时间太长,出现干眼症症状,每天刚睡醒的时候,眼睛看不清手机屏幕,这时才引起我的重视,现在我已经大幅减少了手机的使用时间。一般就是饭后刷15分钟,大多数事情都在电脑端处理,处理的一般都是工作问题,很难上瘾。感觉远离手机之后,逐渐从手机的奴隶变成了手机的主人,自主意识得到了显著增强,大脑感觉清爽了好多。专注的做一件事情,就好比用己方的精兵强将去攻打对方吊儿郎当的军队,作战效率肯定杠杠的。
熟能生快
熟不仅能生巧,也能生快。提高效率的发力点之一就是把不会的事情学会,把会做的事情做到极致,既快又好。 对于绝大多数芸芸众生来说,要快得先下慢功夫,除非你是和数学家高斯一样的天才,天赋异禀,才智超群。不然你就得向愚公学习。有一句话不是这样说的嘛,所有看起来的毫不费力,其实背后都是拼尽全力。干一行,爱一行,爱一行,精一行,在日常的工作和生活中,勤学苦练,不断精进,逐渐把自己打磨成细分行业细分领域细分生态圈的佼佼者,届时你每天收获的不仅是薪资,还有因效率提高带来的工作流畅感和优越感。
善用工具
生产工具是生产力发展水平的重要标志,也是衡量生产效率的标志。要想提高工作效率,而不借助工具,就犹如鸟缺少了一只翅膀,肯定飞不高,飞不快。你随便去哪个招聘网站去看看许多岗位的招聘要求,不难发现,除了要掌握相应岗位的专业知识外,也要熟练掌握这个专业经常使用的一些工具。学校教育一般只教导我们要学好专业知识,对专业内使用的工具重视度不足。笔者是做前端开发的,我觉得如下工具,是要熟练掌握的:
现代主流浏览器(Google Chrome、Opera及Safari,Mozilla Firefox、Microsoft Edge)的开发调试方法,常用快捷键,常用的浏览器插件,绝大多数菜单的功能
至少三种代码编辑器的近乎所有菜单功能及常用的扩展
至少三种网络抓包工具
至少两种取色工具
至少两种移动端页面调试工具
至少两种代码智能补全工具
至少两种持续集成,持续部署 CI/CD工具
至少两种测试工具的用法
至少两种JSON格式化与查看工具
至少两种图片压缩处理工具
至少两种代码质量检测工具
至少两种代码文档生成工具
至少两种接口API文档生成工具
至少两种接口数据mock工具
至少两种正则可视化工具
至少两种在线运行JS代码工具
至少两种UI设计工具
至少两种富文本编辑器工具
至少两种图表类工具
至少两种流程图类工具
至少两种字体图标工具
至少两种页面性能分析工具
等等
善用搜索
善于搜索引擎
我们如果一开始遇到一个完全不懂的问题,肯定会使用搜索引擎搜答案。可是在解决一个自己觉得自己懂的问题,卡在了半道的时候,你的第一反应肯定不是使用搜索引擎,都是尝试自己解决,然后磕磕绊绊,乱想瞎碰试了半天,碰了一鼻子灰,问题最终还未解决。才想起使用搜索引擎。你使用搜索引擎的反应时间,需要缩短一下,我觉得5分钟之内你自感熟悉的问题还解决不了,就要考虑使用搜索引擎了,一般都是事半功倍。当然搜索引擎要想用的好,也有一些讲究:
搜索引擎的选择
某度的搜索结果广告多得让人心生厌烦,对题的文章排版也不太好。推荐用Google(如何出去方法很多,网上自行查找,一般都是付费的,为了提高搜索质量,这点费用是值得的,建议以月为单位付费,万一平台跑了你的损失比较小)或者必应,还有当下很火的搜索引擎新锐chatGPT(可以在京东和淘宝上买到账号)。
需要你有一定的背景知识
一是如果你不知道专业的用语是什么,输入的搜索关键词不精确,搜索出来的答案肯定离题万里。二是,有时候正确的答案被你搜索到了,由于你欠缺专业知识,虽然每个汉字都认识,但就是不知道整句话表达的是什么含义,看不懂答案或者对答案似懂非懂。
善用代码编辑器的全局搜索功能
日常编码,查找代码片段是高频操作,如果凭靠自己的记忆去项目下的特定文件夹特定文件中找某一行,无疑是比较低效的(但我发现许多人却都是这样做的)。更高效的做法是使用代码编辑器的全局代码搜索功能,输入有区分度的代码关键字,很快很精准的就能进入到某个文件夹下某个文件的第多少行。查找修改效率都比较高。
碎片化时间的妙用
碎片化时间很难做需要深度思考或者任务量规模比较大的事情,可是尺有所短,寸有所长。下面的两件事情,适合用碎片化的时间去做。
工作或生活规划
凡事预则立,不预则废。只有对生活与工作进行统筹规划,才不会出现对时间利用出现极端的情形。闲来闲的无聊至极,百无聊赖,生无可恋;忙来忙得天昏地暗,透支健康,作息混乱。利用碎片化的时间对今天,明天,接下来一周,做一下简单规划,什么时间做什么事情,需要多少时间,需要提前准备什么。这么做了之后,一方面你会发现每天都有事做,生活或工作井井有条,生活和工作中重要的事情,一件也没落下。另一方面,会促使你充实和丰富生活。给生活和工作不断立项一些有益的事情,什么无聊,虚度光阴这样的负面情绪体验,在你的生活字典里,是没有的。
阅读
每天上下班的路途上,排队吃饭的时候, 中午饭后午休之前,可以忙里偷闲,阅读一些不太耗费脑力,消遣类的文章,放松一下。有张有弛,才能长久的精力充沛。
保持身心健康
什么,身心健康也与提高效率有关系。当然有关系了,你病殃殃的,身体不舒适,哪有心劲提高工作效率。或者身体无病无疾,但好钢就是不往刀刃上用,有许多事情需要你做,但因为你一时意志薄弱,过度娱乐不能自拔。那么如何保持身心健康呢?
睡眠要充足
睡不好醒来之后人脑子里如有一团雾。比较困倦,反应也比较迟钝,意志力薄弱也与睡眠不足,睡眠质量较差有关。要想睡好,睡觉之前是关键:
首先睡前2小时,不要让大脑兴奋。不要剧烈运动,看恐怖片。睡前半小时,关掉手机等一切电子设备准备入睡,睡觉也需要时间酝酿,不是一下子就能睡着的。
把空调调节到一个宜睡的温度,推荐温度稍低一点,比如说20度,有利于入睡。
睡前1小时,不要再大量饮水,睡前喝水太多,夜间憋尿或者上厕所,都会影响睡眠。
要用被子把脚包裹住,脚暴露在被子外面的话,大概率人会做噩梦。
夏天要给床安装蚊帐,被蚊子叮咬了的话,肯定会让人睡不好。
保持心情平和
心怀感恩惜福的心态, 过好每一天。不要有太多的贪念和妄念,人间正道是沧桑。平平淡淡不是真,而是福气。每天没有意料之外的坏事情发生,就应该庆幸这一天过得很平安。
管理好自己的情绪。不要一点就炸,出现矛盾和冲突时,与人为善,说柔和说, 温柔而坚定的与之沟通。
最后
可能道理大家都懂,正如一句话所说,我懂得许多大道理,却依然过不好这一生。问题出在哪里?我觉得是执行力的问题。如果仅仅停留在道理我懂了的层面,那你获得不了任何实质性的收益。只有身体力行,践行经过生活实践反复检验依然正确的道理,你才能真真切切感受到这些有益的意见给你带来的益处。
作者:去伪存真
来源:https://juejin.cn/post/7199106370825109564
大厂996三个月,我曾迷失了生活的意义,努力找回中
作为一个没有啥家底的小镇做题家,在去年选Offer阶段时,工作强度是我最不看重的一个点,当时觉得自己年轻、身体好、精神足,996算起来一天不过12个小时,去掉吃饭时间,一天也就9到10个小时,完全没有任何问题,对当时热衷于外企、国企、考公的同学非常的不理解,于是毫不犹豫的签了一个外界风评不太佳但是包裹给的相对多的Offer,然后便有了现在的心酸感悟。
入职前的忐忑
在一波三折终于拿到学位证后,怀着忐忑的心入职了。忐忑的原因主要是入职之前我并不知道我要入职什么部门,很怕我一个只会Java的后端被分配去写C++,毕竟Java是最好的语言,打死不学C++(手动狗头)。 也担心被分配到一个没有啥业务复杂度、数据复杂度的业务部门,每天CRUD迎接着产品的一个又一个需求,最后活成了CRUD Boy没有什么技术沉淀。又担心去和钱相关的部门,害怕自己代码出Bug,导致公司产生资损。
就这样忐忑着听完了入职当日上午的培训,中午便被我的mentor接走了,很不幸,我被我的mentor告知,我恰好被分在了和钱最直接相关的部门,我的心陡然沉重起来。
这里给出我最诚挚的建议,选Offer最好选一个实习过的部分,次之就是签了三方后去实习一段时间,如果发现部门的味儿不对或者和自己八字不合,此时还有机会跑路,以很小的代价换一家公司,不然毕业后入职就宛如开盲盒,万一遇到了很不适应的部门,交了社保、几个月的工作经验,到了市场上可谓是爹不疼娘不爱,比着校招时候的境遇差太多了。
熟悉项目的第一个月
得益于和钱相关,我部门的需求都不是很紧急,领导的态度是宁愿需求不上,也不能上出问题。所以每一个需求都没有说产品火急火燎的推动着要上线,都是稳扎稳打的在做,给予了开发比较充足的自测时间。但是呢,另外一方面,由于部门的业务领域比较底层,所以接手的项目往往都已经有了两三年的历史,相信写过代码的同学都知道,写代码的场景中最痛苦的那就是读懂别人的代码然后在别人的基础上进行开发,尤其是读懂几年前已经几经几手的项目代码。
第一个月刚进入公司,只是在熟悉项目代码,没有啥需求上的压力,相对来说还是比较轻松。遇到不熟悉的直接问靠谱的mentor,mentor也给热心的解答还是很幸运的。每天吃完公司订的盒饭。下楼转悠一圈就觉得美滋滋。
这个时候其实觉得,996不过如此嘛,好像也没有啥压力,真不搞不明白有啥可怕的。
进入开发状态的第二个月
在熟悉的差不多后,我就开始慢慢接手业务需求了,坦白的说,由于我接手的项目比较成熟,新接入业务需求往往不需要做什么开发工作,只需要做一些配置项,需求就完成了。 然而呢,作为一个几年的老项目,当然是处处埋的有彩蛋,你永远不知道哪里就会给你来一个惊喜。于是呢,我的工作开始变成,寻找代码中的彩蛋,搞明白各个配置项的含义,以及他们究竟是怎么组合的,然后和上下游联合对数据,发现数据对不上,就需要再埋进项目中一丝一缕的分析。
这个时候已经有些许的压力了,如果因为自己成为整个需求的卡点,那太过意不去了。于是开始每天勤勤恳恳,吃盒饭也没有那么香了,饭后散步的脚步也不再那么的愉悦,这时候开始感受到了肩上的压力。
本来我是坚决第一个离开工位下班,决心整治职场的人,但是往往在debug的路上,不经历的就把下班时间延长了一点又一点。而又由于在北京、上海这种大城市,住在公司旁边往往是一种奢望,导致我每天有较长的通勤时间。工作日一天下来,差不多就是晚上回去睡觉,早上醒来没有多久就出门赶地铁。
日复一日,就有一种流水线上螺丝钉的麻木感,周末往往一觉睡醒就结束了,感觉日子很重复,没有一些自己生活过的痕迹。
努力调整状态的第三个月
积极主动,是《高效能人士的七个习惯》中的第一个习惯,也是我印象最深的一个习惯。既然困难无法克服,那么咱们就要主动解决。
工作中,努力开拓自己的视野,搭理好手中的一亩三分地的同时,仰头看看上游,低头往往下游,对他们的业务也多一些学习,理清楚自己工作的业务价值,同时呢,在当好一名螺丝钉之外,也尝试着找出整个流水线的可优化点和风险点,尝试着给出自己的解决方案,同时积极梳理已有的项目代码的技术难点,是如何通过配置化来应对复杂的业务场景,是如何通过自动重试保证数据一致性。
生活中,周末即使比较累了,但是努力也不再宅在家中,一刷手机一整天,而是尝试着做一些比较有挑战或者更有回忆的事情。比如沿着黄浦江骑行。
比如自己下厨做几个菜
比如邀请三五好友玩个桌游
比如通过图书馆借一些杂书来消遣
对后来人想说的话
部门与部门之间的差异,很有可能比公司之间的都要大,选择Offer尽可能的选一个实习过的、或者比较熟悉的部门,能有效避免开盲盒踩雷的风险。没有绝对完美的公司,即使好评如潮的外企、券商类公司,我仍然有一些不幸运的同学,遇到了很卷的部门,平时要自愿加班或者在公司“学习”。
即使遇到了困境,也需要保持积极良好的心态,退一万步想,即使工作丢了,但是咱们的身心健康不能丢。为了这几斗米,伤了身体,是非常得不偿失的。
在选Offer的时候尽量一步到位,以终为始,如果目标瞄定了二线城市,其实我个人不太建议为了某些原因比如对大厂技术的热衷、对一线城市繁华的向往而选择当北漂沪漂,漂泊在外的日子都比较苦,而且吃这种苦往往是没有啥意义的。
我是日暮与星辰之间,一名努力学习成长的后端练习生,创作不易,求点赞、求关注、求收藏,如果你有什么想法或者求职路上、工作路上遇到了什么问题,欢迎在评论区里和我一起交流讨论。
作者:日暮与星辰之间
来源:juejin.cn/post/7159960105759277070
程序员能有什么好玩意?
从业10年了,看看一枚老成员都有什么好玩意(有个人的、同事的、公司的……)。【多图预警!!!摸鱼预警!!!】
桌面预警
桌面上放了个二层小架子,之前还有个盆栽的,可惜死掉了,悼念&缅怀+1。
喷雾预警
好几年前的习惯,之前是理肤泉的喷雾。当年的我还是很暴躁的,需要一点水分帮我降降温,不过,当编程没有啥思路的时候,喷一喷感觉还不错。
养生预警
西洋参
有个同事是吉林的,某一天送给我一个山货大礼包,其中就有这瓶西洋参参片。偶尔会取几片泡水,当然喝茶的时候更多一些。【咖啡基本是戒了】
手串
年前,我领导说想弄个串儿盘着,防止老年痴呆。
我就买了些散珠自己串了些串,团队内,每人分了一串儿。
自己也留了些手串,每天选一串佩戴,主要是绕指柔的玩法。
茶事
喝茶也又些年头了,喝过好喝的,也扔过不好喝的。最近主要喝云南大白,家里的夫人也比较喜欢,
香道
疫情的风刮过来,听说艾草的盘香可以消毒杀菌,就买了盘香,还有个小香炉。周末在家会点一点,其实没那么好闻,但是仪式感满满的。
手霜
大概是东北恶劣的天气原因,办公室的手霜还是不少的,擦一擦,编码也有了仪式感。
盆栽
公司之前定了好多盆栽,我也选了一盆(其实是产品同学的,我的那盆已经养死了)。
打印机
家里买了台打印机,主要是打印一些孩子的东西,比如涂鸦的模版、还有孩子的照片。
工作预警
笔记本
大多用的是Mac,大概也不会换回Windows了。
耳机
还是用的有线耳机,没赶上潮流。哈哈
键盘
依然没赶上机械键盘的潮流,用的妙控……
面对疾风吧!
之前客户送的,小摆件。
证书
证书不少,主要是毕业时候发的,哈哈哈。
- 前年,公司组织学习了PMP,完美拿到了毕业后的第一个证书。
- 公司组织的活动的证书OR奖杯(干瞪眼大赛、乒乓球大赛、羽毛球大赛等),最贵的奖品应该是之前IDEA PK大赛获得的iwatch。
- 年会时发的证书。作为优秀的摸鱼份子,每年收到的表彰并不少,大多是个人的表彰,还有就是团队的证书,当然我更关心证书下面的奖金。
- 社区的证书。大致是技术社区的证书,嗯嗯,掘金的就一个,某年的2月优秀创作者,应该是这个。
家里的办公桌
夫人是个文艺女青年,喜欢装点我们的家,家里的办公桌的氛围还是很OK的。当然工作之余,也喜欢和夫人喝点小酒,我喜欢冰白,同好可以探讨哈。
悲伤的事情
疫情
疫情对我们的生活影响还是比较大的,特别是对我一个大龄程序员而言。
未来
今年打算给家庭计划一些副业,有余力的情况下,能够增加一些收入。人生已经过去了半数,感悟到生命的可贵,感情的来之不易,愿我们身边的人都越来越幸福。
链接:https://juejin.cn/post/7195814363692089403
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2023面试真题之CSS篇
恐惧就是这样,你直视它、向前一步的时候它就消失了,选择相信自己能克服一切困难,勇敢向前,直面恐惧,就会发现之前的害怕,变成了心里的能量。
大家好,我是柒八九。
今天,我们继续2023前端面试真题系列。我们来谈谈关于CSS的相关知识点。
如果,想了解该系列的文章,可以参考我们已经发布的文章。如下是往期文章。
文章list
你能所学到的知识点
盒模型 推荐阅读指数⭐️⭐️⭐️⭐️
CSS的display属性有哪些值 推荐阅读指数⭐️⭐️⭐️⭐️
position 里面的属性有哪些 推荐阅读指数⭐️⭐️⭐️⭐️
flex里面的属性 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
flex布局的应用场景 推荐阅读指数⭐️⭐️⭐️⭐️
CSS的长度单位有哪些 推荐阅读指数⭐️⭐️⭐️⭐️
水平垂直居中 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
{块级格式化上下文|Block Formatting Context} 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
层叠规则 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
重绘和重排 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
CSS引入方式(4种) 推荐阅读指数⭐️⭐️⭐️⭐️
硬件加速 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
元素超出宽度...处理 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
元素隐藏 推荐阅读指数⭐️⭐️⭐️⭐️⭐️
Chrome支持小于12px 的文字 推荐阅读指数⭐️⭐️⭐️⭐️
好了,天不早了,干点正事哇。
盒模型
一个盒子由四个部分组成:content、padding、border、margin
content,即
实际内容
,显示文本和图像
content属性大都是用在::before/::after这两个伪元素中
padding,即内边距,内容周围的区域
内边距是透明的
取值不能为负
受盒子的
background属性影响padding百分比值无论是水平还是垂直方向均是相对于宽度计算
boreder,即边框,围绕元素内容的内边距的一条或多条线,由粗细、样式、颜色三部分组成margin,即外边距,在元素外创建额外的空白,空白通常指不能放其他元素的区域
标准盒模型
盒子总宽度 =
width+padding+border+margin;盒子总高度 =
height+padding+border+margin
也就是,width/height 只是内容宽高,不包含 padding 和 border 值
IE 怪异盒子模型
盒子总宽度 =
width+margin;盒子总高度 =
height+margin;
也就是,width/height 包含了 padding 和 border 值
更改盒模型
CSS 中的 box-sizing 属性定义了渲染引擎应该如何计算一个元素的总宽度和总高度
box-sizing: content-box|border-box
复制代码content-box(默认值),元素的width/height不包含padding,border,与标准盒子模型表现一致border-box元素的width/height包含padding,border,与怪异盒子模型表现一致
CSS的display属性有哪些值
CSS
display属性设置元素是否被视为块或者内联元素以及用于子元素的布局,例如流式布局、网格布局或弹性布局。
形式上,display 属性设置元素的内部和外部的显示类型。
外部类型设置元素参与流式布局;
内部类型设置子元素的布局(子元素的
格式化上下文)
常见属性值(8个)
inline:默认blockinline-blockflexgridtablelist-item双值的:只有
Firefox70支持了这一语法
position 里面的属性有哪些
定义和用法:
position属性规定元素的定位类型。
说明:这个属性定义建立元素布局所用的 定位机制 。
任何元素都可以定位
绝对或固定元素会生成一个块级框,而不论该元素本身是什么类型。
相对定位元素会相对于它在正常流中的默认位置偏移。
position 有以下可选值:(6个)
CSS 有三种基本的定位机制:普通流、浮动和绝对定位。
flex里面的属性
容器的属性 (6个)
flex-direction决定主轴的方向(即项目的排列方向)
row(默认值):主轴为水平方向,起点在左端。row-reverse:主轴为水平方向,起点在右端。column:主轴为垂直方向,起点在上沿。column-reverse:主轴为垂直方向,起点在下沿。
flex-wrapflex-wrap属性定义,如果一条轴线排不下,如何换行nowrap:(默认):不换行。wrap:换行,第一行在上方。wrap-reverse:换行,第一行在下方
flex-flowflex-flow属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。
justify-contentjustify-content属性定义了项目在主轴上的对齐方式。flex-start(默认值):左对齐flex-end:右对齐center: 居中space-between:两端对齐,项目之间的间隔都相等。space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
align-itemsalign-items属性定义项目在交叉轴上如何对齐。stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。flex-start:交叉轴的起点对齐。flex-end:交叉轴的终点对齐。center:交叉轴的中点对齐。baseline: 项目的第一行文字的基线对齐。
align-content
align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
项目的属性(6个)
order
order属性定义项目的排列顺序。数值越小,排列越靠前,默认为0。
flex-grow
flex-grow属性定义项目的放大比例默认为0,即如果存在剩余空间,也不放大
如果所有项目的
flex-grow属性都为1,则它们将等分剩余空间(如果有的话)
flex-shrink
flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
如果所有项目的
flex-shrink属性都为1,当空间不足时,都将等比例缩小
flex-basis
flex-basis属性定义了在分配多余空间之前,项目占据的{主轴空间|main size}。浏览器根据这个属性,计算主轴是否有多余空间。
它的默认值为auto,即项目的本来大小。
flex
flex属性是flex-grow,flex-shrink和flex-basis的简写,默认值为0 1 auto。后两个属性可选。flex: 1=flex: 1 1 0%flex: auto=flex: 1 1 auto
align-self
flex:1 vs flex:auto
flex:1和flex:auto的区别,可以归结于flex-basis:0和flex-basis:auto的区别
当设置为0时(绝对弹性元素),此时相当于告诉flex-grow和flex-shrink在伸缩的时候不需要考虑我的尺寸
当设置为auto时(相对弹性元素),此时则需要在伸缩时将元素尺寸纳入考虑
flex布局的应用场景
网格布局
Grid-
display:flexGrid-Cell -
flex: 1;flex:1使得各个子元素可以等比伸缩,flex: 1 = flex: 1 1 0%
百分比布局
col2 -
flex: 0 0 50%;col3 -
flex: 0 0 33.3%;
圣杯布局
页面从上到下,分成三个部分:头部(
header),躯干(body),尾部(footer)。其中躯干又水平分成三栏,从左到右为:导航、主栏、副栏container-display: flex; -flex-direction: column;-min-height: 100vh;header/footer-flex: 0 0 100px;body-display: flex;-flex:1content-flex: 1;ads/av-flex: 0 0 100px;nav-order: -1;
侧边固定宽度
侧边固定宽度,右边自适应
aside1-flex: 0 0 20%;body1-flex:1
流式布局
每行的项目数固定,会自动分行
container2-display: flex;-flex-flow: row wrap;
CSS的长度单位有哪些
相对长度
相对长度单位指的是这个单位没有一个固定的值,它的值受到其它元素属性(例如浏览器窗口的大小、父级元素的大小)的影响,在响应式布局方面相对长度单位非常适用
绝对长度
绝对长度单位表示一个真实的物理尺寸,它的大小是固定的,不会因为其它元素尺寸的变化而变化
水平垂直居中
宽&高固定
absolute+ 负marginabsolute+margin autoabsolute+calc
宽&高不固定
absolute+transform: translate(-50%, -50%);flex布局
grid 布局
宽&高固定
absolute + 负 margin
.parent {
+ position: relative;
}
.child {
width: 300px;
height: 100px;
padding: 20px;
+ position: absolute;
+ top: 50%;
+ left: 50%;
+ margin: -70px 0 0 -170px;
}
复制代码初始位置为方块1的位置
当设置
left、top为50%的时候,内部子元素为方块2的位置设置
margin为负数时,使内部子元素到方块3的位置,即中间位置
absolute + margin auto
absolute + calc
宽&高不固定
absolute + transform: translate(-50%, -50%);
.parent {
position: relative;
}
.child {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
复制代码flex布局
.parent {
display: flex;
justify-content: center;
align-items: center;
}
复制代码grid布局
.parent {
display:grid;
}
.parent .child{
margin:auto;
}
复制代码{块级格式化上下文|Block Formatting Context}
{块级格式化上下文|Block Formatting Context}(BFC),它是页面中的一块渲染区域,并且有一套属于自己的渲染规则:(6个)
内部的盒子会在垂直方向一个接一个的放置
对于同一个
BFC的俩个相邻的盒子的margin会发生重叠,与方向无关。每个元素的左外边距与包含块的左边界相接触(页面布局方向从左到右),即使浮动元素也是如此
BFC的区域不会与float的元素区域重叠计算BFC的高度时,浮动子元素也参与计算
BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素,反之亦然
触发条件 (5个)RFODP
根元素,即
HTML元素浮动元素:
float值为left、rightoverflow值不为visible,为auto、scroll、hiddendisplay的值为inline-block、table、inline-table、flex、inline-flex、grid、inline-gridposition的值为absolute或fixed
应用场景
防止
margin
重叠
将位于同一个BFC的元素,分割到不同的BFC中
高度塌陷
计算BFC的高度时,浮动子元素也参与计算
子元素浮动
父元素
overflow: hidden;构建BFC
多栏自适应
BFC的区域不会与
float的元素区域重叠aside-float:leftmain-margin-left:aside-width-overflow: hidden构建BFC
层叠规则
所谓层叠规则,指的是当网页中的元素发生层叠时的表现规则。
z-index:z-index属性只有和定位元素(position不为static的元素)在一起的时候才有作用。
CSS3中,z-index已经并非只对定位元素有效,flex盒子的子元素也可以设置z-index属性。
层叠上下文的特性
层叠上下文的层叠水平要比普通元素高
层叠上下文可以阻断元素的混合模式
层叠上下文可以嵌套,内部层叠上下文及其所有元素均受制于外部的层叠上下文
每个层叠上下文和兄弟元素独立
当进行层叠变化或渲染的时候,只需要考虑后代元素
每个层叠上下文是自成体系的,当元素发生层叠的时候,整个元素被认为是在父层叠上下文的层叠顺序中
层叠上下文的创建(3类)
由一些CSS属性创建
天生派
页面根元素天生具有层叠上下文
根层叠上下文
正统派
z-index值为数值的定位元素的传统层叠上下文
扩招派
其他CSS3属性
根层叠上下文
指的是页面根元素,页面中所有的元素一定处于至少一个层叠结界中
定位元素与传统层叠上下文
对于position值为relative/absolute的定位元素,当z-index值不是auto的时候,会创建层叠上下文。
CSS3属性(8个)FOTMFIWS
元素为
flex布局元素(父元素display:flex|inline-flex),同时z-index值不是auto - flex布局元素的
opactity值不是1 - {透明度|opactity}元素的
transform值不是none- {转换|transform}元素
mix-blend-mode值不是normal- {混合模式|mix-blend-mode}元素的
filter值不是none- {滤镜|filter}元素的
isolation值是isolate- {隔离|isolation}元素的
will-change属性值为上面②~⑥的任意一个(如will-change:opacity)元素的
-webkit-overflow-scrolling设为touch
重绘和重排
页面渲染的流程, 简单来说,初次渲染时会经过以下6步:
构建DOM树;
样式计算;
布局定位;
图层分层;
图层绘制;
合成显示;
在CSS属性改变时,重渲染会分为回流、重绘和直接合成三种情况,分别对应从布局定位/图层绘制/合成显示开始,再走一遍上面的流程。
元素的CSS具体发生什么改变,则决定属于上面哪种情况:
回流(又叫重排):元素位置、大小发生变化导致其他节点联动,需要重新计算布局;
重绘:修改了一些不影响布局的属性,比如颜色;
直接合成:合成层的
transform、opacity修改,只需要将多个图层再次合并,而后生成位图,最终展示到屏幕上;
触发时机
回流触发时机
回流这一阶段主要是计算节点的位置和几何信息,那么当页面布局和几何信息发生变化的时候,就需要回流。
添加或删除可见的DOM元素
元素的位置发生变化
元素的尺寸发生变化(包括外边距、内边框、边框大小、高度和宽度等)
内容发生变化,比如文本变化或图片被另一个不同尺寸的图片所替代
页面一开始渲染的时候(这避免不了)
浏览器的窗口尺寸变化(因为回流是根据视口的大小来计算元素的位置和大小的)
获取一些特定属性的值
offsetTop、offsetLeft、 offsetWidth、offsetHeightscrollTop、scrollLeft、scrollWidth、scrollHeightclientTop、clientLeft、clientWidth、clientHeight这些属性有一个共性,就是需要通过即时计算得到。因此浏览器为了获取这些值,也会进行回流。
重绘触发时机
触发回流一定会触发重绘
除此之外还有一些其他引起重绘行为:
颜色的修改
文本方向的修改
阴影的修改
浏览器优化机制
由于每次重排都会造成额外的计算消耗,因此大多数浏览器都会通过队列存储重排操作并批量执行来优化重排过程。浏览器会将修改操作放入到队列里,直到过了一段时间或者操作达到了一个阈值,才清空队列。
当你获取布局信息的操作的时候,会强制队列刷新,例如offsetTop等方法都会返回最新的数据。
因此浏览器不得不清空队列,触发回流重绘来返回正确的值
减少回流
对于那些复杂的动画,对其设置
position: fixed/absolute,尽可能地使元素脱离文档流,从而减少对其他元素的影响使用css3硬件加速,可以让
transform、opacity、filters这些动画不会引起回流重绘在使用
JavaScript动态插入多个节点时, 可以使用DocumentFragment.创建后一次插入.通过设置元素属性
display: none,将其从页面上去掉,然后再进行后续操作,这些后续操作也不会触发回流与重绘,这个过程称为离线操作
CSS引入方式(4种)
内联方式
<div style="background: red"></div>
嵌入方式
在
HTML头部中的<style>标签下书写CSS代码
链接方式
使用
HTML头部的<head>标签引入外部的CSS文件。<link rel="stylesheet" type="text/css" href="style.css">
导入方式
使用
CSS规则引入外部CSS文件
比较链接方式和导入方式
链接方式(用 link )和导入方式(用 @import)都是引入外部的 CSS 文件的方式
link属于HTML,通过<link>标签中的href属性来引入外部文件,而@import属于CSS,所以导入语句应写在CSS中,要注意的是导入语句应写在样式表的开头,否则无法正确导入外部文件;@import是CSS2.1才出现的概念,所以如果浏览器版本较低,无法正确导入外部样式文件;
当
HTML文件被加载时,link引用的文件会同时被加载,而@import引用的文件则会等页面全部下载完毕再被加载;
硬件加速
浏览器中的层分为两种:渲染层和合成层。
渲染层
渲染层的概念跟层叠上下文密切相关。简单来说,拥有z-index属性的定位元素会生成一个层叠上下文,一个生成层叠上下文的元素就生成了一个渲染层。
层叠上下文的创建(3类)
由一些CSS属性创建
天生派
页面根元素天生具有层叠上下文
根层叠上下文
正统派
z-index值为数值的定位元素的传统层叠上下文
扩招派 (CSS3属性)
元素为
flex布局元素(父元素display:flex|inline-flex),同时z-index值不是auto - flex布局元素的
opactity值不是1 - {透明度|opactity}元素的
transform值不是none- {转换|transform}元素
mix-blend-mode值不是normal- {混合模式|mix-blend-mode}元素的
filter值不是none- {滤镜|filter}元素的
isolation值是isolate- {隔离|isolation}元素的
will-change属性值为上面②~⑥的任意一个(如will-change:opacity)元素的
-webkit-overflow-scrolling设为touch
合成层
只有一些特殊的渲染层才会被提升为合成层,通常来说有这些情况:
transform:3D变换:translate3d,translateZ;will-change:opacity | transform | filter对
opacity|transform|fliter应用了过渡和动画(transition/animation)video、canvas、iframe
硬件加速
浏览器为什么要分层呢?答案是硬件加速。就是给HTML元素加上某些CSS属性,比如3D变换,将其提升成一个合成层,独立渲染。
之所以叫硬件加速,就是因为合成层会交给GPU(显卡)去处理,在硬件层面上开外挂,比在主线程(CPU)上效率更高。
利用硬件加速,可以把需要重排/重绘的元素单独拎出来,减少绘制的面积。
避免重排/重绘,直接进行合成,合成层的transform 和 opacity的修改都是直接进入合成阶段的;
可以使用
transform:translate代替left/top修改元素的位置;使用
transform:scale代替宽度、高度的修改;
元素超出宽度...处理
单行 (AKA: TWO)
text-overflow:ellipsis:当文本溢出时,显示省略符号来代表被修剪的文本white-space:nowrap:设置文本不换行overflow:hidden:当子元素内容超过容器宽度高度限制的时候,裁剪的边界是border box的内边缘
p{
text-overflow: ellipsis;
white-space: nowrap;
overflow: hidden;
width:400px;
}
复制代码多行
基于高度截断(伪元素 + 定位)
基于行数截断()
基于高度截断
关键点 height + line-height + ::after + 子绝父相
核心的css代码结构如下:
.text {
position: relative;
line-height: 20px;
height: 40px;
overflow: hidden;
}
.text::after {
content: "...";
position: absolute;
bottom: 0;
right: 0;
padding: 0 20px 0 10px;
}
复制代码基于行数截断
关键点:box + line-clamp + box-orient + overflow
display: -webkit-box:将对象作为弹性伸缩盒子模型显示-webkit-line-clamp: n:和①结合使用,用来限制在一个块元素显示的文本的行数(n)-webkit-box-orient: vertical:和①结合使用 ,设置或检索伸缩盒对象的子元素的排列方式overflow: hidden
p {
width: 300px;
display: -webkit-box;
-webkit-line-clamp: 3;
-webkit-box-orient: vertical;
overflow: hidden;
}
复制代码元素隐藏
可按照隐藏元素是否占据空间分为两大类(6 + 3)
元素不可见,不占空间
(
3absolute
+
1relative
+
1script
+
1display
)
<script>display:noneabsolute+visibility:hiddenabsolute+clip:rect(0,0,0,0)absolute+opacity:0relative+left负值
元素不可见,占据空间
(3个)
visibility:hiddenrelative+z-index负值opacity:0
元素不可见,不占空间
<script>
<script type="text/html">
<img src="1.jpg">
</script>
复制代码display:none
其他特点:辅助设备无法访问,资源加载,DOM可访问
对一个元素而言,如果display计算值是none,则该元素以及所有后代元素都隐藏
.hidden {
display:none;
}
复制代码absolute + visibility
.hidden{
position:absolute;
visibility:hidden;
}
复制代码absolute + clip
.hidden{
position:absolute;
clip:rect(0,0,0,0);
}
复制代码absolute + opacity
.hidden{
position:absolute;
opacity:0;
}
复制代码relative+负值
.hidden{
position:relative;
left:-999em;
}
复制代码元素不可见,占据空间
visibility:hidden
visibility 的继承性
父元素设置
visibility:hidden,子元素也看不见但是,如果子元素设置了
visibility:visible,则子元素又会显示出来
.hidden{
visibility:hidden;
}
复制代码relative + z-index
.hidden{
position:relative;
z-index:-1;
}
复制代码opacity:0
.hidden{
opacity:0;
filter:Alpha(opacity=0)
}
复制代码总结
最常用的还是display:none和visibility:hidden,其他的方式只能认为是奇招,它们的真正用途并不是用于隐藏元素,所以并不推荐使用它们。
关于display: none、visibility: hidden、opacity: 0的区别,如下表所示:
Chrome支持小于12px 的文字
Chrome 中文版浏览器会默认设定页面的最小字号是12px,英文版没有限制
原由 Chrome 团队认为汉字小于12px就会增加识别难度
中文版浏览器 与网页语言无关,取决于用户在Chrome的设置里(
chrome://settings/languages)把哪种语言设置为默认显示语言系统级最小字号 浏览器默认设定页面的最小字号,用户可以前往
chrome://settings/fonts根据需求更改
解决方案(3种)
zoomtransform:scale()-webkit-text-size-adjust:none
zoom
zoom 可以改变页面上元素的尺寸,属于真实尺寸。
其支持的值类型有:
zoom:50%,表示缩小到原来的一半zoom:0.5,表示缩小到原来的一半
.span10{
font-size: 12px;
display: inline-block;
zoom: 0.8;
}
复制代码transform:scale()
用transform:scale()这个属性进行放缩
使用scale属性只对可以定义宽高的元素生效,所以,需要将指定元素转为行内块元素
.span10{
font-size: 12px;
display: inline-block;
transform:scale(0.8);
}
复制代码text-size-adjust
该属性用来设定文字大小是否根据设备(浏览器)来自动调整显示大小
属性值:
auto:默认,字体大小会根据设备/浏览器来自动调整;percentage:字体显示的大小none:字体大小不会自动调整
存在兼容性问题,chrome受版本限制,safari可以。
后记
分享是一种态度。
全文完,既然看到这里了,如果觉得不错,随手点个赞和“在看”吧。
作者:前端小魔女
来源:https://juejin.cn/post/7203153899246780453
非科班三本程序员入行这几年
一直以来都想写下自己的经历,今天看了下掘金的前辈们写的经历,觉得也有点感慨,恰逢最近工作也不是很如意。也想写点什么,缓解下焦虑紧张的心情。
我09年中考,考了512分,没能过县里的一中公费分数线。家里条件不好,所以去的县二中。一开始我也没想好到底是继续读书还是去打工,家里的姐姐初中毕业就因为家里穷辍学去打工了,老父亲从小也是上过高中的,那个年代上高中还是很少的,可能对读书也有点执念,希望我继续读下去。当时去二中的想法很简单,虽然成绩不是很好,但是觉得年龄还小,出去打工感觉这辈子还有的是时间,不如去高中试下水读的好就继续读,读不好就像老家大多数年轻壮劳力一样,出国打黑工赚点快钱,过个几年回家娶个媳妇,大家不都是这么过的吗?心里暗暗觉得也是不错的。
09年开始了高中的学习生活,虽然刚开始来的时候是抱着试试的态度,但实际上我也算是个有干啥像啥的本性,在高中一直也都算是努力学习着,虽说高考成绩不尽如意,但也算是尽力了。我们高中是县里的二中,每年的二本上线的学生屈指可数,我一般的考试成绩基本维持在全年级理科13名左右,高考考了457分,当时也纠结要不要复读一年,县一中打电话说我的成绩可以在县一中免费复读,我又抱着要考个好学校的决心决定再试一次,可到了复习班以后,根本没这个心情,复习班在7月就开始了上课,我只读了三天就回家了,当时在复读班静不下心来学习,实在是读不下去。
12年7月10号左右,跟随着几个高中同学去了市里的工地,干起了暑假工。一边干暑假工,一边想着填报志愿。虽说考的分不高,但是还是决定要继续读书,说不好到底为什么要读书,家里条件又不好,可能冥冥中就是宿命吧,也可能是对打工生涯的一种逃避,也可能是对大学的幻想,也可能是幻想着读了大学就会实现阶级的跨越。
到工地第一天的早晨,早上吃的看不见几个饭粒的稀米粥,不知道食堂老头从哪里搞来的很难吃的馒头,像是假的一样没有一点面的味道,菜就是那种最便宜的萝卜咸菜。这吃食,就算监狱也不过如此吧! 吃饭完,宿舍门口来了一车木板,那种木匠用来支模板的木板子,上面还有好多钉子,我在车上卸货,被扎了好几次,天上还下着濛濛细雨,但工长丝毫没有让我们停下来进屋的意思。就这样顶着雨卸完了一车货。工地的宿舍也是常人无法想象的脏乱差,那种很多年的砖瓦房,里面的床铺能大幅度晃动,我在上铺根本不敢动,上去了就是稳稳的趴着或坐着。宿舍长度大概有两间房那么大,里面还在过道摆满了几根大铁管子,铺下面摆满了垃圾和剩饭,还有写日常的脸盆饭缸等。
宿舍大概有十来个人,我下铺住着的是两个开塔吊的工友,当时听说一天150元,我们这种力工一天80元。门口住着的是小工长,负责给大家分活。里面的有调度塔吊的师傅,有开搅拌机的,还有个老头专门筛沙子,还有个老滑头是在楼上负责清理垃圾的。宿舍的晚上呼噜声震天响,7月的天气要把人蒸熟了,不知道这样的日子我能坚持到多久,感觉这种生活真的是折磨。每天早上七点上班,晚上七点下班,中午休息一个半小时。我在这期间,刚开始几天跟着工长放线,超平,后来跟着大叔开了几天搅拌机,听这个大叔说,他家的孩子也读了大学了,他还给孩子在市里买了楼。我心想我要有这么能挣钱的爸爸就好了。再后来工地打灰,也就是用那种水泥罐车和喷水泥的机器来给楼上供水泥。在打灰时候,我负责拎着那个震动棒的电机,水泥灰喷到哪里,就要用震动棒震一下,确保水泥凝固时没有空心的。震动棒的电机是真的沉啊,还要在水泥路里面来回趟着走,还要再拎着电线。当时我还是个18岁的孩子,感觉人生真的好难啊!再后来工地没活时候跟着大叔去其他工地做售后,給人家的下水道通下水,当时是去了六个核桃的研发单位,里面开着空调,到处飘着核桃露的香味,每罐核桃露打开抽取少部分的样品就倒掉了,我心想要是不到掉让我喝个痛快该有多好啊。在修下水道这几天,庆幸的是这里有空调,比起外面像烤箱一样的日子,感觉更舒服一些。
在工地干了十多天后,实在是受不了工地的生活就回家了。最后报考了省里的一所三本院校,到了大学以后,好像一下没了目标,每天除了上课学习外,也有更多自己的时间了,有的人想去学生会锻炼一下,有的人趁有时间开始谈恋爱,那时候12年手机还没有那么多娱乐的应用,用的最多的还是qq,游戏也只有奋斗小鸟,削水果,赛车等。我刚上学用的酷派的什么3gs,花了300块买的,是同学中最次的那种。心里莫名有一种自卑的感觉。当时觉得学生会真的没啥锻炼人的,像是一种虚假的官职一样,好多学生觉得当上了学生会就是领导,高别人一等。这种做派实在看不惯,也就一直没加入其中。谈恋爱就更没我啥事了,家里穷没自信,虽然有时候也有萌动的时候,但是清醒后,还是觉得谈恋爱不适合我。回顾大学的生活,现在也令人向往,没有赚钱的压力,也没有学习的压力,还有很多随意支配的时间,还有很多同学可以一起陪着玩,也许这就是这辈子最幸福的时光吧。
14年夏天,时间一晃大二结束了,我学的是土木工程,那个暑假在学校附近找了个设计院打算提前感受下工作的生活。我进的组是设计院的结构设计组。相对互联网行业的产品,开发,测试,运营。设计院也有一套的研发流程,有整体方案设计,建筑设计,结构设计,给排水等。虽然每天没有工资,但是也每天都按时上下班,14年的时候,在设计院里已经预感到行业的萧条,我们设计院在我们市里还算不错的私企,但是都没有什么活,好多人工作几年还是拿着一千块的基本工资,住着公司提供的免费宿舍,这样的待遇别说买房娶媳妇了,维持生活都难。那时候开始我就想着要作出点行动了,这个行业已经不行了,不能以后眼看着自己往火堆里跳。大概在设计院呆了一个月后,我回家了,我觉得在设计院没啥前景,学习也没啥太大意思。
到大三结束,好多人开始找实习单位了,也有一些牛鬼蛇神的公司来学校宣讲,看了下没有啥正经工作,除了销售就是些没人去的工作。我内心也有点荒,家里没钱,也没背景,自己这三年更是没学到一点本事。接着开始逛了下人才市场,发现根本没有啥正经岗位,索性直接去了几个工地,问家人要人不,工地的人可能也没见过这样的找工作的,对我们来工地找工作感到很奇怪,没等我们多说就把我们打发走了。恰好后来同学群里说我老家有个人招房屋土地测量的,管吃住还能有1200的实习工资。我心想反正也比呆着强,就去试试吧。到了单位应该是6月17号左右,所在地是一个工厂里面,租了几间办公室和宿舍。做的工作是到农村里面测量每家房屋实际占用的大小,天气很炎热,我干了大概一个月左右吧,就辞职不干了,觉得是在是没啥意思,学不到本事,以后也不可能做这个行业了,当时觉得以后是不会再从事建筑行业了,没有一点希望。
2015年7月13号,我直接买的票从保定到北京报名培训。在北京报名了android开发的培训。当时我一个高中同学在那里,我也算投奔她去的吧。当时我觉得趁现在还没有毕业,还有时间踏踏实实静下心来学点本事,要真等到毕业,那可真的就没时间也没机会了。同时也觉得建筑行业看不到未来,计算机起码是凭个人能力找工作,总不可能啥也不会凭关系进公司吧。之前在设计院实习时候,有个同事是研发经理,大学时候学的是机械的,我想着他都能转行我肯定也可以。还有就是在实习期间,有个考研宿舍可以住,就和计算机专业的几个同学一起住一个宿舍,也算是稍微了解了下这个行业。就这样误打误撞进入了这个行业,有时候甚至觉得冥冥之中是命中注定要从事这一行。有些事真的是说不清楚,可能就是命里的安排,当时报名费是一万五千元,我这么穷的家庭居然也敢报名,能上学都是极限了。可真到报名时候,我爸居然同意了,同意我花钱培训。虽然我本来打算贷款培训,但是需要家里人签字,家里人觉得要真的想培训那就全款交学费吧,在她们印象中,贷款还是太危险了,觉得搞不好就陷入高利贷中一样。
即使站在风口上,也没有一帆风顺的事。找工作入行也同样费尽了周折。12月培训结束后,跟着同一期的同学投简历,觉得自己还是啥也不会,很幼稚的也跟着去面试,以为也许某个傻瓜公司领导能看中我。现在想想自己那时候还是想当然了,以为像培训公司宣传的一样,培训完了就能找到工作,甚至能月薪过万。我想着自己虽然不过万,能找个五千月薪的也行啊,起码能自己养活自己,不用在工地上忍受风吹日晒,而且周六日都不休息。跟着投了一周简历后没有收到任何面试通知,可笑的是,我舍友有面试机会,后来我就和他一起去面试了,只要他收到面试邀请,我也跟着一起去,他面试完了,我也顺便面试一下。结果也可想而知,根本没人要我。
眼看着在这耗下去也不是个办法,吃住用度也比学校贵,就先回学校了。在学校一边复习培训的内容,一边准备学校的考试。想着过了年再去北京试试。
过了年,也就是大四的最后一个学期了。我这时候虽然没有培训的贷款,也没有助学贷款,但是因为买了个新电脑和平时用度比较多,借了点贷款。同时来北京找工作租房子等花费也比较多,找工作也就压力更大了。好在找到了一个工作,在丰台那边,月薪3500,虽然低点,但是总算能入行了,心里很高兴。这家公司基本都是应届生或者没毕业的,做的工作也都不是很懂,都是些很低端的外包工作,我和CTO说我的领导啥也不会,写的东西我觉得还如我写的呢,啥也不是。领导说那要不你来搭个框架?我说我也没这个实力,结果没过几天,我被通知走人。就这样我职业生涯的第一份工作还不到一个月就结束了。后来又在朝阳区找了个月薪4000的工作,同样也是因为能力不足,被老板赶走了,第二份工作也是一个月左右。这时候也快毕业了,开始回学校准备毕业设计,一边准备毕业设计,一边学习编程技能,盼望着毕业后能找个如意的工作,做毕设期间,是最后一段无忧无虑在的大学时光,不在北京那种高节奏环境下,不再想找工作的烦恼,感觉身心很放松,拍毕业照,吃散伙饭,送走一个个同学,大学生活仿佛像一场梦一样,梦醒了,人生的烦恼接踵而至。
本来想记录下最近几年的焦虑,没想到一写起来就铺垫太多了,写了好多关于上学和家庭的琐碎。
16年夏天,大学毕业后,又杀回了北京,虽然接近半年的学习和有小部分的工作经历,但是投简历还是仿佛石沉大海,看着招聘网站上写的要求3年工作经验,仿佛是我无法逾越的鸿沟。我痛苦着,绝望着,也许是毕业与失业的同时遭遇,一个人在出租屋里终于爆发了,一下子开始痛哭流涕,想起了前几天毕业时候有的同学难过的哭了,当时我没哭,这一刻终究还是没忍住。振作起来后,又开始找工作,去了一个清华硕士的创业项目,同样也是做了一周,工资也没要我就又离职了。我觉得这个人也太不靠谱了,招几个人啥都没有就开始创业?更像是忽悠人。这时候我想着既然北京没机会,何妨不去天津试试呢,就这样,我投了几家天津的公司,从北京坐火车去天津面试。恰好有一家要我了,看上去这家公司还挺靠谱的,有宽敞的大会议室,整洁的工位。当时心里很开心,希望这次能稳下来。
入职天津公司后,工作了一年多,到17年10月我裸辞来北京面试了,因为我知道,迟早是要来北京的,和天津的工资差太多了,工作时间越长差距越大,想趁着年轻多在北京赚点钱。就这样又入职了北京一家做零售的小公司,给自动贩卖机上的android系统做售卖。干了三天又跑路了,觉得和互联网行业仿佛是两个行业,公司也小,人也很少,即便稳定,我也不想留下来。过了几天又面试了一家小的创业公司,在慈云寺那边,同样是因为和同事不合,干了将近五个月,觉得老板不靠谱又离职了。
再后来从18年4月到现在又先后入职了三家公司,都算是比较靠谱的公司,年薪也从20+到现在的40+,最近感觉又遇到了瓶颈。虽然这几年一直从事安卓开发。但是说实话没有什么真本事,能力更谈不上有啥大的突破,每次跳槽都是临时背题。本来这篇文章想写写这几年我是怎么混的这么惨的,工作六年多还是没有达到六年经验应有的水平。
从16年下半年开始就跟着动脑学院的安卓视频课程学习,学的越多,感觉不会的越多,自己基础差,学历低,又不是科班出身,所以压力很大。结果可能是走了很多歪路,到17年下半年,花了很多精力在乱学,没有什么章法,虽然平时也注重安卓的一些基础,但是觉得进大公司还差的太多。后来18年学了很多音视频相关的ffmpeg,C语言,WebRtc,音视频编解码基础,OpenGl,还有黑马程序员的JavaWeb开发等等学的很杂。当时想着虽然主营安卓,但是如果靠着音视频这条专项应该会很吃香吧,结果并没有学到音视频开发应有的高度,Android相关的也没有太大的提高,导致在开发市场并不是很吃香。学JavaWeb主要是想着以后去别的新一线城市能够更有优势。
后来想多学习下Grade.Kotlin等,发现项目中用不到的话,光学效果也不是很好。所以又开始学习计算机基础相关的,这也是受陈皓指点的吧,想成为高手就要从计算机系统,网络,C语言等开始学起,也确实坚持了小半年,看了计算机操作系统,汇编语言,还有些极客时间里面的一些Linux等。也有跟着哈工大的李志军老师学习计算机操作系统。看了这些之后,还是觉得自己真的没办法踏下心来一心学下去,这里有大神坚持下去并有收获的可以指点一下。
总之吧,入行程序员做Android开发这几年,我不后悔选择这一行,是这份工作让我从一穷二白,到现在靠自己结了婚,也买了房子。但是也有遗憾,遗憾的是没能够像众多优秀的开发者一样,达到行业内较高的高度,现在只能说是一个没有任何核心竞争力的随时可替换的螺丝钉。
现如今还是想找到自己的目标,希望自己能够朝着这个目标不断努力,能够让自己能够在开发的行业里多干几年,尤其是今年这种环境,谁也说不好明天还是不是还在公司。但是什么才是目标呢?每天刷题准备面试让自己保持这种面试的竞争力难道就是目标吗?没完没了的看框架源码,学习新知识这样让自己能够不被这个行业淘汰难道就是普通开发者的目标吗?
还是像那些大神那样下狠功夫把各种基础的计算机理论学透?如果是这样只是学不运用于工作又能有多大的收获呢?
哎 可能是上高中时候被洗脑养成的焦虑的性格,也可能是身处这个行业,这个城市让自己无形之中就会有思想上的包袱。先写到这里吧,后面有新的理解和收获再来补充。
链接:https://juejin.cn/post/7199555741630595133
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
工作 7 年的老程序员,现在怎么样了
犹记得高中班主任说:“大家努力考上大学,大学没人管,到时候随便玩”。我估计很多老师都这么说过。
我考上大学(2010年)之前也是这么过的。第一年哥哥给买了个一台华硕笔记本电脑。那个年代买华硕的应该不少,我周边就好几个。有了电脑之后,室友就拉着我一起 cs,四个人组队玩,那会觉得很嗨,上头。
后来看室友在玩魔兽世界,那会不知道是什么游戏,就感觉很好玩,再后来就入坑了。还记得刚开始玩,完全不会,玩个防骑,但是打副本排DPS,结果还被人教育,教育之后还不听(因为别的职业不会玩),就经常被 T 出组。之后,上课天天看游戏攻略和玩法,或者干脆看小说。前两年就这么过去了
1 跟风考研
大三开始,觉得这么混下去不行了。在豆瓣上找了一些书,平时不上课的时候找个自习室学习。那会家里打电话说有哪个亲戚家的孩子考研了,那是我第一次知道“考研”这个词。那会在上宏微观经济学的课,刚好在豆瓣上看到一本手《牛奶面包经济学》,就在自习室里看。刚好有个同院系的同学在里面准备考研,在找小伙伴一起战斗(毕竟,考研是一场长跑,没有同行者,会很艰难)。我一合计,就加入了他们的小团队。从此成为“中国合伙人”(刚好四个人)中的一员。
我那会也不知道毕业了之后能去哪些公司,能找哪些岗位,对于社会完全不了解,对于考研也是完全不了解。小团队中的三个人都是考金融学,我在网上查,知道了学硕和专硕的区别,也知道专硕学费贵。我家里没钱,大学时期的生活费都是自己去沃尔玛、麦当劳、发传单挣得,大学四年,我在沃尔玛工作超过了 2 年、麦当劳半年,食堂倒盘子半年,中途还去发过传单,暑假还去实习。没钱,他们考金融学专硕,那我就靠经济学学硕吧,学硕学费便宜。
从此开始了考研之路。
2 三次考研
大三的时候,报名不是那么严格,混进去报了名,那会还没开始看书,算是体验了一把考研流程;
还记得那次政治考了 48 分,基本都过了很多学校的单科线,那会就感觉政治最好考(最后发现,还是太年轻)。
大四毕业那年,把所有考研科目的参数书都过了 2 遍,最后上考场,最后成绩也就刚过国家线。
毕业了,也不知道干啥,就听小伙伴的准备再考一次,之前和小伙伴一起来了北京,租了个阳台,又开始准备考研。结果依然是刚过国家线。这一年也多亏了一起来北京的几个同学资助我,否则可能都抗不过考试就饿死街头了。
总结这几次考研经历,失败的最大原因是,我根本不知道考研是为了什么。只是不知道如果工作的话,找什么工作。刚好别人提供了这样一个逃避工作的路,我麻木的跟着走而已。这也是为什么后面两次准备的过程中,一有空就看小说的原因。
但是,现在来看,我会感谢那会没有考上,不然就错过了现在喜欢的技术工作。因为如果真的考上了经济学研究生,我毕业之后也不知道能干啥,而且金融行业的工作我也不喜欢,性格上也不合适,几个小伙伴都是考的金融,去的券商,还是比较了解的。
3 入坑 JAVA 培训
考完之后,大概估了分,知道自己大概率上不了就开始找工作了。那会在前程无忧上各种投简历。开始看到一个做外汇的小公司,因为我在本科在一个工作室做过外汇交易相关的工作,还用程序写了一段量化交易的小程序。
所以去培训了几天,跟我哥借了几千块钱,注册了一个账号,开始买卖外汇。同时在网上找其他工作。
后面看介绍去西二旗的一家公司面试,说我的技术不行,他们提供 Java 培训(以前的套路),没钱可以贷款。
我自己也清楚本科一行 Java 代码没写过,直接工作也找不到工作。就贷款培训了,那会还提供住宿,跟学校宿舍似的,上下铺。
4 三年新手&非全研究生
培训四个月之后,开始找工作。那会 Java 还没这么卷,而且自己还有个 211 学历,一般公司的面试还是不少的。但是因为培训的时候学习不够刻苦(也是没有基础)。最后进了一个小公司,面试要 8000,最后给了 7000。这也是我给自己的最底线工资,少于这个工资就离开北京了,这一年是 2015 年。
这家公司是给政府单位做内部系统的,包括中石油、气象局等。我被分配其中一个组做气象相关系统。第二年末的时候,组内的活对我来说已经没什么难度了,就偷偷在外面找工作,H3C 面试前 3 面都通过了,结果最后大领导面气场不符,没通过。最后被另外一家公司的面试官劝退了。然后公司团建的时候,大领导也极力挽留我,最后没走成。
这次经历的经验教训有 2 个,第 1 个是没有拿到 offer 之前,尽量不要被领导知道。第 2 个是,只要领导知道你要离职,就一定要离职。这次就是年终团建的时候,被领导留下来了。但是第二年以各种理由不给工资。
之前自己就一直在想出路,但是小公司,技术成长有限,看书也对工作没有太大作用,没有太大成长。之后了解到研究生改革,有高中同学考了人大非全。自己也就开始准备非全的考试。最后拿到录取通知书,就开始准备离职了。PS:考研准备
在这家公司马上满 3 年重新签合同的时候,偷偷面试了几家,拿到了 2 个还不错的 offer。第二天就跟直属领导提离职了。这次不管直属领导以及大领导如何劝说,还是果断离职了。
这个公司有两个收获。一个是,了解了一般 Java Web 项目的全流程,掌握了基本开发技能,了解了一些大数据开发技术,如Hadoop套件。另外一个是,通过准备考研的过程,也整理出了一套开发过程中应该先思而后行。只有先整理出
5 五年开发经历
第二家公司是一家央企控股上市公司,市场规模中等。主要给政府提供集成项目。到这家公司第二年就开始带小团队做项目,但是工资很低,可能跟公司性质有关。还好公司有宿舍,有食堂。能省下一些钱。
到这家公司的时候,非全刚好开始上课,还好我们 5 点半就下班,所以我天天卡点下班,大领导天天给开发经理说让我加班。但是第一学期要上课,领导对我不爽,也只能这样了。
后来公司来了一个奇葩的产品经理,但是大领导很挺他,大领导下面有 60 号人,研发、产品、测试都有。需求天天改,还不写在文档上。研发都开发完了,后面发现有问题,要改回去,产品还问,谁让这么改的。
是否按照文档开发,也是大领导说的算,最后你按照文档开发也不对,因为他们更新不及时;不按照文档开发也不对,写了你不用。
最后,研发和产品出差,只能同时去一波人,要是同时去用户现场,会打架。最后没干出成绩,产品和大领导一起被干走了。
后面我们整体调整了部门,部门领导是研发出身。干了几个月之后,领导也比较认可我的能力,让我带团队做一个中型项目,下面大概有 10 号人,包括前后端和算法。也被提升为开发经理。
最后因为工资、工作距离(老婆怀孕,离家太远)以及工作内容等原因,跳槽到了下一家互联网公司。
6 入行互联网
凭借着 5 年的工作经历,还算可以的技术广度(毕竟之前啥都干),985 学校的非全研究生学历,以及还过得去的技术能力。找到了一家知名度还可以的互联网公司做商城开发。
这个部门是公司新成立的部门,领导是有好几家一线互联网经验的老程序员,技术过硬,管理能力强,会做人。组内成员都年轻有干劲。本打算在公司大干一场,涨涨技术深度(之前都是传统企业,技术深度不够,但是广度可以)。
结果因为政策调整,整个部门被裁,只剩下直属领导以及领导的领导。这一年是 2020 年。这个时候,我在这个公司还不到 1 年。
7 再前行
拿着上家公司的大礼包,马上开始改简历,投简历,面试,毕竟还有房贷要还(找了个好老婆,她们家出了大头,付了首付),马上还有娃要养,一天也不敢歇息。
经过一个半月的面试,虽然挂的多,通过的少。最终还是拿了 3 个不错的offer,一个滴滴(滴滴面经)、一个XXX网络(最终入职,薪资跟滴滴基本差不多,技术在市场上认可度也还不错。)以及一个建信金科的offer。
因为大厂部门也和上家公司一样,是新组建的部门,心有余悸。然后也还年轻,不想去银行躺平,也怕银行也不靠谱,毕竟现在都是银行科技公司,干几年被裁,更没有出路。最终入职XXX网络。
8 寒冬
入职XXX网络之后,开始接入公司的各种技术组件,以及看到比较成熟的需求提出、评估、开发、测试、发布规范。也看到公司各个业务中心、支撑中心的访问量,感叹还是大公司好,流程规范,流量大且有挑战性。
正要开心的进入节奏,还没转正呢(3 个月转正),组内一个刚转正的同事被裁,瞬间慌得一批。
刚半年呢,听说组内又有 4 个裁员指标,已经开始准备简历了。幸运的是,这次逃过一劫。
现在已经 1 年多了,在这样一个裁员消息满天飞的年代,还有一份不错的工作,很幸运、也很忐忑,也在慢慢寻找自己未来的路,共勉~
9 总结
整体来看,我对自己的现状还算满意,从一个高中每个月 300 块钱生活费家里都拿不出来;高考志愿填报,填学校看心情想去哪,填专业看专业名字的的村里娃,走到现在在北京有个不错的工作,组建了幸福的家庭,买了个不大不小的房子的城里娃。不管怎么样,也算给自己立足打下了基础,留在了这个有更多机会的城市;也给后代一个更高的起点。
但是,我也知道,现在的状态并不稳固,互联网工作随时可能会丢,家庭成员的一场大病可能就会导致整个家庭回到解放前。
所以,主业上,我的规划就是,尽力提升自己的技术能力和管理能力,争取能在中型公司当上管理层,延迟自己的下岗年龄;副业上,提升自己的写作能力,尝试各种不同的主题,尝试给各个自媒体投稿,增加副业收入。
希望自己永远少年,不要下岗~
链接:https://juejin.cn/post/7173506418506072101
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简历写得好,offer不会少!
转眼时间已经到2月下旬了,按照往年各个公司的招聘进度,估计近期各个公司的春招就会开启了。
春招作为校招生们求职的黄金时间,把握好金三银四的招聘季,不仅可以为金九银十的秋招做好铺垫,运气好的话可以直接通过实习转正一步到位免去秋招。
因此,准备在春招中大显身手的朋友,也该把写简历提上日程了!
为什么要写简历
简历作为求职者的名片,是HR衡量求职者岗位匹配度的重要因素,也是面试前留给面试官的第一印象。
一份内容丰富、排版精美的简历不仅可以增大简历筛选的通过率,也能让面试官在面试中更愿意去挖掘出你的闪光点。
毕竟求职者有没有用心、求职意愿是否强烈都是可以从简历中窥探一二的!
与此同时,一份排版混乱、内容随意的简历,如果被石沉大海也就情有可原了。
毕竟简历代表的是一种态度!
如何写简历
简历的目的是向HR和面试官清晰展示自己是否与岗位匹配。
一份简历的制作,通常需要从格式和内容两个方面来考虑。
格式
一份还算不错的简历格式应该考虑到如下几个因素:
最近帮一些同学修改简历,我发现很多同学的简历在排版方面存在如下几个方面的问题:
x 简历色彩太多
理解大家想要突出亮点的心情。但是过于花里胡哨可能会分散阅读者的注意力,从而导致适得其反的结果。
x 内容没有边距
很多同学的经历很丰富,想在简历中充分展现自我,因此密密麻麻写了很多内容。但没有突出亮点,也没有合理的设置边距,这可能会给阅读者带来不好的阅读体验。
x 个人照过于随意
为了在视觉上给招聘官良好的印象,很多同学会放自己的一寸照片在简历上。诚然,良好的求职形象是一个加分项,但是在照片的选择上,大家应该以合适出发,生活照和艺术照确实不太适合在简历上出现。
负责招聘的HR一天可能要阅读上百上千份简历,视觉上的体验也是写简历时需要考虑的因素。
对于理工科的同学们来说,简历排版可能是大家不擅长或者不太care的点,其实目前市面上有很多制作简历的网站,大家可以去这些平台选择合适的模板!
内容
如果说简历的格式只是起到印象分的作用,那么简历的内容就是简历能否选中的决定性因素了!
记得之前去线下招聘会应聘时,HR在拿到我的简历后,手上的笔一直在简历上圈重点,包括我的教育背景、求职意向、实习经历、项目经历、获奖情况等等...
现在回想起来,这应该就是大家常说的star法则吧!
因此,强烈建议大家按照star法则来填充自己简历的内容:
具体到简历中的每个模块,需要包含的内容有以下几个方面:
01 基本信息&求职意向(非常重要)
基本信息是HR联系求职者的主要途径,而求职意向则是岗位匹配度的重要衡量标准。
02 教育背景
成绩好的同学可以放上自己的绩点&排名,学校好的同学可以标注985、211。
03 自我评价&技术栈
自我评价是从性格方面展示求职者的岗位匹配度,技术栈是从能力上体现求职者实力。
对于致力于从事技术岗位的同学,可以在技术栈部分展示出自己的能力。
比如:熟练掌握原生 HTML、CSS、JavaScript 的使用,熟悉 React 框架、了解 Webpack、 TypeScript,熟练使用代码托管工具 Git等等。
如果有持续更新的技术博客或者开源项目,也可以在这里用数字量化加粗体现访问量和star数...
04 实习经历&项目经历(篇幅至少占3/5)
某种程度上说,有和求职岗位相匹配的大厂实习背景的同学在简历筛选中会更容易通过。
如果没有实习经历,有和求职岗位相匹配的项目经历也是star之一。
因为实习经历本质上也是项目经历。
在表述项目经历时,应重点突出自己的工作内容及成果,按照star原则写出技术难点和技术亮点,并量化展示成果,减少口水话的表述。
05 获奖经历和校园经历
获奖经历是软实力的体现, 如果在求职岗位所在的领域获得过有含金量的证书,会给阅读者留下更好的印象。或者在校期间拿到过学业奖学金,也是软实力的体现哦~
总结
一份好的简历,通常会经历多次打磨。
在这期间,我们也可以根据简历来进行阶段性的有效复盘,找出自己的亮点和待提升点,并在下一个版本中进一步提高。
与此同时,建议大家将每个版本的简历保存为word和pdf两个版本。word版本便于进一步修改简历,pdf版本用于求职投递, 防止因设备问题导致格式错乱!
链接:https://juejin.cn/post/7202818813511041082
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
程序员35岁不是坎,是一把程序员自己设计的自旋锁
有时候,我是悲伤的,这一路走来,从大专第一次接触电脑,学习编程,到现在这四五年的摸爬滚打,好不容易让自己拥有经验,灵活工作了,却要思考35岁这个程序员的诅咒,确切来说是中国程序员的独有的诅咒。
优秀的程序员思维逻辑严谨,弄清楚需求的本质是每天重复的工作,也是对工作的态度,那弄清楚诅咒的来源,义不容辞。
被诅咒的35岁
- 35岁后找不到工作了!
- 35岁后被开了!
- 程序员的年轻饭,就是35岁!
- 昨天群里还有同学在聊,如何利用硬件加Linux绕过35岁的梦魇。
其实有人这么说过,也有公司这么做过,他们认为人在35岁以后,注意,说的是人,这一个庞大的群体,而不单指程序员,他们认为在当今互联网快速发展的时代,程序员在35岁后会有以下限制
技术变化快:技术的更新换代速度非常快,一些老旧的编程语言和技术已经被新技术所取代,这些新技术可能需要程序员重新学习和适应。所以有些人认为年龄大的程序员可能不如年轻的程序员适应新技术。
年龄歧视:有些雇主可能会偏向招聘年轻的程序员,认为他们更具有创新和学习新技术的能力。
职业发展:程序员的职业发展路径通常是从程序员到高级程序员,然后是技术主管或项目经理等。他们认为在这个年龄段还没有对应到这个发展行列中的人能力可能是欠缺的。
完全是年龄歧视的,他们不会在意你能创造的价值,就是认为你不行。
其实分析上述几个点之后,发现,企业拒绝的不是一个35岁的人,而是一个35岁后不满足需求的人,试着分析一下,企业为什么会这样思考?
知己知彼,百战不殆
经过五六年的开发,我可以从我观察的角度分析一下,为什么会将不满足需求的人加上35岁的枷锁。
其实,一个35岁的程序员自己应该要达到35岁程序员应有的高度。
而企业要求的不是一个未满35岁的程序员,而是拒绝一个35岁了,经验还不满足需求的程序员。
从开发中总结,什么样的程序员在给35的程序员不断自旋枷锁
在从零到一的项目中,新手程序员往往会更加注重技术的应用,对今对技术、对需求、对公司存在敬畏之心,他们在开发当中不会随便的乱用一些技术,他们也对项目的规范存在尊敬的态度。一个经验丰富的程序员。假设他不遵守项目的规范,你给他任意一个需求,他都能轻松的完成,但是他从来不会care设计模式,从来不会思考需求的扩展维护以及健壮。那长此以往下去之后这个项目将会面临以下两个问题。
说白了,一个经验丰富的程序员,如果不听从领导的安排自己又对自己代码的要求特别低,因为他们编写的程序一般会按时按点完成需求,测试仪不会存在大量的bug,所以他们认为他们在公司当中是稳定的存在。这就导致企业认为指挥不了的程序员就是这些年龄大的程序员,就是这些程序员,再给自己的35岁自旋加锁。
从0到1的项目,经验丰富而低要求的程序员更容易造成项目的失败
代码人生中介绍了架构和开发的关系,一个项目在经历一段时间的开发之后,往往体现的是研发的规模、投入的成本、增长的效益都会增大,这也是一个公司发展壮大的必经之路。
从开发的角度分析
一个项目第一个版本的投入,可能是三个程序员在两个月的时间完成了第一个版本的发布,并且第一个版本的发布当中基本覆盖了这个应用的90%的功能,从第二个版本开始,每一次需求的研发,时间都将比第一个版本开发的时间更长,而做的东西更少,并且在这个过程当中开发的人数会逐渐增多,简单来讲,研发的人数和需要研发相同需求的时间看下面这一张表。
从企业的角度分析
在他们的眼中,当初三个人两个月开发的代码数量,是我们现在大版本当中,10个人两个月开发数量的好几倍,就在他们眼中是我们开发的生产力太低了,但是在扩张招聘当中,从程序员的角度,招聘的一定是经验丰富的程序员,这就让企业认为我们有经验的程序员,也就是说,年龄大的程序员造成的生产力的底下。
失败的原因真的是大龄程序员吗?
其实我们简单分析一下就可以知道,造成这个像失败的原因,从技术角度单纯来讲,就是因为架构的失败,或者是没有约束的开发模式造成的,因为我们开发一个需求的时间长短,更多的是在维护之前的代码,一个新的需求的插入需要改动太多太多的代码,屎山的代码也就是这么来的。
打破年龄枷锁,其实企业需要的是这样的程序员
所以我们不能浪费多年的开发经验,时刻谨记导致上述问题的原因,不管你是领导者还是程序员,一定要杜绝上述问题的发生,从企业的角度出发,规范自己的编程行为,从现在开始解掉这个枷锁。晋级的思想系列中会总结更多的技巧,总结更多的经验。
主要还是需要将架构的思想深刻到记忆里,让每一行代码都透露着设计的气息,让代码优雅,让内存合理,让扩展更强,让程序更健壮,努力让自己保持以下状态,也要养成一些好的习惯。
- 技术能力和知识面:一个经验丰富的程序员应该掌握广泛的编程语言和开发工具,对计算机科学原理、数据结构和算法等基础知识有深刻的理解。此外,一个架构能力强劲的程序员应该能够将技术知识转化为实用的解决方案,设计出高效、可扩展、可维护的系统。
- 代码质量:一个经验丰富的程序员应该写出易读易懂、清晰简洁的代码,并遵守编程规范。一个架构能力强劲的程序员应该对代码结构、模块化、可重用性等方面有很高的要求,避免代码臃肿、不易维护的情况。
- 项目经验:一个经验丰富的程序员应该具备多个项目的经验,能够处理项目中出现的各种问题,并能够在团队中合作开发。一个架构能力强劲的程序员应该能够根据项目需求制定适合的架构方案,提高系统性能和可扩展性。
- 学习能力和思维方式:一个经验丰富的程序员应该能够持续学习新技术和知识,保持对行业的敏锐度。一个架构能力强劲的程序员应该能够独立思考和解决问题,具有系统化思维方式和架构设计的能力。
- 持续学习:程序员需要不断学习新的技术和工具,了解行业最新的趋势和发展方向,以便在架构设计和代码编写中使用最新的技术和最佳实践。
- 阅读优秀的代码:阅读优秀的代码可以让程序员学习到别人的优秀经验和架构设计,借鉴别人的思路和方法,以此提高自己的写作和设计能力。
- 代码重构:程序员需要对自己的代码进行重构,将代码进行整理、简化和优化,使其更加易读易懂、易于扩展和维护。代码重构可以帮助程序员不断改进自己的代码质量和架构设计。
- 设计模式和架构模式:程序员需要学习和掌握各种设计模式和架构模式,以此帮助自己设计出更加稳定和可扩展的系统。
- Code Review:让别人对自己的代码进行Review是提高自己的写作和架构能力的一种有效方式,因为Review者可以帮助发现代码中的问题并给出改进意见。
- 编写文档:程序员需要编写清晰、易懂的文档,以便让其他人了解自己的代码和架构设计,这可以帮助自己更好地理解自己的设计思路,发现潜在的问题并进行改进。
总结
虽然可能会对年长的程序员造成一些挑战,但这并不意味着35岁是程序员的限制年龄或诅咒。年长的程序员通常具有更多的经验和技能,并且会在其他方面表现更优秀,比如领导能力、项目管理和客户沟通等。
因此,年龄并不应该成为评价程序员的唯一标准。
链接:https://juejin.cn/post/7201668416171262011
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从事架构师岗位快2年了,聊一聊我对架构的一些感受和看法
作者简介
架构师李肯(全网同名)
在深圳白手起家,毕业不到4年实现一线城市核心地段的安家梦,从0开始谱写励志人生!一个专注于嵌入式物联网架构设计的攻城狮,2022年度RT-Thread社区杰出布道者,期待您的支持与关注!
标题:从事架构师岗位快2年了,聊一聊我对架构的一些感受和看法
职位不分高低,但求每天都能有新的进步,永远向着更高的目标前进。
时间是过得真快,就这么一晃就快过了2年了。自2021年5年以来,跌跌爬爬,在架构师的岗位上也快“混”迹2年了,是时候好好静下心来梳理梳理,好好想一想接下来的路该怎么走,如何才能获得更大的提升,毕竟留给快35岁程序猿的时间已经不多了。
下面,我想结合自己的经历,谈一谈自己对架构师岗位的感受和想法,也是希望这样能够更好地提醒和鞭策自己,时刻不要忘了,你的本职工作是一个【架构师】。
踏上新的征程
时钟拨回到2年前,那是2021年5月的那个夏天,因个人原因我向前东家提出了离开,留下曾经一起奋斗过的小伙伴。
在前东家时,我是挂职【资深嵌入式软件工程师】,也曾带领过一个小团队,7-8人,做出过一些成绩,也曾为公司的业绩扛过一些靶子,但终究还是职业发展的考虑,我选择了退出。
正是有萌生提出之意时,在脉脉上有位HR找到我,说是有个【嵌入式架构师】的岗位要找资深研发,对嵌入式开发的要求比较高,有没有兴趣试试。
说实在,之前我也不知道有公司会专门招聘【嵌入式架构师】这样的岗位,但我是知道一般的研发团队中,总是会有人要负责【架构】的工作,而且肯定得是团队中最资深的那一帮人在搞架构的事情。
就这样抱着好奇心,我就参加了那场面试,没想到的是那场面试非常的愉快,跟我的面试官(也就是我现在的老大)聊得非常投机,再后来工作上也的确给予了最大力度的支持和认可,有一种求得知音的感觉。
就这样,一场很顺利的面试结束,复试了2轮,顺利拿到Offer,于2021年5月份入职。
而在2022年末的特殊时期,我也顺利得到老板的认可,成为了公司的小股东。
祥文可见:成为了公司股东,而我却失眠了!
也是从那时候开始,我萌生了【架构师李肯】这个技术IP。
架构是什么?
架构,本文中特指【软件架构】。坦白说,架构是一个比较虚的东西,它不像实物那样看得见摸得着,而是一种抽象的概念在里面。
恰巧,最近ChatGPT不是非常火吗?要不,我们来问一下它,看看它对架构的理解是怎么样的?
提问:架构是什么? 回答:架构是一种分层模型,用于描述软件系统的结构和行为。它定义了软件系统的模块、接口、职责和关系,从而使软件系统可以更好地满足用户的需求。
下面谈一下我对架构的理解:
架构是一种抽象的软件设计,它要着力于用技术的手段解决业务上遇到的可伸缩、可扩展、性能优、易用性等难题。
一般来说,一个优秀的软件架构,必须要满足横向可扩展,纵向可伸缩,系统性能还要能够看得住一定的压力测试,同时,对架构的使用者而言,应该有非常清晰易用的API接口,在整个设计中需要充分考虑架构的易用性。
就拿我现在做的嵌入式系统架构来说,毫无疑问,这里需要的架构就是必须支持各种对接业务的功能模块可以可快速扩展和和裁减,同时对硬件底层的抽象设计足够抽象,以便于架构快速地移植在各个芯片平台上。而且,各个芯片平台的性能特性需要发挥到最佳状态,满足各种商用的需求。另外,对应用开发团队也需要提供非常明确的API接口和文档,以便于基于该软件架构快速输出软件,达到商业落地的目的。
架构师到底是干什么的?
这个问题我相信外行人都比较迷,于是我先用这个问题问了一下ChatGPT,得到的答案是:
提问:架构师到底是干什么的? 回答:架构师是一种计算机技术专家,负责设计和构建软件系统或网络架构,以满足业务需求。架构师需要深入理解业务和技术,以确定系统的需求,并设计合适的架构,以满足这些需求。架构师还负责评估和选择合适的技术,实施和监控系统,以及维护系统的性能和安全性。
嗯,好像有点道理。那么,我顺着这层思路再补充谈一下我的看法。
回到了上面【什么是架构】这个问题后,我再结合我的实际工作内容说说我的这个架构师到底是干嘛的。我分为几个点来阐述:
- 架构师首要解决的,就是复杂多变的业务需求中,分析并提取中核心需求,并加以抽象设计,以便于使用软件技术解决这样的需求难题;这就要求架构师一定是对核心业务非常熟悉的,否则可能你设计的架构就偏离了实际业务需求,这无异于纸上谈兵,哪怕架构设计得再优秀,都无法落地。
- 对提取的核心需求进行拆解:提取出对应的可扩展性、可伸缩性、易用性、性能要求等各个方面的需求,形成需求矩阵,针对各个需求,分别设计核心架构,满足业务需求。
- 架构师可以说是业务需求跟应用开发的一个衔接者,对上是对业务需求团队负责,对下是对应用开发团队负责,这里面的汇总、分析、设计、协调都是必备的技能;他所要解决的是两个团队面临的迫切问题。
- 对内,还需要负责核心技术难题的攻关:遇到团队中的疑难技术问题,需要攻关介入的时候,毫无疑问,架构师团队要冲在最前面,为后面的业务团队和应用开发团队铺平前进的道路。
- 对外,还需要负责业内核心前沿技术的调研和学习:这里面是一个进阶学习的过程,每个架构师团队必须要保持一定的学习能力,观测业内的技术架构方向,不一定非得追最新最热的技术方向,但至少你要能懂,这项新技术能帮我们解决什么样的问题。也许,将来我们就能用上它。
你的终极目标又是什么?
去年年末的时候,我写过一篇文章,叫 【架构师李肯】带你走进架构师的一天
里面有这么一章节:
正好俗语所说:“不想当将军的士兵,不是一个好的士兵!”
换到我身上,我认为是:“不想当CTO的架构师,不是一个好的架构师!”
我的更远大目标就是,有朝一日,挂帅CTO,至于迎娶白富美的后话,就还是别了,早已心有所属。
回想自己一路升级打怪,从技术小白,踏入助理工程师的岗位,慢慢提升自己,开始走向中级工程师,逐渐可以独立接项目了,锻炼了一些日子,开始担任高级工程师,开始考虑更全面了,需要承担技术攻坚的重任;再后来,跨越到资深工程师,也开始带团队了,不再单兵作战,需要为团队负责到底;而现在,架构师一职,承担的不仅仅是本部门的技术工作,还需要宏观考虑技术的延展性和前瞻性,某些情况下甚至关乎着整条业务线的生存,不可谓影响不大。
而如果走向CTO的岗位,那直接就关系整个公司的技术脉络,这可直接影响公司的存亡,压力和挑战并存。
我有时候也问我自己,准备好了吗?我希望我自己能给出肯定的答案:“ Yes,I’m ready !"
回到现实吧,朝着你的目标前进就好了,希望就在眼前。
如果你想成为架构师该如何提升自己?
这个问题可能也是大家比较关心的,同样的,我们也问一下ChatGPT吧。
提问:如果你想成为架构师该如何提升自己? 回答:
- 学习计算机基础:要想成为架构师,首先要掌握计算机的基础知识,包括计算机硬件和操作系统等。
- 熟悉编程语言:掌握多种编程语言,比如C,C++,Java,Python,Go等。
- 学习网络技术:熟悉TCP/IP,HTTP,FTP等网络技术,了解网络安全技术。
- 熟悉数据库:学习并掌握多种数据库,包括MySQL,Oracle,MongoDB,Redis等。
- 了解框架:掌握各种框架,比如Spring,Hibernate,Struts,MyBatis等。
- 学习容器技术:学习容器技术,比如Docker,Kubernetes等,掌握微服务架构。
- 了解分布式:学习分布式计算,掌握分布式存储,消息队列,大数据,云计算等技术。
- 实践经验:多积累实践经验,学习不同的架构设计思想,不断完善自己的技术水平。
好吧,答案跟我想的完全不太一样。毕竟我目前专注的嵌入式系统架构设计这一块。
但是我认为架构的核心理念是一致的,你需要扎实的基础技术知识来铺垫,最重要的是培养自己敏锐的【架构】思维。
比如用到一个很好用的框架,一个很帮的开源项目,多去想想别人是如何从【架构】去考虑问题的,同时又是如何设计这个【架构】已满足这些需求问题的,多动脑子去思考和整理,慢慢积累起来就会有比较敏锐的【架构】观。
又比如我们学习和使用的Linux系统,它里面可是浓缩了世界各地最优秀的那帮码农的精华,包含了大量的【架构】设计理念,而我们作为它的使用者和开发者,更是应该深入学习它,可以是某一模块的设计,或者某一类模型的设计,等你能把这些架构摸透了,差不多你也就成了架构师。
常言道:【书中自有黄金屋】,我个人觉得看对应领域的专家级书籍,也是一种非常棒的学习方式。站在巨人的肩膀上,可以帮助你爬得更快,升得更高。
经常在后台收到小伙伴的私信,问我有没有在架构方面比较优秀的书籍推荐。
这不,最近刚出了一本书籍,叫《持续架构实践》,它的一推出,立马轰动业界。
作为架构领域的从业者,我第一时间拿到了书本,匆匆看了几章,有种酣畅淋漓的感觉,甚至有种相见恨晚的意味。
软件架构领域正在爆发一场新的革命。Gartner权威发布2023年十大科技趋势之一 “可持续IT架构” ,可持续架构得到越来越多从业人员认同。创建和维护可持续的软件架构对于架构师和工程师而言也是一项巨大的挑战。
感兴趣的朋友,可以多关注一下这本书,尤其是希望从事架构师岗位的小伙伴,也许它能帮你解开很多心中的疑团。
更多关于《持续架构设计》书籍的介绍,请参考社区帖子介绍,详见 bbs.csdn.net/topics/6134…。
附图
这里有朋友好奇ChatGPT的玩法,又没有合适的工具来体验,所以来问到我,我用我那8毛钱的Python技术写了一个小工具,只需要输入API-KEY就可以了,不需要代理,也不需要fanqiang,可以试用试用。
这个小工具,有需要的可以私我,友情共享。
链接:https://juejin.cn/post/7200221724045508667
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
改行后我在做什么?(2022-9-19日晚)
闲言碎语
今天回了趟家里,陪父母一起吃了个饭。父母照例是在唠叨,这个年纪了还不结婚,也没个稳定的工作,巴拉巴拉的一大堆。吃完饭我匆匆的就回到了我租住的地方。在现阶段,其实我对于父母所诉说的很多东西,我都是认同的。
但在我这个年纪,这个阶段,看似有很多选择,但其实我没有选择。能做的也只是多挣点钱。
在这个信息爆炸的时代,我们知道更高的地方在哪里。但当你想要再往上走一步的时候,你发现你的
上限,其实从出生或从你毕业的那一刻就已经注定了。可能少部分人通过自身的努力,的确能突破壁垒达到理想的高度。但这只是小概率事件罢了。在我看来整个社会的发展,其实早就已经陷入了一种怪圈。
在我,早些年刚刚进入社会的时候。那时的想法特别简单。就想着努力工作,努力提升自身的专业素养。被老板赏识,升职加薪成为一名管理者。如果,被淘汰了那应该是自己不够优秀,不够努力,专业技能不过硬,自己为人处事不够圆滑啥的。
当
内卷这个词语引爆网络的时候;当35岁被裁员成为常态的时候。再回头看我以前的那些想法那真的是一个笑话。(我觉得我可能是在为自己被淘汰找借口)
当前的状态
游戏工作室的项目,目前基本处于停滞的状态。我不敢加机器也不敢关机。有时候我都在想,是不是全中国那3-4亿的人都在搞这个?一个国外的游戏,金价直接拉成这个逼样。
汽配这边的话,只能说喝口稀饭。(我花了太多精力在游戏工作室上了)
梦想破灭咯
其实按照正常情况来说,游戏工作室最开始的阶段,我应该是能够稍微挣点钱的。我感觉我天时、地利、人和。我都占的。现在来看的话,其实我只占了
人和。我自己可以编码,脚本还是从驱动层模拟键鼠,写的一套脚本。这样我都没赚钱,我擦勒。
接下来干嘛
接下来准备进厂打螺丝。(开玩笑的)
还是老老实实跟着我弟学着做生意吧。老老实实做汽配吧!在这个时代,好像有一技之长(尤其是IT)的人,好像并不能活得很好。除非,你这一技之长,特别特别长。(当下的中国不需要太多的这类专业技术人员吧。)
我感受到的大环境
我身边有蛮多的大牛。从他们的口中和我自己看到的。我感觉在IT这个领域,国内的环境太恶劣了。在前端,除开UI库,我用到的很多多的库全是老外的。为什么没有国人开源呢?因为,国人都忙着996了。我们可以在什么都不知道的情况下,通过复制粘贴,全局搜索解决大部分问题。 机械视觉、大数据分析、人工智能 等很多东西。这一切的基石很多年前就有了,为什么没人去研究他?为什么我们这波人,不断的在学习:这样、那样的框架。搭积木虽然很好玩。但创造一个积木,不应该也是一件更有挑战性的事情么?
在招聘网站还有一个特别奇怪的现象。看起来这家公司是在招人,但其实是培训机构。 看起来这家公司正儿八经是在招聘兼职,但其实只想骗你去办什么兼职卡。看起来是在招送快递,送外卖的,招聘司机的,但其实只是想套路你买车。我擦勒。这是怎样的一个恶劣的生存环境。这些个B人就不能干点,正经事?
卖菜的、拉车的、搞电商的、搞短视频、搞贷款的、卖保险的、这些个公司市值几百亿。很难看到一些靠创新,靠创造,靠产品质量,发展起来的公司。
链接:https://juejin.cn/post/7144770465741946894
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
DIO源码浅析——揭开面纱后是你印象中的样子吗
DIO源码解析
dio是一个强大的Dart Http请求库,支持Restful API、FormData、拦截器、请求取消、Cookie管理、文件上传/下载、超时、自定义适配器等
Dio版本号:4.0.6
基本使用
final dio = Dio();
final result = await dio.get('https://xxxx.ccc');
源码分析
源码分析通常情况下是一个逆推的过程,首先熟悉api的使用,然后通过api的调用思考功能是如何实现的。这里就从Dio()和get()方法作为切入点,看看Dio的内部实现。切忌直接下载源码通读一遍,容易找不到重点。
Dio
查看源码发现Dio是个抽象类,定义了Dio支持的所有功能。有面向对象经验的应该都知道抽象类无法直接实例化,但是这里却可行其实这是dart的factory语法糖,方便开发者使用工厂模式创建对象。
简化的Dio代码,例举出比较具有代表性的属性和方法。
abstract class Dio {
factory Dio([BaseOptions? options]) => createDio(options);
late BaseOptions options;
Interceptors get interceptors;
late HttpClientAdapter httpClientAdapter;
late Transformer transformer;
...
Future<Response<T>> get<T>(
String path, {
Map<String, dynamic>? queryParameters,
Options? options,
CancelToken? cancelToken,
ProgressCallback? onReceiveProgress,
});
Future<Response<T>> request<T>(
String path, {
data,
Map<String, dynamic>? queryParameters,
CancelToken? cancelToken,
Options? options,
ProgressCallback? onSendProgress,
ProgressCallback? onReceiveProgress,
});
...
}1. 工厂方法创建Dio对象
factory Dio([BaseOptions? options]) => createDio(options);
这是上面提到的为何抽象类能实例化对象,就是个语法糖起了作用,跟进去发现createDio(options)这个方法定义在entry_stub.dart里,并且是个空实现。先不深究,反正最后的实现要么是DioForBrowser、要么是DioForNative至于加了什么魔法不是本期的重点
2. BaseOptions
options保存通用的请求信息,比如baseUrl、headers、超时时间等参数。用来设置全局配置。
3. Interceptors
这就是所有http请求框架里都会用到的拦截器在Dio里的实现,里面的关键源码一个线性列表存储所有的拦截器,和重写的下标操作符。在发起请求时会使用Interceptors存储的拦截器按顺序进行拦截处理。4. HttpClientAdapter
HttpClientAdapter是Dio真正发起请求的地方,他是一个抽象类,实现类通过依赖注入注入进来。Dio这里运用了职责分离的思想进行接耦,Dio定义请求方法和请求拦截等操作,使用HttpClientAdapter建立连接发起请求。这样设计的好处在于,如若对网络请求库有改动的需求可以自己实现一个HttpClientAdapter子类进行替换就行,无需改动原有代码。
5. Transformer
Transformer的作用是在请求前后可以对请求参数,和请求结果进行修改。在请求时生效在请求拦截器之后,响应时发生在响应拦截器之前。对于了解过洋葱模型的同学来说,这很好理解,Transformer处于Interceptors的里面一层。6. 诸如get、post、request...方法
Dio里定义的方法全部都是抽象方法,需要子类来实现。这里的作用是定义一个通用的请求接口,包含http常用的一些方法。按照程序看完抽象类就该看实现类了,Android Studio里在抽象类Dio的左边有个向下的箭头,点击一下发现有三个子类。
1. DioMixin
DioMixin也是一个抽象类,实现了Dio接口几乎所有的方法,只有两个属性未实现:
HttpClientAdapter
BaseOptions
这两个属性交由DioForNative和DioForBrowser各自进行注入。
class DioForBrowser with DioMixin implements Dio {
DioForBrowser([BaseOptions? options]) {
this.options = options ?? BaseOptions();
httpClientAdapter = BrowserHttpClientAdapter();
}
}class DioForNative with DioMixin implements Dio {
singleton.
DioForNative([BaseOptions? baseOptions]) {
options = baseOptions ?? BaseOptions();
httpClientAdapter = DefaultHttpClientAdapter();
}
}这个很好理解,因为native和web的发起请求肯定是不一样的。dio默认使用的http_client来自于dart_sdk暂未直接支持web。所以需要通过创建不同的http_client适配web和native。
好了,到这里基本确定DioMixin这个类就是Dio最重要的实现类了。DioForNative和DioForBrowser只是针对不同平台的适配而已。继续分析DioMixin:
同样从get方法开始跟进
Future<Response<T>> get<T>(
String path, {
Map<String, dynamic>? queryParameters,
Options? options,
CancelToken? cancelToken,
ProgressCallback? onReceiveProgress,
}) {
return request<T>(
path,
queryParameters: queryParameters,
options: checkOptions('GET', options),
onReceiveProgress: onReceiveProgress,
cancelToken: cancelToken,
);
}get方法里设置了一下method为‘GET’,然后把参数全数传递给了request方法,继续看看request方法
Future<Response<T>> request<T>(
String path, {
data,
Map<String, dynamic>? queryParameters,
CancelToken? cancelToken,
Options? options,
ProgressCallback? onSendProgress,
ProgressCallback? onReceiveProgress,
}) async {
options ??= Options();
var requestOptions = options.compose(
this.options,
path,
data: data,
queryParameters: queryParameters,
onReceiveProgress: onReceiveProgress,
onSendProgress: onSendProgress,
cancelToken: cancelToken,
);
requestOptions.onReceiveProgress = onReceiveProgress;
requestOptions.onSendProgress = onSendProgress;
requestOptions.cancelToken = cancelToken;
...
return fetch<T>(requestOptions);
}request方法里主要干了两件事
- 合并BaseOptions和外部传进来的请求参数
- 绑定上传、下载、取消等回调到请求对象
然后将处理好的请求参数交给fetch方法。继续跟进(前方高能,fetch方法是dio的核心了)
Future<Response<T>> fetch<T>(RequestOptions requestOptions) async {
final stackTrace = StackTrace.current;
if (requestOptions.cancelToken != null) {
requestOptions.cancelToken!.requestOptions = requestOptions;
}
//这里是根据请求参数,简单判断下返回的type。意思是T如果声明了类型,要么是普通文本要么是json对象
if (T != dynamic &&
!(requestOptions.responseType == ResponseType.bytes ||
requestOptions.responseType == ResponseType.stream)) {
if (T == String) {
requestOptions.responseType = ResponseType.plain;
} else {
requestOptions.responseType = ResponseType.json;
}
}
//请求拦截包装器:interceptor就是拦截器里的onRequest方法,作为参数传过来
//1.开始分析这个包装器的作用,仅当状态处于next时开始工作
//2.listenCancelForAsyncTask方法作用是,cancelToken的Future和请求的拦截器Future同时执行,cancelToken先执行完成的话就抛出异常终止请求。
//3.创建一个requestHandler,并调用interceptor方法(在request这里就是onRequest方法),然后返回requestHander.future(了解Completer的同学应该都知道,这是可以手动控制future的方法)。这就解释了为何拦截器里的onRequest方法,开发者需要手动调用next等方法进入下一个拦截器。
FutureOr Function(dynamic) _requestInterceptorWrapper(
InterceptorSendCallback interceptor,
) {
return (dynamic _state) async {
var state = _state as InterceptorState;
if (state.type == InterceptorResultType.next) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.requestLock, () {
var requestHandler = RequestInterceptorHandler();
interceptor(state.data as RequestOptions, requestHandler);
return requestHandler.future;
});
}),
);
} else {
return state;
}
};
}
//响应拦截包装器:
//实现方式参考_requestInterceptorWrapper基本类似,但是要注意这里放宽了state的条件多了一个resolveCallFollowing,这个后续再讲
FutureOr<dynamic> Function(dynamic) _responseInterceptorWrapper(
InterceptorSuccessCallback interceptor,
) {
return (_state) async {
var state = _state as InterceptorState;
if (state.type == InterceptorResultType.next ||
state.type == InterceptorResultType.resolveCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.responseLock, () {
var responseHandler = ResponseInterceptorHandler();
interceptor(state.data as Response, responseHandler);
return responseHandler.future;
});
}),
);
} else {
return state;
}
};
}
// 错误拦截包装器
FutureOr<dynamic> Function(dynamic, StackTrace) _errorInterceptorWrapper(
InterceptorErrorCallback interceptor) {
return (err, stackTrace) {
if (err is! InterceptorState) {
err = InterceptorState(
assureDioError(
err,
requestOptions,
),
);
}
if (err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.errorLock, () {
var errorHandler = ErrorInterceptorHandler();
interceptor(err.data as DioError, errorHandler);
return errorHandler.future;
});
}),
);
} else {
throw err;
}
};
}
// Build a request flow in which the processors(interceptors)
// execute in FIFO order.
// Start the request flow
// 初始化请求拦截器第一个元素,第一个InterceptorState的type为next
var future = Future<dynamic>(() => InterceptorState(requestOptions));
// Add request interceptors to request flow
// 这是形成请求拦截链的关键,遍历拦截器的onRequest方法,并且使用_requestInterceptorWrapper对onRequest方法进行包装。
//上面讲到_requestInterceptorWrapper返回的是一个future
//future = future.then(_requestInterceptorWrapper(fun));这段代码就是让拦截器形成一个链表,只有上一个拦截器里的onRequest内部调用了next()才会进入下一个拦截器。
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleRequest
: interceptor.onRequest;
future = future.then(_requestInterceptorWrapper(fun));
});
// Add dispatching callback to request flow
// 发起请求的地方,发起请求时也处在future链表里,方便response拦截器和error拦截器的处理后续。
//1. reqOpt即,经过拦截器处理后的最终请求参数
//2. _dispatchRequest执行请求,并根据请求结果判断执行resolve还是reject
future = future.then(_requestInterceptorWrapper((
RequestOptions reqOpt,
RequestInterceptorHandler handler,
) {
requestOptions = reqOpt;
_dispatchRequest(reqOpt)
.then((value) => handler.resolve(value, true))
.catchError((e) {
handler.reject(e as DioError, true);
});
}));
//request处理执行完成后,进入response拦截处理器,遍历形成response拦截链表
// Add response interceptors to request flow
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleResponse
: interceptor.onResponse;
future = future.then(_responseInterceptorWrapper(fun));
});
// 请求拦截链表添加完成后,添加错误的链表
// Add error handlers to request flow
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleError
: interceptor.onError;
future = future.catchError(_errorInterceptorWrapper(fun));
});
// Normalize errors, we convert error to the DioError
// 最终返回经过了拦截器链表的结果
return future.then<Response<T>>((data) {
return assureResponse<T>(
data is InterceptorState ? data.data : data,
requestOptions,
);
}).catchError((err, _) {
var isState = err is InterceptorState;
if (isState) {
if ((err as InterceptorState).type == InterceptorResultType.resolve) {
return assureResponse<T>(err.data, requestOptions);
}
}
throw assureDioError(
isState ? err.data : err,
requestOptions,
stackTrace,
);
});
}关于fetch的源码分析在关键点写了注释,各位同学自行享用。像这种比较长的源码分析一直在思考该如何写,分块解析怕代码逻辑关联不上来,索性直接全部拿来写上注释。再通过实例问题解释代码,各位如果有好的建议去分析代码,请在评论区留言
关于拦截器的几个实例问题
拦截器不手动调用RequestInterceptorHandler.next会怎么样?
答:根据我们梳理的流程来看,Dio在发起请求时会根据拦截器生成一个future的链表,future只有等到上一个执行完才会执行下一个。如果拦截器里不手动调用next则会停留在链表中的某个节点。
拦截器onError中可以做哪些操作?
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleError
: interceptor.onError;
future = future.catchError(_errorInterceptorWrapper(fun));
});对这段代码进行分析,可以看到onError的执行,是在future链表的catchError(捕获future里的错误)方法中进行的。
onError的方法签名如下
void onError(DioError err,ErrorInterceptorHandler handler)
可以在onError方法调用 next、resolve、reject三个方法处理。next 使用的completeError,会让future产生一个错误,被catch到交给下一个拦截器处理。
void next(DioError err) {
_completer.completeError(
InterceptorState<DioError>(err),
err.stackTrace,
);
_processNextInQueue?.call();
} resolve 使用complete会正常返回数据,不会触发catchError,所以跳过后续的onError拦截器
void resolve(Response response) {
_completer.complete(InterceptorState<Response>(
response,
InterceptorResultType.resolve,
));
_processNextInQueue?.call();
}reject 和next代码类似,但是设置了状态为InterceptorResultType.reject,结合_errorInterceptorWrapper代码看,包装器里只处理err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing条件,其他状态直接抛出异常。所以reject的效果就是抛出错误直接完成请求
void reject(DioError error) {
_completer.completeError(
InterceptorState<DioError>(
error,
InterceptorResultType.reject,
),
error.stackTrace,
);
_processNextInQueue?.call();
}
//error包装器
FutureOr<dynamic> Function(dynamic, StackTrace) _errorInterceptorWrapper(
InterceptorErrorCallback interceptor) {
return (err, stackTrace) {
if (err is! InterceptorState) {
err = InterceptorState(
assureDioError(
err,
requestOptions,
),
);
}
//仅会处理InterceptorResultType.next和InterceptorResultType.rejectCallFollowing,而reject的类型是reject,所以直接执行elese的throw
if (err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.errorLock, () {
var errorHandler = ErrorInterceptorHandler();
interceptor(err.data as DioError, errorHandler);
return errorHandler.future;
});
}),
);
} else {
throw err;
}
};
}- 在onRequest里抛出异常,后续的onRequest和onResponse还会回调吗?
- 在onResponse里抛出异常,后续的onResponse还会回调吗?
答:回顾一下请求的流程,发起请求->onRequest(1)->onRequest(2)->onRequest(3)->http请求->onResponse(1)->onResponse(2)->onResponse(3)->catchError(1)->catchError(2)->catchError(3)。
这就很明显无论是onRequest还是onResponse抛出异常都会被catchError(1)给捕获,跳过了后续的onRequest和onResponse。
补充
- 在requestWrapper、responseWrapper、errorWrapper里都可以看到listenCancelForAsyncTask,第一个参数是cancelToken。这是因为Dio的取消请求是在拦截器里进行的,只要请求还未走完拦截器就可以取消请求。这就有个新的问题,如果咱们未设置拦截器取消请求就无法使用了吗?显然不是。在发起请求的时候还会把cancelToken再次传递进去,监听是否需要取消请求,如果取消的话就关闭连接,感兴趣的同学自行查看相关源码。
Future<Response<T>> _dispatchRequest<T>(RequestOptions reqOpt) async {
var cancelToken = reqOpt.cancelToken;
ResponseBody responseBody;
try {
var stream = await _transformData(reqOpt);
responseBody = await httpClientAdapter.fetch(
reqOpt,
stream,
cancelToken?.whenCancel,
);
...
}- InterceptorResultType在拦截器里发挥的作用,上面也提过了其实就是在调用InterceptorHandler的next,resolve,reject时设着一个标记,用于判断是继续下一个拦截器还是跳过后续拦截方法
2. DioForNative 和 DioForBrowser
下面这段代码是DioMixin发起请求的地方,可以看到真正执行http请求的是HttpClientAdapter的fetch方法。那DioForNative和DioForBrowser是针对不同平台的实现,那最简单的方法就是对fetch方法进行定制就好了。上面也提到了他们各自创建了不同的HttpClientAdapter,感兴趣的同学可以看看BrowserHttpClientAdapter和DefaultHttpClientAdapter
Future<Response<T>> _dispatchRequest<T>(RequestOptions reqOpt) async {
var cancelToken = reqOpt.cancelToken;
ResponseBody responseBody;
try {
var stream = await _transformData(reqOpt);
responseBody = await httpClientAdapter.fetch(
reqOpt,
stream,
cancelToken?.whenCancel,
);
...
}总结
Dio也是一个网络封装库,本身并不负责建立http请求等操作。除此之外还集成了请求拦截,取消请求的功能。采用了面向接口的方式,所以替换http请求库代价很小,只需要自己实现HttpClientAdapter替换下即可。
链接:https://juejin.cn/post/7202793493826781241
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 仿闲鱼动画效果
前言
目前正在做的项目,为了增加用户的体验度,准备增加一些动画效果,其中底部栏中间按钮的点击事件参考了闲鱼的动效,便在此基础上仿写了该动效,并增加了一些新的效果。
动效
闲鱼动效
仿写效果
思路
根据UI的设计图,对每个模块设计好动画效果,本人主要设计了以下四个效果。
1、底部返回键旋转动画
底部返回按钮动画其实就是个旋转动画,利用Transform.rotate设置angle的值即可,这里使用了GetX来对angle进行动态控制。
//返回键旋转角度,初始旋转45度,使其初始样式为 +
var angle = (pi / 4).obs;
///关闭按钮旋转动画控制器
late final AnimationController closeController;
late final Animation<double> closeAnimation;
///返回键旋转动画
closeController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
///返回键旋转动画
closeController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
///页面渲染完才开始执行,不然第一次打开不会启动动画
WidgetsBinding.instance.addPostFrameCallback((duration) {
closeAnimation =
Tween(begin: pi / 4, end: pi / 2).animate(closeController)
..addListener(() {
angle.value = closeAnimation.value;
});
closeController.forward();
});
///关闭按钮点击事件
void close() {
///反转动画,并关闭页面
Future.delayed(
const Duration(milliseconds: 120), () {
Get.back();
});
closeController.reverse();
}
IconButton(
onPressed: null,
alignment: Alignment.center,
icon: Transform.rotate(
angle: controller.angle.value,
child: SvgPicture.asset(
"assets/user/ic-train-car-close.svg",
width: 18,
height: 18,
color: Colors.black,
),
))2、底部四个栏目变速上移动画+渐变动画
四个栏目其实就是个平移动画,只不过闲鱼是四个栏目一起平移,而我选择了变速平移,这样视觉效果上会好一点。
//透明度变化
List<AnimationController> opacityControllerList = [];
//上移动画,由于每个栏目的移动速度不一样,需要用List保存四个AnimationController,
//如果想像闲鱼那种整体上移,则只用一个AnimationController即可。
List<AnimationController> offsetControllerList = [];
List<Animation<Offset>> offsetAnimationList = [];
//之所以用addIf,是因为项目中这几个栏目的显示是动态显示的,这里就直接写成true
Column(
children: []
..addIf(
true,
buildItem('assets/user/ic-train-nomal-car.webp',"学车加练","自主预约,快速拿证"))
..addIf(
true,
buildItem('assets/user/ic-train-fuuxn-car.webp',"有证复训","优质陪练,轻松驾车"))
..addIf(
true,
buildItem('assets/user/ic-train-jiaxun-car.webp',"模拟加训","考前加训,临考不惧"))
..addIf(
true,
buildItem('assets/user/ic-train-jiakao-car.webp',"驾考报名","快捷报名无门槛"))
..add(playWidget())
..addAll([
17.space,
]),
)
//仅仅是为了在offsetController全部初始化完后执行play()
Widget playWidget() {
//执行动画
play();
return Container();
}
int i = 0;
Widget buildItem(String img,String tab,String slogan) {
//由于底部栏目是动态显示的,需要在创建Widget时一同创建offsetController和offsetAnimation
i++;
AnimationController offsetController = AnimationController(
duration: Duration(milliseconds: 100 + i * 20),
vsync: this,
);
Animation<Offset> offsetAnimation = Tween<Offset>(
begin: const Offset(0, 2.5),
end: const Offset(0, 0),
).animate(CurvedAnimation(
parent: offsetController,
// curve: Curves.easeInOutSine,
curve: const Cubic(0.12, 0.28, 0.48, 1),
));
AnimationController opacityController = AnimationController(
duration: const Duration(milliseconds: 500),
lowerBound: 0.2,
upperBound: 1.0,
vsync: this);
opacityControllerList.add(opacityController);
offsetControllerList.add(offsetController);
offsetAnimationList.add(offsetAnimation);
return SlideTransition(
position: offsetAnimation,
child: FadeTransition(
opacity: opacityController,
child: Container(
margin: EdgeInsets.only(bottom: 16),
height: 62,
decoration: BoxDecoration(
borderRadius: BorderRadius.all(Radius.circular(12)),
color: const Color(0xfffafafa)),
child:
Row(mainAxisAlignment: MainAxisAlignment.center, children: [
24.space,
Image.asset(img, width: 44, height: 44),
12.space,
Column(
crossAxisAlignment: CrossAxisAlignment.start,
mainAxisSize: MainAxisSize.min,
children: [
Text(tab,
style: const TextStyle(
color: Color(0XFF000000),
fontSize: 16,
fontWeight: FontWeight.bold)),
Text(slogan,
style: const TextStyle(
color: Color(0XFF6e6e6e), fontSize: 12)),
]).expanded,
Image.asset("assets/user/ic-train-arrow.webp",
width: 44, height: 44),
17.space
])).inkWell(
onTap: () {},
delayMilliseconds: 50)),
);
}
//执行动画
void play() async {
for (int i = 0; i < offsetControllerList.length; i++) {
opacityControllerList[i].forward();
///栏目正序依次延迟(40 + 2 * i) * i的时间,曲线速率
Future.delayed(Duration(milliseconds: (40 + 2 * i) * i), () {
offsetControllerList[i]
.forward()
.whenComplete(() => offsetControllerList[i].stop());
});
}
}
///关闭按钮点击事件
void close() {
///反转动画,并关闭页面
Future.delayed(
const Duration(milliseconds: 120), () {
Get.back();
});
for (int i = offsetControllerList.length - 1; i >= 0; i--) {
///栏目倒叙依次延迟(40 + 2 * (offsetControllerList.length-1-i)) * (offsetControllerList.length-1-i))的时间
Future.delayed(
Duration(
milliseconds:
(40 + 2 * (offsetControllerList.length-1-i)) * (offsetControllerList.length-1-i)), () {
offsetControllerList[i].reverse();
});
}
opacityTopController.reverse();
}3、中间图片渐变动画
渐变动画使用FadeTransition即可。
///图片透明度渐变动画控制器
late final AnimationController imgController;
///图片透明度渐变动画
imgController = AnimationController(
duration: const Duration(milliseconds: 500),
lowerBound: 0.0,
upperBound: 1.0,
vsync: provider);
imgController.forward().whenComplete(() => imgController.stop());
///渐变过渡
FadeTransition(
opacity: imgController,
child:
Image.asset("assets/user/ic-traincar-guide.webp"),
),
///关闭按钮点击事件
void close() {
imgController.reverse();
}
4、顶部文案渐变动画+下移动画
///顶部标题下移动画控制器
late final AnimationController offsetTopController;
late final Animation<Offset> offsetTopAnimation;
///顶部标题渐变动画控制器
late final AnimationController opacityTopController;
///顶部标题上移动画
offsetTopController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
offsetTopController
.forward()
.whenComplete(() => offsetTopController.stop());
offsetTopAnimation = Tween<Offset>(
begin: const Offset(0, -0.8),
end: const Offset(0, 0),
).animate(CurvedAnimation(
parent: offsetTopController,
curve: Curves.easeInOutCubic,
));
offsetTopController
.forward()
.whenComplete(() => offsetTopController.stop());
//UI
SlideTransition(
position: offsetTopAnimation,
child: FadeTransition(
opacity: opacityTopController,
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
mainAxisAlignment: MainAxisAlignment.start,
mainAxisSize: MainAxisSize.min,
children: [
80.space,
const Text(
'练车指南',
style: TextStyle(
color: Color(0XFF141414),
fontSize: 32,
fontWeight: FontWeight.w800,
),
),
2.space,
const Text('易练只为您提供优质教练,为您的安全保驾护航',
style: TextStyle(
color: Color(0XFF141414),
fontSize: 15)),
],
))),
///关闭按钮点击事件
void close() {
offsetTopController.reverse();
opacityTopController.reverse();
}5、注销动画
最后,在关闭页面的时候不要忘记注销动画。
///关闭时注销动画
void dispose() {
for (int i = offsetControllerList.length - 1; i > 0; i--) {
offsetControllerList[i].dispose();
}
offsetTopController.dispose();
opacityTopController.dispose();
imgController.dispose();
closeController.dispose();
}链接:https://juejin.cn/post/7202537103933964346
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android源码—为什么onResume方法中不可以获取View宽高
前言
有一个经典的问题,我们在Activity的onCreate中可以获取View的宽高吗?onResume中呢?
对于这类八股问题,只要看过都能很容易得出答案:不能。
紧跟着追问一个,那为什么View.post为什么可以获取View宽高?
今天来看看这些问题,到底为何?
今日份问题:
- 为什么onCreate和onResume中获取不到view的宽高?
- 为什么View.post为什么可以获取View宽高?
基于Android API 29版本。
问题1、为什么onCreate和onResume中获取不到view的宽高?
首先我们清楚,要拿到View的宽高,那么View的绘制流程(measure—layout—draw)至少要完成measure,【记住这一点】。
还要弄清楚Activity的生命周期,关于Activity的启动流程,后面单独写一篇,本文会带一部分。
另外布局都是通过setContentView(int)方法设置的,所以弄清楚setContentView的流程也很重要,后面也补一篇。
首先要知道Activity的生命周期都在ActivityThread中, 当我们调用startActivity时,最终会走到ActivityThread中的performLaunchActivity
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
……
Activity activity = null;
try {
java.lang.ClassLoader cl = appContext.getClassLoader();
// 【关键点1】通过反射加载一个Activity
activity = mInstrumentation.newActivity(
cl, component.getClassName(), r.intent);
……
} catch (Exception e) {
……
}
try {
……
if (activity != null) {
……
// 【关键点2】调用attach方法,内部会初始化Window相关信息
activity.attach(appContext, this, getInstrumentation(), r.token,
r.ident, app, r.intent, r.activityInfo, title, r.parent,
r.embeddedID, r.lastNonConfigurationInstances, config,
r.referrer, r.voiceInteractor, window, r.configCallback,
r.assistToken);
……
if (r.isPersistable()) {
// 【关键点3】调用Activity的onCreate方法
mInstrumentation.callActivityOnCreate(activity, r.state, r.persistentState);
} else {
mInstrumentation.callActivityOnCreate(activity, r.state);
}
……
}
……
return activity;
}performLaunchActivity中主要是创建了Activity对象,并且调用了onCreate方法。
onCreate流程中的setContentView只是解析了xml,初始化了DecorView,创建了各个控件的对象;即将xml中的 转化为一个TextView对象。并没有启动View的绘制流程。
上面走完了onCreate,接下来看onResume生命周期,同样是在ActivityThread中的performResumeActivity
@Override
public void handleResumeActivity(IBinder token, boolean finalStateRequest, boolean isForward,
String reason) {
……
// 【关键点1】performResumeActivity 中会调用activity的onResume方法
final ActivityClientRecord r = performResumeActivity(token, finalStateRequest, reason);
……
final Activity a = r.activity;
……
if (r.window == null && !a.mFinished && willBeVisible) {
r.window = r.activity.getWindow();
View decor = r.window.getDecorView();
decor.setVisibility(View.INVISIBLE); // 设置不可见
ViewManager wm = a.getWindowManager();
WindowManager.LayoutParams l = r.window.getAttributes();
a.mDecor = decor;
……
if (a.mVisibleFromClient) {
if (!a.mWindowAdded) {
a.mWindowAdded = true;
// 【关键点2】在这里,开始做View的add操作
wm.addView(decor, l);
} else {
……
a.onWindowAttributesChanged(l);
}
}
} else if (!willBeVisible) {
……
}
……
}handleResumeActivity中两个关键点
- 调用
performResumeActivity, 该方法中r.activity.performResume(r.startsNotResumed, reason);会调用Activity的onResume方法。 - 执行完Activity的
onResume后调用了wm.addView(decor, l);,到这里,开始将此前创建的DecorView添加到视图中,也就是在这之后才开始布局的绘制流程
到这里,我们应该就能理解,为何onCreate和onResume中无法获取View的宽高了,一句话就是:View的绘制要晚于onResume。
问题2、为什么View.post为什么可以获取View宽高?
那接下来我们开始看第二个问题,先看看View.post的实现。
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
// 添加到AttachInfo的Handler消息队列中
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
// 加入到这个View的消息队列中
getRunQueue().post(action);
return true;
}post方法中,首先判断attachInfo成员变量是否为空,如果不为空,则直接加入到对应的Handler消息队列中。否则走getRunQueue().post(action);
从Attach字面意思来理解,其实就可以知道,当View执行attach时,才会拿到mAttachInfo, 因此我们在onResume或者onCreate中调用view.post(),其实走的是getRunQueue().post(action)。
接下来我们看一下mAttachInfo在什么时机才会赋值。
在View.java中
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
}dispatch相信大家都不会陌生,分发;那么一定是从根布局上开始分发的,我们可以全局搜索,可以看到
不要问为什么一定是这个,因为我看过,哈哈哈
其实ViewRootImpl就是一个布局管理器,这里面有很多内容,可以多看看。
在ViewRootImpl中直接定位到performTraversals方法中;这个方法一定要了解,而且特别长,下面我抽取几个关键点。
private void performTraversals() {
……
// 【关键点1】分发mAttachInfo
host.dispatchAttachedToWindow(mAttachInfo, 0);
……
//【关键点2】开始测量
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
……
//【关键点3】开始布局
performLayout(lp, mWidth, mHeight);
……
// 【关键点4】开始绘制
performDraw();
……
}再强调一遍,这个方法很长,内部很多信息,但其实总结来看,就是View的绘制流程,上面的【关键点2、3、4】。也就是这个方法执行完成之后,我们就能拿到View的宽高了;到这里,我们终于看到和View的宽高相关的东西了。
但还没结束,我们post出去的任务,什么时候执行呢,上面host可以看成是根布局,一个ViewGroup,通过一层一层的分发,最后我们看看View的dispatchAttachedToWindow方法。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
……
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
}这里可以看到调用了mRunQueue.executeActions(info.mHandler);
public void executeActions(Handler handler) {
synchronized (this) {
final HandlerAction[] actions = mActions;
for (int i = 0, count = mCount; i < count; i++) {
final HandlerAction handlerAction = actions[i];
handler.postDelayed(handlerAction.action, handlerAction.delay);
}
mActions = null;
mCount = 0;
}
}这就很简单了,就是将post中的Runnable,转移到mAttachInfo中的Handler, 等待接下来的调用执行。
这里要结合Handler的消息机制,我们post到Handler中的消息,并不是立刻执行,不要认为我们是先dispatchAttachedToWindow的,后执行的测量和绘制,就没办法拿到宽高。实则不是,我们只是将Runnable放到了handler的消息队列,然后继续执行后面的内容,也就是绘制流程,结束后,下一个主线程任务才会去取Handler中的消息,并执行。
结论
- onCreate和onResume中无法获取View的宽高,是因为还没执行View的绘制流程。
- view.post之所以能够拿到宽高,是因为在绘制之前,会将获取宽高的任务放到Handler的消息队列,等到View的绘制结束之后,便会执行。
水平有限,若有不当,请指出!!!
链接:https://juejin.cn/post/7202231477253095479
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
IM等成熟框架是否可以支持到UE接入应用?
IM 的聊天框架是否可以,作为组件,集成到UE工程中?这个方向,我们可以做出哪些努力?
勇敢的小伙是回家妥协还是趁年轻再拼一把(我的七年)
你好
我是小李,今年还不到23周岁,是一个工作不到4年的前端程序员。
你可能好奇为什么一个23岁的人能有3年多的经验,这也是面试时很多HR问我的问题。
其实答案很简单,我17岁的时候就开始上班了。
讲讲我的故事:
我从前是一个不爱学习的坏学生,迷恋游 戏导致从老师口中的优等生变成一个没考上高中的学渣。知道中考结果的时候对我震惊很大,但也在意料之中。该怎么办,去电子厂打工,还是去上职校?
最终选择还是去了济南某3+2大专,因为非常喜欢玩游戏,所以选择了计算机专业。但我选的班级又跟普通3+2大专有所不同,因为他是跟北大某鸟联合创办的就业班。在学校学了很多东西,Java,C#,前端,数据库,设计都有,毕竟外面的培 训机构一般是学三个月,我们学了两年。但当时也是年纪尚小,也没学会多少东西就面临着第一次实习。(我们3+2是上两年学实习一年再上两年)
进入社会开始工作:
第一次步入社会找工作的时光也挺怀念,同学们三五结伴出去,穿着西装打好领带出去面试。没错穿西装,学校强制要求的,一群17 18岁的小孩穿西装去面试。那时候有很多培训机构给以招人的名义让你去面试,然后忽悠要培训,我们回来就把不靠谱的公司写黑板上,当时写了一黑板的公司名称。
后来侥幸让一家算上老板行政共三个人的公司录取,写VB.NET(现在后端技术已经忘干净了)。但干了一周就跑了,一个人当八个人干,天天加班。
然后就开始面试,顺利的被某内的人事忽悠学了设计,学习三个月,两万块钱。因为老师一直催要实习证明,自己比较着急,某内当时以UI设计师的岗位邀我去面试,后来说技术不行,但给你一个内部培训的机会,那个人事给我说了很多,弄得我当时脑子一片空白,糊里糊涂就签了培训合同,后来想明白已经为时已晚。
其实我当时在某内学的还算不错,因为在前两年的课程中学过一些PS的东西,当时想要不以后就转行做设计师吧,就放弃了后两年大专的课程,去考了个成考大专。找工作的时候还算顺利,被一家医疗器械公司录取,做起了平面设计。
在这家医疗器械公司认识了很多朋友,并且现在还有几个一直保持联系,体会到了挣钱的不容易。一次公司要做一个简单的企业宣传网站,知道我是学软件开发的,就安排给了我。当时设计工作很闲,这个网站不需要后端,前端死页面贴几张图那种。这个网站做了三个周左右吧,当时技术菜,并且前端课程中占比很少,就边做边查资料,搞定自适应,调浏览器的兼容性。在做的过程中,突然有了不甘的心理,学了两年的软件就此转行真的不甘心,每天上下班近三个小时的车程就在看前端教学视频(当时看的是渡一教育,那个老师讲的很好)。
随后工作了一段时间就提了离职,离职原因:我要做软件开发,我要当程序员。
离职后找了几家工作,有一家正好招前端和设计的,看我两个都会,把我招了去面试。很巧面试官了解我的学历情况他说他也是北大某鸟的,也是我这种3+2,不过是济南另一个校区的。技术没怎么问,就问我会不会,会不会的我都回答了会,然后济南项目部的老大就问我能不能接受出差,去上海总部,我说能,第一天面试入职第二天早上六点就坐上了去上海的火车(那时我还没18岁)。
坐了12个多小时的火车腰酸背痛,虽然是硬卧但也不舒服。出了车站第一次去大城市,看着外面的灯红酒绿,感叹着十里洋场烟花地的美丽。后来上海的同事说要在站内坐地铁去,就去售票机买了地铁票,坐了人生中的第一次地铁。
出了地铁按着导航到了五角场,晚上的五角场真好看。跟着导航进入了五角场的一个商场,不争气的手机进去就没信号了,说实话当时真的慌,偌大个商场找不到出口在哪,东西南北也分不清,拎着个行李箱满地跑。后来上海的同事来接的我,才安全到公司。
到了公司没有想象的这么好,公司主要做硬件的,各种设备各种工具堆得满办公室都是,每个人就一个小隔间作为办公桌。公司领导看我没吃饭给我订了盒饭,大概到了11点跟着加班的同事回了宿舍。宿舍的环境也是相当的差,马桶是坏的,要自己用舀水冲,幸好住的地方离五角场近,没事可以去那里玩玩。
就这样过了两周吧,老板突然说要拉我去现场,他开车带着我们走了好久,打开地图看居然都出了上海,到了江苏。目的地是江苏的一个汽车组装厂,公司做的物联网系统要放在一辆概念车的展车上,为近期的虹桥车展做准备。组装厂是封闭的,24小时开着灯,不看手机不知道外面是白天还是黑天。每天都有饭送到跟前,睡醒了吃,吃完了干活,累了就睡觉那种。
终于熬到了车展,第一次逛了虹桥会展中心,真的很大,看到很多很帅的车。车展后待了没几天就提了离职,这种睡醒上班,累了就睡的工作太折磨人了。其实一直是想去外滩看看的,但到离职也没去成。
离职后就回了家,在家玩了一段时间又回到了济南,找了一个外包公司的工作。这家外包公司主要用的技术是uniapp框架,员工近百人,入职要求很低,只要是一周内能用uniapp框架做项目就行。我之前看过vue的视频,学起来uniapp也很容易,成功入职。
这里的门槛低,接的项目多,做成的却没几个,平均一个月一个App项目,隔三岔五就有找上门的甲方。最终以公司发不下来工资结束了这份工作。
这时候到了2019年12月份也是武汉疫情爆发的时候,因为是农村,可以出门但不能出村,整天和发小一起打王者,放了个小长假。
年后三月份,看着疫情没有那么严重了,就签了离乡保证书(就是出了当地无论目的地有没有住处能不能找到工作你都不能回来),回了济南。
因为会了uniapp这项技能入职了一家做养老项目的公司。开始后端就两个,前端没有,是一个实施在弄前端,他也会,但会的不多。公司不大,到最后也才不到十个人,前端基本上是我自己在弄,或者我写一个简单的页面让几个实施去改成类似的页面。就这样过了一年,感觉项目没有前景,并且公司一年涨薪50元人民币感觉太少了就离职再次去了上海。
为什么选择上海,对比北京这里住房比较方便,北京住四环五环工作地点却在二环每天要挤地铁太麻烦,对比广东深圳那两个又太远了。
到了上海,第一目的地是北蔡。在家的时候联系了一个租房中介,想在浦东找一份工作。跟着中介到了小区,算是个老破小吧,房子很旧,小区门口的垃圾堆了很多。到了屋子里床垫里面的弹簧都出来了,窗子的玻璃坏了一半,另一半是塑料布糊上去了,风一刮哗哗的响。那也没办法,1900多的房租押一付一还要给中介一千多的中介费,也可能被坑了,但就这样吧,一个外地人到一个城市现找工作只能这样。出门去超市买了床被子还不是棉的,自己带的夏凉被当褥子垫身子底下。三月份的上海到了晚上比北方好不了多少,床垫的弹簧硌的腰疼,冷风通过墙上空调管道开的洞传到屋子里,被子上盖着羽绒服也不顶用,第二天睡醒浑身疼。后来的几天都是穿着一份睡,但也好不了太多。
紧接着就是找工作,不得不说大城市工作机会就是多,但外包外派也多,前两周只考虑浦东和黄浦的工作,面了好多,要么是技术不行被拒要么工资给的低,有几个拿学历低压低工资,但我都没去。到了第三周有点着急,因为就准备找一个月的工作,找不到就回山东,所以把面试范围扩大到了整个上海,只要是不太偏远都行。第二天下午去杨浦面了一家互联网公司,面的时候很不顺利,面技术的时候面了两个多小时。那天就早晨吃了一块面包,面到一半又饿又渴,头晕眼花的。当时我的vue技术也不算是很好,之前主要做uniapp项目了,面完认为自己会凉,可能公司缺人吧,说来试岗一周,可以的话就留下。当时自己感觉这里的办公环境还不错,旁边就是复旦大学,就同意了。
试岗开始是熟悉项目,后来上手做一些东西,前端老大就是面试我的小哥。不懂的他也教我,开始跟他关系不是很好,可能他教我的时候太凶了,我没事就不理他。试岗还算顺利,不是什么很难的东西,但签正式合同的时候我就傻眼了,为什么是一份外派合同,就是说是外派到这个公司的,我问他周围的同事,他们也是这样,我之前是一直抵制进外派的,面试的时候也没跟我说,没办法,在这里待了一周了,每天工作很轻松,外派就外派吧。
每天工作进行着,就是浦东到杨浦通勤时间太久了,就不要租房押金到杨浦复旦大学的对面小区租了一个2360一个月,小区离公司园区就隔着复旦大学。
在公司的工作比较清闲每天准时下班,很少有加班,有很长一段时间没有工作,每天就干坐着翻掘金看技术文档看一天,这段时间对我技术提升很大,小哥有时也会教我一些新东西,慢慢接触发现他人也挺好。当时感觉自己学历不够,报了个网络教育的专升本。周六周天就去外面玩,晚上去黄埔江边吹一吹江风。
突然有一天中午吃饭的时候发现公司园区被封了一栋楼,说是有密接,从这开始上海疫情来了。公司一天天人越来越少,新闻中确诊人数日渐增加。后来上海政府要“鸳鸯锅”式封城法,先封浦东,再封浦西,以黄浦江为界,各封一周。我当时就猜一周是不行的,就准备了两周的泡面零食应对疫情管控。只能说我还是太天真了,疫情封了两个多月,这两个多月我都在吃泡面,一天吃两桶,吃多了不够吃的,买泡面只能通过美团跑腿买,两箱桶面要了我230多块钱。每天核酸检测,抗原检测,新闻上确诊人数疯狂的增加。泡面吃腻了怎么办,就把社区发的油菜叶跟泡面一起泡,但量很少,几次就吃完了。
过了差不多两个月,疫情得到缓解,风险等级也渐渐下降,居家办公的也开始去公司上班了。那时候接近项目交付,开始了加班,有时候加到一两点,但我工作不忙,很多都是后端服务器的问题,我在那加班也只是应对突发问题。后来在上海的那段时间非常想家,我猜应该是因为疫情的太折磨人感觉家无比的温暖,没多久就离职回家。
在家休息了一个多月又回到了济南,找到了一份薪资还算可以的工作,在上海攒了点钱,考了摩托车驾-照,买了辆摩托车。奈何公司产品经理太垃圾,也到了年底,准备离职年后重新找。(谁也不想到最后做出一堆垃圾项目)
时间回到了现在,从老家过完年回济南两周了,年前裸辞的多潇洒年后找工作多狼狈。
boos上投了好多,但都是送达。就算是已读不回也行,但大部分都是HR根本没有看。后来在开发群里问了都是这样,很多公司都是在裁人,很少有招的。找了两周工作回我的大部分是外派,弄得我很焦虑,我在想是不是一线城市好找些,要不卖了摩托车再去上海深圳闯一闯又或者回老家找个稳定的工作开始与柴米油盐为伴。
不知不觉写了这么多了,我还以为第一次写不了几个字呢。写了一半的时候跟我妈打了个电话,平时我很少与家人联系,都是她们主动跟我打电话,我妈让我不急慢慢找,打完电话后焦虑的心情放松了下来。
作者:世间有灵
来源:juejin.cn/post/7199235508665008188
数据可视化大屏设计器开发-多选拖拽
开头
本文是数据可视化开始的开发细节第五章。关于画布中的元素的各种鼠标拖拽操作。
简单声明
本人只是一个菜鸡,以下方法仅个人思路,如有错误,轻喷🙏🏻 。
开头说明
下面所说的元素表示的是组或者组件的简称。
开始
大屏设计当中,不乏需要调整图表组件的位置和尺寸。
相较于网页低代码,图表大屏低代码可能需要更复杂的操作,比如嵌套成组、多选、单元素拖拽缩放、多元素拖拽缩放。
并且需要针对鼠标的动作做相应的区分,当中包含了相当的细节,这里就一一做相应的讲解。
涉及的依赖
react-rnd
react-rnd是一个包含了拖拽和缩放两个功能的react组件,并且有非常丰富的配置项。
内部是依赖了拖拽(react-draggable)和缩放(re-resizable)两个模块。
奈何它并没有内置多元素的响应操作,本文就是针对它来实现对应的操作。react-selecto
react-selecto是一个简单的简单易用的多选元素组件。eventemitter3
eventemitter3是一个自定义事件模块,能够在任何地方触发和响应自定义的事件,非常的方便。
相关操作
多选
画布当中可以通过鼠标点击拖拽形成选区,选区内的元素即是被选中的状态。
这里即可以使用react-selecto来实现此功能。
从图上操作可以看到,在选区内的元素即被选中(会出现黑色边框)。
import ReactSelecto from 'react-selecto';
const Selecto = () => {
return (
<ReactSelecto
// 会被选中元素的父容器 只有这个容器里的元素才会被选中
dragContainer={'#container'}
// 被选择的元素的query
selectableTargets={['.react-select-to']}
// 表示元素有被选中的百分比为多少时才能被选中
hitRate={10}
// 当已经存在选中项时,按住指定按键可进行继续选择
toggleContinueSelect={'shift'}
// 可以通过点击选择元素
selectByClick
// 是否从内部开始选择(?)
selectFromInside
// 拖拽的速率(不知道是不是这个意思)
ratio={0}
// 选择结束
onSelectEnd={handleSelectEnd}
></ReactSelecto>
);
};
复制代码这里有几个需要注意的地方。
操作互斥
画布当中的多选和拖拽都是通过鼠标左键来完成的,所以当一个元素是被选中的时候,鼠标想从元素上开始拖拽选择组件是不被允许的,此时应该是拖拽元素,而不是多选元素。
而元素如果没有被选中时,上面的操作则变成了多选。
内部选中
画布当中有组的概念,它是一个组与组件无限嵌套的结构,并且可以单独选中组内的元素。
当选中的是组内的元素时,即说明最外层的组是被选中的状态,同样需要考虑上面所说的互斥问题。
单元素拖拽缩放
单元素操作相对简单,只需要简单使用react-rnd提供的功能即可完成。
多元素拖拽缩放
这里就是本文的重点了,结合前面介绍的几个依赖,实现一个简单的多选拖拽缩放的功能。
具体思路
多个元素拖拽,说到底其实鼠标拖拽的还是一个元素,就是鼠标拖动的那一个元素。
而其余被选中的元素,仅仅需要根据被拖动的元素的尺寸位置变动来做相应的加减处理即可。
相关问题
信息计算
联动元素的位置尺寸信息该如何计算。组件间通信
因为每一个图表组件并非是单纯的同级关系,如果是通过层层props传递,免不了会有多余的刷新,造成性能问题。
而通过全局的dva状态同样在更新的时候会让组件刷新。数据刷新
图表数据是来自于dva全局的数据,现在频繁自刷新相当于是一直更新全局的数据,同样会造成性能问题。其他
一些细节问题
解决方法
信息计算
关于位置的计算相对简单,只需要单纯的将操作的元素的位置和尺寸差值传递给联动组件即可。组件间通信
根据上面问题的解析,可以使用eventemitter3来完成任意位置、层级的数据通信,并且它和react渲染无任何关系。
import { useCallback, useEffect } from 'react'
import EventEmitter from 'eventemitter3'
const eventemitter = new EventEmitter()
const SonA = () => {
console.log('刷新')
useEffect(() => {
const listener = (value) => {
console.log(value)
}
eventemitter.addListener('change', listener)
return () => {
eventemitter.removeListener('change', listener)
}
}, [])
return (
<span>son A</span>
)
}
const SonB = () => {
const handleClick = useCallback(() => {
eventemitter.emit('change', 'son B')
}, [])
return (
<span>
<button onClick={handleClick}>son B</button>
</span>
)
}
const Parent = () => {
return (
<div>
<SonA />
<br />
<SonB />
</div>
)
}运行上面的例子可以发现,点击SonB组件的按钮,可以让SonA接收到来自其的数据,并且并没有触发SonA的刷新。
需要接收数据的组件只需要监听(addListener)指定的事件即可,比如上面的change事件。
而需要发送数据的组件则直接发布(emit)事件即可。
这样就避免了一些不必要的刷新。
数据刷新
频繁刷新全局数据,会导致所有依赖其数据的组件都会刷新,所以考虑为需要刷新数据的组件在内部单独维护一份状态。
当开始操作时,记录下状态,标识开始使用内部状态表示图表的信息,结束操作时处理下内部数据状态,将数据更新到全局中去。
import { useMemo, useEffect, useState, useRef } from 'react'
import EventEmitter from 'eventemitter3'
const eventemitter = new EventEmitter()
const Component = (props: {
position: {left: number, top: number}
}) => {
const [ position, setPosition ] = useState({
left: 0,
top: 0
})
const isDrag = useRef(false)
const dragStart = () => {
isDrag.current = true
setPosition(props.position)
}
const drag = (position) => {
setPosition(position)
}
const dragEnd = () => {
isDrag.current = false
// TODO
// 更新数据到全局
}
useEffect(() => {
eventemitter.addListener('dragStart', dragStart)
eventemitter.addListener('drag', drag)
eventemitter.addListener('dragEnd', dragEnd)
return () => {
eventemitter.removeListener('dragStart', dragStart)
eventemitter.removeListener('drag', drag)
eventemitter.removeListener('dragEnd', dragEnd)
}
}, [])
return (
<span
style={{
left: (isDrag.current ? position : props.position).left,
top: (isDrag.current ? position : props.position).top
}}
>图表组件</span>
)
}上面的数据更新还可以更加优化,对于短时间的多次更新操作,可以控制一下更新频率,将多次更新合并为一次。
其他
控制刷新
这里的控制刷新指的是上述的内部刷新,不需要每次都响应react-rnd发出的相关事件,可以做对应的节流(throttle)操作,减少事件触发频率。通信冲突问题
因为所有的组件都需要监听拖拽的事件,包括当前被拖拽的组件,所以在传递信息时,需要把自身的id类似值传递,防止冲突。组件的缩放属性
这里是关于前文说到的成组的逻辑相关,因为组存在scaleX和scaleY两个属性,所以在调整大小的时候,也要兼顾此属性(本文先暂时不考虑这个问题)。单元素选中情况
自定义事件的监听是无差别的,当只选中了一个元素进行拖拽缩放操作时,无须触发相应的事件。
最后的DEMO
成品
其实在之前就已经发现其实react-selecto的作者也有研发其他的可视化操作模块,包括本文所说的多选拖拽的操作,但是奈何无法满足本项目的需求,故自己实现了功能。
如果有兴趣可以去看一下这个成品moveable。
总结
通过上面的思路,即可完成一个简单的多元素拖拽缩放的功能,其核心其实就是eventemitter3的自定义事件功能,它的用途在平常的业务中非常广泛。
比如我们完全可以在以上例子的基础上,加上元素拖拽时吸附的功能。
结束
结束🔚。
顺便在下面附上相关的链接。
作者:写代码请写注释
来源:juejin.cn/post/7202445722972815417
手把手教你实现一个自定义 eslint 规则
ESlint 概述
ESLint 是一个代码检查工具,通过静态的分析,寻找有问题的模式或者代码。默认使用 Espree 解析器将代码解析为 AST 抽象语法树,然后再对代码进行检查。
抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
随着前端工程化体系的不断发展,Eslint 已经前端工程化不可缺失的开发工具。它解决了前端工程化中团队代码风格不统一的问题,避免了一些由于代码规范而产生的 Bug, 同时它提高了了团队的整体效率。
运行机制
Eslint的内部运行机制不算特别复杂,主要分为以下几个部分:
preprocess,把非 js 文本处理成 js确定
parser(默认是espree)调用
parser,把源码parse成SourceCode(AST)调用
rules,对SourceCode进行检查,返回linting problems扫描出注释中的
directives,对problems进行过滤postprocess,对problems做一次处理基于字符串替换实现自动
fix
具体描述,这里就不补充了。详细的运行机制推荐大家去学习一下Eslint的底层实现原理和源码。
常用规则
为了让使用者对规则有个更好的理解, Eslint 官方将常用的规则进行了分类并且定义了一个推荐的规则组 "extends": "eslint:recommended"。具体规则详情请见官网
示例规则如下:
array-element-newline :
<string|object>
"always"(默认) - 需要数组元素之间的换行符
"never" - 不允许数组元素之间换行
"consistent" - 数组元素之间保持一致的换行符
配置详解
Eslint 配置我们主要通过.eslintrc配置来描述
extends
extends 的内容为
一个 ESLint配置文件,一旦扩展了(即从外部引入了其他配置包),就能继承另一个配置文件的所有属性(包括rules, plugins, and language option在内),然后通过 merge合并/覆盖所有原本的配置。最终得到的配置是前后继承和覆盖前后配置的并集。
extends属性的值可以是:
定义一个配置的字符串(配置文件的路径、可共享配置的名称,如
eslint:recommended或eslint:all)定义规则组的字符串。
plugin:插件名/规则名称 (插件名取eslint-plugin-之后的名称)
"extends": [
"eslint:recommended",
"plugin:react/recommended"
],parserOptions
指定你想要支持的 JavaScript 语言选项。默认支持 ECMAScript 5 语法。你可以覆盖该设置,以启用对 ECMAScript 其它版本和 JSX 的支持。
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
}rules
ESLint 拥有大量的规则。你可以通过配置插件添加更多规则。使用注释或配置文件修改你项目中要使用的规则。要改变一个规则,你必须将规则 ID 设置为下列值之一:
"off"或0- 关闭规则"warn"或1- 开启规则,使用警告级别的错误:warn(不会导致程序退出)"error"或2- 开启规则,使用错误级别的错误:error(当被触发的时候,程序会退出)
"plugins": [
"plugin-demo",
],
"rules": {
"quotes": ["error", "double"], // 修改eslint recommended中quotes规则
"plugin-demo/rule1": "error", // 配置eslint-plugin-plugin-demo 下rule1规则
}对于 Eslint recommended 规则组中你不想使用的规则,也可以在这里进行关闭。
plugin
ESLint 支持使用第三方插件。要使用插件,必须先用 npm进行安装
"plugins": [
"plugin-demo", // // 配置 eslint-plugin-plugin-demo 插件
],这里做一下补充,extends 和 plugin 的区别在于,extends 是 plugin 的子集。就好比如 Eslint 中除了 recommended 规则组还有其他规则
自定义Eslint插件
团队开发中,我们经常会使用一些 eslint 规则插件来约束代码开发,但偶尔也会有一些个性定制化的团队规范,而这些规范就需要通过一些自定义的 ESlint 插件来实现。
我们先看一段简短的代码:
import { omit } from 'lodash';上述代码是我们在使用lodash的一个习惯性写法,但是这段代码会导致全量引入lodash,造成工程包体积偏大。
正确的引用方式如下:
import omit from 'lodash/omit';
// 或
import { omit } from 'lodash-es';我们希望可以通过插件去约束开发者的使用习惯。但是 Eslint 自带的规则对于这个定制化的场景就无法满足了。此时, 就需要去使用 Eslint 提供的开放能力去定制化一个 Eslint 规则。接下来我将从创建到使用去实现一个lodash引用规范的Eslint自定义插件
创建
工程搭建
Eslint 官方提供了脚手架来简化新规则的开发, 如不使用脚手架搭建,只需保证和脚手架一样的结构就可以啦。
创建工程前,先全局安装两个依赖包:
$ npm i -g yo
$ npm i -g generator-eslint再执行如下命令生成 Eslint 插件工程。
$ yo eslint:plugin这是一个交互式命令,需要你填写一些基本信息,如下
$ yo eslint:rule
? What is your name? // guming-eslint-plugin-custom-lodash
? What is the plugin ID? // 插件名 (eslint-plugin-xxx)
? Type a short description of this plugin: // 描述你的插件是干啥的
? Does this plugin contain custom ESLint rules? Yes // 是否为自定义Eslint 校验规则
? Does this plugin contain one or more processors? No // 是否需要处理器接下来我们为插件创建一条规则,执行如下命令:
$ npx yo eslint:rule这也是一个交互式命令,如下:
? What is your name? // guming-eslint-plugin-custom-lodash
? Where will this rule be published? ESLint Plugin
? What is the rule ID? // 规则名称 lodash-auto-import
? Type a short description of this rule: // 规则的描述
? Type a short example of the code that will fail: // 这里写你这条规则校验不通过的案例代码填写完上述信息后, 我们可以得到如下的一个项目目录结构:
guming-eslint
├─ .eslintrc.js
├─ .git
├─ README.md
├─ docs
│ └─ rules
│ └─ lodash-auto-import.md
├─ lib // 规则
│ ├─ index.js
│ └─ rules
│ └─ lodash-auto-import.js
├─ node_modules
├─ package-lock.json
├─ package.json
└─ tests // 单测
└─ lib
└─ rules
└─ lodash-auto-import.jseslint 规则配置
Eslint 官方制定了一套开发自定义规则的规范。我们只需要根据规范配置相应的内容就可以轻松的实现我们的自定义Eslint规则。具体配置详情可见官网
相关配置的说明如下:
module.exports = {
meta: {
// 规则的类型 problem|suggestion|layout
// problem: 这条规则识别的代码可能会导致错误或让人迷惑。应该优先解决这个问题
// suggestion: 这条规则识别的代码不会导致错误,但是建议用更好的方式
// layout: 表示这条规则主要关心像空格、分号等这种问题
type: "suggestion",
// 对于自定义规则,docs字段是非必须的
docs: {
description: "描述你的规则是干啥的",
// 规则的分类,假如你把这条规则提交到eslint核心规则里,那eslint官网规则的首页会按照这个字段进行分类展示
category: "Possible Errors",
// 假如你把规则提交到eslint核心规则里
// 且像这样extends: ['eslint:recommended']继承规则的时候,这个属性是true,就会启用这条规则
recommended: true,
// 你的规则使用文档的url
url: "https://eslint.org/docs/rules/no-extra-semi",
},
// 定义提示信息文本 error-name为提示文本的名称 定义后我们可以在规则内部使用这个名称
messages: {
"error-name": "这是一个错误的命名"
},
// 标识这条规则是否可以修复,假如没有这属性,即使你在下面那个create方法里实现了fix功能,eslint也不会帮你修复
fixable: "code",
// 这里定义了这条规则需要的参数
// 比如我们是这样使用带参数的rule的时候,rules: { myRule: ['error', param1, param2....]}
// error后面的就是参数,而参数就是在这里定义的
schema: [],
},
create: function (context) {
// 这是最重要的方法,我们对代码的校验就是在这里做的
return {
// callback functions
};
},
};本次Eslint 校验规则是推荐使用更好的lodash引用方式,所以常见规则类型 type为 suggestion
AST 结构
Eslint 的本质是通过代码生成的 AST 树做代码的静态分析,我们可以使用 astexplorer 快速方便地查看解析成 AST 的结构。
我们将如下代码输入
import { omit } from 'lodash'得到的 AST 结构如下:
{
"type": "Program",
"start": 0,
"end": 29,
"body": [
{
"type": "ImportDeclaration",
"start": 0,
"end": 29,
"specifiers": [
{
"type": "ImportSpecifier",
"start": 9,
"end": 13,
"imported": {
"type": "Identifier",
"start": 9,
"end": 13,
"name": "omit"
},
"local": {
"type": "Identifier",
"start": 9,
"end": 13,
"name": "omit"
}
}
],
"source": {
"type": "Literal",
"start": 21,
"end": 29,
"value": "lodash",
"raw": "'lodash'"
}
}
],
"sourceType": "module"
}分析 AST 的结构,我们可以知道:
type为 包的引入方式source为 资源名(依赖包名)specifiers为导出的模块
节点访问方法
Eslint 规则中的 create 函数create (function) 返回一个对象,其中包含了 ESLint 在遍历 JavaScript 代码的抽象语法树 AST (ESTree 定义的 AST) 时,用来访问节点的方法。其中, 访问节点的方法如下:
VariableDeclaration,则返回声明中声明的所有变量。如果节点是一个
VariableDeclarator,则返回 declarator 中声明的所有变量。如果节点是
FunctionDeclaration或FunctionExpression,除了函数参数的变量外,还返回函数名的变量。如果节点是一个
ArrowFunctionExpression,则返回参数的变量。如果节点是
ClassDeclaration或ClassExpression,则返回类名的变量。如果节点是一个
CatchClause子句,则返回异常的变量。如果节点是
ImportDeclaration,则返回其所有说明符的变量。如果节点是
ImportSpecifier,ImportDefaultSpecifier或ImportNamespaceSpecifier,则返回声明的变量。
本次我们是校验资源导入规范,所以我们使用ImportDeclaration获取我们导入资源的节点结构
代码修复
report()函数返回一个特定结构的对象,它用来发布警告或错误, 我们可以通过配置对象去配置错误AST 节点,错误提示的内容(可使用 meta 配置的 meaasge 名称)以及修复方式
实例配置代码如下
context.report({
node: node,
message: "Missing semicolon",
fix: function(fixer) {
return fixer.insertTextAfter(node, ";");
}
});编写代码
了解完上述内容,我们就可以开始愉快的编写代码了。
自定义规则代码如下:
// lib/rules/lodash-auto-import.js
/**
* @fileoverview 这是一个lodash按需引入的eslint规则
* @author guming-eslint
*/
"use strict";
//------------------------------------------------------------------------------
// Rule Definition
//------------------------------------------------------------------------------
/** @type {import('eslint').Rule.RuleModule} */
const SOURCElIST = ["lodash", "lodash-es"];
module.exports = {
// eslint-disable-next-line eslint-plugin/prefer-message-ids
meta: {
type: "suggestion", // `problem`, `suggestion`, or `layout`
docs: {
description: "这是一个lodash按需引入的eslint规则",
recommended: true,
url: null, // URL to the documentation page for this rule
},
messages: {
autoImportLodash: "请使用lodash按需引用",
invalidImport: "lodash 导出依赖不为空",
},
fixable: "code",
schema: [],
},
create: function (context) {
// 获取lodash中导入的函数名称,并返回
function getImportSpecifierArray(specifiers) {
const incluedType = ["ImportSpecifier", "ImportDefaultSpecifier"];
return specifiers
.filter((item) => incluedType.includes(item.type))
.map((item) => {
return item.imported ? item.imported.name : item.local.name;
});
}
// 生成修复文本
function generateFixedImportText(importedList, dependencyName) {
let fixedText = "";
importedList.forEach((importName, index) => {
fixedText += `import ${importName} from "${dependencyName}/${importName}";`;
if (index != importedList.length - 1) fixedText += "\n";
});
return fixedText;
}
return {
ImportDeclaration(node) {
const source = node.source.value;
const hasUseLodash = SOURCElIST.inclues(source);
// 使用lodash
if (hasUseLodash) {
const importedList = getImportSpecifierArray(node.specifiers || []);
if (importedList.length <= 0) {
return context.report({
node,
messageId: "invalidImport",
});
}
const dependencyName = getImportDependencyName(node);
return context.report({
node,
messageId: "autoImportLodash",
fix(fixer) {
return fixer.replaceTextRange(
node.range,
generateFixedImportText(importedList, dependencyName)
);
},
});
}
},
};
},
};配置规则组
// lib/rules/index.js
const requireIndex = require("requireindex");
// 在这里导入了我们上面写的自定义规则
const rules = requireIndex(__dirname + "/rules");
module.exports = {
// rules是必须的
rules,
// 增加configs配置
configs: {
// 配置了这个之后,就可以在其他项目中像下面这样使用了
// extends: ['plugin:guming-eslint/recommended']
recommended: {
plugins: ['guming-eslint'],
rules: {
'guming-eslint/lodash-auto-import': ['error'],
}
}
}
}补充测试用例
// tests/lib/rules/lodash-auto-import.js
/**
* @fileoverview 这是一个lodash按需引入的eslint规则
* @author guming-eslint
*/
"use strict";
//------------------------------------------------------------------------------
// Requirements
//------------------------------------------------------------------------------
const rule = require("../../../lib/rules/lodash-auto-import"),
RuleTester = require("eslint").RuleTester;
//------------------------------------------------------------------------------
// Tests
//------------------------------------------------------------------------------
const ruleTester = new RuleTester();
ruleTester.run("lodash-auto-import", rule, {
valid: ['import omit from "lodash/omit";', 'import { omit } from "lodash-es";'],
invalid: [
// eslint-disable-next-line eslint-plugin/consistent-output
{
code: 'import {} from "lodash";',
errors: [{ message: "invalidImport" }],
output: 'import xxx from lodash/xxx'
},
{
code: 'import {} from "lodash-es";',
errors: [{ message: "invalidImport" }],
output: 'import { xxx } from lodash-es'
},
{
code: 'import { omit } from "lodash";',
errors: [{ message: "directlyImportLodash" }],
output: 'import omit from "lodash/omit";',
},
{
code: 'import { omit as _omit } from "lodash";',
errors: [{ message: "directlyImportLodash" }],
output: 'import omit from "lodash/omit";',
},
{
code: 'import { omit, debounce } from "lodash";',
errors: [{ message: "directlyImportLodash" }],
output:
'import omit from "lodash/omit"; \n import debounce from "lodash/debounce";',
},
],
});可输入如下指令,执行测试
$ yarn run test注意事项
开发这个插件的一些注意事项如下
多个模块导出
lodash具名导出和默认导出模块别名(
as)
使用
插件安装
npm包发布安装调试
$ yarn add eslint-plugin-guming-eslintnpm link本地调试(推荐使用) 插件项目目录执行如下指令
$ npm link项目目录执行如下指令
$ npm link eslint-plugin-guming-eslint项目配置
添加你的 plugin 包名(eslint-plugin- 前缀可忽略) 到 .eslintrc 配置文件的 extends 字段。
.eslintrc 配置文件示例:
module.exports = {
// 你的插件
extends: ["plugin:guming-eslint/recommended"],
parserOptions: {
ecmaVersion: 7,
sourceType: "module",
},
};效果
作者:古茗前端团队
来源:juejin.cn/post/7202413628807938108
用一周时间开发了一个微信小程序,我遇到了哪些问题?
功能截图
| 特别说明:由于本项目是用于教学案例,并没有上线的二维码供大家体验。 |
开发版本
微信开发者工具版本:1.06
调试基础库:2.30
代码仓库
gitee:gitee.com/guigu-fe/gu…
github:github.com/xiumubai/gu…
建议全文参考源代码观看效果更佳,代码可直接在微信开发者工具当中打开预览,appid需要替换成自己的。
获取用户信息变化
用户头像昵称获取规则已调整,现在微信小程序已经获取不到用户昵称和头像了,只能已通过用户回填(提供给用户一个修改昵称和头像的表单页面)的方式来实现。不过还是可以获取到code跟后端换取token的方式来进行登录。
具体参考 *用户信息接口调整说明*、小程序用户头像昵称获取规则调整公告
vant weapp组件库的使用
1.需要使用npm构建的能力,用 npm 构建前,请先阅读微信官方的 npm 支持。初始化package.json
npm init2.安装@vant/weapp
# 通过 npm 安装
npm i @vant/weapp -S --production
# 通过 yarn 安装
yarn add @vant/weapp --production
# 安装 0.x 版本
npm i vant-weapp -S --production2.修改 app.json 将 app.json 中的 "style": "v2" 去除,小程序的新版基础组件强行加上了许多样式,难以覆盖,不关闭将造成部分组件样式混乱。 3.修改 project.config.json 开发者工具创建的项目,miniprogramRoot 默认为 miniprogram,package.json 在其外部,npm 构建无法正常工作。 需要手动在 project.config.json 内添加如下配置,使开发者工具可以正确索引到 npm 依赖的位置。
{
...
"setting": {
...
"packNpmManually": true,
"packNpmRelationList": [
{
"packageJsonPath": "./package.json",
"miniprogramNpmDistDir": "./miniprogram/"
}
]
}
}注意: 由于目前新版开发者工具创建的小程序目录文件结构问题,npm构建的文件目录为miniprogram_npm,并且开发工具会默认在当前目录下创建miniprogram_npm的文件名,所以新版本的miniprogramNpmDistDir配置为'./'即可。 4.构建 npm 包 打开微信开发者工具,点击 工具 -> 构建 npm,并勾选 使用 npm 模块 选项,构建完成后,即可引入组件。
使用组件
引入组件
// 通过 npm 安装
// app.json
"usingComponents": {
"van-button": "@vant/weapp/button/index"
}使用组件
<van-button type="primary">按钮</van-button>如果预览没有效果,从新构建一次npm,然后重新打开此项目。
自定义tabbar
这里我的购物车使用了徽标,所以需要自定义一个tabbar,这里自定义以后,会引发后面的一系列连锁反应(比如内容区域高度塌陷,导致tabbar遮挡内容区域),后面会讲如何计算。效果如下图:
1. 配置信息
在 app.json 中的 tabBar 项指定 custom 字段,同时其余 tabBar 相关配置也补充完整。
所有 tab 页的 json 里需声明 usingComponents 项,也可以在 app.json 全局开启。
示例:
{
"tabBar": {
"custom": true,
"color": "#000000",
"selectedColor": "#000000",
"backgroundColor": "#000000",
"list": [{
"pagePath": "page/component/index",
"text": "组件"
}, {
"pagePath": "page/API/index",
"text": "接口"
}]
},
"usingComponents": {}
}
2. 添加 tabBar 代码文件
需要跟pages目录同级,创建一个custom-tab-bar目录。
.wxml代码如下:
<!--miniprogram/custom-tab-bar/index.wxml-->
<cover-view class="tab-bar">
<cover-view class="tab-bar-border"></cover-view>
<cover-view wx:for="{{list}}"
wx:key="index"
class="tab-bar-item"
data-path="{{item.pagePath}}"
data-index="{{index}}"
bindtap="switchTab">
<cover-view class="tab-img-wrap">
<cover-image src="{{selected === index ? item.selectedIconPath : item.iconPath}}"></cover-image>
<cover-view wx-if="{{item.info && cartCount > 0}}"class="tab-badge">{{cartCount}}</cover-view>
</cover-view>
<cover-view style="color: {{selected === index ? selectedColor : color}}">{{item.text}}</cover-view>
</cover-view>
</cover-view>
注意这里的徽标控制我是通过info字段来控制的,然后数量cartCount单独第一个了一个字段,这个字段是通过store来管理的,后面会讲为什么通过stroe来控制的。
3. 编写 tabBar 代码
用自定义组件的方式编写即可,该自定义组件完全接管 tabBar 的渲染。另外,自定义组件新增 getTabBar 接口,可获取当前页面下的自定义 tabBar 组件实例。
import { storeBindingsBehavior } from 'mobx-miniprogram-bindings';
import { store } from '../store/index';
Component({
behaviors: [storeBindingsBehavior],
storeBindings: {
store,
fields: {
count: 'count',
},
actions: [],
},
observers: {
count: function (val) {
// 更新购物车的数量
this.setData({ cartCount: val });
},
},
data: {
selected: 0,
color: '#252933',
selectedColor: '#FF734C',
cartCount: 0,
list: [
{
pagePath: '/pages/index/index',
text: '首页',
iconPath: '/static/tabbar/home-icon1.png',
selectedIconPath: '/static/tabbar/home-icon1-1.png',
},
{
pagePath: '/pages/category/category',
text: '分类',
iconPath: '/static/tabbar/home-icon2.png',
selectedIconPath: '/static/tabbar/home-icon2-2.png',
},
{
pagePath: '/pages/cart/cart',
text: '购物车',
iconPath: '/static/tabbar/home-icon3.png',
selectedIconPath: '/static/tabbar/home-icon3-3.png',
info: true,
},
{
pagePath: '/pages/info/info',
text: '我的',
iconPath: '/static/tabbar/home-icon4.png',
selectedIconPath: '/static/tabbar/home-icon4-4.png',
},
],
},
lifetimes: {},
methods: {
// 改变tab的时候,记录index值
switchTab(e) {
const { path, index } = e.currentTarget.dataset;
wx.switchTab({ url: path });
this.setData({
selected: index,
});
},
},
});
这里的store大家不用理会,只需要记住是设置徽标的值就可以了。
4.设置样式
.tab-bar {
position: fixed;
bottom: 0;
left: 0;
right: 0;
height: 48px;
background: white;
display: flex;
padding-bottom: env(safe-area-inset-bottom);
}这里的样式单独贴出来说明一下:
padding-bottom: env(safe-area-inset-bottom);可以让出底部安全区域,不然的话tabbar会直接沉到底部 别忘了在
index.json中设置component=true
{
"component": true
}5.tabbar页面设置index
上面的代码添加完毕以后,我们的tabbar就出来了,但是有个问题,就是在点击tab的时候,样式不会改变,必须再点击一次,这是因为当你切换页面或者刷新页面的时候,index的值会重置,为了解决这个问题,我们需要在每个tabbar的页面添加下面的代码:
/**
* 生命周期函数--监听页面显示
*/
onShow() {
if (typeof this.getTabBar === 'function' && this.getTabBar()) {
this.getTabBar().setData({
selected: 0,
});
}
},当页面每次show的时候,设置一下selected的值,也就是选中的index就可以了。其他的tabbar页面同样也是如此设置即可。
添加store状态管理
接下来我们来讲讲微信小程序如何用store来管理我们的数据。 上面我们说了我们需要实现一个tabbar的徽标,起初我想的是直接用个缓存来解决就完事了,后来发现我太天真了,忘记了这个字段是一个响应式的,它是需要渲染到页面上的,它变了,页面中的数据也得跟着一起变。后来我想通过globalData来实现,也不行。后来我又又想到了把这个数据响应式监听一下不就行了?于是通过proxy,跟vue3的处理方式一样,监听一下这个字段的改变就可以了。在购物车这个页面触发的时候是挺好,可当我切换到其他tabbar页面的时候它就不见了。我忽略了一个问题,它是全局响应的啊。于是最后才想到了使用store的方式来实现。 我找到了一个针对微信小程序的解决方法,就是使用mobx-miniprogram-bindings和mobx-miniprogram这两个库来解决。真是帮了我的大忙了。 下面我们直接来使用。 先安装两个插件:
npm install --save mobx-miniprogram mobx-miniprogram-bindings方式跟安装vant weapp一样,npm安装完成以后,在微信开发者工具当中构建npm即可。 下面我们来通过如何实现一个tabbar徽标的场景来学习如何在微信小程序中使用store来管理全局数据。
tabbar徽标实现
1.定义store
import { observable, action, runInAction } from 'mobx-miniprogram';
import { getCartList } from './cart';
// 获取购物车数量
export const store = observable({
/** 数据字段 */
count: 0,
/** 异步方法 */
getCartListCount: async function () {
const num = await getCartList();
runInAction(() => {
this.count = num;
});
},
/** 更新购物车的数量 */
updateCount: action(function (num) {
this.count = num;
}),
});
看起来是不是非常简单。这里我们定义了一个count,然后定义了两个方法,这两个方法有点区别:
updateCount用来更新countgetCartListCount用来异步更新count,因为这里我们在进入小程序的时候就需要获取count的初始值,这个值的计算又的依赖接口,所以需要使用异步的方式。
好了,现在我们字段有了,设置初始值的方法有了,更新字段的方法也有了。下面我们来看一下如何使用。
2.使用store
回到我们的tabbr组件,在custom-tab-bari/ndex.js中,我们贴一下主要的代码:
import { storeBindingsBehavior } from 'mobx-miniprogram-bindings';
import { store } from '../store/index';
Component({
behaviors: [storeBindingsBehavior],
storeBindings: {
store,
fields: {
count: 'count',
},
actions: [],
},
observers: {
count: function (val) {
// 更新购物车的数量
this.setData({ cartCount: val });
},
},
data: {
cartCount: 0,
},
});
解释一下,这里我们只是获取了count的值,然后通过observers的方式监听了一下count,然后赋值给了cartCount,这里你直接使用count渲染到页面上也是没有问题的。我这里只是为了演示一下observers的使用方式才这么写的。这样设置以后,tabbar上面的徽标数字已经可以正常展示了。 现在当我们的购物车数字改变以后,就要更新count的值了。
3.使用action
找到我们的cart页面,下面是具体的逻辑:
import {
findCartList,
deleteCart,
checkCart,
addToCart,
checkAllCart,
} from '../../utils/api';
import { createStoreBindings } from 'mobx-miniprogram-bindings';
import { store } from '../../store/index';
import { getCartTotalCount } from '../../store/cart';
const app = getApp();
Page({
data: {
list: [],
totalCount: 0,
},
/**
* 生命周期函数--监听页面加载
*/
onLoad(options) {
this.storeBindings = createStoreBindings(this, {
store,
fields: ['count'],
actions: ['updateCount'],
});
},
/**
* 声明周期函数--监听页面卸载
*/
onUnload() {
this.storeBindings.destroyStoreBindings();
},
/**
* 生命周期函数--监听页面显示
*/
onShow() {
if (typeof this.getTabBar === 'function' && this.getTabBar()) {
this.getTabBar().setData({
selected: 2,
});
}
this.getCartList();
},
/**
* 获取购物车列表
*/
async getCartList() {
const res = await findCartList();
this.setData({
list: res.data,
});
this.computedTotalCount(res.data);
},
/**
* 修改购物车数量
*/
async onChangeCount(event) {
const newCount = event.detail;
const goodsId = event.target.dataset.goodsid;
const originCount = event.target.dataset.count;
// 这里如果直接拿+以后的数量,接口的处理方式是直接在上次的基础累加的,
// 所以传给接口的购物车数量的计算方式如下:
// 购物车添加的数量=本次的数量-上次的数量
const count = newCount - originCount;
const res = await addToCart({
goodsId,
count,
});
if (res.code === 200) {
this.getCartList();
}
},
/**
* 计算购物车总数量
*/
computedTotalCount(list) {
// 获取购物车选中数量
const total = getCartTotalCount(list);
// 设置购物车徽标数量
this.updateCount(total);
},
});
上面的代码有所删减。在page和component中使用action方法有所区别,需要在onUnload的时候销毁一下我们的storeBindings。当修改购物车数量的时候,我这里会重新请求一次接口,然后计算一下totalCount的数量,通过updateCount来修改count的值。到了这里,我们的徽标就可以正常的使用了。不管是切换到哪一个tabbar页面,徽标都会保持状态。
4.使用异步action
现在还剩最后一个问题,就是如何设置count的初始值,这个值还得从接口获取过来。下面是实现思路。 首先我们在store中定义了一个一步方法:
import { observable, action, runInAction } from 'mobx-miniprogram';
import { getCartList } from './cart';
// 获取购物车数量
export const store = observable({
/** 数据字段 */
count: 0,
/** 异步方法 */
getCartListCount: async function () {
const num = await getCartList();
runInAction(() => {
this.count = num;
});
},
/** 更新购物车的数量 */
updateCount: action(function (num) {
this.count = num;
}),
});
可以看到,异步action的实现跟同步的区别很大,使用了runInAction这个方法,在它的回调函数中去修改count的值。很坑的是,这个方法在[mobx-miniprogram-bindings](https://www.npmjs.com/package/mobx-miniprogram-bindings)中的官方文档中没有做任何说明,我百度了好久才找到。 现在,我们有了这个方法,在哪里触发好合适呢?答案是app.js中的onShow生命周期函数中。也就是每次我们进入小程序,就会设置一下count的初始值了。下面是代码:
// app.js
import { createStoreBindings } from 'mobx-miniprogram-bindings';
import { store } from './store/index';
App({
onShow() {
this.storeBindings = createStoreBindings(this, {
store,
fields: [],
actions: ['getCartListCount'],
});
// 在页面初始化的时候,更新购物车徽标的数量
this.getCartListCount();
},
});
到此为止,整个完整的徽标响应式改变和store的使用完美的融合了。 参考文章:blog.csdn.net/ice_stone_k…
如何获取tabbar的高度
当我们自定义tabbar以后,由于tabbar是使用的fixed定位,我们的内容区域如果不做任何限制,底部的内容就会被tabbar遮挡,所以我们需要给内容区域整体设置一个padding-bottom,那这个值是多少呢?有的人可能会说,直接把tabbar的高度固定,然后padding-bottom设置成这个高度的值不就可以了吗?你别忘了,现在五花八门的手机下面还有一个叫做安全区域的东西,如下图:
如果你没有把这个高度加上,那内容区域还是会被tabbar遮挡。下面我们就来看看这个高度具体如何计算呢? 我们以通过wx.getSystemInfoSync()获取机型的各种信息。
其中screenHeight是屏幕高度,safeArea的bottom属性会自动计算安全区域也就是去除tabBar下面的空白区域后有用区域的纵坐标。如此我们就可以就算出来tabber的高度:
const res = wx.getSystemInfoSync()
const { screenHeight, safeArea: { bottom } } = res
if (screenHeight && bottom){
let safeBottom = screenHeight - bottom
const tabbarHeight = 48 + safeBottom
}这里48是tabbar的高度,我们固定是48px。拿到tabbarHeight以后,把它设置成一个globalData,我们就可以给其他页面设置padding-bottom了。 我这里还使用了其他的一些属性,具体参考代码如下:
// app.js
App({
onLaunch() {
// 获取高度
this.getHeight();
},
onShow() {
},
globalData: {
// tabber+安全区域高度
tabbarHeight: 0,
// 安全区域的高度
safeAreaHeight: 0,
// 内容区域高度
contentHeight: 0,
},
getHeight() {
const res = wx.getSystemInfoSync();
// 胶囊按钮位置信息
const menuButtonInfo = wx.getMenuButtonBoundingClientRect();
const {
screenHeight,
statusBarHeight,
safeArea: { bottom },
} = res;
// console.log('resHeight', res);
if (screenHeight && bottom) {
// 安全区域高度
const safeBottom = screenHeight - bottom;
// 导航栏高度 = 状态栏到胶囊的间距(胶囊距上距离-状态栏高度) * 2 + 胶囊高度 + 状态栏高度
const navBarHeight =
(menuButtonInfo.top - statusBarHeight) * 2 +
menuButtonInfo.height +
statusBarHeight;
// tabbar高度+安全区域高度
this.globalData.tabbarHeight = 48 + safeBottom;
this.globalData.safeAreaHeight = safeBottom;
// 内容区域高度,用来设置内容区域最小高度
this.globalData.contentHeight = screenHeight - navBarHeight;
}
},
});
假如我们需要给首页设置一个首页设置一个padding-bottom:
// components/layout/index.js
const app = getApp();
Component({
/**
* 组件的属性列表
*/
properties: {
bottom: {
type: Number,
value: 48,
},
},
/**
* 组件的方法列表
*/
methods: {},
});
<view style="padding-bottom: {{bottom}}px">
<slot></slot>
</view>这里我简单粗暴的直接在外层套了一个组件,统一设置了padding-bottom。 除了自定义tabbar,还可以自定义navbar,这里我没这个功能,所以不展开讲了,这里放一个参考文章: 获取状态栏的高度。这个文章把如何自定义navbar,如何获取navbar的高度,讲的很通透,感兴趣的仔细拜读。
分页版上拉加载更多
为什么我称作是分页版本的上拉加载更多呢,因为就是上拉然后多加载一页,没有做那种虚拟加载,感兴趣的可以参考这篇文章(我觉得写的非常到位了)。下面我以商品列表为例,代码在pages/goods/list下,讲讲简单版本的实现:
<!--pages/goods/list/index.wxml-->
<view style="min-height: {{contentHeight}}px; padding-bottom: {{safeAreaHeight}}px">
<view wx:if="{{list.length > 0}}">
<goods-card wx:for="{{list}}" wx:key="index" item="{{item}}"></goods-card>
<!-- 上拉加载更多 -->
<load-more
list-is-empty="{{!list.length}}"
status="{{loadStatus}}"
/>
</view>
<van-empty wx:else description="该分类下暂无商品,去看看其他的商品吧~">
<van-button
round
type="danger"
bindtap="gotoBack">
查看其他商品
</van-button>
</van-empty>
</view>
// pages/goods/list/index.js
import { findGoodsList } from '../../../utils/api';
const app = getApp();
Page({
/**
* 页面的初始数据
*/
data: {
page: 1,
limit: 10,
list: [],
options: {},
loadStatus: 0,
contentHeight: app.globalData.contentHeight,
safeAreaHeight: app.globalData.safeAreaHeight,
},
/**
* 生命周期函数--监听页面加载
*/
onLoad(options) {
this.setData({ options });
this.loadGoodsList(true);
},
/**
* 页面上拉触底事件的处理函数
*/
onReachBottom() {
// 还有数据,继续请求接口
if (this.data.loadStatus === 0) {
this.loadGoodsList();
}
},
/**
* 商品列表
*/
async loadGoodsList(fresh = false) {
// wx.stopPullDownRefresh();
this.setData({ loadStatus: 1 });
let page = fresh ? 1 : this.data.page + 1;
// 组装查询参数
const params = {
page,
limit: this.data.limit,
...this.data.options,
};
try {
// loadstatus说明: 0-加载完毕,隐藏加载状态 1-正在加载 2-全部加载 3-加载失败
const res = await findGoodsList(params);
const data = res.data.records;
if (data.length > 0) {
this.setData({
list: fresh ? data : this.data.list.concat(data),
loadStatus: data.length === this.data.limit ? 0 : 2,
page,
});
} else {
// 数据全部加载完毕
this.setData({
loadStatus: 2,
});
}
} catch {
// 错误请求
this.setData({
loadStatus: 3,
});
}
},
});
代码已经很详细了,我再展开说明一下。
onLoad的时候第一次请求商品列表数据loadGoodsList,这里我加了一个fresh字段,用来区分是不是第一次加载,从而且控制page是不是等于1触发
onReachBottom的时候,先判断loadStatus === 0,表示接口数据还没加载完,继续请求loadGoodsList在
loadGoodsList里面,先设置loadStatus = 1,表示状态为加载中。如果fresh为false,则表示要请求下一页的数据了,page+1。接口请求成功,给了list添加数据的时候要注意了,这里需要再上次list的基础上拼接数据,所以得用
concat。同时修改loadStatus状态,如果当前请求回来的数据条数小与limit(每页数据大小),则表示没有更对的数据了,loadStatus = 2,反之为0。最后为了防止特殊情况出现,还有个
loadStatus = 3,表示加载失败的情况。
这里我封装了一个load-more组件,里面就是对loadStatus各种不同状态的处理。具体详情看看源码。 思考:如果加上个下拉刷新,跟上拉加载放在一起,如何实现呢?
如何分包
为什么要做小程序分包?先来看看小程序对文件包的大小限制 在不使用分包的时候,代码总包的大小限制为2M,如果使用了分包,总包大小可以达到20M,也就是我们能分10个包。 那么如何分包?非常的简单。代码如下:
{
"pages": [
"pages/index/index",
"pages/category/category",
"pages/cart/cart",
"pages/info/info",
"pages/login/index"
],
"subpackages": [
{
"root": "pages/goods",
"pages": [
"list/index",
"detail/index"
]
},
{
"root": "pages/address",
"pages": [
"list/index",
"add/index"
]
},
{
"root": "pages/order",
"pages": [
"pay/index",
"list/index",
"result/index",
"detail/index"
]
}
],
}目录结构如下: 解释一下: 我们subpackages下面的就是分包的内容,里面的每一个root就是一个包,pages里面的内容只能是这样的字符串路径,添加别的内容会报错。分包的逻辑:业务相关的页面放在一个包下,也就是一个目录下即可。 ⚠️注意:
tabbar的页面不能放在分包里面。 下面是分包以后的代码依赖分析截图:
后续更新计划
小程序如何自定义navbar
小程序如何添加typescript
在小程序中如何做表单校验的小技巧
微信支付流程
如何在小程序中mock数据
如何优化小程序
本文章可以随意转载。转给更多需要帮助的人。看了源码觉得有帮助的可以点个star。我会持续更新更多系列教程。
作者:白哥学前端
来源:https://juejin.cn/post/7202495679397511227
手把手教你实现MVVM架构
引言
现在的前端真可谓是百花齐放,百家争鸣,各种框架层出不穷,但是主要目前用的最多的还是要数Vue、React、以及Angular,这三种,当然不乏近期新出的一些其他框架,但是她们都有一个显著的特点,那就是使用了MVVM的架构。
首先我们要搞清楚什么是
MVVM?
MVVM就是Model-View-ViewModel的缩写,MVVM最早由微软提出来,它借鉴了桌面应用程序的MVC思想,在前端页面中,把Model用纯JavaScript对象表示,View负责显示,两者做到了最大限度的分离。把Model和View关联起来的就是ViewModel。ViewModel负责把Model的数据同步到View显示出来,还负责把View的修改同步回Model。改变
JavaScript对象的状态,会导致DOM结构作出对应的变化!这让我们的关注点从如何操作DOM变成了如何更新JavaScript对象的状态,而操作JavaScript对象比DOM简单多了。这就是
MVVM的设计思想:关注Model的变化,让MVVM框架去自动更新DOM的状态,从而把开发者从操作DOM的繁琐步骤中解脱出来!
接下来我会带着你们如何去实现一个简易的MVVM架构。
一、构建MVVM构造函数
创建一个MVVM构造函数,用于接收参数,如:data、methods、computed等:
function MVVM(options) {
this.$options = options;
let data = this._data = this.$options.data;
observe(data);
for (let key in data) {
Object.defineProperty(this, key, {
enumerable: true,
get() {
return this._data[key];
},
set(newVal) {
this._data[key] = newVal;
}
});
};
initComputed.call(this);
new Compile(options.el, this);
options.mounted.call(this);
}二、构建Observe构造函数
创建一个Observe构造函数,用于监听数据变化:
function Observe(data) {
let dep = new Dep();
for (let key in data) {
let val = data[key];
observe(val);
Object.defineProperty(data, key, {
enumerable: true,
get() {
Dep.target && dep.addSub(Dep.target);
return val;
},
set(newVal) {
if (val === newVal) {
return;
}
val = newVal;
observe(newVal);
dep.notify();
}
});
};
};三、构建Compile构造函数
创建一个Compile构造函数,用于解析模板指令:
function Compile(el, vm) {
vm.$el = document.querySelector(el);
let fragment = document.createDocumentFragment();
while (child = vm.$el.firstChild) {
fragment.appendChild(child);
}
replace(fragment);
function replace(frag) {
Array.from(frag.childNodes).forEach(node => {
let txt = node.textContent;
let reg = /\{\{(.*?)\}\}/g;
if (node.nodeType === 3 && reg.test(txt)) {
let arr = RegExp.$1.split('.');
let val = vm;
arr.forEach(key => { val = val[key]; });
node.textContent = txt.replace(reg, val).trim();
new Watcher(vm, RegExp.$1, newVal => {
node.textContent = txt.replace(reg, newVal).trim();
});
}
if (node.nodeType === 1) {
let nodeAttr = node.attributes;
Array.from(nodeAttr).forEach(attr => {
let name = attr.name;
let exp = attr.value;
if (name.includes('')) {
node.value = vm[exp];
}
new Watcher(vm, exp, newVal => {
node.value = newVal;
});
node.addEventListener('input', e => {
let newVal = e.target.value;
vm[exp] = newVal;
});
});
};
if (node.childNodes && node.childNodes.length) {
replace(node);
}
});
}
vm.$el.appendChild(fragment);
}四、构建Watcher构造函数
创建一个Watcher构造函数,用于更新视图:
function Watcher(vm, exp, fn) {
this.fn = fn;
this.vm = vm;
this.exp = exp;
Dep.target = this;
let arr = exp.split('.');
let val = vm;
arr.forEach(key => {
val = val[key];
});
Dep.target = null;
}
Watcher.prototype.update = function() {
let arr = this.exp.split('.');
let val = this.vm;
arr.forEach(key => {
val = val[key];
});
this.fn(val);
}五、构建Dep构造函数
创建一个Dep构造函数,用于管理Watcher:
function Dep() {
this.subs = [];
}
Dep.prototype.addSub = function(sub) {
this.subs.push(sub);
}
Dep.prototype.notify = function() {
this.subs.forEach(sub => {
sub.update();
});
}六、构建initComputed构造函数
创建一个initComputed构造函数,用于初始化计算属性:
function initComputed() {
let vm = this;
let computed = this.$options.computed;
Object.keys(computed).forEach(key => {
Object.defineProperty(vm, key, {
get: typeof computed[key] === 'function' ? computed[key] : computed[key].get,
set() {}
});
});
}总结:
至此我们就完成了一个简易的MVVM框架,虽然简易,但是基本的核心思想差不多都已经表达出来了,最后还是希望大家不要丢在收藏文件夹里吃灰,还是要多多动手练习一下,所谓眼过千遍,不如手过一遍。
作者:前端第一深情阿斌
来源:juejin.cn/post/7202431872968851517
Nginx基本介绍+跨域解决方案
Nginx简介
Nginx 是一款由俄罗斯的程序设计师 Igor Sysoev 所开发的高性能的 http 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,它的主要功能有:
- 反向代理
- 负载均衡
- HTTP 服务器
目前大部分运行的 Nginx 服务器都在使用其负载均衡的功能作为服务集群的系统架构。
功能说明
在上文中介绍了三种 Nginx 的主要功能,下面来讲讲具体每个功能的作用。
一、反向代理(Reverse Proxy)
介绍反向代理前,我们先理解下正向代理的概念。打个比方,你准备去看周杰伦的巡演,但是发现官方渠道的票已经卖完了,所以你只好托你神通广大的朋友A去内部购票,你如愿以偿地得到了这张门票。在这个过程中,朋友A就起到了一个正向代理的作用,即代理了客户端(你)去向服务端(售票方)发请求,但服务端(售票方)并不知道源头是谁发起的请求,只知道是代理服务(朋友A)向自己请求的。由这个例子,我们再去理解下反向代理,比如我们经常接到10086或者10000的电话,但是每次打过来的人都不一样,这是因为10086是中国移动的总机号,分机打给用户的时候,都是通过总机代理显示的号码,这个时候客户端(你)无法知道是谁发起的请求,只知道是代理服务(总机)向自己请求的。
而官方的解释说明就是,反向代理方式是指以代理服务器来接受 Internet 上 的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 Internet 上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
下面贴一段简单实现反向代理的 Nginx 配置代码:
server {
listen 80;
server_name localhost;
client_max_body_size 1024M;
location / {
proxy_pass http://localhost:8080;
proxy_set_header Host $host:$server_port;
}
}
复制代码其中的 http://localhost:8080 就是反代理的目标服务端,80是 Nginx 暴露给客户端访问的端口。
二、负载均衡(Load Balance**)**
负载均衡,顾名思义,就是将服务负载均衡地分摊到多个服务器单元上执行,来提高网站、应用等服务的性能和可靠性。
下面我们来对比一下两个系统拓扑,首先是未设计负载均衡的拓扑:
下面是设计了负载均衡的拓扑:
从图二可以看到,用户访问负载均衡器,再由负载均衡器将请求转发给后端服务器,在这种情况下,服务C故障后,用户访问负载会分配到服务A和服务B中,避免了系统崩溃,如果这种故障出现在图一中,该系统一定会会直接崩溃。
负载均衡算法
负载均衡算法决定了后端的哪些健康服务器会被选中。几个常用的算法:
- **Round Robin(轮询):**为第一个请求选择列表中的第一个服务器,然后按顺序向下移动列表直到结尾,然后循环。
- **Least Connections(最小连接):**优先选择连接数最少的服务器,在普遍会话较长的情况下推荐使用。
- **Source:**根据请求源的 IP 的散列(hash)来选择要转发的服务器。这种方式可以一定程度上保证特定用户能连接到相同的服务器。
如果你的应用需要处理状态而要求用户能连接到和之前相同的服务器。可以通过 Source 算法基于客户端的 IP 信息创建关联,或者使用粘性会话(sticky sessions)。
负载均衡同时需要配合反向代理功能才能发挥其作用。
三、HTTP服务器
除了以上两大功能外,Nginx也可以作为静态资源服务器使用,例如没有使用 SSR(Server Side Render)的纯前端资源,就可以依托Nginx来实现资源托管。
下面看一段实现静态资源服务器的配置:
server {
listen 80;
server_name localhost;
client_max_body_size 1024M;
location / {
root e:\wwwroot;
index index.html;
}
}
复制代码root 配置就是具体资源存放的根目录,index 配置的则是访问根目录时默认的文件。
动静分离
动静分离也是Nginx作为Http服务器使用的一个重要概念,要搞清楚动静分离,首先要弄明白什么是动态资源,什么是静态资源:
- **动态资源:**需要从服务器中实时获取的资源内容,如 JSP, SSR 渲染页面等,不同时间访问,资源内容会发生变化。
- **静态资源:**如 JS、CSS、Img 等,不同时间访问,资源内容不会发生变化。
由于Nginx可以作为静态资源服务器,但无法承载动态资源,因此出现需要动静分离的场景时,我们需要拆分静态、动态资源的访问策略:
upstream test{
server localhost:8080;
server localhost:8081;
}
server {
listen 80;
server_name localhost;
location / {
root e:\wwwroot;
index index.html;
}
# 所有静态请求都由nginx处理,存放目录为html
location ~ \.(gif|jpg|jpeg|png|bmp|swf|css|js)$ {
root e:\wwwroot;
}
# 所有动态请求都转发给tomcat处理
location ~ \.(jsp|do)$ {
proxy_pass http://test;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root e:\wwwroot;
}
}
复制代码从这段配置可以大概理解到,当客户端访问不同类型的资源时,Nginx 会自动按照类型分配给自己的静态资源服务或者是远程的动态资源服务上,这样就能满足一个完整的资源服务器的功能了。
配置介绍
一、基本介绍
说完 Nginx 的功能,我们来简单进一步介绍下 Nginx 的配置文件。作为前端人员来讲,使用 Nginx 基本上就是修改配置 -> 启动/热重启 Nginx,就能搞定大部分日常和 Nginx 相关的工作了。
这里我们看下一份 Nginx 的默认配置,即安装 Nginx 后,默认的 nginx.conf 文件的内容:
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# proxy the PHP scripts to Apache listening on 127.0.0.1:80
#
#location ~ \.php$ {
# proxy_pass http://127.0.0.1;
#}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
#
#location ~ \.php$ {
# root html;
# fastcgi_pass 127.0.0.1:9000;
# fastcgi_index index.php;
# fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name;
# include fastcgi_params;
#}
# deny access to .htaccess files, if Apache's document root
# concurs with nginx's one
#
#location ~ /\.ht {
# deny all;
#}
}
# another virtual host using mix of IP-, name-, and port-based configuration
#
#server {
# listen 8000;
# listen somename:8080;
# server_name somename alias another.alias;
# location / {
# root html;
# index index.html index.htm;
# }
#}
# HTTPS server
#
#server {
# listen 443 ssl;
# server_name localhost;
# ssl_certificate cert.pem;
# ssl_certificate_key cert.key;
# ssl_session_cache shared:SSL:1m;
# ssl_session_timeout 5m;
# ssl_ciphers HIGH:!aNULL:!MD5;
# ssl_prefer_server_ciphers on;
# location / {
# root html;
# index index.html index.htm;
# }
#}
}
复制代码对应的结构大致是:
... #全局块
events { #events块
...
}
http #http块
{
... #http全局块
server #server块
{
... #server全局块
location [PATTERN] #location块
{
...
}
location [PATTERN]
{
...
}
}
server
{
...
}
... #http全局块
}
复制代码以上几个代码块对应功能是:
- 全局块:配置影响 Nginx 全局的指令。一般有运行 Nginx 服务器的用户组,Nginx 进程 pid 存放路径,日志存放路径,配置文件引入,允许生成 worker process 数等。
- events块:配置影响 Nginx 服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
- http块:可以嵌套多个 server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type 定义,日志自定义,是否使用 sendfile 传输文件,连接超时时间,单连接请求数等。
- server块:配置虚拟主机的相关参数,一个 http 中可以有多个 server。
- location块:配置请求的路由,以及各种页面的处理情况。
各代码块详细的配置方式可以参考 Nginx 文档
二、Nginx 解决跨域问题
下面展示一段常用于处理前端跨域问题的 location代码块,方面各位读者了解及使用 Nginx 去解决跨域问题。
location /cross-server/ {
set $corsHost $http_origin;
set $allowMethods "GET,POST,OPTIONS";
set $allowHeaders "broker_key,X-Original-URI,X-Request-Method,Authorization,access_token,login_account,auth_password,user_type,tenant_id,auth_code,Origin, No-Cache, X-Requested-With, If-Modified-Since, Pragma, Last-Modified, Cache-Control, Expires, Content-Type, X-E4M-With, usertoken";
if ($request_method = 'OPTIONS'){
add_header 'Access-Control-Allow-Origin' $corsHost always;
add_header 'Access-Control-Allow-Credentials' true always;
add_header 'Access-Control-Allow-Methods' $allowMethods always;
add_header 'Access-Control-Allow-Headers' $allowHeaders;
add_header 'Access-Control-Max-Age' 90000000;
return 200;
}
proxy_hide_header Access-Control-Allow-Headers;
proxy_hide_header Access-Control-Allow-Origin;
proxy_hide_header Access-Control-Allow-Credentials;
add_header Access-Control-Allow-Origin $corsHost always;
add_header Access-Control-Allow-Methods $allowMethods always;
add_header Access-Control-Allow-Headers $allowHeaders;
add_header Access-Control-Allow-Credentials true always;
add_header Access-Control-Expose-Headers *;
add_header Access-Control-Max-Age 90000000;
proxy_pass http://10.117.20.54:8000/;
proxy_set_header Host $host:443;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_redirect http:// $scheme://;
}
复制代码可以看到,前段使用 set 设置了 location 中的局部变量,然后分别在下方的各处指令配置中使用了这些变量,以下是各指令的作用:
- add_header:用于给请求添加返回头字段,当且仅当状态码为以下列出的那些时有效:200, 201 (1.3.10), 204, 206, 301, 302, 303, 304, 307 (1.1.16, 1.0.13), or 308 (1.13.0)
- **proxy_hide_heade:**可以隐藏响应头中的信息。
- **proxy_redirect:**指定修改被代理服务器返回的响应头中的location头域跟refresh头域数值。
- **proxy_set_header:**重定义发往后端服务器的请求头。
- **proxy_pass:**被代理的转发服务路径。
以上这段配置可以直接复制到 nginx.conf 中,然后修改 /cross-server/ (Nginx 暴露给客户端访问的路径)和 http://10.117.20.54:8000/(被转发的服务路径)即可实避免服务跨域问题。
跨域技巧补充
开发环境下,如果不想使用 Nginx 来处理跨域调试问题,也可以采用修改 Chrome 配置的方式来实现跨域调试,本质上跨域是一种浏览器的安全策略,所以从浏览器出发去解决这个问题反而更加方便。
Windows 系统:
1、复制chrome浏览器快捷方式,对快捷方式图标点右键打开“属性” 如图:
2、在“目标”后添加 --disable-web-security --user-data-dir,例如图中修改完成后为:"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --disable-web-security --user-data-dir 。
3、点击确定后重新打开浏览器,出现:
此时,屏蔽跨域设置修改完毕,点开此快捷方式访问的页面均会忽略跨域规则,避免了开发环境下,服务端配置跨域的麻烦。
Mac 系统:
以下内容转载自:Mac上解决Chrome浏览器跨域问题
首先创建一个文件夹,这个文件夹是用来保存关闭安全策略后的用户信息的,名字可以随意取,位置也可以随意放。
创建一个文件夹
然后打开控制台,输入下面这段代码
open -n /Applications/Google\ Chrome.app/ --args --disable-web-security --user-data-dir=/Users/LeoLee/Documents/MyChromeDevUserData
关闭安全策略代码
大家需要根据自己存放刚刚创建的文件夹的地址来更改上面的代码,也就是下面图中的红框区域,而网上大多数的教程中也正是缺少了这部分的代码导致很多用户在关闭安全策略时失败
用户需要根据自己的文件夹地址修改代码
输入代码,敲下回车,接下来Chrome应该会弹出一个窗口
Chrome弹窗
点击启动Google Chrome,会发现与之前的Chrome相比,此时的Chrome多了上方的一段提示,告诉你现在使用的模式并不安全
浏览器上方会多出一行提示
其原理和 Windows 版本差不多,都是通过修改配置来绕过安全策略。
来源:juejin.cn/post/7202252704978026551
从输入 URL 到页面显示,这中间发生了什么?
前言
从输入 URL 到页面显示的发生过程,这是一个在面试中经常会被问到的问题,此问题能比较全面地考察应聘者知识的掌握程度。其中涉及到了网络、操作系统、Web 等一系列的知识。
以 Chrome 浏览器为例,目前的 Chrome 浏览器有以下几个进程:
浏览器进程。主要负责界面显示、用户交互、子进程管理,同时提供存储等功能。
渲染进程。主要职责是把从网络下载的 HTML、JavaScript、CSS、图片等资源解析为可以显示和交互的页面。
GPU 进程。其实,Chrome 刚开始发布的时候是没有 GPU 进程的。而 GPU 的使用初衷是为了实现 3D CSS 的效果,只是随后网页、Chrome 的 UI 界面都选择采用 GPU 来绘制,这使得 GPU 成为浏览器普遍的需求。
网络进程。主要负责页面的网络资源加载,之前是作为一个模块运行在浏览器进程里面的,后面才独立出来,成为一个单独的进程。
插件进程。主要是负责插件的运行,因插件易崩溃,所以需要通过插件进程来隔离,以保证插件进程崩溃不会对浏览器和页面造成影响。
1. 用户输入
如果输入的是内容,地址栏会使用浏览器默认的搜索引擎,来合成新的带搜索关键字的 URL。
如果输入的是 URL,那么地址栏会根据规则,把这段内容加上协议,合成为完整的 URL。
2. URL 请求过程
浏览器进程会通过进程间通信(IPC)把 URL 请求发送至网络进程,网络进程接收到 URL 请求后,会在这里发起真正的 URL 请求流程。那具体流程是怎样的呢?
网络进程会查找本地缓存是否缓存了该资源。如果有缓存资源,那么直接返回资源给浏览器进程;如果在缓存中没有查找到资源,那么直接进入网络请求流程。这请求前的第一步是要进行
DNS解析,以获取请求域名的服务器IP地址。如果请求协议是HTTPS,那么还需要建立TLS连接。接下来就是利用
IP地址和服务器建立TCP连接 (三次握手)。连接建立之后,浏览器端会构建请求行、请求头等信息,并把和该域名相关的cookie等数据附加到请求头中,然后向服务器发送构建的请求信息。服务器接收到请求信息后,会根据请求信息生成响应数据(包括响应行、响应头和响应体等信息),并发给网络进程。等网络进程接收了响应行和响应头之后,就开始解析响应头的内容了。
Content-Type 是 HTTP 头中一个非常重要的字段, 它告诉浏览器服务器返回的响应体数据是什么类型,然后浏览器会根据 Content-Type 的值来决定如何显示响应体的内容。
如果 Content-Type 字段的值被浏览器判断为下载类型,那么该请求会被提交给浏览器的下载管理器,同时该 URL 请求的导航流程就此结束。但如果是 HTML,那么浏览器则会继续进行导航流程。
3. 准备渲染进程
如果协议和根域名相同,则属于同一站点。
但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。
渲染进程准备好之后,还不能立即进入文档解析状态,因为此时的文档数据还在网络进程中,并没有提交给渲染进程,所以下一步就进入了提交文档阶段。
4. 提交文档
所谓提交文档,就是指浏览器进程将网络进程接收到的 HTML 数据提交给渲染进程,具体流程是这样的:
首先当浏览器进程接收到网络进程的响应头数据之后,便向渲染进程发起“提交文档”的消息。
渲染进程接收到“提交文档”的消息后,会和网络进程建立传输数据的“管道”。
等文档数据传输完成之后,渲染进程会返回“确认提交”的消息给浏览器进程。
浏览器进程在收到“确认提交”的消息后,会更新浏览器界面状态,包括了安全状态、地址栏的 URL、前进后退的历史状态,并更新 Web 页面。
5. 渲染阶段
一旦文档被提交,渲染进程便开始页面解析和子资源加载。
渲染进程将
HTML内容转换为能够读懂的DOM树结构。渲染引擎将
CSS样式表转化为浏览器可以理解的styleSheets,计算出DOM节点的样式。创建布局树,并计算元素的布局信息。
对布局树进行分层,并生成分层树。
为每个图层生成绘制列表,并将其提交到合成线程。
合成线程将图层分成图块,并在光栅化线程池中将图块转换成位图。
合成线程发送绘制图块命令
DrawQuad给浏览器进程。浏览器进程根据
DrawQuad消息生成页面,并显示到显示器上。
最后
以上就是笔者对这一常考面试题的一些总结,对于其中的一些具体过程并没有详细地列举出来。如有不足欢迎大家在评论区指出......
作者:codinglin
来源:juejin.cn/post/7202602022355779644
被泼冷水后,谁能超越微服务?
历史总会重演。一切刚过去的,又会被重新提起。开源项目Codename One的联合创始人Shai,曾是Sun Microsystems开源LWUIT项目的共同作者,参与了无数开源项目。作为最早一批Java开发者,最近感慨道:单体,又回来了!
Shai说道:我已经在这个圈子里很久时间了,看到了一次次被抛弃、被重新发现的想法,超越“时髦词汇”,并凯旋而归。
他进一步举例,“近年来,SQL也挣扎过后,死而复生。我们再次热爱关系数据库。我认为单体架构将再次迎来奇幻之旅。微服务和无服务器是云供应商推动的趋势,目的当然是在向我们兜售更多的云计算资源。然而对于大多数用例来说,微服务在财务上意义不大。是的,供应商当然也可以降低成本。但当他们扩大规模时,他们会以股息来覆盖掉成本。单是可观测性成本的增加,就让‘大型云’供应商的腰包鼓起来了!”
作为从业近30年的资深技术大神,为何做此感叹?本文通过一场“利用模块降低架构成本”的探讨,帮助大家梳理现在的架构设计难题,希望对诸君有所启发。
问题背景
我最近领导了一个会议小组,讨论了微服务与单体服务的主题。组内认为,单块的规模不如微服务。这对于亚马逊、eBay等所取代的那些庞然大物来说可能是正确的。这些确实是巨大的代码库,其中的每一次修改都是痛苦的,而且它们的扩展都是具有挑战性的。但这不是一个公平的比较。较新的方法通常优于旧的方法。但如果我们用更新的工具构建一个整体,我们会得到更好的可扩展性吗?它的局限性是什么?现代的单体(也称巨石)到底该是什么样子?
单体回归范例:Modulith
Spring Modulith是一个模块化的单体结构,可以让我们使用动态隔离件构建单体结构。通过这种方法,我们可以分离测试、开发、文档和依赖项。这有助于微服务开发的独立方面,而所涉及的开销很少。它消除了远程调用和功能复制(存储、身份验证等)的开销。
Spring Modulith不是基于Java平台模块化(Jigsaw)。他们在测试期间和运行时强制分离,这是一个常规的Spring Boot项目。它有一些额外的运行时功能,可以实现模块化的可观测性,但它主要是“最佳实践”的执行者。这种分离的价值超出了我们通常使用微服务的价值,但也有一些权衡。
举个例子,传统的Spring monolith将采用分层架构,其包如下:
com.debugagent.myapp
com.debugagent.myapp.services
com.debugagent.myapp.db
com.debugagent.myapp.rest
这很有价值,因为它可以帮助我们避免层之间的依赖关系;例如,DB层不应依赖于服务层。我们可以使用这样的模块,并有效地将依赖关系图推向一个方向:向下。但随着我们的成长,这没有多大意义。每一层都将充满业务逻辑类和数据库复杂性。
有了Modulith,我们的架构看起来更像这样:
com.debugagent.myapp.customers
com.debugagent.myapp.customers.services
com.debugagent.myapp.customers.db
com.debugagent.myapp.customers.rest
com.debugagent.myapp.invoicing
com.debugagent.myapp.invoicing.services
com.debugagent.myapp.invoicing.db
com.debugagent.myapp.invoicing.rest
com.debugagent.myapp.hr
com.debugagent.myapp.hr.services
com.debugagent.myapp.hr.db
com.debugagent.myapp.hr.rest
这看起来非常接近一个合适的微服务架构。我们根据业务逻辑分离了所有部分。在这里,可以更好地控制交叉依赖关系,团队可以专注于自己的孤立区域,而不必互相踩脚。这是微服务的价值之一,且没有开销。
我们可以使用注释进一步深入地和声明性地实现分离。我们可以定义哪个模块使用哪个并强制单向依赖关系,因此人力资源模块将与发票无关。客户模块也不会。我们可以在客户和发票之间建立单向关系,并使用事件进行反馈。Modulith中的事件是简单、快速和事务性的。它们消除了模块之间的依赖关系,无需麻烦。这可以用微服务实现,但很难实现。比如,开票需要向不同的模块公开接口。如何防止客户使用该界面?
有了模块,我们就可以做到。对用户可以更改代码并提供访问权限,但这需要经过代码审查,这会带来自己的问题。请注意,对于模块,我们仍然可以依赖常见的微服务,如功能标志、消息传递系统等。您可以在文档和Nicolas Fränkel的博客中阅读有关Spring Modulith的更多信息。
模块系统中的每个依赖项都被映射并记录在代码中。Spring实现包括使用方便的最新图表自动记录所有内容的能力。你可能会认为,依赖性是Terraform的原因。对于这样的“高级”设计来说,这是正确的地方吗?
对于Modulith部署,像Terraform这样的基础设施即代码(IaC)解决方案仍然存在,但它们会简单得多。问题是责任的划分。正如下图所展示,微服务并没有消除整体结构的复杂性。我们只把“难啃的骨头”踢给了DevOps团队。更糟糕的是,我们没有给他们正确的工具来理解这种复杂性,所以他们不得不从外部管理。

图源:Twitter
这就是为什么我们行业的基础设施成本在上升,而传统行业的基础设施价格却在下降。当DevOps团队遇到问题时,他们会投入资源。这显然不是正确的做法。
其他模块
我们可以使用标准Java平台模块(Jigsaw)来构建Spring Boot应用程序。这样做的好处是可以分解应用程序和标准Java语法,但有时可能会很尴尬。当使用外部库或将一些工作拆分为通用工具时,可能会更有效。
另一个选项是Maven中的模块系统。这个系统允许我们将构建分解为多个单独的项目。这是一个非常方便的过程,可以让我们省去大量项目的麻烦。每个项目都是独立的,易于使用。它可以使用自己的构建过程。然后,当我们构建主项目时,这些全部都变成了一个单体。在某种程度上,这才是我们真正想要的。
单体架构:扩展,有解吗
可以使用大多数微服务扩展工具来扩展我们的单体们。许多与扩展和集群相关的开发都是在单体架构的情况下进行的。这是一个更简单的过程,因为只有一个移动部分:应用程序。我们复制其他实例并观察它们。没有哪项服务是失败的。我们有细粒度的性能工具,所有的功能都可以作为一个统一的版本。
我认为扩展单体为微服务比直接构建微服务更简单——
我们可以使用分析工具,并获得瓶颈的合理近似值。
我们的团队可以轻松地(并且经济实惠地)设置运行测试的登台环境。
我们拥有整个系统及其依赖关系的单一视图。
我们可以单独测试单个模块并验证性能假设。
跟踪和可观测性工具非常棒。但它们也会影响生产,有时还会产生噪音。当我们试图解决伸缩瓶颈或性能问题时,这些工具可能会让设计者踩一些坑。
我们可以将Kubernetes与monolits一起使用,就像将其与微服务一起使用一样有效。镜像尺寸会更大(如果我们使用GraalVM这样的工具,则可能不会太大)。有了这一点,我们可以跨区域复制monolith ,并提供与微服务相同的故障转移行为。相当多的开发人员将monolics部署到Lambdas。笔者不太喜欢这种方法,因为非常昂贵。
单体的瓶颈问题:有解
但仍有一点是巨大的障碍:数据库。由于微服务固有地具有多个独立的数据库,因此它们实现了巨大的规模。单体架构通常与单个数据存储一起工作。这通常是应用程序的真正瓶颈。有多种方法可以扩展现代数据库。集群和分布式缓存是强大的工具,可以让我们达到在微服务架构中很难达到的性能水平。
在一个单体结构中,也并不需要单个数据库。例如:在使用Redis进行缓存时,选择使用SQL数据库也是很常见的事情。但我们也可以为时间序列或空间数据使用单独的数据库。我们也可以使用单独的数据库来提高性能,尽管根据笔者经验,这种情况从未发生过。将数据保存在同一数据库中的好处是巨大的。
回归单体的好处
事实上,这样做有一个惊人的好处,我们可以在不依赖“最终一致性”的情况下完成交易。当我们尝试调试和复制分布式系统时,可能会遇到一个很难在本地复制的过渡状态,甚至很难通过查看可观测性数据来完全理解。
原始性能消除了大量网络开销。通过适当调整的二级缓存,我们可以进一步删除80-90%的读IO。在微服务中,要实现这一点要困难得多,而且可能不会删除网络调用的开销。
正如我之前提到的,应用程序的复杂性在微服务架构中不会消失。我们只是把它搬到了另一个地方。所以从这个层面讲,微服务并不算真正的进步,因为在此过程中平白添加了许多移动部件,增加了整体复杂性。因此,回归更智能、更简单的统一架构更有意义。
再看微服务的卖点
编程语言的选择是微服务亲和力的首要指标之一。微服务的兴起与Python和JavaScript的兴起相关。这两种语言非常适合小型应用程序,对于较大型的应用就不太适用了。
Kubernetes使得扩展此类部署相对容易,因此为已经增长的趋势增添了动力。微服务也有一些相对快速的升降能力。这可以以更细粒度的方式控制成本。在这方面,微服务被出售给组织,作为降低成本的一种方式。
这并非完全没有优点。如果以前的服务器部署需要强大(昂贵)的服务器,那么这一论点可能有一定道理。这可能适用于极端使用的情况,比如:突然面临非常高的负载,但随后没有堵塞。在这些情况下,可以从托管的Kubernetes提供商动态(廉价)获取资源。
微服务的主要卖点之一是组织调度方面。这使得各个敏捷团队能够在不完全了解“大局”的情况下解决小问题。问题也在于此,这就会创造一种“单干”文化,让每个团队都“自己做自己的事情”。在缩减规模的过程中,尤其是在代码“腐烂”的情况下,问题更甚。系统可能仍能工作数年,但实际上无法维护。
互联网建立在单体之上为什么要离开呢
笔者组内中的一个共识是,我们应该始终从单体开始。它更容易构建,如果我们选择使用微服务,我们可以稍后将单体分解。
提及具体某个软件相关的复杂性,我们讨论单个模块而不是单个应用程序要更有意义些。二者在资源使用和财务浪费上的差异是巨大的。在这个追求“降本”的时代,为什么人们还要不知变通地默认构建微服务,而不是动态的模块化单体架构呢?
我们可以从这两大“架构阵营”学到很多东西。诚然,微服务为亚马逊创造了奇迹。但公平地说,他们的云成本已包含在这个奇迹之中。所以,一位的搞微服务教条肯定是有问题的。
另一方面,互联网是建立在单体之上的。它们中的大多数都不是模块化的。两者都有普遍适用的技术。因此,笔者看来,正确的选择是构建一个模块化的单体结构,先搭建好合适的身份验证基础设施,如果我们想在未来转向微服务,我们可以利用这些基础设施来进行解构拆分。
后记
在设计应用时,我们目前更多是面临“二选一”的架构选择:单体和微服务。它们二者通常被视为相反的方法。
在小型系统演进过程中,有这样一个不争的事实:单体应用程序往往会随着时间的推移而在架构上降级,即使在其生命周期开始阶段就定义其为架构。随着时间的推移,各种架构的禁止事项会不知不觉地进入项目,久而久之,系统变得更难改变,进化性受到影响。
另一方面,微服务提供了更强的分离手段,但同时也带来了许多复杂性,因为即使对于小型应用程序,团队也必须应对分布式系统的挑战。
单体回归,也是具体的有条件的回归。我们看到,趋势的改变,代表着某段时期具体任务或者目标正在变化。出于目标的变化,我们对于微服务和单体架构的二选一的选择问题,也不能再教条式的看待。
事物往往都在螺旋式的演进,对于架构而言,亦如是。
来源:mp.weixin.qq.com/s/2peN_MezvkR9UwtalhG6kA
原文链接:dzone.com/articles/is-it-time-to-go-back-to-the-monolith
收起阅读 »我尽然突然焦虑,并且迷茫了
最近是怎么了
最近几个朋友,突然询问我,现在应该怎么学习,将来才会更好的找工作,怕毕业以后没有饭吃,我说我其实也不太清楚,我目前三段实习我都没有找到一份真正意义的好工作,就是那种我喜欢这门领域,并且喜欢公司的氛围,并且到老了还能保持竞争力(莫有35岁危机)。
所以说我真的没有一个准确的答案回复。但是我以为目前的眼光来看一份好工作必备的条件就是,我在这个领域学的越多,我的工资和个人发展瓶颈越高,这份工作是一个持续学习的过程,并且回报和提高是肉眼可见的!
回忆那个时候
其实说实话,这个疑惑我上大一就开始有,但是那个时候是从高考的失落中寻找升学的路径,开始无脑的刷那种考研短视频
(看过可能都知道真的一下子励志的心就有了,但是回到现实生活中,看到身边人的状态~~~没错人就是一个从众的种群,你可能会问你会不会因为大一没有那么努力学习而后悔,但是其实我不会,因为那一年我的经历也是我最开心大学生活,虽然也干了很多被室友做成梗的糗事,但是想一想那不就是青春嘛,要是从小就会很有尺度的为人处世,想一想活着也很累嘛,害,浅浅致敬一下充满快乐和遗憾的青春呀!)
个人看法
哈哈,跑题了。给大家点力量把!前面满满的焦虑。其实我感觉我们都应该感谢我们来到计算机类的专业,从事这方面的学习和研究。
因为计算机的扩展性,不得不说各行各业都开始越来越喜欢我们计算机毕业的大学生(就业方向更加广),我也因为自己会计算机,成功进入一个一本高校以上的教育类公司实习(同时也是这个时候知道了更多优秀学校的毕业年轻人,真正认识到学校的层次带给人的很多东西真正的有差距);
虽然我是二本的学生,但是在亲戚朋友眼里,虽然学校比不上他们的孩子,但是计算机专业也能获得浅浅的也是唯一一点可以骄傲的东西(活在别人嘴这种思考方式肯定不是对的,但是现实就是在父母那里,我们考上什么大学和进入了哪里工作真的是他们在外人的脸面,这种比较情况在大家族或者说农村尤为严重);
技术论打败学校论,计算机专业是在“广义”上为数不多能打破学校出身论的学科,在公司上只要你能干活,公司就愿意要你,这个时候肯定有人diss我,现在培训班出来的很多都找不到工作呀,我的回答只能是:的确,因为这个行业的红利期展示达到了瓶颈期,加上大环境的不理想,会受到一些影响,但是我还是相信会好的,一切都会好的。
做技术既然这样了
关于最近论坛上说“前段已死”“后端当牛做马”“公司磨刀霍霍向测试”......
这个东西怎么说,我想大部分人看到这个都会被这个方向劝退,我从两个角度分析一下,上面说了,真滴卷,简历真滴多,存在过饱和;第二点,希望这个领域新人就不要来了,就是直接劝退,被让人来卷,狭义上少卷一些......
现在就是导致我也不敢给朋友做建议了,因为当他看到这些的时候,和进入工作环境真的不好,我真的怕被喷死
包括现在我的实习,大家看我的朋友圈看出工作环境不错很好,但是和工作的另一面,是不能发的呀,有时候我都笑称自己是“产业工人”(这个词是一个朋友调侃我的)
不行了,在传播焦虑思想,我该被喷死了,现在我给建议都变得很含蓄,因为时代红利期真的看不透,我也不敢说能维持多少年,而且我工作也一般,我不敢耽误大家(哈哈哈,突然想起一句话,一生清贫怎敢入繁华,二袖清风怎敢误佳人,又是emo小文案,都给我开E)
个人总结
本文就是调侃一下现在的环境啊,下面才是重点,只有干活和真话放在后面(印证一个道理:看到最后的才是真朋友才敢给真建议,我也不怕被骂)
心态方面:我们这个年纪就是迷茫的年纪,迷茫是一种正常的状态,因为作为一名成年人你真正在思考你的个人发展的状态,所以请把心放大,放轻松,你迷茫了已经比身边的人强太多了,如果真正焦虑的不能去学习了,去找个朋友聊一聊,实在不行,drink个两三瓶,好好睡一觉,第二天继续干,这摸想,这些都算个啥,没事你还有我,实在不行微我聊一聊,我永远都在,我的朋友!
工作方面:俗话说:女怕入错行,男怕娶错人!(突然发现引用没什么用,哈哈)我们可以多去实践,没错就是去实习,比如你想做前端的工作,你就可以直接去所在的城市(推荐省会去找实习)但是朋友其实实习很难,作为过来人,我能理解你,一个人在陌生的城市而且薪资很可怜,面对大城市的租房和吃饭有很多大坑,你要一一面对,但是在外面我们真要学会保护自己,而且实习生活中经济方面肯定要父母支持,所以一定要和父母好好沟通,其实你会发现我们越长大,和父母相处的时光越短。(我今年小年和十五都没在家过,害,那种心理苦的滋味很不好受)
升学方面:不是每一个都适合考研,不要盲从考研。但是这句话又是矛盾的,在我的实习生涯中,学历问题是一个很重要的问题,我们的工作类型真的不同,还是那句话,学历只是一个门槛,只要你迈入以后看的是你的个人能力。说一句悄悄话,我每天工作,最想的事情就是上学,心想老子考上研,不在干这活了,比你们都强。所以你要想考研,请此刻拿出你的笔,在纸上写下你要考研主要三个理由,你会更好的认识自己,更好选择。
好吧,今天的随想录就这摸多,只是对最近看文章有了灵感写下自己的看法,仅供参考哦!
回答问题
回应个问题:很多朋友问我为什么给这摸无私的建议,这是你经历了很多才得到的,要是分享出去,不是很亏?
(你要这摸问,的确你有卷到我的可能性,快给我爬。哈哈哈)可能是博客圈给的思想把,其实我说不上开源的思想,但是我遇到的人对我都是无私分享自己的经验和自己走过的坑,就是你懂吗,他们对我帮助都很大,他们在我眼里就是伟大的人,所以我也想要跟随他们,做追光的人!(上价值了哦,哈哈)
写在最后
最后一句话,迷茫这个东西,走着走着就清晰了,迷茫的时候,搞一点学习总是没错的。
链接:https://juejin.cn/post/7201752978259378232
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
祖传代码重构:从25万行到5万行的血泪史
背景
一、接手
7 月份组织架构调整后,我们组接手了搜索链路中的 Query 理解基础模块,包括本次重构对象 Query Optimizer,负责 query 的分词、词权、紧密度、意图识别。
二、为什么重构
面对一份 10年+ 历史包袱较重的代码,大多数开发者认为“老项目和人有一个能跑就行”,不愿意对其做较大的改动,而我们选择重构,主要有这些原因:
1.生产工具落后,无法使用现代 C++,多项监控和 TRACE 能力缺失
2.单进程内存消耗巨大——114G
3.服务不定期出现耗时毛刺
4.进程启动需要 18 分钟
5.研效低下,一个简单的功能需要开发 3 人天
基于上述原因,也缘于我们热爱挑战、勇于折腾,我们决定进行拆迁式的重构。
编码实现
一、重写与复用
我们对老 QO 的代码做分析,综合考虑三个因素:是否在使用、是否Query理解功能、是否高频迭代,将代码拆分为四种处理类型:1、删除;2、lib库引入;3、子仓库引入;4、重写引入。
二、整体架构
老服务代码架构堪称灾难,整体遵守“想到哪就写到哪,需要啥就拷贝啥”的设计原则,完全不考虑单一职责、接口隔离、最少知识、模块化、封装复用等。下图介绍老服务的抽象架构:
请求进来先后执行 3 次分词:
1.不带标点符号的分词结果,用于后续紧密度词权算子的计算输入;
2.带标点符号的分词结果,用于后续基于规则的意图算子的计算输入;
3.不带标点符号的分词结果,用于最终结果 XML queryTokens 字段的输出。
1 和 3 的唯一区别,就是调用内核分词的代码位置不同。
下一个环节,请求 Query 分词时,分词接口中竟然包含了 RPC 请求下游 GPU 模型服务获取意图。这是此服务迭代最频繁的功能块,当想要实验模型调整、增减意图时,需要在 QO 仓库进行实验参数解析,将参数万里长征传递到 word_segmentor 仓库的分词接口里,再根据参数修改 RPC 意图调用逻辑。一个简单参数实验,要修改 2个仓库中的多个模块。设计上不符合模块内聚的设计原理,会造成霰弹式代码修改,影响迭代效率,又因为 Query 分词是处理链路中的耗时最长步骤,不必要的串行增加了服务耗时,可谓一举三失。
除此之外,老服务还有其他各类问题:多个函数超过一千行,圈复杂度破百,接口定义 50 多个参数并且毫无注释,代码满地随意拷贝,从以下 CodeCC 扫描结果可见一斑:
新的服务求追架构合理性,确保:
1.类和函数实现遵守单一职责原则,功能内聚;
2.接口设计符合最少知识原则,只传入所需数据;
3. 每个类、接口都附上功能注释,可读性高。
项目架构如下:
CodeCC 扫描结果:
三、核心实现
老服务的请求处理流程:
老服务采用的是原始的线程池模型。服务启动时初始化 20 条线程,每条线程分别持有自身的分词和意图对象,监听任务池中的任务。服务接口收到请求则投入任务池,等待任意一条线程处理。单个请求的处理基本是串行执行,只少量并行处理了几类意图计算。
新服务中,我们实现了一套基于 tRPC Fiber 的简单 DAG 控制器:
1.用算子数初始化 FiberLatch,初始化算子任务间的依赖关系
2.StartFiberDetached 启动无依赖的算子任务,FiberLatch Wait 等待全部算子完成
3.算子任务完成时,FiberLatch -1 并更新此算子的后置算子的前置依赖数
4.计算前置依赖数规 0 的任务,StartFiberDetached 启动任务
通过 DAG 调度,新服务的请求处理流程如下,最大化的提升了算子并行度,优化服务耗时:
DIFF 抹平
完成功能模块迁移开发后,我们进入 DIFF 测试修复期,确保新老模块产出的结果一致。原本预计一周的 DIFF 修复,实际花费三周。解决掉逻辑错误、功能缺失、字典遗漏、依赖版本不一致等问题。如何才能更快的修复 DIFF,我们总结了几个方面:DIFF 对比工具、DIFF 定位方法、常见 DIFF 原因。
一、DIFF 比对工具
工欲善其事必先利其器,通过比对工具找出存在 DIFF 的字段,再针对性地解决。由于老服务对外接口使用 XML 协议,我们开发基于 XML 比对的 DIFF 工具,并根据排查时遇到的问题,为工具增加了一些个性选项:基于XML解析的DIFF工具。
我们根据排查时遇到的问题为工具增加了一些个性选项:
1.支持线程数量与 qps 设置(一些 DIFF 问题可能在多线程下才能复现);
2.支持单个 query 多轮比对(某些模块结果存在一定波动,譬如下游超时了或者每次计算浮点数都有一定差值,初期排查对每个query可重复请求 3-5 轮,任意一轮对上则认为无 DIFF ,待大块 DIFF 收敛后再执行单轮对比测试);
3.支持忽略浮点数漂移误差;
4.在统计结果中打印出存在 DIFF 的字段名、字段值、原始 query 以便排查、手动跟踪复现。
二、DIFF 定位方法
获取 DIFF 工具输出的统计结果后,接下来就是定位每个字段的 DIFF 原因。
逻辑流梳理确认
梳理计算该字段的处理流,确认是否有缺少处理步骤。对流程的梳理也有利于下面的排查。
对处理流的多阶段查看输入输出
一个字段的计算在处理流中一定是由多个阶段组成,检查各阶段的输入输出是否一致,以缩小排查范围,再针对性地到不一致的阶段排查细节。
例如原始的分词结果在 QO 上是调用分词库获得的,当发现最后返回的分词结果不一致时,首先查看该接口的输入与输出是否一致,如果输入输出都有 DIFF,那说明是请求处理逻辑有误,排查请求处理阶段;如果输出无 DIFF,但是最终结果有DIFF,那说明对结果的后处理中存在问题,再去排查后处理阶段。以此类推,采用二分法思想缩小排查范围,然后再到存在 DIFF 的阶段细致排查、检查代码。
查看 DIFF 常见有两种方式:日志打印比对, GDB 断点跟踪。采用日志打印的话,需要在新老服务同时加日志,发版启动服务,而老服务启动需要 18 分钟,排查效率较低。因此我们在排查过程中主要使用 GDB 深入到 so 库中打断点,对比变量值。
三、常见 DIFF 原因
外部库的请求一致,输出不一致
这是很头疼的 case,明明调用外部库接口输入的请求与老模块是完全一致的,但是从接口获取到的结果却是不一致,这种情况可能有以下原因:
1.初始化问题:遗漏关键变量初始化、遗漏字典加载、加载的字典有误,都有可能会造成该类DIFF,因为外部库不一定会因为遗漏初始化而返回错误,甚至外部库的初始化函数加载错字典都不一定会返回 false,所以对于依赖文件数据这块需要细致检查,保证需要的初始化函数及对应字典都是正确的。
有时可能知道是初始化有问题,但找不到是哪里初始化有误,此时可以用 DIFF 的 query,深入到外部库的代码中去,新老两模块一起单步调试,看看结果从哪里开始出现偏差,再根据那附近的代码推测出可能原因。
2.环境依赖:外部库往往也会有很多依赖库,如果这些依赖库版本有 DIFF,也有可能会造成计算结果 DIFF。
外部库的输出一致,处理后结果不一致
这种情况即是对结果的后处理存在问题,如果确认已有逻辑无误,那可能原因是老模块本地会有一些调整逻辑 或 屏蔽逻辑,把从外部库拿出来原始结果结合其他算子结果进行本地调整。例如老 QO 中的百科词权,它的原始值是分词库出的词权,结合老 QO 本地的老紧密度算子进行了 3 次结果调整才得到最终值。
将老模块代码重写后输出不一致
重构过程中对大量的过时写法做重写,如果怀疑是重写导致的 DIFF,可以将原始函数替代掉重写的函数测一下,确认是重写函数带来的 DIFF 后,再细致排查,实在看不出可以在原始函数上一小块一小块的重写。
请求输入不一致
可能原因包括:
1.缺少 query 预处理逻辑:例如 QO 输入分词库的 query 是将原始 query 的各短语经过空格分隔的,且去除了引号;
2.query 编码有误:例如 QO 输入分词库的 query 的编码流程经过了:utf16le → gb13080 → gchar_t (内部自定义类型) → utf16le → char16_t;
3.缺少接口请求参数。
预期内的随机 DIFF
某些库/业务逻辑自身存在预期内的不稳定,譬如排序时未使用 stable_sort,数组元素分数一致时,不能保证两次计算得出的 Top1 是同一个元素。遇到 DIFF 率较低的字段,需根据最终结果的输入值,结果计算逻辑排除业务逻辑预期内的 DIFF。
coredump 问题修复
在进行 DIFF 抹平测试时,我们的测试工具支持多线程并发请求测试,等于同时也在进行小规模稳定性测试。在这段期间,我们基本每天都能发现新的 coredump 问题,其中部分问题较为罕见。下面介绍我们遇到的一些典型 CASE。
一、栈内存被破坏,变量值随机异常
如第 2 章所述,分词库属于不涉及 RPC 且未来不迭代的模块,我们将其在 GCC 8.3.1 下编译成 so 引入。在稳定性测试时,进程会在此库的多个不同代码位置崩溃。没有修改一行代码挂载的 so,为什么老 QO 能稳定运行,而我们会花式 coredump?本质上是因为此代码历史上未重视编译告警,代码存在潜藏漏洞,升级 GCC 后才暴露出来,主要是如下两种漏洞:
1.定义了返回值的函数实际没有 return,栈内存数据异常。
2.sprintf 越界,栈内存数据异常。
排查这类问题时,需要综合上下文检查。以下图老 QO 代码为例:
sprintf 将数字以 16 进制形式输出到 buf_1 ,输出内容占 8 个字节,加上 '\0' 实际需 9 个字节,但 buf_1 和 buf_2 都只申请了 8 个字节的空间,此处将栈内存破坏,栈上的变量 query_words 值就异常了。
异常的表现形式为,while 循环的第一轮,query_words 的数组大小是 x,下一轮 while 循环时,还没有 push 元素,数组大小就变成了 y,因内存被写坏,导致异常新增了 y - x 个不明物体。在后续逻辑中,只要访问到这几个异常元素,就会发生崩溃。
光盯着 query_words 数组,发现不了问题,因为数组的变幻直接不符合基本法。解决此类问题,需联系上下文分析,最好是将代码单独提取出来,在单元测试/本地客户端测试复现,缩小代码范围,可以更快定位问题。而当代码量较少,编译器的 warning 提示也会更加明显,辅助我们定位问题。
上段代码的编译器提示信息如下:(开启了 -Werror 编译选项)
二、请求处理中使用了线程不安全的对象
在代码接手时,我们看到了老的分词模块“怪异”的初始化姿势:一部分数据模型的初始化函数定义为 static 接口,在服务启动时全局调用一次;另一部分则定义为类的 public 接口,每个处理线程中构造一个对象去初始化,为什么不统一定义为 static,在服务启动时进行初始化?每个线程都持有一个对象,不是会浪费内存吗?没有深究这些问题,我们也就错过了问题的答案:因为老的分词模块是线程不安全的,一个分词对象只能同时处理一个请求。
新服务的请求处理实现是,定义全局管理器,管理器内挂载一个唯一分词对象;请求进来后统一调用此分词对象执行分词接口。当 QPS 稍高,两个请求同时进入到线程不安全的函数内部时,就可能把内存数据写坏,进而发生 coredump。
为解决此问题,我们引入了 tRPC 内支持任务窃取的 MQ 线程池,利用 c++11 的 thread_local 特性,为线程池中的每个线程都创建线程私有的分词对象。请求进入后,往线程池内抛入分词任务,单个线程同时只处理一个请求,解决了线程安全问题。
三、tRPC 框架使用问题
函数内局部变量较大 && v0.13.3 版 tRPC 无法正确设置栈大小
稳定性测试过程中,我们发现服务会概率性的 coredump 在老朋友分词 so 里,20 个字以内的 Query 可以稳定运行,超过 20 个字则有可能会崩溃,但老服务的 Query 最大长度是 40 个字。从代码来看,函数中根据 Query 长度定义了不同长度的字节数组,Query 越长,临时变量占据内存越大,那么可能是栈空间不足,引发的 coredump。
根据这个分析,我们首先尝试使用 ulimit -s 命令调整系统栈大小限制,毫无效果。经过在码客上搜寻,了解到 tRPC Fiber 模型有独立的 stack size 参数,我们又满怀希望的给框架配置加上了 fiber stack size 属性,然而还是毫无效果。
无计可施之下,我们将崩溃处相关的函数提取到本地,分别用纯粹客户端(不使用 tRPC), tRPC Future 模型, tRPC Fiber 模型承载这段代码逻辑,循环测试。结果只有 Fiber 模型的测试程序会崩溃,而 Future / 本地客户端的都可以稳定运行。
最后通过在码客咨询,得知我们选用的框架版本 Fiber Stack Size 设置功能恰好有问题,无法正确设置为业务配置值,升级版本后,问题解决。
Redis 连接池模式,不能同时使用一应一答和单向调用的接口
我们尝试打开结果缓存开关后,“惊喜”的发现新的 coredump,并且是 core 在了 tRPC 框架层。与 tRPC 框架开发同事协作排查,发现原因是 Redis 采取连接池模式连接时,不可同时使用一应一答接口和单向调用接口。而我们为了极致性能,在读取缓存执行 Get 命令时使用的是一应一答接口,在缓存更新执行 Set 命令时,采用的是单向调用方式,引发了 coredump。
快速解决此问题,我们将缓存更新执行 Set 命令也改为了应答调用,后续调优再改为异步 Detach 任务方式。
重构效果
最终,我们的成果如下:
【DIFF】
- 算子功能结果无 DIFF
【性能】
- 平均耗时:优化 28.4% (13.01 ms -> 9.31 ms)
- P99 耗时:优化 16.7%(30ms -> 25ms)
- 吞吐率:优化 12%(728qps—>832qps)
【稳定性】
- 上游主调成功率从 99.7% 提升至 99.99% ,消除不定期的 P99 毛刺问题
- 服务启动速度从 18 分钟 优化至 5 分钟
- 可观察可跟踪性提升:建设服务主调监控,缓存命中率监控,支持 trace
- 规范研发流程:单元测试覆盖率从 0% 提升至 60%+,建设完整的 CICD 流程
【成本】
- 内存使用下降 40 G(114 GB -> 76 GB)
- CPU 使用率:基本持平
- 代码量:减少 80%(25 万行—> 5万行)
【研发效率】
- 需求 LeadTime 由 3 天降低至 1 天内
附-性能压测:
(1)不带cache:新 QO 优化平均耗时 26%(13.199ms->9.71ms),优化内存 32%(114.47G->76.7G),提高吞吐率 10%(695qps->775qps)
(2)带cache:新 QO 优化平均耗时 28%(11.15ms->8.03ms),优化内存 33%(114G->76G),提高吞吐率 12%(728qps->832qps)
腾讯工程师技术干货直达:
链接:https://juejin.cn/post/7173485990252642334
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
外包仔的自我救赎
为什么做外包仔?
开始是没得选
毕业的第三年,通过培训班转行Java,包装了两年经验。非科班出身又是半路出家,当时也不懂外包的概念,于是就糊里糊涂进了外包公司。第一家公司只干了三个多月就跑路了,一方面是工资太低(8K),另一方面是技术比较老旧(SSH)。第二家公司也是外包,但是项目还不错(spring cloud),薪资也可以接受(12K)。
后来是给的多
做开发工作的第二年,跳槽时本来想着找一家自研公司,但是没忍住外包公司开的价格,一时脑热又进了外包,也就是现在这家大厂外包。薪资比较满意(18K),项目也很不错(toC业务,各种技术都有涉及)。
下定决心跳出外包
为什么要离开
干过外包的小伙伴们多多少少会有一些低人一等的感觉,说实话笔者自己也有。就感觉你虽然在大厂,但你是这里身份最低的存在,很多东西是需要权限才能接触到的。再者就是没有归属感,没有年会、没有团建、甚至不知道自己公司领导叫什么(只跟甲方主管和外包公司交付经理有接触)。
潜心修炼技术
在最近这个项目里确实学到了很多生产经验,自己写的接口也确实发生过线上故障,不再是单单的CRUD,也会参与一些接口性能的优化。对业务有了一定的的理解,技术上也有了一定的提升,大厂的开发流程、开发规范确实比较健全。
背诵八股文
三月份开始就在为跳槽做准备,先后学习了并发编程、spring源码、Mysql优化、JVM优化、RocketMQ以及分布式相关的内容(分布式缓存、分布式事务、分布式锁、分布式ID等)。学到后面居然又把前面的忘了。
大环境行情和现状
大范围裁员
今年从金三银四开始,各大互联网公司就都在裁员,直到现在还有公司在裁员,说是互联网的寒冬也不为过。笔者所在的厂也是裁员的重灾区,包括笔者自己(做外包都会被优化,说是压缩预算)也遭重了,但是外包公司给换了另外一个项目组(从北京换到了杭州)。
招聘网站行情
笔者八月份先在北京投了一波简历(自研公司,外包不考虑了),三十多家公司只有一家公司给了回应(做了一道算法笔试题,然后说笔者占用内存太多就没有后续了),九月中旬又在杭州投了一波简历(也是只投自研),六十多家公司回复也是寥寥无几,甚至没约到面试(有大把的外包私聊在下,是被打上外包仔的标签了吗)。
如何度过这个寒冬
继续努力
工作之余(摸鱼的时候),笔者仍然坚持学习,今天不学习,明天变垃圾。虽然身在外包,但是笔者仍有一颗向往自研的心,仍然想把自己学到的技术运用到实际生产中(现在项目用到的技术都是甲方说了算,当然我也会思考哪些场景适合哪些技术)。
千万不要辞职
现在的项目组做的是内部业务,并发几乎没有,但是业务相对复杂。笔者只能继续狗着(简历还是接着投,期望降低一些),希望互联网的寒冬早日结束,希望笔者和正在找工作的小伙伴们早日找到心仪的公司(respect)。
链接:https://juejin.cn/post/7146220688800481294
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大梦难觉,又是一年
这篇2022年的年终总结拖到了2023年开工第二周才开始动笔,当真是老拖延症了,哈哈哈。虽然新年已至,旧岁已除,但过去这一年的经历和感悟还是需要简单总结记录一下。(注意:以下内容无关技术,纯粹的个人随笔)
一、动荡的互联网,艰难的打工人
本来想要先分享一下去年发生的一些事情作为开篇,但是想了想最大的事情其实还是席卷互联网的这场风暴,相比这场风暴来说其他事情就会显得不是那么重要,所以还是来谈一谈闲宇身处这场风暴时的一些体验。
其实真要说这次互联网动荡的开始时间应该是在21年下半年,不过在2022年这场风暴变得更加强烈了。感谢万能的互联网,让相关不相关的人员都能深切地感受到这场风暴来得是多么的强烈,”寒冬“、”毕业“这些看起来就让人哆嗦的字眼遍布在了网络上的每一个角落。作为一个暂时挺过这场风暴的幸存者,我可以较为肯定地表示作为打工人的我们无人可以幸免,只是时间长短问题(个人观点,不喜勿喷)。说是幸存者是因为我所在的公司也进行了看起来规模不小的人员优化活动,一切来得那么突然、那么匆忙,当真是让人猝不及防。当时前脚正在和我讨论问题的小朋友(我带的组员)后脚就开始整理东西上交电脑,未写完文档、未提交的代码、未完成的工作一下子全部涌到我这里。虽然整个过程很匆忙,但是那天我们还是好好地完成了一次告别,并没有像歌里写的一样:“还没来得及说再见”。之后的时间里,作为留下来的幸存者,我接手着之前没有接触的业务,维护着未曾见过的代码和逻辑。每每遇到一个问题想要找个知情人的时候,一问基本上就是“人已经走了,我也不太清楚”,这就导致了为了解决这样一个问题,我需要不停去追溯和了解上下游整体的方案逻辑以及部分开发细节,工作量呈几何倍的增加。就是在这种极度残缺和混乱的情况下,我竟然摇摇晃晃地度过了人员优化后的困顿期,没有发生一次线上事故。说实话,真的很难,如果可以相同的经历还是不要让我体验第二次了(此处应该配一张”我真的太难了“,哈哈哈)。
以上是作为一个幸存者的体验,很艰难也很痛苦,但是作为亲历者大概会比我更加艰难和痛苦吧(当然也有不少同学拿了满意的赔偿回家也是很开心的,祝福他们)。在之后的日子里,我也找过被优化的小朋友吃过一次饭,在吃饭时的闲聊中我一定程度上也能感受到那天收到这样一个通知时他内心的崩溃和难过。他说那天一起时人多还没有太大感受,但是到晚上夜深人静一个人独处时那种难过和迷茫的情绪涌上心头的感受,着实让人崩溃。听到他这样说,我只能无奈地张了张嘴,叹了一口气。不得不说,在这场风暴面前打工人显得是如此卑微和无奈。
二、内自省,改变思维模式
在经历了这几年的互联网打工生活之后(尤其是经历去年的动荡之后),我时不时会进行一些反思,尝试改变自身在学习、工作和生活上的一些惯性思维。这些惯性思维的形成可能是来自于以往的所学所知,也有可能是来自于社会环境或者周边人群的公共认知。这些惯性思维在最开始时可以说是对我益处非常大,毕竟这些都是来自于前人或者他人的经验总结得来的,但是随着经历的越多,心中的疑惑和对职业生涯的不安也越来越多,这些惯性思维对于我的限制也变得越来越大。我开始反思这些惯性思维是否依然有效,依然能够支撑陪伴我走到最后。
专业技能只能满足工作需要吗?
其实在一年前我就在思考一个问题,作为一个Web服务端开发的我所学所知只能运用于当前的工作当中吗?仔细思考一下,好像确实只能适用于当前的工作。虽然我能够吹牛皮说自己精熟常用中间件、数据库、企业开发框架,但是正经让我流畅地独立开发一个能够用于日常的小软件好像都做不到,比如去年我突发奇想想要开发一款小巧的Markdown编辑器(MacOS桌面应用程序)用于自己写博客使用,但是我发现作为一个Web服务端程序员,对于这样一个简单的应用程序都没有办法开发实现。我不由惊觉:我的知识体系中为什么缺失了这么一块拼图?
仔细想一想,也不难理解。大部分服务端程序员的所知所学其实主要围绕一个核心两个基本点,即以工作为核心,坚持技术深度(内卷) 和八股文熟练度(面试) 两个基本点。对于技术的追捧已经完全迷住了我们的眼睛,完全忘记了更应该追寻的是如何完整、高效地完成一个让用户喜爱、满足用户需求的产品。当然,闲宇并不是说追求技术深度不重要,相反追求技术深度很重要,因为只有明白这些工具背后使用的技术和对应的原理,我们才能更好的使用这些工具,甚至在必要时刻改造对应的工具来适配特定的业务场景。但是该说不说,有些时候我们去拓展自身的技术深度其实是为了内卷而不是为了更好地使用工具(有时我就是这样的,哈哈哈),再者说你的程序写得计算比花还好看也没有办法像李白的诗一样流传千古的。讲到这里大家应该不难发现,我的所学所知其实都是围绕着工作来开展的,这就导致出现上面所说的专业知识只能满足工作的情况(前端工程师这种情况应该会少不少)。除了专业知识的限制,我们的思维模式、创造力也同样都被限制在工作场景,超脱工作场景之外普通人的奇思妙想可能都比我们这些“专业领域人员”要多得多。这也导致了我们这个群体普遍存在一种职业生涯无法长久的认知和焦虑。
在深刻反省之后,我开始尝试接触一些其他领域(前端、产品、设计等等)的知识,尝试将目光从单纯地聚焦工作改变为平等关注工作和生活,从生活中发现和尝试实现一些简单的需求(比如写一个天气预报通知的服务,同时还能针对一些突发天气进行播报)。此时我去学习对应技能和知识时会非常地愉悦,因为我知道这种学习不单纯是为了工作需要,而是能够服务于自身生活的,相信大家应该也能感受到这种将自己的所学所知用于生活的快乐的。
我是否只能成为一名软件工程师?
这个问题实际上是针对前一个问题的拓展和延伸。在毕业之初,绝大部分人都选择了从事软件开发工程师,基本没有人回去思考是否有其他领域适合自己,因为我们有一种惯性思考:大家都是这么选的。感谢这一公共认知,至少毕业这几年我的工作相对顺遂稳定,薪资尚可。但是这同样带来一个比较严重的问题,对于自己的职业规划我们没有自己做过相对明确的思考,只是大家都是这么干的或者大家都是这么认为的我们就去做了。未来如何走?自己应该成为什么样的人?这些问题大概都没有时间去好好思考一下。可能有同学要说,我未来要成为技术专家、架构师,但是仔细思考一下,这些目标真的是我们自己定的吗?难道不是市面这些标准的程序员晋升模版已经为我们制定好的吗?好吧,可能你是真的就在最初就已经想要成为一名技术专家,但是在成为技术专家之外,你难道不想成为一些其他角色?
至少对于我来说,经过这几年的技术学习和博客分享之后,我渐渐发现我热爱上了这种将自己所学所得分享给别人的快乐,可能在未来的某一天我会去兼职做一名讲师也说不定。除此以外,我也开始喜欢上了编写小作文的感受,说不定未来的某天我还会兼职成为一名三流网络写手,每天写着富婆爱上我的爽文也未可知。当然以上都是一些设想,未必会成为现实,但我们需要突破一些自己思维的限制,毕竟生活中唯一不变的就是变化,有时候走出舒适圈你会看到另外一片美好的天地。
三、人生路长,未来可期
上面的这些思考完全是基于个人观点和内心的不安分,并非适用于所有人,不喜勿喷。当然之所以出现这些不安分的思考除了有互联网不景气和“35岁失业”魔咒这两柄达摩克斯之剑外,还有就是如果这一辈子都是按照固定道路走完大致确实有点无聊,花一点时间追求一下自己喜欢的事情,闯一闯、拼一拼,说不定能够看到一个不一样的风景。(当然,这个是我此时的想法,未来说不定就会打脸了,此处先标记一下,哈哈哈)
诸位,人生路长,未来可期,可适当焦虑,但也要满怀希望勇往向前。
链接:https://juejin.cn/post/7199631784060780599
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
互联网大裁员原因分析
继谷歌、微软之后,Zoom、eBay、波音、戴尔加入最新一波“裁员潮”中。
2 月 7 日,美国在线会议平台 Zoom 宣布将裁减 1300 名员工,成为最新一家进行裁员的公司,大约 15% 的员工受到影响。
同日,总部位于亚特兰大的网络安全公司 Secureworks 在一份提交给美国证券交易委员会( SEC )的文件中宣布,将裁员 9%,因为该公司希望在“一些世界经济体处于不确定时期”减少开支。据数据供应商 PitchBook估计,该公司近 2500 名员工中约有 225 人将在此轮裁员中受到影响。
此外,电商公司eBay于2月7日在一份SEC文件中宣布,计划裁员500人,约占其员工总数的4%。据悉,受影响的员工将在未来24小时内得到通知。
2月6日,飞机制造商波音公司证实,今年计划在财务和人力资源部门裁减约 2000 个职位,不过该公司表示,将增加 1 万名员工,“重点是工程和制造”。
个人电脑制造商戴尔的母公司,总部位于美国德克萨斯州的戴尔科技,2 月 6 日在一份监管文件中表示,公司计划裁减约 5% 的员工。戴尔有大约 13.3 万名员工,在这个水平上,约 6650 名员工将在新一轮裁员中受到影响。
除了 Zoom、eBay、波音、戴尔 等公司,它们的科技同行早已经采取了同样的行动。
从去年 11 月开始,许多硅谷公司员工就开始增加了关注邮箱的频率,害怕着某封解除自己公司内网访问权限的邮件来临,在仅仅在 2022 年 11 月,裁员数字就达到了近 6 万人,而如果从 2022 开始计算,各家已经陆续裁员了近十五万人。
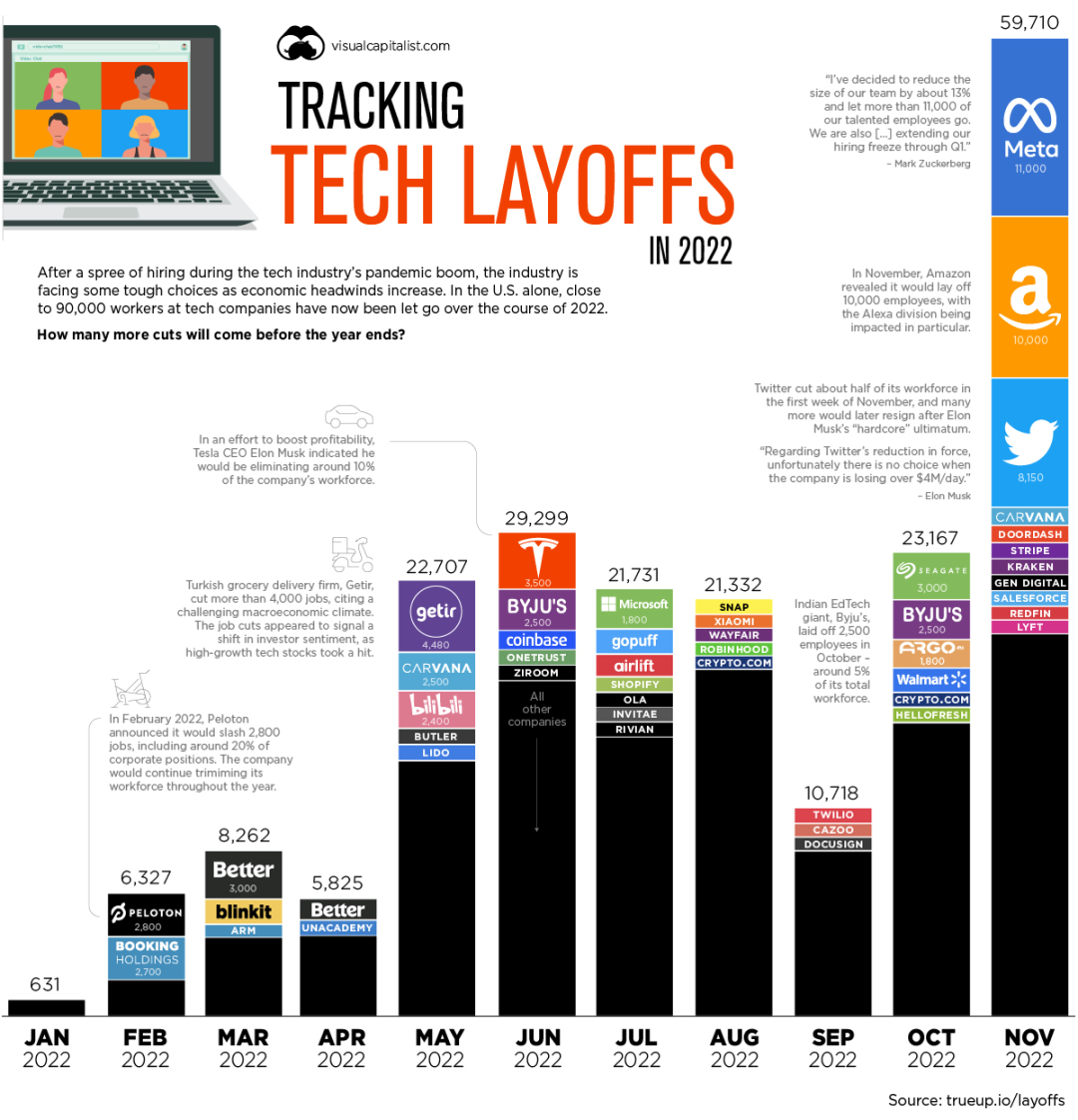
但本次裁员并非是因为营收的直接下降:事实上,硅谷各家 2022 年营收虽然略有下跌,但总体上仍然保持了平稳,甚至部分业务略有上涨,看起来并没有到「危急存亡之秋」,需要动刀进行大规模裁员,才能在寒冬中存活的程度。
相较于备受瞩目的裁员,一组来自美国政府的就业数据就显得比较有意思了。据美国劳工统计局 2 月 3 日公布的数据,美国失业率 1 月份降至 3.4%,为 1969 年 5 月以来最低。
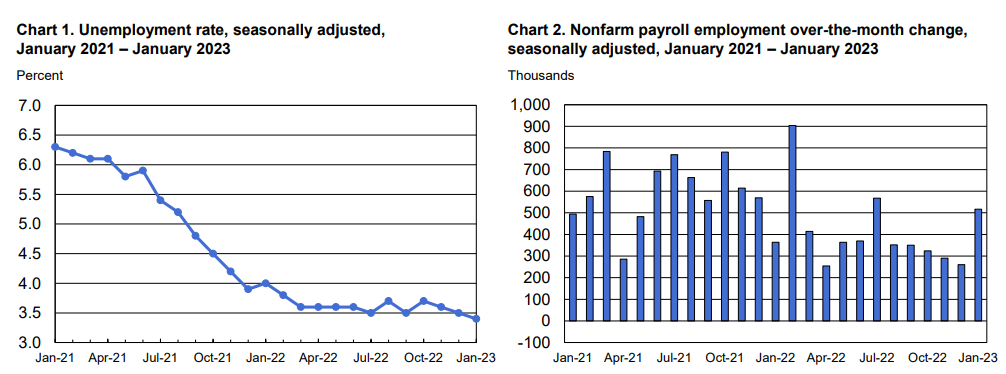
美国 1 月份非农就业人数新增 51.7 万人,几乎是经济学家预期的三倍,即使最近主要在科技行业裁员,但建筑、酒店和医疗保健等行业带来了就业增长。
一方面是某些企业的大规模裁员,仅 1 月份就影响超过 10 万人;而另一方面,政府报告显示就业市场强劲。这样来看,美国的就业市场情况似乎有些矛盾。
2022 年 12 月初,多名B站员工在社交媒体上表示,B站开始了新一轮裁员,B端、漫画、直播、主站、Goods等部门均有涉及,整体裁员比例在30%左右。12月19日,小米大规模裁员的消息又有曝出,裁员涉及手机部、互联网部、中国部等多部门,个别部门裁员比例高达75%。12月20日,知乎又传裁员10%。
似乎全球的科技公司都在裁员,而我们想要讨论裁员的问题,肯定绕不开两个大方向:经济下行和人员问题。
下行环境
联合国一月发布的《2023年世界经济形势与展望》中指出,2022 年,一系列相互影响的严重冲击,包括新冠疫情、乌克兰战争及其引发的粮食和能源危机、通胀飙升、债务收紧以及气候紧急状况等,导致世界经济遭受重创。美国、欧盟等发达经济体增长势头明显减弱,全球其他经济体由此受到多重不利影响。与新冠疫情相关的反复封锁以及房地产市场的长期压力,延缓了中国的经济复苏进程。
在此背景下,2023 年世界经济增速预计将从 2022 年估计的 3.0% 下降至 1.9%。2024 年,由于部分不利因素将开始减弱,预计全球经济增速将适度回升至 2.7%。不过,这在很大程度上将取决于货币持续紧缩的速度和顺序、乌克兰战争的进程和后果以及供应链进一步中断的可能性。
在通货膨胀高企、激进的货币紧缩政策以及不确定性加剧的背景下,当前全球经济低迷,导致全球经济从新冠疫情的危机中复苏的步伐减缓,对部分发达国家和发展中国家均构成威胁,使其 2023 年可能面临衰退的前景。
2022 年,美国、欧盟等发达经济体增长势头明显减弱。报告预计,2023 年美国和欧盟的经济增速分别为 0.4% 和 0.2%,日本为 1.5%,英国和俄罗斯的经济则将分别出现 0.8% 和 2.9% 的负增长。
与此同时,全球金融状况趋紧,加之美元走强,加剧了发展中国家的财政和债务脆弱性。自 2021 年末以来,为抑制通胀压力、避免经济衰退,全球超过85%的央行纷纷收紧货币政策并上调利率。
报告指出,2022 年,全球通胀率约为 9%,创数十年来的新高。2023 年,全球通胀率预计将有所缓解,但仍将维持在 6.5% 的高水平。
据美国商务部经济分析局(BEA)统计,第二、三季度,美国私人投资分别衰退 14.1% 和 8.5%。加息不仅对美国企业活动产生抑制作用,而且成为美国经济复苏的最主要阻力。尤其是,非住宅类建筑物固定投资已连续六个季度衰退。预计 2023 年美国联邦基金利率将攀升至 4.6%,远远超过 2.5% 的中性利率水平,经济衰退风险陡增,驱动对利率敏感的金融、房地产和科技等行业采取裁员等必要紧缩措施。
发展上限
美国企业的业务增长和经营利润出现问题。据美国多家媒体报道,第三季度,谷歌利润率急剧下滑,Meta 等社交媒体的广告收入迅速降温,微软等其他科技企业业务增长也大幅放缓。自7月以来,美国服务业PMI已连续5个月陷入收缩区间,制造业 PMI 也于 11 月进入收缩区间。在美国经济前景和行业增长空间出现问题的背景下,部分行业采取裁员、紧缩开支等“准备过冬”计划也就在意料之中了。
2022年,在市值方面,作为中概股的代表阿里、腾讯、快手等很多企业的市值都跌了 50%,甚至70%、80%。在收入方面,BAT 已经停止增长几个季度了,阿里和腾讯为代表的企业已经开始负增长。在经济下行的背景下,向内开刀、降本增效成为企业生存的必然之举。除了裁员,收缩员工福利、业务调整,也是企业降本增效的举动之一。
如果说 2021 年的裁员,很多是由于业务受到冲击,比如字节跳动的教育业务,以及滴滴、美团等公司的社区团购项目。但到了 2022 年,更多企业裁员的背后是降本增效、去肥增肌。
全球宏观经济表现不佳,由产业资本泡沫引发的危机感传导到科技企业的经营层,科技企业不得不面对现实。科技行业处在重要的结构转型期。iPhone 的横空出世开创了一个移动互联网的新时代,而当下的科技巨头也都是移动互联网的大赢家。但十多年过去了,随着智能手机全球高普及率的完成,移动互联网的时代红利逐渐消失,也再没有划时代的创新和新的热点。
这两年整个移动互联网时代的赢家都在焦急地寻找新的创新增长点。比如谷歌和 Meta 多年来一直尝试投资新业务,如谷歌云、Web3.0等,但实际收入仍然依赖于广告业务,未能找到真正的新增长点。这使得其中一些公司容易受到持有突破性技术的初创公司影响。
科技企业倾力“烧钱”打造新赛道,但研发投入和预期产出始终不成正比,不得不进行战略性裁员。
我们这里以这两年爆火的元宇宙举例:
各大券商亦争相拥抱元宇宙,不仅元宇宙研究团队在迅速组建,元宇宙首席分析师也纷纷诞生。 2021 年下半年,短短半年内便有数百份关于元宇宙的专题研报披露。
可以说,在扎克伯格和Meta的带领下,全世界的大厂小厂都在跟着往元宇宙砸钱。
根据麦肯锡的计算,自2021年以来,全世界已经向虚拟世界投资了令人瞠目结舌的数字——1770亿美元。
但即使作为元宇宙领军的 Meta 现实实验室(Reality Labs)2022 年三季度收入 2.85 亿美元,运营亏损 36.7 亿美元,今年以来已累计亏损 94 亿美元,去年亏损超过 100亿 美元。显然,Meta 的元宇宙战略还未成为 Meta的机遇和新增长点。
虽然各 KOL 高举“元宇宙是未来”的大旗,依旧无法改写“元宇宙未至”的局面。刨除亟待解决的关键性技术问题,如何兼顾技术、成本与可行性,实现身临其境的体验,更是为之尚远。元宇宙还在遥远的未来。
早在 2021 年12 月底,人民日报等官方媒体曾多次下场,呼吁理性看待“元宇宙”。中央纪委网站发布的《元宇宙如何改写人类社会生活》提及“元宇宙”中可能会涉及资本操纵、舆论吹捧、经济风险等多项风险。就连春晚的小品中,“元宇宙”也成为“瞎忽悠”的代名词。
2022 年 2月18日,中国银保监会发布了《关于防范以“元宇宙”名义进行非法集资的风险提示》,并指出了四种常见的犯罪手法,包括编造虚假元宇宙投资项目、打着元宇宙区块链游戏旗号诈骗、恶意炒作元宇宙房地产圈钱、变相从事元宇宙虚拟币非法谋利。
2022 年 2月7日,英国《金融时报》报道称,随着《网络安全法案》逐步落实,元宇宙将会受到严格的英国监管,部分公司可能面临数十亿英镑的潜在罚款。
2022 年 2月6日,据今日俄罗斯电视台(RT)报道,俄罗斯监管机构正在研究对虚拟现实技术实施新限制的可能性,他们担心应用该技术可能会协助非法活动。
各个国家的法律监管的到来,使得元宇宙的泡沫迅速炸裂。无数的元宇宙公司迅速破产,例如白鹭科技从 H5 游戏引擎转型到元宇宙在泡沫破裂的情况下个人举债 4000 万,公司破产清算。
本质上来说如今互联网行业已经到了一个明显的发展瓶颈,大家吃的都是移动网络和智能手机的普及带来的红利。在新的设备和交互方式诞生前,大家都没了新故事可讲,过去的圈地跑马模式在这样的大环境下行不通了。
法律监管
过去十年时间,互联网世界的马太效应越来越明显。一方面,几大巨头们在各自领域打造了占据了主导份额的互联网平台,不断推出包罗万象的全生态产品与服务,牢牢吸引着绝大多数用户与数据。他们的财务业绩与股价市值急剧增长,苹果、谷歌、亚马逊的市值先后突破万亿甚至是两万亿美元。
而另一方面,诸多规模较小的互联网公司却面临着双重竞争劣势。他们不仅财力与体量都无法与网络巨头抗衡,还要在巨头们打造的平台上,按照巨头制定偏向自己的游戏规则,与包括巨头产品在内的诸多对手激烈竞争用户。
2020 年 10 月,在长达 16 个月的调查之后,美国众议院司法委员会发布了一份长达 449 页的科技反垄断调查报告,直指谷歌、苹果、Facebook、亚马逊四大科技巨头滥用市场支配地位、打压竞争者、阻碍创新,并损害消费者利益。
2020 年 10 月 20 日,美国司法部连同美国 11 个州的检察长向 Google 发起反垄断诉讼,指控其在搜索和搜索广告市场通过反竞争和排他性行为来非法维持垄断地位。
2021 年明尼苏达州民主党参议员艾米·克洛布查尔(Amy Klobuchar)和爱荷华州共和党参议员查克·格拉斯利(Chuck Grassley)共同提出的《美国创新与选择在线法案》和 《开放应用市场法案》旨在打击谷歌母公司 Alphabet、亚马逊、Facebook 母公司 Meta 和苹果公司等科技巨头的一些垄断行为,这将是互联网向公众开放近30年来的首次重要法案。
《美国创新与选择在线法案》的内容包括禁止占主导地位的平台滥用把关权,给予营产品服务特权,使竞争对手处于不利地位;禁止施行对小企业和消费者不利,有碍于竞争的行为,例如要求企业购买平台的商品或服务以获得在平台上的优先位置、滥用数据进行竞争、以及操纵搜索结果偏向自身等。
不公平地限制大平台内其他商业用户的产品、服务或业务与涵盖平台经营者自己经营的产品、服务或业务相竞争能力,从而严重损害涵盖平台中的竞争。
除了出于大平台安全或功能的需要,严重限制或阻碍平台用户卸载预装的软件应用程序,将大平台用户使用大平台经营者提供的产品或服务设置为默认或引导为默认设置。
《开放应用市场法案》针对“守门人”执行,预计将会在应用商店、定向广告、互联操作性,以及垄断并购等方面,对相应企业做出一系列规范要求。此外欧盟方面还曾透露,如“守门人”企业不遵守上述规则,将按其上一财政年度的全球总营业额对其处以“不低于 4%、但不超过20%”的罚款。法案允许应用程序侧载(在应用商店之外下载应用程序),旨在打破应用商店对应用程序的垄断能力,将对苹果、谷歌的应用商店商业模式产生重要影响。
大型科技公司们史无前例搁置竞争,并且很有默契地联合起来。他们和他们的贸易团体在两年内耗费大约 1 亿美元进行游说,超过了制药和国防等高支出行业。他们向政界人士捐赠了 500 多万美元,科技游说人士向负责捍卫民主党多数席位的政治行动委员会(PAC)捐赠了 100 多万美元。他们还向不需要披露资金来源的黑钱组织、非营利组织和行业协会投入了数百万美元。几位国会助手表示,他们收到的有关这些法案的宣传比他们多年来处理的任何其他法案都要多。
这两项法案已通过国会相关委员会的审查,依然在等待众议院和参议院的表决。而美国即将开始中期选举。Deese 称,共和党已经明确表示,如果共和党重新控制国会两院,他们将不会支持这些法案。但如果民主党当选的话,科技巨头们估计不好过了。
很遗憾的是,2023年,新一届美国国会开幕后,众议院议长的选举经多轮投票仍然“难产”,导致新一届国会众议院无法履职。开年的这一乱象凸显美国政治制度失灵与破产,警示美国党争极化的趋势恐正愈演愈烈;
欧盟也多次盯上四大公司,仅谷歌一家,欧盟近三年来对其开出的反垄断处罚的金额已累计超过 90 亿美元。
而中国的举措也不小。
2020 年年初,实施了近 12 年的《反垄断法》(2008 年 8 月 1 日生效)首次进入“大修”——国家市场监督管理总局在其官网公布了《反垄断法修订草案(公开征求意见稿)》(以下简称“征求意见稿”)。
《法制日报》报道指出,征求意见稿中共有 8 章 64 条,较现行法要多出 7 条。可见,这次修法,已与另立新法有同等规模。
值得注意的是,征求意见稿还首次将互联网业态纳入其中,新增互联网领域的反垄断条款,针对性地列明相关标准和适用规程。
以市场支配地位认定为例,征求意见稿根据互联网企业的特点,新增了包括网络效应、规模经济、锁定效应、掌握和处理相关数据的能力等因素。
11 月 10 日,赶在双 11 前一天,国家市场监管管理总局再次出手,发布了《关于平台经济领域的反垄断指南(征求意见稿)》(以下简称《指南》)公开征求意见的公告。
《指南》不仅对“互联网平台”做了进一步界定,还结合个案更为具体详尽地对垄断协议,滥用市场支配地位行为,经营者集中,滥用行政权力排除、限制竞争四个方面作出分析和规定。
国家在平台经济领域、反垄断领域的法律规范,在《反垄断指南》出台以后,已经有了相当程度的完善。后续随着《反垄断法》修正案的通过,二者结合基本构建了我国反垄断领域的法律框架。
随着《反垄断法》的完善,在互联网领域的处罚案例逐渐浮出水面,针对阿里巴巴、美团等互联网公司都开出了大额罚单。
2021年我国在网络安全方面也加速发展。2021年6月10日颁布《中华人民共和国数据安全法》,2021年8月20日颁布《中华人民共和国个人信息保护法》。有关部门相继出台了《网络安全审查办法》《常见类型移动互联网应用程序必要个人信息范围规定》《数据出境安全评估办法(征求意见稿)》等部门规章和政策性文件。
可以预见的是,未来监管部门的监管措施更能兼顾互联网行业发展特征和社会整体福利,监管部门会不断完善规章、政策文件和标准文件,提供给企业明确和细化的指引。同时,相关部门的监管反应速度会越来越及时,监管层面对违法查处的力度也会越来越严。
人口红利
我们依然处在人口规模巨大的惯性中,人口规模巨大意味着潜在市场规模巨大,伴随经济持续发展、收入水平提高、消费能力强劲,由此带来的超大市场规模不可估量。而现在人口红利没了。
中国国家统计局 1 月 17 日公布,2022年末全国人口(包括 31 个省、自治区、直辖市和现役军人的人口,不包括居住在 31 个省、自治区、直辖市的港澳台居民和外籍人员) 141175 万人,比上年末减少 85 万人。这是近61年来中国首次人口负增长。人口负增长的早期阶段是一种温和的人口减少,所以依然会沿袭人口规模巨大的惯性;但在人口负增长的远期阶段,如果生育率仍未有所回升的话,就有可能导致一种直线性的减少。
目前所有行业都不得不面临从人口红利转向素质红利的转变。
人员过剩
微软在过去两年员工数新增 6 万,Google 则是新增了 7 万,Meta 则是直接从疫情之前的 4 万翻倍至 2022 年的 8.7 万。而依赖物流服务的亚马逊则最为激进,两年时间全球全职员工数增长了令人咂舌的 8.1 万,全职员工数近乎翻倍。
高盛的经济学家在一份报告中指出“那些正在裁员的科技公司有一些共同点,希望重新平衡业务的结构性转变,并为更好的利润开路。我们发现,许多最近宣布大规模裁员的公司都有三个共同特征。首先,许多都是在科技领域。其次,许多公司在疫情期间大肆招聘。第三,它们的股价出现了更大幅度的下跌,从峰值平均下跌了 43%。”
平均而言,那些进行裁员的公司在疫情期间的员工数量增长了 41%,此举往往是因为他们过度推断了与疫情相关的趋势,比如商品需求或在线时间的增长。
行裁员的公司并不能代表更广泛的情况,最近许多裁员公告并不一定意味着需求状况会减弱。与此一致的是,高盛预计更具代表性的实时估计的裁员率最近虽有所增加,但仅恢复到疫情前的水平,以历史标准衡量,裁员率水平较低。
结论
全球经济下行是大势,层层增加的法律监管是推动,没有人口红利和新玩法股价要大跌。
全球通胀激增,激进的货币紧缩政策以及不确定性加剧、俄乌战争等影响,全球经济低迷。新冠疫情带来的影响难以快速恢复。而中国还得面临人口红利消失、房地产饮鸩止渴的深远影响。而法律的层层监管和反垄断的推进在逐步打压科技巨头的已有市场,没有新技术的突破和新玩法让科技巨头们也没了新增和突破的空间。对于未来的经济发展的错误预估和疫情特殊时期的大量增长让科技巨头们大肆招聘,这些都成为了股价下跌和缩减利润的元凶。目前的大裁员可以算是一种虚假繁荣的泡沫爆裂后的回调,虽然不知道这个回调什么时候结束,但是随着人工智能的出圈和将来新技术的突破,也许整个行业可以浴火重生。
链接:https://juejin.cn/post/7201047960825774139
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


