简介
Koa 是一个新的 web 框架,由 Express 幕后的原班人马打造, 致力于成为 web 应用和 API 开发领域中的一个更小、更富有表现力、更健壮的基石。 通过利用 async 函数,Koa 帮你丢弃回调函数,并有力地增强错误处理。 Koa 并没有捆绑任何中间件, 而是提供了一套优雅的方法,帮助您快速而愉快地编写服务端应用程序。
简单来说,Koa也是一个web框架,但是比Express更轻量,并且有更好的异步机制。
本文适合有Koa基础,急需需要搭建项目的同学食用,如果对Koa完全不了解的建议先去看看Koa官方文档。
在讲Koa的使用之前,我们先来介绍一下非常出名的洋葱模型,这对后面代码的理解有很好的帮助
洋葱模型
前面我们在介绍Express的时候就说过了洋葱模型,如下图所示,Koa中的中间件执行机制也类似一个洋葱模型,只不过和Express还是有些许区别。
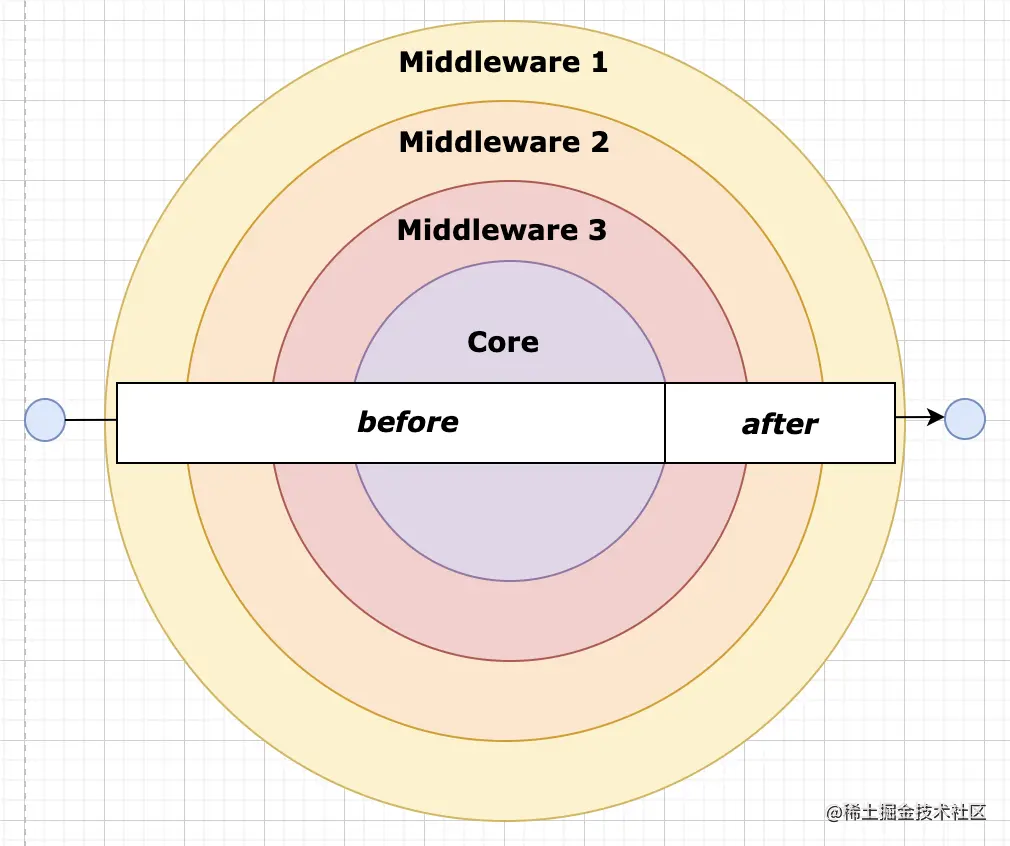
我们来看看Koa中的中间件是怎么样执行的。与Express不同的是在Koa中,next是支持异步的。
app.use(async (ctx, next) => {
console.log(
"start In comes a " + ctx.request.method + " to " + ctx.request.url
);
next();
console.log(
"end In comes a " + ctx.request.method + " to " + ctx.request.url
);
});
router.get(
"/select",
async (ctx, next) => {
console.log("我是单独中间件 start");
const result = await Promise.resolve(123);
console.log(result);
next();
console.log("我是单独中间件 end");
},
async (ctx) => {
console.log("send result start");
ctx.body = "get method!";
console.log("send result end");
}
);
看看上面的输出结果,可以看到它的执行顺序和Express是一样的。
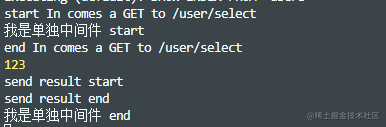
前面说了,在Koa中next是支持异步的。也就是可以await,我们添加await来测试下
app.use(async (ctx, next) => {
console.log(
"start In comes a " + ctx.request.method + " to " + ctx.request.url
);
await next();
console.log(
"end In comes a " + ctx.request.method + " to " + ctx.request.url
);
});
router.get(
"/select",
async (ctx, next) => {
console.log("我是单独中间件 start");
const result = await Promise.resolve(123);
console.log(result);
await next();
console.log("我是单独中间件 end");
},
async (ctx) => {
console.log("send result start");
ctx.body = "get method!";
console.log("send result end");
}
);
看看运行结果
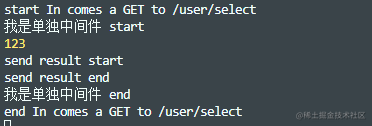
可以看到,在Koa中,await会阻塞所有后续代码的执行,完全保证了按洋葱模型执行代码。以next为分水岭,先从前往后执行next前半部分代码,然后从后往前执行next下半部分代码。
在Express中,next方法是不支持异步await的,这个是Koa和Express洋葱模型里面最大的一个区别。
创建应用
首先我们需要安装koa
npm i koa
然后引入使用
const Koa = require("koa");
const app = new Koa();
app.listen(3000, () => {
console.log("serve running on 3000");
});
这个和Express还是很相似的。
路由
Koa的路由和Express还是有差别的。Koa的app是不支持直接路由的,需要借助第三方插件koa-router。
我们先来安装
npm i @koa/router
然后就可以引入使用了
const Router = require("@koa/router");
const router = new Router({ prefix: "/user" });
router.get("/select", (ctx) => {
ctx.body = "get";
});
router.post("/add", (ctx) => {
ctx.body = "post";
});
router.delete("/delete", (ctx) => {
ctx.body = "delete";
});
router.put("/update", (ctx) => {
ctx.body = "put";
});
router.all("/userall", (ctx) => {
ctx.body = "所有请求都可以?" + ctx.method;
});
router.get("/testredirect", (ctx) => {
ctx.redirect("/user/select");
});
module.exports = router;
然后在入口文件,引入路由并注册就可以使用了
const Koa = require("koa");
const app = new Koa();
const userRouter = require("./routes/user");
app.use(userRouter.routes()).use(userRouter.allowedMethods());
这样我们就可以通过localhost:3000/user/xxx来调用接口了。
自动注册路由
同样的,如果模块很多的话,我们还可以优化,通过fs模块读取文件,自动完成路由的注册。
const fs = require("fs");
module.exports = (app) => {
fs.readdirSync(__dirname).forEach((file) => {
if (file === "index.js") {
return;
}
const route = require(`./${file}`);
app.use(route.routes()).use(route.allowedMethods());
});
};
在入口文件,我们可以通过该方法批量注册路由了
const registerRoute = require("./routes/index");
registerRoute(app);
这样我们就可以通过localhost:3000/模块路由前缀/xxx来调用接口了。
路由说完了,我们再来看看怎么获取参数
参数获取
参数的获取分为query、param、body三种形式
query参数
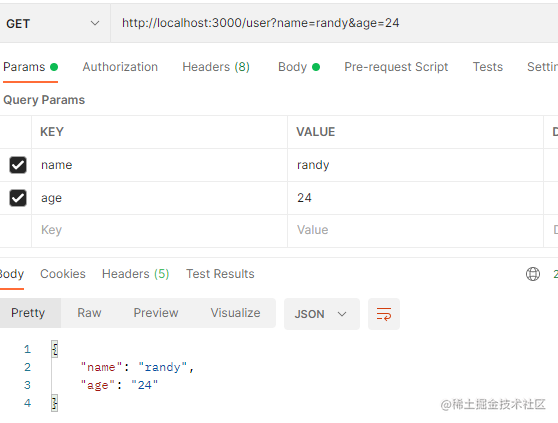
对于query参数,通过req.query获取
router.get("/", (ctx) => {
const query = ctx.query;
ctx.body = query;
});
参数能正常获取
我们再来看看路径参数
路径参数
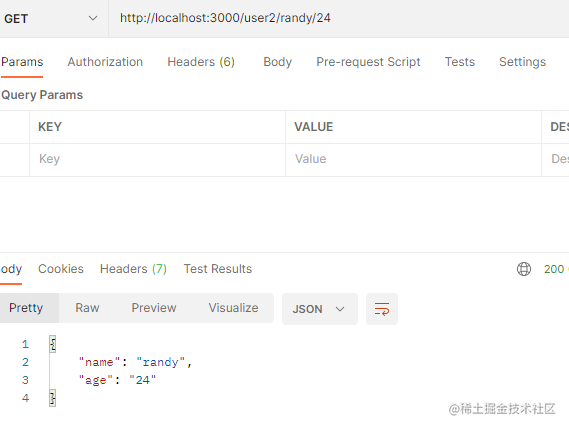
对于路径参数,通过:变量定义,然后通过request.params获取。
router.get("/user2/:name/:age", (ctx) => {
const params = ctx.params;
ctx.body = params
});
参数能正常获取
body参数
对于body参数,也就是请求体里面的参数,就需要借助koa-body插件。但是在新版的Express中已经自身支持了。
首先安装koa-body插件
npm i koa-body
然后在入口文件使用
const { koaBody } = require("koa-body");
app.use(koaBody());
然后通过ctx.request.body就可以获取到参数啦。
router.post("/", (ctx) => {
const body = ctx.request.body;
ctx.body = body;
});
设置完后,我们来测试下,参数正常获取。
文件上传
说完参数的获取,我们再来看看怎么处理文件上传。
在koa中,对于文件上传也是借助koa-body插件,只需要在里面配置上传文件的参数即可。相较Express要简单很多。
app.use(
koaBody({
multipart: true,
formidable: {
uploadDir: path.join(__dirname, "./uploads"),
keepExtensions: true,
},
})
);
配置好后,我们来测试一下
跟Express不同的是,不管是单文件还是多文件,都是通过ctx.request.files获取文件。
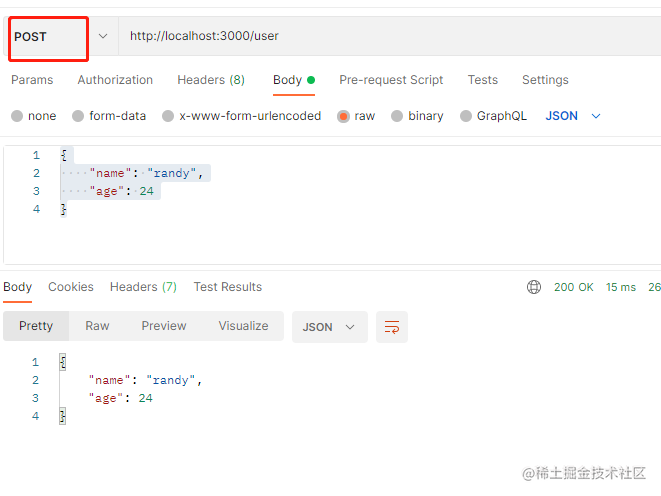
单文件上传
router.post("/file", (ctx) => {
const files = ctx.request.files;
ctx.body = files;
});
我们可以看到,它返回的是一个对象,并且在没填写表单字段的时候,它的key是空的。
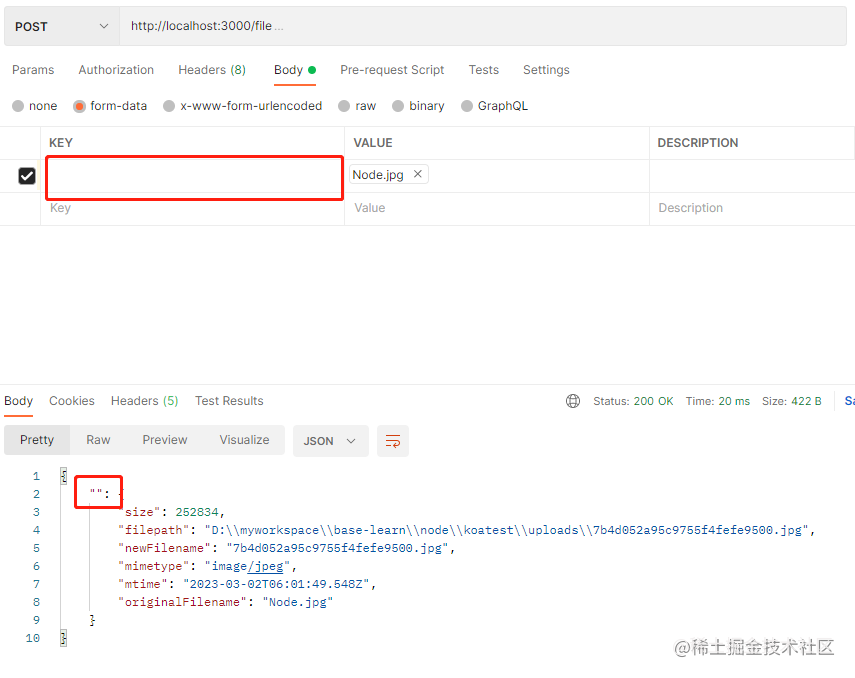
我们再来看看有表单字段的
router.post("/file2", (ctx) => {
const files = ctx.request.files;
ctx.body = files;
});
可以看到,它返回的对象key就是我们的表单字段名。
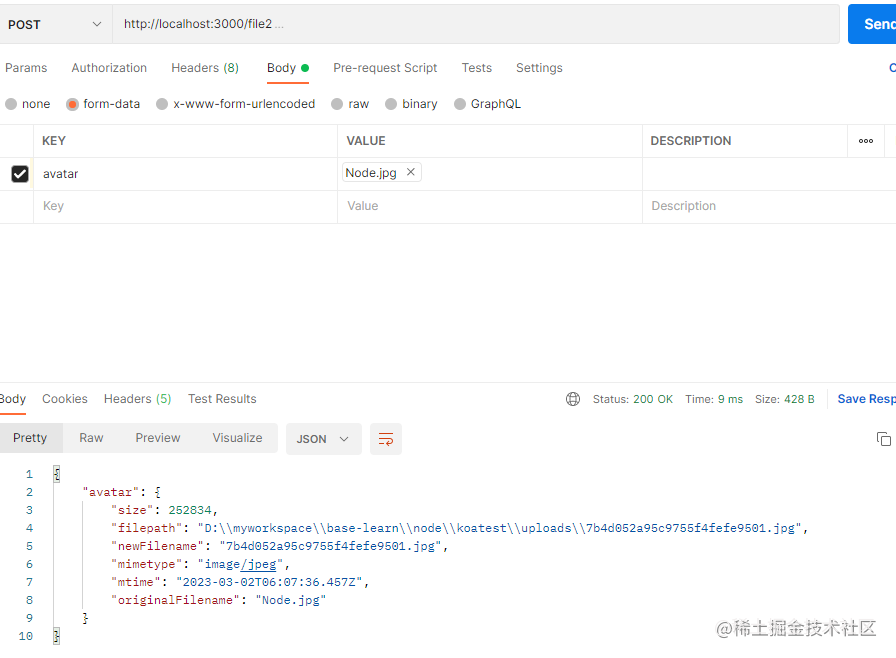
我们再来看看多文件上传的情况
多文件上传
我们先来看看多文件不带表单字段的情况
router.post("/files", (ctx) => {
const files = ctx.request.files;
ctx.body = files;
});
可以看到,它返回的还是一个对象,只不过属性值是数组。
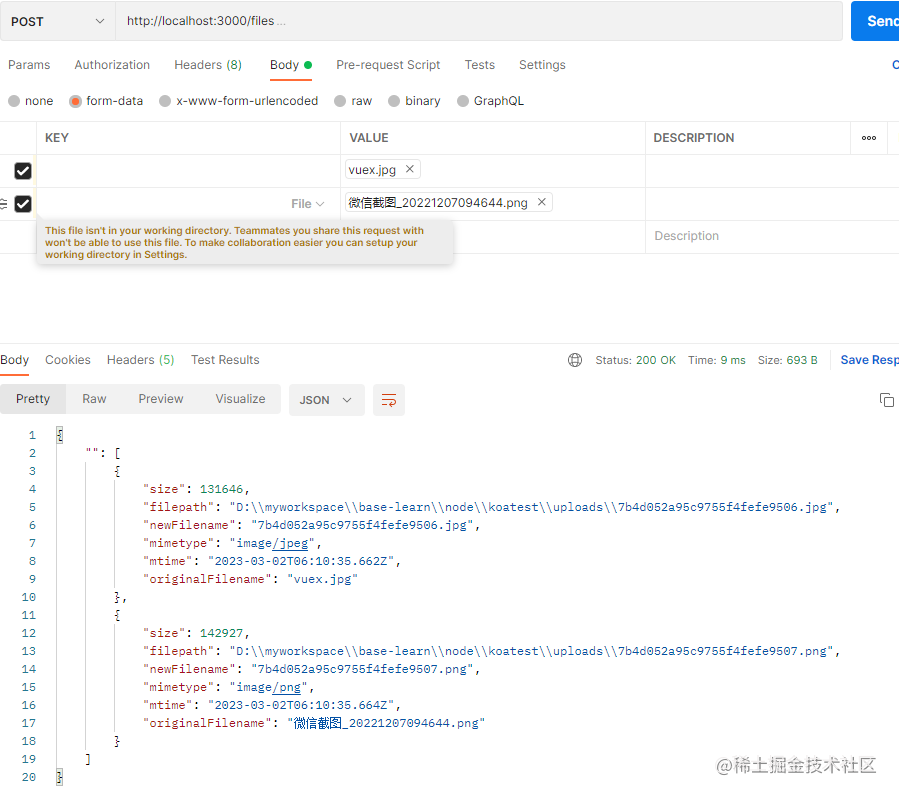
我们来看看带表单字段的情况,对于带表单字段的多文件上传,它返回的对象里面的key值就不是空值,并且如果是多个文件,它是以数组形式返回。
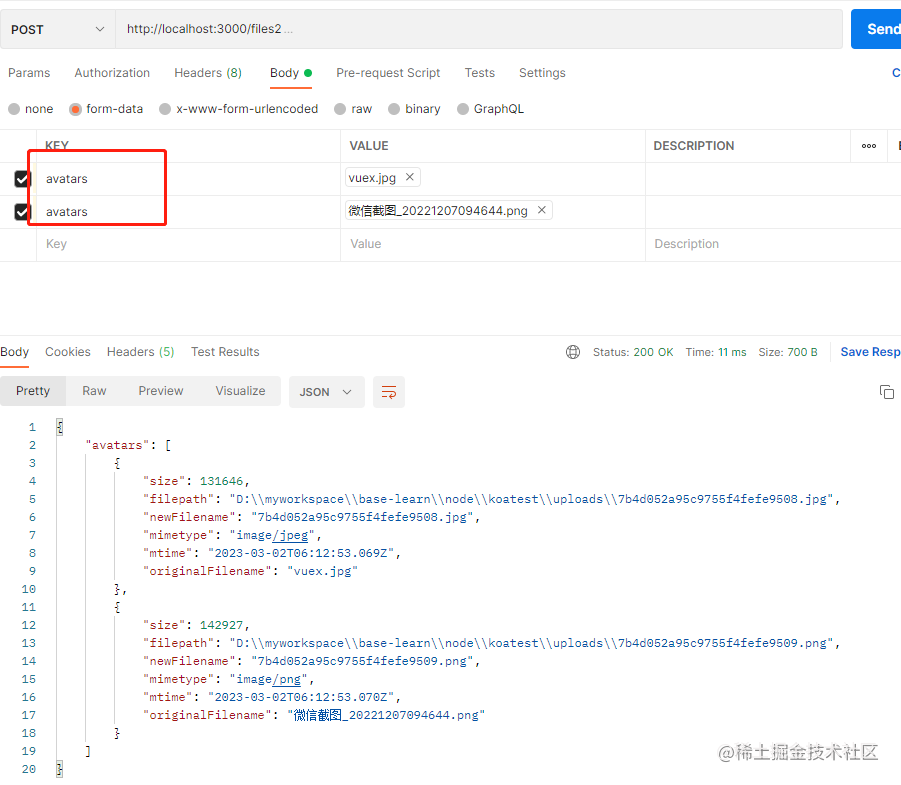
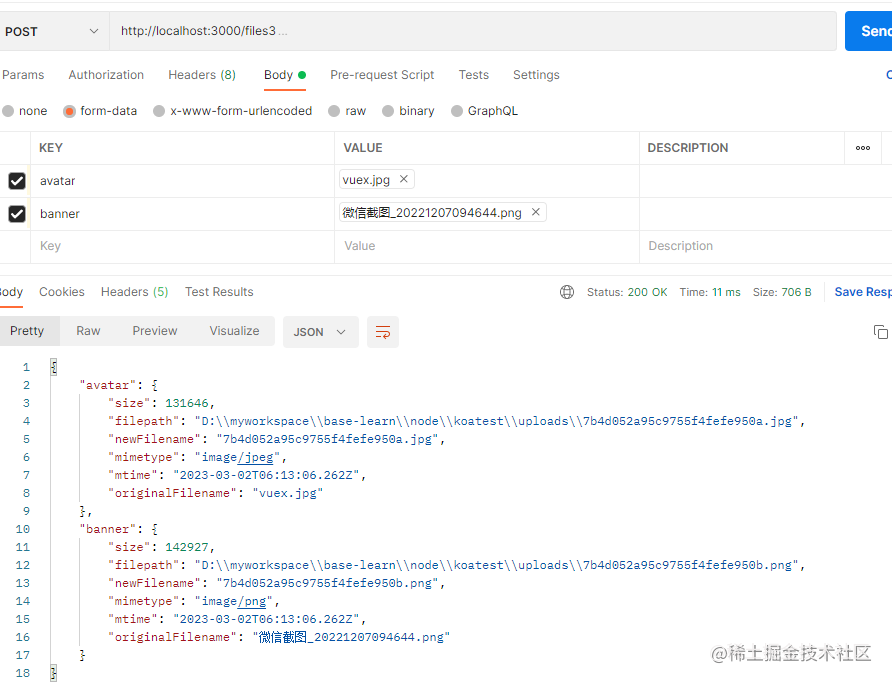
静态目录
文件上传我们介绍完毕了,如果我们想访问我们上传的图片该怎么办呢?能直接访问吗
对于文件,我们需要开启静态目录才能通过链接访问到我们目录里面的内容。与Express不同,koa需要借助koa-static插件才能开启静态目录。
下面的配置就是将我们系统的uploads目录设置为静态目录,这样我们通过域名就能直接访问该目录下的内容了。
const koaStatic = require("koa-static");
app.use(koaStatic(path.join(__dirname, "uploads")));
可以看到,图片能正确访问。
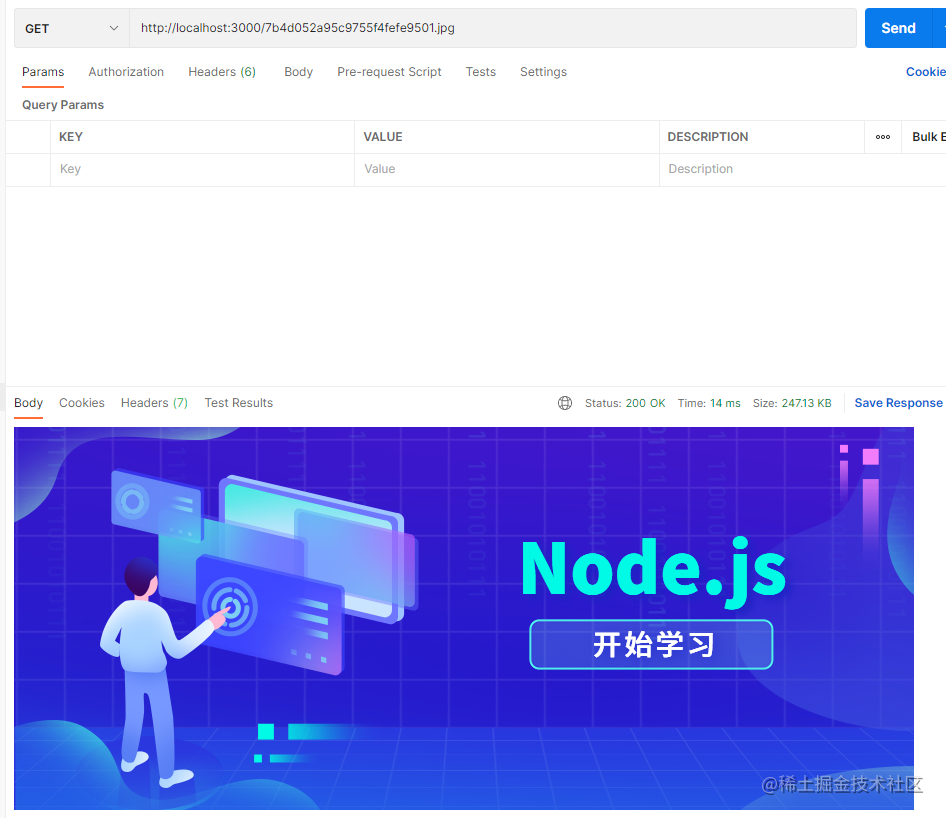
细心的同学可能发现了它是直接在域名后面访问,并没有像Express一样有个static前缀。那怎么实现这种自定义前缀的效果呢?
自定义静态资源目录前缀
在Koa中,需要借助koa-mount插件
我们先来安装一下
npm i koa-mount
然后和koa-static搭配使用
app.use(mount("/static", koaStatic(path.join(__dirname, "uploads"))));
然后我们就可以带上/static前缀访问静态资源了。
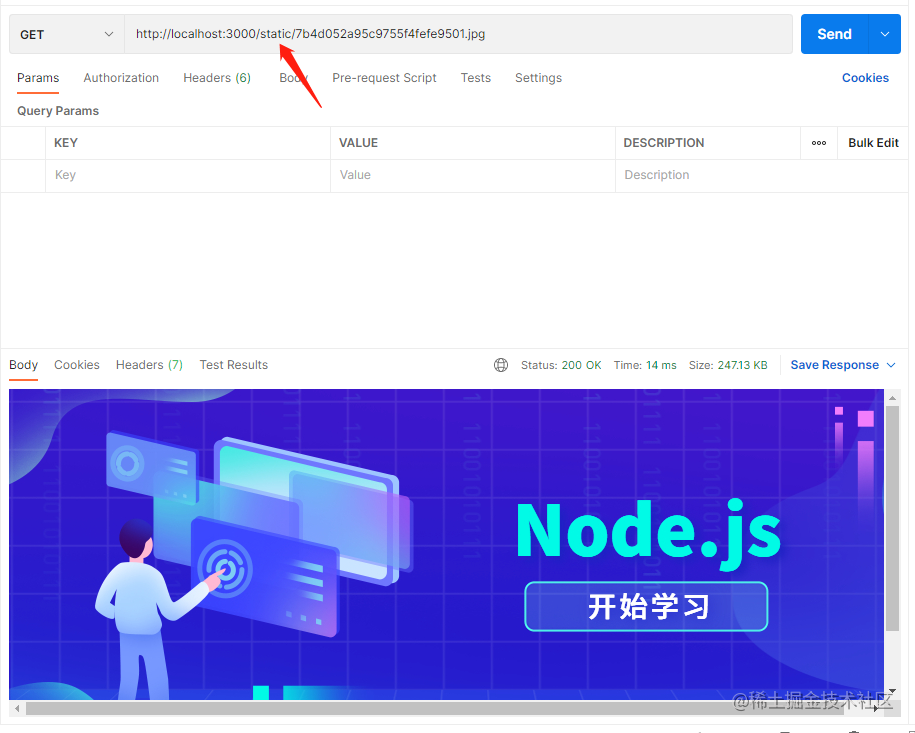
错误处理
koa也可以通过中间件来捕获错误,但是需要注意,这个中间件需要写在前面。
app.use(async (ctx, next) => {
try {
await next();
} catch (error) {
ctx.status = error.status || 500;
ctx.body = error.message || "服务端错误";
}
});
我们来测试一下
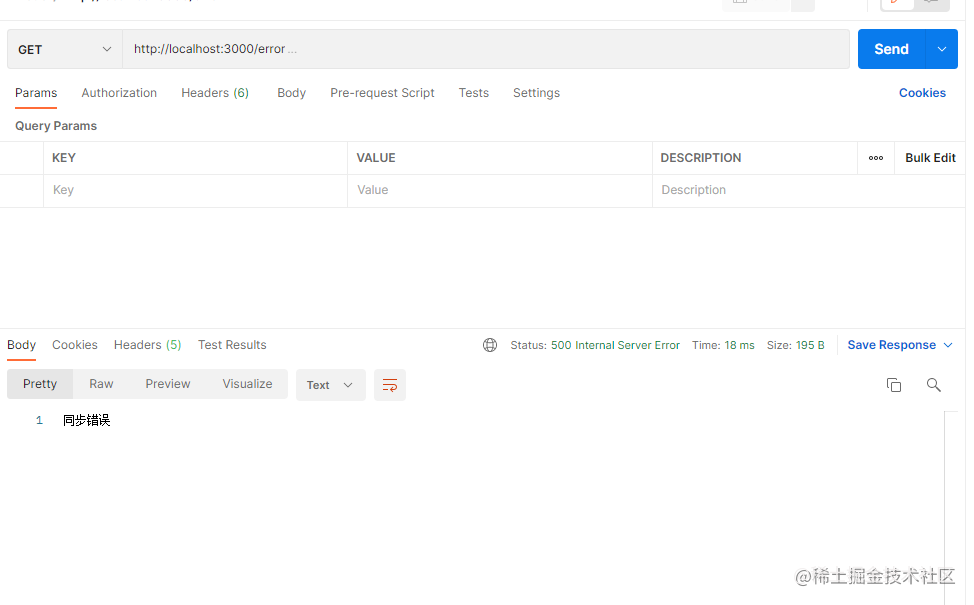
router.get("/error", function (ctx, next) {
throw new Error("同步错误");
});
可以看到,错误被中间件捕获并正常返回了。
我们再来看看异步错误
router.get("/error2", async function (ctx, next) {
await Promise.reject(new Error("异步错误"));
});
也能被正常捕获。
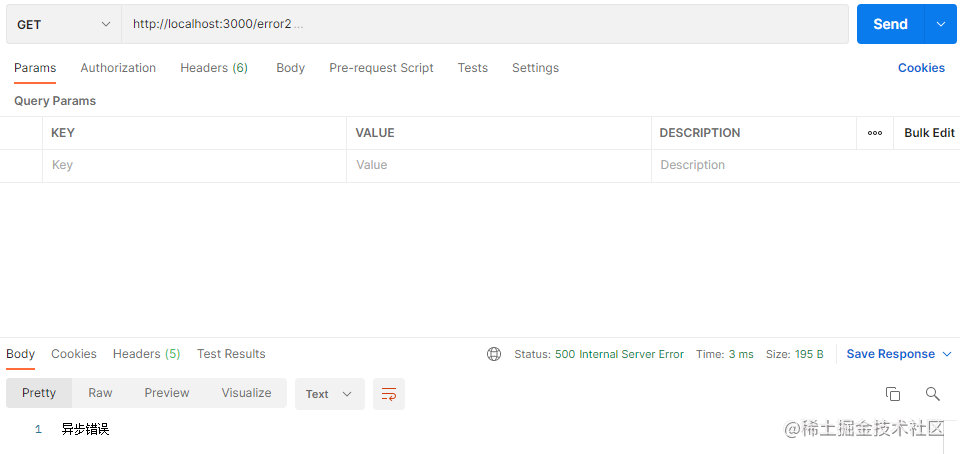
可以看到,相较于Express的错误处理,Koa变得更简单了,不管是同步错误还是异步错误都能正常捕获。
日志
对于线上项目用来说,日志是非常重要的一环。log4js是使用得比较多的一个日志组件,经常跟Express一起配合使用。本文简单讲解下在Express怎么使用log4js
我们首先来安装该插件,笔者这里安装的版本是6.8.0
npm install log4js
然后我们创建一个utils文件夹下创建log.js,用来创建一个logger。
const log4js = require("log4js");
const logger = log4js.getLogger();
logger.level = "debug";
module.exports = logger;
在需要的地方引入logger就可以了,我们来测试下
app.get("/logtest", (req, res) => {
logger.debug("Some debug messages");
logger.info("Some info messages");
logger.warn("Some warn messages");
logger.error("Some error messages");
res.send("test log");
});
可以看到,日志都打印出来了

日志等级
我们再来改变下输出日志的等级
logger.level = "warn";
再来测试下,发现只输出了warn和error等级的日志,debug和info等级的过滤掉了。

日志输出到文件
日志如果想输出到文件,我们还可以配置log4js
const log4js = require("log4js");
log4js.configure({
appenders: { test: { type: "file", filename: "applog.log" } },
categories: { default: { appenders: ["test"], level: "warn" } },
});
const logger = log4js.getLogger();
module.exports = logger;
我们再来测试下,发现它自动创建了applog.log文件,并将日志写入到了里面。

连接数据库
数据库目前主要有关系型数据库、非关系型数据库、缓存数据库,这三种数据库我们各举一个例子。
连接mongodb
为了方便操作mongodb,我们使用mongoose插件。
首先我们来安装
npm i mongoose
安装完后我们先创建db文件夹,然后创建mongodb.js,在这里来连接我们的mongodb数据库
const mongoose = require("mongoose");
module.exports = () => {
return new Promise((resolve, reject) => {
mongoose
.connect("mongodb://localhost/ExpressApi", {
})
.then(() => {
console.log("mongodb数据库连接成功");
resolve();
})
.catch((e) => {
console.log(e);
console.log("mongodb数据库连接失败");
reject();
});
});
};
然后在我们的入口文件引用使用
const runmongodb = require("./db/mongodb.js");
runmongodb();
保存,我们运行一下,可以看到mongodb连接成功。

我们查看mongodb面板,可以看到KoaApi数据库也创建成功了
数据库连接成功了,下面我们正式来创建接口。
我们以mvc模式,创建model、controller、route三个文件夹分别来管理模型、控制器、路由。
项目总体目录如下
model
controller
route
db
index.js
创建接口总共分为四步
- 创建模型
- 创建控制器
- 创建路由
- 使用路由
我们先来创建一个user model
const mongoose = require("mongoose");
const UserSchema = new mongoose.Schema(
{
username: {
type: String,
unique: true,
},
password: {
type: String,
select: false,
},
},
{ timestamps: true }
);
module.exports = mongoose.model("User", UserSchema);
然后创建user控制器,定义一个保存和一个查询方法。
const User = require("../model/user");
class UserController {
async create(ctx) {
const { username, password } = ctx.request.body;
const repeatedUser = await User.findOne({ username, password });
if (repeatedUser) {
ctx.status = 409;
ctx.body = {
message: "用户已存在",
};
} else {
const user = await new User({ username, password }).save();
ctx.body = user;
}
}
async query(ctx) {
const users = await User.find();
ctx.body = users;
}
}
module.exports = new UserController();
然后我们在路由里面定义好查询和创建接口
const Router = require("@koa/router");
const router = new Router({ prefix: "/user" });
const { create, query } = require("../controller/userController");
router.post("/create", create);
router.get("/query", query);
module.exports = router;
最后我们在入口文件使用该路由,前面我们说啦,路由少可以一个一个引入使用,对于路由多的话还是推荐使用自动注入的方式。
为了方便理解,这里我们还是使用引入的方式
const userRouter = require("./routes/user");
app.use(userRouter.routes()).use(userRouter.allowedMethods())
好啦,通过这四步,我们的接口就定义好啦,我们来测试一下
先来看看新增,接口正常返回
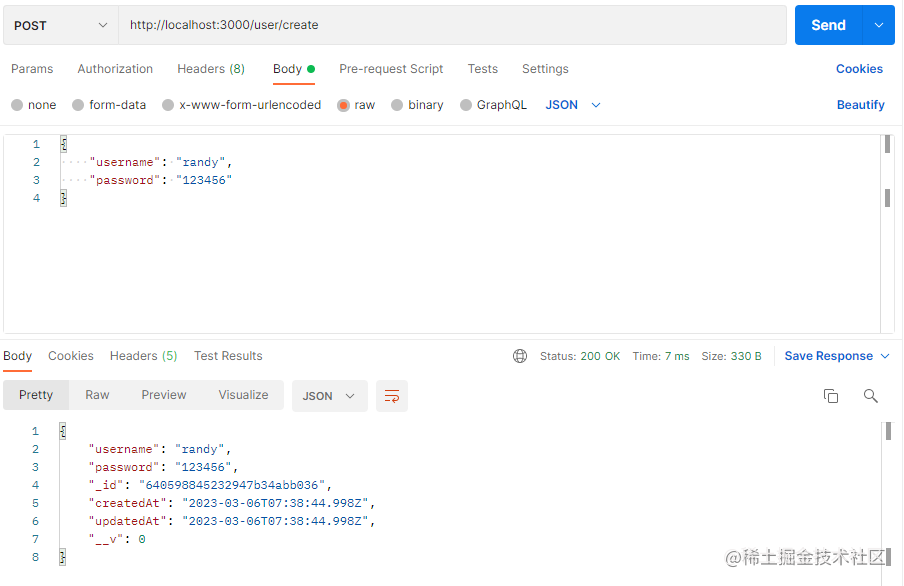
我们来看看数据库,发现user表添加了一条新记录。

我们再来看看查询接口,数据也能正常返回。
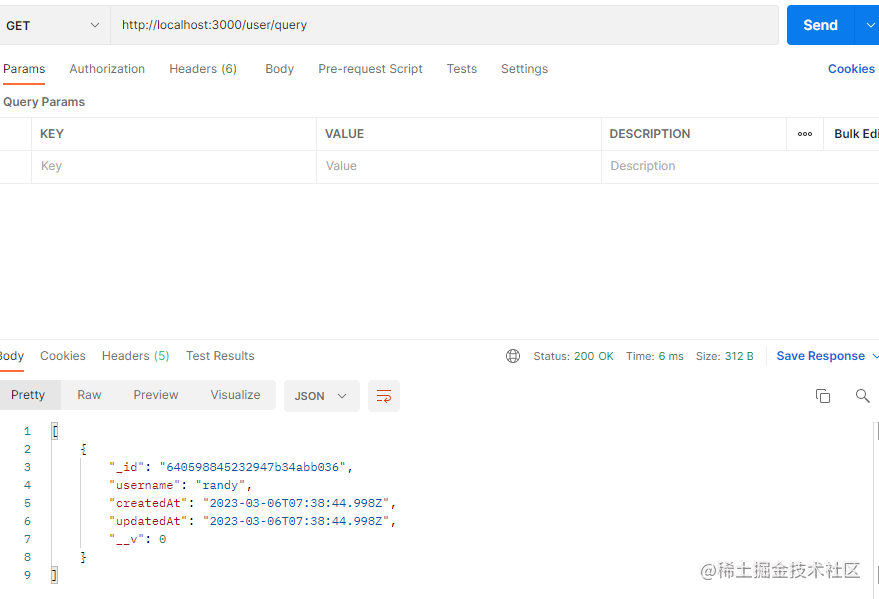
至此,我们的mongodb接口就创建并测试成功啦。
连接mysql
为了简化我们的操作,这里我们借助了ORM框架sequelize。
我们先来安装这两个库
npm i mysql2 sequelize
然后在db目录下创建mysql.js用来连接mysql。
const Sequelize = require("sequelize");
const sequelize = new Sequelize("KoaApi", "root", "123456", {
host: "localhost",
dialect: "mysql",
});
sequelize
.authenticate()
.then(() => {
console.log("数据库连接成功");
})
.catch((err) => {
console.error(err);
throw err;
});
module.exports = sequelize;
这里要注意,需要先把数据库koaapi提前创建好。它不会自动创建。
跟前面一样,创建接口总共分为四步
- 创建模型
- 创建控制器
- 创建路由
- 使用路由
首先我们创建model,这里我们创建user2.js
const Sequelize = require("sequelize");
const sequelize = require("../db/mysql");
const User2 = sequelize.define("user", {
username: {
type: Sequelize.STRING,
},
password: {
type: Sequelize.STRING,
},
});
User2.sync();
module.exports = User2;
然后创建控制器,定义一个保存和一个查询方法。
const User2 = require("../model/user2.js");
class user2Controller {
async create(ctx) {
const { username, password } = ctx.request.body;
try {
const user = await User2.create({ username, password });
ctx.body = user;
} catch (error) {
ctx.status = 500;
ctx.body = { code: 0, message: "保存失败" };
}
}
async query(ctx) {
const users = await User2.findAll();
ctx.body = users;
}
}
module.exports = new user2Controller();
然后定义两个路由
const router = new Router({ prefix: "/user2" });
const { query, create } = require("../controller/user2Controller");
// 获取用户
router.get("/query", query);
// 添加用户
router.post("/create", create);
module.exports = router;
最后在入口文件使用该路由
const user2Router = require("./routes/user2");
app.use(user2Router.routes()).use(user2Router.allowedMethods())
好啦,通过这四步,我们的接口就定义好啦,我们来测试一下
先来看看新增,接口正常返回
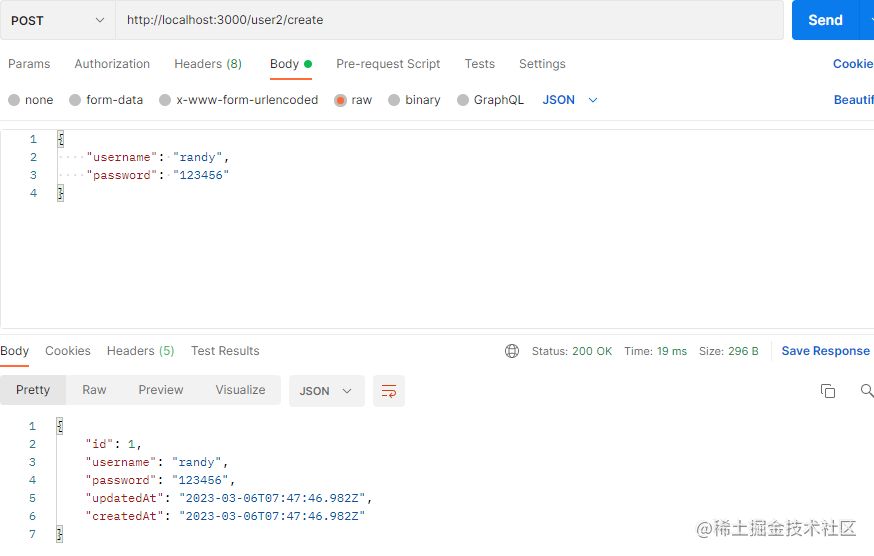
我们来看看数据库,发现users表添加了一条新记录。

我们再来看看查询接口,数据也能正常返回。
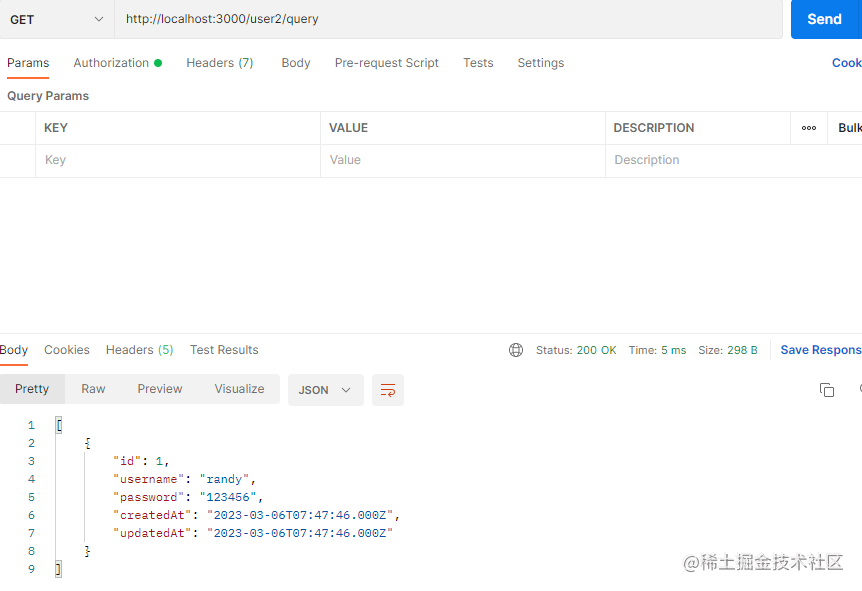
至此,我们的mysql接口就创建并测试成功啦。
我们再来看看缓存数据库redis。
连接redis
这里我们也需要借助node-redis插件
我们先来安装
npm i redis
然后在db目录下创建redis.js用来连接redis
const { createClient } = require("redis");
const client = createClient();
client.connect();
client.on("connect", () => console.log("Redis Client Connect Success"));
client.on("error", (err) => console.log("Redis Client Error", err));
module.exports = client;
然后我们创建一个简单的路由来测试一下
const Router = require("@koa/router");
const router = new Router({ prefix: "/dbtest" });
const client = require("../db/redis");
router.get("/redis", async (ctx) => {
await client.set("name", "randy");
const name = await client.get("name");
ctx.body = { name };
});
module.exports = router;
然后把该路由在入口文件注册使用
const dbtestRouter = require("./routes/dbtest");
app.use(dbtestRouter.routes()).use(dbtestRouter.allowedMethods())
最后我们来测试下接口,可以看到接口正常返回
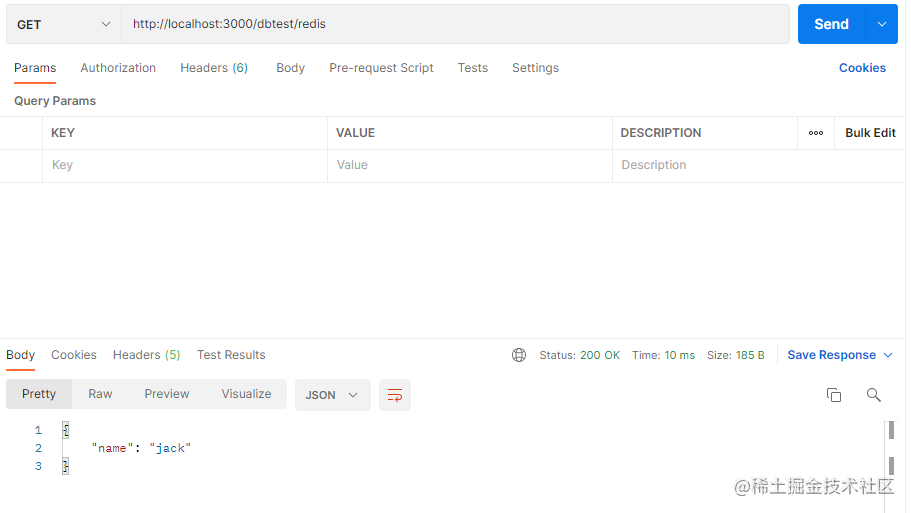
我们再来查看一下我们的redis数据库,发现数据保存成功。
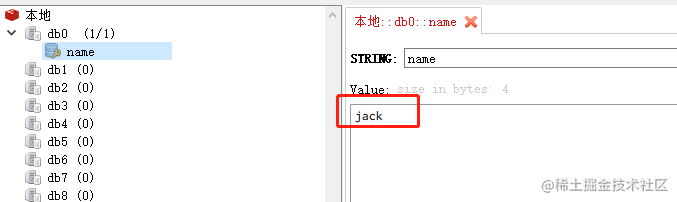
当然,这里只是一个简单的入门,redis的操作还有很多,大家可以看官方文档,这里笔者就不再详细说啦。
token验证
对于token的认证,我们这里使用目前比较流行的方案 jsonwebtoken。
生成token
我们首先安装jsonwebtoken。
npm i jsonwebtoken
安装完后,我们来实现一个登录接口,在接口里生成token并返回给前端。
注意这里因为是演示,所以将密钥写死,真实项目最好从环境变量里面动态获取。
const jwt = require("jsonwebtoken");
async login(ctx) {
const { username, password } = ctx.request.body;
const user = await User.findOne({ username, password });
if (user) {
const token = jwt.sign(
{ id: user.id, username: user.username },
"miyao",
{ expiresIn: 60 }
);
ctx.body = {
token,
};
} else {
ctx.status = 401;
ctx.body = {
message: "账号或密码错误",
};
}
}
这里生成token的接口我们就定义好了,我们来测试一下。
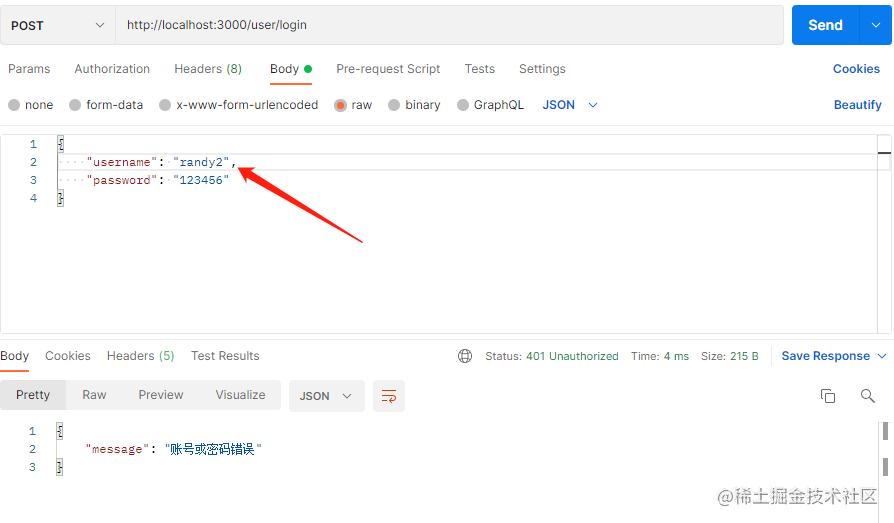
首先输入错误的账号,看到它提示账号密码错误了
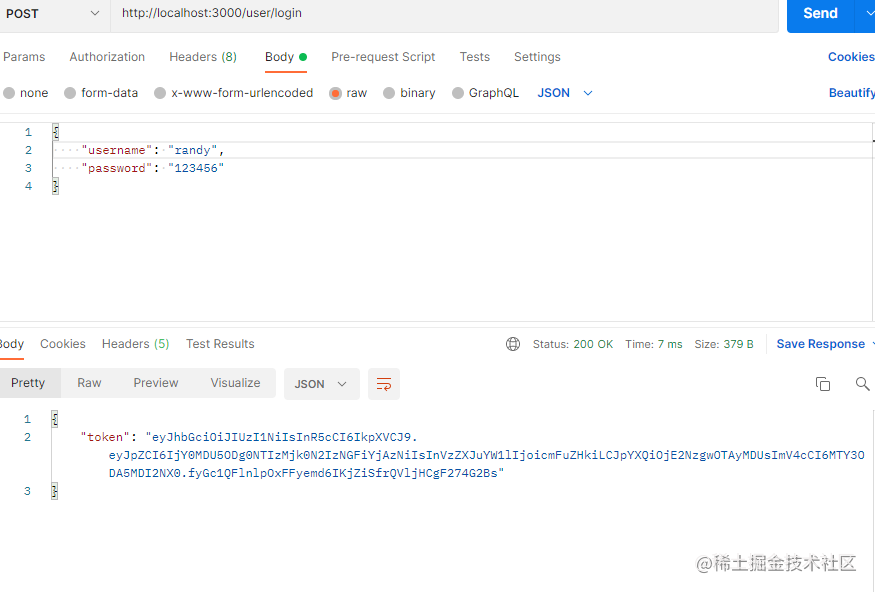
然后我们输入正确的账号密码试一下,可以看到,token被正常返回出来了。
到这里我们通过jsonwebtoken生成token就没问题了。接下来就是怎么验证token了。
token解密
在说token验证前,我们先来说个token解密,一般来说token是不需要解密的。但是如果非要看看里面是什么东西也是有办法解密的,那就得用到jwt-decode插件了。
该插件不验证密钥,任何格式良好的JWT都可以被解码。
我们来测试一下,
首先安装该插件
npm i jwt-decode
然后在登录接口里面使用jwt-decode解析token
const decoded = require("jwt-decode");
async login(req, res) {
console.log("decoded token", decoded(token));
}
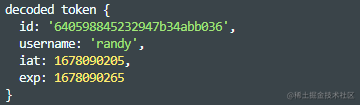
可以看到,就算没有秘钥也能将我们的token正确解析出来。
这个插件一般在我们前端用的比较多,比如想解析token,看看里面的数据是什么。它并不能验证token是否过期。如果想验证token的话还得使用下面的方法。
token验证
在Koa中,验证token是否有效我们一般会选择koa-jwt插件。
下面笔者来演示下怎么使用
首先还是安装
npm install koa-jwt
然后在入口文件以全局中间件的形式使用。
这个中间件我们要尽量放到前面,因为我们要验证所有接口token是否有效。
然后记得和错误中间件结合使用。
如果有些接口不想验证,可以使用unless排除,比如登录接口、静态资源。
const koaJwt = require("koa-jwt");
app.use(
koaJwt({ secret: "miyao" }).unless({ path: [/^\/user\/login/, "/static"] })
);
app.use(async (ctx, next) => {
try {
await next();
} catch (error) {
ctx.status = error.status || 500;
ctx.body = error.message || "服务端错误";
}
});
下面我们测试下,
我们先来看看不要token的接口,来访问一个静态资源。可以看到,没有token能正常获取资源。
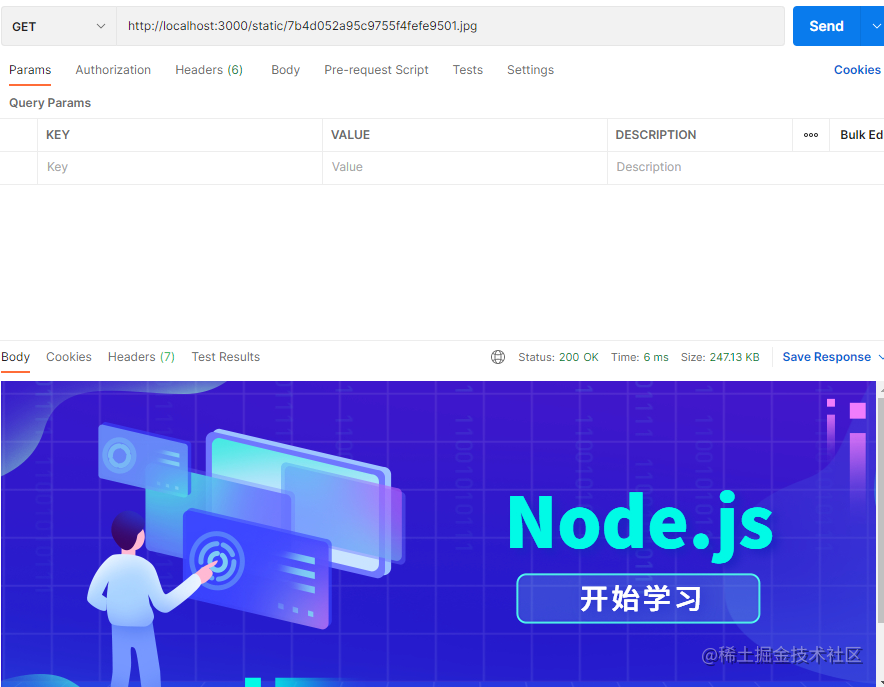
我们再来访问一个需要token的接口,可以看到它提示错误了,说是没有token
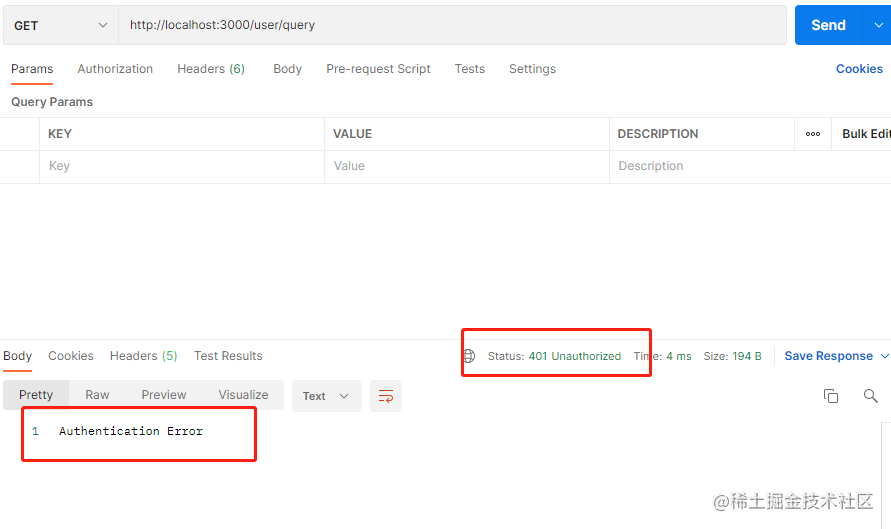
我们用登录接口生成一个token,然后给该接口加上来测试下,可以看到接口正常获取到数据了。
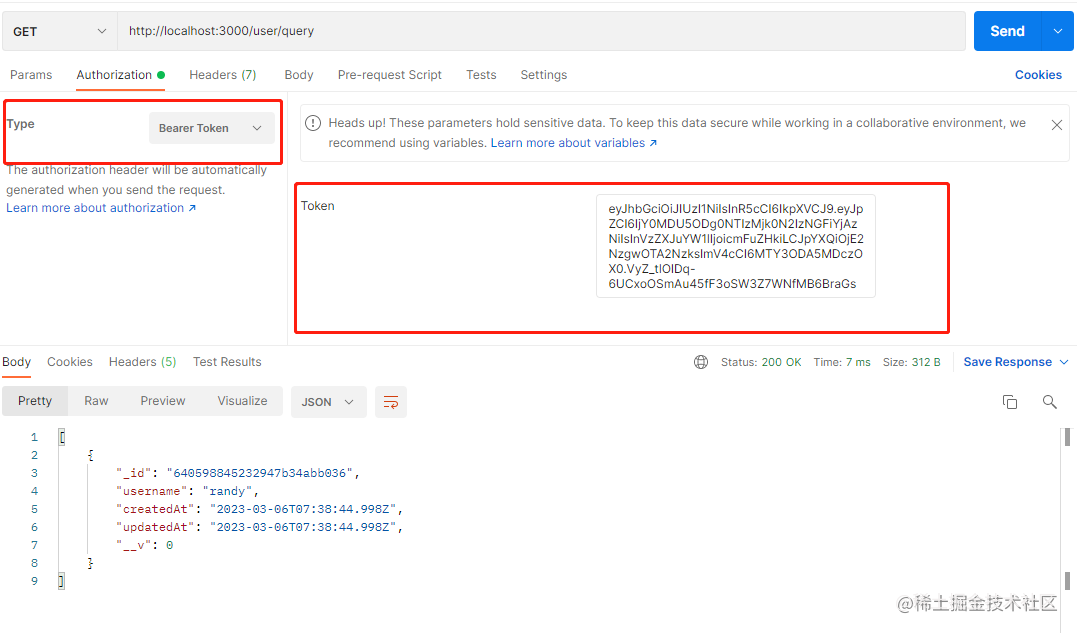
因为我们的token设置了一分钟有效,所以我们过一分钟再来请求该接口。可以看到,它提示token错误了。
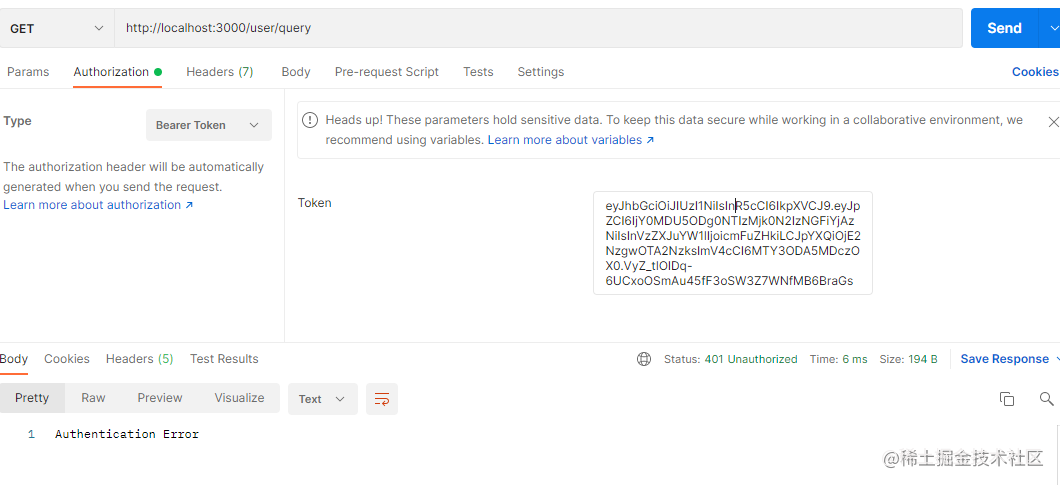
好啦,关于token验证我们就讲到这里。
启动
在node中,一般我们会使用node xx.js来运行某js文件。这种方式不仅不能后台运行而且如果报错了可能直接停止导致整个服务崩溃。
PM2 是 Node 进程管理工具,可以利用它来简化很多 Node 应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,而且使用非常简单。
首先我们需要全局安装
npm i pm2 -g
下面简单说说它的一些基本命令
- 启动应用:
pm2 start xxx.js
- 查看所有进程:
pm2 list
- 停止某个进程:
pm2 stop name/id
- 停止所有进程:
pm2 stop all
- 重启某个进程:
pm2 restart name/id
- 删除某个进程:
pm2 delete name/id
比如我们这里,启动当前应用,可以看到它以后台的模式将应用启动起来了。

当然关于pm2的使用远不止如此,大家可以查看PM2 文档自行学习。
总结
总体来说,koa更轻量,很多功能都不内置了而是需要单独安装。并且对异步有更好的支持,就是await会阻塞后面代码的执行(包括中间件)。
系列文章
Node.js入门之什么是Node.js
Node.js入门之path模块
Node.js入门之fs模块
Node.js入门之url模块和querystring模块
Node.js入门之http模块和dns模块
Node.js入门之process模块、child_process模块、cluster模块
听说你还不会使用Express
听说你还不会使用Koa?
后记
感谢小伙伴们的耐心观看,本文为笔者个人学习笔记,如有谬误,还请告知,万分感谢!如果本文对你有所帮助,还请点个关注点个赞~,您的支持是笔者不断更新的动力!
作者:苏苏同学
来源:juejin.cn/post/7208005547004919867