问题背景
最近跟群友讨论一个技术问题:
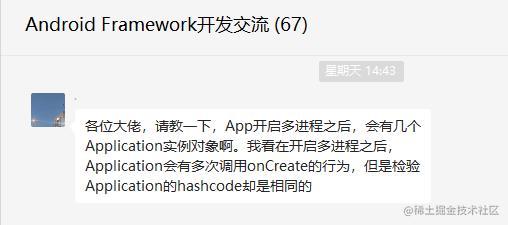
一个应用开启了多进程,最终到底会创建几个application对象,执行几次onCreate()方法?
有的群友根据自己的想法给出了猜想
甚至有的群友直接咨询起了ChatGPT
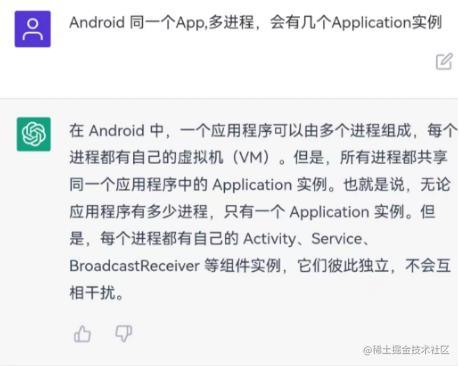
但至始至终都没有一个最终的结论。于是乎,为了弄清这个问题,我决定先写个demo测试得出结论,然后从源码着手分析原因
Demo验证
首先创建了一个app项目,开启多进程
<?xml version="1.0" encoding="utf-8"?>
<manifest
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
android:name=".DemoApplication"
android:allowBackup="true"
android:dataExtractionRules="@xml/data_extraction_rules"
android:fullBackupContent="@xml/backup_rules"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/Theme.Demo0307"
tools:targetApi="31">
<activity
android:name=".MainActivity"
android:exported="true"
android:process=":remote">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>
然后在DemoApplication的onCreate()方法打印application对象的地址,当前进程名称
public class DemoApplication extends Application {
private static final String TAG = "jasonwan";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "Demo application onCreate: " + this + ", processName=" + getProcessName(this));
}
private String getProcessName(Application app) {
int myPid = Process.myPid();
ActivityManager am = (ActivityManager) app.getApplicationContext().getSystemService(Context.ACTIVITY_SERVICE);
List<ActivityManager.RunningAppProcessInfo> runningAppProcesses = am.getRunningAppProcesses();
for (ActivityManager.RunningAppProcessInfo runningAppProcess : runningAppProcesses) {
if (runningAppProcess.pid == myPid) {
return runningAppProcess.processName;
}
}
return "null";
}
}
运行,得到的日志如下
2023-03-07 11:15:27.785 19563-19563/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote
查看当前应用所有进程

说明此时app只有一个进程,且只有一个application对象,对象地址为@fb06c2d
现在我们将进程增加到多个,看看情况如何
<?xml version="1.0" encoding="utf-8"?>
<manifest
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
android:name=".DemoApplication"
android:allowBackup="true"
android:dataExtractionRules="@xml/data_extraction_rules"
android:fullBackupContent="@xml/backup_rules"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/Theme.Demo0307"
tools:targetApi="31">
<activity
android:name=".MainActivity"
android:exported="true"
android:process=":remote">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<activity
android:name=".TwoActivity"
android:process=":remote2" />
<activity
android:name=".ThreeActivity"
android:process=":remote3" />
<activity
android:name=".FourActivity"
android:process=":remote4" />
<activity
android:name=".FiveActivity"
android:process=":remote5" />
</application>
</manifest>
逻辑是点击MainActivity启动TwoActivity,点击TwoActivity启动ThreeActivity,以此类推。最后我们运行,启动所有Activity得到的日志如下
2023-03-07 11:25:35.433 19955-19955/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote
2023-03-07 11:25:43.795 20001-20001/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote2
2023-03-07 11:25:45.136 20046-20046/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote3
2023-03-07 11:25:45.993 20107-20107/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote4
2023-03-07 11:25:46.541 20148-20148/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote5
查看当前应用所有进程
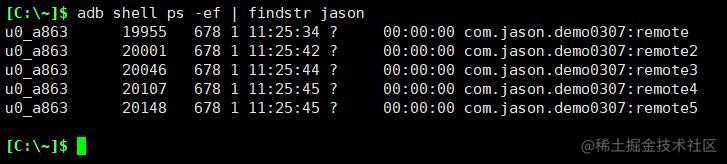
此时app有5个进程,但application对象地址均为@fb06c2d,地址相同意味着它们是同一个对象。
那是不是就可以得出结论,无论启动多少个进程都只会创建一个application对象呢?并不能妄下此定论,我们将MainActivity的process属性去掉再运行,得到的日志如下
2023-03-07 11:32:10.156 20318-20318/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@5d49e29, processName=com.jason.demo0307
2023-03-07 11:32:15.143 20375-20375/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote2
2023-03-07 11:32:16.477 20417-20417/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote3
2023-03-07 11:32:17.582 20463-20463/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote4
2023-03-07 11:32:18.882 20506-20506/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote5
查看当前应用所有进程
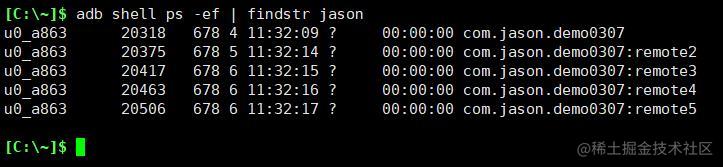
此时app有5个进程,但有2个application对象,对象地址为@5d49e29和@fb06c2d,且子进程的application对象都相同。
上述所有进程的父进程ID为678,而此进程正是zygote进程

根据上面的测试结果我们目前能得出的结论:
- 结论1:单进程只创建一个
Application对象,执行一次onCreate()方法;
- 结论2:多进程至少创建2个
Application对象,执行多次onCreate()方法,几个进程就执行几次;
结论2为什么说至少创建2个,因为我在集成了JPush的商业项目中测试发现,JPush创建的进程跟我自己创建的进程,Application地址是不同的。

这里三个进程,分别创建了三个Application对象,对象地址分别是@f31ba9d,@2c586f3,@fb06c2d
源码分析
这里需要先了解App的启动流程,具体可以参考《App启动流程》
Application的创建位于frameworks/base/core/java/android/app/ActivityThread.java的handleBindApplication()方法中
@UnsupportedAppUsage
private void handleBindApplication(AppBindData data) {
long st_bindApp = SystemClock.uptimeMillis();
Process.setStartTimes(SystemClock.elapsedRealtime(), SystemClock.uptimeMillis());
Process.setArgV0(data.processName);
Application app;
final StrictMode.ThreadPolicy savedPolicy = StrictMode.allowThreadDiskWrites();
final StrictMode.ThreadPolicy writesAllowedPolicy = StrictMode.getThreadPolicy();
try {
app = data.info.makeApplication(data.restrictedBackupMode, null);
try {
if ("com.jason.demo0307".equals(app.getPackageName())){
Log.d("jasonwan", "execute app onCreate(), app=:"+app+", processName="+getProcessName(app)+", pid="+Process.myPid());
}
mInstrumentation.callApplicationOnCreate(app);
} catch (Exception e) {
if (!mInstrumentation.onException(app, e)) {
throw new RuntimeException(
"Unable to create application " + app.getClass().getName()
+ ": " + e.toString(), e);
}
}
} finally {
if (data.appInfo.targetSdkVersion < Build.VERSION_CODES.O_MR1
|| StrictMode.getThreadPolicy().equals(writesAllowedPolicy)) {
StrictMode.setThreadPolicy(savedPolicy);
}
}
}
实际创建过程在frameworks/base/core/java/android/app/LoadedApk.java中的makeApplication()方法中,LoadedApk顾名思义就是加载好的Apk文件,里面包含Apk所有信息,像包名、Application对象,app所在的目录等,这里直接看application的创建过程
@UnsupportedAppUsage
public Application makeApplication(boolean forceDefaultAppClass,
Instrumentation instrumentation) {
if ("com.jason.demo0307".equals(mApplicationInfo.packageName)) {
Log.d("jasonwan", "makeApplication: mApplication="+mApplication+", pid="+Process.myPid());
}
if (mApplication != null) {
return mApplication;
}
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "makeApplication");
Application app = null;
String appClass = mApplicationInfo.className;
if (forceDefaultAppClass || (appClass == null)) {
appClass = "android.app.Application";
}
try {
java.lang.ClassLoader cl = getClassLoader();
if (!mPackageName.equals("android")) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER,
"initializeJavaContextClassLoader");
initializeJavaContextClassLoader();
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
ContextImpl appContext = ContextImpl.createAppContext(mActivityThread, this);
app = mActivityThread.mInstrumentation.newApplication(
cl, appClass, appContext);
if ("com.jason.demo0307.DemoApplication".equals(appClass)){
Log.d("jasonwan", "create application, app="+app+", processName="+mActivityThread.getProcessName()+", pid="+Process.myPid());
}
appContext.setOuterContext(app);
} catch (Exception e) {
Log.d("jasonwan", "fail to create application, "+e.getMessage());
if (!mActivityThread.mInstrumentation.onException(app, e)) {
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
throw new RuntimeException(
"Unable to instantiate application " + appClass
+ ": " + e.toString(), e);
}
}
mActivityThread.mAllApplications.add(app);
mApplication = app;
if (instrumentation != null) {
try {
instrumentation.callApplicationOnCreate(app);
} catch (Exception e) {
if (!instrumentation.onException(app, e)) {
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
throw new RuntimeException(
"Unable to create application " + app.getClass().getName()
+ ": " + e.toString(), e);
}
}
}
return app;
}
为了看清application到底被创建了几次,我在关键地方埋下了log,TAG为jasonwan的log是我自己加的,编译验证,得到如下log
启动app,进入MainActivity
03-08 17:20:29.965 4069 4069 D jasonwan: makeApplication: mApplication=null, pid=4069
//创建application对象,地址为@c2f8311,当前进程id为4069
03-08 17:20:29.967 4069 4069 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:29.988 4069 4069 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:29.989 4069 4069 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:36.614 4069 4069 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4069
点击MainActivity,跳转到TwoActivity
03-08 17:20:39.686 4116 4116 D jasonwan: makeApplication: mApplication=null, pid=4116
//创建application对象,地址为@c2f8311,当前进程id为4116
03-08 17:20:39.687 4116 4116 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.688 4116 4116 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.688 4116 4116 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.733 4116 4116 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4116
点击TwoActivity,跳转到ThreeActivity
03-08 17:20:41.473 4147 4147 D jasonwan: makeApplication: mApplication=null, pid=4147
//创建application对象,地址为@c2f8311,当前进程id为4147
03-08 17:20:41.475 4147 4147 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.475 4147 4147 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.476 4147 4147 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.519 4147 4147 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4147
点击ThreeActivity,跳转到FourActivity
03-08 17:20:42.966 4174 4174 D jasonwan: makeApplication: mApplication=null, pid=4174
//创建application对象,地址为@c2f8311,当前进程id为4174
03-08 17:20:42.968 4174 4174 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:42.969 4174 4174 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:42.969 4174 4174 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:43.015 4174 4174 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4174
点击FourActivity,跳转到FiveActivity
03-08 17:20:44.426 4202 4202 D jasonwan: makeApplication: mApplication=null, pid=4202
//创建application对象,地址为@c2f8311,当前进程id为4202
03-08 17:20:44.428 4202 4202 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.429 4202 4202 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.430 4202 4202 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.473 4202 4202 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4202
结果很震惊,我们在5个进程中创建的application对象,地址均为@c2f8311,也就是至始至终创建的都是同一个Application对象,那么上面的结论2显然并不成立,只是测试的偶然性导致的。
可真的是这样子的吗,这也太颠覆我的三观了,为此我跟群友讨论了这个问题:
不同进程中的多个对象,内存地址相同,是否代表这些对象都是同一个对象?
群友的想法是,java中获取的都是虚拟内存地址,虚拟内存地址相同,不代表是同一个对象,必须物理内存地址相同,才表示是同一块内存空间,也就意味着是同一个对象,物理内存地址和虚拟内存地址存在一个映射关系,同时给出了java中获取物理内存地址的方法Android获取对象地址,主要是利用Unsafe这个类来操作,这个类有一个作用就是直接访问系统内存资源,具体描述见Java中的魔法类-Unsafe,因为这种操作是不安全的,所以被标为了私有,但我们可以通过反射去调用此API, 然后我又去请教了部门搞寄存器的大佬,大佬肯定了群友的想法,于是我添加代码,尝试获取对象的物理内存地址,看看是否相同
public class DemoApplication extends Application {
public static final String TAG = "jasonwan";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "DemoApplication=" + this + ", address=" + addressOf(this) + ", pid=" + Process.myPid());
}
public static long addressOf(Object o) {
Object[] array = new Object[]{o};
long objectAddress = -1;
try {
Class cls = Class.forName("sun.misc.Unsafe");
Field field = cls.getDeclaredField("theUnsafe");
field.setAccessible(true);
Object unsafe = field.get(null);
Class unsafeCls = unsafe.getClass();
Method arrayBaseOffset = unsafeCls.getMethod("arrayBaseOffset", Object.class.getClass());
int baseOffset = (int) arrayBaseOffset.invoke(unsafe, Object[].class);
Method size = unsafeCls.getMethod("addressSize");
int addressSize = (int) size.invoke(unsafe);
switch (addressSize) {
case 4:
Method getInt = unsafeCls.getMethod("getInt", Object.class, long.class);
objectAddress = (int) getInt.invoke(unsafe, array, baseOffset);
break;
case 8:
Method getLong = unsafeCls.getMethod("getLong", Object.class, long.class);
objectAddress = (long) getLong.invoke(unsafe, array, baseOffset);
break;
default:
throw new Error("unsupported address size: " + addressSize);
}
} catch (Exception e) {
e.printStackTrace();
}
return objectAddress;
}
}
运行后得到如下日志
2023-03-10 11:01:54.043 6535-6535/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@930d275, address=8050489105119022792, pid=6535
2023-03-10 11:02:22.610 6579-6579/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119027136, pid=6579
2023-03-10 11:02:36.369 6617-6617/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119029912, pid=6617
2023-03-10 11:02:39.244 6654-6654/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119032760, pid=6654
2023-03-10 11:02:40.841 6692-6692/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119036016, pid=6692
2023-03-10 11:02:52.429 6729-6729/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119038720, pid=6729
可以看到,虽然Application的虚拟内存地址相同,都是331b3b9,但它们的真实物理地址却不同,至此,我们可以得出最终结论:
- 单进程,创建1个application对象,执行一次
onCreate()方法
- 多进程(N),创建N个application对象,执行N次
onCreate()方法
作者:小迪vs同学
来源:juejin.cn/post/7208345469658415159












