一、序
我之前发布了个图片加载框架,在JCenter关闭后,“闭关修炼”,想着改好了出个2.0版本。
后来觉得仅增加功能和改进实现不够,得补充一下用例。
相册列表的加载就是很好的用例,然后在Github找了一圈,没有找到满意的,有的甚至好几年没维护了,于是就自己写了一个。
代码链接:github.com/BillyWei01/…
相比于图片加载,相册加载在Github上要多很多。
其原因大概是图片加载的input/output比较规范,不涉及UI布局;
而相册则不然,几乎每个APP都会有自己独特的需求,有自己的UI风格。
因此,相册库很难做到通用于大部分APP。
我所实现的这个也一样,并非以实现通用的相册组件为目的,而是作为一个样例,以供参考。
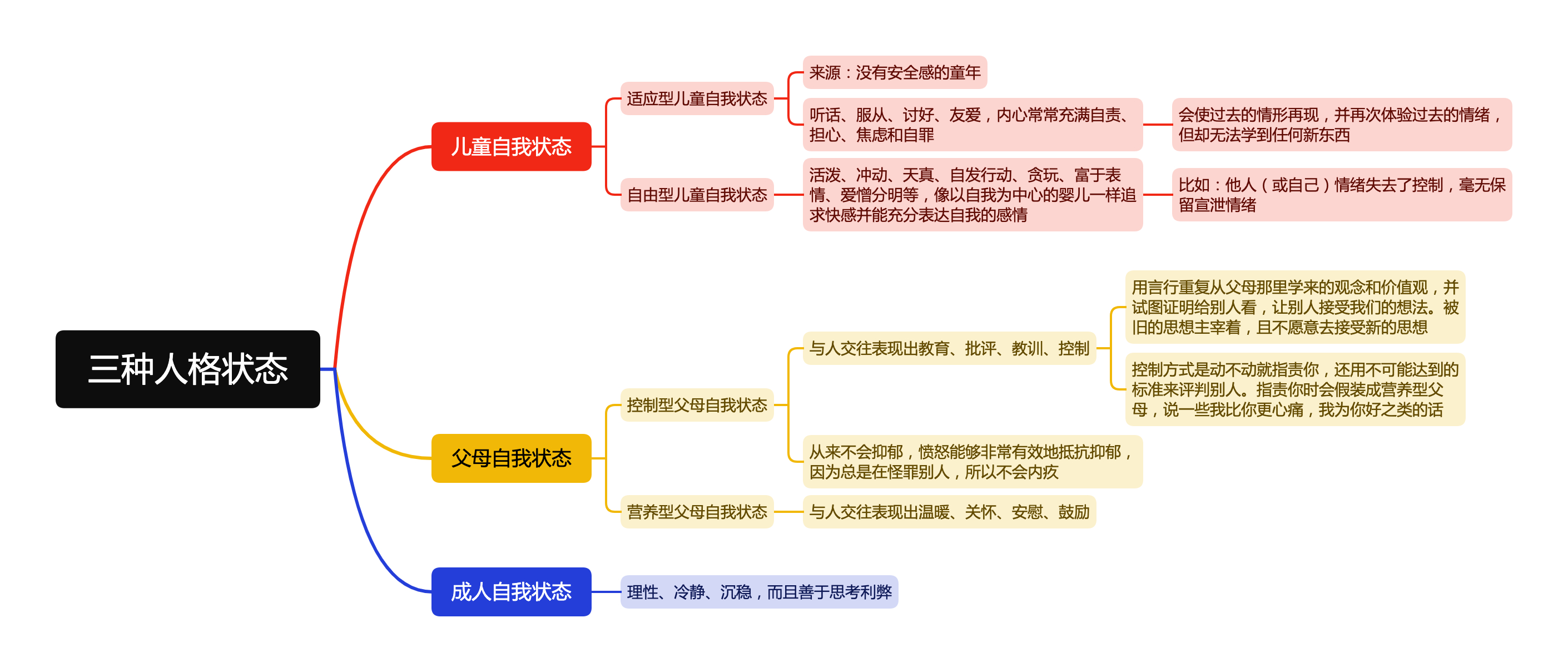
二、 需求描述
网上不少相册的开源库,都是照微信相册来搭的界面,我也是跟着这么做吧,要是说涉及侵权什么的,那些前辈应该先比我收到通知……
主要是自己也不会UI设计,不找个参照对象怕实现的太难看。
话说回来,要是真的涉及侵权,请联系我处理。
相册所要实现的功能,概括来说,就是显示相册列表,点击缩略图选中,点击完成结束选择,返回选择结果。
需求细节,包括但不限于以下列表:
- 实现目录列表,相册列表,预览页面;
- 支持单选/多选;
- 支持显示选择顺序和限定选择数量;
- 支持自定义筛选条件;
- 支持自定义目录排序;
- 支持“原图”选项;
- 支持再次进入相册时传入已经选中的图片/视频;
- 支持切换出APP外拍照或删除照片后,回到相册时自动刷新;
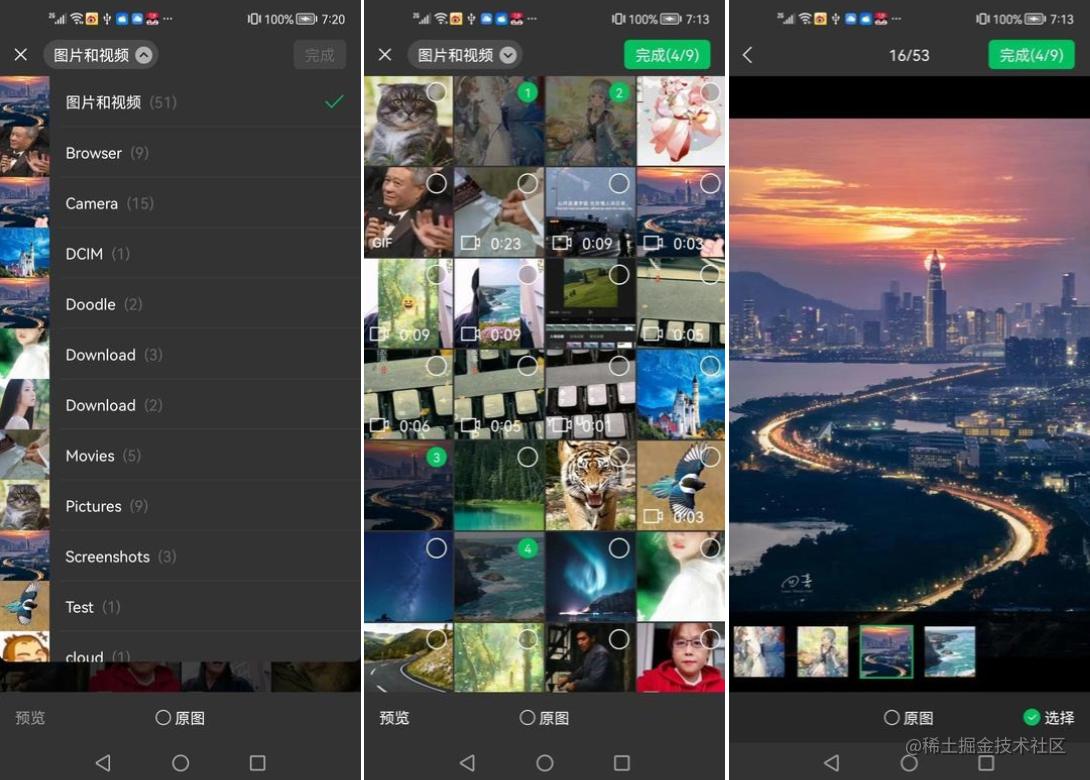
效果如图:
三、API设计
由于不同的页面可能需求不一样,所以可以将需求参数封装到”Request“中;
对于通用的选项,以及相册组件的全局配置,可以更封装到“Config"中。
而Request/Config最好是用链式API去设置参数,链式API尤其适合参数是“可选项”的场景。
3.1 全局设置
EasyAlbum.config()
.setImageLoader(GlideImageLoader)
.setDefaultFolderComparator { o1, o2 -> o1.name.compareTo(o2.name)}
GlideImageLoader是相册组件定义的ImageLoader接口的实现类。
public interface ImageLoader {
void loadPreview(MediaData data, ImageView imageView, boolean asBitmap);
void loadThumbnail(MediaData data, ImageView imageView, boolean asBitmap);
}
不同的APP使用的图片加载框架不一样,所以相册组件最好不要强依赖图片加载框架,而是暴露接口给调用者。
当然,对于整个APP而言,不建议定义这样的ImageLoader类,因为APP使用图片加载的地方很多,
定义这样的类,要么需要重载很多方法,要么就是参数列表很长,也就丧失链式API的优点了。
关于目录排序,EasyAlbum中定义的默认排序是按照更新时间(取最新的图片的更新时间)排序。
上面代码举例的是按目录名排序。
如果需要某个目录排在列表前面,可以这样定义(以“Camera”为例):
private val priorityFolderComparator = Comparator<Folder> { o1, o2 ->
val priorityFolder = "Camera"
if (o1.name == priorityFolder) -1
else if (o2.name == priorityFolder) 1
else o1.name.compareTo(o2.name)
}
出个思考题:
如果需要“优先排序”的不只一个目录,比如希望“Camera"第一优先,"Screenshots"第二优先,“Pictures"第三优先……
改如何定义Comparator?
3.2 启动相册
EasyAlbum启动相册以from起头,以start结束。
EasyAlbum.from(this)
.setFilter(TestMediaFilter(option))
.setSelectedLimit(selectLimit)
.setOverLimitCallback(overLimitCallback)
.setSelectedList(mediaAdapter?.getData())
.setAllString(option.text)
.enableOriginal()
.start { result ->
mediaAdapter?.setData(result.selectedList)
}
具体到实现,就是from返回 Request, Request的start方法启动相册页(AlbumActivity)。
public class EasyAlbum {
public static AlbumRequest from(@NonNull Context context) {
return new AlbumRequest(context);
}
}
public final class AlbumRequest {
private WeakReference<Context> contextRef;
AlbumRequest(Context context) {
this.contextRef = new WeakReference<>(context);
}
public void start(ResultCallback callback) {
Session.init(this, callback, selectedList);
if (contextRef != null) {
Context context = contextRef.get();
if (context != null) {
context.startActivity(new Intent(context, AlbumActivity.class));
}
contextRef = null;
}
}
}
启动AlbumActivity,就涉及传参和结果返回。
有两种思路:
- 通过intent传参数到AlbumActivity, 用startActivityForResult启动,通过onActivityResult接收。
- 通过静态变量传递参数,通过Callback回调结果。
第一种方法,需要所有的参数都能放入Intent, 基础数据可以传,自定义数据类可以实现Parcelable,
但那对于接口的实现,就没办法放 intent 了,到头来还是要走静态变量。
因此,干脆就都走静态变量传递好了。
这个方案可行的前提是, AlbumActivity是封闭的,不会在跳转其他Activity。
在这个前提下,App不会同一个时刻打开多个AlbumActivity,不需要担心共享变量相互干扰的情况。
然后就是,在Activity结束时,做好清理工作。
可以将“启动相册-选择图片-结束相册”抽象为一次“Session”, 在相册结束时,执行一下clear操作。
final class Session {
static AlbumRequest request;
static AlbumResult result;
private static ResultCallback resultCallback;
static void init(AlbumRequest req, ResultCallback callback, List<MediaData> selectedList) {
request = req;
resultCallback = callback;
result = new AlbumResult();
if (selectedList != null) {
result.selectedList.addAll(selectedList);
}
}
static void clear() {
if (request != null) {
request.clear();
request = null;
resultCallback = null;
result = null;
}
}
}
四、媒体文件加载
媒体文件加载似乎很简单,就调ContentResolver query一下的事,但要做到尽量完备,需要考虑的细节还是不少的。
4.1 MediaStore API
查询媒体数据库,需走ContentResolver的qurey方法:
public final Cursor query(
Uri uri,
String[] projection,
String selection,
String[] selectionArgs,
String sortOrder,
CancellationSignal cancellationSignal) {
}
媒体数据库记录了各种媒体类型,要过滤其中的“图片”和“视频”,有两种方法:
1、用SDK定义好的MediaStore.Video和MediaStore.Images的Uri。
MediaStore.Video.Media.EXTERNAL_CONTENT_URI
MediaStore.Images.Media.EXTERNAL_CONTENT_URI
2、直接读取"content://external", 通过MEDIA_TYPE字段过滤。
private static final Uri CONTENT_URI = MediaStore.Files.getContentUri("external");
private static final String TYPE_SELECTION = "(" + MediaStore.Files.FileColumns.MEDIA_TYPE + "="
+ MediaStore.Files.FileColumns.MEDIA_TYPE_VIDEO
+ " OR " + MediaStore.Files.FileColumns.MEDIA_TYPE + "="
+ MediaStore.Files.FileColumns.MEDIA_TYPE_IMAGE
+ ")";
如果需要同时读取图片和视频,第2种方法更省事一些。
至于查询的字段,视需求而定。
以下是比较常见的字段:
private static final String[] PROJECTIONS = new String[]{
MediaStore.MediaColumns._ID,
MediaStore.MediaColumns.DATA,
MediaStore.Files.FileColumns.MEDIA_TYPE,
MediaStore.MediaColumns.DATE_MODIFIED,
MediaStore.MediaColumns.MIME_TYPE,
MediaStore.Video.Media.DURATION,
MediaStore.MediaColumns.SIZE,
MediaStore.MediaColumns.WIDTH,
MediaStore.MediaColumns.HEIGHT,
MediaStore.Images.Media.ORIENTATION
};
DURATION, SIZE, WIDTH, HEIGHT,ORIENTATION等字段有可能是无效的(0或者null),
如果是无效的,可以去从文件本身获取,但读文件比较耗时,
所以可以先尝试从MediaStore读取,毕竟是都访问到这条记录了,从空间局部原理来说,读取这些字段是顺便的事情,代价要比另外读文件本身低很多。
当然,如果确实不需要这些信息,可以直接不读取。
4.2 数据包装
数据查询出来,需要定义Entity来包装数据。
public final class MediaData implements Comparable<MediaData> {
private static final String BASE_VIDEO_URI = "content://media/external/video/media/";
private static final String BASE_IMAGE_URI = "content://media/external/images/media/";
static final byte ROTATE_UNKNOWN = -1;
static final byte ROTATE_NO = 0;
static final byte ROTATE_YES = 1;
public final boolean isVideo;
public final int mediaId;
public final String parent;
public final String name;
public final long modifiedTime;
public String mime;
long fileSize;
int duration;
int width;
int height;
byte rotate = ROTATE_UNKNOWN;
public String getPath() {
return parent + name;
}
public Uri getUri() {
String baseUri = isVideo ? BASE_VIDEO_URI : BASE_IMAGE_URI;
return Uri.parse(baseUri + mediaId);
}
public int getRealWidth() {
if (rotate == ROTATE_UNKNOWN || width == 0 || height == 0) {
fillData();
}
return rotate != ROTATE_YES ? width : height;
}
public int getRealHeight() {
if (rotate == ROTATE_UNKNOWN || width == 0 || height == 0) {
fillData();
}
return rotate != ROTATE_YES ? height : width;
}
}
4.2.1 数据共享
字段的定义中,没有直接定义path字段,而是定义了parent和name,因为图片/视频文件可能有成千上万个,但是目录大概率不会超过3位数,所以,我们可以通过复用parent来节约内存。
同理,mime也可以复用。
截取部分查询的代码:
int count = cursor.getCount();
List<MediaData> list = new ArrayList<>(count);
while (cursor.moveToNext()) {
String path = cursor.getString(IDX_DATA);
String parent = parentPool.getOrAdd(Utils.getParentPath(path));
String name = Utils.getFileName(path);
String mime = mimePool.getOrAdd(cursor.getString(IDX_MIME_TYPE));
}
复用字符串,可以用HashMap来做,我这边是仿照HashMap写了一个专用的类来实现。
getOrAdd方法:传入一个字符串,如果容器中已经有这个字符串,返回容器保存的字符串,
否则,保存当前字符串并返回。
如此,所有的MediaData共用相同parent和mime字符串对象。
4.2.2 处理无效数据
前面提到,从MediaStore读取的数据,有部分是无效的。
这些可能无效的字段不要直接public, 而是提供get方法,并在返回之前检查数据的有效性,如果数据无效则读文件获取数据。
当然,读文件是耗时操作,虽然一般情况下时间是可控的,但是最好还是放IO线程去访问比较保险。
也有比较折中的做法:
- 数据只是用作参考,有的话更好,没有也没关系。
如果是这样的话,提供不做检查直接返回数据的方法:
public int getWidth() {
return rotate != ROTATE_YES ? width : height;
}
public int getHeight() {
return rotate != ROTATE_YES ? height : width;
}
- 数据比较重要,但也不至于没有就不行。
这种case,当数据无效时,可以先尝试读取,但是加个timeout, 在规定时间内没有完成读取则直接返回。
public int getDuration() {
if (isVideo && duration == 0) {
checkData();
}
return duration;
}
void checkData() {
if (!hadFillData) {
FutureTask<Boolean> future = new FutureTask<>(this::fillData);
try {
AlbumConfig.getExecutor().execute(future);
future.get(300, TimeUnit.MILLISECONDS);
} catch (Throwable ignore) {
}
}
}
4.3 数据加载
数据加载部分是最影响相册体验的因素之一。
等待时间、数据刷新,数据有效性等都会影响相册的交互。
4.3.1 缓存MediaData
媒体库查询是一个综合IO读取和CPU密集计算的操作,文件少的时候还好,一旦文件比较多,耗时几秒钟也是有的。
如果用户每次打开相册都要等几秒钟才刷出数据,那体验就太糟糕了。
加个MediaData的缓存,再次进入相册时,就不需要再次读所有字段了,
只需读取MediaStore的ID字段,然后结合缓存,做下Diff, 已删除的移除出缓存,新增的根据ID检索其记录,创建MediaData添加到缓存。
再次进入相册,即使有增删也不会太多。
缓存MediaData的好处不仅仅是加速再次查询MediaStore,还可以减少对象的创建,不需要每次查询都重新创建MediaData对象;
另外,前面也提到,MediaData部分字段有的是无效的,在无效时需要读取原文件获取,缓存MediaData可免去再次读文件获取数据的时间(如果对象是读取MediaStore重新创建的,就又回到无效的状态了)。
还有就是,有缓存的话,就可以做预加载了。
当然这个得看APP是否有这个需求,如果APP是媒体相关的,大概率要访问相册的,可以考虑预加载。
做缓存的代价就是要占用些内存,这也是前面MediaData为什么复用parent和mime的原因。
缓存是空间换时间,复用对象是时间换空间,总体而言这个对冲是赚的,因为读取IO更耗时。
另外,如果有必要,可以提供clearCache接口,在适当的时机清空缓存。
4.3.2 组装结果
相册的UI层所需要的是: 根据Request的查询条件过滤后的MediaData,以目录为分组,按更新时间降序排列的数据。
缓存的MediaData并非查询的终点,但却提供了一个好的起点。
在有缓存好的MediaData列表的前提下,可直接根据MediaData列表做过滤,排序和分组,
而不需要每次都将过滤条件拼接SQL到数据库中查询,而且相比于拼接SQL,在上层直接根据MediaData过滤要更加灵活。
下面是EasyAlbum基于MediaData缓存的查询:
private static List<Folder> makeResult(AlbumRequest request) {
AlbumRequest.MediaFilter filter = request.filter;
ArrayList<MediaData> totalList = new ArrayList<>(mediaCache.size());
if (filter == null) {
totalList.addAll(mediaCache.values());
} else {
for (MediaData item : mediaCache.values()) {
if (filter.accept(item)) {
totalList.add(item);
}
}
}
Collections.sort(totalList);
Map<String, ArrayList<MediaData>> groupMap = new HashMap<>();
for (MediaData item : totalList) {
String parent = item.parent;
ArrayList<MediaData> subList = groupMap.get(parent);
if (subList == null) {
subList = new ArrayList<>();
groupMap.put(parent, subList);
}
subList.add(item);
}
final List<Folder> result = new ArrayList<>(groupMap.size() + 1);
for (Map.Entry<String, ArrayList<MediaData>> entry : groupMap.entrySet()) {
String folderName = Utils.getFileName(entry.getKey());
result.add(new Folder(folderName, entry.getValue()));
}
Collections.sort(result, request.folderComparator);
result.add(0, new Folder(request.getAllString(), totalList));
return result;
}
MediaFilter的定义如下:
public interface MediaFilter {
boolean accept(MediaData media);
String tag();
}
基于MediaData缓存列表的查询虽然比基于数据库的查询快不少,但是当文件很多时,也还是要花一些时间的。
所以我们可以再加一个缓存:缓存最终结果。
再加一个结果缓存,只是增加了些容器,容器指向的对象(MediaData)是之前MediaData缓存列表所引用的对象,所以代价还好。
再次进入相册时,可以先直接取结果显示,然后再去检查MediaStore相对于缓存有没有变更,有则刷新缓存和UI,否则直接返回。
APP可能有多个地方需要相册,不同地方查询条件可能不一样,所以MediaFilter定义了tag接口,用来区分不同的查询。
4.3.3 加载流程
流程图如下:
注意,下图的“结果”是提供给相册页面显示的数据,并非相册返回给调用者的“已选中的媒体”。
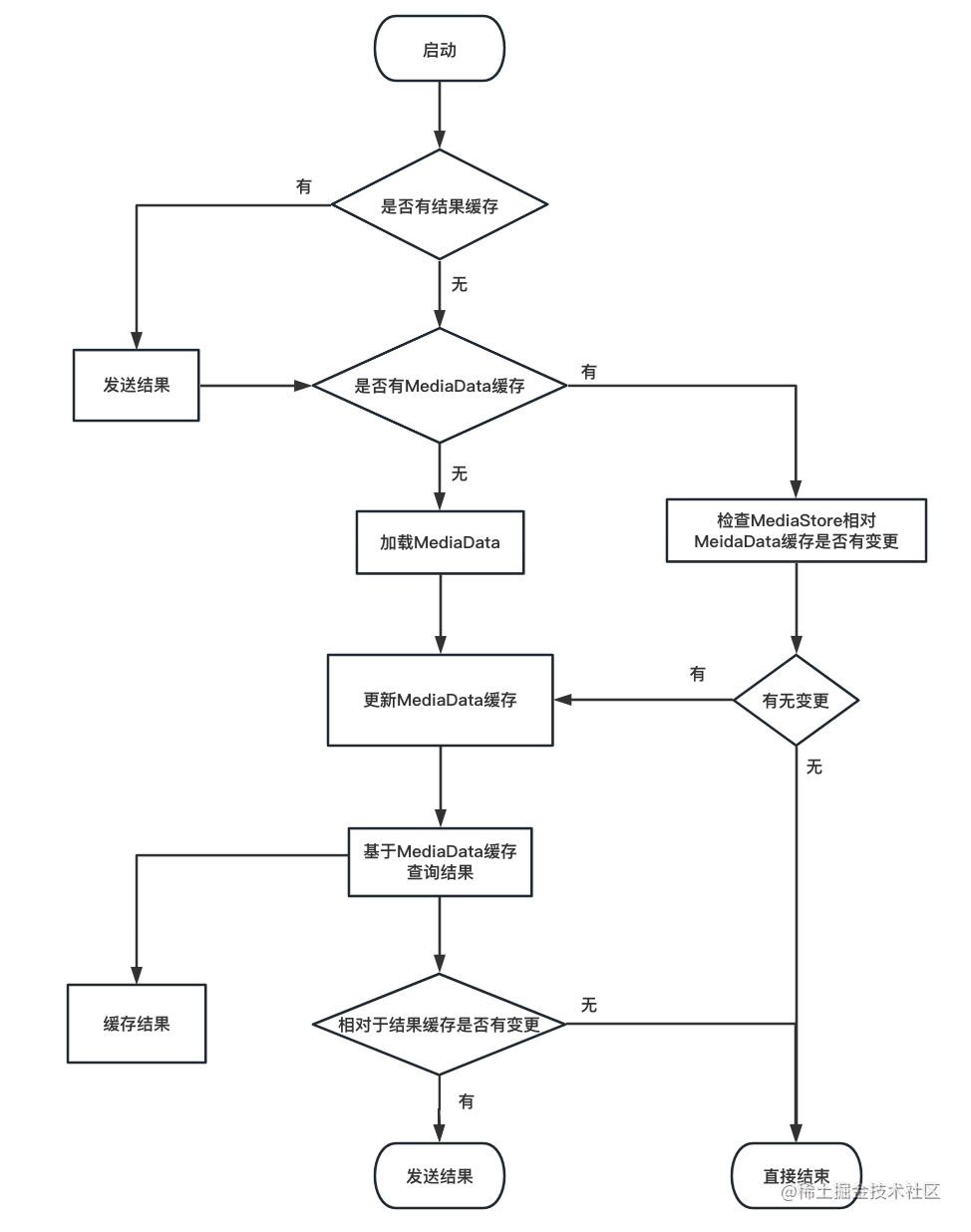
做了两层缓存,加载流程是复杂一些。
但好处也是显而易见的,增加了结果缓存之后,再次启动相册就基本是“秒开”了。
查询过程是在后台线程中执行的,结果通过handler发送给AlbumActivity。
图中还有一些小处理没画出来。
比如,首次加载,在发送结果给相册界面之后,还会继续执行一个“检查文件是否已删除”的操作。
针对的是这么一种情况:MediaStore中的记录,DATA字段所对应的文件不存在。
我自己的设备上是没有出现过这种case, 我也是听前辈讲的,或许他们遇到过。
如果确实有设备存在这样的情况,的确应该检查一下,否则相册滑动到这些“文件不存在”的记录时,会只看到一片黑,稍微影响体验。
但由于我自己没有具体考证,所以在EasyAblum的全局配置中留了option, 可以设置不执行。
关于这点大家按具体情况自行评估。
加载流程一般在进入相册页时启动。
考虑到用户在浏览相册时,有时候可能会切换出去拍照或者删除照片,可在onResume的时候也启动一下加载流程,检查是否有媒体文件增删。
五、相册列表
5.1 媒体缩略图
Android系统对相册文件提供了获取缩略图的API,通过该API获取图片要比直接读取媒体文件本身要快很多。
一些图片加载框架中有实现相关逻辑,比如Glide的实现了MediaStoreImageThumbLoader和MediaStoreVideoThumbLoader,但是所用API比较旧,在我的设备(Android 10)上已经不生效了。
如果使用Glide的朋友可以自行实现ModelLoader和ResourceDecoder来处理。
EasyAlbum的Demo中有实现,感兴趣的朋友可以参考一下。
5.2 列表布局
相册列表通常是方格布局,如果RecycleView布局,最好能让每一列都等宽。
下面这个ItemDecoration的实现是其中一种方法:
public class GridItemDecoration extends RecyclerView.ItemDecoration {
private final int n;
private final int space;
private final int part;
public GridItemDecoration(int n, int space) {
this.n = n;
this.space = space;
part = space * (n - 1) / n;
}
@Override
public void getItemOffsets(
@NonNull Rect outRect,
@NonNull View view,
@NonNull RecyclerView parent,
@NonNull RecyclerView.State state) {
int position = parent.getChildLayoutPosition(view);
int i = position % n;
outRect.left = Math.round(part * i / (float) (n - 1));
outRect.right = part - outRect.left;
outRect.top = 0;
outRect.bottom = space;
}
}
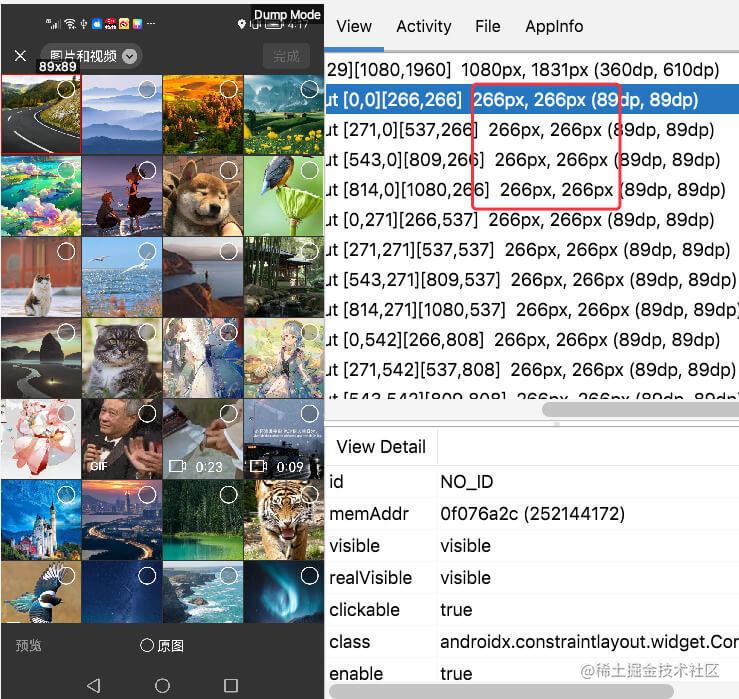
其原理就是将所有space加起来,等分为n份,每个item分摊1份。
其中第i列(index从0开始)的左边部分的间隔的计算公式为:space * i / n 。
比方说colomn = 4, 那么就有3个space; 如果每个space=4px, 则每个item分摊4 * (4-1)/ 4 = 3px。
第1个item, left=0px, right = 3px;
第2个item, left=1px, right = 2px;
第3个item, left=2px, right =1px;
第4个item, left=3px, right =0px。
于是,每个间隔看起来都是4px, 且每个item的left+right都是相等的,所以留给view的宽度是相等的。
效果如下图:
有的地方是这么去分配left和right的:
outRect.left = column == 0 ? 0 : space / 2;
outRect.right = column == (n - 1) ? 0 : space / 2;
这样能让每个间隔的大小相等,但是view本身的宽度就不相等了。
效果如下图:
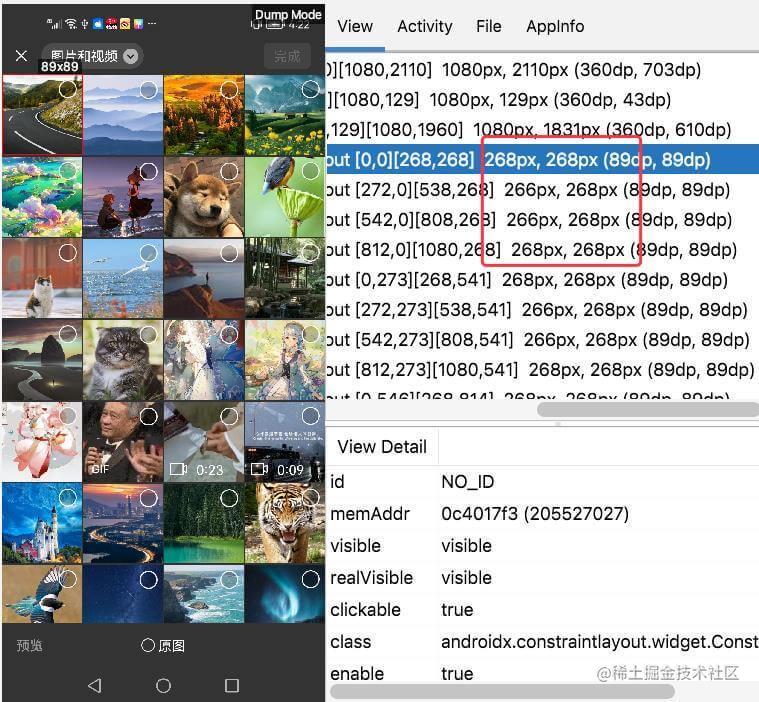
左右两个item分别比中间的item多了2px。
这2px看上去不多,但是可能会导致列表变更(增删)时,图片框架的缓存失效。
例如:
如果删除了最接近的一张照片,原第2-4列会移动到1-3列,原第1列会移动到第4列。
于是第2列的宽度从266变为288,第4列的宽度从288变为266,
而图片加载框架的target宽高是缓存key的计算要素之一,宽度变了,就不能命中之前的缓存了。
六、后序
相册的实现可简单可复杂,我见过的最简单的实现是直接在主线程查询媒体数据库的……
本文从各个方面分享了一些相册实现的经验,尤其是相册加载部分。
目前这个时代,手机存几千上万张图片是很常见的,优化好相册的加载,能提升不少用户体验。
项目已发布到Github和Maven Central:
Githun地址:
github.com/BillyWei01/…
下载方式:
implementation 'io.github.billywei01:easyalbum:1.0.6'
作者:呼啸长风
来源:juejin.cn/post/7215163152907092024