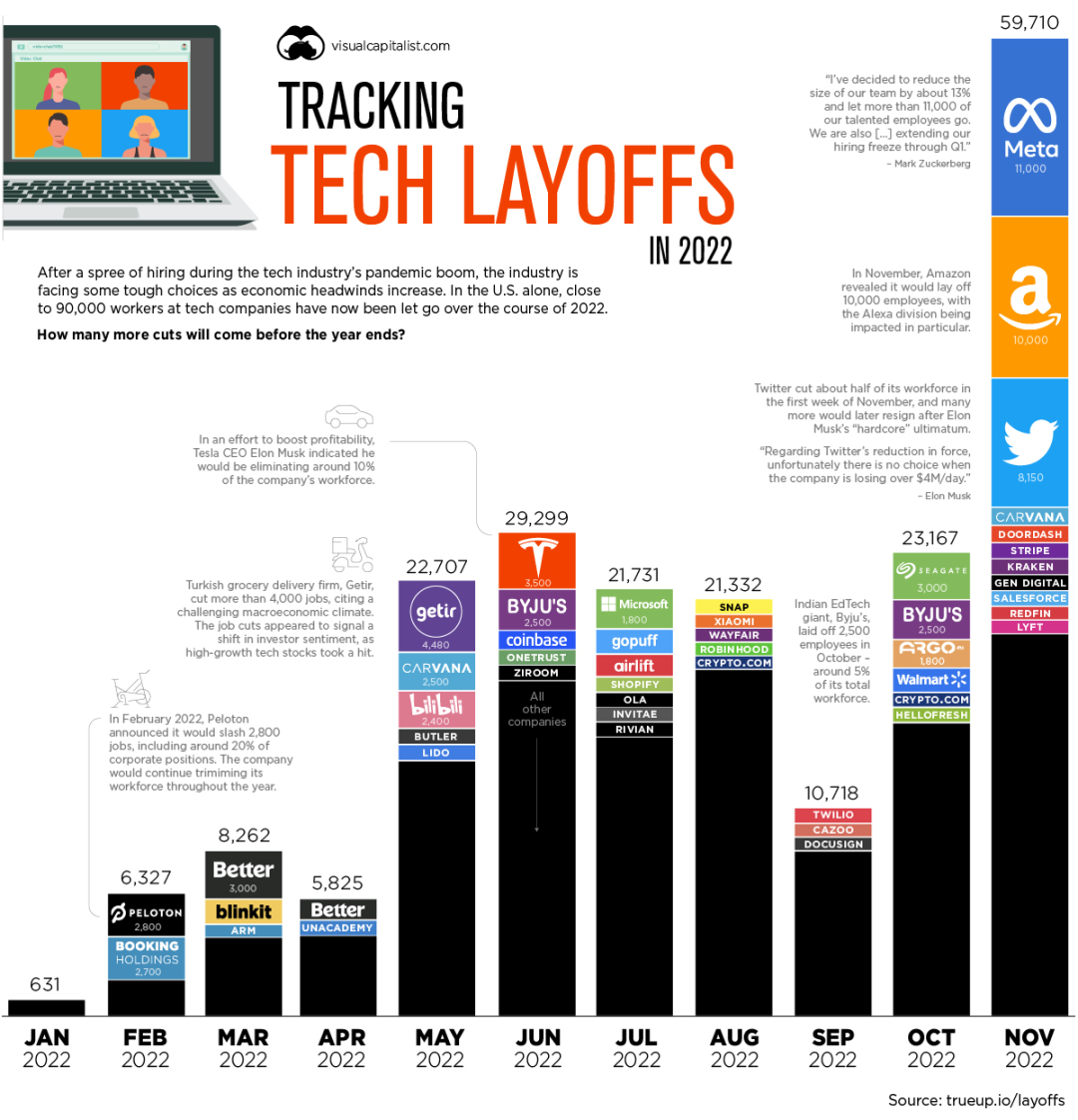
波浪形温度刻度表实现
前言
之前的绘制圆环,我们了解了如何绘制想要的形状和进度的一些特点,那么此篇文章我们更近一步,绘制一个稍微复杂一点的刻度与波浪。来一起复习一下Android的绘制。
相对应的这种类型的自定义View网上并不少见,但是如果我们要做一些个性化的效果,最好还是自己绘制一份,也相对的比较容易控制效果,如果想实现上面的效果,我们一般来说分为以下几个步骤:
- 重写测量方法,确保它是一个正方形
- 绘制刻度
- 绘制中心的圆与文字
- 水波纹的动画
- 设置进度与动画,一起动起来
思路我们已经有了,下面一步一步的来实现吧。
话不多说,Let's go

1、onMeasure重新测量
之前的圆环进度,我们并没有重写 onMeasure 方法,而是在布局中指定为固定的宽高,其实兼容性和健壮性并不好,万一写错了就会变形导致显示异常。
最好的办法是不管xml中设置为什么值,这里都能保证为一个正方形,要么是取宽度为准,让高度和宽度一致,要么就是宽度高度取最大值,让他们保持一致。由于我们是竖屏的应用,所以我就取宽度为准,让高度和宽度一致。
前面我们只是讲了 onDraw 并没有讲到 onMeasure , 这里简单的说一下。
我们为什么要重写 onMeasure ?
- 为了自定义View尺寸的规则,如果你的自定义View的尺寸是根据父控件行为一致,就不需要重写onMeasure()方法。
- 如果不重写onMeasure方法,那么自定义view的尺寸默认就和父控件一样大小,当然也可以在布局文件里面写死宽高,而重写该方法可以根据自己的需求设置自定义view大小。
一般来说我们重写的 onMeasure 长这样:
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec,heightMeasureSpec)
}
复制代码
widthMeasureSpec ,heightMeasureSpec 并不是真正的宽高,看名字就知道,它只是宽高测量的规格,我们通过 MeasureSpec 的一些静态方法,通过它们拿到一些信息。
static int getMode(int measureSpec):根据提供的测量值(规格)提取模式(上述三个模式之一)
测量的 Model 一共有三种
- UNSPECIFIED(未指定),父元素部队自元素施加任何束缚,子元素可以得到任意想要的大小;
- EXACTLY(完全),父元素决定自元素的确切大小,子元素将被限定在给定的边界里而忽略它本身大小;
- AT_MOST(至多),子元素至多达到指定大小的值。
我们常用的就是 EXACTLY 和 AT_MOST ,EXACTLY 对应的就是我们设置的match_parent或者300这样的精确值,而 AT_MOST 对应的就是wrap_content。
static int getSize(int measureSpec):根据提供的测量值(规格)提取大小值(这个大小也就是我们通常所说的大小)
通过此方法就能获取控件的宽度和高度值。
static int makeMeasureSpec(int size,int mode):根据提供的大小值和模式创建一个测量值(规格)
通过具体的宽高和model,创建对应的宽高测量规格,用于确定View的测量
而 onMeasure 的最终设置确定宽度的测量有两种方式,
- setMeasuredDimension(width, height)
- super.onMeasure(widthMeasureSpec,heightMeasureSpec)
实战:
比如我们的自定义温度刻度View,我们整个View要确保一个正方形,那么就拿到宽度,设置同样的高度,然后确定测量,流程如下:
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
int widthMode = MeasureSpec.getMode(widthMeasureSpec);
int newWidthMeasureSpec = widthMeasureSpec;
if (widthMode != MeasureSpec.EXACTLY) {
newWidthMeasureSpec = MeasureSpec.makeMeasureSpec(200, MeasureSpec.EXACTLY);
}
int width = MeasureSpec.getSize(newWidthMeasureSpec) - getPaddingLeft() - getPaddingRight();
int height = width;
centerPosition.x = width / 2;
centerPosition.y = height / 2;
radius = width / 2f;
mRectF.set(0f, 0f, width, height);
super.onMeasure(
MeasureSpec.makeMeasureSpec(width, MeasureSpec.EXACTLY),
MeasureSpec.makeMeasureSpec(height, MeasureSpec.EXACTLY)
);
}
复制代码
这里有详细的注释,大致实现的效果如下:

2、绘制刻度
由于原本的 Canvas 内部没有绘制刻度这么一说,所以我们只能用绘制线条的方式,就是 drawLine 方法。
为了了解到坐标系和方便实现,我们可以先绘制一个圆环,定位我们刻度需要绘制的位置。
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
canvas.drawArc(
mRectF.left + 2f, mRectF.top + 2f, mRectF.right - 2f, mRectF.bottom - 2f,
mStartAngle, mSweepAngle, false, mDegreeCirPaint
);
}
复制代码
这个圆环是之前讲到过了,就不过多赘述了,实现效果如下:
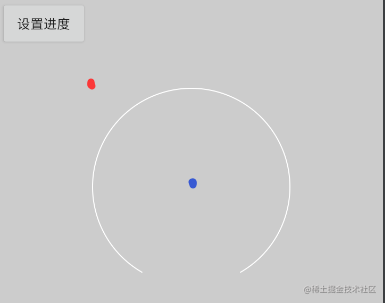
由于开始绘制的地方在左上角位置,我们要移动到圆的中心点开始绘制,也就是红色点移动到蓝色点。
我们就需要x轴和y轴做一下偏移 canvas.translate(radius, radius);
默认的 drawLine 都是横向绘制,我们想要实现效果图的效果,就需要旋转一下画笔,也就是用到 canvas.rotate(rotateAngle);
那么旋转多少了,如果说最底部是90度,我们的起始角度是120度开始的,我们就起始旋转30度。后面每一次旋转就按照百分比来,比如我们100度的温度,那么就相当于要画100个刻度,我们就用需要绘制的角度除以100,就是每一个刻度的角度。
具体的刻度实现代码:
private float mStartAngle = 120f;
private float mSweepAngle = 300f;
private float mTargetAngle = 300f;
private void drawDegreeLine(Canvas canvas) {
canvas.save();
canvas.translate(radius, radius);
canvas.rotate(30);
float rotateAngle = mSweepAngle / 100;
float currentAngle = 0;
for (int i = 0; i <= 100; i++) {
if (currentAngle <= mTargetAngle && mTargetAngle != 0) {
float percent = currentAngle / mSweepAngle;
mDegreelinePaint.setColor(evaluateColor(percent, Color.GREEN, Color.RED));
canvas.drawLine(0, radius, 0, radius - 20, mDegreelinePaint);
currentAngle += rotateAngle;
} else {
mDegreelinePaint.setColor(Color.WHITE);
canvas.drawLine(0, radius, 0, radius - 20, mDegreelinePaint);
}
canvas.rotate(rotateAngle);
}
canvas.restore();
}
复制代码
加上圆环与刻度的效果图:
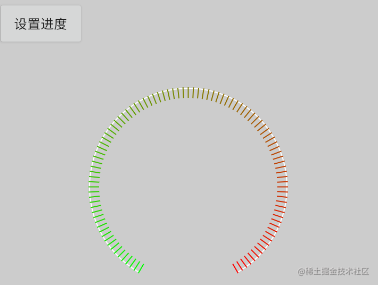
3. 设置刻度动画
前面的一篇我们使用的是属性动画不停的绘制从而实现进度的效果,那么这一次我们使用定时任务的方式也是可以实现动画的效果。
由于我们之前的 drawDegreeLine 方法内部控制绘制进度的变量就是 targetAngle 来控制的,所以我们通过入口方法设置温度的时候通过定时任务的方式来控制。
代码如下:
private boolean isAnimRunning;
private int[] slow = {10, 10, 10, 8, 8, 8, 6, 6, 6, 6, 4, 4, 4, 4, 2};
private int goIndex = 0;
public void setupTemperature(float temperature) {
mCurPercent = 0f;
totalAngle = (temperature / 100) * mSweepAngle;
targetAngle = 0f;
mCurPercent = 0f;
mCurTemperature = "0.0";
mWaveUpValue = 0;
startTimerAnim();
}
private void startTimerAnim() {
if (isAnimRunning) {
return;
}
mAnimTimer = new Timer();
mAnimTimer.schedule(new TimerTask() {
@Override
public void run() {
isAnimRunning = true;
targetAngle += slow[goIndex];
goIndex++;
if (goIndex == slow.length) {
goIndex--;
}
if (targetAngle >= totalAngle) {
targetAngle = totalAngle;
isAnimRunning = false;
mAnimTimer.cancel();
}
mCurPercent = targetAngle / mSweepAngle;
mCurTemperature = mDecimalFormat.format(mCurPercent * 100);
mWaveUpValue = (int) (mCurPercent * (mSmallRadius * 2));
postInvalidate();
}
}, 250, 30);
}
复制代码
那么刻度动画的效果如下:

4. 绘制中心的圆与文字
我们再动画中记录动画的百分比进度,和动画当前的温度。
...
mCurPercent = targetAngle / mSweepAngle;
mCurTemperature = mDecimalFormat.format(mCurPercent * 100);
postInvalidate();
...
复制代码
我们记录一下小圆的半径和文本的画笔资源
private float mSmallRadius = 0f;
private Paint mTextPaint;
private Paint mSmallCirclePaint;
private float mCurPercent = 0f;
private String mCurTemperature = "0.0";
private DecimalFormat mDecimalFormat;
private void init() {
...
mTextPaint = new Paint();
mTextPaint.setAntiAlias(true);
mTextPaint.setTextAlign(Paint.Align.CENTER);
mTextPaint.setColor(Color.WHITE);
mSmallCirclePaint = new Paint();
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
...
drawSmallCircle(canvas, evaluateColor(mCurPercent, Color.GREEN, Color.RED));
drawTemperatureText(canvas);
}
复制代码
具体的文本与小圆的绘制
private void drawSmallCircle(Canvas canvas, int evaluateColor) {
mSmallCirclePaint.setColor(evaluateColor);
mSmallCirclePaint.setAlpha(65);
canvas.drawCircle(centerPosition.x, centerPosition.y, mSmallRadius, mSmallCirclePaint);
}
private void drawTemperatureText(Canvas canvas) {
mTextPaint.setTextSize(mSmallRadius / 6f);
canvas.drawText("当前温度", centerPosition.x, centerPosition.y - mSmallRadius / 2f, mTextPaint);
mTextPaint.setTextSize(mSmallRadius / 2f);
canvas.drawText(mCurTemperature, centerPosition.x, centerPosition.y + mSmallRadius / 4f, mTextPaint);
mTextPaint.setTextSize(mSmallRadius / 6f);
canvas.drawText("°C", centerPosition.x + (mSmallRadius / 1.5f), centerPosition.y, mTextPaint);
}
复制代码
由于进度和温度都是动画在 invalidate 之前赋值的,所以我们的文本和小圆天然就支持动画的效果了。
效果如下:

5. 水波纹动画
水波纹的效果,我们不能直接用 Canvas 来绘制,我们可以用刻度的方法用 drawLine的方式来绘制,如何绘制呢?相信大家也有了解,就是正弦函数了。
由于我们的效果是两个水波纹相互叠加起起伏伏的效果,所以我们定义两个函数。
总体的思路是:我们定义两个数组来管理我们的Y轴的值,通过正弦函数给Y轴赋值,然后在drawLine的时候取出对应的x轴的y值就可以绘制出来。
x轴其实就是我们的控件宽度,我们先用一个数组保存起来
private float[] mFirstWaterLine;
private float[] mSecondWaterLine;
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
int widthMode = MeasureSpec.getMode(widthMeasureSpec);
int newWidthMeasureSpec = widthMeasureSpec;
if (widthMode != MeasureSpec.EXACTLY) {
newWidthMeasureSpec = MeasureSpec.makeMeasureSpec(200, MeasureSpec.EXACTLY);
}
int width = MeasureSpec.getSize(newWidthMeasureSpec) - getPaddingLeft() - getPaddingRight();
int height = width;
mFirstWaterLine = new float[width];
mSecondWaterLine = new float[width];
super.onMeasure(
MeasureSpec.makeMeasureSpec(width, MeasureSpec.EXACTLY),
MeasureSpec.makeMeasureSpec(height, MeasureSpec.EXACTLY)
);
}
复制代码
然后我们再绘制之前就先对x轴对应的y值赋值,然后绘制的时候就取出对应的y值来 drawLine,具体的代码如下:
动画的时候先对横向运动和垂直运动的变量做一个赋值:
private int mWaveUpValue = 0;
private float mWaveMoveValue = 0f;
private void startTimerAnim() {
if (isAnimRunning) {
return;
}
mAnimTimer = new Timer();
mAnimTimer.schedule(new TimerTask() {
@Override
public void run() {
...
mCurPercent = targetAngle / mSweepAngle;
mCurTemperature = mDecimalFormat.format(mCurPercent * 100);
mWaveUpValue = (int) (mCurPercent * (mSmallRadius * 2));
postInvalidate();
}
}, 250, 30);
}
public void moveWaterLine() {
mWaveTimer = new Timer();
mWaveTimer.schedule(new TimerTask() {
@Override
public void run() {
mWaveMoveValue += 1;
if (mWaveMoveValue == 100) {
mWaveMoveValue = 1;
}
postInvalidate();
}
}, 500, 200);
}
复制代码
拿到了对应的变量值之后,然后开始绘制:
private void drawWaterWave(Canvas canvas, int color) {
int len = (int) mRectF.right;
float mCycleFactorW = (float) (2 * Math.PI / len);
for (int i = 0; i < len; i++) {
mFirstWaterLine[i] = (float) (10 * Math.sin(mCycleFactorW * i + mWaveMoveValue) - mWaveUpValue);
}
for (int i = 0; i < len; i++) {
mSecondWaterLine[i] = (float) (15 * Math.sin(mCycleFactorW * i + mWaveMoveValue + 10) - mWaveUpValue);
}
canvas.save();
Path path = new Path();
path.addCircle(len / 2f, len / 2f, mSmallRadius, Path.Direction.CCW);
canvas.clipPath(path);
path.reset();
canvas.translate(0, centerPosition.y + mSmallRadius);
mSmallCirclePaint.setColor(color);
for (int i = 0; i < len; i++) {
canvas.drawLine(i, mFirstWaterLine[i], i, len, mSmallCirclePaint);
}
for (int i = 0; i < len; i++) {
canvas.drawLine(i, mSecondWaterLine[i], i, len, mSmallCirclePaint);
}
canvas.restore();
}
复制代码
一个是对Y轴赋值,一个是取出x轴对应的y轴进行绘制,这里需要注意的是我们裁剪出了一个小圆的图形,并且覆盖在小圆上面实现出效果图的样子。
运行的效果如下:

要记得对定时器进行资源你的关闭哦。
@Override
protected void onDetachedFromWindow() {
super.onDetachedFromWindow();
if (mWaveTimer != null) {
mWaveTimer.cancel();
}
if (mAnimTimer != null && isAnimRunning) {
mAnimTimer.cancel();
}
}
复制代码
使用的时候我们只需要设置温度即可开始动画。
findViewById(R.id.set_progress).click {
val temperatureView = findViewById(R.id.temperature_view)
temperatureView .setupTemperature(70f)
}
复制代码
后记
由于是自用定制的,本人也比较懒,所以并没有对一些配置的属性做自定义属性的抽取,比如圆环的间距,大小,颜色,波纹的间距,动画的快慢等等。
内部加了一点点测量的用法,但是主要还是绘制的流程,基本上把常用的几种绘制方式都用到了。以后有类似的效果大家也可以按需修改即可。
由于是自用的一个View,相对圆环进度没有那么多场景使用,就没有抽取出来上传到Maven,如果大家有兴趣可以查看源码点击【传送门】。
同时,你也可以关注我的这个Kotlin项目,我有时间都会持续更新。
惯例,我如有讲解不到位或错漏的地方,希望同学们可以指出交流。
如果感觉本文对你有一点点的启发,还望你能点赞支持一下,你的支持是我最大的动力。
Ok,这一期就此完结。

作者:newki
来源:https://juejin.cn/post/7166151382154608670