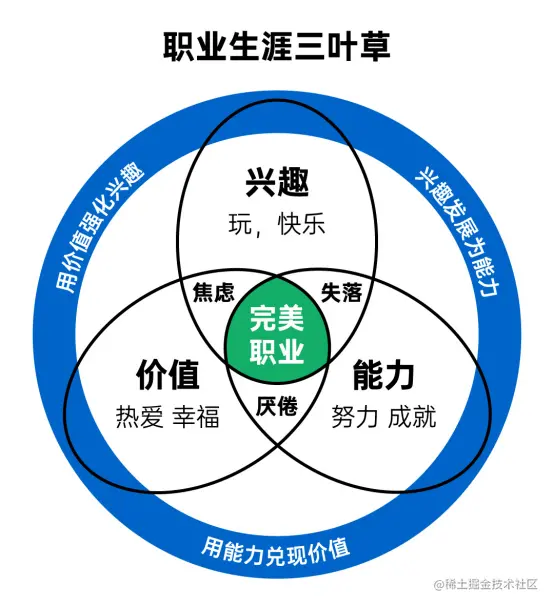
在日常工作中,尤其是程序员时时刻刻都会与英文打交道,虽然我们尽可能的在互联网和中文书籍中寻找我们需要的信息,但是,有时候总是不尽人意。对待翻译过来的文档或者书本可能有些定义依然无法明确理解,回到它原有的场景中才能明白究竟是什么意思?阅读英文文档应该是我们的基本技能。
本文笔者将会从以下几个方面来分享一个月的时间,笨方法跨越英文障碍的落地方法:
- 遇到的 Bug 百度没有结果怎么办
- 中文翻译文献模棱两可怎么办
- 寻找外文文献的发现过程是什么样的
- 如何解决英文文档中的复杂句子
- 如何结合文档学习语法
- 结合实例带你操作“笨”方法找到适合自己的路
在本文内,笔者想在这儿分享的一点工作体会。在标题中重点引号标注的一个字——“笨”。既然是“笨”方法,就说明我们都很容易理解,很容易上手,很容易操作,很容易见效。
之所以没有说,两天速成,七天见效,因为这些似乎是赤脚医生行走江湖的招数。工作或者学习,还是务实一点比较能走长远。
那么笔者的方法究竟“笨”在哪儿呢?展示几张图就很快明白了。
- 如果在出差的路上,或者咖啡馆,或者自习室,可以拿出英文资料,或者是需要查看的技术文档,或者需要学习的产品手册。将不能够准确理解的段落、句子、单词摘抄到随身携带的抄写本上,这样便于针对细节深入处理。

(图片来自手机拍摄,不太美观)
上图是笔者曾经在了解 JWT 的涉及到的实现机制的过程中,对于 Auth0 提供的 JWT 指南的阅读过程中留下的笔记。
当再次看到笔记的时候对 JWT-handbook 第 16 页的部分内容就能够了然于心。
那么我们在来看它对应的原始的手册中的内容如下:

(图片来自:jwt-handbook)
通过这种方式,相信一定程度上就能感受到对于英文手册,技术指南的文档也能够看上一看,并获取到一些有意义的信息。
- 接着上面,如下的内容是笔者对于原文流程图下方的注解的学习过程。

通过剖析一张图和图对应的注解,就能够发现能够很轻松的干掉一篇 122 页技术手册中的其中一页,前前后后可能也不到几分钟的时间,如果基础比较好的情况下,也许几秒钟就解决了无法在各式各样的解读后的博客中看到的原始概念和流程。进而对关键的技术点有更加清晰的认识。
- 如果在家的情况下,有时候会觉得使用电脑打字的速度要比用手抄本写笔记的速度要快,你就可以像下图这样,在电脑主屏幕上用文本编辑器来记下笔记,用扩展显示器显示 pdf,这样不用切来切去,影响阅读速度。

- 要说上面是笔者使用的“笨”方法, 那下面就可以说明,它“笨”的程度。笔者大概记下了这么多页的笔记,看完一遍 JWT handbook 和 The OAuth 2.0 Authorization Framework。这个过程大概花了一个月的空闲时间。所以如果你的英语基础更好的话,那就更不用担心了,连一个月的时间都用不了。

曾经多次看到全英文的技术指南,都只能看几句话就放弃,在阅读两篇英文技术文档之后,对于其他的文档来说,都会尝试拿来读一读,而且随着阅读量的增加速度和理解能力都会逐渐增强。
上面分享完了笔者曾经的经历,便能直观的认识到,对于技术人员或者产品经理,应对工作中的英语非要先背诵大量的词汇,并不像想象的那样:买两本厚厚的语法书,啃上半年一年才能够掌握它。
知识点来源于生活和工作,同样它又应用于生活和工作。就像我们的母语汉语一样,从咿呀学语到长篇大论,也并不是长篇大论之前一直在背诵汉字,学习句法。这需要一个过程,但是在这个过程中,随着知识的积累,在积累的过程中一定不耽误成长和认识新的事物。
所以,我们不必恐惧我们遇到的其他语种的文献,它像我们学习汉语一样,只是有一个过程。相对于曾经考试过程中遇到的令人头疼的“完形填空”,“阅读理解”这些,兴许比我们看到的技术文档要更难,因为技术文档对于技术人来说,它所涉及的内容与我们工作的范畴是高度结合的。
如果要学习 Spring Security,那么我们自然不会去看关于发表的“新冠肺炎”的最新文献。随着技术词汇的总结,我们便能够对于相关的技术文档更容易理解,更快速的阅读掌握。因为它首先在行业上就存在一定的专一性,这样就为我们学习圈定了范围。
接下来,从以下几个方面来分享。
遇到的 Bug 百度没有结果怎么办
我们在工作中如果遇到的问题,经常会去百度一些问题,尤其是具体的 IDE 中的一些异常。例如,在 Eclipse 中有如下的错误提示:
MongoDB shell version v3.4.5 connecting to: mongodb://127.0.0.1:27017 2020-0
如果第一次遇见这个问题,无从下手的时候,可能首先会去百度,查找结果,如下:

如果得到的答案,没有我想要的,或者是解决不了我的问题的情况下怎么办呢?
Google

不同的搜索引擎,由于它的搜索机制不一样,自然呈现给我们的检索结果就不一样,所以当无路可走的时候,常常会使用这几种方法综合起来,来搜寻符合需要的方案。
必应
有时候,我们无法访问谷歌的情况下,可以尝试使用必应的国际版。

(图片来自:cn.bing.com)
输入我们之前的问题,得到如下结果:

上面几种检索结果的区别对于我们来说有时候未必不是一件好事,因为它能够展现出更多的推荐方案供我们选择。
Stack Overflow
仔细的从谷歌和必应国际版的检索结果中会发现它得到的结果都有 Stack Overflow 提供的方案。那么 Stack Overflow 是何方神圣呢?可以把它看成是中国的 CSDN、博客园这一类的技术问答网站。
如果无法登陆 Google,而且不习惯于 biying 的搜索引擎的情况下,那么可以直接去 Stack Overflow 查找或者询问你自己的问题。

(图片来自:stackoverflow.com/)
MSDN
如果是微软技术栈的工程师或者是产品经理,可以考虑使用 MSDN。

(图片来自:docs.microsoft.com)

(图片来自:docs.microsoft.com)
在使用 MSDN 的时候有一个优点,就是它支持中文,也支持英文。这样可能能够为我们阅读英文文档提供一个参照。如果英文的版本的确无法看下去的情况下,便可以参考中文的说明。
其他
当然不乏一些其他优秀的网站、论坛,比如日本的 Fresheye、俄罗斯的 Yandex、韩国的 NAVER,如下图:

(图片来自:search.fresheye.com)

(图片来自:yandex.com)

(图片来自:search.naver.com/)
从这也能看出来,尽管我们是学习技术的,或者是产品部门的一个产品专员,但我们一样能够通过我们的努力打开世界上每一扇我们感兴趣的大门。
接下来,说一说文章起始位置的第二个问题。
中文翻译文献模棱两可怎么办
对于这一点,我们引用 DAN OLSEN 的一本书的封面的内容来说明。如图:

(图片来自:THE LEAN PRODUCT PLAYBOOK)
封面上能够得到的信息是:
DAN OLSEN
THE LEAN PRODUCT PLAYBOOK
HOW TO INNOVATE WITH MINIMUM VIABLE PRODUCTS AND RAPID CUSTOMER FEEDBACK
WILEY
其中 DAN OLSEN 是作者、WILEY 是指这本书是由 WILEY 出版的。从领英上的介绍来看,这本书是 DAN OLSEN 是他很得意的一本畅销书。

(图片来自:http://www.linkedin.com)
这也是笔者接触到的第一本专业的关于产品的书。通过它来印证我们遇到模棱两可的解释的时候,该如何处理。
THE LEAN PRODUCT PLAYBOOK
HOW TO INNOVATE WITH MINIMUM VIABLE PRODUCTS AND RAPID CUSTOMER FEEDBACK
WILEY
假设你不知道它的意思的情况下,分别在 Google 翻译和百度翻译上翻译的结果如下:

(图片来自:translate.google.cn)

(图片来自:fanyi.baidu.com)
通过对比就能够知道它的含义就是精益产品手册,对于 PLAYBOOK 的翻译结果稍有不同,如果深究的情况下, 我们可以去看一下 PLAYBOOK 的英文解释。

(图片来自:dictionary.cambridge.org)

(图片来自:http://www.merriam-webster.com)

(图片来自:http://www.oxfordlearnersdictionaries.com)
相信对于你的感到模糊的词汇或者句子,在谷歌、百度、韦氏、剑桥、牛津五家线上词典的围攻下将你的疑问降低到零。
这就是笔者在日常工作和学习中遇到的模棱两可的问题的解决方案。
当时引起笔者注意的是如下这一段话:(引自:THE LEAN PRODUCT PLAYBOOK)
The Lean Product Process will guide you through the critical thinking steps required to achieve product-market fit. In the next chapter, I begin describing the details of the process, but before I do, I want to share an important hight-level concept: seperating problem space from solution space. I have been discussing this concept in my talks for years and am glad to see those terms used more frequently these days.
Any product that you actually build exists in solution space,as do any product designs that you create-such as mockups,wireframes,or prototypes. Solution space includes any product or representation of a product that is used by or intended for use by a customer It is the opposite of a blank slate.When you build a product,you have chosen a specific implementation.Whether you've done so explicitly or not, you've determined how the product looks,what it does,and how it works.
In contrast,there is no product or design that exists in problem space. Instead, problem space is where all the customer needs that you'd like your product to deliver live. You shouldn't interpret the word "needs" too narrowly: Whether it's a customer pain point, a desire, a job to be done, or a user story, it lives in problem space.
如果我是一名产品经理或者产品专员,我想在这里我便应该仔细的去推敲 DAN OLSEN 说的这一句话中包含了些什么信息?
什么是 problem space,什么是 solution space,这两个概念是它的范畴中包含了哪些元素,它们之间有什么关系,它们又是如何促进产品创新的。可以带着这些问题去别的章节中去寻找答案。
另外,这里想要提醒的一点是,在国内我们是可以使用谷歌翻译的,它对应的域名是 translate.google.cn,而不是 translate.google.com,笔者曾经由于一直输入 .com 所以导致困惑了好多天。
寻找外文文献的发现过程是什么样的
白岩松老师在一个《对白》中曾经说过一句这样的话,笔者很赞同。“人找书是很难的,但是书找书是容易的,越读书,越知道该读什么书”。
在工作过程中,我们如果需要找到一个问题的解决方案,可能需要在搜索过程中不断调整检索词,希望能够通过检索词来搜索出自己需要的有价值的内容。
在工作中,常常为了对项目结构有清晰的认知,需要我们能够画出“软件架构图” ,如果你搜索,“软件架构图”,检索后可以看到几乎第一屏展现出来的有一多半的都是实现软件架构的工具的广告。这往往是一件令人很头疼的事情。
调整检索词,改为“software architecture”,在百度中的结果会得到一些相对有用的信息。

这时候标注出来的 PDF、读书、图文的字样便出现了。
再次细化检索词,使用“Software Architecture Patterns”。
通过查看能够进一步得到某一本书的信息:

(图片来自:http://www.oreilly.com/library)
这种情况下,就能够对这本书中的部分内容,查看是否是存在自己想要调研的相关内容,而后便能进一步去学习。
- 如果你需要查看这本书,继续在搜索引擎中搜索,比如“software architecture patterns pdf”,能够看到很多好心人分享出来的书,这种方法往往都比较有效,只要耐心的搜索检索词。

- 找到后打开对应的文件,浏览目录,这时候看到了它对架构师经常要打交道的”层图“的介绍,这就为我们平时的工作中的画图能够提供参考和建议。

(图片来自:Software Architecture Patterns)
这一部分,基本就介绍了,在我们对于英文文献的寻找过程是怎样的,输入中文检索词,如果中文检索词无法满足要求情况下,可以考虑将中文检索词转换为英文检索词,用转换的英文检索词,一步步优化,结合不同搜索引擎的检索结果去找到符合自己目标的内容。
另外上面的例子中提到的 Software Architecture Patterns 篇幅比较小,也比较适合查看。同时架构图在软件设计过程中又比较重要,我们可以尝试通过这种方式的查找和学习、阅读,逐渐地对于架构图不会敬而远之,不会感觉遥不可及。
有些情况下在某些书中,会对于一些概念在脚注或者引用文献都会进行说明,这样便可以在阅读过程中对于相关的概念,去其他的书中寻找,这就形成了一个书找书的过程,它是实现起来还是比较便捷有价值的。但是在阅读过程中想要提醒的一点是,我们不要过度发散,导致忘记了最初需要解决的问题,导致花费大量的时间,需要解决的问题没有解决。
如何解决英文文档中的复杂句子
在阅读过程中,我们可能会发现长句理解起来相对麻烦一点,这里我们拿上文中提到的 Software Architecture Patterns 的一个段落来解剖:
Each layer in the architecture forms an abstraction around the work that needs to be done to satisfy a particular business request. For example, the presentation layer doesn’t need to know or worry about how to get customer data; it only needs to display that information on a screen in particular format. Similarly, the business layer doesn’t need to be concerned about how to format customer data for display on a screen or even where the customer data is coming from; it only needs to get the data from the persistence layer, perform business logic against the data (e.g., calculate values or aggregate data), and pass that information up to the presentation layer.
文章无非就是通过这种类似的长短句形成的段落堆砌出来的,所以解决了词,解决了句子,自然没什么可怕的。看到这种段落的时候,可以试试去拆分:

将一个段落拆分,按照标点符号拆分成四个部分。再对每一个部分进行分解,再把其中一句单独分离出来。
比如第一句:

只要能够找到句子中的主语、谓语、宾语,基本上就能确定大概的意思。这类比于汉语中实际上,也比较容易理解,“谁”“干了”“什么”。其余的内容只是对这几个元素的修饰和补充说明。
架构中的每一层,形成一个围绕工作的抽象,什么工作?需要被实现用来满足业务需求的工作。
那么上一句就能够基本理解它的意思,架构中的每一层实际上是对于满足特定业务需要的抽象,再简化就是架构图中的层,是对于特定业务的抽象。
回到原文中结合上下文,便能够对第一句进一步理解。
而这时候,如果你不加分析,直接去 Google 翻译或者百度翻译上看它的翻译结果,可能会让你更加迷糊。


从这个结果来看,我们在阅读过程中,所有的工具只能是参考,需要我们结合自己实际情况,不断补充,不断调查,不断积累和完善。
如何结合文档学习语法
从上文中的复杂句子的分解过程中,实际上就能看到语法的影子,如果只是在文档的学习中遇到的问题解决的情况下,如果无法正确理解的时候,从词性、时态、句型、从句等方面去针对性的查找。这儿就不再深入扩展了。
可以查找关于高中、托福、雅思一类的专业英语语法书籍,比如在世界上颇有影响力的 Practical English Usage,它的中译本是《牛津英语用法指南》。
笔者从书中摘抄一段内容,兴许这一小段就会纠正原本的错误认识:
动词形式(”时态“)和时间
动词形式和时间没有直接关系。例如,像 went 这样的动词过去式不但可以表示过去的事情(如 We went to Morocco last January 我们去年 1 月份去了摩洛哥),而且可以表示发生在现在或将来的不真实的或不确定的事情(如 It would be better if we went home how 我们现在回家更好)。动词现在式可以表示将来(如 I'm seeing Peter tomorrow 我明天要见彼得)。另外,进行式和完成式不单单表示时间有关的概念,还可表示动作的持续、完成或目前的重要性。
(摘自:《牛津英语用法指南》)
这就熟悉又陌生的语法,可能从高中毕业后再也没有系统的学习过过于英语语法的内容,但是没关系,只要用到就有机会学习。
结合实例带你操作“笨”方法找到适合自己的路
前面的内容,笔者分享了关于在工作中遇到的问题,查找、分解的方法。总的来说大概几个方面,包括了:
希望这些能够对你的工作中遇到的头疼的英语问题有所帮助。
下面推荐了相关的文档,你可以使用它,也可以按照前面介绍的方法结合自己遇到的实际问题去寻找对应的文献。
研发的同学可以尝试去读一下,Windows 上 ZIP 版本 Redis 的三个文档:

(图片来自:github.com/)
- Redis on Windows Release Notes
- Redis on Windows
- Windows Service Documentation
产品的同学,笔者目前只发现了上文提到的 DAN OLSEN 的 THE LEAN PRODUCT PLAYBOOK,有好资源的同学可以分享,共同学习。
另外,闲暇时有兴趣的同学可以去浏览、了解日常的消息(国内可访问)

(图片来自:apnews.com/)

(图片来自: http://www.afp.com)

(图片来自:globalnews.ca/)
这次的分享到这儿基本结束了,希望你可以用更快的,更简单的方法,去克服工作中遇到的问题。欢迎共同学习,携手共进。
作者:问问计算机
来源:juejin.cn/post/7149197829477662728



























 为什么会给后端吵架,因为后端不处理逻辑,还要怪我什么都不给他说,什么都不给讲,这是我最气的点,我每次都要给他讲,为什么需要这个数据,为什么你要这么给我,需要什么,我每次都在他没写之前就进行沟通。他最后怪我没讲,并且侮辱我。有的人这时候会说,你为什么不他给你什么就要什么呢?然后自己处理逻辑。降低了耦合性,再往后说 你自己可以写一个node.js啊 为什么不呢?这些都挺对的,但是吧,你不能每次都这么处理问题吧。一个选择题,他应该给你abcd,结果给你1234,然后他要abcd,你说这个转换你做不做?你好说歹说他给你改了,然后一道题4个选项 我回答完以后,他给你答案你自己判断对错,这个逻辑前端写吗,当然也可以,如果他给你的答案是 1呢 1就是a,这时候你又该如何是好?可能你觉得我不信后端会这个对你,一定是你的问题,哈哈 上图片
为什么会给后端吵架,因为后端不处理逻辑,还要怪我什么都不给他说,什么都不给讲,这是我最气的点,我每次都要给他讲,为什么需要这个数据,为什么你要这么给我,需要什么,我每次都在他没写之前就进行沟通。他最后怪我没讲,并且侮辱我。有的人这时候会说,你为什么不他给你什么就要什么呢?然后自己处理逻辑。降低了耦合性,再往后说 你自己可以写一个node.js啊 为什么不呢?这些都挺对的,但是吧,你不能每次都这么处理问题吧。一个选择题,他应该给你abcd,结果给你1234,然后他要abcd,你说这个转换你做不做?你好说歹说他给你改了,然后一道题4个选项 我回答完以后,他给你答案你自己判断对错,这个逻辑前端写吗,当然也可以,如果他给你的答案是 1呢 1就是a,这时候你又该如何是好?可能你觉得我不信后端会这个对你,一定是你的问题,哈哈 上图片