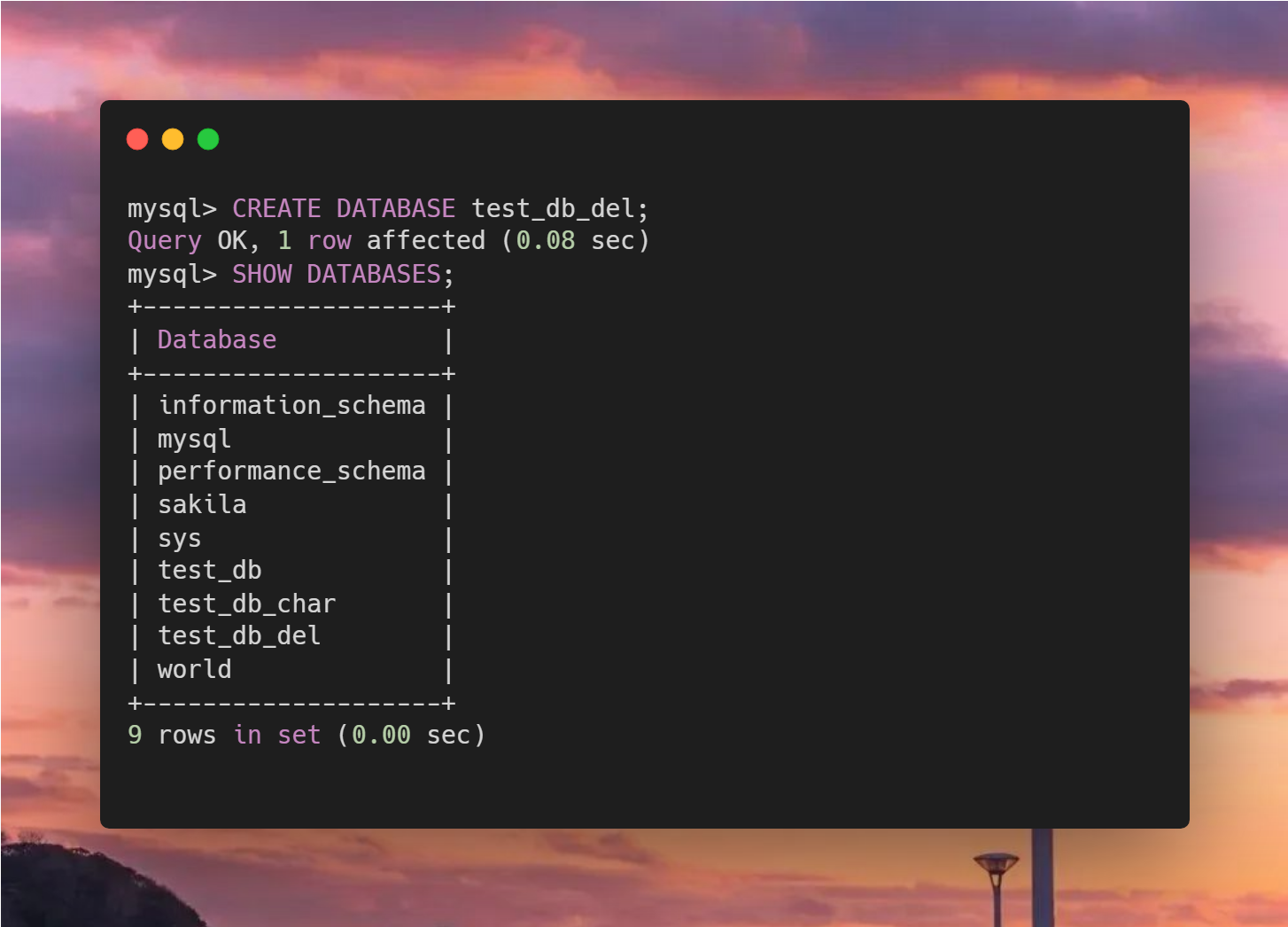
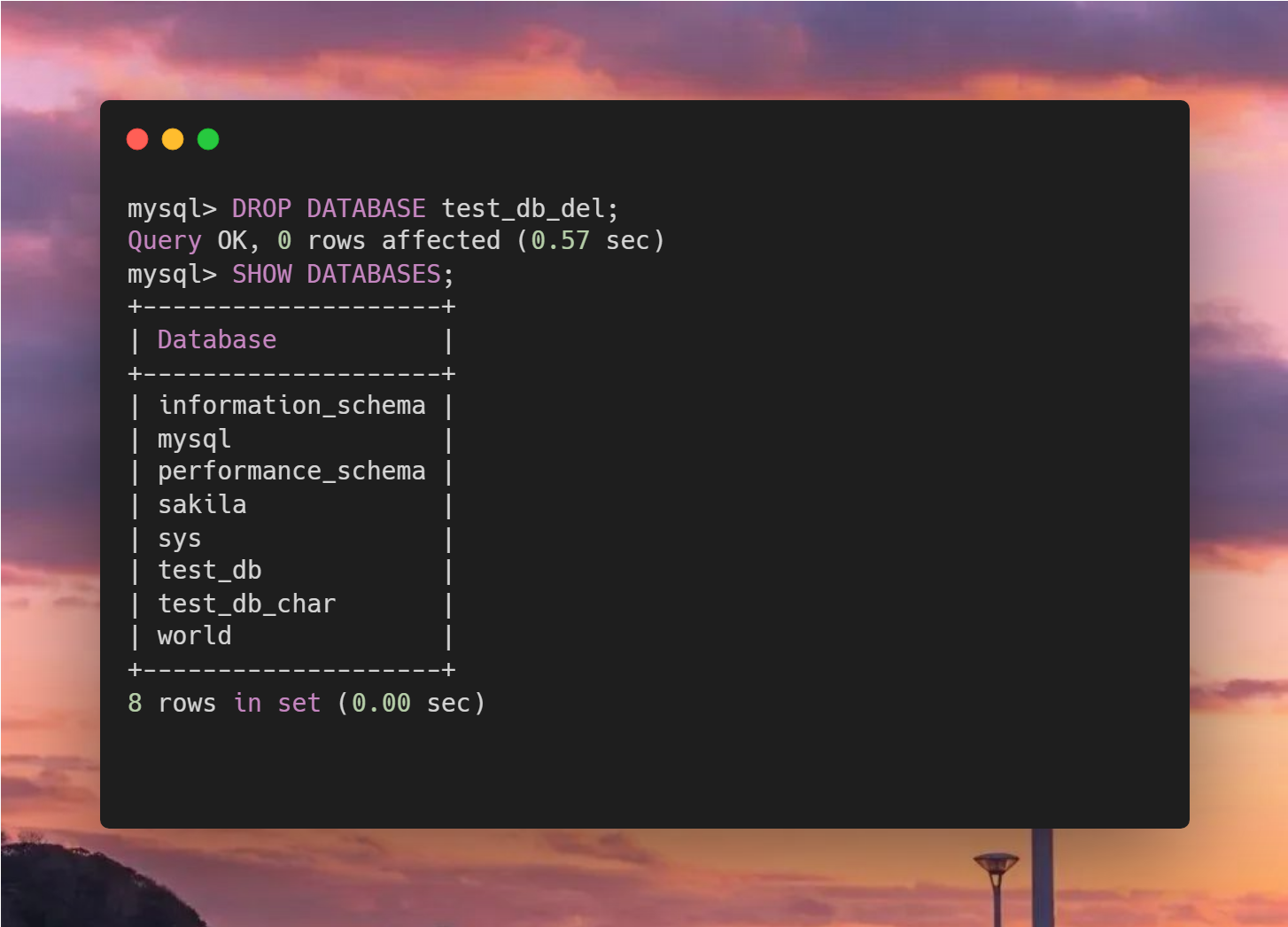
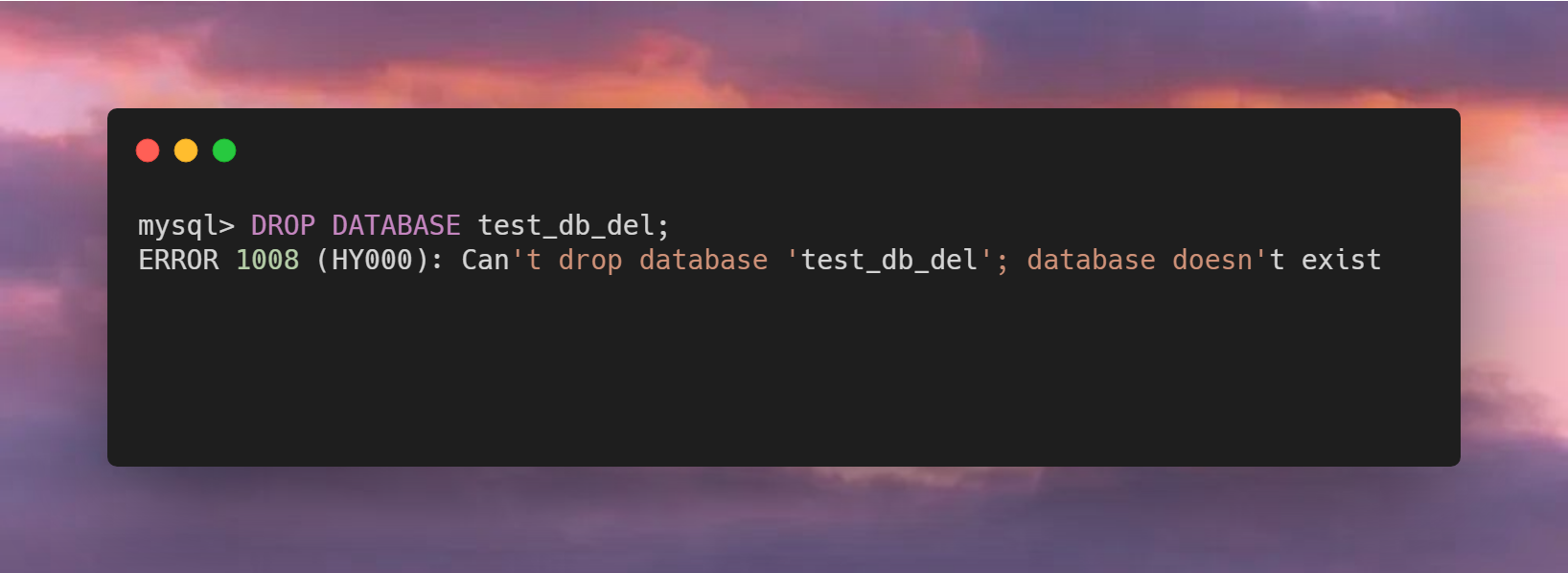
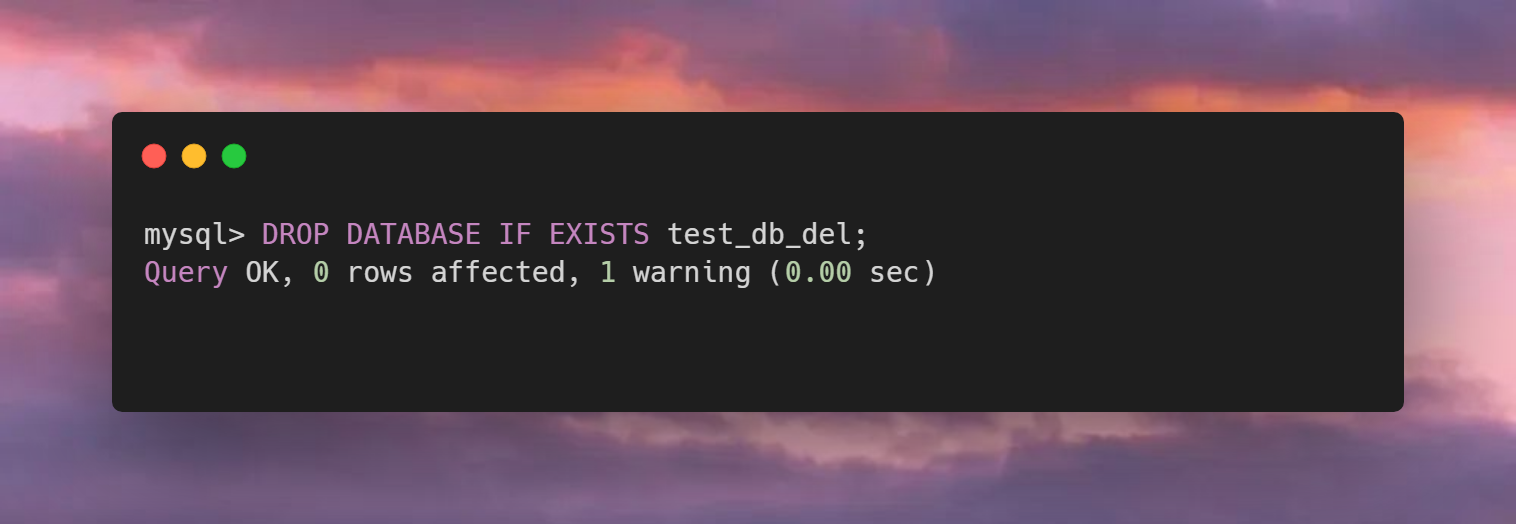
今天,五阳哥不打算聊技术,而是聊一下炒股的话题。我自认为在这方面有发言权,自述一个程序员的炒股经历。
2019年,我开始涉足股市,在2021年中旬为了购房,将持有的股票全部卖出,赚了十多万元。在最高峰时期,我获利超过了二十多万元,但后来又回吐了一部分利润。虽然我的炒股成绩不是最出色的,但也超过了很多人。因为大多数股民都是亏损的,能够在股市长期盈利的人真的是凤毛麟角。
股市中普遍流传的七亏二平一赚的说法并不只是传闻,事实上,现实中的比例更加残酷,能够长期赚钱的人可能连10%都达不到。
接下来,我想谈谈我的炒股经历和心路历程,与大家分享一下我的内心体验,为那些有意向或正在炒股的朋友提供一些参考。希望劝退大家,能救一个是一个!
本文倒叙描述,先聊聊最后的疯狂和偏执!
不甘失败,疯狂上杠杆
股市有上涨就有下跌,在我卖出以后,股市继续疯涨了很多。当时长春高新,我是四百一股买入,六百一股就卖出了,只赚了2万。可是在我卖出去的两个月以后,它最高涨到了一千。相当于我本可以赚六万,结果赚了两万就跑了。
我简直想把大腿拍烂了,这严重的影响了我的认知。我开始坚信,这只股票和公司就是好的,非常牛,是我始乱终弃,我不应该早早抛弃人家。 除了悔恨,我还在期盼它下跌,好让我再次抄底,重新买入,让我有重新上车的机会!
终于这只股票后来跌了10%,我觉得跌的差不多了,于是我开始抄底买入!抄底买入的价格在900一股(复权前)。
没想到,这次抄底是我噩梦的开始。我想抄他的底,他想抄我的家!

这张图,完美的诠释了我的抄底过程。地板底下还有底,深不见底,一直到我不再敢抄底为止。一直抄到,我天天睡不着觉!
当时我九百多一股开始抄底买入,在此之前我都是100股,后来我开始投入更多的资金在这只股票上。当时的我 定下了规矩,鸡蛋不能放在一个篮子里;不能重仓一只股票,要分散投资;这些道理我都明白,但是真到了节骨眼上,我不想输,我想一把赢回来,我要抄底,摊平我的成本。
正所谓:高位加仓,一把亏光。之前我赚的两万块钱,早就因为高位加仓,亏回去了。可是我不甘心输,我想赢回来。当时意识不到也不愿意承认:这就是赌徒心理。
后来这只股票,从1000,跌倒了600,回调了40%。而我已经被深深的套牢。当时我盈利时,只买了1股。等我被套牢时,持有了9股。 按照1000一股,就是九十万。按照600一股,就是54万。
我刚毕业,哪来的那么多钱!
我的钱,早就在800一股的时候,我就全投进去了,我认为800已经算是底了吧,没想到股价很快就击穿了800。
于是我开始跟好朋友借钱。一共借了10万,商量好借一年,还他利息。后来这10万块钱,也禁不住抄底,很快手里没钱了,股价还在暴跌。我已经忘记当时亏多少钱了,我当时已经不敢看账户了,也不敢细算亏了多少钱!
于是,我又开始从支付宝和招商银行借贷,借钱的利率是相当高的,年利息在6%以上。当时一共借了30万。但是股价还不见底,我开始焦虑的睡不着觉。
不光不见底,还在一直跌,我记得当时有一天,在跌了很多以后,股价跌停 -10%。当时的我已经全部资金都投进去了,一天亏了5万,我的小心脏真的要受不了了。跌的我要吐血! 同事说,那天看见我的脸色很差,握着鼠标手还在发抖!
跌成这样,我没有勇气打开账户…… 我不知道什么时候是个头,除了恐惧只有恐惧,每天活在恐惧之中。
我盘算了一下,当时最低点的我,亏了得有二十多万。从盈利六万,一下子到亏二十多万。只需要一个多月的时间。
我哪里经历过这些,投资以来,我都是顺风顺水的,基本没有亏过钱,从来都是挣钱,怎么会成这个样子。
当时的我,没空反思,我只希望,我要赚回来!我一定会赚回来,当时能借的支付宝和招行都已经借到最大额度了…… 我也没有什么办法了,只能躺平。
所以股价最低点的时候,基本都没有钱加仓。
侥幸反弹,但不忍心止盈
股价跌了四个月,这是我人生极其灰暗的四个月。后来因为种种原因,股价涨回来了,当时被传闻的事情不攻自破,公司用实际的业绩证明了自己。
股价开始慢慢回暖,后来开始凶猛的反弹,当时的我一直认为:股价暴跌时我吃的所有苦,所有委屈,我都要股市给我补回来!
后来这段时间,股价最高又回到了1000元一股(复权前)。最高点,我赚了二十多万,但是我不忍心止盈卖出。
我觉得还会继续涨,我还在畅想:公司达到,万亿市值。
我觉得自己当时真的 失了智了。
结婚买房,卖在最高点
这段时间,不光股市顺丰顺水,感情上也比较顺利,有了女朋友,现在是老婆了。从那时起,我开始反思自己的行为,我开始意识到,自己彻彻底底是一个赌徒。
因为已经回本了,也赚了一点钱,我开始不断的纠结要不要卖出,不再炒股了。
后来因为两件事,第一件是我姐姐因为家里要做小买卖,向我借钱。 当时的我,很纠结,我的钱都在股市里啊,借她钱就得卖股票啊,我有点心疼。奈何是亲姐,就借了。
后来我盘算着,不对劲。我还有贷款没还呢,一共三十万。我寻思,我从银行借钱收6%的利息,我借给别人钱,我一分利息收不到。 我TM 妥妥的冤大头啊。
不行,我要把贷款全部还上,我Tm亏大了,于是我逐渐卖股票。一卖出便不可收拾。
我开始担心,万一股价再跌回去,怎么办啊。我和女朋友结婚时,还要买房,到时候需要一大笔钱,万一要是被套住了,可怎么办啊!
在这这样的焦虑之下,我把股票全部都卖光了!
冥冥之中,自有天意。等我卖出之后的第二周,长春高新开启了下一轮暴跌,而这一轮暴跌之后,直至今日,再也没有翻身的机会。从股价1000元一股,直至今天 300元一股(复权前是300,当前是150元)。暴跌程度大达 75%以上!

全是侥幸
我觉得我是幸运的,如果我迟了那么一步!假如反应迟一周,我觉得就万劫不复。因为再次开启暴跌后,我又会开始赌徒心理。
我会想,我要把失去的,重新赢回来!我不能现在卖,我要赢回来。再加上之前抄底成功一次,我更加深信不疑!
于是我可能会从1000元,一路抄底到300元。如果真会如此,我只能倾家荡产!
不是每个人都有我这么幸运,在最高点,跑了出去。 雪球上之前有一个非常活泼的用户, 寒月霖枫,就是因为投资长春高新,从盈利150万,到亏光100万本金,还倒欠银行!
然而这一切,他的家人完全不知道,他又该如何面对家人,如何面对未来的人生。他想自杀,想过很多方式了结。感兴趣的朋友可以去 雪球搜搜这个 用户,寒月霖枫。
我觉得 他就是世界上 另一个自己。我和他完全类似的经历,除了我比他幸运一点。我因为结婚买房和被借钱,及时逃顶成功,否则我和他一样,一定会输得倾家荡产!
我觉得,自己就是一个赌狗!


然而,在成为赌狗之前,我是非常认真谨慎对待投资理财的!
极其谨慎的理财开局
一开始,我从微信理财通了解到基金,当时2019年,我刚毕业两年,手里有几万块钱,一直存在活期账户里。其中一个周末,我花时间研究了一下理财通,发现有一些债券基金非常不错。于是分几批买了几个债券基金,当时的我对于理财既谨慎又盲目。
谨慎的一面是:我只敢买债券基金,就是年利息在 5%上下的。像股票基金这种我是不敢买的。
盲目的一面是:我不知道债券基金也是风险很大的,一味的找利息最多的债券基金。
后来的我好像魔怔了,知道了理财这件事,隔三差五就看看收益,找找有没有利息更高的债券基金。直到有一天,我发现了一个指数基金,收益非常稳定。
是美股的指数基金,于是我买了1万块钱,庆幸的是,这只指数基金,三个月就赚了八百多,当时的我很高兴。那一刻,我第一次体会到:不劳而获真的让人非常快乐!
如饥似渴的学习投资技巧
经过一段时间的理财,我对于理财越来越熟悉。
胆子也越来越大,美股的指数基金赚了一点钱,我害怕亏回去,就立即卖了。卖了以后就一直在找其他指数基金,这时候我也在看国内 A股的指数基金,甚至行业主题的基金。
尝到了投资的甜头以后,我开始花更多的时间用来 找基。我开始从方方面面评估一只基金。
有一段时间,我特别自豪,我在一个周末,通过 天天基金网,找到了一个基金,这只基金和社保投资基金的持仓 吻合度非常高。当时的我思想非常朴素, 社保基金可是国家队,国家管理的基金一定非常强,非常专业,眼光自然差不了。这只基金和国家队吻合度如此高,自然也差不了。
于是和朋友们,推荐了这只基金。我们都买了这只基金,而后的一个月,这只基金涨势非常喜人,赚了很多钱,朋友们在群里也都感谢我,说我很厉害,投资眼光真高!
那一刻,我飘飘然……
我开始投入更多的时间用来理财。下班后,用来学习的时间也不学习了,开始慢慢的过度到学习投资理财。我开始不停地 找基。当时研究非常深入,我会把这只基金过往的持仓记录,包括公司都研究到。花费的时间也很多。
我也开始看各种财经分析师对于股市的分析,他们会分析大盘何时突破三千点,什么时候股市情绪会高昂起来,什么行业主题会热门,什么时候该卖出跑路了。
总之,投资理财,可以学习的东西多种多样!似乎比编程有趣多了。
换句话说:我上头了
非常荒谬的炒股开局
当时我还是非常谨慎地,一直在投资基金,包括 比较火爆的 中欧医疗创新C 基金,我当时也买了。当时葛兰的名气还很响亮呢。后来股市下行,医疗股票都在暴跌,葛兰的基金 就不行了,有句话调侃:家里有钱用不完,中欧医疗找葛兰。腰缠万贯没人分,易方达那有张坤。
由此可见,股市里难有常胜将军!
当时的我,进入股市,非常荒谬。有一天,前同事偷偷告诉我,他知道用友的内幕,让我下午开盘赶紧买,我忙追问,什么内幕,他说利润得翻五倍。 我寻思一下,看了一眼用友股票还在低位趴着,心动了。于是我中午就忙不迭的线上开户,然后下午急匆匆的买了 用友。 事后证明,利润不光没有翻五倍,还下降了。当然在这之前,我早就跑了,没赚着钱,也没咋亏钱。
当时的我,深信不疑这个假的小道消息,恨不得立即买上很多股票。害怕来不及上车……
自从开了户,便一发不可收拾,此时差2个月,快到2019年底!席卷全世界的病毒即将来袭
这段时间,股市涨势非常好,半导体基金涨得非常凶猛! 我因为初次进入股市,没有历史包袱,哪个股票是热点,我追哪个,胆子非常大。而且股市行情非常好,我更加相信,自己的炒股实力不凡!
换句话说:越来越上头,胆子越来越大。 学习编程,学个屁啊,炒股能赚钱,还编个屁程序。

刚入股市,就赶上牛市,顺风顺水
2019年底到2020年上半年,A股有几年不遇的大牛市,尤其是半导体、白酒、医疗行业行情非常火爆。我因为初入股市,没有历史包袱,没有锚点。当前哪个行业火爆,我就买那个,没事就跑 雪球 刷股票论坛的时间,比上班的时间还要长。
上班摸鱼和炒股 是家常便饭。工作上虽然不算心不在焉,但是漫不经心!

在这之前,我投入的金额不多。最多时候,也就投入了10万块钱。当时基金收益达到了三万块。我开始飘飘然。
开始炒股,也尝到了甜头,一开始,我把基金里的钱,逐渐的转移到股市里。当时的我给自己定纪律。七成资金投在基金里,三成资金投在股市里。做风险平衡,不能完全投入到风险高的股市里。
我自认为,我能禁得住 炒股这个毒品。
但是逐渐的,股票的收益越来越高,这个比例很快就倒转过来,我开始把更多资金投在股市中,其中有一只股票,我非常喜欢。这只股票后来成为了很多人的噩梦,成为很多股民 人生毁灭的导火索!
长春高新 股票代码:000661。我在这只股票上赚的很多,后来我觉得股市涨了那么多,该跌了吧,于是我就全部卖出,清仓止盈。 当时的我利润有六万,我觉得非常多了,我非常高兴。
其中 长春高新 一只股票的利润在 两万多元。当时这是我最喜欢的一只股票。我做梦也想不到,后来这只股票差点让我倾家荡产……
当时每天最开心的事情就是,打开基金和证券App,查看每天的收益。有的时候一天能赚 两千多,比工资还要高。群里也非常热闹,每个人都非常兴奋,热烈的讨论哪个股票涨得好。商业互吹成风……
换句话说:岂止是炒股上头,我已经中毒了!

之后就发生了,上文说的一切,我在抄底的过程中,越套越牢……
总结
以上都是我的个人真实经历。 我没有谈 A 股是否值得投资,也不评论当前的股市行情。我只是想分享自己的个人炒股经历。
炒股就是赌博
我想告诉大家,无论你在股市赚了多少钱,迟早都会还回去,越炒股越上头,赚的越多越上头。
赌徒不是一天造成的,谁都有赢的时候,无论赚多少,最终都会因为人性的贪婪 走上赌徒的道路。迟早倾家荡产。即使你没有遇到长春高新,也会有其他暴跌的股票等着你!
什么🐶皮的价值投资! 谈价值投资,撒泡尿照照自己,你一个散户,你配吗?
漫漫人生路,总会错几步。股市里错几步,就会让你万劫不复!
”把钱还我,我不玩了“
”我只要把钱赢回来,我就不玩了“
这都是常见的赌徒心理,奉劝看到此文的 程序员朋友,千万不要炒股和买基金。
尤其是喜欢打牌、打德州扑克,喜欢买彩-票的 赌性很强的朋友,一定要远离炒股,远离投资!
能救一个是一个!
作者:五阳神功
来源:juejin.cn/post/7303348013934034983




















































 临时CEO Mira Murati、首席战略官Jason Kwon、首席运营官Brad Lightcap,都站在了Altman这一边,希望董事会辞职。董事们让步了,原则上同意辞职,但还未正式执行,正在评估新董事的人选。截止发稿时,双方还在僵持中。但Altman,应该是已经掌握了主动权。
临时CEO Mira Murati、首席战略官Jason Kwon、首席运营官Brad Lightcap,都站在了Altman这一边,希望董事会辞职。董事们让步了,原则上同意辞职,但还未正式执行,正在评估新董事的人选。截止发稿时,双方还在僵持中。但Altman,应该是已经掌握了主动权。 而在Altman被离职的同时也一起辞职的OpenAI总裁
而在Altman被离职的同时也一起辞职的OpenAI总裁 与此同时,OpenAI最主要的风投支持者们,包括其第二大股东Thrive Capital、Tiger Global、
与此同时,OpenAI最主要的风投支持者们,包括其第二大股东Thrive Capital、Tiger Global、 这不由得让人想起硅谷的另一起著名事件——众所周知,史蒂夫·乔布斯在1985年的时候被自己亲手创立的苹果解雇。随后,他创立了NeXT,一家生产高端计算机的公司。而彼时的苹果,已经风雨飘摇。1997年,乔布斯正式回归。很快,他就把苹果从一个苦苦挣扎的科技公司转变为一个全球巨头。
这不由得让人想起硅谷的另一起著名事件——众所周知,史蒂夫·乔布斯在1985年的时候被自己亲手创立的苹果解雇。随后,他创立了NeXT,一家生产高端计算机的公司。而彼时的苹果,已经风雨飘摇。1997年,乔布斯正式回归。很快,他就把苹果从一个苦苦挣扎的科技公司转变为一个全球巨头。
 随着事情的发酵,Altman发推表示:我太爱OpenAI团队了。
随着事情的发酵,Altman发推表示:我太爱OpenAI团队了。 同时,大量OpenAI的核心员工和高管,都转发了Altman的推特,纷纷po出爱心,表示支持。
同时,大量OpenAI的核心员工和高管,都转发了Altman的推特,纷纷po出爱心,表示支持。 这些OpenAI核心员工对于Altman的支持,似乎在告诉董事会,开了他,OpenAI很有可能面临大量的员工流失。
这些OpenAI核心员工对于Altman的支持,似乎在告诉董事会,开了他,OpenAI很有可能面临大量的员工流失。 而这些人,正是OpenAI能够走到今天,成为科技圈最受瞩目,甚至能够改变科技行业未来的公司的原因。
而这些人,正是OpenAI能够走到今天,成为科技圈最受瞩目,甚至能够改变科技行业未来的公司的原因。 为了安抚员工,OpenAI和Altman展开复职谈判之后,OpenAI高管在一份发给员工的备忘录中称,他们对Altman和Brockman的回归「非常乐观」。
为了安抚员工,OpenAI和Altman展开复职谈判之后,OpenAI高管在一份发给员工的备忘录中称,他们对Altman和Brockman的回归「非常乐观」。 根据外媒报道,如果董事会真的重组,新加入董事会的成员可能会包括:Salesforce Inc.前联席首席执行官Bret Taylor。
根据外媒报道,如果董事会真的重组,新加入董事会的成员可能会包括:Salesforce Inc.前联席首席执行官Bret Taylor。 以及另一位来自微软的高管。而推动前董事会裁掉Altman的OpenAI首席科学家Ilya,能否继续留在董事会之中,就不得而知了。毕竟,矛盾的地方在于,不久前的开发者大会已经充分昭示了Altman的商业野心。而董事会成员,尤其以Ilya为主,则对AI的安全性产生了担忧。对此,马斯克也不忘趁此时机倒油,表达对Ilya的支持,同时也就间接表达了对Altman的质疑。
以及另一位来自微软的高管。而推动前董事会裁掉Altman的OpenAI首席科学家Ilya,能否继续留在董事会之中,就不得而知了。毕竟,矛盾的地方在于,不久前的开发者大会已经充分昭示了Altman的商业野心。而董事会成员,尤其以Ilya为主,则对AI的安全性产生了担忧。对此,马斯克也不忘趁此时机倒油,表达对Ilya的支持,同时也就间接表达了对Altman的质疑。









 Altman亮出了自己的最后王牌,「权力转换卡」!
Altman亮出了自己的最后王牌,「权力转换卡」! 相同的姿势,相同的结局,只是Altman效率高太多了。
相同的姿势,相同的结局,只是Altman效率高太多了。 和一年前马老板收购推特后相似的场景再次上演!
和一年前马老板收购推特后相似的场景再次上演!



















































































 项目名称、包名、存储路径、编译SDK版本、模型,语言、设备类型等。
项目名称、包名、存储路径、编译SDK版本、模型,语言、设备类型等。