一、前言
启动性能是App使用体验的门面,耗时过长会降低用户使用兴趣。对于开发者来说,通过各种技术手段来提升启动性能缩减启动时长,对整站业务的各项指标提升都会有较大帮助。因此,秒开率优化也成为了各个客户端团队在体验优化方向上十分重要的一环。
本文将会结合我自己在项目中优化启动速度的经验,跟大家分享下,我眼里的科学的启动速度优化思路。
在我的眼里,科学的优化策略是通用的,不管是针对什么性能指标不管是针对什么课题,思路是差不多的。比如这期的分享是启动优化,其实跟上期分享的 如何科学的进行Android包体积优化 - 掘金 (juejin.cn) 是类似的,在那篇分享里我总结了基本思想:
- 抓各个环节
- 系统化方案先行,再来实操
- 明确风险收益比及成本收益比
- 明确指标以及形成一套监控防劣化体系
- 把包体积这个指标刻在脑子里
那放在启动优化里,基本思想长啥样呢?其实是差不多的,我认为唯一的差别就是启动优化会包含着许多前期调研和计划过程考虑不到或者甚至无法提前考虑的问题点和可优化点。
- 抓各个环节
- 系统化方案先行,再来实操
- 从各个角度死磕各个角落,寻找可优化点
- 明确风险收益比及成本收益比
- 明确指标以及形成一套监控防劣化体系
- 把秒开率这个指标刻在脑子里
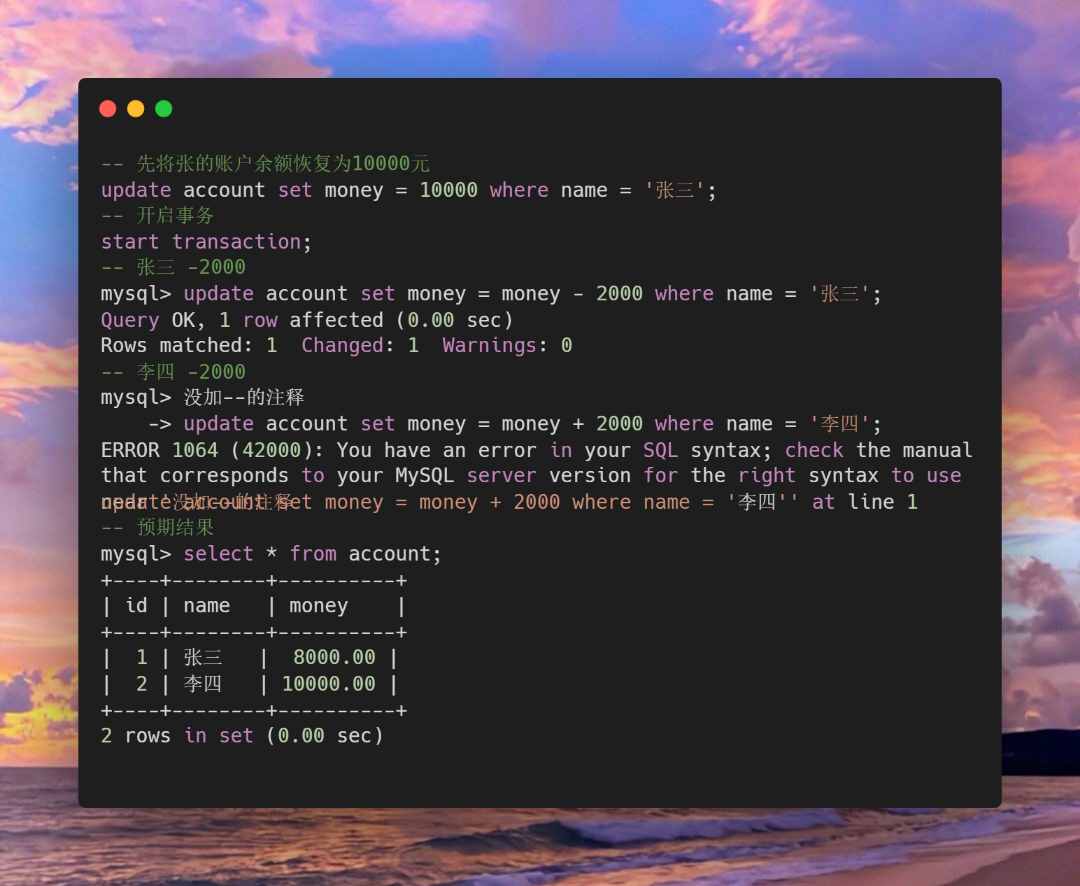
我们调研了市面上几乎所有的优化方案,并结合项目现有情况,针对启动阶段各方面、各阶段进行针对性的优化,加上后期不断的调优,将Android客户端的主版本秒开率由 17% 优化到了 75+%,90 分位 App的启动耗时从 2800ms 优化到 1500 ms,大幅提升app的启动体验。此外,我们还建立了一系列的线上监控、防劣化体系,以确保优化效果可持续。
二、评估优化需求
在开展工作前,我们首先得先有两点判断:
那具体应该如何进行判断呢?有个比较简单的方法就是对标,找到对标对象进行对标。
对于小厂来说,一般对标对象有:
基于对标对象,我们可以粗略的有如下判断:
- 如果我们App跟竞品App启动速度差不多甚至略高,那就有必要进行启动速度优化。当然,在许多厂不缺人力和资源的时候,并不需要这一步判断过程哈
- 优化到业内人气App中启动速度最快那一档即可
上述判断还是基于用户视角,从用户使用App的意愿去出发,那从业务或者技术的视角出发的话,肯定是越快越好,不废话了,下面直接进入主题。
三、秒开率定义 / 启动速度指标定义
既然要讨论秒开率,必须得明确以下问题:
- 用户启动app的耗时如何定义?
- 多长时间内app启动完成才算秒开?
3.1 用户启动app的耗时如何定义?
我们这里的定义是:进程启动 -> 用户看见Feed流卡片/内容
业内常见的app启动过程阶段一般分为「启动阶段」和「首刷阶段」。
- 启动阶段:指用户点击icon到见到app的首页
- 首刷阶段:指用户见到app的首页到首页列表内容展现

很多厂在谈论启动优化时,只涉及到第一步。对用户而言,他并不知道所谓的启动阶段和首刷阶段都是些什么东西,他只知道 看没看到预期的内容和能不能开始消费内容 ,既然要讨论秒开率,必然是用户期待的内容秒开,所以仅以「启动阶段」作为秒开率的指标依据并不能代表用户的真实用户体验。假如用户1s就看到首页了,但是feed流过了10s才有内容的展现,这显然不能算作秒开,这也不能代表用户的体验就是好的。当然,以 启动阶段 + 首刷阶段 认定为需要秒开的时间段,挑战也自然而然增大许多,环节越多,不可控和不可抗因素就越多。
3.2多长时间内app启动完成才算秒开?
1秒
既然谈论的目标是秒开率,那必然是需要 1s 内完成用户的启动流程。
四、认识自家App的启动流程
为什么要认识自家App的启动过程?
知彼知己者,百战不殆。 --《孙子·谋攻》
对启动过程作业务层面、系统层面的全路径分析,有利于我们发现全路径上各个阶段的耗时点及潜在耗时点。
4.1 从业务角度看启动过程
为什么要从业务角度看启动过程?这是因为我们既然要优化的是秒开率,而我们的秒开率指标又是与业务强相关的指标,所以我们必须从业务的角度出发,找到对启动流程影响最大的以及会block启动流程的业务,以他们为切入点尝试寻求启动速度更优的解法。
启动过程最大的不确定性因素来自于网络请求,如果App启动过程中,需要等待网络请求完成才能进入下一阶段,当出现弱网、慢网等情况时,启动时长就无法预估了,我们从下图中可以看到两处网络依赖:开屏广告请求、Feed列表请求。其他的初始化任务都不依赖网络,自然而然的执行时长在同一机器、同一环境是比较稳定的,也是可观测的。
根据业务流程,我们想要优化启动速度,需要进行如下考虑:
- 开屏广告接口尽量早的发出请求
- 等待开屏接口过程中,尽量完成更多的对启动流程有 block 的启动任务
- feed列表的第一屏数据尽量走缓存
(下图画的有点粗略,意会就行)

4.2 从系统角度看启动过程
从系统角度来看自家App的启动路径,与大多数App是类似的。整体分为 Application 阶段、Activity阶段、RN阶段(业务页面阶段)。

4.2.1 Application阶段
在Application阶段中,有两个子阶段需要我们重点关注:
- Install provider,现在许多的三方库为了追求使用的便利性以及能够轻松的获取到Application上下文,会选择通过注册ContentProvider来实现库的初始化,然而正是由于过于便利,导致我们在排查启动过程的三方库初始化情况时,容易忽略掉这些隐式初始化的三方库。
- Application#onCreate,一般来说,项目本身模块的初始化、各种三方库初始化、业务前置环境初始化都会在 Application#onCreate 这个生命周期里干,往往这个生命周期里的任务是非常臃肿的,我们优化Application流程的大部分目光也集中在这里,也是我们通过异步、按需、预加载等各种手段做优化的主要时机。
4.2.2 Activity阶段
Activity阶段的起点来自于 ActivityThread#performLaunchActivity 的调用,在 performLaunchActivity 方法中,将会创建Activity的上下文,并且反射创建Activity实例,如果是App的冷启动(即 Application 并未创建),则会先创建Application并调用Application的onCreate方法,再初始化Activity,创建Window对象(PhoneWindow)并实现Activity和Window相关联,最终调用到Activity的onCreate生命周期方法。
在启动优化的专项中,Activity阶段最关键的生命周期是 Activity#onCreate,这个阶段中包含了大量的 UI 构建、首页相关业务初始化等耗时任务,是我们在优化启动过程中非常重要的一环,我们可以通过异步、预加载、延迟执行等手段做各方面的优化。
4.2.3 RN阶段(首页页面业务阶段)
在我们App中,有着非常大量的 react native(RN) 技术栈的使用,面首页也是采用 RN 开发,在目前客户端团队配置下,对 RN 这个大项目的源码进行优化的空间是比较小的,考虑到成本收益比,本文几乎不会涉及对 RN 架构的直接正向优化,尽管 RN 的渲染性能可能是启动流程中非常大的瓶颈点。
五、衡量App启动时长
5.1 线上大盘观测
为了量化指标、找出线上用户瓶颈以及衡量后续的优化效果,我们对线上用户的启动时长进行了埋点统计,用来观测用户从点击icon到看到feed流卡片的总时长以及各阶段的时长。
通过细化、量化的指标监控,能够很好的观测线上用户启动耗时大盘的版本变化以及各个阶段的分位数版本变化,同时我们也需要依赖线上的性能监控统计来判断我们在某个版本上上线的某个优化是否有效,是否能真实反映在大盘指标以及用户体验上,因为本地用测试机器去跑平均启动时间,受限于运行环境的不稳定,总是会有数据波动的。当进行了某项优化之后,能通过本地测试大概跑出来是否有正向优化、优化了大概多少毫秒,但是具体反映到秒开率指标上,只能依赖大盘,本地无法做上线前的优化预估。
启动流程终点选取
终点不需要完全准确,尽量准就足够了
大多数的 App 在选择冷启动启动流程终点时,会选择首页 Activity 的 onWindowFocusChanged 时机,此时首页 Activity 已经可见但其内部的 View 还不可见,对于用户侧已经可以看见首页背景,同时会将首页内 View 绘制归入首刷过程中。
但是我们期望的终点是用户看到 Feed 流卡片的时刻,上面也说了,我们优化目标就是 「启动阶段」 + 「首刷阶段」,由于首页里的feed tab是RN 开发的,我们无法轻易的去精准到卡片的绘制阶段,于是我们将终点的选取选在了「ReactScrollView 的子 View onViewAttachedToWindow 回调时」,指RN feed流卡片View ready并且添加到了 window 上,可以大致认为卡片用户可见。
启动性能指标校准
由于启动路径十分复杂,在添加了相应的埋点之后还需要进行额外的校准,确保启动性能面板能正确反映用户正常打开app看到首页的完整不间断流程的性能。因此,我们对于许多的边缘case进行了剔除:
- 进程后台被唤起,这种情况进程在后台早早的被唤起,三方sdk以及一些其他模块也早早的初始化完成,只是MainActivity没有被启动,这种case下,我们通过进程启动时,读取进程当前的 importance 进行过滤。
- 启动过程中App退后台
- 用户未登录场景
- 特殊场景下的开屏广告,比如有复杂的联动动效
- push、deeplink拉起
- 点开app第一个页面非首页,这种场景常见的就是 push、deeplink,但是还会有一些其他的站内逻辑进其他tab或者其他二级页面,所以这里统一做一个过滤。
启动性能大盘建设
首先要明确我们建设的性能大盘是以什么形式从什么角度监控什么指标,在启动速度这种场景下,分位数指标更加适合去进行全面监控,因为其波动较小,不会被极端的case影响曲线,所以我们在进行启动性能的优化时,最关注的就是分位数的性能。所以我们的整体监控面板分为:
- 秒开率、2秒开率、3秒开率、5秒以上打开率
- 90分位总体性能、90分位各阶段性能。
- 分版本各阶段各项指标、整体各阶段各项指标、主版本各阶段各项指标。
- 分场景,如有无广告等等
- ...
5.2 Method Trace
除了线上对性能指标进行监控,在开发环境下我们想要去优化启动时长,必须得有方法知道瓶颈在哪儿,是哪个方法太耗时,还是哪些逻辑不合理,哪些能优化,哪些没法优化。Method Trace就是其中手段之一,我们通过 Method Trace能看到每个线程的运行情况,每个方法、方法栈耗时情况如何。
Profiler
看method trace有两种方式,一种是直接启动 Android Studio 自带的Profiler工具,attach上进程之后就可以选择 “sample java methods” 来进行 cpu profiling了,但是这种方式不支持release包使用,只能在debug包上面使用,且性能损耗大,会让问题的分析产生误差

Debug.startMethodTracingSamping
我们也可以通过代码去抓取 method trace:
Application
File file = new File(FileUtils.getCacheDir(application), "trace_" + System.currentTimeMillis())
Debug.startMethodTracing(file.getAbsolutePath(), 200000000)
Debug.startMethodTracingSamping(file.getAbsolutePath(), 200000000, 100)
StartupFlow
Debug.stopMethodTracing()
在开启 MethodTracing 时,更加推荐使用 startMethodTracingSamping,这样性能损耗比调用startMethodTracing进行的完全的 Method Tracing低非常非常多, 这样抓到的性能窗口误差也小很多。而且抓到的 trace 文件也小很多,用Android Studio直接打开的话,不会有啥问题,当文件足够大时,用Android Studio打开可能会失败或者直接卡死。

5.3 System Trace
Perfetto
Perfetto 是 Android 10 中引入的全新平台级跟踪工具。这是适用于 Android、Linux 和 Chrome 的更加通用和复杂的开源跟踪项目。与 Systrace 不同,它提供数据源超集,可让你以 protobuf 编码的二进制流形式记录任意长度的跟踪记录。你可以在 Perfetto 界面中打开这些跟踪记录,可以理解成如果开发机器是 Android 10 以下,就用 Systrace,如果是 Android 10 及以上,就用 Perfetto,但是 Perfetto跟Systrace一样,抓取到的报告是不包含 App 进程的代码执行情况的。文章后续也会给用Perfetto找到待优化点的案例。

六、优化实践
经过上面的理论分析、现状分析以及大盘指标的建立之后,其实大致对哪些需要优化以及大致如何排查、如何优化会有一个整体认知。在小厂里,由于开发资源有限,所以实际上在优化实践阶段对能进行的但是进行人力成本比较高的优化项会做一轮筛查,我们通过调研市面公开的资料、技术博客了解各大场以及各个博主分享的启动优化思路和方案,再结合自身场景做出取舍,在做取舍的过程中,衡量一个任务是否要启动有两个关键指标:“投入产出比”、“产出风险比”。
- 投入产出比:很容易理解,当优化一个点需要 3人/天,能收获90分位 100ms 的优化产出,另一个点需要 3人/天,但只能收获90分位 10ms 的优化产出,谁先谁后、谁要做谁不做其实显而易见,因为优化的前期追求的一个很重要的点必然是优化收益。等到后续开启二期任务、三期任务需要做到更加极致时,才会考虑成本高但收益低的任务。
- 产出风险比:在我们做启动优化过程中,必然会有一些方案有产出但是可能会有风险点的,可能是影响某个业务,也可能影响所有业务,我们需要在启动优化的过程中,不断的衡量一个优化任务是否有风险,风险影响范围如何,风险影响大小如何,最后整体衡量甚至跟业务方进行商讨对他们造成的劣化是否能够接受,最后才能敲定相关的任务是否要排上日程。
所以大致的思路可以总结为:
- 前期低成本低风险快速降低大盘启动耗时
- 后期高成本突破各个瓶颈
- 全期加强监控,做好防劣化
下面我们就将会按照文章一开始提过的启动流程顺序来分享在启动加速项目中的一些案例。
6.1 Application流程
6.1.1 启动任务删减与重排
这里我多提两嘴。我个人觉得在启动优化中,删减和重排启动任务是最为复杂的,特别是对于中大型App,业务过于多,甚至过于杂乱。但是在小厂中,完全可以冲着 删除和延后所有首页无关业务、模块、SDK代码 的目标去,前提是能理清所有业务的表面和隐藏逻辑,这里需要对整个App启动阶段的业务代码和业务流程全盘掌控。
你也许可以通过奇技淫巧让启动过程中业务B反序列化时间无限变短,而我可以从启动过程中删掉业务B逻辑
在App的启动流程中,有非常多的启动任务全部在Application的onCreate里被执行,有主线程的有非主线程的,但是不可避免的是,二者都会对启动的性能带来损耗。所以我们需要做的第一件重要的事情就是 减少启动任务。
我们通过逐个排查启动任务,同时将他们分为几类:
- 刚需任务:不可延迟,必须第一时间最高优先级执行完成,比如网络库、存储库等基础库的初始化。如果不在启动阶段初始化完成,根本无法进入到后续流程。
- 非刚需高优任务:这类任务的特征就是高优,但是并非刚需,并不是说不初始化完成后续首页就没法进没法用,比如拉取ab实验配置、ip直连、push、长链接相关非刚需基础建设项,这类可以高优在启动阶段执行,但是没必要放在 UI 线程 block 执行,就可以放到启动阶段的后台工作线程中去跑。
- 非刚需低优任务:这类任务常见的特征就是对业务能否运作无决定性影响或者业务本身流程靠后,完全可以放在我们认为的启动阶段结束之后再后台执行,比如 x5内核初始化、在线客服sdk预初始化 之类的。
- 可删除任务:这类任务完全不需要存在于启动流程,可能是任务本身无意义,也可能是任务本身可以懒加载,即在用到的时候再初始化都不迟。
将任务分类之后,我们就能大概知道如何去进行优化。
- 拉高刚需任务优先级
- 非刚需高优 异步化
- 非刚需低优任务 异步化+延迟化
- 可删除任务 删除
6.1.2 任务排布框架
为了更加方便的对启动任务进行排布,我们自己实现了一套用于启动过程的任务排布框架TaskManager。TaskManager具有以下几个特性:
- 支持优先级
- 支持依赖关系
- 提供超时、失败机制以供 fallback
- 支持在关键时间阶段运行任务,如MainActivity某个生命周期、启动流程结束后
大致使用方式为:
TaskManager.getInstance().beginWith(A)
.then(B)
.then(C, D)
.then(E)
.enqueue();
TaskManager.getInstance().runAfterStartup({ xxx; })
通过任务的大致非精细化的排布,我们不仅仅可以对启动任务能够很好的进行监控,还可以更加容易的找出不合理项。
6.1.3 实现runAfterStartup机制 + idleHandler
这玩意儿十分重要,我通过昏天黑地的梳理业务,将启动流程中原先可能超过一半的代码任务非常方便的放到了启动流程之后。
我们通过提供 runAfterStartup 的API,用于更加容易的支持各种场景、各种业务把自己的启动过程任务或者非启动过程任务放在启动流程结束之后运行,这也有助于我们自己在优化的过程中,更加轻松的将上面的非刚需低优任务进行排布。
runAfterStartup的那些任务,应该在什么时候去执行呢?
这里我们认定的启动流程结束是有几个关键点的:
- 首页tab的feed流渲染完成
- 首页tab加载、渲染失败
- 用户进入了二级页面
- 用户退后台
- 用户在首页有 tab 切换操作
通过TaskManager的使用以及我们对各业务的逐一排查分析,我们将原先在启动阶段一股脑无脑运行的任务进行了拆解和细化,该延后的延后,该异步的异步,该按需的按需。
6.2 Activity流程
接下来将分享一下 Activity 阶段的一些相关优化的典型案例。
6.2.1 SplashActivity与MainActivity合并
原先的 launcher activity 是SplashActivity,主要承载广告逻辑,当App启动时,先进入SplashActivity,死等广告接口判断是否有开屏广告,如果有则展示,没有则跳转进MainActivity,这里流程的不合理性影响最大的点是:SplashActivity在死等开屏接口时,根本无法对业务本身做一些预加载或者并发加载,首页的业务都在MainActivity里面,同时启动阶段需要连续启动两个Activity,至少带来 百毫秒 级别的劣化。

当然,将SplashActivity承接的所有内容转移到MainActivity上,有哪几个挑战又该如何解决?
1. MainActivity 作为launch activity之后的单实例问题
- MainAcitvity 的 launch mode 需要设置为 singleTop,否则会出现 App从后台进前台,非MainActivity走生命周期的现象
- 同时,作为首页,需要满足另一个条件就是跳转到首页之后,其他二级页面需要全部都关闭掉,站内跳转到 MainActivity 则附带 CLEAR_TOP | NEW_TASK 的标记
2. 广告以什么形式展现
- 广告原先是以Activity的形式在展现,当 launcher 换掉之后,广告被抽离成 View 的形式去承载逻辑,在 MainActivity#onCreate 中,通过将广告View添加进 DecorView中,完成对首页布局的遮罩,这种方式还有一个好处就是在广告View展示白屏logo图时,底下首页框架是可以进行预加载的。
- 这里其实还需要实现以下配套设施:
- 首页弹出层管理器,管理弹窗、页面跳转等各种可能弹出的东西,在广告View覆盖在上面时,先暂停弹出层管理器的生命周期,避免出现其他内容盖住广告
6.2.2 异步预加载布局
使用异步加载布局时,可以对AsyncLayoutInflater小小改造下,如单线程变线程池,调高线程优先级等,提升预加载使用率
在Android中,其实有封装较好的 AsyncLayoutInflater 用于进行布局的异步加载,我们在App的启动阶段启动异步加载View的任务,同时调高工作线程优先级以尽量在使用View之前就 inflate 结束,这样在首页上要使用该布局时,就可以直接从内存中读取。
异步加载布局容易出问题的点有:
- Context的替换
- 使用MutableContextWrapper,在使用时替换为对应的 Activity 即可
- theme问题
- 当异步创建 TabLayout 等Matrials组件时,由于Application的主题并没有所谓的 AppCompat 主题,会抛出异常
You need to use a Theme.AppCompat theme 。这时需要在 xml 中加上 android:theme="@style/AppCompatTheme" 即可。
但是异步预加载布局有一个点是非常关键的:使用前一定要确认,异步创建的这个布局大部分时候或者绝大部分时候,都能在使用前创建好,不然的话不仅没有优化的效果,还会增加启动阶段的任务从而对启动性能带来一定程度上的劣化。
6.2.3 多Tab懒加载
我们App的首页结构非常复杂,一共有着三层的tab切换器。底部tab负责切换大tab,首页的tab还有着两层tab用于切换二三级子页面。原先由于代码设计使然,首页Tab的其他所有子页面都会在 App 的启动阶段被加载,只是说不进行 RN 页面的渲染,这其实会占据 UI 线程非常多的时间。
我们做启动优化的过程中,将一二三级tab全部懒加载,同时由于 我们App存在首页其他 Tab 的预加载技术建设,目的是为了实现当用户切到其他tab时,完全去除加载过程,因此我们也将预加载的逻辑延迟到了启动流程之后,即:
StartupFlow.runAfterStartup{ preload() }
6.2.4 懒加载布局
Tab懒加载其实也算是布局懒加载的一部分,但又不全是,所以给拆开了。这部分讲的布局懒加载是指:
- 启动过程不一定会需要用上的布局,可以完全在需要时被加载,比如:
- 广告View,完全可以在后端广告接口返回可用的广告数据结构且经过了素材校验等流程确定要开始渲染广告时,进行布局的加载。
- 首页上其他非全量的布局,比如其他广告位、首页上并不一定会出现的搜索框、banner 组件等。这些组件的特性是根据不同的配置来决定是否展示,跟广告类似。
我们用上的布局懒加载的手段分几种:
- ViewStub,在开屏广告的布局中非常常见,因为广告有多种类型,如视频、图片、其他类型广告等,每次的开屏又是确定的只有一种,因此就可以将不同类型的广告容器布局用 ViewStub 来处理
- Kotlin by lazy,这种就是适用于 布局是动态加载的场景,假如上面描述的开屏广告的各种不同类型素材的布局都是在代码中动态的 inflate 并且 add 到根View上的话,其实也可以通过 by lazy 的方式来实现。所以其实很多时候 by lazy 用起来会更加方便,比如下图,对 binding 使用 by lazy ,这样只有在真正要使用 binding 时,才会去 进行 inflate。

6.2.5 xml2Code
用开源项目可以,自己实现也可以,当然,搭配异步加载更可以。
6.2.6 减少布局层级、优化过度绘制
这个就需要自己通过LayoutInspector和Android的调试工具去各自分析了,如果打开LayoutInspector肉眼可见都是红色,赶紧改。。
6.3 RN流程
这里也顺带吐槽下吧,用 RN 写首页 feed 流的app真的不多哈,一般来说随着公司的发展,往往会越来越注重关键页面的性能,我们项目是我见过的为数不多的进 App 第一个页面还是RN的。如果首页不是RN,上面提到的秒开率指标、启动耗时应该会更加好一些才对。

先直面 RN 页面作为首页的加载流程,在页面进行渲染前,会比 native 页面多几个前置任务:
- RN 框架初始化(load各种so,初始化各种东西),RN init
- RN bundle 文件准备,find RN bundle
- RN bundle 文件加载,load RN bundle
- 开启RN渲染流程,start react application
又因为 RN 的 js 和 native 层进行通信,又有引擎开销和线程调度开销,所以我个人认为 RN 是不足以胜任主流 app 的搭载首页业务的任务的。
吐槽归吐槽,能尽量优化点是一点:
6.3.1 无限提前 RN init
如题,由于后续所有的RN流程都依赖RN环境的初始化,所以必须将这坨初始化调用能放多前面,就放多前面,当然,该子线程的还是子线程哈,不可能主线程去初始化这东西。
6.3.2 前置 RN bundle 的完整性校验
当我们在使用 RN 的 bundle 文件时,往往需要校验一下 md5,看看从CDN上下载或者更新的 bundle 文件是否完整,但是启动流程如果进行 bundle 文件的 md5 校验,往往是一个比较2的举动,因此我们通过调整下载流程和加载流程,让下载/更新流程进行完整性校验的保护,确保要加载的所有 bundle 都是完整的可用的就行了,就不需要在启动流程校验bundle完整性了。
6.3.3 page cache
给首页的feed流增加页面级别缓存,让首页首刷不依赖接口返回
6.3.4 三方库的初始化优化
部分的三方 RN package,会在RN初始化的时候,同步的去初始化一堆耗时玩意或者执行耗时逻辑,可以通过修改三方库代码,让他们变成异步执行,不要拖慢整体的RN流程。
6.4 其他优化
6.4.1 Webview非预期初始化
在我们使用 Perfetto 进行性能观测时,在 UI 线程发现了一段 几十毫秒接近百毫秒 的非预期Webview初始化的耗时(机器环境:小米10 pro),在线上用户机器上这段代码执行时间可能会更长。为什么说非预期呢:
- 首页没有WebView的使用、预加载
- X5内核的初始化也在启动流程之后

我们从perfetto的时序图中可以看到,堆栈的调用入口是WebViewChromiumAwInit.startChromiumLocked,由于 Perfetto 并看不到 App 相关的堆栈信息,所以我们无法直接知道到底是哪行代码引起的。这里感谢一下 抖音团队 分享的启动优化案例解析中的案例,了解到 WebViewFactory 实现的 WebViewFactoryProvider 接口的 getStatics、 getGeolocationPermission、createWebView 等多个方法的首次调用都会触发 WebViewChromiumAwInit#ensureChromiumStartedLocked ,随之往主线程 post 一个 runnable,这个runnable的任务体就是 startChromiumLocked 函数的调用。
所以只要我们知道谁在调用 WebViewFactoryProvider 的接口方法,就能知道调用栈来自于哪儿。于是乎我们开始对 WebViewFactoryProvider 进行动态代理,用代理对象去替换掉 WebViewFactory 内部的 sProviderInstance。同时通过断点、打堆栈的形式来查找调用源头。
##WebViewFactory
@SystemApi
public final class WebViewFactory{
@UnsupportedAppUsage
private static WebViewFactoryProvider sProviderInstance;
}
##动态代理
try {
Class clas = Class.forName("android.webkit.WebViewFactory");
Method method = clas.getDeclaredMethod("getProvider");
method.setAccessible(true);
Object obj = method.invoke(null);
Object hookService = Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj.getClass().getSuperclass().getInterfaces(),
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Log.d("zttt", "hookService method: " + method.getName());
new RuntimeException(method.getName()).printStackTrace();
return method.invoke(obj, args);
}
});
Field field = clas.getDeclaredField("sProviderInstance");
field.setAccessible(true);
field.set(null, hookService);
} catch (Exception e) {
e.printStackTrace();
}
替换掉 sProviderInstance 之后,我们就可以在我们的代理逻辑中,加上断点来进行调试,最终找到了造成 WebView非预期初始化的始作俑者:WebSettings.getDefaultUserAgent

事情到这里就好解决了,只需要对 WebSettings.getDefaultUserAgent 进行编译期的Hook,重定向到带缓存defaultUserAgent 的相关方法就行了,本地有缓存则直接读取,本地没有则立即读取,得益于我们项目中使用方便的 配置化 Hook 框架,这种小打小闹的 Hook 工作不到一分钟就能完成。
参考:
基于 Booster ASM API的配置化 hook 方案封装 - 掘金 (juejin.cn)
AndroidSimpleHook-github


当然,这里还需要考虑一个问题,那就是当用户机器的 defaultUserAgent 发生变化之后,怎么才能及时的更新本地缓存以及网络请求中用上新的defaultUserAgent。我们的做法是:
- 当本地没有缓存时,立刻调用 WebSettings.getDefaultUserAgent 拿值并更新缓存;
- 每次App启动阶段结束之后,会在子线程中去调用WebSettings.getDefaultUserAgent 拿值并更新缓存。
这样处理之后,将 defaultUserAgent 发生变化之后的影响最小化,系统 WebView 升级本身就是极度不频繁的事情,在这种 case 下我们舍弃了下一次 App 打开前几个网络请求的 defaultUserAgent 正确性也是合理的,这也是我们考量 「风险收益比」的一个经典case。
6.4.2 启动阶段 IO 优化
更加高级的做法是进行请求合并,当我们将50+个网络请求优化到十来个的时候,如果再对一些实时性不是极高的接口进行合并,会更加优雅。不过小厂没资源做。
前面说的都是优化 UI 线程相关的耗时,实际上在启动阶段,不仅仅 UI 线程执行太多耗时任务会影响启动速度,工作线程执行太多的耗时任务也会影响到启动速度,特别是重IO的任务。
在我们App的启动流程里,首页完成渲染前需要发送50+个网络请求,包含:
- 业务预拉取数据
- 业务拉取各种配置、开关、实验变量
- 多次的badge请求
- 多次的 IM 拉消息的请求
- 各种首页阶段是否展示引导的请求,如push引导权限
- 其他莫名奇妙的请求,可能业务都废弃了,还在发送请求
在优化这一项时,还是秉承着前面所说的得谨慎的考虑 “收益风险比”,毕竟我们不是对所有业务都非常了解,且公司现有研发也不是对所有业务都非常了解。通过一波深入的调研和调整之后,我们将 App 首页渲染完成前的网络请求数量,控制在 10 个左右,大大的减少了启动阶段的网络请求量。
6.4.3 大对象反序列化优化
我们App中,对象的反序列化、序列化用的是谷歌亲儿子 - Gson。Gson 是 Google 推出的一个 json 解析库,其具有接入成本低、使用便捷、功能扩展性良好等优点,但是其也有一个比较明显的弱点,那就是对于它在进行某个 Model 的首次解析时会比较耗时,并且随着 Model 复杂程度的增加,其耗时会不断膨胀。
而我们在启动过程中,需要用 Gson 反序列化非常多的数据,特别是某些大对象,如:
- Global config:顾名思义,是一个全局配置,里面包含着各个业务的配置信息,是非常大的
- user info:这是用户信息的描述对象,里面包含着非常多的用户属性、标签,在App 启动过程中如果主线程去初始化,往往需要几十甚至上百毫秒。
针对这种启动阶段必须进行复杂对象序列化,我们进行了:
- 用Gson解的,自定义 TypeAdapter,属于正面优化反序列化操作本身(市面上有现成的一些通过添加注解自动生成TypeAdapter的框架,通过一个注解就能够很轻松的给对应的类生成 TypeAdapter并注册到 Gson 中)
- 又大又乱又不好改的直接读磁盘然后 JSON 解析的大对象(没想到还有这种的吧),提前子线程预加载,避免在 UI 线程反序列化,能解决部分问题,并非完全的解法
6.4.4 广告流程优化
其实聊到启动优化,必然会涉及的肯定是 开屏广告 的业务流程。首先要搞清楚一个问题。
启动优化优化的是什么?
启动优化优化的是用户体验,优化的是用户看到内容的速度,那么开屏的内容怎么就不算呢?所以实际上加速用户看到开屏也能一定程度上让用户体感更加的好。而且由于我们进首页的时间依赖于广告流程结束,即需要等待广告流程结束,我们App才会跳过logo的全屏等待页面进入首页,那么优化广告流程耗时实际上也是在优化进入首页的速度,即用户可以更加快速的看到首页框架。

原先的广告流程如上图,业务流程本身可能没什么问题,问题出在了两次的往主线程post runnable来控制流程前进。已知 App 启动流程是非常繁忙的,当一个 runnable 被post到 UI 线程的队列中之后不会立即执行,可能需要等上百甚至几百毫秒,而且由于启动过程中有着许多的耗时大的 runnable 在被执行,就算 mainHandler.postAtFrontOfQueue 都无济于事。

因此我们对广告流程做了调整,去掉了其中一次的消息抛回主线程执行的逻辑,加快了广告业务的流程执行速度,同时,受益于我们前面说的 View 的异步预加载、懒加载等手段,广告流程的执行速度被全面优化。
6.4.5 GC 抑制
实现的花可以参考大佬博客: 速度优化:GC抑制 - 掘金 (juejin.cn)
大家如果只是想本地测试下 GC 抑制在自己项目里的效果,反编译某些大厂App,从里面把相关 so 文件捞出来,copy 下JNI声明,放自己项目里测试用就行。
自动垃圾回收的Java特性相对于C语言来说,确实是能够让开发人员在开发时提高效率,不需要去考虑手动分配内存和分配的内存什么时候去手动回收,但是对于Java程序来说,垃圾回收机制真实让人又爱又恨,不过如果开发人员仅在乎业务而不在乎性能的话,确实是不会垃圾回收恨起来。这里需要明确一点,垃圾回收是有代价的,会占 CPU 资源甚至导致我们线程被挂起。
App在启动过程中,由于任务众多而且涉及到的sdk、模块也众多,非常容易在启动阶段发生一次或者多次的GC,这往往会带来比较多的性能损耗。
针对这种启动容易触发 GC 的场景,我们有两种方式去减少 GC 次数以及降低 GC 发生的可能。
- 通过 profiler 去排查启动过程中的对象创建、分配,找出分配过于频繁明显不正常的case
- 影响 ART 虚拟机的默认垃圾回收行为和机制,进行 GC 抑制,这里由于我们 App 的 minSdk 是 Api 24,所以仅涉及 ART 虚拟机上的 GC 抑制。
不过鉴于以下几点,我们最终并没有自己去实现和上线无稳定性、兼容性隐患的GC抑制能力:
- Android 10 及以上,官方实际上已经在 framework 中添加了 App 启动提高 GC 阈值的逻辑。cs.android.com/android/_/a…
- 由于我们在启动任务重排和删减用例很大,线上对 启动阶段的 GC 次数进行了统计,发现 80 分位的用户 GC 次数为0。也就是说启动优化上线之后线上至少 80% 的用户在启动阶段都不会发生 GC。监听 GC 发生可以简单的用 WeakReference 来包装重写了 finalize 方法的自定义对象。
- 不满足对于收益成本比、风险收益比的要求
6.4.6 高频方法
排查高频方法可以通过 method trace + 插桩记录函数调用来做
比如在我们App的场景中,日志库、网络库上拼接公共参数时,会反复调用许多耗时且无缓存的方法去获取参数值,其中包括:
- Binder调用,如 push enable 等
- 每次都需要反序列化的取值,如 反序列化 global config,从中取得一个配置值。
- ...
针对这几类问题,我们做了如下优化:
6.4.7 binder 调用优化
想要优化启动过程中的binder调用,必须得先知道有哪些binder调用,不考虑来自Framework代码的调用的话,可以通过hook工具来先检查一下。同时打印下调用耗时摸个底
基于 Booster ASM API的配置化 hook 方案封装 - 掘金 (juejin.cn)
binder是android提供的IPC的方式。android许多系统服务都是运行在system_server进程而非app进程,比如判断网络,获取电量,加密等,当通过binder调用去调用到相关的api之后,app线程会挂起等待binder驱动返回数据,因此IPC 调用是比较耗时的,而且可能会出现比预期之内的耗时更加耗时的现象。
针对binder调用的耗时现象,主要做了:
- 对反复调用的 binder 调用结果进行缓存,合适的时机进行更新
- 通过 hook 框架统一收拢这些调用进缓存逻辑
比如 push enable,这种总不能启动过程变来变去吧,再比如网络状态,也不能启动过程变来变去吧。
当然,上面举的例子,也完全可以用于App全局场景,比如通知权限状态,完全可以app进前台检查下就行,比如网络状态,监听网络状态变化去更新就行。
七、验收优化效果
再次强调一下,我们统计的 App 启动耗时是「启动阶段」+ 「首刷阶段」
7.1 App 启动耗时分位数
90 分位 App的启动耗时从 2800 左右 下降到 1500 左右。降幅47%

7.2 主版本秒开率
从图中也能看到,整体稳定,但部分天波动较大,是因为开屏广告接入了程序化平台,接口时长、素材大小等都不是很好控制,尽管后端已经限制了请求程序化的超时时长,但是迫于无奈,无法将程序化平台接口请求超时时长设定在一个我满意的情况下,毕竟是收入部门。
Android 主版本秒开率由原先的约 17% 提升到 76%

7.3 两秒打开率
Android 主版本两秒打开率由原先的 75% 提升到了 93%

八、总结与展望
回顾秒开率优化的这一期工作,是立项之后的第一期,在优化项选型过程中,除了优化效果之外,人力成本是我们考虑的最多的因素,由于团队人力不充裕,一些需要比较高成本去研究、去做的优化项,也都暂时搁置留做二期任务或者无限搁置。启动优化本身就是个需要持续迭代、持续打磨的任务,我们在优化的过程中始终秉承着 高收益成本比、低风险收益比 的思想,所以后续我们还会继续钻研,继续将之前没有开展的任务排上日程,技术之路,永无止境。
防劣化跟优化一样重要
在线上优化工作开展完成且取得了相应成果后,绝对不能放松警惕,优化这一下获得了效果并不是最重要的,最重要的是要有持续的、稳定的优化效果。对于线上用户来说,其实可能并不关心这个版本或者这几个版本是不是变快了,大家可能更需要的是长时间的良好体验,对于我们这些开发者来说,长时间的良好体验可能才能改变大家对 自家 App 的性能印象,让大家认可自家 App 的启动性能,这也是我们优化的初衷。因此,防劣化跟优化一样重要!
其他
做性能优化往往是比较枯燥的,可能很长时间没有进展,但是当有成果出来时,会收获到一些幸福感和满足感。希望大家都能在遇到瓶颈很难再往前迈步时,再努力挣扎一下,如果不出意外的话,这一路一定很精彩。
作者:邹阿涛涛涛涛涛涛
来源:juejin.cn/post/7306692609497546752





































































 能看到Assets文件夹里,有着75M的RN bundle
能看到Assets文件夹里,有着75M的RN bundle 由于我们App是兼容包,即同时兼容64位、32位,所以lib目录很大
由于我们App是兼容包,即同时兼容64位、32位,所以lib目录很大






 增加后,可在xml文件中查看反转后的效果 2. 新增value-ar文件夹
增加后,可在xml文件中查看反转后的效果 2. 新增value-ar文件夹

 把values/strings.xml文件复制到values-ar文件中,逐条翻译即可。
把values/strings.xml文件复制到values-ar文件中,逐条翻译即可。






 此时会影响hint的展示:在勾选时,hint的结束字符在右侧;不勾选时,hint的结束字符在左侧。
此时会影响hint的展示:在勾选时,hint的结束字符在右侧;不勾选时,hint的结束字符在左侧。



























































































































































 国企出差时去过最远的地方
国企出差时去过最远的地方















































































