背景
本需求的提出基于谷歌应用商店的硬性要求:需要在xxx日前于谷歌商店上架账号注销的网页,保证玩家能够通过网页进行账号注销,从而满足谷歌商店的硬性需求。(问了产品和运营在谷歌商店哪,结果都找不到在哪,离谱)账号注销
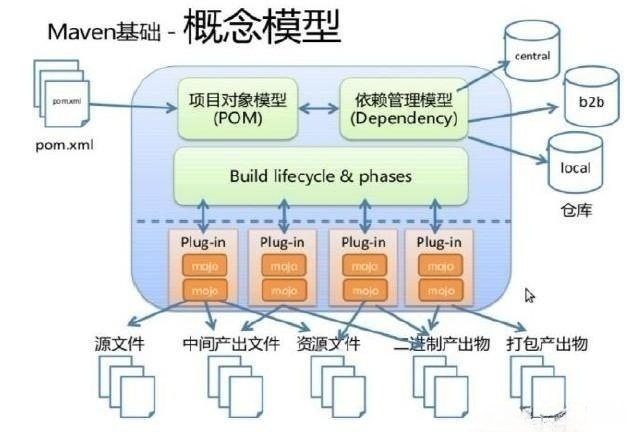
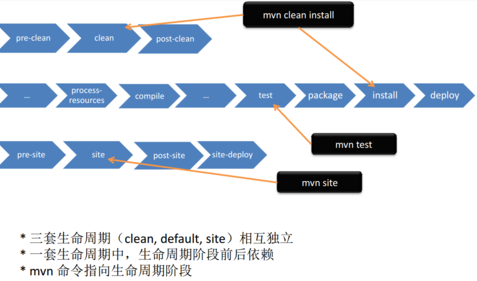
配置解析
package.json
我个人拉项目的时候比较喜欢从package.json中开始了解项目,比如项目中用了哪些第三方依赖,项目使用的是vue-cli启动还是webpack启动等等......
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
"postinstall": "patch-package"
},
比如上述中使用的是vue-cli(vue官方脚手架)启动的项目
serve:不用说,使用vue-cli启动项目
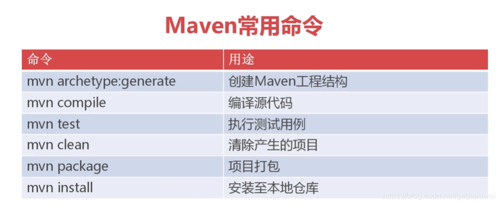
build:使用vue-cli打包项目,打包成js,css,html文件,具体看下图(这里是vue-cli打包为样例,vite打包的话未说明)

这里统一说明,下列所有文件,
前面的那串类似190.xxx.xxx,是由Webpack 为每个模块分配一个唯一的数字标识,这个标识通常代表了模块在整个打包中的位置。
中间的那串类似xxx.a768c482.xxx,都是由webpack或者vue-cli在构建(build)时,通过计算文件内容生成的哈希值,这样可以确保文件内容的唯一性和变化时生成不同的哈希值。所以在文件内容发生变化时,生成的文件名也会相应变化,从而避免浏览器缓存旧的文件。
注:每个css和js的前缀都基本对应,并且由于是webacpk生成的,所以可以自己额外的对其命名进行配置。
css(压缩过)

- chunk-vendors:以
chunk-vendors开头的,主要是对于引入的第三方依赖的样式,比如项目中使用的ant-design-vue,这里面就包含了ant-design-vue的样式

- app:项目自身的样式代码,除了路由router里配置的组件
- 其他:路由router中配置的组件里的样式(删掉路由配置的组件后,相应的打包样式文件消失了)
js(压缩过)
与css类似,多了map(映射文件)和-legacy后缀
source map文件包含了源代码与生成代码之间的映射关系,用于在浏览器中调试时将生成代码映射回源代码。
-legacy 的后缀通常表示这部分代码是针对不支持现代 JavaScript 特性的旧版浏览器生成的。

img 项目中使用过的图片,没使用的不会进行打包
index.html 原项目中public/index.html压缩后的
favicon.icon 原项目中public/favicon.ico图标
lint: 检查代码风格和潜在错误的方法。
也可以在项目根目录下的 .eslintrc.js 文件中进行自定义的规则定制
module.exports = {
root: true,
env: {
node: true,
},
extends: [
"plugin:vue/essential",
"eslint:recommended",
"@vue/typescript/recommended",
"plugin:prettier/recommended",
],
parserOptions: {
ecmaVersion: 2020,
},
rules: {
"no-console": process.env.NODE_ENV === "production" ? "warn" : "off",
"no-debugger": process.env.NODE_ENV === "production" ? "warn" : "off",
"vue/multi-word-component-names": "off",
},
};
检查警告效果图:

postinstall:会检测 node_modules 中的包是否有需要修复的问题,并自动打补丁。
gitHooks
"gitHooks": {
"pre-commit": "lint-staged"
}
指定了在执行 Git 提交前(pre-commit 钩子)运行 lint-staged。这是一种通过 git 钩子(git hooks)来自动化代码检查和格式化的方法。(即当你执行git commit 后会进行检查)可以在lint-staged.config.js中配置,也可以在package.json中。
module.exports = {
"*.{js,jsx,vue,ts,tsx}": "vue-cli-service lint",
};
env环境变量
环境变量在不同的环境下是不同的,比如现在下面的环境变量是开发环境的,当到正式环境时,baseUrl会换成类似https://juejin.cn/,也就是把原本32进制的ip地址换成了这种形式。
后端是对打包(build)后项目进行部署的,而env文件后端需要看到并且对你的环境变量相应的替换,才能正式上线部署。
window.$$env = {
baseUrl: "/test/apis",
appId: "test",
publicPath: "/test",
};
export interface Env {
baseUrl: string;
appId: string;
publicPath: string;
}
const env = (window as any).$$env as Env;
export default env;
封装网络拦截
先使用枚举定义状态码
export enum HttpCode {
Ok = 0,
ServerError = 500,
COOKIE_INVALID = 204,
INFO_INVALID = 205,
ERR_PRODUCT_CHANGE = 402,
SUSPENSION = 503,
}
封装一个网路拦截
export class apiService {
static instance: AxiosInstance | null = null;
static resetConfig(config?: AxiosRequestConfig, appId?: string) {
this.instance = this.createAxiosInstance(config, appId);
}
static getInstance() {
return this.instance || this.createAxiosInstance();
}
static createAxiosInstance(config?: AxiosRequestConfig, appId?: string) {
xxx
xxx
xxx
return instance;
}
}
创建axios实例
const instance = Axios.create({
withCredentials: true,
baseURL: env.baseUrl,
timeout: 30 * 1000,
...config,
});
请求拦截
根据项目需求传请求头,比如用户信息,Authorization等
instance.interceptors.request.use((config) => {
config.headers = {
...config.headers,
"x-yh-appid": env.appId,
};
return config;
});
响应拦截
根据后端传回来的状态码处理相应的状态
instance.interceptors.response.use(
(response: AxiosResponse<any>) => {
const { code = -1, data = {}, msg = "" } = response.data;
if (handleUnlogin(code)) {
return Promise.reject(msg);
}
if (code === HttpCode.SUSPENSION) {
redirectSuspension();
return Promise.reject(msg);
}
if (code === HttpCode.Ok) {
return Promise.resolve(data);
}
return Promise.reject(msg);
},
(error) => {
return handleHttpError(error);
}
);
根据后端发送的状态码,判断用户是否登录
export function handleUnlogin(code: number) {
if ([HttpCode.COOKIE_INVALID, HttpCode.INFO_INVALID].includes(code)) {
localStorage.removeItem(LOCALSTORAGE_CURRENCY_CODE);
redirectLogin();
return true;
}
return false;
}
处理后端返回的错误信息
export function handleHttpError(error: any) {
const { status = 500, data = {} } = error.response || {};
let msg = data.msg || error.message;
switch (status) {
case HttpCode.ServerError:
msg = "Server internal error";
break;
}
return Promise.reject(msg);
}
功能设计
国际化设计
没配置翻译前但使用了vue-i18n
export enum Direction {
UP = "上",
DOWN = "下",
LEFT = "左",
RIGHT = "右",
}
使用方法,vue中通过$t()来注入翻译文本
<script lang="ts">
import { Translate } from "@/constants";
import { defineComponent } from "vue";
export default defineComponent({
setup() {
return { Translate };
},
});
</script>
<span>{{ $t(Translate.UP) }}</span>
<input :placeholder="$t(Translate.UP)" />
实际展示
<span>上</span>
<input placeholder="上" />
配置翻译后
import i18n from "./locales";
new Vue({
router,
i18n,
render: (h) => h(App),
}).$mount("#app");
在src/locales/index中
import VueI18n from "vue-i18n";
import en from "./language/en";
const i18n = new VueI18n({
locale: "en",
messages: {
en,
},
});
在src/locales/language/en中
import { Translate } from "@/translate";
export default {
[Translate.UP]: "Up",
[Translate.DOWN]: "Downe",
[Translate.LEFT]: "Left",
[Translate.RIGHT]: "Right",
}
实际展示
<span>Up</span>
<input placeholder="Up" />
在main.ts中引入了配置好后的i18n,就会对每个组件中$t(Translate.xx)进行翻译,然后如果想翻译成其他语言,只需要修改在src/locales/index并且在src/locales/language中新增一个其他语言的文件
比如日文(看看就行,翻译别当真)
const i18n = new VueI18n({
locale: "ja",
messages: {
ja,
},
});
import { Translate } from "@/translate";
export default {
[Translate.UP]: "じょうげ",
[Translate.DOWN]: "さゆう"
}
pc端和移动端适配设计(适用于结构类似,各自两套样式)
适配原理
export class SettingService {
readonly mode: "pc" | "mobile";
constructor() {
this.mode = isAndriod() || isIos(false) ? "mobile" : "pc";
Vue.prototype.$global = { mode: this.mode };
}
isPc() {
return this.mode === "pc";
}
}
export const settingService = new SettingService();
整个项目适配
pc端和移动端各自展示的窗口样式是不同的,所以需要在容器中设置不同的样式
{
path: "/",
component: settingService.isPc() ? PcLayout : MobileLayout,
name: "layout",
redirect: "/notice",
}
// pc端
<template>
<div class="layout">
<layout-header />
<div class="layout-kv"></div>
<router-view></router-view>
<layout-footer />
</div>
</template>
// 移动端
<template>
<div class="layout">
<layout-header />
<router-view class="layout-body"></router-view>
<layout-footer />
</div>
</template>
在App.vue中设置了 <body> 元素的 screen-mode 属性,属性值为 settingService.mode。这样,通过在 <body> 元素上设置这个属性,可以影响到整个页面中使用了相应选择器的样式。
<template>
<loading v-if="initing" />
<router-view v-else />
</template>
// App.vue
export default {
name: "App",
mounted() {
document.body.setAttribute("screen-mode", settingService.mode);
}
}
适配案例(即使用方法)
<div class="myClass1">不会覆盖</div>
<div class="myClass2">会覆盖</div>
默认为[screen-mode="mobile"]上面的样式,当切换到移动端时,下面的会覆盖上面同一类名的样式。
.myClass1 {
color: red
}
.myClass2 {
color: red;
font-size: 16px;
}
[screen-mode="mobile"] {
.myClass2 {
color: blue;
font-size: 32dpx;
}
}
解决页面显示的是缓存的内容而不是最新的内容
window.addEventListener("pageshow", (event) => {
if (event.persisted) {
window.location.reload();
}
});
监听了 pageshow 事件,该事件在页面显示时触发,包括页面加载和页面回退(从缓存中重新显示页面)。
window.addEventListener("pageshow", (event) => {...});: 给 window 对象添加了一个 pageshow 事件监听器。当页面被显示时,这个监听器中的回调函数将被执行。
if (event.persisted) {...}: event.persisted 是一个布尔值,表示页面是否是从缓存中恢复显示的。如果为 true,表示页面是通过浏览器的后退/前进按钮从缓存中加载的。
window.location.reload(): 如果页面是从缓存中加载的,就调用 window.location.reload() 强制刷新页面,以确保页面的状态和内容是最新的。
这种逻辑通常用于解决缓存导致的页面状态不一致的问题。在有些情况下,浏览器为了提高性能会缓存页面,但有时这可能导致页面显示的是缓存的内容而不是最新的内容。通过在 pageshow 事件中检测 event.persisted,可以判断页面是否是从缓存中加载的,如果是,则强制刷新页面,确保它是最新的状态。
实时监听登录状态设计(操作浏览器前进回退刷新)
popstate 事件监听器,它会在浏览器的历史记录发生变化(比如用户点击浏览器的后退或前进或刷新按钮,或者执行了类似 history.back()、history.forward()、history.go(-1) 等 JavaScript 操作导致页面的 URL 发生了变化)。但使用router.push之类的操作不会触发。
window.addEventListener("popstate", () => {
if (!settingService.hasUser() && !isLogin()) {
router.push("/login");
return;
}
});
对用户进行埋点(埋点时机)
埋点是对用户的一些信息进行收集,比如用户登录网站的时间,用户的昵称等等。
业务功能
1. 阅读须知,滑到底部并且勾选了同意按钮才能执行下一步

<div
ref="scrollContainer"
style="height: 340px;overflow-y: auto;"
@scroll="handleScroll"
>
文本内容
</div>
<div>
<input @change="handleScroll" type="checkbox" v-model="isChecked" />
<label for="customCheckbox">I know and satisfy all the conditions</label>
</div>
// 如果阅读完了并且勾选了同意按钮,则可以执行下一步,否则不能
<button
v-if="isReaded && isChecked"
@submit="gotoPage"
/>
<button v-else disabled/>
const scrollContainer: any = ref(null);
let isReaded = ref<boolean>(false);
const isChecked = ref<boolean>(false);
const handleScroll = () => {
if (scrollContainer.value) {
【1】const height = scrollContainer.value.scrollHeight - scrollContainer.value.scrollTop;
const isAtBottom = height <= scrollContainer.value.clientHeight + 20;
if (isAtBottom && isChecked.value) {
isReaded.value = true;
}
}
};
【1】// 滑动框的总高度 scrollContainer.value.scrollHeight = 974
// scrollContainer.value.scrollTop = 滑动条距离顶部的距离
// 滑动框的可见高度 scrollContainer.value.clientHeight = 340
// 当scrollHeight-scrollTop 达到340时,即滚动到底部了
// 在上述基础上增加一个区域20,即360,防止不同设备的滚动条滚动高度不一致
2. 勾选原因才能执行下一步

该部分主要是勾选了“other"才会弹出文本框,并且后端传的数据是数组,因此需要对其进行处理。
<div v-for="option in options" :key="option.id">
<input
type="radio"
:id="option.id"
:value="option.id"
name="group"
v-model="selectedOption"
/>
<label :for="option.id">{{ option.label }}</label>
</div>
// 只有勾选了btn4才会展示
<textarea
v-if="selectedOption === 'btn4'"
v-model="textareaValue"
placeholder="If you do have any comments or suggestions please fill in here"
></textarea>
// 如果勾选了按钮,或者选择勾选了btn4并且输入了值
<button
v-if="(selectedOption && selectedOption !== 'btn4') || textareaValue"
@submit="gotoPage"
/>
<button v-else disabled />
const textareaValue = ref("");
const selectedOption = ref(null);
let options = ref([
{ id: "btn1", label: "1" },
{ id: "btn2", label: "2" },
{ id: "btn3", label: "3" },
{ id: "btn4", label: "4" },
]);
options.value.forEach((option, index) => {
option.label = resp.reason[index];
});
const gotoPage = () => {
const reasonList = options.value.map((item) => {
if (selectedOption.value === item.id) {
if (selectedOption.value === "btn4") {
return textareaValue.value;
} else {
return item.label;
}
}
});
let reason = reasonList.filter((item) => item !== undefined)[0];
router.push({
path: "/reconfirm",
query: { reason: reason }
});
};
3. 文本框右下角显示输入值和限制
主要是样式,通过定位来进行布局。

<div v-if="selectedOption === 'bnt4'" style="position: relative">
<textarea
v-model="textareaValue"
:maxlength="maxCharacters"
></textarea>
<div
:class="{
'character-count': true,
'red-text': textareaValue.length === maxCharacters,
}"
>
{{ textareaValue.length }} / {{ maxCharacters }}
</div>
</div>
const maxCharacters = 140;
const textareaValue = ref("");
.character-count {
position: absolute;
right: 10px;
bottom: 10px;
color: #888;
font-size: 12px;
}
.red-text {
color: red;
}
4. 输入指定的字才能执行下一步

主要是对@input的使用,然后进行判断
<div>
<textarea
type="text"
v-model="textareaValue"
:placeholder="reConfirmText"
@input="inputChange"
/>
</div>
<button v-if="isEqual" @submit="gotoPage" />
<button v-else disabled />
const reConfirmText = "I confirm to delete Ninja Must Die account";
const textareaValue = ref("");
const isEqual = ref(false);
const gotoPage = () => {
router.push("/hesitation");
};
const inputChange = () => {
if (textareaValue.value === reConfirmText) {
isEqual.value = true;
} else {
isEqual.value = false;
}
}
5. 登录界面需要使用iframe全屏引入
<iframe src="example.com" class="iframe"></iframe>
.iframe {
position: fixed;
top: 0;
left: 0;
width: 100%;
height: 100%;
border: none;
margin: 0;
padding: 0;
overflow: hidden;
z-index: 9999;
}
其他
代码优化(导师指点)
- 关于跳转路径的变量,用env传递,不要写死
- 常量尽量抽离出来,可以做成枚举的做成枚举
- 关于find,map之类的函数,能抽离出来的抽离出来,不要直接用,太抽象了
使用到的git操作(非常规)
1. 从一个仓库的代码放到另一个仓库上
场景:从第一个仓库中拉取代码到本地(比如团队中的模板仓库),但你需要把本地开发的代码(处于第一个仓库)推到第二个仓库中(真正开发仓库)
但你首先得在仓库上加ssh地址,打开powershell粘贴下述命令
ssh-keygen -t rsa -C "xxx@xxx.com"
回车到底

cat ~/.ssh/id_rsa.pub
复制所有

打开仓库,找到SSH Keys复制上去点击Add key即可




接下来就是正式操作了
git remote remove origin
git remote add origin xxx(目标的仓库ssh地址)
git checkout -b 'feature/zyj20231114'(在目标仓库新建一个开发分支)
git push --set-upstream origin feature/zyj20231114
git add
git commit
git push
2. 提交一个空白内容的提交
场景:由于是新项目,创建完主分支后,后端才会其打镜像,但需要前端再提交一次来触发dockek里镜像更新的脚本。(应该是这样,我个臭前端怎么可能太清楚后端弄镜像的啊,)
git commit --allow-empty -m “Message”
作者:吃腻的奶油
来源:juejin.cn/post/7311368716804603944