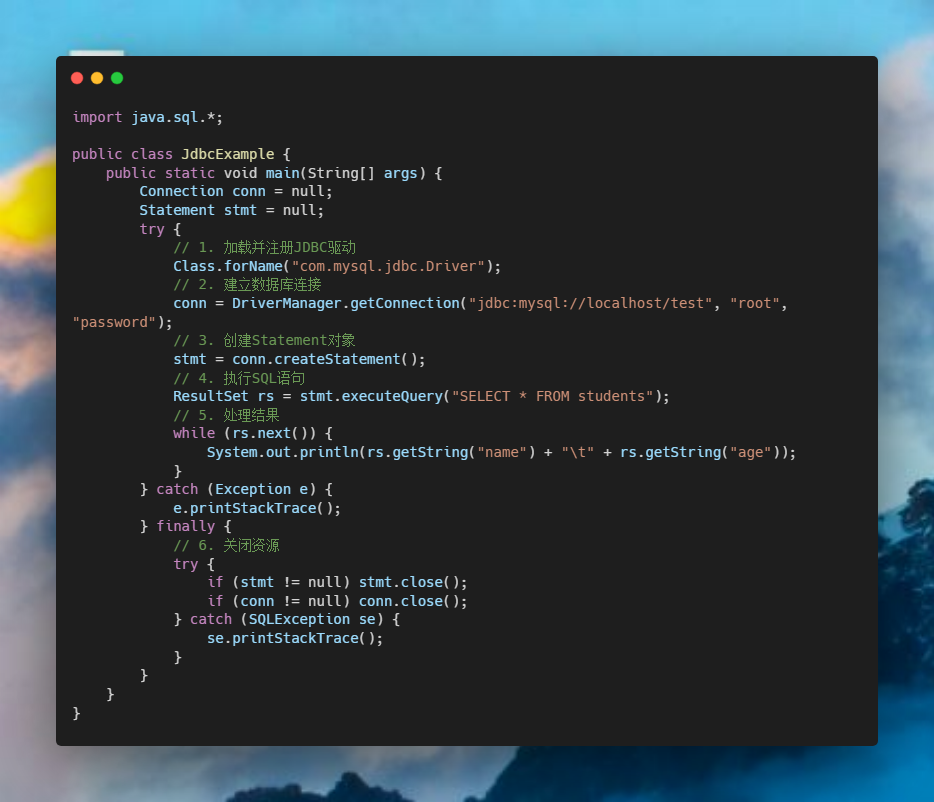
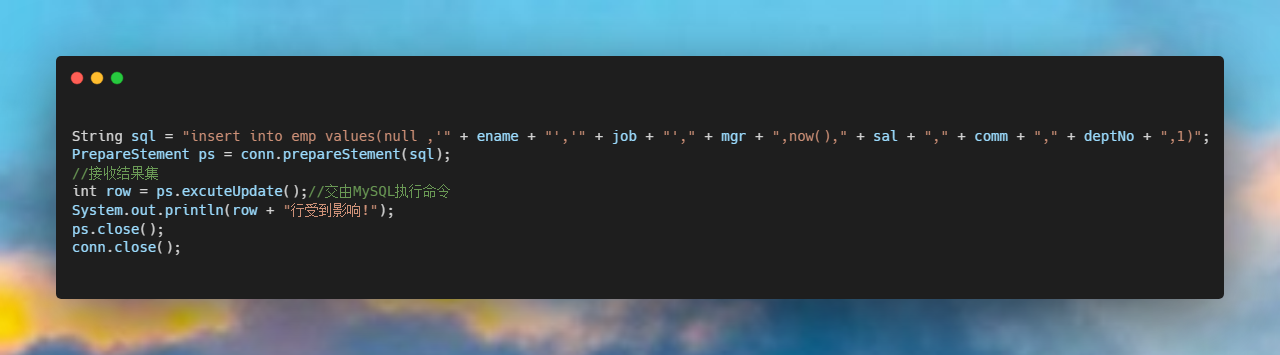
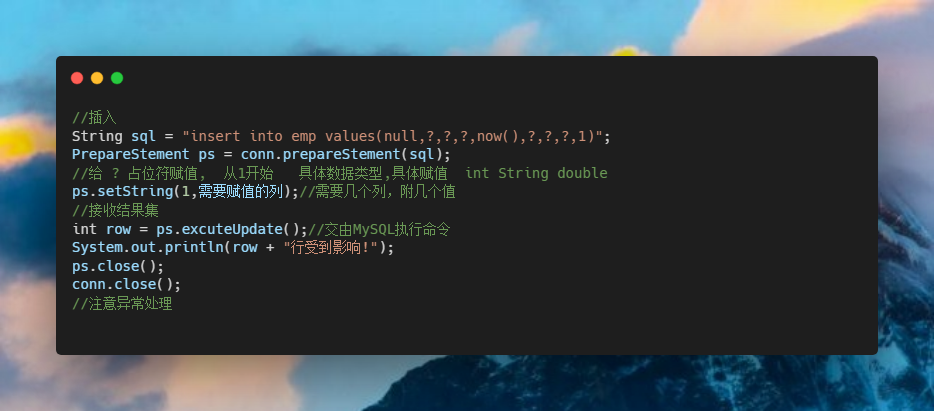
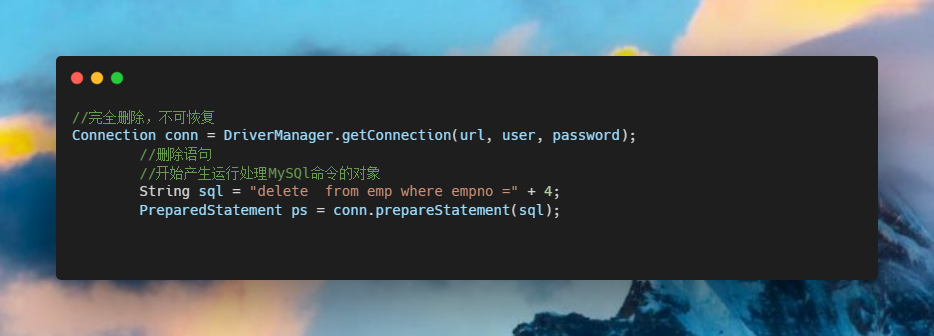
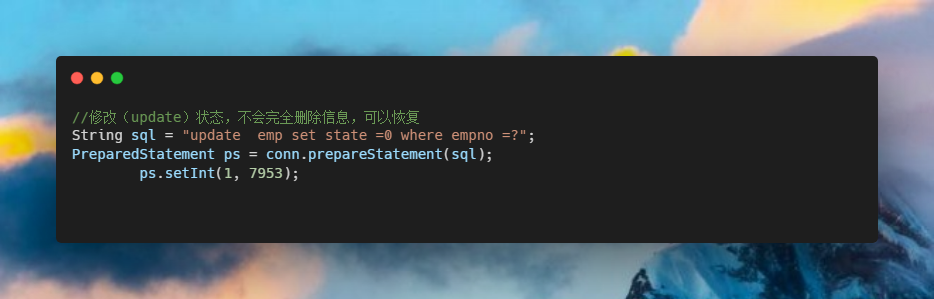
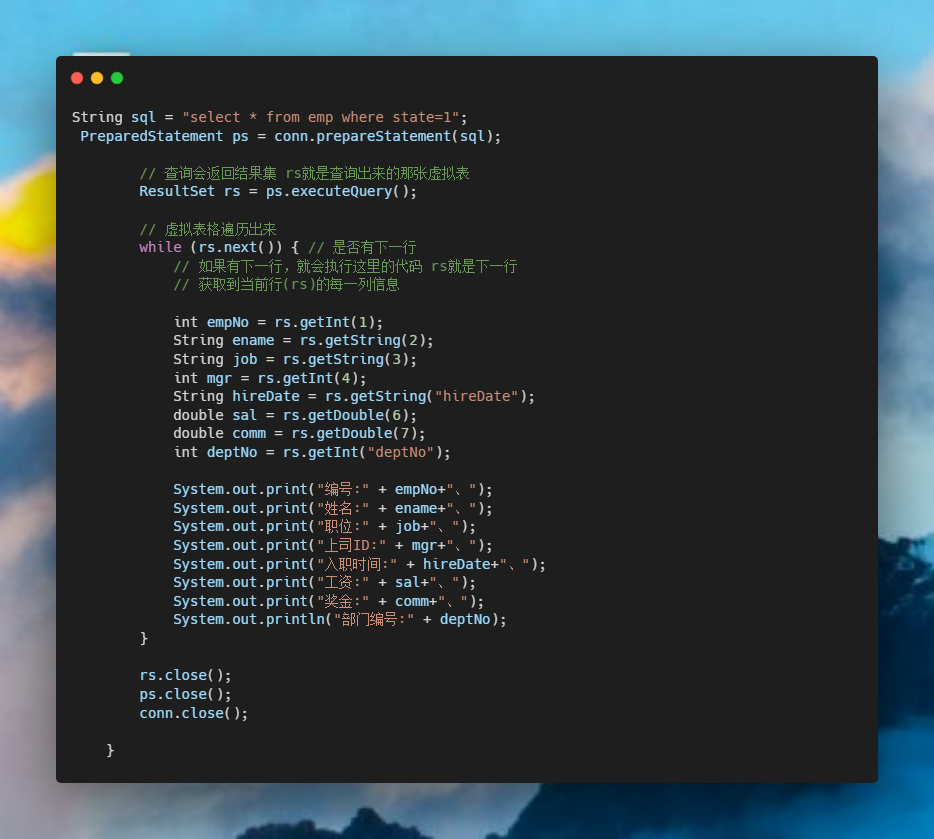
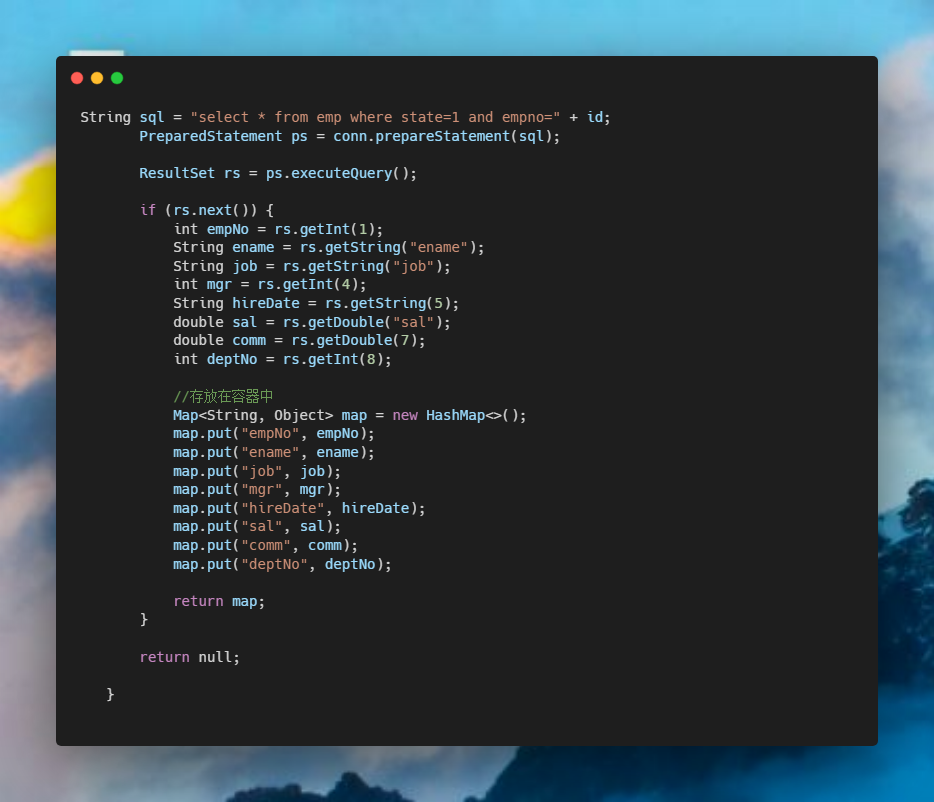
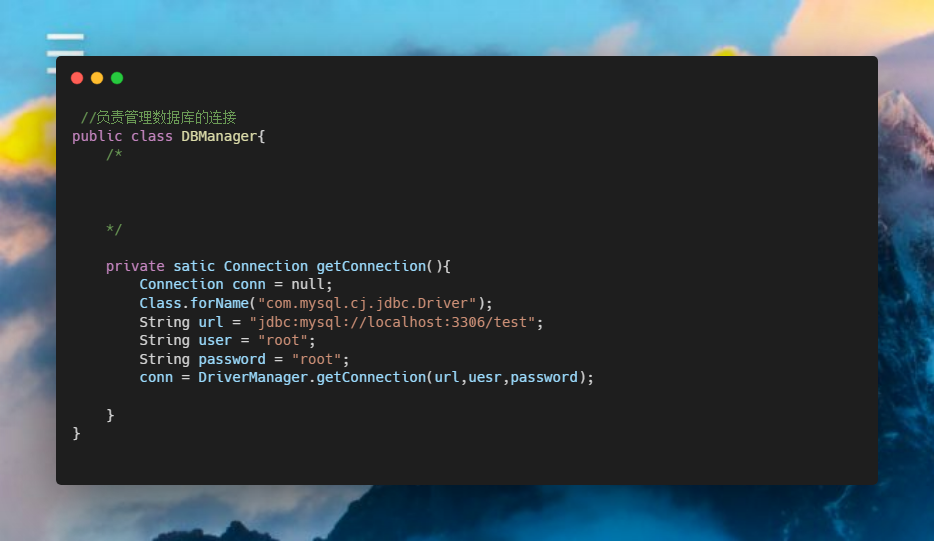
flutter 漂亮聊天UI界面实现 flutter chat UI
之前写了一个聊天界面,但是只是花架子,并不能使用,无法点击,无法活动,并且由于时间问题也没有完全完成,右侧的聊天界面没有实现。现在,我准备完成一个比较美观且能使用的聊天界面。
寻找聊天界面模板
先找一个美观的模板来模仿吧。找模板的标准是简介、美丽、大方、清新。

这次选的是一个比较简洁的界面,淡蓝色为主色,横向三个大模块排列开来,有设置界面、好友列表、聊天界面,就选定用这个了。
chatUI聊天界面实现
整体分析
最外层使用横向布局,分别放置三个大组件,每个组件里面使用竖向布局来放置各种按钮、好友列表、聊天界面。每个组件里面的细节我们边实现边学习。
外层框架
我们先实现最外边的框架。用SelectionArea包裹所有后续组件,实现所有文字可以选定。Selection现在有了官方的正式支持,该功能补全了Flutter长时间存在Selection异常等问题,尤其是在Web框架下经常会有选择文本时与预期的行为不匹配的情况。接着用Row水平布局组件来包裹三大块细分功能组件,代码里先用text组件代替。这样框架就设置好了。
import 'package:flutter/material.dart';
void main() {
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
debugShowCheckedModeBanner: false,
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: const SelectionArea(
child: Scaffold(
body: MyAppbody(),
),
),
);
}
}
class MyAppbody extends StatelessWidget {
const MyAppbody({super.key});
@override
Widget build(BuildContext context) {
return Center(
child: Row(
children: const <Widget>[
Expanded(
flex: 1,
child: Text("按钮组件"), ),
Expanded(
flex: 1,
child: Text("好友列表组件"), ),
Expanded(
flex: 3,
child: Text("聊天框组件"), ),
],
),
);
}
}
效果图:

第一个模块设计
新建一个fistblock文件夹放置我们的第一个模块代码,实现代码分块抽离。还是先写大框架,外围放置竖向排列组件Column,然后再依次放进去头像模块和设置模块。Column是垂直布局,在Y轴排列,也就是纵轴上的排列方式,可以使其包含的子控件按照垂直方向排列,Column是Widget的容器,存放的是一组Widget,而Container里面一次只能存放一个child。
import 'package:flutter/material.dart';
class FistBlockMain extends StatelessWidget {
const FistBlockMain({super.key});
@override
Widget build(BuildContext context) {
return Center(
child: Column(
children: const <Widget>[
Expanded(
flex:1,
child: Text("头像"),
),
Expanded(
flex: 1,
child: Text("设置"),
),
Expanded(
flex:1,
child: Text("帮助"),
),
],
),
);
}
}
效果图:

头像模块实现
头像模块我们之前也实现过,现在可以直接拿来用,例子里在线状态小圆点在右上角,这里我们依旧利用Badge实现小圆点,同时圆点位置可以自由设置,我比较习惯放在右下角,当然,你也可以通过设置Badge的position参数改变位置。Badge是flutter的插件,flutter也有很多其他的优秀的插件可以使用,有了插件的帮忙,我们可以很方便的实现各种功能。
class User extends StatelessWidget {
const User({super.key});
@override
Widget build(BuildContext context) {
return ListTile(
leading: Badge(
badgeColor: Colors.green,
position: const BadgePosition(
start: 35, top: 35, end: 0, bottom: 0),
borderSide:
const BorderSide(color: Colors.white, width: 1.5),
child: const CircleAvatar(
radius: 25,
backgroundColor: Colors.white,
backgroundImage: AssetImage(
"images/5.jpeg",
),
),
),
title: const Text(
"George",
style: TextStyle(
fontSize: 15,
fontWeight: FontWeight.bold,
),
),
);
}
}
效果图:

第一模块蓝色背景模块实现
写完头像模块突然想起来,第一模块的蓝色背景还没实现呢,现在来实现一个蓝色的背景。因为是背景,所以应该用层叠Stack组件。背景颜色用Container的decoration来设置,实际使用BoxDecoration实现背景颜色盒子的设置,同时还需要设置阴影。BoxDecoration类提供了多种绘制盒子的方法,这个盒子有边框、主体、阴影组成,盒子的形状可能是圆形或者长方形。如果是长方形,borderRadius属性可以控制边界的圆角大小。
class FistBlockMain extends StatelessWidget {
const FistBlockMain({super.key});
@override
Widget build(BuildContext context) {
return Stack(children: <Widget>[
const Backgroud(),
Column(
children: const <Widget>[
Expanded(
flex: 1,
child: User(),
),
Expanded(
flex: 1,
child: Text("设置"),
),
Expanded(
flex: 1,
child: Text("帮助"),
),
],
),
]);
}
}
class Backgroud extends StatelessWidget {
const Backgroud({super.key});
@override
Widget build(BuildContext context) {
return Container(
decoration: const BoxDecoration(
color: Color.fromARGB(220, 100, 149, 237),
boxShadow: [
BoxShadow(
color: Color.fromARGB(220, 100, 149, 237),
blurRadius: 30,
spreadRadius: 1
)
],
),
);
}
}
效果图:

模板的这个颜色我找了半天也没找到,后来就找个相似的先用着,但是总是看起来没有原来的好看。当个程序员难道还需要懂美术和艺术吗。。。
按钮模块实现
接着要实现若干带图标的按钮了。模板是一个带图标的按钮,我们用TextButton.icon组件实现。按钮能被选定会影响操作体验,这里使用SelectionContainer是他不能被选中。外层使用Column布局依次放置按钮组件。使用Padding调整间距,是他更好看一些。图标和文字大小都是可以设置的。通过Text组件的TextStyle设置文字的颜色、大小,这里我们使用白色的文字。图标使用Icon组件实现,直接使用Icons.lock_clock内置的icon图标。按钮的onPressed和autofocus需要设置,这样的话点击按钮才会有动画显示。Padding组件再一次使用,这个组件我感觉很好用,可以通过他进一步调整部件的位置,进行美化。
class Buttonblock extends StatelessWidget {
const Buttonblock({super.key});
@override
Widget build(BuildContext context) {
return SelectionContainer.disabled(
child: Column(
children: <Widget>[
Padding(
padding: const EdgeInsets.fromLTRB(0, 20, 0, 20),
child: TextButton.icon(
icon: const Icon(
size: 22,
Icons.lock_clock,
color: Colors.white,
),
label: const Text(
"Timeline",
style: TextStyle(
fontSize: 14,
fontWeight: FontWeight.bold,
color: Colors.white
),
),
onPressed: (){},
autofocus: true,
),
),
Padding(
padding: const EdgeInsets.fromLTRB(0, 20, 0, 20),
child: TextButton.icon(
icon: const Icon(
size: 22,
Icons.message,
color: Colors.white,
),
label: const Text(
"Message",
style: TextStyle(
fontSize: 14,
fontWeight: FontWeight.bold,
color: Colors.white
),
),
onPressed: () {
},
autofocus: true,
),
),
],
),
);
}
}
效果图:

按钮点击弹窗showDialog实现
是按钮当然需要被点击,点击之后我们可以弹一个窗给用户进行各种操作。这里用showDialog实现弹窗。在TextButton.icon的onPressed下实现一个点击弹窗操作。在Flutter里有很多的弹出框,比如AlertDialog、SimpleDialog,调用函数是showDialog。对话框也是一个UI布局,通常会包含标题、内容,以及一些操作按钮。这里实现一个最简单的对话框,如果有需求可以在这个基础上进行修改。
Padding(
padding: const EdgeInsets.fromLTRB(0, 20, 0, 20),
child: TextButton.icon(
icon: const Icon(
size: 22,
Icons.message,
color: Colors.white,
),
label: const Text(
"Message",
style: TextStyle(
fontSize: 14,
fontWeight: FontWeight.bold,
color: Colors.white
),
),
onPressed: () {
showDialog<void>(
context: context,
builder: (BuildContext context) {
return SimpleDialog(
title: const Text('选择'),
children: <Widget>[
SimpleDialogOption(
child: const Text('选项 1'),
onPressed: () {
Navigator.of(context).pop();
},
),
SimpleDialogOption(
child: const Text('选项 2'),
onPressed: () {
Navigator.of(context).pop();
},
),
],
);
},
).then((val) {
});
},
autofocus: true,
),
),
效果图:

第二个模块设计
第二个模块是两部分,上边部分是一个在线状态展示区域,下边部分是好友列表,中间有一道分隔线。所以第二部分外层使用Column竖直布局组件,结合Stack组件做一个背景色。Stack可以容纳多个组件,以叠加的方式摆放子组件,后者居上,覆盖上一个组件。Stack也是可以存放一组Widget的组件。
class SecondBlockMain extends StatelessWidget {
const SecondBlockMain({super.key});
@override
Widget build(BuildContext context) {
return
Stack(children: <Widget>[
const Backgroud(),
Column(
children: const <Widget>[
Expanded(
flex: 1,
child: Text("上边"),
),
Expanded(
flex:4,
child: Text("下边"),
),
],
),
]);
}
}
第二个模块灰色背景颜色实现
仔细看第二部分发现也是有背景颜色的和阴影的,只不过很浅,不容易看出来。刚才已经实现了带阴影的背景,稍微改一下颜色就可以了,依旧要结合Stack组件。BoxShadow的两个参数blurRadius和spreadRadius经常使用,其中blurRadius是模糊半径,也就是阴影半径,SpreadRadius是阴影膨胀数值,也就是阴影面积扩大几倍。
class Backgroud extends StatelessWidget {
const Backgroud({super.key});
@override
Widget build(BuildContext context) {
return Container(
decoration: BoxDecoration(
color: const Color.fromARGB(255, 238, 235, 235).withOpacity(0.6),
boxShadow: [
BoxShadow(
color: const Color.fromARGB(255, 204, 203, 203).withOpacity(0.5),
blurRadius: 20,
spreadRadius: 20 ,
offset:const Offset(20,20),
)
],
),
);
}
}
效果图:

在线状态展示区域实现
本来想着放一个图片在这个位置就好了,这样简单。但是如果拖动界面,改变小大,那么图片就会变形,很不美观。所以利用横向布局组件Row放在外层,里面包裹Badge组件实现小圆点,通过position、badgeColor等组件调整圆点位置和颜色。
class Top extends StatelessWidget {
const Top({super.key});
@override
Widget build(BuildContext context) {
return Row(children: [
Expanded(
flex: 1,
child: ListTile(
leading: Padding(
padding: const EdgeInsets.fromLTRB(20, 0, 0, 0),
child: Badge(
badgeColor: Colors.orange,
position: const BadgePosition(
start: -70, top: 0, end: 0, bottom: 0),
borderSide: const BorderSide(
color: Colors.white, width: 1.5),
child: const Text(
"Family",
style: TextStyle(
fontSize: 12,
fontWeight: FontWeight.bold,
color: Colors.black),
),
),
),
)),
Expanded(
flex: 1,
child: ListTile(
leading: Padding(
padding: const EdgeInsets.fromLTRB(20, 0, 0, 0),
child: Badge(
badgeColor: Colors.cyan,
position: const BadgePosition(
start: -70, top: 0, end: 0, bottom: 0),
borderSide: const BorderSide(
color: Colors.white, width: 1.5),
child: const Text(
"Friend",
style: TextStyle(
fontSize: 12,
fontWeight: FontWeight.bold,
color: Colors.black),
),
),
),
)),
]);
}
}
效果图:

好友列表实现
好友列表之前也实现过,这次在以前的基础上修改。我们使用ListView组件实现列表,ListView是最常用的可滚动组件之一,它可以沿一个方向线性排布所有子组件。底层使用Column结合ListTile组件,ListTile结合CircleAvatar可以实现圆形头像效果,同时也可以设置主副标题,设置 focusColor改变鼠标悬停时列表颜色,
List listData = [ {"title": 'First', "imageUrl": "images/1.jpg", "description": '09:15'}, {"title": 'Second', "imageUrl": "images/2.jpg", "description": '13:10'},];
class FriendList extends StatelessWidget {
const FriendList({super.key});
@override
Widget build(BuildContext context) {
return ListView(
children: listData.map((value) {
return Column(
children: <Widget>[
ListTile(
onTap: (){},
hoverColor: Colors.black,
focusColor: Colors.white,
autofocus:true,
leading: CircleAvatar(
backgroundImage: AssetImage(value["imageUrl"]),
),
title: Text(
value["title"],
style: const TextStyle(
fontSize: 25,
color: Colors.black),
),
subtitle: Text(value["description"])),
const Padding(
padding: EdgeInsets.fromLTRB(70, 10, 0, 30),
child: Text(
maxLines: 2,
"There are moments in life when you miss someone so much that you just want to pick them from your dreams and hug them for real!",
style: TextStyle(
fontSize: 12,
height: 2,
color: Colors.grey),
),
)
],
);
}).toList(),
);
}
}
效果图:

第三个模块设计
现在来第三个模块,聊天界面。分析模板布局,从上到下依次是一个搜索框,分隔线,聊天主界面,输入框,表情、视频、语音工具栏和发送按钮。我们,从上到下把他分成四个小部分来实现,外层使用Column组件。
class ThirdBlockMain extends StatelessWidget {
const ThirdBlockMain({super.key});
@override
Widget build(BuildContext context) {
return Stack(children: <Widget>[
Column(
children: const <Widget>[
Text("1"),
Divider(
height: 0.5,
indent: 20.0,
color: Colors.grey,
),
Text("2"),
Divider(
height: 0.5,
indent: 20.0,
color: Colors.grey,
),
Text("3"),
Text("4"),
],
),
]);
}
}
效果图:

搜索框实现
之前实现过搜索框,直接拿过来改一改。外层添加一个SizedBox组件来控制一下搜索框的大小和位置。
class SearchWidget extends StatefulWidget {
const SearchWidget(
{Key? key,
this.height,
this.width,
this.hintText,
this.onEditingComplete})
: super(key: key);
@override
State<SearchWidget> createState() => _SearchWidgetState();
}
class _SearchWidgetState extends State<SearchWidget> {
var controller = TextEditingController();
@override
void initState() {
super.initState();
}
@override
Widget build(BuildContext context) {
return LayoutBuilder(builder: (context, constrains) {
return SizedBox(
width: 400,
height: 40,
child: TextField(
controller: controller,
decoration: InputDecoration(
prefixIcon: const Icon(Icons.search),
filled: true,
fillColor: Colors.grey.withAlpha(50),
hintText: "Search people",
hintStyle: const TextStyle(color: Colors.grey, fontSize: 14),
contentPadding: const EdgeInsets.only(bottom: 20),
border: OutlineInputBorder(
borderRadius: BorderRadius.circular(15),
borderSide: BorderSide.none,
),
suffixIcon: IconButton(
icon: const Icon(
Icons.close,
size: 17,
),
onPressed: clearKeywords,
splashColor: Theme.of(context).primaryColor,
)),
),
);
});
}
}
效果图:

聊天,信息发送界面实现
因为我的这个并不能真的实现聊天,所以就先放text组件在这把吧,后边再进一步完善。这里简单做一些美化操作,输入框不需要背景颜色,图标需要设置成蓝色,同时调节两个模块的长宽高来适应屏幕。输入框使用TextField,与搜索框使用一致。这里要用到StatefulWidget来完成情况输入框的操作。
class ChatUi extends StatelessWidget {
const ChatUi({super.key});
@override
Widget build(BuildContext context) {
return const SizedBox(
width: 100,
height: 400,
child: Text(""),
);
}
}
class InPutUi extends StatefulWidget {
const InPutUi(
{Key? key,
this.height,
this.width,
this.hintText,
this.onEditingComplete})
: super(key: key);
@override
State<InPutUi> createState() => _InPutUi();
}
class _InPutUi extends State<InPutUi> {
var controller = TextEditingController();
@override
void initState() {
super.initState();
}
@override
Widget build(BuildContext context) {
return LayoutBuilder(builder: (context, constrains) {
return TextField(
controller: controller,
decoration: InputDecoration(
filled: true,
fillColor: Colors.white.withAlpha(50),
hintText: "Write something...",
hintStyle: const TextStyle(color: Colors.grey, fontSize: 14),
contentPadding: const EdgeInsets.only(bottom: 20),
border: const OutlineInputBorder(
borderSide: BorderSide.none,
),
suffixIcon: IconButton(
color: Colors.blue,
icon: const Icon(
Icons.send,
size: 16,
),
onPressed: clearKeywords,
splashColor: Theme.of(context).primaryColor,
)),
);
});
}
}
效果图:

底部工具界面实现
最后来实现底部工具栏。外层使用横向布局来依次放入带图标按钮。这里用到IconButton、MaterialButton两种组件来实现按钮,一种是图标按钮,一种是普通按钮,之前已经实现过,拿来就可以用了。外围使用Padding组件进行填充,方便后期调整每个组件的位置,使它更好看一点。
class Bottom extends StatelessWidget {
const Bottom({super.key});
@override
Widget build(BuildContext context) {
return Row(children: [
Padding(
padding: const EdgeInsets.fromLTRB(30, 0, 0, 0),
child: IconButton(
icon: const Icon(Icons.mood),
tooltip: 'click IconButton',
onPressed: () {},
),
),
Padding(
padding: const EdgeInsets.fromLTRB(580, 20, 0, 22),
child: MaterialButton(
height: 35,
color: Colors.blue,
onPressed: () {},
autofocus: true,
child: const Text(
'Send',
style: TextStyle(
fontSize: 12,
fontWeight: FontWeight.bold,
color: Colors.white),
),
),
),
]);
}
}
效果图:

总结
到这里基本上就完成了, 当然,他是不能实际使用的,因为点击、数据交互等功能还没实现,因为我还不会。后期再边学边写吧。
模板图:

完成图:

自己实现的与模板还是差距很大的。自己的看起来就没那么美观,我应该去学学美术了,一点艺术细胞都没有。
作者:头好晕呀
来源:juejin.cn/post/7232274061283115045