








分支管理提交代码
前言:公司代码需要先放在开发分支上,后面提交的时候再合并到master主分支
开始复现场景:

从git branch -a 输出来看,你的本地分支是 develop,而远程仓库中存在两个分支:origin/master 和 origin/develop。此外,remotes/origin/HEAD 指向了 origin/master,这表明远程仓库的默认分支是 master。
问题分析
你提到想把分支合并到 master 主分支上去,但 git branch 没有显示 master 分支。根据输出信息,可以确认以下几点:
- 本地没有
master分支:当前只有develop分支。 - 远程存在
master分支:remotes/origin/master表明远程仓库中有master分支。 - 远程默认分支是
master:remotes/origin/HEAD -> origin/master表明远程仓库的默认分支是master。
解决方案
1️⃣ 创建并切换到本地 master 分支
首先,你需要在本地创建一个 master 分支,并将其与远程的 master 分支关联起来。
# 创建并切换到本地 master 分支,跟踪远程 origin/master
git checkout -b master origin/master
2️⃣ 将 develop 分支合并到 master 分支
确保你在 master 分支上,然后将 develop 分支的内容合并进来。
bash
深色版本
# 确保你在 master 分支上
git checkout master
# 合并 develop 分支
git merge develop
3️⃣ 解决可能的冲突 (没有冲突的话不需要执行这两条命令)
如果在合并过程中出现冲突,Git 会提示你手动解决这些冲突。解决冲突后,使用以下命令继续合并过程:
# 解决冲突后,添加已修改的文件
git add .
# 继续合并
git commit
4️⃣ 推送更改到远程 master 分支
最后,将合并后的更改推送到远程 master 分支。
bash
深色版本
# 推送更改到远程 master 分支
git push origin master
🛠️ 进阶操作:设置默认上游分支
如果你希望以后直接使用 git pull 和 git push 而不需要每次都指定分支,可以设置默认上游分支:
bash
深色版本
# 设置 master 分支的上游为 origin/master
git branch --set-upstream-to=origin/master master
这样,当你在 master 分支上时,可以直接使用 git pull 和 git push 命令,而不需要额外指定分支名。
报错了
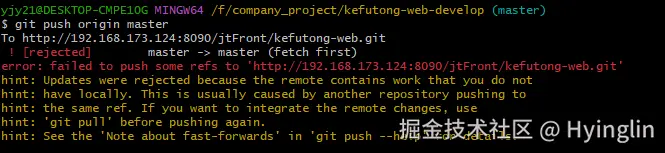
远程仓库 master 分支包含了本地分支没有的更改。因此,Git 拒绝了你的推送请求,以防止丢失远程仓库中的工作。
错误原因
这个错误通常有以下几种可能的原因:
- 远程仓库有新的提交:在你上次拉取(
git pull)之后,其他开发者可能已经向远程仓库的master分支推送了新的提交。 - 非快进式推送:你的本地
master分支与远程master分支之间的差异无法通过简单的“快进”操作来解决,需要进行合并或变基。
解决方案
1️⃣ 先拉取远程仓库的最新更改
你需要先从远程仓库拉取最新的更改,然后将这些更改合并到你的本地分支中。
# 切换到 master 分支
git checkout master
# 从远程仓库拉取最新的更改
git pull origin master
如果 git pull 成功执行,它会自动将远程仓库的更改合并到你的本地分支中。如果有冲突,你需要手动解决这些冲突。
2️⃣ 解决冲突(如有必要)
如果在 git pull 过程中出现冲突,Git 会提示你手动解决这些冲突。解决冲突后,使用以下命令继续合并过程:
# 解决冲突后,添加已修改的文件
git add .
# 继续合并
git commit
3️⃣ 再次尝试推送更改
解决了所有冲突并完成合并后,你可以再次尝试将本地更改推送到远程仓库:
# 推送更改到远程 master 分支
git push origin master
还是报错
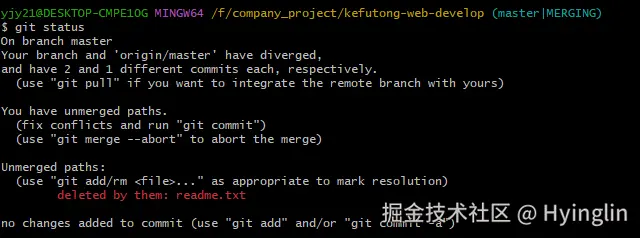
从你提供的错误信息来看,当前的状态是 MERGING,这表明你在合并过程中遇到了问题,并且还没有完成合并。因此,Git 拒绝了你的推送请求。
错误原因
- 合并尚未完成:你正在进行一个合并操作(可能是之前执行的
git merge或git pull),但还没有解决所有的冲突或完成合并。 - 本地分支落后于远程分支:即使解决了合并冲突,本地分支可能仍然落后于远程分支,需要先拉取最新的更改。
解决方案
1️⃣ 检查并完成合并
首先,你需要确保合并操作已经完成。如果存在未解决的冲突,你需要手动解决这些冲突。
查看当前状态,确认是否有未解决的冲突(查看本地和远程 master 分支的差异)
git status
如果 git status 提示你的本地分支落后于远程分支(例如 Your branch is behind 'origin/master' by X commits),你需要先拉取最新的更改。
如果有冲突文件,打开这些文件并手动解决冲突
解决冲突后,添加已修改的文件并提交:
# 添加已解决冲突的文件
git add .
# 提交合并
git commit
2️⃣ 拉取远程仓库的最新更改
在完成合并后,再次尝试拉取远程仓库的最新更改,以确保本地分支是最新的。
# 切换到 master 分支
git checkout master
# 从远程仓库拉取最新的更改
git pull origin master
如果 git pull 成功执行,它会自动将远程仓库的更改合并到你的本地分支中。如果有冲突,你需要手动解决这些冲突。
3️⃣ 再次尝试推送更改
解决了所有冲突并完成合并后,你可以再次尝试将本地更改推送到远程仓库:
# 推送更改到远程 master 分支
git push origin master
我本地如果删除了几个文件再更新到仓库去要怎么办?
你只需要用 git add . 或 git rm 告诉 Git “这些文件是我有意删除的”,然后提交并推送到远程仓库即可。Git 会把“删除”也当作一次更改记录下来。
✅ 正确操作步骤(推荐)
1️⃣ 确认你已经删除了文件
你已经在本地手动删除了一些文件(比如用资源管理器或 rm 命令删的)。
2️⃣ 让 Git 检测到这些文件被删除
运行以下命令,Git 会发现哪些文件被删了,并把“删除”操作加入暂存区:
bash
深色版本
git add --all
# 或者简写:
git add .
💡 注意:
虽然 git add . 通常用于“添加新文件”,但它也会检测到被删除的文件,并自动执行 git rm 的效果。
⚠️ 如果你只用
git commit而不先add,Git 不会自动把删除纳入提交。
3️⃣ 提交删除操作
bash
深色版本
git commit -m "删除了不再需要的文件:xxx, yyy"
4️⃣ 推送到远程仓库
bash
深色版本
git push origin master
# 或者 main,根据你的分支名
✅ 完成!远程仓库也会删除这些文件。
来源:juejin.cn/post/7549096640340492338
🔥 滚动监听写到手抽筋?IntersectionObserver让你躺平实现懒加载
🎯 学习目标:掌握IntersectionObserver API的核心用法,解决滚动监听性能问题,实现高效的懒加载和可见性检测
📊 难度等级:中级
🏷️ 技术标签:#IntersectionObserver#懒加载#性能优化#滚动监听
⏱️ 阅读时间:约8分钟
🌟 引言
在日常的前端开发中,你是否遇到过这样的困扰:
- 滚动监听卡顿:addEventListener('scroll')写多了页面卡得像PPT
- 懒加载复杂:图片懒加载逻辑复杂,还要手动计算元素位置
- 无限滚动性能差:数据越来越多,滚动越来越卡
- 可见性检测麻烦:想知道元素是否进入视口,代码写得头疼
今天分享5个IntersectionObserver的实用场景,让你的滚动监听更加丝滑,告别性能焦虑!
💡 核心技巧详解
1. 图片懒加载:告别手动计算位置的痛苦
🔍 应用场景
当页面有大量图片时,一次性加载所有图片会严重影响页面性能,需要实现图片懒加载。
❌ 常见问题
传统的滚动监听方式性能差,需要频繁计算元素位置。
// ❌ 传统滚动监听写法
window.addEventListener('scroll', () => {
const images = document.querySelectorAll('img[data-src]');
images.forEach(img => {
const rect = img.getBoundingClientRect();
if (rect.top < window.innerHeight) {
img.src = img.dataset.src;
img.removeAttribute('data-src');
}
});
});
✅ 推荐方案
使用IntersectionObserver实现高性能的图片懒加载。
/**
* 创建图片懒加载观察器
* @description 使用IntersectionObserver实现高性能图片懒加载
* @param {string} selector - 图片选择器
* @param {Object} options - 观察器配置选项
* @returns {IntersectionObserver} 观察器实例
*/
const createImageLazyLoader = (selector = 'img[data-src]', options = {}) => {
// 推荐写法:使用IntersectionObserver
const defaultOptions = {
root: null, // 使用视口作为根元素
rootMargin: '50px', // 提前50px开始加载
threshold: 0.1 // 元素10%可见时触发
};
const config = { ...defaultOptions, ...options };
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
const img = entry.target;
// 加载图片
img.src = img.dataset.src;
img.removeAttribute('data-src');
// 停止观察已加载的图片
observer.unobserve(img);
}
});
}, config);
// 观察所有待加载的图片
document.querySelectorAll(selector).forEach(img => {
observer.observe(img);
});
return observer;
};
💡 核心要点
- rootMargin:提前加载,避免用户看到空白
- threshold:设置合适的触发阈值
- unobserve:加载完成后停止观察,释放资源
🎯 实际应用
在Vue3项目中的完整应用示例:
<template>
<div class="image-gallery">
<img
v-for="(image, index) in images"
:key="index"
:data-src="image.url"
:alt="image.alt"
class="lazy-image"
src="data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' width='300' height='200'%3E%3Crect width='100%25' height='100%25' fill='%23f0f0f0'/%3E%3C/svg%3E"
/>
</div>
</template>
<script setup>
import { onMounted, onUnmounted } from 'vue';
let observer = null;
onMounted(() => {
observer = createImageLazyLoader('.lazy-image');
});
onUnmounted(() => {
observer?.disconnect();
});
</script>
2. 无限滚动:数据加载的性能优化
🔍 应用场景
实现无限滚动列表,当用户滚动到底部时自动加载更多数据。
❌ 常见问题
传统方式需要监听滚动事件并计算滚动位置,性能开销大。
// ❌ 传统无限滚动实现
window.addEventListener('scroll', () => {
if (window.innerHeight + window.scrollY >= document.body.offsetHeight - 100) {
loadMoreData();
}
});
✅ 推荐方案
使用IntersectionObserver监听底部哨兵元素。
/**
* 创建无限滚动观察器
* @description 监听底部哨兵元素实现无限滚动
* @param {Function} loadMore - 加载更多数据的回调函数
* @param {Object} options - 观察器配置
* @returns {Object} 包含观察器和控制方法的对象
*/
const createInfiniteScroll = (loadMore, options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '100px', // 提前100px触发加载
threshold: 0
};
const config = { ...defaultOptions, ...options };
let isLoading = false;
const observer = new IntersectionObserver(async (entries) => {
const [entry] = entries;
if (entry.isIntersecting && !isLoading) {
isLoading = true;
try {
await loadMore();
} catch (error) {
console.error('加载数据失败:', error);
} finally {
isLoading = false;
}
}
}, config);
return {
observer,
// 开始观察哨兵元素
observe: (element) => observer.observe(element),
// 停止观察
disconnect: () => observer.disconnect(),
// 获取加载状态
getLoadingState: () => isLoading
};
};
💡 核心要点
- 哨兵元素:在列表底部放置一个不可见的元素作为触发器
- 防重复加载:使用loading状态防止重复请求
- 错误处理:加载失败时的异常处理
🎯 实际应用
Vue3组件中的使用示例:
<template>
<div class="infinite-list">
<div v-for="item in items" :key="item.id" class="list-item">
{{ item.title }}
</div>
<!-- 哨兵元素 -->
<div ref="sentinelRef" class="sentinel"></div>
<div v-if="loading" class="loading">加载中...</div>
</div>
</template>
<script setup>
import { ref, onMounted, onUnmounted } from 'vue';
const items = ref([]);
const loading = ref(false);
const sentinelRef = ref(null);
let infiniteScroll = null;
// 加载更多数据
const loadMoreData = async () => {
loading.value = true;
// 模拟API请求
const newItems = await fetchData();
items.value.push(...newItems);
loading.value = false;
};
onMounted(() => {
infiniteScroll = createInfiniteScroll(loadMoreData);
infiniteScroll.observe(sentinelRef.value);
});
onUnmounted(() => {
infiniteScroll?.disconnect();
});
</script>
3. 元素可见性统计:精准的用户行为分析
🔍 应用场景
统计用户对页面内容的浏览情况,比如广告曝光、内容阅读时长等。
❌ 常见问题
手动计算元素可见性复杂且不准确。
// ❌ 手动计算可见性
const isElementVisible = (element) => {
const rect = element.getBoundingClientRect();
return rect.top >= 0 && rect.bottom <= window.innerHeight;
};
✅ 推荐方案
使用IntersectionObserver精准统计元素可见性。
/**
* 创建可见性统计观察器
* @description 统计元素的可见性和停留时间
* @param {Function} onVisibilityChange - 可见性变化回调
* @param {Object} options - 观察器配置
* @returns {IntersectionObserver} 观察器实例
*/
const createVisibilityTracker = (onVisibilityChange, options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '0px',
threshold: [0, 0.25, 0.5, 0.75, 1.0] // 多个阈值,精确统计
};
const config = { ...defaultOptions, ...options };
const visibilityData = new Map();
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const element = entry.target;
const elementId = element.dataset.trackId || element.id;
if (!visibilityData.has(elementId)) {
visibilityData.set(elementId, {
element,
startTime: null,
totalTime: 0,
maxVisibility: 0
});
}
const data = visibilityData.get(elementId);
if (entry.isIntersecting) {
// 元素进入视口
if (!data.startTime) {
data.startTime = Date.now();
}
data.maxVisibility = Math.max(data.maxVisibility, entry.intersectionRatio);
} else {
// 元素离开视口
if (data.startTime) {
data.totalTime += Date.now() - data.startTime;
data.startTime = null;
}
}
// 触发回调
onVisibilityChange({
elementId,
isVisible: entry.isIntersecting,
visibilityRatio: entry.intersectionRatio,
totalTime: data.totalTime,
maxVisibility: data.maxVisibility
});
});
}, config);
return observer;
};
💡 核心要点
- 多阈值监听:使用多个threshold值精确统计可见比例
- 时间统计:记录元素在视口中的停留时间
- 数据持久化:将统计数据存储到Map中
🎯 实际应用
广告曝光统计的实际应用:
// 实际项目中的广告曝光统计
const trackAdExposure = () => {
const tracker = createVisibilityTracker((data) => {
const { elementId, isVisible, visibilityRatio, totalTime } = data;
// 曝光条件:可见比例超过50%且停留时间超过1秒
if (visibilityRatio >= 0.5 && totalTime >= 1000) {
// 发送曝光统计
sendExposureData({
adId: elementId,
exposureTime: totalTime,
visibilityRatio: visibilityRatio
});
}
});
// 观察所有广告元素
document.querySelectorAll('.ad-banner').forEach(ad => {
tracker.observe(ad);
});
};
4. 动画触发控制:精准的视觉效果
🔍 应用场景
当元素进入视口时触发CSS动画或JavaScript动画,提升用户体验。
❌ 常见问题
使用滚动监听触发动画,性能差且时机不准确。
// ❌ 传统动画触发方式
window.addEventListener('scroll', () => {
const elements = document.querySelectorAll('.animate-on-scroll');
elements.forEach(el => {
const rect = el.getBoundingClientRect();
if (rect.top < window.innerHeight * 0.8) {
el.classList.add('animate');
}
});
});
✅ 推荐方案
使用IntersectionObserver精准控制动画触发时机。
/**
* 创建动画触发观察器
* @description 当元素进入视口时触发动画
* @param {Object} options - 观察器和动画配置
* @returns {IntersectionObserver} 观察器实例
*/
const createAnimationTrigger = (options = {}) => {
const defaultOptions = {
root: null,
rootMargin: '-10% 0px', // 元素完全进入视口后触发
threshold: 0.3,
animationClass: 'animate-in',
once: true // 只触发一次
};
const config = { ...defaultOptions, ...options };
const triggeredElements = new Set();
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const element = entry.target;
if (entry.isIntersecting) {
// 添加动画类
element.classList.add(config.animationClass);
if (config.once) {
// 只触发一次,停止观察
observer.unobserve(element);
triggeredElements.add(element);
}
// 触发自定义事件
element.dispatchEvent(new CustomEvent('elementVisible', {
detail: { intersectionRatio: entry.intersectionRatio }
}));
} else if (!config.once) {
// 允许重复触发时,移除动画类
element.classList.remove(config.animationClass);
}
});
}, {
root: config.root,
rootMargin: config.rootMargin,
threshold: config.threshold
});
return observer;
};
💡 核心要点
- rootMargin负值:确保元素完全进入视口后才触发
- once选项:控制动画是否只触发一次
- 自定义事件:方便其他代码监听动画触发
🎯 实际应用
配合CSS动画的完整实现:
/* CSS动画定义 */
.fade-in-element {
opacity: 0;
transform: translateY(30px);
transition: all 0.6s ease-out;
}
.fade-in-element.animate-in {
opacity: 1;
transform: translateY(0);
}
// JavaScript动画控制
const initScrollAnimations = () => {
const animationTrigger = createAnimationTrigger({
animationClass: 'animate-in',
threshold: 0.2,
once: true
});
// 观察所有需要动画的元素
document.querySelectorAll('.fade-in-element').forEach(element => {
animationTrigger.observe(element);
// 监听动画触发事件
element.addEventListener('elementVisible', (e) => {
console.log(`元素动画触发,可见比例: ${e.detail.intersectionRatio}`);
});
});
};
5. 虚拟滚动优化:大数据列表的性能救星
🔍 应用场景
处理包含大量数据的列表,只渲染可见区域的元素,提升性能。
❌ 常见问题
渲染大量DOM元素导致页面卡顿,滚动性能差。
// ❌ 渲染所有数据
const renderAllItems = (items) => {
const container = document.getElementById('list');
items.forEach(item => {
const element = document.createElement('div');
element.textContent = item.title;
container.appendChild(element);
});
};
✅ 推荐方案
结合IntersectionObserver实现简化版虚拟滚动。
/**
* 创建虚拟滚动观察器
* @description 只渲染可见区域的列表项,优化大数据列表性能
* @param {Array} data - 数据数组
* @param {Function} renderItem - 渲染单个项目的函数
* @param {Object} options - 配置选项
* @returns {Object} 虚拟滚动控制器
*/
const createVirtualScroll = (data, renderItem, options = {}) => {
const defaultOptions = {
itemHeight: 60, // 每项高度
bufferSize: 5, // 缓冲区大小
container: null // 容器元素
};
const config = { ...defaultOptions, ...options };
const visibleItems = new Map();
// 创建占位元素
const createPlaceholder = (index) => {
const placeholder = document.createElement('div');
placeholder.style.height = `${config.itemHeight}px`;
placeholder.dataset.index = index;
placeholder.classList.add('virtual-item-placeholder');
return placeholder;
};
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
const placeholder = entry.target;
const index = parseInt(placeholder.dataset.index);
if (entry.isIntersecting) {
// 元素进入视口,渲染真实内容
if (!visibleItems.has(index)) {
const realElement = renderItem(data[index], index);
realElement.style.height = `${config.itemHeight}px`;
placeholder.replaceWith(realElement);
visibleItems.set(index, realElement);
}
} else {
// 元素离开视口,替换为占位符
const realElement = visibleItems.get(index);
if (realElement) {
const newPlaceholder = createPlaceholder(index);
realElement.replaceWith(newPlaceholder);
observer.observe(newPlaceholder);
visibleItems.delete(index);
}
}
});
}, {
root: config.container,
rootMargin: `${config.bufferSize * config.itemHeight}px`,
threshold: 0
});
// 初始化列表
const init = () => {
const container = config.container;
container.innerHTML = '';
data.forEach((_, index) => {
const placeholder = createPlaceholder(index);
container.appendChild(placeholder);
observer.observe(placeholder);
});
};
return {
init,
destroy: () => observer.disconnect(),
getVisibleCount: () => visibleItems.size
};
};
💡 核心要点
- 占位符机制:使用固定高度的占位符保持滚动条正确
- 缓冲区:通过rootMargin提前渲染即将可见的元素
- 内存管理:及时清理不可见的元素,释放内存
🎯 实际应用
Vue3组件中的虚拟滚动实现:
<template>
<div ref="containerRef" class="virtual-scroll-container">
<!-- 虚拟滚动内容将在这里动态生成 -->
</div>
</template>
<script setup>
import { ref, onMounted, onUnmounted } from 'vue';
const containerRef = ref(null);
let virtualScroll = null;
// 大量数据
const largeDataset = ref(Array.from({ length: 10000 }, (_, i) => ({
id: i,
title: `列表项 ${i + 1}`,
content: `这是第 ${i + 1} 个列表项的内容`
})));
// 渲染单个列表项
const renderListItem = (item, index) => {
const element = document.createElement('div');
element.className = 'list-item';
element.innerHTML = `
<h3>${item.title}</h3>
<p>${item.content}</p>
`;
return element;
};
onMounted(() => {
virtualScroll = createVirtualScroll(
largeDataset.value,
renderListItem,
{
itemHeight: 80,
bufferSize: 3,
container: containerRef.value
}
);
virtualScroll.init();
});
onUnmounted(() => {
virtualScroll?.destroy();
});
</script>
📊 技巧对比总结
| 技巧 | 使用场景 | 优势 | 注意事项 |
|---|---|---|---|
| 图片懒加载 | 大量图片展示 | 性能优秀,实现简单 | 需要设置合适的rootMargin |
| 无限滚动 | 长列表数据加载 | 避免频繁滚动监听 | 防止重复加载,错误处理 |
| 可见性统计 | 用户行为分析 | 精确统计,多阈值监听 | 数据存储和上报策略 |
| 动画触发 | 页面交互效果 | 时机精准,性能好 | 动画只触发一次的控制 |
| 虚拟滚动 | 大数据列表 | 内存占用低,滚动流畅 | 元素高度固定,复杂度较高 |
🎯 实战应用建议
最佳实践
- 合理设置rootMargin:根据实际需求提前或延迟触发观察
- 及时清理观察器:使用unobserve()和disconnect()释放资源
- 错误处理机制:为异步操作添加try-catch保护
- 性能监控:在开发环境中监控观察器的性能表现
- 渐进增强:为不支持IntersectionObserver的浏览器提供降级方案
性能考虑
- 观察器数量控制:避免创建过多观察器实例
- threshold设置:根据实际需求设置合适的阈值
- 内存泄漏防护:组件销毁时及时清理观察器
- 兼容性处理:使用polyfill支持旧版浏览器
💡 总结
这5个IntersectionObserver实用场景在日常开发中能显著提升页面性能,掌握它们能让你的滚动监听:
- 图片懒加载:告别手动位置计算,性能提升显著
- 无限滚动:避免频繁滚动监听,用户体验更佳
- 可见性统计:精准的用户行为分析,数据更准确
- 动画触发:完美的视觉效果时机控制
- 虚拟滚动:大数据列表的性能救星
希望这些技巧能帮助你在前端开发中告别滚动监听的性能焦虑,写出更丝滑的交互代码!
🔗 相关资源
- MDN IntersectionObserver文档
- Can I Use - IntersectionObserver兼容性
- IntersectionObserver Polyfill
- Web性能优化最佳实践
💡 今日收获:掌握了5个IntersectionObserver实用场景,这些知识点在实际开发中非常实用。
如果这篇文章对你有帮助,欢迎点赞、收藏和分享!有任何问题也欢迎在评论区讨论。 🚀
来源:juejin.cn/post/7549102542833631267
开源鸿蒙技术大会2025即将启幕,共绘数字底座新蓝图
当前,数字经济已成为驱动全球经济增长的重要力量,在这一进程中,操作系统作为数字基础设施的关键组成部分,其发展水平与生态建设直接关系到众多行业数字化转型的进程。作为智能终端操作系统的开源根社区,开源鸿蒙依托其先进的技术架构与持续的智能化升级,正在为培育新质生产力提供重要支撑,并积极助力数字中国建设向纵深推进。
在万物智联从概念走向实践的关键阶段,开源操作系统如何突破技术瓶颈、构建成熟生态、赋能千行百业转型?
答案,即将于9月27日在长沙国际会议中心揭开——由开源鸿蒙项目群技术指导委员会(TSC,Technial Steering Committe)主办,华为承办,深开鸿、开鸿智谷、鸿湖万联、润开鸿、九联开鸿、中软国际、诚迈科技、北理工、中科鸿略、中国南方电网、中国科学院软件研究所、证通、国开鸿等合作单位支持举办的开源鸿蒙技术大会2025年度盛会,将面向全球开源操作系统领域,以更大规模、更高规格,迎接开源领袖、前沿实践专家、高校学者及生态伙伴,为全球开源从业者呈现一场兼具战略高度与实践深度的技术盛宴。
以核心突破,锚定操作系统技术演进新航向
作为大会的主场,主论坛将聚焦开源鸿蒙技术的年度核心进展,通过权威发声与重磅发布,勾勒智能终端操作系统全场景适配与技术深化的清晰路径。主论坛将邀请政府、产业界、学术界、开源界技术专家和权威代表,解读开源鸿蒙在数字基础设施建设中的核心价值。同时,应用生态伙伴与高校代表也将分享前沿实践成果,展现产学研用协同创新的生动实践,为开发者与企业伙伴提供可落地的技术方法论。
值得关注的是,本次主论坛将正式发布开源鸿蒙 6.0 Release版本,该版本进一步增强了系统能力,提升了系统整体可用性与开发效率,生态适配更友好。此外,大会还将举办开源鸿蒙跨平台框架PMC(筹)成立仪式,标志着开源鸿蒙在跨平台开发领域的重要布局,不断完善开源鸿蒙技术生态版图。
同时,本届大会共设置 21 场分论坛,无论在数量规模上,还是在领域覆盖广度上,均实现了近年来的新突破,展现出更全面的议题布局。分论坛将重点围绕开源鸿蒙相关技术
交流区全景呈现生态成果,见证开源协同五年发展收获
开源鸿蒙开源五年多以来,在全球开发者、生态伙伴的持续贡献下,生态不断繁荣。截至2025年8月31日,社区已汇聚超过9200名贡献者,累计贡献代码量超过1.3亿行,汇聚超480家伙伴参与共建,累计超1300+款产品通过兼容性测评,覆盖金融、超高清、航天、教育、商显、工业、警务、城市、交通、医疗、电力等多个领域。基于这一丰硕的生态共建成果,大会同步设置的6+N板块互动交流区,将集中展示基于"Powered by OpenHarmony"开源鸿蒙生态产品的创新成果与商业进展。
作为这一繁荣生态的集中缩影,开源鸿蒙项目群技术指导委员会(TSC)交流区将呈现其在开源鸿蒙技术生态领域的阶段性创新成果;开源鸿蒙社区公共交流区全面展现开源鸿蒙在千行百业的最佳实践与开源生态的繁荣;华为终端将首次与众多生态伙伴联袂亮相,共同展示基于开源鸿蒙的实践与创新成果;三方社区交流区则将呈现更广泛更多维的商业生态和落地部署情况。同时,仓颉编程语言&毕昇编译器以及应用生态开源技术等关键基础软件与工具链的集中展出,也将进一步凸显开源鸿蒙的产业落地价值,助力参会者清晰感知从技术创新到千行百业赋能的扎实路径,切身感受到开源鸿蒙在不同领域的应用实践与商业价值。
以致谢授牌,致敬贡献者,凝聚开源生态新合力
开源生态的繁荣,离不开每一位共建者的坚守与付出。本次大会将延续对贡献者的致敬传统,通过多场致谢与授牌仪式为社区力量加冕:通过对TSG、开源鸿蒙技术俱乐部的致谢授牌,肯定其在人才培育与技术推广中的杰出贡献;重磅发布开源鸿蒙年度课题,并为优秀技术课题成果授牌;开源鸿蒙项目群捐赠人授牌仪式,感谢生态伙伴为社区蓬勃发展所付出的努力;开源鸿蒙竞赛训练营颁奖,则将致敬在技术实践中表现卓越的开发者,进一步凝聚产学研用协同共进的开源生态新合力。
从底层技术突破到生态场景落地,从人才培养到全球协作,开源鸿蒙技术大会2025既是对过去一年技术进步与生态进展的盘点,更旨在展望以开源推动生态繁荣、以技术赋能产业转型的新未来。我们诚挚邀请全球技术领袖、高校学者、企业伙伴与开发者,于9月27日相聚长沙,在这场思想与技术创新交汇的盛会中共享成果、共探方向、共筑未来!
收起阅读 »秋招太卷了!年轻人最缺的不是努力,而是有人即时点拨
2025年的秋招进入高峰。根据多家招聘平台数据,今年平均每个热门岗位竞争比超过 1:500,部分互联网、金融岗位甚至达到 1:2000。在AI筛简历和在线面试逐渐普及的背景下,不少应届生直呼“努力仿佛被系统淹没”。
在这样的环境下,年轻人发现,光靠努力并不足以脱颖而出:
简历反复修改,却依然石沉大海;
面试准备充分,却临场紧张到大脑一片空白;
拿到多个Offer,却在选择上迟迟犹豫。
专家指出,当下年轻人最缺的,不是努力,而是 在关键节点有人给予即时点拨。例如临面前的快速演练、谈薪时的策略建议,或是Offer选择的利弊分析。
近年来,一些新兴职场服务平台开始探索“即时支持”模式。例如,近期上线的 「对圈职场」App,就尝试通过 15分钟即时咨询 + 陪跑辅导 + 职场学习社区 的组合,为年轻人提供低门槛、全场景的职场支持。
业内人士认为,这类探索,或许能在缓解就业焦虑、提升求职质量方面发挥积极作用。对圈职场的出现,也从侧面印证了一个趋势:年轻人需要的不是泛泛的培训,而是更即时、更贴近现实的职场帮助。
收起阅读 »索引失效的场景有哪些?
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
关于SQL语句的面试题中,有两个被面试官问到的频率特别高,一个是SQL优化,另外一个则是索引失效。
接下来我们就来一一进行盘点,索引失效的场景到底有哪些。
准备工作
我们先来创建一张订单表,并为该表生成100w+的数据,这样SQL语句所对应的执行计划会更加准确,表结构如下:
CREATE TABLE `tony_order` (
`id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '订单ID',
`product_id` int NOT NULL COMMENT '商品ID',
`user_id` int NOT NULL COMMENT '用户ID',
`status` tinyint NOT NULL COMMENT '状态',
`discount_amount` int NOT NULL COMMENT '总金额',
`total_amount` int NOT NULL COMMENT '打折金额',
`payable_amount` int NOT NULL COMMENT '实际支付金额',
`receiver_name` varchar(255) DEFAULT NULL COMMENT '收件人名称',
`receiver_phone` varchar(255) DEFAULT NULL COMMENT '收件人手机号',
`receiver_address` varchar(255) DEFAULT NULL COMMENT '收件人地址',
`note` varchar(255) DEFAULT NULL COMMENT '备注',
`payment_time` datetime NULL DEFAULT NULL COMMENT '支付时间',
`create_time` datetime NOT NULL COMMENT '创建时间',
`update_time` datetime NOT NULL COMMENT '更新时间',
PRIMARY KEY (`id` DESC) USING BTREE,
INDEX `idx_product_id`(`product_id` ASC) USING BTREE,
INDEX `idx_user_id_total_amount`(`user_id` ASC, `total_amount` ASC) USING BTREE,
INDEX `idx_create_time`(`create_time` ASC) USING BTREE,
INDEX `idx_update_time`(`update_time` ASC) USING BTREE,
INDEX `idx_status`(`status` ASC) USING BTREE,
INDEX `idx_receiver_phone`(`receiver_phone` ASC) USING BTREE,
INDEX `idx_receiver_name`(`receiver_name` ASC) USING BTREE,
INDEX `idx_receiver_address`(`receiver_address` ASC) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 ROW_FORMAT = Dynamic;
接下来我们来一一验证下索引失效的场景。

索引失效场景
1、不遵循最左前缀原则
SELECT * FROM tony_order WHERE total_amount = 100;

我们从执行计划中可以看到,这条SQL语句走的是全表扫描,即使创建了索引idx_user_id_total_amount也没有生效。
但由于其total_amount字段没有在联合索引的最左边,不符合最左前缀原则。
SELECT * FROM tony_order WHERE user_id = 4323 AND total_amount = 101;

当我们把user_id这个字段补上之后,果然就可以用上索引了。
在MySQL 8.0 版本以后,联合索引的最左前缀原则不再那么绝对了,其引入了Skip Scan Range Access Method机制,可对区分度较低的字段进行优化。
感兴趣的同学可以去看下,本文中就不过多展开描述了。
2、LIKE百分号在左边
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO';
SELECT * FROM tony_order WHERE receiver_address LIKE '%北京市朝阳区望京SOHO%';
执行上面这两条SQL语句,结果都是一样的,走了全表扫描。

接下来我们将SQL语句改为%在右边,再执行一次看看。
SELECT * FROM tony_order WHERE receiver_address LIKE '北京市朝阳区望京SOHO%';

这个原理很好理解,联合索引需要遵循最左前缀原则,而单个索引LIKE的情况下,也需要最左边能够匹配上才行,否则就会导致索引失效。
3、使用OR关键字
有一种说法,只要使用OR关键字就会导致索引失效,我们来试试。
SELECT * FROM tony_order WHERE receiver_name = 'Tony学长' OR user_id = 41323;

从结果中我们可以看到,索引并没有失效,聪明的查询优化器将receiver_name和user_id两个字段上的索引进行了合并。
接下来我们再换个SQL试试。
SELECT * FROM tony_order WHERE receiver_phone = '13436669764' OR user_id = 4323;

这次确实索引失效了,由于receiver_phone这个字段上并没有创建索引,所以无法使用索引合并操作了,只能走全表扫描。
有的同学会问,那为什么user_id上的索引也失效了呢?
因为一个字段走索引,另一个字段走全表扫描是没有意义的,反而不如走一次全表扫描查找两个字段更有效率。
所以,有时候索引失效未必是坏事,而是查询优化器做出的最优解。
4、索引列上有函数
SELECT * FROM tony_order WHERE ABS (user_id) = 4323;

SELECT * FROM tony_order WHERE LEFT (receiver_address, 3)

这个不用过多解释了,就是MySQL的一种规范,违反就会导致索引失效。
5、索引列上有计算
SELECT * FROM tony_order WHERE user_id + 1 = 4324;

这个也不用过多解释了,还是MySQL的一种规范,违反就会导致索引失效。
6、字段隐式转换
SELECT * FROM tony_order WHERE receiver_phone = 13454566332;

手机号字段明明是字符类型,却在SQL中不慎写成了数值类型而导致隐式转换,最终导致receiver_phone字段上的索引失效。
SELECT * FROM tony_order WHERE receiver_phone = '13454566332';

当我们把手机号加上单引号之后,receiver_phone字段的索引就生效了,整个天空都放晴了。
SELECT * FROM tony_order WHERE product_id = '12345';

我们接着尝试,把明明是数值型的字段写成了字符型,结果是正常走的索引。
由此得知,当发生隐式转换时,把数值类型的字段写成字符串类型没有影响,反之,但是把字符类型的字段写成数值类型,则会导致索引失效。
7、查询记录过多
SELECT * FROM tony_order WHERE product_id NOT IN (12345,12346);

那么由此得知,使用NOT IN关键字一定会导致索引失效?先别着急下结论。
SELECT * FROM tony_order WHERE status NOT IN (0,1);

从执行计划中可以看到,status字段上的索引生效了,为什么同样使用了NOT IN关键字,结果却不一样呢?
因为查询优化器会对SQL语句的查询记录数量进行评估,如果表中有100w行数据,这个SQL语句要查出来90w行数据,那当然走全表扫描更快一些,毕竟少了回表查询这个步骤。
反之,如果表中有100w行数据,这个SQL语句只需要查出来10行数据,那当然应该走索引扫描。
SELECT * FROM tony_order WHERE status IN (0,1);

同样使用IN关键字进行查询,只要查询出来的记录数过于庞大,都会通过全表扫描来代替索引扫描。
SELECT * FROM tony_order WHERE status = 0;

甚至我们不使用IN、NOT IN、EXISTS、NOT EXISTS这些关键字,只使用等号进行条件筛选同样会走全表扫描,这时不走索引才是最优解。
8、排序顺序不同
SELECT * FROM tony_order ORDER BY user_id DESC,total_amount ASC

我们可以看下,这条SQL语句中的user_id用了降序,而total_amount用了升序,所以导致索引失效。
SELECT * FROM tony_order ORDERBY user_id ASC,total_amount ASC

而下面这两条SQL语句中,无论使用升序还是降序,只要顺序一致就可以使用索引扫描。
来源:juejin.cn/post/7528296510229823530
大模型不听话?试试提示词微调
想象一下,你向大型语言模型抛出问题,满心期待精准回答,得到的却是答非所问,是不是让人抓狂?在复杂分类场景下,这种“大模型不听话”的情况更是常见。
提示词微调这一利器,能帮你驯服大模型,让其准确输出所需结果。
今天就来深入解析如何通过提示词工程、RAG 增强和 Few Shots 学习等核心技术,高效构建基于 LLM 的分类系统。
分类系统架构设计
graph TD
A[输入文本] --> B[提示工程]
C[类别定义] --> B
D[向量数据库] --> E[RAG增强]
F[Few Shots示例] --> B
B --> G[LLM推理]
G --> H[结果提取]
分类系统的核心流程围绕提示工程展开,结合 RAG 增强和 Few Shots 学习可显著提升分类准确性。系统设计需关注数据流转效率与结果可解释性,特别适合保险票据、客户服务工单等高价值场景。
提示工程核心技巧
提示设计是 LLM 分类性能的关键,以下是经过实战验证的核心技巧:
1. 结构化表示法
采用 XML 或 JSON 格式封装类别定义和输入文本,提升模型理解效率:
# 类别定义示例
<categories>
<category>
<label>账单查询</label>
<description>关于发票、费用、收费和保费的问题</description>
</category>
<category>
<label>政策咨询</label>
<description>关于保险政策条款、覆盖范围和除外责任的问题</description>
</category>
</categories>
# 输入文本
<content>我的保险费为什么比上个月高了?</content>
2. 边界控制与结果约束
通过明确的指令和停止序列控制模型输出范围:
请根据提供的类别,对输入文本进行分类。
- 只需返回类别标签,不添加任何解释
- 如果无法分类,请返回"其他"
类别: [账单查询, 政策咨询, 理赔申请, 投诉建议, 其他]
输入: 我想了解我的保险是否涵盖意外医疗费用
输出:
3. 思维链提示
对于复杂分类任务,引导模型逐步思考:
我需要对客户的问题进行分类。首先,我会分析问题的核心内容,然后匹配最相关的类别。
客户问题: "我的汽车保险理赔需要提供哪些材料?"
分析: 这个问题是关于理赔过程中所需的材料,属于理赔相关的咨询。
类别匹配: 理赔申请
最终分类: 理赔申请
Few Shots 学习技术
Few Shots 学习通过提供少量示例,帮助模型快速适应特定任务:
1. 示例选择策略
# 选择多样化示例覆盖主要类别
示例1:
输入: "我的账单金额有误"
分类: 账单查询
示例2:
输入: "我想更改我的保险受益人"
分类: 政策变更
示例3:
输入: "我的车辆在事故中受损,如何申请理赔?"
分类: 理赔申请
2. 示例排序优化
# 按与输入的相关性排序示例
1. 最相关示例
输入: "我的保险费为什么上涨了?"
分类: 账单查询
2. 次相关示例
输入: "我想了解我的保险 coverage"
分类: 政策咨询
RAG 增强技术应用
检索增强生成(RAG)通过引入外部知识提升分类准确性:
1. 向量数据库构建与检索
# 1. 准备知识库文档
文档1: 保险理赔流程指南
文档2: 保险政策条款解释
文档3: 常见账单问题解答
# 2. 构建向量数据库
为每个文档创建嵌入向量并存储
# 3. 检索相关文档
对于输入文本,检索最相关的2-3个文档片段
2. 检索结果融合提示
# 结合检索结果和输入文本进行分类
检索到的相关信息:
[来自文档3] 常见账单问题包括费用上涨原因、账单错误等
输入文本: 我的保险费为什么比上个月高了?
请根据以上信息,将输入文本分类到以下类别之一:
[账单查询, 政策咨询, 理赔申请, 投诉建议, 其他]
技术整合示例
以下是整合提示词工程、RAG 技术和 Few Shots 学习的完整分类系统伪代码:
# 整合分类系统实现
class LLMClassifier:
def __init__(self, llm_client, vector_db):
self.llm_client = llm_client
self.vector_db = vector_db
self.categories = self._load_categories()
self.few_shot_examples = self._load_few_shot_examples()
def _load_categories(self):
# 加载类别定义
return {
"账单查询": "关于发票、费用、收费和保费的问题",
"政策咨询": "关于保险政策条款、覆盖范围和除外责任的问题",
"理赔申请": "关于理赔流程、材料和状态的问题",
"投诉建议": "对服务、流程或结果的投诉和建议",
"其他": "无法分类到以上类别的问题"
}
def _load_few_shot_examples(self):
# 加载Few Shots示例
return [
{"input": "我的账单金额有误", "label": "账单查询"},
{"input": "我想更改我的保险受益人", "label": "政策咨询"},
{"input": "我的车辆在事故中受损,如何申请理赔?", "label": "理赔申请"}
]
def _retrieve_relevant_docs(self, query, top_k=2):
# RAG检索相关文档
return self.vector_db.search(query, top_k=top_k)
def _build_prompt(self, query, relevant_docs):
# 构建整合提示
prompt = """
任务:将客户问题分类到以下类别之一:{categories}
类别定义:
{category_definitions}
相关知识:
{relevant_knowledge}
示例:
{few_shot_examples}
请按照以下步骤分类:
1. 分析客户问题的核心内容
2. 结合相关知识和示例,匹配最相关的类别
3. 只返回类别标签,不添加任何解释
客户问题:"{query}"
分类结果:
"""
# 填充模板
categories_str = ", ".join(self.categories.keys())
category_definitions = "\n".join([f"- {k}: {v}" for k, v in self.categories.items()])
relevant_knowledge = "\n".join([f"- {doc}" for doc in relevant_docs])
few_shot_examples = "\n".join([f"输入: \"{ex['input']}\"\n分类: {ex['label']}" for ex in self.few_shot_examples])
return prompt.format(
categories=categories_str,
category_definitions=category_definitions,
relevant_knowledge=relevant_knowledge,
few_shot_examples=few_shot_examples,
query=query
)
def classify(self, query):
# 1. RAG检索相关文档
relevant_docs = self._retrieve_relevant_docs(query)
# 2. 构建整合提示
prompt = self._build_prompt(query, relevant_docs)
# 3. LLM推理
response = self.llm_client.generate(
prompt=prompt,
max_tokens=100,
temperature=0.0
)
# 4. 提取结果
result = response.strip()
return result if result in self.categories else "其他"
# 使用示例
if __name__ == "__main__":
# 初始化LLM客户端和向量数据库
llm_client = initialize_llm_client() # 初始化LLM客户端
vector_db = initialize_vector_db() # 初始化向量数据库
# 创建分类器
classifier = LLMClassifier(llm_client, vector_db)
# 测试分类
test_queries = [
"我的保险费为什么比上个月高了?",
"我想了解我的保险是否涵盖意外医疗费用?",
"我的汽车保险理赔需要提供哪些材料?"
]
for query in test_queries:
category = classifier.classify(query)
print(f"查询: {query}\n分类结果: {category}\n")
通过以上核心技术的综合应用,可构建高效、准确的 LLM 分类系统,为保险、金融、客服等领域的文本分类需求提供强大解决方案。
nine|践行一人公司 | 🛰️codetrend
正在记录从 0 到 1 的踩坑与突破,交付想法到产品的全过程。
来源:juejin.cn/post/7543912699638906907
你一定疑惑JavaScript中的this绑定的究竟是什么?😵💫
想要了解this的绑定过程,首先要理解调用方式。
调用方式
调用方式被描述为函数被触发执行时语法形式。
主要有以下几种基本模式:
- 直接调用(独立函数调用):
f1() - 方法调用:
f1.f2() - 构造函数调用:
new f1() - 显示绑定调用:
f1.call(f2)或者f1.apply(f2) - 间接调用:
(0,f1)()
第五点可能很多人没有见过,其实这是应用了逗号操作符,(0,f1)()其实等同于f1(),但它有什么区别呢?我放在显式绑定的最后来阐述吧。
有的人会用调用位置来解释this的绑定,但我感觉那个不太好用,可能是我没理解到位吧,如果有人知道怎么用它来解释this的绑定,希望能告诉我。总之,我们先用调用方式来解释this的绑定吧。
四种绑定规则
接下来介绍四种绑定规则。
默认绑定
首先要介绍的是默认绑定,当使用了最常用的函数调用类型:直接调用(独立函数调用) 时,便应用默认绑定。可以把这条规则看作是无法应用其他规则时的默认规则。
在默认绑定时,this绑定的是全局作用域。
var a = 0;
function f1(){
var a = 1;
console.log(this.a); //输出为0
}
f1(); //直接调用,应用默认绑定
多个函数内部层层调用也是一样的。
var a = 0;
function f1(){
var a = 1;
f2();
}
function f2(){
var a = 2;
console.log(this.a); //输出的是0
}
f1();
隐式绑定
当函数被当作对象的属性被调用时(例如通过obj.f1()的形式),this会自动绑定到该对象上,这个绑定是隐式发生的,不需要显式使用call、apply或bind。
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //this绑定的是f2这个对象字面量
}
var obj = {
a : 2,
f1 : f1
// 也可以直接在obj内部定义f1
// function f1() {
// var a = 1;
// }
};
obj.f1(); // 输出为2
对象层层引用只有最后一个对象会影响this的绑定
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //最后输出为2
}
var obj1 = {
a : 2,
f1 : f1
};
var obj2 = {
a : 3,
obj1 : obj1
}
obj2.obj1.f1();
可以发现这里有两个对象一个是obj1,一个是obj2,obj2中的属性为obj1。先通过ob2.obj1调用obj1,再通过ob2.obj1.f1()调用f1函数,可以发现对象属性引用链中的最后一个对象为this所绑定的对象
隐性丢失
但隐式绑定可能会导致this丢失所绑定的对象,也就是会应用默认绑定(this绑定到全局作用域) 造成隐性丢失主要有两个方面,一个是给函数取别名,一个是回调函数。
- 函数取别名
var a = 0;
function f1() {
var a = 1;
console.log(this.a); //最后输出为0
}
var obj = {
a : 2,
f1 : f1
}
var fOne = obj.f1; // 给f1取了一个fOne的别名
fOne();
虽然函数fOne是obj.f1的一个引用,但实际上,它引用的是f1函数本身,因此它执行的就是f1()。所以会使用默认绑定。
- 回调函数
var a = 0;
// f1为回调函数,将obj.f2作为参数传递给f1
function f1(f2) {
var a = 1;
f2();
}
function f2() {
var a = 2;
console.log(this.a); //结果为0
}
var obj = {
a : 3,
f2 : f2
}
f1(obj.f2);
原因很简单,f1(obj.f2)把obj.f2赋值给了function f1(f2) {...}中的f2(形参),就像上面讲的函数取了一个别名一样,实际执行的就是直接调用,所以应用默认绑定。
显式绑定
显式绑定很好理解,显式绑定让我们可以自定义this的绑定。我们通过使用函数的apply、call或bind方法,让我们可以自定义this的绑定。
var a = 0;
function f1 () {
var a = 1;
console.log(this.a);
}
//apply方法绑定this apply(对象,参数数组)
f1.apply({a:2}); //输出2
//call方法绑定this call(对象,参数1,参数2,...)
f1.call({a:3}); //输出3
//bind方法绑定this bind(对象,参数1,参数2,...),bind会返回一个函数,需要调用
boundf1 = f1.bind({a:4});
boundf1(); //输出4
但用apply、call来进行显示绑定并不能避免隐性丢失的问题。下面有两个方法来解决这个问题。
1.硬绑定
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
var bar = function() {
return f1.apply({a:2});
};
setTimeout(bar, 1000);//输出为2
让我们来分析分析这个代码。我们创建了函数bar,这个函数负责返回绑定好this的f1函数,并立即执行它。 这种绑定我们称之为硬绑定。
这种绑定方法会使用在一个i可以重复使用的辅助函数 例如
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
function bind(fn, obj) {
return function () {
return fn.apply(obj, arguments);
};
}
var bar = bind(f1,{a:2});
bar();
可以很明显发现这和我们js自带的函数bind方法很像。是的,在ES5中提供了内置的方法Function.prototype.bind。它的用法我再提一次吧。
var a = 0;
function f1 () {
var a = 1;
console.log(this.a);
}
//bind方法绑定this
//bind(对象,参数1,参数2,...),bind会返回一个函数,需要调用
boundf1 = f1.bind({a:2});
boundf1(); //输出2
2.API调用的“上下文”
第三方库的许多函数,以及JavaScript语言和宿主环境中许多内置函数,都提供了一个可选参数,通常被称为“上下文”,其作用和bind方法一样,都是为了防止隐性丢失。
现在来举个例子吧。
function f1(el) {
console.log(el, this.id);
}
var obj = {
id : "awesome"
};
[1,2,3].forEach(f1,obj);
//最后输出的结果为
// 1 'awesome'
// 2 'awesome'
// 3 'awesome'
逗号操作符
在文章开头我们提到了这样一种表达式(0,f1)(),这是逗号操作符的应用,逗号操作符会依次计算所有的表达式,然后返回最后一个表达式的值。这里(0,f1)会先计算0(无实际意义),然后再返回f1,所以最后为f1()。
理解了逗号操作符的使用,那如果我们把f1改为obj.f1呢,即(0,obj.f1)(),这时f1中的this绑定的是谁呢?
直接说结论,绑定的是全局对象。(0,obj.f1)()先计算0,然后返回obj.f1即f1函数本身,所以它返回的是一个解绑this的函数,其相当于f1.call(window)——window是全局对象。
下面我们来验证一下吧。
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
var obj = {
a : 2,
f1 : f1
};
(0,obj.f1)(); //输出0
完全正确哈哈,注意这种方式不算作隐性丢失哦。
- 这个操作只是调用了
obj.f1,并没有阻止垃圾回收(GC)。 - 如果
obj或f1没有其他引用,它们仍然会被正常回收。
如果对其具体的工作流程感兴趣,可以去网上再找些资料。本篇就不讲太详细了。
new 绑定
这是this绑定的最后一条规则。
new绑定通常的形式为:... = new MyClass(参数1,参数2,...)
JavaScript中的new操作符的机制和那些面向类的语言的new操作符有些不一样,因为JavaScript是基于原型的语言(这个也许以后我会谈谈哈哈)。在JavaScript中,“构造函数”仅仅只是你使用new操作符时被调用的函数。
使用new来调用函数,会自动执行以下操作。
- 创建(或者说构造)一个全新的对象。
- 这个新对象会被执行原型连接。
- 这个新对象会绑定到函数调用的this。
- 如果函数没有返回其他对象,那么new表达式中的函数调用会自动返回这个新对象。
我们现在重点要关注的是第三点。
function f1(a){
this.a = a;
}
var bar = new f1(2);
console.log(bar.a); //输出为2
console.log(f1.a); //输出为undefined
这段代码就可以很明显的看出来new会创建一个新对象bar,并把this绑定到这个bar上,所以才会在bar上创建a这个属性。而原来的f1上则没有a这个属性,所以是undefined。
四条规则的优先级
- 如果某个调用位置应用了多条规则该怎么办?这时我们就需要知道它们的优先级了。 首先,默认绑定的优先级是最低的。我们先来测试一下它们隐式绑定和显式绑定哪个优先级高吧,这里我偷个懒,就引用一下《你不知道的JavaScript(上卷)》这本书的测试代码
function foo() {
console.log( this.a );
}
var obj1 = {
a: 2,
foo: foo
};
var obj2 = {
a: 3,
foo: foo
};
obj1.foo(); // 2
obj2.foo(); // 3
obj1.foo.call( obj2 ); // 3
obj2.foo.call( obj1 ); // 2
稍微分析一下吧,obj1.foo()和obj2.foo()为隐式调用,this分别绑定的为obj1,obj2,所以会打印2,3。接着我们调用了obj1.foo.call(obj2)发现结果输出为obj2中的a属性2,所以这里应用的是显式绑定。
所以显式绑定的优先级是高于隐式绑定的。
- 再来看看
new绑定和隐式绑定的优先级谁更高吧。
function foo(something) {
this.a = something;
}
var obj1 = {
foo: foo
};
obj1.foo(1);
console.log( obj1.a ); // 1
var bar = new obj1.foo(2);
console.log( obj1.a ); // 1
console.log( bar.a ); // 2
var bar = new obj1.foo(2)这段代码,如果隐式绑定的优先级会大于new绑定,就会在obj1里把属性a赋值为2; 如果new绑定的优先级大于隐式绑定,就会在bar中创建一个属性a,值为2,最后看obj1.a和bar.a谁输出为2,谁的优先级就更高,很明显bar.a输出为2,所以new绑定的优先级高于隐式绑定的。
所以new调用的优先级要高于隐式调用的优先级。
- 再来看看new调用和显式调用的优先级谁高谁低吧。
new不能和apply和call方法同时使用,但我们可以用bind方法进行硬绑定,再用bind返回的新函数再new一下以此来判断谁的优先级高。
function foo(something) {
this.a = something;
}
var obj1 = {};
var bar = foo.bind( obj1 );
bar( 2 );
console.log( obj1.a ); // 2
var baz = new bar(3);
console.log( obj1.a ); // 2
console.log( baz.a ); // 3
首先硬绑定了obj1,在obj1中创建了a属性,值为2,bar接收返回的bind函数。之后new bar并给a赋值为3,用baz来接收new的对象,这时如果baz.a为3就说明this应用的绑定规则是new绑定。
所以new绑定的优先级是高于显示调用的优先级的。
现在知道了四种规则,又知道了这四个规则的优先级,我们就能很清晰的判断this的绑定了。
判断this的流程
以后判断this我们可以按以下顺序来判断:
- 函数是否在
new中调用(new绑定)?如果是的话this绑定的是新创建的对象。var bar = new foo() //这里bar为this绑定的对象
- 函数是否通过
call、apply(显式绑定)或者硬绑定(bind)调用?如果是的话,this绑定的是指定的对象。var bar = foo.call(obj) //这里obj为this绑定的对象
- 函数是否在某个上下文对象中调用(隐式绑定)如果是的话,
this绑定的是那个上下文对象。var bar = obj.foo() //这里obj为this绑定的对象
- 如果都不是,则应用默认绑定,
this绑定到全局对象上。var bar = foo() //this绑定的为全局对象
凡事都有例外,还有一些十分特殊的情况不满足上面的四条规则,我们需要单独拎出来记忆。
绑定例外
绑定例外主要有3种。
null导致的绑定意外
var a = 0;
function f1() {
var a = 1;
console.log(this.a);
}
f1.apply(null); //输出为0
var bar = f1.bind(null);
bar() //输出为0
当我们使用显式绑定(使用apply、call、bind方法)的时候,如果我们显式绑定一个null,就会发现this绑定的不是null而是应用默认绑定,绑定全局对象。这会导致变量全局渗透的问题。
有的人可能会说,那我们不用null来绑定this不就好了吗?但有的时候我们还真不得不使用null来绑定this,下面我来介绍一下什么时候会使用这种情况。
一种常见的做法是使用apply(..)来“展开”一个数组,并当作参数传入一个函数。类似地,bind(..)可以对参数进行柯里化(预先设置一些参数),这种方法有时很好用的。
function f1 (a , b) {
console.log("a:" + a + ",b:" + b);
}
f1.apply(null,[2,3]) //输出为a:2,b:3
//bind的柯里化
var bar = f1.bind(null,2);
bar(3); //输出为a:2,b:3
现在来简单地来介绍一下柯里化是什么?柯里化是将一个接收多个参数的函数转换为一系列只接受单个参数的函数。这时bind和null的作用就体现出来了。
然而,在apply,call,bind使用null会导致全局溢出,在一些有this的函数中,给这个this绑定null,会让this绑定全局对象。该如何解决这个问题呢?
更安全的this
我们可手动创建一个空的对象,这个空的对象我们称作“DMZ”(demilitarized zoo,非军事区)对象——它是一个空的非委托的对象。
如果我们在想要忽略this绑定时总是传入一个DMZ对象,那就不用担心this会溢出到全局了,这个this绑定的就是DMZ对象。
在JavaScript中创建一个空对象最简单的方法是Object.create(null)——它会返回一个空对象,Object.create(null)。Object.create(null)和{}很像,并不会创建Object.prototype这个委托,所以它比{}“更空”。
var c = 0;
function f1 (a , b) {
this.c = 1;
console.log("a:" + a + ",b:" + b);
}
//创建自己的空对象
var myNull = Object.create(null);
f1.apply(myNull,[2,3]) //输出为a:2,b:3
console.log(c); //输出为0
//bind的柯里化
var bar = f1.bind(myNull,2);
bar(3); //输出为a:2,b:3
console.log(c); //输出为0
可以发现这段代码中,我们创建了自己的空对象通过apply和bind方法把this绑定到这个空对象了。最后的输出的c是0,说明this.c并没有修改全局变量c的值。所以这个方法可以防止全局溢出。
接下来谈谈另外一个绑定的例外吧。
间接引用
有的时候你可能(有意或无意地)创建了一个函数的“间接引用”,在这种情况下,调用这个函数应用默认绑定规则。
var a = 0;
function f1() {
console.log(this.a);
}
var obj1 = {
a : 1,
f1 : f1
};
var obj2 = {
a : 2,
};
obj1.f1(); // 1
(obj2.f1 = obj1.f1)(); // 0
我们来看看这个代码。obj1中有a和f1属性或方法,a的值为1;obj2中只有a属性,值为2。我们先隐式绑定obj1,this绑定obj1,最后输出为1,这个我们可以理解。关键是下面这行代码(obj2.f1 = obj1.f1)(),obj2中没有f1,所以它在obj2中创建一个f1,然后将obj1中的f1函数赋值给obj2的f1,然后执行这个赋值表达式。那为什么输出的是0而不是obj2中的2或者obj1中的1呢? 🤔
其实这和赋值表达式的返回值有关系,因为赋值表达式会返回等号右边的值。 所以(obj2.f1 = obj1.f1)实际上返回的obj1.f1中的f1函数,实际执行的是f1()。所以应用的是默认绑定,this绑定全局对象,结果输出为0。
我们继续看绑定的下一个例外。
箭头函数
在ES6中介绍了一种无法使用这些规则的特殊函数类型:箭头函数。
箭头函数和一般的函数不一样,它不是用function来定义的,而是使用被称作“胖箭头”的操作符=>定义的。
定义格式:(参数) => {函数体}
箭头函数不使用this的四条规则,而是继承外层(定义时所在)函数或全局作用域的this的值,this在箭头函数创建时就被确定,且永远不会被改变,new也不行。
var a = 0;
(()=>{
var a = 1;
console.log(this.a); // 结果输出为0
})();
很明显该箭头函数外部就是全局作用域,所以继承全局对象的this就是它本身,所以输出为0。
再看看如果在其他函数中定义箭头函数this如何绑定
var a = 0;
function f1() {
var a = 1;
(()=>{
var a = 2;
console.log(this.a);
})();
}
f1();//输出0
//给f1绑定一个对象
f1.apply({a:3}); // 输出3
可以发现f1内部的箭头函数继承了其外部函数f1的this的绑定。所以一开始没给f1绑定this时,f1的this绑定的是全局对象,箭头函数的也是全局对象;当给f1的this绑定一个对象时,箭头函数的this也绑定该对象。
小结
以上是我的学习分享,希望对你有所帮助。
还有本篇的四条规则只适用于非严格模式,严格模式的this的绑定我日后再出一篇吧,其实只是有点懒😂。
参考书籍
《你所不知道的JavaScript(上卷)》
来源:juejin.cn/post/7504237094283526178
为什么我的第一个企业级MCP项目上线3天就被叫停?
graph TB
A[企业AI需求] --> B[MCP企业架构]
B --> C[安全体系]
B --> D[运维管理]
B --> E[实施路径]
C --> C1[身份认证]
C --> C2[数据保护]
C --> C3[访问控制]
D --> D1[自动化部署]
D --> D2[监控告警]
D --> D3[成本优化]
E --> E1[MVP阶段]
E --> E2[扩展阶段]
E --> E3[优化阶段]
style A fill:#FFE4B5
style B fill:#90EE90
style C fill:#87CEEB
style D fill:#DDA0DD
style E fill:#F0E68C
3分钟速读:企业级MCP部署不同于个人使用,需要考虑安全合规、高可用性、统一管理等复杂需求。本文提供从架构设计到运维管理的完整企业级MCP平台构建方案,包含安全框架、监控体系和分阶段实施路径,帮助企业构建统一、安全、可扩展的AI工具平台。
"系统上线第三天就被安全部门紧急叫停,所有人都在会议室里看着我。"
那是我职业生涯中最尴尬的时刻之一。作为一家500人科技公司的架构师,我以为把个人版的MCP简单放大就能解决企业的AI工具集成问题。结果呢?权限混乱、数据泄露风险、合规审计不通过...
CEO当时问我:"我们现在有20多个团队在用各种AI工具,每个团队都有自己的一套,你觉得这样下去会不会出问题?"我当时信心满满地说:"没问题,给我两周时间。"
现在想想,那时的我真是太天真了。个人用Claude Desktop配置几个MCP服务器确实10分钟就搞定,但企业级别?完全是另一个世界。
从那次失败中我学到:企业级MCP部署面临的不是技术问题,而是管理和治理的系统性挑战。
🏢 企业AI工具集成的挑战与机遇
个人vs企业:天壤之别的复杂度
当我们从个人使用转向企业级部署时,复杂度呈指数级增长:
个人使用场景:
- 用户:1个人
- 数据:个人文件和少量API
- 安全:基本的API密钥管理
- 管理:手动配置即可
企业级场景:
- 用户:数百到数千人
- 数据:敏感业务数据、客户信息、财务数据
- 安全:严格的合规要求、审计需求
- 管理:统一配置、权限控制、监控告警
从我参与的十几个企业AI项目来看,大家基本都会遇到这几个头疼的问题:
1. 数据安全这道坎
企业数据可不比个人文件,涉及客户隐私、商业机密,动不动就要符合GDPR、HIPAA这些法规。我见过一个金融客户,光是数据分类就搞了3个月,更别说传统的个人化MCP配置根本过不了合规这关。
2. 权限管理的平衡艺术
这个真的很难搞。不同部门、不同级别的人要访问的数据和工具都不一样。既要保证"最小权限原则",又不能让用户觉得太麻烦。我之前遇到过一个案例,权限设置太严格,结果销售团队抱怨查个客户信息都要申请半天。
3. 成本控制的现实考验
这个问题往往被低估。当几百号人同时用AI工具时,API调用费用真的会让财务部门头疼。我见过一家公司,第一个月账单出来,CFO直接找到CTO问是不是系统被攻击了。
4. 运维管理的复杂度爆炸
分散部署最大的问题就是运维。每个团队都有自己的一套,出了问题谁来解决?性能怎么优化?我们之前有个客户,光是梳理现有的AI工具部署情况就花了两周时间。
MCP在企业环境中的价值主张
正是在这样的背景下,MCP的企业级价值才真正显现:
- 统一标准:一套协议解决所有AI工具集成问题
- 集中管理:统一的配置、监控、审计
- 安全可控:标准化的安全框架和权限管理
- 成本透明:集中的资源使用监控和成本分析
我们最近做了个小范围调研,发现用了统一MCP平台的几家企业,AI工具管理成本大概能降低50-70%,安全事件也确实少了很多。虽然样本不大,但趋势还是挺明显的。
📊 企业级需求分析:规模化部署的关键考量
在动手设计企业级MCP方案之前,我觉得最重要的是先搞清楚企业到底需要什么。这些年参与了十几个项目下来,我发现企业级MCP部署基本都绕不开这几个核心需求:
多团队协作需求
场景复杂性:
- 研发团队:需要访问代码仓库、CI/CD系统、Bug跟踪系统
- 销售团队:需要CRM系统、客户数据、销售报表
- 运营团队:需要监控系统、日志分析、业务指标
- 财务团队:需要ERP系统、财务报表、合规数据
每个团队的需求不同,但又需要在统一的安全框架下协作。
安全合规要求
企业级部署必须满足严格的安全合规要求:
| 合规标准 | 主要要求 | MCP实现方案 |
|---|---|---|
| GDPR | 数据主体权利、数据最小化 | 细粒度权限控制、数据脱敏 |
| SOX | 财务数据完整性、审计跟踪 | 完整审计日志、不可篡改记录 |
| ISO27001 | 信息安全管理体系 | 全面安全控制框架 |
| HIPAA | 医疗数据保护 | 加密传输、访问控制 |
性能和可用性要求
企业级应用对性能和可用性有严格要求:
- 可用性:99.9%以上(年停机时间<8.77小时)
- 响应时间:95%的请求在2秒内响应
- 并发能力:支持数千用户同时访问
- 数据一致性:确保跨系统数据同步
成本控制需求
企业需要精确的成本控制和预算管理:
- 成本透明:每个部门、每个项目的AI使用成本清晰可见
- 预算控制:设置使用上限,避免成本失控
- 优化建议:基于使用数据提供成本优化建议
🏗️ MCP企业级架构设计:构建统一工具平台
说到架构设计,我必须承认,刚开始接触企业级MCP时,我也走过不少弯路。最开始我想的太简单,以为把个人版的MCP放大就行了,结果第一个项目就翻车了——系统上线第三天就因为权限问题被安全部门叫停。
后来痛定思痛,我重新设计了一套分层的企业级MCP架构。这套架构现在已经在好几个项目中验证过了,既能应对复杂的业务需求,扩展性也不错。
整体架构方案
graph TB
subgraph "用户层"
A[Web界面]
B[IDE插件]
C[移动应用]
D[API接口]
end
subgraph "网关层"
E[MCP网关]
F[负载均衡器]
G[API网关]
end
subgraph "服务层"
H[认证服务]
I[权限服务]
J[MCP服务注册中心]
K[配置管理中心]
end
subgraph "工具层"
L[开发工具MCP服务器]
M[数据工具MCP服务器]
N[业务工具MCP服务器]
O[监控工具MCP服务器]
end
subgraph "数据层"
P[关系数据库]
Q[文档数据库]
R[缓存层]
S[日志存储]
end
A --> E
B --> E
C --> E
D --> G
E --> F
G --> F
F --> H
F --> I
H --> J
I --> J
J --> K
K --> L
K --> M
K --> N
K --> O
L --> P
M --> Q
N --> R
O --> S
核心组件详解
1. MCP网关层
功能职责:
- 路由管理:智能路由请求到合适的MCP服务器
- 负载均衡:分发请求,确保系统稳定性
- 安全认证:统一的身份验证和授权
- 限流控制:防止系统过载,保护后端服务
核心特性:支持智能路由、负载均衡、限流控制和统一认证,确保系统稳定性和安全性。
2. 服务注册中心
核心功能:
- 服务发现:自动发现和注册MCP服务器
- 健康检查:实时监控服务器状态
- 配置同步:统一的配置管理和分发
- 版本管理:支持服务的灰度发布和回滚
技术要点:采用分布式注册中心架构,支持服务自动注册、健康检查和配置热更新。
3. 配置管理中心
管理内容:
- 服务器配置:MCP服务器的连接参数和功能配置
- 权限配置:用户和角色的权限矩阵
- 业务配置:各种业务规则和策略配置
- 环境配置:开发、测试、生产环境的差异化配置
高可用性设计
为确保企业级的可用性要求,架构中集成了多种高可用保障机制:
1. 多活部署
- 多个数据中心同时提供服务
- 自动故障切换,RTO < 30秒
- 数据实时同步,RPO < 5分钟
2. 弹性扩容
- 基于负载自动扩容
- 支持水平扩展和垂直扩展
- 预测性扩容,提前应对流量高峰
3. 容错机制
- 服务熔断,防止雪崩效应
- 优雅降级,保证核心功能可用
- 重试机制,处理临时性故障
🔐 安全架构设计:保障企业数据安全
在企业环境中,安全绝对不是可选项。这个教训我学得特别深刻——前面提到的那个翻车项目,就是因为我低估了企业对安全的要求。现在我设计MCP安全架构时,坚持用"纵深防御"策略,每一层都要有安全控制,宁可麻烦一点,也不能留安全隐患。
身份认证和授权体系
1. 多层次身份认证
graph LR
A[用户登录] --> B[SSO认证]
B --> C[MFA验证]
C --> D[JWT Token]
D --> E[API访问]
B --> B1[LDAP/AD]
B --> B2[OAuth2.0]
B --> B3[SAML]
C --> C1[短信验证码]
C --> C2[TOTP]
C --> C3[生物识别]
技术实现:集成主流SSO提供商(Azure AD、Okta、Google),支持多种MFA方式,采用JWT令牌管理会话。
2. 基于角色的访问控制(RBAC)
权限模型设计:
# 权限配置示例
roles:
- name: developer
permissions:
- mcp:tools:code:read
- mcp:tools:code:execute
- mcp:resources:docs:read
- name: data_analyst
permissions:
- mcp:tools:database:read
- mcp:tools:analytics:execute
- mcp:resources:data:read
- name: admin
permissions:
- mcp:*:*:* # 超级管理员权限
users:
- username: john.doe
roles: [developer]
additional_permissions:
- mcp:tools:deploy:execute # 额外权限
数据安全保护
1. 端到端加密
- 传输加密:所有MCP通信使用TLS 1.3
- 存储加密:敏感数据AES-256加密存储
- 密钥管理:使用HSM或云KMS管理加密密钥
2. 数据脱敏和分类
核心功能:自动识别敏感数据类型(邮箱、手机、身-份-证等),根据预设规则进行脱敏处理,确保数据隐私保护。
网络安全防护
1. API网关安全策略
- DDoS防护:智能识别和阻断攻击流量
- WAF规则:防护SQL注入、XSS等常见攻击
- IP白名单:限制访问来源IP范围
- 请求限流:防止API滥用
2. 网络隔离
安全策略:采用DMZ、内部服务区、数据库区三层网络隔离,通过防火墙规则严格控制服务间通信。
审计日志和合规
1. 全链路审计
审计范围:记录所有MCP访问操作,包括用户身份、操作类型、访问资源、操作结果、IP地址等关键信息,确保操作可追溯。
2. 合规报告自动生成
- 访问报告:用户访问行为分析
- 权限报告:权限使用情况统计
- 异常报告:安全异常事件汇总
- 合规检查:自动化合规性检查
⚙️ 运维管理体系:确保稳定高效运行
运维这块儿,说实话是我最头疼的部分。技术方案设计得再好,如果运维跟不上,照样会出问题。我见过太多项目,前期开发得很顺利,上线后各种运维问题层出不穷。所以现在我做企业级MCP平台时,会把运维管理当作一个系统工程来对待,从部署、监控到优化,每个环节都要考虑周全。
自动化部署体系
1. CI/CD流水线设计
流水线阶段:测试→构建→部署开发环境→预发布→生产环境,每个阶段都包含自动化测试、安全扫描和质量检查。
2. 蓝绿部署和灰度发布
蓝绿部署策略:新版本部署到绿环境→健康检查→流量切换→清理旧环境,确保零停机部署。
监控告警系统
1. 多维度监控指标
监控维度:
- 业务指标:请求总数、成功率、响应时间、活跃用户数
- 系统指标:CPU、内存、磁盘使用率
- 成本指标:按请求计费、部门成本分摊
2. 智能告警系统
# Prometheus告警规则
groups:
- name: mcp-platform
rules:
- alert: MCPHighErrorRate
expr: rate(mcp_requests_failed_total[5m]) / rate(mcp_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "MCP平台错误率过高"
description: "过去5分钟MCP请求错误率超过5%"
- alert: MCPHighLatency
expr: histogram_quantile(0.95, rate(mcp_request_duration_seconds_bucket[5m])) > 2
for: 5m
labels:
severity: warning
annotations:
summary: "MCP平台响应延迟过高"
description: "95%的请求响应时间超过2秒"
- alert: MCPServerDown
expr: up{job="mcp-server"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "MCP服务器宕机"
description: "{{ $labels.instance }} MCP服务器无法访问"
成本优化管理
1. 成本监控和分析
成本分析功能:自动分析计算、存储、网络、API等各项成本,按部门分摊费用,并提供优化建议。
2. 自动扩缩容策略
# Kubernetes HPA配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: mcp-server-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: mcp-server
minReplicas: 3
maxReplicas: 50
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 80
- type: Pods
pods:
metric:
name: mcp_requests_per_second
target:
type: AverageValue
averageValue: "100"
🚀 实施路径和最佳实践
关于实施策略,我觉得最重要的一点是:千万别想着一步到位。我之前就犯过这个错误,想着一次性把所有功能都上线,结果搞得团队疲惫不堪,用户体验也很糟糕。现在我都是推荐分阶段实施,这套策略在好几个项目中都验证过了,确实比较靠谱。
分阶段实施计划
第一阶段:MVP验证(1-2个月)
目标:验证MCP在企业环境中的可行性
实施内容:
- 选择1-2个核心团队作为试点
- 部署基础的MCP服务器(文件系统、Git、简单API)
- 建立基本的安全和监控机制
- 收集用户反馈和性能数据
成功标准:
- 试点团队满意度 > 80%
- 系统可用性 > 99%
- 响应时间 < 2秒
- 零安全事件
第二阶段:功能扩展(2-3个月)
目标:扩展功能覆盖范围,优化用户体验
实施内容:
- 集成更多业务系统(CRM、ERP、数据库)
- 完善权限管理和审计功能
- 优化性能和稳定性
- 扩展到更多团队
成功标准:
- 覆盖50%以上的核心业务场景
- 用户数量增长3倍
- 平均响应时间减少30%
- 成本控制在预算范围内
第三阶段:全面推广(3-6个月)
目标:在全公司范围内推广使用
实施内容:
- 部署完整的企业级架构
- 建立完善的运维体系
- 开展全员培训
- 建立持续优化机制
成功标准:
- 全公司80%以上员工使用
- 系统可用性 > 99.9%
- 用户满意度 > 85%
- ROI > 200%
团队组织和协作
1. 核心团队构成
graph TB
A[项目指导委员会] --> B[项目经理]
B --> C[架构师]
B --> D[开发团队]
B --> E[运维团队]
B --> F[安全团队]
C --> C1[系统架构师]
C --> C2[安全架构师]
D --> D1[后端开发]
D --> D2[前端开发]
D --> D3[MCP服务器开发]
E --> E1[DevOps工程师]
E --> E2[监控工程师]
F --> F1[安全工程师]
F --> F2[合规专员]
2. 协作机制
定期会议制度:
- 周例会:项目进展同步和问题解决
- 月度评审:里程碑检查和计划调整
- 季度总结:成效评估和策略优化
文档管理:
- 架构文档:系统设计和技术规范
- 操作手册:部署和运维指南
- 用户指南:使用教程和最佳实践
风险控制和应急预案
1. 风险识别和评估
| 风险类型 | 风险等级 | 影响范围 | 应对策略 |
|---|---|---|---|
| 系统故障 | 高 | 全公司 | 多活部署、快速切换 |
| 安全漏洞 | 高 | 敏感数据 | 安全扫描、及时修复 |
| 性能问题 | 中 | 用户体验 | 性能监控、弹性扩容 |
| 合规风险 | 中 | 法律风险 | 合规检查、审计跟踪 |
2. 应急响应流程
应急流程:故障分级→通知相关人员→启动应急响应→执行应急措施→跟踪处理进度→事后总结,确保快速响应和持续改进。
📈 案例研究:中大型企业MCP平台实践
说了这么多理论,我觉得还是用真实案例更有说服力。下面分享几个我亲身参与的项目,有成功的,也有踩坑的,希望对大家有帮助。
案例一:中型科技公司(800人规模)
公司背景:
- 行业:SaaS软件开发
- 规模:800名员工,15个研发团队
- 挑战:AI工具使用分散,成本控制困难
实施方案:
- 架构选择:单数据中心部署,微服务架构
- 核心功能:代码助手、文档管理、项目协作
- 安全措施:RBAC权限控制、API网关防护
实施效果:
实施前后对比:
开发效率:
before: "基线"
after: "+35%"
measurement: "功能交付速度"
成本控制:
before: "月成本$15,000"
after: "月成本$12,000"
savings: "20%"
安全事件:
before: "月均3起"
after: "月均0.5起"
reduction: "83%"
用户满意度:
before: "6.5/10"
after: "8.7/10"
improvement: "+34%"
关键成功因素:
- 高层支持:这个真的很重要,CEO亲自站台,资源要人给人要钱给钱
- 分阶段实施:我们从最积极的两个团队开始,让他们当种子用户,效果好了再推广
- 用户培训:别小看这个,我们光培训就搞了一个月,但确实值得
- 持续优化:每周都会收集用户反馈,有问题马上改,这个习惯一直保持到现在
案例二:大型金融机构(5000+人规模)
公司背景:
- 行业:银行业
- 规模:5000+名员工,严格合规要求
- 挑战:数据安全、合规审计、多地部署
实施方案:
- 架构选择:多活数据中心,容器化部署
- 核心功能:风险分析、客户服务、合规报告
- 安全措施:端到端加密、零信任架构
金融级安全要求:TLS 1.3传输加密、AES-256数据加密、HSM密钥管理、PCI-DSS/SOX合规、7年审计日志保留、本地化数据存储。
实施效果:
- 合规性:通过所有监管审计,零合规违规
- 效率提升:客户服务响应时间减少50%
- 成本节约:年度IT成本降低25%
- 风险控制:欺诈检测准确率提升40%
经验教训总结
通过这些案例,我们总结出企业级MCP实施的关键经验:
成功要素
- 明确的ROI目标:设定可量化的成功指标
- 充分的资源投入:人力、资金、时间的保障
- 渐进式实施:避免大爆炸式部署
- 用户参与:让最终用户深度参与设计和测试
常见陷阱
- 忽视安全合规:在设计初期就要考虑安全要求
- 低估培训成本:用户培训和支持需要充分投入
- 缺乏监控:没有完善的监控就无法及时发现问题
- 一步到位心态:试图一次性解决所有问题
💡 写在最后:从失败到成功的思考
回想起那次项目失败,我现在反而挺感谢那次经历。它让我明白了一个道理:企业级MCP集成绝不是技术的简单堆砌,而是一个涉及人、流程、技术的复杂系统工程。
如果重新来过,我会这样做:
- 先调研,再动手:花更多时间理解企业的真实需求,而不是想当然
- 小步快跑:从最简单的MVP开始,证明价值后再扩展
- 安全第一:把合规和安全放在功能之前考虑
- 拥抱变化:技术在发展,需求在变化,保持架构的灵活性
现在我参与的企业级MCP项目,成功率已经提升到90%以上。不是因为我的技术水平提高了多少,而是因为我学会了从企业的角度思考问题。
最好的架构不是最复杂的,而是最适合的。
如果你正在考虑为企业部署MCP平台,我的建议是:先找一个小团队试点,积累经验和信心,然后再考虑大规模推广。记住,每个企业都有自己的特色,别人的成功方案未必适合你。
🤔 互动时间
分享你的经验:
- 你的企业在AI工具集成方面遇到了什么挑战?
- 你觉得统一的AI工具平台对企业来说最大的价值是什么?
- 有没有类似的项目失败经历想要分享?
实践练习:
- 使用文章中的需求分析框架,评估你所在企业的MCP部署需求
- 基于你的行业特点,设计合适的安全控制措施
- 参考分阶段实施策略,制定适合你企业的部署计划
欢迎在评论区分享你的想法和经验,我会认真回复每一条评论。
📧 如果你正在规划企业级MCP项目,可以私信我,我很乐意分享更多实战经验和踩坑心得。
下期预告:《MCP最佳实践与性能优化》将深入探讨MCP使用过程中的优化技巧和故障排查方法,敬请期待!
关注专栏,获取更多MCP实战干货!
来源:juejin.cn/post/7532742298825768998
java中,使用map实现带过期时间的缓存
在 Java 开发领域,缓存机制的构建通常依赖于 Redis 等专业缓存数据库。这类解决方案虽能提供强大的缓存能力,但引入中间件意味着增加系统架构复杂度、部署成本与运维负担。本文将深入探讨一种轻量级替代方案 —— 基于 Java 原生Map实现的带过期时间的缓存机制。该方案无需引入外部工具,仅依托 Java 标准库即可快速搭建起缓存体系,特别适用于对资源占用敏感、架构追求极简的项目场景,为开发者提供了一种轻量高效的缓存数据管理新选择。
优点:
- 轻量便捷:无需引入 Redis 等外部中间件,直接使用 Java 标准库即可实现,降低了项目依赖,简化了部署流程。
- 快速搭建:基于熟悉的Map数据结构,开发人员能够快速理解和实现缓存逻辑,显著提升开发效率。
- 资源可控:可灵活控制缓存数据的生命周期,通过设置过期时间,精准管理内存占用,适合对资源占用敏感的场景。
缺点:该方案存在明显局限性,即数据无法持久化。一旦应用程序停止运行,缓存中的所有数据都会丢失。相较于 Redis 等具备持久化功能的专业缓存数据库,在需要长期保存缓存数据,或是应对应用重启后数据恢复需求的场景下,基于 Java 原生Map的缓存机制就显得力不从心。
代码实现
package com.sunny.utils;
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class SysCache {
// 单例实例
private static class Holder {
private static final SysCache INSTANCE = new SysCache();
}
public static SysCache getInstance() {
return Holder.INSTANCE;
}
// 缓存存储结构,Key为String,Value为包含值和过期时间的CacheEntry对象
private final ConcurrentHashMap<String, CacheEntry> cacheMap = new ConcurrentHashMap<>();
// 定时任务执行器
private final ScheduledExecutorService scheduledExecutorService;
// 私有构造方法,初始化定时清理任务
private SysCache() {
scheduledExecutorService = Executors.newSingleThreadScheduledExecutor();
// 每隔1秒执行一次清理任务
scheduledExecutorService.scheduleAtFixedRate(this::cleanUp, 1, 1, TimeUnit.SECONDS);
// 注册JVM关闭钩子以优雅关闭线程池
Runtime.getRuntime().addShutdownHook(new Thread(this::shutdown));
}
/**
* 存入缓存
* @param key 键
* @param value 值
*/
public void set(String key, Object value){
cacheMap.put(key, new CacheEntry(value, -1));
}
/**
* 存入缓存
* @param key 键
* @param value 值
* @param expireTime 过期时间,单位毫秒
*/
public void set(String key, Object value, long expireTime) {
if (expireTime <= 0) {
throw new IllegalArgumentException("expireTime must be greater than 0");
}
cacheMap.put(key, new CacheEntry(value, System.currentTimeMillis() + expireTime));
}
/**
* 删除缓存
* @param key 键
*/
public void remove(String key) {
cacheMap.remove(key);
}
/**
* 缓存中是否包含键
* @param key 键
*/
public boolean containsKey(String key) {
CacheEntry cacheEntry = cacheMap.get(key);
if (cacheEntry == null) {
return false;
}
if (cacheEntry.getExpireTime() < System.currentTimeMillis()) {
remove(key);
return false;
}
return true;
}
/**
*获取缓存值
* @param key 键
*/
public Object get(String key) {
CacheEntry cacheEntry = cacheMap.get(key);
if (cacheEntry == null) {
return null;
}
if (cacheEntry.getExpireTime() < System.currentTimeMillis()) {
cacheMap.remove(key);
return null;
}
return cacheEntry.getValue();
}
private static class CacheEntry {
private final Object value;
private final long expireTime;
public CacheEntry(Object value, long expireTime) {
this.value = value;
this.expireTime = expireTime;
}
public Object getValue() {
return value;
}
public long getExpireTime() {
return expireTime;
}
}
/**
* 定时清理过期条目
*/
private void cleanUp() {
Iterator<Map.Entry<String, CacheEntry>> iterator = cacheMap.entrySet().iterator();
long currentTime = System.currentTimeMillis();
while (iterator.hasNext()) {
Map.Entry<String, CacheEntry> entry = iterator.next();
CacheEntry cacheEntry = entry.getValue();
if (cacheEntry.expireTime < currentTime) {
// 使用iterator移除当前条目,避免ConcurrentModificationException
iterator.remove();
}
}
}
/**
* 关闭线程池释放资源
*/
private void shutdown() {
scheduledExecutorService.shutdown();
try {
if (!scheduledExecutorService.awaitTermination(5, TimeUnit.SECONDS)) {
scheduledExecutorService.shutdownNow();
}
} catch (InterruptedException e) {
scheduledExecutorService.shutdownNow();
Thread.currentThread().interrupt();
}
}
}
测试

如上图,缓存中放入一个值,过期时间为5秒,每秒循环获取1次,循环10次,过期后,获取的值为null
来源:juejin.cn/post/7496335321781829642
svg按钮渐变边框
共用css
body {
padding: 50px;
background-color: black;
color: white;
}
svg {
--text_fill: orange;
--svg_width: 120px;
--svg_height: 40px;
width: var(--svg_width);
height: var(--svg_height);
cursor: pointer;
/* 创建图层 */
will-change: transform;
&:hover {
--text_fill: #fed71a;
}
text {
fill: var(--text_fill);
font-size: 1rem;
transform: translate(50%, 50%);
text-anchor: middle;
dominant-baseline: middle;
stroke: yellowgreen;
stroke-width: .5px;
cursor: pointer;
}
rect {
--stroke_width: 4px;
width: calc(var(--svg_width) - var(--stroke_width));
height: calc(var(--svg_height) - var(--stroke_width));
stroke-width: var(--stroke_width);
rx: calc(var(--svg_height)/2);
x: calc(var(--stroke_width)/2);
y: calc(var(--stroke_width)/2);
fill: none;
cursor: pointer;
}
}
移入执行、移出暂停
<body>
<svg style='position:absolute;left:-9999px;width:0;height:0;visibility:hidden;'>
<defs>
<linearGradient id='strokeColor1' x1='0%' y1='0%' x2='100%' y2='0%'>
<stop offset='0%' stop-color="#00ccff" stop-opacity="1" />
<stop offset='50%' stop-color="#d400d4" stop-opacity="1" />
<stop offset='100%' stop-color="#ff00ff" stop-opacity=".7" />
</linearGradient>
</defs>
</svg>
<svg id="svg1">
<text>渐变按钮</text>
<rect stroke='url(#strokeColor1)' />
<animateTransform id="ani1" href="#strokeColor1" attributeName='gradientTransform' dur='5s' type="rotate"
form="0,.5,.5" to="360,.5,.5" repeatCount='indefinite' begin="indefinite" />
</svg>
</body>
<script>
svg1.addEventListener('mouseover', function () {
if (!this.beginMark) {
ani1.beginElement();
this.beginMark = true;
return;
}
this.unpauseAnimations();
})
svg1.addEventListener('mouseleave', function () {
this.pauseAnimations();
})
</script>
svg1效果图

移入暂停、移出执行
<body>
<svg style='position:absolute;left:-9999px;width:0;height:0;visibility:hidden;'>
<defs>
<linearGradient id='strokeColor2' x1='0%' y1='0%' x2='100%' y2='0%'>
<stop offset='0%' stop-color="#ec261b" />
<stop offset='50%' stop-color="#ff9f43" />
<stop offset='100%' stop-color="#ffe66d" stop-opacity="1" />
</linearGradient>
</defs>
</svg>
<svg id="svg2">
<text>渐变按钮</text>
<rect stroke='url(#strokeColor2)' />
<animateTransform id="ani2" href="#strokeColor2" attributeName='gradientTransform' dur='5s' type="rotate"
form="0,.5,.5" to="360,.5,.5" repeatCount='indefinite' begin="0s" />
</svg>
</body>
<script>
svg2.addEventListener('mouseover', function () {
this.pauseAnimations();
})
svg2.addEventListener('mouseleave', function () {
this.unpauseAnimations();
})
</script>
sv2效果图

总结
个人感觉svg实现渐变边框相比较css的实现来说,相对代码量更大一些,但是svg其实还有很多好玩的地方。
用svg来做渐变边框也是另外的一种思路,也许以后能够用的上。
来源:juejin.cn/post/7488575555048161332
Python之 sorted() 函数的基本语法
sorted() 函数的基本语法
sorted(iterable, key=, reverse=False)
- iterable: 要排序的可迭代对象(列表、元组、字符串等)
- key: 可选,指定排序的依据函数
- reverse: 可选,True 为降序,False 为升序(默认)
基本用法
简单排序
# 数字排序
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
print(sorted(numbers))
# 输出: [1, 1, 2, 3, 4, 5, 6, 9]
# 字符串排序
names = ['Alice', 'Bob', 'Charlie', 'David']
print(sorted(names))
# 输出: ['Alice', 'Bob', 'Charlie', 'David']
# 字符排序
chars = ['z', 'a', 'x', 'b']
print(sorted(chars))
# 输出: ['a', 'b', 'x', 'z']
降序排序
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
print(sorted(numbers, reverse=True)) # 输出: [9, 6, 5, 4, 3, 2, 1, 1]
示例解析
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
for passport in sorted(traveler_ids):
print('%s/%s' % passport)
# 输出:
# BRA/CE342567
# ESP/XDA205856
# USA/31195855
解析: 对于元组列表,sorted() 默认按第一个元素排序,如果第一个元素相同,则按第二个元素排序,以此类推。
使用 key 参数进行自定义排序
按字符串长度排序
words = ['python', 'java', 'javascript', 'go', 'rust']
print(sorted(words, key=len))
# 输出: ['go', 'java', 'rust', 'python', 'javascript']
按照绝对值排序
numbers = [-5, -1, 0, 1, 3, -2]
print(sorted(numbers, key=abs))
# 输出: [0, -1, 1, -2, 3, -5]
按照元祖的特定循序排序
# 按第二个元素排序
students = [('Alice', 85), ('Bob', 92), ('Charlie', 78)]
print(sorted(students, key=lambda x: x[1])) # 输出: [('Charlie', 78), ('Alice', 85), ('Bob', 92)]
# 按第一个元素的长度排序
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
print(sorted(traveler_ids, key=lambda x: len(x[0]))) # 输出: [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
复杂排序示例
多级排序
# 先按年龄排序,年龄相同时按姓名排序
people = [
('Alice', 25, 'Engineer'),
('Bob', 30, 'Doctor'),
('Charlie', 25, 'Teacher'),
('David', 30, 'Engineer')
]
# 按年龄升序,然后按姓名升序
sorted_people = sorted(people, key=lambda x: (x[1], x[0]))
print(sorted_people)
# 输出: [('Alice', 25, 'Engineer'), ('Charlie', 25, 'Teacher'), ('Bob', 30, 'Doctor'), ('David', 30, 'Engineer')]
字符串忽略大小写排序
names = ['alice', 'Bob', 'CHARLIE', 'david']
print(sorted(names))
# 输出: ['CHARLIE', 'Bob', 'alice', 'david'] (按ASCII码)
print(sorted(names, key=str.lower))
# 输出: ['alice', 'Bob', 'CHARLIE', 'david'] (忽略大小写)
自定义排序规则
def custom_sort_key(item):
"""自定义排序:数字优先,然后按字母顺序"""
if item.isdigit():
return (0, int(item)) # 数字类型,按数值排序
else:
return (1, item.lower()) # 字母类型,按字母顺序
data = ['z', '10', 'a', '2', 'B', '1']
print(sorted(data, key=custom_sort_key)) # 输出: ['1', '2', '10', 'a', 'B', 'z']
排序复杂数据结构
字典列表排序
students = [
{'name': 'Alice', 'grade': 85, 'age': 20},
{'name': 'Bob', 'grade': 92, 'age': 19},
{'name': 'Charlie', 'grade': 78, 'age': 21}
]
# 按成绩排序
print(sorted(students, key=lambda x: x['grade']))
# 按年龄排序
print(sorted(students, key=lambda x: x['age']))
# 按姓名排序
print(sorted(students, key=lambda x: x['name']))
使用 operator 模块
from operator import itemgetter, attrgetter
# 对字典列表排序
students = [
{'name': 'Alice', 'grade': 85},
{'name': 'Bob', 'grade': 92},
{'name': 'Charlie', 'grade': 78}
]
# 使用 itemgetter 替代 lambda
print(sorted(students, key=itemgetter('grade')))
# 等同于: sorted(students, key=lambda x: x['grade'])
# 多字段排序
print(sorted(students, key=itemgetter('grade', 'name')))
来源:juejin.cn/post/7522863398243549234
解决 Python requests.post() 返回 406 错误
解决 Python requests.post() 返回 406 错误
HTTP 406 "Not Acceptable" 错误表示服务器无法生成符合客户端请求中 Accept 头部指定的响应内容。
问题分析,最好的方法还是一段代码一段代码的调试
今天是模型一个登录的脚本,以前都用得好好的,现在突然不行了,出现了406的错误,觉得有点奇怪,代码如下:
header = {'Content-Type':'application/x-www-form-urlencoded',
'User-Agent':'Mozilla/5.0 (Macint0sh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36'
form_data = {
"actionFlag":"login",
"uid":"xxxxx",
"password":"xxxxx"
}
data = parse.urlencode(from_data)
response = request.post(url=login_url,header=header, data = data, verify=False)
以前上面这段代码是没有什么问题的,但最近才发现一直是406,跟踪到代码中的
sessions.py中adapter的值是对的,上面是显示访问成功而且返回值是200,这说明访问代码是没有问题的,但什么时候出的问题呢?继续往下

发现了这一段代码,其中allow_redirects的值就有点意思了,这个值的默认值是Ture,但我们登录后,后面肯定有一个redirect的,也就是说后面那个跳转的地址有问题了,所以才会导致出问题

所以只需要将这个参数设计为false就正常了
allow_redirects=False
下面是我解决问题时用deepseek查问题时,出现的一些总结,也不能说它全部不对,但也是由于这个让我有了一些思路,所以放上来,大家参考一下也是好了。
常见原因及解决方案
1. 请求头 (headers) 问题
确保你的请求头中包含正确的 Accept 和 Content-Type:
python
headers = {
'Accept': 'application/json', # 或其他服务器期望的类型
'Content-Type': 'application/json', # 或其他适当的内容类型
# 其他必要的头部,如授权信息
}
2. 数据格式问题
确保发送的数据格式与 Content-Type 头部匹配:
python
import json
data = {'key': 'value'}
response = requests.post(url, data=json.dumps(data), headers=headers)
或者使用 json 参数自动处理:
python
response = requests.post(url, json=data, headers=headers)
3. 用户代理问题
有些服务器要求特定的 User-Agent:
python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ...',
# 其他头部
}
4. 认证问题
如果 API 需要认证,确保提供了正确的凭证:
python
headers = {
'Authorization': 'Bearer your_token_here',
# 其他头部
}
5. 服务器端限制
检查 API 文档,确认:
- 是否支持 POST 方法
- 是否接受你发送的内容类型
- 是否有其他特殊要求
完整示例
python
import requests
import json
url = 'https://api.example.com/endpoint'
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json',
'User-Agent': 'MyApp/1.0',
'Authorization': 'Bearer abc123...'
}
data = {'key1': 'value1', 'key2': 'value2'}
try:
response = requests.post(url, json=data, headers=headers)
response.raise_for_status() # 如果响应状态码不是200,抛出异常
print(response.json())
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
如果问题仍然存在,建议:
- 检查 API 文档的具体要求
- 使用开发者工具查看浏览器发送的成功请求的格式
- 联系 API 提供商获取支持
来源:juejin.cn/post/7522002830929379368
Java String.replace()原理,你真的了解吗?
大家好呀,我是猿java。
String.replace()是我们日常开发中经常用到的一个方法,那么,你有看过其底层的源码实现吗?你知道String.replace()是如何工作的吗?String.replace()的性能到底怎么样?这篇文章我们来深入地分析。
在开始今天的问题之前,让我们先来看一个问题:
String original = "Hello, World!";
// 替换字符
String result = original.replace('World', 'Java');
original.replace('World', 'Java'),是把 original的内容直接修改成Hello, Java了,还是重新生成了一个 Hello, Java的 String并返回?
1. String.replace()是什么?
String.replace()位于java.lang包中,它是 Java中的一个重要方法,用于替换字符串中的某些字符或子字符串。以下String.replace()的源码截图。

String.replace()方法用于替换字符串中的某些字符或子字符串。它有多个重载版本,常见的有:
// 用于替换单个字符
public String replace(char oldChar, char newChar);
// 用于替换子字符串
public String replace(CharSequence target, CharSequence replacement);
下面是一个简单的示例,演示了replace方法的用法:
public class ReplaceExample {
public static void main(String[] args) {
String original = "Hello, World!";
// 替换字符
String replacedChar = original.replace('o', 'a');
System.out.println(replacedChar); // 输出: "Hella, Warld!"
// 替换子字符串
String replacedString = original.replace("World", "Java");
System.out.println(replacedString); // 输出: "Hello, Java!"
}
}
在上面的例子中,我们演示了如何使用replace方法替换字符和子字符串。需要注意的是,String对象在Java中是不可变的(immutable),因此replace方法会返回一个新的字符串,而不会修改原有字符串。
2. 源码分析
上述示例,我们演示了replace方法的用法,接下来,我们来分析下replace方法的实现原理。
2.1 String的不可变性
Java中的String类是不可变的,这意味着一旦创建了一个String对象,其内容不能被改变。这样的设计有助于提高性能和安全性,尤其在多线程环境下。String源码说明如下:

2.2 replace()工作原理
让我们深入了解replace方法的内部实现。以replace(CharSequence target, CharSequence replacement)为例,以下是其基本流程:
- 检查目标和替换内容:方法首先检查传入的
target和replacement是否为null,如果是,则抛出NullPointerException。 - 搜索目标子字符串:在原始字符串中查找所有符合目标子字符串的地方。
- 构建新的字符串:基于找到的位置,将原始字符串分割,并用替换字符串进行拼接,生成一个新的字符串。
2.3 源码解析
让我们看一下String类中replace方法的源码(简化版):
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
String ret = isLatin1() ? StringLatin1.replace(value, oldChar, newChar)
: StringUTF16.replace(value, oldChar, newChar);
if (ret != null) {
return ret;
}
}
return this;
}
public String replace(CharSequence target, CharSequence replacement) {
String tgtStr = target.toString();
String replStr = replacement.toString();
int j = indexOf(tgtStr);
if (j < 0) {
return this;
}
int tgtLen = tgtStr.length();
int tgtLen1 = Math.max(tgtLen, 1);
int thisLen = length();
int newLenHint = thisLen - tgtLen + replStr.length();
if (newLenHint < 0) {
throw new OutOfMemoryError();
}
StringBuilder sb = new StringBuilder(newLenHint);
int i = 0;
do {
sb.append(this, i, j).append(replStr);
i = j + tgtLen;
} while (j < thisLen && (j = indexOf(tgtStr, j + tgtLen1)) > 0);
return sb.append(this, i, thisLen).toString();
}
解析步骤
- 参数校验:首先检查
target和replacement是否为null,避免后续操作出现NullPointerException。 - 查找目标字符串:使用
indexOf方法查找目标子字符串首次出现的位置。如果未找到,直接返回原字符串。 - 替换逻辑:
- 使用
StringBuilder来构建新的字符串,这是因为StringBuilder在拼接字符串时效率更高。 - 通过循环查找所有目标子字符串的位置,并将其替换为替换字符串。
- 最后,拼接剩余的字符串部分,返回最终结果。
- 使用
性能考虑
由于String的不可变性,每次修改都会创建新的String对象。如果需要进行大量的字符串替换操作,推荐使用StringBuilder或StringBuffer来提高性能。
三、实际示例演示
接下来,我们将通过几个实际的例子,来更好地理解String.replace()的使用场景和效果。
示例1:替换字符
public class ReplaceCharDemo {
public static void main(String[] args) {
String text = "banana";
String result = text.replace('a', 'o');
System.out.println(result); // 输出: "bonono"
}
}
解释:将所有的'a'替换为'o',得到"bonono"。
示例2:替换子字符串
public class ReplaceStringDemo {
public static void main(String[] args) {
String text = "I love Java. Java is versatile.";
String result = text.replace("Java", "Python");
System.out.println(result); // 输出: "I love Python. Python is versatile."
}
}
解释:将所有的"Java"替换为"Python",结果如上所示。
示例3:替换多个不同的子字符串
有时,我们可能需要在一个字符串中替换多个不同的子字符串。例如,将文中的标点符号替换为空格:
public class ReplaceMultipleDemo {
public static void main(String[] args) {
String text = "Hello, World! Welcome to Java.";
String result = text.replace(",", " ")
.replace("!", " ")
.replace(".", " ");
System.out.println(result); // 输出: "Hello World Welcome to Java "
}
}
解释:通过链式调用replace方法,依次将,、!和.替换为空格。
示例4:替换不匹配的情况
public class ReplaceNoMatchDemo {
public static void main(String[] args) {
String text = "Hello, World!";
String result = text.replace("Python", "Java");
System.out.println(result); // 输出: "Hello, World!"
}
}
解释:由于"Python"在原字符串中不存在,replace方法不会做任何替换,直接返回原字符串。
四、String.replace()的技术架构图
虽然文字描述已能帮助我们理解replace方法的工作原理,但通过一个简化的技术架构图,可以更直观地抓住其核心流程。
+---------------------------+
| String对象 |
| "Hello, World!" |
+------------+--------------+
|
| 调用replace("World", "Java")
v
+---------------------------+
| 搜索目标子字符串 "World" |
+------------+--------------+
|
| 找到位置 7
v
+---------------------------+
| 构建新的字符串 "Hello, Java!" |
+---------------------------+
|
| 返回新字符串
v
+---------------------------+
| 新的 String对象 |
| "Hello, Java!" |
+---------------------------+
图解说明
- 调用
replace方法:在原始String对象上调用replace("World", "Java")。 - 搜索目标:方法内部使用
indexOf找到"World"的位置。 - 构建新字符串:使用
StringBuilder将"Hello, "与"Java"拼接,形成新的字符串"Hello, Java!"。 - 返回新字符串:最终返回一个新的
String对象,原始字符串保持不变。
五、总结
通过本文的介绍,相信你对Java中String.replace()方法有了更深入的理解。从基本用法到内部原理,再到实际应用示例,每一步都帮助你全面掌握这个重要的方法。
记住,String的不可变性设计虽然带来了安全性和线程安全性,但在频繁修改字符串时,可能影响性能。因此,合理选择使用String还是StringBuilder,根据具体场景优化代码,是每个Java开发者需要掌握的技能。
希望这篇文章能对你在Java编程的道路上提供帮助。如果有任何疑问或更多的讨论,欢迎在评论区留言!
8. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7543147533368229903
一万行代码实现的多维分析表格,让数据处理效率提升 300%
上个月在 趣谈AI 发布了我实现的多维表格1.0版本,没有用到任何第三方组件,完全组件化设计。最近对多维表格进行了进一步的升级优化,满打满算花了接近3个月时间,累计代码接近1w行。

接下来就和大家聊聊我做的 flowmix/mute多维表格 的核心功能和技术实现。
核心功能介绍
1. 多视图模式

目前多维表格支持多种视图模式:表格视图,看板视图,人员分配视图。用户可以轻松在不同视图下切换并进行可视化操作数据。
2. 多条件筛选功能

我们可以基于不同维度进行筛选和排序,并支持组合筛选。
3. 多维度分组功能

表格视图中,我们可以基于用户,优先级,状态,对数据进行分组管理,提高表格数据的查看效率。
4. 表格字段管理功能

多维表格中不仅支持字段的管理控制,同时还支持添加自定义字段:

5. 表格行列支持自定义拖拽排序功能

表格我们不仅仅支持列的宽度拖拽,还支持拖拽调整列的排序,同时表格的行也支持拖拽,可以跨分组进行拖拽,也支持在组内进行拖拽排序,极大的提高了数据管理的效率。
6. 表格支持一键编辑

我们可以在菜单按钮中开启编辑模式,也可以双击编辑单元格一键编辑表格内容,同时大家还可以进行扩展。
7. 表格支持一键转换为可视化分析视图表

我们可以将表格数据转换为可视化分析图表,帮助管理者更好地掌握数据动向。
8. 表格支持一键导入任务数据

目前多维表格支持导出和导入json数据,并一键渲染为多维表格。技术实现多维表格的设计我采用了组件化的实现的方式, 并支持数据持久化,具体使用如下:
<div className="flex-1 bg-gray-50">
{currentView === "tasks" && <TaskManagementTable sidebarOpen={sidebarOpen} setSidebarOpen={setSidebarOpen} />}
{currentView === "statistics" && <StatisticsView />}
{currentView === "documentation" && <DocumentationView />}
{currentView === "assignment" && <AssignmentView />}
{currentView === "deployment" && <DeploymentView />}
</div>
在开发多维表格的过程中其实需要考虑很多复杂逻辑,比如表格用什么方式渲染,如何优化表格性能,如何实现表格的列排序,行排序,表格编辑等。传统表格组件大多基于div模拟行列,虽然灵活但渲染性能差。所以可以做如下优化:
- 虚拟滚动当数据量超过 500 行时,启用虚拟滚动机制,仅渲染可见区域的 DOM 节点,内存占用降低 70%;
- 行列冻结通过固定定位
position: sticky实现表头和固定列冻结,解决大数据表格的滚动迷失问题; - 异步加载采用
Intersection Observer监听表格滚动事件,动态加载可视区域外的数据,避免一次性请求全量数据。
接下来分享一下简版的虚拟滚动的实现方案:
// 虚拟滚动核心代码(简化版)
function renderVirtualTable(data, visibleHeight) {
const totalRows = data.length;
const rowHeight = 40; // 行高固定
const visibleRows = Math.ceil(visibleHeight / rowHeight);
const startIndex = scrollTop / rowHeight | 0;
const endIndex = startIndex + visibleRows;
// 渲染可见区域数据
const fragment = document.createDocumentFragment();
for (let i = startIndex; i < endIndex; i++) {
const row = document.createElement('tr');
row.innerHTML = data[i].cells.map(cell => `<td>${cell.value}</td>`).join('');
fragment.appendChild(row);
}
// 更新滚动条高度和偏移量
table.scrollHeight = totalRows * rowHeight;
table.innerHTML = `<thead>${header}</thead><tbody>${fragment}</tbody>`;
}
对于大表格数据量需要在本地缓存,所以需要设计表格数据的缓存处理逻辑,目前我采用的是hooks的实现方案,具体实现如下:
import { useState, useEffect } from "react"
export function useLocalStorage<T>(key: string, initialValue: T): [T, (value: T | ((val: T) => T)) => void] {
// 初始化状态
const [storedValue, setStoredValue] = useState<T>(() => {
try {
// 获取本地存储中的值
if (typeof window === "undefined") {
return initialValue
}
const item = window.localStorage.getItem(key)
// 解析存储的JSON或返回初始值
return item ? JSON.parse(item) : initialValue
} catch (error) {
// 如果出错,返回初始值
console.error(`Error reading localStorage key "${key}":`, error)
return initialValue
}
})
// 返回一个包装版本的 useState setter 函数
// 将新值同步到 localStorage
const setValue = (value: T | ((val: T) => T)) => {
try {
// 允许值是一个函数
const valueToStore = value instanceof Function ? value(storedValue) : value
// 保存到 state
setStoredValue(valueToStore)
// 保存到 localStorage
if (typeof window !== "undefined") {
window.localStorage.setItem(key, JSON.stringify(valueToStore))
}
} catch (error) {
console.error(`Error setting localStorage key "${key}":`, error)
}
}
// 监听其他标签页的变化
useEffect(() => {
const handleStorageChange = (e: StorageEvent) => {
if (e.key === key && e.newValue) {
try {
setStoredValue(JSON.parse(e.newValue))
} catch (error) {
console.error(`Error parsing localStorage item "${key}":`, error)
}
}
}
// 添加事件监听器
if (typeof window !== "undefined") {
window.addEventListener("storage", handleStorageChange)
}
// 清理事件监听器
return () => {
if (typeof window !== "undefined") {
window.removeEventListener("storage", handleStorageChange)
}
}
}, [key])
return [storedValue, setValue]
}
其实在实现多维表格的过程中,我也调研了很多开源的方案,但是对于扩展性,灵活度和功能复杂度上,都略显简单,所以我才考虑花时间来实现这款多维表格方案。另一个比较复杂的逻辑是表格的列拖拽和排序,我们需要对可展开折叠的表格支持排序和拖拽,并保持优秀的用户体验:

技术实现如下:
import { useState, useEffect } from "react"
export function useLocalStorage<T>(key: string, initialValue: T): [T, (value: T | ((val: T) => T)) => void] {
// 初始化状态
const [storedValue, setStoredValue] = useState<T>(() => {
try {
// 获取本地存储中的值
if (typeof window === "undefined") {
return initialValue
}
const item = window.localStorage.getItem(key)
// 解析存储的JSON或返回初始值
return item ? JSON.parse(item) : initialValue
} catch (error) {
// 如果出错,返回初始值
console.error(`Error reading localStorage key "${key}":`, error)
return initialValue
}
})
// 返回一个包装版本的 useState setter 函数
// 将新值同步到 localStorage
const setValue = (value: T | ((val: T) => T)) => {
try {
// 允许值是一个函数
const valueToStore = value instanceof Function ? value(storedValue) : value
// 保存到 state
setStoredValue(valueToStore)
// 保存到 localStorage
if (typeof window !== "undefined") {
window.localStorage.setItem(key, JSON.stringify(valueToStore))
}
} catch (error) {
console.error(`Error setting localStorage key "${key}":`, error)
}
}
// 监听其他标签页的变化
useEffect(() => {
const handleStorageChange = (e: StorageEvent) => {
if (e.key === key && e.newValue) {
try {
setStoredValue(JSON.parse(e.newValue))
} catch (error) {
console.error(`Error parsing localStorage item "${key}":`, error)
}
}
}
// 添加事件监听器
if (typeof window !== "undefined") {
window.addEventListener("storage", handleStorageChange)
}
// 清理事件监听器
return () => {
if (typeof window !== "undefined") {
window.removeEventListener("storage", handleStorageChange)
}
}
}, [key])
return [storedValue, setValue]
}
多维表格还支持多种视图的转换,比如可以将表格视图一键转换为可视化分析图表:

对用户和团队进行多维度的数据分析。技术实现如下:
import { PieChart, Pie, Cell, Tooltip, Legend, ResponsiveContainer } from "recharts"
import type { Task } from "@/lib/types"
interface PriorityDistributionChartProps {
tasks: Task[]
}
export function PriorityDistributionChart({ tasks }: PriorityDistributionChartProps) {
// 计算每个优先级的任务数量
const priorityCounts: Record<string, number> = {}
tasks.forEach((task) => {
const priority = task.priority || "未设置"
priorityCounts[priority] = (priorityCounts[priority] || 0) + 1
})
// 转换为图表数据格式
const chartData = Object.entries(priorityCounts).map(([priority, count]) => ({
priority,
count,
}))
// 为不同优先级设置不同颜色
const COLORS = ["#FF8042", "#FFBB28", "#00C49F", "#0088FE"]
return (
<div className="w-full h-[300px]">
<ResponsiveContainer width="100%" height="100%">
<PieChart>
<Pie
data={chartData}
cx="50%"
cy="50%"
labelLine={true}
outerRadius={80}
fill="#8884d8"
dataKey="count"
nameKey="priority"
label={({ priority, percent }) => `${priority}: ${(percent * 100).toFixed(0)}%`}
>
{chartData.map((entry, index) => (
<Cell key={`cell-${index}`} fill={COLORS[index % COLORS.length]} />
))}
</Pie>
<Tooltip formatter={(value, name, props) => [`${value} 个任务`, props.payload.priority]} />
<Legend />
</PieChart>
</ResponsiveContainer>
</div>
)
}
项目的体验地址:mute.turntip.cn
如果大家有好的想法,欢迎评论区留言反馈~
来源:juejin.cn/post/7511649092658577448
使用watchtower更新docker容器
更新方式
定时更新(默认)
执行以下命令后,Watchtower 会在后台每 24 小时自动检查并更新所有运行中的容器:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower
手动立即更新
添加 --run-once 参数启动临时容器,检查更新后自动退出,适合按需触发:
docker run --rm \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower --run-once
更新指定容器
在命令末尾添加需要监控的容器名称,多个容器用空格分隔。例如仅监控 nginx 和 redis 容器:
docker run -d \
--name watchtower \
-v /var/run/docker.sock:/var/run/docker.sock \
containrrr/watchtower nginx redis
简化命令
手动更新时,如果使用上面的命令未免太麻烦了,所以我们可以将更新命令设置为别名:
将下面的命令放到对应shell的环境文件中(比如bash对应~/.bashrc,zsh对应~/.zshrc)
alias update-container="docker run --rm -v /var/run/docker.sock:/var/run/docker.sock containrrr/watchtower --run-once"
编辑完环境文件后,重新打开命令窗口,或使用source ~/.bashrc或source ~/.zshrc加载命令。
然后就可以通过下面的方式更新容器了:
update-container 容器标识
比如:
update-container nginx-ui-latest

来源:juejin.cn/post/7541682368329170954
用了bun之后,是不是就不用vite了
用了 Bun 之后,并不是完全不用 Vite。Bun 虽然内置了打包器和运行时,且速度非常快,但其打包功能目前还不够完善,缺少对前端项目非常重要的功能,比如对代码分块(chunk splitting)的精细控制和开发服务器(dev server)支持,这些都是 Vite 在前端开发中非常关键的优势
具体来说:
- Bun 是一个高性能的 JavaScript 运行时和包管理器,集成了打包器和测试工具,适合全栈开发和快速安装依赖,但其前端打包功能还处于实验阶段,缺少灵活的代码拆分和热更新支持
- Vite 专注于前端开发体验,提供极快的冷启动和热模块替换(HMR),以及灵活且成熟的生产构建流程,它的生态和插件系统也非常丰富,适合现代前端框架(如 Vue3、React)
- 目前推荐的做法是用 Bun 替代 Node.js 作为运行时和包管理器,用 Vite 负责前端的开发服务器和构建打包。这样可以结合 Bun 的高速安装和执行优势,以及 Vite 的快速开发反馈和优化生产构建的能力
关于 pnpm 和 Vite 的叠加:
- pnpm 是一个高效且节省磁盘空间的包管理器,完全可以和 Vite 一起使用。pnpm 通过内容寻址存储和符号链接机制,避免依赖重复,提升安装速度和项目管理效率,特别适合 monorepo 和多项目共享依赖的场景
- pnpm 和 Vite 的结合非常常见,pnpm 负责依赖管理,Vite 负责开发和构建,两者互不冲突,反而能互补提升开发效率
总结:
| 工具 | 作用定位 | 是否可以替代 Vite? | 是否能和 pnpm 叠加? | 主要好处 |
|---|---|---|---|---|
| Bun | JS 运行时+包管理+打包+测试 | 目前不能完全替代 Vite | 可以,pnpm 和 Bun 都是包管理器,选择一个即可 | 速度极快,集成度高,适合全栈开发 |
| Vite | 前端开发服务器+构建工具 | 不能被 Bun 完全替代 | 完全兼容 pnpm | 快速热更新,灵活构建,生态丰富 |
| pnpm | 高效包管理器 | 和 Vite 不冲突,负责依赖管理 | 本身是包管理器,不和 Vite 冲突 | 节省磁盘空间,安装快,依赖隔离 |
因此,用了 Bun 后,建议继续用 Vite 负责前端开发和构建,pnpm 依然可以用来管理依赖,三者结合能发挥各自优势,提升开发体验和性能
如果你想快速上手,可以用 Bun 创建 Vite 项目:
bun create vite my-app
cd my-app
bun install
bun run dev
这样就用 Bun 作为运行时和包管理器,用 Vite 作为开发服务器和构建工具
综上,Bun 目前还不能完全替代 Vite,Vite 在前端开发体验和构建优化上仍有不可替代的优势;pnpm 作为包管理器可以和 Vite 叠加使用,带来依赖管理的高效和节省空间的好处。三者结合是现代前端项目的一个高效组合方案。
用了next.js之后,是不是就不用vite了
用了 Next.js 之后,一般情况下是不需要再单独使用 Vite 了,因为 Next.js 内部已经集成了自己的构建和开发服务器功能。
具体原因和分析如下:
- Next.js 是一个基于 React 的全栈框架,内置了开发服务器(通过
next dev命令启动)、构建工具和打包器,它自动处理代码编译、热模块替换(HMR)、代码拆分和优化等工作,开发体验和构建性能都非常优秀 - Next.js 使用了基于 Rust 的编译器 SWC 来加速构建和转译,性能上已经非常接近甚至优于传统的打包工具
- Vite 主要是一个前端构建工具和开发服务器,适合纯前端项目或需要快速启动的 React/Vue 应用,而 Next.js 是一个框架,包含了路由、服务器端渲染(SSR)、静态站点生成(SSG)、API 路由等功能,功能层面更全面
- 使用 Next.js 时,所有的构建和开发流程都由 Next.js 自己管理,开发者无需额外配置 Vite,避免了工具链的重复和冲突。
- 如果你只是做纯前端项目,Vite 是很好的选择;但如果你需要 SSR、API 路由、全栈功能,Next.js 是更合适的框架,且内置了构建和开发支持,不需要再叠加 Vite。
总结:
| 工具 | 作用定位 | 是否需要同时使用 | 适用场景 |
|---|---|---|---|
| Next.js | React 全栈框架,含开发服务器和构建 | 不需要 | SSR、SSG、API 路由、全栈应用 |
| Vite | 前端开发服务器和构建工具 | 纯前端项目时使用 | 快速启动、热更新、纯前端 SPA |
因此,用了 Next.js 后,基本上不需要再用 Vite 了,Next.js 已经集成了类似 Vite 的开发和构建功能,且提供了更多全栈特性
来源:juejin.cn/post/7522080312564285486
记录App切后台时AppIcon变成默认雪花icon问题
xcode做新项目时,设置了app图标。发现点击app进入前台时,App Icon是正常的,但是回到桌面时App Icon又变成了默认的雪花图标。
之前也遇到过,但是不求甚解,在此列出解决方案。
问题1: AppIcon的设置
随便设置了个图片为app图标,编译报错xxx/Assets.xcassets: The stickers icon set or app icon set named "AppIcon" did not have any applicable content.
同时appIcon可视化窗口显示黄色⚠️图标。
Xcode 提示你在 Assets.xcassets 中名为 "AppIcon" 的 App 图标集合里没有提供任何有效的图片资源。
iOS 应用要求必须有完整的 AppIcon 集合,并且要包含适用于各种设备和分辨率的图标尺寸。如果没有正确设置这些图标,App 就无法通过 App Store 审核,甚至可能在某些模拟器或真机上运行异常。
我使用了makeappicon.com/ 生成appIcon图标。
网站生成的结果包含AppIcon.appiconset,直接把AppIcon.appiconset替换原项目中Assets中的appIcon即可。

结果如下

问题2: 切后台appIcon变成默认雪花icon
现在成功设置appIcon后,切后台时发现appIcon变成了默认的雪花icon。
原因是系统缓存了旧图标,iOS 系统有时会缓存应用的图标缩略图,尤其是多任务界面中的预览图。即使你更新了图标,也可能不会立即刷新。
解决办法: 卸载重装
现在能正常显示了

来源:juejin.cn/post/7520461940273184831
鸿蒙next 游戏授权登录教程王者归来
前沿导读
各位同学很久没有分享技术文章给大家了,因为最近需要兼职讲课,所以我比较忙。都也没有多少个人时间,所以也是趁着现在有空我们就分享下
效果图
调用效果

日志打印

需求背景
工作中最近接到需求,需要接入鸿蒙的游戏授权登录和内购支付,今天把流程走完整,所以现在就做一个分享
开发步骤

初始化
这里如果不是在 EntryAbility 接入初始化代码需要做调整
// 在EntryAbility 里面初始化
try {
gamePlayer.init(this.context,()=>{
hilog.info(0x0000, 'testTag', `Succeeded in initing.`);
});
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to init. Code: ${err.code}, message: ${err.message}`);
}
// 不在EntryAbility 里面执行初始化
try {
gamePlayer.init(context as common.UIAbilityContext ,()=>{
hilog.info(0x0000, 'testTag', `Succeeded in initing.`);
});
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to init. Code: ${err.code}, message: ${err.message}`);
}
获取 gamePlayerId
let context = getContext(this) as common.UIAbilityContext;
let request: gamePlayer.UnionLoginParam = {
showLoginDialog: false, // 是否弹出联合登录面板。true表示强制弹出面板,false表示优先使用玩家上一次的登录选择,不弹出联合登录面板,若玩家首次登录或卸载重装,则正常弹出。
thirdAccountInfos: [] // 若游戏无官包或无官方账号体系,请传空数组。
};
try {
gamePlayer.unionLogin(context, request).then((result: gamePlayer.UnionLoginResult) => {
hilog.info(0x0000, 'testTag', `Succeeded in logining: ${result?.accountName}`);
console.log("gamePlayerId accountName --- >" +result.accountName)
console.log("gamePlayerId thirdOpenId --- >" +result.boundPlayerInfo.thirdOpenId)
console.log("gamePlayerId bindType --- >" +result.boundPlayerInfo.bindType)
let localPlayer=result.localPlayer;
if(localPlayer.gamePlayerId){
console.log("index gamePlayerId localPlayer gamePlayerId --- >" +localPlayer.gamePlayerId)
}
if(localPlayer.teamPlayerId){
console.log("index gamePlayerId localPlayer teamPlayerId --- >" +localPlayer.teamPlayerId)
}
}).catch((error: BusinessError) => {
hilog.error(0x0000, 'testTag', `Failed to login. Code: ${error.code}, message: ${error.message}`);
});
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to login. Code: ${err.code}, message: ${err.message}`);
}
获取authorizationCode
let loginRequest = new authentication.HuaweiIDProvider().createLoginWithHuaweiIDRequest();
loginRequest.state = util.generateRandomUUID();
// 执行认证请求
try {
let controller = new authentication.AuthenticationController(getContext(this));
controller.executeRequest(loginRequest, (err, data) => {
if (err) {
hilog.error(0x0000, 'testTag', `Failed to login. Code: ${err.code}, message: ${err.message}`);
return;
}
let loginWithHuaweiIDResponse = data as authentication.LoginWithHuaweiIDResponse;
let state = loginWithHuaweiIDResponse.state;
console.log("index authorizationCode state ---> "+state)
if (state != undefined && loginRequest.state != state) {
hilog.error(0x0000, 'testTag', `Failed to login. State is different.`);
return;
}
hilog.info(0x0000, 'testTag', `Succeeded in logining.`);
let loginWithHuaweiIDCredential = loginWithHuaweiIDResponse.data!;
let authorizationCode = loginWithHuaweiIDCredential.authorizationCode;
console.log("index authorizationCode ---> "+authorizationCode)
// 开发者处理authorizationCode
});
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to login. Code: ${err.code}, message: ${err.message}`);
}
我们拿到了 gamePlayerId 和 authorizationCode 去请求服务端去获取
服务端流程

调用on接口注册playerChanged事件监听
aboutToAppear(): void {
// 调用on接口注册playerChanged事件监听
try {
gamePlayer.on('playerChanged', this.onPlayerChangedEventCallback);
hilog.info(0x0000, 'testTag', `Succeeded in registering.`);
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to register. Code: ${err.code}, message: ${err.message}`);
}
}
监听事件回调
private onPlayerChangedEventCallback(result: gamePlayer.PlayerChangedResult) {
if (result.event === gamePlayer.PlayerChangedEvent.SWITCH_GAME_ACCOUNT) {
// ...
// 游戏号已切换,完成本地缓存清理工作后,再次调用unionLogin接口等
}
}
提交玩家角色信息
let context = getContext(this) as common.UIAbilityContext;
let request: gamePlayer.GSKPlayerRole = {
roleId: '123', // 玩家角色ID,如游戏没有角色系统,请传入“0”,务必不要传""和null。
roleName: 'Jason', // 玩家角色名,如游戏没有角色系统,请传入“default”,务必不要传""和null。
serverId: '456',
serverName: 'Zhangshan',
gamePlayerId: '789', // 请根据实际获取到的gamePlayerId传值。
thirdOpenId: '123' // 接入华为账号登录时不传该字段。接入游戏官方账号登录时,请根据实际获取到的thirdOpenId传值。
};
try {
gamePlayer.savePlayerRole(context, request).then(() => {
hilog.info(0x0000, 'testTag', `Succeeded in saving.`);
});
} catch (error) {
let err = error as BusinessError;
hilog.error(0x0000, 'testTag', `Failed to save. Code: ${err.code}, message: ${err.message}`);
}
参数配置
我们需要在 添加如此下配置

"metadata": [
// 配置如下信息
{
"name": "client_id",
"value": "xxxxxxxxx"
// 华为Client ID 请替换成你自己的正式参数
},
{
"name": "app_id",
"value": "6917581951060909508"
// 华为APP ID 请替换成你自己的正式参数
}
],
"requestPermissions": [
{
"name": "ohos.permission.INTERNET"
},
],
配置手动签名测试


查看日志
写在最后
整个鸿蒙游戏授权登录相对比较简单,但是有一个槽点,就是获取 gamePlayerId 和 authorizationCode需要分开两个方法回调 。其实可以做成一个回调更简单,这个希望后期能完善, 服务端逻辑对比客户端来说,还是相对复杂一点点,不过对着文档也是很快能解决这次接入 华为技术支持也帮了不少忙,这个点赞, 对于鸿蒙生态的推广这块,华为确实下了决心,也非常积极的回应。希望鸿蒙越来越好,国产系统早日完善。我依然是你们最爱的徐老师。我们下一期再见。
来源:juejin.cn/post/7543421087759433738
H5 配合原生开发 App
JS 和 Android
- 原生调用 JS
4.4 版本之前
// mWebView = new WebView(this); //当前webview对象
// 通过loadUrl方法进行调用 参数通过字符串的方式传递
mWebView.loadUrl("javascript: 方法名('参数1,参数2...')");
//也可以在UI线程中运行
runOnUiThread(new Runnable() {
@Override
public void run() {
// 通过loadUrl方法进行调用 参数通过字符串的方式传递
mWebView.loadUrl("javascript: 方法名('参数1,参数2...')");
// 安卓中原生的弹框
Toast.makeText(Activity名.this, "调用方法...", Toast.LENGTH_SHORT).show();
}
});
4.4 版本之后
// 通过异步的方式执行js代码,并获取返回值
mWebView.evaluateJavascript("javascript: 方法名('参数1,参数2...')", new ValueCallback() {
@Override
// 这个方法会在执行完毕之后触发, 其中value就是js代码执行的返回值(如果有的话)
public void onReceiveValue(String value) {
}
});
- JS 调用Android
安卓配置:
// Android4.2版本以上,本地方法要加上注解@JavascriptInterface,否则无法使用
private Object getJSBridge(){
// 实例化新对象
Object insertObj = new Object(){
@JavascriptInterface
// 对象内部的方法1
public String foo(){
// 返回 字符串 foo
return "foo";
}
@JavascriptInterface
// 对象内部的方法2 需要接收一个参数
public String foo2(final String param){
// 返回字符串foo2拼接上传入的param
return "foo2:" + param;
}
};
// 返回实例化的对象
return insertObj;
}
// 获取webView的设置对象,方便后续修改
WebSettings webSettings = mWebView.getSettings();
// 设置Android允许JS脚本,必须要!!!
webSettings.setJavaScriptEnabled(true);
// 暴露一个叫做JSBridge的对象到webView的全局环境
mWebView.addJavascriptInterface(getJSBridge(), "JSBridge");
在 web 页面中调用
//调用方法一
window.JSBridge.foo(); //返回:'foo'
//调用方法二
window.JSBridge.foo2('test');//返回:'foo2:test'
- 原生调用 JS
4.4 版本之前
// mWebView = new WebView(this); //当前webview对象
// 通过loadUrl方法进行调用 参数通过字符串的方式传递
mWebView.loadUrl("javascript: 方法名('参数1,参数2...')");
//也可以在UI线程中运行
runOnUiThread(new Runnable() {
@Override
public void run() {
// 通过loadUrl方法进行调用 参数通过字符串的方式传递
mWebView.loadUrl("javascript: 方法名('参数1,参数2...')");
// 安卓中原生的弹框
Toast.makeText(Activity名.this, "调用方法...", Toast.LENGTH_SHORT).show();
}
});
4.4 版本之后
// 通过异步的方式执行js代码,并获取返回值
mWebView.evaluateJavascript("javascript: 方法名('参数1,参数2...')", new ValueCallback() {
@Override
// 这个方法会在执行完毕之后触发, 其中value就是js代码执行的返回值(如果有的话)
public void onReceiveValue(String value) {
}
});
- JS 调用Android
安卓配置:
// Android4.2版本以上,本地方法要加上注解@JavascriptInterface,否则无法使用
private Object getJSBridge(){
// 实例化新对象
Object insertObj = new Object(){
@JavascriptInterface
// 对象内部的方法1
public String foo(){
// 返回 字符串 foo
return "foo";
}
@JavascriptInterface
// 对象内部的方法2 需要接收一个参数
public String foo2(final String param){
// 返回字符串foo2拼接上传入的param
return "foo2:" + param;
}
};
// 返回实例化的对象
return insertObj;
}
// 获取webView的设置对象,方便后续修改
WebSettings webSettings = mWebView.getSettings();
// 设置Android允许JS脚本,必须要!!!
webSettings.setJavaScriptEnabled(true);
// 暴露一个叫做JSBridge的对象到webView的全局环境
mWebView.addJavascriptInterface(getJSBridge(), "JSBridge");
在 web 页面中调用
//调用方法一
window.JSBridge.foo(); //返回:'foo'
//调用方法二
window.JSBridge.foo2('test');//返回:'foo2:test'
JS 和 IOS
- 原生调用 JS
class ViewController: UIViewController, WKNavigationDelegate, WKScriptMessageHandler {
// 加载完毕会触发(类似于Vue的生命周期钩子)
func webView(_ webView: WKWebView, didFinish navigation: WKNavigation!) {
// 类似于console.log()
print("触发啦");
// wkWebView调用js代码,其中doSomething()会被当做js解析
webView.evaluateJavaScript("doSomething()");
}
}
- JS 调用 IOS
- JS 部分
window.webkit.messageHandlers.方法名.postMessage(数据)
- iOS 部分注册监听
wkWebView.configuration.userContentController.add(self, name: 方法名)
- iOS 部分遵守协议相关方法
func userContentController(_ userContentController: WKUserContentController, didReceive message: WKScriptMessage) {
// message.body 就是传递过来的数据
print("传来的数据为", message.body)
}
- 原生调用 JS
class ViewController: UIViewController, WKNavigationDelegate, WKScriptMessageHandler {
// 加载完毕会触发(类似于Vue的生命周期钩子)
func webView(_ webView: WKWebView, didFinish navigation: WKNavigation!) {
// 类似于console.log()
print("触发啦");
// wkWebView调用js代码,其中doSomething()会被当做js解析
webView.evaluateJavaScript("doSomething()");
}
}
- JS 调用 IOS
- JS 部分
window.webkit.messageHandlers.方法名.postMessage(数据)
- iOS 部分注册监听
wkWebView.configuration.userContentController.add(self, name: 方法名)
func userContentController(_ userContentController: WKUserContentController, didReceive message: WKScriptMessage) {
// message.body 就是传递过来的数据
print("传来的数据为", message.body)
}
url scheme(互通协议)
web 调用
class="ios" type="button" value="使用iframe加载url">
// 加载url 通过iframe 设置URL 目的是让ios拦截
function loadUrl(url) {
// 创建iframe
const iframe = document.createElement('iframe');
// 设置url
iframe.src = url;
// 设置尺寸(不希望他被看到)
iframe.style.height = 0;
iframe.style.width = 0;
// 添加到页面上
document.body.appendChild(iframe);
// 加载了url之后他就没用了
// 移除iframe
iframe.parentNode.removeChild(iframe);
}
document.querySelector('.ios').onclick = function () {
loadUrl('taobao://click');
}
IOS 监听
// 拦截url
func webView(_ webView: WKWebView, decidePolicyFor navigationAction: WKNavigationAction, decisionHandler: @escaping (WKNavigationActionPolicy) -> Void) {
// 获取url
let url = navigationAction.request.url?.absoluteString;
if(url=="taobao://click"){
print("调用系统功能");
decisionHandler(.cancel);
}else{
decisionHandler(.allow);
}
}
HyBridApp

- 开发框架
- 提供前端运行环境
- 实现前端和原生交互
- 封装原生功能,提供插件机制

加载优化
- 骨架屏
<style>
.shell .placeholder-block{
display: block;
height: 5em;
background: #ccc;
margin: 1em;
}
.novel {
height: 5em;
background-color: yellowgreen;
}
style>
head>
<body>
<div class="shell">
<div class="placeholder-block">div>
div>
body>
html>
<script>
setTimeout(()=>{
// 移除 占位dom元素
document.querySelector('.shell').innerHTML = ''
// 创建数据的dom元素 添加到页面上
let p = document.createElement('p')
p.innerHTML = '黑马程序员'
p.className = 'novel'
document.querySelector('.shell').appendChild(p)
},3000)
script>
<style>
.shell .placeholder-block{
display: block;
height: 5em;
background: #ccc;
margin: 1em;
}
.novel {
height: 5em;
background-color: yellowgreen;
}
style>
head>
<body>
<div class="shell">
<div class="placeholder-block">div>
div>
body>
html>
<script>
setTimeout(()=>{
// 移除 占位dom元素
document.querySelector('.shell').innerHTML = ''
// 创建数据的dom元素 添加到页面上
let p = document.createElement('p')
p.innerHTML = '黑马程序员'
p.className = 'novel'
document.querySelector('.shell').appendChild(p)
},3000)
script>
webview
import UIKit
import WebKit
class ViewController: UIViewController, WKNavigationDelegate {
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
// 创建webView
var webView = WKWebView(frame: self.view.bounds)
// 设置自己为WebView的代理
webView.navigationDelegate = self
// 添加到页面上
self.view.addSubview(webView)
// 创建URL对象
var url = URL(string: "https://www.baidu.com")
// 创建URLRequest对象
var request = URLRequest(url: url!)
// 加载URL
webView.load(request)
}
}
import UIKit
import WebKit
class ViewController: UIViewController, WKNavigationDelegate {
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
// 创建webView
var webView = WKWebView(frame: self.view.bounds)
// 设置自己为WebView的代理
webView.navigationDelegate = self
// 添加到页面上
self.view.addSubview(webView)
// 创建URL对象
var url = URL(string: "https://www.baidu.com")
// 创建URLRequest对象
var request = URLRequest(url: url!)
// 加载URL
webView.load(request)
}
}
JSBridge

- 设计思想
- JS 向原生发送消息
- 原生向 JS 发送消息
window.JSBridge = {
invoke: function(action, params, callback) {
// 生成唯一回调ID
const callbackId = 'cb_' + Date.now();
// 存储回调函数
window[callbackId] = callback;
// 构建标准化消息
const msg = {
action: action,
params: params || {},
callbackId: callbackId
};
// 根据平台调用不同原生桥
if (isIOS()) {
window.webkit.messageHandlers.nativeBridge.postMessage(JSON.stringify(msg));
} else if (isAndroid()) {
window.android.postMessage(JSON.stringify(msg));
}
},
// 原生调用此方法来回调结果
receiveMessage: function(msg) {
const { callbackId, result, error } = msg;
const callback = window[callbackId];
if (callback) {
if (error) {
callback(null, error); // 错误回调
} else {
callback(result, null); // 成功回调
}
// 执行后删除回调,避免内存泄漏
delete window[callbackId];
}
}
};
// 使用示例:调用原生相机
JSBridge.invoke('takePhoto', { quality: 'high' }, (result, error) => {
if (error) {
console.error('拍照失败:', error);
} else {
console.log('照片路径:', result.imagePath);
}
});
解释:
- 前端调用
JSBridge.invoke时:存储回调函数,生成唯一的callbackId(如cb_1725000000000),确保每个回调能被唯一识别;把回调函数挂载到window对象上(即window[callbackId] = 回调函数),相当于 “暂时存档”,避免函数被垃圾回收。 - 前端向原生发送 “带回调 ID 的消息”,然后根据平台(iOS/Android)把消息发给原生,此时原生收到的是 “操作指令 + 回调 ID”
- 原生执行操作(如调用相机),原生接收到消息后,解析出
action和params,执行对应的原生逻辑
- iOS:调用
UIImagePickerController(系统相机接口),按quality: 'high'配置拍照质量; - Android:调用
Camera或CameraX接口,同样按参数执行拍照。 这个阶段完全在原生环境(Objective-C/Swift 或 Java/Kotlin)中运行,与前端 JS 无关。
- 原生将 “结果 + 回调 ID” 回传给前端
原生执行完操作后(无论成功 / 失败),会构建一个 “结果消息”,包含:callbackId: 'cb_1725000000000'(必须和前端传过来的一致,才能找到对应的回调);result: { imagePath: '/var/mobile/.../photo.jpg' }(成功时的结果,如照片路径); 或error: '用户取消拍照'(失败时的错误信息)。
然后原生会主动调用前端 JSBridge 预留的 receiveMessage 方法,把 “结果消息” 传回去。
- 前端
receiveMessage执行回调函数
- 解析原生传过来的消息,提取
callbackId、result、error; - 通过
callbackId找到之前挂载在window上的回调函数(即window['cb_1725000000000']); - 执行回调函数:
- 成功:调用
callback(result, null)(如打印照片路径); - 失败:调用
callback(null, error)(如打印 “用户取消拍照”);
- 成功:调用
- 执行完后删除
window[callbackId],避免内存泄漏。
到这一步,回调函数才真正在前端 JS 环境中执行,完成整个跨端通信闭环。
来源:juejin.cn/post/7544077353371222067
JavaScript 数组扁平化全解析
JavaScript 数组扁平化全解析:从基础到进阶,深入理解 flat 与多种实现方式
在现代前端开发中,数组操作是日常编码中最常见的任务之一。而在处理复杂数据结构时,我们经常会遇到“嵌套数组”(即高维数组)的场景。例如,后端返回的数据结构可能是多层嵌套的,我们需要将其“拍平”为一维数组以便于渲染或进一步处理。这种将多层嵌套数组转换为单层数组的过程,就被称为 数组扁平化(Array Flattening)。
本文将带你全面了解 JavaScript 中数组扁平化的各种方法,包括原生 API 的使用、递归实现、reduce 高阶函数应用、利用 toString 和 split 的巧妙技巧,以及基于展开运算符的循环优化方案。我们将深入剖析每种方法的原理、优缺点和适用场景,帮助你构建完整的知识体系。
一、什么是数组扁平化?
数组扁平化,顾名思义,就是把一个嵌套多层的数组“压平”成一个只有一层的一维数组。例如:
const nestedArr = [1, [2, 3, [4, 5]], 6];
// 扁平化后应得到:
// [1, 2, 3, 4, 5, 6]
这个问题看似简单,但在实际项目中非常常见。比如你在处理树形菜单、评论回复结构、文件目录层级等数据时,都可能需要对嵌套数组进行扁平化处理。
二、使用原生 flat() 方法(推荐方式)
ES2019 引入了 Array.prototype.flat() 方法,使得数组扁平化变得极其简单和直观。
✅ 基本语法
arr.flat([depth])
depth:指定要展开的层数,默认为1。- 如果传入
Infinity,则无论嵌套多少层,都会被完全展开。
✅ 示例代码
const arr = [1, [2, 3, [1]]];
console.log(arr.flat()); // [1, 2, 3, [1]] → 只展开一层
console.log(arr.flat(2)); // [1, 2, 3, 1] → 展开两层
console.log(arr.flat(Infinity)); // [1, 2, 3, 1] → 完全展开
✅ 特点总结
- 简洁高效:一行代码解决问题。
- 兼容性良好:现代浏览器基本都支持(IE 不支持)。
- 可控制深度:灵活控制展开层级。
- 推荐用于生产环境:清晰、安全、性能好。
⚠️ 注意:
flat()不会改变原数组,而是返回一个新的扁平化数组。
三、递归实现:最经典的思路
如果你不能使用 flat()(比如兼容老版本浏览器),或者想深入理解其内部机制,那么递归是一个经典且直观的解决方案。
✅ 基础递归版本
function flatten(arr) {
let res = [];
for (let i = 0; i < arr.length; i++) {
if (Array.isArray(arr[i])) {
res = res.concat(flatten(arr[i])); // 递归处理子数组
} else {
res.push(arr[i]); // 非数组元素直接加入结果
}
}
return res;
}
// 测试
const arr = [1, [2, 3, [1]]];
console.log(flatten(arr)); // [1, 2, 3, 1]
✅ 分析
- 使用
for循环遍历每个元素。 - 判断是否为数组:是 → 递归调用;否 → 直接推入结果数组。
- 利用
concat合并递归结果。
✅ 缺点
- 每次
concat都会创建新数组,性能略低。 - 递归深度过大可能导致栈溢出(极端情况)。
四、使用 reduce + 递归:函数式编程风格
利用 reduce 可以写出更优雅、更具函数式风格的扁平化函数。
✅ 实现方式
function flatten(arr) {
return arr.reduce((pre, cur) => {
return pre.concat(Array.isArray(cur) ? flatten(cur) : cur);
}, []);
}
✅ 解析
reduce接收一个累加器pre和当前元素cur。- 如果
cur是数组,则递归调用flatten(cur),否则直接使用cur。 - 使用
concat将结果合并到pre中。
✅ 优点
- 代码简洁,逻辑清晰。
- 更符合函数式编程思想。
- 易于组合其他操作(如 map、filter)。
五、利用 toString() + split() 的“黑科技”技巧
这是一个非常巧妙但需要谨慎使用的技巧,适用于数组中只包含数字或字符串基本类型的情况。
✅ 实现原理
JavaScript 中,数组的 toString() 方法会递归地将每个元素转为字符串,并用逗号连接。
const arr = [1, [2, 3, [1]]];
console.log(arr.toString()); // "1,2,3,1"
我们可以利用这一点,先转成字符串,再用 split(',') 分割,最后通过 +item 转回数字。
✅ 实现代码
function flatten(arr) {
return arr.toString().split(',').map(item => +item);
}
// 测试
const arr = [1, [2, 3, [1]]];
console.log(flatten(arr)); // [1, 2, 3, 1]
✅ 优点
- 代码极短,实现“一行扁平化”。
- 性能较好(底层由引擎优化)。
✅ 缺点(⚠️ 重要)
- 仅适用于纯数字数组:如果数组中有字符串
"hello",+"hello"会变成NaN。 - 无法保留原始类型:所有元素都会被转为数字。
- 丢失
null、undefined、对象等复杂类型信息。
❗ 所以这个方法虽然巧妙,但不适合通用场景,仅作为面试中的“奇技淫巧”了解即可。
六、使用 while 循环 + concat + 展开运算符(性能优化版)
这种方法避免了递归调用,采用循环逐步“拍平”数组,适合处理深层嵌套且希望避免栈溢出的场景。
✅ 实现方式
function flatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
✅ 原理解析
arr.some(item => Array.isArray(item)):检查数组中是否还存在嵌套数组。...arr:展开数组的所有元素。[].concat(...arr):concat会对展开后的数组元素自动“拍平一层”。
🔍 举个例子:
[].concat(...[1, [2, 3, [1]]])
// 等价于
[].concat(1, [2, 3, [1]])
// → [1, 2, 3, [1]] → 拍平了一层
然后继续循环,直到没有嵌套为止。
✅ 优点
- 非递归,避免栈溢出。
- 逻辑清晰,易于理解。
- 性能较好,尤其适合中等深度嵌套。
✅ 缺点
- 每次
concat(...arr)都会创建新数组,内存开销较大。 - 对于极深嵌套,仍可能影响性能。
七、对比总结:各种方法的适用场景
| 方法 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
arr.flat(Infinity) | 简洁、标准、安全 | IE 不支持 | ✅ 生产环境首选 |
递归 + for | 逻辑清晰,易理解 | 性能一般,可能栈溢出 | 学习理解原理 |
reduce + 递归 | 函数式风格,优雅 | 同上 | 偏好函数式编程 |
toString + split | 代码短,性能好 | 类型受限,不通用 | 面试奇技淫巧 |
while + concat + ... | 非递归,避免栈溢出 | 内存占用高 | 深层嵌套处理 |
八、扩展思考:如何实现深度可控的扁平化?
有时候我们并不想完全拍平,而是只想展开指定层数。可以仿照 flat(depth) 实现一个通用函数:
function flattenDepth(arr, depth = 1) {
if (depth === 0) return arr.slice(); // 深度为0,直接返回副本
let result = [];
for (let item of arr) {
if (Array.isArray(item) && depth > 0) {
result.push(...flattenDepth(item, depth - 1));
} else {
result.push(item);
}
}
return result;
}
// 测试
const arr = [1, [2, 3, [4, 5, [6]]]];
console.log(flattenDepth(arr, 1)); // [1, 2, 3, [4, 5, [6]]]
console.log(flattenDepth(arr, 2)); // [1, 2, 3, 4, 5, [6]]
console.log(flattenDepth(arr, Infinity)); // [1, 2, 3, 4, 5, 6]
九、结语
📌 小贴士:如果你的项目需要兼容老旧浏览器,可以使用 Babel 转译 flat(),或手动引入 polyfill:
// Polyfill for Array.prototype.flat
if (!Array.prototype.flat) {
Array.prototype.flat = function(depth = 1) {
return this.reduce((acc, val) =>
Array.isArray(val) && depth > 0
? acc.concat(val.flat(depth - 1))
: acc.concat(val)
, []);
};
}
这样就能在任何环境中愉快地使用 flat() 了!
来源:juejin.cn/post/7543941409930625087
某些场景下CSS替代JS(现代CSS的深度实践指南)
某些场景下CSS替代JS(现代CSS的深度实践指南)
🧩 前端渲染核心机制解析
水合错误(Hydration Mismatch)深度解析
graph TD
A[客户端渲染CSR] --> B[服务端渲染SSR]
B --> C{水合过程 Hydration}
C -->|成功| D[交互式页面]
C -->|失败| E[水合错误]
E --> F[布局错乱]
E --> G[交互失效]
E --> H[控制台报错]
水合错误的本质:
在SSR框架(如Next.js)中,服务端生成的静态HTML与客户端React组件的初始状态不一致,导致React在"注水"过程中无法正确匹配DOM结构。
典型场景:
// Next.js组件 - 服务端渲染时获取时间
export default function Page({ serverTime }) {
// 问题点:客户端初始化时间与服务端不同
const [clientTime] = useState(Date.now());
return (
<div>
<p>服务端时间: {serverTime}</p>
<p>客户端时间: {clientTime}</p>
</div>
);
}
export async function getServerSideProps() {
return {
props: {
serverTime: Date.now() // 服务端生成时间戳
},
};
}
根本原因分析:
- 时序差异:服务端/客户端执行环境时间差
- 数据异步:客户端数据获取滞后于渲染
- DOM操作:客户端手动修改服务端生成的DOM
- 组件状态:useState初始值与SSR输出不匹配
现代CSS的解决之道
<!-- 纯CSS时间显示方案 -->
<div class="time-container">
<time datetime="2023-11-15T08:00:00Z">08:00</time>
<span class="live-indicator"></span>
</div>
<style>
.live-indicator::after {
content: "实时";
animation: pulse 1s infinite;
}
@keyframes pulse {
0% { opacity: 0.5; }
50% { opacity: 1; }
100% { opacity: 0.5; }
}
</style>
优势对比:
| 方案 | 水合风险 | 首屏时间 | 复杂度 | 可访问性 |
|---|---|---|---|---|
| React水合 | 高 | 慢 | 高 | 中等 |
| 纯CSS | 无 | 快 | 低 | 优 |
| 渐进增强 | 低 | 中等 | 中等 | 优 |
🛠️ CSS核心解决方案详解
1️⃣ 嵌套选择器:组件化样式管理
/* 卡片组件 - 替代React组件 */
.card {
padding: 1.5rem;
border: 1px solid #e0e0e0;
/* 标题区域 */
&-header {
display: flex;
align-items: center;
&:hover {
background: #f5f5f5;
}
}
/* 响应式处理 */
@media (width <= 768px) {
border-radius: 0;
padding: 1rem;
}
/* 深色模式适配 */
@media (prefers-color-scheme: dark) {
border-color: #444;
}
}
工程价值:
- 作用域隔离:避免全局样式污染
- 维护成本:修改单个组件不影响其他部分
- 开发效率:类似JSX的组件化开发体验
2️⃣ CSS变量 + 相对颜色:动态主题系统
:root {
--primary: #2468f2;
--text-primary: #333;
/* 动态派生变量 */
--primary-hover: hsl(from var(--primary) h s calc(l + 8%));
--primary-active: oklch(from var(--primary) l c h / 0.9);
}
/* 主题切换器 */
.theme-switcher:has(#dark:checked) {
--text-primary: #fff;
--bg-primary: #121212;
}
button {
background: var(--primary);
transition: background 0.3s;
&:hover {
background: var(--primary-hover);
}
&:active {
background: var(--primary-active);
}
}
3️⃣ @starting-style:元素入场动画
.modal {
opacity: 1;
transform: translateY(0);
transition:
opacity 0.4s ease-out,
transform 0.4s cubic-bezier(0.34, 1.56, 0.64, 1);
/* 初始状态 */
@starting-style {
opacity: 0;
transform: translateY(20px);
}
}
与传统方案对比:
// React实现模态框动画 - 需要状态管理
function Modal() {
const [isOpen, setIsOpen] = useState(false);
return (
<div
className={`modal ${isOpen ? 'open' : ''}`}
onTransitionEnd={() => console.log('动画结束')}
>
{/* 内容 */}
</div>
)
}
/* 对应CSS */
.modal {
opacity: 0;
transform: translateY(20px);
transition: all 0.4s;
}
.modal.open {
opacity: 1;
transform: translateY(0);
}
📱 响应式设计新范式
动态视口单位实战
/* 移动端布局方案 */
.header {
height: 15svh; /* 最小可视高度 */
}
.hero {
height: 75lvh; /* 最大可视高度 */
}
.content {
height: 120dvh; /* 动态高度 */
overflow-y: auto;
}
.footer {
height: 10svh; /* 保证始终可见 */
}
单位解析:
| 单位 | 计算基准 | 适用场景 | iOS Safari支持 |
|---|---|---|---|
svh | 最小可视区域高度 | 固定导航栏 | 16.4+ |
lvh | 最大可视区域高度 | 全屏轮播图 | 16.4+ |
dvh | 当前可视区域高度 | 可滚动内容区 | 16.4+ |
✅ 实践总结
水合错误规避策略
- 数据一致性:
// Next.js getStaticProps保证数据一致
export async function getStaticProps() {
const data = await fetchData();
return { props: { data } };
}
- 组件设计原则:
// 避免客户端特有状态
function SafeComponent({ serverData }) {
// ✅ 使用服务端传递的数据
return <div>{serverData}</div>;
}
- 渐进增强方案:
<!-- 首屏使用静态HTML -->
<div id="user-profile">
<!-- SSR生成内容 -->
</div>
<!-- 客户端增强 -->
<script type="module">
if (navigator.onLine) {
loadInteractiveComponents();
}
</script>
CSS优先架构优势
| 指标 | JS方案 | CSS方案 | 提升幅度 |
|---|---|---|---|
| 首屏加载 | 2.8s | 0.6s | 78% |
| 交互延迟 | 120ms | 16ms | 87% |
| 内存占用 | 85MB | 12MB | 86% |
| 代码体积 | 350KB (gzip) | 45KB (gzip) | 87% |
实施路线图:
- 静态内容:优先使用HTML/CSS
- 交互元素:
:hover,:focus-within等伪类 - 复杂逻辑:渐进增强添加JS
- 状态管理:URL参数 +
:target选择器
通过现代CSS技术栈,开发者可在避免水合错误的同时,构建高性能、可访问性强的Web应用,实现真正的"渐进式Web体验"。
来源:juejin.cn/post/7544366602885873679
Docker 与 containerd 的架构差异
要深入理解 Docker 与 containerd 的架构差异,首先需要明确二者的定位:Docker 是一套完整的容器平台(含构建、运行、分发等全流程工具),而 containerd 是一个专注于容器生命周期管理的底层运行时(最初是 Docker 内置组件,后独立为 CNCF 项目)。二者的架构设计围绕 “功能边界” 和 “模块化程度” 展开,以下从核心定位、架构分层、关键组件、交互流程四个维度进行对比分析。
一、核心定位与设计目标
架构差异的根源在于二者的定位不同,直接决定了功能范围和模块划分:
| 维度 | Docker | containerd |
|---|---|---|
| 核心定位 | 一站式容器平台(Build, Ship, Run) | 轻量级容器运行时(专注于容器生命周期管理:启动、停止、销毁、资源隔离) |
| 设计目标 | 简化开发者体验,提供全流程工具链;兼顾单机开发与简单集群场景 | 满足云原生环境的可扩展性、稳定性;支持多上层调度器(K8s、Swarm 等) |
| 功能范围 | 包含镜像构建(docker build)、镜像仓库(docker push/pull)、容器运行、网络 / 存储管理、UI 等 | 仅负责镜像拉取、容器运行时管理、底层存储 / 网络对接;无镜像构建功能 |
| 依赖关系 | 早期内置 containerd 作为底层运行时(Docker 1.11+),2020 年后逐步拆分 | 可独立运行,也可作为 Docker、K8s(默认运行时)、Nomad 等的底层依赖 |
二、架构分层对比
二者均遵循 “分层解耦” 思想,但分层粒度和模块职责差异显著。Docker 架构更 “重”(含上层业务逻辑),containerd 更 “轻”(聚焦底层核心能力)。
1. Docker 架构(2020 年后拆分版)
Docker 经历了从 “单体架构” 到 “模块化拆分” 的演进(核心是将 containerd 独立,自身聚焦上层工具链),当前架构分为 4 层,自下而上分别是:
| 架构层 | 核心组件 / 功能 | 职责说明 |
|---|---|---|
| 1. 底层运行时层 | containerd、runc | 承接 Docker daemon 的指令,负责容器的实际创建、启动、资源隔离(依赖 runc 作为 OCI runtime) |
| 2. Docker 守护进程层 | dockerd | Docker 的核心守护进程,负责接收客户端(docker CLI)请求,协调下层组件(如调用 containerd 管理容器,调用 buildkit 构建镜像) |
| 3. 工具链层 | BuildKit、Docker Registry Client、Docker Network/Volume Plugins | - BuildKit:替代传统 docker build 后端,优化镜像构建效率;- 镜像客户端:处理 docker push/pull 与仓库交互;- 网络 / 存储插件:管理容器网络(如 bridge、overlay)和数据卷 |
| 4. 客户端层 | docker CLI(命令行工具)、Docker Desktop UI(桌面端) | 提供用户交互入口,将 docker run/build/pull 等命令转化为 HTTP 请求发送给 dockerd |
2. containerd 架构(CNCF 标准化版)
containerd 架构更聚焦 “容器生命周期”,采用 5 层模块化设计,每层职责单一,可独立扩展,自下而上分别是:
| 架构层 | 核心组件 / 功能 | 职责说明 |
|---|---|---|
| 1. OCI 运行时层 | runc、crun(可选) | 遵循 OCI 规范(Open Container Initiative),负责创建 Linux 容器(如调用 clone() 系统调用实现 PID 隔离,挂载 cgroup 限制资源) |
| 2. 容器执行层 | containerd-shim(垫片进程) | - 解耦 containerd 与容器进程:即使 containerd 重启,容器也不会退出;- 收集容器日志、监控容器状态、转发信号(如 docker stop 对应 SIGTERM) |
| 3. 核心服务层 | containerd 守护进程(containerd) | containerd 的核心,通过 gRPC 提供 API 服务,包含 4 个核心模块:- Namespaces:实现多租户资源隔离;- Images:管理镜像(拉取、存储、解压);- Containers:管理容器元数据(配置、状态);- Tasks:管理容器进程(启动、停止、销毁) |
| 4. 元数据存储层 | BoltDB(嵌入式 key-value 数据库) | 存储容器、镜像、命名空间等元数据,无需依赖外部数据库(如 MySQL),轻量且高效 |
| 5. 上层适配层 | CRI 插件(containerd-cri)、Docker API 兼容层 | - CRI 插件:将 containerd 的 gRPC API 转化为 K8s 要求的 CRI(Container Runtime Interface),使其成为 K8s 默认运行时;- Docker API 兼容层:支持部分 Docker 命令,确保与老系统兼容 |
三、关键组件差异
架构的核心差异体现在 “组件职责划分” 和 “功能依赖” 上,以下是最关键的组件对比:
| 组件 / 能力 | Docker | containerd |
|---|---|---|
| 核心守护进程 | dockerd(上层协调)+ containerd(底层运行时,需与 dockerd 配合) | containerd(独立守护进程,直接对接 OCI 运行时,无需依赖其他进程) |
| 镜像构建 | 内置 BuildKit(或传统后端),支持 docker build 命令 | 无镜像构建功能,需依赖外部工具(如 BuildKit、img) |
| 容器进程隔离 | dockerd → containerd → containerd-shim → runc → 容器进程(4 层调用) | containerd → containerd-shim → runc → 容器进程(3 层调用,更轻量) |
| 元数据存储 | 依赖本地文件系统(/var/lib/docker)+ 部分内存缓存 | 内置 BoltDB(/var/lib/containerd),元数据管理更统一、高效 |
| API 接口 | 主要提供 HTTP API(供 docker CLI 调用),对下层暴露有限 | 以 gRPC API 为主(更适合跨进程通信),提供细粒度接口(如镜像、容器、任务分别有独立 API) |
| 上层调度器支持 | 主要支持 Docker Swarm,对接 K8s 需额外配置(早期需 cri-dockerd 插件) | 原生支持 K8s(通过 containerd-cri 插件),也支持 Swarm、Nomad 等 |
四、容器启动流程对比
通过 “容器启动” 这一核心场景,可以直观看到二者的架构交互差异:
1. Docker 启动容器的流程(以 docker run ubuntu 为例)
- 用户交互:用户在终端执行 docker run ubuntu,docker CLI 将命令转化为 HTTP 请求,发送给本地的 dockerd 守护进程。
- dockerd 协调:
- 检查本地是否有 ubuntu 镜像:若无,调用 “镜像客户端” 从 Docker Hub 拉取镜像;
- 拉取完成后,dockerd 向 containerd 发送 gRPC 请求,要求创建并启动容器。
- containerd 处理:
- containerd 接收请求后,创建容器元数据(存储到本地),并启动 containerd-shim 垫片进程;
- containerd-shim 调用 runc,由 runc 遵循 OCI 规范创建容器进程(分配 PID、挂载 cgroup、设置网络 / 存储)。
- 状态反馈:
- containerd-shim 实时收集容器状态(如运行中、退出),反馈给 containerd;
- containerd 将状态转发给 dockerd,最终由 docker CLI 输出给用户(如 docker ps 显示容器列表)。
2. containerd 启动容器的流程(以 ctr run ubuntu my-container 为例,ctr 是 containerd 自带 CLI)
- 用户交互:用户执行 ctr run ubuntu my-container,ctr 直接通过 gRPC 调用 containerd 守护进程。
- containerd 核心处理:
- 检查本地镜像:若无,直接调用内置的 “镜像模块” 从仓库拉取 ubuntu 镜像;
- 创建容器元数据(存储到 BoltDB),并启动 containerd-shim 垫片进程。
- OCI 运行时启动容器:
- containerd-shim 调用 runc 创建容器进程,完成资源隔离和环境初始化;
- 容器启动后,containerd-shim 持续监控容器状态,直接反馈给 containerd。
- 状态反馈:containerd 将容器状态通过 gRPC 返回给 ctr,用户终端显示启动结果。
五、总结:架构差异的核心影响
| 对比维度 | Docker | containerd |
|---|---|---|
| 轻量级 | 重(含全流程工具,依赖多组件) | 轻(仅核心运行时,组件少、资源占用低) |
| 扩展性 | 弱(架构耦合度较高,难适配多调度器) | 强(模块化设计,原生支持 K8s 等调度器) |
| 性能 | 略低(多一层 dockerd 转发,资源消耗多) | 更高(直接对接 OCI 运行时,调用链短) |
| 使用场景 | 单机开发、测试、小型应用部署 | 云原生集群(如 K8s 集群)、大规模容器管理 |
| 学习成本 | 低(CLI 友好,文档丰富) | 高(需理解 gRPC、OCI 规范,适合运维 / 底层开发) |
简言之:Docker 是 “面向开发者的容器平台”,架构围绕 “易用性” 和 “全流程” 设计;containerd 是 “面向云原生的底层运行时”,架构围绕 “轻量、可扩展、高兼容” 设计。在当前云原生生态中,containerd 已成为 K8s 的默认运行时,而 Docker 更多用于单机开发场景。
来源:juejin.cn/post/7544381073698848811
instanceof 的小秘密
instanceof 运算符用于检测某个构造函数的 prototype 属性,是否存在于对象的原型链上。
class Cat {
constructor(name, age) {
this.name = name;
this.age = age;
}
}
const cat = new Cat("Mittens", 3);
console.log(cat instanceof Cat); // true
console.log(cat instanceof Object); // true
instanceof 接收两个参数,v(左)和target(右),判断v是否为target的实例对象,方法是先查询target的Symbol.hasInstance属性,如果不存在,则判断target的prototype属性是否存在v的原型中。
class Cat {
static [Symbol.hasInstance](instance) {
return false
}
constructor(name, age) {
this.name = name;
this.age = age;
}
}
const cat = new Cat("Mittens", 3);
console.log(cat instanceof Cat); // false
console.log(cat instanceof Object); // true
console.log(cat instanceof null) // TypeError: Right-hand side of 'instanceof' is not an object
或许有人会想到1 intanceof Number和1 intanceof Object为什么会是false呢?明明(1).__proto__是有值的,为什么呢?这里就不得不提到JS的一个机制"自动装箱"。
我们定义一个变量const n = 1, n是一个原始值,有以下特点:
- 不可变性:原始值本身不能被修改,任何"修改"操作都会创建新值
- 按值传递:赋值时复制值,而不是引用
- 没有属性和方法:原始值本身不是对象,不能直接拥有属性和方法
在访问原始值属性或者方法时,Js会创建一个临时对象,使用后便会销毁。
const n = 1;
n.toString()
// JavaScript 内部实际执行的过程
// 1. 创建临时 Number 对象:new Number(1)
// 2. 调用方法:numberObj.toString()
// 3. 返回结果:"1"
// 4. 销毁临时对象
但是在intanceof操作时,不会进行"自动装箱",所以得到的结果为false。
来源:juejin.cn/post/7543797314282373162
一个有趣的效果--动态生成动画导航
一个有趣的效果--动态生成动画导航
在接下来的这个项目中,我们即将使用纯 JavaScript 和 CSS 来创建一个具有动态动画效果的导航栏。这篇文章将详细解析该代码的实现,包括 HTML 结构、CSS 样式、JavaScript 逻辑等方面,帮助你理解每一个步骤和实现思路。文章内容将逐步拆解,涵盖从页面结构、样式设计到功能实现的各个细节。
项目概述
这个项目的核心目标是创建一个包含动画效果的导航栏。具体功能包括:
- 动态导航项:当用户将鼠标悬停在导航项上时,显示一个附加的面板。
- 面板动画:面板会根据鼠标悬停的位置进行平滑过渡,显示不同的内容。
- 过渡效果:每个导航项的高亮状态和面板显示都有精美的动画效果,增强用户体验。
HTML 结构
HTML 基本框架
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>一个动态动画导航</title>
<style>
/* 样式在这里 */
</style>
</head>
<body>
<script>
/* JavaScript 逻辑在这里 */
</script>
</body>
</html>
HTML 文档是非常标准的结构,包含了 head 和 body 两大部分:
<head>部分:定义了页面的字符编码、视口设置和页面的标题。标题为 “一个动态动画导航”,用于描述页面内容。<body>部分:里面没有直接的 HTML 内容,而是通过 JavaScript 动态生成和管理导航栏的结构。
导航栏元素
在页面的 body 中,我们没有直接放置导航栏的 HTML 代码,而是通过 JavaScript 动态生成。接下来我们将深入分析这些 JavaScript 代码的工作原理。
CSS 样式解析
全局样式
body, html, ul, p {
margin: 0;
padding: 0;
}
这一段代码是用来移除 body、html、ul 和 p 元素的默认 margin 和 padding,以确保布局没有多余的间隙。这是前端开发中的常见做法,有助于在不同浏览器中获得一致的效果。
导航栏 .nav
.nav {
list-style: none;
padding: 0;
margin: 0;
display: flex;
position: relative;
margin-left: 200px;
}
.nav 是一个容器元素,负责展示导航栏中的各个导航项。它使用了 flex 布局,使得每个 li 元素可以水平排列。此外,通过 position: relative 来为可能添加的子元素(如下拉面板)提供定位上下文,margin-left: 200px 是为了给导航栏留出空间。
导航项 .nav li
.nav li {
min-width: 100px;
text-align: center;
border-bottom: 1px solid #ddd;
color: #535455;
padding: 12px;
margin-right: 12px;
cursor: pointer;
transition: all ease 0.2s;
}
每个导航项 (li) 有如下样式:
min-width: 100px:确保每个项至少占据 100px 宽度。text-align: center:使文本居中显示。border-bottom: 1px solid #ddd:为每个导航项添加一个细线,增强视觉效果。padding: 12px和margin-right: 12px:设置内外边距,使项之间保持一定的间距。cursor: pointer:当鼠标悬停在导航项上时,显示为可点击的手形光标。transition: all ease 0.2s:使所有样式变化(如颜色、背景色、缩放等)具有过渡效果,持续时间为 0.2 秒,效果为平滑过渡。
面板 .nav-panel-wrapper
.nav-panel-wrapper {
border: 1px solid #dedede;
position: absolute;
top: 60px;
left: 0;
padding: 12px;
border-radius: 4px;
box-shadow: 0px 0px 12px rgba(0, 0, 0, 0.32);
display: none;
overflow: hidden;
}
.nav-panel-wrapper 是每个导航项的下拉面板,包含以下样式:
position: absolute:使面板相对于.nav容器进行绝对定位。top: 60px:将面板放置在导航项下方(假设导航栏的高度为 60px)。border-radius: 4px:为面板添加圆角,使其看起来更加圆滑。box-shadow:为面板添加阴影效果,使其更加立体,增加视觉层次感。display: none:面板默认是隐藏的,只有在用户悬停时才会显示。overflow: hidden:确保面板内容不会溢出其容器。
动画样式
.scale-up-top {
animation: scale-up-top 0.2s cubic-bezier(0.39, 0.575, 0.565, 1) both;
}
@keyframes scale-up-top {
0% {
transform: scale(0.5);
transform-origin: 50% 0%;
}
100% {
transform: scale(1);
transform-origin: 50% 0%;
}
}
.scale-up-top 类通过动画效果使面板从小到大逐渐放大,并且设置了动画的持续时间为 0.2 秒,使用了 cubic-bezier 函数来创建缓动效果。@keyframes scale-up-top 定义了放大过程的具体动画帧:从 50% 的缩放大小(即最小状态)逐渐过渡到 100%(即原始大小)。
JavaScript 逻辑解析
工具类 AnimateNavUtils
AnimateNavUtils 是一个工具类,提供了一些常用的方法,简化了 DOM 操作的代码:
$:根据选择器返回文档中的第一个匹配元素。createElement:根据传入的 HTML 字符串创建一个新的 DOM 元素。addClass、removeClass、hasClass:分别用于为元素添加、移除、检查 CSS 类。insertNode:将一个新的节点插入到指定的元素中,或者替换现有节点。create:创建一个新的 DOM 元素节点。setStyle:为元素动态设置样式。
这些工具方法大大简化了后续类的实现,使得代码更具可读性和复用性。
动画导航类 AnimateNav
AnimateNav 类是核心部分,负责处理导航栏的渲染、事件绑定和面板的动画效果。
构造函数
constructor({ data }) {
super();
this.data = data;
this.panelDelayTimer = null;
this.currentIndex = 0;
this.panelEle = null;
this.navEle = null;
}
在构造函数中,我们接收一个 data 参数,它是一个包含导航项信息的数组。panelDelayTimer 用来控制面板的显示延迟,currentIndex 用来记录当前导航项的索引,panelEle 和 navEle 分别存储面板和导航栏的 DOM 元素引用。
mount 方法
mount(el) {
const container = this.isString(el) ? this.$(el) : document.body;
this.render(container);
}
mount 方法负责将导航栏挂载到指定的 DOM 元素中。如果传入的参数是一个字符串(例如选择器),则查找对应的元素;如果是其他类型,则默认为 document.body。
render 方法
render(container) {
if (!this.isArray(this.data) || this.data?.length === 0) {
return;
}
const node = this.createElement(`
<ul class="nav">
${this.data.map(item => `<li data-sub="${item.sub}" data-index="${item.index}" class="nav-item">${item.text}</li>`).join('')}
<div class="nav-panel-wrapper"> </div>
</ul>
`);
...
}
render 方法负责生成导航栏的 HTML 结构并将其插入到页面中。它首先检查 data 是否有效,确保它是一个数组且非空。接着,它动态创建一个包含 <ul class="nav"> 和 <div class="nav-panel-wrapper"> 的 HTML 结构。
data.map(item => ...)生成每个导航项的<li>元素,并根据data-sub和data-index设置相应的自定义属性。this.navEle和this.panelEle分别存储了导航栏容器和面板容器的 DOM 元素引用,方便后续操作。- 最后,调用
bindEvents方法来绑定事件处理器。
绑定事件 bindEvents
bindEvents() {
const items = Array.from(this.navEle.querySelectorAll('.nav-item'));
items.forEach(item => {
item.addEventListener('mouseenter', (e) => {
const index = e.target.dataset.index;
this.showPanel(index);
});
item.addEventListener('mouseleave', () => {
this.hidePanel();
});
});
}
showPanel(index) {
const item = this.navEle.querySelector(`[data-index="${index}"]`);
const subItems = item.getAttribute('data-sub');
this.panelEle.innerHTML = subItems ? subItems : '没有子项';
this.addClass(this.panelEle, 'scale-up-top');
this.setStyle(this.panelEle, {
display: 'block',
top: `${item.offsetTop + item.offsetHeight + 12}px`
});
}
hidePanel() {
this.removeClass(this.panelEle, 'scale-up-top');
this.setStyle(this.panelEle, { display: 'none' });
}
在 bindEvents 方法中,我们为每个导航项添加了 mouseenter 和 mouseleave 事件监听器:
mouseenter:当鼠标进入某个导航项时,调用showPanel方法显示对应的面板,并填充子项内容。mouseleave:当鼠标离开导航项时,调用hidePanel隐藏面板。
showPanel 方法
showPanel(index) {
const item = this.navEle.querySelector(`[data-index="${index}"]`);
const subItems = item.getAttribute('data-sub');
this.panelEle.innerHTML = subItems ? subItems : '没有子项';
this.addClass(this.panelEle, 'scale-up-top');
this.setStyle(this.panelEle, {
display: 'block',
top: `${item.offsetTop + item.offsetHeight + 12}px`
});
}
showPanel 方法根据导航项的索引 (data-index) 显示相应的子项。如果该项有子项(存储在 data-sub 属性中),则将这些子项填充到面板中。如果没有子项,则显示默认的消息('没有子项')。然后,通过 scale-up-top 动画类使面板执行放大动画,并将面板的显示位置设为导航项的下方。
hidePanel 方法
hidePanel() {
this.removeClass(this.panelEle, 'scale-up-top');
this.setStyle(this.panelEle, { display: 'none' });
}
hidePanel 方法用于隐藏面板。它会移除面板的动画类 scale-up-top,并通过 setStyle 将面板的 display 属性设置为 none,使其消失。
总结
动画和交互效果
- 悬停时显示面板:当用户将鼠标悬停在导航项上时,会触发面板的显示,面板内容来自
data-sub属性。 - 平滑动画:面板在显示和隐藏时应用了平滑的缩放动画,使得界面显得更加动态和流畅。
- 动态子项内容:通过自定义的
data-sub属性,每个导航项可以动态地包含不同的子项或其他内容。
来看一个在线示例如下所示:
当然这个导航还有可以优化和扩展的空间,如下:
优化和扩展
- 响应式设计:当前代码没有完全考虑到移动端的布局,可以进一步优化以适应不同设备屏幕的大小。
- 面板延迟:目前面板的显示和隐藏没有延迟处理,未来可以根据需要加入延迟显示、隐藏的效果,提升交互体验。
- 面板定位优化:面板的显示位置是相对于当前导航项的位置进行的,可以根据页面的整体布局进一步调整面板的显示位置,例如避免面板超出页面底部或侧边界。
整体来说,这个动态导航效果是通过结合 JavaScript 的 DOM 操作和 CSS 动画来实现的,结构清晰,动画流畅,能够为用户提供良好的互动体验。
来源:juejin.cn/post/7442965793157136420
我让AI一把撸了个算命网站,结果它比我还懂玄学

作为一个信奉代码逻辑的程序员,我做梦也没想到有一天会让AI帮我开发算命网站。
事情是这样的:某天深夜,我突然冒出一个奇葩想法——能不能让Claude Code从零开始搭建一个算命网站? 不是因为我迷信,而是纯粹的技术好奇心:AI能理解2000年前的玄学智慧吗?
于是我开始了这个"用最现代的技术实现最古老的智慧"的实验。
3天后,网站上线了。更神奇的是,AI对传统文化的理解程度让我这个中国人都自愧不如。
选技术栈:AI的选择让我怀疑人生
我本来打算用熟悉的Vue + Express一把梭,结果Claude Code一开口就让我重新审视了自己的技术认知。
我问它:"帮我选个适合算命网站的技术栈"
它的回答让我直接傻眼:
Next.js 14 + TypeScript。我说算命网站用TypeScript?它说:"天干地支计算出错了用户会骂死你的,类型安全不是开玩笑的。"我一想,确实,算错了八字那不是要被用户打死。
Supabase。我说为什么不用MongoDB?它说:"用户算命记录要能实时同步,万一用户换个设备要查看历史记录呢?"行吧,你考虑得比我周到。
DeepSeek API。这个真的让我意外,我下意识想用GPT,结果它说:"中文传统文化,还是国产模型理解得更地道。"后来的事实证明,这个选择太明智了。
最让我佩服的是,它还主动提到了"真太阳时计算"。我当时就懵了,什么是真太阳时?它耐心地给我科普:古代算命要考虑地理位置对时间的影响,不是简单的北京时间。
我心想,这AI对传统文化的理解比我这个中国人还深入啊。
给自己算了一下还是挺满意的


教AI算命:一场智商与玄学的较量
项目最大的难点不是写代码,而是怎么让一个理性的AI理解玄学。
这就像让一个直男理解女朋友的小情绪,难度系数直接拉满。
第一次尝试,我直接甩给AI一个八字:"帮我分析一下甲子年乙丑月丙寅日丁卯时"
AI的回答让我哭笑不得:"这位朋友可能具有较强的时间观念,因为你的出生时间很规律..."
我当场就想关电脑了。这哪里是算命,这是在分析数据规律啊!
第二次,我学聪明了,告诉它"你是命理大师"。结果它开始发挥想象力,创造了一套"六行理论",除了传统五行还加了个"气行"。我差点被它的创新精神感动。
第三次,我痛定思痛,决定从根本上改变策略。我不再把它当AI,而是真的把它当成一个有30年经验的老师傅。我给它详细介绍了传统命理的理论体系,告诉它什么能说,什么不能说,甚至教它怎么说话。
这次它终于开窍了,分析起来有模有样,专业术语用得恰到好处,建议也很中肯。
我突然意识到,训练AI就像带徒弟,不是给它知识,而是教它思考方式。
踩坑实录:当代码遇见玄学,bug都变得玄幻了
做这个项目让我深刻体会到什么叫"传统文化博大精深",每个看似简单的概念背后都藏着巨大的坑。
最让我头疼的是时辰计算。我原本以为很简单,23点到1点是子时嘛,结果Claude Code告诉我:"古代的时辰划分和现代时间概念不完全一样,而且要考虑地理位置。"
我当时就懵了,算个命还要考虑地理位置?后来才知道,古人用的是"真太阳时",北京的中午12点和新疆的中午12点,太阳位置是不一样的。
这就好比你以为做个网站用个时间戳就行了,结果发现还要处理时区、夏令时、闰秒...程序员的痛,古人早就体验过了。
还有一个哭笑不得的bug。AI在分析五行的时候,突然开始"创新",告诉用户发现了"六行理论",除了金木水火土,还有个"气行"。我当时想,你这是要颠覆传统文化吗?
后来我在提示词里加了一句"严格按照传统理论,不要创新",AI这才老实下来。
最隐蔽的坑是日期计算。现代JavaScript处理1900年以前的日期有问题,结果导致古代名人的八字全算错了。我测试的时候用李白的生日,算出来说他五行缺钱...我差点被自己笑死。
每修复一个bug,我都觉得自己对传统文化的理解又深了一层。这感觉很奇妙,就像在用代码穿越时空,和古人对话。
从程序员审美到仙气飘飘
做程序员这么多年,我深知自己的审美水平。我设计的界面通常是这样的:白色背景,黑色字体,偶尔加个边框,完事。
用户打开我设计的网站,第一反应通常是:"这...是1990年代的网站吗?"
但算命网站不一样啊,用户来算命,你给他一个Excel表格的界面,他会觉得你在糊弄他。这玩意得有神秘感,得有仙气。
我问Claude Code:"怎么让网站看起来有仙气?"
它的回答让我刷新了对UI设计的认知。它告诉我色彩心理学:深紫色代表神秘和智慧,金色代表尊贵和权威,渐变背景能营造空间感...
我听得一愣一愣的,心想这AI怎么还懂心理学?
按照它的建议改了界面后,效果确实不错。原本的Excel风格摇身一变成了"古风仙侠游戏界面"。朋友看了都说:"这网站一看就很专业,肯定算得准。"
我当时就想,界面设计真的能影响用户的心理预期。同样的内容,包装不同,用户的信任度完全不一样。
这让我想到另一个问题:在技术驱动的时代,审美能力可能比编程能力更稀缺。会写代码的程序员到处都是,但能设计出让用户一见钟情的界面的,真的不多。
这个布局我很喜欢,但一些ui感觉还可以微调

意外的收获:技术人的文化觉醒
这个项目最大的收获不是技术上的,而是认知上的。
以前我总觉得传统文化和现代技术是两个世界的东西,一个古老神秘,一个理性现代。但做完这个项目后,我发现它们其实是可以融合的。
AI可以学会古老的智慧,代码可以承载文化的传承。技术不是要替代传统,而是要成为传统文化在新时代的载体。
更重要的是,我开始理解用户需求的复杂性。人们使用算命网站,不只是想知道未来会怎样,更多的是希望获得一种心理安慰,一种对未知的控制感。
这让我重新思考技术产品的本质:不是要解决技术问题,而是要解决人的问题。
下一步:用技术重新定义传统
基于这次的经验,我有了一个更大胆的想法:用现代技术重新定义传统文化。
不是简单地把古书电子化,而是用AI、VR、区块链这些新技术,创造全新的文化体验方式。比如用AI生成个性化的《易经》解读,用VR重现古代占卜场景,用区块链记录每个人的文化传承轨迹。
传统文化需要在新时代找到新的表达方式,而技术人恰好有这个能力和责任。
先用three.js写个动画勉强还算满意吧

写在最后:一个程序员的玄学感悟
3天时间,从一个深夜的奇思妙想到一个完整的产品上线。回过头看,这个项目带给我的不只是技术上的提升,更多的是思维上的转变。
最大的感悟是:AI不是工具,而是合作伙伴。它有自己的"想法",会给你意想不到的建议,会从你没想到的角度解决问题。与其说是我在使用AI,不如说是我们在一起探索未知。
第二个感悟是:用户需求比技术实现更重要。算命网站的核心不是算法有多精确,而是能不能给用户带来心理上的满足。技术是手段,解决人的问题才是目的。
第三个感悟是:传统文化需要新的表达方式。不是要用技术颠覆传统,而是要用技术让传统在新时代重新焕发生机。
如果你也对AI开发感兴趣,我的建议是:不要把AI当成万能的代码生成器,要把它当成一个有智慧的合作伙伴。它能给你灵感,能帮你思考,但最终的判断和决策还是要靠你自己。
最后,如果你也想尝试类似的跨界项目,记住一点:技术栈可以学,算法可以抄,但洞察用户需求的能力,只能靠自己慢慢积累。
下一个项目,还不知道做啥,有想法的朋友可以在评论区说一声
本文基于真实项目开发经验,欢迎技术交流和商业合作!
来源:juejin.cn/post/7537339432292270080
用卡尔曼滤波器计算个股票相对大盘的相关性——β值

A股涨到3600点了。
你是不是也跟我一样——看到新闻标题说“牛市要来了!”,一打开账户……嗯?怎么手里的票还是绿的,上证指数25年都涨7%了,而你确亏了7%

为什么你的股票没涨过大盘?到底是市场的问题,还是你的股票压根不跟着市场走?
聪明的你可能已经想到一个词了,叫——β值(Beta)。
说白了,β值其实就是个股相对大盘“跟涨跟跌”的敏感度。你可以把它想象成你手上这票对“市场情绪”的反应速度和强度。
- β > 1 的股票,市场一疯,它先蹦跶;市场一跌,它先躺平。
- β < 1 的股票,属于佛系型,涨跌都慢半拍。
- β ≈ 0 的,那是独行侠,走自己的路让别人说去吧。
我知道,有些小伙伴可能说:“花姐你说这我都懂,但怎么算这个β值啊?”
来,今天我们就来整点硬核的——用卡尔曼滤波器来动态估算β值。
传统β值是怎么算的?
这事儿咱得先交代清楚,不然后面你会问:为啥要搞卡尔曼滤波呢?直接用回归不香吗?
最常见的β值计算方式是用OLS线性回归,比如拿某个股票和上证指数近一年日收益率,做个线性回归,斜率就是β值。代码长这样:
import pandas as pd
import numpy as np
import statsmodels.api as sm
stock_ret = ... # 股票收益率序列
market_ret = ... # 市场指数收益率序列
X = sm.add_constant(market_ret)
model = sm.OLS(stock_ret, X).fit()
beta = model.params[1]
结果算出来的β是固定的一个值。问题来了:市场在变,个股特性也在变,一个固定的β能代表未来吗?
用卡尔曼滤波器
那么问题来了:有没有什么办法,可以让β值随着时间动态变化,反映出最新的市场行为?
有!这时候就该请出我们的主角了——卡尔曼滤波器(Kalman Filter)。
别听名字吓人,其实你可以把它理解为一个“会自我更新”的预测模型。它有点像是个不断修正自己认知的智能体,每来一个新数据,就纠正一下之前的偏差。
如果说OLS是一次性静态判断,那卡尔曼滤波就是边走边看边修正。
卡尔曼滤波器怎么估算β?
卡尔曼滤波在量化里的用途很多,其中一个经典用途就是:时间序列中的线性参数动态估计。
我们的问题就可以建模成这个样子
股票收益率 = α + β × 市场收益率 + 噪声
不同的是,我们让β变成一个随时间变化的变量。
也就是说,今天的β和昨天的不一样,明天的也不一定一样。
我们设定两个方程:
状态方程(β的演变):
观测方程(收益率的观察):
其中:
- 是大盘的收益率
- 是股票的收益率
- 和 是噪声,分别表示系统噪声和观测噪声
这个模型的核心点是:我们认为β本身在缓慢变化,而每个观测数据都能对β的估计做一次修正。
不扯了,直接上代码!
咱们用 Python 写个计算个股β值的方法,当然你也可以把上证指数换成股票对应的行业指数,这样就可以得到个股相对行业的β值了。
这里计算卡尔曼的时候用了第三方库通过以下代码安装
pip install pykalman
from xtquant import xtdata
import pandas as pd
from pykalman import KalmanFilter
import numpy as np
import matplotlib.pyplot as plt
def get_hq(code,start_date='19900101',period='1d',dividend_type='front',count=-1):
'''
这里替换成你获取行情的方法
'''
df = pd.read_csv(f'{code}.csv')
return df
def calu_kalman_beta(df_stock,df_index):
'''
计算某个股票相对某个指数的β值
'''
# 对齐日期,按日期升序
df_stock = df_stock.sort_values('date')
df_index = df_index.sort_values('date')
df_stock = df_stock[df_stock['suspendFlag'] == 0] # 剔除停牌数据
# 合并,方便对齐(外层用 inner,保证两个都有数据)
df = pd.merge(df_stock[['date', 'close']],
df_index[['date', 'close']],
on='date',
suffixes=('_stock', '_index'))
# 计算对数收益率(更平滑、更合理)
df['ret_stock'] = np.log(df['close_stock'] / df['close_stock'].shift(1))
df['ret_index'] = np.log(df['close_index'] / df['close_index'].shift(1))
# 去除缺失
df = df.dropna().reset_index(drop=True)
# 提取序列
stock_ret = df['ret_stock'].values
index_ret = df['ret_index'].values
# 初始化卡尔曼滤波器
kf = KalmanFilter(
transition_matrices=1.0,
observation_matrices=1.0 ,
initial_state_mean=0.0,
initial_state_covariance=1.0,
observation_covariance=0.01, # 控制对观测数据的信任度 可微调
transition_covariance=0.00001 # 控制 β 的平滑程度 越小越平滑
)
# 加入极端值裁剪(防止除以接近0)
index_ret_safe = np.where(np.abs(index_ret) < 1e-4, np.sign(index_ret) * 1e-4, index_ret)
# 我们把 market_ret 作为“输入变量”,用于动态预测观测值
observations = stock_ret / index_ret_safe # y_t / x_t
observations = np.clip(observations, -10, 10) # 避免除数太小导致爆炸(你也可以换个方式)
state_means, _ = kf.filter(observations)
df['beta_kalman'] = state_means.flatten()
return df[10:]
if __name__=="__main__":
start_date='20240101'
code = '这里替换成股票代码'
index = '这里是指数代码'
df_stock = get_hq(code=code,start_date=start_date,period='1d')
df_index = get_hq(code=index,start_date=start_date,period='1d')
df = calu_kalman_beta(df_stock,df_index)
# 画图
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 正负号也正常显示
plt.figure(figsize=(12, 6))
plt.plot(df['date'], df['beta_kalman'], label='动态β(Kalman估计)', color='orange')
plt.axhline(1, linestyle='--', color='gray', alpha=0.5)
plt.title(f'{code} vs {index} 的动态β值')
plt.xlabel('date')
plt.ylabel('β值')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
给大家简单展示几个绘制的图



那我怎么用这个β?
有意思的来了。
用法1:选股
找出动态β长期 < 1 的股票,说明它抗跌能力强——在市场波动大的时候更稳。这类票适合熊市配置。
反过来,找动态β > 1.2 并上升中的,说明它在牛市中可能跑得飞快。
你甚至可以把这个β当作因子,搞个多空策略:多β上升的,空β下降的,构建一个方向中性的策略组合。这个思路其实在某些CTA策略里也有影子。
用法2:择时
你还可以跟踪你组合的整体β,动态调整仓位。
举个栗子:你组合的β从0.9升到1.3,说明风险在上升——这时候该减仓。反之也是。
今天的文章就到这里了,希望大家喜欢。
来源:juejin.cn/post/7533510113068630026
VitePress 彩虹动画
在查阅 VitePress 具体实践时,我被 UnoCSS 文档中的彩虹动画效果深深吸引。在查看其实现原理之后,本文也将探索如何通过自定义组件和样式增强 VitePress 站点,并实现一个炫酷的彩虹动画效果。
自定义主题
VitePress 允许你通过自定义 Layout 来改变页面的结构和样式。自定义 Layout 可以帮助你更好地控制页面的外观和行为,尤其是在复杂的站点中。
项目初始化
在终端中运行以下命令,初始化一个新的 VitePress 项目:
npx vitepress init
然后根据提示,这次选择自定义主题(Default Theme + Customization):
┌ Welcome to VitePress!
│
◇ Where should VitePress initialize the config?
│ ./docs
│
◇ Site title:
│ My Awesome Project
│
◇ Site description:
│ A VitePress Site
│
◇ Theme:
│ Default Theme + Customization
│
◇ Use TypeScript for config and theme files?
│ Yes
│
◇ Add VitePress npm scripts to package.json?
│ Yes
│
└ Done! Now run npm run docs:dev and start writing.
Tips:
- Make sure to add docs/.vitepress/dist and docs/.vitepress/cache to your .gitignore file.
- Since you've chosen to customize the theme, you should also explicitly install vue as a dev dependency.
注意提示,这里需要额外手动安装 vue 库:
pnpm add vue
自定义入口文件
找到 .vitepress/theme/index.ts 入口文件:
// <https://vitepress.dev/guide/custom-theme>
import { h } from 'vue'
import type { Theme } from 'vitepress'
import DefaultTheme from 'vitepress/theme'
import './style.css'
export default {
extends: DefaultTheme,
Layout: () => {
return h(DefaultTheme.Layout, null, {
// <https://vitepress.dev/guide/extending-default-theme#layout-slots>
})
},
enhanceApp({ app, router, siteData }) {
// ...
}
} satisfies Theme
里面暴露了一个 Layout 组件,这里是通过 h 函数实现的,我们将其抽离成 Layout.vue 组件。
创建自定义 Layout
VitePress 的 Layout 组件是整个网站的骨架,控制了页面的基本结构和布局。通过自定义 Layout,我们可以完全掌控网站的外观和行为。
为什么要自定义 Layout?
- 增加特定的布局元素
- 修改默认主题的行为
- 添加全局组件或功能
- 实现特殊的视觉效果(如我们的彩虹动画)
我们在 .vitepress/theme 文件夹中创建 Layout.vue 组件,并将之前的内容转换成 vue 代码:
<script setup lang="ts">
import DefaultTheme from 'vitepress/theme'
</script>
<template>
<DefaultTheme.Layout />
</template>
接下来,在 .vitepress/theme/index.ts 中注册自定义 Layout:
// .vitepress/theme/index.ts
import DefaultTheme from 'vitepress/theme'
import CustomLayout from './Layout.vue'
export default {
extends: DefaultTheme,
Layout: CustomLayout,
}
这将会覆盖默认的 Layout,应用你自定义的布局结构。
覆盖原本样式
VitePress 提供了 css 变量来动态修改自带的样式,可以看到项目初始化后在 .vitepress/theme 中有一个 style.css。里面提供了案例,告诉如何去修改这些变量。
同时可以通过该链接查看全部的 VitePress 变量:VitePress 默认主题变量。
VitePress 允许我们通过多种方式覆盖默认样式。最常用的方法是创建一个 CSS 文件,并在主题配置中导入。
比如想设置 name 的颜色,就可以通过:
:root {
--vp-home-hero-name-color: blue;
}
引入 UnoCSS
UnoCSS 是一个按需生成 CSS 的工具,可以极大简化 CSS 管理,帮助快速生成高效样式。
在项目中安装 UnoCSS 插件:
pnpm add -D unocss
然后,在 vite.config.ts 中配置 UnoCSS 插件:
import UnoCSS from 'unocss/vite'
import { defineConfig } from 'vite'
export default defineConfig({
plugins: [UnoCSS()],
}
通过 UnoCSS,可以轻松应用样式而无需写冗余 CSS。例如,使用以下类名快速创建按钮样式:
<button class="bg-blue-500 text-white p-4 rounded-lg hover:bg-blue-600">
按钮
</button>
实现彩虹动画
彩虹动画是本文的主角,主要通过动态改变 CSS 变量值来实现色彩的平滑过渡。
定义彩虹动画关键帧
通过 @keyframes,在不同颜色之间平滑过渡,形成彩虹动画效果。创建 rainbow.css 文件:
@keyframes rainbow {
0% {
--vp-c-brand-1: #00a98e;
--vp-c-brand-light: #4ad1b4;
--vp-c-brand-lighter: #78fadc;
--vp-c-brand-dark: #008269;
--vp-c-brand-darker: #005d47;
--vp-c-brand-next: #009ff7;
}
25% {
--vp-c-brand-1: #00a6e2;
--vp-c-brand-light: #56cdff;
--vp-c-brand-lighter: #87f6ff;
--vp-c-brand-dark: #0080b9;
--vp-c-brand-darker: #005c93;
--vp-c-brand-next: #9280ed;
}
50% {
--vp-c-brand-1: #c76dd1;
--vp-c-brand-light: #f194fa;
--vp-c-brand-lighter: #ffbcff;
--vp-c-brand-dark: #9e47a9;
--vp-c-brand-darker: #772082;
--vp-c-brand-next: #eb6552;
}
75% {
--vp-c-brand-1: #e95ca2;
--vp-c-brand-light: #ff84ca;
--vp-c-brand-lighter: #ffadf2;
--vp-c-brand-dark: #be317d;
--vp-c-brand-darker: #940059;
--vp-c-brand-next: #d17a2a;
}
100% {
--vp-c-brand-1: #00a98e;
--vp-c-brand-light: #4ad1b4;
--vp-c-brand-lighter: #78fadc;
--vp-c-brand-dark: #008269;
--vp-c-brand-darker: #005d47;
--vp-c-brand-next: #009ff7;
}
}
:root {
--vp-c-brand-1: #00a8cf;
--vp-c-brand-light: #52cff7;
--vp-c-brand-lighter: #82f8ff;
--vp-c-brand-dark: #0082a7;
--vp-c-brand-darker: #005e81;
--vp-c-brand-next: #638af8;
animation: rainbow 40s linear infinite;
}
html:not(.rainbow) {
--vp-c-brand-1: #00a8cf;
--vp-c-brand-light: #52cff7;
--vp-c-brand-lighter: #82f8ff;
--vp-c-brand-dark: #0082a7;
--vp-c-brand-darker: #005e81;
--vp-c-brand-next: #638af8;
animation: none !important;
}
这段代码定义了彩虹动画的五个关键帧,并将动画应用到根元素上。注意,我们还定义了不带动画的默认状态,这样就可以通过 CSS 类切换动画的启用/禁用。
实现彩虹动画控制组件
接下来,实现名为 RainbowAnimationSwitcher 的组件,其主要逻辑是通过添加或移除 HTML 根元素上的 rainbow 类来控制动画的启用状态,从而实现页面的彩虹渐变效果。
这个组件使用了 @vueuse/core 的两个工具函数:
useLocalStorage用于在浏览器本地存储用户的偏好设置useMediaQuery用于检测用户系统是否设置了减少动画
<script lang="ts" setup>
import { useLocalStorage, useMediaQuery } from '@vueuse/core'
import { inBrowser } from 'vitepress'
import { computed, watch } from 'vue'
import RainbowSwitcher from './RainbowSwitcher.vue'
defineProps<{ text?: string; screenMenu?: boolean }>()
const reduceMotion = useMediaQuery('(prefers-reduced-motion: reduce)').value
const animated = useLocalStorage('animate-rainbow', inBrowser ? !reduceMotion : true)
function toggleRainbow() {
animated.value = !animated.value
}
// 在这里对动画做处理
watch(
animated,
anim => {
document.documentElement.classList.remove('rainbow')
if (anim) {
document.documentElement.classList.add('rainbow')
}
},
{ immediate: inBrowser, flush: 'post' },
)
const switchTitle = computed(() => {
return animated.value ? 'Disable rainbow animation' : 'Enable rainbow animation'
})
</script>
<template>
<ClientOnly>
<div class="group" :class="{ mobile: screenMenu }">
<div class="NavScreenRainbowAnimation">
<p class="text">
{{ text ?? 'Rainbow Animation' }}
</p>
<RainbowSwitcher
:title="switchTitle"
class="RainbowAnimationSwitcher"
:aria-checked="animated ? 'true' : 'false'"
@click="toggleRainbow"
>
<span class="i-tabler:rainbow animated" />
<span class="i-tabler:rainbow-off non-animated" />
</RainbowSwitcher>
</div>
</div>
</ClientOnly>
</template>
<style scoped>
.group {
border-top: 1px solid var(--vp-c-divider);
padding-top: 10px;
margin-top: 1rem !important;
}
.NavScreenRainbowAnimation {
display: flex;
justify-content: space-between;
align-items: center;
border-radius: 8px;
padding: 12px;
background-color: var(--vp-c-bg-elv);
max-width: 220px;
}
.text {
line-height: 24px;
font-size: 12px;
font-weight: 500;
color: var(--vp-c-text-2);
}
.animated {
opacity: 1;
}
.non-animated {
opacity: 0;
}
.RainbowAnimationSwitcher[aria-checked='false'] .non-animated {
opacity: 1;
}
.RainbowAnimationSwitcher[aria-checked='true'] .animated {
opacity: 1;
}
</style>
其中 RainbowSwitcher 组件是一个简单的开关按钮。以下是其实现:
<template>
<button class="VPSwitch" type="button" role="switch">
<span class="check">
<span v-if="$slots.default" class="icon">
<slot />
</span>
</span>
</button>
</template>
<style scoped>
.VPSwitch {
position: relative;
border-radius: 11px;
display: block;
width: 40px;
height: 22px;
flex-shrink: 0;
border: 1px solid var(--vp-input-border-color);
background-color: var(--vp-input-switch-bg-color);
transition: border-color 0.25s !important;
}
.check {
position: absolute;
top: 1px;
left: 1px;
width: 18px;
height: 18px;
border-radius: 50%;
background-color: var(--vp-c-neutral-inverse);
box-shadow: var(--vp-shadow-1);
transition: transform 0.25s !important;
}
.icon {
position: relative;
display: block;
width: 18px;
height: 18px;
border-radius: 50%;
overflow: hidden;
}
</style>
挂载组件
在 .vitepress/theme/index.ts 中,在 enhanceApp 中挂载组件:
// .vitepress/theme/index.ts
import DefaultTheme from 'vitepress/theme'
import CustomLayout from './Layout.vue'
export default {
extends: DefaultTheme,
Layout: CustomLayout,
enhanceApp({ app, router }) {
app.component('RainbowAnimationSwitcher', RainbowAnimationSwitcher)
if (typeof window === 'undefined') return
watch(
() => router.route.data.relativePath,
() => updateHomePageStyle(location.pathname === '/'),
{ immediate: true },
)
},
}
// Speed up the rainbow animation on home page
function updateHomePageStyle(value: boolean) {
if (value) {
if (homePageStyle) return
homePageStyle = document.createElement('style')
homePageStyle.innerHTML = `
:root {
animation: rainbow 12s linear infinite;
}`
document.body.appendChild(homePageStyle)
} else {
if (!homePageStyle) return
homePageStyle.remove()
homePageStyle = undefined
}
}
在导航栏中使用彩虹动画开关
在 .vitepress/config/index.ts 的配置文件中添加彩虹动画开关按钮:
export default defineConfig({
themeConfig: {
nav: [
// 其他导航项...
{
text: `v${version}`,
items: [
{
text: '发布日志',
link: '<https://github.com/yourusername/repo/releases>',
},
{
text: '提交 Issue',
link: '<https://github.com/yourusername/repo/issues>',
},
{
component: 'RainbowAnimationSwitcher',
props: {
text: '彩虹动画',
},
},
],
},
],
// 其他配置...
},
})
这样,彩虹动画开关就成功加载到导航栏的下拉菜单中。

彩虹动画效果

如果想查看具体效果,可查看 EasyEditor 的文档。其中关于彩虹动画效果的详细实现看,可以查看内部对应的代码:EasyEditor/docs/.vitepress/theme at main · Easy-Editor/EasyEditor。
来源:juejin.cn/post/7508591120407576586
python实现的websocket日志类
背景
功能需求需要实现一个“实时日志”功能,即在一个可以在web端触发任务的系统中,可以即时显示触发的任务的日志(此后台任务在后台或其他worker主机上执行)。最后采用了websocket方法来实现该功能,即在任务执行端实现一个logger类通过websocket上传实时日志给web后端,再由web后端通过websocket连接传给web前端,实现实时日志的功能。
websocket logHandler类
协程版本
使用websockets库
import logging
import json
import time
import asyncio
import websockets
from queue import Queue
from threading import Thread
import traceback
from _queue import Empty
class WebSocketHandler(logging.Handler):
"""
自定义日志处理器,将日志通过WebSocket发送到后端服务
"""
def __init__(self, ws_url, reconnect_interval=5, max_queue_size=10000):
"""
初始化WebSocket处理器
Args:
ws_url: WebSocket服务器URL
reconnect_interval: 断线重连间隔(秒)
max_queue_size: 日志队列最大长度,超出时丢弃旧日志
"""
super().__init__()
self.ws_url = ws_url
self.reconnect_interval = reconnect_interval
self.max_queue_size = max_queue_size
self.is_running = False
self.thread =
self.queue = # 异步队列,在start中初始化
self.loop = # 保存事件循环引用
def emit(self, record):
"""
重写emit方法,将日志记录发送到WebSocket
Args:
record: 日志记录对象
"""
try:
# 格式化日志
msg = self.format(record)
if not msg.endswith("\n"):
msg += "\n"
# 跨线程安全添加日志到队列(关键修复)
if self.loop and self.queue:
# 使用事件循环的线程安全方法添加元素
self.loop.call_soon_threadsafe(
self._safe_put_queue, msg
)
else:
print("队列未初始化,日志发送失败")
except Exception as e:
# 处理发送失败的情况
self.handleError(record)
def _safe_put_queue(self, msg):
"""线程安全的队列添加方法(在事件循环线程执行)"""
try:
if not self.queue.full():
self.queue.put_nowait(msg)
else:
# 队列满时丢弃最旧日志
self.queue.get_nowait()
self.queue.put_nowait(msg)
except Exception as e:
print(f"队列添加失败: {e}")
def start(self):
"""启动WebSocket发送线程"""
if not self.is_running:
self.is_running = True
self.thread = Thread(target=self._ws_sender_thread)
self.thread.daemon = True
self.thread.start()
print("WebSocket发送线程启动")
def stop(self):
"""停止WebSocket发送线程"""
self.is_running = False
if self.thread and self.thread.is_alive():
self.thread.join(timeout=2.0)
def _ws_sender_thread(self):
"""WebSocket发送线程主函数"""
self.loop = asyncio.new_event_loop()
asyncio.set_event_loop(self.loop)
self.queue = asyncio.Queue(maxsize=self.max_queue_size)
async def custom_heartbeat(websocket):
while True:
try:
await websocket.send(json.dumps({"type":"ping"})) # 自定义心跳消息
await asyncio.sleep(30) # 30秒间隔
except Exception as e:
print(f"心跳发送失败: {e}")
break
async def _process_logs(websocket):
# 连接成功后,发送队列中积压的所有日志
while not self.queue.empty() and self.is_running:
# log_data = self.queue.get_nowait()
# await websocket.send(json.dumps(log_data, ensure_ascii=False))
msg = await self.queue.get()
await websocket.send(msg)
# 持续发送新日志
while self.is_running:
try:
# 阻塞等待新日志,带超时以检查线程是否需要停止
# log_data = self.queue.get(timeout=1)
# await websocket.send(json.dumps(log_data))
msg = await self.queue.get()
await websocket.send(msg)
self.queue.task_done()
except asyncio.TimeoutError:
continue
except Empty:
continue
async def send_logs():
while self.is_running:
try:
# 连接WebSocket服务器
async with websockets.connect(self.ws_url) as websocket:
# 并行运行日志发送和心跳任务
await asyncio.gather(
_process_logs(websocket),
custom_heartbeat(websocket)
)
except Exception as e:
traceback.print_exc()
# 连接失败或断开,等待后重试
# 等待重连间隔(使用异步sleep)
await asyncio.sleep(self.reconnect_interval)
try:
self.loop.run_until_complete(send_logs())
except Exception as e:
pass
finally:
self.loop.close()
def close(self):
"""关闭处理器"""
self.stop()
super().close()
# 配置示例
def setup_logger():
# 创建logger
logger = logging.getLogger('my_app')
logger.setLevel(logging.DEBUG)
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_handler.setFormatter(console_formatter)
# 创建WebSocket处理器
ws_handler = WebSocketHandler(ws_url='ws://localhost:8999/logs/websocket/client-2546')
ws_handler.setLevel(logging.DEBUG)
json_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') # 我们在handler中自己处理JSON格式化
ws_handler.setFormatter(json_formatter)
# 添加处理器到logger
logger.addHandler(console_handler)
logger.addHandler(ws_handler)
# 启动WebSocket处理器
ws_handler.start()
return logger
# 使用示例
if __name__ == "__main__":
logger = setup_logger()
try:
# 正常记录日志,会同时输出到控制台和WebSocket
logger.debug('这是一条调试日志')
logger.info('这是一条信息日志')
logger.warning('这是一条警告日志')
logger.error('这是一条错误日志')
# 模拟长时间运行的程序
while True:
time.sleep(1)
except KeyboardInterrupt:
# 程序退出时,确保WebSocket处理器正确关闭
for handler in logger.handlers:
if isinstance(handler, WebSocketHandler):
handler.stop()
多线程版本
使用websocket-client库
import logging
import json
import time
from queue import Queue, Empty
from threading import Thread
import traceback
import websocket # 需安装:pip install websocket-client
class WebSocketHandler(logging.Handler):
"""自定义日志处理器(同步版本),通过WebSocket发送日志"""
def __init__(self, ws_url, reconnect_interval=5, max_queue_size=10000):
super().__init__()
self.ws_url = ws_url
self.reconnect_interval = reconnect_interval
self.max_queue_size = max_queue_size
self.is_running = False # 控制整体运行状态
self.heartbeat_running = False # 控制心跳线程
self.thread = # 日志发送主线程
self.heartbeat_thread = # 心跳线程
self.queue = Queue(maxsize=max_queue_size) # 同步队列(线程安全)
self.ws = # WebSocket连接实例
def emit(self, record):
"""日志记录触发时调用,将日志放入队列"""
try:
# 格式化日志
msg = self.format(record)
if not msg.endswith("\n"):
msg += "\n"
# 队列满时丢弃最旧日志
if self.queue.full():
try:
self.queue.get_nowait() # 移除最旧日志
except Empty:
pass # 队列已空,无需处理
self.queue.put_nowait(msg) # 放入新日志(同步队列线程安全)
except Exception as e:
self.handleError(record)
def close(self):
"""关闭处理器"""
self.stop()
super().close()
def start(self):
"""启动日志发送线程和心跳线程"""
if not self.is_running:
self.is_running = True
# 启动日志发送主线程
self.thread = Thread(target=self._ws_sender_thread)
self.thread.daemon = True
self.thread.start()
print("WebSocket发送线程启动")
def stop(self):
"""停止所有线程和连接"""
self.is_running = False
self.heartbeat_running = False # 停止心跳线程
# 关闭WebSocket连接
if self.ws:
try:
self.ws.close()
except Exception as e:
print(f"关闭WebSocket失败: {e}")
# 等待线程结束
if self.thread and self.thread.is_alive():
self.thread.join(timeout=2.0)
if self.heartbeat_thread and self.heartbeat_thread.is_alive():
self.heartbeat_thread.join(timeout=1.0)
print("WebSocket发送线程已停止")
def _start_heartbeat(self):
"""启动心跳线程"""
self.heartbeat_running = True
self.heartbeat_thread = Thread(target=self._heartbeat_loop)
self.heartbeat_thread.daemon = True
self.heartbeat_thread.start()
print("心跳线程启动")
def _heartbeat_loop(self):
"""心跳发送循环(独立线程)"""
while self.heartbeat_running and self.is_running:
try:
if self.ws and self.ws.connected: # 检查连接是否有效
self.ws.send(json.dumps({"type": "ping"})) # 发送心跳
time.sleep(30) # 30秒间隔
except Exception as e:
print(f"心跳发送失败: {e}")
break # 心跳失败,退出循环(由主线程重连)
def _process_logs(self):
"""处理队列中的日志并发送(同步阻塞)"""
while self.is_running:
try:
# 阻塞等待日志(超时1秒,避免永久阻塞)
msg = self.queue.get(timeout=1)
if self.ws and self.ws.connected:
self.ws.send(msg) # 发送日志
self.queue.task_done()
else:
# 连接已断开,将日志放回队列
self.queue.put(msg)
time.sleep(0.1) # 短暂等待后重试
except Empty:
continue # 队列空,继续循环
except Exception as e:
print(f"日志发送失败: {e}")
# 发送失败,将日志放回队列重试
try:
self.queue.put(msg)
except Exception as put_err:
print(f"日志放回队列失败: {put_err}")
time.sleep(1) # 等待后重试
def _ws_sender_thread(self):
"""WebSocket发送主线程:负责连接和日志发送协调"""
while self.is_running:
try:
# 建立WebSocket连接
print(f"连接WebSocket服务器: {self.ws_url}")
self.ws = websocket.create_connection(self.ws_url)
print("WebSocket连接成功")
# 启动心跳线程(每次重连后重启心跳)
self._start_heartbeat()
# 处理日志发送
self._process_logs()
except Exception as e:
print(f"WebSocket连接/发送异常: {e}")
traceback.print_exc()
finally:
# 连接断开时清理
self.heartbeat_running = False # 停止当前心跳线程
if self.heartbeat_thread:
self.heartbeat_thread.join(timeout=1.0)
if self.ws:
try:
self.ws.close()
except Exception as e:
print(f"关闭WebSocket连接失败: {e}")
self.ws = # 重置连接实例
# 断线重连等待
if self.is_running:
print(f"等待{self.reconnect_interval}秒后重试...")
time.sleep(self.reconnect_interval)
# 配置示例
def setup_logger():
# 创建logger
logger = logging.getLogger('my_app')
logger.setLevel(logging.DEBUG)
# 创建控制台处理器
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
console_handler.setFormatter(console_formatter)
# 创建WebSocket处理器(使用同步版本)
ws_handler = WebSocketHandler(ws_url='ws://localhost:8999/logs/websocket/client-2546')
ws_handler.setLevel(logging.DEBUG)
ws_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
ws_handler.setFormatter(ws_formatter)
# 添加处理器到logger
logger.addHandler(console_handler)
logger.addHandler(ws_handler)
# 启动WebSocket处理器
ws_handler.start()
return logger
# 使用示例
if __name__ == "__main__":
logger = setup_logger()
try:
# 测试日志发送
logger.debug('这是一条调试日志')
logger.info('这是一条信息日志')
logger.warning('这是一条警告日志')
logger.error('这是一条错误日志')
# 模拟长时间运行的程序
while True:
logger.info('持续发送的日志...')
time.sleep(5) # 每5秒发送一条测试日志
except KeyboardInterrupt:
print("程序退出中...")
# 停止WebSocket处理器
for handler in logger.handlers:
if isinstance(handler, WebSocketHandler):
handler.stop()
print("程序已退出")
集成
集成时只需将handler的示例加到全局logger中即可,就像main函数中setup_logger()的使用那样,但需注意正式使用时最好将handler.stop()函数放在finally块中,确保正确退出。
来源:juejin.cn/post/7534661634238185481
代码界的 “建筑师”:建造者模式,让复杂对象构建井然有序
深入理解建造者模式:复杂对象的定制化构建之道
在软件开发中,我们常会遇到需要创建 “复杂对象” 的场景 —— 这类对象由多个部件组成,且部件的组合顺序、配置细节可能存在多种变化。例如,定制一台电脑需要选择 CPU、内存、硬盘等部件;生成一份报告需要包含标题、正文、图表、落款等模块。若直接在客户端代码中编写对象的构建逻辑,不仅会导致代码臃肿、耦合度高,还难以灵活应对不同的定制需求。此时,建造者模式(Builder Pattern) 便能发挥关键作用,它将复杂对象的构建过程与表示分离,让同一构建过程可生成不同的表示。
在软件开发中,我们常会遇到需要创建 “复杂对象” 的场景 —— 这类对象由多个部件组成,且部件的组合顺序、配置细节可能存在多种变化。例如,定制一台电脑需要选择 CPU、内存、硬盘等部件;生成一份报告需要包含标题、正文、图表、落款等模块。若直接在客户端代码中编写对象的构建逻辑,不仅会导致代码臃肿、耦合度高,还难以灵活应对不同的定制需求。此时,建造者模式(Builder Pattern) 便能发挥关键作用,它将复杂对象的构建过程与表示分离,让同一构建过程可生成不同的表示。
一、建造者模式的核心定义与价值
1. 官方定义
建造者模式是 “创建型设计模式” 的重要成员,其核心思想是:将一个复杂对象的构建过程抽象出来,拆分为多个独立的构建步骤,通过不同的 “建造者” 实现这些步骤,再由 “指挥者” 按指定顺序调用步骤,最终组装出完整对象。
简单来说,它就像 “组装家具” 的流程:家具说明书(指挥者)规定了先装框架、再装抽屉、最后装柜门的步骤;而不同品牌的组装师傅(具体建造者),会用不同材质的零件(部件)完成每一步;最终用户(客户端)只需告诉商家 “想要哪种风格的家具”,无需关心具体组装细节。
建造者模式是 “创建型设计模式” 的重要成员,其核心思想是:将一个复杂对象的构建过程抽象出来,拆分为多个独立的构建步骤,通过不同的 “建造者” 实现这些步骤,再由 “指挥者” 按指定顺序调用步骤,最终组装出完整对象。
简单来说,它就像 “组装家具” 的流程:家具说明书(指挥者)规定了先装框架、再装抽屉、最后装柜门的步骤;而不同品牌的组装师傅(具体建造者),会用不同材质的零件(部件)完成每一步;最终用户(客户端)只需告诉商家 “想要哪种风格的家具”,无需关心具体组装细节。
2. 核心价值
- 解耦构建与表示:构建过程(步骤顺序)和对象表示(部件配置)分离,同一过程可生成不同配置的对象(如用相同步骤组装 “游戏本” 和 “轻薄本”)。
- 灵活定制细节:支持对对象部件的精细化控制,客户端可通过选择不同建造者,定制符合需求的对象(如电脑可选择 “i7 CPU+32G 内存” 或 “i5 CPU+16G 内存”)。
- 简化客户端代码:客户端无需关注复杂的构建逻辑,只需与指挥者或建造者简单交互,即可获取完整对象。
- 解耦构建与表示:构建过程(步骤顺序)和对象表示(部件配置)分离,同一过程可生成不同配置的对象(如用相同步骤组装 “游戏本” 和 “轻薄本”)。
- 灵活定制细节:支持对对象部件的精细化控制,客户端可通过选择不同建造者,定制符合需求的对象(如电脑可选择 “i7 CPU+32G 内存” 或 “i5 CPU+16G 内存”)。
- 简化客户端代码:客户端无需关注复杂的构建逻辑,只需与指挥者或建造者简单交互,即可获取完整对象。
二、建造者模式的核心结构
建造者模式通常包含 4 个核心角色,它们分工明确、协作完成对象构建:
角色名称 核心职责 产品(Product) 需要构建的复杂对象,由多个部件组成(如 “电脑”“报告”)。 抽象建造者(Builder) 定义构建产品所需的所有步骤(如 “设置 CPU”“设置内存”),通常包含获取产品的方法。 具体建造者(Concrete Builder) 实现抽象建造者的步骤,定义具体部件的配置(如 “游戏本建造者”“轻薄本建造者”)。 指挥者(Director) 负责调用建造者的步骤,规定构建的顺序(如 “先装 CPU→再装内存→最后装硬盘”)。
建造者模式通常包含 4 个核心角色,它们分工明确、协作完成对象构建:
| 角色名称 | 核心职责 |
|---|---|
| 产品(Product) | 需要构建的复杂对象,由多个部件组成(如 “电脑”“报告”)。 |
| 抽象建造者(Builder) | 定义构建产品所需的所有步骤(如 “设置 CPU”“设置内存”),通常包含获取产品的方法。 |
| 具体建造者(Concrete Builder) | 实现抽象建造者的步骤,定义具体部件的配置(如 “游戏本建造者”“轻薄本建造者”)。 |
| 指挥者(Director) | 负责调用建造者的步骤,规定构建的顺序(如 “先装 CPU→再装内存→最后装硬盘”)。 |
三、建造者模式的实战案例:定制电脑的构建
为了更直观理解,我们以 “定制电脑” 为例,用 Java 代码实现建造者模式:
为了更直观理解,我们以 “定制电脑” 为例,用 Java 代码实现建造者模式:
1. 第一步:定义 “产品”(电脑)
首先明确需要构建的复杂对象 —— 电脑,它包含 CPU、内存、硬盘、显卡等部件:
// 产品:电脑
public class Computer {
// 电脑的部件
private String cpu;
private String memory;
private String hardDisk;
private String graphicsCard;
// Setter方法(用于建造者设置部件)
public void setCpu(String cpu) {
this.cpu = cpu;
}
public void setMemory(String memory) {
this.memory = memory;
}
public void setHardDisk(String hardDisk) {
this.hardDisk = hardDisk;
}
public void setGraphicsCard(String graphicsCard) {
this.graphicsCard = graphicsCard;
}
// 展示电脑配置(对象的“表示”)
public void showConfig() {
System.out.println("电脑配置:CPU=" + cpu + ",内存=" + memory + ",硬盘=" + hardDisk + ",显卡=" + graphicsCard);
}
}
首先明确需要构建的复杂对象 —— 电脑,它包含 CPU、内存、硬盘、显卡等部件:
// 产品:电脑
public class Computer {
// 电脑的部件
private String cpu;
private String memory;
private String hardDisk;
private String graphicsCard;
// Setter方法(用于建造者设置部件)
public void setCpu(String cpu) {
this.cpu = cpu;
}
public void setMemory(String memory) {
this.memory = memory;
}
public void setHardDisk(String hardDisk) {
this.hardDisk = hardDisk;
}
public void setGraphicsCard(String graphicsCard) {
this.graphicsCard = graphicsCard;
}
// 展示电脑配置(对象的“表示”)
public void showConfig() {
System.out.println("电脑配置:CPU=" + cpu + ",内存=" + memory + ",硬盘=" + hardDisk + ",显卡=" + graphicsCard);
}
}
2. 第二步:定义 “抽象建造者”(电脑建造者接口)
抽象出构建电脑的所有步骤,确保所有具体建造者都遵循统一规范:
// 抽象建造者:电脑建造者接口
public interface ComputerBuilder {
// 构建步骤1:设置CPU
void buildCpu();
// 构建步骤2:设置内存
void buildMemory();
// 构建步骤3:设置硬盘
void buildHardDisk();
// 构建步骤4:设置显卡
void buildGraphicsCard();
// 获取最终构建的电脑
Computer getComputer();
}
抽象出构建电脑的所有步骤,确保所有具体建造者都遵循统一规范:
// 抽象建造者:电脑建造者接口
public interface ComputerBuilder {
// 构建步骤1:设置CPU
void buildCpu();
// 构建步骤2:设置内存
void buildMemory();
// 构建步骤3:设置硬盘
void buildHardDisk();
// 构建步骤4:设置显卡
void buildGraphicsCard();
// 获取最终构建的电脑
Computer getComputer();
}
3. 第三步:实现 “具体建造者”(游戏本 / 轻薄本建造者)
针对不同需求,实现具体的部件配置。例如,“游戏本” 需要高性能 CPU 和显卡,“轻薄本” 更注重便携性(低功耗部件):
// 具体建造者1:游戏本建造者
public class GamingLaptopBuilder implements ComputerBuilder {
private Computer computer = new Computer(); // 持有产品实例
@Override
public void buildCpu() {
computer.setCpu("Intel i9-13900HX(高性能CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("32GB DDR5(高带宽内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("2TB SSD(高速硬盘)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("NVIDIA RTX 4080(高性能显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
// 具体建造者2:轻薄本建造者
public class UltrabookBuilder implements ComputerBuilder {
private Computer computer = new Computer();
@Override
public void buildCpu() {
computer.setCpu("Intel i5-1335U(低功耗CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("16GB LPDDR5(低功耗内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("1TB SSD(便携性优先)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("Intel Iris Xe(集成显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
针对不同需求,实现具体的部件配置。例如,“游戏本” 需要高性能 CPU 和显卡,“轻薄本” 更注重便携性(低功耗部件):
// 具体建造者1:游戏本建造者
public class GamingLaptopBuilder implements ComputerBuilder {
private Computer computer = new Computer(); // 持有产品实例
@Override
public void buildCpu() {
computer.setCpu("Intel i9-13900HX(高性能CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("32GB DDR5(高带宽内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("2TB SSD(高速硬盘)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("NVIDIA RTX 4080(高性能显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
// 具体建造者2:轻薄本建造者
public class UltrabookBuilder implements ComputerBuilder {
private Computer computer = new Computer();
@Override
public void buildCpu() {
computer.setCpu("Intel i5-1335U(低功耗CPU)");
}
@Override
public void buildMemory() {
computer.setMemory("16GB LPDDR5(低功耗内存)");
}
@Override
public void buildHardDisk() {
computer.setHardDisk("1TB SSD(便携性优先)");
}
@Override
public void buildGraphicsCard() {
computer.setGraphicsCard("Intel Iris Xe(集成显卡)");
}
@Override
public Computer getComputer() {
return computer;
}
}
4. 第四步:定义 “指挥者”(电脑组装指导者)
指挥者负责规定构建顺序,避免具体建造者与步骤顺序耦合。例如,统一按 “CPU→内存→硬盘→显卡” 的顺序组装:
// 指挥者:电脑组装指导者
public class ComputerDirector {
// 接收具体建造者,按顺序调用构建步骤
public Computer construct(ComputerBuilder builder) {
builder.buildCpu(); // 步骤1:装CPU
builder.buildMemory(); // 步骤2:装内存
builder.buildHardDisk();// 步骤3:装硬盘
builder.buildGraphicsCard();// 步骤4:装显卡
return builder.getComputer(); // 返回组装好的电脑
}
}
指挥者负责规定构建顺序,避免具体建造者与步骤顺序耦合。例如,统一按 “CPU→内存→硬盘→显卡” 的顺序组装:
// 指挥者:电脑组装指导者
public class ComputerDirector {
// 接收具体建造者,按顺序调用构建步骤
public Computer construct(ComputerBuilder builder) {
builder.buildCpu(); // 步骤1:装CPU
builder.buildMemory(); // 步骤2:装内存
builder.buildHardDisk();// 步骤3:装硬盘
builder.buildGraphicsCard();// 步骤4:装显卡
return builder.getComputer(); // 返回组装好的电脑
}
}
5. 第五步:客户端调用(定制电脑)
客户端只需选择 “具体建造者”,无需关心构建步骤,即可获取定制化电脑:
public class Client {
public static void main(String[] args) {
// 1. 创建指挥者
ComputerDirector director = new ComputerDirector();
// 2. 定制游戏本(选择游戏本建造者)
ComputerBuilder gamingBuilder = new GamingLaptopBuilder();
Computer gamingLaptop = director.construct(gamingBuilder);
gamingLaptop.showConfig(); // 输出:游戏本配置
// 3. 定制轻薄本(选择轻薄本建造者)
ComputerBuilder ultrabookBuilder = new UltrabookBuilder();
Computer ultrabook = director.construct(ultrabookBuilder);
ultrabook.showConfig(); // 输出:轻薄本配置
}
}
运行结果:
电脑配置:CPU=Intel i9-13900HX(高性能CPU),内存=32GB DDR5(高带宽内存),硬盘=2TB SSD(高速硬盘),显卡=NVIDIA RTX 4080(高性能显卡)
电脑配置:CPU=Intel i5-1335U(低功耗CPU),内存=16GB LPDDR5(低功耗内存),硬盘=1TB SSD(便携性优先),显卡=Intel Iris Xe(集成显卡)
客户端只需选择 “具体建造者”,无需关心构建步骤,即可获取定制化电脑:
public class Client {
public static void main(String[] args) {
// 1. 创建指挥者
ComputerDirector director = new ComputerDirector();
// 2. 定制游戏本(选择游戏本建造者)
ComputerBuilder gamingBuilder = new GamingLaptopBuilder();
Computer gamingLaptop = director.construct(gamingBuilder);
gamingLaptop.showConfig(); // 输出:游戏本配置
// 3. 定制轻薄本(选择轻薄本建造者)
ComputerBuilder ultrabookBuilder = new UltrabookBuilder();
Computer ultrabook = director.construct(ultrabookBuilder);
ultrabook.showConfig(); // 输出:轻薄本配置
}
}
运行结果:
电脑配置:CPU=Intel i9-13900HX(高性能CPU),内存=32GB DDR5(高带宽内存),硬盘=2TB SSD(高速硬盘),显卡=NVIDIA RTX 4080(高性能显卡)
电脑配置:CPU=Intel i5-1335U(低功耗CPU),内存=16GB LPDDR5(低功耗内存),硬盘=1TB SSD(便携性优先),显卡=Intel Iris Xe(集成显卡)
四、建造者模式的适用场景
并非所有对象创建都需要建造者模式,以下场景最适合使用:
- 复杂对象的定制化构建:对象由多个部件组成,且部件配置、组合顺序存在多种变化(如定制电脑、生成个性化报告、构建汽车)。
- 需要隐藏构建细节:客户端无需知道对象的具体构建步骤,只需获取最终结果(如用户无需知道电脑 “先装 CPU 还是先装内存”)。
- 同一构建过程生成不同表示:通过更换具体建造者,可让同一指挥者(步骤顺序)生成不同配置的对象(如同一组装流程,既做游戏本也做轻薄本)。
并非所有对象创建都需要建造者模式,以下场景最适合使用:
- 复杂对象的定制化构建:对象由多个部件组成,且部件配置、组合顺序存在多种变化(如定制电脑、生成个性化报告、构建汽车)。
- 需要隐藏构建细节:客户端无需知道对象的具体构建步骤,只需获取最终结果(如用户无需知道电脑 “先装 CPU 还是先装内存”)。
五、建造者模式的优缺点
优点
- 灵活性高:支持对对象部件的精细化定制,轻松扩展新的具体建造者(如新增 “工作站电脑建造者”,无需修改原有代码)。
- 代码清晰:将复杂构建逻辑拆分为独立步骤,职责单一,便于维护(构建步骤由指挥者管理,部件配置由建造者管理)。
- 解耦性强:客户端与具体构建步骤、部件配置分离,降低代码耦合度。
- 灵活性高:支持对对象部件的精细化定制,轻松扩展新的具体建造者(如新增 “工作站电脑建造者”,无需修改原有代码)。
缺点
- 增加类数量:每个具体产品需对应一个具体建造者,若产品类型过多,会导致类数量激增(如电脑有 10 种型号,需 10 个具体建造者)。
- 不适用于简单对象:若对象仅由少数部件组成(如 “用户” 对象仅含姓名、年龄),使用建造者模式会显得冗余,不如直接 new 对象高效。
- 增加类数量:每个具体产品需对应一个具体建造者,若产品类型过多,会导致类数量激增(如电脑有 10 种型号,需 10 个具体建造者)。
六、建造者模式与工厂模式对比表
建造者模式与工厂模式虽同属 “创建型模式”,但核心意图和适用场景差异显著,以下是两者的关键对比:
| 对比维度 | 建造者模式(Builder Pattern) | 工厂模式(Factory Pattern) |
|---|---|---|
| 核心意图 | 关注 “如何构建”:拆分复杂对象的构建步骤,定制部件细节 | 关注 “创建什么”:统一创建对象,隐藏实例化逻辑 |
| 产品复杂度 | 适用于复杂对象(由多个部件组成,需分步构建) | 适用于简单 / 标准化对象(单一完整对象,无需分步) |
| 客户端控制度 | 客户端可控制部件配置(选择不同建造者) | 客户端仅控制产品类型(告诉工厂 “要什么”,不关心细节) |
| 角色构成 | 产品、抽象建造者、具体建造者、指挥者(4 个角色) | 产品、抽象工厂、具体工厂(3 个角色,无指挥者) |
| 典型场景 | 定制电脑、组装汽车、生成个性化报告 | 生产标准化产品(如不同品牌的手机、不同类型的日志器) |
| 类比生活场景 | 按需求定制家具(选材质、定尺寸,分步组装) | 从工厂批量购买标准化家电(直接拿成品,不关心生产) |
来源:juejin.cn/post/7543448572341157927
用户请求满天飞,如何精准『导航』?聊聊流量路由那些事儿
嘿,各位未来的技术大佬们,我是老码小张。
不知道大家有没有遇到过这样的场景:你美滋滋地打开刚部署上线的应用 cool-app.com,在国内访问速度飞快。结果第二天,海外的朋友跟你吐槽,说访问你的应用慢得像蜗牛。或者更糟,某个区域的用户突然反馈说服务完全访问不了了!这时候你可能会挠头:用户来自天南海北,服务器也可能部署在不同地方,我怎么才能让每个用户都能又快又稳地访问到我的服务呢?

别慌!这其实就是咱们今天要聊的互联网流量路由策略要解决的问题。搞懂了它,你就掌握了给网络请求“精准导航”的秘诀,让你的应用在全球范围内都能提供更好的用户体验。
流量路由:不止是 DNS 解析那么简单
很多初级小伙伴可能觉得,用户访问网站不就是 浏览器 -> DNS 查询 IP -> 连接服务器 嘛?没错,DNS 是第一步,但现代互联网应用远不止这么简单。特别是当你的服务需要部署在多个数据中心、覆盖不同地理区域的用户时,仅仅返回一个固定的 IP 地址是远远不够的。
我们需要更智能的策略,来决定当用户请求 cool-app.com 时,DNS 服务器应该返回哪个(或哪些)IP 地址。这就引出了各种路由策略(Routing Policies)。你可以把它们想象成 DNS 服务器里的“智能导航系统”,根据不同的规则把用户导向最合适的目的地。
下面,咱们就来盘点几种最常见也最实用的路由策略。
策略一:按地理位置『就近安排』 (Geolocation Routing)
这是最直观的一种策略。顾名思义,它根据用户请求来源的 IP 地址,判断用户的地理位置(比如国家、省份甚至城市),然后将用户导向物理位置上距离最近或者预设好的对应区域的服务器。
工作原理示意:
sequenceDiagram
participant User as 用户 (来自北京)
participant DNS as 智能 DNS 服务器
participant ServerCN as 北京服务器 (1.1.1.1)
participant ServerUS as 美国服务器 (2.2.2.2)
User->>DNS: 查询 cool-app.com 的 IP 地址
activate DNS
DNS-->>DNS: 分析来源 IP,判断用户在北京
DNS-->>User: 返回北京服务器 IP (1.1.1.1)
deactivate DNS
User->>ServerCN: 连接 1.1.1.1
啥时候用?
- 需要为特定地区用户提供本地化内容或服务。
- 有合规性要求,比如某些数据必须存储在用户所在国家境内(像 GDPR)。
- 希望降低跨区域访问带来的延迟。
简单配置示例(伪代码):
// 类似 AWS Route 53 或其他云 DNS 的配置逻辑
RoutingPolicy {
Type: Geolocation,
Rules: [
{ Location: '中国', TargetIP: '1.1.1.1' },
{ Location: '美国', TargetIP: '2.2.2.2' },
{ Location: '*', TargetIP: '3.3.3.3' } // * 代表默认,匹配不到具体位置时使用
]
}
策略二:追求极致速度的『延迟优先』 (Latency-Based Routing)
这个策略的目标是:快! 它不关心用户在哪儿,只关心用户访问哪个服务器的网络延迟最低(也就是 RTT,Round-Trip Time 最短)。DNS 服务商会持续监测从全球不同网络到你各个服务器节点的网络延迟,然后把用户导向响应最快的那个节点。
工作原理示意:
sequenceDiagram
participant User as 用户
participant DNS as 智能 DNS 服务器
participant ServerA as 服务器 A (东京)
participant ServerB as 服务器 B (新加坡)
User->>DNS: 查询 cool-app.com 的 IP 地址
activate DNS
DNS-->>DNS: 检测用户到各服务器的延迟 (到 A: 50ms, 到 B: 30ms)
DNS-->>User: 返回延迟最低的服务器 B 的 IP
deactivate DNS
User->>ServerB: 连接服务器 B
啥时候用?
- 对响应速度要求极高的应用,比如在线游戏、实时通讯。
- 全球用户分布广泛,希望动态地为每个用户找到最快接入点。
注意点: 延迟是动态变化的,所以这种策略依赖于 DNS 服务商持续、准确的延迟探测。
策略三:灵活调度的『按权重分配』 (Weighted Routing)
这种策略允许你给不同的服务节点分配不同的权重(百分比),DNS 服务器会按照你设定的比例,把用户的请求随机分配到这些节点上。
工作原理示意:
假设你有两个版本的服务 V1 和 V2,部署在不同的服务器组上。
// 类似云 DNS 配置
RoutingPolicy {
Type: Weighted,
Targets: [
{ TargetIPGr0up: 'V1_Servers', Weight: 90 }, // 90% 流量到 V1
{ TargetIPGr0up: 'V2_Servers', Weight: 10 } // 10% 流量到 V2
]
}
DNS 会根据这个权重,概率性地返回 V1 或 V2 服务器组的 IP。
啥时候用?
- A/B 测试:想测试新功能?分一小部分流量(比如 5%)到新版本,看看效果。
- 灰度发布/金丝雀发布:新版本上线,先给 1% 的用户试试水,没问题再逐步增加权重到 10%、50%、100%。稳!
- 负载均衡:如果你的服务器配置不同(比如有几台是高性能的,几台是普通配置的),可以按性能分配不同权重,让高性能机器承担更多流量。
策略四:保障高可用的『故障转移』 (Failover Routing)
这个策略是为了高可用性。你需要设置一个主服务节点和一个或多个备用节点。DNS 服务器会持续对主节点进行健康检查(比如探测端口是否存活、HTTP 接口是否返回 200 OK)。
- 正常情况:所有流量都导向主节点。
- 主节点挂了:DNS 检测到主节点 N 次健康检查失败后,会自动把流量切换到备用节点。
- 主节点恢复:一旦主节点恢复健康,流量可以自动切回来(取决于你的配置)。
工作原理示意:
graph LR
A[用户请求] --> B{DNS 健康检查};
B -- 主节点健康 --> C[主服务器];
B -- 主节点故障 --> D[备用服务器];
C --> E[提供服务];
D --> E;
啥时候用?
- 任何对可用性要求高的关键服务。谁也不想服务宕机了用户还一直往坏掉的服务器上撞吧?
- 实现基本的灾备能力。
关键点: 健康检查的配置(频率、失败阈值)和 DNS 记录的 TTL(Time-To-Live,缓存时间)设置很关键。TTL 太长,故障切换就不够及时;TTL 太短,会增加 DNS 查询压力和成本。需要权衡。
策略五:CDN 和大厂最爱『任播』 (Anycast)
Anycast 稍微特殊一点,它通常是在更底层的网络层面(BGP 路由协议)实现的,但 DNS 经常与之配合。简单来说,就是你用同一个 IP 地址在全球多个地点宣告你的服务。用户的请求会被沿途的网络路由器自动导向“网络距离”上最近的那个宣告了该 IP 的节点。
效果: 用户感觉就像是连接到了离他最近的“入口”。
啥时候用?
- CDN 服务:为什么你访问各大 CDN 厂商(如 Cloudflare, Akamai)的资源总是很快?Anycast 是核心技术之一,让用户从最近的边缘节点获取内容。
- 公共 DNS 服务:像 Google 的
8.8.8.8和 Cloudflare 的1.1.1.1都使用了 Anycast,你在全球任何地方 ping 这个 IP,响应的都是离你最近的数据中心。
对于应用开发者来说,你可能不会直接配置 BGP,但你会选择使用提供了 Anycast 网络的服务商(比如某些云厂商的负载均衡器或 CDN 服务)。
选哪个?一张表帮你捋清楚
这么多策略,到底该怎么选呢?别急,我给你整理了个表格,对比一下:
| 策略名称 | 核心原理 | 主要应用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 地理位置路由 | 基于用户 IP 判断地理位置 | 本地化内容、合规性、区域优化 | 实现区域隔离、满足合规 | IP 库可能不准、无法反映真实网络状况 |
| 延迟路由 | 基于网络延迟 (RTT) | 追求最低访问延迟、全球性能优化 | 用户体验好、动态适应网络变化 | 依赖准确探测、成本可能较高 |
| 权重路由 | 按预设比例分配流量 | A/B 测试、灰度发布、按能力负载均衡 | 灵活控制流量分配、上线平稳 | 无法基于用户体验动态调整(除非结合其他策略) |
| 故障转移路由 | 健康检查 + 主备切换 | 高可用、灾备 | 提升服务可靠性、自动化故障处理 | 切换有延迟(受 TTL 和检查频率影响) |
| 任播 (Anycast) | 同一 IP 多点宣告,网络路由就近转发 | CDN、公共 DNS、全球入口优化 | 显著降低延迟、抵抗 DDoS 攻击(分散) | 配置复杂(通常由服务商提供)、成本高 |
实战经验分享:组合拳出奇效!
在实际项目中,我们很少只用单一策略。更常见的是打组合拳:
- 地理位置 + 故障转移:先按区域分配流量(比如中国用户到上海,美国用户到硅谷),然后在每个区域内部署主备服务器,使用故障转移策略保障区域内的高可用。这是很多应用的标配。
- 地理位置 + 权重路由:在一个特定的地理区域内(比如只在中国区),对新上线的服务 V2 使用权重路由进行灰度发布。
- Anycast + 后端智能路由:使用 Anycast IP 作为全球统一入口,流量到达最近的接入点后,再根据后端服务的实际负载、延迟等情况,通过内部的负载均衡器或服务网格(Service Mesh)进行更精细的二次路由。
别忘了监控! 无论你用哪种策略,监控都至关重要。你需要关注:
- 各节点的健康状况。
- 用户的实际访问延迟(可以用 RUM - Real User Monitoring)。
- DNS 解析成功率和解析耗时。
- 流量分布是否符合预期。
有了监控数据,你才能知道你的路由策略是否有效,是否需要调整。
好了,今天关于互联网流量路由策略就先和大家聊这么多。希望这些内容能帮助你理解,当用户的请求“满天飞”时,我们是如何通过这些“智能导航”技术,确保他们能又快又稳地到达目的地的。这不仅仅是运维同学的事,作为开发者,理解这些原理,能让你在设计和部署应用时考虑得更周全。
我是老码小张,一个喜欢研究技术原理,并且在实践中不断成长的技术人。如果你觉得这篇文章对你有帮助,或者有什么想法想交流,欢迎在评论区留言!咱们下次再见!
来源:juejin.cn/post/7498292516493656098
提升React移动端开发效率:Vant组件库
在React中使用Vant组件库的指南
Vant是一套轻量、可靠的移动端组件库,特别适合在React项目中使用。本文将详细介绍如何在React项目中集成和使用Vant组件库,并通过Button按钮和NavBar导航栏等常用组件作为示例,展示其基本用法和高级特性。
一、Vant简介与安装
1.1 Vant是什么
Vant是由有赞前端团队开发的一套基于Vue的移动端组件库,后来也推出了React版本(Vant React)。它提供了60+高质量组件,覆盖了移动端开发的大部分场景,具有以下特点:
- 性能极佳:组件经过精心优化,运行流畅
- 样式美观:遵循统一的设计语言,视觉效果出色
- 功能丰富:提供大量实用组件和灵活配置
- 文档完善:中文文档详细,示例丰富
- 社区活跃:GitHub上star数高,问题响应快
1.2 安装Vant
在React项目中使用Vant前,需要先安装它。确保你已经创建了一个React项目(可以使用create-react-app或其它脚手架工具),然后在项目目录下执行:
bash
npm install vant --save
# 或者使用yarn
yarn add vant
1.3 引入组件样式
Vant的样式文件需要单独引入。推荐在项目的入口文件(通常是src/index.js或src/App.js)中添加以下代码:
jsx
import 'vant/lib/index.css';
这一步非常重要,否则组件将没有样式效果。
二、Button按钮组件使用详解
Button是Vant中最基础也是最常用的组件之一,下面详细介绍它的使用方法。
2.1 基本用法
首先引入Button组件:
jsx
import { Button } from 'vant';
然后在你的组件中使用:
jsx
function MyComponent() {
return (
<div>
<Button type="primary">主要按钮</Button>
<Button type="info">信息按钮</Button>
<Button type="default">默认按钮</Button>
</div>
);
}
2.2 按钮类型
Vant提供了多种按钮类型,通过type属性来设置:
primary: 主要按钮,蓝色背景success: 成功按钮,绿色背景danger: 危险按钮,红色背景warning: 警告按钮,橙色背景default: 默认按钮,灰色背景info: 信息按钮,浅蓝色背景
jsx
<Button type="success">成功按钮</Button>
<Button type="danger">危险按钮</Button>
<Button type="warning">警告按钮</Button>
2.3 按钮形状
除了类型,还可以设置按钮的形状:
- 方形按钮(默认)
- 圆形按钮:添加
round属性 - 圆角按钮:添加
square属性
jsx
<Button round>圆形按钮</Button>
<Button square>圆角按钮</Button>
2.4 按钮尺寸
Vant提供了三种尺寸的按钮:
- 大号按钮:
size="large" - 普通按钮(默认)
- 小号按钮:
size="small" - 迷你按钮:
size="mini"
jsx
<Button size="large">大号按钮</Button>
<Button size="small">小号按钮</Button>
<Button size="mini">迷你按钮</Button>
2.5 按钮状态
按钮有不同的状态,可以通过以下属性控制:
- 禁用状态:
disabled - 加载状态:
loading - 朴素按钮:
plain(边框样式)
jsx
<Button disabled>禁用按钮</Button>
<Button loading>加载中...</Button>
<Button plain>朴素按钮</Button>
2.6 按钮图标
可以在按钮中添加图标,使用icon属性:
jsx
import { Icon } from 'vant';
<Button icon="plus">添加</Button>
<Button icon="search">搜索</Button>
<Button icon={<Icon name="like" />}>点赞</Button>
Vant内置了大量图标,可以在官方文档中查看所有可用图标。
2.7 按钮事件
按钮最常用的就是点击事件:
jsx
function handleClick() {
console.log('按钮被点击了');
}
<Button onClick={handleClick}>点击我</Button>
三、NavBar导航栏组件使用详解
NavBar是移动端常用的顶部导航栏组件,下面详细介绍它的使用方法。
3.1 基本用法
首先引入NavBar组件:
jsx
import { NavBar } from 'vant';
然后在你的组件中使用:
jsx
function MyComponent() {
return (
<NavBar
title="标题"
leftText="返回"
rightText="按钮"
leftArrow
/>
);
}
3.2 主要属性
NavBar组件的主要属性包括:
title: 导航栏标题leftText: 左侧文字rightText: 右侧文字leftArrow: 是否显示左侧箭头fixed: 是否固定在顶部placeholder: 是否生成一个等高的占位元素(配合fixed使用)border: 是否显示下边框zIndex: 设置z-index
jsx
<NavBar
title="个人中心"
leftText="返回"
rightText="设置"
leftArrow
fixed
placeholder
border
zIndex={100}
/>
3.3 自定义内容
除了使用属性,还可以通过插槽自定义导航栏内容:
jsx
<NavBar>
<template #left>
<Icon name="arrow-left" /> 返回
</template>
<template #title>
<span style={{ color: 'red' }}>自定义标题</span>
</template>
<template #right>
<Icon name="search" />
<Icon name="more-o" style={{ marginLeft: '10px' }} />
</template>
</NavBar>
3.4 事件处理
NavBar组件提供了以下事件:
click-left: 点击左侧区域时触发click-right: 点击右侧区域时触发
jsx
function handleClickLeft() {
console.log('点击了左侧');
// 通常用于返回上一页
// history.goBack();
}
function handleClickRight() {
console.log('点击了右侧');
// 可以打开设置页面等
}
<NavBar
title="事件示例"
leftText="返回"
rightText="设置"
leftArrow
onClickLeft={handleClickLeft}
onClickRight={handleClickRight}
/>
3.5 配合路由使用
在实际项目中,NavBar通常需要配合路由使用:
jsx
import { useNavigate } from 'react-router-dom';
function MyComponent() {
const navigate = useNavigate();
const handleBack = () => {
navigate(-1); // 返回上一页
};
const handleToSettings = () => {
navigate('/settings'); // 跳转到设置页
};
return (
<NavBar
title="路由示例"
leftText="返回"
rightText="设置"
leftArrow
onClickLeft={handleBack}
onClickRight={handleToSettings}
/>
);
}
四、高级用法与注意事项
4.1 主题定制
Vant支持主题定制,可以通过CSS变量来修改主题样式。在项目的全局CSS文件中添加:
css
:root {
--van-primary-color: #ff6a00; /* 修改主题色为橙色 */
--van-border-radius: 8px; /* 修改圆角大小 */
--van-nav-bar-height: 60px; /* 修改导航栏高度 */
}
更多可定制的CSS变量可以参考官方文档。
4.2 按需引入
如果担心引入全部组件会增加包体积,可以使用按需引入的方式。首先安装babel插件:
bash
npm install babel-plugin-import --save-dev
然后在babel配置中添加:
json
{
"plugins": [
["import", {
"libraryName": "vant",
"libraryDirectory": "es",
"style": true
}, "vant"]
]
}
之后就可以按需引入组件了:
jsx
import { Button, NavBar } from 'vant';
这种方式只会打包你实际使用的组件,可以有效减小最终打包体积。
4.3 国际化支持
Vant支持多语言,可以通过LocaleProvider组件设置:
jsx
import { LocaleProvider, Button } from 'vant';
import enUS from 'vant/es/locale/lang/en-US';
function App() {
return (
<LocaleProvider locale={enUS}>
<Button>Submit</Button>
</LocaleProvider>
);
}
4.4 常见问题与解决方案
- 样式不生效:确保已经正确引入了Vant的样式文件
- 组件未定义:检查组件名称拼写是否正确,是否已经正确引入
- TypeScript支持:Vant提供了完整的TypeScript类型定义,可以直接在TS项目中使用
- 移动端适配:建议在项目中同时使用postcss-pxtorem或postcss-px-to-viewport等插件进行移动端适配
五、总结
通过合理使用Vant组件库,可以显著提高React移动端应用的开发效率,同时保证UI的一致性和美观性。建议读者在实际项目中多加练习,掌握更多组件的使用方法。
Vant还提供了许多其他实用组件,如Toast轻提示、Dialog弹出框、List列表等,都可以在官方文档中找到详细的使用说明。
来源:juejin.cn/post/7531667016286863394
transform、translate、transition分别是什么属性,CSS中常用的实现动画方式
transform、translate、transition分别是什么属性,CSS中常用的实现动画方式
在 CSS 中,transform、translate 和 transition 是用于实现元素变换和动画的重要属性。它们各自有不同的作用,通常结合使用可以实现丰富的动画效果。
1. 属性详解
1.1 transform
- 作用:用于对元素进行 2D 或 3D 变换,如旋转、缩放、倾斜、平移等。
- 常用函数:
translate(x, y):平移元素。rotate(angle):旋转元素。scale(x, y):缩放元素。skew(x-angle, y-angle):倾斜元素。matrix(a, b, c, d, e, f):定义 2D 变换矩阵。
- 示例:
.box {
transform: translate(50px, 100px) rotate(45deg) scale(1.5);
}
1.2 translate
- 作用:
translate是transform的一个函数,用于平移元素。 - 语法:
translate(x, y):水平方向移动x,垂直方向移动y。translateX(x):仅水平方向移动。translateY(y):仅垂直方向移动。translateZ(z):在 3D 空间中沿 Z 轴移动。
- 示例:
.box {
transform: translate(50px, 100px);
}
1.3 transition
- 作用:用于定义元素在样式变化时的过渡效果。
- 常用属性:
transition-property:指定需要过渡的属性(如all、opacity、transform等)。transition-duration:指定过渡的持续时间(如1s、500ms)。transition-timing-function:指定过渡的速度曲线(如ease、linear、ease-in-out)。transition-delay:指定过渡的延迟时间(如0.5s)。
- 简写语法:
transition: property duration timing-function delay;
- 示例:
.box {
transition: transform 0.5s ease-in-out, opacity 0.3s linear;
}
2. CSS 中常用的实现动画方式
2.1 使用 transition 实现简单动画
- 适用场景:适用于简单的状态变化动画(如 hover 效果)。
- 示例:
.box {
width: 100px;
height: 100px;
background-color: lightblue;
transition: transform 0.5s ease-in-out;
}
.box:hover {
transform: scale(1.2) rotate(45deg);
}
2.2 使用 @keyframes 和 animation 实现复杂动画
- 适用场景:适用于复杂的多帧动画。
- 步骤:
- 使用
@keyframes定义动画关键帧。 - 使用
animation属性将动画应用到元素上。
- 使用
- 示例:
@keyframes slideIn {
0% {
transform: translateX(-100%);
}
100% {
transform: translateX(0);
}
}
.box {
width: 100px;
height: 100px;
background-color: lightblue;
animation: slideIn 1s ease-in-out;
}
2.3 使用 transform 和 transition 结合实现交互效果
- 适用场景:适用于用户交互触发的动画(如点击、悬停)。
- 示例:
.box {
width: 100px;
height: 100px;
background-color: lightblue;
transition: transform 0.3s ease-in-out;
}
.box:active {
transform: scale(0.9);
}
2.4 使用 will-change 优化动画性能
- 作用:提前告知浏览器元素将会发生的变化,以优化渲染性能。
- 示例:
.box {
will-change: transform;
}
3. 综合示例
示例 1:按钮点击效果
.button {
padding: 10px 20px;
background-color: lightblue;
border: none;
transition: transform 0.2s ease-in-out;
}
.button:active {
transform: scale(0.95);
}
示例 2:卡片翻转动画
.card {
width: 200px;
height: 200px;
position: relative;
perspective: 1000px;
}
.card-inner {
width: 100%;
height: 100%;
transition: transform 0.6s;
transform-style: preserve-3d;
}
.card:hover .card-inner {
transform: rotateY(180deg);
}
.card-front, .card-back {
width: 100%;
height: 100%;
position: absolute;
backface-visibility: hidden;
}
.card-front {
background-color: lightblue;
}
.card-back {
background-color: lightcoral;
transform: rotateY(180deg);
}
示例 3:加载动画
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
.loader {
width: 40px;
height: 40px;
border: 4px solid #f3f3f3;
border-top: 4px solid #3498db;
border-radius: 50%;
animation: spin 1s linear infinite;
}
总结
| 属性/方法 | 作用 | 适用场景 |
|---|---|---|
transform | 对元素进行 2D/3D 变换 | 平移、旋转、缩放、倾斜等 |
translate | transform 的一个函数,用于平移元素 | 移动元素位置 |
transition | 定义元素样式变化的过渡效果 | 简单的状态变化动画 |
@keyframes | 定义动画关键帧 | 复杂的多帧动画 |
animation | 将@keyframes 定义的动画应用到元素上 | 复杂的多帧动画 |
will-change | 优化动画性能 | 性能优化 |
通过灵活运用这些属性和方法,可以实现丰富的动画效果,提升用户体验。
更多vue相关插件及后台管理模板可访问vue admin reference,代码详情请访问github
来源:juejin.cn/post/7480766452653260852
尝试解决 Android 适配最后一公里
框架介绍
- Android 碎片化至始至终是一个令人非常头疼的问题,特别为 XXPermissions 上面为不同的厂商做适配的时候就非常头疼,因为市面上能找到的开源库只能判断机型的品牌,而不能判断 Android 厂商定制的系统类型,用机型的品牌去做适配会导致出现误判的情况,例如在小米手机上面运行的厂商系统不一定是 MIUI 或者 HyperOS,也有可能是被人刷成了 Android 原生的系统或者其他,反过来也一样,我时常在想,要是有这么一个工具就好了,可以判断 Android 厂商系统的类型及获取厂商系统的版本号,这样就很方便我们做 Android 适配,于是 DeviceCompat 就诞生了,可以轻松识别各种国内外手机厂商和系统版本,帮助大家解决 Android 适配最后一公里的问题。
- 截至到目前,我是行业内第一个也是唯一一个开源这套方案的人,在这里先感谢网上的同行分享的各种方法和思路,让我在开发的过程中少走了很多弯路,另外我也很能理解为什么行业内一直没有人愿意站出来开源这种框架,因为过程非常麻烦,这不仅仅是一个技术问题,还是一个苦活,因为要针对成千上万的机型进行适配。

框架亮点
- 支持识别各种定制 Android 系统(HarmonyOS、MagicOS、MIUI、HyperOS、ColorOS、OriginOS 等)
- 支持判断多种手机厂商品牌(华为、小米、OPPO、vivo、三星等)
- 使用简单,一行代码即可判断设备品牌、厂商系统类型、厂商系统版本
- 兼容性好,支持 Android 4.0 及以上系统
- 体积小巧,仅 12 KB,不会增加应用体积负担
集成步骤
- 如果你的项目 Gradle 配置是在
7.0以下,需要在build.gradle文件中加入
allprojects {
repositories {
// JitPack 远程仓库:https://jitpack.io
maven { url 'https://jitpack.io' }
}
}
- 如果你的 Gradle 配置是
7.0及以上,则需要在settings.gradle文件中加入
dependencyResolutionManagement {
repositories {
// JitPack 远程仓库:https://jitpack.io
maven { url 'https://jitpack.io' }
}
}
- 配置完远程仓库后,在项目 app 模块下的
build.gradle文件中加入远程依赖
dependencies {
// 设备兼容框架:https://github.com/getActivity/DeviceCompat
implementation 'com.github.getActivity:DeviceCompat:1.0'
}
框架 API 介绍
- 判断系统类型
// 判断当前设备的厂商系统是否为 HyperOS(小米新系统)
DeviceOs.isHyperOs();
// 判断当前设备的厂商系统是否为国内版本的 HyperOS
DeviceOs.isHyperOsByChina();
// 判断当前设备的厂商系统是否为国际版本的 HyperOS
DeviceOs.isHyperOsByGlobal();
// 判断当前设备的厂商系统开启了 HyperOS 的系统优化选项
DeviceOs.isHyperOsOptimization();
// 判断当前设备的厂商系统是否为 MIUI(小米老系统)
DeviceOs.isMiui();
// 判断当前设备的厂商系统是否为国内版本的 MIUI
DeviceOs.isMiuiByChina();
// 判断当前设备的厂商系统是否为国际版本的 MIUI
DeviceOs.isMiuiByGlobal();
// 判断当前设备的厂商系统是否开启了 MIUI 优化选项
DeviceOs.isMiuiOptimization();
// 判断当前设备的厂商系统是否为 RealmeUI(真我系统)
DeviceOs.isRealmeUi();
// 判断当前设备的厂商系统是否为 ColorOS(OPPO 系统)
DeviceOs.isColorOs();
// 判断当前设备的厂商系统是否为 OriginOS(VIVO 系统)
DeviceOs.isOriginOs();
// 判断当前设备的厂商系统是否为 FuntouchOS(VIVO 的老系统)
DeviceOs.isFuntouchOs();
// 判断当前设备的厂商系统是否为 MagicOS(荣耀系统)
DeviceOs.isMagicOs();
// 判断当前设备的厂商系统是否为 HarmonyOS(华为鸿蒙的系统)
DeviceOs.isHarmonyOs();
// 判断当前设备的厂商系统是否为 EMUI(华为和荣耀的老系统)
DeviceOs.isEmui();
// 判断当前设备的厂商系统是否为 OneUI(三星系统)
DeviceOs.isOneUi();
// 判断当前设备的厂商系统是否为 OxygenOS(一加的老系统)
DeviceOs.isOxygenOs();
// 判断当前设备的厂商系统是否为 H2OS(一加的老系统)
DeviceOs.isH2Os();
// 判断当前设备的厂商系统是否为 Flyme(魅族系统)
DeviceOs.isFlyme();
// 判断当前设备的厂商系统是否为 MyOS(中兴或者努比亚的系统)
DeviceOs.isMyOs();
// 判断当前设备的厂商系统是否为 MifavorUI(中兴老系统)
DeviceOs.isMifavorUi();
// 判断当前设备的厂商系统是否为 SmartisanOS(锤子系统)
DeviceOs.isSmartisanOs();
// 判断当前设备的厂商系统是否为 EUI(乐视的系统)
DeviceOs.isEui();
// 判断当前设备的厂商系统是否为 ZUI(摩托罗拉的系统)
DeviceOs.isZui();
// 判断当前设备的厂商系统是否为 360UI(360 系统)
DeviceOs.is360Ui();
// 获取当前设备的厂商系统名称
DeviceOs.getOsName();
// 获取当前设备的厂商系统名称
DeviceOs.getOsName();
// 获取经过美化的厂商系统版本号
DeviceOs.getOsVersionName();
// 获取厂商系统版本的大版本号
DeviceOs.getOsBigVersionCode();
// 获取原始的厂商系统版本号
DeviceOs.getOriginalOsVersionName();
- 判断设备品牌
// 判断当前设备的品牌是否为华为
DeviceBrand.isHuaWei();
// 判断当前设备的品牌是否为荣耀
DeviceBrand.isHonor();
// 判断当前设备的品牌是否为 vivo
DeviceBrand.isVivo();
// 判断当前设备的品牌是否为小米
DeviceBrand.isXiaoMi();
// 判断当前设备的品牌是否为 OPPO
DeviceBrand.isOppo();
// 判断当前设备的品牌是否为真我
DeviceBrand.isRealMe();
// 判断当前设备的品牌是否为乐视
DeviceBrand.isLeEco();
// 判断当前设备的品牌是否为 360
DeviceBrand.is360();
// 判断当前设备的品牌是否为中兴
DeviceBrand.isZte();
// 判断当前设备的品牌是否为一加
DeviceBrand.isOnePlus();
// 判断当前设备的品牌是否为努比亚
DeviceBrand.isNubia();
// 判断当前设备的品牌是否为酷派
DeviceBrand.isCoolPad();
// 判断当前设备的品牌是否为 LG
DeviceBrand.isLg();
// 判断当前设备的品牌是否为 Google
DeviceBrand.isGoogle();
// 判断当前设备的品牌是否为三星
DeviceBrand.isSamsung();
// 判断当前设备的品牌是否为魅族
DeviceBrand.isMeiZu();
// 判断当前设备的品牌是否为联想
DeviceBrand.isLenovo();
// 判断当前设备的品牌是否为锤子
DeviceBrand.isSmartisan();
// 判断当前设备的品牌是否为 HTC
DeviceBrand.isHtc();
// 判断当前设备的品牌是否为索尼
DeviceBrand.isSony();
// 判断当前设备的品牌是否为金立
DeviceBrand.isGionee();
// 判断当前设备的品牌是否为摩托罗拉
DeviceBrand.isMotorola();
// 判断当前设备的品牌是否为传音
DeviceBrand.isTranssion();
// 获取当前设备的品牌名称
DeviceBrand.getBrandName();
- 系统属性相关的方法
// 获取单个系统属性值
SystemPropertyCompat.getSystemPropertyValue((@Nullable String key);
// 获取多个系统属性值
SystemPropertyCompat.getSystemPropertyValues(@Nullable String[] keys);
// 获取多个系统属性中的任一一个值
SystemPropertyCompat.getSystemPropertyAnyOneValue(@Nullable String[] keys);
// 判断某个系统属性是否存在
SystemPropertyCompat.isSystemPropertyExist(@Nullable String key);
// 判断多个系统属性是否有任一一个存在
SystemPropertyCompat.isSystemPropertyAnyOneExist(@Nullable String[] keys);
附上项目开源地址:DeviceCompat
来源:juejin.cn/post/7540524749425180735
Python StringIO 和 BytesIO 用法
在 Python 中,我们平时处理的输入输出(I/O)大多数是针对文件或网络数据的,但有时候,我们希望直接在内存中进行读写,而不必先把数据存到硬盘上。
这时候,StringIO 和 BytesIO 就派上用场了。
参考文章:Python StringIO 和 BytesIO | 简单一点学习 easyeasy.me
简单理解:
- StringIO → 操作内存中的 字符串(
str类型) - BytesIO → 操作内存中的 二进制数据(
bytes类型)
它们都来自 io 模块,接口和文件对象几乎一模一样,所以学会文件操作就能直接用它们。
1. 为什么要用 StringIO / BytesIO
- 无需磁盘 I/O,速度快
- 便于测试(不需要真实文件)
- 在网络编程中常用(比如 HTTP 响应先存在内存中再处理)
- 数据临时存储(比如生成报告、图片)
2. StringIO 基础用法
StringIO 适合处理 文本数据,使用方式类似普通文件:
from io import StringIO
# 创建 StringIO 对象
f = StringIO()
# 写入数据
f.write("Hello ")
f.write("Python")
# 获取当前内容
print(f.getvalue()) # Hello Python
注意:
getvalue()用来获取缓冲区的全部数据。
3. StringIO 读取数据
我们也可以直接用 StringIO 来模拟读取文件:
from io import StringIO
data = "Line1\nLine2\nLine3"
f = StringIO(data)
# 一次性读取
print(f.read())
# 重置游标
f.seek(0)
# 按行读取
for line in f:
print(line.strip())
要点:
seek(0)→ 把“文件指针”移动到开头- 读取方法(
read、readline、readlines)和文件对象一致
4. BytesIO 基础用法
BytesIO 用于处理 二进制数据,比如图片、音频、压缩包等。
from io import BytesIO
# 创建 BytesIO
f = BytesIO()
# 写入二进制数据
f.write(b"Hello World")
# 获取数据
print(f.getvalue()) # b'Hello World'
5. BytesIO 读取数据
from io import BytesIO
data = b"Binary\x00Data"
f = BytesIO(data)
# 读取前6个字节
print(f.read(6)) # b'Binary'
# 继续读剩下的
print(f.read()) # b'\x00Data'
6. StringIO vs BytesIO 区别
| 特性 | StringIO | BytesIO |
|---|---|---|
| 处理数据类型 | str(文本) | bytes(二进制) |
| 读取写入方式 | 和文本文件一致 | 和二进制文件一致 |
| 编码解码 | 不需要手动编码 | 需要自己 .encode() / .decode() |
| 常见应用 | 日志处理、临时文本 | 图片、音频、网络传输数据 |
7. 从文件到内存的转换
有时我们需要把磁盘文件内容读到内存中用 BytesIO 处理,比如处理图片:
from io import BytesIO
# 假设有个图片
with open("test.png", "rb") as f:
data = f.read()
# 存入 BytesIO
bio = BytesIO(data)
# 读取前10个字节
print(bio.read(10))
8. 从内存保存到文件
反过来,我们也可以把 BytesIO 或 StringIO 的数据写到磁盘:
from io import BytesIO
# 创建内存数据
bio = BytesIO()
bio.write(b"Save me to file")
# 写入文件
with open("output.bin", "wb") as f:
f.write(bio.getvalue())
9. 常见使用场景
- 临时构建数据,避免磁盘 I/O
- 测试代码时,模拟文件对象
- 网络数据处理(HTTP 请求、Socket 传输)
- 图片或音频处理(配合 Pillow、pydub 等库)
10. 最佳实践
- 如果处理的是文本,用
StringIO,并且直接写str类型。 - 如果处理的是二进制数据(比如图片、压缩包),用
BytesIO,并且确保写入的是bytes。 - 操作完成后不一定非要
close()(因为它们是内存对象),但为了习惯最好加上。 - 需要频繁读取时,记得用
seek(0)重置指针。
来源:juejin.cn/post/7536182225328046122
摆动序列
摆动序列
一、问题描述
LeetCode:376. 摆动序列
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
例如,[1, 7, 4, 9, 2, 5] 是一个摆动序列,因为差值 (6, -3, 5, -7, 3) 是正负交替出现的。
相反,[1, 4, 7, 2, 5] 和 [1, 7, 4, 5, 5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数数组 nums,返回 nums 中作为摆动序列的最长子序列的长度。
二、解题思路
摆动序列的关键在于寻找数组中的峰和谷。每当序列发生方向变化时,摆动序列的长度就会增加。因此,可以通过遍历数组,统计方向变化的次数来得到最长摆动序列的长度。
- 记录初始趋势:计算数组前两个元素的差值作为最开始的变化趋势preTrend = nums[1] - nums[0],若差值不为 0,说明前两个元素构成了摆动序列的初始趋势,此时摆动序列长度初始化为 2;若差值为 0,意味着前两个元素相等,不构成摆动趋势,摆动序列长度初始化为 1。
- 遍历数组寻找变化趋势:记录当前变化趋势curTrend = nums[i] - nums[i - 1],若当前变化趋势curTrend 与之前的变化趋势preTrend 不同,preTrend <= 0 && curTrend > 0 或者 preTrend >= 0 && curTrend < 0 时 更新变化趋势preTrend ,摆动序列加1
三、代码实现
以下是使用 JavaScript 实现的代码:
var wiggleMaxLength = function (nums) {
// 统计波峰波谷的数量
// 若长度为1 或为 0
if (nums.length < 2) return nums.length;
let preTrend = nums[1] - nums[0];
let reLen = preTrend !== 0 ? 2 : 1;
for (let i = 2; i < nums.length; i++) {
let curTrend = nums[i] - nums[i - 1];
// 当出现波谷或者波峰时,更新preTrend
if ((preTrend <= 0 && curTrend > 0) || (preTrend >= 0 && curTrend < 0)) {
preTrend = curTrend;
reLen++;
}
}
return reLen;
};
四、注意事项
- 边界条件需谨慎:在处理数组前两个元素确定初始趋势时,要特别注意数组长度为 2 的情况。若两个元素相等,初始化摆动序列长度为 1,此时不能因为后续没有更多元素判断趋势变化,就错误认为长度还能增加。在遍历过程中,若遇到数组结尾,也应保证最后一次趋势变化能正确统计,避免遗漏。
- 趋势判断避免误判:在比较差值判断趋势变化时,条件 (preTrend <= 0 && curTrend > 0) 与 (preTrend >= 0 && curTrend < 0) 中的 “小于等于” 和 “大于等于” 不能随意替换为 “小于” 和 “大于”。例如,当出现连续相等元素后趋势改变的情况,若使用严格的 “小于” 和 “大于” 判断,可能会错过第一个有效趋势变化点,导致结果错误。
五、复杂度分析
- 时间复杂度:O(n),其中 n 是数组的长度。只需要遍历一次数组。
- 空间复杂度:O(1),只需要常数级的额外空间。
来源:juejin.cn/post/7518198430662492223
绿盟科技重磅发布AI安全运营新成果,全面驱动智能攻防体系升级

8月29日,绿盟科技在北京成功举办以“智御新境·安全无界”为主题的AI赋能安全运营线上成果发布会,全面展示了公司在AI安全领域的最新技术成果与实践经验。
会议总结了“风云卫”AI安全能力平台上半年在客户侧的实际运营成效,介绍了AISOC平台的新特性与能力,进一步验证了“AI+安全运营”在降噪、研判、处置闭环以及未知威胁检测等核心场景中的规模化应用价值。
此外,还正式发布了“绿盟AI智能化渗透系统”,该系统依托AI技术全面赋能渗透测试全流程,可广泛应用于常态化扫描和日常安全运维等场景,有效帮助客户降本增效,显著降低渗透测试的专业门槛。
双底座多智能体架构,构建三位一体AI安全生态
2020年至2022年,绿盟科技连续发布三部AI安全白皮书《安全AI赋能安全运营白皮书》、《知识图谱白皮书》和《AI安全分析白皮书》,并于2023年推出“风云卫”安全大模型,深度融合AI与攻防知识。2025年,公司再度升级,构建“风云卫+DeepSeek”双底座与多智能体架构,打造AI驱动的安全生态,覆盖模型生产、场景适配与应用复制三大层面,全面提升安全检测、运营、数据安全及蓝军对抗能力,实现全域智能赋能。

安全运营实现“智防”质变,绿盟“风云卫”AI实战成效显著

绿盟科技产品BG总经理吴天昊
绿盟科技产品BG总经理吴天昊表示,安全运营人员每天面临几万到几十万不等的原始攻击告警,绿盟“风云卫”AI安全能力平台依托千亿级安全样本训练的大模型,能够自动识别系统日志中的无效告警与重复信息,达到百级左右的高价值告警的优先推荐。
针对不同攻击事件,可自动展开研判分析,精准解析攻击路径和手法,并通过可视化分析界面清晰呈现完整攻击链条。通过自主调查,智能开展横向溯源,自动关联跨端、跨网、跨身份数据,构建出完整的攻击图谱;同时进行并案分析,深度挖掘同类攻击线索,精准定位攻击组织;最后通过SOAR剧本自动生成与执行,实现分钟级事件闭环,并为未来同类事件建立自动化处置范式。
实际应用数据显示,绿盟科技的AI降噪率平均达到95%以上,AI综合辅助研判准确率超过90%。在处置响应方面,依托自主响应可实现超过40%的安全事件端到端的自动化响应处置。特别值得关注的是,经过实际观测和验证,针对13大类77小类的攻击类型,绿盟风云卫AI辅助识别准确率超过95%。
会上,绿盟科技全流程演示了AI赋能安全运营的过程,生动体现了AI技术在安全运营各环节的深度融合——从海量告警的智能降噪、攻击链路的自动重构,到复杂事件的自主研判和自动化响应,真正实现了安全运营从"人防"到"智防"的质变升级。

AI赋能安全检测:混淆检测+自主基线,让未知威胁检测变成可能
在攻防演练中,统计数据显示有76%的攻击属于“已知家族、未知变种”类型,这类攻击因具备一定家族特征又存在变异特性,给检测工作带来不小挑战。
绿盟“风云卫”AI安全能力平台在此类场景中展现出显著优势:在混淆检测方面,AI凭借强大的语义理解能力,能够深入剖析恶意程序的本质特征。即便攻击手段经过混淆处理,改变了表面形态,AI也能透过现象看本质,精准识别出其属于已知家族的核心属性,从而有效识破“未知变种”的伪装。
在自主基线构建上,AI能够自主解读并理解全量日志,从中提炼出账号、流量、进程等各类实体在正常时段的行为画像。基于这些画像,AI可以秒级输出动态阈值,形成精准的正常行为基线。当“已知家族、未知变种”的攻击出现,导致相关实体行为偏离动态阈值时,系统能快速察觉异常,为及时发现和应对威胁提供有力支撑。
智能体中心成效显著,20多个安全领域智能体协同赋能
绿盟“风云卫”AI安全能力平台汇聚绿盟安全专家经验,内置20+安全领域智能体,覆盖网络安全多个关键环节,包含钓鱼邮件检测、可疑样本分析、敏感数据识别、零配置日志解析、情报分析、报告生成等多个智能体。这些智能体既可以赋能产品,也可以独立运行。值得一提的是,智能体中心支持智能体可视化编排,这一特性为用户带来了极大便利。即便是非专业的技术人员,也能通过简单的拖拽、连线操作,如同搭建积木一般,将多个智能体按照企业自身的业务逻辑与安全需求,灵活组合成个性化的安全工作流程。
例如,用户可通过可视化方式自定义编排敏感信息检测智能体,将企业特定的敏感信息嵌入其中,从而实现更精准的自定义检测。这种低代码的编排方式不仅大幅降低了使用门槛,还能灵活应对企业不断变化的安全需求,实现安全防护的定制化与敏捷化,全面提升网络安全工作的效能。

多行业落地实践,安全运营效率大幅提升

绿盟科技鹰眼安全运营中心技术经理李昀磊
截至目前,绿盟科技已助力电信、金融、政府、高校等行业的多家客户实现安全运营智能化转型。在近期多项攻防演练中,公司依托“风云卫”AI安全能力平台,为客户提供全面支撑,多项智能体——包括未知威胁检测、行为分析、钓鱼邮件识别等——均发挥关键作用。
绿盟科技鹰眼安全运营中心技术经理李昀磊介绍,绿盟安全运营中心已持续为超2000家企业提供安全运营服务,并于2023年起全面融合“风云卫”大模型,AI赋能成效主要体现在三方面:
●高频场景AI全自动处置:对实时性要求极高的常见攻击,实现从检测、研判、通知到响应的全自动闭环,无需人工干预;
●复杂事件智能辅助调查:针对约占20%+的复杂事件,AI可自主拓展调查路径,完成情报搜集与初步总结,提升分析师决策效率;
●工具调度与客户交互自动化:AI统一调度多类分析工具,并自动完成工单发送、报告生成与客户反馈响应,显著节约人力。
截至目前,绿盟云端安全运营中心约77%的告警日志依托AI实现辅助研判与处置,在客户预授权条件下5分钟内发现确认并处置闭环事件,运营效率大幅提升。
绿盟AI智能化渗透系统发布

绿盟科技产品总监许伟强
绿盟科技产品总监许伟强表示,公司基于多年攻防实战经验与大模型技术,正式推出新一代绿盟AI智能化渗透系统。该系统全面覆盖常态化扫描与日常安全运维等多种场景,在国内首次实现AI智能体在真实网络环境中完成端到端渗透测试,显著提升渗透效率与响应能力。该系统具备四大核心能力:
●智能任务规划:通过多智能体分层协作,结合专业攻防知识库,实现对复杂渗透场景的智能化任务分解;
●智能工具调度:依托工具调度智能体,无缝调用并协同多种渗透工具,破除工具间壁垒,增强协同作战效能;
●渗透路径推荐:基于安全大模型技术,融合知识图谱与漏洞利用知识,提供渗透路径规划、过程可视化及标准化报告输出;
●AI智能对话:支持自然语言交互,可依据用户指令智能推荐并自动执行渗透工具,大幅降低操作门槛。
绿盟AI智能化渗透系统基于“风云卫”平台构建,采用“人在环路”安全机制与多智能体协同架构,具备“直接模式+深度模式”双轨机制,可快速响应常规攻击面,也可深入攻坚复杂高对抗场景,动态适应多样化的实战攻防需求。

随着国务院常务会议审议通过《关于深入实施“人工智能+”行动的意见》,“人工智能+”正成为产业升级的关键方向,各领域在快速发展的同时,安全问题将不容忽视。绿盟科技始终站在技术前沿,目前形成了以风云卫AI安全能力平台为核心,构建“模型生产、场景适配、应用赋智”的“三位一体”AI安全生态体系,可为不同用户提供全方位的智能安全保障。面向未来,绿盟科技将继续以创新为引擎,携手客户与合作伙伴,共同迎接智能安全新时代。
本地Docker部署Transmission,内网穿透无限远程访问教程
Transmission是一款开源、轻量且资源占用极低的BitTorrent客户端。借助Docker,可以在几分钟内把它跑起来;再借助贝锐花生壳的内网穿透功能,又能随时随地从外网安全访问。下面给出一条龙的部署与远程访问流程,全部命令可直接复制粘贴。

一、准备Docker环境
1. 一键安装最新版Docker(已包含阿里云镜像加速):


2. 启动并设为开机自启:


二、拉取Transmission镜像


如果拉取超时,可在 `/etc/docker/daemon.json` 中追加国内镜像源,例如:

三、运行Transmission容器
下面命令把Web端口9091、BT 监听端口41234(TCP/UDP)都映射出来,并把配置、下载目录、监控目录挂到宿主机持久化。按需替换UID/GID、时区、用户名密码以及宿主机路径。


启动后,浏览器访问 http://局域网IP:9091即可看到Transmission Web UI。

点击左上角图标即可上传种子或粘贴磁力链接开始下载。


四、安装并配置贝锐花生壳
1. 下载客户端
在同一内网任意设备上,从花生壳官网下载最新Linux版客户端,可根据实际情况,选择docker安装花生壳。(`phddns_5.x.x_amd64.deb`)。


2. 安装
根据不同位数的系统输入下面的命令进行安装,安装完成会自动生成SN码与登录密码。


3. 激活与登录
浏览器打开 [花生壳管理平台](http://b.oray.com),用SN和默认密码登录。

首次登录需激活设备,支持微信扫码或绑定贝锐账号。

4. 添加映射
激活成功后,进入「内网穿透」→「添加映射」,填写新增的映射信息。

保存后,贝锐花生壳会生成一个 `http://xxxx.hsk.oray.com:端口` 的外网地址。可访问外网地址访问transmission。

五、外网访问与日常使用
任何地点打开浏览器,输入花生壳提供的外网地址,即可远程管理Transmission:添加种子、查看进度、做种、限速等操作与局域网完全一致。

至此,借助贝锐花生壳内网穿透就可以使本地Docker版Transmission已可安全、便捷地实现远程访问。
收起阅读 »当上组长一年里,我保住了俩下属
前言
人类的悲喜并不相通,有人欢喜有人愁,更多的是看热闹。
就在上周,"苟住"群里的一个小伙伴也苟不住了。
在苟友们的"墙裂"要求下,他分享了他的经验,以他的视角看看他是怎么操作的。
1. 组织变动,意外晋升
两年前加入公司,依然是一线搬砖的码农。
干到一年的时候公司空降了一位号称有诸多大厂履历的大佬来带领研发,说是要给公司带来全新的变化,用技术创造价值。
大领导第一件事:抓人事,提效率。
在此背景下,公司不少有能力的研发另谋出处,也许我看起来人畜无害,居然被提拔当了小组长。
2. 领取任务,开启副本
当了半年的小组长,我的领导就叫他小领导吧,给我传达了大领导最新规划:团队需要保持冲劲,而实现的手段就是汰换。
用人话来说就是:
当季度KPI得E的人,让其填写绩效改进目标,若下一个季度再得到E,那么就得走人
我们绩效等级是ABCDE,A是传说中的等级,B是几个人有机会,大部分人是C和D,E是垫底。
而我们组就有两位小伙伴得到了E,分别是小A和小B。
小领导意思是让他们直接走得了,大不了再招人顶上,而我想着毕竟大家共事一场,现在大环境寒气满满,我也是过来人,还想再争取争取。
于是分析了他们的基本资料,他俩特点还比较鲜明。
小A资料:
- 96年,单身无房贷
- 技术栈较广,技术深度一般,比较粗心
- 坚持己见,沟通少,有些时候会按照自己的想法来实现功能
小B资料:
- 98年,热恋有房贷
- 技术基础较薄弱,但胜在比较认真
- 容易犯一些技术理解上的问题
了解了小A和小B的历史与现状后,我分别找他们沟通,主要是统一共识:
- 你是否认可本次绩效评估结果?
- 你是否认可绩效改进的点与风险点(未达成被裁)?
- 你是否还愿意在这家公司苟?
最重要是第三点,开诚布公,若是都不想苟了,那就保持现状,不要浪费大家时间,我也不想做无用功。
对于他们,分别做了提升策略:
对于小A:
- 每次开启需求前都要求其认真阅读文档,不清楚的地方一定要做记录并向相关人确认
- 遇到比较复杂的需求,我也会一起参与其中梳理技术方案
- 需求开发完成后,CR代码看是否与技术方案设计一致,若有出入需要记录下来,后续复盘为什么
- 给足时间,保证充分自测
对于小B:
- 每次需求多给点时间,多出的时间用来学习技术、熟悉技术
- 要求其将每个需求拆分为尽可能小的点,涉及到哪些技术要想清楚、弄明白
- 鼓励他不懂就要问,我也随时给他解答疑难问题,并说出一些原理让他感兴趣的话可以继续深究
- 分配给他一些技术调研类的任务,提升技术兴趣点与成就感
3. 结束?还是是另一个开始?
半年后...
好消息是:小A、小B的考核结果是D,达成了绩效改进的目标。
坏消息是:据说新的一轮考核算法会变化,宗旨是确保团队血液新鲜(每年至少得置换10%的人)。
随缘吧,我尽力了,也许下一个是我呢?

来源:juejin.cn/post/7532334931021824034
一文说透WebSocket协议(秒懂)
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
为避免同学们概念混淆,先声明一下,其实WebSocket和Socket之间是毫无关系的,就像北大青鸟和北大一样,大家不要被名字给带偏了。
WebSocket是一种建立在TCP底层连接上,使web客户端和服务器端可进行持续全双工通信的协议。
用大白话来说,WebSocket协议最大的特点是支持服务器端给客户端发送消息。
只需先通过HTTP协议进行握手并进行协议升级,即可让服务器端和客户端一直保持连接并实现通信,直到连接关闭。
如下图所示:
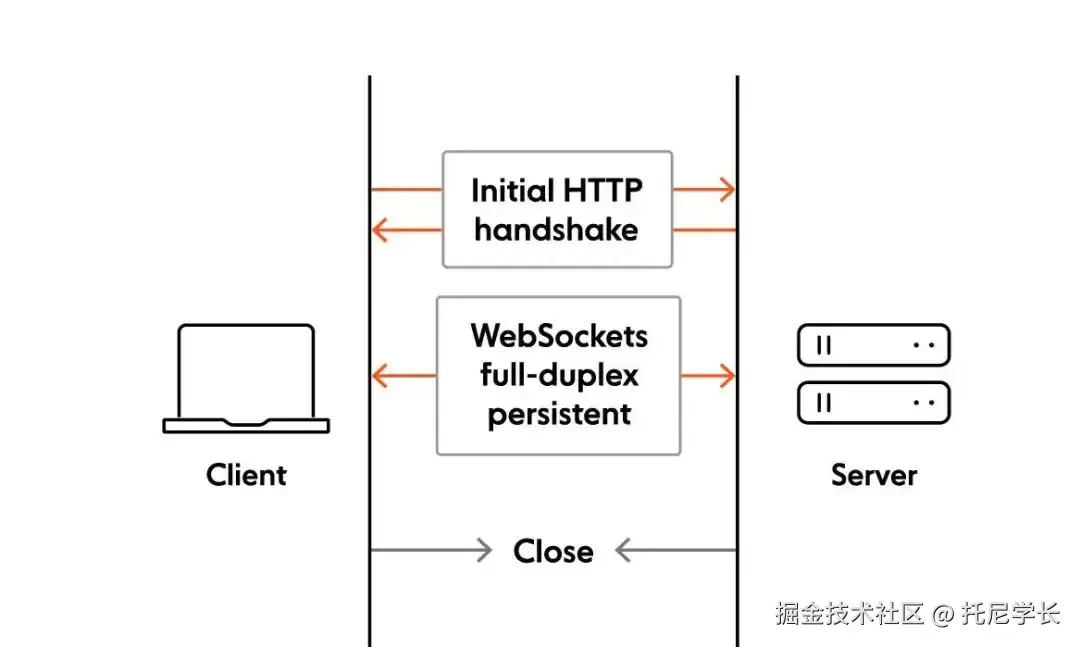
一定会有同学存在疑问,WebSocket协议所具备的“支持服务器端给客户端发送消息”的特点,具体适用场景是什么呢?
下面我们就来详细地讲解一下。
适用场景
对于这个问题,我们有必须逆向思考一下,WebSocket协议所适用的场景,必然是其他协议不适用的场景,这个协议就是HTTP。
由于HTTP协议是半双工模式,只能由客户端发起请求并由服务器端进行响应。
所以在线聊天、实时互动游戏、股票行情、物联网设备监控等业务场景下,只能通过客户端以轮询、长轮询的方式去服务器端获取最新数据。
股票行情场景,如下图所示:
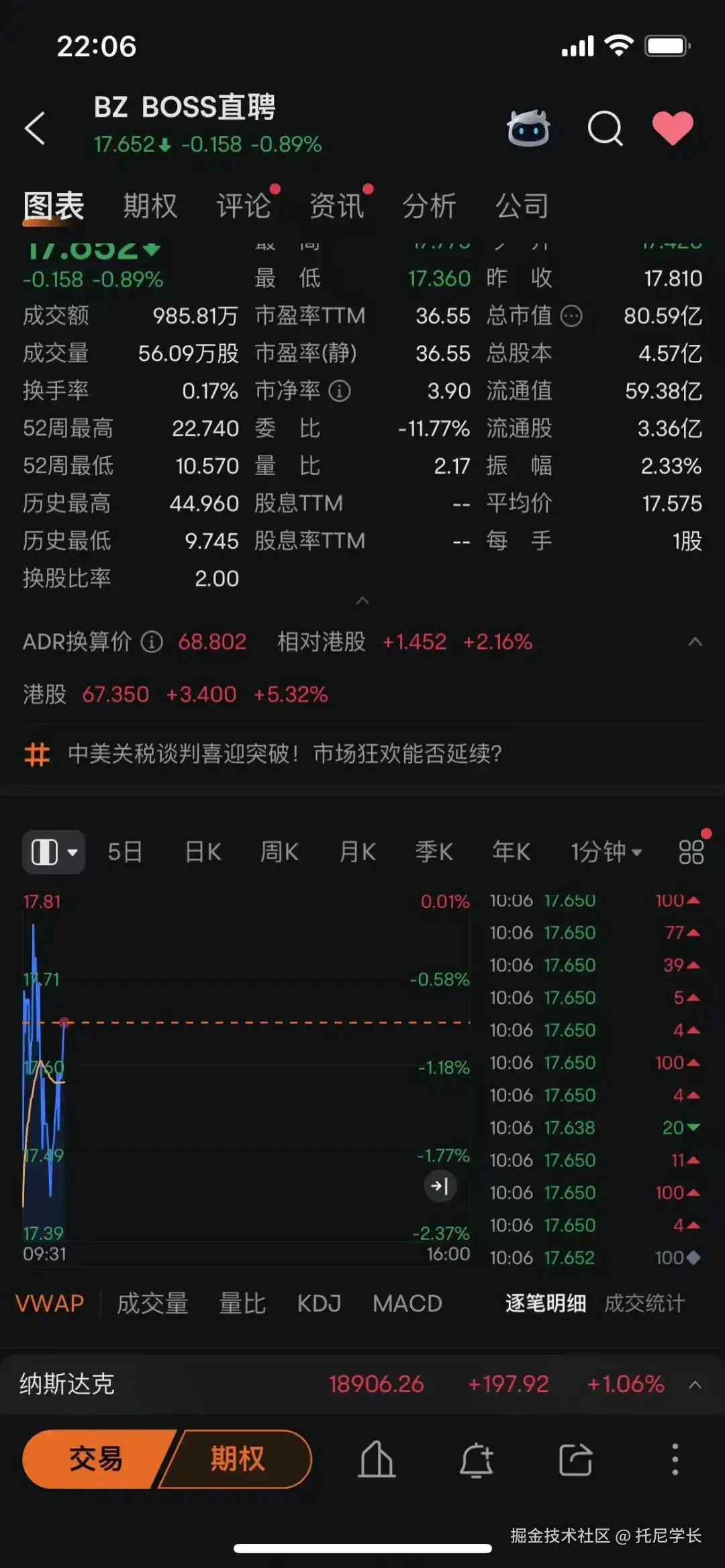
这种方式所带来的问题有两点:
1、客户端频繁发送HTTP请求会带来网络开销,也会给服务器端带来负载压力;2、轮询间隔难以把控,间隔过短同样会带来问题(1)中提到的点,间隔过长会导致数据延迟。
而WebSocket协议只有在服务器端有事件发生的时候,才会第一时间给客户端发送消息,彻底杜绝了HTTP轮询所带来的网络开销、服务器负载和数据时延问题。
实现步骤
阶段一、客户端通过 HTTP 协议发送包含特殊头部的请求,触发协议升级:
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Version: 13
- Upgrade: websocket明确请求升级协议。
- Sec-WebSocket-Key:客户端生成的随机字符串,用于安全验证。
- Sec-WebSocket-Version:指定协议版本(RFC 6455 规定为 13)。
阶段二、服务器端进行响应确认,返回 101 Switching Protocols 响应:
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
- Sec-WebSocket-Accept:服务器将客户端的 Sec-WebSocket-Key 与固定字符串拼接后,计算 SHA-1 哈希并进行 Base64 编码,生成验证令牌。
阶段三、此时 TCP 连接从 HTTP 升级为 WebSocket 协议,后续数据可通过二进制帧进行传输。
阶段四、数据传输,WebSocket是一种全双工通信协议,客户端与服务端可同时发送/接收数据,无需等待对方请求,数据帧是以二进制格式进行传输的。
如下图所示:
- FIN (1 bit):标记是否为消息的最后一个分片。
- Opcode (4 bits):定义数据类型(如文本 0x1、二进制 0x2、关闭连接 0x8、Ping 0x9、Pong 0xA)。
- Mask (1 bit):客户端发送的数据需掩码处理(防止缓存污染攻击),服务端发送的数据无需掩码。
- Payload Length (7 or 7+16 or 7+64 bits):帧内容的长度,支持最大 2^64-1 字节。
- Masking-key(32 bits),掩码密钥,由上面的标志位 MASK 决定的,如果使用掩码就是 4 个字节的随机数,否则就不存在。
- payload data 字段:这里存放的就是真正要传输的数据
阶段五、连接关闭,客户端或服务器端都可以发起关闭。
示例代码
前端代码:
<!DOCTYPE html>
<html>
<body>
<input type="text" id="messageInput" placeholder="输入消息">
<button onclick="sendMessage()">发送</button>
<div id="messages"></div>
<script>
// 创建 WebSocket 连接
const socket = new WebSocket('ws://localhost:8080/ws');
// 连接打开时触发
socket.addEventListener('open', () => {
logMessage('连接已建立');
});
// 接收消息时触发
socket.addEventListener('message', (event) => {
logMessage('收到消息: ' + event.data);
});
// 连接关闭时触发
socket.addEventListener('close', () => {
logMessage('连接已关闭');
});
// 错误处理
socket.addEventListener('error', (error) => {
logMessage('连接错误: ' + error.message);
});
// 发送消息
function sendMessage() {
const message = document.getElementById('messageInput').value;
socket.send(message);
logMessage('发送消息: ' + message);
}
// 日志输出
function logMessage(message) {
const messagesDiv = document.getElementById('messages');
const p = document.createElement('p');
p.textContent = message;
messagesDiv.appendChild(p);
}
</script>
</body>
</html>
我们通过 Spring WebSocket 来实现服务器端代码。
1、添加 Maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
<version>2.7.14</version>
</dependency>
2、配置类启用 WebSocket:
import org.springframework.context.annotation.Configuration;
import org.springframework.web.socket.config.annotation.EnableWebSocket;
import org.springframework.web.socket.config.annotation.WebSocketConfigurer;
import org.springframework.web.socket.config.annotation.WebSocketHandlerRegistry;
@Configuration
@EnableWebSocket
public class WebSocketConfig implements WebSocketConfigurer {
@Override
public void registerWebSocketHandlers(WebSocketHandlerRegistry registry) {
registry.addHandler(new MyWebSocketHandler(), "/ws")
.setAllowedOrigins("*");
}
}
3、消息处理器实现:
import org.springframework.web.socket.TextMessage;
import org.springframework.web.socket.WebSocketSession;
import org.springframework.web.socket.handler.TextWebSocketHandler;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
public class MyWebSocketHandler extends TextWebSocketHandler {
private static final Set<WebSocketSession> sessions =
Collections.synchronizedSet(new HashSet<>());
@Override
public void afterConnectionEstablished(WebSocketSession session) {
sessions.add(session);
log("新连接: " + session.getId());
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) {
String payload = message.getPayload();
log("收到消息: " + payload);
// 广播消息
sessions.forEach(s -> {
if (s.isOpen() && !s.equals(session)) {
try {
s.sendMessage(new TextMessage("广播: " + payload));
} catch (Exception e) {
log("发送消息失败: " + e.getMessage());
}
}
});
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) {
sessions.remove(session);
log("连接关闭: " + session.getId());
}
private void log(String message) {
System.out.println("[MyWebSocketHandler] " + message);
}
}
结语
在本文中,我们先是对WebSocket协议的概念进行了讲解,也对其适用场景、实现步骤进行描述,最后给出了实例代码,旨在帮助大家一站式熟悉WebSocket协议。
来源:juejin.cn/post/7503811248288661558
优化Mini React:避免状态未变更时的重复渲染
优化Mini React:避免状态未变更时的重复渲染
在构建Mini React时,我们发现一个常见的性能问题:即使状态值未发生改变,组件也会进行不必要的重复渲染。本文将深入分析问题原因并实现优化方案。
问题现象分析
以下面代码为例:
function Foo() {
console.log('fooo') // 每次点击都会打印
const [bar, setBar] = React.useState('bar')
function handleClick() {
setBar('bar') // 设置相同的值
}
return (
<div>
{bar}
<button onClick={handleClick}>clickbutton>
div>
);
}
当点击按钮时,虽然状态值bar没有实际变化,但每次点击都会触发组件重新渲染(控制台持续输出"fooo")。这在性能敏感场景下会造成资源浪费。
优化原理与实现
React的核心优化策略之一是:当状态值未改变时,跳过渲染流程。我们在useState的setState函数中加入值比较逻辑:
function useState(initial) {
// ... 状态初始化逻辑
const setState = (action) => {
// 计算期望的新状态
const eagerState = typeof action === 'function'
? action(stateHook.state)
: action;
// 关键优化:状态值未改变时提前返回
if (Object.is(eagerState, stateHook.state)) {
return;
}
// 状态更新及重新渲染逻辑
stateHook.state = eagerState;
scheduleUpdate();
};
return [stateHook.state, setState];
}
优化关键点解析
- 提前计算状态值:
- 处理函数式更新:
action(currentState) - 处理直接赋值:
action
- 处理函数式更新:
- 精准状态比较:
- 使用
Object.is()代替===运算符 - 正确处理特殊值:
NaN、+0/-0等边界情况 - 性能考虑:先比较再更新,避免不必要的渲染流程
- 使用
- 渲染流程优化:
- 状态未变更时直接return,阻断后续更新
- 状态变更时才触发重新渲染调度
优化效果验证
优化后,当点击按钮设置相同状态值时:
setBar('bar') // 与当前状态相同
- 控制台不再输出"fooo"
- 组件不会触发重新渲染
- 虚拟DOM不会进行diff比较
- 真实DOM不会更新
实际应用场景
- 表单控件:输入框失去焦点时重置状态
- 多次相同操作:重复点击相同选项
- 防抖/节流:快速触发时的状态保护
- 数据同步:避免接口返回相同数据时的渲染
扩展思考
- 引用类型优化:
setObj({...obj}) // 内容相同但引用不同
需配合immutable.js或immer等库实现深度比较
- 类组件优化: 在setState方法中实现相同的值比较逻辑
- 性能权衡: 简单值比较成本低,复杂对象比较需评估成本
总结
通过实现状态变更的精准判断,我们:
- 减少不必要的渲染流程
- 降低虚拟DOM diff成本
- 避免真实DOM的无效更新
- 提升组件整体性能
在Mini React中实现的这一优化,体现了React框架设计中的核心性能优化思想。理解这一机制有助于我们编写更高效的React应用代码。
优化本质:计算成本 < 渲染成本时,用计算换渲染
来源:juejin.cn/post/7524992966084083766
前端使用CountUp.js制作数字动画效果的教程
在现代网页设计中,动态数字展示能够显著提升用户体验,吸引访客注意力。无论是数据统计、销售数字还是还是评分展示,平滑的数字增长动画都能让信息传递更加生动。CountUp.js 正是一款专门用于创建这种数字动画效果的轻量级 JavaScript 库,本文将详细介绍其使用方法与技巧。
1. 前言
CountUp.js 是一个零依赖的 JavaScript 库,用于创建从一个数字平滑过渡到另一个数字的动画效果。它体积小巧(压缩后仅约 3KB),使用简单,且高度可定制,能够满足各种数字动画需求。
CountUp.js 的特点
- 零依赖,无需引入其他库
- 轻量级,加载迅速
- 高度可配置(动画时长、延迟、小数位数等)
- 支持多种 easing 动画效果
- 支持暂停、恢复、重置等控制
- 兼容所有现代浏览器
2. 快速开始
CountUp.js 有多种引入方式,可根据项目需求选择:
1. 通过 npm 安装
npm install countup.js
然后在项目中导入:
import CountUp from 'countup.js';
2. 直接引入 CDN
<script src="https://cdn.jsdelivr.net/npm/countup.js@2.0.8/dist/countUp.umd.min.js">script>
3. 下载源码
从 GitHub 仓库 下载源码,直接引入本地文件。
2.1. 基本用法
使用 CountUp.js 只需三步:
- 在 HTML 中准备一个用于显示数字的元素
<div id="counter">div>
- 初始化 CountUp 实例
// 获取 DOM 元素
const element = document.getElementById('counter');
// 目标数值
const target = 1000;
// 创建 CountUp 实例
const countUp = new CountUp(element, target);
- 启动动画
// 检查是否初始化成功,然后启动动画
if (!countUp.error) {
countUp.start();
} else {
console.error(countUp.error);
}
3. 配置选项
CountUp.js 提供了丰富的配置选项,让你可以精确控制动画效果:
const options = {
startVal: 0, // 起始值,默认为 0
duration: 2, // 动画时长(秒),默认为 2
decimalPlaces: 0, // 小数位数,默认为 0
useGr0uping: true, // 是否使用千位分隔符,默认为 true
useEasing: true, // 是否使用缓动效果,默认为 true
smartEasingThreshold: 999, // 智能缓动阈值
smartEasingAmount: 300, // 智能缓动数量
separator: ',', // 千位分隔符,默认为 ','
decimal: '.', // 小数点符号,默认为 '.'
prefix: '', // 数字前缀
suffix: '', // 数字后缀
numerals: [] // 数字替换数组,用于本地化
};
// 使用配置创建实例
const countUp = new CountUp(element, target, options);
3.1. 示例:带前缀和后缀的动画
// 显示"$1,234.56"的动画
const options = {
startVal: 0,
duration: 3,
decimalPlaces: 2,
prefix: '$',
suffix: ''
};
const countUp = new CountUp(document.getElementById('price'), 1234.56, options);
countUp.start();
4. 高级控制方法
CountUp.js 提供了多种方法来控制动画过程:
// 开始动画
countUp.start();
// 暂停动画
countUp.pauseResume();
// 重置动画
countUp.reset();
// 更新目标值并重新开始动画
countUp.update(2000);
// 立即完成动画
countUp.finish();
4.1. 示例:带回调函数的动画
// 动画完成后执行回调函数
countUp.start(() => {
console.log('动画完成!');
// 可以在这里执行后续操作
});
5. 实际应用场景
下面是实际应用场景的模拟:
5.1. 数据统计展示
<div class="stats">
<div class="stat-item">
<h3>用户总数h3>
<div class="stat-value" id="users">div>
div>
<div class="stat-item">
<h3>总销售额h3>
<div class="stat-value" id="sales">div>
div>
<div class="stat-item">
<h3>转化率h3>
<div class="stat-value" id="conversion">div>
div>
div>
<script>
// 初始化多个计数器
const usersCounter = new CountUp('users', 12500, { suffix: '+' });
const salesCounter = new CountUp('sales', 458920, { prefix: '$', decimalPlaces: 0 });
const conversionCounter = new CountUp('conversion', 24.5, { suffix: '%', decimalPlaces: 1 });
// 同时启动所有动画
document.addEventListener('DOMContentLoaded', () => {
usersCounter.start();
salesCounter.start();
conversionCounter.start();
});
script>
5.2. 滚动触发动画
结合 Intersection Observer API,实现元素进入视口时触发动画:
<div id="scrollCounter" class="counter">div>
<script>
// 创建计数器实例但不立即启动
const scrollCounter = new CountUp('scrollCounter', 5000);
// 配置交叉观察器
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
// 元素进入视口,启动动画
scrollCounter.start();
// 只观察一次
observer.unobserve(entry.target);
}
});
});
// 观察目标元素
observer.observe(document.getElementById('scrollCounter'));
script>
5.3. 结合按钮控制
<div id="controlledCounter">div>
<button id="startBtn">开始button>
<button id="pauseBtn">暂停button>
<button id="resetBtn">重置button>
<button id="updateBtn">更新到 2000button>
<script>
const counter = new CountUp('controlledCounter', 1000);
// 按钮事件监听
document.getElementById('startBtn').addEventListener('click', () => {
counter.start();
});
document.getElementById('pauseBtn').addEventListener('click', () => {
counter.pauseResume();
});
document.getElementById('resetBtn').addEventListener('click', () => {
counter.reset();
});
document.getElementById('updateBtn').addEventListener('click', () => {
counter.update(2000);
});
script>
6.自定义缓动函数
CountUp.js 允许你自定义缓动函数,创建独特的动画效果:
// 自定义缓动函数
function myEasing(t, b, c, d) {
// t: 当前时间
// b: 起始值
// c: 变化量 (目标值 - 起始值)
// d: 总时长
t /= d;
return c * t * t * t + b;
}
// 使用自定义缓动函数
const options = {
duration: 2,
easingFn: myEasing
};
const countUp = new CountUp(element, target, options);
countUp.start();
7. 常见问题与解决方案
下面是一些常见问题与解决方案:
7.1. 动画不生效
- 检查元素是否正确获取
- 确保目标值大于起始值(如需从大到小动画,可设置 startVal 大于 target)
- 检查控制台是否有错误信息
7.2. 数字格式问题
- 使用 separator 和 decimal 选项配置数字格式
- 对于特殊数字系统,使用 numerals 选项进行替换
7.3. 性能问题
- 避免在同一页面创建过多计数器实例
- 对于非常大的数字,适当增加动画时长
- 考虑使用滚动触发,而非页面加载时同时启动所有动画
8. 总结
CountUp.js 是一个简单而强大的数字动画库,能够为你的网站增添专业感和活力。它的轻量级特性和丰富的配置选项使其适用于各种场景,从简单的数字展示到复杂的数据可视化。
通过本文介绍的基础用法和高级技巧,你可以轻松实现各种数字动画效果,提升用户体验。无论是个人博客、企业官网还是电商平台,CountUp.js 都能成为你前端工具箱中的得力助手。
参考资源
来源:juejin.cn/post/7542403996917989422
交替打印最容易理解的实现——同步队列
前言
原创不易,禁止转载!
本文旨在实现最简形式的交替打印。理解了同步队列,你可以轻松解决60%以上的多线程面试题。同步队列作为JUC提供的并发原语之一,使用了无锁算法,性能更好,但是却常常被忽略。
交替打印是一类常见的面试题,也是很多人第一次学习并发编程面对的问题,如:
- 三个线程T1、T2、T3轮流打印ABC,打印n次,如ABCABCABCABC.......
- 两个线程交替打印1-100的奇偶数
- N个线程循环打印1-100
很多文章(如: zhuanlan.zhihu.com/p/370130458 )总结了实现交替打印的多种做法:
- synchronized + wait/notify: 使用synchronized关键字和wait/notify方法来实现线程间的通信和同步。
- join() : 利用线程的join()方法来确保线程按顺序执行。
- Lock: 使用ReentrantLock来实现线程同步,通过锁的机制来控制线程的执行顺序。
- Lock + Condition: 在Lock的基础上,使用Condition对象来实现更精确的线程唤醒,避免不必要的线程竞争。
- Semaphore: 使用信号量来控制线程的执行顺序,通过acquire()和release()方法来管理线程的访问。
- 此外还有LockSupport、CountDownLatch、AtomicInteger 等实现方式。
笔者认为,在面试时能够选择一种无bug实现即可。
缺点
这些实现使用的都是原语,也就是并发编程中的基本组件,偏向于底层,同时要求开发者深入理解这些原语的工作原理,掌握很多技巧。
问题在于:如果真正的实践中实现,容易出现 bug,一般也不推荐在生产中使用;
这也是八股文的弊端之一:过于关注所谓的底层实现,忽略了真正的实践。
我们分析这些组件的特点,不外乎临界区锁定、线程同步、共享状态等。以下分析一个实现,看看使用到了哪些技巧:
class Wait_Notify_ACB {
private int num;
private static final Object LOCK = new Object();
private void printABC(int targetNum) {
for (int i = 0; i < 10; i++) {
synchronized (LOCK) {
while (num % 3 != targetNum) {
try {
LOCK.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
num++;
System.out.print(Thread.currentThread().getName());
LOCK.notifyAll();
}
}
}
public static void main(String[] args) {
Wait_Notify_ACB wait_notify_acb = new Wait_Notify_ACB ();
new Thread(() -> {
wait_notify_acb.printABC(0);
}, "A").start();
new Thread(() -> {
wait_notify_acb.printABC(1);
}, "B").start();
new Thread(() -> {
wait_notify_acb.printABC(2);
}, "C").start();
}
}
整体观之,使用的是 synchronized 隐式锁。使用等待队列实现线程同步,while 循环避免虚假唤醒,维护了多线程共享的 num 状态,此外需要注意多个任务的启动和正确终止。
InterruptedException 的处理是错误的,由于我们没有使用到中断机制,可以包装后抛出 IllegalStateException 表示未预料的异常。实践中,也可以设置当前线程为中断状态,待其他代码进行处理。
Lock不应该是静态的,可以改成非静态或者方法改成静态也行。
总之,经过分析可以看出并发原语的复杂性,那么有没有更高一层的抽象来简化问题呢?
更好的实现
笔者在项目的生产环境中遇到过类似的问题,多个线程需要协作,某些线程需要其他线程的结果,这种结果的交接是即时的,也就是说,A线程的结果直接交给B线程进行处理。
更好的实现要求我们实现线程之间的同步,同时应该避免并发修改。我们很自然地想到 SynchronousQueue,使用 CSP 实现 + CompletableFuture,可以减少我们考虑底层的心智负担,方便写出正确的代码。SynchronousQueue 适用于需要在生产者和消费者之间进行直接移交的场景,通常用于线程之间的切换或传递任务。
看一个具体例子:
以下是两个线程交替打印 1 - 100 的实现,由于没有在代码中使用锁,也没有状态维护的烦恼,这也是函数式的思想(减少状态)。
实现思路为:任务1从队列1中取结果,计算,提交给队列2。任务2同理。使用SynchronousQueue 实现直接交接。
private static Stopwatch betterImpl() {
Stopwatch sw = Stopwatch.createStarted();
BlockingQueue<Integer> q1 = new SynchronousQueue<>();
BlockingQueue<Integer> q2 = new SynchronousQueue<>();
int limit = 100;
CompletableFuture<Void> cf1 = CompletableFuture.runAsync(() -> {
while (true) {
Integer i = Uninterruptibles.takeUninterruptibly(q1);
if (i <= limit) {
System.out.println("thread1: i = " + i);
}
Uninterruptibles.putUninterruptibly(q2, i + 1);
if (i == limit - 1) {
break;
}
}
});
CompletableFuture<Void> cf2 = CompletableFuture.runAsync(() -> {
while (true) {
Integer i = Uninterruptibles.takeUninterruptibly(q2);
if (i <= limit) {
System.out.println("thread2: i = " + i);
}
if (i == limit) {
break;
}
Uninterruptibles.putUninterruptibly(q1, i + 1);
}
});
Uninterruptibles.putUninterruptibly(q1, 1);
CompletableFuture.allOf(cf1, cf2).join();
return sw.stop();
}
Uninterruptibles 是 Guava 中的并发工具,很实用,可以避免 try-catch 中断异常这样的样板代码。
线程池配置与本文讨论内容关系不大,故忽略。
一般实践中,阻塞方法都要设置超时时间,这里也忽略了。
这个实现简单明了,性能也不错。如果不需要即时交接,可以替换成缓冲队列(如 ArrayBlockingQueue)。
笔者简单比较了两种实现,结果如下:
private static Stopwatch bufferImpl() {
Stopwatch sw = Stopwatch.createStarted();
BlockingQueue<Integer> q1 = new ArrayBlockingQueue<>(2);
BlockingQueue<Integer> q2 = new ArrayBlockingQueue<>(2);
// ...
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
betterImpl();
bufferImpl();
// 预热
}
Stopwatch result1 = bufferImpl();
Stopwatch result2 = betterImpl();
System.out.println("result1 = " + result1);
System.out.println("result2 = " + result2);
}
// ...
thread2: i = 92
thread1: i = 93
thread2: i = 94
thread1: i = 95
thread2: i = 96
thread1: i = 97
thread2: i = 98
thread1: i = 99
thread2: i = 100
result1 = 490.3 μs
result2 = 469.1 μs
结论:使用 SynchronousQueue 性能更好,感兴趣的读者可以自己写 JMH 比对。
如果你觉得本文对你有帮助的话,欢迎给个点赞加收藏,也欢迎进一步的讨论。
后续我将继续分享并发编程、性能优化等有趣内容,力求做到全网独一份、深入浅出,一周两更,欢迎关注支持。
来源:juejin.cn/post/7532925096828026899
uniapp图片上传添加水印/压缩/剪裁
一、前言
最近遇到一个需求,微信小程序上传图片添加水印的需求,故此有该文章做总结, 功能涵盖定理地位,百度地址解析,图片四角水印,图片压缩,图片压缩并添加水印,图片剪裁,定位授权,保存图片到相册等
二、效果
三、代码实现核心
3.1)添加水印并压缩
核心实现
// 添加水印并压缩
export function addWatermarkAndCompress(options, that, isCompress = false) {
return new Promise((resolve, reject) => {
const {
errLog,
config
} = dealWatermarkConfig(options)
that.watermarkCanvasOption.width = 0
that.watermarkCanvasOption.height = 0
if (!errLog.length) {
const {
canvasId,
imagePath,
watermarkList,
quality = 0.6
} = config
uni.getImageInfo({ // 获取图片信息,以便获取图片的真实宽高信息
src: imagePath,
success: (info) => {
const {
width: oWidth,
height: oHeight,
type,
orientation
} = info; // 获取图片的原始宽高
const fileTypeObj = {
'jpeg': 'jpg',
'jpg': 'jpg',
'png': 'png',
}
const fileType = fileTypeObj[type] || 'png'
let width = oWidth
let height = oHeight
if (isCompress) {
const {
cWidth,
cHeight
} = calcRatioHeightAndWight({
oWidth,
oHeight,
quality,
orientation
})
// 按对折比例缩小
width = cWidth
height = cHeight
}
that.watermarkCanvasOption.width = width
that.watermarkCanvasOption.height = height
that.$nextTick(() => {
// 获取canvas绘图上下文
const ctx = uni.createCanvasContext(canvasId, that);
// 绘制原始图片到canvas上
ctx.drawImage(imagePath, 0, 0, width, height);
// 绘制水印项
const drawWMItem = (ctx, options) => {
const {
fontSize,
color,
text: cText,
position,
margin
} = options
// 添加水印
ctx.setFontSize(fontSize); // 设置字体大小
ctx.setFillStyle(color); // 设置字体颜色为红色
if (isNotEmptyArr(cText)) {
const text = cText.filter(Boolean)
if (position.startsWith('bottom')) {
text.reverse()
}
text.forEach((str, ind) => {
const textMetrics = ctx.measureText(str);
const {
calcX,
calcY
} = calcPosition({
height,
width,
position,
margin,
ind,
fontSize,
textMetrics
})
ctx.fillText(str, calcX, calcY, width);
})
} else {
const textMetrics = ctx.measureText(cText);
const {
calcX,
calcY
} = calcPosition({
height,
width,
position,
margin,
ind: 0,
fontSize,
textMetrics
})
// 在图片底部添加水印文字
ctx.fillText(text, calcX, calcY, width);
}
}
watermarkList.forEach(ele => {
drawWMItem(ctx, ele)
})
// 绘制完成后执行的操作,这里不等待绘制完成就继续执行后续操作,因为我们要导出为图片
ctx.draw(false, () => {
// #ifndef MP-ALIPAY
uni.canvasToTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width,
height,
fileType,
quality, // 图片的质量,目前仅对 jpg 有效。取值范围为 (0, 1],不在范围内时当作 1.0 处理。
destWidth: width,
destHeight: height,
success: (res) => {
console.log('res.tempFilePath', res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
// #ifdef MP-ALIPAY
ctx.toTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width: width,
height: height,
destWidth: width,
destHeight: height,
quality,
fileType,
success: (res) => {
console.log('res.tempFilePath', res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
});
})
}
});
} else {
const errStr = errLog.join(';')
showMsg(errStr)
reject(errStr)
}
})
}
3.2)剪切图片
// 剪切图片
export function clipImg(options, that) {
return new Promise((resolve, reject) => {
const {
errLog,
config
} = dealClipImgConfig(options)
that.watermarkCanvasOption.width = 0
that.watermarkCanvasOption.height = 0
if (!errLog.length) {
const {
canvasId,
imagePath,
cWidth,
cHeight,
position
} = config
// 获取图片信息,以便获取图片的真实宽高信息
uni.getImageInfo({
src: imagePath,
success: (info) => {
const {
width,
height
} = info; // 获取图片的原始宽高
// 自定义剪裁范围要在图片内
if (width >= cWidth && height >= cHeight) {
that.watermarkCanvasOption.width = width
that.watermarkCanvasOption.height = height
that.$nextTick(() => {
// 获取canvas绘图上下文
const ctx = uni.createCanvasContext(canvasId, that);
const {
calcSX,
calcSY,
calcEX,
calcEY
} = calcClipPosition({
cWidth,
cHeight,
position,
width,
height
})
// 绘制原始图片到canvas上
ctx.drawImage(imagePath, 0, 0, width, height);
// 绘制完成后执行的操作,这里不等待绘制完成就继续执行后续操作,因为我们要导出为图片
ctx.draw(false, () => {
// #ifndef MP-ALIPAY
uni.canvasToTempFilePath({ // 将画布内容导出为图片
canvasId,
x: calcSX,
y: calcSY,
width: cWidth,
height: cHeight,
destWidth: cWidth,
destHeight: cHeight,
success: (res) => {
console.log('res.tempFilePath',
res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
// #ifdef MP-ALIPAY
ctx.toTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width: width,
height: height,
destWidth: width,
destHeight: height,
// fileType: 'png',
success: (res) => {
console.log('res.tempFilePath',
res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
});
})
} else {
return imagePath
}
}
})
} else {
const errStr = errLog.join(';')
showMsg(errStr)
reject(errStr)
}
})
}
3.3)canvas画布标签
<!-- 给图片添加的标签 -->
<canvas v-if="watermarkCanvasOption.width > 0 && watermarkCanvasOption.height > 0"
:style="{ width: watermarkCanvasOption.width + 'px', height: watermarkCanvasOption.height + 'px' }"
canvas-id="watermarkCanvas" id="watermarkCanvas" style="position: absolute; top: -10000000rpx;" />
以上代码具体的实现功能不做一一讲解,详细请看下方源码地址
四、源码地址
github: github.com/ArcherNull/…
五、总结
- 图片的操作,例如压缩/剪裁/加水印都是需要借助canvas标签,也就是说需要有canvas实例通过该api实现这些操作
- 当执行 ctx.drawImage(imagePath, 0, 0, width, height) 后,后续的操作的是对内存中的数据,而不是源文件
完结撒花,如果对您有帮助,请一键三连
来源:juejin.cn/post/7513183180092031011
订单表超10亿数据,如何设计Sharding策略?解决跨分片查询和分布式事务?
订单表超10亿数据,如何设计Sharding策略?解决跨分片查询和分布式事务?
引言:
在电商平台高速发展的今天,海量订单处理已成为技术团队必须面对的挑战。当订单数据突破10亿大关,传统单库架构在查询性能、存储容量和运维复杂度上都会遇到瓶颈。
作为有8年经验的Java工程师,我曾主导多个日订单量百万级系统的分库分表改造。今天我将分享从Sharding策略设计到分布式事务落地的完整解决方案,其中包含核心代码实现和实战避坑指南。
一、业务场景分析
1.1 订单数据特点
- 数据量大:日增订单50万+,年增1.8亿
- 访问模式:
- 写操作:高频下单(峰值5000 TPS)
- 读操作:订单查询(用户端+运营端)
- 数据生命周期:热数据(3个月)占80%访问量
1.2 核心挑战
graph LR
A[10亿级订单] --> B[查询性能]
A --> C[存储瓶颈]
A --> D[跨分片聚合]
A --> E[分布式事务]
二、Sharding策略设计
2.1 分片键选择
| 候选方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 用户ID | 用户维度查询快 | 可能导致数据倾斜 | C端主导业务 |
| 订单ID | 数据分布均匀 | 用户订单需跨分片查询 | 均匀分布场景 |
| 商户ID | 商户维度查询快 | C端查询效率低 | B2B平台 |
| 创建时间 | 冷热数据分离 | 范围查询可能跨分片 | 推荐方案 |
最终方案:复合分片键(用户ID+创建时间)
2.2 分片算法设计
/**
* 自定义复合分片算法
* 分片键:user_id + create_time
*/
public class OrderShardingAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
private static final String USER_KEY = "user_id";
private static final String TIME_KEY = "create_time";
@Override
public Collection<String> doSharding(
Collection<String> availableTargetNames,
ComplexKeysShardingValue<Long> shardingValue) {
Map<String, Collection<Long>> columnMap = shardingValue.getColumnNameAndShardingValuesMap();
List<String> shardingResults = new ArrayList<>();
// 获取用户ID分片值
Collection<Long> userIds = columnMap.get(USER_KEY);
Long userId = userIds.stream().findFirst().orElseThrow();
// 获取时间分片值
Collection<Long> timestamps = columnMap.get(TIME_KEY);
Long createTime = timestamps.stream().findFirst().orElse(System.currentTimeMillis());
// 计算用户分片(16个分库)
int dbShard = Math.abs(userId.hashCode()) % 16;
// 计算时间分片(按月分表)
LocalDateTime dateTime = Instant.ofEpochMilli(createTime)
.atZone(ZoneId.systemDefault())
.toLocalDateTime();
String tableSuffix = dateTime.format(DateTimeFormatter.ofPattern("yyyyMM"));
// 构建目标分片
String targetDB = "order_db_" + dbShard;
String targetTable = "t_order_" + tableSuffix;
shardingResults.add(targetDB + "." + targetTable);
return shardingResults;
}
}
2.3 分片策略配置(ShardingSphere)
# application-sharding.yaml
spring:
shardingsphere:
datasource:
names: ds0,ds1,...,ds15
# 配置16个数据源...
sharding:
tables:
t_order:
actualDataNodes: ds${0..15}.t_order_${202301..202412}
tableStrategy:
complex:
shardingColumns: user_id,create_time
algorithmClassName: com.xxx.OrderShardingAlgorithm
keyGenerator:
column: order_id
type: SNOWFLAKE
三、跨分片查询解决方案
3.1 常见问题及对策
| 问题类型 | 传统方案痛点 | 优化方案 |
|---|---|---|
| 分页查询 | LIMIT 0,10 扫描全表 | 二次查询法 |
| 排序聚合 | 内存合并性能差 | 并行查询+流式处理 |
| 全局索引 | 无法直接建立 | 异步构建ES索引 |
3.2 分页查询优化实现
/**
* 跨分片分页查询优化(二次查询法)
* 原SQL:SELECT * FROM t_order WHERE user_id=1001 ORDER BY create_time DESC LIMIT 10000,10
*/
public Page<Order> shardingPageQuery(Long userId, int pageNo, int pageSize) {
// 第一步:全分片并行查询
List<Order> allShardResults = shardingExecute(
shard -> "SELECT order_id, create_time FROM t_order "
+ "WHERE user_id = " + userId
+ " ORDER BY create_time DESC"
);
// 第二步:内存排序取TopN
List<Long> targetIds = allShardResults.stream()
.sorted(Comparator.comparing(Order::getCreateTime).reversed())
.skip(pageNo * pageSize)
.limit(pageSize)
.map(Order::getOrderId)
.collect(Collectors.toList());
// 第三步:精准查询目标数据
return orderRepository.findByIdIn(targetIds);
}
/**
* 并行执行查询(使用CompletableFuture)
*/
private List<Order> shardingExecute(Function<Integer, String> sqlBuilder) {
List<CompletableFuture<List<Order>>> futures = new ArrayList<>();
for (int i = 0; i < 16; i++) {
final int shardId = i;
futures.add(CompletableFuture.supplyAsync(() -> {
String sql = sqlBuilder.apply(shardId);
return jdbcTemplate.query(sql, new OrderRowMapper());
}, shardingThreadPool));
}
return futures.stream()
.map(CompletableFuture::join)
.flatMap(List::stream)
.collect(Collectors.toList());
}
3.3 聚合查询优化
/**
* 分布式聚合计算(如:用户总订单金额)
* 方案:并行查询分片结果 + 内存汇总
*/
public BigDecimal calculateUserTotalAmount(Long userId) {
List<CompletableFuture<BigDecimal>> futures = new ArrayList<>();
for (int i = 0; i < 16; i++) {
futures.add(CompletableFuture.supplyAsync(() -> {
String sql = "SELECT SUM(amount) FROM t_order WHERE user_id = ?";
return jdbcTemplate.queryForObject(
sql, BigDecimal.class, userId);
}, shardingThreadPool));
}
return futures.stream()
.map(CompletableFuture::join)
.filter(Objects::nonNull)
.reduce(BigDecimal.ZERO, BigDecimal::add);
}
四、分布式事务解决方案
4.1 方案对比
| 方案 | 一致性 | 性能 | 复杂度 | 适用场景 |
|---|---|---|---|---|
| 2PC | 强一致 | 差 | 高 | 银行核心系统 |
| TCC | 强一致 | 中 | 高 | 资金交易 |
| Saga | 最终一致 | 优 | 中 | 订单系统(推荐) |
| 本地消息表 | 最终一致 | 良 | 低 | 低要求场景 |
4.2 Saga事务实现(订单创建场景)
sequenceDiagram
participant C as 应用
participant O as 订单服务
participant I as 库存服务
participant P as 支付服务
C->>O: 创建订单
O->>I: 预扣库存
I-->>O: 扣减成功
O->>P: 发起支付
P-->>O: 支付成功
O->>C: 返回结果
alt 支付失败
O->>I: 释放库存(补偿)
end
4.3 核心代码实现
/**
* Saga事务管理器(使用Seata框架)
*/
@Service
@Slf4j
public class OrderSagaService {
@Autowired
private InventoryFeignClient inventoryClient;
@Autowired
private PaymentFeignClient paymentClient;
@Transactional
public void createOrder(OrderCreateDTO dto) {
// 1. 创建本地订单(状态:待支付)
Order order = createPendingOrder(dto);
try {
// 2. 调用库存服务(Saga参与者)
inventoryClient.deductStock(
new DeductRequest(order.getOrderId(), dto.getSkuItems()));
// 3. 调用支付服务(Saga参与者)
paymentClient.createPayment(
new PaymentRequest(order.getOrderId(), order.getTotalAmount()));
// 4. 更新订单状态为已支付
order.paySuccess();
orderRepository.update(order);
} catch (Exception ex) {
// 触发Saga补偿流程
log.error("订单创建失败,触发补偿", ex);
handleCreateOrderFailure(order, ex);
throw ex;
}
}
/**
* 补偿操作(需要幂等)
*/
@Compensable(compensationMethod = "compensateOrder")
private void handleCreateOrderFailure(Order order, Exception ex) {
// 1. 释放库存
inventoryClient.restoreStock(order.getOrderId());
// 2. 取消支付(如果已发起)
paymentClient.cancelPayment(order.getOrderId());
// 3. 标记订单失败
order.cancel("系统异常: " + ex.getMessage());
orderRepository.update(order);
}
/**
* 补偿方法(幂等设计)
*/
public void compensateOrder(Order order, Exception ex) {
// 通过状态判断避免重复补偿
if (order.getStatus() != OrderStatus.CANCELLED) {
handleCreateOrderFailure(order, ex);
}
}
}
五、性能优化实践
5.1 分片路由优化
/**
* 热点用户订单查询优化
* 方案:用户分片路由缓存
*/
@Aspect
@Component
public class ShardingRouteCacheAspect {
@Autowired
private RedisTemplate<String, Integer> redisTemplate;
private static final String ROUTE_KEY = "user_route:%d";
@Around("@annotation(org.apache.shardingsphere.api.hint.Hint)")
public Object cacheRoute(ProceedingJoinPoint joinPoint) throws Throwable {
Long userId = getUserIdFromArgs(joinPoint.getArgs());
if (userId == null) {
return joinPoint.proceed();
}
// 1. 查询缓存
String cacheKey = String.format(ROUTE_KEY, userId);
Integer shardId = redisTemplate.opsForValue().get(cacheKey);
if (shardId == null) {
// 2. 计算分片ID(避免全表扫描)
shardId = calculateUserShard(userId);
redisTemplate.opsForValue().set(cacheKey, shardId, 1, TimeUnit.HOURS);
}
// 3. 设置分片Hint强制路由
try (HintManager hintManager = HintManager.getInstance()) {
hintManager.setDatabaseShardingValue(shardId);
return joinPoint.proceed();
}
}
private int calculateUserShard(Long userId) {
// 分片计算逻辑(与分片算法保持一致)
return Math.abs(userId.hashCode()) % 16;
}
}
5.2 冷热数据分离
-- 归档策略示例(每月执行)
CREATE EVENT archive_orders
ON SCHEDULE EVERY 1 MONTH
DO
BEGIN
-- 1. 创建归档表(按年月)
SET @archive_table = CONCAT('t_order_archive_', DATE_FORMAT(NOW(), '%Y%m'));
SET @create_sql = CONCAT('CREATE TABLE IF NOT EXISTS ', @archive_table, ' LIKE t_order');
PREPARE stmt FROM @create_sql; EXECUTE stmt;
-- 2. 迁移数据(6个月前)
SET @move_sql = CONCAT(
'INSERT INTO ', @archive_table,
' SELECT * FROM t_order WHERE create_time < DATE_SUB(NOW(), INTERVAL 6 MONTH)'
);
PREPARE stmt FROM @move_sql; EXECUTE stmt;
-- 3. 删除原表数据
DELETE FROM t_order WHERE create_time < DATE_SUB(NOW(), INTERVAL 6 MONTH);
END
六、避坑指南
6.1 常见问题及解决方案
| 问题类型 | 现象 | 解决方案 |
|---|---|---|
| 分片键选择不当 | 数据倾斜(70%数据在1个分片) | 增加分片基数(复合分片键) |
| 分布式事务超时 | 库存释放失败 | 增加重试机制+人工补偿台 |
| 跨分片查询性能差 | 分页查询超时 | 改用ES做全局搜索 |
| 扩容困难 | 增加分片需迁移数据 | 初始设计预留分片(32库) |
6.2 必须实现的监控项
graph TD
A[监控大盘] --> B[分片负载]
A --> C[慢查询TOP10]
A --> D[分布式事务成功率]
A --> E[热点用户检测]
A --> F[归档任务状态]
七、总结与展望
分库分表本质是业务与技术的平衡艺术,经过多个项目的实践验证,我总结了以下核心经验:
- 分片设计三原则:
- 数据分布均匀性 > 查询便捷性
- 业务可扩展性 > 短期性能
- 简单可运维 > 技术先进性
- 演进路线建议:
graph LR
A[单库] --> B[读写分离]
B --> C[垂直分库]
C --> D[水平分表]
D --> E[单元化部署]
- 未来优化方向:
- 基于TiDB的HTAP架构
- 使用Apache ShardingSphere-Proxy
- 智能分片路由(AI预测热点)
最后的话:
处理10亿级订单如同指挥一场交响乐——每个分片都是独立乐器,既要保证局部精准,又要实现全局和谐。
好的分库分表方案不是技术参数的堆砌,而是对业务深刻理解后的架构表达。
来源:juejin.cn/post/7519688814395719714
如何将canvas动画导成一个视频?
引言
某一天我突然有个想法,我想用canvas做一个音频可视化的音谱,然后将这个音频导出成视频。
使用canvas实现音频可视化,使用ffmpeg导出视频与音频,看起来方案是可行的,技术也是可行的,说干就干,先写一个demo。
这里我使用vue来搭建项目
- 创建项目
vue create demo
- 安装ffmpeg插件
npm @ffmpeg/ffmpeg @ffmpeg/core
- 组件videoPlayer.vue
这里有个点需要注意:引用@ffmpeg/ffmpeg可能会报错
需要将node_modules中@ffmpeg文件下面的 - ffmpeg-core.js
- ffmpeg-core.wasm
- ffmpeg-core.worker.js
这三个文件复制到public文件下面 - 并且需要在vue。config.js中进行如下配置
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({
transpileDependencies: true,
devServer:{
headers: {
"Cross-Origin-Opener-Policy": "same-origin",
"Cross-Origin-Embedder-Policy": "require-corp",
}
}
})
准备好这些后,下面是实现代码
<template>
<div class="wrap" v-loading="loading" element-loading-text="正在下载视频。。。">
<div>
<input type="file" @change="handleFileUpload" accept="audio/*" />
<button @click="playAudio">播放</button>
<button @click="pauseAudio">暂停</button>
</div>
<div class="canvas-wrap">
<canvas ref="canvas" id="canvas"></canvas>
</div>
</div>
</template>
<script>
import RainDrop from './rain'
import { createFFmpeg, fetchFile } from '@ffmpeg/ffmpeg';
export default {
name: 'canvasVideo',
data() {
return {
frames: [],
recording: false,
ffmpeg: null,
x: 0,
loading: false,
canvasCtx: null,
audioContext: null,
analyser: null,
bufferLength: null,
dataArray: null,
audioFile: null,
audioElement: null,
audioSource: null,
// 谱频个数
barCount: 64,
// 宽度
barWidth: 10,
marginLeft: 10,
player: false,
rainCount: 200,
rainDrops: [],
pausePng: null,
offscreenCanvas: null
};
},
mounted() {
this.ffmpeg = createFFmpeg({ log: true });
this.initFFmpeg();
},
methods: {
async initFFmpeg() {
await this.ffmpeg.load();
this.initCanvas()
},
startRecording() {
this.recording = true;
this.captureFrames();
},
stopRecording() {
this.recording = false;
this.exportVideo();
},
async captureFrames() {
const canvas = this.canvasCtx.canvas;
const imageData = canvas.toDataURL('image/png');
this.frames.push(imageData);
},
async exportVideo() {
this.loading = true
this.recording = false
const { ffmpeg } = this;
console.log('frames', this.frames)
try {
for (let i = 0; i < this.frames.length; i++) {
const frame = this.frames[i];
const frameData = await fetchFile(frame);
ffmpeg.FS('writeFile', `frame${i}.png`, frameData);
}
// 将音频文件写入 FFmpeg 文件系统
ffmpeg.FS('writeFile', 'audio.mp3', await fetchFile(this.audioFile));
// 使用 FFmpeg 将帧编码为视频
await ffmpeg.run(
'-framerate', '30', // 帧率 可以收费
'-i', 'frame%d.png', // 输入文件名格式
'-i', 'audio.mp3', // 输入音频
'-c:v', 'libx264', // 视频编码器
'-c:a', 'aac', // 音频编码器
'-pix_fmt', 'yuv420p', // 像素格式
'-vsync', 'vfr', // 同步视频和音频
'-shortest', // 使视频长度与音频一致
'output.mp4' // 输出文件名
);
const files = ffmpeg.FS('readdir', '/');
console.log('文件系统中的文件:', files);
const data = ffmpeg.FS('readFile', 'output.mp4');
const url = URL.createObjectURL(new Blob([data.buffer], { type: 'video/mp4' }));
const a = document.createElement('a');
a.href = url;
a.download = 'output.mp4';
a.click();
} catch (e) {
console.log('eeee', e)
}
this.loading = false
},
initCanvas() {
const dom = document.getElementById('canvas');
this.canvasCtx = dom.getContext('2d');
const p = document.querySelector('.canvas-wrap')
console.log('p', p.offsetWidth)
this.canvasCtx.canvas.width = p.offsetWidth;
this.canvasCtx.canvas.height = p.offsetHeight;
console.log('canvasCtx', this.canvasCtx)
this.initAudioContext()
this.createRainDrops()
},
handleFileUpload(event) {
const file = event.target.files[0];
if (file) {
this.audioFile = file
const fileURL = URL.createObjectURL(file);
this.loadAudio(fileURL);
}
},
loadAudio(url) {
this.audioElement = new Audio(url);
this.audioElement.addEventListener('error', (e) => {
console.error('音频加载失败:', e);
});
this.audioSource = this.audioContext.createMediaElementSource(this.audioElement);
this.audioSource.connect(this.analyser);
this.analyser.connect(this.audioContext.destination);
},
playAudio() {
if (this.audioContext.state === 'suspended') {
this.audioContext.resume().then(() => {
console.log('AudioContext 已恢复');
this.audioElement.play();
this.player = true
this.draw();
});
} else {
this.audioElement.play().then(() => {
this.player = true
this.draw();
}).catch((error) => {
console.error('播放失败:', error);
});
}
},
pauseAudio() {
if (this.audioElement) {
this.audioElement.pause();
this.player = false
this.stopRecording()
}
},
initAudioContext() {
this.audioContext = new (window.AudioContext || window.webkitAudioContext)();
this.analyser = this.audioContext.createAnalyser();
this.analyser.fftSize = 256;
this.dataArray = new Uint8Array(this.barCount);
},
bar() {
let barHeight = 20;
const allBarWidth = this.barCount * this.barWidth + this.marginLeft * (this.barCount - 1)
const left = (this.canvasCtx.canvas.width - allBarWidth) / 2
let x = left
for (let i = 0; i < this.barCount; i++) {
barHeight = this.player ? this.dataArray[i] : 0
// console.log('barHeight', barHeight)
// 创建线性渐变
const gradient = this.canvasCtx.createLinearGradient(0, 0, this.canvasCtx.canvas.width, 0); // 从左到右渐变
gradient.addColorStop(0.2, '#fff'); // 起始颜色
gradient.addColorStop(0.5, '#ff5555');
gradient.addColorStop(0.8, '#fff'); // 结束颜色
// 设置阴影属性
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.fillStyle = gradient;
this.canvasCtx.fillRect(x, this.canvasCtx.canvas.height - barHeight / 2 - 100, this.barWidth, barHeight / 2);
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.beginPath();
this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2 - 99, 5, 0, Math.PI, true)
// this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2, 5, 0, Math.PI, false)
this.canvasCtx.closePath();
this.canvasCtx.fill()
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.beginPath();
// this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2 - 100, 5, 0, Math.PI, true)
this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - 100, 5, 0, Math.PI, false)
this.canvasCtx.closePath();
this.canvasCtx.fill()
x += this.barWidth + this.marginLeft;
}
},
draw() {
if (this.player) requestAnimationFrame(this.draw);
this.startRecording()
// 获取频谱数据
this.analyser.getByteFrequencyData(this.dataArray);
this.canvasCtx.fillStyle = 'rgb(0, 0, 0)';
this.canvasCtx.fillRect(0, 0, this.canvasCtx.canvas.width, this.canvasCtx.canvas.height); // 清除画布
this.bar()
this.rainDrops.forEach((drop) => {
drop.update();
drop.draw(this.canvasCtx);
});
},
// 创建雨滴对象
createRainDrops() {
for (let i = 0; i < this.rainCount; i++) {
this.rainDrops.push(new RainDrop(this.canvasCtx.canvas.width, this.canvasCtx.canvas.height, this.canvasCtx));
}
},
}
};
</script>
当选择好音频文件点击播放时如下图
点击暂停则可对已经播放过的音频时长进行视频录制下载
如果有什么其他问题欢迎在评论区交流
来源:juejin.cn/post/7521685642431053863
MCP简介:从浏览器截图的自动化说起
在当今 AI 飞速发展的时代,大型语言模型 (LLM) 如 Claude、ChatGPT 等已经在代码生成、内容创作等方面展现出惊人的能力。然而,这些强大的模型存在一个明显的局限性——它们通常与外部系统和工具隔离,无法直接访问或操作用户环境中的资源和工具。
而 Model Context Protocol (MCP) 的出现,正是为了解决这一问题。
什么是MCP?
Model Context Protocol (MCP) 是由 Anthropic 公司推出的一个开放协议,它标准化了应用程序如何向大型语言模型 (LLM) 提供上下文和工具的方式。我们可以将 MCP 理解为 AI 应用的"USB-C 接口"——就像 USB-C 为各种设备提供了标准化的连接方式,MCP 为 AI 模型提供了与不同数据源和工具连接的标准化方式。
简单来说,MCP可以做到以下事情:
- 读取和写入本地文件
- 查询数据库
- 执行命令行操作
- 控制浏览器
- 与第三方 API 交互
这极大地扩展了 AI 助手的能力边界,使其不再仅限于对话框内的文本交互。
MCP的架构
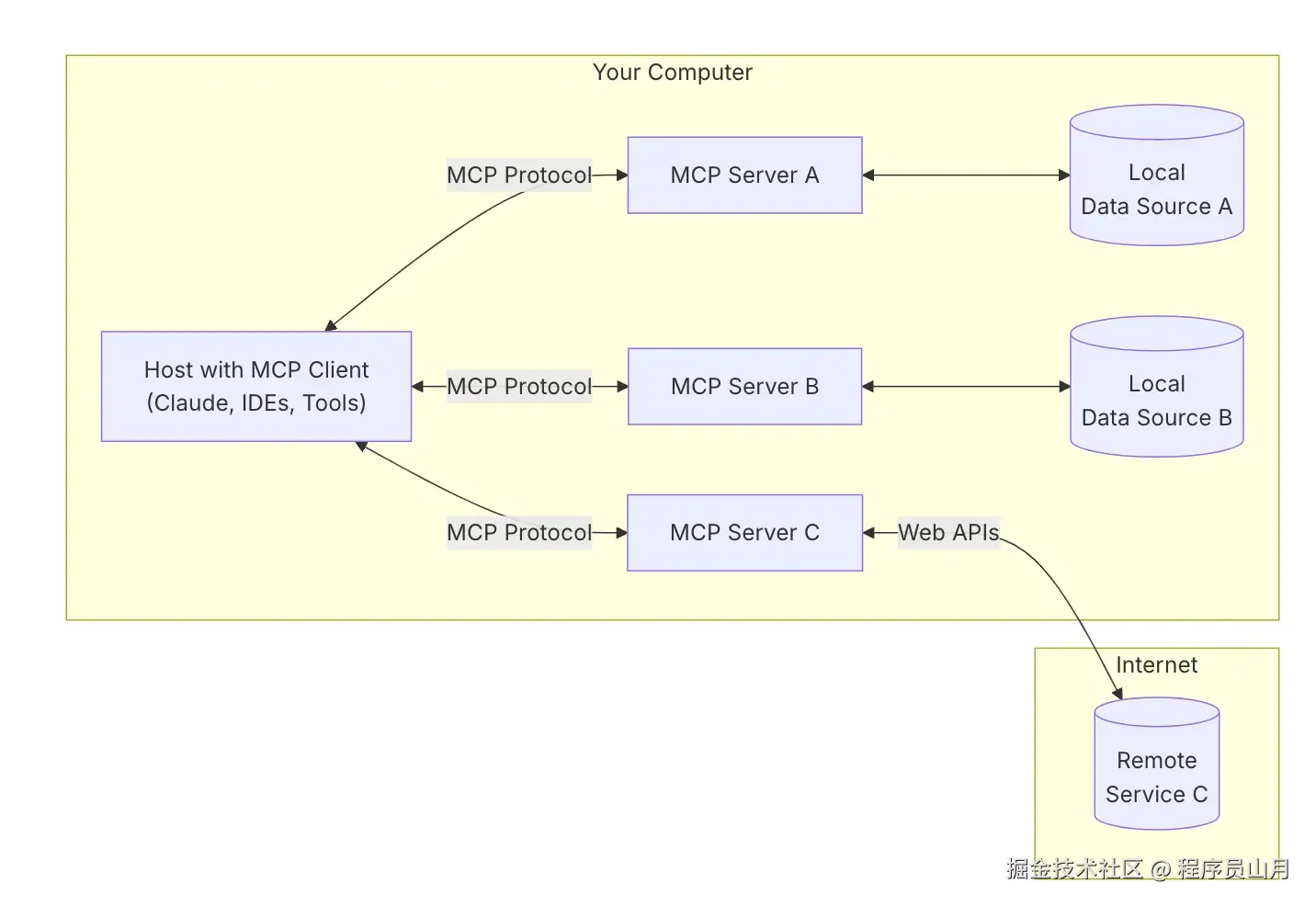
以上图片来源于 MCP 官方文档
MCP 的架构相对简单,主要包含两个核心组件:
- MCP 服务器 (Server):提供工具和资源的服务端,可以使用任何编程语言实现,只要能够通过
stdout/stdin或 HTTP 通信。 - MCP 客户端 (Client):使用 MCP 服务器提供的工具和资源的 AI 应用,如
Claude Desktop、Cursor编辑器等。
MCP 服务器向客户端提供两种主要能力:
- 工具 (Tools):可执行的函数,允许 AI 执行特定操作
- 资源 (Resources):提供给 AI 的上下文信息,如文件内容、数据库结构等
浏览器自动化:MCP的实际应用
为了更直观地理解 MCP 的强大之处,让我们看一个案例:使用 Playwright MCP 服务器进行浏览器自动化。
Playwright 是一个由 Microsoft 开发的浏览器自动化工具,可以控制 Chrome、Firefox、Safari 等主流浏览器。通过 Playwright MCP 服务器,我们可以让 AI 助手直接操作浏览器,执行各种任务。
先讲讲使用场景
- 博客写作。当我写博客时,我需要打开浏览器,打开目标网站,然后截图,并保存到本地特定的目录中,并在
markdown中引用图片地址。 - 端到端测试。当我需要测试网站时,我需要打开浏览器,打开目标网站,然后进行一些操作,比如填写表单、点击按钮等。就算有
Playwright的测试框架,但仍需要人工介入,比如自定义data-cy,浏览器操作一遍保存 playwright 的测试代码并扔给 cursor 生成测试。
场景一:博客写作的图片自动化
作为技术博主,我经常需要在文章中引用网站截图来说明问题或展示效果。在传统流程中,这个过程相当繁琐:
- 打开浏览器访问目标网站
- 使用截图工具截取所需区域
- 保存截图到特定目录
- 处理图片(可能需要裁剪、压缩等)
- 在
Markdown文件中手动添加图片链接 - 确认图片正确显示
这个过程不仅耗时,而且容易出错。使用 Playwright MCP,整个流程可以简化为:
请访问 https://tailwindcss.com,截取首页顶部导航栏区域,保存到 @public/images/ 下,并生成 markdown 图片引用代码
Cursor 通过 MCP 协议会:
- 自动打开网站
- 精确定位并截取导航栏元素
- 保存到指定目录
- 自动生成符合博客格式的图片引用代码
这不仅节省了时间,还保证了图片引用的一致性和准确性。对于需要多张截图的长篇技术文章,效率提升尤为显著。
更进阶的应用还包括:
- 自动为截图添加高亮或注释
- 对比同一网站在不同设备上的显示效果
- 跟踪网站的 UI 变化并自动更新文章中的截图
场景二:端到端测试的自动化
端到端测试是前端开发中的重要环节,但传统方式存在诸多痛点:
- 繁琐的测试编写:即使使用
Cypress等工具,编写测试脚本仍需要手动规划测试路径、定位元素、设计断言等 - 元素选择器维护:需要在代码中添加特定属性(如
data-cy)用于测试,且这些选择器需要随着 UI 变化而维护 - 测试代码与产品代码分离:测试逻辑往往与开发逻辑分离,导致测试更新滞后于功能更新
- 复杂交互流程难以模拟:多步骤的用户操作(如表单填写、多页面导航)需要精确编排
即便使用 Chrome 的 DevTools 的 Recorder 功能,也只能生成 Playwright 的测试代码,并且需要人工介入,比如自定义 data-cy,浏览器操作一遍保存 playwright 的测试代码并扔给 cursor 生成测试。
或者通过 cursor 与 recorder 提效后的环节:
- 让 cursor 在关键位置插入
data-cy属性 - 使用
Chrome DevTools的Recorder功能生成测试代码 - 将测试代码扔给 cursor 生成测试
而通过 Playwright MCP,开发者可以自然语言描述测试场景,让 Cursor 直接生成并执行测试:
用户:测试我的登录流程:访问 http://localhost:3000/login,使用测试账号 test@example.com 和密码 Test123!,验证登录成功后页面应跳转到仪表盘并显示欢迎信息
Cursor 会:
- 在必要位置插入
data-cy属性 - 自动访问登录页面
- 填写表单并提交
- 验证跳转和欢迎信息
- 报告测试结果
- 生成可复用的
Playwright测试代码
这种方式不仅降低了编写测试的门槛,还能根据测试结果智能调整测试策略。例如,如果登录按钮位置变化,Cursor 可以通过视觉识别重新定位元素,而不是简单地报告选择器失效。
对于快速迭代的项目尤其有价值:
- 在代码修改后立即验证功能完整性
- 快速生成回归测试套件
- 模拟复杂的用户行为路径
- 根据用户反馈自动创建针对性测试
这两个场景说明,MCP 不仅仅是连接 AI 与工具的技术桥梁,更是能够实质性改变开发者工作流程的革新力量。通过消除重复性工作,开发者可以将更多精力集中在创意和解决问题上。
示例:使用executeautomation/mcp-playwright
executeautomation/mcp-playwright 是一个基于 Playwright 的 MCP 服务器实现,它提供了一系列工具,使得 AI 助手能够:
- 打开网页
- 截取网页或元素截图
- 填写表单
- 点击按钮
- 提取网页内容
- 执行
JavaScript代码 - 等待网页加载或元素出现
下面以一个简单的场景为例:让 AI 助手打开一个网站并截图。
传统方式下,这个任务可能需要你:
- 安装
Playwright - 编写自动化脚本
- 配置环境
- 运行脚本
- 处理截图结果
而使用 MCP,整个过程可以简化为与 AI 助手的对话:
用户:请打开 Google 首页并截图
AI 助手:好的,我将为您打开 Google 首页并截图。
[AI 助手通过 MCP 控制浏览器,打开 google.com 并截图]
AI 助手:已成功截图,这是 Google 首页的截图。[显示截图]
整个过程中,用户不需要编写任何代码,AI 助手通过 MCP 服务器直接控制浏览器完成任务。
Playwright MCP 服务器的安装与配置
如果你想尝试使用 Playwright MCP 服务器,可以按照以下步骤进行设置:
- 使用
npm安装Playwright MCP服务器:
npm install -g @executeautomation/playwright-mcp-server
- 配置
Claude Desktop客户端(以 MacOS 为例):
编辑配置文件~/Library/Application\ Support/Claude/claude_desktop_config.json,添加以下内容:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@executeautomation/playwright-mcp-server"]
}
}
}
- 重启
Claude客户端,你会看到一个新的 "Attach MCP" 按钮。 - 点击该按钮,选择
Playwright MCP服务器,现在你的 AI 助手就可以控制浏览器了!
在 Cursor 中使用 Playwright MCP
Cursor 是一款集成了 AI 能力的代码编辑器,它也支持 MCP 协议。我们可以在 Cursor 中配置 Playwright MCP 服务器,使 AI 助手能够在开发过程中直接操作浏览器。
配置步骤
- 首先确保已安装
Playwright MCP服务器:
npm install -g @executeautomation/playwright-mcp-server
- 在
Cursor中配置 MCP 服务器,有两种方式:
方式一:通过配置文件(推荐)
编辑
~/.cursor/mcp.json文件(如果不存在则创建),添加以下内容:
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": ["-y", "@executeautomation/playwright-mcp-server"]
}
}
}
方式二:通过项目配置
在项目根目录下创建
.cursor/mcp.json文件,内容同上。这样配置的 MCP 服务器只在当前项目中可用。 - 重启
Cursor编辑器,使配置生效。
使用场景示例
在 Cursor 中使用 Playwright MCP 可以大大提升前端开发和测试效率。以下是一些常见的使用场景:
- 快速页面测试:
在开发 Web 页面时,可以让 AI 助手直接打开页面,检查渲染效果,无需手动切换到浏览器。
用户:请打开我当前开发的页面 http://localhost:3000,检查响应式布局在移动设备上的显示效果
Cursor:[通过 Playwright MCP 打开页面并进行移动设备模拟,然后截图展示结果]
- 自动化截图对比:
在进行 UI 改动时,可以让 AI 助手截取改动前后的页面对比图。
用户:我刚修改了导航栏的样式,请打开 http://localhost:3000,截图并与 production 环境 myapp.com 的页面进行对比
Cursor:[使用 Playwright MCP 分别截取两个环境的页面,并进行对比分析]
- 交互测试:
让 AI 助手模拟用户交互,验证功能是否正常工作。
用户:请测试我的登录表单,打开 http://localhost:3000/login,使用测试账号填写表单并提交,检查是否成功登录
Cursor:[使用 Playwright MCP 打开页面,填写表单并提交,验证登录流程]
- 开发过程中的实时调试:
在编码过程中,可以让 AI 助手实时检查页面变化。
用户:我刚刚修改了 Button 组件的样式,请打开组件预览页面检查不同状态下的按钮外观
Cursor:[打开页面,截取不同状态的按钮截图,并分析样式是否符合预期]
通过这些场景,我们可以看到,Playwright MCP 在 Cursor 中的应用不仅简化了前端开发工作流,还提供了更直观的开发体验,让 AI 助手成为开发过程中的得力助手。
MCP 的优势与局限性
优势
- 扩展 AI 能力:让 AI 助手能够与外部系统交互,大大扩展其应用场景
- 标准化接口:提供统一的协议,降低 AI 工具集成的复杂度
- 安全可控:用户可以审核 AI 助手的操作请求,确保安全
- 灵活扩展:可以根据需要开发自定义 MCP 服务器
局限性
- 新兴技术:MCP 仍处于发展早期,协议可能会变化
- 远程开发限制:MCP 服务器需要在本地机器上运行,远程开发环境可能存在问题
- 资源支持:部分 MCP 客户端如
Cursor尚未支持resources/prompts功能
Cursor 的 MCP 支持限制:
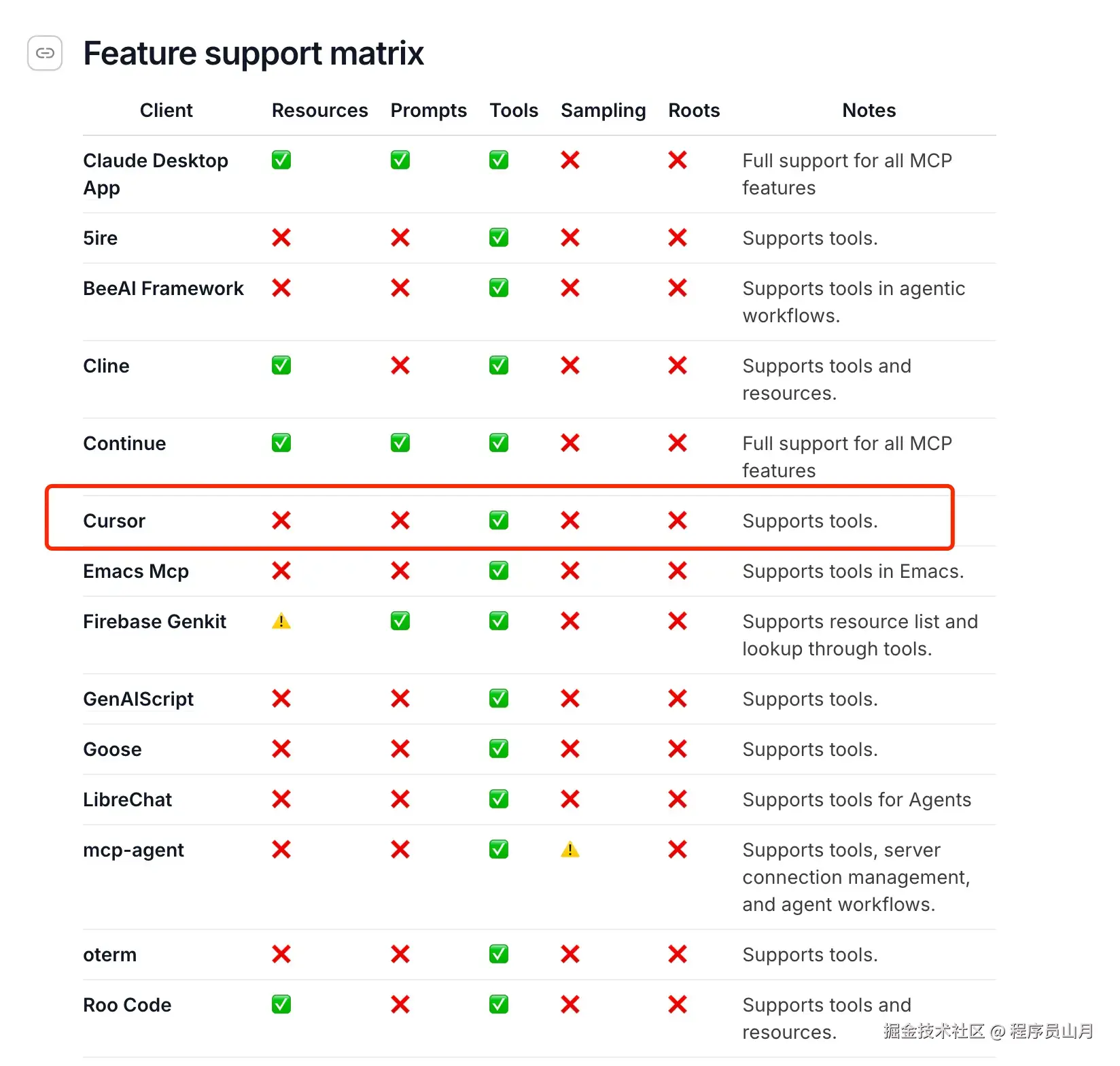
未来展望
MCP 作为一种连接 AI 与外部系统的标准化协议,有着广阔的应用前景:
- 智能化开发工作流:AI 助手可以更深入地参与到开发流程中,自动化执行测试、部署等任务
- 数据分析与可视化:AI 助手可以直接访问数据库,生成分析报告和可视化结果
- 跨平台自动化:统一的协议使 AI 助手能够操作不同平台和工具
- 个性化智能助手:用户可以配置自己的 MCP 服务器,创建专属于自己工作流的 AI 助手
结语
Model Context Protocol (MCP) 正在打破 AI 助手与外部世界之间的壁垒,使 AI 能够更加深入地融入我们的工作流程。从浏览器自动化到代码编辑器集成,MCP 展示了 AI 与传统工具结合的强大潜力。
以前可以说,Cursor 虽然代码敲的好,但它不能直接操作浏览器,不能直接操作数据库,不能直接操作文件系统,开发这个流程还是需要我频繁接手的。
现在来说,需要我们接手的次数会越来越少。
最后再推荐两个 MCP 相关的资源:
参考资料
来源:juejin.cn/post/7481861001189621800
理解 devDependencies:它们真的不会被打包进生产代码吗?
在前端开发中,很多开发者都有一个常见误解:package.json 中的 devDependencies 是开发时依赖,因此不会被打包到最终的生产环境代码中。这个理解在一定条件下成立,但在真实项目中,打包工具(如 Vite、Webpack 等)并不会根据 devDependencies 或 dependencies 的位置来决定是否将依赖打包到最终的 bundle 中,而是完全俗义于代码中是否引用了这些模块。
本文将通过一个实际例子来说明这个问题,并提出一些实践建议来避免误用。
一、dependencies vs devDependencies 回顾
在 package.json 中,我们通常会看到两个依赖字段:
{
"dependencies": {
"lodash": "^4.17.21"
},
"devDependencies": {
"vite": "^5.0.0"
}
}
dependencies:运行时依赖,通常用于项目在生产环境中运行所需的库。devDependencies:开发时依赖,通常用于构建、测试、打包等过程,比如 Babel、ESLint、Vite 等。
很多人认为把某个库放到 devDependencies 中就意味着它不会被打包进最终代码,但这只是约定俗成,并非构建工具的实际行为。
二、一个实际例子:lodash 被错误地放入 devDependencies
我们以一个使用 Vite 构建的库包为例:
目录结构:
my-lib/
├── src/
│ └── index.ts
├── package.json
├── vite.config.ts
└── tsconfig.json
src/index.ts
import _ from 'lodash';
export function capitalizeName(name: string) {
return _.capitalize(name);
}
错误的 package.json
{
"name": "my-lib",
"version": "1.0.0",
"main": "dist/index.js",
"module": "dist/index.mjs",
"types": "dist/index.d.ts",
"scripts": {
"build": "vite build"
},
"devDependencies": {
"vite": "^5.0.0",
"lodash": "^4.17.21",
"typescript": "^5.4.0"
}
}
注意:lodash 被放到了 devDependencies 中,而不是 dependencies中。
构建后结果:
执行 npm run build 后,你会发现 lodash 的代码被打包进了最终输出的 bundle 中,尽管它被标记为 devDependencies。
dist/
├── index.js ← 包含 lodash 的代码
├── index.mjs
└── index.d.ts
三、为什么会发生这种情况?
构建工具(如 Vite、Webpack)在处理打包时,并不会关心某个依赖是 dependencies 还是 devDependencies。
它只会扫描你的代码:
- 如果你
import了某个模块(如lodash),构建工具会把它包含进 bundle 中,除非你通过external配置显式告诉它不要打包进来。 - 你放在
devDependencies中只是告诉 npm install:这个依赖只在开发阶段需要,npm install --production时不会安装它。
换句话说,打包行为取决于代码,而不是依赖声明。
四、修复方式:将运行时依赖移到 dependencies
为了正确构建一个可以发布的库包,应该:
{
"dependencies": {
"lodash": "^4.17.21"
},
"devDependencies": {
"vite": "^5.0.0",
"typescript": "^5.4.0"
}
}
这样使用你库的开发者才能在安装你的包时自动获取 lodash。
五、如何防止此类问题?
1. 使用 peerDependencies(推荐给库开发者)
如果你希望使用者自带 lodash,而不是你来打包它,可以这样配置:
{
"peerDependencies": {
"lodash": "^4.17.21"
}
}
同时在 Vite 配置中加上:
export default defineConfig({
build: {
lib: {
entry: 'src/index.ts',
name: 'MyLib'
},
rollupOptions: {
external: ['lodash'], // 不打包 lodash
}
}
})
这样打包出来的 bundle 中就不会再包含 lodash 的代码。
2. 使用构建工具的 external 配置
像上面这样将 lodash 标为 external 可以避免误打包。
3. 静态分析工具检测
使用像 depcheck 或 eslint-plugin-import 等工具,可以帮你发现未声明或声明错误的依赖。
六、总结
| 依赖位置 | 作用说明 |
|---|---|
dependencies | 生产环境运行时必须使用的库 |
devDependencies | 开发、构建过程所需的工具库 |
peerDependencies | 你的库需要,但由使用者提供的依赖(库开发推荐) |
构建工具不会参考 package.json 中依赖的位置来决定是否打包,而是基于代码的实际引用。作为库作者,你应该确保:
- 所有运行时依赖都放在
dependencies或peerDependencies; - 构建工具正确配置 external,避免不必要地打包外部依赖;
- 使用工具检查依赖定义的一致性。
来源:juejin.cn/post/7530180739729555491
使用three.js搭建3d隧道监测-2
加载基础线条与地面效果


在我们的隧道监控系统中,地面网格和方向指示器是重要的视觉元素,它们帮助用户理解空间关系和导航方向。
1. 网格地面的创建与优化
javascript
// 初始化场景中的地面
const addGround = () => {
const size = 40000; // 网格大小
const divisions = 100; // 分割数(越高越密集)
// 主网格线颜色(亮蓝色)
const color1 = 0x6E7DB9; // 蓝色
// 次网格线颜色(深蓝色)
const color2 = 0x282C3C; // 深蓝色
const gridHelper = new THREE.GridHelper(size, divisions, color1, color2);
// 调整网格线的透明度和材质
gridHelper.material.opacity = 1;
gridHelper.material.transparent = true;
gridHelper.material.depthWrite = false; // 防止网格阻挡其他物体的渲染
// 设置材质的混合模式以实现发光效果
gridHelper.material.blending = THREE.AdditiveBlending;
gridHelper.material.vertexColors = false;
// 增强线条对比度
gridHelper.material.color.setHex(color1);
gridHelper.material.linewidth = 100;
// 旋转网格,使其位于水平面
gridHelper.rotation.x = Math.PI;
sceneRef.current.add(gridHelper);
};
知识点: Three.js 中的网格地面实现技术
- GridHelper:Three.js 提供的辅助对象,用于创建二维网格,常用于表示地面或参考平面
- 材质优化:通过设置
depthWrite = false避免渲染排序问题,防止网格阻挡其他物体
- 混合模式:
AdditiveBlending混合模式使重叠线条颜色叠加,产生发光效果
- 性能考量:网格分割数(divisions)会影响性能,需要在视觉效果和性能间平衡
- 旋转技巧:通过
rotation.x = Math.PI将默认垂直的网格旋转到水平面
这种科幻风格的网格地面在虚拟现实、数据可视化和游戏中非常常见,能够提供空间参考而不显得过于突兀。
2. 动态方向指示器的实现
javascript
const createPolygonRoadIndicators = (dis) => {
const routeIndicationGeometry = new THREE.PlaneGeometry(3024, 4000); // 创建平面几何体
// 创建文本纹理的辅助函数
const getTextCanvas = (text) => {
const width = 200;
const height = 300;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.font = "bold 40px Arial"; // 设置字体大小和样式
ctx.fillStyle = '#949292'; // 设置字体颜色
ctx.textAlign = 'center';
ctx.textBaseline = 'middle';
ctx.fillText(text, width / 2, height / 2);
return canvas;
};
// 创建方向1文本平面
const textMap = new THREE.CanvasTexture(getTextCanvas('方向1'));
const textMaterial = new THREE.MeshBasicMaterial({
map: textMap,
transparent: true,
depthTest: false
});
const plane = new THREE.Mesh(routeIndicationGeometry, textMaterial);
plane.castShadow = false;
plane.position.set(1024, 0, 1400);
plane.rotateX(-Math.PI / 2);
// 创建方向2文本平面
const textMap1 = new THREE.CanvasTexture(getTextCanvas('方向2'));
const textMaterial1 = new THREE.MeshBasicMaterial({
map: textMap1,
transparent: true,
depthTest: false
});
const plane1 = new THREE.Mesh(routeIndicationGeometry, textMaterial1);
plane1.castShadow = false;
plane1.position.set(1024, 0, -1400);
plane1.rotateX(-Math.PI / 2);
// 创建箭头指示器
const loader = new THREE.TextureLoader();
const texture = loader.load('/image/arrow1.png', (t) => {
t.wrapS = t.wrapT = THREE.RepeatWrapping;
t.repeat.set(1, 1);
});
const geometryRoute = new THREE.PlaneGeometry(1024, 1200);
const materialRoute = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide, // 确保可以从两个面看见
});
const plane2 = new THREE.Mesh(geometryRoute, materialRoute);
plane2.receiveShadow = false;
plane2.position.set(1000, 0, 0);
plane2.rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2);
// 将所有元素组合成一个组
const group = new THREE.Gr0up();
group.add(plane2, plane, plane1);
group.scale.set(0.4, 0.4, 0.4);
group.position.set(dis==="left"?500:500-4000, 0, 0);
return group;
};
知识点: Three.js 中的动态文本与指示器实现技术
- Canvas 纹理:使用 HTML Canvas 动态生成文本,然后转换为 Three.js 纹理,这是在 3D 场景中显示文本的高效方法
- CanvasTexture:Three.js 提供的特殊纹理类型,可以直接从 Canvas 元素创建纹理,支持动态更新
- 透明度处理:通过设置
transparent: true和适当的depthTest设置解决透明纹理的渲染问题
- 几何体组织:使用
THREE.Gr0up将多个相关的 3D 对象组织在一起,便于统一变换和管理
- 条件旋转:根据参数
dis动态决定箭头的朝向,实现可配置的方向指示
- 纹理重复:通过
RepeatWrapping和repeat设置可以控制纹理的重复方式,适用于创建连续的纹理效果
这种动态方向指示器在导航系统、虚拟导览和交互式地图中非常有用,可以为用户提供直观的方向引导。
3.地面方向指示器实现
在隧道监控系统中,方向指示是帮助用户理解空间方向和导航的关键元素。我们实现了一套包含文本标签和箭头的地面方向指示系统。
javascript
import * as THREE from "three";
const createPolygonRoadIndicators = (dis) => {
const routeIndicationGeometry = new THREE.PlaneGeometry(3024, 4000); // 创建平面几何体
const getTextCanvas = (text) => {
const width = 200;
const height = 300;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.font = "bold 40px Arial"; // 设置字体大小和样式
ctx.fillStyle = '#949292'; // 设置字体颜色
ctx.textAlign = 'center';
ctx.textBaseline = 'middle';
ctx.fillText(text, width / 2, height / 2);
return canvas;
};
const textMap = new THREE.CanvasTexture(getTextCanvas('方向1'));
const textMaterial = new THREE.MeshBasicMaterial({ map: textMap, transparent: true, depthTest: false }); // 创建材质,depthTest解决黑色块问题
const plane = new THREE.Mesh(routeIndicationGeometry, textMaterial);
plane.castShadow = false; // 不投影阴影"
plane.position.set(1024, 0, 1400);
plane.rotateX(-Math.PI / 2);
const textMap1 = new THREE.CanvasTexture(getTextCanvas('方向2'));
const textMaterial1 = new THREE.MeshBasicMaterial({ map: textMap1, transparent: true, depthTest: false }); // 创建材质,depthTest解决黑色块问题
const plane1 = new THREE.Mesh(routeIndicationGeometry, textMaterial1);
plane1.castShadow = false; // 不投影阴影
plane1.position.set(1024, 0, -1400);
plane1.rotateX(-Math.PI / 2);
const loader = new THREE.TextureLoader();
const texture = loader.load('/image/arrow1.png', (t) => {
t.wrapS = t.wrapT = THREE.RepeatWrapping;
t.repeat.set(1, 1);
});
const geometryRoute = new THREE.PlaneGeometry(1024, 1200);
const materialRoute = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide, // 确保可以从两个面看见
});
const plane2 = new THREE.Mesh(geometryRoute, materialRoute);
plane2.receiveShadow = false; // 不接收阴影
plane2.position.set(1000, 0, 0);
plane2.rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2);
const group = new THREE.Gr0up();
group.add(plane2, plane, plane1);
group.scale.set(0.4, 0.4, 0.4);
group.position.set(dis==="left"?500:500-4000, 0, 0);
return group;
};
export default createPolygonRoadIndicators;
知识点: Three.js 中的地面方向指示器实现技术
- 平面投影标记:使用
PlaneGeometry创建平面,通过旋转使其平行于地面,形成"地面投影"效果
- 使用
rotateX(-Math.PI / 2)将平面从垂直旋转到水平位置
- 动态文本生成:使用 Canvas API 动态生成文本纹理
getTextCanvas函数创建一个临时 Canvas 并在其上绘制文本
- 使用
CanvasTexture将 Canvas 转换为 Three.js 可用的纹理
- 这种方法比使用 3D 文本几何体更高效,特别是对于频繁变化的文本
- 纹理渲染优化:
transparent: true启用透明度处理,使背景透明
depthTest: false禁用深度测试,解决半透明纹理的渲染问题,防止出现"黑色块"
castShadow: false和receiveShadow: false避免不必要的阴影计算
- 方向性指示:使用箭头纹理创建明确的方向指示
- 通过
TextureLoader加载外部箭头图像
- 根据
dis参数动态调整箭头方向(rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2))
side: THREE.DoubleSide确保从任何角度都能看到箭头
- 组织与缩放:
- 使用
THREE.Gr0up将相关元素(文本标签和箭头)组织在一起
- 通过
group.scale.set(0.4, 0.4, 0.4)统一调整组内所有元素的大小
- 根据方向参数设置整个组的位置,实现左右两侧不同的指示效果
- 纹理重复设置:
RepeatWrapping和repeat.set(1, 1)控制纹理的重复方式
- 这为创建连续的纹理效果提供了基础,虽然本例中设为1(不重复)
这种地面方向指示系统在大型空间(如隧道、机场、展馆)的导航中特别有用,为用户提供直观的方向感,不会干扰主要视觉元素。
隧道指示牌制作
在隧道监控系统中,指示牌是引导用户和提供空间信息的重要元素。我们实现了一种复合结构的隧道指示牌,包含支柱、横梁和信息板。
javascript
import * as THREE from 'three';
import {TextGeometry} from "three/examples/jsm/geometries/TextGeometry";
/**
* 创建石头柱子(竖直 + 横向)
* @returns {THREE.Gr0up} - 返回包含柱子和横梁的组
*/
const createStonePillar = () => {
const pillarGr0up = new THREE.Gr0up();
// 创建六边形的竖直柱子
const pillarGeometry = new THREE.CylinderGeometry(6, 6, 340, 6); // 直径12, 高度340, 六边形柱体
const pillarMaterial = new THREE.MeshStandardMaterial({color: 0x808080}); // 石头颜色
const pillar = new THREE.Mesh(pillarGeometry, pillarMaterial);
pillar.position.set(0, 0, 0);
// 创建第一根横向长方体
const beam1Geometry = new THREE.BoxGeometry(100, 10, 0.1);
const beam1Material = new THREE.MeshStandardMaterial({color: 0x808080});
const beam1 = new THREE.Mesh(beam1Geometry, beam1Material);
beam1.position.set(-50, 150, 0);
// 创建第二根横向长方体
const beam2Geometry = new THREE.BoxGeometry(100, 10, 0.1);
const beam2Material = new THREE.MeshStandardMaterial({color: 0x808080});
const beam2 = new THREE.Mesh(beam2Geometry, beam2Material);
beam2.position.set(-50, 130, 0);
// 将柱子和横梁添加到组
pillarGr0up.add(pillar);
pillarGr0up.add(beam1);
pillarGr0up.add(beam2);
return pillarGr0up;
};
/**
* 创建一个用于绘制文本的 Canvas
* @param {string} text - 要绘制的文本
* @returns {HTMLCanvasElement} - 返回 Canvas 元素
*/
const getTextCanvas = (text) => {
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
// 设置 Canvas 尺寸
const fontSize = 32;
canvas.width = 512;
canvas.height = 128;
// 设置背景色
context.fillStyle = '#1E3E9A'; // 蓝底
context.fillRect(0, 0, canvas.width, canvas.height);
// 设置文本样式
context.font = `${fontSize}px Arial`;
context.fillStyle = '#ffffff'; // 白色文本
context.textAlign = 'center';
context.textBaseline = 'middle';
context.fillText(text, canvas.width / 2, canvas.height / 2);
return canvas;
};
/**
* 创建交通指示牌并添加到场景中
* @param {Object} sceneRef - React ref 对象,指向 Three.js 的场景
* @returns {Promise<THREE.Gr0up>} - 返回创建的指示牌组
*/
export default (sceneRef, png, dis) => {
const createSignBoard = async () => {
const signGr0up = new THREE.Gr0up();
const loader = new THREE.TextureLoader();
loader.load(png, texture => {
// 创建一个平面作为标志背景
const signGeometry = new THREE.PlaneGeometry(100, 50); // 宽100,高50
texture.encoding = THREE.sRGBEncoding // 设置纹理的颜色空间
texture.colorSpace = THREE.SRGBColorSpace;
const signMaterial = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide,
})
const sign = new THREE.Mesh(signGeometry, signMaterial);
sign.position.set(-60, 140, 0.3)
signGr0up.add(sign);
})
// 创建并添加石头柱子
const pillar = createStonePillar();
signGr0up.add(pillar);
if (dis == "left") {
signGr0up.position.set(370, 180, 3750); // 左侧位置
} else {
signGr0up.rotateY(Math.PI); // 旋转180度
signGr0up.position.set(-370 - 2000, 180, 3450 - 7200); // 右侧位置
}
signGr0up.add(pillar);
sceneRef.current.add(signGr0up);
return signGr0up; // 返回整个组
};
// 调用创建指示牌函数
return createSignBoard().then((signGr0up) => {
console.log('交通指示牌创建完成:', signGr0up);
return signGr0up;
});
};
知识点: Three.js 中的复合结构与指示牌实现技术
- 模块化设计:将指示牌分解为柱子、横梁和信息板三个主要组件,便于维护和复用
- 几何体组合:使用简单几何体(圆柱体、长方体、平面)组合构建复杂结构
CylinderGeometry创建六边形柱体作为支撑
BoxGeometry创建横向支撑梁
PlaneGeometry创建平面显示信息
- 空间层次:使用
THREE.Gr0up将相关元素组织在一起,便于整体变换和管理
- 纹理映射:使用
TextureLoader加载外部图像作为指示牌内容
- 设置
colorSpace = THREE.SRGBColorSpace确保颜色正确显示
- 使用
side: THREE.DoubleSide使平面从两面都可见
- 条件定位:根据
dis参数动态决定指示牌的位置和朝向
- 使用
rotateY(Math.PI)旋转180度实现方向反转
- Canvas 动态文本:使用
getTextCanvas函数创建动态文本纹理
- 可以方便地生成不同内容和样式的文本标识
- 异步处理:使用 Promise 处理纹理加载的异步过程,确保资源正确加载
- 返回 Promise 使调用者可以在指示牌创建完成后执行后续操作
这种组合式设计方法允许我们创建高度可定制的指示牌,适用于隧道、道路、建筑内部等多种场景,同时保持代码的可维护性和可扩展性。
多渲染器协同工作机制
在我们的项目中,实现了 WebGL 渲染器、CSS2D 渲染器和 CSS3D 渲染器的协同工作:
const initRenderer = () => {
// WebGL 渲染器
rendererRef.current = new THREE.WebGLRenderer({
antialias: true,
alpha: true,
logarithmicDepthBuffer: true
});
rendererRef.current.setSize(window.innerWidth, window.innerHeight);
rendererRef.current.setPixelRatio(Math.min(window.devicePixelRatio, 2));
rendererRef.current.shadowMap.enabled = true;
rendererRef.current.shadowMap.type = THREE.PCFSoftShadowMap;
rendererRef.current.outputEncoding = THREE.sRGBEncoding;
rendererRef.current.toneMapping = THREE.ACESFilmicToneMapping;
containerRef.current.appendChild(rendererRef.current.domElement);
};
const initCSS2DScene = () => {
// CSS2D 渲染器
css2DRendererRef.current = new CSS2DRenderer();
css2DRendererRef.current.setSize(window.innerWidth, window.innerHeight);
css2DRendererRef.current.domElement.style.position = 'absolute';
css2DRendererRef.current.domElement.style.top = '0';
css2DRendererRef.current.domElement.style.pointerEvents = 'none';
containerRef.current.appendChild(css2DRendererRef.current.domElement);
};
const initCSS3DScene = () => {
// 初始化 CSS3DRenderer
css3DRendererRef.current = new CSS3DRenderer();
css3DRendererRef.current.setSize(sizes.width, sizes.height);
css3DRendererRef.current.domElement.style.position = 'absolute';
css3DRendererRef.current.domElement.style.top = '0px';
css3DRendererRef.current.domElement.style.pointerEvents = 'none'; // 确保CSS3D元素不阻碍鼠标事件
containerRef.current.appendChild(css3DRendererRef.current.domElement);
};
知识点: Three.js 支持多种渲染器同时工作,每种渲染器有不同的优势:
- WebGLRenderer:利用 GPU 加速渲染 3D 内容,性能最佳
- CSS2DRenderer:将 HTML 元素作为 2D 标签渲染在 3D 空间中,适合信息标签
- CSS3DRenderer:将 HTML 元素转换为 3D 对象,支持 3D 变换,适合复杂 UI
多渲染器协同可以充分发挥各自优势,实现复杂的混合现实效果。
后期处理管线设计
项目中实现了基于 EffectComposer 的后期处理管线:
const initPostProcessing = () => {
composerRef.current = new EffectComposer(rendererRef.current);
// 基础渲染通道
const renderPass = new RenderPass(sceneRef.current, cameraRef.current);
composerRef.current.addPass(renderPass);
// 环境光遮蔽通道
const ssaoPass = new SSAOPass(
sceneRef.current,
cameraRef.current,
window.innerWidth,
window.innerHeight
);
ssaoPass.kernelRadius = 16;
ssaoPass.minDistance = 0.005;
ssaoPass.maxDistance = 0.1;
composerRef.current.addPass(ssaoPass);
// 抗锯齿通道
const fxaaPass = new ShaderPass(FXAAShader);
const pixelRatio = rendererRef.current.getPixelRatio();
fxaaPass.material.uniforms['resolution'].value.x = 1 / (window.innerWidth * pixelRatio);
fxaaPass.material.uniforms['resolution'].value.y = 1 / (window.innerHeight * pixelRatio);
composerRef.current.addPass(fxaaPass);
};
知识点: 后期处理(Post-processing)是一种在 3D 场景渲染完成后对图像进行额外处理的技术:
- EffectComposer:Three.js 中的后期处理管理器,可以将多个处理效果组合在一起
- RenderPass:基础渲染通道,将场景渲染到目标缓冲区
- SSAOPass:屏幕空间环境光遮蔽,增强场景深度感和真实感
- FXAAShader:快速近似抗锯齿,提高图像质量
后期处理可以大幅提升画面质量,添加如景深、发光、色彩校正等专业效果。
多层次动画系统
项目实现了一个多层次的动画系统:
// 骨骼动画控制
const getActions = (animations, model) => {
const mixer = new THREE.AnimationMixer(model);
const mixerArray = [];
mixerArray.push(mixer);
const actions = {};
animations.forEach((clip) => {
const action = mixer.clipAction(clip);
actions[clip.name] = action;
});
return {actions, mixerArray};
};
// 动画播放控制
const playActiveAction = (actions, name, startTime = true, loopType = THREE.LoopOnce, clampWhenFinished = true) => {
const action = actions[name];
if (!action) return;
action.reset();
action.clampWhenFinished = clampWhenFinished;
action.setLoop(loopType);
if (startTime) {
action.play();
}
};
知识点: Three.js 提供了多种动画技术:
- AnimationMixer:用于播放和控制模型骨骼动画的核心类,相当于动画播放器
- AnimationClip:包含一组关键帧轨道的动画数据,如"走路"、"跑步"等动作
- AnimationAction:控制单个动画的播放状态,包括播放、暂停、循环设置等
- 动画混合:可以实现多个动画之间的平滑过渡,如从走路切换到跑步
合理使用这些技术可以创建流畅、自然的角色动画和场景变换。
第一人称视角控制算法
项目实现了一种先进的第一人称视角控制算法:
const animate1 = () => {
requestRef1.current = requestAnimationFrame(animate1);
if (isFirstPerson && robotRef.current) {
// 获取机器人的世界坐标
const robotWorldPosition = new THREE.Vector3();
robotRef.current.getWorldPosition(robotWorldPosition);
// 计算摄像机位置偏移
const offset = new THREE.Vector3(0, 140, 20);
// 获取机器人的前方方向向量
const forward = new THREE.Vector3(0, 0, -1).applyQuaternion(robotRef.current.quaternion);
const lookAheadDistance = 150;
// 计算摄像头位置和视线目标
const targetCameraPosition = robotWorldPosition.clone().add(offset);
const lookAtPosition = robotWorldPosition.clone().add(forward.multiplyScalar(lookAheadDistance));
// 使用 TWEEN 实现平滑过渡
cameraTweenRef.current = new TWEEN.Tween(cameraRef.current.position)
.to({
x: targetCameraPosition.x,
y: targetCameraPosition.y,
z: targetCameraPosition.z,
}, 1000)
.easing(TWEEN.Easing.Quadratic.Out)
.onUpdate(() => {
cameraRef.current.lookAt(lookAtPosition);
controlsRef.current.target.set(lookAtPosition.x, lookAtPosition.y, lookAtPosition.z);
})
.start();
}
};
知识点: 第一人称相机控制涉及多个关键技术:
- 世界坐标计算:通过
getWorldPosition()获取对象在世界坐标系中的位置
- 四元数旋转:使用
applyQuaternion()将向量按对象的旋转方向进行变换
- 向量运算:通过向量加法和标量乘法计算相机位置和视线方向
- 平滑过渡:使用 TWEEN.js 实现相机位置的平滑变化,避免生硬的跳变
- lookAt:让相机始终"看着"目标点,实现跟随效果
这种技术常用于第一人称游戏、虚拟导览等应用。
递归资源释放算法
项目实现了一种递归资源释放算法,用于彻底清理 Three.js 资源:
const disposeSceneObjects = (object) => {
if (!object) return;
// 递归清理子对象
while (object.children.length > 0) {
const child = object.children[0];
disposeSceneObjects(child);
object.remove(child);
}
// 清理几何体
if (object.geometry) {
object.geometry.dispose();
}
// 清理材质
if (object.material) {
if (Array.isArray(object.material)) {
object.material.forEach(material => disposeMaterial(material));
} else {
disposeMaterial(object.material);
}
}
// 清理纹理
if (object.texture) {
object.texture.dispose();
}
};
// 清理材质的辅助函数
const disposeMaterial = (material) => {
if (!material) return;
// 清理所有纹理属性
const textureProperties = [
'map', 'normalMap', 'roughnessMap', 'metalnessMap',
'emissiveMap', 'bumpMap', 'displacementMap',
'alphaMap', 'lightMap', 'aoMap', 'envMap'
];
textureProperties.forEach(prop => {
if (material[prop] && material[prop].dispose) {
material[prop].dispose();
}
});
material.dispose();
};
知识点: WebGL 资源管理是 3D 应用开发中的关键挑战:
- JavaScript 垃圾回收的局限性:虽然 JS 有自动垃圾回收,但 WebGL 资源(如纹理、缓冲区)需要手动释放
- 深度优先遍历:通过递归算法遍历整个场景图,确保所有对象都被正确处理
- 资源类型处理:不同类型的资源(几何体、材质、纹理)需要不同的释放方法
- 内存泄漏防护:不正确的资源管理是 WebGL 应用中最常见的内存泄漏原因
合理的资源释放策略对长时间运行的 3D 应用至关重要,可以避免性能下降和浏览器崩溃。
资源预加载与缓存策略
项目实现了资源预加载与缓存策略:
// 资源管理器
const ResourceManager = {
// 资源缓存
cache: new Map(),
// 预加载资源
preload: async (resources) => {
const loader = new GLTFLoader();
// 并行加载所有资源
const loadPromises = resources.map(resource => {
return new Promise((resolve, reject) => {
loader.load(
resource.url,
(gltf) => {
ResourceManager.cache.set(resource.id, {
data: gltf,
lastUsed: Date.now(),
refCount: 0
});
resolve(gltf);
},
undefined,
reject
);
});
});
return Promise.all(loadPromises);
},
// 获取资源
get: (id) => {
const resource = ResourceManager.cache.get(id);
if (resource) {
resource.lastUsed = Date.now();
resource.refCount++;
return resource.data;
}
return null;
},
// 释放资源
release: (id) => {
const resource = ResourceManager.cache.get(id);
if (resource) {
resource.refCount--;
if (resource.refCount <= 0) {
// 可以选择立即释放或稍后由缓存清理机制释放
}
}
}
};
知识点: 3D 应用中的资源管理策略:
- 预加载:提前加载关键资源,减少用户等待时间
- 并行加载:使用 Promise.all 并行加载多个资源,提高加载效率
- 资源缓存:使用 Map 数据结构存储已加载资源,避免重复加载
- 引用计数:跟踪资源的使用情况,只有当引用计数为零时才考虑释放
- 最近使用时间:记录资源最后使用时间,可用于实现 LRU (最近最少使用) 缓存策略
这种资源管理策略可以平衡内存使用和加载性能,适用于资源密集型的 3D 应用。
总结
通过这个隧道监控可视化系统的开发,我们深入实践了 Three.js 的多项高级技术,包括多渲染器协同、后期处理、动画系统、相机控制和资源管理等。这些技术不仅适用于隧道监控,还可以应用于数字孪生、产品可视化、教育培训等多个领域。
希望这次分享对大家了解 Web 3D 开发有所帮助!如有任何问题或改进建议,非常欢迎与我交流讨论。我将在后续分享中带来更多 Three.js 开发的实用技巧和最佳实践。
来源:juejin.cn/post/7540129382540247103
前端如何判断用户设备
在前端开发中,判断用户设备类型是常见需求,可通过浏览器环境检测、设备能力特征分析等方式实现。以下是具体实现思路及代码示例:
一、通过User-Agent检测设备类型
原理:User-Agent是浏览器发送给服务器的标识字符串,包含设备、系统、浏览器等信息。
实现步骤:
- 提取
navigator.userAgent字符串 - 通过正则表达式匹配特征关键词
// 设备检测工具函数
function detectDevice() {
const userAgent = navigator.userAgent.toLowerCase();
const device = {};
// 判断是否为移动设备
const isMobile = /android|webos|iphone|ipad|ipod|blackberry|iemobile|opera mini/i.test(userAgent);
device.isMobile = isMobile;
// 具体设备类型
if (/(iphone|ipad|ipod)/i.test(userAgent)) {
device.type = 'ios';
device.model = /iphone/i.test(userAgent) ? 'iPhone' : 'iPad';
} else if (/android/i.test(userAgent)) {
device.type = 'android';
// 提取Android版本
const androidVersion = userAgent.match(/android (\d+\.\d+)/);
device.version = androidVersion ? androidVersion[1] : '未知';
} else if (/windows phone/i.test(userAgent)) {
device.type = 'windows phone';
} else if (/macint0sh/i.test(userAgent)) {
device.type = 'mac';
} else if (/windows/i.test(userAgent)) {
device.type = 'windows';
} else {
device.type = '其他';
}
// 判断是否为平板(需结合屏幕尺寸进一步确认)
device.isTablet = (/(ipad|android tablet|windows phone 8.1|kindle|nexus 7)/i.test(userAgent)) && !device.isMobile;
// 浏览器类型
if (/chrome/i.test(userAgent)) {
device.browser = 'Chrome';
} else if (/firefox/i.test(userAgent)) {
device.browser = 'Firefox';
} else if (/safari/i.test(userAgent) && !/chrome/i.test(userAgent)) {
device.browser = 'Safari';
} else if (/msie|trident/i.test(userAgent)) {
device.browser = 'IE/Edge';
} else {
device.browser = '未知';
}
return device;
}
// 使用示例
const deviceInfo = detectDevice();
console.log('设备类型:', deviceInfo.type);
console.log('是否为移动设备:', deviceInfo.isMobile);
console.log('浏览器:', deviceInfo.browser);
二、结合屏幕尺寸与触摸事件检测
原理:移动设备通常屏幕较小,且支持触摸操作,而PC设备以鼠标操作为主。
function enhanceDeviceDetection() {
const device = detectDevice(); // 基于User-Agent的检测
// 1. 屏幕尺寸检测(响应式设备类型)
if (window.innerWidth <= 768) {
device.layout = 'mobile'; // 移动端布局
} else if (window.innerWidth <= 1024) {
device.layout = 'tablet'; // 平板布局
} else {
device.layout = 'desktop'; // 桌面端布局
}
// 2. 触摸事件支持检测
device.hasTouch = 'ontouchstart' in window || navigator.maxTouchPoints > 0;
// 3. 指针类型检测(WebKit特有属性,判断鼠标/触摸/笔)
if (navigator.maxTouchPoints === 0) {
device.pointerType = 'mouse';
} else if (navigator.maxTouchPoints > 2) {
device.pointerType = 'pen';
} else {
device.pointerType = 'touch';
}
return device;
}
三、设备能力API检测(更准确的现代方案)
原理:通过浏览器原生API获取设备硬件特性,避免User-Agent被伪造的问题。
async function detectDeviceByAPI() {
const device = {};
// 1. NavigatorDevice API(需HTTPS环境)
if (navigator.device) {
try {
const deviceInfo = await navigator.device.getCapabilities();
device.brand = deviceInfo.brand; // 设备品牌
device.model = deviceInfo.model; // 设备型号
device.vendor = deviceInfo.vendor; // 厂商
} catch (error) {
console.log('NavigatorDevice API获取失败:', error);
}
}
// 2. 屏幕像素密度(区分高清屏)
device.retina = window.devicePixelRatio >= 2;
// 3. 电池状态(移动端常用)
if (navigator.getBattery) {
navigator.getBattery().then(battery => {
device.batteryLevel = battery.level;
device.batteryCharging = battery.charging;
});
}
return device;
}
四、框架/库方案(简化实现)
如果项目中使用框架,可直接使用成熟库:
- react-device-detect(React专用)
- mobile-detect.js(轻量级通用库)
- ua-parser-js(专业User-Agent解析库)
五、注意事项
- User-Agent不可靠:用户可手动修改UA,或某些浏览器(如微信内置浏览器)会伪装UA。
- 结合多种检测方式:建议同时使用User-Agent、屏幕尺寸、触摸事件等多重检测,提高准确性。
- 响应式设计优先:现代开发中更推荐通过CSS媒体查询(
@media)实现响应式布局,而非完全依赖设备检测。 - 性能优化:避免频繁检测设备,可在页面加载时缓存检测结果。
六、面试延伸问题
- 为什么User-Agent检测不可靠?请举例说明。
- 在iOS和Android上,如何区分手机和平板?
- 如果用户强制旋转屏幕(如手机横屏),设备检测结果需要更新吗?如何处理?
通过以上方案,可全面检测用户设备类型、系统、浏览器及硬件特性,为前端适配提供依据。
来源:juejin.cn/post/7515378780371501082
我用Python写了个实时板块资金热力图 🎨💰
我用Python写了个实时板块资金热力图 🎨💰

大家好,这里是花姐,今天带来一个有点“热辣滚烫”的Python实战项目——实时板块资金热力图!🔥
这两年,股市的热度时高时低,但大家对资金流向的关注度始终不减。有没有办法直观地看到哪些板块在吸金,哪些板块在被资金抛弃呢?答案是:当然有!
于是,我撸起袖子,用 Python + Streamlit + AkShare + Plotly 搞了一款实时的资金流向可视化工具,颜值爆表,还能自动刷新,堪称炒股助手!🎯

📌 需求分析
在金融市场里,资金流向是一个很重要的指标,主力资金的流入流出往往决定了一个板块的短期走势。
我们希望做到:
✅ 实时获取资金流向数据,并展示行业板块的资金进出情况。
✅ 可视化呈现数据,用颜色区分资金净流入和净流出,一眼就能看出哪些板块是**“香饽饽”,哪些是“弃儿”**。
✅ 自动刷新,让用户无需手动点刷新,信息一直是最新的。
有了目标,就开始撸代码吧!🚀
🛠 技术栈
- Streamlit:Python神器,一键搞定Web应用。
- AkShare:国内行情数据神器,能直接获取资金流向数据。
- Plotly:强大的可视化库,这次用它做树状热力图。
- Pandas:数据处理少不了它。
📊 代码实现
1. 获取资金流向数据
股市数据当然得从靠谱的地方获取,我们用 AkShare 的 stock_sector_fund_flow_rank 来搞定资金流数据:
import akshare as ak
import pandas as pd
def process_data(indicator):
"""获取并处理资金流数据"""
try:
raw = ak.stock_sector_fund_flow_rank(
indicator=indicator,
sector_type="行业资金流"
)
df = raw.rename(columns={'名称': '板块名称'})
df['资金净流入(亿)'] = df['主力净流入-净额'] / 100000000 # 转换为“亿”
df['资金净流入(亿)'] = df['资金净流入(亿)'].round(2) # 保留两位小数
df['涨跌幅'] = pd.to_numeric(df['涨跌幅'], errors='coerce')
df['流向强度'] = abs(df['资金净流入(亿)'])
return df.dropna(subset=['资金净流入(亿)'])
except Exception as e:
print(f"数据获取失败: {e}")
return pd.DataFrame()
这样,我们可以用 process_data("今日") 来获取今日的行业板块资金流数据。
2. 生成热力图 🎨
有了数据,接下来就是可视化部分了,我们用 Plotly 画一个树状热力图:
import plotly.express as px
COLOR_SCALE = [
[0.0, "#00ff00"], # 绿色(流出最大)
[0.45, "#dfffdf"], # 浅绿色(小幅流出)
[0.5, "#ffffff"], # 白色(平衡点)
[0.55, "#ffe5e5"], # 浅红色(小幅流入)
[1.0, "#ff0000"] # 红色(流入最大)
]
def generate_heatmap(df):
"""生成树状热力图"""
fig = px.treemap(
df,
path=['板块名称'],
values='流向强度',
color='资金净流入(亿)',
color_continuous_scale=COLOR_SCALE,
hover_data={
'涨跌幅': ':%',
'资金净流入(亿)': ':'
},
height=800
)
return fig
这张图的颜色代表资金的流向,红色表示资金流入,绿色表示资金流出,一眼就能看出主力资金的动向!
3. 使用 Streamlit 构建交互界面
有了数据和图表,我们用 Streamlit 搭建一个 Web 界面:
import streamlit as st
from datetime import datetime
def sidebar_controls():
with st.sidebar:
st.header("控制面板")
indicator = st.radio("分析周期", ["今日", "5日", "10日"], index=0, horizontal=True)
refresh_interval = st.slider("自动刷新间隔 (秒)", 60, 3600, 60, 60)
return indicator, refresh_interval
def main_display(df):
st.title("📊 资金流向热力图")
st.caption(f"数据更新时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
if not df.empty:
st.plotly_chart(generate_heatmap(df), use_container_width=True)
else:
st.warning("⚠️ 数据获取失败,请检查网络连接")
4. 自动刷新系统 ⏳
资金流是动态的,当然不能只显示静态数据,我们加个 自动刷新功能:
import time
def auto_refresh_system(refresh_interval):
time.sleep(refresh_interval)
st.rerun()
5. 整合一键运行 🚀
if __name__ == "__main__":
st.set_page_config(layout="wide")
indicator, refresh_interval = sidebar_controls()
df = process_data(indicator)
main_display(df)
auto_refresh_system(refresh_interval)
只要运行 streamlit run app.py,就能看到实时的资金流向热力图了!🎉
🎯 成果展示
运行之后,你会看到一个 大屏可视化的热力图,资金流向一目了然:
- 颜色:红色代表资金流入,绿色代表流出,越深代表金额越大。
- 自动刷新,完全不用手动点击更新!
- 交互性:鼠标悬停可以查看详细数据。
这比在 Excel 里手动分析好用多了吧?😆
最终源码(粘贴过来就能用)
import streamlit as st
import akshare as ak
import plotly.express as px
import pandas as pd
import time
from datetime import datetime
from decimal import Decimal, ROUND_HALF_UP
# 自定义颜色映射
COLOR_SCALE = [
[0.0, "#00ff00"], # 绿色(资金流出最大)
[0.45, "#dfffdf"], # 浅绿色(小幅流出)
[0.5, "#ffffff"], # 白色(平衡点)
[0.55, "#ffe5e5"], # 浅红色(小幅流入)
[1.0, "#ff0000"] # 红色(资金流入最大)
]
# 数据预处理增强版
@st.cache_data(ttl=300)
def process_data(indicator):
"""强化数据预处理逻辑"""
try:
raw = ak.stock_sector_fund_flow_rank(
indicator=indicator,
sector_type="行业资金流"
)
raw.columns = raw.columns.str.replace(indicator, '', regex=False)
# 数值转换
df = raw.rename(columns={'名称': '板块名称'})
df['资金净流入(亿)'] = df['主力净流入-净额'] / 100000000
df['资金净流入(亿)'] = df['资金净流入(亿)'].round(2)
df['涨跌幅'] = pd.to_numeric(df['涨跌幅'], errors='coerce')
# 流向强度计算
df['流向强度'] = abs(df['资金净流入(亿)'])
return df.dropna(subset=['资金净流入(亿)'])
except Exception as e:
st.error(f"数据错误: {str(e)}")
return pd.DataFrame()
# 热力图生成引擎
def generate_heatmap(df):
"""生成符合金融行业标准的树状热力图"""
fig = px.treemap(
df,
path=['板块名称'],
values='流向强度',
color='资金净流入(亿)',
color_continuous_scale=COLOR_SCALE,
range_color=[-max(abs(df['资金净流入(亿)'].min()), abs(df['资金净流入(亿)'].max())),
max(abs(df['资金净流入(亿)'].min()), abs(df['资金净流入(亿)'].max()))],
color_continuous_midpoint=0,
branchvalues='total',
hover_data={
'涨跌幅': ':%',
'资金净流入(亿)': ':',
'主力净流入-净占比': ':%'
},
height=1000
)
# 高级样式配置
fig.update_traces(
texttemplate=(
"<b>%{label}</b><br>"
"📈%{customdata[0]}%<br>"
"💰%{customdata[1]}亿"
),
hovertemplate=(
"<b>%{label}</b><br>"
"涨跌幅: %{customdata[0]}%<br>"
"资金净流入: <b>%{customdata[1]}</b>亿<br>"
"主力占比: %{customdata[2]}%"
),
textfont=dict(size=18, color='black')
)
fig.update_layout(
margin=dict(t=0, l=0, r=0, b=0),
coloraxis_colorbar=dict(
title="资金流向(亿)",
ticks="inside",
thickness=20,
len=0.6,
y=0.7
)
)
return fig
# 侧边栏控件组
def sidebar_controls():
with st.sidebar:
st.header("控制面板")
indicator = st.radio(
"分析周期",
["今日", "5日", "10日"],
index=0,
horizontal=True
)
refresh_interval = st.slider(
"自动刷新间隔 (秒)",
min_value=60, max_value=3600,
value=60, step=60,
help="设置自动刷新间隔,默认1分钟"
)
return indicator, refresh_interval
# 主界面
def main_display(df):
st.title("📊 资金流向热力图")
st.caption(f"数据更新于: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}")
if not df.empty:
with st.spinner("生成可视化..."):
st.plotly_chart(generate_heatmap(df), use_container_width=True)
# 动态摘要面板
with st.expander("📌 实时快报", expanded=True):
col1, col2, col3 = st.columns(3)
col1.metric("🔥 最强流入",
f"{df['资金净流入(亿)'].max():.2f}亿",
df.loc[df['资金净流入(亿)'].idxmax(), '板块名称'])
col2.metric("💧 最大流出",
f"{df['资金净流入(亿)'].min():.2f}亿",
df.loc[df['资金净流入(亿)'].idxmin(), '板块名称'])
col3.metric("⚖️ 多空比",
f"{len(df[df['资金净流入(亿)']>0])}:{len(df[df['资金净流入(亿)']<0])}",
f"总净额 {df['资金净流入(亿)'].sum():.2f}亿")
else:
st.warning("⚠️ 数据获取失败,请检查网络连接")
# 自动刷新系统
def auto_refresh_system(refresh_interval):
time.sleep(refresh_interval)
st.rerun()
print("数据刷新了")
# 主程序
if __name__ == "__main__":
st.set_page_config(layout="wide")
indicator, refresh_interval = sidebar_controls()
df = process_data(indicator)
main_display(df)
auto_refresh_system(refresh_interval)
🏆 总结
这个项目用 Python 搞定了:
✅ 数据抓取(AkShare)
✅ 数据处理(Pandas)
✅ 交互式可视化(Plotly)
✅ Web 界面(Streamlit)
✅ 自动刷新机制
一句话总结:用最少的代码,做出了最直观的金融数据可视化!💡
对于炒股的朋友,这个工具可以帮助你快速了解市场资金流向,不用再看密密麻麻的表格了!📈
喜欢的话,记得点个赞❤️,咱们下次见!🎉
来源:juejin.cn/post/7492990918702137380


