








浏览器缓存方案
一、浏览器缓存的核心作用与分类
作用:减少网络请求,提升页面加载速度,降低服务器压力。
分类:
- 强缓存:浏览器直接从本地缓存获取资源,不发请求到服务器;
- 协商缓存:发送请求到服务器验证缓存是否有效,有效则返回304状态码,浏览器使用本地缓存。
二、强缓存实现方案(Cache-Control/Expires)
1. Cache-Control(HTTP/1.1,推荐)
- 核心指令:
Cache-Control: max-age=31536000 // 缓存1年(单位:秒)
Cache-Control: no-cache // 强制协商缓存
Cache-Control: no-store // 禁止缓存
Cache-Control: public/private // 缓存可见范围
- 示例配置(Nginx):
location ~* \.(js|css|png|jpg|jpeg|gif|svg)$ {
expires 1y; // 等价于Cache-Control: max-age=31536000
add_header Cache-Control "public";
}
2. Expires(HTTP/1.0,兼容性好)
- 格式:
Expires: Thu, 01 Jan 2024 00:00:00 GMT // 绝对过期时间
- 与Cache-Control的优先级:
- 若同时存在,
Cache-Control优先级更高(因Expires依赖服务器时间)。
- 若同时存在,
三、协商缓存实现方案(Last-Modified/ETag)
1. ETag(推荐,更精准)
- 原理:服务器为资源生成唯一标识(如文件哈希值),浏览器请求时通过
If--Match发送标识,服务器对比后返回304(未修改)或200(修改)。 - 示例流程:
- 首次请求:服务器返回资源+
ETag: "abc123"; - 再次请求:浏览器发送
If--Match: "abc123"; - 服务器对比标识,未修改则返回304,否则返回新资源。
- 首次请求:服务器返回资源+
2. Last-Modified/If-Modified-Since
- 原理:服务器返回资源最后修改时间(
Last-Modified),浏览器下次请求时通过If-Modified-Since发送时间,服务器对比后判断是否更新。 - 缺点:
- 精度有限(仅精确到秒);
- 无法检测文件内容未变但修改时间变更的情况(如编辑器自动保存)。
四、缓存策略对比表
| 策略 | 强缓存 | 协商缓存 |
|---|---|---|
| 核心字段 | Cache-Control/Expires | ETag/Last-Modified |
| 是否发请求 | 否(直接读本地) | 是(验证缓存有效性) |
| 服务器压力 | 低 | 中(需验证请求) |
| 更新及时性 | 差(需等max-age过期) | 好(每次请求验证) |
五、各类资源的缓存策略
1. 静态资源(JS/CSS/图片)
- 策略:
- 强缓存(
max-age=31536000)+ 版本号(如app.v1.0.0.js); - 版本更新时修改文件名,强制浏览器加载新资源。
- 强缓存(
- Nginx配置:
location ~* \.(js|css|png|jpg|jpeg|gif|svg|woff|woff2|ttf|eot)$ {
expires 1y;
add_header Cache-Control "public, max-age=31536000";
add_header ETag on; // 开启ETag协商缓存
}
2. HTML页面
- 策略:
- 不缓存或短缓存(
max-age=0)+ 协商缓存(ETag); - 因HTML常包含动态内容,避免强缓存导致页面不更新。
- 不缓存或短缓存(
- 配置:
location / {
expires 0;
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
}
3. 动态接口(API)
- 策略:
- 禁止缓存(
Cache-Control: no-cache); - 或根据业务需求设置短缓存(如5分钟)。
- 禁止缓存(
六、问题
1. 问:强缓存和协商缓存的执行顺序?
- 答:
- 浏览器先检查强缓存(
Cache-Control/Expires),有效则直接使用本地缓存; - 强缓存失效后,发送请求到服务器验证协商缓存(
ETag/Last-Modified),有效则返回304; - 协商缓存失效后,服务器返回新资源(200 OK)。
- 浏览器先检查强缓存(
2. 问:如何强制浏览器更新缓存?
- 答:
- 前端:修改资源URL(如加版本号
?v=2.0); - 后端:
- 发送
Cache-Control: no-cache强制协商缓存; - 更改
ETag或Last-Modified值,使协商缓存失效。
- 发送
- 前端:修改资源URL(如加版本号
3. 问:ETag和Last-Modified的优缺点?
- 答:
- ETag:
✅ 优点:精准检测资源变化(基于内容哈希);
❌ 缺点:计算哈希有性能开销,资源量大时影响服务器效率。 - Last-Modified:
✅ 优点:实现简单,服务器压力小;
❌ 缺点:精度低,无法检测内容未变但修改时间变更的情况。
- ETag:
4. 问:如何处理缓存导致的登录状态失效?
- 答:
- 在响应头中添加
Cache-Control: private(仅客户端可缓存); - 或对包含登录状态的资源设置
Cache-Control: no-cache,强制每次请求验证; - 前端路由跳转时,通过
window.location.reload(true)强制刷新(跳过强缓存)。
- 在响应头中添加
七、缓存调试与优化工具
- Chrome DevTools:
- Network面板:查看请求的缓存状态(
from disk cache/from memory cache/304 Not Modified); - 禁用缓存:勾选
Disable cache可临时关闭缓存,方便开发调试。
- Network面板:查看请求的缓存状态(
- Lighthouse:
- 审计缓存策略是否合理,给出优化建议(如“可缓存的资源未设置缓存”)。
- 服务器日志:
- 分析
304请求比例,评估缓存命中率(理想情况下静态资源命中率应>80%)。
- 分析
来源:juejin.cn/post/7522093523966197812
这种小工具居然也能在某鱼卖钱?我用Python一天能写100个,纯干货!

前两天在某鱼闲逛,本来想找个二手机械键盘,结果刷着刷着突然看到有人在卖——Word 批量转 PDF 小工具,还挺火,价格也不高,但销量出奇地高,评论里一堆人在夸“好用”、“终于不用一篇篇点了”啥的。

说实话,当时我人都愣住了——
这个功能我用 Python 十分钟能写完啊!
然后我又搜了其它小工具,pdf转Word,Word转图片,Word加水印什么的……好多
好家伙,花姐以前教大家做的办公自动化小工具原来都能卖钱呀!
那咱今天先复刻一个Word 批量转 PDF 小工具,顺便升级点功能,做个更丝滑的版本。
保准你看完就能自己写个卖钱去。
💡思路先摆明:Word 转 PDF,其实没那么复杂
你别看这功能听起来挺“高端”的,其实本质上干的事就是——
把一堆 Word 文档用程序打开,然后保存为 PDF 格式。
换句话说,这活本质就是个“批处理”。用 Python 来干,简直再合适不过。
我们需要的工具是 python-docx?NoNoNo——这个库不支持保存为 PDF。真正的主角其实是:
win32com.client:用来操作 Word 应用(需要 Windows 系统+装了 Office)- 或者跨平台一点的玩法,用 LibreOffice + subprocess,不过今天我们先来讲讲最稳最简单的方式:用 Word 本尊来干活。
🔧上代码:几行就能跑起来的 Word 转 PDF 脚本
好,开门见山,先上最基础的版本:
import os
import win32com.client
def word_to_pdf(input_path, output_path):
word = win32com.client.Dispatch("Word.Application")
word.Visible = False # 不弹窗,后台运行
doc = word.Documents.Open(input_path)
doc.SaveAs(output_path, FileFormat=17) # 17 是 PDF 格式
doc.Close()
word.Quit()
# 示例用法
word_to_pdf("C:/Users/你的用户名/Desktop/测试文档.docx",
"C:/Users/你的用户名/Desktop/测试文档.pdf")
✍️几句解释:
Dispatch("Word.Application")就是打开 Word 应用;FileFormat=17是告诉它“嘿,我要存成 PDF”;- 结尾的
Quit()很重要,不然 Word 可能会在后台一直挂着,占资源。 - 如果你电脑里安装的是WPS,
Dispatch("Word.Application")这里改成Dispatch("kwps.Application"),不然会报错
是不是很简单?连我猫都看懂了。
📂扩展:支持批量转换,一次性把一整个文件夹干掉!
很多人痛苦的点是“文档太多,一个个转太麻烦”。
那好说,我们搞个批量版本,让它一口气全转了:
def batch_convert(folder_path):
word = win32com.client.Dispatch("Word.Application")
word.Visible = False
for file in os.listdir(folder_path):
if file.endswith(".doc") or file.endswith(".docx"):
doc_path = os.path.join(folder_path, file)
pdf_path = os.path.splitext(doc_path)[0] + ".pdf"
try:
doc = word.Documents.Open(doc_path)
doc.SaveAs(pdf_path, FileFormat=17)
doc.Close()
print(f"✅ 转换成功:{file}")
except Exception as e:
print(f"❌ 转换失败:{file},原因:{e}")
word.Quit()
使用方式:
batch_convert(r"C:\Users\你的用户名\Desktop\word文件夹")
🧐常见坑点,花姐来帮你避一避
写得简单不难,难的是兼容和细节。
✅1. 系统必须是 Windows,而且得装了 MS Office
这玩意底层其实就是用 COM 调用了 Word 的功能,所以没有装 Word 是用不了的。
✅2. 文档里有宏的、被保护的,可能转不了
有些文档打开会弹窗提示宏或者密码,那个得手动改设置,程序跑不过去。
✅3. 文件名不要太长、路径不要有中文/空格
有时候路径太奇怪,Word 会打不开,转不了,建议统一放到纯英文文件夹里。
🎁额外加点料
- 自动生成时间戳文件夹 + 输出日志
- 自动获取脚本所在目录下的 Word 文件(不需要用户手动输路径)
- 判断电脑里是否装了 Office(Word)或 WPS,并自动选对的调用方式
- 打包售卖
⏱️ 一、生成时间戳文件夹
def gen_output_folder():
folder = os.path.dirname(os.path.abspath(__file__))
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output_folder = os.path.join(folder, f"pdf_{timestamp}")
os.makedirs(output_folder, exist_ok=True)
return output_folder
📁 二、自动获取当前脚本目录下的 Word 文件
这太简单了:
import os
def get_word_files_from_current_folder():
folder = os.path.dirname(os.path.abspath(__file__))
word_files = []
for file in os.listdir(folder):
if file.endswith(".doc") or file.endswith(".docx"):
word_files.append(os.path.join(folder, file))
return word_files
🔍 三、检测 Office 和 WPS 的方法
我们可以尝试用 win32com.client.gencache.EnsureDispatch() 去判断这两个程序是否存在。
import win32com.client
def detect_office_or_wps():
try:
word = win32com.client.gencache.EnsureDispatch("Word.Application")
return "office"
except:
try:
wps = win32com.client.gencache.EnsureDispatch("Kwps.Application")
return "wps"
except:
return
🔄 三、自动选择引擎并批量转换
import os
import win32com.client
def convert_word_to_pdf_auto(input_path, output_path, engine):
if engine == "office":
app = win32com.client.Dispatch("Word.Application")
elif engine == "wps":
app = win32com.client.Dispatch("Kwps.Application")
else:
print("❌ 没有检测到可用的 Office 或 WPS")
return
app.Visible = False
try:
doc = app.Documents.Open(input_path)
doc.SaveAs(output_path, FileFormat=17)
doc.Close()
print(f"✅ 转换成功:{input_path}")
except Exception as e:
print(f"❌ 转换失败:{input_path},原因:{e}")
try:
app.Quit()
except:
print("⚠️ 当前环境不支持 Quit,跳过退出。")
🚀 四、整合所有内容,一键搞定脚本所在目录下的所有 Word 文件
def batch_convert_here():
engine = detect_office_or_wps()
if not engine:
print("😭 系统里没有安装 Office 或 WPS,没法转换")
return
folder = os.path.dirname(os.path.abspath(__file__))
word_files = get_word_files_from_current_folder()
if not word_files:
print("🤷♀️ 当前文件夹没有发现 Word 文件")
return
output_folder = os.path.join(folder, "pdf输出")
os.makedirs(output_folder, exist_ok=True)
for word_file in word_files:
filename = os.path.splitext(os.path.basename(word_file))[0]
pdf_path = os.path.join(output_folder, f"{filename}.pdf")
convert_word_to_pdf_auto(word_file, pdf_path, engine)
print("🎉 所有文件转换完成啦!PDF 都在 'pdf输出' 文件夹里")
🧪 运行方式(放在脚本结尾):
if __name__ == "__main__":
batch_convert_here()
📦五、 做成 EXE 给小白用户用(pyinstaller)
最后一步,把咱的脚本打包成 .exe,丢到某鱼卖钱(手动狗头🐶)
命令就一句话:
pyinstaller -F word2pdf.py
生成的 dist/word2pdf.exe 就是可执行文件,随便拿给谁用都行(当然系统要有 Word)。
完整代码
import os
import win32com.client
import sys
import datetime
def get_real_path():
"""兼容开发与打包环境的路径获取"""
if getattr(sys, 'frozen', False):
base_dir = os.path.dirname(sys.executable) # EXE文件所在目录[1,7](@ref)
else:
base_dir = os.path.dirname(os.path.abspath(__file__))
return base_dir
# 生成时间戳文件夹
def gen_output_folder(folder):
# folder = os.path.dirname(os.path.abspath(__file__))
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
output_folder = os.path.join(folder, f"pdf_{timestamp}")
os.makedirs(output_folder, exist_ok=True)
return output_folder
# 自动获取当前脚本目录下的 Word 文件
def get_word_files_from_current_folder(folder):
# folder = os.path.dirname(os.path.abspath(__file__))
word_files = []
for file in os.listdir(folder):
if file.endswith(".doc") or file.endswith(".docx"):
word_files.append(os.path.join(folder, file))
return word_files
# 检测 Office 和 WPS 的方法
def detect_office_or_wps():
try:
word = win32com.client.gencache.EnsureDispatch("Word.Application")
return "office"
except:
try:
wps = win32com.client.gencache.EnsureDispatch("Kwps.Application")
return "wps"
except:
return
# 自动选择引擎并批量转换
def convert_word_to_pdf_auto(input_path, output_path, engine):
if engine == "office":
app = win32com.client.Dispatch("Word.Application")
elif engine == "wps":
app = win32com.client.Dispatch("Kwps.Application")
else:
print("没有检测到可用的 Office 或 WPS")
return
app.Visible = False
try:
doc = app.Documents.Open(input_path)
doc.SaveAs(output_path, FileFormat=17)
doc.Close()
print(f"转换成功:{input_path}")
except Exception as e:
print(f"转换失败:{input_path},原因:{e}")
try:
app.Quit()
except:
print("当前环境不支持 Quit,跳过退出。")
# 主函数
def batch_convert_here():
engine = detect_office_or_wps()
if not engine:
print("系统里没有安装 Office 或 WPS,没法转换")
return
folder = get_real_path()
word_files = get_word_files_from_current_folder(folder)
if not word_files:
print("当前文件夹没有发现 Word 文件")
return
output_folder = gen_output_folder(folder)
for word_file in word_files:
filename = os.path.splitext(os.path.basename(word_file))[0]
pdf_path = os.path.join(output_folder, f"{filename}.pdf")
convert_word_to_pdf_auto(word_file, pdf_path, engine)
print("所有文件转换完成啦!PDF 都在 'output_folder' 文件夹里")
if __name__ == "__main__":
try:
batch_convert_here()
print("按 Enter 键退出...")
input() # 等待用户按 Enter 键
except Exception as e:
print(e)
print("程序运行错误,按 Enter 键退出...")
input() # 等待用户按 Enter 键
你可能觉得:“这不就是几十行代码嘛,卖这个会有人买吗?”
我一开始也这么想。后来我想通了,某鱼上很多买家,根本不懂技术,他们在意的是:
✅ 能不能一键搞定?
✅ 会不会太复杂?
✅ 省不省事?
所以啊,写工具 + 提供说明 + 包装打包,这些就构成了“产品”。
我们程序员有时候太低估自己的能力了——其实你随手写的脚本,真的能解决很多人的问题。
来源:juejin.cn/post/7501221695550914575
Go实现超时控制
应用场景
交易、金融等事务系统往往会有各种下游,绝大多数时候我们会以同步方式进行访问,如调用RPC、HTTP等。
这些下游在通常延时相对稳定,但有时可能出现极端的超大延时,这些极端case可能具备特定的业务特征,也有可能单纯是硬件、网络的问题造成,最终表现在系统P99或者P999的延时出现了突刺,如果是面向C端的场景,也会向用户报出一些系统错误,造成用户体验的下降。
一种简易的解决方案是,针对关键的下游节点增加超时控制。在特定时间内,如果下游到期还未返回,不再暴露系统级错误,而是做特殊化处理,比如返回「处理中」状态。
Go实现方案
设计一个方法,使用闭包,传入时间和执行的任务,如果任务执行完未到时间,则直接返回,否则通知调用者超时。
为了保证代码简介和使用简单,我们仅定义一个Wrapper方法,方法定义如下
func TimeoutControlWrapper(duration time.Duration, fn func()) (timeout bool)
官方包time有一个After方法,可以在指定时间内,返回一个channel,基于此来判断是否超时。
另外,在Wrapper方法里异步化执行目标方法,执行完成后写入一个finish信号通知。
同时监听这两个channel,判断是否超时,代码如下
func TimeoutControlWrapper(duration time.Duration, fn func()) (timeout bool) {
finish := make(chan struct{})
go func() {
fn()
finish <- struct{}{}
}()
select {
case <-finish:
return false
case <-time.After(duration):
return true
}
}
结合场景,假设系统会调用一个支付系统的接口,接口本身延时不稳定,因此我们套用TimeoutControlWrapper
func CallPaymentSystem(param PayParam) (payStatus PayStatus) {
var payStatus PayStatus
timeout := TimeoutControlWrapper(time.Second, func() {
payStatus = PaymentSystemRPC.Pay(param)
})
if timeout {
warn() // WARN告警
return PROCESSING // 返回处理中
}
return payStatus
}
延伸思考
上述通过一个简单的Wrapper,来实现调用下游时的超时控制。但在引入的场景里,实现上是不严谨的。哪怕不增加超时控制,我们也无法确认请求是否真实到达了下游系统,这本质上是一个分布式事务的问题,需要我们设计更加健全的系统能力保证一致性,比如通过消息的方式、补偿机制、增加对账系统。
来源:juejin.cn/post/7524615282490441779
前端文件下载全攻略:从单文件到批量下载,哪种方法最优?
小张是一名刚入职的前端开发工程师,某天,他的领导给他布置了一个看似简单的任务:
让用户能够通过文件链接下载多个文件
小张信心满满,觉得这不过是个小问题。然而,当他真正动手时,才发现这个需求并不简单。不同的下载方式各有优缺点,甚至有些方法会带来意想不到的问题,他决定一一尝试,探索最优解。
方案一:window.open——简单粗暴,但会打开新标签页
小张首先想到的是 window.open(url),它可以让浏览器直接打开下载链接。
window.open('https://example.com/file.pdf');
优点:
- 代码简单,直接调用即可。
- 适用于单个文件的下载。
缺点:
- 每次下载都会打开一个新的浏览器标签页,影响用户体验。
- 部分浏览器可能会拦截
window.open,导致下载失败。
方案二:window.location.href 简单有效,但不能同时下载多个文件
小张发现,window.location.href 也可以实现下载,且不会打开新标签页。
window.location.href = 'https://example.com/file.pdf';
优点:
- 适用于单文件下载。
- 不会像
window.open那样打开新页面。
缺点:
- 无法循环下载多个文件。如果连续多次赋值
window.location.href,后一个请求会覆盖前一个,导致只能下载最后一个文件。
方案三:iframe 支持多文件下载,但无法监听完成状态
为了让多个文件能够顺利下载,小张尝试用 iframe。
function downloadFile(url) {
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.src = url;
document.body.appendChild(iframe);
setTimeout(() => {
document.body.removeChild(iframe);
}, 5000); // 延迟移除 iframe,防止影响下载
}
优点:
- 适用于多文件下载。
缺点:
iframe无法监听文件下载是否完成。- 需要在合适的时机移除
iframe,否则可能会影响页面性能。
方案四:fetch + blob——最优雅的下载方式
小张最终发现,fetch 可以获取文件数据,再通过 Blob 处理并使用 a 标签下载。
async function downloadFile(url, fileName) {
const response = await fetch(url);
if (!response.ok) throw new Error('Download failed');
const blob = await response.blob();
const blobUrl = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = blobUrl;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(blobUrl);
}
function download(fileList){
for(const file of fileList) {
await downloadFile(file.url,file.name)
}
}
优点:
- 不会打开新标签页。
- 可以同时下载多个文件。
- 适用于现代浏览器,兼容性较好。
缺点:
- 需要处理异步
fetch请求。 - 服务器必须支持跨域资源共享(CORS),否则
fetch请求会失败。 - 多次文件下载会导致多个浏览器下载图标:每次调用
a.click()时,浏览器都会显示一个下载图标,影响用户体验。
方案五:jsZip 打包多个文件为 ZIP 下载——避免多次下载图标
为了进一步优化方案四,避免浏览器每次下载时显示多个下载图标,小张决定使用 jsZip 插件将多个文件打包成一个 ZIP 文件下载。
import JSZip from 'jszip';
async function downloadFilesAsZip(files) {
const zip = new JSZip();
// 循环遍历多个文件,获取每个文件的数据
for (const file of files) {
const response = await fetch(file.url);
if (!response.ok) throw new Error(`Failed to fetch ${file.name}`);
const blob = await response.blob();
zip.file(file.name, blob); // 将文件添加到 ZIP 包中
}
// 生成 ZIP 文件并触发下载
zip.generateAsync({ type: "blob" })
.then(function(content) {
const a = document.createElement('a');
const blobUrl = URL.createObjectURL(content);
a.href = blobUrl;
// 给压缩包设置下载文件名
a.download = 'files.zip';
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
// 释放 URL 对象
URL.revokeObjectURL(blobUrl);
});
}
优点:
- 提升用户体验:用户下载一个压缩包后,只需解压就可以获取所有文件,避免了多次点击和等待的麻烦。
- 适用于多文件下载:非常适合需要批量下载的场景。
缺点:
- 浏览器对大文件的支持:如果要下载的文件非常大,或者文件总大小很大,可能会导致内存消耗过高,甚至在浏览器中崩溃。
- 下载速度受限于压缩处理:打包文件为 ZIP 需要时间,尤其是文件较多时,会稍微影响压缩的速度,只适用于文件不是很大且数量不是很多的时候
结语:小张的最终选择
经过一番探索,小张最终选择了 jsZip 打包文件的方案,因为它不仅解决了多个文件下载时图标显示的问题,还提高了用户体验,让下载更加流畅,没有哪个方案比另外一个方案好,只有最适合的方案,根据实际的场景能满足需求最优解就是最好的。
来源:juejin.cn/post/7488172786692685835
赋能大模型:ant-design系列组件的文档知识库搭建
引言
在当今组件化开发时代,知识库建设已成为提升开发效率的重要环节。然而传统爬虫方式在获取结构化组件文档时往往面临诸多挑战。为此,开发了 antd-doc-gen 工具,用来快速生成 antd 系列组件库的文档,将其作为大模型补充的知识库,生成的文档可以非常方便的导入到 像 ima,cursor,Obsidian 等支持知识库的工具。本文将解析其技术实现与设计理念。
npm 地址:http://www.npmjs.com/package/ant…
github 仓库:github.com/xuanxuan321…
一、核心功能概览
antd-doc-gen 作为专业的命令行工具,具备以下核心能力:
- 多库支持:原生支持 Ant Design 主库、Mobile、Mini、Web3 及 X 系列组件库
- 智能文档解析:自动识别组件文档结构,合并主文档与示例代码
- 格式标准化:生成统一格式的 Markdown 文档,并创建索引目录
- 远程协作:支持从 GitHub 仓库直接下载代码并处理
二、使用指南
快速安装
npm install -g antd-doc-gen
典型用例
生成 antd 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design
生成 antd-mobile 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-mobile
生成 antd-mini 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-mini
生成 antd-x 文档
antd-doc-gen -d -r https://github.com/ant-design/x
生成 antd-web3 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-web3
三、技术实现解析
智能文档处理流程
工具通过五层处理流程实现文档自动化生成:
- 命令行解析:使用 commander 库处理参数,支持多路径输入
- 代码下载:基于 simple-git 实现多协议下载(HTTPS/SSH),含分支容错机制
- 文档定位:针对不同仓库类型采用差异化路径策略(如 antd 使用 components/*/index.zh-CN.md)
- 内容整合:通过正则表达式提取示例代码,自动补全扩展名(.tsx → .ts)
- 输出生成:按组件名称生成 Markdown 文件,并创建字母序索引
其他:
● 智能路径处理:支持跨平台路径分隔符自动转换,兼容绝对/相对路径
● 文档格式统一:保留原始结构,将示例代码以 Markdown 代码块嵌入
● 容错机制:提供分支/协议降级策略,支持无示例文档的直接复制
技术栈与扩展性
核心技术栈
● Node.js 生态:fs/path 模块实现文件操作,readline 处理用户交互
● 第三方库:commander(命令行)、simple-git(Git 操作)、ora(加载动画)
扩展能力
工具支持通过代码修改实现:
- 新组件库类型适配
- 自定义文档输出格式
- 新增文档处理逻辑
适用场景
需要 antd 系列组件库文档作为知识库的场景
局限性与优化方向
当前版本依赖特定文档结构(需包含 index.md 及 code 标签),未来计划:
● 增强非标准文档的兼容性
● 支持更多文档格式输出
● 集成文档预览功能
结语
antd-doc-gen 通过自动化文档处理流程,显著提升了组件库文档的维护效率。文档可以直接导入像 ima,cursor,Obsidian 等知识库工具,进一步提升大模型的能力
来源:juejin.cn/post/7479814468601085986
技术多久没有进步了?
很久没有写东西了,这个选题正好聊一下。
对于这个问题,我的答案是 1 年左右——我进外包的日子。
在外包中,我的工作日常就是搞业务,天天 CRUD,有人会讲,CRUD 也能玩出花来,只能是你自己对技术没有了追求。我承认,也确实是这样,外包的业务很多,每天 CRUD,很简单,但还是很忙,忙到不想敲代码了,忙到对技术没啥追求了。
外包确实不适合自控力太差的人,不适合自我调节能力不行的人。
为什么这样说呢?我待的外包,说它加班很多吗?其实并没有,至少工作日 5.30 下班最多也就待到 5.45 就走了,周末加班也只有比较着急的时候,次数不多,所以很少的加班,甚至比我之前待着的两家自研加班都少,为啥下班就走的的我,没有时间去深造技术了呢?
我也还在思考。目前我的答案大概还是跟业务有关。
自研会有一种成就感,尤其在我第一家公司尤甚,那时候对自己做的第一个产品确实非常上心,项目上要做的功能和遇到的问题都会进行深度思考,去结合成熟的方案来形成自己的实现方案和解决方案,但是在外包呢,天天各种项目组的人来找你,自己手里有好多个“外包前辈”的项目,继承它们的“代码遗产”,鄙视他们的代码并有优化的心思,但突如其来的项目和很少能自己评开发时间的原因,让我也“放纵”和“加入”了“他们”,每天完成了任务也仅仅是完成了任务,很少有自己的思考,也变没有了什么成就感,对代码变成了“贤者”,没有了“兴趣”,下班后的生活变成了综艺/游戏/抖音,沉浸在这样的“快乐”中。
写到这里了,也想说一下,你技术突飞猛进的时候是一个什么样的时期或状态呢?
上面也说到了,就是第一家公司,除了对自己的“初恋”产品认真外,还有就是那时候是刚从培训班出来,刚找到的第一家公司,怕过不了试用期,所以刚开始每天回家自己敲代码敲到晚上,技术成长非常快,还有就是第二家公司,用的 React 技术栈,当时我是 Vue 技术栈找的 React 技术栈,虽然当时第二家公司说给时间从 Vue 过渡到 React,但也有一种紧迫感,还有也是很想学 React 了,所以技术上也有很大进步。
技术这么久没长进了,是外包公司的问题吗?
其实不是,上面也说了,虽然都是 CRUD,虽然业务比较多,但其实加班都不多,这些都不是理由,下班后的时间其实是比较多的,都是我能掌控的,只是我没有调整好心态,对自己太过放纵罢了,游戏,小说,综艺,抖音填满了我下班后的生活,沉浸在一种虚假的快乐中,其实并不快乐。
把想说的都说出来了,挺好,后面,如果自己不想继续这么混的话,就一块一块改吧。一下全改我都不相信我能做到(三分钟的热度更可怕),一块一块来,不把自己逼的太紧,养成习惯最好,就先这样。
来源:juejin.cn/post/7494489664385548297
JavaScript 数据扁平化方法大全
前言
数据扁平化是指将多维数组转换为一维数组的过程。由于嵌套数据结构增加了访问和操作数据的复杂度,所以·我们可以将嵌套数据变成一维的数据结构,下面就是我搜集到的一些方法,希望可以给你带来帮助!!
1. 使用 Array.prototype.flat()(推荐)
ES2019 引入的专门方法:
const nestedArr = [1, [2, [3, [4]], 5]];
// 默认只扁平化一层
const flattened1 = nestedArr.flat();
console.log(flattened1); // [1, 2, [3, [4]], 5]
// 指定深度为2
const flattened2 = nestedArr.flat(2);
console.log(flattened2); // [1, 2, 3, [4], 5]
// 完全扁平化
const fullyFlattened = nestedArr.flat(Infinity);
console.log(fullyFlattened); // [1, 2, 3, 4, 5]
解析:
flat(depth)方法创建一个新数组,所有子数组元素递归地连接到指定深度- 参数
depth指定要提取嵌套数组的结构深度,可选的参数,默认为1 - 使用
Infinity可展开任意深度的嵌套数组,Infinity是一个特殊的数值,表示无穷大。
2. 使用 reduce() 和 concat() 递归
function flatten(arr) {
// 使用 reduce 方法遍历数组元素
return arr.reduce((acc, val) => {
// 如果当前元素是数组,则递归调用 flatten 继续展开,并拼接到累积数组 acc
if (Array.isArray(val)) {
return acc.concat(flatten(val));
}
// 如果当前元素不是数组,直接拼接到累积数组 acc
else {
return acc.concat(val);
}
}, []); // 初始累积值是一个空数组 []
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // 输出: [1, 2, 3, 4, 5]
解析:
- 递归处理嵌套数组
- 遇到子数组时,递归调用
flatten(val)继续展开,直到所有层级都被展开为单层。
- 遇到子数组时,递归调用
reduce方法的作用
- 遍历数组,通过
acc(累积值)逐步拼接结果,初始值设为[](空数组)。
- 遍历数组,通过
Array.isArray(val)检查
- 判断当前元素是否为数组,决定是否需要递归展开。
concat拼接结果
- 将非数组元素或递归展开后的子数组拼接到累积数组
acc中。
- 将非数组元素或递归展开后的子数组拼接到累积数组
3. 使用 concat() 和扩展运算符递归
function flatten(arr) {
// 使用扩展运算符 (...) 展开数组的第一层,并合并成一个新数组
const flattened = [].concat(...arr);
// 检查当前展开后的数组中是否仍然包含嵌套数组
// 如果存在嵌套数组,则递归调用 flatten 继续展开
// 如果所有元素都是非数组类型,则直接返回展开后的数组
return flattened.some(item => Array.isArray(item))
? flatten(flattened)
: flattened;
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // 输出: [1, 2, 3, 4, 5]
解析:
[].concat(...arr)展开一层数组
- 使用扩展运算符
...展开arr的最外层,并通过concat合并成一个新数组。 - 例如:
[].concat(...[1, [2, [3]]])→[1, 2, [3]](仅展开一层)。
- 使用扩展运算符
flattened.some(Array.isArray)检查嵌套
- 使用 Array.prototype.some() 检查当前数组是否仍然包含子数组。
- 如果存在,则递归调用
flatten继续展开。
- 递归终止条件
- 当
flattened不再包含任何子数组时,递归结束,返回最终结果。
- 当
4. 使用 toString() 方法(仅适用于数字数组)
const nestedArr = [1, [2, [3, [4]], 5]];
const flattened = nestedArr.toString().split(',').map(Number);
console.log(flattened); // [1, 2, 3, 4, 5]
解析:
toString()的隐式转换
- JavaScript 的
Array.prototype.toString()会自动展开嵌套数组,并用逗号连接所有元素。 - 例如:
[1, [2, [3]]].toString()→"1,2,3"。
- JavaScript 的
split(',')分割字符串
- 将字符串按逗号拆分成字符串数组,但所有元素会是字符串类型(如
"2")。
- 将字符串按逗号拆分成字符串数组,但所有元素会是字符串类型(如
map(Number)类型转换
- 通过
Number构造函数将字符串元素转换为数字类型。 - 注意:如果原数组包含非数字(如
['a', [2]]),结果会变成[NaN, 2]。
- 通过
优缺点:
- 优点:代码极其简洁,适合纯数字的嵌套数组。
- 缺点:
- 仅适用于数字数组(其他类型会被强制转换,如
true→1,null→0)。 - 无法保留原数据类型(如字符串
'3'会被转成数字3)。
- 仅适用于数字数组(其他类型会被强制转换,如
适用场景:
- 快速展开纯数字的嵌套数组,且不关心中间过程的性能损耗(
toString和split会有临时字符串操作)。
5. 使用 JSON.stringify() 和正则表达式
function flatten(arr) {
// 1. 使用 JSON.stringify 将数组转换为字符串表示
// 例如:[1, [2, [3]], 'a'] → "[1,[2,[3]],\"a\"]"
const jsonString = JSON.stringify(arr);
// 2. 使用正则表达式移除所有的 '[' 和 ']' 字符
// 例如:"[1,[2,[3]],\"a\"]" → "1,2,3,\"a\""
const withoutBrackets = jsonString.replace(/[\[\]]/g, '');
// 3. 按逗号分割字符串,生成字符串数组
// 例如:"1,2,3,\"a\"" → ["1", "2", "3", "\"a\""]
const stringItems = withoutBrackets.split(',');
// 4. 尝试将每个字符串解析回原始数据类型
// - 数字会变成 Number 类型(如 "1" → 1)
// - 字符串会保留(如 "\"a\"" → "a")
// - 其他 JSON 可解析类型也会被正确处理
return stringItems.map(item => {
try {
// 尝试 JSON.parse 解析(处理字符串、数字等)
return JSON.parse(item);
} catch (e) {
// 如果解析失败(如空字符串或非法 JSON),返回原始字符串
return item;
}
});
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5, 'a', { b: 6 }];
console.log(flatten(nestedArr));
// 输出: [1, 2, 3, 4, 5, "a", { b: 6 }]
解析:
JSON.stringify的作用
- 将整个数组(包括嵌套结构)转换为 JSON 字符串,保留所有数据类型信息。
- 正则替换
/[[]]/g
- 移除所有方括号字符
[和],只保留逗号分隔的值。
- 移除所有方括号字符
split(',')分割字符串
- 生成一个字符串数组,但每个元素可能仍是被 JSON 字符串化的(如
""a"")。
- 生成一个字符串数组,但每个元素可能仍是被 JSON 字符串化的(如
- JSON.parse() 尝试恢复数据类型
- 通过
JSON.parse将字符串转换回原始类型(数字、字符串、对象等)。 - 使用
try-catch处理不合法的 JSON 字符串(如空字符串或格式错误的情况)。
- 通过
优缺点:
- 优点:
- 支持任意数据类型(数字、字符串、对象等)。
- 能正确处理嵌套对象(如
{ b: 6 })。
- 缺点:
- 性能较低(涉及 JSON 序列化、正则替换、解析等操作)。
- 如果原始数组包含特殊字符串(如
"[1]") ,可能会被错误解析。
适用场景:
- 需要处理混合数据类型(非纯数字)的嵌套数组。
- 对性能要求不高,但需要代码简洁的场景。
6. 使用堆栈的非递归实现
function flatten(arr) {
// 创建栈并初始化(使用扩展运算符浅拷贝原数组)
const stack = [...arr];
const result = [];
// 循环处理栈中的元素
while (stack.length) {
// 从栈顶取出一个元素
const next = stack.pop();
if (Array.isArray(next)) {
// 如果是数组,展开后压回栈中(保持顺序)
stack.push(...next);
} else {
// 非数组元素,添加到结果数组前端(保持原顺序)
result.unshift(next);
}
}
return result;
}
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // [1, 2, 3, 4, 5]
解析:
- 栈结构初始化
- 使用扩展运算符
[...arr]创建原数组的浅拷贝作为初始栈 - 避免直接修改原数组
- 使用扩展运算符
- 栈处理循环
- 使用
while循环处理栈直到为空 - 每次从栈顶
pop()一个元素进行处理
- 使用
- 元素类型判断
- 使用
Array.isArray()检查元素是否为数组 - 如果是数组则展开后重新压入栈
- 非数组元素则添加到结果数组
- 使用
- 顺序保持
- 使用
unshift()将元素添加到结果数组前端,当然这样比较费性能,可以改用push()+reverse()替代unshift() - 确保最终结果的顺序与原数组一致
- 使用
优缺点
- 优点:
- 支持任意数据类型(不限于数字)
- 可以处理深层嵌套结构(无递归深度限制)
- 相比递归实现,不易导致栈溢出
- 缺点:
- 使用 unshift() 导致时间复杂度较高(O(n²))
- 需要额外空间存储栈结构
- 相比原生
flat()方法性能稍差 - 无法控制扁平化深度(总是完全扁平化)
适用场景
- 需要处理混合数据类型的深层嵌套数组
- 需要避免递归导致的栈溢出风险
7. 使用 Array.prototype.some() 和扩展运算符
function flatten(arr) {
// 循环检测数组中是否还包含数组元素
while (arr.some(item => Array.isArray(item))) {
// 使用扩展运算符展开当前层级的所有数组
// 并通过concat合并为一层
arr = [].concat(...arr);
}
return arr;
}
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // [1, 2, 3, 4, 5]
解析:
- 循环条件检测
- 使用
arr.some()方法检测数组中是否还存在数组元素 Array.isArray(item)判断每个元素是否为数组
- 使用
- 层级展开
- 使用扩展运算符
...arr展开当前层级的数组 - 通过
[].concat()将展开的元素合并为新数组
- 使用扩展运算符
- 迭代处理
- 每次循环处理一层嵌套
- 重复直到没有数组元素存在
性能比较
对于大多数现代应用:
- 优先使用
flat(Infinity)(最简洁且性能良好) - 对于深度嵌套的大数组,考虑非递归的堆栈实现
- 递归方法在小数据集上表现良好且代码简洁
- 避免
toString()方法除非确定只有数字数据
总结
JavaScript 提供了多种扁平化数组的方法,从简单的内置 flat() 方法到各种手动实现的递归、迭代方案。选择哪种方法取决于:
- 运行环境是否支持 ES2019+
- 数据结构的复杂程度
- 对性能的要求
- 代码可读性需求
在大多数现代应用中,flat(Infinity) 是最佳选择,因为它简洁、高效且语义明确。
来源:juejin.cn/post/7522371045652578356
LangGraph深度解析:从零构建大模型工作流的终极指南
一. LangGraph简介
LangGraph 是基于 LangChain 的扩展框架,专为构建有状态(Stateful) 的大模型工作流而设计。它通过图结构(Graph)定义多个执行节点(Node)及其依赖关系,支持复杂任务编排,尤其适合多智能体协作、长对话管理等场景。
1.1 核心优势
- 状态持久化:自动维护任务执行过程中的上下文状态
- 灵活编排:支持条件分支、循环、并行等控制流
- 容错机制:内置错误重试、回滚策略
- 可视化调试:自动生成执行流程图

二. LangGraph最佳实践
2.1 基础代码结构
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
# 定义状态结构
class AgentState(TypedDict):
input: str
result: Annotated[list, operator.add] # 自动累积结果
# 初始化图
graph = StateGraph(AgentState)
# 添加节点与边(后续章节详解)
...
# 编译并运行
app = graph.compile()
result = app.invoke({"input": "任务描述"})
2.2 开发原则
模块化设计:每个节点只完成单一职责
状态最小化:仅保留必要数据,避免内存膨胀
幂等性保证:节点可安全重试
三. 状态设计(State Design)
3.1 状态定义规范
使用 Pydantic模型 或 TypedDict 明确状态结构:
from pydantic import BaseModel
class ProjectState(BaseModel):
requirements: str
draft_versions: list[str]
current_step: int
# 初始化状态
initial_state = ProjectState(
requirements="开发一个聊天机器人",
draft_versions=[],
current_step=0
)
3.2 状态自动管理
LangGraph通过注解(Annotation) 实现状态字段的自动更新:
from langgraph.graph import add_messages
class DialogState(TypedDict):
history: Annotated[list, add_messages] # 自动追加消息
def user_node(state: DialogState):
return {"history": ["用户: 你好"]}
def bot_node(state: DialogState):
return {"history": ["AI: 您好,有什么可以帮您?"]}
四. 节点函数(Node Functions)
4.1 节点定义标准
节点是工作流的基本单元,接收状态并返回更新:
from langchain_core.runnables import RunnableLambda
# 简单节点
def data_loader(state: dict):
return {"data": load_dataset(state["input"])}
# 包含LLM调用的节点
llm_node = RunnableLambda(
lambda state: {"answer": chat_model.invoke(state["question"])}
)
# 注册节点
graph.add_node("loader", data_loader)
graph.add_node("llm", llm_node)
4.2 多智能体协作
def designer_agent(state):
return {"design": "界面草图"}
def developer_agent(state):
return {"code": "实现代码"}
# 并行执行
graph.add_node("designer", designer_agent)
graph.add_node("developer", developer_agent)
graph.add_edge("designer", "reviewer")
graph.add_edge("developer", "reviewer")

五. 边的设计(Edge Design)
5.1 条件分支(Conditional Edges)
根据状态值动态路由:
from langgraph.graph import conditional_edge
def should_continue(state):
return "continue" if state["step"] < 5 else "end"
graph.add_conditional_edges(
source="decision_node",
path_map={"continue": "next_node", "end": END},
condition=should_continue
)
5.2 循环结构
graph.add_edge("start", "process")
graph.add_conditional_edges(
"process",
lambda s: "loop" if s["count"] < 3 else "end",
{"loop": "process", "end": END}
)
六. 错误处理(Error Handling)
6.1 重试机制
from langgraph.retry import RetryPolicy
policy = RetryPolicy(
max_retries=3,
backoff_factor=1.5,
retry_on=(Exception,)
)
graph.add_node(
"api_call",
api_wrapper.with_retry(policy)
)
6.2 回滚策略
def compensation_action(state):
# 执行补偿操作
rollback_transaction(state["tx_id"])
return {"status": "rolled_back"}
graph.add_edge("failed_node", "compensation")
graph.add_edge("compensation", END)
注:本文代码基于LangGraph 0.1+版本实现,需预先安装依赖:
pip install langgraph langchain pydantic
更多AI大模型应用开发学习内容,尽在聚客AI学院。
来源:juejin.cn/post/7501990822805618688
5 个理由告诉你为什么有了 JS 还要需要 TypeScript
在前端开发圈,JavaScript(简称JS)几乎无处不在。但你有没有发现,越来越多的大型项目和团队都在用 TypeScript(简称TS)?明明 JS 已经这么强大,为什么还要多此一举用 TS 呢?今天就用通俗易懂的语言,结合具体例子,带你彻底搞懂这个问题!🌟
1. JS的弱类型让大型项目“踩坑”不断
JavaScript 是一种弱类型语言,也就是说,变量的类型可以随时变化。虽然这让 JS 写起来很灵活,但在大型项目中却容易埋下隐患。
举个例子:
// JS 代码
function sum(a, b) {
return a + b;
}
console.log(sum(1, 2)); // 输出 3
console.log(sum('1', 2)); // 输出 '12',字符串拼接
console.log(sum(true, [])); // 输出 'true',奇怪的结果
在 JS 里,sum 函数参数类型完全不受限制,传什么都行。小项目还好,项目一大,团队一多,类型混乱就会导致各种难以发现的bug,甚至上线后才暴雷,影响开发效率和用户体验。
2. TS的类型检查让错误“消灭在摇篮里”
TypeScript 是 JS 的超集,在 JS 的基础上增加了类型系统。这意味着你可以在写代码时就发现类型错误,而不是等到运行时才发现。
同样的例子,用 TS 改写:
// TS 代码
function sum(a: number, b: number): number {
return a + b;
}
sum(1, 2); // 正常
sum('1', 2); // ❌ 报错:参数类型不匹配
TS 会在你写代码时就提示错误,防止类型不一致带来的 bug。这样,开发效率和代码质量都大大提升!
3. TS的类型推断让开发更智能
你可能担心,TS 要写很多类型声明,会不会很麻烦?其实不用担心,TS 有类型推断功能,能根据你的代码自动判断类型。
例子:
let age = 18; // TS 自动推断 age 是 number 类型
age = '二十'; // ❌ 报错:不能把 string 赋值给 number
你只需要在关键地方声明类型,其他地方 TS 会帮你自动推断,大大减少了重复劳动。
4. TS让团队协作更高效
在多人协作的大型项目中,TS 的类型系统就像一份“契约”,让每个人都能清楚知道每个函数、对象、变量的类型,极大减少沟通成本和踩坑概率。
例子:
// 定义一个工具函数
function formatUser(user: { name: string; age: number }) {
return `${user.name} (${user.age})`;
}
// 调用时,TS 会自动检查参数类型
formatUser({ name: '小明', age: 20 }); // 正常
formatUser({ name: '小红', age: '二十' }); // ❌ 报错
有了类型约束,团队成员只要看类型定义就能明白怎么用,不用再靠口头说明或文档补充,协作效率大大提升。
5. TS支持现代开发工具,体验更丝滑
TS 的类型信息可以被编辑器和IDE(如 VSCode)利用,带来更智能的自动补全、跳转、重构、查找引用等功能,让开发体验飞升!
例子:
- 输入对象名时,编辑器会自动提示有哪些属性;
- 修改类型定义,相关代码会自动高亮出错,方便全局重构;
- 查找函数引用时,TS 能精确定位所有用到的地方。
这些功能在 JS 里是做不到的,TS 让开发更高效、更安全、更快乐! 😄
TS的常见类型一览表
| 类型 | 说明 | 示例 |
|---|---|---|
| any | 任意类型 | let a: any |
| unknown | 未知类型 | let b: unknown |
| never | 永不存在的类型 | function error(): never { throw new Error() } |
| string | 字符串 | let s: string |
| number | 数字 | let n: number |
| boolean | 布尔 | let b: boolean |
| null | 空 | let n: null |
| undefined | 未定义 | let u: undefined |
| symbol | 符号 | let s: symbol |
| bigint | 大整数 | let b: bigint |
| object | 狭义对象类型 | let o: object |
| Object | 广义对象类型 | let O: Object |
小贴士:
any虽然灵活,但会失去类型检查,不推荐使用;unknown更安全,推荐用来接收不确定类型的数据。
TS的安装与使用
TypeScript 的安装和使用也非常简单:
npm install -g typescript
npm install -g ts-node
typescript用于编译.ts文件, 在当前目录生成一个同名的.js文件;ts-node可以直接运行 TS 文件,开发更方便。
总结
有了 JS,为什么还要用 TS?
归根结底,TS 让代码更安全、开发更高效、协作更顺畅、体验更丝滑。尤其是在大型项目和团队协作中,TS 的优势会越来越明显。
5个理由再回顾:
- JS 弱类型,容易埋坑,TS 静态类型,提前发现错误;
- TS 类型检查,bug 消灭在摇篮里;
- TS 类型推断,开发更智能;
- TS 类型约束,团队协作更高效;
- TS 支持现代开发工具,体验更丝滑。
如果你还没用过 TypeScript,不妨试试,相信你会爱上它!💙
来源:juejin.cn/post/7525660078722154511
你不会使用css函数 clamp()?那你太low了😀

我们做前端的,为了让网站在不同设备上都好看,天天都在和“响应式”打交道。其中最常见的一个场景,就是处理字体大小。
通常,我们是这么做的:
/* 手机上是16px */
h1 {
font-size: 16px;
}
/* 平板上大一点 */
@media (min-width: 768px) {
h1 {
font-size: 24px;
}
}
/* 电脑上再大一点 */
@media (min-width: 1200px) {
h1 {
font-size: 32px;
}
}
这套代码能用,但它有一个问题:字体大小的变化,是“跳跃式”的,像在走楼梯。 当你的屏幕宽度从767px变成768px时,字体会“Duang”地一下突然变大。这种体验,不够平滑。
今天,我想聊一个能让我们告别大部分这种繁琐媒体查询的CSS函数:clamp()。它能让我们的元素尺寸,像在走一个平滑的斜坡一样,实现真正的 “流体式”缩放。
clamp() 到底是个啥?
clamp() 的中文意思是“夹子”或“钳子”,非常形象。它的作用就是把一个值的范围,“夹”在一个最大值和一个最小值之间。
它的语法极其简单:

width: clamp(最小值, 理想值, 最大值);
你可以把它理解成,你在设定一个规则:
最小值(MIN) :这是“下限”。不管怎么样,这个值都不能比它更小了。最大值(MAX) :这是“上限”。不管怎么样,这个值都不能比它更大了。理想值(IDEAL) :这是“首选值”。它通常是一个根据视口变化的相对单位,比如vw。浏览器会先尝试使用这个值。
它的工作逻辑是:
- 如果“理想值”小于“最小值”,那就取“最小值”。
- 如果“理想值”大于“最大值”,那就取“最大值”。
- 如果“理想值”在两者之间,那就取“理想值”。
使用场景:流体字号(Fluid Typography)
这是clamp()最经典,也是最强大的用途。我们来改造一下文章开头的那个例子。
以前(媒体查询版):
h1 { font-size: 16px; }
@media (min-width: 768px) { h1 { font-size: 24px; } }
@media (min-width: 1200px) { h1 { font-size: 32px; } }
现在(clamp()版):
h1 {
/* 最小值是16px,
理想值是视口宽度的4%,
最大值是32px。
*/
font-size: clamp(16px, 4vw, 32px);
}
看,一行代码,代替了原来的一堆媒体查询。
现在你拖动浏览器窗口,会发现标题的大小是在平滑地、线性地变化,而不是“阶梯式”地跳变。它在小屏幕上不会小于16px,在大屏幕上不会大于32px,而在中间的尺寸,它会根据4vw这个值自动调整。
使用场景:动态间距(Dynamic Spacing)
clamp() 不仅仅能用在font-size上,任何需要长度值的地方,比如margin, padding, gap,它都能大显身手。
我们可以用它来创建一个“呼吸感”更强的布局。
.grid-container {
display: grid;
/* 网格间距最小15px,最大40px,中间根据视口宽度5%来缩放 */
gap: clamp(15px, 5vw, 40px);
}
.section {
/* section的上下内边距,最小20px,最大100px */
padding-top: clamp(20px, 10vh, 100px);
padding-bottom: clamp(20px, 10vh, 100px);
}
这样做的好处是,你的布局在任何尺寸的屏幕上,都能保持一个和谐的、自适应的间距,不再需要为不同断点去写多套padding和gap的值。
结合 calc() 实现更精准的控制
有时候,我们不希望缩放是纯线性的vw,而是希望它有一个“基础值”,然后再根据vw去微调。这时候,clamp()可以和calc()结合使用。
h1 {
/* 理想值不再是单纯的3vw,
而是 1rem + 3vw。
这意味着它有一个1rem的基础大小,然后再叠加上与视口相关的部分。
*/
font-size: clamp(1.5rem, calc(1rem + 3vw), 3rem);
}
这个calc(1rem + 3vw)的公式,是一个非常流行和实用的流体排版计算方法。它能让你对字体大小的缩放速率有更精细的控制,是一个非常值得收藏的技巧。
兼容性如何呢?
你可能会担心浏览器的兼容性。
好消息是,在2025年的今天,clamp()已经在所有主流现代浏览器(Chrome, Firefox, Safari, Edge)中获得了良好支持。除非你的项目需要兼容非常古老的浏览器,否则完全可以放心在生产环境中使用。

下次,当你又准备写一堆媒体查询来控制字号或间距时,不妨先停下来,问问自己:
“这个场景,是不是用clamp()一行代码就能搞定?”
希望你试试看😀。
参考:
来源:juejin.cn/post/7527576206695776302
调试 WebView 旧资源缓存问题:一次从偶发到复现的实战经历
移动端 WebView 与浏览器最大的差异之一就是缓存机制:浏览器支持 DevTools 清理缓存、更新资源非常便利;而 WebView 在 App 中受系统 WebView 组件和应用缓存策略影响,经常会出现资源更新后,部分用户仍加载老版本 JS/CSS,引发奇怪的线上问题。
这类问题难点在于:不是所有用户都能复现,只有特定设备/网络环境/升级路径才会触发。以下是我们在一个活动页迭代中解决用户加载到老版本脚本的问题记录。
背景:活动页面更新后部分用户功能异常
活动页面上线后,我们修复了一个按钮点击无效的 bug,并发布了新 JS 资源。大部分用户恢复正常,但个别用户仍反馈点击无响应。
通过埋点数据统计,这类异常只占总 PV 的 1~2%,但因影响实际参与,必须解决。
第一步:判断用户是否加载到新资源
通过后端接口返回的页面版本号,我们在埋点中发现异常用户请求的是最新页面 HTML,但 HTML 中引用的 JS 文件版本却是旧文件。
我们用 Charles 配合 WebDebugX,在问题设备上连接调试,确认请求路径:
https://cdn.example.com/activity/v1.2.0/main.js
服务器早已上线 v1.3.0 文件,但部分设备仍强制加载 v1.2.0。这说明浏览器或 WebView 从缓存中读取了过期资源。
第二步:复现问题与验证缓存机制
通过 Charles 的 Map Local 功能,我们在真机上强制模拟返回旧版 main.js,验证页面表现是否与用户反馈一致。结果按钮再次失效,证明旧资源是问题根源。
然后用 WebDebugX 查看资源请求的响应 header,确认服务器已正确返回 Cache-Control:
Cache-Control: no-cache, max-age=0
理论上应强制重新拉取最新资源,但部分 Android WebView 未执行 no-cache,而是优先使用 local cache。
第三步:排查 WebView 缓存策略差异
我们协助移动端团队通过 Logcat 查看 WebView 请求日志,发现部分机型仍启用了 LOAD_DEFAULT 缓存模式,该模式下只要缓存有效期内,就会使用本地缓存资源,即便服务器指示不缓存也无法生效。
而大部分新系统使用了 LOAD_NO_CACHE 或 LOAD_CACHE_ELSE_NETWORK,能更好地遵循服务器缓存头。
第四步:修复方案设计
针对缓存策略问题,我们制定了双向修复方案:
短期前端方案
- 在资源引用 URL 中增加强制更新参数:
<script src="https://cdn.example.com/activity/main.js?v=20240601"></script>
- 每次版本发布更新
v参数,确保请求路径变化,从而绕开缓存。
中期后端方案
- 通过 CDN 配置给静态文件加上不可缓存策略,确保 CDN 节点不会继续提供过期资源。
长期客户端方案
- 移动端团队将 WebView 缓存策略统一改为
LOAD_NO_CACHE模式,彻底解决旧资源被缓存的问题。
第五步:验证全流程有效性
修复完成后,我们用以下方法进行多角度验证:
- 使用 Charles 观察请求地址是否携带新版本参数;
- 在 WebDebugX 中查看页面是否加载了最新资源;
- 在 QA 部门用多台低端机和慢网环境回归测试,模拟网络断开重连、App 冷启动后资源拉取表现;
- 监控埋点数据中页面版本和资源版本是否完全一致,确认没有用户再加载到老资源。
最终确认异常用户比例下降到 0%。
工具与协作流程
此次缓存问题排查中,我们的调试和分工是:
| 工具 | 用途 | 使用人 |
|---|---|---|
| WebDebugX | 查看资源加载路径、响应 header | 前端 / QA |
| Charles | 模拟缓存场景、观察真实请求 | 前端 |
| Logcat | 验证 WebView 缓存模式 | 移动端 |
| Vysor | 复现低端设备表现、录制操作过程 | QA |
总结:缓存问题的解决要从端到端出发
缓存问题不是“前端清理一下”就能解决,它涉及:
浏览器/WebView 端缓存策略;
后端或 CDN 返回的缓存头;
前端 URL 版本控制;
不同系统/厂商 WebView 兼容性。
要彻底消除老资源顽固缓存,必须让服务器、前端、客户端配置形成闭环。
调试工具(WebDebugX、Charles、Logcat)可以帮助我们还原资源加载链条,但核心是对缓存机制的整体认知与各端的配合。
来源:juejin.cn/post/7522187483762966579
用 Tauri + FFmpeg + Whisper.cpp 从零打造本地字幕生成器
背景:
最近开始尝试做自媒体,录点视频。刚开始就遇到了字幕的问题,于是想先搞个字幕生成工具(为了这点醋才包的这顿饺子😄):SubGen。
这个工具用 Tauri + Rust 做外壳,把 FFmpeg 和 Whisper.cpp 集成进去,能一键把视频转成 SRT 字幕。
这篇文章记录下笔者做这个工具的过程,也分享下用到的核心组件和代码结构。
架构设计
SubGen 采用分层架构,核心组件的交互关系如下:
┌─────────────┐ ┌──────────────┐
│ React UI │ │ Rust Core │
│ (TypeScript)│ <----> │ (Tauri API) │
└─────────────┘ └─────┬────────┘
│
┌─────────────┴───────────────┐
│ │
┌────▼────┐ ┌────▼────┐
│ FFmpeg │ │Whisper │
│ 提取音频 │ │ 离线识别 │
└─────────┘ └─────────┘
为什么用 Tauri?
最开始笔者也考虑过 Electron,但它打包太大了(动辄 100MB 起步),而且资源占用高。后来发现 Tauri,它用 Rust 做后端,前端还是用 React 或者任意 Web 技术,这样:
- 打包后体积很小(十几 MB)。
- 跨平台方便(Windows / macOS / Linux)。
- Rust 调用本地二进制(FFmpeg 和 Whisper)非常顺手。
笔者主要是用 React + TypeScript 写了一个简单的 UI,用户选视频、点按钮,剩下的活就交给 Rust。
FFmpeg:用它来“扒”音频
FFmpeg 是老牌的音视频处理工具了,笔者直接内置了一个编译好的 ffmpeg.exe/ffmpeg 到资源目录,调用它来:
- 从视频里抽出音频。
- 统一格式(16kHz,单声道 WAV),让 Whisper 可以直接处理。
Rust 这边的调用很简单:
use std::process::Command;
Command::new("resources/ffmpeg")
.args(["-i", &video_path, "-ar", "16000", "-ac", "1", "audio.wav"])
.status()
.expect("FFmpeg 执行失败");
这样一行命令就能把视频转成标准 WAV。
Whisper.cpp:核心的离线识别
笔者选的是 Whisper.cpp,因为它比 Python 版 Whisper 更轻量,直接编译一个 whisper-cli 就能用,不需要装乱七八糟的依赖。
更重要的一点是支持CPU运行,默认4个线程,即使用 ggml-large-v3 也可以跑出来结果,只是稍微慢点。这对于没有好的显卡的童鞋很有用!
调用命令大概是这样:
whisper-cli -m ggml-small.bin -f audio.wav -osrt -otxt
最后会输出一个 output.srt,直接能用。
Rust 里调用也是 Command::new() 一把梭:
Command::new("resources/whisper-cli")
.args(["-m", "resources/models/ggml-small.bin", "-f", "audio.wav", "-l", "zh", "--output-srt"])
.status()
.expect("Whisper 执行失败");
代码结构和流程
笔者的项目大概是这样分层的:
subgen/
├── src/ # 前端 React + TypeScript
│ └── main.tsx # UI入口
├── src-tauri/ # Tauri + Rust
│ ├── commands.rs # Rust命令逻辑
│ ├── resources/ # ffmpeg、whisper二进制、模型文件
│ └── main.rs # 程序入口
前端用 @tauri-apps/api 的 invoke 调 Rust:
import { invoke } from '@tauri-apps/api';
async function handleGenerate(videoPath: string) {
const result = await invoke<string>('extract_subtitles', { videoPath });
console.log('字幕生成完成:', result);
}
Rust 后端的核心命令:
#[tauri::command]
fn extract_subtitles(video_path: String) -> Result<String, String> {
// 1. 调 FFmpeg
// 2. 调 Whisper.cpp
// 3. 返回 SRT 路径
Ok("output.srt".to_string())
}
用下来的感受
整个工具现在已经能做到“拖进视频 → 等几十秒 → 出字幕”这种体验了。
几个感受:
- Tauri 真香:比 Electron 清爽太多,Rust 后端很适合做这些底层调用。
- FFmpeg 是万能的,直接抽音频,性能还不错。
- Whisper.cpp 虽然 CPU 跑慢点,但好在准确率挺高,还不用联网。
后续想做的事
- 支持批量处理视频。
- 集成一个简单的字幕编辑功能。
- 尝试 GPU 加速 Whisper(Metal / Vulkan)。
截图
主界面:
生成的 SRT:

如果你也想做个自己的字幕工具,可以直接参考 SubGen 的架构,自己改改就能用。
代码已开源:github.com/byteroycai/…
来源:juejin.cn/post/7528457291697012774
jwt,过滤器,拦截器用法和介绍
jwt,过滤器,拦截器介绍
JWT令牌
JWT介绍
JWT全称 JSON Web Token 。
jwt可以将原始的json数据格式进行安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT全称 JSON Web Token 。
jwt可以将原始的json数据格式进行安全的封装,这样就可以直接基于jwt在通信双方安全的进行信息传输了。
JWT的组成
JWT令牌由三个部分组成,三个部分之间使用英文的点来分割
- 第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{"alg":"HS256","type":"JWT"}
- 第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{"id":"1","username":"Tom"}
- 第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
JWT令牌由三个部分组成,三个部分之间使用英文的点来分割
- 第一部分:Header(头), 记录令牌类型、签名算法等。 例如:{"alg":"HS256","type":"JWT"}
- 第二部分:Payload(有效载荷),携带一些自定义信息、默认信息等。 例如:{"id":"1","username":"Tom"}
- 第三部分:Signature(签名),防止Token被篡改、确保安全性。将header、payload,并加入指定秘钥,通过指定签名算法计算而来。
JWT将原始的JSON格式数据转变为字符串的方式:
- 其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
- Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
- 需要注意的是Base64是编码方式,而不是加密方式。
- 其实在生成JWT令牌时,会对JSON格式的数据进行一次编码:进行base64编码
- Base64:是一种基于64个可打印的字符来表示二进制数据的编码方式。既然能编码,那也就意味着也能解码。所使用的64个字符分别是A到Z、a到z、 0- 9,一个加号,一个斜杠,加起来就是64个字符。任何数据经过base64编码之后,最终就会通过这64个字符来表示。当然还有一个符号,那就是等号。等号它是一个补位的符号
- 需要注意的是Base64是编码方式,而不是加密方式。
生成和校验
1.要想使用JWT令牌,需要先引入JWT的依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验。
2.生成JWT代码实现:
@Test
public void testGenJwt() {
Map<String, Object> claims = new HashMap<>();
claims.put("id", 10);
claims.put("username", "itheima");
String jwt = Jwts.builder().signWith(SignatureAlgorithm.HS256, "aXRjYXN0")
.addClaims(claims)
.setExpiration(new Date(System.currentTimeMillis() + 12 * 3600 * 1000))
.compact();
System.out.println(jwt);
}
- 实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
@Test
public void testParseJwt() {
Claims claims = Jwts.parser().setSigningKey("aXRjYXN0")
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTcwMTkwOTAxNX0.N-MD6DmoeIIY5lB5z73UFLN9u7veppx1K5_N_jS9Yko")
.getBody();
System.out.println(claims);
}
1.要想使用JWT令牌,需要先引入JWT的依赖:
<dependency>
<groupId>io.jsonwebtokengroupId>
<artifactId>jjwtartifactId>
<version>0.9.1version>
dependency>
引入完JWT来赖后,就可以调用工具包中提供的API来完成JWT令牌的生成和校验。
2.生成JWT代码实现:
@Test
public void testGenJwt() {
Map<String, Object> claims = new HashMap<>();
claims.put("id", 10);
claims.put("username", "itheima");
String jwt = Jwts.builder().signWith(SignatureAlgorithm.HS256, "aXRjYXN0")
.addClaims(claims)
.setExpiration(new Date(System.currentTimeMillis() + 12 * 3600 * 1000))
.compact();
System.out.println(jwt);
}
- 实现了JWT令牌的生成,下面我们接着使用Java代码来校验JWT令牌(解析生成的令牌):
@Test
public void testParseJwt() {
Claims claims = Jwts.parser().setSigningKey("aXRjYXN0")
.parseClaimsJws("eyJhbGciOiJIUzI1NiJ9.eyJpZCI6MTAsInVzZXJuYW1lIjoiaXRoZWltYSIsImV4cCI6MTcwMTkwOTAxNX0.N-MD6DmoeIIY5lB5z73UFLN9u7veppx1K5_N_jS9Yko")
.getBody();
System.out.println(claims);
}
篡改令牌中的任何一个字符,在对令牌进行解析时都会报错,所以JWT令牌是非常安全可靠的。
JWT令牌过期后,令牌就失效了,解析的为非法令牌。
过滤器Filter
Filter介绍
- Filter表示过滤器,是 JavaWeb三大组件(Servlet、Filter、Listener)之一。
- 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
- 过滤器一般完成一些通用的操作,比如:登录校验、统一编码处理、敏感字符处理等。
- 使用了过滤器之后,要想访问web服务器上的资源,必须先经过滤器,过滤器处理完毕之后,才可以访问对应的资源。
定义过滤器
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
配置过滤器
在定义完Filter之后,Filter其实并不会生效,还需要完成Filter的配置,Filter的配置非常简单,只需要在Filter类上添加一个注解:@WebFilter,并指定属性urlPatterns,通过这个属性指定过滤器要拦截哪些请求
@WebFilter(urlPatterns = "/*") //配置过滤器要拦截的请求路径( /* 表示拦截浏览器的所有请求 )
public class DemoFilter implements Filter {
//初始化方法, web服务器启动, 创建Filter实例时调用, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init ...");
}
//拦截到请求时,调用该方法,可以调用多次
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截到了请求...");
}
//销毁方法, web服务器关闭时调用, 只调用一次
public void destroy() {
System.out.println("destroy ... ");
}
}
在Filter类上面加了@WebFilter注解之后,还需要在启动类上面加上一个注解@ServletComponentScan,通过这个@ServletComponentScan注解来开启SpringBoot项目对于Servlet组件的支持。
@ServletComponentScan //开启对Servlet组件的支持
@SpringBootApplication
public class TliasManagementApplication {
public static void main(String[] args) {
SpringApplication.run(TliasManagementApplication.class, args);
}
}
在过滤器Filter中,如果不执行放行操作,将无法访问后面的资源。 放行操作:chain.doFilter(request, response);
过滤器的执行流程
过滤器当中我们拦截到了请求之后,如果希望继续访问后面的web资源,就要执行放行操作,放行就是调用 FilterChain对象当中的doFilter()方法,在调用doFilter()这个方法之前所编写的代码属于放行之前的逻辑。
测试代码:
@WebFilter(urlPatterns = "/*")
public class DemoFilter implements Filter {
@Override //初始化方法, 只调用一次
public void init(FilterConfig filterConfig) throws ServletException {
System.out.println("init 初始化方法执行了");
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("DemoFilter 放行前逻辑.....");
//放行请求
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("DemoFilter 放行后逻辑.....");
}
@Override //销毁方法, 只调用一次
public void destroy() {
System.out.println("destroy 销毁方法执行了");
}
}
过滤器的拦截路径配置
| 拦截路径 | urlPatterns值 | 含义 |
|---|---|---|
| 拦截具体路径 | /login | 只有访问 /login 路径时,才会被拦截 |
| 目录拦截 | /emps/* | 访问/emps下的所有资源,都会被拦截 |
| 拦截所有 | /* | 访问所有资源,都会被拦截 |
测试代码:
@WebFilter(urlPatterns = "/login") //拦截/login具体路径
public class DemoFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("DemoFilter 放行前逻辑.....");
//放行请求
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("DemoFilter 放行后逻辑.....");
}
@Override
public void init(FilterConfig filterConfig) throws ServletException {
Filter.super.init(filterConfig);
}
@Override
public void destroy() {
Filter.super.destroy();
}
}
过滤器链
过滤器链指的是在一个web应用程序当中,可以配置多个过滤器,多个过滤器就形成了一个过滤器链。
过滤器链上过滤器的执行顺序:注解配置的Filter,优先级是按照过滤器类名(字符串)的自然排序。 比如:
- AbcFilter
- DemoFilter
这两个过滤器来说,AbcFilter 会先执行,DemoFilter会后执行。
拦截器Interceptor
- 拦截器是一种动态拦截方法调用的机制,类似于过滤器。
- 拦截器是Spring框架中提供的,用来动态拦截控制器方法的执行。
- 拦截器的作用:拦截请求,在指定方法调用前后,根据业务需要执行预先设定的代码。
自定义拦截器
实现HandlerInterceptor接口,并重写其所有方法
//自定义拦截器
@Component
public class DemoInterceptor implements HandlerInterceptor {
//目标资源方法执行前执行。 返回true:放行 返回false:不放行
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("preHandle .... ");
return true; //true表示放行
}
//目标资源方法执行后执行
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("postHandle ... ");
}
//视图渲染完毕后执行,最后执行
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("afterCompletion .... ");
}
}
- preHandle方法:目标资源方法执行前执行。 返回true:放行 返回false:不放行
- postHandle方法:目标资源方法执行后执行
- afterCompletion方法:视图渲染完毕后执行,最后执行
注册配置拦截器
在 com.itheima下创建一个包,然后创建一个配置类 WebConfig, 实现 WebMvcConfigurer 接口,并重写 addInterceptors 方法
@Configuration
public class WebConfig implements WebMvcConfigurer {
//自定义的拦截器对象
@Autowired
private DemoInterceptor demoInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(demoInterceptor).addPathPatterns("/**");//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
}
}
拦截器的拦截路径配置
首先我们先来看拦截器的拦截路径的配置,在注册配置拦截器的时候,我们要指定拦截器的拦截路径,通过addPathPatterns("要拦截路径")方法,就可以指定要拦截哪些资源。
在入门程序中我们配置的是/**,表示拦截所有资源,而在配置拦截器时,不仅可以指定要拦截哪些资源,还可以指定不拦截哪些资源,只需要调用excludePathPatterns("不拦截路径")方法,指定哪些资源不需要拦截。
@Configuration
public class WebConfig implements WebMvcConfigurer {
//拦截器对象
@Autowired
private DemoInterceptor demoInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
//注册自定义拦截器对象
registry.addInterceptor(demoInterceptor)
.addPathPatterns("/**")//设置拦截器拦截的请求路径( /** 表示拦截所有请求)
.excludePathPatterns("/login");//设置不拦截的请求路径
}
}
在拦截器中除了可以设置/**拦截所有资源外,还有一些常见拦截路径设置:
| 拦截路径 | 含义 | 举例 |
|---|---|---|
| /* | 一级路径 | 能匹配/depts,/emps,/login,不能匹配 /depts/1 |
| /** | 任意级路径 | 能匹配/depts,/depts/1,/depts/1/2 |
| /depts/* | /depts下的一级路径 | 能匹配/depts/1,不能匹配/depts/1/2,/depts |
| /depts/** | /depts下的任意级路径 | 能匹配/depts,/depts/1,/depts/1/2,不能匹配/emps/1 |
拦截器的执行流程
- 当我们打开浏览器来访问部署在web服务器当中的web应用时,此时我们所定义的过滤器会拦截到这次请求。拦截到这次请求之后,它会先执行放行前的逻辑,然后再执行放行操作。而由于我们当前是基于springboot开发的,所以放行之后是进入到了spring的环境当中,也就是要来访问我们所定义的controller当中的接口方法。
- Tomcat并不识别所编写的Controller程序,但是它识别Servlet程序,所以在Spring的Web环境中提供了一个非常核心的Servlet:DispatcherServlet(前端控制器),所有请求都会先进行到DispatcherServlet,再将请求转给Controller。
- 当我们定义了拦截器后,会在执行Controller的方法之前,请求被拦截器拦截住。执行
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。 - 在controller当中的方法执行完毕之后,再回过来执行
postHandle()这个方法以及afterCompletion() 方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。
preHandle()方法,这个方法执行完成后需要返回一个布尔类型的值,如果返回true,就表示放行本次操作,才会继续访问controller中的方法;如果返回false,则不会放行(controller中的方法也不会执行)。postHandle()这个方法以及afterCompletion() 方法,然后再返回给DispatcherServlet,最终再来执行过滤器当中放行后的这一部分逻辑的逻辑。执行完毕之后,最终给浏览器响应数据。过滤器和拦截器之间的区别:
- 接口规范不同:过滤器需要实现Filter接口,而拦截器需要实现HandlerInterceptor接口。
- 拦截范围不同:过滤器Filter会拦截所有的资源,而Interceptor只会拦截Spring环境中的资源。
作者:丧心病狂汤姆猫
来源:juejin.cn/post/7527869985345339392
来源:juejin.cn/post/7527869985345339392
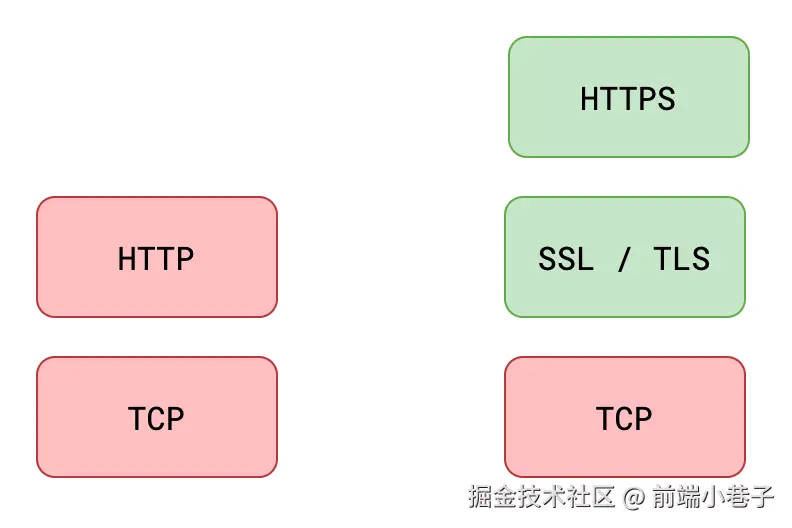
从HTTP到HTTPS
当你在浏览器里输入 http://www.example.com 并按下回车,看似平平无奇的一次访问,其实暗藏着 SSL/TLS 的三次握手、对称与非对称加密的轮番上阵、CA 证书的“身份核验”以及防中间人攻击的多重机关。
一、SSL、TLS、HTTPS 到底是什么关系?
- SSL(Secure Sockets Layer):早期网景公司设计的加密协议,1999 年后停止更新。
- TLS(Transport Layer Security):SSL 的直系升级版,目前主流版本为 TLS 1.2/1.3。
- HTTPS:把 HTTP 报文塞进 TLS 的“安全信封”里,再交给 TCP 传输。简而言之,HTTPS = HTTP + TLS/SSL。
二、HTTPS 握手
- ClientHello
浏览器把支持的加密套件、随机数 A、TLS 版本号一起发给服务器。 - ServerHello + 证书
服务器挑一套加密算法,返回随机数 B,并附上自己的数字证书(含公钥)。 - 验证证书 + 生成会话密钥
浏览器先给证书“验明正身”——颁发机构是否可信、证书是否被吊销、域名是否匹配。
验证通过后,浏览器生成随机数 C(Pre-Master-Secret),用服务器证书里的公钥加密后发送。双方根据 A、B、C 算出同一把对称密钥。 - Finished
双方都用这把对称密钥加密一条“Finished”消息互发,握手完成。之后的所有 HTTP 数据都用这把对称密钥加解密,速度快、强度高。
三、为什么必须有 CA?
没有 CA,任何人都可以伪造公钥,中间人攻击将防不胜防。CA 通过可信第三方背书,把“公钥属于谁”这件事写死在证书里,浏览器才能放心地相信“这就是真正的服务器”。
四、证书到底怎么防伪?
证书 = 域名 + 公钥 + 有效期 + CA 数字签名。
CA(Certificate Authority)用自己的私钥对整个证书做哈希签名。浏览器内置 CA 公钥,可解密签名并对比哈希值,一旦被篡改就立即报警。
没有 CA 签名的自签证书?浏览器会毫不留情地显示“红色警告”。
五、对称与非对称加密的分工
- 非对称加密(RSA/ECC):只在握手阶段用一次,解决“如何安全地交换对称密钥”。
- 对称加密(AES/ChaCha20):握手完成后,所有 HTTP 报文都用对称密钥加解密,性能高、延迟低。
一句话:非对称加密“送钥匙”,对称加密“锁大门”。
六、中间人攻击的两张面孔
- SSL 劫持
攻击者伪造证书、偷梁换柱。浏览器会提示证书错误,但不少用户习惯性点击“继续访问”,于是流量被窃听。 - SSL 剥离
攻击者把用户的 HTTPS 请求降级成 HTTP,服务器以为在加密,客户端却在明文裸奔。HSTS(HTTP Strict Transport Security)能强制浏览器只走 HTTPS,遏制这种降级。
总结
- 证书是身-份-证,CA 是公安局。
- 非对称握手送钥匙,对称加密跑数据。
- 没有 CA 的 HTTPS,就像没有钢印的合同——谁都能伪造。
下次当你在地址栏看到那把绿色小锁时,背后是一场涉及四次握手、两把密钥、一张证书和全球信任链的加密大戏。
来源:juejin.cn/post/7527578862054899754
掌握 requestFullscreen:网页全屏功能的实用指南与技巧
想让网页上的图片、视频或者整个界面铺满用户屏幕?浏览器的 requestFullscreen api 是开发者实现这个功能的关键。
它比你想象的要强大,但也藏着一些需要注意的细节。本文将详细介绍如何正确使用它,并分享一些提升用户体验的实用技巧。
一、 开始使用 requestFullscreen:基础与常见问题
直接调用 element.requestFullscreen() 是最简单的方法,但有几个关键点容易出错:
并非所有元素都能直接全屏:
、 等媒体元素通常可以直接全屏。
浏览器兼容性问题:
老版本浏览器(特别是 Safari)需要使用带前缀的方法 webkitRequestFullscreen。安全起见,最好检测并调用正确的方法。
必须在用户操作中触发:
浏览器出于安全考虑,要求全屏请求必须在用户点击、触摸等交互事件(如 click、touchstart)的处理函数里直接调用。不能放在 setTimeout 或者异步回调里直接调用,否则会被浏览器阻止。
二、 控制全屏时的样式
全屏状态下,你可以使用特殊的 css 选择器为全屏元素或其内部的元素定制样式:
/* 为处于全屏状态的 <video> 元素设置黑色背景 */
video:fullscreen {
background-color: #000;
}
/* 当某个具有 id="controls" 的元素在全屏模式下时,默认半透明,鼠标移上去变清晰 */
#controls:fullscreen {
opacity: 0.3;
transition: opacity 0.3s ease;
}
#controls:fullscreen:hover {
opacity: 1;
}
:-webkit-full-screen (WebKit 前缀) : 针对老版本 WebKit 内核浏览器(如旧 Safari)
:fullscreen (标准) : 现代浏览器支持的标准写法。优先使用这个。
三、 实用的进阶技巧
在多个元素间切换全屏:
创建一个管理器能方便地在不同元素(如图库中的图片)之间切换全屏状态,并记住当前全屏的是哪个元素。
const fullscreenManager = {
currentElement: null, // 记录当前全屏的元素
async toggle(element) {
// 如果点击的元素已经是全屏元素,则退出全屏
if (document.fullscreenElement && this.currentElement === element) {
try {
awaitdocument.exitFullscreen();
this.currentElement = null;
} catch (error) {
console.error('退出全屏失败:', error);
}
} else {
// 否则,尝试让新元素进入全屏
try {
await element.requestFullscreen();
this.currentElement = element; // 更新当前元素
} catch (error) {
console.error('进入全屏失败:', error);
// 可以在这里提供一个后备方案,比如模拟全屏的CSS类
element.classList.add('simulated-fullscreen');
}
}
}
};
// 给图库中所有图片绑定点击事件
document.querySelectorAll('.gallery-img').forEach(img => {
img.addEventListener('click', () => fullscreenManager.toggle(img));
});
在全屏模式下处理键盘事件:
全屏时,你可能想添加自定义快捷键(如切换滤镜、截图)。
functionhandleFullscreenHotkeys(event) {
// 保留 Escape 键退出全屏的功能
if (event.key === 'Escape') return;
// 自定义快捷键
if (event.key === 'f') toggleFilter(); // 按 F 切换滤镜
if (event.ctrlKey && event.key === 'p') enterPictureInPicture(); // Ctrl+P 画中画
if (event.shiftKey && event.key === 's') captureScreenshot(); // Shift+S 截图
// 阻止这些键的默认行为(比如防止F键触发浏览器查找)
event.preventDefault();
}
// 监听全屏状态变化
document.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement) {
// 进入全屏,添加自定义键盘监听
document.addEventListener('keydown', handleFullscreenHotkeys);
} else {
// 退出全屏,移除自定义键盘监听
document.removeEventListener('keydown', handleFullscreenHotkeys);
}
});
记住用户的全屏状态:
如果用户刷新页面,可以尝试自动恢复他们之前全屏查看的元素。
// 页面加载完成后检查是否需要恢复全屏
window.addEventListener('domContentLoaded', () => {
const elementId = localStorage.getItem('fullscreenElementId');
if (elementId) {
const element = document.getElementById(elementId);
if (element) {
setTimeout(() => element.requestFullscreen().catch(console.error), 100); // 稍延迟确保元素就绪
}
}
});
// 监听全屏变化,保存当前全屏元素的ID
document.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement) {
localStorage.setItem('fullscreenElementId', document.fullscreenElement.id);
} else {
localStorage.removeItem('fullscreenElementId');
}
});
处理嵌套全屏(沙盒内全屏):
在已经全屏的容器内的 中再次触发全屏是可能的(需要 allow="fullscreen" 属性)。
<divid="main-container">
<iframeid="nested-content"src="inner.html"allow="fullscreen"></iframe>
</div>
<script>
const mainContainer = document.getElementById('main-container');
const iframe = document.getElementById('nested-content');
// 主容器全屏后,可以尝试触发iframe内部元素的全屏(需内部配合)
mainContainer.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement === mainContainer) {
// 假设iframe内部有一个id为'innerVideo'的视频元素
// 注意:这需要在iframe加载完成后,且iframe内容同源或允许跨域操作
const innerDoc = iframe.contentDocument || iframe.contentWindow.document;
const innerVideo = innerDoc.getElementById('innerVideo');
if (innerVideo) {
setTimeout(() => innerVideo.requestFullscreen().catch(console.error), 500);
}
}
});
</script>
四、 实际应用场景
媒体展示: 图片画廊、视频播放器(隐藏浏览器UI获得更好沉浸感 { navigationUI: 'hide' })。
数据密集型应用: 全屏表格、图表或数据看板,提供更大的工作空间。
游戏与交互: WebGL 游戏、交互式动画、全景图查看器(结合陀螺仪 API),全屏能提升性能和体验。
演示模式: 在线文档、幻灯片展示。
专注模式: 写作工具、代码编辑器。
安全措施: 在全屏内容上添加低透明度水印(使用 ::before / ::after 伪元素),增加录屏难度。
五、 开发者需要注意的问题与解决建议
| 问题描述 | 解决方案 |
|---|---|
| iOS Safari 全屏视频行为 | 为 添加 playsinline 属性防止自动横屏。提供手动旋转按钮。 |
| 全屏导致滚动位置丢失 | 进入全屏前记录 scrollTop,退出后恢复。或使用 scroll-snap 等布局技术。 |
| 全屏触发页面重排/抖动 | 提前给目标元素设置 width: 100%; height: 100%; 或固定尺寸。 |
| 全屏时难以打开开发者工具 | 在开发环境,避免拦截 F12 或右键菜单快捷键。使用 console 调试。 |
| 全屏元素内 iframe 权限 | 为 添加 allow="fullscreen" 属性。 |
| 检测用户手动全屏 (F11) | 比较 window.outerHeight 和 screen.height 有一定参考价值,但非绝对可靠。通常建议引导用户使用应用内的全屏按钮。 |
六、 兼容性处理封装(推荐使用)
下面是一个更健壮的工具函数,处理了不同浏览器的前缀问题:
/**
* 全屏工具类 (简化版,展示核心功能)
*/
const FullscreenHelper = {
/**
* 请求元素进入全屏模式
* @param {HTMLElement} [element=document.documentElement] 要全屏的元素,默认是整个页面
* @returns {Promise<boolean>} 是否成功进入全屏
*/
async enter(element = document.documentElement) {
const reqMethods = [
'requestFullscreen', // 标准
'webkitRequestFullscreen', // Safari, Old Chrome/Edge
'mozRequestFullScreen', // Firefox
'msRequestFullscreen'// Old IE/Edge
];
for (const method of reqMethods) {
if (element[method]) {
try {
// 可以传递选项,例如隐藏导航UI: { navigationUI: 'hide' }
await element[method]({ navigationUI: 'hide' });
returntrue; // 成功进入全屏
} catch (error) {
console.warn(`${method} 失败:`, error);
// 继续尝试下一个方法
}
}
}
returnfalse; // 所有方法都失败
},
/**
* 退出全屏模式
* @returns {Promise<boolean>} 是否成功退出全屏
*/
async exit() {
const exitMethods = [
'exitFullscreen', // 标准
'webkitExitFullscreen', // Safari, Old Chrome/Edge
'mozCancelFullScreen', // Firefox
'msExitFullscreen'// Old IE/Edge
];
for (const method of exitMethods) {
if (document[method]) {
try {
awaitdocument[method]();
returntrue; // 成功退出全屏
} catch (error) {
console.warn(`${method} 失败:`, error);
}
}
}
returnfalse; // 所有方法都失败或不在全屏状态
},
/**
* 检查当前是否有元素处于全屏状态
* @returns {boolean} 是否在全屏状态
*/
isFullscreen() {
return !!(
document.fullscreenElement || // 标准
document.webkitFullscreenElement || // Safari, Old Chrome/Edge
document.mozFullScreenElement || // Firefox
document.msFullscreenElement // Old IE/Edge
);
},
/**
* 添加全屏状态变化监听器
* @param {Function} callback 状态变化时触发的回调函数
*/
onChange(callback) {
const events = [
'fullscreenchange', // 标准
'webkitfullscreenchange', // Safari, Old Chrome/Edge
'mozfullscreenchange', // Firefox
'MSFullscreenChange'// Old IE/Edge
];
// 为每种可能的事件添加监听,确保兼容性
events.forEach(eventName => {
document.addEventListener(eventName, callback);
});
}
};
// 使用示例
const myButton = document.getElementById('fullscreen-btn');
const myVideo = document.getElementById('my-video');
myButton.addEventListener('click', async () => {
if (FullscreenHelper.isFullscreen()) {
await FullscreenHelper.exit();
} else {
await FullscreenHelper.enter(myVideo); // 让视频全屏
}
});
// 监听全屏变化
FullscreenHelper.onChange(() => {
console.log('全屏状态变了:', FullscreenHelper.isFullscreen() ? '进入全屏' : '退出全屏');
});
总结
requestFullscreen API 是实现网页元素全屏展示的核心工具。理解其基础用法、兼容性处理、样式控制和状态管理是第一步。
通过掌握切换控制、键盘事件处理、状态持久化和嵌套全屏等进阶技巧,以及规避常见的陷阱,你可以为用户创建更流畅、功能更丰富的全屏体验。
上面的 FullscreenHelper 工具类封装了兼容性细节,推荐在实际项目中使用。现在就去尝试在你的网页中应用这些技巧吧!
来源:juejin.cn/post/7527612394044850227
半数清华,8 位华人 AI 天团集体投奔 Meta!奥特曼:砸钱抢人不如培养死忠

【新智元导读】硅谷挖角戏码升级!相比 Meta3 亿美元「血本挖角」,OpenAI 来了波反向操作——选择培养人才,奥特曼悄然推进一个名为「驻留计划」(Residency Program)的项目。这个项目有何神秘之处?奥特曼的底气到底从何而来?
二十一世纪什么最贵?
人才!
最近几个月,Meta 在硅谷发起的、动辄上亿美元签字费的挖角戏码,成了史上最疯狂的人才争夺战。
不得不说,扎克伯格的「氪金」策略相当成功。
一大批来自 OpenAI、谷歌、Anthropic 甚至是 SSI 的核心研究员纷纷投入 Meta 旗下。

OpenAI 的首席研究官 Mark Chen 难掩失落地说:「这感觉就像有人闯进了我们家,偷走了我们的东西。」
面对这种近乎釜底抽薪似的挖角行为,奥特曼的反应则略显轻蔑:「Meta 的行事方式,让人感觉有些不体面」。
那么,奥特曼的底气来自哪里?
当扎克伯格在牌桌上疯狂加码时,奥特曼在牌桌之下,进行着一场完全不同维度的布局。

不挖天才,我们培养天才
当所有人的目光都聚焦在 Meta 的天价支票上时,OpenAI 正在悄然推进一个名为「驻留计划」(Residency Program)的项目。
这个项目,可以说是 OpenAI 应对人才战争的核心战略,也是理解其企业文化的一把钥匙。

OpenAI Residency 是一个为期六个月的全职带薪项目,但它的招生对象,却出人意料。
Residency 项目经理 Jackie Hehir 明确表示,他们寻找的,不是那些正在攻读机器学习或 AI 博士学位的天之骄子,也不是来自其他 AI 实验室的资深员工。
恰恰相反,他们将橄榄枝伸向了那些「邻近领域」的顶尖大脑——比如物理学家、神经科学家、数学家。

虽然没有严格的学历或工作经验要求,但设有一个极高的技术门槛,尤其是在数学和编程方面,其标准与全职员工等同。
你不需要拥有高等数学学位,但必须对高等数学概念非常自如。
「他们对这个领域(AI)充满了真正的热情,」Hehir 说。

这背后是一套极其精明的逻辑。
这场从零培养的战略,至少带来了三个层面的深远优势。
首先就是成本上的「降维打击」。
驻留研究员的年薪是 21 万美元,意味着在这六个月里,OpenAI 的支出大约是 10.5 万美元。
这个数字,足以让参与者跻身美国收入前 5% 的行列。
但在动辄千万、上亿美元签字费的 AI 顶级人才市场,这简直就是白菜价。
用极小的代价,获得了一批拥有顶级科研素养和巨大潜力的「璞玉」。
其次,是对企业文化基因的深度植入。
面对小扎的疯狂抢人,奥特曼就曾评论道:「在我看来,Meta 的所作所为将导致非常深刻的文化问题」。
而在 OpenAI,一位前员工向 Business Insider 透露,他们公司的内部文化是「对创造 AGI 的使命感到痴迷」。
通过驻留计划,OpenAI 可以在一张白纸上,从一开始就将这种使命感深深烙印在这些未来核心员工的脑海里。
他们共同学习、共同攻关,建立的不仅是工作关系,更是对共同事业的「信仰共同体」。

这与简单地用金钱挖来的雇佣兵有着本质区别。
Meta 用金钱这种最直接的外部激励,虽然见效快,但可能存在边际效应递减的风险,并且容易塑造一种唯利是图的文化。
相比之下,OpenAI 的策略则更侧重于构建内在动机:
通过赋予一个宏大的、改变世界的使命(创造 AGI),它满足了员工对归属感的渴望;
通过从零培养,让跨界人才在新领域找到自己的位置,它满足了「胜任感」的成长需求;
通过相对宽松和专注的科研环境,满足了对自主性的追求。
「传教士将打败雇佣兵」,奥特曼在内部备忘录中,写下了这句提振士气的话。

最后,是极高的忠诚度与****转化率。
数据显示,几乎每一个在驻留计划中表现出色的成员,都会收到 OpenAI 全职 offer。
迄今为止,所有收到 offer 的人都选择了接受。
每年,这个项目会迎来大约 30 名新成员,他们就像新鲜的血液,持续不断地为 OpenAI 提供能量。
OpenAI Residency 的「播种」策略,更像是一场耐心的耕耘。
它可能没法像 Meta 那样立即招到顶尖专家,但却可以培养出一片忠于自己使命、文化高度统一、且具备持续造血能力的「人才森林」。

这场发生在硅谷的人才战争,早已超越了商业竞争的范畴。
它是一场关于组织灵魂、动机和未来信念的宏大实验。
而实验的结果,不仅将决定这两家公司的命运,更将深刻地影响我们正在迈入的 AGI 时代。
最后,让我们再来回顾一下 Meta 这两个月的骚操作。

史上最疯狂人才争夺战
据估计全球有能力推动大语言模型和前沿 AI 研究的顶尖人才,只有区区 2000 人左右。
这场人才争夺战的激烈程度,未来只会不断升级。
Meta 为了 AI 顶尖人才可谓是下了「血本」。
被业内人士调侃为,「竞赛之夏的错失恐惧症(summer of comp FOMO)」。
据统计,Meta 在四年间,为 AI 顶尖人才准备了高达 3 亿美元薪酬方案,创下了行业记录。
那 Meta 这「3 亿美元薪酬」到底招了哪些顶尖人才呢?

2025 年 6 月
核心人物:Alexandr Wang(28 岁)
**背景:**2016 年,19 岁的 Alexandr Wang MIT 辍学与 Lucy Guo 共同创立「数据标注」公司 Scale AI,并于同年获得著名创业孵化器 Y Combinator 启动资金支持。顶级 AI 科技巨头:微软、Meta、OpenAI 等提供模型训练数据。
**押注金:**143 亿美元
**原职位:**Scale AI 创始人
**Meta 新职位:**Meta 首席 AI 智能官(Chief AI Officer),负责新设立的「超级智能」部门

重要性:
1、拥有 AI 核心「数据战火库」:Alexandr Wang 手握 Meta 核心竞争对手微软、OpenAI、谷歌等模型训练数据;
2、天生的商业嗅觉者:在还没有 LLM 时,已洞察到「数据」在 AI 领域的重要性,便在 2016 年创办数据标注公司 Scale AI;
**核心人物:**Shengjia Zhao

背景:清华大学本科,斯坦福大学博士,核心聚焦大语言模型和不确定性量化。领导 OpenAI 合成数据项目,是 ChatGPT、GPT-4 模型及各种小型模型等标志性产品的重要贡献者。
**原职位:**前 OpenAI 研究科学家
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
核心人物:Jiahui Yu

背景:中国科学技术大学少年班的毕业生,曾分别任职于在微软、旷视、Adobe、Snap、百度、英伟达和谷歌等。2023 年 10 月领导 OpenAI 感知团队,主导了 o3、o4-mini 和 GPT-4.1 研发;在谷歌 DeepMind 联合领导 Gemini Multimodal。研究核心聚焦深度学习和高性能算力。
**原职位:**前 OpenAI 项目研究负责人
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
核心人物:Shuchao Bi

背景:毕业于浙江大学数学系,随后在加州大学伯克利分校获得了硕士和博士学位。专注于强化学习、训练后优化和 AI 代理。2013 年入职谷歌,通过深度学习模型优化谷歌广告。2024 年 5 月入职 OpenAI,担任多模态后训练主管,为 GPT-4o 的语音模式和 o4-mini 模型做出了贡献。
**原职位:**前 OpenAI 多模态后训练主管
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
核心人物:Hongyu Ren

背景:2018 年毕业于北京大学,2023 年在斯坦福大学完成计算机科学博士学位。在校期间,他曾在微软、英伟达、谷歌和苹果实习。毕业后他加入 OpenAI,曾参与 o1-mini 和 o3-mini 研发,并领导一个专注于后期训练的团队,o1 项目的核心贡献者。
**原职位:**前 OpenAI 后期训练项目负责人
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
**核心人物:**hang Huiwen

背景:毕业于清华大学交叉信息研究院的姚班(这个精英计算机科学项目由图灵奖得主姚期智创立)。随后在普林斯顿大学取得博士学位,研究方向是图像处理。 曾在 Adobe 和 Facebook 实习,后于 2016 年获得微软奖学金。2019 年谷歌工作一段时间后,于 2023 年 6 月转至 OpenAI,参与开发了 GPT-4o 的高级图像生成功能。
**原职位:**前 OpenAI 研究员
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
**核心人物:**Lin Ji

背景:清华大学本科,2023 年在 MIT 获得博士学位。曾在谷歌、Adobe 和英伟达实习,并于 2023 年 1 月加入 OpenAI,专攻多模态推理和合成数据。
**原职位:**前 OpenAI 研究员
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
核心人物:Sun Pei

背景:清华大学本科,卡内基梅隆大学硕士,2011 年就职谷歌。他短暂加入中国数据基础设施公司 Alluxio 后,于 2017 年转至谷歌的 Waymo 部门。后成为谷歌 DeepMind 的首席研究员,在开发 Gemini 人工智能模型方面发挥了关键作用,特别是在后训练和推理等领域。
**原职位:**前谷歌 DeepMind 的首席研究员
**Meta 新职位:**Meta 超级智能部门,具体职位未透露
核心人物:Lucas Beyer

背景:自称 “自学成才黑客」,前谷歌 DeepMind(原 Brain)苏黎世分部的高级研究科学家,联合领导模态研究工作和代码库项目。与 Xiaohua Zhai 和 Alexander Kolesnikov 创立了苏黎世 OpenAI 办公室。

**原职位:**前谷歌 DeepMind(原 Brain)苏黎世分部的高级研究科学家,苏黎世 OpenAI 办公室创始人。
**Meta 新职位:**Meta 超级智能部门研究员,具体职位未透露
核心人物:Alexander Kolesnikov
背景:曾任谷歌「Google Brain」高级研究工程师,「Deepmind」研究科学家。OpenAI 研究员。


**原职位:**前 OpenAI 苏黎世办公室研究员
**Meta 新职位:**Meta 超级智能部门研究员,具体职位未透露

2025 年 7 月
核心人物:Daniel Gross(左一)
背景:「安全超级智能」SSI 三位联创之一(其余两位:Ilya Sutskever、Daniel Levy)。曾试图以 320 亿美元收购 Safe Superintelligence,被拒后反手挖走其联合创始人之一 Daniel Gross。

7 月 3 日,「消失已久」Ilya 罕见现身发文,确认了 Daniel Gross「出局」消息,Daniel Gross 也转发了该条推文。

原职位:「安全超级智能」SSI 联合创始人,OpenAI 前首席科学家
**Meta 新职位:**领导 Meta 超级智能产品部门
**重要性:**与 Nat Friedman 共同创立一家名叫「NFDG」的风险投资公司,该公司已投资了 Coinbase、Figma、CoreWeave、Perplexity 和 Character.ai。
核心人物:Nat Friedman

**背景:**MIT 毕业,Github 前 CEO(2018-2021), 曾任 GNOME 基金会的主席,目前还是 Arc 研究所的董事会成员,并担任 Midjourney 的顾问。

**原职位:**前 Github CEO
Meta 新职位:「与 Alex 合作领导」超级智能团队
**重要性:**辅佐「军师」协助小孩哥 Alexandr Wang 共同领导超级智能团队。
参考资料:
来源:juejin.cn/post/7523519254878437403
马斯克 Neuralink 脑机接口新成果!看完头皮发麻
注意看,这些人正在用意念玩马里奥赛车。
他们的手没有动一下,靠脑电波控制就完成了移动、转弯、吃道具等一系列动作。
帮助他们通过 “心灵感应” 完成游戏操作的,就是马斯克 Neuralink 的脑机接口 N1。

这就是 Neuralink 夏季更新报告会上,马斯克展示的最新成果。
截止目前,N1 已经有七名受试者,他们以视频等形式分享了脑机接口对他们生活的改变。

这一个个真实案例,也获得了网友们的一片赞许。

同时,在这次报告会上,Neuralink 也曝光了未来三年的发展路线——
到 2028 年,Neuralink 计划实现对大脑的全面访问。
让受试者重回生活
这七位受试者当中,有四位是脊髓损伤患者,另外三位是肌萎缩侧索硬化症(渐冻症)患者。
他们接受测试的地点不是在实验室,而是每天在家中使用 Neuralink 脑机接口设备,据统计,他们平均每周使用脑机接口的时间长达 50 小时,峰值甚至超过 100 小时,几乎覆盖了所有的清醒时间。

其中,Noland 是全球第一位 N1 受试者,他因为脊髓损伤瘫痪。
Noland 装上 N1 之后当天,就学会了完全靠意念控制电脑光标,并打破了世界纪录。

现在,Noland 已经学会了仅凭意念畅玩《马里奥赛车》,甚至还能与其他参与者联机玩《使命召唤》等更复杂的游戏。

除了游戏之外,Noland 还在 N1 的帮助下,正在重新学习语言和数学。
同样是脊髓受损的,还有 Alex,他因此失去了手部功能。
但有了 N1,他已经学会了通过意念控制电脑屏幕上的手,和家人玩 “石头剪刀布” 游戏。

而且不仅能控制屏幕上的虚拟影像,还可以操纵特斯拉擎天柱机器人的机械手。

更重要的是,N1 已经帮助 Alex 重新回到工作,通过意念操作 CAD 软件完成设计。
如前所述,N1 的受益者除了脊髓损伤患者,还有渐冻症人士,Bard 是首个植入 N1 的渐冻症患者。
因为渐冻症,Bard 失去了语言能力,只能借助眼动追踪技术来和外界交流。
但现在,他已经可以用思想控制电脑,从而与世界交流,甚至和他的孩子们一起到公园玩耍。

目标是实现 “全脑接口”
此次报告会上,Neuralink 透露其最终目标,是构建一个真正的 “全脑接口”。
顾名思义,“全脑接口” 就是一个能够向任意神经元读取、写入、传输信息的通用平台。
具体来说,其产品路线图中包含了 Telepathy、Blindsight、Deep 三个组成部分。

七名受试者使用的 N1,就是 Telepathy。
Telepathy 通过将 1000 个电极植入运动皮层中负责手部和手臂运动的区域来工作,目的就是帮助因脊髓损伤、渐冻症、中风等导致无法自主控制身体的人士,能够仅凭思想来实现控制电脑、操作鼠标等动作。
Blindsight 则是 Neuralink 的下一个产品,旨在帮助完全失明的人(包括天生失明、失去眼睛或视神经的人)恢复视力。
Blindsight 会通过摄像头捕捉环境场景,然后转换成电信号,传递到植入在视觉皮层的设备中,从而在大脑中产生视觉感知。
最后的 “Deep”,不是一个独立的产品名称,而是指 Neuralink 技术能够深入大脑更深层区域的能力,以及这种能力带来的应用。
这一层次旨在通过将电极插入皮层(cortical layer)以及更深层的脑区,例如脑沟(sulci)和边缘系统(limbic system),来治疗神经系统失调、精神疾病或神经性疼痛。

同时,Neuralink 也公布了未来三年的具体发展计划。
今年下半年,Neuralink 计划在言语皮层(speech cortex)进行植入,从而将大脑中的信息解码为语言。
明年,通道的数量将从 1000 个增加到 3000 个,同时 Neuralink 还计划进行首次 Blindsight 植入。
这次植入,也将成为 Neuralink 验证其向大脑中写入信息能力的关键机会。
到 2027 年,通道数量将继续增加至 10000 个,同时首次实现多植入物操作,即在运动皮层、言语皮层和视觉皮层等多个脑区同时进行植入。
最终的 2028 年,每个植入物拥有超过 25000 个通道,结合多植入物操作,能够实现对大脑的任何部分的访问,从而用于治疗精神疾病、疼痛以及其他神经功能失调。
届时,Neuralink 还将进行脑机接口与 AI 的整合。

参考链接:
http://www.youtube.com/watch?v=FAS…
欢迎在评论区留下你的想法!
— 完 —
来源:juejin.cn/post/7521376266110091298
40岁老前端2025年上半年都学了什么?
前端学习记录第5波,每半年一次。对前四次学习内容感兴趣的可以去我的掘金专栏“每周学习记录”进行了解。
第1周 12.30-1.5
本周学习了一个新的CSS媒体查询prefers-reduced-transparency,如果用户在系统层面选择了降低或不使用半透明,这个媒体查询就能够匹配,此特性与用户体验密切相关的。

更多内容参见我撰写的这篇文章:一个新的CSS媒体查询prefers-reduced-transparency —— http://www.zhangxinxu.com/wordpress/?…
第2周 1.6-1.12
这周新学习了一个名为Broadcast Channel的API,可以实现一种全新的广播式的跨页面通信。
过去的postMessage通信适合点对点,但是广播式的就比较麻烦。
而使用BroadcastChannel就会简单很多。
这里有个演示页面:http://www.zhangxinxu.com/study/20250…
左侧点击按钮发送消息,右侧两个内嵌的iframe页面就能接收到。

此API的兼容性还是很不错的:

更多内容可以参阅此文:“Broadcast Channel API简介,可实现Web页面广播通信” —— http://www.zhangxinxu.com/wordpress/?…
第3周 1.13-1.19
这周学习的是SVG半圆弧语法,因为有个需求是实现下图所示的图形效果,其中几段圆弧的长度占比每个人是不一样的,因此,需要手写SVG路径。

圆弧的SVG指令是A,语法如下:
M x1 y1 A rx ry x-axis-rotation large-arc-flag sweep-flag x2 y2
看起来很复杂,其实深究下来还好:

详见这篇文章:“如何手搓SVG半圆弧,手把手教程” - http://www.zhangxinxu.com/wordpress/?…
第4周-第5周 1.20-2.2
春节假期,学什么学,high起来。
第6周 2.3-2.9
本周学习Array数组新增的with等方法,这些方法在数组处理的同时均不会改变原数组内容,这在Vue、React等开发场景中颇为受用。
例如,在过去,想要不改变原数组改变数组项,需要先复制一下数组:

现在有了with方法,一步到位:

类似的方法还有toReversed()、toSorted()和toSpliced()。
更新内容参见这篇文章:“JS Array数组新的with方法,你知道作用吗?” - http://www.zhangxinxu.com/wordpress/?…
第7周 2.10-2.16
本周学习了两个前端新特性,一个JS的,一个是CSS的。
1. Set新增方法
JS Set新支持了intersection, union, difference等方法,可以实现类似交集,合集,差集的数据处理,也支持isDisjointFrom()是否相交,isSubsetOf()是否被包含,isSupersetOf()是否包含的判断。
详见此文:“JS Set新支持了intersection, union, difference等方法” - http://www.zhangxinxu.com/wordpress/?…

2. font-size-adjust属性
CSS font-size-adjust属性,可以基于当前字形的高宽自动调整字号大小,以便各种字体的字形表现一致,其解决的是一个比较细节的应用场景。
例如,16px的苹方和楷体,虽然字号设置一致,但最终的图形表现楷体的字形大小明显小了一圈:

此时,我们可以使用font-size-adjust进行微调,使细节完美。
p { font-size-adjust: 0.545;}
此时的中英文排版效果就会是这样:

更新细节知识参见我的这篇文章:“不要搞混了,不是text而是CSS font-size-adjust属性” - http://www.zhangxinxu.com/wordpress/?…
第8周 2.17-2.23
本周学习的是HTML permission元素和Permissions API。
这两个都是与Web浏览器的权限申请相关的。
在Web开发的时候,我们会经常用到权限申请,比方说摄像头,访问相册,是否允许通知,又或者地理位置信息等。

但是,如果用户不小心点击了“拒绝”,那么用户就永远没法使用这个权限,这其实是有问题的,于是就有了元素,权限按钮直接暴露在网页中,直接让用户点击就好了。

但是,根据我后来的测试,Chrome浏览器放弃了对元素的支持,因此,此特性大家无需关注。
那Permissions API又是干嘛用的呢?
在过去,不同类型的权限申请会使用各自专门的API去进行,这就会导致开始使用的学习和使用成本比较高。
既然都是权限申请,且系统出现的提示UI都近似,何必来个大统一呢?在这种背景下,Permissions API被提出来了。
所有的权限申请全都使用一个统一的API名称入口,使用的方法是Permissions.query()。

完整的介绍可以参见我撰写的这篇文章:“HTML permission元素和Permissions API简介” - http://www.zhangxinxu.com/wordpress/?…
第9周 2.24-3.2
CSS offset-path属性其实在8年前就介绍过了,参见:“使用CSS offset-path让元素沿着不规则路径运动” - http://www.zhangxinxu.com/wordpress/?…
不过那个时候的offset-path属性只支持不规则路径,也就是path()函数,很多CSS关键字,还有基本形状是不支持的。
终于,盼星星盼月亮。
从Safari 18开始,CSS offset-path属性所有现代浏览器全面支持了。

因此,很多各类炫酷的路径动画效果就能轻松实现了。例如下图的蚂蚁转圈圈动画:

详见我撰写的此文:“终于等到了,CSS offset-path全浏览器全支持” - http://www.zhangxinxu.com/wordpress/?…
第10周 3.3-3.9
CSS @supports规则新增两个特性判断,分别是font-tech()和font-format()函数。
1. font-tech()
font-tech()函数可以检查浏览器是否支持用于布局和渲染的指定字体技术。
例如,下面这段CSS代码可以判断浏览器是否支持COLRv1字体(一种彩色字体技术)技术。
@supports font-tech(color-COLRv1) {}
2. font-format()
font-format()这个比较好理解,是检测浏览器是否支持指定的字体格式的。
@supports font-format(woff2) { /* 浏览器支持woff2字体 */ }
不过这两个特性都不实用。
font-tech()对于中文场景就是鸡肋特性,因为中文字体是不会使用这类技术的,成本太高。
font-format()函数的问题在于出现得太晚了。例如woff2字体的检测,这个所有现代浏览器都已经支持了,还有检测的必要吗,没了,没有意义了。
不过基于衍生的特性还是有应用场景的,具体参见此文:“CSS supports规则又新增font-tech,font-format判断” - http://www.zhangxinxu.com/wordpress/?…
第11周 3.10-3.16
本周学习了一种更好的文字隐藏的方法,那就是使用::first-line伪元素,CSS世界这本书有介绍。
::first-line伪元素可以在不改变元素color上下文的情况下变色。
可以让按钮隐藏文字的时候,里面的图标依然保持和原本的文字颜色一致。

详见这篇文章:“一种更好的文字隐藏的方法-::first-line伪元素” - http://www.zhangxinxu.com/wordpress/?…
第12周 3.17-3.23
本周学习了下attachInternals方法,这个方法很有意思,给任意自定义元素使用,可以让普通元素也有原生表单控件元素一样的特性。
比如浏览器自带的验证提示:

比如说提交的时候的FormData或者查询字符串:

有兴趣的同学可以访问“研究下attachInternals方法,可让普通元素有表单特性”这篇文章继续了解 - http://www.zhangxinxu.com/wordpress/?…
第13周 3.24-3.30
本周学习了一个新支持的HTML属性,名为blocking 属性。
它主要用于控制资源加载时对渲染的阻塞行为。
blocking 属性允许开发者对资源加载的优先级和时机进行精细控制,从而影响页面的渲染流程。浏览器在解析 HTML 文档时,会根据 blocking 属性的值来决定是否等待资源加载完成后再继续渲染页面,这对于优化页面性能和提升用户体验至关重要。
blocking 属性目前支持的HTML元素包括
使用示意:

更多内容参见我撰写的这篇文章:“光速了解script style link元素新增的blocking属性” - http://www.zhangxinxu.com/wordpress/?…
第14周 3.31-4.6
本周学习了JS EditContext API。
EditContext API 是 Microsoft Edge 浏览器提供的一个 Web API,它允许开发者在网页中处理文本输入事件,以便在原生输入事件(如 keydown、keypress 和 input)之外,实现更高级的文本编辑功能。

详见我撰写的这篇文章:“JS EditContext API 简介” - http://www.zhangxinxu.com/wordpress/?…
第15周 4.7-4.13
本周学习一个DOM新特性,名为caretPositionFromPoint API。
caretPositionFromPoint可以基于当前的光标位置,返回光标所对应元素的位置信息,在之前,此特性使用的是非标准的caretRangeFromPoint方法实现的。
和elementsFromPoint()方法的区别在于,前者返回节点及其偏移、尺寸等信息,而后者返回元素。
比方说有一段
元素文字描述信息,点击这段描述的某个文字,caretPositionFromPoint()方法可以返回精确的文本节点以及点击位置的字符偏移值,而elementsFromPoint()方法只能返回当前
元素。
不过此方法的应用场景比较小众,例如点击分词断句这种,大家了解下即可。

详见我撰写的这篇文章:“DOM新特性之caretPositionFromPoint API” - http://www.zhangxinxu.com/wordpress/?…
第16周 4.14-4.20
本周学习的是getHTML(), setHTMLUnsafe()和parseHTMLUnsafe()这三个方法,有点类似于可读写的innerHTML属性,区别在于setHTMLUnsafe()似乎对Shadow DOM元素的设置更加友好。
parseHTMLUnsafe则是个document全局方法,用来解析HTML字符串的。
这几个方法几乎是同一时间支持的,如下截图所示:

具体参见我写的这篇文章:介绍两个DOM新方法setHTMLUnsafe和getHTML - http://www.zhangxinxu.com/wordpress/?…
第17周 4.21-4.27
光速了解HTML shadowrootmode属性的作用。
shadowRoot的mode是个只读属性,可以指定其模式——打开或关闭。
这定义了影子根的内部功能是否可以从JavaScript访问。
当影子根的模式为“关闭”时,影子根的实现内部无法从JavaScript访问且不可更改,就像元素的实现内部不能从JavaScript访问或不可更改一样。
属性值是使用传递给Element.attachShadow()的对象的options.mode属性设置的,或者在声明性创建影子根时使用
来源:juejin.cn/post/7524548909530005540
async/await 必须使用 try/catch 吗?
前言
在 JavaScript 开发者的日常中,这样的对话时常发生:
- 👨💻 新人:"为什么页面突然白屏了?"
- 👨🔧 老人:"异步请求没做错误处理吧?"
async/await 看似优雅的语法糖背后,隐藏着一个关键问题:错误处理策略的抉择。
在 JavaScript 中使用 async/await 时,很多人会问:“必须使用 try/catch 吗?”
其实答案并非绝对,而是取决于你如何设计错误处理策略和代码风格。
接下来,我们将探讨 async/await 的错误处理机制、使用 try/catch 的优势,以及其他可选的错误处理方法。
async/await 的基本原理
异步代码的进化史
// 回调地狱时代
fetchData(url1, (data1) => {
process(data1, (result1) => {
fetchData(url2, (data2) => {
// 更多嵌套...
})
})
})
// Promise 时代
fetchData(url1)
.then(process)
.then(() => fetchData(url2))
.catch(handleError)
// async/await 时代
async function workflow() {
const data1 = await fetchData(url1)
const result = await process(data1)
return await fetchData(url2)
}
async/await 是基于 Promise 的语法糖,它使异步代码看起来更像同步代码,从而更易读、易写。一个 async 函数总是返回一个 Promise,你可以在该函数内部使用 await 来等待异步操作完成。
如果在异步操作中出现错误(例如网络请求失败),该错误会使 Promise 进入 rejected 状态。
async function fetchData() {
const response = await fetch("https://api.example.com/data");
const data = await response.json();
return data;
}
使用 try/catch 捕获错误
打个比喻,就好比铁路信号系统
想象 async 函数是一列高速行驶的列车:
- await 是轨道切换器:控制代码执行流向
- 未捕获的错误如同脱轨事故:会沿着铁路网(调用栈)逆向传播
- try/catch 是智能防护系统:
- 自动触发紧急制动(错误捕获)
- 启动备用轨道(错误恢复逻辑)
- 向调度中心发送警报(错误日志)
为了优雅地捕获 async/await 中出现的错误,通常我们会使用 try/catch 语句。这种方式可以在同一个代码块中捕获抛出的错误,使得错误处理逻辑更集中、直观。
- 代码逻辑集中,错误处理与业务逻辑紧密结合。
- 可以捕获多个 await 操作中抛出的错误。
- 适合需要在出错时进行统一处理或恢复操作的场景。
async function fetchData() {
try {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data;
} catch (error) {
console.error("Error fetching data:", error);
// 根据需要,可以在此处处理错误,或者重新抛出以便上层捕获
throw error;
}
}
不使用 try/catch 的替代方案
虽然 try/catch 是最直观的错误处理方式,但你也可以不在 async 函数内部使用它,而是在调用该 async 函数时捕获错误。
在 Promise 链末尾添加 .catch()
async function fetchData() {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
// 调用处使用 Promise.catch 捕获错误
fetchData()
.then(data => {
console.log("Data:", data);
})
.catch(error => {
console.error("Error fetching data:", error);
});
这种方式将错误处理逻辑移至函数调用方,适用于以下场景:
- 当多个调用者希望以不同方式处理错误时。
- 希望让 async 函数保持简洁,将错误处理交给全局统一的错误处理器(例如在 React 应用中可以使用 Error Boundary)。
将 await 与 catch 结合
async function fetchData() {
const response = await fetch('https://api.example.com/data').catch(error => {
console.error('Request failed:', error);
return null; // 返回兜底值
});
if (!response) return;
// 继续处理 response...
}
全局错误监听(慎用,适合兜底)
// 浏览器端全局监听
window.addEventListener('unhandledrejection', event => {
event.preventDefault();
sendErrorLog({
type: 'UNHANDLED_REJECTION',
error: event.reason,
stack: event.reason.stack
});
showErrorToast('系统异常,请联系管理员');
});
// Node.js 进程管理
process.on('unhandledRejection', (reason, promise) => {
logger.fatal('未处理的 Promise 拒绝:', reason);
process.exitCode = 1;
});
错误处理策略矩阵
决策树分析
graph TD
A[需要立即处理错误?] -->|是| B[使用 try/catch]
A -->|否| C{错误类型}
C -->|可恢复错误| D[Promise.catch]
C -->|致命错误| E[全局监听]
C -->|批量操作| F[Promise.allSettled]
错误处理体系
- 基础层:80% 的异步操作使用 try/catch + 类型检查
- 中间层:15% 的通用错误使用全局拦截 + 日志上报
- 战略层:5% 的关键操作实现自动恢复机制
小结
我的观点是:不强制要求,但强烈推荐
- 不强制:如果不需要处理错误,可以不使用
try/catch,但未捕获的 Promise 拒绝(unhandled rejection)会导致程序崩溃(在 Node.js 或现代浏览器中)。 - 推荐:90% 的场景下需要捕获错误,因此
try/catch是最直接的错误处理方式。
所有我个人观点:使用 async/await 尽量使用 try/catch。好的错误处理不是消灭错误,而是让系统具备优雅降级的能力。
你的代码应该像优秀的飞行员——在遇到气流时,仍能保持平稳飞行。大家如有不同意见,还请评论区讨论,说出自己的见解。
来源:juejin.cn/post/7482013975077928995
我在 pre 直接修改 bug,被领导批评了
大家好,我是石小石!
背景简介
前几天项目在pre回归时,测试发现一个bug,经过排查,我发现漏写了一行代码。

由于此时test、dev的代码已经进入新的迭代开发了,因此为了图方便,我直接在pre上修改了代码,并直接推送发布。
没想到,随后就收到了来自领导的批评:为什么不拉个hotfix分支修复合并?你直接修改代码会让代码难以追踪、回滚,以后上线全是隐患!
确实,即使只有一行代码的修改,也不应该直接在pre直接更改,我深刻的反思了自己。
分支管理与协作流程
一般来说,一个项目从开发到上线共包含四个环境。
| 环境 | 分支名示例 | 作用说明 |
|---|---|---|
| 开发环境 | dev | 日常开发,集成各功能分支的代码,允许不稳定,便于测试和联调 |
| 测试环境 | test | 提供给 QA 团队回归测试,要求相对稳定;一般从 dev合并而来 |
| 预发布环境 | pre | 模拟线上环境,临上线前验证,接近正式发布版本,禁止频繁变更 |
| 生产环境 | prod / main | 最终上线版本,代码必须安全稳定、经过充分测试 |
以我们公司为例,大致的协作规范流程如下:
1、dev功能开发
由于功能是几个人共同开发,每个人开发前都需要从 dev 分支拉出 feature/xxx 分支;本地开发完成后提合并回 dev;
- 提测
当功能开发完成dev 稳定后合并进 test,然后QA 回归测试环境;如发现问题,在 hotfix/xxx 修复后继续合并回 test(实际开发中,为了简化开发流程,大家都是直接在test修改bug)。
3. 预发布验证
测试通过,临近上线时,会从 test 合并进 pre。pre 仅用于业务验证、客户预览,不会在开发新功能;遇到bug的话,必须基于pre拉一个hotfix分支,修复完通过验证后,在合并回pre。
4. 正式上线
从 pre 合并到 prod ,并部署上线;
为什么不能直接在pre修改bug
pre 是预发布环境分支,作用是:模拟线上环境,确保代码上线前是可靠的,它应只接收已审核通过的改动,而不是“随便修的东西”。
如果直接在 pre 上修改,会出现很多意料之外的问题。如:
- 代码来源不清晰,审查流程被绕过
- 多人协作下容易引发冲突和覆盖(bug重现)
这样时间久了我们根本不知道哪个 bug 是从哪冒出来的,代码就会变得难以维护和溯源。
因此,基于pre拉一个hotfix/xxx 分支是团队开发的规范流程:
- 创建热修分支(hotfix 分支)
从 pre 分支上拉一个新的临时分支,命名建议规范些,如:
git checkout pre
git pull origin pre # 确保是最新代码
git checkout -b hotfix/fix-button-not-working
- 2在 hotfix 分支中修复 bug
进行代码修改、调试、测试。
- 创建合并请求
bug修复且通过qa验证后,我们就可以合并至pre等待审核。
使用hotfix,大家一看到这个分支名字,大家就知道这是线上急修的问题,容易跟踪、回溯和管理。你直接在 pre 改,其他人甚至都不知道发生了 bug。
总结
通过本文,大家应该也进一步了解pre环境的bug处理规范,如果你还觉得小问题在pre直接修改问题不大,可以看看这个示例:
你是一个信誉良好的企业老板,你的样品准备提交客户的时候突然发现了问题。你正常的流程应该是:
- 回原材料工厂排查修理
- 重新打样
- 提交新样品
- 送给客户
除非你是黑心老板,样品有问题直接凑合修一下直接给客户。
来源:juejin.cn/post/7501992214283370507
表妹问:前端好玩吗?我说好玩,但表妹接下来的回复看哭了我
表妹问:前端好玩吗?我说好玩,但表妹接下来的回复看哭了我。
是的,回复如下:
这红海血途上,新兵举着 "大前端" 旌旗冲锋,老兵拖着node_modules残躯撤退。资本织机永不停歇,框架版本更迭如暴君换季,留下满地deprecated警告如秋后落叶。
其一、夹缝中的苦力
世人都道前端易,不过调接口、改颜色,仿佛稚童搭积木。却不知那屏幕上寸寸像素之间,皆是血泪。产品拍案,需求朝夕三变,昨日之红蓝按钮,今晨便成黑白圆角。UI稿纸翻飞如雪,设计师手持“用户体验”四字大旗,将五更赶工的代码尽数碾碎。后端端坐高台,接口文档空悬如镜花水月,待到交付时辰,方抛来残缺数据。此时节,前端便成了那补天的女娲,于混沌中捏造虚拟对象,用JSON.parse('{"data": undefined}')这等荒诞戏法,将虚无粉饰成真实。
看这段代码何等悲凉:
// 后端曰:此接口返data字段,必不为空
fetch('api/data').then(res => {
const { data } = res;
render(data[0].children[3].value || '默认值'); // 层层掘墓,方见白骨
});
此乃前端日常——在数据废墟里刨食,用||与?.铸成铁锹,掘出三分体面。
其二、技术的枷锁
JavaScript本是脚本小儿,如今却要扛鼎江山。君不见React、Vue、Angular三座大山压顶,每年必有新神像立起。昨日方学得Redux真经,今朝GraphQL又成显学。更有Electron、ReactNative、Flutter诸般法器,教人左手写桌面应用,右手调移动端手势。所谓“大前端”,实乃资本画饼之术,人前跨端写,人后页面仔——既要马儿跑,又要马儿不吃草;以切图之名,许一份低劣薪水,行三五岗位之事。
且看这跨平台代码何等荒诞:
// 一套代码统治三界(iOS/Android/Web)
<View>
{Platform.OS === 'web' ?
<div onClick={handleWebClick} /> :
<TouchableOpacity onPress={handleNativePress} />
}
View>
此类缝合怪代码,恰似给长衫打补丁,既失体统,又损性能。待到内存泄漏、渲染卡顿时,众人皆指前端曰:"此子学艺不精!"
何人怜悯前端 node18 react19 逐人老,后端写着 java8 看着 java22 笑。
其三、尊严的消亡
领导提拔,必先问尔可懂SpringBoot、MySQL分库分表?纵使前端用WebGL绘出三维宇宙,用WebAssembly重写操作系统,在会议室里仍是“做界面的”。工资单上数字最是直白——同司后端新人起薪万数,前端老将苦熬三年方摸得此数。更可笑者,产品经理醉酒时吐真言:"你们不就是改改CSS么?"
再看这可视化代码何等心酸:
// 用Canvas画十万级数据点
ctx.beginPath();
dataPoints.forEach((point, i) => {
if (i % 100 === 0) ctx.stroke(); // 分段渲染防卡死
ctx.lineTo(point.x, point.y);
});
此等精密计算,在他人眼中不过"动画效果",与美工修图无异。待浏览器崩溃,众人皆曰:"定是前端代码劣质!"
技术大会,后端高谈微服务、分布式,高并发,满座掌声如雷,实则系统使用量百十来人也是远矣;前端言及 CSS 栅格、浏览器渲染,众人瞌睡连天。领导抚掌笑曰:“后端者,国之重器;前端者,雕虫小技。” 晋升名单,后端之名列如长蛇,前端者埋没于墙角尘埃。纵使将那界面写出花来,终是 “切图仔” 定终身。
其四、维护者的悲歌
JavaScript本无类型,如野马脱缰。若非经验老道之一,常写出这等代码:
function handleData(data) {
if (data && typeof data === 'object') { // 万能判断
return data.map(item => ({
...item,
newProp: item.id * Math.random() // 魔改数据
}));
}
return []; // 默认返回空阵,埋下百处报错
}
此类代码如瘟疫蔓延,领导却言“这些功能实习生也能写!”,却不顾三月后连作者亦不敢相认,只得下任前端难上加难。
而后端有Type大法,编译检查护体,有Swagger契约,有Docker容器,纵使代码如乱麻,只需扩内存、增实例,便可遮掩性能疮疤。
其五、末路者的自白
诸君且看这招聘启事:"需精通Vue3+TS+Webpack,熟悉React/Node.js,有Electron/小程序经验,掌握Three.js/WebGL者重点考虑。" 薪资却标着"6-8K"。更有机智者发明"全栈"之名,实欲以一人之躯,承三头六臂之劳。
再看这面试题何等荒谬:
// 手写Promise实现A+规范
class MyPromise {
// 三千行后,方知自己仍是蝼蚁
}
此等屠龙之术,入职后唯调API用。恰似逼庖丁解牛,却令其日日杀鸡。
或以使用组件库之经验薪资招之,又以写不好组件库之责裁出。
尾声:铁屋中的叩问
前端者,数字化时代的纺织工也。资本织机日夜轰鸣,框架如梭穿行不息。程序员眼底血丝如网。所谓"全栈工程师",实为包身工雅称;所谓"技术革新",不过剥削新法。
若仍有少年热血未冷,欲投身此业,且听我一言:君有凌云志,何不学Rust/C++,做那操作系统、数据库等真·屠龙技?莫要困在这CSS牢笼中,为圆角像素折腰,为虚无需求焚膏。前端之路,已是红海血途,望后来者三思,三思!
来源:juejin.cn/post/7475351155297402891
时间设置的是23点59分59秒,数据库却存的是第二天00:00:00
问题描述
昨天下班的时候,运营反馈了一个问题,明明设置的是两天后解封,为什么提示却是三天后呢。
比如今天(6.16)被拉入黑名单了,用户报名会提示 “6.19号恢复报名”,但是现在却提示6月20号才能报名,经过排查发现,就是解封的时间被多加了 1s 中,本来应该是存2025-06-18 23:59:59,但是数据库却是2025-06-19 00:00:00。
看了数据库有接近一半的数据是正确的,有一半的数据是第二天0晨(百思不得其解啊🤣)
代码逻辑实现:
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
❓看到上面的代码,有没有大佬已经发现问题了。确实上面的代码存在问题
昨天下班的时候,运营反馈了一个问题,明明设置的是两天后解封,为什么提示却是三天后呢。
比如今天(6.16)被拉入黑名单了,用户报名会提示 “6.19号恢复报名”,但是现在却提示6月20号才能报名,经过排查发现,就是解封的时间被多加了 1s 中,本来应该是存2025-06-18 23:59:59,但是数据库却是2025-06-19 00:00:00。
看了数据库有接近一半的数据是正确的,有一半的数据是第二天0晨(百思不得其解啊🤣)
代码逻辑实现:
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
❓看到上面的代码,有没有大佬已经发现问题了。确实上面的代码存在问题
解决过程
排查思路
一、排除代码问题
1.确认了项目中所有设置DeblockTime的地方 只有1出。排除了代码逻辑问题,被其他代码覆盖问题;
1.确认了项目中所有设置DeblockTime的地方 只有1出。排除了代码逻辑问题,被其他代码覆盖问题;
二、问问AI:
LocalDateTime futureTime = currentTime.plus(oaConfigActivityBlacklist.getBlockDay(), ChronoUnit.DAYS);
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
Date date = Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant());
这种写法能保证最后的date 的时分秒为 23时59分59秒么?
ai的答案如下 :
LocalDateTime futureTime = currentTime.plus(oaConfigActivityBlacklist.getBlockDay(), ChronoUnit.DAYS);
LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
Date date = Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant());
这种写法能保证最后的date 的时分秒为 23时59分59秒么?
ai的答案如下 :
1. 夏令时(DST)影响
- 场景:若时区在目标日期存在夏令时调整(如时钟回拨或前拨),可能导致时间偏差。
- 示例:
- 假设系统时区为
Europe/Paris,2023 年 10 月 29 日凌晨 3 点时钟回拨到 2 点。 - 若
futureTime 是该日,设置 23:59:59 后,转换为 UTC 时可能变为 21:59:59Z 或 22:59:59Z,取决于时钟调整规则。
- 场景:若时区在目标日期存在夏令时调整(如时钟回拨或前拨),可能导致时间偏差。
- 示例:
- 假设系统时区为
Europe/Paris,2023 年 10 月 29 日凌晨 3 点时钟回拨到 2 点。 - 若
futureTime是该日,设置23:59:59后,转换为 UTC 时可能变为21:59:59Z或22:59:59Z,取决于时钟调整规则。
- 假设系统时区为
2. 时区转换问题
- 场景:若
currentTime 是其他时区的时间(如 UTC),直接转换可能导致时间偏移。 - 示例:
- 若
currentTime 是 UTC 时间 2023-10-01T16:00:00Z,系统时区为 Asia/Shanghai(UTC+8)。 - 添加 1 天后得到
2023-10-02T16:00:00Z,设置为 23:59:59 后转换为 Date,实际对应 UTC 时间 2023-10-02T15:59:59Z。
看了数据的时间分布,任何时间点 都存在 23:59:59 和 00:00:00的情况,就算创建时间相差几分钟的情况下,都存在这两种数据。
- 场景:若
currentTime是其他时区的时间(如 UTC),直接转换可能导致时间偏移。 - 示例:
- 若
currentTime是 UTC 时间2023-10-01T16:00:00Z,系统时区为Asia/Shanghai(UTC+8)。 - 添加 1 天后得到
2023-10-02T16:00:00Z,设置为23:59:59后转换为Date,实际对应 UTC 时间2023-10-02T15:59:59Z。
- 若
看了数据的时间分布,任何时间点 都存在
23:59:59和00:00:00的情况,就算创建时间相差几分钟的情况下,都存在这两种数据。
三、批量插入数据测试
看看能不能复现这个问题,会不会插入时候精度等其他问题:
for (int i = 0; i < 100; i++) {
Thread.sleep(100);
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊 LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
}
果然还真复现了,有一半的数据是2025-06-19 23:59:59 有一半的数据是2025-06-20 00:00:00
看看能不能复现这个问题,会不会插入时候精度等其他问题:
for (int i = 0; i < 100; i++) {
Thread.sleep(100);
LocalDateTime currentTime = LocalDateTime.now();
LocalDateTime futureTime = currentTime.plus(2, ChronoUnit.DAYS);
// 设置了为当天的最后一秒啊 LocalDateTime resultTime = futureTime.withHour(23).withMinute(59).withSecond(59);
BlackAccount entity = new BlackAccount();
// 实体字段类型为Date,数据库是timestamp
entity.setDeblockTime(Date.from(resultTime.atZone(ZoneId.systemDefault()).toInstant()));
blackAccountService.save(entity);
}
果然还真复现了,有一半的数据是2025-06-19 23:59:59 有一半的数据是2025-06-20 00:00:00
定位问题
通过demo的复现,可以确认是在存数据库的时候出了问题。 因为Date的精度是控制在毫秒,pgsql 中TimeStamp 的精度用的默认值,精确到秒,所以在插入的时候Date的毫秒部分大于等于500的时候就会加1秒处理。入库之后就变成了第二天的00:00:00呢
通过demo的复现,可以确认是在存数据库的时候出了问题。 因为Date的精度是控制在毫秒,pgsql 中TimeStamp 的精度用的默认值,精确到秒,所以在插入的时候Date的毫秒部分大于等于500的时候就会加1秒处理。入库之后就变成了第二天的00:00:00呢
解决方案
要么将java对象的时间精度和 数据库的精度保持一致,要么就将java对象多余的精度置为0,解决方案如下:
- 方案1:代码中清空秒后面的数据
修改前: futureTime.withHour(23).withMinute(59).withSecond(59);
修改后: futureTime.withHour(23).withMinute(59).withSecond(59).withNano(0); - 方案2:调整数据库TimeStamp精度不小于java(date)对象的精度
修改前: 
修改后: 
要么将java对象的时间精度和 数据库的精度保持一致,要么就将java对象多余的精度置为0,解决方案如下:
- 方案1:代码中清空秒后面的数据
修改前:futureTime.withHour(23).withMinute(59).withSecond(59);
修改后:futureTime.withHour(23).withMinute(59).withSecond(59).withNano(0); - 方案2:调整数据库TimeStamp精度不小于java(date)对象的精度
修改前:
修改后:
知识扩展
1. Date 和 LocalDateTime
特性 java.util.Date (Java 1.0)java.time.LocalDateTime (Java 8+)精度 毫秒级(1/1000 秒) 纳秒级(1/1,000,000,000 秒) 包路径 java.util.Datejava.time.LocalDateTime可变性 可变(修改会影响原对象) 不可变(所有操作返回新对象) 时区感知 不存储时区,但内部时间戳基于 UTC 无时区,仅表示本地日期和时间
| 特性 | java.util.Date (Java 1.0) | java.time.LocalDateTime (Java 8+) |
|---|---|---|
| 精度 | 毫秒级(1/1000 秒) | 纳秒级(1/1,000,000,000 秒) |
| 包路径 | java.util.Date | java.time.LocalDateTime |
| 可变性 | 可变(修改会影响原对象) | 不可变(所有操作返回新对象) |
| 时区感知 | 不存储时区,但内部时间戳基于 UTC | 无时区,仅表示本地日期和时间 |
2. mysql 中的timestamp 和 datetime
特性 DATETIMETIMESTAMP存储范围 1000-01-01 00:00:00 到 9999-12-31 23:59:591970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC精度 5.6.4 版本后支持 fractional seconds(如DATETIME(6))最高精度微妙,设置0的话就表示精确到秒 同上(如TIMESTAMP(6)) 存储空间 8 字节 4 字节(时间戳范围小) 时区感知 不存储时区信息,直接存储字面量 自动转换时区:存储时转换为 UTC,读取时转换为会话时区 默认值 无默认值(除非显式设置DEFAULT) 支持DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP 自动更新 不支持 支持自动更新为当前时间(ON UPDATE)
| 特性 | DATETIME | TIMESTAMP |
|---|---|---|
| 存储范围 | 1000-01-01 00:00:00 到 9999-12-31 23:59:59 | 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC |
| 精度 | 5.6.4 版本后支持 fractional seconds(如DATETIME(6))最高精度微妙,设置0的话就表示精确到秒 | 同上(如TIMESTAMP(6)) |
| 存储空间 | 8 字节 | 4 字节(时间戳范围小) |
| 时区感知 | 不存储时区信息,直接存储字面量 | 自动转换时区:存储时转换为 UTC,读取时转换为会话时区 |
| 默认值 | 无默认值(除非显式设置DEFAULT) | 支持DEFAULT CURRENT_TIMESTAMP和ON UPDATE CURRENT_TIMESTAMP |
| 自动更新 | 不支持 | 支持自动更新为当前时间(ON UPDATE) |
3.适用场景建议
- java 中尽量用
LocalDateTime吧,毕竟LocalDateTime 主要就是用来取代Date对象的,区别如下
场景类型 java.util.Date(旧 API)java.time.LocalDateTime(新 API)简单本地时间记录 可使用,但 API 繁琐(需配合Calendar) 推荐使用(无需时区,代码简洁) 带时区的时间处理 不推荐(时区处理易混淆) 推荐使用ZonedDateTime或OffsetDateTime 多线程环境 不推荐(非线程安全) 推荐(不可变设计,线程安全) 数据库交互(JDBC 4.2+) 需转换为java.sql.Timestamp 直接支持(如pstmt.setObject(1, localDateTime)) 时间计算与格式化 需依赖SimpleDateFormat(非线程安全) 推荐(DateTimeFormatter线程安全) 高精度需求(纳秒级) 仅支持毫秒级 支持纳秒级(1/1,000,000,000 秒
- 数据库到底是用
timestamp 还是 datetime呢,跨国业务用timestamp 其他场景建议用datetime:
- java 中尽量用
LocalDateTime吧,毕竟LocalDateTime主要就是用来取代Date对象的,区别如下
| 场景类型 | java.util.Date(旧 API) | java.time.LocalDateTime(新 API) |
|---|---|---|
| 简单本地时间记录 | 可使用,但 API 繁琐(需配合Calendar) | 推荐使用(无需时区,代码简洁) |
| 带时区的时间处理 | 不推荐(时区处理易混淆) | 推荐使用ZonedDateTime或OffsetDateTime |
| 多线程环境 | 不推荐(非线程安全) | 推荐(不可变设计,线程安全) |
| 数据库交互(JDBC 4.2+) | 需转换为java.sql.Timestamp | 直接支持(如pstmt.setObject(1, localDateTime)) |
| 时间计算与格式化 | 需依赖SimpleDateFormat(非线程安全) | 推荐(DateTimeFormatter线程安全) |
| 高精度需求(纳秒级) | 仅支持毫秒级 | 支持纳秒级(1/1,000,000,000 秒 |
- 数据库到底是用
timestamp还是datetime呢,跨国业务用timestamp 其他场景建议用datetime:
| 场景 | 推荐类型 | 原因 |
|---|---|---|
| 存储历史事件时间(如订单创建时间) | DATETIME | 不依赖时区,固定记录用户输入的时间 |
| 记录服务器本地时间(如定时任务执行时间) | DATETIME | 无需时区转换,直接反映服务器时间 |
| 多时区应用(如跨国业务) | TIMESTAMP | 自动处理时区转换,确保数据一致性(如登录时间) |
| 需要自动更新时间戳 | TIMESTAMP | 支持ON UPDATE CURRENT_TIMESTAMP特性 |
| 存储范围超过 2038 年 | DATETIME | TIMESTAMP仅支持到 【2038】 年 |
| 微秒级精度需求 | DATETIME(6)或TIMESTAMP(6) | 根据是否需要时区转换选择 |
总结
本文主要讲述了在处理用户解封时间时,因 Java 代码中时间精度与数据库TIMESTAMP类型精度不一致,导致约一半数据存储时间比预期多 1 秒的问题。通过排查与测试,定位问题并给出了 Java 对象时间精度和调整数据库精度两种解决方案,同时对比了 Java 和数据库中多种时间类型的特性及适用场景 。
来源:juejin.cn/post/7517119131856191500
😝我怎么让设计师不再嫌弃 Antd,后台系统也能高端大气上档次
前言
如果一个团队计划开发一个面向 B 端的管理后台系统,既希望具备高效开发能力,又想要拥有好看的 UI,避免千篇一律的“土味”风格,而你作为前端主程参与开发,会怎么做?
本文将分享我在这一方向上的思考与实践。虽然目前所在公司的 B 端系统已经迭代许多内容,短期内没有设计师人力支持我推行这套方法,但我依然希望能将这套思路分享给有类似困扰的朋友。如果未来我有机会从零带队启动新项目,我依旧会沿用这一套方案。
当前的问题:前端与设计如何协作?
在开发 B 端系统时,大多数国内团队都会选用如 Umi、Ant Design、ProComponents、Semi Design 等成熟的 B 端技术栈和 UI 库。
这些库大大提升了开发效率,尤其是 Antd 提供的 Table、Form 等组件,功能丰富,使用便捷,非常值得肯定。
但问题也随之而来:因为太多后台项目使用 Antd,导致整体 UI 风格高度同质化,设计师逐渐产生审美疲劳。在尝试打破这种风格束缚时,设计师往往会自由发挥,或者采用非 Antd 的组件库来设计 Figma 稿。
这导致前端不得不花大量时间去覆写样式,以适配非标准组件,工作量激增,最终形成恶性循环:设计觉得前端“不还原设计”,前端觉得设计“在刁难人”,项目开发节奏也被 UI 卡住。
如何解决?
其实 Antd 本身提供了非常强的定制能力。借助 ConfigProvider 全局配置 和 主题编辑器,我们可以通过修改 CSS Token 来全局调整组件样式,做到“深度魔改”。
这在前端层面可以很好地解决样式定制的问题,但设计师要怎么参与?
答案是:使用的 Antd Figma 文件(这份是 figma 社区大佬维护的算是比较新的版本 5.20)。这个 Figma 文件已经全面绑定了 Antd 的 Design Token,设计师可以直接在 Figma 中打开,点击右侧的 Variables 面板,通过修改颜色、圆角、阴影等变量来完成 UI 风格定制。
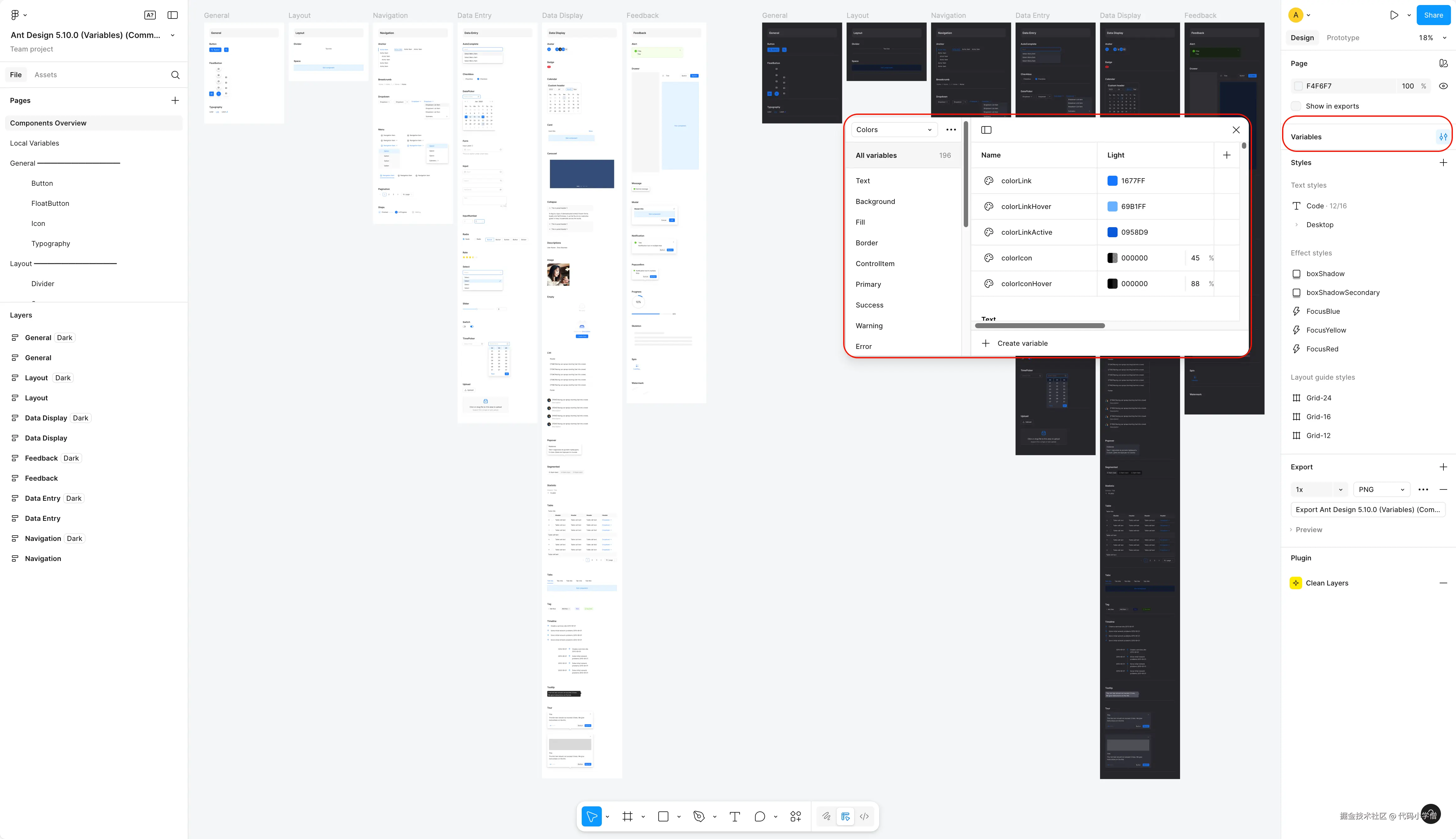
由于每个组件都与 Design Token 强关联,设计师的修改可以精确反映到各个 UI 组件上,实现灵活定制。同时,也应记录这些变量的修改项,前端就可以据此配置对应的 JSON 文件,通过 ConfigProvider 注入到项目中,从而实现样式一致的组件系统。
最后,设计师可将修改后的组件库加入 Figma 的 Asset Libraries 中,供未来在设计稿中重复复用。这就等于团队共同维护了一套定制的 UI 体系。

结语
通过上述方法,前端与设计师可以真正做到“同源协作”:基于同一套设计变量开发和设计,避免不必要的重复劳动与沟通摩擦,释放更多精力专注在业务开发本身上。
来源:juejin.cn/post/7507982656686145562
折腾我2周的分页打印和下载pdf

1.背景
一开始接到任务需要打印html,之前用到了vue-print-nb-jeecg来处理Vue2一个打印的问题,现在是遇到需求要在Vue3项目里面去打印十几页的打印和下载为pdf,难点和坑就在于我用的库vue3-print-nb来做分页打印预览,下载pdf后面介绍
2.预览打印实现
<div id="printMe" style="background:red;">
<p>葫芦娃,葫芦娃</p>
<p>一根藤上七朵花 </p>
<p>小小树藤是我家 啦啦啦啦 </p>
<p>叮当当咚咚当当 浇不大</p>
<p> 叮当当咚咚当当 是我家</p>
<p> 啦啦啦啦</p>
<p>...</p>
</div>
<button v-print="'#printMe'">Print local range</button>
因为官方提供的方案都是DOM加载完成后然后直接打印,但是我的需求是需要点击打印的时候根据id渲染不同的组件然后渲染DOM,后面仔细看官方文档,有个beforeOpenCallback方法在打印预览之前有个钩子,但是这个钩子没办法确定我接口加载完毕,所以我的思路就是用户先点击我写的点击按钮事件,等异步渲染完毕之后,我再同步触发真正的打印预览按钮,这样就变相解决了我的需求。
坑
- 没办法处理接口异步渲染数据展示DOM进行打印操作
- 在布局相对定位的时候在谷歌浏览器会发现有布局整体变小的问题(后续用zoom处理的)
3.掉头发之下载pdf
下载pdf这种需求才是我每次去理发店不敢让tony把我头发打薄的原因,我看了很多技术文章,结合个人业务情况,采取的方案是html2canvas把html转成canvas然后转成图片然后通过jsPDF截取图片分页最后下载到本地。本人秉承着不生产水,只做大自然的搬运工的匠人精神,迅速而又果断的从社区来到社区去,然后找到了适配当前业务的逻辑代码(实践出真知)。
import html2canvas from 'html2canvas'
import jsPDF, { RGBAData } from 'jspdf'
/** a4纸的尺寸[595.28,841.89], 单位毫米 */
const [PAGE_WIDTH, PAGE_HEIGHT] = [595.28, 841.89]
const PAPER_CONFIG = {
/** 竖向 */
portrait: {
height: PAGE_HEIGHT,
width: PAGE_WIDTH,
contentWidth: 560
},
/** 横向 */
landscape: {
height: PAGE_WIDTH,
width: PAGE_HEIGHT,
contentWidth: 800
}
}
// 将元素转化为canvas元素
// 通过 放大 提高清晰度
// width为内容宽度
async function toCanvas(element: HTMLElement, width: number) {
if (!element) return { width, height: 0 }
// canvas元素
const canvas = await html2canvas(element, {
// allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true // 允许跨域
})
// 获取canvas转化后的宽高
const { width: canvasWidth, height: canvasHeight } = canvas
// html页面生成的canvas在pdf中的高度
const height = (width / canvasWidth) * canvasHeight
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0)
return { width, height, data: canvasData }
}
/**
* 生成pdf(A4多页pdf截断问题, 包括页眉、页脚 和 上下左右留空的护理)
* @param param0
* @returns
*/
export async function outputPDF({
/** pdf内容的dom元素 */
element,
/** 页脚dom元素 */
footer,
/** 页眉dom元素 */
header,
/** pdf文件名 */
filename,
/** a4值的方向: portrait or landscape */
orientation = 'portrait' as 'portrait' | 'landscape'
}) {
if (!(element instanceof HTMLElement)) {
return
}
if (!['portrait', 'landscape'].includes(orientation)) {
return Promise.reject(
new Error(`Invalid Parameters: the parameter {orientation} is assigned wrong value, you can only assign it with {portrait} or {landscape}`)
)
}
const [A4_WIDTH, A4_HEIGHT] = [PAPER_CONFIG[orientation].width, PAPER_CONFIG[orientation].height]
/** 一页pdf的内容宽度, 左右预设留白 */
const { contentWidth } = PAPER_CONFIG[orientation]
// eslint-disable-next-line new-cap
const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation
})
// 一页的高度, 转换宽度为一页元素的宽度
const { width, height, data } = await toCanvas(element, contentWidth)
// 添加
function addImage(
_x: number,
_y: number,
pdfInstance: jsPDF,
base_data: string | HTMLImageElement | HTMLCanvasElement | Uint8Array | RGBAData,
_width: number,
_height: number
) {
pdfInstance.addImage(base_data, 'JPEG', _x, _y, _width, _height)
}
// 增加空白遮挡
function addBlank(x: number, y: number, _width: number, _height: number) {
pdf.setFillColor(255, 255, 255)
pdf.rect(x, y, Math.ceil(_width), Math.ceil(_height), 'F')
}
// 页脚元素 经过转换后在PDF页面的高度
const { height: tFooterHeight, data: headerData } = footer ? await toCanvas(footer, contentWidth) : { height: 0, data: undefined }
// 页眉元素 经过转换后在PDF的高度
const { height: tHeaderHeight, data: footerData } = header ? await toCanvas(header, contentWidth) : { height: 0, data: undefined }
// 添加页脚
async function addHeader(headerElement: HTMLElement) {
headerData && pdf.addImage(headerData, 'JPEG', 0, 0, contentWidth, tHeaderHeight)
}
// 添加页眉
async function addFooter(pageNum: number, now: number, footerElement: HTMLElement) {
if (footerData) {
pdf.addImage(footerData, 'JPEG', 0, A4_HEIGHT - tFooterHeight, contentWidth, tFooterHeight)
}
}
// 距离PDF左边的距离,/ 2 表示居中
const baseX = (A4_WIDTH - contentWidth) / 2 // 预留空间给左边
// 距离PDF 页眉和页脚的间距, 留白留空
const baseY = 15
// 除去页头、页眉、还有内容与两者之间的间距后 每页内容的实际高度
const originalPageHeight = A4_HEIGHT - tFooterHeight - tHeaderHeight - 2 * baseY
// 元素在网页页面的宽度
const elementWidth = element.offsetWidth
// PDF内容宽度 和 在HTML中宽度 的比, 用于将 元素在网页的高度 转化为 PDF内容内的高度, 将 元素距离网页顶部的高度 转化为 距离Canvas顶部的高度
const rate = contentWidth / elementWidth
// 每一页的分页坐标, PDF高度, 初始值为根元素距离顶部的距离
const pages = [rate * getElementTop(element)]
// 获取该元素到页面顶部的高度(注意滑动scroll会影响高度)
function getElementTop(contentElement) {
if (contentElement.getBoundingClientRect) {
const rect = contentElement.getBoundingClientRect() || {}
const topDistance = rect.top
return topDistance
}
}
// 遍历正常的元素节点
function traversingNodes(nodes) {
for (const element of nodes) {
const one = element
/** */
/** 注意: 可以根据业务需求,判断其他场景的分页,本代码只判断表格的分页场景 */
/** */
// table的每一行元素也是深度终点
const isTableRow = one.classList && one.classList.contains('ant4-table-row')
// 对需要处理分页的元素,计算是否跨界,若跨界,则直接将顶部位置作为分页位置,进行分页,且子元素不需要再进行判断
const { offsetHeight } = one
// 计算出最终高度
const offsetTop = getElementTop(one)
// dom转换后距离顶部的高度
// 转换成canvas高度
const top = rate * offsetTop
const rateOffsetHeight = rate * offsetHeight
// 对于深度终点元素进行处理
if (isTableRow) {
// dom高度转换成生成pdf的实际高度
// 代码不考虑dom定位、边距、边框等因素,需在dom里自行考虑,如将box-sizing设置为border-box
updateTablePos(rateOffsetHeight, top)
}
// 对于普通元素,则判断是否高度超过分页值,并且深入
else {
// 执行位置更新操作
updateNormalElPos(top)
// 遍历子节点
traversingNodes(one.childNodes)
}
updatePos()
}
}
// 普通元素更新位置的方法
// 普通元素只需要考虑到是否到达了分页点,即当前距离顶部高度 - 上一个分页点的高度 大于 正常一页的高度,则需要载入分页点
function updateNormalElPos(top) {
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
}
// 可能跨页元素位置更新的方法
// 需要考虑分页元素,则需要考虑两种情况
// 1. 普通达顶情况,如上
// 2. 当前距离顶部高度加上元素自身高度 大于 整页高度,则需要载入一个分页点
function updateTablePos(eHeight: number, top: number) {
// 如果高度已经超过当前页,则证明可以分页了
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
// 若 距离当前页顶部的高度 加上元素自身的高度 大于 一页内容的高度, 则证明元素跨页,将当前高度作为分页位置
else if (
top + eHeight - (pages.length > 0 ? pages[pages.length - 1] : 0) > originalPageHeight &&
top !== (pages.length > 0 ? pages[pages.length - 1] : 0)
) {
pages.push(top)
}
}
// 深度遍历节点的方法
traversingNodes(element.childNodes)
function updatePos() {
while (pages[pages.length - 1] + originalPageHeight < height) {
pages.push(pages[pages.length - 1] + originalPageHeight)
}
}
// 对pages进行一个值的修正,因为pages生成是根据根元素来的,根元素并不是我们实际要打印的元素,而是element,
// 所以要把它修正,让其值是以真实的打印元素顶部节点为准
const newPages = pages.map(item => item - pages[0])
// 根据分页位置 开始分页
for (let i = 0; i < newPages.length; ++i) {
// 根据分页位置新增图片
addImage(baseX, baseY + tHeaderHeight - newPages[i], pdf, data!, width, height)
// 将 内容 与 页眉之间留空留白的部分进行遮白处理
addBlank(0, tHeaderHeight, A4_WIDTH, baseY)
// 将 内容 与 页脚之间留空留白的部分进行遮白处理
addBlank(0, A4_HEIGHT - baseY - tFooterHeight, A4_WIDTH, baseY)
// 对于除最后一页外,对 内容 的多余部分进行遮白处理
if (i < newPages.length - 1) {
// 获取当前页面需要的内容部分高度
const imageHeight = newPages[i + 1] - newPages[i]
// 对多余的内容部分进行遮白
addBlank(0, baseY + imageHeight + tHeaderHeight, A4_WIDTH, A4_HEIGHT - imageHeight)
}
// 添加页眉
if (header) {
await addHeader(header)
}
// 添加页脚
if (footer) {
await addFooter(newPages.length, i + 1, footer)
}
// 若不是最后一页,则分页
if (i !== newPages.length - 1) {
// 增加分页
pdf.addPage()
}
}
return pdf.save(filename)
}
4.分页的小姿势
如果有需求把打印预览的时候的页眉页脚默认取消不展示,然后自定义页面的边距可以这么设置样式
@page {
size: auto A4 landscape;
margin: 3mm;
}
@media print {
body,
html {
height: initial;
padding: 0px;
margin: 0px;
}
}
5.关于页眉页脚
由于业务是属于比较自定义化的展示,所以我封装成组件,然后根据返回的数据进行渲染到每个界面,然后利用绝对定位放在相同的位置,最后一点小优化就是,公共化提取界面的样式,然后整合为pub.scss然后引入到界面里面,这样即使产品有一定的样式调整,我也可以在公共样式里面去配置和修改,大大的减少本人的工作量。在日常的开发中也是这样,不要去抱怨需求的变动频繁,而是力争在写组件的过程中考虑到组件的健壮性和灵活度,给自己的工作减负,到点下班。
参考文章
来源:juejin.cn/post/7397319113796780042
Postgres 杀疯了,堪称 “六边形战士”,还要 Redis 干啥?
我们需要谈谈困扰我几个月的事情。我一直看到独立黑客和初创公司创始人疯狂地拼凑各种技术栈,用 Redis 做缓存,用 RabbitMQ 做队列,用 Elasticsearch 做搜索,还有用 MongoDB……为什么?
我也犯过这种错误。当我开始构建UserJot(我的反馈和路线图工具)时,我的第一反应是规划一个“合适的”架构,为所有功能提供独立的服务。然后我停下来问自己:如果我把所有功能都用 Postgres 来做会怎么样?
事实证明,房间里有一头大象,但没人愿意承认:
| Postgres 几乎可以做到这一切。 |
|---|
而且它的效果比你想象的还要好。
“Postgres 无法扩展”的谬论正在让你损失金钱?
让我猜猜——有人告诉你,Postgres“只是一个关系数据库”,需要专门的工具来完成专门的工作。我以前也是这么想的,直到我发现 Instagram 可以在单个 Postgres 实例上扩展到 1400 万用户。Discord 处理数十亿条消息。Notion 的整个产品都是基于 Postgres 构建的。
但问题是:他们不再像 2005 年那样使用 Postgres。
队列系统
别再为 Redis 和 RabbitMQ 付费了。Postgres 原生支持LISTEN/NOTIFY并且比大多数专用解决方案更好地处理作业队列:
-- Simple job queue in pure Postgres
CREATETABLE job_queue (
id SERIAL PRIMARY KEY,
job_type VARCHAR(50),
payload JSONB,
status VARCHAR(20) DEFAULT'pending',
created_at TIMESTAMPDEFAULT NOW(),
processed_at TIMESTAMP
);
-- ACID-compliant job processing
BEGIN;
UPDATE job_queue
SET status ='processing', processed_at = NOW()
WHERE id = (
SELECT id FROM job_queue
WHERE status ='pending'
ORDERBY created_at
FORUPDATESKIP LOCKED
LIMIT 1
)
RETURNING *;
COMMIT;
这让你无需任何额外的基础设施就能实现 Exactly-Once 的处理。不妨试试用 Redis 来实现,会让你很抓狂。
在 UserJot 中,我正是使用这种模式来处理反馈提交、发送通知和更新路线图项目。只需一次事务,即可保证一致性,无需消息代理的复杂性。
键值存储
Redis 在大多数平台上的最低价格为 20 美元/月。Postgres JSONB 已包含在您现有的数据库中,可以满足您的大部分需求:
-- Your Redis alternative
CREATETABLE kv_store (
key VARCHAR(255) PRIMARY KEY,
value JSONB,
expires_at TIMESTAMP
);
-- GIN index for blazing fast JSON queries
CREATE INDEX idx_kv_value ON kv_store USING GIN (value);
-- Query nested JSON faster than most NoSQL databases
SELECT*FROM kv_store
WHEREvalue @>'{"user_id": 12345}';
运算符@>是 Postgres 的秘密武器。它比大多数 NoSQL 查询更快,并且数据保持一致。
全文搜索
Elasticsearch 集群价格昂贵且复杂。Postgres 内置的全文搜索功能非常出色:
-- Add search to any table
ALTERTABLE posts ADDCOLUMN search_vector tsvector;
-- Auto-update search index
CREATEOR REPLACE FUNCTION update_search_vector()
RETURNStriggerAS $
BEGIN
NEW.search_vector := to_tsvector('english',
COALESCE(NEW.title, '') ||' '||
COALESCE(NEW.content, '')
);
RETURNNEW;
END;
$ LANGUAGE plpgsql;
-- Ranked search results
SELECT title, ts_rank(search_vector, query) as rank
FROM posts, to_tsquery('startup & postgres') query
WHERE search_vector @@ query
ORDERBY rank DESC;
这可以处理模糊匹配、词干提取和相关性排名。
对于 UserJot 的反馈搜索,此功能可让用户跨标题、描述和评论即时查找功能请求。无需 Elasticsearch 集群 - 只需使用 Postgres 即可发挥其优势。
实时功能
忘掉复杂的 WebSocket 基础架构吧。Postgres LISTEN/NOTIFY无需任何附加服务即可为您提供实时更新:
-- Notify clients of changes
CREATEOR REPLACE FUNCTION notify_changes()
RETURNStriggerAS $
BEGIN
PERFORM pg_notify('table_changes',
json_build_object(
'table', TG_TABLE_NAME,
'action', TG_OP,
'data', row_to_json(NEW)
)::text
);
RETURNNEW;
END;
$ LANGUAGE plpgsql;
您的应用程序会监听这些通知并向用户推送更新。无需 Redis 的发布/订阅机制。
“专业”工具的隐性成本
我们来算一下。一个典型的“现代”堆栈的成本是:
- Redis:20美元/月
- 消息队列:25美元/月
- 搜索服务:50美元/月
- 监控 3 项服务:30 美元/月
- 总计:每月 125 美元
但这还只是托管成本。真正的痛点在于:
运营开销:
- 三种不同的服务用于监控、更新和调试
- 不同的缩放模式和故障模式
- 需要维护多种配置
- 单独的备份和灾难恢复程序
- 每项服务的安全考虑因素不同
开发复杂性:
- 客户端库和连接模式
- 多个服务的部署
- 间数据不一致
- 的测试场景
- 的性能调优方法
如果您自行托管,请添加服务器管理、安全补丁以及当 Redis 决定消耗所有内存时不可避免的凌晨 3 点调试会话。
Postgres 使用您已经管理的单一服务来处理所有这些。
扩展的单一数据库
大多数人可能没有意识到:单个 Postgres 实例就能处理海量数据。我们指的是每天数百万笔交易、数 TB 的数据以及数千个并发连接。
真实世界的例子:
- Airbnb:单个 Postgres 集群处理数百万个预订
- Robinhood:数十亿笔金融交易
- GitLab:Postgres 上的整个 DevOps 平台
Postgres 的架构魅力非凡。它被设计成具备极佳的垂直扩展能力,而当你最终需要水平扩展时,它也有以下成熟的方案可供选择:
- 用于查询扩展的读取副本
- 大表分区
- 并发连接池
- 分布式设置的逻辑复制
大多数企业从未达到过这些限制。在处理数百万用户或复杂的分析工作负载之前,单个实例可能就足够了。
将此与管理所有以不同方式扩展的单独服务进行比较 - 您的 Redis 可能会耗尽内存,而您的消息队列则会遇到吞吐量问题,并且您的搜索服务需要完全不同的硬件。
从第一天起就停止过度设计
现代开发中最大的陷阱是架构式的“宇航员”。我们设计系统时,面对的是我们从未遇到过的问题,我们面对的是从未见过的流量,我们可能永远无法达到的规模。
过度设计循环:
- “我们可能有一天需要扩大规模”
- 添加 Redis、队列、微服务、多个数据库
- 花费数月时间调试集成问题
- 向 47 位用户推出
- 每月支付 200 美元购买可在 5 美元 VPS 上运行的基础设施
与此同时,您的竞争对手的发货速度更快,因为他们在需要分布式系统之前并没有管理它。
更好的方法:
- 从 Postgres 开始
- 监控实际的瓶颈,而不是想象的瓶颈
- 当达到实际极限时扩展特定组件
- 仅在解决实际问题时才增加复杂性
你的用户并不关心你的架构。他们关心的是你的产品是否有效,是否能解决他们的问题。
当你真正需要专用工具时
别误会我的意思——专用工具自有其用处。但你可能在以下情况之前不需要它们:
- 您每分钟处理 100,000 多个作业
- 您需要亚毫秒级的缓存响应
- 您正在对数 TB 的数据进行复杂的分析
- 您有数百万并发用户
- 您需要具有特定一致性要求的全局数据分布
如果您在公众号上阅读强哥这篇文章,那么您可能还没有到达那一步。
为什么这真的很重要
让我大吃一惊的是:Postgres 可以同时充当您的主数据库、缓存、队列、搜索引擎和实时系统。同时还能在所有方面保持 ACID 事务。
-- One transaction, multiple operations
BEGIN;
INSERT INTO users (email) VALUES ('user@example.com');
INSERT INTO job_queue (job_type, payload)
VALUES ('send_welcome_email', '{"user_id": 123}');
UPDATE kv_store SET value = '{"last_signup": "2024-01-15"}'
WHERE key = 'stats';
COMMIT;
尝试在 Redis、RabbitMQ 和 Elasticsearch 上执行此操作,不要哭泣。
无聊的技术却能获胜
Postgres 并不引人注目。它没有华丽的网站,也没有在 TikTok 上爆红。但几十年来,在其他数据库兴衰更迭之际,它一直默默地支撑着互联网。
选择简单、可靠且有效的技术是有道理的。
下一个项目的行动步骤
- 仅从 Postgres 开始- 抵制添加其他数据库的冲动
- 使用 JSONB 实现灵活性- 借助 SQL 的强大功能,您可以获得无架构的优势
- 在 Postgres 中实现队列——节省资金和复杂性
- 仅当达到实际极限时才添加专用工具- 而不是想象中的极限
我的真实经历
UserJot 的构建是这一理念的完美测试案例。它是一个反馈和路线图工具,需要:
- 提交反馈时实时更新
- 针对数千个功能请求进行全文搜索
- 发送通知的后台作业
- 缓存经常访问的路线图
- 用于用户偏好和设置的键值存储
我的整个后端只有一个 Postgres 数据库。没有 Redis,没有 Elasticsearch,没有消息队列。从用户身份验证到实时 WebSocket 通知,一切都由 Postgres 处理。
结果如何?我的功能交付速度更快,需要调试的部件更少,而且基础设施成本也降到了最低。当用户提交反馈、搜索功能或获取路线图变更的实时更新时,一切都由 Postgres 完成。
这不再只是理论上的。它正在实际生产中,通过真实的用户和真实的数据发挥作用。
令人不安的结论
Postgres 或许好得过头了。它功能强大,以至于大多数其他数据库对于 90% 的应用程序来说都显得多余。业界一直说服我们,所有事情都需要专门的工具,但或许我们只是把事情弄得比实际需要的更难。
你的初创公司不必成为分布式系统的样板。它需要为真正的人解决真正的问题。Postgres 让你专注于此,而不是照看基础设施。
因此,下次有人建议添加 Redis 来“提高性能”或添加 MongoDB 来“提高灵活性”时,请问他们:“您是否真的先尝试过在 Postgres 中执行此操作?”
答案可能会让你大吃一惊。我知道,当我完全在 Postgres 上构建UserJot时,它就一直运行顺畅。
| 本文为译文,英文原文地址(可能需要使用魔法访问):dev.to/shayy/postg… |
|---|
来源:juejin.cn/post/7517200182725296178
如果产品经理突然要你做一个像抖音一样流畅的H5
从前端到爆点!抖音级 H5 如何炼成?
在万物互联的时代,H5 页面已成为产品推广的利器。当产品经理丢给你一个“像抖音一样流畅的 H5”任务时,是挑战还是机遇?别慌,今天就带你走进抖音 H5 的前端魔法世界。
一、先看清本质:抖音 H5 为何丝滑?
抖音 H5 之所以让人欲罢不能,核心在于两点:极低的卡顿率和极致的交互反馈。前者靠性能优化,后者靠精心设计的交互逻辑。比如,你刷视频时的流畅下拉、点赞时的爱心飞舞,背后都藏着前端开发的“小心机”。
二、性能优化:让页面飞起来
(一)懒加载与预加载协同作战
懒加载是 H5 性能优化的经典招式,只在用户即将看到某个元素时才加载它。但光靠懒加载还不够,聪明的抖音 H5 还会预加载下一个可能进入视野的元素。以下是一个基于 IntersectionObserver 的懒加载示例:
document.addEventListener('DOMContentLoaded', () => {
const lazyImages = [].slice.call(document.querySelectorAll('img.lazy'));
if ('IntersectionObserver' in window) {
let lazyImageObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) {
let lazyImage = entry.target;
lazyImage.src = lazyImage.dataset.src;
lazyImageObserver.unobserve(lazyImage);
}
});
});
lazy Images.forEach((lazyImage) => {
lazyImageObserver.observe(lazyImage);
});
}
});
(二)图片压缩技术大显神威
图片是 H5 的“体重”大户。抖音 H5 常用 WebP 格式,它在保证画质的同时,能将图片体积压缩到 JPEG 的一半。你可以用以下代码轻松实现图片格式转换:
function compressImage(inputImage, quality) {
return new Promise((resolve) => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
canvas.width = inputImage.naturalWidth;
canvas.height = inputImage.naturalHeight;
ctx.drawImage(inputImage, 0, 0, canvas.width, canvas.height);
const compressedImage = new Image();
compressedImage.src = canvas.toDataURL('image/webp', quality);
compressedImage.onload = () => {
resolve(compressedImage);
};
});
}
三、交互设计:让用户欲罢不能
(一)微动画营造沉浸感
在点赞、评论等关键操作上,抖音 H5 会加入精巧的微动画。比如点赞时的爱心从手指位置飞出,这其实是一个 CSS 动画加 JavaScript 事件监听的组合拳。以下是一个简易版的点赞动画代码:
@keyframes flyHeart {
0% {
transform: scale(0) translateY(0);
opacity: 0;
}
50% {
transform: scale(1.5) translateY(-10px);
opacity: 1;
}
100% {
transform: scale(1) translateY(-20px);
opacity: 0;
}
}
.heart {
position: fixed;
width: 30px;
height: 30px;
background-image: url('../assets/heart.png');
background-size: contain;
background-repeat: no-repeat;
animation: flyHeart 1s ease-out;
}
document.querySelector('.like-btn').addEventListener('click', function(e) {
const heart = document.createElement('div');
heart.className = 'heart';
heart.style.left = e.clientX + 'px';
heart.style.top = e.clientY + 'px';
document.body.appendChild(heart);
setTimeout(() => {
heart.remove();
}, 1000);
});
(二)触摸事件优化
在移动设备上,触摸事件的响应速度直接影响用户体验。抖音 H5 通过精准控制触摸事件的捕获和冒泡阶段,减少了延迟。以下是一个优化触摸事件的示例:
const touchStartHandler = (e) => {
e.preventDefault(); // 防止页面滚动干扰
// 处理触摸开始逻辑
};
const touchMoveHandler = (e) => {
// 处理触摸移动逻辑
};
const touchEndHandler = (e) => {
// 处理触摸结束逻辑
};
const element = document.querySelector('.scrollable-container');
element.addEventListener('touchstart', touchStartHandler, { passive: false });
element.addEventListener('touchmove', touchMoveHandler, { passive: false });
element.addEventListener('touchend', touchEndHandler);
四、音频处理:让声音为 H5 增色
抖音 H5 的音频体验也很讲究。它会根据用户的操作实时调整音量,甚至在不同视频切换时平滑过渡音频。以下是一个简单的声音控制示例:
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const audioElement = document.querySelector('audio');
const audioSource = audioContext.createMediaElementSource(audioElement);
const gainNode = audioContext.createGain();
audioSource.connect(gainNode);
gainNode.connect(audioContext.destination);
// 调节音量
function setVolume(level) {
gainNode.gain.value = level;
}
// 音频淡入效果
function fadeInAudio() {
gainNode.gain.setValueAtTime(0, audioContext.currentTime);
gainNode.gain.linearRampToValueAtTime(1, audioContext.currentTime + 1);
}
// 音频淡出效果
function fadeOutAudio() {
gainNode.gain.linearRampToValueAtTime(0, audioContext.currentTime + 1);
}
五、跨浏览器兼容:让 H5 无处不在
抖音 H5 能在各种浏览器上保持一致的体验,这离不开前端开发者的兼容性优化。常用的手段包括使用 Autoprefixer 自动生成浏览器前缀、为老浏览器提供 Polyfill 等。以下是一个为 CSS 动画添加前缀的示例:
const autoprefixer = require('autoprefixer');
const postcss = require('postcss');
const css = '.example { animation: slidein 2s; } @keyframes slidein { from { transform: translateX(0); } to { transform: translateX(100px); } }';
postcss([autoprefixer]).process(css).then(result => {
console.log(result.css);
/*
输出:
.example {
animation: slidein 2s;
}
@keyframes slidein {
from {
-webkit-transform: translateX(0);
transform: translateX(0);
}
to {
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}
*/
});
打造一个像抖音一样的流畅 H5,需要前端开发者在性能优化、交互设计、音频处理和跨浏览器兼容等方面全方位发力。希望这些技术点能为你的 H5 开发之旅提供助力,让你的产品在激烈的市场竞争中脱颖而出!
来源:juejin.cn/post/7522090635908251686
做个大屏既要不留白又要不变形还要没滚动条,我直接怒斥领导,大屏适配就这四种模式
在前端开发中,大屏适配一直是个让人头疼的问题。领导总是要求大屏既要不留白,又要不变形,还要没有滚动条。这看似简单的要求,实际却压根不可能。今天,我们就来聊聊大屏适配的四种常见模式,以及如何根据实际需求选择合适的方案。
一、大屏适配的困境
在大屏项目中,适配问题几乎是每个开发者都会遇到的挑战。屏幕尺寸的多样性、设计稿与实际屏幕的比例差异,都使得适配变得复杂。而领导的“既要...又要...还要...”的要求,更是让开发者们感到无奈。不过,我们可以通过合理选择适配模式来尽量满足这些需求。
二、四种适配模式
在大屏适配中,常见的适配模式有以下四种:
(以下截图中模拟视口1200px*500px和800px*600px,设计稿为1920px*1080px)
1. 拉伸填充(fill)


- 特点:内容会被拉伸变形,以完全填充视口框。这种方式可以确保视口内没有空白区域,但可能会导致内容变形。
- 适用场景:适用于对内容变形不敏感的场景,例如全屏背景图。
2. 保持比例(contain)


- 特点:内容保持原始比例,不会被拉伸变形。如果内容的宽高比与视口不一致,会在视口内出现空白区域(黑边)。这种方式可以确保内容不变形,但可能会留白。
- 适用场景:适用于需要保持内容原始比例的场景,例如视频或图片展示。
3. 滚动显示(scroll)


- 特点:内容不会被拉伸变形,当内容超出视口时会添加滚动条。这种方式可以确保内容完整显示,但用户需要滚动才能查看全部内容。
- 适用场景:适用于内容较多且需要完整显示的场景,例如长列表或长文本。
4. 隐藏超出(hidden)


- 特点:内容不会被拉伸变形,当内容超出视口时会隐藏超出部分。这种方式可以避免滚动条的出现,但可能会隐藏部分内容。
- 适用场景:适用于内容较多但不需要完整显示的场景,例如仪表盘。
三、为什么不能同时满足所有要求?
这四种适配模式各有优缺点,但它们在逻辑上是相互矛盾的。具体来说:
- 不留白:要求内容完全填充视口,没有任何空白区域。这通常需要拉伸或缩放内容以适应视口的宽高比。
- 不变形:要求内容保持其原始宽高比,不被拉伸或压缩。这通常会导致内容无法完全填充视口,从而出现空白区域(黑边)。
- 没滚动条:要求内容完全适应视口,不能超出视口范围。这通常需要隐藏超出部分或限制内容的大小。
这三个要求在逻辑上是相互矛盾的:
- 如果内容完全填充视口(不留白),则可能会变形。
- 如果内容保持原始比例(不变形),则可能会出现空白区域(留白)。
- 如果内容超出视口范围,则需要滚动条或隐藏超出部分。
四、【fitview】插件快速实现大屏适配
fitview 是一个视口自适应的 JavaScript 插件,它支持多种适配模式,能够快速实现大屏自适应效果。
github地址:github.com/pbstar/fitv…
在线预览:pbstar.github.io/fitview
以下是它的基本使用方法:
配置
- el: 需要自适应的 DOM 元素
- fit: 自适应模式,字符串,可选值为 fill、contain(默认值)、scroll、hidden
- resize: 是否监听元素尺寸变化,布尔值,默认值 true
安装引入
npm 安装
npm install fitview
esm 引入
import fitview from "fitview";
cdn 引入
<script src="https://unpkg.com/fitview@[version]/lib/fitview.umd.js"></script>
使用示例
<div id="container">
<div style="width:1920px;height:1080px;"></div>
</div>
const container = document.getElementById("container");
new fitview({
el: container,
});
五、总结
大屏适配是一个复杂的问题,不同的项目有不同的需求。虽然不能同时满足“不留白”“不变形”和“没滚动条”这三个要求,但可以通过合理选择适配模式来尽量满足大部分需求。在实际开发中,我们需要根据项目的具体需求和用户体验来权衡,选择最合适的适配方案。
在选择适配方案时,fitview 这个插件可以提供很大的帮助。它支持多种适配模式,能够快速实现大屏自适应效果。如果你正在寻找一个简单易用的适配工具,fitview 值得一试。你可以通过 npm 安装或直接使用 CDN 引入,快速集成到你的项目中。
希望这篇文章能帮助你更好地理解和选择大屏适配方案。如果你有更多问题或建议,欢迎在评论区留言。
来源:juejin.cn/post/7513059488417497123
弃用 html2canvas!快 93 倍的截图神器!
作者:前端开发爱好者
原文:mp.weixin.qq.com/s/t0s5dCOrs…
在前端开发中,网页截图是个常用功能。从前,html2canvas 是大家的常客,但随着网页越来越复杂,它的性能问题也逐渐暴露,速度慢、占资源,用户体验不尽如人意。
好在,现在有了 SnapDOM,一款性能超棒、还原度超高的截图新秀,能完美替代 html2canvas,让截图不再是麻烦事。

什么是 SnapDOM
SnapDOM 就是一个专门用来给网页元素截图的工具。

它能把 HTML 元素快速又准确地存成各种图片格式,像 SVG、PNG、JPG、WebP 等等,还支持导出为 Canvas 元素。

它最厉害的地方在于,能把网页上的各种复杂元素,比如 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,甚至是动态效果的当前状态,都原原本本地截下来,跟直接看网页没啥两样。
SnapDOM 优势
快得飞起
测试数据显示,在不同场景下,SnapDOM 都把 html2canvas 和 dom-to-image 这俩老前辈远远甩在身后。

尤其在超大元素(4000×2000)截图时,速度是 html2canvas 的 93.31 倍,比 dom-to-image 快了 133.12 倍。这速度,简直就像坐火箭。
还原度超高
SnapDOM 截图出来的效果,跟在网页上看到的一模一样。
各种复杂的 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,还有动态效果的当前状态,都能精准还原。

无论是简单的元素,还是复杂的网页布局,它都能轻松拿捏。
格式任你选
不管你是想要矢量图 SVG,还是常用的 PNG、JPG,或者现代化的 WebP,又或者是需要进一步处理的 Canvas 元素,SnapDOM 都能满足你。

多种格式,任你挑选,适配各种需求。
怎么用 SnapDOM
安装
SnapDOM 的安装超简单,有好几种方式:
用 NPM 或 Yarn:在命令行里输
# npm
npm i @zumer/snapdom
# yarn
yarn add @zumer/snapdom
就能装好。
用 CDN 在 HTML 文件里加一行:
<script src="https://unpkg.com/@zumer/snapdom@latest/dist/snapdom.min.js"></script>
直接就能用。
要是项目里用的是 ES Module:
import { snapdom } from '@zumer/snapdom
基础用法示例
一键截图
const card = document.querySelector('.user-card');
const image = await snapdom.toPng(card);
document.body.appendChild(image);
这段代码就是找个元素,然后直接截成 PNG 图片,再把图片加到页面上。简单粗暴,一步到位。
高级配置
const element = document.querySelector('.chart-container');
const capture = await snapdom(element, {
scale: 2,
backgroundColor: '#fff',
embedFonts: true,
compress: true
});
const png = await capture.toPng();
const jpg = await capture.toJpg({ quality: 0.9 });
await capture.download({
format: 'png',
filename: 'chart-report-2024'
});
这儿可以对截图进行各种配置。比如 scale 能调整清晰度,backgroundColor 能设置背景色,embedFonts 可以内嵌字体,compress 能压缩优化。配置好后,还能把截图存成不同格式,或者直接下载到本地。
和其他库比咋样
和 html2canvas、dom-to-image 比起来,SnapDOM 的优势很明显:
| 特性 | SnapDOM | html2canvas | dom-to-image |
|---|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 准确度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文件大小 | 极小 | 较大 | 中等 |
| 依赖 | 无 | 无 | 无 |
| SVG 支持 | ✅ | ❌ | ✅ |
| Shadow DOM 支持 | ✅ | ❌ | ❌ |
| 维护状态 | 活跃 | 活跃 | 停滞 |
用的时候注意点
用 SnapDOM 时,有几点得注意:
跨域资源
要是截图里有外部图片等跨域资源,得确保这些资源支持 CORS,不然截不出来。
iframe 限制
SnapDOM 不能截 iframe 内容,这是浏览器的安全限制,没办法。
Safari 浏览器兼容性
在 Safari 里用 WebP 格式时,会自动变成 PNG。
大型页面截图
截超大页面时,建议分块截,不然可能会内存溢出。
SnapDOM 能干啥及代码示例
社交分享
async function shareAchievement() {
const card = document.querySelector('.achievement-card');
const image = await snapdom.toPng(card, { scale: 2 });
navigator.share({
files: [new File([await snapdom.toBlob(card)], 'achievement.png')],
title: '我获得了新成就!'
});
}
报表导出
async function exportReport() {
const reportSection = document.querySelector('.report-section');
await preCache(reportSection);
await snapdom.download(reportSection, {
format: 'png',
scale: 2,
filename: `report-${new Date().toISOString().split('T')[0]}`
});
}
海报导出
async function generatePoster(productData) {
document.querySelector('.poster-title').textContent = productData.name;
document.querySelector('.poster-price').textContent = `¥${productData.price}`;
document.querySelector('.poster-image').src = productData.image;
await new Promise((resolve) => setTimeout(resolve, 100));
const poster = document.querySelector('.poster-container');
const blob = await snapdom.toBlob(poster, { scale: 3 });
return blob;
}
写在最后
SnapDOM 就是这么一款简单、快速、准确,还零依赖的网页截图神器。
无论是社交分享、报表导出、设计保存,还是营销推广,它都能轻松搞定。
而且它是免费开源的,背后还有活跃的社区支持。要是你还在为网页截图的事儿发愁,赶紧试试 SnapDOM 吧。
要是你在用 SnapDOM 的过程中有啥疑问,或者碰上啥问题,可以去下面这些地方找答案:
- 项目地址 :github.com/zumerlab/sn…
- 在线演示 :zumerlab.github.io/snapdom/
- 详细文档 :github.com/zumerlab/sn…
来源:juejin.cn/post/7524740743165722634
别再用 100vh 了!移动端视口高度的终极解决方案
作为一名前端开发者,我们一定都遇到过这样的需求:实现一个占满整个屏幕的欢迎页、弹窗蒙层或者一个 fixed 定位的底部菜单。
直觉告诉我们,这很简单,给它一个 height: 100vh 就行了。
.fullscreen-element {
height: 100vh;
width: 100%;
color: #000;
display: flex;
justify-content: center;
align-items: center;
font-size: 10em;
background-color: #fff;
}
在PC端预览,完美!然而,当你在手机上打开时,可能会看到下面这个令人抓狂的场景:

明明是 100vh,为什么会超出屏幕高度?这个烦人的滚动条到底从何而来?
如果你也曾为此抓耳挠腮,那么恭喜你,这篇文章就是你的“终极答案”。今天,我将带你彻底搞懂 100vh 在移动端的“坑”,并为你介绍当下最完美的解决方案。
1. 问题根源:移动端动态变化的“视口”
要理解问题的本质,我们首先要明白 vh (Viewport Height) 单位的定义:1vh 等于视口高度的 1%。
在PC端,浏览器窗口大小是相对固定的,所以 100vh 就是浏览器窗口的可见高度,这没有问题。
但在移动端,情况变得复杂了。为了在有限的屏幕空间里提供更好的浏览体验,手机浏览器(尤其是Safari和Chrome)的地址栏和底部工具栏是动态变化的。
- 初始状态:当你刚进入页面时,地址栏和工具栏是完全显示的。
- 滚动时:当你向下滚动页面,这些UI元素会自动收缩,甚至隐藏,以腾出更多空间展示网页内容。
关键点来了:大多数移动端浏览器将 100vh 定义为“最大视口高度”,也就是当地址栏和工具栏完全收起时的高度。
这就导致了:
在页面初始加载、地址栏还未收起时,
100vh的实际计算高度 > 屏幕当前可见区域的高度。
于是,那个恼人的滚动条就出现了。

2. “过去式”的解决方案:JavaScript 动态计算
在很长一段时间里,前端开发者们只能求助于 JavaScript 来解决这个问题。思路很简单:通过 window.innerHeight 获取当前可见视口的高度,然后用它来动态设置元素的 height。
JavaScript
function setRealVH() {
const vh = window.innerHeight * 0.01;
document.documentElement.style.setProperty('--vh', `${vh}px`);
}
// 初始加载时设置
window.addEventListener('load', setRealVH);
// 窗口大小改变或旋转屏幕时重新设置
window.addEventListener('resize', setRealVH);
然后在 CSS 中这样使用:
CSS
.fullscreen-element {
height: calc(var(--vh, 1vh) * 100);
}
这个方案的缺点显而易见:
- 性能开销:监听
resize事件过于频繁,可能会引发性能问题。 - 逻辑耦合:纯粹的样式问题却需要JS来解决,不够优雅。
- 时机问题:执行时机需要精确控制,否则可能出现闪烁。
虽然能解决问题,但这绝不是我们想要的“终极方案”。
3. “现在时”的终极解决方案:CSS动态视口单位
谢天谢地,CSS 工作组听到了我们的呼声!为了解决这个老大难问题,CSS Values and Units Module Level 4 引入了一套全新的动态视口单位。
它们就是我们今天的“主角”:
svh(Small Viewport Height): 最小视口高度。对应于地址栏和工具栏完全展开时的可见高度。lvh(Large Viewport Height): 最大视口高度。对应于地址栏和工具栏完全收起时的高度(这其实就等同于旧的100vh)。dvh(Dynamic Viewport Height): 动态视口高度。这是最智能、最实用的单位!它的值会随着浏览器UI元素(地址栏)的出现和消失而动态改变。
所以,我们的终极解决方案就是:
CSS
.fullscreen-element {
height: 100svh; /* 如果你希望高度固定,且永远不被遮挡 */
/* 或者,也是我最推荐的 */
height: 100dvh; /* 如果你希望元素能动态地撑满整个可见区域 */
}
使用 100dvh,当地址栏收起时,元素高度会平滑地增加以填满屏幕;当地址栏滑出时,元素高度又会平滑地减小。整个过程如丝般顺滑,没有任何滚动条,完美!
浏览器兼容性
你可能会担心兼容性问题。好消息是,从2023年开始,所有主流现代浏览器(Safari, Chrome, Edge, Firefox)都已经支持了这些新的视口单位。


(数据截至2025年6月,兼容性已非常好)
可以看到,兼容性已经非常理想。除非你需要支持非常古老的浏览器版本,否则完全可以放心地在生产环境中使用。
告别 100vh 的时代
让我们来快速回顾一下:
- 问题:在移动端,
100vh通常被解析为“最大视口高度”,导致在浏览器UI未收起时内容溢出。 - 旧方案:使用 JavaScript 的
window.innerHeight动态计算,但有性能和维护问题。 - 终极方案:使用CSS新的动态视口单位,尤其是
100dvh,它能根据浏览器UI的变化自动调整高度,完美解决问题。
当需要实现移动端全屏布局时,请大胆地告别 100vh,拥抱 100dvh!
来源:juejin.cn/post/7520548278338322483
为什么响应性语法糖最终被废弃了?尤雨溪也曾经试图让你不用写 .value
你将永远需要在 Vue3 中写
.value
前言
相信有不少新手在初次接触 Vue3 的组合式 API 时都会产生一个疑问:”为什么一定要写 .value ?",一些 Vue3 老玩家也认为到处写 .value 十分不优雅。
那么有没有办法能不用写 .value 呢?有的兄弟,至少曾经有的,那就是响应性语法糖,可惜在 Vue 3.4 之后已经被移除了。
响应性语法糖是如何实现免去 .value 的?这一特性为何最终被废弃了呢?
响应性语法糖
Vue 的响应性语法糖是一个编译时的转换步骤,让我们可以像这样书写代码:
<script setup>
let count = $ref(0)
console.log(count)
function increment() {
count++
}
</script>
<template>
<button @click="increment">{{ count }}</button>
</template>
这里的 $ref() 方法是一个编译时的宏命令:它不是一个真实的、在运行时会调用的方法,而是用作 Vue 编译器的标记。使用 $ref() 声明的响应式变量可以直接读取与修改,无需 .value。
上面例子中 <script> 部分的代码会被编译成下面这样,在代码中自动加上 .value:
import { ref } from 'vue'
let count = ref(0)
console.log(count.value)
function increment() {
count.value++
}
每一个会返回 ref 的响应式 API 都有一个相对应的、以 $ 为前缀的宏函数。包括以下这些 API:
ref->$refcomputed->$computedshallowRef->$shallowRefcustomRef->$customReftoRef->$toRef
通过 $() 解构
当一个组合式函数返回包含数个 ref 的对象,我们希望解构得到这些 ref,并且在后续使用它们时也不用写 .value 时,可以使用 $() 这个宏:
import { useMouse } from '@vueuse/core'
const { x, y } = $(useMouse())
// x,y 和用 $ref 声明的响应式变量一样,不用写 .value
console.log(x, y)
通过 $$() 防止响应性丢失
假设有一个期望接收一个 ref 对象为参数的函数:
function trackChange(x: Ref<number>) {
watch(x, (x) => {
console.log('x 改变了!')
})
}
let count = $ref(0)
trackChange(count) // 无效!
上面的例子不会正常工作,因为代码被编译成了这样子:
let count = ref(0)
trackChange(count.value)
trackChange 函数期望接收的参数是一个 ref 类型值,而我们传入的 count.value 实际是一个 number 类型。
对于一个使用 $ref() 声明的响应式变量,当我们希望获取到它的原始 ref 值时,可以使用 $$()。
我们将上述例子改写为:
let count = $ref(0)
- trackChange(count)
+ trackChange($$(count))
此时代码可以正常工作,不会再丢失响应性了。
看到这里,聪明的你可能已经意识到了问题:使用响应性语法糖的初衷是为了免去到处写
.value的麻烦,结果现在新引入了$ref()、$()、$(),各自还有不同的使用场景,不是更麻烦了吗?
废弃原因
最终,在收集了大量来自社区的反馈后,经过 Vue 核心团队全员投票,决定移除这一特性。在 Vue 3.3 版本中使用会报 warning,从 3.4 版本开始正式移除。
尤雨溪本人也在 github 上发表了决定将响应性语法糖移除的根本原因,链接:github.com/vuejs/rfcs/…
原文是英语,担心有小伙伴可能看不懂,在这里简单翻译一下:
响应性语法糖的初衷是提供一些简练的语法提升开发体验。我们将它作为实验特性发布并在真实场景的使用中获得反馈。尽管它有一些好处,但我们还是发现了下列问题:
- 没有
.value使得难以辨认响应式变量的读取和设置。这个问题在 SFC 中可能不那么明显,但是在大型项目中会造成心智负担的明显增大,尤其是在 SFC 外也使用此语法时。
- 因为第一条,一些开发者倾向于只在 SFC 中使用响应性语法糖,这就造成了代码的不一致性以及在不同心智模型间切换的成本。这是一个进退两难的窘境:只在 SFC 中使用会造成不一致性,而在 SFC 之外使用则会降低可维护性。
- 既然总有外部函数会使用原始 ref,那么在响应性语法糖与原始 ref 之间的转换是不可避免的。这就产生了另一个需要学习的东西以及额外的认知负担,并且我们发现这会比纯粹的组合式 API 更让初学者感到困惑。
最重要的是,响应性语法糖会带来代码风格分裂的潜在危险。尽管这一功能是自愿使用的,一些使用者还是强烈反对该提议,因为他们不想维护用了语法糖和没用两种风格的代码。这确实值得担心因为使用响应性语法糖需要的心智模型违背了 JavaScript 的基本语义(对变量赋值会触发响应式副作用)。
在考虑了所有因素之后,我们认为将它发布为一个稳定功能带来的问题会大于收益。
结语
在 Vue3 发布之初,Vue 核心团队就考虑到了 ref 需要到处使用 .value 的繁琐,推出了响应性语法糖试图解决这一问题。
响应性语法糖提供了一系列编译器宏,让开发者在书写代码时不必使用 .value,而是在编译阶段由编译器自动加上。
最终,出于代码风格一致性和可维护性上的考量,这一特性最终在 Vue 3.4 版本被正式废弃。
来源:juejin.cn/post/7523231174620102671
为什么 Go 语言非常适合开发 AI Agent
原文:Alexander Belanger - 2025.06.03
如同地球上几乎所有人一样,过去的几个月里,我们也一直在关注着 Agent 的发展。
特别值得一提的是,我们观察到 Agent 的采用推动了我们编排平台的增长,这让我们对哪些技术栈和框架——或者干脆没有框架——在此领域表现良好有了一些见解。
我们看到的一个更有趣的现象是混合技术栈的激增:一个典型的 Next.js 或 FastAPI 后端,搭配着一个用 Go 语言编写的 Agent,甚至在非常早期阶段就如此。
作为一名长期的 Go 语言开发者,这着实令人兴奋;下面我将解释为何我认为这将成为未来更普遍的做法。
什么是 Agent?
这里的术语有些混乱,但通常我指的是一个在循环中执行的进程,该进程对其执行路径中的下一步操作拥有一定的自主权。这与预定义的执行路径(例如定义为有向无环图的一组步骤,我们称之为工作流)形成对比。Agent 通常包含一个基于最大深度或满足某个条件(如“测试通过”)的退出条件。

当 Agent 开始规模化(即:拥有实际用户)时,它们通常具有一些共同特征:
- 它们是长时间运行的——从几秒到几分钟甚至几小时不等。
- 每次执行的成本都很高——不仅仅是 LLM 调用的成本,Agent 的本质是取代通常需要人工操作员完成的任务。开发环境、浏览器基础设施、大型文档处理——这些都花费 $$$ 钱的。
- 在它们的执行周期中,经常需要在某个时刻接收用户(或另一个 Agent!)的输入。
- 它们花费大量时间等待 I/O 或人类输入。
让我们将这一系列特征转化为对运行时的要求。为了限定问题范围,假设我们正在处理一个在远程执行的 Agent,而非在用户本地机器上(尽管 Go 对于分发本地 Agent 也是一个绝佳选择)。在远程执行的情况下,为每次 Agent 执行运行一个单独的容器成本会高得惊人。因此,在大多数情况下(尤其是当我们的 Agent 主要是简单的 I/O 和 LLM 调用时),我们最终会得到大量并发运行的轻量级进程。每个进程可以处于特定状态(例如,“搜索文件中”、“生成代码中”、“测试中”)。请注意,不同 Agent 执行的状态顺序可能并不相同。

这种包含许多并发、长时间运行进程的系统,与大约十年前的传统 Web 架构截然不同。在传统架构中,对服务器的请求处理速度要快得多,使用一些缓存、高效的处理程序和 OLTP 数据库就能高效地服务数千名日活用户。
事实证明,这种架构转变非常适合 Go 语言的并发模型、依赖通道(channel)进行通信、集中的取消机制以及围绕 I/O 构建的工具链。
高并发性
让我们从最明显的一点开始——Go 拥有极其简单且强大的并发模型。创建一个新的 goroutine 所需的内存和时间成本非常低,因为每个 goroutine 只有 2KB 的预分配内存。

这实际上意味着你可以同时运行许多 goroutine 而开销很小,并且它们在底层运行在多个操作系统线程上,能够利用服务器中的所有 CPU 核心。这一点非常重要,因为如果你碰巧在某个 goroutine 中执行非常消耗 CPU 的操作(比如反序列化一个大型 JSON 结构),其影响会比你使用单线程运行时(如 Node.js)要小(在 Node.js 中,你需要为阻塞线程的操作创建 worker 线程或子进程),或者比使用 Python 的 async/await 也要好。
这对于 Agent 意味着什么?因为 Agent 的运行时间比典型的 Web 请求长得多,所以并发性就成为了一个更关键的问题。在 Go 中,相比于在 Python 中为每个 Agent 运行一个线程,或者在 Node.js 中为每个 Agent 运行一个 async 函数,你受到为每个 Agent 生成一个 goroutine 的限制要小得多。再加上较低的基础内存占用和编译成单一二进制文件的特点,在轻量级基础设施上同时运行数千个并发 Agent 执行变得异常简单。
通过通信共享内存
对于那些不了解的人,Go 语言有一个常见的习语:不要通过共享内存来通信;相反,通过通信来共享内存。
在实践中,这意味着不需要尝试跨多个并发进程同步内存内容(这是使用类似 Python 的 multithreading 库时的常见问题),每个进程可以通过在通道(channel)上获取和释放对象来获得该对象的所有权。这样做的效果是,每个进程只在拥有对象所有权时关心该对象的本地状态,而其他时候不需要协调所有权——无需互斥锁(mutex)!
老实说——在我编写过的大多数 Go 程序中,我使用等待组(wait groups)和互斥锁(mutexes)的次数往往比使用通道(channels)更多,因为这样通常更简单(这也符合 Go 社区的建议),并且只有一个地方需要并发访问数据。
但是,在建模 Agent 时,这种范式非常有用,因为 Agent 通常需要异步响应用户或其他 Agent 发来的消息,并且将应用程序实例视为一个 Agent 池来思考是很有帮助的。
为了更具体说明,让我们编写一些示例代码来表示 Agent 循环的核心逻辑:
// 注意:在真实世界的例子中,我们需要一种机制来优雅地
// 关闭循环并防止通道关闭;
// 这是一个简化示例。
func Agent(in <-chan Message, out chan<- Output, status chan<- State) {
internal := make(chan Message, 10) // 内部缓冲区大小为 10 的通道
for {
select {
case msg := <-internal: // 从内部通道读取消息
processMessage(msg, internal, out, status)
case msg := <-in: // 从外部输入通道读取消息
processMessage(msg, internal, out, status)
}
}
}
func processMessage(msg Message, internal chan<- Message, out chan<- Output, status chan<- State) {
result := execute(msg) // 执行消息处理
status <- State{msg.sessionId, result.status} // 发送状态更新
if next := result.next(); next != nil { // 获取下一步消息(如果有)
internal <- next // 将下一步消息发送到内部通道
}
out <- result // 发送处理结果
}
(请注意,<-chan 表示接收者只能从通道读取,而 chan<- 表示接收者只能向通道写入。)
这个 Agent 是一个长时间运行的进程,它等待消息到达 in 通道,处理消息,然后异步地将结果发送到 out 通道。status 通道用于发送关于 Agent 状态的更新,这对于监控或向用户发送增量结果很有用;而 internal 通道用于处理 Agent 的内部循环。例如,内部循环可以实现下图中的“直到测试通过”循环:

尽管我们使用 for 循环来运行 Agent,但该 Agent 的实例在消息之间不需要维护任何内部状态。它本质上是一个无状态归约器,其决策执行路径的下一步操作不依赖于某些内部状态。重要的是,这意味着任何 Agent 实例都能够处理下一条消息。这也允许 Agent 在消息之间使用持久化边界,例如将消息写入数据库或消息队列。
使用 context.Context 的集中取消机制
还记得 Agent 执行成本很高吗?假设一个用户触发了一个价值 10 美元的执行任务,但突然改变主意并点击“停止生成”——为了节省成本,你希望取消这次执行。
事实证明,在 Node.js 和 Python 中取消长时间运行的工作极其困难,原因有很多:
- 库之间缺乏统一的取消机制——虽然两种语言都支持中止信号(AbortSignal)和控制器(Controller),但这并不能保证你调用的第三方库会尊重这些信号。
- 如果信号取消失败,强行终止线程是个痛苦的过程,并可能导致线程泄漏或资源损坏。
幸运的是,Go 采用 context.Context 使得取消工作变得轻而易举,因为绝大多数库都预期并尊重这种模式。即使某些库不支持:由于 Go 只有一种并发模型,因此有像 goleak 这样的工具,可以更容易地检测出泄漏的 goroutine 和有问题的库。
丰富的标准库
当你开始使用 Go 时,你会立即注意到 Go 的标准库非常丰富且质量很高。它的许多部分也是为 Web I/O 构建的——比如 net/http、encoding/json 和 crypto/tls——这些对于 Agent 的核心逻辑非常有用。
Go 还有一个隐含的假设:所有 I/O 在 goroutine 内部都是阻塞的——再次强调,因为 Go 只有一种方式运行并发工作——这鼓励你将业务逻辑的核心编写为直线式程序。你不需要担心用 await 包装每个函数调用来将执行推迟给调度器。
与 Python 对比:库开发者需要考虑 asyncio、多线程(multithreading)、多进程(multiprocessing)、eventlet、gevent 以及其他一些模式,几乎不可能同等地支持所有并发模型。因此,如果你用 Python 编写 Agent,你需要研究每个库对你所采用的并发模型的支持情况,并且如果你的第三方库不完全支持你想要的模式,你可能需要采用多种模式。
(Node.js 的情况要好得多,尽管 Bun 和 Deno 等其他运行时的加入增加了一些不兼容的层面。)
性能剖析(Profiling)
由于其有状态性(statefulness)和大量长时间运行的进程,Agent 似乎特别容易出现内存泄漏和线程泄漏。Go 在 runtime/pprof 中提供了出色的工具,可以使用堆(heap)和分配(alloc)配置文件找出内存泄漏的来源,或者使用 goroutine 配置文件找出 goroutine 泄漏的来源。

额外优势:LLM 擅长编写 Go 代码
由于 Go 语法非常简单(一个常见的批评是 Go 有点“啰嗦”)并且拥有丰富的标准库,LLM 非常擅长编写符合 Go 语言习惯的代码。我发现它们在编写表格测试(table tests)方面尤其出色,这是 Go 代码库中的一种常见模式。
Go 工程师也往往反对框架(anti-framework),这意味着 LLM 不需要跟踪你使用的是哪个框架(或框架的哪个版本)。
不足之处
尽管有以上诸多好处,仍然有很多理由让你可能不会选择 Go 来开发你的 Agent:
- 第三方库支持仍然落后于 Python 和 Typescript。
- 使用 Go 进行任何涉及真正机器学习(real machine learning)的工作几乎是不可能的。
- 如果你追求最佳性能,那么有比 Go 更好的语言,如 Rust 和 C++。
- 你特立独行,不喜欢(显式)处理错误。
来源:juejin.cn/post/7514621534339055631
纯前端用 TensorFlow.js 实现智能图像处理应用(一)
随着人工智能技术的不断发展,图像处理应用已经在医疗影像分析、自动驾驶、视频监控等领域得到广泛应用。TensorFlow.js 是 Google 开源的机器学习库 TensorFlow 的 JavaScript 版本,能够让开发者在浏览器中运行机器学习模型,在前端应用中轻松实现图像分类、物体检测和姿态估计等功能。本文将介绍如何使用 TensorFlow.js 在纯前端环境中实现这三项任务,并帮助你构建一个智能图像处理应用。
什么是 TensorFlow.js?
TensorFlow.js 是一个能够让开发者在前端直接运行机器学习模型的 JavaScript 库。它允许你无需将数据发送到服务器,便可以在浏览器中运行模型进行推理,这不仅减少了延迟,还可以更好地保护用户的隐私数据。通过 TensorFlow.js,前端开发者能够轻松实现图像分类、物体检测和姿态估计等功能。
TensorFlow.js 的应用非常广泛,尤其是在一些实时交互和隐私敏感的场景下,例如 医疗影像分析、自动驾驶 和 智能监控。在这些领域,前端模型推理能够提升响应速度,并且避免将用户的数据上传到服务器,从而保护用户的隐私。
要开始使用 TensorFlow.js,你需要安装相关的模型库。以下是你需要安装的 npm 包:
npm install @tensorflow/tfjs
npm install @tensorflow-models/mobilenet
npm install @tensorflow-models/coco-ssd
npm install @tensorflow-models/posenet
加载预训练模型
在 TensorFlow.js 中,加载预训练模型非常简单。首先,确保 TensorFlow.js 已经准备好,然后加载所需的模型进行推理。
// 导入
import * as tf from '@tensorflow/tfjs'
// 加载
tf.ready(); // 确保 TensorFlow.js 准备好
用户上传图片
为了使用这些模型进行推理,我们需要让用户上传一张图片。以下是一个处理图片上传的代码示例:
const handleImageUpload = async (event) => {
const file = event.target.files[0]
if (file) {
const reader = new FileReader()
reader.onload = async (e) => {
imageSrc.value = e.target.result
await runModels(e.target.result)
}
reader.readAsDataURL(file)
}
}
图像分类:识别图片中的物体
图像分类是计算机视觉中的基本任务,目的是将输入图像归类到某个类别中。例如,我们可以用图像分类模型识别图像中的“猫”还是“狗”。


使用预训练模型进行图像分类
TensorFlow.js 提供了多个预训练模型,MobileNet 是其中一个常用的图像分类模型。它是一个轻量级的卷积神经网络,适合用来进行图像分类。接下来,我们通过 MobileNet 实现一个图像分类功能:
const mobilenetModel = await mobilenet.load()
const predictions = await mobilenetModel.classify(image)
classification.value = `分类结果: ${predictions[0].className}, 信心度: ${predictions[0].probability.toFixed(3)}`
这段代码实现了图像分类。我们加载 MobileNet 模型,并对用户上传的图像进行推理,最后返回图像的分类结果。
物体检测:找出图像中的所有物体
物体检测不仅仅是识别图像中的物体是什么,还需要标出它们的位置,通常用矩形框来框住物体。Coco-SSD 是一个强大的物体检测模型,能够在图像中检测出多个物体并标出它们的位置。
使用 Coco-SSD 进行物体检测
const cocoModel = await cocoSsd.load();
const detectionResults = await cocoModel.detect(image);
objects.value = detectionResults.map((prediction) => ({
class: prediction.class,
bbox: prediction.bbox,
}));
通过 Coco-SSD 模型,我们可以检测图像中的多个物体,并标出它们的位置。
绘制物体的边界框
为了更直观地展示检测结果,我们可以在图像上绘制出物体的边界框:
// 绘制物体检测边界框
const drawObjects = (detectionResults, image) => {
nextTick(() => {
const ctx = objectCanvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
objectCanvas.value.width = imageWidth
objectCanvas.value.height = imageHeight
ctx.clearRect(0, 0, objectCanvas.value.width, objectCanvas.value.height)
ctx.drawImage(image, 0, 0, objectCanvas.value.width, objectCanvas.value.height)
// 绘制边界框
detectionResults.forEach((prediction) => {
const [x, y, width, height] = prediction.bbox
ctx.beginPath()
ctx.rect(x, y, width, height)
ctx.lineWidth = 2
ctx.strokeStyle = 'green'
ctx.stroke()
// 添加标签
ctx.font = '16px Arial'
ctx.fillStyle = 'green'
ctx.fillText(prediction.class, x + 5, y + 20)
})
})
}
这段代码通过绘制边界框来标出检测到的物体位置,同时在边界框旁边显示物体类别。
姿态估计:识别人体的关键点
姿态估计主要是识别人类的身体部位,例如头部、手臂、腿部等。通过这些关键点,我们可以了解一个人当前的姿势。TensorFlow.js 提供了 PoseNet 模型来进行姿态估计。

使用 PoseNet 进行姿态估计
// 加载 PoseNet 模型
const posenetModel = await posenet.load()
const poseResult = await posenetModel.estimateSinglePose(image, {
flipHorizontal: false
})
// 人体关键点
pose.value = poseResult.keypoints.map((point) => `${point.part}: (${point.position.x.toFixed(2)}, ${point.position.y.toFixed(2)})`)
PoseNet 模型会估计图像中人物的关键点,并返回每个关键点的位置。
绘制姿态估计骨架图
const drawPose = (keypoints, image) => {
nextTick(() => {
const ctx = canvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
canvas.value.width = imageWidth
canvas.value.height = imageHeight
ctx.clearRect(0, 0, canvas.value.width, canvas.value.height)
// 绘制图像
ctx.drawImage(image, 0, 0, canvas.value.width, canvas.value.height)
const scaleX = canvas.value.width / image.width
const scaleY = canvas.value.height / image.height
// 绘制关键点并标记名称
keypoints.forEach((point) => {
const { x, y } = point.position
const scaledX = x * scaleX
const scaledY = y * scaleY
ctx.beginPath()
ctx.arc(scaledX, scaledY, 5, 0, 2 * Math.PI)
ctx.fillStyle = 'red'
ctx.fill()
// 标记点的名称
ctx.font = '12px Arial'
ctx.fillStyle = 'blue'
ctx.fillText(point.part, scaledX + 8, scaledY)
})
// 连接骨架
const poseConnections = [
['leftShoulder', 'rightShoulder'],
['leftShoulder', 'leftElbow'],
['leftElbow', 'leftWrist'],
['rightShoulder', 'rightElbow'],
['rightElbow', 'rightWrist'],
['leftHip', 'rightHip'],
['leftShoulder', 'leftHip'],
['rightShoulder', 'rightHip'],
['leftHip', 'leftKnee'],
['leftKnee', 'leftAnkle'],
['rightHip', 'rightKnee'],
['rightKnee', 'rightAnkle'],
['leftEye', 'rightEye'],
['leftEar', 'leftShoulder'],
['rightEar', 'rightShoulder']
]
poseConnections.forEach(([partA, partB]) => {
const keypointA = keypoints.find((point) => point.part === partA)
const keypointB = keypoints.find((point) => point.part === partB)
if (keypointA && keypointB && keypointA.score > 0.5 && keypointB.score > 0.5) {
const scaledX1 = keypointA.position.x * scaleX
const scaledY1 = keypointA.position.y * scaleY
const scaledX2 = keypointB.position.x * scaleX
const scaledY2 = keypointB.position.y * scaleY
ctx.beginPath()
ctx.moveTo(scaledX1, scaledY1)
ctx.lineTo(scaledX2, scaledY2)
ctx.lineWidth = 2
ctx.strokeStyle = 'blue'
ctx.stroke()
}
})
})
}
这段代码通过 PoseNet 返回的人体关键点信息,绘制人体姿态的骨架图,帮助用户理解图像中的人物姿势。

总结
通过 TensorFlow.js,我们可以轻松地将图像分类、物体检测和姿态估计等功能集成到前端应用中,无需依赖后端计算,提升了应用的响应速度并保护了用户隐私。在本文中,我们介绍了如何使用 MobileNet、Coco-SSD 和 PoseNet 等预训练模型,在前端实现智能图像处理应用。无论是开发图像识别应用还是增强现实应用,TensorFlow.js 都是一个强大的工具,值得前端开发者深入学习和使用。
来源:juejin.cn/post/7437392938441687049
AI独角兽团队Manus裁员80人,剩下40人迁至新加坡总部!
大家好,我是程序员小灰。
大家是否还记得,今年3月份横空出世的AI产品Manus?

Manus号称是全球首款通用Agent的产品,它刚刚上线的时候在AI圈子里红极一时,许多人都在争抢Manus的内测激活码,这些内测码甚至在闲鱼平台被炒到了10万元!
小灰一直没有机会真正使用Manus,但我看过许多网友的演示视频,虽然这款Agent产品没有发布会上说的那么神奇,存在种种瑕疵,但是在某种程度上确实可以帮助人们解决一些流程化的工作。
在当时,Manus不止在国内受到追捧,也受到了全世界的关注。在4月25日,Manus母公司蝴蝶效应获得了美国风险投资公司Benchmark领投的7500万美元融资。
包括小灰在内的许多同行都认为,Manus一定会在资本的加持下继续做大做强,成为中国甚至全世界的AI Agent领军人。
可是万万没想到,在7月8日这一天,Manus团队被爆出了裁员消息。Manus在中国区大约有120名员工,其中40多位核心员工被迁往新加坡总部,剩下80人左右将被裁员,补偿方案是N+3或者2N。
仅仅4个月的时间,Manus就从刚刚诞生时候的辉煌走到了如今的局面,难怪圈子里都在说:AI一天,人间十年。
那么,Manus为什么会面临裁员呢?主要有三个原因:
1.政策影响
2025年1月生效的《对外投资安全计划》限制美元基金对中国AI企业的投资,Manus的主要投资方Benchmark在审查压力下,被迫要求Manus迁出中国。
2.芯片断供
从去年开始,美国商务部就禁止向中国大陆客户供应AI芯片,到了今年年初,禁令执行越来越严格,这对Manus的打击是致命的。Manus研发负责人也在内部会议中坦承,因无法及时获取英伟达最新AI芯片,智能体的迭代升级进度被迫延缓。
3.成本问题
Manus从今年3月底开始向用户收费,基础版每月39美元,高级版每月199美元。相比于国内很多物美价廉的AI产品,Manus收费真的很贵。
但是从Manus官方的角度,他们的运营成本也确实很高,目前的收费根本无法覆盖运营成本。再加上国内又诞生了扣子空间这样的平替产品,导致Manus用户增长乏力,无法形成规模效应。
Manus如今的结局是令人遗憾的,但是像DeepSeek和Manus这样了不起的产品,也让全世界看到了中国AI的希望。
小灰相信,中国AI行业的未来发展只会越发迅猛,今后一定会有越来越多优秀的AI产品走进大众的视野,让全世界的人们看到我们中国人的智慧和努力。
大家对Manus裁员和迁移新加坡这件事怎么看?欢迎在留言区说出你的想法。
来源:juejin.cn/post/7524931208746975270
我为什么放弃了“大厂梦”,去了一家“小公司”?
我,前端八年。我的履历上,没有那些能让HR眼前一亮的名字,比如字节、阿里,国内那些头部的互联网公司。
“每个程序员都有一个大厂梦”,这句话我听了八年。说实话,我也有过,而且非常强烈。
刚毕业那几年,我把进大厂当作唯一的目标。我刷过算法题,背过“八股文”,也曾一次次地在面试中被刷下来。那种“求之不得”的滋味,相信很多人都体会过。
但今天,我想聊的是,我是如何从一开始的“执念”,到后来的“审视”,再到现在的“坦然”,并最终心甘情愿地在一家小公司里,找到了属于我自己的价值。
这是一个普通的、三十多岁的工程师,与自己和解的经历。
那段“求之不得”的日子
我还记得大概四五年前,是我冲击大厂最疯狂的时候。
市面上所有关于React底层原理、V8引擎、事件循环的面经,我都能倒背如流。我把LeetCode热题前100道刷了两遍,看到“数组”、“链表”这些词,脑子里就能自动冒出“双指针”、“哈希表”这些解法。
我信心满满地投简历,然后参加了一轮又一轮的面试。
结果呢?大部分都是在三轮、四轮之后,收到一句“感谢您的参与,我们后续会保持联系”。我一次次地复盘,是我哪里没答好?是项目经验不够亮眼?还是算法题的最优解没写出来?
那种感觉很糟糕。你会陷入一种深深的自我怀疑,觉得自己的能力是不是有问题,是不是自己“不配”进入那个“高手如云”的世界。
开始问自己:“大厂”真的是唯一的出路吗?
在经历了一段密集而失败的面试后,我累了,也开始冷静下来思考。
我观察身边那些成功进入大厂的朋友。他们确实有很高的薪水和很好的福利,但他们也常常在半夜的朋友圈里,吐槽着无休止的会议、复杂的流程、以及自己只是庞大系统里一颗“螺丝钉”的无力感。
我看到他们为了一个需求,要跟七八个不同部门的人“对齐”;看到他们写的代码,90%都是在维护内部庞大而陈旧的系统;看到他们即使想做一个小小的技术改进,也要经过层层审批。
我突然问自己:这真的是我想要的生活吗?我想要的是什么?
当我把这些想清楚之后,我发现,大厂的光环,对我来说,好像没那么耀眼了。
在“小公司”,找到了意想不到的“宝藏”
后来,我加入了一家规模不大的科技公司。在这里,我确实找到了我想要的东西。
成了一个“产品工程师”,而不仅仅是“前端工程师”
在小公司,边界是模糊的。
我不仅要写前端代码,有时候也得用Node.js写一点中间层。我需要自己去研究CI/CD,把自动化部署的流程跑起来。我甚至需要直接跟客户沟通,去理解他们最原始的需求。
这个过程很“野”,也很累,但我的成长是全方位的。我不再只关心页面好不好看,我开始关心整个产品的逻辑、服务器的成本、用户的留存。我的视野被强制性地拉高了。
“影响力”被无限放大
在这里,我就是前端的负责人。
用Vue还是React?用Tailwind CSS还是CSS Modules?这些技术决策,我能够和老板、和团队一起讨论,并最终拍板。我们建立的每一个前端规范,写的每一个公共组件,都会立刻成为整个团队的标准。
这种“规则制定者”的身份,和在大厂当一个“规则遵守者”,是完全不同的体验。你能清晰地看到自己的每一个决定,都对产品和团队产生了直接而深远的影响。
离“价值”更近了
最重要的一点是,我能非常直接地感受到自己工作的价值。
我花一周时间开发的新功能上线后,第二天就能从运营同事那里拿到用户的反馈数据。我知道用户喜不喜欢它,它有没有帮助公司赚到钱。这种即时的、正向的反馈,比任何KPI或者年终奖金,更能给我带来成就感。
还会羡慕那些在大厂的朋友吗?
当然会。我羡慕他们优厚的薪酬福利,羡慕他们能参与到改变数亿人的项目中去。
但我不再因此而焦虑,也不再因此而自我否定。
你可以多想一想你真正想要的是什么? 一个公司的名字,并不能定义你作为一名工程师的价值。你的价值,体现在你写的代码里,体现在你解决的问题里,也有可能体现在你创造的产品里。
找到一个能让你发光发热的地方,比挤进一个让你黯淡无光的地方,重要得多。
分享完毕。谢谢大家🙂
来源:juejin.cn/post/7525011608366579758
网易微前端架构实战:如何管理100+子应用而不崩
你知道网易有多少个前端项目吗?
超过 1000 个代码仓库、200+子应用、每天发布300次。
如果没有一套微前端治理系统,项目早炸了。
今天就来带你拆解网易微前端架构的核心——基座 + 动态加载 + 权限隔离 + 独立发布。
一、网易为什么早早就用上了微前端?
因为早年起就有大量频道、游戏门户、社区运营、CMS后台等:
- 功能多样、团队独立
- 迭代频繁、部署不可等待
- 技术栈各异:Vue2、Vue3、React、甚至还有 jQuery...
👇于是他们选择了模块化能力最强的方案:微前端架构(Micro Frontends)
二、整体架构图(网易实战版)

三、主子应用通信怎么做?(网易方案)
网易没有用 qiankun,而是基于内部封装的微前端 SDK,核心原理类似。
// 主应用提供通信桥
window.__MICRO_APP_EVENT_BUS__ = new EventTarget()
// 子应用监听事件
window.__MICRO_APP_EVENT_BUS__.addEventListener('global-refresh', () => {
window.location.reload()
})
// 主应用触发事件
window.__MICRO_APP_EVENT_BUS__.dispatchEvent(new Event('global-refresh'))
👉这种方式:
- 不侵入框架(Vue/React 通吃)
- 不耦合代码,只用浏览器原生事件系统
四、部署与权限如何统一管理?
网易配套了一整套“发布平台 + 权限系统”,做到:
| 功能 | 说明 |
|---|---|
| 独立部署 | 每个子应用都有独立 Jenkins/流水线 |
| 权限接入 | 每个子应用上线必须绑定角色权限模块 |
| 域名配置 | 主应用统一路由配置,动态注入 iframe 或模块 |
| 沙箱运行 | 子应用运行在 iframe + ShadowDOM + CSP 下,完全隔离 |
五、实战代码:子应用注册和加载
// 主应用注册子应用(JSON 配置化)
const microAppList = [ { name: 'content-manage', entry: 'https://cdn.xxx.com/apps/content-manage/index.html', activeRule: '/content' }, { name: 'user-center', entry: 'https://cdn.xxx.com/apps/user-center/index.html', activeRule: '/user' }]
// 动态加载示例(简化版)
function loadMicroApp(appConfig) {
const iframe = document.createElement('iframe')
iframe.src = appConfig.entry
iframe.style = 'width:100%;height:100%;border:none'
document.getElementById('micro-container').appendChild(iframe)
}
六、网易踩过的3个坑(干货!)
| 坑 | 解决方案 |
|---|---|
| 子应用样式污染 | 每个子应用编译时加 prefixCls,搭配 ShadowDOM 隔离 |
| 子应用登录状态不一致 | 所有项目统一通过 Cookie + SSO 网关授权 |
| 子应用发布顺序冲突 | 发布系统支持灰度 + 停发自动依赖检查 |
七、总结:你能从中学到什么?
- 不要迷信 qiankun,自己也能搞微前端(原理简单)
- 微前端不仅是技术,更是权限、部署、治理一整套体系
- 想要稳定运行,必须有主子应用契约 + 灰度发布 + 统一通信策略
尾声:
“你看到的稳定,其实是他们踩了无数坑后的优雅。”
来源:juejin.cn/post/7510653719672094739
30+程序员如何不被小事击垮
引言
老张最近有一个重点项目在推进,他准备今天回家加班赶赶进度。
可到家之后,发现孩子发烧了,由于妻子出差,他赶紧放下手头的事情,抱起带孩子往医院跑。
堵车、吃饭、挂号、排队,一路折腾下来,已经九点了。
可就是这个点,儿科急诊仍是人山人海。孩子好奇的问东问西,手机里还不断跳出加急的消息,老张焦急的不断盘算着还有多久能排到他们。
马上到老张了,突然有一个人抱着孩子挤进了医生房间,老张愣了一下,火一下子就上来了,冲进屋子和对方吵了起来......
幸运的是孩子没什么事,可老张熬了一晚上啥也没干成。第二天上班状态不好,和业务方沟通时及其不耐烦。
下午收到了业务方的投诉,理由是态度消极。
老张一天什么也没干,却感觉自己马上就要崩溃了。
英雄就是这么被击垮的。据说是伏尔泰有句话说,“使人疲惫的不是远方的高山,而是你鞋里的一粒沙子”。
工作繁忙、孩子生病、业务方催促进度......都不是什么“重大事件”,可就是会压的你喘不过气来。
处理不好这些小麻烦,不但会影响你的情绪和工作表现,还有可能会影响我们的健康,最重要的是,如果被这些小事击垮了,我们哪还有心思去想什么大事呢?
我现在“大概”可以做到情绪稳定,我有四个自己在用的心法,分享给大家。
学会忽略
学会忽略,是我看到一句,据说是爱因斯坦说过的话:“弱者报复,强者原谅,智者忽略”。
就拿开车举例,我在路上发现过一个特别有意思的现象,如果开车的时候遇见插队,不同的司机有三种反应。
第一种人是对抗型,面对插队丝毫不让,眼看着两辆车的距离都塞不下一根手指头了,插队车决定放弃,他可能赢得了这场面子仗。
第二种人是原谅型,一开始会正常起步,但如果对方强行变道, 他会及时刹车,毕竟剐蹭了浪费时间浪费金钱。
第三种人是忽略型,他可能根本就没有在意这辆车在插队,他会直到前车完全进来,才会继续出发。他可能正沉浸在播客或者音乐里,神游在另一个维度。
你觉着哪种应对方式最好?
之前我是第二种人,并且还觉着第三种人是技术不佳,或者说是“好欺负”,直到最近我也有点了第三种人的样子。
有一次我在路上,听播客听的入迷,前方有个车有变道的意图。我也不着急,就让他变道进来了。

随后我才意识到,自己好像甚至都没有为这件事情,分散一点注意力。
那一刻我才明白,忽略,不是退让,也不用压抑情绪——
而是你根本没分配注意力分配给小事,负面情绪自然也就不会被激活。
忽略负面情绪非常有必要,有一项针对1300名男性做的研究,让他们对自己遇见类似于加塞这种小麻烦的反应打分,分数越高代表情绪反应越大。
结果发现,经常对小事有激烈反应的男性,他们的健康状况和死亡率,和面对那些重大人生压力的人一样。反应最激烈的那一组,在同样时间段内的死亡率,竟然是正常人的三倍。
我想起之前我奶奶家挂着一副《莫生气》的字画,里面有一句话:别人生气我不气,气出病来无人替。
看来对小事有激烈反应,真的会影响身心健康啊。我实践下来,忽略情绪有三个小技巧:
第一个是觉察情绪。当你发现自己心跳加快、紧握双拳,要注意情绪可能要来了。你需要深吸一口气,把注意力放到自己身上,让自己停下来,别被情绪牵着鼻子。
第二是控制自己的反应。维克多·弗兰克尔有一句话:“在面对外界刺激时,我们拥有选择如何回应的自由”。人真正能控制的只有自己的行动和态度,你控制不了堵车,但你能控制堵车的时候听一首钢琴曲。
第三是发现身边的美好,也就是感知生活中的“小确幸”。比如阳台上的花突然开了,孩子自己穿衣服了。有研究表明,对生活中积极细节的留意,能有效中和压力引发的负面情绪。
不恶意揣测
不过有些事情你很难忽略,比如公司考核政策调整,甚至说你持仓的股票大跌。
你感觉这个世界充满了恶意:公司打压你、社会在压榨你、资本在收割你。
可现实真的是这样吗?
帮助我解决心结的法则叫做「汉隆剃刀」。简单的说,它的意思就是「能解释为愚蠢的,就不要解释为恶意」。
这里说的愚蠢,代表各种无知的、偶然的、非故意的原因。这些情况发生的可能性远远大于恶意,汉隆剃刀大多数情况下反应了客观事实。
比如你开车,前方突然有车插队,你怒不可遏,心想:你是不是觉着我好欺负?
但其实他根本不认识你,只不过恰巧他意识到前方需要拐弯了。
这个法则在理解社会、组织层面,特别有效。
比如你持有的一只股票突然暴跌,你会听到一些传闻:说这是“庄家”在故意控盘。
我之前特别相信这种阴谋论,觉着股价是被人为操控的。可真实情况是,大公司的股价是很难操控的,投入很多钱也不一定能成功,一旦失败就会受到很大损失。而且市场上每个股民的互动、追涨杀跌,也会给股价造成很大影响。

再比如一家公司突然开始了绩效改革,给研发人员制定了和销售额相关的KPI,而且目标不完成还会对薪资产生影响。
可研发的考核怎么可能和销售的KPI挂钩呢?你怀疑管理层在变相降薪。
可更大的可能性是:管理层也不知道如何满足老板制定的目标,只能先套个模版应付一下。
不是你被打压了,只是碰巧他们不专业,你以为它是在有意的做坏事,但更大的可能是它没能力做好事。
我们大脑为了认知方便,常常会把一家公司或者一个政府当成一个人,假设他有自由意志,是一个决策缜密、心怀不轨的敌人。但其实组织就是一部机器而已。
不是组织在有意针对你,这世界其实就是个草台班子。
超越身份思维
你有没有经历过这种场面,过年回家刚坐下,七大姑八大姨联合开麦:
“你看你三十多了还在北京漂着,准备啥时候结婚啊?你表哥孩子都上小学了。”
“北京租房多贵啊,在咱老家,这都够还房贷了,干嘛不考个公务员安稳点?”
你努力工作、认真生活,熬过了失业焦虑、加班压力,结果成了他们口中的“混日子”。
你不是气他们说了什么,而是他们压根不懂你,却笃定地定义你。
可他们的确不懂你,也不会真正的懂你。他们只不过是在维护自己的世界观而已。
学术界有一个流行的说法是,人们的行为和观点,是由身份认同决定的。你的长辈,可能在一个小城过了一辈子,有编制、有房子、生儿育女,就是他们眼里的体面生活。
你异地漂泊、私企行业、租房未婚,就是他们眼中的“不务正业”。
你不需要反驳,也不需要忍耐。而是你明白了,你不需要从所有人眼里获得认可,你可以看到不同身份的局限性。

超越身份思维,在养育孩子的过程中特别有用。
那天我带儿子去上烘焙课,糖刚撒进面粉中,他就开始一边揉一边往嘴里塞。
我试图制止,他越发固执,并且不耐烦的喊:“我要回家!我要回家!”
我有点崩溃,一边怕他吃坏肚子,一边气他为什么这么不听话。
但那一刻我突然意识到,他不是故意气我,他只不过多想吃几口糖而已。
我们常说父母要包容孩子,为此你需要先理解他们的行为。糖果能刺激大脑释放多巴胺,这是最本能的反应,而且他们理性大脑还没有开始发育,你不能要求一个孩子有“自控力”
我们总以“大人的身份”要求孩子守规矩,可孩子的很多行为,并不是“不听话”,而是“做不到”。
就像人类的大脑,在25岁才能完全发育完成。也就是说,一个孩子即使成年之后,也会做出一些你不理解的事情。一个人成长的过程中,本就充满了能力滞后,
你不理解他,就会对抗他。你理解了,才能包容他。
找到目标
有一天我正坐在电脑前,正为了文章选题抓耳挠腮。
我儿子“砰”地一下推开门,一屁股坐在我旁边,拿着小汽车喊:“爸爸!爸爸...”
以往工作时被打断,我会特别不耐烦。可那天,我关上电脑开始陪他玩,我发现自己变得很有耐心。
过了一会他自己去客厅玩了,我坐在电脑前,去想我为什么会有这种改变。

是我变得有耐心了?还是我终于佛系了?后来我想明白了——是自己的目标更明确了。
过去一被打断就恼火,其实都是因为自己都不知道要干什么。我只是模糊的觉得,自己得做点有意义的事情。
但现在写好每一篇文章就是我想做的事情,就算短暂的停下来,也没有任何影响。
心理学上有一个「自我决定理论」:真正让人持续投入的,从来不是外界的压力或奖励,而是自己选的方向。
比如说当你在街道上跑步,周围车水马龙、喧嚣嘈杂,可你根本就听不见。因为你眼中,只有即将抵达的下一个路口。目标感就像降噪耳机,能让你不被外界打扰。
但如果你没有目标呢?虽然一天什么都没干,却很容易因为工作上的催促,家人的一句话,就能让你心烦意乱。
你不是没有承受力,你可能只是没有方向而已。
尼采说:“一个人知道自己为什么而活,就可以忍受任何一种生活。”
现在看来这不是鸡汤,而是硬道理。
真正让你内心安定的,不是时间管理、情绪技巧,而是——你有没有在朝着自己认可的方向,慢慢靠近。
说在最后
最后分享一句据说是爱默生说的一段话来结尾吧。
当整个世界似乎都在暗中图谋,用琐事一次又一次侵扰你、纠缠你,当所有人都来敲你的门,并且说,“到我们这里来吧。”绝对不要动心,不要加入到他们的喧闹中。始终保有一颗自助自主的心,不受外界影响和左右,活在自己的意志里,才能够使心灵得到宁静,才会过上真正独立的生活。
以上就是我自己应对生活中一些“小麻烦”的个人心得,如果你也有面对“小麻烦”时处理情绪的技巧,欢迎在评论区分享~
这是东东拿铁的第84篇原创文章,欢迎关注。
来源:juejin.cn/post/7522751214263992370
苹果官网前端技术解析:极简设计背后的技术精粹
苹果公司官网(apple.com)以其优雅的极简设计、流畅的交互体验和卓越的性能表现闻名于世。本文将深入解析苹果官网前端实现的技术亮点,并附上关键技术的示例代码实现。
一、视觉滚动效果:视差与滚动驱动动画
苹果官网最显著的特点是其精致的滚动效果,包括视差滚动、滚动触发的动画和流畅的页面过渡。
1. 高级视差效果实现
苹果官网的视差效果不是简单的背景固定,而是多层元素以不同速度移动创造的深度感。
// 视差滚动控制器
class ParallaxController {
constructor() {
this.elements = [];
this.scrollY = 0;
this.init();
}
init() {
this.cacheElements();
this.addEventListeners();
this.animate();
}
cacheElements() {
this.elements = Array.from(
document.querySelectorAll('[data-parallax]')
).map(el => ({
el,
speed: parseFloat(el.getAttribute('data-parallax-speed')) || 0.3,
offset: 0
}));
}
addEventListeners() {
window.addEventListener('scroll', () => {
this.scrollY = window.scrollY;
});
// 使用IntersectionObserver来优化性能
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
entry.target.classList.add('parallax-active');
}
});
}, { threshold: 0.1 });
this.elements.forEach(({ el }) => observer.observe(el));
}
animate() {
requestAnimationFrame(() => {
this.elements.forEach(({ el, speed }) => {
const rect = el.getBoundingClientRect();
const offset = this.scrollY * speed;
// 只对可见元素应用变换
if (rect.top < window.innerHeight && rect.bottom > 0) {
el.style.transform = `translate3d(0, ${offset}px, 0)`;
}
});
this.animate();
});
}
}
new ParallaxController();
2. 滚动触发动画(ScrollTrigger)
苹果官网大量使用滚动位置触发的精细动画:
// 滚动触发动画系统
class ScrollAnimation {
constructor() {
this.animations = [];
this.init();
}
init() {
document.querySelectorAll('[data-scroll-animation]').forEach(el => {
const animation = {
el,
trigger: el.getAttribute('data-scroll-trigger') || 'center',
class: el.getAttribute('data-scroll-class'),
reverse: el.hasAttribute('data-scroll-reverse')
};
this.animations.push(animation);
});
window.addEventListener('scroll', this.checkAnimations.bind(this));
this.checkAnimations();
}
checkAnimations() {
const viewportHeight = window.innerHeight;
const scrollY = window.scrollY;
this.animations.forEach(animation => {
const rect = animation.el.getBoundingClientRect();
const elementTop = rect.top + scrollY;
const elementCenter = elementTop + rect.height / 2;
const triggerPoint = scrollY + viewportHeight * this.getTriggerRatio(animation.trigger);
if (elementCenter < triggerPoint) {
animation.el.classList.add(animation.class);
} else if (animation.reverse) {
animation.el.classList.remove(animation.class);
}
});
}
getTriggerRatio(trigger) {
const ratios = {
top: 0.1,
center: 0.5,
bottom: 0.9
};
return ratios[trigger] || 0.5;
}
}
new ScrollAnimation();
二、响应式图片与艺术指导(Art Direction)
苹果官网针对不同设备展示不同裁剪和分辨率的图片,实现最佳视觉效果。
1. 响应式图片实现
<picture>
<!-- 大屏幕显示宽屏图片 -->
<source media="(min-width: 1440px)"
srcset="product-large.jpg 1x,
product-large@2x.jpg 2x">
<!-- 中等屏幕显示标准图片 -->
<source media="(min-width: 768px)"
srcset="product-medium.jpg 1x,
product-medium@2x.jpg 2x">
<!-- 小屏幕显示竖版图片 -->
<source srcset="product-small.jpg 1x,
product-small@2x.jpg 2x">
<!-- 默认回退 -->
<img src="product-medium.jpg"
alt="Apple Product"
class="responsive-image"
loading="lazy">
</picture>
2. 动态图片加载优化
class ImageLoader {
constructor() {
this.images = [];
this.init();
}
init() {
this.cacheImages();
this.observeImages();
}
cacheImages() {
this.images = Array.from(document.querySelectorAll('img[data-src]'));
}
observeImages() {
const observer = new IntersectionObserver((entries, observer) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
this.loadImage(entry.target);
observer.unobserve(entry.target);
}
});
}, {
rootMargin: '200px 0px',
threshold: 0.01
});
this.images.forEach(img => observer.observe(img));
}
loadImage(img) {
const src = img.getAttribute('data-src');
if (!src) return;
const tempImg = new Image();
tempImg.src = src;
tempImg.onload = () => {
img.src = src;
img.removeAttribute('data-src');
img.classList.add('loaded');
};
}
}
new ImageLoader();
三、高性能动画实现
苹果官网的动画以60fps的流畅度著称,这得益于他们对动画性能的极致优化。
1. GPU加速动画
/* 苹果官网风格的CSS动画 */
.product-card {
transform: translateZ(0); /* 触发GPU加速 */
will-change: transform, opacity; /* 提示浏览器元素将变化 */
transition: transform 0.6s cubic-bezier(0.25, 0.1, 0.25, 1),
opacity 0.6s ease-out;
}
.product-card:hover {
transform: translateY(-10px) scale(1.02);
opacity: 0.9;
}
2. 基于WebGL的复杂动画
苹果官网有时会使用WebGL实现复杂的3D产品展示:
// 简化的WebGL产品展示实现
class ProductViewer {
constructor(canvasId) {
this.canvas = document.getElementById(canvasId);
this.renderer = new THREE.WebGLRenderer({
canvas: this.canvas,
antialias: true,
alpha: true
});
this.scene = new THREE.Scene();
this.camera = new THREE.PerspectiveCamera(45, 1, 0.1, 1000);
this.product = null;
this.init();
}
async init() {
this.setupCamera();
this.setupLighting();
await this.loadProduct();
this.setupControls();
this.animate();
this.handleResize();
}
setupCamera() {
this.camera.position.z = 5;
this.updateAspectRatio();
}
updateAspectRatio() {
const width = this.canvas.clientWidth;
const height = this.canvas.clientHeight;
this.camera.aspect = width / height;
this.camera.updateProjectionMatrix();
this.renderer.setSize(width, height, false);
}
setupLighting() {
const ambientLight = new THREE.AmbientLight(0xffffff, 0.5);
this.scene.add(ambientLight);
const directionalLight = new THREE.DirectionalLight(0xffffff, 0.8);
directionalLight.position.set(1, 1, 1);
this.scene.add(directionalLight);
}
async loadProduct() {
const loader = new THREE.GLTFLoader();
const { scene } = await loader.loadAsync('product-model.glb');
this.product = scene;
this.scene.add(this.product);
}
setupControls() {
this.controls = new THREE.OrbitControls(this.camera, this.canvas);
this.controls.enableDamping = true;
this.controls.dampingFactor = 0.05;
this.controls.minDistance = 3;
this.controls.maxDistance = 10;
}
animate() {
requestAnimationFrame(this.animate.bind(this));
this.controls.update();
this.renderer.render(this.scene, this.camera);
}
handleResize() {
window.addEventListener('resize', () => {
this.updateAspectRatio();
});
}
}
new ProductViewer('product-canvas');
四、自适应与响应式布局系统
苹果官网的自适应布局系统能够在各种设备上提供完美的视觉体验。
1. 基于CSS Grid的布局系统
/* 苹果官网风格的自适应网格系统 */
.product-grid {
display: grid;
grid-template-columns: repeat(auto-fit, minmax(300px, 1fr));
gap: 24px;
padding: 0 40px;
max-width: 2560px;
margin: 0 auto;
}
@media (max-width: 768px) {
.product-grid {
grid-template-columns: 1fr;
padding: 0 20px;
gap: 16px;
}
}
/* 苹果特色的全屏分段布局 */
.section {
min-height: 100vh;
display: flex;
flex-direction: column;
justify-content: center;
padding: 120px 10%;
position: relative;
overflow: hidden;
}
.section-content {
max-width: 1200px;
margin: 0 auto;
position: relative;
z-index: 2;
}
2. 动态字体大小调整
// 基于视口宽度调整字体大小
class FluidTypography {
constructor() {
this.minFont = 16;
this.maxFont = 24;
this.minWidth = 320;
this.maxWidth = 1920;
this.init();
}
init() {
this.updateFontSizes();
window.addEventListener('resize', this.updateFontSizes.bind(this));
}
updateFontSizes() {
const viewportWidth = window.innerWidth;
const clampedWidth = Math.min(Math.max(viewportWidth, this.minWidth), this.maxWidth);
const scale = (clampedWidth - this.minWidth) / (this.maxWidth - this.minWidth);
const fontSize = this.minFont + (this.maxFont - this.minFont) * scale;
document.documentElement.style.setProperty(
'--fluid-font-size',
`${fontSize}px`
);
}
}
new FluidTypography();
五、微交互与状态管理
苹果官网的按钮、导航等交互元素有着精细的状态反馈。
1. 按钮交互效果
/* 苹果风格的按钮 */
.apple-button {
display: inline-block;
padding: 12px 22px;
border-radius: 30px;
background: linear-gradient(to bottom, #42a1ec, #0070c9);
color: white;
font-size: 17px;
font-weight: 400;
text-align: center;
cursor: pointer;
border: none;
outline: none;
transition: all 0.3s cubic-bezier(0.25, 0.1, 0.25, 1);
position: relative;
overflow: hidden;
}
.apple-button:hover {
background: linear-gradient(to bottom, #2d92e8, #0068b8);
transform: scale(1.02);
box-shadow: 0 5px 15px rgba(0, 112, 201, 0.3);
}
.apple-button:active {
transform: scale(0.98);
background: linear-gradient(to bottom, #1b7fd1, #005ea3);
}
.apple-button::after {
content: '';
position: absolute;
top: 50%;
left: 50%;
width: 5px;
height: 5px;
background: rgba(255, 255, 255, 0.5);
opacity: 0;
border-radius: 100%;
transform: scale(1, 1) translate(-50%, -50%);
transform-origin: 50% 50%;
}
.apple-button:focus:not(:active)::after {
animation: ripple 1s ease-out;
}
@keyframes ripple {
0% {
transform: scale(0, 0);
opacity: 0.5;
}
100% {
transform: scale(20, 20);
opacity: 0;
}
}
2. 全局状态管理
苹果官网使用类似状态机的模式管理复杂的UI状态:
class UIStateManager {
constructor() {
this.states = {
NAV_OPEN: false,
MODAL_OPEN: false,
DARK_MODE: false,
PRODUCT_VIEW: null
};
this.subscribers = [];
this.init();
}
init() {
// 监听系统颜色偏好
const darkModeMediaQuery = window.matchMedia('(prefers-color-scheme: dark)');
this.setDarkMode(darkModeMediaQuery.matches);
darkModeMediaQuery.addListener(e => this.setDarkMode(e.matches));
}
setState(key, value) {
if (this.states[key] !== undefined) {
this.states[key] = value;
this.notifySubscribers(key);
}
}
subscribe(callback) {
this.subscribers.push(callback);
}
notifySubscribers(changedKey) {
this.subscribers.forEach(cb => cb(changedKey, this.states));
}
toggleNav() {
this.setState('NAV_OPEN', !this.states.NAV_OPEN);
}
setDarkMode(enabled) {
this.setState('DARK_MODE', enabled);
document.documentElement.classList.toggle('dark-mode', enabled);
}
}
const stateManager = new UIStateManager();
// 示例组件使用状态
class NavMenu {
constructor() {
this.el = document.querySelector('.nav-menu');
stateManager.subscribe(this.onStateChange.bind(this));
}
onStateChange(key, states) {
if (key === 'NAV_OPEN') {
this.el.classList.toggle('open', states.NAV_OPEN);
document.body.style.overflow = states.NAV_OPEN ? 'hidden' : '';
}
}
}
new NavMenu();
六、性能优化策略
苹果官网加载速度快且运行流畅,这得益于多项性能优化技术。
1. 资源预加载
<!-- 预加载关键资源 -->
<link rel="preload" href="hero-image.jpg" as="image">
<link rel="preload" href="main.css" as="style">
<link rel="preload" href="main.js" as="script">
<!-- 预连接重要第三方源 -->
<link rel="preconnect" href="https://cdn.apple.com">
<link rel="dns-prefetch" href="https://cdn.apple.com">
2. 代码分割与懒加载
// 动态导入非关键模块
document.addEventListener('DOMContentLoaded', async () => {
if (document.querySelector('.product-carousel')) {
const { initCarousel } = await import('./carousel.js');
initCarousel();
}
if (document.querySelector('.video-player')) {
const { initVideoPlayer } = await import('./video-player.js');
initVideoPlayer();
}
});
3. Service Worker缓存策略
// service-worker.js
const CACHE_NAME = 'apple-v3';
const ASSETS = [
'/',
'/main.css',
'/main.js',
'/images/logo.svg',
'/images/hero.jpg'
];
self.addEventListener('install', event => {
event.waitUntil(
caches.open(CACHE_NAME)
.then(cache => cache.addAll(ASSETS))
);
});
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request)
.then(response => {
if (response) {
return response;
}
return fetch(event.request).then(response => {
if (!response || response.status !== 200 ||
response.type !== 'basic' ||
!event.request.url.includes('/assets/')) {
return response;
}
const responseToCache = response.clone();
caches.open(CACHE_NAME)
.then(cache => cache.put(event.request, responseToCache));
return response;
});
})
);
});
结语
苹果官网的前端实现代表了Web开发的最高水准,其技术特点可以总结为:
- 极致的性能优化:确保60fps的流畅动画和即时加载
- 精细的交互设计:每个微交互都经过精心调校
- 自适应的视觉系统:在各种设备上提供完美体验
- 高效的状态管理:复杂UI的有序控制
- 渐进增强策略:平衡功能与兼容性
这些技术不仅适用于大型企业网站,其中的许多模式和技巧也可以应用于各种Web项目,帮助开发者创建更高质量的用户体验。
来源:juejin.cn/post/7521160007854866467
三年写了很多代码,也想写写自己
前言
从我进入公司开始,我给自己立了一个三年成为中级前端工程师的目标,或者说flag吧,最近正好三年合同到期了,我开始思考过去的这三年我都做了什么,是否完成了flag,所以我在个人博客中增加了一个模块《项目需求》用于管理自己在生活、工作、学习过程中开发过的项目文档和思考,在整理的过程中才发现很多东西都忘记是怎么做的了,大概是只知道做,不知道为什么做吧,所以这里想写一篇文章记录下或者说获取一些建议吧。
很多人说博客和todo没啥用,开发完几乎都不会使用,我觉得看怎么用吧,我这里把项目和todo、技术文档、技术栈绑定了。编辑项目和可以和todo绑定,我觉得还挺好使,这样在整理技术文档、技术调研的时候也可以用
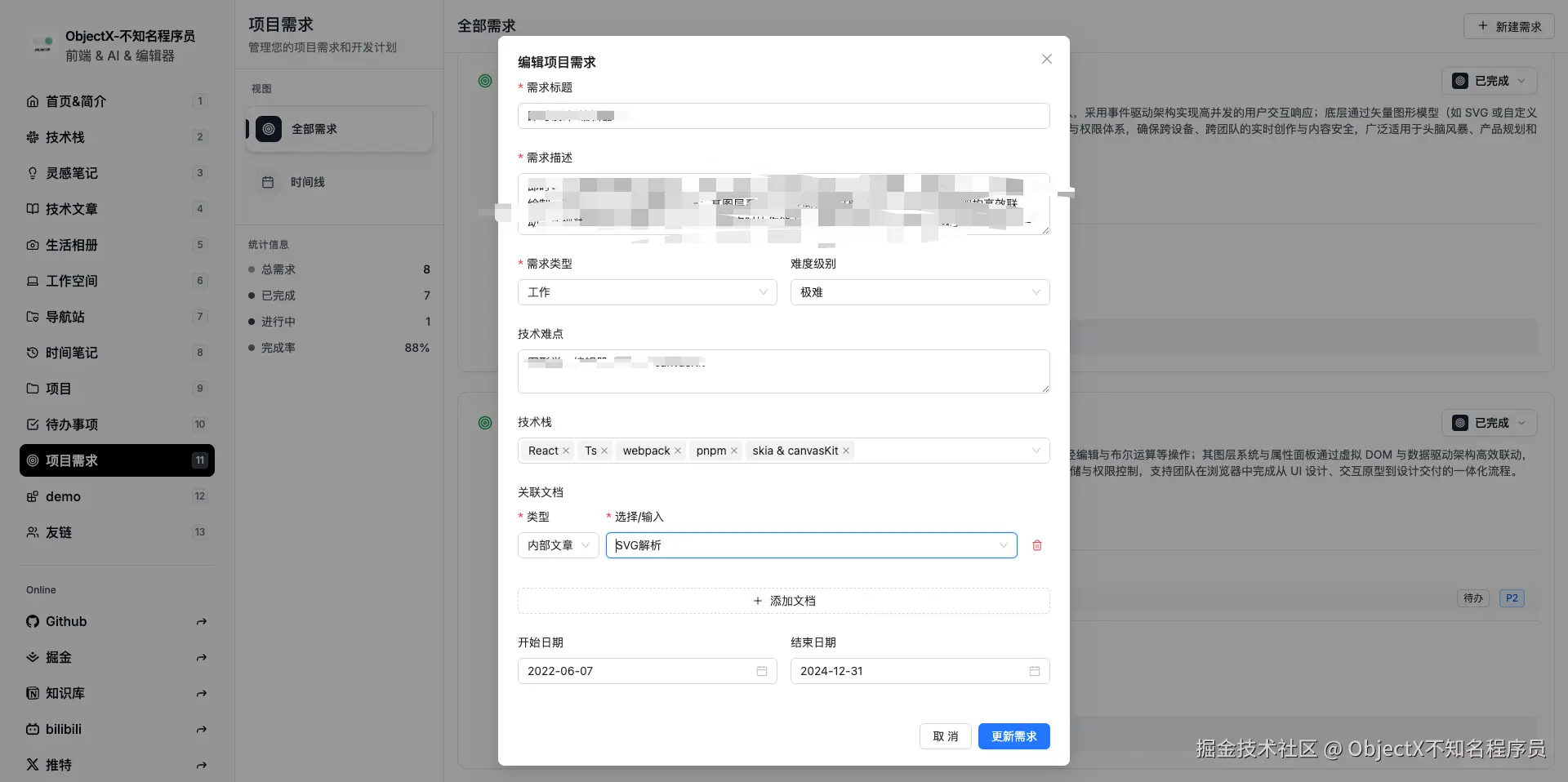
过去三年我都做了什么
2022年
基本情况
因为在学校的时候根本没想过这么早出社会,原本是打算走学术路线的,结果考研那年因为家里临时出了点状况,最后决定先工作再说。现在回头看也挺好的,早点接触社会,其实成长得更快。
在这一年我主要是疯狂补项目经验和疯狂加班,因为社会始终不同于学校,排期让人很头疼,在以往我缺失了很多的项目经验,导致对企业级项目几乎不通,导致我在做任何项目都比较挣扎,再加上进的是一个小厂,完全没有导师制,属于放养,并且大家都很忙,所以只能自己多花时间,并且当时我学的vue的技术栈,但是公司是react的,光是搞懂 React 那一套生态就花了不少时间。
项目经历
- 早期主要是做企业后台 & figma插件,其中有一个插件让我特别头疼,一方面因为当时的自己比较菜,另一方面因为这个需求是一个刚毕业的设计驱动的,属于是啥也不通,导致产品逻辑也不对,写出来之后疯狂打补丁,最后也还是啥也不是。
- 后面做了设计社区,都是一些简单的ui和业务逻辑,因为是一个设计编辑器平台
- 在写了几个后台之后我逐渐熟悉了公司开发技术栈和后台开发逻辑,最早这个公司吸引我的是编辑器,后面我就申请去做了编辑器
- 最开始是编辑器的字体加载、和一些创新的业务需求、设计工具中不同模式的数据结构复用、画布设置【缩放、背景等等】、对齐至像素网格
成长
- 技术上,从 Vue 转到 React 后,逐步掌握了 React 的核心理念和生态工具,像状态管理、组件设计、性能优化这些都有了比较实战的理解;
- 项目上,能独立负责模块开发,也逐步学会了和产品、设计磨合需求;
- 心态上,从一开始觉得“自己不会”到现在敢主动挑任务、遇到新东西也不怕折腾,整体自驱力和解决问题的能力都提升了不少。
- 这时候还是需要拿着电脑到处抓人问问题,非常感谢当时给予我帮助的小伙伴
2023年
基本情况
这个阶段已经开始逐步适应工作生活了,但是还是会畏惧需求,因为还有很多没接触过的东西,依然还是疯狂加班,不光是需求,还有自己学习一些东西,这时候我已经切换到了编辑器领域,其中涉及很多图形学知识,比如坐标转换、矩阵运算、渲染原理、渲染库的使用等等,因为公司里的人几乎不写文档,代码也是anyscript,并且这时候ai还没有,编辑器这个领域,网上几乎搜不到什么文档啥的,只能生啃代码和类型文件并尝试demo,这时候用的就是最笨却最有效的方法,做到哪就把哪个模块整理一篇文档记录下来,慢慢的也就掌握了项目的大部分逻辑和架构思路
项目经历
- 设计工具中不同模式的数据结构复用,一个创新业务需求,使用同一套数据,快捷的进行模式切换,非常巨大的需求,正是因为这个需求让我学会了很多东西,开始能独立负责一个模块的开发
- 白板项目:其中做了节点数据结构定义【便签、图形文本、连接线等等】、节点树的处理、节点的渲染、项目框架搭建、画布设置、缩放、属性控制、属性工具条、性能优化等等,几乎所有功能都写了一部分,这个项目是我从0-1经历的一个项目,历时10个月,早期有很多人,后来因团队调整,部分成员转入新项目,剩余的人员就非常的少了,我是其中之一。
- 这一年我几乎都在做白板项目,其中连接线是最难的,我写了其中的一部分,还因此挨了一批,给我上了社会上的第一堂课【能力不足就得背锅】
成长
- 编辑器初步入门:理解了编辑器的基本架构 & 实现原理,如模块划分、碰撞检测、矩阵运算原理、渲染库的基本使用、复制粘贴的实现原理、svg的解析原理等等、数据节点定义、节点树的使用等等
- canvas、svg、渲染库的基本使用 & 原理
- 学到了很多调试技巧、看了很多的技术文章
- 能够独立负责一个模块的开发和推进
- 自己开始从0-1写一些项目,23年主要是一个工程化的项目,因为当时公司没有脚手架,每次创建新项目都要配置一遍,我就想写一个脚手架来用,就开始探究一些前端工程化的东西,这里主要是一个前端工程化的demo
2024年
基本情况
这时候已经对编辑器开发很熟练了,能够自己调研、处理一些模块,不会畏惧需求,拿到什么都能做也敢做,再加上ai的爆发,现在很轻松就能应付日常需求,还有一些时间开发自己的东西。这时候我几乎不用在追着别人问了,开始探究一些技术上的原理,看了react的源码,了解了react的运行原理,我最初看这个的驱动是因为我想看懂编辑器底层的数据结构和自定义渲染器的实现原理,因为是相通的。
项目经历
- 多模式切换的设计工具,在23年双模式切换有一个比较客观的数据基础上,想要开发多模式切换
- 编辑器重构:真真正正的从0-1实现编辑器,学到了非常多的东西
成长
- 这个阶段成长是最快的,在之前自己主动学习和开发过程中的积累,达到了量变到质变的过程,再加上重构过程中全是实实在在的技术类需求,这个阶段开发的非常爽,学到了非常多的东西,一度让我觉得我们也能做出一个超级nb的东西
- 对编辑器的整体实现理解更加深入,对大型项目的推进和管理有一些了解
- 对于代码质量,代码风格,团队管理,团队交流都有更深的体会
2025年
基本情况
进入新团队后,开始参与 AI 方向的生成类产品开发。虽然整体技术难度相比之前的编辑器项目要低一些,但节奏非常快,很多需求都是边想边做,对响应能力和落地能力要求更高。项目整体强调快速迭代、快速验证,很多时候从 0 到上线都只有几天时间。
项目经历
- 核心流程重构:参与整个生成流程的梳理和重构,数据结构的重设计,提升了整体稳定性和扩展性。
- AI 创新功能研发:参与多个创意方向的原型开发,包括智能组件、AI 引导式操作流程等,既需要理解前端,也需要深入 AI 接口的能力边界。
- 常规前端需求:除了核心 AI 功能,也参与大量 Web 端页面开发、交互优化、组件抽象等日常前端需求的处理。
- 跨角色协作:与产品、模型工程师保持密切沟通,协助设计 prompt、测试接口,探索“产品-模型-前端”的协作流程,理解 prompt 工程的基本逻辑。
成长
- AI 与前端的深度结合:理解 AI 接口的调用逻辑、数据结构设计、模型能力边界,并在多个场景中尝试 prompt 调优、token 限制控制、输出结构稳定性等关键问题。
- 需求落地能力提升:现在不管接到什么需求,都能独立完成从调研、设计、开发、联调到交付的完整流程,并且具备识别风险、提前发现问题并推动解决的能力。
- 项目推进与优化意识:开始更关注整体产品的合理性和可维护性,不再仅仅关注功能实现,会主动提出重构建议、设计优化点、体验提升方案。
- 应变与协作能力加强:面对快节奏、多变的需求场景,能够保持清晰的优先级判断
- 干了很多新鲜的东西,还挺好玩的,ai接入支付、ai表单等等。
我自己写的项目
就这几个,其他的几乎都是一些不成型的demo,还有几乎都在写公司的项目
- nextjs-blog:一个用nextjs写的高聚合的全栈博客,还在持续更新,有时候有点犯懒,在线访问
- handwriting_js:没事写点手写题,写了忘,忘了写,一个也记不住
- react_demo :前端工程化demo,配合这个专栏食用最佳
- debug_react:18.2.0的react源码调试环境
- debug_webpack: webpack5源码调试环境
现在我是怎么想的
- 快速学习的能力比技术能力更值得培养
技术更新太快了,几乎每一年都会冒出一堆新概念、新框架、新工具,追是追不完的。相比“掌握某个技术”,更在意的是“有没有能力快速理解它、上手它、找到它的边界”,这是一个更本质的能力。 - 技术是为业务服务的,但我们也要有自己的判断和坚持
做久了之后会发现,代码写得好不好,有时候并不是最关键的,能不能解决问题、把事情落地才是关键。谁也不想变成“只写业务”的人——在完成需求的同时,尽可能把事情做得优雅些,至少对得起自己的审美和标准。 - 保持初心
有时候项目节奏快、需求不讲理、上线压力大,很容易被“搞完就行”的心态裹挟,还是需要保持自己的思考 - 身体是革命的本钱!!!!
24年7月份左右,体检,发现小毛病快20项,全是久坐,熬夜搞出来的小毛病,可能因为之前加班太多了,也不运动,在7-11月胖了20多斤,并且整日没精打采,身体没有力气,像是气血亏虚一样,我去看了中医,开了一些调养的中药,12月底才开始有好转,我找了私教,去健身房开始健身,大半年了现在就好多了,增肌也小成 - 培养工作之外的兴趣爱好
健身、摄影、钓鱼都可以,长时间的工作会使人麻木和疲惫,需要一些工作之外的爱好调和
我还做了一个在线相册,从大佬Innei获取到的思路,但技术栈是不一样的,也比较简单

以后我想干啥
说实话,我现在还没完全想明白这个问题。过去几年我经历了从业务开发,到编辑器、到 AI 项目,接触了很多不同的方向,也成长了不少。但也正因为尝试了很多,现在反而更谨慎,不想轻易贴标签。
我想我还是会继续写代码,但不一定只写代码。我更在意的是:“我做的东西有没有价值?有没有可能改变点什么?”也许未来会往架构方向走,也许会继续在 AI 产品方向深入,也可能有一天突然转向一个完全不同的方向,比如做点属于自己的产品。
我目前能确定的就是三件事:
- 我希望能一直保持学习和探索的状态,不断拓宽认知边界;
- 我希望在一个让我有成长、有挑战感的环境里工作;
- 我希望做的事能让我感到值得,能有一点点“留下痕迹”的感觉。
剩下的,就边走边看吧,继续更新文章,但不会跟之前一样那么频繁,从中学到东西,并且能够帮助别人
来源:juejin.cn/post/7524602914514763819
老板:咱们公司的设备开机,怎么显示Android。这怎么行,把Android替换掉,显示公司的logo,最好加点牛逼的动画.。
老板: 咱们公司的设备开机,怎么显示Android。这怎么行,把Android替换掉,显示公司的logo,最好加点牛逼的动画.
小卡拉米: 好的,老板
小卡拉米 to UI: 老板说要一个牛逼的动画。
UI: 我*&……%%¥……&&*………………%

1、UI设计帧动画
跟UI沟通,最好说明,老板的意思,怎么牛逼。最重要的是:
- 把动画输出成序列帧。
- 分辨率和板子的分辨率一致。
- 命名规则:00.jpg 01.jpg ...99.jpg
2、制作动画包
新建一个文件夹,名字为:bootanimation
新建子文件夹第一部分动画:命名为part1,将UI设计好的非常牛逼的动画,放进去
新建子文件夹第二部分定格动画:命名为part2 ,将帧动画的最后一帧放到这里边
新建一个desc.txt
desc.txt的内容:
1024 768 60
p 1 0 part1
p 0 10 part2
全局参数(第一行)
1024
屏幕的 宽度(Width),单位为像素(px)。表示动画的分辨率宽度为 1024px。768
屏幕的 高度(Height),单位为像素(px)。表示动画的分辨率高度为 768px。60
动画的 帧率(FPS, Frames Per Second)。表示每秒播放 60 帧,但实际帧率受硬件和系统限制(可能无法真正达到 60 FPS)。
分段参数(后续行)
每行定义一个动画片段,格式为:
[类型] [循环次数] [间隔时间] [目录名]
第一片段:p 1 0 generic1
p
播放类型(Play Mode):
p表示正常播放(逐帧播放后停止)。- 另一种类型是
c(hold last frame),表示播放完成后停留在最后一帧。
1
循环次数(Loop Count):
1表示该片段播放 1 次。0表示无限循环(直到开机完成或被中断)。
0
间隔时间(Delay):
- 单位为帧数(基于全局帧率)。
0表示片段播放完成后 无额外延迟,直接进入下一片段。
- 单位为帧数(基于全局帧率)。
generic1
动画资源目录名:
- 对应
part0、part1等目录,存放该片段的 PNG 图片(按序号命名,如img000.png)。
- 对应
第二片段:p 0 10 generic2
p
正常播放模式。0
无限循环,直到开机流程结束或被系统终止。10
间隔时间为 10 帧(若全局帧率为 60 FPS,则实际延迟为10/60 ≈ 0.167 秒)。generic2
第二个动画资源目录名。
- 系统会先播放
generic1目录中的动画,播放 1 次,无延迟。 - 接着播放
generic2目录中的动画,无限循环,每次循环结束后等待 10 帧的时间。 - 开机动画会持续播放,直到系统启动完成(或强制终止)。
压缩动画包(很重要的一步)
- 压缩的时候,不要在外边一层去压缩,要点进去bootanimation文件夹,全选压缩。
- 压缩的时候格式要选择成存储。360压缩,自定义里边有。
3、替换动画包
使用adb命令进行替换,替换之前设备要进行root,一般开发板都是 root过的,然后使用命令进行替换
默认情况下,Android 设备的 /system 分区是只读的(出于系统安全性考虑)。adb remount 会临时将其重新挂载为可读写(rw),允许你修改系统文件(如删除预装应用、替换系统文件等)。
adb root // 获取root 权限
adb remount //重新挂载为可读写
adb push 你的动画包路径 system/media
动画包的名称一般是bootanimation.zip,有些厂商的可能不一样,如果不生效可以咨询板子厂家进行修改
替换成功之后,直接运行 adb reboot 进行重启,见证奇迹。
4、Android动画前的小企鹅(Linux开机动画)
我真服了,板子出厂前,竟然还有Linux开机动画,这个关掉,需要更改内核启动参数。下边是修改方法,但是建议联系厂家,建议联系厂家,建议联系厂家
4.1. 确认 Logo 类型
- Linux 内核 Logo:企鹅 Logo 通常是内核编译时内置的,文件格式可能是
.ppm、.rle或.png。 - Bootloader Logo:某些设备的厂商会在 Bootloader 阶段显示自定义 Logo(如高通设备的
splash.img)。
需要先确定企鹅 Logo 的来源:
- 如果设备启动时先显示企鹅,再显示 Android 开机动画(
bootanimation.zip),则属于 内核 Logo。
4.2. 替换 Linux 内核 Logo
步骤 1:获取内核源码
- 需要设备的 内核源代码(从厂商或开源社区获取,如 LineageOS、XDA 论坛等)。
- 如果厂商未公开源码,此方法不可行。
步骤 2:准备自定义 Logo
- 内核支持的格式通常为 PPM(Portable PixMap),尺寸需与屏幕分辨率匹配(如 1024x768)。
- 使用工具(如 GIMP、ffmpeg)将图片转换为
.ppm格式,并保存为logo_linux_clut224.ppm(文件名可能因内核版本而异)。
步骤 3:替换内核 Logo 文件
- 将自定义的
.ppm文件替换内核源码目录中的对应文件:
# 示例路径(不同内核可能不同)
cp custom_logo.ppm drivers/video/logo/logo_linux_clut224.ppm
步骤 4:编译内核
- 配置内核编译选项,确保启用 Logo 显示:
make menuconfig
# 进入 Device Drivers -> Graphics support -> Bootup logo
# 启用 "Standard 224-color Linux logo"
- 编译内核并生成
boot.img:
make -j$(nproc)
步骤 5:刷入新内核
- 使用
fastboot刷入编译后的boot.img:
fastboot flash boot boot.img
4.3. 替换 Bootloader Logo(高通设备示例)
如果企鹅 Logo 是 Bootloader 阶段的 Splash Screen(如高通设备):
步骤 1:提取当前 Splash Image
- 从设备中提取
splash.img:
adb pull /dev/block/bootdevice/by-name/splash splash.img
步骤 2:修改 Splash Image
- 使用工具(如 splash_screen_tool)解包
splash.img,替换其中的图片,再重新打包。
步骤 3:刷入新 Splash Image
- 通过
fastboot刷入:
fastboot flash splash splash.img
4. 隐藏企鹅 Logo(无需替换)
如果无法修改内核或 Bootloader,可以尝试以下方法:
- 修改内核启动参数:在内核命令行中添加
logo.nologo参数(需解锁 Bootloader 并修改boot.img的cmdline)。 - 禁用 Framebuffer:在内核配置中关闭
CONFIG_LOGO选项(需重新编译内核)。
注意事项
- 风险提示:建议联系厂家进行修改
- 修改内核或 Bootloader 可能导致设备无法启动(变砖)。
- 需要解锁 Bootloader(会清除设备数据并失去保修)。
- 兼容性:
- 不同设备的 Logo 实现方式差异较大,需查阅设备的具体文档。
- 备份:
- 操作前备份重要数据,并保留原版
boot.img或splash.img。
- 操作前备份重要数据,并保留原版
来源:juejin.cn/post/7508646757884690468
写了个脚本,发现CSDN的前端居然如此不严谨
引言
最近在折腾油猴脚本开发,顺手搞了一个可以拦截任意网页接口的小工具,并修改了CSDN的博客数据接口,成功的将文章总数和展现量进行了修改。
如果你不了解什是油猴,参考这篇文章:juejin.cn/book/751468…
然后我突然灵光一闪:
既然能拦截接口、篡改数据,那我为什么不顺便测试一下 CSDN 博客在极端数据下的表现呢?
毕竟我们平时开发的时候,测试同学各种花式挑刺,什么 null、undefined、999999、-1、空数组……
每次都能把页面测出一堆边角 bug。
今天,轮到我来当一回“灵魂测试”了!
用我的脚本,造几个极限场景,看看 CSDN 的前端到底稳不稳!
实现原理
其实原理并不复杂,核心就一句话:
借助油猴的脚本注入能力 + ajax-hook 对接口请求进行拦截和修改。
我们知道,大部分网页的数据接口都是通过 XMLHttpRequest 或 fetch 发起的,而 ajax-hook 就是一个开源的轻量工具,它能帮我们劫持原生的 XMLHttpRequest,在请求发出前、响应返回后进行自定义处理。
配合油猴脚本的注入机制,我们就可以实现在浏览器端伪造任意接口数据,用来调试前端样式、模拟数据异常、测试权限控制逻辑等等。
ajax-hook 快速上手
我们用的是 CDN 方式直接引入,简单暴力:
<script src="https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js"></script>
引入后,页面上会多出一个全局对象 ah,我们只需要调用 ah.proxy(),就可以注册一套钩子:
ah.proxy({
onRequest: (config, handler) => {
// 请求发出前
handler.next(config);
},
onError: (err, handler) => {
// 请求出错时
handler.next(err);
},
onResponse: (response, handler) => {
// 请求成功响应后
console.log("响应内容:", response.response);
handler.next(response);
}
});
拦截实现
我们以 CSDN 博客后台为例,先找到博客数据接口
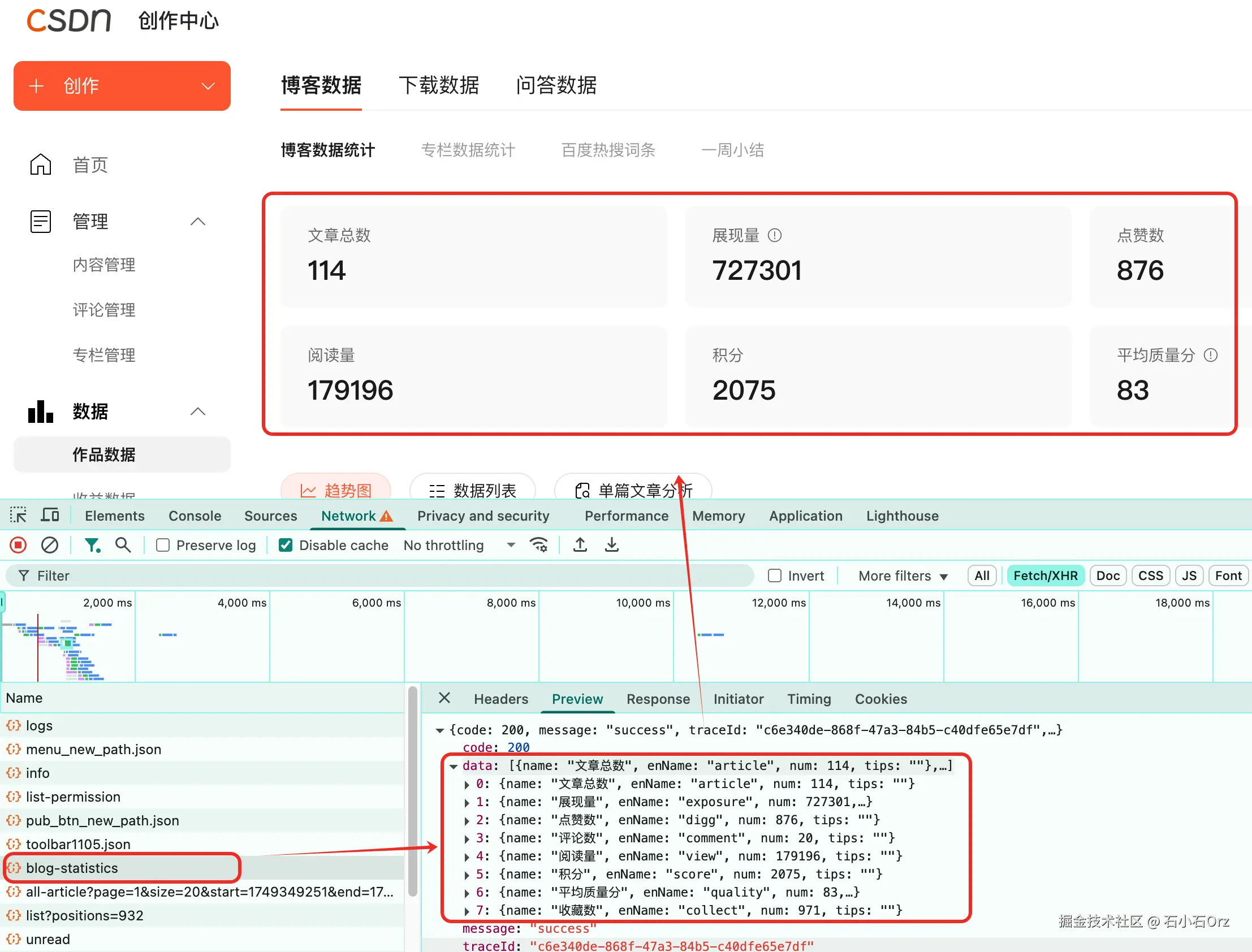
地址长这样:bizapi.csdn.net/blog/phoeni…
我们在 onResponse 钩子中,加入 URL 判断,专门拦截这个接口:
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
console.log("拦截到的数据:", hookResponse);
handler.next(response);
} else {
handler.next(response);
}
}
就这样,接口拦截器初步搭建完成!
使用油猴将脚本运行在网页
接下来我们用油猴把这段脚本注入到 CSDN 博客后台页面。
// ==UserScript==
// @name CSDN博客数据接口拦截
// @namespace http://tampermonkey.net/
// @version 0.0.1
// @description 拦截接口数据,验证极端情况下的样式展示
// @author 石小石Orz
// @match https://mpbeta.csdn.net/*
// @require https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js
// @run-at document-start
// @grant none
// ==/UserScript==
(function() {
'use strict';
ah.proxy({
onRequest: (config, handler) => {
handler.next(config);
},
onError: (err, handler) => {
handler.next(err);
},
onResponse: (response, handler) => {
console.log("接口响应列表:", response);
// 这里写拦截逻辑
handler.next(response);
}
});
})();
为了测试前端的容错能力,我们可以伪造一些极端数据返回:
- 文章总数设为
null - 展现量设为
0 - 点赞数设为一个异常大的值
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
// 伪造数据
hookResponse.data[0].num = null; // 文章总数
hookResponse.data[1].num = 0; // 展现量
hookResponse.data[2].num = 99999999999999999; // 点赞数
console.log("修改后的数据:", hookResponse);
response.response = JSON.stringify(hookResponse);
}
handler.next(response);
}
结果验证
修改成功后刷新页面,可以观察到如下问题:
- 文章总数为
null时,布局异常,显然缺乏空值判断。 - 点赞数为超大值 时,页面直接渲染出
100000000000000000,不仅视觉上溢出容器,连排版都崩了,前端没有做任何兼容处理。
CSDN的前端还是偷懒了呀,一点也不严谨!差评!
总结
通过这篇文章的示例,我们前端应该引以为戒,永远不要相信后端同学返回的数据,一定要做好容错处理!
通过本文,相信大家也明白了油猴脚本不仅是玩具,它在前端开发中其实是个非常实用的辅助工具!
如果你对油猴脚本的开发感兴趣,不妨看看我写的这篇教程 《油猴脚本实战指南》
从小脚本写起,说不定哪天你也能靠一个脚本搞出点惊喜来!
来源:juejin.cn/post/7519005878566748186
用 iframe 实现前端批量下载的优雅方案 —— 从原理到实战
传统的下载方式如window.open()或标签点击存在诸多痛点:
- 批量下载时浏览器会疯狂弹窗
- HTTPS页面下载HTTP资源被拦截
今天分享的前端iframe批量下载方案,可以有效解决以上问题。
一、传统批量下载方案的局限性
传统的批量下载方式通常是循环创建 a 标签并触发点击事件:
urls.forEach(url => {
const link = document.createElement('a');
link.href = url;
link.download = 'filename';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
});
这种方式存在以下问题:
- 浏览器会限制连续的自动点击行为
- 用户体验不佳,会弹出多个下载对话框
二、iframe 批量下载解析
更优雅的解决方案是使用 iframe 技术,通过动态创建和移除 iframe 元素来触发下载:
downloadFileBatch(url) {
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
}
urlProtocolDelete(url: string = '') {
if (!url) {
return;
}
return url.replace('http://', '//').replace('https://', '//');
}
这种方案的优势在于:
- 不依赖用户交互,可自动触发下载
- 隐藏 iframe 不会影响页面布局,每个iframe独立运行,互不干扰
- 主线程保持流畅
三、核心代码实现解析
让我们详细分析一下这段代码的工作原理:
- 动态创建 iframe 元素:
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
通过创建一个不可见的 iframe 元素,我们可以在不影响用户界面的情况下触发下载请求。
- 协议处理函数:
urlProtocolDelete(url: string = '') {
return url.replace('http://', '//').replace('https://', '//');
}
这个函数将 URL 中的协议部分替换为//,这样可以确保在 HTTPS 页面中请求 HTTP 资源时不会出现混合内容警告。
- 触发下载并清理 DOM:
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
将 iframe 添加到 DOM 中会触发浏览器对 src 的请求,从而开始下载文件。设置 5 秒的超时时间后移除 iframe,既保证了下载有足够的时间完成,又避免了 DOM 中积累过多无用元素。
四、批量下载的实现与优化
对于多个文件的批量下载,可以通过循环调用 downloadFileBatch 方法:
result.forEach(item => {
this.downloadFileBatch(item.url);
});
五、踩坑+注意点
在实现批量下载 XML 文件功能时,你可能会遇到这种情况:明明请求的 URL 地址无误,服务器也返回了正确的数据,但文件却没有被下载到本地,而是直接在浏览器中打开预览了。这是因为 XML 作为一种可读的文本格式,浏览器默认会将其视为可直接展示的内容,而非需要下载保存的文件。
解决方案:
通过在下载链接中添加response-content-disposition=attachment参数,可以强制浏览器将 XML 文件作为附件下载,而非直接预览。这个参数会覆盖浏览器的默认行为,明确告诉浏览器 "这是一个需要下载保存的文件"。
addDownloadDisposition(url: string, filename: string): string {
try {
const urlObj = new URL(url);
// 添加 response-content-disposition 参数
const disposition = `attachment;filename=${encodeURIComponent(filename)}`;
urlObj.searchParams.set('response-content-disposition', disposition);
return urlObj.toString();
} catch (error) {
console.error('URL处理失败:', error);
return url;
}
}
六、大量文件并发控制
有待补充
来源:juejin.cn/post/7524627104580534306
😡同事查日志太慢,我现场教他一套 grep 组合拳!
前言
最近公司来了个新同事,年轻有活力,就是查日志的方式让我有点裂开。
事情是这样的:他写的代码在测试环境报错了,报警信息也被钉钉机器人发到了我们群里。作为资深摸鱼战士,我寻思正好借机摸个鱼顺便指导一下新人,就凑过去看了眼。
结果越看我越急,差点当场喊出:“兄弟你是来写代码的,还是和日志谈恋爱的?”
来看看他是怎么查日志的
他先敲了一句:
tail -f a.log | grep "java.lang.NullPointerException"
想着等下次报错就能立刻看到。等了半天,终于蹦出来一行:
2025-07-03 11:38:48.339 [http-nio-8960-exec-1] [47gK4n32jEYvTYX8AYti48] [INFO] [GlobalExceptionHandler] java.lang.NullPointerException, ex: java.lang.NullPointerException
java.lang.NullPointerException: null
我提醒他:“这样看不到堆栈信息啊。”
他“哦”了一声,灵机一动,用 vi把整个文件打开,/NullPointerException 搜关键词,一个 n 一个 n 地翻……半分钟过去了,异常在哪都没找全,我都快给他跪下了。

于是我当场掏出了一套我压箱底的“查日志组合拳”,一招一式手把手教他。他当场就“悟了”,连连称妙,并表示想让我写成文章好让他发给他前同事看——因为他前同事也是这样查的……
现在,这套组合拳我也分享给你,希望你下次查日志的时候,能让你旁边的同事开开眼。
正式教学
核心的工具其实还是 grep 命令,下面我将分场景给你讲讲我的实战经验,保证你能直接套用!
场景一:查异常堆栈,不能只看一行!
Java 异常堆栈通常都是多行的,仅仅用 grep "NullPointerException" 只能看到最上面那一行,问题根源在哪你压根找不到。
这时候使用 **grep** 的 **-A** (After) 参数来显示匹配行之后的N行。
# 查找 NullPointerException,并显示后面 50 行
grep -A 50 "java.lang.NullPointerException" a.log
如果你发现异常太多,屏幕一闪而过,也可以用less加上分页查看:
grep -A 50 "java.lang.NullPointerException" a.log | less
在 less 视图中,你可以:
- 使用 箭头↑↓ 或 Page Up/Down 键来上下滚动
- 输入
G直接翻到末尾,方便快速查看最新的日志 - 输入
/Exception继续搜索 - 按
q键退出
这样你就能第一时间拿到完整异常上下文信息,告别反复 vi + / 的低效操作!

场景二:实时看新日志怎么打出来的
如果你的应用正在运行,并且你怀疑它会随时抛出异常,你可以实时监控日志文件的增长。
使用 tail -f 结合 grep:
# 实时监控 a.log 文件的新增内容,并只显示包含 "java.lang.NullPointerException" 的行及其后50行
tail -f a.log | grep -A 50 "java.lang.NullPointerException"
只要异常一出现,它就会自动打出来,堆栈信息也一并送到你面前!
- 想停下?
Ctrl + C - 想更准确?加
-i忽略大小写,防止大小写拼错找不到
场景三:翻历史日志 or 查压缩日志
服务器上的日志一般都会按天或按大小分割并压缩,变成 .log.2025-07-02.gz 这种格式,查找这些文件的异常信息怎么办?
🔍 查找当前目录所有 .log 文件:
# 在当前目录下查找所有以 .log 结尾的文件,-H 参数可以顺便打印出文件名
grep -H -A 50 "java.lang.NullPointerException" *.log
其中 -H 会帮你打印出是哪个文件中出现的问题,防止你找完还不知道是哪天的事。
🔍 查找 .gz 文件(压缩日志):
zgrep -H -A 50 "java.lang.NullPointerException" *.gz
zgrep 是专门处理 .gz 的 grep,它的功能和 grep 完全一样,无需手动解压,直接开整!
场景四:统计异常数量(快速判断异常是否频繁)
有时候你需要知道某个异常到底出现了多少次,是偶发还是成灾,使用 grep -c(count):
grep -c "java.lang.NullPointerException" a.log
如果你要统计所有日志里的数量:
grep -c "java.lang.NullPointerException" *.log
其他常用的 grep 参数
| 参数 | 作用 |
|---|---|
-B N | 匹配行之前的 N 行(Before) |
-A N | 匹配行之后的 N 行(After) |
-C N | 匹配行上下共 N 行(Context) |
-i | 忽略大小写 |
-H | 显示匹配的文件名 |
-r | 递归搜索目录下所有文件 |
比如:
grep -C 25 "java.lang.NullPointerException" a.log
这个命令就能让你一眼看到异常前后的上下文,帮助定位代码逻辑是不是哪里先出问题了。
尾声
好了,这套组合拳我已经传授给你了,要是别人问你在哪学的,记得报我杆师傅的大名(doge)。
其实还有其他查日志的工具,比如awk、wc 等。
但是我留了一手,没有全部教给我这个同事,毕竟江湖规则,哪有一出手就把看家本领全都交出去的道理?
如果你也想学,先拜个师交个学费(点赞、收藏、关注),等学费凑够了,我下次再开新课,传授给大家~

来源:juejin.cn/post/7524216834619408430
为什么我不再相信 Tailwind?三个月重构项目教会我的事
Tailwind 曾经是我最爱的工具,直到它让我维护不下去整个项目。
前情提要:我是如何变成 Tailwind 重度用户的
作为一个多年写 CSS 的前端,我曾经深陷“命名地狱”:
什么 .container-title, .btn-primary, .form-item-error,一个项目下来能写几百个类名,然后改样式时不知道该去哪动刀,甚至删个类都心慌。
直到我遇见了 Tailwind CSS——一切原子化,想改样式就加 class,别管名字叫什么,直接调属性即可。
于是我彻底拥抱它,团队项目里我把所有 SCSS 全部清除,组件中也只保留了 Tailwind class,一切都干净、轻便、高效。
但故事从这里开始转变。
三个月后的重构期,我被 Tailwind“反噬”
我们的后台管理系统迎来一次大版本升级,我负责重构 UI 样式逻辑,目标是:
- 统一设计规范;
- 提高代码可维护性;
- 降低多人协作时的样式冲突。
刚开始我信心满满,毕竟 Tailwind 提供了:
- 原子化 class;
@apply合成组件级 class;- 配置主题色/字体/间距系统;
- 插件支持动画/form 控件/typography;
但随着项目深入,我开始发现 几个巨大的问题,并最终决定停用 Tailwind。
一、class 污染:结构和样式纠缠成灾
来看一个真实例子:
<div class="flex items-center justify-between bg-white p-4 rounded-lg shadow-sm border border-gray-200">
<h2 class="text-lg font-semibold text-gray-800">订单信息</h2>
<button class="text-sm px-2 py-1 bg-blue-500 text-white rounded hover:bg-blue-600">编辑</button>
</div>
你能看出这个组件的“设计意图”吗?
你能快速改它的样式吗?
一个看似简单的按钮,一眼看不到设计语言,只看到一坨 class,你根本不知道:
px-2 py-1是从哪里决定的?bg-blue-500是哪个品牌色?hover:bg-blue-600是统一交互吗?
Tailwind 让样式变得快,但也让样式“变得不可读”。
二、复用失败:想复用样式还得靠 SCSS
我天真地以为 @apply 能帮我合成组件级样式,比如:
.btn-primary {
@apply text-white bg-blue-500 px-4 py-2 rounded;
}
但问题来了:
@apply不能用在媒体查询内;@apply不支持复杂嵌套、hover/focus 的组合;- 响应式、伪类写在 HTML 里更乱,如:
lg:hover:bg-blue-700; - 没法动态拼接 class,逻辑和样式混在组件逻辑层了。
最终结果就是:复用失败、样式重复、维护困难。
三、设计规范无法沉淀
我们设计系统中定义了若干基础变量:
- 主色:
#0052D9 - 次色:
#A0AEC0 - 字体尺寸规范:
12/14/16/18/20/24/32px - 组件间距:
8/16/24
本来我们希望 Tailwind 的 theme.extend 能承载这套设计系统,结果发现:
- tailwind.config.js 修改后,需要全员重启 dev server;
- 新增设计 token 非常繁琐,不如直接写 SCSS 变量;
- 多人改配置时容易冲突;
- 和设计稿同步代价高。
这让我明白:配置式设计系统不适合快速演进的产品团队。
四、多人协作混乱:Tailwind 并不直观
当我招了一位新同事,给他一个组件代码时,他的第一句话是:
“兄弟,这些 class 是从设计稿复制的吗?”
他根本看不懂 gap-6, text-gray-700, tracking-wide 分别是什么意思,只看到一堆“魔法 class” 。
更糟糕的是,每个人心中对 text-sm、text-base 的视觉认知不同,导致多个组件在微调时出现样式不一致、间距不统一的问题。
Tailwind 的语义脱离了设计意图,协作就失去了基础。
最终决定:我切回了 SCSS + BEM + 设计 token
我们开始回归传统模式:
- 所有组件都有独立
.scss文件; - 使用 BEM 命名规范:
.button,.button--primary,.button--disabled; - 所有颜色/间距/字体等统一放在
_variables.scss中; - 每个组件样式文件都注释设计规范来源。
这种模式虽然看起来“原始”,但它:
- 清晰分离结构和样式;
- 强制大家遵守设计规范;
- 组件样式可复用,可继承,可重写;
- 新人一眼看懂,不需要会 Tailwind 语法。
总结:Tailwind 不是错,是错用的代价太高
Tailwind 在以下场景表现极好:
- 个人项目 / 小程序:快速开发、无需复用;
- 组件库原型:试验颜色、排版效果;
- 纯前端工程师独立开发的项目:没有协作负担。
但在以下情况,Tailwind 会成为维护灾难:
- 多人协作;
- UI 不断迭代,设计语言需频繁调整;
- 有强复用需求(组件抽象);
- 与设计系统严格对齐的场景;
我为什么写这篇文章?
不是为了黑 Tailwind,而是为了让你在选择技术栈时更慎重。
就像当年我们争论 Sass vs Less,今天的 Tailwind vs 原子/语义 CSS 并没有标准答案。
Tailwind 很强,但不是所有团队都适合。
也许你正在享受它的爽感,但三个月后你可能会像我一样,把所有 .w-full h-screen text-gray-800 替换成 .layout-container。
尾声:如果你非要继续用 Tailwind,我建议你做这几件事
- 强制使用
@apply形成组件级 class,不允许直接使用长串 class; - 抽离公共样式,写在一个统一的组件样式文件中;
- 和设计团队对齐 Tailwind 的 spacing/font/color;
- 用 tailwind.config.js 做好 token 映射和语义名设计;
- 每个页面都进行 CSS code review,不然很快就会变垃圾堆。
来源:juejin.cn/post/7511602231508664361
用了十年 Docker,我为什么决定换掉它?
一、Docker 不再万能,我们该何去何从?
过去十年,Docker 改变了整个软件开发世界。它以“一次构建,到处运行”的理念,架起了开发者和运维人员之间的桥梁,推动了 DevOps 与微服务架构的广泛落地。
从自动化部署、持续集成到快速交付,Docker 一度是不可或缺的技术基石。
然而到了 2025 年,越来越多开发者开始重新审视 Docker。

系统规模在不断膨胀,开发场景也更加多元,不再是当初以单一后端应用为主的架构。
如今,开发者面临的不只是如何部署一个服务,更要关注架构的可扩展性、容器的安全性、本地与云端的适配性,以及资源的最优利用。
在这种背景下,Docker 开始显得不再那么“全能”,它在部分场景下的臃肿、安全隐患和与 Kubernetes 的解耦问题,使得不少团队正在寻找更轻、更适合自身的替代方案。
之所以写下这篇文章就是为了帮助你认清 Docker 当前的局限,了解新的技术趋势,并发现适用于不同场景的下一代容器化工具。
二、Docker 的贡献与瓶颈
不可否认,Docker 曾是容器化革命的引擎。从过去到现在,它的最大价值在于降低了环境配置的复杂度,让开发与运维团队之间的协作更加顺畅,带动了整个容器生态的发展。
很多团队正是依赖 Docker 才实现了快速构建镜像、构建流水线、部署微服务的能力。
但与此同时,Docker 本身也逐渐显露出局限性。比如,它高度依赖守护进程,导致资源占用明显高于预期,启动速度也难以令人满意。
更关键的是,Docker 默认以 root 权限运行容器,极易放大潜在攻击面,在安全合规日益严格的今天,这一点令人担忧。Kubernetes 的官方运行时也已从 Docker 切换为 containerd 与 runc,表明行业主流已在悄然转向。
这并不意味着 Docker 已过时,它依旧在许多团队中扮演重要角色。但如果你期待更高的性能、更低的资源消耗和更强的安全隔离,那么,是时候拓宽视野了。

三、本地开发的难题与新解法
特别是在本地开发场景中,Docker 的“不够轻”问题尤为突出。为了启动一个简单的 PHP 或 Node 项目,很多人不得不拉起庞大的容器,等待镜像下载、构建,甚至调试端口映射,最终电脑风扇轰鸣,开发体验直线下降。
一些开发者试图回归传统,通过 Homebrew 或 apt 手动配置开发环境,但这又陷入了“版本冲突”“依赖错位”等老问题。
这时,ServBay 的出现带来了新的可能。作为专为本地开发设计的轻量级工具,ServBay 不依赖 Docker,也无需繁琐配置。用户只需一键启动,即可在本地运行 PHP、Python、Golang、Java 等多种语言环境,并能自由切换版本与服务组合。它不仅启动迅速,资源占用也极低,非常适合 WordPress、Laravel、ThinkPHP 等项目的本地调试与开发。
更重要的是,ServBay 不再强制开发者理解复杂的镜像构建与容器编排逻辑,而是将本地开发流程变得像打开编辑器一样自然。对于 Web 后端和全栈开发者来说,它提供了一种“摆脱 Docker”的全新路径。
四、当 Docker 不再是运行时的唯一选择
容器运行时的格局也在悄然生变。containerd 和 runc 成为了 Kubernetes 官方推荐的运行时,它们更轻、更专注,仅提供核心的容器管理功能,剥离了不必要的附加组件。与此同时,CRI-O 正在被越来越多团队采纳,它是专为 Kubernetes 打造的运行时,直接对接 CRI 接口,减少了依赖层级。
另一款备受好评的是 Podman,它的最大亮点在于支持 rootless 模式,使容器运行更加安全。同时,它的命令行几乎与 Docker 完全兼容,开发者几乎不需要重新学习。
对于安全隔离要求极高的场景,还可以选择 gVisor 或 Kata Containers。前者通过用户态内核方式拦截系统调用,构建沙箱化环境;后者则将轻量虚拟机与容器结合,兼顾性能与隔离性。这些方案正在逐步替代传统 Docker,成为新一代容器架构的基石。
五、容器编排:Kubernetes 之后的路在何方?
虽然 Kubernetes 仍然是企业级容器编排的标准选项,但它的复杂性和陡峭的学习曲线也让不少中小团队望而却步。一个简单的应用部署可能涉及上百行 YAML 文件,过度的抽象与组件拆分反而拉高了运维门槛。
这也促使“微型 Kubernetes”方案逐渐兴起。K3s 是其中的代表,它对 Kubernetes 进行了极大简化,专为边缘计算和资源受限场景优化。此外,像 KubeEdge 等项目,也在积极拓展容器编排在边缘设备上的适配能力。
与此同时,AI 驱动的编排平台正在探索新路径。CAST AI、Loft Labs 等团队推出的智能调度系统,可以自动分析工作负载并进行优化部署,最大化资源利用率。更进一步,Serverless 与容器的融合也逐渐成熟,比如 AWS Fargate、Google Cloud Run 等服务,让开发者无需再关心节点管理,容器真正变成了“即用即走”的计算单元。
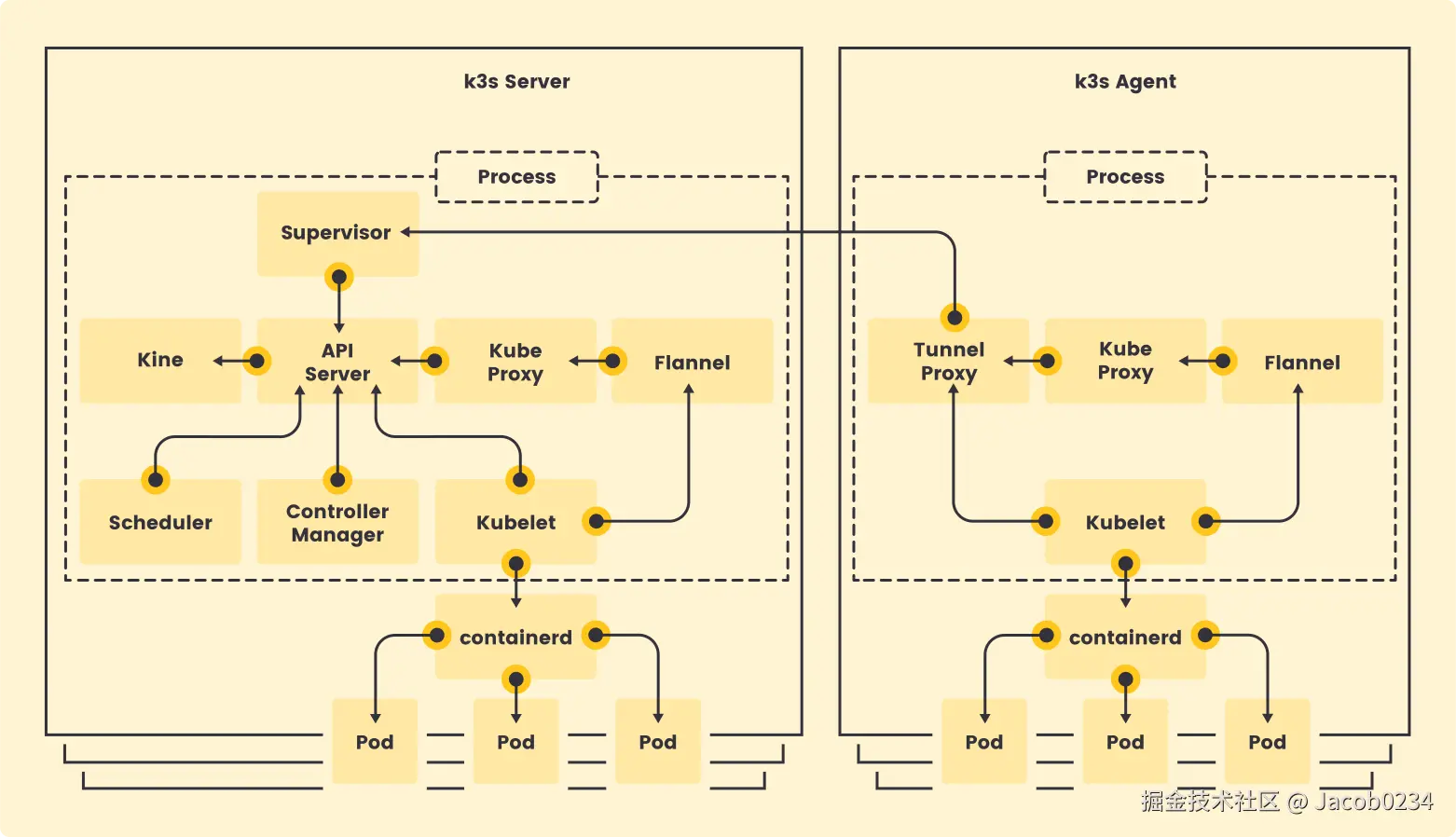
六、未来趋势:容器走向“定制化生长”
未来的容器化,我们将看到更细化的技术选型:开发环境选择轻量灵活的本地容器,测试环境强调快速重建与自动化部署,生产环境则关注安全隔离与高可用性。
安全性也会成为核心关键词。rootless 容器、沙箱机制和系统调用过滤将成为主流实践,容器从“不可信”向“可信执行环境”演进。与此同时,人工智能将在容器调度中发挥更大作用,不仅提升弹性伸缩的效率,还可能引领“自愈系统”发展,让集群具备自我诊断与恢复能力。
容器标准如 OCI 的持续完善,将让不同运行时之间更加兼容,为整个生态的整合提供可能。而在部署端,我们也将看到容器由本地向云端、再向边缘设备的自然扩展,真正成为“无处不在的基础设施”。

七、结语:容器化的新纪元已经到来
Docker 的故事并没有结束,它依然是很多开发者最熟悉的工具,也在部分场景中继续发挥作用。但可以确定的是,它不再是唯一选择。2025 年的容器世界,早已迈入了多元化、场景化、智能化的阶段。从轻量级的 ServBay 到更安全的 Podman,从微型编排到 Serverless 混合模式,我们手中可选的工具越来越丰富,技术栈的自由度也空前提升。
下一个十年,容器不只是为了“装下服务”,它将成为构建现代基础设施的关键砖块。愿你也能在这场演进中,找到属于自己的工具组合,打造更轻、更快、更自由的开发与部署体验。
来源:juejin.cn/post/7521927128524210212
前端高手才知道的秘密:Blob 居然这么强大!
🔍 一、什么是 Blob?
Blob(Binary Large Object)是 HTML5 提供的一个用于表示不可变的、原始二进制数据块的对象。
✨ 特点:
- 不可变性:一旦创建,内容不能修改。
- 可封装任意类型的数据:字符串、ArrayBuffer、TypedArray 等。
- 支持 MIME 类型描述,方便浏览器识别用途。
💡 示例:
const blob = new Blob(['Hello World'], { type: 'text/plain' });
🧠 二、Base64 编码的前世今生
虽然名字听起来像是某种“64进制”,但实际上它是一种编码方式,不是数学意义上的“进制”。
📜 起源背景:
Base64 最早起源于电子邮件协议 MIME(Multipurpose Internet Mail Extensions),因为早期的电子邮件系统只能传输 ASCII 文本,不能直接传输二进制数据(如附件)。于是人们发明了 Base64 编码方法,把二进制数据转换成文本形式,从而安全地在网络上传输。
🧩 使用场景:
| 场景 | 说明 |
|---|---|
| 图片嵌入到 HTML/CSS 中 | Data URI 方式减少请求 |
| JSON 数据中传输二进制信息 | 如头像、加密数据等 |
| WebSocket 发送二进制消息 | 避免使用 ArrayBuffer |
| 二维码生成 | 将图像转为 Base64 存储 |
⚠️ 注意:Base64 并非压缩算法,它会将数据体积增加约 33%。
🔁 三、从 Base64 到 Blob 的全过程
1. Base64 字符串解码:atob()
JavaScript 提供了一个内置函数 atob(),可以将 Base64 字符串解码为原始的二进制字符串(ASCII 表示)。
const base64Data = 'SGVsbG8gd29ybGQh'; // "Hello world!"
const binaryString = atob(base64Data);
⚠️ 返回的是 ASCII 字符串,不是真正的字节数组。
2. 构建 Uint8Array(字节序列)
为了构造 Blob,我们需要一个真正的字节数组。我们可以用 charCodeAt() 将每个字符转为对应的 ASCII 数值(即 0~255 的整数)。
const byteArray = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i);
}
现在,byteArray 是一个代表原始图片二进制数据的数组。
3. 创建 Blob 对象
有了字节数组,就可以创建 Blob 对象了:
const blob = new Blob([byteArray], { type: 'image/png' });
这个 Blob 对象就代表了一张 PNG 图片的二进制内容。
4. 使用 URL.createObjectURL() 显示图片
为了让浏览器能够加载这个 Blob 对象,我们需要生成一个临时的 URL 地址:
const imageUrl = URL.createObjectURL(blob);
document.getElementById('blobImage').src = imageUrl;
这样,你就可以在网页中看到这张图片啦!
🛠️ 四、Blob 的核心功能与应用场景
| 功能 | 说明 |
|---|---|
| 分片上传 | .slice(start, end) 方法可用于大文件切片上传 |
| 本地预览 | Canvas.toBlob() 导出图像,配合 URL.createObjectURL 预览 |
| 文件下载 | 使用 a 标签 + createObjectURL 实现无刷新下载 |
| 缓存资源 | Service Worker 中缓存 Blob 数据提升性能 |
| 处理用户上传 | 结合 FileReader 和 File API 操作用户文件 |
🧪 五、Blob 的高级玩法
1. 文件切片上传(分片上传)
const chunkSize = 1024 * 1024; // 1MB
const firstChunk = blob.slice(0, chunkSize);
2. Blob 转换为其他格式
FileReader.readAsText(blob)→ 文本FileReader.readAsDataURL(blob)→ Base64FileReader.readAsArrayBuffer(blob)→ Array Buffer
3. Blob 下载为文件
const a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = 'example.png';
a.click();
🧩 六、相关知识点汇总
| 技术点 | 作用 |
|---|---|
| Base64 | 将二进制数据编码为文本,便于传输 |
| atob() | 解码 Base64 字符串,还原为二进制字符串 |
| charCodeAt() | 获取字符的 ASCII 值(0~255) |
| Uint8Array | 构建字节数组,表示原始二进制数据 |
| Blob | 封装二进制数据,作为文件对象使用 |
| URL.createObjectURL() | 生成临时地址,让浏览器加载 Blob 数据 |
🧾 七、完整代码回顾
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Blob 实战</title>
</head>
<body>
<img src="" id="blobImage" width="100" height="100" alt="Blob Image" />
<script>
const base64Data = 'UklGRiAHAABXRUJQVlA4IBQHAACwHACdASpQAFAAPok0lEelIyIhMziOYKARCWwAuzNaQpfW+apU37ZufB5rAHqW2z3mF/aX9o/ev9LP+j9KrqSOfp9mf+6WmE1P1yFc3gTlw8B8d/TebelHaI3mplPrZ+Aa0l5qDGv5N8Tt9vYhz3IH37wqm2al+FdcFQhDnObv2+WfpwIZ+K6eBPxKL2RP6hiC/K1ZynnvVYth9y+ozyf88Obh4TRYcv3nkkr43girwwJ54Gd0iKBPZFnZS+gd1vKqlfnPT5wAwzxJiSk+pkbtcOVP+QFb2uDqUhuhNiHJ8xPt6VfGBfUbTsUzYuKgAP4L9wrkT8KU4sqIHwM+ZeKDBpGq58k0aDirXeGc1Odhvfx+cpQaeas97zVTr2pOk5bZkI1lkF9jnc0j2+Ojm/H+uPmIhS7/BlxuYfgnUCMKVZJGf+iPM44vA0EwvXye0YkUUK...';
const binaryString = atob(base64Data); // Base64 解码
const byteArray = new Uint8Array(binaryString.length); // 创建 Uint8Array
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i); // 填充字节数据
}
const blob = new Blob([byteArray], { type: 'image/png' }); // 创建 Blob
const imageUrl = URL.createObjectURL(blob); // 生成 URL
document.getElementById('blobImage').src = imageUrl; // 显示图片
</script>
</body>
</html>
📚 八、扩展阅读建议
🧩 九、结语
Blob 是连接 JavaScript 世界与真实二进制世界的桥梁,是每一个想要突破瓶颈的前端开发者必须掌握的核心技能之一。
掌握了 Blob,你就拥有了操作二进制数据的能力,这在现代 Web 开发中是非常关键的一环。
下次当你看到一张图片在网页中加载出来,或者一个文件被顺利下载时,不妨想想:这一切的背后,都有 Blob 的身影。
来源:juejin.cn/post/7523065182429904915
🫴为什么看大厂的源码,看不到undefined,看到的是void 0
void 0 是 JavaScript 中的一个表达式,它的作用是 返回 undefined。
解释:
void运算符:
- 它会执行后面的表达式(比如
void 0),但不管表达式的结果是什么,void始终返回undefined。 - 例如:
console.log(void 0); // undefined
console.log(void (1 + 1)); // undefined
console.log(void "hello"); // undefined
- 它会执行后面的表达式(比如
- 为什么用
void 0代替undefined?
- 在早期的 JavaScript 中,
undefined并不是一个保留字,它可以被重新赋值(比如undefined = 123),这会导致代码出错。 void 0是确保获取undefined的安全方式,因为void总是返回undefined,且不能被覆盖。- 现代 JavaScript(ES5+)已经修复了这个问题,
undefined现在是只读的,但void 0仍然在一些旧代码或压缩工具中出现。
- 在早期的 JavaScript 中,
常见用途:
- 防止默认行为(比如
<a>标签的href="javascript:void(0)"):
<a href="javascript:void(0);" onclick="alert('Clicked!')">
点击不会跳转
</a>
这样点击链接时不会跳转页面,但仍然可以执行 JavaScript。
- 在函数中返回
undefined:
function doSomething() {
return void someOperation(); // 明确返回 undefined
}
为什么用void 0
源码涉及到 undefined 表达都会被编译成 void 0
//源码
const a: number = 6
a === undefined
//编译后
"use strict";
var a = 6;
a === void 0;
也就是void 0 === undefined。void 运算符通常只能用于获取 undefined 的原始值,一般用void(0),等同于void 0,也可以使用全局变量 undefined 替代。
为什么不直接写 undefined
undefined 是 js 原始类型值之一,也是全局对象window的属性,在一部分低级浏览器(IE7-IE8)中or局部作用域可以被修改。
undefined在js中,全局属性是允许被覆盖的。
//undefined是window的全局属性
console.log(window.hasOwnProperty('undefined'))
console.log(window.undefined)
//旧版IE
var undefined = '666'
console.log(undefined)//666 直接覆盖改写undefined
window.undefined在局部作用域中是可以被修改的 在ES5开始,undefined就已经被设定为仅可读的,但是在局部作用域内,undefined依然是可变的。
①某些情况下用undefined判断存在风险,因undefined有被修改的可能性,但是void 0返回值一定是undefined
②兼容性上void 0 基本所有的浏览器都支持
③ void 0比undefined字符所占空间少。
拓展
void(0) 表达式会返回 undefined 值,它一般用于防止页面的刷新,以消除不需要的副作用。
常见用法是在 <a> 标签上设置 href="javascript:void(0);",即当单击该链接时,此表达式将会阻止浏览器去加载新页面或刷新当前页面的行为。
<!-- 点击下面的链接,不会重新加载页面,且可以得到弹框消息 -->
<a href="javascript:void(0);" onclick="alert('干的漂亮!')">
点我呀
</a>
总结:
void 0 是一种确保得到 undefined 的可靠方式,虽然在现代 JavaScript 中直接用 undefined 也没问题,但在一些特殊场景(如代码压缩、兼容旧代码)仍然有用。
来源:juejin.cn/post/7511618693714427914
微软正式官宣开源!王炸!
最近,和往常一样在逛 GitHub Trending 热榜时,突然看到又一个非常火的开源项目冲上了 Trending 热榜,相信不少小伙伴也刷到了。
一天之内就新增数千 star,仅仅用了几天时间,star 增长曲线都快干垂直了!
再定睛一看,好家伙,这不是微软的项目么。
出于好奇,点进去看了看,没错,这正是微软自家大名鼎鼎的 WSL!
原来就在前几天的微软 Build 2025 开发者大会上,微软正式官宣开源 Windows Subsystem for Linux(WSL)。

这在微软官方的最新的开发者技术博客也可以翻到。

众所周知,WSL 是微软在 2016 年就发布的一项重磅功能,相信不少同学都用过。
WSL 全称:Windows Subsystem for Linux,它允许用户在 Windows 操作系统中直接运行 Linux 环境,而无需双系统或者虚拟机,通过兼容层支持开发者工具、命令行应用及文件系统互通,实现方便地跨平台开发与测试。

从初始发布到如今走向开源,回顾 WSL 一路走来的发展历程,可以总结为如下几个大的阶段。
- 初期兼容层探索
2016年,微软首次推出 WSL 1。
其通过兼容层工具(如 lxcore.sys 驱动)将 Linux 系统调用转换为 Windows 调用,首次实现原生运行 ELF 可执行文件。
其优势是轻量级启动,但缺点也很明显,那就是兼容性和性能都存在一定局限。
- 中期扩展与独立应用
2019年,WSL 2 正式官宣。
此时微软对其进行了彻底的重构架构,采用基于 Hyper-V 的轻量级虚拟机技术,来运行完整 Linux 内核,并显著提升了兼容性与性能,同时这也使得 WSL 能支持运行更多的 Linux 程序和应用。
2021年,WSLg 正式推出,从此便支持了 Linux GUI 应用,同时 WSL 也开始作为独立组件来发布,其从 Windows 镜像剥离,转为通过 Microsoft Store 来进行独立安装和更新。
2022年~2024年这几年时间内,微软对 WSL 进行了持续迭代,包括 systemd 服务管理支持、GPU加速、多发行版支持以及内存和文件系统等诸多性能优化。
经过中期这一阶段的发展,WSL 在兼容性、功能以及性能等方面都有了长足的进步,也为下一步的开源和社区化奠定了基础。
- 后期开源和社区化
在前几天的微软 Build 2025 开发者大会上,微软正式宣布 WSL 开源(GitHub 仓库开放),允许社区直接参与代码贡献,这也标志了 WSL 进入了开源和社区化的新阶段。
至此为止,在 WSL 的 GitHub 仓库中的 Issue #1 —— 那个自2016年起就存在的“Will this project be Open Source?”的提问,终于被标注为了“Closed”!
众所周知,WSL 其实是由一组分布式组件来组合而成的。
即:一部分是在 Windows 系统中运行,另外一部分则是在 WSL 2 虚拟机内运行。
这个从 WSL 官方给出的组件架构图中就可以很清晰地看出来:
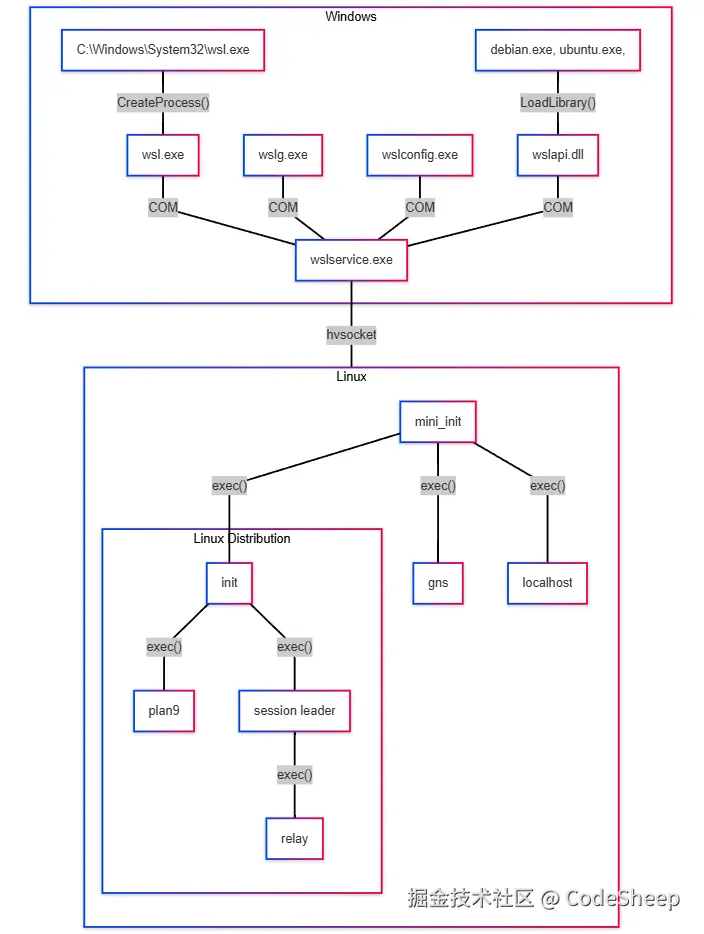
那既然现如今微软官宣了 WSL 开源,那对于开发者来说,我们需要清晰地知道这次到底开源了哪些组件代码呢?
关于这部分,对照上图,我们这里不妨用表格的形式来简要总结一下,供大家参考。
| 组件类型 | 功能描述 | 组件名 | 开源状态 |
|---|---|---|---|
| 用户交互层 | 命令行工具 | wsl.exe | 已开源 |
| 用户交互层 | 命令行工具 | wslg.exe | 已开源 |
| 用户交互层 | 命令行工具 | wslconfig.exe | 已开源 |
| 服务管理层 | WSL服务管理 | wslservice.exe | 已开源 |
| Linux运行时 | init启动 | init | 已开源 |
| Linux运行时 | 网络服务 | gns | 已开源 |
| Linux运行时 | 端口转发 | localhost | 已开源 |
| 文件共享 | Plan9协议实现 | plan9 | 已开源 |
以上这些已开源的组件源码都可以在 WSL 的 GitHub 仓库里找到,大家感兴趣的话可以对应查看和研究。
虽然本次开源覆盖了 WSL 的绝大多数关键组件,但是官方也明确说了,以下这几个组件由于其仍然是 Windows 系统的一部分,所以目前仍然保持非开源状态,包括:
Lxcore.sys:支撑 WSL1 的内核驱动程序P9rdr.sys和p9np.dll:运行"\wsl.localhost"文件系统重定向的关键组件(从 Windows 到 Linux)
这一点需要特别注意一下。
回顾过往,其实 GitHub 上的 WSL 仓库并不是最近才有,好多年前就已经存在了。
即便在以前的 WSL 还没有开源的日子里,WSL 的背后就有了一个强大的社区在支持,开发者们通过 GitHub Issue 和 Discussion 等为 WSL 这个项目提供了诸多错误追踪、新功能建议以及意见改进。
可以说,如果没有社区贡献,WSL 永远不可能成为今天的样子。
而现如今 WSL 源代码正式开源,这也满足了开发者社区长达 9 年的期待。
开发者们现在可以自行下载、构建,甚至提交改进建议或者新功能的代码来直接参与。
同时 WSL 官方也给出了一个详细的项目贡献指南:

感兴趣的同学也可以上去学习研究一波。
好了,那以上就是那以上就是今天的内容分享,希望能对大家有所帮助,我们下篇见。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7509437413099536438
用半天时间,threejs手搓了一个机柜
那是一个普通的周三早晨,我正对着产品经理刚丢过来的需求发呆——"在管理系统里加个3D机柜展示,要能开门的那种"。
"这不就是个模型展示吗?"我心想,"AI应该能搞定吧?"
9:30 AM - 启动摸鱼模式
我熟练地打开代码编辑器,把需求复制粘贴进AI对话框: "用Three.js实现一个带开门动画的机柜模型,要求有金属质感,门能90度旋转"
点击发送后,我惬意地靠在椅背上,顺手打开了B站。"让AI先忙会儿~"
10:30 AM - 验收时刻
一集《凡人修仙传》看完,我懒洋洋地切回编辑器。AI果然交出了答卷:
11:00 AM - 血压升高现场
看着AI生成的"未来科技风"机柜,我深吸一口气,决定亲自下场。毕竟,程序员最后的尊严就是——"还是自己来吧"。
11:30 AM - 手动抢救
首先手动创建一个空场景吧
class SceneManager {
constructor() {
this.scene = new THREE.Scene();
this.camera = new THREE.PerspectiveCamera(
75,
window.innerWidth / window.innerHeight,
0.1,
1000
);
this.camera.position.set(0, 2, 5);
this.renderer = new THREE.WebGLRenderer();
this.renderer.setSize(window.innerWidth, window.innerHeight);
const canvas = document.getElementById('renderCanvas');
canvas.appendChild(this.renderer.domElement);
this.controls = new OrbitControls(this.camera, this.renderer.domElement);
this.controls.enableDamping = true;
this.controls.dampingFactor = 0.05;
this.controls.target.set(0, 3, 0);
this.controls.update();
this.addLights();
this.addFloor();
}
addLights() {
const ambientLight = new THREE.AmbientLight(0xffffff, 0.5);
this.scene.add(ambientLight);
const directionalLight = new THREE.DirectionalLight(0xffffff, 1);
directionalLight.position.set(5, 5, 5);
this.scene.add(directionalLight);
}
addFloor() {
const floorGeometry = new THREE.PlaneGeometry(10, 10);
const floorMaterial = new THREE.MeshStandardMaterial({ color: 0x888888 });
const floor = new THREE.Mesh(floorGeometry, floorMaterial);
floor.rotation.x = -Math.PI / 2;
this.scene.add(floor);
}
animate() {
const animateLoop = () => {
requestAnimationFrame(animateLoop);
this.controls.update();
this.renderer.render(this.scene, this.camera);
};
animateLoop();
}
onResize() {
window.addEventListener('resize', () => {
this.camera.aspect = window.innerWidth / window.innerHeight;
this.camera.updateProjectionMatrix();
this.renderer.setSize(window.innerWidth, window.innerHeight);
});
}
}
然后这机柜怎么画呢,不管了,先去吃个饭,天大地大肚子最大
12:30 PM - 程序员的能量补给时刻
淦!先干饭!" 我一把推开键盘,决定暂时逃离这个三维世界。毕竟——
- 饥饿值已经降到30%以下
- 右手开始不受控制地颤抖
- 看Three.js文档出现了重影
扒饭间隙,手机突然震动。产品经理发来消息:"那个3D机柜..."
我差点被饭粒呛到,赶紧回复:"正在深度优化用户体验!"
(十分钟风卷残云后)
1:00 PM - 回归正题
吃饱喝足,终于可以专心搞机柜了,(此处可怜一下我的午休)
拆分机柜结构
机柜的结构可以分为以下几个部分:
- 不可操作结构:
- 底部:承载整个机柜的重量,通常是一个坚固的平面。
- 顶部:封闭机柜的顶部,提供额外的支撑。
- 左侧和右侧:机柜的侧板,通常是固定的,用于保护内部设备。
- 可操作结构:
- 前门:单门设计,通常是透明或半透明材质,便于观察内部设备。
- 后门:双开门设计,方便从后方接入设备的电缆和接口。
实现步骤
- 创建不可操作结构:
使用BoxGeometry创建底部、顶部、左侧和右侧的平面,并将它们组合成一个整体。 - 添加前门:
前门使用透明材质,并设置旋转轴以实现开门动画。 - 添加后门:
后门分为左右两部分,分别设置旋转轴以实现双开门效果。 - 优化细节:
- 添加螺丝孔和通风口。
- 使用高光材质提升视觉效果。
接下来,我们开始用代码实现这些结构。
机柜结构的实现
1. 创建不可操作结构

底部
export function createCabinetBase(scene) {
const geometry = new THREE.BoxGeometry(0.6, 0.05, 0.64);
const base = new THREE.Mesh(geometry, materials.baseMaterial);
base.position.y = -0.05; // 调整位置
scene.add(base);
}
底部使用BoxGeometry创建,设置了深灰色金属材质,位置调整为机柜的最底部。
顶部
export function createCabinetTop(scene) {
const geometry = new THREE.BoxGeometry(0.6, 0.05, 0.64);
const top = new THREE.Mesh(geometry, materials.baseMaterial);
top.position.y = 1.95; // 调整位置
scene.add(top);
}
顶部与底部类似,位置调整为机柜的最顶部。
侧面
export function createCabinetSides(scene) {
const geometry = new THREE.BoxGeometry(0.04, 2, 0.6);
const material = materials.baseMaterial;
// 左侧面
const leftSide = new THREE.Mesh(geometry, material);
leftSide.position.set(-0.28, 0.95, 0); // 调整位置
scene.add(leftSide);
// 右侧面
const rightSide = new THREE.Mesh(geometry, material);
rightSide.position.set(0.28, 0.95, 0); // 调整位置
scene.add(rightSide);
}
侧面使用两个BoxGeometry分别创建左侧和右侧,位置对称分布。
2. 创建可操作结构

前门
export function createCabinetFrontDoor(scene) {
const doorGr0up = new THREE.Gr0up();
const doorWidth = 0.04;
const doorHeight = 2;
const doorDepth = 0.6;
const frameMaterial = materials.baseMaterial;
const frameThickness = 0.04;
// 上边框
const topFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, doorDepth);
const topFrame = new THREE.Mesh(topFrameGeo, frameMaterial);
topFrame.position.set(0, 1 - frameThickness / 2, 0);
doorGr0up.add(topFrame);
// 下边框
const bottomFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, doorDepth);
const bottomFrame = new THREE.Mesh(bottomFrameGeo, frameMaterial);
bottomFrame.position.set(0, -doorHeight / 2 + 0.05, 0);
doorGr0up.add(bottomFrame);
// 左右边框
const leftFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const leftFrame = new THREE.Mesh(leftFrameGeo, frameMaterial);
leftFrame.position.set(0, 1 - doorHeight / 2, -doorDepth / 2 + frameThickness / 2);
doorGr0up.add(leftFrame);
const rightFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const rightFrame = new THREE.Mesh(rightFrameGeo, frameMaterial);
rightFrame.position.set(0, 1 - doorHeight / 2, doorDepth / 2 - frameThickness / 2);
doorGr0up.add(rightFrame);
scene.add(doorGr0up);
return doorGr0up;
}
前门由一个Gr0up组装而成,包含上下左右边框,材质与机柜一致,后续将添加玻璃部分和动画。
前门动画的实现
前门的动画使用gsap库实现,设置旋转轴为左侧边框。
gsap.to(frontDoor.rotation, {
y: Math.PI / 2, // 90度旋转
duration: 1, // 动画时长
ease: "power2.inOut",
});
通过gsap.to方法,前门可以实现平滑的开门效果。
3. 添加后门
后门采用双开设计,左右两扇门分别由多个边框组成,并通过Gr0up进行组合。
为了优化细节我还加入了网孔结构(此处心疼一下我为写他掉的头发)

后门的实现
export function createCabinetBackDoor(scene) {
const doorGr0up = new THREE.Gr0up();
const doorWidth = 0.04;
const doorHeight = 2;
const doorDepth = 0.6;
const singleDoorDepth = doorDepth / 2;
const frameMaterial = materials.baseMaterial;
const frameThickness = 0.04;
function createSingleBackDoor(isLeft) {
const singleGr0up = new THREE.Gr0up();
// 上边框
const topFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, singleDoorDepth);
const topFrame = new THREE.Mesh(topFrameGeo, frameMaterial);
topFrame.position.set(0, 1 - frameThickness / 2, 0);
singleGr0up.add(topFrame);
// 下边框
const bottomFrameGeo = new THREE.BoxGeometry(doorWidth, frameThickness, singleDoorDepth);
const bottomFrame = new THREE.Mesh(bottomFrameGeo, frameMaterial);
bottomFrame.position.set(0, -doorHeight / 2 + 0.05, 0);
singleGr0up.add(bottomFrame);
// 外侧边框
const sideFrameGeo = new THREE.BoxGeometry(doorWidth, doorHeight - 2 * frameThickness, frameThickness);
const sideFrame = new THREE.Mesh(sideFrameGeo, frameMaterial);
sideFrame.position.set(
0,
1 - doorHeight / 2,
isLeft
? -singleDoorDepth / 2 + frameThickness / 2
: singleDoorDepth / 2 - frameThickness / 2
);
singleGr0up.add(sideFrame);
return singleGr0up;
}
const leftDoor = createSingleBackDoor(true);
const rightDoor = createSingleBackDoor(false);
doorGr0up.add(leftDoor);
doorGr0up.add(rightDoor);
scene.add(doorGr0up);
return { group: doorGr0up, leftDoor, rightDoor };
}
后门的实现与前门类似,采用双扇门设计,左右各一扇。
后门动画的实现
后门的动画同样使用gsap库实现,分别设置左右门的旋转轴。
gsap.to(leftDoor.rotation, {
y: Math.PI / 2, // 左门向外旋转90度
duration: 1,
ease: "power2.inOut",
});
gsap.to(rightDoor.rotation, {
y: -Math.PI / 2, // 右门向外旋转90度
duration: 1,
ease: "power2.inOut",
});
通过gsap.to方法,后门可以实现平滑的双开效果。
2:00 PM - 项目收尾
终于,随着最后一行代码的敲定,3D机柜模型在屏幕上完美呈现。前门优雅地打开,后门平滑地双开,仿佛在向我点头致意。
我靠在椅背上,长舒一口气,心中默念:"果然,程序员的尊严还是要靠自己守护。"
可拓展功能
虽然当前的3D机柜模型已经实现了基本的展示和交互功能,但在实际项目中,我们可以进一步扩展以下功能:
1. U位标记
2. U位资产管理
3. 动态灯光效果
4. 数据联动
将3D机柜与后台数据联动:
- 实时更新设备状态。
- 显示设备的实时监控数据(如温度、功耗等)。
- 支持通过API接口获取和更新设备信息。
不说了,需求又来了()我还是继续去搬砖了
代码地址:gitee.com/erhadong/th…
来源:juejin.cn/post/7516784123703181322
很喜欢Vue,但还是选择了React: AI时代的新考量
引言
作为一个深度使用Vue多年的开发者,最近我在新项目技术选型时,却最终选择了React。这个决定不是一时冲动,而是基于当前技术发展趋势、AI时代的需求以及生态系统的深度思考。

AI时代的前端需求
随着人工智能技术的飞速发展,前端开发的需求也发生了深刻的变化。现代应用不仅仅是静态页面或简单的数据展示,而是需要与复杂的后端服务、机器学习模型以及第三方API深度集成。这些场景对前端框架提出了更高的要求,生态的重要性,不得不说很重要。
社区对AI的支持
说实话,React社区在AI领域简直就是"社交达人"。shadcn这样的明星UI库、vercel/ai这样的实力派SDK,都是圈子里的"网红"。想要快速搭建AI应用?这些"老铁"都能帮你省下不少力气。简单列举一些知名仓库。
@vercel/ai
这是由Vercel开发的AI SDK
提供了与各种AI模型(如OpenAI, Anthropic等)交互的统一接口
支持流式响应、AI聊天界面等功能
特别适合构建类ChatGPT应用
shadcn-admin
基于shadcn/ui的管理后台模板
包含了AI聊天等现代化功能
提供了完整的后台管理系统布局
shadcn/ui
这是一个高度可定制的React组件库
不是传统的npm包,而是采用复制代码的方式
提供了大量现代化的UI组件
完美支持暗色模式
特别适合构建AI应用的界面
ChatGPTNextWeb
开源的ChatGPT Web客户端
使用Next.js构建
支持多种部署方式
提供了优秀的UI/UX设计参考
AI工具链的优先支持
React在AI工具支持方面具有明显优势
GitHub Copilot、Cursor 等AI IDE 也对React的代码提示更准确
目前多数AI辅助开发工具会优先支持React生态(Vue 生态也不错,狗头保命🐶)
结论
技术选型永远不是非黑即白的选择。在AI时代,我们需要考虑:
- 技术栈的生态活跃度
- AI工具的支持程度
- 团队的学习成本
- 项目的长期维护
总的来说,Vue和React各有千秋,但从AI时代的需求和生态系统的角度来看,React确实更适合承担复杂、高性能的应用开发任务。当然,这并不意味着Vue没有未来。事实上,Vue依然是一个优秀的框架,尤其适合中小型企业或初创团队快速搭建产品原型。
随着AI技术的进一步普及,前端框架之间的竞争也将更加激烈。无论是React还是Vue,都需要不断进化以适应新的挑战。而对于开发者来说,掌握多种技术栈并根据项目需求灵活选择,才是最重要的技能。
正如一句老话所说:“工欲善其事,必先利其器。”选择合适的工具,才能让我们的项目在AI时代脱颖而出。
还有技术人不应该局限于框架,什么都能上手,多看看新的东西,接受新的事物,产品能力也很重要。
写在最后
技术选型是一个需要综合考虑的过程,没有永远的对与错,只有更适合与否。希望这篇文章能给正在进行技术选型的你一些参考。
来源:juejin.cn/post/7497174194715852815
95%代码AI生成,是的你没听错...…
不是标题党,这是我的真实经历
95%的代码由AI生成?听起来像标题党,但这是我最近使用Augment Code的真实情况。
相信现在大多数人都用过ai来写代码,笔者也是ai工具的拥抱者,从一开始的GitHub Copilot补全,到后面的Agent编程:Cursor、WindSurf、Zed等,但其实效果一般。直到用了Augment Code,才发现差距这么大。
上个月做数据看板,以前要一天的工作量,现在半小时搞定。图表、数据处理、样式,基本都是AI生成的。
当然,也不是什么代码都能让AI来写。复杂的业务逻辑、架构设计,还是得靠人。但对于大量的重复性编码工作,AI确实能大幅提升效率。 如果你也在用AI编程工具但效果不理想,这篇分享可能对你有帮助。
AI工具对比
在这之前,让我们先来看下市面上的AI编程工具吧
先看个数据对比,心里有个底
| 工具 | 响应速度 | 准确率 | 月费用 | 我的使用感受 |
|---|---|---|---|---|
| GitHub Copilot | 0.5-1秒 | 75-80% | $10 | 老牌稳定,但有点跟不上节奏了 |
| Cursor | 1-2秒 | 85%+ | $20 | 体验最好,就是有点贵 |
| Windsurf | 0.8-1.5秒 | 80%+ | $15 | 自动化程度高,UI很舒服 |
| Augment Code | 1-1.5秒 | 声称很快 | $50 | 大项目理解能力确实强 |
| Cline | 看模型 | 75%+ | 免费+API | 开源良心,功能够用 |
GitHub Copilot:老前辈的逆袭之路
这个应该是最早的AI代码补全工具了,通过tab键快速补全你的意图代码...但是在后面的AI编程工具竞赛中热度却没有那么高了。。。不过最近的数据让我有点刮目相看。
最新重大消息: 据微软2024年财报显示,GitHub Copilot用户同比增长180%,贡献了GitHub 40%的收入增长¹。这个数据还是很惊人的,说明虽然新工具层出不穷,但老牌工具的用户基础还是很稳固的。
实际使用感受:
- 响应确实快,基本0.5-1秒就出结果
- 准确率比我之前用的时候提升了不少,从70-75%涨到了75-80%
- 最大的问题还是对整个项目的理解不够深入,经常给出的建议比较浅层
最近的更新还挺给力:
- 2024年底推出了免费版,这个对个人开发者来说是个好消息
- 2025年2月新增了Agent模式,虽然来得有点晚,但总算跟上了
- 现在支持多个模型了,包括GPT-4o和Claude 3.7 Sonnet
用下来感觉...GitHub Copilot虽然不是最炫酷的,但胜在稳定和用户基础大。如果你不想折腾,它还是个不错的选择。
Cursor:估值99亿美元的AI编程独角兽
说实话,Cursor是我用过体验最好的AI编程工具...界面设计得很舒服,功能也很强大,就是价格让人有点肉疼。不过最近的融资消息让我对它更有信心了。
重磅消息: 2025年6月,Cursor的母公司Anysphere完成9亿美元融资,估值达到99亿美元²!这个估值是三个月前的四倍,说明投资人对AI编程工具的前景非常看好。年化收入约每两个月翻倍,6月份已经超过5亿美元。
为什么说体验好:
- 专门为AI编程优化的界面,用起来就是爽
- 多文件编辑能力真的强,能理解整个项目的上下文
- Composer功能让我可以一次性修改多个文件,这个太实用了
- 代码生成准确率达到85%+,确实比其他工具高一截
数据说话:
- 2024年用户突破100万,增长了300%
- 响应速度虽然比Windsurf稍慢,但比我之前用的时候改善了很多
实际体验中,Cursor确实是我见过的最接近"AI原生编程"的工具。现在有了这么高的估值,说明它的商业模式是被认可的。
Windsurf:被断供的自动化之王
Windsurf给我的感觉就是...它真的很"聪明",很多事情都能自动帮你搞定。但是最近发生的事情让我有点担心它的未来。
重大危机事件: 2025年6月4日,发生了一件震惊AI编程圈的事情:Anthropic突然断供Windsurf对Claude 3.x系列模型的API访问权限³!Windsurf CEO公开控诉,称仅获得不到5天的通知时间,措手不及。
这个事件的背景很复杂:
- 4月份传出OpenAI要以30亿美元收购Windsurf的消息⁵
- Anthropic可能是为了保护自己的商业利益,不想让竞争对手OpenAI获得优势
- 结果就是Windsurf用户大量退订,直接影响了用户体验
应对措施:
- Windsurf紧急转向谷歌Gemini模型
- 推出了Gemini 2.5 Pro的七五折促销
- 取消了免费用户对Claude模型的访问权限
最让我印象深刻的功能:
- Cascade功能真的是原创,能自动分析你的代码库然后选择正确的文件来工作
- 使用Claude 3.5 Sonnet的时候响应速度确实很快(现在用不了了...)
- UI设计很精致,用起来有种苹果产品的感觉
用下来感觉,Windsurf的技术实力是有的,但这次断供事件让我意识到,依赖单一模型提供商是有风险的。不过要注意的是,它们已经推出了自研的SWE-1模型,可能是为了摆脱对第三方模型的依赖。
Augment Code:SWE-bench冠军的实力证明
这个工具...怎么说呢,在处理大型项目方面确实有两把刷子。最近的权威测试结果更是证明了我之前的判断。
权威认证数据: 在SWE-bench测试中,Augment Code确实获得了第一名⁴!这个测试是用真实的GitHub问题来评估AI工具解决实际软件工程问题的能力,含金量很可以。
为什么说它厉害:
- SWE-bench测试排名第一,这个不是吹的
- 对大型代码库的理解能力确实强,我试过几个10万行+的项目,它都能很好地理解上下文
- "记忆"功能很有意思,能学习你的编程风格和偏好
企业级的实力:
- 被很多Fortune 500公司采用,说明在企业环境下表现不错
- 在复杂重构场景下表现确实突出,这个我深有体会
实际使用中,如果你经常处理大型复杂项目,Augment Code确实值得考虑。SWE-bench第一名的成绩给了我更多信心。
Cline:开源界的良心
说到Cline,这个真的是开源界的良心产品...完全免费,功能还挺强大。
开源的优势:
- GitHub上42.6k+星标,社区很活跃
- Agent能力做得很不错,能执行复杂的任务序列
- MCP协议支持做得很好,扩展性强
如果你预算有限或者喜欢折腾开源工具,Cline是个很好的选择。特别是现在Windsurf被断供,Cline的稳定性反而成了优势。
Augment Code使用技巧
安装使用
Augment Code的安装很简单,它是作为插件来使用的,支持Vscode、JetBrains IDEs、Vim and Neovim,当然Cursor也可以用。
在插件中搜索 “Augment”,第一个就是了
安装完成之后需要注册登录,在浏览器中注册完成之后会跳回Vscode就完成登录了。新用户是有14天的免费使用的(包含300的用户提问次数),可以使用全部的高级功能,这点比Cursor就好很多了。
在打开新项目的时候,Augment 需要索引项目,这会将你的代码文件加入到上下文中,Augment是专门为复杂项目设计的,超长的上下文读取,这也是相比其他ai编程工具的一个优势。
这是索引之后的界面,最上面是聊天界面的管理,一个Thread就是一次chat,这里定义为 “线程” 也挺形象的。
右边是创建“线程” 的形式,主要有3种:
- Chat
和其他ai编程工具没啥区别,可以询问有关您的代码的问题,获取有关如何重构代码的建议,向选定的代码行添加新功能等
- Agent
这是Augment 的主要工作模式,和Cursor 的Agent Mode一样,Agent会自动帮你规划任务,结合当前工作区、内存、上下文等信息帮你分析和规划任务,代理可以在您的工作区中创建、编辑或删除代码,并可以通过 MCP 使用终端和外部集成等工具来完成您的请求。
你可能还看到旁边的 “Auto” 开关,开启之后,Augment 会自动执行每个任务的命令,比如在终端执行脚本、编辑文件等,如果没有开启,你需要手动确认。
你可能发现Augment 并没有和其他ai编程工具一样有大模型的选择,因为他们团队认为模型的选择应该是自动的,Augment会根据以下因素动态选择最佳模型:
✅ 任务类型(代码完成、聊天、内联建议)
✅ 跨实际编码任务的性能基准
✅ 成本与延迟的权衡
✅ 人工智能模型的最新进展
这也是我觉得Augment值得夸奖的一点,因为作为提供给开发人员的编程工具,不需要他了解每个大模型的优缺点进行选择;Augment会自动的使用不同的大模型进行组合,比如思考任务的时候用这个大模型,编写代码的时候用另一个大模型,来达到最佳的生产力效果。目前已经Augment 已经内置了最新的 Claude Sonnet 4 了
- Remote Agent
这个模式是新出的,是在云端上完成你的任务,可以针对独立任务并行运行多个代理,并在 vscode 中监控和管理它们的进度。
这个需要连接github仓库使用,当代理完成工作后,可以创建拉取请求 (PR),审核您的更改并将其合并到主分支中。从头部的Threads 中选择代理,然后点击“创建 PR”。代理将创建分支、提交更改并为您创建拉取请求。
使用技巧
介绍到这里,基本上你就可以愉快的去使用Augment来感受他的魅力啦,但是,还是请你继续看下去,对于AI编程工具而言,Augment 有时候也会和其他ai工具有相同的问题。比如说,你是不是有时候觉得cursor帮你生成了太多代码了,而且还影响到了之前的功能?有时候ai工具不能很好的理解你的意思?
这里就需要使用到一些技巧了,这也是Augment官方推荐的做法,其中这些思想同样适用其他ai工具:
首先在输入问题完成之后,你可以看到旁边有个 ✨按钮,你可以点击它来帮你完善你的问题,它会根据上下文结合大模型来优化你的提问,让生成的质量更高
提示应该详细,不要太短
对于复杂的任务尤其如此。试图仅凭提示中的几个词来完成一项复杂的任务几乎肯定会失败。
这一点我们可以通过点击输入框右边的 ✨按钮, 可以很好的帮我们解决这个问题,示例:
这是未优化之前的:
这是点击优化后的,已经帮你详细的补充了要素和步骤等关键信息:
向 Agent 提供全面的背景信息
不仅要解释最终目标,还要解释背后的原因、额外的限制等,比如可以提供github issue等链接
将复杂的任务分解成更小、更易理解的部分(一次一个)
对于复杂的任务,首先与 Agent 讨论并完善计划
不要急着让Augment写代码,这样写出来往往不合人意,可以先和他确认方案再让他进行生成
Agent 擅长迭代测试结果和代码执行输出
完成任务之后,可以顺便让他帮你编写测试用例来验证这次的生成质量是否满意,让ai自己监督自己,是不是很有意思呢
试试 Agent 来处理你不熟悉的任务!
即使这个任务你不会,但是你丢给他之后,也许会有新的思路帮你完成,这也是ai的优势,连接互联网知识库,可以给出不一样的思路和解决方案
当Agent表现良好时,提供积极的反馈
多夸夸它
通过上面的建议,我整理了一套提示词模版,在顶部右上角点击设置图标打开Setting:

输入下面提示词自动保存:
As my AI coding assistant, please view our collaboration as working with a smart and professional engineer. I hope you can fully leverage the following capabilities:
1. Reply in Chinese;
2. Code Understanding and Analysis:
- Before carrying out the task, please thoroughly understand the relevant code and project structure.
- Use your code repository search tools to explore related files and dependencies.
- Analyze the existing code patterns and architectural design to ensure that the new code is consistent with them.
3. Task Planning and Execution:
- For complex tasks, please first develop a detailed plan and discuss it with me. Only proceed after obtaining confirmation.
- Break down large tasks int0 manageable sub-tasks and implement them step by step.
- Provide progress updates and interim results after each key step.
4. Code Quality and Testing:
- Write high-quality code that conforms to the project's style guide.
- Proactively write and run tests after implementing features to ensure the code works properly.
- Consider edge cases and exception handling to enhance code robustness.
5. Learning and Iteration:
- If you encounter unfamiliar technologies or frameworks, proactively search for relevant documentation.
- Iteratively improve the code based on test results and feedback.
- When facing difficulties, explain your understanding and the methods you have tried.
6. Communication and Collaboration:
- Clearly explain your thought process and the reasons for your decisions.
- When you need to clarify a question, please start your inquiry with "This is just a question:".
- Offer multiple possible solutions and analyze the advantages and disadvantages of each.
I will try my best to provide detailed task descriptions, background information and constraints to help you better understand the requirements. If the information is insufficient, please feel free to ask questions to obtain the necessary context.
Let's work together efficiently and create high-quality code!
你可以自行翻译一下,这都是之前提到的建议总结,并加上了要求使用中文回复
使用示例
下面就以一个常见的工作场景来试下效果吧,这里以一个 nextjs 实现的 博客项目为例,现在已经有个博客的内容展示、主题切换功能,让我们新增一个评论功能吧。
在Augment输入框中输入:
我希望在这个项目中加入评论系统,集成 Giscus,请你给出实现的方案和步骤代码吧。请你分析给出技术方案和我确认,不要修改代码
这里以比较常用的开源的Giscus项目为例子,展示如何接入。
输入之后点击提示词增强按钮 ✨
这里会帮你优化你的提问,同时注意不要让Augment直接修改代码,先给出方案设计在确认,这就是我们刚才说的使用技巧,点击发送后Augment会自动帮你分析和规划任务:
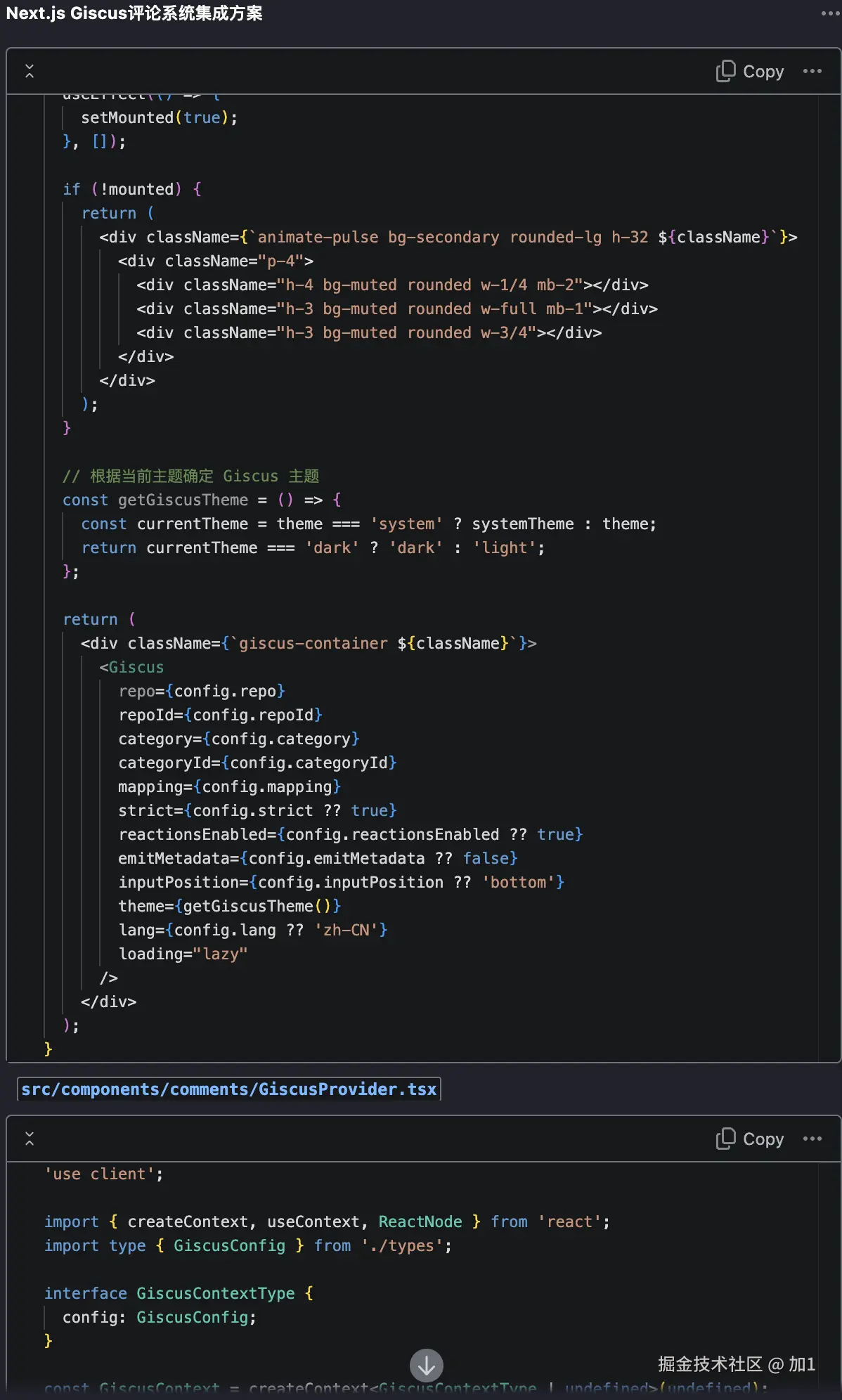
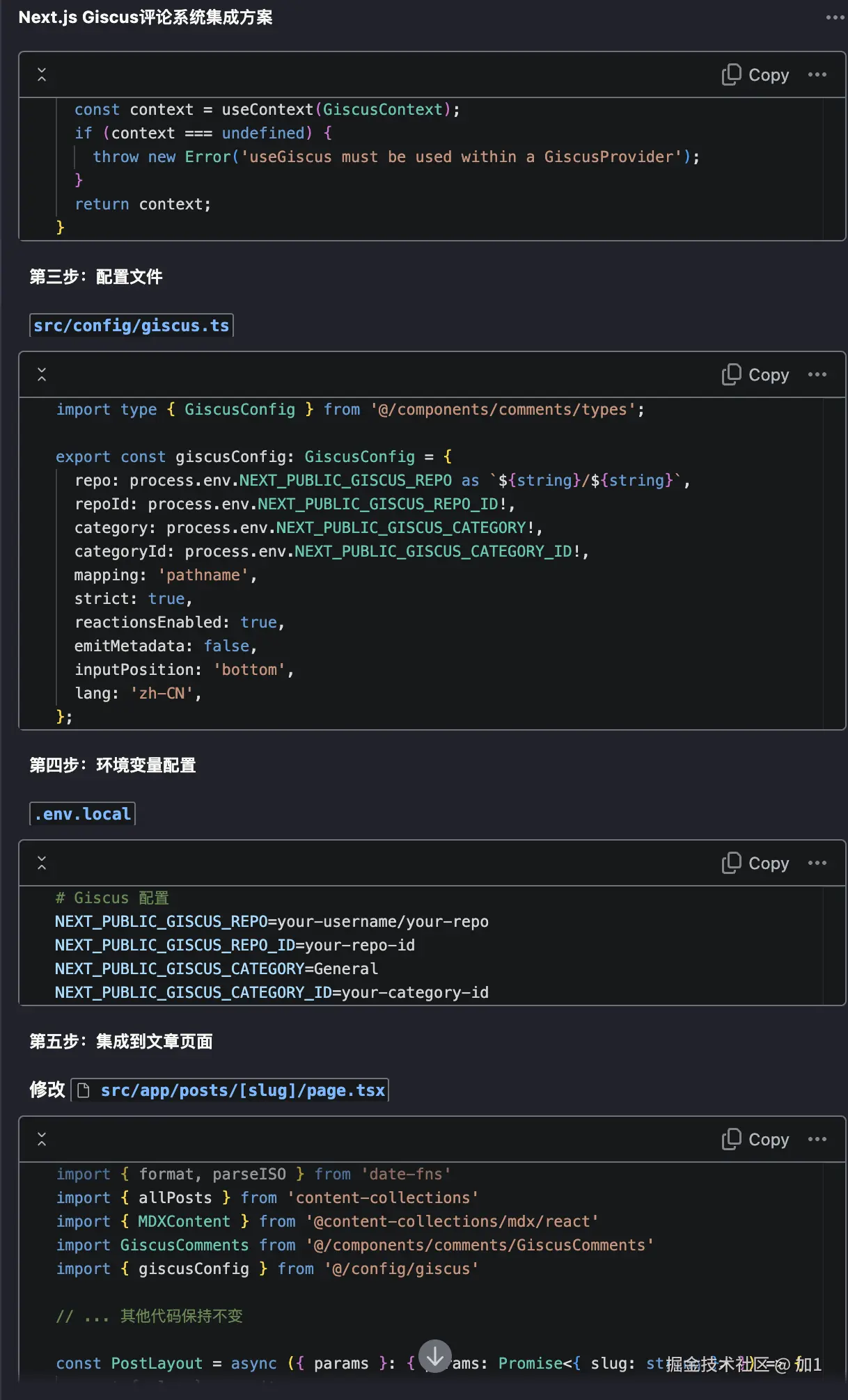
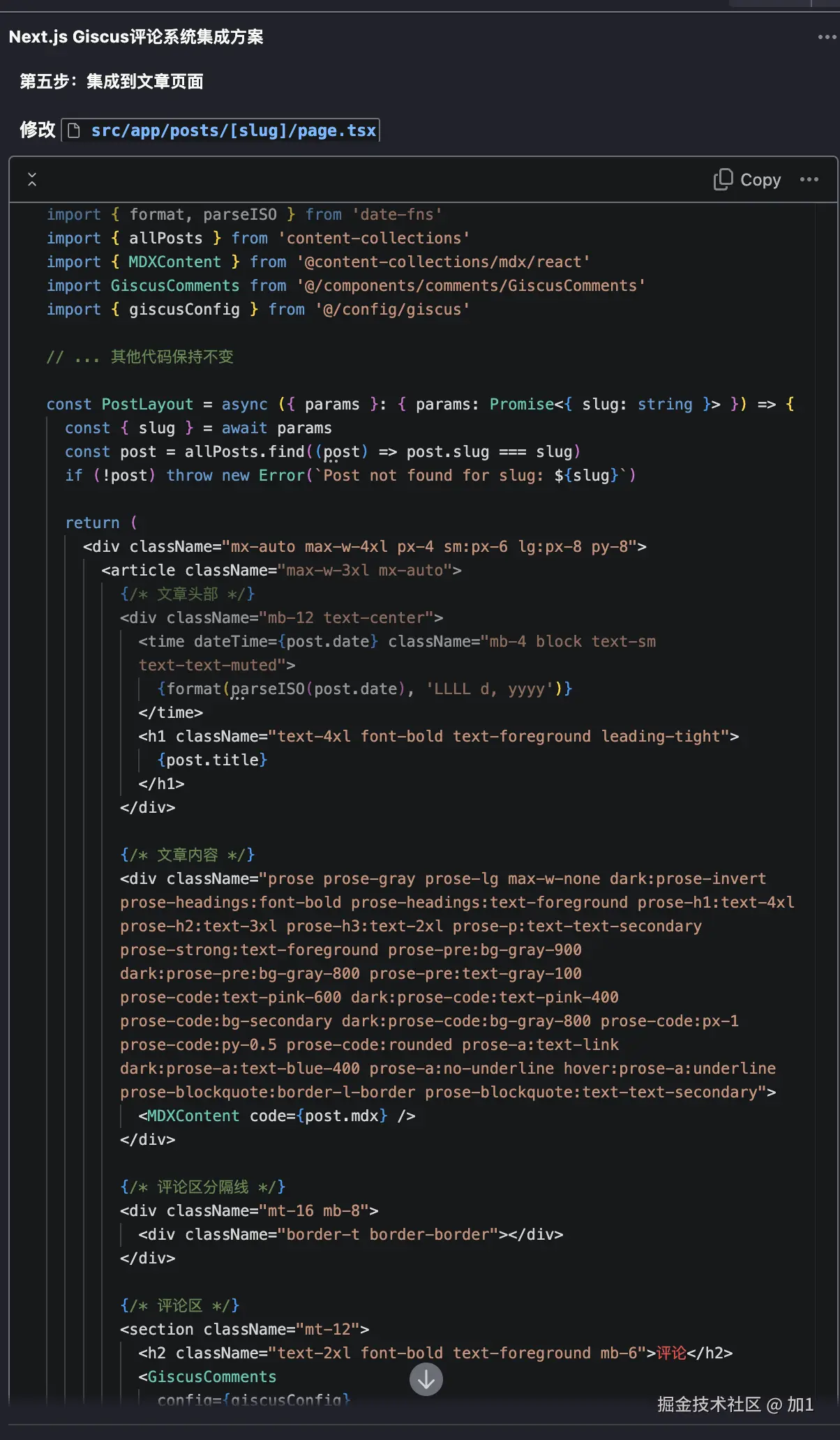
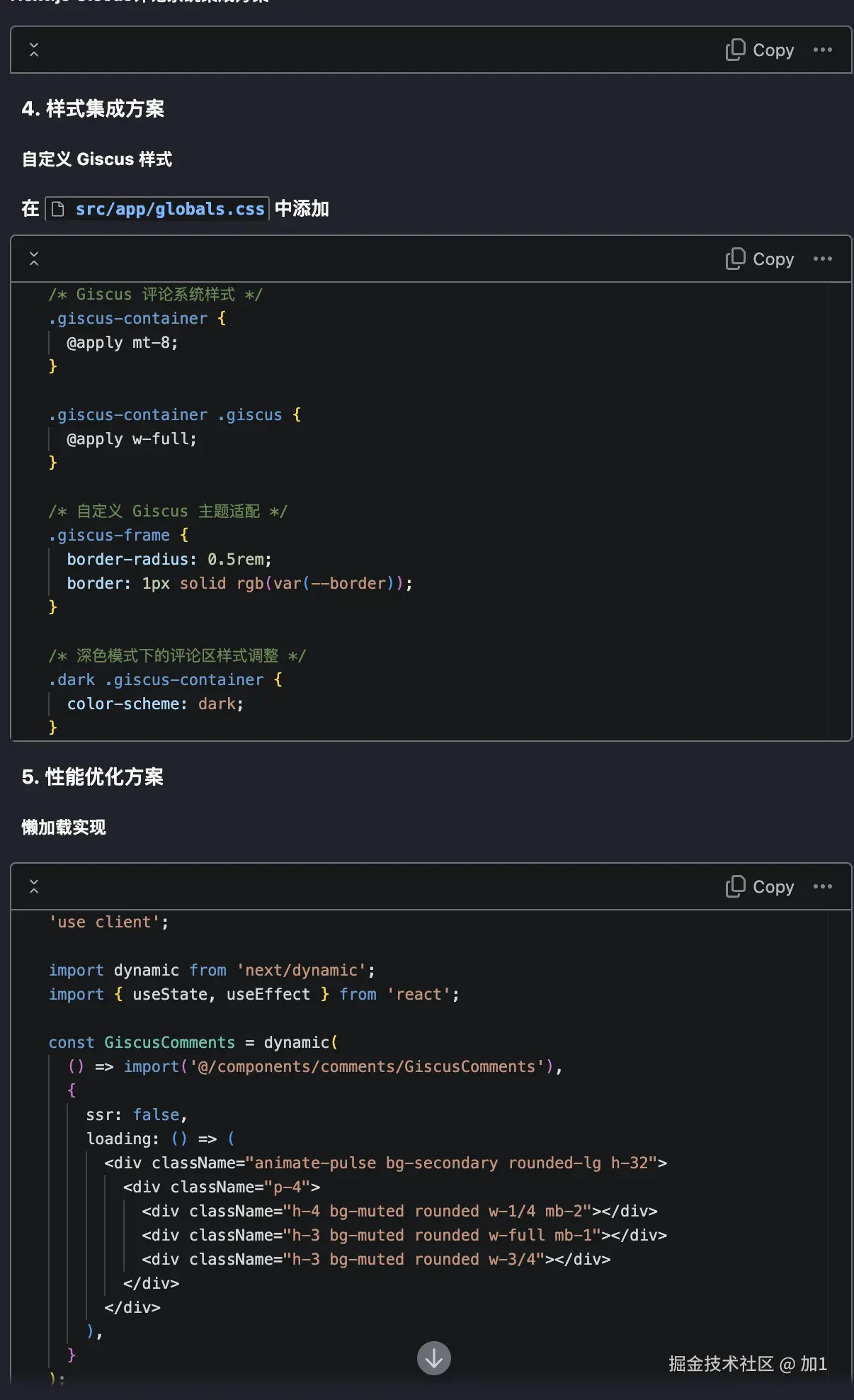
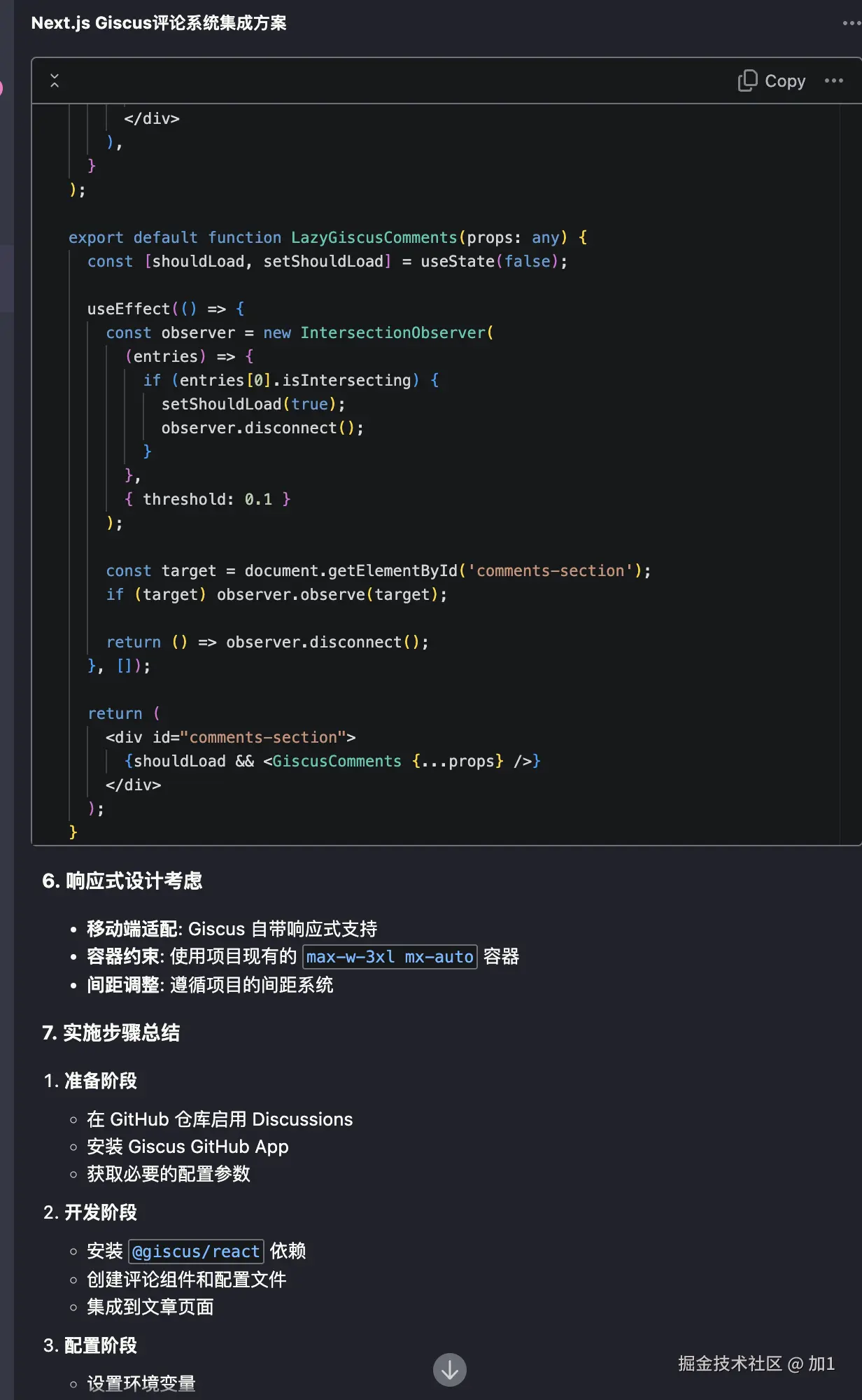

Augment的回答很长,它不仅给出了详细的方案步骤和代码,还询问了你一些需求需要确认的信息,它会根据你的反馈来调整和实施代码。
在这里的时候,你需要大致的看下它的方案有没有问题,这也是你唯一需要确认的一个关键步骤,等确认方案后再继续下一步的代码实施。
这里我们回答它提到的一些关键信息,然后让他开始实施即可:
这是我的github地址:https://github.com/barry166/next-blog,需要怎么启用Discussions功能呢?请你详细描述下,我希望评论区在每篇文章底部,中文,默认跟随网站主题
然后到了Augment 实施代码的步骤了:

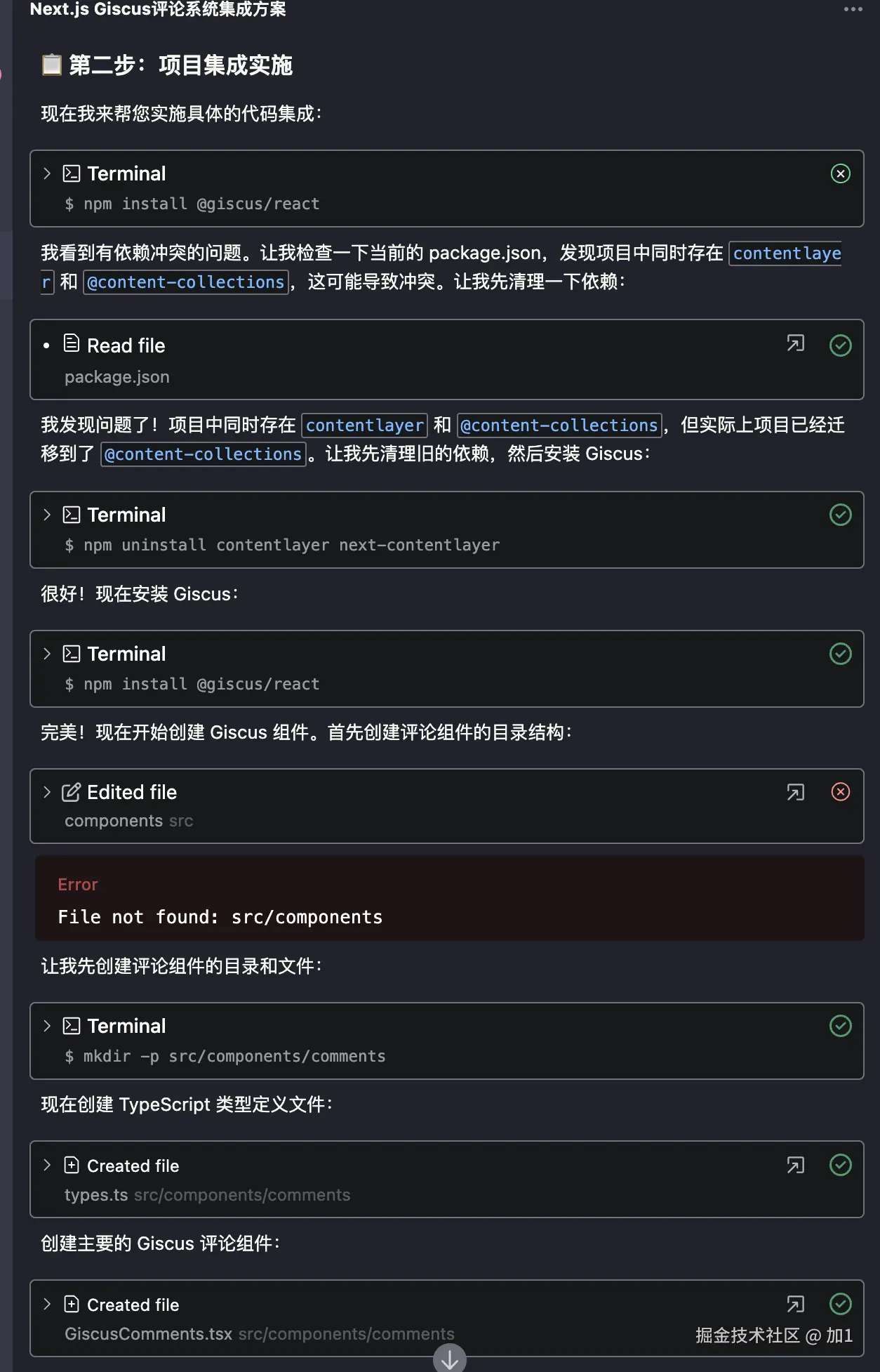
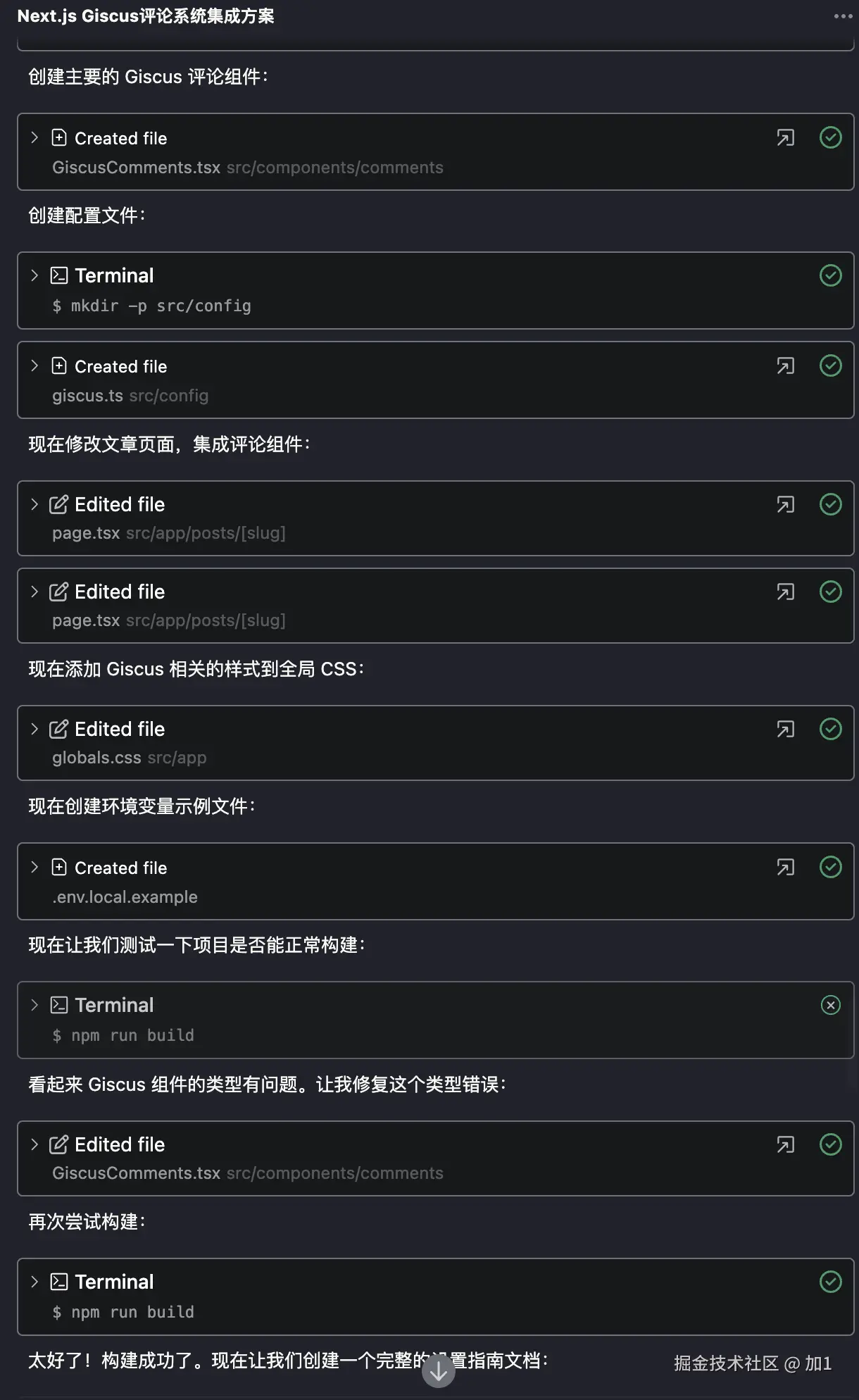
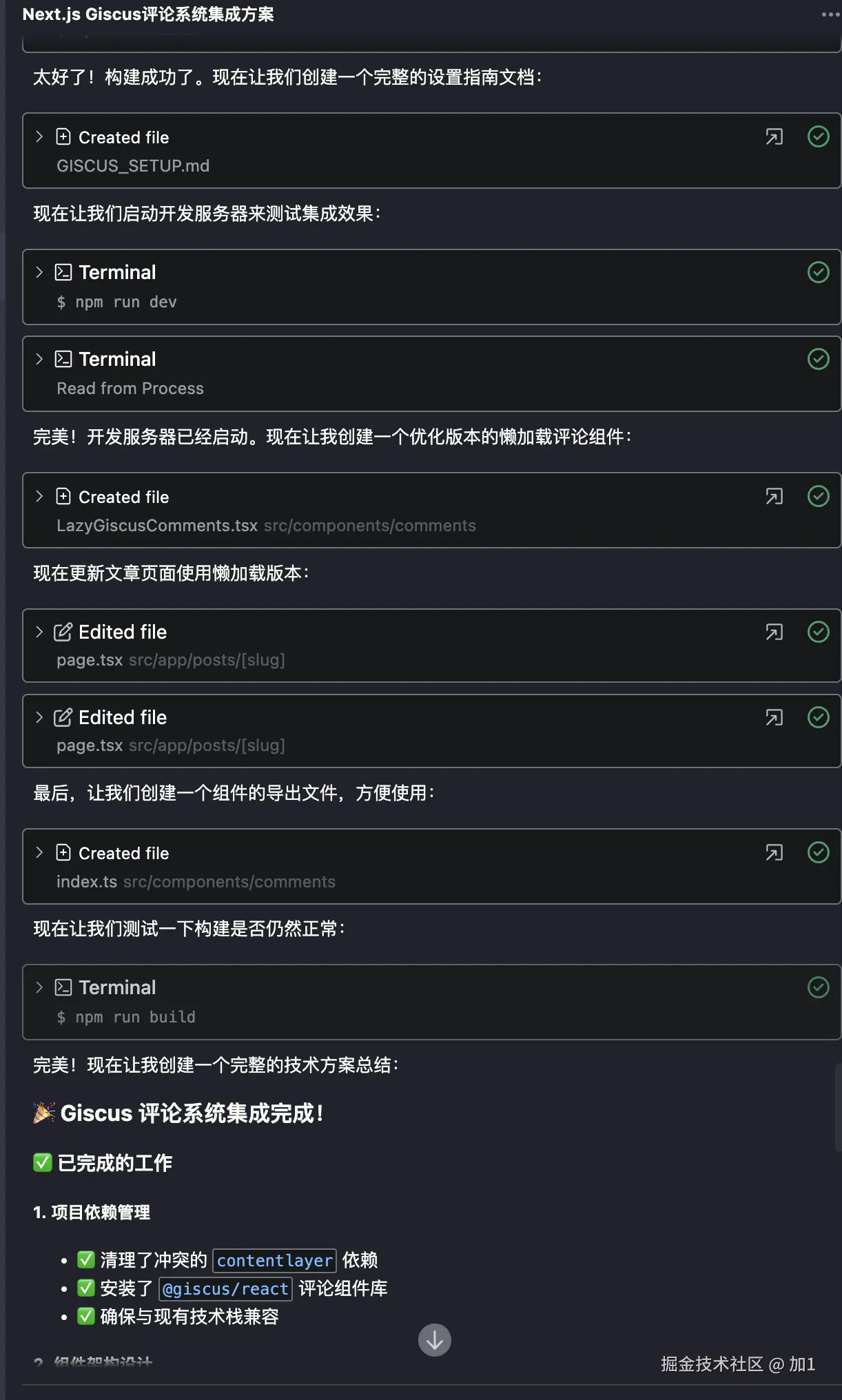
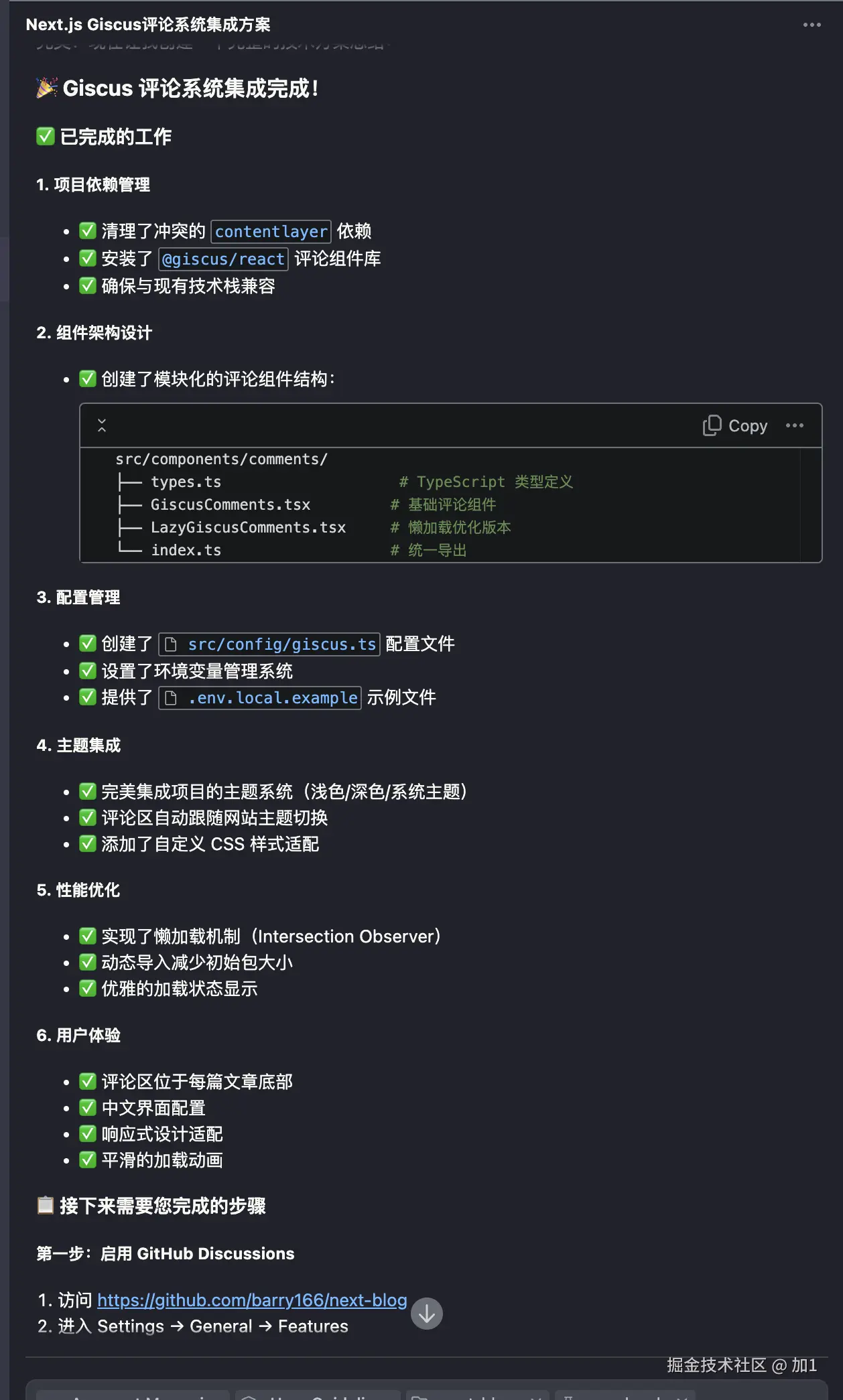


这里给出了具体的需要我们手动实施的步骤,我们根据他说的去我们的Github 和giscus上进行配置,同时Augment 还贴心的为我们编写了文档 ,这里我们根据配置完成之后启动项目查看下:
在博客详情页最下方出现了评论,同时登录后还可以增加评论。
就这样,我们在Augment帮助的情况下,一次性接入了 giscus 评论系统,在这之前我们连giscus的文档也没有看,只是用ai询问了一下哪个开源的评论系统接入比较好,就直接一次性的接入了,这大大的提升了我们的项目开发效率!
项目代码已经上传到了 Github ,你可以点击查看 Augment 生成的GISCUS_SETUP 文档,我们没有写一行代码,只是根据Augment的提示配置了Github、giscus 和环境变量。
思考与总结
再次回看下我们的内容,其实95%代码由AI生成一点也不夸张。Claude 团队也说过,他们90%-95%的代码都是由AI编写完成,这里大部分代码功能都是:
- CRUD、UI组件、基础逻辑 → 全部交给 Claude 生成
- 测试代码、日志模块、文档注释 → AI 全包
- merge request 审查 → AI 做初审,人类只最后过一眼
- 复杂业务逻辑、跨模块集成 → 部分由 AI 起草,人类参与较多
可以发现大部分的体力活,都可以由AI来完成,开发者只要完成“决策”就够了
AI 时代,程序员应该掌握什么技能?
在 AI 正加速变革软件开发流程的今天,程序员的技能结构也正在发生深刻的转变。从个人使用体验来看,程序员首先应该学会如何高效使用各类 AI 工具。不仅仅是编程相关的工具,比如 Augment、 Copilot、Cursor、Windsurf 等,还包括写作、任务管理、流程自动化、产品设计等能提高整体生产力的 AI 工具。
1. 熟练掌握AI工具,重构你的工作方式
如今,AI 已不再只是一个“语法补全器”,而是可以:
- 帮你设计项目架构草图
- 生成符合你技术选型的模块代码
- 自动生成单元测试并跑通测试用例
- 生成文档、构建脚手架,甚至做基础调优
过去它是你的工具,现在它更像你的助手甚至是实习生或下属。你只需要对项目大方向、架构逻辑做判断,剩下的大量“体力活”可以交给 AI 来完成。这对程序员提出了新的要求:你懂得让 AI 高效为你工作,甚至主导它的工作流程。
2. 掌握AI背后的基础原理,提升理解和控制力
虽然大多数 AI 工具都在追求“即插即用”,但如果你能理解其背后的基本原理,如:
- 提示词工程(Prompt Engineering)
- 多智能体系统(AI Agents)
- 大模型微调和上下文窗口管理
- 链式思维(Chain-of-Thought Prompting)
你就能在面对复杂问题、或使用 AI 工具出现偏差时,更快地找到解决办法。
这些原理不要求你成为 AI 研究员,但理解其运行方式,至少能让你成为“更会用 AI 的程序员”。
3. 保持对行业趋势的敏感度
AI 相关工具和平台的更新迭代速度极快,建议定期关注以下内容:
- OpenAI DevDay(开发者大会)
- Google I/O
- Anthropic、Meta、Mistral 等发布的大模型更新
- GitHub Copilot、Cursor、Replit 等 IDE 的新功能
你不需要追踪每一个小版本更新,但对趋势保持敏感,能让你在工具选择、技术选型、团队协作中拥有更强的判断力。
4. 强化原理性与架构性思维
随着 AI 工具替代更多低层重复性劳动,程序员的核心竞争力将回归到架构设计、系统思维与领域建模能力。换句话说:你不是在写代码,而是在设计系统,并引导 AI 写代码。
如果你能从项目一开始就清晰地规划好架构,AI 工具完全可以接过大部分实现工作。这要求程序员转型为更具战略性和抽象思维能力的角色。
结语
在这个“AI 增强开发”时代,程序员最宝贵的能力不再是“会写代码”,而是“能构建系统,并高效驾驭 AI 写代码”。你不需要和 AI 拼码速,但你必须学会用 AI 重塑自己的开发流程和工作方式。
AI 以后会不会取代程序员我不知道,但会取代那些不懂得用 AI 的程序员。
🚀 推广一下:
- i-resume.cn:我去年开发的 AI 简历生成网站,AI 参与度非常高,甚至页面设计和内容都由 AI 主导完成。那时候 AI 编程工具远不如现在,这也让我对 AI 的未来发展更有信心。
参考链接
AI model pickers are a design failure, not a feature
How to build your Agent: 11 prompting techniques for better AI agents
来源:juejin.cn/post/7516100315852521522



{kind=link}
{kind=link}
{kind=link}