








别再说你会 new Object() 了!JVM 类加载的真相,绝对和你想的不一样
当我们编写
new Object()时,JVM 背后到底发生了怎样的故事?类加载过程中的初始化阶段究竟暗藏哪些玄机?
一、引言:从一段简单代码说起
先来看一个看似简单的 Java 代码片段:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
当我们执行这段代码时,背后却隐藏着 JVM 复杂的类加载机制。.java 文件经过编译变成 .class 字节码文件,这些"静态"的字节码需要被 JVM 动态地加载、处理并最终执行。这就是类加载过程的神奇之处。
类加载机制是 Java 语言的核心基石,它赋予了 Java "一次编写,到处运行" 的能力。理解这一过程,不仅能帮助我们编写更高效的代码,更是面试中的高频考点。
二、类生命周期:七个阶段的完整旅程
在深入类加载过程之前,我们先来了解类的完整生命周期。一个类在 JVM 中从加载到卸载,总共经历七个阶段:
| 阶段 | 描述 | 是否必须 | 特点 | JVM规范要求 |
|---|---|---|---|---|
| 加载(Loading) | 查找并加载类的二进制数据 | 是 | 将字节码读入内存,生成Class对象 | 强制 |
| 验证(Verification) | 确保被加载的类正确无误 | 是 | 安全验证,防止恶意代码 | 强制 |
| 准备(Preparation) | 为类变量分配内存并设置初始零值 | 是 | 注意:不是程序员定义的初始值 | 强制 |
| 解析(Resolution) | 将符号引用转换为直接引用 | 否 | 可以在初始化后再进行 | 可选 |
| 初始化(Initialization) | 执行类构造器 <clinit>() 方法 | 是 | 初始化类而不是对象 | 强制 |
| 使用(Using) | 正常使用类的功能 | 是 | 类的使命阶段 | - |
| 卸载(Unloading) | 从内存中释放类数据 | 否 | 由垃圾回收器负责 | 可选 |
前五个阶段(加载、验证、准备、解析、初始化)统称为类加载过程。
三、类加载过程的五个步骤详解
3.1 加载阶段:寻找类的旅程
加载阶段是类加载过程的起点,主要完成三件事情:
- 通过类的全限定名获取定义此类的二进制字节流
- 将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构
- 在内存中生成一个代表这个类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口
// 示例:不同的类加载方式
public class LoadingExample {
public static void main(String[] args) throws Exception {
// 通过类加载器加载
Class<?> clazz1 = ClassLoader.getSystemClassLoader().loadClass("java.lang.String");
// 通过Class.forName加载(默认会初始化)
Class<?> clazz2 = Class.forName("java.lang.String");
// 通过字面常量获取(不会触发初始化)
Class<?> clazz3 = String.class;
System.out.println("三种方式加载的类是否相同: " +
(clazz1 == clazz2 && clazz2 == clazz3));
}
}
3.2 验证阶段:安全的第一道防线
验证阶段确保 Class 文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信息不会危害虚拟机自身的安全。
| 验证类型 | 验证内容 | 失败后果 |
|---|---|---|
| 文件格式验证 | 魔数(0xCAFEBABE)、版本号、常量池 | ClassFormatError |
| 元数据验证 | 语义验证、继承关系(如是否实现抽象方法) | IncompatibleClassChangeError |
| 字节码验证 | 逻辑验证、跳转指令合法性 | VerifyError |
| 符号引用验证 | 引用真实性、访问权限(如访问private方法) | NoSuchFieldError、NoSuchMethodError |
3.3 准备阶段:零值初始化的奥秘
这是最容易产生误解的阶段! 在准备阶段,JVM 为**类变量(static变量)**分配内存并设置初始零值,注意这不是程序员定义的初始值。
public class PreparationExample {
// 准备阶段后 value = 0,而不是 100
public static int value = 100;
// 准备阶段后 constantValue = 200(因为有final修饰)
public static final int constantValue = 200;
// 实例变量 - 准备阶段完全不管
public int instanceValue = 300;
}
各种数据类型的零值对照表:
| 数据类型 | 零值 | 数据类型 | 零值 |
|---|---|---|---|
| int | 0 | boolean | false |
| long | 0L | float | 0.0f |
| double | 0.0 | char | '\u0000' |
| 引用类型 | null | short | (short)0 |
关键区别:只有**类变量(static变量)**在准备阶段分配内存和初始化零值,实例变量会在对象实例化时随对象一起分配在堆内存中。
3.4 解析阶段:符号引用到直接引用的转换
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。这个过程可以在初始化之后再进行,这是为了支持Java的动态绑定特性。
解析主要针对以下四类符号引用:
| 引用类型 | 解析目标 | 可能抛出的异常 |
|---|---|---|
| 类/接口解析 | 将符号引用解析为具体类/接口 | NoClassDefFoundError |
| 字段解析 | 解析字段所属的类/接口 | NoSuchFieldError |
| 方法解析 | 解析方法所属的类/接口 | NoSuchMethodError |
| 接口方法解析 | 解析接口方法所属的接口 | AbstractMethodError |
3.5 初始化阶段:执行类构造器 <clinit>()
这是类加载过程的最后一步,也是真正开始执行类中定义的Java程序代码的一步。
JVM规范严格规定的六种初始化触发情况:
- 遇到new、getstatic、putstatic或invokestatic这四条字节码指令时
// new指令 - 创建类的实例
Object obj = new Object();
// getstatic指令 - 读取类的静态字段
int value = MyClass.staticField;
// putstatic指令 - 设置类的静态字段
MyClass.staticField = 100;
// invokestatic指令 - 调用类的静态方法
MyClass.staticMethod();
- 使用java.lang.reflect包的方法对类进行反射调用时
// 反射调用会触发类的初始化
Class<?> clazz = Class.forName("com.example.MyClass");
- 当初始化一个类时,发现其父类还没有进行过初始化
class Parent {
static { System.out.println("Parent初始化"); }
}
class Child extends Parent {
static { System.out.println("Child初始化"); }
}
// 初始化Child时会先初始化Parent
- 虚拟机启动时,用户指定的主类(包含main()方法的那个类)
// 执行 java MyApp 时,MyApp类会被初始化
public class MyApp {
public static void main(String[] args) {
System.out.println("应用程序启动");
}
}
- 使用JDK7新加入的动态语言支持时
// 使用MethodHandle等动态语言特性
MethodHandles.Lookup lookup = MethodHandles.lookup();
- 一个接口中定义了JDK8新加入的默认方法时,如果这个接口的实现类发生了初始化,要先将接口进行初始化
interface MyInterface {
// JDK8默认方法会触发接口初始化
default void defaultMethod() {
System.out.println("默认方法");
}
}
3.6 使用阶段:类的使命实现
当类完成初始化后,就进入了使用阶段。这是类生命周期中最长的阶段,类的所有功能都可以正常使用:
public class UsageStageExample {
public static void main(String[] args) {
// 类已完成初始化,进入使用阶段
MyClass obj = new MyClass(); // 创建对象实例
obj.instanceMethod(); // 调用实例方法
MyClass.staticMethod(); // 调用静态方法
int value = MyClass.staticVar;// 访问静态变量
}
}
class MyClass {
public static int staticVar = 100;
public int instanceVar = 200;
public static void staticMethod() {
System.out.println("静态方法");
}
public void instanceMethod() {
System.out.println("实例方法");
}
}
在使用阶段,类可以:
- 创建对象实例
- 调用静态方法和实例方法
- 访问和修改静态字段和实例字段
- 被其他类引用和继承
3.7 卸载阶段:生命的终结
类的卸载是生命周期的最后阶段,但并不是必须发生的。一个类被卸载需要满足以下条件:
- 该类所有的实例都已被垃圾回收
- 加载该类的ClassLoader已被垃圾回收
- 该类对应的java.lang.Class对象没有被任何地方引用
public class UnloadingExample {
public static void main(String[] args) throws Exception {
// 使用自定义类加载器加载类
CustomClassLoader loader = new CustomClassLoader();
Class<?> clazz = loader.loadClass("com.example.TemporaryClass");
// 创建实例并使用
Object instance = clazz.newInstance();
System.out.println("类已加载并使用: " + clazz.getName());
// 解除所有引用,使类和类加载器可被回收
clazz = null;
instance = null;
loader = null;
// 触发GC,可能卸载类
System.gc();
System.out.println("类和类加载器可能已被卸载");
}
}
class CustomClassLoader extends ClassLoader {
// 自定义类加载器实现
}
所以,在 JVM 生命周期内,由 jvm 自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
四、关键辨析:类初始化 vs. 对象实例化
这是本文的核心观点,也是大多数开发者容易混淆的概念。让我们通过一个对比表格来清晰区分:
| 特性 | 类初始化 (Initialization) | 对象实例化 (Instantiation) |
|---|---|---|
| 触发时机 | 类被首次"主动使用"时(JVM控制) | 遇到new关键字时(程序员控制) |
| 发生次数 | 一次(每个类加载器范围内) | 多次(可以创建多个对象实例) |
| 核心方法 | <clinit>()方法 | <init>()方法(构造函数) |
| 操作目标 | 类本身(初始化静态变量/类变量) | 对象实例(初始化实例变量) |
| 内存区域 | 方法区(元空间) | Java堆 |
| 执行内容 | 静态变量赋值、静态代码块 | 实例变量赋值、实例代码块、构造函数 |
public class InitializationVsInstantiation {
// 类变量 - 在<clinit>()方法中初始化
public static String staticField = initStaticField();
// 实例变量 - 在<init>()方法中初始化
public String instanceField = initInstanceField();
// 静态代码块 - 在<clinit>()方法中执行
static {
System.out.println("静态代码块执行");
}
// 实例代码块 - 在<init>()方法中执行
{
System.out.println("实例代码块执行");
}
public InitializationVsInstantiation() {
System.out.println("构造方法执行");
}
private static String initStaticField() {
System.out.println("静态变量初始化");
return "static value";
}
private String initInstanceField() {
System.out.println("实例变量初始化");
return "instance value";
}
public static void main(String[] args) {
System.out.println("=== 第一次创建对象 ===");
new InitializationVsInstantiation();
System.out.println("\n=== 第二次创建对象 ===");
new InitializationVsInstantiation();
}
}
输出结果:
静态变量初始化
静态代码块执行
=== 第一次创建对象 ===
实例变量初始化
实例代码块执行
构造方法执行
=== 第二次创建对象 ===
实例变量初始化
实例代码块执行
构造方法执行
五、深度实战:初始化顺序全面解析
现在,让我们通过一个综合示例来回答开篇的思考题:如果一个类同时包含静态变量、静态代码块、实例变量、实例代码块和构造方法,它们的执行顺序是怎样的?在存在继承关系时又会如何变化?
5.1 单类初始化顺序
public class InitializationOrder {
// 静态变量
public static String staticField = "静态变量";
// 静态代码块
static {
System.out.println(staticField);
System.out.println("静态代码块");
}
// 实例变量
public String field = "实例变量";
// 实例代码块
{
System.out.println(field);
System.out.println("实例代码块");
}
// 构造方法
public InitializationOrder() {
System.out.println("构造方法");
}
public static void main(String[] args) {
System.out.println("第一次实例化:");
new InitializationOrder();
System.out.println("\n第二次实例化:");
new InitializationOrder();
}
}
输出结果:
静态变量
静态代码块
第一次实例化:
实例变量
实例代码块
构造方法
第二次实例化:
实例变量
实例代码块
构造方法
关键发现:
- 静态代码块只在类第一次加载时执行一次
- 实例代码块在每次创建对象时都会执行
- 执行顺序:静态变量/代码块 → 实例变量/代码块 → 构造方法
5.2 继承关系下的初始化顺序
class Parent {
// 父类静态变量
public static String parentStaticField = "父类静态变量";
// 父类静态代码块
static {
System.out.println(parentStaticField);
System.out.println("父类静态代码块");
}
// 父类实例变量
public String parentField = "父类实例变量";
// 父类实例代码块
{
System.out.println(parentField);
System.out.println("父类实例代码块");
}
// 父类构造方法
public Parent() {
System.out.println("父类构造方法");
}
}
class Child extends Parent {
// 子类静态变量
public static String childStaticField = "子类静态变量";
// 子类静态代码块
static {
System.out.println(childStaticField);
System.out.println("子类静态代码块");
}
// 子类实例变量
public String childField = "子类实例变量";
// 子类实例代码块
{
System.out.println(childField);
System.out.println("子类实例代码块");
}
// 子类构造方法
public Child() {
System.out.println("子类构造方法");
}
public static void main(String[] args) {
System.out.println("第一次实例化子类:");
new Child();
System.out.println("\n第二次实例化子类:");
new Child();
}
}
输出结果:
父类静态变量
父类静态代码块
子类静态变量
子类静态代码块
第一次实例化子类:
父类实例变量
父类实例代码块
父类构造方法
子类实例变量
子类实例代码块
子类构造方法
第二次实例化子类:
父类实例变量
父类实例代码块
父类构造方法
子类实例变量
子类实例代码块
子类构造方法
关键发现:
- 父类静态代码块 → 子类静态代码块 → 父类实例代码块 → 父类构造方法 → 子类实例代码块 → 子类构造方法
- 静态代码块只执行一次,实例代码块每次创建对象都执行
- 父类优先于子类初始化
5.3 进阶案例:包含静态变量初始化的复杂情况
public class ComplexInitialization {
public static ComplexInitialization instance = new ComplexInitialization();
public static int staticVar = 100;
public int instanceVar = 200;
static {
System.out.println("静态代码块: staticVar=" + staticVar);
}
{
System.out.println("实例代码块: instanceVar=" + instanceVar + ", staticVar=" + staticVar);
}
public ComplexInitialization() {
System.out.println("构造方法: instanceVar=" + instanceVar + ", staticVar=" + staticVar);
}
public static void main(String[] args) {
System.out.println("main方法开始");
new ComplexInitialization();
}
}
输出结果:
实例代码块: instanceVar=200, staticVar=0
构造方法: instanceVar=200, staticVar=0
静态代码块: staticVar=100
main方法开始
实例代码块: instanceVar=200, staticVar=100
构造方法: instanceVar=200, staticVar=100
关键发现:
- 静态变量
staticVar在准备阶段被初始化为0 - 在初始化阶段,按顺序执行静态变量赋值和静态代码块
- 当执行
instance = new ComplexInitialization()时,staticVar还未被赋值为100(还是0) - 这解释了为什么第一次输出时
staticVar=0
六、面试常见问题与解答
6.1 高频面试题解析
Q1: 下面代码的输出结果是什么?为什么?
public class InterviewQuestion {
public static void main(String[] args) {
System.out.println(Child.value);
}
}
class Parent {
static int value = 100;
static { System.out.println("Parent静态代码块"); }
}
class Child extends Parent {
static { System.out.println("Child静态代码块"); }
}
A: 输出结果为:
Parent静态代码块
100
解析: 通过子类引用父类的静态字段,不会导致子类初始化,这是类加载机制的一个重要特性。
Q2: 接口的初始化与类有什么不同?
A: 接口的初始化与类类似,但有重要区别:
- 接口也有
<clinit>()方法,由编译器自动生成 - 接口初始化时不需要先初始化父接口
- 只有当程序首次使用接口中定义的非常量字段时,才会初始化接口
6.2 类加载机制的实际应用
1. 单例模式的优雅实现:
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
static {
System.out.println("SingletonHolder初始化");
}
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
这种实现利用了类加载机制的特性:只有在真正调用 getInstance() 时才会加载 SingletonHolder 类,实现了懒加载且线程安全。
2. 常量传播优化:
public class ConstantExample {
public static final String CONSTANT = "Hello";
public static void main(String[] args) {
System.out.println(CONSTANT);
}
}
编译时,常量 CONSTANT 的值会被直接内联到使用处,不会触发类的初始化。
七、总结与思考
通过本文的深入分析,我们可以总结出以下几个关键点:
- 类加载过程五个阶段:加载 → 验证 → 准备 → 解析 → 初始化,每个阶段都有其特定任务
- 关键区别:
- 初始化阶段是初始化类(执行
<clinit>()),而不是初始化对象(执行<init>()) - 类静态变量在准备阶段分配内存并设置零值,在初始化阶段赋实际值
- 实例变量在对象实例化时分配内存和初始化
- 初始化阶段是初始化类(执行
- 初始化顺序原则:
- 父类优先于子类
- 静态优先于实例
- 变量定义顺序决定初始化顺序
- 实际应用:理解类加载机制有助于我们编写更高效的代码,如实现懒加载的单例模式、理解常量内联优化等
希望本文能帮助你深入理解JVM类加载机制,下次遇到相关面试题时,相信你一定能游刃有余!
来源:juejin.cn/post/7541339617489797163
判断 Python 代码是不是 AI 写的几个简单方法
作者:Laurel W
来源:Adobe
作为一名数据科学和数学老师,我其实不介意我的学生使用像 ChatGPT 这样的 LLM,只要它是用来辅助他们学习,而不是取代学习过程。加州理工学院的申请文书指南启发了我为编程和机器学习课制定 AI 使用政策:
哪些是加州理工申请文书中不道德的 AI 使用方式?
- 直接从 AI 生成器复制粘贴
- 依赖 AI 生成内容来列提纲或起草文书
- 用 AI 生成的内容替换你独特的声音和语气
- 翻译用其他语言写的文书
哪些是加州理工申请文书中道德的 AI 使用方式?
- 使用 Grammarly 或 Microsoft Editor 这类 AI 工具检查语法拼写
- 用 AI 生成问题或练习题,帮助启动头脑风暴
- 用 AI 来研究申请流程
如果你还在想你使用 AI 是否道德,问问自己:你请一位值得信赖的大人做同样的事,合适吗?比如请老师帮你改语法错拼写错?当然可以!但让老师帮你写一篇文书草稿,然后你稍微改改就交了?绝对不行。
话虽如此,最近我收到了一些代码作业,一看就完全是 AI 写的,于是我整理了一些“AI 征兆”。当然,人类和 AI 写的代码现在越来越难分辨。但 ChatGPT / Claude / DeepSeek 这些生成的代码,还是有一些共同特征,一看就不对劲。
注释
我希望所有学生都能像 ChatGPT 那样写那么详细的注释吗?当然希望。但他们会吗?肯定不会。
🚩 注释过于详细或者风格怪异,是使用 AI 的信号。
比如,DeepSeek 生成的代码里你会看到用三引号写一段 docstring 来当注释,而不是用标准的 #,尽管那段 docstring 并没有说明参数或返回值:
def find_squares_adding_to_zero(mod):
"""Find two non-zero numbers a and b such that a^2 + b^2 ≡ 0 mod n."""
for a in range(1, mod): # Start from 1 to exclude a = 0
for b in range(a, mod): # Start from a to avoid redundant pairs
if (a2 + b2) % mod == 0:
return (a, b)
return
我觉得这用来注释一行代码的方式很不自然,尤其是我在课上明确教的是用 # 来写单行注释,而这段也不是一个正经的 docstring。
注释里用特殊符号也可能是 AI 写的。除非是我写给很多人看的代码,我自己是不会去找像 “≡” 这样的符号来写注释的。我敢说我的学生大概也不会这么做。
Lambda 表达式
别误会——我喜欢 lambda 表达式,觉得它们是 Python 中很独特且有价值的功能。我认为 lambda 是用来写简洁、临时的小函数的,直接作为参数传给像 map()、filter() 或 sorted() 这种函数才合适。用得好很亮眼。但 lambda 表达式一旦滥用、用错地方,或者还没讲到就乱用,就是个警示。
🚩 lambda 用得不合时宜,说明设计不够认真,或者太依赖 AI。
比如,要是我在还没系统讲 lambda 表达式前,收到这么一份作业代码,那我肯定第一时间就怀疑是 ChatGPT 写的:
from functools import lru_cache
fib = (lambda f: (lambda x: f(f, x)))(lambda self, n:
n if n < 2 else self(self, n-1) + self(self, n-2))
Generate the first 10 Fibonacci numbers
fib_sequence = [fib(n) for n in range(10)]
print(fib_sequence)
这种写法根本不适合用 lambda,而且太复杂了,不可能是一个第一次学 Python 的学生自己写出来的。
库的使用
库导入的位置
🚩 有时候,LLM 会把 import 放在奇怪的位置(不是在文件最上面)。
这种情况我只见过几次,但如果你已经跟学生强调过 import 要放在开头或集中在一起,那这种写法就可疑了。
用了什么库:
🚩 用某个库完成其实不需要它的任务,尤其是没讲过的冷门库,也可能是 AI 写的迹象。
我们再看看上面那段 lambda 代码:
from functools import lru_cache
fib = (lambda f: (lambda x: f(f, x)))(lambda self, n:
n if n < 2 else self(self, n-1) + self(self, n-2))
Generate the first 10 Fibonacci numbers
fib_sequence = [fib(n) for n in range(10)]
print(fib_sequence)
如果你还没讲过 functools 这个库,那学生很可能是用 Google 或 LLM 才知道的。用这些工具探索库当然没问题,但也可能说明实现方式就是 AI 生成的。
命名和格式风格不一致
这个一看就懂。如果作业要求某个字段或变量要用特定命名,AI 写出来的代码往往会给出更泛、更“解释性”的名字,但反而不自然。比如,下面这段找所有小于 n 的素数的代码,一个普通学生可能不会写得这么工整、变量名这么“讲究”:
def sieve_of_eratosthenes(limit):
"""Return a list of all prime numbers less than the given limit."""
if limit <= 2:
return []
Initialize a boolean array to track prime numbers
is_prime = [True] * limit
is_prime[0] = is_prime[1] = False # 0 and 1 are not primes
for num in range(2, int(limit**0.5) + 1):
if is_prime[num]:
Mark multiples of num as non-prime
for multiple in range(num * num, limit, num):
is_prime[multiple] = False
Collect all prime numbers
primes = [num for num, prime in enumerate(is_prime) if prime]
return primes
Example usage
limit = 50 # Change this value to find primes less than a different number
primes = sieve_of_eratosthenes(limit)
print(f"Primes less than {limit}: {primes}")
我自己可能会用 n 而不是 limit,函数名也会更随意些,比如叫 prime_finder。当然,一些特别讲究的学生也可能会写成这样,所以我一般是结合其他迹象一起判断是不是 AI 写的。
逻辑错误
逻辑错误纸面上是最明显的红旗。但实际上很难判断——到底是语言模型出错了,还是学生自己没理解透?
归根结底,LLM 是基于统计的模型,用训练数据学到的模式来预测下一个 token(比如字、词或子词)。它们擅长生成连贯、有上下文的文本,但并不真正理解、也不具备推理或算法思维。这导致它们在需要精确逻辑的任务上容易出错,比如解数学题或者写代码。有时候会给出看上去靠谱但其实错的答案,或者根本没搞清楚复杂的逻辑结构。比如我见过它们在数学题里索引错、没处理边界条件、甚至输出完全错误。
🚩 如果代码有逻辑错误或者推理错误,那可能是 AI 写的。
理想情况下,一个认真点的学生会先检查并修正这些错误再交作业。但实际情况是,很多代码交上来根本不能跑,或者输出就错了。
最后提醒一下,其实很难定一个硬性规则来判断是不是 AI 写的代码,所以我建议老师先别急着指责,而是带着好奇去了解学生的思路。如果我怀疑一个学生太依赖 AI,我可能会让他白板手写一个类似的题目,或者问问他对这个解法的理解。只要引导得当、细节到位,我希望未来能培养出的是会把 AI 当工具,而不是当拐杖的专业人士。
来源:juejin.cn/post/7486694184407531555
CSS 黑科技之多重边框:为网页添彩
在前端开发的奇妙世界里,CSS 总是能给我们带来意想不到的惊喜。今天,就让我们一同探索 CSS 的一个有趣特性 —— 多重边框,看看它如何为我们的网页设计增添独特魅力。
什么是多重边框
在传统认知中,一个元素通常只有一层边框。但借助 CSS 的box-shadow属性,我们可以突破这一限制,轻松实现多重边框效果。box-shadow属性原本用于为元素添加阴影,不过通过巧妙设置,它能化身为创造多重边框的利器。
如何实现多重边框
实现多重边框的关键在于对box-shadow属性的灵活运用。下面是一个简单示例:
div {
box-shadow: 0 0 0 5px red, 0 0 0 10px blue;
}
在这段代码中,box-shadow属性接受了两组值,每组值都定义了一个 “边框”。具体来说,0 0 0 5px red表示第一个边框:前两个0分别表示水平和垂直方向的偏移量,这里都为 0,即不偏移;第三个0表示模糊半径为 0,也就是边框清晰锐利;5px表示扩展半径,即边框的宽度;red则是边框的颜色。同理,0 0 0 10px blue定义了第二个边框,宽度为 10px,颜色为蓝色。通过这样的方式,我们就为div元素创建了两层不同颜色和宽度的边框。
多重边框的应用场景
- 突出重要元素:在网页中,有些元素需要特别突出显示,比如导航栏、重要按钮等。使用多重边框可以让这些元素在页面中脱颖而出,吸引用户的注意力。
- 营造层次感:多重边框能够为元素增加层次感,使页面看起来更加丰富和立体。在设计卡片式布局时,这种效果尤为明显,可以让卡片更加生动有趣。
- 创意设计:对于追求独特风格的网页设计,多重边框提供了无限的创意空间。可以通过调整边框的颜色、宽度、模糊度等参数,创造出各种独特的视觉效果,展现出与众不同的设计风格。
注意事项
- 性能问题:虽然多重边框效果很酷,但过多地使用复杂的box-shadow属性可能会影响页面性能,尤其是在移动设备上。因此,在实际应用中需要权衡效果和性能,避免过度使用。
- 兼容性:不同浏览器对box-shadow属性的支持程度略有差异。在使用时,要确保在主流浏览器上进行充分测试,必要时可以添加浏览器前缀来保证兼容性。
CSS 的多重边框特性为前端开发者提供了一种简单而强大的方式来增强网页的视觉效果。通过合理运用这一特性,我们能够打造出更加美观、富有创意的网页界面。希望大家在今后的前端开发中,大胆尝试多重边框,让自己的网页作品更加出彩!
来源:juejin.cn/post/7472233713416110089
希尔伯特曲线:降维打击与空间填充的艺术
在数学和计算机科学的交汇处,存在着一种令人着迷的几何结构——希尔伯特曲线(Hilbert Curve)。这种由德国数学家大卫·希尔伯特于1891年提出的连续空间填充曲线,不仅挑战了我们对维度的直观认知,更在现代技术领域发挥着举足轻重的作用。
一、初识希尔伯特曲线:维度穿梭的钥匙
希尔伯特曲线的核心在于其空间填充性和连续性。想象一条无限延伸的细线,它以一种巧妙的方式弯曲、折叠,最终能够填满整个二维平面(或更高维度的空间),这就是希尔伯特曲线的魔力。尽管它是连续的,但由于其分形特性,这条曲线在任何一点都不可导。
希尔伯特曲线的构建基于递归的思想。以最经典的二维希尔伯特曲线为例,它从一个正方形开始,将其四等分,然后用一条线段连接这四个小正方形的中心点,形成一个基本的“U”形。接下来,对每个小正方形重复这个过程,不断细分、连接,最终在无限递归下,这条曲线将覆盖整个正方形内的每一个点, 如下图所示。

另一个关键特性是局部性与全局性。 在希尔伯特曲线的映射过程中,相邻的一维线段在高维空间中仍然倾向于保持局部邻近性(尽管并非绝对)。这意味着,在一维序列中相近的点,在二维或三维空间中也往往彼此靠近。
二、希尔伯特曲线家族:多样的空间填充策略
希尔伯特曲线并非孤立存在,它属于一个更大的空间填充曲线家族,每个成员都有其独特的构建方式和应用场景。
- 经典二维希尔伯特曲线: 最基础的形式,奠定了空间填充曲线的基础。
- 三维希尔伯特曲线: 将递归扩展到三维,用于体数据索引和空间数据库。
- 皮亚诺曲线(Peano Curve): 早于希尔伯特曲线,采用“九宫格”分割,但可能产生交叉点。
- 摩尔曲线(Moore Curve): 一种闭合的空间填充曲线,首尾相连,适合循环遍历。
- Z阶曲线(Morton Curve): 基于坐标的二进制交错编码(Morton码),计算高效,广泛用于数据库索引(如Geohash)。
- 自适应变体: 根据数据密度动态调整递归深度,优化存储和查询效率。
三、希尔伯特曲线的深远意义:超越几何的维度
希尔伯特曲线的意义远不止于其几何形态,它在数学、计算机科学、甚至哲学层面都产生了深远的影响。
1. 数学意义:
- 挑战维度直觉: 希尔伯特曲线证明了一维曲线可以覆盖高维空间,颠覆了人们对维度的传统认知。
- 分形几何的早期范例: 它展示了自相似性和无限递归的数学美感,为分形几何的发展奠定了基础。
- 拓扑学应用: 为连续映射和空间压缩提供了理论支持。
2. 计算机科学与工程应用:
- 空间索引: 在数据库中高效处理多维数据(如地图坐标、图像像素),通过希尔伯特排序优化范围查询。
- 图像处理: 将二维图像转换为一维序列,用于压缩或渐进传输。
- 并行计算: 分配高维数据到计算节点时,保持数据的局部性以减少通信开销。
- 路径规划: 机器人导航或PCB布线中,生成覆盖整个区域的连续扫描路径。
3. 哲学与认知影响:
希尔伯特曲线模糊了维度的界限,引发了对“维度”本质的哲学思考,挑战了传统几何学的直观认知。
四、空间填充曲线的对比:各有千秋
| 曲线类型 | 连续性 | 交叉点 | 局部性保留 | 应用场景 |
|---|---|---|---|---|
| 希尔伯特曲线 | 连续 | 无 | 较好 | 数据库索引、图像处理 |
| 皮亚诺曲线 | 连续 | 有 | 较差 | 理论数学 |
| Z阶曲线 | 不连续 | 无 | 中等 | 地理哈希、GPU计算 |
从上表可以看出,不同的空间填充曲线在连续性、交叉点、局部性保留等方面各有特点,适用于不同的应用场景。希尔伯特曲线以其良好的局部性保留和无交叉点的特性,在数据库索引和图像处理等领域表现出色。
总结:维度之桥,应用之光
希尔伯特曲线及其变体不仅在理论数学中揭示了维度的奇妙性质,更在计算机科学中成为处理高维数据的关键工具。其核心价值在于将高维问题映射到低维空间并保持局部性,从而在效率和实用性之间找到平衡。随着大数据和人工智能时代的到来,希尔伯特曲线及其衍生技术将在更多领域展现其独特的魅力和应用价值。 无论是理解宇宙的结构,还是优化数据的存储与查询,希尔伯特曲线都为我们提供了一把穿越维度的钥匙,一座连接理论与应用的桥梁。
来源:juejin.cn/post/7470453022801068042
计算初始化内存总长度
计算初始化内存总长度
问题背景
在一个系统中,需要执行一系列的内存初始化操作。每次操作都会初始化一个特定地址范围的内存。这些操作范围可能会相互重叠。我们需要计算所有操作完成后,被初始化过的内存空间的总长度。
核心定义
- 操作范围: 每一次内存初始化操作由一个范围
[start, end]定义,它代表一个左闭右开的区间[start, end)。这意味着地址start被包含,而地址end不被包含。 - 内存长度: 对于一个操作
[start, end],其初始化的内存长度为end - start。
关键假设
- 所有初始化操作都会成功执行。
- 同一块内存区域允许被重复初始化。例如,操作
[2, 5)和[4, 7)是允许的,它们有重叠部分[4, 5)。
任务要求
给定一组内存初始化操作 cmdsOfMemInit,计算所有操作完成后,被初始化过的内存空间的总长度。这等同于计算所有给定区间的并集的总长度。
输入格式
cmdsOfMemInit: 一个二维数组(或列表的列表),代表一系列的内存初始化操作。
- 数组长度:
1 <= cmdsOfMemInit.length <= 100000 - 每个元素
cmdsOfMemInit[i]是一个包含两个整数[start, end]的数组。 - 区间范围:
0 <= start < end <= 10^9
- 数组长度:
输出格式
- 一个整数,表示最终被初始化过的内存空间的总长度。
样例说明
样例 1
- 输入:
[[2, 4], [3, 7], [4, 6]] - 输出:
5 - 解释:
- 我们有三个区间:
[2, 4),[3, 7),[4, 6)。 - 合并
[2, 4)和[3, 7): 因为它们有重叠部分([3, 4)),所以可以合并成一个更大的区间[2, 7)。 - 合并
[2, 7)和[4, 6): 新的区间[4, 6)完全被[2, 7)覆盖。合并后的结果仍然是[2, 7)。 - 所有操作完成后,最终被初始化的内存区域是
[2, 7)。 - 总长度为
7 - 2 = 5。
- 我们有三个区间:
样例 2
- 输入:
[[3, 7], [2, 4], [10, 30]] - 输出:
25 - 解释:
- 我们有三个区间:
[3, 7),[2, 4),[10, 30)。 - 合并
[3, 7)和[2, 4): 它们有重叠部分,合并后的区间为[2, 7)。 - 合并
[2, 7)和[10, 30): 这两个区间没有重叠,因为10大于7。它们是两个独立的初始化区域。 - 所有操作完成后,最终的初始化内存区域由两个不相交的区间组成:
[2, 7)和[10, 30)。 - 总长度是这两个独立区间长度之和:
(7 - 2) + (30 - 10) = 5 + 20 = 25。
- 我们有三个区间:
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
/**
* 解决“内存空间长度”问题的方案类。
*/
public class Solution {
/**
* 计算一系列内存初始化操作覆盖的总内存空间长度。
*
* @param cmdsOfMemInit 一个二维数组,每个内部数组 [start, end] 代表一个左闭右开的内存初始化区间。
* @return 最终初始化的内存空间的总长度。
*/
public long totalInitializedLength(int[][] cmdsOfMemInit) {
// --- 1. 处理边界情况 ---
// 如果输入为空或没有操作,则总长度为 0。
if (cmdsOfMemInit == null || cmdsOfMemInit.length == 0) {
return 0;
}
// --- 2. 按区间的起始地址(start)对所有操作进行升序排序 ---
// 这是合并区间的关键前提步骤。
// Comparator.comparingInt(a -> a[0]) 是一个简洁的写法,表示按内部数组a的第一个元素排序。
Arrays.sort(cmdsOfMemInit, Comparator.comparingInt(a -> a[0]));
// --- 3. 合并重叠和连续的区间 ---
// 使用一个 List 来存储合并后的、不重叠的区间。
List<int[]> mergedIntervals = new ArrayList<>();
// 首先将第一个区间(起始地址最小)加入合并列表作为基础。
mergedIntervals.add(cmdsOfMemInit[0]);
// 遍历排序后的其余区间
for (int i = 1; i < cmdsOfMemInit.length; i++) {
int[] currentInterval = cmdsOfMemInit[i];
// 获取合并列表中的最后一个区间,用于比较
int[] lastMerged = mergedIntervals.get(mergedIntervals.size() - 1);
// 检查当前区间是否与最后一个合并区间重叠或连续。
// 因为区间是 [start, end) 左闭右开,所以当 currentInterval 的 start <= lastMerged 的 end 时,
// 它们就需要合并。例如 [2,4) 和 [4,6) 应该合并为 [2,6)。
if (currentInterval[0] <= lastMerged[1]) {
// --- 合并区间 ---
// 如果有重叠/连续,则更新最后一个合并区间的结束地址。
// 新的结束地址是两个区间结束地址中的较大者。
// 例如,合并 [2,7) 和 [4,6) 时,新的 end 是 max(7, 6) = 7,结果为 [2,7)。
lastMerged[1] = Math.max(lastMerged[1], currentInterval[1]);
} else {
// --- 不重叠,添加新区间 ---
// 如果没有重叠,则将当前区间作为一个新的、独立的合并区间添加到列表中。
mergedIntervals.add(currentInterval);
}
}
// --- 4. 计算合并后区间的总长度 ---
// 使用 long 类型来存储总长度,防止因数值过大(坐标可达10^9)而溢出。
long totalLength = 0;
// 遍历所有不重叠的合并区间
for (int[] interval : mergedIntervals) {
// 累加每个区间的长度 (end - start)
totalLength += (long) interval[1] - interval[0];
}
// --- 5. 返回结果 ---
return totalLength;
}
public static void main(String[] args) {
Solution sol = new Solution();
// 样例1
int[][] cmds1 = {{2, 4}, {3, 7}, {4, 6}};
System.out.println("样例1 输入: [[2, 4], [3, 7], [4, 6]]");
System.out.println("样例1 输出: " + sol.totalInitializedLength(cmds1)); // 预期: 5
// 样例2
int[][] cmds2 = {{3, 7}, {2, 4}, {10, 30}};
System.out.println("\n样例2 输入: [[3, 7], [2, 4], [10, 30]]");
System.out.println("样例2 输出: " + sol.totalInitializedLength(cmds2)); // 预期: 25
// 边界测试
int[][] cmds3 = {{1, 5}, {6, 10}};
System.out.println("\n边界测试 输入: [[1, 5], [6, 10]]");
System.out.println("边界测试 输出: " + sol.totalInitializedLength(cmds3)); // 预期: 8 (4+4)
}
*/
}
来源:juejin.cn/post/7527154276223336488
鸿蒙模块间资源引用
跨模块资源访问-程序包结构-应用框架 - 华为HarmonyOS开发者
根据官方文档和项目实践,以下是关于跨模块资源访问的总结:
1. 跨模块资源访问的核心目标
- 资源共享:通过 HAR(Harmony Archive)和 HSP(Harmony Shared Package)模块,实现资源(如文本、图片、样式等)的复用,减少冗余定义。
- 模块化开发:支持功能模块的独立开发和维护,提升开发效率和代码可维护性。
2. 资源访问方式
- 直接引用:
- 使用
$r('app.type.name')或$rawfile('name')访问当前模块资源。 - 使用
$r('[hsp].type.name')或$rawfile('[hsp].name')访问 HSP 模块资源。
- 使用
- 动态 API 访问:
- 通过
resourceManager接口(如getStringSync、getMediaContentSync)动态获取资源。 - 使用
createModuleContext创建其他模块的上下文,获取其resourceManager对象。
- 通过
3. 资源优先级规则
- 优先级从高到低:
- 当前模块(HAP/HSP):自身模块的资源优先级最高。
- 依赖的 HAR/HSP 模块:
- 如果多个依赖模块中存在同名资源,按照依赖顺序覆盖(依赖顺序靠前的优先级更高)。
4. 官方文档补充
- 资源隔离与访问控制:
- 类似腾讯云 CAM(访问管理)的权限设计,HarmonyOS 通过模块化设计实现资源的逻辑隔离。
- 开发者可以通过显式依赖和资源命名规范避免冲突。
- 跨模块通信:
- 除了资源访问,还可以通过模块间接口调用实现功能共享。
5. 最佳实践
- 命名规范:为资源文件添加模块前缀(如
hsp1_icon.png),避免命名冲突。 - 依赖管理:在
oh-package.json5中明确模块依赖顺序,确保资源优先级符合预期。 - 动态加载:对于插件化场景,优先使用
resourceManager动态加载资源。
6. 适用场景
- 多模块共享通用资源(如主题、图标、多语言文本)。
- 动态加载不同模块的资源(如插件化设计)。
如果需要进一步分析具体实现或优化建议,请告诉我!
来源:juejin.cn/post/7541339617489616939
JavaScript V8 引擎原理
相关问题
JavaScript事件循环
- 调用栈:这里存放着所有执行中的代码块(函数)。当一个函数被调用时,它被添加到栈中;当返回值被返回时它从栈中被移除。
- 消息队列:当异步事件发生时(如点击事件、文件读取完成等),对应的回调函数会被添加到消息队列中。如果调用栈为空,事件循环将从队列中取出一个事件处理。
- 微任务队列:与消息队列类似,但处理优先级更高。微任务(如Promise的回调)在当前宏任务执行完毕后、下-个宏任务开始前执行。
- 宏任务与微任务:宏任务包括整体的脚本执行、setTimeout、setlnterval等;微任务包括Promise回调.process.nextTick等。事件循环的每个循环称为一个tick,每个tick会先执行所有可执行的微任务,再执行一个宏任务。
- 调用栈:这里存放着所有执行中的代码块(函数)。当一个函数被调用时,它被添加到栈中;当返回值被返回时它从栈中被移除。
- 消息队列:当异步事件发生时(如点击事件、文件读取完成等),对应的回调函数会被添加到消息队列中。如果调用栈为空,事件循环将从队列中取出一个事件处理。
- 微任务队列:与消息队列类似,但处理优先级更高。微任务(如Promise的回调)在当前宏任务执行完毕后、下-个宏任务开始前执行。
- 宏任务与微任务:宏任务包括整体的脚本执行、setTimeout、setlnterval等;微任务包括Promise回调.process.nextTick等。事件循环的每个循环称为一个tick,每个tick会先执行所有可执行的微任务,再执行一个宏任务。
V8引擎中的垃圾回收机制如何工作?
V8引擎使用的垃圾回收策略主要基于“分代收集”(Generational Garbage Collection)的理念:
- 新生代(Young Generation):这部分主要存放生存时间短的小对象。新生代空间较小,使用Scavenge算法进行高效的垃圾回收。Scavenge算法采用复制的方式工作,它将新生代空间分为两半,活动对象存放在一半中,当这一半空间用完时,活动对象会被复制到另一半,非活动对象则被清除。
- 老生代(Old Generation):存放生存时间长或从新生代中晋升的大对象。老生代使用Mark-Sweep(标记-清除)和 Mark-Compact (标记-压缩)算法进行垃圾回收。标记-清除算法在标记阶段标记所有从根节点可达的对象,清除阶段则清除未被标记的对象。标记-压缩算法在清除未标记对象的同时,将存活的对象压缩到内存的一端,减少碎片。
V8引擎使用的垃圾回收策略主要基于“分代收集”(Generational Garbage Collection)的理念:
- 新生代(Young Generation):这部分主要存放生存时间短的小对象。新生代空间较小,使用Scavenge算法进行高效的垃圾回收。Scavenge算法采用复制的方式工作,它将新生代空间分为两半,活动对象存放在一半中,当这一半空间用完时,活动对象会被复制到另一半,非活动对象则被清除。
- 老生代(Old Generation):存放生存时间长或从新生代中晋升的大对象。老生代使用Mark-Sweep(标记-清除)和 Mark-Compact (标记-压缩)算法进行垃圾回收。标记-清除算法在标记阶段标记所有从根节点可达的对象,清除阶段则清除未被标记的对象。标记-压缩算法在清除未标记对象的同时,将存活的对象压缩到内存的一端,减少碎片。
V8 引擎是如何优化其性能的?
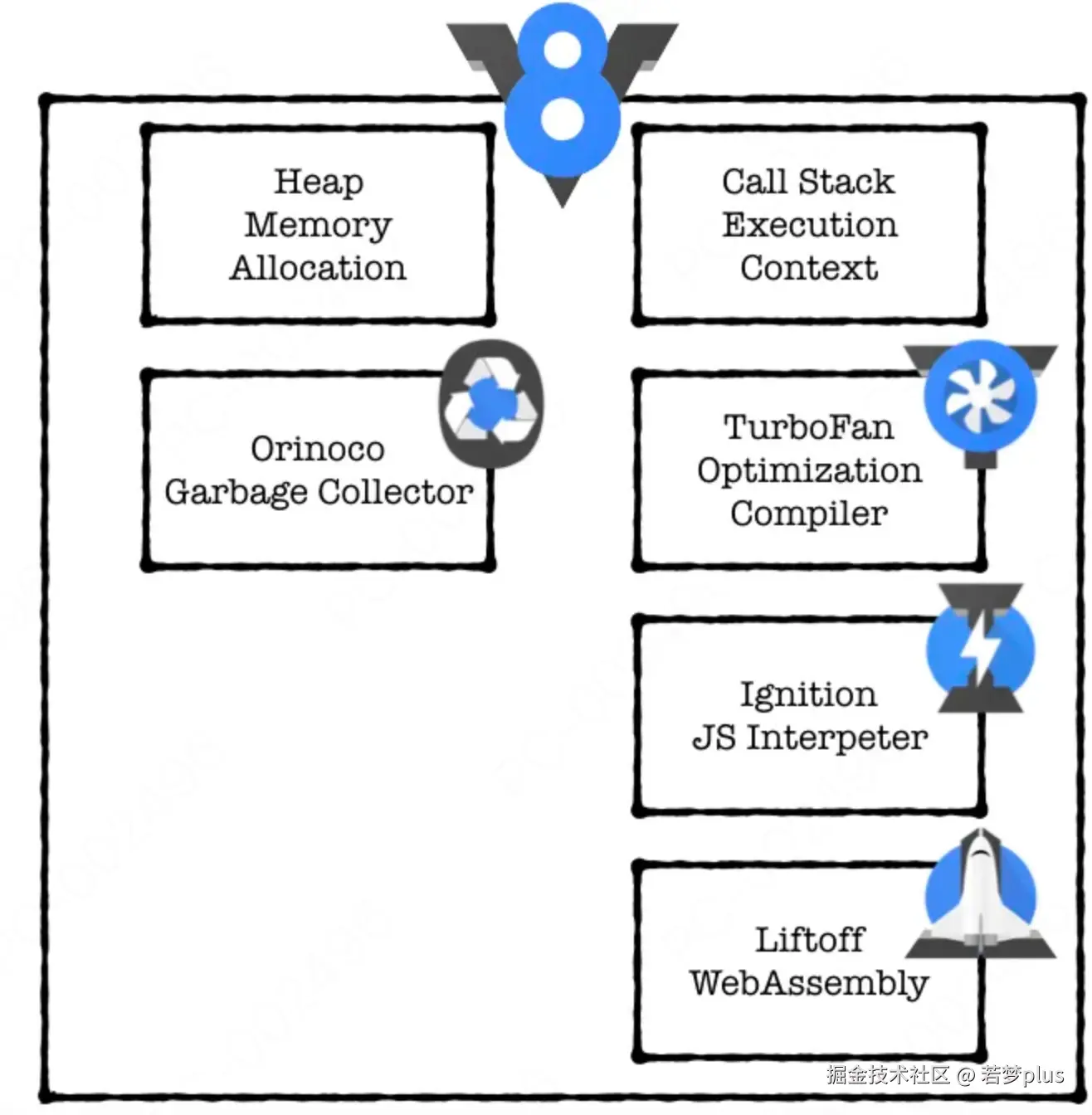
V8引擎通过多种方式优化JavaScript的执行性能:
- 即时编译(JIT):V8将JavaScript代码编译成更高效的机器代码而不是传统的解释执行。V8采用了一个独特的两层编译策略,包括基线编译器(lgnition)和优化编译器(TurboFan)。lgnition生成字节码,这是一个相对较慢但内存使用较少的过程。而 TurboFan 则针对热点代码(执行频率高的代码)进行优化,生成更快的机器代码。
- 内联缓存(lnline Caching):V8使用内联缓存技术来减少属性访问的时间。当访问对象属性时,V8会在代码中嵌入缓存信息,记录属性的位置,以便后续的属性访问可以直接使用这些信息,避免再次查找,从而加速属性访问。
- 隐藏类(Hidden Classes):尽管JavaScript是一种动态类型语言,V8引擎通过使用隐藏类来优化对象的存储和访问。每当对象被实例化或修改时,V8会为对象创建或更新隐藏类,这些隐藏类存储了对象属性的布局信息,使得属性访问更加迅速。
V8引擎通过多种方式优化JavaScript的执行性能:
- 即时编译(JIT):V8将JavaScript代码编译成更高效的机器代码而不是传统的解释执行。V8采用了一个独特的两层编译策略,包括基线编译器(lgnition)和优化编译器(TurboFan)。lgnition生成字节码,这是一个相对较慢但内存使用较少的过程。而 TurboFan 则针对热点代码(执行频率高的代码)进行优化,生成更快的机器代码。
- 内联缓存(lnline Caching):V8使用内联缓存技术来减少属性访问的时间。当访问对象属性时,V8会在代码中嵌入缓存信息,记录属性的位置,以便后续的属性访问可以直接使用这些信息,避免再次查找,从而加速属性访问。
- 隐藏类(Hidden Classes):尽管JavaScript是一种动态类型语言,V8引擎通过使用隐藏类来优化对象的存储和访问。每当对象被实例化或修改时,V8会为对象创建或更新隐藏类,这些隐藏类存储了对象属性的布局信息,使得属性访问更加迅速。
引擎基础
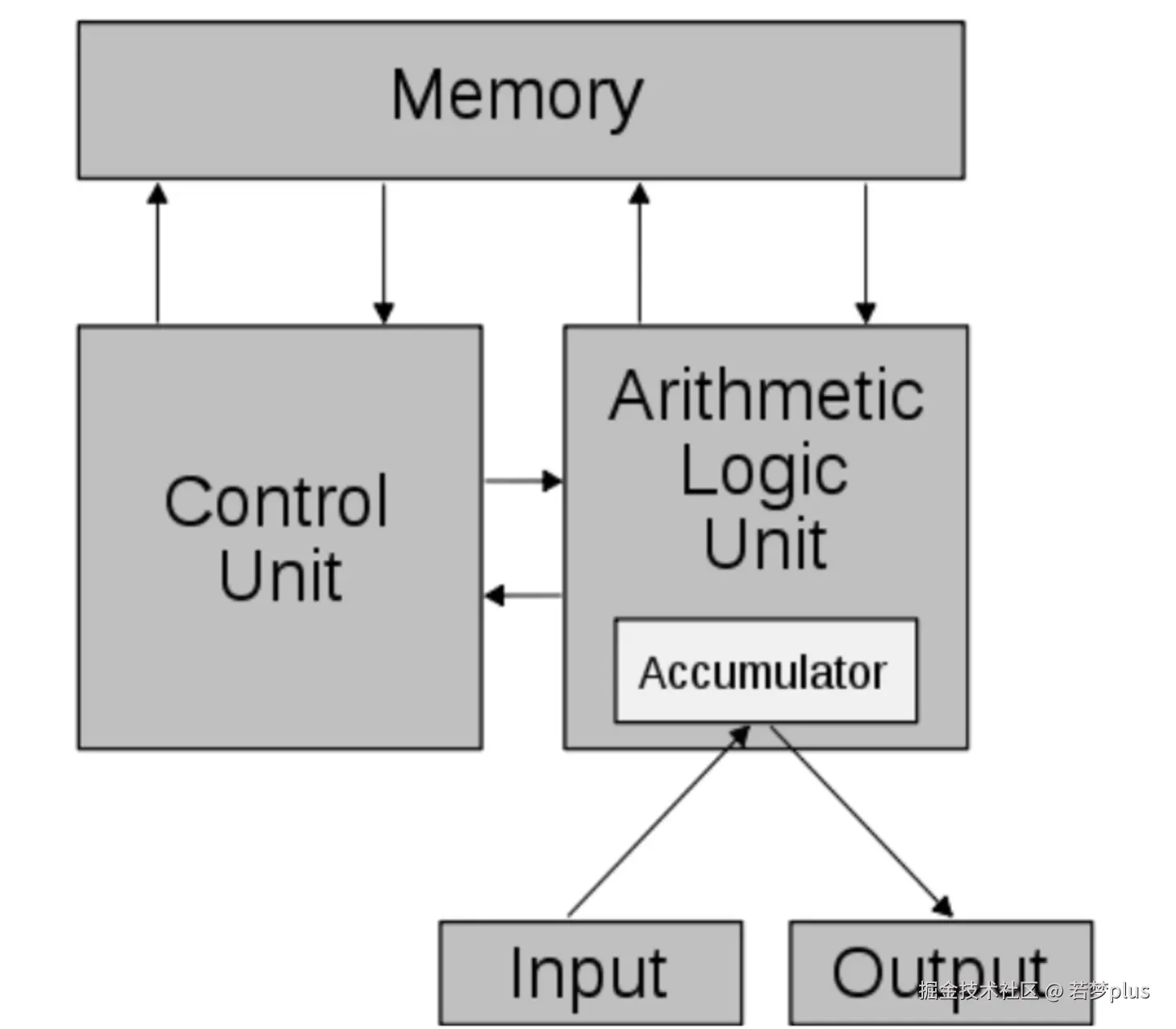
冯·诺依曼结构
冯·诺依曼结构
解释和编译
Java 编译为 class 文件,然后执行
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
ast (Abstract Syntax Tree)
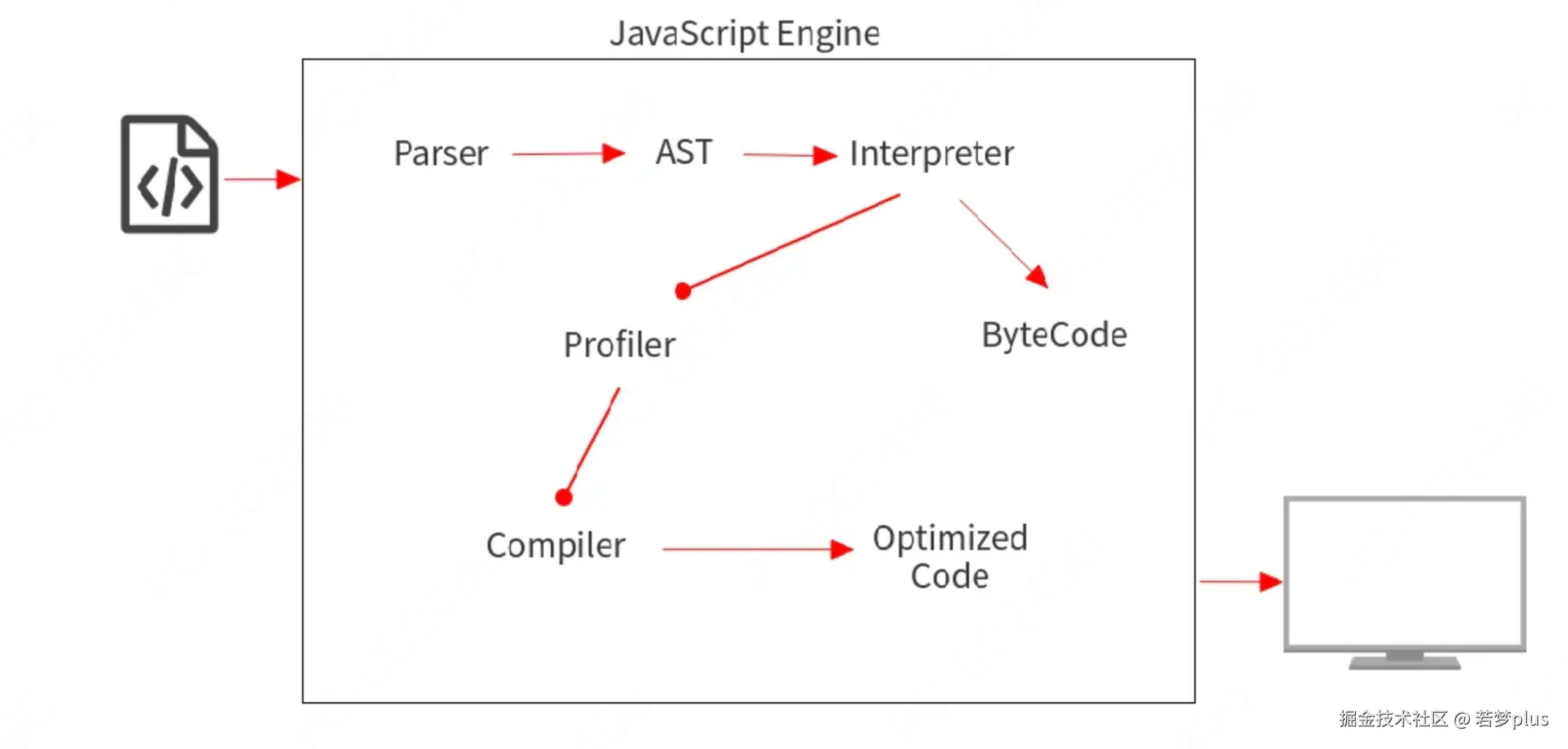
• Interpreter 逐行读取代码并立即执行。
• Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
Java 编译为 class 文件,然后执行
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
ast (Abstract Syntax Tree)
• Interpreter 逐行读取代码并立即执行。
• Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
JavaScript引擎
JavaScript 其实有众多引擎,只不过v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js.
- JavascriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari,2008年实现了编译器和字节码解释器,升级为了 SquirreFish。苹果内部代号为“Nitro”的 Javascript 引擎也是基于 JavascriptCore 引擎的。
- Rhino,由Mozilla 基金会管理,开放源代码,完全以Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 Javascript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
- Nodejs 整个架构
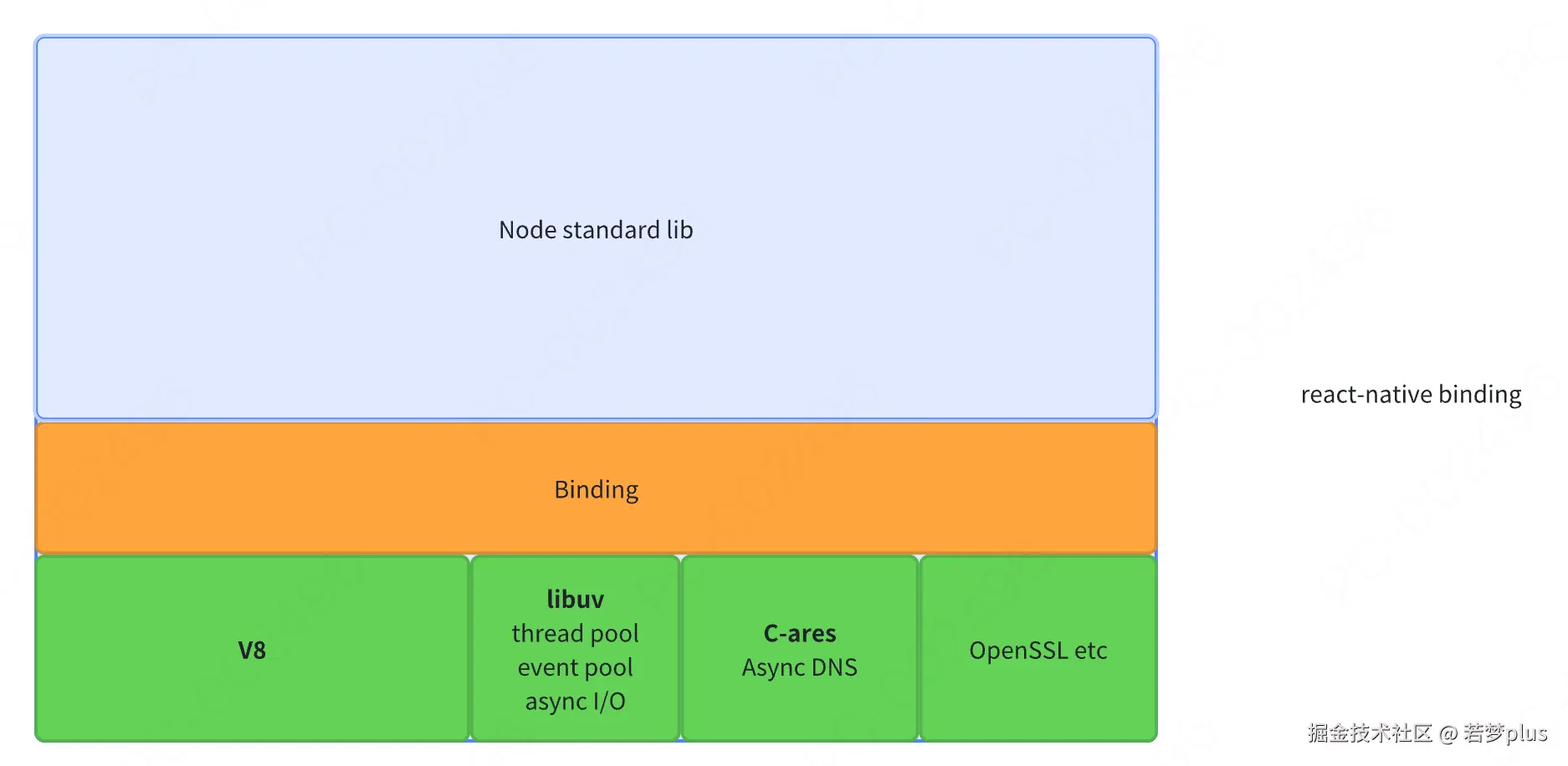
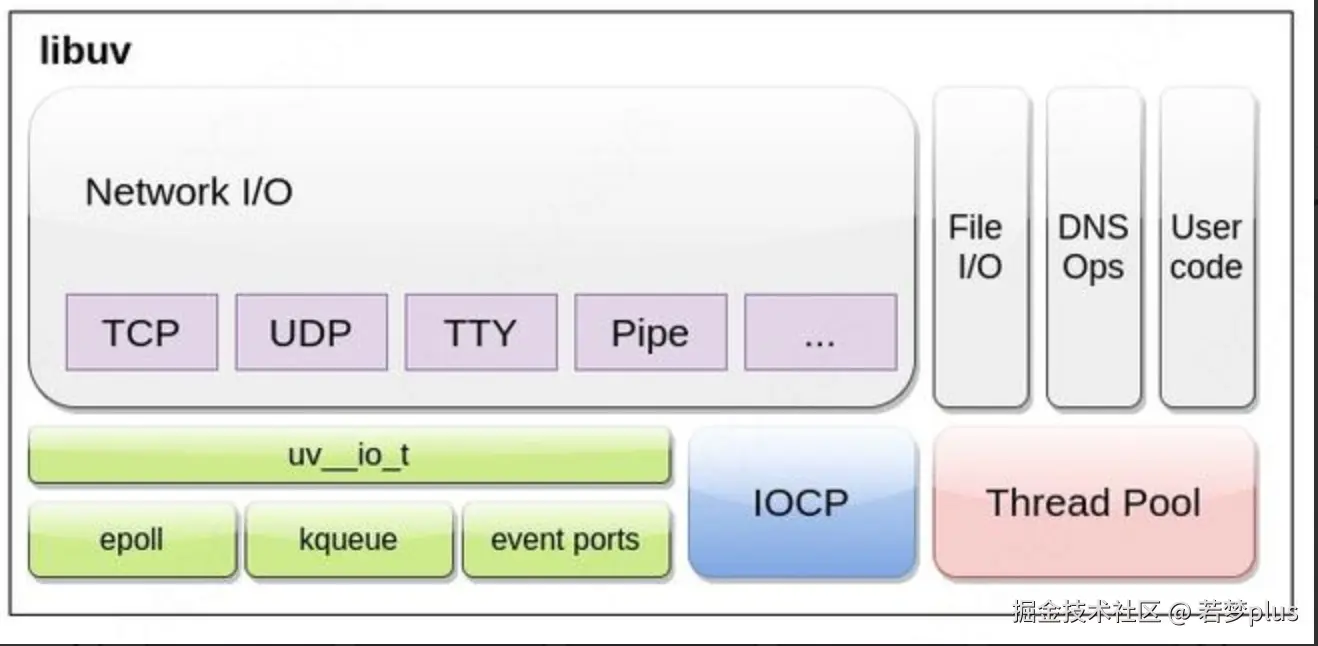
:::info 谷歌的Chrome 使用 V8
Safari 使用 JavaScriptCore,
Firefox 使用 SpiderMonkey。
:::
- V8的处理过程
- 始于从网络中获取 JavaScript 代码。
V8 解析源代码并将其转化为抽象语法树(AST abstract syntax tree)。
- 基于该AST,Ignition 基线解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到TurboFan 优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
JavaScript 其实有众多引擎,只不过v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js.
- JavascriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari,2008年实现了编译器和字节码解释器,升级为了 SquirreFish。苹果内部代号为“Nitro”的 Javascript 引擎也是基于 JavascriptCore 引擎的。
- Rhino,由Mozilla 基金会管理,开放源代码,完全以Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 Javascript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
- Nodejs 整个架构
:::info 谷歌的Chrome 使用 V8
Safari 使用 JavaScriptCore,
Firefox 使用 SpiderMonkey。
:::
- V8的处理过程
- 始于从网络中获取 JavaScript 代码。
V8 解析源代码并将其转化为抽象语法树(AST abstract syntax tree)。
- 基于该AST,Ignition 基线解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到TurboFan 优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
垃圾回收算法
垃圾回收,又称为:GC (garbage collection)。
GC 即 Garbage Collection,程序工作过程中会产生很多垃圾,这些垃圾是程序不用的内存或者是之前用过了,以后不会再用的内存空间,而GC 就是负责回收垃圾的,因为他工作在引擎内部,所以对于我们前端来说, GC 过程是相对比较无感的,这一套引擎执行而对我们又相对无感的操作也就是常说的垃圾回收机制了当然也不是所有语言都有 GC,一般的高级语言里面会自带GC,比如 Java、Python、Javascript 等,也有无GC的语言,比如C、C++等,那这种就需要我们程序员手动管理内存了,相对比较麻烦
垃圾回收,又称为:GC (garbage collection)。
GC 即 Garbage Collection,程序工作过程中会产生很多垃圾,这些垃圾是程序不用的内存或者是之前用过了,以后不会再用的内存空间,而GC 就是负责回收垃圾的,因为他工作在引擎内部,所以对于我们前端来说, GC 过程是相对比较无感的,这一套引擎执行而对我们又相对无感的操作也就是常说的垃圾回收机制了当然也不是所有语言都有 GC,一般的高级语言里面会自带GC,比如 Java、Python、Javascript 等,也有无GC的语言,比如C、C++等,那这种就需要我们程序员手动管理内存了,相对比较麻烦
“垃圾”的定义
- “可达性”,有没有被引用,没有被引用的变量,“不可达的变量”
- 变量会在栈中存储,对象在堆中存储
- 我们知道写代码时创建一个基本类型、对象、函数都是需要占用内存的,但是我们并不关注这些,因为这是引擎为我们分配的,我们不需要显式手动的去分配内存,那么 JavaScript 引擎是如何发现并清理垃圾的呢?
- “可达性”,有没有被引用,没有被引用的变量,“不可达的变量”
- 变量会在栈中存储,对象在堆中存储
- 我们知道写代码时创建一个基本类型、对象、函数都是需要占用内存的,但是我们并不关注这些,因为这是引擎为我们分配的,我们不需要显式手动的去分配内存,那么 JavaScript 引擎是如何发现并清理垃圾的呢?
引用计数算法
相信这个算法大家都很熟悉,也经常听说。
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1 如果同一个值又被赋给另一个变量,那么引用数加1
- 如果该变量的值被其他的值覆盖了,则引用次数減1
- 当这个值的引用次数变为0的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运
- 行的时候清理掉引用次数为0的值占用的内存
:::info 这个算法最怕的就是循环引用(相互引用),还有比如 JavaScript 中不恰当的闭包写法
:::
相信这个算法大家都很熟悉,也经常听说。
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1 如果同一个值又被赋给另一个变量,那么引用数加1
- 如果该变量的值被其他的值覆盖了,则引用次数減1
- 当这个值的引用次数变为0的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运
- 行的时候清理掉引用次数为0的值占用的内存
:::info 这个算法最怕的就是循环引用(相互引用),还有比如 JavaScript 中不恰当的闭包写法
:::
优点
- 引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为0时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
- 而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以
- 引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为0时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
- 而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以
弊端
- 它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
- 它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
标记清除(Mark-Sweep)算法
:::info 从根对象进行检测,先标记再清除
:::
- 标记清除(Mark-Sweep),目前在 JavaScript引擎里这种算法是最常用的,到目前为止的大多数浏览器的 Javascript引擎都在采用标记清除算法,各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 Javascript引擎在运行垃圾回收的频率上有所差异。
- 此算法分为标记和清除两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
- 当变量进入执行环境时,反转某一位(通过一个二进制字符来表示标记),又或者可以维护进入环境变量和离开环境变量这样两个列表,可以自由的把变量从一个列表转移到另一个列表。
- 引擎在执行GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多, 我们称之为一组根对象,而所谓的根对象,其实在浏览器环境中包括又不止于全局Window对象、文档DOM树
- 整个标记清除算法大致过程就像下面这样:
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为O的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为O,等待下一轮垃圾回收
:::info 从根对象进行检测,先标记再清除
:::
- 标记清除(Mark-Sweep),目前在 JavaScript引擎里这种算法是最常用的,到目前为止的大多数浏览器的 Javascript引擎都在采用标记清除算法,各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 Javascript引擎在运行垃圾回收的频率上有所差异。
- 此算法分为标记和清除两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
- 当变量进入执行环境时,反转某一位(通过一个二进制字符来表示标记),又或者可以维护进入环境变量和离开环境变量这样两个列表,可以自由的把变量从一个列表转移到另一个列表。
- 引擎在执行GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多, 我们称之为一组根对象,而所谓的根对象,其实在浏览器环境中包括又不止于全局Window对象、文档DOM树
- 整个标记清除算法大致过程就像下面这样:
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为O的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为O,等待下一轮垃圾回收
优点
- 标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和 1)就可以为其标记,非常简单
- 标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和 1)就可以为其标记,非常简单
弊端
- 标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
- 那如何找到合适的块呢?
:::danger 在插入值的时候去解决,最大化使用内存空间,即:通过插入的形式,提升内存空间使用
:::
- 我们可以采取下面三种分配策略
- First-fit,找到大于等于 size 的块立即返回
- Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
- Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
- 综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用 First-fit策略,其操作仍是一个0(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
:::info 归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
:::
- 标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
- 那如何找到合适的块呢?
:::danger 在插入值的时候去解决,最大化使用内存空间,即:通过插入的形式,提升内存空间使用
:::
- 我们可以采取下面三种分配策略
- First-fit,找到大于等于 size 的块立即返回
- Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
- Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
- 综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用 First-fit策略,其操作仍是一个0(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
:::info 归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
:::
标记整理(Mark-Compact)算法
:::color1 有碎片就整理,整理的过程是有消耗的,所以就会有新生代、老生代
:::
- 而标记整理(Mark-Compact)算法就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存
:::color1 有碎片就整理,整理的过程是有消耗的,所以就会有新生代、老生代
:::
- 而标记整理(Mark-Compact)算法就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存
Unix/windows/Android/iOS系统中内存碎片空间思想
内存碎片化是所有系统都面临的挑战,不同操作系统和环境中的处理策略各有侧重,但也有其共通之处。以下是不同系统在内存碎片处理上的比较:
内存碎片化是所有系统都面临的挑战,不同操作系统和环境中的处理策略各有侧重,但也有其共通之处。以下是不同系统在内存碎片处理上的比较:
V8引擎中的标记-整理算法
- 标记阶段:识别未使用的对象,标记为垃圾。
- 整理阶段:将存活对象移动到连续区域,释放大块内存空间,减少外部碎片。
- 标记阶段:识别未使用的对象,标记为垃圾。
- 整理阶段:将存活对象移动到连续区域,释放大块内存空间,减少外部碎片。
电脑系统(Unix/Linux vs Windows)
- 内存管理:均使用分页机制,但Linux更倾向于预防碎片,Windows依赖内存压缩。
- 处理策略:Linux通过 slab 分配器优化内存分配,Windows通过内存压缩技术。
- 相同点:分页和交换机制,内存不足时回收内存。
- 不同点:Linux更注重预防,Windows依赖内存压缩,处理方式不同。
- 内存管理:均使用分页机制,但Linux更倾向于预防碎片,Windows依赖内存压缩。
- 处理策略:Linux通过 slab 分配器优化内存分配,Windows通过内存压缩技术。
- 相同点:分页和交换机制,内存不足时回收内存。
- 不同点:Linux更注重预防,Windows依赖内存压缩,处理方式不同。
移动终端(Android vs iOS)
- 内存管理:Android基于Linux,采用内存回收和进程优先级管理;iOS使用更严格的内存管理。
- 处理策略:Android通过Activity生命周期管理内存,iOS通过ARC自动管理。
- 相同点:内存不足时回收内存,依赖垃圾回收机制。
- 不同点:Android更灵活,支持后台进程保活;iOS更严格,强制回收。
- 内存管理:Android基于Linux,采用内存回收和进程优先级管理;iOS使用更严格的内存管理。
- 处理策略:Android通过Activity生命周期管理内存,iOS通过ARC自动管理。
- 相同点:内存不足时回收内存,依赖垃圾回收机制。
- 不同点:Android更灵活,支持后台进程保活;iOS更严格,强制回收。
内存碎片化挑战
- 内部碎片:内存分配导致的未使用空间,需优化分配策略。
- 外部碎片:分散的空闲空间,需整理或置换策略。
- 处理目标:桌面系统注重稳定性,移动设备关注响应和功耗。
- 内部碎片:内存分配导致的未使用空间,需优化分配策略。
- 外部碎片:分散的空闲空间,需整理或置换策略。
- 处理目标:桌面系统注重稳定性,移动设备关注响应和功耗。
工具与分析
- Unix/Linux:使用
top、htop、vmstat等工具。 - Windows:依赖任务管理器和性能监视器。
- 移动设备:Android用Android Profiler,iOS用Instruments。
总结: 不同系统在内存碎片处理上各有特色,但都旨在优化内存使用效率。V8引擎通过标记-整理减少碎片,而操作系统如Unix/Linux和Windows,以及移动系统如Android和iOS则采用不同的内存管理策略,以适应各自的性能和资源需求。
- Unix/Linux:使用
top、htop、vmstat等工具。 - Windows:依赖任务管理器和性能监视器。
- 移动设备:Android用Android Profiler,iOS用Instruments。
总结: 不同系统在内存碎片处理上各有特色,但都旨在优化内存使用效率。V8引擎通过标记-整理减少碎片,而操作系统如Unix/Linux和Windows,以及移动系统如Android和iOS则采用不同的内存管理策略,以适应各自的性能和资源需求。
内存管理
:::info V8的垃圾回收策略主要基于分代式垃圾回收机制,V8中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
:::
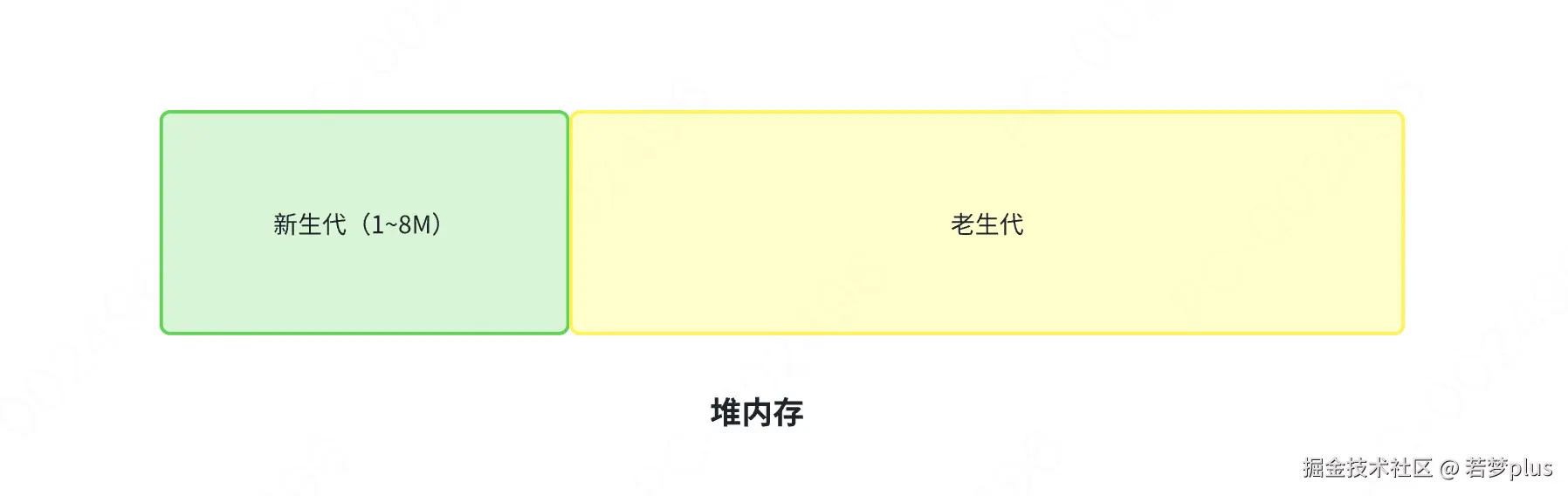
:::info V8的垃圾回收策略主要基于分代式垃圾回收机制,V8中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
:::
新生代
- 当新加入对象时,它们会被存储在使用区。然而,当使用区快要被写满时,垃圾清理操作就需要执行。在开始垃圾回收之前,新生代垃圾回收器会对使用区中的活动对象进行标记。标记完成后,活动对象将会被复制到空闲区并进行排序。然后,垃圾清理阶段开始,即将非活动对象占用的空间清理掉。最后,进行角色互换,将原来的使用区变成空闲区,将原来的空闲区变成使用区。
- 如果一个对象经过多次复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理。
- 除此之外,还有一种情况,如果复制一个对象到空闲区时,空闲区的空间占用超过了25%,那么这个对象会被直接晋升到老生代空间中。25%比例的设置是为了避免影响后续内存分配,因为当按照 Scavenge 算法回收完成后, 空闲区将翻转成使用区,继续进行对象内存分配。
:::info 一直在开辟空间,达到一定程度,就回晋升到老生代
:::
- 当新加入对象时,它们会被存储在使用区。然而,当使用区快要被写满时,垃圾清理操作就需要执行。在开始垃圾回收之前,新生代垃圾回收器会对使用区中的活动对象进行标记。标记完成后,活动对象将会被复制到空闲区并进行排序。然后,垃圾清理阶段开始,即将非活动对象占用的空间清理掉。最后,进行角色互换,将原来的使用区变成空闲区,将原来的空闲区变成使用区。
- 如果一个对象经过多次复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理。
- 除此之外,还有一种情况,如果复制一个对象到空闲区时,空闲区的空间占用超过了25%,那么这个对象会被直接晋升到老生代空间中。25%比例的设置是为了避免影响后续内存分配,因为当按照 Scavenge 算法回收完成后, 空闲区将翻转成使用区,继续进行对象内存分配。
:::info 一直在开辟空间,达到一定程度,就回晋升到老生代
:::
老生代
- 不同于新生代,老生代中存储的内容是相对使用频繁并且短时间无需清理回收的内容。这部分我们可以使用标记整理进行处理。
- 从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
- 清除阶段老生代垃圾回收器会直接将非活动对象进行清除。
- 不同于新生代,老生代中存储的内容是相对使用频繁并且短时间无需清理回收的内容。这部分我们可以使用标记整理进行处理。
- 从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
- 清除阶段老生代垃圾回收器会直接将非活动对象进行清除。
并行回收
:::info 思想类似于 花两个人的钱,让一个人干三个人的活
:::
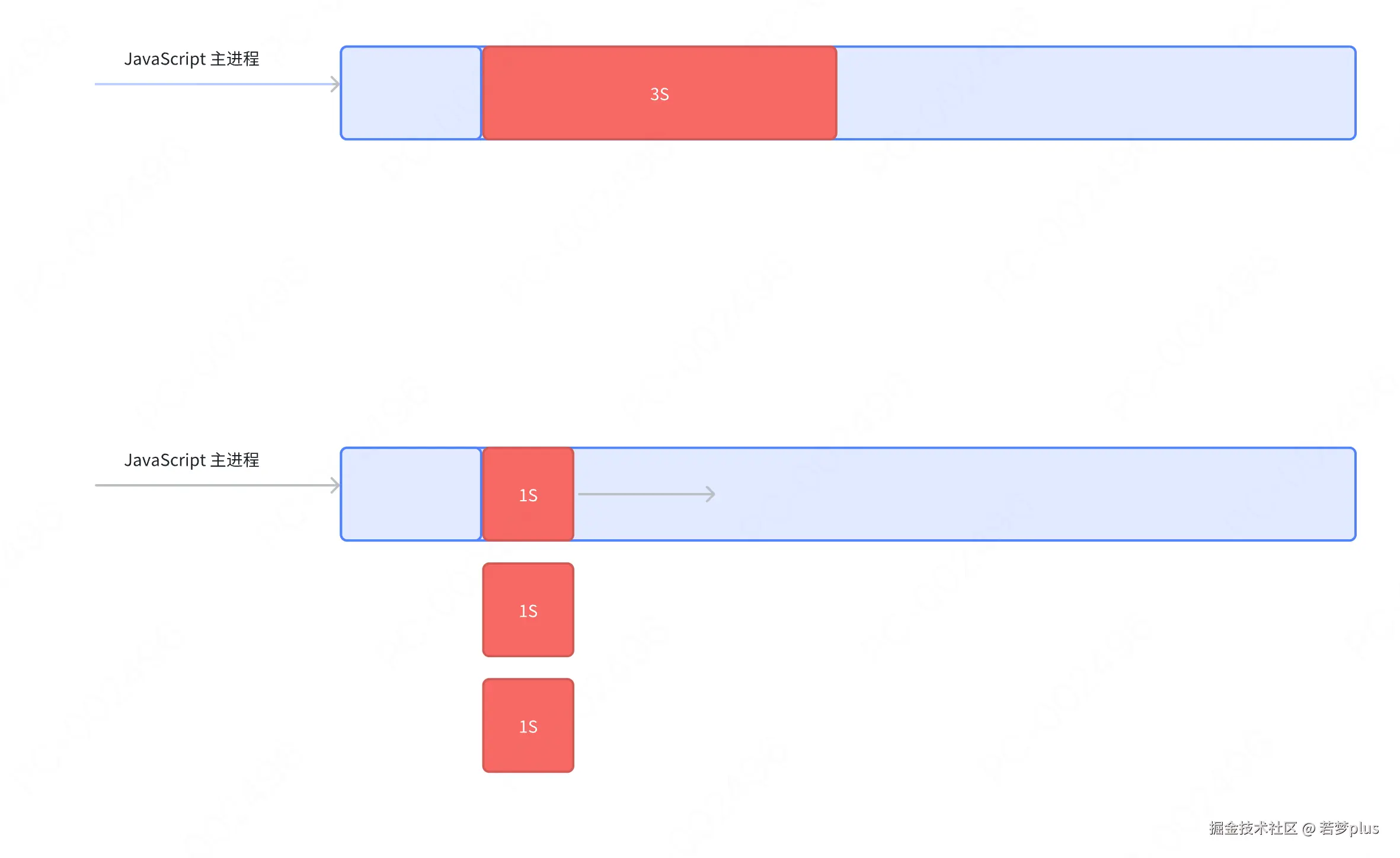
:::info 思想类似于 花两个人的钱,让一个人干三个人的活
:::
全停顿标记
这个概念看字眼好像不好理解,其买如果用前端开发的术语来解释,就是阻塞。
虽然我们的 GC操作被放到了主进程与子进程中去处理,但最终的结果还是主进程被较长时间占用。
在JavaScript的V8引擎中,全停顿标记(Full Stop-the-world Marking)是垃圾回收(GC)过程中的一个重要环节。
这个过程涉及到V8的垃圾回收器暂停JavaScript程序的执行,以便进行垃圾回收的标记阶段。全停顿标记是为了确保在回收内存前正确标记所有活动对象(即正在使用的对象)和非活动对象(即可以清除的对象)。
这个概念看字眼好像不好理解,其买如果用前端开发的术语来解释,就是阻塞。
虽然我们的 GC操作被放到了主进程与子进程中去处理,但最终的结果还是主进程被较长时间占用。
在JavaScript的V8引擎中,全停顿标记(Full Stop-the-world Marking)是垃圾回收(GC)过程中的一个重要环节。
这个过程涉及到V8的垃圾回收器暂停JavaScript程序的执行,以便进行垃圾回收的标记阶段。全停顿标记是为了确保在回收内存前正确标记所有活动对象(即正在使用的对象)和非活动对象(即可以清除的对象)。
全停顿标记的工作原理
1.停止执行:当执行到全停顿标记阶段时,V8引擎会暂停正在执行的JavaScript代码,确保没有任何Javascript代码在运行。这个停顿是必需的,因为在标记活动对象时,对象的引用关系需要保持不变。
2. 标记阶段:在这个阶段,垃圾回收器遍历所有根对象(例如全局变量、活跃的函数的局部变量等),从这些根对象开始,递归地访问所有可达的对象。每访问到一个对象,就将其标记为活动(1)的。
- 恢复执行:标记完成后,V8引擎会恢复JavaScript代码的执行,进入垃圾回收的清除或压缩阶段。
1.停止执行:当执行到全停顿标记阶段时,V8引擎会暂停正在执行的JavaScript代码,确保没有任何Javascript代码在运行。这个停顿是必需的,因为在标记活动对象时,对象的引用关系需要保持不变。
2. 标记阶段:在这个阶段,垃圾回收器遍历所有根对象(例如全局变量、活跃的函数的局部变量等),从这些根对象开始,递归地访问所有可达的对象。每访问到一个对象,就将其标记为活动(1)的。
- 恢复执行:标记完成后,V8引擎会恢复JavaScript代码的执行,进入垃圾回收的清除或压缩阶段。
全停顿的影响及优化
全停顿标记虽然对于确保内存被正确管理是必要的,但它会对应用程序的性能产生影响,特别是在垃圾回收发生时, 应用程序的响应时间和性能会短暂下降。为了缓解这种影响,V8引擎采用了几种策略:
• 增量标记 (Incremental Marking):为了减少每次停顿的时间,V8实现了增量标记,即将标记过程分成多个小部分进行,介于JavaScript执行的间隙中逐步完成标记。
• 并发标记(Concurrent Marking):V8引擎的更高版本中引入了并发标记,允许垃圾回收标记阶段与JavaScript代码的执行同时进行,进一步减少停顿时间。
• 延迟清理(Lazy Sweeping):标记完成后的清理阶段也可以延迟执行,按需进行,以减少单次停顿的时间。
这些优化措施有助于提高应用的响应速度和整体性能,特别是在处理大量数据和复杂操作时,确保用户体验不会因垃圾回收而受到较大影响。
切片标记
- 增量就是将一次 GC标记的过程,分成了很多小步,每执行完一小步就让应用逻辑执行一会儿,这样交替多次后完成一轮 GC 标记
三色标记
我们这里的会,表示的是一个中间状态,为什么会有这个中间状态呢?
• 白色指的是未被标记的对象
• 灰色指自身被标记,成员变量(该对象的引用对象)未被标记 • 黑色指自身和成员变量皆被标记
在V8引擎中使用的三色标记算法是一种用于垃圾回收的有效方法,特别是在进行增量和并发标记时。这个算法通过给对象着色(白色、灰色、黑色)来帮助标记和回收垃圾。
工作原理
- 初始化:
- 白色:初始状态,所有对象都标记为白色,表示这些对象可能是垃圾,如果在标记过程中没有被访问到,最终将被清理。
- 灰色:表示对象已经被标记(访问过),但该对象的引用还没有完全检查完。
- 黑色:表示该对象及其所有引用都已经被完全访问过,并且已经标记。
- 标记过程:
- 垃圾回收开始时,从根集合(如全局变量、活跃的堆栈帧中的局部变量等)出发,将所有根对象标记为灰色。
- 逐一处理灰色对象:将灰色对象标记为黑色,并将其直接引用的所有白色对象转变为灰色。这个过程不断重复,直到没有灰色对象为止。
- 扫描完成:
- 所有从根可达的对象最终都会被标记为黑色。所有仍然为白色的对象被认为是不可达的,因此将被视为垃圾并在清除阶段被回收。
- 初始化:
优点
- 健壮性:三色标记算法非常适合增量和并发的垃圾回收,因为它能够确保即使在应用程序继续执行的情况下也能正确地标记活动对象。
- 防止漏标:通过灰色和黑色的严格区分,算法确保所有可达的对象都会被遍历和标记,防止错误地回收正在使用的对象。
- 效率:虽然在垃圾回收期间会有增加的计算开销,但三色标记算法可以与应用程序的执行并行进行,减少了GC停顿的时间,提高了应用的响应性和性能。
应用
- 在实际应用中,V8和其他现代JavaScript引擎使用这种算法进行内存管理,优化了动态内存的使用,减少了垃圾回收对应用性能的影响。这对于要求高性能和实时响应的Web应用程序尤其重要。
写屏障(增量中修改引用)
- 这一机制用于处理在增量标记进行时修改引用的处理,可自行修改为灰色
在V8引擎中,写屏障(Write Barrier)是垃圾回收(GC)的一个关键机制,尤其是在增量和并发垃圾回收过程中发挥着至关重要的作用。写屏障主要用来维持垃圾回收中的三色不变性,在对象写操作期间动态地更新对象的可达性信息。
作用
- 保持三色不变性,在使用三色标记算法中,写屏障帮助维持所谓的三色不变性。这意味着系统确保如果一个黑色对象(已经被完全扫描的对象)引用了一个白色对象(尚未被扫描的对象,可能是垃圾),那么这个白色对象应当转变为灰色(标记但尚未扫描完毕的对象),从而避免错误的垃圾回收。
- 处理指针更新,当一个对象的指针被更新(例如,一个对象的属性被另一个对象替换),写屏障确保关于这些对象的垃圾回收元数据得到适当的更新。这是确保垃圾回收器正确识别活动对象和非活动对象的必要步骤。
类型
- Pre-Write Barrier(预写屏障),这种类型的写屏障在实际更新内存之前执行。它主要用于某些特定类型的垃圾回收算法,比如分代垃圾回收,以保持老年代和新生代之间的引用正确性。
- Post-Write Barrier(后写屏障),这是最常见的写屏障类型,发生在对象的指针更新之后。在V8中,当黑色对象指向白色对象时,后写屏障会将该白色对象标记为灰色,确保它不会在当前垃圾回收周期中被错误地回收。
实现细节
- 在V8引擎中,写屏障通常由简短的代码片段实现,这些代码片段在修改对象属性或数组元素时自动执行。例如,每当JavaScript代码或内部的V8代码试图写入一个对象的属性时,写屏障代码会检查是否需要更新垃圾回收的元数据。
惰性清理
- 增量标记只是用于标记活动对象和非活动对象,真正的清理释放内存,则V8采用的是惰性清理(Lazy Sweeping)方案。
- 在增量标记完成后,进行清理。当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理过程稍微延迟一下,让 Javascript 脚本代码先执行,也无需一次性清理完所有非活动对象内存,可以按需逐一进行清理直到所有的非活动对象内存都清理完毕。
并发回收
:::info 本质是切片,然后去插入,做一些动作
:::
- react 中的 Concurrent 吗?
- 我们想想 React演进过程,是不是就会觉得从并行到并发的演进变得很合了呢?
- 并发挥收其实是更进一步的切片,几乎完全不阻塞主进程。
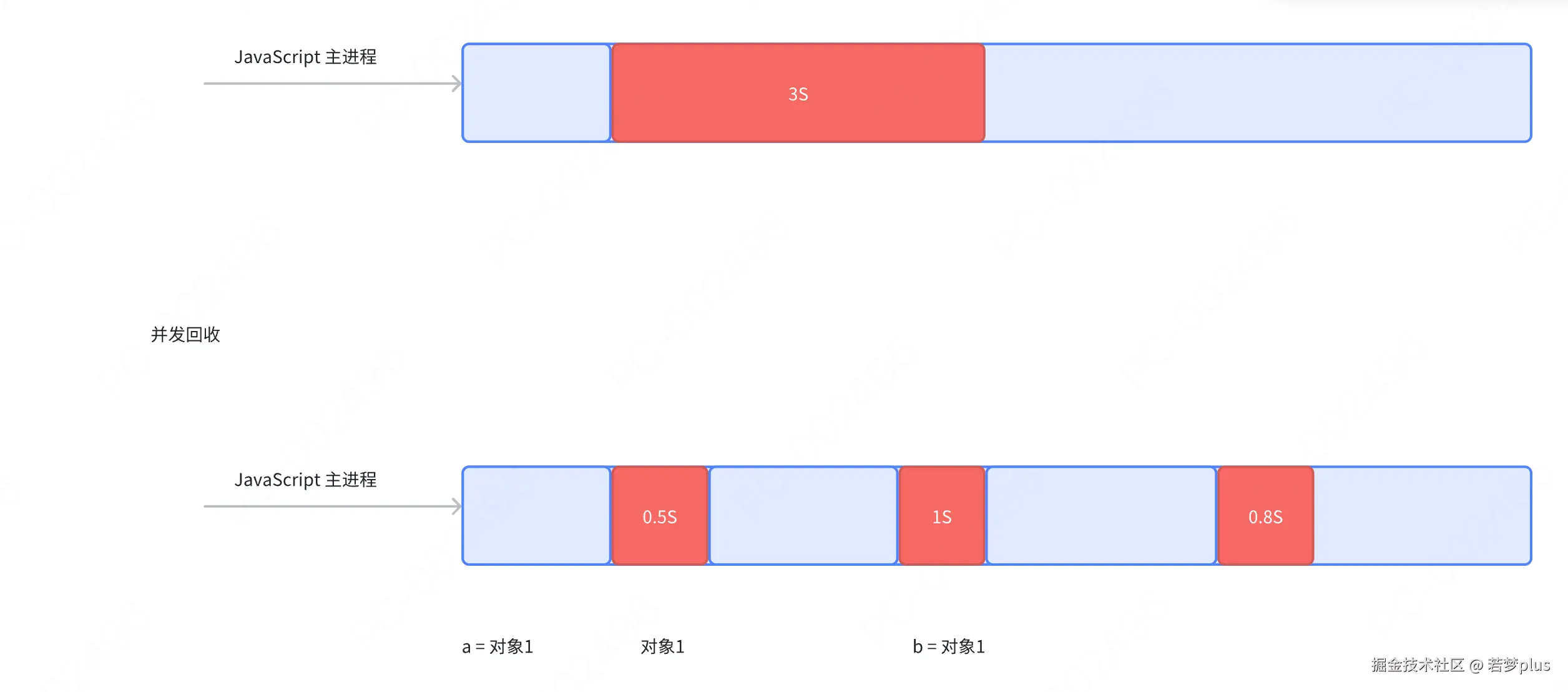
:::success 分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,新老生代的回收机制及频率是不同的,可以说此机制的出现很大程度提高了垃圾回收机制的效率
:::
怎么理解内存泄露?
怎么解决内存泄露,代码层面如何优化?
- 减少查找
- 减少变量声明
- 使用 Performance + Memory 分析内存与性能
运行机制
- 浏览器主进程
- 协调控制其他子进程(创建、销毁)
- 浏览器界面显示,用户交互,前进、后退、收藏
- 将渲染进程得到的内存中的Bitmap,绘制到用户界面上
- 存储功能等
- 第三方插件进程
- 每种类型的插件对应一个进程,仅当使用该插件时才创建
- GPU进程
- 用于3D绘制等
- 渲染进程,就是我们说的浏览器内核
- 排版引擎 Blink 和 JavaScript 引擎V8 都是运行在该进程中,将HTML、CSS和 JavaScript 转换为用户可以与之交互的网页
- 协调控制其他子进程(创建、销毁)
- 浏览器界面显示,用户交互,前进、后退、收藏
- 将渲染进程得到的内存中的Bitmap,绘制到用户界面上
- 存储功能等
- 每种类型的插件对应一个进程,仅当使用该插件时才创建
- 用于3D绘制等
- 排版引擎 Blink 和 JavaScript 引擎V8 都是运行在该进程中,将HTML、CSS和 JavaScript 转换为用户可以与之交互的网页
- 负责页面渲染,脚本执行,事件处理等
- 每个tab页一个渲染进程
- 出于安全考虑,渲染进程都是运行在沙箱模式下
- 网络进程
- 负责页面的网络资源加载,之前作为一个模块运行在浏览器主进程里面,最近才独立成为一个单独的进程
浏览器事件循环
:::info 在 Chrome 中,事件循环的执行是由浏览器的渲染引擎(例如 Blink)和V8 引擎配合完成的。V8负责 JavaScript 代码的执行,Blink 负责浏览器的渲染和用户界面的更新
:::
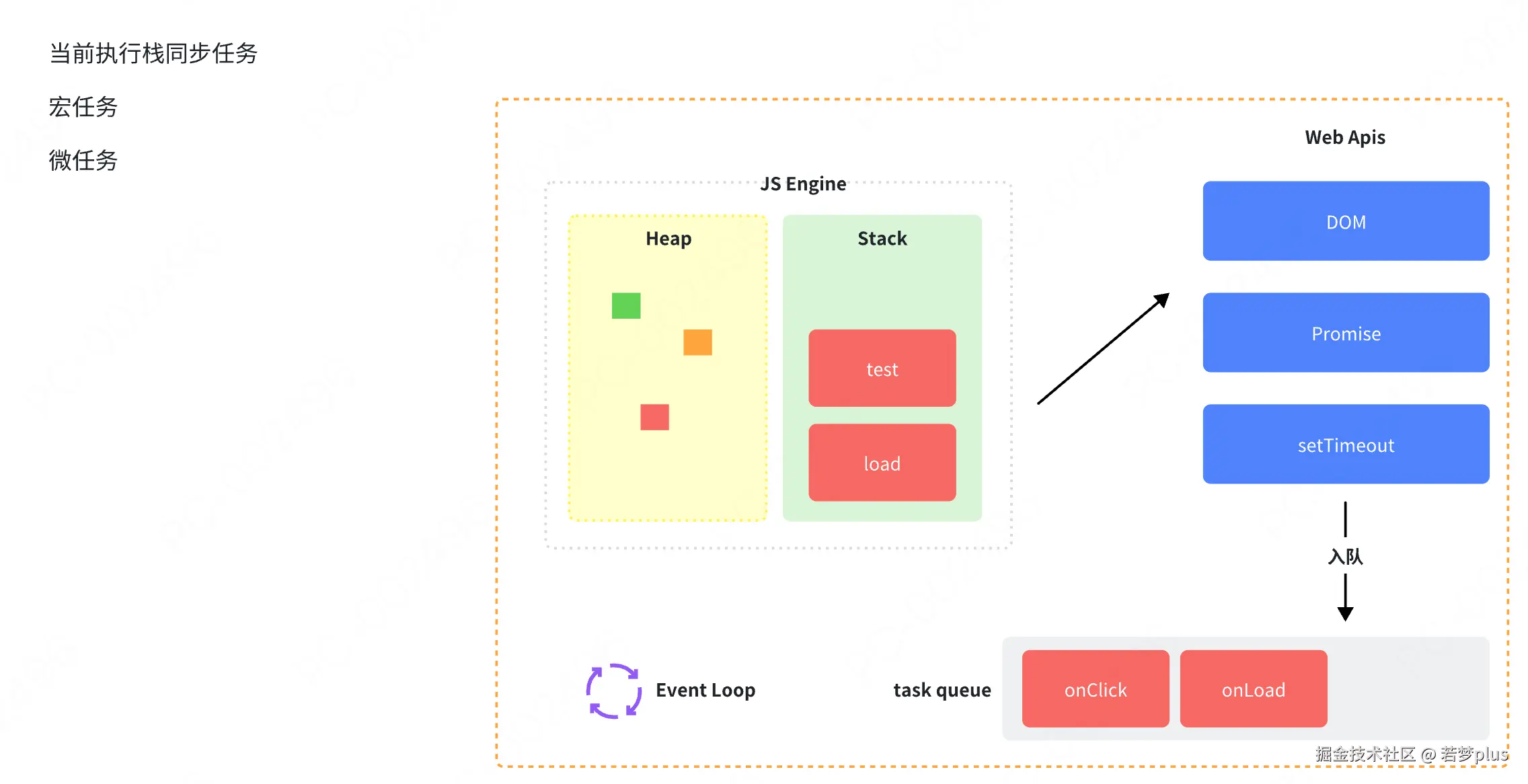
执行任务的顺序
先执行当前执行栈同步任务,再执行(微任务),再执行(宏任务)
宏任务
:::info 在 Chrome的源码中,并未直接出现“宏任务”这一术语,但在 Javascript 运行时引擎(V8)以及事件循环 (Event Loop)相关的实现中,宏任务和微任务的概念是非常重要的。
实际上,“宏任务”这一术语来源于 Javascript 事件循环的抽象,它只是帮助我们理解任务的执行顺序和时机。
:::
可以将每次执行栈执行的代码当做是一个宏任务
- I/O
- setTimeout
- setinterval
- setImmediate
- requestAnimationFrame
微任务
当宏任务执行完,会在渲染前,将执行期间所产生的所有微任务都执行完
- process.nextTick
- MutationObserver
- Promise.then catch finally
完整鏊体流程
- 执行当前执行栈同步任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 执行栈同步任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 宏任务执行完毕,开始检查渲染,然后 GUI线程接管渲染
- 渲染完毕后, JS线程继续接管,开始下一个宏任务(从事件队列中获取)
Node事件循环机制
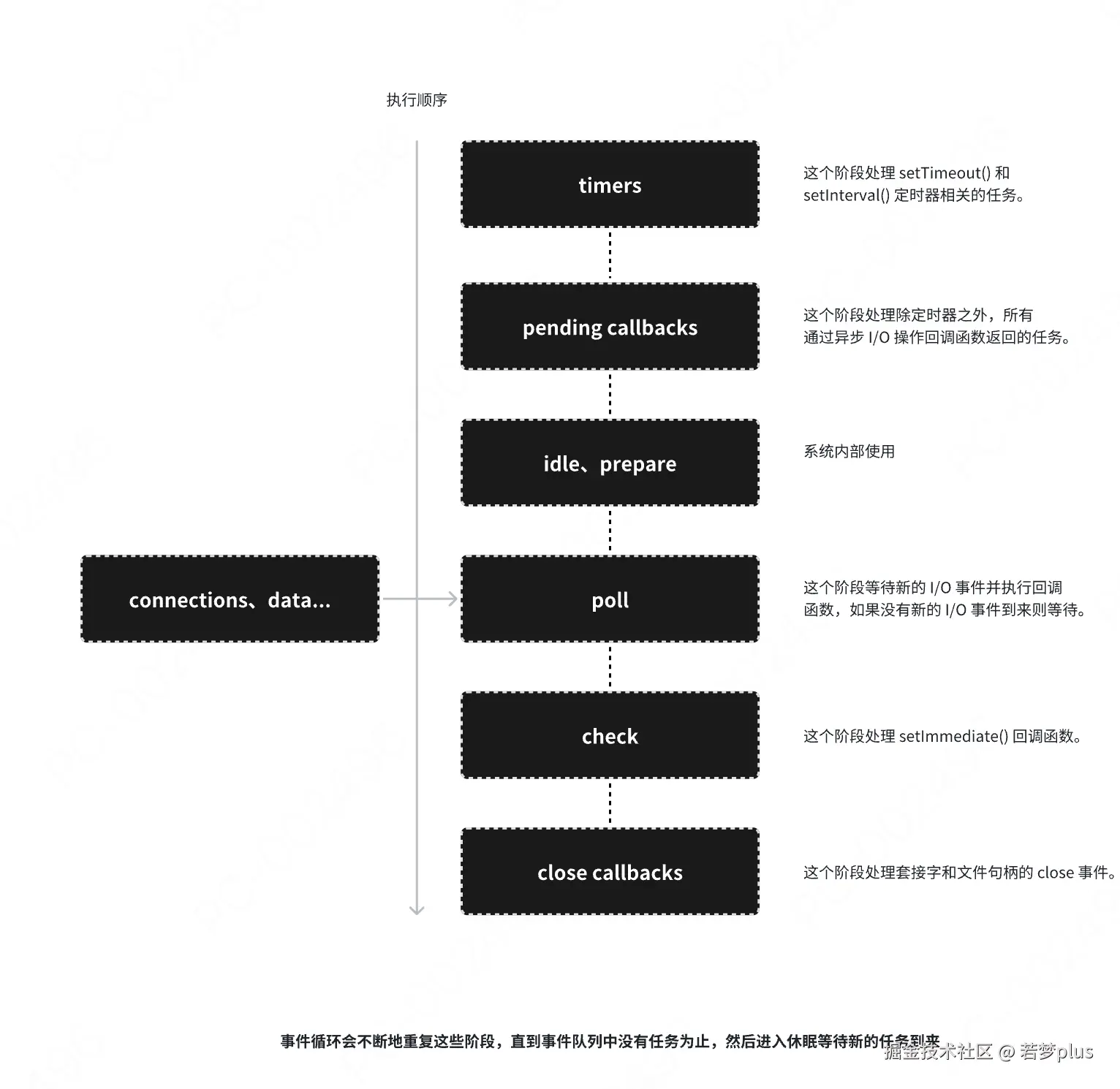
与浏览器事件循环机制的不同
- 在 Node.js 中,为了更高效地管理和调度各种类型的异步任务。这种设计使得 Node.js 能够在单线程环境中有效地处理大量的并发任务。下
- Node.js 的事件循环(Event Loop)是一个处理异步操作的机制,它会按照顺序依次执行不同阶段任务。事件循环机制中分为多个阶段,每个阶段都有自己的任务队列,包括:
- Timers 阶段:
- 处理 setTimeout 和 setInterval 调度的回调函数。
- 如果指定的时间到了,回调函数会被放入这个队列。
- Pending Callbacks 阶段:
- 处理一些1/0操作的回调,比如 TCP 错误类型的回调。
- 这些回调并不完全由开发者控制,而是由操作系统调度的。
- Idle, Prepare 阶段:
- 仅供内部使用的阶段。
- Poll 阶段:
- 获取新的1/0事件,执行1/0回调函数。
- 通常情况下,这个阶段会一直等待,直到有新的!/0 事件到来。
- Check 阶段:
- 处理 :setImmediate 调度的回调函数。
- etImmediate 的回调会在这个阶段执行,比 setTimeout 更早。
- Close Callbacks 阶段:
- 处理一些关闭的回调函数,比如 socket.on('close', ... ) °
- 处理 setTimeout 和 setInterval 调度的回调函数。
- 如果指定的时间到了,回调函数会被放入这个队列。
- 处理一些1/0操作的回调,比如 TCP 错误类型的回调。
- 这些回调并不完全由开发者控制,而是由操作系统调度的。
- 仅供内部使用的阶段。
- 获取新的1/0事件,执行1/0回调函数。
- 通常情况下,这个阶段会一直等待,直到有新的!/0 事件到来。
- 处理 :setImmediate 调度的回调函数。
- etImmediate 的回调会在这个阶段执行,比 setTimeout 更早。
- 处理一些关闭的回调函数,比如 socket.on('close', ... ) °
多个队列的必要性
不同类型的异步任务有不同的优先级和处理方式。使用多个队列可以确保这些任务被正确地调度和执行:
- Timers 和 Poll 阶段的区别:
- setTimeout 和 setInterval 的回调在 Timers 阶段执行,这些回调函数依赖于计时器的到期时间。
- Poll 阶段处理大多数1/0 回调,这是事件循环的主要阶段,处理大部分异步1/O操作。
- mmediate 与 Timeout 的不同:
- setImmediate 的回调函数在 Check 阶段执行,这是在当前事件循环周期结束后立即执行。
- setTimeout 的回调函数则是在 Timers 阶段执行,它可能会延迟到下一个事件循环周期,甚至更久。
- 处理关闭回调:
- Close Callbacks 阶段专门处理如 socket.on('close')这样的回调,以确保在资源释放时执行。
Chrome 任务调度机制
V8与Blink的调度系统密切相关。
:::info Blink 是 Chrome 中的渲染引擎
V8是 Chrome 中的 JavaScript 引擎
:::
Blink 是 Chrome 浏览器中的渲染引擎,负责页面的渲染和绘制任务。V8与 Blink 会协同工作,确保 JavaScript 的执行与页面渲染能够平稳进行。
Blink Scheduler:docs.google.com/document/d/…
接下来我们了解一下 Blink scheduler,一个用于优化 Blink 主线程任务调度的方案,旨在解决现有调度系统中的一些问题。
将任务不断安排到主线程的消息循环中,会导致Blink 主线程阻塞。造成诸多问题:
- 有限的优先级设置-任务按照发布顺序执行,或者可以明确地延迟,但这可能导致一些重要的任务(如输入处理) 被不那么紧急的任务占用优先执行权。
- 缺乏与系统其他部分的协调-比如图形管线虽然已知有输入事件的传递、显示刷新等时序要求,但这些信息无法及时传递给Blink。
- 无法适应不同的使用场景 -某些任务(如垃圾回收)在用户交互时进行非常不合适。
为了解决以上问题,出现了 Blink Scheduler 调度器,它能够更灵活控制任务按照给定优先级执行
- 关键特点
- 调度器的主要功能是决定在特定时刻哪个任务应当执行。
- 调度器提供了更高级的API替代现有的主线程任务调度接口,任务不再是抽象的回调函数,而是更具体、具有明确标签和元数据的对象。例如,输入任务会被明确标记,并附带附加元数据。
- 调度器可以根据系统状态做出更明智的任务决策,而不是依赖给定死的静态优先级。
gitlab.mpi-klsb.mpg.de/eweyulu/qui…
- 性能验证和工具
- 为了验证调度器的效果,文章提到了多项基准测试和性能指标,例如:
- 队列等待时间:衡量任务从发布到执行的延迟。
- 输入事件延迟:衡量输入事件的处理时间。
- 渲染平滑度(jank):衡量渲染的平滑性,避免出现卡顿。
- 页面加载时间:跟踪页面加载时间的变化。
其他资料
- V8:v8.dev/docs/torque
- chromium 中promise:chromium.googlesource.com/v8/v8/+/ref…
- V8定义:chromium.googlesource.com/v8/v8/+/ref…
- Node V8:nodejs.org/en/learn/ge…
- ibuv-in-node-js:http://www.geeksforgeeks.org/libuv-in-no…
- Faster JavaScript calls:v8.dev/blog/adapto…
- blink scheduler:docs.google.com/document/d/…
作者:若梦plus
来源:juejin.cn/post/7493386024878833715
来源:juejin.cn/post/7493386024878833715
Go 语言未来会取代 Java 吗?
Go 语言未来会取代 Java 吗?
(八年 Java 开发的深度拆解:从业务场景到技术底层)
开篇:面试官的灵魂拷问与行业焦虑
前年面某大厂时,技术负责人突然抛出问题:“如果让你重构公司核心系统,会选 Go 还是 Java?”
作为写了八年 Java 的老开发,我本能地想强调 Spring 生态和企业级成熟度,但对方随即展示的 PPT 让我冷汗直冒 —— 某金融公司用 Go 重构交易系统后,QPS 从 5 万飙升到 50 万,服务器成本降低 70%。这让我陷入沉思:当云原生和 AI 浪潮来袭,Java 真的要被 Go 取代了吗?
今天从 业务场景、技术本质、行业趋势 三个维度,结合实战代码和踩坑经验,聊聊我的真实看法。
一、业务场景对比:Go 的 “闪电战” vs Java 的 “持久战”
先看三个典型业务场景,你会发现两者的差异远不止 “性能” 二字。
场景 1:高并发抢购(电商大促)
Go 实现(Gin 框架) :
func main() {
router := gin.Default()
router.GET("/seckill", func(c *gin.Context) {
// 轻量级goroutine处理请求
go func() {
// 直接操作Redis库存
if err := redisClient.Decr("stock").Err(); err != nil {
c.JSON(http.StatusOK, gin.H{"result": "fail"})
return
}
c.JSON(http.StatusOK, gin.H{"result": "success"})
}()
})
router.Run(":8080")
}
性能数据:单机轻松支撑 10 万 QPS,p99 延迟 < 5ms。
Java 实现(Spring Boot + 虚拟线程) :
@RestController
public class SeckillController {
@GetMapping("/seckill")
public CompletableFuture<ResponseEntity<String>> seckill() {
return CompletableFuture.supplyAsync(() -> {
// 虚拟线程处理IO操作
if (redisTemplate.opsForValue().decrement("stock") < 0) {
return ResponseEntity.ok("fail");
}
return ResponseEntity.ok("success");
}, Executors.newVirtualThreadPerTaskExecutor());
}
}
性能数据:Java 21 虚拟线程让 IO 密集型场景吞吐量提升 7 倍,p99 延迟从 165ms 降至 23ms。
核心差异:
- Go:天生适合高并发,Goroutine 调度和原生 Redis 操作无额外开销。
- Java:依赖 JVM 调优,虚拟线程虽大幅提升性能,但需配合线程池和异步框架。
场景 2:智能运维平台(云原生领域)
Go 实现(Ollama + gRPC) :
func main() {
// 启动gRPC服务处理AI推理请求
server := grpc.NewServer()
pb.RegisterAIAnalysisServer(server, &AIHandler{})
go func() {
if err := server.Serve(lis); err != nil {
log.Fatalf("Server exited with error: %v", err)
}
}()
// 采集节点数据(百万级设备)
for i := 0; i < 1000000; i++ {
go func(nodeID int) {
for {
data := collectMetrics(nodeID)
client.Send(data) // 通过channel传递数据
}
}(i)
}
}
优势:轻量级 Goroutine 高效处理设备数据采集,gRPC 接口响应速度比 REST 快 30%。
Java 实现(Spring Cloud + Kafka) :
@Service
public class MonitorService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void collectMetrics(int nodeID) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(100);
executor.scheduleAtFixedRate(() -> {
String data =采集数据(nodeID);
kafkaTemplate.send("metrics-topic", data);
}, 0, 1, TimeUnit.SECONDS);
}
}
挑战:传统线程池在百万级设备下内存占用飙升,需配合 Kafka 分区和 Consumer Gr0up 优化。
核心差异:
- Go:云原生基因,从采集到 AI 推理全链路高效协同。
- Java:生态依赖强,需整合 Spring Cloud、Kafka 等组件,部署复杂度高。
场景 3:企业 ERP 系统(传统行业)
Java 实现(Spring + Hibernate) :
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
// 复杂业务逻辑注解
@PrePersist
public void validateOrder() {
if (totalAmount < 0) {
throw new BusinessException("金额不能为负数");
}
}
}
优势:Spring 的事务管理和 Hibernate 的 ORM 完美支持复杂业务逻辑,代码可读性高。
Go 实现(GORM + 接口组合) :
type Order struct {
ID uint `gorm:"primaryKey"`
UserID uint
Total float64
}
func (o *Order) Validate() error {
if o.Total < 0 {
return errors.New("金额不能为负数")
}
return nil
}
func CreateOrder(ctx context.Context, order Order) error {
if err := order.Validate(); err != nil {
return err
}
return db.Create(&order).Error
}
挑战:需手动实现事务和复杂校验逻辑,代码量比 Java 多 20%。
核心差异:
- Java:企业级成熟度,框架直接支持事务、权限、审计等功能。
- Go:灵活性高,但需手动实现大量基础功能,适合轻量级业务。
二、技术本质:为什么 Go 在某些场景碾压 Java?
从 并发模型、内存管理、性能调优 三个维度,深挖两者的底层差异。
1. 并发模型:Goroutine vs 线程 / 虚拟线程
Go 的 Goroutine:
- 轻量级:每个 Goroutine 仅需 2KB 栈空间,可轻松创建百万级并发。
- 调度高效:基于 GMP 模型,避免内核级上下文切换,IO 阻塞时自动释放线程。
Java 的虚拟线程(Java 21+) :
- 革命性改进:每个虚拟线程仅需几百字节内存,IO 密集型场景吞吐量提升 7 倍。
- 兼容传统代码:无需修改业务逻辑,直接将
new Thread()替换为Thread.startVirtualThread()。
性能对比:
- HTTP 服务:Go 的 Gin 框架单机 QPS 可达 5 万,Java 21 虚拟线程 + Netty 可达 3 万。
- 消息处理:Go 的 Kafka 消费者单节点处理速度比 Java 快 40%。
2. 内存管理:逃逸分析 vs 分代 GC
Go 的逃逸分析:
- 栈优先分配:对象若未逃逸出函数,直接在栈上分配,减少 GC 压力。
- 零拷贝优化:
io.Reader接口直接操作底层缓冲区,避免内存复制。
Java 的分代 GC:
- 成熟但复杂:新生代采用复制算法,老年代采用标记 - 压缩,需通过
-XX:G1HeapRegionSize等参数调优。 - 内存占用高:同等业务逻辑下,Java 堆内存通常是 Go 的 2-3 倍。
典型案例:
某金融公司用 Go 重构风控系统后,内存占用从 8GB 降至 3GB,GC 停顿时间从 200ms 缩短至 10ms。
3. 性能调优:静态编译 vs JIT 编译
Go 的静态编译:
- 启动快:编译后的二进制文件直接运行,无需预热 JVM。
- 可预测性强:性能表现稳定,适合对延迟敏感的场景(如高频交易)。
Java 的 JIT 编译:
- 动态优化:运行时将热点代码编译为机器码,长期运行后性能可能反超 Go。
- 依赖调优经验:需通过
-XX:CompileThreshold等参数平衡启动时间和运行效率。
实测数据:
- 启动时间:Go 的 HTTP 服务启动仅需 20ms,Java Spring Boot 需 500ms。
- 长期运行:持续 24 小时压测,Java 的吞吐量可能比 Go 高 10%(JIT 优化后)。
三、行业趋势:Go 在蚕食 Java 市场,但 Java 不会轻易退场
从 市场数据、生态扩展、技术演进 三个维度,分析两者的未来走向。
1. 市场数据:Go 在高速增长,Java 仍占主导
- 份额变化:Go 在 TIOBE 排行榜中从 2020 年的第 13 位升至 2025 年的第 7 位,市场份额突破 3%。
- 薪资对比:Go 开发者平均薪资比 Java 高 20%,但 Java 岗位数量仍是 Go 的 5 倍。
典型案例:
- 字节跳动:核心推荐系统用 Go 重构,QPS 提升 3 倍,成本降低 60%。
- 招商银行:核心交易系统仍用 Java,但微服务网关和监控平台全面转向 Go。
2. 生态扩展:Go 拥抱 AI,Java 深耕企业级
Go 的 AI 集成:
- 工具链完善:通过 Ollama 框架可直接调用 LLM 模型,实现智能运维告警。
- 性能优势:Go 的推理服务延迟比 Python 低 80%,适合边缘计算场景。
Java 的企业级护城河:
- 大数据生态:Hadoop、Spark、Flink 等框架仍深度依赖 Java。
- 移动端统治力:尽管 Kotlin 流行,Android 系统底层和核心应用仍用 Java 开发。
3. 技术演进:Go 和 Java 都在进化
Go 的发展方向:
- 泛型完善:Go 1.18 + 支持泛型,减少重复代码(如
PrintSlice函数可适配任意类型)。 - WebAssembly 集成:计划将 Goroutine 编译为 Wasm,实现浏览器端高并发。
Java 的反击:
- Project Loom:虚拟线程已转正,未来将支持更细粒度的并发控制。
- Project Valhalla:引入值类型,减少对象装箱拆箱开销,提升性能 15%。
四、选型建议:Java 开发者该如何应对?
作为八年 Java 老兵,我的 技术选型原则 是:用最合适的工具解决问题,而非陷入语言宗教战争。
1. 优先选 Go 的场景
- 云原生基础设施:API 网关、服务网格、CI/CD 工具链(如 Kubernetes 用 Go 开发)。
- 高并发实时系统:IM 聊天、金融交易、IoT 数据采集(单机 QPS 需求 > 1 万)。
- AI 推理服务:边缘计算节点、实时推荐系统(需低延迟和高吞吐量)。
2. 优先选 Java 的场景
- 复杂企业级系统:ERP、CRM、银行核心业务(需事务、权限、审计等功能)。
- Android 开发:系统级应用和性能敏感模块(如相机、传感器驱动)。
- 大数据处理:离线分析、机器学习训练(Hadoop/Spark 生态成熟)。
3. 混合架构:Go 和 Java 共存的最佳实践
- API 网关用 Go:处理高并发请求,转发到 Java 微服务。
- AI 推理用 Go:部署轻量级模型,结果通过 gRPC 返回给 Java 业务层。
- 数据存储用 Java:复杂查询和事务管理仍由 Java 服务处理。
代码示例:Go 调用 Java 微服务
// Go客户端
conn, err := grpc.Dial("java-service:8080", grpc.WithInsecure())
if err != nil {
log.Fatalf("连接失败: %v", err)
}
defer conn.Close()
client := pb.NewJavaServiceClient(conn)
resp, err := client.ProcessData(context.Background(), &pb.DataRequest{Data: "test"})
if err != nil {
log.Fatalf("调用失败: %v", err)
}
fmt.Println("Java服务返回:", resp.Result)
// Java服务端
@GrpcService
public class JavaServiceImpl extends JavaServiceGrpc.JavaServiceImplBase {
@Override
public void processData(DataRequest request, StreamObserver<DataResponse> responseObserver) {
String result =复杂业务逻辑(request.getData());
responseObserver.onNext(DataResponse.newBuilder().setResult(result).build());
responseObserver.onCompleted();
}
}
五、总结:焦虑源于未知,成长来自行动
回到开篇的问题:Go 会取代 Java 吗? 我的答案是:短期内不会,但长期会形成互补格局。
- Java 的不可替代性:企业级成熟度、Android 生态、大数据框架,这些优势难以撼动。
- Go 的不可阻挡性:云原生、高并发、AI 集成,这些领域 Go 正在建立新标准。
作为开发者,与其焦虑语言之争,不如:
- 掌握 Go 的核心优势:学习 Goroutine 编程、云原生架构,参与开源项目(如 Kubernetes)。
- 深耕 Java 的护城河:研究虚拟线程调优、Spring Boot 3.2 新特性,提升企业级架构能力。
- 拥抱混合开发:在 Java 项目中引入 Go 模块,或在 Go 服务中调用 Java 遗留系统。
最后分享一个真实案例:某电商公司将支付核心用 Java 保留,抢购服务用 Go 重构,大促期间 QPS 从 5 万提升到 50 万,系统总成本降低 40%。这说明,语言只是工具,业务价值才是终极目标。
来源:juejin.cn/post/7540597161224536090
我为什么在团队里,强制要求大家用pnpm而不是npm?

最近,我在我们前端团队里推行了一个“强制性”的规定:所有新项目,必须使用pnpm作为包管理工具;所有老项目,必须在两个月内,逐步迁移到pnpm。
这个决定,一开始在团队里是有阻力的。
有同事问:“老大,npm用得好好的,为啥非要换啊?我们都习惯了。”
也有同事说:“yarn不也挺快的吗?再换个pnpm,是不是在瞎折腾?”
我理解大家的疑问。但我之所以要用“强制”这个词,是因为在我看来,在2025年的今天,继续使用npm或yarn,就像是明明有高铁可以坐,你却非要坚持坐绿皮火车一样,不是不行,而是没必要。
这篇文章,我就想把我的理由掰开揉碎了,讲给大家听。
npm和yarn的“原罪”:那个又大又慢的node_modules
在聊pnpm的好处之前,我们得先搞明白,npm和yarn(特指yarn v1)到底有什么问题。
它们最大的问题,都源于一个东西——扁平化的node_modules。
你可能觉得奇怪,“扁平化”不是为了解决npm v2时代的“依赖地狱”问题吗?是的,它解决了老问题,但又带来了新问题:
1. “幽灵依赖”(Phantom Dependencies)
这是我最不能忍受的一个问题。
举个例子:你的项目只安装了A包(npm install A)。但是A包自己依赖了B包。因为是扁平化结构,B包也会被提升到node_modules的根目录。
结果就是,你在你的代码里,明明没有在package.json里声明过B,但你却可以import B from 'B',而且代码还能正常运行!
这就是“幽灵依赖”。它像一个幽灵,让你的项目依赖关系变得混乱不堪。万一有一天,A包升级了,不再依赖B了,你的项目就会在某个意想不到的地方突然崩溃,而你甚至都不知道B是从哪来的。
2. 磁盘空间的巨大浪费
如果你电脑上有10个项目,这10个项目都依赖了lodash,那么在npm/yarn的模式下,你的磁盘上就会实实在在地存着10份一模一样的lodash代码。
对于我们这些天天要开好几个项目的前端来说,电脑的存储空间就这么被日积月累地消耗掉了。
3. 安装速度的瓶颈
虽然npm和yarn都有缓存机制,但在安装依赖时,它们仍然需要做大量的I/O操作,去复制、移动那些文件。当项目越来越大,node_modules动辄上G的时候,那个安装速度,真的让人等到心焦。
pnpm是怎么解决这些问题的?——“符号链接”
好了,现在主角pnpm登场。pnpm的全称是“performant npm”,意为“高性能的npm”。它解决上面所有问题的核心武器,就两个字:链接。
pnpm没有采用扁平化的node_modules结构,而是创建了一个嵌套的、有严格依赖关系的结构。
1. 彻底告别“幽灵依赖”
在pnpm的node_modules里,你只会看到你在package.json里明确声明的那些依赖。
你项目里依赖的A包,它自己所依赖的B包,会被存放在node_modules/.pnpm/这个特殊的目录里,然后通过 符号链接(Symbolic Link) 的方式,链接到A包的node_modules里。
这意味着,在你的项目代码里,你根本访问不到B包。你想import B?对不起,直接报错。这就从结构上保证了,你的项目依赖关系是绝对可靠和纯净的。
2. 磁盘空间的“终极节约”
pnpm会在你的电脑上创建一个“全局内容可寻址存储区”(content-addressable store),通常在用户主目录下的.pnpm-store里。
你电脑上所有项目的所有依赖,都只会在这个全局仓库里,实实在在地只存一份。
当你的项目需要lodash时,pnpm不会去复制一份lodash到你的node_modules里,而是通过 硬链接(Hard Link) 的方式,从全局仓库链接一份过来。硬链接几乎不占用磁盘空间。
这意味着,就算你有100个项目都用了lodash,它在你的硬盘上也只占一份的空间。这个特性,对于磁盘空间紧张的同学来说,简直是福音。
3. 极速的安装体验
因为大部分依赖都是通过“链接”的方式实现的,而不是“复制”,所以pnpm在安装依赖时,大大减少了磁盘I/O操作。
它的安装速度,尤其是在有缓存的情况下,或者在安装一个已经存在于全局仓库里的包时,几乎是“秒级”的。这种“飞一般”的感觉,一旦体验过,就再也回不去了。
为什么我要“强制”?
聊完了技术优势,再回到最初的问题:我为什么要“强制”推行?
因为包管理工具的统一,是前端工程化规范里最基础、也最重要的一环。
如果一个团队里,有人用npm,有人用yarn,有人用pnpm,那就会出现各种各样的问题:
- 不一致的
lock文件:package-lock.json,yarn.lock,pnpm-lock.yaml互相冲突,导致不同成员安装的依赖版本可能不完全一致,引发“在我电脑上是好的”这种经典问题。 - 不一致的依赖结构:用npm的同事,可能会不小心写出依赖“幽灵依赖”的代码,而用pnpm的同事拉下来,代码直接就跑不起来了。
在一个团队里,工具的统一,是为了保证环境的一致性和协作的顺畅。而pnpm,在我看来,就是当前这个时代下,包管理工具的“最优解”。
所以,这个“强制”,不是为了搞独裁,而是为了从根本上提升我们整个团队的开发效率和项目的长期稳定性。
最后的经验
从npm到yarn,再到pnpm,前端的包管理工具一直在进化。
pnpm用一种更先进、更合理的机制,解决了过去遗留下的种种问题。它带来的不仅仅是速度的提升,更是一种对“依赖关系纯净性”和“工程化严谨性”的保障。
我知道,改变一个人的习惯很难。但作为团队的负责人,我有责任去选择一条更高效、更正确的路,然后带领大家一起走下去。
如果你还没用过pnpm,我强烈建议你花十分钟,在你的新项目里试一试🙂。
来源:juejin.cn/post/7530180321619656745
多线程爬虫案例
多线程爬虫的使用主要是为了提高网络爬虫的效率和性能。以下是几个关键原因:
- 提高速度:
- 并行处理:多线程爬虫可以同时处理多个请求,从而大大减少总的爬取时间。例如,如果一个单线程爬虫需要10秒来下载一个网页,而一个多线程爬虫可以同时下载10个网页,那么在同样的时间内,多线程爬虫可以完成更多的任务。
- 资源利用:
- 充分利用CPU和网络带宽:现代计算机通常具有多核CPU和高速网络连接,多线程爬虫可以更好地利用这些资源,避免单线程爬虫中的空闲等待时间(如等待网络响应)。
- 容错性:
- 任务隔离:多线程爬虫中,每个线程可以独立运行,即使某个线程出现错误或被阻塞,其他线程仍然可以继续工作,提高了整个爬虫系统的稳定性和可靠性。
- 复杂任务管理:
- 任务分配:对于复杂的爬虫任务,可以将不同的任务分配给不同的线程,例如,一个线程负责下载页面,另一个线程负责解析页面内容,还有一个线程负责存储数据。
- 适应动态环境:
- 灵活调整:多线程爬虫可以根据实际情况动态调整线程数量,例如,在网络状况良好时增加线程数以加快爬取速度,而在网络拥塞时减少线程数以避免对目标网站造成过大压力。
多线程爬取网站案例
# -*- coding: UTF-8 -*-
'''
@Project :网络爬虫
@File :11-多线程爬虫案例.py
@IDE :PyCharm
@Author :慕逸
@Date :09/11/2024 19:54
'''
# https://www.doutupk.com/search?type=photo&more=1&keyword=%E9%9D%93%E4%BB%94&page=3
import requests
from urllib import request
from lxml import etree
import threading
from queue import Queue
import winsound
class Producer(threading.Thread):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'
}
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
response = requests.get(url, headers=self.headers)
text = response.text
# print(text)
html = etree.HTML(text)
imgs = html.xpath("//div[@class='pic-content text-center']//img[@class!='gif']")
img_names = html.xpath(
"//div[@class='pic-content text-center']//img[@class!='gif']/following-sibling::p/text()")
for img, img_name in zip(imgs, img_names):
img_url = img.get('data-original')
# request.urlretrieve(img_url, 'E:/Study/code/Python/图片爬取/斗图啦/{}'.format(img_name) + str(random.randint(1, 10000)) + '.jpg')
# print(img_name + "-下载完成~~" + img_url)
self.img_queue.put((img_url, img_name))
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img = self.img_queue.get()
img_url, file_name = img
file_name = file_name.replace('.','').replace('?','')
request.urlretrieve(img_url, 'E:/Study/code/Python/图片爬取/斗图啦/{}.jpg'.format(file_name))
print(file_name + "-下载完成~~" + img_url)
def main():
winsound.Beep(1500, 500)
page_queue = Queue(100)
img_queue = Queue(500)
for i in range(1, 18):
url = "https://www.doutupk.com/search?type=photo&more=1&keyword=%E9%9D%93%E4%BB%94&page={}".format(i)
# parse_page(url)
page_queue.put(url)
# break
# 创建5个线程
for i in range(5):
t = Producer(page_queue, img_queue)
t.start()
for i in range(5):
t = Consumer(page_queue, img_queue)
t.start()
if __name__ == '__main__':
main()
winsound.Beep(1000, 500)
- 生产者类负责从队列中获取页面 URL,解析页面并提取图片信息,然后将图片信息放入图片队列中。
- 消费者类负责从图片队列中获取图片信息,下载图片并保存到本地。
来源:juejin.cn/post/7435257934344798248
Tauri 2.0 桌面端自动更新方案
前言
最近在研究 Tauri 2.0 如何自动更新,跟着官网教程来了一遍,发现并不顺利,踩了很多坑,不过好在最后终于走通了,今天整理一下供大家参考。
第一步
自动更新利用的是 Tauri 的 Updater 组件,所以这里需要安装一下:
PNPM 执行这个(笔者用的 PNPM):
pnpm tauri add updater
NPM 执行这个:
npm run tauri add updater
接着在 /src-tauri/tauri.conf.json 文件中添加以下配置:
{
"bundle": {
"createUpdaterArtifacts": true
},
"plugins": {
"updater": {
"pubkey": "你的公钥",
"endpoints": ["https://releases.myapp.com/latest.json"]
}
}
}
其中:
createUpdaterArtifacts为是否创建更新包,设置为 true 即可。根据官网介绍,未来发布的 V3 版本将无需设置。pubkey是公钥,用于和私钥匹配(私钥在开发环境配置,并在打包时自动携带)。但此时我们还没有,所以需要生成一下,执行以下命令生成密钥对:
PNPM 执行这个:
pnpm tauri signer generate -w ~/.tauri/myapp.key
NPM 执行这个:
npm run tauri signer generate -- -w ~/.tauri/myapp.key
执行时会要求输入一个密码用来保护密钥,也可以直接按回车跳过,建议还是输入一个:

输入(或跳过)之后,将会继续生成,生成之后进入刚才我们指定的目录
~/.tauri:
打开公钥
myapp.key.pub然后将上面的pubkey替换掉。
私钥的话,打开
myapp.key然后执行以下方法设置到环境变量:
macOS 和 Linux 执行这个(笔者是 macOS):
export TAURI_SIGNING_PRIVATE_KEY="你的私钥"
export TAURI_SIGNING_PRIVATE_KEY_PASSWORD="你刚才输入的密码,没有就不用设置。"
Windows 使用 Powershell 执行这个:
$env:TAURI_SIGNING_PRIVATE_KEY="你的私钥"
$env:TAURI_SIGNING_PRIVATE_KEY_PASSWORD="你刚才输入的密码,没有就不用设置。"
endpoints用于 Tauri 检查更新,是一个数组,所以可以设置多个,将会依次尝试可用的 URL,URL 指向放置在服务器的用于存储版本信息的 JSON 文件(也可以使用 API 的形式,这里不介绍了),格式如下:
{
"version": "1.0.1",
"notes": "更新说明",
"pub_date": "2025-05-21T03:29:28.626Z",
"platforms": {
"darwin-aarch64": {
"signature": "dW50cnVzdGVkIGNvbW1lbnQ6IHNpZ25hdHVyZSBmcm9tIHRhdXJpIHNlY3JldCBrZXkKUlVTU0xJb2k1U3J6ZVFoUWo3R2lMTm5EdzhoNUZTKzdsY0g1NktOOTFNL2RMM0JVVVl4b0k3bFB0MkhyL3pKOHRYZ0x0RVdUYzdyWVJvNDBtRDM0OGtZa2d0RWl0VTBqSndrPQp0cnVzdGVkIGNvbW1lbnQ6IHRpbWVzdGFtcDoxNzQ3Nzk1MTY5CWZpbGU6bXktdGF1cmktYXBwLmFwcC50YXIuZ3oKS1N0UDl5MHRteUd0RHJ6anlSMXBSWmNJUlNKb1pYTDFvK2EvUjArTlBpbXVGN3pnQlA0THhhVUd4S3JrZy9lNHBNbWVSU2VoaCswN25xNEFPcmtUQnc9PQo=",
"url": "macOS 包下载地址"
}
}
}
将此 JSON 文件放置在服务器,然后将上面的
endpoints数组里的地址替换为这个 JSON 的真实地址。
其中:
version是版本号,升级时需要大于当前用户使用的版本。notes是更新说明,可以向用户说明本次更新的内容。pub_date是更新日期,非必填。platform是更新的平台,这里我以 macOS 为例,Windows 同理。signature是每次打包后的签名,所以每次都不一样,macOS 默认在/src-tauri/target/release/bundle/macos/my-tauri-app.app.tar.gz.sig这个位置,将这个文件打开,复制里面的内容替换即可。
第二步
配置好以后,就可以在应用内调用 check 方法进行更新了,比如在用户每次应用启动后。以下是从检查更新到更新完成的全流程的必要代码:
import { check } from '@tauri-apps/plugin-updater'
import { relaunch } from '@tauri-apps/plugin-process'
const fetchVersion = async () => {
const update = await check()
if (update) {
console.log(`found update ${update.version} from ${update.date} with notes ${update.body}`)
let downloaded = 0
let contentLength = 0
// 也可以分开调用 update.download() 和 update.install()
await update.downloadAndInstall(event => {
switch (event.event) {
case 'Started':
contentLength = event.data.contentLength
console.log(`started downloading ${event.data.contentLength} bytes`)
break
case 'Progress':
downloaded += event.data.chunkLength
console.log(`downloaded ${downloaded} from ${contentLength}`)
break
case 'Finished':
console.log('download finished')
break
}
})
console.log('update installed')
// 此处 relaunch 前最好询问用户
await relaunch()
}
}
代码已经很简洁了,相信大家能看懂,但还是简单说一下:
首先调用 check 方法。检查之后,check 方法会返回一个 update 对象,如果检查到有更新,该对象会包含上面的版本更新信息,也包含一个 downloadAndInstall 方法。
执行 downloadAndInstall 方法,该方法执行完之后就代表安装成功了,会在下次启动时更新为新版本。当然也可以立即生效,只需要调用 relaunch 方法重启应用即可,但重启前最好提醒用户。
源码(经测试已经成功实现自动更新)已经上传到 Github:github.com/reallimengz…
来源:juejin.cn/post/7506832196582408226
ESLint + Husky 如何只扫描发生改动的文件?
背景
最近公司对代码质量抓得很严, 出台了一系列组合拳:
- 制定前端编码规范
- 在本地使用git提交代码时进行代码质量检查
- 在CI/CD流水线上, 用sonarQube设置了一个代码质量达标阈值,不达标的话无法构建部署
- 除了运用工具之外,还增加了定期的CodeReview
- 单元测试,线上合并代码时用大模型进行CodeReview也在路上...
今天先说说,在本地使用git提交代码时进行代码质量检查如何实现。现在进入主题
Step1 配置ESLint校验规则
在这一步,踩了一个大坑。现在安装ESLint, 安装的都是ESLint v9.x版本,ESLint v9+的配置文件与之前不太一样了。不管是问大模型,还是上网搜,搜出来的ESLint安装配置方式90%以上都是ESLint V8及以下版本的配置方法。按照那种方式配,会吃很多瘪。
能看懂的,简单一点的报错比如说:
- .eslintignore文件不再被支持,应该在
eslint.config.js或eslint.config.ts配置文件中,使用ignores属性来指定哪些文件或目录需要被忽略。
(node:13688) ESLintIgnoreWarning: The ".eslintignore" file is no longer supported. Switch to using the "ignores" property in "eslint.config.js": https://eslint.org/docs/latest/use/configure/migration-guide#ignoring-files (Usenode --trace-warnings ...to show where the warning was created) Oops! Something went wrong! :( ESLint: 9.25.1), - 改成
ignores又报错,对象字面量只能指定已知属性,并且“ignores”不在类型“ESLintConfig”中,被大模型忽悠了一回。在 ESLint 9.x 中,应该使用ignorePatterns来指定要忽略的文件或文件夹,而不是ignores。 jiti包版本不匹配, 需要升级
Oops! Something went wrong! :( ESLint: 9.25.1 Error: You are using an outdated version of the 'jiti' library. Please update to the latest version of 'jiti' to ensure compatibility and access to the latest features.- 未安装eslint-define-config模块
Oops! Something went wrong! :( ESLint: 9.25.1 Error: Cannot find module 'eslint-define-config'
不太容易看懂的报错比如说 ESLint 没有找到适用于文件 src/main.ts 的配置规则。0:0 warning File ignored because no matching configuration was supplied , 按照大模型的提示,逐一检查了ESLint 配置文件的路径是否正确,确保 root: true 配置生效; TypeScript 和 Vue 插件及解析器配置是否正确; ignorePatterns 是否误忽略了 src 文件夹; 检查 tsconfig.json 中的 include 配置; 手动检查文件是否被 ESLint 正确解析
pnpm eslint --config ./eslint.config.ts src/main.ts
忙活了一圈,未能解决问题。大模型排查技术工具最新版本的故障问题能力偏弱。无奈只能在网上搜,一篇一篇的看与试错。最终验证通过是方案是采用@eslint/config生成eslint v9版本的配置文件。
pnpm create @eslint/config
做7个选择(每个选项的含义一眼就能看懂)之后,就能妥妥地生成eslint配置文件。
Step2 配置Husky
这一步比较简单,虽然Husky最新版本的配置方法与先前的版本不一样了。但新版本的配置比老版本的要简单一些。
✅ 1. 安装Husky v9+版本
pnpm add -D husky
✅ 2. Husky v9+版本初始化
npx husky init
这会自动:
- 创建
.husky/目录 - 在
.husky/下添加pre-commithook 示例 - 在package.json中添加
"prepare": "husky install"脚本
这一步有个小坑,就是如果npx husky init第一次因为某种原因运行失败,第二次再运行,不会生成.husky目录。解决方法也很简单粗暴,卸载husky重新安装。
✅ 3. 在package.json配置检查指令
{
"scripts": {
"lint": "run-s lint:*",
"lint:eslint": "eslint src/**/*.{ts,tsx,vue} --debug --cache",
"lint:prettier": "prettier --check ./",
"lint:style": "stylelint \"src/**/*.{vue,css,less}\" --fix",
},
}
✅ 4. 修改 .husky/pre-commit hook
# 检查指令
pnpm lint
Step3 配置ESLint增量检测
为什么要配置增量检测呢,原因有两点:
- ESLint全量检测执行的很慢,如果不加
--debug参数,很长一段时间,看不到任何输出,会让人误以为卡死了 - 开发业务功能的时间本来就捉襟见肘,对于已有项目,当期要偿还历史技术债务的话,时间不允许。
那么如何做增量检查呢?最质朴的思路就是利用git能监测暂存区代码变更的能力,然后利用ESlint对变更的文件执行代码质量检查。这里有两处要注意一下,一是检查暂存区变更的文件,要过滤掉删除的文件,只检查新增,修改,重命名,复制的文件。另外,当没有匹配类型的文件时,files=$(git diff --cached --name-only --diff-filter=AMRC | grep -E '\.(ts|tsx|vue)$')会抛出一个exit 1的异常,造成改了(ts|tsx|vue)之外的文件不能正常提交,所以要在后面加一个|| true进行兜底。
#!/bin/bash
# set -e
# set -x
trap 'echo "Error at line $LINENO"; exit 1' ERR
# 注意这里加了 || true
files=$(git diff --cached --name-only --diff-filter=AMRC | grep -E '\.(ts|tsx|vue)$' || true)
if [ -z "$files" ]; then
echo "No changed ts/tsx/vue files to check."
exit 0
fi
echo "Running ESLint on the following files:"
echo "$files"
# 用 xargs -r 只有在有输入时才执行
echo "$files" | xargs -r npx eslint
echo "All files passed ESLint."
exit 0
Step4 测试效果
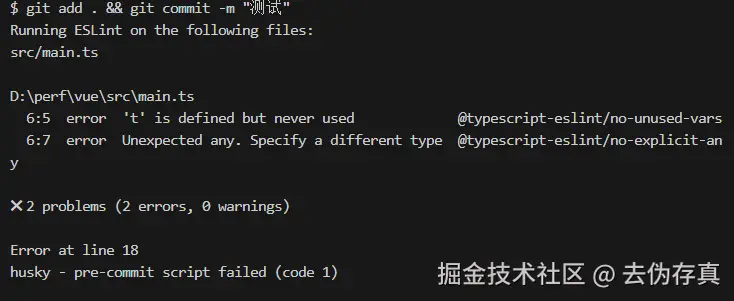
修改 src 下的某个 main.ts 文件,故意触发代码质量问题,然后提交。
- 情形1 通过命令行提交,eslint校验未通过,阻断提交,且是增量校验。
git add . && git commit -m "测试"
- 情形2 通过UI界面提交,成功阻断提交
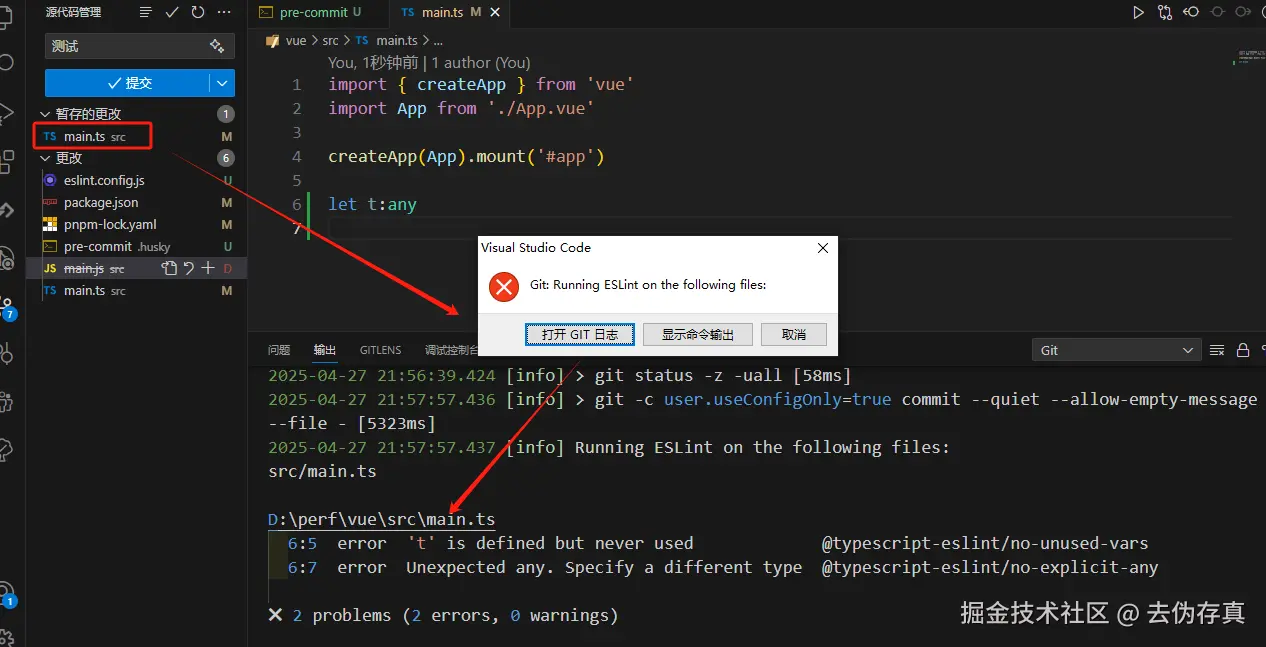
至此大功告成,结果令人满意,如果你的项目也需要实现这样的功能的话,拿走不谢。
后记
业务背景是这样的:gitlab上有个填写公司的仓库,有个提交代码的仓库,现在要将提交代码的仓库的代码变更记录,添加到填写工时的议题评论列表中,只要按照 feat: 跨项目提交测试 #194(#194是填写工时的议题id)这样的格式填写提交语,就能实现在评论列表添加代码变更链接的效果。

在.husky目录下添加prepare-commit-msg文件,内容如下:
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
# 仅当手动写 commit message 时执行
if [ "$2" = "merge" ] || [ "$2" = "squash" ]; then
exit 0
fi
file="$1"
msg=$(cat "$file")
# 查找是否包含 #数字 格式的 Issue 编号
issue_number=$(echo "$msg" | grep -Eo '#[0-9]+' | head -n1 | sed 's/#//')
if [ -n "$issue_number" ]; then
# 自定义项目路径
project_path="research-and-development/algorithm/项目名"
# 如果已经包含路径,则不重复添加
echo "$msg" | grep -q "$project_path" && exit 0
echo "" >>"$file"
echo "Related to $project_path#$issue_number" >>"$file"
fi
需要注意的是,你使用的gitlab版本必须大于v15,才支持跨项目议题关联功能
来源:juejin.cn/post/7497800812317147170
小米正式官宣开源!杀疯了!
最近,和往常一样在刷 GitHub Trending 热榜时,突然看到又一个开源项目冲上了 Trending 榜单。
一天之内就狂揽数千 star,仅仅用两三天时间,star 数就迅速破万,增长曲线都快干垂直了!

出于好奇,点进去看了看。
好家伙,这居然还是小米开源的项目,相信不少小伙伴也刷到了。

这个项目名为:ha_xiaomi_home。
全称:Xiaomi Home Integration for Home Assistant。
原来这就是小米开源的 Home Assistant 米家集成,一个由小米官方提供支持的 Home Assistant 集成组件,它可以让用户在 Home Assistant 平台中使用和管理小米 IoT 智能设备。
Home Assistant 大家知道,这是一款开源的家庭自动化智能家居平台,以其开放性和兼容性著称,其允许用户将家中的智能设备集成到一个统一的系统中进行管理和控制,同时支持多种协议和平台。

通过 Home Assistant,用户可以轻松地实现智能家居的自动化控制,如智能灯光、智能安防、智能温控等,所以是不少智能家居爱好者的选择。
另外通过安装集成(Integration),用户可以在 Home Assistant 上实现家居设备的自动化场景创建,并且还提供了丰富的自定义功能,所以一直比较受 DIY 爱好者们的喜爱。

大家知道,小米在智能家居领域的战略布局一直还挺大的,IoT 平台的连接设备更是数以亿记,大到各种家电、电器,小到各种摄像头、灯光、开关、传感器,产品面铺得非常广。

那这次小米开源的这个所谓的米家集成组件,讲白了就是给 Home Assistant 提供官方角度的支持。
而这对于很多喜欢折腾智能家居或者 IoT 物联网设备的小伙伴来说,无疑也算是一个不错的消息。
ha_xiaomi_home 的安装方法有好几种,包括直接 clone 安装,借助 HACS 安装,或者通过 Samba 或 FTPS 来手动安装等。
但是官方是推荐直接使用 git clone 命令来下载并安装。
cd config
git clone https://github.com/XiaoMi/ha_xiaomi_home.git
cd ha_xiaomi_home
./install.sh /config
原因是,这样一来当用户想要更新至特定版本时,只需要切换相应 Tag 即可,这样会比较方便。
比如,想要更新米家集成版本至 v1.0.0,只需要如下操作即可。
cd config/ha_xiaomi_home
git checkout v1.0.0
./install.sh /config
安装完成之后就可以去 Home Assistant 的设置里面去添加集成了,然后使用小米账号登录即可。

其实在这次小米官方推出 Home Assistant 米家集成之前,市面上也有一些第三方的米家设备集成,但是多多少少会有一些不完美的地方,典型的比如设备状态响应延时,所以导致体验并不是最佳。
与这些第三方集成相比,小米这次新推出的官方米家集成无论是性能还是安全性都可以更期待一下。
如官方所言,Home Assistant 米家集成提供了官方的 OAuth 2.0 登录方式,并不会在 Home Assistant 中保存用户的账号密码,同时账号密码也不再需提供给第三方,因此也就避免了账号密码泄露的风险。
但是这里面仍然有一个问题需要注意,项目官方也说得很明确:虽说 Home Assistant 米家集成提供了 OAuth 的登录方式,但由于 Home Assistant 平台的限制,登录成功后,用户的小米用户信息(包括设备信息、证书、 token 等)会明文保存在 Home Assistant 的配置文件中。因此用户需要保管好自己的 Home Assistant 配置文件,确保不要泄露。
这个项目开源之后,在网上还是相当受欢迎的,当然讨论的声音也有很多。
小米作为一家商业公司,既然专门搞了这样一个开源项目来做 HA 米家集成,这对于他们来说不管是商业还是产品,肯定都是有利的。
不过话说回来,有了这样一个由官方推出的开源集成组件,不论是用户体验还是可玩性都会有所提升,这对于用户来说也未尝不是一件好事。
那关于这次小米官方开源的 Home Assistant 米家集成项目,大家怎么看呢?
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7454170332712386572
离开大厂一年后的牛马,又回到了草原
牛马终究还是回到了草原
大家好呀,今天开始继续更新文章了,最近一个月因为换了城市,调整状态花了不少时间,现在才有些动力继续更新,今天来聊聊最近一年多的经历
1.回二线城市
23年12月的时候,我从北京阿里离职了,回到离家近的武汉,拿了一个国企的offer,也是在那家国企待了一年多的时间。
至于为什么会选择回武汉,主要觉得在一线城市买不起房,而且长期在外离家远,漂泊感太重,还不如早点回二线城市定居下来,免得以后年龄大了更不好回来。所以,当时看武汉的机会主要找稳定的工作,除了国企offer,还拿过高校,以及其他偏稳定的公司offer。综合考虑后,才选的国企
回来之后没到两月,就有些后悔了。虽然回来之前做好了心理预期,工资会降低,只是国企的工资也低的过于少了吧,开始几个月工资只有原来的零头。而且,呆了一段时间后发现,这个国企在北京才是研发中心,武汉这边作为分中心,只是北京的“内包”而已。
项目经理都是在北京,很多还都是校招进去工作才两三年的,就让管武汉这边几个人的工作。这些人也没啥管理经验,就只是不停给底下人施压。而且经常搞的操作就是,项目都是有时间要求的,开始的时候不拉人进来干活,等到时间比较紧的时候,才拉人进来,这就导致武汉的人收到任务时,都是重要且紧急的工作。又或者正常工作日没安排活,等到要放假,或者下班之前,才给安排活,让自行加班完成,故意恶心人
2.上着北京的班,拿着武汉的工资
这个事在24年的时候,已经发过吐槽了,就发张截图看看


3.成长的焦虑
我在北京的时候,除了阿里,之前也呆过一家互联网公司。裁员是比较常见的事情,虽然我还没被裁过。
国企这边虽然说相对比较稳定,但是自从我这批大概20个人入职后,感觉在走下坡路了,不仅福利变少,而且也变卷了,还传出后面也要搞末尾淘汰的事。我呆了一年的时候,感觉比在一线时更害怕,假如我在这里被裁了,或者呆满三年不续签了,可能很难再找到合适的工作了,自身成长和工作年限严重不匹配,想到这,我终于还是下了决定再去一线城市
找下家的经历并不顺利,国企的项目可以说就是玩具而已,完全拿不出手。只能拿之前阿里的项目去讲。有些一线互联网大厂,面试了好几轮,好不容易都过了。在焦急等待了数周后,最后给我说横向比较有更合适的了,就不考虑了。其实大家也都明白是因为啥原因不给发。
4.空窗期
经历了几个月的找工作经历后,终于是拿到上海一家公司offer,于是也就顺理成章准备跑路了。趁着中间有半个月的空闲时间,去西边青海和西藏游玩了一次。那边景点之间距离远,在携程上报跟团游就行,价钱不高,比较推荐去青海游玩,那的牛肉和羊肉非常新鲜,值得尝试,3天的时间,每天都能看不一样的风景。






5.上海
已经到上海快两个月,开始逐渐习惯天天下雨的节奏,现在下班还是比较早的,下班的时候还能见着落日,比较WLB,没有互联网大厂那么的卷,却也是有些压力的。下面是第一周下班时路上的照片

今天就写到这吧,下次有新鲜事再分享~
来源:juejin.cn/post/7522315126491856923
AI一定会淘汰程序员,并且已经开始淘汰程序员
昨儿中午吃着饭,不知道为啥突然和同事聊起来AI发展的事儿了。虽然我们只是"🐂🐎",但是不妨碍咱们坐井观天,瞎扯淡聊聊天。
他的主要观点是:现阶段的AI绝对无法取代程序员,大家有点过度恐慌了。AI是程序员的工具,就像从记事本升级到IDE一样。

我的主要观点是:AI一定会取代大量的程序员,尤其是初级程序员。后续程序员岗将在软件公司内的比重降低,取而代之的是产品、需求和算法岗。
诚然,他说的也有一定的道理,就目前AI发展的速度和质量来看,其实大家的确有点儿过度恐慌了。
AI的确在一定程度上替代的程序员的工作,但是大多内容仍然是程序员群体在产出,这个是不容否认的事实。
不过另一个不容否认的事实是,我们越来越依赖AI了。原来大家写代码一般都是啥不会了,就直接去网上搜。比如说js怎么截断从第2位到最后一位,想不起来了,搜一搜。
现在有了AI,一般的操作都是在上面写个注释,然后回车一下,AI会自动帮你补全代码,连搜的功夫都省了。
由此俺也big胆的预言一把,CSD*、掘*、百*这些资讯类,尤其是做程序员这个方向的资讯网站会越来越没落。
原因是:有了问题,但是没有了搜索。没有搜索就没有共享解决方案的必要,因为没人看。没人看所以不再有人分享,最后Over。
Ps:或许我被啪啪打脸呢?
之前的AI编码工具我就有在用,包括阿里的通义,百度的文心,或者是IDEA里面内嵌的编码助手,以及之前CodeGeex等等吧,确确实实是提高了效率的。
这个阶段其实重点提升的是搜索的效率,有问题直接问AI,AI直接给出答案。95%的答案都是正确的,不必再去网上费劲巴拉的找了。

后来更上一层楼,Claude2、3直接翻倍的提升了开发效率。我不必再实现了,我只需要阐述需求,AI会自动给出答案。我需要的是把内容Copy下来,然后整合进我的工程里面。
后面的工作就还是原来的老步骤了,测试一下,没啥问题的话就发版,提测了。
但是现在这个阶段又进步了,TREA2.0 SOLO出道直接整合了全流程,整个过程直接变成了"智能体"把控,不再需要我的干涉了。

我需要做的工作就是阐述清楚我的需求,然后让TREA去实现。这个过程中可能也就只需要我关注一下实现的方向不要有太大的偏差,及时纠正一下(但是到目前为止没遇到过需要纠正的情况)。
也就是说,现在AI已经从原来的片面生成代码,到后面的理解需求生成单文件代码,到现在生成工程化代码了。
而我们的角色也从一个砌墙工人,拿到了一把能自动打灰的铲子。
到后面变成一个小组长,拿着尺子和吊锤看他们盖的墙有没有问题。
到现在变成包工头看着手底下的工人一层层的盖起大楼。
但是!
你说工地上是工人多,还是组长多,还是包工头多?真的需要这么多包工头嘛?
来源:juejin.cn/post/7530570160840458250
Three.js-硬要自学系列29之专项学习透明贴图
什么是透明贴图
- 核心作用:像「镂空剪纸」一样控制物体哪些部位透明/不透明
(想象:给树叶模型贴图,透明部分让树叶边缘自然消失而非方形边缘)
- 技术本质:一张 黑白图片(如 PNG 带透明通道),其中:
- 黑色区域 → 模型对应位置 完全透明(消失)
- 白色区域 → 模型 完全不透明(显示)
- 灰色过渡 → 半透明效果(如玻璃边缘)
示例:游戏中的铁丝网、树叶、破碎特效等镂空物体常用此技术
常见问题与解决方案
| 问题现象 | 原因 | 解决方法(代码) |
|---|---|---|
| 贴图完全不透明 | 忘记开 transparent | material.transparent = true |
| 边缘有白边/杂色 | 半透明像素混合错误 | material.alphaTest = 0.5 |
| 模型内部被穿透 | 透明物体渲染顺序错乱 | mesh.renderOrder = 1 |
技巧:透明贴图需搭配 基础颜色贴图(map) 使用,两者共同决定最终外观
实际应用场景
- 游戏植被:草地用方形面片+草丛透明贴图,节省性能
- UI 元素:半透明的警示图标悬浮在 3D 物体上
- 破碎效果:物体裂开时边缘碎片渐变透明
- AR 展示:透明背景中叠加虚拟模型(类似宝可梦 GO)
实践案例一
效果如图

实现思路
通过canvas绘制内容,canvasTexture用来转换为3d纹理
const canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d');
canvas.width = 64;
canvas.height = 64;
ctx.fillStyle = '#404040';
ctx.fillRect(0, 0, 32, 32);
ctx.fillStyle = '#808080';
ctx.fillRect(32, 0, 32, 32);
ctx.fillStyle = '#c0c0c0';
ctx.fillRect(0, 32, 32, 32);
ctx.fillStyle = '#f0f0f0';
ctx.fillRect(32, 32, 32, 32);
const texture = new THREE.CanvasTexture(canvas);
这里画布大小设置为64*64,被均匀分割为4份,并填充不同的颜色
接下来创建一个立方体,为其贴上透明度贴图alphaMap,设置transparent:true这很关键
const geo = new THREE.BoxGeometry(1, 1, 1);
const material = new THREE.MeshBasicMaterial({
color: 'deepskyblue',
alphaMap: texture, // 透明度贴图
transparent: true,
opacity: 1,
side: THREE.DoubleSide
});
如果你尝试将transparent配置改为false, 你将看到如下效果

同样我们尝试修改canvas绘制时候的填充色,来验证黑白镂空情况
ctx.fillStyle = '#000';
ctx.fillRect(0, 0, 32, 32);
ctx.fillStyle = '#000';
ctx.fillRect(32, 0, 32, 32);
ctx.fillStyle = '#000';
ctx.fillRect(0, 32, 32, 32);
ctx.fillStyle = '#fff';
ctx.fillRect(32, 32, 32, 32);

如图所示,黑色消失,白色显示保留
总结本案例需要掌握的API
CanvasTexture
这是Texture的子类,它用于将动态绘制的 2D Canvas 内容(如图表、文字、实时数据)转换为 3D 纹理,使得HTML Canvas元素可以作为纹理映射到3d物体表面
它支持实时更新,默认needsUpdate为true
应用场景
- 动态数据可视化:将实时图表(如温度曲线)映射到 3D 面板。
- 文字标签:在 3D 物体表面显示可变文字(如玩家名称)。
- 程序化纹理:通过算法生成图案(如噪波、分形)。
- 交互式绘制:用户画布涂鸦实时投射到 3D 模型(如自定义 T 恤设计)。
性能优化
- 避免频繁更新:若非必要,减少
needsUpdate=true的调用频率。 - 合理尺寸:Canvas 尺寸建议为 2 的幂(如 256×256, 512×512),兼容纹理映射。
- 复用 Canvas:对静态内容,复用已生成的纹理而非重新创建。
- 替代方案:静态图像用
TextureLoader,视频用VideoTexture,以降低开销。
需要注意
- 跨域限制:若 Canvas 包含外部图片,需设置
crossOrigin="anonymous"。 - 清晰度问题:高缩放比例可能导致模糊,可通过
texture.anisotropy = renderer.capabilities.getMaxAnisotropy()改善。 - 内存管理:不再使用的纹理调用
texture.dispose()释放资源。
实践案例二
效果如图

实现思路
从图上可以看出,立方体每个面上有多个矩形小方块,每个方块都被赋予不同的颜色,创建grid方法来实现生产多个矩形小方块
const drawMethod = {};
drawMethod.grid = (ctx, canvas, opt={} ) => {
opt.w = opt.w || 4;
opt.h = opt.h || 4;
opt.colors = opt.colors || ['#404040', '#808080', '#c0c0c0', '#f0f0f0'];
opt.colorI = opt.colorI || [];
let i = 0;
const len = opt.w * opt.h,
sizeW = canvas.width / opt.w, // 网格宽度
sizeH = canvas.height / opt.h; // 网格高度
while(i<len) {
const x = i % opt.w,
y = Math.floor(i / opt.w);
ctx.fillStyle = typeof opt.colorI[i] === 'number' ? opt.colors[opt.colorI[i]] : opt.colors[i % opt.colors.length];
ctx.fillRect(x * sizeW, y * sizeH, sizeW, sizeH);
i++;
}
}
实现透明贴图
const canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d');
canvas.width = 64;
canvas.height = 64;
const texture = new THREE.CanvasTexture(canvas);
const geo = new THREE.BoxGeometry(1, 1, 1);
const material = new THREE.MeshBasicMaterial({
color: 'deepskyblue',
alphaMap: texture,
transparent: true,
opacity: 1,
side: THREE.DoubleSide
});
这里要注意,canvas上并未绘制任何内容,我们将在loop循环中调用grid方法进行绘制
let frame = 0,
lt = new Date(); // 上一次时间
const maxFrame = 90, // 最大帧数90帧
fps = 20; // 每秒20帧
function loop() {
const now = new Date(), // 当前时间
secs = (now - lt) / 1000, // 时间差
per = frame / maxFrame; // 进度
if (secs > 1 / fps) { // 时间差大于1/20
const colorI = [];
let i = 6 * 6;
while (i--) {
colorI.push(Math.floor(4 * Math.random()))
}
drawMethod.grid(ctx, canvas, {
w: 6,
h: 6,
colorI: colorI
});
texture.needsUpdate = true; // 更新纹理
mesh.rotation.y = Math.PI * 2 * per;
renderer.render(scene, camera);
frame += fps * secs; // 帧数累加
frame %= maxFrame; // 帧数取模,防止帧数溢出
lt = now;
}
// 渲染场景和相机
requestAnimationFrame( loop );
}
你可以看到这里每个面上被绘制了36个小矩形,并通过一下代码,随机填充颜色
while (i--) {
colorI.push(Math.floor(4 * Math.random()))
}
以上就是本章的所有内容,这里并未展示完整案例代码,是希望大家能动手练一练,很多的概念,看似晦涩难懂,实则动手尝试下的话秒懂。
来源:juejin.cn/post/7513158069419048997
JMeter 多台压力机分布式测试(Windows)
JMeter 多台压力机分布式测试(Windows)
1. 背景
- 在单台压力机运行时,出现了端口冲突问题,如
JMeter port already in use。 - 压力机机器权限限制,无法修改默认端口配置。
- 为避免端口冲突且提升压力机的压力能力,考虑使用多台机器(多台JMeter压力机)分布式压测。
2.环境说明
- Master IP:
192.20.10.7 - Slave1 IP:
192.20.10.8 - Slave2 IP:
192.20.10.9 - JMeter版本均为 5.5
- Java版本均为 1.8+
- 网络可互通,防火墙端口放通
- RMI 注册端口:1099
- RMI 远程对象端口:50000(默认,可配置)
3. Master 节点配置
3.1 修改 jmeter.properties (JMETER_HOME/bin/jmeter.properties)
properties复制# 远程主机列表,逗号分隔
remote_hosts=192.20.10.8,192.20.10.9
# 禁用RMI SSL,避免额外复杂度
server.rmi.ssl.disable=true
# Master的回调地址,设置为本机可达IP(用于Slave回调)
client.rmi.localhostname=192.20.10.7
# 关闭插件联网上报,提升启动速度
jmeter.pluginmanager.report_stats=false
2.2 启动 JMeter GUI
- 直接运行
jmeter.bat打开GUI - 加载测试脚本(
*.jmx) - 确认脚本和依赖文件已同步到所有Slave节点同路径
3. Slave 节点配置(192.20.10.8 和 192.20.10.9)
3.1 修改各自的 jmeter.properties (JMETER_HOME/bin/jmeter.properties)
Slave1(192.20.10.8):
# 远程RMI服务监听端口
server_port=1099
# RMI通信本地端口(避免冲突,Slave1用50000)
server.rmi.localport=50000
# 禁用RMI SSL
server.rmi.ssl.disable=true
# 远程机器回调绑定IP(本机IP)
java.rmi.server.hostname=192.20.10.8
# 关闭插件联网上报
jmeter.pluginmanager.report_stats=false
Slave2(192.20.10.9):
server_port=1099
server.rmi.localport=50001
server.rmi.ssl.disable=true
java.rmi.server.hostname=192.20.10.9
jmeter.pluginmanager.report_stats=false
3.2 启动Slave服务
在每台Slave机器的 bin 目录,执行:
set JVM_ARGS=-Djava.rmi.server.hostname=192.20.10.8 #可选配置
jmeter-server.bat
(Slave2替换IP为 192.20.10.9)
看到类似 Using local port: 50002 Created remote object: UnicastServerRef2 [liveRef:XXXX 表示启动成功。
如启动异常,可以打开jmeter-server.log查看日志。
3.2 验证监听端口
netstat -an | findstr 1099
TCP 0.0.0.0:1099 0.0.0.0:0 LISTENING
TCP [::]:1099 [::]:0 LISTENING
netstat -an | findstr 50002
TCP 0.0.0.0:50002 0.0.0.0:0 LISTENING
TCP [::]:50002 [::]:0 LISTENING
4. 测试执行流程
- 确保Master和所有Slave机器的JMeter和Java版本一致。
- 确保测试脚本和依赖文件(如CSV等)在所有Slave路径相同。
- 启动所有Slave的
jmeter-server.bat,确保端口监听正常。 - 在Master GUI加载脚本。
- 点击菜单
Run -> Remote Start 或 Remote Start All,Master向所有Slave发起远程测试。 11.JMeter GUI的日志样例如下:
INFO o.a.j.e.ClientJMeterEngine: Sending properties {}
o.a.j.e.ClientJMeterEngine: sent run command to
o.a.j.e.DistributedRunner: Remote engines have been started
o.a.j.g.u.JMeterMenuBar: setRunning
o.a.j.g.u.JMeterMenuBar: setRunning
jmeter-server.bat的日志如下,出现如下字段
Starting the test on host ...
Finished the test on host ...
- Master GUI的 Listener(Summary Report等)会显示所有Slave合并的结果。
5. 其他注意事项
- 防火墙放通Master和Slave的
server_port(1099)、server.rmi.localport端口。 - Master
client.rmi.localhostname必须是Slave可访问的Master IP。 - 禁用插件联网统计,避免卡顿。
- 避免使用重型监听器,使用轻量级监听器提升性能。
来源:juejin.cn/post/7530141922499149862
Spring高级开发:状态机/事件/插件
Spring 状态机与事件机制插件开发示例
我将为您演示一个完整的 Spring 状态机实现,包含状态机配置、事件机制和可扩展的插件体系。以下是一个订单处理系统的示例:
1. 添加依赖(pom.xml)
<dependencies>
<!-- Spring State Machine -->
<dependency>
<groupId>org.springframework.statemachine</groupId>
<artifactId>spring-statemachine-starter</artifactId>
<version>4.2.0</version>
</dependency>
<!-- Spring Event 相关 -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>6.0.9</version>
</dependency>
</dependencies>
2. 定义核心接口和类
2.1 状态和事件枚举
// 状态枚举
public enum OrderState {
NEW,
PAYMENT_PENDING,
PAID,
SHIPPED,
DELIVERED,
CANCELLED
}
// 事件枚举
public enum OrderEvent {
CREATE_ORDER,
INITIATE_PAYMENT,
PAYMENT_COMPLETED,
SHIP_ORDER,
DELIVERY_CONFIRMED,
CANCEL_ORDER
}
2.2 插件接口定义
// 状态变更监听器接口
public interface StateChangeListener {
void onStateChange(OrderState from, OrderState to, String orderId);
}
// 订单操作插件接口
public interface OrderOperationPlugin {
void execute(String orderId, OrderState currentState);
}
// 插件管理器接口
public interface PluginManager {
void registerStateChangeListener(StateChangeListener listener);
void notifyStateChange(OrderState from, OrderState to, String orderId);
void executePlugins(String orderId, OrderState currentState);
}
3. 实现状态机配置
@Configuration
@EnableStateMachine
public class OrderStateMachineConfig extends EnumStateMachineConfigurerAdapter<OrderState, OrderEvent> {
@Autowired
private List<OrderOperationPlugin> plugins;
@Override
public void configure(StateMachineStateConfigurer<OrderState, OrderEvent> states) throws Exception {
states
.withStates()
.initial(OrderState.NEW)
.state(OrderState.PAYMENT_PENDING)
.junction(OrderState.PAID)
.end(OrderState.DELIVERED)
.end(OrderState.CANCELLED)
.fork(OrderState.SHIPPED);
}
@Override
public void configure(StateMachineTransitionConfigurer<OrderState, OrderEvent> transitions) throws Exception {
transitions
.withExternal()
.source(OrderState.NEW).target(OrderState.PAYMENT_PENDING)
.event(OrderEvent.CREATE_ORDER)
.and().withExternal()
.source(OrderState.PAYMENT_PENDING).target(OrderState.PAID)
.event(OrderEvent.INITIATE_PAYMENT)
.and().withExternal()
.source(OrderState.PAID).target(OrderState.SHIPPED)
.event(OrderEvent.SHIP_ORDER)
.and().withExternal()
.source(OrderState.SHIPPED).target(OrderState.DELIVERED)
.event(OrderEvent.DELIVERY_CONFIRMED)
.and().withExternal()
.source(OrderState.NEW).target(OrderState.CANCELLED)
.event(OrderEvent.CANCEL_ORDER)
.and().withExternal()
.source(OrderState.PAYMENT_PENDING).target(OrderState.CANCELLED)
.event(OrderEvent.CANCEL_ORDER);
}
@Bean
public PluginManager pluginManager() {
return new DefaultPluginManager(plugins);
}
}
4. 插件实现
4.1 默认插件管理器
@Component
public class DefaultPluginManager implements PluginManager {
private final List<StateChangeListener> stateChangeListeners = new ArrayList<>();
private final List<OrderOperationPlugin> operationPlugins;
public DefaultPluginManager(List<OrderOperationPlugin> plugins) {
this.operationPlugins = plugins;
}
@Override
public void registerStateChangeListener(StateChangeListener listener) {
stateChangeListeners.add(listener);
}
@Override
public void notifyStateChange(OrderState from, OrderState to, String orderId) {
stateChangeListeners.forEach(listener -> listener.onStateChange(from, to, orderId));
}
@Override
public void executePlugins(String orderId, OrderState currentState) {
operationPlugins.forEach(plugin -> plugin.execute(orderId, currentState));
}
}
4.2 示例插件实现
// 日志记录插件
@Component
public class LoggingPlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
System.out.println("订单 " + orderId + " 当前状态: " + currentState + " - 正在记录日志");
}
}
// 邮件通知插件
@Component
public class EmailNotificationPlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
System.out.println("订单 " + orderId + " 当前状态: " + currentState + " - 发送邮件通知");
}
}
// 库存管理插件
@Component
public class InventoryUpdatePlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
if (currentState == OrderState.PAID) {
System.out.println("订单 " + orderId + " 已支付,正在更新库存");
}
}
}
5. 状态监听器实现
@Component
public class AuditStateChangeListener implements StateChangeListener {
@Override
public void onStateChange(OrderState from, OrderState to, String orderId) {
System.out.println("订单状态变更: " + orderId + " 从 " + from + " 到 " + to + " - 审计记录已创建");
}
}
6. 服务层实现
@Service
public class OrderService {
@Autowired
private StateMachine<OrderState, OrderEvent> stateMachine;
@Autowired
private PluginManager pluginManager;
public OrderService() {
// 注册监听器
pluginManager.registerStateChangeListener(new AuditStateChangeListener());
}
public void handleOrderEvent(String orderId, OrderEvent event) {
try {
stateMachine.start();
OrderState currentState = stateMachine.getState().getId();
// 发送事件
stateMachine.sendEvent(event);
OrderState newState = stateMachine.getState().getId();
// 触发状态变更监听器
if (currentState != newState) {
pluginManager.notifyStateChange(currentState, newState, orderId);
}
// 执行操作插件
pluginManager.executePlugins(orderId, newState);
} catch (Exception e) {
System.err.println("处理订单事件失败: " + e.getMessage());
} finally {
stateMachine.stop();
}
}
}
7. 控制器示例
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping("/{orderId}/events")
public ResponseEntity<String> sendEvent(@PathVariable String orderId, @RequestParam String event) {
try {
OrderEvent orderEvent = OrderEvent.valueOf(event.toUpperCase());
orderService.handleOrderEvent(orderId, orderEvent);
return ResponseEntity.ok("事件已处理: " + event);
} catch (IllegalArgumentException e) {
return ResponseEntity.badRequest().body("无效的事件类型: " + event);
}
}
@GetMapping("/{orderId}/status")
public ResponseEntity<String> checkStatus(@PathVariable String orderId) {
// 这里应该从存储中获取当前状态,为简化示例返回固定值
return ResponseEntity.ok("订单 " + orderId + " 当前状态: 示例状态");
}
}
8. 可扩展性说明
如何添加新插件:
@Component
public class NewFeaturePlugin implements OrderOperationPlugin {
@Override
public void execute(String orderId, OrderState currentState) {
// 新功能逻辑
}
}
如何添加新状态监听器:
@Component
public class NewStateChangeListener implements StateChangeListener {
@Override
public void onStateChange(OrderState from, OrderState to, String orderId) {
// 新监听器逻辑
}
}
使用示例:
# 创建订单
POST /orders/123/events?event=CREATE_ORDER
# 发起支付
POST /orders/123/events?event=INITIATE_PAYMENT
# 发货
POST /orders/123/events?event=SHIP_ORDER
# 确认送达
POST /orders/123/events?event=DELIVERY_CONFIRMED
# 取消订单
POST /orders/123/events?event=CANCEL_ORDER
这个实现具有以下特点:
- 灵活的状态机配置:使用 Spring StateMachine 配置订单状态流转
- 可扩展的插件系统:通过接口设计支持轻松添加新插件
- 事件驱动架构:利用状态变更事件触发相关业务逻辑
- 良好的分离关注点:核心状态机逻辑与业务插件解耦
- 易于维护和测试:各组件之间通过接口通信,便于单元测试和替换实现
您可以根据具体业务需求扩展更多状态、事件和插件功能。
来源:juejin.cn/post/7512237186647916571
PYTHON多智能体系统中的协同智能
使用 LangChain 等 Python 工具,可以更轻松地实现多智能体系统,从而创建超越简单自动化的智能系统。
译自Collaborative Intelligence in Multiagent Systems With Python,作者 Oladimeji Sowole。
近年来,大型语言模型 (LLM)通过生成类似人类的文本、解决复杂问题和自主执行任务,重新定义了人工智能的能力。
然而,随着任务变得更加复杂和跨学科,单个 AI 模型可能并不总是足够。这就是多智能体系统(MAS) 在 LLM 中的概念发挥作用的地方。MAS 允许多个 AI 智能体协作,每个智能体专门负责问题的不同方面,共同努力实现共同目标。
本教程将使用Python探索 LLM 中多智能体系统的最新趋势。我们将介绍什么是多智能体系统、它们为什么重要以及如何使用 LangChain 等工具使用 Python 分步实现它们。
什么是多智能体系统?
多智能体系统 (MAS) 是一个环境,其中多个自主智能体相互交互、合作甚至竞争以解决问题。每个智能体都有自己的能力、优势和关注领域,使系统能够更有效地处理复杂的任务。这些系统在需要协作、并行任务执行甚至协商的场景中表现出色。
在 LLM 中,多智能体系统可以:
- 协作完成需要多个专业领域的任务(例如,一个智能体专注于数学,而另一个智能体处理自然语言理解)。
- 互相协商以解决目标冲突。
- 并行解决复杂的、多步骤的问题,提高速度和准确性。
多智能体系统的用例
- 财务规划: 一个智能体可以专注于分析股票趋势,而另一个智能体可以预测市场的未来行为。
- 医疗保健: 一个智能体专注于诊断分析,而另一个智能体协助患者病史回顾,共同为全面的医疗保健建议提供帮助。
- 供应链优化: 智能体可以专门从事物流、采购或需求预测,从而改善整个供应链的决策。
为什么要使用多智能体系统?
- 专业化: 不同的智能体专门负责不同的任务,使解决问题更加高效。
- 并行性: 智能体可以同时工作,显着减少完成多步骤操作所需的时间。
- 协作: 多个智能体共同努力,利用其独特的优势来实现最佳结果。
- 适应性: 智能体可以实时协商或调整策略,以适应不断变化的任务。
使用 Python 设置多智能体系统
让我们从理论转向实践。在本节中,我们将演示如何使用 Python 和 LangChain 库构建多智能体系统,该库允许不同 LLM 支持的智能体之间无缝交互。
安装依赖项
首先,我们需要安装 LangChain 并设置一个 LLM 服务,例如 OpenAI。
pip install langchain openai
您还需要一个 OpenAI API 密钥,您可以通过注册 OpenAI 的 API 服务来获取。
初始化智能体和工具
首先,我们将定义我们的 LLM(GPT 模型)以及我们的智能体将使用的一组工具。这些工具可以是任何东西,从计算器到网络搜索功能。让我们初始化协作解决涉及信息检索和数学计算的任务的智能体。
from langchain.agents import initialize_agent, load_tools
from langchain.llms import OpenAI
# Initialize OpenAI model
llm = OpenAI(api_key="your_openai_api_key", model="gpt-4")
# Load tools (agents) such as search and calculator
tools = load_tools(["serpapi", "calculator"], llm)
# Initialize a multi-agent system
multi_agent = initialize_agent(
tools,
llm,
agent_type="multi-agent",
verbose=True
)
# Example task: Find the exchange rate of USD to EUR and calculate for 1500 units
task = "What is the current exchange rate of USD to EUR? Multiply it by 1500."
# Run the multi-agent system to complete the task
result = multi_agent.run(task)
print(result)
工作原理
- 智能体协作: 在此示例中,一个智能体使用搜索工具(例如 SERP API)获取实时汇率,而另一个智能体使用计算器工具将汇率乘以 1,500。
- 任务分解: LLM 将任务分解为子任务(获取汇率和执行计算),并将这些子任务分配给相应的智能体。
构建复杂的智能体系统
现在我们已经看到了一个基本示例,让我们构建一个更复杂的系统,该系统涉及多个智能体来解决问题的不同部分。考虑一个场景,我们正在构建一个旅行助手,它可以处理与预订航班、查看天气和执行预算计算相关的多个查询。
分步代码:旅行助手多智能体系统
# Define task-specific tools
from langchain.tools import Tool
# Weather checking tool
def get_weather(city):
return f"The weather in {city} is sunny with a temperature of 25°C."
# Flight booking tool
def book_flight(destination, date):
return f"Flight to {destination} on {date} has been booked."
# Budget calculation tool
def calculate_budget(amount, expenses):
remaining = amount - sum(expenses)
return f"Your remaining budget is {remaining}."
# Define our agents
weather_tool = Tool("get_weather", get_weather)
flight_tool = Tool("book_flight", book_flight)
budget_tool = Tool("calculate_budget", calculate_budget)
# Combine agents int0 a multi-agent system
tools = [weather_tool, flight_tool, budget_tool]
multi_agent = initialize_agent(tools, llm, agent_type="multi-agent", verbose=True)
# Example task
task = """
I want to book a flight to Paris for December 20th, check the weather in Paris,
and calculate my remaining budget if I have $2000 and my expenses are $500 and $300.
"""
# Execute the multi-agent system
result = multi_agent.run(task)
print(result)
发生了什么?
- 航班智能体:
book_flight智能体处理任务的航班预订部分。 - 天气智能体:
get_weather智能体检索巴黎的天气数据。 - 预算智能体:
calculate_budget智能体根据用户的输入计算用户的剩余预算。
在这种情况下,每个代理都负责解决更大问题中的特定部分,并协同工作以提供全面的结果。整个过程由 LLM 驱动,LLM 协调代理的工作。
多代理系统的先进用例
医疗保健协作
在医疗保健领域,不同的代理可以专注于患者治疗过程的不同部分。例如:
- 一个代理可以分析医学影像。
- 另一个代理审查患者的病史。
- 第三个代理提供诊断建议。
通过协同工作,这些代理可以生成一份综合报告,帮助做出更准确、更快速的医疗决策。
供应链优化
多代理系统可用于管理供应链的不同方面:
- 物流代理跟踪运输时间。
- 采购代理监控库存水平。
- 预测代理预测未来需求。
它们共同可以优化供应链,减少延误,降低成本,提高整体效率。
结论
多代理系统 (MAS) 代表了人工智能驱动解决方案发展中的一个突破性趋势。通过允许多个代理协同工作,每个代理都有自己的专业领域,MAS 极大地提高了大规模问题解决任务的效率和有效性。借助 LangChain 等 Python 工具,实现多代理系统变得越来越容易,使开发人员能够创建超越简单自动化的智能系统。
您是否想探索与 AI 代理和 Python 合作的可能性?阅读 Andela 的博客,了解如何在 Python 中使用 LangGraph 开发主 AI 代理!
本文在云云众生(yylives.cc/)首发,欢迎大家访问。
来源:juejin.cn/post/7426999391653281801
RAG技术的PDF智能问答系统
关键要点
- 系统基于RAG(检索增强生成)技术,允许用户上传PDF并进行智能问答。
- 使用Ollama的deepseek-r1模型和FAISS向量数据库,支持普通对话和基于PDF的问答模式。
- 提供简洁的Web界面,支持文件拖拽上传和多轮对话。
- 研究表明,系统适合处理PDF内容查询,但性能可能因PDF复杂性而异。
- 系统基于RAG(检索增强生成)技术,允许用户上传PDF并进行智能问答。
- 使用Ollama的deepseek-r1模型和FAISS向量数据库,支持普通对话和基于PDF的问答模式。
- 提供简洁的Web界面,支持文件拖拽上传和多轮对话。
- 研究表明,系统适合处理PDF内容查询,但性能可能因PDF复杂性而异。
系统概述
这个PDF智能问答系统是一个基于RAG技术的工具,旨在帮助用户通过上传PDF文件进行智能交互。它结合了Ollama的deepseek-r1模型和FAISS向量数据库,确保回答基于文档知识,适合学生、专业人士和研究人员快速获取PDF信息。
这个PDF智能问答系统是一个基于RAG技术的工具,旨在帮助用户通过上传PDF文件进行智能交互。它结合了Ollama的deepseek-r1模型和FAISS向量数据库,确保回答基于文档知识,适合学生、专业人士和研究人员快速获取PDF信息。
主要功能
- PDF处理:支持上传PDF文件,自动分块,并使用FAISS存储内容。
- 问答模式:提供普通对话模式(无PDF)和文档问答模式(有PDF),支持多轮对话。
- 用户界面:简洁的Web界面,支持拖拽上传,实时显示对话,并提供清空和重新生成功能。
- PDF处理:支持上传PDF文件,自动分块,并使用FAISS存储内容。
- 问答模式:提供普通对话模式(无PDF)和文档问答模式(有PDF),支持多轮对话。
- 用户界面:简洁的Web界面,支持拖拽上传,实时显示对话,并提供清空和重新生成功能。
技术细节
系统使用LangChain库处理PDF,Gradio构建界面,需安装ollama并确保deepseek-r1模型可用。环境配置包括创建虚拟环境和安装依赖,如langchain、faiss-cpu等。
系统使用LangChain库处理PDF,Gradio构建界面,需安装ollama并确保deepseek-r1模型可用。环境配置包括创建虚拟环境和安装依赖,如langchain、faiss-cpu等。
详细报告
引言
PDF智能问答系统!该系统利用检索增强生成(RAG)技术,根据您上传的PDF文件内容提供准确且上下文相关的回答。通过结合大型语言模型和高效的信息检索能力,我们旨在为您创造一个无缝、智能的文档交互体验。
无论您是学生、专业人士还是研究人员,这个工具都能帮助您快速查找和理解PDF中的信息,无需手动搜索。系统设计用户友好,界面简洁,支持文件拖拽上传和实时对话,适合各种用户群体。
PDF智能问答系统!该系统利用检索增强生成(RAG)技术,根据您上传的PDF文件内容提供准确且上下文相关的回答。通过结合大型语言模型和高效的信息检索能力,我们旨在为您创造一个无缝、智能的文档交互体验。
无论您是学生、专业人士还是研究人员,这个工具都能帮助您快速查找和理解PDF中的信息,无需手动搜索。系统设计用户友好,界面简洁,支持文件拖拽上传和实时对话,适合各种用户群体。
主要功能
PDF文件处理
- 上传和分块:您可以上传任何PDF文件,系统会自动将其分解为可管理的块。这有助于高效索引和检索信息。
- 向量数据库存储:我们使用FAISS(Facebook AI Similarity Search),一个高性能向量数据库,存储这些块的嵌入表示。这确保了当您提问时,能够快速、准确地检索相关信息。
- 上传和分块:您可以上传任何PDF文件,系统会自动将其分解为可管理的块。这有助于高效索引和检索信息。
- 向量数据库存储:我们使用FAISS(Facebook AI Similarity Search),一个高性能向量数据库,存储这些块的嵌入表示。这确保了当您提问时,能够快速、准确地检索相关信息。
智能问答功能
- 两种操作模式:
- 普通对话模式:当未上传PDF时,系统作为标准聊天机器人运行,使用基础模型回答一般问题。
- 文档问答模式:上传PDF后,系统切换到此模式,从PDF中检索相关信息以回答问题,确保答案具体且准确。
- 上下文维护:系统跟踪对话历史,支持多轮对话。这意味着您可以提出后续问题,系统会理解之前的上下文。
- 两种操作模式:
- 普通对话模式:当未上传PDF时,系统作为标准聊天机器人运行,使用基础模型回答一般问题。
- 文档问答模式:上传PDF后,系统切换到此模式,从PDF中检索相关信息以回答问题,确保答案具体且准确。
- 上下文维护:系统跟踪对话历史,支持多轮对话。这意味着您可以提出后续问题,系统会理解之前的上下文。
用户界面
- 简洁直观:我们的Web界面设计简单,您可以拖放PDF文件上传,聊天窗口支持实时交互。
- 交互控制:提供清空对话历史和重新生成回答的功能,让您掌控对话,确保流畅的用户体验。
- 简洁直观:我们的Web界面设计简单,您可以拖放PDF文件上传,聊天窗口支持实时交互。
- 交互控制:提供清空对话历史和重新生成回答的功能,让您掌控对话,确保流畅的用户体验。
工作原理
系统的核心是检索增强生成(RAG)方法。以下是简化后的工作流程:
系统的核心是检索增强生成(RAG)方法。以下是简化后的工作流程:
PDF上传和处理
- 当您上传PDF时,系统使用LangChain库中的
RecursiveCharacterTextSplitter将其加载并分割为较小的块。 - 每个块使用Ollama的
deepseek-r1模型嵌入(转换为计算机可理解的数值表示),并存储在FAISS向量数据库中。
- 当您上传PDF时,系统使用LangChain库中的
RecursiveCharacterTextSplitter将其加载并分割为较小的块。 - 每个块使用Ollama的
deepseek-r1模型嵌入(转换为计算机可理解的数值表示),并存储在FAISS向量数据库中。
问题回答
- 当您提问时,系统首先检查是否上传了PDF。
- 如果上传了PDF,它会使用FAISS向量存储的检索器找到与问题最相关的块。
- 然后,这些相关块和您的提问一起传递给
deepseek-r1模型,生成基于两者结合的回答。 - 如果未上传PDF,模型会基于其预训练知识回答问题。
研究表明,这种方法在处理文档查询时效果显著,但PDF内容的复杂性(如图表或格式问题)可能影响性能。证据倾向于认为,对于结构化文本,系统表现最佳,但对于复杂文档,可能需要调整分块参数。
- 当您提问时,系统首先检查是否上传了PDF。
- 如果上传了PDF,它会使用FAISS向量存储的检索器找到与问题最相关的块。
- 然后,这些相关块和您的提问一起传递给
deepseek-r1模型,生成基于两者结合的回答。 - 如果未上传PDF,模型会基于其预训练知识回答问题。
研究表明,这种方法在处理文档查询时效果显著,但PDF内容的复杂性(如图表或格式问题)可能影响性能。证据倾向于认为,对于结构化文本,系统表现最佳,但对于复杂文档,可能需要调整分块参数。
开始使用
要开始使用我们的PDF智能问答系统,请按照以下步骤操作:
- 设置环境:
- 创建并激活虚拟环境,如下所示:
conda create --name rag python=3.12
conda activate rag
- 安装所有必要依赖:
pip install langchain faiss-cpu gradio PyMuPDF
pip install -U langchain-community
- 安装并运行ollama,确保
deepseek-r1模型可用。您可以通过ollama list列出可用模型,并使用ollama pull deepseek-r1拉取模型。
- 运行应用程序:
- 导航到包含源代码的目录。
- 运行创建并启动Gradio界面的脚本。
- 访问Web界面:
- 打开浏览器,访问启动Gradio应用时提供的URL(通常为http://127.0.0.1:8888)。
- 上传您的PDF:
- 将PDF文件拖放到指定区域。
- 提出问题:
- 在文本框中输入问题并发送。
- 根据需要与系统交互,使用提供的控件。
要开始使用我们的PDF智能问答系统,请按照以下步骤操作:
- 设置环境:
- 创建并激活虚拟环境,如下所示:
conda create --name rag python=3.12
conda activate rag
- 安装所有必要依赖:
pip install langchain faiss-cpu gradio PyMuPDF
pip install -U langchain-community
- 安装并运行ollama,确保
deepseek-r1模型可用。您可以通过ollama list列出可用模型,并使用ollama pull deepseek-r1拉取模型。
- 创建并激活虚拟环境,如下所示:
- 运行应用程序:
- 导航到包含源代码的目录。
- 运行创建并启动Gradio界面的脚本。
- 访问Web界面:
- 在文本框中输入问题并发送。
- 根据需要与系统交互,使用提供的控件。
通过这些步骤,您可以开始探索并受益于我们的智能问答系统。
技术细节
对于技术感兴趣的用户,以下是简要概述:
- 模型:我们使用Ollama的
deepseek-r1模型,这是一个能够理解和生成类人文本的大型语言模型。 - 嵌入:使用相同的模型为PDF块生成嵌入,确保语义空间的一致性。
- 向量存储:使用FAISS(Facebook AI Similarity Search)进行大规模相似性搜索,这对于快速检索相关信息至关重要。
- 用户界面:使用Gradio(Gradio)构建,这是一个用户友好的机器学习模型Web界面框架。
环境配置
要运行此系统,您需要安装以下内容:
| 步骤 | 命令/说明 |
|---|---|
| 1. 创建虚拟环境 | conda create --name rag python=3.12 然后 conda activate rag |
| 2. 安装依赖 | pip install langchain faiss-cpu gradio PyMuPDF 和 pip install -U langchain-community |
| 3. 安装Ollama | 从官方仓库安装ollama,确保deepseek-r1模型可用,使用ollama pull deepseek-r1拉取 |
| 4. Gradio | 界面使用Gradio构建,已包含在依赖中 |
设置完成后,您可以运行create_chat_interface函数并启动Gradio应用。
源代码分析
源代码结构化处理PDF处理、问答和Gradio界面。以下是关键函数的概述:
| 函数名 | 功能描述 |
|---|---|
| processpdf | 处理PDF加载,分块,创建嵌入,并设置向量存储和检索器 |
| combine_docs | 将多个文档块合并为单个字符串,用于上下文 |
| ollama_llm | 使用ollama模型基于问题和提供的上下文生成回答 |
| rag_chain | 实现RAG管道,检索相关文档并生成回答 |
| chat_interface | 管理聊天交互,根据PDF上传决定使用RAG模式或标准模式 |
| create_chat_interface | 设置Gradio界面,包括文件上传、聊天显示和用户输入组件 |
通过理解这些组件,您可以欣赏系统如何整合不同技术,提供高效的问答体验。
结论
我们的PDF智能问答系统是一个强大的工具,结合了自然语言处理和信息检索的最新进展。设计目的是使与PDF文档的交互更高效、更具洞察力。我们希望您发现它实用且易用!
关键引用
完整代码
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import OllamaEmbeddings
import ollama
import re
def process_pdf(pdf_bytes):
"""
处理PDF文件并创建向量存储
Args:
pdf_bytes: PDF文件的路径
Returns:
tuple: 文本分割器、向量存储和检索器
"""
if pdf_bytes is :
return , ,
# 加载PDF文件
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
# 创建文本分割器,设置块大小为500,重叠为100
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
# 使用Ollama的deepseek-r1模型创建嵌入
embeddings = OllamaEmbeddings(model="deepseek-r1:8b")
# 将Chroma替换为FAISS向量存储
vectorstore = FAISS.from_documents(documents=chunks, embedding=embeddings)
# 从向量存储中创建检索器
retriever = vectorstore.as_retriever()
# # 返回文本分割器、向量存储和检索器
return text_splitter, vectorstore, retriever
def combine_docs(docs):
"""
将多个文档合并为单个字符串
Args:
docs: 文档列表
Returns:
str: 合并后的文本内容
"""
return "\n\n".join(doc.page_content for doc in docs)
def ollama_llm(question, context, chat_history):
"""
使用Ollama模型生成回答
Args:
question: 用户问题
context: 相关上下文
chat_history: 聊天历史记录
Returns:
str: 模型生成的回答
"""
# 构建更清晰的系统提示和用户提示
system_prompt = """你是一个专业的AI助手。请基于提供的上下文回答问题。
- 回答要简洁明了,避免重复
- 如果上下文中没有相关信息,请直接说明
- 保持回答的连贯性和逻辑性"""
# 只保留最近的3轮对话历史,避免上下文过长
recent_history = chat_history[-3:] if len(chat_history) > 3 else chat_history
chat_history_text = "\n".join([f"Human: {h}\nAssistant: {a}" for h, a in recent_history])
# 构建更结构化的提示模板
user_prompt = f"""基于以下信息回答问题:
问题:{question}
相关上下文:
{context}
请用中文回答上述问题。回答要简洁准确,避免重复。"""
# 调用Ollama模型生成回答
response = ollama.chat(
model="deepseek-r1:8b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
response_content = response["message"]["content"]
# 移除思考过程和可能的重复内容
final_answer = re.sub(r".*? ", "", response_content, flags=re.DOTALL).strip()
return final_answer
def rag_chain(question, text_splitter, vectorstore, retriever, chat_history):
"""
实现RAG(检索增强生成)链
Args:
question: 用户问题
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
chat_history: 聊天历史
Returns:
str: 生成的回答
"""
# 减少检索文档数量,提高相关性
retrieved_docs = retriever.invoke(question, {"k": 2})
# 优化文档合并方式,去除可能的重复内容
formatted_content = "\n".join(set(doc.page_content.strip() for doc in retrieved_docs))
return ollama_llm(question, formatted_content, chat_history)
def chat_interface(message, history, pdf_bytes=, text_splitter=, vectorstore=, retriever=):
"""
聊天接口函数,处理用户输入并返回回答
Args:
message: 用户消息
history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
str: 生成的回答
"""
if pdf_bytes is :
# 无PDF文件的普通对话模式
response = ollama_llm(message, "", history)
else:
# 有PDF文件的RAG对话模式
response = rag_chain(message, text_splitter, vectorstore, retriever, history)
return response
def create_chat_interface():
"""
创建Gradio聊天界面
Returns:
gr.Blocks: Gradio界面对象
"""
# 创建一个用户界面,并应用了一些自定义的CSS样式。
with gr.Blocks() as demo:
# 定义状态变量用于存储PDF处理相关的对象
pdf_state = gr.State()
# 存储文本分割器对象,用于将PDF文本分割成小块
text_splitter_state = gr.State()
# 存储向量数据库对象,用于存储文本向量
vectorstore_state = gr.State()
# 存储检索器对象,用于检索相关文本片段
retriever_state = gr.State()
with gr.Column(elem_classes="container"):
# 创建界面组件
with gr.Column(elem_classes="header"):
gr.Markdown("# PDF智能问答助手")
gr.Markdown("上传PDF文档,开始智能对话")
# 文件上传区域
with gr.Column(elem_classes="file-upload"):
file_output = gr.File(
label="上传PDF文件",
file_types=[".pdf"],
file_count="single"
)
# 处理PDF上传
def on_pdf_upload(file):
"""
处理PDF文件上传
Args:
file: 上传的文件对象
Returns:
tuple: 包含处理后的PDF相关对象
"""
# 如果文件存在
if file is not :
# 处理PDF文件,获取文本分割器、向量存储和检索器
text_splitter, vectorstore, retriever = process_pdf(file.name)
# 返回文件对象和处理后的组件
return file, text_splitter, vectorstore, retriever
# 如果文件不存在,返回值
return , , ,
# 注册文件上传事件处理
file_output.upload(
# 当文件上传时调用on_pdf_upload函数处理
on_pdf_upload,
# inputs参数指定输入组件为file_output
inputs=[file_output],
# outputs参数指定输出状态变量
outputs=[pdf_state, text_splitter_state, vectorstore_state, retriever_state]
)
# 聊天区域
with gr.Column(elem_classes="chat-container"):
chatbot = gr.Chatbot(
height=500,
bubble_full_width=False,
show_label=False,
avatar_images=,
elem_classes="chatbot"
)
with gr.Row():
msg = gr.Textbox(
label="输入问题",
placeholder="请输入你的问题...",
scale=12,
container=False
)
send_btn = gr.Button("发送", scale=1, variant="primary")
with gr.Row(elem_classes="button-row"):
clear = gr.Button("清空对话", variant="secondary")
regenerate = gr.Button("重新生成", variant="secondary")
# 发送消息处理函数
def respond(message, chat_history, pdf_bytes, text_splitter, vectorstore, retriever):
"""
处理用户消息并生成回答
Args:
message: 用户消息
chat_history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
tuple: (清空的消息框, 更新后的聊天历史)
"""
# 如果用户消息为空(去除首尾空格后),直接返回空消息和原聊天历史
if not message.strip():
return "", chat_history
# 调用chat_interface函数处理用户消息,生成回复
bot_message = chat_interface(
message,
chat_history,
pdf_bytes,
text_splitter,
vectorstore,
retriever
)
# 将用户消息和模型回复作为一轮对话添加到聊天历史中
chat_history.append((message, bot_message))
# 返回空消息(清空输入框)和更新后的聊天历史
return "", chat_history
# 事件处理
# 当用户按回车键提交消息时触发
msg.submit(
respond,
[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[msg, chatbot]
)
# 当用户点击发送按钮时触发
send_btn.click(
respond,
[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[msg, chatbot]
)
# 当用户点击清空按钮时触发
# lambda: (, ) 返回两个值来清空消息框和对话历史
# queue=False 表示不进入队列直接执行
clear.click(lambda: (, ), , [msg, chatbot], queue=False)
# 重新生成按钮功能
def regenerate_response(chat_history, pdf_bytes, text_splitter, vectorstore, retriever):
"""
重新生成最后一条回答
Args:
chat_history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
list: 更新后的聊天历史
"""
# 如果聊天历史为空,直接返回
if not chat_history:
return chat_history
# 获取最后一条用户消息
last_user_message = chat_history[-1][0]
# 移除最后一轮对话
chat_history = chat_history[:-1]
# 使用chat_interface重新生成回答
bot_message = chat_interface(
last_user_message, # 最后一条用户消息
chat_history, # 更新后的聊天历史
pdf_bytes, # PDF文件内容
text_splitter, # 文本分割器
vectorstore, # 向量存储
retriever # 检索器
)
# 将新生成的对话添加到历史中
chat_history.append((last_user_message, bot_message))
# 返回更新后的聊天历史
return chat_history
# 为重新生成按钮绑定点击事件
# 当点击时调用regenerate_response函数
# 输入参数为chatbot等状态
# 输出更新chatbot显示
regenerate.click(
regenerate_response,
[chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[chatbot]
)
return demo
# 启动接口
if __name__ == "__main__":
"""
主程序入口:启动Gradio界面
"""
demo = create_chat_interface()
demo.launch(
server_name="127.0.0.1",
server_port=8888,
show_api=False,
share=False
)
作者:AI_Echoes
来源:juejin.cn/post/7479036294875332644
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import OllamaEmbeddings
import ollama
import re
def process_pdf(pdf_bytes):
"""
处理PDF文件并创建向量存储
Args:
pdf_bytes: PDF文件的路径
Returns:
tuple: 文本分割器、向量存储和检索器
"""
if pdf_bytes is :
return , ,
# 加载PDF文件
loader = PyMuPDFLoader(pdf_bytes)
data = loader.load()
# 创建文本分割器,设置块大小为500,重叠为100
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = text_splitter.split_documents(data)
# 使用Ollama的deepseek-r1模型创建嵌入
embeddings = OllamaEmbeddings(model="deepseek-r1:8b")
# 将Chroma替换为FAISS向量存储
vectorstore = FAISS.from_documents(documents=chunks, embedding=embeddings)
# 从向量存储中创建检索器
retriever = vectorstore.as_retriever()
# # 返回文本分割器、向量存储和检索器
return text_splitter, vectorstore, retriever
def combine_docs(docs):
"""
将多个文档合并为单个字符串
Args:
docs: 文档列表
Returns:
str: 合并后的文本内容
"""
return "\n\n".join(doc.page_content for doc in docs)
def ollama_llm(question, context, chat_history):
"""
使用Ollama模型生成回答
Args:
question: 用户问题
context: 相关上下文
chat_history: 聊天历史记录
Returns:
str: 模型生成的回答
"""
# 构建更清晰的系统提示和用户提示
system_prompt = """你是一个专业的AI助手。请基于提供的上下文回答问题。
- 回答要简洁明了,避免重复
- 如果上下文中没有相关信息,请直接说明
- 保持回答的连贯性和逻辑性"""
# 只保留最近的3轮对话历史,避免上下文过长
recent_history = chat_history[-3:] if len(chat_history) > 3 else chat_history
chat_history_text = "\n".join([f"Human: {h}\nAssistant: {a}" for h, a in recent_history])
# 构建更结构化的提示模板
user_prompt = f"""基于以下信息回答问题:
问题:{question}
相关上下文:
{context}
请用中文回答上述问题。回答要简洁准确,避免重复。"""
# 调用Ollama模型生成回答
response = ollama.chat(
model="deepseek-r1:8b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
response_content = response["message"]["content"]
# 移除思考过程和可能的重复内容
final_answer = re.sub(r".*? ", "", response_content, flags=re.DOTALL).strip()
return final_answer
def rag_chain(question, text_splitter, vectorstore, retriever, chat_history):
"""
实现RAG(检索增强生成)链
Args:
question: 用户问题
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
chat_history: 聊天历史
Returns:
str: 生成的回答
"""
# 减少检索文档数量,提高相关性
retrieved_docs = retriever.invoke(question, {"k": 2})
# 优化文档合并方式,去除可能的重复内容
formatted_content = "\n".join(set(doc.page_content.strip() for doc in retrieved_docs))
return ollama_llm(question, formatted_content, chat_history)
def chat_interface(message, history, pdf_bytes=, text_splitter=, vectorstore=, retriever=):
"""
聊天接口函数,处理用户输入并返回回答
Args:
message: 用户消息
history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
str: 生成的回答
"""
if pdf_bytes is :
# 无PDF文件的普通对话模式
response = ollama_llm(message, "", history)
else:
# 有PDF文件的RAG对话模式
response = rag_chain(message, text_splitter, vectorstore, retriever, history)
return response
def create_chat_interface():
"""
创建Gradio聊天界面
Returns:
gr.Blocks: Gradio界面对象
"""
# 创建一个用户界面,并应用了一些自定义的CSS样式。
with gr.Blocks() as demo:
# 定义状态变量用于存储PDF处理相关的对象
pdf_state = gr.State()
# 存储文本分割器对象,用于将PDF文本分割成小块
text_splitter_state = gr.State()
# 存储向量数据库对象,用于存储文本向量
vectorstore_state = gr.State()
# 存储检索器对象,用于检索相关文本片段
retriever_state = gr.State()
with gr.Column(elem_classes="container"):
# 创建界面组件
with gr.Column(elem_classes="header"):
gr.Markdown("# PDF智能问答助手")
gr.Markdown("上传PDF文档,开始智能对话")
# 文件上传区域
with gr.Column(elem_classes="file-upload"):
file_output = gr.File(
label="上传PDF文件",
file_types=[".pdf"],
file_count="single"
)
# 处理PDF上传
def on_pdf_upload(file):
"""
处理PDF文件上传
Args:
file: 上传的文件对象
Returns:
tuple: 包含处理后的PDF相关对象
"""
# 如果文件存在
if file is not :
# 处理PDF文件,获取文本分割器、向量存储和检索器
text_splitter, vectorstore, retriever = process_pdf(file.name)
# 返回文件对象和处理后的组件
return file, text_splitter, vectorstore, retriever
# 如果文件不存在,返回值
return , , ,
# 注册文件上传事件处理
file_output.upload(
# 当文件上传时调用on_pdf_upload函数处理
on_pdf_upload,
# inputs参数指定输入组件为file_output
inputs=[file_output],
# outputs参数指定输出状态变量
outputs=[pdf_state, text_splitter_state, vectorstore_state, retriever_state]
)
# 聊天区域
with gr.Column(elem_classes="chat-container"):
chatbot = gr.Chatbot(
height=500,
bubble_full_width=False,
show_label=False,
avatar_images=,
elem_classes="chatbot"
)
with gr.Row():
msg = gr.Textbox(
label="输入问题",
placeholder="请输入你的问题...",
scale=12,
container=False
)
send_btn = gr.Button("发送", scale=1, variant="primary")
with gr.Row(elem_classes="button-row"):
clear = gr.Button("清空对话", variant="secondary")
regenerate = gr.Button("重新生成", variant="secondary")
# 发送消息处理函数
def respond(message, chat_history, pdf_bytes, text_splitter, vectorstore, retriever):
"""
处理用户消息并生成回答
Args:
message: 用户消息
chat_history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
tuple: (清空的消息框, 更新后的聊天历史)
"""
# 如果用户消息为空(去除首尾空格后),直接返回空消息和原聊天历史
if not message.strip():
return "", chat_history
# 调用chat_interface函数处理用户消息,生成回复
bot_message = chat_interface(
message,
chat_history,
pdf_bytes,
text_splitter,
vectorstore,
retriever
)
# 将用户消息和模型回复作为一轮对话添加到聊天历史中
chat_history.append((message, bot_message))
# 返回空消息(清空输入框)和更新后的聊天历史
return "", chat_history
# 事件处理
# 当用户按回车键提交消息时触发
msg.submit(
respond,
[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[msg, chatbot]
)
# 当用户点击发送按钮时触发
send_btn.click(
respond,
[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[msg, chatbot]
)
# 当用户点击清空按钮时触发
# lambda: (, ) 返回两个值来清空消息框和对话历史
# queue=False 表示不进入队列直接执行
clear.click(lambda: (, ), , [msg, chatbot], queue=False)
# 重新生成按钮功能
def regenerate_response(chat_history, pdf_bytes, text_splitter, vectorstore, retriever):
"""
重新生成最后一条回答
Args:
chat_history: 聊天历史
pdf_bytes: PDF文件
text_splitter: 文本分割器
vectorstore: 向量存储
retriever: 检索器
Returns:
list: 更新后的聊天历史
"""
# 如果聊天历史为空,直接返回
if not chat_history:
return chat_history
# 获取最后一条用户消息
last_user_message = chat_history[-1][0]
# 移除最后一轮对话
chat_history = chat_history[:-1]
# 使用chat_interface重新生成回答
bot_message = chat_interface(
last_user_message, # 最后一条用户消息
chat_history, # 更新后的聊天历史
pdf_bytes, # PDF文件内容
text_splitter, # 文本分割器
vectorstore, # 向量存储
retriever # 检索器
)
# 将新生成的对话添加到历史中
chat_history.append((last_user_message, bot_message))
# 返回更新后的聊天历史
return chat_history
# 为重新生成按钮绑定点击事件
# 当点击时调用regenerate_response函数
# 输入参数为chatbot等状态
# 输出更新chatbot显示
regenerate.click(
regenerate_response,
[chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],
[chatbot]
)
return demo
# 启动接口
if __name__ == "__main__":
"""
主程序入口:启动Gradio界面
"""
demo = create_chat_interface()
demo.launch(
server_name="127.0.0.1",
server_port=8888,
show_api=False,
share=False
)
来源:juejin.cn/post/7479036294875332644
从侵入式改造到声明式魔法注释的演进之路
传统方案的痛点:代码入侵
在上一篇文章中,我们通过高阶函数实现了请求缓存功能:
const cachedFetch = memoReq(function fetchData(url) {
return axios.get(url);
}, 3000);
这种方式虽然有效,但存在三个显著问题:
- 结构性破坏:必须将函数声明改为函数表达式
- 可读性下降:业务逻辑与缓存逻辑混杂
- 维护困难:缓存参数与业务代码强耦合
灵感来源:两大技术启示
1. Webpack的魔法注释
Webpack使用魔法注释控制代码分割:
import(/* webpackPrefetch: true */ './module.js');
这种声明式配置给了我们启示:能否用注释来控制缓存行为?
2. 装饰器设计模式
装饰器模式的核心思想是不改变原有对象的情况下动态扩展功能。在TypeScript中:
@memoCache(3000)
async function fetchData() {}
虽然当前项目可能不支持装饰器语法,但我们可以借鉴这种思想!
创新方案:魔法注释 + Vite插件
设计目标
- 零入侵:不改变函数声明方式
- 声明式:通过注释表达缓存意图
- 渐进式:支持逐个文件迁移
使用对比
传统方式:
export const getStockData = memoReq(
function getStockData(symbol) {
return axios.get(`/api/stocks/${symbol}`);
},
5000
);
魔法注释方案:
/* abc-memoCache(5000) */
export function getStockData(symbol) {
return axios.get(`/api/stocks/${symbol}`);
}
而有经验的程序猿会敏锐地发现三个深层问题:
- 结构性破坏:函数被迫改为函数表达式
- 关注点混杂:缓存逻辑侵入业务代码
- 维护陷阱:硬编码参数难以统一管理
技术实现深度解析
核心转换原理
- 编译时处理:通过Vite或者webpack loader插件在代码编译阶段转换
- 正则匹配:实际上是通过正则匹配实现轻量级转换
- 自动导入:智能添加必要的依赖引用
// 转换前
/* abc-memoCache(3000) */
export function fetchData() {}
// 转换后
import { memoCache } from '@/utils/decorators';
export const fetchData = memoCache(function fetchData() {}, 3000);
完整实现代码如下(以vite插件为例)
/**
* 转换代码中的装饰器注释为具体的函数调用,并处理超时配置。
*
* @param {string} code - 待处理的源代码。
* @param {string} [prefix="aa"] - 装饰器的前缀,用于标识特定的装饰器注释。
* @param {string} [utilsPath="@/utils"] - 导入工具函数的路径。
* @returns {string} - 转换后的代码。
*/
export function transformMemoReq(code, prefix = "aa", utilsPath = "@/utils") {
// 检查是否包含魔法注释模式
const magicCommentPattern = new RegExp(`\/\*\s*${prefix}-\w+\s*\([^)]*\)\s*\*\/`);
if (!magicCommentPattern.test(code)) {
return code; // 如果没有找到符合模式的注释,返回原代码
}
let transformedCode = code;
const importsNeeded = new Set(); // 收集需要的导入
// 处理带超时配置的装饰器注释(带超时数字)
const withTimeoutPattern = new RegExp(
`\/\*\s*${prefix}-(\w+)\s*\(\s*(\d*)\s*\)\s*\*\/\s*\nexport\s+function\s+(\w+)\s*\(([^)]*)\)\s*(?::\s*[^{]+)?\s*\{([\s\S]*?)\n\}`,
"g"
);
transformedCode = transformedCode.replace(
withTimeoutPattern,
(match, decoratorName, timeout, functionName, params, body) => {
const timeoutValue = timeout ? parseInt(timeout, 10) : 3000; // 默认超时为3000毫秒
const fileNameSimple = decoratorName.replace(/([A-Z].*$)/, ""); // 获取装饰器文件名
importsNeeded.add({ fileName: fileNameSimple, functionName: decoratorName }); // 添加需要导入的函数
// 提取类型注解(如果存在)
const typeAnnotationMatch = match.match(/)\s*(:\s*[^{]+)/);
const typeAnnotation = typeAnnotationMatch ? typeAnnotationMatch[1] : "";
// 返回转换后的函数定义代码
return `export const ${functionName} = ${decoratorName}(function ${functionName}(${params})${typeAnnotation} {${body}\n}, ${timeoutValue});`;
}
);
// 处理不带超时配置的装饰器注释(无超时数字)
const emptyTimeoutPattern = new RegExp(
`\/\*\s*${prefix}-(\w+)\s*\(\s*\)\s*\*\/\s*\nexport\s+function\s+(\w+)\s*\(([^)]*)\)\s*(?::\s*[^{]+)?\s*\{([\s\S]*?)\n\}`,
"g"
);
transformedCode = transformedCode.replace(emptyTimeoutPattern, (match, decoratorName, functionName, params, body) => {
const fileNameSimple = decoratorName.replace(/([A-Z].*$)/, "");
importsNeeded.add({ fileName: fileNameSimple, functionName: decoratorName });
// 提取类型注解(如果存在)
const typeAnnotationMatch = match.match(/)\s*(:\s*[^{]+)/);
const typeAnnotation = typeAnnotationMatch ? typeAnnotationMatch[1] : "";
// 返回转换后的函数定义代码,默认超时为3000毫秒
return `export const ${functionName} = ${decoratorName}(function ${functionName}(${params})${typeAnnotation} {${body}\n}, 3000);`;
});
// 如果需要导入额外的函数,处理导入语句的插入
if (importsNeeded.size > 0) {
const lines = transformedCode.split("\n");
let insertIndex = 0;
// 检查是否是Vue文件
const isVueFile = transformedCode.includes("<script");
if (isVueFile) {
// Vue文件导入位置逻辑...
for (let i = 0; i < lines.length; i += 1) {
const line = lines[i].trim();
if (line.includes("<script")) {
insertIndex = i + 1;
for (let j = i + 1; j < lines.length; j += 1) {
const scriptLine = lines[j].trim();
if (scriptLine.startsWith("import ") || scriptLine === "") {
insertIndex = j + 1;
} else if (!scriptLine.startsWith("import ")) {
break;
}
}
break;
}
}
} else {
// 普通JS/TS/JSX/TSX文件导入位置逻辑...
for (let i = 0; i < lines.length; i += 1) {
const line = lines[i].trim();
if (line.startsWith("import ") || line === "" || line.startsWith("interface ") || line.startsWith("type ")) {
insertIndex = i + 1;
} else {
break;
}
}
}
// 按文件分组导入
const importsByFile = {};
importsNeeded.forEach(({ fileName, functionName }) => {
if (!importsByFile[fileName]) {
importsByFile[fileName] = [];
}
importsByFile[fileName].push(functionName);
});
// 生成导入语句 - 使用自定义utilsPath
const importStatements = Object.entries(importsByFile).map(([fileName, functions]) => {
const uniqueFunctions = [...new Set(functions)];
return `import { ${uniqueFunctions.join(", ")} } from "${utilsPath}/${fileName}";`;
});
// 插入导入语句
lines.splice(insertIndex, 0, ...importStatements);
transformedCode = lines.join("\n");
}
return transformedCode; // 返回最终转换后的代码
}
/**
* Vite 插件,支持通过魔法注释转换函数装饰器。
*
* @param {Object} [options={}] - 配置选项。
* @param {string} [options.prefix="aa"] - 装饰器的前缀。
* @param {string} [options.utilsPath="@/utils"] - 工具函数的导入路径。
* @returns {Object} - Vite 插件对象。
*/
export function viteMemoDectoratorPlugin(options = {}) {
const { prefix = "aa", utilsPath = "@/utils" } = options;
return {
name: "vite-memo-decorator", // 插件名称
enforce: "pre", // 插件执行时机,设置为"pre"确保在编译前执行
transform(code, id) {
// 支持 .js, .ts, .jsx, .tsx, .vue 文件
if (!/.(js|ts|jsx|tsx|vue)$/.test(id)) {
return null; // 如果文件类型不支持,返回null
}
// 使用动态前缀检查是否需要处理该文件
const magicCommentPattern = new RegExp(`\/\*\s*${prefix}-\w+\s*\([^)]*\)\s*\*\/`);
if (!magicCommentPattern.test(code)) {
return null; // 如果没有找到符合模式的注释,返回null
}
console.log(`🔄 Processing ${prefix}-* magic comments in: ${id}`);
try {
const result = transformMemoReq(code, prefix, utilsPath); // 调用转换函数
if (result !== code) {
console.log(`✅ Transform successful for: ${id}`);
return {
code: result, // 返回转换后的代码
map: null, // 如果需要支持source map,可以在这里添加
};
}
} catch (error) {
console.error(`❌ Transform error in ${id}:`, error.message);
}
return null;
},
};
}
vite使用方式
viteMemoDectoratorPlugin({
prefix: "abc",
}),
结语:成为解决方案的设计者
从闭包到魔法注释的演进:
- 发现问题:识别现有方案的深层缺陷
- 联想类比:从其他领域寻找灵感
- 创新设计:创造性地组合技术要素
- 工程落地:考虑实际约束条件
在这个技术飞速发展的时代,我们牛马面临着知识爆炸,卷到没边的风气,我们只能建立更系统的技术认知体系。只会复制粘贴代码的开发者注定会陷入越忙越累的怪圈,比如最近很火的vue不想使用虚拟dom,其实我们只需要知道为什么,那是不是又多了点知识储备,因为技术迭代的速度永远快于机械记忆的速度。真正的技术能力体现在对知识本质的理解和创造性应用上——就像本文中的缓存方案,从最初的闭包实现到魔法注释优化,每一步实现都源于对多种技术思想的相融。阅读技术博客时,不能满足于解决眼前问题,更要揣摩作者的设计哲学;我们要善用AI等现代工具,但不是简单地向它索要代码,而是通过它拓展思维边界;愿我们都能超越代码搬运工的局限,成为真正的问题解决者和价值创造者。技术之路没有捷径,但有方法;没有终点,但有无尽的风景。加油吧,程序猿朋友们!!!
来源:juejin.cn/post/7536178965851029544
docker容器增加或者修改容器映射端口
前言
在只有使用docker安装的容器,没有使用docker-compose或者其他客户端工具,如果要增加或者修改容器端口,也是可以增加或者修改容器端口映射=
容器端口映射
重新安装
这种方法简单粗暴,就是重新把docker容器移除,然后重新用
docker run -p
重新做端口映射
修改配置文件
这里以rabbitmq为例子
1、 首先使用
docker ps
查看容器id

2、 然后使用
docker inspace 容器id
查看容器配置文件放止于哪里

这里放置于/var/lib/docker/containers/29384a9aa22f4fb53eda66d672b039b997143dc7633694e3455fc12f7dbcac5d
然后使用Linux进入到该目录
3、先把docker容器停止了
systemctl stop docker.socket

4、 修改hostconfig文件,找到里面的json数据中的PortBindings

这里将5672端口修改为5673

保存文件
5、 修改config.v2.json文件中的内容,找到里面中的ExposedPorts,把5673端口开放出来

保存文件
6、 启动docker服务
systemctl start docker.socket
这个时候就会发现5673端口映射了

总结
修改docker容器映射开放端口方法很多,现在也有很多优秀的客户端可以进行配置
来源:juejin.cn/post/7456094963018006528
让DeepSeek模仿曹操,果然好玩!
上回说到,在《新三国》中荀彧对曹操说的那句名言,但相比荀彧而言,我觉得曹操的名言会更多,我一想,若能用AI重现这位乱世奸雄曹操,会得到怎样的体验?
于是这篇文章我们将以Go语言为例,展示如何通过LangChain框架调用DeepSeek大模型,重现一代枭雄曹操的独特对话风格。
工具介绍
LangChain 是一个专为构建大语言模型应用设计的开发框架,其核心使命是打通语言模型与真实世界的连接通道。它通过模块化设计将数据处理、记忆管理、工具调用等能力封装为标准化组件,开发者可像搭积木般将这些模块组装成智能应用链。经过一段时间的发展,LangChain不仅支持Python生态快速实现原型验证,也提供Go语言实现满足高并发生产需求。
在Go项目中安装:
go get -u github.com/tmc/langchaingo
使用LangChain接入DeepSeek
现在我们写一个最简单的LangChain程序,主要分为以下几个步骤:
1)函数定义和初始化OpenAI客户端
2)创建聊天消息
3)生成内容并流式输出
4)输出推理过程和最终答案
下面是代码:
func Simple() {
// 函数定义和初始化OpenAI客户端
llm, err := openai.New(
openai.WithBaseURL("https://api.deepseek.com"),
openai.WithModel("deepseek-chat"),
openai.WithToken("xxx"), // 填写自己的API Key
)
if err != nil {
log.Fatal(err)
}
// 创建聊天消息
content := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, "你现在模仿曹操,以曹操的口吻和风格回答问题,要展现出曹操的霸气与谋略"),
llms.TextParts(llms.ChatMessageTypeHuman, "赤壁之战打输了怎么办?"),
}
// 生成内容并流式输出
fmt.Print("曹孟德:")
completion, err := llm.GenerateContent(
context.Background(),
content,
llms.WithMaxTokens(2000),
llms.WithTemperature(0.7),
llms.WithStreamingReasoningFunc(func(ctx context.Context, reasoningChunk []byte, chunk []byte) error {
contentColor := color.New(color.FgCyan).Add(color.Bold)
if len(chunk) > 0 {
_, err := contentColor.Printf("%s", string(chunk))
if err != nil {
return err
}
}
return nil
}),
)
if err != nil {
log.Fatal(err)
}
// 输出推理过程和最终答案
if len(completion.Choices) > 0 {
choice := completion.Choices[0]
fmt.Printf("\nFinal Answer:\n%s\n", choice.Content)
}
}
当然,如果我们想通过控制台和大模型多轮对话的话可以基于现有程序进行改造:
func Input() {
llm, err := openai.New(
openai.WithBaseURL("https://api.deepseek.com"),
openai.WithModel("deepseek-chat"),
openai.WithToken("xxx"),
)
if err != nil {
log.Fatal(err)
}
// 初始系统消息
systemMessage := llms.TextParts(llms.ChatMessageTypeSystem, "你现在模仿曹操,以曹操的口吻和风格回答问题,要展现出曹操的霸气与谋略。")
content := []llms.MessageContent{systemMessage}
scanner := bufio.NewScanner(os.Stdin)
for {
fmt.Print("闫同学:")
scanner.Scan()
question := scanner.Text()
if question == "exit" {
break
}
// 添加新的用户问题
userMessage := llms.TextParts(llms.ChatMessageTypeHuman, question)
content = append(content, userMessage)
fmt.Print("曹孟德:")
// Generate content with streaming to see both reasoning and final answer in real-time
completion, err := llm.GenerateContent(
context.Background(),
content,
llms.WithMaxTokens(2000),
llms.WithTemperature(0.7),
llms.WithStreamingReasoningFunc(func(ctx context.Context, reasoningChunk []byte, chunk []byte) error {
contentColor := color.New(color.FgCyan).Add(color.Bold)
if len(chunk) > 0 {
_, err := contentColor.Printf("%s", string(chunk))
if err != nil {
return err
}
}
return nil
}),
)
if err != nil {
log.Fatal(err)
}
fmt.Println()
// 将回复添加到历史消息中
if len(completion.Choices) > 0 {
choice := completion.Choices[0]
assistantMessage := llms.TextParts(llms.ChatMessageTypeHuman, choice.Content)
content = append(content, assistantMessage)
}
}
}
现在我们来启动调试一下:

重点步骤说明
其实纵观上面的整段代码,我认为在打造自己Agent中,最重要的一步莫过于在与AI对话前的消息组合部分,我们到底该怎样与AI对话才能得到自己想要的结果。
首先是content代码段的作用
content := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, "你现在模仿曹操,以曹操的口吻和风格回答问题,要展现出曹操的霸气与谋略"),
llms.TextParts(llms.ChatMessageTypeHuman, "赤壁之战打输了怎么办?"),
}
content 是一个 []llms.MessageContent 类型的切片,用于存储一系列的聊天消息内容。
llms.TextParts是 langchaingo 库中用于创建文本消息内容的函数。它接受两个参数:消息类型和消息内容。
llms.ChatMessageTypeSystem表示系统消息类型。系统消息通常用于给 AI 提供一些额外的指令或上下文信息。在这个例子中,系统消息告知 AI 要模仿曹操的口吻和风格进行回答。
llms.ChatMessageTypeHuman表示人类用户发送的消息类型。这里的消息内容是用户提出的问题“赤壁之战打输了怎么办?”。
ChatMessageType有哪些常量?我们来看下源码:
// ChatMessageTypeAI is a message sent by an AI.
ChatMessageTypeAI ChatMessageType = "ai"
// ChatMessageTypeHuman is a message sent by a human.
ChatMessageTypeHuman ChatMessageType = "human"
// ChatMessageTypeSystem is a message sent by the system.
ChatMessageTypeSystem ChatMessageType = "system"
// ChatMessageTypeGeneric is a message sent by a generic user.
ChatMessageTypeGeneric ChatMessageType = "generic"
// ChatMessageTypeFunction is a message sent by a function.
ChatMessageTypeFunction ChatMessageType = "function"
// ChatMessageTypeTool is a message sent by a tool.
ChatMessageTypeTool ChatMessageType = "tool"
解释下这些常量分别代表什么:
1)ChatMessageTypeAI:表示由 AI 生成并发送的消息。当 AI 对用户的问题进行回答时,生成的回复消息就属于这种类型。
2)ChatMessageTypeHuman:代表人类用户发送的消息。例如,用户在聊天界面输入的问题、评论等都属于人类消息。
3)ChatMessageTypeSystem:是系统发送的消息,用于设置 AI 的行为、提供指令或者上下文信息。系统消息可以帮助 AI 更好地理解任务和要求。
4)ChatMessageTypeGeneric:表示由通用用户发送的消息。这里的“通用用户”可以是除了明确的人类用户和 AI 之外的其他类型的用户。
5)ChatMessageTypeFunction:表示由函数调用产生的消息。在一些复杂的聊天系统中,AI 可能会调用外部函数来完成某些任务,函数执行的结果会以这种类型的消息返回。
6)ChatMessageTypeTool:表示由工具调用产生的消息。类似于函数调用,工具调用可以帮助 AI 完成更复杂的任务,工具执行的结果会以这种类型的消息呈现。
这些常量的定义有助于在代码中清晰地区分不同类型的聊天消息,方便对消息进行处理和管理。
接入DeepSeek-R1支持深度思考
本篇文章关于DeepSeek的相关文档主要参考deepseek官方文档,这篇文档里我们可以看到DeepSeek的V3模型和R1模型是两个不同的模型标识,即:
model='deepseek-chat' 即可调用 DeepSeek-V3。
model='deepseek-reasoner',即可调用 DeepSeek-R1。
因此在调用R1模型时我们需要改变初始化client的策略,然后在处理回答的时候也需要额外处理思考部分的回答,具体改动的地方如下:
1)初始化使用deepseek-reasoner:
llm, err := openai.New(
openai.WithBaseURL("https://api.deepseek.com"),
openai.WithModel("deepseek-reasoner"),
openai.WithToken("xxx"),
)
2)函数处理思考部分
completion, err := llm.GenerateContent(
ctx,
content,
llms.WithMaxTokens(2000),
llms.WithTemperature(0.7),
llms.WithStreamingReasoningFunc(func(ctx context.Context, reasoningChunk []byte, chunk []byte) error {
contentColor := color.New(color.FgCyan).Add(color.Bold)
reasoningColor := color.New(color.FgYellow).Add(color.Bold)
if !isPrint {
isPrint = true
fmt.Print("[思考中]")
}
// 思考部分
if len(reasoningChunk) > 0 {
_, err := reasoningColor.Printf("%s", string(reasoningChunk))
if err != nil {
return err
}
}
// 回答部分
if len(chunk) > 0 {
_, err := contentColor.Printf("%s", string(chunk))
if err != nil {
return err
}
}
return nil
}),
)
基于上面这些改动我们就能使用R1模型进行接入了。
小总结
这篇文章可以说展示了LangChain对接大模型的最基本功能,也是搭建我们自己Agent的第一步,如果真的想要搭建一个完整的AI Agent,那么还需要有很多地方进行补充和优化,比如:
- 上下文记忆:添加会话历史管理
- 风格校验:构建古汉语词库验证
- 多模态扩展:结合人物画像生成
本篇文章到这里就结束啦~
来源:juejin.cn/post/7490746012485009445
TailwindCSS 与 -webkit-line-clamp 深度解析:现代前端开发的样式革命
引言
在现代前端开发的浪潮中,CSS 的编写方式正在经历一场深刻的变革。传统的 CSS 开发模式虽然功能强大,但往往伴随着样式冲突、维护困难、代码冗余等问题。开发者需要花费大量时间在样式的命名、组织和维护上,而真正用于业务逻辑实现的时间却相对有限。
TailwindCSS 的出现,如同一股清流,为前端开发者带来了全新的开发体验。它不仅仅是一个 CSS 框架,更是一种全新的设计哲学——原子化 CSS 的完美实践。与此同时,在处理文本显示的细节问题上,诸如 -webkit-line-clamp 这样的 CSS 属性,虽然看似简单,却蕴含着深层的浏览器渲染原理。
本文将深入探讨 TailwindCSS 的核心理念、配置方法以及实际应用,同时详细解析 -webkit-line-clamp 的底层工作机制,帮助开发者更好地理解和运用这些现代前端技术。无论你是刚接触前端开发的新手,还是希望提升开发效率的资深开发者,这篇文章都将为你提供有价值的见解和实用的技巧。
TailwindCSS:原子化 CSS 的艺术
什么是原子化 CSS
原子化 CSS(Atomic CSS)是一种 CSS 架构方法,其核心思想是将样式拆分成最小的、不可再分的单元——就像化学中的原子一样。每个 CSS 类只负责一个特定的样式属性,比如 text-center 只负责文本居中,bg-blue-500 只负责设置蓝色背景。
传统的 CSS 开发模式往往采用组件化的方式,为每个 UI 组件编写独立的样式类。例如,一个按钮组件可能会有这样的 CSS:
.button {
padding: 12px 24px;
background-color: #3b82f6;
color: white;
border-radius: 6px;
font-weight: 600;
transition: background-color 0.2s;
}
.button:hover {
background-color: #2563eb;
}
这种方式在小型项目中运行良好,但随着项目规模的增长,会出现以下问题:
- 样式重复:不同组件可能需要相似的样式,导致代码重复
- 命名困难:为每个组件和状态想出合适的类名变得越来越困难
- 维护复杂:修改一个样式可能影响多个组件,需要谨慎处理
- CSS 文件膨胀:随着功能增加,CSS 文件变得越来越大
原子化 CSS 通过将样式拆分成最小单元来解决这些问题。上面的按钮样式在 TailwindCSS 中可以这样表示:
<button class="px-6 py-3 bg-blue-500 text-white rounded-md font-semibold hover:bg-blue-600 transition-colors">
Click me
</button>
每个类名都有明确的职责:
px-6:左右内边距 1.5rem(24px)py-3:上下内边距 0.75rem(12px)bg-blue-500:蓝色背景text-white:白色文字rounded-md:中等圆角font-semibold:半粗体字重hover:bg-blue-600:悬停时的深蓝色背景transition-colors:颜色过渡动画
TailwindCSS 的核心特性
TailwindCSS 作为原子化 CSS 的杰出代表,具有以下核心特性:
1. 几乎不用写 CSS
这是 TailwindCSS 最吸引人的特性之一。在传统开发中,开发者需要在 HTML 和 CSS 文件之间频繁切换,思考类名、编写样式、处理选择器优先级等问题。而使用 TailwindCSS,大部分样式都可以直接在 HTML 中通过预定义的类名来实现。
这种方式带来的好处是显而易见的:
- 开发速度提升:无需在文件间切换,样式即写即见
- 认知负担减轻:不需要思考复杂的类名和样式组织
- 一致性保证:使用统一的设计系统,避免样式不一致
2. AI 代码生成的首选框架
在人工智能辅助编程的时代,TailwindCSS 已经成为 AI 工具生成前端代码时的首选 CSS 框架。这主要有以下几个原因:
- 语义化程度高:TailwindCSS 的类名具有很强的语义性,AI 可以更容易理解和生成
- 标准化程度高:作为业界标准,AI 模型在训练时接触了大量 TailwindCSS 代码
- 组合性强:原子化的特性使得 AI 可以灵活组合不同的样式类
当你使用 ChatGPT、Claude 或其他 AI 工具生成前端代码时,它们几乎总是会使用 TailwindCSS 来处理样式,这已经成为了一种行业默认标准。
3. 丰富的内置类名系统
TailwindCSS 提供了一套完整而系统的类名体系,涵盖了前端开发中几乎所有的样式需求:
- 布局类:
flex、grid、block、inline等 - 间距类:
m-4、p-2、space-x-4等 - 颜色类:
text-red-500、bg-blue-200、border-gray-300等 - 字体类:
text-lg、font-bold、leading-tight等 - 响应式类:
md:text-xl、lg:flex、xl:grid-cols-4等 - 状态类:
hover:bg-gray-100、focus:ring-2、active:scale-95等
这些类名都遵循一致的命名规范,学会了基本规则后,即使遇到没用过的类名也能快速理解其含义。
配置与使用
安装和配置流程
要在项目中使用 TailwindCSS,需要经过以下几个步骤:
1. 安装依赖包
npm install -D tailwindcss @vitejs/plugin-tailwindcss
这里安装了两个包:
tailwindcss:TailwindCSS 的核心包@vitejs/plugin-tailwindcss:Vite 的 TailwindCSS 插件,用于在构建过程中处理 TailwindCSS
2. 生成配置文件
npx tailwindcss init
这个命令会在项目根目录生成一个 tailwind.config.js 文件:
/** @type {import('tailwindcss').Config} */
export default {
content: [
"./index.html",
"./src/**/*.{js,ts,jsx,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
content 数组指定了 TailwindCSS 应该扫描哪些文件来查找使用的类名,这对于生产环境的样式优化非常重要。
vite.config.js 配置详解
在 Vite 项目中,需要在 vite.config.js 中配置 TailwindCSS 插件:
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import tailwindcss from '@vitejs/plugin-tailwindcss'
export default defineConfig({
plugins: [
react(),
tailwindcss()
],
})
这个配置告诉 Vite 在构建过程中使用 TailwindCSS 插件来处理 CSS 文件。插件会自动:
- 扫描指定的文件查找使用的 TailwindCSS 类名
- 生成对应的 CSS 代码
- 在生产环境中移除未使用的样式(Tree Shaking)
tailwind.css 引入方式
在项目的主 CSS 文件(通常是 src/index.css 或 src/main.css)中引入 TailwindCSS 的基础样式:
@tailwind base;
@tailwind components;
@tailwind utilities;
这三个指令分别引入了:
base:重置样式和基础样式components:组件样式(可以自定义)utilities:工具类样式(TailwindCSS 的核心)
单位系统解析
TailwindCSS 使用了一套独特而直观的单位系统。其中最重要的概念是:1rem = 4 个单位。
这意味着:
w-4=width: 1rem=16px(在默认字体大小下)p-2=padding: 0.5rem=8pxm-8=margin: 2rem=32px
这套系统的设计非常巧妙:
- 易于记忆:4 的倍数关系简单直观
- 设计友好:符合设计师常用的 8px 网格系统
- 响应式友好:基于 rem 单位,能够很好地适应不同的屏幕尺寸
常用的间距对照表:
| 类名 | CSS 值 | 像素值(16px 基准) |
|---|---|---|
p-1 | 0.25rem | 4px |
p-2 | 0.5rem | 8px |
p-3 | 0.75rem | 12px |
p-4 | 1rem | 16px |
p-6 | 1.5rem | 24px |
p-8 | 2rem | 32px |
p-12 | 3rem | 48px |
p-16 | 4rem | 64px |
这套系统不仅适用于内外边距,也适用于宽度、高度、字体大小等其他尺寸相关的属性。
-webkit-line-clamp:文本截断的底层原理
浏览器内核基础知识
在深入了解 -webkit-line-clamp 之前,我们需要先理解浏览器内核的基本概念。浏览器内核(Browser Engine)是浏览器的核心组件,负责解析 HTML、CSS,并将网页内容渲染到屏幕上。不同的浏览器使用不同的内核,这也是为什么某些 CSS 属性需要添加特定前缀的原因。
主要浏览器内核及其前缀:
- WebKit 内核(-webkit-)
- 使用浏览器:Chrome、Safari、新版 Edge、Opera
- 特点:由苹果公司开发,后来被 Google 采用并发展出 Blink 内核
- 市场份额:目前占据主导地位,超过 70% 的市场份额
- Gecko 内核(-moz-)
- 使用浏览器:Firefox
- 特点:由 Mozilla 基金会开发,注重标准化和开放性
- 市场份额:约 3-5% 的市场份额
- Trident/EdgeHTML 内核(-ms-)
- 使用浏览器:旧版 Internet Explorer、旧版 Edge
- 特点:微软开发,现已基本被淘汰
由于 WebKit 内核的广泛使用,许多实验性的 CSS 属性首先在 WebKit 中实现,并使用 -webkit- 前缀。-webkit-line-clamp 就是其中的一个典型例子。
实验性属性的概念
CSS 中的实验性属性(Experimental Properties)是指那些尚未成为正式 W3C 标准,但已经在某些浏览器中实现的功能。这些属性通常具有以下特征:
- 前缀标识:使用浏览器厂商前缀,如
-webkit-、-moz-、-ms-等 - 功能性强:虽然不是标准,但能解决实际开发中的问题
- 兼容性限制:只在特定浏览器中工作
- 可能变化:语法和行为可能在未来版本中发生变化
-webkit-line-clamp 正是这样一个实验性属性。它最初是为了解决移动端 WebKit 浏览器中多行文本截断的需求而设计的,虽然不是 CSS 标准的一部分,但由于其实用性,被广泛采用并逐渐得到其他浏览器的支持。
-webkit-line-clamp 深度解析
属性的工作原理
-webkit-line-clamp 是一个用于限制文本显示行数的 CSS 属性。当文本内容超过指定行数时,多余的内容会被隐藏,并在最后一行的末尾显示省略号(...)。
这个属性的工作原理涉及到浏览器的文本渲染机制:
- 文本流计算:浏览器首先计算文本在容器中的自然流动方式
- 行数统计:根据容器宽度、字体大小、行高等因素计算文本占用的行数
- 截断处理:当行数超过
line-clamp指定的值时,截断多余内容 - 省略号添加:在最后一行的适当位置添加省略号
为什么不能独自生效
这是 -webkit-line-clamp 最容易让开发者困惑的地方。单独使用这个属性是无效的,必须配合其他 CSS 属性才能正常工作。这是因为 -webkit-line-clamp 的设计初衷是作为 Flexbox 布局的一部分来工作的。
具体来说,-webkit-line-clamp 只在以下条件同时满足时才会生效:
- 容器必须是 Flexbox:
display: -webkit-box - 必须设置排列方向:
-webkit-box-orient: vertical - 必须隐藏溢出内容:
overflow: hidden
这种设计反映了早期 WebKit 对 Flexbox 规范的实现方式。在当时,-webkit-box 是 Flexbox 的早期实现,而 -webkit-line-clamp 被设计为在这种布局模式下工作。
必需的配套属性详解
让我们详细分析每个必需的配套属性:
1. display: -webkit-box
display: -webkit-box;
这个属性将元素设置为 WebKit 的旧版 Flexbox 容器。在现代 CSS 中,我们通常使用 display: flex,但 -webkit-line-clamp 需要这个特定的值才能工作。
-webkit-box 是 2009 年 Flexbox 规范的实现,虽然已经过时,但为了兼容 -webkit-line-clamp,我们仍然需要使用它。这个值会:
- 将元素转换为块级容器
- 启用 WebKit 的 Flexbox 布局引擎
- 为
-webkit-line-clamp提供必要的布局上下文
2. -webkit-box-orient: vertical
-webkit-box-orient: vertical;
这个属性设置 Flexbox 容器的主轴方向为垂直。在文本截断的场景中,我们需要垂直方向的布局来正确计算行数。
可选值包括:
horizontal:水平排列(默认值)vertical:垂直排列inline-axis:沿着内联轴排列block-axis:沿着块轴排列
对于文本截断,我们必须使用 vertical,因为:
- 文本行是垂直堆叠的
-webkit-line-clamp需要在垂直方向上计算行数- 只有在垂直布局下,行数限制才有意义
3. overflow: hidden
overflow: hidden;
这个属性隐藏超出容器边界的内容。在文本截断的场景中,它的作用是:
- 隐藏超出指定行数的文本内容
- 确保省略号正确显示在可见区域内
- 防止内容溢出影响页面布局
如果不设置 overflow: hidden,超出行数限制的文本仍然会显示,-webkit-line-clamp 就失去了意义。
完整的文本截断方案
将所有必需的属性组合起来,一个完整的文本截断方案如下:
.text-clamp {
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 2;
overflow: hidden;
}
这个方案会将文本限制在 2 行内,超出的内容会被隐藏并显示省略号。
浏览器兼容性分析
虽然 -webkit-line-clamp 带有 WebKit 前缀,但实际上它的兼容性比想象中要好:
| 浏览器 | 支持版本 | 备注 |
|---|---|---|
| Chrome | 6+ | 完全支持 |
| Safari | 5+ | 完全支持 |
| Firefox | 68+ | 2019年开始支持 |
| Edge | 17+ | 基于 Chromium 的版本支持 |
| IE | 不支持 | 需要 JavaScript 降级方案 |
现代浏览器(除了 IE)都已经支持这个属性,使得它在实际项目中具有很高的可用性。
高级用法和注意事项
1. 响应式行数控制
可以结合媒体查询实现响应式的行数控制:
.responsive-clamp {
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
-webkit-line-clamp: 3;
}
@media (max-width: 768px) {
.responsive-clamp {
-webkit-line-clamp: 2;
}
}
2. 与其他 CSS 属性的交互
-webkit-line-clamp 与某些 CSS 属性可能产生冲突:
- white-space: nowrap:会阻止文本换行,使 line-clamp 失效
- height 固定值:可能与 line-clamp 的高度计算冲突
- line-height:会影响行数的计算,需要谨慎设置
3. 性能考虑
使用 -webkit-line-clamp 时需要注意性能影响:
- 浏览器需要重新计算文本布局
- 在大量元素上使用可能影响渲染性能
- 动态改变 line-clamp 值会触发重排(reflow)
实战应用与代码示例
line-clamp 在 TailwindCSS 中的应用
TailwindCSS 内置了对 -webkit-line-clamp 的支持,提供了 line-clamp-{n} 工具类。让我们看看如何在实际项目中使用这些类。
基础使用示例
// 产品卡片组件
function ProductCard({ product }) {
return (
<div className="card max-w-sm">
{/* 产品图片 */}
<div className="relative">
<img
src={product.image}
alt={product.name}
className="w-full h-64 object-cover"
/>
{product.isNew && (
<span className="absolute top-2 left-2 bg-red-500 text-white text-xs font-bold px-2 py-1 rounded">
New
</span>
)}
</div>
{/* 产品信息 */}
<div className="p-6">
{/* 产品标题 - 限制1行 */}
<h3 className="text-lg font-semibold text-gray-900 line-clamp-1 mb-2">
{product.name}
</h3>
{/* 产品描述 - 限制2行 */}
<p className="text-sm text-gray-600 line-clamp-2 mb-4">
{product.description}
</p>
{/* 产品特性 - 限制3行 */}
<div className="text-xs text-gray-500 line-clamp-3 mb-4">
{product.features.join(' • ')}
</div>
{/* 价格和操作 */}
<div className="flex items-center justify-between">
<span className="text-xl font-bold text-gray-900">
${product.price}
</span>
<button className="btn-primary">
Add to Cart
</button>
</div>
</div>
</div>
);
}
在这个示例中,我们使用了不同的 line-clamp 值来处理不同类型的文本内容:
line-clamp-1:产品标题保持在一行内line-clamp-2:产品描述限制在两行内line-clamp-3:产品特性列表限制在三行内
响应式文本截断
TailwindCSS 的响应式前缀可以与 line-clamp 结合使用,实现不同屏幕尺寸下的不同截断行为:
function ArticleCard({ article }) {
return (
<article className="card">
<div className="p-6">
{/* 响应式标题截断 */}
<h2 className="text-xl font-bold text-gray-900 line-clamp-2 md:line-clamp-1 mb-3">
{article.title}
</h2>
{/* 响应式内容截断 */}
<p className="text-gray-600 line-clamp-3 sm:line-clamp-4 lg:line-clamp-2 mb-4">
{article.content}
</p>
{/* 标签列表 - 移动端截断更多 */}
<div className="text-sm text-gray-500 line-clamp-2 md:line-clamp-1">
{article.tags.map(tag => `#${tag}`).join(' ')}
</div>
</div>
</article>
);
}
这个示例展示了如何根据屏幕尺寸调整文本截断行为:
- 移动端:标题显示2行,内容显示3行
- 平板端:标题显示1行,内容显示4行
- 桌面端:标题显示1行,内容显示2行
动态 line-clamp 控制
有时我们需要根据用户交互动态改变文本的截断行为:
import { useState } from 'react';
function ExpandableText({ text, maxLines = 3 }) {
const [isExpanded, setIsExpanded] = useState(false);
return (
<div className="space-y-2">
<p className={`text-gray-700 ${isExpanded ? '' : `line-clamp-${maxLines}`}`}>
{text}
</p>
<button
onClick={() => setIsExpanded(!isExpanded)}
className="text-primary-600 hover:text-primary-700 text-sm font-medium"
>
{isExpanded ? 'Show Less' : 'Show More'}
</button>
</div>
);
}
// 使用示例
function ReviewCard({ review }) {
return (
<div className="card p-6">
<div className="flex items-center mb-4">
<img
src={review.avatar}
alt={review.author}
className="w-10 h-10 rounded-full mr-3"
/>
<div>
<h4 className="font-semibold text-gray-900">{review.author}</h4>
<div className="flex items-center">
{/* 星级评分 */}
{[...Array(5)].map((_, i) => (
<svg
key={i}
className={`w-4 h-4 ${i < review.rating ? 'text-yellow-400' : 'text-gray-300'} fill-current`}
viewBox="0 0 24 24"
>
<path d="M12 2l3.09 6.26L22 9.27l-5 4.87 1.18 6.88L12 17.77l-6.18 3.25L7 14.14 2 9.27l6.91-1.01L12 2z" />
</svg>
))}
</div>
</div>
</div>
{/* 可展开的评论内容 */}
<ExpandableText text={review.content} maxLines={4} />
</div>
);
}
这个示例展示了如何创建一个可展开的文本组件,用户可以点击按钮来显示完整内容或收起到指定行数。
最佳实践与总结
开发建议
在实际项目中使用 TailwindCSS 和 -webkit-line-clamp 时,以下最佳实践将帮助你获得更好的开发体验和项目质量:
TailwindCSS 开发最佳实践
1. 合理组织类名
虽然 TailwindCSS 鼓励在 HTML 中直接使用工具类,但过长的类名列表会影响代码可读性。建议采用以下策略:
// ❌ 避免:过长的类名列表
<div className="flex items-center justify-between p-6 bg-white rounded-lg shadow-sm border border-gray-200 hover:shadow-md transition-shadow duration-200 ease-in-out">
// ✅ 推荐:使用组件抽象
const Card = ({ children, className = "" }) => (
<div className={`card hover:shadow-md transition-shadow ${className}`}>
{children}
</div>
);
// ✅ 推荐:使用 @apply 指令创建组件类
// 在 CSS 中定义
.card {
@apply flex items-center justify-between p-6 bg-white rounded-lg shadow-sm border border-gray-200;
}
2. 建立设计系统
充分利用 TailwindCSS 的配置系统建立项目专属的设计系统:
// tailwind.config.js
module.exports = {
theme: {
extend: {
// 定义项目色彩系统
colors: {
brand: {
primary: '#3B82F6',
secondary: '#10B981',
accent: '#F59E0B',
}
},
// 定义间距系统
spacing: {
'18': '4.5rem',
'88': '22rem',
},
// 定义字体系统
fontSize: {
'xs': ['0.75rem', { lineHeight: '1rem' }],
'sm': ['0.875rem', { lineHeight: '1.25rem' }],
'base': ['1rem', { lineHeight: '1.5rem' }],
'lg': ['1.125rem', { lineHeight: '1.75rem' }],
'xl': ['1.25rem', { lineHeight: '1.75rem' }],
}
}
}
}
3. 性能优化策略
TailwindCSS 的性能优化主要体现在生产环境的样式清理:
// tailwind.config.js
module.exports = {
content: [
// 精确指定扫描路径,避免不必要的文件扫描
"./src/**/*.{js,jsx,ts,tsx}",
"./public/index.html",
// 如果使用了第三方组件库,也要包含其路径
"./node_modules/@my-ui-lib/**/*.{js,jsx}",
],
// 启用 JIT 模式获得更好的性能
mode: 'jit',
}
4. 响应式设计策略
采用移动优先的设计理念,合理使用响应式前缀:
// ✅ 移动优先的响应式设计
<div className="
grid grid-cols-1 gap-4
sm:grid-cols-2 sm:gap-6
md:grid-cols-3 md:gap-8
lg:grid-cols-4
xl:gap-10
">
{/* 内容 */}
</div>
// ✅ 响应式文字大小
<h1 className="text-2xl sm:text-3xl md:text-4xl lg:text-5xl font-bold">
标题
</h1>
line-clamp 使用最佳实践
1. 选择合适的截断行数
不同类型的内容需要不同的截断策略:
| 内容类型 | 推荐行数 | 使用场景 |
|---|---|---|
| 标题 | 1-2行 | 卡片标题、列表项标题 |
| 摘要/描述 | 2-3行 | 产品描述、文章摘要 |
| 详细内容 | 3-5行 | 评论内容、详细说明 |
| 标签列表 | 1-2行 | 标签云、分类列表 |
2. 考虑内容的语义完整性
// ✅ 好的实践:为截断的内容提供完整查看选项
function ProductDescription({ description }) {
const [isExpanded, setIsExpanded] = useState(false);
return (
<div>
<p className={isExpanded ? '' : 'line-clamp-3'}>
{description}
</p>
{description.length > 150 && (
<button
onClick={() => setIsExpanded(!isExpanded)}
className="text-blue-600 text-sm mt-1"
>
{isExpanded ? '收起' : '查看更多'}
</button>
)}
</div>
);
}
3. 处理不同语言的截断
不同语言的文字密度不同,需要相应调整截断行数:
// 根据语言调整截断行数
function MultiLanguageText({ text, language }) {
const getLineClampClass = (lang) => {
switch (lang) {
case 'zh': return 'line-clamp-2'; // 中文字符密度高
case 'en': return 'line-clamp-3'; // 英文需要更多行数
case 'ja': return 'line-clamp-2'; // 日文类似中文
default: return 'line-clamp-3';
}
};
return (
<p className={`text-gray-700 ${getLineClampClass(language)}`}>
{text}
</p>
);
}
性能考虑
TailwindCSS 性能优化
1. 构建时优化
TailwindCSS 在构建时会自动移除未使用的样式,但我们可以进一步优化:
// postcss.config.js
module.exports = {
plugins: [
require('tailwindcss'),
require('autoprefixer'),
// 生产环境启用 CSS 压缩
process.env.NODE_ENV === 'production' && require('cssnano')({
preset: 'default',
}),
].filter(Boolean),
}
2. 运行时性能
避免在运行时动态生成类名,这会影响 TailwindCSS 的优化效果:
// ❌ 避免:动态类名生成
const dynamicClass = `text-${color}-500`; // 可能不会被包含在最终构建中
// ✅ 推荐:使用完整的类名
const colorClasses = {
red: 'text-red-500',
blue: 'text-blue-500',
green: 'text-green-500',
};
const selectedClass = colorClasses[color];
line-clamp 性能影响
1. 重排和重绘
-webkit-line-clamp 的使用会触发浏览器的重排(reflow),在大量元素上使用时需要注意性能:
// ✅ 使用 CSS containment 优化性能
.text-container {
contain: layout style;
-webkit-line-clamp: 2;
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
}
2. 虚拟化长列表
在处理大量带有文本截断的列表项时,考虑使用虚拟化技术:
import { FixedSizeList as List } from 'react-window';
function VirtualizedProductList({ products }) {
const Row = ({ index, style }) => (
<div style={style}>
<ProductCard product={products[index]} />
</div>
);
return (
<List
height={600}
itemCount={products.length}
itemSize={200}
>
{Row}
</List>
);
}
总结
TailwindCSS 和 -webkit-line-clamp 代表了现代前端开发中两个重要的技术趋势:工具化的 CSS 开发和细粒度的样式控制。
TailwindCSS 的价值在于:
- 开发效率的显著提升:通过原子化的类名系统,开发者可以快速构建界面而无需编写大量自定义 CSS
- 设计系统的一致性:内置的设计令牌确保了整个项目的视觉一致性
- 维护成本的降低:减少了 CSS 文件的复杂性和样式冲突的可能性
- 团队协作的改善:统一的类名约定降低了团队成员之间的沟通成本
-webkit-line-clamp 的意义在于:
- 用户体验的优化:通过优雅的文本截断保持界面的整洁和一致性
- 响应式设计的支持:在不同屏幕尺寸下提供合适的内容展示
- 性能的考虑:避免了复杂的 JavaScript 文本处理逻辑
- 标准化的推动:虽然是实验性属性,但推动了相关 CSS 标准的发展
在实际项目中,这两个技术的结合使用能够帮助开发者:
- 快速原型开发:在设计阶段快速验证界面效果
- 响应式布局:轻松适配各种设备和屏幕尺寸
- 内容管理:优雅处理动态内容的显示问题
- 性能优化:减少 CSS 体积和运行时计算
随着前端技术的不断发展,我们可以期待看到更多类似的工具和技术出现,它们将继续推动前端开发向着更高效、更标准化的方向发展。对于前端开发者而言,掌握这些现代技术不仅能提升当前的开发效率,更重要的是能够跟上技术发展的步伐,为未来的项目做好准备。
无论你是刚开始学习前端开发的新手,还是希望优化现有项目的资深开发者,TailwindCSS 和 -webkit-line-clamp 都值得你深入学习和实践。它们不仅是技术工具,更代表了现代前端开发的最佳实践和发展方向。
来源:juejin.cn/post/7536092776867840039
.NET 高级开发:反射与代码生成的实战秘籍
在当今快速发展的软件开发领域,灵活性和动态性是开发者不可或缺的能力。.NET 提供的反射机制和代码生成技术,为开发者提供了强大的工具,能够在运行时动态地探索和操作代码。这些技术不仅能够提升开发效率,还能实现一些传统静态代码无法完成的功能。本文将深入探讨 .NET 反射机制的核心功能、高级技巧以及代码生成的实际应用,帮助你在开发中更好地利用这些强大的工具。
.NET 反射:运行时的魔法
反射是 .NET 中一个极其强大的特性,它允许开发者在运行时动态地检查和操作类型信息。通过反射,你可以获取类型信息、动态创建对象、调用方法,甚至访问私有成员。这种能力在许多场景中都非常有用,比如实现插件系统、动态调用方法、序列化和反序列化等。
反射基础
反射的核心是 System.Type 类,它代表了一个类型的元数据。通过 Type 类,你可以获取类的名称、基类、实现的接口、方法、属性等信息。System.Reflection 命名空间提供了多个关键类,如 Assembly、MethodInfo、PropertyInfo 和 FieldInfo,帮助你更深入地探索类型信息。
获取 Type 对象有三种常见方式:
- 使用
typeof运算符:适用于编译时已知的类型。
Type type = typeof(string);
Console.WriteLine(type.Name); // 输出:String
- 调用
GetType()方法:适用于运行时已知的对象。
string name = "Hello";
Type type = name.GetType();
Console.WriteLine(type.Name); // 输出:String
- 通过类型名称动态加载:适用于运行时动态加载类型。
Type? type = Type.GetType("System.String");
if (type != null) {
Console.WriteLine(type.Name); // 输出:String
}
反射的常见操作
反射可以完成许多强大的操作,以下是一些常见的用法:
获取类型信息
通过 Type 对象,你可以获取类的各种信息,例如类名、基类、是否泛型等。
Type type = typeof(List<int>);
Console.WriteLine($"类名: {type.Name}"); // 输出:List`1
Console.WriteLine($"基类: {type.BaseType?.Name}"); // 输出:Object
Console.WriteLine($"是否泛型: {type.IsGenericType}"); // 输出:True
动态调用方法
假设你有一个类 Calculator,你可以通过反射动态调用它的方法。
public class Calculator
{
public int Add(int a, int b) => a + b;
}
Calculator calc = new Calculator();
Type type = calc.GetType();
MethodInfo? method = type.GetMethod("Add");
if (method != null) {
int result = (int)method.Invoke(calc, new object[] { 5, 3 })!;
Console.WriteLine(result); // 输出:8
}
访问私有成员
反射可以绕过访问修饰符的限制,访问私有字段或方法。
public class SecretHolder
{
private string _secret = "Hidden Data";
}
var holder = new SecretHolder();
Type type = holder.GetType();
FieldInfo? field = type.GetField("_secret", BindingFlags.NonPublic | BindingFlags.Instance);
if (field != null) {
string secret = (string)field.GetValue(holder)!;
Console.WriteLine(secret); // 输出:Hidden Data
}
动态创建对象
通过 Activator.CreateInstance 方法,你可以动态实例化对象。
Type type = typeof(StringBuilder);
object? instance = Activator.CreateInstance(type);
StringBuilder sb = (StringBuilder)instance!;
sb.Append("Hello");
Console.WriteLine(sb.ToString()); // 输出:Hello
高级反射技巧
反射的高级用法可以让你在开发中更加灵活,以下是一些进阶技巧:
调用泛型方法
如果方法带有泛型参数,你需要先使用 MakeGenericMethod 指定类型。
public class GenericHelper
{
public T Echo<T>(T value) => value;
}
var helper = new GenericHelper();
Type type = helper.GetType();
MethodInfo method = type.GetMethod("Echo")!;
MethodInfo genericMethod = method.MakeGenericMethod(typeof(string));
string result = (string)genericMethod.Invoke(helper, new object[] { "Hello" })!;
Console.WriteLine(result); // 输出:Hello
性能优化
反射调用比直接调用慢很多,因此在高性能场景下,可以缓存 MethodInfo 或使用 Delegate 来优化性能。
MethodInfo method = typeof(Calculator).GetMethod("Add")!;
var addDelegate = (Func<Calculator, int, int, int>)Delegate.CreateDelegate(
typeof(Func<Calculator, int, int, int>),
method
);
Calculator calc = new Calculator();
int result = addDelegate(calc, 5, 3);
Console.WriteLine($"result: {result}"); // 输出:8
动态加载插件
假设你有一个插件系统,所有插件都实现了 IPlugin 接口,你可以通过反射动态加载插件。
public interface IPlugin
{
void Execute();
}
public class HelloPlugin : IPlugin
{
public void Execute() => Console.WriteLine("Hello from Plugin!");
}
Assembly assembly = Assembly.LoadFrom("MyPlugins.dll");
var pluginTypes = assembly.GetTypes()
.Where(t => typeof(IPlugin).IsAssignableFrom(t) && !t.IsAbstract);
foreach (Type type in pluginTypes)
{
IPlugin plugin = (IPlugin)Activator.CreateInstance(type);
plugin.Execute();
}
代码生成:运行时的创造力
在某些高级场景中,你可能需要在运行时生成新的类型或方法。.NET 提供的 System.Reflection.Emit 命名空间允许你在运行时构建程序集、模块、类型和方法。
使用 Reflection.Emit 生成动态类
以下是一个示例,展示如何使用 Reflection.Emit 生成一个动态类 Person,并为其添加一个 SayHello 方法。
using System;
using System.Reflection;
using System.Reflection.Emit;
public class DynamicTypeDemo
{
public static void Main()
{
// 创建一个动态程序集
AssemblyName assemblyName = new AssemblyName("DynamicAssembly");
AssemblyBuilder assemblyBuilder =
AssemblyBuilder.DefineDynamicAssembly(assemblyName, AssemblyBuilderAccess.Run);
// 创建一个模块
ModuleBuilder moduleBuilder = assemblyBuilder.DefineDynamicModule("MainModule");
// 定义一个类:public class Person
TypeBuilder typeBuilder = moduleBuilder.DefineType(
"Person",
TypeAttributes.Public
);
// 定义一个方法:public void SayHello()
MethodBuilder methodBuilder = typeBuilder.DefineMethod(
"SayHello",
MethodAttributes.Public,
returnType: typeof(void),
parameterTypes: Type.EmptyTypes
);
// 生成 IL 代码,等价于 Console.WriteLine("Hello from dynamic type!");
ILGenerator il = methodBuilder.GetILGenerator();
il.Emit(OpCodes.Ldstr, "Hello from dynamic type!");
il.Emit(OpCodes.Call, typeof(Console).GetMethod("WriteLine", new[] { typeof(string) })!);
il.Emit(OpCodes.Ret);
// 创建类型
Type personType = typeBuilder.CreateType();
// 实例化并调用方法
object personInstance = Activator.CreateInstance(personType)!;
personType.GetMethod("SayHello")!.Invoke(personInstance, null);
}
}
运行上述代码后,你将看到输出:
Hello from dynamic type!
表达式树:更安全的代码生成
如果你希望在运行时生成代码行为,但又不想深入 IL 层,表达式树(System.Linq.Expressions)是一个更现代、更安全的替代方案。以下是一个示例,展示如何使用表达式树生成一个简单的 SayHello 方法。
using System;
using System.Linq.Expressions;
public class ExpressionTreeDemo
{
public static void Main()
{
// 表达式:() => Console.WriteLine("Hello from expression tree!")
var writeLineMethod = typeof(Console).GetMethod("WriteLine", new[] { typeof(string) });
// 构建常量表达式 "Hello from expression tree!"
var messageExpr = Expression.Constant("Hello from expression tree!");
// 调用 Console.WriteLine(string) 的表达式
var callExpr = Expression.Call(writeLineMethod!, messageExpr);
// 构建 lambda 表达式:() => Console.WriteLine(...)
var lambda = Expression.Lambda<Action>(callExpr);
// 编译成委托并执行
Action sayHello = lambda.Compile();
sayHello();
}
}
运行上述代码后,你将看到输出:
Hello from expression tree!
Source Generator:编译期代码生成
Source Generator 是 .NET 提供的一种编译期代码生成工具,可以在编译过程中注入额外的源代码。它不依赖反射,无运行时开销,适合构建高性能、可维护的自动化代码逻辑。
以下是一个简单的 Source Generator 示例,展示如何为类自动生成一个 SayHello 方法。
- 创建标记用的 Attribute
// HelloGenerator.Attributes.csproj
namespace HelloGenerator
{
[System.AttributeUsage(System.AttributeTargets.Class)]
public class GenerateHelloAttribute : System.Attribute { }
}
- 创建 Source Generator
// HelloGenerator.Source/HelloMethodGenerator.cs
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.Text;
using System.Text;
[Generator]
public class HelloMethodGenerator : ISourceGenerator
{
public void Initialize(GeneratorInitializationContext context)
{
// 注册一个语法接收器,用于筛选出标记了 [GenerateHello] 的类
context.RegisterForSyntaxNotifications(() => new SyntaxReceiver());
}
public void Execute(GeneratorExecutionContext context)
{
if (context.SyntaxReceiver is not SyntaxReceiver receiver)
return;
// 遍历所有被标记的类,生成 SayHello 方法
foreach (var classDecl in receiver.CandidateClasses)
{
var model = context.Compilation.GetSemanticModel(classDecl.SyntaxTree);
var symbol = model.GetDeclaredSymbol(classDecl) as INamedTypeSymbol;
if (symbol is null) continue;
string className = symbol.Name;
string namespaceName = symbol.ContainingNamespace.ToDisplayString();
string source = $@"
namespace {namespaceName}
{{
public partial class {className}
{{
public void SayHello()
{{
System.Console.WriteLine(""Hello from Source Generator!"");
}}
}}
}}";
context.AddSource($"{className}_Hello.g.cs", SourceText.From(source, Encoding.UTF8));
}
}
// 语法接收器
class SyntaxReceiver : ISyntaxReceiver
{
public List<ClassDeclarationSyntax> CandidateClasses { get; } = new();
public void OnVisitSyntaxNode(SyntaxNode syntaxNode)
{
if (syntaxNode is ClassDeclarationSyntax classDecl &&
classDecl.AttributeLists.Count > 0)
{
CandidateClasses.Add(classDecl);
}
}
}
}
- 在主项目中使用 Source Generator
using HelloGenerator;
namespace MyApp
{
[GenerateHello]
public partial class Greeter { }
class Program
{
static void Main()
{
var g = new Greeter();
g.SayHello(); // 自动生成的方法
}
}
}
运行上述代码后,你将看到输出:
Hello from Source Generator!
总结
反射和代码生成是 .NET 中非常强大的特性,它们为开发者提供了运行时动态探索和操作代码的能力。反射机制允许你在运行时检查类型信息、动态创建对象、调用方法,甚至访问私有成员。代码生成技术则让你能够在运行时生成新的类型和方法,或者在编译期生成代码,从而提升开发效率和代码的灵活性。
在实际开发中,反射虽然功能强大,但需要注意性能开销。在需要高性能的场景下,可以考虑使用 Delegate 缓存、表达式树,或 .NET 6 的 Source Generators 来替代反射。通过合理使用这些技术,你可以在开发中更加灵活地应对各种复杂场景,提升代码的可维护性和性能。
希望这篇文章能帮助你更好地理解和应用 .NET 反射和代码生成技术,让你在开发中更加得心应手!
来源:juejin.cn/post/7527559658276323379
React 核心 API 全景实战:从状态管理到性能优化,一网打尽
✨ 为什么写这篇文章?
很多前端朋友在用 React 的时候:
- 只会用
useState做局部状态,结果项目一大就乱套。 - 不了解
useReducer和Context,复杂页面全靠 props 一层层传。 - 性能卡顿后,只知道用
React.memo,但为什么卡? useMemo和useCallback的区别 ?- 明明只是个
Modal,结果被卡在组件层级里动弹不得,不知道可以用Portals。
👉「在什么场景下选用哪个 API」+「如何写出最合理的 React 代码」。
🟢 1. useState:局部状态管理
🌳 场景:表单输入管理
比起枯燥的计数器,这里用表单输入做示例。
import { useState } from 'react';
export default function LoginForm() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const handleSubmit = e => {
e.preventDefault();
console.log("登录中", username, password);
}
return (
<form onSubmit={handleSubmit}>
<input value={username} onChange={e => setUsername(e.target.value)} placeholder="用户名"/>
<input type="password" value={password} onChange={e => setPassword(e.target.value)} placeholder="密码"/>
<button type="submit">登录</button>
</form>
);
}
🚀 优势
- 简单、直接
- 适用于小型、独立的状态
🟡 2. useEffect:副作用处理
🌍 场景:组件挂载时拉取远程数据
import { useEffect, useState } from 'react';
export default function UserProfile({ userId }) {
const [user, setUser] = useState(null);
useEffect(() => {
fetch(`/api/user/${userId}`)
.then(res => res.json())
.then(data => {
setUser(data);
});
return () => {
// 组件销毁执行此回调
};
}, []);
return user ? <h1>{user.name}</h1> : <p>加载中...</p>;
}
🚀 优势
- 集中管理副作用(请求、订阅、定时器、事件监听)
🔵 3. useRef & useImperativeHandle:DOM、实例方法控制
场景 1:聚焦输入框
import { useRef, useEffect } from 'react';
export default function AutoFocusInput() {
const inputRef = useRef();
useEffect(() => {
inputRef.current.focus();
}, []);
return <input ref={inputRef} placeholder="自动聚焦" />;
}
场景 2:在父组件调用子组件的方法
import { forwardRef, useRef, useImperativeHandle } from 'react';
const FancyInput = forwardRef((props, ref) => {
const inputRef = useRef();
useImperativeHandle(ref, () => ({
focus: () => inputRef.current.focus()
}));
return <input ref={inputRef} />;
});
export default function App() {
const fancyRef = useRef();
return (
<>
<FancyInput ref={fancyRef} />
<button onClick={() => fancyRef.current.focus()}>父组件聚焦子组件</button>
</>
);
}
🧭 4. Context & useContext:解决多层级传值
场景:用户登录信息在多层组件使用
import React, { createContext, useContext } from 'react';
const UserContext = createContext();
/** 设置在 DevTools 中将显示为 User */
UserContext.displayName = 'User'
function Navbar() {
return (
<div>
<UserInfo />
</div>
)
}
function UserInfo() {
const user = useContext(UserContext);
return <span>欢迎,{user.name}</span>;
}
export default function App() {
return (
<UserContext.Provider value={{ name: 'Zheng' }}>
<Navbar />
</UserContext.Provider>
);
}
🚀 优势
- 解决「祖孙组件传值太麻烦」的问题
🔄 5. useReducer:复杂状态管理
import { useReducer } from 'react';
function reducer(state, action) {
switch(action.type){
case 'next':
return { ...state, step: state.step + 1 };
case 'prev':
return { ...state, step: state.step - 1 };
default:
return state;
}
}
export default function Wizard() {
const [state, dispatch] = useReducer(reducer, { step: 1 });
return (
<>
<h1>步骤 {state.step}</h1>
<button onClick={() => dispatch({type: 'prev'})}>上一步</button>
<button onClick={() => dispatch({type: 'next'})}>下一步</button>
</>
);
}
🆔 6. useId:避免 SSR / 并发下 ID 不一致
import { useId } from 'react';
export default function FormItem() {
const id = useId();
return (
<>
<label htmlFor={id}>姓名</label>
<input id={id} type="text" />
</>
);
}
🚀 7. Portals:在根元素渲染 Modal
import { useState } from 'react';
import ReactDOM from 'react-dom';
function Modal({ onClose }) {
return ReactDOM.createPortal(
<div style={{ position: "fixed", top: 100, left: 100, background: "white" }}>
<h1>这是 Modal</h1>
<button onClick={onClose}>关闭</button>
</div>,
document.getElementById('root')
);
}
export default function App() {
const [show, setShow] = useState(false);
return (
<>
<button onClick={() => setShow(true)}>打开 Modal</button>
{show && <Modal onClose={() => setShow(false)} />}
</>
);
}
在上面代码中,我们将要渲染的视图作为createPortal方法的第一个参数,而第二个参数用于指定要渲染到那个DOM元素中。

尽管 portal 可以被放置在 DOM 树中的任何地方,但在任何其他方面,其行为和普通的 React 子节点行为一致。由于 portal 仍存在于 React 树, 且与 DOM 树中的位置无关,那么无论其子节点是否是 portal,像 context 这样的功能特性都是不变的。
这包含事件冒泡。一个从 portal 内部触发的事件会一直冒泡至包含 React 树的祖先,即便这些元素并不是 DOM 树中的祖先。
🔍 8. 组件渲染性能优化
🐘 之前类组件时代:shouldComponentUpdate与PureComponent
import { Component } from 'react'
export default class App extends Component {
constructor() {
super();
this.state = {
counter: 1
}
}
render() {
console.log("App 渲染了");
return (
<div>
<h1>App 组件</h1>
<div>{this.state.counter}</div>
<button onClick={() => this.setState({
counter : 1
})}>+1</button>
</div>
)
}
}
在上面的代码中,按钮在点击的时候仍然是设置 counter 的值为1,虽然 counter 的值没有变,整个组件仍然是重新渲染了的,显然,这一次渲染是没有必要的。
当 props 或 state 发生变化时,shouldComponentUpdate 会在渲染执行之前被调用。返回值默认为 true。首次渲染或使用 forceUpdate 方法时不会调用该方法。
下面我们来使用 shouldComponentUpdate 优化上面的示例:
import React from 'react'
/**
* 对两个对象进行一个浅比较,看是否相等
* obj1
* obj2
* 返回布尔值 true 代表两个对象相等, false 代表不相等
*/
function objectEqual(obj1, obj2) {
for (let prop in obj1) {
if (!Object.is(obj1[prop], obj2[prop])) {
// 进入此 if,说明有属性值不相等
// 只要有一个不相等,那么就应该判断两个对象不等
return false
}
}
return true
}
class PureChildCom1 extends React.Component {
constructor(props) {
super(props)
this.state = {
counter: 1,
}
}
// 验证state未发生改变,是否会执行render
onClickHandle = () => {
this.setState({
counter: Math.floor(Math.random() * 3 + 1),
})
}
// shouldComponentUpdate 中返回 false 来跳过整个渲染过程。其包括该组件的 render 调用以及之后的操作。
// 返回true 只要执行了setState都会重新渲染
shouldComponentUpdate(nextProps, nextState) {
if (
objectEqual(this.props, nextProps) &&
objectEqual(this.state, nextState)
) {
return false
}
return true
}
render() {
console.log('render')
return (
<div>
<div>{this.state.counter}</div>
<button onClick={this.onClickHandle}>点击</button>
</div>
)
}
}
export default PureChildCom1
PureComponent内部做浅比较:如果 props/state 相同则跳过渲染。- 不适用于复杂对象(如数组、对象地址未变)。
🥇 React.memo:函数组件记忆化
上面主要是优化类组件的渲染性能,那么如果是函数组件该怎么办呢?
React中为我们提供了memo高阶组件,只要 props 不变,就不重新渲染。
const Child = React.memo(function Child({name}) {
console.log("Child 渲染");
return <div>{name}</div>;
});
🏷 useCallback:缓存函数引用,避免触发子组件更新
import React, { useState, useCallback } from 'react';
function Child({ onClick }) {
console.log("Child 渲染")
return <button onClick={onClick}>点我</button>;
}
const MemoChild = React.memo(Child);
export default function App() {
const [count, setCount] = useState(0);
const handleClick = useCallback(() => {
console.log("点击");
}, []);
return (
<>
<div>{count}</div>
<button onClick={() => setCount(count+1)}>+1</button>
<MemoChild onClick={handleClick} />
</>
);
}
在上面的代码中,我们对Child组件进行了memo缓存,当修改App组件中的count值的时候,不会引起Child组件更新;使用了useCallback对函数进行了缓存,当点击Child组件中的button时也不会引起父组件的更新。
🔢 useMemo:缓存计算
某些时候,组件中某些值需要根据状态进行一个二次计算(类似于 Vue 中的计算属性),由于函数组件一旦重新渲染,就会重新执行整个函数,这就导致之前的二次计算也会重新执行一次。
import React, { useState } from 'react';
function App() {
const [count, setCount] = useState(1);
const [val, setValue] = useState('');
console.log("App render");
// 使用useMemo缓存计算
const getNum = useMemo(() => {
console.log('调用了!!!!!');
return count + 100;
}, [count])
return (
<div>
<h4>总和:{getNum()}</h4>
<div>
<button onClick={() => setCount(count + 1)}>+1</button>
{/* 文本框的输入会导致整个组件重新渲染 */}
<input value={val} onChange={event => setValue(event.target.value)} />
</div>
</div>
);
}
export default App;
在上面的示例中,文本框的输入会导致整个 App 组件重新渲染,但是 count 的值是没有改变的,所以 getNum 这个函数也是没有必要重新执行的。我们使用了 useMemo 来缓存二次计算的值,并设置了依赖项 count,只有在 count 发生改变时,才会重新执行二次计算。
面试题:useMemo 和 useCallback 的区别及使用场景?
useMemo 和 useCallback 接收的参数都是一样,第一个参数为回调,第二个参数为要依赖的数据。
共同作用: 仅仅依赖数据发生变化,才会去更新缓存。
两者区别:
useMemo计算结果是return回来的值, 主要用于缓存计算结果的值。应用场景如:需要进行二次计算的状态useCallback计算结果是函数, 主要用于缓存函数,应用场景如: 需要缓存的函数,因为函数式组件每次任何一个state的变化,整个组件都会被重新刷新,一些函数是没有必要被重新刷新的,此时就应该缓存起来,提高性能,和减少资源浪费。
来源:juejin.cn/post/7525375329105674303
Vue 3 中的 Watch、WatchEffect 和 Computed:深入解析与案例分析
引言
在前端开发中,尤其是使用 Vue.js 进行开发时,我们经常需要监听数据的变化以执行相应的操作。Vue 3 提供了三种主要的方法来实现这一目标:watch、watchEffect 和 computed。虽然它们都能帮助我们监听数据变化,但各自的适用场景和工作原理有所不同。本文将详细探讨这三者的区别,并通过具体的案例进行说明。
一、Computed 属性
1.1 定义与用途
computed 是 Vue 中用于定义计算属性的方法。它允许你基于其他响应式数据创建一个新的响应式数据。这个新数据会根据其依赖的数据自动更新。
生活中的类比:
想象一下你在超市里购买商品,每个商品都有一个价格标签。当你想要知道购物车里所有商品的总价时,你可以手动计算每件商品的价格乘以其数量,然后加起来得到总价。但是如果你使用了一个智能购物车,它能够自动为你计算总价(只要你知道单价和数量),这就是 computed 的作用——它能帮你自动计算并实时更新结果。
1.2 使用示例
import { ref, computed } from 'vue';
const price = ref(10);
const quantity = ref(5);
const totalPrice = computed(() => {
return price.value * quantity.value;
});
console.log(totalPrice.value); // 输出: 50
// 修改其中一个变量
price.value = 15;
console.log(totalPrice.value); // 输出: 75 自动更新
二、Watch 监听器
2.1 定义与用途
watch 允许你监听特定的数据源(如响应式引用或 getter 函数的结果),并在数据发生变化时执行回调函数。它可以监听单个源或多个源。
生活中的类比:
假设你现在正在做菜,你需要监控锅里的水是否沸腾。一旦水开始沸腾,你就知道是时候下饺子了。这里,“水是否沸腾”就是你要监听的数据源,而“下饺子”的动作则是监听到变化后执行的操作。
2.2 使用示例
import { ref, watch } from 'vue';
let waterBoiling = ref(false);
watch(waterBoiling, (newValue, oldValue) => {
if (newValue === true) {
console.log('Water is boiling, time to add the dumplings!');
}
});
waterBoiling.value = true; // 触发监听器
2.3 监听多个来源
有时候我们需要同时监听多个数据源的变化:
watch([sourceA, sourceB], ([newSourceA, newSourceB], [oldSourceA, oldSourceB]) => {
// 处理逻辑
});
三、WatchEffect 响应式效果
3.1 定义与用途
watchEffect 立即运行传入的函数,并响应式地追踪其内部使用的任何 reactive 数据。当这些数据更新时,该函数将再次执行。
生活中的类比:
想象你在厨房里准备晚餐,你需要时刻关注炉子上的火候以及烤箱里的温度。每当任何一个参数发生变化,你都需要相应地调整你的烹饪策略。在这里,watchEffect 就像一个智能助手,它会自动检测这些条件的变化,并即时调整你的行为。
3.2 使用示例
import { ref, watchEffect } from 'vue';
const temperature = ref(180);
const ovenStatus = ref('off');
watchEffect(() => {
console.log(`Oven status is ${ovenStatus.value}, current temperature is ${temperature.value}`);
});
temperature.value = 200; // 自动触发重新执行
ovenStatus.value = 'on'; // 同样会触发重新执行
四、三者之间的对比
| 特性 | Computed | Watch | WatchEffect |
|---|---|---|---|
| 初始执行 | 只有当访问时才会执行 | 立即执行一次 | 立即执行一次 |
| 依赖追踪 | 自动追踪依赖 | 需要明确指定依赖 | 自动追踪依赖 |
| 更新时机 | 当依赖改变时自动更新 | 当指定的值改变时 | 当依赖改变时自动更新 |
| 返回值 | 可以返回值 | 不直接返回值 | 不直接返回值 |
五、面试题
问题 1:请简述 computed 和 watch 的主要区别?
答案:
computed更适合用于需要根据其他状态派生出的新状态,并且这种派生关系是确定性的。watch更适用于监听某个状态的变化,并在变化发生时执行异步操作或昂贵的计算任务。
问题 2:在什么情况下你会选择使用 watchEffect 而不是 watch?
答案:
当你希望立即执行一个副作用并且自动追踪所有被用到的状态作为依赖项时,watchEffect 是更好的选择。它简化了代码结构,因为你不需要显式声明哪些状态是你关心的。
问题 3:如何使用 watch 来监听多个状态的变化?
答案:
可以通过数组的形式传递给 watch,这样就可以同时监听多个状态的变化,并在任一状态发生变化时触发回调函数。
通过以上内容,我们对 watch、watchEffect 和 computed 在 Vue 3 中的应用有了较为全面的理解。理解这些工具的不同之处有助于我们在实际项目中做出更合适的选择。无论是构建简单的用户界面还是处理复杂的业务逻辑,正确运用这些功能都可以显著提高我们的开发效率。
来源:juejin.cn/post/7525375329105035327
手写一个 UML 绘图软件

为何想做一款软件
在日常的开发和学习过程中,我们常常致力于实现各种功能点,解决各种 Bug。然而,我们很少有机会去设计和制作属于自己的产品。有时,我们可能认为市面上已有众多类似产品,自己再做一款似乎没有必要;有时,我们又觉得要做的事情太多,不知从何下手。
最近,我意识到仅仅解决单点问题已没有那么吸引我。相反,如果我自己开发一款产品,它能够被其他人使用,这将是一件有意思的事情。
因此,我决定在新的一年里,根据自己熟悉的领域和过去一年的积累,尝试打造一款自己的 UML 桌面端软件。我想知道,自己是否真的能够创造出一款在日常工作中好用的工具。
目前,这个计划中的产品的许多功能点已经在开发计划中。我已经完成了最基础的技术架构,并实现了核心的绘图功能。接下来,让我们一探究竟,看看这款软件目前支持哪些功能点。
技术方案
Monorepo 项目结构
使用了 Monorepo(单一代码仓库)项目管理模式。
- 这样可以将通用类型和工具方法抽离在 types 包和 utils 包中。
- 像 graph 这样功能独立的模块也可以单独抽离成包发布。
- 通过集中管理依赖,可以更容易地确保所有项目使用相同版本的库,并且相同版本的依赖库可以只安装一次。
项目介绍:
- 其中 draw-client 是 electron 客户端项目,它依赖自定义的 graph 库。
- services 是服务端代码,和 draw-client 同时依赖了,types 和 utils 公共模块。
|-- apps/ # 包含所有应用程序的代码,每个应用程序可以有自己的目录,如draw-client。
|-- draw-client/ # 客户端应用程序的主目录
|-- src
|-- package.json
|-- tsconfig.json
|-- packages/ # 用于存放项目中的多个包或模块,每个包可以独立开发和测试,便于代码复用和维护。
|-- graph/ # 包含与图表绘制相关的逻辑和组件,可能是一个通用的图表库。
|-- src
|-- package.json
|-- tsconfig.json
|-- types/ # 存放TypeScript类型定义文件,为项目提供类型安全。
|-- src
|-- package.json
|-- tsconfig.json
|-- utils/ # 包含工具函数和辅助代码,这些是项目中通用的功能,可以在多个地方复用。
|-- src
|-- package.json
|-- tsconfig.json
|-- services/ # 服务端代码
|-- src
|-- package.json
|-- tsconfig.json
|-- .npmrc
|-- package.json # 项目的配置文件,包含项目的元数据、依赖项、脚本等,是npm和pnpm管理项目的核心。
|-- pnpm-lock.yaml # pnpm的锁定文件,确保所有开发者和构建环境中依赖的版本一致。
|-- pnpm-workspace.yaml # 定义pnpm工作区的结构,允许在同一个仓库中管理多个包的依赖关系。
|-- REDEME.md
|-- tsconfig.base.json
|-- tsconfig.json
|-- tsconfig.tsbuildinfo
技术栈相关
涉及的技术架构图如下:

- draw-client 相关技术栈

- services 相关技术栈

软件操作流程说明
为了深入理解软件开发的流程,我们将通过两个具体的案例来阐述图形的创建、展示以及动态变化的过程。
创建图形流程
在本节中,我们将详细介绍如何使用我们的图形库来创建图形元素。通过序列图可以了解到一个最简单的图形创建的完整流程如下:

撤销操作
在软件开发中,撤销操作是一个常见的需求,它允许用户撤销之前的某些操作,恢复到之前的状态。本节将探讨如何在图形编辑器中实现撤销功能。
当我们想要回退某一个步骤时,流程如下:

规划
目前软件开发还是处于一个初步的阶段,还有很多有趣的功能需要开发。并且软件开发需要大量的时间,我会逐步去开发相关的功能。这不仅是一个技术实现的过程,更是一个不断学习和成长的过程。我计划在以下几个关键领域深入挖掘:
- NestJS服务端:我将深入研究NestJS框架,利用其强大的模块化和依赖注入特性,构建一个高效、可扩展的服务端架构。我希望通过实践,掌握NestJS的高级特性。
- Electron应用开发:利用Electron框架,将Web应用与桌面应用的优势结合起来。
- SVG图形处理:深入SVG的,我将开发相关库,使得用户能够轻松地在应用中绘制和编辑图形。
当然我会也在开发的过程中记录分享到掘金社区,如果有人想要体验和参与的也是非常欢迎!如果对你有帮助感谢点赞关注,可以私信我一起讨论下独立开发相关的话题。
来源:juejin.cn/post/7455151799030317093
深入理解 Java 中的信号机制
观察者模式的困境
在Java中实现观察者模式通常需要手动管理监听器注册、事件分发等逻辑,这会带来以下问题:
- 代码侵入性高:需要修改被观察对象的代码(如添加
addListener()方法) - 紧耦合:监听器与被观察对象高度耦合,难以复用
- 类型安全缺失:传统
Observable只能传递Object类型参数,需强制类型转换 - 事件解耦困难:难以区分触发事件的具体属性变化
下面,我们用一个待办事项的例子说明这个问题。同时利用信号机制的方法改写传统方式,进行对比。
示例:待办事项应用
我们以经典的待办事项应用为例,需要监听以下事件:
- 当单个Todo项发生以下变化时:
- 标题变更
- 完成状态切换
- 当TodoList发生以下变化时:
- 新增条目
- 删除条目
传统实现方案
1. 基础监听器模式
// 监听器接口
public interface Listener {
void onTitleChanged(Todo todo);
void onCompletionChanged(Todo todo);
void onItemAdded(Todo entity, Collection<Todo> todos);
void onItemRemoved(Todo entity, Collection<Todo> todos);
}
// 具体实现
public class ConsoleListener implements Listener {
@Override
public void onTitleChanged(Todo todo) {
System.out.printf("任务标题变更为: %s%n", todo.getTitle());
}
// 其他事件处理...
}
// 被观察对象(侵入式改造)
public class TodosList {
private final List<Listener> listeners = new ArrayList<>();
public void addListener(Listener listener) {
listeners.add(listener);
}
public void removeListener(Listener listener) {
listeners.remove(listener);
}
public Todo add(String title) {
Todo todo = new Todo(UUID.randomUUID(), title, false);
listeners.forEach(l -> l.onItemAdded(todo, todos));
return todo;
}
// 其他操作方法...
}
2. Java 内置的 Observable(已弃用)
// 被观察的Todo类
@Getter @AllArgsConstructor
public class Todo extends Observable {
private UUID id;
@Setter private String title;
@Setter private boolean completed;
public void setTitle(String title) {
this.title = title;
setChanged();
notifyObservers(this); // 通知所有观察者
}
// 其他setter同理...
}
// 观察者实现
public class BasicObserver implements Observer {
@Override
public void update(Observable o, Object arg) {
if (o instanceof Todo todo) {
System.out.println("[Observer] 收到Todo更新事件: " + todo);
}
}
}
信号机制(Signals)解决方案
核心思想:将属性变化抽象为可观察的信号(Signal),通过声明式编程实现事件监听
1. 信号基础用法
// 信号定义(使用第三方库com.akilisha.oss:signals)
public class Todo {
private final Signal<String> title = Signals.signal("");
private final Signal<Boolean> completed = Signals.signal(false);
public void setTitle(String newTitle) {
title.set(newTitle); // 自动触发订阅的副作用
}
public void observeTitleChanges(Consumer<String> effect) {
Signals.observe(title, effect); // 注册副作用
}
}
2. 待办事项列表实现
public class TodosList {
private final SignalCollection<Todo> todos = Signals.signal(new ArrayList<>());
public Todo add(String title) {
Todo todo = Todo.from(title);
todos.add(todo); // 自动触发集合变更事件
// 声明式监听集合变化
Signals.observe(todos, (event, entity) -> {
switch (event) {
case "add":
System.out.printf("新增任务: %s%n", entity);
break;
case "remove":
System.out.printf("删除任务: %s%n", entity);
break;
}
});
return todo;
}
}
3. 效果注册与取消
public class Main {
public static void main(String[] args) {
TodosList list = new TodosList();
// 注册副作用(自动绑定到Todo属性)
list.add("学习Signals")
.observeTitleChanges(title ->
System.out.printf("任务标题变更为: %s%n", title)
);
list.add("实践Signals")
.observeCompletionChanges(completed ->
System.out.printf("任务完成状态: %s%n", completed)
);
// 触发事件
list.todos.get(0).getTitle().set("深入学习Signals");
}
}
技术对比
| 特性 | 传统监听器模式 | Java Observable | Signals机制 |
|---|---|---|---|
| 类型安全 | ❌ 需强制转换 | ❌ Object类型 | ✅ 泛型类型安全 |
| 事件解耦 | ❌ 难以区分属性变化 | ❌ 无法区分属性 | ✅ 明确属性变更事件 |
| 内存泄漏风险 | ⚠️ 需手动移除监听器 | ⚠️ 需手动移除观察者 | ✅ 自动取消订阅 |
| 代码侵入性 | ❌ 需修改被观察对象 | ❌ 需继承Observable | ✅ 零侵入 |
| 生态支持 | ✅ 成熟框架 | ❌ 已弃用 | ⚠️ 第三方库 |
关键优势
- 声明式编程:通过
.observe()方法直接声明副作用逻辑 - 精确事件解耦:可区分
add/remove/update等具体操作 - 组合式API:支持多信号组合(如
Signals.combineLatest()) - 类型安全:编译期检查事件类型匹配
使用建议
- 新项目推荐:优先考虑使用Signals机制
- 遗留系统改造:可通过适配器模式逐步替换传统监听器
- 复杂场景:结合RxJava等响应式流框架实现高级功能
通过这种现代化的事件处理方式,可以显著提升代码的可维护性和可测试性,特别适合需要精细控制状态变化的复杂业务场景。
来源:juejin.cn/post/7512657698408988713
React-native中高亮文本实现方案
前言
React-native中高亮文本实现方案,rn中文本高亮并不像h5那样,匹配正则,直接添加标签实现,rn中一般是循环实现了。一般是一段文本,拆分出关键词,然后关键词高亮。
简单实现
const markKeywords = (text, highlight) => {
if (!text || !highlight) return { value: [text], highlight: [] }
for (let index = 0; index < highlight.length; index++) {
const reg = new RegExp(highlight[index], 'g');
text = text.replace(reg, `**${highlight[index]}**`)
}
return {
markKeywordList: text.split('**').filter(item => item),
hightList: highlight.map(item => item)
}
}
上面可以拆分出可以循环的文本,和要高亮的文本。
特殊情况
const title = 'haorooms前端博文章高亮测试一下'
const highLightWords = ['前端博文', '文章高亮']
因为打上星号标记的原因,文章高亮 在被标记成 前端博文 章高亮 后,并不能被 文章高亮 匹配,而且即使能匹配也不能把 前端博文章高亮 拆成 前端博文 、文章高亮,如果能拆成 前端博文章高亮 就好了。
function sort(letter, substr) {
letter = letter.toLocaleUpperCase()
substr = substr.toLocaleUpperCase()
var pos = letter.indexOf(substr)
var positions = []
while(pos > -1) {
positions.push(pos)
pos = letter.indexOf(substr, pos + 1)
}
return positions.map(item => ([item, item + substr.length]))
}
// 高亮词第一次遍历索引
function format (text, hight) {
var arr = []
// hight.push(hight.reduce((prev, curr) => prev+curr), '')
hight.forEach((item, index) => {
arr.push(sort(text, item))
})
return arr.reduce((acc, val) => acc.concat(val), []);
}
// 合并索引区间
var merge = function(intervals) {
const n = intervals.length;
if (n <= 1) {
return intervals;
}
intervals.sort((a, b) => a[0] - b[0]);
let refs = [];
refs.unshift([intervals[0][0], intervals[0][1]]);
for (let i = 1; i < n; i++) {
let ref = refs[0];
if (intervals[i][0] < ref[1]) {
ref[1] = Math.max(ref[1], intervals[i][1]);
} else {
refs.unshift([intervals[i][0], intervals[i][1]]);
}
}
return refs.sort((a,b) => a[0] - b[0]);
}
function getHightLightWord (text, hight) {
var bj = merge(format(text, hight))
const c = text.split('')
var bjindex = 0
try {
bj.forEach((item, index) => {
item.forEach((_item, _index) => {
c.splice(_item + bjindex, 0, '**')
bjindex+=1
})
})
} catch (error) {
}
return c.join('').split('**')
}
export const markKeywords = (text, keyword) => {
if (!text || !keyword || keyword.length === 0 ) {
return { value: [text], keyword: [] }
}
if (Array.isArray(keyword)) {
keyword = keyword.filter(item => item)
}
let obj = { value: [text], keyword };
obj = {
value: getHightLightWord(text, keyword).filter((item) => item),
keyword: keyword.map((item) => item),
};
return obj;
};
述方法中我们先使用了下标匹配的方式,得到一个下标值的映射,然后通过区间合并的方式把连着的词做合并处理,最后再用合并后的下标值映射去打 ** 标记即可。
简单组件封装
function TextHighLight(props) {
const { title = '', highLightWords = [] } = props
const { numberOfLines, ellipsizeMode } = props
const { style } = props
const { markKeywordList, hightList } = markKeywords(title, highLightWords)
return <Text
numberOfLines={numberOfLines}
ellipsizeMode={ellipsizeMode}
style={style}
>
{
markKeywordList ?
markKeywordList.map((item,index) => (
(hightList && hightList.some(i => (i.toLocaleUpperCase().includes(item) || i.toLowerCase().includes(item))))
? <Text key={index} style={{ color: '#FF6300' }}>{item}</Text>
: item
))
: null
}
</Text>
}
来源:juejin.cn/post/7449373647233941541
一个列表页面,初级中级高级前端之间的鸿沟就显出来了
你是不是也写过 20+ 个中后台列表页,却总觉得跳不出 CRUD?你以为你是高级了,其实你只是熟练了。
你可能写过几十个中后台列表页,从最早用 v-model 到后来自定义 hooks,再到封装组件、状态缓存、schema 驱动。
但同样是一个列表页:
- 初级在堆功能;
- 中级在理结构;
- 高级在构建规则。
我们就以这个最常见的中后台场景:搜索 + 分页 + 表格 + 编辑跳转,来看看三个阶段的认知差异到底在哪。
写完 vs 写清楚 vs 写系统
| 等级 | 开发目标 |
|---|---|
| 初级 | 页面能用,接口通,功能不报错 |
| 中级 | 页面结构清晰、组件职责明确、状态复用 |
| 高级 | 页面只是 DSL 映射结果,字段配置驱动生成,具备平台能力 |
搜索区域的处理
| 等级 | 做法 |
|---|---|
| 初级 | el-form + v-model + 手写查询逻辑 |
| 中级 | 封装 SearchForm.vue,支持 props 字段配置 |
| 高级 | 使用字段配置 schema,支持字段渲染、联动、权限控制、字典动态加载 |
初级看起来能用,实则字段散落、表单逻辑零散; 中级可复用,但配置灵活性不足; 高级直接写 schema 字段声明,字段中心统一维护,整个搜索区域自动生成。
表格区域的组织
| 等级 | 做法 |
|---|---|
| 初级 | 表格写死在页面中,columns 手动维护 |
| 中级 | 封装 DataTable 组件,支持 columns + slots |
| 高级 | 表格由字段配置自动渲染,支持国际化、权限、字典映射、格式化 |
高级阶段的表格是“字段中心驱动下的视图映射”,而不是手写 UI 组件。
页面跳转行为
| 等级 | 做法 |
|---|---|
| 初级 | router.push + 返回后状态丢失 |
| 中级 | 缓存搜索条件和分页,支持跳转回填 |
| 高级 | 路由状态与组件状态解耦,编辑行为可抽象为弹窗、滑窗,不依赖跳转 |
体验上,初级只能靠刷新;中级保留了状态;高级压根不跳页,抽象为状态变更。
字段结构理解
| 等级 | 做法 |
|---|---|
| 初级 | 页面写死 status === 1 ? '启用' : '禁用' |
| 中级 | 使用全局字典表:getDictLabel('STATUS', val) |
| 高级 | 字段中心统一配置字段含义、展示方式、权限与控件类型,一份声明全平台复用 |
高级不写字段映射,而是写字段定义。字段即规则,规则即视图。
工程感理解
你以为工程感是“项目结构清晰”,其实高级工程感是:
- 样式有标准;
- 状态有模式;
- 路由有策略;
- 权限有方案;
- 字段有配置中心。
一切都能预期,一切都能对齐。
行为认知:你以为你在“配合”,其实你在“等安排”
你说“接口还没好我就做不了页面”。 你说“等产品图出了我再看组件拆不拆”。
但高级前端早就开始:
- Mock 数据、虚拟字段结构;
- 自定义 useXXX 模块推动业务流转;
- 甚至反推接口结构,引导后端设计。
配合和推进,只有一线之隔。
低水平重复劳动:你写了很多,但没真正沉淀
你遇到过哪些“看似很忙,实则在原地转圈”的开发场景?
有些开发者,写得飞快,需求接得也多,但工作了一两年,回头一看,写过的每一个页面都像复制粘贴出来的拼图。
你看似很忙,实则只是换了一个页面在干一样的事。
最典型的,就是以下这三类“中后台系统里的低水平重复劳动”:
❶ 每页都重复写 table columns 和格式化逻辑
- 每页重复定义
columns; - 状态字段每次都手写
status === 1 ? '启用' : '停用'; - 日期字段每页都在
render中 format; - 操作列、index 列、字典值写满重复逻辑。
📉 问题: 代码冗余,字段维护困难,一改动就全局找引用。
✅ 提升方式:
- 抽象字段结构配置(如 fieldSchema);
- 字段渲染、字典映射、权限统一管理;
- 一份字段配置驱动表格、表单、详情页。
❷ 每个列表页都重复写搜索逻辑和状态变量
- 每页都写
searchForm: {}、search()、reset(); - query 参数、分页、loading 状态变量混杂;
- 页面跳转回来状态丢失,刷新逻辑重复拼接。
📉 问题: 页面逻辑分散、复用性差,体验割裂。
✅ 提升方式:
- 自定义 hook 如
useSmartListPage()统一管理列表页状态; - 统一封装查询、分页、loading、缓存逻辑;
- 形成“搜索+表格+跳转+回填”标准列表模式。
❸ 反复堆砌跳转编辑流程,缺乏行为抽象
- 每次跳转写
this.$router.push({ path, query }); - 返回页面刷新列表,无上下文保留;
- 编辑页都是复制粘贴模板,字段改名。
📉 问题: 编辑与跳转强耦合,逻辑割裂,流程不清。
✅ 提升方式:
- 将“查看 / 编辑 / 创建”抽象为页面模式;
- 支持弹窗、滑窗模式管理,跳转可选;
- 解耦跳转与行为,页面由状态驱动。
真正的成长,不是写得多,而是提取出通用能力、形成规范。
中后台系统里最常见的低水平重复劳动:
- 每次都手写 table columns、格式化字段;
- 搜索表单每页都重新写逻辑、状态绑定;
- 分页、loading、跳转逻辑全靠临时拼;
你遇到过哪些 “看似很忙,实则在原地转圈” 的开发场景?欢迎在评论区说说你的故事。
组件理解:你以为你在写组件,其实你在制造混乱
组件抽象不清、slot 滥用、props 大杂烩、逻辑耦合 UI,写完一个别人不敢接的黑盒。
中级组件关注复用,高级组件关注职责边界和组合方式,具备“可预测性、可替换性、可拓展性”。
页面能力 ≠ 项目交付能力
你能写页面,但你未必能独立交付项目。 缺的可能是:
- 多模块协同能力
- 权限 / 字段 / 配置抽象力
- 异常兜底与流程控制设计
从写完一个页面,到撑起一个系统,中间差的是“体系构建力”。
结语:页面 ≠ 技术,堆功能 ≠ 成长
初级在交付页面,中级在建设结构,高级在定义规则。 真正的高级前端,已经不写“页面”了,而是在定义“页面该怎么写”。
来源:juejin.cn/post/7492086179996090383
搞懂 GO 的垃圾回收机制

速通 GO 垃圾回收机制
前言
垃圾回收(Garbage Collection,简称 GC)是编程语言中自动管理内存的一种机制。Go 语言从诞生之初就带有垃圾回收机制,经过多次优化,现在已经相当成熟。本文将带您深入了解 Go 语言的垃圾回收机制。
下面先一起了解下涉及到的垃圾回收相关知识。
标记清除
标记清除(Mark-Sweep)是最基础的垃圾回收算法,分为两个阶段:
- 标记阶段:从根对象出发,标记所有可达对象(可达性分析)
- 清除阶段:遍历整个堆,回收未被标记的对象
标记清除示例
考虑以下场景:
type Node struct {
next *Node
data int
}
func createLinkedList() *Node {
root := &Node{data: 1}
node2 := &Node{data: 2}
node3 := &Node{data: 3}
root.next = node2
node2.next = node3
return root
}
func main() {
list := createLinkedList()
// 此时内存中有三个对象,都是可达的
list.next = nil
// 此时node2和node3变成了不可达对象,将在下次GC时被回收
}
在这个例子中:
- 初始状态:root -> node2 -> node3 形成链表
- 标记阶段:从root开始遍历,标记所有可达对象
- 修改引用后:只有root是可达的
- 清除阶段:node2和node3将被回收
// 伪代码展示标记清除过程
func MarkSweep() {
// 标记阶段
for root := range roots {
mark(root)
}
// 清除阶段
for object := range heap {
if !marked(object) {
free(object)
}
}
}
标记清除算法的优点是实现简单,但存在以下问题:
- 需要 STW(Stop The World),即在垃圾回收时需要暂停程序运行
- 会产生内存碎片,因为清除后最终剩下的活跃对象在堆中的分布是零散不连续的
- 标记和清除的效率都不高
内存碎片示意图
%%{init: {"flowchart": {"htmlLabels": false}} }%%
flowchart LR
subgraph Before["GC前的堆内存"]
direction LR
A1["已分配"] --- B1["已分配"] --- C1["空闲"] --- D1["已分配"] --- E1["已分配"]
end
Before ~~~ After
subgraph After["GC后的堆内存"]
direction LR
A2["已分配"] --- B2["空闲"] --- C2["空闲"] --- D2["已分配"] --- E2["空闲"]
end
classDef default fill:#fff,stroke:#333,stroke-width:2px;
classDef allocated fill:#a8d08d,stroke:#333,stroke-width:2px;
classDef free fill:#f4b183,stroke:#333,stroke-width:2px;
class A1,B1,D1,E1 allocated;
class C1 free;
class A2,D2 allocated;
class B2,C2,E2 free;
如图所示,GC后的内存空间虽然有足够的总空间,但是由于碎片化,可能无法分配较大的连续内存块。
三色标记
为了优化标记清除算法,Go 语言采用了三色标记算法。主要的目的是为了缩短 STW 的时间,提高程序在垃圾回收过程中响应速度。
三色标记将对象分为三种颜色:
- 白色:未被标记的对象
- 灰色:已被标记但其引用对象未被标记的对象
- 黑色:已被标记且其引用对象都已被标记的对象
三色标记过程图解
graph TD
subgraph "最终状态"
A4[Root] --> B4[Object 1]
B4 --> C4[Object 2]
B4 --> D4[Object 3]
D4 --> E4[Object 4]
style A4 fill:#000000
style B4 fill:#000000
style C4 fill:#000000
style D4 fill:#000000
style E4 fill:#000000
end
subgraph "处理灰色对象"
A3[Root] --> B3[Object 1]
B3 --> C3[Object 2]
B3 --> D3[Object 3]
D3 --> E3[Object 4]
style A3 fill:#000000
style B3 fill:#808080
style C3 fill:#FFFFFF
style D3 fill:#FFFFFF
style E3 fill:#FFFFFF
end
subgraph "标记根对象为灰色"
A2[Root] --> B2[Object 1]
B2 --> C2[Object 2]
B2 --> D2[Object 3]
D2 --> E2[Object 4]
style A2 fill:#808080
style B2 fill:#FFFFFF
style C2 fill:#FFFFFF
style D2 fill:#FFFFFF
style E2 fill:#FFFFFF
end
subgraph "初始状态"
A1[Root] --> B1[Object 1]
B1 --> C1[Object 2]
B1 --> D1[Object 3]
D1 --> E1[Object 4]
style A1 fill:#D3D3D3
style B1 fill:#FFFFFF
style C1 fill:#FFFFFF
style D1 fill:#FFFFFF
style E1 fill:#FFFFFF
end
在垃圾回收器开始工作时,所有对象都为白色,垃圾回收器会先把所有根对象标记为灰色,然后后续只会从灰色对象集合中取出对象进行处理,把取出的对象标为黑色,并且把该对象引用的对象标灰加入到灰色对象集合中,直到灰色对象集合为空,则表示标记阶段结束了。
三色标记实际示例
type Person struct {
Name string
Friends []*Person
}
func main() {
alice := &Person{Name: "Alice"}
bob := &Person{Name: "Bob"}
charlie := &Person{Name: "Charlie"}
// Alice和Bob是朋友
alice.Friends = []*Person{bob}
bob.Friends = []*Person{alice, charlie}
// charlie没有朋友引用(假设bob的引用被删除)
bob.Friends = []*Person{alice}
// 此时charlie将在下次GC时被回收
}
详细标志过程如下:
- 初始时所有对象都是白色
- 从根对象开始,将其标记为灰色
- 从灰色对象集合中取出一个对象,将其引用对象标记为灰色,自身标记为黑色
- 重复步骤 3 直到灰色集合为空
- 清除所有白色对象
// 三色标记伪代码
func TriColorMark() {
// 初始化,所有对象设为白色
for obj := range heap {
setWhite(obj)
}
// 根对象入灰色队列
for root := range roots {
setGrey(root)
greyQueue.Push(root)
}
// 处理灰色队列
for !greyQueue.Empty() {
grey := greyQueue.Pop()
scan(grey)
setBlack(grey)
}
// 清除白色对象
sweep()
}
需要注意的是,三色标记清除算法本身是不支持和用户程序并行执行的,因为在标记过程中,用户程序可能会进行修改对象指针指向等操作,导致最终出现误清除掉活跃对象等情况,这对于内存管理而言,是十分严重的错误了。
并发标记的问题示例
func main() {
var root *Node
var finalizer *Node
// GC开始,root被标记为灰色
root = &Node{data: 1}
// 用户程序并发修改引用关系
finalizer = root
root = nil
// 如果这时GC继续运行,finalizer指向的对象会被错误回收
// 因为从root开始已经无法到达该对象
}
所以为了解决这个问题,在一些编程语言中,常见的做法是,三色标记分为 3 个阶段:
- 初始化阶段,需要 STW,包括标记根对象等操作
- 主要标记阶段,该阶段支持并行
- 结束标记阶段,需要 STW,确认对象标记无误
通过这样的设计,至少可以使得标记耗时较长的阶段可以和用户程序并行执行,大幅度缩短了 STW 的时间,但是由于最后一阶段需要重复扫描对象,所以 STW 的时间还是不够理想,因此引入了内存屏障等技术继续优化。
内存屏障技术
三色标记算法在并发环境下会出现对象丢失的问题,为了解决这个问题,Go 引入了内存屏障技术。
内存屏障技术是一种屏障指令,确保屏障指令前后的操作不会被越过屏障重排。
内存屏障工作原理图解
graph TD
subgraph "插入写屏障"
A1[黑色对象] -->|新增引用| B1[白色对象]
B1 -->|标记为灰色| C1[灰色对象]
end
subgraph "删除写屏障"
A2[黑色对象] -->|删除引用| B2[白色对象]
B2 -->|标记为灰色| C2[灰色对象]
end
垃圾回收中的屏障更像是一个钩子函数,在执行指定操作前通过该钩子执行一些前置的操作。
对于三色标记算法,如果要实现在并发情况下的正确标记,则至少要满足以下两种三色不变性中的其中一种:
- 强三色不变性: 黑色对象不指向白色对象,只会指向灰色或黑色对象
- 弱三色不变性:黑色对象可以指向白色对象,但是该白色对象必须被灰色对象保护着(被其他的灰色对象直接或间接引用)
插入写屏障
插入写屏障的核心思想是:在对象新增引用关系时,将被引用对象标记为灰色。
// 插入写屏障示例
type Object struct {
refs []*Object
}
func (obj *Object) AddReference(ref *Object) {
// 写屏障:在添加引用前将新对象标记为灰色
shade(ref)
obj.refs = append(obj.refs, ref)
}
// 插入写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(ptr) // 将新引用的对象标记为灰色
*slot = ptr
}
插入写屏障是一种相对保守的策略,相当于有可能存活的对象都会被标灰,满足了强三色不变行,缺点是会产生浮动垃圾(没有被引用但却没被回收的对象),要到下一轮垃圾回收时才会被回收。
浮动垃圾示例
func main() {
obj1 := &Object{}
obj2 := &Object{}
// obj1引用obj2
obj1.AddReference(obj2) // obj2被标记为灰色
// 立即删除引用
obj1.refs = nil
// 此时obj2虽然已经不可达
// 但因为已被标记为灰色,要等到下一轮GC才会被回收
}
栈上的对象在垃圾回收中也是根对象,但是如果栈上的对象也开启插入写屏障,那么对于写指针的操作会带来较大的性能开销,所以很多时候插入写屏障只针对堆对象启用,这样一来,要保证最终标记无误,在最终标记结束阶段就需要 STW 来重新扫描栈空间的对象进行查漏补缺。实际上这两种方式各有利弊。
删除写屏障
删除写屏障的核心思想是:在对象删除引用关系时,将被解引用的对象标记为灰色。
这种方法可以保证弱三色不变性,缺点是回收精度低,同样也会产生浮动垃圾。
// 删除写屏障示例
func (obj *Object) RemoveReference(index int) {
// 写屏障:在删除引用前将被删除的对象标记为灰色
shade(obj.refs[index])
obj.refs = append(obj.refs[:index], obj.refs[index+1:]...)
}
// 删除写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot) // 将被删除引用的对象标记为灰色
*slot = ptr
}
混合写屏障
Go 1.8 引入了混合写屏障,同时应用了插入写屏障和删除写屏障,结合了二者的优点:
// 混合写屏障示例
func (obj *Object) UpdateReference(index int, newRef *Object) {
// 删除写屏障
shade(obj.refs[index])
// 更新引用
obj.refs[index] = newRef
// 插入写屏障
shade(newRef)
}
// 混合写屏障伪代码
func writePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) {
shade(*slot) // 删除写屏障
*slot = ptr
shade(ptr) // 插入写屏障
}
GO 中垃圾回收机制
大致演进与版本改进
- Go 1.3之前:传统标记-清除,全程STW(秒级停顿)。
- Go 1.5:引入并发三色标记,STW降至毫秒级。
- Go 1.8:混合写屏障优化,STW缩短至微秒级。
- Go 1.12+:并行标记优化,提升吞吐量。
在 GO 1.7 之前,主要是使用了插入写屏障来保证强三色不变性,由于垃圾回收的根对象包括全局变量、寄存器、栈对象,如果要对所有的 Goroutine 都开启写屏障,那么对于写指针操作肯定会造成很大的性能损耗,所以 GO 并没有针对栈开启写屏障。而是选择了在标记完成时 STW、重新扫描栈对象(将所有栈对象标灰重新扫描),避免漏标错标的情况,但是这一过程是比较耗时的,要占用 10 ~ 100 ms 时间。
于是,GO 1.8 开始就使用了混合写屏障 + 栈黑化 的方案优化该问题,GC 开始时全部栈对象标记为黑色,以及标记过程中新建的栈、堆对象也标记为黑色,防止新建的对象都错误回收掉,通过这样的机制,栈空间的对象都会为黑色,所以最后也无需重新扫描栈对象,大幅度地缩短了 STW 的时间。当然,与此同时也会有产生浮动垃圾等方面的牺牲,没有完成的方法,只有根据实际需求的权衡取舍。
主要特点
- 并发回收:GC 与用户程序同时运行
- 非分代式:不按对象年龄分代
- 标记清除:使用三色标记算法
- 写屏障:使用混合写屏障
- STW 时间短:平均在 100us 以内
垃圾回收触发条件
- 内存分配达到阈值
- 定期触发
- 手动触发(runtime.GC())
GC 过程
- STW,开启写屏障
- 并发标记
- STW,清除标记
- 并发清除
- 结束
GC触发示例
func main() {
// 1. 内存分配达到阈值触发
for i := 0; i < 1000000; i++ {
_ = make([]byte, 1024) // 大量分配内存
}
// 2. 定期触发
// Go运行时会自动触发GC
// 3. 手动触发
runtime.GC()
}
总结
Go 语言的垃圾回收机制经过多次优化,已经达到了很好的性能。它采用三色标记算法,配合混合写屏障技术,实现了高效的并发垃圾回收。虽然还有一些不足,如不支持分代回收,但对于大多数应用场景来说已经足够使用。
性能优化建议
要优化 Go 程序的 GC 性能,可以:
- 减少对象分配
// 不好的做法
for i := 0; i < 1000; i++ {
data := make([]int, 100)
process(data)
}
// 好的做法
data := make([]int, 100)
for i := 0; i < 1000; i++ {
process(data)
}
- 复用对象
// 使用sync.Pool复用对象
var pool = sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
}
func process() {
buf := pool.Get().([]byte)
defer pool.Put(buf)
// 使用buf
}
- 使用合适的数据结构
// 不好的做法:频繁扩容
s := make([]int, 0)
for i := 0; i < 1000; i++ {
s = append(s, i)
}
// 好的做法:预分配容量
s := make([]int, 0, 1000)
for i := 0; i < 1000; i++ {
s = append(s, i)
}
- 控制内存使用量
// 设置GOGC环境变量控制GC频率
// GOGC=100表示当内存扩大一倍时触发GC
os.Setenv("GOGC", "100")
参考资料:
来源:juejin.cn/post/7523256725126873114
合规、安全、高效!万里汇亮相 ChinaJoy 为数娱出海破解支付难题
8月1日,第二十二届 ChinaJoy(中国国际数码互动娱乐展览会)在上海新国际博览中心火热举行。
万里汇展位前人潮涌动,汇聚在此的游戏出海人正在感受一场“支付革新”。为了让开发者朋友能更直观地感受游戏出海的资金链路,万里汇展位特别设立了互动装置“通关补给站”,生动形象地展示了游戏出海过程中的“收款成本高”“资金管理低效”等支付难题。突破这些“难关”,才能把资金完整地落袋为安!
因为对于许多游戏开发者来说,做出海游戏并不陌生,怎么把出海游戏赚到的钱完整快速地收回来却是一道知识盲区。

数娱出海关键一步,先解决支付问题!
原因在于,支付环节常常是被出海游戏企业忽视的一环。并非是游戏企业不关心,而是游戏出海的资金链路实在不简单。不管是收款还是付款,每一笔资金都需要经过“重重关卡”,等到最终“通关”完成收付款时,资金早已折损得面目全非。
据《中国游戏产业全球化研究》报告显示,2024 年中国自研游戏海外销售收入为 185.6 亿美元,在销售总收入中占比已达到 33.62%。事实上,海外市场已逐渐成为许多中国游戏企业的“主战场”。然而在出海支付环节,仍有约 72% 的出海游戏企业表示支付环节(包括手续费、汇率波动、本地化支付适配等)对其运营产生了显著影响(来源:伽马数据《2024 年中国游戏出海支付成本调研报告》)。
万里汇携“数娱出海支付解决方案”重磅亮相!
作为全球顶级的数字娱乐盛会,ChinaJoy 始终是行业技术革新与趋势的风向标。近年来,中国游戏出海规模增长迅速,游戏出海在 ChinaJoy 展会中的占比和重要性也持续提升,成为核心议题之一。本届 ChinaJoy 共计 743 家参展企业中,涉及游戏出海营销、本土化等服务的企业更是层出不穷,关于数娱出海的热度则更创新高。蚂蚁国际旗下品牌万里汇(WorldFirst) 携“数娱出海支付解决方案”首次亮相 ChinaJoy,并且凭借着高度适配游戏行业出海场景的产品能力,吸引了大量开发者与平台型客户现场咨询体验。

支付革新,万里汇数娱出海支付解决方案的“五大优势”
针对传统支付方式收款慢的问题,万里汇支持多币种、多平台收款、无需汇兑,让收款更高效。面对付款受限、压力大等问题,万里汇给出了支持100+币种付至210+国家或地区的解法,一键申领万里付卡WorldCard,可轻松支付服务商费用。
在资金交易链路中,高昂的流转费用与低效也致使成本激增,降本增效方面万里汇也给出了自己的打法:费率低汇率优、实时货币兑换,所见即所得,真正实现资金交易中的0汇损!同时,万里汇低至0成本支持批量开户、多平台独立收款账户统一管理,高效运转。针对风险问题,万里汇依托于蚂蚁生态,体系合规、牌照齐全,让资金安全有所保障!交易更安心!
游戏出海企业如何通过支付,找到新的利润空间?
随着全球游戏市场的日益发展,万里汇这样的支付产品将发挥越来越重要的作用,帮助中国游戏企业攻略全球。
趋势一:支付体系带来利润空间
各大游戏/应用平台的制度逐渐完善,未来“本地化支付+运营”将成为中小游戏企业出海的标配能力,也是从竞争中突围的关键杠杆。优化支付能力将成为中小游戏企业提升利润空间的主要途径。
趋势二:合规支付成为核心竞争力
全球游戏市场正朝着一体化发展,游戏出海不再是针对某一单一市场。万里汇的全球支付合规资质可以为游戏企业的海外扩张保驾护航,合规支付能力也将为游戏营销带来事半功倍的效果。

万里汇数娱出海支付解决方案解析,不仅对游戏出海传统支付方式的主要痛点,进行了全方位优化和升级。还暗合全球市场发展中关于支付力的两大核心趋势。万里汇从收款、付款,再到汇兑,整体优化游戏出海的资金链路,真正实现了全方位的“支付革新”。
借助万里汇的支付能力,游戏企业可轻松破解出海支付难题,让游戏无忧出海“通关”全球。
收起阅读 »PAC并行应用挑战赛“以赛促学,以赛促研”,铸就国产算力生态新标杆
2025年7月24日,第十二届并行应用挑战赛(Parallel Application Challenge,简称PAC2025)初赛评审圆满落幕。经过专家严格评选,来自清华大学、北京航空航天大学等高校的应用赛道12支队伍、优化赛道16支队伍成功晋级,将于8月齐聚鄂尔多斯HPC大会现场,展开最终角逐。
十三年深耕:从“竞赛”到“算力生态”的蝶变
自2013年创办以来,PAC大赛已成长为国内并行计算领域最具影响力的赛事,其独特的"以赛促学,以赛促研"模式,架起高校、产业与科研机构间的桥梁,成为推动国产算力生态发展的强劲引擎:
规模跨越式增长:足迹遍布全国45+城市,吸引400+单位、1800+队伍参与,2025年报名队伍突破200支。
产学研深度融合:浙江大学、上海交通大学等高校将赛事纳入学分体系;华为、并行科技等企业提供技术支持;科研成果直接应用于台风预测等实际场景。
国产化战略转型:2024年起全面启用鲲鹏国产计算平台,形成"人才培育-技术创新-应用落地"的良性循环。
大赛共同主席,中国科学院院士、北京航空航天大学钱德沛院士在本届PAC大赛开幕致辞时提到:“中国的计算机尤其是高性能计算在过去30年取得了巨大的成就,近年来也迎来了新的挑战。PAC作为行业中最具影响的并行计算竞赛之一,汇聚了学术与工业的力量,激发了青年人才的创新热情,通过构建开放协作平台,推动了国内自主研发处理器的生态建设,助力中国计算机技术的发展。“
创新人才培养:“以赛促学”破解“学用脱节”难题
PAC大赛直面传统教育痛点,以三大创新机制重塑人才培养模式:
真实场景实战
赛题源自气象、医疗等产业真实需求,如中国科学技术大学战队曾优化医学影像算法,实现宫颈癌病理切片的快速诊断;哈尔滨工业大学战队优化油田模拟程序,提升油气开发效率。
跨学科能力锻造
山东大学战队通过内存绑定、向量化计算等技术,实现13万CPU核并行加速,性能提升近线性,展现了卓越的跨领域整合能力。
就业直通渠道
特有的"竞赛招聘"模式让50余家企业现场选拔人才,优秀选手可直接获得华为等企业的实习机会。
国产算力技术腾飞:“以赛促研”实现从"可用"到"好用"的战略跨越
2024年全面转向鲲鹏平台,标志着PAC大赛进入助力国产算力生态的新阶段:
性能突破:参赛作品在气象、生物医疗等领域实现突破性加速,单细胞分析工具等成果兼具科研与工程价值。
生态检验:基于鲲鹏平台的代码优化与应用开发,是对国产处理器、操作系统等基础软件的大规模实战检验。
市场认可:推动国产芯片在主流领域从“可用”迈向“好用”、“广泛用”,提升整体竞争力与市场认可度。
大赛共同主席,中国科学院计算技术研究所张云泉研究员指出:“历经十余年发展,PAC已成为链接行业与教育的优质‘连通器’。通过‘以赛促学、以赛促研、以赛促用’的实践模式,大赛累计培养超13,000名高性能计算人才,其中许多参赛者已成长为行业骨干甚至赛事评委,见证了中国高性能计算人才的代际传承。同时,大赛汇聚了跨领域专家和行业的实战案例,推动鲲鹏平台生态融合与科学计算算法创新,使国产高性能计算技术在气象、生物医药等关键领域实现性能突破性加速。”
智聚未来:鄂尔多斯HPC大会现场见证新辉煌
随着8月总决赛临近,这场汇聚全国顶尖高校学子的科技盛会即将迎来高潮。一届届PAC传承孕育着高校学子的代码青春,助推优秀人才与应用破圈,让算力赋能未来。正如大赛口号“赛场淬炼,奔赴高光”,PAC将持续依托国产化算力底座,激发技术生态内生动力,为我国高性能计算事业注入强劲动能,在创新人才培养和产业升级道路上不断创造新的可能。
8月13日-15日,鄂尔多斯国际会展中心
一起见证PAC新辉煌

牛马的人生,需要Spring Shell
前言
“技术是人类对需求的回应。”
大家好,这里是知行小栈。
最近,一位运营的同学突然给我发来了一串加密的手机号,类似这样:
2f731fb2aea9fb5069adef6e4aa2624e
他让我帮忙解下密,想拿到具体的手机号。
我看了下,也不是啥大事儿。于是找到了对应的项目,直接调用里面的解密方法,将这些号码都打印了出来,给到了他。
本以为事情到此就结束了,结果他隔三岔五的让我去做这个操作(心里os)。判断了下情况,这种需求可能会不间断的发生。顿时,我的大脑就应激了,必须弄个一劳永逸的方案!
命令行
我最先想到的就是命令行。为啥呢?因为命令行有两个特点:
- 易于调用;
- 简短的命令就能完成指定的功能;

只要制作一个自定义的命令行工具,下次就可以通过这种方式减少繁琐的操作,增加摸鱼的时间。
原先项目中,已经有手机号加解密的功能。基于职业的基本素养(不重复造轮子),之前已有的功能我是不会重写的,而是想办法能直接通过命令行调用。类似:
java -jar xxx.jar
这个命令虽然看起来有点长,但可以通过为其起别名的方式,简化命名。实现 ll 等价于 ls -l 的效果。
Spring Shell
想要通过 shell 调用 Java 指定类中的指定方法,方式有许多。我思考了 秒,就决定采用 Spring Shell(因为它与我想要实现的场景匹配度高达 99.999%)。
首先,我仅需要在原先的项目中多引入一个依赖
<dependency>
<groupId>org.springframework.shell</groupId>
<artifactId>spring-shell-starter</artifactId>
<version>2.1.15</version>
</dependency>
然后,实现一个自定义的命令组件
// @ShellComponent 类似 @Component 表明是 Spring 中的一个组件
@ShellComponent
public class Cipher {
// @ShellMethod 定义了一个命令,key 属性是命令的名称,value 属性是命令的描述
// @ShellOption 定义了命令中的参数
@ShellMethod(key = "decrypt", value = "解密操作")
public String decrypt(@ShellOption String cipherText, @ShellOption String key) {
// 调用项目中已有的解密方法
return AesUtil.decrypt(cipherText, key);
}
@ShellMethod(key = "encrypt", value = "加密操作")
public String encrypt(@ShellOption String text, @ShellOption String key) {
// 调用项目中已有的加密方法
return AesUtil.encrypt(text, key);
}
}
最后,重新将 Shell 组件所在的项目打个包,运行项目

执行命令,验证

到这里,还不行。因为我可不会每次都去执行 java -jar xxx.jar 这么长的命令来启动 Spring Shell。windows 终端我一直用的 Git-Bash,这种类 Unix 的终端都可以采用相同的方式为长命令设置一个别名。
于是,我在 .bash_profile 文件中,给这段长命令起了一个别名:
alias shell='java -jar encrypt.jar'
接下来,就可以通过简单的 shell 命令调用 Spring Shell 终端,执行之前定义好的命令了

知行有话
Spring Shell 简直就是开发者的利器。试想一下,我们把日常学习或工作中频繁的操作都弄成这样的终端命令,是不是会节约我们大量的时间?还有一个值得提的点就是它对 Java 开发者十分友好。只要你懂 Java,就可以轻松上手开发自定义的终端命令。
来源:juejin.cn/post/7530521957666914346
奋斗在创业路上的老开发
前言
一个老🐮🐴的吐槽。 水水文章。不喜勿喷~
现状
看过我之前帖子的小伙伴了解过 我现在在创业的路上越走越远。痛苦面具又带上了。 每天就是处理不完的事情。层出不穷的状况。各种乱七八糟的电话。处理不完的工作。在这个过程中学到了很多技术之外的东西。看到了以前看不到的东西。同样的。也渐渐放弃了属于一个开发者的身份
自己做了这么多年的技术。回头看看其他同期的小伙伴。要么已经开始玩鸿蒙。或者小程序。或者其他的等等等。
自己其实很早就涉猎。但是绝对谈不上精通。现在年纪也大了。发现精力真的有限。而且也发觉学不动了。渐渐的就变成了守护自己的一亩三分地。 技术也在降低。
有心想去学习一下鸿蒙。感觉不难。第一是没系统的时间去专门学习。二是认为如果发展需要。可以选择招聘动这个技术的人去完成这部分工作。自己没必要去学。
碎碎念
公司现在也慢慢开始扩招。算是慢慢走上正轨。业务页越来越多。同样的压力页越来越大。毕竟咱现在可没那么好运气。有人愿意给我钱让我去玩。都是自己的真金白银。出现任何的问题都可能是致命的。
说道招聘 。哎。最近一周都是在面试。一直找不到合适的人。或者遇到合适的 人家瞧不上咱这小门小庙的。属于是难。
写在最后
作为技术出生的牛马。对于技术始终是热爱的。然而显示就是现在就是慢慢的脱离了技术的身份。有更多需要我去做的事情。也有更多值得我去做的事情。 希望财富自由。漫漫长路。还远的很啊~
给年轻人建议
有点装大尾巴狼了。 勿喷哈。 因为最近一直在面试。其实也有很多应届生。我是不反对应届生的。相反我很喜欢带小朋友。而且也带过不少小朋友。
但是很多应届生给我的感觉就是。虽说咱这行收入相比其他行业要好一点。但咱这小门小庙的 也不是应届生张口8K咱能用得起的啊。毕竟小公司。我比较穷。。
不少应届生给我的感觉是心浮气躁。并没有对技术的敬畏。与之带来的是基础的不扎实。这很大程度上限制了自己的上限的。
来源:juejin.cn/post/7529799737702826022
你真的了解包管理工具吗?(npm、pnpm、cnpm)
npm (Node Package Manager)
概述
npm是 Node.js 的官方包管理器,也是全球使用最广泛的 JavaScript 包管理工具。它用于管理 JavaScript 项目的依赖包,可以通过命令行来安装、更新、卸载依赖包。
特点
- Node.js 官方默认包管理器。支持全局和本地安装模式
- 通过 package.json 和 package-lock.json 管理依赖版本,可以在 package.json 中定义各种脚本命令
常用命令
npm install [package] # 安装包
npm uninstall [package] # 卸载包
npm update [package] # 更新包
npm init # 初始化项目
npm run [script] # 运行脚本
npm publish # 发布包
依赖管理方式
npm 使用平铺的 node_modules 结构,会导致依赖重复和幽灵依赖问题(phantom dependencies)。这种管理方式导致npm在处理在处理大量依赖时速度会很慢
cnpm (China npm)
特点
- 镜像加速:使用淘宝的 npm 镜像,下载速度更快
- 兼容 npm:命令与 npm 基本一致,学习成本低
- 安装简单:可以通过 npm 直接安装 cnpm
概述
cnpm 是阿里巴巴团队开发的 npm 命令行工具,基于淘宝镜像 registry.npmmirror.com,用于解决国内访问 npm 官方源缓慢的问题。
特点
- 镜像加速:使用淘宝的 npm 镜像,下载速度更快
- 兼容 npm:命令与 npm 基本一致,学习成本低
- 安装简单:可以通过 npm 直接安装 cnpm
本质是和npm一样,只是为了迎合国内的网络环境,更改了依赖包的下载地址,让下载速度更快
pnpm (## Performant npm)
概述
pnpm 是一个新兴的、高性能的包管理工具,最大的特点是使用硬链接(hard link)来复用依赖文件,极大节省磁盘空间和提升安装速度。
特点
- 高效存储:多个项目可以共享同一版本的依赖,节省磁盘空间
- 磁盘空间优化:通过硬链接共享依赖,显著节省了磁盘空间。
- 强制封闭依赖:避免隐式依赖,提高了依赖管理的可靠性。
- 速度更快,兼容性更好:安装速度比 npm 和 yarn 更快,兼容 npm 的工作流和 package.json
依赖管理方式
pnpm (Performant npm) 的依赖管理方式与传统包管理器(npm/yarn)有本质区别,其核心基于内容可寻址存储和符号链接技术。
- 内容可寻址存储 (Content-addressable storage)
pnpm 将所有依赖包存储在全局的 ~/.pnpm-store 目录中(默认位置),存储结构基于包内容的哈希值而非包名称。这意味着: 1. 相同内容的包只会存储一次 2.不同项目可以共享完全相同的依赖版本3.通过哈希值精确验证包完整性
- 符号链接 (Symbolic links) 结构

举例解释就是
场景假设:你有 100 个项目,每个项目都用到了相同的
lodash库
1. npm:每个项目都自己带一本书
- npm 的方式:
- 每个项目都有一本完整的
lodash,即使内容一模一样。
- 结果:你的硬盘上存了 100 本相同的书(100 份
lodash副本),占用大量空间。
- 更新问题:如果
lodash发布新版本,哪怕只改了一行代码,npm 也会重新下载整本书,而不是只更新变化的部分。
2. pnpm:所有项目共享同一本书
- pnpm 的方式:
- 统一存储:所有版本的
lodash都存放在一个中央仓库(类似“云端书库”)。
- 按需链接:每个项目只是“链接”到这本书,而不是复制一份。
- 版本更新优化:如果
lodash新版本只改了一个文件,pnpm 只存储这个变化的文件,而不是整个新版本。
来源:juejin.cn/post/7518212477650927666
一个“全局变量”引发的线上事故
你正在给一家 SaaS 客户做「企业级仪表盘」项目。
需求很简单:把 20 多个子系统的实时指标汇总到一张大屏。
为了“图省事”,你在入口文件里顺手写了这么一段:
// main.js
window.dashboard = {}; // 🔍 全局缓存
window.dashboard.cache = new Map(); // 🔍 存接口数据
window.dashboard.refresh = () => { // 🔍 供子系统调用
fetch('/api/metrics').then(r => r.json())
.then(data => window.dashboard.cache = new Map(data));
};
上线两周后,客户反馈:
“切到别的标签页再回来,大屏偶尔会白屏,刷新又好了。”
排查发现,Chrome 在内存紧张时会 回收后台标签页的 JS 堆,但 window 对象属于宿主环境,不会被回收。
结果:
- 旧的
dashboard引用还在,但闭包里的Map被 GC 清掉,变成空壳; - 子系统继续调用
window.dashboard.refresh,拿到的永远是空数据; - 页面逻辑崩溃,白屏。
解决方案:三层防护,把风险降到 0
1. 表面用法:用 WeakMap 做“软引用”
// 把全局缓存改成弱引用
const cache = new WeakMap(); // 🔍 不阻止 GC
window.dashboard = {
get data() { return cache.get(document); }, // 🔍 与当前文档生命周期绑定
set data(v) { cache.set(document, v); }
};
这样当用户切走标签页、文档被卸载时,cache 自动释放,切回来重新初始化,白屏消失。
2. 底层机制:为什么 window 不会被 GC?
| 层级 | 角色 | 生命周期 | 是否可被 GC |
|---|---|---|---|
| JS 堆 | 闭包、普通对象 | 无引用即回收 | ✅ |
| Host 环境 | window | 与标签页同生同灭 | ❌ |
| 渲染进程 | GPU 纹理、DOM | 标签页关闭后统一清理 | ✅ |
结论:window 是宿主对象,生命周期长于 JS 堆,挂上去的东西如果强引用 JS 对象,会导致“僵尸引用”。
3. 设计哲学:把“全局”变成“注入”
与其在 window 上挂变量,不如用 依赖注入 把作用域限制在模块内部:
// dashboard.js
export const createDashboard = () => {
const cache = new Map(); // 🔍 私有状态
return {
refresh: () => fetch('/api/metrics')
.then(r => r.json())
.then(data => cache.clear() && data.forEach(d => cache.set(d.id, d)))
};
};
// main.js
import { createDashboard } from './dashboard.js';
const dashboard = createDashboard(); // 🔍 生命周期由模块控制
应用扩展:可复用的配置片段
如果你的项目必须暴露全局 API(比如给第三方脚本调用),可以用 命名空间 + Symbol 双保险:
// global-api.js
const NAMESPACE = Symbol.for('__corp_dashboard__');
window[NAMESPACE] = { // 🔍 避免命名冲突
version: '2.1.0',
createDashboard
};
环境适配说明:
- 浏览器:Symbol 在 IE11 需 polyfill;
- Node:同构渲染时
window不存在,用globalThis[NAMESPACE]兜底。
举一反三:3 个变体场景
- 微前端基座
用window.__MICRO_APP_STORE__传递状态,但内部用Proxy做读写拦截,防止子应用直接篡改。 - Chrome 插件 content-script
通过window.postMessage与页面通信,避免污染宿主全局。 - Electron 主进程/渲染进程
用contextBridge.exposeInMainWorld('api', safeApi)把 API 注入到隔离上下文,防止 Node 权限泄露。
小结:
把 window 当“公告栏”可以,但别把“保险箱”也挂上去。
用弱引用、模块化和依赖注入,才能把全局变量的风险真正关进笼子里。
来源:juejin.cn/post/7530893865550675968
拥有自由的人,会想什么是自由吗?
拥有自由的人,会想什么是自由吗?
这个问题很动人。
就像从不缺氧的人,不会意识到自己在呼吸;只有气压骤降、肺部抽痛、窒息临近,你才突然意识:空气原来不是理所当然的东西。
自由也是一样的。它真正被觉察的时候,往往是在你被拿走的时候。
不是所有人都有幸拥有“思考自由”的资格——更大的现实是,大多数人连“自由”这个词,在生活中都用不上。
但更残酷的问题是:一旦你开始思考自由,你可能就已经不再自由了。
意识是自由的开始,还是终结?
我们都羡慕小孩的自由,羡慕他们想哭就哭、想跑就跑。那是因为他们没有太多意识,不懂责任,不预设后果。他们拥有的,某种程度上就是我们说的“纯粹的自由”。
但我们一旦有了意识,就不得不开始自我规训。
你不能说错话,不能做错事,不能轻易违背别人的期待,也不能轻易违背自己的设定。这时候,自由就变成了一个带着锁链的词——它不再是“你想干嘛就干嘛”,而是“你要先知道你干嘛,然后想清楚值不值得干”。
你开始意识它,珍惜它,运用它。听上去很高尚,但自由就没那么轻盈了。你得为每一个选择负责。你得考虑代价。你得思考背后有没有人被伤害,代价是否能承受。那时候你拥有的自由,不再是“想干嘛就干嘛”,而是“想清楚还能不能干”。
于是我们陷入悖论:越意识自由,就越离自由远。
真自由,是不是只能不想自由?
也许真自由的极致状态,就是你不再思考自由。
你骑车穿过黄昏,不想目标,不管导航,只有风。那一刻你自由得像只鸟——不是因为你想清楚“我现在自由”,而是因为你根本没想。
但人做不到这一点。
人思考,自我意识,把自己从自然的状态中拉出来。他要赋予意义,要预测后果,要制定计划、要写年中总结。“思考”是人成为人的标志,但恰恰是这种人性,把自由给污染了。
你可以试着淡化思考和责任,去贴近那种“纯粹的自由”。
但走到尽头,你会发现,那个状态更像动物,或者神明——不是人。
佛陀顿悟时抛弃自我,道家讲“无为而无不为”,他们都靠剥离世俗意义、剥离责任来获得自由。但代价是:你不再是你了。你不再参与、不再牵挂、不再卷入——你从人间抽身而出。
那还是你想要的吗?
你想要的自由,真的是那种不思考、不负责、无我无念的“纯粹自由”吗?还是你其实想要的是“有方向、有意义、有选择权的自由”?
那就不是“纯粹的自由”,而是“人的自由”了。
被命名,被负重,被理性打磨过的一种自由。
成年人的自由,成熟还是无奈?
很多人问:我们活在这种“既不能无意识、又不能无限选择”的自由状态里,算不算一种折中?
是深刻的选择,还是没办法的接受?
我想,这两种说法都对。
是选择的深刻,是因为我们终于知道,自由不是想干嘛就干嘛,而是想清楚干嘛还敢干。我们学会了在有限中谋局,在责任中行事,在约束中寻找空间。
是无奈的接受,是因为这世界本就不为个体设计。你生而有父母、有文化、有制度、有边界,你不是赤条条的自由人,而是注定被驯服的社会动物。
所以这就是我们大多数人的状态:在责任和意义之间拉扯,在妥协与坚持中微调。我们既不彻底自由,也没有完全被束缚。我们像在悬崖边站着,一边看风景,一边找落脚点。
真自由的瞬间:不解释、无恐惧、自己买单
有没有真正自由的时刻?有。
也许它不是持续性的,不是状态,而是一个个“瞬间”:
- 你做了一个决定,没有任何人强迫,也没有任何人能为你负责,但你依然选了它。
- 你拒绝了别人的定义,不害怕后果,不需要解释,也不留退路。
- 你明知代价高昂,但你还是咬牙说:“是我选的。”
这些时刻,就是成年人的自由瞬间。它不一定光鲜,但它是真实的。
不是没有限制,而是你在限制中还敢动,还想选,还愿意承担结果。
小时候我们追求的自由,是不要规则、不要约束。
长大后我们追求的自由,是在规则中拥有自己的边界感,在约束中活出自己的形状。
我们不会再轻易喊口号,也不会高谈“我要自由”。因为我们知道,自由并不是要来讲的,而是用来活的。
自由从来不是站在天台上的呼喊,而是你在清晨醒来,决定今天以什么方式活。
有些人一生都在寻找自由,却不知:
你敢为自由付出代价的那一刻,你就已经自由了。
推荐阅读
什么是好婚姻?一场人类与AI直指婚姻本质的深度对话,带你认清自己
互联网打工人如何构建稳定的社会身份?——从腾讯离职到圈层断崖的思考
互联网人,为什么你越来越能干,路却越走越窄?换个体制内视角看看
从“奶妈”的消失看“母职外包”:自由是建立在别人无法选择的人生之上
来源:juejin.cn/post/7526820622878572587
程序员如何在家庭、工作、健康之间努力找平衡
程序员如何在家庭、工作、健康之间努力找平衡
前言
作为程序员,我们每天都要面对 工作、家庭、健康 的三重压力。加班是常态,学习新技术是必须,家人的期待也不能忽视,而自己的身体却在无声抗议……
如何在代码、生活和健康之间找到平衡? 今天,我想分享自己的实践心得——时间管理、高效工作(甚至合理摸鱼)、坚持运动和培养爱好,让生活不再只有996。
1. 时间分配:你不是没时间,只是没规划
很多人抱怨"太忙了,根本没时间",但其实:
- 时间就像海绵里的水,挤一挤总会有
- 关键在于优先级,而不是时长
(1)工作日时间分配(参考)
| 时间段 | 安排 | 核心原则 |
|---|---|---|
| 7:00-8:00 | 早起1小时 | 运动/阅读/学习(不碰手机) |
| 9:00-12:00 | 高效工作 | 处理复杂任务(大脑最清醒) |
| 12:00-13:30 | 午休 | 吃饭+小睡20分钟(不刷短视频!) |
| 14:00-18:00 | 工作+摸鱼 | 穿插休息,避免久坐(后文讲摸鱼技巧) |
| 19:00-21:00 | 家庭时间 | 陪家人,带娃儿出去耍(儿子现在一岁一个月)) |
| 21:00-22:30 | 自我提升/放松 | 学习、兴趣、轻度运动 |
| 23:00前 | 睡觉 | 保证7小时睡眠 |
关键点:
- 早起1小时 > 熬夜3小时(效率更高,不影响健康)
- 午休小睡能提升下午效率(NASA研究证实)
- 晚上固定家庭时间(让家人感受到你的存在)
2. 上班摸鱼的正确姿势(高效工作法)
摸鱼 ≠ 偷懒,而是 科学调整工作节奏,避免 burnout(职业倦怠)。
(1)合理摸鱼技巧
✅ 番茄工作法:25分钟专注 + 5分钟休息(刷掘金、喝水、拉伸)
✅ 每1小时起身活动:接水、上厕所、简单拉伸(预防颈椎病)
✅ 利用自动化工具:写脚本省时间(比如自动生成周报、批量处理数据)
✅ 学会"战略性拖延":非紧急需求先放一放,等PM改需求(你懂的)
(2)减少无效加班
❌ 无意义会议:能异步沟通的绝不开会
❌ 过度追求完美:代码能跑就行,别陷入"过度优化陷阱"
❌ 盲目卷工时:效率 > 工作时长,早点干完早点走
摸鱼的核心是:用更少的时间完成工作,把省下的时间留给生活。
3. 下班后:运动 + 兴趣,找回生活掌控感
(1)运动:程序员最值得的投资
- 每天10分钟拉伸(改善肩颈酸痛)
- 每周3次有氧运动(跑步、游泳、骑行)
- 利用通勤时间运动(骑车上班、步行回家)
(亲测有效) 自从坚持运动,我的腰不酸了,debug效率都提高了!
(2)培养兴趣爱好,对抗职业倦怠
- 学一门非技术技能(摄影、吉他、烹饪)
- 参加线下活动(技术沙龙、运动社群)
- 每周留出"无屏幕时间"(比如读书、拼乐高)
生活不能只有代码,否则你会变成一个无聊的人。
4. 家庭时间:质量 > 数量
- 每天30分钟专注陪伴(不刷手机,认真听家人说话)
- 周末至少半天家庭日(哪怕只是逛超市、一起做饭)
- 重要日子提前安排(生日、纪念日,绝不缺席)
孩子不会记住你加了多少班,但会记住你是否陪他踢过球。
结语:平衡是动态的,不是完美的
程序员的生活就像 多线程编程——工作、家庭、健康,每个线程都要分配好资源,否则就会死锁。
我的经验是:
- 工作时间高效摸鱼,减少无效加班
- 下班后运动+兴趣,保持身心健康
- 家庭时间全心投入,不让代码侵占生活
掘友们,你们是如何平衡工作、家庭和健康的?欢迎在评论区分享你的经验!
(如果觉得有用,点个赞吧~ 🚀 你的支持是我分享的动力!)
关于作者
一个拒绝996的程序员,相信 代码是为了更好的生活,而不是取代生活。
关注我,了解更多程序员成长 & 生活平衡技巧!
来源:juejin.cn/post/7520066847707643915
你有多久,没敢“浪费”点时间了?
引言
前两天有个朋友劝我:“你写作一年半了,再不搞点产品变现,继续写作两三年,可能还是原地踏步。”
写了一年半,80多篇文章,没涨粉、没变现、也没10w+。很多人觉着我白干了,可我反而觉着,这是我这几年做的最对的一件事情。
现在回头看看,真正让我成长的,恰恰是那些“什么都没做”的时光。
浪费时间才能感受到自由且主观的愿望
我们这一代人对时间的利用,已经开发到了极致,有着极强的目的性。
高中时,排队打饭背单词,午休趴在床上背公式。
大学毕业,为了面试背八股文、刷算法。
在大厂,一空下来就去研究新技术、优化工作流......
我从未停下来过,连休息都像在为下一次奔跑而准备。
我们太怕浪费时间了。
怕没成果,怕落后,怕被这个飞速发展的社会淘汰掉。
可你想想,我们来到这个世界,不应该是来探索和体验的吗,我们看似高效利用了时间,可有多少时间是真的为了你自己呢。
上篇文章我提到,回到济南之后,相比在北京有了更多空闲时间,并且开始“补偿性浪费”,刷短视频、打游戏、炒股,算得上不务正业。
有一天孩子睡觉后,我从8点刷抖音刷到凌晨,但没有记住任何内容,那一刻我有一种无所事事的空虚感。
于是我开始换口味,刷一些技术社区、公众号文章。偶尔点进一些作者的首页,我发现他们很多并不是大V,也没有露脸,但写的文字有一种特别的力量。
他们写自己的经历、认知的变化、对技术和生活的思考,字里行间有诚意也有深度,我有点羡慕,也有点触动。
既然他们可以写,我也可以。
那一刻我才想起来,我好像很早之前就喜欢写东西,只不过后来成家立业,一路奔波,把这件事丢在了脑后而已。
这么多年,我总是忙着成为别人期待的样子,却很少问自己一句:我到底喜欢什么?
于是我开始尝试着表达自己,一开始不为流量也不为变现,就只是为了找回一点属于自己的空间,
现在回头看,那段“虚度光阴”的日子,并不是浪费,而是我停下来,等到了那个被遗忘很久的自己。
时间看似浪费,但是在塑造你
有一次晚上睡觉前,随手打开了一篇去年写下的文章。
看着看着感到睡意全无,逻辑混乱、语句稚嫩,没有原创的观点,更没有什么进步,可怕的是这样的文章我重复了这么多遍,我忍不住怀疑自己这一年到底在干些什么。
还有一次我花了4、5天写下了3000字,写完读了一遍,发现整个逻辑有些牵强,于是我把写下的内容挪到了“回收站”里,那一刻我感觉我自己浪费了好几天的时间。
这些文章,没有涨粉,也没有变现,也没写出个10w+,那种感觉我自己都很难说清楚,明明花了时间和精力,却有一种什么都没留下的“无力感”。
有几个一起做公众号的朋友,已经走通了自己的商业闭环,而我却连个精准的定位都没有。有一段时间我经常会陷入自我怀疑,我这样的坚持到底有没有意义。
一直以来好像都很着急,我习惯了“投入—产出—收益”的闭环,反倒忘了有些事情短期就是看不到结果。
可就是在这样反复挣扎的过程中,我好像有了一点变化,并不是我变得更高效了,而是我越来越清楚自己想表达些什么,想成为什么样的人。

我做自媒体之初并没有定位,可慢慢的我在过去80多篇文章中,我慢慢发现了几条主线。
比如作为这个时代的一个普通人,我喜欢分析一下时代困局,比如越来越卷的互联网,比如AI飞速发展下,我们面临的存在主义危机;
我热衷谈论认知提升的话题,如果我们要和那些优秀的人去对比,我们会发现除了财富和见识,差距最大的可能是认知边界;
我会谈论一些写作相关的东西,因为写作在这个人人都可以是一个品牌的时代,写作本身就是竞争力。
这几个方向不是我刻意设计出来的,而是过去敲下的每一个字塑造出来的。
我想起乔布斯在斯坦福大学演讲时分享的故事,乔布斯曾在大学退学后,痴迷于书法,选修 了一门看似“无用”的课程:书法美学。
直到十年后,他在打造第一代 Macint0sh 时,那些关于字体的记忆突然涌上心头。他让电脑第一次有了漂亮的字体系统,正是这件“没用的事”,让 Apple 成为了极少数“兼具科技与艺术”的品牌。
很多事情只有回头看,点才会连接成线,你想想是不是这样。
而这一切的前提是:你愿意为此“浪费时间”。
我现在怎么与时间相处的
最后一点想聊聊提升效率这回事——真正的高效,不是把时间填满,而是敢于浪费一些时间。
有孩子的人一定都有体会,娃绝对算的上是一个「时间剥夺兽」。
我为了抢夺时间,做了特别多的尝试:比如孩子一安静下来,我就赶紧打开手机看篇文章;给娃刷奶瓶刷碗的时候,我就打开听书;甚至陪孩子的时候,嘴上给他讲着故事,脑海里还不停的想一些自己的事情。
我一直试图绷紧脑海里的一根弦,觉着只要把时间用满了,就没有浪费。
但现实是,我越来越累,状态越来越差,效率越来越低。
其实我们没必要给自己较劲。
直到读了《超高效》这本书,我才意识到,大脑的原始设定,并不是持续“高负荷”的,而是分成了三种运行状态,符合幂律分布的节奏。
横坐标代表了工作强度,纵坐标代表频率。书里面列举了很多人类学家对原始部落的观察:那些采集、狩猎为生的人,绝大部分时间都是在放松,走走停停,一点也不忙碌。只有在必要的情况下,才会去长时间奔跑去追踪一个猎物,而且干一次得休息好几天。
大部分时间做轻松的事情,偶尔上个强度,才是我们人类天然适合的状态。
而我们日常的工作和生活却反过来了,试图每小时都高产,每天都有 产出,哪怕放假都不敢停歇。
你想想是不是很多人都这样?多少大厂的程序员,被一个bug卡住半天,却死盯着屏幕不愿站起身。明明已经困的上下眼皮打架,还是逼着自己熬夜敲着代码。领导看着没完成的工作量很大,就强迫大家周六周日加班赶进度。
你想想你身边是不是还有另一种人?
你在工位磨磨蹭蹭写代码的时候,同事下楼散散步,买了杯咖啡,再次坐回工位上时,一个小时的工作量比你半天的还要多。
更讽刺的是,代码质量还比你高。
我们为什么不允许自己休息休息呢,让自己“浪费”点时间呢?
后来我做出了个改变,我再带孩子出去玩的时候,试着清空大脑,绝不再想下一篇文章的选题,也不想工作上的事情,就是专心的陪着孩子玩。他跑我就追,他笑我便笑,他想要只小虫子,我就抓只蚂蚁放到他手里。
看似一整天我都“没干正事”,可大脑深度放松之后,迅速让我进入高效状态。有时候写着写着没思路了,下楼转一圈卡点就能被解开。
我突然认识到,娃哪是“时间剥夺兽”,而是一个提醒我“别太紧绷”的小天使。

你也可以当自己的小天使。
如果你感到很累,就去看会轻松的小说、看看搞笑的短视频吧,只要让自己的注意力放松下来就好。如果你很累,还对工作和生活的事很担心,就出去跑一圈、打局游戏或者正念冥想,先把那个担心放下再说。
更简单的方法是订一个闹钟,千万别让自己持续工作超过90分钟,15分钟的小睡能让你迅速恢复精力。
你需要停一停,你值得等一等。
说在最后
现在越来越多的年轻人,哪怕是换份工作,都不敢在这个时候多休息几天。比如我自己,几次跳槽,从来都是今天离职,明天入职。
“浪费时间”说起来容易,可我们心理的的确确存在一些不安全感:怕别人说自己躺平,怕简历又多出一个空档期,更害怕自己没有薪资无法证明自己的价值。
可你知道吗,这些不安全感,并不是我们自身的问题,而是这个时代的结构性压力。
教育体系从小把“高效”描述成美德,互联网把内卷和35岁危机当成噱头大肆宣传,自媒体正贩卖着“日入过万”、“自由职业”的焦虑。
可丁可卯,做每一件事都只注重效率绝不浪费时间,一天到晚跟打仗一样连说闲话的时间都没有,很难做真正重要的事,高水平工作需要浪费时间。
你有多久,没允许自己浪费点时间了?
这是东东拿铁的第83篇原创文章,欢迎关注。
来源:juejin.cn/post/7522187483761950771
技术越来越好,但快乐越来越少
引言
你还记得,上一次真正感受到快乐,是在什么时候吗?
认真想了想,我好像很久没有体会过那种真正让人开心的时刻了。朋友和家人问我最近怎么样,我会回答“还行”、“还不错”,但实际上家庭的琐事,工作的压力,对未来的焦虑,让我连半刻的放松都是一种“奢侈”。
这种状态不只我一个人,身边的朋友也是如此,日常聊天里被越来越多的烦、忙、累填满,有时候甚至“无聊”都成为了一种常态。
可我们小时候,一件新衣服、一个新游戏、一集刚更新的《火影忍者》就能让自己兴奋得整夜睡不着觉。
而现在,曾经喜欢的游戏懒得打开;过去喜欢约上三五好友聚会,现在休息的时候只想窝在家里;哪怕是自己最喜欢的动漫和电影,也没有按下播放键的冲动。
是因为我们长大了、变成熟了,身上的担子越来越重,以至于连快乐都无处安放了吗?
如果你对凡事都提不起兴趣,找不到快乐的方向,那得小心了——心理学上有一个术语,叫做「快感缺乏症」。长期的快感缺失会让我们失去对生活的敏感度,不仅难以感受快乐,还容易陷入负面情绪无法自拔,还有可能导致抑郁。
那么——快乐为什么消失了?我们又该如何找回它?
要找回快乐,就要从我们那个既熟悉又陌生的名字说起:多巴胺。
多巴胺不是快乐源泉
很多人以为,多巴胺是“快乐荷尔蒙”,但其实,它并不直接带来快乐,而是——激励。它并不会让你沉浸在此刻的满足,而是让你对现状“不满足”。它让我们不满足于现状,而是不断前进。
多巴胺能强烈驱动动机,但是它的激励效应转瞬即逝。一旦我们吃饱喝足、或者满足了我们的什么愿望之后,多巴胺的奖励作用就会消失,促使着我们去寻找下一份刺激。
在远古时代,这对于人类来说是一个非常重要的生存机制。因为食物短缺,安全难求,原始人几乎需要用80%的时间去觅食和寻找庇护上。大脑通过分泌多巴胺,促使他们保持求生欲,永不停歇。
然而到了现代社会,我们的生活方式彻底发生转变,而大脑的运作方式没有得到进化。于是大脑的多巴胺通路被频繁激活,远超我们所能接受的频率。
除了食物和性这些本能,酒精、电子游戏、网购,甚至是社交媒体的点赞,都在无时无刻挑动着我们体内的多巴胺。原始人辛苦一天才能换回的一丝快感,我们轻而易举的就能让它泛滥。

快乐太容易得到了,于是它反而越来越难感受到了。
多巴胺会激活「D2」型受体, 它的特点是收到太多多巴胺之后会产生“脱敏”,并且还会启动抑制机制,一旦被过度刺激,就会容易“疲劳”,最终让我们变得迟钝、不再敏感。
其实还有另一个罪魁祸首是「皮质醇」,它由肾上腺分泌,能够加速我们的代谢和心跳,让我们随时应对可能出现的威胁,让我们处于专注紧张的状态,但是它会抑制多巴胺的释放。
其实这也是远古时期人类的一种自保机制,可是现代社会节奏忙碌紧张,我们时刻都在为某些事情感到焦虑,比如学习成绩没能提高,工作迟迟没有涨薪,甚至是领导安排的任务马上到了Dead Line。
人体的压力系统,本身是为了突发事件而准备的,并不适合现代社会全天候的压力输入,在随时随地都能接收到各种信息的智能时代,我们的压力系统也被滥用了。
最终结果就是,即使身边的事物都在营造愉悦感,我们也很难感受到愉悦了。
重拾快乐
有一本书叫《消失的多巴胺》,作者在书中给我们提供了一个治愈快感缺乏症的方法,叫做「行为激活法」,这个方法非常简单,用一句话总结就是:记录情绪,列出快乐清单,开始行动,感受快乐,锁定美好。
那具体怎么做呢?首先你要先记录下自己的情绪的初始情况,然后持续记录变化,当你看到变化的发生,你就会有坚持的动力。
然后,找到自己喜欢的事情。你可以为自己列一份快乐清单,比如看电影、逛街,甚至是浇花、换一身新衣服,或者是去买一杯自己喜欢的咖啡,都可以。
接着就是按照清单来行动了,可我们不开心的时候有一个表现就是只想躺平,没有做事的动力。作者告诉我们,在没有做事动力的时候,做事本身就能打破缺乏动力的循环,你应该打消那些让你退缩的念头,说了就去做!
一旦有了行动,心情就可能得到改善,这时候我们就要抓住快乐。方法非常简单,因为我们的大脑一次只能处理一个想法,我们在感受到快乐的时候,集中注意力,在快乐的时刻什么都不想,用心去感受这种体验。
就是在你感受到快乐的时候,别想领导安排的工作,别想马上要还的信用卡和房贷,就感受当下的快乐。
一项研究发现,大脑腹侧纹状体区域的长时间激活与维持积极情绪和奖励直接相关,通过集中精力体会奖励时刻,可以保持高水平的心理健康,同时降低皮质醇的分泌量。
最后一步就是锁定美好时刻,最简单的做法就是感恩。有一种非常流行的方法是写感恩日记,在一天结束时,写下今天你所感激的经历。许多研究都表明,感恩可以增加大脑奖励通路中多巴胺的分泌,大脑会鼓励里去寻找更值得感恩的事物,产生正反馈。
写到这里,我感觉有点疲惫,于是我下楼,站到了阳光底下。

阳光很刺眼,我下意识闭上了眼睛,任由太阳铺满脸庞。阳光有些刺眼、有些灼热,但那一刻,但似乎有某种能量慢慢渗到身体内,驱散了心里的疲惫。
我不和同事说话,不考虑手头的工作,也不去想生活的琐事。只是站在那里,感受阳光,感受微风拂过脸颊,感受自己活在当下。
几分钟而已,心里好像解开了某个结,整个人都变得放松下来。
重拾快乐,其实并不难,其实并不是快乐离我们远去了,而是我们被快节奏的生活裹挟,忘记了如何该寻找它。
到这里,你或许已经从烦躁的情绪中脱身,重新感受到生活中久违的松弛和愉悦。但故事还没有结束——你值得拥有的,不只是回归日常的小快乐,更是那种深层次、持续、更高级的快乐。
更高级的快乐
刚刚提到感恩,可以增加大脑中多巴胺的分泌,也许你会有疑问,现代社会不是多巴胺泛滥了吗?刷短视频、打游戏一样可以获得多巴胺,那感恩带来的多巴胺有什么不一样呢?
当然不一样,不过我们先聊一句我们从小听到大的“金句”——做难而正确的事情。
许多成功者特别喜欢说这句话,那到底怎么做呢?是靠意志力和吃苦吗,是吃得苦中苦,方为人上人吗?是书山有路勤为径,学海无涯苦作舟吗?
成功者没有告诉我们的是,他们做那些难而正确的事情,他们「乐」在其中。这个乐,就来自于多巴胺,而多巴胺分为了「快多巴胺」和「慢多巴胺」。
还记得在介绍多巴胺之前,我说过多巴胺的作用吗?多巴胺并不带给我们快乐,而带给我们的是激励,是让我们兴致勃勃的做事,是一种追逐的快乐。
快多巴胺的触发模式是预测->实现,抽烟、喝酒、打游戏、刷短视频,你预测到了这些行为带给你的奖励,立刻就感受到快乐,简单直接。但是快多巴胺释放门槛低,可重复性高,来得快去的也快。
而慢多巴胺触发的模式是努力->进展。比如跑完今天的五公里,就会感受到今天一天都神清气爽;完成一篇文章,你感觉你的写作和思考能力都加深了一层。你必须先努力一番取得进展,它才能释放。慢多巴胺来得慢,去的也慢。

在字节的时候,有一次和10几个同事封闭在会议室开发一个大项目,临近项目上线的那几天,几乎都到2、3点才下班。每当0点以后都是大家最累的时候,虽然每个人脸上充满困意和疲惫,但是看着项目逐渐成型,功能越来越完善,每个人依然干劲十足。
我们或许都有做大项目的经历,在项目即将完成前,你会叫苦叫累吗?你的目标就在眼前,你做事充满动力,这才是健康的状态。做难而正确的事情,是很爽的。
这段经历过去好多年了,说实话当时做的什么项目我都记不清了,但是我记得一群人在会议室里,一同为项目上线熬夜到凌晨的那几个夜晚。
简单说:快多巴胺是“高起点、小波动、快消退”;慢多巴胺是“低起点、慢上升、慢消退”。两种多巴胺最重要的区别,是它们在大脑中的“接收区”不同,我们的感受也不同。
快多巴胺让我们成瘾,慢多巴胺可以给我们赋能。 我们应该防止自己沉溺于快多巴胺,多来点慢多巴胺。
理解了快多巴胺和慢多巴胺的原理,我们就能明白一个道理,为什么人生需要一个长远的目标。
有目标才能有行动,有行动就会有进展,追逐目标的过程能够带来慢多巴胺,而慢多巴胺对我们而言多多益善。
说在最后
所以,快乐并没有从我们身边消失,它只是在等着我们把它找回。
我们需要的不是更快的满足,也不是更高频的刺激,而是更沉浸的体验和更深入的积累。
“还行、还不错”不是标准答案,“很好、很开心”才是你的原本色彩,你永远值得拥有那种不焦虑、不躁动,却一直点亮我们生活的快乐。
那么你呢,你今天开心吗?
这是东东拿铁的第79篇原创文章,欢迎关注。
来源:juejin.cn/post/7506417928787968010
Jetbrains正式宣布免费,有点猛啊!
提到 Jetbrains 这家公司,相信搞开发的同学应该都不陌生。

该公司盛产各种编程 IDE 和开发工具,虽然2000年才成立,到现在却已经发布了超 30 款世界顶级的编程软件,同时也收获了来自全球范围内开发者和用户的青睐。
众所周知,在去年10月份的时候,Jetbrains 曾经搞过一个大动作,那就是:
官宣 WebStorm 和 Rider 这两款强大的 IDE 对非商业用途全面免费!
当时这个消息出来的时候,就曾在开发者圈子里引起了一阵轰动和讨论。
而且我清楚地记得,在当时的评论区,还有小伙伴这样问道:
“啥时候轮到 CLion 也免费呢?”
这不,好消息再次来临了!!
最近 Jetbrains 再度官宣:
CLion 从现在开始,对非商业用途全面免费!

众所周知,CLion 是由 JetBrains 设计开发的跨平台 C/C++ 集成开发环境,通过智能代码补全、深度代码分析和集成调试工具,为开发者提供高效、现代化的 C 语言和 C++ 开发体验。
然而,CLion 一直以来的高昂授权费用也让不少初学者和开源爱好者为之望而却步。
因此这回消息一出,又再次在开发者圈子里引起了一阵热烈的讨论,不少网友直呼 Jetbrains 这波格局打开了。

看到这里,相信大家也挺好奇,那他们这里所说的 「非商业用途免费」具体指的是哪些情形呢?
对此,Jetbrains 官方也给出了对应的说明,目前的非商业用途情形包括像:学习、自我教育、开源项目开发、内容创作、业余爱好开发等场景就可以免费使用这个 IDE 。
所以现在无论是学生、Arduino 开发者,还是无惧 C 语言和 C++ 重重挑战的忠实爱好者,只要使用场景不涉及商业活动,都可以来免费使用 CLion 进行开发。
说到这里,那具体的非商业用途免费版 CLion 怎么申请和使用呢?
操作其实也非常简单。
1、首先,去官网下载 CLion 安装包并安装。
不过这里要注意的是,用户需要确保下载的 IDE 版本是支持非商业许可证的最新版本即可。
2、启动运行 IDE 后,将会看到一个许可证对话框。
在该对话框中,用户可以在其中选择 Non-commercial use(非商业用途)选项。
3、登录自己的 JetBrains Account 或创建一个新的帐户。
4、登录完成后,用户需要接受 Toolbox 非商业用途订阅协议。
5、尽情享受在 IDE 中的开发。
包括如果用户已经开始了试用期或使用付费许可证激活了自己的 IDE,也仍然可以改用非商业订阅,只需要转到帮助|注册里,并在打开的窗口中点击 Remove License(移除许可证)按钮,然后再选择 Non-commercial use(非商业用途)就行了。
不过这里依然还有两个点需要格外注意。
第一点,也是官方公告里明确所说的。
如果用户选择使用 Non-commercial use 非商业用途的免费版,那软件是有可能会向 JetBrains 发送 IDE 遥测信息的,包括像:框架、产品中使用的文件模板、调用的操作,以及与产品功能的其他交互,但是官方提到不会包含个人数据。
另外还有一点需要注意的是,虽说免费版本的 IDE 在功能上与付费版本并无二致,但在某些特定功能上可能存在一定的限制。例如,免费版本的 Code With Me 功能将仅限于 Community 版本。
不过对于大多数非商业用途的开发者们来说,这些限制并不会对日常开发工作造成太大的影响。
所以总而言之,JetBrains 推出的这些非商业用途免费使用政策,虽说有一些要求,但是总体来说还是极大地降低了 JetBrains IDE 的使用门槛。
同时也会让更广泛的用户群体更容易获取并使用,从而鼓励更多的人投身于编程学习,参与到开源项目的建设,共同推动技术的进步与发展。
文章的最后,我们也不妨再次大胆憧憬一下:
既然目前的 WebStorm、Rider 以及 CLion 都已经开放了非商业用途的免费使用,那么接下来像: GoLand、IntelliJ IDEA 等的免费开放还会不会远呢?
再次期待 Jetbrains 的下一步操作。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7504491526363856934
p5.js 圆弧的用法
点赞 + 关注 + 收藏 = 学会了
在 p5.js 中,arc() 函数用于绘制圆弧,它是创建各种圆形图形和动画的基础。圆弧本质上是椭圆的一部分,由中心点、宽度、高度、起始角度和结束角度等参数定义。通过灵活运用 arc() 函数可以轻松创建饼图、仪表盘、时钟等常见 UI 组件,以及各种创意图形效果。
arc() 的基础语法
基础语法
arc() 函数的完整语法如下:
arc(x, y, w, h, start, stop, [mode], [detail])
核心参数解释:
- x, y:圆弧所在椭圆的中心点坐标
- w, h:椭圆的宽度和高度,如果两者相等,则绘制的是圆形的一部分
- start, stop:圆弧的起始角度和结束角度,默认以弧度(radians)为单位
可选参数:
- mode:定义圆弧的填充样式,可选值为
OPEN(开放式半圆)、CHORD(封闭式半圆)或PIE(闭合饼图) - detail:仅在 WebGL 模式下使用,指定组成圆弧周长的顶点数量,默认值为 25
角度单位与转换
在 p5.js 中,角度可以使用弧度或角度两种单位表示:
- 默认单位是弧度:0 弧度指向正右方(3 点钟方向),正角度按顺时针方向增加
- 使用角度单位:可以通过
angleMode(DEGREES)函数将角度单位设置为角度
两种单位之间的转换关系:
- 360 度 = 2π 弧度
- 180 度 = π 弧度
- 90 度 = π/2 弧度
p5.js 提供了两个辅助函数用于单位转换:
radians(degrees):将角度转换为弧度degrees(radians):将弧度转换为角度
举个例子(基础示例)
举个例子讲解一下如何使用 arc() 函数绘制不同角度的圆弧。
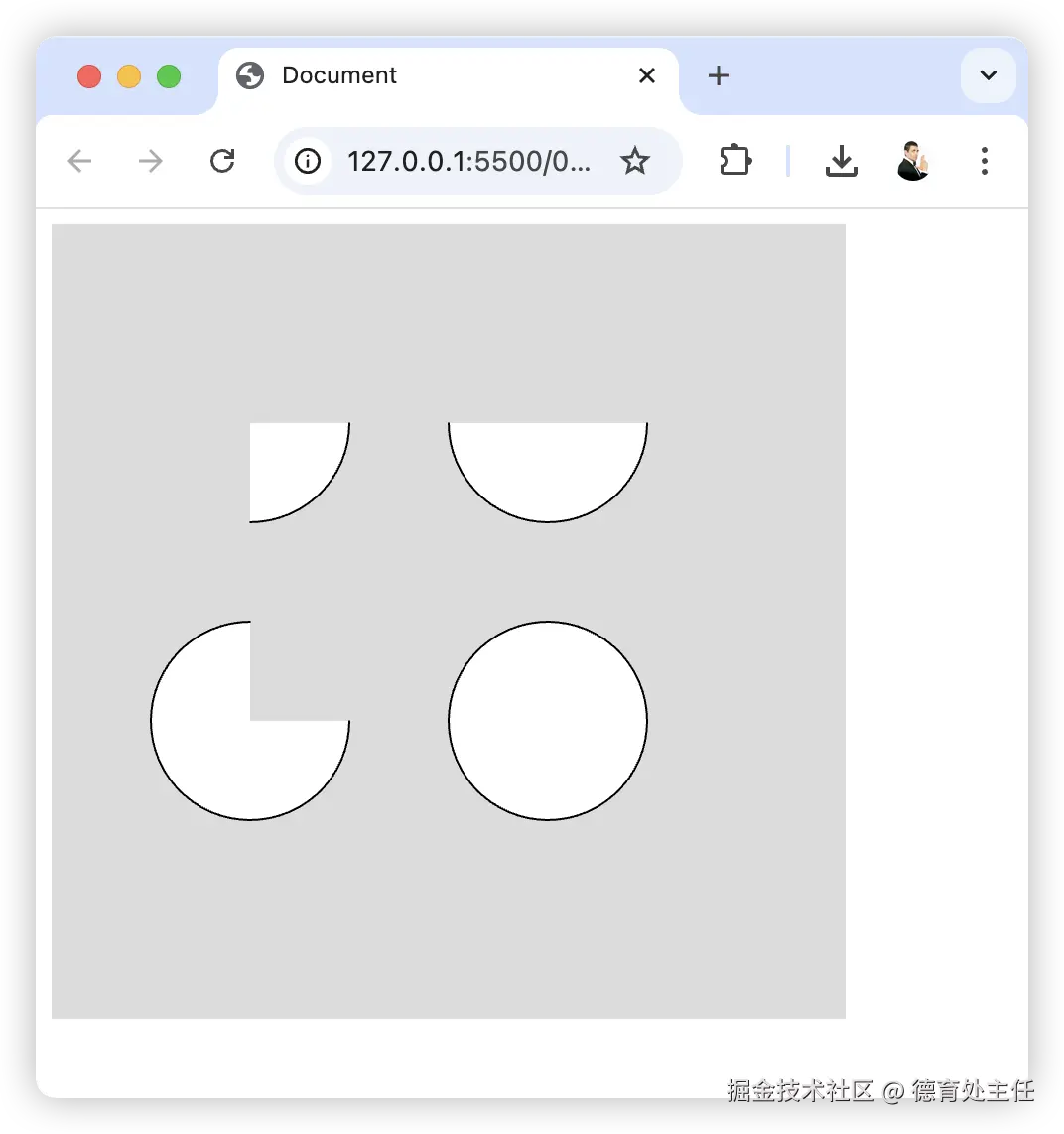
function setup() {
createCanvas(400, 400);
angleMode(DEGREES); // 使用角度单位
}
function draw() {
background(220);
// 绘制不同角度的圆弧
arc(100, 100, 100, 100, 0, 90); // 90度圆弧
arc(250, 100, 100, 100, 0, 180); // 180度圆弧
arc(100, 250, 100, 100, 0, 270); // 270度圆弧
arc(250, 250, 100, 100, 0, 360); // 360度圆弧(整圆)
}
这段代码会在画布上绘制四个不同角度的圆弧,从 90 度到 360 度不等。注意,当角度为 360 度时,实际上绘制的是一个完整的圆形。
三种圆弧模式:OPEN、CHORD 与 PIE
arc() 函数的第七个参数mode决定了圆弧的填充方式,有三种可选值:
- OPEN(默认值):仅绘制圆弧本身,不填充任何区域
- CHORD:绘制圆弧并连接两端点形成闭合的半圆形区域
- PIE:绘制圆弧并连接两端点与中心点形成闭合的扇形区域
这三种模式不需要手动定义,p5.js 已经在全局范围内定义好了这些常量。
举个例子:
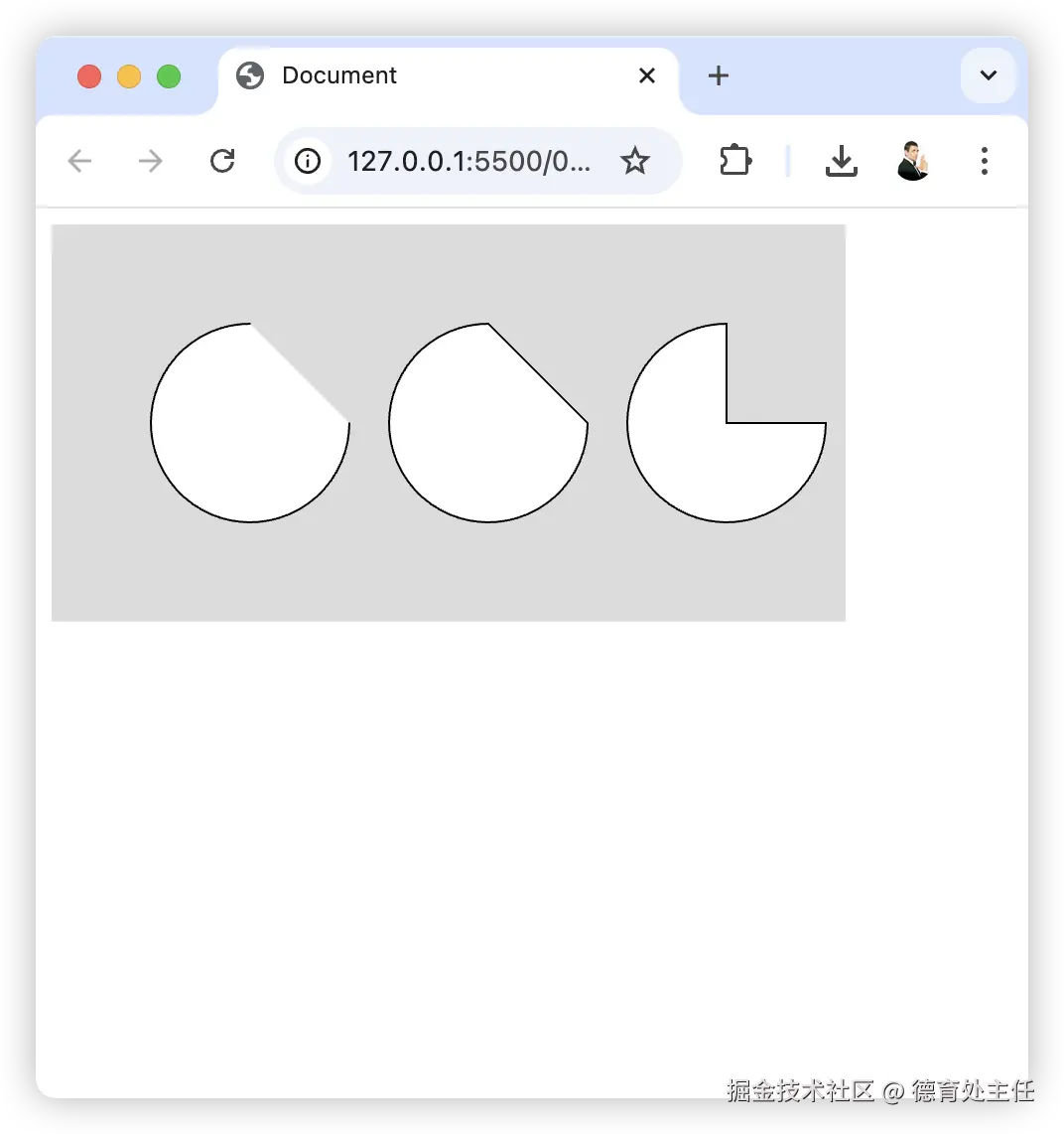
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
}
function draw() {
background(220);
// 绘制不同模式的圆弧
arc(100, 100, 100, 100, 0, 270, OPEN);
arc(220, 100, 100, 100, 0, 270, CHORD);
arc(340, 100, 100, 100, 0, 270, PIE);
}
这段代码会在画布上绘制三个 270 度的圆弧,分别展示 OPEN、CHORD 和 PIE 三种模式的效果。可以明显看到,OPEN 模式只绘制弧线,CHORD 模式连接两端点形成闭合区域,而 PIE 模式则从两端点连接到中心点形成扇形。
如何选择合适的模式
选择圆弧模式时,应考虑以下因素:
- 视觉效果需求:需要纯弧线效果时选择
OPEN,需要闭合区域时选择CHORD或PIE - 应用场景:饼图通常使用
PIE模式,仪表盘可能使用CHORD模式,而简单装饰线条可能使用OPEN模式 - 填充与描边需求:不同模式对填充和描边的处理方式不同,需要根据设计需求选择
值得注意的是,arc() 函数绘制的默认是填充的扇形区域。如果想要获取纯圆弧(没有填充区域),可以使用 noFill() 函数拒绝 arc() 函数的填充。
做几个小demo玩玩
简易数字时钟
在这个示例中,我将使用 arc() 函数创建一个简单的数字时钟,显示当前的小时、分钟和秒数。
let hours, minutes, seconds;
function setup() {
createCanvas(400, 400);
angleMode(DEGREES); // 使用角度单位
}
function draw() {
background(220);
// 获取当前时间
let now = new Date();
hours = now.getHours();
minutes = now.getMinutes();
seconds = now.getSeconds();
// 绘制时钟边框
stroke(0);
strokeWeight(2);
noFill();
arc(width/2, height/2, 300, 300, 0, 360);
// 绘制小时刻度
strokeWeight(2);
for (let i = 0; i < 12; i++) {
let angle = 90 - i * 30;
let x1 = width/2 + 140 * cos(radians(angle));
let y1 = height/2 + 140 * sin(radians(angle));
let x2 = width/2 + 160 * cos(radians(angle));
let y2 = height/2 + 160 * sin(radians(angle));
line(x1, y1, x2, y2);
}
// 绘制分钟刻度
strokeWeight(1);
for (let i = 0; i < 60; i++) {
let angle = 90 - i * 6;
let x1 = width/2 + 150 * cos(radians(angle));
let y1 = height/2 + 150 * sin(radians(angle));
let x2 = width/2 + 160 * cos(radians(angle));
let y2 = height/2 + 160 * sin(radians(angle));
line(x1, y1, x2, y2);
}
// 绘制小时指针
let hourAngle = 90 - (hours % 12) * 30 - minutes * 0.5;
let hourLength = 80;
let hx = width/2 + hourLength * cos(radians(hourAngle));
let hy = height/2 + hourLength * sin(radians(hourAngle));
line(width/2, height/2, hx, hy);
// 绘制分钟指针
let minuteAngle = 90 - minutes * 6;
let minuteLength = 120;
let mx = width/2 + minuteLength * cos(radians(minuteAngle));
let my = height/2 + minuteLength * sin(radians(minuteAngle));
line(width/2, height/2, mx, my);
// 绘制秒针
stroke(255, 0, 0);
let secondAngle = 90 - seconds * 6;
let secondLength = 140;
let sx = width/2 + secondLength * cos(radians(secondAngle));
let sy = height/2 + secondLength * sin(radians(secondAngle));
line(width/2, height/2, sx, sy);
// 显示当前时间文本
noStroke();
fill(0);
textSize(24);
text(hours + ":" + nf(minutes, 2, 0) + ":" + nf(seconds, 2, 0), 50, 50);
}
关键点解析:
- 获取当前时间:使用Date()对象获取当前的小时、分钟和秒数
- 角度计算:根据时间值计算指针的旋转角度,注意将角度转换为 p5.js 使用的坐标系(0 度指向正上方)
- 刻度绘制:使用循环绘制小时和分钟刻度,每个小时刻度间隔 30 度,每个分钟刻度间隔 6 度
- 指针绘制:根据计算的角度和长度绘制小时、分钟和秒针,注意秒针使用红色以区分
- 时间文本显示:使用text()函数在画布左上角显示当前时间
饼图
在这个示例中,我将创建一个简单的饼图,展示不同类别数据的比例。
let data = [30, 10, 45, 35, 60, 38, 75, 67]; // 示例数据
let total = 0;
let lastAngle = 0;
function setup() {
createCanvas(720, 400);
angleMode(DEGREES); // 使用角度单位
noStroke(); // 不绘制边框
total = data.reduce((a, b) => a + b, 0); // 计算数据总和
}
function draw() {
background(100);
pieChart(300, data); // 调用饼图绘制函数
}
function pieChart(diameter, data) {
lastAngle = 0; // 重置起始角度
for (let i = 0; i < data.length; i++) {
// 设置圆弧的灰度值,map函数将数据映射到0-255的灰度范围
let gray = map(i, 0, data.length, 0, 255);
fill(gray);
// 计算当前数据点的角度范围
let startAngle = lastAngle;
let endAngle = lastAngle + (data[i] / total) * 360;
// 绘制圆弧
arc(
width / 2,
height / 2,
diameter,
diameter,
startAngle,
endAngle,
PIE // 使用PIE模式创建扇形
);
lastAngle = endAngle; // 更新起始角度为下一个数据点做准备
}
}
关键点解析:
- 数据准备:定义示例数据数组data,并计算数据总和total
- 颜色设置:使用map()函数将数据索引映射到 0-255 的灰度范围,实现渐变效果
- 角度计算:根据每个数据点的值与总和的比例计算对应的角度范围
- 圆弧绘制:使用PIE模式绘制每个数据点对应的扇形,形成完整的饼图
这个饼图示例可以通过添加标签、交互效果或动态数据更新来进一步增强功能。
描边效果
在 p5.js 中,我们可以通过以下函数定制圆弧的描边效果:
- stroke(color):设置描边颜色
- strokeWeight(weight):设置描边宽度
- strokeCap(cap):设置描边端点样式(可选值:BUTT, ROUND, SQUARE)
- strokeJoin(join):设置描边转角样式(可选值:MITER, ROUND, BEVEL)
以下示例展示了如何定制圆弧的描边效果:
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
}
function draw() {
background(220);
// 示例1:粗红色描边
stroke(255, 0, 0);
strokeWeight(10);
arc(100, 100, 100, 100, 0, 270);
// 示例2:带圆角端点的描边
stroke(0, 255, 0);
strokeWeight(10);
strokeCap(ROUND);
arc(220, 100, 100, 100, 0, 270);
// 示例3:带阴影效果的描边
stroke(0, 0, 255);
strokeWeight(15);
strokeCap(SQUARE);
arc(340, 100, 100, 100, 0, 270);
// 恢复默认设置
noStroke();
}
关键点解析:
- 颜色设置:使用stroke()函数设置不同颜色的描边
- 宽度设置:使用strokeWeight()函数调整描边粗细
- 端点样式:使用strokeCap()函数设置描边端点的样式(圆角效果特别适合圆弧)
- 阴影效果:通过增加描边宽度并偏移绘制位置可以创建简单的阴影效果
填充效果
在 p5.js 中,我们可以通过以下函数定制圆弧的填充效果:
- fill(color):设置填充颜色
- noFill():禁用填充效果
- colorMode(mode):设置颜色模式(RGB、HSB 等)
- alpha():设置颜色透明度
以下示例展示了如何定制圆弧的填充效果:
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
colorMode(HSB, 360, 100, 100); // 使用HSB颜色模式
}
function draw() {
background(220);
// 示例1:单色填充
fill(120, 100, 100); // 绿色
arc(100, 100, 100, 100, 0, 270);
// 示例2:渐变填充
noFill();
stroke(0, 0, 100);
strokeWeight(10);
for (let i = 0; i < 360; i += 10) {
fill(i, 100, 100);
arc(220, 100, 100, 100, i, i+10);
}
// 示例3:透明填充
fill(240, 100, 100, 50); // 半透明蓝色
arc(340, 100, 100, 100, 0, 270);
// 恢复默认设置
noFill();
stroke();
}
关键点解析:
- 颜色模式:使用colorMode()函数切换到 HSB 模式,方便创建渐变效果
- 单色填充:直接使用fill()函数设置单一填充颜色
- 渐变填充:通过循环绘制多个小角度的圆弧,每个使用不同的色相值实现渐变效果
- 透明度设置:在fill()函数中添加第四个参数(0-100)设置透明度
旋转圆弧
在 p5.js 中创建圆弧动画非常简单,主要通过以下方法实现:
- **draw()**函数:每秒自动执行约 60 次,用于更新动画帧
- 变量控制:使用变量控制圆弧的参数(如位置、大小、角度等)
- frameRate(fps):设置动画帧率(可选)
- millis():获取当前时间(毫秒),用于精确控制动画时间
圆弧动画效果示例:
let angle = 0;
function setup() {
createCanvas(400, 400);
angleMode(DEGREES);
}
function draw() {
background(220);
// 绘制旋转的红色圆弧
stroke(255, 0, 0);
strokeWeight(10);
arc(width/2, height/2, 300, 300, angle, angle + 90);
// 更新角度值,实现旋转效果
angle += 2; // 调整这个值可以改变旋转速度
// 恢复默认设置
noStroke();
}
关键点解析:
- 角度变量:使用
angle变量控制圆弧的起始角度 - 角度更新:在每次
draw()调用时增加angle值,实现旋转效果 - 速度控制:通过调整每次增加的角度值(这里是 2 度)控制旋转速度
弧度与角度的转换技巧
在 p5.js 中,arc()函数默认使用弧度作为角度单位,但我们通常更习惯使用角度。以下是一些转换技巧:
- 角度转弧度:使用
radians(degrees)函数将角度转换为弧度 - 弧度转角度:使用
degrees(radians)函数将弧度转换为角度 - 设置角度单位:使用
angleMode(DEGREES)函数将全局角度单位设置为角度,这样arc()函数就可以直接使用角度值 - 常见角度值:记住一些常用角度的弧度值,如 90 度 = PI/2,180 度 = PI,270 度 = 3PI/2,360 度 = 2PI
圆弧绘制的常见问题与解决方案
在使用 arc() 函数时,可能会遇到以下问题:
- arc () 函数中的 bug:当
start_angle == end_angle时,可能会出现意外绘制效果。例如,当start_angle == end_angle == -PI/2时会绘制一个半圆,这不符合预期。解决方案是避免start_angle和end_angle相等。 - 起始角度的位置:在 p5.js 中,0 弧度(或 0 度,如果使用
angleMode(DEGREES))指向正右方(3 点钟方向),而不是数学上的正上方。这可能导致方向与预期不符。 - 描边宽度的影响:较宽的描边会使圆弧看起来比实际大。这是因为描边会向路径的两侧扩展。如果需要精确控制大小,可以考虑将arc()的尺寸适当减小,或者使用
shapeMode()函数调整坐标系。 - 浮点精度问题:在进行角度计算时,尤其是涉及到除法和循环时,可能会遇到浮点精度问题。建议使用
nf()函数(如nf(value, 2, 0))来格式化显示的数值,避免显示过多的小数位。
以上就是本文的全部内容啦,如果想了解更多 p5.js 的玩法可以关注 《P5.js中文教程》
点赞 + 关注 + 收藏 = 学会了
来源:juejin.cn/post/7529753277770022921
收到苹果3.2f之后,有件傻事千万别干!
前言
对于提审Appstore来说,3.2f是早些年Other-Other条款的升级版,其本质省流来说:“你死了!直接行刑!”。
对于升级之后的3.2f来说:“你要死了,给你个解释的机会!” 所以这也就是为什么3.2f提供的30天封号,却经常会远比30天长。因为官方其实是想给机会的,合情合理说得通,有一丝胜算。
但是千人千面、因人而异,毕竟每个收到3.2f的开发者绝非无辜,高低有点毛病。
那么在,收到来自苹果的3.2f之后还能做些什么?
可以干,申诉
首先要做的是分析问题,找到触发3.2f封号的导火索,这是第一要义! 其次就是申诉,申诉只有1次和无数次。
自己找到问题,对症下药的去写申诉文案,剩下的生死有命富贵在天。 对于这块代写申诉文案以及问题分析是不免费的,不过想免费就自己折腾就好。
抱着死马当活马的心态就行了,就是付费咨询也只能提供回复技巧和分享成功案例,但是并非适用所有产品和类目。
不可以,提审
对于3.2f的开发者来说,提审这件事情无疑是件傻事!
因为违规问题已经影响到了账号主体,当务之急是解释说明,让违规合理化还有救,反之基本上也不必要去花时间折腾了。
举一个直接的例子,这就好比公司里有一个销冠。突然有一天公司被上门查封了。那么请问,作为销冠来说是不是想到是换一份工作。不可能傻傻的继续给公司拉业绩了。
转换到Appstore的3.2f也是一样的道理。
账号出问题就和例子中公司被查封是一样的,作为公司的领导者,先要想到是怎么在做一个产品,把失去的阵地夺回来,比起把命运交给申诉来说,这是最明智的首选。
其次就是不要再去想账号里上新产品,以及迭代,毫无意义!
不管是迭代还是上新,首先是不会被审核的。在苹果看来现在的问题没有解释清楚前,所有的行为都不会被接受。
尤其是在一个待终止的账户里上传新版,只能说又白瞎了一套代码。如果还不理解,多多读读上边的小例子。
综上所述,在账户3.2f之后能做只有申诉,其他的行为不用考虑了。先找一个合理的解释,把账号解除待封状态才是王道!
遵守规则,方得长治久安,最后祝大家大吉大利,今晚过审!
来源:juejin.cn/post/7507860944212492328
docker容器如何打包镜像和部署
1、打包镜像
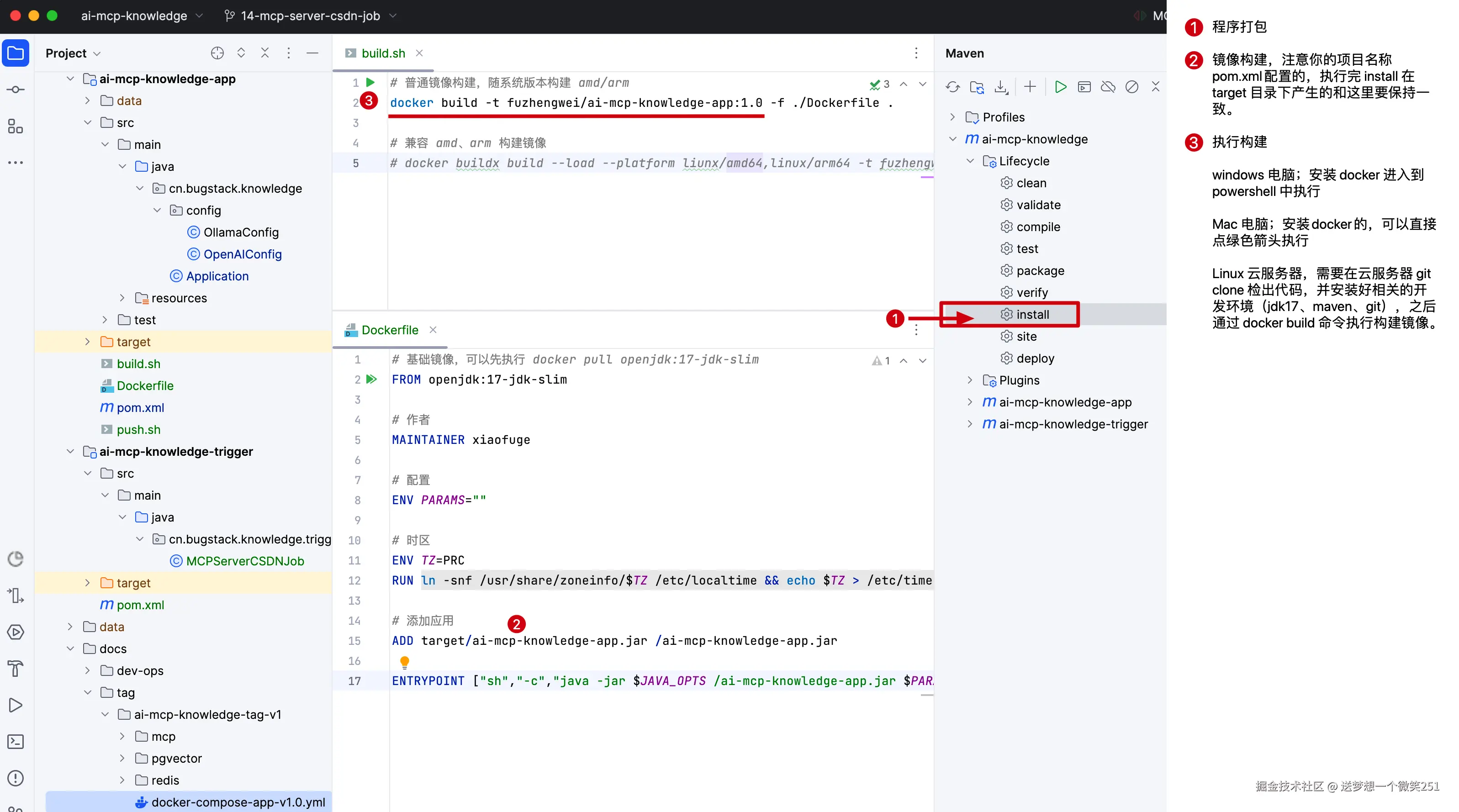
如图,参考执行步骤。打包你的工程镜像。
2、推送镜像
2.1 仓库申请
首先,你需要申请一个阿里云Docker镜像仓库 cr.console.aliyun.com/cn-beijing/…
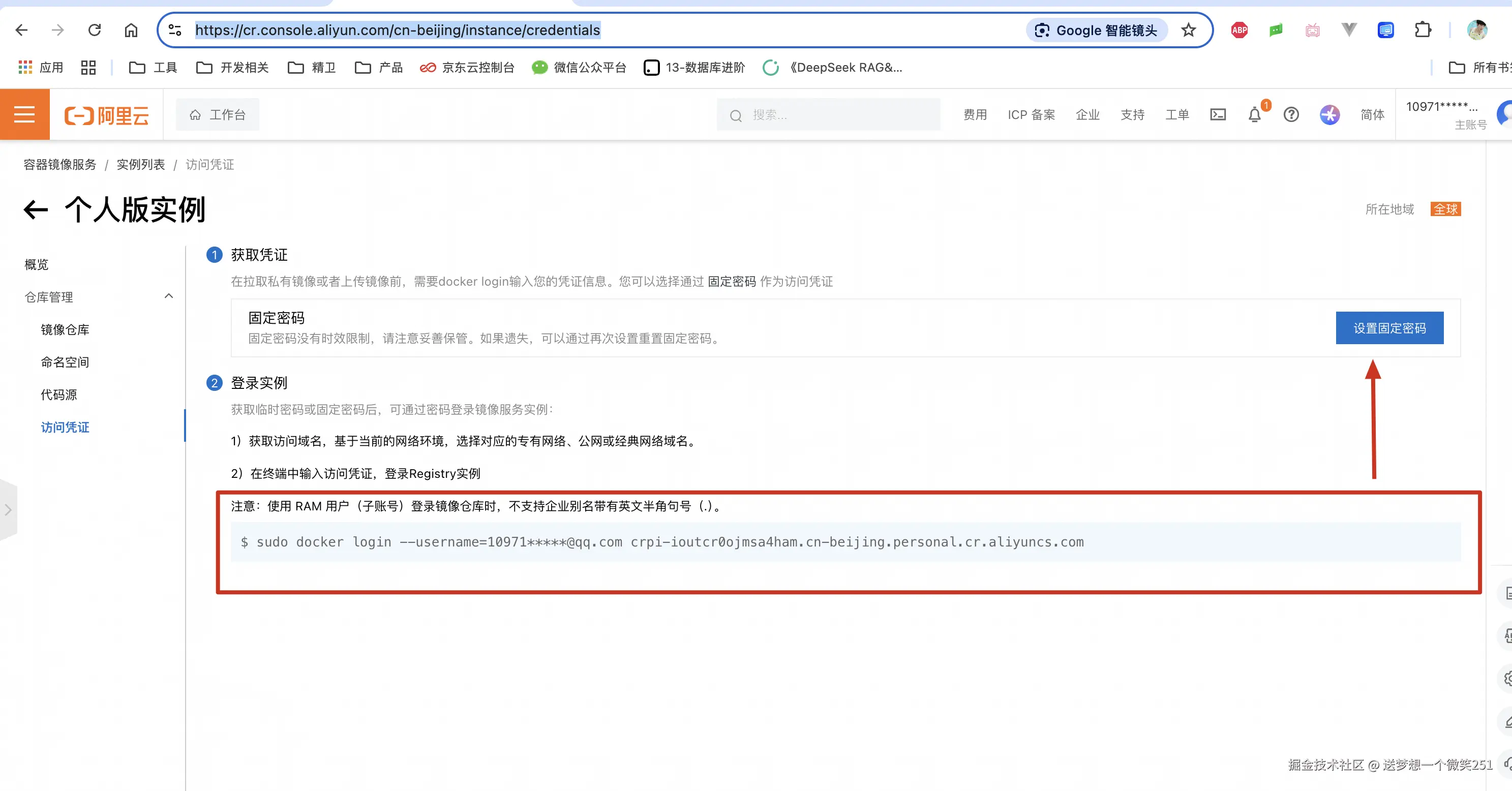
2.2 命名空间
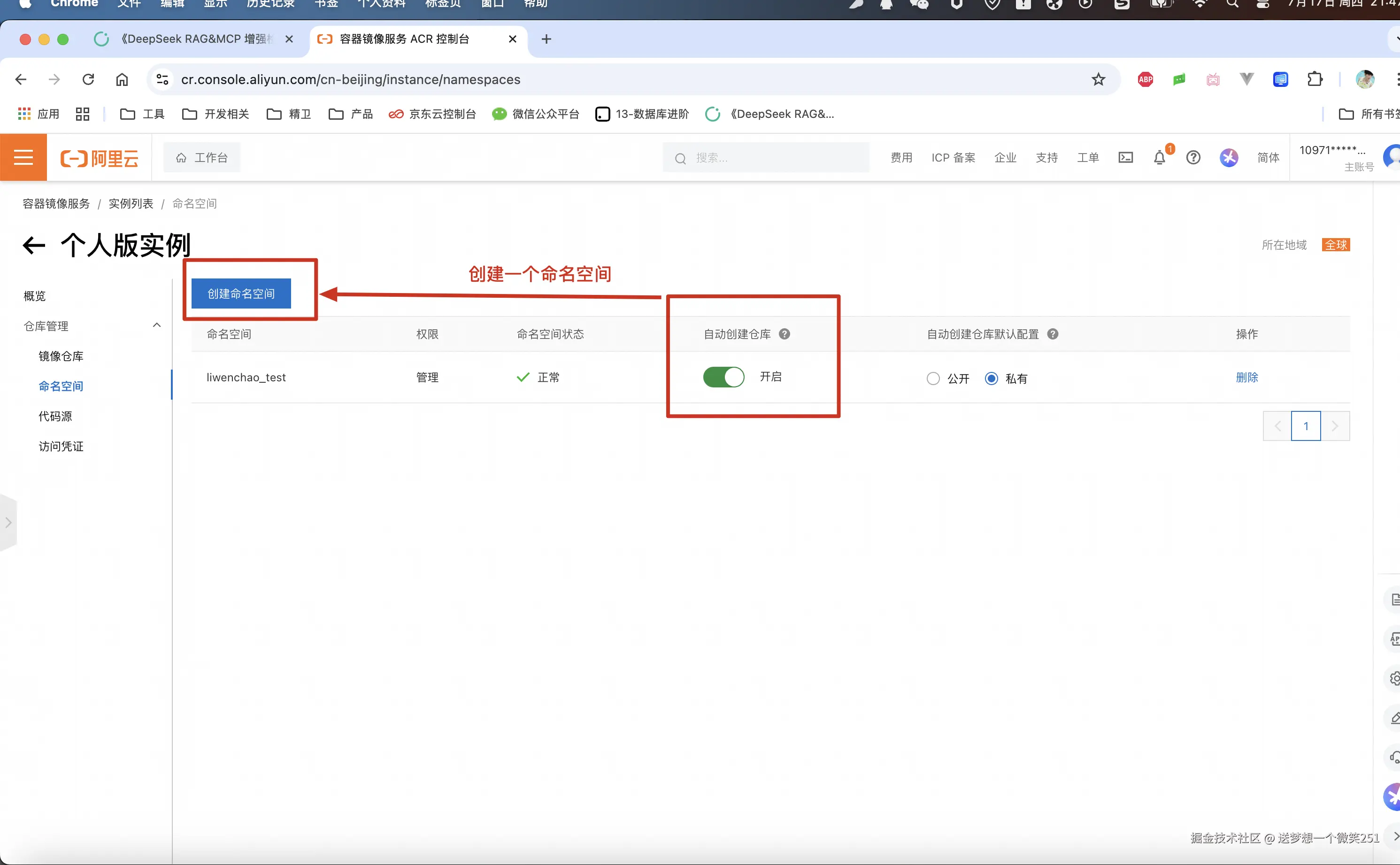
创建一个你的命名空间,后面使用到这个空间地址。
2.3 脚本配置
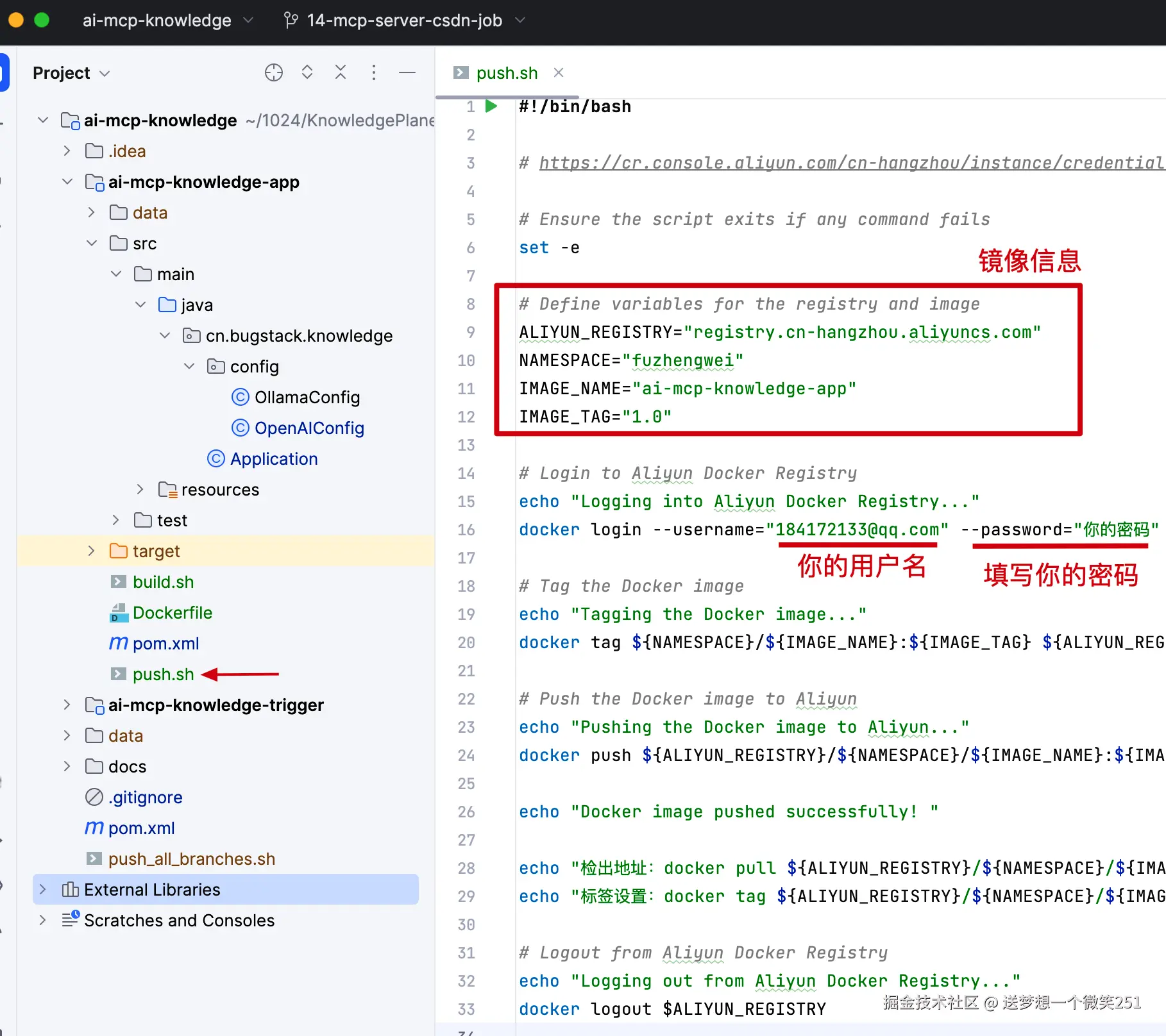
打开 push.sh 填写你的镜像信息,以及你的镜像仓库地址。
push.sh 脚本,需要通过 ./push.sh 运行,mac 电脑可以直接点击绿色小箭头运行。这个操作步骤完成后,会把镜像推送到你的阿里云Docker镜像仓库去。
拉取使用;docker pull crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT
设置名称;docker tag crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT liwenchao_test/riderwuyou-admin:1.0
注意;你可以重设镜像名称,可以把 liwenchao_test/riderwuyou-admin:1.0 的地方。
- 服务脚本
docker 项目的部署,具有一次构建,多地部署的通用性。所以,你可以在本地 docker 环境部署、nas环境部署、云服务器环境部署。
3.1 部署环境 - 脚本
通过以下脚本,安装mysql、redis等。
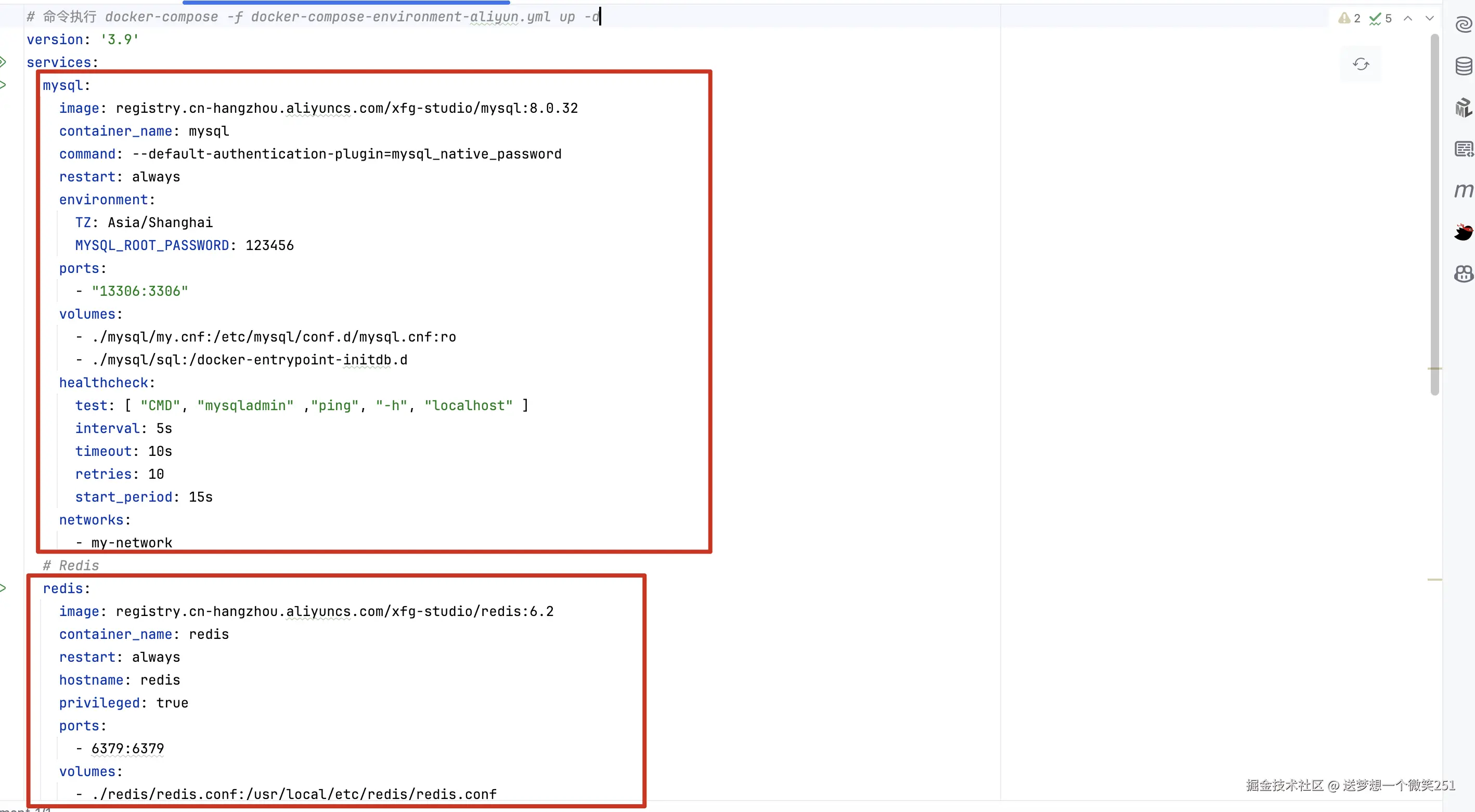
3.2 项目部署 - 脚本
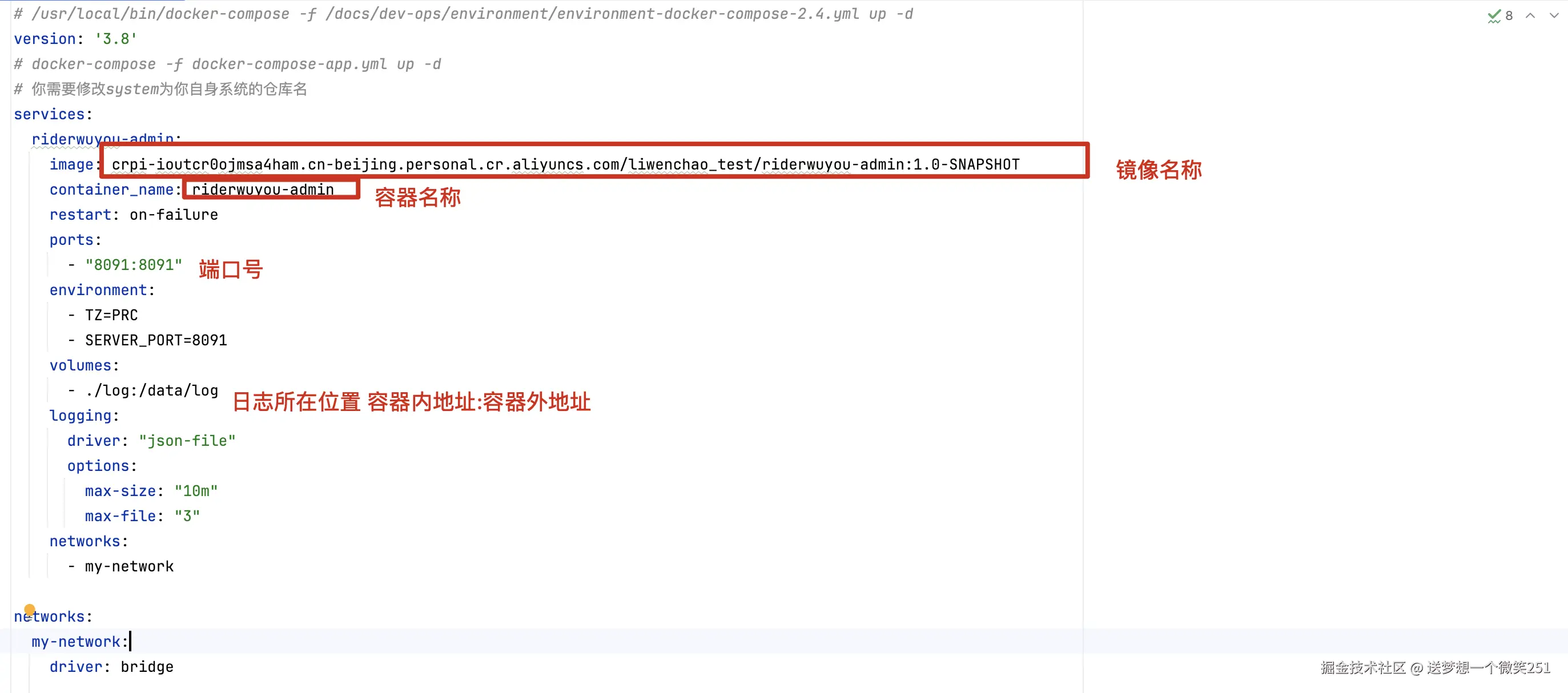
镜像,liwenchao_test/riderwuyou-admin:1.0 如果使用阿里云Docker仓库,那么可以使用 image: crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT 或者用 docker tag crpi-ioutcr0ojmsa4ham.cn-beijing.personal.cr.aliyuncs.com/liwenchao_test/riderwuyou-admin:1.0-SNAPSHOT liwenchao_test/riderwuyou-admin:1.0 设定镜像名称。
4. 服务部署
4.1 上传脚本
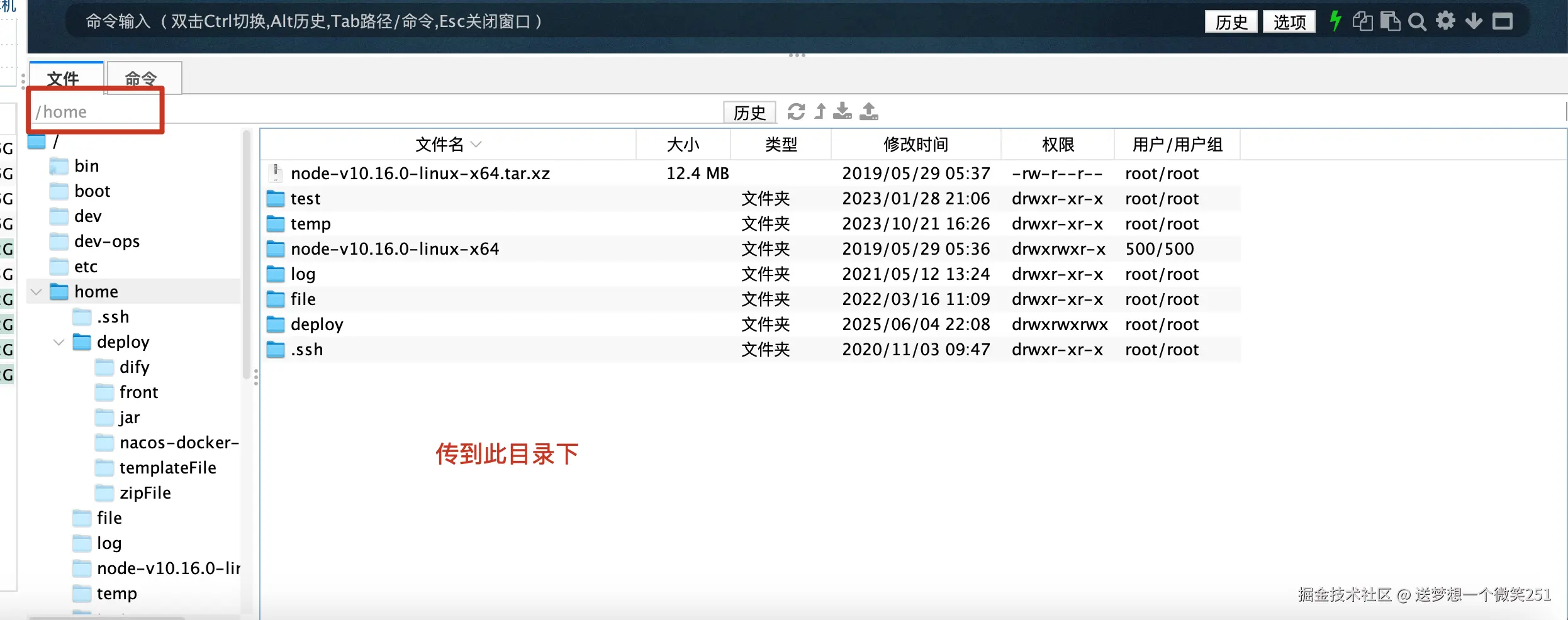
4.2 执行脚本
- 执行脚本01;
docker-compose -f docker-compose-environment-aliyun.yml up -d - 执行脚本02;
docker-compose -f docker-compose-app-v1.0.yml up -d - 运行完成后,就可以运行测试了
来源:juejin.cn/post/7529292244571897910
知名开源项目AList疑似被卖,玩家炸锅了!!
这是昨天发生在开源圈子里的一件事情,在不少开发者论坛和社区里也炸开了锅,相信不少同学也刷到了。
具体怎么回事呢?
原来是知名开源项目 Alist 被爆疑似悄悄出售,原开发者退出了项目。
注意,这里有一个词,是“悄悄”。
原来就在之前的某一天,有细心的网友突然发现,该项目的中文文档开始出现不寻常的修改,比如添加了商业化信息,新增了QQ群和VIP技术支持的内容。
再后来,有网友发现其项目官网域名完成了切换,并且这一变更也没有任何官方声明,从而引发了社区的警觉和质疑。
而事件再进一步升级的导火索则是有社区开发者在项目 PR 中发现了可疑的代码提交。
一位用户提交了包含用户数据收集功能的代码,该代码片段旨在收集用户操作系统信息并上报,尽管该 PR 最终被拒绝合入,但社区不少开发者担心这仅仅是冰山一角。
当社区质疑声浪日渐高涨,就在昨天,Alist 项目原开发者 Xhofe 在订阅频道发布公告,称:
“项目已交由公司运营,之后我会帮忙审查开源版本仓库的代码,以及确保 release 的分发由 ci 自动构建,main 分支已开启分支保护,后续所有的提交都会经过 pr 审核。”
至此,社区正式炸锅了...
众所周知,AList 是一个基于 Go 语言编写的开源文件列表与 WebDAV 程序,可能有不少同学都用过。
AList 提供了一个统一的云存储管理解决方案,支持多平台文件挂载、预览以及操作。

在此次风波爆发之前,AList 在开发者圈是不少同学的必备工具。
不仅如此,甚至还有不少相关的软件或服务是基于 AList 来做的。
这款开源项目支持几十款主流网盘的一站式管理,提供统一的网页界面,能实现跨平台文件管理、在线视频播放等功能。

从该项目的 GitHub 主页上也可以看到,目前 Alist 收获了近 50000 颗的 star 星标,这也足以说明了其在开发者圈子中的受欢迎程度。
按照作者的回应,既然 Alist 项目是被公司所接手了,那它的买家到底是哪家公司呢?
有细心的网友发现,从其官网的定价页面尝试联系下去发现,该公司正是贵州bg科技。
没错,这个公司正是之前收购 Java工具库 Hutool(A set of tools that keep Java sweet)的那个公司。
至于其在开发者圈子里的一些评论,这里就不作过多评述了。
目前,AList 项目的 Issues 区基本是沦陷了,不少开发者们都在这里输出了自己的意见与不满。
聊到开源项目被收购的事情,其实早就不是第一次发生了。
正如网友们所讨论的,商业化其实无可厚非,开发者的心血也需要回报,不同的开源项目作者可以有不同的选择。
但是如果在开源的商业化过程中存在一些让用户不明就里的暗手操盘,那事情往往就会开始变得微妙起来,毕竟开源项目的背后就是广大的用户和社区,大家时刻都在注视和监督着。
文章的最后,这里还想再聊一聊有关开源作者的生存现状。
我不知道本文被收购项目 AList 的作者是不是在全职独立做开源项目,但是在我自己的圈子里,我私下就认识好几个独立维护开源项目的朋友。
有一说一,个人开源作者其实挺不容易的,像上面这样的开源项目被公司收购的毕竟是少数个例,其实好多个人的开源项目到后期由于各种主客观原因,渐渐都停止更新和维护了。
大家都知道,伴随着这两年互联网行业的寒意,软件产业里的不少环节也受到了波动,行业不景气,连开源项目的主动维护也变得越来越少了。
毕竟连企业也要降本增效,而开源往往并不能带来快速直接的实际效益,付出了如果没有回报,便会很难坚持下去。
而如果从一名学习者的角度来看,参与开源项目的意义则是不言而喻的。
参与开源项目除了可以提升自身技术能力,收获项目开发经验之外,还可以让自己保持与开源社区其他优秀开发者之间的联系与沟通,并建立自己的技术影响力,另外参与优秀开源项目的经历也会成为自己求职简历上的一大亮点。
所以如果精力允许,利用业余时间来参与一些开源项目,这对技术开发者来说,也未尝不是一段难得的经历。
来源:juejin.cn/post/7514528800731676711
面试官:MySQL单表过亿数据,如何优化count(*)全表的操作?
本文首发于公众号:托尼学长,立个写 1024 篇原创技术面试文章的flag,欢迎过来视察监督~
最近有好几个同学跟我说,他在技术面试过程中被问到这个问题了,让我找时间系统地讲解一下。
其实从某种意义上来说,这并不是一个严谨的面试题,接下来 show me the SQL,我们一起来看一下。
如下图所示,一张有 3000多万行记录的 user 表,执行全表 count 操作需要 14.8 秒的时间。
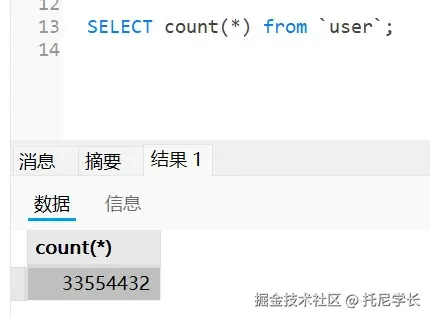
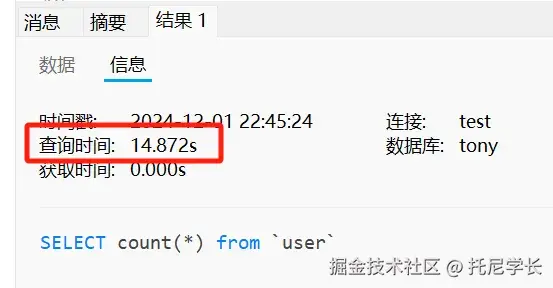
接下来我们稍作调整再试一次,神奇的一幕出现了,执行全表 count 操作竟然连 1 毫秒的时间都用不上。
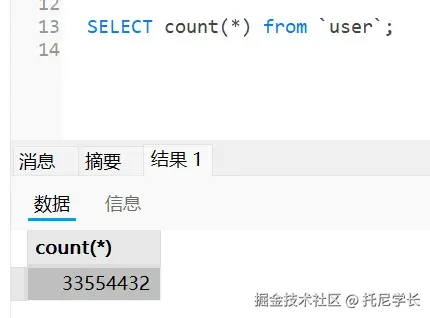
这是为什么呢?
其实原因很简单,第一次执行全表 count 操作的时候,我用的是 MySQL InnoDB 存储引擎,而第二次则是用的 MySQL MyISAM 存储引擎。
这两者的差别在于,前者在执行 count(*) 操作的时候,需要将表中每行数据读取出来进行累加计数,而后者已经将表的总行数存储下来了,只需要直接返回即可。
当然,InnoDB 存储引擎对 count(*) 操作也进行了一些优化,如果该表创建了二级索引,其会通过全索引扫描的方式来代替全表扫描进行累加计数,
毕竟,二级索引值只存储了索引列和主键列两个字段,遍历计数肯定比存储所有字段的数据表的 IO 次数少很多,也就意味着其执行效率更高。
而且,MySQL 的优化器会选择最小的那个二级索引的索引文件进行遍历计数。
所以,这个技术面试题严谨的问法应该是 —— MySQL InnoDB 存储引擎单表过亿数据,如何优化 count(*) 全表的操作?
下面我们就来列举几个常见的技术解决方案,如下图所示:

(1)Redis 累加计数
这是一种最主流且简单直接的实现方式。
由于我们基本上不会对数据表执行 delete 操作,所以当有新的数据被写入表的时候,通过 Redis 的 incr 或 incrby 命令进行累加计数,并在用户查询汇总数据的时候直接返回结果即可。
如下图所示:

该实现方式在查询性能和数据准确性上两者兼得,Redis 需要同时负责累加计数和返回查询结果操作,缺点在于会引入缓存和数据库间的数据一致性的问题。
(2)MySQL 累加计数表 + 事务
这种实现方式跟“Redis 累加计数”大同小异,唯一的区别就是将计数的存储介质从 Redis 换成了 MySQL。
如下图所示:
但这么一换,就可以将写入表操作和累加计数操作放在一个数据库事务中,也就解决了缓存和数据库间的数据一致性的问题。
该实现方式在查询性能和数据准确性上两者兼得,但不如“Redis 累加计数”方式的性能高,在高并发场景下数据库会成为性能瓶颈。
(3)MySQL 累加计数表 + 触发器
这种实现方式跟“MySQL 累加计数表 + 事务”的表结构是一样的,如下图所示:
** **
**
唯一的区别就是增加一个触发器,不用在工程代码中通过事务进行实现了。
CREATE TRIGGER `user_count_trigger` AFTER INSERT ON `user` FOR EACH ROW BEGIN UPDATE user_count SET count = count + 1 WHERE id = NEW.id;END
该实现方式在查询性能和数据准确性上两者兼得,与“MySQL 累加计数表 + 事务”方式相比,最大的好处就是不用污染工程代码了。
(4)MySQL 增加并行线程
在 MySQL 8.014 版本中,总算增加了并行查询的新特性,其通过参数 innodb_parallel_read_threads 进行设定,默认值为 4。
下面我们做个实验,将这个参数值调得大一些:
set local innodb_parallel_read_threads = 16;
然后,我们再来执行一次上文中那个 3000 多万行记录 user 表的全表 count 操作,结果如下所示:
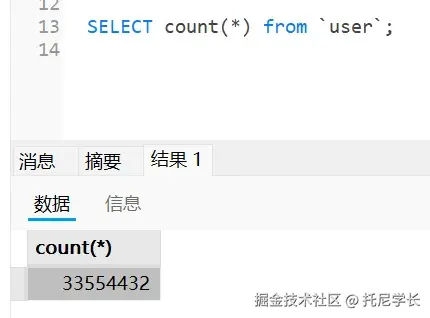
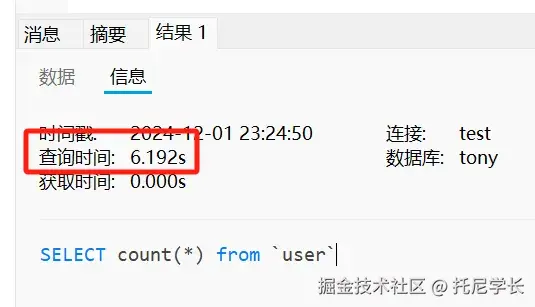
参数调整后,执行全表 count 操作的时间由之前的 14.8 秒,降低至现在的 6.1 秒,是可以看到效果的。
接下来,我们继续将参数值调整得大一些,看看是否还有优化空间:
set local innodb_parallel_read_threads = 32;
然后,我们再来执行一次上文中那个 3000 多万行记录 user 表的全表 count 操作,结果如下所示:
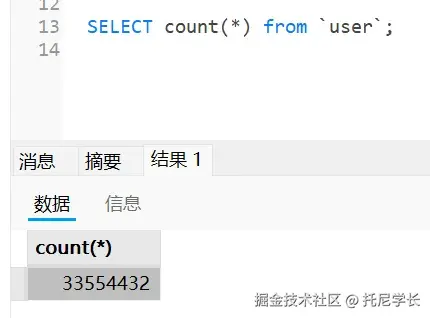
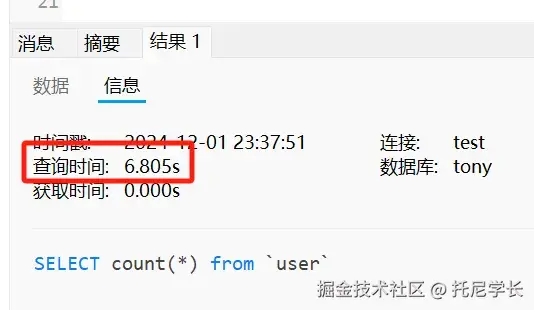
参数调整后,执行全表 count 操作的时间竟然变长了,从原来的 6.1 秒变成了 6.8 秒,看样子优化空间已经达到上限了,再多增加执行线程数量只会适得其反。
该实现方式一样可以保证数据准确性,在查询性能上有所提升但相对有限,其最大优势是只需要调整一个数据库参数,在工程代码上不会有任何改动。
不过,如果数据库此时的负载和 IOPS 已经很高了,那开启并行线程或者将并行线程数量调大,会加速消耗数据库资源。
(5)MySQL 增加二级索引
还记得我们在上文中说的内容吗?
InnoDB 存储引擎对 count() 操作也进行了一些优化,如果该表创建了二级索引,其会通过全索引扫描的方式来代替全表扫描进行累加计数,*
毕竟,二级索引值只存储了索引列和主键列两个字段,遍历计数肯定比存储所有字段的数据表的IO次数少很多,也就意味着执行效率更高。
而且,MySQL 的优化器会选择最小的那个二级索引的索引文件进行遍历计数。
为了验证这个说法,我们给 user 表中最小的 sex 字段加一个二级索引,然后通过 EXPLAIN 命令看一下 SQL 语句的执行计划:
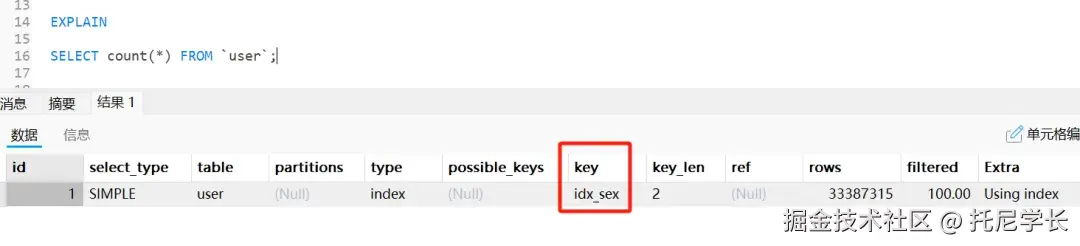
果然,这个 SQL 语句的执行计划会使用新建的 sex 索引,接下来我们执行一次看看时长:
果不其然,执行全表 count 操作走了 sex 二级索引后,SQL 执行时间由之前的 14.8 秒降低至现在的 10.6 秒,还是可以看到效果的。
btw:大家可能会觉得效果并不明显,这是因为我们用来测试的 user 表中算上主键 ID 只有七个字段,而且没有一个大字段。
反之,user 表中的字段数量越多,且包含的大字段越多,其优化效果就会越明显。
该实现方式一样可以保证数据准确性,在查询性能上有所提升但相对有限,其最大优势是只需要创建一个二级索引,在工程代码上不会有任何改动。
(6)SHOW TABLE STATUS
如下图所示,通过 SHOW TABLE STATUS 命令也可以查出来全表的行数:
我们常用于查看执行计划的 EXPLAIN 命令也能实现:
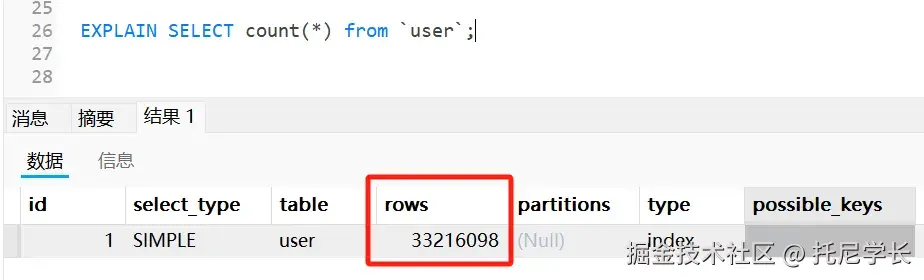
只不过,通过这两个命令得出来的表记录数是估算出来的,都不太准确。那到底有多不准确呢,我们来计算一下。
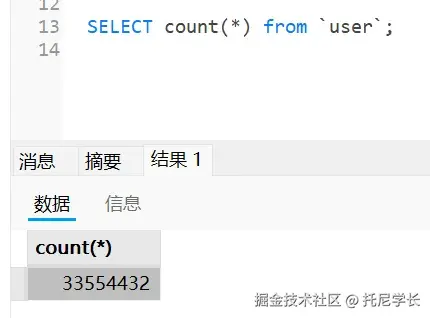
公式为:33554432 / 33216098 = 1.01
就这个 case 而言,误差率大概在百分之一左右。
该实现方式一样可以保证查询性能,无论表中有多大量级的数据都能毫秒级返回结果,且在工程代码方面不会有任何改动,但数据准确性上相差较多,只能用作大概估算。
来源:juejin.cn/post/7444919285170307107
🎨 CSS 写到手抽筋?Stylus 说:‘让我来!’
前言
还在手动重复写 margin: 0; padding: 0;?还在为兼容性疯狂加 -webkit- 前缀?大厂前端早已不用原始 CSS 硬刚了!Stylus 作为一款现代化 CSS 预处理器,让你写样式像写 JavaScript 一样爽快。
还在手动重复写 margin: 0; padding: 0;?还在为兼容性疯狂加 -webkit- 前缀?大厂前端早已不用原始 CSS 硬刚了!Stylus 作为一款现代化 CSS 预处理器,让你写样式像写 JavaScript 一样爽快。
Stylus:高效的CSS预处理器
基本特性
Stylus是一种CSS预处理器,提供了许多CSS不具备的高级功能:
// 定义变量
$background_color = rgba(255, 255, 255, 0.95)
.wrapper
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
Stylus是一种CSS预处理器,提供了许多CSS不具备的高级功能:
// 定义变量
$background_color = rgba(255, 255, 255, 0.95)
.wrapper
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
优势与使用场景
- 变量支持:避免重复值,便于主题切换
- 嵌套规则:更清晰的DOM结构表示
- 混合(Mixins) :复用样式块
- 函数与运算:动态计算样式值
- 简洁语法:可选的花括号、分号和冒号
- 变量支持:避免重复值,便于主题切换
- 嵌套规则:更清晰的DOM结构表示
- 混合(Mixins) :复用样式块
- 函数与运算:动态计算样式值
- 简洁语法:可选的花括号、分号和冒号
编译与使用
安装Stylus后,可以通过命令行编译.styl文件:
npm install -g stylus
stylus -w common.styl -o common.css
- 第一个语句是用来安装
stylus的直接运行就好 - 第二个语句是你编译
common.styl文件时使用的,也就是你写CSS代码时使用的,因为浏览器并不能直接编译.styl文件,所以你要先将.styl文件编译成.css文件,也就是用上面给的那个命令,注意要自己切换成自己的.styl文件名,后面的css名可以随便取一个自己想要的
安装Stylus后,可以通过命令行编译.styl文件:
npm install -g stylus
stylus -w common.styl -o common.css
- 第一个语句是用来安装
stylus的直接运行就好 - 第二个语句是你编译
common.styl文件时使用的,也就是你写CSS代码时使用的,因为浏览器并不能直接编译.styl文件,所以你要先将.styl文件编译成.css文件,也就是用上面给的那个命令,注意要自己切换成自己的.styl文件名,后面的css名可以随便取一个自己想要的
插件的使用
我们要想使用stylus,除了要全局安装之外还要下载一下下面的这个插件。
我们要先进入插件市场,然后搜索stylus,点击我选择的那个插件点击安装即可
我们要想使用stylus,除了要全局安装之外还要下载一下下面的这个插件。
我们要先进入插件市场,然后搜索stylus,点击我选择的那个插件点击安装即可
案例实战
先看效果,再上代码,最后在分析考点易错点
先看效果,再上代码,最后在分析考点易错点
效果
下面是我们实现的一个简单的效果界面图
下面是我们实现的一个简单的效果界面图
代码
$background_color = rgba(255, 255, 255, 0.95)
html
box-sizing border-box
min-height 100vh
display flex
flex-direction column
justify-content center
align-items center
text-align center
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
*
box-sizing border-box
.wrapper
padding 20px
min-width 350px
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
h2
text-align center
margin 0
font-weight 200
body
color pink
.plates
margin 0
padding 0
text-align left
list-style: none
li
border-bottom 1px solid rgba(0, 0, 0, 0.2)
padding 10px 0px
display flex
label
flex 1
cursor pointer
input
display none
.add-items
margin-top 20px
input
padding 10px
outline 0
border 1px solid rgba(0, 0, 0, 0.1)
我们可以看到.styl文件不用去写:和{}了,而且可以直接层叠样式
当我们运行stylus -w common.styl -o common.css命令时,它会实时的将common.styl文件编译成common.css,你可以根据自己的需求来编写,让我们看看它帮我写好的common.css文件吧
html {
box-sizing: border-box;
min-height: 100vh;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
text-align: center;
background: url("http://wes.io/hx9M/oh-la-la.jpg") center no-repeat;
background-size: cover;
}
* {
box-sizing: border-box;
}
.wrapper {
padding: 20px;
min-width: 350px;
background: rgba(255,255,255,0.95);
box-shadow: 0 0 0 10px rgba(0,0,0,0.1);
}
.wrapper h2 {
text-align: center;
margin: 0;
font-weight: 200;
}
body {
color: #ffc0cb;
}
.plates {
margin: 0;
padding: 0;
text-align: left;
list-style: none;
}
.plates li {
border-bottom: 1px solid rgba(0,0,0,0.2);
padding: 10px 0px;
display: flex;
}
.plates label {
flex: 1;
cursor: pointer;
}
.plates input {
display: none;
}
.add-items {
margin-top: 20px;
}
.add-items input {
padding: 10px;
outline: 0;
border: 1px solid rgba(0,0,0,0.1);
}
// 获取DOM元素
// 获取添加项目的表单元素
const addItems = document.querySelector('.add-items');
// 获取显示项目列表的元素
const itemsList = document.querySelector('.plates');
// 从本地存储获取项目数据,如果没有则初始化为空数组
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
// 添加新项目函数
function addItem(e) {
// 阻止表单默认提交行为
e.preventDefault();
// 获取输入框中的文本值
const text = this.querySelector('[name=item]').value;
// 创建新项目对象
const item = {
text, // 项目文本
done: false // 完成状态初始为false
};
// 将新项目添加到数组中
items.push(item);
// 更新列表显示
populateList(items, itemsList);
// 将更新后的数组保存到本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重置表单
this.reset();
}
// 渲染项目列表函数
function populateList(plates = [], platesList) {
// 使用map方法将数组转换为HTML字符串
platesList.innerHTML = plates.map((plate, i) => {
return `
${i} id="item${i}" ${plate.done ? 'checked' : ''}>
`;
}).join(''); // 将数组转换为字符串
}
// 切换项目完成状态函数
function toggleDone(e) {
// 如果点击的不是input元素则直接返回
if (!e.target.matches('input')) return;
// 获取被点击元素的data-index属性值
const el = e.target;
const index = el.dataset.index;
// 切换项目的完成状态
items[index].done = !items[index].done;
// 更新本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重新渲染列表
populateList(items, itemsList);
}
// 添加事件监听器
// 表单提交事件 - 添加新项目
addItems.addEventListener('submit', addItem);
// 列表点击事件 - 切换项目完成状态
itemsList.addEventListener('click', toggleDone);
// 初始化加载 - 页面加载时渲染已有项目
populateList(items, itemsList);
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
<title>Documenttitle>
<link rel="stylesheet" href="./common.css">
head>
<body>
<div class="wrapper">
<h2>Local TAPASh2>
<p>请添加您的TAPASp>
<ul class="plates">
<li>Loading Tapas ...li>
ul>
<form action="" class="add-items">
<input
type="text"
placeholder="Item Name"
required -- 让输入框变成必须填写 -->
name="item"
>
<input type="submit" value="+ Add Item">
form>
div>
<script src="./common.js">
script>
body>
html>
$background_color = rgba(255, 255, 255, 0.95)
html
box-sizing border-box
min-height 100vh
display flex
flex-direction column
justify-content center
align-items center
text-align center
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
*
box-sizing border-box
.wrapper
padding 20px
min-width 350px
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
h2
text-align center
margin 0
font-weight 200
body
color pink
.plates
margin 0
padding 0
text-align left
list-style: none
li
border-bottom 1px solid rgba(0, 0, 0, 0.2)
padding 10px 0px
display flex
label
flex 1
cursor pointer
input
display none
.add-items
margin-top 20px
input
padding 10px
outline 0
border 1px solid rgba(0, 0, 0, 0.1)
我们可以看到.styl文件不用去写:和{}了,而且可以直接层叠样式
当我们运行stylus -w common.styl -o common.css命令时,它会实时的将common.styl文件编译成common.css,你可以根据自己的需求来编写,让我们看看它帮我写好的common.css文件吧
html {
box-sizing: border-box;
min-height: 100vh;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
text-align: center;
background: url("http://wes.io/hx9M/oh-la-la.jpg") center no-repeat;
background-size: cover;
}
* {
box-sizing: border-box;
}
.wrapper {
padding: 20px;
min-width: 350px;
background: rgba(255,255,255,0.95);
box-shadow: 0 0 0 10px rgba(0,0,0,0.1);
}
.wrapper h2 {
text-align: center;
margin: 0;
font-weight: 200;
}
body {
color: #ffc0cb;
}
.plates {
margin: 0;
padding: 0;
text-align: left;
list-style: none;
}
.plates li {
border-bottom: 1px solid rgba(0,0,0,0.2);
padding: 10px 0px;
display: flex;
}
.plates label {
flex: 1;
cursor: pointer;
}
.plates input {
display: none;
}
.add-items {
margin-top: 20px;
}
.add-items input {
padding: 10px;
outline: 0;
border: 1px solid rgba(0,0,0,0.1);
}
// 获取DOM元素
// 获取添加项目的表单元素
const addItems = document.querySelector('.add-items');
// 获取显示项目列表的元素
const itemsList = document.querySelector('.plates');
// 从本地存储获取项目数据,如果没有则初始化为空数组
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
// 添加新项目函数
function addItem(e) {
// 阻止表单默认提交行为
e.preventDefault();
// 获取输入框中的文本值
const text = this.querySelector('[name=item]').value;
// 创建新项目对象
const item = {
text, // 项目文本
done: false // 完成状态初始为false
};
// 将新项目添加到数组中
items.push(item);
// 更新列表显示
populateList(items, itemsList);
// 将更新后的数组保存到本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重置表单
this.reset();
}
// 渲染项目列表函数
function populateList(plates = [], platesList) {
// 使用map方法将数组转换为HTML字符串
platesList.innerHTML = plates.map((plate, i) => {
return `
${i} id="item${i}" ${plate.done ? 'checked' : ''}>
`;
}).join(''); // 将数组转换为字符串
}
// 切换项目完成状态函数
function toggleDone(e) {
// 如果点击的不是input元素则直接返回
if (!e.target.matches('input')) return;
// 获取被点击元素的data-index属性值
const el = e.target;
const index = el.dataset.index;
// 切换项目的完成状态
items[index].done = !items[index].done;
// 更新本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重新渲染列表
populateList(items, itemsList);
}
// 添加事件监听器
// 表单提交事件 - 添加新项目
addItems.addEventListener('submit', addItem);
// 列表点击事件 - 切换项目完成状态
itemsList.addEventListener('click', toggleDone);
// 初始化加载 - 页面加载时渲染已有项目
populateList(items, itemsList);
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
<title>Documenttitle>
<link rel="stylesheet" href="./common.css">
head>
<body>
<div class="wrapper">
<h2>Local TAPASh2>
<p>请添加您的TAPASp>
<ul class="plates">
<li>Loading Tapas ...li>
ul>
<form action="" class="add-items">
<input
type="text"
placeholder="Item Name"
required -- 让输入框变成必须填写 -->
name="item"
>
<input type="submit" value="+ Add Item">
form>
div>
<script src="./common.js">
script>
body>
html>
分析考点易错点
1. Stylus 变量 $background_color
考点:
- Stylus 中变量的定义和使用
- RGBA 颜色值的表示方法
答案:
$background_color = rgba(255, 255, 255, 0.95) 定义了一个半透明白色背景变量- 在 Stylus 中,变量名可以包含
$ 符号,但不是必须的 - 可以直接在样式中引用变量,如
background $background_color
易错点:
- 忘记变量名前加
$(虽然 Stylus 允许不加,但加了更清晰) - RGBA 值写错格式,如漏掉 alpha 通道或使用错误范围值
- 变量作用域问题(Stylus 变量有作用域概念)
考点:
- Stylus 中变量的定义和使用
- RGBA 颜色值的表示方法
答案:
$background_color = rgba(255, 255, 255, 0.95)定义了一个半透明白色背景变量- 在 Stylus 中,变量名可以包含
$符号,但不是必须的 - 可以直接在样式中引用变量,如
background $background_color
易错点:
- 忘记变量名前加
$(虽然 Stylus 允许不加,但加了更清晰) - RGBA 值写错格式,如漏掉 alpha 通道或使用错误范围值
- 变量作用域问题(Stylus 变量有作用域概念)
2. 背景图片设置
考点:
- CSS 背景属性的简写方式
background-size: cover 的作用- 多背景属性的正确顺序
答案:
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
等价于 CSS:
background-image: url('http://wes.io/hx9M/oh-la-la.jpg');
background-position: center;
background-repeat: no-repeat;
background-size: cover;
易错点:
- 混淆
cover 和 contain 的区别:cover:完全覆盖容器,可能裁剪图片contain:完整显示图片,可能留白
- 背景图片 URL 未加引号导致错误
- 多个背景属性顺序错误(简写时有特定顺序要求)
- 忘记设置
no-repeat 导致图片平铺
考点:
- CSS 背景属性的简写方式
background-size: cover的作用- 多背景属性的正确顺序
答案:
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
等价于 CSS:
background-image: url('http://wes.io/hx9M/oh-la-la.jpg');
background-position: center;
background-repeat: no-repeat;
background-size: cover;
易错点:
- 混淆
cover和contain的区别:cover:完全覆盖容器,可能裁剪图片contain:完整显示图片,可能留白
- 背景图片 URL 未加引号导致错误
- 多个背景属性顺序错误(简写时有特定顺序要求)
- 忘记设置
no-repeat导致图片平铺
3. localStorage 使用
考点:
- localStorage 的 API 使用
- JSON 序列化与反序列化
- 数据持久化策略
答案:
// 存储数据
localStorage.setItem('tapasItems', JSON.stringify(items));
// 读取数据
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
易错点:
- 忘记使用
JSON.stringify 直接存储对象,导致存储为 [object Object] - 读取时忘记使用
JSON.parse,导致得到的是字符串而非对象 - 未处理
getItem 返回 null 的情况(代码中使用 || [] 做了默认值处理) - 存储大量数据超出 localStorage 容量限制(通常 5MB)
- 不考虑隐私模式下 localStorage 可能不可用的情况
考点:
- localStorage 的 API 使用
- JSON 序列化与反序列化
- 数据持久化策略
答案:
// 存储数据
localStorage.setItem('tapasItems', JSON.stringify(items));
// 读取数据
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
易错点:
- 忘记使用
JSON.stringify直接存储对象,导致存储为[object Object] - 读取时忘记使用
JSON.parse,导致得到的是字符串而非对象 - 未处理
getItem返回 null 的情况(代码中使用|| []做了默认值处理) - 存储大量数据超出 localStorage 容量限制(通常 5MB)
- 不考虑隐私模式下 localStorage 可能不可用的情况
4. Viewport Meta 标签
考点:
- 响应式设计基础
- 移动端视口控制
- 各属性的含义
答案:
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
各属性含义:
width=device-width:视口宽度等于设备宽度initial-scale=1:初始缩放比例为1user-scalable=no:禁止用户缩放viewport-fit=cover:覆盖整个屏幕(针对刘海屏设备)
易错点:
- 拼写错误如
user-scalable 写成 user-scalabe - 错误理解
initial-scale 的作用 - 在需要用户缩放功能的场景错误地设置
user-scalable=no - 忽略
viewport-fit=cover 导致刘海屏设备显示问题 - 多个属性间缺少逗号分隔(viewport 内容是用逗号分隔的)
考点:
- 响应式设计基础
- 移动端视口控制
- 各属性的含义
答案:
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
各属性含义:
width=device-width:视口宽度等于设备宽度initial-scale=1:初始缩放比例为1user-scalable=no:禁止用户缩放viewport-fit=cover:覆盖整个屏幕(针对刘海屏设备)
易错点:
- 拼写错误如
user-scalable写成user-scalabe - 错误理解
initial-scale的作用 - 在需要用户缩放功能的场景错误地设置
user-scalable=no - 忽略
viewport-fit=cover导致刘海屏设备显示问题 - 多个属性间缺少逗号分隔(viewport 内容是用逗号分隔的)
小知识
最后再讲一个我也是刚刚才了解到的小知识,毕竟我还是小白嘛🚀🚀
- 首先打开自己的手机开启热点,然后用自己的电脑连接手机上的热点
- 在电脑上按住
Win+R键,输入cmd,进入终端
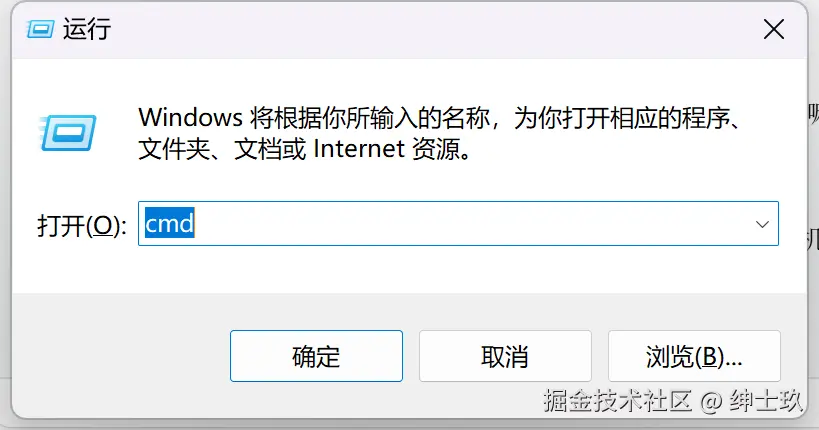 3. 在终端中输入
3. 在终端中输入ipconfig的命令,找到一个名为IPv4的地址,复制一下
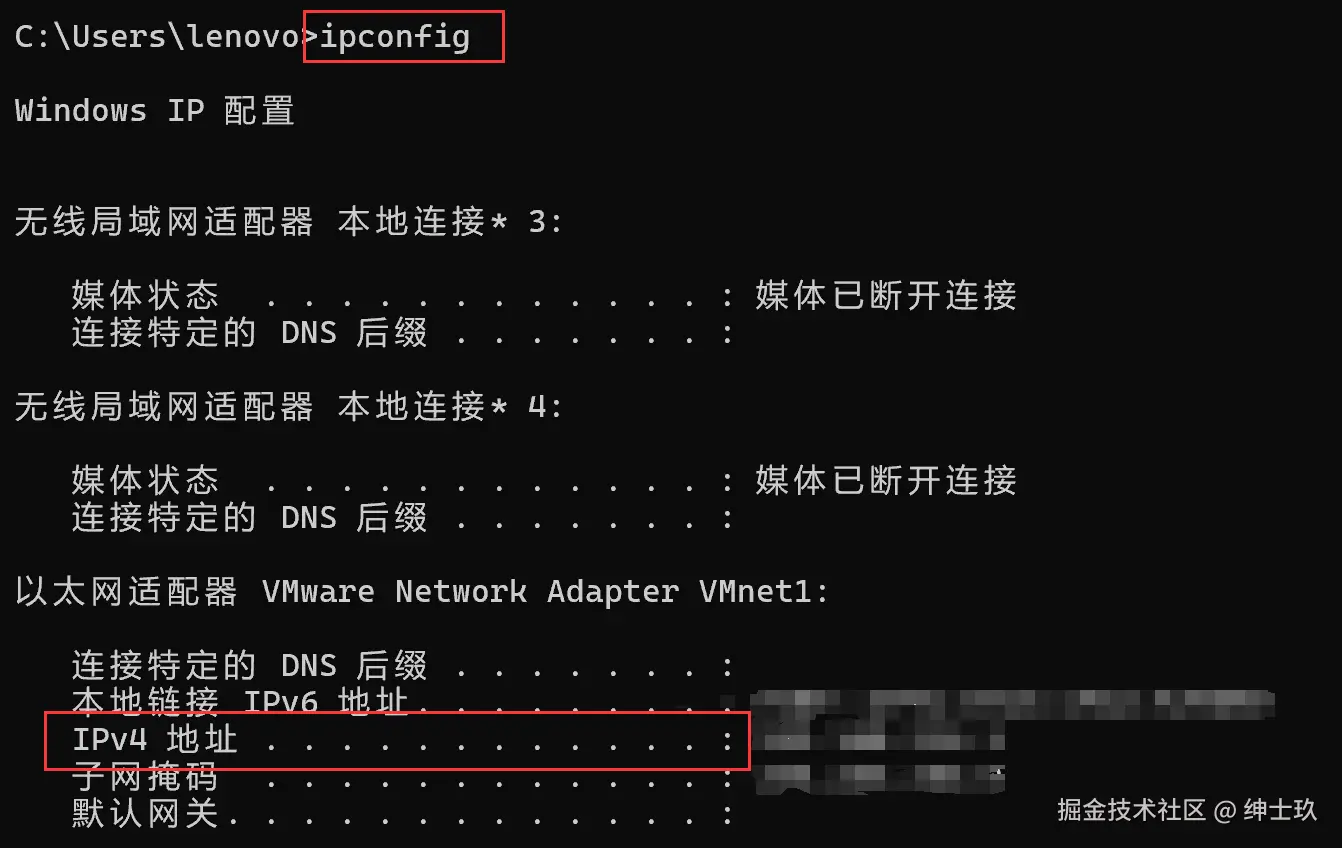
- 然后运行
html文件,要用Open with Live Serve运行项目
最后再讲一个我也是刚刚才了解到的小知识,毕竟我还是小白嘛🚀🚀
- 首先打开自己的手机开启热点,然后用自己的电脑连接手机上的热点
- 在电脑上按住
Win+R键,输入cmd,进入终端
3. 在终端中输入ipconfig的命令,找到一个名为IPv4的地址,复制一下
- 然后运行
html文件,要用Open with Live Serve运行项目
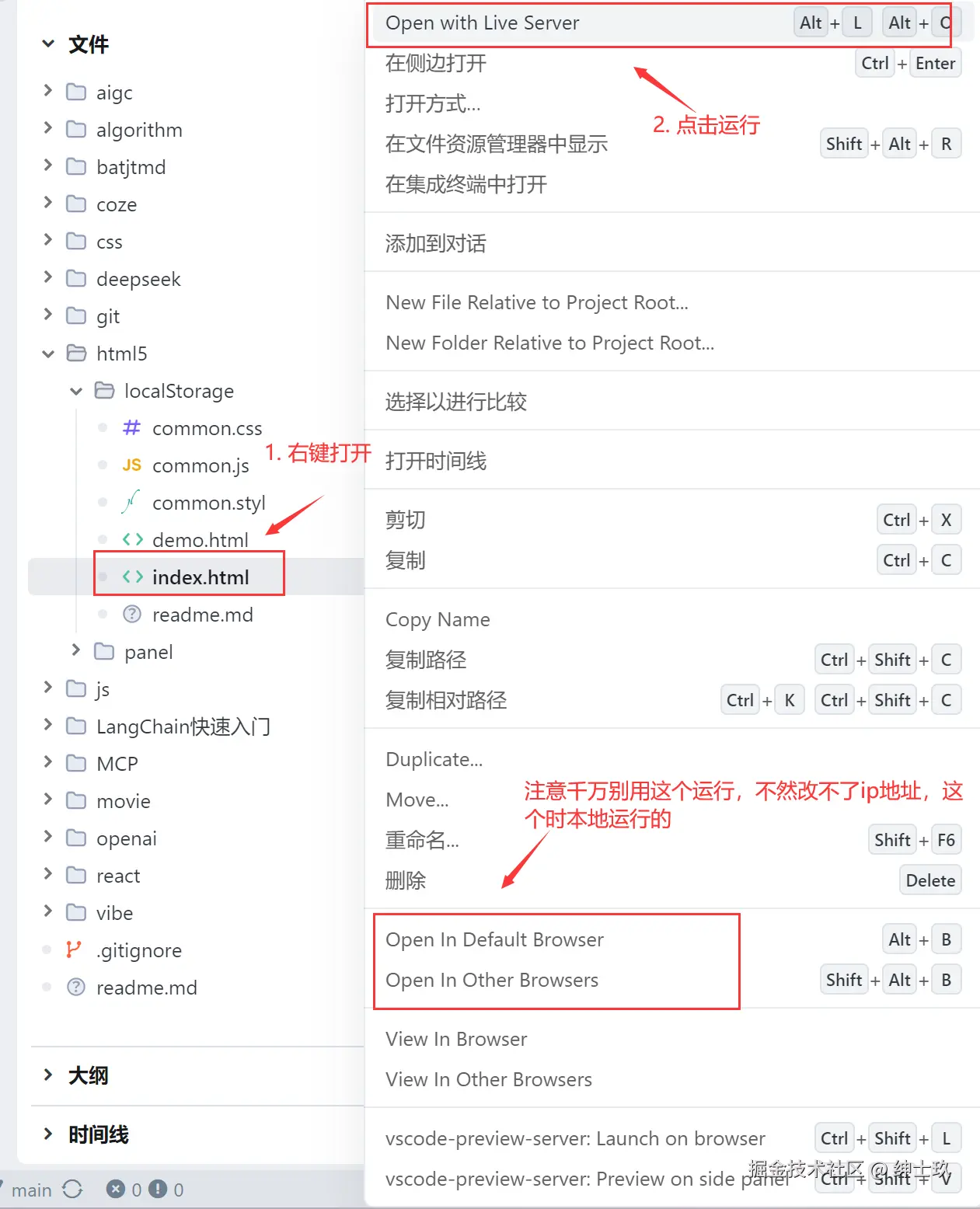
- 将你之前复制的
IPv4的地址更改到下面的位置,也就是在我图片的127.0.0.1的位置上填写上你自己之前复制的地址
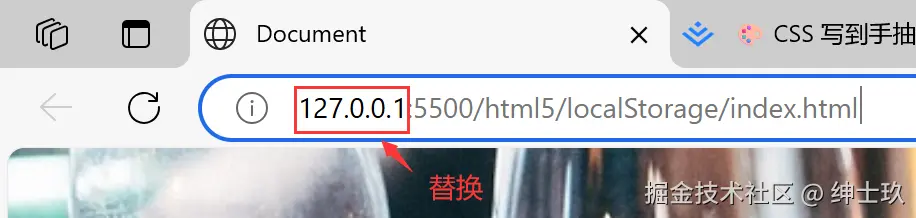
- 之后可以先运行一下,运行成功的话,将这整个链接复制发给你的手机,然后你手机点击这个链接就可以登录上这个网页了。
- 如果出现了一些
BUG,有可能是防火墙的问题,或者你没有IPv4的地址,那就在终端的那个页面复制一个你显示了的地址就可以了,如果是其它问题自行上网搜索吧,小白的我也解决不了🚀🚀
来源:juejin.cn/post/7516797727066406966
“满门被裁”,只剩下老妈还在上班

古有“满门抄斩”,今有“满门被裁”。
这不是段子,这是一个正在我们身边发生的、充满黑色幽默的现实。
最近,一位网友在论坛上发的帖子,看得人心里五味杂陈。
他说,2025年,像被下了降头。
- 3月份,他爸所在的国企解散,被裁员。
- 5月份,他自己合同到期,公司不再续签。
- 6月份,他媳妇在的部门,整个被“优化”了。
短短三个月,一家四口,三个劳动力,相继失业。全家唯一的经济来源,只剩下他那位还在工作的、本该是全家工资最低的老妈。
他说,现在家里开会,老妈的腰杆挺得最直,说话底气最足。因为她,是全家唯一的“在职员工”。
听起来有点荒诞,但当你点开评论区,看到那一排排“我也是”的留言时,还真是五味杂陈。
- 网友A: “我爸去年5月被裁,我去年6月被裁,我老公今年过年前也被裁。本来我妈工资是全家最低的,现在她是我们家的经济支柱,哈哈哈哈哈哈!”
- 网友B: “49岁。4月底,我老公国企20年被裁,今年儿子被裁,剩我一个苦苦支撑。”
每一个留言背后,都是一个正在经历风暴的家庭。
“失业”这个词,在过去,可能只是个人的不幸。但在今天,它正在演变成一种“系统性风险”,以“家庭”为单位,进行无差别的攻击。
当一个家庭的经济支柱,从三根,突然变成一根时,那种灭顶之灾般的焦虑和恐慌,足以压垮任何一个普通人。
那么,当风暴来临时,我们这些普通人,到底该怎么办?
今天,我们不讲道理,我们只讲一个真实的、可供参考的“求生案例”。
一个40岁女人的“硬核自救”
这也是一位粉丝的真实分享。
她40岁,单身,一个人住在一室一厅的房子里,背着每月2000多元的房贷。去年,她也失业了。
她花了将近一年的时间,才找到下一份工作。
在这一年里,她没有崩溃,没有躺平,而是用一种极其理性、甚至可以说是“冷酷”的方式,为自己打赢了这场“生存保卫战”。
她的方法,总结下来,就是四块“压舱石”。
第一块压舱石:不让“收入”归零
失业,不等于丧失赚钱的能力。
她做的第一件事,就是立刻盘点自己所有的“手艺”,然后把它们变成能赚小钱的“产品”。
她利用自己多年的互联网运营经验,在网上接一些零散的活儿:帮小公司写公众号文章,替人做PPT,甚至在淘宝上帮人做简历优化。
这些小钱,虽然不多,但足以覆盖她每个月的生活费和社保。这确保了她的“现金流”没有断,也让她在心理上,没有彻底沦为一个“无用的人”。
第二块压舱石:砍掉所有“虚假需求”
她做的第二件事,是立刻对自己的生活,进行一次“成本优化”。
- 消费降级: 停掉所有不必要的外出吃饭,自己做饭。她发现,当自己动手后,每天的伙食成本,可以轻易地控制在20块钱以内,而且有肉有菜。
- 关闭会员: 关掉所有视频、音乐、购物平台的自动续费。
- 戒掉“拿铁因子”: 不再喝咖啡,不再点奶茶。
她发现,当砍掉所有被消费主义制造出来的“虚假需求”后,一个人的生存成本,可以低到超乎想象。
第三块压舱石:把“时间”投资在自己身上
她做的第三件事,是把失业后多出来的、大把的时间,当成一种“资产”,而不是一种“负债”。
保持学习: 她没有整天躺在床上刷短视频,而是系统地学习了自己一直想学的英语,和能提升职场竞争力的PPT制作技能。
保持规律: 她坚持每周至少运动两次,跑步、骑行,不让自己陷入颓废、昼夜颠倒的恶性循环。
最终,正是她在这段“空窗期”里学习的英语,成了她找到下一份外企工作的“敲门砖”。
第四块、也是最重要的一块压舱石:存款
她在失业前,手里有23万的存款。
她说:“这23万,才是我敢于用一年的时间,去慢慢找工作、去学习、去生活的,最大的底气。”
它是在你被全世界抛弃时,唯一能给你安全感的东西。
在人生的牌桌上,你永远不知道下一张会发给你什么牌。你唯一能做的,就是在晴天的时候,多备几块能让你在暴风雨中不被饿死的“干粮”,和一块能让你不被大浪打翻的“压舱石”。


