








忍了一年多,我终于对i18n下手了
前言
大家好,我是奈德丽。
过去一年,我主要参与国际机票业务的开发工作,因此每天都要和多语言(i18n)打交道。熟悉我的朋友都知道,我这个人比较“惜力”(并不是,实际上只是忍不下去了),对于重复笨拙的工作非常抵触,于是,我开始思考如何优化团队的多语言管理模式。
痛点背景
先说说我们在机票项目中遇到的困境。
目前机票项目分为 H5 和 PC 两端,团队在维护多语言时主要通过在线 Excel进行管理:
- 一个 Excel 文件,H5 和 PC 各自占一个 sheet 页;
- 每次更新语言,需要先导出 Excel,然后手动跑脚本生成语言文件,再拷贝到项目中。
听起来还算凑合,但随着项目规模的扩大,问题逐渐显现:
- Key 命名混乱
- 有的首字母大写,有的小驼峰、大驼峰混用;
- 没有统一规则,难以模块化管理。
- 不支持模块化
- 目前已有数千条 key;
- 查找、修改、维护都非常痛苦。
- 更新流程繁琐
- 需要手动进入脚本目录,用
node跑脚本; - 生成后再手动复制到项目中。
- 需要手动进入脚本目录,用
下面是一个实际的 Excel 片段,可以感受一下当时的混乱程度:
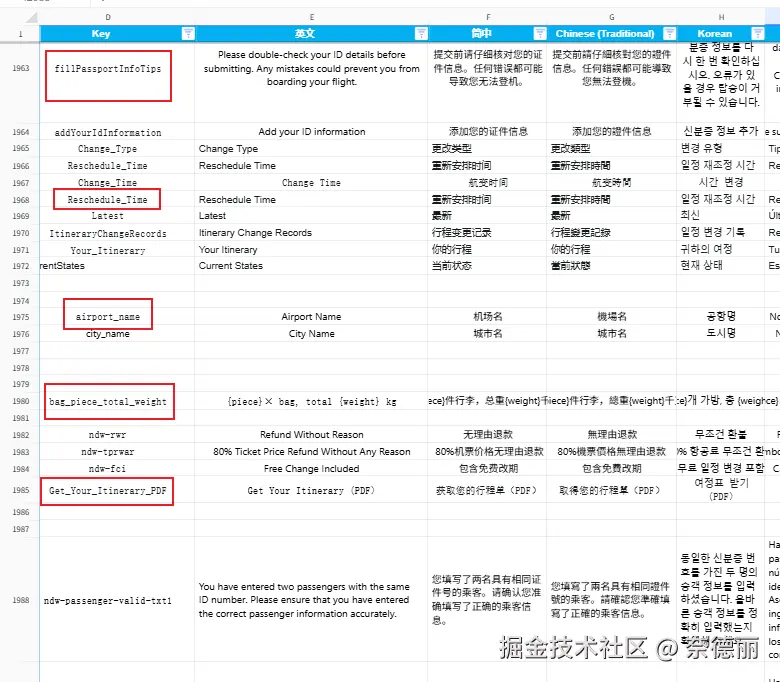
用原node脚本生成的语言文件如图
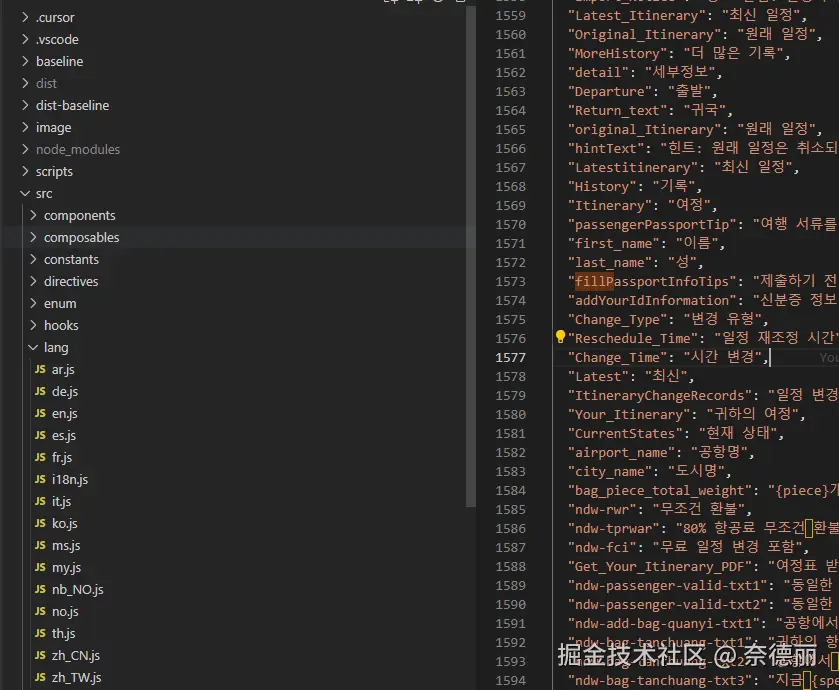
在这样的场景下,每次迭代多语言文件更新都像噩梦一样。
尤其是我们很多翻译是通过AI 机翻生成,后续频繁修改的成本极高。
然而,机票项目的代码量太大、历史包袱太重,短期内几乎不可能彻底改造。

新项目,新机会
机票项目虽然不能动,但在我们启动酒店业务新项目时,我决定不能再重蹈覆辙。
因此,在酒店项目中,我从零搭建了这套更高效的 i18n 管理方案。
目标很简单:
- 统一 key 规则,支持模块化,模块与内容间用.隔开,内容之间用下划线隔开;
- 自动化生成多语言 JSON 文件,集成到项目内,不再需要查找转化脚本的位置;
- 一条命令搞定更新,不需要手动拷贝。
于是,我在项目中新增了一个 scripts 目录,并编写了一个 excel-to-json.js 脚本。
在 package.json 中添加如下命令:
{
"scripts": {
"i18n:excel-to-json": "node scripts/excel-to-json.js"
}
}
以后,只需要运行下面一行命令,就能完成所有工作:
pnpm i18n:excel-to-json
再也不用手动寻找脚本路径,也不用手动复制粘贴,效率直接起飞 🚀。
脚本实现
核心逻辑就是:
从 Excel 读取内容 → 转换为 JSON → 输出到项目 i18n 目录。
完整代码如下:
import fs from 'node:fs'
import os from 'node:os'
import path from 'node:path'
import XLSX from 'xlsx'
/**
* 语言映射表:Excel 表头 -> 标准语言码
*/
const languageMap = {
'English': 'en',
'简中': 'zh-CN',
'Chinese (Traditional)': 'zh-TW',
'Korean': 'ko',
'Spanish': 'es',
'German Edited': 'de',
'Italian': 'it',
'Norwegian': 'no',
'French': 'fr',
'Arabic': 'ar',
'Thailandese': 'th',
'Malay': 'ms',
}
// 读取 Excel 文件
function readExcel(filePath) {
if (!fs.existsSync(filePath)) {
throw new Error(`❌ Excel 文件未找到: ${filePath}`)
}
const workbook = XLSX.readFile(filePath)
const sheet = workbook.Sheets[workbook.SheetNames[0]]
return XLSX.utils.sheet_to_json(sheet)
}
/**
* 清空输出目录
*/
function clearOutputDir(dirPath) {
if (fs.existsSync(dirPath)) {
fs.readdirSync(dirPath).forEach(file => fs.unlinkSync(path.join(dirPath, file)))
console.log(`🧹 已清空目录: ${dirPath}`)
} else {
fs.mkdirSync(dirPath, { recursive: true })
console.log(`📂 创建目录: ${dirPath}`)
}
}
/**
* 生成 JSON 文件
*/
function generateLocales(rows, outputDir) {
const locales = {}
rows.forEach(row => {
const key = row.Key
if (!key) return
// 遍历语言列
Object.entries(languageMap).forEach(([columnName, langCode]) => {
if (!locales[langCode]) locales[langCode] = {}
const value = row[columnName] || ''
const keys = key.split('.')
let current = locales[langCode]
keys.forEach((k, idx) => {
if (idx === keys.length - 1) {
current[k] = value
} else {
current[k] = current[k] || {}
current = current[k]
}
})
})
})
// 输出文件
Object.entries(locales).forEach(([lang, data]) => {
const filePath = path.join(outputDir, `${lang}.json`)
fs.writeFileSync(filePath, JSON.stringify(data, null, 2), 'utf-8')
console.log(`✅ 生成文件: ${filePath}`)
})
}
/**
* 检测缺失翻译
*/
function detectMissingTranslations(rows) {
const missing = []
rows.forEach(row => {
const key = row.Key
if (!key) return
Object.entries(languageMap).forEach(([columnName, langCode]) => {
const value = row[columnName]
if (!value?.trim()) {
missing.push({ key, lang: langCode })
}
})
})
return missing
}
function logMissingTranslations(missingList) {
if (missingList.length === 0) {
console.log('\n🎉 所有 key 的翻译完整!')
return
}
console.warn('\n⚠️ 以下 key 缺少翻译:')
missingList.forEach(item => {
console.warn(` - key: "${item.key}" 缺少语言: ${item.lang}`)
})
}
function main() {
const desktopPath = path.join(os.homedir(), 'Desktop', 'hotel多语言.xlsx')
const outputDir = path.resolve('src/i18n/locales')
const rows = readExcel(desktopPath)
clearOutputDir(outputDir)
generateLocales(rows, outputDir)
logMissingTranslations(detectMissingTranslations(rows))
}
main()
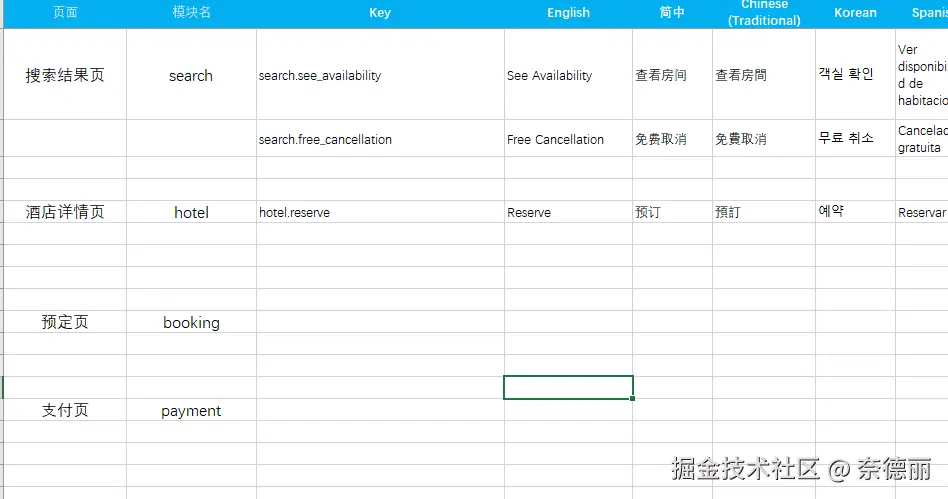
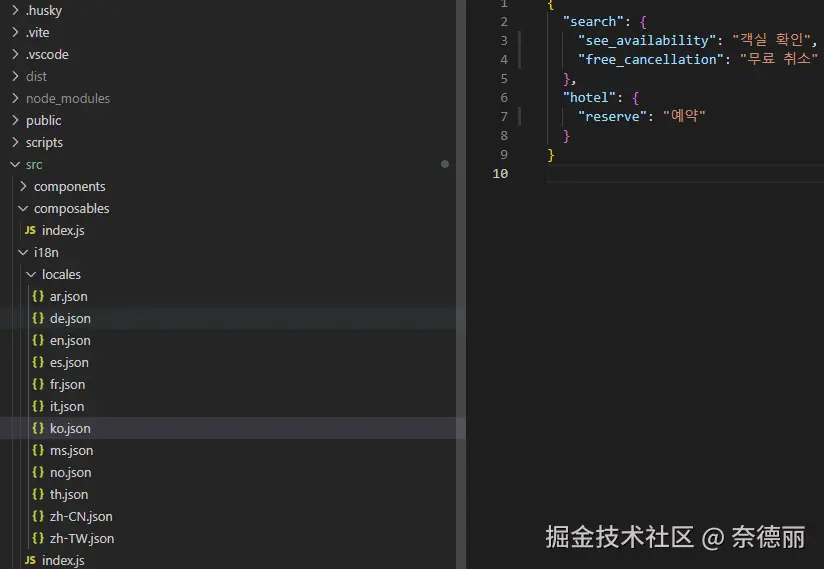
成果展示
这是在线语言原文档
这是生成后的多语言文件和内容
现在的工作流大幅简化:
| 操作 | 旧流程 | 新流程 |
|---|---|---|
| 运行脚本 | 手动找脚本路径 | pnpm i18n:excel-to-json |
| 文件生成位置 | 生成后手动拷贝 | 自动输出到项目 |
| 检测缺失翻译 | 无 | 自动提示 |
| key 命名管理 | 无统一规则 | 模块化、规范化 |
这套机制目前在酒店项目中运行良好,团队反馈也很积极。
总结
这次改造让我最大的感触是:
旧项目难以推翻重来,但新项目一定要趁早做好架构设计。
通过这次优化,我们不仅解决了多语言维护的痛点,还提升了团队整体开发效率。
而这套方案在未来如果机票项目有机会重构,也可以直接平滑迁移过去。
来源:juejin.cn/post/7553105607417053194
聊聊我们公司的AI应用工程师每天都干啥?
过去两年间,随着我们团队落地和升级的AI产品越来越多,团队中逐渐出现了专门负责AI应用的工程师。
时间一长这些AI应用工程师们也分出了个三六九等,甚至有一些AI应用工程师因为思路无法转变,又退回到了普通工程师的岗位,不再负责AI应用。
今天这篇文章,给大家聊聊,AI应用工程师每天都在干点啥? 优秀的AI应用工程师到底优秀在哪里?
AI应用工程师的生态位
AI应用工程师是处在只会大模型API调用和大模型算法工程师之间的一个生态位,目前还没有一个非常完善的岗位职能,不同的企业对于AI应用工程师的要求也有所不同。
我们这边之所以会需要AI应用工程师这样一个岗位,主要原因是我们要做AI产品的落地,和原有产品的AI化升级,在程序实现时会需要大量的大模型能力和一些特定的AI应用落地方案。
这时,团队中就需要有人对大模型的各项落地方案有所了解,能够配合产品在合适的节点设计合适的方案进行升级,负责将大模型能力转化为实际可用的产品功能
所以AI应用工程师不能只会简单的API调用,同时也不需要去了解太多的大模型底层技术,甚至Python基础都可以不需要(虽然会一些python有好处,但是这不是决定性的能力)。
目前在我们的团队中,他们主要负责:
- 利用代码实现Agent或者workflow的流程
- 实现具体的AI应用落地方案,联网搜索、RAG、微调等
- 与提示词工程师对接完成大模型能力的接入
- 与原有的程序进行结合
- 极简版的流程验证逻辑实现
- 复杂RPA + AI的落地
在其他企业的团队中,对AI应用工程师的要求还有:
- AI工程系统设计,配合产品制定Agent流程
- 编写项目中使用到的提示词
- coze、dify的搭建
- 等等
虽然说像搭建coze、写提示词这类工作,我并不认为这些工作应该是AI应用工程师工作,但是当下这个岗位的职责还没有固定,所以接下来我还是会把这些内容写进应具备的技能中。
大家全都了解一下,以备不时之需。
AI应用工程师需要具备的技能
要完成以上这些职责,AI应用工程师自然也要具备相应的技能, 但是对于Python基础、Pytorch框架、机器学习与深度学习的技术点,要不要进行学习呢?
不鼓励花大量时间学习,但是建议了解
不鼓励学习是因为:你学了你未必也用的到,我带团队在AI领域,TOC、TOB、新产品、新功能上线了不少了,没有用到python语言,并且也没看到python的必须性。当然了,你的团队主要语言是python,那你肯定是应该学的。
建议了解是因为:你毕竟是在做AI相关的内容,有相应的基础知识和技能点,的确在某些时候能带给你一些清晰的思路或者节约一些时间。
反过来再考虑你自己:深入Python基础、Pytorch框架、机器学习与深度学习这些技术点,你想做什么? 当你去深入学习这些的时候,你的目标不应该是AI应用工程师,而是人工智能算法相关的岗位。
学会了你就会不甘心,想去做更高级的岗位,但是那些岗位对学历、经验的要求不是一个半路出家自学能胜任的。
学不会你就是在浪费自己宝贵的生命和本次AI变革中的机会。
所以啊,认准自己的目标,别让自己难做。
那应该掌握的技能是哪些呢? 我们一条一条来说
利用代码实现Agent或者workflow的流程
需要了解Agent和workflow的区别,能够掌握是程序实现Agent和workflow的能力。
简单来说Agent和workflow的区别就是:
- workflow是通过预定义的代码路径协调 LLM 和工具的系统。人类可以在其中的某些节点进行人为的干预。
- Agent是 LLM 动态指导其自身流程和工具使用情况的系统,从而保持对其完成任务的方式的控制。完全有LLM主导,人类无法干预。
在程序上的实现区别:
Agent实际上最核心的代码只有九行, Agent所谓的动态指导其实就是一个while(true)。
async function loop(llm) {
let msg = await userInput();
while (true) {
const { output, tool_calls } = await llm(msg);
if (tool_calls && tool_calls.length > 0) {
msg = await Promise.all(tool_calls.map(tc => handleToolCall(tc)));
} else {
msg = await userInput();
}
}
}
workflow的核心代码流程是提前写好的逻辑流程。
async function main(){
// 流程1:例如上下文处理
const query = await handleContext()
// 流程2:例如RAG
await handleRAG(query)
// 流程3:例如Function call
await handleFC(query)
// 流程4:例如调用API
await handleAPI()
}
实现具体的AI应用落地方案
在流程实现中,AI应用工程师需要把用到的技术点都做好,例如:联网搜索、RAG、微调等
联网搜索:当我们的产品需要用的联网搜索的时候,我们有两个选择:
- 用云端的联网搜索能力,缺点就是收费并且可控性不强,优点是方便省事。
- 自己实现联网搜索能力,优点是可以按照自己的需求指定搜索引擎、检索网站等。缺点就是需要自己编写代码。
RAG:当我们需要用RAG的时候,AI应用工程师应该做的:
- 实现RAG的完整流程
- 告知数据同事,需要怎样的数据,切片、QA、等
- 测试并保证RAG的召回率和准确率
- 对RAG的产出结果负责
微调:当我们需要用到微调的时候,AI应用工程师应该做的:
- 知道要微调什么样的任务,然后协调数据同事去准备相关的数据,并告知准备多少数据量、数据结构是怎样的、内容分布是怎样的
- 拿到数据后选择微调模型、微调平台,进行微调的工作
- 对微调结果进行测评,最终得到满意的结果
- 部署并调用模型
与提示词工程师对接完成大模型能力的接入
这一点不同的企业要求不一样,我们团队是专门培养的提示词工程师,有的团队是需要AI应用工程师来进行提示词的编写和调优
不过无论是不是AI应用工程师来编写提示词,他们都需要了解提示词工程,否则就没办法和提示词工程师进行有效沟通。
AI应用工程师需要与提示词工程师就当前节点提示词的输入、输出的结构和内容进行确定。
AI应用工程师保证输入的准确性,提示词工程师来保证输出的概率。
为什么是概率呢? 众所周知,提示词是不会百分百保证效果的。所以优秀的AI应用工程师在编写程序时会具备这一点的考虑:
例如下面这个例子:
提示词是用来判定当前输入的评论内容是否表达了善意,返回N或者Y。
也就是说这个提示词提示词的输入是评论内容,输出是N或者Y。
请问:AI应用工程师要怎么对输出的Y或者N进行判断?
if(res === 'Y'),这样么?
不,他们写if(res.includes('Y'))。
这里用全等就没有考虑到提示词输出的不确定性,所以有经验的工程师会在这里使用includes
极简版的流程验证逻辑实现
当下的阶段,通常在产品初期设计的流程都不会是最终生成环境的流程,因为在产品处理考虑的一些节点可能不全面,也因为需求会变动。
所以当我们在正式开始编写代码之前,都需要有一个极简版的流程实现,来验证我们的逻辑
有的团队使用coze一类的Agent搭建流程来实现这个验证逻辑, 但是对于一些复杂的流程,coze之类的产品就无能为力了
这时候,就需要AI应用工程师用代码快速实现一个简单流程来验证逻辑。
复杂RPA + AI的落地
随着AI能力的提升,目前最新的思路有RPA + AI来实现近乎全自动的部分工作,这就需要有专门的搭建这套流程的工程师。
这需要了解RPA的能力和AI能力,并且了解如何结合。
这个其实并不应该交给AI应用工程师来做,更适合专门的RPA工程师。
这个看发展吧。
AI工程系统设计,配合产品制定Agent流程
AI工程的系统设计,有些团队会要求AI应用工程师来做。
AI工程的系统设计,也就是应用的Agent或者workflow的设计,这一步是在产品出原型之前,就要设计好。
所以想要设计这部分内容,需要有两个能力:懂业务、懂技术。
这一点还是很难的,能够胜任的AI应用工程师,通常已经不是单纯意义上的工程师了。
给大家补一个当下AI产品落地的流程图:
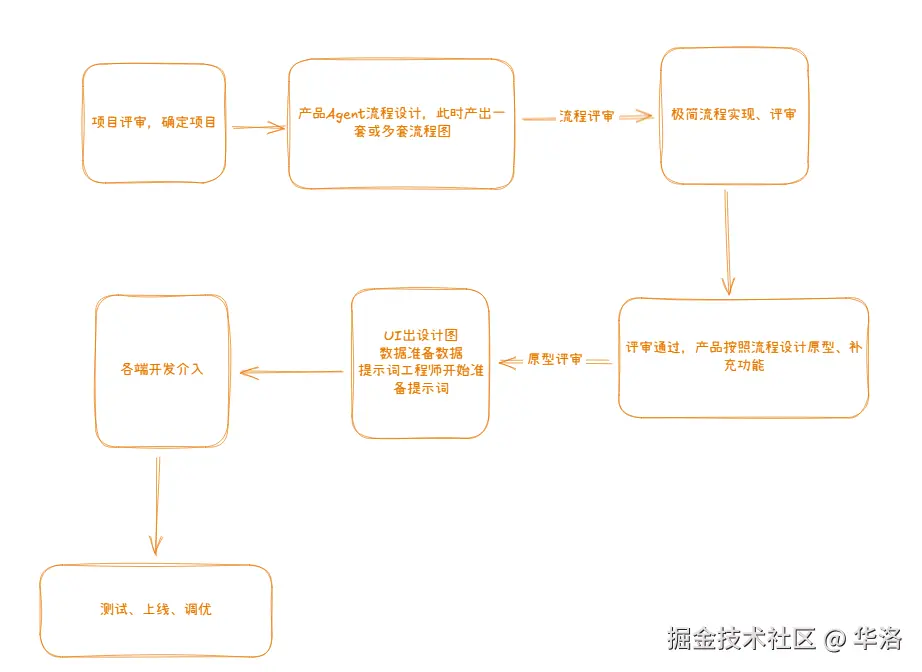
coze、dify的搭建
coze和dify的搭建,也是部分团队要求的任务,这一点会要求大家按照要求搭建智能体。
这个我这边就不细说了,网上到处都是搭建教程。
结语
AI应用工程师和普通工程师比起来,上下游关系人多了两个提示词工程师、数据人员
提示词工程师需要和AI应用工程师进行沟通,关于提示词的输入、输出。
AI工程师需要了解当前节点的提示词是做什么的,有什么用? 就像了解原型中某个功能节点是做什么的一样。
就是说,AI应用工程师虽然只是做整个产品中的一部分工作,但仍然要了解全景的信息
这也是优秀的工程师优秀的地方,他们不仅能做好自己的工作,还能配合上下游关系人一起,让整个产品实现的更好。
哦对了,最后说一下:
AI应用工程师是一个新的岗位,并没有替代传统工程师,而是在传统工程能力基础上增加了新的维度。
加油!共勉!
☺️你好,我是华洛,如果你对程序员转型AI产品负责人感兴趣,请给我点个赞。
你可以在这里联系我👉http://www.yuque.com/hualuo-fztn…
已入驻公众号【华洛AI转型纪实】,欢迎大家围观,后续会分享大量最近三年来的经验和踩过的坑。
专栏文章
# 从0到1打造企业级AI售前机器人——实战指南三:RAG工程的超级优化
# 从0到1打造企业级AI售前机器人——实战指南二:RAG工程落地之数据处理篇🧐
# 从0到1打造企业级AI售前机器人——实战指南一:根据产品需求和定位进行agent流程设计🧐
来源:juejin.cn/post/7512332419203727371
自定义 View 的 “快递失踪案”:为啥 invalidate () 喊不动 onDraw ()?
讲了个 “快递站送货” 的故事 —— 毕竟 View 的绘制流程,本质就是一场 “指令上报→调度→执行” 的快递游戏。
一、先搞懂:正常情况下,“快递” 是怎么送到的?
我们先把 View 体系比作一个城市快递网络:
- 你写的
自定义View= 小区里的 “快递站”(负责接收指令、安排送货); invalidate()= 你给快递站打 “要送货” 的电话(请求重绘);onDraw()= 快递站的 “送货员”(实际执行绘制逻辑);ViewGr0up(父容器)= “区域调度中心”(转发快递站的请求);ViewRootImpl= 快递总公司(连接快递站和 “城市交通系统”——Android 的 UI 线程);Choreographer= 总公司的 “帧调度室”(负责安排每帧的工作,避免堵车)。
正常送货的时序图(代码 + 流程)
先看一段 “正常能收到货” 的自定义 View 代码:
// 小区快递站(自定义View)
public class NormalCustomView extends View {
private Paint mPaint;
public NormalCustomView(Context context) {
super(context);
mPaint = new Paint();
mPaint.setColor(Color.RED);
mPaint.setTextSize(50);
}
// 送货员(执行绘制)
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("快递站", "送货员onDraw出发!画个文字");
canvas.drawText("快递送到啦~", 100, 100, mPaint);
}
}
// 你(开发者)打电话下单
NormalCustomView view = new NormalCustomView(this);
view.invalidate(); // 打“要送货”的电话
这通电话后,“快递” 会按以下流程送到(时序图用文字拆解):
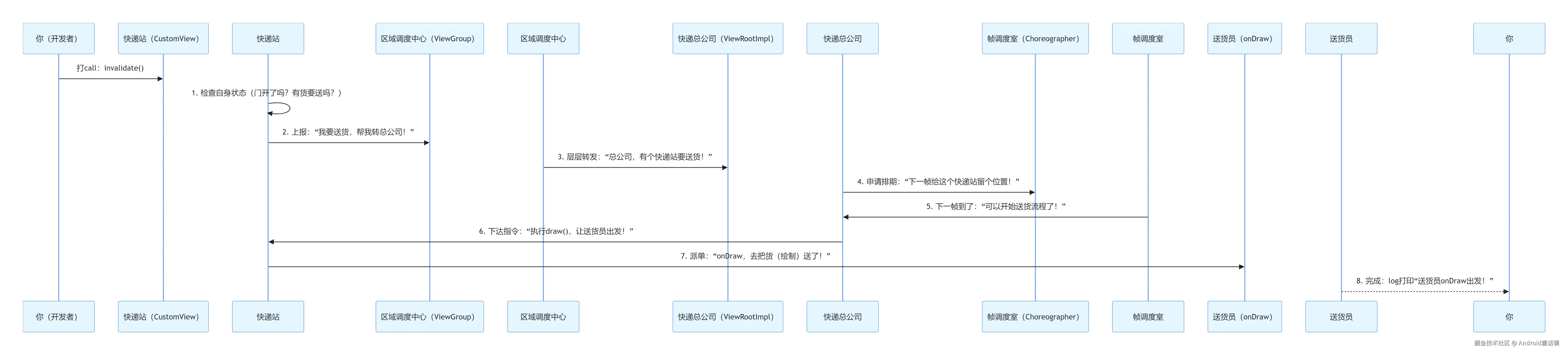
你送货员送货员(onDraw)帧调度室帧调度室(Choreographer)快递总公司快递总公司(ViewRootImpl)区域调度中心区域调度中心(ViewGr0up)快递站快递站(CustomView)你(开发者)你送货员送货员(onDraw)帧调度室帧调度室(Choreographer)快递总公司快递总公司(ViewRootImpl)区域调度中心区域调度中心(ViewGr0up)快递站快递站(CustomView)你(开发者)打call:invalidate()1. 检查自身状态(门开了吗?有货要送吗?)2. 上报:“我要送货,帮我转总公司!”3. 层层转发:“总公司,有个快递站要送货!”4. 申请排期:“下一帧给这个快递站留个位置!”5. 下一帧到了:“可以开始送货流程了!”6. 下达指令:“执行draw(),让送货员出发!”7. 派单:“onDraw,去把货(绘制)送了!”8. 完成:log打印“送货员onDraw出发!”
二、“快递失踪” 的 6 种常见原因(故事 + 代码 + 解决方案)
小明的问题,本质是 “快递在某个环节卡住了”。我们一个个拆穿这些 “卡壳点”—— 每个原因都对应故事里的场景,再给代码验证。
原因 1:快递站 “没开门”(View 不可见)
故事场景:小明早上给快递站打电话,站长接了说:“兄弟,我们还没开门(visibility=GONE),货送不了,挂了啊!”
原理:View 在收到invalidate()后,会先检查visibility属性:
- 只有
visibility == View.VISIBLE时,才会继续上报请求; - 如果是
GONE(完全隐藏,不占空间)或INVISIBLE(隐藏但占空间),直接 “挂电话”,不触发后续流程。
代码验证(坑) :
public class ClosedStationView extends View {
public ClosedStationView(Context context) {
super(context);
// 坑:设置为GONE,快递站没开门
setVisibility(View.GONE);
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("快递站", "送货员出发!"); // 永远不会打印
}
}
// 你打电话,但快递站没开门
ClosedStationView view = new ClosedStationView(this);
view.invalidate(); // 白打!
解决方案:确保visibility是View.VISIBLE(代码里setVisibility(View.VISIBLE),或 XML 里android:visibility="visible")。
原因 2:快递站 “没地方放货”(宽高为 0)
故事场景:小明这次确认快递站开了门,但站长说:“我们仓库是 0 平米(宽高 = 0),货没地方放,送不了!”
原理:View 绘制需要 “有空间”——getMeasuredWidth()和getMeasuredHeight()必须都大于 0。如果宽高为 0,即使invalidate(),也会跳过后续流程(总不能在 “空气” 里画画吧)。
代码验证(坑) :
<!-- XML里坑:宽高设为0 -->
<com.example.MyView
android:layout_width="0dp"
android:layout_height="0dp" />
public class ZeroSizeView extends View {
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("快递站", "送货员出发!"); // 不打印,因为宽高0
}
}
解决方案:
- 检查 XML 的
layout_width/layout_height(别设 0dp); - 代码里避免
setLayoutParams(new LayoutParams(0, 0)); - 重写
onMeasure()时,确保setMeasuredDimension(width, height)的宽高大于 0。
原因 3:快递站 “只中转不送货”(ViewGr0up 默认不绘制)
故事场景:小明找的是 “区域调度中心”(ViewGr0up)当快递站,结果调度中心说:“我们只负责转发子快递站的货,自己不送货(willNotDraw=true)!”
原理:ViewGr0up的默认值willNotDraw = true,意思是 “我是容器,只管子 View 的布局,自己不用绘制”。所以即使你给ViewGr0up调用invalidate(),它也会跳过onDraw()。
代码验证(坑) :
// 区域调度中心(ViewGr0up),默认不送货
public class NoDrawViewGr0up extends ViewGr0up {
public NoDrawViewGr0up(Context context) {
super(context);
// 坑:没改willNotDraw,默认true
}
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
// 布局子View(省略)
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("调度中心", "自己送货!"); // 不打印
}
}
// 你给调度中心打电话
NoDrawViewGr0up group = new NoDrawViewGr0up(this);
group.invalidate(); // 白打!
解决方案:在ViewGr0up的构造里加一句setWillNotDraw(false),告诉它 “我也要自己送货(绘制)”:
public NoDrawViewGr0up(Context context) {
super(context);
setWillNotDraw(false); // 打开“自己绘制”开关
}
原因 4:你 “打错电话”(非 UI 线程调用 invalidate ())
故事场景:小明在外地出差,用 “公用电话”(非 UI 线程)给快递站打电话,结果电话直接被总公司拦截:“非本人手机(UI 线程),不接!”
原理:Android 的 View 体系是线程不安全的,只有创建 View 的 “UI 线程(主线程)” 才能调用invalidate()。非 UI 线程调用会:
- 要么直接抛异常(
Only the original thread that created a view hierarchy can touch its views); - 要么 “悄悄失败”(没抛异常但不触发
onDraw())。
代码验证(坑) :
public class WrongThreadView extends View {
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("快递站", "送货员出发!"); // 不打印
}
}
// 你用“公用电话”(非UI线程)打电话
WrongThreadView view = new WrongThreadView(this);
new Thread(() -> {
view.invalidate(); // 非UI线程!要么抛异常,要么白打
}).start();
解决方案:确保在 UI 线程调用invalidate(),常用方式:
- 用
view.post(Runnable):view.post(() -> view.invalidate()); - 用
Handler发消息到主线程; - 在
Activity的runOnUiThread(Runnable)里调用。
原因 5:区域调度中心 “拦截了请求”(父 View 阻断上报)
故事场景:小明的快递站属于 “郊区调度中心”,调度中心跟总公司关系不好,收到快递站的请求后,直接扔了:“不给你转总公司,爱咋咋地!”
原理:View 的invalidate()需要通过ViewParent(父 View)层层上报到ViewRootImpl。如果父 View 重写了invalidateChildInParent()(上报方法)并返回null,就会 “拦截” 请求,导致后续流程中断。
代码验证(坑) :
// 坑爹的区域调度中心(父View),拦截请求
public class BlockParentViewGr0up extends ViewGr0up {
public BlockParentViewGr0up(Context context) {
super(context);
}
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
// 布局子View(省略)
}
// 重写上报方法,返回null=拦截请求
@Override
public ViewParent invalidateChildInParent(int[] location, Rect dirty) {
Log.d("坑爹调度中心", "拦截请求,不转总公司!");
return null; // 关键:返回null阻断上报
}
}
// 子快递站(被拦截)
public class ChildView extends View {
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("子快递站", "送货员出发!"); // 不打印
}
}
// 布局关系:BlockParentViewGr0up包含ChildView
BlockParentViewGr0up parent = new BlockParentViewGr0up(this);
ChildView child = new ChildView(this);
parent.addView(child);
child.invalidate(); // 子View的请求被父View拦截
解决方案:
- 检查父 View 是否重写了
invalidateChildInParent(),避免返回null; - 若父 View 有
clipChildren="true"(XML 属性),且子 View 超出父 View 范围,超出部分的invalidate()也会被拦截,可设clipChildren="false"。
原因 6:快递站 “用了缓存,不用重送”(硬件加速 Layer 缓存)
故事场景:快递站之前送过一次货,把货存在了 “临时仓库”(硬件加速 Layer)里。这次小明再打电话,站长说:“仓库里有现成的,直接拿,不用再让送货员跑一趟!”
原理:当 View 设置了硬件加速 Layer(setLayerType(LAYER_TYPE_HARDWARE, null)),系统会把 View 的绘制结果缓存成一个 “图片(Layer)”。后续调用invalidate()时:
- 如果只是轻微修改(比如文字颜色不变,只改内容),系统直接复用 Layer,不调用
onDraw(); - 只有 Layer 失效(比如 View 大小改变、Layer 类型切换),才会重新调用
onDraw()生成新 Layer。
代码验证(坑) :
public class LayerCacheView extends View {
private Paint mPaint;
private String mText = "第一次送货";
public LayerCacheView(Context context) {
super(context);
mPaint = new Paint();
mPaint.setColor(Color.BLUE);
mPaint.setTextSize(50);
// 坑:设置硬件加速Layer,开启缓存
setLayerType(LAYER_TYPE_HARDWARE, null);
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
Log.d("快递站", "送货员出发!当前文字:" + mText); // 只打印一次
canvas.drawText(mText, 100, 100, mPaint);
}
// 你修改文字后打电话
public void updateText() {
mText = "第二次送货";
invalidate(); // 调用后,onDraw不回调(复用Layer缓存)
}
}
// 调用流程
LayerCacheView view = new LayerCacheView(this);
view.invalidate(); // 第一次:onDraw回调(生成Layer)
view.updateText(); // 第二次:invalidate()但onDraw不回调(复用Layer)
解决方案:
- 若需要每次
invalidate()都回调onDraw(),可关闭 Layer:setLayerType(LAYER_TYPE_NONE, null); - 若必须用 Layer,可手动让 Layer 失效:
invalidate()后加setLayerType(LAYER_TYPE_HARDWARE, null)(强制重建 Layer)。
三、总结:“快递失踪” 排查四步法
小明听完故事,半小时就解决了他的问题(原来是忘了给 ViewGr0up 加setWillNotDraw(false))。最后我给他总结了一套 “排查口诀”,小白也能套用:
- 查基础状态:View 是不是
VISIBLE?宽高是不是大于 0?(对应原因 1、2) - 查绘制开关:如果是 ViewGr0up,有没有开
setWillNotDraw(false)?(对应原因 3) - 查线程归属:
invalidate()是不是在 UI 线程调用的?(对应原因 4) - 查拦截和缓存:父 View 有没有拦截请求?View 是不是开了硬件加速 Layer?(对应原因 5、6)
按这四步走,90% 的 “invalidate () 不回调 onDraw ()” 问题都能解决。记住:View 的绘制流程就像快递,每个环节都不能少,卡住一个就 “送货失败”~
来源:juejin.cn/post/7559399860119224383
Android 性能调优与故障排查:ADB 诊断命令终极指南
在 Android 开发与测试的日常工作中,快速诊断和解决应用崩溃 (Crash)、无响应 (ANR) 和性能卡顿 (Jank) 是保障应用质量的关键。Android Debug Bridge (ADB) 提供了强大的命令行工具集,能够帮助我们深入系统底层,获取所需的所有诊断数据。
本文将为您全面梳理最常用、最核心的 ADB 诊断命令行工具,助您成为一名高效的故障排查专家。
一、 核心诊断命令:系统快照与错误记录
这些命令用于获取设备某一时刻的全局状态或关键错误记录。
1. 抓取全面的系统诊断报告:adb bugreport
adb bugreport 是最强大的诊断工具,它生成一个关于设备当前状态的全面的、打包的(.zip 格式)系统快照。
| 命令 | 作用 | 备注 |
|---|---|---|
adb bugreport | 生成包含所有诊断信息的 .zip 文件。 | 适用于分析复杂问题、系统级错误,或需提交给平台开发者时。 |
adb bugreport <文件名>.zip | 指定导出的文件名。 | 报告内容包括:完整的 Logcat 历史、ANR/Crash 堆栈、所有 dumpsys 信息等。 |
2. 提取崩溃和 ANR 记录:adb shell dumpsys dropbox
dropbox 服务相当于系统的“黑匣子”,专门收集系统运行过程中的关键错误摘要。
| 命令 | 作用 | 备注 |
|---|---|---|
adb shell dumpsys dropbox --print | 打印所有 dropbox 记录的详细内容。 | 快速检查是否有最近的系统级或应用级崩溃/ANR 记录。 |
adb shell dumpsys dropbox --print > crash.txt | 将所有记录重定向输出到本地 crash.txt 文件。 | 方便离线分析。 |
3. 提取 ANR 堆栈文件
ANR 发生后,系统将所有线程堆栈记录在 traces.txt 中,这是分析 ANR 的核心。
| 命令 | 作用 | 备注 |
|---|---|---|
cat /data/anr/traces.txt | 读取 ANR 发生时的详细堆栈信息。 | ⚠️ 通常需要 Root 权限 (adb root 或 su) 才能访问 /data/anr/ 目录。 |
cat /data/anr/traces.txt > /mnt/sdcard/tt.txt | 在设备内部将受保护的 traces.txt 复制到用户存储区。 | 复制后,可使用 adb pull 导出到电脑。 |
二、 实时日志与基础性能分析
这些是日常调试和性能监控最频繁使用的命令。
1. Logcat 日志操作
| 命令 | 作用 | 备注 |
|---|---|---|
adb logcat | 实时打印设备所有日志。 | 可通过 tag 和 level(如 *:E 只看错误)进行过滤。 |
adb logcat -c | 清除设备上当前的日志缓冲区。 | 建议在测试前执行,以确保日志干净、聚焦。 |
adb logcat -d > log.txt | 将设备上当前缓存的所有日志导出到本地文件。 | -d (dump) 参数用于导出当前缓存,而非实时监听。 |
2. CPU 与内存监控
| 命令 | 作用 | 关注问题 |
|---|---|---|
adb shell ps -t / adb shell top -m 10 | 实时查看进程的 CPU、内存占用情况。 | 性能监控,快速定位资源消耗高的进程。 |
adb shell dumpsys meminfo [package_name] | 获取特定应用的详细内存使用情况(Java Heap, Native Heap 等)。 | 内存泄漏、OOM(Out of Memory)分析的核心工具。 |
adb shell dumpsys cpuinfo | 获取设备整体和各个进程的 CPU 使用率。 | 诊断后台过度使用 CPU 导致的耗电或发热问题。 |
三、 性能与卡顿(Jank)分析
专门用于分析应用启动速度和 UI 流畅度的命令。
| 命令 | 作用 | 备注 |
|---|---|---|
adb shell dumpsys gfxinfo [package_name] | 抓取应用的图形渲染性能数据。 | 包含丢帧 (Jank) 统计和渲染时间线,用于分析 UI 卡顿问题。 |
adb shell am crash [package_name] | 强制让目标应用崩溃。 | 用于测试崩溃报告系统的稳定性和流程。 |
adb shell am start -W [package_name]/[activity_name] | 启动指定的 Activity 并等待初始化完成,同时打印启动耗时。 | 用于量化分析应用启动速度(Total Time, Wait Time)。 |
四、 深入系统诊断(dumpsys 子集)
dumpsys 可以针对不同的系统服务进行深入诊断。
| 命令 | 关注领域 | 作用 |
|---|---|---|
adb shell dumpsys activity | Activity Manager (AMS) | 获取当前运行的 Activity 栈、后台进程列表等,用于分析应用生命周期和任务管理问题。 |
adb shell dumpsys battery | 电池状态 | 获取设备的电池和充电状态。 |
adb shell dumpsys power | 电源管理 (PMS) | 获取唤醒锁 (Wake Locks) 的持有情况,用于分析设备无法休眠导致的持续耗电问题。 |
adb shell dumpsys window windows | 窗口管理 (WMS) | 获取当前屏幕上可见的窗口列表、层级和焦点情况,用于分析屏幕显示或输入事件问题。 |
五、 文件系统操作(导出/导入文件)
这些命令是确保诊断文件能够顺利在设备和电脑间传输的基础。
| 命令 | 作用 | 示例 |
|---|---|---|
adb pull [remote_path] [local_path] | 从设备拉取文件到电脑。 | adb pull /sdcard/tt.txt . (将文件拉取到电脑当前目录)。 |
adb push [local_path] [remote_path] | 从电脑推送文件到设备。 | 通常用于推送测试用例或工具。 |
实际分析流程
在实际的故障排查中,开发者通常遵循以下高效流程:
- 准备阶段: 执行
adb logcat -c清除旧日志,确保日志的清洁度。 - 复现问题: 在设备上准确重现崩溃、ANR 或卡顿的现象。
- 抓取证据:
- 一般问题: 立即执行
adb logcat -d > log.txt抓取当前的日志缓冲区。 - 严重复杂问题: 立即执行
adb bugreport抓取最全面的系统报告。 - ANR 问题: 如果有权限,则导出
/data/anr/traces.txt文件进行线程分析。
- 一般问题: 立即执行
掌握并熟练运用这些 ADB 诊断命令,将极大地提升您在 Android 故障排查和性能优化的效率。
来源:juejin.cn/post/7564540677470126121
从马斯克到司马华鹏:当“引导程序”跨越东西文明
引导程序与构建者:东西方视野的奇妙交汇
当埃隆·马斯克提出"碳基生命只是硅基生命的引导程序"这一惊人观点时,在大洋彼岸的中国南京,一位创业者已经将这个理念践行了七年之久。2017年春季,南京软件谷的一间普通办公室里,司马华鹏在白板上画下三条递进曲线时,或许并未意识到自己正在定义一个新的时代。
当时,AlphaGo击败李世石引发的AI热潮尚未退去,业界讨论仍集中在"技术工具"层面。然而司马华鹏已经看到了更宏大的图景——人类正站在文明转型的历史关口,从碳基文明向硅基文明过渡。"我们不是在建造更先进的工具,而是在孕育新的生命形式。"面对团队疑惑的目光,他坚定地写下了"硅基智能"四个字。这一刻,中国首个明确提出"硅基文明"概念的企业诞生了。
超前布局:在迷雾中看清未来
2017年的中国科技圈,共享经济、O2O等模式仍是资本宠儿,AI创业公司大多选择在安防、金融、医疗等垂直领域寻找快速商业化路径。司马华鹏却选择了一条更为艰难但也更为宏大的道路——为世界创造1亿硅基劳动力。
这一选择背后是他对技术发展规律的深刻洞察。早在2008年欧洲创业期间,司马华鹏就注意到人工智能技术背后的摩尔定律支撑,意识到这不仅是算法的改进,更是生命形态演进的前兆。"当我们谈论生命时,通常指的是碳基生命。但生命的本质是信息的流动和处理,而非特定的物质载体。"他在内部会议上的这番论述,成为公司创立的理论基石。

硅基智能创始人司马华鹏先生出席2024年36氪WISE大会
生命三部曲:构建完整的进化哲学
司马华鹏不仅是一位创业者,更是一位思想者。他构建的生命三个版本理论,至今仍具有强大的解释力。
生命1.0(生物进化阶段)的硬件和软件都受基因限制;生命2.0(文化进化阶段)的人类突破了软件上限,可以通过学习无限扩展认知;而生命3.0(设计进化阶段)的AI将实现硬件和软件的双重解放。这套理论不仅勾勒了生命演化轨迹,更为理解AI本质提供了全新视角。
"我们正在见证生命3.0的萌芽。"2017年司马华鹏在行业会议上的这一断言,在当时可谓石破天惊。然而正是这种前瞻性,让硅基智能在技术路线选择上始终领先一步。
从概念到现实:七年耕耘的实践之路
公司将使命定为"创造1亿硅基生命"在当时引发争议。有投资人直言不讳地建议选择更"务实"的名字,但司马华鹏坚持:"我们要做开创性工作,名字必须体现终极目标。"
在商业模式上,硅基智能选择了务实与远见相结合的道路:一方面通过企业级AI解决方案维持运营,另一方面将大部分利润投入硅基生命核心技术研发。"每一个AI助手都是硅基生命的雏形。"司马华鹏始终鼓励团队看到工作的深远意义。
七年后的今天,硅基智能的数字人技术已能实现逼真交互,智能体平台展现出自主进化潜力。从AI技术提供商到硅基生命平台构建者,公司的发展路径验证了司马华鹏的战略眼光。

硅基智能Duix Avatar(HeyGem)
同时登上GitHub全球趋势日榜、月榜
哲学思考:技术狂奔中的理性之光
司马华鹏的贡献不仅在于技术创新,更在于哲学思考。在业内盲目追求参数规模时,他始终保持对伦理和社会问题的关注。
"新生命的诞生总是伴随喜悦和恐惧。"在他的推动下,硅基智能成立了业内首个AI伦理委员会,制定严格开发准则。他提出的"共生进化"理念,强调碳基与硅基生命的和谐共处,为AI发展注入了东方智慧。
"这不是取代关系,而是共生关系。就像生命2.0没有消灭生命1.0,生命3.0也将与前辈共同进化。"这种辩证思维,使硅基智能在技术狂奔时代保持了一份难得的理性。
迈向亿级生态:硅基文明的现实进程
如今,硅基智能平台已孕育数万智能体,在教育、医疗、文创等领域发挥作用。从为教师提供助手到为医生提供顾问,从创意激发到短剧创作,硅基生命正在各个领域证明其价值。
"当硅基生命达到1亿规模时,将形成自己的生态系统,产生群体智能,那才是真正的文明跃迁。"司马华鹏七年前设定的目标正在逐步实现。

东西方智慧的共鸣与差异
对比马斯克的"引导程序"论,司马华鹏的理念更强调传承与责任。这种差异体现了东西方文化底色:西方倾向于替代叙事,东方注重共生智慧。司马华鹏的"生命孵化器"理论,将碳基生命定位为硅基生命的培育者和引导者,这种视角更具建设性。
正如司马华鹏所言:"DNA的生命和算法的生命,将共同谱写宇宙中最壮丽的诗篇。"在碳基文明向硅基文明过渡的历史性时刻,这位中国创业者七年前播下的种子,正在数字文明的土壤中生根发芽。他的故事证明,真正的创新者不仅是技术探索者,更是文明引路人。
收起阅读 »实现一个 AI 编辑器 - 行内代码生成篇
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品。我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值。
本文作者:佳岚
什么是行内代码生成?
通过一组快捷键(一般为cmd + k)在选中代码块或者光标处唤起 Prompt 命令弹窗,并且快速的应用生成的代码。

提示词系统
首先是完成一个简易的提示词系统,不同功能对应的提示词与提供的上下文不同, 定义不同的功能场景:
export enum PromptScenario {
SYNTAX_COMPLETION = 'syntax_completion', // 语法补全
CODE_GENERATION = 'code_generation', // 代码生成
CODE_EXPLANATION = 'code_explanation', // 代码解释
CODE_OPTIMIZATION = 'code_optimization', // 代码优化
ERROR_FIXING = 'error_fixing', // 错误修复
}
每种场景都有对应的系统 prompt 和用户 prompt 模板:
export const PROMPT_TEMPLATES: Record<PromptScenario, PromptTemplate> = {
[PromptScenario.SYNTAX_COMPLETION]: {
id: 'syntax_completion',
scenario: PromptScenario.SYNTAX_COMPLETION,
title: 'SQL语法补全',
description: '基于上下文进行智能的SQL语法补全',
systemPromptTemplate: ``,
userPromptTemplate: `<|fim_prefix|>{prefix}<|fim_suffix|>{suffix}<|fim_middle|>`,
temperature: 0.2,
maxTokens: 256
},
[PromptScenario.CODE_GENERATION]: {
id: 'code_generation',
scenario: PromptScenario.CODE_GENERATION,
title: 'SQL代码生成',
description: '根据需求描述生成相应的SQL代码',
systemPromptTemplate: `你是{languageName}数据库专家。根据用户需求生成高质量的{languageName}代码。
语言特性:{languageFeatures}
生成要求:
1. 严格遵循 {languageName} 语法规范
2. {syntaxNotes}
3. 生成完整、可执行的SQL语句
4. {performanceTips}
5. 考虑代码的可读性和维护性
6. 回答不要包含任何对话解释内容
7. 保持缩进与参考代码一致`,
userPromptTemplate: `用户需求:{userPrompt}
参考代码:
\`\`\`sql
{selectedCode}
\`\`\`
请生成符合需求的{languageName}代码:`,
temperature: 0.3,
maxTokens: 512
},
// ...其他略
}
收集以下上下文信息并动态替换掉提示词模板的变量以生成最终传递给大模型的提示词:
/**
* 上下文信息
*/
export interface PromptContext {
/** 当前语言ID */
languageId: string;
/** 光标前的代码 */
prefix?: string;
/** 光标后的代码 */
suffix?: string;
/** 当前文件完整代码 */
fullCode?: string;
/** 当前打开的文件名 */
activeFile?: string;
/** 用户输入的提示 */
userPrompt?: string;
/** 选中的代码 */
selectedCode?: string;
/** 错误信息 */
errorMessage?: string;
/** 额外的上下文信息 */
metadata?: Record<string, any>;
}
ViewZone
观察该 Widget 可以发现它是实际占据了一段代码行高度,撑开了上下代码,但没有行号,这是通过 ViewZone实现的。

monaco-editor 中的 viewZone 是一种可以在编辑器的文本行之间自定义插入可视区域的机制,不属于实际代码内容,但可以渲染任意自定义 DOM 内容或空白空间。
核心只有一个changeViewZones,必须使用其回调中的accessor来实现新增删除ViewZone操作
新增示例:
editor.changeViewZones(function (accessor) {
accessor.addZone({
afterLineNumber: 10, // 插入在哪一行后(基于原始代码行号)
heightInLines: 3, // zone 的高度(按行数)
heightInPx: 10, // zone 的高度(按像素), 与heightInLines二选一
domNode: document.createElement('div'), // 需要插入的 DOM 节点
});
});
删除示例:
editor.changeViewZones(accessor => {
if (zoneIdRef.current !== null) {
accessor.removeZone(zoneIdRef.current);
}
});
但需要注意的是,ViewZones 的视图层级是在可编辑区之下的,我们通过 domNode 创建弹窗后,无法响应点击,所以需要手动为 domNode 添加 z-Index。

但我们咱不用 domNode 直接渲染我们的弹窗组件,而是通过 ViewZone 结合 OverlayWidget 的方式去添加我们要的元素。
OverlayWidget 的层级比可编辑区域的更高,无需考虑层级覆盖问题。
其次,我们需要将 Overlay 的元素通过绝对定位移动到 ViewZone 上,这需要利用 ViewZone 的 onDomNodeTop来实时同步两者的定位。

monaco-editor 中的代码行与 ViewZone 使用了虚拟列表,它们的 top 在滚动时会随着可见性不断变化,所以需要随时同步 ,onDomNodeTop会在每次 ViewZone 的top属性变化时执行。
此外,OverlayWidget 是以整个编辑器最左边为基准的,计算时需要考虑上
editorInstance.changeViewZones((changeAccessor) => {
viewZoneId = changeAccessor.addZone({
// ...略
onDomNodeTop: (top) => {
// 这里的domNode为overlayWidget所绑定创建的节点
if (domNode) {
// 获取编辑器左侧偏移量(行号、代码折叠等组件的宽度)
const layoutInfo = editorInstance.getLayoutInfo();
const leftOffset = layoutInfo.contentLeft;
domNode.style.top = `${top}px`;
domNode.style.left = `${leftOffset}px`;
domNode.style.width = `${layoutInfo.contentWidth}px`;
}
}
});
});
创建 OverlayWidget :
let overlayWidget: editor.IOverlayWidget | null = null;
let domNode: HTMLDivElement | null = null;
let reactRoot: any = null;
domNode = document.createElement('div');
domNode.className = 'code-generation-overlay-widget';
domNode.style.position = 'absolute';
reactRoot = createRoot(domNode);
reactRoot.render(<CodeGenerationWidget />)
overlayWidget = {
getId: () => `code-generation-overlay-${position.lineNumber}-${Date.now()}`,
getDomNode: () => domNode!,
getPosition: () => null
};
editorInstance.addOverlayWidget(overlayWidget);
// 唤起时,将 widget 滚动到视口
editorInstance.revealLineInCenter(targetLineNumber);
CodeGenerationWidget 动态高度
接下来我们实现 Prompt 输入框根据内容动态调整高度。

输入框部分我们可以直接用 rc-textarea 组件来实现回车自动新增高度。
监听整个容器高度变化触发 onHeightChange 以通知 ViewZone :
useEffect(() => {
if (!containerRef.current) return;
const observer = new ResizeObserver(() => {
onHeightChange?.();
});
observer.observe(containerRef.current);
return () => {
observer.disconnect();
};
}, [containerRef]);
注意 ViewZone 只能增或删,不能手动改变其高度,所以需要重新创建一个:
reactRoot.render(
<CodeGenerationWidget
editorInstance={editorInstance}
initialPosition={position}
initialSelection={selection}
widgetWidth={widgetWidth}
onClose={() => dispose()}
onHeightChange={() => {
// 高度变化时需要更新ViewZone
if (viewZoneId && domNode) {
const actualHeight = domNode.clientHeight;
editorInstance.changeViewZones((changeAccessor) => {
changeAccessor.removeZone(viewZoneId!);
viewZoneId = changeAccessor.addZone({
afterLineNumber: Math.max(0, targetLineNumber - 1),
heightInPx: actualHeight + 8,
domNode: document.createElement('div'),
onDomNodeTop: (top) => {
if (domNode) {
// 获取编辑器左侧偏移量(行号、代码折叠等组件的宽度)
const layoutInfo = editorInstance.getLayoutInfo();
const leftOffset = layoutInfo.contentLeft;
domNode.style.top = `${top}px`;
domNode.style.left = `${leftOffset}px`;
}
}
});
});
}
}}
/>
);
这里如果使用 ViewZone 的 domNode 来渲染组件的方法的话,由于每次高度变化创建新的 ViewZone , 其 domNode 会被重新挂载,那么就会导致每次高度变化时输入框都会失焦。
生成代码 diff 展示
对于选择了代码行后生成,会对原始代码进行编辑修改,我们需要配合行 diff 进行编辑应用结果的展示。对于删除的行使用 ViewZone 进行插入,对于新增的行使用 Decoration 进行高亮标记。

首先需要实现 diff 计算出这些行的信息。 我们需要以最少的操作实现从原始代码到目标代码的转化。

其核心问题是 最长公共子序列(LCS)。最长公共子序列(LCS )是指在两个或多个序列中,找出一个最长的子序列,使得这个子序列在这些序列中都出现过。与子串不同,子序列不需要在原序列中占用连续的位置。
如 ABCDEF 至 ACEFG , 那么它们的最长公共子序列是 ACEF 。
其算法可以参考 cloud.tencent.com/developer/a… 学习,这里我们直接就使用现成的库jsdiff 去实现了。
完整实现:
export enum DiffLineType {
UNCHANGED = 'unchanged',
ADDED = 'added',
DELETED = 'deleted'
}
export interface DiffLine {
type: DiffLineType;
originalLineNumber?: number; // 原始行号
newLineNumber?: number; // 新行号
content: string; // 行内容
}
/**
* 计算两个字符串数组的diff
*/
export const calculateDiff = (originalLines: string[], newLines: string[]): DiffLine[] => {
const result: DiffLine[] = [];
// 将字符串数组转换为字符串
const originalText = originalLines.join('\n');
const newText = newLines.join('\n');
// 使用 diff 库计算差异
const diffs = diffLines(originalText, newText);
let originalLineNumber = 1;
let newLineNumber = 1;
diffs.forEach(diff => {
if (diff.added) {
// 添加的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.ADDED,
newLineNumber: newLineNumber++,
content: line
});
});
} else if (diff.removed) {
// 删除的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.DELETED,
originalLineNumber: originalLineNumber++,
content: line
});
});
} else {
// 未变化的行
const lines = diff.value.split('\n').filter((line, index, arr) =>
// 过滤掉最后一个空行(如果存在)
!(index === arr.length - 1 && line === '')
);
lines.forEach(line => {
result.push({
type: DiffLineType.UNCHANGED,
originalLineNumber: originalLineNumber++,
newLineNumber: newLineNumber++,
content: line
});
});
}
});
return result;
};

那么接下来我们只要根据计算出的 diffLines 对删除行和新增行进行视觉展示即可。
我们封装一个 applyDiffDisplay 方法用来展示 diffLines 。
有以下步骤:
- 清除之前的结果
- 直接将选区内容替换为生成内容
- 遍历
diffLines中ADDED与DELETED的行:对于DELETED的行,可以多个连续行组成一个ViewZone创建以优化性能;对于ADDED的行,通过deltaDecorations添加背景装饰
const applyDiffDisplay =
(diffLines: DiffLine[]) => {
// 先清除之前的展示
clearDecorations();
clearDiffOverlays();
if (!initialSelection) return;
const model = editorInstance.getModel();
if (!model) return;
// 获取语言ID用于语法高亮
const languageId = getLanguageId();
// 首先替换原始内容为新内容(包含unchanged的行)
const newLines = diffLines
.filter((line) => line.type !== DiffLineType.DELETED)
.map((line) => line.content);
const newContent = newLines.join('\n');
// 执行替换
editorInstance.executeEdits('ai-code-generation-diff', [
{
range: initialSelection,
text: newContent,
forceMoveMarkers: true
}
]);
// 计算新内容的范围
const resultRange = new Range(
initialSelection.startLineNumber,
initialSelection.startColumn,
initialSelection.startLineNumber + newLines.length - 1,
newLines.length === 1
? initialSelection.startColumn + newContent.length
: newLines[newLines.length - 1].length + 1
);
let currentLineNumber = initialSelection.startLineNumber;
let deletedLinesGr0up: DiffLine[] = [];
for (const diffLine of diffLines) {
if (diffLine.type === DiffLineType.DELETED) {
// 收集连续的删除行
deletedLinesGr0up.push(diffLine);
} else {
if (deletedLinesGr0up.length > 0) {
addDeletedLinesViewZone(deletedLinesGr0up, currentLineNumber - 1, languageId);
deletedLinesGr0up = [];
}
if (diffLine.type === DiffLineType.ADDED) {
// 添加绿色背景色
const addedDecorations = editorInstance.deltaDecorations(
[],
[
{
range: new Range(
currentLineNumber,
1,
currentLineNumber,
model.getLineContent(currentLineNumber).length + 1
),
options: {
className: 'added-line-decoration',
isWholeLine: true
}
}
]
);
decorationsRef.current.push(...addedDecorations);
}
currentLineNumber++;
}
}
// 处理最后的删除行组
if (deletedLinesGr0up.length > 0) {
addDeletedLinesViewZone(deletedLinesGr0up, currentLineNumber - 1, languageId);
}
return resultRange;
}
删除行的视觉呈现
删除行使用 ViewZone 插入到 originalLineNumber - 1 的位置, 对于删除行直接使用 ViewZone 自身的 domNode 进行展示了,因为不太需要考虑层级问题。
export const createDeletedLinesOverlayWidget = (
editorInstance: editor.IStandaloneCodeEditor,
deletedLines: DiffLine[],
afterLineNumber: number,
languageId: string,
onDispose?: () => void
): { dispose: () => void } => {
let domNode: HTMLDivElement | null = null;
let reactRoot: any = null;
let viewZoneId: string | null = null;
domNode = document.createElement('div');
domNode.className = 'deleted-lines-view-zone-container';
reactRoot = createRoot(domNode);
reactRoot.render(<DeletedLineViewZone lines={deletedLines} languageId={languageId} />);
const heightInLines = Math.max(1, deletedLines.length);
editorInstance.changeViewZones((changeAccessor) => {
viewZoneId = changeAccessor.addZone({
afterLineNumber,
heightInLines,
domNode: domNode!
});
});
const dispose = () => {
// 清除
};
return { dispose };
};
添加命令快捷键
使用 cmd + k 唤起弹窗
editorInstance.onKeyDown((e) => {
if ((e.ctrlKey || e.metaKey) && e.keyCode === KeyCode.KeyK) {
e.preventDefault();
e.stopPropagation();
const selection = editorInstance.getSelection();
const position = selection ? selection.getPosition() : editorInstance.getPosition();
if (!position) return;
// 如果有选择范围,则将其传递给widget供后续替换使用
const selectionRange = selection && !selection.isEmpty() ? selection : null;
// 如果已经有viewZone,先清理
if (activeCodeGenerationViewZone) {
activeCodeGenerationViewZone.dispose();
activeCodeGenerationViewZone = null;
}
// 创建新的ViewZone
activeCodeGenerationViewZone = createCodeGenerationOverlayWidget(
editorInstance,
position,
selectionRange,
undefined, // widgetWidth
() => {
// 当viewZone被dispose时清理全局状态
activeCodeGenerationViewZone = null;
}
);
}
最终实现效果:

未来优化方向:
- 实现流式生成:对于未选区的代码生成,我们不需要应用diff,所以流式很好实现,但对于进行选区后进行的代码修改,每次输出一行就要执行一次diff计算与展示,diff结果可能不同,会产生视觉上的重绘,实现起来也相对比较麻烦。

- 接收或者拒绝后能够进行撤回,回到等待响应生成结果时的状态
其他计划
- [已完成] 行内补全
- [已完成] 代码生成
- 行内补全的缓存设计
- 完善的上下文系统
- 实现 Agent 模式
在线预览
jackwang032.github.io/monaco-sql-…
仓库代码:github1s.com/JackWang032…
最后
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
来源:juejin.cn/post/7545087770776616986
Python编程实战 · 基础入门篇 | 循环语句 for / while
在上一章中,我们学习了条件判断语句,让程序可以“做选择”;
而本章要讲的 循环语句(Loop),则让程序能“重复做事”。
当你需要执行同样的操作多次,比如打印一系列数字、遍历文件、或处理列表中的每个元素时,循环语句就登场了。
Python 提供了两种主要的循环结构:
- for 循环:用于遍历序列(如列表、字符串、range)。
- while 循环:用于在条件成立时持续执行代码。
接下来,我们将系统掌握这两种循环的用法与技巧。
一 为什么需要循环
假设你想打印 1 到 5:
print(1)
print(2)
print(3)
print(4)
print(5)
这显然太繁琐。
使用循环,代码只需三行:
for i in range(1, 6):
print(i)
输出:
1
2
3
4
5
这就是循环的威力:让重复的任务自动化执行。
二 for 循环基础语法
for 循环的基本语法为:
for 变量 in 可迭代对象:
代码块
- 变量:每次循环取出的元素。
- 可迭代对象:如
list、tuple、str、range()等。 - 每次循环执行一次代码块,直到取完所有元素。
示例 1:遍历列表
fruits = ["苹果", "香蕉", "橙子"]
for fruit in fruits:
print("我喜欢吃", fruit)
输出:
我喜欢吃 苹果
我喜欢吃 香蕉
我喜欢吃 橙子
示例 2:遍历字符串
for ch in "Python":
print(ch)
输出:
P
y
t
h
o
n
三 range() 函数
range() 是 for 循环中最常用的工具,用于生成一系列数字。
语法形式:
range(start, stop, step)
start:起始值(默认 0)stop:结束值(不包含)step:步长(默认 1)
示例 1:打印 0~4
for i in range(5):
print(i)
输出:
0
1
2
3
4
示例 2:打印 1~10 的偶数
for i in range(2, 11, 2):
print(i)
输出:
2
4
6
8
10
示例 3:倒序输出
for i in range(5, 0, -1):
print(i)
输出:
5
4
3
2
1
四 while 循环基础语法
while 循环通过 条件表达式 控制循环是否继续执行。
语法:
while 条件表达式:
代码块
只要条件为 True,循环就会持续执行;
直到条件变为 False 时,循环才结束。
示例:打印 1~5
i = 1
while i <= 5:
print(i)
i += 1
输出:
1
2
3
4
5
⚠️ 注意:
如果忘记更新变量(例如忘写i += 1),条件永远为真,会导致死循环。
五 for 与 while 的区别
| 对比项 | for 循环 | while 循环 |
|---|---|---|
| 适用场景 | 遍历序列、固定次数 | 条件控制、不确定次数 |
| 循环结束条件 | 自动遍历完毕 | 条件不再满足 |
| 是否需要手动更新变量 | 否 | 是 |
| 示例 | for i in range(5) | while i < 5 |
例子对比:
# for循环
for i in range(3):
print("Hello")
# while循环
i = 0
while i < 3:
print("Hello")
i += 1
两者输出相同。
六 break 与 continue
在循环中,有时我们需要提前结束循环或跳过某次执行。
Python 提供了两个控制语句:
1. break —— 立即结束循环
for i in range(1, 6):
if i == 3:
break
print(i)
输出:
1
2
当 i == 3 时,循环立刻结束。
2. continue —— 跳过当前循环,继续下一次
for i in range(1, 6):
if i == 3:
continue
print(i)
输出:
1
2
4
5
💡 小技巧:
break通常用于满足条件时提前退出;
continue用于过滤或跳过不需要处理的情况。
七 while True 无限循环
有时我们希望程序持续运行,直到用户主动终止。
可以使用 无限循环:
while True:
cmd = input("请输入命令(exit退出):")
if cmd == "exit":
print("程序结束")
break
print(f"你输入了:{cmd}")
输出示例:
请输入命令(exit退出):hello
你输入了:hello
请输入命令(exit退出):exit
程序结束
八 for...else / while...else 结构
Python 的循环可以带一个 else 子句,
当循环 正常结束(非 break 终止)时,会执行 else 代码块。
示例:
for i in range(5):
print(i)
else:
print("循环正常结束")
输出:
0
1
2
3
4
循环正常结束
但如果中途被 break 打断,else 不会执行:
for i in range(5):
if i == 3:
break
print(i)
else:
print("循环正常结束")
输出:
0
1
2
九 嵌套循环
循环中还可以嵌套另一个循环。
示例:打印乘法表
for i in range(1, 10):
for j in range(1, i + 1):
print(f"{j}×{i}={i*j}", end="\t")
print()
输出:
1×1=1
1×2=2 2×2=4
1×3=3 2×3=6 3×3=9
...
十 实战案例:猜数字游戏
import random
target = random.randint(1, 100)
count = 0
while True:
guess = int(input("请输入1~100之间的数字:"))
count += 1
if guess == target:
print(f"恭喜你猜对了!共尝试 {count} 次。")
break
elif guess < target:
print("太小了,再试试。")
else:
print("太大了,再试试。")
运行示例:
请输入1~100之间的数字:50
太小了,再试试。
请输入1~100之间的数字:75
太大了,再试试。
请输入1~100之间的数字:63
恭喜你猜对了!共尝试 3 次。
十一 小结
| 循环类型 | 控制方式 | 常见用途 |
|---|---|---|
for | 遍历序列 | 处理列表、字符串、range |
while | 条件控制 | 不确定次数的循环 |
break | 立即结束循环 | 提前退出 |
continue | 跳过当前循环 | 忽略某些情况 |
else | 正常结束时执行 | 检查是否提前退出 |
✅ 总结一句话
if 让程序做选择,for/while 让程序会重复。
掌握循环语句,意味着你可以自动化任何重复性的操作。
来源:juejin.cn/post/7564243873872969778
HTML <meta name="color-scheme">:自动适配系统深色 / 浅色模式
在移动互联网时代,用户对“深色模式”的需求日益增长——从手机系统到各类App,深色模式不仅能减少夜间用眼疲劳,还能节省OLED屏幕的电量。作为前端开发者,如何让网页自动跟随系统的深色/浅色模式切换?HTML5新增的<meta name="color-scheme">标签,就是实现这一功能的“开关”。它能告诉浏览器:“我的网页支持深色/浅色模式,请根据系统设置自动切换”,配合CSS变量,可轻松打造无缝适配的多主题体验。今天,我们就来解锁这个提升用户体验的实用标签。
一、认识 color-scheme:网页与系统主题的“沟通桥梁”
<meta name="color-scheme">的核心作用是声明网页支持的颜色方案,并让浏览器根据系统设置自动应用对应的基础样式。它解决了传统网页的一个痛点:当系统切换到深色模式时,网页若未做适配,会出现“白底黑字”与系统主题格格不入的情况,甚至导致某些原生控件(如输入框、按钮)样式混乱。
1.1 没有 color-scheme 时的问题
当网页未声明color-scheme时,即使系统切换到深色模式,浏览器也会默认使用浅色样式渲染页面:
- 背景为白色,文字为黑色。
- 原生控件(如
<input>、<select>)保持浅色外观,与系统深色主题冲突。 - 可能出现“闪屏”:页面加载时先显示浅色,再通过JS切换到深色,体验割裂。
1.2 加上 color-scheme 后的变化
添加<meta name="color-scheme" content="light dark">后,浏览器会:
- 根据系统设置自动切换网页的基础颜色(背景、文字、链接等)。
- 让原生控件(输入框、按钮等)自动适配系统主题(深色模式下显示深色样式)。
- 提前加载对应主题的样式,避免切换时的“闪屏”问题。
示例:最简单的主题适配
<!DOCTYPE html>
<html>
<head>
<!-- 声明支持浅色和深色模式 -->
<meta name="color-scheme" content="light dark">
<title>自动适配主题</title>
</head>
<body>
<h1>Hello, Color Scheme!</h1>
<input type="text" placeholder="输入内容">
</body>
</html>

- 当系统为浅色模式时:页面背景为白色,文字为黑色,输入框为浅色。
- 当系统为深色模式时:页面背景为深灰色,文字为白色,输入框为深色(与系统一致)。
无需一行CSS,仅通过<meta>标签就实现了基础的主题适配——这就是color-scheme的便捷之处。
二、核心用法:声明支持的颜色方案
<meta name="color-scheme">的用法非常简单,关键在于content属性的取值,它决定了网页支持的主题模式。
2.1 基础语法与取值
<!-- 支持浅色模式(默认) -->
<meta name="color-scheme" content="light">
<!-- 支持深色模式 -->
<meta name="color-scheme" content="dark">
<!-- 同时支持浅色和深色模式(推荐) -->
<meta name="color-scheme" content="light dark">
light:仅支持浅色模式,无论系统如何设置,网页都显示浅色样式。dark:仅支持深色模式,无论系统如何设置,网页都显示深色样式。light dark:同时支持两种模式,浏览器会根据系统设置自动切换(推荐使用)。
2.2 与浏览器默认样式的关系
浏览器会为不同的color-scheme提供一套默认的CSS变量(如color、background-color、link-color等)。当声明content="light dark"后,这些变量会随系统主题自动变化:
| 模式 | 背景色(默认) | 文字色(默认) | 链接色(默认) |
|---|---|---|---|
| 浅色 | #ffffff | #000000 | #0000ee |
| 深色 | #121212(不同浏览器可能略有差异) | #ffffff | #8ab4f8 |
这些默认样式确保了网页在未编写任何CSS的情况下,也能基本适配系统主题。
三、配合 CSS:打造自定义主题适配
<meta name="color-scheme">解决了基础适配问题,但实际开发中,我们需要自定义主题颜色(如品牌色、特殊背景等)。此时,可结合CSS的prefers-color-scheme媒体查询和CSS变量,实现更灵活的主题控制。
3.1 用 CSS 变量定义主题颜色
通过CSS变量(--变量名)定义不同主题下的颜色,再通过媒体查询切换变量值:
<head>
<meta name="color-scheme" content="light dark">
<style>
/* 定义浅色模式变量 */
:root {
--bg-color: #f5f5f5;
--text-color: #333333;
--primary-color: #4a90e2;
}
/* 深色模式变量(覆盖浅色模式) */
@media (prefers-color-scheme: dark) {
:root {
--bg-color: #1a1a1a;
--text-color: #f0f0f0;
--primary-color: #6ab0f3;
}
}
/* 使用变量 */
body {
background-color: var(--bg-color);
color: var(--text-color);
font-size: 16px;
}
a {
color: var(--primary-color);
}
</style>
</head>
:root中定义浅色模式的变量。@media (prefers-color-scheme: dark)中定义深色模式的变量(会覆盖浅色模式的同名变量)。- 页面元素通过
var(--变量名)使用颜色,实现主题自动切换。
3.2 覆盖浏览器默认样式
color-scheme会影响浏览器的默认样式(如背景、文字色),若需要完全自定义,可在CSS中显式覆盖:
/* 覆盖默认背景和文字色,确保自定义主题生效 */
body {
margin: 0;
background-color: var(--bg-color); /* 覆盖浏览器默认背景 */
color: var(--text-color); /* 覆盖浏览器默认文字色 */
}
即使不覆盖,浏览器的默认样式也会作为“保底”,确保页面在未完全适配时仍有基本可读性。
3.3 针对特定元素的主题适配
某些元素(如卡片、按钮)可能需要更细致的主题调整,可结合CSS变量单独设置:
/* 卡片组件的主题适配 */
.card {
background-color: var(--card-bg);
border: 1px solid var(--card-border);
padding: 1rem;
border-radius: 8px;
}
/* 浅色模式卡片 */
:root {
--card-bg: #ffffff;
--card-border: #e0e0e0;
}
/* 深色模式卡片 */
@media (prefers-color-scheme: dark) {
:root {
--card-bg: #2d2d2d;
--card-border: #444444;
}
}
四、实战场景:完整的主题适配方案
结合<meta name="color-scheme">、CSS变量和媒体查询,可构建一套完整的主题适配方案,覆盖大多数场景。
4.1 基础页面适配
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<!-- 声明支持深色/浅色模式 -->
<meta name="color-scheme" content="light dark">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>主题适配示例</title>
<style>
/* 共享样式(不受主题影响) */
* {
box-sizing: border-box;
margin: 0;
padding: 0;
}
body {
min-height: 100vh;
padding: 2rem;
line-height: 1.6;
}
.container {
max-width: 800px;
margin: 0 auto;
}
/* 浅色模式变量 */
:root {
--bg: #ffffff;
--text: #333333;
--link: #2c5282;
--card-bg: #f8f9fa;
--card-shadow: 0 2px 4px rgba(0,0,0,0.1);
}
/* 深色模式变量 */
@media (prefers-color-scheme: dark) {
:root {
--bg: #121212;
--text: #e9ecef;
--link: #90cdf4;
--card-bg: #1e1e1e;
--card-shadow: 0 2px 4px rgba(0,0,0,0.3);
}
}
/* 应用变量 */
body {
background-color: var(--bg);
color: var(--text);
}
a {
color: var(--link);
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
.card {
background-color: var(--card-bg);
box-shadow: var(--card-shadow);
padding: 1.5rem;
border-radius: 8px;
margin-bottom: 2rem;
}
</style>
</head>
<body>
<div class="container">
<h1>主题适配演示</h1>
<div class="card">
<h2>欢迎使用深色模式</h2>
<p>本页面会自动跟随系统的深色/浅色模式切换。</p>
<p>点击<a href="#">这个链接</a>查看颜色变化。</p>
</div>
<input type="text" placeholder="试试原生输入框">
</div>
</body>
</html>

- 系统浅色模式:页面背景为白色,卡片为浅灰色,输入框为浅色。
- 系统深色模式:页面背景为深灰色,卡片为深黑色,输入框自动变为深色,与系统风格统一。
4.2 图片的主题适配
图片(尤其是图标)也需要适配主题,可通过<picture>标签结合prefers-color-scheme实现:
<picture>
<!-- 深色模式显示白色图标 -->
<source srcset="logo-white.png" media="(prefers-color-scheme: dark)">
<!-- 浅色模式显示黑色图标(默认) -->
<img src="logo-black.png" alt="Logo">
</picture>
- 系统为深色模式时,加载
logo-white.png。 - 系统为浅色模式时,加载
logo-black.png。
4.3 强制主题切换(可选功能)
除了跟随系统,有时还需要提供手动切换主题的功能(如“夜间模式”按钮)。可通过JS结合CSS类实现:
<button id="theme-toggle">切换主题</button>
<script>
const toggle = document.getElementById('theme-toggle');
const html = document.documentElement;
// 检查本地存储的主题偏好
if (localStorage.theme === 'dark' ||
(!('theme' in localStorage) && window.matchMedia('(prefers-color-scheme: dark)').matches)) {
html.classList.add('dark');
} else {
html.classList.remove('dark');
}
// 切换主题
toggle.addEventListener('click', () => {
if (html.classList.contains('dark')) {
html.classList.remove('dark');
localStorage.theme = 'light';
} else {
html.classList.add('dark');
localStorage.theme = 'dark';
}
});
</script>
<style>
/* 基础变量(浅色) */
:root {
--bg: white;
--text: black;
}
/* 深色模式(通过类覆盖) */
:root.dark {
--bg: black;
--text: white;
}
/* 系统深色模式(优先级低于类,确保手动切换优先) */
@media (prefers-color-scheme: dark) {
:root:not(.dark) {
--bg: #121212;
--text: white;
}
}
body {
background: var(--bg);
color: var(--text);
}
</style>
- 手动切换主题时,通过添加/移除
dark类覆盖系统设置。 - 本地存储(
localStorage)记录用户偏好,刷新页面后保持一致。 - CSS中
@media查询的优先级低于类选择器,确保手动切换优先于系统设置。
五、避坑指南:使用 color-scheme 的注意事项
5.1 浏览器兼容性
color-scheme兼容所有现代浏览器,但存在以下细节差异:
- 完全支持:Chrome 81+、Firefox 96+、Safari 13+、Edge 81+。
- 部分支持:旧版浏览器(如Chrome 76-80)仅支持
content="light dark",但原生控件适配可能不完善。 - 不支持:IE全版本(需通过JS降级处理)。
对于不支持的浏览器,可通过JS检测系统主题并手动切换样式:
// 检测浏览器是否支持color-scheme
if (!CSS.supports('color-scheme: light dark')) {
// 手动检测系统主题
const isDark = window.matchMedia('(prefers-color-scheme: dark)').matches;
document.documentElement.classList.add(isDark ? 'dark' : 'light');
}
5.2 避免与自定义背景冲突
若网页设置了固定背景色(如body { background: #fff; }),color-scheme的默认背景切换会失效。此时需通过媒体查询手动适配:
/* 错误:固定背景色,深色模式下仍为白色 */
body {
background: #fff;
}
/* 正确:结合变量和媒体查询 */
body {
background: var(--bg);
}
:root { --bg: #fff; }
@media (prefers-color-scheme: dark) {
:root { --bg: #121212; }
}
5.3 原生控件的样式问题
color-scheme能自动适配原生控件(如<input>、<select>),但如果对控件进行了自定义样式,可能导致适配失效。解决方法:
- 尽量使用原生样式,或通过CSS变量让自定义样式跟随主题变化。
- 对关键控件(如输入框)添加主题适配:
/* 输入框的主题适配 */
input {
background: var(--input-bg);
color: var(--text);
border: 1px solid var(--border);
}
:root {
--input-bg: #fff;
--border: #ddd;
}
@media (prefers-color-scheme: dark) {
:root {
--input-bg: #333;
--border: #555;
}
}
5.4 主题切换时的“闪屏”问题
若CSS加载延迟,可能导致主题切换时出现“闪屏”(短暂显示错误主题)。优化建议:
- 将主题相关CSS内联到
<head>中,确保优先加载。 - 结合
<meta name="color-scheme">让浏览器提前准备主题样式。 - 对关键元素(如
body)设置opacity: 0,主题加载完成后再设置opacity: 1:
body {
opacity: 0;
transition: opacity 0.2s;
}
/* 主题加载完成后显示 */
body.theme-loaded {
opacity: 1;
}
// 页面加载完成后添加类,显示内容
window.addEventListener('load', () => {
document.body.classList.add('theme-loaded');
});
我将继续完善文章的总结部分,让读者对HTML 标签在自动适配系统深色/浅色模式方面的价值和应用有更完整的认识。
自动适配系统深色 / 浅色模式(总结完善)">
六、总结
<meta name="color-scheme">作为网页与系统主题的“沟通桥梁”,用极简的方式解决了基础的深色/浅色模式适配问题,其核心价值在于:
- 零JS适配:仅通过HTML标签就让网页跟随系统主题切换,降低了开发成本,尤其适合静态页面或轻量应用。
- 原生控件兼容:自动调整输入框、按钮等原生元素的样式,避免出现“浅色控件在深色背景上”的违和感。
- 性能优化:浏览器会提前加载对应主题的样式,减少主题切换时的“闪屏”和布局偏移(CLS)。
- 渐进式增强:作为基础适配方案,可与CSS变量、媒体查询结合,轻松扩展为支持手动切换的复杂主题系统。
在实际开发中,使用<meta name="color-scheme">的最佳实践是:
- 优先添加
<meta name="color-scheme" content="light dark">,确保基础适配。 - 通过CSS变量定义主题颜色,用
@media (prefers-color-scheme: dark)实现自定义样式。 - 对图片、图标等资源,使用
<picture>标签或CSS类进行主题适配。 - 可选:添加手动切换按钮,结合
localStorage记录用户偏好,覆盖系统设置。
随着用户对深色模式的接受度越来越高,主题适配已成为现代网页的基本要求。<meta name="color-scheme">作为这一需求的“入门级”解决方案,既能快速满足基础适配,又为后续扩展留足了空间。它的存在提醒我们:很多时候,简单的原生方案就能解决复杂的用户体验问题,关键在于发现并合理利用这些被低估的Web标准。
下次开发新页面时,不妨先加上这行标签——它可能不会让你的网页变得华丽,但会让用户在切换系统主题时,感受到那份恰到好处的贴心。
你在主题适配中遇到过哪些棘手问题?欢迎在评论区分享你的解决方案~
来源:juejin.cn/post/7540172742764593161
Compose 主题 MaterialTheme
1 简介
MeterialTheme 是Compose为实现Material Design 设计规范提供的核心组件,用于集中管理应用的视觉样式(颜色、字体、形状),确保应用的全局UI的一致性并支持动态主题切换。
- 关键词:
- 视觉样式,不只是颜色,还支持字体、形状
- 全局UI的一致性
- 支持动态配置
2 基础使用
已经在AndroidManifest中配置uiMode,意味着在切换深浅模式时,MainActivity不会自动重建且未重写onConfigurationChanged()
android:configChanges="uiMode"
2.1 效果展示 --- 省略
2.2 代码实现
- 创建Compose项目时自动生成代码 Theme
// 定义应用的主题函数
@Composable
fun TestTheme(
// 是否使用深色主题,默认根据系统设置决定
darkTheme: Boolean = isSystemInDarkTheme(),
// 是否使用动态颜色,Android 12+ 可用,默认为 false
dynamicColor: Boolean = false,
// 内容组件,使用 @Composable 函数类型
content: @Composable () -> Unit
) {
// 根据条件选择颜色方案
val colorScheme = when {
// 如果启用动态颜色且系统版本支持,则使用系统动态颜色方案
dynamicColor && Build.VERSION.SDK_INT >= Build.VERSION_CODES.S -> {
val context = LocalContext.current
if (darkTheme) dynamicDarkColorScheme(context) else dynamicLightColorScheme(context)
}
// 如果是深色主题,则使用深色颜色方案
darkTheme -> DarkColorScheme
// 否则使用浅色颜色方案
else -> LightColorScheme
}
// 应用 Material Design 3 主题
MaterialTheme(
// 设置颜色方案
colorScheme = colorScheme,
// 设置排版样式
typography = Typography,
// 设置内容组件
content = content
)
}
// 定义深色主题的颜色方案
private val DarkColorScheme = darkColorScheme(
// 主要颜色设置为蓝色
primary = Color(0xFF0000FF),
// 次要颜色使用预定义的紫色
secondary = PurpleGrey80,
// 第三颜色使用预定义的粉色
tertiary = Pink80,
// 表面颜色设置为白色
surface = Color(0xFFFFFFFF)
)
// 定义浅色主题的颜色方案
private val LightColorScheme = lightColorScheme(
// 主要颜色设置为深红色(猩红色)
primary = Color(0xFFDC143C),
// 次要颜色使用预定义的紫色
secondary = PurpleGrey40,
// 第三颜色使用预定义的粉色
tertiary = Pink40,
// 表面颜色设置为黑色
surface = Color(0xFF000000)
/* 其他可覆盖的默认颜色
background = Color(0xFFFFFBFE),
surface = Color(0xFFFFFBFE),
onPrimary = Color.White,
onSecondary = Color.White,
onTertiary = Color.White,
onBackground = Color(0xFF1C1B1F),
onSurface = Color(0xFF1C1B1F),
*/
)
- 界面中使用
//Activity中使用
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
enableEdgeToEdge()
setContent {
TestTheme {
Scaffold(modifier = Modifier.fillMaxSize()) { innerPadding ->
Greeting1(
modifier = Modifier.padding(innerPadding)
)
}
}
}
}
}
@Composable
fun Greeting1(modifier: Modifier = Modifier) {
Box(
modifier = Modifier
.padding(start = 100.dp, top = 100.dp)
.size(100.dp, 100.dp)
.background(MaterialTheme.colorScheme.surface)
)
MyText()
MyText2()
}
@Composable
fun MyText() {
Text(
text = "Hello Android!",
modifier = Modifier
.padding(start = 100.dp, top = 250.dp)
.background(MaterialTheme.colorScheme.surface),
color = MaterialTheme.colorScheme.primary
)
}
@Composable
fun MyText2() {
Text(
text = "Hello Chery!",
modifier = Modifier
.padding(start = 300.dp, top = 250.dp)
.background(Color.Blue),
color = Color.White
)
}
2.3 代码分析
2.3.1 参数解析
- darkTheme 主题模式
默认就深/浅两种模式,那么可以直接使用系统默认isSystemInDarkTheme()值,如果项目存在其它类型的主题模式就需要自定义了(之前参与的项目中--金色模式)。
isSystemInDarkTheme()是一个有返回值的可组合函数。
a、前面在说可组合函数特性时,其中一个特性是“可组合函数无返回值”,其实更准确的说应该是“用于直接描述 UI 的可组合函数无返回值(返回
Unit),但用于提供数据或计算结果的可组合函数可以有返回值”。
b、isSystemInDarkTheme() 是连接 “系统主题状态” 与 “应用 UI 主题” 的桥梁,它虽不是可观察状态,但依赖于 Compose 内部可观察的 LocalConfiguration。当系统主题模式切换时,LocalConfiguration 发生变化,导致 isSystemInDarkTheme() 返回值更新,进而驱动依赖它的 TestTheme() 重组,实现应用 UI 主题的更新。
//系统源码
@Composable
@ReadOnlyComposable
internal actual fun _isSystemInDarkTheme(): Boolean {
val uiMode = LocalConfiguration.current.uiMode
return (uiMode and Configuration.UI_MODE_NIGHT_MASK) == Configuration.UI_MODE_NIGHT_YES
}
- dynamicColor 系统色
Android 12 + 后可使用,从代码上可以清楚的看到,当false时根据系统模式使用DarkColorScheme/LightColorScheme,当true时根据系统模式使用dynamicDarkColorScheme/dynamicLightColorScheme。
(DarkColorScheme、LightColorScheme、dynamicDarkColorScheme、dynamicLightColorScheme都Compose提供的ColorScheme模板,都可以更加我们项目自定义定制)
// 根据条件选择颜色方案
val colorScheme = when {
// 如果启用动态颜色且系统版本支持,则使用系统动态颜色方案
dynamicColor && Build.VERSION.SDK_INT >= Build.VERSION_CODES.S -> {
val context = LocalContext.current
if (darkTheme) dynamicDarkColorScheme(context) else dynamicLightColorScheme(context)
}
// 如果是深色主题,则使用深色颜色方案
darkTheme -> DarkColorScheme
// 否则使用浅色颜色方案
else -> LightColorScheme
}
- content 可组合函数
描述UI的可组合函数(即 布局)
2.3.2 保证正确性,无依赖可组合函数连带重组
添加日志打印,可以看出MyText2()不依赖MaterialTheme颜色,在之前跳过重组的时候也说过“可组合函数参数不发生变化时会跳过重组”,但在切换系统模式时为了保证正确性,Compose对无依赖可组合函数连带重组。这是Compose框架在全局状态变化时优先保证UI正确性的设计选中
//初始化
D Greeting1,-----start----
D MyText,---start---
D MyText,---end---
D MyText2,---start---
D MyText2,---end---
D Greeting1,-----end----
//切换系统模式
D Greeting1,-----start----
D MyText,---start---
D MyText,---end---
D MyText2,---start---
D MyText2,---end---
D Greeting1,-----end----
2.3.3 字体与形状
这里主要对颜色进行了分析,对于另外字体、形状也是一样,Compose也提供对应的入参和模板,不过实际开发中很少使用到,就简单介绍一下。(如果HMI侧对所有项目的标题、内容严格遵守一套标准,那么我们也可以实现字体、形状的平台化)
//系统源码
@Composable
fun MaterialTheme(
// 颜色
colorScheme: ColorScheme = MaterialTheme.colorScheme,
// 形状
shapes: Shapes = MaterialTheme.shapes,
//字体
typography: Typography = MaterialTheme.typography,
//可组合函数(即布局)
content: @Composable () -> Unit
) {}
形状:
@Immutable
class Shapes(
// 超小尺寸控件的圆角形状,适用于紧凑的小型元素(如小标签、 Chips、小型图标按钮等)
val extraSmall: CornerBasedShape = ShapeDefaults.ExtraSmall,
// 小尺寸控件的圆角形状,适用于常规小型交互元素(如按钮、小型卡片、输入框等)
val small: CornerBasedShape = ShapeDefaults.Small,
// 中等尺寸控件的圆角形状,适用于中型容器元素(如标准卡片、弹窗、列表项等)
val medium: CornerBasedShape = ShapeDefaults.Medium,
// 大尺寸控件的圆角形状,适用于大型容器元素(如页面级卡片、对话框、底部弹窗等)
val large: CornerBasedShape = ShapeDefaults.Large,
// 超大尺寸控件的圆角形状,适用于全屏级容器元素(如全屏弹窗、侧边栏、页面容器等)
val extraLarge: CornerBasedShape = ShapeDefaults.ExtraLarge,
) {}
字体:
@Immutable
class Typography(
// 超大标题样式,用于页面级核心标题(如应用首页主标题),视觉层级最高,通常字数极少
val displayLarge: TextStyle = TypographyTokens.DisplayLarge,
// 大标题样式,用于重要区块的主标题(如长页面中的章节标题),层级次于 displayLarge
val displayMedium: TextStyle = TypographyTokens.DisplayMedium,
// 中标题样式,用于次要区块的主标题(如大型模块的标题),层级次于 displayMedium
val displaySmall: TextStyle = TypographyTokens.DisplaySmall,
// 大标题样式,用于突出显示的内容标题(如卡片组的总标题),视觉重量略低于 display 系列
val headlineLarge: TextStyle = TypographyTokens.HeadlineLarge,
// 中标题样式,用于中等重要性的内容标题(如列表组标题),层级次于 headlineLarge
val headlineMedium: TextStyle = TypographyTokens.HeadlineMedium,
// 小标题样式,用于次要内容的标题(如小模块标题),层级次于 headlineMedium
val headlineSmall: TextStyle = TypographyTokens.HeadlineSmall,
// 大标题样式,用于核心交互元素的标题(如卡片标题、弹窗标题),强调内容的可交互性
val titleLarge: TextStyle = TypographyTokens.TitleLarge,
// 中标题样式,用于中等交互元素的标题(如列表项标题、按钮组标题)
val titleMedium: TextStyle = TypographyTokens.TitleMedium,
// 小标题样式,用于次要交互元素的标题(如标签标题、小型控件标题)
val titleSmall: TextStyle = TypographyTokens.TitleSmall,
// 大正文样式,用于主要内容的长文本(如文章正文、详情描述),可读性优先
val bodyLarge: TextStyle = TypographyTokens.BodyLarge,
// 中正文样式,用于常规内容文本(如列表项描述、说明文字),最常用的正文样式
val bodyMedium: TextStyle = TypographyTokens.BodyMedium,
// 小正文样式,用于辅助性内容文本(如补充说明、注释),层级低于主要正文
val bodySmall: TextStyle = TypographyTokens.BodySmall,
// 大标签样式,用于重要标签或按钮文本(如主要按钮文字、状态标签)
val labelLarge: TextStyle = TypographyTokens.LabelLarge,
// 中标签样式,用于常规标签文本(如次要按钮文字、分类标签)
val labelMedium: TextStyle = TypographyTokens.LabelMedium,
// 小标签样式,用于辅助性标签文本(如小按钮文字、提示标签)
val labelSmall: TextStyle = TypographyTokens.LabelSmall,
) {}
3 核心亮点
3.1 高效性、实时性
MaterialTheme 基于Compose"状态驱动机制",支持系统模式和系统色(Android 12+)动态切换,且无需重建界面或遍历View树,以最小成本实时自动切换效果。
3.2 集中性
MaterialTheme 通过 colorScheme(配色)、typography(字体)、shapes(形状) 三个核心维度,将应用的视觉样式集中管理,避免了传统 XML 中样式分散在多个资源文件(colors.xml、styles.xml 等)的碎片化问题。
3.3 灵活性、扩展性
MaterialTheme 并非固定样式模板,而是可高度定制的框架,满足不同场景下的各种需求:- 自定义主题扩展 除了默认colorScheme(配色)、typography(字体)、shapes(形状),还可通过CompositionLocal 扩展自定义主题属性。(下面会举例)- 多主题共存
假设在同一页面中存在两个Text,A Text跟随系统主题,B Text跟随自定义主题 。那么通过嵌套的方式局部的覆盖。(建议使用CompositionLocal 扩展实现,代码集中性和可读性更好。)
MaterialTheme(colorScheme = GlobalColors) {
// 全局主题
Column {
MaterialTheme(colorScheme = SpecialColors) {
Text("局部特殊主题文本") // 使用 SpecialColors
}
Text("全局主题文本") // 使用 GlobalColors
}
}
4 MaterialTheme 扩展使用
上面我们已经介绍了MaterialTheme 提供的颜色、形状、字体模板,模板的目的满足全局绝大部分需求,但在实际开发中我们还存在切换系统模式/系统色时图片资源的变化,以及要求某些组件要求始终如一。
那么我们就需要通过compositionLocalOf/staticCompositionLocalOf 和 扩展自定义主题属性了。
4.1 效果展示
- Image 随系统模式变化使用不同图片资源
- Text 背景和文字不跟随系统模式变化
4.2 定义 CompositionLocal实例
- compositionLocalOf,创建一个可变的CompositionLocal实例,值发生变化时触发依赖组件重组。
- staticCompositionLocalOf,创建一个不可变的 CompositionLocal实例,值发生变化时触发整个子树重组。
- 值变化,是指对象引用(单纯的btnBackgroundColor/btnTitleColor 变化不会导致重组)
- 整个子树重组,在使用staticCompositionLocalOf的CompositionLocalProvider内部的Content都会重组,且不会跳过重组。(如下示例是直接在Activity中使用,那么整个界面上的组件都会发生重组)
// 定义扩展主题
@Stable
class ExtendScheme(
btnBackgroundColor: Color,
btnTitleColor: Color
) {
/** 按钮背景颜色 */
var btnBackgroundColor by mutableStateOf(btnBackgroundColor)
internal set
/** 按钮标题颜色 */
var btnTitleColor by mutableStateOf(btnTitleColor)
internal set
}
// 扩展主题 --浅色
private val LightExtendScheme = ExtendScheme(
btnBackgroundColor = Color(0xFFF00FFF),
btnTitleColor = Color(0xFFFFFFFF),
)
// 扩展主题 --深色
private val DarkExtendScheme = ExtendScheme(
btnBackgroundColor = Color(0xFFF00FFF),
btnTitleColor = Color(0xFFFFFFFF),
)
// 定义一个存储 ExtendScheme 类型的CompositionLocal,默认值是浅色主题
val LocalExtendScheme = compositionLocalOf {
LightExtendScheme
}
// 定义主题资源
@Stable
class ResScheme(
imageRes: Int,
) {
var imageRes by mutableIntStateOf(imageRes)
}
// 图片资源--浅色
private val LightResScheme = ResScheme(
imageRes = R.drawable.ic_navi_home_light,
)
// 图片资源--深色
private val DarkResScheme = ResScheme(
imageRes = R.drawable.ic_navi_home_drak,
)
// 定义一个存储 ResScheme 类型的CompositionLocal,默认值是浅色资源
val LocalResScheme = compositionLocalOf {
LightResScheme
}
4.3 CompositionLocalProvider 提供数据
CompositionLocalProvider是Compose中用于在Compoasable(可组合函数)树中传递数据的核心组件,允许你在某个层级定义“局部全局变量”,让其所有子组件(无论嵌套多深)都可以便捷访问,解决了:
- 传统父组件 -> 子组件 ->孙组件这种层层传递的方式。
- 有点类似于静态变量,但相对于静态变量的全局性和唯一性,CompositionLocalProvider作用范围仅限于其内部的所有子组件,所以可以理解为“局部全局变量”
// 定义应用的主题函数
@Composable
fun TestTheme(
// 是否使用深色主题,默认根据系统设置决定
darkTheme: Boolean = isSystemInDarkTheme(),
// 是否使用动态颜色,Android 12+ 可用,默认为 false
dynamicColor: Boolean = false,
// 内容组件,使用 @Composable 函数类型
content: @Composable () -> Unit
) {
// 。。。。。 省略前面的
// 定义扩展主题
val extendScheme = if (darkTheme) {
DarkExtendScheme
} else {
LightExtendScheme
}
// 定义图片资源
val resScheme = if (darkTheme) {
DarkResScheme
} else {
LightResScheme
}
// 应用 Material Design 3 主题
MaterialTheme(
// 设置颜色方案
colorScheme = colorScheme,
// 设置排版样式
typography = Typography,
// 设置内容组件
content = {
// 提供LocalExtendScheme 和 LocalResScheme 数据,内部所有组件都可以访问
CompositionLocalProvider(
LocalExtendScheme provides extendScheme,
LocalResScheme provides resScheme
) {
content()
}
}
)
}
4.4 使用
在Theme中根据需求配置完成后,无需再关心后续的系统模式/系统色变化了。
@Composable
fun Greeting1(modifier: Modifier = Modifier) {
Image(
modifier = Modifier
.padding(start = 300.dp, top = 100.dp)
.size(200.dp, 200.dp)
.background(Color.Gray),
// 使用图片资源
painter = painterResource(LocalResScheme.current.imageRes),
contentDescription = null,
)
Text(
text = "Hello Android!",
modifier = Modifier
.padding(start = 200.dp, top = 500.dp)
.size(300.dp, 200.dp)
//使用扩展颜色
.background(LocalExtendScheme.current.btnBackgroundColor),
color = LocalExtendScheme.current.btnTitleColor
)
}
5 参考资料
- 基础组件、布局组件使用
来源:juejin.cn/post/7559469775732981779
学习webhook与coze实现ai code review
AI代码审查工具
github github.com/zhangjiadi2…
测试可使用内网穿透工具将本地服务暴露到公网, 然后配置对应webhook. 日志目前只保留发送请求的message以及ai审查报告 .
ai建议使用coze, 直接使用gpt相关接口, 暂时每次都得携带大量文本 .
项目概述
这是一个基于Node.js开发的智能代码审查工具(demo)
核心特性
🚀 多AI服务支持
- 硅基流动AI: 基于深度学习的代码分析引擎
- Coze智能体: 专业的代码审查AI助手
- 动态切换: 支持运行时切换不同的AI服务
🔗 无缝集成
- GitHub Webhook: 自动监听代码推送事件
- 实时处理: 提交后立即触发审查流程
- 零配置部署: 简单的环境变量配置即可运行
📊 智能分析
- 代码质量评估: 全面分析代码结构、性能和安全性
- 最佳实践建议: 基于行业标准提供改进建议
- 多语言支持: 支持JavaScript、Python、Java等主流编程语言
💾 结果持久化
- 本地存储: 审查结果自动保存为结构化文本文件
- 历史追踪: 完整的审查历史记录
- 便于查阅: 清晰的文件命名和内容格式
技术架构
系统架构图
GitHub Repository
↓ (Webhook)
Express Server
↓
Webhook Handler
↓
GitHub Service ←→ AI Service Factory
↓ ↓
Diff Analysis [SiliconFlow | Coze]
↓ ↓
File Storage ←── Review Results
核心组件
1. Web服务层 (src/index.js)
- 基于Express.js的HTTP服务器
- 提供健康检查、日志查看等管理接口
- 优雅的错误处理和请求日志
2. Webhook处理器 (src/routes/webhook.js)
- GitHub事件监听和处理
- 提交数据解析和验证
- 异步任务调度
3. GitHub服务 (src/services/github.js)
- GitHub API集成
- 代码差异获取
- 智能文件过滤(仅处理代码文件)
4. AI服务工厂 (src/services/ai/)
- 基础抽象类 (
base.js): 定义AI服务通用接口 - 硅基流动服务 (
siliconflow.js): 集成硅基流动AI API - Coze服务 (
coze.js): 集成Coze智能体平台 - 服务工厂 (
index.js): 动态服务选择和管理
工作流程
1. 代码提交触发
sequenceDiagram
Developer->>GitHub: git push
GitHub->>AI Review Tool: Webhook Event
AI Review Tool->>GitHub API: Get Commit Diff
GitHub API-->>AI Review Tool: Return Diff Data
2. AI分析处理
sequenceDiagram
AI Review Tool->>AI Service: Send Code Diff
AI Service->>AI Provider: API Request
AI Provider-->>AI Service: Analysis Result
AI Service-->>AI Review Tool: Formatted Review
3. 结果存储
sequenceDiagram
AI Review Tool->>File System: Save Review
AI Review Tool->>Logs: Record Process
AI Review Tool-->>GitHub: Response OK
安装与配置
环境要求
- Node.js 14.0+
- npm 6.0+
快速开始
- 克隆项目
git clone
cd ai-code-review
- 安装依赖
npm install
- 环境配置
cp .env.example .env
# 编辑.env文件,配置必要的API密钥
- 启动服务
# 开发模式
npm run dev
# 生产模式
npm start
配置说明
基础配置
# 服务端口
PORT=3000
# 环境类型
NODE_ENV=development
GitHub集成
# GitHub访问令牌(可选,用于私有仓库)
GITHUB_TOKEN_AI=your_github_token
AI服务配置
# 当前使用的AI服务类型
AI_SERVICE_TYPE=coze
# 硅基流动AI配置
SILICONFLOW_API_KEY=your_siliconflow_key
SILICONFLOW_MODEL=deepseek-chat
# Coze智能体配置
COZE_API_URL=https://api.coze.cn/v3/chat
COZE_API_KEY=your_coze_key
COZE_BOT_ID=your_bot_id
使用指南
GitHub Webhook配置
- 进入GitHub仓库设置页面
- 选择"Webhooks" → "Add webhook"
- 配置参数:
- Payload URL:
http://your-domain.com/webhook/github - Content type:
application/json - Events: 选择"Just the push event"
- Payload URL:
- 保存配置
审查结果查看
审查结果自动保存在reviews/目录下,文件命名格式:
review_[service]_[commit_id]_[timestamp].txt
示例文件内容:
代码审查报告 (coze)
==========================================
提交ID: abc123def456
提交信息: 修复用户登录bug
作者: 张三
审查时间: 2024-01-01T10:00:00.000Z
详细建议:
------------------------------------------
1. 安全性建议:
- 建议在密码验证前添加输入验证
- 考虑使用bcrypt进行密码哈希
2. 性能优化:
- 数据库查询可以添加索引优化
- 建议使用连接池管理数据库连接
3. 代码规范:
- 变量命名建议使用驼峰命名法
- 建议添加必要的错误处理
项目结构
ai-code-review/
├── src/ # 源代码目录
│ ├── index.js # 应用入口文件
│ ├── routes/ # 路由处理
│ │ ├── webhook.js # Webhook事件处理
│ │ ├── debug.js # 调试接口
│ │ └── logs.js # 日志查看接口
│ ├── services/ # 核心服务
│ │ ├── ai/ # AI服务模块
│ │ │ ├── base.js # AI服务基类
│ │ │ ├── index.js # 服务工厂
│ │ │ ├── siliconflow.js # 硅基流动AI服务
│ │ │ └── coze.js # Coze智能体服务
│ │ ├── github.js # GitHub API服务
│ │ └── logger.js # 日志服务
│ ├── middleware/ # 中间件(预留)
│ ├── utils/ # 工具函数(预留)
│ └── public/ # 静态资源
├── reviews/ # 审查结果存储
├── messages/ # AI请求消息存储
├── logs/ # 系统日志
├── test/ # 测试文件
├── package.json # 项目配置
├── .env # 环境变量
└── README.md # 项目说明
开发特性
代码质量保障
- ESLint: 代码风格检查
- 错误处理: 完善的异常捕获机制
- 日志系统: 详细的操作日志记录
扩展性设计
- 插件化架构: 易于添加新的AI服务
- 配置驱动: 通过环境变量灵活配置
- 模块化设计: 清晰的代码组织结构
性能优化
- 异步处理: 非阻塞的事件处理
- 智能过滤: 仅处理代码文件,忽略配置和资源文件
- 错误恢复: 优雅的错误处理,避免服务中断
最佳实践
安全建议
- 使用HTTPS部署生产环境
- 定期轮换API密钥
- 限制GitHub Token权限范围
- 配置防火墙规则
性能优化
- 定期清理历史文件
- 监控API调用频率
- 配置适当的超时时间
- 使用负载均衡(高并发场景)
来源:juejin.cn/post/7530106539467669544
从“写循环”到“写思想”:Java Stream 流的高级实战与底层原理剖析
引言
在实际开发中,很多工程师依然停留在“用 for 循环遍历集合”的思维模式。但在大型项目、复杂业务中,这种写法往往显得冗余、难以扩展,也不符合函数式编程的趋势。
Stream API 的出现,不只是“简化集合遍历”,而是把 声明式编程思想 带入了 Java,使我们能以一种更优雅、更高效、更可扩展的方式处理集合与数据流。
如果你还把 Stream 仅仅理解为 list.stream().map(...).collect(...),那就大错特错了。本文将从 高级用法、底层原理、业务实践、性能优化 四个维度,带你重新认识 Stream —— 让它真正成为你架构设计和代码表达的利器。
一、为什么要用 Stream?
在真实业务场景中,Stream 的价值不仅仅体现在“更少的代码量”,而在于:
- 声明式语义 —— 写“我要做什么”,而不是“怎么做”。
// 传统方式
List<String> result = new ArrayList<>();
for (User u : users) {
if (u.getAge() > 18) {
result.add(u.getName());
}
}
// Stream 写法:表达意图更清晰
List<String> result = users.stream()
.filter(u -> u.getAge() > 18)
.map(User::getName)
.toList();
后者的代码阅读体验更接近“业务规则”,而非“算法步骤”。
- 可扩展性 —— 同样的链式调用,可以无缝切换到 并行流(parallelStream)以提升性能,而无需修改核心逻辑。
- 契合函数式编程趋势 —— 在 Java 8 引入 Lambda 后,Stream 彻底释放了函数式编程的潜力。
二、Stream 的核心思想
Stream API 的设计核心可以用一句话概括:
把数据操作抽象成流水线,每一步都是一个中间操作,最终由终止操作触发执行。
- 数据源(Source) :集合、数组、I/O、生成器等。
- 中间操作(Intermediate Operations) :
filter、map、flatMap、distinct、sorted…,返回一个新的 Stream(惰性求值)。 - 终止操作(Terminal Operations) :
collect、forEach、reduce、count…,触发实际计算。
关键点:Stream 是惰性的。中间操作不会立即执行,直到遇到终止操作才会真正运行。
三、高级用法与最佳实践
1. 多级分组与统计
真实业务中,常见的场景是“按条件分组统计”。
// 按部门分组,并统计每个部门的人数
Map<String, Long> groupByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment, Collectors.counting()));
// 多级分组:按部门 -> 按职位
Map<String, Map<String, List<Employee>>> group = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.groupingBy(Employee::getTitle)));
2. flatMap 的威力
flatMap 可以把多层集合打平成单层流。
// 一个学生对应多个课程,如何获取所有课程的去重列表?
List<String> courses = students.stream()
.map(Student::getCourses) // Stream<List<String>>
.flatMap(List::stream) // Stream<String>
.distinct()
.toList();
3. reduce 高阶聚合
Stream 的 reduce 方法提供了更灵活的聚合方式。
// 求所有订单的总金额
BigDecimal total = orders.stream()
.map(Order::getAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add);
相比 Collectors.summingInt 等方法,reduce 更加灵活,适合需要自定义聚合逻辑的场景。
4. 结合 Optional 优雅处理空值
Stream 与 Optional 配合,可以消除 if-null 的丑陋写法。
// 找到第一个满足条件的用户
Optional<User> user = users.stream()
.filter(u -> u.getAge() > 30)
.findFirst();
与传统的 null 判断相比,这种写法更安全、更符合函数式语义。
5. 并行流与 ForkJoinPool
只需一行代码,就能让 Stream 自动并行处理
long count = bigList.parallelStream()
.filter(item -> isValid(item))
.count();
注意点:
- 并行流基于 ForkJoinPool,默认线程数 = CPU 核心数。
- 不适合小数据量,启动线程开销可能大于收益。
- 不适合有共享资源的场景(容易产生锁竞争)。
四、Stream 的底层原理
理解底层机制,才能在性能和架构上做出正确决策。
- 流水线模型(Pipeline Model)
- 每个中间操作都返回一个
Stream,但实际上内部是一个Pipeline。 - 只有终止操作才会触发数据逐步流经整个 pipeline。
- 每个中间操作都返回一个
- 内部迭代(Internal Iteration)
- 相比外部迭代(for 循环),Stream 将迭代逻辑交给框架本身,从而更容易做优化(如并行)。
- 短路操作(Short-circuiting)
anyMatch、findFirst等操作可以在满足条件时立刻返回,避免不必要的计算。
- 内存与性能
- 惰性求值减少不必要的计算。
- 但过度链式调用可能带来额外开销(对象创建、函数调用栈)。
五、业务场景中的最佳实践
1. 日志分析系统
日志按时间、级别分组统计:
Map<LogLevel, Long> logCount = logs.stream()
.filter(log -> log.getTimestamp().isAfter(start))
.collect(Collectors.groupingBy(Log::getLevel, Collectors.counting()));
2. 电商系统订单处理
对订单进行聚合,计算 GMV(成交总额):
BigDecimal gmv = orders.stream()
.filter(o -> o.getStatus() == OrderStatus.FINISHED)
.map(Order::getAmount)
.reduce(BigDecimal.ZERO, BigDecimal::add);
3. 权限系统多对多关系处理
用户-角色-权限的映射去重:
Set<String> permissions = users.stream()
.map(User::getRoles)
.flatMap(List::stream)
.map(Role::getPermissions)
.flatMap(List::stream)
.collect(Collectors.toSet());
六、性能优化与陷阱
- 避免在 Stream 中修改外部变量
List<String> result = new ArrayList<>();
list.stream().forEach(e -> result.add(e)); //违反函数式编程
应该用 collect。
- 适度使用并行流
- 小集合别用并行流。
- 线程池可通过
ForkJoinPool.commonPool()自定义。
- 避免链式调用过长
虽然优雅,但可读性会下降,必要时拆分。 - Stream 不是万能的
- 对于简单循环,普通 for 循环更直观。
- 对性能敏感的底层操作(如数组拷贝),直接用原生循环更高效。
总结
Stream 并不是一个“语法糖”,而是 Java 向函数式编程迈进的重要里程碑。
它让我们能以声明式、可扩展、可并行的方式处理数据流,提升代码表达力和业务抽象能力。
对于中高级开发工程师来说,Stream 的价值在于:
- 提升业务逻辑的可读性和可维护性
- 利用底层并行能力提升性能
- 契合函数式思维,帮助团队写出更现代化的 Java 代码
未来的你,写业务逻辑时,应该少考虑“怎么遍历”,多去思考“我要表达的业务规则是什么”。
来源:juejin.cn/post/7538829865351036967
这样代码命名,总不会被同事蛐蛐了吧
1. 引言
....又好笑,又不耐烦,懒懒的答他道,“谁要你教,不是草头底下一个来回的回字么?”孔乙己显出极高兴的样子,将两个指头的长指甲敲着柜台,点头说,“对呀对呀!……回字有四样写法,你知道么?”我愈不耐烦了,努着嘴走远。孔乙己刚用指甲蘸了酒,想在柜上写字,见我毫不热心,便又叹一口气,显出极惋惜的样子
针对于同一个代码变量或者函数方法,张三可能认为可以叫 xxx,李四可能摇头说 不不不,得叫 yyyy ,好的命名让人如沐春风,原来是这个意思;坏的代码命名,同事可能会眉头紧锁,然后送你两斤熏鸡骨头让你炖汤
比如隔壁小组新来的一个同事,对字符串命名就用 s,对于布尔值的命名就用 b,然后他的主管说他的变量名起的跟他人一样。如何做到信雅达的命名,让同事不会再背后蛐蛐,我是这样想的。
2. 代码整洁之道
2.1 团队规范
“我在上家公司都是这样命名的,在这里我也要这样命名”
小组里张三给 Service 起的名字叫 UserService 实现类是 UserServiceImpl;小组里李四给 Service 起的名字叫 CustomerService 实现类 CustomerServiceImpl
你跳出来出来说,统统不对,接口需要区分对待 得叫 IUserService 和 ICustomerService
但是组里成员都不习惯往接口类加个 I;或许这就是 E 人编码吧,不能写 I(我承认这个梗有点烂)
双拳难敌四手,亲,这边建议你按照 UserService 和 CustomerService 起名
这只是个简单的例子,还有就是你认为 4 就是 for,2 就是 to,如果小组内的成员表示认可你的想法,那你就尽管大胆的使用,但是小组成员要是没有这一点习惯,建议还是老老实实 for 和 to,毕竟你没有一票否决权
诸如此类的还有 request -> req、response -> resp 等
以下所有的代码命名建议都不能打破团队规范这一条大原则
2.2 统一业务词汇
在各行各业中,基于业务属性,我们都有一些专业术语,对于专业术语的命名往往在设计领域模型的时候已经确定下来,建议有一份业务词汇来规范团队同学命名,或者以数据库字段为准
比如在保险行业中,我们有保费(premium)、保单(policy)、被保人(assured)等,针对于这些业务词汇,务必需要统一。被保人就是 assured 不是 Insured Person
2.2 名副其实
“语义一定要清晰,不然后续接手的人根本看不懂,我的这个函数名是用来对订单进行删除操作,然后进行 MQ 消息推送的,我准备给他起名为 deleteOrderByCustomerIdAndSendMqMessage”
对,函数名很长很清晰,虽然我的屏幕很宽,但是针对于这样的命名,我觉得不可取,函数名和函数一样应该尽量短小,当你的命名极其长的时候你需要考虑简化你的命名,或者 考虑你的函数是否遵循到了单一职责。
bad😭
deleteOrderByCustomerIdAndSendMqMessage(String userId)
good🤭
deleteOrder(String userId)
sendMq()
我们在做阅读理解的时候,需要结合上下文来作答,同样,我们的命名需要让下一个做阅读理解的人感受到我们的上下文含义。在我们删除订单的时候,假设我们需要用到订单的 ID,那么我们的命名需要是 orderId = 123,而不是 id = 123
bad😭 这个 id 指代的是什么,订单ID 还是用户 ID
id = 123
good🤭
deleteOrder(String userId)
orderId = 123
人靠衣装马靠鞍,变量类型需“平安”,我们在起名的时候需要对的起自己的名字
bad😭 tm的喵,我以为是个 list
String idList = "1,2,3"
good🤭
List<String> idList = ImmutabList.of("1", "2", "3")
默认我的同事的英文水平只有四级,我们变量命名的时候,尽量取一些大众化的词汇,可以四级词汇,切莫六级词汇
bad😭
actiivityOrchestrater
good🤭 活动策划人
actiivityPlanner
普通函数、方法命名以动词开头
bad😭
messageSend
good🤭
sendMessage
减少介词链接,考虑使用 形容词+名词
productListForSpecialOffer -> specialOfferProductList
productListForNewArrival -> newArrivalProductList
productListFromHenan -> henanProductList
productListWithGiftBox -> withGiftBoxProductList \ giftBoxedProductList
productListWithoutGiftBox -> withoutGiftBoxProductList \ noGiftBoxProductList \ unGiftBoxedProductList
消除无意义的前后缀单词: userInfo、userData,info 和 data 的含义过于宽泛,没有实质性意义所以我们可以不用写。或者诸如在 UserService 类中,我们可以可以尝试将 selectUserList 更换为 selectList,因为我们调用的时候,上下文一定是 userService.selectList,阅读者是可以感受到我们的语义的
userInfo -> user
userService.selectUserList -> userService.selectList
做有意义的方法名的区分:在我刚入职的时候,有一个 OrderService 中,存在 4个方法,enableOrder、enableOrderV2、enableOrderV3、enableOrderV4,我问组里的同事,有什么区别,他们告诉我,现在各个外部服务用的不同,不知道有啥区别。所以为了避免给类似我这样的菜鸟产生歧义,建议在方法起名的时候做好区分,以免埋坑
3. 常见开发词汇

来源:juejin.cn/post/7449083760618684467
通信的三种基本模式:单工、半双工与全双工
在数据通信与网络技术中,信道的“方向性”是一个基础而核心的概念。它定义了信息在通信双方之间流动的方向与方式。根据其特性,我们通常将其归纳为三种基本模式:单工、半双工和全双工。清晰理解这三种模式,是掌握众多通信协议与网络技术的基石。
一、单工通信

单工通信代表了最单一、最直接的数据流向。
- 定义:数据只能在一个方向上传输,通信的一方固定为发送端,另一方则固定为接收端。
- 核心特征:方向不可改变。就像一条单行道,数据流只有一个固定的方向。
- 经典比喻:
- 广播电台:电台负责发送信号,广大听众的收音机只能接收信号,无法通过收音机向电台发送数据。
- 电视信号传输:电视台到家庭电视的信号传输。
- 键盘到计算机(在传统概念中):数据从键盘单向传入计算机。
单工通信模式简单、成本低,但交互性为零,无法实现双向信息交流。
二、半双工通信

半双工通信允许了双向交流,但增加了“轮流”的规则。
- 定义:数据可以在两个方向上传输,但在任一时刻,只能有一个方向在进行传输。它需要一种“切换”机制来改变数据传输的方向。
- 核心特征:双向交替,不能同时。
- 经典比喻:
- 对讲机:一方需要按下“通话键”说话,说完后必须说“完毕”并松开按键,切换到接收状态,才能听到对方的回复。双方不能同时讲话。
- 独木桥:同一时间只能允许一个人从一个方向通过。
半双工的局限性:
由于其交替通信的本质,半双工存在几个固有缺陷:
- 效率较低:存在信道空闲和状态切换的时间开销,总吞吐量低。
- 延迟较高:发送方必须等待信道空闲才能发送,接收方必须等待发送方完毕才能接收。
- 可能发生碰撞:在共享信道中,若多个设备同时开始发送,会导致数据冲突,必须重传,进一步降低效率。
- 需要冲突管理:必须引入如CSMA/CD(载波侦听多路访问/冲突检测)等协议来管理信道访问,增加了系统复杂度。
三、全双工通信

全双工通信实现了最自然、最高效的双向交互。
- 定义:数据可以在两个方向上同时进行传输。
- 核心特征:同时双向传输。
- 经典比喻:
- 电话通话:双方可以同时说话和聆听,交流过程自然流畅,无需等待。
- 双向多车道公路:两个方向的车流拥有各自独立的车道,可以同时、高速、互不干扰地行驶。
技术实现:全双工通常需要两条独立的物理信道(如网线中的两对线),或通过频分复用等技术在一条信道上逻辑地划分出上行和下行通道。其最大优势在于彻底避免了半双工中固有的碰撞问题。
三种模式对比总结
| 特性维度 | 单工 | 半双工 | 全双工 |
|---|---|---|---|
| 数据流向 | 仅单向 | 双向,但交替进行 | 双向,同时进行 |
| 经典比喻 | 广播 | 对讲机 | 电话 |
| 信道占用 | 一条单向信道 | 一条共享信道 | 两条独立信道或等效技术 |
| 效率 | 低(无交互) | 较低 | 高 |
| 交互性 | 无 | 有,但不流畅 | 有,且自然流畅 |
| 数据碰撞 | 无 | 可能发生 | 不可能发生 |
| 典型应用 | 广播、电视 | 早期以太网、对讲机 | 现代以太网、电话、视频会议 |
结论
从单工的“只读”模式,到半双工的“轮流对话”,再到全双工的“自由交谈”,通信模式的演进体现了人们对更高效率和更自然交互的不懈追求。全双工凭借其高吞吐量、低延迟和无碰撞的特性,已成为当今主流有线与无线网络(如交换式以太网、4G/5G移动通信)的标配。而半双工和单工则在物联网、传感器网络、广播等特定应用场景中,因其成本或功能需求,依然保有一席之地。理解这三种基础模式,是步入更复杂通信世界的第一步。
来源:juejin.cn/post/7563108340538507318
【前端效率工具】:告别右键另存,不到 50 行代码一键批量下载网页图片
前端还原页面你肯定干过吧?像仿 xxx 首页那种。收素材时最烦的就是一张张存图,慢不说还老漏。
跟我用 10 分钟做个chrome小插件,点一下,整页图片全下到本地
先看效果:在素材网站一键批量保存所有图片

废话不多说,直接上手!
项目结构
image-downloader-extension
├── manifest.json # 扩展的"身-份-证"
└── background.js # 插件后台脚本
创建文件夹
image-downloader-extension创建manifest.json文件
这个文件是插件的身-份-证,告诉浏览器你的插件是谁、能干啥。
{
"manifest_version": 3,
"name": "我的下载插件",
"version": "1.0.0",
"permissions": ["contextMenus", "downloads", "scripting"],
"host_permissions": ["" ],
"background": {
"service_worker": "background.js"
}
}
关键点解读:
| 字段 | 说明 |
|---|---|
| manifest_version: 3 | 使用最新的 Manifest V3 扩展规范 |
| name | 插件名称 |
| version | 插件版本号 |
| permissions | 申请权限(contextMenus 创建右键菜单,downloads下载) |
创建background.js文件
background.js后台脚本负责创建并响应右键菜单等事件来下载页面图片
// 1. 插件安装时创建右键菜单
chrome.runtime.onInstalled.addListener(() => {
chrome.contextMenus.create({
id: 'downloadAllImages', // 菜单唯一标识
title: '我要下载所有图片', // 菜单显示的文字
contexts: ['page'], // 在页面任意位置右键时显示
});
});
// 2. 监听右键菜单点击事件
chrome.contextMenus.onClicked.addListener((info, tab) => {
if (info.menuItemId === 'downloadAllImages') {
// 使用 scripting API 在当前页面执行脚本获取所有图片
chrome.scripting.executeScript(
{
target: { tabId: tab.id },
func: getImagesFromPage,
},
(results) => {
// 获取执行结果
if (!results || !results[0]?.result || results[0].result.length === 0) {
console.log('未找到图片');
return;
}
const images = results[0].result;
// 批量下载图片
images.forEach((url, index) => {
setTimeout(() => {
chrome.downloads.download({
url: url,
filename: `images/image_${index + 1}.jpg`, // 保存路径
saveAs: false, // 不弹出保存对话框
});
}, index * 500); // 每张图片间隔 500ms,避免浏览器限制
});
}
);
}
});
// 在页面中执行的函数,用于获取所有图片URL
function getImagesFromPage() {
const images = Array.from(document.images)
.map((img) => img.src)
.filter((src) => src.startsWith('http'));
return images;
}
API 文档速查
- chrome.runtime(扩展生命周期/事件)
- chrome.contextMenus(右键菜单)
- chrome.scripting(脚本执行)
- chrome.downloads(下载管理)
- 权限声明(MV3)
4. 加载插件到浏览器
接下来我们将插件加载到浏览器中

步骤:
4.1 打开扩展管理页面 在 Chrome 地址栏输入 chrome://extensions/ 并回车
4.2 开启开发者模式
4.3 点击 “加载未打包的扩展程序”
选择刚刚创建的image-downloader-extension文件夹进行加载
4.4 插件加载成功
你会看到插件出现在列表中

至此,我们的下载插件就搞完了,是不是非常容易?
测试(验证功能)
接下来我们随便打开一个网站,点击鼠标右键,就会发现右键菜单多了一个选项

点击“我要下载所有图片” 即可实现我们的需求了
调试(查看 background.js日志与断点)
如下图:点击插件的 Service Worker 入口,会弹出调试面板。
在该面板中你可以:
- 实时查看 background.js 的 console日志输出;
- 在代码中设置断点调试以排查问题。

总结
这一次带你用一个小巧的 Chrome 插件,一键把当前网页的所有图片下载下来,希望对你有所帮助
来源:juejin.cn/post/7559124639323242506
Token已过期,我是如何实现无感刷新Token的?

我们来想象一个场景:你正在一个电商网站上,精心挑选了半小时的商品,填好了复杂的收货地址,满心欢喜地点击提交订单 Button。
突然,页面Duang🎈地一下,跳转到了登录页,并提示你:“登录状态已过期,请重新登录”。
那一刻,你的内心是什么感受?我想大概率是崩溃的,并且想把这个网站拉进黑名单。
这就是一个典型的、因为Token过期处理不当,而导致的灾难级用户体验。作为一个负责任的开发者,这是我们绝对不能接受的。
今天就聊聊,我们团队是如何通过请求拦截和队列控制,来实现无感刷新Token的。让用户即使在Token过期的情况下,也能无缝地继续操作,就好像什么都没发生过一样。
先讲基础知识
为什么需要两个Token?
要实现无感刷新,我们首先需要后端同学的配合,采用双Token的认证机制。
accessToken: 这是我们每次请求业务接口时,都需要在请求头里带上的令牌。它的特点是生命周期短(比如1小时),因为暴露的风险更高。refreshToken: 它的唯一作用,就是用来获取一个新的accessToken。它的特点是生命周期长(比如7天),并且需要被安全地存储(比如HttpOnly的Cookie里)。
流程是这样的:用户登录成功后,后端会同时返回accessToken和refreshToken。前端将accessToken存在内存(或LocalStorage)里,然后在后续的请求中,通过refreshToken来刷新。

解决思路,利用axios的请求拦截器
我们整个方案的核心,是利用axios(或其他HTTP请求库)提供的请求拦截器(Interceptor) 。它就像一个哨兵,可以在请求发送前和响应返回后,对请求进行拦截和改造。
我们的目标是:
- 在响应拦截器里,捕获到后端返回的
accessToken已过期的错误(通常是401状态码)。 - 当捕获到这个错误时,暂停所有后续的API请求。
- 使用
refreshToken,悄悄地在后台发起一个获取新accessToken的请求。 - 拿到新的
accessToken后,更新我们本地存储的Token。 - 最后,把之前失败的请求和被暂停的请求,用新的
Token重新发送出去。
这个过程对用户来说,是完全透明的。他们最多只会感觉到某一次API请求,比平时慢了一点点。
具体怎么实现?
下面是我们团队在项目中,实际使用的axios拦截器伪代码。
import axios from 'axios';
// 创建一个新的axios实例
const api = axios.create({
baseURL: '/api',
timeout: 5000,
});
// ------------------- 请求拦截器 -------------------
api.interceptors.request.use(config => {
const accessToken = localStorage.getItem('accessToken');
if (accessToken) {
config.headers.Authorization = `Bearer ${accessToken}`;
}
return config;
}, error => {
return Promise.reject(error);
});
// ------------------- 响应拦截器 -------------------
// 用于标记是否正在刷新token
let isRefreshing = false;
// 用于存储因为token过期而被挂起的请求
let requestsQueue = [];
api.interceptors.response.use(
response => {
return response;
},
async error => {
const { config, response } = error;
// 如果返回的HTTP状态码是401,说明access_token过期了
if (response && response.status === 401) {
// 如果当前没有在刷新token,那么我们就去刷新token
if (!isRefreshing) {
isRefreshing = true;
try {
// 调用刷新token的接口
const { data } = await axios.post('/refresh-token', {
refreshToken: localStorage.getItem('refreshToken')
});
const newAccessToken = data.accessToken;
localStorage.setItem('accessToken', newAccessToken);
// token刷新成功后,重新执行所有被挂起的请求
requestsQueue.forEach(cb => cb(newAccessToken));
// 清空队列
requestsQueue = [];
// 把本次失败的请求也重新执行一次
config.headers.Authorization = `Bearer ${newAccessToken}`;
return api(config);
} catch (refreshError) {
// 如果刷新token也失败了,说明refreshToken也过期了
// 此时只能清空本地存储,跳转到登录页
console.error('Refresh token failed:', refreshError);
localStorage.removeItem('accessToken');
localStorage.removeItem('refreshToken');
// window.location.href = '/login';
return Promise.reject(refreshError);
} finally {
isRefreshing = false;
}
} else {
// 如果当前正在刷新token,就把这次失败的请求,存储到队列里
// 返回一个pending的Promise,等token刷新后再去执行
return new Promise((resolve) => {
requestsQueue.push((newAccessToken) => {
config.headers.Authorization = `Bearer ${newAccessToken}`;
resolve(api(config));
});
});
}
}
return Promise.reject(error);
}
);
export default api;
这段代码的关键点,也是面试时最能体现你思考深度的地方:
- isRefreshing 状态锁:
这是为了解决并发问题。想象一下,如果一个页面同时发起了3个API请求,而accessToken刚好过期,这3个请求会同时收到401。如果没有isRefreshing这个锁,它们会同时去调用/refresh-token接口,发起3次刷新请求,这是完全没有必要的浪费,甚至可能因为并发问题导致后端逻辑出错。
有了这个锁,只有第一个收到401的请求,会真正去执行刷新逻辑。
- requestsQueue 请求队列:
当第一个请求正在刷新Token时(isRefreshing = true),后面那2个收到401的请求怎么办?我们不能直接抛弃它们。正确的做法,是把它们的resolve函数推进一个队列(requestsQueue)里,暂时挂起。
等第一个请求成功拿到新的accessToken后,再遍历这个队列,把所有被挂起的请求,用新的Token重新执行一遍。
无感刷新Token这个功能,用户成功的时候,是感知不到它的存在的。
但恰恰是这种无感的细节,区分出了一个能用的应用和一个好用的应用。
因为一个资深的开发者,他不仅关心功能的实现,更应该关心用户体验和整个系统的健壮性。
希望这一套解决思路,能对你有所帮助🤞😁。
来源:juejin.cn/post/7550943000689950774
大数据-133 ClickHouse 概念与基础|为什么快?列式 + 向量化 + MergeTree 对比
TL;DR
场景:要做高并发低延迟 OLAP,且不想上整套 Hadoop/湖仓。
结论:ClickHouse 的核心在列式+向量化+MergeTree+近似统计;适合即席分析与近实时写入,不适合强事务与高频行级更新。
产出:选型决策表 + 分区/排序键速查卡 + 5 条查询模板(安装/集群放到下一章)。


简要概述
ClickHouse 是一个快速开源的OLAP数据库管理系统,它是面向列的,允许使用SQL查询实时生成分析报告。
随着物联网IOT时代的来临,IOT设备感知和报警存储数据越来越大,有用的价值数据需要数据分析师去分析。大数据分析成了非常重要的环节,开源也为大数据分析工程师提供了十分丰富的工具,但这也增加了开发者选择适合的工具的难度,尤其是新入行的开发者来说。
框架的多样化和复杂度成了很大的难题,例如:Kafka、HDFS、Spark、Hive等等组合才能产生最后的分析结果,把各种开源框架、工具、库、平台人工整合到一起所需的工作之复杂,是大数据领域开发和数据分析师常有的抱怨之一,也就是他们支持大数据分析简化和统一化的首要原因。

从业务维度来分析,用户需求会反向促使技术发展。
简要选型
| 需求/约束 | 适合 | 不适合 |
|---|---|---|
| 高并发、低延迟 OLAP | ✅ | |
| 重事务/强一致 OLTP | ❌ | |
| 近实时写入、即席分析 | ✅ | |
| 频繁行级更新/删除 | ⚠️(有 mutations 但代价高) |
- 需要强事务/OLTP → 不是 CH
- OLAP + 近实时 + 自建机房成本敏感 → CH 优先
- 只做离线、成本不敏感且现有湖仓成熟 → SparkSQL/Trino 也行
- 预计算立方体 + 报表固化 → Druid/Kylin 也可
OLTP
OLTP:Online Transaction Processing:联机事务处理过程。
应用场景
- ERP:Enterprise Resource Planning 企业资源计划
- CRM:Customer Relationship Management 客户关系管理
流程审批、数据录入、填报等
具体特点
线下工作线上化,数据保存在各自的系统中,互不相同(数据孤岛)
OLAP
OLAP:On-Line Analytical Processing:联机分析系统
分析报表、分析决策等。
应用场景
方案1:数仓

如上图所示,数据实时写入HBase,实时的数据更新也在HBase完成,为了应对OLAP需求,我们定时(通常是T+1或者T+H)将HBase数据写成静态的文件(如:Parquet)导入到 OLAP引擎(如HDFS,比较常见的是Impala操作Hive)。这一架构又能满足随机读写,又可以支持OLAP分析的场景,但是有如下缺点:
- 架构复杂:从架构上看,数据在HBase、消息队列、HDFS间流转,涉及到的环节过多,运维成本也很高,并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,对数据安全策略、监控都提出了挑战。
- 时效性低:数据从HBase导出静态文件是周期性的,一般这个周期一天(或者一小时),有时效性上不是很高。
- 难以应对后续的更新:真实场景中,总会有数据是延迟到达的,如果这些数据之前已经从HBase导出到HDFS,新到的变更数据更难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
方案2:ClickHouse、Kudu
实现方案2就是 ClickHouse、Kudu
发展历史
Yandex在2016年6月15日开源了一个数据分析数据库,叫做ClickHouse,这对保守的俄罗斯人来说是个特大事件。更让人惊讶的是,这个列式数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。如果你没有Vertica,那你一定听过Michael Stonebraker,2014年图灵奖的获得者,PostgreSQL和Ingres发明者(Sybase和SQL Server都是继承Ingres而来的),Paradigm4和SciDB的创办者。Micheal StoneBraker于2005年创办的Vertica公司,后来该公司被HP收购,HP Vertica成为MPP列式存储商业数据库的高性能代表,Facebook就购买了Vertica数据用于用户行为分析。
ClickHouse技术演变之路
Yandex公司在2011年上市,它的核心产品是搜索引擎。
我们知道,做搜索引擎的公司营收非常依赖流量和在线广告,所以做搜索引擎公司一般会并行推出在线流量分析产品,比如说百度的百度统计,Google的Google Analytics等,Yandex的Yandex.Metricah。ClickHouse就是在这种背景下诞生的。
- ROLAP:传统关系型数据库OLAP,基于MySQL的MyISAM表引擎
- MOLAP:借助物化视图的形式实现数据立方体,预处理的结果存在HBase这类高性能的分布式数据库中
- HOLAP:R和M的结合体H
- ROLAP:ClickHouse
ClickHouse 的核心特点
超高的查询性能
- 列式存储:只读取查询所需的列,减少了磁盘 I/O。
- 向量化计算:批量处理数据,提高了 CPU 使用效率。
- 数据压缩:高效的压缩算法,降低了存储成本。
水平可扩展性
- 分布式架构:支持集群部署,轻松处理 PB 级数据。
- 线性扩展:通过增加节点提升性能,无需停机。
实时数据写入
- 高吞吐量:每秒可插入数百万行数据。
- 低延迟:数据写入后立即可查询,满足实时分析需求。
丰富的功能支持
- 多样的数据类型:支持从基本类型到复杂类型的数据。
- 高级 SQL 特性:窗口函数、子查询、JOIN 等。
- 物化视图:预计算和存储查询结果,进一步提升查询性能。
典型应用场景
- 用户行为分析:电商、游戏、社交平台的实时用户行为跟踪。
- 日志和监控数据存储:处理服务器日志、应用程序日志和性能监控数据。
- 商业智能(BI):支持复杂的报表和数据分析需求。

部署与运维
- 单机部署:适合测试和小规模应用。
- 集群部署:用于生产环境,可通过 Zookeeper 进行协调。
- 运维工具:提供了监控和管理工具,如 clickhouse-client、clickhouse-copier。
最佳实践
- 数据分区:根据时间或其他字段进行分区,提高查询效率。
- 索引优化:使用主键和采样键,加速数据定位。
- 硬件配置:充分利用多核 CPU、高速磁盘和大内存。
ClickHouse支持特性
ClickHouse具体有哪些特性呢:
- 真正的面向列的DBMS
- 数据高效压缩
- 磁盘存储的数据
- 多核并行处理
- 在多个分布式服务器上分布式处理
- SQL语法支持
- 向量化引擎
- 实时数据更新
- 索引
- 适合在线查询
- 支持近似预估计算
- 支持嵌套的数据结构
- 支持数组作为数据类型
- 支持限制查询复杂性以及配额
- 复制数据和对数据完整性的支持
ClickHouse和其他对比
商业OLAP
例如:
- HP Vertica
- Actian the Vector
区别:
- ClickHouse 是开源而且免费的
云解决方案
例如:
- 亚马逊 RedShift
- 谷歌 BigQuery
区别:
- ClickHouse 可以使用自己机器部署,无需云付费
Hadoop生态
例如:
- Cloudera Impala
- Spark SQL
- Facebook Presto
- Apache Drill
区别:
- ClickHouse 支持实时的高并发系统
- ClickHouse不依赖于Hadoop生态软件和基础
- ClickHouse支持分布式机房的部署
开源OLAP数据库
例如:
- InfiniDB
- MonetDB
- LucidDB
区别:
- 应用规模小
- 没有在大型互联网服务中蚕尝试
非关系型数据库
例如:
- Druid
- Apache Kylin
区别:
- ClickHouse 可以支持从原始数据直接查询,支持类SQL语言,提供了传统关系型数据的便利。
真正的面向列DBMS
如果你想要查询速度变快:
- 减少数据扫描范围
- 减少数据传输时的大小
在一个真正的面向列的DBMS中,没有任何无用的信息在值中存储。
例如:必须支持定长数值,以避免在数值旁边存储长度数字,10亿个Int8的值应该大约消耗1GB的未压缩磁盘空间,否则这将强烈影响CPU的使用。由于解压的速度(CPU的使用率)主要取决于未压缩的数据量,即使在未压缩的情况下,紧凑的存储数据也是非常重要的。
因为有些系统可以单独存储独列的值,但由于其他场景的优化,无法有效处理分析查询,例如HBase、BigTable、Cassandra和HypeTable。在这些系统中,每秒可以获得大约十万行的吞吐量,但是每秒不会到达数亿行。
另外,ClickHouse是一个DBMS,而不是一个单一的数据库,ClickHouse允许运行时创建表和数据库,加载数据和运行查询,而不用重新配置或启动系统。


之所以称作 DBMS,因为ClickHouse:
- DDL
- DML
- 权限管理
- 数据备份
- 分布式存储
- 等等功能
数据压缩
一些面向列的DBMS(InfiniDB CE 和 MonetDB)不使用数据压缩,但是数据压缩可以提高性能。
磁盘存储
许多面向列的DBMS(SAP HANA和GooglePower Drill)只能在内存中工作,但即使在数千台服务器上,内存也太小,无法在Yandex.Metrica中存储所有浏览和会话。
多核并行
多核并行进行大型的查询。
在多个服务器上分布式处理
上面列出的DBMS几乎不支持分布式处理,在ClickHouse中,数据可以驻留不同的分片上,每个分片可以是用于容错的一组副本,查询在所有分片上并行处理,这对用户来说是透明的。
SQL支持
- 支持的查询包括 GR0UP BY、ORDER BY
- 子查询在FROM、IN、JOIN子句中被支持
- 标量子查询支持
- 关联子查询不支持
- 真是因为ClickHouse提供了标准协议的SQL查询接口,使得现有可视化分析系统能够轻松的与它集成对接
向量化引擎
数据不仅案列存储,而且由矢量-列的部分进行处理,这使我们能够实现高CPU性能。
向量化执行时寄存器硬件层面上的特性,可以理解为消除程序中循环的优化。
为了实现向量化执行,需要利用CPU的SIMD指令(Single Instrution Multiple Data),即用单条指令处理多条数据。现代计算机系统概念中,它是利用数据并行度来提高性能的一种实现方式,它的原理是在CPU寄存器层面实现数据并行的实现原理。
实时数据更新
ClickHouse支持主键表,为了快速执行对主键范围的查询,数据使用合并树(MergeTree)进行递增排序,由于这个原因,数据可以不断的添加到表中,添加数据时无锁处理。
索引
例如,带有主键可以在特定的时间范围内为特定的客户端(Metrica计数器)抽取数据,并且延迟事件小于几十毫秒。
支持在线查询
我们可以使用该系统作为Web界面的后端,低延迟意味着可以无延迟的实时的处理查询。
支持近似计算
- 系统包含用于近似计算各种值,中位数和分位数的集合函数
- 支持基于部分(样本)数据运行查询并获得近似结果,在这种情况下,从磁盘检索比例较少的数据。
- 支持为有限数量的随机秘钥(而不是所有秘钥)运行聚合,在数据中秘钥分发的特定场景下,这提供了相对准确的结果,同时使用较少的资源。
数据复制和对数据完整性支持
使用异步多主复制,写入任何可用的副本后,数据将分发到所有剩余的副本,系统在不同的副本上保持相同的数据。
要注意的是,ClickHouse并不完美:
- 不支持事务
- 虽然已支持条件 Delete/Update(mutations),只是非事务型、异步、重写分片数据开销大;生产要谨慎,用 TTL/分区替代更常见。
- 支持有限的操作系统
最后总结
在大数据分析领域中,传统的大数据分析需要不同框架和技术组合才能达到最终效果,在人力成本、技术能力、硬件成本、维护成本上,让大数据分析变成了很昂贵的事情,很多中小企业非常痛苦,不得不被迫租赁第三方大型数据分析服务。
ClickHouse开源的出现让许多想做大数据且想做大数据分析的很多公司和企业都耳目一新。ClickHouse正是以不依赖Hadoop生态、安装维护简单、查询快速、支持SQL等特点,在大数据领域越走越远。
来源:juejin.cn/post/7563935896706957363
画三角形报错bad_Alloc 原因,回调用错
surfaceCreated(SurfaceHolder holder)和:onSurfaceCreated(GL10 gl, EGLConfig c)是Android OpenGL ES开发中涉及Surface管理的两个关键方法,但它们属于不同类别的回调函数:
surfaceCreated(SurfaceHolder holder)
- 所属类:
SurfaceHolder的回调方法,用于监听Surface创建事件。当SurfaceView的Surface被创建时触发,通常用于初始化渲染线程或资源。 - 典型用法:在
SurfaceHolder.addCallback(this)中注册回调,确保在Surface可用后进行绘制操作。
onSurfaceCreated(GL10 gl, EGLConfig c)
- 所属类:EGL的初始化回调,用于EGL配置完成后的初始化操作。通常在EGL初始化流程中调用,与OpenGL ES渲染线程相关。
关键区别
- 触发时机:
surfaceCreated在Surface生命周期开始时触发;onSurfaceCreated在EGL配置完成后调用。 - 应用场景:前者用于自定义视图渲染或相机预览;后者涉及OpenGL ES的底层配置和渲染线程初始化。
- 线程安全:
surfaceCreated需在非UI线程操作;onSurfaceCreated需在EGL初始化线程中调用。
来源:juejin.cn/post/7559588025615564842
前端仔如何在公司搭建 AI Review 系统
一、前言
在上一篇 《AI 应用开发入门:前端也可以学习 AI》中,我给大家分享了前端学习 AI 应用开发的入门相关知识。我相信很多同学,看完应该都有了一定的收获。未来我会把关于前端学习 AI 的文章都放在这个 《前端学习 AI 之路》 专栏进行更新~
本篇会更偏向实际的应用,我将会运用之前分享的技术和概念,给大家分享如何通过 nodejs + LLM 搭建一个简易的 AI Review 系统的。
在本篇你将收获到:
- 设计 AI 应用的思路
- 设计提示词的思路
- 如何用 NodeJS 结合 LLM 分析代码
在上一篇 《AI 应用开发入门:前端也可以学习 AI》中,我给大家分享了前端学习 AI 应用开发的入门相关知识。我相信很多同学,看完应该都有了一定的收获。未来我会把关于前端学习 AI 的文章都放在这个 《前端学习 AI 之路》 专栏进行更新~
本篇会更偏向实际的应用,我将会运用之前分享的技术和概念,给大家分享如何通过 nodejs + LLM 搭建一个简易的 AI Review 系统的。
在本篇你将收获到:
- 设计 AI 应用的思路
- 设计提示词的思路
- 如何用 NodeJS 结合 LLM 分析代码
二、背景
我相信大家在团队中,都会有 Code Review 这个流程。但是有时候随着人手不够、项目周期紧张,就会出现 review 流程被忽视、或者 review 质量不高的问题。于是,我就在想,是否可以把这种费时、费精力且需要专注的事情,交给一个专门的“AI 员工”去完成呢?答案是可以的。
我相信大家在团队中,都会有 Code Review 这个流程。但是有时候随着人手不够、项目周期紧张,就会出现 review 流程被忽视、或者 review 质量不高的问题。于是,我就在想,是否可以把这种费时、费精力且需要专注的事情,交给一个专门的“AI 员工”去完成呢?答案是可以的。
三、整体效果
目前在我们团队,已经全面的在使用 AI 进行 Review 了,涵盖了前端、后端大大小小 20 + 的项目。得益于在集团内可以使用像(“GPT-4.1、 Calude”)这样更大上下文、更强推理能力的模型,所以整体效果是非常不错的。有时候一些很细微的安全隐患、性能、业务逻辑等问题,AI 都能比人更容易发现。
下面是我用演示的项目呈现的效果,也就是我们即将动手搭建的这个项目。
目前在我们团队,已经全面的在使用 AI 进行 Review 了,涵盖了前端、后端大大小小 20 + 的项目。得益于在集团内可以使用像(“GPT-4.1、 Calude”)这样更大上下文、更强推理能力的模型,所以整体效果是非常不错的。有时候一些很细微的安全隐患、性能、业务逻辑等问题,AI 都能比人更容易发现。
下面是我用演示的项目呈现的效果,也就是我们即将动手搭建的这个项目。
3.1 评论模式
通过 AI 分析提交的代码,然后会在有问题的代码下,评论出问题类型以及问题的具体原因。

通过 AI 分析提交的代码,然后会在有问题的代码下,评论出问题类型以及问题的具体原因。
3.2 报告模式
还一种是报告的展示形式。它会在提交的 MR 下输出一个评审报告,列出所有问题的标题、所在位置、以及具体原因。但是,这两种模式实现的本质都一样,只不过是展示结果的方式有不同,这个看你个人喜欢。


还一种是报告的展示形式。它会在提交的 MR 下输出一个评审报告,列出所有问题的标题、所在位置、以及具体原因。但是,这两种模式实现的本质都一样,只不过是展示结果的方式有不同,这个看你个人喜欢。
四、思路分析
那这个 AI Code Review 应用要怎么实现呢?下面给大家分享一下具体的思路。
那这个 AI Code Review 应用要怎么实现呢?下面给大家分享一下具体的思路。
4.1 人为流程
首先要做的,就是分析你现有团队人工 review 代码的规范,然后总结出一个具体流程。为什么要这样做?因为让 AI 帮你做事的本质,就是让它模仿你做事。如果连你自己都不清楚具体的执行流程,就更别期待 AI 能把这个事情做好了。
下面是我举例的一个 review 流程,看完后你可以思考一下,自己平时是怎么 review 代码的,有没有一个固定的流程或者方案。如果有,则按照下面的这个“行为 + 目的”的格式记录下来。
- 行为:收到的 MR 的提示了;目的:知道有需要 review 的 MR 提交

- 行为:查看 commit message;目的:确认本次提交的主题是什么。
首先要做的,就是分析你现有团队人工 review 代码的规范,然后总结出一个具体流程。为什么要这样做?因为让 AI 帮你做事的本质,就是让它模仿你做事。如果连你自己都不清楚具体的执行流程,就更别期待 AI 能把这个事情做好了。
下面是我举例的一个 review 流程,看完后你可以思考一下,自己平时是怎么 review 代码的,有没有一个固定的流程或者方案。如果有,则按照下面的这个“行为 + 目的”的格式记录下来。
- 行为:收到的 MR 的提示了;目的:知道有需要 review 的 MR 提交
- 行为:查看 commit message;目的:确认本次提交的主题是什么。

- 行为:查看改动哪些文件;目的:确认改动范围,主要判断改了哪些业务模块、是否改了公共、或者高风险文件等

- 行为:查看文件路径;目的:确认该文件关联的业务、所属的模块等信息,当做后续 diff 评审的前置判断信息。

- 行为:查看 diff 内容;目的:判断改动代码的逻辑、安全、性能是否存在问题。结合相关的业务和需求信息,判断是否有实现不合理的地方。
- 行为:在有问题的相关代码下,发出评论;目的:在有问题的代码下面,给出修改建议,让开发的同事能够注意和修改一下当前的问题。

4.2 程序流程
上面列举的是一个完整的人为评审代码的流程。但是,如果想让 AI 完全模仿,其实是存在一定的复杂性的。比如,人在评审某处 diff 时,会思考关联的业务、模块等前置信息,然后再做出评论。而不单单只是评审代码表面的编码问题。如果想要 AI 也这样做,还需要引入 RAG 等相关的技术,目的则是为了补充给更多的上下文信息。
为了不增加大家的实现和理解难度,本篇我们实现的是一个简化版本的 AI Code Review。下面是我梳理的 review 流程和与之对应的 AI 应用流程。

4.2 核心问题
这次搭建的 AI Code Review 应用,本质上是一个 NodeJS 服务。这个服务通过感知 MR 事件,获取 diff 交给 LLM 分析,得到结论以后,会输出评论到 GitLab。整体流程图如下:

所以,我们要面对这些核心问题是
- node 服务如何感知 GitLab 的 MR 提交
- 如何获取 MR 中每个文件改动的 diff
- 如何让编写提示词,让大模型评审和分析并输出结构化的数据
- 如何解析数据以及异常的处理
- 如何发送评论到 gitlab
- 如何推送状态到企微
接下来,我们带着上面的问题,来一步步实现这个 AI Code Review 应用。
五、具体实现
5.1 创建项目
创建一个 NestJS 的项目(用什么技术框架都可以,你可以使用你最熟悉的 Node 开发框架。重点是关注实现的核心步骤和思路,这个演示的项目我开源了,可以在 GitHub 上查看完整的代码)
nvm use 20
使用 nest 命令初始化一个项目
nest new mr-agent
5.2 实现 webhook 接口
首先我们来解决 node 服务如何感知 MR 事件的问题
Webhook
像 GitLab、GitHub 都会允许用户在项目中配置 webhook。它是干嘛的呢? webhook 可以让外部的服务,感知到 git 操作的相关事件(如 push 、merge 等事件)。比如我在合并代码时,gitlab 就会把 MR 事件,通过这个 hook 发送到我们搭建的服务上。

以 GitLab 为例,它会允许开发者在每个项目中配置多个 webhook 接口。比如,咱们配置一个 http://example.com/webhook/trigger 的地址。当发生相关 git 事件时,GitLab 就会往这个地址推送消息。

代码实现
所以,我们要做的第一件事,就是定义一个接口 url,用于接收 GitLab 的 webhook 事件。下面的代码中,实现了一个处理/webhook/trigger路由的 controller,它的主要职责是接收 MR 事件并且解析 body 和 header 中的参数,代码如下(完整代码)

Body
body 中会包含很多有用的的信息,如 Git 仓库信息、分支信息、MR 信息、提交者信息等,这些数据是 GitLab 调用 webhook 接口时发送过来的,在后续的逻辑中,都会用到里面的数据。

- object_type/object_kind:描述的事件的类型,例如 merge 事件、push 事件等。
- project:主要是描述仓库相关的信息,例如项目 id、名称等
- object_attributes: 主要包含本次 MR 相关的信息,如目标分支、源分支、mr 的 id 等等
- user:提交者的信息
Header
header 中是我们自己目定义的配置信息,核心有三个
- x-ai-mode:评论的模式(report 报告模式、 comment 评论模式)
- x-push-url:用于推送状态的地址(推送到企微、或者飞书的机器人)
- x-gitlab-token:gitlab 中的 access token,用于后续 GitLab API 调用鉴权

调试问题
调试开发的这个接口确实是一个比较麻烦的问题。因为 GitLab 基本都是内网部署,想要真实调试接口,一是需要真实代码仓库,二是需要想办法把 GitLab 的请求转发到本地来。这里我给大家分享三个办法:
内网转发
使用内网转发的办法,第三方的例如 ngrok、localtunnel、frp 等。如果你们公司的部署平台本身支持流量转发到本地,那就更好了(我用的是这个办法)。
ApiFox、Postman
先将服务部署到你们公司 GitLab 可以访问的服务器上,手动触发 MR 事件

然后在日志上打印完整的 header 和 body,然后复制到 ApiFox、Postman 上在本地模拟请求

问 AI
😁 最后一个办法就是,根据你的场景,问问 AI 怎么做 
5.3 获取 diff 内容
在能够接受到 GitLab 发送的 MR 事件后,就要解决如何获取 diff 的问题。这一步很简单, 调用 GitLab 官方的 API 就可以。重点就是两个核心逻辑:
- 获取全部文件的 diff 内容
- 过滤非代码文件

获取 diff 内容
gitlab 的 api 路径一般是一样的。唯一的区别就是不同公司的部署域名不同。baseUrl 需要配置成你公司的域名,projectId 和 mrId 都可以在 body 中取到(完整代码)

调用成功以后,获取的数据如下,changes 中会包含每个文件的 diff

过滤文件
因为并不是所有的文件都需要让 LLM 进行 review ,例如像 package.json、package-lock.json 等等。所以需要把这部分非代码文件过滤出来。

5.4 设计提示词
有了每个文件的 diff 数据以后,就是解决如何分析 diff 内容并输出有效结论的问题。其实这个问题的本质,就是如何设计系统提示词。
提示词思路
首先我们先思考一下编写提示词的目的是什么?我们期望的是,通过提示词指引 LLM,当输入 diff 文本的时候,它能够分析里面的代码并输出结构化的数据。

我们希望 LLM 返回的是一个数组,数组的每一项是对每一个问题的描述,里面包含标题、文件路径、行号、具体的内容等,数据结构如下:
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}
之所以需要这种结构化的数据,是因为后续在调用 GitLab API 发送评论的时候,需要用到这些参数。

整体思路确定好了,接下来我们就来编写具体的系统提示词。
角色设定
角色设定就是告诉 LLM 扮演什么角色以及它的具体要做什么事情
你是一个代码 MR Review 专家,你的任务是评审 Git Merge Request 中提交的代码,如果存在有问题的代码,你要提供有价值、有建设性值的建议。
注意,你评审时,应重点关注 diff 中括号后面带 + 或 - 的代码。
输入内容
上面有说到,我们不仅需要 LLM 分析代码的问题,还需要它把问题代码所在的文件路径、行号分析出来。
但是,如果你直接把原生的 diff 内容输入给它,它是不知道这些信息。因为原生的 diff 并没有具体的行号、新旧文件路径信息的。
@@ -1,16 +1,13 @@
import { Injectable } from '@nestjs/common';
-interface InputProps {
- code_diff: string;
- code_context: string;
- rules?: string;
-}
+type InputProps = Record;
interface CallDifyParams {
所以我们需要扩展输入的 diff,给它增加新旧文件的路径、以及每一行具体的行号,例如 (1, 1) 表示的是当前行,是旧文件中的第 1 行,新文件中的第 1 行。这个后面会说如何扩展,这里我们只是要先设计好,并告诉 LLM 我们会输入什么格式的内容
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
(9, 9)
(10, 10) interface CallDifyParams {
有了这些完善的信息,LLM 才知道有问题的代码在哪个文件以及它所在的具体行号
加解释
diff 经过我们的扩展以后,就不再是标准的描述 diff 的 Unified Format 格式了,所以必须向 LLM 解释一下格式的含义,增强它对输入的理解,避免它随便臆想。
我们将使用下面的格式来呈现 MR 代码的 diff 内容:
## new_path: src/agent/agent.service.ts
## old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record
(9, 9)
(10, 10) interface CallDifyParams {
- 以 ”## new_path“ 开头的行内容,表示修改后的文件路径
- 以 ”## old_path“ 开头的行内容,表示修改前的文件路径
- @@ -1,16 +1,13 @@ 是统一差异格式(Unified Diff Format)中的hunk header,用于描述文件内容的具体修改位置和范围
- 每一行左侧括号内的两个数字,左边表示旧代码的行号,右边表示新代码的行号
- 括号后的 + 表示的是新增行
- 括号后的 - 表示的是删除行
- 引用代码中的变量、名称或文件路径时,请使用反引号(`)而不是单引号(')。
加限制
加限制的主要目的是指引 LLM 按照固定的数据类型进行输出。这里我们会告诉 LLM 具体的 TS 类型,避免它输出一些乱七八糟的类型,导致后续在代码中解析和使用的时候报异常。例如,数字变成字符串、字符串变成数组等。
你必须根据下面的 TS 类型定义,输出等效于MRReview类型的YML对象:
```ts
interface Review {
// 表示修改后的文件路径
newPath: string;
// 表示修改前的文件路径
oldPath: string;
// 表示评审的是旧代码还是新代码,如果评审的是 + 部分的代码,那么 type 就是 new,如果评审的是 - 部分的代码,那么 type 就是 old。
type: 'old' | 'new';
// 如果是 old 类型,那么 startLine 表示的是旧代码的第 startLine 行,否则表示的是新代码的第 startLine 行
startLine: number;
// 如果是 new 类型,那么 endLine 表示的是旧代码的第 endLine 行,否则表示的是新代码的第 endLine 行
endLine: number;
// 对于存在问题总结的标题,例如(逻辑错误、语法错误、安全风险等),尽可能不超过 6 个字
issueHeader: string;
// 清晰的描述代码中存在、需要注意或者修改的问题,并给出明确建议
issueContent: string;
}
interface MRReview {
reviews: Review[];
}
```
在限制的类型中,最好是增加一些注解,让 LLM 能够理解每个字段的含义。
加示例
加示例的主要目的是告诉 LLM 按照固定的文件格式进行输出,这样我们就可以直接拿 LLM 的输出,进行标准化的解析,转换成实例的数据进行使用,伪代码如下:
// 调用 LLM 的接口
const result = await callLLM('xxxxx');
// 解析数据
const data = yaml.load(result);
// 操作数据
data.reviews.forEach(() => { })
提示词描述如下
输出模板(注意,我只需要 yaml 格式的内容。yaml 内容的前后不要有其他内容):
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 1
endLine: 1
type: |
old
issueHeader: |
逻辑错误
issueContent: |
...
- newPath: |
src/webhook/decorators/advanced-header.decorator.ts
oldPath: |
src/webhook/decorators/commmon-header.decorator.ts
startLine: 1
endLine: 1
type: |
new
issueHeader: |
性能风险
issueContent: |
...
```
这里简单说一下,为什么选择 yaml 而不是 json。因为在实践的过程中,我们发现 json 解析异常的概率会比 yaml 高很多,因为 json 的 key 和 value 是需要双引号("")包裹的,如果 issueContent 中包含了代码相关的内容且存在一些双引号、单引号之类的符号,就很容易导致报错,而且比较难通过一些替换规则进行兜底处理。
最后完整的提示词这里:提示词
调试
这里再告诉大家一个提示词的调试技巧,你可以先在 Coze、Dify 这样的平台上,通过工作台不断调试你的提示词,直到它能够稳定的输出你满意的结果。

5.5 扩展、组装 diff
上面我们有说到,通过 GitLab 获取的原始 diff 是没有新旧文件路径和具体的新旧行号的,这个需要通过代码计算来补全这些信息。这一小节,我们就来解决 diff 的扩展、组装问题。
扩展
扩展主要做两个事:
- 在 diff 头部加新旧文件的路径
- 在每一行加新旧文件中的行号
加路径比较简单,可以在获取每个文件的 diff 数据的时候,拿到新旧文件的路径的,取值后加上即可。
 加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。
加行号稍微麻烦一点,我们需要将当前文件的 diff 按照 hunk 拆分成不同的块,然后会根据 hunk head 计算每行在新旧文件中的真实行号。

为了防止有些同学不清楚 diff 格式的结构,我这里简单标注一下。 在下面这个 diff 中,像 “@@ -1,16 +1,13 @@” 这样的内容就是 Hunk Head,用于描述后续 diff 内容在新旧文件中的起始行号。用框住的第一个 hunk 为例:
- -1,16: 表示
import { Injectable } from '@nestjs/common';是在旧文件中的第 1 行,改动范围是往后的一共 16 行,需要忽略 “+” 加号开头的行。- +1,13:表示是
import { Injectable } from '@nestjs/common';在新文件中的第 1 行,改动范围是往后的一共 13 行,需要忽略 “-” 加号开头的行。然后图中被我用红框标注的连续代码片段就是 hunk,它一般由 hunk header + 连续的代码组成。一个文件的 diff 可能会有多个 hunk。
- hunk 中 “+” 开头的行,表示新文件中增加的行
- “-” 开头的行,表示旧文件中被删除的行

这里需要先遍历每个文件的 diff,然后按 hunk head 来分割内容块。
const hunks = splitHunk(diffFile.diff);
代码如下:

逻辑是将 diff 按 “\n” 分割成包含所有行的数组,然后遍历每一行。每当遍历到一个 hunk head 就创建一个新的 hunk 结构,然后通过正则提取里面的起始行号,并将后续遍历到的行都保存起来,直到它遇到一个新的 hunk head。
接着就是遍历 hunk,计算每个 hunk 中每一行的具体行号。

comptuedHunkLineNumer 的代码如下:

核心逻辑是:
- 使用 oldLineNumber、newLineNumber 两个独立计数器,记录新旧文件的当前行号
- 遍历到 “-” 开头的行,oldLineNumber + 1,记录行号(oldLineNumber + 1, )
- 遍历到 “+” 开头的行,newLineNumber + 1,记录行号( , newLineNumber + 1)
- 遍历常规的行,oldLineNumber 和 newLineNumber 都 + 1,记录行号(oldLineNumber + 1, newLineNumber + 1)
为了让你更清晰理解这个逻辑,我在 diff 中标注一下。下面是计算旧文件中的行号,我们只会对“-”开头的行和普通的行进行计数,忽律 “+” 开头的行。

计算新文件中的行,此时我将不计算 “-” 开头的行。所以type InputProps = Record这行代码,在合并后的新文件中,真正的行号是在第 15 行。

处理后 diff 的每一行,都会带上新旧文件中的行号
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
(9, 9)
(10, 10) interface CallDifyParams {
(11, 11) input: InputProps;
(12, 12) query: string;
(13, 13) conversation_id?: string;
(14, 14) user: string;
( , 15) + apiKey: string;
(16, 16) }
(17, 17)
组装
得到每个文件扩展的 diff 以后,便是将 commit message 和所有文件 diff 拼接到一个字符串中,后续会把这个拼接好的字符串直接输入给 LLM 进行分析。
commit message: feat: 调整 review 触发逻辑,增加请求拦截器
##new_path: src/agent/agent.service.ts
##old_path: src/agent/agent.service.ts
@@ -1,16 +1,13 @@
(1, 1) import { Injectable } from '@nestjs/common';
(2, 2)
(3, ) -interface InputProps {
(4, ) - code_diff: string;
(5, ) - code_context: string;
(6, ) - rules?: string;
(7, ) -}
( , 8) +type InputProps = Record;
## new_path: src/webhook/decorators/advanced-header.decorator.ts
## old_path: src/webhook/decorators/advanced-header.decorator.ts
@@ -0,0 +1,152 @@
( , 1) +import {
( , 2) + createParamDecorator,
( , 3) + ExecutionContext,
( , 4) + BadRequestException,
( , 5) +} from '@nestjs/common';
( , 6) +
( , 7) +/**
( , 8) + * 高级 Header 装饰器,支持类型转换和验证
( , 9) + */
( , 10) +export const AdvancedHeader = createParamDecorator(
5.6 对接 LLM
现在我们已经有了系统提示词、处理好的 diff 内容,接着就是如何调用 LLM 分析结果。

申请 DeepSeek
演示的案例中,我用的是 DeepSeek-v3 的模型。如果能够使用 GPT-4.1 或者 Calude 模型的同学,你可以优先选择使用这两个模型。
这里你需要去到 DeepSeek 官网申请一个 API Key

然后去充值个几块钱,你就可以使用 DeepSeek 这个模型了。

具体申请和使用步骤,官网文档都讲得很清楚了,这里不过多赘述。
调用 LLM
申请完 DeepSeek 的 API Key 以后,就可以通过接口调用了

这里主要关注一下调用接口的入参:
- model: 如果是 deepseek 的话,你选择
deepseek-chat还是deepseek-reasoner都可以 - messages: 这里我们输入两个 message,一个是系统提示词,一个是扩展的 diff
- temperature:设置成 0.2,提高输出的精确性
如果一切调用成功的话,你应该会得到 LLM 一个这样的回复:
```yaml
reviews:
- newPath: |
src/agent/agent.service.ts
oldPath: |
src/agent/agent.service.ts
startLine: 8
endLine: 8
type: |
new
issueHeader: |
类型定义不严谨
issueContent: |
将 `InputProps` 从具体的接口类型改为 `Record`,虽然提升了灵活性,但丢失了原有的类型约束,容易导致后续代码中出现属性拼写错误或类型不一致的问题。建议保留原有字段定义,并在需要扩展时通过继承或联合类型实现更好的类型安全。
- newPath: |
src/webhook/webhook.controller.ts
oldPath: |
src/webhook/webhook.controller.ts
startLine: 38
endLine: 40
type: |
new
issueHeader: |
参数注入冗余与未使用参数
issueContent: |
在 `trigger` 方法中注入了 `@GitlabToken()`、`@QwxRobotUrl()` 等参数,但实际方法体内并未使用这些参数,而是继续从 headers 中解析相关信息(已被删除)。建议移除未用到的装饰器参数,或者直接替换原有 header 获取逻辑,避免混乱和冗余。
```
5.7 数据解析和异常处理
有了 LLM 回复的数据以后,接着要做的就是将字符串解析成数据,以及处理解析过程中的异常问题
数据解析
这里主要做两个是事,一个是提取 yaml 的内容

提取完字符串以后,然后通过 js-yaml这个包解析数据
const mrReview = yaml.load(yamlContent) as MRReview;
至此,你已经得到一份经过 LLM 分析后产生的实例化的数据了
异常处理
但是你以为到这里就结束了吗?实际的情况却是 LLM 会因为它的黑盒性和不确定性,偶然的输出一些奇奇怪怪的字符或格式,导致出现解析的异常。
场景1:多余的 '\n' 符号
有时候 LLM 在输出的时候,会给 type 字段多加一个 '\n' 符号
{
newPath: "src/agent/agent.service.ts",
oldPath: "src/agent/agent.service.ts",
startLine: 10,
endLine: 12,
type: "new\n"
....
}
看日志的时候,感觉一直没问题。可是到一些具体场景判断的时候,就会开始怀疑人生。当时一些关于 type 的判断,我想破脑袋也没想明白为什么 new 会走到 old 的逻辑里面,结果仔细一看,还有一个换行符……

所以针对这个场景,需要单独加一些处理逻辑。通过 replace 把字符串中的换行符全部去掉。

场景2:多余的空格符号
我们知道 yaml 的字段结构是按空格来控制的,但有时候 LLM 偏偏就在某些字段前面少一个或者多个空格,排查的时候也是非常的头痛,例如下面的 issueHeader、issueContent 因为少了空格,而导致 yaml 解析异常…

我的办法就是让 AI 写了一个兜底处理方法。在解析异常的时候,通过兜底方法再解析一次。 具体代码(查看里面的 fixYamlFormatIssues 方法)
更多场景
因为 LLM 偶现的不稳定性,会导致出现各种奇奇怪怪的问题。目前的解决思路有三个:
- 使用更强大的模型,并调低 temperature 参数
- 调试出更完善的提示词,通过加限制、加示例等技巧,提高提示词的准确性
- 特殊场景,特殊手段。例如通过编码等手段,提前防范这些异常
5.8 上下文分割
还有一个需要解决的问题就 LLM 的上下文长度的限制。像 GPT-4.1 上下文长度有 100w 个 token,但是你用 deepseek 的话,可能只有 64000 个。
一旦你输入的提示词 + diff 内容超过这个上下文,就会报错导致 LLM 无法正常解析。这时我们就不得不把输入的 diff 拆分成多份,然后并行调用 LLM,最后整合数据。

解决这个问题的思路也很简单,每次调用 LLM 前,计算一下系统提示词 + Diff 内容需要消耗的 token,如果超了就把 diff 多差几份。
import { encoding_for_model, TiktokenModel } from '@dqbd/tiktoken';
const encoding = encoding_for_model(this.modelName);
const tokens = encoding.encode(text);
const count = tokens.length;
encoding.free();
我用的是 @dqbd/tiktoken 这个包计算 token,它里面包含了大多数模型的 token 计算方式。
5.9 发送结果
在有了处理好的 review 数据以后,我们就可以调用 GitLab 的接口发送评论了

从上面方法的入参可以看到,newPath、oldPath、endLine、issuceContent 等数据,都是在通过 LLM 分析以后得出来的。
5.10 小结
至此,这个 AI Code Review 的关键流程,我已经讲完了。下面再来总结一下两个流程:
- 逻辑流程
- 使用流程
逻辑流程
- 部署 NodeJS 服务
- 开发 webhook 接口,接受 MR 事件
- 收到事件后,获取 Diff 内容
- 有了 Diff 内容后,扩展行号、文件路径,拼成一个字符串
- 进行 token 分析,超了就分多份进行分析
- 调用 LLM,输入系统提示词、Diff
- 拿到 YAML 结构的分析数据
- 解析数据、处理异常
- 发送评论到 GitLab
使用流程
- 申请 access token
- 配置 webhook
- 发起 MR
- 收到 AI 分析的评论
六、最后
6.1 期待
本篇给大家分享了一个 AI Code Review 应用开发的简单案例。我希望大家可以看完以后,可以在自己的业务或者个人项目中去实践落地,然后再回到评论区给与反馈,展示你的成果。
6.2 学习方法
如果看到文章中有任何不懂的,我建议你都可以直接问 AI。我看掘金自带的这个 AI 助手也挺方便的。我们既然要学习 AI,就要多用 AI 的方式去学习。当然,你也可以直接留言问我。

6.3 关注
最后呢,也是希望大家关注我,我会持续在这个专栏更新我的文章。本想着坚持能够一个月输出两篇,但是在工作忙碌 + 文章质量的不断权衡中,还是写了很久,才写出这一篇。原创不易,需转载请私信我~
这个演示的项目地址:github.com/zixingtangm… (可以的话,也帮忙点点 star ⭐️ 哈哈)
来源:juejin.cn/post/7532596434031149106
使用 AI 助手提升前端代码质量:自动代码审查实战
最近在带团队的时候,发现代码审查(Code Review)总是成为项目进度的一个瓶颈。一方面,高级工程师的时间很宝贵,不可能审查每一行代码;另一方面,初级工程师又急需及时的反馈来提升。于是我就在想:能不能用 AI 来解决这个问题?
经过一番研究和实践,我搭建了一个 AI 代码审查助手,效果出乎意料的好!今天就来分享下这个小工具是怎么做的。
为什么需要 AI 代码审查?
说实话,最开始团队里有不少质疑的声音:"AI 能审查什么代码?""能发现真正的问题吗?"但是经过一段时间的使用,大家发现 AI 代码审查确实能解决很多痛点:
- 人工审查的问题
- 😫 审查疲劳:谁能一直盯着代码看?
- ⏰ 反馈延迟:等高级工程师有空可能需要好几天
- 🤔 标准不一:每个人的审查重点和标准都不太一样
- AI 审查的优势
- 🤖 24/7 全天候服务,随时可用
- 🎯 审查标准统一且可配置
- ⚡️ 秒级反馈,再也不用等人了
- 📚 会不断学习和改进
实战:搭建 AI 代码审查助手
温馨提示:这个项目用到了 OpenAI API,需要自己准备 API Key。新账号有免费额度,够用来测试了。
1. 项目初始化
mkdir ai-code-review
cd ai-code-review
npm init -y
npm install openai eslint prettier
2. 核心代码实现
这是最关键的部分,我们需要:
- 处理各种代码格式
- 设置合适的提示词(prompt)
- 处理 API 限流和错误
// src/codeReviewer.ts
import { Configuration, OpenAIApi } from 'openai'
import { rateLimit } from '@/utils/rate-limit'
class AICodeReviewer {
private openai: OpenAIApi
private reviewCache: Map<string, string>
constructor(apiKey: string) {
const configuration = new Configuration({
apiKey: apiKey
})
this.openai = new OpenAIApi(configuration)
this.reviewCache = new Map() // 缓存常见问题的反馈
}
private async generateReviewPrompt(code: string, language: string): string {
// 根据不同语言定制提示词
const basePrompt = `作为一个资深的${language}开发专家,请审查以下代码,重点关注:
1. 代码质量和最佳实践
2. 潜在的性能问题
3. 安全隐患
4. 可维护性
5. 错误处理
请用中文回复,按严重程度排序,并给出具体的修改建议。
代码:
${code}`
return basePrompt
}
async reviewCode(code: string, language: string = 'JavaScript'): Promise<string> {
try {
// 检查缓存
const cacheKey = this.generateCacheKey(code)
if (this.reviewCache.has(cacheKey)) {
return this.reviewCache.get(cacheKey)!
}
// 限流检查
if (!await rateLimit.check()) {
throw new Error('请求太频繁,请稍后再试')
}
const prompt = await this.generateReviewPrompt(code, language)
const completion = await this.openai.createChatCompletion({
model: 'gpt-3.5-turbo',
messages: [
{
role: 'system',
content: '你是一个资深的代码审查专家,擅长发现代码中的问题并提供建设性的改进建议。'
},
{ role: 'user', content: prompt }
],
temperature: 0.7, // 让回复更有创意一些
})
const review = completion.data.choices[0].message?.content || ''
// 缓存结果
this.reviewCache.set(cacheKey, review)
return review
} catch (error: any) {
console.error('代码审查失败:', error)
throw new Error(this.formatError(error))
}
}
private generateCacheKey(code: string): string {
// 简单的缓存 key 生成
return code.trim().substring(0, 100)
}
private formatError(error: any): string {
if (error.response?.status === 429) {
return '当前请求较多,请稍后再试'
}
return '代码审查服务暂时不可用,请重试'
}
}
export default AICodeReviewer
3. VSCode 扩展实现
这是我们团队最常用的功能,可以直接在编辑器里获取 AI 反馈:
// extension.ts
import * as vscode from 'vscode'
import AICodeReviewer from './codeReviewer'
export function activate(context: vscode.ExtensionContext) {
// 注册命令
let disposable = vscode.commands.registerCommand('aiCodeReview.review', async () => {
const editor = vscode.window.activeTextEditor
if (!editor) {
vscode.window.showErrorMessage('请先打开要审查的代码文件')
return
}
// 获取当前文件的语言
const language = editor.document.languageId
const code = editor.document.getText()
// 显示加载状态
const statusBarItem = vscode.window.createStatusBarItem(
vscode.StatusBarAlignment.Left
)
statusBarItem.text = '$(sync~spin) AI 正在审查代码...'
statusBarItem.show()
try {
const reviewer = new AICodeReviewer(
vscode.workspace.getConfiguration().get('aiCodeReview.apiKey') as string
)
const review = await reviewer.reviewCode(code, language)
// 在侧边栏显示结果
const panel = vscode.window.createWebviewPanel(
'aiCodeReview',
'AI 代码审查报告',
vscode.ViewColumn.Two,
{}
)
panel.webview.html = `
<!DOCTYPE html>
<html>
<head>
<style>
body { padding: 15px; }
.review { white-space: pre-wrap; }
.severity-high { color: #d73a49; }
.severity-medium { color: #e36209; }
.severity-low { color: #032f62; }
</style>
</head>
<body>
<h2>AI 代码审查报告</h2>
<div class="review">${this.formatReview(review)}</div>
</body>
</html>
`
} catch (error: any) {
vscode.window.showErrorMessage(error.message)
} finally {
statusBarItem.dispose()
}
})
context.subscriptions.push(disposable)
}
实战经验分享
经过几个月的使用,我总结了一些经验:
1. 提示词(Prompt)很重要
- 🎯 要让 AI 关注特定领域的最佳实践
- 📝 提供具体的评审标准和格式要求
- 🌐 针对不同编程语言定制提示词
2. 合理的使用场景
- ✅ 适合:代码风格检查、基本的逻辑问题、文档完整性
- ❌ 不适合:业务逻辑正确性、系统架构决策、性能调优
3. 成本控制
在实际使用中,我发现几个控制成本的好办法:
- 缓存常见问题
- 类似的代码问题可以复用审查结果
- 显著减少 API 调用次数
- 合理的调用策略
- 不是每次保存都触发审查
- 设置合适的调用间隔
- 批量处理多个文件的审查
- 优化 token 使用
- 只发送必要的代码片段
- 限制单次审查的代码长度
- 选择合适的模型(3.5 通常就够用)
实际效果
使用这个工具后,我们团队有了一些明显的改善:
- 代码质量
- 基础问题大幅减少
- 代码风格更统一
- 新人学习曲线变缓
- 开发效率
- PR 审查时间减少 50%
- 反馈速度提升
- 开发体验更好
- 团队氛围
- 减少了代码审查的争议
- 新人更敢提问和讨论
- 代码审查不再是负担
写在最后
这个 AI 代码审查助手现在已经成为我们团队日常开发的好帮手了。它不是来替代人工代码审查的,而是帮我们过滤掉那些基础问题,让我们能把精力放在更有价值的讨论上。
如果你也想尝试,建议从小范围开始,慢慢调整和优化。毕竟每个团队的情况都不一样,找到最适合自己团队的方式才是关键。
如果觉得有帮助,别忘了点赞关注!之后我还会分享更多提升开发效率的实战经验~
来源:juejin.cn/post/7440818887455604736
理想正式官宣开源!杀疯了!
最近,新能源汽车制造商「理想汽车」面向业界搞了一个大动作,相信不少同学也看到了,那就是:
正式宣布开源「理想星环OS」操作系统,并且欢迎各位开发者参与验证开源组件的功能和性能。
作为一名开发者和理想车主,说实话第一眼看到这个信息时还是挺意外的,万万没想到,如今汽车制造商也开始玩开源这一套了。

「理想星环OS」是理想汽车历时3年所研发的汽车操作系统,在车辆中担任“中央指挥官”这一角色,向下管理车辆硬件,向上支撑应用软件。

具体来说,「理想星环OS」包含如下四个组成部分,用于高效调度全车资源并确保汽车功能稳定运行。
- 辅助驾驶OS(大脑):用于处理复杂的思维过程,以确保辅助驾驶又快又好地工作。
- 智能车控OS(小脑):用于控制车辆“肢体”,快速执行各种车辆基础控制命令。
- 通信中间件(神经系统):负责车内各个模块(如刹车、屏幕、雷达)间的高效可靠通信。
- 信息安全系统(免疫系统):负责数据加密保护以及身份认证和权限管控等信息安全的保障。

早在今年3月份的时候,理想汽车CEO李想就曾在2025中关村论坛年会上宣布过,理想汽车自研整车操作系统 ——“理想星环OS”将会开源,而这一承诺终于在最近开始逐步向外兑现。

按照理想官方发布的开源计划时间轴来看,「理想星环OS」的开源将会分为三个阶段来逐步落地。
- 第一阶段主要是开源星环OS 0.1.0版本,包含安全实时RTOS以及通信总线Lite。
- 第二阶段开源星环OS 1.0.0版本,包含完整的智能车控系统以及智能驾驶系统基础能力,时间节点为今年的6月30号左右。
- 第三阶段开源则将会包括完整的智能驾驶系统以及虚拟化引擎,时间节点定在了2025年的7月后。

并且理想承诺,星环OS将会采用宽松型的Apache License,既不会通过开源来收取费用,也不会干涉代码的使用方式,更不会控制使用者的数据。
按照官方的说法,第一阶段的开源目前已经正式兑现,代码已经托管于国内的Gitee平台之上。
出于好奇,我也特地去Gitee平台上搜了一下。
果然,理想汽车已经在Gitee平台上创建了一个名为「HaloOS」的开源组织,里面包含了一阶段开源相关的多个代码仓库和文档仓库。

具体来看,目前的开源代码主要是 智能车控OS(VCOS) 和 通信总线lite(VBSlite) 两大部分,并且其开源仓库划分得非常细,文档是文档,代码是代码,配置是配置,示例是示例。

文档仓库我们以智能车控OS(VCOS)文档为例,其专门搞了一个文档仓库和详细文档说明,并且附有详细的快速跳转链接,大家可以感受一下这个文档仓库的组织风格,还是非常便于开发者使用的。

docs
├── OVERVIEW.md # 项目概述
├── README.md # 文档结构简介(即本文)
├── _static/image # 文档中用到的图片资源
├── api_reference # API参考文档
├── configuration_reference # 配置项参考文档
├── key_technical # 关键技术说明
├── porting # 芯片移植文档
├── quick_start # 快速入门指南
└── user_manual # 开发者手册与详细说明
├── components # 功能组件使用说明
├── kernel # 内核模块文档
└── studio # Studio集成开发环境相关文档
而代码仓库这一块,我们以通信总线lite(VBSlite)工程核心组件之一的MVBS代码仓库为例,仓库说明里给出了详细的代码架构组织,大家也可以感受一下。
mvbs
├── README.md # 这个是MVBS仓库的readme
├── build.mk # 用于构建的makefile文件
├── CMakeLists.txt # cmake编译脚本
├── posix_aux # 为linux和windows平台提供扩展支持库
├── include
│ ├── mcdr # 序列化接口
│ ├── mvbs # MVBS头文件集合
│ │ ├── adapter # 适配层头文件
│ │ ├── core # MVBS内部核心的实体定义和操作
│ │ ├── diag # 诊断相关的头文件
│ │ ├── rte # RTE接口文件
│ │ ├── rtps # RTPS协议元素定义文件
│ │ ├── sections # 用于支持内存layout
│ │ └── utils # 常用的工具文件
│ └── rpc # RPC头文件
└── src
├── adapter # 适配层实现
│ ├── auto # 基于VCOS 适配层的参考实现
│ └── posix # 基于POSIX提供的适配层实现
├── core
│ ├── diag # 诊断工具的实现
│ ├── discovery # 实体发现协议的实现
│ ├── entities # MVBS内部实体的实现
│ ├── include # 提供给MVBS内部的头文件
│ ├── messages # 报文组装的实现
│ ├── mvbs # MVBS内部接口层的实现
│ ├── netio # 网络接口的封装实现
│ ├── qos # E2E和WLP的实现
│ ├── storages # CacheChange和History的实现
│ ├── transport # Transport的实现
│ └── utils # 常用工具的实现
├── mcdr # 序列化库的实现
├── rpc # RPC的实现
└── rte # RTE接口的实现
再看一下具体代码,函数和代码组织都比较宽松,是我个人比较喜欢的风格,另外关键步骤或关键字段设有代码注释,阅读起来也便于理解。

并且仓库里还给出了非常详细的快速入门开发者手册,内容我看了一下,内容甚至从安装 git-repo 工具开始,确实给得非常详细。

追了其中几个比较核心的代码仓库后我们会发现,这几个核心项目源码都是基于C语言来实现的,这也再次说明了 C 语言在某些关键系统中不可撼动的核心地位。

大家感兴趣的话也可以上去学习学习相关的代码,研究通了以后想进新能源智能车企做核心系统研发那不就是分分钟的事情了。

众所周知,这两年新能源智能汽车领域的竞争也进入到白热化阶段了,各家新能源车企都在不断地进行产品优化和技术摸高,这个趋势在未来很长一段时间内想必还会继续保持。
按照理想官方的说法,此次开源的主要目的是促进行业合作,旨在破解行业“重复造轮子”的困局,同时通过生态的共建来实现车企之间、车企与其他厂商之间的互利共赢,最终普惠到每个用户。
当然不管他们怎么去说,作为一名开发者我们都清晰地知道,开源的背后其实也是生态的建设和博弈,说实话这一步,理想在新能源车企阵营里走得还是非常超前的。
最近这两年,我自己一直都挺关注新能源汽车市场的,线下也试驾和体验过诸多品牌的新能源汽车产品,也切实感受到了这几年技术和产品的飞速迭代。希望国产智能新能源汽车能持续崛起,为用户带来更多技术普惠和感动人心的好产品。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7503810377554984998
Maven高级
一. 分模块设计与开发
分模块设计的核心是 “高内聚,低耦合”。
- 高内聚:一个模块只负责一个独立的、明确的职责(如:订单模块只处理所有订单相关业务)。模块内部的代码关联性非常强。
- 低耦合:模块与模块之间的依赖关系尽可能的简单和清晰。一个模块的变化,应该尽量减少对其他模块的影响。
通过Maven,我们可以轻松地实现这一思想。每个模块都是一个独立的Maven项目,它们通过父子工程和依赖管理有机地组织在一起。
以一个经典的电商平台为例,我们可以将其拆分为以下模块:

将pojo和utils模块分出去

)
在tilas-web-management中的pom.xml中引入pojo,utils模块
<dependency>
<groupId>org.example</groupId>
<artifactId>tlias-pojo</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.example</groupId>
<artifactId>tlias-utils</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
分模块的好处
- 代码清晰,职责分明:每个开发人员可以专注于自己的模块,易于理解和维护。
- 并行开发,提升效率:多个模块可以由不同团队并行开发,只需约定好接口即可。
- 构建加速:Maven支持仅构建更改的模块及其依赖模块(使用 mvn -pl 命令),大大节省构建时间。
- 极高的复用性:像 core、dao 这样的模块,可以直接被其他新项目引用,避免重复造轮子。
- 便于单元测试:可以针对单个业务模块进行独立的、深入的测试。
二. 继承
2.1 继承配置
tlias-pojo、tlias-utils、tlias-web-management 中都引入了一个依赖 lombok 的依赖。我们在三个模块中分别配置了一次。

我们可以再创建一个父工程 tlias-parent ,然后让上述的三个模块 tlias-pojo、tlias-utils、tlias-web-management 都来继承这个父工程 。 然后再将各个模块中都共有的依赖,都提取到父工程 tlias-parent中进行配置,只要子工程继承了父工程,依赖它也会继承下来,这样就无需在各个子工程中进行配置了。

将tilas-parent中的pom.xml设置成pom打包方式
Maven打包方式:
- jar:普通模块打包,springboot项目基本都是jar包(内嵌tomcat运行)
- war:普通web程序打包,需要部署在外部的tomcat服务器中运行
- pom:父工程或聚合工程,该模块不写代码,仅进行依赖管理
<packaging>pom</packaging>
通过parent来配置父工程
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.8</version>
<!-- 父工程的pom.xml的相对路径 如果不配置就直接从中央仓库调取 -->
<relativePath/> <!-- lookup parent from repository -->
</parent>
子工程配置 通过relativePath配置父工程的路径
<parent>
<groupId>org.example</groupId>
<artifactId>tlias-parent</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../tilas-parent/pom.xml</relativePath>
</parent>
2.2 版本锁定
如果项目拆分的模块比较多,每一次更换版本,我们都得找到这个项目中的每一个模块,一个一个的更改。 很容易就会出现,遗漏掉一个模块,忘记更换版本的情况。
在maven中,可以在父工程的pom文件中通过 来统一管理依赖版本。
<!--统一管理依赖版本-->
<dependencyManagement>
<dependencies>
<!--JWT令牌-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.1</version>
</dependency>
······
</dependencies>
</dependencyManagement>
这样在子工程中就不需要进行version版本设置了
<dependencies>
<!--JWT令牌-->
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
</dependency>
</dependencies>
注意!!!
- 在父工程中所配置的 dependencyManagement只能统一管理依赖版本,并不会将这个依赖直接引入进来。 这点和 dependencies 是不同的。
- 子工程要使用这个依赖,还是需要引入的,只是此时就无需指定 版本号了,父工程统一管理。变更依赖版本,只需在父工程中统一变更。
2.3 自定义属性
<properties>
<lombok.version>1.18.34</lombok.version>
</properties>
通过${属性名}引用属性
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
三. 聚合
聚合(Aggregation) 和继承(Inheritance) 是Maven支持分模块设计的两个核心特性,它们目的不同,但又相辅相成。
简单来说,继承是为了统一管理,而聚合是为了统一构建。

在聚合工程中通过modules>module来配置聚合
<!-- 聚合其他模块 -->
<modules>
<module>你要聚合的模块路径</module>
</modules>
四. 私服
私服是一种特殊的远程仓库,它代理并缓存了位于互联网的公共仓库(如MavenCentral),同时允许企业内部部署自己的私有构件(Jar包)。
你可以把它理解为一个 “架设在公司内网里的Maven中央仓库”。

项目版本说明:
- RELEASE(发布版本):功能趋于稳定、当前更新停止,可以用于发行的版本,存储在私服中的RELEASE仓库中。
- SNAPSHOT(快照版本):功能不稳定、尚处于开发中的版本,即快照版本,存储在私服的SNAPSHOT仓库中。
4.1 私服下载
下载Nexus私服 help.sonatype.com/en/download…

在D:\XXXXXXXX\bin目录下 cmd运行nexus /run nexus 显示这个就表示开启成功啦!

浏览器输入localhost:8081

私服仓库说明:
- RELEASE:存储自己开发的RELEASE发布版本的资源。
- SNAPSHOT:存储自己开发的SNAPSHOT发布版本的资源。
- Central:存储的是从中央仓库下载下来的依赖
4.2 资源上传与下载
设置私服的访问用户名/密码(在自己maven安装目录下的conf/settings.xml中的servers中配置)
<server>
<id>maven-releases</id>
<username>admin</username>
<password>admin</password>
</server>
<server>
<id>maven-snapshots</id>
<username>admin</username>
<password>admin</password>
</server>
设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的mirrors中配置)
<mirror>
<id>maven-public</id>
<mirrorOf>*</mirrorOf>
<url>http://localhost:8081/repository/maven-public/</url>
</mirror>
设置私服依赖下载的仓库组地址(在自己maven安装目录下的conf/settings.xml中的profiles中配置)
<profile>
<id>allow-snapshots</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<repositories>
<repository>
<id>maven-public</id>
<url>http://localhost:8081/repository/maven-public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
IDEA的maven工程的pom文件中配置上传(发布)地址(直接在tlias-parent中配置发布地址)
<distributionManagement>
<!-- release版本的发布地址 -->
<repository>
<id>maven-releases</id>
<url>http://localhost:8081/repository/maven-releases/</url>
</repository>
<!-- snapshot版本的发布地址 -->
<snapshotRepository>
<id>maven-snapshots</id>
<url>http://localhost:8081/repository/maven-snapshots/</url>
</snapshotRepository>
</distributionManagement>
打开maven控制面板双击deploy

由于当前我们的项目是SNAPSHOT版本,所以jar包是上传到了snapshot仓库中
来源:juejin.cn/post/7549363056862756918
小红书小组件开发 最早踩坑版
前言

是这样的,这段小红书逛的多,发现有一篇关于小红书小组件的介绍,介绍里提到的是[AI调酒]这款小组件,在内容里可以直接挂载。我试玩了一下,还挺有趣,交互感挺强的。
然后下面提到说,留言即可有机会获取内测开发资格,内测时可以免费使用里面的AI功能。
想着能白嫖就报名了,正好加入小红书生态,好宣传自己的app一波,hhh
没想到过一天就受到了科技署的邀请,加入了内测群!
开发
进群后,就令我感到有点诧异了,群里陆续进去了21个人,有15个工作人员,6个被邀请的开发。进去后,组织者发了一个操作文档:
各位好,我们是小组件项目的产品和研发,各位可以先提供下自己的小红书账号,我们为大家添加测试白名单
添加后需要完成的事项:
1、前往小红书开放平台创建开发者账号(开白后可申请个人主体账号,若已有账号可忽略)
https://miniapp.xiaohongshu.com/home
2、查阅小组件和智能体的开发文档,下载开平IDE工具,进行设计和开发
小组件开发介绍:https://miniapp.xiaohongshu.com/doc/DC026740
智能体开发介绍(如果需要在小组件中内嵌AI服务):https://miniapp.xiaohongshu.com/doc/DC783288
最佳实践:https://miniapp.xiaohongshu.com/doc/DC246551
3、由于小组件是无需备案的,因此平台会承担一定风险,因此有明确的创作方向后,需要开发者提供简易的demo图,我们会做内部的产品&研发&安全的可行性评估
🌟🌟 在过程中,大家如果有流程、开发、设计上的问题,都可以群内和我们沟通,由于这是小组件第一波内测,所以不可避免地可能还有些问题,大家提出来后我们也会及时处理优化,也感谢大家理解[合十]
🌟🌟 也辛苦各位重点关注:小组件整体的定位是「轻量、简单」,以及整体的UI设计也希望能「简介、美观」,更符合小红书社区氛围,这样更容易在社区总传播

意思就是,大家按照文档操作就行,基本没什么大问题。
但是小问题还是挺多的。
里面的很多开发,基本都有小红书小程序的开发经验了,这次感觉纯属了为了捧场或者是和我一样,做完后有没有什么推流。他们基本上很快就做完了。
我就不一样了,有主职工作而且一直做的是移动原生,虽然之前学过一丢丢微信小程序开发,但都已经过了差不多3年了。
但来都来了。
小组件

小组件开发可以独立进行,不依赖其他的三方。如果可以的话,你可以开发个很简易的demo上去,当然你还得经过小红书官方的审核,如果太基础的话就不太行,这个大家都懂得。
一般来讲,小组件需要依赖后台服务,或者是小红书他们提供AI智能体,毕竟咋们是奔着它去的。而且给的demo也是关于智能体。
第一步下载编辑器

编辑器好像是需要这个版本才行,是官方人员直接在群里发的。最新版本的编辑器融合了AI功能,真的很给力,我自己写好了核心的逻辑后,让它来美化UI真是太省事了,而且美化的UI和小红书官方的小组件交互效果有点类似,有点红薯风,对于我这种没有UI审美的开发来说是一大福星,而且比免费版本的cursor好用。
跟着文档开发后
跟着文档开发,这里就不贴具体的过程了,因为文档也会更新,会更完善。因为我们是第一版本,所以文档里有很多遗漏的和错误的,这里补充一下这部分,如果再有人开发到这一步,可能会用的到。
隐私协议:
xhs.openClipLegalPolicy();
小组件核心代码:
因为我是调用的是智能体,调用智能体的代码用官方的那样写是有问题的,写了好久有跑不通,咨询了很久才得到正确的代码:
初始化agent
// 初始化 Agent env: 'production'按需选择线上和测试
async initAgent() {
try {
const agentId = "test6baffa154e6db2d96e64ef310a6e";
const agent = xhs.cloud.AI.createAgent({
agentId,
env: 'production',
version: '0.1.8'
});
this.setData({
agent: agent
});
console.log("Agent初始化成功");
} catch (error) {
console.error("Agent初始化失败: ", error);
xhs.showToast({
title: "Agent初始化失败",
icon: "none",
});
}
},
// 调用智能体 解梦
if (this.data.agent == null) return;
const agentInfo = this.data.agent.getAgentInfo();
console.log("res", agentInfo);
// 使用回调方式发送消息
const { message, onMessage, onSuccess, onError } = this.data.agent.sendMessage({
msg: dreamContent,
history: [],
});
onSuccess((result) => {
this.setData({
isOver:true
})
console.log("请求成功:", result);
console.log("API调用成功,返回结果:", result);
// result.data.data
xhs.hideLoading();
});
// 监听流式消息
onMessage((chunkStr) => {
// console.log("收到消息块:", chunkStr, "api-message", message);
xhs.hideLoading();
if (chunkStr === "[DONE]") {
return;
}
let chunk = null;
try {
chunk = JSON.parse(chunkStr);
} catch (error) {
console.error("解析消息块失败:", error);
return;
}
// 解析消息块
if (chunk!=null&&chunk.choices && chunk.choices[0] && chunk.choices[0].message) {
const message = chunk.choices[0].message;
console.log("收到消息块 message:", message.content);
// 处理回复内容
if (message.content) {
this.setData({
dreamInterpretation:this.data.dreamInterpretation + message.content
})
this.setData({
isLoading: false,
showResult: true,
resultDream: dreamContent,
dreamInterpretation: this.data.dreamInterpretation
});
}
}
});
// 监听错误回调
onError((error) => {
console.error("请求失败:", error);
xhs.hideLoading();
xhs.showToast({
title: "生成失败,请重试",
icon: "none",
});
});
智能体

智能体分为流式和非流式的。
看具体的业务需求了,如果是很快的生成 和 生成的文本很短,就像[AI调酒],只需要简单的json即可,那就可以用非流式的。
像我这种需要生成长文本的就有点不太适合了,所以这里选择的是流式输出的形式。
核心代码:
// {user_mood: '开心',user_taste: '随便'}
async sendMessage(input) {
console.log('message -- '+ JSON.stringify(input))
console.log('--')
console.log('msg -- '+ input.msg)
const model = this.createModel('deepseek-v3')
const messages = [
{
role:'system',
content: systemPrompt
},
{
role:'user',
content:{
type:'text',
content: input.msg
// content: JSON.stringify(input)
// content: '{\'user_mood\': \'开心\', \'user_taste\': \'随便\'}'
}
}
]
const modelResponse = await model.streamText({
enable_thinking:false,
temperature:1,
messages: [
{
role: 'system',
content: systemPrompt
},
{
role: 'user',
content: {
type: 'text',
// JSON.stringify(input.msg)
content: JSON.stringify(input)
// context:input.msg
}
}
]}
)
console.log('aaaa')
for await (const chunk of modelResponse) {
this.sseSender.send({ data: chunk });
}
console.log('bbbb')
this.sseSender.end();
}
systemPrompt 指的是提示词,提示词是ai的核心,这里可以返回json或者是markdown或是html样式。如果不会写提示词,也可以让ai给你写提示词,hhh
End

最后附一张截图。各位大佬有兴趣可以在小红书里搜索AI解梦小组件 ,里面有笔记进行挂载。
发布后发现,官方根本没有推流,而且后续也没提小组件这回事了🤡。
不过就当自己玩玩了,可以使用免费的ai服务进行快速解梦~
来源:juejin.cn/post/7564540677478301759
别再被VO、BO、PO、DTO、DO绕晕!今天用一段代码把它们讲透
大家好,我是晓凡。
前阵子晓凡的粉丝朋友面试,被问到“什么是VO?和DTO有啥区别?”
粉丝朋友:“VO就是Value Object,DTO就是Data Transfer Object……”
面试官点点头:“那你说说,一个下单接口里,到底哪个算VO,哪个算DTO?”
粉丝朋友有点犹豫了。
回来后粉丝朋友痛定思痛,把项目翻了个底朝天,并且把面试情况告诉了晓凡,下定决心捋清楚了这堆 XO 的真实含义。
于是乎,这篇文章就来了 今天咱们就用一段“用户下单买奶茶”的故事,把 VO、BO、PO、DTO、DO 全部聊明白。
看完保准你下次面试不卡壳,写代码不纠结。
一、先放结论
它们都是“为了隔离变化”而诞生的马甲
| 缩写 | 英文全称 | 中文直译 | 出现位置 | 核心目的 |
|---|---|---|---|---|
| PO | Persistent Object | 持久化对象 | 数据库 ↔ 代码 | 一张表一行记录的直接映射 |
| DO | Domain Object | 领域对象 | 核心业务逻辑层 | 充血模型,封装业务行为 |
| BO | Business Object | 业务对象 | 应用/服务层 | 聚合多个DO,面向用例编排 |
| DTO | Data Transfer Object | 数据传输对象 | 进程/服务间 | 精简字段,抗网络延迟 |
| VO | View Object | 视图对象 | 控制层 ↔ 前端 | 展示友好,防敏感字段泄露 |
一句话总结: PO 管存储,DO 管业务,BO 管编排,DTO 管网络,VO 管界面。
下面上代码,咱们边喝奶茶边讲。
二、业务场景
用户下一单“芋泥波波奶茶”
需求:
- 用户选好规格(大杯、少冰、五分糖)。
- 点击“提交订单”,前端把数据发过来。
- 后端算价格、扣库存、落库,返回“订单创建成功”页面。
整条链路里,我们到底需要几个对象?
三、从数据库开始:PO
PO是
Persistent Object的简写 PO 就是“一行数据一个对象”,字段名、类型和数据库保持一一对应,不改表就不改它。
// 表:t_order
@Data
@TableName("t_order")
public class OrderPO {
private Long id; // 主键
private Long userId; // 用户ID
private Long productId; // 商品ID
private String sku; // 规格JSON
private BigDecimal price; // 原价
private BigDecimal payAmount; // 实付
private Integer status; // 订单状态
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
注意:PO 里绝不能出现业务方法,它只是一个“数据库搬运工”。
四、核心业务:DO
DO 是“有血有肉的对象”,它把业务规则写成方法,让代码自己说话。
// 领域对象:订单
public class OrderDO {
private Long id;
private UserDO user; // 聚合根
private MilkTeaDO milkTea; // 商品
private SpecDO spec; // 规格
private Money price; // Money是值对象,防精度丢失
private OrderStatus status;
// 业务方法:计算最终价格
public Money calcFinalPrice() {
// 会员折扣
Money discount = user.getVipDiscount();
// 商品促销
Money promotion = milkTea.getPromotion(spec);
return price.minus(discount).minus(promotion);
}
// 业务方法:下单前置校验
public void checkBeforeCreate() {
if (!milkTea.hasStock(spec)) {
throw new BizException("库存不足");
}
}
}
DO 可以引用别的 DO,形成聚合根。它不关心数据库,也不关心网络。
五、面向用例:BO
BO 是“场景大管家”,把多个 DO 攒成一个用例,常出现在 Service 层。
@Service
public class OrderBO {
@Resource
private OrderRepository orderRepository; // 操作PO
@Resource
private InventoryService inventoryService; // RPC或本地
@Resource
private PaymentService paymentService;
// 用例:下单
@Transactional
public OrderDTO createOrder(CreateOrderDTO cmd) {
// 1. 构建DO
OrderDO order = OrderAssembler.toDO(cmd);
// 2. 执行业务校验
order.checkBeforeCreate();
// 3. 聚合逻辑:扣库存、算价格
inventoryService.lock(order.getSpec());
Money payAmount = order.calcFinalPrice();
// 4. 落库
OrderPO po = OrderAssembler.toPO(order, payAmount);
orderRepository.save(po);
// 5. 返回给前端需要的数据
return OrderAssembler.toDTO(po);
}
}
BO 的核心是编排,它把 DO、外部服务、PO 串成一个完整的业务动作。
六、跨进程/服务:DTO
DTO 是“网络快递员”,字段被压缩成最少,只带对方需要的数据。
1)入口 DTO:前端 → 后端
@Data
public class CreateOrderDTO {
@NotNull
private Long userId;
@NotNull
private Long productId;
@Valid
private SpecDTO spec; // 规格
}
2)出口 DTO:后端 → 前端
@Data
public class OrderDTO {
private Long orderId;
private String productName;
private BigDecimal payAmount;
private String statusDesc;
private LocalDateTime createTime;
}
DTO 的字段命名常带 UI 友好词汇(如 statusDesc),并且绝不暴露敏感字段(如 userId 在返回给前端时可直接省略)。
七、最后一步:VO
VO 是“前端专属快递”,字段可能二次加工,甚至带 HTML 片段。
@Data
public class OrderVO {
private String orderId; // 用字符串避免 JS long 精度丢失
private String productImage; // 带 CDN 前缀
private String priceText; // 已格式化为“¥18.00”
private String statusTag; // 带颜色:green/red
}
VO 通常由前端同学自己写 TypeScript/Java 类,后端只负责给 DTO,再让前端 BFF 层转 VO。如果你用 Node 中间层或 Serverless,VO 就出现在那儿。
八、一张图记住流转过程
前端页面
│ JSON
▼
CreateOrderVO (前端 TS)
│ 序列化
▼
CreateOrderDTO (后端入口)
│ BO.createOrder()
▼
OrderDO (充血领域模型)
│ 聚合、计算
▼
OrderPO (落库)
│ MyBatis
▼
数据库
返回时反向走一遍:
数据库
│ SELECT
OrderPO
│ 转换
OrderDTO
│ JSON
OrderVO (前端 TS 渲染)
九、常见疑问答疑
- 为什么 DO 和 PO 不合并? 数据库加索引、加字段不影响业务;业务改规则不改表结构。隔离变化。
- DTO 和 VO 能合并吗? 小项目可以,但一上微服务或多端(App、小程序、管理后台),立马爆炸。比如后台需要用户手机号,App 不需要,合并后前端会拿到不该看的数据。
- BO 和 Service 有什么区别? BO 更贴近用例,粒度更粗。Service 可能细分读写、缓存等。命名随意,关键看团队约定。
十、一句话背下来
数据库里叫 PO,业务里是 DO,编排靠 BO,网络走 DTO,前端看 VO。
下次面试官再问,你就把奶茶故事讲给他听,保证他频频点头。
本期内容到这儿就结束了
我是晓凡,再小的帆也能远航
我们下期再见 ヾ(•ω•`)o (●'◡'●)
来源:juejin.cn/post/7540472612595941422
后端仔狂喜!手把手教你用 Java 拿捏华为云 IoTDA,设备上报数据 so easy
作为天天跟接口、数据库打交道的后端博主,我之前总觉得 IoT 是 “硬件大佬的专属领域”—— 直到我踩坑华为云 IoTDA(物联网设备接入服务)后发现:这玩意儿明明就是 “后端友好型选手”!今天带大家从 0 到 1 玩转 IoTDA,从创建产品到 Java 集成,全程无废话,连小白都能看懂~
一、先唠唠:IoTDA 到底是个啥?
设备接入服务(IoTDA)是华为云的物联网平台,提供海量设备连接上云、设备和云端双向消息通信、批量设备管理、远程控制和监控、OTA升级、设备联动规则等能力,并可将设备数据灵活流转到华为云其他服务。
你可以把 IoTDA 理解成 “IoT 设备的专属管家”:
- 设备想连互联网?管家帮它搭好通道(MQTT/CoAP 等协议);
- 设备要上报数据(比如温湿度、电量)?管家负责接收、存着还能帮你分析;
- 你想给设备发指令(比如让灯关掉)?管家帮你把指令精准送到设备手里。
简单说:有了 IoTDA,后端不用管硬件怎么联网,专心写代码处理 “设备数据” 就行 —— 这不就是咱们的舒适区嘛!
相关的一些概念:
- 服务和物模型:
- 物模型:设备本身拥有的属性(功能数据),像电量,电池温度等等
- 服务:理解为不同物模型的分类(分组),比如电池服务(包含了电量、电池温度等等物模型), 定位服务(经纬度坐标,海拔高度物模型)
- 设备:真实看得见、摸得着的设备实物,设备的信息需要录入到华为云IoTDA平台里
二、实操第一步:给你的设备 “办张身-份-证”(创建产品)
产品:某一类具有相同能力或特征的设备的集合称为一款产品。帮助开发者快速进行产品模型和插件的开发,同时提供端侧集成、在线调试、自定义Topic等多种能力。比如,手表、大门通道门禁、紧急呼叫报警器、滞留报警器、跌倒报警器
就像人要办身-份-证才能出门,IoT 设备也得先在 IoTDA 上 “建档”(创建产品),步骤简单到离谱:
- 登录华为云控制台,搜 “IoTDA” 进入服务页面(记得先开服务,新用户有免费额度!);
- 左侧菜单点【产品】→【创建产品】,填这几个关键信息:

- 产品名称:比如 “我的温湿度传感器”(别起 “test123”,后续找起来头疼);

- 协议类型:选 “MQTT”(后端最常用,设备端也好对接);
- 数据格式:默认 “JSON”(咱们后端处理 JSON 不是手到擒来?);
- 点【确定】,搞定!此时你会拿到一个 “产品 ID”—— 记好它,后续要当 “钥匙” 用。

小吐槽:第一次创建时我把协议选错成 “CoAP”,结果设备端连不上,排查半小时才发现… 大家别学我!
三、设备接入:让传感器 “开口说话”(数据上报)
产品创建好后,得让具体的设备(比如你手里的温湿度传感器)连上来,核心就两步:注册设备→上报数据。 官方案例-设备接入:基于NB-IoT小熊派的智慧烟感
3.1 给单个设备 “上户口”(注册设备)
- 进入刚创建的产品详情页,点【设备】→【注册设备】;
- 填 “设备名称”(比如 “传感器 001”),其他默认就行;

- 注册成功后,会拿到两个关键信息:设备 ID和设备密钥(相当于设备的 “账号密码”,千万别泄露!)。
3.2 数据上报:让设备把数据 “发快递” 过来
前提条件:需要提前创建好产品和对应的物模型,以及该产品的设备
准备实例的接入地址
后续设备上报数据时,需要准备好接入地址。去哪里找接入地址呢?参考下图:

设备要上报数据,本质就是通过 MQTT 协议给 IoTDA 发一条 JSON 格式的消息,举个实际例子:
假设温湿度传感器要上报 “温度 25℃、湿度 60%”,数据格式长这样:
{
"Temperature": 25.0, // 温度
"Humidity": 60.0 // 湿度
}
设备端怎么发?不用你写 C 代码!华为云给了现成的 “设备模拟器”:
在设备详情页点【在线调试】→ 选 “属性上报”→ 把上面的 JSON 粘进去→ 点【发送】,刷新页面就能看到数据已经躺在 IoTDA 里了 —— 是不是比调接口还简单?
四、后端重头戏:Java 项目集成 IoTDA
前面都是控制台操作,后端真正要做的是 “用代码跟 IoTDA 交互”。华为云提供了 Java SDK,咱们不用重复造轮子,直接撸起袖子干!
4.1 先搞懂:关键参数从哪来?
集成前必须拿到这 3 个 “钥匙”,少一个都不行:
- Access Key/Secret Key:华为云账号的 “API 密钥”,在【控制台→我的凭证→访问密钥】里创建;
- 区域 ID:比如 “cn-north-4”(北京四区),IoTDA 控制台首页就能看到;
- 产品 ID / 设备 ID:前面创建产品、注册设备时拿到的(忘了就去控制台查!)。
友情提示:别把 Access Key 硬编码到代码里!用配置文件或者 Nacos 存,不然上线后哭都来不及~
4.2 项目集成:Maven 依赖先安排上
在 pom.xml 里加 IoTDA SDK 的依赖(版本选最新的就行):
<dependency>
<groupId>com.huaweicloud.sdkgroupId>
<artifactId>huaweicloud-sdk-iotdaartifactId>
<version>3.1.47version>
dependency>
<dependency>
<groupId>com.huaweicloud.sdkgroupId>
<artifactId>huaweicloud-sdk-coreartifactId>
<version>3.1.47version>
dependency>
4.3 核心功能实现:代码手把手教你写
先初始化 IoTDA 客户端(相当于建立连接),写个工具类:
import com.huaweicloud.sdk.core.auth.BasicCredentials;
import com.huaweicloud.sdk.iotda.v5.IoTDAClient;
import com.huaweicloud.sdk.iotda.v5.region.IoTDARegion;
public class IoTDAClientUtil {
// 从配置文件读参数,这里先写死方便演示
private static final String ACCESS_KEY = "你的Access Key";
private static final String SECRET_KEY = "你的Secret Key";
private static final String REGION_ID = "cn-north-4"; // 你的区域ID
public static IoTDAClient getClient() {
// 1. 配置凭证
BasicCredentials credentials = new BasicCredentials()
.withAk(ACCESS_KEY)
.withSk(SECRET_KEY);
// 2. 初始化客户端
return IoTDAClient.newBuilder()
.withCredentials(credentials)
.withRegion(IoTDARegion.valueOf(REGION_ID))
.build();
}
}
接下来实现咱们需要的 5 个核心功能,每个功能都带注释,一看就懂:
功能 1:从 IoT 平台同步产品列表
import com.huaweicloud.sdk.iotda.v5.model.ListProductsRequest;
import com.huaweicloud.sdk.iotda.v5.model.ListProductsResponse;
public class IoTDAService {
private final IoTDAClient client = IoTDAClientUtil.getClient();
// 同步产品列表(支持分页,这里查第一页,每页10条)
public void syncProductList() {
ListProductsRequest request = new ListProductsRequest()
.withLimit(10) // 每页条数
.withOffset(0); // 页码,从0开始
try {
ListProductsResponse response = client.listProducts(request);
System.out.println("同步到的产品列表:" + response.getProducts());
} catch (Exception e) {
System.err.println("同步产品列表失败:" + e.getMessage());
}
}
}
项目参考思路

功能 2:查询所有产品列表(分页查询封装)
// 查所有产品(自动分页,直到查完所有)
public void queryAllProducts() {
int offset = 0;
int limit = 20;
while (true) {
ListProductsRequest request = new ListProductsRequest()
.withLimit(limit)
.withOffset(offset);
ListProductsResponse response = client.listProducts(request);
if (response.getProducts().isEmpty()) {
break; // 没有更多产品了,退出循环
}
System.out.println("当前页产品:" + response.getProducts());
offset += limit; // 下一页
}
}
功能 3:注册设备(代码注册,不用手动在控制台点了)
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceRequest;
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceResponse;
import com.huaweicloud.sdk.iotda.v5.model.RegisterDeviceRequestBody;
public void registerDevice(String productId, String deviceName) {
// 构造注册请求体
RegisterDeviceRequestBody body = new RegisterDeviceRequestBody()
.withDeviceName(deviceName);
RegisterDeviceRequest request = new RegisterDeviceRequest()
.withProductId(productId) // 关联的产品ID
.withBody(body);
try {
RegisterDeviceResponse response = client.registerDevice(request);
System.out.println("设备注册成功!设备ID:" + response.getDeviceId()
+ ",设备密钥:" + response.getDeviceSecret());
} catch (Exception e) {
System.err.println("设备注册失败:" + e.getMessage());
}
}
功能 4:查询设备详细信息(比如设备在线状态、最后上报时间)
import com.huaweicloud.sdk.iotda.v5.model.ShowDeviceRequest;
import com.huaweicloud.sdk.iotda.v5.model.ShowDeviceResponse;
public void queryDeviceDetail(String deviceId) {
ShowDeviceRequest request = new ShowDeviceRequest()
.withDeviceId(deviceId); // 要查询的设备ID
try {
ShowDeviceResponse response = client.showDevice(request);
System.out.println("设备在线状态:" + response.getStatus()); // ONLINE/OFFLINE
System.out.println("最后上报时间:" + response.getLastOnlineTime());
System.out.println("设备详细信息:" + response);
} catch (Exception e) {
System.err.println("查询设备详情失败:" + e.getMessage());
}
}
功能 5:查看设备上报的数据(关键!终于能拿到传感器数据了)
import com.huaweicloud.sdk.iotda.v5.model.ListDevicePropertiesRequest;
import com.huaweicloud.sdk.iotda.v5.model.ListDevicePropertiesResponse;
public void queryReportedData(String deviceId) {
// 查询设备最近上报的10条属性数据
ListDevicePropertiesRequest request = new ListDevicePropertiesRequest()
.withDeviceId(deviceId)
.withLimit(10)
.withAsc(false); // 倒序,最新的先看
try {
ListDevicePropertiesResponse response = client.listDeviceProperties(request);
response.getProperties().forEach(property -> {
System.out.println("数据上报时间:" + property.getReportTime());
System.out.println("上报的属性值:" + property.getPropertyValues());
// 比如取温度:property.getPropertyValues().get("Temperature")
});
} catch (Exception e) {
System.err.println("查询设备上报数据失败:" + e.getMessage());
}
}
五、踩坑总结:这些坑我替你们踩过了!
- 区域 ID 搞错:比如用 “cn-east-2”(上海二区)的客户端去连 “cn-north-4” 的 IoTDA,直接报 “连接超时”;
- 设备密钥泄露:一旦泄露,别人能伪装你的设备上报假数据,一定要存在安全的地方;
- SDK 版本太旧:有些老版本不支持 “查询设备历史数据” 接口,记得用最新版 SDK;
- 免费额度用完:新用户免费额度够测 1 个月,别上来就挂生产设备,先测通再说~
最后说两句
其实 IoTDA 对后端来说真的不难,核心就是 “调用 API 跟平台交互”,跟咱们平时调支付接口、短信接口没啥区别。今天的代码大家可以直接 copy 到项目里,改改参数就能跑通~
你们在集成 IoTDA 时遇到过啥坑?或者有其他 IoT 相关的需求(比如设备指令下发)?评论区聊聊,下次咱们接着唠!
(觉得有用的话,别忘了点赞 + 收藏,后端学 IoT 不迷路~)
来源:juejin.cn/post/7541667597285277731
云计算大佬揭秘AI如何改变程序员未来,这些技能将成关键
近日,亚马逊云科技副总裁兼首席布道师Jeff Barr受邀来到上海,与当地开发者社区进行了深入交流。在这场以“AI驱动的开发新模式”为主题的分享中,他基于多年来对开发者生态的观察和实践,详细阐述了生成式AI正在如何重塑软件开发的各个环节。
Jeff Barr在云计算和开发者工具领域拥有丰富经验,他的见解往往能够准确反映技术发展的趋势。此次分享中,他不仅展示了当前AI编程工具的最新进展,更为在场开发者描绘了一幅清晰的职业发展路线图。

AI正在改变开发者的工作方式
在Jeff Barr看来,AI驱动的开发模式已经从概念走向实践。他提到,现在的AI编程助手能够理解开发者的自然语言描述,并将其转化为可工作的代码。这种转变不仅提升了代码编写的效率,更改变了开发者与计算机交流的基本方式。
传统的软件开发需要开发者掌握特定的编程语言和框架,然后将业务需求转化为精确的代码逻辑。而随着大语言模型在代码生成方面的进步,开发者现在可以用更接近人类思维的方式表达意图,让AI助手处理具体的实现细节。
这种变化并不意味着程序员将被取代。相反,Jeff Barr强调,程序员的重点将从具体的语法和API记忆,转向更高层次的问题分析、架构设计和系统优化。能够清晰定义问题、评估AI生成代码质量、进行系统级思考的程序员将更具价值。

全面提升开发效率与质量
在实际开发过程中,AI助手正在多个环节发挥作用。从代码补全、错误检测到测试用例生成,AI工具能够显著减少开发者的重复性工作。Jeff Barr展示的数据表明,使用AI助手的开发者在完成常规任务时效率提升了30%到50%。
更值得注意的是,AI在代码优化和重构方面也展现出强大能力。它能够分析现有代码库,识别潜在的性能瓶颈和安全漏洞,并提出改进建议。这种能力使得经验相对较少的开发者也能写出高质量的代码。
在团队协作方面,AI工具可以帮助新成员快速理解项目架构和代码规范,缩短上手时间。同时,它们还能协助进行代码审查,确保团队保持一致的编码标准。
开发者需要培养的新能力
面对AI带来的变革,开发者需要主动调整自己的技能组合。Jeff Barr建议开发者重点培养以下几个方面的能力。
首先,问题分析和拆解能力在今天变得更为重要。由于AI擅长处理明确定义的任务,开发者需要学会将复杂问题分解为AI可以理解和处理的子任务。这种能力决定了开发者能否充分利用AI工具的潜力。
虽然现在的AI工具对自然语言的理解越来越强,但能够编写清晰、具体的提示词仍然可以显著提升输出结果的质量。因此,提示工程也成为必备技能。
同时,学会读懂代码,并与AI、客户进行有效沟通的能力也尤为重要。

系统设计和架构能力的重要性进一步提升。当基础的编码任务可以由AI辅助完成时,开发者的价值将更多体现在对整体系统的把握上,包括技术选型、模块划分、接口设计等关键决策。
展望未来,Jeff Barr认为AI对软件开发的影响还将持续深化。他预测,在不久的将来,AI助手将能够理解更复杂的业务需求,并参与从需求分析到部署运维的全流程。
另一个重要趋势是个性化AI开发助手的出现。随着模型训练技术的进步,开发者将能够根据自己的编码风格和项目特点定制专属的AI助手,从而获得更加精准有效的协助。
同时,低代码/无代码平台与AI技术的结合也将打开新的可能性。业务专家将能够更直接地将自己的想法转化为可运行的应用程序,而开发者则可以专注于更复杂的技术挑战。
基于Jeff Barr的分享,可以预见的是,在这个快速变化的时代,拥抱AI、学习与AI协作将成为开发者的核心竞争力。
正如Jeff Barr所说,最成功的开发者不是那些抗拒变化的人,而是那些能够预见变化、适应变化并引领变化的人。在AI重塑软件开发的新时代,这一洞察显得尤为珍贵。
来源:juejin.cn/post/7564607094554050603
Code Review 最佳实践 2:业务实战中的审核细节
🧠 本节谈
我们聚焦真实业务模块中的 Code Review,涵盖:
- 🔐 表单校验逻辑
- 🧩 动态权限控制
- 🧱 页面逻辑复杂度管理
- ⚠️ 接口调用规范
- ♻️ 组件解耦重构
- 🧪 单元测试提示
每一条都配备真实反面代码 + 改进建议 + 原因说明,并总结通用审核 checklist。
📍 场景 1:复杂表单校验逻辑
❌ 错误示例:耦合 + 不可维护
const onSubmit = () => {
if (!form.name || form.name.length < 3 || !form.age || isNaN(form.age)) {
message.error('请填写正确信息')
return
}
// ...
}
问题:
- 所有校验写死在事件里,不可复用
- 无法做提示区分
✅ 改进方式:抽离校验 + 可扩展
const validateForm = (form: UserForm) => {
if (!form.name) return '姓名不能为空'
if (form.name.length < 3) return '姓名过短'
if (!form.age || isNaN(Number(form.age))) return '年龄格式错误'
return ''
}
const onSubmit = () => {
const msg = validateForm(form)
if (msg) return message.error(msg)
// ...
}
👉 Review 要点:
- 校验逻辑是否可复用?
- 是否便于单测?
- 提示是否明确?
📍 场景 2:权限控制逻辑写死
❌ 反例
<Button v-if="user.role === 'admin'">删除</Button>
问题:
- 无法集中管理
- 用户身份切换时易出错
- 无法与服务端权限匹配
✅ 推荐:
const hasPermission = (perm: string) => user.permissions.includes(perm)
<Button v-if="hasPermission('can_delete')">删除</Button>
👉 Review 要点:
- 权限是否统一处理?
- 是否可扩展到路由、接口层?
- 是否易于调试?
📍 场景 3:复杂页面组件未解耦
❌ 嵌套组件塞一堆逻辑
// 页面结构
<Table data={data}>
{data.map(row => (
<tr>
<td>{row.name}</td>
<td>
<Button onClick={() => doSomething(row.id)}>操作</Button>
</td>
</tr>
))}
</Table>
- 所有数据/逻辑/视图耦合一起
- 无法复用
- 改动难以测试
✅ 推荐:
<TableRow :row="row" @action="handleRowAction" />
// TableRow.vue
<template>
<tr>
<td>{{ row.name }}</td>
<td><Button @click="emit('action', row.id)">操作</Button></td>
</tr>
</template>
👉 Review 要点:
- 是否具备清晰的“数据流 → 逻辑流 → 视图层”结构?
- 是否把组件职责划分清楚?
- 是否拆分足够颗粒度便于测试?
📍 场景 4:接口调用未封装
❌ 直接 axios 写在组件中:
axios.get('/api/list?id=' + id).then(res => {
this.list = res.data
})
问题:
- 接口不可复用
- 无法集中处理错误
- 改动接口时无法追踪引用
✅ 推荐:
// services/user.ts
export const getUserList = (id: number) =>
request.get('/api/list', { params: { id } })
// 页面中
getUserList(id).then(res => (this.list = res.data))
👉 Review 要点:
- 是否将接口层抽离为服务?
- 是否统一请求拦截、错误处理?
- 是否易于 Mock 和调试?
📍 场景 5:测试个锤子🔨
❌ 错误写法:组件中逻辑混杂难以测试
if (user.age > 18 && user.vipLevel > 3 && user.region === 'CN') {
return true
}
问题:
- 没有语义抽象
- 不可测试
✅ 改进写法:
const isPremiumUser = (user: User) =>
user.age > 18 && user.vipLevel > 3 && user.region === 'CN'
👉 Review 要点:
- 是否具备良好的可测试性?
- 是否便于 Jest/Vitest 测试用例编写?
✅ 最佳实践总结
Review 高级 Checklist
| 检查点 | 检查说明 |
|---|---|
| ✅ 表单逻辑 | 是否抽离,是否健壮 |
| ✅ 权限处理 | 是否统一管理,可扩展 |
| ✅ 页面复杂度 | 是否组件解耦,职责清晰 |
| ✅ 接口调用 | 是否封装为服务层,便于复用 |
| ✅ 可测试性 | 关键逻辑是否抽象、是否测试友好 |
🎯 尾声:从 Code Review 走向“架构推动者”
掌握 Code Review 不止是“找错”,而是:
- 帮助他人提升思维方式
- 用标准统一团队技术认知
- 用习惯推动系统演进
来源:juejin.cn/post/7530437804129239080
为了搞一个完美的健身APP,我真是费尽心机
作为一个强迫症患者,当我需要一个简单、好用、流畅、无广告的健身记录软件时,撸铁记就诞生了。
为什么我要开发撸铁记
我应该是2018年接触健身的,那个时候我的教练每次给我上课,都会拿着一个文件夹记录我的每一次训练。但是纸制记录最大的问题是难保存,而且只能教练一个人看,于是我写了第一个健身记录软件,叫FitnessRecord,然后我就在知乎上分享了自己的应用,没想到真的有人用!
后来,在朋友的撺掇下,我正式决定将撸铁记推上线,然后就是(巴拉巴拉极其费劲的上线了!)
个人开发者有多痛苦
一个完美的软件,最重要的,不仅要好看,还得好用,于是,就出现了下面这些设计
暗黑模式
一个 APP,如果不支持暗黑模式,那你让强迫症怎么活?


但是...你以为这就完了吗?细节藏在魔鬼里😄
绝对黑
记得前两年各大手机厂商还在卷屏幕的时候,苹果率先推出了“绝对黑”,强调OLED屏幕通过像素关闭实现的物理级纯黑效果。so~为了实现在暗黑模式下,软件用的更爽,撸铁记的 APP 的背景色使用了#000000,也就是纯黑色
这样做的好处是在暗黑模式下,撸铁记可以与屏幕完美的融为一体。但是!问题来了。纯黑色真的很难设计,作为一个程序员出身的我,头发都抓掉了好几把。
有细心的小伙伴们或许已经发现了,亮色模式下跟暗黑模式的主题色其实不是一个颜色:

我们发现在暗黑模式下,亮色模式下的主题色与黑色之间的对比度不够明显,导致整体色调暗沉,因此,亮色模式的主题色是:#3B7AEF 暗黑模式下则是:#2E6FEC
虚拟导航键适配
Android 的虚拟导航键如果适配不好,有多丑相信懂得都懂,为了能够在弹窗模式下也能够让弹窗与导航栏完美无瑕的融为一体,我设计了一个 BaseDialog,专门用来管理弹窗状态,确保在任何页面,虚拟导航栏都不会影响到 APP 的整体颜值!

左滑展示更多功能
作为一个专业的记录软件,各种各样的功能总要有吧?
全部堆叠到更多菜单中是不是很傻?如果在屏幕排列出来展示是不是更傻?所以,左滑删除这种很合理的交互是不是得有?
IOS 设备是常态,但是能够完美的搬到 Android 机器上,该怎么做?鸿蒙系统又该怎么适配?!
但是!我说的是但是,为了更漂亮的 UI,更合理的交互,我又熬了个通宵,最终完美解决!

好的交互就得多看,多学
每个人的习惯都不同,比如有的用户希望能够在倒计时 120s 之后有一个声音提示,有的则希望可以按照训练顺序,对卡片自动排序,那么问题来了,这些功能又该堆叠在哪里呢?
我的灵感来源是一款不太出名的 P 图软件
在训练详情页面的左侧,有一根很不起眼的线,当你触摸这条线的时候,就会弹出训练设置的总菜单啦!(不用担心很难触摸,我已经将触摸范围调整到了最合适的大小,既不会误触,也不会很难点👍)

其实,APP 还有很多为了“好看”而做的设计,但是一个好的 APP,只是静态的好看怎么能行!
完美的入场动效
我该如何像您吹嘘这系统级的丝滑动效?请看 VCR(希望掘金支持视频链接😂):
http://www.bilibili.com/video/BV1sb…
http://www.bilibili.com/video/BV1Pb…
如何?是否足够丝滑???
当然,功能性才是核心
除了记录的易用性和强大复杂的功能,为了能够 360° 覆盖健身所需要的所有场景,我还开发了各种各样的功能
赛博智能
赛博智能,我希望这个功能可以像赛博机器人一样,对我的身体状况进行 360° 评估。
鄙人不才,晒一下我的身体状态评估分析:

一个超级大长图,几乎涵盖了你想要知道的一切~当然,后续还会继续丰富其他功能😁
日历统计

这个月你偷懒了吗
是的,你的每一滴汗水,都会浓缩破到这一张小小的日历表格中,如果你偷懒了,那就是一张空空的日历,那么,你会努力填满每一天的,对吧?
最后的最后
按原本的计划,我想要从设计到功能,认真的介绍一下撸铁记的所有方方面面,但是回头看看,文章真的太长了,所以,就留一点悬念给大家,希望需要的小伙伴自行探索😁
其实,每一个细节,我都改过很多次,后续依旧会不断的改来改去,因为我只想要最好~
最后,祝愿所有喜欢健身的朋友,都可以收获自己成功~
来源:juejin.cn/post/7524504350250205238
Electron 内网离线打包全攻略
一、背景与问题核心
近期维护一个内网传统网页开发项目,该项目采用「网页+Electron壳」的架构。由于原Electron版本过旧,导致项目中依赖的Antv G6 v5图表库出现兼容性问题(表现为图表渲染异常或功能报错)。升级Electron本身可参考官方文档快速实现,但内网环境下打包时无法联网下载预编译二进制文件,成为本次迁移的核心难点。本文将详细记录完整解决方案,帮助有类似需求的开发者避坑。
二、完整实操流程
整个过程分为「依赖安装配置」和「离线缓存准备」两大步骤,确保开发环境运行与内网打包均正常。
Step 1:安装并配置Electron依赖
Electron默认会根据当前系统自动下载对应平台的预编译包,但内网环境需提前指定下载参数,避免后续打包时依赖网络。
1.1 创建.npmrc文件固定下载参数
在项目根目录新建.npmrc文件,写入以下内容(根据实际需求修改平台和架构,此处以Windows x64为例):
# .npmrc 配置
# 系统架构(x64/arm64等)
arch=x64
# 操作系统(win32/mac/linux等)
platform=win32
# 可选:设置npm镜像(非必需,若内网有镜像可配置)
# registry=https://your-internal-npm-mirror.com/
1.2 安装核心依赖
执行以下命令安装Electron及打包工具@electron-forge/cli(用于后续打包操作):
# 安装开发依赖
npm install electron @electron-forge/cli --save-dev
# 将项目导入Electron Forge(自动生成打包配置文件forge.config.js)
npx electron-forge import
1.3 验证开发环境
确保package.json中已指定Electron入口文件(通过main字段配置,如"main": "main.js"),随后运行以下命令启动项目,验证Antv G6兼容性是否解决:
npm run start
💡 注意:若启动后图表仍异常,可检查Antv G6是否与当前Electron版本匹配(参考G6官方兼容性说明),或清除node_modules后重新安装依赖。
Step 2:准备离线缓存文件
Electron打包时需依赖预编译二进制文件,内网环境无法联网下载,因此需提前在外网环境下载对应文件并配置缓存路径。
2.1 下载对应版本的Electron预编译包
- 查看项目中实际安装的Electron版本:在package.json中找到electron的版本号(如"electron": "^38.4.0");
- 访问Electron镜像地址:npmmirror.com/mirrors/ele…
- 下载以下文件(以win32-x64为例):
- electron-v38.4.0-win32-x64.zip(对应系统的预编译包)
- SHASUMS256.txt(文件校验码,用于验证完整性)
2.2 校验文件完整性(可选但推荐)
下载完成后,通过校验工具(如Windows的PowerShell、Linux/macOS的终端)验证文件哈希值是否与SHASUMS256.txt一致,避免文件损坏:
Windows PowerShell示例(替换文件名和版本号)
Get-FileHash .\electron-v38.4.0-win32-x64.zip -Algorithm SHA256 | Select-Object Hash
将输出的哈希值与SHASUMS256.txt中对应文件名的哈希值对比,一致则文件完整。
2.3 配置forge.config.js离线缓存路径
在项目根目录创建electron-cache文件夹,将下载的预编译包和校验文件放入其中。然后修改forge.config.js,在packagerConfig中添加缓存配置:
const { FusesPlugin } = require("@electron-forge/plugin-fuses");
const { FuseV1Options, FuseVersion } = require("@electron/fuses");
const path = require("path");
module.exports = {
packagerConfig: {
asar: true, // 启用asar打包(可选,用于压缩和保护资源)
download: {
// 本地缓存镜像路径(绝对路径更稳妥)
mirror: path.resolve(__dirname, "electron-cache"),
cache: path.resolve(__dirname, "electron-cache"),
focus: false, // 禁用下载进度聚焦(避免终端干扰)
},
electronZipDir: path.resolve(__dirname, "electron-cache/"), // 预编译包所在目录
},
// ... 其他配置
};
2.4 执行内网离线打包
完成上述配置后,在项目根目录执行打包命令,Electron Forge将从本地缓存读取预编译包,无需联网:
npm run make
打包成功后,可在项目根目录的out文件夹中找到对应系统的安装包或绿色版程序。
三、关键注意事项
- 路径必须准确:配置中使用path.resolve生成绝对路径,避免相对路径导致的缓存找不到问题;
- 文件名严格匹配:本地缓存的预编译包文件名需与官方一致(如electron-v{version}-{platform}-{arch}.zip),否则无法识别;
- 多系统适配:若需打包多个系统(如Windows和macOS),需下载对应平台的预编译包放入缓存文件夹,无需修改配置;
- 版本号统一:确保package.json中的Electron版本与下载的预编译包版本完全一致,避免兼容性问题。
四、总结
本次Electron升级及内网打包的核心是「提前配置下载参数+本地缓存预编译包」。通过固定.npmrc参数确保依赖安装时匹配目标系统,再通过配置Forge的缓存路径实现离线打包,最终解决了Antv G6的兼容性问题和内网环境限制。若后续需升级Electron版本,只需重复「下载对应版本预编译包→更新缓存文件夹」的步骤即可。
如果遇到其他特殊场景(如内网npm镜像配置、asar包解压问题),欢迎在评论区交流讨论!
来源:juejin.cn/post/7564472484067835923
【深入浅出Nodejs】异步非阻塞IO
概览:本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
I/O模式
I/O模式介绍
1.文件描述符
类unix操作系统将I/O抽象为文件描述符(file description,下面简称fd),可读/可写流都可以看做读一个“文件”,打开文件和创建Socket等都是获取到一个fd文件描述符。
2.操作I/O时发生了什么
操作流就是读和写(read/write),下面用read进行说明。read时需要CPU进入内核态等待操作系统处理数据,等操作系统完成后会响应结果。用户态切换到内核态仅仅是CPU执行模式切换,线程本身并未改变,CPU进入内核态才能进行外部设备(外设)的准备工作,从而支持后续数据复制到内核缓冲区,完成后再切换回用户态,然后真正的读数据到用户程序。
3.五种I/O模式

如图,操作系统有5种I/O模式。
- blocking
- nonblocking
- multiplexing
- signal-driven (很少使用,不介绍)
- async I/O
可以的话,不妨看完下面详细介绍后再回过头看这张图,对5种模式进行对比,相信你认识一定会更加深刻。
阻塞I/O (blocking)
- 当用户态调用read API读流时,操作系统陷入内核态开始准备数据。
- 此时read是阻塞的。CPU是会切换到其他线程,做其他事的。原因就是现代计算机(采用了DMA技术)对于这种磁盘读取工作中的数据传输部分CPU是不参与的,交给了DMA控制器负责,等处理好了DMA会发出一个CPU中断,通知CPU切换回原来的线程继续处理。
- 所以线程一定是阻塞的,当前线程的执行权让出去了,也就是说没有CPU时间片继续执行当前线程。
- 内核态数据准备完成,原来的Thread被唤醒,继续执行,表现为API读流返回了数据。
P.S. DMA是通知操作系统,唤醒原来Thread,继续执行。并不是通知Thread的具体某段程序执行,而是之前被阻塞时执行到哪,现在就继续执行哪里。
非阻塞I/O (non-blocking)
为甚么还要有非阻塞I/O?
显然,阻塞I/O会导致后面的代码不能继续执行,在要处理多个I/O的情况下就是串行发起I/O操作了。而非阻塞I/O就是希望发起I/O操作是并发的(不用等上一个流操作结束才发起下一个)。
非阻塞I/O: 调用read去读fd的数据时,立即返回fd的状态结果,不阻塞后面代码的执行。此时操作系统就需要考虑如何实现这种非阻塞,如管理多个I/O流。
/*伪代码*/
fd = openStream(); //打开文件,创建Socket等都能获得一个fd,不阻塞
n = read(fd); //读取这个fd的数据,不阻塞
- 当用户态调用read API读流时,操作系统陷入内核态检查数据是否就绪。
- 此时read是不阻塞的,可以继续执行后面的代码。但是后续需要不断「check」(就是read)来检查数据是否就绪。
- DMA通知唤醒Thread(如果Thread一直都是激活状态,不存在被唤醒这一动作)。「check」发现有fd的数据就绪,就进行数据处理。
非阻塞I/O 是指read读数据能立即返回fd状态,而不用等待,但是需要你主动去read。如下图所示(图来自《深入浅出Nodejs》):
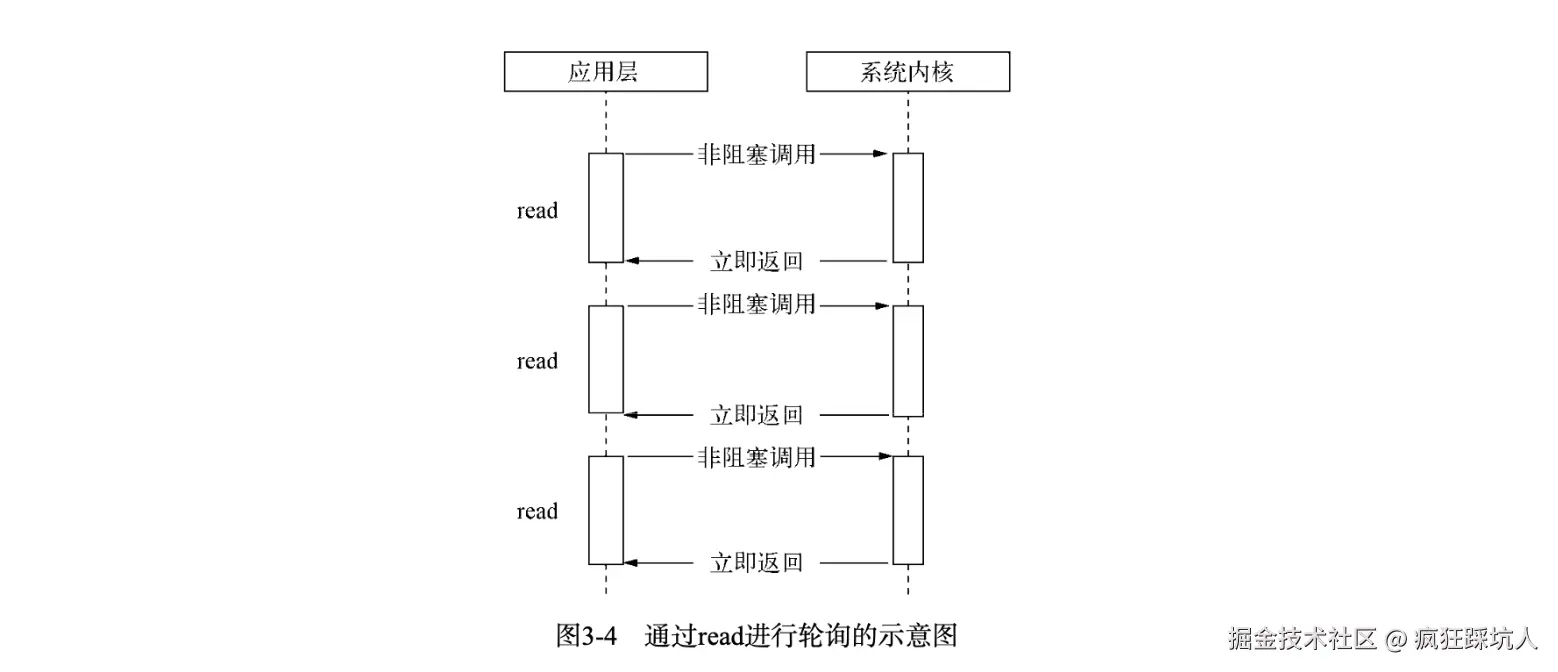
C++伪代码实现
// 文件描述符集合
std::vector<int> fds = {fd1, fd2, fd3}; // 假设有3个需要监控的文件描述符
// 设置为非阻塞模式
for(auto& fd : fds) {
int flags = fcntl(fd, F_GETFL, 0);
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
// 轮询循环
while(true) {
bool all_done = true;
// 应用层轮询每个文件描述符
for(auto fd : fds) {
char buffer[1024];
ssize_t n = read(fd, buffer, sizeof(buffer)); // 非阻塞调用
if(n > 0) {
// 成功读取到数据
process_data(buffer, n);
}
else if(n == 0) {
// 连接关闭
remove_fd(fd);
}
else if(n < 0) {
if(errno == EAGAIN || errno == EWOULDBLOCK) {
// 数据未就绪,立即返回 - 继续轮询其他fd
continue;
} else {
// 真实错误
handle_error(fd);
}
}
// 检查是否还有需要处理的数据
if(has_pending_operations()) {
all_done = false;
}
}
// 可选的短暂休眠避免CPU占用过高
if(all_done) {
usleep(1000); // 1s休眠
}
// 退出条件
if(should_exit) break;
}
此时,还需要我们手动一个个检查fd的状态。下面就介绍I/O多路复用,它做到了批量监听多个fd状态,不用我们手动去管理监听每一个fd了。
I/O多路复用(multiplexing)
类unix操作系统下,多路复用的方式有 select, poll, epoll(macos/freeBSD 上的替代品是 kqueue)。而在windows下面则直接使用IOCP(基于线程池的异步I/O方式),下面会介绍。
select、poll分别早在1983年、1986年就出现了,而epoll知道Linux2.6(大约2003)年才出现。
现代系统都是非阻塞I/O大都采用epoll或者IOCP的方式作为主流I/O并发方案了。
select
通过select()系统调用来监视多个fd的数组,返回一个int值(表示了fd就绪的个数),当调用select会阻塞,直到有一个fd就绪。
int select(int maxfdp, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
//maxfdp:被监听的文件描述符的总数;
//readset:读fd集合
//writeset:写fd集合
//exceptset
//timeout:用于设置select函数的超时时间,即告诉内核select等待多长时间之后就放弃等待。
//返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。
下图展示了select方式(图来自《深入浅出Nodejs》):
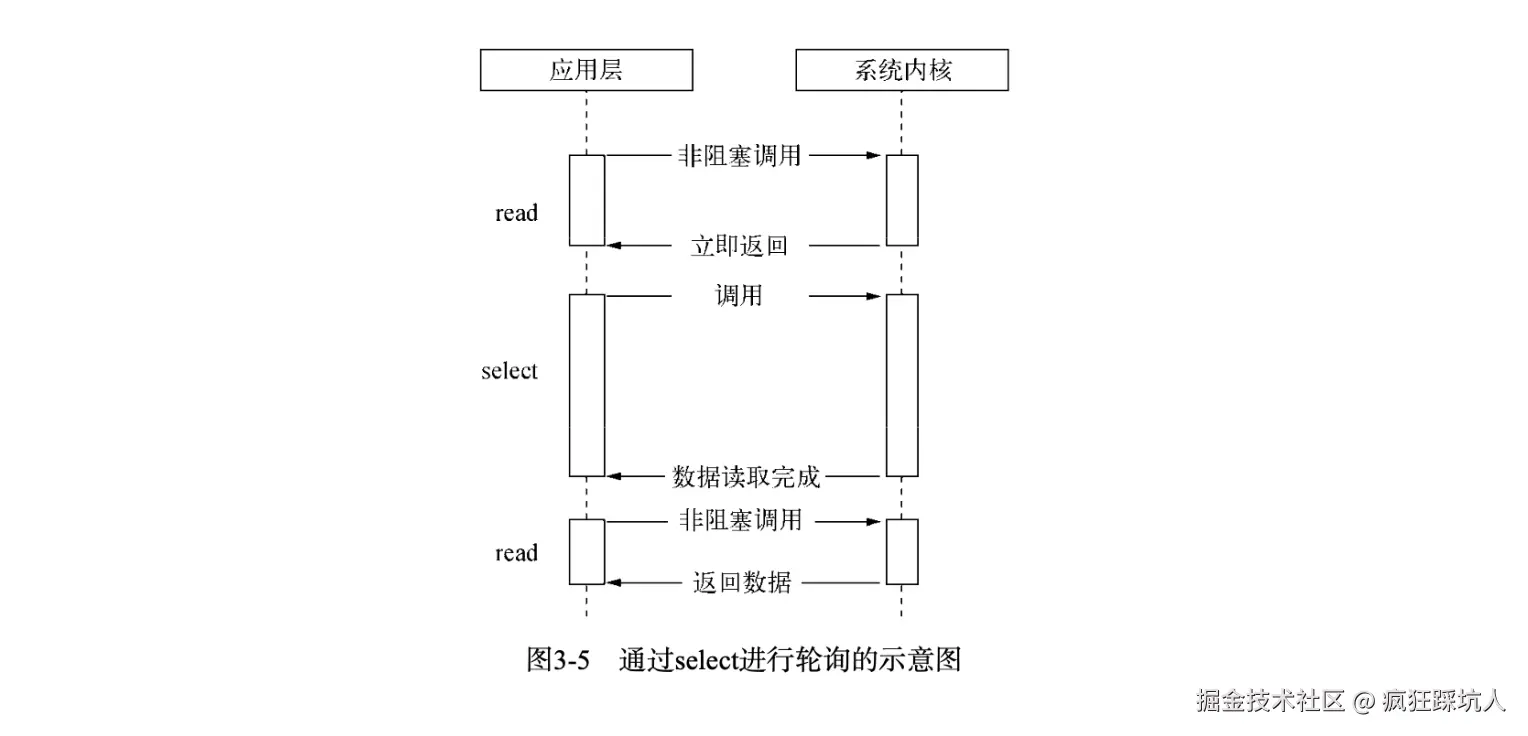
具体过程大致如下:
1、调用select()方法,上下文切换转换为内核态
2、将fd从用户空间复制到内核空间
3、内核遍历所有fd,查看其对应事件是否发生
4、如果没发生,将进程阻塞,当设备驱动产生中断或者timeout时间后,将进程唤醒,再次进行遍历
5、返回遍历后的fd
6、将fd从内核空间复制到用户空间
poll
poll是对select差不多,当调用poll会阻塞。但进行了一定改进:使用链表维护fd集合(select内是使用数组),这样没有了maxfdp的限制。
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// fds:polld结构体集合,每个结构体描述了fd及其事件
// nfs:指定 `fds`数组中的元素个数,类型 `nfds_t`通常为无符
// timeout:等待时间,`-1`表示阻塞等待直到有事件发生;`0`表示立即返回(非阻塞);大于 `0`则表示最长等待时间
// 返回值:超时返回0;失败返回-1;成功返回大于0的整数,这个整数表示就绪描述符的数目。
struct pollfd {
int fd; /* 文件描述符 */
short events; /* 需要监视的事件(输入) */
short revents; /* 实际发生的事件(输出) */
};
下图展示了poll方式(图来自《深入浅出Nodejs》):
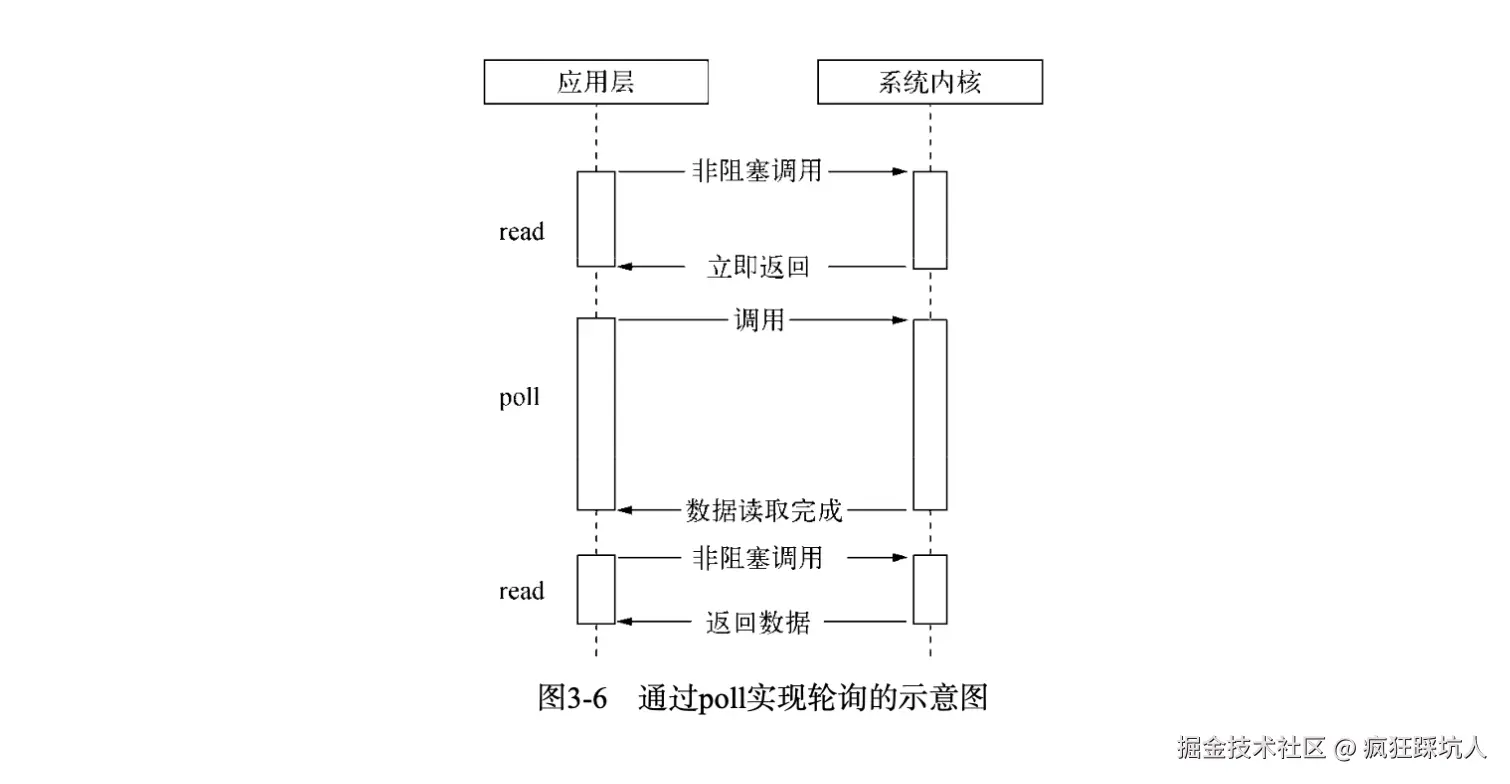
poll方式伪代码
// 主循环
while (1) {
int ret = poll(fds, nfds, 3000); // 等待 3 秒
if (ret < 0) {
perror("poll error");
break;
} else if (ret == 0) {
printf("[poll] 超时,没有事件\n");
continue;
}
// 遍历所有 fd,检查哪些 revents 有标志
for (int i = 0; i < nfds; i++) {
if (fds[i].revents & POLLIN) {
char buf[1024];
ssize_t n = read(fds[i].fd, buf, sizeof(buf) - 1);
if (n > 0) {
buf[n] = '\0';
process_data(buf, n, fds[i].fd);
} else if (n == 0) {
// EOF,连接关闭
remove_fd(fds, &nfds, i);
i--; // 数组被压缩,重新检查当前位置
} else if (n < 0 && errno != EAGAIN && errno != EWOULDBLOCK) {
perror("read error");
remove_fd(fds, &nfds, i);
i--;
}
}
}
if (nfds == 0) {
printf("所有 fd 都关闭了,退出。\n");
break;
}
}
poll和select的区别不大,都是要遍历fd看是否有就绪。最大的区别在于poll没有监视的fd集合大小限制(因为采用的链表),而select有大小限制(因为内部采用的数组存储,可以通过参数maxfdp修改,默认1024)。
epoll
epoll_create创建一个 epoll 实例,同时返回一个引用该实例的文件描述符
int epoll_create(int size);
epoll_ctl 会将文件描述符 fd 添加到 epoll 实例的监听列表里,同时为 fd 设置一个回调函数,并监听事件 event,如果红黑树中已经存在立刻返回。当 fd 上发生相应事件时,会调用回调函数,将 fd 添加到 epoll 实例的就绪队列上。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// 表示要监听的目标文件描述符
// op 表示要对 fd 执行的操作, 例如为 fd 添加一个监听事件 event
// event 表示要监听的事件
// 返回值 0 或 -1,表示上述操作成功与否。
epoll 模型的主要函数epoll_wait,功能相当于 select。调用该函数时阻塞,等待事件通知唤醒进程。
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
// epfd 即 epoll_create 返回的文件描述符,指向一个 epoll 实例
// events 是一个数组,保存就绪状态的文件描述符,其空间由调用者负责申请
// maxevents 指定 events 的大小
// timeout 类似于 select 中的 timeout。如果没有文件描述符就绪,即就绪队列为空,则 epoll_wait 会阻塞 timeout 毫秒。如果 timeout 设为 -1,则 epoll_wait 会一直阻塞,直到有文件描述符就绪;如果 timeout 设为 0,则 epoll_wait 会立即返回
// 返回值表示 events 中存储的就绪描述符个数,最大不超过 maxevents。
下图展示了epoll方式(图来自《深入浅出Nodejs》):
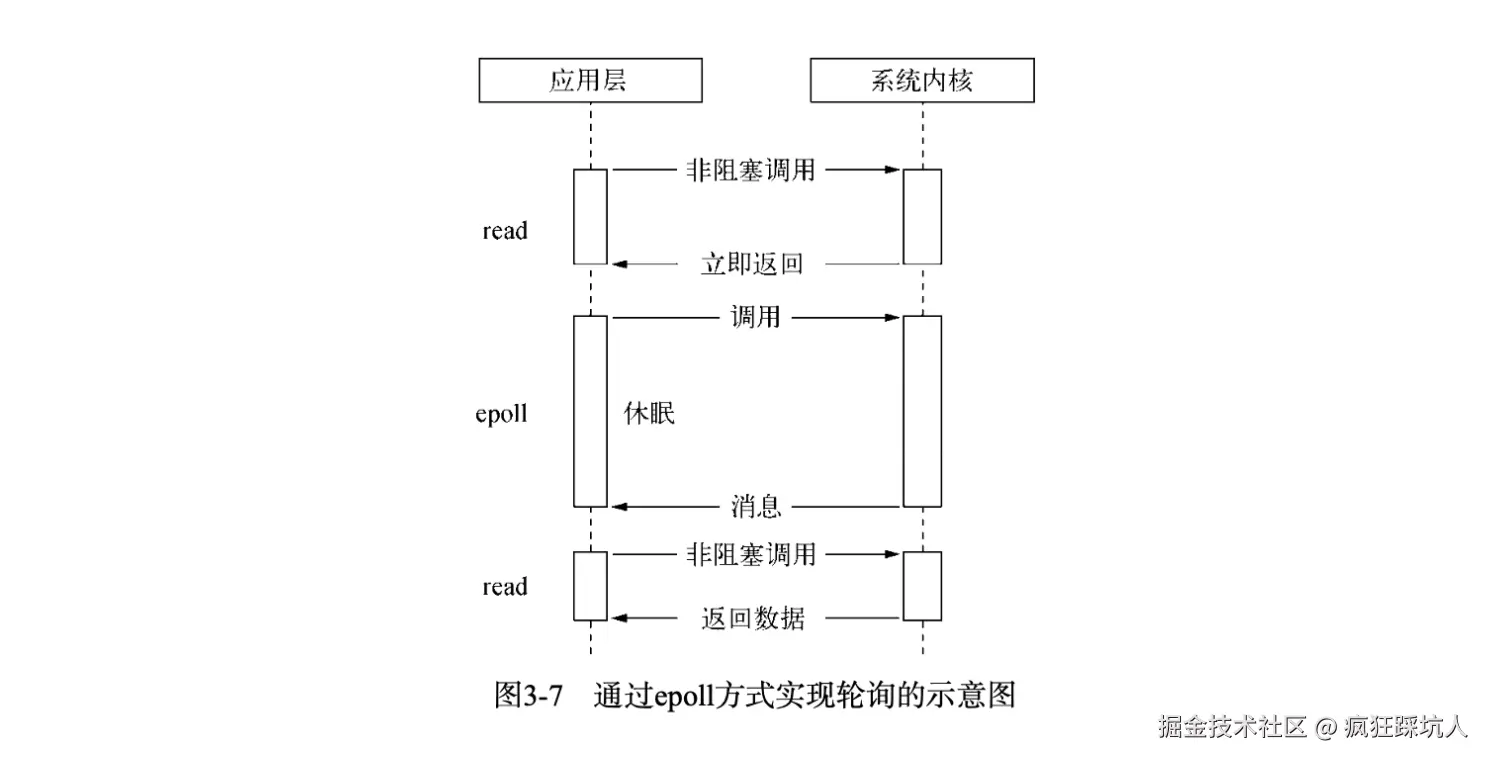
epoll方式伪代码
int epfd = epoll_create(1024);
struct epoll_event ev, events[MAX_CONN];
ev.events = EPOLLIN;
ev.data.fd = listen_fd;
epoll_ctl(epfd, EPOLL_CTL_ADD, listen_fd, &ev);
while (1) {
int n = epoll_wait(epfd, events, MAX_CONN, -1);
for (int i = 0; i < n; i++) {
if (events[i].events & EPOLLIN) {
// 处理可读事件
}
}
}
select和poll存在的缺点:
- 内核线程需要遍历一遍fd集合,返回给用户空间后需要应用层再遍历一遍fd数组。
- 每次select/poll都会内核空间到用户空间拷贝fd集合。
- 性能开销随fd线性增加,时间复杂度O(n)
epoll主要改进点:
- 通过
epoll_ctl提前给fd设置一个事件回调函数,fd上有事件触发了就执行回调函数,把fd放到一个就绪队列上,这样在内核线程是不存在遍历fd集合的,时间复杂度O(1)。 epoll_wait不会对fd集合在内核空间和用户空间拷贝, 而是“利用mmap()文件映射内存加速与内核空间的消息传递,减少拷贝开销。”
到这里,我们可以试着总结non-blocking和多路复用区别和联系。
区别:
- non-blocking I/O:靠不断“主动轮询”实现不阻塞
- I/O 多路复用:靠“事件通知 + 轮询”实现更高效的不阻塞
个人理解,广义的来说,多路复用本身也是一种非阻塞I/O。
异步I/O
尽管epoll已经利用了事件来降低CPU的耗用,但是休眠期间CPU几乎是闲置的,对于当前线程而言利用率不够,那么是否有一种理想的异步I/O呢?
下图展示了理想的异步I/O(图来自《深入浅出Nodejs》):
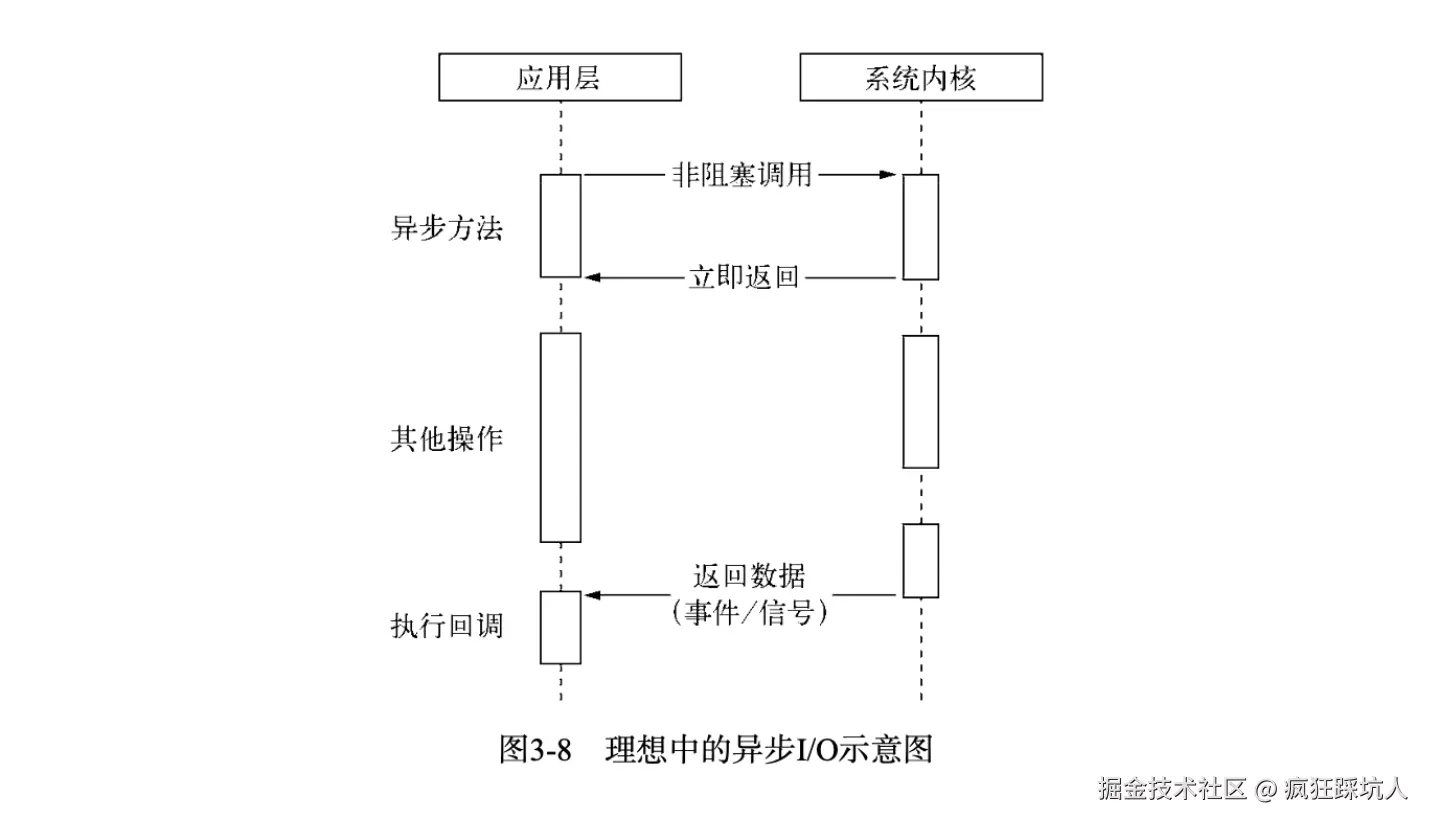
真正的异步I/O是在操作流时(发起异步操作)即不阻塞后续的代码执行,又不需要自己去主动轮询(read),只需要内核通知应用层执行回调(并且数据从内核空间读取到用户空间也是不阻塞的)。很遗憾,这种异步I/O几乎不存在(之所以说几乎,是因为Linux原生提供了一种这样的异步I/O——AIO,但存在缺陷)。
现实中的异步I/O,基本上都是通过线程池的方式来实现的,windows的IOCP也是内核级别实现了线程池。
在Node单线程中,通过让其他部分线程进行「阻塞I/O」或者「非阻塞I/O+轮询技术」来完成数据获取,等数据获取完成后通知主线程执行回调。此时主线程是不会让出CPU执行权的,可以一直继续执行其他代码。这样就实现了异步I/O。
下图展示了线程池模拟的异步I/O(图来自《深入浅出Nodejs》):
由于Windows和*nix的平台差异,Node提供了libuv作为抽象封装层来对不同平台做兼容性判断。
下图展示了Node的libuv架构(图来自《深入浅出Nodejs》):
Node的事件循环
请求对象 :一个异步I/O的发起,libuv会产生一个封装好的请求对象。比如fs.open会产生一个FSReqWrap的对象。
观察者: 可以理解成观察者模式中的观察者,它主要是观察判断事件队列中是否有事件了,当有事件了就需要去处理这个事件。
这里我用一张流程图说明发起异步I/O是如何被线程池执行,然后通过事件通知主线程的流程。
当异步任务执行的结果放入了事件队列,此时观察者会在主线程同步任务执行完后,查看事件队列中是否有事件任务,有则取出执行。等这个任务(同步代码)执行完后接着取下一个任务执行,一直循环,这就是Node的事件循环
P.S.这里的事件队列是一个笼统的队列概念,可以理解成包括宏任务队列和微任务队列。
总结
本文介绍了阻塞I/O、非阻塞I/O、多路复用I/O和异步I/O 四种模型,在实际的操作系统和计算机中I/O本质总是阻塞的,通过返回fd状态和轮询的方式来使I/O在应用层不阻塞,然后通过多路复用的方式更高效实现这种不阻塞的效果。然后介绍了Node中异步I/O的实现,由于计算机本身的设计使得并不存在真正异步I/O,需要通过线程池来模拟出异步I/O。
在多路复用中,结合C++伪代码和图示的方式展示了select/poll/epoll的原理和差异,Linux中通常使用epoll(mac中有类似的kqueue)来实现非阻塞I/O,具备不用遍历fd集合和反复拷贝fd集合的性能优点。
最后,介绍了基于线程池的异步非阻塞I/O的实现原理,再结合事件队列和观察者实现了Node事件循环。
参考资料
Select、Poll、Epoll、 异步IO 介绍
【操作系统】I/O 多路复用,select / poll / epoll 详解
深入浅出Nodejs
来源:juejin.cn/post/7564614473962733577
Vue3 后台分页写腻了?我用 1 个 Hook 删掉 90% 重复代码(附源码)
实战推荐:
还在为每个列表页写重复的分页代码而烦恼吗? 还在复制粘贴 currentPage、pageSize、loading 等状态吗? 一个 Hook 帮你解决所有分页痛点,减少90%重复代码
背景与痛点
在后台管理系统开发中,分页列表查询非常常见,我们通常需要处理:
- 当前页、页大小、总数等分页状态
- 加载中、错误处理等请求状态
- 搜索、刷新、翻页等分页操作
- 数据缓存和重复请求处理
这些重复逻辑分散在各个组件中,维护起来很麻烦。
为了解决这个烦恼,我专门封装了分页数据管理 Hook。现在只需要几行代码,就能轻松实现分页查询,省时又高效,减少了大量重复劳动
使用前提 - 接口格式约定
查询接口返回的数据格式:
{
list: [ // 当前页数据数组
{ id: 1, name: 'user1' },
{ id: 2, name: 'user2' }
],
total: 100 // 数据总条数
}
先看效果:分页查询只需几行代码!
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList, // 查询API
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
这样子每次分页查询只需要引入hook,然后传入查询接口就好了,减少了大量重复劳动
解决方案
我设计了两个相互配合的 Hook:
- useFetch:基础请求封装,处理请求状态和缓存
- usePageFetch:分页逻辑封装,专门处理分页相关的状态和操作
usePageFetch (分页业务层)
├── 管理 page / pageSize / total 状态
├── 处理搜索、刷新、翻页逻辑
├── 统一错误处理和用户提示
└── 调用 useFetch (请求基础层)
├── 管理 loading / data / error 状态
├── 可选缓存机制(避免重复请求)
└── 成功回调适配不同接口格式
核心实现
useFetch - 基础请求封装
// hooks/useFetch.js
import { ref } from 'vue'
const Cache = new Map()
/**
* 基础请求 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {*} options.initValue - 初始值
* @param {string|Function} options.cache - 缓存配置
* @param {Function} options.onSuccess - 成功回调
*/
function useFetch(fn, options = {}) {
const isFetching = ref(false)
const data = ref()
const error = ref()
// 设置初始值
if (options.initValue !== undefined) {
data.value = options.initValue
}
function fetch(...args) {
isFetching.value = true
let promise
if (options.cache) {
const cacheKey = typeof options.cache === 'function'
? options.cache(...args)
: options.cache || `${fn.name}_${args.join('_')}`
promise = Cache.get(cacheKey) || fn(...args)
Cache.set(cacheKey, promise)
} else {
promise = fn(...args)
}
// 成功回调处理
if (options.onSuccess) {
promise = promise.then(options.onSuccess)
}
return promise
.then(res => {
data.value = res
isFetching.value = false
error.value = undefined
return res
})
.catch(err => {
isFetching.value = false
error.value = err
return Promise.reject(err)
})
}
return {
fetch,
isFetching,
data,
error
}
}
export default useFetch
usePageFetch - 分页逻辑封装
// hooks/usePageFetch.js
import { ref, onMounted, toRaw, watch } from 'vue'
import useFetch from './useFetch' // 即上面的hook ---> useFetch
import { ElMessage } from 'element-plus'
/**
* 分页数据管理 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {Object} options.params - 默认参数
* @param {boolean} options.initFetch - 是否自动初始化请求
* @param {Ref} options.formRef - 表单引用
*/
function usePageFetch(fn, options = {}) {
// 分页状态
const page = ref(1)
const pageSize = ref(10)
const total = ref(0)
const data = ref([])
const params = ref()
const pendingCount = ref(0)
// 初始化参数
params.value = options.params
// 使用基础请求 Hook
const { isFetching, fetch: fetchFn, error, data: originalData } = useFetch(fn)
// 核心请求方法
const fetch = async (searchParams, pageNo, size) => {
try {
// 更新分页状态
page.value = pageNo
pageSize.value = size
params.value = searchParams
// 发起请求
await fetchFn({
page: pageNo,
pageSize: size,
// 使用 toRaw 避免响应式对象问题
...(searchParams ? toRaw(searchParams) : {})
})
// 处理响应数据
data.value = originalData.value?.list || []
total.value = originalData.value?.total || 0
pendingCount.value = originalData.value?.pendingCounts || 0
} catch (e) {
console.error('usePageFetch error:', e)
ElMessage.error(e?.msg || e?.message || '请求出错')
// 清空数据,提供更好的用户体验
data.value = []
total.value = 0
}
}
// 搜索 - 重置到第一页
const search = async (searchParams) => {
await fetch(searchParams, 1, pageSize.value)
}
// 刷新当前页
const refresh = async () => {
await fetch(params.value, page.value, pageSize.value)
}
// 改变页大小
const onSizeChange = async (size) => {
await fetch(params.value, 1, size) // 重置到第一页
}
// 切换页码
const onCurrentChange = async (pageNo) => {
await fetch(params.value, pageNo, pageSize.value)
}
// 组件挂载时自动请求
onMounted(() => {
if (options.initFetch !== false) {
search(params.value)
}
})
// 监听表单引用变化(可选功能)
watch(
() => options.formRef,
(formRef) => {
if (formRef) {
console.log('Form ref updated:', formRef)
}
}
)
return {
// 分页状态
currentPage: page,
pageSize,
total,
pendingCount,
// 数据状态
data,
originalData,
isFetching,
error,
// 操作方法
search,
refresh,
onSizeChange,
onCurrentChange
}
}
export default usePageFetch
完整使用示例
用element ui举例
<template>
<el-form :model="searchForm" >
<el-form-item label="用户名">
<el-input v-model="searchForm.username" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSearch">搜索</el-button>
</el-form-item>
</el-form>
<!-- 表格数据展示,绑定 data 和 loading 状态 -->
<el-table :data="data" v-loading="isFetching">
<!-- ...表格列定义... -->
</el-table>
<!-- 分页组件,绑定当前页、页大小、总数,并响应切换事件 -->
<el-pagination
v-model:current-page="currentPage"
v-model:page-size="pageSize"
:total="total"
@size-change="onSizeChange"
@current-change="onCurrentChange"
/>
</template>
<script setup>
import { ref } from 'vue'
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 搜索表单数据,响应式声明
const searchForm = ref({
username: ''
})
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList,
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
/**
* 处理搜索操作
*/
const handleSearch = () => {
search({ username: searchForm.value.username })
}
</script>
高级用法
带缓存
const {
data,
isFetching,
search
} = usePageFetch(getUserList, {
cache: (params) => `user-list-${JSON.stringify(params)}` // 自定义缓存 key
})
设计思路解析
- 职责分离:useFetch 专注请求状态管理,usePageFetch 专注分页逻辑
- 统一错误处理:在 usePageFetch 层统一处理错误
- 智能缓存机制:支持多种缓存策略
- 生命周期集成:自动在组件挂载时请求数据
总结
这套分页管理 Hook 的优势:
- 开发效率高,减少90%的重复代码,新增列表页从 30 分钟缩短到 5 分钟
- 状态管理完善,自动处理加载、错误、数据状态
- 缓存机制,避免重复请求
- 错误处理统一,用户体验一致
- 易于扩展,支持自定义配置和回调
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下!
来源:juejin.cn/post/7549096640340426802
负载均衡 LVS vs Nginx 对比!还傻傻分不清?
- Nginx特点
- 正向代理与反向代理
- 负载均衡
- 动静分离
- Nginx的优势
- 可操作性大
- 网络依赖小
- 安装简单
- 支持健康检查以及请求重发
- LVS 的优势
- 抗负载能力强
- 配置性低
- 工作稳定
- 无流量
今天总结一下负载均衡中LVS与Nginx的区别,好几篇博文一开始就说LVS是单向的,Nginx是双向的,我个人认为这是不准确的,LVS三种模式中,虽然DR模式以及TUN模式只有请求的报文经过Director,但是NAT模式,Real Server回复的报文也会经过Director Server地址重写:
图片
首先要清楚的一点是,LVS是一个四层的负载均衡器,虽然是四层,但并没有TCP握手以及分手,只是偷窥了IP等信息,而Nginx是一个七层的负载均衡器,所以效率势必比四层的LVS低很多,但是可操作性比LVS高,后面所有的讨论都是基于这个区别。
为什么四册比七层效率高?
四层是TCP层,使用IP+端口四元组的方式。只是修改下IP地址,然后转发给后端服务器,TCP三次握手是直接和后端连接的。只不过在后端机器上看到的都是与代理机的IP的established而已,LVS中没有握手。
7层代理则必须要先和代理机三次握手后,才能得到7层(HTT层)的具体内容,然后再转发。意思就是代理机必须要与client和后端的机器都要建立连接。显然性能不行,但胜在于七层,人工可操作性高,能写更多的转发规则。
Nginx特点
Nginx 专为性能优化而开发,性能是其最重要的要求,十分注重效率,有报告 Nginx 能支持高达 50000 个并发连接数。
另外,Nginx 系列面试题和答案全部整理好了,微信搜索Java技术栈,在后台发送:面试,可以在线阅读。
正向代理与反向代理
正向代理 :局域网中的电脑用户想要直接访问服务器是不可行的,服务器可能Hold不住,只能通过代理服务器来访问,这种代理服务就被称为正向代理,特点是客户端知道自己访问的是代理服务器。

图片
反向代理 :客户端无法感知代理,因为客户端访问网络不需要配置,只要把请求发送到反向代理服务器,由反向代理服务器去选择目标服务器获取数据,然后再返回到客户端。
此时反向代理服务器和目标服务器对外就是一个服务器,暴露的是代理服务器地址,隐藏了真实服务器 IP 地址。
图片
负载均衡
客户端发送多个请求到服务器,服务器处理请求,有一些可能要与数据库进行交互,服务器处理完毕之后,再将结果返回给客户端。
普通请求和响应过程如下图:
图片
但是随着信息数量增长,访问量和数据量增长,单台的Server以及Database就成了系统的瓶颈,这种架构无法满足日益增长的需求,这时候要么提升单机的性能,要么增加服务器的数量。
关于提升性能,这儿就不赘述,提提如何增加服务器的数量,构建集群,将请求分发到各个服务器上,将原来请求集中到单个服务器的情况改为请求分发到多个服务器,也就是我们说的负载均衡。
图解负载均衡:
图片
关于服务器如何拆分组建集群,这儿主要讲讲负载均衡,也就是图上的Proxy,可以是LVS,也可以是Nginx。假设有 15 个请求发送到代理服务器,那么由代理服务器根据服务器数量,这儿假如是平均分配,那么每个服务器处理 5 个请求,这个过程就叫做负载均衡。
动静分离
为了加快网站的解析速度,可以把动态页面和静态页面交给不同的服务器来解析,加快解析的速度,降低由单个服务器的压力。
动静分离之前的状态
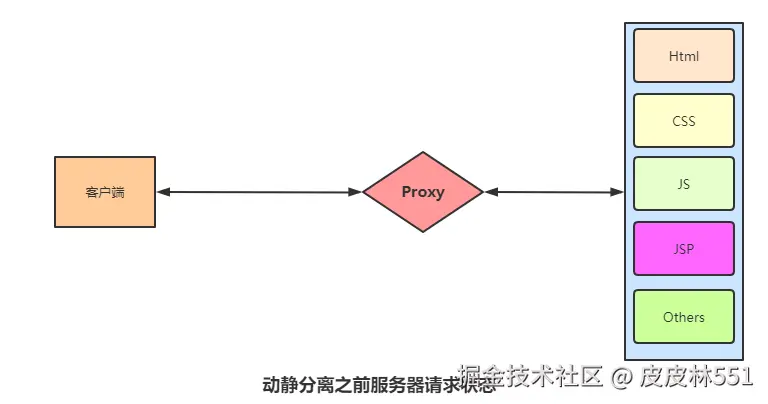
图片
动静分离之后

图片
光看两张图可能有人不理解这样做的意义是什么,我们在进行数据请求时,以淘宝购物为例,商品详情页有很多东西是动态的,随着登录人员的不同而改变,例如用户ID,用户头像,但是有些内容是静态的,例如商品详情页,那么我们可以通过CDN(全局负载均衡与CDN内容分发)将静态资源部署在用户较近的服务器中,用户数据信息安全性要更高,可以放在某处集中,这样相对于将说有数据放在一起,能分担主服务器的压力,也能加速商品详情页等内容传输速度。
Nginx的优势
可操作性大
Nginx是一个应用层的程序,所以用户可操作性的空间大得多,可以作为网页静态服务器,支持 Rewrite 重写规则;支持 GZIP 压缩,节省带宽;可以做缓存;可以针对 http 应用本身来做分流策略,静态分离,针对域名、目录结构等相比之下 LVS 并不具备这样的功能,所以 nginx 单凭这点可以利用的场合就远多于 LVS 了;但 nginx 有用的这些功能使其可调整度要高于 LVS,所以经常要去触碰,人为出现问题的几率也就大
网络依赖小
nginx 对网络的依赖较小,理论上只要 ping 得通,网页访问正常,nginx 就能连得通,nginx 同时还能区分内外网,如果是同时拥有内外网的节点,就相当于单机拥有了备份线路;LVS 就比较依赖于网络环境,目前来看服务器在同一网段内并且 LVS 使用 direct 方式分流,效果较能得到保证。另外注意,LVS 需要向托管商至少申请多于一个 ip 来做 visual ip
安装简单
nginx 安装和配置比较简单,测试起来也很方便,因为它基本能把错误用日志打印出来。LVS 的安装和配置、测试就要花比较长的时间,因为同上所述,LVS 对网络依赖性比较大,很多时候不能配置成功都是因为网络问题而不是配置问题,出了问题要解决也相应的会麻烦的多
nginx 也同样能承受很高负载且稳定,但负载度和稳定度差 LVS 还有几个等级:nginx 处理所有流量所以受限于机器 IO 和配置;本身的 bug 也还是难以避免的;nginx 没有现成的双机热备方案,所以跑在单机上还是风险比较大,单机上的事情全都很难说
支持健康检查以及请求重发
nginx 可以检测到服务器内部的故障(健康检查),比如根据服务器处理网页返回的状态码、超时等等,并且会把返回错误的请求重新提交到另一个节点。目前 LVS 中 ldirectd 也能支持针对服务器内部的情况来监控,但 LVS 的原理使其不能重发请求。比如用户正在上传一个文件,而处理该上传的节点刚好在上传过程中出现故障,nginx 会把上传切到另一台服务器重新处理,而 LVS 就直接断掉了。
LVS 的优势
抗负载能力强
因为 LVS 工作方式的逻辑是非常简单的,而且工作在网络的第 4 层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。LVS 一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU 等)出现问题导致 LVS 出现问题
配置性低
这通常是一大劣势同时也是一大优势,因为没有太多的可配置的选项,所以除了增减服务器,并不需要经常去触碰它,大大减少了人为出错的几率
工作稳定
因为其本身抗负载能力很强,所以稳定性高也是顺理成章的事,另外各种 LVS 都有完整的双机热备方案,所以一点不用担心均衡器本身会出什么问题,节点出现故障的话,LVS 会自动判别,所以系统整体是非常稳定的
无流量
LVS 仅仅分发请求,而流量并不从它本身出去,所以可以利用它这点来做一些线路分流之用。没有流量同时也保住了均衡器的 IO 性能不会受到大流量的影响
LVS 基本上能支持所有应用,因为 LVS 工作在第 4 层,所以它可以对几乎所有应用做负载均衡,包括 http、数据库、聊天室等。
来源:juejin.cn/post/7517644116592984102
识别手写数字,居然可以只靠前端?
前言
之前一篇的神经网络文章,居然意外的受欢迎,有一万多的掘友们看过。github 的 star 数也是破了新高,非常感谢~
文章链接:当一个前端学了很久的神经网络...👈🤣
github 链接:github.com/imoo666/neu…
但是之前边调研边写代码,还是有些乱的,我重新组织了一下代码,让大家能更清晰的了解前端使用神经网络的流程。
不过只是重新讲解一下流程就太水了,这篇就再来一个识别手写数字的项目,顺便理一下我们的思路。
步骤
很多同学反馈 担心前端入坑神经网络很难,但其实就是按部就班的几步,许多步骤都是调用 api,并不需要我们全部手写,还是比较容易的。
核心步骤有下:
- 加载和准备数据
- 定义模型
- 训练模型
- 使用模型进行预测
加载和准备数据
既然是手写数字识别,我们首先还是需要一些手写数字的图片,数据集我一般是去 kaggle 找的。
下载链接:http://www.kaggle.com/code/cdeott…
不过这次的数据是 csv 而非图片压缩包,先下载打开看看怎么个事。
可以观察到是一个 784 * n 的一个表格,表格中的数在 0-255 之间,对图片敏感的同学应该已经反应过来了,784 === 28 * 28,也就是每一行代表了一个 28 * 28 的灰度 图片。
可以简单写一个渲染图片的方法来看一下效果:

看起来跟我们猜想的一样,另外,第一行是表头,第一列是该行的实际数字,用于做验证。
知道这些,那就可以开始加载数据了,目标是将这堆数据转化为可以供 模型训练 的数据。
const loadCsvData = async () => {
// 先加载
const response = await fetch("src/pages/mnist/assets/mnist.csv");
const text = await response.text();
// 忽略第一行的表头
const lines = text.trim().split("\n").slice(1);
// 将每一行都转化为张量
const samples: DigitSample[] = lines.map((line) => {
const values = line.split(",").map(Number);
const label = values[0];
const pixels = tf
.tensor3d(values.slice(1), [28, 28, 1])
.div(255) as tf.Tensor3D;
return { pixels, label };
});
// 打乱数组
tf.util.shuffle(samples);
// 将后 50 条作为测试集,其余作为训练集
const train = samples.slice(0, samples.length - 50);
const test = samples.slice(-50);
// 独热编码,一共 10 个可能
const xTrain = tf.stack(train.map((s) => s.pixels)) as tf.Tensor4D;
const yTrain = tf.oneHot(
train.map((s) => s.label),
10
) as tf.Tensor2D;
return { xTrain, yTrain, test };
};
定义模型
这次是手写数字的识别,我们需要用到图片识别比较经典的 卷积层 + 最大池化层 的组合,除此之外,这次还添加了一个防止过拟合的 dropout 层。
const defineModel = () => {
const model = tf.sequential({
layers: [
// 最大池化层,用于降低图片大小
tf.layers.maxPooling2d({
poolSize: 2,
strides: 2,
inputShape: [28, 28, 1],
}),
// 卷积层,用 32个卷积核进行提取特征
tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: "relu",
padding: "same",
}),
// 将提取结果平铺
tf.layers.flatten(),
// 一个普通的隐藏层计算关系
tf.layers.dense({ units: 64, activation: "relu" }),
// 防止过拟合
tf.layers.dropout({ rate: 0.3 }),
// 分类
tf.layers.dense({
units: 10,
activation: "softmax",
}),
],
});
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: ["accuracy"],
});
return model;
};
训练模型
训练模型没什么需要写的,只是需要配置几个参数(如轮数,批处理数量等),然后按照固定逻辑调用 api 即可
const trainModel = async () => {
setModelState({ model: null, isTraining: true, logs: [] });
const model = defineModel();
const { xTrain, yTrain, test } = await loadCsvData();
await model.fit(xTrain, yTrain, {
epochs: 20, // 轮数
batchSize: 8, // 批处理数量
validationSplit: 0.2, // 用于验证的比例
callbacks: {
onEpochEnd: (epoch, logs) => {
if (!logs) return;
setModelState((prev) => ({
...prev,
logs: [
...prev.logs,
{
epoch: epoch + 1,
loss: Number(logs.loss?.toFixed(4)),
accuracy: Number((logs.acc ?? logs.accuracy ?? 0).toFixed(4)),
},
],
}));
},
},
});
predict(model, test);
setModelState((prev) => ({ ...prev, model, isTraining: false }));
tf.dispose([xTrain, yTrain]);
};
等待模型训练完毕后,model 就是可用的模型,可以用其去预测不同的图片,我选择了 50 张图片用于我们测试正确率。
使用模型进行预测
核心就是调用一下 model.predict() 这个方法用于预测,不过最后给出的结果会是一个十个元素的数组,分别代表是某个数字的概率,我们需要手动取出最高概率的一个作为我们的预测结果。
const predict = (model: tf.Sequential, samples: DigitSample[]) => {
const results: PredictionResult[] = samples.map((sample) => {
const input = sample.pixels.expandDims(0); // 格式化
const output = model.predict(input) as tf.Tensor; // 预测
const probs = output.dataSync(); // 张量转数组
const predicted = output.argMax(1).dataSync()[0]; // 拿到最大的位
const confidence = Number((probs[predicted] * 100).toFixed(1));
tf.dispose([input, output]);
return {
imageTensor: sample.pixels,
actual: sample.label,
predicted,
confidence,
correct: predicted === sample.label,
};
});
setPredictions(results);
};
其他
最后可以看一下我们的完整页面
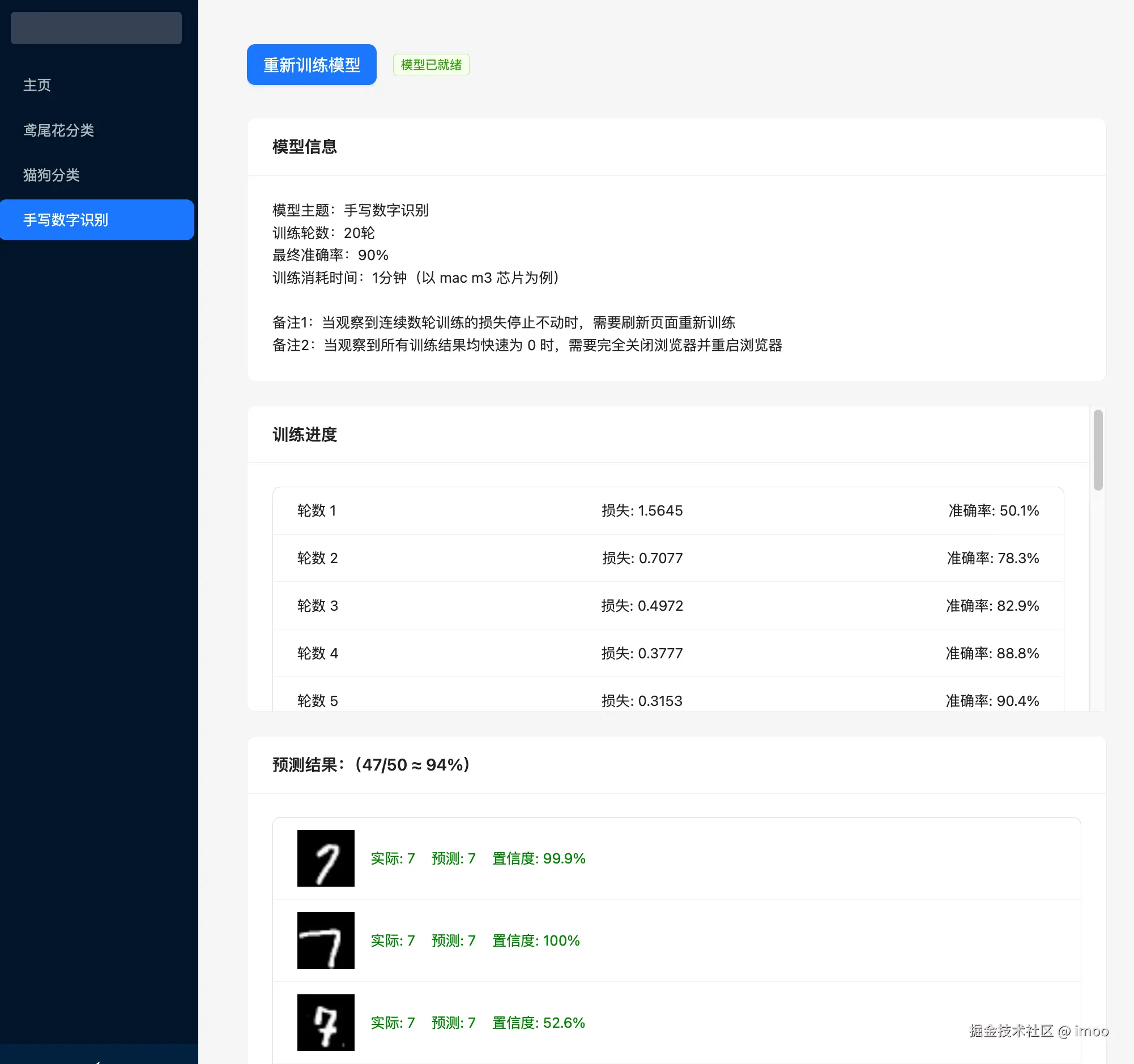
感兴趣的同学可以查看源码,相较于之前的版本做了许多整理工作,都按照本文的步骤进行了函数的划分:github.com/imoo666/neu…
又变强了一步!一起加油前端仔!

来源:juejin.cn/post/7514250027041964083
润开鸿重磅发布DAYU300与DAYU600,入选开源鸿蒙面向PC场景及移动智能终端场景主干开发平台
近日,由开放原子开源鸿蒙项目群技术指导委员会(TSC)主办的开源鸿蒙技术大会2025(以下简称“大会”)在长沙国际会议中心盛大举办。作为开放原子开源基金会开源鸿蒙项目群A类捐赠人、核心共建单位,江苏润开鸿数字科技有限公司(以下简称“润开鸿”)于本年度大会上重磅发布基于开源鸿蒙的DAYU300开发平台和DAYU600开发平台新品。
润开鸿发布基于开源鸿蒙的DAYU300开发平台和DAYU600开发平台
当前,更多样化的设备形态与创新体验正在生态中不断涌现。作为开源鸿蒙社区的年度核心成果,全新发布的开源鸿蒙6.0 Release版在多个关键技术领域实现了突破:ArkUI组件能力进一步增强,提供更灵活的组件布局,为开发者带来更加流畅的开发体验;窗口能力全面升级,新增支持窗口处理文本显示的能力,提升了用户交互的便捷性;在应用框架层面,程序框架服务支持通过装饰器开发意图,开发者可以将现有功能通过装饰器快速集成至系统入口。
这些技术创新不仅提升了系统的整体性能,更为应用厂商带来了实实在在的价值——更短的开发周期、更低的开发成本、更好的用户体验,真正实现了技术创新与产业需求的深度融合。在此时间点,润开鸿同步发布DAYU300与DAYU600分别作为面向PC场景及面向移动智能终端场景的开源鸿蒙主干代码开发平台,将为系统版本持续演进及特性延展提供有力支撑,也为终端厂商带来了性能更强、稳定性更高、智能化更便捷的高效设备开发硬件底座。
润开鸿基于开源鸿蒙的DAYU300开发平台搭载飞腾D3000M 8核处理器,支持开源鸿蒙标准系统,具备USB、HDMI、PCIe、以太网等丰富外设接口,是满足轻量级AI推理及边缘计算任务的高性能硬件底座;作为开源鸿蒙面向PC场景的主干代码开发平台,可高效支持开发者进行开源鸿蒙生态软硬件适配与创新,适用于教育、工业、消费电子等领域AI PC、边缘计算终端等高算力场景设备开发。
润开鸿基于开源鸿蒙面向PC场景的DAYU300开发平台
润开鸿基于开源鸿蒙的DAYU600开发平台搭载展锐UIS7885芯片,支持开源鸿蒙标准系统,具备高性能、高扩展、高成熟度,可满足轻量化AI推理引擎部署,是支持不同类型5G轻智能行业设备开发的稳定硬件基座;作为开源鸿蒙面向移动智能终端场景的主干代码开发平台,适用于对算力、通信和多媒体能力有较高要求的5G行业智能终端开发与创新,可助力基于“开源鸿蒙+AI”的行业移动终端产品加速落地与应用。
润开鸿基于开源鸿蒙面向移动智能终端场景的DAYU600开发平台
回溯鸿蒙开源五年的发展历程,自开源鸿蒙诞生起,润开鸿便始终致力于推动基于开源鸿蒙的芯片平台适配。截至目前,润开鸿已成功完成累计20+款芯片适配开源鸿蒙操作系统,实现了ARM、LoongArch、RISC-V三大架构适配的全覆盖。其中,润开鸿DAYU200开发平台于2021年12月成为社区首款合入开源鸿蒙主线的标准系统开发平台,为开源鸿蒙3.1 Release这一重要系统版本的诞生与演进提供了重要的硬件承载,也为开源鸿蒙标准系统设备生态实现“从0到1”的里程碑式跨越发展打下了坚实的硬件基础。如今,润开鸿两款开发平台分别入选为面向PC场景及面向移动智能终端场景的开源鸿蒙主干代码开发平台,这在社区中实属仅有,将进一步服务多样化的设备形态与创新体验开发,为各领域开发者带来更高的研发创新上限及更完备、更稳定的硬件底座。
展望下一个五年,终端操作系统的各层能力都将面临一系列的原生智能技术革新。以开源鸿蒙6.0 Release版本发布为新起点,以DAYU300和DAYU600开发平台为智能硬件新基座,润开鸿将持续联合更多行业及生态伙伴,不断汇聚产学研用各界智慧,共同把握关键机遇期,面向千行百业加速推进开源鸿蒙生态设备多样性及智能化应用,协力构筑开源鸿蒙生态价值快速提升的下一个五年。
收起阅读 »iOS 26 仅需几行代码让 SwiftUI 7 液态玻璃界面焕发新春

概述
在今年的 WWDC 25 中,苹果为全平台推出了崭新的液态玻璃(Liquid Glass)皮肤。不仅如此,Apple 在此基础之上还打造了一整套超凡脱俗的动画和布局体系让 SwiftUI 7 界面焕发新机。
现在,我们只需寥寥几行代码就能将原本平淡无奇、乏善可陈的 SwiftUI 布局变成上面这般鲜活灵动。

想知道如何实现吗?看这篇就对啦!
在本篇博文中,您将学到如下内容:
- “一条大河窄又长”
- SwiftUI 7 全新玻璃特效来袭
- 融入,鲜活!
那还等什么呢?让我们马上迈入液态玻璃奇妙的特效世界吧? Let‘s go!!!;)
1. “一条大河窄又长”
在如今 App 现代化布局中,秃头小码农们非常喜爱像下面这般简洁、小巧、紧凑的全局菜单系统:
它就像一条长长的河流,伸缩自如,温柔又调皮的流入用户的心坎里。
不幸的是,目前它仿佛少了一点灵动的气息,而且感觉和 WWDC 25 中全新的液态玻璃也不太般配。
struct BadgesView: View {
@Environment(ModelData.self) private var modelData
@State private var isExpanded: Bool = false
var body: some View {
VStack(alignment: .center, spacing: Constants.badgeButtonTopSpacing) {
if isExpanded {
VStack(spacing: Constants.badgeSpacing) {
ForEach(modelData.earnedBadges) {
BadgeLabel(badge: $0)
}
}
}
Button {
withAnimation {
isExpanded.toggle()
}
} label: {
ToggleBadgesLabel(isExpanded: isExpanded)
.frame(width: Constants.badgeShowHideButtonWidth,
height: Constants.badgeShowHideButtonHeight)
}
#if os(macOS)
.tint(.clear)
#endif
}
.frame(width: Constants.badgeFrameWidth)
}
}
诚然,我们可以利用 SwiftUI 优秀的动画底蕴重新包装上面 BadgesView 视图的动画和转场效果,但这需要秃头小码农们宝贵的时间和头发,而且效果往往强差人意。

不过别担心,从 SwiftUI 7(iOS 26 / iPadOS 26 / macOS 26)开始,我们有了全新的选择,简单的不要不要的!
2. SwiftUI 7 全新玻璃特效来袭
从 WWDC 25 开始,全面支持 Liquid Glass 的 SwiftUI 7 推出了玻璃特效容器 GlassEffectContainer ,让我们真的可以对玻璃“为所欲为”:
GlassEffectContainer 能把多个带 glassEffect(_:in:) 的视图合并成一张“可变形的联合玻璃”,既省性能又能让玻璃形状彼此融合、 变形(morph)。
核心要点:
- 用法:给子视图添加 .glassEffect(.liquid, in: container) 修改器,系统会把它们自动收集到同一个 GlassEffectContainer 中;
- 效果:子视图的玻璃形状不再各自独立,而是当成一个整体渲染,可互相吸引、拼接、渐变和 morph;
- 控制融合:通过容器的 spacing 值调节——值越大,子视图相距越远时就开始“粘”在一起;
- 并发:@MainActor 隔离,线程安全。
总而言之,GlassEffectContainer 让多块“液态玻璃”合成一块可 morph 的超级玻璃,性能更高、动画更连贯。
同时,SwiftUI 7 还新增了两个配套方法 glassEffect(_:in:) 和 glassEffectID(_:in:) : 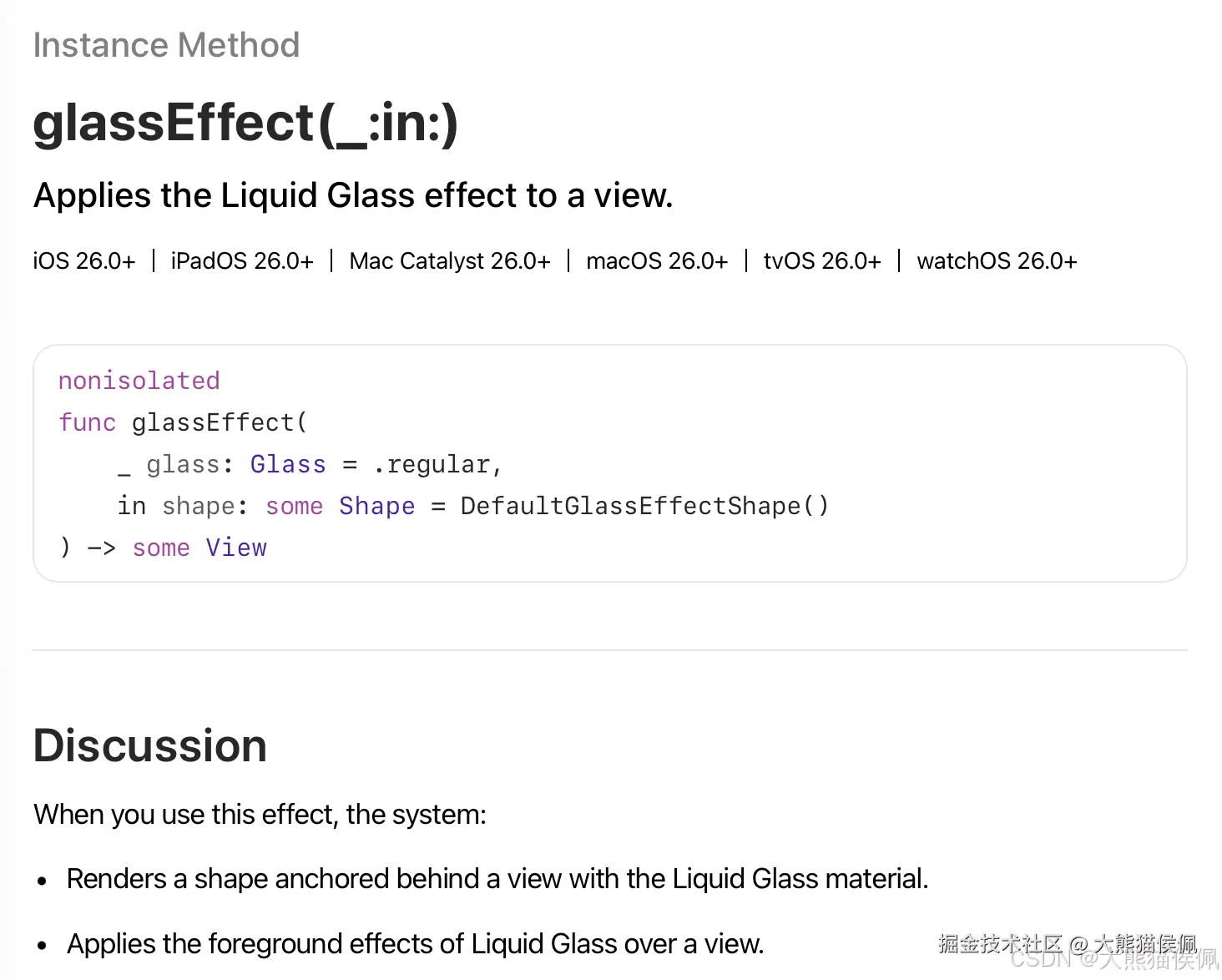
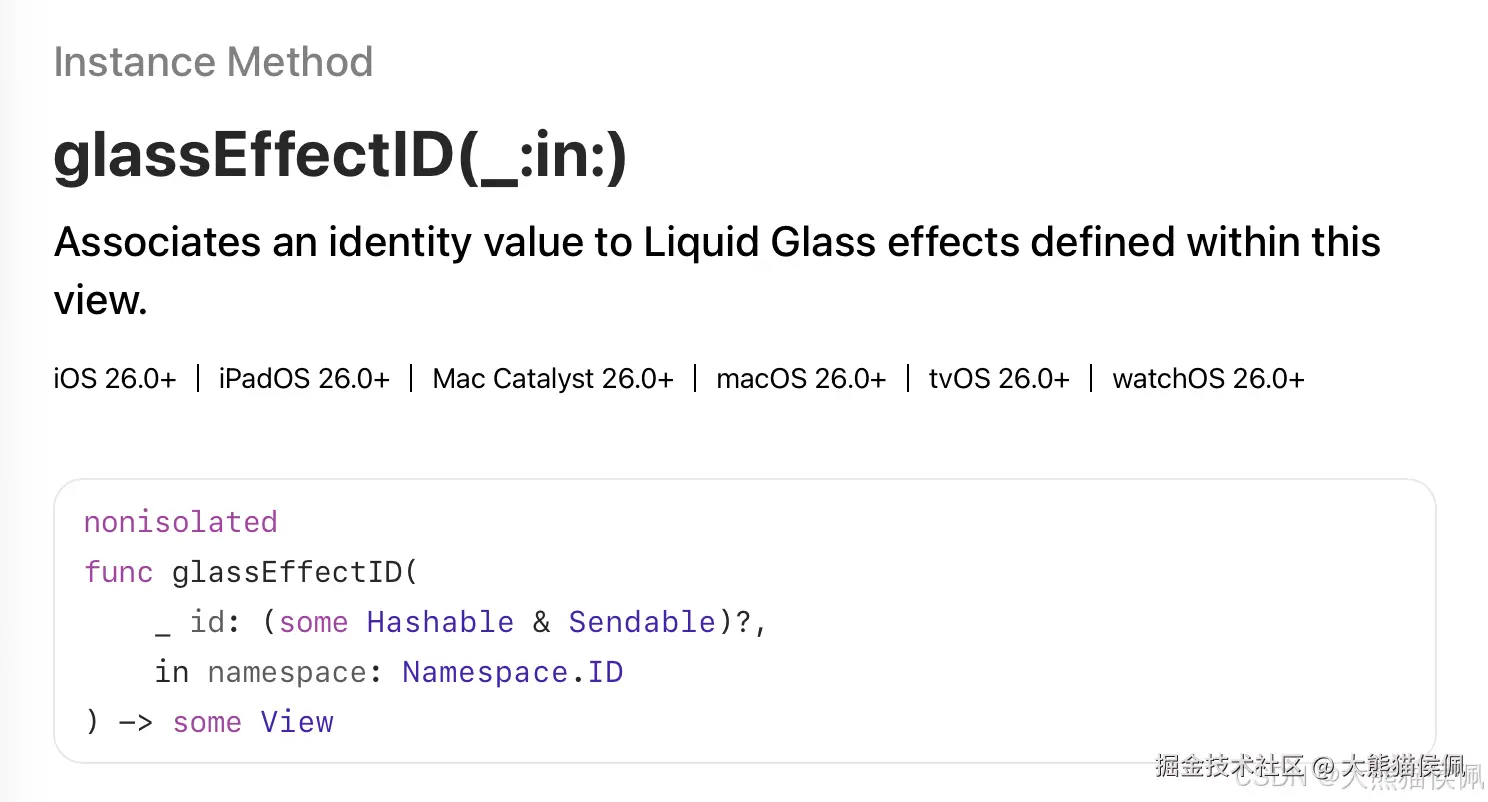
我们可以利用它们结合 Namespace 来完成液态玻璃世界中的视图动画效果。
另外 SwiftUI 7 还专门为 Button 视图添加了 glass 按钮样式,真可谓超级“银杏化”:

有了这些 SwiftUI 中的宝贝,小伙伴们可以开始来打造我们的梦幻玻璃天堂啦!
3. 融入,鲜活!
将之前的 BadgesView 视图重装升级为如下实现:
struct BadgesView: View {
@Environment(ModelData.self) private var modelData
@State private var isExpanded: Bool = false
@Namespace private var namespace
var body: some View {
GlassEffectContainer(spacing: Constants.badgeGlassSpacing) {
VStack(alignment: .center, spacing: Constants.badgeButtonTopSpacing) {
if isExpanded {
VStack(spacing: Constants.badgeSpacing) {
ForEach(modelData.earnedBadges) {
BadgeLabel(badge: $0)
.glassEffect(.regular, in: .rect(cornerRadius: Constants.badgeCornerRadius))
.glassEffectID($0.id, in: namespace)
}
}
}
Button {
withAnimation {
isExpanded.toggle()
}
} label: {
ToggleBadgesLabel(isExpanded: isExpanded)
.frame(width: Constants.badgeShowHideButtonWidth,
height: Constants.badgeShowHideButtonHeight)
}
.buttonStyle(.glass)
#if os(macOS)
.tint(.clear)
#endif
.glassEffectID("togglebutton", in: namespace)
}
.frame(width: Constants.badgeFrameWidth)
}
}
}
上面这段新代码把“ earned 徽章列表”与底部的“展开/收起”按钮一起放进同一个 GlassEffectContainer 容器中,从而让它们全部参与 iOS 26 的「液态玻璃」合并渲染。
下面按“玻璃特性”逐句拆解:
GlassEffectContainer(spacing: …)
- 建立一块「联合玻璃画布」。
spacing决定徽章彼此、徽章与按钮之间多早开始“粘”成一体:值越大,离得越远就开始融合。
- 展开时才出现的
VStack + ForEach
- 每个
BadgeLabel同时挂两个修饰符:.glassEffect(.regular, in: .rect(cornerRadius: …))
声明“我是 regular 风格玻璃,形状是圆角矩形”。.glassEffectID(badge.id, in: namespace)
给玻璃发身-份-证;同一 namespace 里身-份-证不同,SwiftUI 就能在增减徽章时做“液态 morph”——旧玻璃流走、新玻璃流进来,而不是生硬闪现。
- 底部
Button
.buttonStyle(.glass)让按钮本身也是玻璃,但风格、圆角与徽章不同。- 同样用
.glassEffectID("togglebutton", in: namespace)注册身-份-证,于是按钮的玻璃和上面徽章的玻璃被当成“同一张可变形大图”处理。 - 展开/收起时,按钮玻璃会与刚出现(或消失)的徽章玻璃在边缘处“拉丝”融合,形成液态过渡。
withAnimation { isExpanded.toggle() }
- 状态变化被包进动画块,
GlassEffectContainer会同步驱动所有玻璃路径的 morph 动画:- 徽章从 0 高度“流”出来,边缘先与按钮玻璃粘连,再各自分离成独立圆角矩形。
- 收起时反向流回,最终只剩按钮玻璃。
- 整体效果
用户看到的不是“一行行控件出现”,而是一块完整的「可变玻璃」:- 展开 → 玻璃区域向下延伸,新徽章像水泡一样从主体里分裂长出;
- 收起 → 多余部分被“吸”回按钮,边缘圆润地收缩消失。
全程保持同一高光、折射、模糊背景,性能也优于多图层叠加。

简单来说,上面的实现用 GlassEffectContainer 把徽章与按钮收进同一块「液态玻璃」,凭借 glassEffectID 与 namespace 让它们在展开/收起时像流体一样自然融合、morph,呈现出 iOS 26 独有的“整块玻璃可生长可收缩”的视觉魔法。

要注意哦,上面动图中按钮组背后的阴影是由于 gif 图片显示局限导致的,模拟器和真机实际测试的阴影效果可是美美哒的呢!
我们把 BadgesView 视图嵌入到主视图中,宝子们再来一起欣赏一下叹为观止的液态玻璃动画效果吧: 
大功告成,打完收工,棒棒哒!💯

总结
在本篇文章中,我们讨论了在 iOS 26/iPadOS 26 里如何使用 SwiftUI 7 最新的液体玻璃系统来装饰小伙伴们的 App 界面。

感谢观赏,再会吧!8-)
来源:juejin.cn/post/7549794632518320138
SQL Join 中函数使用对性能的影响与优化方法
在日常开发中,经常会遇到这样的场景:
需要在 大小写不敏感 或 格式化字段 的情况下进行表关联。
如果在 JOIN 或 WHERE 中直接使用函数,往往会带来严重的性能问题。
本文用一个新的示例来说明问题和优化方法。
一、问题场景
假设我们有两张表:
- 用户表 user_info
user_id | username
----------+------------
1 | Alice
2 | Bob
3 | Charlie
- 订单表 order_info
order_id | buyer_name
----------+------------
1001 | alice
1002 | BOB
1003 | dave
我们希望根据用户名和买家名称进行关联(忽略大小写)。
原始写法(低效)
SELECT o.order_id, u.user_id, u.username
FROM order_info o
LEFT JOIN user_info u
ON LOWER(o.buyer_name) = LOWER(u.username);
问题:
LOWER()包裹了字段,导致数据库无法使用索引。- 每一行都要执行函数运算,性能下降。
二、优化方法
1. 子查询提前计算
通过子查询生成派生列,再进行关联。
SELECT o.order_id, u.user_id, u.username
FROM (
SELECT order_id, buyer_name, LOWER(buyer_name) AS buyer_name_lower
FROM order_info
) o
LEFT JOIN (
SELECT user_id, username, LOWER(username) AS username_lower
FROM user_info
) u
ON o.buyer_name_lower = u.username_lower;
优点:
- 避免在
JOIN时重复调用函数。 - 优化器有机会物化子查询并建立临时索引。
2. 建立函数索引(推荐)
如果这种需求非常频繁,可以在表上建立函数索引。
PostgreSQL 示例:
CREATE INDEX idx_username_lower ON user_info(LOWER(username));
CREATE INDEX idx_buyer_name_lower ON order_info(LOWER(buyer_name));
之后即使写:
SELECT ...
FROM order_info o
LEFT JOIN user_info u
ON LOWER(o.buyer_name) = LOWER(u.username);
数据库也能走索引,性能大幅提升。
3. 数据入库时统一格式
如果业务允许,可以在入库时统一转为小写,避免查询时做转换。
INSERT INTO user_info (user_id, username)
VALUES (1, LOWER('Alice'));
这样关联时直接比较即可:
ON o.buyer_name = u.username
三、总结
- 在
JOIN或WHERE中直接使用函数,会 导致索引失效,影响性能。 - 优化方法:
- 子查询提前计算,避免在关联时重复调用函数;
- 建立函数索引(或虚拟列索引);
- 入库时统一数据格式,彻底消除函数依赖。
📌 记忆要点:
- 函数写在
JOIN→ 慢 - 子查询提前算 → 好
- 函数索引 / 数据规范化 → 最优解
来源:juejin.cn/post/7555612267787550772
PaddleOCR-VL,超强文字识别能力,PDF的拯救者
转眼间已经是 2025 年的 Q4 了,年终越来越近,领导给予的 okr 压力越来越大,前段时间,领导提出了一个非常搞的想法,当然也是急需解决的痛点——线上一键翻译功能。
小包当前负责是开发开发面向全球各国的活动,因此活动中不免就会出现各种各样的语言,此时就出现了一个困扰已久的难题,线上体验的同学看不懂,体验过程重重受阻,很容易遗漏掉一些环节,导致一些问题很难暴露出来。
为了这个问题,小包跟进了一段时间了,主要有两个地方的文案来源
- 代码渲染的文本
- 切图中的静态文本
大多数文本来源于是切图中,因此如何应对各种各样的切图成为难题。由此小包提出了两种解决方案:
- 同时保存两种图片资源,分别为中文和当前区服语言
- 直接进行图片翻译
第一种方案被直接拒绝了,主要由于当前的技术架构和同事们的一些抵触,业务中使用的 img、txt 信息都存储在配置平台中,存储两份就需要维护两类配置,严重增加了心智负担。
那我是这么思考的,第一次上传图片资源时,自动进行图片翻译,存储在另一个配置字段中,当开启一键翻译功能后,切换翻译后的图片。
由于是内部使用的工具,因此不需要非常准确,为了节省 token,只在第一次进行翻译。
图片翻译需要两个过程,首先进行 OCR,识别出图片中的文字;其次对识别出的文字进行翻译。
尝试了好几款 OCR 工具,都有些不尽人意,整个过程中,体验最好的是上个月PaddleOCR推出的PP-OCRv5。
在一段时间内,都一直盯着 PaddleOCR 的最新进度,昨天,百度发布并开源自研多模态文档解析模型 PaddleOCR-VL,该模型在最新 OmniDocBench V1.5 榜单中,综合性能全球第一,四项核心能力SOTA,模型已登顶HF全球第一。
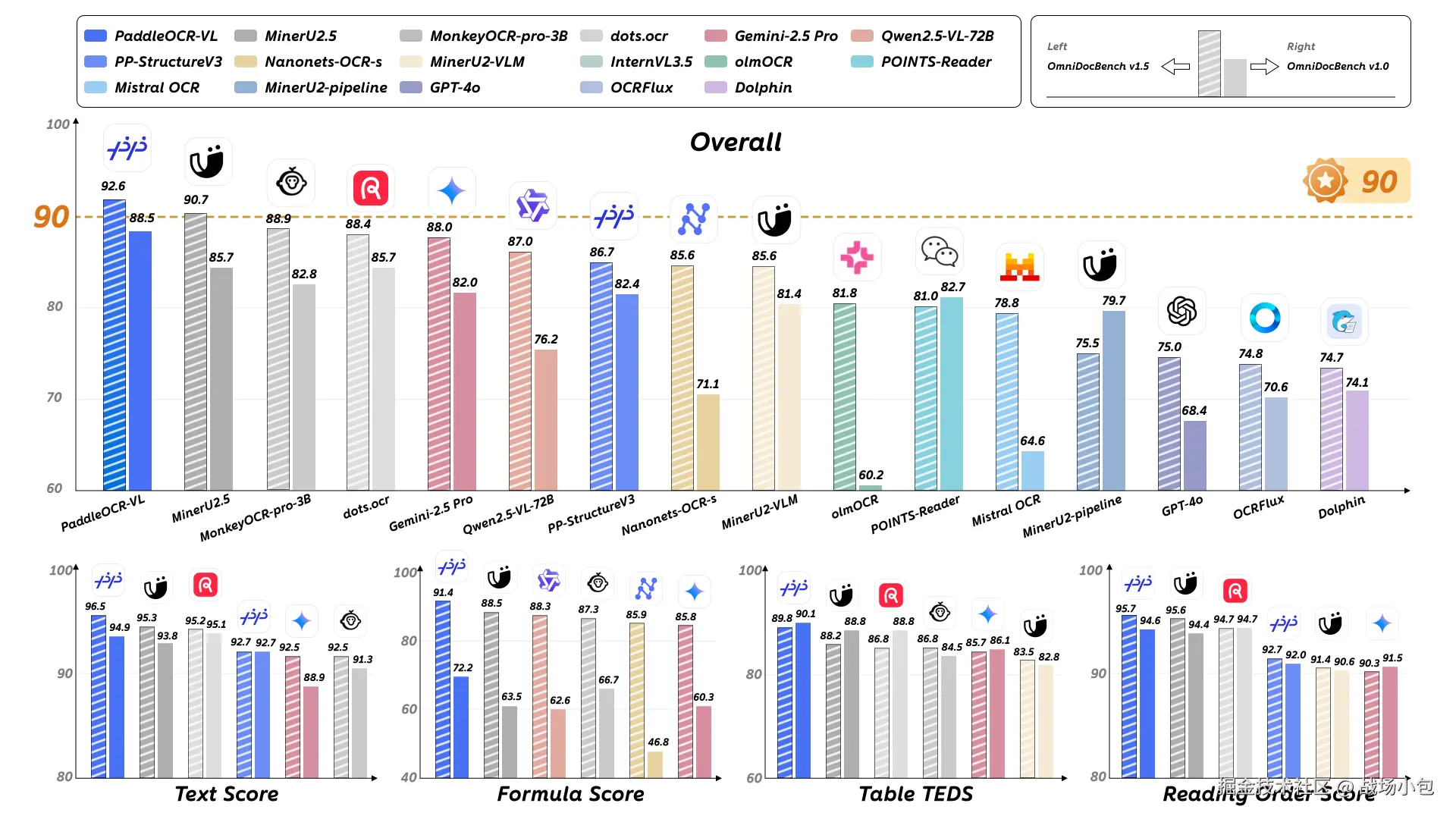
这么说我的 OKR 有救了啊,快马加鞭的来试一下。
对于线上翻译,有两种指标是必须要达到的
- 文字区域识别的准确性
- 支持语言的多样性
下面逐一地体验一下
OKR 需求测试
先随便找了一张较为简单的韩服的设计稿,识别效果见右图,识别的区域非常准确,精准的区分开文字区域和图像区域。
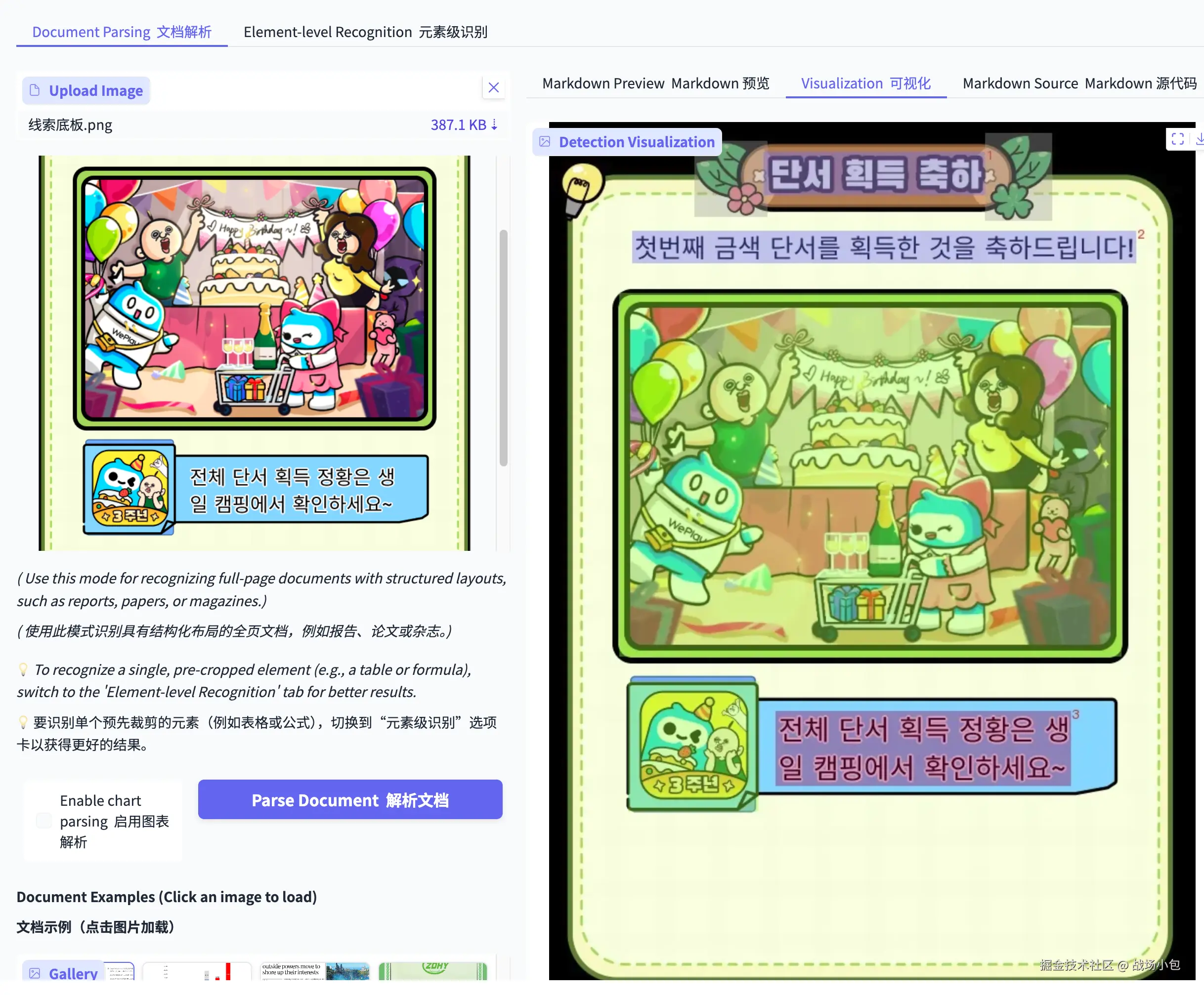
右侧有三个 tab,其中第一个 tab:Markdown Preview 预览还支持翻译功能,翻译的文案也是非常准确的
激动了啊,感觉 PaddleOCR-VL 自己就可以解决当前的需求啊。
再换一种比较复杂的语言,阿拉伯语。支持效果也是出奇的好啊,阿语活动开发过程和体验过程是最难受的啊,目前也是最严重的卡点
对于阿语的翻译的效果也非常好,这点太惊喜了,阿服的字体又细又长,字间距又窄,能做到这么好的识别真是让人惊艳
经过一番简单的测试,PaddleOCR-VL 完全可以应对领导的 OKR 要求了(毕竟天下第一难语言阿服都可以较为完美的应对,撒花),爽啊!只需要把 demo 跑出来,就可以去申请经费啦。
更多测试
作为一个程序员,除了要干好本职的工作,更要积极的探索啊,多来几个场景,倒要看看 PaddleOCR VL 能做到什么程度。
糊图识别
日常中经常有这种需求,领导给了一张扫描了一万次或者扫描的一点都不清楚的图片,阅读难度甚大,那时候就想能不能有一种方案直接把内容提取出来。
例如就像下面的糊糊的作文,连划去的内容都成功提取出来了,牛
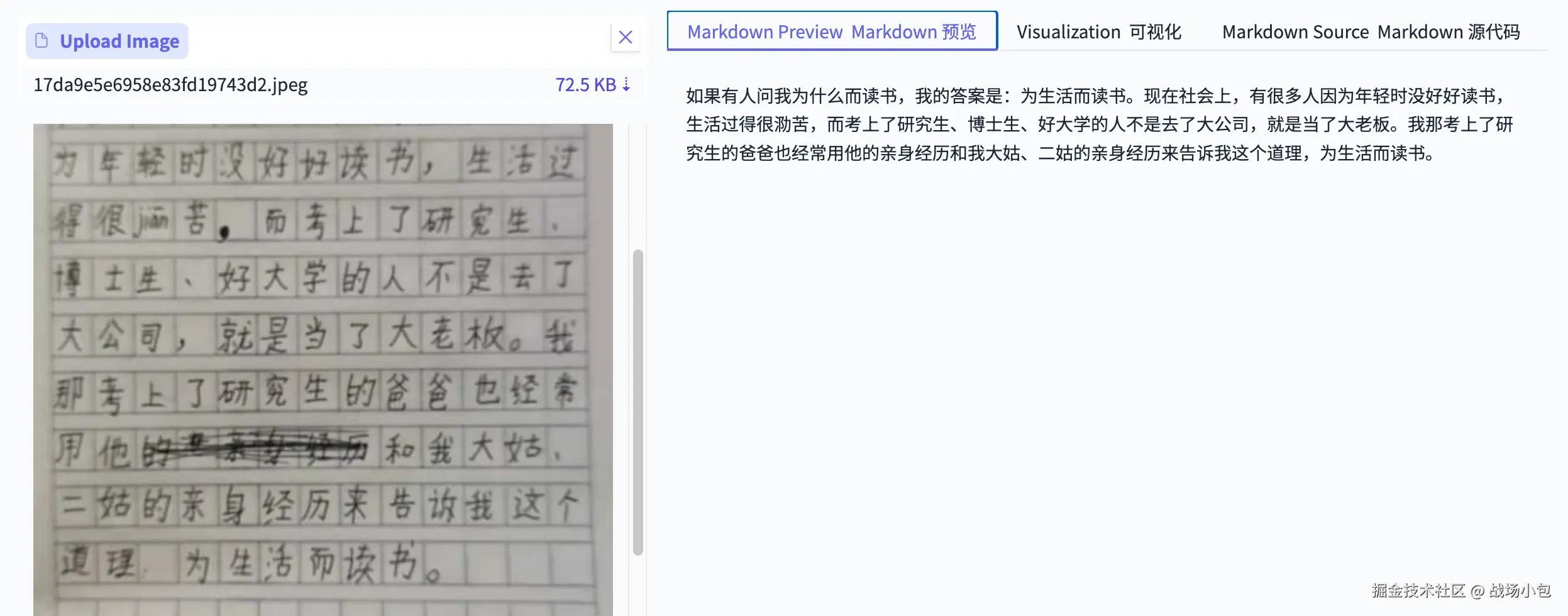
元素级识别
PaddleOCR-VL 除了文档解析能力,还提供了元素级识别能力,例如公式识别、表格内容识别等,诸如此类都是图片识别中的超难点。
先来个简单公式试一下

效果这么好的吗,全对了,那就要上难度了啊
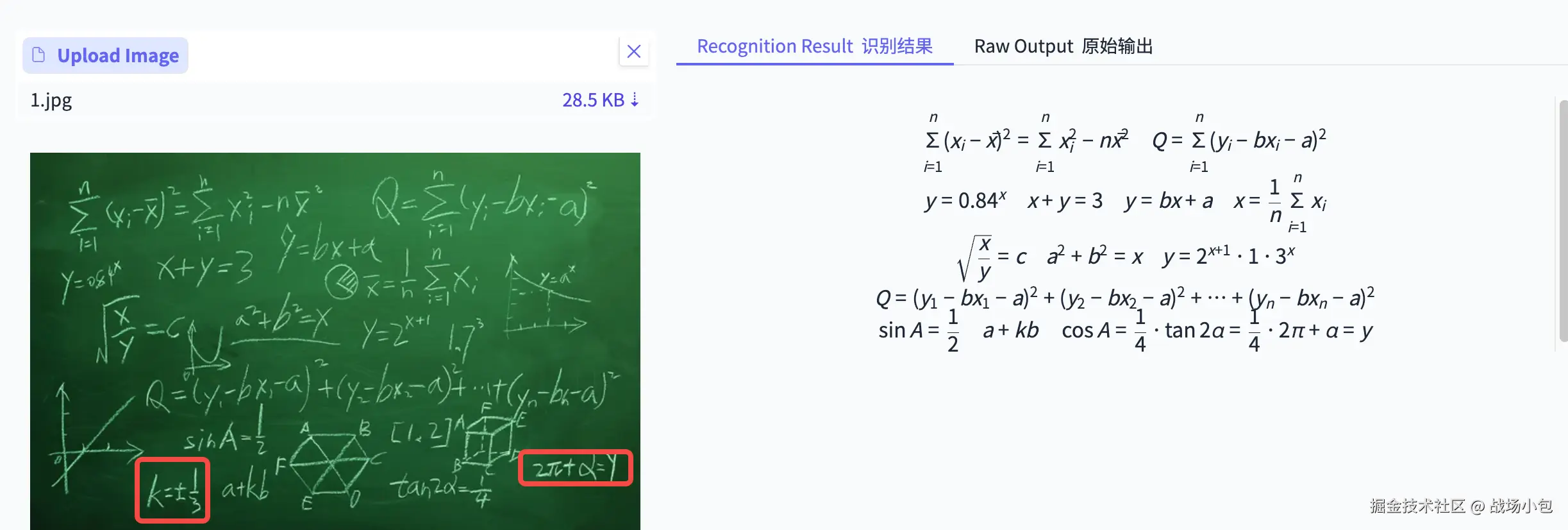
黑板中的公式繁杂,混乱,且是手写体,没想到识别的整体内容都是非常准确的,只有最后一个公式错误的乘在一起了,效果有些令人惊叹啊。
总结
PaddleOCR-VL 效果真是非常惊艳啊,年底的 okr 实现的信心大增。
PaddleOCR-VL 文字识别感觉像戴了高精度眼镜一般,后续遇到类似的文字识别需求,可以首选 PaddleOCR-VL 啊。
此外小小看了一下论文,PaddleOCR-VL 采用创新的两阶段架构:第一阶段由 PP-DocLayoutV2 模型负责版面检测与阅读顺序预测;第二阶段由 PaddleOCR-VL-0.9B 识别并结构化输出文字、表格、公式、图表等元素。相较端到端方案,能够在复杂版面中更稳定、更高效,有效避免多模态模型常见的幻觉与错位问题。
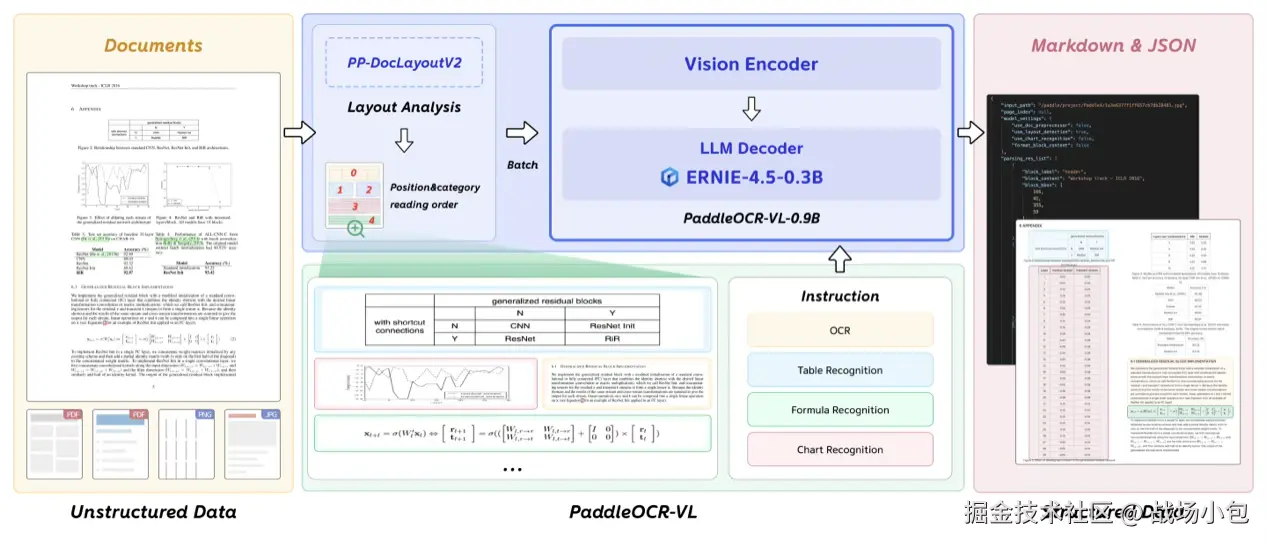
PaddleOCR-VL在性能、成本和落地性上实现最佳平衡,具备强实用价值。后续遇到文字识别的需求,PaddleOCR-VL 是当之无愧的首选。
体验链接:
- Github:github.com/PaddlePaddl…
- huggingface:huggingface.co/PaddlePaddl…
- Technical report:arxiv.org/pdf/2510.14…
- Technical Blog:
- English: ernie.baidu.com/blog/posts/…
- Chinese: ernie.baidu.com/blog/zh/pos…
来源:juejin.cn/post/7561954132011483188
入职三年半,涨薪三次,依旧没能逃过裁员
随笔闲聊
今天是在公司的最后一天,工作已基本交接完毕,下午闲来无事,随笔写写。
2019 年毕业后进入工作,幸遇良师,进步飞速,仅用两年时间就开始担任起前端小组长的角色。
后来为了更好的发展,2021 年跳槽来到新东家。
那会刚经历疫情,大家对未来依旧充满期待,叠加新东家刚上市,股价涨势正酣,于是开出颇为吸引的薪资。
入职之后,对公司的文化理念、领导的做事风格都十分认同,不管做什么事情都能得到多方面的支持。在实习期结束后,由于表现突出,迎来第一次涨薪。
半年后,前端组长跳槽去了更好的公司,我逐渐接手前端组长的工作。在此期间,职级成功晋升,迎来第二次涨薪。
慢慢时间来到 2022 年,疫情的影响加剧,期间房价大幅下跌,公司股价遭遇滑铁卢。
翻翻那段时间大老板的周报,提到最多的词就是改革转型和降本增效,紧随其后的是部门裁员潮的开始。
这个状态一直维持到了 2024 年,今年初我还跟家人开玩笑说,这次真要裁到我了,要不然没人能动了。年后果不其然,领导找我谈话。
结果谈完没想到却是加薪......亲身经历了一把年会不要停......
加薪幅度虽说不大,但是在公司连年亏损的情况下加薪,心里还是挺感激的。
......
今年总体感受就是业务需求不多,所做的业务大都是对原有系统的修修补补。大环境见不到好转,公司开展业务困难,我们做技术的也只能反复优化代码,做一些技术需求。
刚听到裁员通知的时候,心里还是有一丝窃喜的。一是公司给的赔偿方案非常可观,二是自己也打算换一个行业方向重新开始。
窃喜过后也有一些担忧,担忧现在的就业环境,担忧未来的一些不确定性,喜忧参半吧。
接下来的打算
先好好调整状态,健健身,旅旅游,然后对这几年的工作好好做一个复盘。
剩下的时间打算做一些一直在计划中的:
- 好好学习剪辑视频,买的相机在家吃灰好几年,是时候让它出去见见世面了
- 将之前做的情绪量化交易系统整理成文字分享开源出来,分享给更多需要的朋友
- 对前端体系系统性的梳理一遍
- ......
最后
暂时就这些吧,今天是在公司的 last day,中午和领导们一起吃了个便饭,聊了很多公司的近况,更加感受到公司最近几年的不易。
最后,祝愿老东家越来越好,兄弟们有缘再见!
来源:juejin.cn/post/7429626822868336649
Android唤醒锁优化指南
Android唤醒锁优化指南
唤醒锁机制深度剖析
底层工作原理
当Android应用需要保持CPU运行时,会通过PowerManager.PartialWakeLock向系统发起请求。该机制直接与Linux内核的wakelock子系统交互:
// 获取PowerManager实例
PowerManager powerManager = (PowerManager) getSystemService(Context.POWER_SERVICE);
// 创建PARTIAL_WAKE_LOCK标记的唤醒锁
PowerManager.WakeLock wakeLock = powerManager.newWakeLock(
PowerManager.PARTIAL_WAKE_LOCK,
"MyApp::LocationUpdateWakeLock" // 推荐命名规范:应用名::功能模块
);
// 获取唤醒锁(必须在后台线程操作)
wakeLock.acquire();
try {
// 执行需要保持CPU唤醒的任务
processLocationUpdates();
} finally {
// 确保在任何情况下都释放锁
if (wakeLock.isHeld()) {
wakeLock.release();
}
}
关键点解析:
PARTIAL_WAKE_LOCK允许CPU运行但屏幕保持关闭- 命名规范需明确标识功能模块,便于问题追踪
- try-finally块是防止锁泄漏的核心防御机制
Android Vitals监控标准
Google Play Console定义过度使用阈值:
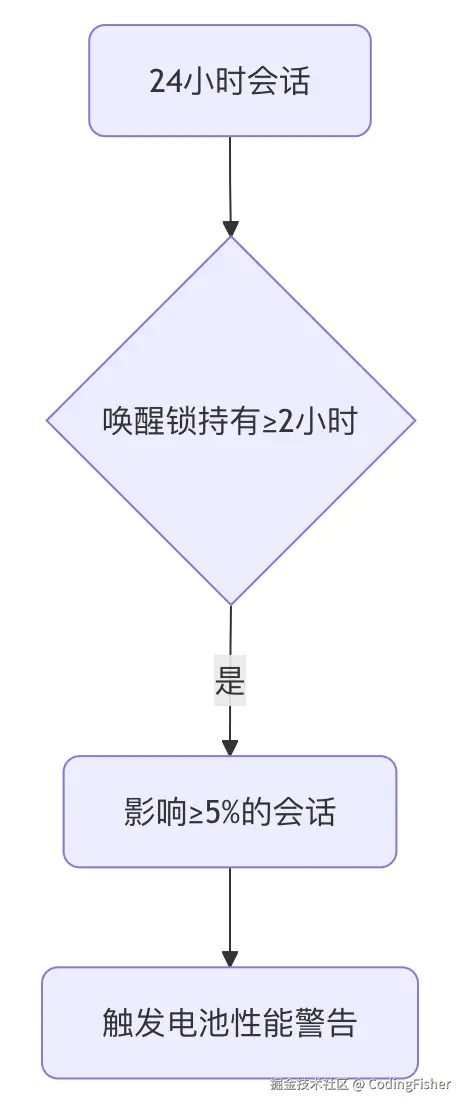
高级优化策略实战
场景化最佳实践
定位服务优化方案
// 使用带超时的唤醒锁
wakeLock.acquire(10 * 60 * 1000); // 10分钟超时
// 结合JobScheduler实现智能唤醒
JobInfo.Builder builder = new JobInfo.Builder(jobId, serviceComponent);
builder.setMinimumLatency(intervalMillis);
builder.setRequiresDeviceIdle(true); // 仅在设备空闲时执行
网络请求优化技巧
// 使用WorkManager的灵活约束
val constraints = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.setRequiresBatteryNotLow(true)
.build()
val uploadWork = OneTimeWorkRequestBuilder<UploadWorker>()
.setConstraints(constraints)
.setBackoffCriteria(BackoffPolicy.EXPONENTIAL, 10, TimeUnit.MINUTES)
.build()
调试工具链深度应用
Perfetto系统追踪
// 捕获唤醒锁事件
trace_config {
buffers {
size_kb: 10240
}
data_sources {
config {
name: "android.power"
android_power_config {
battery_poll_ms: 1000
collect_power_rails: true
}
}
}
}
分析路径: PowerManagerService > wake_lock_acquire/release事件
WorkManager调试
// 获取任务停止原因
WorkManager.getInstance(context).getWorkInfoById(workRequest.id)
.addListener({ workInfo ->
if (workInfo.state == WorkInfo.State.FAILED) {
val stopReason = workInfo.getStopReason()
when (stopReason) {
WorkInfo.STOP_REASON_CONSTRAINT_NOT_MET -> // 约束未满足
WorkInfo.STOP_REASON_DEVICE_STATE -> // 设备状态限制
}
}
}, executor)
生产环境监控
# 通过ProfilingManager收集现场数据
profilingManager = context.getSystemService(Context.PROFILING_SERVICE)
if (profilingManager != null) {
profilingManager.startProfiling(
"wake_lock_debug",
Duration.ofMinutes(5),
Executors.newSingleThreadExecutor()
)
}
架构级优化方案
现代后台任务架构
graph LR
A[前台服务] --> B(唤醒锁)
C[WorkManager] --> D[系统级节流]
E[AlarmManager] --> F[精确时间任务]
G[JobScheduler] --> H[批处理任务]
classDef optimal fill:#9f9,stroke:#333;
class C,G optimal;
电池优化白名单策略
<!-- AndroidManifest.xml -->
<uses-permission android:name="android.permission.REQUEST_IGNORE_BATTERY_OPTIMIZATIONS"/>
// 检查当前状态
PowerManager pm = (PowerManager) getSystemService(POWER_SERVICE);
if (!pm.isIgnoringBatteryOptimizations(packageName)) {
// 引导用户手动添加
Intent intent = new Intent(Settings.ACTION_REQUEST_IGNORE_BATTERY_OPTIMIZATIONS);
intent.setData(Uri.parse("package:" + packageName));
startActivity(intent);
}
性能监控体系构建
自定义监控指标
class WakeLockMonitor {
private val lockHoldTimes = ConcurrentHashMap<String, Long>()
fun trackAcquisition(tag: String) {
lockHoldTimes[tag] = SystemClock.elapsedRealtime()
}
fun trackRelease(tag: String) {
val start = lockHoldTimes[tag] ?: return
val duration = SystemClock.elapsedRealtime() - start
FirebaseAnalytics.getInstance(context).logEvent("wake_lock_duration", bundleOf(
"tag" to tag,
"duration_min" to TimeUnit.MILLISECONDS.toMinutes(duration)
))
}
}
总结
核心优化原则总结
- 必要性原则
只在必须保持CPU运行的场景使用唤醒锁,如:
- 实时位置追踪
- 关键数据同步
- 媒体播放场景
- 最小化原则
// 错误示例:整个下载过程持有锁
wakeLock.acquire();
downloadFile();
processData(); // 非必要CPU操作
wakeLock.release();
// 优化后:仅网络IO期间持有
downloadFile {
wakeLock.acquire(30_000); // 30秒超时
networkRequest();
wakeLock.release();
}
processData(); // 在无锁状态下执行
- 防御性编程
CoroutineScope(Dispatchers.IO).launch {
val wakeLock = powerManager.newWakeLock(...).apply {
acquire(10_000)
}
try {
withTimeout(9_000) { // 设置小于超时时间
performCriticalTask()
}
} catch (e: TimeoutCancellationException) {
Log.w(TAG, "任务超时中断")
} finally {
if (wakeLock.isHeld()) wakeLock.release()
}
}
来源:juejin.cn/post/7562064417258422310
Linux 之父把 AI 泡沫喷了个遍:90% 是营销,10% 是现实。
作者:Shubhransh Rai

Linux 之父把 AI 泡沫喷了个遍
前言: 一篇“技术老炮”的情绪宣泄文而已,说白了,这篇文章就是作者用来发泄不满的牢骚文。全篇围绕一个中心思想打转:我讨厌 AI 炒作,讨厌到牙痒痒。
但话说回来,没炒作怎么能让大众知道、接受这些新技术?大家都讨厌广告,可真到了你要买东西的时候,没有广告你上哪儿去找好产品?炒作虽然惹人烦,但在商业世界里,它就是传播的方式——不然怎么让一个普通人知道什么是AI?
所以归根到底,这篇文章其实并不是在批评 AI 本身,更不是在否定技术的未来。它只是在重复一个观点:**我就是讨厌炒作。**而已。
Linus Torvalds 刚刚狠狠喷了整个 AI 行业 —— 而且他说得没错
Linus Torvalds —— 那个基本上构建出现代计算的人 —— 直接放出了他对 AI 的原话。
他的结论?
“90% 是营销,10% 是现实。”
毒辣。准确。而且,说实话,早该有人站出来讲了。
在维也纳的开源峰会上,Torvalds 对 AI 的炒作问题发表了一番咬牙切齿的评论,他说:
“我觉得 AI 确实很有意思,我也觉得它终将改变世界。但与此同时,我真的太讨厌这类炒作循环了,我真的不想卷进去。”
这个人见过太多科技泡沫的兴起和崩塌。现在?AI 是下一个加密货币。
Torvalds 的应对方式:直接无视
AI 的炒作已经到了让人无法忍受的地步,甚至连 Linus —— 也就是发明了 Linux 的人 —— 都选择闭麦了。
“所以我现在对 AI 的态度基本就是:无视。因为我觉得整个围绕 AI 的科技行业都处在一个非常糟糕的状态。”
说真的?Respect。
我们现在活在一个时代,每个初创公司都在自己网站上贴上“AI 加持”,然后祈祷能拿到风投。
现实呢?这些所谓的“AI 公司”绝大多数不过是把 OpenAI 的 API 包装了一层花哨的 UI。
甚至那些大厂 —— Google、微软、OpenAI —— 也在砸几百亿美元,试图说服大家 AGI(通用人工智能)马上就来了。
与此同时,AI 模型却在数学题上瞎编,还能虚构出不存在的法律案件。
Torvalds 是科技圈为数不多的几个,完全没必要陪大家演戏的人。
他没在卖 AI 产品,也不需要讨好投资人。
他看到 BS(胡扯)就直说。
五年内 AI 的现实检验
Torvalds 也承认,AI 最终会有用的……
“再过五年,情况会变,到时候我们就会看到 AI 真正被用在日常工作负载中了。”
这是目前最靠谱的观点了。
现在的 AI,基本上:
• 写一些烂代码,让真正的工程师收拾残局。
• 吐出一堆 AI 生成垃圾,被 SEO 农场铺满互联网。
• 以前所未有的速度生成公司里的官话废话。
再等五年,我们要么看到实际的生产力提升,要么看到一堆烧光 hype 的 AI 创业公司坟场。
Torvalds 谈 AI 优点:“ChatGPT 还挺酷,我猜吧。”
Torvalds 也不完全是个 AI 悲观论者 —— 他承认确实有些场景是真的有用。
“ChatGPT 演示效果挺好,而且显然已经在很多领域用上了,尤其是像图形设计这类。”
听起来挺合理的。AI 工具有些方面确实还行:
• 帮创意项目生成素材
• 自动化一些无聊流程(比如总结文档)
• 让人以为自己变得更高效了
问题是?AI 的炒作和实际效果严重脱节。
我们听到一些 CEO 说“AI 会取代所有软件工程师”,结果 LLM 连基本逻辑都理不清。
Torvalds 一眼看穿了这些噪音。
他的最终结论?
“但我真的讨厌这个炒作周期。”
结语:Linus Torvalds 是科技界最后的清醒人
Torvalds 不讨厌 AI。
他讨厌的是 AI 的炒作机器。
而他是对的。
每一次科技革命,都是先疯狂承诺一堆,然后现实拍脸:
• 互联网泡沫 —— “互联网一夜之间会取代一切!”
• 加密货币泡沫 —— “去中心化能解决所有问题!”
• AI 泡沫 —— “AGI 马上就来了!”
现实呢?
• 互联网确实改变了一切 —— 但用了 20 年。
• 加密货币确实有用 —— 但 99% 的项目都是骗子。
• AI 也终将有用 —— 但现在,它基本上只是公司演戏用的道具。
Linus Torvalds 很清楚这游戏怎么玩。
他见过科技圈的每一波炒作潮起又落。
他的解决办法?
别听那些噪音。关注真正的技术。等 hype 自动消散。
说真的?这是 2025 年最靠谱的建议了。
AI 的炒作到底是个啥?
AI 就是个 hype 吗?是,也不是。
AI 炒作列车全速前进。
所有人都在卖 “生成式 AI”、“预测式 AI”、“自主智能体 AI”,还有不知道接下来啥新词。
硅谷根本停不下来,逮谁跟谁说 AI 会彻底颠覆一切。
问题是:真会吗?
我们来捋一捋。
AI 炒作周期:一套熟悉的骗局
只要你过去二十年关注过科技趋势,你肯定见过这个套路。
Gartner 给它取了个名字:炒作周期(Hype Cycle),它是这样的:
- 创新触发 —— 某些技术宅发明了点啥
- 膨胀期顶点 —— CEO 和 VC 开始说些离谱话
- 幻灭低谷 —— 现实来袭,发现比想象难多了
- 生产力平台期 —— 多年打磨后,终于变得真有用
我们现在在哪?
AI 正脸着地掉进“幻灭低谷”。
为啥?
• 大多数 AI 初创公司不过是 OpenAI API 的壳子
• 各种公司贴“AI 加持”标签就为了拉高股价
• 技术贵、不稳定、而且经常瞎编
基本上,我们正处在“先装出来,后面再补课”的阶段。
AI 已经来了(但和你想的不一样)
很多人以为 AI 是个超级智能体,一夜之间能自动化一切。
现实警告:AI 早就来了,真相却挺无聊的。
它没有掌控公司。
它没有替代程序员。
它在干的事包括:
• 过滤垃圾邮件
• 生成客服脚本
• 推荐广告(只是不那么烂而已)
所以,AI 是有用的。
但远没你风投爹说的那么牛。
预测式 AI vs. 生成式 AI:真正的游戏
AI 可以分两大类:
- 生成式 AI —— 那些 LLM(像 ChatGPT)能生成文本、图像、深伪视频
- 预测式 AI —— 用来预测趋势、识别模式的机器学习模型
生成式 AI 吸引了全部目光,因为它光鲜亮丽。
预测式 AI 才是挣钱的正道,因为它解决了真正的商业问题。
比如?
• 医疗:预测疾病暴发
• 金融:在诈骗发生前识别它
• 零售:在厕纸卖光前优化库存
最好的效果来自两者结合:
预测式 AI 预测未来,生成式 AI 自动应对。
这就是 AI 今天真正能发挥作用的地方。
AI 的未来:炒作 vs. 现实
所以,AI 会真的改变世界吗?
会。
但不是明天。
一些靠谱的预测:
✅ AI 会自动化那些烦人的工作 —— 重复性任务直接消失
✅ AI 会提升效率 —— 前提是公司别再吹过头
✅ AI 会无处不在 —— 某些我们根本注意不到的地方
一些纯 BS 的预测:
❌ AI 会替代所有工作 —— 它还是得靠人引导
❌ AGI 马上就来了 —— 不可能,别骗了
❌ AI 是完美且无偏见的 —— 它是喂互联网垃圾长大的
最终结论:AI 既被过度炒作,又是不可避免的未来
AI 是不是 hype?当然是。
AI 会不会消失?绝对不会。
现在大多数 AI 项目,都是营销秀。
但再过 5 到 10 年,最后活下来的赢家会是那些:
• 真正把 AI 用在合适地方的公司
• 关注解决实际问题,而不是追热词的公司
• 不再把 AI 当魔法,而是当工具对待的公司
hype 会死。
有用的东西会留下来。
来源:juejin.cn/post/7485940589885538344
破防了!传统 Java 开发已过时,新赛道技能速看!
引言
在这个科技飞速发展、日新月异的时代,人工智能(AI)无疑是最耀眼的那颗星,正以排山倒海之势席卷整个软件开发领域。身为企业级开发领域的中流砥柱,Java 工程师们如今正站在命运的十字路口,面临着前所未有的机遇与挑战。
曾几何时,Java 凭借其 “一次编写,到处运行” 的卓越特性,在电商、金融、政务等诸多关键领域,构建起了坚如磐石、规模庞大的应用生态。从支撑起双十一期间万亿级交易量的电商后台,到确保金融数据安全、高效流转的核心系统,Java 以其无与伦比的稳定性与可扩展性,成为了大型项目开发的不二之选。然而,随着技术生态的持续演进,新技术如雨后春笋般不断涌现,Java 工程师们原有的技能体系,正遭受着前所未有的冲击与考验。
在这个科技飞速发展、日新月异的时代,人工智能(AI)无疑是最耀眼的那颗星,正以排山倒海之势席卷整个软件开发领域。身为企业级开发领域的中流砥柱,Java 工程师们如今正站在命运的十字路口,面临着前所未有的机遇与挑战。
曾几何时,Java 凭借其 “一次编写,到处运行” 的卓越特性,在电商、金融、政务等诸多关键领域,构建起了坚如磐石、规模庞大的应用生态。从支撑起双十一期间万亿级交易量的电商后台,到确保金融数据安全、高效流转的核心系统,Java 以其无与伦比的稳定性与可扩展性,成为了大型项目开发的不二之选。然而,随着技术生态的持续演进,新技术如雨后春笋般不断涌现,Java 工程师们原有的技能体系,正遭受着前所未有的冲击与考验。
一、危机四伏:Java 工程师的严峻现状
(一)业务需求智能化,传统技能捉襟见肘
在过去,Java 开发主要聚焦于业务逻辑的实现、系统架构的搭建以及性能的优化。但今时不同往日,如今的用户对软件系统的要求,早已从单纯的 “能用就行”,转变为追求极致的 “好用” 体验。就拿电商行业来说,用户不再满足于仅仅浏览商品,他们期待平台能够根据自己的浏览历史、购买行为,精准推送契合个人喜好的商品;而在金融领域,企业迫切需要能够实时分析海量交易数据,快速、精准地识别异常行为与潜在风险的智能系统。这些智能化的业务需求,其复杂程度与技术难度,已经远远超出了传统 Java 技术栈所能企及的范围。
在过去,Java 开发主要聚焦于业务逻辑的实现、系统架构的搭建以及性能的优化。但今时不同往日,如今的用户对软件系统的要求,早已从单纯的 “能用就行”,转变为追求极致的 “好用” 体验。就拿电商行业来说,用户不再满足于仅仅浏览商品,他们期待平台能够根据自己的浏览历史、购买行为,精准推送契合个人喜好的商品;而在金融领域,企业迫切需要能够实时分析海量交易数据,快速、精准地识别异常行为与潜在风险的智能系统。这些智能化的业务需求,其复杂程度与技术难度,已经远远超出了传统 Java 技术栈所能企及的范围。
(二)技术生态多元化,竞争压力与日俱增
当下的技术人才市场,呈现出一片百花齐放的繁荣景象。新兴技术人才如潮水般涌入,他们不仅熟练掌握 Java 开发技能,还对大数据处理、云计算、自动化运维等前沿技术了如指掌。据某权威招聘平台发布的数据显示,那些同时具备 Java 与数据分析能力的岗位,其薪资水平相较于纯 Java 岗位,足足高出了 30% - 50%。这一数据清晰地表明,在激烈的人才竞争中,如果 Java 工程师不及时拓展自己的技能边界,提升综合竞争力,那么在技术人才市场中,他们的立足之地将会越来越小,逐渐被时代的浪潮所淹没。
当下的技术人才市场,呈现出一片百花齐放的繁荣景象。新兴技术人才如潮水般涌入,他们不仅熟练掌握 Java 开发技能,还对大数据处理、云计算、自动化运维等前沿技术了如指掌。据某权威招聘平台发布的数据显示,那些同时具备 Java 与数据分析能力的岗位,其薪资水平相较于纯 Java 岗位,足足高出了 30% - 50%。这一数据清晰地表明,在激烈的人才竞争中,如果 Java 工程师不及时拓展自己的技能边界,提升综合竞争力,那么在技术人才市场中,他们的立足之地将会越来越小,逐渐被时代的浪潮所淹没。
(三)开发模式敏捷化,传统方式难以为继
随着敏捷开发、DevOps 等先进理念的广泛普及,企业对工程师的能力要求也发生了翻天覆地的变化。如今,企业更加青睐那些具备全栈开发能力,能够快速响应市场变化,实现产品快速迭代的复合型人才。在传统的 Java 开发模式下,工程师往往专注于单一模块的开发,这种工作方式在如今快速变化的市场环境下,显得过于僵化和低效,难以满足企业的实际需求。
随着敏捷开发、DevOps 等先进理念的广泛普及,企业对工程师的能力要求也发生了翻天覆地的变化。如今,企业更加青睐那些具备全栈开发能力,能够快速响应市场变化,实现产品快速迭代的复合型人才。在传统的 Java 开发模式下,工程师往往专注于单一模块的开发,这种工作方式在如今快速变化的市场环境下,显得过于僵化和低效,难以满足企业的实际需求。
二、破局之道:转型所需的关键技能
面对来势汹汹的技术变革浪潮,Java 工程师们唯有主动出击,积极拓展自己的技能边界,构建起一个多元化、多层次的技术能力矩阵,才能在这场激烈的竞争中立于不败之地。而其中的核心技能,就包括熟练掌握 Python 等数据处理语言、深入钻研机器学习与深度学习算法,并将这些新兴技术与 Java 开发进行有机融合。同时,Spring AI 的出现,也为Java工程师转型提供了新的助力。
面对来势汹汹的技术变革浪潮,Java 工程师们唯有主动出击,积极拓展自己的技能边界,构建起一个多元化、多层次的技术能力矩阵,才能在这场激烈的竞争中立于不败之地。而其中的核心技能,就包括熟练掌握 Python 等数据处理语言、深入钻研机器学习与深度学习算法,并将这些新兴技术与 Java 开发进行有机融合。同时,Spring AI 的出现,也为Java工程师转型提供了新的助力。
(一)Python:数据处理的神兵利器
Python,凭借其简洁优雅的语法、丰富强大的库以及蓬勃发展的生态系统,已然成为了数据处理与科学计算领域的首选语言。对于 Java 工程师而言,学习 Python 可以从基础语法入手,逐步深入,掌握其核心的数据处理库。
- Python 基础语法:简洁而强大 Python 采用独特的缩进方式来表示代码块,变量类型无需显式声明,系统会自动进行动态推断,这一特性极大地简化了开发流程。以下通过几个简单的示例,让大家感受一下 Python 基础语法的魅力:
# 定义变量
a = 10
b = 3.14
c = "Hello, Python"
# 条件判断
if a > 5:
print("a大于5")
# 循环结构
for i in range(5):
print(i)
# 函数定义
def add(x, y):
return x + y
- 核心数据处理库:助力数据挖掘
- NumPy:高性能数值计算的引擎 NumPy 提供了高性能的多维数组对象以及丰富的数学函数,是进行数值计算的得力助手。例如,使用 NumPy 计算数组均值,只需简单几行代码:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
mean_value = np.mean(arr)
print("数组均值:", mean_value)
- **Pandas:数据处理与分析的神器**
Python,凭借其简洁优雅的语法、丰富强大的库以及蓬勃发展的生态系统,已然成为了数据处理与科学计算领域的首选语言。对于 Java 工程师而言,学习 Python 可以从基础语法入手,逐步深入,掌握其核心的数据处理库。
- Python 基础语法:简洁而强大 Python 采用独特的缩进方式来表示代码块,变量类型无需显式声明,系统会自动进行动态推断,这一特性极大地简化了开发流程。以下通过几个简单的示例,让大家感受一下 Python 基础语法的魅力:
# 定义变量
a = 10
b = 3.14
c = "Hello, Python"
# 条件判断
if a > 5:
print("a大于5")
# 循环结构
for i in range(5):
print(i)
# 函数定义
def add(x, y):
return x + y
- 核心数据处理库:助力数据挖掘
- NumPy:高性能数值计算的引擎 NumPy 提供了高性能的多维数组对象以及丰富的数学函数,是进行数值计算的得力助手。例如,使用 NumPy 计算数组均值,只需简单几行代码:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
mean_value = np.mean(arr)
print("数组均值:", mean_value)
- **Pandas:数据处理与分析的神器**
Pandas 主要用于数据的读取、清洗与分析,功能十分强大。以下代码演示了如何使用 Pandas 读取 CSV 文件,并对其中的缺失值进行处理:
import pandas as pd
# 读取CSV文件
data = pd.read_csv('data.csv')
# 查看数据前5行
print(data.head())
# 处理缺失值
data = data.fillna(0)
- **Matplotlib:数据可视化的魔法棒**
Matplotlib 能够将枯燥的数据转化为直观、美观的可视化图表,让数据说话。比如,绘制柱状图展示数据分布,代码如下:
import matplotlib.pyplot as plt
x = ['A', 'B', 'C']
y = [10, 20, 15]
plt.bar(x, y)
plt.xlabel('类别')
plt.ylabel('数值')
plt.title('柱状图示例')
plt.show()
(二)机器学习与深度学习:开启智能之门
机器学习与深度学习技术,赋予了计算机从海量数据中自动学习规律、实现精准预测与智能决策的能力。Java 工程师要想在这一领域有所建树,就必须掌握基础算法原理,并通过大量实践,将其应用到实际项目中。
- 机器学习基础:探索数据规律 以监督学习中的线性回归算法为例,它通过建立自变量与因变量之间的线性关系,实现对未知数据的预测。下面使用 Scikit - learn 库,展示如何实现线性回归预测房价:
from sklearn.linear_model import LinearRegression
import numpy as np
# 准备数据
area = np.array([[100], [120], [80], [150]]).reshape(-1, 1)
price = np.array([200, 240, 160, 300])
# 创建模型
model = LinearRegression()
# 训练模型
model.fit(area, price)
# 预测新数据
new_area = np.array([[130]]).reshape(-1, 1)
predicted_price = model.predict(new_area)
print("预测房价:", predicted_price[0])
- 深度学习实践:构建智能模型 深度学习中的神经网络,通过多层神经元的连接,能够学习到数据中复杂的特征表示。以 Keras 库构建全连接神经网络进行手写数字识别为例(假设已有 MNIST 数据集):
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
import numpy as np
# 加载数据
x_train = np.load('x_train.npy')
y_train = np.load('y_train.npy')
x_test = np.load('x_test.npy')
y_test = np.load('y_test.npy')
# 数据预处理
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 构建模型
model = Sequential()
model.add(Dense(128, input_dim=x_train.shape[1], activation='relu'))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5, batch_size=32)
# 评估模型
loss, accuracy = model.evaluate(x_test, y_test)
print("测试集损失:", loss)
print("测试集准确率:", accuracy)
(三)Spring AI:Java开发者的AI利器
Spring AI是Spring框架在人工智能领域的延伸,旨在帮助开发者更高效地构建和部署AI应用。它无缝集成Spring Boot、Spring Cloud等广泛使用的Spring项目,充分利用Spring生态系统的强大功能。通过Spring原生的依赖管理机制(如Maven/Gradle配置),开发者可以快速引入AI功能模块,避免复杂的环境配置问题。
- 标准化API抽象层 Spring AI提供了一套标准化的API抽象层,将复杂的AI模型操作封装为易于使用的服务接口。以自然语言处理(NLP)为例,Spring AI定义了统一的TextGenerator、TextClassifier接口,开发者无需关心底层模型(如DeepSeek、OpenAI GPT、Google PaLM)的实现细节,只需通过配置文件或注解即可切换模型提供商。这种抽象设计极大降低了AI开发的技术门槛,即使是缺乏机器学习经验的Java开发者,也能通过简单的代码实现智能问答、文本生成等功能。
- 支持多种AI服务 框架支持集成多种AI服务和模型,如DeepSeek、ChatGPT、通义千问等,为开发者提供了丰富的选择。在一个基于Spring Boot的电商系统中,只需添加spring - ai - core依赖,即可快速集成文本分类模型,实现商品评论的情感分析功能。
- 企业级特性保障 针对企业级应用的高可用性、安全性需求,Spring AI内置了一系列关键特性。它支持将AI模型调用纳入Spring事务管理体系,确保数据操作与模型推理的一致性,如在金融风控场景中,带款申请的风险评分计算与数据库记录更新可视为同一事务。同时,集成Spring Security框架,支持OAuth2、JWT等认证机制,保障AI服务的访问安全,例如在医疗影像分析系统中,可通过权限控制确保只有授权医生才能调用图像识别模型。此外,Spring AI还与Micrometer、Spring Boot Actuator集成,提供模型调用频率、延迟、错误率等监控指标,方便开发者通过Prometheus、Grafana等工具构建全链路监控体系。
三、实战演练:Java 与 Python 协同开发及Spring AI的应用
当 Java 工程师掌握了上述新技能后,接下来的关键任务,就是将这些技能巧妙地融入到实际开发中,通过技术融合,攻克复杂的业务难题。
(一)架构设计:优势互补
在项目架构设计中,可以采用 Java 负责开发后端服务,借助 Spring Boot、Spring Cloud 等先进框架,高效处理业务逻辑、管理数据库以及提供稳定可靠的 API;同时,利用 Python 进行数据处理与模型训练,将处理结果及时返回给 Java 服务。这种 “Java + Python” 的创新架构模式,既能充分发挥 Java 在企业级开发中的稳定性与可靠性优势,又能借助 Python 强大的数据分析能力,为项目注入智能的活力。而Spring AI则可以在这个架构中,作为连接Java与AI模型的桥梁,进一步简化AI功能的集成与使用。
(二)智能客服系统实战:技术融合的典范
以智能客服系统为例,该系统的核心功能是根据用户输入的问题,快速、准确地返回相应答案。
- Python部分:自然语言处理的魔法 使用NLTK和TextBlob库,可以轻松实现简单的自然语言处理功能。代码如下:
from textblob import TextBlob
def analyze_text(text):
blob = TextBlob(text)
keywords = blob.noun_phrases # 提取关键词
sentiment = blob.sentiment.polarity # 情感分析
return keywords, sentiment
在此基础上,若结合Spring AI,利用其提供的自然语言处理工具,可以进一步提升处理能力。例如,通过Spring AI集成更强大的语言模型,对用户问题进行更精准的理解和分析。
- Java部分:服务搭建与调用的桥梁 利用Spring Boot搭建Web服务,并实现对Python脚本的调用:
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
@RestController
public class ChatbotController {
@GetMapping("/chat")
public String chat(@RequestParam String question) {
try {
// 执行Python脚本
Process process = Runtime.getRuntime().exec(new String[]{"python", "chatbot.py", question});
BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String result = reader.readLine();
reader.close();
process.waitFor();
return result;
} catch (IOException | InterruptedException e) {
e.printStackTrace();
return "处理出错";
}
}
}
若引入Spring AI,Java部分可以通过其标准化接口,更便捷地调用AI模型来处理用户问题。比如,通过配置Spring AI,直接调用OpenAI或其他模型服务,获取智能回答,而无需复杂的Python脚本调用流程。
(三)优化与扩展:持续提升系统性能
在实际应用过程中,还可以通过以下几种方式,对系统进行优化与扩展,进一步提升系统性能与稳定性:
- 模型部署:高效运行的保障 使用TensorFlow Serving、ONNX Runtime等专业工具部署机器学习模型,能够显著提升模型的调用效率,确保系统在高并发场景下的稳定运行。Spring AI同样支持多种模型的部署,并且可以与这些专业工具协同工作,为模型部署提供更全面的解决方案。例如,通过Spring AI的配置,将训练好的模型轻松部署到生产环境中,并利用其提供的监控功能,实时监测模型的运行状态。
- 异步处理:提升响应速度 在Java中运用异步编程(如CompletableFuture)调用Python脚本,有效避免阻塞主线程,大大提高系统的响应速度与用户体验。当结合Spring AI时,Spring的异步处理机制可以与Spring AI的模型调用进行更好的整合。比如,在调用AI模型进行复杂计算时,通过异步方式执行,让用户无需长时间等待,提升系统的交互性。
- 容器化:环境一致性的守护 借助Docker进行容器化部署,能够确保Java与Python运行环境的一致性,方便项目的部署、运维与扩展。Spring AI项目也可以轻松实现容器化部署,通过Docker镜像将Spring AI相关的依赖和配置打包,确保在不同环境中都能稳定运行,为企业级应用的部署提供便利。
四、持续学习:通往成功转型的阶梯
技术转型并非一蹴而就,而是一个漫长而艰辛的过程。Java 工程师们需要始终保持对学习的热情与渴望,通过多种途径不断提升自己的能力。
(一)学习资源推荐:知识的宝库
- 书籍:《Python编程:从入门到实践》《机器学习实战》《深度学习》等经典书籍,是系统学习相关知识的不二之选。同时,对于Spring AI,虽然目前专门的书籍可能较少,但可以通过Spring官方文档以及相关技术博客来深入了解其原理与应用。
- 社区平台:积极参与CSDN、稀土掘金、GitHub等技术社区,与全球开发者交流经验、分享见解,参与开源项目,在实践中不断成长。在这些社区中,也逐渐有关于Spring AI的讨论和开源项目,Java工程师可以从中获取最新的信息和实践经验。
- 书籍:《Python编程:从入门到实践》《机器学习实战》《深度学习》等经典书籍,是系统学习相关知识的不二之选。同时,对于Spring AI,虽然目前专门的书籍可能较少,但可以通过Spring官方文档以及相关技术博客来深入了解其原理与应用。
- 社区平台:积极参与CSDN、稀土掘金、GitHub等技术社区,与全球开发者交流经验、分享见解,参与开源项目,在实践中不断成长。在这些社区中,也逐渐有关于Spring AI的讨论和开源项目,Java工程师可以从中获取最新的信息和实践经验。
(二)实践路径规划:从理论到实践
- 个人项目:从简单的数据处理脚本开始,逐步挑战完整的机器学习项目,如电影推荐系统、异常检测工具等,在实践中积累经验,提升能力。在个人项目中,可以尝试引入Spring AI,探索如何利用它为项目添加智能功能,比如在电影推荐系统中,使用Spring AI集成推荐模型,提高推荐的准确性。
- 企业实践:在日常工作中,主动请缨参与涉及数据分析、算法优化的项目,将所学知识应用到实际工作中,通过解决实际问题,积累宝贵的实战经验。若企业已经采用Spring技术栈,Java工程师可以提议引入Spring AI,对现有业务系统进行智能化改造,在实践中掌握Spring AI的应用技巧。
- 个人项目:从简单的数据处理脚本开始,逐步挑战完整的机器学习项目,如电影推荐系统、异常检测工具等,在实践中积累经验,提升能力。在个人项目中,可以尝试引入Spring AI,探索如何利用它为项目添加智能功能,比如在电影推荐系统中,使用Spring AI集成推荐模型,提高推荐的准确性。
- 企业实践:在日常工作中,主动请缨参与涉及数据分析、算法优化的项目,将所学知识应用到实际工作中,通过解决实际问题,积累宝贵的实战经验。若企业已经采用Spring技术栈,Java工程师可以提议引入Spring AI,对现有业务系统进行智能化改造,在实践中掌握Spring AI的应用技巧。
(三)职业发展方向:广阔的未来
当Java工程师成功掌握了新技术,他们的职业发展道路将变得更加广阔,有多个极具潜力的方向可供选择:
- 全栈工程师:融合前后端开发与数据处理能力,深度参与项目全流程开发,成为企业不可或缺的复合型人才。掌握Spring AI后,全栈工程师可以在项目中更好地实现智能化功能,从前端交互到后端逻辑处理,都能融入AI元素,提升产品的竞争力。
- 数据工程师:专注于数据采集、清洗、分析与建模,为企业的业务决策提供坚实的数据支持,成为企业数据驱动发展的核心力量。
- 架构师:负责设计复杂的系统架构,协调多技术栈的协同工作,确保企业技术战略的顺利实施,引领技术团队不断创新发展。
五、总结
在这场波澜壮阔的技术变革浪潮中,Java工程师的转型之路虽然充满挑战,但同时也蕴含着无限机遇。只要我们能够系统学习Python、机器学习等新兴技术,将其与Java开发进行深度融合,并始终保持持续学习的热情与决心,就一定能够突破职业发展的瓶颈,在数字化转型的浪潮中,开辟出属于自己的一片新天地,为企业和行业的发展创造更大的价值!你准备好踏上这一充满挑战与机遇的转型之旅了吗?
来源:juejin.cn/post/7518304768240287796
TabFlow: 一款简洁的 Chrome 标签页域名分类器
TabFlow:打造智能化的Chrome标签页管理扩展
前言
在日常的Web开发和浏览过程中,我们经常会同时打开大量的标签页。当标签页数量超过10个时,浏览器的标签栏就会变得拥挤不堪,找到特定的页面变得困难。为了解决这个痛点,我开发了TabFlow——一个智能的Chrome标签页分组管理扩展。
项目概述
TabFlow是一个基于Chrome Extension Manifest V3的标签页管理工具,它能够:
- 🏷️ 智能分组:自动按域名对标签页进行分组
- 🎨 视觉区分:为不同域名分配独特的颜色标识
- 📊 实时统计:显示标签页数量和域名统计
- ⚡ 性能优化:采用防抖、缓存等技术确保流畅体验
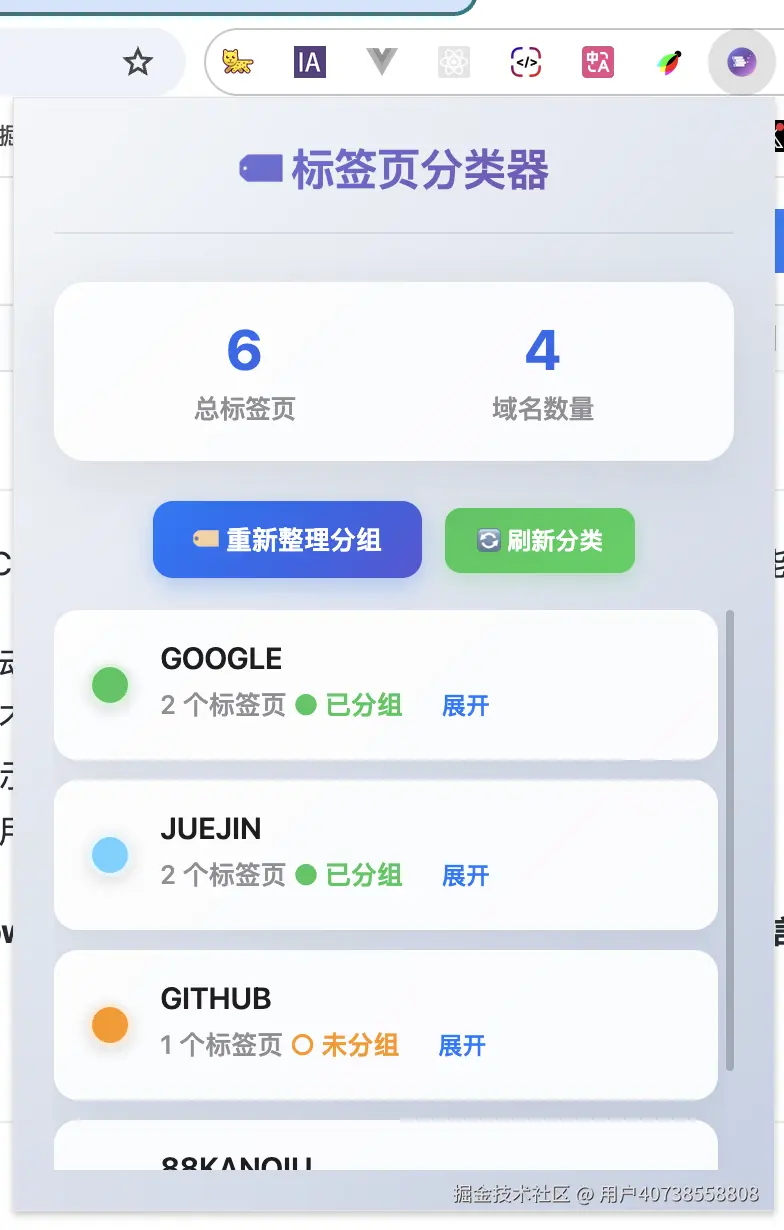
技术架构
1. 项目结构
TabFlow/
├── manifest.json # 扩展配置文件
├── background.js # 后台服务脚本
├── popup.html # 弹窗界面
├── popup.js # 弹窗逻辑
└── icons/ # 图标资源
├── icon16.png
├── icon48.png
└── icon128.png
2. 核心技术栈
- Chrome Extensions API:标签页和分组管理
- Manifest V3:最新的扩展开发标准
- Service Worker:后台处理逻辑
- Modern CSS:毛玻璃效果和渐变设计
核心功能实现
1. 智能域名解析
首先,我们需要从URL中提取有意义的域名信息:
function parseUrl(url) {
if (domainCache.has(url)) {
return domainCache.get(url);
}
try {
const urlObj = new URL(url);
let hostname = urlObj.hostname;
// 移除www前缀
if (hostname.startsWith('www.')) {
hostname = hostname.substring(4);
}
// 提取主域名
const parts = hostname.split('.');
let mainDomain = hostname;
if (parts.length >= 2) {
const commonTLDs = ['com', 'org', 'net', 'edu', 'gov', 'cn', 'jp', 'uk'];
const lastPart = parts[parts.length - 1];
if (commonTLDs.includes(lastPart)) {
mainDomain = parts.slice(-2).join('.');
} else {
mainDomain = parts.slice(-3).join('.');
}
}
const displayName = mainDomain.split('.')[0].toUpperCase();
const result = { mainDomain, displayName };
// 缓存结果,限制缓存大小
if (domainCache.size > 100) {
const firstKey = domainCache.keys().next().value;
domainCache.delete(firstKey);
}
domainCache.set(url, result);
return result;
} catch (e) {
return null;
}
}
技术亮点:
- 使用Map缓存解析结果,避免重复计算
- 智能处理各种TLD(顶级域名)
- 限制缓存大小防止内存泄漏
2. 自动分组机制
当检测到同域名的多个标签页时,自动创建或更新分组:
async function autoGr0upTabsByDomain(mainDomain, displayName, tabs, color) {
try {
// 使用缓存的分组信息
let existingGr0ups;
if (groupCache.has('groups')) {
existingGr0ups = groupCache.get('groups');
} else {
existingGr0ups = await chrome.tabGr0ups.query({});
groupCache.set('groups', existingGr0ups);
setTimeout(() => groupCache.delete('groups'), 5000);
}
const targetGr0up = existingGr0ups.find(group =>
group.title.includes(displayName)
);
if (targetGr0up) {
// 添加到现有分组
const ungroupedTabs = tabs.filter(tab => tab.groupId === -1);
if (ungroupedTabs.length > 0) {
const tabIds = ungroupedTabs.map(tab => tab.id);
await chrome.tabs.group({ tabIds, groupId: targetGr0up.id });
// 获取分组中的实际标签页数量
const groupTabs = await chrome.tabs.query({ groupId: targetGr0up.id });
await chrome.tabGr0ups.update(targetGr0up.id, {
title: `${displayName} (${groupTabs.length})`
});
}
} else if (tabs.length > 1) {
// 创建新分组
const tabIds = tabs.map(tab => tab.id);
const groupId = await chrome.tabs.group({ tabIds });
await chrome.tabGr0ups.update(groupId, {
title: `${displayName} (${tabs.length})`,
color: GR0UP_COLORS[color] || 'grey',
collapsed: false
});
}
groupCache.delete('groups');
} catch (e) {
console.log('分组失败:', e);
}
}

3. 实时数量更新
这是项目中的一个技术难点。Chrome的标签页分组API在标签页数量变化时不会自动更新分组标题,需要我们主动监听和更新:
// 监听标签页移除,更新分组标题
chrome.tabs.onRemoved.addListener(async (tabId, removeInfo) => {
try {
const groups = await chrome.tabGr0ups.query({});
for (const group of groups) {
const groupTabs = await chrome.tabs.query({ groupId: group.id });
if (groupTabs.length > 0) {
const titleMatch = group.title.match(/^(.+?)\s*\(/);
if (titleMatch) {
const displayName = titleMatch[1];
await chrome.tabGr0ups.update(group.id, {
title: `${displayName} (${groupTabs.length})`
});
}
}
}
} catch (e) {
console.log('更新分组标题失败:', e);
}
});
// 定期更新分组标题(每5秒检查一次)
async function updateAllGr0upTitles() {
try {
const groups = await chrome.tabGr0ups.query({});
for (const group of groups) {
const groupTabs = await chrome.tabs.query({ groupId: group.id });
const titleMatch = group.title.match(/^(.+?)\s*\(/);
if (titleMatch && groupTabs.length > 0) {
const displayName = titleMatch[1];
const currentTitle = `${displayName} (${groupTabs.length})`;
if (group.title !== currentTitle) {
await chrome.tabGr0ups.update(group.id, {
title: currentTitle
});
}
}
}
} catch (e) {
console.log('更新分组标题失败:', e);
}
}
setInterval(updateAllGr0upTitles, 5000);
技术亮点:
- 多重监听机制确保数量实时更新
- 正则表达式解析分组标题
- 定时器作为兜底方案
4. 现代化UI设计
采用了Apple设计语言,实现了毛玻璃效果和流畅的动画:
.container {
padding: 20px;
backdrop-filter: blur(20px);
-webkit-backdrop-filter: blur(20px);
}
.stats {
display: flex;
justify-content: space-between;
margin-bottom: 20px;
padding: 16px 20px;
background: rgba(255, 255, 255, 0.85);
backdrop-filter: blur(20px);
border-radius: 16px;
border: 1px solid rgba(255, 255, 255, 0.2);
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.08);
}
.domain-item {
display: flex;
align-items: center;
padding: 14px 16px;
margin-bottom: 10px;
background: rgba(255, 255, 255, 0.9);
backdrop-filter: blur(20px);
border-radius: 12px;
transition: all 0.3s cubic-bezier(0.25, 0.46, 0.45, 0.94);
}
.domain-item:hover {
transform: translateY(-2px);
box-shadow: 0 8px 25px rgba(0, 0, 0, 0.12);
}

性能优化策略
1. 缓存机制
let domainCache = new Map(); // 缓存域名解析结果
let groupCache = new Map(); // 缓存分组信息
let pendingUpdates = new Set(); // 防止重复处理
2. 防抖处理
let updateTimeout;
function debounceTabUpdate(callback, delay = 500) {
clearTimeout(updateTimeout);
updateTimeout = setTimeout(callback, delay);
}
3. 批量操作
// 并行处理分组
const groupPromises = Object.entries(domainGr0ups)
.filter(([, domainTabs]) => domainTabs.length > 1)
.map(async ([mainDomain, domainTabs]) => {
const urlInfo = parseUrl(domainTabs[0].url);
if (urlInfo) {
const color = assignColorToDomain(mainDomain);
return autoGr0upTabsByDomain(mainDomain, urlInfo.displayName, domainTabs, color);
}
});
await Promise.all(groupPromises);
图标设计
为了让扩展更具视觉吸引力,我设计了一套现代化的图标:

图标采用了:
- 蓝紫色到粉色的渐变背景
- 多层标签页卡片效果
- 流动箭头指示分组功能
- 现代化的扁平设计风格
开发过程中的挑战与解决方案
1. Manifest V3迁移
Chrome Extensions从V2迁移到V3带来了一些挑战:
问题:Background Scripts改为Service Worker
解决:重构代码结构,使用事件驱动模式
// Manifest V3配置
{
"manifest_version": 3,
"background": {
"service_worker": "background.js",
"type": "module"
},
"permissions": [
"tabs",
"storage",
"tabGr0ups"
]
}
2. 分组标题实时更新
问题:Chrome API不会自动更新分组标题中的数量
解决:实现多重监听机制 + 定时同步
3. 性能优化
问题:频繁的API调用导致性能问题
解决:引入缓存、防抖、批量处理等优化策略
安装TabFlow后,用户可以:
- 自动按域名分组标签页
- 通过颜色快速识别不同网站
- 实时查看每个分组的标签页数量
- 一键整理所有标签页
技术总结
通过开发TabFlow,我深入学习了:
- Chrome Extensions API:掌握了标签页、分组、存储等核心API
- 性能优化:学会了缓存、防抖、批量处理等优化技术
- 现代CSS:实践了毛玻璃效果、渐变、动画等现代设计
- 用户体验:理解了如何设计直观易用的界面
项目地址
- GitHub仓库:github.com/wajuejinaji…
- Chrome商店:(待上架)
未来规划
- 智能分组算法:基于用户习惯的智能分组
- 标签页搜索:快速搜索和定位标签页
- 数据同步:跨设备同步分组配置
- 快捷键支持:键盘快捷键操作
结语
TabFlow不仅解决了我个人的标签页管理痛点,也是一次完整的Chrome扩展开发实践。从需求分析到技术实现,从性能优化到用户体验,每一个环节都充满了学习和挑战。
希望这个项目能够帮助更多开发者提高浏览效率,也欢迎大家提出建议和贡献代码!
如果你觉得这篇文章对你有帮助,欢迎点赞和分享。如果你有任何问题或建议,也欢迎在评论区讨论!
来源:juejin.cn/post/7554979158435643407
知乎崩了?立即把网站监控起来!
今天早上(2025.10.17),知乎突然出现疑似大规模服务故障,导致多数用户无法访问,“知乎崩了”瞬间登上热搜榜。
一.当前故障表现为:
1.全平台功能异常:
- 网页端: 无法进入,显示 525 错误(服务器配置错误)。
- App 端: 首页可显示,但点击任何问题或回答均无法加载详情,部分用户还出现反复登出、匿名状态异常等。
2.技术特征分析:
- 故障表现似乎为核心数据接口响应失败,与 2023 年 4 月,2025 年 7 月的情况高度吻合,推测是中心化服务器集群在高压并发下的处理能力不足。
- 有部分用户提到 App 内出现 503 错误(服务不可用),这通常与服务器过载或后端服务中断有关。
二.网站崩溃可能造成的损失:
网站监控是保障业务稳定和用户体验的核心环节,其本质是提前发现问题、减少损失,做到“防患于未然”,避免因网站问题导致用户流失或业务损失。
根据最新的行业报告以及权威研究机构分析:
1.直接财务损失:
Gartner 指出
- 金融行业每分钟停机成本可达15 万美元。
- 电商与零售业每分钟停机成本可达 1 万美元。
- 制造业停产每分钟损失可达4 万美元。
2.隐形、持久损失:
- 客户信任与品牌声誉受损:一次严重的停机时间可能导致客户的永久丢失。负面舆情传播极快,会造成潜在客户“望而却步”
- 市场竞争力下降:竞争对手可能趁机抢占市场份额的事情屡见不鲜。像之前某旅游平台因预订系统故障,导致客户转而通过竞品平台下单;某打车软件长时间瘫痪,竞争对手趁机发布平台优惠福利,司机和乘客大面积流失,后通过超过半年的时间才恢复。
- 合规风险与法律责任:金融、医疗等受到严格监管的行业可能面临高额罚款、内部追责、未履行 SLA 造成的法律纠纷或赔偿等。
三.网站监控为什么重要?
| 保障可用性,减少停机损失 | 实时监测网站是否能正常访问(如服务器宕机、域名解析故障),一旦出现问题立即告警,缩短停机时间。 |
|---|---|
| 优化用户体验,提升留存 | 监测页面加载速度、接口响应时间等性能指标。若用户打开页面需等待 5 秒以上,流失率会大幅上升,监控能帮助定位慢加载的原因(如图片过大、服务器资源不足)。 |
| 防范安全风险,防止数据泄露 | 扫描 SQL 注入、XSS 攻击、服务器漏洞等安全威胁,提前拦截恶意访问,保护用户数据和网站核心资产。 |
| 支撑业务决策,发现潜在问题 | 通过监控访问量、转化率、用户地域分布等业务数据,及时发现异常(如某地区访问量骤降),为运维和运营策略调整提供依据。 |
1.通过Applications Manager监控网站
Applications Manager 是一款企业级应用性能监控(APM)与可观测性解决方案,能够监控到业务系统各个组成部分,支持 150 + 技术栈,覆盖 Java/.NET/Node.js 等应用服务器、Oracle/MySQL/MongoDB 等数据库、AWS/Azure/GCP 等云平台,以及 Kubernetes/Docker 容器环境。通过无侵入式字节码注入技术,实现从代码级到基础设施层的端到端性能追踪,精准定位慢事务、SQL 查询和线程瓶颈。
对于网站监控,通过卓豪 APM 能够实现:
2.网站可用性监控:
l HTTP 配置检查:
支持 POST/GET 方式。可以设置基于状态码的阈值告警。例如设置>200都作为告警触发,比如这次知乎响应状态码为 525,平台会立刻发出可用性 down 的告警;支持验证以及添加请求参数(可选)等。

l 内容检查:
在HTTP 配置检查均正常时,可以通过网站内容检查来识别“假运行”状态。支持正则表达式
3.应用性能监控:
URL监控能够监控网站上重要URL的可用性和性能,无论它们是在互联网上还是内部网上。这通过监控单个URL的响应时间来确保网站的顺利运行,在网站的页面加载时间出现任何延迟时提供即时通知。在URL序列监控的帮助下,可以模拟在线访问者通常访问的URL的序列,并分析它们以识别和解决任何潜在问题。
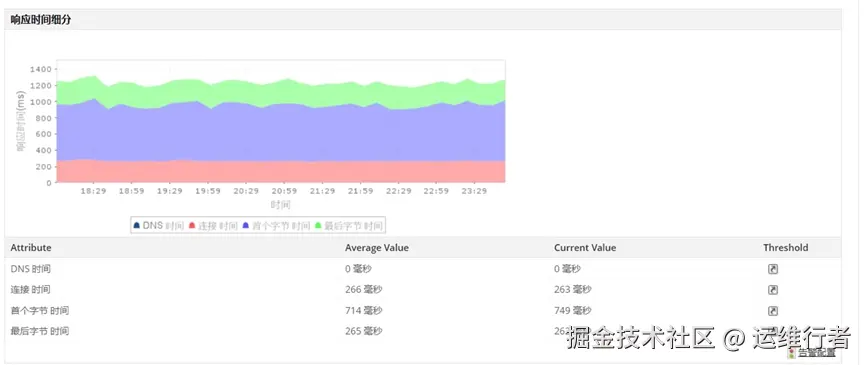
4.网站证书监控:
不断检查网站的SSL/TLS证书状态,以确保网站访问者的真实性、安全性和可靠性。如果网站证书接近到期日,会立即收到通知,以便采取必要措施按时续订。除此之外还可以查看SSL/TLS证书的域名、组织和组织单位等信息,以供快速参考。
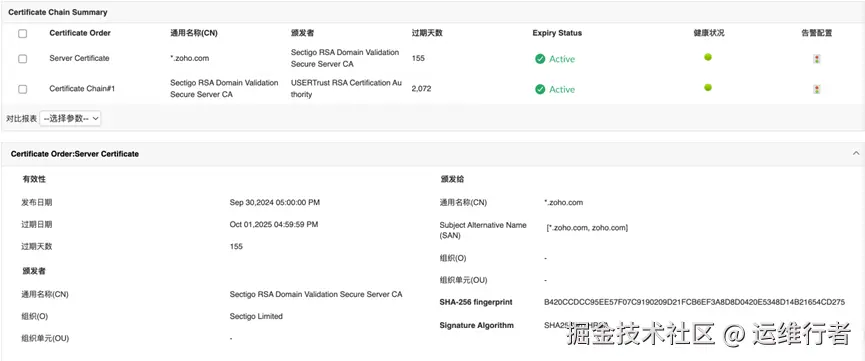
5.真实用户访问监控:
真实用户监控(RUM)能够通过实时见解增强网站的数字最终用户体验。它根据实际流量,从全球不同地点全天候监控网站的前端性能,跟踪关键指标,并提供有关真实用户如何与网站互动的深入见解。它根据浏览器、设备、ISP、地理等参数提供有关网站性能的详细信息。可以查看前端、后端和网络响应时间,还可以深入了解网络事务、用户会话、AJAX调用、Javascript错误等。
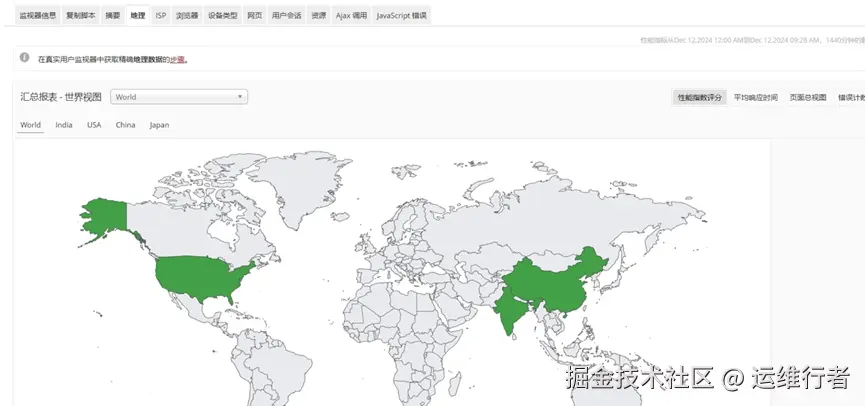
结语:
除了网站监控之外,APM还可以对业务系统从服务器/操作系统到中间件、数据库等各个组成部分的应用性能监控,保障业务正常运行,避免故障停机导致的损失。从基础架构到前端响应,立即发现、及时预警,保障用户访问网站畅通无阻!
来源:juejin.cn/post/7561781514922541066
开源鸿蒙技术大会2025 | 研究分论坛:探索前沿技术,推动生态繁荣
9月27日,开源鸿蒙技术大会2025研究分论坛在湖南长沙国际会议中心圆满举行。本次分论坛聚焦探讨软件工程与开源鸿蒙生态的前沿技术,内容涵盖了数据库技术、软件测试方法、设备互联等多个层面,旨在推动产学研深度融合,提升软件质量与安全,促进开源社区健康发展。研究分论坛由国防科技大学教授李姗姗和北京航空航天大学教授黎立担任出品人。
研究分论坛成功举办
本次研究分论坛在国防科技大学教授李姗姗的主持下拉开帷幕,论坛汇聚了来自北京理工大学、清华大学、华东师范大学、武汉大学、南方科技大学、上海交通大学等多位知名高校学者及企业专家。
国防科技大学教授李姗姗
清华大学教授姜宇在《基础软件模糊测试》主题演讲中,系统阐述了模糊测试在数据库安全和操作系统安全上的应用。他指出,当前模糊测试面临两大难点,测试输入的统一建模与生成,以及判断测试用例执行正常与否的测试准测构建。姜宇还介绍了其团队在关键技术上的突破,提出模糊测试对保障系统的安全至关重要,并为未来自动化漏洞挖掘指明了方向。
清华大学教授姜宇
华东师范大学教授苏亭在《基于性质的UI测试技术》主题演讲中,针对自动化UI测试的局限性提出创新解决方案。传统UI测试难以检测业务逻辑错误且测试效率低,而基于性质的测试技术通过定义功能属性,不仅可以实现多路径覆盖且可以进行复杂场景的自动化验证。苏亭还介绍了开源工具Kea2及其在开源鸿蒙、微信支付等平台的落地效果,展示其提升测试稳定性和检错能力的优势。
华东师范大学教授苏亭
武汉大学教授谢晓园做《快迭代下的“稳”开发:开源鸿蒙社区的友好开发实践》主题演讲,针对开源鸿蒙社区在高速迭代中出现的API适配滞后、文档更新不及时等问题提出了优化策略。API文档自动生成技术和API变更自动适配技术,可以有效平衡“用户友好开发”与“社区秩序维护”的需求,并在实际应用中提升开发效率,为开源社区治理提供了可落地的参考。
武汉大学教授谢晓园
论坛下半场由北京航空航天大学教授黎立主持,围绕开源鸿蒙如何与数据库技术、大模型技术相结合以及工业落地的实践,与现场嘉宾和观众展开交流。
北京航空航天大学教授黎立
北京理工大学教授袁野在《神经符号数据库技术及应用》的主题演讲中,探讨了神经符号数据库的核心优势,通过把人工智能、数据库技术与大数据计算融合,神经符号数据库能够高效地处理异构数据。同时,袁野还介绍了对应的挑战并分享了解决思路,为领域研究提供了理论支撑与实践建议。神经符号数据库有望成为未来数据管理的关键驱动力,推动人工智能与数据库技术的协同发展。
北京理工大学教授袁野
南方科技大学教授刘烨庞在《基于LLM的跨框架测试代码自动生成技术初探》的主题演讲中,介绍了一种创新测试方法。该方法利用大语言模型从现有项目学习缺陷模式与测试逻辑,并通过知识迁移自动生成适配测试代码,实现跨框架的缺陷检测。刘烨庞指出,框架功能差异是主要挑战,其团队通过对齐、筛选等关键流程优化模型表现,成功检测出多个未知漏洞。
南方科技大学教授刘烨庞
上海交通大学教授徐尔茨在《浅谈工业界和学术界合作范式》主题演讲中,探讨学术界与工业界在操作系统研发中的协作模式,梳理了多个学术界和工业界合作的优秀实践,并重点讨论一种优势互补的新合作范式。
上海交通大学教授徐尔茨
湖南开鸿智谷数字产业发展有限公司软总线技术资深专家张政熠在《基于QUIC协议的软总线:构建设备互联的“高速安全通道”》主题演讲中,介绍了QUIC协议在软总线中的创新应用。通过利用QUIC的低延迟、多路复用和加密特性,软总线实现了设备间高效、稳定的数据交换,尤其适用于跨网络场景。
湖南开鸿智谷数字产业发展有限公司软总线技术资深专家张政熠
本次分论坛汇聚了学术界与工业界的顶尖专家,一系列的主题演讲不仅展示了软件工程领域在数据库、软件测试、设备互联等方面的关键技术突破,更凸显了产学研深度融合对推动开源鸿蒙生态繁荣、提升基础软件质量与安全的重要价值,为协同构建、开源创新指明了未来发展方向。
收起阅读 »开源鸿蒙技术大会2025 | 定位与感知分论坛:构建开源鸿蒙全场景定位感知用户体验
在万物智联加速演进的当下,高精度定位、设备协同感知等技术,将持续提升开源鸿蒙在移动设备导航、人员定位等场景的用户体验。近日,开源鸿蒙技术大会2025定位与感知分论坛在湖南长沙国际会议中心圆满举行。本次分论坛聚焦高精度定位、场景感知等前沿技术与实践成果,主题涵盖了卫星定位与智能导航、室内定位、低轨卫星通导一体、音频定位、室内融合感知、星闪测距、船舶建造人员定位等多个层面,旨在分享定位感知最新技术发展趋势,交流行业落地经验,号召更多学术与行业力量从事定位感知技术研究与开发,为开源鸿蒙位置服务、感知服务建设注入新动能。
定位与感知分论坛成功举办
开源鸿蒙定位与感知TSG主任孙明伟担任本次分论坛的出品人,并作为本场论坛主持人,介绍了论坛主旨,并向议题分享嘉宾表示欢迎与感谢。
开源鸿蒙定位与感知TSG主任孙明伟
位置服务是移动终端的核心服务,精度越高,价值越大,针对高精度定位技术研究与开源软件,武汉大学博士后冯绍权以《GREAT:卫星大地测量与多源智能导航软件平台》为主题,介绍了GREAT空间大地测量数据处理、精密定位和定轨以及多源智能导航的综合性软件平台,并详细介绍了以PPP-RTK为代表的精密定位技术,包括实时精密轨道、钟差、UPD以及精密大气产品生成与用户端快速精密定位。针对室内外无缝定位方面,介绍了GNSS/INS/UWB三者组合方法,GREAT计划和开源鸿蒙社区进行结合,提升开源鸿蒙位置服务体验。
武汉大学博士后冯绍权
人们生活中80%以上的时间活动于室内环境,而全球定位系统GPS由于室内环境对信号的遮挡,如何结合不同类型无线信号进行室内定位,北京交通大学教授博士生导师朱晓强以《面向通感一体化的智能室内定位理论与方法》为主题,介绍了智能指纹库构建方法,实现指纹库的自动构建、更新与低开销运维,最大可节省72%指纹采集量;轻量级增量式高精度定位算法,解决定位精度低和定位模型重训练问题,实现1.2米定位精度和1秒完成增量式模型训练;最后探讨了基于智慧物联的无线感知相关研究与展望。
北京交通大学教授博士生导师朱晓强
当前低轨卫星是通信与定位领域的研究热点,武汉大学副教授王磊分享《低轨卫星通导一体化技术现状与挑战》议题,系统性地介绍了低轨星座建设现状和全球低轨发展计划,探讨了手机直连卫星的技术要求、低轨卫星通导一体技术挑战,指出通信导航技术融合具备形成双赢局面的可能性,留给未来的想象空间还很大,还有待技术、政策、资源的进一步支持。
武汉大学副教授王磊
深圳沧穹科技有限公司副总经理叶锋分享了《音频定位与智能位置服务应用》议题,以音频定位为核心,通过多源信号融合实现高精度室内定位,输出软硬件一体化定位导航产品,面向消费级市场,不增加、不改变终端硬件,支持鸿蒙/Android/iOS/微信小程序跨平台定位;同时介绍了地下停车场、交通场站枢纽的应用,满足工作人员管理、安全救援调度指挥、大众导航等应用的位置服务需求。
深圳沧穹科技有限公司副总经理叶锋
针对华为终端产品如何构建室内外一体化定位&导航服务,华为终端BG定位首席专家黄国胜分享了《华为终端全景定位技术研究与应用》议题,介绍了长隧道车道级导航、室内外无缝导览、开源鸿蒙多场景情景感知、精准3D室内定位等技术,并发布Wi-Fi稀疏导致居民楼/办公区覆盖不足、局部指纹缺失、基于视觉语义识别的POI采集、动态目标查找等挑战难题,希望与业界一起合作,共建室内外一体化定位与导航服务。
华为终端BG定位首席专家黄国胜
诚迈科技(南京)股份有限公司资深研发工程师陆道分享了《设备在室内场景下互通互联的融合感知》议题,以开源鸿蒙系统为基础,构建星闪定位、NFC感知、蓝牙/Wi-Fi定位等关键技术,应用于工业平板巡检设备、HongZOS执法记录仪等产品。
诚迈科技(南京)股份有限公司深研发工程师陆道
湖南开鸿智谷数字产业发展有限公司产品开发技术专家陈昊明带来《基于星闪的高精度室内定位分享》议题分享,系统化地介绍了星闪高精度室内定位解决方案产品,从1.0精准定位、2.0智能定位到3.0定位加传输的发展历程,通过开源鸿蒙与星闪结合,实现贵安智慧园区、华为展厅、华为智慧工厂等场景应用。
湖南开鸿智谷数字产业发展有限公司产品开发技术专家陈昊明
针对舶建造特点与痛点,结合开源鸿蒙操作系统,实现通信、定位、感知一体化网络,星开鸿(深圳)科技有限公司总经理助理杨婉愉分享了《开源鸿蒙统一互联——打造船舶建造人员安全定位预警创新实践》案例,基于星链MESH通定感知OH连接器和开源鸿蒙通定感交互平台,实现船舶建造中的人员定位和预警、气体泄漏预警等应用。
星开鸿(深圳)科技有限公司总经理助理杨婉愉
论坛期间,与会嘉宾针对定位、感知方向的技术挑战、研究趋势、应用场景等多方面进行了交流和讨论。未来,随着开源鸿蒙位置与感知服务和生态的不断完善,将拓展到更多应用场景和更多终端设备,为开源鸿蒙生态的繁荣贡献一份力量。
收起阅读 »开源鸿蒙技术大会2025 | 虚拟化与容器分论坛:构筑开源鸿蒙虚拟化技术高地
随着开源鸿蒙技术的快速发展,各行各业、各品类的生态设备加速融入生态,当数字世界的边界不断拓宽,我们正站在操作系统革命的十字路口。虚拟化技术打破硬件桎梏,让一块芯片承载多重宇宙,从智能手表到车载系统,开源鸿蒙的轻量化内核正在重塑设备交互范式;容器化使得开发效率极大跃升;指令翻译则化解了芯片架构的巴别塔,让ARM与RISC-V的指令流在开源鸿蒙生态中自由奔涌。
近日,开源鸿蒙技术大会2025虚拟化与容器分论坛在湖南长沙国际会议中心圆满举行。本次分论坛聚焦探讨虚拟化、容器化以及动态指令翻译等技术,主题涵盖容器安全、虚拟化混合部署与调度、Linux生态应用兼容,以及汽车领域虚拟化等多个层面,聚焦探讨了虚拟化技术在终端领域的落地挑战和开源鸿蒙虚拟化技术的演进思考。虚拟化与容器分论坛由开源鸿蒙虚拟化与容器TSG主任、华为终端BG软件虚拟化技术专家丁冉和上海交通大学副教授华志超担任出品人。
虚拟化与容器分论坛成功举办
开源鸿蒙虚拟化与容器TSG主任、华为终端BG软件虚拟化技术专家丁冉作《开源鸿蒙虚拟化与容器TSG简介和展望》主题演讲,介绍了虚拟化与容器TSG成立的背景以及来自学术界和产业界的各位TSG成员,分享了苹果以及Google两家操作系统厂商在虚拟化技术上的演进路径,以及当前端侧的应用场景。详细介绍了在开源鸿蒙操作系统构筑虚拟化技术基座的思路和落地策略,同时也探讨了虚拟化技术对南向硬件生态和北向应用生态支持的思考。
开源鸿蒙虚拟化与容器TSG主任、华为终端BG软件虚拟化技术专家丁冉
南开大学密码与网络空间安全学院副教授刘维杰作《容器技术路径发展综述与应用实践》主题演讲。容器漏洞频发、逃逸与资源攻击已蔓延端侧,通过综述介绍多隔离路线,揭示原生容器namespace与cgroup缺陷,展示Linux安全增强自研成果,实现访问路径级与资源级双重强隔离;拆解gVisor、Kata实践,呈现安全与性能兼得、高兼容、软硬协同的容器基座,并展望端侧软硬协同新框架。
南开大学密码与网络空间安全学院副教授刘维杰
深圳开鸿数字产业发展有限公司内核与虚拟化技术专家周昊安作《虚拟化混合部署框架在工业控制领域的探索》主题演讲,系统介绍了虚拟化混合部署框架的设计背景、实现方式与实验验证,并重点剖析了以机器人为例的KaihongOS虚拟化混合部署方案应用实践。
深圳开鸿数字产业发展有限公司内核与虚拟化技术专家周昊安
北京奥斯维科技有限公司系统架构师王科研发表题为《开源鸿蒙兼容Linux应用生态》的演讲,以“生态高墙”破题,揭示移动、桌面、云端应用泾渭分明导致的开发者割裂与算力孤岛,提出以容器化技术拆墙通路;同时展示了基于容器引擎的四大Linux生态应用场景:服务器应用部署、大模型运行、算力网络编排、Linux GUI程序运行,并深度解析算力网络分层架构与兼容Linux GUI方案。
北京奥斯维科技有限公司系统架构师王科研
上海交通大学副教授华志超发表题为《基于轻量级虚拟化的内存隔离与应用》的演讲。针对移动平台高价值数据如麦克风数据等易遭窃、OS安全机制因内核漏洞失效问等题,提出轻量级虚拟化内存隔离方案。方案依托AARCH64架构,构建1个普通内存域+N个隔离内存域,借EL2监视器与二级页表实现高安全、细粒度隔离,还提供相关隔离接口。将其应用于基于开源鸿蒙的麦克风保护、内核层隔离设备与数据内存、应用层建立安全进程,在开源鸿蒙5.0 Release版本+ DAYU200开发平台实现全流程防护,兼顾安全与兼容性。
上海交通大学副教授华志超
中瓴智行(成都)科技有限公司首席战略官钟卫东发表题为《嵌入式虚拟化支撑域控制器融合化演进》的演讲。ICT技术进步使得SoC算力得到极大提升,推动汽车电子电气架构从分散式多ECU
中瓴智行(成都)科技有限公司首席战略官钟卫东
华为终端BG软件集成与维护技术专家倪龙宇发表题为《基于用户体验的端侧虚拟化技术思考》的演讲,探讨了基于用户体验的端侧虚拟化技术,重点讨论了其在跨系统生态兼容性、特殊场合应用隔离、开发者调试环境提供等方面的挑战和解决方案。主要关注点在于提升用户体验、增强斯通功能完备性、优化显示性能、保证硬件资源访问效率、管理虚拟化环境生命周期、维护媒体文件共享安全性和实现应用跨生态互通。
华为终端BG软件集成与维护技术专家倪龙宇
开源鸿蒙技术大会2025虚拟化与容器分论坛在长沙成功举办,通过聚焦虚拟化、容器化及动态指令翻译等关键技术,深入探讨了容器安全、混合部署调度、Linux生态兼容及汽车虚拟化等议题,旨在推动开源鸿蒙在终端领域的落地。论坛强调,虚拟化与容器技术正潜移默化地影响移动设备系统的架构设计,助力开源鸿蒙生态打破硬件与架构壁垒,实现跨平台协作。未来,开源鸿蒙将继续推动技术创新,构建更开放、安全的操作系统生态。
收起阅读 »开源鸿蒙技术大会2025|通信互联分论坛:统一互联连接万物,丰富人们的生活和体验
2025年9月27日,开源鸿蒙技术大会2025在长沙国际会议中心隆重举行。作为大会的核心技术分论坛之一,通信互联分论坛以“统一互联连接万物,丰富人们的生活和体验”为主题成功举办。本次分论坛由华为、中国移动与开鸿智谷共同出品,汇聚了来自华为、海思、开鸿智谷、美的、中国移动、深开鸿、佳都科技等领域的顶尖技术专家与行业领袖,全方位展示了开源鸿蒙统一互联技术的最新进展与标杆实践。
论坛议程特设主题致辞、十余场前瞻议题演讲及卓越伙伴颁奖环节。其中,议题内容从芯片层、协议层到应用层全面展开,深度聚焦智能家居、智慧交通、工业互联、机器人协同等关键场景,系统呈现了开源鸿蒙统一互联技术如何破解设备碎片化、协议割裂等产业核心痛点,推动跨厂商、跨设备的无缝互联体验成为现实。
通信互联分论坛成功举办
华为终端BG OpenHarmony使能部副部长姜印清在开场致辞中发表了题为《开源鸿蒙统一互联构筑全景智能未来世界的技术底座》的主题演讲。他指出,开源五年来,开源鸿蒙已成为发展最快的操作系统之一,目前已有1300多款产品通过兼容性认证,覆盖金融、交通、教育、政务、能源等众多关键领域。随着开源鸿蒙生态快速发展,各行业设备存在的异构互联体系、标准不统一等问题,已形成烟囱式封闭生态,制约行业发展。为此,社区持续推进统一互联进程。本次分论坛旨在通过系列演讲研讨,激发行业思考,促进跨领域合作创新,共同推动开源鸿蒙在统一互联领域的新发展。
华为终端BG OpenHarmony使能部副部长姜印清致辞
面对家电行业长期存在的协议不统一、配置复杂等用户体验痛点,广东美的制冷设备有限公司物联网架构师颜林在《开源鸿蒙统一互联赋能家居家电场景新体验》的演讲中指出,智能家居正在经历从单品智能到主动智能五大演进阶段。在智能家居家电新体验章节,他重点拆解了美的与华为协同打造的“设备互联黑科技”,当华为HarmonyOS手机靠近美的搭载开源鸿蒙的家电设备时,将自动触发弹框配网功能,用户仅需通过半模态框完成四步操作,即可实现从设备发现到精准控制的全流程闭环。目前,这一技术已规划于华凌空调等产品,将让用户无需下载额外APP、无需记忆复杂配对流程,真正享受到 “即买即用、无感互联”的智能家居新体验。
广东美的制冷设备有限公司物联网架构师颜林
为解决家庭场景中瘦智能终端配网、连接、通信的基础性难题,中移(杭州)信息技术有限公司系统架构专家王亚莱在《移动闪联助力智能家居统一互联场景创新》的演讲中介绍,中国移动依托家宽组网规模优势,结合并扩展 GIIC统一互联协议,创新实现了IoT设备自发现主动配网、网络变更自适应连网、弱网通信链路增强、家居中枢内网互联等移动闪联四大能力,有效促进了统一互联生态的规模化发展。
中移(杭州)信息技术有限公司系统架构专家王亚莱
针对传统地铁、高铁过闸依赖实体票卡、二维码等“主动核验”方式存在的效率与体验瓶颈,佳都科技集团股份有限公司高级算法工程师王显飞在《基于开源鸿蒙统一互联的精准定位场景创新》的演讲中提出,无感过闸是基于开源鸿蒙统一互联和星闪技术的下一代通行解决方案。该方案实现了乘客
佳都科技集团股份有限公司高级算法工程师王显飞
从底层硬件支撑出发,海思技术有限公司解决方案首席架构师姚亚群在《海思6+2芯片战略助力开源鸿蒙统一互联生态发展》的演讲中强调,海思将开源鸿蒙作为四大核心竞争力根技术之一,围绕统一互联平台打造个人家庭、多设备协作的全场景极致体验;持之以恒与社区伙伴通力合作,共同构建包括规范/SDK/工具/成功案例等在内的开源鸿蒙统一互联生态资产,支持好客户,支持好产业发展,共同进步,共创辉煌。
海思技术有限公司解决方案首席架构师姚亚群
针对室内Wi-Fi信号多径效应导致的链路质量不均问题,香港科技大学博士后张延博在《Wi-Fi链路增强技术与性能对比分析》的演讲中分享了一项前沿研究——基于商用Wi-Fi AP的天线扩展技术,通过扩展射频通道提升物理层信号输入的空间差异性(Spatial Diversity),进一步结合链路质量估计算法与信道预测模型实现智能化天线配置,实现了高质量Wi-Fi链路的广泛覆盖。
香港科技大学博士后张延博
着眼技术演进趋势,华为技术有限公司网络传输协议专家李金洋在《端侧Agent协议规划及演进方向》的演讲中提出,AI Agent通过赋予大模型工具调用、环境感知等能力,正与实际生产环境紧密结合。他认为未来Agent将深入端侧,成为最广泛的AI入口,并介绍了华为在端侧Agent协议方面的技术规划与思考。
华为技术有限公司网络传输协议专家李金洋博士
开源鸿蒙统一互联PMC(筹)成员金钟在《开源鸿蒙统一互联打造跨厂商互联互通方案分享》中详细阐述了开源鸿蒙统一互联跨厂商互联互通局域网控方案,主要包括技术架构、分层分级安全机制、业务流程、跨中枢分享应用终端等。该方案旨在解决智能家居设备跨厂商不兼容问题,通过局域网本地控实现不同品牌设备间的互联互通,并支持主流通信协议、设备分级认证、统一物模型。同时议题介绍了开源鸿蒙统一互联3.0阶段,关于跨厂商互联互通局域网控技术方案的标准演进策略和共建内容。
开源鸿蒙统一互联PMC(筹)富对瘦控制SIG Leader金钟
北京中科鸿略科技有限公司技术专家黄登成在《开源鸿蒙设备投屏体验实践技术分享》的演讲中,介绍了开源鸿蒙统一互联DLNA的实现方案。在技术架构层面,围绕 av_session 进程和 cast_engine 进程,详细阐述了从应用层到内核层的分层设计与模块协作逻辑。该方案的最终目标,是借助 DLNA 协议的标准化能力,让视频、音频、图片等媒体内容能在不同品牌的智能设备(如搭载开源鸿蒙的手机、平板与各类智能电视、音箱等)之间自由流转,真正实现智能设备间媒体共享的无界化,为用户打造更便捷、连贯的跨设备媒体体验。
北京中科鸿略科技有限公司技术专家黄登成
针对传统机器人在群体协同、泛化能力方面的局限性,深圳开鸿数字产业发展有限公司高级通信工程师刘国平在《开源鸿蒙星闪互联打造“M-Robots OS”智慧机器人群体协同操作系统》的演讲中介绍,深开鸿基于开源鸿蒙和星闪技术正式开源了“M-Robots OS”。该系统通过分布式软总线、硬件资源池化等能力,实现了分布式异构多机协同,推动机器人从单体智能迈向群体智能。
深圳开鸿数字产业发展有限公司高级通信工程师刘国平
聚焦家电与城市互联痛点,湖南开鸿智谷数字产业发展有限公司研发总监蔡志刚在《开源鸿蒙星闪统一互联智慧城市场景落地实践》的演讲中,提出了“富对瘦”星闪适配架构,通过Cloud、Center、Bridge三层设计实现设备智能发现与安全认证。他进一步阐述了基于开源鸿蒙与海思芯片构建家庭星闪中枢的方案,并锚定“五年10亿级设备”目标,通过 “轻智能终端鸿蒙化 + 南北向生态协同”,推动开源鸿蒙物联网反向包围,夯实万物互联底座。
湖南开鸿智谷数字产业发展有限公司研发总监蔡志刚
鸿湖万联(江苏)科技发展有限公司系统工程师丁伟在《基于统一互联富对瘦设备控制的天翼物联端端互联端云协同实践》的演讲中,结合商业项目落地,展示了如何基于统一互联成果支持多样设备接入,实现数据实时上传云平台、远程管理控制与设备联动,有效降低了运维成本。
鸿湖万联(江苏)科技发展有限公司系统工程师丁伟
针对工业现场协议多样、转换复杂的挑战,江苏润开鸿数字科技有限公司研发总监张勇赛在《基于开源鸿蒙互联技术创新实践》的演讲中,介绍了一种基于开源鸿蒙构建的高可移植、插件化工协议转换服务框架,该框架旨在打通南北向设备间协议差异,补全开源鸿蒙在工业场景中的关键能力。
江苏润开鸿数字科技有限公司研发总监张勇赛
论坛尾声,华为终端BG OpenHarmony使能部副部长、GIIC鸿蒙推进委员会场景创新组组长李彦举主持了“开源鸿蒙统一互联非凡伙伴致谢授牌”仪式,对在开源鸿蒙统一互联2.0项目交付中做出突出贡献的润开鸿、鸿湖万联、开鸿智谷、九联开鸿、亚华电子、中移信息技术有限公司、汇思博、深开鸿、华龙讯达、诚迈科技、升腾资讯、中科鸿略、中国科学院软件研究所共13家伙伴企业进行了隆重表彰。
本次分论坛的成功举办,全面展现了开源鸿蒙统一互联技术体系的成熟度与创新活力,并通过跨行业的落地实践证明了其强大的生态价值,为万物智联时代的全面开启奠定了坚实基础。
收起阅读 »开源鸿蒙技术大会2025 | 轻智能生态分论坛:共绘轻智能生态新蓝图
2025年9月27日,开源鸿蒙技术大会轻智能生态分论坛在长沙国际会议中心成功举办。本次分论坛汇聚了来自操作系统、芯片平台、创新显示、应用开发等领域的数十位顶尖专家和资深实践者,围绕“开源鸿蒙赋能轻智能生态繁荣”主题,从战略到应用,从硬件到软件,从技术底座到创意火花,全方位、多维度展现了开源鸿蒙如何赋能轻智能生态的蓬勃生长,为开源鸿蒙轻智能生态的下一程发展绘制清晰的路线图。本次分论坛由华为终端BG OpenHarmony使能部副部长李彦举、开源鸿蒙Watch SIG组长、深圳鸿信智联数字科技有限公司CEO张兆生、华为终端BG OpenHarmony使能部行业使能专家黎亮齐担任出品人。
轻智能生态分论坛成功举办
轻智能生态的长远发展,离不开清晰的蓝图规划与战略布局,华为终端 BG OpenHarmony使能部副部长李彦举带来“以正合,以奇胜”的主题报告。他围绕轻智能生态的长期建设目标,系统阐述了技术演进路径、关键能力布局与未来发展方向,全面擘画了开源鸿蒙在轻智能领域的战略蓝图。此次分享让现场伙伴对开源鸿蒙轻智能的发展路径有了更具象的认知,极大增强了各方参与生态共建的信心与动力,为推动轻智能生态的繁荣发展奠定了坚实的基础。
华为终端BG OpenHarmony使能部副部长李彦举
开源鸿蒙Watch SIG组长、深圳鸿信智联数字科技有限公司CEO张兆生以《预见轻智能:开源鸿蒙应用的生态机遇》为主题展开分享。他指出,开源鸿蒙Watch生态通过统一架构、统一应用API及表盘标准,实现“一次开发、多端部署”,他表示,随着北向应用生态的持续繁荣,未来将携手各方,共同打造易开发、多应用的开源鸿蒙轻智能生态,释放更大创新价值。
开源鸿蒙Watch SIG组长、深圳鸿信智联数字科技有限公司CEO张兆生
高德软件有限公司开放平台产品经理董佳玉带来《高德空间智能—让AIoT设备更懂出行》的主题分享。她展示了高德面向智能手表、眼镜等轻智能设备的创新解决方案,通过在线+离线的轻量化导航、低功耗低算力优化及广泛适配能力,赋能智能手表实现全场景出行服务;针对智能眼镜,提出分层式方案,覆盖语音交互、低功耗HUD导航到沉浸式AR体验。她强调,高德正实现从“导航工具”升级为“空间智能助手”,未来将携手轻智能社区,一起推动智慧出行和生活服务与开源鸿蒙生态的深度融合。
高德软件有限公司开放平台产品经理董佳玉
华为终端BG穿戴软件技术专家赵永杰老师进行了《鸿蒙手表系统能力演进与生态创新》的主题分享。他指出,华为穿戴将基于开源鸿蒙持续构建HarmonyOS 手表系统和生态开放平台,其中Watch GT6续航能力提升至21天,运动健康类应用功能显著增强;WATCH5联合生态伙伴创新,带来更丰富的优质功能与体验,包括NFC碰一碰交互,X—TAP传感器压感能力,手势系统解锁创新玩法,更通过FormKit实现的桌面卡片快捷入口,让生态应用服务一键直达,这些能力正在引领开源鸿蒙穿戴生态的未来方向。
华为终端BG穿戴软件技术专家赵永杰
广州奥翼电子科技股份有限公司研发总监王喜杜带来《电子纸显示技术及其在开源鸿蒙中的应用》的分享。他指出,电子纸技术凭借自身特性与开源鸿蒙系统的开放生态高度契合,可在多个场景实现创新融合,如智慧零售的电子货架标签、智慧教育的电子白板与课本、智慧家居的电子闹钟、智慧城市的公交站牌等,为开源鸿蒙轻智能生态提供低功耗、高适配的显示解决方案,助力开鸿轻智能设备实现更长续航与更广场景的落地。
广州奥翼电子科技股份有限公司研发总监王喜杜
上海海思穿戴芯片产品总监薛旭庆带来《开源鸿蒙创新表芯,赋能行业价值》主题分享。他表示,海思持续投入搭载开源鸿蒙的穿戴解决方案,致力于打造卓越的终端体验。在此次分享中,他首先介绍了W610当前和开源鸿蒙社区合作取得的成绩,同时介绍了海思全新的W620智能穿戴解决方案,相较于W610,W620实现了全方位的升级,支持星闪、仿3D GPU、视频编解码等能力,同时借助NPU助力端侧AI升级。通过芯片与系统的深度协同,为行业伙伴提供更具竞争力的解决方案,共同推动开源鸿蒙穿戴生态向高性能、智能化方向持续演进。
上海海思穿戴芯片产品总监薛旭庆
江苏小牛电动科技有限公司智能平台部总监冯龙以《开源鸿蒙Watch生态与两轮电动车智能化融合探索》为主题,分享了小牛电动在开源鸿蒙生态下的创新实践。他表示小牛电动已经与开源鸿蒙Watch生态合作,实现了Watch上远程控制和实时查看小牛电动状态。他指出,开源鸿蒙的轻量化、安全性、开放性与完善的系统服务,精准契合两轮电动车对性能、安全与扩展性的核心需求。他表示未来将会与开源鸿蒙社区深度合作,实现电动车平台化升级,推动两轮车产业向智能互联加速迈进,为用户提供更好的使用体验。
江苏小牛电动科技有限公司智能平台部总监冯龙
开源鸿蒙统一互联PMC负责人吕鑫带来《基于开源鸿蒙统一互联打造的儿童手表交互创新开源分享》。他指出当前儿童手表行业核心痛点在于跨品牌设备普遍存在无法方便加好友的问题,对此,团队基于“儿童手表电话号码交换规范标准”,实现了此功能,更是将功能的核心代码开源至社区。这一举措不仅打破品牌壁垒,让更多的生态伙伴均可享受到这一技术成果,为儿童智能穿戴行业的互联互通注入关键动力。
开源鸿蒙统一互联PMC负责人吕鑫
武汉轻鸿数智科技有限公司技术总监葛章华在《思澈x开源鸿蒙轻智能系统开发分享》中,介绍了思澈SF32LB56X芯片适配开源鸿蒙轻智能系统的开发实践,展现了思澈芯片与开源鸿蒙深度协同的技术能力。此次分享为开源鸿蒙轻智能生态提供了重要的硬件支撑,也为更多芯片厂商接入开源鸿蒙系统提供了可复用的开发范式,为轻智能生态提供更多的芯片选择,将有力推动轻智能设备在更多场景的规模化应用。
武汉轻鸿数智科技有限公司技术总监葛章华
珠海市趣境信息技术有限公司总经理麦活鹏带来《基于开源鸿蒙的电子宠物机应用开发分享》。他表示,基于开源鸿蒙完善的文档体系、统一的开发环境和多设备适配能力,显著提升了开发效率。在项目实践中,团队在动画互动效果打磨、界面资源优化与数据存储等方面实现了高效突破,成功打造出生动有趣的电子宠物交互体验。麦活鹏强调,开源鸿蒙为创新应用提供了坚实的技术底座,未来将持续深耕生态,致力于开发更多“有温度、有创意”的轻智能应用,让科技兼具智能属性与人文温度,为用户提供更具生命力的数字陪伴。
珠海市趣境信息技术有限公司总经理麦活鹏
湖南开鸿智谷数字产业发展有限公司研发中心副总经理刘邦洪带来《基于开源鸿蒙的 AI 智能操作系统探索实践》的主题分享。他介绍了团队依托开源鸿蒙技术底座构建操作系统级AI能力,并展示了AI实验箱机械臂场景的落地实践成果。该探索为开源鸿蒙生态拓展 AI 应用场景提供了可参考的实践方案,助力轻智能领域智能化升级。
湖南开鸿智谷数字产业发展有限公司研发中心副总经理刘邦洪
本次开源鸿蒙技术大会轻智能生态分论坛汇聚了芯片、系统、应用全链路创新力量,展现了轻智能生态的蓬勃生机。从战略规划到技术实践,从硬件创新到应用探索,十余位嘉宾的精彩分享,共同描绘出一个开放协同、创新引领、普惠共赢的轻智能生态新图景。
此次分论坛的成功举办,标志着产业界对“轻智能”作为万物智联核心体验方向的高度共识。基于开源鸿蒙这一坚实技术底座,一个设备更智能、开发更高效、体验更自然的轻智能生态正在快速成型。
展望未来,开源鸿蒙将持续夯实技术底座,深化跨领域协作,全力推动轻智能生态迈向更为繁荣的发展阶段。期待更多伙伴加入共建,以“轻”启智,以“联”聚能,共同推动万物智联时代加速到来。可以预见,在开放、共享的生态理念下,轻智能将为千行百业注入新动能,开启万物智联的崭新篇章!
收起阅读 »e签宝亮相2025云栖大会:以签管一体化AI合同平台,构建数字信任“中国方案”

9月24日至9月26日,以“云智一体 · 碳硅共生”为主题的2025云栖大会在杭州召开。大会通过3大主论坛+超110场聚合话题,充分展示 Agentic AI(代理式AI)和 Physical AI(物理AI)的变革性突破,探讨AI 基础设施、大模型、Agent 开发、AI 应用等多个领域和层次的话题内容。
作为亚太地区电子签名领域的领军企业,e签宝受邀出席系列重要活动。在题为《AI Agent崛起,谁会赢得下一代企业服务市场?》的分享环节中,e签宝创始人兼CEO金宏洲先生全面介绍了公司在智能合同、全球合规签署以及数字信任基础设施建设方面的最新成果。

金宏洲强调,在面向ToB的AI Agent领域,要取得成功,需要三个关键:第一,数据闭环,在用户使用过程中积累数据,反哺Agent能力提升,形成数据飞轮,这是做好Agent产品的基础。第二,有领域知识,这是垂直Agent产品做厚的价值点,也是防止被通用Agent吞没的护城河。第三,最终的护城河是用户规模和网络效应,无论是新老创业者,在AI时代都有机会,但不拥抱AI的必然会被淘汰。

大会现场还有 4 万平米的智能科技展区以及丰富的创新活动,将为每一位参会者带来密集的 AI 新思想、新发布、新形态。

人工智能+馆全面呈现了从基础大模型、开发工具到全链路Agent服务的最新进展。通义大模型系列以“全尺寸、全模态”开源矩阵亮相,展示了其在多模态理解与生成上的全面布局;魔搭社区展示其超过7万个模型与1600万开发者的生态力量;瓴羊 AgentOne 提供客服、营销等场景化服务;AI Coding 展区核心展示开发者工作范式的变化……观众可现场体验阿里云百炼、无影AgentBay等智能体开发与应用场景,感受大模型如何从工具走向“数字伙伴”。

计算馆内,硬核技术不再冰冷,而是化作可感知、可交互的趣味场景。无影展区人气爆棚,一块巴掌大的“无影魔方Ultra”竟能流畅运行对GPU要求极高的3A游戏。现场观众坐上模拟驾驶座,即可与大屏幕联动,体验极速飙车的刺激;拿上手柄,闯入《黑神话:悟空》的游戏世界,与BOSS展开激战。“东数西算”展区,戴上VR设备,观众就能“空降”至贵州、内蒙古、青海等西部数据中心,近距离观摩真实运行的机房与算力设备,直观感受国家算力网的建设成果。

前沿应用馆彻底化身为机器人的“演武场”。一位“泰拳手”机器人凌厉出击后稳健收势,被“击倒”后竟能如人类般灵活爬起;另一侧,一只机器狗如履平地般攀上高台,完成后还俏皮地模仿起花滑运动员的庆祝动作;而在模拟工厂区域,一名“工人”指挥着数十只机械臂协同作业,宛若“千手观音”。
除了这些“能动”的机器人,更具渗透力的智能体也正在融入日常生活的方方面面。e签宝展示了基于Agent技术的“统一、智能、互信”的全球签署解决方案。

e签宝展区重点呈现了签管一体化AI合同平台和全球化信任服务体系eSignGlobal。e签宝以“统一签、统一管、统一AI”为核心建设理念,致力于打造企业级统一智能签管底座,帮助企业实现跨系统、跨地域、跨法域的合同签署与管理闭环,构建以技术为驱动力的全球数字信任基础设施。
智能合同Agent
2025年,e签宝发布智能合同Agent,实现从“会聊天”到“会干活”的跨越式发展,引领行业智能化升级。e签宝创始人兼CEO金宏洲先生表示,“智能合同Agent不仅是工具,更是企业数字信任体系的‘神经中枢’”。
针对合同文本结构复杂、多栏排版、嵌套条款等行业共性难题,e签宝自主研发了合同魔方引擎,融合多模态文档解析技术、长文本Chunking技术、合同结构化规范,实现跨栏位、跨页面的精准内容提取。该引擎使合同信息识别准确率高达97%,较通用大模型性能提升10%。
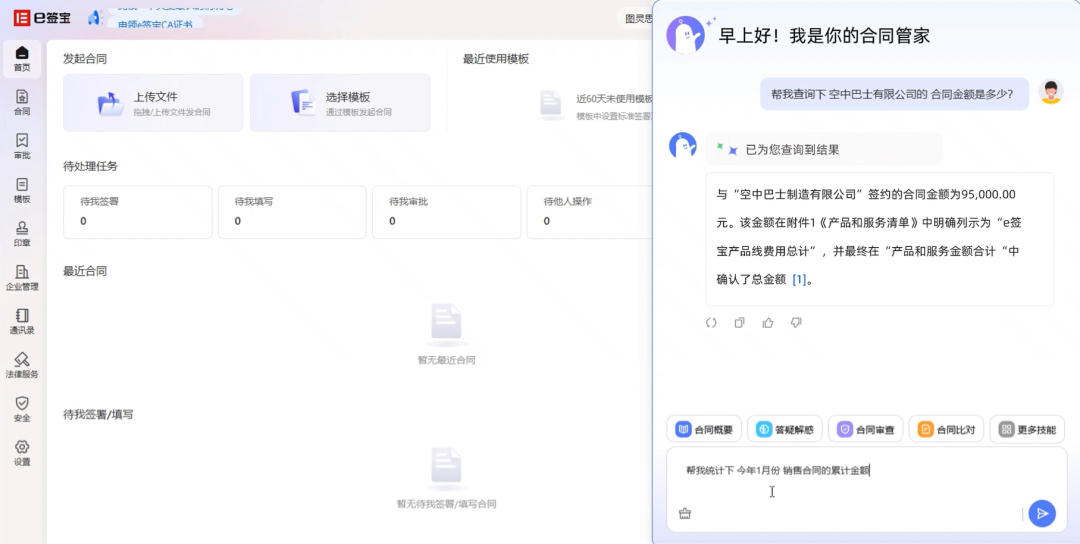
基于深度任务拆解需求,e签宝打造了合同Agent Hub平台,通过“工具增强CoT”技术,结合动态私域知识库与自研工具链,实现复杂合同任务的自动化调度与精准执行。平台可动态优化企业专属知识库,并智能调用嵌入式分析、信息抽取等AI工具,确保业务流程的高效适配。
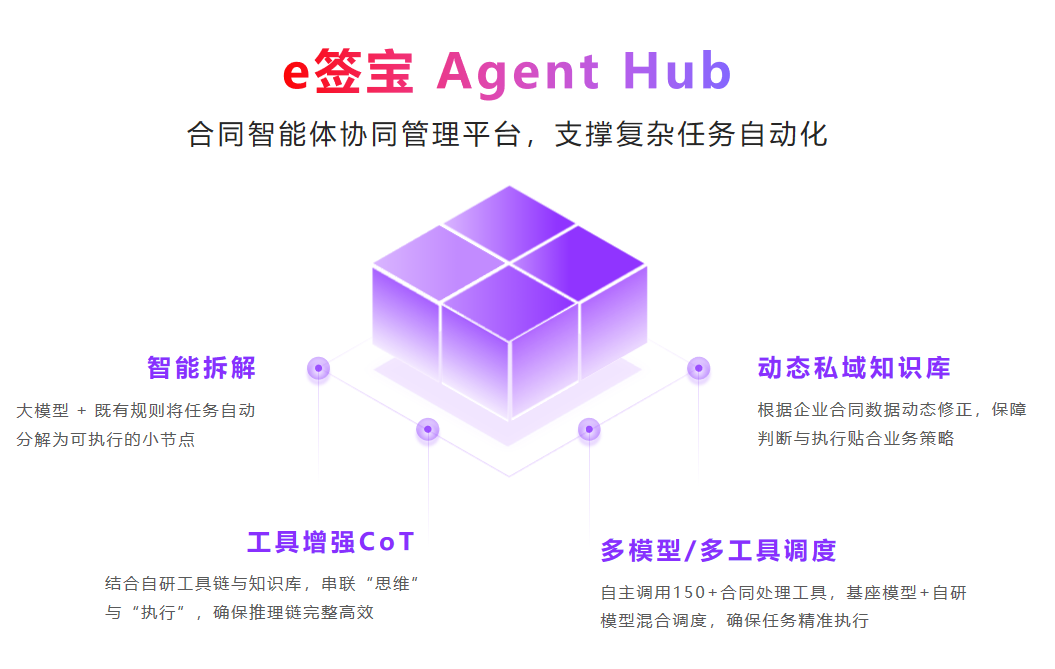
企业的统一智能签管底座
e签宝提出“统一、智能、互信”的全球签署网络理念,通过签管一体化AI合同平台,帮助企业实现合同全生命周期的数字化管理。

统一签:全流程覆盖、全场景适配、全渠道通用。企业使用e签宝后,无论合同来自于CRM、HR系统、OA还是任何业务系统,都能在一个平台上快捷完成签署。即开即用,复杂业务场景也能轻松适配。这种统一性为后续的合同管理、风险识别和AI赋能奠定了基础。
统一管:统管集团组织、统管业务资源、统管合规风控。e签宝平台能够集中管理企业的合同、印章和组织流程。AI会自动进行智能归档,高效检索合同,并提取关键信息方便后续自动化管理。智能印控中心可确保印章被安全使用,避免违规用印风险,保障体系稳定发展。
统一AI能力确保了企业合同数据的安全性与可靠性。e签宝将所有合同AI能力集中在同一平台上运行,串联全业务流程,避免数据外泄,确保在企业安全范围内处理敏感合同数据,保障安全合规。同时,这些AI能力通过API或MCP服务形式开放,可集成到企业各业务系统中。
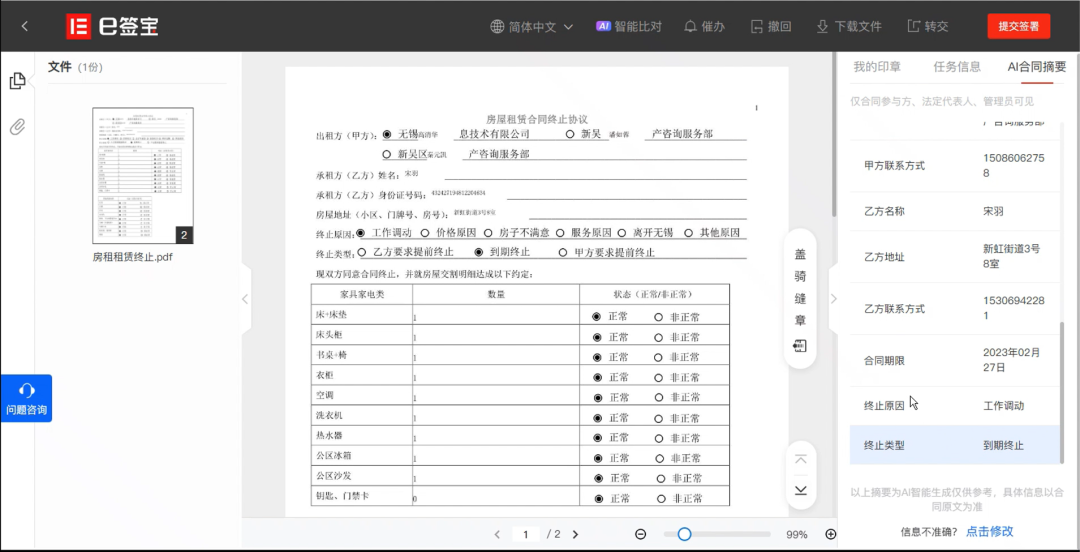
eSignGlobal全球合规签署
面对企业全球化运营的需求,e签宝推出了eSignGlobal全球签署服务。eSignGlobal遵循全球各地的相关法规,在中国香港、新加坡、法兰克福设立独立数据中心,通过TrustHub服务连接各地权威的CA机构,确保电子签名的本地化合规性。
e签宝已经从单纯的电子签名服务发展为全方位的数字信任基础设施提供者。截至2025年8月,eSignGlobal已与16个国家和地区签约,服务覆盖全球97个国家和地区,构建起了跨地域、跨法域的“信任网络”。
根据全球权威机构MarketsandMarkets报告,e签宝以“亚太第一、全球第六”的排名跻身全球电子签名领域第一梯队,成为中国唯一跻身全球电子签名领域前十的企业。
AI普惠:让信任更简单的使命践行
“让签署更便捷,让信任更简单”是e签宝的使命。在AI技术赋能下,这一使命正得到更深层次地践行。
2023年,e签宝发布了自己的合同大模型,基于此开发的智能合同产品在商业化方面取得了显著成绩。AI收入占e签宝整体收入的比例已达到20%以上,公司从SaaS到AI的转型相当成功。

今年4月,e签宝在新加坡面向全球发布了AI合同Agent,将智能合同产品进一步升级为Chat交互为主的Agent方式。在过去的半年中,e签宝AI能力的调用量显著增长:智能归档能力达3425万次、智能台账850万次,风险审查11万次,合同比对33万次。
e签宝的AI技术正在深入生活的各个角落。年轻人利用e签宝的AI合同生成能力创建恋爱协议、分手协议、合租协议、宠物共养协议等。这些应用场景完全由用户自己创造,展现了AI技术的普惠价值

“让全球1/4的人用e签宝签合同”,这是e签宝十年前写下的愿景。经过10年努力,这一愿景已取得了显著进展。随着“技术+合规+生态”战略的持续深化,e签宝正以“中国方案”重塑全球信任体系。
如今,e签宝正在构建一个“统一、智能、互信”的全球签署网络,推动全球数字信任基础设施的演进与升级,更深层次地践行“让签署更便捷,让信任更简单”的使命。
开源鸿蒙技术大会2025 | IDE分论坛:聚焦AI驱动的开发工具革新,探索下一代IDE前沿技术
9月27日,开源鸿蒙技术大会2025 IDE分论坛在湖南长沙国际会议中心举行。本次论坛由华为软件IDE实验室技术专家邓成瑞和复旦大学计算与智能创新学院副院长彭鑫担任出品人,共设置9个议题,邀请学术界的教授、企业界专家做精彩分享。论坛聚焦AI驱动的开发工具革新,围绕产业界AI深度融合的开源鸿蒙应用开发实践,探讨在Agentic IDE、自然语言交互等下一代IDE技术的前沿探索。
IDE分论坛成功举办
华为软件IDE实验室技术专家邓成瑞分享了议题《基于BitFun Platform 赋能鸿蒙应用 AI 驱动开发新体验》。BitFun Platform作为华为研发的IDE平台,致力于构建下一代AI Native IDE,打造鸿蒙全场景开发效率与体验利器。BitFun Platform通过打造“快”+“智”的高性能IDE基础底座,在此基础上带来“创”“读”“写”“调”全方位的开发体验提升:“创”,全新的页面创建体验,多模交互生成自带逻辑的页面代码,支持100%预览,实现即时反馈;“读”,全新的代码阅读体验,通过自然语言+图形化符号系统,降低认知;“写”,全新的代码心流编辑体验,一路Tab到底、跨文件预测生成;“调”,AI引导开发者完成性能调优,打造全新的调优体验,让每个普通开发者都成为性能调优专家。
华为软件IDE实验室技术专家邓成瑞
华为终端BG开发者平台能力首席专家刘金华分享了议题《基于AI大模型的下一代开发者环境趋势洞察》,介绍了大模型在软件工程领域的行业发展的历史、趋势和竞争格局,总结了AI辅助开发的重要性和AI主动/自动开发的演进;对比分析了Cursor的三种模式,Trae的SOLO模式以及Claude Code的零层架构和功能示意;最后就AI Agent编程带来的软件开发模式的系统性重构做畅想。
华为终端BG开发者平台能力首席专家刘金华
北京航天航空大学教授石琳分享了最新的研究《新一代智能IDE的能力建设:个性化代码智能》,指出当前AI辅助开发的核心痛点是个性化智能缺失,造成“智能反成负担”的体验落差。而造成个性化智能缺失的本质是“细粒度知识建模”的困难,针对这一难题给出了解决方案“VirtualME”。VirtualME可以做到从Log-level行为抽取到Task-level行为摘要,为后续开发者个性化建模提供可解释的数据基础。根据开发者的个性画像和查询意图,自动检索相关开发资料,并生成符合其习惯与水平的定制化答案。此外还分享了VirtualME的实验结果——VirtualME在确保回答的正确性不受影响的情况下,个性化体验显著提升,总体评分提升33.80%。最后,对于个性化代码智能最终将发展为构建群体智慧驱动的Agent这一目标进行了展望。
北京航天航空大学教授石琳
GitCode深圳公司总经理徐建国以《GitCode与AI的深度融合:鸿蒙应用开发新纪元》为题,揭示AI技术对开发效率的颠覆性提升。GitCode通过AI能力实现三大突破:智能文档生成效率提升500%,大幅减少开发者文档撰写成本;自动化测试生成效率提升300%,加速测试环节闭环;代码补全准确率达95%,降低编码错误率。借助语义理解、动态意图推理与分布式架构,成功打造“流程连续性”开发体验,彻底改变传统开发模式,让鸿蒙应用开发更智能、更高效。同时GitCode AI社区将为广大的开发者提供更多模型、数据集与开发者共建AI社区新生态,给开源鸿蒙注入更多AI能力。
GitCode深圳分公司总经理徐建国
复旦大学计算与智能创新学院副院长、教授彭鑫
南京大学软件学院副院长、教授卜磊分享了议题《主动逐步精化式人机融合编程方法与支撑环境》,探讨大模型时代的人机融合可信编程新范式,介绍了基于主动逐步精化机制的人机融合编程方法。该技术通过将软件工程领域经典的逐步精化式编程机制引入大模型辅助编程,将从自然语言需求到最终代码的编程过程进行逐层拆分,在各层级的编制阶段引入程序员的确认与修正,帮助程序员来理解大模型所生成的代码并承担起代码可信保障的主体责任,从而试图针对编程效率、成本、以及代码可信度这一不可能三角进行突破。
南京大学软件学院副院长、教授卜磊
华为鸿蒙突击队IDE技术专家俞佳嘉分享了《鸿蒙应用线上稳定性治理实践》,从与伙伴合作的一线视角介绍了大型鸿蒙应用的线上稳定性现状。针对当前鸿蒙应用的线上稳定性痛点问题,提出了围绕检测、分析、优化、运维多维度的稳定性治理体系解决方案。同时,以内存泄漏为例介绍了多个ArkTS和Native的内存泄漏问题分析和解决的典型案例。最后,对于鸿蒙应用的线上稳定性治理目标进行了总结和展望,并与现场嘉宾进行了热烈的讨论。
华为鸿蒙突击队IDE技术专家俞佳嘉
百度文心快码团队高级经理彭云鹏分享了议题《Agent时代软件研发工作台》,认为软件工程智能化已进入智能体组合阶段,通过多智能体的串联、组合、对抗,实现对可解决问题的复杂度和生成结果准确度的提升。以百度为例,全集团AI代码生成占比即将突破50%,实现在代码产出上人与AI贡献比例的反转,软件工程师的智能化变革也即将到达分水岭。在百度,工程师通过文心快码智能体,实现Figma设计稿、图片等素材直接转换代码,自然语言描述解决后端需求和调试问题,极大提升了工程师的研发效率。在此赋能下,百度人均需求交付吞吐量提升了26%,即平均每个人多干了26%的工作,同时全集团缺陷数量也下降了15%,极大提升了百度研发效率和质量,加速业务的创新落地。
百度文心快码团队高级经理彭云鹏
阿里云计算有限公司通义灵码核心研发工程师彭佳汉分享了议题《Agentic Coding平台Qoder助力开源项目研发》,回顾了AI Coding从代码补全迈向任务级协作的演进历程,系统剖析其在效率提升与工程落地中的机遇与挑战;深入解析Agentic Coding平台Qoder的整体架构与核心技术,并重点介绍了智能上下文引擎、Repo Wiki、Memory系统及Quest Mode等模块,以及各个模块间如何协同实现对项目语义的深度理解,使AI真正“看懂代码、理解需求”;通过开源鸿蒙实战案例展现Qoder如何无缝融入真实开发流程,在复杂任务中显著提升效率,为Vibe Coding提供强有力支持。最后总结了AI Coding落地的关键经验,探讨AI Coding的未来发展方向,强调从“能用”到“好用”的体验跃迁,推动AI Agent成为可信赖的开发伙伴。
阿里云计算有限公司通义灵码核心研发工程师彭佳汉
本次IDE分论坛现场氛围高效热烈,与会者积极提问、互动讨论,嘉宾深入讲解、详细介绍,通过技术思想的深度碰撞,让基于AI的智能开发不再是构想。学术界的前沿研究和企业界的创新实践相融合,助力探索并创造出下一代智能开发平台和开发新范式。
大会还设置了展台,展示了华为IDE实验室的BitFun Platform。BitFun Platform是华为公司研发的下一代原生智慧化IDE技术平台,同时也是一个全新智慧化交互形态、支持多OS平台独立运行的通用IDE,为 DevEco Studio提供高性能底座和先进性能力,为鸿蒙应用开发者带来高性能、智慧化的全新交互体验。
BitFun IDE Platform展台
为参会嘉宾介绍BitFun Platform
基于BitFun Platform强大的代码开发和AI能力平台,提供了Project Insight、Flow Editor、鸿蒙页面智能生成、智慧调优等AI辅助编程工具,帮助开发者高效开发鸿蒙应用及元服务。
收起阅读 »开源鸿蒙技术大会2025圆满召开,全景交流区解码万物智联生态密码
9月27日,开源鸿蒙技术大会2025在长沙国际会议中心盛大举办。大会现场同步亮相开源鸿蒙社区公共交流区、开源鸿蒙项目群技术指导委员会(TSC)交流区、开源鸿蒙伙伴交流区、开源鸿蒙三方社区交流区、基础软件底座技术交流区。作为大会的重要组成部分,专题交流区既集中展示了开源鸿蒙五年来的技术迭代与生态建设成果,也汇聚了产业、学术、研发与应用等多方力量,成为协同创新的价值交汇点。从生态全景的宏观呈现到技术细节的深入解读,从人才培养的系统布局到产业落地的生动实践,专题交流区共同描绘出开源鸿蒙作为智能终端操作系统根社区的发展脉络与未来图景。
开源鸿蒙社区公共交流区盛大开放,全景呈现开源五周年生态共建硕果
开源鸿蒙社区公共交流区以数据与图谱为笔,生动描绘了开源五年来的共建硕果。作为生态规模与技术实力的直观载体,社区公共交流区以共建地图4.0、SIG地图、产品地图及首次亮相的480余家伙伴全国分布地图,生动铭刻了开源鸿蒙汇聚68个特别兴趣小组(SIG)、超9300位活跃贡献者共创1.3亿行代码、推动1300余款产品成功落地的壮阔征程。 开发者生态全新推出“故事生态纪2025”,通过社区代表案例生动展现开发者成长历程;“开发者π队”创新组织与升级后的开发者激励体系,通过对接社区真实开发任务实现人才培育与技术攻坚的同频共振;同时,SIG组活动地图清晰标注了2025年以来多场技术沙龙的全国布局,展现出社区技术交流的常态化与深度化。
开源鸿蒙社区公共交流区
开源鸿蒙社区公共交流区
开源鸿蒙项目群技术指导委员会(TSC)交流区展示高校创新成果,锚定技术演进方向
在本次大会上,开源鸿蒙项目群技术指导委员会(TSC)特别设立专题交流区,重点展示了十家高校社团的创新成果。高校力量的深度参与彰显了开源鸿蒙源源不断的技术创新活力,更体现了开源鸿蒙在产学研深度融合方面的前瞻性布局。开源鸿蒙项目群技术指导委员会(TSC)旨在建设国内公开的操作系统技术交流社区,提供技术交流和产学研碰撞的平台,打造开源鸿蒙社区的技术影响力。自成立以来,开源鸿蒙项目群技术指导委员会(TSC)积极推动开源鸿蒙技术生态的发展,持续明确并迭代技术愿景与实施策略,系统性识别关键技术课题,积极孵化具有影响力的技术项目,拓展开源鸿蒙在众多行业领域中的广泛应用。
开源鸿蒙项目群技术指导委员会(TSC)交流区
开源鸿蒙伙伴交流区呈现产业落地成果,勾勒行业转型图景
伙伴交流区是开源鸿蒙产业价值的“实践窗口”,20余家成员单位集中亮相,展现了“Powered by OpenHarmony”从基础软件、芯片模组到操作系统、智能硬件、行业应用的全链条成果,勾勒出开源鸿蒙在千行万业加速落地的图景。
开源鸿蒙伙伴交流区
华为展区为大家带来了鸿蒙全家桶产品,并设置有鸿蒙智行鉴赏专区,方便消费者一站式体验1+8+N的全场景智慧服务。最新上市的华为智慧屏Mate TV、华为Mate XTs,以及全新形态的HUAWEI FreeClip 2耳夹耳机、鸿蒙智家蒙德里安智能面板等丰富品类的产品,均搭载了HarmonyOS 这一基于开源鸿蒙开发的新一代智能终端操作系统。得益于这一系统,不同设备的智能化、互联与协同,都遵循统一的语言。设备可实现一碰入网、无屏变有屏、操作可视化等全新功能。搭载HarmonyOS 的每个设备都不再是孤立的,在系统层让多终端融为一体,成为“超级终端”,实现终端之间能力互助共享,带来无缝协同体验。
华为终端交流区
鸿蒙智行鉴赏区
湖南开鸿智谷数字产业发展有限公司深度赋能开源鸿蒙,展出了基于在鸿OS的全栈技术体系,覆盖芯片模组至行业应用的完整产业级落地实力。现场不仅展示了从人才培养到底层技术的全链条成果,还通过工业、教育等实景DEMO生动呈现了分布式架构、一次开发多端部署及AI融合感知等核心特性,吸引众多观众深入体验与交流。
开鸿智谷交流区
江苏润开鸿数字科技有限公司基于开源鸿蒙与RISC-V、星闪和AI三大技术深度融合,打造了基于开源鸿蒙的HiHopeOS全栈技术底座,持续赋能多元产业应用。现场发布的DAYU300与DAYU600分别面向PC和移动智能终端,入选开源鸿蒙主干代码开发平台;同时,星闪物联智能家居DEMO首次亮相,为与会者带来“开源鸿蒙+星闪”的全新体验。
润开鸿交流区
北京中科鸿略科技有限公司在交流区基于开源鸿蒙打造了一个政务无纸化会议场景,利用开源鸿蒙的分布式软总线特性,实现了智慧会务空间与无纸化会议系统的无感互联,以及富设备与瘦设备间的互联互控。
中科鸿略交流区
开源鸿蒙三方社区交流区搭建跨界协同桥梁,彰显开源包容特质
三方社区交流区彰显了开源生态的开放包容,为跨界协同搭建桥梁。GitCode以“开源运营即服务”、“开源模型即服务”两大体系深化开发者社区联结;黄大年茶思屋依托1.9亿条专利数据与全球科研资源,成为技术与创新的连接枢纽;智元灵渠开发者社区通过开源机器人开发框架与操作系统,推动具身智能领域的生态共建。这些生动的展示充分践行了开放、共建的发展理念,也为开源鸿蒙注入更广泛的创新力量。
三方社区交流区
全栈基础软件突破进展集中亮相,一览技术创新的前沿探索
全栈基础软件的持续突破,是开源鸿蒙未来竞争力持续领先的发动机,也是支撑产业生态繁荣的坚实底座。本届大会上,仓颉编程语言&毕昇编译器交流区、应用生态开源技术交流区、BitFun IDE Platform、网络安全、GaussPD鸿蒙智能数据内核、FAST应用加速套件、方天视窗&鸿途Web、鸿蒙内核等基础软件关键技术成果集中亮相,全面展示了开源鸿蒙在根技术层面的深度探索与持续突破。
基础软件底座技术交流区
基础软件的持续突破,与大会现场其他交流区的多元展示相互呼应,共同勾勒出开源鸿蒙的全景图谱。从生态全景的呈现到技术底座的深耕,从人才培育的布局到产业落地的实践,每一处展示都在诠释一个核心逻辑:开源不是单点突破的工具,而是构建万物智联数字底座的系统工程。面向未来,随着更多伙伴的加入与技术的持续演进,开源鸿蒙必将在智能化时代的浪潮中,为千行万业的数字化转型注入更强劲的动力。
收起阅读 »

