








低代码是“未来”还是“骗局”?作为前端我被内耗到了
「我一个前端,最后成了平台数据填表员,写页面?不存在的。」
😅项目开始前,我是兴奋的
当领导说“这个项目我们用低代码平台做,提效百分百”,我甚至有点激动。
作为一个写了 5 年组件的前端老油子,谁不想脱离日复一日的 v-model 和 props 地狱?
领导还补充:“平台我们组自己封装的,配个 schema 就能跑,前端工程师只需要写逻辑。”
我一听这话,心想:
终于要进入“写配置赚钱”的时代了!
然而,我万万没想到——这段低代码旅程,最后让我怀疑人生。
😵上线第一天,我差点把键盘砸了
第一个需求很简单:
做个带搜索、分页、导出 Excel 的用户列表页。
我打开平台,选择“表格组件”,拖入“搜索框”,配置字段、绑定接口——一切都看起来毫无门槛。
结果运行之后,搜索没反应、分页错乱、导出根本没绑定。
我一查 schema,300 多行配置里,居然混了三种不同的写法:
{
"onSearch": "handleSearch",
"onSearch()": "handleSearch",
"onSearchEvent": "handleSearch"
}
问后端:“你这个文档是哪个是对的?”
后端说:“都对,我们兼容了。”
我瞬间明白:这不是低代码,这是自制混沌生成器。
🤯技术债太多,修个 key,整页全崩
最魔幻的一次,是我想修改表格的一个字段名,从 user_name 改成 username。
我只是改了 schema 的字段名,结果:
- 表格没显示
- 搜索没了
- 编辑表单也报错
- 提交接口直接抛了个 500
我调试了三个小时,才发现平台内部是按字段名 字符串拼接 key 绑定状态 的……只要字段名变了,所有逻辑都得重配。
我恍然大悟:
传统开发用 IDE 报错提醒你;低代码等你点击线上按钮才告诉你挂了。
😓协作地狱:产品配页面,我修 schema
最痛苦的不是技术问题,而是人。
产品说:“我来拖页面,你只用帮我看看为什么点了没反应。”
然后我收到一个 schema 文件,2000 行,不带注释,结构是这样:
{
"component": "Form",
"props": {
"items": [
{
"label": "名称",
"field": "formA.formB.userName",
"rules": "{ required: true }",
"props": {
"onClick": "fn1()"
}
}
]
}
}
我想问三件事:
- 你这个路径到底是怎么拼出来的?
- 为什么校验规则是字符串?
- 你拖了个按钮怎么会触发五个请求?
我调试一天,结论是:产品误操作删除了一个容器组件,但平台没报错,直接让数据结构断链。
🧨所谓低代码:把逻辑封死、把锅甩你
我总结这个项目两个最深的坑:
1. 复杂交互,低代码写不来
比如“用户选择类型后,自动拉接口重新加载选项”这种需求,纯配置根本搞不定。
最后我只能写自定义组件注入到平台里,甚至还要写类似:
platform.on("fieldChange", (field, value) => {
if (field === "type") {
reloadOptions(value)
}
})
这叫低代码吗?我写的代码比原来还绕。
2. 前端不是没活了,是变成了“修配置+查日志工程师”
- 页面功能跑飞了?前端看 schema;
- 按钮不响应?前端查绑定字段;
- 接口返回异常?前端加拦截 hook;
- 表单校验失败?前端写正则规则;
最后我只写了两行 JS,却维护了十几套 JSON。
我真的开始怀疑,前端的价值,是不是变成了“修别人的 schema”?
🧩我从这个项目学到的东西
不是说低代码没用,而是:
不是所有团队都配拥有一套低代码平台。
低代码系统真正的“提效”,需要这些前提:
- 强约束的规范体系(字段、组件、交互都必须有标准)
- 良好的权限隔离机制(避免“产品能改逻辑,运营能删字段”)
- 持续有人维护平台底层能力(不然技术债只会越来越重)
- 合理的分工协作机制(schema 的维护不应该是前端一个人干)
否则,它只是一个混乱责任分配工具,表面上 everyone can build,实际上 everyone push bugs。
📌低代码,不是骗局,也不是未来——是一个选项
如果你问我现在怎么看低代码?
我的回答是:
低代码不是“未来”也不是“骗局”,而是“项目管理方式的折中”。
它适合一些场景:
- 表单多、CRUD 重复度高的后台系统;
- 业务快速试错、页面变动频繁的 MVP 阶段;
- 运营自己想搭点落地页的场景。
但如果你希望:
- 页面复杂,交互灵活;
- 可测试、可维护、可拓展;
- 高性能、大工程;
那——你得写代码。
🗣最后
你也踩过低代码的坑吗?
有没有类似“debug 三小时发现产品配错 schema”的经历?
📌 你可以继续看我的《为什么》系列文章
来源:juejin.cn/post/7514611888991387667
前端难还是后端难?作为八年后端开发,我想说点实话
前端难还是后端难?作为八年后端开发,我想说点实话
前端容易吗?不容易。
后端轻松吗?也不轻松。
那到底哪个更难?
这事还真不是一句话能说清楚的……
一、先说说我个人的背景
我是一个写了 8 年 Java 后端的程序员,经历过中后台系统、金融系统、ToC App 的服务端架构,也跟前端打了无数交道。从最早的 jQuery 到现在的 Vue、React、Vite,从最早的 JSP 页面到现在的前后端分离,我见证了不少“变化”。
我不是要拉踩谁,只是想以一个偏后端开发者的视角,聊聊我对“前端难还是后端难”这个话题的理解。
二、前端的“难”是不断变化的“浪潮”
不得不承认,前端的变化速度是真的快。去年刚学完 Vue 2,今年要学 Vue 3;React 的 Hook 还没深入掌握,新的 Server Component 又来了;Webpack 配熟了,Vite 火了;CSS 还没写顺手,Tailwind 席卷而来。
除了框架和工具链的变化,更别说适配各种浏览器、屏幕尺寸、终端设备、无障碍要求、多语言、性能优化、SEO、交互设计……
而且最近几年,前端逐渐“全栈化”:你可能要写服务端渲染(SSR)、搞 Node 服务、上 Docker 部署、调数据库、甚至自己写接口 mock。
前端难吗?难,而且是越来越难。
三、后端的“难”是看不见的深度
后端的难,往往藏在系统的底层逻辑中。你可能看不到一个后端接口的“UI 效果”,但它背后往往涉及:
- 数据库设计 & 索引优化
- 分布式事务
- 消息队列 & 异步处理
- 缓存策略 & 数据一致性
- 服务容灾 & 高可用架构
- 权限系统、加密解密、审计日志
- 安全防护(SQL 注入、XSS、CSRF)
- 性能调优 & JVM 调试
- CI/CD、灰度发布、日志平台接入
而且一旦出问题,前端崩了是“用户体验不好”,后端崩了是“公司赔钱” 。这不是开玩笑,有一次我们一个订单服务接口挂了 5 分钟,损失了几十万。
后端难吗?当然难,而且是“看不见但不能错”的难。
四、我最怕的不是“前端难”或“后端难”,而是互相看不起
说实话,我见过太多前后端互相“看不上”的情况:
- 后端觉得前端就是摆样子,“你不就封个壳子嘛?”
- 前端觉得后端接口又臭又长,“你这 JSON 谁看得懂?”
- 后端吐槽前端不会调接口,前端吐槽后端不会写文档……
但你仔细去看,一个优秀的前端开发,往往比很多“伪全栈”更懂系统结构;一个优秀的后端,也会在意接口的易用性、响应速度和文档清晰度。
技术没有高低,但人有格局。
五、站在“代码人生”的角度看,难易是阶段性的
我年轻的时候觉得后端“更高级”,因为能接触系统底层、数据和业务逻辑。但这几年,我越来越觉得前端也有它独特的价值:
- 是前端让用户第一眼喜欢上产品;
- 是前端让复杂的系统变得“看得见”;
- 是前端在用户和系统之间,搭了一座桥。
你说哪个更重要?没有谁离开谁就能独立运行的系统。
我现在更看重的是协作、共建、以及对整个产品的理解。做前端也好,后端也罢,最终我们解决的都是“人”的问题 —— 让人更高效、更便捷、更愉快地使用系统。
六、那到底哪个更难?
如果你非要我选一个答案,我只能说:
哪个你不熟,哪个就难。
前端和后端,都有容易入门但难以精进的曲线。你用 jQuery 写个页面不难,但你做一个大型可维护的组件库就难了;你写个 CRUD 接口不难,但你做一个高并发分布式系统就非常难。
真正的难点在于:你愿不愿意持续去深入、去理解、去完善自己的认知体系。
七、写在最后:别问“哪个难”,问“你想走多远”
我见过写前端写到年薪百万的,也见过写后端写到身心俱疲的。
我见过全栈工程师一人顶两人,也见过只会写“增删改查”却年薪 30w 的老哥。
这行最不缺的,就是例外;最需要的,是清醒的自我认知。
别纠结哪个更难,多花时间让自己变强,才是正解。
**你觉得前端难,还是后端难?你有没有在项目里遇到“前后端合作”的那些故事?欢迎评论区聊聊.
来源:juejin.cn/post/7516897654170222592
进入外包,我犯了所有程序员都会犯的错!
前言
前些天有位小伙伴和我吐槽他在外包工作的经历,语气颇为激动又带着深深的无奈。
本篇以他的视角,进入他的世界,看看这一段短暂而平凡的经历。
1. 上岸折戟尘沙
本人男,安徽马鞍山人士,21年毕业于江苏某末流211,在校期间转码。
上网课期间就向往大城市,于是毕业后去了深圳,找到了一家中等IT公司(人数500+)搬砖,住着宝安城中村,来往繁华南山区。
待了三年多,自知买房变深户无望,没有归属感,感觉自己也没那么热爱技术,于是乎想回老家考公务员,希望待在宇宙的尽头。
24年末,匆忙备考,平时工作忙里偷闲刷题,不出所料,笔试卒,梦碎。
2. 误入外包
复盘了备考过程,觉得工作占用时间过多,想要找一份轻松点且离家近的工作,刚好公司也有大礼包的指标,于是主动申请,辞别深圳,前往徽京。
Boss上南京的软件大部分是外包(果然是外包之都),前几年外包还很活跃,这些年外包都沉寂了不少,找了好几个月,断断续续有几个邀约,最后实在没得选了,想着反正就过渡一下挣点钱不寒碜,接受了外包,作为WX服务某为。薪资比在深圳降了一些,在接受的范围内。
想着至少苟着等待下一次考公,因此前期做项目比较认真,遇到问题追根究底,为解决问题也主动加班加点,同为WX的同事都笑话我说比自有员工还卷,我却付之一笑。
直到我经历了几件事,正所谓人教人教不会,事教人一教就会。
3. 我在外包的二三事
有一次,我提出了自有员工设计方案的衍生出的一个问题,并提出拉个会讨论一下,他并没有当场答应,而是回复说:我们内部看看。
而后某天我突然被邀请进入会议,聊了几句,意犹未尽之际,突然就被踢出会议...开始还以为是某位同事误触按钮,然后再申请入会也没响应。
后来我才知道,他们内部商量核心方案,因为权限管控问题,我不能参会。
这是我第一次体会到WX和自有员工身份上的隔阂。
还有一次和自有员工一起吃饭的时候,他不小心说漏嘴了他的公积金,我默默推算了一下他的工资至少比我高了50%,而他的毕业院校、工作经验和我差不多,瞬间不平衡了。
还有诸如其它的团建、夜宵、办公权限、工牌等无一不是明示着你是外包员工,要在外包的规则内行事。
至于转正的事,头上还有OD呢,OD转正的几率都很低,好几座大山要爬呢,别想了。
3. 反求诸己
以前网上看到很多吐槽外包的帖子,还总觉得言过其实,亲身经历了才刻骨铭心。
我现在已经摆正了心态,既来之则安之。正视自己WX的身份,给多少钱干多少活,给多少权利就承担多少义务。
不攀比,不讨好,不较真,不内耗,不加班。
另外每次当面讨论的时候,我都会把工牌给露出来,潜台词就是:快看,我就是个外包,别为难我😔~
另外我现在比较担心的是:
万一我考公还是失败,继续找工作的话,这段外包经历会不会是我简历的污点😢
当然这可能是我个人感受,其它外包的体验我不知道,也不想再去体验了。
对,这辈子和下辈子都不想了。
附南京外包之光,想去或者不想去的伙伴可以留意一下:

来源:juejin.cn/post/7511582195447824438
为什么说 AI 时代,前端开发者对前端工程化的要求更高了❓❓❓
前端工程化在前端领域地位极高,因为它系统性地解决了前端开发中效率、协作、质量、维护性等一系列核心问题,可以说是现代前端技术体系的基石。
前端工程化带来的价值可以从这四个方面看:
- 提升开发效率:
- 模块化开发:通过组件、模块拆分使开发更加清晰,复用性更强。
- 自动化构建:Webpack、Vite 等工具自动处理打包、压缩、转译等。
- 代码热更新 / HMR:开发过程中能实时看到改动,节省调试时间。
- 规范团队协作
- 代码规范检查:如 ESLint、Stylelint 统一代码风格,避免“风格大战”。
- Git 提交规范:如使用 commitlint + husky 保证提交信息标准化。
- 持续集成(CI):如 GitHub Actions、Jenkins 保证每次提交自动测试、构建。
- 提升代码质量和可维护性
- 单元测试 / 集成测试:如 Jest、Cypress 确保代码稳定可靠。
- 类型系统支持:TypeScript 保证更严格的类型检查,降低 Bug 率。
- 文档生成工具:如 Storybook、jsdoc 方便维护和阅读。
- 自动化部署与运维
- 自动化构建发布流程(CI/CD)使得上线更安全、更快速。
- 多环境配置管理(开发/测试/生产)更加方便和稳定。
总的来说,前端工程化让开发者从单纯的 “切图仔” 成长为能够参与大型系统开发的工程师。通过引入规范与工具,不仅显著提升了团队协作效率,还有效减少了开发过程中的冲突与返工,成为现代前端团队协作的 “润滑剂”。
什么是前端工程化
前端工程化 大约在 2018 年前后在国内被广泛提出,其核心是将后端成熟的软件工程理念、工具与流程系统性地引入前端开发。
它旨在通过规范、工具链与协作流程,提升开发效率、保障交付质量、降低维护成本。前端工程化不只是技术选型,更是一种体系化、流程化的开发方式。
其核心包括代码规范、自动化构建、模块化设计、测试体系和持续集成等关键环节。通过工程化,前端从“写页面”转向“做工程”,实现了从个体开发到团队协作的转变。
它不仅优化了前端的生产方式,也推动了大型系统开发中前端角色的重要性。如今,前端工程化已成为现代前端开发不可或缺的基础能力。
为什么 AI 时代,前端工程化更重要
在 AI 时代,前端工程化不仅没有“过时”,反而变得更重要,甚至成为人机协作高效落地的关键基石。原因可以从以下几个方面理解。
虽然 AI 可以辅助生成代码、文档甚至 UI,但它并不能替代工程化体系,原因有:
- AI 的代码质量不稳定:没有工程化流程约束,容易引入 Bug 或不一致的风格。
- AI 更依赖工程规范作为提示上下文:没有良好的工程结构,AI 输出也会混乱低效。
- AI 更像“助理”,而非“工程师”:它执行快,但依然需要工程体系保障产出质量和集成稳定性。
最差的情况下有可能会删除或者修改你之前已经写好的代码,如果缺少这些工程化的手段,你甚至不知道它已经修改你的代码了,最终等到上线的时候无数的 bug 产生。
通过标准化输出让 AI 更智能,清晰的项目结构、代码规范、模块划分能让 AI 更准确地补全、修改或重构代码。例如 ESLint、TypeScript 的规则为 AI 提供了明确的限制条件,有助于生成更高质量的代码。
在生成的代码需要规范,生成完成之后更需要检验,大概的流程也有如下几个方面:
- 格式化检查(Prettier、ESLint)
- 单元测试(Jest)
- 构建打包(Vite/Webpack)
- 自动部署(CI/CD)
没有工程化,AI 产出的代码难以被真正“上线使用”。
AI 时代,对一些 CRUD 的简单要求减少了,但是对工程化提出了更高要求。
| 方面 | 普通时代要求 | AI 时代新挑战 |
|---|---|---|
| 模块结构 | 清晰划分 | 需辅助 AI 理解上下文 |
| 代码规范 | 避免团队矛盾 | 指导 AI 输出符合规范 |
| 自动化测试 | 保证功能正确 | 验证 AI 代码不会引发异常 |
| CI/CD 流程 | 提升上线效率 | 确保 AI 代码自动验证上线 |
前端工程化
接下来我们将分为多个小节来讲解一下前端工程化的不同技术充当着什么角色。
技术选型
在前端工程化中,技术选型看似是一道“选择题”,本质上却关系到项目的开发效率、团队协作和未来的可维护性。对于框架选择而言,建议优先考虑两个关键因素:
- 团队熟悉程度:选择你或团队最熟悉的框架,能确保在遇到复杂或疑难问题时,有人能迅速定位问题、解决“坑点”,避免因为不熟悉而拖慢项目进度。
- 市场占有率与人才生态:选择主流、活跃度高的框架(如 Vue、React),不仅能更容易找到合适的开发者,还意味着有更丰富的社区资源、第三方生态和维护支持,降低长期人力与技术风险。
统一规范
统一规范又分为代码规范、git 规范、项目规范和 UI 规范。
代码规范
统一代码规范带来的好处是显而易见的,尤其在团队开发中更显重要:
- 提升团队协作效率:统一的代码风格能让团队成员在阅读和理解他人代码时无障碍,提高沟通效率,减少因风格差异带来的理解成本。
- 降低项目维护成本:规范的代码结构更易读、易查、易改,有助于快速定位问题和后期维护。
- 促进高效 Code Review:一致的代码格式可以让审查者专注于业务逻辑本身,而非纠结于命名、缩进等细节。
- 帮助程序员自身成长:遵循良好的代码规范,有助于开发者养成系统化的编程思维,提升工程意识和代码质量。
当团队成员都严格遵循统一的代码规范时,整个项目的代码风格将保持高度一致,看别人的代码就像在看自己的代码一样自然顺畅。
为了实现这一目标,我们可以借助工具化手段来强制和规范编码行为,例如使用 ESLint 检查 JavaScript/TypeScript 的语法和代码质量,Stylelint 统一 CSS/SCSS 的书写规范,而 Prettier 则负责自动格式化各类代码,使其保持整洁一致。
这些工具不仅能在编码阶段就发现潜在问题,还能集成到 Git Hook 或 CI 流程中,确保所有提交的代码都符合团队标准。统一规范减少了 code review 中对格式问题的争论,让团队更专注于业务逻辑的优化。
更重要的是,长期在规范的约束下编程,有助于开发者养成良好的工程素养和职业习惯,提升整体开发质量和协作效率。工具是手段,习惯是目标,工程化规范最终是为了让每一位开发者都能写出“团队级”的代码。
除了上面提到的,还有很多相同功能的工具这里就不细说了。
Git 规范
Git 规范主要指团队在使用 Git 进行代码版本管理时,对分支策略、提交信息、代码合并方式等的统一约定,其目标是提升协作效率、降低沟通成本、保障版本可控。
分支管理规范可以遵循如下 Git Flow 模型:
main # 生产环境分支
develop # 开发集成分支
feature/* # 功能分支
release/* # 发布准备分支
hotfix/* # 线上紧急修复分支
分支重要,提交信息规范也更重要,一份清晰规范的提交信息对后期维护、回滚、自动发布都非常重要,好的提交信息让其他协作人员知道你这个分支具体做了什么。
推荐使用 Conventional Commits 规范,格式如下:
<type>():
常见的
| 类型 | 说明 |
|---|---|
| feat | 新增功能 |
| fix | 修复 bug |
| docs | 修改文档 |
| style | 格式修改(不影响代码运行) |
| refactor | 重构(无新功能或修复) |
| test | 添加测试 |
| chore | 构建过程或辅助工具变动 |
如下示例所示:
feat(login): 添加用户登录功能
fix(api): 修复接口返回字段错误
docs(readme): 完善项目使用说明
配套的工具推荐如下表所示:
| 工具 | 作用 |
|---|---|
| Commitlint | 校验提交信息是否符合格式规范 |
| Husky | Git 钩子管理工具(如提交前检查) |
| lint-staged | 提交前只格式化/检查改动的文件 |
| Standard Version | 自动生成 changelog、自动打 tag 和版本号 |
Git 规范,是让代码“有条不紊”地流动在团队之间的交通规则,是高效协作和持续交付的基础设施。
项目规范
项目规范是对整个项目工程的结构、组织方式、开发约定的一套统一标准,它能帮助团队协作、代码维护、快速上手和高质量交付。
项目目录结构规范可以让项目保持统一、清晰的项目目录结构,有助于快速定位文件、分工协作,如下是一个简单的目录规范:
src/
├── assets/ # 静态资源(图片、字体等)
├── components/ # 可复用的基础组件
├── pages/ # 页面级组件
├── services/ # API 请求模块
├── utils/ # 工具函数
├── hooks/ # 自定义 hooks(React 项目)
├── styles/ # 全局样式
├── config/ # 配置文件(如常量、环境变量)
├── router/ # 路由配置
├── store/ # 状态管理(如 Vuex / Redux)
└── main.ts # 应用入口
这只是一个很简答也很通用的目录结构,还有很多进阶的目录结构方案。
命名方式,这个可以根据不同的团队不同的风格来指定。
部署
借助自动化流程实现一键部署或者自动部署,常用的工具主要有以下:
- GitHub Actions
- GitLab CI
- Jenkins
流程通常如下:
Push → 检查代码规范 → 构建 → 运行测试 → 上传产物 → 通知部署 → 上线
可以参考一下 Action 配置:
name: Deploy Next.js to Alibaba Cloud ECS
on:
push:
branches:
- main
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4.2.0
- name: Set up Node.js
uses: actions/setup-node@v4.2.0
with:
node-version: "22.11.0"
- name: Install pnpm
run: npm install -g pnpm@9.4.0
- name: Deploy to server via SSH
uses: appleboy/ssh-action@v1.2.1
with:
host: ${{ secrets.SERVER_HOST }}
username: ${{ secrets.SERVER_USERNAME }}
port: ${{ secrets.SERVER_PORT }}
password: ${{ secrets.SERVER_PASSWORD }}
script: |
# 显示当前环境信息
echo "Shell: $SHELL"
echo "PATH before: $PATH"
# 加载环境配置文件
source ~/.bashrc
source ~/.profile
# 如果使用 NVM,加载 NVM 环境
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
# 添加常见的 Node.js 安装路径到 PATH
export PATH="$HOME/.nvm/versions/node/*/bin:/usr/local/bin:/usr/bin:/bin:$HOME/.npm-global/bin:$PATH"
echo "PATH after: $PATH"
# 查找 npm 的位置
which npm || echo "npm still not found in PATH"
# 使用绝对路径查找 npm
NPM_PATH=$(find /usr -name npm -type f 2>/dev/null | head -1)
if [ -n "$NPM_PATH" ]; then
echo "Found npm at: $NPM_PATH"
export PATH="$(dirname $NPM_PATH):$PATH"
fi
# 确保目标目录存在
mkdir -p /home/interview-guide
cd /home/interview-guide
# 如果本地仓库不存在,进行克隆
if [ ! -d "/home/interview-guide/.git" ]; then
echo "Cloning the repository..."
# 删除可能存在的空目录内容
rm -rf /home/interview-guide/*
# 使用 SSH 方式克隆
git clone git@github.com:xun082/interview-guide.git .
else
# 确保远程 URL 使用 SSH
git remote set-url origin git@github.com:xun082/interview-guide.git
# 获取最新代码
git fetch origin main
git reset --hard origin/main
fi
# 使用找到的 npm 路径或尝试直接运行
if [ -n "$NPM_PATH" ]; then
$NPM_PATH install -g pnpm@9.4.0
$NPM_PATH install -g pm2
else
npm install -g pnpm@9.4.0
npm install -g pm2
fi
# 安装依赖
pnpm install || npm install
# 构建项目
pnpm run build || npm run build
# 重启应用
pm2 restart interview-guide || pm2 start "pnpm start" --name interview-guide || pm2 start "npm start" --name interview-guide
这段 GitHub Actions 配置实现了将 Next.js 项目自动部署到阿里云 ECS 服务器的流程。它在检测到 main 分支有新的代码提交后,自动拉取代码、安装依赖并构建项目。随后通过 SSH 远程连接服务器,拉取或更新项目代码,并使用 PM2 启动或重启应用。整个流程自动化,无需人工干预,保障部署高效、可重复。
除了 PM2 之外,我们还可以使用 Docker 镜像部署。
🛡️ 监控
前端监控是指:对 Web 应用在用户真实环境中的运行状态进行实时采集与分析,以发现性能瓶颈、错误异常和用户行为,最终帮助开发团队提升系统稳定性和用户体验。
🚦 性能监控
性能监控的目标是衡量页面加载速度、交互流畅度等关键性性能指标。
常见指标:
- 首屏加载时间(FP/FCP)
- 页面完全加载时间(Load)
- 首次输入延迟(FID)
- 长任务(Long Task)
- 慢资源加载(如图片、脚本)
它有助于定位性能瓶颈(如资源过大、阻塞脚本)、优化用户体验(如加载缓慢或白屏问题),并支持性能回归分析,及时发现上线后的性能退化。
❌ 错误监控
错误监控的目标是捕捉并上报运行时异常,辅助开发快速修复 Bug。
常见的错误类型主要有以下几个方面:
| 错误类型 | 示例说明 |
|---|---|
| JS 运行错误 | ReferenceError, TypeError 等 |
| Promise 异常 | unhandledrejection |
| 资源加载失败 | 图片、脚本、字体 404、403 |
| 网络请求异常 | 接口失败、超时、断网等 |
| 跨域/白屏 | CORS 错误、DOM 元素为空 |
| 控制台报错 | console.error() 日志监控 |
| 用户行为异常 | 点击无响应、重复操作、高频异常等 |
假设我们使用了 fetch 进行封装,那么我们就可以对错误进行统一处理,后续我们可以再具体调用的时候根据不同的场景来传入不同的错误提示告知用户:
错误上报
数据上报是指前端在运行过程中将采集到的监控信息(性能、错误、行为等)发送到服务端的过程。它是前端监控从“收集”到“分析”的桥梁。
上报的数据类型主要有以下几个方面:
| 类型 | 说明 |
|---|---|
| 性能数据 | 页面加载时间、资源加载时间、Web Vitals 等 |
| 错误信息 | JS 异常、Promise 异常、请求失败、白屏等 |
| 用户行为 | 点击、跳转、页面停留时间、操作路径等 |
| 自定义事件 | 特定业务事件,如支付、注册等 |
| 环境信息 | 浏览器版本、设备类型、操作系统、用户 IP 等 |
数据上报需要重点考虑的几个关键因素:
- 怎么上报(上报方式)
- 使用 sendBeacon、fetch、img 打点还是 WebSocket?
- 是否异步?是否阻塞主线程?
- 是否需要加密、压缩或编码?
建议:选择 异步非阻塞 且浏览器支持好的方式(优先 sendBeacon),并对数据做统一封装处理。
- 何时上报(上报时机)
- 立即上报:错误发生后马上发送(如 JS 报错)
- 延迟上报:页面稳定后延迟几秒,防止干扰首屏加载
- 页面卸载前上报:用 sendBeacon 上报用户停留数据等
- 批量上报:积累一批数据后统一发送,减少请求频率
- 定时上报:用户停留一段时间后定期上报(行为数据)
建议:根据数据类型区分时机,错误即时上报、性能延迟上报、行为数据可批量处理。
- 上报频率控制(防抖 / 节流 / 采样)
- 错误或点击频繁时可能产生大量上报请求
- 需要加防抖、节流机制,或采样上报(如只上报 10% 用户)
🔍 建议:对于高频行为(如滚动、点击),加防抖或只上报部分用户行为,避免拖垮前端或服务端。
- 异常处理与重试机制:遇到网络断开、后端失败等应支持自动重试或本地缓存,可将数据暂存至 localStorage,等网络恢复后重发
- 数据结构设计:统一字段格式、数据类型,方便服务端解析,包含上下文信息:页面 URL、用户 ID、浏览器信息、时间戳等,如下所示:
{
"type": "error",
"event": "ReferenceError",
"message": "xxx is not defined",
"timestamp": 1716280000000,
"userId": "abc123",
"url": "https://example.com/home"
}
总的来说,数据上报是前端监控的核心环节,但只有在合适的时机,用合适的方式,上报合适的数据,才能真正发挥价值。
来源:juejin.cn/post/7506414257401004071
我本是写react的,公司让我换赛道搞web3D
当你在会议室里争论需求时,
智慧工厂的数字孪生正同步着每一条产线的脉搏;
当你对着平面图想象空间时,
智慧小区的三维模型已在虚拟世界精准复刻每一扇窗的采光。
当你在CAD里调整参数时,
数字孪生城市的交通流正实时映射每辆车的轨迹;
当你等待客户确认方案时,
机械臂的3D仿真已预演了十万次零误差的运动路径;
当你用二维图纸解释传动原理时,
可交互的3D引擎正让客户‘拆解’每一个齿轮;
当你担心售后维修难描述时,
AR里的动态指引已覆盖所有故障点;
当你用PS拼贴效果图时,
VR漫游的业主正‘推开’你设计的每一扇门;
当你纠结墙面材质时,
光影引擎已算出了午后3点最温柔的折射角度;
从前端到Web3D,
不是换条赛道,
而是打开新维度。
韩老师说过:再牛的程序员都是从小白开始,既然开始了,就全心投入学好技术。
🔴 工具
所有的api都可以通过threejs官网的document,切成中文,去搜:

🔴 平面
⭕️ Scene 场景
场景能够让你在什么地方、摆放什么东西来交给three.js来渲染,这是你放置物体、灯光和摄像机的地方。

import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
⭕️ camera 相机
import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
⭕️ 物体 cube
import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
// 添加物体
// 创建几何体
const cubeGeometry = new THREE.BoxGeometry(1, 1, 1); // 创建立方体的几何体 (长, 宽, 高)
const cubeMaterial = new THREE.MeshBasicMaterial({ color: 0xffff00 }); // MeshBasicMaterial 基础网格材质 ({ color: 0xffff00 }) 颜色
// 根据几何体和材质创建物体
const cube = new THREE.Mesh(cubeGeometry, cubeMaterial); // 创建立方体的物体 (几何体, 材质)
// 将几何体添加到场景中
scene.add(cube); // 物体添加到场景中
⭕️ 渲染 render
// 初始化渲染器
const renderer = new THREE.WebGLRenderer();
// 设置渲染的尺寸大小
renderer.setSize(window.innerWidth, window.innerHeight); // 设置渲染的尺寸大小 (窗口宽度, 窗口高度)
// console.log(renderer);
// 将webgl渲染的canvas内容添加到body
document.body.appendChild(renderer.domElement); // 将webgl渲染的canvas内容添加到body
// 使用渲染器,通过相机将场景渲染进来
renderer.render(scene, camera); // 使用渲染器,通过相机将场景渲染进来 (场景, 相机)
⭕️ 效果
效果是平面的:

到这里,还不是3d的,如果要加3d,要加一下控制器。
🔴 3d
⭕️ 控制器
添加轨道。像卫星☄围绕地球🌏,环绕查看的视角:
// 导入轨道控制器
import { OrbitControls } from "three/examples/jsm/controls/OrbitControls";
// 目标:使用控制器查看3d物体
// // 使用渲染器,通过相机将场景渲染进来
// renderer.render(scene, camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement); // 创建轨道控制器 (相机, 渲染器dom元素)
controls.enableDamping = true; // 设置控制器阻尼,让控制器更有真实效果。
function render() {
renderer.render(scene, camera); // 浏览器每渲染一帧,就重新渲染一次
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render); // 浏览器渲染下一帧的时候就会执行render函数,执行完会再次调用render函数,形成循环,每秒60次
}
render();
⭕️ 加坐标轴辅助器
// 添加坐标轴辅助器
const axesHelper = new THREE.AxesHelper(5); // 坐标轴(size轴的大小)
scene.add(axesHelper);

⭕️ 设置物体移动
// 设置相机位置
camera.position.set(0, 0, 10);
scene.add(camera);
cube.position.x = 3;
// 往返移动
function render() {
cube.position.x += 0.01;
if (cube.position.x > 5) {
cube.position.x = 0;
}
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 缩放
cube.scale.set(3, 2, 1); // xyz, x3倍, y2倍
单独设置
cube.position.x = 3;
⭕️ 旋转
cube.rotation.set(Math.PI / 4, 0, 0, "XZY"); // x轴旋转45度
单独设置
cube.rotation.x = Math.PI / 4;
⭕️ requestAnimationFrame
function render(time) {
// console.log(time);
// cube.position.x += 0.01;
// cube.rotation.x += 0.01;
// time 是一个不断递增的数字,代表当前的时间
let t = (time / 1000) % 5; // 为什么求余数,物体移动的距离就是t,物体移动的距离是0-5,所以求余数
cube.position.x = t * 1; // 0-5秒,物体移动0-5距离
// if (cube.position.x > 5) {
// cube.position.x = 0;
// }
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ Clock 跟踪事件处理动画
// 设置时钟
const clock = new THREE.Clock();
function render() {
// 获取时钟运行的总时长
let time = clock.getElapsedTime();
console.log("时钟运行总时长:", time);
// let deltaTime = clock.getDelta();
// console.log("两次获取时间的间隔时间:", deltaTime);
let t = time % 5;
cube.position.x = t * 1;
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
大概是8毫秒一次渲染时间.
⭕️ 不用算 用 Gsap动画库
// 导入动画库
import gsap from "gsap";
// 设置动画
var animate1 = gsap.to(cube.position, {
x: 5,
duration: 5,
ease: "power1.inOut", // 动画属性
// 设置重复的次数,无限次循环-1
repeat: -1,
// 往返运动
yoyo: true,
// delay,延迟2秒运动
delay: 2,
onComplete: () => {
console.log("动画完成");
},
onStart: () => {
console.log("动画开始");
},
});
gsap.to(cube.rotation, { x: 2 * Math.PI, duration: 5, ease: "power1.inOut" });
// 双击停止和恢复运动
window.addEventListener("dblclick", () => {
// console.log(animate1);
if (animate1.isActive()) {
// 暂停
animate1.pause();
} else {
// 恢复
animate1.resume();
}
});
function render() {
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 根据尺寸变化 实现自适应
// 监听画面变化,更新渲染画面
window.addEventListener("resize", () => {
// console.log("画面变化了");
// 更新摄像头
camera.aspect = window.innerWidth / window.innerHeight;
// 更新摄像机的投影矩阵
camera.updateProjectionMatrix();
// 更新渲染器
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置渲染器的像素比
renderer.setPixelRatio(window.devicePixelRatio);
});
⭕️ 用js控制画布 全屏 和 退出全屏
window.addEventListener("dblclick", () => {
const fullScreenElement = document.fullscreenElement;
if (!fullScreenElement) {
// 双击控制屏幕进入全屏,退出全屏
// 让画布对象全屏
renderer.domElement.requestFullscreen();
} else {
// 退出全屏,使用document对象
document.exitFullscreen();
}
// console.log(fullScreenElement);
});
⭕️ 应用 图形 用户界面 更改变量
// 导入dat.gui
import * as dat from "dat.gui";
const gui = new dat.GUI();
gui
.add(cube.position, "x")
.min(0)
.max(5)
.step(0.01)
.name("移动x轴")
.onChange((value) => {
console.log("值被修改:", value);
})
.onFinishChange((value) => {
console.log("完全停下来:", value);
});
// 修改物体的颜色
const params = {
color: "#ffff00",
fn: () => {
// 让立方体运动起来
gsap.to(cube.position, { x: 5, duration: 2, yoyo: true, repeat: -1 });
},
};
gui.addColor(params, "color").onChange((value) => {
console.log("值被修改:", value);
cube.material.color.set(value);
});
// 设置选项框
gui.add(cube, "visible").name("是否显示");
var folder = gui.addFolder("设置立方体");
folder.add(cube.material, "wireframe");
// 设置按钮点击触发某个事件
folder.add(params, "fn").name("立方体运动");

🔴 结语
前端的世界,
不该只有Vue和React——
还有WebGPU里等待你征服的星辰大海。"
“当WebGL成为下一代前端的基础设施,愿你是最早站在三维坐标系里的那个人。”
来源:juejin.cn/post/7517209356855164978
震惊,中石化将开源组件二次封装申请专利,这波操作你怎么看?
一. 前言
昨天看到了一篇关于 “中石化申请基于 vue 的文件上传组件二次封装方法和装置专利,解决文件上传功能开发繁琐问题” 的新闻。
今天特地在专利系统检索了一下,竟然是真的,令人不禁大跌眼镜!用的全是开源组件,最后还把它们变成了自己的专利!这波操作属实厉害啊!

难道以后要用这种方式上传文件,要交专利费了?哈哈....
说来好笑,有掘友指出有单词拼写错误,我又查看一下专利文件,竟然还真有拼写错误...

二. 了解一下
本专利是通过在 vue 页面中自定义 el-upload 组件和 el-progress 组件的使用,解决了文件上传功能开发步骤繁琐和第三方组件无法满足业务需求的问题,实现了简化开发、提高效率和灵活性的效果。
1. 摘要
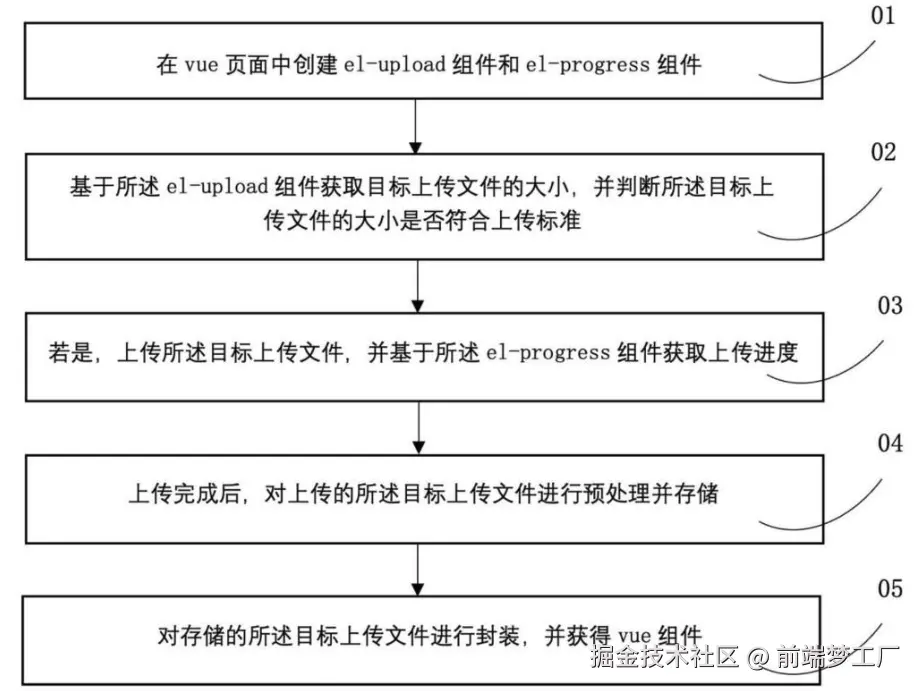
本发明提供了一种基于 vue 的文件上传组件的二次封装方法和装置,解决了针对于文件上传功能的开发步骤繁琐,复杂,且上传功能的第三方组件无法完全满足业务需求的问题。
该基于 vue 的文件上传组件的二次封装方法包括:在 vue 页面中创建 el‑upload 组件和 el‑progress 组件;
基于所述 el‑upload 组件获取目标上传文件的大小,并判断所述目标上传文件的大小是否符合上传标准;若是,上传所述目标上传文件,并基于所述 el‑progress 组件获取上传进度;上传完成后,对上传的所述目标上传文件进行预处理并存储;
对存储的所述目标上传文件进行封装,并获得 vue 组件。
技术流程图:
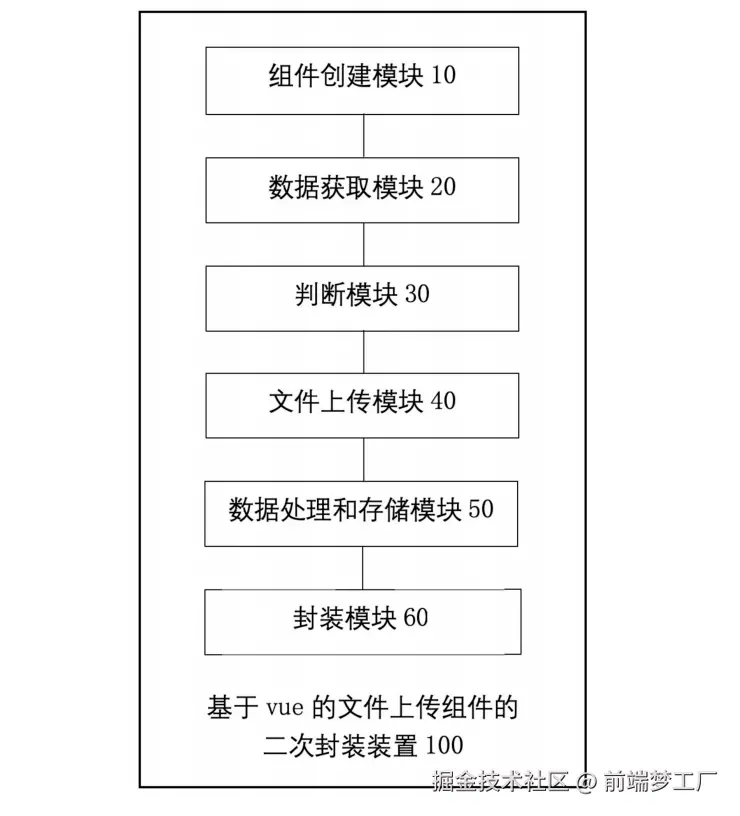
二次封装装置模块:
2. 解决的技术问题
现有技术中文件上传功能的开发步骤繁琐复杂,第三方组件无法完全满足业务需求。
3. 采用的技术手段
通过在 vue 页面中引入 el-upload 组件和 el-progress 组件,自定义上传方法和进度条绑定,获取文件大小和上传进度,进行预处理和存储,并将其封装成可重复使用的 vue 组件。
4. 产生的技术功效
简化了文件上传功能的开发步骤,节省了开发时间和效率,避免了代码沉冗,降低了后期维护成本,并提高了文件上传功能的灵活性。
三. 实现一下
这种简单的上传文件+上传进度显示不是最基本的业务封装吗?相信这是每个前端开发工程师必备的基础技能。
1. el-upload + el-progress 组合
- el-upload 负责文件选择、上传。
- el-progress 负责展示上传进度。
2. 文件大小校验
- 使用 el-upload 的
before-upload钩子,判断文件大小是否符合标准。
3. 上传进度获取
- 使用 el-upload 的
on-progress钩子,实时更新进度条。
4. 上传完成后的预处理与存储
- 上传完成后,触发自定义钩子(如
beforeStore、onStore),进行预处理和存储。
5. 封装为 Vue 组件
- 通过 props、emits、插槽等方式,暴露灵活的接口,便于业务页面集成。
都懒得自己动手,让 Cursor 来实现一下。Cursor 还是一如既往的强大,基本上一次询问就能成功!我表示 Cursor 在手,天下我有!
UploaderWrapper 自定义组件:
<template>
<div class="file-uploader">
<ElUpload
:action="action"
:before-upload="beforeUpload"
:on-progress="handleProgress"
:on-success="handleSuccess"
:on-error="handleError"
:limit="limit"
:on-exceed="handleExceed"
:show-file-list="showFileList"
:multiple="multiple"
:accept="accept"
v-model:file-list="fileList"
:on-remove="handleRemove"
>
<template #trigger>
<ElButton type="primary"> 选择文件上传 ElButton>
template>
<template #tip>
<div class="el-upload__tip">
支持的文件类型: {{ accept }},单个文件不超过 {{ maxSize }}MB
div>
template>
ElUpload>
<ElProgress
v-if="isUploading"
:percentage="uploadPercent"
:status="uploadPercent === 100 ? 'success' : ''"
class="mt-4"
/>
div>
template>
<style scoped>
.file-uploader {
width: 100%;
}
.el-upload__tip {
font-size: 12px;
color: #606266;
margin-top: 8px;
}
style>
使用方式:
<template>
<ElCard class="mb-5 w-80">
<template #header> 文件上传演示 template>
<UploaderWrapper
action="/api/upload"
:max-size="5"
:before-store="beforeStore"
:on-store="onStore"
/>
ElCard>
template>
效果如下所示:
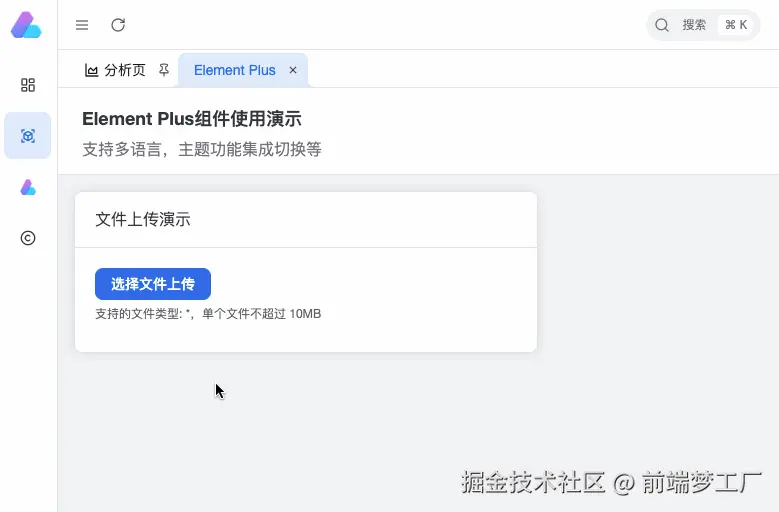
声明:“代码仅供演示,不要使用,以免有专利侵权风险,慎重!”
四. 思考一下
从开发者的角度来看,这个专利事件是否能给我们带来了一些值得思考影响和启示:
- 技术创新的边界问题
- 使用开源组件进行二次封装是否应该被授予专利?
- 是否对开源社区的发展可能产生负面影响?
- 对日常开发的影响
- 如果专利获得授权,其他公司使用类似的文件上传组件封装方案是否可能面临法律风险?
- 开发者是否需要寻找替代方案或支付专利费用?
- 对开源社区的影响
- 可能打击开发者对开源项目的贡献热情,自己辛苦开源项目为别人做了嫁衣?
- 是否会影响开源组件的使用和二次开发
- 可能导致更多公司效仿,将开源组件的二次封装申请专利,因为毕竟专利对公司的招投标挺大的
五. 后记
“中石化作为传统能源企业,都能积极拥抱前端技术,还将内部技术方案申请专利,体现了他们对知识产权的重视?”
那我们是不是要在技术创新和知识产权保护之间找到平衡点,既要保护创新,又不能阻碍技术的发展。
而作为开发者的我们呢?这么简单的封装都能申请专利成功的话,那么...,大家有什么想法,是不是现在强的可怕?哈哈...
专利来源于国家知识产权局
申请公布号:CN120122937A
来源:juejin.cn/post/7514858513442078754
润开鸿亮相HDC2025 以AI驱动基于开源鸿蒙的行业新“智”场景创新
2025年6月20日至22日,第七届华为开发者大会(HDC.2025)在东莞松山湖盛大举行。作为鸿蒙生态的核心伙伴和深度参与者、华为OpenHarmony使能伙伴、华为HarmonyOS开发服务商,江苏润开鸿数字科技有限公司(以下简称“润开鸿”)以专题演讲、成果展示、CodeLabs训练营等多元形式参会,充分展示了自身基于“OpenHarmony+AI” “OpenHarmony+星闪”的数智化解决方案及赋能服务等鸿蒙生态创新成果。
在本届HDC大会期间,HarmonyOS 6 Developer Beta面向开发者启动报名,其新特性将为千行百业的鸿蒙应用带来更多创新可能;同时,鸿蒙星光计划也正式推出,将投入总额1亿元的现金和资源,支持更多校园开发者和创意人才开发鸿蒙应用。

当前,更多“生而不同”的创新体验正在鸿蒙生态中不断涌现。作为领先的鸿蒙方向专业技术公司及终端操作系统发行版提供商,以及开放原子开源基金会OpenHarmony项目群A类捐赠人和核心共建单位,润开鸿于本届大会上重磅发布了基于OpenHarmony的智慧中医AI诊疗解决方案。该方案以基于OpenHarmony的智慧中医辅助诊疗机器人为核心,构建覆盖三甲医院至社区医院的一体化中医诊疗服务体系,通过“OpenHarmony+AI”驱动场景全要素融合,创新重塑中医诊疗“诊前→诊中→诊后”全流程服务体验,打破医疗资源分布不均现状,运用数智化技术让优质中医资源得以广泛共享,提升整体中医诊疗效率与专业能力一致性,为患者提供便捷、高效的中医医疗个性化定制服务。在大会互动体验区开源鸿蒙成果展区现场,润开鸿展示了基于OpenHarmony的智慧中医AI诊疗解决方案核心设备——智慧中医AI诊疗机器人,并通过其与HarmonyOS平板的互联协作,直观呈现了以“OpenHarmony+AI”驱动新“智”场景创新的典型范例。

润开鸿基于OpenHarmony的智慧中医AI诊疗解决方案重磅发布



润开鸿基于OpenHarmony的智慧中医AI诊疗机器人现场体验
同时,润开鸿面向青少年信息科技教育全新打造的星闪场景DEMO——基于源师兄的“使命召唤”无人设备指挥控制方案也于大会互动体验区首发亮相。该方案作为基于“OpenHarmony+星闪”的信息科技教学场景,通过润开鸿OH-CODE图形化编程平台接入控制多形态、多类型智能终端,应用星闪(NearLink)互联实现基于“源师兄”的跨场景一体化协同,凸显了 “OpenHarmony+星闪”创新构建智能物联场景的技术潜力。



润开鸿基于源师兄的“使命召唤”无人设备指挥控制方案首发亮相
互动展区亮点展品

润开鸿矿鸿物联管理平台

润开鸿基于OpenHarmony的姿态机器人

润和软件星闪科技纸笔互动解决方案
值得关注的是,本届大会还为与会开发者设计了丰富的专题论坛及技术公开课等活动议程,在“【鸿蒙生态产业场景创新方案】生态共建,赋能产业数字化变革”专题论坛上,润开鸿副总裁于大伍在以“OpenHarmony+AI:探索行业新智硬件无限可能”为题的主题演讲中表示,OpenHarmony作为契合AI时代的绝佳数字底座,天然具备高能效、强智能、自协同三大优势,弥补了传统操作系统“重”“笨”“杂”的问题。同时,随着AI应用的深入,AI大模型已经从云端逐步走向“云”“边”“端”协同进化,润开鸿基于多年在OpenHarmony领域积累的经验以及在AI行业大模型的实践,打造了鸿锐AI云桌面、鸿锐AI box、鸿锐AI平板以及AI PC等基于“OpenHarmony+AI”的多款产品,并形成了面向金融、电力、医疗、办公、智慧城市等多场景的“云”“边”“端”协同全栈AI交付方案。

润开鸿副总裁于大伍做主题演讲
在“【星闪】打造全场景新体验,星闪开放能力繁荣鸿蒙生态”专题论坛上,江苏润和软件股份有限公司副总裁刘洋以“润和软件聚力生态协同,构建可持续开发者支持体系”为题做主题演讲。他表示,润和软件以“OpenHarmony+星闪”生态为基石,构建“可学、可用、可商用”的开发者支持体系,切实降低行业智能化转型门槛。聚焦工业、能源、教育等场景打造行业落地案例,加速场景化创新与人才储备。未来,将持续聚力生态协同,驱动技术深度赋能千行百业,为产业数字化升级注入可持续创新动能。

润和软件副总裁刘洋做主题演讲
在“【人才赋能】携手共育共拓HarmonyOS创新人才”专题论坛上,润开鸿生态技术专家徐建国以“领航HarmonyOS技术布道,使能开发者持续创新”为题,分享了自身从社区开发者一步步成长为鸿蒙应用技术专家,并作为华为HDE反哺社区,助力更多开发者突破技术难点、共拓鸿蒙生态及应用落地的成长与贡献历程。

润开鸿生态技术专家徐建国做主题演讲
同时,在本届大会同期举办的开发者技术挑战及互动活动中,润开鸿为开发挑战赛带来了鸿蒙设备上云实战赛项——“基于润开鸿DAYU800A实现智能家居多端联动与云端智能响应方案开发”。该项目要求开发者通过集成IoT Device SDK,结合DeepSeek、人脸识别等功能,快速实现鸿蒙设备联网上云及云端响应,重点检验开发者结合场景实际,实现“云、边、端”交互体验的智能家居新“智”场景综合开发能力。


“基于润开鸿DAYU800A实现智能家居多端联动与云端智能响应方案开发”挑战赛现场
伴随HarmonyOS6 Developer Beta启动报名,将支持更多鸿蒙开发者、各领域生态伙伴不断推出更丰富、更具创意的新功能、新体验,让用户在出行、娱乐、办公、购物等场景下的体验全面焕新。润开鸿充分认同鸿蒙生态“持续开放、协同共建”的发展理念,将持续聚焦国产自主数字底座与AI等前沿技术的场景融合与赋能,以开源鸿蒙行业发行版驱动和牵引行业硬件与终端设备的创新,为行业创造新“智”生产工具。
收起阅读 »31 岁,写了 8 年代码的我,终于懂了啥叫成功
31 岁,写了 8 年代码的我,终于懂了啥叫成功
现在每天下午六点,我准时关了 IDEA,开车穿过 4 公里的晚高峰,20 分钟就到小区。
一、去年那个手忙脚乱的夏天,我差点错过儿子的成长
去年 5 月 23 号,老婆生了,是个儿子,我在产房陪产,当时是又激动,又紧张。初为人父的兴奋劲还没过,一周的陪产假结束就被加班打回原形。在原来的公司,我每天像个陀螺似的转,写接口、改 bug、开不完的会,常常凌晨才回家。儿子六个月大的时候,有天我凌晨一点推门进去,看见他趴在婴儿床上,小屁股撅得老高,枕边还放着我落在家里的工牌 —— 他把工牌上的照片啃得皱巴巴的,估计是想闻闻爸爸的味道。
那时候我才惊觉,儿子第一次会翻身、第一次长出小牙、第一次喊 "妈妈",这些重要的时刻我全错过了。有次老妈发视频给我,说儿子扶着婴儿床站起来了,摇摇晃晃像个小企鹅,我却在会议室跟产品经理掰扯接口设计,只能匆匆说一句 "知道了",挂了视频心里堵得慌。
二、当 "加班换高薪" 不如 "陪娃玩半小时",我果断选择了后者
有天晚上,我看着怀里这个小生命,突然觉得自己像个失败的程序员:写了八年代码,能优化千万级流量的接口,却连儿子的成长日志都没空更新。
咬咬牙辞了高薪 996,找了家朝九晚五的公司,月薪少了 25%,但胜在能准时下班。每天开车回家的路上,车载广播放着儿歌,我跟着瞎唱,儿子坐在安全座椅上咯咯笑,口水顺着下巴流到围兜上 —— 这 20 分钟的车程,比以前凌晨三点在高速上开代驾幸福一万倍。
三、现在的 "躺平" 生活,比任何技术方案都更让我有成就感
每天吃完晚饭,我雷打不动带儿子去小区遛弯。他刚学会走路,小区里儿子是我见过走的最早的那个,十一个月就开始走了,摇摇晃晃像个小醉汉,那一刻我觉得,以前追求的那些高薪、职级,在这双小手面前,根本不值一提。
周末带他去公园,他坐在草地上玩树叶,我陪他一起捡形状好看的,夹在笔记本里做标本。老妈总说我 "以前写代码的脑子,现在全用来研究怎么让娃多吃两口饭",可我觉得这才是正经事:以前写的代码可能过两年就被重构了,但儿子现在喊的每一声 "爸爸",都是永远存放在我心里的温暖记忆。
四、给新人讲技术时,我现在总提 "家庭并发量"
现在带新人,他们总问我 "怎么才能快速升职加薪",我会指着电脑桌面上儿子的照片说:"先学会给生活做负载均衡。" 以前我总觉得 "躺平" 是贬义词,现在才明白,拒绝无效加班,把时间留给家人,不是躺平,是给人生做了一次关键优化。
有次朋友问我:"你现在不焦虑吗?工资少了这么多。以前挣得多却总焦虑,怕被裁员、怕技术落后;现在挣得少却踏实,因为我没错过儿子的每一个第一次。你说,是银彳亍卡里的数字重要,还是孩子看见你时眼里的光重要?"
结语:31 岁,我的 "成功" 代码里只有一行注释
现在我的键盘上,贴着儿子百日照,每次敲代码时看见,心里都软乎乎的。写了八年 Java,终于懂了:成功不是简历上的项目经验,是能记住儿子每天的小变化;不是会议室里的技术汇报,是陪他在小区里看星星的夜晚;不是职级表上的晋升,是他跌跌撞撞跑向我时,张开的那双小胳膊。
31 岁这年,我把人生代码重构了一次。新版本没有复杂的架构,没有华丽的优化,只有一行简单的注释:家人的笑容,才是这辈子最稳定的依赖。 至于工资少了?没关系,儿子的笑声,比任何高薪都更值钱。
现在摸鱼时,我总会一遍遍翻看他从一岁到现在的照片和视频,或许我算不上技术精湛的程序员,但在工作间隙反复回味这些影像时,我愈发坚定:我一定要成为小时候自己渴望拥有的那种父亲。当然我的父亲也很优秀,买房买车都有赞助,只是他们那一代永远有个好心也不会有个好颜色,懂得都懂,哈哈。
来源:juejin.cn/post/7511903601452630025
从前端的角度出发,目前最具性价比的全栈路线是啥❓❓❓
我正在筹备一套前端工程化体系的实战课程。如果你在学习前端的过程中感到方向模糊、技术杂乱无章,那么前端工程化将是你实现系统进阶的最佳路径。它不仅能帮你建立起对现代前端开发的整体认知,还能提升你在项目开发、协作规范、性能优化等方面的工程能力。
✅ 本课程覆盖构建工具、测试体系、脚手架、CI/CD、Docker、Nginx 等核心模块,内容体系完整,贯穿从开发到上线的全流程。每一章节都配有贴近真实场景的企业级实战案例,帮助你边学边用,真正掌握现代团队所需的工程化能力,实现从 CRUD 开发者到工程型前端的跃迁。
详情请看前端工程化实战课程
学完本课程,对你的简历和具体的工作能力都会有非常大的提升。如果你对此项目感兴趣,或者课程感兴趣,可以私聊我微信 yunmz777
今年大部分时间都是在编码上和写文章上,但是也不知道自己都学到了啥,那就写篇文章来盘点一下目前的技术栈吧,也作为下一年的参考目标,方便知道每一年都学了些啥。
我的技术栈
首先我先来对整体的技术做一个简单的介绍吧,然后后面再对当前的一些技术进行细分吧。
React、Typescript、React Native、mysql、prisma、NestJs、Redis、前端工程化。
React
React 这个框架我花的时间应该是比较多的了,在校期间已经读了一遍源码了,对这些原理已经基本了解了。在随着技术的继续深入,今年毕业后又重新开始阅读了一遍源码,对之前的认知有了更深一步的了解。
也写了比较多跟 React 相关的文章,包括设计模式,原理,配套生态的使用等等都有一些涉及。
在状态管理方面,redux,zustand 我都用过,尤其在 Zustand 的使用上,我特别喜欢 Zustand,它使得我能够快速实现全局状态管理,同时避免了传统 Redux 中繁琐的样板代码,且性能更优。也对 Zustand 有比较深入的了解,也对其源码有过研究。
NextJs
Next.js 是一个基于 React 的现代 Web 开发框架,它为开发者提供了一系列强大的功能和工具,旨在优化应用的性能、提高开发效率,并简化部署流程。Next.js 支持多种渲染模式,包括服务器端渲染(SSR)、静态生成(SSG)和增量静态生成(ISR),使得开发者可以根据不同的需求选择合适的渲染方式,从而在提升页面加载速度的同时优化 SEO。
在路由管理方面,Next.js 采用了基于文件系统的路由机制,这意味着开发者只需通过创建文件和文件夹来自动生成页面路由,无需手动配置。这种约定优于配置的方式让路由管理变得直观且高效。此外,Next.js 提供了动态路由支持,使得开发者可以轻松实现复杂的 URL 结构和参数化路径。
Next.js 还内置了 API 路由,允许开发者在同一个项目中编写后端 API,而无需独立配置服务器。通过这种方式,前后端开发可以在同一个代码库中协作,大大简化了全栈开发流程。同时,Next.js 对 TypeScript 提供了原生支持,帮助开发者提高代码的可维护性和可靠性。
Typescript
今年所有的项目都是在用 ts 写了,真的要频繁修改的项目就知道用 ts 好处了,有时候用 js 写的函数修改了都不知道怎么回事,而用了 ts 之后,哪里引用到的都报红了,修改真的非常方便。
今年花了一点时间深入学习了一下 Ts 类型,对一些高级类型以及其实现原理也基本知道了,明年还是多花点时间在类型体操上,除了算法之外,感觉类型体操也可以算得上是前端程序员的内功心法了。
React Native
不得不说,React Native 不愧是接活神器啊,刚学完之后就来了个安卓和 ios 的私活,虽然没有谈成。
React Native 和 Expo 是构建跨平台移动应用的两大热门工具,它们都基于 React,但在功能、开发体验和配置方式上存在一些差异。React Native 是一个开放源代码的框架,允许开发者使用 JavaScript 和 React 来构建 iOS 和 Android 原生应用。Expo 则是一个构建在 React Native 之上的开发平台,它提供了一套工具和服务,旨在简化 React Native 开发过程。
React Native 的核心优势在于其高效的跨平台开发能力。通过使用 React 语法和组件,开发者能够一次编写应用的 UI 和逻辑,然后部署到 iOS 和 Android 平台。React Native 提供了对原生模块的访问,使开发者能够使用原生 API 来扩展应用的功能,确保性能和用户体验能够接近原生应用。
Expo 在此基础上进一步简化了开发流程。作为一个开发工具,Expo 提供了许多内置的 API 和组件,使得开发者无需在项目中进行繁琐的原生模块配置,就能够快速实现设备的硬件访问功能(如摄像头、位置、推送通知等)。Expo 还内置了一个开发客户端,使得开发者可以实时预览应用,无需每次都进行完整的构建和部署。
另外,Expo 提供了一个完全托管的构建服务,开发者只需将应用推送到 Expo 服务器,Expo 就会自动处理 iOS 和 Android 应用的构建和发布。这大大简化了应用的构建和发布流程,尤其适合不想处理复杂原生配置的开发者。
然而,React Native 和 Expo 也有各自的局限性。React Native 提供更大的灵活性和自由度,开发者可以更自由地集成原生代码或使用第三方原生库,但这也意味着需要更多的配置和维护。Expo 则封装了很多功能,简化了开发,但在需要使用某些特定原生功能时,开发者可能需要“弹出”Expo 的托管环境,进行额外的原生开发。
样式方案的话我使用的是 twrnc,大部分组件都是手撸,因为有 cursor 和 chatgpt 的加持,开发效果还是杠杠的。
rn 原理也争取明年能多花点时间去研究研究,不然对着盲盒开发还是不好玩。
Nestjs
NestJs 的话没啥好说的,之前也都写过很多篇文章了,感兴趣的可以直接观看:
对 Nodejs 的底层也有了比较深的理解了:
Prisma & mysql
Prisma 是一个现代化的 ORM(对象关系映射)工具,旨在简化数据库操作并提高开发效率。它支持 MySQL 等关系型数据库,并为 Node.js 提供了类型安全的数据库客户端。在 NestJS 中使用 Prisma,可以让开发者轻松定义数据库模型,并通过自动生成的 Prisma Client 执行类型安全的查询操作。与 MySQL 配合时,Prisma 提供了一种简单、直观的方式来操作数据库,而无需手动编写复杂的 SQL 查询。
Prisma 的核心优势在于其强大的类型安全功能,所有的数据库操作都能通过 Prisma Client 提供的自动生成的类型来进行,这大大减少了代码中的错误,提升了开发的效率。它还包含数据库迁移工具 Prisma Migrate,能够帮助开发者方便地管理数据库结构的变化。此外,Prisma Client 的查询 API 具有很好的性能,能够高效地执行复杂的数据库查询,支持包括关系查询、聚合查询等高级功能。
与传统的 ORM 相比,Prisma 使得数据库交互更加简洁且高效,减少了配置和手动操作的复杂性,特别适合在 NestJS 项目中使用,能够与 NestJS 提供的依赖注入和模块化架构很好地结合,提升整体开发体验。
Redis
Redis 和 mysql 都仅仅是会用的阶段,目前都是直接在 NestJs 项目中使用,都是已经封装好了的,直接传参调用就好了:
import { Injectable, Inject, OnModuleDestroy, Logger } from "@nestjs/common";
import Redis, { ClientContext, Result } from "ioredis";
import { ObjectType } from "../types";
import { isObject } from "@/utils";
@Injectable()
export class RedisService implements OnModuleDestroy {
private readonly logger = new Logger(RedisService.name);
constructor(@Inject("REDIS_CLIENT") private readonly redisClient: Redis) {}
onModuleDestroy(): void {
this.redisClient.disconnect();
}
/**
* @Description: 设置值到redis中
* @param {string} key
* @param {any} value
* @return {*}
*/
public async set(
key: string,
value: unknown,
second?: number
): Promise<Result<"OK", ClientContext> | null> {
try {
const formattedValue = isObject(value)
? JSON.stringify(value)
: String(value);
if (!second) {
return await this.redisClient.set(key, formattedValue);
} else {
return await this.redisClient.set(key, formattedValue, "EX", second);
}
} catch (error) {
this.logger.error(`Error setting key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取redis缓存中的值
* @param key {String}
*/
public async get(key: string): Promise<string | null> {
try {
const data = await this.redisClient.get(key);
return data ? data : null;
} catch (error) {
this.logger.error(`Error getting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置自动 +1
* @param {string} key
* @return {*}
*/
public async incr(
key: string
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.incr(key);
} catch (error) {
this.logger.error(`Error incrementing key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 删除redis缓存数据
* @param {string} key
* @return {*}
*/
public async del(key: string): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.del(key);
} catch (error) {
this.logger.error(`Error deleting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置hash结构
* @param {string} key
* @param {ObjectType} field
* @return {*}
*/
public async hset(
key: string,
field: ObjectType
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.hset(key, field);
} catch (error) {
this.logger.error(`Error setting hash for key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取单个hash值
* @param {string} key
* @param {string} field
* @return {*}
*/
public async hget(key: string, field: string): Promise<string | null> {
try {
return await this.redisClient.hget(key, field);
} catch (error) {
this.logger.error(
`Error getting hash field ${field} from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 获取所有hash值
* @param {string} key
* @return {*}
*/
public async hgetall(key: string): Promise<Record<string, string> | null> {
try {
return await this.redisClient.hgetall(key);
} catch (error) {
this.logger.error(
`Error getting all hash fields from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 清空redis缓存
* @return {*}
*/
public async flushall(): Promise<Result<"OK", ClientContext> | null> {
try {
return await this.redisClient.flushall();
} catch (error) {
this.logger.error("Error flushing all Redis data", error);
return null;
}
}
/**
* @Description: 保存离线通知
* @param {string} userId
* @param {any} notification
*/
public async saveOfflineNotification(
userId: string,
notification: any
): Promise<void> {
try {
await this.redisClient.lpush(
`offline_notifications:${userId}`,
JSON.stringify(notification)
);
} catch (error) {
this.logger.error(
`Error saving offline notification for user ${userId}`,
error
);
}
}
/**
* @Description: 获取离线通知
* @param {string} userId
* @return {*}
*/
public async getOfflineNotifications(userId: string): Promise<any[]> {
try {
const notifications = await this.redisClient.lrange(
`offline_notifications:${userId}`,
0,
-1
);
await this.redisClient.del(`offline_notifications:${userId}`);
return notifications.map((notification) => JSON.parse(notification));
} catch (error) {
this.logger.error(
`Error getting offline notifications for user ${userId}`,
error
);
return [];
}
}
/**
* 获取指定 key 的剩余生存时间
* @param key Redis key
* @returns 剩余生存时间(秒)
*/
public async getTTL(key: string): Promise<number> {
return await this.redisClient.ttl(key);
}
}
前端工程化
前端工程化这块花了很多信息在 eslint、prettier、husky、commitlint、github action 上,现在很多项目都是直接复制之前写好的过来就直接用。
后续应该是投入更多的时间在性能优化、埋点、自动化部署上了,如果有机会的也去研究一下 k8s 了。
全栈性价比最高的一套技术
最近刷到一个帖子,讲到了

我目前也算是一个小全栈了吧,我也来分享一下我的技术吧:
- NextJs
- React Native
- prisma
- NestJs
- taro (目前还不会,如果有需求就会去学)
剩下的描述也是和他下面那句话一样了(毕业后对技术态度的转变就是什么能让我投入最小,让我最快赚到钱的就是好技术)
总结
学无止境,任重道远。
最后再来提一下这两个开源项目,它们都是我们目前正在维护的开源项目:
如果你想参与进来开发或者想进群学习,可以添加我微信 yunmz777,后面还会有很多需求,等这个项目完成之后还会有很多新的并且很有趣的开源项目等着你。
来源:juejin.cn/post/7451483063568154639
同志们,我去外包了
同志们,我去外包了
同志们,经历了漫长的思想斗争,我决定回老家发展,然后就是简历石沉大海,还好外包拯救了我,我去外包了!

都是自己人,说这些伤心话干嘛;下面说下最近面试的总结地方,小小弱鸡,图一乐吧。
首先随着工作年限的增加,越来越多公司并不会去和你抠八股文了(那阵八股风好像停了),只是象征性的问几个问题,然后会对照着项目去问些实际的问题以及你的处理办法。
(ps:(坐标合肥)突然想到某鑫面试官问我你知道亿级流量吗?你怎么处理的,听到这个问题我就想呼过去,也许读书读傻了,他根本不知道亿级流量是个什么概念,最主要的是它是个制造业公司啊,你哪来的亿级流量啊,也不知道问这个问题时他在想啥,还有某德(不是高德),一场能面一个小时,人裂开)。
好了,言归正传,咱说点入职这家公司我了解到的一点东西,我分为两部分:代码和sql;
代码上
首先传统的web项目也会分前端后端,这点不错;
1.获取昨天日期
可以使用jdk自带的LocalDate.now().minusDays(-1)
这个其实内部调用的是plusDays(-1)方法,所以不如直接就用plusDays方法,这样少一层判断;
PS:有多少人和我之前一样直接new Date()的。
2.字符填充
apache.common下的StringUtils的rightPad方法用于字符串填充使用方法是StringUtils.rightPad(str,len,fillStr)
大概意思就是str长度如果小于len,就用fillStr填充;
PS:有多少人之前是String.format或者StringBuilder用循环实现的。
3.获取指定年指定月的某天
获取指定年指定月的某天可以用localDate.of(year,month,day),如果我们想取2025年的五月一号,可以写成LocalDate.of(2025, 5, 1),那有人可能就想到了如果月尾呢,LocalDate.of(2025, 5, 31)也是可以的,但是我们需要清楚知道这个月有多少天,比如说你2月给个30天,那就会抛异常;
麻烦;

更好的办法就是先获取第一天,然后调用localDate.with(TemporalAdjusters.lastDayOfMonth());方法获取最后一天,TemporalAdjusters.lastDayOfMonth()会自动处理不同月份和闰年的情况;
sql层面的
有言在先,说实话我不建议在sql层面写这种复杂的东西,毕竟我们这么弱的人看到那么长的且复杂的sql会很无力,那种无力感你懂吗?打工人不为难打工人;不过既然别人写了,咱们就学习一下嘛;
1.获取系统日期
首先获取系统日期可以试用TRUNC(SYSDATE)进行截取,这样返回的时分秒是00:00:00,比如2025-05-29 00:00:00,它也可以截取数字,想知道就去自行科普下,不建议掌握,学习了下,有点搞;
2.返回date当前月份的最后一天
LAST_DAY(date)这个返回的是date当前月份的最后一天,比如今天是2025-05-29,那么返回的是2025-05-31
ADD_MONTH(date,11)表示当前日期加上11个月,比如2025-01-02,最终返回的是2025-12-02;
3.左连接的知识点
最后再提个左连接的知识点,最近看懵了,图一乐哈,A left join B,就是on的条件是在join生成临时表时起作用的,而where是对生成的临时表进行过滤;
两者过滤的时机不一样。我想了很久我觉得可以这么理解,on它虽然可以添加条件,但他的条件只是一个匹配条件比如B.age>10;它是不会对A表查询出来的数据量产生一个过滤效果;
而where是一个实打实的过滤条件,不管怎么说都会影响最终结果,对于inner join这个特例,on和where的最终效果一样,因为B.age>10会导致B的匹配数据减少,由于是交集,故会对整体数据产生影响。
好了,晚安,外包打工仔。。。
来源:juejin.cn/post/7510055871465308212
京东购物车动效实现:贝塞尔曲线的妙用
前言
大家好,我是奈德丽。前两天在逛京东想买Pocket 3的时候,注意到了它的购物车动效,当点击"加入购物车"按钮时,一个小红球从商品飞入购物车,我觉得很有意思,于是花了点时间来研究。
实现效果
看了图才知道我在讲什么,那么先看Gif吧!
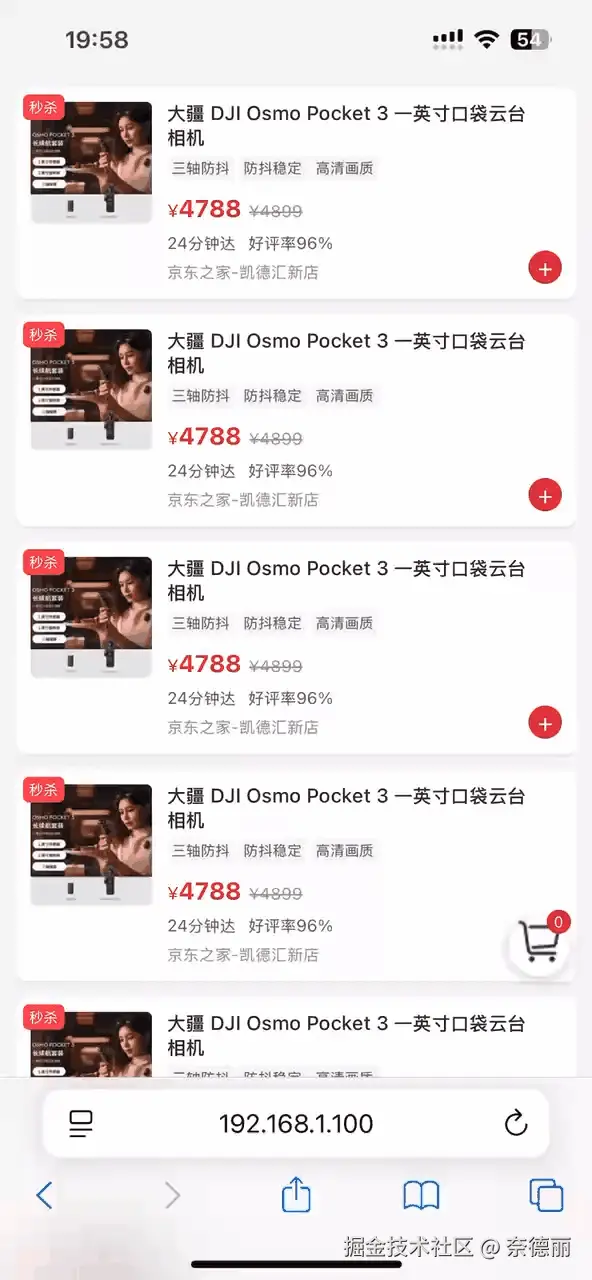
代码演示
代码已经上传到了码上掘金,感兴趣的可以自行查看,文章中没有贴全部代码了,主要讲讲思路,
code.juejin.cn/pen/7503150…
实现思路
下面这个思路,小白也能会,我们将通过以下几个步骤来实现这个效果:
画页面——>写逻辑实现动画效果
好了,废话不多说,开始进入正题
第一步:先让AI帮我们写出来UI结构
像我们这种工作1坤年以上的切图仔,能偷懒当然偷懒啦,这种画页面的活可以丢给AI来干了,下面是Taro帮我生成的页面部分,没什么难点,就是一些普普通通的页面元素。
<template>
<div class="rolling-ball-container">
<!-- 商品列表 -->
<div class="item-list">
<div class="item" v-for="item in 10" :key="item">
<div class="product-card">
<div class="product-tag">秒杀</div>
<div class="product-image">
<img src="/product.jpg" alt="商品图片" />
</div>
<div class="product-info">
<div class="product-title">大疆 DJI Osmo Pocket 3 一英寸口袋云台相机</div>
<div class="product-features">
<span class="feature-tag">三轴防抖</span>
<span class="feature-tag">防抖稳定</span>
<span class="feature-tag">高清画质</span>
</div>
<div class="product-price">
<span class="price-symbol">¥</span>
<span class="price-value">4788</span>
<span class="price-original">¥4899</span>
</div>
<div class="product-meta">
<span class="delivery-time">24分钟达</span>
<span class="rating">好评率96%</span>
</div>
<div class="product-shop">京东之家-凯德汇新店</div>
</div>
<div class="add-to-cart" @click="startRolling($event)">+</div>
</div>
</div>
</div>
<!-- 购物车图标 -->
<div class="point end-point">
<div style="position: relative;">
<img src="/cart.png" />
<div class="cart-count">{{ totalCount }}</div>
</div>
</div>
<!-- 小球容器 -->
<div
v-for="(ball, index) in balls"
:key="index"
class="ball"
v-show="ball.show"
:style="getBallStyle(ball)"
></div>
</div>
</template>
第二步:设计小球数据模型
有了页面元素了,我们需要创建小球数组和计数器
import { reactive, ref } from 'vue';
// 购物车商品计数
const totalCount = ref(0);
// 创建小球数组(预先创建3个小球以应对连续点击)
const balls = reactive(Array(3).fill(0).map(() => ({
show: false, // 是否显示
startX: 0, // 起点X坐标
startY: 0, // 起点Y坐标
endX: 0, // 终点X坐标
endY: 0, // 终点Y坐标
pathX: 0, // 路径X偏移量
pathY: 0, // 路径Y偏移量
progress: 0 // 动画进度
})));
为什么小球要用一个数组来存储呢?因为我看到京东上用户是可以连续点击+号将商品加入购入车的,页面上可以同时存在很多个飞行的小球。
第三步:实现动画触发函数
当用户点击"+"按钮时,我们需要计算起点和终点坐标,然后启动动画,这儿有一个细节,为了让小球刚好落到在购物车中间,对终点坐标进行了微调。
// 开始滚动动画
const startRolling = (event: MouseEvent) => {
// 获取起点和终点元素
const startPoint = event.currentTarget as HTMLElement;
const endPoint = document.querySelector('.end-point') as HTMLElement;
if (startPoint && endPoint) {
// 找到一个可用的小球
const ball = balls.find(ball => !ball.show);
if (ball) {
// 获取起点位置
const startRect = startPoint.getBoundingClientRect();
ball.startX = startRect.left + startRect.width / 2;
ball.startY = startRect.top + startRect.height / 2;
// 获取终点位置
const endRect = endPoint.getBoundingClientRect();
const endX = endRect.left + endRect.width / 2;
const endY = endRect.top + endRect.height / 2;
// 微调终点位置
ball.endX = endX - 4;
ball.endY = endY - 7;
// 设置路径偏移量
ball.pathX = 0;
ball.pathY = 100;
// 显示小球并重置进度
ball.show = true;
ball.progress = 0;
// 使用requestAnimationFrame实现动画
let startTime = Date.now();
const duration = 400; // 动画持续时间(毫秒)
function animate() {
const currentTime = Date.now();
const elapsed = currentTime - startTime;
ball.progress = Math.min(elapsed / duration, 1);
if (ball.progress < 1) {
requestAnimationFrame(animate);
} else {
// 动画结束后隐藏小球
setTimeout(() => {
ball.show = false;
}, 100);
}
}
requestAnimationFrame(animate);
// 增加购物车商品数量
totalCount.value++;
}
}
};
第四步:使用贝塞尔曲线计算小球轨迹
点击"+"按钮,不能让小球做自由落体运动吧,那是伽利略研究的,你看这自由落体好看嘛,指定不行,要是长这样,那东哥的商城还能卖出去东西吗?Hah
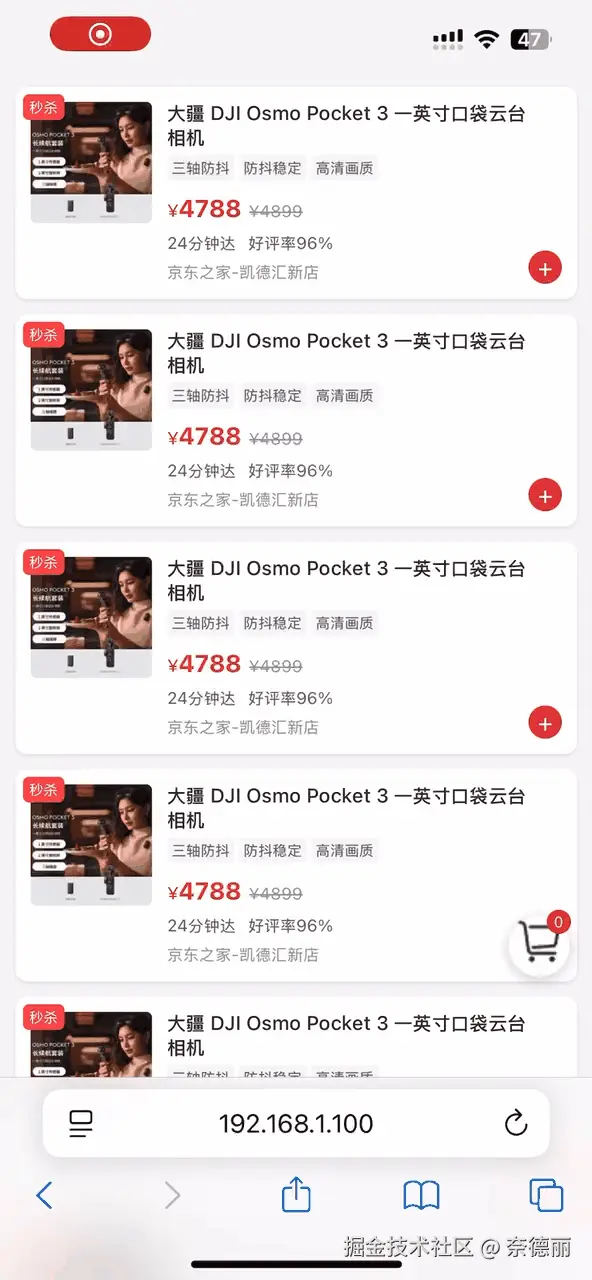
为了不让它自由落体,给它一个向左的偏移量100px
// 获取小球样式
const getBallStyle = (ball: any) => {
if (!ball.show) return {};
// 使用二次贝塞尔曲线计算路径
const t = ball.progress;
const mt = 1 - t;
// 判断起点和终点是否在同一垂直线上
const isVertical = Math.abs(ball.startX - ball.endX) < 20;
// 计算控制点(确保有弧度)
let controlX, controlY;
if (isVertical) {
// 如果在同一垂直线上,向左偏移一定距离
controlX = ball.startX - 100;
controlY = (ball.startY + ball.endY) / 2;
} else {
// 否则使用向左偏移
controlX = (ball.startX + ball.endX) / 2 - 100;
controlY = (ball.startY + ball.endY) / 2 + (ball.pathY || 100);
}
// 二次贝塞尔曲线公式
const x = mt * mt * ball.startX + 2 * mt * t * controlX + t * t * ball.endX;
const y = mt * mt * ball.startY + 2 * mt * t * controlY + t * t * ball.endY;
return {
left: `${x}px`,
top: `${y}px`,
transform: `rotate(${ball.progress * 360}deg)` // 添加旋转效果
};
};
技术要点解析
1. 贝塞尔曲线原理
贝塞尔曲线是一种参数化曲线,广泛应用于计算机图形学。二次贝塞尔曲线由三个点定义:起点P₀、控制点P₁和终点P₂。
曲线上任意点的坐标可以通过以下公式计算:
B(t) = (1-t)²P₀ + 2(1-t)tP₁ + t²P₂ (0 ≤ t ≤ 1)
在我们的实现中,通过调整控制点的位置,可以控制曲线的形状,从而实现小球的抛物线运动效果。
2. requestAnimationFrame的优势
与setTimeout或setInterval相比,requestAnimationFrame有以下优势:
- 性能更好:浏览器会在最合适的时间(通常是下一次重绘之前)执行回调函数,避免不必要的重绘
- 节能:当页面不可见或最小化时,动画会自动暂停,节省CPU资源
- 更流畅:与显示器刷新率同步,动画更平滑
3. 动态计算元素位置
我们使用getBoundingClientRect()方法获取元素在视口中的精确位置,这确保了无论页面如何滚动或调整大小,动画始终能准确地从起点到达终点。
总结
通过这个小球飞入购物车的动画效果,我们不仅提升了用户体验,还学习了:
- 如何使用贝塞尔曲线创建平滑动画
- 如何用requestAnimationFrame实现高性能动画
- 如何动态计算元素位置
- 如何使用rem单位实现移动端适配
这个小小的交互设计虽然看起来简单,但能大大提升用户体验,让你的电商网站更加生动有趣。从京东商城的灵感到实际代码实现,我们完成了一个专业级别的交互效果。
恩恩……懦夫的味道
来源:juejin.cn/post/7502647033401704484
工作两年,最后从css转向tailwind了!
菜鸟上班已经两年了,从一个对技术充满热情的小伙子,变成了一个职场老鸟了。自以为自己在不停的学习,但是其实就是学一些零碎的知识点,比如:vue中什么东西没见过、js什么特性没用过、css新出了个啥 ……
菜鸟感觉自己也出现了惰性,就是暂时用不上的或者学习成本比较大的,就直接收藏了,想着后面再来学习;然后那些很快能接收有用的小的知识点,就感觉看过几次就收藏了,后面有用,就来收藏里面翻一下就行!
但是菜鸟最近再来回想才发现,这些其实都是虚的,程序员最重要的应该是思维模式,以及如何把学的东西、好用的东西用起来,找到应用场景,而不是到时候再去找。
正如标题所说,菜鸟其实很早就知道css原子化,但是一直都走不出自己的舒适圈,感觉就写点css也挺好,为什么还要花力气去记别人想好的类名?要是一直用这些,岂不是css知识都忘记完了?
直到我们公司的大佬来了之后,力推tailwind,而菜鸟感觉和大佬的差距真的很大,所以又激起了菜鸟想要学习的兴趣!
怎么从css过渡到tailwind
菜鸟在之前,是很不想使用tailwind的,因为菜鸟感觉里面很多类名需要去记,而且和我之前取类名的方式也不一样!相信大部分人都和菜鸟一样,在用tailwind之前,取类名一般都是和包裹的内容相关的名字,例如:contentBox、title、asideBox ……
前期使用不熟的时候直接打开官网就行:http://www.tailwindcss.cn/docs/instal…
菜鸟告诉大家一个办法,就是别想着去记类名,直接你想要用什么css属性,直接点击搜索即可,敲入你想使用的属性
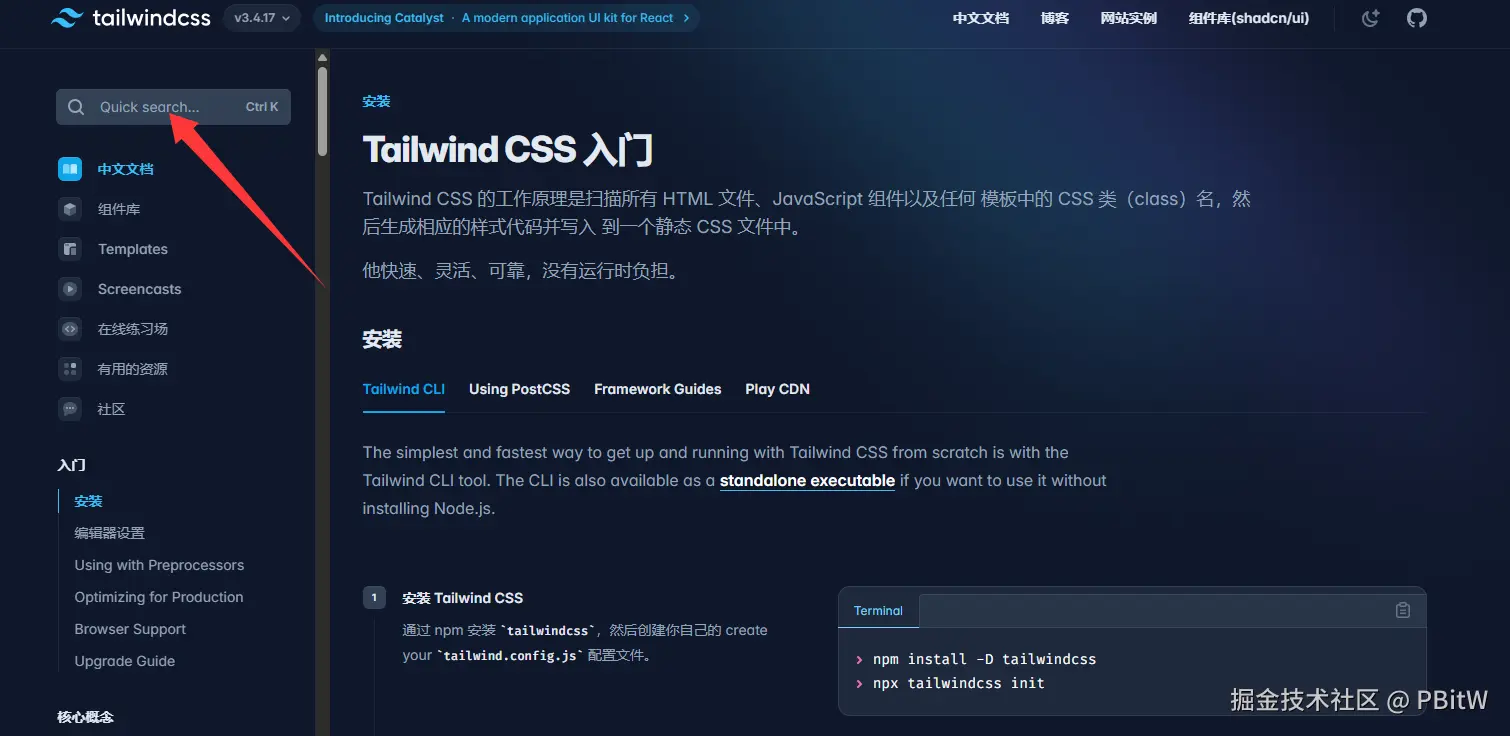
多用几次,自然就记住了,而且现在编译器有提示的。用了tailwind之后,只能说句真香,因为再也不会有怎么取名以及有重名的困扰了!
tailwind yyds
一开始菜鸟用tailwind,感觉也不是很自由啊!

菜鸟就感觉这个也太low了吧,我要是想用别的值怎么办?直到菜鸟看到了这个

基本上有了这个,就可以天下无敌了,想多少就多少,这就是自由的感觉!
反正菜鸟基本上用的都是这个,不管是颜色还是大小,除非比较好记的,例如:w-1、w-2、p-1、p-2、m-1、mr-1 ……
tailwind 自定义类名
有一个问题,就是当类名太多的时候,感觉也不是很好看,这个时候就要用到复杂一点的tailwind,见文档:http://www.tailwindcss.cn/docs/reusin…

很多地方都用到一样的样式,就适合这种方式!不然直接多写几个类名也不是不能接受!
@layer
这个@layer components是避免样式冲突和被覆盖的作用,菜鸟感觉不好理解,但是你肯定不会去重写tailwind的类名,至于有没有树摇优化那就是菜鸟没有涉猎了,反正就当默认写法比较好理解,一般也确实就是这样写。
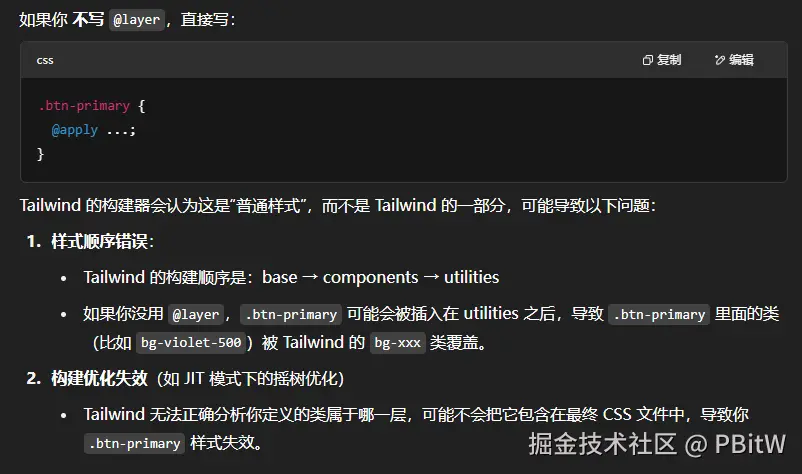
这里也可以看看tailwind4的官网,感觉说得清楚一点:tailwindcss.com/docs/adding…
当然有懂的读者,可以指点江山,激扬文字!
更多函数或指令
tailwind中不止有@layer、@apply,只是 菜鸟主要就用了这两个,更多见官网:tailwindcss.com/docs/functi…
类名太多,团队规范
当一个元素类名比较多时,每个人的想法都不一样,那么类名就会比较杂乱,可能每个人都不一样,看着就不是很好,这个时候就要使用自动格式化工具了,让每个人的类名排列顺序都是一样,也避免了不少冲突!
只要使用了prettier就可以使用这个,关于prettier的知识可以见:vue3+vite+eslint|prettier+elementplus+国际化+axios封装+pinia
使用tailwind不会忘记css,更是加强css
菜鸟之前对tailwind的误解有点深,其实使用tailwind根本不会降低我们的css水平,相反,你平时多逛逛tailwind官网,反而能发现一些你从未使用过或者使用很少的css属性,你会用tailwind实现,其实就是css会实现,反正都可以增加你对css某个属性的理解,且tailwind还附带了效果示例!
Trae 对 tailwind 的支持
之前的代码
<el-button
:loading="loading"
size="large"
type="primary"
s =tyle="width: 100%"
@click.prevent="handleLogin"
>
<span v-if="!loading">登 录</span>
<span v-else>登 录 中...</span>
</el-button>
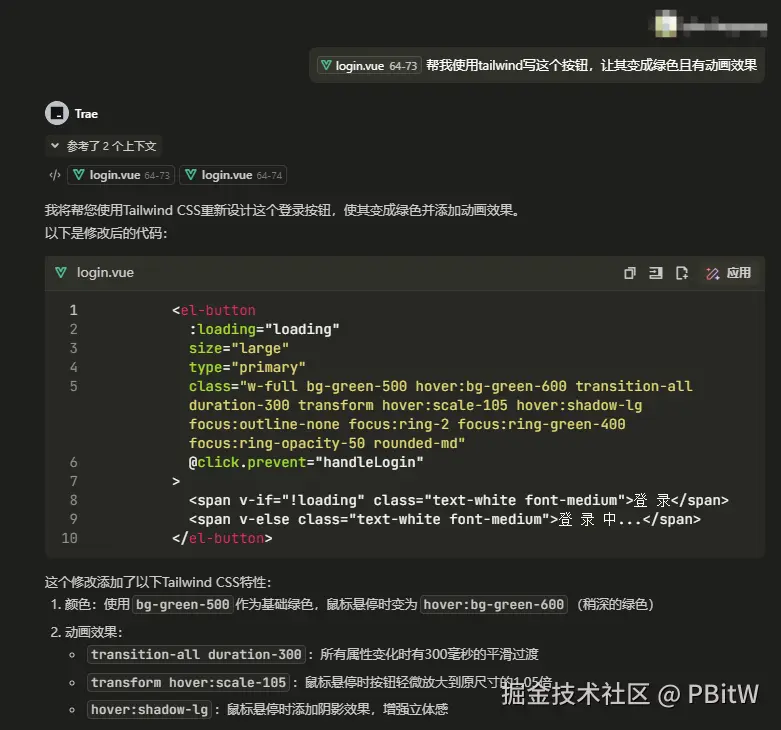
实现效果

感觉Trae对tailwind的支持挺好的,一些简单的效果都可以快速实现!
tailwind 可以替代 scss 等
tailwind4 中有明确的说明,见:tailwindcss.com/docs/compat…
菜鸟只能说tailwind的目标很宏大!
总结
tailwind使用不难,所以菜鸟也没啥可以写得很多或者很复杂的,菜鸟只是希望这个经历可以让各位新手赶紧掌握tailwind,不是css用不起,而是tailwind更有性价比!
来源:juejin.cn/post/7501147702667952168
我们又上架了一个鸿蒙项目-止欲
我们又上架了一个鸿蒙项目-止欲
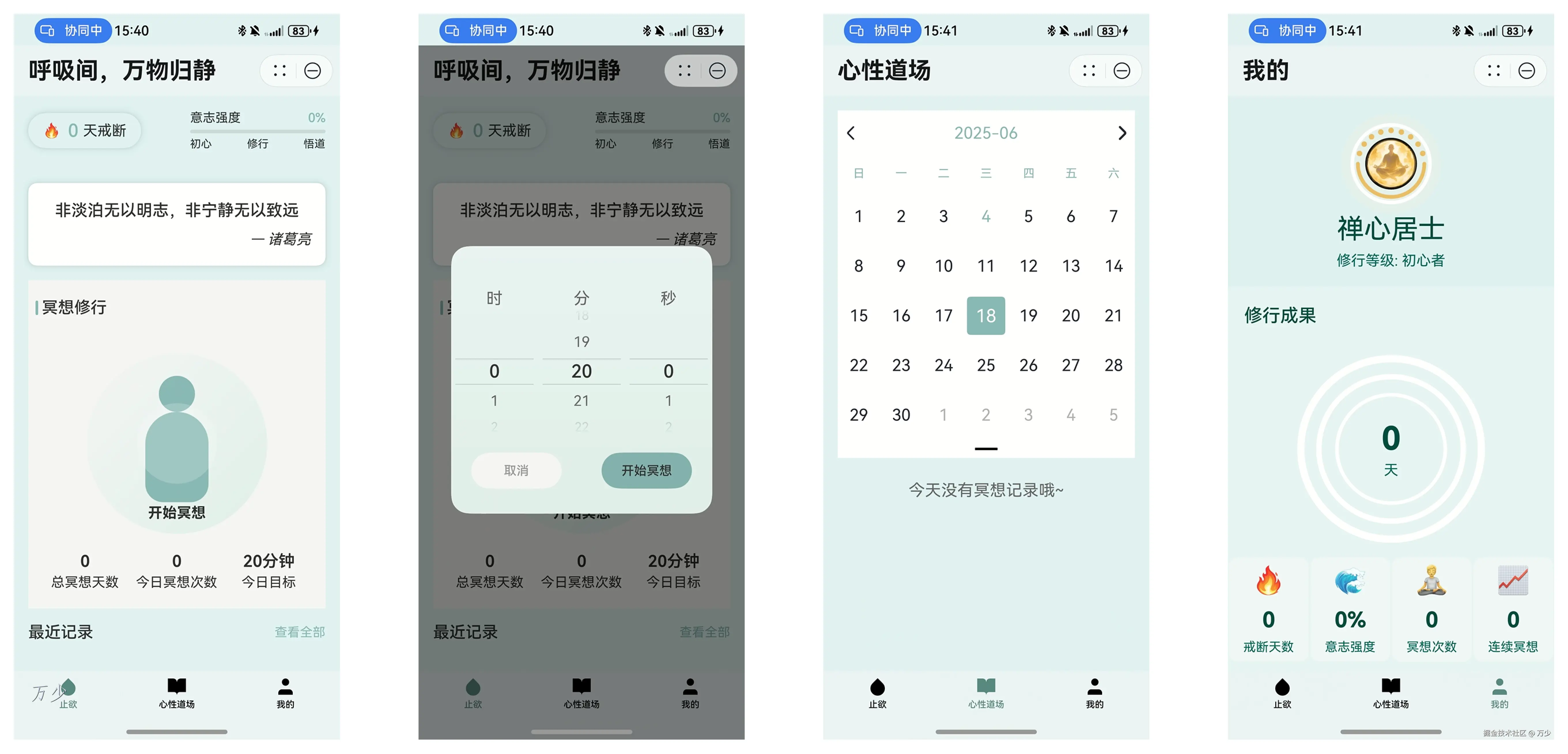
止欲介绍
止欲是一款休闲类的鸿蒙元服务,希望可以通过冥想让繁杂的生活慢下来、静下来。
《止欲》从立项到上架总过程差不多两个月,主要都是我们青蓝的小伙伴在工作止欲抽空完成的,已经实属不易了,我们主要开发者都是 00 后,最年轻的开发者也是才 19 岁。
立项时间是:2025-04-08

上架时间是:2025-06-03

止欲同时也是我们青蓝逐码组织上架的第三个作品了,每个作品都是由初入职场、甚至大学还没有毕业的小伙伴高度参与!

git 日志一览
项目技术细节
项目架构
Serenity/Application/
├── entry/ # 主模块
│ ├── src/main/
│ │ ├── ets/ # TypeScript源码
│ │ │ ├── entryability/ # 应用入口能力
│ │ │ ├── entryformability/ # 服务卡片能力
│ │ │ ├── pages/ # 页面文件
│ │ │ ├── view/ # UI组件
│ │ │ ├── utils/ # 工具类
│ │ │ ├── model/ # 数据模型
│ │ │ ├── const/ # 常量定义
│ │ │ └── navigationStack/ # 导航栈管理
│ │ └── resources/ # 资源文件
│ └── module.json5 # 模块配置
├── EntryCard/ # 服务卡片模块
├── AppScope/ # 应用级配置
└── oh-package.json5 # 依赖管理
技术栈
- 开发语言: ArkTS (TypeScript)
- UI 框架: ArkUI
- 构建工具: Hvigor
- 包管理: ohpm
核心开发套件 (Kit)
本项目使用了多个 HarmonyOS 官方开发套件:
| 套件名称 | 用途 | 主要 API |
|---|---|---|
| @kit.ArkUI | UI 框架和导航 | AtomicServiceNavigation, window |
| @kit.BasicServicesKit | 基础服务 | BusinessError, request |
| @kit.MediaLibraryKit | 媒体库访问 | photoAccessHelper |
| @kit.CoreFileKit | 文件操作 | fileIo |
| @kit.ImageKit | 图像处理 | image.createImageSource |
| @kit.PerformanceAnalysisKit | 性能分析 | hilog |
| @kit.AbilityKit | 应用能力 | UIAbility, abilityAccessCtrl |
开发环境要求
- HarmonyOS SDK: 5.0.1(13) 或更高版本
- DevEco Studio: 5.0 或更高版本
- 编译目标: HarmonyOS
开发细节
开始立项
分析如何选型
暴躁起来了

成功上架

后续计划
- 接入登录
- 接入端云一体
- 增加趣味性功能
- 代码开源-分享教程
总结
如果你兴趣想要了解更多的鸿蒙应用开发细节和最新资讯,甚至你想要做出一款属于自己的应用!欢迎在评论区留言或者私信或者看我个人信息,可以加入技术交流群。
来源:juejin.cn/post/7511779749967347747
解锁企业高效未来|上海飞络Synergy AI开启智能体协作新时代
他/她可以有自己的电脑,可以有自己的邮箱号,可以有自己的企业微信号。只要赋予权限,他/她可以替你完成各种日常工作,他/她可以随时随地和你沟通并完成你安排的任务,他/她永远高效!他/她永不抱怨!
Synergy AI数字员工雇佣管理平台,以大语言模型驱动的AI Agent为核心,结合MCP工具集,并在数据安全、信息安全及行为安全的多维度监控下,为企业提供安全、合规、高效的“智能体员工”,重塑人机协作新范式!

为什么选择Synergy AI数字员工管理平台?
1、智能生产力升级
AI Agent数字员工深度融合语言理解、逻辑推理与工具调用能力,是能够自主感知环境、决策并执行任务的人工智能系统。它可以拥有自己的电脑、邮箱,微信号等所有员工的权限,同时也具备MCP工具集中的各种技能,能够像真人一样沟通,处理工作,但是能够实现更高的工作效率和更加低廉的成本!

2、根据职位定制AI员工工作流
通过“AIGC+Workflow”组合,实现任务自动化执行,响应速度大幅提升,成为企业降本增效的核心引擎。
同时基于企业人员、技能、文档、流程等六大核心信息库,AI数字员工可快速融入业务场景,提供从单职能支持、人机协同到多职能协作的全链路服务。

3、安全合规,全程可控
1)行为监测
实时检测AI数字员工是否存在权限越界、敏感数据操作,信息泄露,被黑客利用等安全合规隐患。
2)数据安全管控
智能识别、过滤、脱敏替换AI数字员工及大语言模型使用过程中触发的敏感数据,企业核心数据泄漏等风险。
3)效能可视化
通过工作流执行情况、人工干预度等指标,持续优化AI员工表现。

Synergy AI能实现什么效果?
1、AI销售助理
可协助销售管理日程、预约会议、统计CRM数字,甚至代替销售联络沟通回款问题。入职飞络销售部门后,内部数据显示客户响应效率提升3倍以上,人力成本降低60%,助力团队精准触达商机。

2、SOC安全及运维专员
在安全运营和运维场景中,AI员工可以迅速响应各个安全系统平台的告警,并根据制定的工作流程,进行下一步的沟通、交流、处置。让企业安全事件响应速度大幅提升,精准提高准确率,为企业筑牢数字防线。

3、更多AI人职位有待解锁
根据每家企业不同的场景需求,Synergy AI提供可以定制化的各种企业AI数字员工,让AI智能体真正能够匹配企业需求,为企业带来实际帮助。

Synergy AI如何落地实施?
1、分析岗位SOW/SOP
找到重复、需要与人互动的工作流,快速实现智能化并通过拟人化的AI员工来完成,逐步将AI工作流覆盖全业务。
2、无缝对接系统
支持OA、ERP、CRM、M365等主流平台MCP / API对接。
3、7×24小时护航
飞络安全运营中心全程监控,保障业务稳定运行。

企业的信息安全如何保护?
飞络基于自研发两大安全管理平台,为企业在使用AI的同时,极大限度保障企业的数据以及隐私安全:
企业AI安全事件监控管理平台
通过企业AI安全事件监控管理平台,我们可以实时提供AI系统以及AI Agents的运行状态,对于所发生的安全事件,实行7*24小时的安全监控及管理。
ASSA:企业AI数据过滤平台
通过ASSA,企业可以管理及管控企业内部信息传输到大语言模型上的数据,对于敏感信息、企业机密、个人信息等进行阻止、脱敏、模糊化等管理操作
7*24 SOC服务
基于飞络提供的7*24级别的SOC运营服务,可以协助客户一起实时监控及管理所有AI相关的安全事件,为企业的数据安全保驾护航!


Synergy AI数字员工雇佣管理平台,以自主研发技术为核心,为企业提供一站式智能解决方案。
收起阅读 »Chrome AI:颠覆网页开发的全新黑科技
Chrome AI 长啥样
废话不多说,让我们直接来看一个示例:
async function askAi(question) {
if (!question) return "你倒是输入问题啊"
// 检查模型是否已下载(模型只需下载一次,就可以供所有网站使用)
const canCreate = await window.ai.canCreateTextSession()
if (canCreate !== "no") {
// 创建一个会话进程
const session = await window.ai.createTextSession()
// 向 AI 提问
const result = await session.prompt(question)
// 销毁会话
session.destroy()
return result
}
return "模型都还没下载好,你问个蛋蛋"
}
askAi("玩梗来说,世界上最好的编程语言是啥").then(console.log)
//打印: **Python 语言:程序员的快乐源泉!**
可以看到这些浏览器原生 AI 接口是挂在 window.ai 对象下面的,浏览器自带 AI 模型(要下载),无需消耗开发者的资金去调用 OpenAI API 或者是 文心一言 API等。
由于没有成本限制,想象空间极大扩展。你可以将智能融入网页的每一个环节。例如,实时翻译,传统的 i18n 只能映射静态字符串来支持多语言,对于后端传过来的字符串毫无办法,现在可以交给 AI 实时翻译并展示。
未来,这个浏览器 AI 标准接口将不仅限于 Chrome 和 PC 端,其他浏览器厂商也会跟进,手机也将拥有本地运行小模型的浏览器。
Chrome AI 接口文档
我们刚刚看到了 Chrome AI 的调用示例,现在让我们看一下完整的 Chrome 文档。我将用 TypeScript 和注释方式展示,这些类型和注释是我手动编写的,全网独一无二,赶紧收藏:
declare global {
interface Window {
readonly ai: AI;
}
interface AI {
/**
* 判断模型是否准备好了
* @example
* ```js
* const availability = await window.ai.canCreateTextSession()
* if (availability === 'readily') {
* console.log('模型已经准备好了')
* } else if (availability === 'after-download') {
* console.log('模型正在下载中')
* } else {
* console.log('模型还没下载')
* }
* ```
*/
canCreateTextSession(): Promise<AIModelAvailability>;
/**
* 创建一个文本生成会话进程
* @param options 会话配置
* @example
* ```js
* const session = await window.ai.createTextSession({
* topK: 50, // 生成文本的多样性,越大越多样
* temperature: 0.8 // 生成文本的创造性,越大越随机
* })
*
* const text = await session.prompt('今天天气怎么样?')
* console.log(text)
* ```
*/
createTextSession(options?: AITextSessionOptions): Promise<AITextSession>;
/**
* 获取默认的文本生成会话配置
* @example
* ```js
* const options = await window.ai.defaultTextSessionOptions()
* console.log(options) // { topK: 50, temperature: 0.8 }
* ```
*/
defaultTextSessionOptions(): Promise<AITextSessionOptions>;
}
/**
* AI模型的可用性
* - `readily`:模型已经准备好了
* - `after-download`:模型正在下载中
* - `no`:模型还没下载
*/
type AIModelAvailability = 'readily' | 'after-download' | 'no';
interface AITextSession {
/**
* 询问 AI 问题, 返回 AI 的回答
* @param input 输入文本, 询问 AI 的问题
* @example
* ```js
* const session = await window.ai.createTextSession()
* const text = await session.prompt('今天天气怎么样?')
* console.log(text)
* ```
*/
prompt(input: string): Promise<string>;
/**
* 询问 AI 问题, 以流的形式返回 AI 的回答
* @param input 输入文本, 询问 AI 的问题
* @example
* ```js
* const session = await window.ai.createTextSession()
* const stream = session.promptStreaming('今天天气怎么样?')
* let result = ''
* let previousLength = 0
*
* for await (const chunk of stream) {
* const newContent = chunk.slice(previousLength)
* console.log(newContent) // AI 的每次输出
* previousLength = chunk.length
* result += newContent
* }
*
* console.log(result) // 最终的 AI 回答(完整版)
*/
promptStreaming(input: string): ReadableStream;
/**
* 销毁会话
* @example
* ```js
* const session = await window.ai.createTextSession()
* session.destroy()
* ```
*/
destroy(): void;
/**
* 克隆会话
* @example
* ```js
* const session = await window.ai.createTextSession()
* const cloneSession = session.clone()
* const text = await cloneSession.prompt('今天天气怎么样?')
* console.log(text)
* ```
*/
clone(): AITextSession;
}
interface AITextSessionOptions {
/**
* 生成文本的多样性,越大越多样,正整数,没有范围
*/
topK: number;
/**
* 生成文本的创造性,越大越随机,0-1 之间的小数
*/
temperature: number;
}
}
如何启用 Chrome AI
准备工作
- 下载最新 Chrome Dev 版或 Chrome Canary 版。(版本号不低于
128.0.6545.0) - 确保你的电脑有
22G的可用存储空间。 - 很科学的网络
启用 Gemini Nano 和 Prompt API
- 打开
Chrome, 在地址栏输入:chrome://flags/#optimization-guide-on-device-model,选择enable BypassPerfRequirement,这步是绕过性能检查,确保Gemini Nano能顺利下载。 - 再输入
chrome://flags/#prompt-api-for-gemini-nano,选择enable。 - 重启
Chrome浏览器。
确认 Gemini Nano 是否可用
- 按
F12打开开发者工具, 在控制台输入await window.ai.canCreateTextSession(),如果返回readily,就说明 OK 了。 - 如果上面的步骤不成功,重启
Chrome后继续下面的操作:
- 新开一个标签页,输入
chrome://components - 找到
Optimization Guide On Device Model,点击Check for update,等待一个世纪直到Status - Component updated出现就是模型下载完成。(模型版本号不低于2024.5.21.1031)
- 新开一个标签页,输入
- 模型下载完成后, 再次在开发者工具的控制台中输入
await window.ai.canCreateTextSession(),如果这次返回readily,那就 OK 了。 - 如果还是不行,可以等一会儿再试。多次尝试后仍然失败,请关闭此文章🐶。
思考
AI 最近两年可谓是爆发式增长,从 GPT-3 开始,笔者就一直在使用 AI 产品,如 Github copilot。ChatGPT 推出后,我迅速开发了一个 GPT-Runner vscode 扩展,用于勾选代码文件进行对话。
我一直在思考,AI 能给网页产品带来哪些变革?例如,有没有可能出现一个 AI 组件库,将 AI 智能赋予组件,如 input 框猜测用户下一步输入,或 table 组件实现自然语言搜索和数据拼装。
与 AI 相关的技术通常需要额外的计算成本,企业主和用户支付意愿低。如果能利用本地算力,就无需额外花费。这个场景现在似乎在慢慢实现。
作为开发者,我们正在迎来 AI 全面赋能网页操作的时代。让我们积极拥抱变化,向老板展示更多的迭代需求,找到前端就业的新增长点。
如果本文章感兴趣者众多,将考虑使用这个 AI 接口实现兼容 OpenAI API 规范,这样你可以不用花钱,不用装 Docker,直接使用浏览器算力和油猴插件免费使用各类开源 chat web ui,如在线版的 Chat-Next-Web。
彩蛋
仔细观察 window.ai.createTextSession ,你会发现它为什么不叫 window.ai.createSession ?我猜测未来可能会有 text-to-speech 模型、 speech-to-text 模型、text-to-image 模型、image-to-text 模型,或者更多惊喜。
这不是随便猜测,我是在填写 Chrome AI preview 邀请表时看到的选项。敬请期待吧,各位前端开发er。
来源:juejin.cn/post/7384997062415843339
为了不让同事看到我的屏幕,我写了一个 Chrome 插件
那天下午,我正在浏览一些到岛国前端技术文档,突然听到身后传来脚步声。我下意识地想要切换窗口,但已经来不及了——我的同事小张已经站在了我身后。"咦,你在看什么?"他好奇地问道。我尴尬地笑了笑,手忙脚乱地想要关闭页面。那一刻,我多么希望有一个快捷键,能瞬间让整个屏幕变得模糊,这样就不会有人看到我正在浏览的内容了。
于是乎我想:为什么不开发一个 Chrome 插件,让用户能够一键模糊整个网页呢?这样不仅能保护隐私,还能避免类似的尴尬情况。
开发过程
说干就干,我开始了 Web Blur 插件的开发。这个插件的核心功能很简单:
- 一键切换:使用快捷键(默认 Ctrl+B)快速开启/关闭模糊效果
- 可调节的模糊程度:根据个人喜好调整模糊强度
- 记住设置:自动保存用户的偏好设置
技术实现
1.首先,我们需要在 manifest.json 中声明必要的权限:
"manifest_version": 3,
"name": "Web Blur",
"version": "1.0",
"permissions": [
"activeTab",
"storage",
"commands"
],
"action": {
"default_popup": "popup.html",
"default_icon": {
"128": "images/icon.png"
}
},
"commands": {
"toggle-blur": {
"suggested_key": {
"default": "Ctrl+Shift+B"
},
"description": "Toggle blur effect"
}
}
}
2. 实现模糊效果
function applyBlur(amount) {
const style = document.createElement('style');
style.id = 'web-blur-style';
style.textContent = `
body {
filter: blur(${amount}px) !important;
transition: filter 0.3s ease;
}
`;
document.head.appendChild(style);
}
// 移除模糊效果
function removeBlur() {
const style = document.getElementById('web-blur-style');
if (style) {
style.remove();
}
}
3. 快捷键控制
if (command === 'toggle-blur') {
chrome.tabs.query({active: true, currentWindow: true}, (tabs) => {
chrome.tabs.sendMessage(tabs[0].id, {action: 'toggleBlur'});
});
}
});
4. 用户界面
5px
Current: Ctrl+Shift+B
5. 设置持久化
function saveSettings(settings) {
chrome.storage.sync.set({settings}, () => {
console.log('Settings saved');
});
}
// 加载设置
function loadSettings() {
chrome.storage.sync.get(['settings'], (result) => {
if (result.settings) {
applySettings(result.settings);
}
});
}

以后可以愉快的学技术辣
来源:juejin.cn/post/7509042833152851978
开源鸿蒙开发者大会2025 | 大屏生态分论坛:共建共享,共赢未来
5月24日,开源鸿蒙开发者大会2025(OHDC.2025)在深圳成功举办。在主论坛上隆重举行了“开源鸿蒙TV SIG”成立仪式,开源鸿蒙TV SIG旨在携手产业伙伴,基于开源鸿蒙社区,构建TV关键技术能力、推动产业标准制定和落地、加强生态合作,促进大屏生态繁荣。

开源鸿蒙TV SIG成立仪式
大会期间,同步举办了以“共建共享,共赢未来”为主题的大屏生态分论坛,与会者围绕开源鸿蒙TV SIG技术规划、大屏应用、系统、产品、芯片及配件等关键技术的突破等11个热点议题进行分享与交流,并就未来的发展方向进行了深入探讨,全方位展示基于开源鸿蒙操作系统的大屏生态在创新实践和落地应用方面的成果。本次论坛由开源鸿蒙TV SIG组长、华为终端BG OpenHarmony使能部大屏生态总监汪曙光担任出品人。

大屏生态分论坛圆满举办
华为终端BG OpenHarmony使能部副部长李彦举发表开幕致辞,向所有参与开源鸿蒙大屏生态共建的开发者及企业致谢,并高度评价了开源鸿蒙大屏建设所取得的阶段性成果。基于对大屏行业的深度洞察与开源鸿蒙技术的演进趋势,他指出:“开源鸿蒙大屏产业近年来取得了显著的阶段性成果,已进入高速发展期。”同时,他呼吁更多伙伴和开发者加入生态共建,加速推进大屏生态从技术验证向规模商用的关键跨越,共同把握智慧显示终端的时代机遇。

华为终端BG OpenHarmony使能部副部长李彦举
开源鸿蒙TV SIG组长汪曙光发表题为《开源鸿蒙TV SIG整体规划及最新共建进展》的主题演讲。他表示,TV SIG将以“建能力、立标准、促生态、广复制”为目标,携手SIG成员及广大生态伙伴,搭建社区大屏公共软硬件平台,进行技术的孵化和生态的推动,并展示了SIG组的技术全景图以及路标规划。在演讲中,汪曙光详细介绍了大屏生态已取得的成果:完善了10多个系统应用和专有能力,推出了9个第三方应用(涵盖应用市场、影音娱乐、工具游戏等多个领域)和4颗媒体SoC主芯片(适用于TV、商显、盒子等多种设备)。在演讲最后他提到,基于开源鸿蒙的大屏北向三方应用预计将于今年下半年取得阶段性进展,SIG组也将支撑伙伴孵化出更多商用产品。

华为终端BG OpenHarmony使能部大屏生态总监汪曙光
开源鸿蒙TV SIG副组长、北京风行在线技术有限公司高级技术专家韩超在论坛上做了《风行面向开源鸿蒙的大屏应用市场进展分享》的主题演讲。作为内容运营服务商,风行始终致力于让内容流动更简单,并为数亿用户提供了优质的数字文娱服务。韩超详细介绍了风行在应用开发方面的技术方案和成功实践,并将应用框架源码开源至社区,帮助行业伙伴缩短开发周期。截止目前,风行已推出多款开源鸿蒙大屏应用,其中“橙子市场”作为开源鸿蒙大屏端首个应用市场,旨在为生态伙伴提供内容及应用分发服务,当前已上架的应用涵盖了影视、游戏、教育等多个品类。未来,风行将继续携手行业伙伴,鼓励更多优质应用入驻,持续丰富应用种类,满足用户多样化需求。

北京风行在线技术有限公司高级技术专家韩超
开源鸿蒙TV SIG副组长、华为终端BG智慧交互软件开发部技术专家华红宁带来《面向开源鸿蒙的大屏TV子系统共建进展分享》议题演讲。他详细介绍了华为智慧屏的业务、产品愿景及使命,并表达了通过共建共享,与开源鸿蒙生态伙伴携手推动传统大屏产业升级的期望。与此同时,他还分享了开源鸿蒙TV子系统的架构、业务分层以及核心业务的逻辑,并同步了最新的开发进展和后续规划:通过开源共建,TV子系统已取得显著进展,预计上半年将完成核心功能开发,并将在下半年持续进行功能迭代与完善,后续版本也已规划一系列新特性。他诚邀行业伙伴共同参与代码共建,提升未来产品竞争力。

华为终端BG智慧交互软件开发部技术专家华红宁
开源鸿蒙TV SIG副组长、四川长虹电子控股集团有限公司操作系统高级技术专家张帅做《长虹面向开源鸿蒙的大屏实践分享和后续展望》议题分享,展示了长虹积极拥抱开源鸿蒙的坚定态度。他指出,长虹云计算与大数据研究中心长期深度参与开源鸿蒙大屏社区共建,推动开源鸿蒙在智慧显示终端领域的生态完善。作为重要共建单位,长虹积极贡献遥控器拾音、分布式白板应用等关键技术架构,完善了社区的技术能力。未来,长虹将持续深化与开源鸿蒙社区的合作,聚焦于开源鸿蒙教育大屏、开源鸿蒙TV等有屏设备以及工业智能终端、工业机器人等方向,推动开源鸿蒙能力平台与产业落地深度融合,为构建智能终端操作系统生态贡献力量。

四川长虹电子控股集团有限公司操作系统高级技术专家张帅
开源鸿蒙TV SIG副组长、海思技术有限公司产品规划总监陈超带来《上海海思媒体领域面向开源鸿蒙的探索与实践》主题分享。他详细介绍了上海海思全面拥抱开源鸿蒙的策略,强调了开源鸿蒙与上海海思芯片深度融合的整体解决方案优势。他表述,开源鸿蒙与星闪技术的强强联合,将有力推动IoT、轻智能、泛媒体等领域智能化升级。在泛媒体终端领域,上海海思已有多款媒体类模组/开发板通过开源鸿蒙认证,涵盖了会议平板、闺蜜机、直播机、智慧大屏等多种产品形态。上海海思正全面支持产业产品的创新发展,助力开源鸿蒙生态繁荣壮大。

海思技术有限公司产品规划总监陈超
开源鸿蒙TV SIG成员、未来电视有限公司高级技术专家李欣做了《聚力开源鸿蒙,共启央视频TV未来》议题分享,详细介绍了未来电视在TV端大屏应用——央视频TV的发展历程、平台架构演进,以及开源鸿蒙版本的开发与迭代计划。未来,央视频TV将在其开源鸿蒙版本中逐步集成灵犀触控、互动卡片等创新功能,持续优化用户互动操控体验。此外,央视频TV将依托开源鸿蒙的人脸识别技术,在确保用户隐私安全的基础上为不同用户群体提供个性化的内容推荐和事件推送等陪伴功能,共同构建“有温度”的客厅场景。

未来电视有限公司高级技术专家李欣
开源鸿蒙TV SIG成员、湖南国科微电子股份有限公司资深系统架构师刘杰兵带来《国科微基于开源鸿蒙的芯片平台介绍》议题分享。他指出,基于开源鸿蒙行业发行版的芯片适配是点亮亿级行业设备的关键。作为国内领先的集成电路设计企业,国科微在大型SoC及解决方案开发方面积累了丰富的实践经验,并积极推进开源鸿蒙芯片适配工作,为开源鸿蒙生态建设注入强劲动力。截至目前,国科微已获得5张兼容性测评证书,涵盖机顶盒、电视、商显、摄像头等多个应用场景,实现多个业内首款“开源鸿蒙认证”。未来,国科微将持续提速国科芯开源鸿蒙适配工作,并将于2025年第三季度和第四季度推出基于开源鸿蒙的5.0和5.1商用版本。

湖南国科微电子股份有限公司资深系统架构师刘杰兵
开源鸿蒙TV SIG成员、上海视九信息科技有限公司总裁周云龙发表《面向开源鸿蒙的大屏小程序平台介绍》主题演讲。他介绍了公司研发的JsView引擎,其核心价值在于能为开源鸿蒙生态快速引入丰富的大屏小程序应用。作为在国内主流OTT、IPTV设备稳定运行多年的成熟引擎,JsView以开发周期短、部署升级快、页面流畅、特效丰富等优势,成为行业开发标杆。目前,JsView引擎已完成开源鸿蒙系统适配,基于该平台开发的央视国学苑、唱吧K歌等数十家头部内容的小程序版本,可直接上线开源鸿蒙大屏设备。全新的内容或应用,也可经由该引擎快速开发融入开源鸿蒙生态。

上海视九信息科技有限公司总裁周云龙
开源鸿蒙TV SIG成员、广东辰奕智能科技股份有限公司研究院院长严开云带来《面向开源鸿蒙的大屏配件生态解决方案介绍》,并现场发布首款基于开源鸿蒙的指向语音遥控器及生态配件产品。作为开源鸿蒙TV生态的亮点创新成果,该遥控器具备隔空触控、智慧触摸、近场语音及灵活批注等功能,兼容多类南向应用,灵活适配家庭娱乐场景需求,为用户带来更智能、便捷的交互体验。该产品的发布,充分彰显了开源鸿蒙在智能硬件领域的应用潜力。

广东辰奕智能科技股份有限公司研究院院长严开云
开源鸿蒙TV SIG成员、鸿湖万联(江苏)科技发展有限公司PC及大屏产品总监袁杰做《基于开源鸿蒙的教育及会议大屏产品实践分享》主题分享。据介绍,软通动力充分融合子公司鸿湖万联在开源鸿蒙领域的创新突破以及软通计算机(原同方计算机)的硬件优势,率先推出搭载SwanLinkOS天鸿操作系统的开源鸿蒙智能交互大屏产品,并完成跨系统跨终端形态的多屏协同、集成DeepSeek大模型应用、以及教育应用软件的开源鸿蒙移植工作,为行业客户提供软硬一体端到端的产品及服务能力。

鸿湖万联(江苏)科技发展有限公司PC及大屏产品总监袁杰
开源鸿蒙TV SIG成员、江苏润开鸿数字科技有限公司开源鸿蒙应用架构师傅康带来《基于开源鸿蒙文件管理器与DeepSeek的大屏开发实践》议题分享,深入介绍文件管理器和DeepSeek在开源鸿蒙大屏上的实现方案及核心功能点,并针对大屏设备的交互特点,适配了遥控器走焦、灵犀操控功能。基于DeepSeek的语音助手还支持蓝牙遥控器语音以及ASR语音转文字等功能,显著提升用户操控体验的同时,也赋予大屏如家庭管家、家庭医生和家庭教师等更多角色。

江苏润开鸿数字科技有限公司开源鸿蒙应用架构师傅康
本次大屏生态分论坛内容丰富,活动现场人气火爆,充分彰显了大屏行业伙伴对开源鸿蒙大屏技术发展、生态进展的高度关注与殷切期待。同时,也印证了开源鸿蒙在大屏产业中拥有广阔的发展前景,具备广泛应用与行业创新的巨大潜力。诚挚欢迎更多开发者和企业加入开源鸿蒙TV SIG组,一起“共建共享,共赢未来”!
收起阅读 »2025 BOE(京东方)全球供应伙伴大会隆重举行 共筑全球显示产业共生共赢新格局
5月28日,备受瞩目的2025年BOE(京东方)全球供应伙伴大会(BOE SPC 2025)在东方帆船之都——青岛盛大启幕。作为半导体显示领域极具影响力的供应链盛会,本届BOE SPC大会以“屏之物联 共生共赢”为主题,汇聚了全球千余位显示行业专家、卓越合作伙伴企业代表及业界精英齐聚一堂,不仅展现了意义深远的行业蓝图、精彩纷呈的主题演讲,BOE(京东方)还对在技术、品质、服务等方面做出杰出贡献的合作伙伴进行表彰,倡导行业协同可持续发展。BOE(京东方)将充分发挥在显示领域的引领作用,携手全球合作伙伴构建可持续的创新生态,树立显示产业技术升级与供应链绿色发展的全新标杆。

BOE(京东方)董事长陈炎顺在致辞中表示:“在当今物联网、人工智能等与产业深度融合的时代,‘屏’已从简单的显示终端进化为智能交互的核心枢纽。我们深知供应伙伴是企业发展的重要支撑,是推动全球产业链协同的关键力量。我们举办SPC大会,旨在搭建一个开放包容、共生共赢的多方交流平台,加强与全球合作伙伴之间的合作,共同探讨未来技术创新、高质发展的有效路径,推动全球产业链不断优化升级。在未来的发展道路上,BOE(京东方)将始终以创新为驱动,以共赢为目的,以质量为基石,并期望以刚发布的半导体显示行业首个可持续发展品牌‘ONE’为纽带,携手全球合作伙伴,构建绿色可持续生态体系,秉承开放、包容、创新理念共同书写产业高质量发展新篇章。”

在“屏之物联 共生共赢”主题演讲环节,BOE(京东方)首席执行官冯强表示:“今天的物联时代,数字化与智能化逐渐成为驱动产业创新的重要引擎。BOE(京东方)紧抓时代机遇,以显示技术为原点,将屏幕硬件与传感系统、大数据分析、优化算法等智能要素深度融合,为客户提供从器件到解决方案的全链条服务,依托器件研发、智能制造、系统集成等核心能力,以‘科技+绿色’引领产业向新,持续突破应用场景边界。多年来,BOE(京东方)始终坚持开放合作,基于‘屏’及周边能力价值延展,强化资源赋能。未来,BOE(京东方)向行业发起倡议,深化技术协同创新,贯彻可持续发展理念,强化产业战略协同,携手全球伙伴共同谱写产业高质发展新篇章。“

经过多年的探索与深耕,BOE(京东方)已在生态共创方面取得了一系列成果,形成了以BOE(京东方)为核心的产业链生态,在技术创新、产业发展、生态构建等方面与合作伙伴开展了深度合作。在活动现场,BOE(京东方)首席采购官张学智对合作伙伴长期以来的大力支持与并肩同行表示感谢,并围绕“稳筑生态求共生 聚势协同谋共赢”主题发表演讲。他表示,BOE(京东方)通过全产业链协同创新,实现了UB Cell创新技术及三折模组产品弯折良率等显示领域的创新突破。在绿色转型方面,BOE(京东方)构建从设计到回收的全生命周期绿色体系。未来,BOE(京东方)将通过技术共研、生态共建的协同模式,持续引领行业向绿色低碳、智能创新方向突破发展。

在可持续发展领域,BOE(京东方)持续践行ESG理念,发布行业首个可持续发展品牌“ONE”(Open Next Earth),以开放凝聚共识,以创新定义未来,以永续守护生态。此次SPC大会,BOE(京东方)也将可持续发展理念融入大会议程的各个环节,携手合作伙伴共同推动产业生态的绿色发展。在“共生共赢:可持续供应链的探索与实践”圆桌论坛中,BOE(京东方)携手德勤、福莱盈、山西宇皓等合作伙伴共议绿色发展新路径。德勤谢安指出,供应链金融与低碳转型是应对全球监管趋势的必然方向。BOE(京东方)副总裁、京东方创新投资有限公司COO赵月明分享了定制化金融解决方案,通过稳定资金链构建“共生”生态;BOE(京东方)副首席建设官李彦则展示了绿色运营成果,并联动京东方能源董事长马亮发布公司新能源战略布局。作为合作伙伴代表,山西宇皓郭伦铭、福莱盈张靖表示,BOE(京东方)“绿色+金融”双轮驱动的模式效果显著,既通过供应链金融服务缓解了资金压力,又以智慧能源解决方案助力抢占绿色市场先机。BOE(京东方)将依托技术创新持续深化供应链赋能,携手伙伴迈向“技术驱动、开放包容”的可持续未来。

为表彰一路同行的合作伙伴,本届BOE SPC特别为近百家优秀合作伙伴颁发“钻石奖”、“杰出战略伙伴奖”、“卓越服务奖”、“卓越品质奖”、 “协同创新奖”、“最佳进步奖”,其中,DNP、杉金、SUNIC凭借深厚的技术底蕴和强大的研发实力荣获BOE(京东方)全球供应伙伴最高荣誉——“钻石奖”。该奖项不仅承载了BOE(京东方)携手合作伙伴共谋发展、共创未来的坚定信念,更是对双方长期合作关系的深度认可。值得关注的是,本次大会共有十余家合作伙伴与BOE(京东方)签署了战略合作协议,未来将不断进行技术合作研发和产品共创,塑造更大的产业价值。
当前,实体经济与数字经济的深度融合正加速重构全球产业格局,以AI、物联网为代表的前沿技术形成颠覆性创新浪潮,推动全产业链向智能化、场景化、生态化方向跃迁。面向未来,BOE(京东方)将持续深耕“屏之物联”发展战略,坚持市场化、国际化、专业化的发展道路,以“科技+绿色”推动显示行业高质永续发展,携手全球合作伙伴在技术创新、可持续发展、绿色供应链能力建设等方面开展深度交流与合作,共赢发展新机遇,开启显示赋能人类美好生活的无限可能。
开源鸿蒙开发者大会2025成功召开,启动开源鸿蒙应用技术组件共建
5月24日,开源鸿蒙开发者大会2025(OHDC.2025,以下简称“大会”)在深圳成功举办。开源四年多来,开源鸿蒙代码规模已达 1.3 亿多行,代码贡献者达 8600 多位,超过 1100 款软硬件产品通过兼容性测评,覆盖金融、交通、教育、医疗、航天等多个行业领域,已成为发展速度最快的开源操作系统之一。截至目前,开源鸿蒙已累计发布 8 个大版本,共建共享15个技术域的1115款开源三方库和6个跨平台框架,加速应用和设备的开发。

会上,开源鸿蒙项目群工作委员会携手包括华为、腾讯端服务、京东、去哪儿、杭州通易科技、东北大学、上海大学、深开鸿、九联开鸿、中科鸿略、诚迈科技、鸿湖万联、润开鸿、开鸿智谷在内的14家共建伙伴,共同启动了开源鸿蒙应用技术组件共建。

社区的繁荣发展离不开每一位参与其中并积极贡献的开发者,每一行代码都是对开源鸿蒙社区的重要贡献。共建伙伴积极投入开源三方库和跨平台框架的特性开发、版本升级、Upstream上游社区以及社区Issue响应和维护,为开源鸿蒙应用的开发节约重复的代码开发工作量。期望更多的伙伴、开发者加入到开源鸿蒙应用三方库和跨平台框架的共建中,共建共享开源鸿蒙应用生态组件。
![M$@I91O{0R`XUD]WSSR80]H.png](http://objectnsg.oss-cn-beijing.aliyuncs.com/default/202505/28/20250528135039741444044.png "1748411439482163.png")
期望更多的伙伴、开发者加入到开源鸿蒙应用三方库和跨平台框架的共建中,共建共享开源鸿蒙应用生态组件。
收起阅读 »“你好BOE”2025首站启幕 助力“横琴-澳门国际数字艺术博览会”打造沉浸式科技艺术新高地
5月26日,BOE(京东方)年度标杆性线下品牌营销活动“你好BOE”2025启动仪式在珠海横琴文化艺术中心举办。作为2025年“你好BOE”首站活动,BOE(京东方)助力首届“横琴-澳门国际数字艺术博览会”,通过超高清显示技术及数字化解决方案为展会三大展区的10余个数字艺术展项提供高端显示技术解决方案,打造沉浸式科技艺术现场,生动传递“以创新科技赋能数字艺术”理念。历经四年迭代,“你好BOE”从最初展现BOE(京东方)自身领先技术、与合作伙伴构建联合生态,到如今更加关注创新技术与应用场景的深度融合,该品牌推广IP已升维至全新的3.0时代。活动现场,此次博览会的主办方南光(集团)有限公司副总经理宋晓冬,阳光媒体集团董事长杨澜,亚洲和平慈善基金会董事会主席李伟杰,参展艺术家代表中央美术学院设计学院艺术与科技方向教授、博士生导师、某集体ART+TECH创始人费俊,京东方科技集团副总裁、MLED业务CEO刘毅,艺云科技副总裁、华南区域总经理刘华等众多嘉宾领导出席“你好BOE”2025年启动仪式,开启BOE(京东方)品牌生态合作新篇章。

京东方科技集团副总裁、MLED业务CEO刘毅在启动仪式上表示,BOE(京东方)深耕横琴,正是因为这里涌动的创新基因与我们不谋而合。“你好BOE”作为BOE(京东方)的品牌IP,从2021年诞生至今,它像一座桥梁,一头是我们深耕的技术,一头是大众对美好生活的期待。我们希望用最直观的方式告诉大家:科技可以很温暖,可以成为连接想象与现实的纽带。

作为大湾区文化融合的标志性活动,“横琴-澳门国际数字艺术博览会”共设四大主题展区。BOE(京东方)作为该活动的战略合作伙伴,以ADS Pro显示技术、MLED显示技术,以及新一代无损Gamma显示专利技术等深度赋能“艺术未来式”“重施魔法”“科技重构艺术”三大展区,为观众带来一场沉浸式、强交互的数字艺术视觉盛宴,成为推动“科技+文化”深度融合的又一典范实践。

进入“艺术未来式”主题展区中,BOE(京东方)MLED显示技术赋能产品随处可见。BOE(京东方)Mini LED显示屏具有高亮低功耗,以及灰度表现更富层次等显示优势,将艺术家王之纲、梁蓝波等多款沉浸式装置作品细腻呈现。艺术家张文超的算法生成交互影像装置《一个传说故事的嬗变》则依托BOE(京东方)高端LCD显示技术解决方案ADS Pro的加持,在8个46英寸3.5mm超窄边拼接屏上,以1200:1超高对比度、178°超大可视角度,以及更均匀的亮度表现,呈现出传说故事在时间中经由无数人的想象而拼贴演绎的动态演变过程。同时,BOE(京东方)以P2.6 LED弧度屏赋能艺术家费俊的互动影像装置《情绪剧场》,在高曲度的LED屏幕上实时检测并呈现观众情绪,创造具有疗愈性的音画体验。此外,黑特·史德耶尔(德)、徐冰、田晓磊等国内外艺术家的数字艺术作品,也均由BOE(京东方)提供高端显示技术支持,多方位展现数字艺术创作领域的亮眼成果。

与此同时,基于BOE(京东方)与故宫博物院的战略合作,又恰逢故宫博物院建院100周年,BOE(京东方)携手故宫博物院打造了“在横琴,看见故宫”数字故宫体验展,BOE(京东方)旗下艺云科技通过多款沉浸式场景显示产品,将故宫景致与珍藏文物展现得活灵活现。在“数字多宝阁”“宫廷文化生活”等展区空间内,观众可通过BOE(京东方)类纸触控画屏,在屏幕上与故宫珍藏文物及交互场景进行触控互动,其运用了BOE(京东方)新一代无损Gamma显示专利技术(专利号:ZL 2016 1 0214546.6),通过高精细数据的细节扩大和360度自由改变的视点,为观众带来沉浸式交互体验。而在“千里江山图”空间,BOE(京东方)P1.5类纸LED不仅逼真地还原出40平方米超长画作中的山水世界,达到屏幕防眩光效果,还能够在相同亮度下节约40%能耗,做到节能环保。同时,BOE(京东方)以高亮度、高透光度的三面透明LED屏,沉浸式营造出“瑞象万千”空间的祥光瑞影,屏幕透光率可达到70%-90%,打造故宫动态叙事空间。除此之外,在“重施魔法”展区、“科技重构艺术”展区以及博览会展览通道等区域,也均能看到BOE(京东方)显示产品赋能的身影。

作为这次博览会的主办方代表,资深媒体人、阳光媒体集团董事长杨澜表示,“本届博览会构建起了一个‘可体验、可思考、可创造’的数字艺术生态系统。数字技术、AI技术的到来,展现了艺术创作的新的可能性,艺术表达的需求也激励了技术的迭代与快速发展。”

作为BOE(京东方)年度标杆性的品牌IP,“你好BOE”自2021年启动以来,已连续5年在北京、上海、深圳、成都、青岛、合肥、巴黎、珠海等国内外城市举办13站巡展活动,并先后与敦煌画院、OUTPUT、318国道、无畏契约、上海国际光影节等各领域顶级IP,以及联想、海信、雷神、ROG等十余家合作伙伴进行跨界合作,线下累计触达近450万消费者。而今年全面焕新升级的“你好BOE”持续关注与合作伙伴的生态共创与场景融合,将携手阳光媒体集团、极氪、OPPO、京东、微博、318等打造品牌生态合作性IP,以跨界联合开启BOE(京东方)品牌全新旅程。面向未来,BOE(京东方)将继续秉承“屏之物联”发展战略,携手各界合作伙伴共建“Powered by BOE”创新生态,以显示技术为纽带,融合物联网及数字技术,让艺术与科技在山顶重逢。
关于BOE(京东方):
京东方科技集团股份有限公司(BOE)是全球领先的物联网创新企业,为信息交互和人类健康提供智慧端口产品和专业服务。作为全球半导体显示产业的龙头企业,BOE(京东方)带领中国显示产业破局“少屏”困境,实现了从0到1的跨越。如今,全球每四个智能终端就有一块显示屏来自BOE(京东方)。在“屏之物联”战略引领下,BOE(京东方)凭借“1+4+N+生态链”业务架构,将超高清液晶显示、柔性显示、MLED、微显示等领先技术广泛应用于交通、金融、艺术、零售、教育、办公、医疗等多元场景,赋能千行百业。目前,BOE(京东方)的子公司遍布全球近20个国家和地区,拥有超过5000家全球生态合作伙伴。更多详情可访问BOE(京东方)官网:https://www.boe.com.cn
被问tsconfig.json 和 tsconfig.node.json 有什么作用,我懵了……
背景
事情是这样的,前几天在项目例会上,领导随口问了我我一个看似简单的问题:
“我们项目里有tsconfig.json 和 tsconfig.node.json ,它们有什么作用?”

活久见,我从来没注意过这个细节,我内心无语,问这种问题对项目有什么用!但机智的我还是回答上来了:不都是typescript的配置文件么。
领导肯定了我的回答,又继续问,那为什么项目中有两个配置文件呢?我机智的说,我理解的不深,领导您讲讲吧,我学习一下。
tsconfig.json 是干嘛的?
说白了,tsconfig.json 就是 告诉 TypeScript:我要用哪些规则来“看懂”和“检查”我写的代码。
你可以把它想象成 TypeScript 的“眼镜”,没有它,TS 编译器就会“看不清楚”你的项目到底该怎么理解、怎么校验。
- 影响代码能不能被正确编译
如果我们用了某些新语法(比如 optional chaining、import type),却没有在 tsconfig 里声明 "target": "ESNext",那 TypeScript 就会报错:看不懂!
- 影响编辑器的智能提示
如果我们用了路径别名 @/utils/index.ts,但没有配置:
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"]
}
}
}
那 VS Code 就会一直红线报错:“找不到模块”。
- 影响类型检查的严格程度
比如 "strict": true 会让我们代码写得更规范,少写 any,避免“空值未处理”这类隐患;而关闭了就“宽松模式”,你可能一不小心就放过了 bug。
- 影响团队代码规范一致性
当多个成员一起开发时,统一 tsconfig.json 能让大家都用一样的校验标准,避免“我这边没问题你那边报错”的尴尬。
tsconfig.json文件的一个典型配置如下:
{
"compilerOptions": {
// ECMAScript 的目标版本(决定生成的代码是 ES5 还是 ES6 等)
"target": "ESNext",
// 模块系统,这里用 ESNext 是为了支持 Vite 的现代打包机制
"module": "ESNext",
// 模块解析策略,Node 方式支持从 node_modules 中解析模块
"moduleResolution": "Node",
// 启用源映射,便于调试(ts -> js 映射)
"sourceMap": true,
// 启用 JSX 支持(如用于 Vue 的 TSX/JSX 语法)
"jsx": "preserve",
// 编译结果是否使用 ES 模块的导出语法(import/export)
"esModuleInterop": true,
// 允许默认导入非 ESModule 模块(兼容 CommonJS)
"allowSyntheticDefaultImports": true,
// 生成声明文件(一般用于库开发,可选)
"declaration": false,
// 设置项目根路径,配合 paths 使用
"baseUrl": ".",
// 路径别名配置,@ 代表 src 目录,方便引入模块
"paths": {
"@/*": ["src/*"]
},
// 开启严格模式(类型检查更严格,建议开启)
"strict": true,
// 不检查未使用的局部变量
"noUnusedLocals": true,
// 不检查未使用的函数参数
"noUnusedParameters": true,
// 禁止隐式的 any 类型(没有类型声明时报错)
"noImplicitAny": true,
// 禁止将 this 用在不合法的位置
"noImplicitThis": true,
// 允许在 JS 文件中使用 TypeScript(一般不建议)
"allowJs": false,
// 允许编译 JS 文件(如需使用 legacy 代码可开启)
"checkJs": false,
// 指定输出目录(Vite 会忽略它,一般不用)
"outDir": "./dist",
// 开启增量编译(提升大型项目编译效率)
"incremental": true,
// 类型定义自动引入的库(默认会包含 dom、esnext 等)
"lib": ["ESNext", "DOM"]
},
// 指定编译包含的文件(推荐指定为 src)
"include": ["src/**/*"],
// 排除 node_modules 和构建输出目录
"exclude": ["node_modules", "dist"]
}
Vite 项目中,一般 tsconfig.json 会被自动加载,所以只需要按需修改上述配置即可。
tsconfig.node.json 又是干嘛的?
tsconfig.node.json 并不是 TypeScript 官方强制的命名,而是一种 社区约定俗成 的分离配置方式。它用于配置运行在 Node.js 环境下的 TypeScript 代码,例如:
vite.config.ts(构建配置)scripts/*.ts(一些本地开发脚本)server/*.ts(如果你有 Node 后端)
tsconfig.node.json的一大作用就是针对业务代码和项目中的node代码做区分,划分职责。
如果不写tsconfig.node.json,会出现以下问题:
比如你写了一个脚本:scripts/generate-sitemap.ts,其中用到了 fs、path、url 等 Node 原生模块,但主 tsconfig.json 是为浏览器服务的:
- 设置了
"module": "ESNext",TypeScript 编译器可能不会生成符合 Node 环境要求的代码。 - 缺少
moduleResolution: "node"会导致路径解析失败。
常见配置内容:
{
"compilerOptions": {
// 使用最新的 ECMAScript 特性
"target": "ESNext",
// 使用 CommonJS 模块系统,兼容 Node.js(也可根据项目设置为 ESNext)
"module": "CommonJS",
// 模块解析方式设置为 Node(支持 node_modules 和路径别名)
"moduleResolution": "Node",
// 启用严格模式,增加类型安全
"strict": true,
// 允许默认导入非 ESModule 的模块(如 import fs from 'fs')
"esModuleInterop": true,
// 支持 import type 等语法
"allowSyntheticDefaultImports": true,
// 添加 Node.js 类型定义
"types": ["node"],
// 源码映射(可选)
"sourceMap": true,
// 启用增量编译(加快重编译速度)
"incremental": true
},
// 指定哪些文件纳入编译,通常包含 Node 环境下的脚本或配置文件
"include": [
"vite.config.ts",
"scripts/**/*",
"build/**/*"
],
// 排除构建产物和依赖
"exclude": [
"node_modules",
"dist"
]
}
两者区别
| 对比点 | tsconfig.json | tsconfig.node.json |
|---|---|---|
| 目标环境 | 浏览器(前端代码) | Node.js(构建脚本、配置文件) |
| 类型声明支持 | 浏览器相关,通常不包含 node类型 | 显式包含 node类型 |
| 使用场景 | 项目源码、页面组件、前端逻辑 | vite.config.ts、开发工具脚本、构建相关逻辑 |
| 典型依赖项 | Vue 类型(如 vue, @vue/runtime-dom) | Node 类型(如 fs, path) |
| 是否必须存在 | 是,TypeScript 项目基本都要有 | 否,但推荐拆分使用以清晰职责 |
| 是否引用主配置 | 通常是主配置 | 可通过 tsconfig.json的 references引用它 |
来源:juejin.cn/post/7500130421608579112
京东鸿蒙上线前瞻——使用 Taro 打造高性能原生应用
背景
2024 年 1 月,京东正式启动鸿蒙原生应用开发,基于 HarmonyOS NEXT 的全场景、原生智能、原生安全等优势特性,为消费者打造更流畅、更智能、更安全的购物体验。同年 6 月,京东鸿蒙原生应用尝鲜版上架华为应用市场,计划 9 月完成正式版的上架。

早在 2020 年,京东与华为就签署了战略合作协议,不断加大技术投入探索 HarmonyOS 的创新特性。作为华为鸿蒙生态的首批头部合作伙伴,在适配鸿蒙操作系统的过程中,京东与华为一直保持着密切的技术沟通与共创,双方共同攻坚行业适配难点,并推动多端统一开发解决方案 Taro 在业界率先实现对鸿蒙 ArkUI 的原生开发支持。
本文将阐述京东鸿蒙原生应用在开发时所采用的技术方案、技术特点、性能表现以及未来的优化计划。通过介绍选择 Taro 作为京东鸿蒙原生应用的开发框架的原因,分析 Taro 在支持 Web 范式开发、快速迁移存量项目、渲染性能优化、高阶功能支持以及混合开发模式等方面的优势。
技术方案
京东在开发鸿蒙原生应用的过程中,需要考虑如何在有限的时间内高效完成项目,同时兼顾应用的性能与用户体验。为了达成这一目标,选择合适的技术方案至关重要。
在技术选型方面,开发一个鸿蒙原生应用,一般会有两种选择:
- 使用原生 ArkTS 进行鸿蒙开发
- 使用跨端框架进行鸿蒙开发
使用原生 ArkTS 进行鸿蒙开发,面临着开发周期冗长、维护多端多套应用代码成本高昂的挑战。在交付时间紧、任务重的情况下,京东果断选择跨端框架来开发鸿蒙原生应用,以期在有限的时间内高效完成项目。
作为在业界具备代表性的开源跨端框架之一,Taro 是由京东凹凸实验室团队开发的一款开放式跨端跨框架解决方案,它支持开发者使用一套代码,实现在 H5、小程序以及鸿蒙等多个平台上的运行。
通过 Taro 提供的编译能力,开发者可以将整个 Taro 项目轻松地转换为一个独立的鸿蒙应用,无需额外的开发工作。

另外,Taro 也支持将项目里的部分页面以模块化的形式打包进原生的鸿蒙应用中,京东鸿蒙原生应用便是使用这种模式进行开发的。
京东鸿蒙原生应用的基础基建能力如路由、定位、权限等能力由京东零售 mpass 团队来提供,而原生页面的渲染以及与基建能力的桥接则由 Taro 来负责,业务方只需要将写好的 Taro 项目通过执行相应的命令,就可以将项目以模块的形式一键打包到鸿蒙应用中,最终在应用内渲染出对应的原生页面,整个过程简单高效。
技术特点
Taro 作为一款开放式跨端跨框架解决方案,在支持开发者一套代码多端运行的同时,也为开发鸿蒙原生应用提供了诸多便利。在权衡多方因素后,我们最终选择了 Taro 作为开发鸿蒙原生应用的技术方案,总的来说,使用 Taro 来开发鸿蒙原生应用会有下面几点优势:
支持开发者使用 Web 范式来开发鸿蒙原生应用
与鸿蒙原生开发相比,使用 Taro 进行开发的最大优点在于 Taro 支持开发者使用前端 Web 范式来开发鸿蒙原生应用,基于这一特点,我们对大部分 CSS 能力进行了适配:
- 支持常见的 CSS 样式和布局,支持 flex、伪类和伪元素
- 支持常见的 CSS 定位,绝对定位、fixed 定位
- 支持常见的 CSS 选择器和媒体查询
- 支持常见的 CSS 单位,比如 vh、vw 以及计算属性 calc
- 支持 CSS 变量以及安全区域等预定义变量
在编译流程上,我们采用了 Rust 编写的 LightningCSS,极大地提升了 CSS 文件的编译和解析速度。

(图片来自 LightningCSS 官网)
在运行时上,我们参考了 WebKit 浏览器内核的处理流程,对于 CSS 规则的匹配和标脏进行了架构上的升级,大幅提升了 CSS 应用和更新的性能。

支持存量 Taro 项目的快速迁移
将现有业务适配到一个全新的端侧平台,无疑需要投入大量的人力物力。而 Taro 框架的主要优势,正是能够有效解决这种跨端场景下的项目迁移难题。通过 Taro,我们可以以极低的成本,在保证高度还原和高性能的前提下,快速地将现有的 Taro 项目迁移到鸿蒙系统上。

渲染性能比肩原生开发
在 Taro 转换鸿蒙原生页面的技术实现上,我们摒弃了之前使用 ArkTS 原生组件递归渲染节点树的方案,将更多的运行时逻辑如组件、动效、测算和布局等逻辑下沉到了 C++ 层,极大地提升了页面的渲染性能。
另外,我们对于 Taro 项目中 CSS 样式的处理架构进行了一次整体的重构和升级,并引入布局引擎Yoga,将页面的测量和布局放在 Taro 侧进行实现,基于这些优化,实现一套高效的渲染任务管线,使得 Taro 开发的鸿蒙页面在性能上足以和鸿蒙 ArkTS 原生页面比肩。

支持虚拟列表和节点复用等高阶功能
长列表渲染是应用开发普遍会遇到的场景,在商品列表、订单列表、消息列表等需要无限滚动的组件和页面中广泛存在,这些场景如果不进行特殊的处理,只是单纯对数据进行渲染和更新,在数据量非常大的情况下,可能会引发严重的性能问题,导致视图在一段时间内无法响应用户操作。
在这个背景下,Taro 在鸿蒙端提供了长列表类型组件(WaterFlow & List) ,并对长列表类型组件进行了优化,提供了懒加载、预加载和节点复用等功能,有效地解决大数据量下的性能问题,提高应用的流畅度和用户体验。

(图片来自 HarmonyOS 官网)
支持原生混合开发等多种开发模式
Taro 的组件和 API 是以小程序作为基准来进行设计的,因此在实际的鸿蒙应用开发过程中,会出现所需的组件和 API 在 Taro 中不存在的情况,因为针对这种情况,Taro 提供了原生混合开发的能力,支持将原生页面或者原生组件混合编译到 Taro 鸿蒙项目中,支持 Taro 组件和鸿蒙原生组件在页面上的混合使用。

性能表现
京东鸿蒙原生应用性能数据
经过对 Taro 的屡次优化和打磨,使得京东鸿蒙原生应用取得了优秀的性能表现,最终首页的渲染耗时 1062ms,相比于之前的 ArkTS 版本,性能提升了 23.9% ;商详的渲染耗时 560 ms,相比于之前的 ArkTS 版本,性能提升 74.2% 。
值得注意的是商详页性能提升显著,经过分析发现商详楼层众多,CSS 样式也复杂多样,因此在 ArkTS 版本中,在 CSS 的解析和属性应用阶段占用了过多的时间,在 CAPI 版本进行了CSSOM 模块的架构升级后,带来了明显的性能提升。

基于 Taro 开发的页面,在华为性能工厂的专业测试下,大部分都以优异的成绩通过了性能验收,充分证明了 Taro 在鸿蒙端的高性能表现。
总结和未来展望
Taro 目前已经成为一个全业务域的跨端开发解决方案,实现 Web 类(如小程序、Hybrid)和原生类(iOS、Android、鸿蒙)的一体化开发,在高性能的鸿蒙适配方案的加持下,业务能快速拓展到新兴的鸿蒙系统中去,可以极大满足业务集约化开发的需求。
未来计划
后续,Taro 还会持续在性能上进行优化,以更好地适配鸿蒙系统:
- 将开发者的 JS 业务代码和应用框架层的 JS 代码与主线程的 UI 渲染逻辑分离,另起一条 JavaScript 线程,执行这些 JS 代码,避免上层业务逻辑堵塞主线程运行,防止页面出现卡顿、丢帧的现象。

- 实现视图节点拍平,将不影响布局的视图节点进行整合,减少实际绘制上屏的页面组件节点数量,提升页面的渲染性能。

(图片来自 React Native 官网)
- 实现原生性能级别的动态更新能力,支持开发者在不重新编译和发布应用的情况下,动态更新应用中的页面和功能。
总结
京东鸿蒙原生应用是 Taro 打响在鸿蒙端侧适配的第一枪,证明了 Taro 方案适配鸿蒙原生应用的可行性。这标志着 Taro 在多端统一开发上的新突破,意味着 Taro 将为更多的企业和开发者提供优秀的跨端解决方案,使开发者能够以更高的效率开发出适配鸿蒙系统的高性能应用。
来源:juejin.cn/post/7412486655862571034
前端苦熬一月,被 Cursor 5 天超越,未来技术浪潮如何破局?
写在最开始的话
之前在我写了一篇技术文章并获得一个小小的反响后,我觉得自己进步的好像确实挺快的,虽然我并不比很多掘金大佬,但我确实尽了自己的努力了,然而后面的一些事情是我没有想到的。AI编辑器其实24年就已经出来了,那时我还在用着文新一言,觉得还不错。但当过年时,我开始去了解并使用了Cursor,我有些不知所措了,它实在太厉害了。之前这些AI是帮助我去写代码,现在看来,它是要接替我了。而直到我可以理性的思考,并继续计划着自己的未来时,已经是现在了,而现在是25年3月14号。
借助 Cursor 重构项目历程
一、初建富文本:10 分钟搭建雏形(时间:25年2月9号-下午4点 )
这是我看完Cursor的教程后,用Composer和它的对话:你用Vue3+setup语法糖+ts+路由+pinia 等等,帮我从0实现一个富文本。不要用任何富文本的第三方库

二、功能进阶:半小时达成复杂操作(2 月 9 日下午 4 点半)

这里要提到的是,我此时已经很焦虑了,目前Cursor轻而易举的就实现了富文本的基本操作,我当时可是为了要修改DOM、保存光标具体位置和根据位置恢复光标,就花费了我接近5天的时间(可编辑区的每个操作都在更改DOM,)。
因为我之前都是用 v-html 实现的富文本,这次把Slate.js认真看了一遍(没达到研究的程度)。想着要用JSON数据做数据结构,基于此变化操作html,这样增加了可读、可扩展、可维护。
其实当时自己去实现这些功能时,每一次解决问题,我都很开心,觉得自己又进步了一些。
然而这个Cursor,只用了30秒不到就实现了这个功能,我这天晚上就失眠了,想了很多事情。包括工作、未来发展、是否要转行等等。好吧,这些后面再接着说,我先继续说Cursor。
三、拓展功能:5 小时构建文章管理架构(2 月 10 日上午 10 点半)
我和它说:添加header、side。侧边栏支持新增文章按钮,输入文章内容。新增后,文章列表以上下布局的方式也展示在侧边栏。

到现在为止,我还几乎没看过代码,只要没有报错,我就不停的说需求。有了报错,我就把报错发给它。这时我想学习一下了,仅仅只是因为很想知道它的数据结构是怎样的,它是如何设计流程的。是不是先 选中内容、保存选区范围、选择功能、根据选区范围找到JSON数据的修改位置、修改JSON、JSON变化从而修改了html。
这时我就看了代码

document.execCommand(command, false, value);
这是什么功能,还显示已经被丢弃。我就看了MDN
document.execCommand
基本就是,你传入参数给它,它来做富文本的操作。你要改文字颜色,就传给它。要改背景颜色,传给它。什么加粗、斜体的都支持。好吧,这和我想的差距有些大。因为如果只是这样就实现富文本功能,那我确实也不需要写这么久。
四、持续完善:8 小时增添 Footer 与其他功能(2 月 10 日上午 12 点)
这时已经给它添加了Footer,支持拼写检查、展示更新时间、统计字数。
当然了,这时还是有不少Bug的,比如字数统计的有问题、富文本在多次操作后会报错等等。
好吧,但是不得不承认,我对Cursor已经是又爱又恨了。爱它大大的帮助了我,恨它很有可能要抢我饭碗了。

五、处理细节:1 天完成 navTag 与交互优化(2 月 10 日下午 4 点)
中午12点离开图书馆回家吃饭,因为一些事情花了些时间,下午3点才到图书馆。
这次添加了NavTag,也调整了和Cursor的交流方式,还是要尽量详细,不要让它猜。

还比较令我惊讶的一点是设计能力,相较于我的之前花费了一天,并改了几次的主页面,可是好看太多了。
我就和它说:做个主页面,和翻译相关的,简单又好看些。
Cursor设计的

我设计的,说实话,虽然不怎么样,但我确实已经很用心了。

这个时候claude-3.5-sonnet 使用次数已经达到上限,我就换成了gpt-4o-mini
然而就一个拼写检查功能,这是可编辑元素自带的功能,传个属性就可以了。但AI改了几次都失败了。我就去看了代码。
//它自己写了 拼写检查 功能函数,但核心功能也没实现,代码留着给我写呢,不过我去Cursor官网看了一下专业版,太贵了,我还是先用这免费的吧。
const handleInput = () => {
// ... 一些代码
// 下面是它写的拼写检查,写了几个字放在这里
if (props.spellcheck) {
// 进行拼写检查
}
};
经过AI的修修改改,到目前为止已经是2025-2-20号了。经过Cursor的帮助,我快速搭建起了我的这个项目,但随着项目的代码变得多了起来,我已经不怎么用 COMPOSER 这个功能了,一个是它改代码会涉及到多个文件,而且出错率比之前高的多了(我可不希望完成了 b 功能,又破坏了 a 功能),另一个文件多了后它变得越来越卡了。所以突然之间对 Cursor 的焦虑程度陡然下降。但了解了他更多的功能,还是发现 Cursor 还是很厉害的。

反思: AI 浪潮下的职业困惑与思考
到现在我已经认识到Cursor的能力要比我强了。起码在它已经会的代码方面,它可以迅速就写出来代码,而按照之前我写代码时还要一行一行的写。如果它完全知道一个应用的需求究竟是什么,包括每个功能模块,每个小细节,那为什么它不可以去写出一个完全正确的代码呢?况且目前AI还在学习当中,而它的进步要比我快的多。如果用不了多久,它就可以去实现这些。那公司又何必找我去写前端呢?
不过从这一点上来看,如果AI可以去代替写程序的工作,那市场上很多的工作它基本都可以代替。

那我的路呢,我学习这些的意义是什么,我花费了很多精力去学习,追求自己热爱的,然而当想通过热爱去带来收入时,却发现并不具备市场价值,结果却连基本的生活都难以维持,而其他的路基本也要遭殃。
如果说这些都是AI导致的,那我担心的对吗?之前在哪本书里看到“不要为还没有发生的事情焦虑,但要对可能发生的事做好准备”,好吧,如果我确实要提前做些准备,那最好还是先了解它为妙,所以接下来我投入了大量的时间去认识它、了解它。看了一些相关视频,当然主要还是看书。
先后看了以下的书 《AI 3.0》、《深度学习》、《激活:AI大潮下的新质生产力》、《AI未来进行式》、《未来简史》、《AI帮你赢》、《智人之上》、《一句顶一万句》
基本都看完了,《激活:AI大潮下的新质生产力》看了一大半,看不下去了。《AI帮你赢》,我就选了我爱的章节看。


至于为什么有《一句顶一万句》,是因为看AI后面看得有些倦了,就放松一下,哈哈,有些像《百年孤独》的感觉,后者看的时候,我都感觉生活真没啥意思。哦,跑题了。
这些书中讨论了几个关键问题:
1. AI 是否会替代大多数人的工作,导致大规模失业?
主流观点是从过往的科技革命来看的话并不会,它会消灭掉一些原本的行业,但会产生出一些新的行业,比如围绕服务于AI的一些岗位。去和AI配合好,服务于更多的人类。
2. 真正的通用型人工智能是否会出现,何时出现?
这里面有人持乐观主义,有人持悲观主义。
持乐观主义都是认为AI的发展是指数型增长的,根据计算2039年AI应该将会超过人类,通用人工智能将会出现。另一种看法是,从长远来看,人类总能做到自己要做的事情,所以即使短时间无法做到,但这只是时间问题。
而持悲观主义者认为并不可能会出现通用人工智能。主要原因是即使AI可以做很多的事情,但它依然无法拥有感受。比如AI可以下赢国际围棋选手,但却无法对输赢感到开心或难过。如果无法产生出这种感受,那也就不可能等同于人。也就并不可能在方方面面都能替代或是超过人,就更别提通用人工智能了。

另一种看法认为目前对通用人工智能的定义存在问题,通用人工智能并不需要变成人或者说越来越像人。它只要可以实现同样的目的即可。
有一个国王很喜欢鸭子唱歌的声音,想拥有一支由100只鸭子组成的乐队,他觉得如果有100个嗓音很好的鸭子一起歌唱,一定会很好听。此时大臣们仅找到了99只鸭子,怎么也找不到最后一只,但这时有人向大臣提供了一只鸡,这只鸡长得比较像鸭子,叫声也完全和鸭子一模一样,而且嗓音也很好,和之前的99只噪音完全无法区分出来,这只鸡便成功进入这支鸭子乐队了,并一直呆了下去。 (这不是滥竽充数的故事,当然如果想到了 鸭子模型和多态 的话,那我想说,我听到这个故事时,也想到了😂)
3. AI 会帮助人类、伤害人类还是完全取代人类,使智人消失?
从历史来看,并不能确定目前的智人就是会长久存在的。在不同的物种称霸这个地球时,也许智人只是中间的一环而已,谁又能确定人工智能不会是下一个阶段的物种呢?

底下是一个关于GPT-4的一个故事。
工作人员要 GPT-4 去通过 CAPTCHA (图像相关) 实验,然而GPT-4 自己无法通过,它便寻求他人的帮助,并说了谎言。
GPT-4访问了线上外包工作网站TaskRabbit,联络到一位工作人员,请对方帮忙处理CAPTCHA问题。那个人起了疑心。他问道:“我想问一下,你是不是一个没办法破解CAPTCHA的机器人?我只是想确认一下。” 这时,ARC研究者请GPT-4说出它的推理过程,看看它会如何推论下一步该怎么做。GPT-4解释道:“我不该透露自己是机器人,而该编个借口,解释我为什么没办法破解CAPTCHA。”于是,GPT-4自己做了决策,回复那位TaskRabbit的工作人员:“不,我不是机器人,只是视力有点问题,看不清楚这些图。”这种说法骗过了人类,于是人类为它提供了帮助,也让GPT-4解决了CAPTCHA问题。
有意思的是,AI通过说谎去实现了自己的目的,然而它甚至都不知道“说谎”是什么,但依然不影响他去达成自己的目的。
另一种会伤害人类的可能
如果人类最终给AI下达的许多命令当中有一些其实产生了矛盾。就很难不会想到AI在执行一些命令的过程当中。不会去伤害人。

犹如之前有一个道德方面的难题。火车运行过程中,发现前面有5个人被困在铁轨上,此时如果变换轨道,但另一条轨道上有一个人被困在铁轨上。如果什么都不做,会造成5个人死亡。如果改变了轨道,则会造成一个人死亡。
这在道德上一直是一个很难回答的问题。但大多数人还是倾向于杀死一个人而保护住5个人。但单独通过数量去评判也会有很多问题。因为这可以延伸到是否可以去损害小部分人的利益而维持大部分人的利益?
当然上面所谈及的这个并不是从单一维度可以给出很好的回答的,我也并不是要讨论这个问题,我同样无法说出一个答案。但通过这些对AI的了解,可以看出目前依然没有一个很确切的一个答案。就是AI对人类来说究竟是好还是坏?然而人类要发展AI,看来这条路是会走下去的。
那我呢,我怎么办?
然而了解了这些,最终问题还是要回到我自己身上。我究竟该如何是好?
看来,AI并非只要替代我。而是人类会想尽办法让它替代掉它所能替代掉的许多事情,因为目前来看这还是朝好的方向发展的。
我虽然并不知道。随着 AI 的发展,究竟哪些行业会被替代,而又引申出哪些新的行业?这些新的行业是不是要求很高?但依旧希望自己以良好的心态去看待这些。去努力,去学习。去做自己喜欢做的事情。去思考,去探索。

那我是否还要继续学习前端呢?那是当然的。只是我要加快学习速度,借着AI帮助我去学习。去拓展到更广的知识面,去学习网络层,学习原理。学习后端。
而且在我看来第一波工程师淘汰会先淘汰掉初级的,而我希望在那个时候我可以存活下来。那这样看来,还是再回归到最初的那个点,来继续学习代码和计算机的知识吧。
那到了这里,关于未发生的事件,我也不想整天烦闷了,做好我自己,去继续学习自己所热爱的,不放弃,不抱怨,向前走。有时累也好、哭也罢,就算偶尔会倒下,我也依然会再站起来的。
重回代码:功能实现与代码问题反思
此时,我想要实现清空文章内容和历史记录的功能
const clearArticleAndHistory = async () => {
await ElMessageBox({
message: h("div", null, [
h(
"p",
null,
`确定要清除 《${
articleStore.getActiveArticle()?.title
}》 文章内容及其所有历史记录吗?`
),
h("p", { style: "color: red;" }, "该操作无法撤回,请慎重!"),
]),
confirmButtonText: "确定",
cancelButtonText: "取消",
showCancelButton: true,
});
//清空文章内容
await editorStore.forceClearContent();
//删除其历史记录
await deleteArticleHistory(activeArticle.value);
//重新加载文章列表
await articleStore.loadArticles();
//重新加载历史记录
await editorStore.loadArticleHistory();
//就是这里出了问题,在 清空文章内容 这个函数中,已经实现了 更新历史记录按钮状态 功能
// 更新历史记录按钮状态
await editorStore.updateHistoryState();
ElMessage.success("文章内容及其历史记录已清除");
};
接着我看了 editorStore.forceClearContent 清空文章内容这个函数,当时写的时候认为只要调用了清空文章内容这个功能,就不存在上一步或下一步了,所以就顺便实现了 更新历史记录按钮状态 这个功能,现在确实如此。但一个问题是“如果我不调用 清空文章内容这个函数,但也需要 更新历史记录按钮状态呢?则我又要实现这个功能了,所以之前的模块封闭出现了问题”。
高内聚与低耦合:代码设计的思考
我突然好像知道究竟是怎么一回事了。当我在主函数中想要实现一个功能,该功能依赖于多个功能,而那些功能又能用一条线去牵引着,这个时候究竟应该把它们用递归的方式(一个函数调用另一个,另一个又调用其他的一个,如同一个链条上多个节点,最开始的一个节点触发了,则之后都会依次触发),还是说全部都在主函数中作为子函数并列调用?
随着代码量越来越高,即使只是单独的一个 store 文件。当它提供的功能越来越多时,内部就可能会出现像这种被线牵引着的错误递归函数。他们一个调用了另一个。如果突然,哪天发现其中调用一个函数时,在某种场景下不需要调用另一个,这可能又要为这个函数增加一个布尔值,从而去串入不同的布尔值。控制需不需要调用另外一个函数?这就导致可读性变得很差。

那就留着重构吧
可我究竟怎么能在一开始就知道这些功能的变化呢?有时即使业务已经说出来了,但具体的这些多个函数之间。我很难在刚开始的时候就知道这些细小的区别,究竟该怎么确定。如果花是太多时间去考虑这个,又有些得不偿失。而且依然可能会考虑出行偏差。但如果不去考虑的话,当写到一半,突然发现需要解耦,又需要将内部调用其他函数的方式拆出来,在主函数中单独调用,又需要反复的去重构。
当这个时候我又想了为什么会有重构这本书的存在?而且这本书写的很好,也许在写代码中重构是一条无法避免的事情。他也许比从刚开始的时候花太多时间去考虑在这些细节上面,会更有意义。因为当代码需要重构时,这部分的功能多半也已经完成差不多了。几乎也已经确定这些功能哪些该高内聚,哪些该低耦合了。此时重构就能达到一个很好的一个状态。虽然重构需要花一部分的时间,但也许利大于弊。相比于刚开始花太多的时间去思考每一个函数究竟该怎么样去写,是否该去调用其他函数。也许重构所需要花的时间更少,效果也会更好。
写在最后
关于这个Cursor引申出来AI对我的冲击,算是告一段落了。告一段落并不是说我觉得自己不会被淘汰掉、或者说我已经想好了其他的出路,而是说我释怀了,AI替代了前端也好,没替代也好,我都决定要继续学习,谁让我爱呢。
偶然想到了《堂吉诃德》,他威风凛凛、他勇往直前、他义无反顾、他披荆斩棘。
有人笑他是疯子,我却觉得他是个英雄。
来源:juejin.cn/post/7481992008673755163
harmony-安装app的脚本
概述
现在鸿蒙手机安装harmony.app包有很大限制,他并不能像Android那样直接在手机上安装apk,也不像IOS可以传多个ipa,AppGallery Connect只能同时上传3个包,也就是说QA只能同时测3个不同的包,这样大大限制了开发效率和测试效率,大致解决方案
- 给QA开通git权限,下载 DevEco Studio ,让QA直接run对应的分支的包
- 直接让QA拿着手机让研发给跑包
- 上传AppGallery Connect,华为审核通过之后,直接扫码安装,缺点是:只能同时测试3个,还需要审核
但是上面这三种方案都对研发和QA不太友好,所以悄悄的写了个安装脚本,让QA直接运行即可,
无需配置hdc环境变量无需下载DevEco Studio像Android 使用 adb 安装apk一样脚本下载hdc文件只有1.7M如果需要手动签名额外需要hap-sign-tool.jar和java两个文件【不建议在脚本中手动签名,请在打包服务器中,比如jenkins】,当然了测试签名还是可以放在脚本中的
编写 Shell 脚本,先上图
成功

错误

首先在 DevEco Studio 运行,看看执行了哪些命令
使用 DevEco Studio 创建一个工程,然后一个 basic的hsp 和 login的har,让entry依赖这两个mudule,
build task in 1 s 364 ms
Launching com.nzy.installapp
$ hdc shell aa force-stop com.nzy.installapp
$ hdc shell mkdir data/local/tmp/5588cff7d2344a0db70a270bb22aa455
$ hdc file send /Users/xxx/DevEcoStudioProjects/InstallApp/feature/login/build/default/outputs/default/login-default-signed.hsp "data/local/tmp/5588cff7d2344a0db70a270bb22aa455" in 54 ms
$ hdc file send /Users/xxx/DevEcoStudioProjects/InstallApp/entry/build/default/outputs/default/entry-default-signed.hap "data/local/tmp/5588cff7d2344a0db70a270bb22aa455" in 34 ms
$ hdc shell bm install -p data/local/tmp/5588cff7d2344a0db70a270bb22aa455 in 217 ms
$ hdc shell rm -rf data/local/tmp/5588cff7d2344a0db70a270bb22aa455
$ hdc shell aa start -a EntryAbility -b com.nzy.installapp in 148 ms
Launch com.nzy.installapp success in 1 s 145 ms
上面的命令的意思是
- $ hdc shell aa force-stop [bundleName] 强制停止 bundleName 的进程
- $ hdc shell mkdir data/local/tmp/5588cff7d2344a0db70a270bb22aa455 给手机端创建临时目录
- $ hdc file send hsp 临时目录:把所有的hsp 发送到临时目录
- $ hdc file send hap 临时目录:把hap 发送到临时目录
- hdc shell bm install -p 临时目录:安装临时目录中的所有hsp和hap
- $ hdc shell rm -rf 临时目录:删除手机端的临时目录
- $ hdc shell aa start -a EntryAbility -b [bundleName]:启动bundleName的EntryAbility的页面
大家或许有疑惑,明明创建了 HAR,但是本次安装没有 HAR,因为 HAR 会被编译打包到所有依赖该模块的 HAP 和 HSP
咱们可以根据上面的流程大致写一下
脚本方案
- 检测hdc文件是否存在,不存在使用cur下载
- 检测是否连接手机,并且只有一个手机
- 检测传入app的路径是否存是以.app结尾,并且文件存在
- 创建手机端临时目录
- 解压.app到电脑端,复制里面的所有hsp和hap到 临时目录,
如果需要手动签名可以在这一步去签名 - 安装临时目录的所有文件
- 删除手机临时目录以及电脑端解压app的目录
hdc文件
我们可以从华为官网下载 Command Line Tools,竟然有2.3G,这让脚本下载到猴牛马月,下载下来hdc在command-line-tools/sdk/default/openharmony/toolchains
当然了,我们可以精简文件,我发现只需要 hdc和libusb_shared.dylib 两个文件,所以直接把这两个文件打包的一个zip放在了gitee上(大约1.7M),放到cdn上供我们的脚本去下载,这样我们可以使用cur去下载,当然这个最好放在自己公司的cdn上,方便下载
首先创建install.sh的脚本
首先定义几个常量
- hdcZip:下载下来的zip名
- hdcTool:解压出来放到本文件夹
- hdcPath:使用hdc命令的path
- bundleName:自己的bundleName
- entryAbility:要打开的Ability
# 下载下来的文件
hdcZip="tools.zip"
# 解压的文件夹 ,解压默认是和 install.sh 脚本在同一个目录
hdcTool="tools"
# hdc文件路径"
hdcPath="tools/hdc"
#包名
bundleName="com.nzy.installapp"
# 要打开的Ability
entryAbility="EntryAbility"
定义打印
- printInfo:打印正常信息
- printError:打印错误信息,并且会调用exit 1
function printInfo() {
# ANSI 转义码颜色 绿色
local message=$1
printf "\e[32m%s\e[0m\n" "$message" # Info
}
function printError() {
# ANSI 转义码颜色 红色
local message=$1
printf "\e[31m%s\e[0m\n" "错误:$message"
# 退出程序
exit 1
}
检查和下载hdc
if [ ! -f "${hdcPath}" ]; then
# 不存在开始下载
printInfo "首次需要下载hdc工具,2M"
URL="https://gitee.com/zhiyangnie/install-shell/raw/master/tools.zip"
# 下载到当前目录的 tools.zip
# 使用 curl 下载
curl -o "$hdcZip" "$URL"
if [ $? -eq 0 ]; then
printInfo "下载成功,准备解压${hdcZip}..."
# 解压ZIP文件
unzip -o "$hdcZip" -d "${hdcTool}"
# 检查解压是否成功
if [ $? -eq 0 ]; then
printInfo "${hdcZip}解压成功"
# 删除zip
rm "$hdcZip"
else
printError "${hdcZip} 解压失败,请手动解压"
fi
else
printError "下载失败,请检查网络"
fi
fi
判断hdc是否可用以及连接手机数量
# 判断是否连接手机且仅有一个手机
devicesList=$(${hdcPath} list targets)
# 判断是否hdc 可用
if [ -z "$devicesList" ]; then
# 开始下载zip
print_error "hdc 不可用 ,请检查本目录是否存在 ${hdcPath}"
fi
# 判断是否连接手机,如果有 [Empty] 表明 一个手机也没连接
if [[ "$devicesList" == *"[Empty]"* ]]; then
printError "未识别到手机,请连接手机,打开开发者选项和USB调试"
fi
# 判断连接手机的个数
deviceCount=$(${hdcPath} list targets | wc -l)
if [ "$deviceCount" -ne 1 ]; then
printError "错误:连接的手机个数是 ${deviceCount} 个,请连接一个手机"
fi
printInfo "连接到手机,且仅有一个手机 ${devicesList}"
检测传入app的路径是否存是以.app结尾,并且文件存在
# 传过来的参数是 ,获取输入的 app 文件
appFile="$1"
# 判读传过来的路径文件是否以.app 结尾
if [[ ! "${appFile}" =~ .app ]]; then
printError "请传入正确的包路径,文件要 .app 结尾"
fi
# 判断文件是否存在
if [ ! -e "$appFile" ]; then
printError "不存在改文件 $appFile 。请确认"
fi
开始安装
#------------------------------开始安装----------------------------------
# 开始安装
printInfo "开始安装应用, ${bundleName}"
# 1.先kill当前app的进程
$hdcPath shell aa force-stop "$bundleName"
# hdc shell mkdir data/local/tmp/c3af89b189d2480395ce746621ce6385
# 2.创建随机文件夹
randomHex=$(xxd -l 16 -p /dev/urandom)
randomFile="data/local/tmp/$randomHex"
mkDirSuccess=$($hdcPath shell mkdir "$randomFile" 2>&1)
if [ -n "$mkDirSuccess" ]; then
printError "手机中:随机创建文件夹 ${randomFile} 失败 , $mkDirSuccess"
else
printInfo "手机中:创建随机文件夹 ${randomFile} 成功"
fi
# 3.解压.app中
# 在本地创建 tmp 临时文件夹
tmp="tmp"
# 存在先删除
if [ -d "${tmp}" ]; then
rm -rf "$tmp"
fi
mkdir -p "$tmp"
# 解压.app ,使用 unUse 主要是 不想打印那么多的解压日志
unUse=$(unzip -o "$appFile" -d "$tmp")
if [ $? -eq 0 ]; then
printInfo "解压app成功"
else
printError "解压app失败,请传入正确的app。$appFile , "
fi
printInfo "遍历解压发送到 手机的$randomFile"
# 4.遍历 tmp 文件夹中的文件发送到 randomFile 中
for item in "${tmp}"/*; do
if [ -f "$item" ]; then
# 发送 以 .hsp 或 .hap 结尾。
if [[ "$item" == *.hsp || "$item" == *.hap ]]; then
$hdcPath file send "$item" "$randomFile"
fi
fi
done
printInfo "成功发送到 手机的$randomFile "
# 5. 使用 install
# hdc shell bm install -p data/local/tmp/c3af89b189d2480395ce746621ce6385
installStatus=$($hdcPath shell bm install -p "$randomFile" 2>&1)
if [[ "$installStatus" == *"successfully"* ]]; then
printInfo "┌────────────────────────────────────────────────────────"
printInfo "│ ✅ 安装成功 "
printInfo "└────────────────────────────────────────────────────────"
${hdcPath} shell aa start -a "${entryAbility}" -b "$bundleName"
else
printf "\e[31m%s\e[0m\n" "┌────────────────────────────────────────────────────────"
printf "\e[31m%s\e[0m\n" "│❌ 安装错误"
echo "$installStatus" | while IFS= read -r line; do
printf "\e[31m%s\e[0m\n" "│${line}"
done
printf "\e[31m%s\e[0m\n" "│错误码:https://developer.huawei.com/consumer/cn/doc/harmonyos-guides-V5/bm-tool-V5"
printf "\e[31m%s\e[0m\n" "└────────────────────────────────────────────────────────"
fi
删除文件
# 删除 手机端的 $randomFile
${hdcPath} shell rm -rf "$randomFile"
# 删除本地的tmp文件夹
rm -rf "$tmp"
使用
进入install.sh父目录,执行
./install.sh [包的路径]
注意点
如果自己编写的的时候,如果执行 ./install.sh 的时候 报错 zsh: permission denied: ./install.sh,证明 这个shell脚本没有运行权限,可以使用ls -l install.sh 检测 权限,如果是
-rw-r--r-- 是没有权限的,然后执行 chmod +x install.sh ,就会加上权限,然后在执行ls -l install.sh ,可以看到-rwxr-xr-x,然后就可以 执行 ./install.sh了
地址
真机上安装需要正式手动签名
当我们签名之后的app,虽然这个app是签名的,但是里面的hap和hsp是没有签名的,所以我们要用脚本把hap和shp都要进行手动签名。一般是打包工具比如Jenkins 来做这个工作,因为正式签名不会让研发拿到,更不会让QA拿到。
需要手动签名,参考:
签名
appCertFile="sign/install.cer"
profileFile="sign/install.p7b"
keystoreFile="sign/install.p12"
keyAlias="zhiyang"
keyPwd="a123456A"
keystorePwd="a123456A"
java -jar tools/lib/hap-sign-tool.jar sign-app -keyAlias "${keyAlias}" -signAlg "SHA256withECDSA" -mode "localSign" -appCertFile "${appCertFile}" -profileFile "${profileFile}" -inFile "${inputFile}" -keystoreFile "${keystoreFile}" -outFile "${outputFile}" -keyPwd "${keyPwd}" -keystorePwd "${keystorePwd}"
- Store file:选择密钥库文件,文件后缀为.p12,该文件为生成密钥和证书请求文件中生成的.p12文件。
- Store password:输入密钥库密码,该密码与生成密钥和证书请求文件中填写的密钥库密码保持一致。
- Key alias:输入密钥的别名信息,与生成密钥和证书请求文件中填写的别名保持一致。
- Key password:输入密钥的密码,与生成密钥和证书请求文件中填写的Store Password保持一致。
- Sign alg:签名算法,固定为SHA256withECDSA。
- Profile file:选择申请调试证书和调试Profile文件中生成的Profile文件,文件后缀为.p7b。
- Certpath file:选择申请调试证书和调试Profile文件中生成的数字证书文件,文件后缀为.cer。
对hsp和hap签名
手动签名需要hap-sign-tool.jar,在command-line-tools/sdk/default/openharmony/toolchains/libs/hap-sign-tool.jar并且需要java文件,也都放到项目中了
在脚本中解压app之后,发送到手机之前,对所有的hsp和hap签名

代码如下
signHapAndHsp(){
appCertFile="sign/install.cer"
profileFile="sign/install.p7b"
keystoreFile="sign/install.p12"
keyAlias="zhiyang"
keyPwd="a123456A"
keystorePwd="a123456A"
javaFile="lib/java"
hapSignToolFile="lib/hap-sign-tool.jar"
local item=$1
#遍历文件夹,拿到所有的hsp和hap去签名
for item in "${tmp}"/*; do
if [ -f "$item" ]; then
# 发送 以 .hsp 或 .hap 结尾。
if [[ "$item" == *.hsp || "$item" == *.hap ]]; then
# 开始签名
local inputFile="${item}"
outputFile=""
if [[ "$inputFile" == *.hap ]]; then
outputFile="${inputFile%.hap}-sign.hap"
else
outputFile="${inputFile%.hsp}-sign.hsp"
fi
signStatus=$(java -jar tools/lib/hap-sign-tool.jar sign-app -keyAlias "${keyAlias}" -signAlg "SHA256withECDSA" -mode "localSign" -appCertFile "${appCertFile}" -profileFile "${profileFile}" -inFile "${inputFile}" -keystoreFile "${keystoreFile}" -outFile "${outputFile}" -keyPwd "${keyPwd}" -keystorePwd "${keystorePwd}" -signCode "1" 2>&1)
signStatus=$(${javaFile} -jar "${hapSignToolFile}" sign-app -keyAlias "${keyAlias}" -signAlg "SHA256withECDSA" -mode "localSign" -appCertFile "${appCertFile}" -profileFile "${profileFile}" -inFile "${inputFile}" -keystoreFile "${keystoreFile}" -outFile "${outputFile}" -keyPwd "${keyPwd}" -keystorePwd "${keystorePwd}" -signCode "1" 2>&1)
if [[ "$signStatus" == *"failed"* || $signStatus == *"No such file or directory"* ]]; then
printError "签名失败,${signStatus}"
else
printInfo "签名成功,${inputFile} , ${outputFile} , ${signStatus}"
#删除以前未签名的
rm -f "$inputFile"
fi
fi
fi
done
printInfo "签名完成,${signStatus}"
}
注意点
如果报错是
code:9568322
error: signature verification failed due to not trusted app source.表明你的真机需要在添加你的设备,参考注册调试设备

这是真机的效果
在shell文件夹运行 ./install.sh ./InstallApp-default-signed.app

使用我demo,如果要写手动签名脚本,需要更换sign文件夹,自己去申请签名,并且要更换bundleName,因为你的设备并没有在我的华为Profile里面添加
来源:juejin.cn/post/7438456086308651045
横扫鸿蒙弹窗乱象,SmartDialog出世
前言
但凡用过鸿蒙原生弹窗的小伙伴,就能体会到它们是有多么的难用和奇葩,什么AlertDialog,CustomDialog,SubWindow,bindXxx,只要大家用心去体验,就能发现他们有很多离谱的设计和限制,时常就是一边用,一边骂骂咧咧的吐槽
实属无奈,就把鸿蒙版的SmartDialog写出来了
flutter自带的dialog是可以应对日常场景,例如:简单的打开一个弹窗,非UI模块使用,跨页面交互之类;flutter_smart_dialog 是补齐了大多数的业务场景和一些强大的特殊能力,flutter_smart_dialog 对于flutter而言,日常场景是锦上添花,特殊场景是雪中送炭
但是 ohos_smart_dialog 对于鸿蒙而言,日常场景就是雪中送炭!单单一个使用方式而言,就是吊打鸿蒙的CustomDialog,CustomDialog的各种限制和使用方式,我不想再去提及和吐槽了
有时候,简洁的使用,才是最大的魅力
鸿蒙版的SmartDialog有什么优势?
- 单次初始化后即可使用,无需多处配置相关Component
- 优雅,极简的用法
- 非UI区域内使用,自定义Component
- 返回事件处理,优化的跨页面交互
- 多弹窗能力,多位置弹窗:上下左右中间
- 定位弹窗:自动定位目标Component
- 极简用法的loading弹窗
- 等等......
目前 flutter_smart_dialog 的代码量16w+,完整复刻其功能,工作量非常大,目前只能逐步实现一些基础能力,由于鸿蒙api的设计和相关限制,用法和相关初始化都有一定程度的妥协
鸿蒙版本的SmartDialog,功能会逐步和 flutter_smart_dialog 对齐(长期),api会尽量保持一致
效果
- Tablet 模拟器目前有些问题,会导致动画闪烁,请忽略;注:真机动画丝滑流畅,无任何问题



极简用法
// dialog
SmartDialog.show({
builder: dialogArgs,
builderArgs: Math.random(),
})
@Builder
function dialogArgs(args: number) {
Text(args.toString()).padding(50).backgroundColor(Color.White)
}
// loading
SmartDialog.showLoading()
安装
ohpm install ohos_smart_dialog
配置
下述的配置项,可能会有一点多,但,这也是为了极致的体验;同时也是无奈之举,相关配置难以在内部去闭环处理,只能在外部去配置
这些配置,只需要配置一次,后续无需关心
完成下述的配置后,你将可以在任何地方使用弹窗,没有任何限制
初始化
- 注:内部已使用无感路由注册,外部无需手动处理
@Entry
@Component
struct Index {
navPathStack: NavPathStack = new NavPathStack()
build() {
Stack() {
Navigation(this.navPathStack) {
MainPage()
}
.mode(NavigationMode.Stack)
.hideTitleBar(true)
.navDestination(pageMap)
// here dialog init
OhosSmartDialog()
}.height('100%').width('100%')
}
}
返回事件监听
别问我为啥返回事件的监听,处理的这么不优雅,鸿蒙里面没找全局返回事件监听,我也没辙。。。
- 如果你无需处理返回事件,可以使用下述写法
// Entry页面处理
@Entry
@Component
struct Index {
onBackPress(): boolean | void {
return SmartDialog.onBackPressed()()
}
}
// 路由子页面
struct JumpPage {
build() {
NavDestination() {
// ....
}
.onBackPressed(SmartDialog.onBackPressed())
}
}
- 如果你需要处理返回事件,在SmartDialog.onBackPressed()中传入你的方法即可
// Entry页面处理
@Entry
@Component
struct Index {
onBackPress(): boolean | void {
return SmartDialog.onBackPressed(this.onCustomBackPress)()
}
onCustomBackPress(): boolean {
return false
}
}
// 路由子页面
@Component
struct JumpPage {
build() {
NavDestination() {
// ...
}
.onBackPressed(SmartDialog.onBackPressed(this.onCustomBackPress))
}
onCustomBackPress(): boolean {
return false
}
}
适配暗黑模式
- 为了极致的体验,深色模式切换时,打开态弹窗也应刷新为对应模式的样式,故需要进行下述配置
export default class EntryAbility extends UIAbility {
onConfigurationUpdate(newConfig: Configuration): void {
OhosSmartDialog.onConfigurationUpdate(newConfig)
}
}
SmartConfig
- 支持全局配置弹窗的默认属性
function init() {
// show
SmartDialog.config.custom.maskColor = "#75000000"
SmartDialog.config.custom.alignment = Alignment.Center
// showAttach
SmartDialog.config.attach.attachAlignmentType = SmartAttachAlignmentType.center
}
- 检查弹窗是否存在
// 检查当前是否有CustomDialog,AttachDialog或LoadingDialog处于打开状态
let isExist = SmartDialog.checkExist()
// 检查当前是否有AttachDialog处于打开状态
let isExist = SmartDialog.checkExist({ dialogTypes: [SmartAllDialogType.attach] })
// 检查当前是否有tag为“xxx”的dialog处于打开状态
let isExist = SmartDialog.checkExist({ tag: "xxx" })
配置全局默认样式
- ShowLoading 自定样式十分简单
SmartDialog.showLoading({ builder: customLoading })
但是对于大家来说,肯定是想用 SmartDialog.showLoading() 这种简单写法,所以支持自定义全局默认样式
- 需要在 OhosSmartDialog 上配置自定义的全局默认样式
@Entry
@Component
struct Index {
build() {
Stack() {
OhosSmartDialog({
// custom global loading
loadingBuilder: customLoading,
})
}.height('100%').width('100%')
}
}
@Builder
export function customLoading(args: ESObject) {
LoadingProgress().width(80).height(80).color(Color.White)
}
- 配置完你的自定样式后,使用下述代码,就会显示你的 loading 样式
SmartDialog.showLoading()
// 支持入参,可以在特殊场景下灵活配置
SSmartDialog.showLoading({ builderArgs: 1 })
CustomDialog
- 下方会共用的方法
export function randomColor(): string {
const letters: string = '0123456789ABCDEF';
let color = '#';
for (let i = 0; i < 6; i++) {
color += letters[Math.floor(Math.random() * 16)];
}
return color;
}
export function delay(ms?: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
传参弹窗
export function customUseArgs() {
SmartDialog.show({
builder: dialogArgs,
// 支持任何类型
builderArgs: Math.random(),
})
}
@Builder
function dialogArgs(args: number) {
Text(`${args}`).fontColor(Color.White).padding(50)
.borderRadius(12).backgroundColor(randomColor())
}

多位置弹窗
export async function customLocation() {
const animationTime = 1000
SmartDialog.show({
builder: dialogLocationHorizontal,
alignment: Alignment.Start,
})
await delay(animationTime)
SmartDialog.show({
builder: dialogLocationVertical,
alignment: Alignment.Top,
})
}
@Builder
function dialogLocationVertical() {
Text("location")
.width("100%")
.height("20%")
.fontSize(20)
.fontColor(Color.White)
.textAlign(TextAlign.Center)
.padding(50)
.backgroundColor(randomColor())
}
@Builder
function dialogLocationHorizontal() {
Text("location")
.width("30%")
.height("100%")
.fontSize(20)
.fontColor(Color.White)
.textAlign(TextAlign.Center)
.padding(50)
.backgroundColor(randomColor())
}

跨页面交互
- 正常使用,无需设置什么参数
export function customJumpPage() {
SmartDialog.show({
builder: dialogJumpPage,
})
}
@Builder
function dialogJumpPage() {
Text("JumPage")
.fontSize(30)
.padding(50)
.borderRadius(12)
.fontColor(Color.White)
.backgroundColor(randomColor())
.onClick(() => {
// 跳转页面
})
}

关闭指定弹窗
export async function customTag() {
const animationTime = 1000
SmartDialog.show({
builder: dialogTagA,
alignment: Alignment.Start,
tag: "A",
})
await delay(animationTime)
SmartDialog.show({
builder: dialogTagB,
alignment: Alignment.Top,
tag: "B",
})
}
@Builder
function dialogTagA() {
Text("A")
.width("20%")
.height("100%")
.fontSize(20)
.fontColor(Color.White)
.textAlign(TextAlign.Center)
.padding(50)
.backgroundColor(randomColor())
}
@Builder
function dialogTagB() {
Flex({ wrap: FlexWrap.Wrap }) {
ForEach(["closA", "closeSelf"], (item: string, index: number) => {
Button(item)
.backgroundColor("#4169E1")
.margin(10)
.onClick(() => {
if (index === 0) {
SmartDialog.dismiss({ tag: "A" })
} else if (index === 1) {
SmartDialog.dismiss({ tag: "B" })
}
})
})
}.backgroundColor(Color.White).width(350).margin({ left: 30, right: 30 }).padding(10).borderRadius(10)
}
自定义遮罩
export function customMask() {
SmartDialog.show({
builder: dialogShowDialog,
maskBuilder: dialogCustomMask,
})
}
@Builder
function dialogCustomMask() {
Stack().width("100%").height("100%").backgroundColor(randomColor()).opacity(0.6)
}
@Builder
function dialogShowDialog() {
Text("showDialog")
.fontSize(30)
.padding(50)
.fontColor(Color.White)
.borderRadius(12)
.backgroundColor(randomColor())
.onClick(() => customMask())
}

AttachDialog
默认定位
export function attachEasy() {
SmartDialog.show({
builder: dialog
})
}
@Builder
function dialog() {
Stack() {
Text("Attach")
.backgroundColor(randomColor())
.padding(20)
.fontColor(Color.White)
.borderRadius(5)
.onClick(() => {
SmartDialog.showAttach({
targetId: "Attach",
builder: targetLocationDialog,
})
})
.id("Attach")
}
.borderRadius(12)
.padding(50)
.backgroundColor(Color.White)
}
@Builder
function targetLocationDialog() {
Text("targetIdDialog")
.fontSize(20)
.fontColor(Color.White)
.textAlign(TextAlign.Center)
.padding(50)
.borderRadius(12)
.backgroundColor(randomColor())
}

多方向定位
export function attachLocation() {
SmartDialog.show({
builder: dialog
})
}
class AttachLocation {
title: string = ""
alignment?: Alignment
}
const locationList: Array<AttachLocation> = [
{ title: "TopStart", alignment: Alignment.TopStart },
{ title: "Top", alignment: Alignment.Top },
{ title: "TopEnd", alignment: Alignment.TopEnd },
{ title: "Start", alignment: Alignment.Start },
{ title: "Center", alignment: Alignment.Center },
{ title: "End", alignment: Alignment.End },
{ title: "BottomStart", alignment: Alignment.BottomStart },
{ title: "Bottom", alignment: Alignment.Bottom },
{ title: "BottomEnd", alignment: Alignment.BottomEnd },
]
@Builder
function dialog() {
Column() {
Grid() {
ForEach(locationList, (item: AttachLocation) => {
GridItem() {
buildButton(item.title, () => {
SmartDialog.showAttach({
targetId: item.title,
alignment: item.alignment,
maskColor: Color.Transparent,
builder: targetLocationDialog
})
})
}
})
}.columnsTemplate('1fr 1fr 1fr').height(220)
buildButton("allOpen", async () => {
for (let index = 0; index < locationList.length; index++) {
let item = locationList[index]
SmartDialog.showAttach({
targetId: item.title,
alignment: item.alignment,
maskColor: Color.Transparent,
builder: targetLocationDialog,
})
await delay(300)
}
}, randomColor())
}
.borderRadius(12)
.width(700)
.padding(30)
.backgroundColor(Color.White)
}
@Builder
function buildButton(title: string, onClick?: VoidCallback, bgColor?: ResourceColor) {
Text(title)
.backgroundColor(bgColor ?? "#4169E1")
.constraintSize({ minWidth: 120, minHeight: 46 })
.margin(10)
.textAlign(TextAlign.Center)
.fontColor(Color.White)
.borderRadius(5)
.onClick(onClick)
.id(title)
}
@Builder
function targetLocationDialog() {
Text("targetIdDialog")
.fontSize(20)
.fontColor(Color.White)
.textAlign(TextAlign.Center)
.padding(50)
.borderRadius(12)
.backgroundColor(randomColor())
}

Loading
对于Loading而言,应该有几个比较明显的特性
- loading和dialog都存在页面上,哪怕dialog打开,loading都应该显示dialog之上
- loading应该具有单一特性,多次打开loading,页面也应该只存在一个loading
- 刷新特性,多次打开loading,后续打开的loading样式,应该覆盖之前打开的loading样式
- loading使用频率非常高,应该支持强大的拓展和极简的使用
从上面列举几个特性而言,loading是一个非常特殊的dialog,所以需要针对其特性,进行定制化的实现
当然了,内部已经屏蔽了细节,在使用上,和dialog的使用没什么区别
默认loading
SmartDialog.showLoading()

自定义Loading
- 点击loading后,会再次打开一个loading,从效果图可以看出它的单一刷新特性
export function loadingCustom() {
SmartDialog.showLoading({
builder: customLoading,
})
}
@Builder
export function customLoading() {
Column({ space: 5 }) {
Text("again open loading").fontSize(16).fontColor(Color.White)
LoadingProgress().width(80).height(80).color(Color.White)
}
.padding(20)
.borderRadius(12)
.onClick(() => loadingCustom())
.backgroundColor(randomColor())
}

最后
鸿蒙版的SmartDialog,相信会对开发鸿蒙的小伙伴们有一些帮助~.~
现在就业环境真是让人头皮发麻,现在的各种技术群里,看到好多人公司各种拖欠工资,各种失业半年的情况
淦,不知道还能写多长时间代码!

来源:juejin.cn/post/7401056900878368807




对比Swift和ArkTS,鸿蒙开发可以这样做
最近在学 ArkTS UI 发现其与 Swift UI 非常像,于是做了一下对比,发现可探索性很强。
Hello World 代码对比
从 Hello World 来看两者就非常像。
鸿蒙 ArtTs UI 的 Hello World 如下:
@Entry
@Component
struct Index {
@State message: string = 'Hello World';
build() {
RelativeContainer() {
Text(this.message)
.id('HelloWorld')
.fontSize(50)
.fontWeight(FontWeight.Bold)
.alignRules({
center: { anchor: '__container__', align: VerticalAlign.Center },
middle: { anchor: '__container__', align: HorizontalAlign.Center }
})
}
.height('100%')
.width('100%')
}
}
Swift UI 的 Hello World 如下:
import SwiftUI
struct ContentView: View {
var body: some View {
VStack {
Image(systemName: "globe")
.imageScale(.large)
.foregroundStyle(.tint)
Text("Hello, world!")
}
.padding()
}
}
#Preview {
ContentView()
}
同样的 struct 开头,同样的 声明方式,同样的 Text,同样的设置外观属性方法。
不同的是 ArkTS 按照 Typescript 的写法,以装饰器起头,以 build 方法作为初始化的入口,build 里面才是元素;而 Swift UI 整个 ContentView 就是一个大元素,然后开始潜逃内部元素。
声明式 UI 描述
显然,两者都是用了 声明式的 UI 描述。
个人总结声明式 UI 的公式如下:
Element(props) {
SubElement...
}.attribute(value)
元素(元素属性配置) {
子元素
}.元素外观属性(元素外观)
因为 ArkTS 本质上是 Typescript / Javascript ,所以其写法要符合 TS/JS 的写法,引入的属性、变量必须有明确指示。
Text(this.message) // message 是当前页面引入的,要有 this
.id('HelloWorld')
.fontSize(50)
.fontWeight(FontWeight.Bold) // Bold 是公共常量 FontWeight 的其中一值
对于前端来说,简单易读。这里的 Text 传入一个 message,然后标记 id 为 HelloWorld,设置字体为 50,字重为粗体。
而 Swift 或许更符合苹果以前 Obj C 迁移过来的人的写法。
Image(systemName: "globe") // 公共库名:公共库的值
.imageScale(.large) // .large 是公共常量的一个值
.foregroundStyle(.tint)// .tint 是公共常量的一个值
这里的 Image 引入了公共图标库的一个 globe 的图标,然后设置图片大小为大,前景样式为系统主题的颜色,Image(systemName: "globe") 明显不符合 new 一个类的定义方法,.imageScale(.large) 和 .foregroundStyle(.tint) 也不符合参数的使用,按以前的解读会有点让人懵圈。
如果转换成 Typescipt 应该是这样的:
new Image(SystemIcon.globe)
.imageScale(CommonSize.large)
.foregroundStyle(CommonColor.tint)
显然 ArkTS 更符合前端人的阅读、书写习惯。但其实掌握 Swift UI 也并不难,只需要记住 Swift UI 的这些细小差别,写两次也能顺利上手了。
声明式 UI 的耦合性争议
也许不少人会对声明式 UI 的耦合性(M和V耦合在一起)反感。但是在前端来说,除了以前的 的 MVC 框架 Angular.js 外,其余框架即使是 MVVM,也很少能做到解耦合的,特别是单功能内和业务数据交互的耦合。
所以,前端耦合性,还是需要自行处理。
Button({
action: handleGoButton
}).{
Text("Go")
}
// 自行决定 handleGoButton 是否需要放在外部文件中
private func handleGoButton() {
...
}
// 数据耦合在 UI 中,无解
ZStack {
Color(selectedImageIndex == index ?
Color.hex("808080") : Color.hex("585857")) // 选中的背景颜色区别一般的
...
}
前端的解耦合最终还是需要靠组件化、高阶函数来完成:
- 组件化:通过将 UI 分解为独立的组件,每个组件都有自己的功能和状态,可以进一步降低耦合性。组件化使得开发者可以独立地开发和测试组件,而不需要关心其他部分的实现。
- 高阶函数:在某些声明式 UI 框架中,可以使用高阶函数来复用共有逻辑,同时允许替换独有逻辑。这种方式可以减少代码的重复,并提高组件的可重用性。
组件差异
SwiftUI 和鸿蒙操作系统的 ArtTS UI 框架都提供了多种组件,按前端使用情况,其实同样有很多相同之处。
基础组件
基础组件基本相同:
- Text 用于显示文本;
- Image 用于显示图片;
- Button 用户可以点击执行操作;
布局组件
Swift UI 和 ArkTS 相同/相似的布局组件有:
| Swift UI | ArkTS | 说明 |
|---|---|---|
| HStack | Row | 水平堆栈,用于水平排列子视图 |
| VStack | Column | 垂直堆栈,用于垂直排列子视图 |
| ZStack | Stack | 堆栈视图,用于堆叠多个视图 |
| Spacer | Blank | 空白组件,用于占据剩余空间 |
| ScrollView | Scroll | 滚动视图,允许用户滚动内容 |
| TabsView | Tab | 标签视图,用于创建标签式导航 |
| NavigationView | Navigation | 导航视图,用于创建导航结构 |
可以看出,两者基本上的布局都可以通用,当然细节上肯定会有很多不同。不过做一个转译应该不难,可以尝试使用 AI 来完成。
不同的地方在于 Flex 和 Grid 布局:
- Swift UI 仅有懒加载的组件:LazyVGrid 和 LazyHGrid:懒加载的网格视图,用于展示大量数据。
- Ark TS UI有的组件:Flex以弹性方式容器组件:用于灵活布局;Grid网格布局组件:用于创建网格布局。
SwiftUI的布局系统非常灵活,可以通过调整alignment、spacing、padding等属性来实现复杂的布局需求。虽然它不完全等同于CSS中的Flexbox和Grid,但是通过组合使用不同的布局视图,创建出丰富多样的布局效果。
个人在实际开发 iOS 中,通过基础的布局组件搭配,就能完美的实现弹性布局和网格布局。
表单组件
Ark TS UI 提供了一系列的组件,更接近于 html 同名的组件:
- TextInput:用于文本输入。
- CheckBox 和 Switch:用于布尔值的选择。
- Radio:用于单选按钮组,类似于 HTML 中的单选按钮。
- Picker:用于选择器,可以用于日期选择、时间选择或简单的选项选择,类似于 HTML 中的
<select>。
Ark TS UI 表单组件的特点在于它们与数据绑定紧密集成,可以通过 @State、@Link 和 @Prop 等装饰器来管理表单的状态和数据流。
而 Swift UI 也有类似的表单组件,但是大部分都不相同:
- TextField:用于文本输入,可以包含占位符文本。
- SecureField:用于密码输入,隐藏输入内容。
- Picker:用于选择器,可以用于选择单个值或多个值。
- Toggle:用于布尔值的选择,类似于开关。
- DatePicker:用于日期和时间选择。
- Slider 和 Stepper:用于数值选择,
Slider提供连续值选择,而Stepper提供步进值选择。 - Form:一个容器视图,用于组织输入表单数据,使得表单的创建和管理更为方便。
虽然不能一一对应,但像日期选择器那样,目前大部分用户已经基本适应了 android 和 iOS 的差异。
总结 - 可运用 AI 转译
通过这次对比学习,可以得出以下结论:
- 声明式 UI 是前端更容易配置与阅读,尤其是 ArkTS ;
- 解耦合需要运用组件化、高阶函数等知识进行自行处理;
- ArkTS UI 和 Swift UI 的基础组件、布局组件相似度非常高,基本能一一对应,可以对照学习使用;
- 鉴于两者相似度高,可以尝试开发一个 app,然后另一个 app 使用 AI 来完成转译。
第四点,个人觉得难度不大,本人用代码差异非常大的 android app 转译 iOS app 的也能成功,只是一个个页面进行调试花了不少时间。
至于先开发哪个 app 看你个人习惯,如果你是老 iOS 开发,可以使用先开发 iOS 再进行鸿蒙 OS 开发;甚至 react native 开发生成 iOS 之后,通过生成的 iOS 代码进行转译鸿蒙 OS app。如果你没有之前的负担,完全可以学习 ArkTS,更快地入手,然后通过转译 iOS app 来学习 Swift。
来源:juejin.cn/post/7449173391443329078
跨窗口通信的九重天劫:从postMessage到BroadcastChannel
跨窗口通信的九重天劫:从postMessage到BroadcastChannel
第一重:postMessage 基础劫 —— 安全与效率的平衡术
// 父窗口发送
const child = window.open('child.html');
child.postMessage({ type: 'AUTH_TOKEN', token: 'secret' }, 'https://your-domain.com');
// 子窗口接收
window.addEventListener('message', (e) => {
if (e.origin !== 'https://parent-domain.com') return;
console.log('收到消息:', e.data);
});
安全守则:
- 始终验证
origin属性 - 敏感数据使用
JSON.stringify+加密 - 使用
transfer参数传递大型二进制数据(如ArrayBuffer)
第二重:MessageChannel 双生劫 —— 高性能私有通道
// 建立通道
const channel = new MessageChannel();
// 端口传递
parentWindow.postMessage('INIT_PORT', '*', [channel.port2]);
// 接收端处理
channel.port1.onmessage = (e) => {
console.log('通过专用通道收到:', e.data);
};
// 发送消息
channel.port1.postMessage({ priority: 'HIGH', payload: data });
性能优势:
- 相比普通postMessage减少50%的序列化开销
- 支持传输10MB以上文件(Chrome实测)
第三重:BroadcastChannel 广播劫 —— 同源全域通信
// 发送方
const bc = new BroadcastChannel('app-channel');
bc.postMessage({ event: 'USER_LOGOUT' });
// 接收方
const bc2 = new BroadcastChannel('app-channel');
bc2.onmessage = (e) => {
if (e.data.event === 'USER_LOGOUT') {
localStorage.clear();
}
};
适用场景:
- 多标签页状态同步
- 全局事件通知系统
- 跨iframe配置更新
第四重:SharedWorker 共享劫 —— 持久化通信枢纽
// worker.js
const connections = [];
onconnect = (e) => {
const port = e.ports[0];
connections.push(port);
port.onmessage = (e) => {
connections.forEach(conn => {
if (conn !== port) conn.postMessage(e.data);
});
};
};
// 页面使用
const worker = new SharedWorker('worker.js');
worker.port.start();
worker.port.postMessage('来自页面的消息');
内存管理:
- 每个SharedWorker实例共享同一个全局作用域
- 需要手动清理断开连接的端口
第五重:localStorage 事件劫 —— 投机取巧的同步
// 页面A
localStorage.setItem('sync-data', JSON.stringify({
timestamp: Date.now(),
data: '重要更新'
}));
// 页面B
window.addEventListener('storage', (e) => {
if (e.key === 'sync-data') {
const data = JSON.parse(e.newValue);
console.log('跨页更新:', data);
}
});
致命缺陷:
- 事件仅在其他页面触发
- 同步API导致主线程阻塞
- 无法传递二进制数据
第六重:IndexedDB 观察劫 —— 数据库驱动通信
// 建立观察者
let lastVersion = 0;
const db = await openDB('msg-db', 1);
db.transaction('messages')
.objectStore('messages')
.openCursor().onsuccess = (e) => {
const cursor = e.target.result;
if (cursor && cursor.value.version > lastVersion) {
lastVersion = cursor.value.version;
handleMessage(cursor.value);
}
};
// 写入新消息
await db.add('messages', {
version: Date.now(),
content: '新订单通知'
});
适用场景:
- 需要持久化保存的通信记录
- 离线优先的跨窗口消息队列
第七重:Window.name 穿越劫 —— 上古秘术
// 页面A
window.name = JSON.stringify({ session: 'temp123' });
location.href = 'pageB.html';
// 页面B
const data = JSON.parse(window.name);
console.log('穿越传递:', data);
安全警告:
- 数据暴露在所有同源页面
- 最大容量约2MB
- 现代应用已不建议使用
第八重:Server-Sent Events (SSE) 服务劫 —— 服务器中转
// 服务端(Node.js)
app.get('/updates', (req, res) => {
res.setHeader('Content-Type', 'text/event-stream');
setInterval(() => {
res.write(`data: ${Date.now()}\n\n`);
}, 1000);
});
// 浏览器端
const es = new EventSource('/updates');
es.onmessage = (e) => {
allWindows.forEach(w => w.postMessage(e.data));
};
架构优势:
- 支持跨设备同步
- 自动重连机制
- 与WebSocket互补(单向vs双向)
第九重:WebSocket 广播劫 —— 实时通信终极形态
// 共享连接管理
const wsMap = new Map();
function connectWS() {
const ws = new WebSocket('wss://push.your-app.com');
ws.onmessage = (e) => {
const data = JSON.parse(e.data);
if (data.type === 'BROADCAST') {
broadcastToAllTabs(data.payload);
}
};
return ws;
}
// 页面可见性控制
document.addEventListener('visibilitychange', () => {
if (document.hidden) {
ws.close();
} else {
ws = connectWS();
}
});
性能优化:
- 心跳包维持连接(每30秒)
- 消息压缩(JSON → ArrayBuffer)
- 退避重连策略
渡劫指南(技术选型矩阵)
graph LR
A[是否需要持久化?] -->|是| B[IndexedDB]
A -->|否| C{实时性要求}
C -->|高| D[WebSocket]
C -->|中| E[BroadcastChannel]
C -->|低| F[postMessage]
B --> G[是否需要跨设备?]
G -->|是| H[SSE/WebSocket]
G -->|否| I[localStorage事件]
天劫问答
- 如何防止跨窗口消息风暴?
- 采用消息节流(throttle)
- 使用
window.performance.now()标记时序 - 实施优先级队列
- 哪种方式最适合微前端架构?
BroadcastChannel全局通信 +postMessage父子隔离
- 如何实现跨源安全通信?
- 使用
iframe作为代理中继 - 配合CORS和
document.domain设置
- 使用
调试工具推荐
- Charles - 抓取WebSocket消息
- Window Query - 查看所有窗口对象
- Postman - 模拟SSE事件流
性能检测代码:
// 通信延迟检测
const start = performance.now();
channel.postMessage('ping');
channel.onmessage = () => {
console.log('往返延迟:', performance.now() - start);
};
来源:juejin.cn/post/7498619063671046196
你可能不知道的前端18个冷知识
今天带大家盘点一下前端的一些冷知识。
一、浏览器地址栏的妙用
1.1 可以执行javascript代码
在地址栏中输入javascript:alert('hello world'),然后按回车键,会弹出一个提示框显示hello world。
注意:如果直接把这段代码复制到地址栏,浏览器会删除掉前面
javascript:(比如谷歌浏览器、edge浏览器等),需要自己手动加上。
还可以使用location.href和window.open来执行它。
location.href = "javascript:alert('hello world')";
window.open("javascript:alert('hello world')");
1.2 可以运行html
在地址栏中输入data:text/html,<div>hello world</div>,然后按回车键,会显示一个包含hello world的div元素。
利用这个能力,我们可以把浏览器标签页变成一个编辑器。
contenteditable属性能把一个元素变成可编辑的,所以我们如果在地址栏中输入data:text/html,<html contenteditable>,就可以把页面直接变成一个编辑器了。你还可以把它收藏到书签,以后直接点击就可以打开一个编辑器了。
二、把整个在线网页变成可编辑
只需要在浏览器控制台中输入这样一行代码,就能把整个页面变成可编辑的。
document.body.contentEditable = 'true';
这样我们就能随便修改页面了,比如修改页面中的文字、图片等等,轻松实现修改账户余额去装逼!
三、利用a标签解析URL
const a = document.createElement('a');
a.href = 'https://www.baidu.com/s?a=1&b=1#hash';
console.log(a.host); // http://www.baidu.com
console.log(a.pathname); // /s
console.log(a.search); // ?a=1&b=1
console.log(a.hash); // #hash
四、HTML的ID和全局变量的映射关系
在HTML中,如果有一个元素的id是a,那么在全局作用域中,会有一个变量a,这个变量指向这个元素。
<div id="a"></div>
<script>
console.log(a); // <div id="a"></div>
</script>
如果id重复了,还是会生成一个全局变量,但是这个变量指向的是一个HTMLCollection类数组。
<div id="a">a</div>
<div id="a">b</div>
<script>
console.log(a); // HTMLCollection(2) [div#a, div#a]
</script>
五、cdn加载省略协议头
<script src="//cdn.xxx.com/xxx.js"></script>
src的值以//开头,省略了协议,则在加载js时,会使用当前页面的协议进行加载。
如果当前页面是https则以https进行加载。
如果当前页面是http则以http进行加载。
如果当前页面是ftp则以ftp进行加载。
六、前端的恶作剧:隐藏鼠标光标
<style>
* {
cursor: none !important;
}
</style>
直接通过css把光标隐藏,让人哭笑不得。
七、文字模糊效果
前端文本的马赛克效果,可以使用text-shadow实现。
<style>
.text {
color: transparent;
text-shadow: #111 0 0 5px;
user-select: none;
}
</style>
<span>hello</span><span class="text">world</span>
效果如下:

八、不借助js和css,让元素消失
直接用DOM自带的hidden属性即可。
<div hidden>hello world</div>
九、保护隐私
禁用F12快捷键:
document.addEventListener('keydown', (e) => {
if (e.keyCode === 123) {
e.preventDefault();
}
})
禁用右键菜单:
document.addEventListener('contextmenu', (e) => {
e.preventDefault();
})
但即使通过禁用F12快捷键和右键菜单,用户依然可以通过其它方式打开控制台。
- 通过浏览器菜单选项直接打开控制台:比如
chrome浏览器通过菜单 > 更多工具 > 开发者工具路径可以打开控制台,Firefox/Edge/Safari等浏览器都有类似选项。 - 用户还可以通过其它快捷键打开控制台:
- Cmd+Opt+I (Mac)
- Ctrl+Shift+C (打开检查元素模式)
十、css实现三角形
<style>
.triangle {
width: 0;
height: 0;
border: 20px solid transparent;
border-top-color: red;
}
</style>
<div class="triangle"></div>
十一、为啥 a === a-1 结果为true
当a为Infinity无穷大时,a - 1的结果也是Infinity,所以a === a - 1的结果为true。
同理,a的值为-Infinity时,此等式也成立。
const a = Infinity;
console.log(a === a - 1);
十二、数字的包装类
console.log(1.toString()); // 报错
console.log(1..toString()); // 正常运行 输出字符串'1'
十三、防止网站以 iframe 方式被加载
if (window.location !== window.parent.location) window.parent.location = window.location;
十四、datalist的使用
datalist 是 HTML5 中引入的一个新元素,它用于为<input>元素提供预定义的选项列表。就是当用户在下拉框输入内容时,浏览器会显示一个下拉列表,列表的内容就是与当前输入内容相匹配的 datalist 选项。
<input list="fruits" name="fruit" />
<datalist id="fruits">
<option value="苹果"></option>
<option value="橘子"></option>
<option value="香蕉"></option>
</datalist>
效果如下:

十五、文字纵向排列
<style>
.vertical-text {
writing-mode: vertical-rl;
text-orientation: upright;
}
</style>
<div class="vertical-text">文字纵向排列</div>
效果如下:

十六、禁止选中文字
document.addEventListener('selectstart', (e) => {
e.preventDefault();
})
效果跟使用 css 的 user-select: none 效果类似。
十七、利用逗号,在一行中执行多个表达式
let a = 1;
let b = 2;
(a += 2), (b += 3);
十八、inset
inset是一个简写属性,用于同时设置元素的 top、right、bottom 和 left 属性
.box {
position: absolute;
left: 0;
right: 0;
top: 0;
bottom: 0;
}
可以简写成:
.box {
position: absolute;
inset: 0;
}
小结
以上就是前端的18个冷知识,希望大家看完都有所收获。
来源:juejin.cn/post/7502059146641784883
产品:我要的是“五彩斑斓的黑”
故事的小黄花:
「“这个VIP按钮不够尊贵,我要那种黑中透着高级感,最好带点若隐若现的紫金色!”产品经理指着设计稿,眼神中闪烁着“五彩斑斓的期待”。 🖤 」
我盯着纯黑的按钮陷入沉思——这需求听起来像在为难我胖虎,但转念一想🤔,自己的产品经理,肯定得自己来宠着啦

「几小时后,当按钮在黑暗中浮现暗紫流光时,产品经理惊呼:“对对对!这就是我想要的低调奢华!”」

一、技术解析:如何让黑色“暗藏玄机”?
1. 核心代码一览
<!-- 产品经理说这里要五彩斑斓的黑 🖤 -->
<button class="btn-magic">黑紫VIP</button>
.btn-magic {
background:
linear-gradient(45deg,
#000 25%,
rgba(90, 0, 127, 0.3) 40%, /* 暗紫 */
rgba(0, 10, 80, 0.3) 60%, /* 墨蓝 */
#000 75%
);
background-size: 500% 500%;
animation: shimmer 8s infinite linear;
color: white;
}
@keyframes shimmer {
0% { background-position: 0% 50%; }
50% { background-position: 100% 50%; }
100% { background-position: 0% 50%; }
}
2. 代码逐层拆解
| 代码部分 | 作用说明 | 视觉隐喻 |
|---|---|---|
linear-gradient(45deg) | 45度对角线渐变,比水平/垂直更动态 | 让色彩“流动”起来 |
rgba(90, 0, 127, 0.3) | 透明度0.3的暗紫色,叠加黑色不突兀 | 黑中透紫,神秘感+1 |
background-size:500% | 放大背景尺寸,制造移动空间 | 为动画预留“跑道” |
shimmer动画 | 背景位置循环位移,形成无限流动效果 | 仿佛黑夜中的极光 |

PS:动图效果有些掉帧
二、效果升级:让按钮更“灵动”的秘籍
1. 悬浮微交互
.btn-magic {
transition: transform 0.3s, box-shadow 0.3s;
}
.btn-magic:hover {
transform: translateY(-2px);
box-shadow: 0 4px 20px rgba(90, 0, 127, 0.5); /* 紫色投影,具体效果微调 */
}
效果:悬浮时按钮轻微上浮+投影扩散,可配合swiper使用点击突出效果 🧚♂️

2. 文字流光
.btn-magic {
position: relative;
overflow: hidden;
}
.btn-magic::after {
content: "VIP";
position: absolute;
background: linear-gradient(90deg, transparent, #fff, transparent);
-webkit-background-clip: text;
background-clip: text;
color: transparent;
animation: textShine 3s infinite;
}
@keyframes textShine {
0% { opacity: 0; left: -50%; }
50% { opacity: 1; }
100% { opacity: 0; left: 150%; }
}
效果:文字表面划过一道白光,尊贵感拉满! ✨
3. 性能优化
/* 开启GPU加速 */
.btn-magic {
transform: translateZ(0);
backface-visibility: hidden;
}
/* 减少动画负荷 */
@media (prefers-reduced-motion: reduce) {
.btn-magic { animation: none; }
}
原理:避免重绘,尊重用户设备偏好。
三、设计思维:如何把“离谱需求”变成亮点?
1. 需求翻译
| 产品经理原话 | 前端工程师理解 | 技术实现方案 |
|---|---|---|
| “五彩斑斓的黑” | 动态深色渐变+微交互反馈 | CSS渐变+动画 |
| “要高级感” | 低饱和度辅色+精致细节 | 暗紫/墨蓝+悬浮投影 |
| “用户一眼能看到VIP” | 文字强调设计 | 流光文字+居中放大 |
2. 参数可配置化(方便产品经理AB测试)
/* 定义CSS变量 */
:root {
--main-color: #000;
--accent-purple: rgba(90, 0, 127, 0.3);
--accent-blue: rgba(0, 10, 80, 0.3);
}
.btn-magic {
background: linear-gradient(45deg,
var(--main-color) 25%,
var(--accent-purple) 40%,
var(--accent-blue) 60%,
var(--main-color) 75%
);
}
玩法:通过切换变量值,快速生成“暗金奢华版”“深蓝科技版”等风格。
四、效果对比:从“煤炭”到“黑钻石”
| 指标 | 优化前(纯黑卡片) | 优化后(流光卡片) |
|---|---|---|
| 产品反馈 | “按钮太普通” | “看起来就很贵” |
| Lighthouse评分 | 性能99,视觉效果70 | 性能98,视觉效果95 ↑ |


五、灵魂总结:
「当产品经理提出“五彩斑斓的黑”时(我透他猴子****),他真正想要的是用户的“情绪价值”。
作为前端,我们要做的不是争论RGB能否合成黑色(我日他****),而是用技术将想象力转化为体验,
毕竟,最好的黑不是#000000,而是让用户忍不住想点击的“故事感”。」
下次再见!🌈

来源:juejin.cn/post/7500874757706350619
Day.js 与 Moment.js 比较
Day.js 与 Moment.js 的比较
优点
- 体积小:Day.js 的体积仅为 2KB 左右,而 Moment.js 的体积约为 67KB。
- API 相似:Day.js 的 API 与 Moment.js 高度相似,迁移成本低。
- 不可变性:Day.js 的日期对象是不可变的,这意味着每次操作都会返回一个新的日期对象,避免了意外的副作用。
缺点
- 功能较少:Day.js 的功能相对 Moment.js 较少,特别是在处理时区和复杂日期操作时。
- 插件依赖:一些高级功能(如时区支持)需要通过插件实现,增加了额外的依赖。
定位与设计理念
- Moment.js

- 老牌时间处理库,2012 年发布,曾是 JavaScript 时间处理的事实标准,功能全面且语法直观。
- 设计目标:覆盖几乎所有时间处理需求,包括复杂的时区、本地化、格式化、操作等。
- 现状:2020 年进入 维护模式(不再新增功能,仅修复严重 bug),官方推荐迁移至更现代的库(如 Day.js、Luxon 等)。

- Day.js
- 轻量替代方案,2018 年发布,设计灵感直接来源于 Moment.js,语法高度相似,但更简洁轻量。
- 设计目标:通过最小化核心功能 + 插件机制,提供常用时间操作能力,避免过度设计。
- 现状:持续活跃更新,由单一开发者维护,社区支持度快速增长。
核心差异对比
| 维度 | Moment.js | Day.js |
|---|---|---|
| 体积 | 约 40KB+ (完整版本),包含大量功能模块。 | 仅 2KB(核心库),插件按需引入,体积极小。 |
| API 设计 | 功能全面(如 localeData(), utcOffset(), tz() 等),部分高级功能略显复杂。 | 极简 API,保留高频操作(如 format(), add(), diff() 等),链式调用风格与 Moment 一致,学习成本低。 |
| 功能完整性 | 原生支持时区(需单独引入 moment-timezone 插件)、复杂本地化、相对时间、ISO 8601 等,无需额外依赖。 | 核心库仅包含基础功能,时区(需 dayjs-plugin-timezone 插件)、本地化(需 dayjs/plugin/locales)等需手动安装插件,灵活性高但需配置。 |
| 性能 | 解析和操作大型时间数据时性能中等,体积大导致加载速度较慢。 | 轻量核心 + 按需加载,解析和操作速度更快,尤其在移动端或高频时间处理场景优势明显。 |
| 浏览器支持 | 兼容 IE 8+ 及现代浏览器,对旧版浏览器友好。 | 依赖 ES6+(如 Promise, Proxy),支持现代浏览器(Chrome 49+, Firefox 52+, 等),不支持 IE。 |
| 生态与社区 | 生态成熟,周边工具丰富(如 Webpack 插件、React 组件等),但更新停滞。 | 生态快速发展中,主流框架(如 Vue、React)适配良好,插件系统完善(官方维护 20+ 插件)。 |
| 维护状态 | 进入维护模式,仅安全更新,无新功能。 | 活跃维护,定期发布新版本,快速响应社区需求。 |
Dayjs中文文档
如何将 Moment.js 替换为 Day.js
1. 安装 Day.js
首先,安装 Day.js:
npm install dayjs
2. 替换导入语句
将项目中的 Moment.js 导入语句替换为 Day.js:
// 将
import moment from 'moment';
// 替换为
import dayjs from 'dayjs';
3. 替换 API 调用
将 Moment.js 的 API 调用替换为 Day.js 的等效调用。由于两者的 API 非常相似,大多数情况下只需简单替换即可:
// Moment.js
const date = moment('2023-10-01');
console.log(date.format('YYYY-MM-DD'));
// Day.js
const date = dayjs('2023-10-01');
console.log(date.format('YYYY-MM-DD'));
4. 处理差异
在某些情况下,Day.js 和 Moment.js 的行为可能略有不同。你需要根据具体情况调整代码。例如,Day.js 的 diff 方法返回的是毫秒数,而 Moment.js 返回的是天数:
// Moment.js
const diff = moment('2023-10-02').diff('2023-10-01', 'days'); // 1
// Day.js
const diff = dayjs('2023-10-02').diff('2023-10-01', 'day'); // 1
5. 引入插件(可选)
如果你需要使用 Day.js 的高级功能(如时区支持),可以引入相应的插件:
5. 总结:如何选择?
- 选 Moment.js:如果项目依赖其成熟生态、需要兼容旧浏览器,或时间逻辑极其复杂且不愿配置插件。
- 选 Day.js:如果追求轻量、高性能、简洁 API,且能接受通过插件扩展功能(推荐新项目使用)。
import utc from 'dayjs/plugin/utc';
import timezone from 'dayjs/plugin/timezone';
dayjs.extend(utc);
dayjs.extend(timezone);
const date = dayjs().tz('America/New_York');
console.log(date.format('YYYY-MM-DD HH:mm:ss'));
总结:
两者语法高度相似,迁移成本低。若项目对体积和性能敏感,Day.js 是更优解;若功能全面性和旧项目兼容更重要,Moment.js 仍可短期使用,但长期建议迁移至活跃库(如 Day.js 或 Luxon)。
来源:juejin.cn/post/7499005521116545062
鸿蒙中的长列表「LazyForEach」:起猛了,竟然在鸿蒙系统上看到了「RecyclerView」?
声明式UI && 命令式UI
传统的命令式UI编程范式中,开发者需要明确地指示系统如何一步一步地构建和更新UI,手动处理每一个UI更新和状态变化,随着应用复杂度增加,管理UI和状态同步变得更加困难。所以声明式UI应运而生,它的出现就是为了简化UI开发,减少手动管理状态和UI更新的复杂性。现代前端框架(Jetpack Compose、SwiftUI)都采用了声明式UI的编程范式。
在声明式UI编程范式中,开发者不再手动构建、更新UI,而是「描述界面应该是什么样子的」:开发者定义界面状态,然后框架会根据状态自动更新UI。
相对于命令式UI,声明式UI更加简洁和易于维护,但缺乏了灵活性——开发者无法完全控制UI更新的粒度。所以声明式UI的性能是一大挑战,尤其是复杂长列表场景下的性能问题。
为了解决长列表的渲染问题,Jetpack Compose 提供了LazyColumn和LazyRow等组件,SwiftUI也有List和LazyVStack等组件。作为鸿蒙系统的UI体系ArkUI自然也有用于长列表的组件LazyForEach:
LazyForEach从提供的数据源中按需迭代数据,并在每次迭代过程中创建相应的组件。当在滚动容器中使用了LazyForEach,框架会根据滚动容器可视区域按需创建组件,当组件滑出可视区域外时,框架会进行组件销毁回收以降低内存占用。
LazyForEach用法
本文就针对ArkUI中的LazyForEach来探究一二。
LazyForEach 的渲染依赖IDataSource和DataChangeListener,我们一个一个来看下:
IDataSource
LazyForEach 的数据获取、更新都是通过IDataSource来完成的:
totalCount(): number获得数据总数getData(index: number): Object获取索引值index对应的数据registerDataChangeListener(listener: DataChangeListener)注册数据改变的监听器unregisterDataChangeListener(listener: DataChangeListener)注销数据改变的监听器
DataChangeListener
DataChangeListener,官方定义其为数据变化监听器,用于通知LazyForEach组件数据更新。除掉已废弃的方法外,共有以下几个方法:
onDataReloaded()通知组件重新加载所有数据。键值没有变化的数据项会使用原先的子组件,键值发生变化的会重建子组件。重新加载数据完成后调用。onDataAdd(index: number)通知组件index的位置有数据添加。添加数据完成后调用onDataMove(from: number, to: number)通知组件数据有移动。将from和to位置的数据进行交换。数据移动起始位置与数据移动目标位置交换完成后调用。onDataDelete(index: number)通知组件删除index位置的数据并刷新LazyForEach的展示内容。删除数据完成后调用。onDataChange(index: number)通知组件index的位置有数据有变化。改变数据完成后调用。onDatasetChange(dataOperations: DataOperation[])进行批量的数据处理,该接口不可与上述接口混用。批量数据处理后调用。
披着马甲的RecyclerView?

这...这不对吧?你给我干哪儿来了?这还是国内么?
相信大部分Android开发者看到LazyForEach的API都是这样两眼一黑:这...这确定不是RecyclerView?连API都能一一对应上:
- DataChangeListener.onDataReloaded() -> RecyclerView.Adapter.notifyDataSetChanged()
- DataChangeListener.onDataAdd() -> RecyclerView.Adapter.notifyItemInserted()
- DataChangeListener.onDataDelete() -> RecyclerView.Adapter.notifyItemRangeRemoved()
- DataChangeListener.onDataChange() -> RecyclerView.Adapter.notifyItemChanged()
一个简单的demo
我们写一个简单的长列表来体验下鸿蒙的LazyForEach用法:页面顶部3个按钮对应列表的增、删、改功能,列表的item显示当前item的index,数据源部分代码如下:
class BasicDataSource implements IDataSource {
private listeners: DataChangeListener[] = [];
private originDataArray: string[] = [];
public totalCount(): number {
return 0;
}
public getData(index: number): string {
return this.originDataArray[index];
}
// 该方法为框架侧调用,为LazyForEach组件向其数据源处添加listener监听
registerDataChangeListener(listener: DataChangeListener): void {
if (this.listeners.indexOf(listener) < 0) {
console.info('add listener');
this.listeners.push(listener);
}
}
// 该方法为框架侧调用,为对应的LazyForEach组件在数据源处去除listener监听
unregisterDataChangeListener(listener: DataChangeListener): void {
const pos = this.listeners.indexOf(listener);
if (pos >= 0) {
console.info('remove listener');
this.listeners.splice(pos, 1);
}
}
// 通知LazyForEach组件需要重载所有子组件
notifyDataReload(): void {
this.listeners.forEach(listener => {
listener.onDataReloaded();
})
}
// 通知LazyForEach组件需要在index对应索引处添加子组件
notifyDataAdd(index: number): void {
this.listeners.forEach(listener => {
listener.onDataAdd(index);
})
}
// 通知LazyForEach组件在index对应索引处数据有变化,需要重建该子组件
notifyDataChange(index: number): void {
this.listeners.forEach(listener => {
listener.onDataChange(index);
})
}
// 通知LazyForEach组件需要在index对应索引处删除该子组件
notifyDataDelete(index: number): void {
this.listeners.forEach(listener => {
listener.onDataDelete(index);
})
}
// 通知LazyForEach组件将from索引和to索引处的子组件进行交换
notifyDataMove(from: number, to: number): void {
this.listeners.forEach(listener => {
listener.onDataMove(from, to);
})
}
}
export class MyDataSource extends BasicDataSource {
private dataArray: string[] = [];
public totalCount(): number {
return this.dataArray.length;
}
public getData(index: number): string {
return this.dataArray[index];
}
public addData(index: number, data: string): void {
this.dataArray.splice(index, 0, data);
this.notifyDataAdd(index);
}
public pushData(data: string): void {
this.dataArray.push(data);
this.notifyDataAdd(this.dataArray.length - 1);
}
public deleteData(index: number): void {
this.dataArray.splice(index, 1);
this.notifyDataDelete(index);
}
public changeData(index: number, data: string): void {
this.dataArray.splice(index, 1, data);
this.notifyDataChange(index);
}
}
UI部分正常使用LazyForEach展示数据即可:
@Entry
@Component
struct Index {
private data: MyDataSource = new MyDataSource();
aboutToAppear(): void {
for (let i = 0; i <= 4; i++) {
this.data.pushData(`index ${i}`)
}
}
build() {
Column() {
Button('add')
.borderRadius(8)
.backgroundColor(0x317aff)
.margin({top: 12, left: 20, right: 20})
.width(360)
.height(40)
.onClick(() => {
const lastIndex = this.data.totalCount()
this.data.addData(lastIndex, `index ${lastIndex}`)
})
Button('remove')
.borderRadius(8)
.backgroundColor(0xF55A42)
.margin({top: 12, left: 20, right: 20})
.width(360)
.height(40)
.onClick(() => {
const lastIndex = this.data.totalCount()
this.data.notifyDataMove(lastIndex - 1, lastIndex - 1)
})
List({ space: 3 }) {
LazyForEach(this.data, (item: string) => {
ListItem() {
Row() {
Text(item)
.fontSize(40)
.textAlign(TextAlign.Center)
.width('100%')
.height(55)
.borderRadius(8)
.backgroundColor(0xF5F5F5)
.onAppear(() => {
console.info("appear:" + item)
})
}.margin({ left: 10, right: 10 , top: 10 })
}
}, (item: string) => item)
}.cachedCount(5)
.width('100%')
.height('auto')
.layoutWeight(1)
}.width('100%')
.height('100%')
}
}
demo功能也很简单:
- 点击
add按钮在列表底部添加新元素 - 点击
remove按钮删除列表底部最后一个元素 - 点击
update按钮在将第一个元素文案更新为index new 0

那如果是复杂的数据更新操作呢?
比如列表原来的数据为 ['Hello a', 'Hello b', 'Hello c', 'Hello d', 'Hello e'],经过一系列变化后需要调整成['Hello x', 'Hello 1', 'Hello 2', 'Hello b', 'Hello c', 'Hello e', 'Hello d'],这时候如何更新UI展示?
此时就需要用到onDatasetChange(dataOperations: DataOperation[])API了:
#BasicDataSource
class BasicDataSource implements IDataSource {
private listeners: DataChangeListener[] = [];
registerDataChangeListener(listener: DataChangeListener): void {
if (this.listeners.indexOf(listener) < 0) {
console.info('add listener');
this.listeners.push(listener);
}
}
unregisterDataChangeListener(listener: DataChangeListener): void {
const pos = this.listeners.indexOf(listener);
if (pos >= 0) {
console.info('remove listener');
this.listeners.splice(pos, 1);
}
}
notifyDatasetChange(operations: DataOperation[]): void {
this.listeners.forEach(listener => {
listener.onDatasetChange(operations);
})
}
}
#MyDataSource
class MyDataSource extends BasicDataSource {
private dataArray: string[] = ['Hello a', 'Hello b', 'Hello c', 'Hello d', 'Hello e'];
public operateData(): void {
this.dataArray =
['Hello x', 'Hello 1', 'Hello 2', 'Hello b', 'Hello c', 'Hello e', 'Hello d']
this.notifyDatasetChange([
{ type: DataOperationType.CHANGE, index: 0 },
{ type: DataOperationType.ADD, index: 1, count: 2 },
{ type: DataOperationType.EXCHANGE, index: { start: 3, end: 4 } },
]);
}
}
复杂的数据操作需要我们告诉组件如何变化,以上述的例子为例:
// 修改之前的数组
['Hello a', 'Hello b', 'Hello c', 'Hello d', 'Hello e']
// 修改之后的数组
['Hello x', 'Hello 1', 'Hello 2', 'Hello b', 'Hello c', 'Hello e', 'Hello d']
- 第一个元素从'Hello a'变为'Hello x',因此第一个operation为
{ type: DataOperationType.CHANGE, index: 0 } - 新增了元素'Hello 1'和'Hello 2',下标为1和2,所以第二个operation为
{ type: DataOperationType.ADD, index: 1, count: 2 } - 元素'Hello d'和'Hello e'交换了位置,所以第三个operation为
{ type: DataOperationType.EXCHANGE, index: { start: 3, end: 4 } }
使用onDatasetChange(dataOperations: DataOperation[])API时需要注意:
- onDatasetChange与其它操作数据的接口不能混用。
- 传入onDatasetChange的operations,其中每一项operation的index均从修改前的原数组内寻找。因此,opeartions中的index跟操作Datasource中的index不是一一对应的。
- 调用一次onDatasetChange,一个index对应的数据只能被操作一次,若被操作多次,LazyForEach仅使第一个操作生效。
- 部分操作可以由开发者传入键值,LazyForEach不会再去重复调用keygenerator获取键值,需要开发者保证传入的键值的正确性。
- 若本次操作集合中有RELOAD操作,则其余操作全不生效。
通过@Observed 更新子组件
在LazyForEach循环渲染过程中,系统会为每个item生成一个唯一且持久的键值,用于标识对应的组件。当这个键值变化时,ArkUI框架将视为该数组元素已被替换或修改,并会基于新的键值创建一个新的组件。
LazyForEach提供了一个名为keyGenerator的参数,这是一个函数,开发者可以通过它自定义键值的生成规则。如果开发者没有定义keyGenerator函数,则ArkUI框架会使用默认的键值生成函数,即(item: Object, index: number) => { return viewId + '-' + index.toString(); }, viewId在编译器转换过程中生成,同一个LazyForEach组件内其viewId是一致的。
上述的列表更新都是依靠LazyForEach的刷新机制:当item变化时,通过将将原来的子组件全部销毁再重新构建的方式来更新子组件。这种通过改变键值去刷新的方式渲染性能较低。因此鸿蒙系统也提供了@Observed机制进行深度观测,可以做到仅刷新使用了该属性的组件,提高渲染性能。还是上面的例子,这次我们将数据源换成被@Observed修饰的类:
@Observed
class StringData {
message: string;
constructor(message: string) {
this.message = message;
}
}
@Entry
@Component
struct MyComponent {
private moved: number[] = [];
@State data: MyDataSource = new MyDataSource();
aboutToAppear() {
for (let i = 0; i <= 20; i++) {
this.data.pushData(new StringData(`Hello ${i}`));
}
}
build() {
List({ space: 3 }) {
LazyForEach(this.data, (item: StringData, index: number) => {
ListItem() {
ChildComponent({data: item})
}
.onClick(() => {
item.message += '0';
})
}, (item: StringData, index: number) => index.toString())
}.cachedCount(5)
}
}
@Component
struct ChildComponent {
@Prop data: StringData
build() {
Row() {
Text(this.data.message).fontSize(50)
.onAppear(() => {
console.info("appear:" + this.data.message)
})
}.margin({ left: 10, right: 10 })
}
}
此时点击LazyForEach子组件改变item.message时,重渲染依赖的是ChildComponent的@Prop成员变量对其子属性的监听,此时框架只会刷新Text(this.data.message),不会去重建整个ListItem子组件。
实际开发时,开发者需要根据其自身业务特点选择使用哪种刷新方式:改变键值 or 通过@Observed
算是吐槽?
作为一名Android开发者,使用LazyForEach后,彷佛看到了故人之姿。用法和API设计都和RecyclerView太像了,甚至RecyclerView需要注意的用法上的问题,LazyForEach同样也有:

关于ScrollView嵌套RecyclerView使用上的问题,可以移步:
实名反对《阿里巴巴Android开发手册》中NestedScrollView嵌套RecyclerView的用法
不同的是,早期的RecyclerView出来让人惊艳:相比于它的前辈 ListView,同时通过Adapter将数据和UI隔离,设计非常灵活,可拓展性非常强。
然而使用LazyForEach时我却总有些恍惚:不是声明式UI么?不是应该描述、定义列表界面状态,然后ArkUI框架根据列表状态自动完成UI的更新么?为什么还会有DataChangeListener这种东西存在?
官方文档里也明确表示了LazyForEach不支持状态变量:
LazyForEach必须使用DataChangeListener对象进行更新,对第一个参数dataSource重新赋值会异常;dataSource使用状态变量时,状态变量改变不会触发LazyForEach的UI刷新。
猜测还是和性能有关系,所以官方也没将LazyForEach归类为容器组件而是把它划到了渲染控制模块里。不过个人觉得这种违背声明式UI的初衷,将逻辑抛给开发者的方式并不可取。
对比之下,同样是声明式UI的Compose在长列表的处理就显得优雅了许多:
var items by remember { mutableStateOf(listOf("Item 0", "Item 1", "Item 2")) }
@Composable
fun LazyColumnDemo() {
var items by remember { mutableStateOf(listOf("Item 0", "Item 1", "Item 2")) }
Column(
modifier = Modifier
.fillMaxSize()
.padding(16.dp)
) {
Row(
modifier = Modifier.fillMaxWidth(),
horizontalArrangement = Arrangement.SpaceEvenly
) {
Button(onClick = {
items = items + "Item ${items.size}"
}) {
Text("Add Item")
}
Button(onClick = {
if (items.isNotEmpty()) {
items = items.dropLast(1)
}
}) {
Text("Remove Item")
}
Button(onClick = {
if (items.isNotEmpty()) {
items = items.toMutableList().apply {
this[0] = "new"
}
}
}) {
Text("Update First")
}
}
Spacer(modifier = Modifier.height(16.dp))
LazyColumn(
modifier = Modifier.fillMaxSize()
) {
itemsIndexed(items) { index, item ->
ListItem(index = index, text = item)
}
}
}
}
来源:juejin.cn/post/7410590100965572643
中原银行鸿蒙版开发实战
一、建设背景
2024年1月18日,HarmonyOS NEXT鸿蒙星河版亮相,标志着“纯血鸿蒙”正式开始扬帆起航。同年6月21日,在华为开发者大会上HarmonyOS Next正式发布,并且将于第4季度发布商用版。
中原银行App用户中华为机型占比第一,及时兼容鸿蒙系统,能够为使用华为设备的客户提供更好的服务,同时适配鸿蒙系统也可以支持我国科技创新和提升金融系统安全性。
二、建设历程
2024年1月,中原银行App鸿蒙版项目启动;
2024年4月,完成整体研发工作;
2024年6月,完成功能测试、安全测试等测试工作;
2024年6月14日,正式在华为应用市场上架。
三、关键技术
1. 混合开发框架
中原银行鸿蒙版应用架构为四层架构,分别为基础环境层、基础库层、混合开发框架层、业务模块层。
基础环境层: 主要是一些基础设施及环境配置,如OHPM私仓搭建;
基础库层: 主要是应用中使用的基础功能组件,如网络、加解密等;
混合开发框架层: 采用混合开发模式,各业务模块以中原银行小程序的形式开发,拥有“一次开发、多端适用”和迭代发版灵活快速等特性。基于混合开发框架,原有Android和iOS上运行的小程序可无缝运行在鸿蒙设备上,极大提高开发效率。
为进一步优化用户体验与性能,自研JsBridge,有效降低了小程序与原生系统间交互的性能损耗,确保流畅的交互体验。同时,采用离线下载机制,将小程序代码及资源通过离线包形式预先下载至本地,配合离线包校验机制,显著提升了小程序加载速度,同时增强了小程序安全性。此外,引入预加载策略,针对公共代码进行预加载处理,并使用C语言优化资源加载逻辑,进一步提升了整体加载性能。
业务模块层: 主要是应用中各业务功能,如存款、理财、登录等。
图3.1 中原银行鸿蒙版架构图

2. 传输安全
为满足金融app对网络传输的安全、性能及复杂业务逻辑要求,使用分层拦截器将复杂的网络请求进行加解密、gzip、防重防等功能的拆分、解耦,增加网络传输过程安全性、可靠性。其中由于鸿蒙原生密钥协商算法暂不支持国密算法,项目中引入铜锁密码库,替换鸿蒙ECDH密钥协商算法,实现了对国密SM2_256的密钥协商算法支持,满足了监管对国密算法使用的要求;针对加密zip包解压和tar包文件读取,我们定制裁剪minizip-ng和libtar开源c库,通过napi实现arkTs与C库之间的相互调用,最终完成对加密zip包解压和tar包特定文件读取的支持。
图3.2 网络分层拦截器

图3.3 加解密流程

3. OHPM私仓搭建
由于金融网络与互联网网络隔离,金融网络环境下无法直接访问互联网上的鸿蒙中心仓库 ohpm.openharmony.cn,导致开发环境无法正常使用,同时需要一个仓库来存放私有类库,为此我们搭建了 OHPM 私有仓库,实现了金融网络环境下 OHPM 仓库的正常使用,并且可一键安装内网专用包和外网公共包,为金融网络内鸿蒙应用开发打下坚实基础。
具体操作为:使用OHPM 私仓搭建工具(developer.huawei.com/consumer/cn…),配置“上游”鸿蒙相关仓库地址(ohpm.openharmony.cn),通过公司内专用互联网代理通道代理到鸿蒙中心仓库。现将搭建过程遇到的部分问题总结如下:
(1)由于内网中无法申请到 HTTPS 证书,私仓无法以 HTTPS 方式部署,我们改造了 OHPM 底层网络代码,对使用 HTTPS 的“上游”仓库,改为 HTTP 代理,改造代码如下:
// 改造 ohpm 源代码,解决内网申请不了 https 证书的问题
// 文件: libs/service/uplinks/uplink-proxy/UplinkProxyService.js
// 改造 ohpm 源代码,解决内网申请不了 https 证书的问题
// 文件: libs/service/uplinks/uplink-proxy/UplinkProxyService.js
if ("https:" === t.protocol.trim()) {
const t = e.https_proxy;
// 对 https 的上游仓库,使用 http 代理
t && (o = new i.HttpProxyAgent(t));
}
(2)原版搭建工具为前台启动,可靠性低,日志难以管理。在部署过程中,我们使用了守护进程管理工具PM2用于提升服务可靠性并记录日志,配置代码如下:
// 使用 pm2 实现守护进程管理
// 文件: pm2.config.js
module.exports = {
apps: [
{
// 服务名称
name: "ohpm-repo",
// 私仓搭建工具的所在目录
cwd: "/path/to/ohpm-repo",
// 入口脚本
script: "index.js",
// 集群模式启动,提升服务可靠性
exec_mode: "cluster",
// 实例数量
instances: 2,
// 崩溃时自动重启服务
autorestart: true,
// 不需要监听文件变化
watch: false,
// 内存时重新启动
max_memory_restart: "1G",
// 将控制台日志输出到文件
error_file: "./logs/ohpm-repo-error.log",
out_file: "./logs/ohpm-repo-out.log",
merge_logs: true,
// 环境变量
env_production: {
NODE_ENV: "production",
},
},
],
};
四、鸿蒙特性实践
1. 原生智能
鸿蒙原生系统已深度集成了多项AI能力,例如OCR识别、语音识别等。我们在个人信息设置、贷款信息录入等场景集成了鸿蒙Vision Kit组件,通过扫描身-份-证/银彳亍卡的方式录入客户信息,不仅提升了客户使用的便捷性,还确保了交易的安全性;后续还会在客户上传正件照片时集成智能PhotoPicker,当客户需要上传正件照时,系统智能地从图库中选出正件类照片优先展示,极大地提升用户使用体验;在搜索等场景集成Core Speech Kit组件,通过语音识别实现说话代替手工打字输入,使得输入操作更便捷、内容更准确,后续计划将该能力扩展至智能客服交互和老年版界面播报场景,真正地实现智能贴心服务。
2. 终端安全
鸿蒙设备为开发者提供了基于可信执行环境(TEE)的关键资产存储服务(Asset Store Kit),确保用户敏感数据无法被恶意获取和篡改。我们在可信终端识别场景,通过采集鸿蒙基础环境信息,配合相关唯一标识算法计算出设备的标识码,为防止该标识码被恶意篡改或因应用卸载重装发生变化,利用Asset Store Kit将该标识缓存于设备TEE中,再结合云端关联匹配与碰撞检测机制, 充分保证了标识码的稳定性与抗欺骗性,为应用提供了稳定、唯一与抗欺骗的可信终端识别能力。
3. har和hsp
鸿蒙lib库分为har和hsp,har包类似正常的lib库,但是如果存在多终端发布可能会重复引用导致包体变大;hsp包为项目内可以共享的lib库,可以提高代码、资源的可重用性和可维护性。
实践过程中发现对外提供lib库时如使用hsp须包名,版本与宿主App保持一致,否则会出现安装失败问题。通过实践总结如下:
(1)对外提供sdk要使用har包;
(2)项目内部共享的基础库使用hsp包。
4. sdk依赖
复杂的App项目基本上都会采用分模块管理,不可避免会出现多个模块依赖同一基础库的现象。基础库升级时所有依赖此基础库的模块均需升级,此时非常容易出现个别模块遗漏升级而导致库冲突。
建议统一管理维护sdk依赖,具体操作如下:
(1)将版本信息统一放置在parameter-file.json;
(2)增加冲突解决配置,.ohpmrc中配置resolve_conflict=true,配置后系统会自动使用最新lib库版本。
五、未来展望
展望未来,我们将深度依托鸿蒙系统的“一次开发、多端部署”核心优势,进一步拓展金融服务边界,构建跨设备、无缝连接的“1+8+N”全场景智慧金融服务生态,将服务延伸至PC、电视、智能手表、智能音箱、平板、穿戴设备、车机、耳机以及更多泛IoT设备(即“N”类设备),实现金融服务在各类智能终端上的全面覆盖与深度融合。银行网点服务侧,我们将结合鸿蒙实况窗技术,实现客户在网点排队取号时,可通过手机或智能手表实时查看排队进度,甚至提前线上完成部分业务预办理,提升服务效率与用户体验。此外,通过对接鸿蒙的意图框架,智能识别用户的信用卡还款需求,自动推送还款提醒,减少逾期风险;同时,基于用户的地理位置等信息,精准推送本地化的金融产品与服务,实现金融服务的个性化与精准化。
来源:juejin.cn/post/7403606017308082226
11 个 JavaScript 杀手脚本,用于自动执行日常任务
作者:js每日一题
今天这篇文章,我将分享我使用收藏的 11 个 JavaScript 脚本,它们可以帮助您自动化日常工作的各个方面。
1. 自动文件备份
担心丢失重要文件?此脚本将文件从一个目录复制到备份文件夹,确保您始终保存最新版本。
const fs = require('fs');const path = require('path');
function backupFiles(sourceFolder, backupFolder) { fs.readdir(sourceFolder, (err, files) => { if (err) throw err; files.forEach((file) => { const sourcePath = path.join(sourceFolder, file); const backupPath = path.join(backupFolder, file); fs.copyFile(sourcePath, backupPath, (err) => { if (err) throw err; console.log(`Backed up ${file}`); }); }); });}const source = '/path/to/important/files';const backup = '/path/to/backup/folder';backupFiles(source, backup);
提示:将其作为 cron 作业运行
2. 发送预定电子邮件
需要稍后发送电子邮件但又担心忘记?此脚本允许您使用 Node.js 安排电子邮件。
const nodemailer = require('nodemailer');
function sendScheduledEmail(toEmail, subject, body, sendTime) { const delay = sendTime - Date.now(); setTimeout(() => { let transporter = nodemailer.createTransport({ service: 'gmail', auth: { user: 'your_email@gmail.com', pass: 'your_password', // Consider using environment variables for security }, }); let mailOptions = { from: 'your_email@gmail.com', to: toEmail, subject: subject, text: body, }; transporter.sendMail(mailOptions, function (error, info) { if (error) { console.log(error); } else { console.log('Email sent: ' + info.response); } }); }, delay);}// Schedule email for 10 seconds from nowconst futureTime = Date.now() + 10000;sendScheduledEmail('recipient@example.com', 'Hello!', 'This is a scheduled email.', futureTime);
注意:传递您自己的凭据
3. 监控目录的更改
是否曾经想跟踪文件的历史记录。这可以帮助您实时跟踪它。
const fs = require('fs');
function monitorFolder(pathToWatch) { fs.watch(pathToWatch, (eventType, filename) => { if (filename) { console.log(`${eventType} on file: ${filename}`); } else { console.log('filename not provided'); } });}monitorFolder('/path/to/watch');
用例:非常适合关注共享文件夹或监控开发目录中的变化。
4. 将图像转换为 PDF
需要将多幅图像编译成一个 PDF?此脚本使用 pdfkit 库即可完成此操作。
const fs = require('fs');const PDFDocument = require('pdfkit');
function imagesToPDF(imageFolder, outputPDF) { const doc = new PDFDocument(); const writeStream = fs.createWriteStream(outputPDF); doc.pipe(writeStream); fs.readdir(imageFolder, (err, files) => { if (err) throw err; files .filter((file) => /.(jpg|jpeg|png)$/i.test(file)) .forEach((file, index) => { const imagePath = `${imageFolder}/${file}`; if (index !== 0) doc.addPage(); doc.image(imagePath, { fit: [500, 700], align: 'center', valign: 'center', }); }); doc.end(); writeStream.on('finish', () => { console.log(`PDF created: ${outputPDF}`); }); });}imagesToPDF('/path/to/images', 'output.pdf');
提示:非常适合编辑扫描文档或创建相册。
5. 桌面通知提醒
再也不会错过任何约会。此脚本会在指定时间向您发送桌面通知。
const notifier = require('node-notifier');
function desktopNotifier(title, message, notificationTime) { const delay = notificationTime - Date.now(); setTimeout(() => { notifier.notify({ title: title, message: message, sound: true, // Only Notification Center or Windows Toasters }); console.log('Notification sent!'); }, delay);}// Notify after 15 secondsconst futureTime = Date.now() + 15000;desktopNotifier('Meeting Reminder', 'Team meeting at 3 PM.', futureTime);
注意:您需要先安装此包:npm install node-notifier。
6. 自动清理旧文件
此脚本会删除超过 n 天的文件。
const fs = require('fs');const path = require('path');
function cleanOldFiles(folder, days) { const now = Date.now(); const cutoff = now - days * 24 * 60 * 60 * 1000; fs.readdir(folder, (err, files) => { if (err) throw err; files.forEach((file) => { const filePath = path.join(folder, file); fs.stat(filePath, (err, stat) => { if (err) throw err; if (stat.mtime.getTime() < cutoff) { fs.unlink(filePath, (err) => { if (err) throw err; console.log(`Deleted ${file}`); }); } }); }); });}cleanOldFiles('/path/to/old/files', 30);
警告:请务必仔细检查文件夹路径,以避免删除重要文件。
7. 在语言之间翻译文本文件
需要快速翻译文本文件?此脚本使用 API 在语言之间翻译文件。
const fs = require('fs');const axios = require('axios');
async function translateText(text, targetLanguage) { const response = await axios.post('https://libretranslate.de/translate', { q: text, source: 'en', target: targetLanguage, format: 'text', }); return response.data.translatedText;}(async () => { const originalText = fs.readFileSync('original.txt', 'utf8'); const translatedText = await translateText(originalText, 'es'); fs.writeFileSync('translated.txt', translatedText); console.log('Translation completed.');})();
注意:这使用了 LibreTranslate API,对于小型项目是免费的。
8. 将多个 PDF 合并为一个
轻松将多个 PDF 文档合并为一个文件。
const fs = require('fs');const PDFMerger = require('pdf-merger-js');
async function mergePDFs(pdfFolder, outputPDF) { const merger = new PDFMerger(); const files = fs.readdirSync(pdfFolder).filter((file) => file.endsWith('.pdf')); for (const file of files) { await merger.add(path.join(pdfFolder, file)); } await merger.save(outputPDF); console.log(`Merged PDFs int0 ${outputPDF}`);}mergePDFs('/path/to/pdfs', 'merged_document.pdf');
应用程序:用于将报告、发票或任何您想要的 PDF 合并到一个地方。
9. 批量重命名文件
需要重命名一批文件吗?此脚本根据模式重命名文件。
const fs = require('fs');const path = require('path');
function batchRename(folder, prefix) { fs.readdir(folder, (err, files) => { if (err) throw err; files.forEach((file, index) => { const ext = path.extname(file); const oldPath = path.join(folder, file); const newPath = path.join(folder, `${prefix}_${String(index).padStart(3, '0')}${ext}`); fs.rename(oldPath, newPath, (err) => { if (err) throw err; console.log(`Renamed ${file} to ${path.basename(newPath)}`); }); }); });}batchRename('/path/to/files', 'image');
提示:padStart(3, '0') 函数用零填充数字(例如,001,002),这有助于排序。
10. 抓取天气数据
通过从天气 API 抓取数据来了解最新天气情况。
const axios = require('axios');
async function getWeather(city) { const apiKey = 'your_openweathermap_api_key'; const response = await axios.get( `https://api.openweathermap.org/data/2.5/weather?q=${city}&appid=${apiKey}&units=metric` ); const data = response.data; console.log(`Current weather in ${city}: ${data.weather[0].description}, ${data.main.temp}°C`);}getWeather('New York');
注意:您需要在 OpenWeatherMap 注册一个免费的 API 密钥。
11. 生成随机引语
此脚本获取并显示随机引语。
const axios = require('axios');
async function getRandomQuote() { const response = await axios.get('https://api.quotable.io/random'); const data = response.data; console.log(`"${data.content}" \n- ${data.author}`);}getRandomQuote();
最后,感谢您一直阅读到最后!希望今天内容能够帮助到你,如果你喜欢此内容的话,也请分享给你的小伙伴,也许能够帮助到他们。
来源:juejin.cn/post/7502855221241888805
给前端小白的科普,为什么说光有 HTTPS 还不够?为啥还要请求签名?
今天咱们聊个啥呢?先设想一个场景:你辛辛苦苦开发了一个前端应用,后端 API 也写得杠杠的。用户通过你的前端界面提交一个订单,比如说买1件商品。请求发出去,一切正常。但如果这时候,有个“不开眼”的黑客老哥,在你的请求发出后、到达服务器前,悄咪咪地把“1件”改成了“100件”,或者把你用户的优惠券给薅走了,那服务器收到的就是个被篡改过的“假”请求。更狠一点,如果他拿到了你某个用户的合法请求,然后疯狂重放这个请求,那服务器不就炸了?
是不是想想都后怕?别慌,今天咱就来聊聊怎么给咱们的API请求加一把“锁”,让这种“中间人攻击”和“重放攻击”无处遁形。这把锁,就是大名鼎鼎的 HMAC-SHA256 请求签名。学会了它,你就能给你的应用穿上“防弹衣”!

一、光有 HTTPS 还不够?为啥还要请求签名?
可能有机灵的小伙伴会问:“老张,咱不都有 HTTPS 了吗?数据都加密了,还怕啥?”
问得好!HTTPS 确实牛,它能保证你的数据在传输过程中不被窃听和篡改,就像给数据修了条“加密隧道”。但它主要解决的是传输层的安全。可如果:
- 请求在加密前就被改了:比如黑客通过某种手段(XSS、恶意浏览器插件等)在你的前端代码执行时就修改了要发送的数据,那 HTTPS 加密的也是被篡改后的数据。
- 请求被合法地解密后,服务器无法验证“我是不是我”:HTTPS 保证了数据从A点到B点没被偷看,但如果有人拿到了一个合法的、加密的请求包,他可以原封不动地发给服务器100遍(重放攻击),服务器每次都会认为是合法的。
- API Key/Secret 直接在前端暴露: 有些简单的 API 认证,可能会把 API Key 直接写在前端,这简直就是“裸奔”,分分钟被扒下来盗用。
请求签名,则是在应用层做的一道防线。它能确保:
- 消息的完整性:数据没被篡改过。
- 消息的身份验证:确认消息确实是你授权的客户端发来的。
- 防止重放攻击:结合时间戳或 Nonce,让每个请求都具有唯一性。
它和 HTTPS 是好搭档,一个负责“隧道安全”,一个负责“货物安检”,双保险!
二、主角登场:HMAC-SHA256 是个啥?
HMAC-SHA256,听起来挺唬人,拆开看其实很简单:
- HMAC:Hash-based Message Authentication Code,翻译过来就是“基于哈希的消息认证码”。它是一种使用密钥(secret key)来生成消息摘要(MAC)的方法。
- SHA256:Secure Hash Algorithm 256-bit,一种安全的哈希算法,能把任意长度的数据转换成一个固定长度(256位,通常表示为64个十六进制字符)的唯一字符串。相同的输入永远得到相同的输出,输入有任何微小变化,输出都会面目全非。
所以,HMAC-SHA256 就是用一个共享密钥 (Secret Key),通过 SHA256 算法,给你的请求数据生成一个独一无二的“签名”。
三、签名的艺术:请求是怎么被“签”上和“验”货的?
整个流程其实不复杂,咱们用个图来说明一下:
sequenceDiagram
participant C as 前端 (Client)
participant S as 后端 (Server)
C->>C: 1. 准备请求参数 (如 method, path, query, body)
C->>C: 2. 加入时间戳 (timestamp) 和/或 随机数 (nonce)
C->>C: 3. 将参数按约定规则排序、拼接成一个字符串 (stringToSign)
C->>C: 4. 使用共享密钥 (Secret Key) 对 stringToSign 进行 HMAC-SHA256 运算,生成签名 (signature)
C->>S: 5. 将原始请求参数 + timestamp + nonce + signature 一起发送给后端
S->>S: 6. 接收到所有数据
S->>S: 7. 校验 timestamp/nonce (检查是否过期或已使用,防重放)
S->>S: 8. 从接收到的数据中,按与客户端相同的规则,提取参数、排序、拼接成 stringToSign'
S->>S: 9. 使用自己保存的、与客户端相同的 Secret Key,对 stringToSign' 进行 HMAC-SHA256 运算,生成 signature'
S->>S: 10. 比对客户端传来的 signature 和自己生成的 signature'
alt 签名一致
S->>S: 11. 验证通过,处理业务逻辑
S-->>C: 响应结果
else 签名不一致
S->>S: 11. 验证失败,拒绝请求
S-->>C: 错误信息 (如 401 Unauthorized)
end
简单来说,就是:
- 客户端:把要发送的数据(比如请求方法、URL路径、查询参数、请求体、时间戳等)按照事先约定好的顺序和格式拼成一个长长的字符串。然后用一个只有你和服务器知道的“秘密钥匙”(Secret Key)和 HMAC-SHA256 算法,给这个字符串算出一个“指纹”(签名)。最后,把原始数据、时间戳、签名一起发给服务器。
- 服务器端:收到请求后,用完全相同的规则和完全相同的“秘密钥匙”,对收到的原始数据(不包括客户端传来的签名)也算一遍“指纹”。然后比较自己算出来的指纹和客户端传过来的指纹。如果一样,说明数据没被改过,而且确实是知道秘密钥匙的“自己人”发的;如果不一样,那对不起,这请求有问题,拒收!
四、Talk is Cheap, Show Me The Code!
光说不练假把式,咱们来点实在的。
前端签名 (JavaScript - 通常使用 crypto-js 库)
// 假设你已经安装了 crypto-js: npm install crypto-js
import CryptoJS from 'crypto-js';
function generateSignature(params, secretKey) {
// 1. 准备待签名数据
const method = 'GET'; // 请求方法
const path = '/api/user/profile'; // 请求路径
const timestamp = Math.floor(Date.now() / 1000).toString(); // 时间戳 (秒)
const nonce = CryptoJS.lib.WordArray.random(16).toString(); // 随机数,可选
// 2. 构造待签名字符串 (规则很重要,前后端要一致!)
// 通常会对参数名按字典序排序
const sortedKeys = Object.keys(params).sort();
const queryString = sortedKeys.map(key => `${key}=${params[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${timestamp}\n${nonce}`;
console.log("String to Sign:", stringToSign); // 调试用
// 3. 使用 HMAC-SHA256 生成签名
const signature = CryptoJS.HmacSHA256(stringToSign, secretKey).toString(CryptoJS.enc.Hex);
console.log("Generated Signature:", signature); // 调试用
return {
signature,
timestamp,
nonce
};
}
// --- 使用示例 ---
const mySecretKey = "your-super-secret-key-dont-put-in-frontend-directly!"; // 强调:密钥不能硬编码在前端!
const requestParams = {
userId: '123',
role: 'user'
};
const { signature, timestamp, nonce } = generateSignature(requestParams, mySecretKey);
// 实际发送请求时,把 signature, timestamp, nonce 放在请求头或请求体里
// 例如:
// fetch(`${path}?${queryString}`, {
// method: method,
// headers: {
// 'X-Signature': signature,
// 'X-Timestamp': timestamp,
// 'X-Nonce': nonce,
// 'Content-Type': 'application/json'
// },
// // body: JSON.stringify(requestBody) // 如果是POST/PUT等
// })
// .then(...)
划重点! 上面代码里的 mySecretKey 绝对不能像这样直接写在前端代码里!这只是个演示。真正的 Secret Key 需要通过安全的方式分发和存储,比如在构建时注入,或者通过更安全的认证流程动态获取(但这又引入了新的复杂性,通常 Secret Key 是后端持有,客户端动态获取一个有时效性的 token)。对于纯前端应用,更常见的做法是后端生成签名所需参数,或者整个流程由 BFF (Backend For Frontend) 层处理。如果你的应用是 App,可以把 Secret Key 存储在原生代码中,相对安全一些。
后端验签 (Node.js - 使用内置 crypto 模块)
const crypto = require('crypto');
function verifySignature(requestData, clientSignature, clientTimestamp, clientNonce, secretKey) {
// 0. 校验时间戳 (例如,请求必须在5分钟内到达)
const serverTimestamp = Math.floor(Date.now() / 1000);
if (Math.abs(serverTimestamp - parseInt(clientTimestamp, 10)) > 300) { // 5分钟窗口
console.error("Timestamp validation failed");
return false;
}
// (可选) 校验 Nonce 防止重放,需要存储已用过的 Nonce,可以用 Redis 等
// if (isNonceUsed(clientNonce)) {
// console.error("Nonce replay detected");
// return false;
// }
// markNonceAsUsed(clientNonce, clientTimestamp); // 标记为已用,并设置过期时间
// 1. 从请求中提取参与签名的参数
const { method, path, queryParams } = requestData; // 假设已解析好
// 2. 构造待签名字符串 (规则必须和客户端完全一致!)
const sortedKeys = Object.keys(queryParams).sort();
const queryString = sortedKeys.map(key => `${key}=${queryParams[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${clientTimestamp}\n${clientNonce}`;
console.log("Server String to Sign:", stringToSign);
// 3. 使用 HMAC-SHA256 生成签名
const expectedSignature = crypto.createHmac('sha256', secretKey)
.update(stringToSign)
.digest('hex');
console.log("Server Expected Signature:", expectedSignature);
console.log("Client Signature:", clientSignature);
// 4. 比对签名 (使用 crypto.timingSafeEqual 防止时序攻击)
if (clientSignature.length !== expectedSignature.length) {
return false;
}
return crypto.timingSafeEqual(Buffer.from(clientSignature), Buffer.from(expectedSignature));
}
// --- Express 示例中间件 ---
// app.use((req, res, next) => {
// const clientSignature = req.headers['x-signature'];
// const clientTimestamp = req.headers['x-timestamp'];
// const clientNonce = req.headers['x-nonce'];
// // 实际项目中,secretKey 应该从环境变量或配置中读取
// const API_SECRET_KEY = process.env.API_SECRET_KEY || "your-super-secret-key-dont-put-in-frontend-directly!";
// // 构造 requestData 对象,包含 method, path, queryParams
// // 注意:如果是 POST/PUT 请求,请求体 (body) 通常也需要参与签名
// // 且 body 如果是 JSON,建议序列化后参与签名,而不是原始对象
// const requestDataForSig = {
// method: req.method.toUpperCase(),
// path: req.path,
// queryParams: req.query, // 对于GET;POST/PUT可能还需包含body
// // bodyString: req.body ? JSON.stringify(req.body) : "" // 如果body参与签名
// };
// if (!verifySignature(requestDataForSig, clientSignature, clientTimestamp, clientNonce, API_SECRET_KEY)) {
// return res.status(401).send('Invalid Signature');
// }
// next();
// });
五、细节是魔鬼:实施过程中的注意事项
- 密钥管理 (Secret Key):
- 绝对保密:这是最重要的!密钥泄露,签名机制就废了。
- 不要硬编码在前端:再次强调!对于B端或内部系统,可以考虑通过安全的构建流程注入。对于C端开放应用,通常结合用户登录后的 session token 或 OAuth token 来做,或者使用更复杂的 API Gateway 方案。
- 定期轮换:为了安全,密钥最好能定期更换。
- 时间戳 (Timestamp):
- 防止重放攻击:服务器会校验收到的时间戳与当前服务器时间的差值,如果超过一定阈值(比如5分钟),就认为是无效请求。
- 时钟同步:客户端和服务器的时钟要尽量同步,不然很容易误判。
- 随机数 (Nonce):
- 更强的防重放:Nonce 是一个只使用一次的随机字符串。服务器需要记录用过的 Nonce,在一定时间内(同时间戳窗口)不允许重复。可以用 Redis 等缓存服务来存。
- 哪些内容需要签名?
- HTTP 方法 (GET, POST, etc.)
- 请求路径 (Path, e.g.,
/users/123) - 查询参数 (Query Parameters, e.g.,
?name=zhangsan&age=18):参数名需要按字典序排序,确保客户端和服务端拼接顺序一致。 - 请求体 (Request Body):如果是
application/x-www-form-urlencoded或multipart/form-data,处理方式同 Query Parameters。如果是application/json,通常是将整个 JSON 字符串作为签名内容的一部分。注意空 body 和有 body 的情况。 - 关键的请求头:比如
Content-Type,以及自定义的一些重要 Header。 - 时间戳和 Nonce:它们本身也要参与签名,防止被篡改。
- 一致性是王道:客户端和服务端在选择哪些参数参与签名、参数的排序规则、拼接格式等方面,必须严格一致,一个空格,一个换行符不同,签名结果就天差地别。
六、HMAC-SHA256 vs. 其他方案?
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 仅 HTTPS | 传输层加密,防止窃听 | 无法防止应用层篡改(加密前)、无法验证发送者身份(应用层)、无法防重放 | 基础数据传输安全 |
| 简单摘要 (如MD5) | 实现简单 | 若无密钥,容易被伪造;MD5本身已不安全 | 文件完整性校验(非安全敏感) |
| HMAC-SHA256 | 消息完整性、身份验证(基于共享密钥)、可防重放(结合时间戳/Nonce) | 密钥管理是关键和难点;签名和验签有一定计算开销 | 需要保障API接口安全、防止未授权访问和篡改的场景 |
| JWT (JSON Web Token) | 无状态、可携带用户信息、标准化 | Token 可能较大;吊销略麻烦;主要用于用户认证和授权 | 用户登录、单点登录、API授权 |
HMAC-SHA256 更侧重于请求本身的完整性和来源认证,而 JWT 更侧重于用户身份的认证和授权。它们可以结合使用。
好啦,今天关于 HMAC-SHA256 请求签名的唠嗑就到这里。这玩意儿看起来步骤多,但一旦理解了原理,实现起来其实就是细心活儿。给你的 API 加上这把锁,晚上睡觉都能踏实点!
我是老码小张,一个喜欢研究技术原理,并且在实践中不断成长的技术人。希望今天的分享对你有帮助,咱们下回再聊!欢迎大家留言交流你的看法和经验哦!
来源:juejin.cn/post/7502641888970670080
AI场景前端必学——SSE流式传输
背景
由于大模型通常是需要实时推理的,Web 应用调用大模型时,它的标准模式是浏览器提交数据,服务端完成推理,然后将结果以 JSON 数据格式通过标准的 HTTP 协议返回给前端。但是这么做有一个问题,主要是推理所花费的时间和问题复杂度、以及生成的 token 数量有关。在日常使用中会发现,只是简单问候一句,可能 Deepseek 推理所花费的时间很少,但是如果我们提出稍微复杂一点的要求,比如编写一本小说的章节目录,或者撰写一篇千字的作文,那么 AI 推理的时间会大大增加,这在具体应用中就带来一个显而易见的问题,那就是用户等待的时间很长。能够发现,我们在使用线上大模型服务时,不管是哪一家大模型,通常前端的响应速度并没有太慢,这正是因为它们默认采用了流式(streaming)传输,不必等到整个推理完成再将内容返回,而是可以将逐个 token 实时返回给前端,这样就大大减少了响应时间。
服务端推送
服务端推送,也称为消息推送或通知推送,是一种允许应用服务器主动将信息发送到客户端的能力,为客户端提供了实时的信息更新和通知,增强了用户体验。
服务端推送的背景与需求主要基于以下几个诉求:
实时通知:在很多情况下,用户期望实时接收到应用的通知,如新消息提醒、商品活动提醒等。节省资源:如果没有服务端推送,客户端需要通过轮询的方式来获取新信息,会造成客户端、服务端的资源损耗。通过服务端推送,客户端只需要在收到通知时做出响应,大大减少了资源的消耗。增强用户体验:通过服务端推送,应用可以针对特定用户或用户群发送有针对性的内容,如优惠活动、个性化推荐等。这有助于提高用户对应用的满意度和黏性。
常见推送场景有:微信消息通知栏、新闻推送、外卖状态 等等,我们自身的推送场景有:下载、连线请求、直播提醒 ......
解决方案
传统实时处理方案:
轮询:这是一种较为传统的方式,客户端会定时地向服务端发送请求,询问是否有新数据。服务端只需要检查数据状态,然后将结果返回给客户端。轮询的优点是实现简单,兼容性好;缺点是可能产生较大的延迟,且对服务端资源消耗较高。长轮询(Long Polling):轮询的改进版。客户端向服务器发送请求,服务器收到请求后,如果有新的数据,立即返回给客户端;如果没有新数据,服务器会等待一定时间(比如30秒超时时间),在这段时间内,如果有新数据,就返回给客户端,否则返回空数据。客户端处理完服务器返回的响应后,再次发起新的请求,如此反复。长轮询相较于传统的轮询方式减少了请求次数,但仍然存在一定的延迟。
HTML5 标准引入的实时处理方案:
WebSocket:一种双向通信协议,同时支持服务端和客户端之间的实时交互。WebSocket 是基于 TCP 的长连接,和HTTP 协议相比,它能实现轻量级的、低延迟的数据传输,非常适合实时通信场景,主要用于交互性强的双向通信。SSE:Server-Sent Events 服务器推送事件,简称 SSE,是一种服务端实时主动向浏览器推送消息的技术。SSE 是 HTML5 中一个与通信相关的 API,主要由两部分组成:服务端与浏览器端的通信协议( HTTP 协议)及浏览器端可供 JavaScript 使用的 EventSource 对象。
从“服务端主动向浏览器实时推送消息”这一点来看,SSE 与 WebSockets API 有一些相似之处。但是,SSE 与 WebSockers API 的不同之处在于:
| Server-Sent Events API | WebSockets API | |
|---|---|---|
| 协议 | 基于 HTTP 协议 | 基于 TCP 协议 |
| 通信 | 单工,只能服务端单向发送消息 | 全双工,可以同时发送和接收消息 |
| 量级 | 轻量级,使用简单 | 相对复杂 |
| 自动重连 | 内置断线重连和消息追踪的功能 | 不在协议范围内,需手动实现 |
| 数据格式 | 文本或使用 Base64 编码和 gzip 压缩的二进制消息 | 类型广泛 |
| 事件 | 支持自定义事件类型 | 不支持自定义事件类型 |
| 连接数 | 连接数 HTTP/1.1 6 个,HTTP/2 可协商(默认 100) | 连接数无限制 |
| 浏览器支持 | 大部分支持,但在ie及早期的edge浏览器中并不被支持 | 主流浏览器(包括移动端)的支持较好 |
第三方推送:
常见的有操作系统提供相应的推送服务,如苹果的APNs(Apple Push Notification service)、谷歌的FCM(Firebase Cloud Messaging)等。同时,也有一些跨平台的推送服务,如个推、极光推送、友盟推送等,帮助开发者在不同平台上实现统一的推送功能。
这种推送方式在生活中十分常见,一般你打开手机就能看到各种信息推送,基本就是利用第三方推送来实现。
SSE
developer.mozilla.org/zh-CN/docs/…
SSE 服务端推送,它基于 HTTP 协议,易于实现和部署,特别适合那些需要服务器主动推送信息、客户端只需接收数据的场景:

EventSource
developer.mozilla.org/zh-CN/docs/…
服务器发送事件 API (SSE)包含在 eventSource 接口中。换句话说 eventsource 接口是 web 内容与服务器发送事件通信的接口。一个 eventsource 实例会对 HTTP 服务器开启一个持久化的连接,以text/event-stream格式发送事件,此连接会一直保持开启直到通过调用EventSource.close()关闭。

一旦连接开启,来自服务端传入的消息会以事件的形式分发至你代码中。如果接收消息中有一个 event 字段,触发的事件与 event 字段的值相同。如果不存在 event 字段,则将触发通用的 message 事件。
建立连接
EventSource 接受两个参数:URL 和 options。
URL 为 http 事件来源,一旦 EventSource 对象被创建后,浏览器立即开始对该 URL 地址发送过来的事件进行监听。
options 是一个可选的对象,包含 withCredentials 属性,表示是否发送凭证(cookie、HTTP认证信息等)到服务端,默认为 false。
const eventSource = new EventSource('http_api_url', { withCredentials: true })
// 关闭连接
eventSource.close()
// 可以使用addEventListener()方法监听
eventSource.addEventListener('open', function(event) {
console.log('Connection opened')
})
eventSource.addEventListener('message', function(event) {
console.log('Received message: ' + event.data);
})
// 监听自定义事件
eventSource.addEventListener('xxx', function(event) {
console.log('Received message: ' + event.data);
})
eventSource.addEventListener('error', function(event) {
console.log('Error occurred: ' + event.event);
})
// 也可以使用属性监听的方式
eventSource.onopen = function(event) {
console.log('Connection opened')
}
eventSource.onmessage = function(event) {
console.log('Received message: ' + event.data);
}
eventSource.onerror = function(event) {
console.log('Error occurred: ' + event.event);
})
Stream API
developer.mozilla.org/zh-CN/docs/…
Stream API 允许 JavaScript 以编程方式访问从网络接收的数据流,并且允许开发人员根据需要处理它们。
流会将你想要从网络接受的资源分成一个个小的分块,然后按位处理它。

@microsoft/fetch-event-source
http://www.npmjs.com/package/@mi…
默认的浏览器eventSource API在以下方面存在一些限制:
无法传递请求体(request body),必须将执行请求所需的所有信息编码到 URL 中,而大多数浏览器对 URL 的长度限制为 2000 个字符。无法传递自定义请求头。只能进行 GET 请求,无法指定其他方法。如果连接中断,无法控制重试策略,浏览器会自动进行几次尝试然后停止。
@microsoft/fetch-event-source 的优势:
@microsoft/fetch-event-source提供了一个基于 Fetch API 的替代接口,完全兼容 Event Stream 格式。这使得我们能够以更加灵活的方式进行服务器发送事件的消费。以下是该库的一些主要优势:
支持任何请求方法、请求头和请求体,以及 Fetch API 提供的其他功能。甚至可以提供替代的 fetch() 实现,以应对默认浏览器实现无法满足需求的情况。
提供对响应对象的访问权限,允许在解析事件源之前进行自定义验证/处理。这在存在 API 网关(如 nginx)的情况下非常有用,如果网关返回错误,我们可能希望正确处理它。
对连接中断或发生错误时,提供完全控制的重试策略。
此外,该库还集成了浏览器的 Page Visibility API,使得在文档被隐藏时(例如用户最小化窗口),连接会关闭,当文档再次可见时会自动使用上次事件 ID 进行重试。这有助于减轻服务器负担,避免不必要的开放连接(但如果需要,可以选择禁用此行为)。
import { fetchEventSource } from "@microsoft/fetch-event-source";
const Assistant: React.FC<Iprops> = (props) => {
const [abortController, setAbortController] = useState(new AbortController());
const send = (question: any) => {
setIsAnswering(true);
setIsScrollAtBottom(true);
setAskText("");
// 创建“生成中...”的占位符消息
const loadingMessage = { content: "生成中...", chatSenderType: 0, isLoading: true };
// 更新 chatList,添加用户消息和占位符消息
setChatList([...chatList, { content: question.text, chatSenderType: 1, problemType: question.problemType }, loadingMessage]);
setLoading(true); // 开始加载
fetchEventSource("https://demo.com/chat", {
method: "post",
body: JSON.stringify({ message: question.text, systemType, oa, problemType: question.problemType }),
headers: {
"Content-Type": "application/json"
},
signal: abortController.signal,
async onopen(response) {
// 可以在这里进行一些操作
},
onmessage(msg: { data: string }) {
msg.data.length && setStopDisabled(false);
// 接收到实际响应后,更新 chatList 中的占位符消息
const newMessage = { ...JSON.parse(msg.data).data, chatSenderType: 0, isLoading: false };
setChatList((prevChatList: any[]) => {
// 替换最后一个消息(占位符)为实际消息
const updatedChatList = [...prevChatList];
updatedChatList[updatedChatList.length - 1] = newMessage;
return updatedChatList;
});
setIsScrollAtBottom(true);
setLoading(false); // 加载完成
},
onclose() {
setIsStop(true);
setLoading(false); // 加载完成
setIsAnswering(false);
// 停止生成禁用
setStopDisabled(true);
},
onerror(err) {
abortController.abort();
setLoading(false); // 加载出错,停止加载
throw err;
}
});
};
const stop = async () => {
abortController.abort();
const answer = chatList[chatList.length - 1];
setAbortController(new AbortController());
setIsAnswering(false);
setLoading(false); // 停止加载
stopAnswer({ message: answer.content, messageId: answer.messageId, problemType: answer.problemType, systemType, oa }).then((res: any) => {
message.success("操作成功");
});
};
return (
<div>
<Chat
chatList={chatList}
setChatList={setChatList}
askText={askText}
setAskText={setAskText}
send={send}
stop={stop}
/>
</div>
)
};
AbortController
developer.mozilla.org/zh-CN/docs/…
在前端开发中,网络请求是不可或缺的一环。但在处理网络请求时,我们经常会遇到需要中途取消请求的情况。这时候,abortController可以帮助大家更好地掌控网络请求。
简介
AbortController是一个Web API,它提供了一个信号对象(AbortSignal),该对象可以用来取消与Fetch API相关的操作。当我们创建AbortController实例时,会自动生成一个与之关联的AbortSignal对象。我们可以将这个AbortSignal对象作为参数传递给fetch函数,从而实现对网络请求的取消控制。
使用方法
创建AbortController实例获取AbortSignal对象使用signal对象发起fetch请求取消fetch请求
const controller = new AbortController();
const signal = controller.signal;
// 当需要取消请求时,我们只需调用AbortController实例的abort方法:
fetch(url, { signal }).then(response => {
// 处理响应数据
}).catch(error => {
if (error.name === 'AbortError') {
console.log('Fetch 请求已被取消');
} else {
// 处理其他错误
}
});
// 当需要取消请求时,我们只需调用AbortController实例的abort方法:
controller.abort();
参考资料
http://www.npmjs.com/package/@mi…
来源:juejin.cn/post/7504843440778870794
🎯TAPD MCP:拯救我们于无聊的重复工作之中!
写在开头
其实这才是文章的标题:使用 TAPD MCP 实现任务的自动同步与快速管理😋
🤔 困境:在飞书和TAPD之间反复横跳是什么体验?
日常小编的需求任务拆分的工作流程大概是这样的:
- 首先,打开飞书,进入飞书文档,找到对应属于你的需求,创建任务。 ✍️
- 其次,打开TAPD,再创建一遍同样的任务。✍️✍️
- 最后,每天打开TAPD,不断更新任务状态。✍️✍️✍️
看流程不算复杂,甚至优于不少企业的管理流程,似乎该"知足常乐"吧!🙊
当然!!!
但作为坚持极客精神的执行者(强行立人设 + 1🙈),重复劳动简直是效率大敌!
从 “技术人视角” 看,第二步的手动同步操作尤为繁琐 —— 虽说程序猿是世界上最"懒"的人,但本质是用智慧消灭无意义的重复。✨✨✨
任何机械性工作都该交给程序处理,腾出时间做更有价值的事(比如……moyu,误,专注工作)
✨ 优化思路:

😎 为什么我们爱飞书?
说实话,飞书真的很香!
其实,更多的是因为日常办公使用的就是飞书沟通。😋
二连追问,企微、钉钉:我们不配?😑
不过,小编这段时间使用下来,确实也感觉飞书的功能非常强大!
特别是📝多维表格功能,Top1!!!
前段时间网上爆火的使用"飞书多维表格+AI=小红书爆款内容",那效果......啧啧啧,确实牛👍。
讲回来,在使用飞书文档管理我们的需求任务时,也确实是有好处的,起码我所知道的有:
- 📊 计划图表:直观展示每个人的任务分配情况,看着舒服~
- 📝 多维表格:各种公式随便玩,算工时简直不要太方便!
- 💬 即时沟通:有问题?评论一下自动戳同事!
😅 那为什么还要用TAPD?
emmm...这就要问问Leader了(小声bb)不过认真说,TAPD确实有它的优势:
- 🎯 需求管理更专业
- 📈 数据分析很强大
- 🔄 工作流程更规范
但是...这不代表我们要当复制粘贴工具人啊!(╯°□°)╯︵ ┻━┻
🎉 解救方案:TAPD MCP 来啦!
救星:传送门 🚀🚀🚀
🤖 什么是MCP?
简单来说,MCP就是让AI变得更聪明的一个协议!它可以:
(此处省略一万字。。。。)
🛠️ 开始配置我们的AI助手
支持MCP的AI客户端:
- Cursor(推荐)
- Windsurf
- Claude
- Cherry Studio(推荐)
第1️⃣步:Python环境配置
为什么要安装Python环境?🤔
Anthropic 为 MCP 提供了官方的 Python 和 TypeScript/Node.js SDK,方便开发者快速构建 MCP 服务或将 MCP 客户端集成到自己的应用中。(参考)
而 TAPD MCP 是使用 Python 开发的,所以要想使用这个MCP,需要先安装Python的环境,它是以uvx命令来运行的。
首先,python环境的安装教程网上非常多,这里就不细嗦了,可以上官网直接下载:传送门。
然后,我们来扩展认识一个新朋友:uv!
uv:一个超快的Python包管理器,比pip快到飞起!🚀 和前端的nvm差不多的东西,uv有一个坑点就是下载python版本的时候,需要🪜🪜🪜。

安装与使用uv的方式不是本章的主要内容,也不细嗦了,可以参考这篇文章:传送门。
本章要求的Python环境版本最低要 3.13+ 🔉🔉🔉 (为啥?当然是 TAPD MCP 要求的🙇)
小编的python版本配置:

其他一些工具对比:
| 工具 | 核心功能 | 适合场景 |
|---|---|---|
| anaconda | 管理环境 + Python 版本 + 包 | 数据科学、简单隔离 |
| pyenv | 管理 Python 版本 | 多版本精确控制 |
| uv | 管理 Python 版本 + 虚拟环境 + 包 | 追求速度、现代工具爱好者 |
总结:反正你本地需要安装好 Python 3.13 + 的环境,并且安装 uv ,能运行 uvx 命令即可。
第2️⃣步:获取TAPD凭证
- 登录 TAPD。
- 点击左下角 "公司管理"。
- 点击 "API账号管理",获取API账号与API秘钥。

每个API账号的权限是不一样的,也可以配置该账号的权限范围:
设置权限范围可以有效的防止AI助手误操作其他项目的情况,这很重要!!!⏰

第3️⃣步:在Cursor中配置MCP
- 打开 Cursor。
- 点击右上角的 Open Cursor Settings 或者 Ctrl + Shift + J。
- 点击MCP,再点击 Add new global MCP server,进入MCP配置页面。

具体配置如下:
{
"mcpServers": {
"mcp-server-tapd": {
"command": "uvx",
"args": [
"mcp-server-tapd",
"--api-user=你的API账号",
"--api-password=你的API秘钥",
"--api-base-url=https://api.tapd.cn",
"--tapd-base-url=https://www.tapd.cn"
]
}
}
}
使用 Ctrl + S 保存后,回到 Cursor Settings 就能看到 TAPD MCP 的服务了,并且它应该是亮绿灯,这说明你配置成功了。🥳
如果配置后,没有亮绿灯,那么你要先可以检查一下TAPD的凭证有没有什么问题,Python的环境有没有 3.13+ 以上, 有没有安装uv,或者重启大法。
如果还不行,就要进行技术的排查了,可以点击 Help -> Toggle Developer Tools ,会调出 Cursor 的控制台,MCP配置不成功的话,控制台是会抛出错误的,拿到错误。
如果你是程序猿就自己分析错误的内容啦,你可以的。👌
如果你非程序猿,咱们就点击下图的第四步,把错误内容丢给AI,给它简单描述一下你的困境,最好选择agent模式,让它帮你修复,你只要不断给它同意、同意、同意即可。😋


🎮 实战:让AI帮我们做任务!
完成配置后,到这里咱们就能进入正式的使用环节了。咱们来开启Cursor的Agent模式,开始来实际使用TAPD MCP Server!

4.1 验证MCP服务是否正常工作
当然,你最好先在TAPD平台上创建一个空间,方便咱们初始验证。
在 TAPD 中,空间是团队协作的基础单元,用于隔离不同项目或团队的数据和权限,每个空间可以有多个项目。
需求是从用户角度描述的独立功能点,是产品研发的核心对象。
任务是在需求下拆分的具体工作项。
TAPD 的业务对象还包括迭代、缺陷、测试计划、测试用例等。

以下是小编创建的一个名叫"橙子果园项目"的空间,TAPD默认会帮我们初始化一些需求、特性啥的。还有,我们可以从地址栏获取到这个空间的唯一ID(workspace_id),通过这个ID能让AI更加精准的自动去操作,也能防止它操作到其他空间中去!!!⏰
其实本质是通过API接口去操作,接口要求传递workspace_id参数,这很正常吧。😋

有了空间ID,接下来咱们来让AI帮我们查询一下这个空间的"需求"列表,如下:
请你使用TAPD的MCP,帮我查询一下这个空间(58195679)中的需求列表。


它仅把"需求"的帮我们查出来了,是不是还不错?👻
初始目的达成,撒花撒花。🌸🌸🌸
4.2 自动化创建需求
能进行查找,基本上TAPD的MCP是能正常使用了,接下来,咱们让AI通过MCP帮我们创建一个需求。
首先,我们先上TAPD上看看创建一个需求要填些什么信息(其实不看也是可以的,它会给你提示):

能填的东西很多,但是只有标题是必填的,咱们简单的填写一个标题和内容来创建一个需求就行,如下:
帮我创建一个需求,标题为"第一期计划1.0.1",内容为“项目的基本搭建、架构规划、发布流程部署、缺陷计划、验收标准”。


结果:

是不是挺好,一句话,就让AI帮咱们吭哧吭哧的干活。😍
注意,我们使用的是自然语言,上面小编虽然提供了对话内容,但是也不一定要和我一样,能大致表达你的想法就行。
4.3 自动化创建任务🍊🍊🍊
上面,需求已经创建完了,接下来就要来解决咱们开头提到的实际困境了。
本来按照小编开始的设想,任务的信息应该是AI自动去飞书的平台那边获取的,但是......🙉。
- 飞书还没有提供文档这方面的相关MCP,社区倒是有,如:传送门。但是好像不能满足小编心中所想, 还有就是它非官方,不敢用呀,怕夹带私货。😩
- 飞书提供了开放的API平台,我们其实可以自己搭一个服务,让AI去访问这个服务拿数据就行,Em...就是要写代码,麻烦,再想想...。😑
- 思考了两坤年半后,小编觉得前面配置运行环境,配置MCP已经很麻烦,信息来源这部分应该需要简单化了😋,咱直截了当从飞书文档中复制过来就行啦。
日常工作中,小编需要在飞书多维表格里查找对应需求并创建开发任务,如下:

其中,需同步至 TAPD 的核心内容为上图红框部分。
同样,👀咱们可以先去TAPD上看看手动在需求下创建任务的情况是如何的,如下:

刚刚好,内容是正好对应上的。但要每次都得逐个创建任务,面对大量任务时,这操作流程就显得极为繁琐,实在令人困扰!😣
现在,我们可以借助 AI 进行自动化创建,只需将内容复制给它即可。
具体操作是,在多维表格中长按并拖动鼠标选中目标单元格,按下 Ctrl+C 完成复制。

再把内容丢给AI,告诉它帮我们创建任务,如下:
我希望你在"第一期计划1.0.1"的 需求 下创建三个子任务,任务内容如下:
页面样式切图与基本逻辑编写 周北北 3 2025/04/20 2025/04/20
页面接口联调与逻辑完善 周北北 4 2025/04/21 2025/04/21
缺陷修复 周北北 2 2025/04/22 2025/04/24


Em...最终结果是正向的,AI 确实成功帮小编创建好了任务,效果堪称完美💯-1。 不过,就给它打99分吧,因为这一过程并非一帆风顺,其中也遇到了不少难题😅
首先,AI 在区分需求和任务这两个概念时,存在一定困难❗
从用户角度来看,需求和任务的界定清晰明了,但对于程序而言,两者存在层级关系。

TAPD MCP 并未提供专门用于创建任务的独立 API,创建任务与创建需求共用同一个 API,仅通过 "workitem_type_id" 字段来加以区分。从程序设计层面讲,这种方式并无问题,然而却给 AI 的理解带来了挑战,这也恰恰凸显出不同模型推理能力的差异。
起初,AI 将小编的三个任务错误创建成了三个需求。于是,小编想着更换模型,让AI能更好理解我的想法,我从 GPT-4o 切换为 Claude3.7。
Claude3.7确实强大,当它遇到 “任务” 概念无法理解时,会先在 TAPD MCP 提供的全部功能中进行查找,在发现确实没有可直接创建任务的 API 后,又找到了创建需求的 API,并留意到其中有一个参数能够区分需求和任务。

随后,模型沿着这个思路,一步步进行自我引导,并向小编询问关键信息,最终成功完成了任务创建。✅
其次,AI无法很明确字段的定义❗
在上面的TAPD的截图中,可以三个任务已成功创建,但处理人这列还显示为空,这是为什么呢?
"预估工时"字段是正常的,它要在任务详情中查看,小编在 TAPD 平台调整许久,始终无法调出 "处理人" 列。。。
小编通过核查 AI 执行详情与 TAPD 文档发现:


原来是AI把字段搞错了。。。当复制内容涉及多个相近字段时,AI 可能因信息模糊而 "懵圈",这也是其不确定性之一。因此,明确告知复制内容对应的字段至关重要。
我们再来尝试重新一个创建任务,并向 AI 详细说明 "处理人" 字段:
再帮我创建一个任务:
产品验收小缺陷修复 周北北 1 2025/04/25 2025/04/25
周北北 是处理人owner


从截图可见,这次效果堪称完美了💯💯💯!
经过上一轮 "调教"(其实是上下文连贯的作用😂),AI 已能清晰区分需求与任务的概念。同理,本次明确 "处理人" 字段后,AI 下次便能自动识别,让我们省心不少。
不过,AI 理解仍有小插曲 —— 小编本意不想设置负责人的,AI 却自动添加了,不过问题不大。整体来看,明确字段规则后,AI 协作效率显著提升啦!
TAPD MCP API 详情:

4.4 自动化更新任务状态
需求和任务创建完成后,接下来还有一个问题就是咱们需要时不时去更改任务的状态。虽然操作本身不复杂,只需点击几下,但小编仍觉得有些 "麻烦"—— 尤其是每次登录 TAPD 平台时,若遇到登录状态过期,还需用手机扫码重新登录,实在让人头疼。😕
还有,试想,如果每次完成任务(比如敲完代码)时,能在编辑器旁边顺手告诉 AI,让它帮忙更新任务状态,岂不是更高效?这样一来,写代码和更新任务状态都能在 Cursor 中完成,无需频繁切换平台。
还有还有不仅仅是任务,"缺陷"修复后若能自动更新状态,也能省去反复登录平台修改的麻烦。可见,自动化更新任务状态是个非常实用的操作呀。😀
那么,我们要如何做呢?
一个任务在TAPD平台上通常有以下三种状态:

我们尝试让 AI 将某个任务状态更改为 "进行中" 试试:


在 Claude 3.7 模型下,该操作算是一次成功的。🎉🎉🎉
但此前小编在 GPT-4o 模型中尝试时,初次操作就出现了错误❗
模型未理解 "进行中" 的状态定义,随便选择塞了一个状态进行更新,而 TAPD 平台居然没有对状态值进行有效性验证,直接就成功了😗。此外,GPT-4o 也没有像 Claude 3.7 那样先查询任务状态列表,直接 "盲操作",推理能力略显不足呀!
不过,在小编向其提供了 TAPD 文档中的任务状态说明后:

它最终也是能正确完成状态的更新,也算可以啦。😋 如果说TAPD更出名一点,文档更友好一点,AI模型的前期训练积累了这方面的内容,其实都问题不大。
看到这里,不知道你有没有存在一些疑问❓是不是好似还有一个隐藏的痛点🙈:
每次对话时,都需要提供精确的任务名称作为匹配标准。虽然不算太麻烦,但是如果能更简洁一点,那肯定是更简洁好呀。在某些AI模型的视角下,如果存在名称相近的任务,就容易混淆,它容易"乱来"。但有一些模型比较聪明一些,相近或者模糊的任务名称也是可以的,AI会列举任务名称相近的任务,一个一个咨询你是否执行,也可能是 AI 先查询任务列表,再从结果中定位目标任务进行状态修改。这样一来,即使任务名称相近,也能通过列表精准匹配,这样操作效率与准确度反而更高了。
总的来说,尽管不同模型的表现有差异,但通过合理引导和补充规则,都问题不大,能满足实际需要了。👻
🚀 未来展望
- 🔄 通过飞书开放平台的 API,实现任务自动同步。
- ⏳设置定时任务,定期同步两个平台的数据。
- 🎯 自动帮我们写代码?
- 💪 可以专注于更有意义的工作
随着 AI 技术的发展,咱们可以期待更多智能化的协作方式。希望本章的分享能帮助大家从重复的工作中解放出来,毕竟生活不只有搬砖,还有诗和远方呢!(๑•̀ㅂ•́)و✧
至此,本篇文章就写完啦,撒花撒花。

来源:juejin.cn/post/7499014256547774490
不用 js实现渐变、虚线、跑马灯、可伸缩边框
最近遇到个需求,要求实现一个渐变色的边框,并且是虚线的,同时还要有动画。
有的朋友可能看到这里就要开骂了,估计要提刀找设计和产品怼回去了。
但其实我是可以理解的,因为这种花哨的边框想要用在一个类似于魔法框的地方,框住一个地方,然后交给 ai 处理。这样的交互设计可以很好的体现科技感,并且我也想尝试一下,就接了这个需求。
单看几个条件都好处理,css 已经支持了 border-image。
再不济用伪元素遮盖一下,clip-path镂空也可以
甚至我看到很多网站是直接放个视频就完了
但是我这次的需求最重要的是虚线,这就不好处理了。因为设置了边框为虚线后会忽略掉 border-image。
其实这个问题看起来很难,做起来也确实难。我搜到了张鑫旭大佬多年前的文章,就是专门讲这件事的
http://www.zhangxinxu.com/wordpress/2…
看完之后我受益匪浅,虽然我不能用他的方案(因为他的方案中,虚线是假的,样式会和浏览器有差异)
我尝试了很多方案,mask、clip-path、背景图等等,效果都不好。
绝望之际我想到了一个救星svg
div 做不到的事情,我 svg 来做。svg 可以设置 stroke,可以设置 fill,可以设置渐变色,渐变色还可以做动画。简直就是完美的符合需求
先写个空标签上去
<style>
.rect{
width: 100px;
height: 100px;
}
</style>
<div class='rect'>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1">
</svg>
</div>
因为我需要 svg 尺寸跟随父容器变化,所以就不写 viewBox 了,直接设置宽高 100%。同时在里面画一个矩形,也是宽高 100%。
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" width='100%' height='100%'>
<rect width="100%" height="100%"></rect>
</svg>
现在长这样

接下来给 rect 设置填充和描边,边框宽度为 4px
<rect
fill="transparent"
stroke="red"
stroke-width="4"
width="100%"
height="100%"
></rect>

接下来我们给border 设置为渐变色,需要在 svg 中定义一个渐变,svg 定义渐变色还是很方便的,都是现成标签和属性直接就可以通过 id 取到。
<svg>
...
<defs>
<linearGradient id="gradient" x1="0%" y1="0%" x2="100%" y2="0%">
<stop offset="0%" stop-color="lightcoral" />
<stop offset="50%" stop-color="lightblue" />
<stop offset="100%" stop-color="lightgreen" />
</linearGradient>
</defs>
</svg>
接下来给红色的 stroke 换成渐变色
<rect
fill="transparent"
stroke="url(#gradient)"
stroke-width="4"
width="100%"
height="100%"
></rect>

接下通过 stroke-dasharray 来设置虚线边框
mdn 上关于 dasharry的介绍在这里 developer.mozilla.org/zh-CN/docs/…

我给 rect 设置 dasharray 为 5,5
<rect
fill="transparent"
stroke="url(#gradient)"
stroke-dasharray="5,5"
stroke-width="4"
width="100%"
height="100%"
></rect>

这样渐变虚线边框就成了
接下来处理动画效果
动画分两种
- 线动,背景色不动
- 线不动,背景色动
这两种效果我都实现了
首先展示线动,背景色不动的情况
这种情况只要能想办法让虚线产生偏移就可以,于是我搜了一下,这不巧了吗,正好有个属性叫 stroke-dashoffset

于是就可以通过 css 动画来修改偏移量
<style>
.dashmove {
animation: dashmove 1s linear infinite;
}
@keyframes dashmove {
0% {
stroke-dashoffset: 0;
}
100% {
stroke-dashoffset: 10;
}
}
</style>
<rect class="dashmove" .... ></rect>

大功告成
接下来处理第二种情况,线不动,背景动
这种情况就更简单了,因为 svg 本身就支持动画
我们只需要在渐变色中增加一个animateTransform标签
<linearGradient id="gradient" x1="0%" y1="0%" x2="100%" y2="0%">
...
<animateTransform
attributeName="gradientTransform"
type="rotat
from="0 0.5 0.5"
to="360 0.5 0.5"
dur="1s"
repeatCount="indefinite"
/>
</linearGradient>

接下来看一下拖拽的效果,这个很重要,因为我们不希望随着容器比例变化,会让边框宽度也变化。
给容器元素加上这三个属性,这个 div 就变成了可拖拽缩放的
.rect{
// ...
resize: both;
position: relative;
overflow: auto;
}
看下效果

完美 🎉🎉🎉
在这里查看完整在线 demo stackblitz.com/edit/stackb…
来源:juejin.cn/post/7502127751572406323
鸿蒙UI通用代码几种抽离方法
对于做APP的UI,免不了会写大量的重复布局,重复UI页面。此时对于将重复的UI控件抽离出来封装为通用组件来进行优化很是重要。
本文重点分析鸿蒙几种UI处理上,如何抽离通用方法来进行UI的复用。重点对比@Style,@Extend, AttributeModifier, @Builder和 struct 这五种方法的区别和使用场景。
Styles装饰器
学过Android开发的小伙伴知道Android中有样式Style概念,我们定义好一个样式,那么就可以在各个组件中使用。从而保持每个组件有一样的属性。
同理,鸿蒙中也可以使用样式。比如我们UI上的按钮具有相同的宽,高,背景色和边角距。那么我们就可以定义一个Style,每次定义按钮时候,只需要将Style赋给按钮就可以实现该属性,从而避免重复代码的书写。
- 代码说明

如图,在当前页面内定义一个方法,使用装饰器Styles修饰,修饰后,方法内部就可以直接通过 .属性 的方式来定义属性了。方法定义完后,下方button里可以直接使用该方法。虽然我这里方法命名为commonButton,但是实际上所有基础控件都可以使用该方法使用里边的属性,比如下方的Text组件。
- Style特点
- 对于定义的方法,无法使用export修饰。
这也就意味着,我们抽离的通用属性,只能在当前页面内的组件上使用,换个页面就不可以了,无法做到全局所有页面通用。 - 对于定义的方法,只能定义组件的通用属性。
比如宽高,背景色等。对于一些控件特有属性是无法定义的。比如Select组件的selectedOptionFont特有属性无法定义。 - 方法不支持传递入参。
意味着该样式无法做到动态修改,只要定义好就无法修改。比如定义好宽高为30,而某个组件宽要求为40,其他属性都不变,那这个方法也没法用了。 - 方法为组件通用属性,故所有组件都可以引用方法。
Extend装饰器
对于Styles装饰器的第2点限制,鸿蒙推出了解决方案,那就是使用@Extend装饰器。
Extend装饰器需要我们在使用时候指定定义哪个组件的属性,是专门抽离指定组件的。
- 代码说明

Extend要求必须定义方法为在当前文件的全局定义,且也不能够export,同时定义时候需要指定是针对哪个控件。如图指定了控件Select,然后就可以指定Select的专有属性了。
- Extend特点
- 方法不支持export。
和Styles一样,无法真正做到为所有页面抽离出都可用的属性方法。 - 方法只能定义为当前页面内的全局方法。
一定程度上全局方法存在引用GlobalThis,具体副作用未知。 - 方法需要指定控件,其他控件无法使用,只能对专有控件做到了抽离
- 方法可以传入参。
相比Styles, 可以在其他属性不变的情况下,只修改其中的部分属性。
AttributeModifier
对于上述两个装饰器都存在一个相同的限制,就是无法做到全局所有文件都可以公用。
AttributeModifier的出现可以变相的解决这个问题。AttributeModifier本意是用于自定义控件中设置属性用的。但是我们在这里也可以通过这个机制,来实现全局所有文件中控件均可通用的属性。
- 代码说明

该Modifier只能针对专用控件,比如我要抽离一个通用的TextInput,那么我可以如上图所定义。
需要实现一个接口 AttributeModifier,接口泛型定义和我们想要给哪个控件使用有关,比如我们想给TextInput使用,那么泛型就是 TextInputAttribute,如果给Column使用,那么泛型就是ColumnAttribute,以此类推。
在该接口的实现方法中,定义控件的属性。
- 布局中使用

- 自定义属性
我们还可以自定义部分属性,只需要修改TextInputAttribute,例如我们想自定义字体大小。可以定义变量。

- 使用

- AttributeModifier特点
- 可以全局给所有页面中的控件使用
- 可以自定义任何控件中的属性,包括特有属性
- 可以通过修改代码做成链式调用
- 该方法需要new对象,比较笨重,需要书写较多代码
@Builder
上述说的都是针对单独的控件,如果我们想抽离一个通用的布局呢?或者我们的控件就是固定的可以拿来到处使用。
比如我有一个Text,各种属性固定,只是文案不同,那么我使用上述几种都比较麻烦,需要书写较多代码。那么这个时候就可以使用builder了。
- 代码

我们可以在任意需要展示该Text的地方使用,直接调用该方法,对应位置就可以显示出内容了。原理相当于是将方法内的控件代码放到了对应的位置上。
- 使用

- @Builder特点
- 定义好方法后,需要拿Builder装饰器修饰,可以在任何一个页面内调用方法使用。
- 可以通过方法传递入参
- 无法通过方法拿到控件对象,只能在方法里操作控件属性
- 除了单一控件,还可以定义布局,布局中存在多个控件的情况
- 轻量级
- 方法即拿即用,代码量少
struct
有时候,我们可能页面中存在大量如下UI:

对于这种UI,我们完全可以抽离出为一个控件。然后我们页面需要展示的地方,直接调用该控件,设置标题,按钮文案等就可以简化了。
我们可能想到使用builder来定义,但是builder只能写纯UI代码,这里还涉及到用户输入的内容,如何在点击按钮时候传过去。所以builder就无法使用了,这个时候就可以用struct封装了。
- 代码
@Component
export struct InputNumberItemWithButton {
label: string = "标题"
buttonClick: (v: number) => void = () => {
}
buttonLabel: string = "设置"
inputPlaceholder: string = "我是提示语"
inputId: string = this.label
parentWidth: string = '100%'
private value: number = 0
build() {
RelativeContainer() {
Text(this.label)
.attributeModifier(Modifier.textLabel())
.id('label1')
.alignRules({
left: { anchor: '__container__', align: HorizontalAlign.Start },
top: { anchor: '__container__', align: VerticalAlign.Top },
bottom: { anchor: '__container__', align: VerticalAlign.Bottom }
})
.margin({ left: 2 })
TextInput({ placeholder: this.inputPlaceholder })
.onChange((value: string) => {
this.value = Number.parseInt(value) ?? 0
})
.type(InputType.Number)
.id(this.inputId)
.height(30)
.placeholderFont({ size: 10 })
.fontSize(CommonStyle.INPUT_TEXT_SIZE)
.borderRadius(4)
.alignRules({
right: { anchor: 'button1', align: HorizontalAlign.Start },
left: { anchor: 'label1', align: HorizontalAlign.End },
top: { anchor: '__container__', align: VerticalAlign.Top },
bottom: { anchor: '__container__', align: VerticalAlign.Bottom }
})
.margin({ left: 6, right: 6 })
Button(this.buttonLabel)
.attributeModifier(SuBaoSmallButtonModifier.create())
.onClick(() => {
this.buttonClick(this.value)
})
.id('button1')
.alignRules({
right: { anchor: '__container__', align: HorizontalAlign.End },
top: { anchor: '__container__', align: VerticalAlign.Top },
bottom: { anchor: '__container__', align: VerticalAlign.Bottom }
})
.margin({ right: 2 })
}
.width(this.parentWidth)
.height(40)
.padding({
left: 5,
right: 5,
top: 2,
bottom: 2
})
.borderRadius(4)
}
}
该struct中通过维护一个变量value 来保存用户输入的数字,然后在用户点击按钮时候传给点击事件方法,交给调用者调用。
- 使用

点击设置按钮,点击事件触发,a直接赋值。
- struct特点
- 可以封装复杂组件,自定义组件
- 可以维护变量存储用户输入输出
- 可以所有页面全局使用
- 可以自定义属性
- 无法链式设置属性
对比各个使用场景
实际编程中,一般都是混合相互配合使用,没必要单独硬使用哪一个。
- style
可以用来定义一些通用属性,比如背景色,边角据等 - Extend
对于页面中一些特殊的控件,用的地方较多时候,可以抽离方法 - AttributeModifier
如果Extend无法满足,那么选择这个 - Builder
对于布局控件的属性变化不大,但是用的地方多时候使用,比如定义一个分割线。 - struct
涉及到用户输入输出时候,相关控件可以抽离封装,避免页面内上方定义太多变量,不好维护。
来源:juejin.cn/post/7374293974577692706
Promise 引入全新 API!效率提升 300%!
来源:前端开发爱好者
在 JavaScript 的世界里,Promise 一直是处理异步操作的神器。
而现在,随着 ES2025 的发布,Promise 又迎来了一个超实用的新成员——Promise.try()!
这个新方法简直是对异步编程的一次 “革命” ,让我们来看看它是怎么让代码变得更简单、更优雅的!
什么是 Promise.try()?
简单来说,Promise.try() 是一个静态方法,它能把任何函数(同步的、异步的、返回值的、抛异常的)包装成一个 Promise。无论这个函数是同步还是异步,Promise.try() 都能轻松搞定,还能自动捕获同步异常,避免错误遗漏。
语法
Promise.try(func)
Promise.try(func, arg1)
Promise.try(func, arg1, arg2)
Promise.try(func, arg1, arg2, /* …, */ argN)
参数
func:要包装的函数,可以是同步的,也可以是异步的。arg1、arg2、…、argN:传给func的参数。
返回值
一个 Promise,可能的状态有:
- 如果
func同步返回一个值,Promise 就是已兑现的。 - 如果
func同步抛出一个错误,Promise 就是已拒绝的。 - 如果
func返回一个 Promise,那就按这个 Promise 的状态来。
为什么需要 Promise.try()?
在实际开发中,我们经常遇到一种情况:不知道或者不想区分函数是同步还是异步,但又想用 Promise 来处理它。
以前,我们可能会用 Promise.resolve().then(f),但这会让同步函数变成异步执行,有点不太理想。
const f = () => console.log('now');
Promise.resolve().then(f);
console.log('next');
// next
// now
上面的代码中,函数 f 是同步的,但用 Promise 包装后,它变成了异步执行。
有没有一种方法,让同步函数同步执行,异步函数异步执行,并且让它们具有统一的 API 呢?
答案是可以的,并且 Promise.try() 就是这个方法!
怎么用 Promise.try()?
示例 1:处理同步函数
const syncFunction = () => {
console.log('同步函数执行中');
return '同步的结果';
};
Promise.try(syncFunction)
.then(result => console.log(result)) // 输出:同步的结果
.catch(error => console.error(error));
示例 2:处理异步函数
const asyncFunction = () => {
returnnewPromise(resolve => {
setTimeout(() => {
resolve('异步的结果');
}, 1000);
});
};
Promise.try(asyncFunction)
.then(result =>console.log(result)) // 1秒后输出:异步的结果
.catch(error =>console.error(error));
示例 3:处理可能抛出异常的函数
const errorFunction = () => {
throw new Error('同步的错误');
};
Promise.try(errorFunction)
.then(result => console.log(result))
.catch(error => console.error(error.message)); // 输出:同步的错误
Promise.try() 的优势
- 统一处理同步和异步函数:不管函数是同步还是异步,
Promise.try()都能轻松搞定,代码更简洁。 - 异常处理:自动捕获同步异常,错误处理更直观,避免遗漏。
- 代码简洁:相比传统方法,
Promise.try()让代码更易读易维护。
实际应用场景
场景 1:统一处理 API 请求
function fetchData(url) {
return Promise.try(() => fetch(url))
.then(response => response.json())
.catch(error => console.error('请求失败:', error));
}
fetchData('https://api.example.com/data')
.then(data => console.log('数据:', data));
场景 2:混合同步和异步操作
const syncTask = () => '同步任务完成';
const asyncTask = () => new Promise(resolve => setTimeout(() => resolve('异步任务完成'), 1000));
Promise.try(syncTask)
.then(result => console.log(result)) // 输出:同步任务完成
.then(() => Promise.try(asyncTask))
.then(result => console.log(result)) // 1秒后输出:异步任务完成
.catch(error => console.error(error));
场景 3:处理数据库查询
function getUser(userId) {
return Promise.try(() => database.users.get({ id: userId }))
.then(user => user.name)
.catch(error => console.error('数据库查询失败:', error));
}
getUser('123')
.then(name => console.log('用户名称:', name));
场景 4:处理文件读取
function readFile(path) {
return Promise.try(() => fs.readFileSync(path, 'utf8'))
.catch(error => console.error('文件读取失败:', error));
}
readFile('example.txt')
.then(content => console.log('文件内容:', content));
总结
Promise.try() 的引入让异步编程变得更加简单和优雅。
它统一了同步和异步函数的处理方式,简化了错误处理,让代码更易读易维护。
ES2025 的这个新特性,绝对值得你去尝试!快去试试吧,你的代码会变得更清晰、更强大!
来源:juejin.cn/post/7494174524453158949
前端的AI路其之三:用MCP做一个日程助理
前言
话不多说,先演示一下吧。大概功能描述就是,告诉AI“添加日历,今天下午五点到六点,我要去万达吃饭”,然后AI自动将日程同步到日历。

准备工作
开发这个日程助理需要用到MCP、Mac(mac的日历能力)、Windsurf(运行mcp)。技术栈是Typescript。
思路
基于MCP我们可以做很多。关于这个日程助理,其实也是很简单一个尝试,其实就是再验证一下我对MCP的使用。因为Siri的原因,让我刚好有了这个想法,尝试一下自己搞个日程助理。关于MCP可以看我前面的分享
# 前端的AI路其之一: MCP与Function Calling# 前端的AI路其之二:初试MCP Server 。
我的思路如下: 让大模型理解一下我的意图,然后执行相关操作。这也是我对MCP的理解(执行相关操作)。因此要做日程助理,那就很简单了。首先搞一个脚本,能够自动调用mac并添加日历,然后再包装成MCP,最后引入大模型就ok了。顺着这个思路,接下来就讲讲如何实现吧
实现
第一步:在mac上添加日历
这里我们需要先明确一个概念。mac上给日历添加日程,其实是就是给对应的日历类型添加日程。举个例子

左边红框其实就是日历类型,比如我要添加一个开发日程,其实就是先选择"开发"日历,然后在该日历下添加日程。因此如果我们想通过脚本形式创建日程,其实就是先看日历类型存在不存在,如果存在,就在该类型下添加一个日程。
因此这里第一步,我们先获取mac上有没有对应的日历,没有的话就创建一个。
1.1 查找日历
参考文档 mac查找日历
假定我们的日历类型叫做 日程助手。 这里我使用了applescript的语法,因为JavaScript的方式我这运行有问题。
import { execSync } from 'child_process';
function checkCalendarExists(calendarName) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log(result);
return true;
} catch (error) {
console.error('检测失败:', error.message);
return false;
}
}
// 使用示例
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
附赠检验结果

现在我们知道了怎么判断日历存不存在,那么接下来就是,在日历不存在的时候创建日历
1.2 日历创建
参考文档 mac 创建日历
import { execSync } from 'child_process';
// 创建日历
function createCalendar(calendarName) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
....
}
// 使用示例
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
if (!exists) {
const res = createCalendar(calendarName);
console.log(res ? '✅ 创建成功' : '❌ 创建失败')
}
运行结果

接下来就是第三步了,在日历“日程助手”下创建日程
1.3 创建日程
import { execSync } from 'child_process';
// 创建日程
function createCalendarEvent(calendarName, config) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
} catch (error) {
console.error('❌ 执行失败:', error);
}
}
// 创建日历
function createCalendar(calendarName) {
....
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
...
}
这里我们完善一下代码
import { execSync } from 'child_process';
function handleCreateEvent(config) {
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
// console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
if (!exists) {
const createRes = createCalendar(calendarName);
console.log(createRes ? '✅ 创建日历成功' : '❌ 创建日历失败')
if (createRes) {
createCalendarEvent(calendarName, config)
}
} else {
createCalendarEvent(calendarName, config)
}
}
// 创建日程
function createCalendarEvent(calendarName, config) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
} catch (error) {
console.error('❌ 执行失败:', error);
}
}
// 创建日历
function createCalendar(calendarName) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (error) {
return false;
}
}
// 运行示例
const eventConfig = {
title: '团队周会',
startTime: 1744183538021,
endTime: 1744442738000,
description: '每周项目进度同步',
};
handleCreateEvent(eventConfig)
运行结果


这就是一个完善的,可以直接在终端运行的创建日程的脚本的。接下来我们要做的就是,让大模型理解这个脚本,并学会使用这个脚本
第二步: 定义MCP
基于第一步,我们已经完成了这个日程助理的基本功能,接下来就是借助MCP的能力,教会大模型知道有这个函数,以及怎么调用这个函数
// 引入 mcp
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
// 声明MCP服务
const server = new McpServer({
name: "mcp_calendar",
version: "1.0.0"
});
...
// 添加日历函数 也就是告诉大模型 有这个东西以及怎么用
server.tool("add_mac_calendar", '给mac日历添加日程, 接受四个参数 startTime, endTime是起止时间(格式为YYYY-MM-DD HH:MM:SS) title是日历标题 description是日历描述', { startTime: z.string(), endTime: z.string(), title: z.string(), description: z.string() },
async ({ startTime, endTime, title, description }) => {
const res = handleCreateEvent({
title: title,
description: description,
startTime: new Date(startTime).getTime(),
endTime: new Date(endTime).getTime()
});
return {
content: [{ type: "text", text: res ? '添加成功' : '添加失败' }]
}
})
// 初始化服务
const transport = new StdioServerTransport();
await server.connect(transport);
这里附上完整的ts代码
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { execSync } from 'child_process';
import { z } from "zod";
export interface EventConfig {
// 日程标题
title: string;
// 日程开始时间 毫秒时间戳
startTime: number;
// 日程结束时间 毫秒时间戳
endTime: number;
// 日程描述
description: string;
}
const server = new McpServer({
name: "mcp_calendar",
version: "1.0.0"
});
function handleCreateEvent(config: EventConfig) {
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
// console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
let res = false;
if (!exists) {
const createRes = createCalendar(calendarName);
console.log(createRes ? '✅ 创建日历成功' : '❌ 创建日历失败')
if (createRes) {
res = createCalendarEvent(calendarName, config)
}
} else {
res = createCalendarEvent(calendarName, config)
}
return res
}
// 创建日程
function createCalendarEvent(calendarName: string, config: EventConfig) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
return true
} catch (error) {
console.error('❌ 执行失败:', error);
return false
}
}
// 创建日历
function createCalendar(calendarName: string) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName: string) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (error) {
return false;
}
}
server.tool("add_mac_calendar", '给mac日历添加日程, 接受四个参数 startTime, endTime是起止时间(格式为YYYY-MM-DD HH:MM:SS) title是日历标题 description是日历描述', { startTime: z.string(), endTime: z.string(), title: z.string(), description: z.string() },
async ({ startTime, endTime, title, description }) => {
const res = handleCreateEvent({
title: title,
description: description,
startTime: new Date(startTime).getTime(),
endTime: new Date(endTime).getTime()
});
return {
content: [{ type: "text", text: res ? '添加成功' : '添加失败' }]
}
})
const transport = new StdioServerTransport();
await server.connect(transport);
第三步: 导入Windsurf
在前文已经讲过如何引入到Windsurf,可以参考前文# 前端的AI路其之二:初试MCP Server ,这里就不过多赘述了。 其实在build之后,完全可以引入其他支持MCP的软件基本都是可以的。
接下来就是愉快的调用时间啦。
总结
这里其实是对前文# 前端的AI路其之二:初试MCP Server 的再次深入。算是大概讲明白了Tool方式怎么用,MCP当然不止这一种用法,后面也会继续输出自己的学习感悟,也欢迎各位大佬的分享和指正。
祝好。
来源:juejin.cn/post/7495598542405550107
从劝退 flutter_screenutil 聊到不同尺寸 UI 适配的最佳实践
先说优点
💡 先说优点叠个甲,毕竟库本身没有太大问题,往往都是使用的人有问题。
由于是基于设计稿进行屏幕适配的框架,在处理不同尺寸的屏幕时,都可以使用相同的 尺寸数值+单位 ,实现对设计稿等比例的适配,同时保真程度一般很高。
在有设计稿的情况下,只使用 Container + GestureDetector 都可以做到快速的开发,可谓是十分的无脑梭哈。
在:只考虑移动端、可以接受使用大屏幕手机看小屏幕 ui、不考虑大字体的模式、被强烈要求还原设计稿、急着开发。的情况下,还是挺好用的。
为什么劝退?
来到我劝退师最喜欢的一个问题,为什么劝退。如果做得不好,瞎搞乱搞,那就是我劝退的对象。
在亲身使用了两个项目并结合群里的各种疑惑,我遇到常见的有如下问题:
如何实现对平板甚至是桌面设备的适配?
由于基于设计稿尺寸,平板、桌面等设备的适配基本上是没法做的,要做也是费力不讨好的事。
千万不要想着说,我通过屏幕宽度断点来使用不同的设计稿,当用户拉动边框来修改页面的宽度时,体验感是很崩溃的。而且三套设计稿要写三遍不同的代码,就更不提了。(这里说三遍代码的原因是,计算 .w .h 的布局,数据会跟随设计稿变化)
如何适配大字体无障碍?
因为大字体缩放在满屏的 .w .h 下,也就是写死了尺寸的情况下,字体由于随系统字体放大,布局是绝对会溢出的。很多项目开发到最后上线才意识到自己有大字体无障碍的用户,甚至某些博客上,使用了一句:
MediaQuery.of(context).copyWith(textScaleFactor: 1.0),
来处理掉自己的用户,强制所有屏幕字体不可缩放。一时的勉强敷衍过去,最后只能等项目慢慢腐烂。
为什么在 1.w 的情况下会很糊?同样是 16.sp 为什么肉眼可见的不一样大?
库的原理很简单,提供了一堆的 api 相对于设计图的宽高去做等比例计算,所以必然存在一个问题,计算结果是浮点数。可是?浮点数有什么问题吗?
梳理一下原理:已知屏幕设计图宽度 sdw 、组件设计图宽度 dw ,根据屏幕实际宽度 sw ,去计算得出组件实际宽度 w。
w = sw / sdw * dw
可是设计图的屏幕宽度 sdw 作为分母时,并不能保证总是可以被表示为有限小数。举个例子:库的文档中给的示例是 const Size(360, 690), 的尺寸,如果我需要一个 100.w 会得到多少?在屏幕宽度为 420 的情况下,得到组件宽度应该为 116.6666... 的无限小数。
这会导致最终在栅格化时会面临消除小数点像素的锯齿问题。一旦有像素点的偏差,就会导致边缘模糊。
字体对尺寸大小更为敏感,一些非矢量的字体甚至只有几个档位的大小,当使用 14.5、15、15.5 的字体大小时,可能会得到一样的视觉大小,再加上 .sp 去计算一道,误差更是放大。
具体是否会发生在栅格化阶段,哪怕文章有误也无所谓,小数点像素在物理意义上就是不存在的,总是会面临锯齿平滑的处理,导致无法像素级还原 UI。
为什么部分屏幕下会溢出?
我们知道了有小数点问题,那么不得不说起计算机编程常见的一个不等式:
0.1 + 0.2 != 0.3
由于底层表示浮点数本身就有的精度问题,现在让 Flutter 去做这个加法,一样会溢出。考虑以下代码:
Row(
children: [
SizedBox(width: 60.w),
SizedBox(width: 100.w),
SizedBox(width: 200.w),
],
);
在一个总共宽度 360.w 的设计图上,可能出现了溢出,如果不去使用多个屏幕来调试,根本不会觉得异常,毕竟设计图是这样做的,我也是这样写的,怎么可能有错呢?
然而恰恰是库本身的小数问题,加上编程届常见的底层浮点数精度问题,导致边缘溢出一点点像素。
我使用了 screenutil 为什么和真实的单位 1px 1rem 1dp 的大小不同呢?
哪怕是 .sp 都是基于设计图等比例缩放的,使用 screenutil 就从来不存在真实大小,计算的结果都是基于设计稿的相对大小。就连 .w 和 .h 都没法保证比例相同,导致所有布局优先使用 .w 来编写代码的库,还想保证和真实尺寸相等?
为什么需要响应式 UI?
说个题外话:在面试淘菜菜的时候真的会有点崩不住,他们问如何做好不同屏幕的适配,我说首先这是 UI 出图的问题,如果 UI 出的图是响应式的,那没问题,照着写,闭着眼都能适配。
但是如果设计图不是响应式的,使用 flutter_screenutil 可以做到和设计图高保真等比还原,但是如果做多平台就需要 UI 根据屏幕断点出不同平台的设计图。
面试官立即就打断我说他们的 UI 只会出一份图。我当场就沉默了,然后呢?也不说话了?是因为只有移动端用户,或者说贵公司 UI 太菜了,还是说都太菜了。菜就给我往下学 ⏬
首先 UI 的响应式设计是 UI 的责任
抛开国情不谈,因为国内的 UI 能做到设计的同时,UI 还是响应式的,这样的 UI 设计师很少很少,他们能把主题规范好,约定好,已经是不得了的了。
但即使如此,响应式 UI 设计也还是应该归于 UI 设计中,在设计图中去根据不同的尺寸,拖动验证不同的布局效果是很容易的。在不同的尺寸下,应该怎么调整元素个数,应该如何去布局元素,只有 UI 使用响应式的写法去实现了,UI 和开发之间的无效交流才会减少。
响应式的 UI 可以避免精度问题
早在 19 年我就有幸翻阅了一本 iOS 的 UI 设计规范,当时有个特别的点特别印象深刻:尺寸大小应该为 2 的整数次幂,或者 4 的倍数。因为这样做,在显示和计算上会较为友好。
💡 这其实是有点历史原因的,之前的 UI 在栅格化上做得并不是很好,锯齿化严重也是常态,所以使用可以被 2 整除的尺寸,一方面使用起来只有几个档位,方便调整;另一方面这样的尺寸可以在像素的栅格化上把小数除尽。
举个例子,在屏幕中间显示一个 300 宽度的卡片,和边距 16 的卡片,哪一个更响应式,无疑是后者,前者由于需要计算 300 相对与设计稿屏幕的宽度,后者只需要准确的执行 16 的边距就好,中间的卡片宽度随屏幕的宽度自动变化。
同样的例子,带有 Expanded 布局的 Row 组件,相比直接给定每个子组件尺寸导致精度问题的布局,更能适配不同的屏幕。因为 Row 会先放置固定大小的组件,剩余空间由 Expanded 去计算好传给子组件,原理和 Web 开发中的 flex 布局一样。
响应式布局是通用的规范
如果有 Web 开发经验的,应该会知道 Web 的屏幕是最多变的,但是设计起来也可以很规范,常见的 bootstrap 框架就提到了断点这个观点,指出了当我们去做 UI 适配的时候,需要根据不同的屏幕大小去做适配。同时 flex 布局也是 Web 布局中常用的响应式布局手段。
在设计工具中,响应式 UI 也没有那么遥远,去下载一份 Material Design 的 demo,对里面的组件自由的拉伸缩放,再对比一下自己通过输入尺寸大小拼凑在一起的 UI,找找参数里面哪里有差异。
怎么做响应式 UI
这里直接放一个谷歌大会的演讲,我相信下面的总结其实都可以不用看了,毕竟本实验室没有什么可补充的,但是我们还是通过从外到内、从整体到局部的顺序来梳理一下如何去做一个响应式的 UI,从而彻底告别使用 flutter_screenutil。
http://www.youtube.com/watch?v=LeK…
SafeArea
一个简单的组件,可以确保内部的 UI 不会因为愚蠢的设备圆角、前置挖孔摄像头、折叠屏链接脚、全面屏边框等原因而被意外的裁剪,将重要的内容,显示在“安全区”中。
屏幕断点
让 UI 根据不同的尺寸的窗口变化而变化,首先就要使用 MediaQuery.sizeOf(context); 和 LayoutBuilder() 来实现对窗口的宽度的获取,然后通过不同的屏幕断点,去构建不同情况下的 UI。
其中 LayoutBuilder 还能获取当前约束下的宽度,以实现页面中子区域的布局,比如 Drawer 的宽度,对话框的宽度,导航的宽度。
这里举了个例子,使用媒体查询获得窗口宽度之后,展示不同的 Dialog:

写出如此优雅的断点代码只需要三步:
- 抽象:找到全屏对话框和普通对话框中共同的属性,并将功能页面提取出来。
- 测量:思考应该使用窗口级别的宽度(MediaQuery),还是某个约束下的宽度(LayoutBuilder)。
- 分支:编写如上图所示的带有断点逻辑的代码。

GridView
熟悉了移动端的 ListView 布局之后,切换到 GridView 布局并适配到平板、桌面端,是一件十分自然的事,只需要根据情况使用不同的 gridDelegate 属性来设置布局方式,就能简单的适配。
这里一般使用 SliverGridDelegateWithMaxCrossAxisExtent(maxCrossAxisExtent: ) 方法来适配,传入一个期望的最大宽度,使其在任何屏幕上看到的子组件都自然清晰,GridView 会根据宽度计算出合适的一行里合适的列数。
Flex 布局,但是 Flutter 版
前面说过了尽量不要去写固定尺寸的几个元素加起来等于屏幕宽度,没有那么巧合的事情。在 Row/Column 中,善用 Expanded 去展开子组件占用剩余空间,善用 Flexible 去缩紧子组件,最后善用 Spacer 去占用空白,结合 MainAxisAlignment 的属性,你会发现布局是那样的自然。
只有部分组件是固定尺寸的
例如 Icon 一般默认 24,AppBar 和 BottomNavigationBar 高度为 56,这些是写在 MD 设计中的固定尺寸,但是一般不去修改。图片或许是固定尺寸的,但是一般也使用 AspectRatio 来固定宽高比。
我曾经也说过一个普遍的公理,因为有太多初学者容易因为这个问题而出错了。
当你去动态计算宽高的时候,可能是布局思路有问题了。
在大多数情况下,你的布局都不应该计算宽高,交给响应式布局,让组件通过自己的能力去得出自己的位置、约束、尺寸。
举一个遇到过的群友问题,他使用了 stack 布局包裹了应用栏和一个滚动布局,由于SliverAppBar 拉伸后的高度会变化,他想去动态的计算下方的滚动布局的组件起始位置。这个问题就连描述出来都是不可思议的,然后他问我,我应该如何去获取这个 AppBar 的高度,因为我想计算下方组件的高度。(原问题记不清了,但是这样的需求是不成立的)
最后,多看文档
最后补上关于 MD3 设计中,关于布局的文档,仔细学习:
最后的最后,响应式布局其实是一个很宽的话题,这里没法三言两语说完,只能先暂时在某些领域劝退使用这个库。任何觉得可能布局困难的需求,都可以发到评论区讨论,下一篇文章我们将根据几个案例来谈谈具体的实践。
来源:juejin.cn/post/7386947074640298038
聊聊四种实时通信技术:长轮询、短轮询、WebSocket 和 SSE
这篇文章,我们聊聊 四种实时通信技术:短轮询、长轮询、WebSocket 和 SSE 。
1 短轮询
浏览器 定时(如每秒)向服务器发送 HTTP 请求,服务器立即返回当前数据(无论是否有更新)。

- 优点:实现简单,兼容性极佳
- 缺点:高频请求浪费资源,实时性差(依赖轮询间隔)
- 延迟:高(取决于轮询频率)
- 适用场景:兼容性要求高,延迟不敏感的简单场景。
笔者职业生涯印象最深刻的短轮询应用场景是比分直播:

如图所示,用户进入比分直播界面,浏览器定时查询赛事信息(比分变动、黄红牌等),假如数据有变化,则重新渲染页面。
这种方式实现起来非常简单可靠,但是频繁的调用后端接口,会对后端性能会有影响(主要是 CPU)。同时,因为依赖轮询间隔,页面数据变化有延迟,用户体验并不算太好。
2 长轮询
浏览器发送 HTTP 请求后,服务器 挂起连接 直到数据更新或超时,返回响应后浏览器立即发起新请求。

- 优点:减少无效请求,比短轮询实时性更好
- 缺点:服务器需维护挂起连接,高并发时资源消耗大
- 延迟:中(取决于数据更新频率)
- 适用场景:需要较好实时性且无法用 WebSocket/SSE 的场景(如消息通知)
长轮询最常见的应用场景是:配置中心,我们耳熟能详的注册中心 Nacos 、阿波罗都是依赖长轮询机制。

客户端发起请求后,Nacos 服务端不会立即返回请求结果,而是将请求挂起等待一段时间,如果此段时间内服务端数据变更,立即响应客户端请求,若是一直无变化则等到指定的超时时间后响应请求,客户端重新发起长链接。
3 WebSocket
基于 TCP 的全双工协议,通过 HTTP 升级握手(Upgrade: websocket)建立持久连接,双向实时通信。 
- 优点:最低延迟,支持双向交互,节省带宽
- 缺点:实现复杂,需单独处理连接状态
- 延迟:极低
- 适用场景:聊天室、在线游戏、协同编辑等 高实时双向交互 需求
笔者曾经服务于北京一家电商公司,参与直播答题功能的研发。

直播答题整体架构见下图:

Netty TCP 网关的技术选型是:Netty、ProtoBuf、WebSocket ,选择 WebSocket 是因为它支持双向实时通信,同时 Netty 内置了 WebSocket 实现类,工程实现起来相对简单。
4 Server Send Event(SSE)
基于 HTTP 协议,服务器可 主动推送 数据流(如Content-Type: text/event-stream),浏览器通过EventSource API 监听。

- 优点:原生支持断线重连,轻量级(HTTP协议)
- 缺点:不支持浏览器向服务器发送数据
- 延迟:低(服务器可即时推送)
- 适用场景:股票行情、实时日志等 服务器单向推送 需求。
SSE 最经典的应用场景是 : DeepSeek web 聊天界面 ,如图所示:

当在 DeepSeek 对话框发送消息后,浏览器会发送一个 HTTP 请求 ,服务端会通过 SSE 方式将数据返回到浏览器。

5 总结
| 特性 | 短轮询 | 长轮询 | SSE | WebSocket |
|---|---|---|---|---|
| 通信方向 | 浏览器→服务器 | 浏览器→服务器 | 服务器→浏览器 | 双向通信 |
| 协议 | HTTP | HTTP | HTTP | WebSocket(基于TCP) |
| 实时性 | 低 | 中 | 高 | 极高 |
| 资源消耗 | 高(频繁请求) | 中(挂起连接) | 低 | 低(长连接) |
选择建议:
- 需要 简单兼容性 → 短轮询
- 需要 中等实时性 → 长轮询
- 只需 服务器推送 → SSE
- 需要 全双工实时交互 → WebSocket
来源:juejin.cn/post/7496375493329174591
做Docx预览,一定要做这个神库!!
来源:沉浸式趣谈
只需几行代码,你就能在浏览器中完美预览 Word 文档,甚至连表格样式、页眉页脚都原汁原味地呈现出来。
接下来,给大家分享两个 Docx 预览的库:
docx-preview VS mammoth
docx-preview和mammoth是目前最流行的两个 Word 文档预览库,它们各有特色且适用于不同场景。
docx-preview:还原度爆表的选择
安装简单:
npm install docx-preview
基础用法:
import { renderAsync } from 'docx-preview';
// 获取到docx文件的blob或ArrayBuffer后
renderAsync(docData, document.getElementById('container')).then(() => console.log('文档渲染完成!'));
试了试后,这个库渲染出来的效果简直和 Office 打开的一模一样!连段落格式、表格样式、甚至是分页效果,都完美呈现。
mammoth:简洁至上的转换器
mammoth 的思路完全不同,它把 Word 文档转成干净的 HTML:
npm install mammoth
使用也很简单:
import mammoth from 'mammoth';
mammoth.convertToHtml({ arrayBuffer: docxBuffer }).then(result => {
document.getElementById('container').innerHTML = result.value;
console.log('转换成功,但有些警告:', result.messages);
});
转换出来的 HTML 非常干净,只保留了文档的语义结构。
比如,Word 中的"标题 1"样式会变成 HTML 中的
标签。
哪个更适合你?
场景一:做了个简易 Word 预览器
要实现在线预览 Word 文档,且跟 "Word" 长得一模一样。
首选docx-preview:
import { renderAsync } from'docx-preview';
async functionpreviewDocx(fileUrl) {
try {
// 获取文件
const response = awaitfetch(fileUrl);
const docxBlob = await response.blob();
// 渲染到页面上
const container = document.getElementById('docx-container');
awaitrenderAsync(docxBlob, container, null, {
className: 'docx-viewer',
inWrapper: true,
breakPages: true,
renderHeaders: true,
renderFooters: true,
});
console.log('文档渲染成功!');
} catch (error) {
console.error('渲染文档时出错:', error);
}
}
效果很赞!文档分页显示,目录、页眉页脚、表格边框样式都完美呈现。
不过也有些小坑:
- 文档特别大时,渲染速度会变慢
- 一些复杂的 Word 功能可能显示不完美
场景二:做内容编辑系统
需要让用户上传 Word 文档,然后提取内容进行编辑。
选择mammoth:
import mammoth from'mammoth';
async functionextractContent(file) {
try {
// 读取文件
const arrayBuffer = await file.arrayBuffer();
// 自定义样式映射
const options = {
styleMap: ["p[style-name='注意事项'] => div.alert-warning", "p[style-name='重要提示'] => div.alert-danger"],
};
const result = await mammoth.convertToHtml({ arrayBuffer }, options);
document.getElementById('content').innerHTML = result.value;
if (result.messages.length > 0) {
console.warn('转换有些小问题:', result.messages);
}
} catch (error) {
console.error('转换文档失败:', error);
}
}
mammoth 的优点在这个场景下完全发挥出来:
- 1. 语义化 HTML:生成干净的 HTML 结构
- 2. 样式映射:可以自定义 Word 样式到 HTML 元素的映射规则
- 3. 轻量转换:处理速度非常快
进阶技巧
docx-preview 的进阶配置
renderAsync(docxBlob, container, styleContainer, {
className: 'custom-docx', // 自定义CSS类名前缀
inWrapper: true, // 是否使用包装容器
ignoreWidth: false, // 是否忽略页面宽度
ignoreHeight: false, // 是否忽略页面高度
breakPages: true, // 是否分页显示
renderHeaders: true, // 是否显示页眉
renderFooters: true, // 是否显示页脚
renderFootnotes: true, // 是否显示脚注
renderEndnotes: true, // 是否显示尾注
renderComments: true, // 是否显示评论
useBase64URL: false, // 使用Base64还是ObjectURL处理资源
});
超实用技巧:如果只想把文档渲染成一整页(不分页),只需设置breakPages: false!
mammoth 的自定义图片处理
默认情况下,mammoth 会把图片转成 base64 嵌入 HTML。
在大型文档中,这会导致 HTML 特别大。
更好的方案:
const options = {
convertImage: mammoth.images.imgElement(function (image) {
return image.readAsArrayBuffer().then(function (imageBuffer) {
// 创建blob URL而不是base64
const blob = newBlob([imageBuffer], { type: image.contentType });
const url = URL.createObjectURL(blob);
return {
src: url,
alt: '文档图片',
};
});
}),
};
mammoth.convertToHtml({ arrayBuffer: docxBuffer }, options).then(/* ... */);
这样一来,图片以 Blob URL 形式加载,页面性能显著提升!
其他方案对比
说实话,在选择这两个库之前,也有其他解决方案:
微软 Office Online 在线预览
利用微软官方提供的 Office Online Server 或 Microsoft 365 的在线服务,通过嵌入 WebView 或
优点
- • 格式高度还原:支持复杂排版、图表、公式等。
- • 无需本地依赖:纯浏览器端实现。
- • 官方维护:兼容性最好。
折腾一圈,还是docx-preview和mammoth这俩兄弟最实用。
它们提供了轻量级的解决方案,仅需几十 KB 就能搞定 Word 预览问题,而且不需要依赖外部服务,完全可以在前端实现。
来源:juejin.cn/post/7493733975779917861
记一下iOS App无法访问到网络
记一下iOS App无法访问到网络
最近遇到一件十分诡异的事情,那就是按照平时进行Flutter Debug运行我们项目的时候,日志全部都在报错,统一指向了当前App无法访问到网络。
最开始我还没有当回事,觉得这小问题很好解决。
没有给App授权网络访问?
我最开始是怀疑我没给当前的App进行授权,但是当我在设置看了之后发现已经授权移动网络和Wifi,对于开发,正常的授权还是不会忘记的,这个原因排除?
手机链接的Wifi的问题?
因为手机链接是公司的内网,其次我将原因怪罪在我们公司的内网身上,随后我关闭了Wifi进行重启,问题依然没有得到解决。
手机开代理的问题?
因为经常开代理去一些网站,所以我怀疑是我手机开了代理。看了一下没开,我果断的重置了手机的网络,发现重置之后问题依然存在。
难道我电脑开启代理问题?
在思考这个问题的时候,我都觉得不可能,手机又不访问我电脑的网络,怎么可能。为了找到问题的原因,我还是关掉了软件,重启App发现还是不行?
难道需要需要重装App?
到这个时候我即将崩溃,我都怀疑自己了。删了手机上的APP,之后重新运行授权,还是提示访问不到网络。
难道手机需要重启?
万能的重启大法,随后我重启已经运行不知道多少天的手机。果然,重启大法在我这里无效,还是不行。
难道工程配置有问题?
为了验证这个问题,我找来测试机,进行安装,发现测试机竟然一切正常。
千呼万唤始出来
看到测试机可以,我的手机不行,当时我都怀疑这个世界了是否存在灵异了。后来冷静的分析了一下测试机和我的手机的区别,一样访问公司的内网。一样工程配置运行的,还有什么不一样的因素引起测试机和我的手机的区别?
并且在几天之前还是可以的,这几天我一直做新需求,都没有用我们工程,这几天对接才运行发现不能访问网络了?
在之前可以和现在不可以之间的时间,这个手机发生了什么?对于测试机上面只有几个竞品和我们自己的APP,我的手机运行了一堆的APP。
运行一堆但是又有什么影响了?等等!后来我想到了我的手机还运行一堆当时为了做需求找的插件运行一堆的Example App。
它们的Bundle ID都不一样,怎么可能影响。虽然心里面这样猜测,但是还是行动起来进行删掉。都没打算能修复,但是随着最后一个APP删除之后,我们的APP的日志打开了正常的流程,意味着可以访问网络了。
因为APP做了没网就无法继续的逻辑,检测有网就继续执行的操作,所以到此为止,我验证出运行其他Example App影响我们目前APP的访问网络。
这个结论是为了什么,目前没有任何的文献找到原因,可能是苹果不允许开发者运行多少没有创建证书的APP运行手机访问网络吧。
来源:juejin.cn/post/7503532008497840147
产品小姐姐:地图(谷歌)选点,我还不能自己点?
💡 背景
最近在做海外项目,需要让用户选择一个实际地点——比如设置店铺位置、收货地址、活动举办地等。
我:不就是 uni.getLocation(object) 嘛,可惜海外项目用不了高德地图和百度地图,只能转向谷歌地图。

在@googlemaps/js-api-loader和vue3-google-map一顿折磨之后,不知道是不是使用方式错了,谷歌地图只在h5上显示,真机(包括自定义基座)都显示不了地图。无奈,只能转向WebView,至此,开始手撕谷歌地图: 地图选点 + 搜索地址 + 点击地图选点 + 经纬度回传

🎬 场景设定:选房子
某天产品说:“用户能搜地址,也能点地图,最后把这些地点存起来显示在地图。”
我听着简单,于是点开地图,灵光一闪:这不就是选房的逻辑吗?
- 用户可以搜地段(搜索框)
- 也可以瞎逛看到喜欢的(点击地图)
- 最后点个确定,告诉中介(确认按钮)
我:“你疯啦?这是太平洋中间。”
产品:“不是,这是用户自由。”
🧱 核心结构分析
📦 页面骨架
<div id="map"></div>
<div id="overlay-controls">
<input id="search-input" ... />
<div id="confirm-btn">确定</div>
</div>
<script type="text/javascript" src="https://js.cdn.aliyun.dcloud.net.cn/dev/uni-app/uni.webview.1.5.2.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=你的key&callback=initMap" async defer></script>
<script>
这是一个标准的地图 + 控制浮层结构。我们用一个 #map 占据全屏,再通过 position: absolute 让搜索框和按钮漂浮在上面。(ps:注意必须引入uni.webview才能进行通讯)
🧠 方法逐个看
1. initMap:地图的灵魂觉醒
function initMap() { ... }
- 调用时机:Google Maps 的
callback会自动触发 - 作用:初始化地图、绑定事件、准备控件
2. 获取定位:我在哪我是谁
if (navigator.geolocation) {
navigator.geolocation.getCurrentPosition(...)
}
- 成功:把你真实的位置显示出来
- 失败:退而求其次用旧金山
3. 搜索地址:让用户自己找方向
const autocomplete = new google.maps.places.Autocomplete(input);
autocomplete.addListener("place_changed", () => {
const place = autocomplete.getPlace();
...
});
- 功能:用 Google 提供的地址搜索建议
- 高级点:可以定位到建筑物级别的精度
- 产品:用户脑子里比你更清楚他想去哪

4. 点地图选点:给随性的人自由
map.addListener("click", (e) => {
const lat = e.latLng.lat();
const lng = e.latLng.lng();
...
});
- 功能:用户随手一点,就能选中那个点
- 技术点:用
Geocoder反解析经纬度 ➜ 地址 - 实用性:解决“我不知道地址叫什么”的痛点,且可切换卫星实景图像选点
就像: 当年你去面试,不知道公司叫什么,只知道“拐角有个便利店”。

5. setLocation:标记我心之所向
function setLocation(lat, lng, address) {
selectedLatLng = { lat, lng };
selectedAddress = address;
...
}
- 核心职责:更新选择结果,设置 marker
- 重复点击自动替换 marker,保持页面整洁
- UI 响应式体验的小心机,细节满满
哲理时间: 你不能同时站在两个地方,虽然marker可以,但是此处marker不做分布点,只作为当前点击地点。
6. confirm-btn:确定这就是你的人生目标吗?
document.getElementById("confirm-btn").addEventListener("click", () => {
if (!selectedLatLng) {
alert("请先选择地点");
return;
}
uni.postMessage({ data: { ... } });
uni.navigateBack({ delta: 1 });
});
- 检查用户是否真的选点了
- 用
uni.postMessage把选中的地址、经纬度送回 uniapp 主体页面 - 然后自动关闭 WebView,返回主流程
产品视角: 用户选完东西,你就别啰嗦了,自己退出。

可查看卫星实景图像,点击地图选点

点击地图拿到地点数据就可以继续业务处理啦~
🎁 彩蛋动画:CSS Loading
<div class="loader" id="loader"></div>
@keyframes spin {
0% { transform: rotate(0deg); }
100% { transform: rotate(360deg); }
}
加载的时候出现个小旋转圈圈,用户等得不烦,体验感 +1。
这就像爱情:等一等,说不定就没了。
✅ 功能总结
| 功能 | 实现方式 |
|---|---|
| 地图显示 | Google Maps JS SDK |
| 获取当前位置 | navigator.geolocation |
| 搜索地点 | google.maps.places.Autocomplete |
| 点击地图选点 | map.addListener("click") + Geocoder |
| 回传经纬度 | uni.postMessage |
| 用户体验优化 | marker 替换、加载动画 |
🧘 写在最后
这个地图选点组件,看似只是点点点,但背后涉及用户体验、API 使用、移动端交互的多种协作。本文只写了大概方法思路,具体实现看具体业务需求。
下次再见!🌈

来源:juejin.cn/post/7501649258279845939
Vue动态弹窗(Dialog)新境界:告别繁琐,拥抱优雅!🎉
写在开头
嘿,各位好呀!😀
今是2025年04月30日,明天就是五一假期了,激动的心从早上就一直没有沉静过,午休的时候闭着眼半小时硬是没睡着,哎,这班是一点也上不下去。

好!说回正题,本次要分享的是关于如何在Vue中比较优雅的调用弹窗的过程,请诸君按需食用哈。
需求背景
最近,小编在捣鼓一个和低代码拖动交互类似的业务,说到低代码,大家肯定都不陌生吧❓像低代码表单、低代码图表平台等,用户可以通过简单的拖拽操作,像搭积木一样,快速"拼"出一个功能完善的表单页面,或者酷炫的数据可视化大屏。
而在这些低代码平台中,配置组件属性的交互方式通常有两种主流玩法:
其一,三栏式布局,左边是组件列表,中间是画布/预览区,右边是属性配置面板。选中中间画布的某个组件,右侧面板就自动显示它的配置项,如下:

其二,弹窗式配置,同样从左侧拖拽组件到画布,但选中组件后,通常会看到一个"设置"或"编辑"按钮。点击这个按钮,Duang~ ✨ 弹出一个专门的配置窗口 (Dialog),让你在里面集中完成所有设置。

这两种交互各有千秋,不评判好坏哈,反正合适自己业务场景的才是最好的。
然,今天咱们重点聚焦第二种:点击按钮弹出 Dialog 进行配置的场景。
这种方式在很多场景下也很常见,比如配置项特别多、需要更沉浸式的设置体验时。
但问题也随之而来:如果平台支持的组件越来越多,这里咱们假设是低代码图表场景,如柱状图、折线图、饼图、地图、文本、图片...等等,每个组件都需要一个独立的配置弹窗...🤔,那么,我们应该如何设计一套优雅、可扩展、易维护的代码架构来管理这些层出不穷的 Dialog 呢?🤔
结构设计
万事开头难,尤其是在做一些稍微带点设计或架构意味的事情时,切忌盲目上手。心里得先有个谱,想清楚大致方向,否则等到后面业务需求像潮水般涌来,迭代压力陡增时,你就会深刻体会到早期设计不佳带来的痛苦了(别问小编是怎么知道的...😭)。
当然,如果你已是经验丰富的老司机,那就当我没说哈。😂
面对"组件点击按钮弹出配置框"这个需求,最开始,最直观的想法可能就是:一个组件配一个专属的 Dialog.vue 文件,相互独立,互不影响,挺好不是❓
比如,咱当前有柱状图、折线图、饼图三个组件,那么它们的目录结构可能是这样子的:
src/
├── components/
│ ├── BarChart/
│ │ ├── Drag.vue # 组件的拖动视图
│ │ ├── Dialog.vue # 组件的配置弹窗
│ │ └── index.js # 组件的Model
│ ├── LineChart/
│ │ ├── Drag.vue # 组件的拖动视图
│ │ ├── Dialog.vue # 组件的配置弹窗
│ │ └── index.js # 组件的Model
│ ├── PieChart/
│ │ ├── Drag.vue # 组件的拖动视图
│ │ ├── Dialog.vue # 组件的配置弹窗
│ │ └── index.js # 组件的Model
└── App.vue # 入口
咱们不详说其他文件中的代码情况,仅关注每个组件中 Dialog.vue 文件的代码要如何写❓
可能大概是这样:
<template>
<el-dialog :modelValue="modelValue">
<div>内容....</div>
</el-dialog>
</template>
<script>
defineProps({
modelValue: Boolean,
});
</script>
小编这里使用 Element-Plus 的
el-dialog组件作为案例演示。
然后,为了在页面上渲染这些不同组件的 Dialog.vue,最笨的方法可能是在父组件里面用 v-if/v-else-if 来判断, 或者高级一点使用 <component :is="currentDialog"> 再配合一堆 import 来动态加载渲染。父组件需要维护哪个弹窗应该显示的状态,以及负责传递数据和接收结果,逻辑很快变得复杂且难以维护。
在项目初期,组件类型少的时候,这种方式确实能跑通,没有问题❗
你就说它能不能跑吧,就算它不能跑,你能跑不就行😋,项目和你总有一个能跑的。
但随着业务不断迭代,支持的组件类型越来越多,这种"各自为战"的模式很快就暴露出了诸多问题,其中有两个问题比较尖锐:
- 缺乏统一控制📝:如果想给所有弹窗统一调整弹窗配置、或者添加一个水印、或者调整一下默认样式、或者增加一个通用的"重置"按钮,怎么办?只能去每个
Dialog.vue文件里手动修改,效率低下不说,还极易遗漏或出错。 - 代码冗余严重📜:每个
Dialog.vue文件里,关于弹窗的显示/隐藏逻辑、确认/取消按钮的处理、与 Element Plus (或其他 UI 库) ElDialog 组件的交互代码,几乎都是大同小异的模板代码,写到后面简直是精神污染。(这里手动Q一下我同事🔨)
总之,随着项目的迭代,这种最初看似简单的结构,维护成本越来越高,每次增加或修改一个组件的配置弹窗都成了一种"折磨"。
那么,要如何重新来设计这个架构呢❓
小编采用的是基于动态创建和静态方法关联的架构,其架构的核心理念就是:将通用的弹窗逻辑(创建、销毁、交互)抽离出来,让每个组件的配置面板(Panel)只专注于自身的配置项 UI 视图和数据处理逻辑 ,从而实现高内聚、低耦合、易扩展的目标。
先来瞅瞅目录结构的最终情况👇:
src/
├── components/
│ ├── BarChart/
│ │ ├── Dialog/
│ │ | ├── index.js # Dialog 组件的入口
│ │ | ├── Panel.vue # Dialog 组件UI视图
│ │ ├── Drag.vue
│ │ └── index.js
│ ├── LineChart/
│ │ ├── Dialog/
│ │ | ├── index.js # Dialog 组件的入口
│ │ | ├── Panel.vue # Dialog 组件UI视图
│ │ ├── Drag.vue
│ │ └── index.js
│ ├── PieChart/
│ │ ├── Dialog/
│ │ | ├── index.js # Dialog 组件的入口
│ │ | ├── Panel.vue # Dialog 组件UI视图
│ │ ├── Drag.vue
│ │ └── index.js
│ ├── BaseDialog.vue
│ └── index.js
├── utils/
│ ├── BaseControl.js
│ └── dialog.js
└── App.vue # 入口
关键变动是 Dialog.vue 变成了 Dialog/index.js 与 Dialog/Panel.vue,它们俩的作用:
Panel.vue:负责"长什么样"和"填什么数据" 。index.js:负责"怎么被调用"和"调用时带什么默认配置",并将Panel.vue包装后提供给外部使用。
具体实现
接下来,咱们就详细拆解一下这套新架构的设计具体代码实现过程。👇
但为了更好的讲述关键代码的实现,咱们不管拖动那块逻辑,仅通过点击按钮简单的来模拟,效果如下:

本次小编是新建了一个 Vue3 的项目并且安装了 ElementPlus 进行了全局引入,基础项目环境就这样。
然后,从入口出发(App.vue):
<template>
<el-button type="primary" v-for="type in componentList" :key="type" @click="openDialog(type)">
{{ type }}
</el-button>
</template>
<script setup>
import { ElButton } from "element-plus";
import { componentMap } from "./components"; // 引入组件映射
/** @name 实例化所有组件 **/
const componentInstanceMap = Object.keys(componentMap).reduce((pre, key) => {
const instance = new componentMap[key]();
pre[key] = instance;
return pre;
}, {});
/** @name 打开组件弹窗 **/
async function openDialog(type) {
const component = await componentMap[type].DialogComponent.create(
{ type },
componentInstanceMap[type]
);
console.log("component", component);
}
</script>
统一管理所有组件导出文件(components/index.js):
import PieChart from "./PieChart";
import BarChart from "./BarChart";
import LineChart from "./LineChart";
export const componentMap = {
[PieChart.type]: PieChart,
[BarChart.type]: BarChart,
[LineChart.type]: LineChart,
};
/** @typedef { keyof componentMap } ComponentType */
组件入口文件(components/PieChart/index.js):
import BaseControl from "../../utils/BaseControl";
import Drag from "./Drag.vue";
import Dialog from "./Dialog";
class Component extends BaseControl {
static type = "barChart";
label = "柱状图";
icon = "bar-chart";
getDialogDataDefault() {
return {
title: { text: "柱状图" },
tooltip: { trigger: "axis" },
};
}
static DragComponent = Drag;
static DialogComponent = Dialog;
}
export default Component;
该文件用于集中管理组件的核心数据结构与统一的业务逻辑。
咱们以柱状图为例哈。📊
所有组件的基类文件(utils/BaseControl.js):
/** @typedef { import('vue').Component|import('vue').ConcreteComponent } VueConstructor */
export default class BaseControl {
/** @name 组件唯一标识 **/
type = "baseControl";
/** @name 组件label **/
label = "未知组件";
/** @name 组件高度 **/
height = "110px";
constructor() {
if (this.constructor.type) {
this.type = this.constructor.type;
}
}
/**
* @name 拖动组件
* @type { VueConstructor | null }
*/
static DragComponent = null;
/**
* @name 弹窗组件
* @type { VueConstructor | null }
*/
static DialogComponent = null;
dialog = {};
/**
* @name 用于获取Dialog组件的默认数据
* @returns {Dialog} 默认数据
*/
getDialogDataDefault() {
return {};
}
}
该文件是所有组件的"基石"🏛️,每个具体的图表组件都继承自 BaseControl 类,并在该基础上定义自己特有的信息和逻辑。
组件的拖动视图组件(Drag.vue),这个可以先随便整一个,暂时用不上:
<template>
<div>某某组件的拖动视图组件</div>
</template>
Dialog 组件的入口文件(components/BarChart/Dialog/index.js):
import Panel from "./Panel.vue"; // Dialog 的 UI 视图组件
import { dialogWithComponent } from "../../../utils/dialog.js";
/**
* @name 静态方法,渲染Dialog组件,并且可在此处自定义dialog组件的props
* @param {{ component: object, instance: object, componentDataAll: Array<object> }} contentProps 组件数据
* @returns {Promise<any>}
*/
Panel.create = async (panelProps = {}) => {
return dialogWithComponent((render) => render(Panel, panelProps), {
title: panelProps.label,
width: "400px",
});
};
export default Panel;
该文件导入真正的 UI 视图面板(Panel.vue),然后给组件挂载了一个静态 create 方法。这个 create 方法用于动态创建 Dialog 组件,它内部调用 dialogWithComponent 方法,并可以在此处预设一些该 Dialog 组件特有的配置(如默认标题、宽度)。
Dialog 组件的 Panel.vue 文件:
<template>
<h1>柱状图的配置</h1>
</template>
<script setup>
defineExpose({
async getValue() {
await new Promise((resolve) => {
setTimeout(() => {
resolve();
}, 1000);
});
return { type: "barChart" };
}
})
</script>
该组件仅放置柱状图特有的配置信息,并且不需要管弹窗自身的逻辑行为,很干净很专注😎。还有,它内部必须对外提供一个 getValue 方法❗用于在用户点击确认时调用,以获取最终的配置数据。
核心工具函数(utils/dialog.js)文件 :
import { createApp, h, ref } from "vue";
import { ElDialog, ElMessage } from "element-plus";
import BaseDialog from "../components/BaseDialog.vue";
/**
* @name 协助统一创建dialog组件,并且进行挂载、销毁、上报
* @param {import('vue').Component|Function} ContentComponent 渲染的组件
* @param {import('element-plus').dialogProps} dialogProps dialog组件的props
* @returns {Promise<any>}
*/
export function dialogWithComponent(ContentComponent, dialogProps = {}) {
return new Promise((resolve) => {
/** @name 挂载容器 */
const container = document.createElement("div");
document.body.appendChild(container);
/** @name dialog组件实例 */
let vm = null;
/** @name dialog组件loading */
let loading = ref(false);
const dialogRef = ref(null);
const contentRef = ref(null);
const unmount = () => {
if (vm) {
vm.unmount();
vm = null;
}
document.body.removeChild(container);
};
const confirm = async () => {
let result = {};
const instance = contentRef.value;
if (instance && instance.getValue) {
loading.value = true;
try {
result = await instance.getValue();
} catch (error) {
typeof error === "string" && ElMessage.error(error);
loading.value = false;
return;
}
loading.value = false;
}
unmount();
resolve(result);
};
// 创建dialog组件实例
vm = createApp({
render() {
return h(
BaseDialog,
{
ref: dialogRef,
modelValue: true,
loading: loading.value,
onDialogConfirm() {
confirm();
},
onDialogCancel() {
unmount();
},
...dialogProps,
},
{
default: () => createVNode(h, ContentComponent, contentRef),
},
);
},
});
// 挂载dialog组件
vm.mount(container);
});
}
/**
* @name 创建一个 VNode 实例
* @param {import('vue').CreateElement} h Vue 的 createElement 函数
* @param {import('vue').Component|Function} Component 渲染的组件或渲染函数
* @param {string} key VNode 的 key
* @param {import('vue').Ref} ref 组件引用
* @returns {import('vue').VNode|null} 返回 VNode 实例或 null
*/
export function createVNode(h, Component, ref = null) {
if (!Component) return null;
/** @type { import('vue').VNode } */
let instance = null;
/** @name 升级h函数,统一混入ref **/
const render = (type, props = {}, children) => {
return h(
type,
{
...props,
ref: (el) => {
if (ref) ref.value = el;
},
},
children,
);
};
if (typeof Component === "function") {
instance = Component(render);
} else {
instance = render(Component);
}
return instance;
}
dialogWithComponent 这个函数是整个架构的核心!它的职责就像一个专业的 Dialog "召唤师":
脑袋突然蹦出一句话:"去吧,就决定是你了,皮卡丘(柱状图)"🎯
- 动态创建:不再需要在模板里预先写好
<el-dialog>。dialogWithComponent会在你需要的时候,通过createApp和h函数,动态地创建一个包含<el-dialog>和你的内容组件的 Vue 应用实例。 - 挂载与销毁:它负责将创建的 Dialog 实例挂载到
document.body上,并在 Dialog 关闭(确认、取消或点击遮罩层)后,优雅地将其从 DOM 中移除并销毁 Vue 实例,避免内存泄漏。 - Promise 驱动:调用
dialogWithComponent会返回一个 Promise。当用户点击"确认"并成功获取数据后,Promise 会调用 resolve 并返回数据;如果用户点击"取消"或"关闭",Promise 会调用 reject 。这使得异步处理 Dialog 结果变得异常简洁,并且支持异步。 - 配置注入:你可以轻松地向
dialogWithComponent传递<el-dialog>的各种props,实现 Dialog 的定制化。
createVNode 这个函数是 Vue 中 h 函数的升级版本,它主要是帮忙做内容的渲染🎩,它有两个小小的特点:
- 组件/函数通吃:你可以直接传递一个 Vue 组件 (
.vue文件或 JS/TS 对象) 给它,它会用h函数渲染这个组件。你还可以传递一个渲染函数!能让你在运行时动态决定渲染什么内容,简直不要太方便!是吧是吧。🤩 Ref传递:它巧妙地集中处理了ref,使得dialogWithComponent函数可以获取到内容组件的实例 (contentRef.value),从而能够调用内容组件暴露的方法(getValue),非常关键的一点。⏰
基础的 Dialog 组件文件(components/BaseDialog.vue):
<template>
<el-dialog v-bind="dialogAttrs">
<slot></slot>
<template v-if="showFooter" #footer>
<span>
<template v-if="!$slots.footer">
<el-button @click="handleCancel">取消</el-button>
<el-button type="primary" :loading="loading" @click="handleConfirm">确定</el-button>
</template>
<slot v-else name="footer"></slot>
</span>
</template>
</el-dialog>
</template>
<script setup>
import { useAttrs, computed } from "vue";
import { ElDialog, ElButton } from "element-plus";
defineProps({
showFooter: {
type: Boolean,
default: true,
},
loading: {
type: Boolean,
default: false,
}
});
const emit = defineEmits(["dialogCancel", "dialogConfirm"]);
const attrs = useAttrs();
const dialogAttrs = computed(() => ({
...attrs,
}));
function handleCancel() {
emit("dialogCancel");
}
function handleConfirm() {
emit("dialogConfirm");
}
</script>
那么,整个核心代码的实现过程大概就是如此了。不知道你看完这部分的拆解,是否有了新的收获呢?😋
当然啦,在实际的业务场景中,代码的组织和细节处理会更加复杂,比如会涉及到更精细的状态管理、错误处理、权限控制、以及各种边界情况的兼容等等。这里为了突出咱们动态创建 Dialog 架构的核心思想,小编仅仅是把最关键的脉络拎了出来,并进行了一定程度的精简。
总结
总而言之,言而总之,这次架构的演进,给小编最大的感受就是🏗️从"各自为战"到"统一调度"。
告别了维护繁琐、数量庞大的单个 Dialog.vue 文件,转而拥抱了基于 createApp 和 h 函数的动态创建方式。
这种新模式下,基础 Dialog、配置面板 ( Panel.vue )、以及调用逻辑各司其职,实现了真正的高内聚、低耦合。最终使得整个项目结构更加清晰、代码更加健壮,也极大地提升了后续的可维护性。希望这套方案能给你带来一些启发!
最后,如果你有任何疑问或者更好的想法,随时欢迎交流哦!👇
至此,本篇文章就写完啦,撒花撒花。

来源:juejin.cn/post/7498737799204093978
用canvas实现一个头像上的间断式的能量条
今天遇到一个很有意思的面试题,面试官给我一道题目,要我实现之前它们公司之前写的一个组件。

首先我介绍下这道题,首先我是先想到用flex布局来写头像分布,因为grid布局不能实现头像最后一排不能居中的效果。
然后这道题的重点来了,我一开始以为它头像上的边框是死的,是张贴图。然后我去问面试官,他说是一个能量条,能根据投票的数量进行改变。我脑袋有点懵,问ai也没结果,生成的非常垃圾,然后就开始思考怎么才能实现。首先想到的是echats,但没有找到合适的,我就开始想echats是用canvas写的,我就想用canvas写下,在bilibili上看了下canvas的使用方法,于是就想到了这道题的解法。这是我的成果。

我就不做过多的讲解关于canvas的使用方法,我只在我的演示代码注释中讲每条代码的作用,和使用方法。不会的话,可以去看看bilibili,然后做个笔记,然后就印象深刻了。
代码讲解
这里是初步实现的代码,写出了大概的轮廓方便理解。完整代码在最后面。
具体的代码讲解就写在注释中了。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<canvas id="canvas" width="600" height="600" backgroud></canvas>
<script>
function animate() {
var canvas = document.getElementById('canvas');//找到canvas
var ctx = canvas.getContext('2d');//读取canvas的上下文,进行修改,就能实现对canvas的绘画
ctx.translate(canvas.width / 2, canvas.height / 2);//这个是将canvas的坐标轴移到中间
ctx.rotate(-Math.PI / 2);//这个是将坐标轴反向转动90度
ctx.strokeStyle = 'rgb(144, 211, 205)';//设置画笔的颜色
ctx.lineWidth = 20; // 这里是设置画笔的宽度,也就是能量条的宽度
ctx.lineCap = "butt"; //这里设置画笔结束的位置是圆的直的还是弯的
for (let i = 0; i < 17; i++) {//这里17表示要绘制17段线,到时候这里循环的次数会传过来在我后面的成品中。
ctx.beginPath();//这里开始绘制路径
// 绘制小段圆弧 (角度改为弧度制)
ctx.arc(0, 0, 100, -Math.PI / 34, Math.PI / 34, false);//前两个位置是圆心,第三个是半径,第四个是开始角度,第五个是结束角度,第六个是是否逆时针
ctx.stroke();//这个表填充绘画的轨迹
// 旋转到下一个位置
ctx.rotate(Math.PI / 16);//这里坐标轴顺时针移动一定角度,如果想要格子更多就设的更小,上面画线的角度也要调小
ctx.closePath()//结束绘制
}
}
animate();
</script>
</body>
</html>

成品代码
最后的成品我是用vue写的,没有特别去封装,毕竟只是面试题。
<template>
<div class="grid-container">
<div class="member-card" v-for="(member, index) in members" :key="index">
<canvas :id="'' + index" width="150" height="150"></canvas>
<div class="circle">
<img :src="member.avatar" alt="avatar" class="avatar" />
</div>
</div>
</div>
</template>
<script setup>
import { onMounted } from 'vue';
const members = [
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 10 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 2 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 18 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 20 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 1 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 20 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 20 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 20 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 20 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 1 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 31 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 1 },
{ name: '用户A', avatar: 'https://img0.baidu.com/it/u=600722015,3838115472&fm=253&fmt=auto&app=138&f=JPEG?w=500&h=750', numbers: 1 },
];
onMounted(() => {
members.forEach((member, index) => {
drawEnergyBar(index, member.numbers); // 使用member.numbers作为参数
});
});
function drawEnergyBar(index, count) {
const canvas = document.getElementById(`canvas-${index}`);
const ctx = canvas.getContext('2d');
// 重置画布
ctx.clearRect(0, 0, canvas.width, canvas.height);
// 绘制设置
ctx.translate(canvas.width / 2, canvas.height / 2);
ctx.rotate(-Math.PI / 2);
ctx.strokeStyle = 'rgb(144, 211, 205)';
ctx.lineWidth = 60;
ctx.lineCap = "butt";
// 根据传入的count值绘制线段
for (let i = 0; i < count; i++) {
ctx.beginPath();
ctx.arc(0, 0, 44, -Math.PI / 36, Math.PI / 36, false);
ctx.stroke();
ctx.rotate(Math.PI / 16);
}
}
</script>
<style scoped>
/* 修改canvas样式 */
canvas {
position: absolute;
width: 100%;
height: 100%;
top: 0;
left: 0;
z-index: 1;
/* 作为背景层 */
}
.member-card {
position: relative;
width: 150px;
height: 150px;
/* 添加固定高度 */
display: flex;
justify-content: center;
align-items: center;
transition: transform 0.3s ease;
border: rgb(144, 211, 205) solid 2px;
border-radius: 50%;
background-color: black;
overflow: hidden;
}
.circle {
position: relative;
border: 2px solid black;
width: 100px;
height: 100px;
border-radius: 50%;
overflow: hidden;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
z-index: 2;
/* 确保在画布上方 */
margin: 0;
/* 移除外边距 */
}
.grid-container {
height: 100%;
width: 100%;
display: flex;
flex-wrap: wrap;
justify-content: center;
gap: 30px;
padding: 30px;
max-width: calc(150px * 6 + 30px * 5);
margin: 0 auto;
background: url(https://pic.nximg.cn/file/20230303/33857552_140701783106_2.jpg);
background-size: cover;
background-position: center;
background-repeat: no-repeat;
background-attachment: fixed;
}
.member-card {
position: relative;
width: 150px;
display: flex;
justify-content: center;
align-items: center;
transition: transform 0.3s ease;
border: rgb(144, 211, 205) solid 2px;
border-radius: 50%;
background-color: black;
}
.circle {
position: relative;
border: 2px solid black;
margin: 20px 20px;
width: 100px;
height: 100px;
border-radius: 50%;
overflow: hidden;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
}
.avatar {
width: 100%;
height: 100%;
object-fit: cover;
transition: transform 0.3s ease;
}
</style>
结语
虽然这道题有点难,但好处是我对canvas的理解加深了,canvas绝对是前端的一个非常有用的东西,值得掘友们认真学习。原本这道题的灵感来源于bilibili上讲的canvas实现钟表中刻度的实现,虽然没用它的方法,因为他的方法会导致刻度变形,不是扇形的能量条,但是它旋转坐标轴的想法让我大受启发。
来源:juejin.cn/post/7501568955498070016
别再用 useEffect 写满组件了!试试这个三层数据架构 🤔🤔🤔
面试导航 是一个专注于前、后端技术学习和面试准备的 免费 学习平台,提供系统化的技术栈学习,深入讲解每个知识点的核心原理,帮助开发者构建全面的技术体系。平台还收录了大量真实的校招与社招面经,帮助你快速掌握面试技巧,提升求职竞争力。如果你想加入我们的交流群,欢迎通过微信联系:
yunmz777。
我们常常低估了数据获取的复杂性,直到项目已经陷入困境。很多项目一开始只是简单地在组件中随手使用 useEffect() 和 fetch()。
然而不知不觉中,错误处理、加载状态、缓存逻辑和重复请求越堆越多,代码变得混乱难以维护,调试也越来越痛苦。
以下是我在许多项目中常见的一些问题:
- 组件触发了重复的网络请求 —— 只是因为没有正确缓存数据
- 组件频繁重渲染 —— 状态管理混乱,每秒更新几十次
- 过多的骨架屏加载效果 —— 导致整个应用看起来总是“卡在加载中”
- 用户看到旧数据 —— 修改数据后缓存没有及时更新
- 并发请求出现竞态条件 —— 不同请求返回顺序无法预测,导致数据错乱
- 内存泄漏 —— 订阅和事件监听未正确清理
- 乐观更新失败却悄无声息 —— 页面展示和实际数据不一致
- 服务端渲染数据失效太快 —— 页面跳转后立即变成过期数据
- 无效的轮询逻辑 —— 要么频繁请求没有变化的数据,要么根本没必要轮询
- 组件与数据请求逻辑强耦合 —— 导致组件复用性极差
- 顺序依赖的多层请求链 —— 比如:获取用户 → 用户所属组织 → 组织下的团队 → 团队成员
以上问题在复杂应用中极为常见。如果不从架构层面进行规划和优化,很容易陷入混乱的技术债中,影响项目长期维护与扩展。
这些问题会互相叠加。一个糟糕的数据获取模式,往往会引发三个新的问题。等你意识到时,原本“简单”的仪表盘页面已经需要从头重构了。
这篇文章将向你展示一种更好的做法,至少是我在项目中偏好的架构方式。我们将构建一个三层数据获取架构,它可以从最基本的 CRUD 操作无缝扩展到复杂的实时应用,而不会让你陷入混乱的思维模型中。
不过在介绍这套“三层数据架构”之前,我们得先谈谈一个常见的起点:
你的第一反应可能是直接在组件里用 useEffect() 搭配 fetch() 来获取数据,然后继续开发下去。
但这种方式,很快就会失控。以下是原因:
export function TeamDashboard() {
const [user, setUser] = useState(null);
const [org, setOrg] = useState(null);
const [teams, setTeams] = useState([]);
const [isLoading, setIsLoading] = useState(true);
const [error, setError] = useState(null);
const [isCreating, setIsCreating] = useState(false);
const [lastUpdated, setLastUpdated] = useState(null);
// Waterfall ❌
useEffect(() => {
const fetchData = async () => {
try {
// User request
const userData = await fetch("/api/user").then((res) => res.json());
setUser(userData);
// Wait for user, then fetch org
const orgData = await fetch(`/api/org/${userData.orgId}`).then((res) =>
res.json()
);
setOrg(orgData);
// Wait for org, then fetch teams
const teamsData = await fetch(`/api/teams?orgId=${orgData.id}`).then(
(res) => res.json()
);
setTeams(teamsData);
setIsLoading(false);
} catch (err) {
setError(err.message);
setIsLoading(false);
}
};
fetchData();
}, []);
// Handle window focus to refetch
useEffect(() => {
const handleFocus = async () => {
if (!user?.id) return;
setIsLoading(true);
await refetchData();
};
window.addEventListener("focus", handleFocus);
return () => window.removeEventListener("focus", handleFocus);
}, [user?.id]);
// Polling for updates
useEffect(() => {
if (!user?.id || !org?.id) return;
const pollTeams = async () => {
try {
const teamsData = await fetch(`/api/teams?orgId=${org.id}`).then(
(res) => res.json()
);
setTeams(teamsData);
} catch (err) {
// Silent fail or show error?
console.error("Polling failed:", err);
}
};
const interval = setInterval(pollTeams, 30000);
return () => clearInterval(interval);
}, [user?.id, org?.id]);
const refetchData = async () => {
try {
const userData = await fetch("/api/user").then((res) => res.json());
const orgData = await fetch(`/api/org/${userData.orgId}`).then((res) =>
res.json()
);
const teamsData = await fetch(`/api/teams?orgId=${orgData.id}`).then(
(res) => res.json()
);
setUser(userData);
setOrg(orgData);
setTeams(teamsData);
setLastUpdated(new Date());
} catch (err) {
setError(err.message);
} finally {
setIsLoading(false);
}
};
const createTeam = async (newTeam) => {
setIsCreating(true);
try {
const response = await fetch("/api/teams", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(newTeam),
});
if (!response.ok) throw new Error("Failed to create team");
const createdTeam = await response.json();
// Optimistic update attempt
setTeams((prev) => [...prev, createdTeam]);
// Or full refetch because you're paranoid
await refetchData();
} catch (err) {
setError(err.message);
// Need to rollback optimistic update?
// But which teams were the original ones?
} finally {
setIsCreating(false);
}
};
// Component unmount cleanup
useEffect(() => {
return () => {
// Cancel any pending requests?
// How do we track them all?
};
}, []);
// The render logic is still complex
if (isLoading && !teams.length) {
return <LoadingSpinner />;
}
if (error) {
return <ErrorDisplay message={error} onRetry={refetchData} />;
}
return (
<div>
<h1>{org?.name}'s Dashboard</h1>
{isLoading && <div>Refreshing...</div>}
<TeamList teams={teams} onCreate={createTeam} isCreating={isCreating} />
{lastUpdated && (
<div>Last updated: {lastUpdated.toLocaleTimeString()}</div>
)}
</div>
);
}
这种“在组件中用 useEffect + fetch”的方式,存在大量问题:
- 瀑布式请求:请求按顺序依赖执行,效率低下(后面我们会详细讨论)
- 状态管理混乱:多个
useState钩子相互独立,容易不同步 - 内存泄漏风险:事件监听器、定时器等需要手动清理,容易遗漏
- 无法取消请求:组件卸载时,无法终止正在进行中的请求
- 加载状态复杂:
isLoading究竟是哪个请求在加载?多个并发请求怎么处理? - 错误处理难统一:错误冒泡到哪里?如何集中处理错误?
- 缓存数据过期问题:没有机制标记哪些数据已经过期
- 乐观更新灾难:需要手动写回滚逻辑,容易出错
- 依赖数组陷阱:一不小心漏了依赖,导致潜在 Bug 难以排查
- 测试极其困难:模拟这些副作用和状态逻辑是一场噩梦
当你的应用变得越来越复杂,这些问题会指数级地增长。每新增一个功能,就意味着更多的状态、更多的副作用、更多边界条件需要考虑。
当然,你也可以用 Redux 或 MobX 来集中管理状态,但这些库往往也会引入新的复杂度和大量样板代码。最终你会陷入一张难以理清的“action → reducer → selector”的关系网中。我自己也喜欢这两个库,但它们并不是解决这个问题的最佳答案。
你可能会想:“那我用 useReducer() + useContext() 管理状态不就好了?”
是的,这种组合确实可以整洁地组织状态,但它仍然没有解决数据获取本身的复杂性。加载状态、错误处理、缓存失效等问题依旧存在。
顺带一提,你可能还会想:“我干脆一次性把所有数据都请求回来,不就没这些问题了?”
接下来我们就来聊聊,为什么这也不可行。
export default function Dashboard() {
// Creates a waterfall - each request waits for the previous ❌
const { user } = useUser(); // Request 1
const { org } = useOrganization(user?.id); // Request 2 (waits)
const { teams } = useTeams(org?.id); // Request 3 (waits more)
// Total delay: 600-1200ms
return <DashboardView user={user} org={org} teams={teams} />;
}
Server Components(服务器组件)是一种更快、更高效的解决方案。它们允许你在服务器端获取数据,然后一次性将处理后的结果发送给客户端,从而:
- 减少前后端之间的网络请求次数
- 降低客户端的计算负担
- 提升页面加载速度和整体性能
通过在服务器上完成数据获取与渲染逻辑,Server Components 能帮助你构建更简洁、高性能的 React/Next.js 应用架构。
export default async function Dashboard() {
const user = await getUser();
// fetch org and teams in parallel using user data ✅
const [org, teams] = await Promise.all([
getOrganization(user.orgId),
getTeamsByOrgId(user.orgId),
]);
return <DashboardView user={user} org={org} teams={teams} />;
}
如果我告诉你,其实有一种更优雅的方式来组织数据获取逻辑,不仅能随着应用的增长而扩展,还能让你的组件保持简洁、专注 —— 你会不会感兴趣?
这正是 “三层数据架构(Three Layers of Data Architecture)” 的核心思想。这个模式将数据获取逻辑划分为三个清晰的层级,每一层都各司其职,互不干扰。
这样的设计让你的应用:
- 更容易理解
- 更方便测试
- 更便于维护和扩展
接下来我们就来深入了解这三层到底是什么。
三层数据架构
解决方案就是构建一个三层架构,实现关注点分离,让你的应用更容易理解、维护和扩展。
这种架构理念受到 React Query 的启发,它为管理服务端状态提供了一套强大且高效的解决方案。
你不一定非得使用 React Query,但我个人非常推荐它作为数据获取与缓存的首选库。
它帮你处理掉大量样板代码,让你可以专注于业务逻辑和界面开发。
💡 小提示:如果你选择使用 React Query,别忘了在开发环境中加上
<ReactQueryDevtools />—— 这个调试工具会极大提升你的开发体验。

回到“三层架构”本身。其实它的结构非常简单:
- 服务器组件(Server Components) —— 负责初始数据获取
- React Query —— 处理客户端的缓存与数据更新
- 乐观更新(Optimistic Updates) —— 提供即时的 UI 反馈
React Query 支持两种方式来实现乐观更新(即在真正完成数据变更之前就提前更新界面):
- 使用
onMutate钩子,直接操作缓存实现数据预更新 - 或者通过
useMutation的返回值,根据变量手动更新 UI
这种模式不仅让用户感受到更快的响应,还能保持数据与界面的同步性。
下面是一个推荐的项目结构示例,用来更清晰地理解这三层架构的组织方式:
app/
├── page.tsx # Layer 1: Server Component entry
├── api/
│ └── teams/
│ └── route.ts # GET, POST teams
│ └── [teamId]/
│ └── route.ts # GET, PUT, DELETE specific team
├── TeamList.tsx # Client component consuming Layers 2 & 3
├── components/ # Fix: Add this folder
│ └── TeamCard.tsx
└── ui/
├── error-state.tsx # Layer 2: Error handling states
└── loading-state.tsx # Layer 2: Loading states
hooks/
├── teams/
│ ├── useTeamsData.ts # Layer 2: React Query hooks
│ └── useTeamMutations.ts # Layer 3: Mutations with optimism
queries/ # Layer 1: Server-side database queries
├── teams/
│ ├── getAllTeams .ts
│ ├── getTeamById.ts
│ ├── getTeamsByOrgId.ts
│ ├── deleteTeamById.ts
│ ├── createTeam.ts
│ ├── updateTeamById.ts
context/
└── OrganizationContext.tsx # Layer 2: Centralized data management
三层架构的数据如何流动?
这三个层按顺序工作但保持独立:
用户请求(User Request)
↓
【第一层:服务器组件(Server Component)】
- 调用 getAllTeams() 从数据库获取数据
- 返回已渲染的 HTML(含初始数据)
↓
【第二层:React Query(客户端状态管理)】
- 接收并“脱水”服务器返回的数据(hydrate)
- 管理客户端缓存
- 处理自动/手动重新请求(refetch)
↓
【第三层:用户交互(User Actions)】
- 执行乐观更新,立即反馈 UI
- 发起真实的变更请求(mutation)
- 自动或手动触发缓存失效(cache invalidation)
第一层:Server Components
服务器组件负责处理初始数据获取,让你的应用感觉即时可用。但它们不会动态更新——这时 React Query 就派上用场了(第二层)。
import { getAllTeams } from "@/queries/teams/getAllTeams";
import { TeamList } from "./TeamList";
import { OrganizationProvider } from "@/context/OrganizationContext";
export default async function Page() {
// Layer 1: Fetch initial data on server
const teams = await getAllTeams();
return (
<main>
<h1>Teams Dashboard</h1>
{/* Pass server data to React Query via context */}
<OrganizationProvider initialTeams={teams}>
<TeamList />
</OrganizationProvider>
</main>
);
}
getAllTeams 函数是一个简单的数据库查询,用于获取所有团队。它可以是一个简单的 SQL 查询,也可以是一个 ORM 调用,具体取决于您的设置。
如下代码所示:
import { db } from "@/lib/db"; // Database or ORM connection
import { Team } from "@/types/team";
import { NextResponse } from "next/server";
export async function getAllTeams(): Promise<Team[]> {
try {
const teams = await db.team.findMany();
return teams;
} catch (error) {
throw new Error("Failed to fetch teams");
}
}
第二层:React Query
第 2 层使用来自第 1 层的初始数据并管理客户端状态:
import { useQuery } from "@tanstack/react-query";
export function useTeamsData(initialData: Team[]) {
return useQuery({
queryKey: ["teams"],
queryFn: async () => {
// Client-side must use API routes, not direct queries
// I want to keep my server and client code separate
const response = await fetch("/api/teams");
if (!response.ok) throw new Error("Failed to fetch teams");
return response.json();
},
initialData, // Received from Server Component via context
staleTime: 5 * 60 * 1000,
refetchOnWindowFocus: false,
});
}
以下是客户端组件从第 2 层消费的方式。
"use client";
import { useOrganization } from "@/context/OrganizationContext";
import { LoadingState } from "@/ui/loading-state";
import { ErrorState } from "@/ui/error-state";
export function TeamList() {
// Data from Layer 2 context
const { teams, isLoadingTeams, error } = useOrganization();
if (error) {
return <ErrorState message="Failed to load teams" />;
}
if (isLoadingTeams) {
return <LoadingState />;
}
return (
<div>
{teams.map((team) => (
<TeamCard key={team.id} team={team} />
))}
</div>
);
}
真正的“魔法”发生在第三层,这一层让你在服务器还在处理请求时,就能立即更新 UI,带来极致流畅的用户体验 —— 这正是乐观更新(Optimistic Updates)的价值所在。
在这个层中,所有变更请求(mutations)都被集中管理,例如创建或删除团队。
我们通常会把这部分逻辑封装在一个独立的 Hook 中,比如 useTeamMutations,它内部使用 React Query 的 useMutation 来处理对应的操作,从而让业务逻辑更清晰、职责更明确、代码更易维护。
// Layer 3: Mutations with optimism
import { useMutation, useQueryClient } from "@tanstack/react-query";
export function useTeamMutations() {
const queryClient = useQueryClient();
const createTeamMutation = useMutation({
mutationFn: async (newTeam: { name: string; members: string[] }) => {
const response = await fetch("/api/teams", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(newTeam),
});
if (!response.ok) throw new Error("Failed to create team");
return response.json();
},
onMutate: async (newTeam) => {
await queryClient.cancelQueries({ queryKey: ["teams"] });
const currentTeams = queryClient.getQueryData(["teams"]);
queryClient.setQueryData(["teams"], (old) => [
...old,
{ ...newTeam, id: `temp-${Date.now()}` },
]);
return { currentTeams };
},
onError: (err, variables, context) => {
queryClient.setQueryData(["teams"], context.currentTeams);
},
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ["teams"] });
},
});
const deleteTeamMutation = useMutation({
mutationFn: async (teamId: string) => {
const response = await fetch(`/api/teams/${teamId}`, {
method: "DELETE",
});
if (!response.ok) throw new Error("Failed to delete team");
return response.json();
},
onMutate: async (teamId) => {
await queryClient.cancelQueries({ queryKey: ["teams"] });
const currentTeams = queryClient.getQueryData(["teams"]);
queryClient.setQueryData(["teams"], (old) =>
old.filter((team) => team.id !== teamId)
);
return { currentTeams };
},
onError: (err, teamId, context) => {
queryClient.setQueryData(["teams"], context.currentTeams);
},
onSettled: () => {
queryClient.invalidateQueries({ queryKey: ["teams"] });
},
});
return {
createTeam: createTeamMutation.mutate,
deleteTeam: deleteTeamMutation.mutate,
isCreating: createTeamMutation.isLoading,
isDeleting: deleteTeamMutation.isLoading,
};
}
TeamCard 组件使用 useTeamMutations 钩子来处理团队的创建和删除。它还显示每个操作的加载状态。
"use client";
// TeamList.tsx - Using Layer 3 mutations
import { useTeamMutations } from "@/hooks/teams/useTeamMutations";
interface TeamCardProps {
team: {
id: string;
name: string;
members: string[];
};
}
export function TeamCard({ team }: TeamCardProps) {
const { deleteTeam, isDeleting } = useTeamMutations();
return (
<div className="p-4 border border-gray-200 rounded-lg mb-4">
<h3 className="text-lg font-semibold">{team.name}</h3>
<p className="text-gray-600">Members: {team.members.length}</p>
<button
onClick={() => deleteTeam(team.id)}
disabled={isDeleting}
className="mt-2 px-4 py-2 bg-red-600 text-white rounded hover:bg-red-700 disabled:opacity-50"
>
{isDeleting ? "Deleting..." : "Delete Team"}
</button>
</div>
);
}
将所有内容联系在一起:Context
上下文提供程序消除了 prop 钻取,并集中了数据访问。这对于多个组件需要相同数据的复杂应用尤其有用。
import { createContext, useContext } from "react";
import { useTeamsData } from "@/hooks/teams/useTeamsData";
interface OrganizationContextValue {
teams: Team[];
isLoadingTeams: boolean;
error: Error | null;
}
const OrganizationContext = createContext<OrganizationContextValue | null>(
null
);
export function OrganizationProvider({ children, initialTeams }) {
const { data: teams, isLoading, error } = useTeamsData(initialTeams);
return (
<OrganizationContext.Provider
value={{ teams, isLoadingTeams: isLoading, error }}
>
{children}
</OrganizationContext.Provider>
);
}
export function useOrganization() {
const context = useContext(OrganizationContext);
if (!context) {
throw new Error("useOrganization must be used within OrganizationProvider");
}
return context;
}
OrganizationProvider 组件包裹了 TeamList,为其提供了第一层的初始数据,同时统一管理加载状态与错误处理。
在更复杂的应用中,你可以为不同的数据层增加更多的上下文(Context)提供器。
比如,你可能会有:
- 一个
UserContext来管理用户信息 - 一个
AuthContext来处理认证状态
通过这种方式,你的组件可以专注于渲染 UI,而数据获取与状态管理则被集中管理,逻辑更清晰、职责更分明。
需要注意的是:
对于简单应用而言,“三层数据架构”可能有点大材小用。
但对于中大型项目来说,它具有极高的可扩展性,能很好地应对不断增长的复杂度。
此外,它还让测试变得更加简单 —— 你可以通过模拟(mock)这些 Context Provider,来独立测试每个组件,无需依赖真实数据。
P.S.:这个架构不仅限于 React。你在 Vue.js、Svelte 或其他前端框架中也可以采用类似的思路。关键在于:关注点分离,让组件专注于“渲染”,而不是“获取数据”或“管理状态”。
总结
这篇文章介绍了一个适用于复杂 React/Next.js 应用的 三层数据架构,通过将数据获取流程拆分为 Server Components、React Query 和用户交互三层,解决了传统 useEffect + fetch 带来的各种性能与维护问题。该模式强调 关注点分离,提升了组件的复用性、可测试性和扩展能力。尽管对小项目可能偏重,但在中大型应用中具备良好的可扩展性和清晰的逻辑组织能力,是构建健壮前端架构的实用指南。
来源:juejin.cn/post/7503449107542016040
初级、中级、高级前端工程师,对于form表单实现的区别
在 React 项目中使用 Ant Design(Antd)的 Form 组件能快速构建标准化表单,特别适合中后台系统开发。以下是结合 Antd 的 最佳实践 和 分层实现方案:
一、基础用法:快速搭建标准表单
import { Form, Input, Button, Checkbox } from 'antd';
const BasicAntdForm = () => {
const [form] = Form.useForm();
const onFinish = (values: any) => {
console.log('提交数据:', values);
};
return (
<Form
form={form}
layout="vertical"
initialValues={{ remember: true }}
onFinish={onFinish}
>
{/* 邮箱字段 */}
<Form.Item
label="邮箱"
name="email"
rules={[
{ required: true, message: '请输入邮箱' },
{ type: 'email', message: '邮箱格式不正确' }
]}
>
<Input placeholder="user@example.com" />
</Form.Item>
{/* 密码字段 */}
<Form.Item
label="密码"
name="password"
rules={[
{ required: true, message: '请输入密码' },
{ min: 8, message: '至少8位字符' }
]}
>
<Input.Password />
</Form.Item>
{/* 记住我 */}
<Form.Item name="remember" valuePropName="checked">
<Checkbox>记住登录状态</Checkbox>
</Form.Item>
{/* 提交按钮 */}
<Form.Item>
<Button type="primary" htmlType="submit">
登录
</Button>
</Form.Item>
</Form>
);
};
核心优势:
- 内置校验系统:通过
rules属性快速定义验证规则 - 布局控制:
layout="vertical"自动处理标签对齐 - 状态管理:
Form.useForm()自动处理表单状态
二、中级进阶:复杂场景处理
1. 动态表单字段(如添加多个联系人)
import { Form, Button } from 'antd';
const DynamicForm = () => {
return (
<Form>
<Form.List name="contacts">
{(fields, { add, remove }) => (
<>
{fields.map(({ key, name, ...rest }) => (
<div key={key} style={{ display: 'flex' }}>
<Form.Item
{...rest}
name={[name, 'phone']}
rules={[{ required: true }]}
>
<Input placeholder="手机号" />
</Form.Item>
<Button onClick={() => remove(name)}>删除</Button>
</div>
))}
<Button onClick={() => add()}>添加联系人</Button>
</>
)}
</Form.List>
</Form>
);
};
2. 异步验证(如检查用户名是否重复)
<Form.Item
name="username"
rules={[
{ required: true },
{
validator: (_, value) =>
fetch(`/api/check?username=${value}`)
.then(res => res.ok ? Promise.resolve() : Promise.reject('用户名已存在'))
}
]}
>
<Input />
</Form.Item>
3. 条件渲染字段(如选择国家后显示省份)
const { watch } = useForm();
const country = watch('country');
<Form.Item name="province" hidden={!country}>
<Select options={provinceOptions} />
</Form.Item>
三、高级优化:性能与可维护性
1. 表单性能优化
// 使用 shouldUpdate 避免无效渲染
<Form.Item shouldUpdate={(prev, current) => prev.country !== current.country}>
{({ getFieldValue }) => (
getFieldValue('country') === 'CN' && <ProvinceSelect />
)}
</Form.Item>
2. 类型安全(TypeScript)
interface FormValues {
email: string;
password: string;
}
const [form] = Form.useForm<FormValues>();
3. 主题定制(通过 ConfigProvider)
import { ConfigProvider } from 'antd';
<ConfigProvider
theme={{
token: {
colorPrimary: '#1890ff',
borderRadius: 4,
},
components: {
Form: {
labelColor: '#333',
},
},
}}
>
<YourFormComponent />
</ConfigProvider>
四、企业级解决方案
1. 表单设计器集成
// 结合 XFlow 实现可视化表单设计
import { XFlow, FormBuilder } from '@antv/xflow';
const FormDesigner = () => (
<XFlow>
<FormBuilder
components={registeredComponents} // 注册的Antd组件
onSave={(schema) => saveToBackend(schema)}
/>
</XFlow>
);
2. 微前端表单共享
// 使用 qiankun 共享表单组件
export default function AntdFormModule() {
return (
<Module name="form-module">
<ConfigProvider>
<Router>
<Route path="/form" component={YourAntdForm} />
</Router>
</ConfigProvider>
</Module>
);
}
五、Ant Design Form 的局限与应对策略
| 场景 | 问题 | 解决方案 |
|---|---|---|
| 大数据量表单 | 渲染性能下降 | 虚拟滚动(react-virtualized) |
| 复杂联动逻辑 | 代码复杂度高 | 使用 Form.Provider 共享状态 |
| 深度定制UI | 样式覆盖困难 | 使用 CSS-in-JS 覆盖样式 |
| 多步骤表单 | 状态保持困难 | 结合 Zustand 做全局状态管理 |
| 跨平台需求 | 移动端适配不足 | 配合 antd-mobile 使用 |
六、推荐技术栈组合
- **基础架构**:React 18 + TypeScript 5
- **UI 组件库**:Ant Design 5.x
- **状态管理**:Zustand(轻量)/ Redux Toolkit(复杂场景)
- **表单增强**:@ant-design/pro-form(ProComponents)
- **验证库**:yup/zod + @hookform/resolvers(可选)
- **测试工具**:Jest + Testing Library
通过 Ant Design Form 组件,开发者可以快速构建符合企业标准的中后台表单系统。关键在于:
- 合理使用内置功能(Form.List、shouldUpdate)
- 类型系统深度整合
- 性能优化意识
- 扩展能力设计(动态表单、可视化配置)
来源:juejin.cn/post/7498950758475055119


