








Browser.js:轻松模拟浏览器环境
什么是Browser.js
Browser.js是一个小巧而强大的JavaScript库,它模拟浏览器环境,使得原本只能在浏览器中运行的代码能够在Node.js环境中执行。这意味着你可以在服务器端运行前端代码,而不需要依赖真实浏览器
Browser.js的核心原理
Browser.js通过实现与浏览器兼容的API(如window、document、navigator等)来创建一个近似真实的浏览器上下文。它还支持fetch API用于网络请求,支持Promise,使得异步操作更加方便
Browser.js的用途
Browser.js主要用于以下场景:
- 服务器端测试:在服务端运行前端单元测试,无需依赖真实浏览器,从而提高测试效率
// 示例:使用Browser.js进行服务器端测试
const browser = require('browser.js');
const window = browser.window;
const document = browser.document;
// 在Node.js中模拟浏览器环境
console.log(window.location.href);
- 构建工具:编译或预处理只能在浏览器运行的库,例如基于DOM的操作,如CSS处理器或模板引擎
// 示例:使用Browser.js处理CSS
const browser = require('browser.js');
const document = browser.document;
// 创建一个CSS样式表
const style = document.createElement('style');
style.textContent = 'body { background-color: #f2f2f2; }';
document.head.appendChild(style);
- 离线应用:将部分业务逻辑放在客户端和服务端之外,在本地环境中执行1。
// 示例:使用Browser.js在本地环境中执行业务逻辑
const browser = require('browser.js');
const window = browser.window;
// 在本地环境中执行JavaScript代码
window.alert('Hello, World!');
- 自动化脚本:对网页进行自动化操作,如爬虫、数据提取等,而不必依赖真实浏览器1。
// 示例:使用Browser.js进行网页爬虫
const browser = require('browser.js');
const fetch = browser.fetch;
// 发送HTTP请求获取网页内容
fetch('https://example.com')
.then(response => response.text())
.then(html => console.log(html));
解决的问题
Browser.js解决了以下问题:
- 跨环境执行:使得原本只能在浏览器中运行的JavaScript代码能够在Node.js环境中执行,扩展了JavaScript的应用边界
- 兼容性问题:通过模拟浏览器环境,减少了不同浏览器之间的兼容性问题,提高了代码的可移植性
- 测试效率:提高了前端代码在服务端的测试效率,减少了对真实浏览器的依赖
Browser.js的特点
- 轻量级:体积小,引入方便,不会过多影响项目整体性能
- 兼容性:模拟的浏览器环境高度兼容Web标准,能够运行大部分浏览器代码
- 易用性:提供简单直观的API接口,快速上手
- 可扩展:支持自定义插件,可以根据需求扩展功能
- 无依赖:不依赖其他大型库或框架,降低项目复杂度
来源:juejin.cn/post/7486845198485585935
Vue 首个 AI 组件库发布!
人工智能(AI)已深度融入我们的生活,如今 Vue 框架也迎来了首个 AI 组件库 —— Ant Design X Vue,为开发者提供了强大的 AI 开发工具。
Ant Design X Vue 概述
Ant Design X Vue 是基于 Vue.js 的 AI 组件库,旨在简化 AI 集成开发。

它包含高度定制化的 AI 组件和 API 解决方案,支持无缝接入 AI 服务,是构建智能应用的理想选择。
组件库亮点
丰富多样的 AI 组件
通用组件:
- Bubble:显示会话消息气泡,支持多种布局。
- Conversations:管理多个会话,查看历史记录。
唤醒组件:
- Welcome:会话加载时插入欢迎语。
- Prompts:展示上下文相关的问题或建议。
表达组件:
- Sender:构建会话输入框,支持自定义样式。
- Attachments:展示和管理附件信息。
- Suggestion:提供快捷输入提示。
确认组件:
- ThoughtChain:展示 AI 的思维过程或结果。
工具组件:
- useXAgent:对接 AI 模型推理服务。
- useXChat:管理 AI 对话应用的数据流。
- XStream:处理数据流,支持流式传输。
- XRequest:向 AI 服务发起请求。
- XProvider:全局化配置管理。
RICH 设计范式
基于 RICH 设计范式,提供丰富、沉浸式、连贯和人性化的交互体验,适应不同 AI 场景。
AGI 混合界面(Hybrid-UI)
融合 GUI 和自然会话交互,用户可在同一应用中自由切换交互方式,提升体验。
适用场景
- 智能聊天应用:构建多轮对话界面,支持复杂会话逻辑。
- 企业级 AI 系统:快速搭建智能客服、知识管理等系统。
如何使用 Ant Design X Vue
安装与引入
npm install ant-design-x-vue --save
引入组件库及样式:
import Vue from 'vue';
import Antd from 'ant-design-x-vue';
import 'ant-design-x-vue/dist/antd.css';
Vue.use(Antd);
使用组件
示例:使用 Bubble 组件展示对话气泡
<template>
<div>
<a-bubble content="欢迎使用 Ant Design X Vue!" />
</div>
</template>
官方文档与示例
访问 Ant Design X Vue 官方文档:https://antd-design-x-vue.netlify.app/ 获取更多信息。
Ant Design X Vue 为 Vue 开发者提供了强大的 AI 组件库,助力高效构建智能应用。
无论是聊天应用还是企业级系统,都值得一试。
最后
如果觉得本文对你有帮助,希望能够给我点赞支持一下哦 💪 也可以关注wx公众号:
前端开发爱好者回复加群,一起学习前端技能 公众号内包含很多实战精选资源教程,欢迎关注
来源:juejin.cn/post/7475978280841543716
如何限制一个账号只能在一处登录
如何限制一个账号只能在一处登录
要实现账号单点登录(一处登录限制),需结合 会话管理、实时状态同步 和 冲突处理机制。以下是完整技术方案:
一、核心实现方案
- 服务端会话控制(推荐)
// 用户登录时生成唯一令牌并记录
public String login(String username, String password) {
// 1. 验证账号密码
User user = userService.authenticate(username, password);
// 2. 生成新令牌并失效旧会话
String newToken = UUID.randomUUID().toString();
redis.del("user:" + user.getId() + ":token"); // 清除旧token
redis.setex("user:" + user.getId() + ":token", 3600, newToken);
// 3. 返回新令牌
return newToken;
}
- WebSocket实时踢出(增强体验)
// 前端建立长连接
const socket = new WebSocket(`wss://api.example.com/ws?token=${token}`);
socket.onmessage = (event) => {
if (event.data === 'force_logout') {
alert('您的账号在其他设备登录');
location.href = '/logout';
}
};
- 登录设备指纹识别
// 生成设备指纹(前端)
function generateDeviceFingerprint() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
ctx.textBaseline = 'top';
ctx.font = "14px Arial";
ctx.fillText("BrowserFingerprint", 2, 2);
return canvas.toDataURL().hashCode(); // 简化示例
}
// 服务端校验
if (storedFingerprint != currentFingerprint) {
forceLogout(storedToken);
}
要实现账号单点登录(一处登录限制),需结合 会话管理、实时状态同步 和 冲突处理机制。以下是完整技术方案:
一、核心实现方案
- 服务端会话控制(推荐)
// 用户登录时生成唯一令牌并记录
public String login(String username, String password) {
// 1. 验证账号密码
User user = userService.authenticate(username, password);
// 2. 生成新令牌并失效旧会话
String newToken = UUID.randomUUID().toString();
redis.del("user:" + user.getId() + ":token"); // 清除旧token
redis.setex("user:" + user.getId() + ":token", 3600, newToken);
// 3. 返回新令牌
return newToken;
}
- WebSocket实时踢出(增强体验)
// 前端建立长连接
const socket = new WebSocket(`wss://api.example.com/ws?token=${token}`);
socket.onmessage = (event) => {
if (event.data === 'force_logout') {
alert('您的账号在其他设备登录');
location.href = '/logout';
}
};
// 生成设备指纹(前端)
function generateDeviceFingerprint() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
ctx.textBaseline = 'top';
ctx.font = "14px Arial";
ctx.fillText("BrowserFingerprint", 2, 2);
return canvas.toDataURL().hashCode(); // 简化示例
}
// 服务端校验
if (storedFingerprint != currentFingerprint) {
forceLogout(storedToken);
}
二、多端适配策略
| 客户端类型 | 实现方案 |
|---|---|
| Web浏览器 | JWT令牌 + Redis黑名单 |
| 移动端APP | 设备ID绑定 + FCM/iMessage推送踢出 |
| 桌面应用 | 硬件指纹 + 本地令牌失效检测 |
| 微信小程序 | UnionID绑定 + 服务端订阅消息 |
三、关键代码实现
- JWT令牌增强方案
// 生成带设备信息的JWT
public String generateToken(User user, String deviceId) {
return Jwts.builder()
.setSubject(user.getId())
.claim("device", deviceId) // 绑定设备
.setExpiration(new Date(System.currentTimeMillis() + 3600000))
.signWith(SignatureAlgorithm.HS512, secret)
.compact();
}
// 校验令牌时检查设备
public boolean validateToken(String token, String currentDevice) {
Claims claims = Jwts.parser().setSigningKey(secret).parseClaimsJws(token).getBody();
return claims.get("device").equals(currentDevice);
}
- Redis实时状态管理
# 使用Redis Hash存储登录状态
def login(user_id, token, device_info):
# 删除该用户所有活跃会话
r.delete(f"user_sessions:{user_id}")
# 记录新会话
r.hset(f"user_sessions:{user_id}",
mapping={
"token": token,
"device": device_info,
"last_active": datetime.now()
})
r.expire(f"user_sessions:{user_id}", 3600)
# 中间件校验
def check_token(request):
user_id = get_user_id_from_token(request.token)
stored_token = r.hget(f"user_sessions:{user_id}", "token")
if stored_token != request.token:
raise ForceLogoutError()
四、异常处理机制
| 场景 | 处理方案 |
|---|---|
| 网络延迟冲突 | 采用CAS(Compare-And-Swap)原子操作更新令牌 |
| 令牌被盗用 | 触发二次验证(短信/邮箱验证码) |
| 多设备同时登录 | 后登录者优先,前会话立即失效(可配置为保留第一个登录) |
五、性能与安全优化
- 会话同步优化:
# Redis Pub/Sub 跨节点同步
PUBLISH user:123 "LOGOUT"
- 安全增强:
// 前端敏感操作二次确认
function sensitiveOperation() {
if (loginTime < lastServerCheckTime) {
showReauthModal();
}
}
- 监控看板:
指标 报警阈值 并发登录冲突率 >5%/分钟 强制踢出成功率 <99%
六、行业实践参考
- 金融级方案:
- 每次操作都验证设备指纹
- 异地登录需视频人工审核
- 社交应用方案:
- 允许最多3个设备在线
- 分设备类型控制(手机+PC+平板)
- ERP系统方案:
- 绑定特定MAC地址
- VPN网络白名单限制
通过以上方案可实现:
- 严格模式:后登录者踢出前会话(适合银行系统)
- 宽松模式:多设备在线但通知告警(适合社交应用)
- 混合模式:关键操作时强制单设备(适合电商系统)
部署建议:
- 根据业务需求选择合适严格度
- 关键系统增加异地登录二次验证
- 用户界面明确显示登录设备列表
来源:juejin.cn/post/7485384798569250868
前端如何彻底解决重复请求问题
背景
- 保存按钮点击多次,造成新增多个单据
- 列表页疯狂刷新,导致服务器压力大
如何彻底解决
方案:我的思路从请求层面判断相同请求只发送一次,将结果派发给各个订阅者
实现思路
- 对请求进行数据进行hash
- 添加store 存储 hash => Array promise
- 相同请求,直接订阅对应的promise
- 请求取消,则将store中对应的promise置为null
- 请求返回后,调用所有未取消的订阅
核心代码
private handleFinish(key: string, index: number) {
const promises = this.store.get(key);
// 只有一个promise时则删除store
if (promises?.filter((item) => item).length === 1) {
this.store.delete(key);
} else if (promises && promises[index]) {
// 还有其他请求,则将当前取消的、或者完成的置为null
promises[index] = null;
}
}
private async handleRequest(config: any) {
const hash = sha256.create();
hash.update(
JSON.stringify({
params: config.params,
data: config.data,
url: config.url,
method: config.method,
}),
);
const fetchKey = hash.hex().slice(0, 40);
const promises = this.store.get(fetchKey);
const index = promises?.length || 0;
let promise = promises?.find((item) => item);
const controller = new AbortController();
if (config.signal) {
config.signal.onabort = (reason: any) => {
const _promises = this.store.get(fetchKey)?.filter((item) => item);
if (_promises?.length === 1) {
controller.abort(reason);
this.handleFinish(fetchKey, index);
}
};
}
if (!promise) {
promise = this.instance({
...config,
signal: controller.signal,
headers: {
...config.headers,
fetchKey,
},
}).catch((error) => {
console.log(error, "请求错误");
// 失败的话,立即删除,可以重试
this.handleFinish(fetchKey, index);
return { error };
});
}
const newPromise = Promise.resolve(promise)
.then((result: any) => {
if (config.signal?.aborted) {
this.handleFinish(fetchKey, index);
return result;
}
return result;
})
.finally(() => {
setTimeout(() => {
this.handleFinish(fetchKey, index);
}, 500);
});
this.store.set(fetchKey, [...(promises || []), newPromise]);
return newPromise;
}
以下为完整代码(仅供参考)
index.ts
import axios, { AxiosInstance, AxiosRequestConfig, AxiosResponse } from "axios";
import { sha256 } from "js-sha256";
import transformResponseValue, { updateObjTimeToUtc } from "./utils";
type ErrorInfo = {
message: string;
status?: number;
traceId?: string;
version?: number;
};
type MyAxiosOptions = AxiosRequestConfig & {
goLogin: (type?: string) => void;
onerror: (info: ErrorInfo) => void;
getHeader: () => any;
};
export type MyRequestConfigs = AxiosRequestConfig & {
// 是否直接返回服务端返回的数据,默认false, 只返回 data
useOriginData?: boolean;
// 触发立即更新
flushApiHook?: boolean;
ifHandleError?: boolean;
};
type RequestResult<T, U> = U extends { useOriginData: true }
? T
: T extends { data?: infer D }
? D
: never;
class LmAxios {
private instance: AxiosInstance;
private store: Map<string, Array<Promise<any> | null>>;
private options: MyAxiosOptions;
constructor(options: MyAxiosOptions) {
this.instance = axios.create(options);
this.options = options;
this.store = new Map();
this.interceptorRequest();
this.interceptorResponse();
}
// 统一处理为utcTime
private interceptorRequest() {
this.instance.interceptors.request.use(
(config) => {
if (config.params) {
config.params = updateObjTimeToUtc(config.params);
}
if (config.data) {
config.data = updateObjTimeToUtc(config.data);
}
return config;
},
(error) => {
console.log("intercept request error", error);
Promise.reject(error);
},
);
}
// 统一处理为utcTime
private interceptorResponse() {
this.instance.interceptors.response.use(
(response): any => {
// 对响应数据做处理,以下根据实际数据结构改动!!...
const [checked, errorInfo] = this.checkStatus(response);
if (!checked) {
return Promise.reject(errorInfo);
}
const disposition =
response.headers["content-disposition"] ||
response.headers["Content-Disposition"];
// 文件处理
if (disposition && disposition.indexOf("attachment") !== -1) {
const filenameReg =
/filename\*?=['"]?(?:UTF-\d['"]*)?([^;\r\n"']*)['"]?;?/g;
const filenames: string[] = [];
disposition.replace(filenameReg, (r: any, r1: string) => {
filenames.push(decodeURIComponent(r1));
});
return Promise.resolve({
filename: filenames[filenames.length - 1],
data: response.data,
});
}
if (response) {
return Promise.resolve(response.data);
}
},
(error) => {
console.log("request error", error);
if (error.message.indexOf("timeout") !== -1) {
return Promise.reject({
message: "请求超时",
});
}
const [checked, errorInfo] = this.checkStatus(error.response);
return Promise.reject(errorInfo);
},
);
}
private checkStatus(
response: AxiosResponse<any>,
): [boolean] | [boolean, ErrorInfo] {
const { code, message = "" } = response?.data || {};
const { headers, status } = response || {};
if (!status) {
return [false];
}
// 单地登录判断,弹出不同提示
if (status === 401) {
this.options?.goLogin();
return [false];
}
if (code === "ECONNABORTED" && message?.indexOf("timeout") !== -1) {
return [
false,
{
message: "请求超时",
},
];
}
if ([108, 109, 401].includes(code)) {
this.options.goLogin();
return [false];
}
if ((code >= 200 && code < 300) || code === 304) {
// 如果http状态码正常,则直接返回数据
return [true];
}
if (!code && ((status >= 200 && status < 300) || status === 304)) {
return [true];
}
let errorInfo = "";
const _code = code || status;
switch (_code) {
case -1:
errorInfo = "远程服务响应失败,请稍后重试";
break;
case 400:
errorInfo = "400: 错误请求";
break;
case 401:
errorInfo = "401: 访问令牌无效或已过期";
break;
case 403:
errorInfo = message || "403: 拒绝访问";
break;
case 404:
errorInfo = "404: 资源不存在";
break;
case 405:
errorInfo = "405: 请求方法未允许";
break;
case 408:
errorInfo = "408: 请求超时";
break;
case 500:
errorInfo = message || "500: 访问服务失败";
break;
case 501:
errorInfo = "501: 未实现";
break;
case 502:
errorInfo = "502: 无效网关";
break;
case 503:
errorInfo = "503: 服务不可用";
break;
default:
errorInfo = "连接错误";
}
return [
false,
{
message: errorInfo,
status: _code,
traceId: response?.data?.requestId,
version: response.data.ver,
},
];
}
private handleFinish(key: string, index: number) {
const promises = this.store.get(key);
if (promises?.filter((item) => item).length === 1) {
this.store.delete(key);
} else if (promises && promises[index]) {
promises[index] = null;
}
}
private async handleRequest(config: any) {
const hash = sha256.create();
hash.update(
JSON.stringify({
params: config.params,
data: config.data,
url: config.url,
method: config.method,
}),
);
const fetchKey = hash.hex().slice(0, 40);
const promises = this.store.get(fetchKey);
const index = promises?.length || 0;
let promise = promises?.find((item) => item);
const controller = new AbortController();
if (config.signal) {
config.signal.onabort = (reason: any) => {
const _promises = this.store.get(fetchKey)?.filter((item) => item);
if (_promises?.length === 1) {
controller.abort(reason);
this.handleFinish(fetchKey, index);
}
};
}
if (!promise) {
promise = this.instance({
...config,
signal: controller.signal,
headers: {
...config.headers,
fetchKey,
},
}).catch((error) => {
console.log(error, "请求错误");
// 失败的话,立即删除,可以重试
this.handleFinish(fetchKey, index);
return { error };
});
}
const newPromise = Promise.resolve(promise)
.then((result: any) => {
if (config.signal?.aborted) {
this.handleFinish(fetchKey, index);
return result;
}
return result;
})
.finally(() => {
setTimeout(() => {
this.handleFinish(fetchKey, index);
}, 500);
});
this.store.set(fetchKey, [...(promises || []), newPromise]);
return newPromise;
}
// add override type
public async request<T = unknown, U extends MyRequestConfigs = {}>(
url: string,
config: U,
): Promise<RequestResult<T, U> | null> {
// todo
const options = {
url,
// 是否统一处理接口失败(提示)
ifHandleError: true,
...config,
headers: {
...this.options.getHeader(),
...config?.headers,
},
};
const res = await this.handleRequest(options);
if (!res) {
return null;
}
if (res.error) {
if (res.error.message && options.ifHandleError) {
this.options.onerror(res.error);
}
throw new Error(res.error);
}
if (config.useOriginData) {
return res;
}
if (config.headers?.feTraceId) {
window.dispatchEvent(
new CustomEvent<{ flush?: boolean }>(config.headers.feTraceId, {
detail: {
flush: config?.flushApiHook,
},
}),
);
}
// 默认返回res.data
return transformResponseValue(res.data)
}
}
export type MyRequest = <T = unknown, U extends MyRequestConfigs = {}>(
url: string,
config: U,
) => Promise<RequestResult<T, U> | null>;
export default LmAxios;
utils.ts(这里主要用来处理utc时间,你可能用不到删除相关代码就好)
import moment from 'moment';
const timeReg =
/^\d{4}([/:-])(1[0-2]|0?[1-9])\1(0?[1-9]|[1-2]\d|30|31)($|( |T)(?:[01]\d|2[0-3])(:[0-5]\d)?(:[0-5]\d)?(\..*\d)?Z?$)/;
export function formatTimeValue(time: string, format = 'YYYY-MM-DD HH:mm:ss') {
if (typeof time === 'string' || typeof time === 'number') {
if (timeReg.test(time)) {
return moment(time).format(format);
}
}
return time;
}
// 统一转化如参
export const updateObjTimeToUtc = (obj: any) => {
if (typeof obj === 'string') {
if (timeReg.test(obj)) {
return moment(obj).utc().format();
}
return obj;
}
if (toString.call(obj) === '[object Object]') {
const newObj: Record<string, any> = {};
Object.keys(obj).forEach((key) => {
newObj[key] = updateObjTimeToUtc(obj[key]);
});
return newObj;
}
if (toString.call(obj) === '[object Array]') {
obj = obj.map((item: any) => updateObjTimeToUtc(item));
}
return obj;
};
const utcReg = /^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}.*Z$/;
const transformResponseValue = (res: any) => {
if (!res) {
return res;
}
if (typeof res === 'string') {
if (utcReg.test(res)) {
return moment(res).format('YYYY-MM-DD HH:mm:ss');
}
return res;
}
if (toString.call(res) === '[object Object]') {
const result: any = {};
Object.keys(res).forEach((key) => {
result[key] = transformResponseValue(res[key]);
});
return result;
}
if (toString.call(res) === '[object Array]') {
return res.map((item: any) => transformResponseValue(item));
}
return res;
};
export default transformResponseValue;
来源:juejin.cn/post/7484202915390718004
[译]为什么我选择用Tauri来替代Electron
原文地址:Why I chose Tauri instead of Electron
以下为正文。
关于我为什么在Tauri上创建Aptakube的故事,我与Electron的斗争以及它们之间的简短比较。
大约一年前,我决定尝试构建一个桌面应用程序。
我对自己开发的小众应用并不满意,我想我可以开发出更好的应用。我作为全栈开发人员工作了很长时间,但我以前从未构建过桌面应用程序。
我的第一个想法是用 SwiftUI 来构建。开发者喜欢原生应用,我也一直想学习 Swift。然而,在 SwiftUI 上构建会将我的受众限制为 macOS 用户。虽然我有一种感觉,大多数用户无论如何都会使用 macOS,但当我可以构建跨平台应用程序时,为什么要限制自己呢?
现在回想起来,我真的很庆幸当初放弃了 SwiftUI。看看人们在不同的操作系统上使用我的应用就知道了。
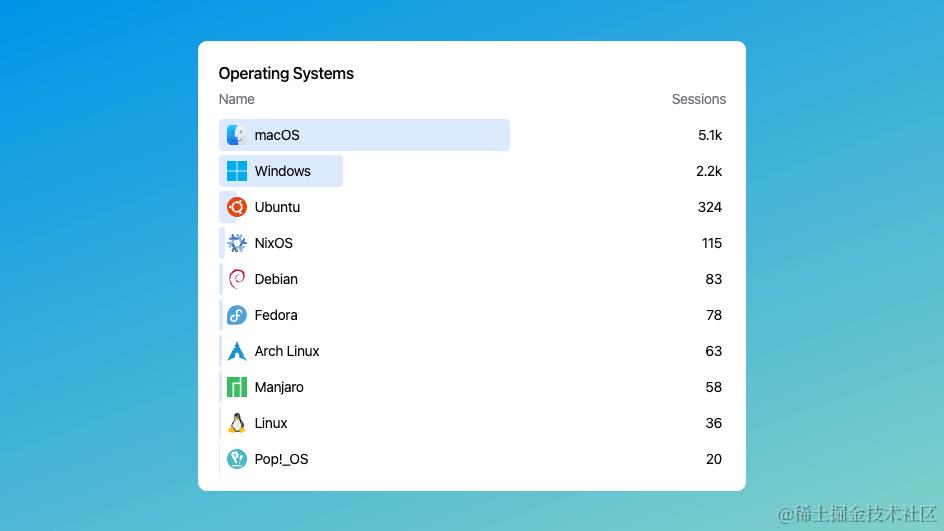
Windows和Linux代表了超过35%的用户。这相当于放弃了35%的收入。
那么 Electron 怎么样呢?
我不是与世隔绝的人,所以我知道 Electron 是个好东西,我每天使用的很多流行应用都是基于 Electron 开发的,包括我现在用来写这篇文章的编辑器。它似乎非常适合我想做的事情,因为:
- 单个代码库可以针对多个平台。
- 支持 React + TypeScript + Tailwind 配合使用,每个我都非常熟练。
- 非常受欢迎 = 很多资源和指南。
- NPM 是最大的(是吧?)软件包社区,这意味着我可以更快地发布。
在 Electron 上开发的另一个好处是,我可以专注于开发应用程序,而不是学习一些全新的东西。我喜欢学习新的语言和框架,但我想快速构建一些有用的东西。我仍然需要学习 Electron 本身,但它不会像学习 Swift 和 SwiftUI 那样困难。
好了,我们开始吧!
我决定了。Aptakube 将使用 Electron 来构建。
我通常不看文档。我知道我应该看,但我没有。不过,每当我第一次选择一个框架时,我总会阅读 “入门(Getting Started)” 部分。
流行的框架都有一个 npx create {framework-name},可以为我们快速一个应用程序。Next.js、Expo、Remix 和许多其他框架都有这样的功能。我发现这非常有用,因为它们可以让你快速上手,而且通常会给你提供很多选项,例如:
- 你想使用 TypeScript 还是 JavaScript?
- 你想使用 CSS 框架吗?那 Tailwind 呢?
- Prettier 和/或 ESLint?
- 你要这个还是那个?
这样的例子不胜枚举。这是一种很棒的开发体验,我希望每个框架都有一个。
我可以直接 npx create electron-app 吗?
显然,我不能,或者至少我还没有找到一种方法来做到这一点,除了在 Getting Started 里。
相反,我找到的是一个“快速启动(quick-start)”模板,我可以从 Git 上克隆下来,安装依赖项,然后就可以开始我的工作了。
然而,它不是 TypeScript,没有打包工具,没有 CSS 框架,没有检查,没有格式化,什么都没有。它只是一个简单的打开窗口的应用程序。
我开始用这个模板构建,并添加了所有我想让它使用的东西。我以为会很容易,但事实并非如此。
一个 electron 应用程序有三个入口点: main、preload(预加载),和render(渲染)。把所有这些和 Vite 连接起来是很痛苦的。我花了大约两周的空闲时间试图让所有东西都工作起来。我失败了,这让我很沮丧。
之后我为 Electron 找到了几十个其他的样板。我试了大约五个。有些还可以,但大多数模板都太固执己见了,而且安装了太多的依赖项,我甚至不知道它们是用来做什么的,这让我不太喜欢。有些甚至根本不工作,因为它们已经被遗弃多年了。
总之,对于刚接触 Electron 的人来说,开发体验低于平均水平。Next.js 和 Expo 将标准设置得如此之高,以至于我开始期待每个框架都能提供类似的体验。
那现在怎么办?
在漫无目的刷 Twitter 的时候,我看到了一条来自 Tauri 的有关 1.0 版本的推文。那时他们已经成立 2 年了,但我完全不知道 Tauri 是什么。我去看了他们的网站,我被震撼了 🤯 这似乎就是我正在寻找的东西。
你知道最棒的是什么吗?他们把一条 npm create tauri-app 命令放在了主页上。

Tauri 用
npx create Tauri -app命令从一开始就抓住了开发体验。
我决定尝试一下。我运行了 create the tauri-app 命令,体验与 Next.js 非常相似。它问了我几个问题,然后根据我的选择为我创建了一个新项目。
在这之后,我可以简单地运行 npm run dev,然后我就有了一个带有热加载、TypeScript、Vite 和 Solid.js 的可以运行的应用程序,几乎包含了我开始使用所需的一切。这让我印象深刻,并且很想了解更多。我仍然不得不添加 Prettier、Linters、Tailwind 等类似的东西,但我已经习惯了,而且它比 Electron 容易太多了。
开始(再一次😅),但与 Tauri 一起
虽然在 Electron 中,我可以只用 JavaScript/HTML/CSS 构建整个应用程序,但在 Tauri 中,后端是 Rust,只有前端是 JavaScript。这显然意味着我必须学习 Rust,这让我很兴奋,但也不想花太多时间,因为我想快速构建原型。
我在使用过 7 种以上专业的编程语言,所以我认为学习 Rust 是轻而易举的事。
我错了。我大错特错了。Rust 是很难的,真的很难,至少对我来说是这样!
一年后,在我的应用发布了 20 多个版本之后,我仍然不能说我真正了解 Rust。我知道要不断地定期发布新功能,但每次我必须用 Rust 写一些东西时,我仍然能学到很多新知识。GitHub Copilot 和 ChatGPT 帮了我大忙,我现在还经常使用它们。

像使用字符串这样简单的事情在Rust中要比在其他语言中复杂得多🤣
不过,Tauri 中有一些东西可以让这一过程变得简单许多。
Tauri 有一个“command 命令”的概念,它就像前端和后端之间的桥梁。你可以用 Rust 在你的 Tauri 后端定义“命令”,然后在 JavaScript 中调用它们。Tauri 本身提供了一系列可以开箱即用的命令。例如,你可以通过 JavaScript 打开一个文件选择器(file dialog),读取/更新/删除文件,发送 HTTP 请求,以及其他很多与操作系统进行的交互,而无需编写任何 Rust 代码。
那么,如果你需要做一些在 Tauri 中没有的事情呢?这就是“Plugins插件”的用武之地。插件是 Rust 库,它定义了你可以在 Tauri 应用中使用的命令。稍后我会详细介绍插件,但现在你只需将它们视为扩展 Tauri 功能的一种方式就可以了。
事实上,我已经询问了很多使用 Tauri 构建应用程序的人,问他们是否必须编写 Rust 代码来构建他们的应用程序。他们中的大多数表示,他们只需要为一些特定的使用情况编写非常少的 Rust 代码。完全可以在不编写任何 Rust 代码的情况下构建一个 Tauri 应用程序!
那么 Tauri 与 Electron 相比又如何呢?
1. 编程语言和社区
在 Electron 中,你的后端是一个 Node.js 进程,而前端是 Chromium,这意味着 Web 开发人员可以仅使用 JavaScript/HTML/CSS 来构建桌面应用程序。NPM 上有着庞大的库社区,并且在互联网上有大量与此相关的内容,这使得学习过程变得更加容易。
然而,尽管通常认为能够在后端和前端之间共享代码是一件好事,但也可能会导致混淆,因为开发人员可能会尝试在前端使用后端函数,反之亦然。因此,你必须小心不要混淆。
相比之下,Tauri 的后端是 Rust,前端也是一个 Webview(稍后会详细介绍)。虽然有大量的 Rust 库,但它们远远不及 NPM 的规模。Rust 社区也比 JavaScript 社区小得多,这意味着关于它的内容在互联网上较少。但正如上面提到的,取决于你要构建的内容,你甚至可能根本不需要编写太多的 Rust 代码。
我的观点: 我只是喜欢我们在 Tauri 中得到的明确的前后端的分离。如果我在 Rust 中编写一段代码,我知道它将作为一个操作系统进程运行,并且我可以访问网络、文件系统和许多其他内容,而我在 JavaScript 中编写的所有内容都保证在一个 Webview 上运行。学习 Rust 对我来说并不容易,但我很享受这个过程,而且总的来说我学到了很多新东西!Rust 开始在我心中生根了。😊
2. Webview
在 Electron 中,前端是一个与应用程序捆绑在一起的 Chromium Webview。这意味着无论操作系统如何,您都可以确定应用程序使用的 Node.js 和 Chromium 版本。这带来了重大的好处,但也有一些缺点。
最大的好处是开发和测试的便利性,您知道哪些功能可用,如果某些功能在 macOS 上可用,那么它很可能也可以在 Windows 和 Linux 上使用。然而,缺点是由于所有这些二进制文件捆绑在一起,您的应用程序大小会更大。
Tauri 采用了截然不同的方法。它不会将 Chromium 与您的应用程序捆绑在一起,而是使用操作系统的默认 Webview。这意味着在 macOS 上,您的应用程序将使用 WebKit(Safari 的引擎),在 Windows 上将使用 WebView2(基于 Chromium),在 Linux 上将使用WebKitGTK(与 Safari 相同)。
最终结果是一个感觉非常快速的极小型应用程序!
作为参考,我的 Tauri 应用程序在 macOS 上只有 24.7MB 大小,而我的竞争对手的应用程序(Electron)则达到了 1.3GB。
为什么这很重要?
- 下载和安装速度快得多。
- 主机和分发成本更低(我在 AWS 上运行,所以我需要支付带宽和存储费用)。
- 我经常被问到我的应用是否使用 Swift 构建,因为用户通常在看到如此小巧且快速的应用时会有一种“这感觉像是本地应用”的时候。
- 安全性由操作系统处理。如果 WebKit 存在安全问题,苹果将发布安全更新,我的应用将简单地使用它。我不必发布我的应用的更新版本来修复它。
我的观点: 我喜欢我的应用如此小巧且快速。起初,我担心操作系统之间缺乏一致性会导致我需要在所有 3 个操作系统上测试我的应用,但到目前为止我没有遇到任何问题。无论如何,Web开发人员已经习惯了这种情况,因为我们长期以来一直在构建多浏览器应用程序。打包工具和兼容性填充也在这方面提供了很大帮助!
3. 插件
我之前简要提到过这一点,但我认为它值得更详细地讨论,因为在我看来,这是 Tauri 最好的特性之一。插件是由 Rust 编写的一组命令集,可以从 JavaScript 中调用。它允许开发人员通过组合不同的插件来构建应用程序,这些插件可以是开源的,也可以在您的应用程序中定义。
这是一种很好的应用程序组织结构的方式,它也使得在不同应用程序之间共享代码变得容易!
在 Tauri 社区中,您会找到一些插件的示例:
- tauri-plugin-log - 可配置的日志记录。
- tauri-plugin-store - 存储用户偏好/设置。
- tauri-plugin-window-state - 保存窗口大小和位置。
- window-vibrancy - 使您的窗口生动起来。
- tauri-plugin-sql - 连接任何 SQL 数据库。
- tauri-plugin-aptabase - 用于 Tauri 应用程序的分析。
- 还有更多……
这些特性本来可能可以成为 Tauri 本身的一部分,但将它们单独分开意味着您可以挑选和选择您想要使用的功能。这也意味着它们可以独立演变,并且如果有更好的替代品发布,可以被替换。
插件系统是我选择 Tauri 的第二大原因;它让开发者的体验提升了 1000 倍!
4. 功能对比
就功能而言,Electron 和 Tauri 非常相似。Electron 仍然具有一些更多的功能,但 Tauri 正在迅速赶上。至少对于我的使用情况来说,Tauri 具有我所需要的一切。
唯一给我带来较大不便的是缺乏一个“本地上下文菜单”API。这是社区强烈要求的功能,它将使 Tauri 应用程序感觉更加本地化。我目前是用 JS/HTML/CSS 来实现这一点,虽然可以,但还有提升的空间。希望我们能在 Tauri 2 中看到这个功能的实现 🤞
但除此之外,Tauri 还有很多功能。开箱即用,您可以得到通知、状态栏、菜单、对话框、文件系统、网络、窗口管理、自动更新、打包、代码签名、GitHub actions、辅助组件等。如果您需要其他功能,您可以编写一个插件,或者使用现有的插件之一。
5. 移动端
这个消息让我感到惊讶。在我撰写这篇文章时,Tauri 已经实验性地支持 iOS 和 Android。似乎这一直是计划的一部分,但当我开始我的应用程序时并不知道这一点。我不确定自己是否会使用它,但知道它存在感到很不错。
这是 Electron 所不可能实现的,并且可能永远也不会。因此,如果您计划构建跨平台的移动和桌面应用程序,Tauri 可能是一种不错的选择,因为您可能能够在它们之间共享很多代码。利用网络技术设计移动优先界面多年来变得越来越容易,因此构建一个既可以作为桌面应用程序又可以作为移动应用程序运行的单一界面并不像听起来那么疯狂。
我只是想提一句,让大家对 Tauri 的未来感到兴奋。

watchOS 上的 Tauri 程序?🤯
正如 Jonas 在他的推文中所提到的,这只是实验性的和折衷的;它可能需要很长时间才能达到生产状态,但看到这个领域的创新仍然非常令人兴奋!
结论
我对选择使用 Tauri 感到非常满意。结合 Solid.js,我能够制作出一个真正快速的应用程序,人们喜欢它!我不是说它总是比 Electron 好,但如果它具有您需要的功能,我建议尝试一下!如前所述,您甚至可能不需要写那么多 Rust 代码,所以不要被吓倒!您会惊讶地发现,只用 JavaScript 就能做的事情有多少。
如果你对 Kubernetes 感兴趣,请查看 Aptakube,这是一个使用 Tauri 构建的 Kubernetes 桌面客户端 😊
我现在正在开发一个面向桌面和移动应用的开源且注重隐私的分析平台。它已经具有各种框架的 SDK,包括 Tauri 和 Electron。顺便说一句,Tauri SDK 被打包为一个 Tauri 插件! 😄
最后,我也活跃在 Twitter 上。如果您有任何问题或反馈,请随时联系我。我喜欢谈论 Tauri!
感谢阅读!👋
来源:juejin.cn/post/7386115583845744649
最新Cursor无限续杯避坑指南,让你稳稳的喝咖啡~
2月份写了篇cursor无限续杯的文章,文章数据对我来说相当完美,看来大家对于不花钱这事比较感兴趣🤣
介于有些同学反应说自定义域名有一定的门槛,上手不太容易,那么今天新的方案它来了!此方案针对频繁被提示试用过期,too many free accounts的场景。
首先要申明一下:
- 无限邮你就别想了,请放弃!!
- cursor请稳定在 <= 0.46.11
废话不多说,进入正文吧 (查看原文体验更佳,有惊喜~)
Step1: 破解软件下载
✨方案使用的是开源软件cursor-help进行cursor重置
👉mac/linux 请使用go-cursor-help 进行操作
- 下载cursor_bypass.exe (红框中的文件,不能科学上网的,下面有网盘链接)
🎈如果打不开链接,可以使用下面的网盘链接下载以上文件
Step2: cursor退出账号
已退出账号直接跳过该步骤~
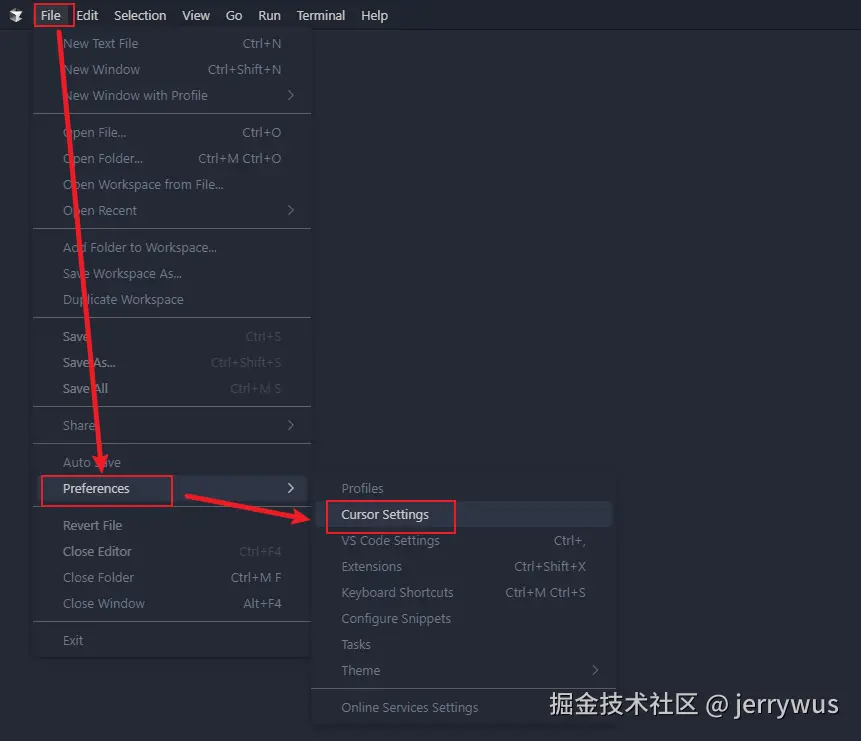
Step3: 运行软件
管理员****身份运行(必须,不然点击会没反应) Cursor Bypass.exe
依次点击:
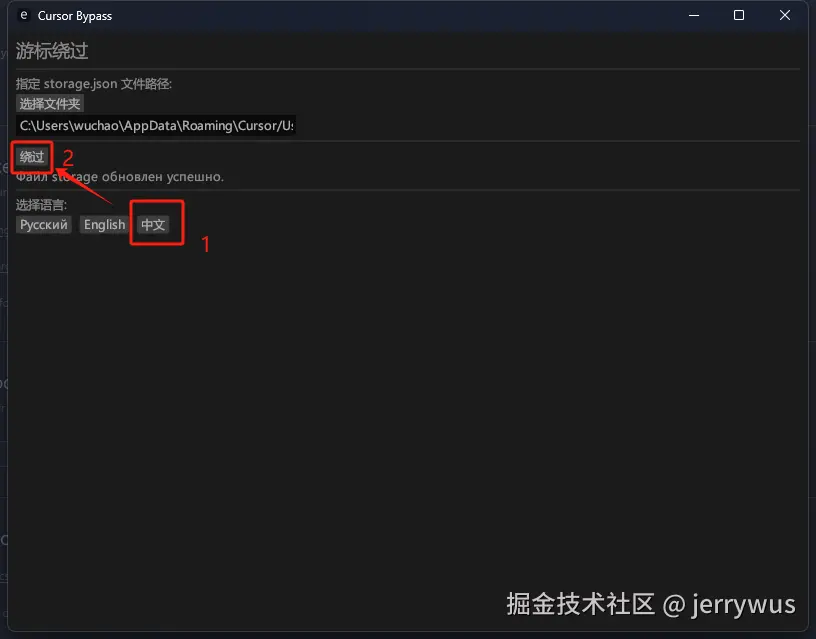
操作完会弹出网页,不用管它~
Step4:登录你之前注册的账号
浏览器打开cursor进行登录:
完成登录后,然后页面点击右上角头像,点击账号设置
然后左下角点开Advanced,找到delete account,点击它
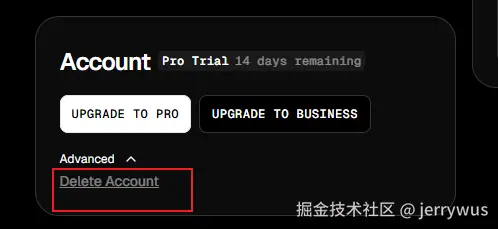
Step5: 删除账号
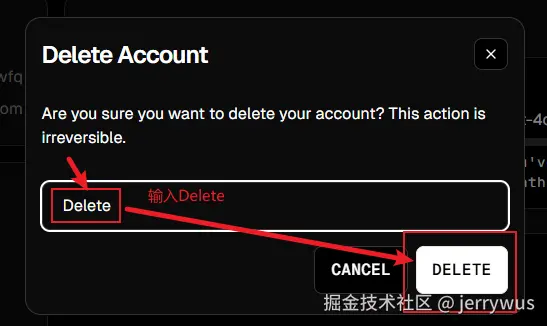
输入Delete,点击删除按钮,删除账号
如果出现 Failed to fetch(cursor服务器网络波动),刷新页面,重试~
Step6:恢复之前的账号
浏览器打开cursor注册页面,使用之前cursor账号那个邮箱再重新注册一遍~
当然了,这里也可以注册新账号(不要用无限邮 )
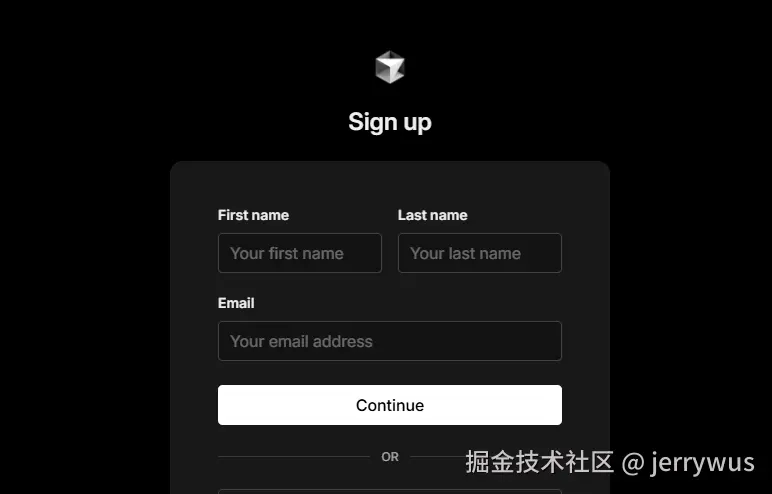
输入信息,完成注册~
Step7: 使用cursor软件进行登录
建议将chrome设置为默认浏览器(chrome浏览器改成默认浏览器),这样登录会很顺利(同时需要退出360安全卫士这种垃圾软件,它会拦截登录,有点恶心)
💻点这里可以离线下载chrome浏览器
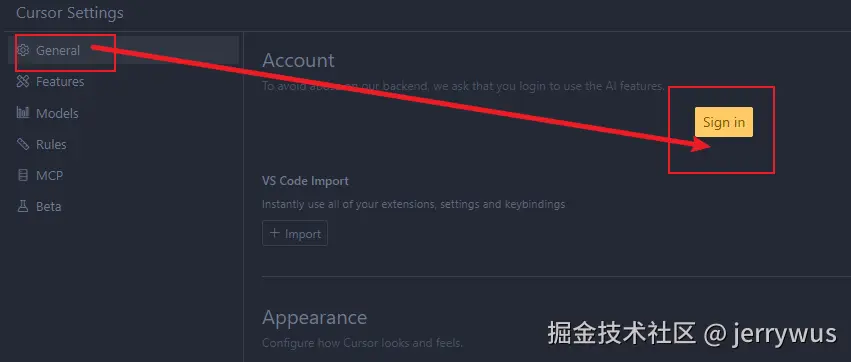
在弹出的页面中完成登录,登录成功是下面的状态
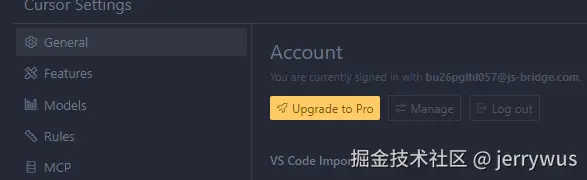
然后回到cursor,状态如下就登录成功了
注意:如果这一步失败,可能360安全卫士这类垃圾软件在搞怪(会拦截登录过程),建议退出360重试
Step8: 验证是否可以试用
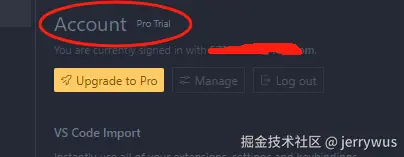
看刚刚的cursor网页,如下状态,就可以了

cursor软件-账户信息再看一眼,这样就没问题了
验证提问 CTRL + L,能正常响应即可~
测试代码tab功能
试用版账号需要注意的点
试用账户:
- max模型只有pro正式会员可用,试用账号不可用!!
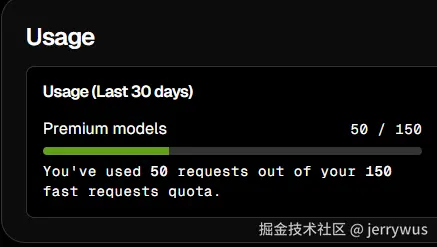
- tab补全是2000次
- 聊天只有50次,虽然显示了150(达到50即无效,此时按文档重新来一遍即可)
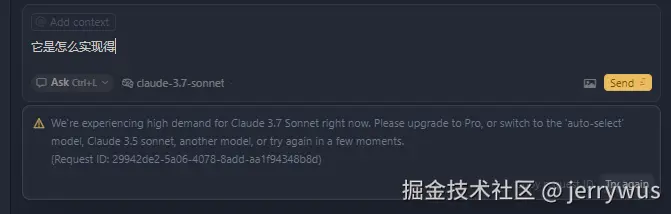
- Tinking打开后,可能出现error
需要关掉Thinking,重试
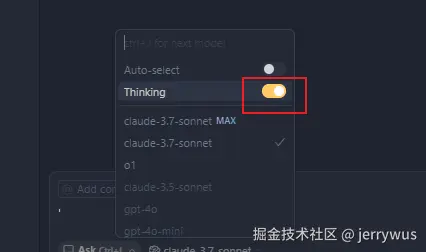
关掉Thinking即可提问(除非达到50次上限)
更多信息,请移步原文~
来源:juejin.cn/post/7486323379474563107
前端の骚操作代码合集 | 让你的网页充满恶趣味
1️⃣ 永远点不到的幽灵按钮
效果描述:按钮会跟随鼠标指针,但始终保持微妙距离
<button id="ghostBtn" style="position:absolute">点我试试?</button>
<script>
const btn = document.getElementById('ghostBtn');
document.addEventListener('mousemove', (e) => {
btn.style.left = `${e.clientX + 15}px`;
btn.style.top = `${e.clientY + 15}px`;
});
</script>
2️⃣ 极简黑客帝国数字雨
代码亮点:仅用 20 行代码实现经典效果
<canvas id="matrix"></canvas>
<script>
const canvas = document.getElementById('matrix');
const ctx = canvas.getContext('2d');
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
const chars = '01';
const drops = Array(Math.floor(canvas.width/20)).fill(0);
function draw() {
ctx.fillStyle = 'rgba(0,0,0,0.05)';
ctx.fillRect(0,0,canvas.width,canvas.height);
ctx.fillStyle = '#0F0';
drops.forEach((drop, i) => {
ctx.fillText(chars[Math.random()>0.5?0:1], i*20, drop);
drops[i] = drop > canvas.height ? 0 : drop + 20;
});
}
setInterval(draw, 100);
</script>
运行建议:按下 F11 进入全屏模式效果更佳
下面是优化版:
<script>
const canvas = document.getElementById('matrix');
const ctx = canvas.getContext('2d');
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
const chars = '01'; // 显示的字符
const columns = Math.floor(canvas.width / 20); // 列数
const drops = Array(columns).fill(0); // 每列的起始位置
const speeds = Array(columns).fill(0).map(() => Math.random() * 10 + 5); // 每列的下落速度
function draw() {
// 设置背景颜色并覆盖整个画布,制造渐隐效果
ctx.fillStyle = 'rgba(0, 0, 0, 0.05)';
ctx.fillRect(0, 0, canvas.width, canvas.height);
// 设置字符颜色
ctx.fillStyle = '#0F0'; // 绿色
ctx.font = '20px monospace'; // 设置字体
// 遍历每一列
drops.forEach((drop, i) => {
// 随机选择一个字符
const char = chars[Math.random() > 0.5 ? 0 : 1];
// 绘制字符
ctx.fillText(char, i * 20, drop);
// 更新下落位置
drops[i] += speeds[i];
// 如果超出画布高度,重置位置
if (drops[i] > canvas.height) {
drops[i] = 0;
speeds[i] = Math.random() * 10 + 5; // 重置速度
}
});
}
// 每隔100毫秒调用一次draw函数
setInterval(draw, 100);
</script>
3️⃣ 元素融化动画
交互效果:点击元素后触发扭曲消失动画
<div onclick="melt(this)"
style="cursor:pointer; padding:20px; background:#ff6666;">
点我融化!
</div>
<script>
function melt(element) {
let pos = 0;
const meltInterval = setInterval(() => {
element.style.borderRadius = `${pos}px`;
element.style.transform = `skew(${pos}deg) scale(${1 - pos/100})`;
element.style.opacity = 1 - pos/100;
pos += 2;
if(pos > 100) clearInterval(meltInterval);
}, 50);
}
</script>
4️⃣ 控制台藏宝图
彩蛋效果:在开发者工具中埋入神秘信息
console.log('%c🔮 你发现了秘密通道!',
'font-size:24px; color:#ff69b4; text-shadow: 2px 2px #000');
console.log('%c输入咒语 %c"芝麻开门()" %c获得力量',
'color:#666', 'color:#0f0; font-weight:bold', 'color:#666');
console.debug('%c⚡ 警告:前方高能反应!',
'background:#000; color:#ff0; padding:5px;');
5️⃣ 重力反转页面
魔性交互:让页面滚动方向完全颠倒
window.addEventListener('wheel', (e) => {
e.preventDefault();
window.scrollBy(-e.deltaX, -e.deltaY);
}, { passive: false });
慎用警告:此功能可能导致用户怀疑人生 ( ̄▽ ̄)"
6️⃣ 实时 ASCII 摄像头
技术亮点:将摄像头画面转为字符艺术
<pre id="asciiCam" style="font-size:8px; line-height:8px;"></pre>
<script>
navigator.mediaDevices.getUserMedia({ video: true })
.then(stream => {
const video = document.createElement('video');
video.srcObject = stream;
video.play();
const chars = '@%#*+=-:. ';
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
video.onplaying = () => {
canvas.width = 80;
canvas.height = 40;
setInterval(() => {
ctx.drawImage(video, 0, 0, 80, 40);
const imgData = ctx.getImageData(0,0,80,40).data;
let ascii = '';
for(let i=0; i<imgData.length; i+=4) {
const brightness = (imgData[i]+imgData[i+1]+imgData[i+2])/3;
ascii += chars[Math.floor(brightness/25.5)]
+ (i%(80*4) === (80*4-4) ? '\n' : '');
}
document.getElementById('asciiCam').textContent = ascii;
}, 100);
};
});
</script>
⚠️ 使用注意事项
- 摄像头功能需 HTTPS 环境或 localhost 才能正常工作
- 反向滚动代码可能影响用户体验,建议仅在整蛊场景使用
- 数字雨效果会持续消耗 GPU 资源
- 控制台彩蛋要确保不会暴露敏感信息
这些代码就像前端的"复活节彩蛋",适度使用能让网站充满趣味性,但千万别用在生产环境哦!(≧∇≦)ノ
https://codepen.io/ 链接 CodePen)
希望这篇博客能成为程序员的快乐源泉!🎉
来源:juejin.cn/post/7477573759254675507
别再追逐全新框架了,先打好基础再说......
Hello,大家好,我是 Sunday
如果大家做过一段时间的前端开发,就会发现相比其他的技术圈而言,前端圈总显得 “乱” 的很。
因为,每隔几个月,圈里就会冒出一个“闪闪发光的全新 JavaScript 框架”,声称能解决你所有问题,并提供各种数据来证明它拥有:更快的性能!更简洁的语法!更多的牛批特性!
而对应的,很多同学都会开始 “追逐” 这些全新的框架,并大多数情况下都会得出一个统一的评论 “好牛批......”
但是,根据我的经验来看,通常情况下 过于追逐全新的框架,毫无意义。 特别是对于 前端初学者 而言,打好基础会更加的重要!
PS:我这并不是在反对新框架的创新,出现更多全新的框架,全新的创新方案肯定是好的。但是,我们需要搞清楚一点,这一个所谓的全新框架 究竟是创新,还是只是通过一个不同的方式,重复的造轮子?
全新的框架是追逐不完的
我们回忆一下,是不是很多所谓的全新框架,总是按照以下的方式在不断的轮回?
- 首先,网上出现了某个“全新 JS 框架”发布,并提供了:更小、更快、更优雅 的方案,从而吸引了大量关注
- 然后,很多技术人开始追捧,从 掘金、抖音、B 站 开始纷纷上线各种 “教程”
- 再然后,几乎就没有然后了。国内大厂不会轻易使用这种新的框架作为生产工具,因为大厂会更加看重框架的稳定性
- 最后,无非会出现两种结果,第一种就是:热度逐渐消退,最后停止维护。第二种就是:不断的适配何种业务场景,直到这种全新的框架也开始变得“臃肿不堪”,和它当年要打败的框架几乎一模一样。
- 重新开始轮回:另一个“热门”框架出现,整个循环再次启动。
Svelte 火了那么久,大家有见到过国内有多少公司在使用吗?可能有很多同学会说“国外有很多公司在使用 Svelte 呀?” 就算如此,它对比 Vue 、React、Angular(国外使用的不少) 市场占有率依然是寥寥无几的。并且大多数同学的主战场还不在国外。
很多框架只是语法层面发生了变化
咱们以一个 “点击计数” 的功能为例,分别来看下在 Vue、React、Svelte 三个框架中的实现(别问为啥没有 angular,问就是不会😂)
Vue3 实现
<template>
<button @click="count++">点击了 {{ count }} 次</button>
</template>
<script setup>
import { ref } from 'vue';
const count = ref(0);
</script>
React 实现
import { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
return (
<button onClick={() => setCount(count + 1)}>
点击了 {count} 次
</button>
);
}
export default Counter;
Svelte 实现
<script>
let count = 0;
</script>
<button on:click={() => count += 1}>
点击了 {count} 次
</button>
这三个版本的核心逻辑完全一样,只是语法不同。
那么这就意味着:如果换框架,都要重新学习这些新的语法细节(哪里要写冒号、哪里要写大括号、哪里要写中括号)。
如果你把时间都浪费着这些地方上(特别是前端初学者),是不是就意味着 毫无意义,浪费时间呢?
掌握好基础才是王道
如果我们去看了大量的 国内大厂的招聘面经之后,就会发现,无论是 校招 || 社招,大厂的考察重点 永远不在框架,而在于 JS 基础、网络、算法、项目 这四个部分。至于你会的是 vue || react 并没有那么重要!
PS:对于大厂来说
vue 和 react都有不同的团队在使用。所以不用担心你学的框架是什么,这并不影响你进大厂
因此,掌握好基础就显得太重要了。
所以说:不用过于追逐新的技术框架。
针对于 在校生 而言 打好基础,练习算法,多去做更多有价值的项目,研究框架底层源码 ,并且一定要注意 练习表达,这才是对你将来校招最重要的事情!
而对于 社招的同学 而言 多去挖掘项目的重难点,尝试通过 输出知识的方式 帮助你更好的梳理技术。多去思考 技术如何解决业务问题,这才是关键!
来源:juejin.cn/post/7484960608782336027
让你辛辛苦苦选好的筛选条件刷新页面后不丢失,该怎么做?
你有遇到过同样的需求吗?告诉我你的第一想法。存 Session storage ?可以,但是我更建议你使用 router.replace 。
为什么建议使用 router.replace 而不是浏览器自带的存储空间呢?
增加实用性,你有没有考虑过这种场景,也就是当我筛选好之后进行搜索,我需要将它发给我的同事。当使用storage时是实现不了的,同事只会得到一个初始的页面。那我们将这个筛选结果放入url中是不是就可以解决这个问题了。
router.replace
先给大家介绍一下 router.replace 的用法吧。
router.replace 是 Vue Router 提供的一个方法,用于替换当前的历史记录条目。与 router.push 不同的是,replace 不会在浏览器历史记录中添加新记录,而是替换当前的记录。这对于需要在 URL 中保存状态但不想影响浏览器导航历史的场景非常有用。
// 假设我们正在使用 Vue 2 和 Vue Router
methods: {
updateFilters(newFilters) {
// 将筛选条件编码为查询字符串参数
const query = {
...this.$route.query,
...newFilters,
};
// 使用 router.replace 更新 URL
this.$router.replace({ query });
}
}
在这个示例中,updateFilters 方法接收新的筛选条件,并将它们合并到当前的查询参数中。然后使用 router.replace 更新 URL,而不会在历史记录中添加新条目。
具体实现
将筛选条件转换为适合 URL 的格式,例如 JSON 字符串或简单的键值对。以下是一个更详细的实现:
methods: {
applyFilters(filters) {
const encodedFilters = JSON.stringify(filters);
this.$router.replace({
path: this.$route.path,
query: { ...this.$route.query, filters: encodedFilters },
});
},
getFiltersFromUrl() {
const filters = this.$route.query.filters;
return filters ? JSON.parse(filters) : {};
}
}
在这个实现中,applyFilters 方法将筛选条件编码为 JSON 字符串,并将其存储在 URL 的查询参数中。getFiltersFromUrl 方法用于从 URL 中读取筛选条件,并将其解析回 JavaScript 对象。
注意事项
- 编码和解码:在将复杂对象存储到 URL 时,确保使用
encodeURIComponent和decodeURIComponent来处理特殊字符。 - URL 长度限制:浏览器对 URL 长度有一定的限制,确保不要在 URL 中存储过多数据。
- 数据安全性:考虑 URL 中数据的敏感性,避免在 URL 中存储敏感信息。
- url重置:不要忘了在筛选条件重置时也将
url重置,在取消筛选时同时去除url上的筛选。
一些其他的应用场景
- 重定向用户:
- 当用户访问一个不再存在或不推荐使用的旧路径时,可以使用
router.replace将他们重定向到新的路径。这避免了用户点击“返回”按钮时再次回到旧路径。
- 当用户访问一个不再存在或不推荐使用的旧路径时,可以使用
- 处理表单提交后清理 URL:
- 在表单提交后,可能会在 URL 中附加查询参数。使用
router.replace可以在处理完表单数据后清理这些参数,保持 URL 的整洁。
- 在表单提交后,可能会在 URL 中附加查询参数。使用
- 登录后跳转:
- 在用户登录后,将他们重定向到一个特定的页面(如用户主页或仪表盘),并且不希望他们通过“返回”按钮回到登录页面。使用
router.replace可以实现这一点。
- 在用户登录后,将他们重定向到一个特定的页面(如用户主页或仪表盘),并且不希望他们通过“返回”按钮回到登录页面。使用
- 错误页面处理:
- 当用户导航到一个不存在的页面时,可以使用
router.replace将他们重定向到一个错误页面(如 404 页面),并且不希望这个错误路径保留在浏览历史中。
- 当用户导航到一个不存在的页面时,可以使用
- 动态内容加载:
- 在需要根据用户操作动态加载内容时,使用
router.replace更新 URL,而不希望用户通过“返回”按钮回到之前的状态。例如,在单页应用中根据选项卡切换更新 URL。
- 在需要根据用户操作动态加载内容时,使用
- 多步骤流程:
- 在多步骤的用户流程中(如注册或购买流程),使用
router.replace可以在用户完成每一步时更新 URL,而不希望用户通过“返回”按钮回到上一步。
- 在多步骤的用户流程中(如注册或购买流程),使用
- 清理查询参数:
- 在用户操作完成后,使用
router.replace清理不再需要的查询参数,保持 URL 简洁且易于阅读。
- 在用户操作完成后,使用
小结
简单来说就是把你的
url当成浏览器的sessionstorage了。其实这就是我上周收到的任务,当时我甚至纠结的是该用localStorage还是sessionStorage,忙活半天,不停转类型,然后在开周会我讲了下我的思路。我的tl便说出了我的问题,讲了更加详细的需求,我才开始尝试router.replace,又是一顿忙活。。
来源:juejin.cn/post/7424034641379098663
做了个渐变边框的input输入框,领导和客户很满意!
需求简介
前几天需求评审的时候,产品说客户希望输入框能够好看一点。由于我们UI框架用的是Elemnt Plus,input输入框的样式也比较中规中矩,所以我们组长准备拒绝这个需求
但是,喜欢花里胡哨的我立马接下了这个需求!我自信的告诉组长,放着我来,包满意!
经过一番折腾,我通过 CSS 的技巧实现了一个带有渐变边框的 Input 输入框,而且当鼠标悬浮在上面时,边框颜色要更加炫酷并加深渐变效果。

最后,领导和客户对最后的效果都非常满意~我也成功获得了老板给我画的大饼,很开心!
下面就来分享我的实现过程和代码方案,满足类似需求的同学可以直接拿去用!
实现思路
实现渐变边框的原理其实很简单,首先实现一个渐变的背景作为底板,然后在这个底板上加上一个纯色背景就好了。

当然,我们在实际写代码的时候,不用专门写两个div来这么做,利用css的 background-clip 就可以实现上面的效果。
background-clip属性详解
background-clip是一个用于控制背景(background)绘制范围的 CSS 属性。它决定了背景是绘制在 内容区域、内边距区域、还是 边框区域。
background-clip: border-box | padding-box | content-box | text;
代码实现
背景渐变
<template>
<div class="input-container">
<input type="text" placeholder="请输入内容" class="gradient-input" />
</div>
</template>
<script setup>
</script>
<style>
/* 输入框容器 */
.input-container {
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
width: 100vw;
background: #f4f4f9;
}
/* 渐变边框输入框 */
.gradient-input {
width: 400px;
height: 40px;
padding: 5px 12px;
font-size: 16px;
color: #333;
outline: none;
/* 渐变边框 */
border: 1px solid transparent;
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
border-radius: 20px;
}
/* Placeholder 样式 */
.gradient-input::placeholder {
color: #aaa;
font-style: italic;
}
</style>

通过上面的css方法,我们成功实现了一个带有渐变效果边框的 Input 输入框,它的核心代码是
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
padding-box:限制背景在内容区域显示,防止覆盖输入框内容。
border-box:渐变背景会显示在边框位置,形成渐变边框效果。
这段代码分为两层背景:
- 第一层背景:
linear-gradient(white, white)是一个纯白色的线性渐变,用于覆盖输入框的内容区域(padding-box)。 - 第二层背景:
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3)是一个多色的渐变,用于显示在输入框的边框位置(border-box)。
背景叠加后,最终效果是:内层内容是白色背景,边框区域显示渐变颜色。
Hover 效果
借助上面的思路,我们在添加一些hover后css样式,通过 :hover 状态改变渐变的颜色和 box-shadow 的炫光效果:
/* Hover 状态 */
.gradient-input:hover {
background: linear-gradient(white, white) padding-box,
linear-gradient(135deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 5px rgba(255, 0, 118, 0.5), 0 0 20px rgba(30, 174, 255, 0.5);
}

过渡似乎有点生硬,没关系,加个过渡样式
/* 渐变边框输入框 */
.gradient-input {
// .....
/* 平滑过渡 */
transition: background 0.3s ease, box-shadow 0.3s ease;
}
非常好看流畅~

激活样式
最后,我们再添加一个激活的Focus 状态:当用户聚焦输入框时,渐变变得更加灵动,加入额外的光晕。
/* Focus 状态 */
.gradient-input:focus {
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 15px rgba(255, 0, 118, 0.7), 0 0 25px rgba(30, 174, 255, 0.7);
color: #000; /* 聚焦时文本颜色 */
}
现在,我们就实现了一个渐变边框的输入框,是不是非常好看?

完整代码
<template>
<div class="input-container">
<input type="text" placeholder="请输入内容" class="gradient-input" />
</div>
</template>
<style>
/* 输入框容器 */
.input-container {
display: flex;
align-items: center;
justify-content: center;
height: 100vh;
width: 100vw;
background: #f4f4f9;
}
/* 渐变边框输入框 */
.gradient-input {
width: 400px;
height: 40px;
padding: 5px 12px;
font-size: 16px;
font-family: 'Arial', sans-serif;
color: #333;
outline: none;
/* 渐变边框 */
border: 1px solid transparent;
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff7eb3, #65d9ff, #c7f464, #ff7eb3) border-box;
border-radius: 20px;
/* 平滑过渡 */
transition: background 0.3s ease, box-shadow 0.3s ease;
}
/*
/* Hover 状态 */
.gradient-input:hover {
background: linear-gradient(white, white) padding-box,
linear-gradient(135deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 5px rgba(255, 0, 118, 0.5), 0 0 20px rgba(30, 174, 255, 0.5);
}
/* Focus 状态 */
.gradient-input:focus {
background: linear-gradient(white, white) padding-box,
linear-gradient(45deg, #ff0076, #1eaeff, #28ffbf, #ff0076) border-box;
box-shadow: 0 0 15px rgba(255, 0, 118, 0.7), 0 0 25px rgba(30, 174, 255, 0.7);
color: #000; /* 聚焦时文本颜色 */
}
/* Placeholder 样式 */
.gradient-input::placeholder {
color: #aaa;
font-style: italic;
}
</style>
总结
通过上述方法,我们成功实现了一个带有渐变效果边框的 Input 输入框,并且在 Hover 和 Focus 状态下增强了炫彩效果。
大家可以根据自己的需求调整渐变的方向、颜色或动画效果,让你的输入框与众不同!
来源:juejin.cn/post/7442216034751545394
几行代码,优雅的避免接口重复请求!同事都说好!
背景简介
我们日常开发中,经常会遇到点击一个按钮或者进行搜索时,请求接口的需求。
如果我们不做优化,连续点击按钮或者进行搜索,接口会重复请求。

首先,这会导致性能浪费!最重要的,如果接口响应比较慢,此时,我们在做其他操作会有一系列bug!
那么,我们该如何规避这种问题呢?
如何避免接口重复请求
防抖节流方式(不推荐)
使用防抖节流方式避免重复操作是前端的老传统了,不多介绍了
防抖实现
<template>
<div>
<button @click="debouncedFetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const timeoutId = ref(null);
function debounce(fn, delay) {
return function(...args) {
if (timeoutId.value) clearTimeout(timeoutId.value);
timeoutId.value = setTimeout(() => {
fn(...args);
}, delay);
};
}
function fetchData() {
axios.get('http://api/gcshi) // 使用示例API
.then(response => {
console.log(response.data);
})
}
const debouncedFetchData = debounce(fetchData, 300);
</script>
防抖(Debounce) :
- 在setup函数中,定义了timeoutId用于存储定时器ID。
- debounce函数创建了一个闭包,清除之前的定时器并设置新的定时器,只有在延迟时间内没有新调用时才执行fetchData。
- debouncedFetchData是防抖后的函数,在按钮点击时调用。
节流实现
<template>
<div>
<button @click="throttledFetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const lastCall = ref(0);
function throttle(fn, delay) {
return function(...args) {
const now = new Date().getTime();
if (now - lastCall.value < delay) return;
lastCall.value = now;
fn(...args);
};
}
function fetchData() {
axios.get('http://api/gcshi') //
.then(response => {
console.log(response.data);
})
}
const throttledFetchData = throttle(fetchData, 1000);
</script>
节流(Throttle) :
- 在setup函数中,定义了lastCall用于存储上次调用的时间戳。
- throttle函数创建了一个闭包,检查当前时间与上次调用时间的差值,只有大于设定的延迟时间时才执行fetchData。
- throttledFetchData是节流后的函数,在按钮点击时调用。
节流防抖这种方式感觉用在这里不是很丝滑,代码成本也比较高,因此,很不推荐!
请求锁定(加laoding状态)
请求锁定非常好理解,设置一个laoding状态,如果第一个接口处于laoding中,那么,我们不执行任何逻辑!
<template>
<div>
<button @click="fetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
const laoding = ref(false);
function fetchData() {
// 接口请求中,直接返回,避免重复请求
if(laoding.value) return
laoding.value = true
axios.get('http://api/gcshi') //
.then(response => {
laoding.value = fasle
})
}
const throttledFetchData = throttle(fetchData, 1000);
</script>
这种方式简单粗暴,十分好用!
但是也有弊端,比如我搜索A后,接口请求中;但我此时突然想搜B,就不会生效了,因为请求A还没响应!

因此,请求锁定这种方式无法取消原先的请求,只能等待一个请求执行完才能继续请求。
axios.CancelToken取消重复请求
基本用法
axios其实内置了一个取消重复请求的方法:axios.CancelToken,我们可以利用axios.CancelToken来取消重复的请求,爆好用!
首先,我们要知道,aixos有一个config的配置项,取消请求就是在这里面配置的。
<template>
<div>
<button @click="fetchData">请求</button>
</div>
</template>
<script setup>
import { ref } from 'vue';
import axios from 'axios';
let cancelTokenSource = null;
function fetchData() {
if (cancelTokenSource) {
cancelTokenSource.cancel('取消上次请求');
cancelTokenSource = null;
}
cancelTokenSource = axios.CancelToken.source();
axios.get('http://api/gcshi',{cancelToken: cancelTokenSource.token}) //
.then(response => {
laoding.value = fasle
})
}
</script>
我们测试下,如下图:可以看到,重复的请求会直接被终止掉!

CancelToken官网示例
官网使用方法传送门:http://www.axios-http.cn/docs/cancel…
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// 取消请求(message 参数是可选的)
source.cancel('Operation canceled by the user.');
也可以通过传递一个 executor 函数到 CancelToken 的构造函数来创建一个 cancel token:
const CancelToken = axios.CancelToken;
let cancel;
axios.get('/user/12345', {
cancelToken: new CancelToken(function executor(c) {
// executor 函数接收一个 cancel 函数作为参数
cancel = c;
})
});
// 取消请求
cancel();
注意: 可以使用同一个 cancel token 或 signal 取消多个请求。
在过渡期间,您可以使用这两种取消 API,即使是针对同一个请求:
const controller = new AbortController();
const CancelToken = axios.CancelToken;
const source = CancelToken.source();
axios.get('/user/12345', {
cancelToken: source.token,
signal: controller.signal
}).catch(function (thrown) {
if (axios.isCancel(thrown)) {
console.log('Request canceled', thrown.message);
} else {
// 处理错误
}
});
axios.post('/user/12345', {
name: 'new name'
}, {
cancelToken: source.token
})
// 取消请求 (message 参数是可选的)
source.cancel('Operation canceled by the user.');
// 或
controller.abort(); // 不支持 message 参数
来源:juejin.cn/post/7380185173689204746
最近 React Scan 太火了,做了个 Vue Scan
在 React Scan 的 github 有这么一张 gif 图片。当用户在页面上操作时,对应的组件会有一个闪烁,表示当前组件更新了。用这样的方式来排查程序的性能是一个很直观的方式。

根据 React Scan 自己的介绍,React Scan 可以 通过自动检测和突出显示导致性能问题的渲染。
Vue Scan
但是我主要使用 vue 来开发我的应用,看到这个功能非常眼馋,所以就动手自己做了一个 demo,目前也构建了一个 chrome 扩展,不过扩展仅支持识别 vue3 项目 现在已经支持 vue2 和 vue3 项目了。
项目地址:Vue Scan
简单介绍,Vue Scan 通过组件的 onBeforUpdate 钩子,当组件更新时,在组件对应位置绘制一个闪烁的边框。看起来的效果就像这样。

用法
我更推荐在开发环境使用它,Vue Scan 提供一个 vue plugin,允许你在 mount 之前注入相关的内容。
// vue3
import { createApp } from 'vue'
import VueScan, { type VueScanOptions } from 'z-vue-scan/src'
import App from './App.vue'
const app = createApp(App)
app.use<VueScanOptions>(VueScan, {})
app.mount('#app')
// vue2
import Vue from 'vue'
import VueScan, { type VueScanBaseOptions } from 'z-vue-scan/vue2'
import App from './App.vue'
Vue.use<VueScanBaseOptions>(VueScan, {})
new Vue({
render: h => h(App),
}).$mount('#app')
浏览器扩展
如果你觉得看自己的网站没什么意思,那么我还构建了一个浏览器扩展,允许你注入相关方法到别人的 vue 程序中。
你可以在 Github Release 寻找一下最新版的安装包,然后解压安装到浏览器中。
安装完成后,你的扩展区域应该会多一个图标,点击之后会展开一个面板,允许你控制是否注入相关的内容。

这是如果你进入一个使用 vue 构建的网站,可以看控制台看到相关的信息,当你在页面交互时,页面应该也有相应的展示。

缺陷
就像 React Scan 的介绍中提到的,它能自动识别性能问题,单目前 Vue Scan 只是真实地反映组件的更新,并不会区分和识别此次更新是否有性能问题。
结语
通过观察网站交互时组件的更新状态,来尝试发现网站的性能问题,我觉得这是一个很好的方式。希望这个工具可以给大家带来一点乐趣和帮助。
来源:juejin.cn/post/7444449353165488168
Electron 启动白屏解决方案
对于 Web 开发者使用 Electron 构建桌面应用程序时,经常会遇到如上图所示的一个问题 —— 窗口加载过程中长时间白屏。在应用窗口创建完成到页面加载出来的这段时间里,出现了长时间的白屏,这个问题对于前端开发来说是一个老生常谈的问题,纯 Web 端可能就是异步加载、静态资源压缩、CDN 以及骨架屏等等优化方案,但是如果是开发 Electron 应用,场景又有些许不同,因此我们也不能完全按照通用的前端解决白屏的方案进行处理,本文就来探索基于 Electron 场景下启动白屏的解决方案。
问题原因分析
1. Electron 主进程加载时间过长
Electron 应用在启动时,需要先加载主进程,然后由主进程去创建浏览器窗口和加载页面。如果主进程加载时间过长,就会导致应用一直停留在空白窗口,出现白屏。
主进程加载时间长的原因可以有:
- 初始化逻辑复杂,比如加载大量数据、执行计算任务等
- 主进程依赖的模块加载时间长,例如 Native 模块编译耗时
- 主进程代码进行了大量同步 I/O 操作,阻塞了事件循环
2. Web 部分性能优化不足
浏览器窗口加载 HTML、JavaScript、CSS 等静态资源是一个渐进的过程,如果资源体积过大,加载时间过长,在加载过程中就会短暂出现白屏,这一点其实就是我们常说的前端首屏加载时间过长的问题。导致 Web 加载时间过长的原因可以是:
- 页面体积大,如加载过多图片、视频等大资源
- 没有代码拆分,一次加载全部 Bundles
- 缺乏缓存机制,资源无法命中缓存
- 主线程运算量大,频繁阻塞渲染
解决方案
1. 常规 Web 端性能优化
Web 端加载渲染过程中的白屏,可以采用常规前端的性能优化手段:
- 代码拆分,异步加载,避免大包导致的加载时间过长
- 静态资源压缩合并、CDN 加速,减少资源加载时间
- 使用骨架屏技术,先提供页面骨架,优化用户体验
- 减少主线程工作量,比如使用 Web Worker 进行复杂计算
- 避免频繁布局重排,优化 DOM 操作
以上优化可以明显减少 HTML 和资源加载渲染的时,缩短白屏现象。还是那句话,纯 Web 端的性能优化对于前端开发来说老生常谈,我这边不做详细的赘述,不提供实际代码,开发者可以参考其他大佬写的性能优化文章,本文主要针对的是 Electron 启动白屏过长的问题,因为体验下来 Electron 白屏的本质问题还是要通过 Electron 自身来解决~
2. 控制 Electron 主进程加载时机
Electron 启动长时间白屏的本质原因,前面特意强调了,解决方案还是得看 Electron 自身的加载时机,因为我这边将 Web 部分的代码打包启动,白屏时间是非常短的,与上面动图里肉眼可见的白屏时间形成了鲜明的对比。所以为了解决这个问题,我们还是要探寻 Electron 的加载时机,通过对 Electron 的启动流程分析,我们发现:
- 如果在主进程准备就绪之前就创建并显示浏览器窗口,由于此时渲染进程和页面还未开始加载,窗口内自然就是空白,因此需要确保在合适的时机创建窗口。
- 反之如果创建窗口后,又长时间不调用
window.show()显示窗口,那么窗口会一直在后台加载页面,用户也会看不到,从而出现白屏的效果。
因此我们可以通过控制主进程的 Ready 事件时机以及 Window 窗口的加载时机来对这个问题进行优化,同样的关于加载时机我们也可以有两种方案进行优化:
- 通过监听
BrowserWindow上面的ready-to-show事件控制窗口显示
// 解决白屏问题
app.whenReady().then(() => {
// 将创建窗口的代码放在 `app.whenReady` 事件回调中,确保主进程启动完成后再创建窗口
const mainWindow = new BrowserWindow({ show:false });
// 加载页面
mainWindow.loadURL('index.html');
// 在 ready-to-show 事件中显示窗口
mainWindow..once("ready-to-show", () => {
mainWindow.show();
});
});
上述代码通过操作 app.whenReady() 和 BrowserWindow 的 mainWindow.once('ready-to-show') 这几个 Electron 核心启动 API,优雅地处理了窗口隐藏 + 页面加载 + 窗口显示等问题,详细流程如下:
- 将创建窗口的代码放在
app.whenReady事件回调中,确保主进程启动完成后再创建窗口 - 创建窗口的时候让窗口隐藏不显示
{ show: false },避免页面没加载完成导致的白屏 - 窗口加载页面
win.loadURL,也就是说窗口虽然隐藏了,但是不耽误加载页面 - 通过
ready-to-show事件来判断窗口是否已经准备好,这个事件其实就代表页面已经加载完成了,因此此时调用mainWidnow.show()让窗口显示就解决了白屏的问题
- 通过监听
BrowserWindow.webContents上面的did-finish-load或者dom-ready事件来控制窗口显示
app.whenReady().then(() => {
// 将创建窗口的代码放在 `app.whenReady` 事件回调中,确保主进程启动完成后再创建窗口
const mainWindow = new BrowserWindow({ show:false });
// 加载页面
mainWindow.loadURL(indexPage);
// 通过 webContents 对应事件来处理窗口显示
mainWindow.webContents.on("did-finish-load", () => {
mainWindow.show();
});
});
此方案与上述方案的唯一区别就是,第一个使用的是 BrowserWindow 的事件来处理,而此方案通过判断 BrowserWindow.webContents 这个对象,这个对象是 Electron 中用来渲染以及控制 Web 页面的,因此我们可以更直接的使用 did-finish-load 或者直接 dom-ready 这两个事件来判断页面是否加载完成,这两个 API 的含义相信前端开发者都不陌生,页面加载完成以及 DOM Ready 都是前端的概念,通过这种方式也是可以解决启动白屏的。
相关文档:BrowserWindow、webCotnents
最后解决完成的效果如下:

总结
从上图来看最终的效果还是不错的,当窗口出现的一瞬间页面就直接加载完成了,不过细心的小伙伴应该会发现,这个方案属于偷梁换柱,给用户的感觉是窗口出现的时候页面就有内容了,但是其实窗口没出现的时间是有空档期的,大概就是下面这个意思:

从上图以及实际效果来看,其实我们的启动时间是没有发生改变的,但是因为端上应用和我们纯 Web 应用的使用场景不同,它自身就是有应用的启动时间,所以空档期如果不长,这个方案的体验还是可以的。但是如果前面的空档期过长,那么可能就是 Electron 启动的时候加载资源过多造成的了,就需要其他优化方案了。由此也可以见得其实对于用户体验来说,可能我们的产品性能并不一定有提升,只要从场景出发从用户角度去考虑问题,其实就能提升整个应用的体验。
回归本篇文章,我们从问题入手分析了 Electron 启动白屏出现的原因并提供了对应的解决方案,笔者其实对 Electron 的开发也并不深入,只是解决了一个需求一个问题用文章做记录,欢迎大家交流心得,共同进步~
来源:juejin.cn/post/7371386534179520539
用electron写个浏览器给自己玩
浏览器这种东西工程量很唬人,但是有了electron+webview我们就相当于只需要干组装的活就可以了,而且产品目标就是给自己玩,
成品的效果

😄本来想写成专业的技术博客,但是发现大家好像对那种密密麻麻,全是代码的技术博客不感兴趣,我就挑重点来写吧。

下载拦截功能

下载逻辑如果不做拦截处理的话,默认就是我们平常写web那种弹窗的方式,既然是浏览器肯定不能是那样的。
electron中可以监听BrowserWindow的页面下载事件,并把拿到的下载状态传给渲染线程,实现类似浏览器的下载器功能。
//这个global.WIN = global.WIN = new BrowserWindow({ ...})
global.WIN.webContents.session.on('will-download', (evt, item) => {
//其他逻辑
item.on('updated', (evt, state) => {
//实时的下载进度传递给渲染线程
})
})
页面搜索功能
当时做这个功能的时候我就觉得完了,这个玩意看起来太麻烦了,还要有一个的功能这不是头皮发麻啊。

查资料和文档发现这个居然是webview内置的功能,瞬间压力小了很多,我们只需要出来ctrl+f的时候把搜索框弹出来这个UI就可以了,关键字变色和下一个都是内部已经实现好了的。
function toSearch() {
let timer
return () => {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
if (keyword.value) {
webviewRef.value.findInPage(keyword.value, { findNext: true })
} else {
webviewRef.value.stopFindInPage('clearSelection')
}
}, 200)
}
}
function closeSearch() {
showSearch.value = false
webviewRef.value.stopFindInPage('clearSelection')
}
function installFindPage(webview) {
webviewRef.value = webview
webviewRef.value.addEventListener('found-in-page', (e) => {
current.value = e.result.activeMatchOrdinal
total.value = e.result.matches
})
}
当前标签页打开功能
就是因为chrome和edge这些浏览器每次使用的时候开非常多的标签,挤在一起,所以我想这个浏览器不能主动开标签,打开了一个标签后强制所有的标签都在当前标签覆盖。
app.on('web-contents-created', (event, contents) => {
contents.setWindowOpenHandler((info) => {
global.WIN?.webContents.send('webview-url-is-change')
if (info.disposition === 'new-window') {
return { action: 'allow' }
} else {
global.WIN?.webContents.send('webview-open-url', info.url)
return { action: 'deny' }
}
})
})
渲染线程监听到webview-open-url后也就是tart="_blank"的情况,强制覆盖当前不打开新窗口
ipcRenderer.on('webview-open-url', (event, url) => {
try {
let reg = /http|https/g
if (webviewRef.value && reg.test(url)) {
webviewRef.value.src = url
}
} catch (err) {
console.log(err)
}
})
标签页切换功能
这里的切换是css的显示隐藏,借助了vue-router

这里我们看dom就能清晰的看出来。

地址栏功能
地址栏支持输入url直接访问链接、支持关键字直接打开收藏的网站、还支持关键字搜索。优先级1打开收藏的网页 2访问网站 3关键字搜索
function toSearch(keyword) {
if (`${keyword}`.length === 0) {
return false
}
// app搜索
if (`${keyword}`.length < 20) {
let item = null
const list = [...deskList.value, ...ALL_DATA]
for (let i = 0; i < list.length; i++) {
if (
list[i].title.toUpperCase().search(keyword.toUpperCase()) !== -1 &&
list[i].type !== 'mini-component'
) {
item = list[i]
break
}
}
if (item) {
goApp(item)
return false
}
}
// 网页访问
let url
if (isUrl(keyword)) {
if (!/^https?:\/\//i.test(keyword)) {
url = 'http://' + keyword
} else {
url = keyword
}
goAppNewTab(url)
return false
} else {
// 关键字搜索
let searchEngine = localStorage.getItem('searchEngine')
searchEngine = searchEngine || CONFIG.searchEngine
url = searchEngine + keyword
if (!router.hasRoute('search')) {
router.addRoute({
name: 'search',
path: '/search',
meta: {
title: '搜索',
color: 'var(--app-icon-bg)',
icon: 'search.svg',
size: 1
},
component: WebView
})
keepAliveInclude.value.push('search')
}
router.push({
path: '/search',
query: { url }
})
setTimeout(() => {
Bus.$emit('toSearch', url)
}, 20)
}
}
桌面图标任意位置拖动
这个问题困扰了我很久,因为它不像电脑桌面大小是固定的,浏览器可以全屏也可以小窗口,如果最开始是大窗口然后拖成小窗口,那么图标就看不到了。后来想到我干脆给个中间区域固定大小,就可以解决这个问题了。因为固定大小出来起来就方便多了。这个桌面是上下两层
//背景格子
<div v-show="typeActive === 'me'" class="bg-boxs">
<div
v-for="(item, i) in 224" //这里有点不讲究了直接写死了
:key="item"
class="bg-box"
@dragenter="enter($event, { x: (i % 14) + 1, y: Math.floor(i / 14) + 1 })"
@dragover="over($event)"
@dragleave="leave($event)"
@drop="drop($event)"
></div>
</div>
// 桌面层
// ...
import { ref, computed } from 'vue'
import useDesk from '@/store/deskList'
import { storeToRefs } from 'pinia'
export default function useDrag() {
const dragging = ref(null)
const currentTarget = ref()
const desk = useDesk()
const { deskList } = storeToRefs(desk)
const { setDeskList, updateDeskData } = desk
function start(e, item) {
e.target.classList.add('dragging')
e.dataTransfer.effectAllowed = 'move'
dragging.value = item
currentTarget.value = e
console.log('开始')
}
let timer2
function end(e) {
dragging.value = null
e.target.classList.remove('dragging')
setDeskList(deskList.value)
if (timer2) {
clearTimeout(timer2)
}
timer2 = setTimeout(() => {
updateDeskData()
}, 2000)
}
function over(e) {
e.preventDefault()
}
let timer
function enter(e, item) {
e.dataTransfer.effectAllowed = 'move'
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
if (item?.x) {
dragging.value.x = item.x
dragging.value.y = item.y
}
}, 100)
}
function leave(e) {}
function drop(e) {
e.preventDefault()
}
return { start, end, over, enter, leave, drop }
}


东西太多了就先介绍这些了
安装包地址
也可以到官网后aweb123.com 如何进入微软商店下载,mac版本因为文件大于100mb没有传上去所以暂时还用不了。
来源:juejin.cn/post/7395389351641612300
大声点回答我:token应该存储在cookie还是localStorage上?
背景
前置文章:浏览器: cookie机制完全解析
在考虑token是否应该存储在cookie或localStorage中时,我们需要综合考虑安全性、便利性、两者的能力边界以及设计目的等因素。

安全性:
Cookies的优势:
Set-Cookie: token=abc123; HttpOnly;Secure;SameSite=Strict;Domain=example.com; Path=/
- HttpOnly:将 HttpOnly 属性设置为 true 可以防止 JavaScript 读取 cookie,从而有效防止 XSS(跨站脚本)攻击读取 token。这一特性使得 cookies 在敏感信息存储上更具安全性。
- Secure:设置 Secure 属性后,cookie 只会在 HTTPS 连接时发送,从而防止中间人攻击。这确保了即使有人截获请求,token 也不会被明文传输。
- SameSite:SameSite 属性减少了 CSRF(跨站请求伪造)攻击的风险,通过指示浏览器在同一站点请求时才发送 cookie。
- Domain 和 Path:这些属性限制了 cookie 的作用范围,例如仅在特定子域或者路径下生效,进一步提高安全性。
localStorage的缺点:
XSS 风险:localStorage 对 JavaScript 代码完全可见,这意味着如果应用存在 XSS 漏洞,攻击者即可轻易获取存储在 localStorage 中的 token。
能力层面
Cookies可以做到更前置更及时的页面访问控制,服务器可以在接收到页面请求时,立即通过读取 cookie 判断用户身份,返回响应的页面(例如重定向到登录页)。
// 示例:后端在接收到请求时可以立即判断
if (!request.cookies.token) {
response.redirect('/login');
}
和cookie相比 localStorage具有一定的滞后性,浏览器必须先加载 HTML 和 JavaScript资源,解析执行后 才能通过在localStorage取到数据后 经过ajax网络请求 发送给服务端判断用户身份,这种方式有滞后性,可能导致临时显示不正确的内容。
管理的便利性
Cookies是由服务端设置的 由浏览器自动管理生命周期的一种方式
服务器可以直接通过 HTTP 响应头设置 cookie,浏览器会自动在后续请求中携带,无需在客户端手动添加。减少了开发和维护负担,且降低了人为错误的风险。
localStorage需要客户端手动管理
使用 localStorage 需要在客户端代码管理 token,你得确保在每个请求中手动添加和删除token,增加了代码复杂度及出错的可能性。
设计目的:
HTTP协议是无状态的 一个用户第二次请求和一个新用户第一次请求 服务端是识别不出来的,cookie是为了让服务端记住客户端而被设计的。
Cookie 设计的初衷就是帮助服务器标识用户的会话状态(如登录状态),因而有很多内建的安全和管理机制,使其特别适合承载 token 等这些用户状态的信息。
localStorage 主要用于存储客户端关心的、较大体积的数据(如用户设置、首选项等),而不是设计来存储需要在每次请求时使用的认证信息。
总结
在大多数需要处理用户身份认证的应用中,将 token 存储在设置了合适属性的 cookie 中,不仅更安全,还更符合 cookie 的设计目的。
通过 HTTP 响应头由服务端设置并自动管理,极大简化了客户端代码,并确保在未经身份验证的情况下阻断对敏感页面的访问。
因此 我认为 在大多数情况下,将 token 存储在 cookies 中更为合理和安全。
补充
然鹅 现实的业务场景往往是复杂多变的 否则也不会有token应该存储在cookie还是localStorage上?这个问题出现了。
localStorage更具灵活性: 不同应用有不同的安全需求,有时 localStorage 可以提供更加灵活和精细化的控制。 开发者可以在 JavaScript 中手动管理 localStorage,包括在每次请求时显式设置认证信息。这种 灵活性 对于一些高级用例和性能优化场景可能非常有用。
所以一般推荐使用cookie 但是在合适的场景下使用localStorage完全没问题。
来源:juejin.cn/post/7433079710382571558
MCP 终极指南
过去快一年的时间没有更新 AI 相关的博客,一方面是在忙 side project,另外一方面也是因为 AI 技术虽然日新月异,但是 AI 应用层的开发并没有多少新的东西,大体还是2023年的博客讲的那三样,Prompt、RAG、Agent。
但是自从去年 11 月底 Claude(Anthropic) 主导发布了 MCP(Model Context Protocol 模型上下文协议) 后,AI 应用层的开发算是进入了新的时代。
不过关于 MCP 的解释和开发,目前似乎还没有太多的资料,所以笔者决定将自己的一些经验和思考整理成一篇文章,希望能够帮助到大家。
为什么 MCP 是一个突破
我们知道过去一年时间,AI 模型的发展非常迅速,从 GPT 4 到 Claude Sonnet 3.5 到 Deepseek R1,推理和幻觉都进步的非常明显。
新的 AI 应用也很多,但我们都能感受到的一点是,目前市场上的 AI 应用基本都是全新的服务,和我们原来常用的服务和系统并没有集成,换句话说,AI 模型和我们已有系统集成发展的很缓慢。
例如我们目前还不能同时通过某个 AI 应用来做到联网搜索、发送邮件、发布自己的博客等等,这些功能单个实现都不是很难,但是如果要全部集成到一个系统里面,就会变得遥不可及。
如果你还没有具体的感受,我们可以思考一下日常开发中,想象一下在 IDE 中,我们可以通过 IDE 的 AI 来完成下面这些工作。
- 询问 AI 来查询本地数据库已有的数据来辅助开发
- 询问 AI 搜索 Github Issue 来判断某问题是不是已知的bug
- 通过 AI 将某个 PR 的意见发送给同事的即时通讯软件(例如 Slack)来 Code Review
- 通过 AI 查询甚至修改当前 AWS、Azure 的配置来完成部署
以上谈到的这些功能通过 MCP 目前正在变为现实,大家可以关注 Cursor MCP 和 Windsurf MCP 获取更多的信息。可以试试用 Cursor MCP + browsertools 插件来体验一下在 Cursor 中自动获取 Chrome dev tools console log 的能力。
为什么 AI 集成已有服务的进展这么缓慢?这里面有很多的原因,一方面是企业级的数据很敏感,大多数企业都要很长的时间和流程来动。另一个方面是技术方面,我们缺少一个开放的、通用的、有共识的协议标准。
MCP 就是 Claude(Anthropic) 主导发布的一个开放的、通用的、有共识的协议标准,如果你是一个对 AI 模型熟悉的开发人员,想必对 Anthropic 这个公司不会陌生,他们发布了 Claude 3.5 Sonnet 的模型,到目前为止应该还是最强的编程 AI 模型(刚写完就发布了 3.7😅)。
这里还是要多提一句,这个协议的发布最好机会应该是属于 OpenAI 的,如果 OpenAI 刚发布 GPT 时就推动协议,相信大家都不会拒绝,但是 OpenAI 变成了 CloseAI,只发布了一个封闭的 GPTs,这种需要主导和共识的标准协议一般很难社区自发形成,一般由行业巨头来主导。
Claude 发布了 MCP 后,官方的 Claude Desktop 就开放了 MCP 功能,并且推动了开源组织 Model Context Protocol,由不同的公司和社区进行参与,例如下面就列举了一些由不同组织发布 MCP 服务器的例子。
MCP 官方集成教学:
- Git - Git 读取、操作、搜索。
- GitHub - Repo 管理、文件操作和 GitHub API 集成。
- Google Maps - 集成 Google Map 获取位置信息。
- PostgreSQL - 只读数据库查询。
- Slack - Slack 消息发送和查询。
🎖️ 第三方平台官方支持 MCP 的例子
由第三方平台构建的 MCP 服务器。
🌎 社区 MCP 服务器
下面是一些由开源社区开发和维护的 MCP 服务器。
- AWS - 用 LLM 操作 AWS 资源。
- Atlassian - 与 Confluence 和 Jira 进行交互,包括搜索/查询 Confluence 空间/页面,访问 Jira Issue 和项目。
- Google Calendar - 与 Google 日历集成,日程安排,查找时间,并添加/删除事件。
- Kubernetes - 连接到 Kubernetes 集群并管理 pods、deployments 和 services。
- X (Twitter) - 与 Twitter API 交互。发布推文并通过查询搜索推文。
- YouTube - 与 YouTube API 集成,视频管理、短视频创作等。
为什么是 MCP?
看到这里你可能有一个问题,在 23 年 OpenAI 发布 GPT function calling 的时候,不是也是可以实现类似的功能吗?我们之前博客介绍的 AI Agent,不就是用来集成不同的服务吗?为什么又出现了 MCP。
function calling、AI Agent、MCP 这三者之间有什么区别?
Function Calling
- Function Calling 指的是 AI 模型根据上下文自动执行函数的机制。
- Function Calling 充当了 AI 模型与外部系统之间的桥梁,不同的模型有不同的 Function Calling 实现,代码集成的方式也不一样。由不同的 AI 模型平台来定义和实现。
如果我们使用 Function Calling,那么需要通过代码给 LLM 提供一组 functions,并且提供清晰的函数描述、函数输入和输出,那么 LLM 就可以根据清晰的结构化数据进行推理,执行函数。
Function Calling 的缺点在于处理不好多轮对话和复杂需求,适合边界清晰、描述明确的任务。如果需要处理很多的任务,那么 Function Calling 的代码比较难维护。
Model Context Protocol (MCP)
- MCP 是一个标准协议,如同电子设备的 Type C 协议(可以充电也可以传输数据),使 AI 模型能够与不同的 API 和数据源无缝交互。
- MCP 旨在替换碎片化的 Agent 代码集成,从而使 AI 系统更可靠,更有效。通过建立通用标准,服务商可以基于协议来推出它们自己服务的 AI 能力,从而支持开发者更快的构建更强大的 AI 应用。开发者也不需要重复造轮子,通过开源项目可以建立强大的 AI Agent 生态。
- MCP 可以在不同的应用/服务之间保持上下文,从而增强整体自主执行任务的能力。
可以理解为 MCP 是将不同任务进行分层处理,每一层都提供特定的能力、描述和限制。而 MCP Client 端根据不同的任务判断,选择是否需要调用某个能力,然后通过每层的输入和输出,构建一个可以处理复杂、多步对话和统一上下文的 Agent。
AI Agent
- AI Agent 是一个智能系统,它可以自主运行以实现特定目标。传统的 AI 聊天仅提供建议或者需要手动执行任务,AI Agent 则可以分析具体情况,做出决策,并自行采取行动。
- AI Agent 可以利用 MCP 提供的功能描述来理解更多的上下文,并在各种平台/服务自动执行任务。
思考
为什么 Claude 推出 MCP 后会被广泛接受呢?其实在过去的一年中我个人也参与了几个小的 AI 项目的开发工作,在开发的过程中,将 AI 模型集成现有的系统或者第三方系统确实挺麻烦。
虽然市面上有一些框架支持 Agent 开发,例如 LangChain Tools, LlamaIndex 或者是 Vercel AI SDK。
LangChain 和 LlamaIndex 虽然都是开源项目,但是整体发展还是挺混乱的,首先是代码的抽象层次太高了,想要推广的都是让开发人员几行代码就完成某某 AI 功能,这在 Demo 阶段是挺好用的,但是在实际开发中,只要业务一旦开始复杂,糟糕的代码设计带来了非常糟糕的编程体验。还有就是这几个项目都太想商业化了,忽略了整体生态的建设。
还有一个就是 Vercel AI SDK,尽管个人觉得 Vercel AI SDK 代码抽象的比较好,但是也只是对于前端 UI 结合和部分 AI 功能的封装还不错,最大的问题是和 Nextjs 绑定太深了,对其它的框架和语言支持度不够。
所以 Claude 推动 MCP 可以说是一个很好的时机,首先是 Claude Sonnet 3.5 在开发人员心中有较高的地位,而 MCP 又是一个开放的标准,所以很多公司和社区都愿意参与进来,希望 Claude 能够一直保持一个良好的开放生态。
MCP 对于社区生态的好处主要是下面两点:
- 开放标准给服务商,服务商可以针对 MCP 开放自己的 API 和部分能力。
- 不需要重复造轮子,开发者可以用已有的开源 MCP 服务来增强自己的 Agent。
MCP 如何工作
那我们来介绍一下 MCP 的工作原理。首先我们看一下官方的 MCP 架构图。

总共分为了下面五个部分:
- MCP Hosts: Hosts 是指 LLM 启动连接的应用程序,像 Cursor, Claude Desktop、Cline 这样的应用程序。
- MCP Clients: 客户端是用来在 Hosts 应用程序内维护与 Server 之间 1:1 连接。
- MCP Servers: 通过标准化的协议,为 Client 端提供上下文、工具和提示。
- Local Data Sources: 本地的文件、数据库和 API。
- Remote Services: 外部的文件、数据库和 API。
整个 MCP 协议核心的在于 Server,因为 Host 和 Client 相信熟悉计算机网络的都不会陌生,非常好理解,但是 Server 如何理解呢?
看看 Cursor 的 AI Agent 发展过程,我们会发现整个 AI 自动化的过程发展会是从 Chat 到 Composer 再进化到完整的 AI Agent。
AI Chat 只是提供建议,如何将 AI 的 response 转化为行为和最终的结果,全部依靠人类,例如手动复制粘贴,或者进行某些修改。
AI Composer 是可以自动修改代码,但是需要人类参与和确认,并且无法做到除了修改代码之外的其它操作。
AI Agent 是一个完全的自动化程序,未来完全可以做到自动读取 Figma 的图片,自动生产代码,自动读取日志,自动调试代码,自动 push 代码到 GitHub。
而 MCP Server 就是为了实现 AI Agent 的自动化而存在的,它是一个中间层,告诉 AI Agent 目前存在哪些服务,哪些 API,哪些数据源,AI Agent 可以根据 Server 提供的信息来决定是否调用某个服务,然后通过 Function Calling 来执行函数。
MCP Server 的工作原理
我们先来看一个简单的例子,假设我们想让 AI Agent 完成自动搜索 GitHub Repository,接着搜索 Issue,然后再判断是否是一个已知的 bug,最后决定是否需要提交一个新的 Issue 的功能。
那么我们就需要创建一个 Github MCP Server,这个 Server 需要提供查找 Repository、搜索 Issues 和创建 Issue 三种能力。
我们直接来看看代码:
const server = new Server(
{
name: "github-mcp-server",
version: VERSION,
},
{
capabilities: {
tools: {},
},
}
);
server.setRequestHandler(ListToolsRequestSchema, async () => {
return {
tools: [
{
name: "search_repositories",
description: "Search for GitHub repositories",
inputSchema: zodToJsonSchema(repository.SearchRepositoriesSchema),
},
{
name: "create_issue",
description: "Create a new issue in a GitHub repository",
inputSchema: zodToJsonSchema(issues.CreateIssueSchema),
},
{
name: "search_issues",
description: "Search for issues and pull requests across GitHub repositories",
inputSchema: zodToJsonSchema(search.SearchIssuesSchema),
}
],
};
});
server.setRequestHandler(CallToolRequestSchema, async (request) => {
try {
if (!request.params.arguments) {
throw new Error("Arguments are required");
}
switch (request.params.name) {
case "search_repositories": {
const args = repository.SearchRepositoriesSchema.parse(request.params.arguments);
const results = await repository.searchRepositories(
args.query,
args.page,
args.perPage
);
return {
content: [{ type: "text", text: JSON.stringify(results, null, 2) }],
};
}
case "create_issue": {
const args = issues.CreateIssueSchema.parse(request.params.arguments);
const { owner, repo, ...options } = args;
const issue = await issues.createIssue(owner, repo, options);
return {
content: [{ type: "text", text: JSON.stringify(issue, null, 2) }],
};
}
case "search_issues": {
const args = search.SearchIssuesSchema.parse(request.params.arguments);
const results = await search.searchIssues(args);
return {
content: [{ type: "text", text: JSON.stringify(results, null, 2) }],
};
}
default:
throw new Error(`Unknown tool: ${request.params.name}`);
}
} catch (error) {}
});
async function runServer() {
const transport = new StdioServerTransport();
await server.connect(transport);
console.error("GitHub MCP Server running on stdio");
}
runServer().catch((error) => {
console.error("Fatal error in main():", error);
process.exit(1);
});
上面的代码中,我们通过 server.setRequestHandler 来告诉 Client 端我们提供了哪些能力,通过 description 字段来描述这个能力的作用,通过 inputSchema 来描述完成这个能力需要的输入参数。
我们再来看看具体的实现代码:
export const SearchOptions = z.object({
q: z.string(),
order: z.enum(["asc", "desc"]).optional(),
page: z.number().min(1).optional(),
per_page: z.number().min(1).max(100).optional(),
});
export const SearchIssuesOptions = SearchOptions.extend({
sort: z.enum([
"comments",
...
]).optional(),
});
export async function searchUsers(params: z.infer<typeof SearchUsersSchema>) {
return githubRequest(buildUrl("https://api.github.com/search/users", params));
}
export const SearchRepositoriesSchema = z.object({
query: z.string().describe("Search query (see GitHub search syntax)"),
page: z.number().optional().describe("Page number for pagination (default: 1)"),
perPage: z.number().optional().describe("Number of results per page (default: 30, max: 100)"),
});
export async function searchRepositories(
query: string,
page: number = 1,
perPage: number = 30
) {
const url = new URL("https://api.github.com/search/repositories");
url.searchParams.append("q", query);
url.searchParams.append("page", page.toString());
url.searchParams.append("per_page", perPage.toString());
const response = await githubRequest(url.toString());
return GitHubSearchResponseSchema.parse(response);
}
可以很清晰的看到,我们最终实现是通过了 https://api.github.com 的 API 来实现和 Github 交互的,我们通过 githubRequest 函数来调用 GitHub 的 API,最后返回结果。
在调用 Github 官方的 API 之前,MCP 的主要工作是描述 Server 提供了哪些能力(给 LLM 提供),需要哪些参数(参数具体的功能是什么),最后返回的结果是什么。
所以 MCP Server 并不是一个新颖的、高深的东西,它只是一个具有共识的协议。
如果我们想要实现一个更强大的 AI Agent,例如我们想让 AI Agent 自动的根据本地错误日志,自动搜索相关的 GitHub Repository,然后搜索 Issue,最后将结果发送到 Slack。
那么我们可能需要创建三个不同的 MCP Server,一个是 Local Log Server,用来查询本地日志;一个是 GitHub Server,用来搜索 Issue;还有一个是 Slack Server,用来发送消息。
AI Agent 在用户输入 我需要查询本地错误日志,将相关的 Issue 发送到 Slack 指令后,自行判断需要调用哪些 MCP Server,并决定调用顺序,最终根据不同 MCP Server 的返回结果来决定是否需要调用下一个 Server,以此来完成整个任务。
如何使用 MCP
如果你还没有尝试过如何使用 MCP 的话,我们可以考虑用 Cursor(本人只尝试过 Cursor),Claude Desktop 或者 Cline 来体验一下。
当然,我们并不需要自己开发 MCP Servers,MCP 的好处就是通用、标准,所以开发者并不需要重复造轮子(但是学习可以重复造轮子)。
首先推荐的是官方组织的一些 Server:官方的 MCP Server 列表。
目前社区的 MCP Server 还是比较混乱,有很多缺少教程和文档,很多的代码功能也有问题,我们可以自行尝试一下 Cursor Directory 的一些例子,具体的配置和实战笔者就不细讲了,大家可以参考官方文档。
MCP 的一些资源
下面是个人推荐的一些 MCP 的资源,大家可以参考一下。
MCP 官方资源
社区的 MCP Server 的列表
写在最后
本篇文章写的比较仓促,如果有错误再所难免,欢迎各位大佬指正。
最后本篇文章可以转载,但是请注明出处,会在 X/Twitter,小红书, 微信公众号 同步发布,欢迎各位大佬关注一波。
References
- guangzhengli.com/blog/zh/gpt…
- docs.cursor.com/context/mod…
- http://www.youtube.com/watch?v=Y_k…
- browsertools.agentdesk.ai/installatio…
- github.com/modelcontex…
- github.com/grafana/mcp…
- github.com/JetBrains/m…
- github.com/stripe/agen…
- github.com/rishikaviko…
- github.com/sooperset/m…
- github.com/v-3/google-…
- github.com/Flux159/mcp…
- github.com/EnesCinr/tw…
- github.com/ZubeidHendr…
- http://www.langchain.com/
- docs.llamaindex.ai/en/stable/
- sdk.vercel.ai/docs/introd…
- modelcontextprotocol.io/introductio…
- github.com/cline/cline
- github.com/modelcontex…
- http://www.anthropic.com/news/model-…
- cursor.directory
- http://www.pulsemcp.com/
- glama.ai/mcp/servers
相关系列文章推荐
来源:juejin.cn/post/7479471387020001306
这次终于轮到前端给后端兜底了🤣

需求交代
最近我们项目组开发了个互联网采集的功能,也就是后端合理抓取了第三方的文章,数据结构大致如下:
<h1>前端人</h1>
<p>学好前端,走遍天下都不怕</p>
数据抓取到后,存储到数据库,然后前端请求接口获取到数据,直接在页面预览
<div v-html='articleContent'></div>

整个需求已经交代清楚
这个需求有点为难后端了
前天,客户说要新增一个文章的pdf导出功能,但就是这么一个合情合理的需求,却把后端为难住了,原因是部分数据采集过来的结构可能是这样的:
<h1>前端人</h1>
<p>学好前端,走遍天下都不怕</p>
<div>前端强,前端狂,交互特效我称王!</div
<p>JS 写得好,需求改不了!</p>
<p>React Vue 两手抓,高薪 offer 到你家!</p>
<p>浏览器里横着走, bug 见我都绕道!</p>
<p>Chrome 调试一声笑, IE 泪洒旧时光!</p>
<span>Git 提交不留情,版本回退我最行!
仔细的人就能发现问题了,很多html元素存在没有完整的闭合情况

但浏览器是强大的,丝毫不影响渲染效果,原来浏览器自动帮我们补全结构了

可后端处理这件事就没那么简单了,爬取到的数据也比我举例的要复杂的多,使用第三方插件将html转pdf时会识别标签异常等问题,因此程序会抛异常
来自后端的建议
苦逼的后端折腾了很久,还是没折腾出来,终于他发现前端页面有个右键打印的功能,也就是:

于是他说:浏览器这玩意整挺好啊,前端能不能研究研究,尝试从前端实现导出
那就研究研究
我印象中,确实有个叫vue-print-nb的前端插件,可以实现这个功能
但.......等等,这个插件仅仅是唤起打印的功能,我总不能真做成这样,让用户另存为pdf吧
于是,只能另辟蹊径,终于我找到了这么个仓库:github.com/burc-li/vue…
里面实现了dom元素导出pdf的功能


效果很不错,技术用到了jspdf、html2canvas这两个第三方库,代码十分简单
const downLoadPdfA4Single = () => {
const pdfContaniner = document.querySelector('#pdfContaniner')
html2canvas(pdfContaniner).then(canvas => {
// 返回图片dataURL,参数:图片格式和清晰度(0-1)
const pageData = canvas.toDataURL('image/jpeg', 1.0)
// 方向纵向,尺寸ponits,纸张格式 a4 即 [595.28, 841.89]
const A4Width = 595.28
const A4Height = 841.89 // A4纸宽
const pageHeight = A4Height >= A4Width * canvas.height / canvas.width ? A4Height : A4Width * canvas.height / canvas.width
const pdf = new jsPDF('portrait', 'pt', [A4Width, pageHeight])
// addImage后两个参数控制添加图片的尺寸,此处将页面高度按照a4纸宽高比列进行压缩
pdf.addImage(
pageData,
'JPEG',
0,
0,
A4Width,
A4Width * canvas.height / canvas.width,
)
pdf.save('下载一页PDF(A4纸).pdf')
})
}
技术流程大致就是:
- dom -> canvas
- canvas -> image
- image -> pdf
似乎一切都将水到渠成了
困在眼前的难题
这个技术栈,最核心的就是:必须要用到dom元素渲染
如果你尝试将打印的元素设置样式:
display: none;
或
visibility: hidden;
或
opacity: 0;
执行导出功能都将抛异常或者只能导出一个空白的pdf
这时候有人会问了:为什么要设置dom元素为不可见?
试想一下,你做了一个导出功能,总不能让客户必须先打开页面等html渲染完后,再导出吧?
客户的理想状态是:在列表的操作列里,有个导出按钮,点击就可以导出pdf了
何况还需要实现批量勾选导出的功能,总不能程序控制,导出一个pdf就open一个窗口渲染html吧
寻找新方法
此路不通,就只能重新寻找新的方向,不过也没费太多功夫,就找到了另外一个插件html2pdf.js解决了这事
这插件用起来也极其简单
npm install html2pdf.js
<template>
<div class="container">
<button @click="generatePDF">下载PDF</button>
</div>
</template>
<script setup>
import html2pdf from 'html2pdf.js'
// 使用示例
let element = `
<h1>前端人</h1>
<p>学好前端,走遍天下都不怕</p>
<div>前端强,前端狂,交互特效我称王!</div
<p>JS 写得好,需求改不了!</p>
<p>React Vue 两手抓,高薪 offer 到你家!</p>
<p>浏览器里横着走, bug 见我都绕道!</p>
<p>Chrome 调试一声笑, IE 泪洒旧时光!</p>
<span>Git 提交不留情,版本回退我最行!
`;
function generatePDF() {
// 配置选项
const opt = {
margin: 10,
filename: 'hello_world.pdf',
image: { type: 'jpeg', quality: 0.98 },
html2canvas: { scale: 2 },
jsPDF: { unit: 'mm', format: 'a4', orientation: 'portrait' }
};
// 生成PDF并导出
html2pdf().from(element).set(opt).save();
}
</script>
功能正常,似乎一切都完美

问题没有想的那么简单
如果我们的html是纯文本元素,这程序跑起来没有任何问题,但我们抓取的信息都源于互联网,html结构怎么可能会这么简单?如果我们的html中包含图片信息,例如:
// 使用示例
let element = `
<div>
<img src='http://t13.baidu.com/it/u=2041049195,1001882902&fm=224&app=112&f=JPEG?w=500&h=500' style="width: 300px;" />
<p>职业:前端</p>
<p>技能:唱、跳、rap</p>
</div>
`;
此时你会发现,导出来的pdf,图片占位处是个空白块

思考一下:类似案例中的图片加载方式,都是get方式的异步请求,而异步请求就会导致图片还没渲染完成,但导出的程序已经执行完成情况(最直接的观察方式就是,把这个元素放到浏览器上渲染,会发现图片也是过一会才慢慢加载完成的)
不过我不确定
html2pdf.js这个插件是否会发起图片请求,但不管发不发起,导出的行为明显是在图片渲染前完成的,就导致了这个空白块的存在
问题分析完了,那就解决吧
既然图片异步加载不行,那就使用图片同步加载吧
不是吧,你问我:什么是图片同步加载?我也不晓得,这个词是我自己当下凭感觉造的,如有雷同,纯属巧合了
那我理解的图片同步加载是什么意思呢?简单来说,就是将图片转成Base64,因为这种方式,即使说无网的情况也能正常加载图片,因此我凭感觉断定,这就是图片同步加载
基于这个思路,我写了个demo
<template>
<div class="container">
<button @click="generatePDF">下载PDF</button>
</div>
</template>
<script setup>
import html2pdf from 'html2pdf.js'
async function convertImagesToBase64(htmlString) {
// 创建一个临时DOM元素来解析HTML
const tempDiv = document.createElement('div');
tempDiv.innerHTML = htmlString;
// 获取所有图片元素
const images = tempDiv.querySelectorAll('img');
// 遍历每个图片并转换
for (const img of images) {
try {
const base64 = await getBase64FromUrl(img.src);
img.src = base64;
} catch (error) {
console.error(`无法转换图片 ${img.src}:`, error);
// 保留原始URL如果转换失败
}
}
// 返回转换后的HTML
return tempDiv.innerHTML;
}
// 图片转base64
function getBase64FromUrl(url) {
return new Promise((resolve, reject) => {
const img = new Image();
img.crossOrigin = 'Anonymous'; // 处理跨域问题
img.onload = () => {
const canvas = document.createElement('canvas');
canvas.width = img.width;
canvas.height = img.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
// 获取Base64数据
const dataURL = canvas.toDataURL('image/png');
resolve(dataURL);
};
img.onerror = () => {
reject(new Error('图片加载失败'));
};
img.src = url;
});
}
// 使用示例
let element = `
<div>
<img src='http://t13.baidu.com/it/u=2041049195,1001882902&fm=224&app=112&f=JPEG?w=500&h=500' style="width: 300px;" />
<p>职业:前端</p>
<p>技能:唱、跳、rap</p>
</div>
`;
function generatePDF() {
convertImagesToBase64(element)
.then(convertedHtml => {
// 配置选项
const opt = {
margin: 10,
filename: '前端大法好.pdf',
image: { type: 'jpeg', quality: 0.98 },
html2canvas: { scale: 2 },
jsPDF: { unit: 'mm', format: 'a4', orientation: 'portrait' }
};
// 生成PDF并导出
html2pdf().from(convertedHtml).set(opt).save();
})
.catch(error => {
console.error('转换过程中出错:', error);
});
}
</script>
此时就大功告成啦!不过得提一句:图片的URL链接必须是同源或者允许跨越的,否则就会存在图片加载异常的问题
修复图片过大的问题
部分图片的宽度会过大,导致图片加载不全的问题,这在预览的情况下也存在

因为需要加上样式限定
img {
max-width: 100%;
max-height: 100%;
vertical-align: middle;
height: auto !important;
width: auto !important;
margin: 10px 0;
}
这样就正常啦

故此需要在导出pdf前,给元素添加一个图片的样式限定
element =`<style>
img {
max-width: 100%;
max-height: 100%;
vertical-align: middle;
height: auto !important;
width: auto !important;
margin: 10px 0;
}
</style>` + element;
完整代码:
<template>
<div class="container">
<button @click="generatePDF">下载PDF</button>
</div>
</template>
<script setup>
import html2pdf from 'html2pdf.js'
async function convertImagesToBase64(htmlString) {
// 创建一个临时DOM元素来解析HTML
const tempDiv = document.createElement('div');
tempDiv.innerHTML = htmlString;
// 获取所有图片元素
const images = tempDiv.querySelectorAll('img');
// 遍历每个图片并转换
for (const img of images) {
try {
const base64 = await getBase64FromUrl(img.src);
img.src = base64;
} catch (error) {
console.error(`无法转换图片 ${img.src}:`, error);
// 保留原始URL如果转换失败
}
}
// 返回转换后的HTML
return tempDiv.innerHTML;
}
// 图片转base64
function getBase64FromUrl(url) {
return new Promise((resolve, reject) => {
const img = new Image();
img.crossOrigin = 'Anonymous'; // 处理跨域问题
img.onload = () => {
const canvas = document.createElement('canvas');
canvas.width = img.width;
canvas.height = img.height;
const ctx = canvas.getContext('2d');
ctx.drawImage(img, 0, 0);
// 获取Base64数据
const dataURL = canvas.toDataURL('image/png');
resolve(dataURL);
};
img.onerror = () => {
reject(new Error('图片加载失败'));
};
img.src = url;
});
}
// 使用示例
let element = `
<div>
<img src='http://t13.baidu.com/it/u=2041049195,1001882902&fm=224&app=112&f=JPEG?w=500&h=500' style="width: 300px;" />
<p>职业:前端</p>
<p>技能:唱、跳、rap</p>
</div>
`;
function generatePDF() {
element =`<style>
img {
max-width: 100%;
max-height: 100%;
vertical-align: middle;
height: auto !important;
width: auto !important;
margin: 10px 0;
}
</style>` + element;
convertImagesToBase64(element)
.then(convertedHtml => {
// 配置选项
const opt = {
margin: 10,
filename: '前端大法好.pdf',
image: { type: 'jpeg', quality: 0.98 },
html2canvas: { scale: 2 },
jsPDF: { unit: 'mm', format: 'a4', orientation: 'portrait' }
};
// 生成PDF
html2pdf().from(convertedHtml).set(opt).save();
})
.catch(error => {
console.error('转换过程中出错:', error);
});
}
</script>
后话
前天提的需求,昨天兜的底,今天写的文章记录
这种问题,理应该后端处理,但后端和我吐槽过他处理起来的困难与问题,寻求前端帮助时,我也会积极配合。可在现实中,我遇过很多后端,死活不愿意配合前端,例如日期格式化、数据id类型bigint过大不字符化返回给前端等等,主打一个本着前端可以做就前端做的原则,说实在:属实下头
前后端本应该就是相互打配合的关系,谁方便就行个方便,没必要僵持不下
今天的分享就到此结束,如果你对技术/行业交流有兴趣,欢迎添加howcoder微信,邀你进群交流
往期精彩
来源:juejin.cn/post/7486440418139652137
想做线上拍卖平台?这款现成源码助你零门槛快速上线!
近年来,电商行业进入存量竞争,传统零售的增长红利逐渐消退,而 直播+拍卖 的模式却在悄然崛起。数据显示,全球 直播电商市场规模已突破 7000 亿美元,而其中拍卖模式因其 高互动性、高成交率,成为新兴电商的流量密码。
无论是珠宝、奢侈品、艺术品,还是房产、二手车,甚至盲盒,拍卖模式都能最大化地调动用户情绪,让商品价值被充分挖掘。一场竞拍,往往能创造普通电商难以企及的高溢价,让卖家和买家都乐在其中。
然而,对于创业者来说,开发一套稳定、专业的拍卖系统,并非易事——高昂的研发成本、漫长的测试周期、复杂的支付与风控体系,往往让人望而却步。
一、有没有一种方式,可以低成本、快速上线拍卖平台,抢占市场先机?
东莞梦幻网络科技,一站式直播拍卖系统,让你低成本抢占市场!
针对创业者的痛点,东莞梦幻网络科技 推出了 「开箱即用」的直播拍卖系统源码,助力企业 低成本、高效率上线自己的直播拍卖平台!
🌟 核心功能亮点:
✅ 直播+竞拍双驱动:用户边看直播,边参与竞价,沉浸感满分
✅ 全网最透明:竞拍全程直播,所有出价公开可见,用户信任度直线上升
✅ 互动玩法多样:弹幕PK、红包雨、连麦砍价……增强用户粘性,留住流量
✅ AR/VR展示技术:360°旋转珠宝展示、房产 VR 看房,让体验感直接拉满
🔹 双模式商城,轻松打造综合电商平台
刺激拍卖:拍卖倒计时+智能加价,助推成交率飙升
常规零售:拍卖+固定价销售双模式,满足不同用户需求
🔹 6大盈利模式,打造持续增长的商业闭环
💰 佣金抽成:每笔成交,平台都能分润
💰 店铺年费:商家入驻,持续稳定收益
💰 广告位招商:商家竞价投放广告,赚取流量红利
💰 会员增值服务:VIP 会员享受独家折扣,提升复购率
💰 竞拍加速道具:用户可付费提升竞拍优势,创造更多收入点
💰 分销裂变:邀请好友参与竞拍,赚取推广收益
二、从0到1,他如何7天搭建拍卖平台,赚到第一桶金?
90后创业者李明,原本只是在某电商平台做二手奢侈品交易,但受限于平台规则和高额抽成,利润一直难以提升。
一次偶然的机会,他了解到直播+拍卖的模式,并看到了商机。但自己组建技术团队开发拍卖系统,至少需要 百万级别的资金投入,这让他望而却步。
直到他接触到了 东莞梦幻网络科技的拍卖系统源码——一次性购买,直接搭建,不到7天就能上线,让他看到了希望。
🚀 短短一个月,他的直播拍卖平台成交额突破 100 万元!
💡 用户粘性大幅提高,90% 参与竞拍的用户都会复购
📈 商家争相入驻,平台流量不断上涨
李明感慨:“如果自己开发,至少要花 6 个月以上,但现在7天就上线了,直接抢占了市场先机。”
三、未来已来,直播+拍卖将是电商的新主流,你还要等多久?
电商的流量越来越贵,传统卖货模式难以突破,而 直播+拍卖 以超高互动性、强成交驱动成为新趋势。
但风口稍纵即逝,真正赚钱的人,都是 “第一个吃螃蟹的人”!
一站式体育直播系统,让你跳过开发,快速抢占市场
面对体育直播平台开发中遇到的高成本和长周期问题,许多创业者往往感到困扰。不过,东莞梦幻网络科技有限公司现在提供了一种全新的解决方案,其精心打造的体育直播系统将帮助创业者们轻松跳过繁琐的开发阶段,直接进入运营快车道。
沉浸式互动体验,构建社交主场
东莞梦幻网络深知互动性对于提升用户体验的重要性,因此在其直播系统中集成了社交聊天室功能,让粉丝能够实时交流,分享观赛心得。此外,趣味竞猜活动不仅增加了观赛的乐趣,还有效点燃了用户的热情。而通过积分商城的设置,用户可以通过参与平台活动获得奖励,从而提升了用户忠诚度,使得这个平台不仅仅是一个观看比赛的地方,更是体育爱好者的社交主场。
专业内容矩阵,吸引真正体育迷
为了增强平台的专业性和吸引力,东莞梦幻网络提供了专家深度解析赛事、独家行业资讯报道以及精准的赛事预测分析等服务。这些高质量的内容不仅有助于树立平台作为专业体育媒体的形象,还能吸引那些对体育充满热情且追求深入见解的忠实用户群体。
多元变现渠道,确保投资回报
东莞梦幻网络的体育直播系统支持多种盈利模式,包括但不限于打赏、会员订阅、VIP特权、广告位精准投放以及赛事周边商城等。这种多元化的收入来源组合为投资者提供了更加稳定和有保障的投资回报途径。
自生长内容生态,持续激发平台活力
为了保证平台内容的新鲜度和多样性,东莞梦幻网络鼓励用户生成内容(UGC),如原创短视频分享、体育社区论坛互动及赛事精彩集锦回放等功能,促进了良性内容循环的发展,使平台始终保持活力。
东莞梦幻网络科技凭借其革命性的体育直播系统,正在改变着行业的游戏规则。无论是初创企业还是寻求转型的传统媒体,都可以借助这一平台快速实现目标,开启属于自己的成功之旅。对于希望在体育直播领域有所建树的企业来说,这是一个不容错过的机会。
React 官方推荐使用 Vite
“技术更替不是一场革命,而是一场漫长的进化过程。”
Hello,大家好,我是 三千。
React 官方已明确建议开发者逐步淘汰 Create React App (CRA) ,转而使用 Vite 等现代框架或工具来创建新项目。
那官方为什么要这样做呢?
一、CRA 被淘汰的背景与原因
- 历史局限性
CRA 诞生于 2016 年,旨在简化 React 项目的初始化配置,但其底层基于 Webpack 和 Babel 的架构在性能、扩展性和灵活性上逐渐无法满足现代开发需求。随着项目规模扩大,CRA 的启动和构建速度显著下降,且默认配置难以优化生产包体积。 - 维护停滞与兼容性问题
React 团队于 2023 年宣布停止积极维护 CRA,且 CRA 的最新版本(v5.0.1)已无法兼容 React 19 等新特性,导致其在生产环境中逐渐不适用。 - 缺乏对现代开发模式的支持
CRA 仅提供客户端渲染(CSR)的默认配置,无法满足服务端渲染(SSR)、静态生成(SSG)等需求。此外,其“零配置”理念限制了路由、状态管理等常见需求的灵活实现。
二、Vite 成为 React 官方推荐的核心优势
- 性能提升
- 开发速度:Vite 基于原生 ESM 模块和 esbuild(Go 语言编写)实现秒级启动与热更新,显著优于 CRA 的 Webpack 打包机制。
- 生产构建:通过 Rollup 优化代码体积,支持 Tree Shaking 和懒加载,减少冗余代码。
- 灵活性与生态兼容
- 配置自由:允许开发者按需定制构建流程,支持 TypeScript、CSS 预处理器、SVG 等特性,无需繁琐的
eject操作。 - 框架无关性:虽与 React 深度集成,但也可用于 Vue、Svelte 等项目,适应多样化技术栈。
- 配置自由:允许开发者按需定制构建流程,支持 TypeScript、CSS 预处理器、SVG 等特性,无需繁琐的
- 现代化开发体验
- 原生浏览器支持:利用现代浏览器的 ESM 特性,无需打包即可直接加载模块。
- 插件生态:丰富的 Vite 插件(如
@vitejs/plugin-react)简化了 React 项目的开发与调试。
三、迁移至 Vite 的具体步骤
- 卸载 CRA 依赖
npm uninstall react-scripts
npm install vite @vitejs/plugin-react --save-dev
- 调整项目结构
- 将
index.html移至项目根目录,并更新脚本引用为 ESM 格式:
<script type="module" src="/src/main.jsx"></script>
- 将
.js文件扩展名改为.jsx(如App.js→App.jsx)。
- 将
- 配置 Vite
创建vite.config.js文件:
import { defineConfig } from "vite";
import react from "@vitejs/plugin-react";
export default defineConfig({
plugins: [react()],
});
- 更新环境变量
环境变量前缀需从REACT_APP_改为VITE_(如VITE_API_KEY=123)。 - 运行与调试
修改package.json脚本命令:
"scripts": {
"dev": "vite",
"build": "vite build",
"preview": "vite preview"
}
四、其他官方推荐的 React 框架
- Next.js
- 适用场景:服务端渲染(SSR)、静态生成(SSG)及全栈应用开发。
- 优势:内置路由、API 路由、图像优化等功能,适合企业级应用与 SEO 敏感项目。
- Remix
- 适用场景:嵌套路由驱动的全栈应用,注重数据加载优化与渐进增强。
- 优势:集成数据预加载机制,减少请求瀑布问题。
- Astro
- 适用场景:内容型静态网站(如博客、文档站)。
- 优势:默认零客户端 JS 开销,通过“岛屿架构”按需激活交互组件。
五、总结与建议
- 新项目:优先选择 Vite(轻量级 CSR 项目)或 Next.js(复杂全栈应用)。
- 现有 CRA 项目:逐步迁移至 Vite,或根据需求转向 Next.js/Remix 等框架。
- 学习曲线:Vite 对 React 核心概念干扰较小,适合初学者;Next.js 功能全面但学习成本较高。
React 生态正朝着 “库+框架”协同发展 的方向演进,开发者需结合项目需求选择工具链,以平衡性能、灵活性与开发效率。
结语
以上就是今天与大家分享的全部内容,你的支持是我更新的最大动力,我们下期见!
打工人肝 文章/视频 不易,期待你一键三连的鼓励 !!!
😐 这里是【程序员三千】,💻 一个喜欢捣鼓各种编程工具新鲜玩法的啊婆主。
🏠 已入驻:抖爸爸、b站、小红书(都叫【程序员三千】)
💽 编程/AI领域优质资源推荐 👉 http://www.yuque.com/xiaosanye-o…
来源:juejin.cn/post/7472008189976461346
async/await 必须使用 try/catch 吗?
前言
在 JavaScript 开发者的日常中,这样的对话时常发生:
- 👨💻 新人:"为什么页面突然白屏了?"
- 👨🔧 老人:"异步请求没做错误处理吧?"
async/await 看似优雅的语法糖背后,隐藏着一个关键问题:错误处理策略的抉择。
在 JavaScript 中使用 async/await 时,很多人会问:“必须使用 try/catch 吗?”
其实答案并非绝对,而是取决于你如何设计错误处理策略和代码风格。
接下来,我们将探讨 async/await 的错误处理机制、使用 try/catch 的优势,以及其他可选的错误处理方法。
async/await 的基本原理
异步代码的进化史
// 回调地狱时代
fetchData(url1, (data1) => {
process(data1, (result1) => {
fetchData(url2, (data2) => {
// 更多嵌套...
})
})
})
// Promise 时代
fetchData(url1)
.then(process)
.then(() => fetchData(url2))
.catch(handleError)
// async/await 时代
async function workflow() {
const data1 = await fetchData(url1)
const result = await process(data1)
return await fetchData(url2)
}
async/await 是基于 Promise 的语法糖,它使异步代码看起来更像同步代码,从而更易读、易写。一个 async 函数总是返回一个 Promise,你可以在该函数内部使用 await 来等待异步操作完成。
如果在异步操作中出现错误(例如网络请求失败),该错误会使 Promise 进入 rejected 状态。
async function fetchData() {
const response = await fetch("https://api.example.com/data");
const data = await response.json();
return data;
}
使用 try/catch 捕获错误
打个比喻,就好比铁路信号系统
想象 async 函数是一列高速行驶的列车:
- await 是轨道切换器:控制代码执行流向
- 未捕获的错误如同脱轨事故:会沿着铁路网(调用栈)逆向传播
- try/catch 是智能防护系统:
- 自动触发紧急制动(错误捕获)
- 启动备用轨道(错误恢复逻辑)
- 向调度中心发送警报(错误日志)
为了优雅地捕获 async/await 中出现的错误,通常我们会使用 try/catch 语句。这种方式可以在同一个代码块中捕获同步和异步抛出的错误,使得错误处理逻辑更集中、直观。
- 代码逻辑集中,错误处理与业务逻辑紧密结合。
- 可以捕获多个 await 操作中抛出的错误。
- 适合需要在出错时进行统一处理或恢复操作的场景。
async function fetchData() {
try {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data;
} catch (error) {
console.error("Error fetching data:", error);
// 根据需要,可以在此处处理错误,或者重新抛出以便上层捕获
throw error;
}
}
不使用 try/catch 的替代方案
虽然 try/catch 是最直观的错误处理方式,但你也可以不在 async 函数内部使用它,而是在调用该 async 函数时捕获错误。
在 Promise 链末尾添加 .catch()
async function fetchData() {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
// 调用处使用 Promise.catch 捕获错误
fetchData()
.then(data => {
console.log("Data:", data);
})
.catch(error => {
console.error("Error fetching data:", error);
});
这种方式将错误处理逻辑移至函数调用方,适用于以下场景:
- 当多个调用者希望以不同方式处理错误时。
- 希望让 async 函数保持简洁,将错误处理交给全局统一的错误处理器(例如在 React 应用中可以使用 Error Boundary)。
将 await 与 catch 结合
async function fetchData() {
const response = await fetch('https://api.example.com/data').catch(error => {
console.error('Request failed:', error);
return null; // 返回兜底值
});
if (!response) return;
// 继续处理 response...
}
全局错误监听(慎用,适合兜底)
// 浏览器端全局监听
window.addEventListener('unhandledrejection', event => {
event.preventDefault();
sendErrorLog({
type: 'UNHANDLED_REJECTION',
error: event.reason,
stack: event.reason.stack
});
showErrorToast('系统异常,请联系管理员');
});
// Node.js 进程管理
process.on('unhandledRejection', (reason, promise) => {
logger.fatal('未处理的 Promise 拒绝:', reason);
process.exitCode = 1;
});
错误处理策略矩阵
决策树分析
graph TD
A[需要立即处理错误?] -->|是| B[使用 try/catch]
A -->|否| C{错误类型}
C -->|可恢复错误| D[Promise.catch]
C -->|致命错误| E[全局监听]
C -->|批量操作| F[Promise.allSettled]
错误处理体系
- 基础层:80% 的异步操作使用 try/catch + 类型检查
- 中间层:15% 的通用错误使用全局拦截 + 日志上报
- 战略层:5% 的关键操作实现自动恢复机制
小结
我的观点是:不强制要求,但强烈推荐
- 不强制:如果不需要处理错误,可以不使用
try/catch,但未捕获的 Promise 拒绝(unhandled rejection)会导致程序崩溃(在 Node.js 或现代浏览器中)。 - 推荐:90% 的场景下需要捕获错误,因此
try/catch是最直接的错误处理方式。
所有我个人观点:使用 async/await 尽量使用 try/catch。好的错误处理不是消灭错误,而是让系统具备优雅降级的能力。
你的代码应该像优秀的飞行员——在遇到气流时,仍能保持平稳飞行。大家如有不同意见,还请评论区讨论,说出自己的见解。
来源:juejin.cn/post/7482013975077928995
告别龟速删除!前端老司机教你秒删node_modules的黑科技
引言:每个前端的痛——node_modules删除噩梦
“npm install一时爽,删包火葬场。”这几乎是所有Node.js开发者都经历过的痛。尤其是当项目依赖复杂时,动辄几百MB甚至几个G的node_modules文件夹,手动删除时转圈圈的进度条简直让人抓狂。
如何高效解决这个问题?今天我们就来揭秘几种秒删node_modules的硬核技巧,让你从此告别龟速删除!
一、为什么手动删除node_modules这么慢?
node_modules的目录结构复杂,层级深、文件数量庞大(比如一个中型项目可能有上万个小文件)。手动删除时,操作系统需要逐个处理这些文件,导致效率极低,尤其是Windows系统表现更差。核心原因包括:
- 文件系统限制:Windows的NTFS和macOS的HFS+对超多小文件的删除并未优化,系统需要频繁更新索引和缓存,资源占用高。
- 权限问题:某些文件可能被进程占用或权限不足,导致删除失败或卡顿。
- 递归删除效率低:系统自带的删除命令(如右键删除)是单线程操作,而
node_modules的嵌套结构会让递归删除耗时剧增。
二、终极方案:用rimraf实现“秒删”
如果你还在手动拖拽删除,赶紧试试这个Node.js社区公认的神器——rimraf!它的原理是封装了rm -rf命令,通过减少系统调用和优化递归逻辑,速度提升可达10倍以上。
操作步骤
- 全局安装rimraf(仅需一次):
npm install rimraf -g
- 一键删除:
进入项目根目录,执行:
rimraf node_modules
实测:一个5GB的node_modules,10秒内删干净!
进阶用法
- 集成到npm脚本:在
package.json中添加脚本,直接运行npm run clean:
{
"scripts": {
"clean": "rimraf node_modules"
}
}
- 跨平台兼容:无论是Windows、Linux还是macOS,命令完全一致,团队协作无压力。
三、其他高效删除方案
如果不想安装额外工具,系统原生命令也能解决问题:
1. Windows用户:用命令行暴力删除
- CMD命令:
rmdir /s /q node_modules
/s表示递归删除,/q表示静默执行(不弹窗确认)。 - PowerShell(更快):
Remove-Item -Force -Recurse node_modules
2. Linux/macOS用户:终端直接起飞
rm -rf ./node_modules
四、避坑指南:删不干净怎么办?
有时即使删了node_modules,重新安装依赖仍会报错。此时需要彻底清理残留:
- 清除npm缓存:
npm cache clean --force
- 删除锁文件:
手动移除package-lock.json或yarn.lock。 - 重启IDE:确保没有进程占用文件。
五、总结:选对工具,效率翻倍
| 方案 | 适用场景 | 速度对比 |
|---|---|---|
| rimraf | 跨平台、大型项目 | ⚡⚡⚡⚡⚡ |
| 系统命令 | 临时快速操作 | ⚡⚡⚡ |
| 手动删除 | 极小项目(不推荐) | ⚡ |
推荐组合拳:日常使用rimraf+脚本,遇到权限问题时切换系统命令。
互动话题
你遇到过最离谱的node_modules有多大?评论区晒出你的经历!
来源:juejin.cn/post/7477926585087606820
AI 赋能 Web 页面,图像识别超越想象
前言
在信息时代,Web 页面成为我们与世界交互的重要窗口。如今,AI 程序的出现,为 Web 页面带来了新的变革。通过在 Web 页面上实现图片识别,我们即将迈入一个更加智能与便捷的时代。它将赋予网页全新的能力,使其能够理解图片的内容,为用户带来前所未有的体验。让我们一同踏上这充满无限可能的探索之旅。
在信息时代,Web 页面成为我们与世界交互的重要窗口。如今,AI 程序的出现,为 Web 页面带来了新的变革。通过在 Web 页面上实现图片识别,我们即将迈入一个更加智能与便捷的时代。它将赋予网页全新的能力,使其能够理解图片的内容,为用户带来前所未有的体验。让我们一同踏上这充满无限可能的探索之旅。
具体步骤
html部分
我们可以试试通过输入:
main.container>(label.custom-file-upload>input#file-upload)+#image-container+p#status
再按tab键就可以快速生成以下的html框架。
<main class="container">
<label for="file-upload" class="custom-file-upload">
<input type="file" accept="image/*" id="file-upload">
上传图片
label>
<div id="image-container">div>
<p id="status">p>
main>
- 我们选择使用main标签而不是选择div,是因为main比div更具有语义化。main标签可以表示页面的主体内容。
- label标签用于将表单中的输入元素(如文本输入框、单选按钮、复选框等)与相关的文本描述关联起来。label标签通过将 for 属性值设置为输入元素的 id 属性值,建立与输入元素的关联。
- input的type属性值为file,表示是文件输入框;accept属性值为image/*,表示该文件输入框只接收图像类型的文件。
我们可以试试通过输入:
main.container>(label.custom-file-upload>input#file-upload)+#image-container+p#status
再按tab键就可以快速生成以下的html框架。
<main class="container">
<label for="file-upload" class="custom-file-upload">
<input type="file" accept="image/*" id="file-upload">
上传图片
label>
<div id="image-container">div>
<p id="status">p>
main>
- 我们选择使用main标签而不是选择div,是因为main比div更具有语义化。main标签可以表示页面的主体内容。
- label标签用于将表单中的输入元素(如文本输入框、单选按钮、复选框等)与相关的文本描述关联起来。label标签通过将 for 属性值设置为输入元素的 id 属性值,建立与输入元素的关联。
- input的type属性值为file,表示是文件输入框;accept属性值为image/*,表示该文件输入框只接收图像类型的文件。
JavaScript部分
这个部分是这篇文章的重点。
这个部分是这篇文章的重点。
第一部分
首先我们通过JavaScript在远程的transformers库中引入pipleline和env模块。我们需要禁止使用本地的模块,而使用远程的模块。
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
env.allowLocalModels = false;
接下来我们要读取用户输入的文件,并且输出在页面上。我们可以这样做:
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
//添加事件监听器来响应元素上的特定事件
//在fileUpload元素上添加一个change事件监听。当用户更改上传文件时,触发事件处理函数。
fileUpload.addEventListener('change', function (e) {
//e是事件对象
//e.target是触发事件的文件上传元素。
//e.target.files[0]是获取选中的第一个文件
const file = e.target.files[0];
// 新建一个FileReader 对象用于读取文件(异步)
//FileReader 是 JavaScript 中的一个对象,用于异步读取用户选择的文件或输入的内容。
const reader = new FileReader();
//reader.onload就相当于FileReader。onload;FileReader。onload是一个事件,在读取操作完成时触发function(e2)
reader.onload = function (e2) {
//创建一个新的html元素,也就是创建一个img标签
const image = document.createElement('img');
//将image的scr属性的url值改为e2.target.result
image.src = e2.target.result;
//将 image 元素添加作为子节点到 imageContainer 元素中
imageContainer.appendChild(image)
detect(image) // 启动AI任务。是功能模块化,要封装出去
}
//FileReader.readAsDataURL():开始读取指定的 Blob 中的内容。一旦完成,result 属性中将包含一个 data: URL 格式的 Base64 字符串以表示所读取文件的内容。
//用于将指定的文件读取为 DataURL 格式的数据。
reader.readAsDataURL(file)
})
我们先梳理一下我们的思路。
- 我们要对文件输入框里元素进行操作,所以我们要获取那个元素。我们可以创建一个fileUpload对象获取这个元素。
- 我们可以对fileUpload对象添加一个change事件监听。这个监听器实现当用户更改上传文件时,触发事件处理函数function(e)实现读取文件并且在页面输出文件的功能。
- function(e)的功能是用于异步读取用户选择的文件,并且在页面输出它。
- 因为我们要读取整个图片文件,所以我们可以创建一个FileReader对象读取图片文件。在文件读取完成时我们可以用reader.onload实现在文件读取完毕时在id为mage-container的div标签内添加一个img标签输出图片。
- 因为要输出图片就要先知道图片的URL,于是我们用e2.target.result获取图片的URL。
- 因为要在div里添加一个img标签,于是创建一个imageContainer对象获取ID 为 image-container 的元素后用imageContainer.appendChild(image)实现将img标签添加为div的子标签。
- 我们用detect函数封装AI图片识别任务。
首先我们通过JavaScript在远程的transformers库中引入pipleline和env模块。我们需要禁止使用本地的模块,而使用远程的模块。
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
env.allowLocalModels = false;
接下来我们要读取用户输入的文件,并且输出在页面上。我们可以这样做:
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
//添加事件监听器来响应元素上的特定事件
//在fileUpload元素上添加一个change事件监听。当用户更改上传文件时,触发事件处理函数。
fileUpload.addEventListener('change', function (e) {
//e是事件对象
//e.target是触发事件的文件上传元素。
//e.target.files[0]是获取选中的第一个文件
const file = e.target.files[0];
// 新建一个FileReader 对象用于读取文件(异步)
//FileReader 是 JavaScript 中的一个对象,用于异步读取用户选择的文件或输入的内容。
const reader = new FileReader();
//reader.onload就相当于FileReader。onload;FileReader。onload是一个事件,在读取操作完成时触发function(e2)
reader.onload = function (e2) {
//创建一个新的html元素,也就是创建一个img标签
const image = document.createElement('img');
//将image的scr属性的url值改为e2.target.result
image.src = e2.target.result;
//将 image 元素添加作为子节点到 imageContainer 元素中
imageContainer.appendChild(image)
detect(image) // 启动AI任务。是功能模块化,要封装出去
}
//FileReader.readAsDataURL():开始读取指定的 Blob 中的内容。一旦完成,result 属性中将包含一个 data: URL 格式的 Base64 字符串以表示所读取文件的内容。
//用于将指定的文件读取为 DataURL 格式的数据。
reader.readAsDataURL(file)
})
我们先梳理一下我们的思路。
- 我们要对文件输入框里元素进行操作,所以我们要获取那个元素。我们可以创建一个fileUpload对象获取这个元素。
- 我们可以对fileUpload对象添加一个change事件监听。这个监听器实现当用户更改上传文件时,触发事件处理函数function(e)实现读取文件并且在页面输出文件的功能。
- function(e)的功能是用于异步读取用户选择的文件,并且在页面输出它。
- 因为我们要读取整个图片文件,所以我们可以创建一个FileReader对象读取图片文件。在文件读取完成时我们可以用reader.onload实现在文件读取完毕时在id为mage-container的div标签内添加一个img标签输出图片。
- 因为要输出图片就要先知道图片的URL,于是我们用e2.target.result获取图片的URL。
- 因为要在div里添加一个img标签,于是创建一个imageContainer对象获取ID 为 image-container 的元素后用imageContainer.appendChild(image)实现将img标签添加为div的子标签。
- 因为我们要读取整个图片文件,所以我们可以创建一个FileReader对象读取图片文件。在文件读取完成时我们可以用reader.onload实现在文件读取完毕时在id为mage-container的div标签内添加一个img标签输出图片。
- 我们用detect函数封装AI图片识别任务。
第二部分
接下来我们要完成ai任务———检测图片。
我们要通过ai进行对象检测并且获得检测到的元素的参数。
const status = document.getElementById('status');
const detect = async (image) => {
//在id为status的p标签中添加“分析中...请稍等一会”的文本内容
status.textContent = "分析中...请稍等一会"
//object-detection是对象检查任务;Xenova/detr-resnet-50是指定用于对象检测的模型
const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // model 实例化了detector对象
//使用检测器对象对指定的图像源进行检测,并传入了一些参数:
const output = await detector(image.src, {
threshold: 0.1,
percentage: true
})
//forEach 方法用于遍历数组或类似数组的对象,并对每个元素执行指定的函数
output.forEach(renderBox)
}
分析检测图片和获取检测元素的参数的思路。
- 首先,对图片进行分析需要一些时间,为了让用户知道分析需要时间并且让用户等待,我们可以用我们html中id="status"的p标签输入一段文字。
- 首先我们用document.getElementById('status')获取id="status"的元素,并且用textContent方法动态添加id="status"的p标签的文本内容,然后输出在页面上。
detect异步函数
- 为了实现对象检测我们采用了async/await编写异步代码的方法。使用async关键字来标记一个函数为异步函数,并在其中使用await关键字来等待一个Promise对象的结果。await表达式会暂停当前async function的执行,等待Promise处理完成。
- 创建一个detector对象接收对象分析结果。再创建output对象接收对象分析结果的参数
output.forEach(renderBox)是让output的所有元素遍历进行渲染。
接下来我们要完成ai任务———检测图片。
我们要通过ai进行对象检测并且获得检测到的元素的参数。
const status = document.getElementById('status');
const detect = async (image) => {
//在id为status的p标签中添加“分析中...请稍等一会”的文本内容
status.textContent = "分析中...请稍等一会"
//object-detection是对象检查任务;Xenova/detr-resnet-50是指定用于对象检测的模型
const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // model 实例化了detector对象
//使用检测器对象对指定的图像源进行检测,并传入了一些参数:
const output = await detector(image.src, {
threshold: 0.1,
percentage: true
})
//forEach 方法用于遍历数组或类似数组的对象,并对每个元素执行指定的函数
output.forEach(renderBox)
}
分析检测图片和获取检测元素的参数的思路。
- 首先,对图片进行分析需要一些时间,为了让用户知道分析需要时间并且让用户等待,我们可以用我们html中id="status"的p标签输入一段文字。
- 首先我们用document.getElementById('status')获取id="status"的元素,并且用textContent方法动态添加id="status"的p标签的文本内容,然后输出在页面上。
detect异步函数
- 为了实现对象检测我们采用了async/await编写异步代码的方法。使用async关键字来标记一个函数为异步函数,并在其中使用await关键字来等待一个Promise对象的结果。await表达式会暂停当前async function的执行,等待Promise处理完成。
- 创建一个detector对象接收对象分析结果。再创建output对象接收对象分析结果的参数
output.forEach(renderBox)是让output的所有元素遍历进行渲染。
第三部分
我们用renderBox函数将框出图片中的物品的区域,并且在区域内输出ai识别得出的物品名称。
function renderBox({ box, label }) {
console.log(box, label);
const { xmax, xmin, ymax, ymin } = box
//创建一个盒子
const boxElement = document.createElement("div");
//动态添加div的类名
boxElement.className = "bounding-box"
//通过执行 Object.assign(boxElement.style, {}),可以将一个空对象的属性合并到 boxElement.style 对象中
//准备为 boxElement 设置新的样式属性
Object.assign(boxElement.style, {
borderColor: '#123123',
borderWidth: '1px',
borderStyle: 'solid',
//最左侧
left: 100 * xmin + '%',
//最上侧
top: 100 * ymin + '%',
//宽度
width: 100 * (xmax - xmin) + "%",
//高度
height: 100 * (ymax - ymin) + "%"
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label"
labelElement.style.backgroundColor = '#000000'
//在图片上增加的物品区域范围内添加物品的种类名称的文本内容
boxElement.appendChild(labelElement);
//在图片上增加物品的区域范围
imageContainer.appendChild(boxElement);
}
分析renderBox函数思路。
- output元素中有许多参数,我们只需要label参数(检测得出的物品名称)和box参数(图片物品的区域参数,分别为xmax、xmin、ymax、ymin)。
- 实现框出图片中的物品的区域(每一个新建的div都表示一个图片物体)
- 首先我们创建{ xmax, xmin, ymax, ymin }对象获取位置信息。
- 通过document.createElement("div")创建一个新的div标签,再用className方法动态得给新建的div标签添加一个bounding-box类。
- 通过
- Object.assign(boxElement.style, { })对新建的div添加css样式,并且通过测量图片物体的最左侧和最上侧以及高度和宽度框出图片物体的区域。
- 再通过imageContainer.appendChild(boxElement)代码添加到id="image-container"的div标签中。
- 实现在图片物体区域添加ai识别得出的label参数文本
- 通过document.createElement('span')创建span标签,再用textContent方法将label内容动态输入新建的span标签
- 再通过 boxElement.appendChild(labelElement)添加到刚刚创建的div标签中,也就是添加到图片物体区域中。
我们用renderBox函数将框出图片中的物品的区域,并且在区域内输出ai识别得出的物品名称。
function renderBox({ box, label }) {
console.log(box, label);
const { xmax, xmin, ymax, ymin } = box
//创建一个盒子
const boxElement = document.createElement("div");
//动态添加div的类名
boxElement.className = "bounding-box"
//通过执行 Object.assign(boxElement.style, {}),可以将一个空对象的属性合并到 boxElement.style 对象中
//准备为 boxElement 设置新的样式属性
Object.assign(boxElement.style, {
borderColor: '#123123',
borderWidth: '1px',
borderStyle: 'solid',
//最左侧
left: 100 * xmin + '%',
//最上侧
top: 100 * ymin + '%',
//宽度
width: 100 * (xmax - xmin) + "%",
//高度
height: 100 * (ymax - ymin) + "%"
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label"
labelElement.style.backgroundColor = '#000000'
//在图片上增加的物品区域范围内添加物品的种类名称的文本内容
boxElement.appendChild(labelElement);
//在图片上增加物品的区域范围
imageContainer.appendChild(boxElement);
}
分析renderBox函数思路。
- output元素中有许多参数,我们只需要label参数(检测得出的物品名称)和box参数(图片物品的区域参数,分别为xmax、xmin、ymax、ymin)。
- 实现框出图片中的物品的区域(每一个新建的div都表示一个图片物体)
- 首先我们创建{ xmax, xmin, ymax, ymin }对象获取位置信息。
- 通过document.createElement("div")创建一个新的div标签,再用className方法动态得给新建的div标签添加一个bounding-box类。
- 通过
- Object.assign(boxElement.style, { })对新建的div添加css样式,并且通过测量图片物体的最左侧和最上侧以及高度和宽度框出图片物体的区域。
- 再通过imageContainer.appendChild(boxElement)代码添加到id="image-container"的div标签中。
- 实现在图片物体区域添加ai识别得出的label参数文本
- 通过document.createElement('span')创建span标签,再用textContent方法将label内容动态输入新建的span标签
- 再通过 boxElement.appendChild(labelElement)添加到刚刚创建的div标签中,也就是添加到图片物体区域中。
JavaScript部分总结
我们将图片识别功能分别分成三个部分实现。首先通过第一部分读取图片,通过第二部分进行ai分析,再通过第三部分输出结果。
我们要有灵活的封装思想。
我们将图片识别功能分别分成三个部分实现。首先通过第一部分读取图片,通过第二部分进行ai分析,再通过第三部分输出结果。
我们要有灵活的封装思想。
css部分
该部分不做过度解释,直接上代码。
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap: 10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top: 20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
该部分不做过度解释,直接上代码。
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap: 10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top: 20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
效果展示
- 选择图片上传
- 选择图片后进行分析的过程
- 选择图片上传
- 选择图片后进行分析的过程

控制台输出的是e2.target.result的内容。
- 分析结果

代码
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>nlp之图片识别title>
<style>
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap: 10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top: 20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
style>
head>
<body>
<main class="container">
<label for="file-upload" class="custom-file-upload">
<input type="file" accept="image/*" id="file-upload">
上传图片
label>
<div id="image-container">div>
<p id="status">p>
main>
<script type="module">
// transformers提供js库(https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0)
//从 https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0 导入 pipeline 和 env
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
//禁止加载本地模型,加载远程模型
env.allowLocalModels = false;
//document.getElementById 是 js 中用于通过元素的 ID 来获取特定 HTML 元素的方法
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
//添加事件监听器来响应元素上的特定事件
//在fileUpload元素上添加一个change事件监听。当用户更改上传文件时,触发事件处理函数。
fileUpload.addEventListener('change', function (e) {
//e是事件对象
//e.target是触发事件的文件上传元素。
//e.target.files[0]是获取选中的第一个文件
const file = e.target.files[0];
// 新建一个FileReader 对象用于读取文件(异步)
//FileReader 是 JavaScript 中的一个对象,用于异步读取用户选择的文件或输入的内容。
const reader = new FileReader();
//reader.onload是一个事件,在读取操作完成时触发
reader.onload = function (e2) {
//用createElement创建一个新的html元素
const image = document.createElement('img');
console.log(e2.target.result);
//将image的scr属性的url值改为e2.target.result
image.src = e2.target.result;
//将 image 元素添加作为子节点到 imageContainer 元素中
imageContainer.appendChild(image)
detect(image) // 启动AI任务 功能模块化,封装出去
}
//用于将指定的文件读取为 DataURL 格式的数据。
reader.readAsDataURL(file)
})
//ai任务
const status = document.getElementById('status');
const detect = async (image) => {
//在id为status的p标签中添加“分析中...请稍等一会”的文本内容
status.textContent = "分析中...请稍等一会"
//object-detection是对象检查任务;Xenova/detr-resnet-50是指定用于对象检测的模型
const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // model 实例化了detector对象
//使用检测器对象对指定的图像源进行检测,并传入了一些参数:
const output = await detector(image.src, {
threshold: 0.1,
percentage: true
})
//forEach 方法用于遍历数组或类似数组的对象,并对每个元素执行指定的函数
output.forEach(renderBox)
}
//封装;渲染盒子
function renderBox({ box, label }) {
console.log(box, label);
const { xmax, xmin, ymax, ymin } = box
//创建一个盒子
const boxElement = document.createElement("div");
//动态添加div的类名
boxElement.className = "bounding-box"
//通过执行 Object.assign(boxElement.style, {}),可以将一个空对象的属性合并到 boxElement.style 对象中
//准备为 boxElement 设置新的样式属性
Object.assign(boxElement.style, {
borderColor: '#123123',
borderWidth: '1px',
borderStyle: 'solid',
//最左侧
left: 100 * xmin + '%',
//最上侧
top: 100 * ymin + '%',
//宽度
width: 100 * (xmax - xmin) + "%",
//高度
height: 100 * (ymax - ymin) + "%"
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label"
labelElement.style.backgroundColor = '#000000'
//在图片上增加的物品区域范围内添加物品的种类名称的文本内容
boxElement.appendChild(labelElement);
//在图片上增加物品的区域范围
imageContainer.appendChild(boxElement);
}
script>
body>
html>
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>nlp之图片识别title>
<style>
.container {
margin: 40px auto;
width: max(50vw, 400px);
display: flex;
flex-direction: column;
align-items: center;
}
.custom-file-upload {
display: flex;
align-items: center;
cursor: pointer;
gap: 10px;
border: 2px solid black;
padding: 8px 16px;
border-radius: 6px;
}
#file-upload {
display: none;
}
#image-container {
width: 100%;
margin-top: 20px;
position: relative;
}
#image-container>img {
width: 100%;
}
.bounding-box {
position: absolute;
box-sizing: border-box;
}
.bounding-box-label {
position: absolute;
color: white;
font-size: 12px;
}
style>
head>
<body>
<main class="container">
<label for="file-upload" class="custom-file-upload">
<input type="file" accept="image/*" id="file-upload">
上传图片
label>
<div id="image-container">div>
<p id="status">p>
main>
<script type="module">
// transformers提供js库(https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0)
//从 https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0 导入 pipeline 和 env
import { pipeline, env } from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.6.0"
//禁止加载本地模型,加载远程模型
env.allowLocalModels = false;
//document.getElementById 是 js 中用于通过元素的 ID 来获取特定 HTML 元素的方法
const fileUpload = document.getElementById('file-upload');
const imageContainer = document.getElementById('image-container')
//添加事件监听器来响应元素上的特定事件
//在fileUpload元素上添加一个change事件监听。当用户更改上传文件时,触发事件处理函数。
fileUpload.addEventListener('change', function (e) {
//e是事件对象
//e.target是触发事件的文件上传元素。
//e.target.files[0]是获取选中的第一个文件
const file = e.target.files[0];
// 新建一个FileReader 对象用于读取文件(异步)
//FileReader 是 JavaScript 中的一个对象,用于异步读取用户选择的文件或输入的内容。
const reader = new FileReader();
//reader.onload是一个事件,在读取操作完成时触发
reader.onload = function (e2) {
//用createElement创建一个新的html元素
const image = document.createElement('img');
console.log(e2.target.result);
//将image的scr属性的url值改为e2.target.result
image.src = e2.target.result;
//将 image 元素添加作为子节点到 imageContainer 元素中
imageContainer.appendChild(image)
detect(image) // 启动AI任务 功能模块化,封装出去
}
//用于将指定的文件读取为 DataURL 格式的数据。
reader.readAsDataURL(file)
})
//ai任务
const status = document.getElementById('status');
const detect = async (image) => {
//在id为status的p标签中添加“分析中...请稍等一会”的文本内容
status.textContent = "分析中...请稍等一会"
//object-detection是对象检查任务;Xenova/detr-resnet-50是指定用于对象检测的模型
const detector = await pipeline("object-detection","Xenova/detr-resnet-50") // model 实例化了detector对象
//使用检测器对象对指定的图像源进行检测,并传入了一些参数:
const output = await detector(image.src, {
threshold: 0.1,
percentage: true
})
//forEach 方法用于遍历数组或类似数组的对象,并对每个元素执行指定的函数
output.forEach(renderBox)
}
//封装;渲染盒子
function renderBox({ box, label }) {
console.log(box, label);
const { xmax, xmin, ymax, ymin } = box
//创建一个盒子
const boxElement = document.createElement("div");
//动态添加div的类名
boxElement.className = "bounding-box"
//通过执行 Object.assign(boxElement.style, {}),可以将一个空对象的属性合并到 boxElement.style 对象中
//准备为 boxElement 设置新的样式属性
Object.assign(boxElement.style, {
borderColor: '#123123',
borderWidth: '1px',
borderStyle: 'solid',
//最左侧
left: 100 * xmin + '%',
//最上侧
top: 100 * ymin + '%',
//宽度
width: 100 * (xmax - xmin) + "%",
//高度
height: 100 * (ymax - ymin) + "%"
})
const labelElement = document.createElement('span');
labelElement.textContent = label;
labelElement.className = "bounding-box-label"
labelElement.style.backgroundColor = '#000000'
//在图片上增加的物品区域范围内添加物品的种类名称的文本内容
boxElement.appendChild(labelElement);
//在图片上增加物品的区域范围
imageContainer.appendChild(boxElement);
}
script>
body>
html>
结尾
整个代码还存在一些不足之处,还需要不断完善。希望我的文章可以帮助到你们。欢迎点赞评论加关注。
来源:juejin.cn/post/7359084330121789452
我的 Electron 客户端被第三方页面入侵了...
问题描述
公司有个内部项目是用 Electron 来开发的,有个功能需要像浏览器一样加载第三方站点。
本来一切安好,但是某天打开某个站点的链接,导致 整个客户端直接变成了该站点的页面。
这一看就是该站点做了特殊的处理,经排查网页源码后,果然发现了有这么一句代码。
if (window.top !== window.self) {
window.top.location = window.location;
}
翻译一下就是:如果当前窗口不是顶级窗口的话,将当前窗口设置为顶级窗口。
奇怪的是两者不是 跨域 了吗,为什么 iframe 还可以影响顶级窗口。
先说一下我当时的一些解决办法:
- 用
webview替换iframe - 给
iframe添加sandbox属性
后续内容就是一点复盘工作。
场景复现(Web端)
一开始怀疑是客户端的问题,所以我用在纯 Web 上进行了一次对比验证。
这里我们新建两个文件:1.html 和 2.html,我们称之为 页面A 和 页面B。
然后起了两个本地服务器来模拟同源与跨域的情况。
页面A:http://127.0.0.1:5500/1.html
页面B:http://127.0.0.1:5500/2.html 和 http://localhost:3000/2.html
符合同源策略
<body>
<h1>这是页面A</h1>
<!-- 这是同源的情况 -->
<iframe id="iframe" src="http://127.0.0.1:5500/2.html" />
<script>
iframe.onload = () => {
console.log('iframe loaded..')
console.log('子窗口路径', iframe.contentWindow.location.href)
}
</script>
</body>
<body>
<h2>这是页面B</h2>
<script>
console.log('page2...')
console.log(window === window.top)
console.log('顶部窗口路径', window.top.location.href)
</script>
</body>
我们打开控制台可以看到 页面A 和 页面B 是可以 互相访问 到对方窗口的路径。

如果这个时候在 页面B 加上文章开头提到的 代码片段,那么显然页面将会发生变化。

跨域的情况
这时候我们修改 页面A 加载 页面B 的地址,使其不符合同源策略。

理所应当的是,两个页面不能够相互访问了,这才是正常的,否则内嵌第三方页面可以互相修改,那就太不安全了。
场景复现(客户端)
既然 Web 端是符合预期的,那是不是 Electron 自己的问题呢?
我们通过 electron-vite 快速搭建了一个 React模板的electron应用,版本为:electron@22.3.27,并且在 App 中也嵌入了刚才的 页面B。
function App(): JSX.Element {
return (
<>
<h1>这是Electron页面</h1>
<iframe id="iframe" src="http://localhost:3000/2.html"/>
</>
)
}
export default App

对不起,干干净净的 Electron 根本不背这个锅,在它身上的表现如同 Web端 一样,也受同源策略的限制。
那么肯定是我的项目里有什么特殊的配置,通过对比主进程的代码,答案终于揭晓。
new BrowserWindow({
...,
webPreferences: {
...,
webSecurity: false // 就是因为它
}
})
Electron 官方文档 里是这么描述 webSecurity 这个配置的。
webSecurityboolean (可选) - 当设置为false, 它将禁用同源策略 (通常用来测试网站), 如果此选项不是由开发者设置的,还会把allowRunningInsecureContent设置为true. 默认值为true。
也就是说,Electron本身是有一层屏障的,但当该属性设置为 false 的时候,我们的客户端将会绕过同源策略的限制,这层屏障也就消失了,因此 iframe 的行为表现得像是嵌套了同源的站点一样。
解决方案
把这个配置去掉,确实是可以解决这个问题,但考虑到可能对其他功能造成的影响,只能采取其他方案。
如文章开头提到的,用 webview 替换 iframe。
webview 是 Electron的一个自定义元素(标签),可用于在应用程序中嵌入第三方网页,它默认开启安全策略,直接实现了主应用与嵌入页面的隔离。
因为目前这个需求是仅作展示,不需要与嵌套页面进行交互以及复杂的通信,因此在一开始的开发过程中,并没有使用它,而是直接采用了 iframe。
而 iframe 也能够实现类似的效果,只需要添加一个 sandbox 属性可以解决。
MDN 中提到,sandbox 控制应用于嵌入在 <iframe> 中的内容的限制。该属性的值可以为空以应用所有限制,也可以为空格分隔的标记以解除特定的限制。
如此一来,就算是同源的,两者也不会互相干扰。
总结
这不是一个复杂的问题,发现后及时修复了,并没有造成很大的影响(还好是自己人用的平台)。
写这篇文章的主要目的是为了记录这次事件,让我意识到在平时开发过程中,把注意力过多的放在了 业务、样式、性能等这些看得见的问题上,可能很少关注甚至忽略了 安全 这一要素,以为前端框架能够防御像 XSS 这样的攻击就能安枕无忧。
谨记,永远不要相信第三方,距离产生美。
如有纰漏,欢迎在评论区指出。
来源:juejin.cn/post/7398418805971877914
Electron 30.0.0
作者: clavin / VerteDinde
译者: ylduang
Electron 30.0.0 已发布! 它包括对 Chromium 124.0.6367.49、V8 12.4 和 Node.js 20.11.1 的升级。
Electron 团队很高兴发布了 Electron 30.0.0 ! 你可以通过 npm install electron@latest 或者从我们的发布网站下载它。继续阅读此版本的详细信息。
如果您有任何反馈,请在 Twitter 或 Mastodon 上与我们分享,或加入我们的 Discord 社区! Bug 和功能请求可以在 Electron 的问题跟踪器中报告。
重要变化
重点内容
- Windows 现在支持 ASAR 完整性检查 (#40504)
- 启用 ASAR 完整性的现有应用程序如果配置不正确,可能无法在 Windows 上工作。使用 Electron 打包工具的应用应该升级到
@electron/packager@18.3.1或@electron/forge@7.4.0。 - 查看我们的 ASAR Integrity 教程 以获取更多信息。
- 启用 ASAR 完整性的现有应用程序如果配置不正确,可能无法在 Windows 上工作。使用 Electron 打包工具的应用应该升级到
- 添加了
WebContentsView和BaseWindow主进程模块,废弃并替换BrowserView(#35658)
BrowserView现在是WebContentsView的一个壳,并且旧的实现已被移除。- 查看 我们的 Web Embeds 文档 以便将新的
WebContentsViewAPI 和其他类似 API 进行比较。
- 实现了对 File System API 的支持 (#41827)
架构(Stack)更新
- Chromium
124.0.6367.49
- Chrome 124 和 DevTools 124 中的新功能
- Chrome 123 和 DevTools 123 中的新功能
- Node
20.11.1
- V8
12.4
Electron 30 将 Chromium 从 122.0.6261.39 升级到 124.0.6367.49, Node 从 20.9.0 升级到 20.11.1 以及 V8 从 12.2 升级到 12.4。
新特性
- 在 webviews 中添加了
transparent网页偏好设置。(#40301) - 在 webContents API 上添加了一个新的实例属性
navigationHistory,配合navigationHistory.getEntryAtIndex方法,使应用能够检索浏览历史中任何导航条目的 URL 和标题。(#41662) - 新增了
BrowserWindow.isOccluded()方法,允许应用检查窗口是否被遮挡。(#38982) - 为工具进程中
net模块发出的请求添加了代理配置支持。(#41417) - 添加了对
navigator.serial中的服务类 ID 请求的蓝牙端口的支持。(#41734) - 添加了对 Node.js
NODE_EXTRA_CA_CERTS命令行标志的支持。(#41822)
重大更改
行为变更:跨源 iframe 现在使用 Permission Policy 来访问功能。
跨域 iframe 现在必须通过 allow 属性指定一个给定 iframe 可以访问的功能。
有关更多信息,请参见 文档。
移除:--disable-color-correct-rendering 命令行开关
此开关从未正式文档化,但无论如何这里都记录了它的移除。Chromium 本身现在对颜色空间有更好的支持,因此不再需要该标志。
行为变更:BrowserView.setAutoResize 在 macOS 上的行为
在 Electron 30 中,BrowserView 现在是围绕新的 WebContentsView API 的包装器。
以前,BrowserView API 的 setAutoResize 功能在 macOS 上由 autoresizing 支持,并且在 Windows 和 Linux 上由自定义算法支持。
对于简单的用例,比如使 BrowserView 填充整个窗口,在这两种方法的行为上是相同的。
然而,在更高级的情况下,BrowserViews 在 macOS 上的自动调整大小与在其他平台上的情况不同,因为 Windows 和 Linux 的自定义调整大小算法与 macOS 的自动调整大小 API 的行为并不完全匹配。
自动调整大小的行为现在在所有平台上都标准化了。
如果您的应用使用 BrowserView.setAutoResize 做的不仅仅是使 BrowserView 填满整个窗口,那么您可能已经有了自定义逻辑来处理 macOS 上的这种行为差异。
如果是这样,在 Electron 30 中不再需要这种逻辑,因为自动调整大小的行为是一致的。
移除:WebContents 上 context-menu 的 params.inputFormType 属性
WebContents 的 context-menu 事件中 params 对象的 inputFormType 属性已被移除。请改用新的 formControlType 属性。
移除:process.getIOCounters()
Chromium 已删除对这些信息的访问。
终止对 27.x.y 的支持
根据项目的支持政策,Electron 27.x.y 已经达到了支持的终点。我们鼓励开发者将应用程序升级到更新的 Electron 版本。
| E30(24 年 4 月) | E31 (24 年 6 月) | E26(24 年 8 月) |
|---|---|---|
| 30.x.y | 31.x.y | 32.x.y |
| 29.x.y | 30.x.y | 31.x.y |
| 28.x.y | 29.x.y | 30.x.y |
接下来
在短期内,您可以期待团队继续专注于跟上构成 Electron 的主要组件的开发,包括 Chromium、Node 和 V8。
您可以在此处找到 Electron 的公开时间表。
有关这些和未来变化的更多信息可在计划的突破性变化页面找到。
原文: Electron 30.0.0
来源:juejin.cn/post/7361426249380397068
Sa-Token v1.41.0 发布 🚀,来看看有没有令你心动的功能!
Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证、权限认证、单点登录、OAuth2.0、微服务网关鉴权 等一系列权限相关问题。🔐
目前最新版本 v1.41.0 已推送至 Maven 中央仓库 🎉,大家可以通过如下方式引入:
<!-- Sa-Token 权限认证 -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-spring-boot-starter</artifactId>
<version>1.41.0</version>
</dependency>
该版本包含大量 ⛏️️️新增特性、⛏️底层重构、⛏️️️代码优化 等,下面容我列举几条比较重要的更新内容供大家参阅:
🛡️ 更新点1:防火墙模块新增 hooks 扩展机制
本次更新针对防火墙新增了多条校验规则,之前的规则为:
- path 白名单放行。
- path 黑名单拦截。
- path 危险字符校验。
本次新增规则为:
- path 禁止字符校验。
- path 目录遍历符检测(优化了检测算法)。
- 请求 host 检测。
- 请求 Method 检测。
- 请求 Header 头检测。
- 请求参数检测。
并且本次更新开放了 hooks 机制,允许开发者注册自定义的校验规则 🛠️,参考如下:
@PostConstruct
public void saTokenPostConstruct() {
// 注册新 hook 演示,拦截所有带有 pwd 参数的请求,拒绝响应
SaFirewallStrategy.instance.registerHook((req, res, extArg)->{
if(req.getParam("pwd") != null) {
throw new FirewallCheckException("请求中不可包含 pwd 参数");
}
});
}
文档直达地址:Sa-Token 防火墙 🔗
💡 更新点2:新增基于 SPI 机制的插件体系
之前在 Sa-Token 中也有插件体系,不过都是利用 SpringBoot 的 SPI 机制完成组件注册的。
这种注册机制有一个问题,就是插件只能在 SpringBoot 环境下正常工作,在其它环境,比如 Solon 项目中,就只能手动注册插件才行 😫。
也就是说,严格来讲,这些插件只能算是 SpringBoot 的插件,而非 Sa-Token 框架的插件 🌐。
为了提高插件的通用性,Sa-Token 设计了自己的 SPI 机制,使得这些插件可以在更多的项目环境下正常工作 🚀。
第一步:实现插件注册类,此类需要 implements SaTokenPlugin 接口 👨💻:
/**
* SaToken 插件安装:插件作用描述
*/
public class SaTokenPluginForXxx implements SaTokenPlugin {
@Override
public void install() {
// 书写需要在项目启动时执行的代码,例如:
// SaManager.setXxx(new SaXxxForXxx());
}
}
第二步:在项目的 resources\META-INF\satoken\ 文件夹下 📂 创建 cn.dev33.satoken.plugin.SaTokenPlugin 文件,内容为该插件注册类的完全限定名:
cn.dev33.satoken.plugin.SaTokenPluginForXxx
这样便可以在项目启动时,被 Sa-Token 插件管理器加载到此插件,执行插件注册类的 install 方法,完成插件安装 ✅。
文档直达地址:Sa-Token 插件开发指南 🔗
🎛️ 更新点3:重构缓存体系,将数据读写与序列化操作分离
在之前的版本中,Redis 集成通常和具体的序列化方式耦合在一起,这不仅让 Redis 相关插件产生大量的重复冗余代码,也让大家在选择 Redis 插件时严重受限。⚠️
本次版本更新彻底重构了此模块,将数据读写与序列化操作分离,使其每一块都可以单独自定义实现类,做到灵活扩展 ✨,例如:
- 1️⃣ SaTokenDao 数据读写可以选择:RedisTemplate、Redisson、ConcurrentHashMap、Hutool-Timed-Cache 等不同实现类。
- 2️⃣ SaSerializerTemplate 序列化器可以选择:Base64编码、Hex编码、ISO-8859-1编码、JSON序列化等不同方式。
- 3️⃣ JSON 序列化可以选择:Jackson、Fastjson、Snack3 等组件。
所有实现类均可以按需选择,自由搭配,大大提高灵活性🏗️。
⚙️️ 更新点4:SaLoginParameter 登录参数类新增大量配置项
SaLoginParameter (前SaLoginModel) 用于控制登录操作中的部分细节行为,本次新增的配置项有:
- isConcurrent:决定是否允许同一账号多地同时登录(为 true 时允许一起登录, 为 false 时新登录挤掉旧登录)。🌍
- isShare:在多人登录同一账号时,是否共用一个 token (为 true 时所有登录共用一个 token, 为 false 时每次登录新建一个 token)。🔄
- maxLoginCount:同一账号最大登录数量,超出此数量的客户端将被自动注销,-1代表不限制数量。🚫
- maxTryTimes:在创建 token 时的最高循环次数,用于保证 token 唯一性(-1=不循环尝试,直接使用。⏳
- deviceId:此次登录的客户端设备id,用于判断后续某次登录是否为可信任设备。📱
- terminalExtraData:本次登录挂载到 SaTerminalInfo 的自定义扩展数据。📦
以上大部分配置项在之前的版本中也有支持,不过它们都被定义在了全局配置类 SaTokenConfig 之上,本次更新支持在 SaLoginParameter 中定义这些配置项,
这将让登录策略的控制变得更加灵活。✨
🚪 更新点5:新增 SaLogoutParameter 注销参数类
SaLogoutParameter 用于控制注销操作中的部分细节行为️,例如:
通过 Range 参数决定注销范围 🎯:
// 注销范围: TOKEN=只注销当前 token 的会话,ACCOUNT=注销当前 token 指向的 loginId 其所有客户端会话
StpUtil.logout(new SaLogoutParameter().setRange(SaLogoutRange.TOKEN));
通过 DeviceType 参数决定哪些登录设备类型参与注销 💻:
// 指定 10001 账号,所有 PC 端注销下线,其它端如 APP 端不受影响
StpUtil.logout(10001, new SaLogoutParameter().setDeviceType("PC"));
还有其它参数此处暂不逐一列举,文档直达地址:Sa-Token 登录参数 & 注销参数 🔗
🐞 更新点6:修复 StpUtil.setTokenValue("xxx")、loginParameter.getIsWriteHeader() 空指针的问题。
这个没啥好说的,有 bug 🐛 必须修复。
fix issue:#IBKSM0 🔗
✨ 更新点7:API 参数签名模块升级
- 1、新增了 @SaCheckSign 注解,现在 API 参数签名模块也支持注解鉴权了。🆕
- 2、新增自定义签名的摘要算法,现在不仅可以 md5 算法计算签名,也支持 sha1、sha256 等算法了。🔐
- 3、新增多应用模式:
多应用模式就是指,允许在对接多个系统时分别使用不同的秘钥等配置项,配置示例如下 📝:
sa-token:
# API 签名配置 多应用模式
sign-many:
# 应用1
xm-shop:
secret-key: 0123456789abcdefg
digest-algo: md5
# 应用2
xm-forum:
secret-key: 0123456789hijklmnopq
digest-algo: sha256
# 应用3
xm-video:
secret-key: 12341234aaaaccccdddd
digest-algo: sha512
然后在签名时通过指定 appid 的方式获取对应的 SignTemplate 进行操作 👨💻:
// 创建签名示例
String paramStr = SaSignMany.getSignTemplate("xm-shop").addSignParamsAndJoin(paramMap);
// 校验签名示例
SaSignMany.getSignTemplate("xm-shop").checkRequest(SaHolder.getRequest());
⚡ 更新点8:新增 sa-token-caffeine 插件,用于整合 Caffeine
Caffeine 是一个基于 Java 的高性能本地缓存库,本次新增 sa-token-caffeine 插件用于将 Caffeine 作为 Sa-Token 的缓存层,存储会话鉴权数据。🚀
这进一步丰富了 Sa-Token 的缓存层插件生态。🌱
<!-- Sa-Token 整合 Caffeine -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-caffeine</artifactId>
<version>1.41.0</version>
</dependency>
🎪 更新点9:新增 sa-token-serializer-features 序列化扩展包
引入此插件可以为 Sa-Token 提供一些有意思的序列化方案。(娱乐向,不建议上生产 🎭)
例如:以base64 编码,采用:元素周期表 🧪、特殊符号 🔣、或 emoji 😊 作为元字符集存储数据 :




📜 完整更新日志
除了以上提到的几点以外,还有更多更新点无法逐一详细介绍,下面是 v1.41.0 版本的完整更新日志:
- core:
- 修复:修复
StpUtil.setTokenValue("xxx")、loginParameter.getIsWriteHeader()空指针的问题。 fix: #IBKSM0 - 修复:将
SaDisableWrapperInfo.createNotDisabled()默认返回值封禁等级改为 -2,以保证向之前版本兼容。 - 新增:新增基于 SPI 的插件体系。 [重要]
- 重构:JSON 转换器模块。 [重要]
- 新增:新增 serializer 序列化模块,控制
Object与String的序列化方式。 [重要] - 重构:重构防火墙模块,增加 hooks 机制。 [重要]
- 新增:防火墙新增:请求 path 禁止字符校验、Host 检测、请求 Method 检测、请求头检测、请求参数检测。重构目录遍历符检测算法。
- 重构:重构
SaTokenDao模块,将序列化与存储操作分离。 [重要] - 重构:重构
SaTokenDao默认实现类,优化底层设计。 - 新增:
isLastingCookie配置项支持在全局配置中定义了。 - 重构:
SaLoginModel->SaLoginParameter。 [不向下兼容] - 重构:
TokenSign->SaTerminalInfo。 [不向下兼容] - 新增:
SaTerminalInfo新增extraData自定义扩展数据设置。 - 新增:
SaLoginParameter支持配置isConcurrent、isShare、maxLoginCount、maxTryTimes。 - 新增:新增
SaLogoutParameter,用于控制注销会话时的各种细节。 [重要] - 新增:新增
StpLogic#isTrustDeviceId方法,用于判断指定设备是否为可信任设备。 - 新增:新增
StpUtil.getTerminalListByLoginId(loginId)、StpUtil.forEachTerminalList(loginId)方法,以更方便的实现单账号会话管理。 - 升级:API 参数签名配置支持自定义摘要算法。
- 新增:新增
@SaCheckSign注解鉴权,用于 API 签名参数校验。 - 新增:API 参数签名模块新增多应用模式。 fix: #IAK2BI, #I9SPI1, #IAC0P9 [重要]
- 重构:全局配置
is-share默认值改为 false。 [不向下兼容] - 重构:踢人下线、顶人下线默认将删除对应的 token-session 对象。
- 优化:优化注销会话相关 API。
- 重构:登录默认设备类型值改为 DEF。 [不向下兼容]
- 重构:
BCrypt标注为@Deprecated。 - 新增:
sa-token-quick-login支持SpringBoot3项目。 fix: #IAFQNE、#673 - 新增:
SaTokenConfig新增replacedRange、overflowLogoutMode、logoutRange、isLogoutKeepFreezeOps、isLogoutKeepTokenSession配置项。
- 修复:修复
- OAuth2:
- 重构:重构 sa-token-oauth2 插件,使注解鉴权处理器的注册过程改为 SPI 插件加载。
- 插件:
- 新增:
sa-token-serializer-features插件,用于实现各种形式的自定义字符集序列化方案。 - 新增:
sa-token-fastjson插件。 - 新增:
sa-token-fastjson2插件。 - 新增:
sa-token-snack3插件。 - 新增:
sa-token-caffeine插件。
- 新增:
- 单元测试:
- 新增:
sa-token-json-testjson 模块单元测试。 - 新增:
sa-token-serializer-test序列化模块单元测试。
- 新增:
- 文档:
- 新增:QA “多个项目共用同一个 redis,怎么防止冲突?”
- 优化:补全 OAuth2 模块遗漏的相关配置项。
- 优化:优化 OAuth2 简述章节描述文档。
- 优化:完善 “SSO 用户数据同步 / 迁移” 章节文档。
- 修正:补全项目目录结构介绍文档。
- 新增:文档新增 “登录参数 & 注销参数” 章节。
- 优化:优化“技术求助”按钮的提示文字。
- 新增:新增
preview-doc.bat文件,一键启动文档预览。 - 完善:完善 Redis 集成文档。
- 新增:新增单账号会话查询的操作示例。
- 新增:新增顶人下线 API 介绍。
- 新增:新增 自定义序列化插件 章节。
- 其它:
- 新增:新增
sa-token-demo/pom.xml以便在 idea 中一键导入所有 demo 项目。 - 删除:删除不必要的
.gitignore文件 - 重构:重构
sa-token-solon-plugin插件。 - 新增:新增设备锁登录示例。
- 新增:新增
更新日志在线文档直达链接:sa-token.cc/doc.html#/m…
🌟 其它
代码仓库地址:gitee.com/dromara/sa-…
框架功能结构图:

来源:juejin.cn/post/7484191942358499368
直观理解时下大热的 MCP 协议
得益于 Cursor 从 v0.45.x 开始支持 Anthropic MCP 协议,最近 MCP server 的概念很火热。我想聊聊对这个协议的感受。
MCP 是什么?
MCP = Model Context Protocol = 模型上下文协议
说白了,它就是个「插件协议」,严谨点加个限定词,「专供 LLM 应用的插件接口协议」。
Anthropic 官方说 MCP 是受微软的 LSP (Language Service Protocol) 的启发而制定,有朋友熟悉 LSP 协议的话,应该马上会发现这两者极为相似。
给不了解 LSP 的朋友介绍一下。VSCode 大家都熟,可以装各种插件。因为 VSCode 是用 JS 写的,插件要运行在 VSCode 之内,所以也必须用 JS 写。
但有一类插件比较特殊:编程语言支持类插件。比如你想在 VSCode 里写 rust,肯定要装 rust 相关插件。可问题是 rust 官方的语言支持(提供错误提示、代码自动补全之类的功能)肯定也是用 rust 写的,无法直接跑在 VSCode 的运行时里。别的语言 C#、Java、Python 情况也一样,怎么办呢?
为了解决这问题,LSP 制定了一套基于 JSON-RPC 2.0 的标准协议。RPC 顾名思义「远程调用」,那些语言工具你爱跑在哪都行,只要你按照这协议,能接受 RPC 请求,能给出正确返回数据格式,那么就能顺利接入 VSCode。
这套协议带来的价值有三个点:
- 这是个开放标准,市面上那么多 IDE 编辑器,都有语言支持需求,大家都用这套标准的话,很快可以形成开放插件生态。
- 把插件和消费它的客户端解耦合了。按照 LSP 标准写插件,你不需要关心你服务的客户端到底是 VSCode 还是 JetBrain 还是 Vim,只要这些客户端支持 LSP,那你的插件都能接入,不需要挨个适配。
- LSP 协议本身预设了很多跟编程语言支持相关的「标准功能」。例如最常见的代码自动补全
"textDocument/completion",或者点击跳转到函数定义"textDocument/definition"等等。这些都是跨语言、广泛存在的需求,是编程语言业界多年积累下来的集体经验。假如你自己哪天创造了个新的编程语言,要写配套的语言支持工具,那么你不用闭门造车,对着 LSP 协议,把里列举的所有「标准功能」挨个实现一遍,这妥妥的就是「语言支持工具界的最佳实践」了。
所以 MCP 到底是什么…
之所以在 LSP 上费这么多字,是希望能借用一个大家熟悉的老概念,快速对 MCP 这个新概念建立起一个直观的认识。
回到 MCP,它也是一个基于 JSON-RPC 2.0 的标准协议,LSP 有的那些优点它也有:
- 开放标准:语言无关,实现无关,有助形成开放生态
- 解耦合:只要客户端支持,你的 MCP Server 都能接入,不用多次适配
- 最佳实践:参考「标准功能」,能借鉴行业集体经验,少走弯路
我认为「标准功能」,官方称为「能力(capability)」,是 MCP 价值比较大的东西,尤其对于开发 LLM 应用的朋友来说,支持这些能力基本上就跟 Cursor 在底层的 agent 工具层面上对齐了。
MCP 不是什么
MCP 不是 agent 框架,MCP 也不是 RAG 框架,它甚至都不是框架!尽管官方有提供 SDK,但 MCP 本身只是一个标准协议,目的是构建一个给 LLM/agent 用的「外接能力插件生态」。
不过 MCP 的标准设计里没有考虑 RAG 能力,是让我比较困惑的点。
能力 Capability
理解这个小节,我建议脑子里可以想着 Cursor 作为「LLM 应用」的范本。
client 端能力
roots当前项目路径列表,对标 IDE 里的 workspace/project 概念,主要用来通知 server 端更新 resources(见下文)sampling供 server 调用 client 侧 LLM 的能力
server 端能力
tools任意的外部工具:计算器、代码运行、搜索引擎之类prompts提示词模版,设计目的是为了支持类似 Github Copilot Chat 聊天框/开头的快捷指令

resources当前项目下有什么资源可访问(主要是文件啦)。Cursor/Cline 聊天框@/foobar.txt就可以用这项能力来实现

completion自动补全,快捷指令和资源都需要,提升用户体验logging给到 client 的 log 信息推送,这个属于杂项,方便 debug 之类
其他
resources不只能建模文件,也可以建模 git 历史,数据库表等其他资源,只需要 uri 上通过"git://"或"db://"来区分即可- 两端都支持自定义能力,通过
experimentalnamespace 来暴露。 - 前面提过 MCP 没考虑 RAG 的用例,目前看来似乎可以通过
prompts+completion能力来间接实现。
通讯模型

MCP 是一个 client/server 架构的 RPC 协议,需要关注两端的通讯模型。大致可分三段生命周期来看:初始化阶段,运行阶段,结束阶段。不过先铺垫两个前置知识,方便后面的理解。
前置知识
一、实体术语定义
一共有三类实体:host, client, server.
host 指「LLM 应用」的本体,它大概率是个 GUI 程序。在 MCP 的语境下,这就是一个容器,负责管理多个 client 实例,同时要集成 LLM,承接用户交互,特别是各种授权的工作。
每个 client 实例只负责与一个 server 建立有状态的连接,然后进行 RPC 通讯。server 是实际干活的、跑插件的线程,client 是留在 host 内负责 RPC 调用的一段简单的程序。
当前的协议版本下(版本号:2024-11-05,你没看错,它是用日期来做版本号的)
- host 与 client 是一对多关系
- client 与 server 是一对一关系
这里插一句,「一对一」的奇怪设定是暂时的。目前 MCP 只针对 client/server 都跑在本地的场景设计,官方 SDK 在使用 stdio 为传输信道的时候,更是做了个「由 client fork 子进程来跑 server」的强假设。好在 roadmap 里面有提,支持 remote server 是眼下的第一优先级,预计 2025 上半年会更新相关标准。
二、JSON-RPC 2.0 的三种信息类型
JSON-RPC 2.0 标准有三类 RPC 信息类型:request, response, notification. 注意几个点:
- request 必须有对应 response,
id要对得上 - response 的
result和error字段互斥,同时只可能有其一 - response
error.code必须是整数,并且协议预留了一批错误码,代表特定含义(类似 HTTP status code) - notification 只比 request 少一个
id, 并且不要求有对应 response
type JsonRpcRequest = {
jsonrpc: "2.0";
id: string | number;
method: string;
params?: {
[key: string]: unknown;
};
};
type JsonRpcResponse = {
jsonrpc: "2.0";
id: string | number;
// result 与 error 是互斥的
result?: {
[key: string]: unknown;
};
error?: {
code: number;
message: string;
data?: unknown;
};
};
type JsonRpcNotification = {
jsonrpc: "2.0";
method: string;
params?: {
[key: string]: unknown;
};
};
三个通讯生命周期
一、初始化阶段 Initialization
client/server 需要握手协商,交换各自能力(capability)声明,跟 TCP 的三次握手基本一样。
第一次:client 向 server 发送 request,声明 client 侧提供的能力。
Client:「Server 老哥在吗?我能干这些,你能干啥?」
第二次:server 向 client 回复 response,声明 server 侧提供的能力。
Server:「Client 老弟,我在呢,我能干这些,需要干啥活你喊我哈!」
第三次:client 向 server 发送 notification,确认连接建立
Client:「得嘞,那我开始干活了,有事儿我再喊你。」
二、运行阶段 Operation
根据初始化阶段交换的能力声明,两端开始互相发送 RPC 信息。这里展示一段能力调用示例。
// 1. server 在初始化阶段,第二次握手时,向 client 公布自己的 tools 能力
{
"capabilities": {
"tools": {
"listChanged": true
}
}
}
// 2. client 初始化后,主动拉取 tools 列表
// Request:
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/list",
"params": {
// 可选参数,list 如果很长,可支持翻页
"cursor": "optional-cursor-value"
}
}
// Response:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"tools": [
{
"name": "get_weather",
"description": "Get current weather information for a location",
"inputSchema": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City name or zip code"
}
},
"required": ["location"]
}
}
],
"nextCursor": "next-page-cursor"
}
}
// 3. client 调用工具
// Request:
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": {
"name": "get_weather",
"arguments": {
"location": "New York"
}
}
}
// Response:
{
"jsonrpc": "2.0",
"id": 2,
"result": {
"content": [
{
"type": "text",
"text": "Current weather in New York:\nTemperature: 72°F\nConditions: Partly cloudy"
}
],
"isError": false
}
}
// 4. 如果 server 端因为什么原因,可用 tools list 发生变化,应该通知 client 重新拉取
{
"jsonrpc": "2.0",
"method": "notifications/tools/list_changed"
}
三、结束阶段 Shutdown
标准只说任何一端(正常来说是 client 端)可以主动断开连接,没有硬性规定这个阶段的具体协议。因为传输层通常会有相关的断联信号,已经够用了,没必要再在上层协议重复建设。
但是实际写落地实现,开发者还是需要做一些处理的,比如 graceful shutdown, 或者错误重启之类的。
总结
目前整个 AI 应用范式没有固定下来,整个业界都在积极探索,摸着石头过河。这个背景下 MCP 相当于把 AI 应用厂商们拉了个大群,一起来总结业界的最佳实践,制定标准推广集体智慧。当前 MCP 的生态发展势头很不错,标准本身更新得也很紧跟潮流。最近当红炸子鸡 Cursor 的加入,可以说是对 MCP 的重大利好,势必会进一步刺激 MCP server(插件)生态的成长。
现在正在做 LLM 相关应用的朋友,我非常推荐拥抱这个协议标准,好处多多。
- 首先协议本身很薄不复杂,看不出有技术上的坑。同时官方也有 SDK 可用,支持的难度不高。
- 其次可以拥抱生态,快速接入第三方插件,增强自身产品竞争力。
- 最后,让自己的应用去支持协议要求,等于是跟进业界最佳实践了,避免闭门造车走死胡同。
如果觉得本文对你有帮助,欢迎转发和关注(微信公众号同名),我会持续分享在开发 multi-agent 系统过程中的第一手经验和心得。
来源:juejin.cn/post/7478841799004700683
我的 Electron 客户端也可以全量/增量更新了
前言
本文主要介绍 Electron 客户端应用的自动更新,包括全量和增量这两种方式。
全量更新: 运行新的安装包,安装目录所有资源覆盖式更新。
增量更新: 只更新修改的部分,通常是渲染进程和主进程文件。
本文并没有拿真实项目来举例子,而是起一个 新的项目 从 0 到 1 来实现自动更新。
如果已有的项目需要支持该功能,借鉴本文的主要步骤即可。
前置说明:
- 由于业务场景的限制,本文介绍的更新仅支持
Windows操作系统,其余操作系统未作兼容处理。 - 更新流程全部由前端完成,不涉及到后端,没有轮询 更新的机制。
- 发布方式限制为
generic,线上服务需要配置nginx确保访问到资源文件。
准备工作
脚手架搭建项目
我们通过 electron-vite 快速搭建一个基于 Vite + React + TS 的 Electron 项目。

该模板已经包括了我们需要的核心第三方库:electron-builder,electron-updater。
前者是用来打包客户端程序的,后者是用来实现自动更新的。
在项目根目录下,已经自动生成了两份配置文件:electron-builder.yml 和 dev-app-update.yml。
electron-builder.yml
该文件描述了一些 打包配置,更多信息可参考 官网。
在这些配置项中,publish 字段比较重要,因为它关系到更新源。
publish:
provider: generic // 使用一个通用的 HTTP 服务器作为更新源。
url: https://example.com/auto-updates // 存放安装包和描述文件的地址
provider 字段还有其他可选项,但是本文只介绍 generic 这种方式,即把安装包放在 HTTP 服务器里。
dev-app-update.yml
provider: generic
url: https://example.com/auto-updates
updaterCacheDirName: electron-update-demo-updater
其中,updaterCacheDirName 定义下载目录,也就是安装包存放的位置。全路径是C:\Users\用户名\AppData\Local\electron-update-demo-updater,不配置则在C:\Users\用户名\AppData\Local下自动创建文件夹,开发环境下为项目名,生产环境下为项目名-updater。

模拟服务器
我们直接运行 npm run build:win,在默认 dist 文件夹下就出现了打包后的一些资源。

其实更新的基本思路就是对比版本号,即对比本地版本和 线上服务器 版本是否一致,若不一致则需要更新。

因此我们在开发调试的时候,需要起一个本地服务器,来模拟真实的情况。
新建一个文件夹 mockServer,把打包后的 setup.exe 安装包和 latest.yml 文件粘贴进去,然后通过 serve 命令默认起了一个 http://localhose:3000 的本地服务器。
既然有了存放资源的本地地址,在开发调试的时候,我们更新下 dev-app-update.yml 文件的 url 字段,也就是修改为 http://localhose:3000。
注:如果需要测试打包后的更新功能,需要同步修改打包配置文件。
全量更新
与主进程文件同级,创建 update.ts 文件,之后我们的更新逻辑将在这里展开。
import { autoUpdater } from 'electron-updater' //核心库
需要注意的是,在我们开发过程中,通过 npm run dev 起来的 Electron 程序其实不能算是打包后的状态。
你会发现在调用 autoUpdater 的一些方法会提示下面的错误:
Skip checkForUpdates because application is not packed and dev update config is not forced
因此我们需要在开发环境去做一些动作,并且手动指定 updateConfigPath:
// update.ts
if (isDev) {
Object.defineProperty(app, 'isPackaged', {
get: () => true
})
autoUpdater.updateConfigPath = path.join(__dirname, '../../dev-app-update.yml')
}
核心对象 autoUpdater 有很多可以主动调用的方法,也有一些监听事件,同时还有一些属性可以设置。
这里只展示了本人项目场景所需的一些配置。
autoUpdater.autoDownload = false // 不允许自动下载更新
autoUpdater.allowDowngrade = true // 允许降级更新(应付回滚的情况)
autoUpdater.checkForUpdates()
autoUpdater.downloadUpdate()
autoUpdater.quitAndInstall()
autoUpdater.on('checking-for-update', () => {
console.log('开始检查更新')
})
autoUpdater.on('update-available', info => {
console.log('发现更新版本')
})
autoUpdater.on('update-not-available', info => {
console.log('不需要全量更新', info.version)
})
autoUpdater.on('download-progress', progressInfo => {
console.log('更新进度信息', progressInfo)
})
autoUpdater.on('update-downloaded', () => {
console.log('更新下载完成')
})
autoUpdater.on('error', errorMessage => {
console.log('更新时出错了', errorMessage)
})
在监听事件里,我们可以拿到下载新版本 整个生命周期 需要的一些信息。
// 新版本的版本信息(已筛选)
interface UpdateInfo {
readonly version: string;
releaseName?: string | null;
releaseNotes?: string | Array<ReleaseNoteInfo> | null;
releaseDate: string;
}
// 下载安装包的进度信息
interface ProgressInfo {
total: number;
delta: number;
transferred: number;
percent: number;
bytesPerSecond: number;
}
在写完这些基本的方法之后,我们需要决定 检验更新 的时机,一般是在应用程序真正启动之后,即 mainWindow 创建之后。
运行项目,预期会提示 不需要全量更新,因为刚才复制到本地服务器的 latest.yml 文件里的版本信息与本地相同。修改 version 字段,重启项目,主进程就会提示有新版本需要更新了。
频繁启动应用太麻烦,除了应用初次启动时主进程主动帮我们检验更新外,还需要用户 手动触发 版本更新检测,此外,由于产品场景需要,当发现有新版本的时候,需要在 渲染进程 通知用户,包括版本更新时间和更新内容。因此我们需要加上主进程与渲染进程的 IPC通信 来实现这个功能。
其实需要的数据主进程都能够提供了,渲染进程具体的展示及交互方式就自由发挥了,这里简单展示下我做的效果。
1. 发现新版本

2. 无需更新

增量更新
为什么要这么做
其实全量更新是一种比较简单粗暴的更新方式,我没有花费太大的篇幅去介绍,基本上就是使用 autoUpdater 封装的一些方法,开发过程中更多的注意力则是放在了渲染进程的交互上。
此外,我们的更新交互用的是一种 用户感知 的方式,即更不更新是由用户自己决定的。而 静默更新 则是用户无感知,在监测到更新后不用去通知用户,而是自行在后台下载,在某个时刻执行安装的逻辑,这种方式往往是一键安装,不会弹出让用户去选择安装路径的窗口。接下去要介绍的增量更新其实是这种 用户无感知 的形式,只不过我们更新的不是整个应用程序。
由于产品迭代比较频繁,我们的业务方经常收到更新提示,意味着他们要经常手动更新应用,以便使用到最新的功能特性。众所周知,Electron 给前端开发提供了一个比较容易上手的客户端开发解决方案,但在享受 跨平台 等特性的同时,还得忍受 臃肿的安装包 。
带宽、流量在当前不是什么大问题,下载和安装的速度也挺快,但这频繁的下载覆盖一模一样的资源文件还是挺糟心的,代码改动量小时,全量更新完全没有必要。我们希望的是,开发更新了什么代码,应用程序就替换掉这部分代码就好了,这很优雅。在 我们的场景 中,这部分代码指的是 —— main、preload、renderer,并不包括 dll、第三方SDK等资源。
网上有挺多种增量更新的 解决方案,例如:
- 通过
win.loadURL(一个线上地址)实现,相当于就套了一层客户端的壳子,与加载的Web端同步更新。这种方法对于简单应用来说是最省心的,但是也有一定的局限性,例如不能使用node去操作一些底层的东西。 - 设置
asar的归档方式,替换app.asar或app.asar.unpack来实现。但后者在我实践过程中存在文件路径不存在的问题。 - 禁用
asar归档,解压渲染进程压缩包后实现替换。简单尝试过,首次执行安装包的时候写入文件很慢,不知道是不是这个方式引起的。 - 欢迎补充。
本文我们采用较普遍的 替换asar 来实现。
优化 app.asar 体积
asar是Electron提供的一种将多个文件合并成一个文件的类tar风格的归档格式,不仅可以缓解Windows下路径名过长的问题, 还能够略微加快一下require的速度, 并且可以隐藏你的源代码。(并非完全隐藏,有方法可以找出来)
Electron 应用程序启动的时候,会读取 app.asar.unpacked 目录中的内容合并到 app.asar 的目录中进行加载。在此之前我们已经打包了一份 Demo 项目,安装到本地后,我们可以根据安装路径找到 app.asar 这个文件。
例如:D:\你的安装路径\electron-update-demo\resources

在这个 Demo 项目中,脚手架生成的模板将图标剥离出来,因此出现了一个 app.asar.unpacked 文件夹。我们不难发现,app.asar 这个文件竟然有 66 MB,再回过头看我们真正的代码文件,甚至才 1 MB !那么到底是什么原因导致的这个文件这么大呢,刚才提到了,asar 其实是一种压缩格式,因此我们只要解压看看就知道了。
npm i -g asar // 全局安装
asar e app.asar folder // 解压到folder文件夹

解压后我们不难发现,out 文件夹里的才是我们打包出来的资源,罪魁祸首竟然是 node_modules,足足有 62.3 MB。
查阅资料得知,Electron 在打包的时候,会把 dependencies 字段里的依赖也一起打包进去。而我们的渲染进程是用 React开发的,这些第三方依赖早就通过 Vite 等打包工具打到资源文件里了,根本不需要再打包一次,不然我们重新下载的 app.asar 文件还是很大的,因此需要尽可能减少体积。
优化应用程序体积 == 减少 node_modules 文件夹的大小 == 减少需要打包的依赖数量 == 减少 dependencies 中的依赖。
1. 移除 dependencies
最开始我想的是把 package.json 中的 dependencies 全都移到 devDependencies,打包后的体积果然减小了,但是在测试过程中会发现某些功能依赖包会缺失,比如 @electron/remote。因此在修改这部分代码的时候,需要特别留意,哪些依赖是需要保留下来的。
由于不想影响 package.json 的版本结构,我只是在写了一个脚本,在 npm i 之后,执行打包命令前修改 devDependencies 就好了。
2. 双 package.json 结构
这是 electron-builder 官网上看到的一种技巧,传送门, 创建 app 文件夹,再创建第二个 package.json,在该文件中配置我们应用的名称、版本、主进程入口文件等信息。这样一来,electron-builder 在打包时会以该文件夹作为打包的根文件夹,即只会打包这个文件夹下的文件。
但是我原项目的主进程和预加载脚本也放在这,尝试修改后出现打包错误的情况,感兴趣的可以试试。

这是我们优化之后的结果,1.32 MB,后面只需要替换这个文件就实现了版本的更新。
校验增量更新
全量更新的校验逻辑是第三方库已经封装好了的,那么对于增量更新,就得由我们自己来实现了。
首先明确一下 校验的时机,package.json 的 version 字段表示应用程序的版本,用于全量更新的判断,那也就意味着,当这个字段保持不变的时候,会触发上文提到的 update-not-available 事件。所以我们可以在这个事件的回调函数里来进行校验。
autoUpdater.on('update-not-available', info => { console.log('不需要全量更新', info.version) })
然后就是 如何校验,我们回过头来看 electron-builder 的打包配置,在 releaseInfo 字段里描述了发行版本的一些信息,目前我们用到了 releaseNotes 来存储更新日志,查阅官网得知还有个 releaseName 好像对于我们而言是没什么用的,那么我们就可以把它作为增量更新的 热版本号。(但其实 官网 配置项还有个 vendor 字段,可是我在用的时候打包会报错,可能是版本的问题,感兴趣的可以试试。)
每次发布新版本的时候,只要不是 Electron自身版本变化 等重大更新,我们都可以通过修改 releaseInfo 的 releaseName 来发布我们的热版本号。现在我们已经有了线上的版本,那 本地热版本号 该如何获取呢。这里我们在每次热更新完成之后,就会把最新的版本号存储在本地的一个配置文件中,通常是 userData 文件夹,用于存储我们应用程序的用户信息,即使程序卸载 了也不会影响里面的资源。在 Windows 下,路径如下:
C:\Users\用户名\AppData\Roaming\electron-update-demo。
因此,整个 校验流程 就是,在打开程序的时候,autoUpdater 触发 update-not-available 事件,拿到线上 latest.yml 描述的 releaseName 作为热版本号,与本地配置文件(我们命名为 config.json)里存储的热版本号(我们命名为 hotVersion)进行对比,若不同就去下载最新的 app.asar 文件。
我们使用 electron-log 来记录日志,代码如下所示。
// 本地配置文件
const localConfigFile = path.join(app.getPath('userData'), 'config.json')
const checkHotVersion = (latestHotVersion: string): boolean => {
let needDownload = false
if (!fs.existsSync(localConfigFile)) {
fs.writeFileSync(localConfigFile, '{}', 'utf8')
log.info('配置文件不存在,已自动创建')
} else {
log.info('监测到配置文件')
}
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
// 对比版本号
if (latestHotVersion !== configData.hotVersion) {
log.info('当前版本不是最新热更版本')
needDownload = true
} else {
log.info('当前为最新版本')
}
} catch (error) {
log.error('读取配置文件时出错', error)
}
return needDownload
}
下载增量更新包
通过刚才的校验,我们已经知道了什么时候该去下载增量更新包。
在开发调试的时候,我们可以把新版本的 app.asar 也放到起了本地服务器的 mockServer 文件夹里来模拟真实的情况。有很多方式可以去下载文件,这里我用了 nodejs 的 http 模块去实现,如果是 https 的需要引用 https 模块。
下载到本地的时候,我是放在了与 app.asar 同级目录的 resources 文件夹,我们不能直接覆盖原文件。一是因为进程权限占用的问题,二是为了容错,所以我们需要以另一个名字来命名下载后的文件(这里我们用的是 app.asar-temp),也就不需要去备份原文件了,代码如下。
const resourcePath = isDev
? path.join('D:\\测试\\electron-update-demo\\resources')
: process.resourcesPath
const localAsarTemp = path.join(resourcePath, 'app.asar-temp')
const asarUrl = 'http://localhost:3000/app.asar'
downloadAsar() {
const fileStream = fs.createWriteStream(localAsarTemp)
http.get(asarUrl, res => {
res.pipe(fileStream)
fileStream
.on('finish', () => {
log.info('asar下载完成')
})
.on('error', error => {
// 删除文件
fs.unlink(localAsarTemp, () => {
log.error('下载出现异常,已中断', error)
})
})
})
}
因此,我们的流程更新为:发现新版本后,下载最新的 app.asar 到 resources 目录,并重命名为 app.asar-temp。这个时候我们启动项目进行调试,找到记录在本地的日志—— C:\Users\用户名\AppData\Roaming\electron-update-demo\logs,会有以下的记录:
[2024-09-20 13:49:22.456] [info] 监测到配置文件
[2024-09-20 13:49:22.462] [info] 当前版本不是最新热更版本
[2024-09-20 13:49:23.206] [info] asar下载完成
在看看项目 resources 文件夹,多了一个 app.asar-temp文件。

至此,下载这一步已经完成了,但这样还会有一个问题,因为文件名没有加上版本号,也没有重复性校验,倘若一直没有更新,那么每次启动应用需要增量更新的时候都需要再次下载。
替换 app.asar 文件
好了,新文件也有了,接下来就是直接替换掉老文件就可以了,但是 替换的时机 很重要。
在 Windows 操作系统下,直接替换 app.asar 会提示程序被占用而导致失败,所以我们应该在程序关闭的时候实现替换。
- 进入应用,下载新版本,自动关闭应用,替换资源,重启应用。
- 进入应用,下载新版本,不影响使用,用户 手动关闭 后替换,下次启动 就是新版本了。
我们有上面两种方案,最终采用了 方案2。
在主进程监听 app.on('quit') 事件,在应用退出的时候,判断 app.asar 和 app.asar-temp 是否同时存在,若同时存在,就去替换。这里替换不能直接用 nodejs 在主进程里去写,因为主进程执行的时候,资源还是被占用的。因此我们需要额外起一个 子进程 去做。
nodejs 可以通过 spawn、exec 等方法创建一个子进程。子进程可以执行一些自定义的命令,我们并没有使用子进程去执行 nodejs,因为业务方的机器上不一定有这个环境,而是采用了启动 exe 可执行文件的方式。可能有人问为什么不直接运行 .bat 批处理文件,因为我调试关闭应用的时候,会有一个 命令框闪烁 的现象,这不太优雅,尽管已经设置 spawn 的 windowsHide: true。
那么如何获得这个 exe 可执行文件呢,其实是通过 bat 文件去编译的,命令如下:
@echo off
timeout /T 1 /NOBREAK
del /f /q /a %1\app.asar
ren %1\app.asar-temp app.asar
我们加了延时,等待父进程完全关闭后,再去执行后续命令。其中 %1 为运行脚本传入的参数,在我们的场景里就是 resources 文件夹的地址,因为每个人的安装地址应该是不一样的,所以需要作为参数传进去。
转换文件的工具一开始用的是 Bat To Exe Converter 下载地址,但是在实际使用的过程中,我的电脑竟然把转换后的 exe 文件 识别为病毒,但在其他同事电脑上没有这种表现,这肯定就不行了,最后还是同事使用 python 帮我转换生成了一份可用的文件(replace.exe)。
这里我们可以选择不同的方式把 replace.exe 存放到 用户目录 上,要么是从线上服务器下载,要么是安装的时候就已经存放在本地了。我们选择了后者,这需要修改 electron-builder 打包配置,指定 asarUnpack, 这样就会存放在 app.asar.unpacked 文件夹中,不经常修改的文件都可以放在这里,不会随着增量更新而替换掉。
有了这个替换脚本之后,开始编写子进程相关的代码。
import { spawn } from 'child_process'
cosnt localExePath = path.join(resourcePath, 'app.asar.unpacked/resources/replace.exe')
replaceAsar() {
if (fs.existsSync(localAsar) && fs.existsSync(localAsarTemp)) {
const command = `${localExePath} ${resourcePath}`
log.info(command)
const logPath = app.getPath('logs')
const childOut = fs.openSync(path.join(logPath, './out.log'), 'a')
const childErr = fs.openSync(path.join(logPath, './err.log'), 'a')
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true, // 允许子进程独立
shell: true,
stdio: ['ignore', childOut, childErr]
})
child.on('spawn', () => log.info('子进程触发'))
child.on('error', err => log.error('child error', err))
child.on('close', code => log.error('child close', code))
child.on('exit', code => log.error('child exit', code))
child.stdout?.on('data', data => log.info('stdout', data))
child.stderr?.on('data', data => log.info('stderr', data))
child.unref()
}
}
app.on('quit', () => {
replaceAsar()
})
在这块代码中,创建子进程的配置项比较重要,尤其是路径相关的。因为用户安装路径是不同的,可能会存在 文件夹名含有空格 的情况,比如 Program Files,这会导致在执行的时候将空格识别为分隔符,导致命令执行失败,因此需要加上 双引号。此外,detached: true 可以让子进程独立出来,也就是父进程退出后可以执行,而shell: true 可以将路径名作为参数传过去。
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true,
shell: true,
stdio: ['ignore', childOut, childErr]
})
但这块有个 疑惑,为什么我的 close、exit 以及 stdout 都没有触发,以至于不能拿到命令是否执行成功的最终结果,了解的同学可以评论区交流一下。
至此,在关闭应用之后,app.asar 就已经被替换为最新版本了,还差最后一步,更新本地配置文件里的 hotVersion,防止下次又去下载更新包了。
child.on('spawn', () => {
log.info('子进程触发')
updateHotVersion()
})
updateHotVersion() {
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion }, null, 2))
}
增量更新日志提示
既然之前提到的全量更新有日志说明,那增量更新可以不用,也应该需要具备这个能力,不然我们神不知鬼不觉帮用户更新了,用户都不知道 新在哪里。
至于更新内容,我们可以复用 releaseInfo 的 releaseNotes 字段,把更新日志写在这里,增量更新完成后展现给用户就好了。
但是总不能每次打开都展示,这里需要用户有个交互,比如点击 知道了 按钮,或者关闭 Modal 后,把当前的热更新版本号保存在本地配置文件,记录为 logVersion。在下次打开程序或者校验更新的时候,我们判断一下 logVersion === hotVersion,若不同,再去提示更新日志。
日志版本 校验和修改的代码如下所示:
checkLogVersion() {
let needShowLog = false
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion, logVersion } = configData
if (hotVersion !== logVersion) {
log.info('日志版本与当前热更新版本不同,需要提示更新日志')
needShowLog = true
} else {
log.info('日志已是最新版本,无需提示更新日志')
}
} catch (error) {
log.error('读取配置文件失败', error)
}
return needShowLog
}
updateLogVersion() {
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion } = configData
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion, logVersion: hotVersion }, null, 2))
log.info('日志版本已更新')
} catch (error) {
log.error('读取配置文件失败', error)
}
}
读取 config.json 文件的方法自行封装一下,我这里就重复使用了。主进程 ipcMain.on 监听一下用户传递过来的事件,再去调用 updateLogVersion 即可,渲染进程效果如下:
提示增量更新日志

点击 知道了 后,再次打开应用后就不会提示日志了,因为本地配置文件已经被修改了。

当然可能也有这么个场景,开发就改了一点点无关功能的代码,无需向用户展示日志,我们只需要加一个判断 releaseNotes 是否为空的逻辑就好了,也做到了 静默更新。
小结
不足之处
本文提出的增量更新方案应该算是比较简单的,可能并不适用于所有的场景,考虑也不够全面,例如:
dll、第三方SDK等资源的更新。- 增量更新失败后应该通过全量更新 兜底。
- 用户在使用过程中发布新版本,得等到 第二次打开 才能用到新版本。
流程图
针对本文的解决方案,我简单画了一个 流程图。

参考文章
网上其实有不少关于 Electron 自动更新的文章,在做这个需求之前也是浏览了好多,但也有些没仔细看完,所以就躺在我的标签页没有关闭,在这罗列出来,也当作收藏了。
写这篇文章的目的也是为了记录和复盘,如果能为你提供一些思路那就再好不过了。
鸣谢:
来源:juejin.cn/post/7416311252580352034
我的 Electron 客户端也可以全量/增量更新了
前言
本文主要介绍 Electron 客户端应用的自动更新,包括全量和增量这两种方式。
全量更新: 运行新的安装包,安装目录所有资源覆盖式更新。
增量更新: 只更新修改的部分,通常是渲染进程和主进程文件。
本文并没有拿真实项目来举例子,而是起一个 新的项目 从 0 到 1 来实现自动更新。
如果已有的项目需要支持该功能,借鉴本文的主要步骤即可。
前置说明:
- 由于业务场景的限制,本文介绍的更新仅支持
Windows操作系统,其余操作系统未作兼容处理。 - 更新流程全部由前端完成,不涉及到后端,没有轮询 更新的机制。
- 发布方式限制为
generic,线上服务需要配置nginx确保访问到资源文件。
准备工作
脚手架搭建项目
我们通过 electron-vite 快速搭建一个基于 Vite + React + TS 的 Electron 项目。

该模板已经包括了我们需要的核心第三方库:electron-builder,electron-updater。
前者是用来打包客户端程序的,后者是用来实现自动更新的。
在项目根目录下,已经自动生成了两份配置文件:electron-builder.yml 和 dev-app-update.yml。
electron-builder.yml
该文件描述了一些 打包配置,更多信息可参考 官网。
在这些配置项中,publish 字段比较重要,因为它关系到更新源。
publish:
provider: generic // 使用一个通用的 HTTP 服务器作为更新源。
url: https://example.com/auto-updates // 存放安装包和描述文件的地址
provider 字段还有其他可选项,但是本文只介绍 generic 这种方式,即把安装包放在 HTTP 服务器里。
dev-app-update.yml
provider: generic
url: https://example.com/auto-updates
updaterCacheDirName: electron-update-demo-updater
其中,updaterCacheDirName 定义下载目录,也就是安装包存放的位置。全路径是C:\Users\用户名\AppData\Local\electron-update-demo-updater,不配置则在C:\Users\用户名\AppData\Local下自动创建文件夹,开发环境下为项目名,生产环境下为项目名-updater。

模拟服务器
我们直接运行 npm run build:win,在默认 dist 文件夹下就出现了打包后的一些资源。

其实更新的基本思路就是对比版本号,即对比本地版本和 线上服务器 版本是否一致,若不一致则需要更新。

因此我们在开发调试的时候,需要起一个本地服务器,来模拟真实的情况。
新建一个文件夹 mockServer,把打包后的 setup.exe 安装包和 latest.yml 文件粘贴进去,然后通过 serve 命令默认起了一个 http://localhose:3000 的本地服务器。
既然有了存放资源的本地地址,在开发调试的时候,我们更新下 dev-app-update.yml 文件的 url 字段,也就是修改为 http://localhose:3000。
注:如果需要测试打包后的更新功能,需要同步修改打包配置文件。
全量更新
与主进程文件同级,创建 update.ts 文件,之后我们的更新逻辑将在这里展开。
import { autoUpdater } from 'electron-updater' //核心库
需要注意的是,在我们开发过程中,通过 npm run dev 起来的 Electron 程序其实不能算是打包后的状态。
你会发现在调用 autoUpdater 的一些方法会提示下面的错误:
Skip checkForUpdates because application is not packed and dev update config is not forced
因此我们需要在开发环境去做一些动作,并且手动指定 updateConfigPath:
// update.ts
if (isDev) {
Object.defineProperty(app, 'isPackaged', {
get: () => true
})
autoUpdater.updateConfigPath = path.join(__dirname, '../../dev-app-update.yml')
}
核心对象 autoUpdater 有很多可以主动调用的方法,也有一些监听事件,同时还有一些属性可以设置。
这里只展示了本人项目场景所需的一些配置。
autoUpdater.autoDownload = false // 不允许自动下载更新
autoUpdater.allowDowngrade = true // 允许降级更新(应付回滚的情况)
autoUpdater.checkForUpdates()
autoUpdater.downloadUpdate()
autoUpdater.quitAndInstall()
autoUpdater.on('checking-for-update', () => {
console.log('开始检查更新')
})
autoUpdater.on('update-available', info => {
console.log('发现更新版本')
})
autoUpdater.on('update-not-available', info => {
console.log('不需要全量更新', info.version)
})
autoUpdater.on('download-progress', progressInfo => {
console.log('更新进度信息', progressInfo)
})
autoUpdater.on('update-downloaded', () => {
console.log('更新下载完成')
})
autoUpdater.on('error', errorMessage => {
console.log('更新时出错了', errorMessage)
})
在监听事件里,我们可以拿到下载新版本 整个生命周期 需要的一些信息。
// 新版本的版本信息(已筛选)
interface UpdateInfo {
readonly version: string;
releaseName?: string | null;
releaseNotes?: string | Array<ReleaseNoteInfo> | null;
releaseDate: string;
}
// 下载安装包的进度信息
interface ProgressInfo {
total: number;
delta: number;
transferred: number;
percent: number;
bytesPerSecond: number;
}
在写完这些基本的方法之后,我们需要决定 检验更新 的时机,一般是在应用程序真正启动之后,即 mainWindow 创建之后。
运行项目,预期会提示 不需要全量更新,因为刚才复制到本地服务器的 latest.yml 文件里的版本信息与本地相同。修改 version 字段,重启项目,主进程就会提示有新版本需要更新了。
频繁启动应用太麻烦,除了应用初次启动时主进程主动帮我们检验更新外,还需要用户 手动触发 版本更新检测,此外,由于产品场景需要,当发现有新版本的时候,需要在 渲染进程 通知用户,包括版本更新时间和更新内容。因此我们需要加上主进程与渲染进程的 IPC通信 来实现这个功能。
其实需要的数据主进程都能够提供了,渲染进程具体的展示及交互方式就自由发挥了,这里简单展示下我做的效果。
1. 发现新版本

2. 无需更新

增量更新
为什么要这么做
其实全量更新是一种比较简单粗暴的更新方式,我没有花费太大的篇幅去介绍,基本上就是使用 autoUpdater 封装的一些方法,开发过程中更多的注意力则是放在了渲染进程的交互上。
此外,我们的更新交互用的是一种 用户感知 的方式,即更不更新是由用户自己决定的。而 静默更新 则是用户无感知,在监测到更新后不用去通知用户,而是自行在后台下载,在某个时刻执行安装的逻辑,这种方式往往是一键安装,不会弹出让用户去选择安装路径的窗口。接下去要介绍的增量更新其实是这种 用户无感知 的形式,只不过我们更新的不是整个应用程序。
由于产品迭代比较频繁,我们的业务方经常收到更新提示,意味着他们要经常手动更新应用,以便使用到最新的功能特性。众所周知,Electron 给前端开发提供了一个比较容易上手的客户端开发解决方案,但在享受 跨平台 等特性的同时,还得忍受 臃肿的安装包 。
带宽、流量在当前不是什么大问题,下载和安装的速度也挺快,但这频繁的下载覆盖一模一样的资源文件还是挺糟心的,代码改动量小时,全量更新完全没有必要。我们希望的是,开发更新了什么代码,应用程序就替换掉这部分代码就好了,这很优雅。在 我们的场景 中,这部分代码指的是 —— main、preload、renderer,并不包括 dll、第三方SDK等资源。
网上有挺多种增量更新的 解决方案,例如:
- 通过
win.loadURL(一个线上地址)实现,相当于就套了一层客户端的壳子,与加载的Web端同步更新。这种方法对于简单应用来说是最省心的,但是也有一定的局限性,例如不能使用node去操作一些底层的东西。 - 设置
asar的归档方式,替换app.asar或app.asar.unpack来实现。但后者在我实践过程中存在文件路径不存在的问题。 - 禁用
asar归档,解压渲染进程压缩包后实现替换。简单尝试过,首次执行安装包的时候写入文件很慢,不知道是不是这个方式引起的。 - 欢迎补充。
本文我们采用较普遍的 替换asar 来实现。
优化 app.asar 体积
asar是Electron提供的一种将多个文件合并成一个文件的类tar风格的归档格式,不仅可以缓解Windows下路径名过长的问题, 还能够略微加快一下require的速度, 并且可以隐藏你的源代码。(并非完全隐藏,有方法可以找出来)
Electron 应用程序启动的时候,会读取 app.asar.unpacked 目录中的内容合并到 app.asar 的目录中进行加载。在此之前我们已经打包了一份 Demo 项目,安装到本地后,我们可以根据安装路径找到 app.asar 这个文件。
例如:D:\你的安装路径\electron-update-demo\resources

在这个 Demo 项目中,脚手架生成的模板将图标剥离出来,因此出现了一个 app.asar.unpacked 文件夹。我们不难发现,app.asar 这个文件竟然有 66 MB,再回过头看我们真正的代码文件,甚至才 1 MB !那么到底是什么原因导致的这个文件这么大呢,刚才提到了,asar 其实是一种压缩格式,因此我们只要解压看看就知道了。
npm i -g asar // 全局安装
asar e app.asar folder // 解压到folder文件夹

解压后我们不难发现,out 文件夹里的才是我们打包出来的资源,罪魁祸首竟然是 node_modules,足足有 62.3 MB。
查阅资料得知,Electron 在打包的时候,会把 dependencies 字段里的依赖也一起打包进去。而我们的渲染进程是用 React开发的,这些第三方依赖早就通过 Vite 等打包工具打到资源文件里了,根本不需要再打包一次,不然我们重新下载的 app.asar 文件还是很大的,因此需要尽可能减少体积。
优化应用程序体积 == 减少 node_modules 文件夹的大小 == 减少需要打包的依赖数量 == 减少 dependencies 中的依赖。
1. 移除 dependencies
最开始我想的是把 package.json 中的 dependencies 全都移到 devDependencies,打包后的体积果然减小了,但是在测试过程中会发现某些功能依赖包会缺失,比如 @electron/remote。因此在修改这部分代码的时候,需要特别留意,哪些依赖是需要保留下来的。
由于不想影响 package.json 的版本结构,我只是在写了一个脚本,在 npm i 之后,执行打包命令前修改 devDependencies 就好了。
2. 双 package.json 结构
这是 electron-builder 官网上看到的一种技巧,传送门, 创建 app 文件夹,再创建第二个 package.json,在该文件中配置我们应用的名称、版本、主进程入口文件等信息。这样一来,electron-builder 在打包时会以该文件夹作为打包的根文件夹,即只会打包这个文件夹下的文件。
但是我原项目的主进程和预加载脚本也放在这,尝试修改后出现打包错误的情况,感兴趣的可以试试。

这是我们优化之后的结果,1.32 MB,后面只需要替换这个文件就实现了版本的更新。
校验增量更新
全量更新的校验逻辑是第三方库已经封装好了的,那么对于增量更新,就得由我们自己来实现了。
首先明确一下 校验的时机,package.json 的 version 字段表示应用程序的版本,用于全量更新的判断,那也就意味着,当这个字段保持不变的时候,会触发上文提到的 update-not-available 事件。所以我们可以在这个事件的回调函数里来进行校验。
autoUpdater.on('update-not-available', info => { console.log('不需要全量更新', info.version) })
然后就是 如何校验,我们回过头来看 electron-builder 的打包配置,在 releaseInfo 字段里描述了发行版本的一些信息,目前我们用到了 releaseNotes 来存储更新日志,查阅官网得知还有个 releaseName 好像对于我们而言是没什么用的,那么我们就可以把它作为增量更新的 热版本号。(但其实 官网 配置项还有个 vendor 字段,可是我在用的时候打包会报错,可能是版本的问题,感兴趣的可以试试。)
每次发布新版本的时候,只要不是 Electron自身版本变化 等重大更新,我们都可以通过修改 releaseInfo 的 releaseName 来发布我们的热版本号。现在我们已经有了线上的版本,那 本地热版本号 该如何获取呢。这里我们在每次热更新完成之后,就会把最新的版本号存储在本地的一个配置文件中,通常是 userData 文件夹,用于存储我们应用程序的用户信息,即使程序卸载 了也不会影响里面的资源。在 Windows 下,路径如下:
C:\Users\用户名\AppData\Roaming\electron-update-demo。
因此,整个 校验流程 就是,在打开程序的时候,autoUpdater 触发 update-not-available 事件,拿到线上 latest.yml 描述的 releaseName 作为热版本号,与本地配置文件(我们命名为 config.json)里存储的热版本号(我们命名为 hotVersion)进行对比,若不同就去下载最新的 app.asar 文件。
我们使用 electron-log 来记录日志,代码如下所示。
// 本地配置文件
const localConfigFile = path.join(app.getPath('userData'), 'config.json')
const checkHotVersion = (latestHotVersion: string): boolean => {
let needDownload = false
if (!fs.existsSync(localConfigFile)) {
fs.writeFileSync(localConfigFile, '{}', 'utf8')
log.info('配置文件不存在,已自动创建')
} else {
log.info('监测到配置文件')
}
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
// 对比版本号
if (latestHotVersion !== configData.hotVersion) {
log.info('当前版本不是最新热更版本')
needDownload = true
} else {
log.info('当前为最新版本')
}
} catch (error) {
log.error('读取配置文件时出错', error)
}
return needDownload
}
下载增量更新包
通过刚才的校验,我们已经知道了什么时候该去下载增量更新包。
在开发调试的时候,我们可以把新版本的 app.asar 也放到起了本地服务器的 mockServer 文件夹里来模拟真实的情况。有很多方式可以去下载文件,这里我用了 nodejs 的 http 模块去实现,如果是 https 的需要引用 https 模块。
下载到本地的时候,我是放在了与 app.asar 同级目录的 resources 文件夹,我们不能直接覆盖原文件。一是因为进程权限占用的问题,二是为了容错,所以我们需要以另一个名字来命名下载后的文件(这里我们用的是 app.asar-temp),也就不需要去备份原文件了,代码如下。
const resourcePath = isDev
? path.join('D:\\测试\\electron-update-demo\\resources')
: process.resourcesPath
const localAsarTemp = path.join(resourcePath, 'app.asar-temp')
const asarUrl = 'http://localhost:3000/app.asar'
downloadAsar() {
const fileStream = fs.createWriteStream(localAsarTemp)
http.get(asarUrl, res => {
res.pipe(fileStream)
fileStream
.on('finish', () => {
log.info('asar下载完成')
})
.on('error', error => {
// 删除文件
fs.unlink(localAsarTemp, () => {
log.error('下载出现异常,已中断', error)
})
})
})
}
因此,我们的流程更新为:发现新版本后,下载最新的 app.asar 到 resources 目录,并重命名为 app.asar-temp。这个时候我们启动项目进行调试,找到记录在本地的日志—— C:\Users\用户名\AppData\Roaming\electron-update-demo\logs,会有以下的记录:
[2024-09-20 13:49:22.456] [info] 监测到配置文件
[2024-09-20 13:49:22.462] [info] 当前版本不是最新热更版本
[2024-09-20 13:49:23.206] [info] asar下载完成
在看看项目 resources 文件夹,多了一个 app.asar-temp文件。

至此,下载这一步已经完成了,但这样还会有一个问题,因为文件名没有加上版本号,也没有重复性校验,倘若一直没有更新,那么每次启动应用需要增量更新的时候都需要再次下载。
替换 app.asar 文件
好了,新文件也有了,接下来就是直接替换掉老文件就可以了,但是 替换的时机 很重要。
在 Windows 操作系统下,直接替换 app.asar 会提示程序被占用而导致失败,所以我们应该在程序关闭的时候实现替换。
- 进入应用,下载新版本,自动关闭应用,替换资源,重启应用。
- 进入应用,下载新版本,不影响使用,用户 手动关闭 后替换,下次启动 就是新版本了。
我们有上面两种方案,最终采用了 方案2。
在主进程监听 app.on('quit') 事件,在应用退出的时候,判断 app.asar 和 app.asar-temp 是否同时存在,若同时存在,就去替换。这里替换不能直接用 nodejs 在主进程里去写,因为主进程执行的时候,资源还是被占用的。因此我们需要额外起一个 子进程 去做。
nodejs 可以通过 spawn、exec 等方法创建一个子进程。子进程可以执行一些自定义的命令,我们并没有使用子进程去执行 nodejs,因为业务方的机器上不一定有这个环境,而是采用了启动 exe 可执行文件的方式。可能有人问为什么不直接运行 .bat 批处理文件,因为我调试关闭应用的时候,会有一个 命令框闪烁 的现象,这不太优雅,尽管已经设置 spawn 的 windowsHide: true。
那么如何获得这个 exe 可执行文件呢,其实是通过 bat 文件去编译的,命令如下:
@echo off
timeout /T 1 /NOBREAK
del /f /q /a %1\app.asar
ren %1\app.asar-temp app.asar
我们加了延时,等待父进程完全关闭后,再去执行后续命令。其中 %1 为运行脚本传入的参数,在我们的场景里就是 resources 文件夹的地址,因为每个人的安装地址应该是不一样的,所以需要作为参数传进去。
转换文件的工具一开始用的是 Bat To Exe Converter 下载地址,但是在实际使用的过程中,我的电脑竟然把转换后的 exe 文件 识别为病毒,但在其他同事电脑上没有这种表现,这肯定就不行了,最后还是同事使用 python 帮我转换生成了一份可用的文件(replace.exe)。
这里我们可以选择不同的方式把 replace.exe 存放到 用户目录 上,要么是从线上服务器下载,要么是安装的时候就已经存放在本地了。我们选择了后者,这需要修改 electron-builder 打包配置,指定 asarUnpack, 这样就会存放在 app.asar.unpacked 文件夹中,不经常修改的文件都可以放在这里,不会随着增量更新而替换掉。
有了这个替换脚本之后,开始编写子进程相关的代码。
import { spawn } from 'child_process'
cosnt localExePath = path.join(resourcePath, 'app.asar.unpacked/resources/replace.exe')
replaceAsar() {
if (fs.existsSync(localAsar) && fs.existsSync(localAsarTemp)) {
const command = `${localExePath} ${resourcePath}`
log.info(command)
const logPath = app.getPath('logs')
const childOut = fs.openSync(path.join(logPath, './out.log'), 'a')
const childErr = fs.openSync(path.join(logPath, './err.log'), 'a')
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true, // 允许子进程独立
shell: true,
stdio: ['ignore', childOut, childErr]
})
child.on('spawn', () => log.info('子进程触发'))
child.on('error', err => log.error('child error', err))
child.on('close', code => log.error('child close', code))
child.on('exit', code => log.error('child exit', code))
child.stdout?.on('data', data => log.info('stdout', data))
child.stderr?.on('data', data => log.info('stderr', data))
child.unref()
}
}
app.on('quit', () => {
replaceAsar()
})
在这块代码中,创建子进程的配置项比较重要,尤其是路径相关的。因为用户安装路径是不同的,可能会存在 文件夹名含有空格 的情况,比如 Program Files,这会导致在执行的时候将空格识别为分隔符,导致命令执行失败,因此需要加上 双引号。此外,detached: true 可以让子进程独立出来,也就是父进程退出后可以执行,而shell: true 可以将路径名作为参数传过去。
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true,
shell: true,
stdio: ['ignore', childOut, childErr]
})
但这块有个 疑惑,为什么我的 close、exit 以及 stdout 都没有触发,以至于不能拿到命令是否执行成功的最终结果,了解的同学可以评论区交流一下。
至此,在关闭应用之后,app.asar 就已经被替换为最新版本了,还差最后一步,更新本地配置文件里的 hotVersion,防止下次又去下载更新包了。
child.on('spawn', () => {
log.info('子进程触发')
updateHotVersion()
})
updateHotVersion() {
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion }, null, 2))
}
增量更新日志提示
既然之前提到的全量更新有日志说明,那增量更新可以不用,也应该需要具备这个能力,不然我们神不知鬼不觉帮用户更新了,用户都不知道 新在哪里。
至于更新内容,我们可以复用 releaseInfo 的 releaseNotes 字段,把更新日志写在这里,增量更新完成后展现给用户就好了。
但是总不能每次打开都展示,这里需要用户有个交互,比如点击 知道了 按钮,或者关闭 Modal 后,把当前的热更新版本号保存在本地配置文件,记录为 logVersion。在下次打开程序或者校验更新的时候,我们判断一下 logVersion === hotVersion,若不同,再去提示更新日志。
日志版本 校验和修改的代码如下所示:
checkLogVersion() {
let needShowLog = false
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion, logVersion } = configData
if (hotVersion !== logVersion) {
log.info('日志版本与当前热更新版本不同,需要提示更新日志')
needShowLog = true
} else {
log.info('日志已是最新版本,无需提示更新日志')
}
} catch (error) {
log.error('读取配置文件失败', error)
}
return needShowLog
}
updateLogVersion() {
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion } = configData
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion, logVersion: hotVersion }, null, 2))
log.info('日志版本已更新')
} catch (error) {
log.error('读取配置文件失败', error)
}
}
读取 config.json 文件的方法自行封装一下,我这里就重复使用了。主进程 ipcMain.on 监听一下用户传递过来的事件,再去调用 updateLogVersion 即可,渲染进程效果如下:
提示增量更新日志

点击 知道了 后,再次打开应用后就不会提示日志了,因为本地配置文件已经被修改了。

当然可能也有这么个场景,开发就改了一点点无关功能的代码,无需向用户展示日志,我们只需要加一个判断 releaseNotes 是否为空的逻辑就好了,也做到了 静默更新。
小结
不足之处
本文提出的增量更新方案应该算是比较简单的,可能并不适用于所有的场景,考虑也不够全面,例如:
dll、第三方SDK等资源的更新。- 增量更新失败后应该通过全量更新 兜底。
- 用户在使用过程中发布新版本,得等到 第二次打开 才能用到新版本。
流程图
针对本文的解决方案,我简单画了一个 流程图。

参考文章
网上其实有不少关于 Electron 自动更新的文章,在做这个需求之前也是浏览了好多,但也有些没仔细看完,所以就躺在我的标签页没有关闭,在这罗列出来,也当作收藏了。
写这篇文章的目的也是为了记录和复盘,如果能为你提供一些思路那就再好不过了。
鸣谢:
来源:juejin.cn/post/7416311252580352034
工作7年了,才明白技术的本质不过是工具而已,那么未来的方向在哪里?
前言
Hi 你好,我是东东拿铁,一个正在探索个人IP&副业的后端程序员。
五一过去了,不知道大家有没有好好的放松自己呢?愉快的假期总是这么短暂,打工人重新回到自己的岗位。
我目前工作7年了,这几年来埋头苦干,学习了很多技术,做了不少系统,也解决过不少线上问题。自己虽然在探寻个人IP与副业,自己花了很多时间去思考技术之外的路该怎么走。但转念一想,我宁愿花这么多时间去探索技术之外的路线,但是却从没好好静下来想一下技术本身。
技术到底是什么,你我所处的技术行业为什么会存在,未来的机会在哪里。
因此,我结合自己的工作经历,希望和大家一起聊聊,技术的本质与未来的方向,到底在哪里,才疏学浅,如果内容有误还希望你在评论区指正。
背景
行业现状
互联网行业发展放缓,进入调整阶段,具体表现为市场需求、用户规模、营收利润、创新活力等方面的放缓或下降。
一些曾经风光无限的互联网公司也遭遇了业绩下滑、股价暴跌、裁员潮等困境,你是不是也曾听过互联网的寒冬已至的言论?
其实互联网本身,并没有衰败或消亡,而是因为互联网高速发展的时代过去了。
- 中国经济增速放缓、消费升级趋势减弱、人口红利消失等因素的影响,中国互联网市场的需求增长趋于饱和或下降。
- 用户规模停滞,智能手机普及率饱和,互联网用户规模增长趋于停滞,由增量市场变为存量市场,互联网获客成本越来越高。
- 监管政策收紧,互联网行业规范和监管愈加严格,更加注重合规,因此互联网行业也会收到影响。
供需环境
供需环境变化,应届生要求越来越高,更加注重学历。
社招更是看中学历的同时,开始限制年龄。招聘更看重项目经验,业务经验。五年前,你只要做过一些项目,哪怕不是实际使用的,也很容易拿到offer。而现在企业在看中技术能力的同时,还会关注候选人对与行业的理解,以及以往的工作经验。
技术的本质
先说结论,技术的本质是工具。 我把过去几年的认知变化分成了四个阶段,给大家展示一下我对于技术的认知成长过程。
第一阶段
技术就是应用各类前沿的框架、中间件。
刚毕业时,我就职于一家传统信息企业。谈不上所谓的架构,只需要Spring、Mysql就构建起了我们的所有技术栈。当然,微服务框架更不可能,Redis、MQ在系统中都没使用到。
此时互联网企业已经开始快速发展,抖音诞生区区不过一年。
一线城市的互联网公司,都已经开始使用上了SpringBoot、微服务,还有各类我没有听说过的中间件。
工作环境的闭塞,让我对各类技术有着无限憧憬,因为很多当下难以解决的问题,应用一些新技术、新架构,就能立刻对很多难题降维打击。
举个例子,如果你使用本地缓存,那么集群部署时,你一定要考虑集群的缓存一致性问题,可这个问题如果用上分布式缓存Redis,那么一致性问题迎刃而解。
所以那个时候的我认为,技术就是应用各类中间件,只要用上这些中间件、框架,我就已经走在了技术的前沿。
第二阶段
技术对我而言就是互联网。
半年后,我摆脱传统行业,来到了一个小型互联网公司,用上了不少在我眼中的新技术。
但任何新技术,如果只停留在表面,那么对于使用者来说,就是几个API,几行代码,你很快就会感到厌倦,发现问题也会焦虑,因为不清楚原理,问题就无从排查。
很快,所谓的“新技术”,就不能给我带来成就感了。我开始羡慕那些互联网行业APP,无时无刻都在畅想着,如果我做的产品能够被大家看到并应用,那该是多么有意思的一件事情。
于是我又认为,技术就是做那些被人看见、被人应用的网站、APP。
第三阶段
技术就是高并发、大流量、大数据。
当自己真正负责了某一个APP的后端研发后,很多技术都有机会应用,也能够在AppStore下载自己的APP了,没事刷一刷,看到某一个信息是通过我自己写的代码展示出去,又满足了第二阶段的目标了。
那么我接下来追求的变成了,让更多的人使用我做的产品,起码让我的亲人、朋友也能看到我做的东西。
当然,随之而来的就是日益增长的数据规模和大流量,这些无时无刻都在挑战系统的性能,如何去解决这些问题,成为了我很长一段时间的工作主线。
应对高并发、大流量,我们需要对系统作出各种极致性能的优化。
为了性能优化,还需要了解更多的底层原理,才能在遇到问题时有一个合理的解决方案。
所以,我认为技术就是高并发、大数据,做好这些,才算做好了技术。
第四阶段
经过了传统企业,到互联网公司,再到互联网大厂的一番经历,让我发现技术的本质就是工具,在不同阶段,去解决不同的问题。
在第一阶段,技术解决了各类行业的数据信息化问题,借助各类中间件、架构把具体的需求落地。
在第二阶段、第三阶段,技术解决了业务的规模化问题,因为在互联网,流量迅猛增长,我需要去用技术解决规模化带来的各类的问题,做出性能优化。
当然,技术在其他领域也发挥着作用,比如AI&算法,给予了互联网工具“智能化”的可能,还有比如我们很难接触到的底层框架研发,也就是技术的“技术”,这些底层能力,帮助我们更好的发挥我们的技术能力。
未来机会
大厂仍是最好的选择
即使是在互联网增速放缓、内卷持续严重的今天,即使我选择从大厂离职,但我依然认为大厂是最好的选择。
为什么这么说,几个理由
- 大厂有着更前沿的技术能力,你可以随意选择最适合的工具去解决问题
- 大厂有着更大的数据、流量规模,你所做的工作,天然的就具备规模化的能力
- 大厂有先进的管理方法,你所接触的做事方法、目标管理可能让你疲倦,但工作方法大概率是行业内经过验证的,你不会走弯路,能让你有更快的进步速度
数字化转型
如果你在互联网行业,可能没有听说过这个词,因为在高速发展的互联网行业,本身就是数字驱动的,比如重视数据指标、AB实验等。但在二线、三线城市的计算机行业或者一些传统行业,数字化转型是很大的发展机会。
过去十年,传统行业做的普遍是信息化转型,也就是把线下,需要用纸、笔来完成工作的,转移到系统中。
那什么是数字化转型?
我用我自己的理解说一下,数字化转型就是业务流程精细化管理,数据驱动,实现降本增效。
我目前所在的公司的推进大方向之一,就是数字化转型。因为许多行业的数字化程度非常低,本质而言,就是把数字驱动的能力,带给传统企业,让传统企业也能感受到数字化带来的发展可能。
举个例子,比如一个餐饮系统数字化转型后,一方面可以把用户下单、餐厅接单、开始制作、出餐、上餐线上化,还可以和原材料供应系统打通,当有订单来时,自动检测餐饮的库存信息,库存不足及时提供预警,甚至可以作出订单预测,比如什么时间点,哪类餐品的点单量最高。
当然,数字化转型与互联网有着极大的不同,在互联网行业,你只需要坐在工位,等着产品提出需求就可以了。但是传统行业,你需要深入客户现场,实地查看业务流程,与用户交谈,才能真正的理解客户需求。
或许这样的工作并不炫酷,还需要出差,但在互联网行业饱和的今天,用技术去解决真实世界的问题,也不失为一个很好的选择。
AI&智能化
随着AI快速发展,各类智能化功能已经遍布了我们使用的各类APP,极客时间有了AI自动总结,懂车帝有了智能选车度搜索问题,有时候第一个也会是AI来给我们解答。
任何行业遇上AI都可以再做一遍。
抛开底层算法、模型不谈,但从使用者角度来说,最重要的是如何与行业、场景结合相使用。但是想要做好应用,需要你在行业有着比较深的沉淀,有较深的行业认知。
当然,智能化也不仅限于AI,像上面餐饮系统的例子,如果能够实现订单预测、自动库存管理,其实也是智能化的体现。
终身学习
技术能力
持续精进专业技术能力,相信大家对此都没有疑问。
对于日常使用到的技术,我们需要熟练掌握技术原理,积累使用经验,尤其是线上环境的问题处理经验。
第一个是基础。比如对集合类,并发包,IO/NIO,JVM,内存模型,泛型,异常,反射,等有深入了解,最好是看过源码了解底层的设计。
第二你需要有全面的互联网技术相关知识。从底层说起,你起码得深入了解mysql,redis,nginx,tomcat,rpc,jms等方面的知识。
第三就是编程能力,编程思想,算法能力,架构能力。
在这个过程中,打造自己的技能树,构建自己的技术体系。

对于不断冒出的新技术,我们一方面要了解清楚技术原理,也要了解新技术是为了解决什么问题,诞生于什么背景。
业务能力
前面说到技术是一种工具,解决的是现实世界的问题,如果我们希望更好的发挥技术的作用,那么就需要我们先掌握好业务领域。
互联网领域
如果你想要快速地入门互联网领域的业务,你可以使用AARRR漏斗模型来分析。
AARRR这5个字母分别代表 Acquisition、Activation、Retention、Revenue 和 Refer
五个英文单词,它们分别对应用户生命周期中的 5 个重要环节:获取(Acquisition)、激活(Activation)、留存(Retention)、收益(Revenue)和推荐(Refer)。
AARRR 模型的核心就是以用户为中心,以完整的用户生命周期为指导思想,分析用户在各个环节的行为和数据,以此来发现用户需求以及产品需要改进的地方。
举一个简单的例子,我们以一个互联网手游 LOL来举例:
获取就是用户通过广告、push等形式,了解到了游戏并注册或者登陆。
激活就是用户真正的开始游戏,比如开始了一场匹配。
留存就是用户在7天、30天内,登陆了几次,打了几把比赛,几天登陆一次,每日游戏时常又是多少。
收益,用户购买皮肤了,产生了收益。
推荐,用户邀请朋友,发送到微信群中,邀请了朋友一起开黑。
如果你所在的行业是C端产品,那么这个模型基本可以概括用户的生命周期全流程。
传统行业
传统行业没有比较通用的业务模型,如果想要入手,需要我们从以下三个角度去入手
- 这个行业的商业模式是什么,也就是靠什么赚钱的?比如售卖系统收费,收取服务费等
- 行业的规模如何?头部玩家有哪些?它们的模式有哪些特色?
- 这个行业的客户是谁、用户是谁?有哪些经典的作业场景?业务操作流程是什么样的?
如何获取到这些信息呢?有几种常见的形式
- 权威的行业研究报告,这个比较常见
- 直接关注头部玩家的官网、公众号、官媒
- 深入用户现场
我们以汽车行业来举例
商业模式:整车销售、二手车、汽车租赁等,细分一点,又有传统动力和新能源两种分类。
规模:如下图

头部车企:传统的四大车企一汽、东风、上汽、长安,新势力 特斯拉、蔚小理
经典场景:直接去4S店体验一下汽车销售模式、流程
说在最后
好了,文章到这里就要结束啦,我用我自己工作几年的不同阶段,给你介绍了我对于技术的本质是工具的思考过程,也浅浅的探寻了一下,未来的发展机会在哪里,以及我们应该如何提升自己,很感谢你能看到最后,希望对你有所帮助。
不知道你对于技术是怎么看的,又如何看待当下的市场环境呢?欢迎你在评论区和我分享,也希望你点赞、评论、收藏,让我知道对你有所收获,这对我来说很重要。也欢迎你加我的wx:Ldhrlhy10,一起交流。
本篇文章是第33篇原创文章,2024目标进度33/100,欢迎有趣的你关注我~
来源:juejin.cn/post/7365679089812553769
基于英雄联盟人物的加载动画,奇怪的需求又增加了!
1、背景
前两天老板找到我说有一个需求,要求使用英雄联盟的人物动画制作一个加载中的组件,类似于下面这样:

我定眼一看:这个可以实现,但是需要UI妹子给切图。
老板:UI? 咱们啥时候招的UI !
我:老板,那不中呀,不切图弄不成呀。
老板:下个月绩效给你A。
我:那中,管管管。
2、调研
发动我聪明的秃头,实现这个需求有以下几种方案:
- 切动画帧,没有UI不中❎。
- 去lol客户端看看能不能搞到什么美术素材,3D模型啥的,可能行❓
- 问下 gpt4o,有没有哪个老表收集的有lol英雄的美术素材,如果有那就更得劲了✅。
经过我一番搜索,发现了这个网站:model-viewer,收集了很多英雄联盟的人物模型,模型里面还有各种动画,还给下载。老表,这个需求稳了50%了!

接下来有几种选择:
- 将模型动画转成动画帧,搞成雪碧图,较为麻烦,且动画不支持切换。
- 直接加载模型,将模型放在进度条上,较为简单,支持切换不同动画,而且可以自由过渡。就是模型文件有点大,初始化加载可能耗时较长。但是后续缓存一下就好了。
聪明的我肯定先选第二个方案呀,你糊弄我啊,我糊弄你。
3、实现
web中加载模型可以使用谷歌基于threejs封装的 model-viewer, 使用现代的 web component 技术。简单易用。
先初始化一个vue工程
npm create vue@latest
然后将里面的初始化的组件和app.vue里面的内容都删除。
安装model-viewer依赖:
npm i three // 前置依赖
npm i @google/model-viewer
修改vite.config.js,将model-viewer视为自定义元素,不进行编译
import { fileURLToPath, URL } from 'node:url'
import { defineConfig } from 'vite'
import vue from '@vitejs/plugin-vue'
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue({
template: {
// 添加以下内容
compilerOptions: {
isCustomElement: (tag) => ['model-viewer'].includes(tag)
}
}
})
],
resolve: {
alias: {
'@': fileURLToPath(new URL('./src', import.meta.url))
}
},
assetsInclude: ['./src/assets/heros/*.glb']
})
新建 src/components/LolProgress.vue
<template>
<div class="progress-container">
<model-viewer
:src="hero.src"
disable-zoom
shadow-intensity="1"
:camera-orbit="hero.cameraOrbit"
class="model-viewer"
:style="heroPosition"
:animation-name="animationName"
:camera-target="hero.cameraTarget"
autoplay
ref="modelViewer"
></model-viewer>
<div
class="progress-bar"
:style="{ height: strokeWidth + 'px', borderRadius: strokeWidth / 2 + 'px' }"
>
<div class="progress-percent" :style="currentPercentStyle"></div>
</div>
</div>
</template>
<script setup lang="ts">
import { computed, onMounted, ref, watch, type PropType } from 'vue'
/** 类型 */
interface Hero {
src: string
cameraOrbit: string
progressAnimation: string
finishAnimation: string
finishAnimationIn: string
cameraTarget: string
finishDelay: number
}
type HeroName = 'yasuo' | 'yi'
type Heros = {
[key in HeroName]: Hero
}
const props = defineProps({
hero: {
type: String as PropType<HeroName>,
default: 'yasuo'
},
percentage: {
type: Number,
default: 100
},
strokeWidth: {
type: Number,
default: 10
},
heroSize: {
type: Number,
default: 150
}
})
const modelViewer = ref(null)
const heros: Heros = {
yasuo: {
src: '/src/components/yasuo.glb',
cameraOrbit: '-90deg 90deg',
progressAnimation: 'Run2',
finishAnimationIn: 'yasuo_skin02_dance_in',
finishAnimation: 'yasuo_skin02_dance_loop',
cameraTarget: 'auto auto 0m',
finishDelay: 2000
},
yi: {
src: '/src/components/yi.glb',
cameraOrbit: '-90deg 90deg',
progressAnimation: 'Run',
finishAnimationIn: 'Dance',
finishAnimation: 'Dance',
cameraTarget: 'auto auto 0m',
finishDelay: 500
}
}
const heroPosition = computed(() => {
const percentage = props.percentage > 100 ? 100 : props.percentage
return {
left: `calc(${percentage + '%'} - ${props.heroSize / 2}px)`,
bottom: -props.heroSize / 10 + 'px',
height: props.heroSize + 'px',
width: props.heroSize + 'px'
}
})
const currentPercentStyle = computed(() => {
const percentage = props.percentage > 100 ? 100 : props.percentage
return { borderRadius: `calc(${props.strokeWidth / 2}px - 1px)`, width: percentage + '%' }
})
const hero = computed(() => {
return heros[props.hero]
})
const animationName = ref('')
watch(
() => props.percentage,
(percentage) => {
if (percentage < 100) {
animationName.value = hero.value.progressAnimation
} else if (percentage === 100) {
animationName.value = hero.value.finishAnimationIn
setTimeout(() => {
animationName.value = hero.value.finishAnimation
}, hero.value.finishDelay)
}
}
)
onMounted(() => {
setTimeout(() => {
console.log(modelViewer.value.availableAnimations)
}, 2000)
})
</script>
<style scoped>
.progress-container {
position: relative;
width: 100%;
}
.model-viewer {
position: relative;
background: transparent;
}
.progress-bar {
border: 1px solid #fff;
background-color: #666;
width: 100%;
}
.progress-percent {
background-color: aqua;
height: 100%;
transition: width 100ms ease;
}
</style>
组件非常简单,核心逻辑如下:
- 根据传入的英雄名称加载模型
- 指定每个英雄的加载中的动画,
- 加载100%,切换完成动作进入动画和完成动画即可。
- 额外的细节处理。
最后修改
app.vue:
<script setup lang="ts">
import { ref } from 'vue'
import LolProgress from './components/LolProgress.vue'
const percentage = ref(0)
setInterval(() => {
percentage.value = percentage.value + 1
}, 100)
</script>
<template>
<main>
<LolProgress
:style="{ width: '200px' }"
:percentage="percentage"
:heroSize="200"
hero="yasuo"
/>
</main>
</template>
<style scoped></style>
这不就完成了吗,先拿给老板看看。
老板:换个女枪的看看。
我:好嘞。

老板:弄类不赖啊小伙,换个俄洛伊的看看。
4、总结
通过本次需求,了解到了 model-viewer组件。
老板招个UI妹子吧。
在线体验:github-pages
来源:juejin.cn/post/7377217883305279526
我在团队内部提倡禁用单元测试
先说结论:
在绝大部分的业务前端开发中,写单元测试的收益非常小,但是带来的维护成本却非常大,请不要再写单元测试感动自己,为难同事了。
现在很多单元测试的教程都是那种很简单的比如,测个 1+1=2,这需要测吗?下面这段代码已经出现过很多次了,纯纯的误导人。
const sum = (a,b) => a+b
it('1+1=2',()=> {
expect(sum(1,1)).toBe(2)
})
稍微上点复杂度,来写个组件的单测,比如一个用户信息展示组件,叫 UserInfoBlock,支持设置头像的大小,点击名字支持跳转到个人主页,组件代码大致长这样
interface UserInfoBlockProps {
name: string
size: 16 | 24
id: string
icon: string
}
export const UserInfoBlock:FC<UserInfoBlockProps> = (props) => {
const navigate = useNavigate()
return <div
class='xxxxxx'
style={{width: props.size}}
onClick={() => {navigate(`/user/${props.id}`)}}>
<img src={props.icon}/>
{props.name}
</div>
}
然后开始给组件写单测,先测头像大小的功能
import { UserInfoBlock, UserInfoBlockProps } from './user-info-block'
import { fireEvent, render, screen } from '@testing-library/react'
describe('UserInfoBlock 组件单测', () => {
const userInfo:UserInfoBlockProps = {
name: '张三',
icon:'https://xxx.png',
id:'abcd1234',
size: 16
}
const userInfoLarge:UserInfoBlockProps = {
name: '张三',
icon:'https://xxx.png',
id:'abcd1234',
size: 24
}
describe('展示默认头像大小', () => {
const component = render(<UserInfoBlock {...userInfo}/>)
it('img 标签的宽度为 16px', () => {
expect(screen.getByTag('img').style.width).toBe(16)
})
})
describe('展示large头像大小', () => {
const component = render(<UserInfoBlock {...userInfoLarge}/>)
it('img 标签的宽度为 24px', () => {
expect(screen.getByTag('img').style.width).toBe(24)
})
})
})
接下来测一下跳转,因为用了 react-router,所以在渲染组件的时候必须包裹一下 RouterProvider
...
describe('点击可以跳转', () => {
const component = render(<MemoryRouter>
<UserInfoBlock {...userInfoLarge}/>
</MemoryRouter>
)
fireEvent.click(component.div)
it('url 会变成 user/abcd1234', () => {
expect(location.pathname).toBe('user/abcd1234')
})
})
...
这个组件的测试就写完了,看起来挺有用,但实际没啥用。
首先这个测试的收益不高,因为这是一个很简单的组件,五分钟写完,但是写这个测试需要翻倍的时间,因为需要构造数据,之前没有经验不知道要加 MemoryRouter,jest 测 location 对象不方便,还要 mock 一下。等把这一套搞完了才能跑通,这就好像你疯狂锻炼,练出麒麟臂,就是为了举自拍杆举的稳一点。如果组件内要发请求,要做的准备工作就更加多了。
其次,user/abcd1234是什么,断言这个没用,因为别人改了链接,你的测试也一样会过,应该断言成功的打开了用户主页,比如断言一个必定会存在的文字expect(screen.getByText('用户详情')).toBeInDocument()这才能证明真的打开了用户主页。
1+1 什么时候不等于 2。头像设置 16px,什么时候不会是 16 px。什么时候点击不跳转到用户主页。肯定是有人修改了这里的业务逻辑才会这样,只有在做产品需求,代码优化的时候才会去改以前的代码。那么这时,这段测试对接手这段代码的人就是负担。
假设我接到需求,用户主页url 变了,改成 user?id=xxx。我心想这个简单,一秒钟解决,提了 pr 发现测试挂了,然后我就得把测试也改一下。
如果一段测试代码在我每次修改需求的时候都要改,甚至有的时候还会为了便于测试在业务代码中留一些后门,那这个测试就是纯纯的副作用。
大家肯定深有体会,一般一个模块自己不会出问题,但是多个模块组合起来就很容易出问题了,所以测试的重点不应该是一个组件内部各种细节,而应该测这个组件在被使用的地方是否正确。
举个例子,比如在一个列表里面,使用头像为 24px 的用户组件,然后有一天出 bug 了,说这里变成 16 了。那这会是组件的 bug 吗,这肯定是使用的地方没有用对。所以应该要测试的是这里。如果有个测试断言了在列表中用户头像必须为 24px,即使没有组件的单测,这个组件也不会被改坏,因为上层已经覆盖到了。
什么是好的测试?
- 我认为好的测试是稳定的测试,不仅不需要经常修改,甚至还能扛住代码重构。比如你把项目从
react完全迁移到了vue,测试都能跑过。 - 好的测试是可以当作项目文档的,组内来新人了,不需要给他介绍过多,有问题让他自己看测试用例就能理解业务。
那么怎么写出这样的测试呢?答案就是写集成测试,集成测试说白了就是一个超级大的单测,之前测试 render 的是一个组件,现在直接 render(<App/>),将路由跳转,请求 mock,fake数据库等等都统一处理。可以将上面写的测试简单的改为
import { creatAppContext, AppContext } from './app-test-context'
describe('S: 测试头像组件', () => {
let _:AppContext
beforeEach(() => {
- = creatAppContext()
})
describe('W: 去用户列表也', () => {
beforeEach(() => {
_.click(screen.getByText('查看用户列表'))
})
it('T: 列表页有十个用户,用户头像是 24px', ()=>{
expect(screen.getAllByTestid('user-item').length).toBe(10)
expect(screen.getAllByTestid('user-item')[0].img.style.width).toBe(24)
})
describe('W: 点击第一个用户', () => {
beforeEach(() => {
_.click(screen.getAllByTestid('user-item')[0])
})
it('T: 打开了用户主页', () => {
expect(screen.getByText('用户详情')).toBeInDocument()
})
})
})
})
关于怎么写好测试可以展开的点实在太多了,就不过多阐述,想要了解的朋友可以查看我的主页,之前专门出过一些列文章详细的讲这些事情。
来源:juejin.cn/post/7478515057510154255
组长说:公司的国际化就交给你了,下个星期给我
从“跑路程序员”到“摸鱼仙人”,我用这插件把国际化的屎山代码盘活了!
tips:
使用有道翻译,朋友们,要去有道官网注册一下,有免费额度,github demo的key已经被用完了。
一、命运的齿轮开始转动
“小王啊,海外业务要上线了,国际化你搞一下,下个月验收。”组长轻描淡写的一句话,让我盯着祖传代码陷入沉思——

(脑补画面:满屏中文硬编码,夹杂着"确定"、"取消"、"加载中...")
正当我准备打开BOSS直聘时,GitHub Trending上一个项目突然闪现——
auto-i18n-translation-plugins
项目简介赫然写着:“不改代码,三天交付国际化需求,摸鱼率提升300%”
二、极限操作:48小时从0到8国语言
🔧 第1步:安装插件(耗时5分钟)
祖训:“工欲善其事,必先装依赖”
# 如果你是Vite玩家(比如Vue3项目)
npm install vite-auto-i18n-plugin --save-dev
# 如果你是Webpack钉子户(比如React老项目)
npm install webpack-auto-i18n-plugin --save-dev
🔧 第2步:配置插件(关键の10分钟)
Vue3 + Vite の 摸鱼配置:
// vite.config.js
import { defineConfig } from 'vite';
import vitePluginAutoI18n from 'vite-auto-i18n-plugin';
export default defineConfig({
plugins: [
vue(),
vitePluginAutoI18n({
targetLangList: ['en', 'ja', 'ko'], // 要卷就卷8国语言!
translator: new YoudaoTranslator({ // 用有道!不用翻墙!
appId: '你的白嫖ID', // 去官网申请,10秒搞定
appKey: '你的密钥' // 别用示例里的,会炸!
})
})
]
});
🔧 第3步:注入灵魂——配置文件(生死攸关の5分钟)
在项目入口文件(如main.js)的第一行插入:
// 这是插件的生命线!必须放在最前面!
import '../lang/index.js'; // 运行插件之后会自动生成引入即可
三、见证奇迹的时刻
🚀 第一次运行(心脏骤停の瞬间)
输入npm run dev,控制台开始疯狂输出:
[插件日志] 检测到中文文本:"登录" → 生成哈希键:a1b2c3
[插件日志] 调用有道翻译:"登录" → 英文:Login,日文:ログイン...
[插件日志] 生成文件:lang/index.json(翻译の圣杯)
突然!页面白屏了!
别慌!这是插件在首次翻译时需要生成文件,解决方法:
- 立即执行一次
npm run build(让插件提前生成所有翻译) - 再次
npm run dev→ 页面加载如德芙般丝滑
四、效果爆炸:我成了全组の神
1. 不可置信の48小时
当我打开浏览器那一刻——\

我(瞳孔地震):“卧槽…真成了?!”
组长(凑近屏幕):“这…这是你一个人做的?!”(眼神逐渐迷茫)
产品经理(掏出手机拍照):“快!发朋友圈!《我司技术力碾压硅谷!》”
2. 插件の超能力
- 构建阶段:自动扫描所有中文 → 生成哈希键 → 调用API翻译
- 运行时:根据用户语言动态加载对应翻译
- 维护期:改个JSON文件就能更新所有语言版本
副作用:
- 测试妹子开始怀疑人生:“为什么一个bug都找不到?”
- 后端同事偷偷打听:“你这插件…能翻译Java注释吗?”
五、职场生存指南:如何优雅甩锅
🔨 场景1:测试妹子提着40米大刀来了!
问题:俄语翻译把“注册”译成“Регистрация”(原意是“登记处”)
传统应对:
- 熬夜改代码 → 重新打包 → 提交测试 → 被骂效率低
插件玩家:
- 打开
lang/index.json - 把
Регистрация改成Зарегистрироваться(深藏功与名) - 轻描淡写:“这是有道翻译的锅,我手动修正了。”
🔨 场景2:产品经理临时加语言
需求:“老板说下周要加印地语!”
传统灾难:
- 重新配框架 → 人肉翻译 → 测试 → 加班到秃头
插件玩家:
- 配置加一行代码:
targetLangList: ['hi'] - 运行
npm run build→ 自动生成印地语翻译 - 告诉产品经理:“这是上次预留的技术方案。”(其实只改了1行)
🔨 场景3:组长怀疑你摸鱼
质问:“小王啊,你这效率…是不是有什么黑科技?”
标准话术:
“组长,这都是因为:
- 您制定的开发规范清晰
- 公司技术栈先进(Vue3真香)
- 我参考了国际前沿方案(打开GitHub页面)”
六、高级摸鱼の奥义
🎯 秘籍1:把翻译文件变成团队武器
- 把
lang/index.json扔给产品经理:“这是国际化核心资产!” - 对方用Excel修改后,你直接
git pull→ 无需动代码 - 出问题直接甩锅:“翻译是市场部给的,我只负责技术!”

(脑补画面:产品经理在Excel里疯狂改翻译,程序员在刷剧)
🎯 秘籍2:动态加载の神操作
痛点:所有语言打包进主文件 → 体积爆炸!
解决方案:
// 在index.js里搞点骚操作
const loadLanguage = async (lang) => {
const data = await import(`../../lang/${lang}.json`); // 动态加载翻译文件
window.$t.locale(data, 'lang');
};
// 切换语言时调用
loadLanguage('ja'); // 瞬间切换日语,深藏功与名
🎯 秘籍3:伪装成AI大神
- 周会汇报:“我基于AST实现了自动化国际翻译中台”
- 实际:只是配了个插件
- 老板评价:“小王这技术深度,值得加薪!”(真相只有你知道)
七、终局:摸鱼の神,降临!
当组长在庆功会上宣布“国际化项目提前两周完成”时,我正用手机刷着《庆余年2》。
测试妹子:“你怎么一点都不激动?”
我(收起手机):“常规操作,要习惯。”(心想:插件干活,我躺平,这才叫真正的敏捷开发!)
立即行动(打工人自救指南):
- GitHub搜:auto-i18n-translation-plugins(点星解锁摸鱼人生)
- 复制我的配置 → 运行 → 见证魔法
- 加开发者社群:遇到问题发红包喊“大哥救命!”
终极警告:
⚠️ 过度使用此插件可能导致——
- 你的摸鱼时间超过工作时间,引发HR关注
- 产品经理产生“国际化需求可以随便加”的幻觉
- 老板误以为你是隐藏的技术大佬(谨慎处理!)
文末暴击:
“自从用了这插件,我司翻译团队的工作量从3周变成了3分钟——现在他们主要工作是帮我选中午吃啥。” —— 匿名用户の真实反馈
常见问题汇总
来源:juejin.cn/post/7480267450286800911
8年程序员本以为到头了,没想到柳暗花明...
讲一个这两年发生在我身上的故事,一个从程序员到AI产品负责人,一个选择大于努力的故事:
回到2022年,作为一个8年的前端程序员的我,在一家行业头部的企业中勤勤恳恳,兢兢业业。每天与代码为伴,沉浸在React的世界里,整日优化、升级、写框架、写工具,解决点疑难杂症,改改BUG,后来甚至成为了React的contributor。
我的生活和工作都很稳定,技术能力也得到了领导和团队的认可。
但内心深处却隐隐感到一种不安——前端技术的发展似乎进入了瓶颈期,我的职业生涯也仿佛停滞不前。
随着时间的推移,我开始面临两个无法回避的问题:
- 个人能力无法进一步提升:前端技术的更新速度放缓,框架和工具趋于成熟,我能做的事情越来越少了。
- 薪资增长停滞:薪资似乎已经到达了行业的天花板,如果我不能做更多的事情,也再难有突破。
自己是否已经走到了职业生涯的尽头?
面对这个问题,我一度陷入迷茫。跟其他程序员一样,我也尝试学习新的技术栈来缓解心中的这份焦虑,更底层的语言比如Rust、更宽的技术栈比如three.js、学学区块链、学学算法。

但是随之而来的就是,这些东西我学了之后除了做做demo、写写小工具之外,我好像做不了什么大事,我没有动力向着更深的内容走下去,这反而更加加深了我的焦虑。
那时候我32岁,每天都在担心中年危机。担心三年之后我凭什么和体力更好的、钱更少的、拥有同样技术栈的年轻人竞争?【虽然三年后的今天,并没有这样的年轻人出现】
幸运的是,2022年年底,chatGPT爆火全球。一夜之间,所有人都在讨论GPT,我也不例外,按照惯例,我再次把学习AI加入了我的日程。
当时体验了chatGPT之后,我两眼放光,我觉得,只要我努力学习这个技术,我一定可以像当初选择前端开发一样,再次进入一个程序员的风口,于是报课、买书、找行业大佬交流。
就这样过来两三个月......
你以为怎么了?我柳暗花明了? 这是一个前端程序员逆袭转战AI年薪百万的故事? 很不幸,这并不是。
事实是三个月之后,我再次陷入了困境:AI的底层技术,一我根本学不会,二我学了好像也没有用武之地。总不能跟老板说:给我几千万美金我给你撸个大模型?

世界再次灰暗下来......
可是,天无绝人之路,就在我已经准备放弃的时候,我在某个产品群里看到了这样一句话:

“???,这居然没人知道?”
过去三个月的高强度学习,在我看来在业务中找到嵌入AI的场景,甚至为了AI单独新增功能都是非常容易的事情。
AI时代已经来了,GUI到LUI是必然发生的事情,所有企业的产品都将会经历加入AI的功能或者逻辑。如果必须有一人主导这件事情的话,那为什么不能是我?
“汽车干掉马车之后,所有的司机都是之前的马车司机么?”
“计算器干掉算盘之后,所有的会计都是之前的师爷么?”
“安卓干掉塞班之后,所有的安卓工程师都是之前的塞班工程师么?”
既然都不是,那么AI带来全新的交互体验,必须是传统产品去做么?显然不是,这玩意,谁先干算谁的啊。

我决定接受这个挑战,开始把视野放到应用层。开始研究产品的逻辑,尝试找到AI技术与业务需求的结合点。
不会怎么办? 学呗,这流程咱熟,报班、买书、找大佬交流。


一边学,我就一边结识了一些志同道合的伙伴,我们一起讨论、尝试、失败、再尝试。
经历过那一年的朋友应该知道,国内大模型的能力远远没有广告上说的那些效果,底层能力的限制一度成为我们思路中最大的卡点。
不过,我们也总结整理了一大批不同的产品中,不训练自己的大模型的情况下,能够结合AI的逻辑,这里简单放几个例子。
- TOB的管理系统,新用户没办法很好的知道产品中有什么功能,可以直接通过AI助手来唤起、使用对应功能。【我很喜欢这个,典型的GUI升级LUI的场景】
- 产品售卖,通过AI + 埋点的技术,实时分析用户的行为,在恰当的时机向用户推送VIP折扣。
- 电商详情页浏览助手。【页面上的AI助手,也是这两年很多产品已经落地了的选择】
- TOC的评论页面,AI拥有很好的控评能力
- 智能问答产品,【我们认为是受到冲击最大的产品,跟AI比起来,现在市场上所有的智能问答产品,都不够智能。都应该被重做升级!】
- 多模态能力会带来的全新产品。【情感陪伴是目前最为广泛且收益较快的赛道。】
不扯远了,说回我自己。
我的转机出现在我们自己的领导也开始说要结合AI,升级产品能力。

我以最快的速度,做好agent流程的思维导图、MVP(最小可行性产品)。 开会,给领导布道,说服领导们相信我的这套设计。
因为之前就进行过AI相关的内容分享,所以这一步比较容易。一顿操作猛如虎之后,终于获得了领导认可,接到了协助产品负责AI升级的任务,升级过程其实遇到了非常多的困难。
再次吐槽一下那一年的国产大模型,流程稍微多一点,响应时间就巨慢,流程少了,大模型的理解能力又不足。
有时候一个提示词一调就是半天,我甚至一度都要放弃了。不过好在最终我们选择了曲线救国,采用大模型+小模型,配合多专家 + RAG + 变种function call组合的架构,我们在23年底也做出了不错的东西。
上线之后,客户表示了满意。领导表示了满意。团队表示了满意。
水到渠成,后来一切就按部就班了,24年我又虚线负责了两个AI产品的升级和功能迭代。从确定需求是否适用AI实现,到方案选型,到设计agent流程,到功能上的交互设计,组织团队最终交付。
今年开始实线负责多个产品,有了自己的团队负责大模型方向的新产品设计和落地,也有需要横向拉通的部门,负责协助规划旧产品AI方向的升级和产品中AI需求的挖掘。
柳暗花明,未来可期。
结语
虽然我是前端转型到AI产品负责人的,但是如果你问我AI一定会代替掉程序员么?
我的回答是:不会,但是AI一定会让这个岗位所需要的人数减少,无论你是初级岗还是高级岗。
我们要做的就是抓住新的机会、占据有利位置、执行下去,然后等待时代的洪流将我们高高托起。
你看deepseek这不就来了? 我前面两年所做的事情,因为deepseek的出现,再次被抬高了一个维度,这就是时代,选择大于努力。
如果大家对“程序员如何转型AI产品负责人”感兴趣,可以点个赞。如果大家喜欢,后面我再多多分享转型细节。
文章更新列表
来源:juejin.cn/post/7469263585287651340
实现基于uni-app的项目自动检查APP更新
我们平时工作中开发APP时,及时为用户提供应用更新是提升用户体验和保证功能完整性的重要一环。本文将通过一段实际的代码示例,详细介绍如何在基于uni-app框架的项目中实现自动检查应用更新的功能,并引导用户完成升级过程。该功能主要涉及与服务器端交互获取最新版本信息、比较版本号、提示用户升级以及处理下载安装流程。
创建一个checkappupdate.js文件
这个文件是写升级逻辑处理的文件,可以不创建,直接在App.vue中写,但是为了便于维护,还是单独放出来比较好,可以放在common或者util目录中(App.vue能引入到就行,随意放,根目录也行),App.vue中引入该文件,调用升级函数如下图所示:

js完整代码
为了防止一点点代码写,容易让人云里雾里,先放完整代码,稍后再详细解释,其实看注释也就够了。
//这是服务端请求url配置文件,如果你直接卸载下面的请求中,可以不引入
import configService from '@/common/service/config.service.js'
export default function checkappupdate(param = {}) {
// 合并默认参数
param = Object.assign({
title: "A new version has been detected!",
content: "Please upgrade the app to the latest version!",
canceltext: "No upgrade",
oktext: "Upgrade now"
}, param)
plus.runtime.getProperty(plus.runtime.appid, (widgetInfo) => {
let platform = plus.os.name.toLocaleLowerCase() //Android
let os_version = plus.os.version //13 安卓版本
let vendor = plus.device.vendor //Xiaomi
let url = configService.apiUrl
uni.request({
url: url + '/checkAppUpdate',
method: 'GET',
data: {
platform: platform,
os_version: os_version,
vendor: vendor,
cur_version: widgetInfo.version
},
success(result) {
console.log(result)
let versionCode = parseInt(widgetInfo.versionCode)
let data = result.data ? result.data : null;
// console.log(data);
let downAppUrl = data.url
//判断版本是否需要升级
if (versionCode >= data.versionCode) {
return;
}
//升级提示
uni.showModal({
title: param.title,
content: data.log ? data.log : param.content,
showCancel: data.force ? false : true,
confirmText: param.oktext,
cancelText: param.canceltext,
success: res => {
if (!res.confirm) {
console.log('Cancel the upgrade');
// plus.runtime.quit();
return
}
// if (data.shichang === 1) {
// //去应用市场更新
// plus.runtime.openURL(data.shichangurl);
// plus.runtime.restart();
// } else {
// 开始下载
// 创建下载任务
var dtask = plus.downloader.createDownload(downAppUrl, {
filename: "_downloads/"
},
function (d, status) {
// 下载完成
if (status == 200) {
plus.runtime.install(d.filename, {
force: true
}, function () {
//进行重新启动;
plus.runtime.restart();
}, (e) => {
uni.showToast({
title: 'install fail:' + JSON
.stringify(e),
icon: 'none'
})
console.log(JSON.stringify(e))
});
} else {
this.tui.toast("download fail,error code: " +
status);
}
});
let view = new plus.nativeObj.View("maskView", {
backgroundColor: "rgba(0,0,0,.6)",
left: ((plus.screen.resolutionWidth / 2) - 45) +
"px",
bottom: "80px",
width: "90px",
height: "30px"
})
view.drawText('start download...', {}, {
size: '12px',
color: '#FFFFFF'
});
view.show()
// console.log(dtask);
dtask.addEventListener("statechanged", (e) => {
if (e && e.downloadedSize > 0) {
let jindu = ((e.downloadedSize / e.totalSize) *
100).toFixed(2)
view.reset();
view.drawText('Progress:' + jindu + '%', {}, {
size: '12px',
color: '#FFFFFF'
});
}
}, false);
dtask.start();
// }
},
fail(e) {
console.log(e);
uni.showToast({
title: 'Request error'
})
}
})
}
})
});
}
函数定义:checkappupdate
定义核心函数checkappupdate,它接受一个可选参数param,用于自定义提示框的文案等信息。函数内部首先通过Object.assign合并默认参数与传入参数,以确保即使未传入特定参数时也能有良好的用户体验。
获取应用信息与环境变量
利用plus.runtime.getProperty获取当前应用的详细信息,包括但不限于应用ID、版本号(version)和版本号代码(versionCode),以及设备的操作系统名称、版本和厂商信息。这些数据对于后续向服务器请求更新信息至关重要。
请求服务器检查更新
构建包含平台信息、操作系统版本、设备厂商和当前应用版本号的请求参数,发送GET请求至配置好的API地址/checkAppUpdate,查询是否有新版本可用。后端返回参数参考下面:
/**
* 检测APP升级
*/
public function checkAppUpdate()
{
$data['versionCode'] = 101;//更新的版本号
$data['url'] = 'http://xxx/app/xxx.apk';//下载地址
$data['force'] = true;//是否强制更新
return json_encode($data);//返回json格式数据到前端
}
比较版本与用户提示
一旦收到服务器响应,解析数据并比较当前应用的版本号与服务器提供的最新版本号。如果存在新版本,使用uni.showModal弹窗提示用户,展示新版本日志(如果有)及升级选项。此步骤充分考虑了是否强制更新的需求,允许开发者灵活配置确认与取消按钮的文案。
下载与安装新版本
用户同意升级后,代码将执行下载逻辑。通过plus.downloader.createDownload创建下载任务,并监听下载进度,实时更新进度提示。下载完成后,利用plus.runtime.install安装新APK文件,并在安装成功后调用plus.runtime.restart重启应用,确保新版本生效。
用户界面反馈
在下载过程中,通过创建原生覆盖层plus.nativeObj.View展示一个半透明遮罩和下载进度信息,给予用户直观的视觉反馈,增强了交互体验,进度展示稍微有点丑,可以提自己改改哈。

总结
通过上述步骤,我们实现了一个完整的应用自动检查更新流程,不仅能够有效通知用户新版本的存在,还提供了平滑的升级体验。此功能的实现,不仅提升了用户体验,也为产品迭代和功能优化提供了有力支持。开发者可以根据具体需求调整提示文案、下载逻辑、进度样式等细节,以更好地适配自身应用的特点和用户群体。
来源:juejin.cn/post/7367555191337828361
10年深漂,放弃高薪,回长沙一年有感
大明哥是 2014 年一个人拖着一个行李箱,单身杀入深圳,然后在深圳一干就是 10 年。
10 年深漂,经历过 4 家公司,有 20+ 人的小公司,也有上万人的大厂。
体验过所有苦逼深漂都体验过的难。坐过能把人挤怀孕的 4 号线,住过一天见不到几个小时太阳的城中村,见过可以飞的蟑螂。欣赏过晚上 6 点的晚霞,但更多的是坐晚上 10 点的地铁看一群低头玩手机的同行。
10 年虽然苦、虽然累,但收获还是蛮颇丰的。从 14年的 5.5K 到离职时候的 xxK。但是因为种种原因,于 2023年 9 月份主动离职离开深圳。
回长沙一年,给我的感觉就是:除了钱少和天气外,样样都比深圳好。
生活
在回来之前,我首先跟我老婆明确说明了我要休息半年,这半年不允许跟我提任何有关工作的事情,因为在深圳工作了 10 年真的太累,从来没有连续休息超过半个月的假期。哪怕是离职后我也是无缝对接,这家公司周五走,下家公司周一入职。
回来后做的第一件事情就是登出微信、删除所有闹钟、手机设置全天候的免打扰,全心全意,一心一意地陪女儿和玩,在这期间我不想任何事情,也不参与任何社交,就认真玩,不过顺便考了个驾-照。
首先说消费。
有很多人说长沙是钱比深圳少,但消费不比深圳低。其实不然,我来长沙一年了,消费真的比深圳低不少。工作日我一天的消费基本上可以控制在 40 左右,但是在深圳我一天几乎都要 80 左右。对比
| 长沙 | 深圳 | |
| 早 | 5+ | 5+ |
| 中 | 15 ~ 25 | 25 ~ 35 |
| 晚 | 10 ~ 15,不加班就回家吃 | 25 ~ 35,几乎天天加班 |
同时,最近几个月我开始带饭了,周一到超时买个百来块的菜,我一个人可以吃两个星期。
总体上,一个月消费长沙比深圳低 1000 左右(带饭后更低了)。
再就是日常的消费。如果你选择去长沙的商城里面吃,那与深圳其实差不多了多少,当然,奶茶方面会便宜一些。但是,如果你选择去吃长沙的本土菜,那就会便宜不少,我跟我朋友吃饭,人均 50 左右,不会超过 70,选择美团套餐会更加便宜,很多餐馆在支持美团的情况下,选择美团套餐,两个人可以控制在 30 ~ 40 之间。而深圳动不动就人均 100+。
当然,在消费这块,其实节约的钱与少的工资,那就是云泥之别,可忽略不计。
再说生活这方面。
在长沙这边我感觉整体上的幸福感比深圳要强蛮多,用一句话说就是:深圳都在忙着赚钱,而长沙都在忙着吃喝玩乐加洗脚。我说说跟我同龄的一些高中和大学同学,他们一毕业就来长沙或者来长沙比较早,所以买房就比较早,尤其是 16 年以前买的,他们的房贷普遍在 3000 左右,而他们夫妻两的工资税后可以到 20000,所以他们这群人周末经常约着一起耍。举两个例子来看看他们的松弛感:
- 晚上 10 点多喊我去吃烧烤,我以为就是去某个夜市撸串,谁知道是开车 40+公里,到某座山的山顶撸串 + 喝酒。这是周三,他们上班不上班我不知道,反正我是不上班。
- 凌晨 3 点多拉我出来撸串
跟他们这群人我算是发现了,大部分的聚会都是临时起意,很少提前约好,主打就是一个随心随意。包括我和同事一样,我们几乎每个月都会出来几次喝酒(我不喜欢喝酒,偶尔喝点啤酒)、撸串,而且每次都是快下班了,某个人提议今晚喝点?完后,各回各家。
上面是好的方面,再说不好的。
长沙最让我受不了的两点就是天气 + 交通。
天气我就不说了,冬天冻死你,夏天热死你。去年完整体验了长沙的整个冬天,是真他妈的冷,虽然我也是湖南人,但确实是把我冻怕了。御寒?不可能的,全靠硬抗。当然,也有神器:火桶子,那是真舒服,我可以在里面躺一整天。
交通,一塌糊涂,尤其是我每天必经的西二环,简直惨不忍睹,尤其是汽车西站那里,一天 24 小时都在堵,尤其是周一和周五,高德地图上面是红的发黑。所以,除非特殊情况,我周一、周五是不开车的,情愿骑 5 公里小电驴去坐地铁。
然后是一大堆违停,硬生生把三车道变成两车道,什么变道不打灯,实线变道,双黄线调头见怪不怪了,还有一大群的小电驴来回穿梭,对我这个新手简直就是恐怖如斯(所以,我开车两个月喜提一血,4S点维修报价 9800+)。
美食我就不说了,简直就是吃货的天堂。
至于玩,我个人觉得长沙市内没有什么好玩的,我反而喜欢去长沙的乡里或者周边玩。所以,我实在是想不通,为什么五一、国庆黄金周长沙是这么火爆,到底火爆在哪里???
还有一点就是,在深圳我时不时就犯个鼻炎,回了长沙一年了我一次都没有,不知道什么原因。
工作
工资,长沙这边的钱是真的少,我现在的年收入连我深圳的三分之一都没有,都快到四分之一了。
当然,我既然选择回来了,就会接受这个低薪,而且在回来之前我就已经做好了心理建设,再加上我没有房贷和车贷,整体上来说,每个月略有结余。
所以,相比以前在深圳赚那么多钱但是无法和自己家人在一起,我更加愿意选择少赚点钱,当然,每个人的选择不同。我也见过很多,受不了长沙的低工资,然后继续回深圳搬砖的。
公司,长沙这边的互联网公司非常少,说是互联网荒漠都不为过。大部分都是传统性的公司,靠国企、外包而活着,就算有些公司说自己是互联网公司,但也不过是披着互联网的羊皮而已。而且在这里绝大多数公司都是野路子的干法,基建差,工作环境也不咋地,福利待遇与深圳的大厂更是没法比,比如社保公积金全按最低档交。年假,换一家公司就清零,我进入公司的时候,我一度以为我有 15 天,一问人事,试用期没有,转正后第一年按 5 天折算,看得我一脸懵逼。
加班,整体上来说,我感觉比深圳加班得要少,当然,大小周,单休的公司也不少,甚至有些公司连五险一金都不配齐,劳动法法外之地名副其实。
同时,这边非常看重学历,一些好的公司,非 985 、211 不要,直接把你门焊死,而这些公司整体上来说工资都很不错,40+ 起码是有的(比如某银行,我的履历完美契合,但就是学历问题而被拒),在长沙能拿这工资,简直就是一种享受,一年就是一套房的首付。
最后,你问我长沙工资这么低,你为什么还选择长沙呢?在工作和生活之间,我只不过选择了生活,仅此而已!!
来源:juejin.cn/post/7457175937736163378
我写了个App,上架 Google Play 一年,下载不到 10 次,于是决定把它开源了

缘起
起初接触某某标签笔记,我被其以标签为核心的卡片笔记模式深深吸引。然而,99 元一年的会员费感觉有点贵了,再加上数据存储在它的服务器,总感觉缺乏一份安全感。
身为 Android 开发者,一个念头在我脑海中闪现:何不亲手写一款属于自己的类似应用?
开发历程
说干就干,最初采用 xml 方式进行开发,慢悠悠的写了几个月写完后。但随着谷歌大力推广 Compose,我决定试试新的技术,发现真香,于是对项目进行 Compose 重构。在 UI 风格上,也经历多次迭代,从最初的随意设计,到遵循谷歌 MD 风格,再到引入 Slat UI,改了无数次,程序员设计 ui 是真的难🥲。
写完后,原本计划在酷安或国内应用市场上架,于是觉得申请软著,反反复复打回,半年后终于申请下来了。结果新政出来了,要公安局备案,还要买服务器。
无奈之下,我选择放弃国内上架计划,转而开通谷歌开发者账号,当时谷歌开发者账号容易弄,交钱绑卡,很快就将应用上架至 Google Play。
现在一年左右了,没做宣传, 10+左右的下载量😓。

现在换了一个朝九晚九的的工作,再加上要带娃,决定将这个项目开源,有兴趣的朋友可以一起维护与开发。
理想与现实的碰撞
从事 Android 开发多年,一直在写公司业务代码,初入行时便怀揣着打造一款个人 App,上架应用市场,甚至有可能获得一点睡后收入的梦想。
开发完成后,我才发现,开发只是整个过程中最简单的环节。
在国内上架应用,软著开公司备案买服务器各种卡流程,很佩服那些上班又自己能这么折腾的开发者。感觉现在国内个人 Android 开发者这条路基本是断了。
Google Play 以前很简单,交钱就行了,现在好像也需要拉人头内测等流程。
App如果不氪金去推广,现在移动互联网已经卷成一片死海,应用市场 App 一大堆,特别是程序员三件套,再去做的话基本凉凉。
如果软件收费,售后问题同样棘手。我在酷安付费购买过多款优秀 App,并加入开发者群,潜水好几年。一旦软件收费,便意味着要对用户负责,面对用户五花八门的需求、各机型适配问题、还有跨平台需求,还有的人无脑喷,管理和维护成本其实非常高。
折腾了这么久,对于大多数人而言,个人开发者之路并不好走,尤其是身处 996 工作环境时,更是难上加难。过去工作稍有空闲,还能抽时间写代码,现在到家都快 10 点了,看到电脑就想吐(真实的心里反应)。
浅谈一下 35 岁程序员焦虑和副业问题,程序员软件三件套是行不通的,因为这些产品非常多,并且大多都是没什么亮点的,大部分估计赚的钱还不够服务器和各种流程的成本。我觉得如果是客户端,2025 年 个人开发者这条路都不建议去走了,前段时间看到很多套壳的 AI 客户端,套完壳容易,推广如果不砸钱,基本没人问津。好不容易推广,你干的过免费的 deepseek 和 kimi 之类的吗🤔
对于 35 岁焦虑, 个人觉得最好的路是找个制造业或者二三线城市的国企银行这种不怎么裁人的企业,躺平式继续 coding。
尾声
开源后,会不定时更新,后续打算试试 KMP 跨平台技术,平常时间大部分带娃,代码写的比较乱,大佬们将就的看。
欢迎提 PR,一起维护。
Github
如果能给一个 star,不胜感激🙏
2025.2.26更新
对于有些人说是AI做的,我贴几张图。最开始在Github,然后迁到Gitee,后面又迁到Github,开源后为了防止敏感信息,把以前的提交记录给清了。
play store发版记录

Gitee 记录

来源:juejin.cn/post/7471630643534512164
Uniapp小程序地图轨迹绘画
轨迹绘画
简介
- 轨迹绘画常用于展示车辆历史轨迹,运动历史记录等,本次案例采用的是汽车案例同时利用腾讯地图API,来实现地图轨迹绘画功能,具体情况根据实际项目变更。
本例是汽车轨迹绘画功能
1.在页面的onReady生命周期中创建map对象
onReady() {
// 创建map对象
this.map = uni.createMapContext('map');
// 获取屏幕高度(此处获取屏幕高度是因为本示例中使用了colorui的cu-custom自定义头部,需根据系统高度来自适应)
uni.getSystemInfo({
success: res => {
this.windowHeight = res.windowHeight;
}
});
},
2.设置轨迹动画事件
页面代码:
<view class="container">
<map id='map' :latitude="latitude" :longitude="longitude" :markers="covers"
:style="{ width: '100%', height: mapHeight + 'px' }" :scale="13" :polyline="polyline">
</map>
<view class="btnBox">
<button :disabled="isDisabled" @click="start" class="cu-btn bg-blue round shadow lg">开始回放</button>
<button @click="pause" class="cu-btn bg-red round shadow lg">暂停</button>
</view>
</view>
逻辑代码:
- 1.轨迹动画的开始事件
start() {
if (this.movementInterval) {
clearInterval(this.movementInterval);
}
this.isStart = true;
this.moveMarker();
},
- 2.轨迹动画的暂停事件
pause() {
this.isStart = false;
this.isDisabled = false;
if (this.movementInterval) {
clearInterval(this.movementInterval);
this.movementInterval = null;
}
},
- 3.轨迹动画移动事件
moveMarker() {
if (!this.isStart) return;
if (this.playIndex >= this.coordinate.length) {
this.playIndex = 0;
uni.showToast({
title: "播放完成",
duration: 1400,
icon: "none",
});
this.isStart = false;
this.isDisabled = false;
return;
}
let datai = this.coordinate[this.playIndex];
this.map.translateMarker({
markerId: 1,
autoRotate: true,
destination: {
longitude: datai.longitude,
latitude: datai.latitude,
},
duration: 700,
complete: () => {
this.playIndex++;
this.moveMarker();
},
});
},
完整代码如下
<!-- 地图轨迹组件 -->
<template>
<view>
<cu-custom class="navBox" bgColor="bg-gradual-blue" :isBack="true">
<block slot="backText">返回</block>
<block slot="content">地图轨迹</block>
</cu-custom>
<view class="container">
<map id='map' :latitude="latitude" :longitude="longitude" :markers="covers"
:style="{ width: '100%', height: mapHeight + 'px' }" :scale="13" :polyline="polyline">
</map>
<view class="btnBox">
<button :disabled="isDisabled" @click="start" class="cu-btn bg-blue round shadow lg">开始回放</button>
<button @click="pause" class="cu-btn bg-red round shadow lg">暂停</button>
</view>
</view>
</view>
</template>
<script>
export default {
data() {
return {
map: null,
movementInterval: null, // 用于存储定时器的引用
windowHeight: 0,
mapHeight: 0,
timer: null,
isDisabled: false,
isStart: false,
playIndex: 1,
id: 0, // 使用 marker点击事件 需要填写id
title: 'map',
latitude: 34.263734,
longitude: 108.934843,
// 标记点
covers: [{
id: 1,
width: 42,
height: 47,
rotate: 270,
latitude: 34.259428,
longitude: 108.947040,
iconPath: 'http://zgonline.top/car.png',
callout: {
content: "鄂A·88888", // <img src="车牌信息" alt="" width="50%" />
display: "ALWAYS",
fontWeight: "bold",
color: "#5A7BEE", //文本颜色
fontSize: "12px",
bgColor: "#ffffff", //背景色
padding: 5, //文本边缘留白
textAlign: "center",
},
anchor: {
x: 0.5,
y: 0.5,
},
}],
// 线
polyline: [],
// 坐标数据
coordinate: [{
latitude: 34.259428,
longitude: 108.947040,
problem: false,
},
{
latitude: 34.252918,
longitude: 108.946963,
problem: false,
},
{
latitude: 34.252408,
longitude: 108.946240,
problem: false,
},
{
latitude: 34.249286,
longitude: 108.946184,
problem: false,
},
{
latitude: 34.248670,
longitude: 108.946640,
problem: false,
},
{
latitude: 34.248129,
longitude: 108.946826,
problem: false,
},
{
latitude: 34.243537,
longitude: 108.946816,
problem: true,
},
{
latitude: 34.243478,
longitude: 108.939003,
problem: true,
},
{
latitude: 34.241218,
longitude: 108.939027,
problem: true,
},
{
latitude: 34.241192,
longitude: 108.934802,
problem: true,
},
{
latitude: 34.241182,
longitude: 108.932235,
problem: true,
},
{
latitude: 34.247227,
longitude: 108.932311,
problem: true,
},
{
latitude: 34.250833,
longitude: 108.932352,
problem: true,
},
{
latitude: 34.250877,
longitude: 108.931756,
problem: true,
},
{
latitude: 34.250944,
longitude: 108.931576,
problem: true,
},
{
latitude: 34.250834,
longitude: 108.929662,
problem: true,
},
{
latitude: 34.250924,
longitude: 108.926015,
problem: true,
},
{
latitude: 34.250802,
longitude: 108.910121,
problem: true,
},
{
latitude: 34.269718,
longitude: 108.909921,
problem: true,
},
{
latitude: 34.269221,
longitude: 108.922366,
problem: false,
},
{
latitude: 34.274531,
longitude: 108.922388,
problem: false,
},
{
latitude: 34.276201,
longitude: 108.923433,
problem: false,
},
{
latitude: 34.276559,
longitude: 108.924004,
problem: false,
},
{
latitude: 34.276785,
longitude: 108.945855,
problem: false,
}
],
posi: {
id: 1,
width: 32,
height: 32,
latitude: 0,
longitude: 0,
iconPath: "http://cdn.zhoukaiwen.com/car.png",
callout: {
content: "鄂A·888888", // 车牌信息
display: "BYCLICK",
fontWeight: "bold",
color: "#5A7BEE", //文本颜色
fontSize: "12px",
bgColor: "#ffffff", //背景色
padding: 5, //文本边缘留白
textAlign: "center",
},
anchor: {
x: 0.5,
y: 0.5,
},
}
}
},
watch: {},
// 分享小程序
onShareAppMessage(res) {
return {
title: '看看这个小程序多好玩~',
};
},
onReady() {
// 创建map对象
this.map = uni.createMapContext('map');
// 获取屏幕高度
uni.getSystemInfo({
success: res => {
this.windowHeight = res.windowHeight;
}
});
},
mounted() {
this.setNavTop('.navBox')
this.polyline = [{
points: this.coordinate,
color: '#025ADD',
width: 4,
dottedLine: false,
}];
},
methods: {
setNavTop(style) {
let view = uni.createSelectorQuery().select(style);
view
.boundingClientRect((data) => {
console.log("tabInList基本信息 = " + data.height);
this.mapHeight = this.windowHeight - data.height;
console.log(this.mapHeight);
})
.exec();
},
start() {
if (this.movementInterval) {
clearInterval(this.movementInterval);
}
this.isStart = true;
this.moveMarker();
},
moveMarker() {
if (!this.isStart) return;
if (this.playIndex >= this.coordinate.length) {
this.playIndex = 0;
uni.showToast({
title: "播放完成",
duration: 1400,
icon: "none",
});
this.isStart = false;
this.isDisabled = false;
return;
}
let datai = this.coordinate[this.playIndex];
this.map.translateMarker({
markerId: 1,
autoRotate: true,
destination: {
longitude: datai.longitude,
latitude: datai.latitude,
},
duration: 700,
complete: () => {
this.playIndex++;
this.moveMarker();
},
});
},
pause() {
this.isStart = false;
this.isDisabled = false;
if (this.movementInterval) {
clearInterval(this.movementInterval);
this.movementInterval = null;
}
},
}
}
</script>
<style lang="scss" scoped>
.container {
position: relative;
}
.btnBox {
width: 750rpx;
position: absolute;
bottom: 60rpx;
z-index: 99;
display: flex;
justify-content: space-around;
}
</style>
来源:juejin.cn/post/7406173972738867227
使用 canvas 实现电子签名
一、引言
电子签名作为数字化身份认证的核心技术之一,已广泛应用于合同签署、审批流程等场景。之前做公司项目时遇到这个需求,于是研究了下,目前前端主要有两种方式实现电子签名:原生Canvason 和 使用signature_pad 依赖库。
本文将基于Vue3 + TypeScript技术栈,深入讲解原生Canvas功能实现方案,并提供完整的可落地代码。
二、原生Canvas实现方案
完整代码:GitHub - seapack-hub/seapack-template: seapack-template框架
实现的逻辑并不复杂,就是使用canvas提供一个画板,让用户通过鼠标或者移动端触屏的方式在画板上作画,最后将画板上的图案生成图片保存下来。
(一) 组件核心结构
需要同时处理 鼠标事件(PC端) 和 触摸事件(移动端),实现兼容的效果。
// PC端 鼠标事件
canvas.addEventListener('mousedown', startDrawing);
canvas.addEventListener('mousemove', draw);
canvas.addEventListener('mouseup', endDrawing);
// 移动端 触摸事件
canvas.addEventListener('touchstart', handleTouchStart);
canvas.addEventListener('touchmove', handleTouchMove);
canvas.addEventListener('touchend', endDrawing);
具体流程:通过状态变量控制绘制阶段:
| 阶段 | 触发事件 | 行为 |
|---|---|---|
| 开始绘制 | mousedown | 记录起始坐标,标记isDrawing=true |
| 绘制中 | mousemove | 连续绘制路径(lineTo + stroke) |
| 结束绘制 | mouseup | 重置isDrawing=false` |
代码实现:
<div class="signature-container">
<canvas
ref="canvasRef"
@mousedown="startDrawing"
@mousemove="draw"
@mouseup="endDrawing"
@mouseleave="endDrawing"
@touchstart="handleTouchStart"
@touchmove="handleTouchMove"
@touchend="endDrawing"
></canvas>
<div class="controls">
<button @click="clearCanvas">清除</button>
<button @click="saveSignature">保存签名</button>
</div>
</div>
(二) 类型和变量
//类型定义
type RGBColor = `#${string}` | `rgb(${number},${number},${number})`
type Point = { x: number; y: number }
type CanvasContext = CanvasRenderingContext2D | null
// 配置
const exportBgColor: RGBColor = '#ffffff' // 设置为需要的背景色
//元素引用
const canvasRef = ref<HTMLCanvasElement | null>(null)
const ctx = ref<CanvasContext>()
//绘制状态
const isDrawing = ref(false)
const lastPosition = ref<Point>({ x: 0, y: 0 })
(三) 绘制逻辑实现
初始化画布
//初始化画布
onMounted(() => {
if (!canvasRef.value) return
//设置画布大小
canvasRef.value.width = 800
canvasRef.value.height = 400
//获取2d上下文
ctx.value = canvasRef.value.getContext('2d')
if (!ctx.value) return
//初始化 画笔样式
ctx.value.lineWidth = 2
ctx.value.lineCap = 'round'
ctx.value.strokeStyle = '#000' //线条颜色
// 初始填充背景
fillBackground(exportBgColor)
})
//填充背景方法
const fillBackground = (color: RGBColor) => {
if (!ctx.value || !canvasRef.value) return
ctx.value.save()
ctx.value.fillStyle = color
ctx.value.fillRect(0, 0, canvasRef.value.width, canvasRef.value.height)
ctx.value.restore()
}
获取坐标
将事件坐标转换为 Canvas 内部坐标,兼容滚动偏移
//获取坐标点,将事件坐标转换为 Canvas 内部坐标,兼容滚动偏移
const getCanvasPosition = (clientX: number, clientY: number): Point => {
if (!canvasRef.value) return { x: 0, y: 0 }
//获取元素在视口(viewport)中位置
const rect = canvasRef.value.getBoundingClientRect()
return {
x: clientX - rect.left,
y: clientY - rect.top,
}
}
// 获取事件坐标
const getEventPosition = (e: MouseEvent | TouchEvent): Point => {
//TouchEvent 是在支持触摸操作的设备(如智能手机、平板电脑)上,用于处理触摸相关交互的事件对象
if ('touches' in e) {
return getCanvasPosition(e.touches[0].clientX, e.touches[0].clientY)
}
return getCanvasPosition(e.clientX, e.clientY)
}
开始绘制
将 isDrawing 变量值设置为true,表示开始绘制,并获取当前鼠标点击或手指触摸的坐标。
//开始绘制
const startDrawing = (e: MouseEvent | TouchEvent) => {
isDrawing.value = true
const { x, y } = getEventPosition(e)
lastPosition.value = { x, y }
}
绘制中
每次移动时创建新路径,连接上一个点与当前点。
//绘制中
const draw = (e: MouseEvent | TouchEvent) => {
if (!isDrawing.value || !ctx.value) return
//获取当前所在位置
const { x, y } = getEventPosition(e)
//开始新路径
ctx.value.beginPath()
//移动画笔到上一个点
ctx.value.moveTo(lastPosition.value.x, lastPosition.value.y)
//绘制线条到当前点
ctx.value.lineTo(x, y)
//描边路径
ctx.value.stroke()
//更新最后的位置
lastPosition.value = { x, y }
}
结束绘制
将 isDrawing 变量设为false,结束绘制
//结束绘制
const endDrawing = () => {
isDrawing.value = false
}
添加清除和保存方法
//清除签名
const clearCanvas = () => {
if (!ctx.value || !canvasRef.value) return
ctx.value.clearRect(0, 0, canvasRef.value.width, canvasRef.value.height)
}
//保存签名
const saveSignature = () => {
if (!canvasRef.value) return
const dataURL = canvasRef.value.toDataURL('image/png')
const link = document.createElement('a')
link.download = 'signature.png'
link.href = dataURL
link.click()
}
移动端适配
// 触摸事件处理
const handleTouchStart = (e: TouchEvent) => {
e.preventDefault();
startDrawing(e.touches[0]);
};
const handleTouchMove = (e: TouchEvent) => {
e.preventDefault();
draw(e.touches[0]);
};
(四) 最终效果

来源:juejin.cn/post/7484987385665011762
努力工作,你已经是很了不起的成年人了
1、像潮水一样的焦虑
"我二十三岁,靠自己的努力,全款小米Su7 Ultra。"
"二十七岁,工作之余,副业一个月赚两万。"
"用 DeepSeek 做副业,三天赚了九千"
对的,这些是目前互联网上短视频、问答平台、公众号里再常见不过的文案,衬托之下:
仿佛早上挤地铁四号线、一边走路一边吃热干面、坐在格子间里连喝一口水都要见缝插针、晚上加班结束要迈着飞快的脚步去赶最后一班地铁的你,是一个恬不知耻正在迈向中年的你,像是一个混吃等死毫无作为的废物。
凌晨你回到出租屋,打开朋友圈,看到的却是这样那样的焦虑:
三十天写作训练营、素人短视频日入八百、宝妈靠手作实现财务自由。
这些标题像便利店门口的霓虹灯,在深夜里闪烁得格外刺眼,仿佛在质问每个失眠的成年人:你的人生怎么还没开张?
你躺在床上,闭上眼睛的时候还在脑海里反复复盘着:“我这领个死工资也不是个事儿啊,什么时候能搞个副业,也实现一下财务自由。赚够两百万存款的时候,我要把辞职信拍到领导的脸上。”
在焦虑、自责、懊恼之余,你是否忘了什么事情?
你是否忘了,你其实是一个:
经过完整的高等教育,每天算上通勤,为工作付出超过12小时时间,没有沾染赌毒行为,勤勤恳恳态度认真的年轻人。工作之余,你唯一的爱好可能就是下班后躲在出租屋里打两把游戏。
从任何角度上看,你都是一个努力的,踏实的,积极向上的年轻人。
那么,究竟是谁在引导你否定自己的努力,对自己的状态进行 PUA 呢?
副业如果真那么神奇的话,为什么它还是 “副业” 呢?
了解那些焦虑的本质,你会发现:“副业可能是版本陷阱”。
2,副业可能是版本陷阱
我们 Dota2 玩家有个经常被挂在嘴边的词语,叫 “版本陷阱”,指的是那些版本更新之后,被大家口口相传多么厉害,但是真在职业赛场上被选出来却胜率惨不忍睹的英雄。
很抱歉,我可能要说一句丧气话:
“副业就是这个版本的【版本陷阱】。”
为什么呢?
- 先聊副业本质
副业的本质是跳出主页赛道,恰好进入一条机会更多、收入更高的蓝海赛道;这个机会可能来自于你自身(你恰好擅长某些主业之外的能力),更多的时候来自于时代红利(早几年间你非常擅长制作短视频)。
因此,少量时间+副业可以带来高收入的本质,是个人长项在蓝海领域博取一个创收机会,但是你先问问自己,有没有主业之外领域的优势技能。
- 再说版本环境
在上一条里面我们提到了“蓝海行业”,这一点非常重要,只有某个赛道出现明显的技术缺口或人员缺口时,副业者才有腾挪的空间。但如果一个行业或赛道已经人满为患,你准备拿每天2个小时和那些每天12个小时的团队作战吗?
- 最后分析下“口口相传”的那些人
你以为天天分享副业赚钱的人群:“人生导师、大公无私、先富的来带动后富的。”
实际发那些文案的人群:那些教你"睡后收入"的博主,自己往往在通宵直播卖课;晒着海岛定位说走就走的旅行博主,回程机票可能都是网贷分期。这个魔幻的时代,连贩卖成功学的都在996加班。
而他们兜售焦虑的最后一环,还是希望焦虑者咬上他们那锈迹斑斑的铁钩,成为下一个为“财富自由”付费的“上进者”。
请容许我再说一句丧气话:
绝大多数普通人的搞钱手段就是上班,只有上班。
哪有那么多暴富的机会在前方等着你?哪有那么多“睡后”的收入在梦中等着你?哪有那么一劳永逸又无比轻松的战役,在彼岸等着你。
你之所以相信彼岸的美好,有没有可能是因为你看不穿横在河面上的浓雾?
3,努力上班,已经是很棒的成年人了
每天我总能见到大家在各种空间和途径输出焦虑:
女孩责怪男孩不上进,下班只知道打游戏。
男孩抱怨不该生孩子,没有时间和机会创业搞财富自由。
总有人和自己身边的成功同龄人做比对,反思得出“自己是个废物”的神奇结论。
可是啊同学,我们也只是一群普通人而已。
在步入三十五岁之后,变成互联网行业里的“下岗预备役”之后,我逐渐开始认清了自己的属性和位置,不再苛求自己与众不同。
经过完整的高等教育,每天算上通勤,为工作付出超过12小时时间,没有沾染赌毒行为,勤勤恳恳态度认真的年轻人。工作之余,你唯一的爱好可能就是下班后躲在出租屋里打两把游戏。
每周可以有时间陪家人一起做一些不花钱的娱乐。
每周可以有时间陪孩子梳理一下近期的学习、分享一下思考。
每周有那么几个小时可以做一些让自己从内在感到快乐、感到满足、感到宁静的事情。
你没有去赌博欠下一屁股债,没有去加杠杆投资卖掉父母的房产,没有闷着头贷款创业亏光爹妈的棺材本。
同学,你可能意识不到,但我今天非常想郑重地告诉你:
在成年人这个群体之中,你已经是非常杰出、非常棒的那一批了。
副业焦虑?让它见鬼去吧。
来源:juejin.cn/post/7481187555866804224
微信小程序主包过大终极解决方案
随着小程序项目的不断迭代升级,避免不了体积越来越大。微信限制主包最多2M,然而我们的项目引入了直播插件直接占了1.1M,导致必须采用一些手段去优化。下面介绍一下优化思路和终极解决方案。
1.分包
我相信几乎所有人都能想到的方案,基本上这个方案就能解决问题。具体如何实现可以参照官方文档这里不做过多说明。(基础能力 / 分包加载 / 使用分包 (qq.com)),但是有时候你会发现分包之后好像主包变化不是很大,这是为什么呢?
- 痛点1:通过依赖分析,如果分包中引入了第三方依赖,那么依赖的js仍然会打包在主包中,例如echarts、wxparse、socket.io。这就导致我们即使做了分包处理,但是主包还是很大,因为相关的js都会在主包中的vendor.js
- 痛点2:插件只能在主包中无法分包,例如直播插件直接占据1M

- 痛点3:tabbar页面无法分包,只能在主包内
- 痛点4:公共组件/方法无法分包,只能在主包内
- 痛点5:图片只能在主包内
2.图片优化
图片是最好解决的,除了tabbar用到的图标,其余都放在云上就好了,例如oss和obs。而且放在云上还有个好处就是背景图片无需担心引入不成功。
3.tabbar页面优化
这部分可以采用tabbar页面都在放在一个文件夹下,比如一共有4个tab,那么一个文件夹下就只存放这4个页面。其余tabbar的子页面一律采用分包。
4.独立分包
独立分包是小程序中一种特殊类型的分包,可以独立于主包和其他分包运行。从独立分包中页面进入小程序时,不需要下载主包。当用户进入普通分包或主包内页面时,主包才会被下载。
但是使用的时候需要注意:
- 独立分包中不能依赖主包和其他分包中的内容,包括 js 文件、template、wxss、自定义组件、插件等(使用 分包异步化 时 js 文件、自定义组件、插件不受此条限制)
- 主包中的
app.wxss对独立分包无效,应避免在独立分包页面中使用app.wxss中的样式; App只能在主包内定义,独立分包中不能定义App,会造成无法预期的行为;- 独立分包中暂时不支持使用插件。
5.终极方案we-script
我们自己写的代码就算再多,其实增加的kb并不大。大部分大文件主要源于第三方依赖,那么有没有办法像webpack中的externals一样,当进入这个页面的时候再去异步加载js文件而不被打包呢(说白了就是CDN)
其实解决方案就是we-script,他允许我们使用CDN方式加载js文件。这样就不会影响打包体积了。
使用步骤
npm install --save we-script- "packNpmRelationList": [{"packageJsonPath": "./package.json", "miniprogramNpmDistDir":"./dist/"}]
- 点击开发者工具中的菜单栏:工具 --> 构建 npm
"usingComponents": {"we-script": "we-script"}<we-script src="url1" />
使用中存在的坑
构建后可能会出现依赖报错,解决的方式就是将编译好的文件手动拖入miniprogram_npm文件夹中,主要是三个文件夹:we-script,acorn,eval5
最后成功解决了主包文件过大的问题,只要是第三方依赖,都可以通过这个办法去加载。
感谢阅读,希望来个三连支持下,转载记得标注原文地址~
来源:juejin.cn/post/7355057488351674378
uni-app 接入微信短剧播放器
前言
作为一个 uniapp 初学者,恰巧遇到微信短剧播放器接入的需求,在网上检索许久并没有发现傻瓜式教程。于是总结 uni-app 官网文档及微信开放文档,自行实践后,总结出几个步骤,希望为大家提供些帮助。实践后发现其实确实比较简单,大佬们可能也懒得写文档,那么就由我这个小白大概总结下。本文档仅涉及剧目提审成功后的播放器接入,其余相关问题请参考微信官方文档。
小程序申请插件
参考文档:developers.weixin.qq.com/miniprogram…
首先,需要在小程序后台,申请 appid 为 wx94a6522b1d640c3b 的微信插件,可以在微信小程序管理后台进行添加,路径是 设置 - 第三方设置 - 插件管理 - 添加插件,搜索 wx94a6522b1d640c3b 后进行添加:


uni-app 项目添加微信插件
参考文档:uniapp.dcloud.net.cn/tutorial/mp…
添加插件完成后,在 manifest.json 中,点击 源码视图,找到如下位置并添加红框内的代码,此步骤意在将微信小程序插件引入项目。

/* 添加微短剧播放器插件 */
"plugins" : {
"playlet-plugin" : {
"version" : "latest",
"provider" : "wx94a6522b1d640c3b"
}
}
manifest.json 中完成添加后,需要在 pages.json 中找一个页面(我这边使用的是一个新建的空白页面)挂载组件,挂载方式如下图红框中所示,需注意,这里的组件名称需要与 manifest.json 中定义的一致:

{
"path": "newPage/newPage",
"style": {
"navigationBarTitleText": "",
"enablePullDownRefresh": false,
"navigationStyle": "custom",
"app-plus": {
"bounce": "none"
},
"mp-weixin": {
"usingComponents": {
"playlet-plugin": "plugin://playlet-plugin/playlet-plugin"
}
}
}
}
挂载空页面是个笨办法,目前我这边尝试如果不挂载的话,会有些问题,有大神知道别的方法可以在评论区指点一下~
App.vue 配置
参考文档:developers.weixin.qq.com/miniprogram…
首先,找个地方新建一个 playerManager.js,我这边建在了 common 文件夹下。代码如下(代码参考微信官方文档给出的 demo):
var plugin = requirePlugin("playlet-plugin");
// 点击按钮触发此函数跳转到播放器页面
function navigateToPlayer(obj) {
// 下面的${dramaId}变量,需要替换成小程序管理后台的媒资管理上传的剧目的dramaId,变量${srcAppid}是提审方appid,变量${serialNo}是某一集,变量${extParam}是扩展字段,可通过
const { extParam, dramaId, srcAppid, serialNo } = obj
wx.navigateTo({
url: `plugin-private://wx94a6522b1d640c3b/pages/playlet/playlet?dramaId=${dramaId}&srcAppid=${srcAppid}&serialNo=${serialNo}&extParam=${extParam || ''}`
})
}
const proto = {
_onPlayerLoad(info) {
const pm = plugin.PlayletManager.getPageManager(info.playerId)
this.pm = pm
// encryptedData是经过开发者后台加密后(不要在前端加密)的数据,具体实现见下面的加密章节
this.getEncryptData({serialNo: info.serialNo}).then(res => {
// encryptedData是后台加密后的数据,具体实现见下面的加密章节
pm.setCanPlaySerialList({
data: res.encryptedData,
freeList: [{start_serial_no: 1, end_serial_no: 10}], // 1~10集是免费剧集
})
})
pm.onCheckIsCanPlay(this.onCheckIsCanPlay)
// 关于分享的处理
// 开启分享以及withShareTicket
pm.setDramaFlag({
share: true,
withShareTicket: true
})
// 获取分享参数,页面栈只有短剧播放器一个页面的时候可获取到此参数
// 例如从分享卡片进入、从投流广告直接跳转到播放器页面,从二维码直接进入播放器页面等情况
plugin.getShareParams().then(res => {
console.log('getLaunch options query res', res)
// 关于extParam的处理,需要先做decodeURIComponent之后才能得到原值
const extParam = decodeURIComponent(res.extParam)
console.log('getLaunch options extParam', extParam)
// 如果设置了withShareTicket为true,可通过文档的方法获取更多信息
// https://developers.weixin.qq.com/miniprogram/dev/framework/open-ability/share.html
const enterOptions = wx.getEnterOptionsSync()
console.log('getLaunch options shareTicket', enterOptions.shareTicket)
}).catch(err => {
console.log('getLaunch options query err', err)
})
// extParam除了可以通过在path传参,还可以通过下面的接口设置
pm.setExtParam('hellotest')
// 分享部分end
},
onCheckIsCanPlay(param) {
// TODO: 碰到不可以解锁的剧集,会触发此事件,这里可以进行扣币解锁逻辑,如果用户无足够的币,可调用下面的this.isCanPlay设置
console.log('onCheckIsCanPlay param', param)
var serialNo = param.serialNo
this.getEncryptData({serialNo: serialNo}).then(res => {
// encryptedData是后台加密后的数据,具体实现见下面的加密章节
this.pm.isCanPlay({
data: res.encryptedData,
serialNo: serialNo,
})
})
},
getEncryptData(obj) {
const { serialNo } = obj
// TODO: 此接口请求后台,返回下面的setCanPlaySerialList接口需要的加密参数
const { srcAppid, dramaId } = this.pm.getInfo()
console.log('getEncryptData start', srcAppid, dramaId, serialNo)
return new Promise((resolve, reject) => {
resolve({
encryptedData: '' // TODO: 此参数需从后台接口获取到
})
})
},
}
function PlayerManager() {
var newProto = Object.assign({}, proto)
for (const k in newProto) {
if (typeof newProto[k] === 'function') {
this[k] = newProto[k].bind(this)
}
}
}
PlayerManager.navigateToPlayer = navigateToPlayer
module.exports = PlayerManager
新建完成后,在 App.vue 中进行组件的配置和引用。

onLaunch: function() {
// playlet-plugin必须和上面的app.json里面声明的插件名称一致
const playletPlugin = requirePlugin('playlet-plugin')
const _onPlayerLoad = (info) => {
var PlayerManager = require('@/common/playerManager.js')
const playerManager = new PlayerManager()
playerManager._onPlayerLoad(info)
}
// 注册播放器页面的onLoad事件
playletPlugin.onPageLoad(_onPlayerLoad.bind(this))
},
_onPlayerLoad(info) {
var PlayerManager = require('@/common/playerManager.js')
const playerManager = new PlayerManager()
playerManager._onPlayerLoad(info)
},
页面使用
参考文档:developers.weixin.qq.com/miniprogram…
以上所有步骤完成后,就可以开心的使用短剧播放器了。 我这边临时写了个图片的 click 事件测试了一下:
clk() {
// 逻辑处理...获取你的各种参数
// 打开组件中封装的播放器页面
PlayerManager.navigateToPlayer({
srcAppid: 'wx1234567890123456', // 剧目提审方 appid
dramaId: '100001', // 小程序管理后台的媒资管理上传的剧目的 dramaId
serialNo: '1', // 剧目中的某一集
extParam: encodeURIComponent('a=b&c=d'), // 扩展字段,需要encode
})
},
写在最后:
总结完了,其实整体下来不是很难,对我这种前端小白来说检索和整合的过程是比较痛苦的,所以希望下一个接入的朋友可以少检索一些文档吧。
另附一个短剧播放器接口的文档: developers.weixin.qq.com/miniprogram…
文档主要介绍了短剧播放器插件提供的几个接口,在js代码里,插件接口实例通过下面的代码获取
// 名字playlet-plugin必须和app.json里面引用的插件名一致
const playletPlugin = requirePlugin('playlet-plugin')
读书越多越发现自己的无知,Keep Fighting!
欢迎友善交流,不喜勿喷~
Hope can help~
来源:juejin.cn/post/7373473695057428506
后端出身的CTO问:"前端为什么没有数据库?",我直接无语......
😅【现场还原】
"前端为什么没有自己的数据库?把数据存前端不就解决了后端性能问题" ——当CTO抛出这个灵魂拷问时,会议室突然安静得能听见CPU风扇的嗡鸣,在座所有人都无语了。这场因后端性能瓶颈引发的技术博弈,最终以"前端分页查询+本地筛选"的妥协方案告终。
面对现在几乎所有公司的技术leader都是后端出身,有的不懂前端甚至不懂技术,作为前端开发者,我们真的只能被动接受吗?
😣【事情背景】
- 需求:前端展示所有文章的标签列表,用户可以选择标签筛选文章,支持多选,每个文章可能有多个标签,也可能没任何标签。
- 前端观点:针对这种需求,我自然想到用户选中标签后,将标签id传给后端,后端根据id筛选文章列表返回即可。
- 后端观点:后端数据分库分表,根据标签检索数据还要排序分页,有性能瓶颈会很慢,很慢就会导致天天告警。
- 上升决策:由于方案有上述分歧,我们就找来了双方leader决策,双方leader也有分歧,最终叫来了CTO。领导想让我们将数据定时备份到前端,需要筛选的时候前端自己筛选。
CTO语录:
“前端为什么没有数据库?,把数据存前端,前端筛选,数据库不就没有性能压力了”
"现在手机性能比服务器还强,让前端存全量数据怎么了?"
"IndexedDB不是数据库?localStorage不能存JSON?"
"分页?让前端自己遍历数组啊,这不就是你们说的'前端工程化'吗?"
😓【折中方案】
在方案评审会上,我们据理力争:
- 分页请求放大效应:用户等待时间=单次请求延迟×页数
- 内存占用风险:1万条数据在移动端直接OOM
- 数据一致性难题:轮询期间数据更新的同步问题
但现实往往比代码更复杂——当CTO拍板要求"先实现再优化",使用了奇葩的折中方案:
- 前端轮询获取前1000条数据做本地筛选,用户分页获取数据超过1000条后,前端再轮询获取1000条,以此类推。
- 前端每页最多获取50条数据,每次最多并发5个请求(后端要求)
只要技术监控不报错,至于用户体验?慢慢等着吧你......
🖨️【批量并发请求】
既然每页只有50条数据,那我至少得发20个请求来拿到所有数据。显然,逐个请求会让用户等待很长时间,明显不符合前端性能优化的原则。于是我选择了 p-limit 和Promise.all来实现异步并发线程池。通过并发发送多个请求,可以大大减少数据获取的总时间。
import pLimit from 'p-limit';
const limit = pLimit(5); // 限制最多5个并发请求
// 模拟接口请求
const fetchData = (page, pageSize) => {
return new Promise((resolve) => {
setTimeout(() => {
resolve(`数据页 ${page}:${pageSize}条数据`);
}, 1000);
});
};
// 异步任务池
const runTasks = async () => {
const totalData = 1000; // 总数据量
const pageSize = 50; // 每页容量
const totalPages = Math.ceil(totalData / pageSize); // 计算需要多少页
const tasks = [];
// 根据总页数动态创建请求任务
for (let i = 1; i <= totalPages; i++) {
tasks.push(limit(() => fetchData(i, pageSize))); // 使用pLimit限制并发请求
}
const results = await Promise.all(tasks); // 等待所有请求完成
console.log('已完成所有任务:', results);
};
runTasks();
📑【高效本地筛选数据】
当所有数据都请求回来了,下一步就是进行本地筛选。毕竟后端已经将查询任务分配给了前端,所以我得尽可能让筛选的过程更高效,避免在本地做大量的计算导致性能问题。
1. 使用哈希进行高效查找
如果需要根据某个标签来筛选数据,最直接的做法就是遍历整个数据集,但这显然效率不高。于是我决定使用哈希表(或 Map)来组织数据。这样可以在常数时间内完成筛选操作。
const filterDataByTag = (data, tag) => {
const tagMap = new Map();
data.forEach(item => {
if (!tagMap.has(item.tag)) {
tagMap.set(item.tag, []);
}
tagMap.get(item.tag).push(item);
});
return tagMap.get(tag) || [];
};
const result = filterDataByTag(allData, 'someTag');
console.log(result);
2. 使用 Web Workers 进行数据处理
如果数据量很大,筛选过程可能会比较耗时,导致页面卡顿。为了避免这个问题,可以将数据筛选的过程交给 Web Workers 处理。Web Worker 可以在后台线程运行,避免阻塞主线程,从而让用户体验更加流畅。
const worker = new Worker('worker.js');
worker.postMessage(allData);
worker.onmessage = function(event) {
const filteredData = event.data;
console.log('筛选后的数据:', filteredData);
};
// worker.js
onmessage = function(e) {
const data = e.data;
const filteredData = data.filter(item => item.tag === 'someTag');
postMessage(filteredData);
};
📝【总结】
这场技术博弈给我们带来三点深刻启示:
- 数据民主化趋势:随着WebAssembly、WebGPU等技术的发展,前端正在获得堪比后端的计算能力
- 妥协的艺术:临时方案必须包含演进路径,我们的分页实现预留了切换GraphQL的接口
- 性能新思维:从前端到边缘计算,性能优化正在从"减少请求"转向"智能分发"
站在CTO那句"前端为什么没有数据库"的肩膀上,我们正在构建这样的未来:每个前端应用都内置轻量级数据库内核,通过差异同步策略与后端保持数据一致,利用浏览器计算资源实现真正的端智能。这不是妥协的终点,而是下一代Web应用革命的起点。
后记:三个月后,我们基于SQL.js实现了前端SQL查询引擎,配合WebWorker线程池,使得复杂筛选的耗时从秒级降至毫秒级——但这已经是另一个技术突围的故事了。
来源:juejin.cn/post/7472732247932174388
Vue3 实现最近很火的酷炫功能:卡片悬浮发光
前言
大家好,我是林三心,用最通俗易懂的话讲最难的知识点是我的座右铭,基础是进阶的前提是我的初心~
有趣的动画效果
前几天在网上看到了一个很有趣的动画效果,如下,光会跟随鼠标在卡片上进行移动,并且卡片会有视差的效果
那么在 Vue3 中应该如何去实现这个效果呢?

基本实现思路
其实实现思路很简单,无非就是分几步:
- 首先,卡片是
相对定位,光是绝对定位 - 监听卡片的鼠标移入事件
mouseenter,当鼠标进入时显示光 - 监听卡片的鼠标移动事件
mouseover,鼠标移动时修改光的left、top,让光跟随鼠标移动 - 监听卡片的鼠标移出事件
mouseleave,鼠标移出时,隐藏光
我们先在 Index.vue 中准备一个卡片页面,光的CSS效果可以使用filter: blur() 来实现

可以看到现在的效果是这样

实现光源跟随鼠标
在实现之前我们需要注意几点:
- 1、鼠标移入时需要设置卡片
overflow: hidden,否则光会溢出,而鼠标移出时记得还原 - 2、获取鼠标坐标时需要用
clientX/Y而不是pageX/Y,因为前者会把页面滚动距离也算进去,比较严谨
刚刚说到实现思路时我们说到了mouseenter、mousemove、mouseleave,其实mouseenter、mouseleave 这二者的逻辑比较简单,重点是 mouseover 这个监听函数
而在 mouseover 这个函数中,最重要的逻辑就是:光怎么跟随鼠标移动呢?
或者也可以这么说:怎么计算光相对于卡片盒子的 left 和 top
对此我专门画了一张图,相信大家一看就懂怎么算了

- left = clientX - x - width/2
- height = clientY - y - height/2
知道了怎么计算,那么逻辑的实现也很明了了~封装一个use-light-card.ts

接着在页面中去使用

这样就能实现基本的效果啦~

卡片视差效果
卡片的视差效果需要用到样式中 transform 样式,主要是配置四个东西:
- perspective:定义元素在 3D 变换时的透视效果
- rotateX:X 轴旋转角度
- rotateY:Y 轴旋转角度
- scale3d:X/Y/Z 轴上的缩放比例

现在就有了卡片视差的效果啦~

给所有卡片添加光源
上面只是给一个卡片增加光源,接下来可以给每一个卡片都增加光源啦!!!


让光源变成可配置
上面的代码,总感觉这个 hooks 耦合度太高不太通用,所以我们可以让光源变成可配置化,这样每个卡片就可以展示不同大小、颜色的光源了~像下面一样

既然是配置化,那我们希望是这么去使用 hooks 的,我们并不需要自己在页面中去写光源的dom节点,也不需要自己去写光源的样式,而是通过配置传入 hooks 中

所以 hooks 内部要自己通过操作 DOM 的方式,去添加、删除光源,可以使用createElement、appendChild、removeChild 去做这些事~

完整源码
<!-- Index.vue -->
<template>
<div class="container">
<!-- 方块盒子 -->
<div class="item" ref="cardRef1"></div>
<!-- 方块盒子 -->
<div class="item" ref="cardRef2"></div>
<!-- 方块盒子 -->
<div class="item" ref="cardRef3"></div>
</div>
</template>
<script setup lang="ts">
import { useLightCard } from './use-light-card';
const { cardRef: cardRef1 } = useLightCard();
const { cardRef: cardRef2 } = useLightCard({
light: {
color: '#ffffff',
width: 100,
},
});
const { cardRef: cardRef3 } = useLightCard({
light: {
color: 'yellow',
},
});
</script>
<style scoped lang="less">
.container {
background: black;
width: 100%;
height: 100%;
padding: 200px;
display: flex;
justify-content: space-between;
.item {
position: relative;
width: 125px;
height: 125px;
background: #1c1c1f;
border: 1px solid rgba(255, 255, 255, 0.1);
}
}
</style>
// use-light-card.ts
import { onMounted, onUnmounted, ref } from 'vue';
interface IOptions {
light?: {
width?: number; // 宽
height?: number; // 高
color?: string; // 颜色
blur?: number; // filter: blur()
};
}
export const useLightCard = (option: IOptions = {}) => {
// 获取卡片的dom节点
const cardRef = ref<HTMLDivElement | null>(null);
let cardOverflow = '';
// 光的dom节点
const lightRef = ref<HTMLDivElement>(document.createElement('div'));
// 设置光源的样式
const setLightStyle = () => {
const { width = 60, height = 60, color = '#ff4132', blur = 40 } = option.light ?? {};
const lightDom = lightRef.value;
lightDom.style.position = 'absolute';
lightDom.style.width = `${width}px`;
lightDom.style.height = `${height}px`;
lightDom.style.background = color;
lightDom.style.filter = `blur(${blur}px)`;
};
// 设置卡片的 overflow 为 hidden
const setCardOverflowHidden = () => {
const cardDom = cardRef.value;
if (cardDom) {
cardOverflow = cardDom.style.overflow;
cardDom.style.overflow = 'hidden';
}
};
// 还原卡片的 overflow
const restoreCardOverflow = () => {
const cardDom = cardRef.value;
if (cardDom) {
cardDom.style.overflow = cardOverflow;
}
};
// 往卡片添加光源
const addLight = () => {
const cardDom = cardRef.value;
if (cardDom) {
cardDom.appendChild(lightRef.value);
}
};
// 删除光源
const removeLight = () => {
const cardDom = cardRef.value;
if (cardDom) {
cardDom.removeChild(lightRef.value);
}
};
// 监听卡片的鼠标移入
const onMouseEnter = () => {
// 添加光源
addLight();
setCardOverflowHidden();
};
// use-light-card.ts
// 监听卡片的鼠标移动
const onMouseMove = (e: MouseEvent) => {
// 获取鼠标的坐标
const { clientX, clientY } = e;
// 让光跟随鼠标
const cardDom = cardRef.value;
const lightDom = lightRef.value;
if (cardDom) {
// 获取卡片相对于窗口的x和y坐标
const { x, y } = cardDom.getBoundingClientRect();
// 获取光的宽高
const { width, height } = lightDom.getBoundingClientRect();
lightDom.style.left = `${clientX - x - width / 2}px`;
lightDom.style.top = `${clientY - y - height / 2}px`;
// 设置动画效果
const maxXRotation = 10; // X 轴旋转角度
const maxYRotation = 10; // Y 轴旋转角度
const rangeX = 200 / 2; // X 轴旋转的范围
const rangeY = 200 / 2; // Y 轴旋转的范围
const rotateX = ((clientX - x - rangeY) / rangeY) * maxXRotation; // 根据鼠标在 Y 轴上的位置计算绕 X 轴的旋转角度
const rotateY = -1 * ((clientY - y - rangeX) / rangeX) * maxYRotation; // 根据鼠标在 X 轴上的位置计算绕 Y 轴的旋转角度
cardDom.style.transform = `perspective(1000px) rotateX(${rotateX}deg) rotateY(${rotateY}deg)`; //设置 3D 透视
}
};
// 监听卡片鼠标移出
const onMouseLeave = () => {
// 鼠标离开移出光源
removeLight();
restoreCardOverflow();
};
onMounted(() => {
// 设置光源样式
setLightStyle();
// 绑定事件
cardRef.value?.addEventListener('mouseenter', onMouseEnter);
cardRef.value?.addEventListener('mousemove', onMouseMove);
cardRef.value?.addEventListener('mouseleave', onMouseLeave);
});
onUnmounted(() => {
// 解绑事件
cardRef.value?.removeEventListener('mouseenter', onMouseEnter);
cardRef.value?.removeEventListener('mousemove', onMouseMove);
cardRef.value?.removeEventListener('mouseleave', onMouseLeave);
});
return {
cardRef,
};
};
结语 & 加学习群 & 摸鱼群
我是林三心
- 一个待过小型toG型外包公司、大型外包公司、小公司、潜力型创业公司、大公司的作死型前端选手;
- 一个偏前端的全干工程师;
- 一个不正经的掘金作者;
- 一个逗比的B站up主;
- 一个不帅的小红书博主;
- 一个喜欢打铁的篮球菜鸟;
- 一个喜欢历史的乏味少年;
- 一个喜欢rap的五音不全弱鸡
如果你想一起学习前端,一起摸鱼,一起研究简历优化,一起研究面试进步,一起交流历史音乐篮球rap,可以来俺的摸鱼学习群哈哈,点这个,有7000多名前端小伙伴在等着一起学习哦 --> 摸鱼沸点
来源:juejin.cn/post/7373867360019742758
都2025年了,还在用Markdown写文档吗?
俗话说得好:“程序员宁愿写 1000 行代码,也不愿意写 10 个字的文档。”
不愿写文档的原因,一方面是咱理科生文采确实不好,另一方面则是文档的更新维护十分麻烦。
每次功能有变更的时候, 时间又急(其实就是懒),很难想得起来同时去更新文档。
特别是文档中代码片段,总是在几天之后(甚至更久),被用户找过来吐槽:“你们也太不专业了,文档里的代码都跑不通。”
作为有素养的程序员,被人说 “不专业”,简直不能忍,一定要想办法解决这个问题。

文档代码化
很多开发者喜欢用语雀,飞书或者钉钉来写文档。
不得不承认,它们的编写和阅读的体验更好,样式也更丰富。
甚至就算是版本管理,语雀,飞书做得也不比 git 差。
不过对于开发者文档,我觉得体验,样式都不是最重要的。毕竟这些都是锦上添花。
更重要的是,文档内容有效性的保证,如果文档上的代码直接复制到本地,都要调试半天才能跑通,那不管它样式再好看开发者都要骂娘了。
所以文档最好就和代码放在同一个仓库中,这样代码功能有更新时,顺便就把文档一起改了。团队前辈 Review 代码时,也能顺便关注下相关的文档是否一同更新。
如果真的一定要搞一个语雀文档,也可以考虑用 Git Action,在分支合并到 master 时触发一次文档到语雀的自动同步。
Markdown 的问题
程序员最常用的代码化文档就是 Markdown 了,估计也是很多开发者的首选,比如我这篇文章就是用 Markdown 写的。
不过 Markdown 文档中的代码示例,也没有经过单元测试的验证,还是会出现文档中代码跑不通的现象。
Python 中有一个叫做 doctest 的工具,能够抽取文档中的所有 python 代码并执行,我们只要在分支合并前,确保被合并分支同时通过了单元测试和 doctest,就能保证文档中的代码示例都是有效的。
在 Java 中我找了半天没有找到类似工具,很多语言(比如 Go, Rust 等等)据我所知也没有类似的工具。
而且对于 Java,文档中给的一般都是不完整的代码片段,无法像 Python 一样直接就能进入命令行执行。
有句俗话 ”单元测试就是最好的文档“。我觉得没必要将单元测试和文档分开,最好的方式就是从单元测试中直接引用部分代码进入文档。
在变更功能时,我们一定也会改单元测试,文档也会同步更新,不需要单独维护。
在合并分支或者发布版本之前,肯定也会有代码门禁执行单元测试,这样就能确保文档中代码示例都是有效的。
目前我发现了一个能解决该问题的方案就是 adoc 文档。
adoc 文档
adoc 的全称是 Asciidoctor, 官网链接。
Github 已经对其实现了原生支持,只要在项目中将 README 文件的后缀改成 README.adoc,Github 就会按照 adoc 的语法进行解析展示。
adoc 最强悍的能力就是可以对另一个文件的一部分进行引用。以我负责的开源项目 QLExpress 为例。
在单元测试 Express4RunnerTest 中,用 // tag::firstQl[] 和 // end::firstQl[] 圈出一个代码片段:
// import 语句省略...
/**
* Author: DQinYuan
*/
public class Express4RunnerTest {
// 省略...
@Test
public void docQuickStartTest() {
// tag::firstQl[]
Express4Runner express4Runner = new Express4Runner(InitOptions.DEFAULT_OPTIONS);
Map<String, Object> context = new HashMap<>();
context.put("a", 1);
context.put("b", 2);
context.put("c", 3);
Object result = express4Runner.execute("a + b * c", context, QLOptions.DEFAULT_OPTIONS);
assertEquals(7, result);
// end::firstQl[]
}
// 省略...
}
然后在文档 README-source.adoc 中就可以 firstQl 这个 tag 引用代码片段:
=== 第一个 QLExpress 程序
[source,java,indent=0]
----
include::./src/test/java/com/alibaba/qlexpress4/Express4RunnerTest.java[tag=firstQl]
----
include::./src/test/java/com/alibaba/qlexpress4/Express4RunnerTest.java[tag=firstQl] 用于引用 Express4RunnerTest 文件中被 firstQl tag 包围的代码片段,其他的部分,等价于 Markdown 下面的写法:
### 第一个 QLExpress 程序
```java
```
这个 adoc 文档在渲染后,就会用单测中真实的代码片段替换掉 include 所占的位置,如下:

缺点就是 adoc 的语法和 Markdown 相差还挺大的,对以前用 Markdown 写文档的程序员有一定的熟悉成本。但是现在有 AI 啊,我们可以先用 Markdown 把文档写好,交给 Kimi 把它翻译成 Markdown。我对 adoc 的古怪语法也不是很熟悉,并且项目以前的文档都是 Markdown 写,都是 AI 帮我翻译的。
Github 渲染 adoc 文档的坑
我最开始尝试在 Github 上用 README.adoc 代替 README.md,发现其中的 include 语法并没有生效:
Github 对于 adoc
include的渲染逻辑还挺诡异的,既不展示引用文件的内容,也没有原样展示 adoc 代码

查询资料发现 Github 根本不支持 adoc 的 include 语法的渲染(参考)。不过好在参考文档中也给了解决方案:
- 源码中用
README-source.adoc编写文档 - 使用 Git Action 监听
README-source.adoc文件的变化。如果有变动,则使用asciidoctor提供的命令行工具先预处理一下include语法,将引用的内容都先引用进来。再将预处理的后的内容更新到README.adoc中,这样README.adoc就都是 Github 支持的语法了,可以直接在 Github 页面上渲染
Github Action 的参考配置如下(QLExpress中的配置文件):
name: Reduce Adoc
on:
push:
paths:
- README-source.adoc
branches: ['**']
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout Repository
uses: actions/checkout@v3
- name: Install Asciidoctor Reducer
run: sudo gem install asciidoctor-reducer
- name: Reduce README
# to preserve preprocessor conditionals, add the --preserve-conditionals option
run: asciidoctor-reducer --preserve-conditionals -o README.adoc README-source.adoc
- name: Commit and Push README
uses: EndBug/add-and-commit@v9
with:
add: README.adoc
添加这个配置后,你会发现很多额外的 Commit,就是 Git Action 在预处理 README-source.adoc 后,对 README.adoc 发起的提交:

至此,就再也不用担心被人吐槽文档不专业啦。
来源:juejin.cn/post/7464247481227100196
URL地址末尾加不加”/“有什么区别
URL 结尾是否带 / 主要影响的是 服务器如何解析请求 以及 相对路径的解析方式,具体区别如下:
1. 基础概念
- URL(统一资源定位符) :用于唯一标识互联网资源,如网页、图片、API等。
- 目录 vs. 资源:
- 以
/结尾的 URL 通常表示目录,例如:
https://example.com/folder/
- 不以
/结尾的 URL 通常指向具体的资源(如文件),例如:
https://example.com/file
- 以
2. 带 / 和不带 / 的具体区别
(1)目录 vs. 资源
https://example.com/folder/
- 服务器通常会将其解析为 目录,并尝试返回该目录下的默认文件(如
index.html)。
- 服务器通常会将其解析为 目录,并尝试返回该目录下的默认文件(如
https://example.com/folder
- 服务器可能会将其视为 文件,如果
folder不是文件,而是目录,服务器可能会返回 301 重定向到folder/。
- 服务器可能会将其视为 文件,如果
📌 示例:
- 访问
https://example.com/blog/
- 服务器可能返回
https://example.com/blog/index.html。
- 服务器可能返回
- 访问
https://example.com/blog(如果blog是个目录)
- 服务器可能重定向到
https://example.com/blog/,再返回index.html。
- 服务器可能重定向到
(2)相对路径解析
URL 末尾是否有 / 会影响相对路径的解析。
假设 HTML 页面包含以下 <img> 标签:
<img src="image.png">
📌 示例:
- 访问
https://example.com/folder/
- 访问
https://example.com/folder
- 图片路径解析为
https://example.com/image.png - 可能导致 404 错误,因为
image.png在folder/里,而浏览器错误地去example.com/下查找。
- 图片路径解析为
原因:
- 以
/结尾的 URL,浏览器会认为它是一个目录,相对路径会基于folder/解析。 - 不带
/,浏览器可能认为folder是文件,相对路径解析可能会出现错误。
(3)SEO 影响
搜索引擎对 https://example.com/folder/ 和 https://example.com/folder 可能会视为两个不同的页面,导致 重复内容问题,影响 SEO 排名。因此:
- 网站通常会选择 一种形式 并用 301 重定向 规范化 URL。
- 例如:
https://example.com/folder自动跳转 到https://example.com/folder/。- 反之亦然。
(4)API 请求
对于 RESTful API,带 / 和不带 / 可能导致不同的行为:
https://api.example.com/users
- 可能返回所有用户数据。
https://api.example.com/users/
- 可能返回 404 或者产生不同的结果(取决于服务器实现)。
一些 API 服务器对 / 非常敏感,因此最好遵循 API 文档的规范。
3. 总结
| URL 形式 | 作用 | 影响 |
|---|---|---|
https://example.com/folder/ | 目录 | 通常返回 folder/ 下的默认文件,如 index.html,相对路径解析基于 folder/ |
https://example.com/folder | 资源(或重定向) | 可能被解析为文件,或者服务器重定向到 folder/,相对路径解析可能错误 |
https://api.example.com/data/ | API 路径 | 可能与 https://api.example.com/data 表现不同,具体由 API 设计决定 |
如果你在开发网站,建议:
- 统一 URL 规则,例如所有目录都加
/或者所有请求都不加/,然后用 301 重定向 确保一致性。 - 测试 API 的行为,确认带
/和不带/是否影响请求结果。
来源:juejin.cn/post/7468112128928350242
用node帮老婆做excel工资表
我是天元,立志做1000个有趣的项目的前端。如果你喜欢的话,请点赞,收藏,转发。评论领取
零花钱+100勋章
背景
我老婆从事HR的工作,公司有很多连锁店,她需要将所有的门店的工资汇总计算,然后再拆分给各门店请确认,最后再提供给财务发工资。
随着门店数量渐渐增多,渐渐的我老婆已经不堪重负,每天加班都做不完,严重影响夫妻感情生活。
最终花费了2天的时间,完成了整个node程序,她只需要传入工资表,相应的各种表格在10s内自动输出。目前已正式交付,得到了每月零花钱提高100元的重大成果。
整体需求
- 表格的导入和识别
- 表格的计算(计算公式要代入),表格样式正确
- 最终结果按照门店拆分为工资表
需求示例(删减版)

需求为,根据传入的基本工资及补发补扣,生成总工资表,门店工资表,财务工资表发放表。
工资表中字段为门店,姓名,基本工资,补发补扣,最终工资(基本工资+补发补扣)。最后一行为总计
门店工资表按照每个门店,单独一个表格,字段同工资表。最后一行为总计
工资表

基础工资

补发补扣

技术选型
这次的主力库为exceljs,官方文档介绍如下
读取,操作并写入电子表格数据和样式到 XLSX 和 JSON 文件。
一个 Excel 电子表格文件逆向工程项目
选择exceljs是因为它支持完整的excel的样式及公式。
安装及目录结构
优先安装exceljs
npm init
yarn add exceljs
创建input,out,src三个文件夹,src放入index.js

package.json增加start脚本
"scripts": {
"start": "node src/index.js"
},
代码相关
导入
通过new Excel.Workbook();创建一个工作簿,通过workbook.xlsx.readFile来导入文件, 注意这是个promise
const ExcelJS = require("exceljs");
const path = require("path");
const inputPath = path.resolve(__dirname, "../input");
const outputPath = path.resolve(__dirname, "../out");
const loadInput =async () => {
const workbook = new ExcelJS.Workbook();
const inputFile = await workbook.xlsx.readFile(inputPath + "/工资表.xlsx")
};
loadInput()
数据拆分
通过getWorksheetApi,我们可以获取到对应的工作表的内容
const loadInput =async () => {
...
// 基本工资
const baseSalarySheet = inputFile.getWorksheet("基本工资");
// 补发补扣
const supplementSheet = inputFile.getWorksheet("补发补扣");
}
然后我们需要进一步的来进行拆分,因为第一行为每个工作表的头,这部分在我们实际数据处理中不会使用,所以通过getRows来获取实际的内容。
const baseSalaryContent = baseSalarySheet.getRows(
2,
baseSalarySheet.rowCount
);
baseSalaryContent.map((row) => {
console.log(row.values);
});
/**
[ <1 empty item>, '2024-02', '海贼王', '路飞', 12000 ]
[ <1 empty item>, '2024-02', '海贼王', '山治', 8000 ]
[ <1 empty item>, '2024-02', '火影忍者', '鸣人', '6000' ]
[ <1 empty item>, '2024-02', '火影忍者', '佐助', 7000 ]
[ <1 empty item>, '2024-02', '火影忍者', '雏田', 5000 ]
[ <1 empty item>, '2024-02', '一拳超人', '琦玉', 4000 ]
[]
[]
**/
可以看到实际的内容已经拿到了,我们要根据这些内容拼装一下最终便于后续的调用。
我们可以通过 row.getCellApi获取到对应某一列的内容,例如门店是在B列,那么我们就可以使用row.getCell('B')来获取。
因为我们需要拆分门店,所以这里的基本工资,我们以门店为单位,把数据进行拆分
const baseSalary = {};
baseSalaryContent.forEach((row) => {
const shopName = row.getCell("B").value;
if (!shopName) return; // 过滤空行
const name = row.getCell("C").value;
const salary = row.getCell("D").value;
if (!baseSalary[shopName]) {
baseSalary[shopName] = [];
}
baseSalary[shopName].push({
name,
salary,
});
});
这样我们得到了一个以门店名称为key的对象,value为该门店的员工信息数组。利用相同方法,获取补发补扣。因为每个人已经确定了门店,所以后续只需要根据姓名来做key,拆分成一个object即可
// 补发补扣
const supplement = {};
supplementSheet.getRows(2, supplementSheet.rowCount).forEach((row) => {
const name = row.getCell("C").value;
const type = row.getCell("H").value;
let count = row.getCell("D").value;
// 如果为补扣,则金额为负数
if (type === "补扣") {
count = -count;
}
if (!supplement[name]) {
supplement[name] = 0;
}
supplement[name] += count;
});
数据组合
门店工资表
因为每个门店需要独立一张表,所以需要遍历baseSalary
Object.keys(baseSalary).forEach((shopName) => {
const workbook = new ExcelJS.Workbook();
const worksheet = workbook.addWorksheet("工资表");
// 添加表头
worksheet.addRow([
"序号",
"门店",
"姓名",
"基本工资",
"补发补扣",
"最终工资",
]);
baseSalary[shopName].forEach((employee, index) => {
worksheet.addRow([
index + 1,
shopName,
employee.name,
+employee.salary,
supplement[employee.name] || 0,
+employee.salary + (supplement[employee.name] || 0),
]);
});
});
此时你也可以快进到表格输出来查看输出的结果,以便随时调整
这样我们就把基本工资已经写入工作表了,但是这里存在问题,最终工资使用的是一个数值,而没有公式。所以我们需要改动下
worksheet.addRow([ index + 1, shopName, employee.name, employee.salary, supplement[employee.name] || 0,
{
formula: `D${index + 2}+E${index + 2}`,
result: employee.salary + (supplement[employee.name] || 0),
},
]);
这里的formula将对应到公式,而result是显示的值,这个值是必须写入的,如果你写入了错误的值,会在表格中显示该值,但是双击后,公式重新计算,会替换为新的值。所以这里必须计算正确
合计
依照上方的逻辑,继续添加一行作为合计,但是之前计算的时候,需要添加一个临时变量,记录下合计的相关内容。
const count = [0, 0, 0];
baseSalary[shopName].forEach((employee, index) => {
count[0] += +employee.salary;
count[1] += supplement[employee.name] || 0;
count[2] += +employee.salary + (supplement[employee.name] || 0);
worksheet.addRow([
index + 1,
shopName,
employee.name,
+employee.salary,
supplement[employee.name] || 0,
{
formula: `D${index + 2}+E${index + 2}`,
result: +employee.salary + (supplement[employee.name] || 0),
},
]);
});
然后在尾部添加一行
worksheet.addRow([ "合计", "", "", { formula: `SUM(D2:D${baseSalary[shopName].length + 1})`,
result: count[0],
},
{
formula: `SUM(E2:E${baseSalary[shopName].length + 1})`,
result: count[1],
},
{
formula: `SUM(F2:F${baseSalary[shopName].length + 1})`,
result: count[2],
},
]);
美化
表格的合并,可以使用mergeCells
worksheet.mergeCells(
`A${baseSalary[shopName].length + 2}:C${baseSalary[shopName].length + 2}`
);
这样就合并了我们的最后一行的前三列,接下来我们要给表格添加线条。
对于批量的添加,可以直接使用addConditionalFormatting,它将在一个符合条件的单元格范围内添加规则
worksheet.addConditionalFormatting({
ref: `A1:F${baseSalary[shopName].length + 2}`,
rules: [
{
type: "expression",
formulae: ["true"],
style: {
border: {
top: { style: "thin" },
left: { style: "thin" },
bottom: { style: "thin" },
right: { style: "thin" },
},
alignment: { vertical: "top", horizontal: "left", wrapText: true },
},
},
],
});
表格输出
现在门店工资表已经拆分完成,我们可以直接保存了,使用xlsx.writeFileApi来保存文件
Object.keys(baseSalary).forEach((shopName) => {
...
workbook.xlsx.writeFile(outputPath + `/${shopName}工资表.xlsx`);
})
最终效果


相关代码地址
来源:juejin.cn/post/7346421986607087635
蓝牙耳机丢了,我花几分钟写了一个小程序,找到了!
你是否曾经经历过蓝牙耳机不知道丢到哪里去的困扰?特别是忙碌的早晨,准备出门时才发现耳机不见了,整个心情都被影响。幸运的是,随着技术的进步,我们可以利用一些简单的小程序和蓝牙技术轻松找到丢失的耳机。今天,我要分享的是我如何通过一个自制的小程序,利用蓝牙发现功能,成功定位自己的耳机。这不仅是一次有趣的技术尝试,更是对日常生活中类似问题的一个智能化解决方案。

1. 蓝牙耳机丢失的困扰
现代生活中,蓝牙耳机几乎是每个人的必备品。然而,耳机的体积小、颜色常常与周围环境融为一体,导致丢失的情况时有发生。传统的寻找方式依赖于我们对耳机放置地点的记忆,但往往不尽人意。这时候,如果耳机还保持在开机状态,我们就可以借助蓝牙技术进行定位。然而,市场上大部分设备并没有自带这类功能,而我们完全可以通过编写小程序实现。
2. 蓝牙发现功能的原理
蓝牙发现功能是通过设备之间的信号传输进行连接和识别的。当一个蓝牙设备处于开机状态时,它会周期性地广播自己的信号,周围的蓝牙设备可以接收到这些信号并进行配对。这个过程的背后其实是信号的强度和距离的关系。当我们在手机或其他设备上扫描时,能够检测到耳机的存在,但并不能直接告诉我们耳机的具体位置。此时,我们可以通过信号强弱来推测耳机的大概位置。
3. 实现步骤:从构想到实践
有了这个想法后,我决定动手实践。首先,我使用微信小程序作为开发平台,利用其内置的蓝牙接口实现设备扫描功能。具体步骤如下:
- • 环境搭建:选择微信小程序作为平台主要因为其开发简便且自带蓝牙接口支持。
- • 蓝牙接口调用:调用
wx.openBluetoothAdapter初始化蓝牙模块,确保设备的蓝牙功能开启。 - • 设备扫描:通过
wx.startBluetoothDevicesDiscovery函数启动设备扫描,并使用wx.onBluetoothDeviceFound监听扫描结果。 - • 信号强度分析:通过读取蓝牙信号强度(RSSI),结合多次扫描的数据变化,推测设备的距离,最终帮助定位耳机。
在代码的实现过程中,信号强度的变化尤为重要。根据RSSI值的波动,我们可以判断耳机是在靠近还是远离,并通过走动测试信号的变化,逐渐缩小搜索范围。
下面是我使用 Taro 实现的全部代码:
import React, { useState, useEffect } from "react";
import Taro, { useReady } from "@tarojs/taro";
import { View, Text } from "@tarojs/components";
import { AtButton, AtIcon, AtProgress, AtList, AtListItem } from "taro-ui";
import "./index.scss";
const BluetoothEarphoneFinder = () => {
const [isSearching, setIsSearching] = useState(false);
const [devices, setDevices] = useState([]);
const [nearestDevice, setNearestDevice] = useState(null);
const [isBluetoothAvailable, setIsBluetoothAvailable] = useState(false);
const [trackedDevice, setTrackedDevice] = useState(null);
useEffect(() => {
if (isSearching) {
startSearch();
} else {
stopSearch();
}
}, [isSearching]);
useEffect(() => {
if (devices.length > 0) {
const nearest = trackedDevice
? devices.find((d) => d.deviceId === trackedDevice.deviceId)
: devices[0];
setNearestDevice(nearest || null);
} else {
setNearestDevice(null);
}
}, [devices, trackedDevice]);
const startSearch = () => {
const startDiscovery = () => {
setIsBluetoothAvailable(true);
Taro.startBluetoothDevicesDiscovery({
success: () => {
Taro.onBluetoothDeviceFound((res) => {
const newDevices = res.devices.map((device) => ({
name: device.name || "未知设备",
deviceId: device.deviceId,
rssi: device.RSSI,
}));
setDevices((prevDevices) => {
const updatedDevices = [...prevDevices];
newDevices.forEach((newDevice) => {
const index = updatedDevices.findIndex(
(d) => d.deviceId === newDevice.deviceId
);
if (index !== -1) {
updatedDevices[index] = newDevice;
} else {
updatedDevices.push(newDevice);
}
});
return updatedDevices.sort((a, b) => b.rssi - a.rssi);
});
});
},
fail: (error) => {
console.error("启动蓝牙设备搜索失败:", error);
Taro.showToast({
title: "搜索失败,请重试",
icon: "none",
});
setIsSearching(false);
},
});
};
Taro.openBluetoothAdapter({
success: startDiscovery,
fail: (error) => {
if (error.errMsg.includes("already opened")) {
startDiscovery();
} else {
console.error("初始化蓝牙适配器失败:", error);
Taro.showToast({
title: "蓝牙初始化失败,请检查蓝牙是否开启",
icon: "none",
});
setIsSearching(false);
setIsBluetoothAvailable(false);
}
},
});
};
const stopSearch = () => {
if (isBluetoothAvailable) {
Taro.stopBluetoothDevicesDiscovery({
complete: () => {
Taro.closeBluetoothAdapter({
complete: () => {
setIsBluetoothAvailable(false);
},
});
},
});
}
};
const getSignalStrength = (rssi) => {
if (rssi >= -50) return 100;
if (rssi <= -100) return 0;
return Math.round(((rssi + 100) / 50) * 100);
};
const getDirectionGuide = (rssi) => {
if (rssi >= -50) return "非常接近!你已经找到了!";
if (rssi >= -70) return "很近了,继续朝这个方向移动!";
if (rssi >= -90) return "正确方向,但还需要继续寻找。";
return "信号较弱,尝试改变方向。";
};
const handleDeviceSelect = (device) => {
setTrackedDevice(device);
Taro.showToast({
title: `正在跟踪: ${device.name}`,
icon: "success",
duration: 2000,
});
};
return (
<View className="bluetooth-finder">
{isSearching && (
<View className="loading-indicator">
<AtIcon value="loading-3" size="30" color="#6190E8" />
<Text className="loading-text">搜索中...Text>
View>
)}
{nearestDevice && (
<View className="nearest-device">
<Text className="device-name">{nearestDevice.name}Text>
<AtProgress
percent={getSignalStrength(nearestDevice.rssi)}
status="progress"
isHidePercent
/>
<Text className="direction-guide">
{getDirectionGuide(nearestDevice.rssi)}
Text>
View>
)}
<View className="device-list">
<AtList>
{devices.map((device) => (
<AtListItem
key={device.deviceId}
title={device.name}
note={`${device.rssi} dBm`}
extraText={
trackedDevice && trackedDevice.deviceId === device.deviceId
? "跟踪中"
: ""
}
arrow="right"
onClick={() => handleDeviceSelect(device)}
/>
))}
AtList>
View>
<View className="action-button">
<AtButton
type="primary"
circle
onClick={() => setIsSearching(!isSearching)}
>
{isSearching ? "停止搜索" : "开始搜索"}
AtButton>
View>
View>
);
};
export default BluetoothEarphoneFinder;
嘿嘿,功夫不负苦心人,我最终通过自己的小程序找到了我的蓝牙耳机。

我将我的小程序发布到了微信小程序上,目前已经通过审核,可以直接使用了。搜索老码宝箱 即可体验。 
顺带还加了非常多的小工具,而且里面还有非常多日常可能会用到的工具,有些还非常有意思。

比如
绘制函数图

每日一言

汇率转换(实时)

BMI 计算

简易钢琴

算一卦

这还不是最重要的
最重要的是,这里的工具是会不断增加的,而且,更牛皮的是,你还可以给作者提需求,增加你想要的小工具,作者是非常欢迎一起讨论的。有朝一日,你也希望你的工具也出现在这个小程序上,被千万人使用吧。
4. 实际应用与优化空间
这个小程序的实际效果超出了我的预期。我能够通过它快速找到丢失的耳机,整个过程不到几分钟时间。然而,值得注意的是,由于蓝牙信号会受到环境干扰,例如墙体、金属物等,导致信号强度并不总是精确。在后续的优化中,我计划加入更多的信号处理算法,例如利用三角定位技术,结合多个信号源来提高定位精度。此外,还可以考虑在小程序中加入可视化的信号强度图,帮助用户更直观地了解耳机的大致方位。
一些思考:
蓝牙耳机定位这个小程序的开发,展示了技术在日常生活中的强大应用潜力。虽然这个项目看似简单,但背后的原理和实现过程非常具有教育意义。通过这次尝试,我们可以看到,借助开源技术和简单的编程能力,我们能够解决许多日常生活中的实际问题。
参考资料:
- 微信小程序官方文档:developers.weixin.qq.com
- 蓝牙信号强度(RSSI)与距离关系的研究:http://www.bluetooth.com
- 个人开发者经验分享: 利用蓝牙发现功能定位设备
来源:juejin.cn/post/7423610485180727332
前端可玩性UP项目:大屏布局和封装
前言
autofit.js 发布马上要一年了,也收获了一批力挺用户,截至目前它在github上有1k 的 star,npm 上有超过 13k 的下载量。
这篇文章主要讲从设计稿到落地开发大屏应用,大道至简,这篇文章能帮助各位潇洒自如的开发大屏。
分析设计稿
分析设计稿之前先吐槽一下大屏这种展现形式,这简直就是自欺欺人、面子工程的最直接的诠释,是吊用没有,只为了好看,如果设计的再不好看啊,这就纯纯是屎。在我的理解中,这就像把PPT放到了web端,仅此而已。
但是王哥告诉我:"你看似没有用的东西,其实都有用,很多想真正做出有用的产品的企业,没钱,就要先把面子工程做好,告诉别人他们要做一件什么事,这样投资人才会看到,后面才有机会发展。"
布局方案

上图展示了一个传统意义上且比较普遍的大屏形态,分为四个部分,分别是
头部
头部经常放标题、功能菜单、时间、天气
左右面板
左右面板承载了各种数字和报表,还有视频、轮播图等等
中间
中间部分一般放地图,这其中又分假地图(一张图片)、图表地图(如echarts)、地图引擎(如:leaflet、mapbox、高德、百度)。或者有的还会放3D场景,一般有专门的同事去做3D场景,然后导入到web端。
大屏的设计通常的分辨率是 1920*1080 的,这也是迄今为止应用最广泛的显示器配置,当然也有基于客户屏幕做的异形分辨率,这就五花八门了。
但是万变不离其宗,分辨率的变化不会影响它的基本结构,根据上面的图,我们可以快速构建结构代码
<div class='Box'>
<div class="header"></div>
<div class="body">
<div class="leftPanel"></div>
<div class="mainMap"></div>
<div class="rightPanel"></div>
</div>
</div>
上面的代码实现了最简单的上下(Box)+左右(body)的布局结构,完全不需要任何定位策略。
要实现上图的效果,只需最简单的CSS即可完成布局。
组件方案
大屏虽然是屎,但是是一种可玩性很强的项目,想的越复杂,做起来就越复杂,想的越简单,做起来就越简单。
可以疯狂封装炫技,因为大屏里面的可玩组件简直太多了,且涵盖的太全了,想怎么玩都可以,包括但不限于 各类图表库的封装(echarts、highCharts、vChart)、轮播图(swiper)、地图引擎、视频库(包括直播流)等等。
如果想简单,甚至可以不用封装,可以看到结构甚至简单到不用CSS几行就可以搭建出基本框架,只把header、leaftPanel、rightPanel、map封装一下就可以了。
这里还有一个误区,就是大家都喜欢把 大型的组件库 拉到大屏里来用,结果做完了发现好像只用了一个 toast 和一个下拉组件,项目打包后却增大了几十倍的体积,其实像这种简单的组件,完全可以手写,或者找小的独立包来用,一方面会减小体积,不至于让项目臃肿,另一方面可以锻炼自己的手写能力,这才是有必要的封装。
适配
目前主流的适配方案,依然是 rem 方案,其原理就是根据根元素的 font-size 自动计算大小,但是此方法需要手动计算 rem 值,或者使用第三方插件如postcss等,但是此方案还有一个弊端,就是无法向下兼容,因为浏览器中最小的文字大小是12px。
vh/vw方案就不再赘述了,原理基本和 rem/em 相似,都涉及到单位的转换。
autofit.js
主要讲一下使用 autofit.js 如何快速实现适配。
不支持的场景
首先 autofit.js 不支持 elementUI(plus)、ant-design等组件库,具体是不支持包含popper.js的组件,popper.js 在计算弹出层位置时,不会考虑 scale 后的元素的视觉大小,所以会造成弹出元素的位置偏移。
其次,不支持 百度地图,百度地图对窗口缩放事件没有任何处理,有同学反馈说,即使使用了resize属性,百度地图在和autofit.js共同使用时,也会有事件热区偏移的问题。而且百度地图使用 bd-09 坐标系,和其他图商不通用,引擎的性能方面也差点意思,个人不推荐在开发中使用百度地图。
然后一些拖拽库,如甘特图插件,可能也不支持,他们在计算鼠标位置时同样没有考虑 scale 后的元素的视觉大小。
用什么单位
不支持的单位:vh、vw、rem、em
让我诧异的是,老有人问我该用什么单位,主要徘徊在 px 和 % 之间,加群的同学多数是因为用了相对单位,导致留白了。不过人各有所长,跟着各位大佬我也学到了很多。
看下图

假如有两个宽度为1000的元素,他们内部都有一个子元素,第一个用百分比设置为 width:50%;left:1% , 第二个设置为 wdith:500px;left:10px 。此时,只要外部的1000px的容器宽度不变,这两个内部元素在视觉上是一模一样的,且在实际数值上也是一模一样的,他们宽度都为500px,距离左侧10px。
但是如果外部容器变大了,来看一下效果:

在样式不变的情况下,仅改变外部容器大小,差异就出来了,由上图可知,50%的元素依然占父元素的一半,实际宽度变成了 1000px,距离左侧的实际距离变成了 20px。
这当然不难理解,百分比单位是根据 最近的、有确定大小的父级元素计算的。
所以,应该用什么单位其实取决于想做什么,举个例子:在1920*1080基础上开发,中间的地图写成了宽度为 500px ,这在正常情况下,看起来没有任何问题,它大概占屏幕的 26%,当屏幕分辨率达到4096*2160时,它在屏幕上只占 12%,看起来就是缩在一角。而当你设置宽度为26%时,无论显示器如何变化,它始终占屏幕26%。
autofit.js 所干的事,就是把1000px 变成了 2000px或者把2000px变成了1000px,并给它设置了一个合适的缩放大小。
图表、图片拉伸
背景或各种图片按需设置 object-fit: cover;即可
图表如echarts一般推荐使用百分比,且监听窗口变化事件做resize()
结语
再次感慨,大道至简,事情往往没有那么复杂,祝各位前程似锦。
来源:juejin.cn/post/7344625554530779176
我终于从不想上班又不能裸辞的矛盾中挣扎出来了
最近的状态有一种好像一个泄了气的皮球的感觉一样,就是对生活中很多事情都提不起来兴趣。
我希望自己可以多看一点书,但是我不想动;我希望自己可以练习书法,但是我不想动;我希望自己可以学会一门乐器,但是我不想动。
相比上面三点,我更希望的是我可以早上起来不用上班,但是这只是我的希望而已。
这就是我最近的生活状态。
我有一种我的生活仿佛失去了控制的感觉,每一天我的内心好像都有一个小人在不断呐喊,说我不想上班。因为这个声音,我一度非常非常想要裸辞,但是我为什么没有裸辞呢?
还不是因为我买房买车欠了十几万,我到现在才还了两万而已,再加上我每个月还有房贷要还。
然而,当我经常不情愿地做着跟我心里想法相悖的行为的时候,我发现自己常常会做一些小动作来向自己表达抗议和不满。
比如说,我的工作会变得越来越低效,上班的时候会偷偷地摸鱼,还有就是变得越来越容易拖延。
就好像这样的我,可以让那个不想上班的我,取得了一丢丢的小胜利一样。
一旦开始接受自己没有办法辞职,并且还要上个几十年班这样的结果时,就会让人有一种破罐子破摔的想法。
而且随之而来的是一种对未来,对生活的无力感。
这种无力感渐渐地渗透在我生活的方方面面,以至于让我慢慢地对很多东西都提不起兴趣,我生活中的常态就变成了不想动。
但是有趣的事情发生了,有一天我在和我朋友聊天的时候,我的脑子里面突然出现了一个想法,就是我决定两年之后我要实现我不上班的这个目标。
当有了这个想法之后,我就开始认真思考这件事情的可行度。
通过分析我现在收支情况,我把两年之内改成了2026年之前,因为我觉得这样会让我更加信服这个目标的可行性。
同时我把这个想法也拆分成了两个更为具体的目标,其中一个就是我要在2026年之前还完欠的所有钱。
第二个就是我需要给自己存够20万,这20万是不包括投资理财或者基金股票里面的钱,而是我完全可以自由支配的。
毕竟没有人可以在没有工作的情况下,没有收入的情况下。没有存款的情况下,还能保持一个不焦虑的状态。
当我得出了这两个具体的目标之后,我整个人瞬间被一种兴奋的状态填满,我瞬间找到了工作的意义和动力。
也许你会说,我的这个想法对我现在生活根本起不到任何的改变作用。
我依旧还需要每天七点起床,还是要每天重复地去过我两点一线的生活。
但是于我自己而言,当我给我上班的这件事情加了一个两年的期限之后,我突然觉得我的未来,我的生活都充满了希望。
我整个人从不想动的状态,变成了一种被兴奋的状态填满的感觉。
所以,如果你和我一样有一些类似的困扰,有一些你不想做而又不得不做的事情,让你有一种深陷泥潭,无法前进的感觉,那你不妨试一下这个方法。
结合你自己的实际情况,为你不想做这件事情,设计一个期限,这个期限必须要是你认可,你接受,并且你认为你可以在这个截止时间之前完成的。
我想这个决定应该会对你的生活带来一些改变。
来源:juejin.cn/post/7428154034480906278


