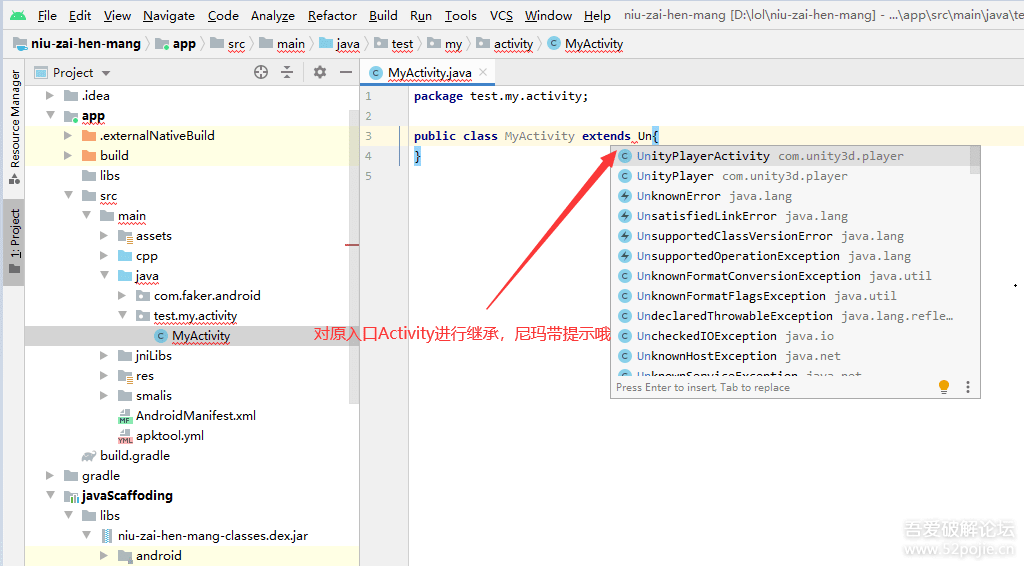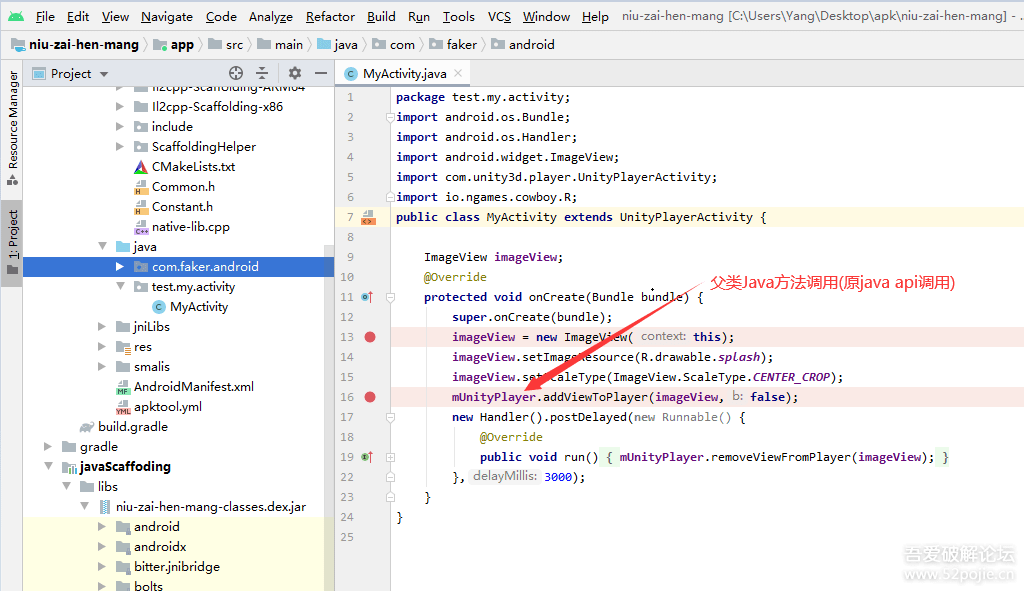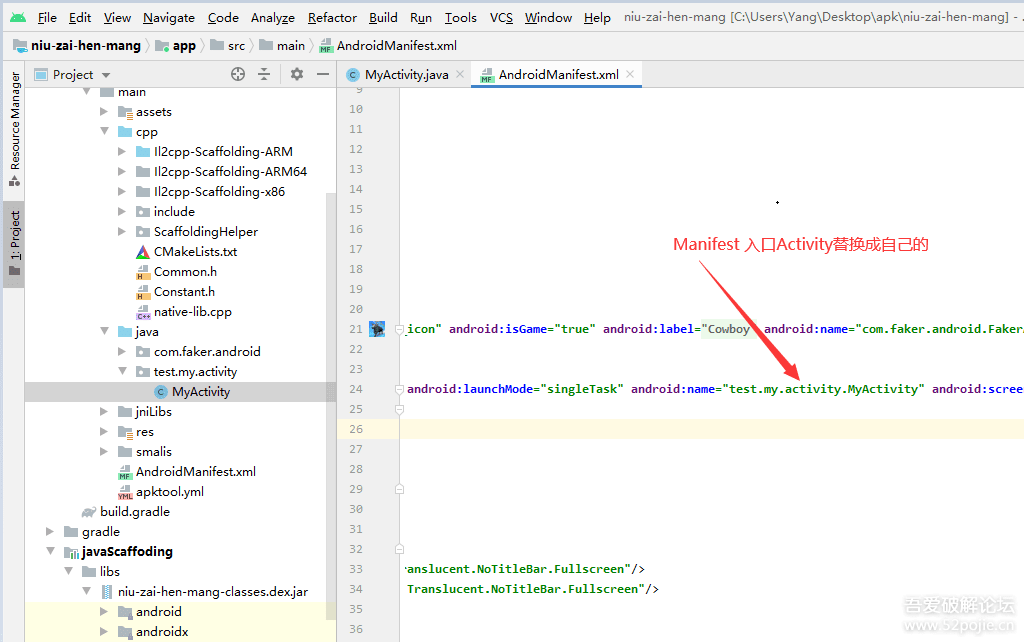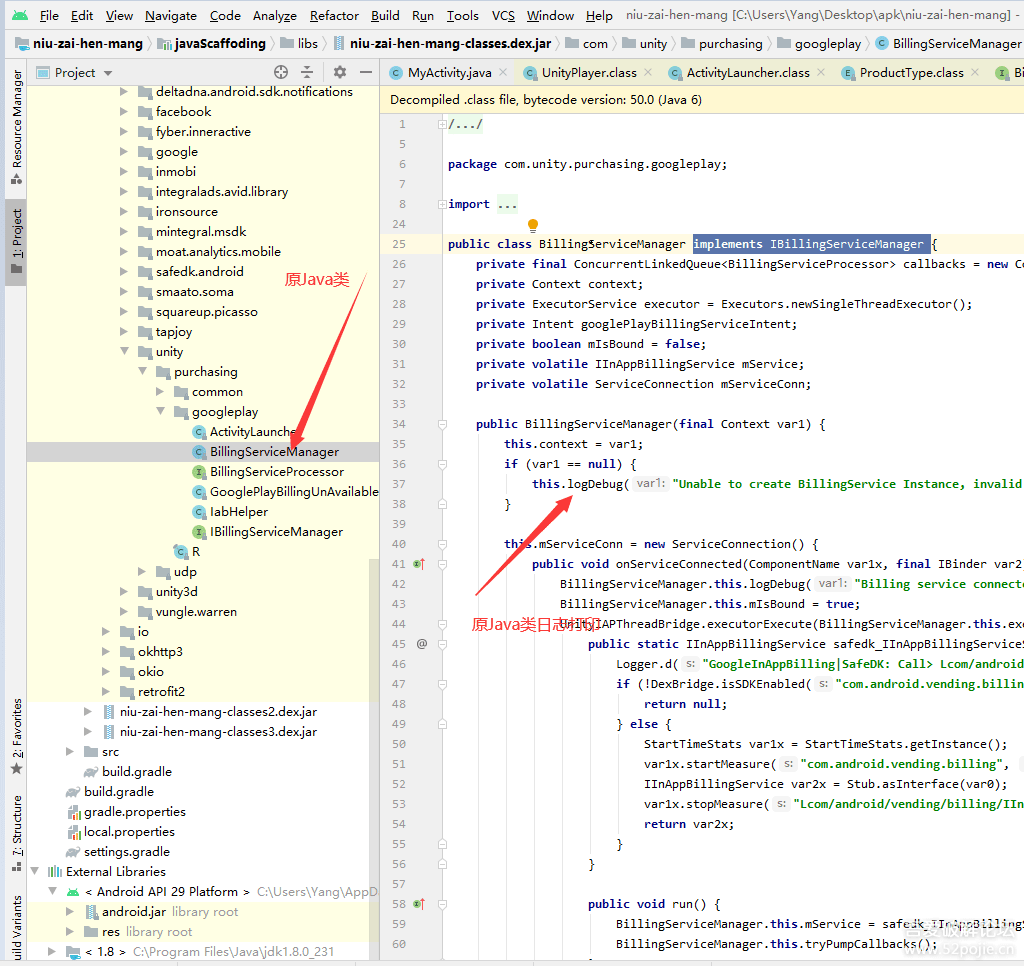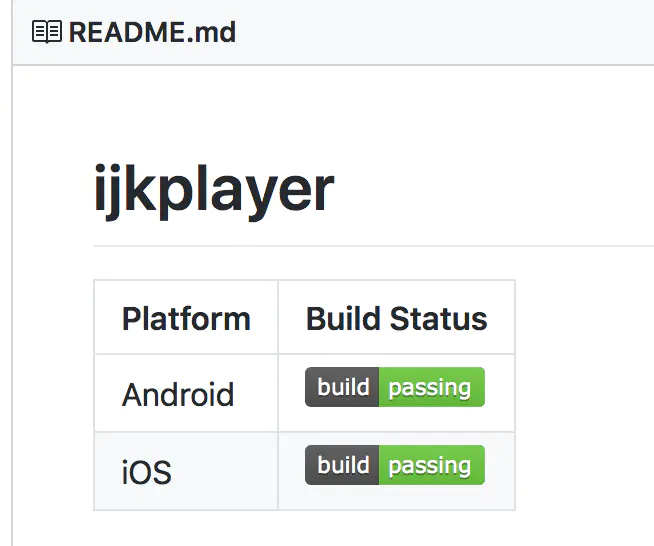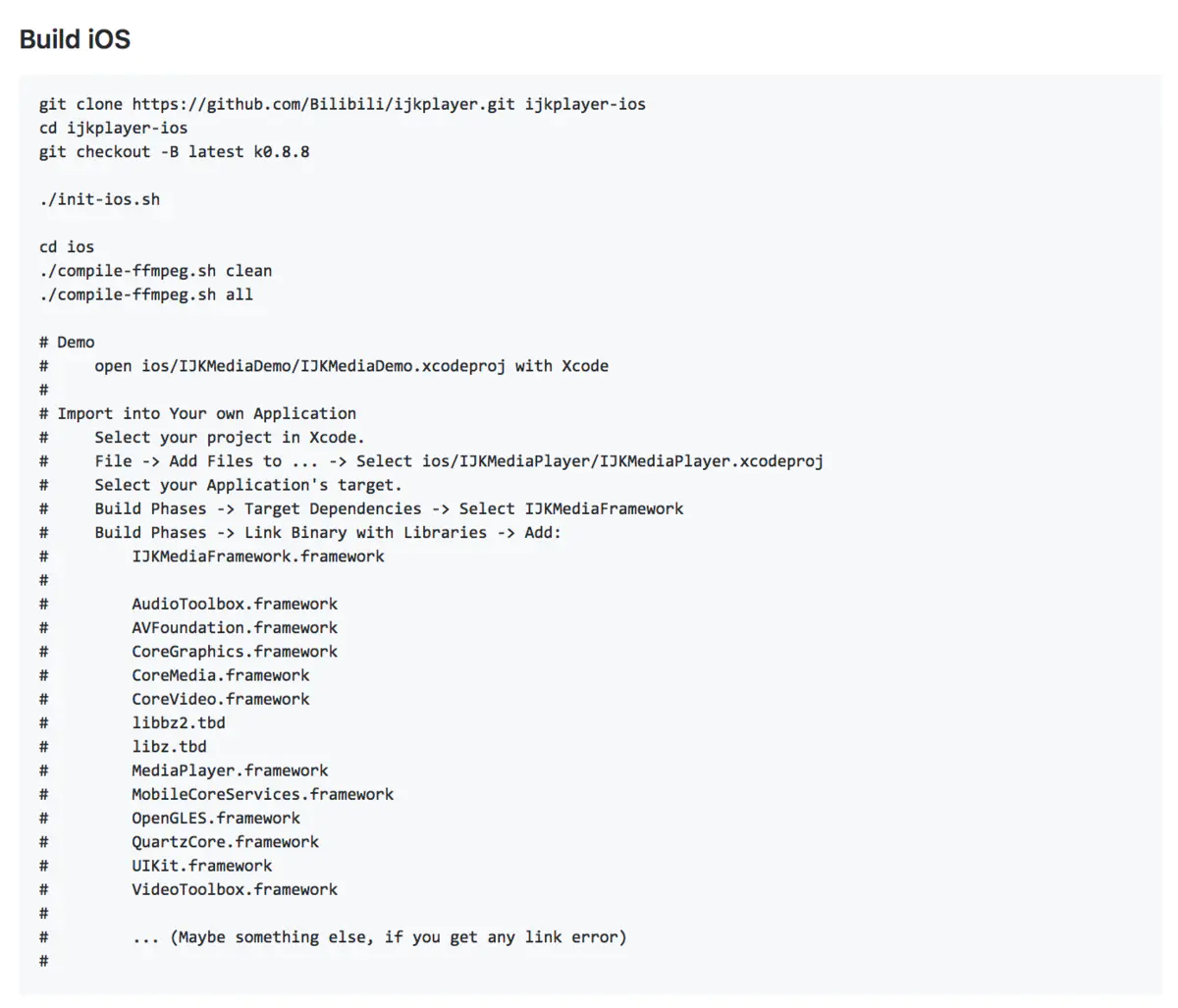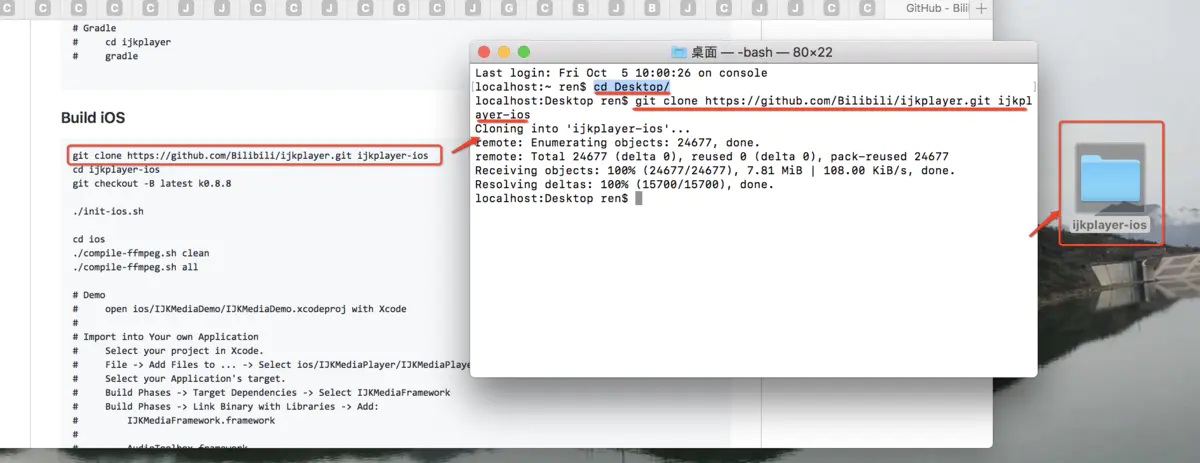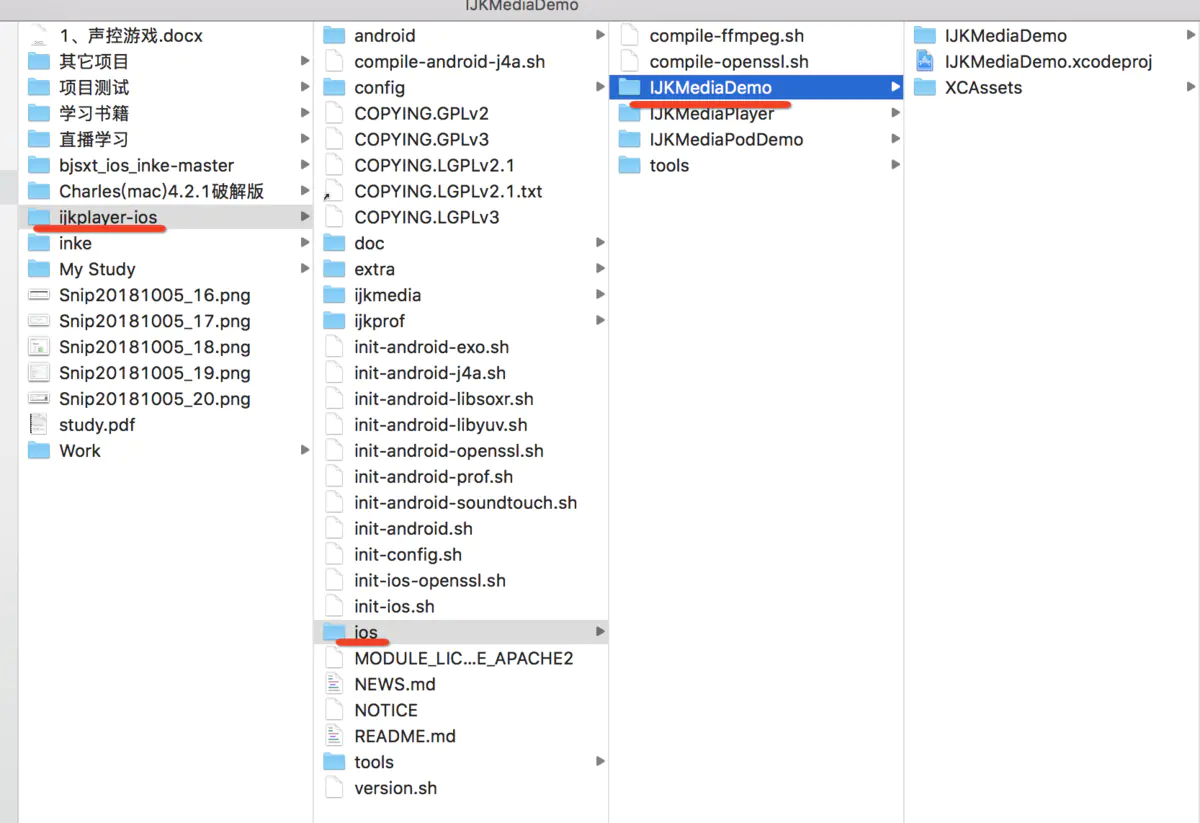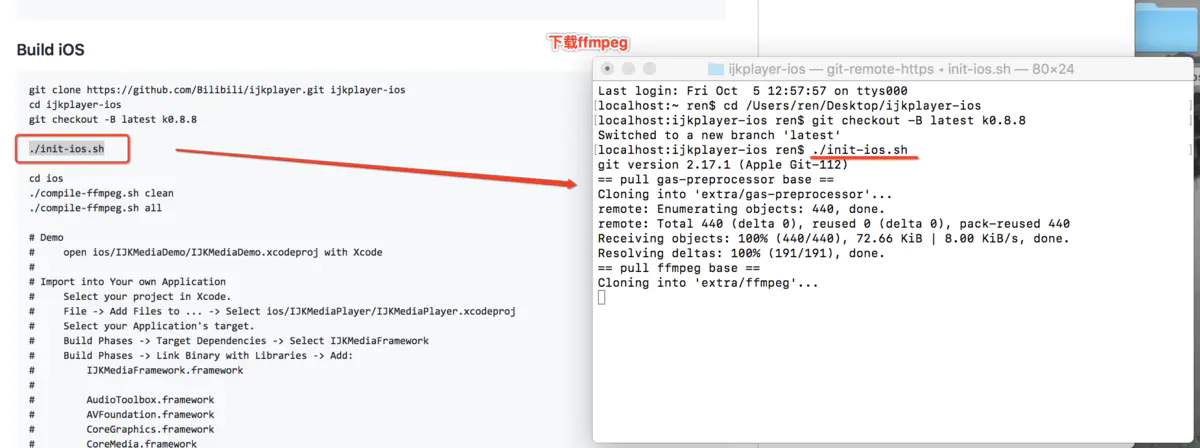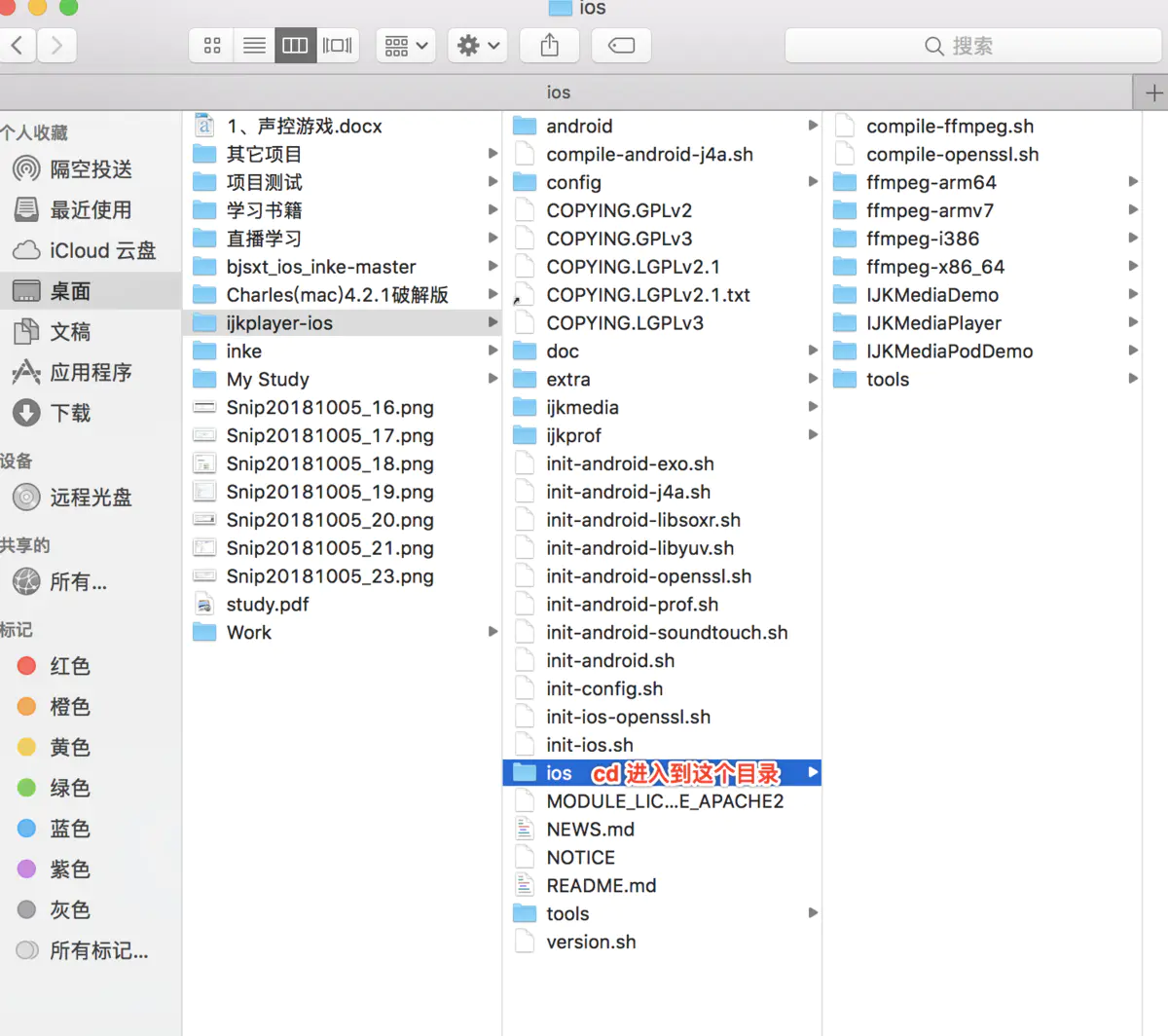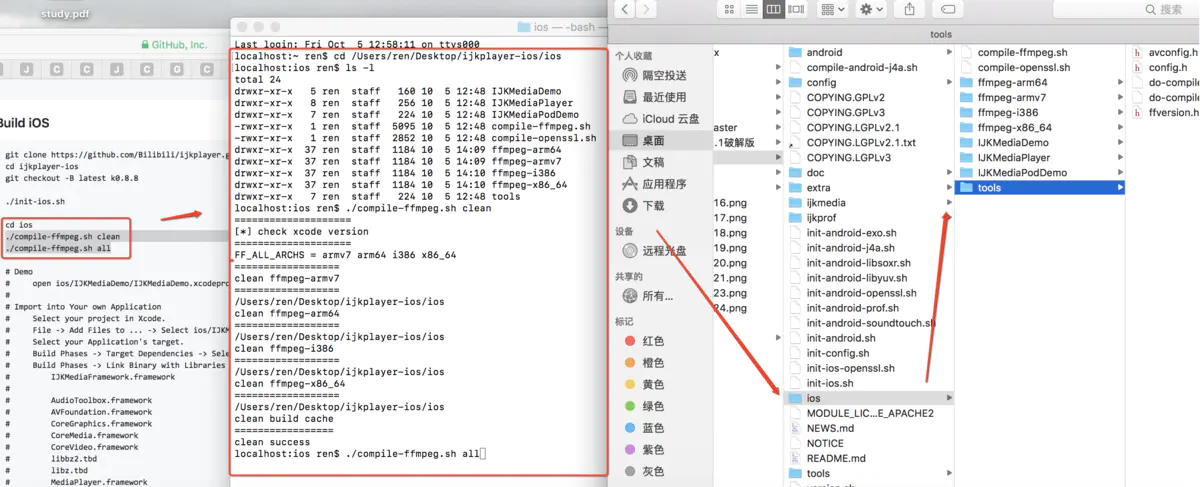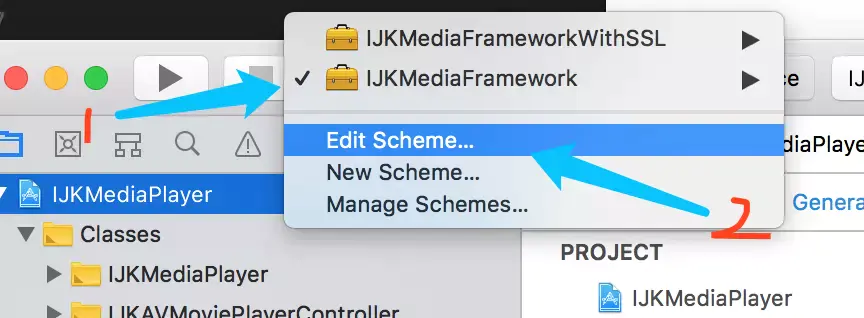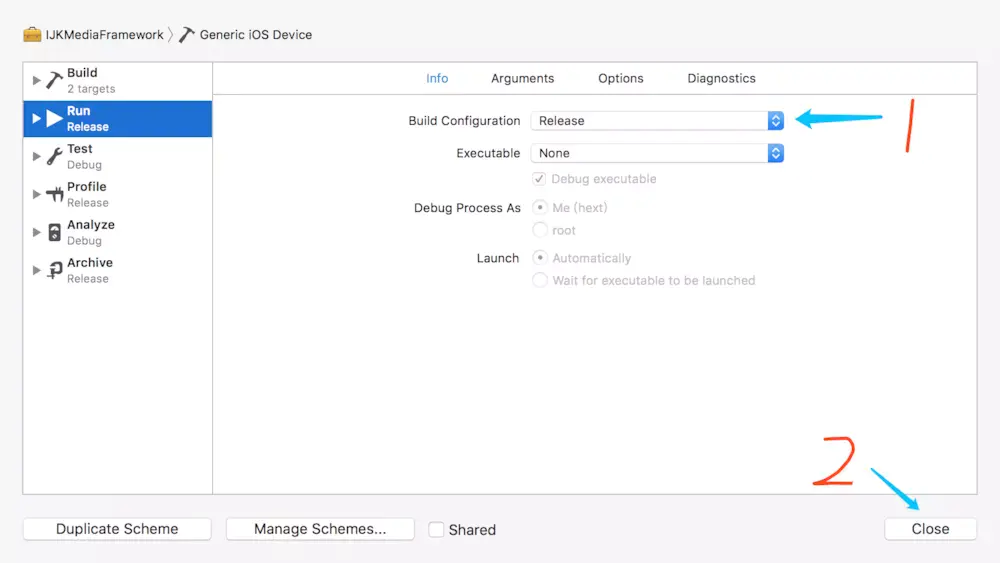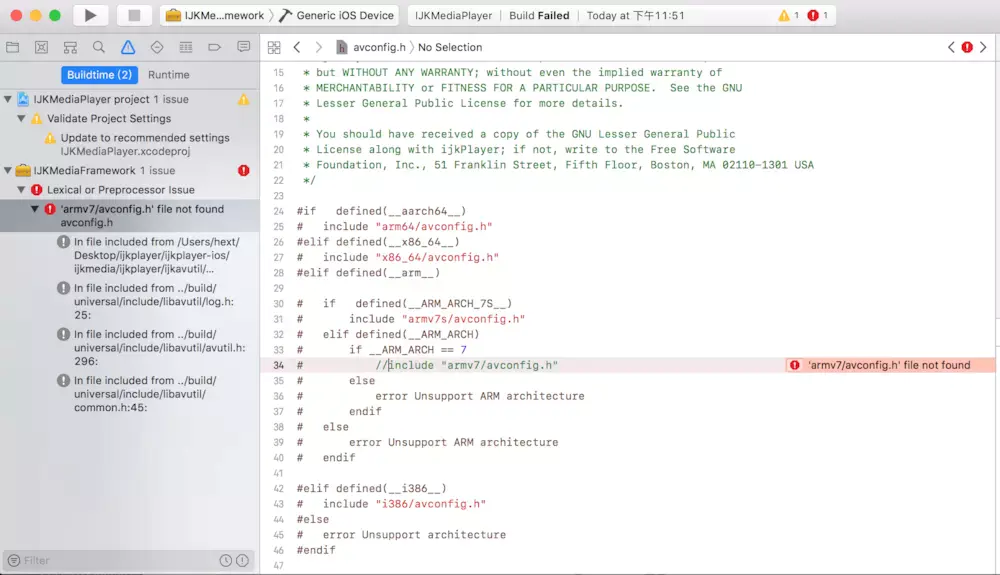



















没有人愿意编写处理 Android 运行时权限的代码,因为它真的太繁琐了。
这是一项没有什么技术含量,但是你又不得不去处理的工作,因为不处理它程序就会崩溃。但如果处理起来比较简单也就算了,可事实上,Android 提供给我们的运行时权限 API 并不友好。
以一个拨打电话的功能为例,因为 CALL_PHONE 权限是危险权限,所以在我们除了要在 AndroidManifest.xml 中声明权限之外,还要在执行拨打电话操作之前进行运行时权限处理才行。
权限声明如下:
然后,编写如下代码来进行运行时权限处理
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
makeCallBtn.setOnClickListener {
if (ContextCompat.checkSelfPermission(this, Manifest.permission.CALL_PHONE) == PackageManager.PERMISSION_GRANTED) {
call()
} else {
ActivityCompat.requestPermissions(this, arrayOf(Manifest.permission.CALL_PHONE), 1)
}
}
}
override fun onRequestPermissionsResult(requestCode: Int, permissions: Array, grantResults: IntArray) {
super.onRequestPermissionsResult(requestCode, permissions, grantResults)
when (requestCode) {
1 -> {
if (grantResults.isNotEmpty() && grantResults[0] == PackageManager.PERMISSION_GRANTED) {
call()
} else {
Toast.makeText(this, "You denied CALL_PHONE permission", Toast.LENGTH_SHORT).show()
}
}
}
}
private fun call() {
try {
val intent = Intent(Intent.ACTION_CALL)
intent.data = Uri.parse("tel:10086")
startActivity(intent)
} catch (e: SecurityException) {
e.printStackTrace()
}
}
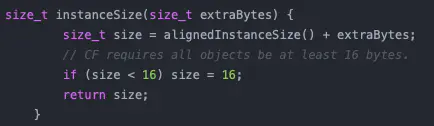
}这段代码中真有正意义的功能逻辑就是 call() 方法中的内容,可是如果直接调用 call() 方法是无法实现拨打电话功能的,因为我们还没有申请 CALL_PHONE 权限。
那么整段代码其他的部分就都是在处理 CALL_PHONE 权限申请。可以看到,这里需要先判断用户是否已授权我们拨打电话的权限,如果没有的话则要进行权限申请,然后还要在 onRequestPermissionsResult() 回调中处理权限申请的结果,最后才能去执行拨打电话的操作。
你可能觉得,这也不算是很繁琐呀,代码量并不是很多。那是因为,目前我们还只是处理了运行时权限最简单的场景,而实际的项目环境中有着更加复杂的场景在等着我们。
比如说,你的 App 可能并不只是单单申请一个权限,而是需要同时申请多个权限。虽然 ActivityCompat.requestPermissions() 方法允许一次性传入多个权限名,但是你在 onRequestPermissionsResult() 回调中就需要判断哪些权限被允许了,哪些权限被拒绝了,被拒绝的权限是否影响到应用程序的核心功能,以及是否要再次申请权限。
而一旦牵扯到再次申请权限,就引出了一个更加复杂的问题。你申请的权限被用户拒绝过了一次,那么再次申请将很有可能再次被拒绝。为此,Android 提供了一个 shouldShowRequestPermissionRationale() 方法,用于判断是否需要向用户解释申请这个权限的原因,一旦 shouldShowRequestPermissionRationale() 方法返回 true,那么我们最好弹出一个对话框来向用户阐明为什么我们是需要这个权限的,这样可以增加用户同意授权的几率。
是不是已经觉得很复杂了?不过还没完,Android 系统还提供了一个 “拒绝,不要再询问” 的选项,如下图所示:
只要用户选择了这个选项,那么我们以后每次执行权限申请的代码都将会直接被拒绝。
可是如果我的某项功能就是必须要依赖这个权限才行呢?没有办法,你只能提示用户去应用程序设置当中手动打开权限,程序方面已无法进行操作。
可以看出,如果想要在项目中对运行时权限做出非常全面的处理,是一件相当复杂的事情。事实上,大部分的项目都没有将权限申请这块处理得十分恰当,这也是我编写 PermissionX 的理由。
PermissionX 的实现原理
在开始介绍 PermissionX 的具体用法之前,我们先来讨论一下它的实现原理。
其实之前并不是没有人尝试过对运行时权限处理进行封装,我之前在做直播公开课的时候也向大家演示过一种运行时权限 API 的封装过程。
但是,想要对运行时权限的 API 进行封装并不是一件容易的事,因为这个操作是有特定的上下文依赖的,一般需要在 Activity 中接收 onRequestPermissionsResult() 方法的回调才行,所以不能简单地将整个操作封装到一个独立的类中。
为此,也衍生出了一系列特殊的封装方案,比如将运行时权限的操作封装到 BaseActivity 中,或者提供一个透明的 Activity 来处理运行时权限等。
不过上述两种方案都不够轻量,因为改变 Activity 的继承结构这可是大事情,而提供一个透明的 Activty 则需要在 AndroidManifest.xml 中进行额外的声明。
现在,业内普遍比较认可使用另外一种小技巧来进行实现。是什么小技巧呢?回想一下,之前所有申请运行时权限的操作都是在 Activity 中进行的,事实上,Android 在 Fragment 中也提供了一份相同的 API,使得我们在 Fragment 中也能申请运行时权限。
但不同的是,Fragment 并不像 Activity 那样必须有界面,我们完全可以向 Activity 中添加一个隐藏的 Fragment,然后在这个隐藏的 Fragment 中对运行时权限的 API 进行封装。这是一种非常轻量级的做法,不用担心隐藏 Fragment 会对 Activity 的性能造成什么影响。
这就是 PermissionX 的实现原理了,书中其实也已经介绍过了这部分内容。但是,在其实现原理的基础之上,后期我又增加了很多新功能,让 PermissionX 变得更加强大和好用,下面我们就来学习一下 PermissionX 的具体用法。
基本用法
要使用 PermissionX 之前,首先需要将其引入到项目当中,如下所示
dependencies {
...
implementation 'com.permissionx.guolindev:permissionx:1.1.1'
}我在写本篇文章时 PermissionX 的最新版本是 1.1.1,想要查看它的当前最新版本,请访问 PermissionX 的主页:github.com/guolindev/P…
PermissionX 的目的是为了让运行时权限处理尽可能的容易,因此怎么让 API 变得简单好用就是我优先要考虑的问题。
比如同样实现拨打电话的功能,使用 PermissionX 只需要这样写:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
makeCallBtn.setOnClickListener {
PermissionX.init(this)
.permissions(Manifest.permission.CALL_PHONE)
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
call()
} else {
Toast.makeText(this, "您拒绝了拨打电话权限", Toast.LENGTH_SHORT).show()
}
}
}
}
...
}是的,PermissionX 的基本用法就这么简单。首先调用 init() 方法来进行初始化,并在初始化的时候传入一个 FragmentActivity 参数。由于 AppCompatActivity 是 FragmentActivity 的子类,所以只要你的 Activity 是继承自 AppCompatActivity 的,那么直接传入 this 就可以了。
接下来调用 permissions() 方法传入你要申请的权限名,这里传入 CALL_PHONE 权限。你也可以在 permissions() 方法中传入任意多个权限名,中间用逗号隔开即可。
最后调用 request() 方法来执行权限申请,并在 Lambda 表达式中处理申请结果。可以看到,Lambda 表达式中有 3 个参数:allGranted 表示是否所有申请的权限都已被授权,grantedList 用于记录所有已被授权的权限,deniedList 用于记录所有被拒绝的权限。
因为我们只申请了一个 CALL_PHONE 权限,因此这里直接判断:如果 allGranted 为 true,那么就调用 call() 方法,否则弹出一个 Toast 提示。
运行结果如下:
怎么样?对比之前的写法,是不是觉得运行时权限处理没那么繁琐了?
核心用法
然而我们目前还只是处理了最普通的场景,刚才提到的,假如用户拒绝了某个权限,在下次申请之前,我们最好弹出一个对话框来向用户解释申请这个权限的原因,这个又该怎么实现呢?
别担心,PermissionX 对这些情况进行了充分的考虑。
onExplainRequestReason() 方法可以用于监听那些被用户拒绝,而又可以再次去申请的权限。从方法名上也可以看出来了,应该在这个方法中解释申请这些权限的原因。
而我们只需要将 onExplainRequestReason() 方法串接到 request() 方法之前即可,如下所示:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.onExplainRequestReason { deniedList ->
}
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
Toast.makeText(this, "所有申请的权限都已通过", Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, "您拒绝了如下权限:$deniedList", Toast.LENGTH_SHORT).show()
}
}这种情况下,所有被用户拒绝的权限会优先进入 onExplainRequestReason() 方法进行处理,拒绝的权限都记录在 deniedList 参数当中。接下来,我们只需要在这个方法中调用 showRequestReasonDialog() 方法,即可弹出解释权限申请原因的对话框,如下所示:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.onExplainRequestReason { deniedList ->
showRequestReasonDialog(deniedList, "即将重新申请的权限是程序必须依赖的权限", "我已明白", "取消")
}
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
Toast.makeText(this, "所有申请的权限都已通过", Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, "您拒绝了如下权限:$deniedList", Toast.LENGTH_SHORT).show()
}
}showRequestReasonDialog() 方法接受 4 个参数:第一个参数是要重新申请的权限列表,这里直接将 deniedList 参数传入。第二个参数则是要向用户解释的原因,我只是随便写了一句话,这个参数描述的越详细越好。第三个参数是对话框上确定按钮的文字,点击该按钮后将会重新执行权限申请操作。第四个参数是一个可选参数,如果不传的话相当于用户必须同意申请的这些权限,否则对话框无法关闭,而如果传入的话,对话框上会有一个取消按钮,点击取消后不会重新进行权限申请,而是会把当前的申请结果回调到 request() 方法当中。
另外始终要记得将所有申请的权限都在 AndroidManifest.xml 中进行声明:
重新运行一下程序,效果如下图所示:
当前版本解释权限申请原因对话框的样式还无法自定义,1.3.0 版本当中已支持了自定义权限提醒对话框样式的功能,详情请参阅 PermissionX 重磅更新,支持自定义权限提醒对话框 。
当然,我们也可以指定要对哪些权限重新申请,比如上述申请的 3 个权限中,我认为 CAMERA 权限是必不可少的,而其他两个权限则可有可无,那么在重新申请的时候也可以只申请 CAMERA 权限:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.ACCESS_FINE_LOCATION)
.onExplainRequestReason { deniedList ->
val filteredList = deniedList.filter {
it == Manifest.permission.CAMERA
}
showRequestReasonDialog(filteredList, "摄像机权限是程序必须依赖的权限", "我已明白", "取消")
}
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
Toast.makeText(this, "所有申请的权限都已通过", Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, "您拒绝了如下权限:$deniedList", Toast.LENGTH_SHORT).show()
}
}这样当再次申请权限的时候就只会申请 CAMERA 权限,剩下的两个权限最终会被传入到 request() 方法的 deniedList 参数当中。
解决了向用户解释权限申请原因的问题,接下来还有一个头疼的问题要解决:如果用户不理会我们的解释,仍然执意拒绝权限申请,并且还选择了拒绝且不再询问的选项,这该怎么办?通常这种情况下,程序层面已经无法再次做出权限申请,唯一能做的就是提示用户到应用程序设置当中手动打开权限。
更多用法
那么 PermissionX 是如何处理这种情况的呢?我相信绝对会给你带来惊喜。PermissionX 中还提供了一个 onForwardToSettings() 方法,专门用于监听那些被用户永久拒绝的权限。另外从方法名上就可以看出,我们可以在这里提醒用户手动去应用程序设置当中打开权限。代码如下所示:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.onExplainRequestReason { deniedList ->
showRequestReasonDialog(deniedList, "即将重新申请的权限是程序必须依赖的权限", "我已明白", "取消")
}
.onForwardToSettings { deniedList ->
showForwardToSettingsDialog(deniedList, "您需要去应用程序设置当中手动开启权限", "我已明白", "取消")
}
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
Toast.makeText(this, "所有申请的权限都已通过", Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, "您拒绝了如下权限:$deniedList", Toast.LENGTH_SHORT).show()
}
}可以看到,这里又串接了一个 onForwardToSettings() 方法,所有被用户选择了拒绝且不再询问的权限都会进行到这个方法中处理,拒绝的权限都记录在 deniedList 参数当中。
接下来,你并不需要自己弹出一个 Toast 或是对话框来提醒用户手动去应用程序设置当中打开权限,而是直接调用 showForwardToSettingsDialog() 方法即可。类似地,showForwardToSettingsDialog() 方法也接收 4 个参数,每个参数的作用和刚才的 showRequestReasonDialog() 方法完全一致,我这里就不再重复解释了。
showForwardToSettingsDialog() 方法将会弹出一个对话框,当用户点击对话框上的我已明白按钮时,将会自动跳转到当前应用程序的设置界面,从而不需要用户自己慢慢进入设置当中寻找当前应用了。另外,当用户从设置中返回时,PermissionX 将会自动重新请求相应的权限,并将最终的授权结果回调到 request() 方法当中。效果如下图所示:
同样,1.3.0 版本也支持了自定义这个对话框样式的功能,详情请参阅 PermissionX 重磅更新,支持自定义权限提醒对话框 。
PermissionX 最主要的功能大概就是这些,不过我在使用一些 App 的时候发现,有些 App 喜欢在第一次请求权限之前就先弹出一个对话框向用户解释自己需要哪些权限,然后才会进行权限申请。这种做法是比较提倡的,因为用户同意授权的概率会更高。
那么 PermissionX 中要如何实现这样的功能呢?
其实非常简单,PermissionX 还提供了一个 explainReasonBeforeRequest() 方法,只需要将它也串接到 request() 方法之前就可以了,代码如下所示:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.explainReasonBeforeRequest()
.onExplainRequestReason { deniedList ->
showRequestReasonDialog(deniedList, "即将申请的权限是程序必须依赖的权限", "我已明白")
}
.onForwardToSettings { deniedList ->
showForwardToSettingsDialog(deniedList, "您需要去应用程序设置当中手动开启权限", "我已明白")
}
.request { allGranted, grantedList, deniedList ->
if (allGranted) {
Toast.makeText(this, "所有申请的权限都已通过", Toast.LENGTH_SHORT).show()
} else {
Toast.makeText(this, "您拒绝了如下权限:$deniedList", Toast.LENGTH_SHORT).show()
}
}这样,当每次请求权限时,会优先进入 onExplainRequestReason() 方法,弹出解释权限申请原因的对话框,用户点击我已明白按钮之后才会执行权限申请。效果如下图所示:
不过,你在使用 explainReasonBeforeRequest() 方法时,其实还有一些关键的点需要注意。
第一,单独使用 explainReasonBeforeRequest() 方法是无效的,必须配合 onExplainRequestReason() 方法一起使用才能起作用。这个很好理解,因为没有配置 onExplainRequestReason() 方法,我们怎么向用户解释权限申请原因呢?
第二,在使用 explainReasonBeforeRequest() 方法时,如果 onExplainRequestReason() 方法中编写了权限过滤的逻辑,最终的运行结果可能和你期望的会不一致。这一点可能会稍微有点难理解,我用一个具体的示例来解释一下。
观察如下代码:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.explainReasonBeforeRequest()
.onExplainRequestReason { deniedList ->
val filteredList = deniedList.filter {
it == Manifest.permission.CAMERA
}
showRequestReasonDialog(filteredList, "摄像机权限是程序必须依赖的权限", "我已明白")
}
...这里在 onExplainRequestReason() 方法中编写了刚才用到的权限过滤逻辑,当有多个权限被拒绝时,我们只重新申请 CAMERA 权限。
在没有加入 explainReasonBeforeRequest() 方法时,一切都可以按照我们所预期的那样正常运行。但如果加上了 explainReasonBeforeRequest() 方法,在执行权限请求之前会先进入 onExplainRequestReason() 方法,而这里将除了 CAMERA 之外的其他权限都过滤掉了,因此实际上 PermissionX 只会请求 CAMERA 这一个权限,剩下的权限将完全不会尝试去请求,而是直接作为被拒绝的权限回调到最终的 request() 方法当中。
效果如下图所示:
针对于这种情况,PermissionX 在 onExplainRequestReason() 方法中提供了一个额外的 beforeRequest 参数,用于标识当前上下文是在权限请求之前还是之后,借助这个参数在 onExplainRequestReason() 方法中执行不同的逻辑,即可很好地解决这个问题,示例代码如下:
PermissionX.init(this)
.permissions(Manifest.permission.CAMERA, Manifest.permission.READ_CONTACTS, Manifest.permission.CALL_PHONE)
.explainReasonBeforeRequest()
.onExplainRequestReason { deniedList, beforeRequest ->
if (beforeRequest) {
showRequestReasonDialog(deniedList, "为了保证程序正常工作,请您同意以下权限申请", "我已明白")
} else {
val filteredList = deniedList.filter {
it == Manifest.permission.CAMERA
}
showRequestReasonDialog(filteredList, "摄像机权限是程序必须依赖的权限", "我已明白")
}
}
...可以看到,当 beforeRequest 为 true 时,说明此时还未执行权限申请,那么我们将完整的 deniedList 传入 showRequestReasonDialog() 方法当中。
而当 beforeRequest 为 false 时,说明某些权限被用户拒绝了,此时我们只重新申请 CAMERA 权限,因为它是必不可少的,其他权限则可有可无。
最终运行效果如下: