前言
在面向对象程序设计过程中,有时会面临要创建大量相同或相似对象实例的问题。创建那么多的对象将会耗费很多的系统资源,它是系统性能提高的一个瓶颈。
例如,围棋和五子棋中的黑白棋子,图像中的坐标点或颜色,局域网中的路由器、交换机和集线器,教室里的桌子和凳子等。这些对象有很多相似的地方,如果能把它们相同的部分提取出来共享,则能节省大量的系统资源,这就是享元模式的产生背景。
定义
运用共享技术来有效地支持大量细粒度对象的复用。它通过共享已经存在的对象来大幅度减少需要创建的对象数量、避免大量相似类的开销,从而提高系统资源的利用率。
优点
相同对象只要保存一份,这降低了系统中对象的数量,从而降低了系统中细粒度对象给内存带来的压力。
缺点
为了使对象可以共享,需要将一些不能共享的状态外部化,这将增加程序的复杂性。
读取享元模式的外部状态会使得运行时间稍微变长。
享元模式的结构与实现
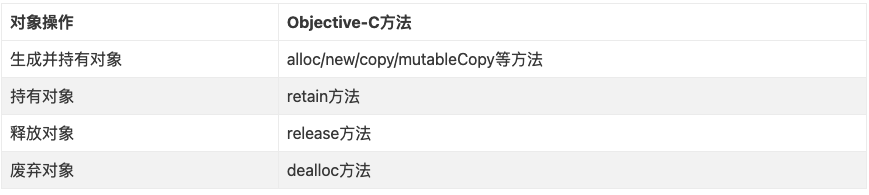
享元模式的定义提出了两个要求,细粒度和共享对象。因为要求细粒度,所以不可避免地会使对象数量多且性质相近,此时我们就将这些对象的信息分为两个部分:内部状态和外部状态。
内部状态指对象共享出来的信息,存储在享元信息内部,并且不回随环境的改变而改变;
外部状态指对象得以依赖的一个标记,随环境的改变而改变,不可共享。
比如,连接池中的连接对象,保存在连接对象中的用户名、密码、连接URL等信息,在创建对象的时候就设置好了,不会随环境的改变而改变,这些为内部状态。而当每个连接要被回收利用时,我们需要将它标记为可用状态,这些为外部状态。
享元模式的本质是缓存共享对象,降低内存消耗。
结构
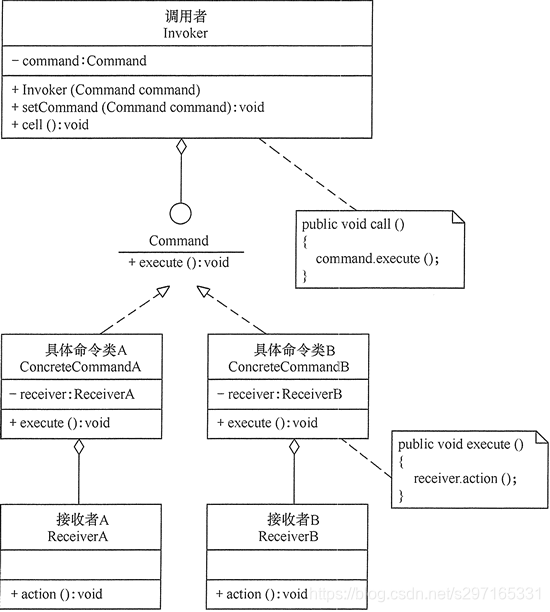
抽象享元角色(Flyweight):是所有的具体享元类的基类,为具体享元规范需要实现的公共接口,非享元的外部状态以参数的形式通过方法传入。
具体享元(Concrete Flyweight)角色:实现抽象享元角色中所规定的接口。
非享元(Unsharable Flyweight)角色:是不可以共享的外部状态,它以参数的形式注入具体享元的相关方法中。
享元工厂(Flyweight Factory)角色:负责创建和管理享元角色。当客户对象请求一个享元对象时,享元工厂检査系统中是否存在符合要求的享元对象,如果存在则提供给客户;如果不存在的话,则创建一个新的享元对象。
享元模式的实现
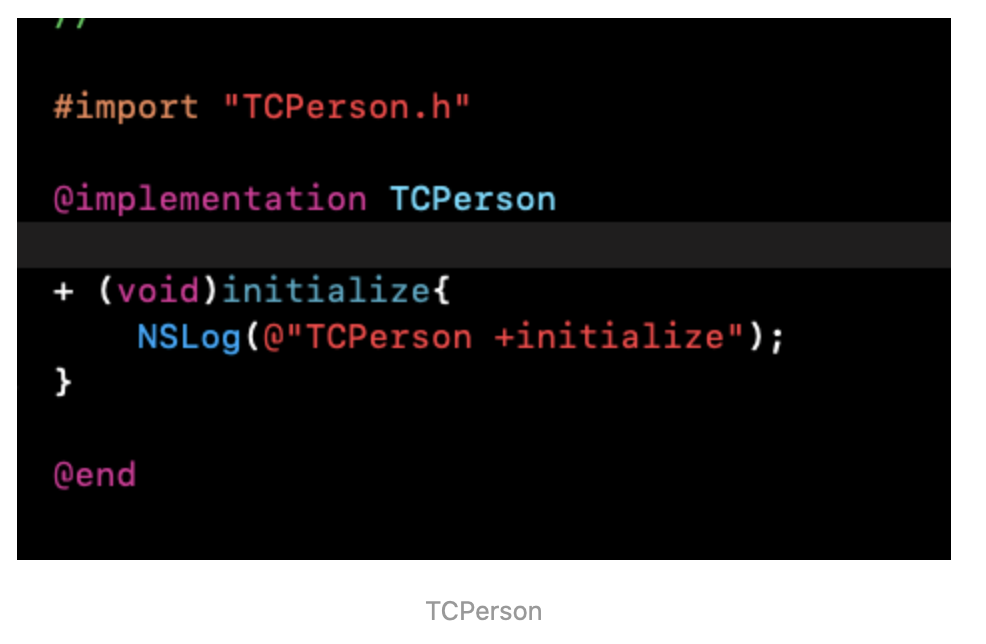
应用实例的话,其实上面的模板就已经是一个很好的例子了,类似于String常量池,没有的对象创建后存在池中,若池中存在该对象则直接从池中取出。
为了更好的理解享元模式,这里再举一个实例,比如接了我一个小型的外包项目,是做一个产品展示网站,后来他的朋友们也希望做这样的网站,但要求都有些不同,我们当然不能直接复制粘贴再来一份,有任希望是新闻发布形式的,有人希望是博客形式的等等,而且因为经费原因不能每个网站租用一个空间。
其实这里他们需要的网站结构相似度很高,而且都不是高访问量网站,如果分成多个虚拟空间来处理,相当于一个相同网站的实例对象很多,这是造成服务器的大量资源浪费。如果整合到一个网站中,共享其相关的代码和数据,那么对于硬盘、内存、CPU、数据库空间等服务器资源都可以达成共享,减少服务器资源;而对于代码,由于是一份实例,维护和扩展都更加容易。
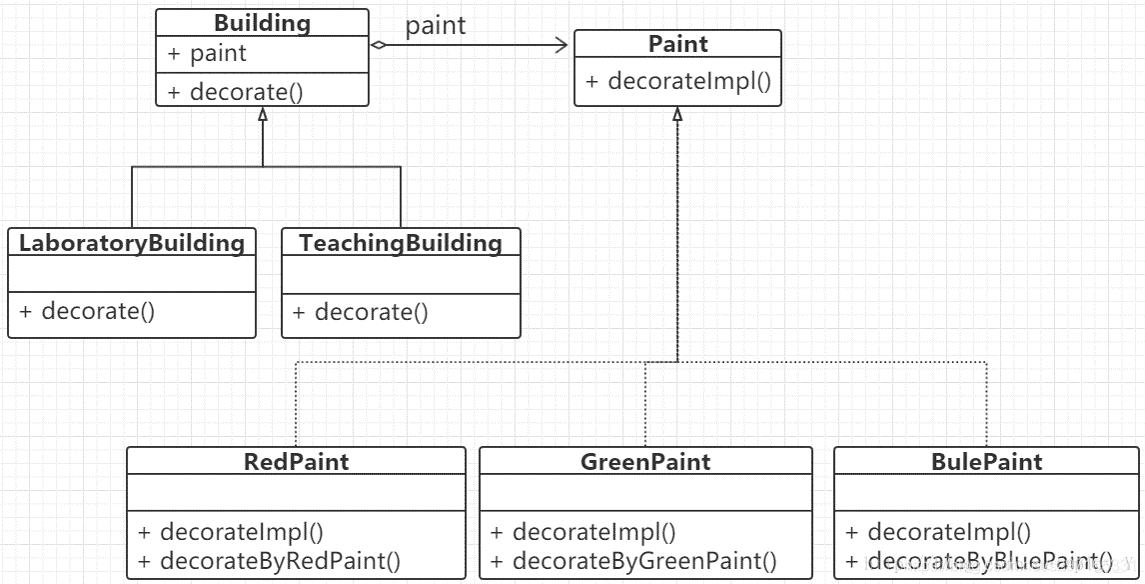
那么此时就可以用到享元模式了。UML图如下:
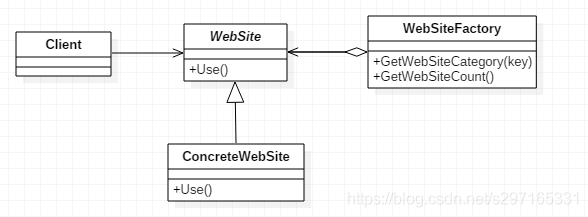
网站抽象类
public abstract class WebSite {
public abstract void use();
}
具体网站类
public class ConcreteWebSite extends WebSite {
private String name = "";
public ConcreteWebSite(String name) {
this.name = name;
}
@Override
public void use() {
System.out.println("网站分类:" + name);
}
}
网络工厂类
这里使用HashMap来作为池,通过put和get方法实现加入池与从池中取的操作。
public class WebSiteFactory {
private HashMap<String, ConcreteWebSite> pool = new HashMap<>();
//获得网站分类
public WebSite getWebSiteCategory(String key) {
if(!pool.containsKey(key)) {
pool.put(key, new ConcreteWebSite(key));
}
return (WebSite)pool.get(key);
}
//获得网站分类总数
public int getWebSiteCount() {
return pool.size();
}
}
Client客户端
这里测试用例给了两种网站,原先我们需要做三个产品展示和三个博客的网站,也即需要六个网站类的实例,但其实它们本质上都是一样的代码,可以利用用户ID号的不同,来区分不同的用户,具体数据和模板可以不同,但代码核心和数据库却是共享的。
public class Client {
public static void main(String[] args) {
WebSiteFactory factory = new WebSiteFactory();
WebSite fx = factory.getWebSiteCategory("产品展示");
fx.use();
WebSite fy = factory.getWebSiteCategory("产品展示");
fy.use();
WebSite fz = factory.getWebSiteCategory("产品展示");
fz.use();
WebSite fa = factory.getWebSiteCategory("博客");
fa.use();
WebSite fb = factory.getWebSiteCategory("博客");
fb.use();
WebSite fc = factory.getWebSiteCategory("博客");
fc.use();
System.out.println("网站分类总数为:" + factory.getWebSiteCount());
}
}
源码中的享元模式
享元模式很重要,因为它能帮你在一个复杂的系统中大量的节省内存空间。在JAVA语言中,String类型就是使用了享元模式。String对象是final类型,对象一旦创建就不可改变。在JAVA中字符串常量都是存在常量池中的,JAVA会确保一个字符串常量在常量池中只有一个拷贝。String a=”abc”,其中”abc”就是一个字符串常量。
熟悉java的应该知道下面这个例子:
Stringa="hello";
Stringb="hello";
if(a==b)
System.out.println("OK");
else
System.out.println("Error");
输出结果是:OK。可以看出if条件比较的是两a和b的地址,也可以说是内存空间 核心总结,可以共享的对象,也就是说返回的同一类型的对象其实是同一实例,当客户端要求生成一个对象时,工厂会检测是否存在此对象的实例,如果存在那么直接返回此对象实例,如果不存在就创建一个并保存起来,这点有些单例模式的意思。通常工厂类会有一个集合类型的成员变量来用以保存对象,如hashtable,vector等。在java中,数据库连接池,线程池等即是用享元模式的应用。
首先String不属于8种基本数据类型,String是一个对象。
因为对象的默认值是null,所以String的默认值也是null;但它又是一种特殊的对象,有其它对象没有的一些特性。
new String()和new String(“”)都是申明一个新的空字符串,是空串不是null;
String str=”kvill”;
String str=new String (“kvill”);的区别:
在这里,我们不谈堆,也不谈栈,只先简单引入常量池这个简单的概念。
常量池(constant pool)指的是在编译期被确定,并被保存在已编译的.class文件中的一些数据。它包括了关于类、方法、接口等中的常量,也包括字符串常量。
看例1:
String s0=”kvill”;
String s1=”kvill”;
String s2=”kv” + “ill”;
System.out.println( s0==s1 );
System.out.println( s0==s2 );
结果为:
true
true
首先,我们要知结果为道Java会确保一个字符串常量只有一个拷贝。
因为例子中的s0和s1中的”kvill”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而”kv”和”ill”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中”kvill”的一个引用。
所以我们得出s0==s1==s2;
用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间。
看例2:
String s0=”kvill”;
String s1=new String(”kvill”);
String s2=”kv” + new String(“ill”);
System.out.println( s0==s1 );
System.out.println( s0==s2 );
System.out.println( s1==s2 );
结果为:
false
false
false
例2中s0还是常量池中”kvill”的应用,s1因为无法在编译期确定,所以是运行时创建的新对象”kvill”的引用,s2因为有后半部分new String(“ill”)所以也无法在编译期确定,所以也是一个新创建对象”kvill”的应用;明白了这些也就知道为何得出此结果了。
String.intern():
再补充介绍一点:存在于.class文件中的常量池,在运行期被JVM装载,并且可以扩充。String的intern()方法就是扩充常量池的一个方法;当一个String实例str调用intern()方法时,Java查找常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常量池中增加一个Unicode等于str的字符串并返回它的引用;看例3就清楚了
例3:
String s0= “kvill”;
String s1=new String(”kvill”);
String s2=new String(“kvill”);
System.out.println( s0==s1 );
System.out.println( “**********” );
s1.intern();
s2=s2.intern(); //把常量池中“kvill”的引用赋给s2
System.out.println( s0==s1);
System.out.println( s0==s1.intern() );
System.out.println( s0==s2 );
结果为:
false
**********
false //虽然执行了s1.intern(),但它的返回值没有赋给s1
true //说明s1.intern()返回的是常量池中”kvill”的引用
true
最后我再破除一个错误的理解:
有人说,“使用String.intern()方法则可以将一个String类的保存到一个全局String表中,如果具有相同值的Unicode字符串已经在这个表中,那么该方法返回表中已有字符串的地址,如果在表中没有相同值的字符串,则将自己的地址注册到表中“如果我把他说的这个全局的String表理解为常量池的话,他的最后一句话,“如果在表中没有相同值的字符串,则将自己的地址注册到表中”是错的:
看例4:
String s1=new String("kvill");
String s2=s1.intern();
System.out.println( s1==s1.intern() );
System.out.println( s1+" "+s2 );
System.out.println( s2==s1.intern() );
结果:
false
kvill kvill
true
在这个类中我们没有声名一个”kvill”常量,所以常量池中一开始是没有”kvill”的,当我们调用s1.intern()后就在常量池中新添加了一个”kvill”常量,原来的不在常量池中的”kvill”仍然存在,也就不是“将自己的地址注册到常量池中”了。
s1==s1.intern()为false说明原来的“kvill”仍然存在;
s2现在为常量池中“kvill”的地址,所以有s2==s1.intern()为true。
关于equals()和==:
这个对于String简单来说就是比较两字符串的Unicode序列是否相当,如果相等返回true;而==是比较两字符串的地址是否相同,也就是是否是同一个字符串的引用。
关于String是不可变的
这一说又要说很多,大家只要知道String的实例一旦生成就不会再改变了,比如说:String str=”kv”+”ill”+” “+”ans”;
就是有4个字符串常量,首先”kv”和”ill”生成了”kvill”存在内存中,然后”kvill”又和” “ 生成 ”kvill “存在内存中,最后又和生成了”kvill ans”;并把这个字符串的地址赋给了str,就是因为String的“不可变”产生了很多临时变量,这也就是为什么建议用StringBuffer的原因了,因为StringBuffer是可改变的。
okhttp3 kotlin ConnectionPool 源码分析
ConnectionPool的说明:
管理http和http/2的链接,以便减少网络请求延迟。同一个address将共享同一个connection。该类实现了复用连接的目标。
class RealConnectionPool(
/** 每个address的最大空闲连接数 */
private val maxIdleConnections: Int,
keepAliveDuration: Long,
timeUnit: TimeUnit
) {
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
//这是一个用于清楚过期链接的线程池,每个线程池最多只能运行一个线程,并且这个线程池允许被垃圾回收
private val executor = ThreadPoolExecutor(
0, // corePoolSize.
Int.MAX_VALUE, // maximumPoolSize.
60L, TimeUnit.SECONDS, // keepAliveTime.
SynchronousQueue(),
threadFactory("OkHttp ConnectionPool", true)
)
//双向队列
private val connections = ArrayDeque<RealConnection>()
//路由的数据库
val routeDatabase = RouteDatabase()
//清理任务正在执行的标志
var cleanupRunning: Boolean = false
- 主要就是connections,可见ConnectionPool内部以队列方式存储连接;
- routDatabase是一个黑名单,用来记录不可用的route,但是看代码貌似ConnectionPool并没有使用它。所以此处不做分析。
- 剩下的就是和清理有关了,所以executor是清理任务的线程池,cleanupRunning是清理任务的标志,cleanupRunnable是清理任务。
class ConnectionPool(
maxIdleConnections: Int,
keepAliveDuration: Long,
timeUnit: TimeUnit
) {
//创建一个适用于单个应用程序的新连接池。
//该连接池的参数将在未来的okhttp中发生改变
//目前最多可容乃5个空闲的连接,存活期是5分钟
constructor() : this(5, 5, TimeUnit.MINUTES)
}
init {
//保持活着的时间,否则清理将旋转循环
require(keepAliveDuration > 0L) { "keepAliveDuration <= 0: $keepAliveDuration" }
}
通过这个构造器我们知道了这个连接池最多维持5个连接,且每个链接最多活5分钟。并且包含一个线程池包含一个清理任务。
所以maxIdleConnections和keepAliveDurationNs则是清理中淘汰连接的的指标,这里需要说明的是maxIdleConnections是值每个地址上最大的空闲连接数。所以OkHttp只是限制与同一个远程服务器的空闲连接数量,对整体的空闲连接并没有限制。
这时候说下ConnectionPool的实例化的过程,一个OkHttpClient只包含一个ConnectionPool,其实例化也是在OkHttpClient的过程。这里说一下ConnectionPool各个方法的调用并没有直接对外暴露,而是通过OkHttpClient的Internal接口统一对外暴露。
然后我们来看下他的transmitterAcquirePooledConnection(获取连接)和put方法
fun transmitterAcquirePooledConnection(
address: Address,
transmitter: Transmitter,
routes: List<Route>?,
requireMultiplexed: Boolean
): Boolean {
//断言,判断线程是不是被自己锁住了
assert(Thread.holdsLock(this))
// 遍历已有连接集合
for (connection in connections) {
if (requireMultiplexed && !connection.isMultiplexed) continue
//如果connection和需求中的"地址"和"路由"匹配
if (!connection.isEligible(address, routes)) continue
//复用这个连接
transmitter.acquireConnectionNoEvents(connection)
return true
}
return false
}
put方法更为简单,就是异步触发清理任务,然后将连接添加到队列中
fun put(connection: RealConnection) {
assert(Thread.holdsLock(this))
if (!cleanupRunning) {
cleanupRunning = true
executor.execute(cleanupRunnable)
}
connections.add(connection)
}
private val cleanupRunnable = object : Runnable {
override fun run() {
while (true) {
val waitNanos = cleanup(System.nanoTime())
if (waitNanos == -1L) return
try {
this@RealConnectionPool.lockAndWaitNanos(waitNanos)
} catch (ie: InterruptedException) {
// Will cause the thread to exit unless other connections are created!
evictAll()
}
}
}
}
这个逻辑也很简单,就是调用cleanup方法执行清理,并等待一段时间,持续清理,其中cleanup方法返回的值来来决定而等待的时间长度。那我们继续来看下cleanup函数:
fun cleanup(now: Long): Long {
var inUseConnectionCount = 0
var idleConnectionCount = 0
var longestIdleConnection: RealConnection? = null
var longestIdleDurationNs = Long.MIN_VALUE
// Find either a connection to evict, or the time that the next eviction is due.
synchronized(this) {
for (connection in connections) {
// If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
inUseConnectionCount++
continue
}
//统计空闲连接数量
idleConnectionCount++
// If the connection is ready to be evicted, we're done.
val idleDurationNs = now - connection.idleAtNanos
if (idleDurationNs > longestIdleDurationNs) {
//找出空闲时间最长的连接以及对应的空闲时间
longestIdleDurationNs = idleDurationNs
longestIdleConnection = connection
}
}
when {
longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections -> {
// We've found a connection to evict. Remove it from the list, then close it below
// (outside of the synchronized block).
//在符合清理条件下,清理空闲时间最长的连接
connections.remove(longestIdleConnection)
}
idleConnectionCount > 0 -> {
// A connection will be ready to evict soon.
//不符合清理条件,则返回下次需要执行清理的等待时间,也就是此连接即将到期的时间
return keepAliveDurationNs - longestIdleDurationNs
}
inUseConnectionCount > 0 -> {
// All connections are in use. It'll be at least the keep alive duration 'til we run
// again.
//没有空闲的连接,则隔keepAliveDuration(分钟)之后再次执行
return keepAliveDurationNs
}
else -> {
// No connections, idle or in use.
cleanupRunning = false
return -1
}
}
}
//关闭socket资源
longestIdleConnection!!.socket().closeQuietly()
// Cleanup again immediately.
//这里是在清理一个空闲时间最长的连接以后会执行到这里,需要立即再次执行清理
return 0
}
这里的首先统计空闲连接数量,然后通过for循环查找最长空闲时间的连接以及对应空闲时长,然后判断是否超出最大空闲连接数(maxIdleConnections)或者或者超过最大空闲时间(keepAliveDurationNs),满足其一则清除最长空闲时长的连接。如果不满足清理条件,则返回一个对应等待时间。
这个对应等待的时间又分二种情况:
- 有连接则等待下次需要清理的时间去清理:keepAliveDurationNs-longestIdleDurationNs;
- 没有空闲的连接,则等下一个周期去清理:keepAliveDurationNs
如果清理完毕返回-1。
综上所述,我们来梳理一下清理任务,清理任务就是异步执行的,遵循两个指标,最大空闲连接数量和最大空闲时长,满足其一则清理空闲时长最大的那个连接,然后循环执行,要么等待一段时间,要么继续清理下一个连接,知道清理所有连接,清理任务才结束,下一次put的时候,如果已经停止的清理任务则会被再次触发
private fun pruneAndGetAllocationCount(connection: RealConnection, now: Long): Int {
val references = connection.transmitters
var i = 0
//遍历弱引用列表
while (i < references.size) {
val reference = references[i]
//若StreamAllocation被使用则接着循环
if (reference.get() != null) {
i++
continue
}
// We've discovered a leaked transmitter. This is an application bug.
val transmitterRef = reference as TransmitterReference
val message = "A connection to ${connection.route().address.url} was leaked. " +
"Did you forget to close a response body?"
Platform.get().logCloseableLeak(message, transmitterRef.callStackTrace)
//若StreamAllocation未被使用则移除引用,这边注释为泄露
references.removeAt(i)
connection.noNewExchanges = true
//如果列表为空则说明此连接没有被引用了,则返回0,表示此连接是空闲连接
// If this was the last allocation, the connection is eligible for immediate eviction.
if (references.isEmpty()) {
connection.idleAtNanos = now - keepAliveDurationNs
return 0
}
}
return references.size
}
pruneAndGetAllocationCount主要是用来标记泄露连接的。内部通过遍历传入进来的RealConnection的StreamAllocation列表,如果StreamAllocation被使用则接着遍历下一个StreamAllocation。如果StreamAllocation未被使用则从列表中移除,如果列表中为空则说明此连接连接没有引用了,返回0,表示此连接是空闲连接,否则就返回非0表示此连接是活跃连接。
接下来让我看下ConnectionPool的connectionBecameIdle()方法,就是当有连接空闲时,唤起cleanup线程清洗连接池
fun connectionBecameIdle(connection: RealConnection): Boolean {
assert(Thread.holdsLock(this))
//该连接已经不可用
return if (connection.noNewExchanges || maxIdleConnections == 0) {
connections.remove(connection)
true
} else {
// Awake the cleanup thread: we may have exceeded the idle connection limit.
//欢迎clean 线程
this.notifyAll()
false
}
}
connectionBecameIdle标示一个连接处于空闲状态,即没有流任务,那么久需要调用该方法,由ConnectionPool来决定是否需要清理该连接。
再来看下evictAll()方法
fun evictAll() {
val evictedConnections = mutableListOf<RealConnection>()
synchronized(this) {
val i = connections.iterator()
while (i.hasNext()) {
val connection = i.next()
if (connection.transmitters.isEmpty()) {
connection.noNewExchanges = true
evictedConnections.add(connection)
i.remove()
}
}
}
for (connection in evictedConnections) {
connection.socket().closeQuietly()
}
}
该方法是删除所有空闲的连接,比较简单,不说了
Integer中的享元模式
那么我们来看看Integer中的享元模式具体是怎么样的吧。
通过如下代码了解一下integer的比较
public static void main(String[] args)
{
Integer integer1 = 9;
Integer integer2 = 9;
System.out.println(integer1==integer2);
Integer integer3 = 129;
Integer integer4 = 129;
System.out.println(integer3==integer4);
}
输出:
true
false
在通过等号赋值的时候,实际上是通过调用valueOf方法的返回一个对象。然后我们观察一下这个方法的源码。
public final class Integer extends Number implements Comparable<Integer> {
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private final int value;
public Integer(int value) {
this.value = value;
}
}
上面是我简化了的Integer类。平常在使用Integer类的时候。你是否思考过用valueOf还是用new创建Integer对象。看完源码就会发现在valueOf这个方法中它会先判断传进去的值是否在IntegerCache中,如果不在就创建新的对象,在就直接返回缓存池里的对象。这个valueOf方法就用到享元模式。它将-128到127的Integer对象先在缓存池里创建好,等我们需要的时候直接返回即可。所以在-128到127中的数值我们用valueOf创建会比new更快。因此我们在使用Integer对象的时候,也一定要记住使用equals(),而不是单纯的使用”==”,否则有可能出现不相等的情况。
收起阅读 »