
细说浏览器输入URL后发生了什么
细说浏览器输入URL后发生了什么
总体概览
大体上,可以分为六步,当然每一步都可以详细都展开来说,这里先放一张总览图:
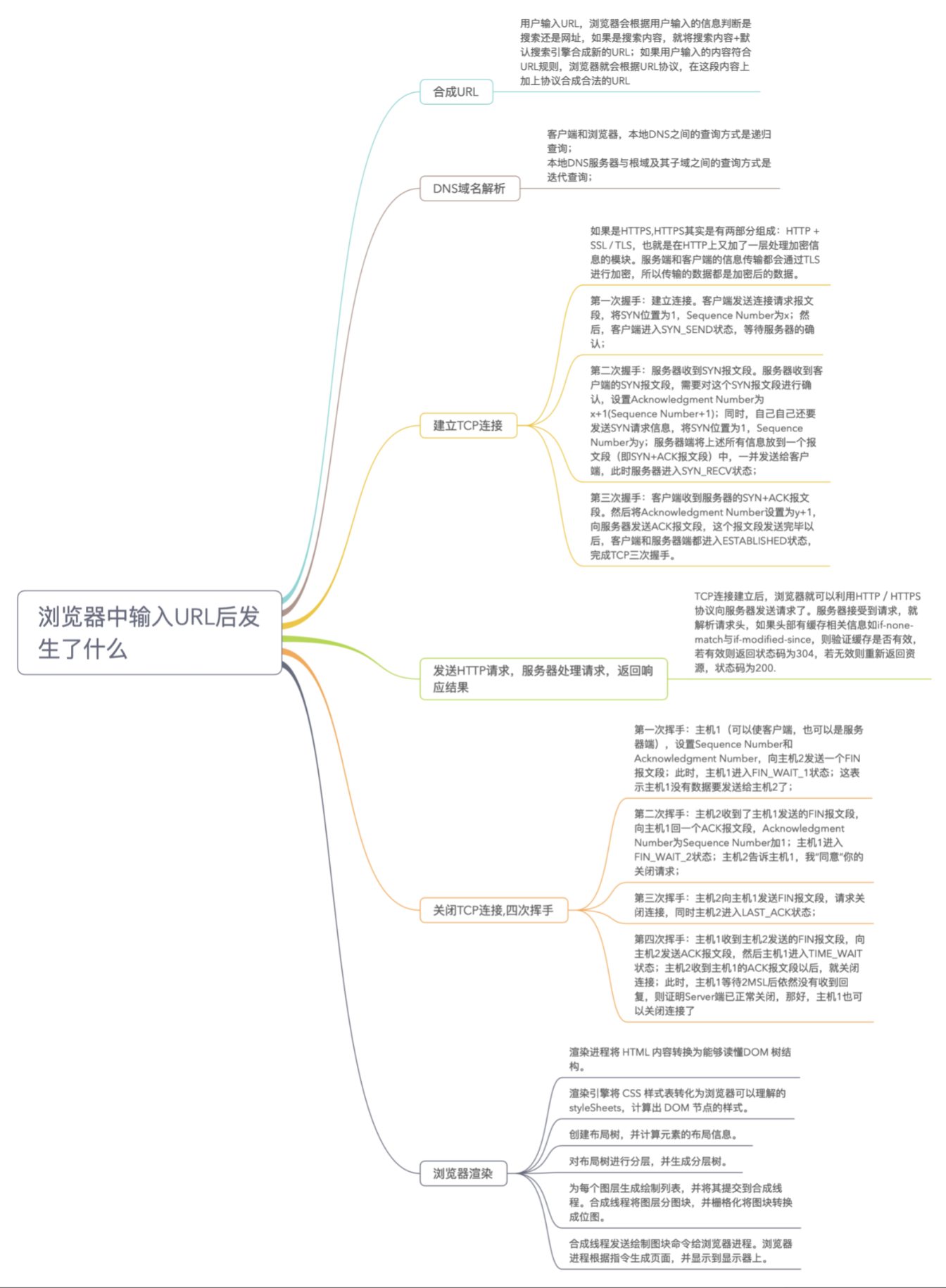
DNS域名解析
在网络世界,你肯定记得住网站的名称,但是很难记住网站的 IP 地址,因而也需要一个地址簿,就是 DNS 服务器。DNS 服务器是高可用、高并发和分布式的,它是树状结构,如图:
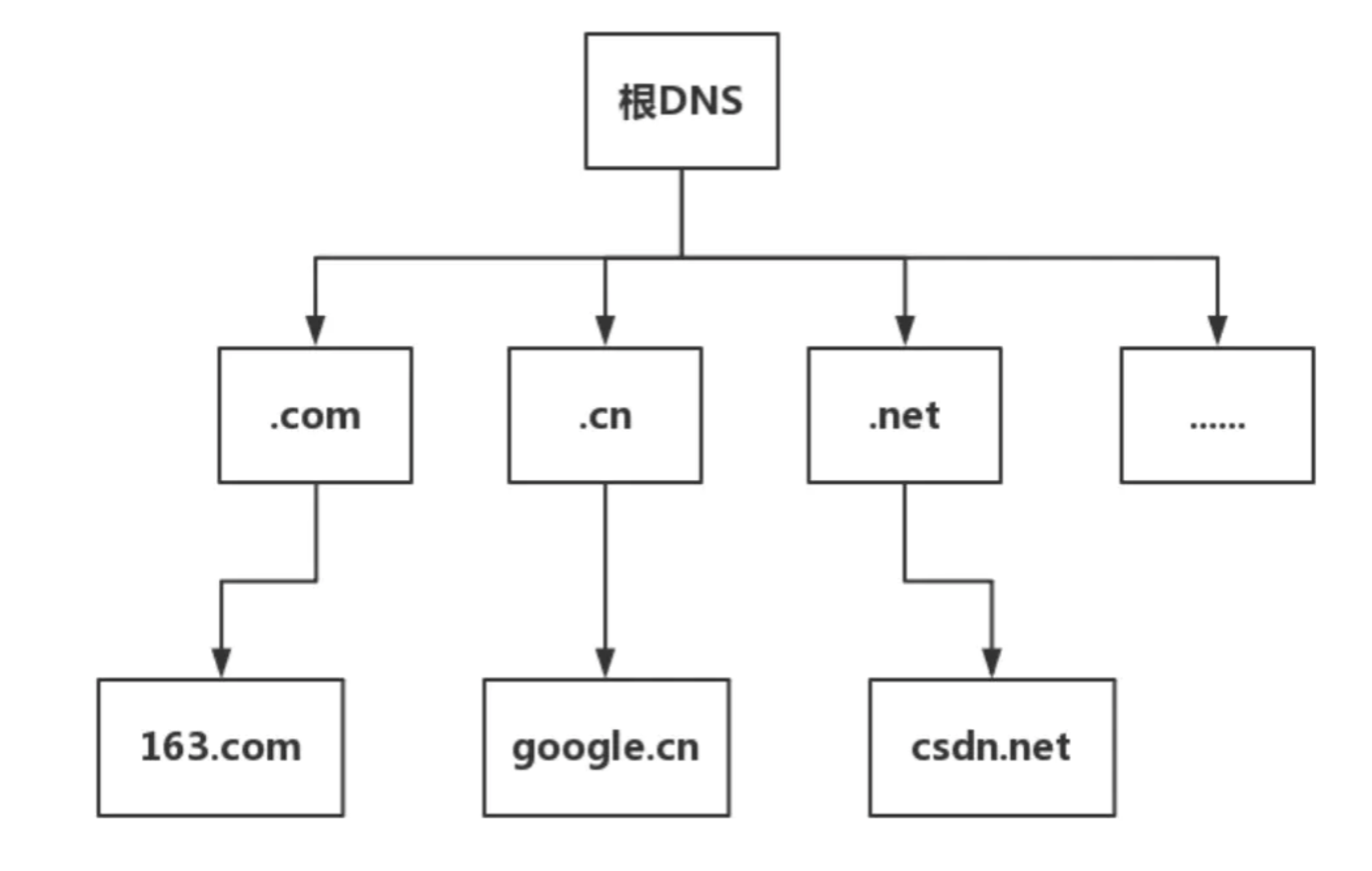
- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS的域名查找,在客户端和浏览器,本地DNS之间的查询方式是递归查询;在本地DNS服务器与根域及其子域之间的查询方式是迭代查询;
递归过程:
在客户端输入 URL 后,会有一个递归查找的过程,从浏览器缓存中查找->本地的hosts文件查找->找本地DNS解析器缓存查找->本地DNS服务器查找,这个过程中任何一步找到了都会结束查找流程。
如果本地DNS服务器无法查询到,则根据本地DNS服务器设置的转发器进行查询。若未用转发模式,则迭代查找过程如下图:
结合起来的过程,可以用一个图表示:
在查找过程中,有以下优化点:
- DNS存在着多级缓存,从离浏览器的距离排序的话,有以下几种: 浏览器缓存,系统缓存,路由器缓存,IPS服务器缓存,根域名服务器缓存,顶级域名服务器缓存,主域名服务器缓存。
- 在域名和 IP 的映射过程中,给了应用基于域名做负载均衡的机会,可以是简单的负载均衡,也可以根据地址和运营商做全局的负载均衡。
建立TCP连接
首先,判断是不是https的,如果是,则HTTPS其实是HTTP + SSL / TLS 两部分组成,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。
进行三次握手,建立TCP连接。
第一次握手:建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入SYN_SEND状态,等待服务器的确认;
第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
SSL握手过程
- 第一阶段 建立安全能力 包括协议版本 会话Id 密码构件 压缩方法和初始随机数
- 第二阶段 服务器发送证书 密钥交换数据和证书请求,最后发送请求-相应阶段的结束信号
- 第三阶段 如果有证书请求客户端发送此证书 之后客户端发送密钥交换数据 也可以发送证书验证消息
- 第四阶段 变更密码构件和结束握手协议
完成了之后,客户端和服务器端就可以开始传送数据。更多 HTTPS 的资料可以看这里:
备注
ACK:此标志表示应答域有效,就是说前面所说的TCP应答号将会包含在TCP数据包中;有两个取值:0和1,为1的时候表示应答域有效,反之为0。TCP协议规定,只有ACK=1时有效,也规定连接建立后所有发送的报文的ACK必须为1。
SYN(SYNchronization):在连接建立时用来同步序号。当SYN=1而ACK=0时,表明这是一个连接请求报文。对方若同意建立连接,则应在响应报文中使SYN=1和ACK=1. 因此, SYN置1就表示这是一个连接请求或连接接受报文。
FIN(finis)即完,终结的意思, 用来释放一个连接。当 FIN = 1 时,表明此报文段的发送方的数据已经发送完毕,并要求释放连接。
发送HTTP请求,服务器处理请求,返回响应结果
TCP连接建立后,浏览器就可以利用HTTP/HTTPS协议向服务器发送请求了。服务器接受到请求,就解析请求头,如果头部有缓存相关信息如if-none-match与if-modified-since,则验证缓存是否有效,若有效则返回状态码为304,若无效则重新返回资源,状态码为200.
这里有发生的一个过程是HTTP缓存,是一个常考的考点,大致过程如图:
其过程,比较多内容,可以参考我的这篇文章《浏览器相关原理(面试题)详细总结一》,这里我就不详细说了~
关闭TCP连接
第一次分手:主机1(可以使客户端,也可以是服务器端),设置Sequence Number和Acknowledgment Number,向主机2发送一个FIN报文段;此时,主机1进入FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;
第二次分手:主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入FIN_WAIT_2状态;主机2告诉主机1,我"同意"你的关闭请求;
第三次分手:主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入LAST_ACK状态;
第四次分手:主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
浏览器渲染
按照渲染的时间顺序,流水线可分为如下几个子阶段:构建 DOM 树、样式计算、布局阶段、分层、栅格化和显示。如图:
- 渲染进程将 HTML 内容转换为能够读懂DOM 树结构。
- 渲染引擎将 CSS 样式表转化为浏览器可以理解的styleSheets,计算出 DOM 节点的样式。
- 创建布局树,并计算元素的布局信息。
- 对布局树进行分层,并生成分层树。
- 为每个图层生成绘制列表,并将其提交到合成线程。合成线程将图层分图块,并栅格化将图块转换成位图。
- 合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上。
构建 DOM 树
浏览器从网络或硬盘中获得HTML字节数据后会经过一个流程将字节解析为DOM树,先将HTML的原始字节数据转换为文件指定编码的字符,然后浏览器会根据HTML规范来将字符串转换成各种令牌标签,如html、body等。最终解析成一个树状的对象模型,就是dom树。
具体步骤:
- 转码(Bytes -> Characters)—— 读取接收到的 HTML 二进制数据,按指定编码格式将字节转换为 HTML 字符串
- Tokens 化(Characters -> Tokens)—— 解析 HTML,将 HTML 字符串转换为结构清晰的 Tokens,每个 Token 都有特殊的含义同时有自己的一套规则
- 构建 Nodes(Tokens -> Nodes)—— 每个 Node 都添加特定的属性(或属性访问器),通过指针能够确定 Node 的父、子、兄弟关系和所属 treeScope(例如:iframe 的 treeScope 与外层页面的 treeScope 不同)
- 构建 DOM 树(Nodes -> DOM Tree)—— 最重要的工作是建立起每个结点的父子兄弟关系
样式计算
渲染引擎将 CSS 样式表转化为浏览器可以理解的 styleSheets,计算出 DOM 节点的样式。
CSS 样式来源主要有 3 种,分别是通过 link 引用的外部 CSS 文件、style标签内的 CSS、元素的 style 属性内嵌的 CSS。,其样式计算过程主要为:
可以看到上面的 CSS 文本中有很多属性值,如 2em、blue、bold,这些类型数值不容易被渲染引擎理解,所以需要将所有值转换为渲染引擎容易理解的、标准化的计算值,这个过程就是属性值标准化。处理完成后再处理样式的继承和层叠,有些文章将这个过程称为CSSOM的构建过程。
页面布局
布局过程,即排除 script、meta 等功能化、非视觉节点,排除 display: none 的节点,计算元素的位置信息,确定元素的位置,构建一棵只包含可见元素布局树。如图:
其中,这个过程需要注意的是
回流和重绘,关于回流和重绘,详细的可以看我另一篇文章《浏览器相关原理(面试题)详细总结二》,这里就不说了~生成分层树
页面中有很多复杂的效果,如一些复杂的 3D 变换、页面滚动,或者使用 z-indexing 做 z 轴排序等,为了更加方便地实现这些效果,渲染引擎还需要为特定的节点生成专用的图层,并生成一棵对应的图层树(LayerTree),如图:
如果你熟悉 PS,相信你会很容易理解图层的概念,正是这些图层叠加在一起构成了最终的页面图像。在浏览器中,你可以打开 Chrome 的"开发者工具",选择"Layers"标签。渲染引擎给页面分了很多图层,这些图层按照一定顺序叠加在一起,就形成了最终的页面。
并不是布局树的每个节点都包含一个图层,如果一个节点没有对应的层,那么这个节点就从属于父节点的图层。那么需要满足什么条件,渲染引擎才会为特定的节点创建新的层呢?详细的可以看我另一篇文章《浏览器相关原理(面试题)详细总结二》,这里就不说了~
栅格化
合成线程会按照视口附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。所谓栅格化,是指将图块转换为位图。如图:
通常一个页面可能很大,但是用户只能看到其中的一部分,我们把用户可以看到的这个部分叫做视口(viewport)。在有些情况下,有的图层可以很大,比如有的页面你使用滚动条要滚动好久才能滚动到底部,但是通过视口,用户只能看到页面的很小一部分,所以在这种情况下,要绘制出所有图层内容的话,就会产生太大的开销,而且也没有必要。
显示
最后,合成线程发送绘制图块命令给浏览器进程。浏览器进程根据指令生成页面,并显示到显示器上,渲染过程完成。
链接:https://juejin.cn/post/6844904054074654728
