








Socket简析与iOS实现
Socket的基本概念
1.定义
网络上两个程序通过一个双向通信连接实现数据交互,这种双向通信的连接叫做Socket(套接字)。
2.本质
网络模型中应用层与TCP/IP协议族通信的中间软件抽象层,是它的一组编程接口(API),也即对TCP/IP的封装。TCP/IP也要提供可供程序员做网络开发所用的接口,即Socket编程接口。
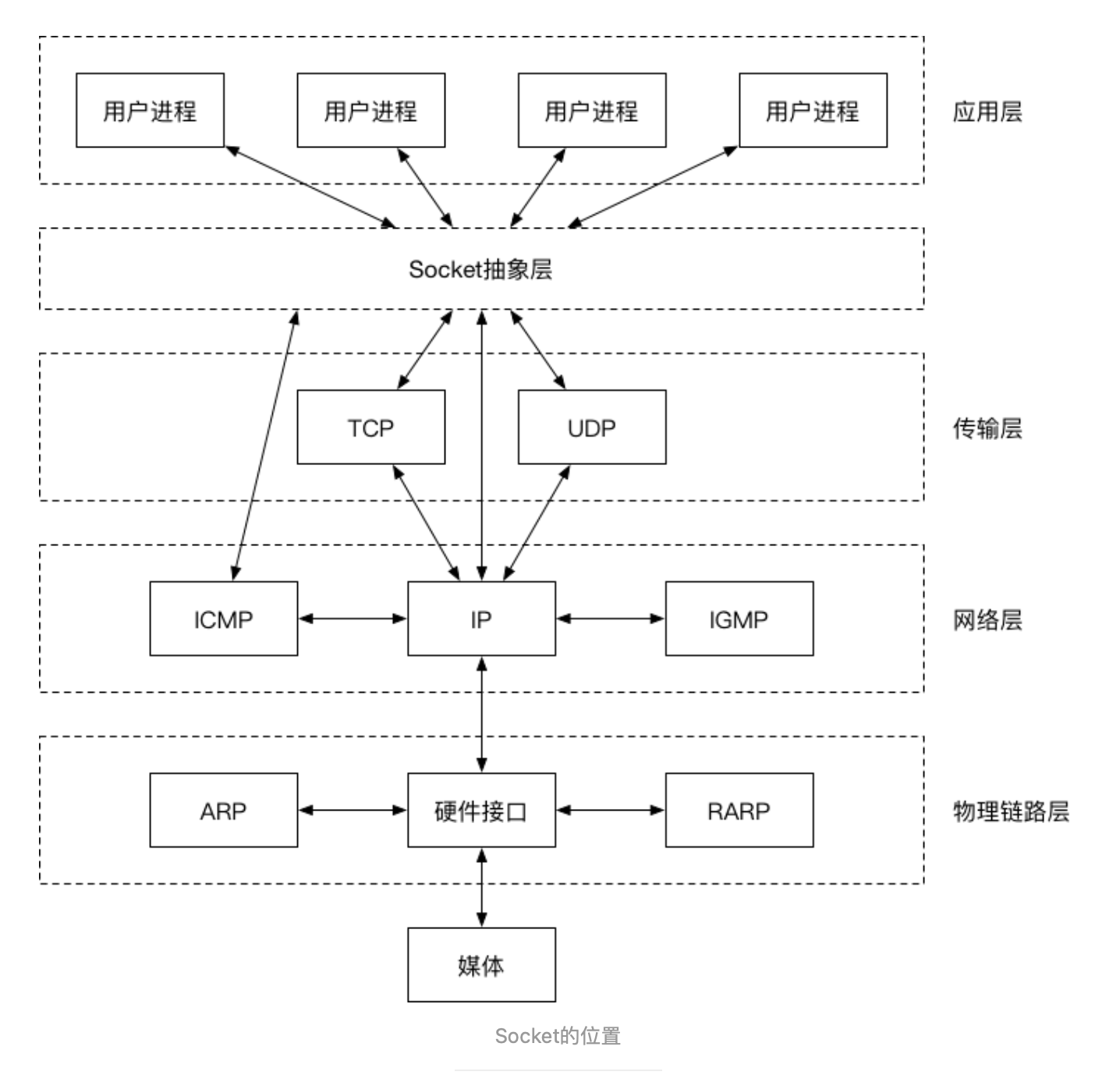
3.要素
Socket是网络通信的基石,是支持TCP/IP协议的网络通信的基本操作单元,包含进行网络通信的必须的五种信息:
- 连接使用的协议
- 本地主机的IP地址
- 本地进程的协议端口
- 远程主机的IP地址
- 远程进程的协议端口
4.特性
Socket可以支持不同的传输协议(TCP或UDP),当使用TCP协议进行连接时,该Socket连接就是一个TCP连接;同理,当使用UDP协议进行连接时,该Socket连接就是一个UDP连接。
多个TCP连接或多个应用程序进程可能需要通过同一个TCP协议端口传输数据。为了区别不同的应用程序进程和连接,计算机操作系统为应用程序与TCP/IP协议交互提供了套接字(Socket)接口。应用层可以和传输层通过Socket接口,区分来自不同应用程序进程或网络连接的通信,实现数据传输的并发服务。5.连接
建立Socket连接至少需要一对套接字,分别运行于服务端(ServerSocket)和客户端(ClientSocket)。套接字直接的连接过程氛围三个步骤:
Step 1 服务器监听
服务端Socket始终处于等待连接状态,实时监听是否有客户端请求连接。
Step 2 客户端请求
客户端Socket提出连接请求,指定服务端Socket的地址和端口号,这时就可以向对应的服务端提出Socket连接请求。
Step 3 连接确认
当服务端Socket监听到客户端Socket提出的连接请求时作出响应,建立一个新的进程,把服务端Socket的描述发送给客户端,该描述得到客户端确认后就可建立起Socket连接。而服务端Socket则继续处于监听状态,继续接收其他客户端Socket的请求。
iOS客户端Socket的实现
1. 数据流方式
- (IBAction)connectToServer:(id)sender {
// 1.与服务器通过三次握手建立连接
NSString *host = @"192.168.1.58";
int port = 1212;
//创建一个socket对象
_socket = [[GCDAsyncSocket alloc] initWithDelegate:self
delegateQueue:dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)];
NSError *error = nil;
// 开始连接
[_socket connectToHost:host
onPort:port
error:&error];
if (error) {
NSLog(@"%@",error);
}
}
#pragma mark - Socket代理方法
// 连接成功
- (void)socket:(GCDAsyncSocket *)sock
didConnectToHost:(NSString *)host
port:(uint16_t)port {
NSLog(@"%s",__func__);
}
// 断开连接
- (void)socketDidDisconnect:(GCDAsyncSocket *)sock
withError:(NSError *)err {
if (err) {
NSLog(@"连接失败");
} else {
NSLog(@"正常断开");
}
}
// 发送数据
- (void)socket:(GCDAsyncSocket *)sock
didWriteDataWithTag:(long)tag {
NSLog(@"%s",__func__);
//发送完数据手动读取,-1不设置超时
[sock readDataWithTimeout:-1
tag:tag];
}
// 读取数据
-(void)socket:(GCDAsyncSocket *)sock
didReadData:(NSData *)data
withTag:(long)tag {
NSString *receiverStr = [[NSString alloc] initWithData:data
encoding:NSUTF8StringEncoding];
NSLog(@"%s %@",__func__,receiverStr);
}2.基于第三方开源库CocoaAsyncSocket
2.1客户端通过地址和端口号与服务端建立Socket连接,并写入相关数据。
- (void)connectToServerWithCommand:(NSString *)command
{
_socket = [[GCDAsyncSocket alloc] initWithDelegate:self delegateQueue:dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0)];
[_socket setUserData:command];
NSError *error = nil;
[_socket connectToHost:WIFI_DIRECT_HOST onPort:WIFI_DIRECT_PORT error:&error];
if (error) {
NSLog(@"__connect error:%@",error.userInfo);
}
[_socket writeData:[command dataUsingEncoding:NSUTF8StringEncoding] withTimeout:10.0f tag:6];
}2.2 实现CocoaAsyncSocket的代理方法
#pragma mark - Socket Delegate
- (void)socket:(GCDAsyncSocket *)sock didConnectToHost:(NSString *)host port:(uint16_t)port
{
NSLog(@"Socket连接成功:%s",__func__);
}
-(void)socketDidDisconnect:(GCDAsyncSocket *)sock withError:(NSError *)err{
if (err) {
NSLog(@"连接失败");
}else{
NSLog(@"正常断开");
}
if ([sock.userData isEqualToString:[NSString stringWithFormat:@"%d",SOCKET_CONNECT_SERVER]])
{
//服务器掉线 重新连接
[self connectToServerWithCommand:@"battery"];
}else
{
return;
}
}
-(void)socket:(GCDAsyncSocket *)sock didWriteDataWithTag:(long)tag {
NSLog(@"数据发送成功:%s",__func__);
//发送完数据手动读取,-1不设置超时
[sock readDataWithTimeout:-1 tag:tag];
}
-(void)socket:(GCDAsyncSocket *)sock didReadData:(NSData *)data withTag:(long)tag {
NSString *receiverStr = [[NSString alloc] initWithData:data encoding:NSUTF8StringEncoding];
NSLog(@"读取数据:%s %@",__func__,receiverStr);
}摘自:https://www.jianshu.com/p/8e599ca5dfe8
收起阅读 »iOS 接入WebSocket
WebSocket是什么
WebSocket协议是 基于TCP 的一种网络协议。
它实现了浏览器与服务器全双工(full-duplex)通信——允许服务器主动发送信息给客户端。
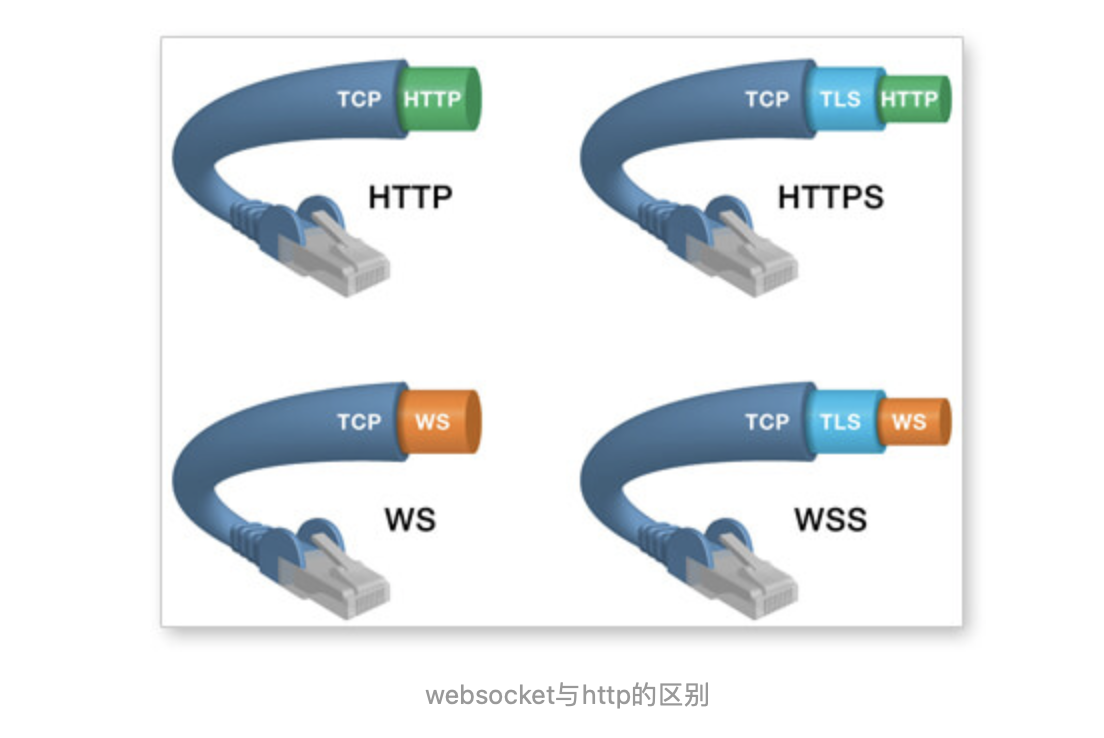
WebSocket基本原理
帧协议:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+- fin(1 bit):指示该帧是否构成该消息的最终帧。大多数情况下,消息适合于一个单一的帧,这一点总是默认设置的。实验表明,Firefox 在 32K 之后创建了第二个帧。
rsv1,rsv2,rsv3(1 bit each):必须为0,除非扩展里协商定义了非零值的含义。如果收到一个非零值,并且协商的扩展中没有一个定义这个非零值的含义,那么接收端必须抛出失败连接。
- opcode(4bits):展示了帧表示什么。以下值目前正在使用:
0x00:这个帧继续前面的有效载荷。
0x01:此帧包含文本数据。
0x02:这个帧包含二进制数据。
0x08:这个帧终止连接。
0x09:这个帧是一个 ping 。
0x0a:这个帧是一个 pong 。
(正如你所看到的,有足够的值未被使用,它们已被保留供将来使用)。 - payload:最可能被掩盖的实际数据。它的长度是 payload_len 的长度。
- masking-key(32 bits):从客户端发送到服务器的所有帧都被帧中包含的 32 位值掩盖。
- 0-125 表示有效载荷的长度。 126 表示以下两个字节表示长度,127 表示接下来的 8 个字节表示长度。所以有效负载的长度在 〜7bit,16bit 和 64bit 括号内。
- payload_len(7 bits):有效载荷的长度。 WebSocket 的帧有以下长度括号:
- mask(1 bit):指示连接是否掩盖。就目前而言,从客户端到服务器的每条消息都必须掩盖,如果规范没有掩盖,规范就会终止连接。
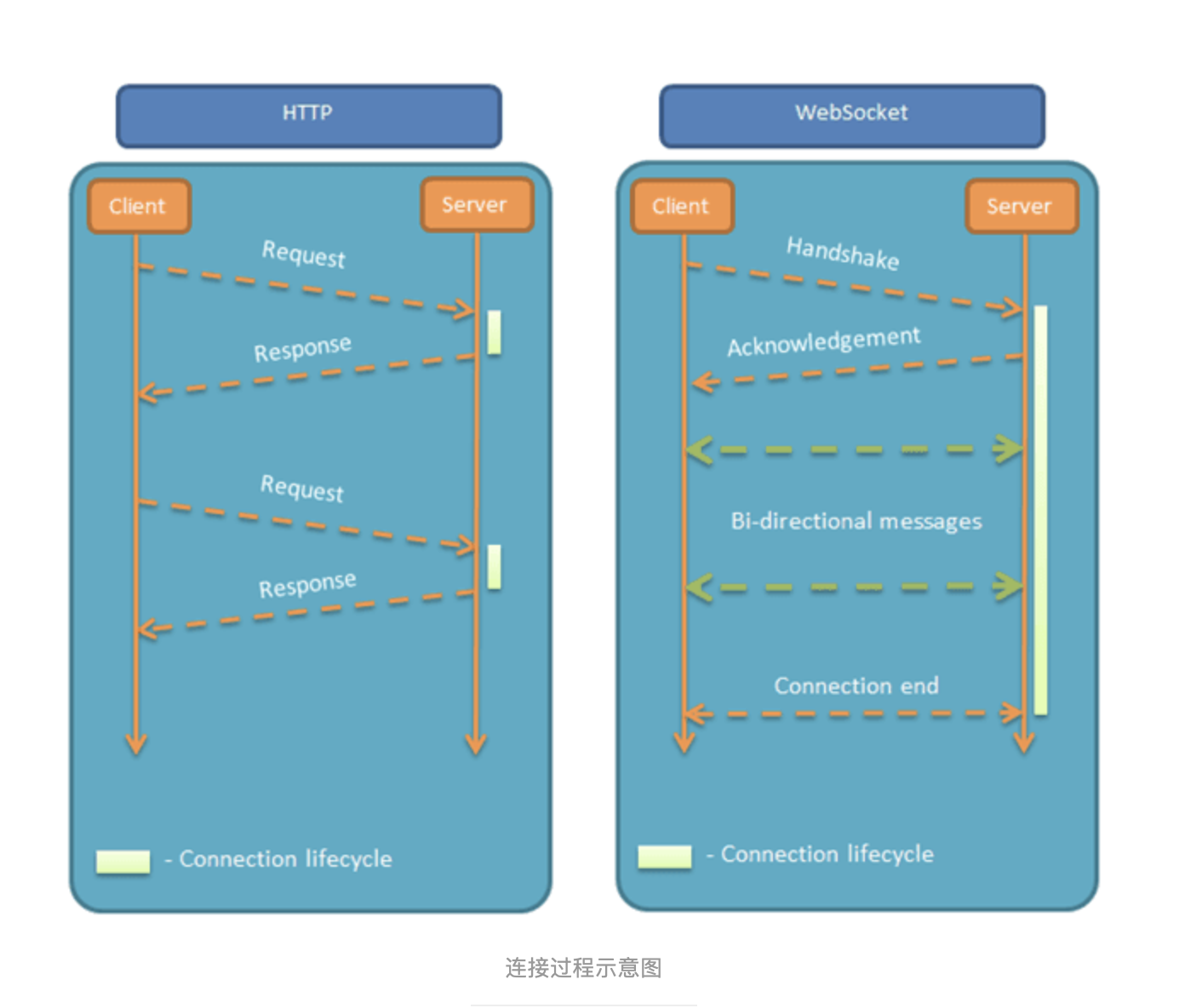
其他特点包括:
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
WebSocket常见的使用场景
要求服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息。(也可以采用HTTP/2)
iOS端实现WebSocket连接的参考方案
SocketRocket
SocketRocket是facebook封装的websocket开源库,采用纯Objective-C编写。
使用者需要自己实现心跳机制,以及适配断网重连等情况。
SocketIO
SocketIO将WebSocket、AJAX和其它的通信方式全部封装成了统一的通信接口,也就是说,我们在使用SocketIO时,不用担心兼容问题,底层会自动选用最佳的通信方式。因此说,WebSocket是SocketIO的一个子集。
另外,如果后端采用的是原生WebSocket,不建议大家使用SocketIO。因为SocketIO定制了专有的协议,并不是纯粹的WebSocket,可能会遭遇适配问题。
不过,SocketIO的API极其易用!!!
Starscream
采用Swift编写,不过笔者暂时还没有用过,不发表任何评论。
iOS端利用SocketRocket实现WebSocket连接
示例代码如下,欢迎指正:
import Foundation
import SocketRocket
import Alamofire
/// Websocket连接中的通知
let FSWebSocketConnectingNotification = NSNotification.Name.init("FSWebSocketConnectingNotification")
/// Websocket连接成功的通知
let FSWebSocketDidOpenNotification = NSNotification.Name.init("FSWebSocketDidOpenNotification")
/// Websocket连接收到新消息的通知
let FSWebSocketDidReceiveMessageNotification = NSNotification.Name.init("FSWebSocketDidReceiveMessageNotification")
/// Websocket连接失败的通知
let FSWebSocketFailWithErrorNotification = NSNotification.Name.init("FSWebSocketFailWithErrorNotification")
/// Websocket连接已关闭的通知
let FSWebSocketDidCloseNotification = NSNotification.Name.init("FSWebSocketDidCloseNotification")
/// websocket连接地址,请输入有效的websocket地址!
let WSAddr = "ws://host:port/ws"
/// 心跳包发送间隔,3分钟
let PingDuration = 180
/// Websocket连接对象
class FSWebsocket: NSObject,SRWebSocketDelegate {
static let `default` = FSWebsocket.init()
/// 是否在断开连接后自动重连
var autoReconnect = true
private var reachabilityManager = NetworkReachabilityManager.init(host: "www.baidu.com")
/// websocket连接地址
private var addr = WSAddr
/// websocket连接
private var ws:SRWebSocket?
/// 心跳包定时发送计时器
private var heartbeatTimer:Timer?
/// 重连计数器
private var reconnectCount = 0
override init() {
super.init()
NotificationCenter.default.addObserver(self, selector: #selector(appWillEnterForeground), name: NSNotification.Name.UIApplicationWillEnterForeground, object: nil)
NotificationCenter.default.addObserver(self, selector: #selector(appDidEnterBackground), name: NSNotification.Name.UIApplicationDidEnterBackground, object: nil)
// 切换网络自动重连
reachabilityManager?.listener = { [weak self] (networkReachabilityStatus) in
// 正在连接中或已经连接成功,不需要重连
if self?.ws?.readyState == .CONNECTING || self?.ws?.readyState == .OPEN{
return
}
// 设置自动重连才会进行自动重连
if let s = self, s.autoReconnect{
self?.reconnect()
}
}
reachabilityManager?.startListening()
}
deinit {
NotificationCenter.default.removeObserver(self)
}
@objc func appDidEnterBackground(){
close()
}
@objc func appWillEnterForeground(){
reconnect()
}
// MARK: - Send Message
@discardableResult
func sendJSON(_ json:[AnyHashable : Any]) -> NSError?{
let jsonData = try? JSONSerialization.data(withJSONObject: json, options: JSONSerialization.WritingOptions.prettyPrinted)
return self.sendData(jsonData)
}
@discardableResult
func sendData(_ data:Data?) -> NSError?{
guard ws?.readyState == SRReadyState.OPEN else{
return NSError.init(domain: "FSWebsocket", code: SRStatusCodeGoingAway.rawValue, userInfo: nil)
}
ws?.send(data)
return nil
}
// MARK: - Connection Management
/// 连接websocket服务器
func open(){
let url = URL(string: self.addr)
assert(url != nil)
self.ws = SRWebSocket.init(url: url!)
ws?.delegate = self
ws?.open()
NotificationCenter.default.post(name: FSWebSocketConnectingNotification, object: self)
}
/// 重新连接
private func reconnect(){
if !autoReconnect{
return
}
if reconnectCount > 64 {
return
}
let seconds = DispatchTime.now().uptimeNanoseconds + UInt64(reconnectCount) * NSEC_PER_SEC
let time = DispatchTime.init(uptimeNanoseconds: seconds)
DispatchQueue.main.asyncAfter(deadline: time) {
self.ws?.close()
self.ws = nil
self.open()
}
if reconnectCount == 0 {
reconnectCount = 1
}
reconnectCount *= 2
}
/// 关闭连接
func close(){
self.destroyHeartbeat()
self.ws?.close()
self.ws = nil
resetConnectCount()
}
/// 发送心跳包
@objc func heartbeat(){
guard ws?.readyState == SRReadyState.OPEN else{
return
}
self.ws?.sendPing(nil)
}
/// 启动心跳
private func startHeartbeat(){
let timer = Timer.init(timeInterval: TimeInterval(PingDuration), target: self, selector: #selector(heartbeat), userInfo: nil, repeats: true)
self.heartbeatTimer = timer
RunLoop.current.add(timer, forMode: RunLoopMode.commonModes)
}
/// 停止心跳
private func destroyHeartbeat(){
self.heartbeatTimer?.invalidate()
self.heartbeatTimer = nil
}
/// 重置重连尝试次数
private func resetConnectCount(){
reconnectCount = 0
}
// MARK: - SRWebSocketDelegate
func webSocketDidOpen(_ webSocket: SRWebSocket!) {
self.resetConnectCount()
self.startHeartbeat()
NotificationCenter.default.post(name: FSWebSocketDidOpenNotification, object: self)
}
func webSocket(_ webSocket: SRWebSocket!, didReceiveMessage message: Any!) {
guard let msgString = message as? NSString else{
return
}
guard let msgData = msgString.data(using: String.Encoding.utf8.rawValue) else{
return
}
// 如果传输的是JSON数据,可以使用JSONSerialization将JSON字符串转换为字典
guard let msgJSON = try? JSONSerialization.jsonObject(with: msgData, options: JSONSerialization.ReadingOptions.allowFragments) else{
return
}
NotificationCenter.default.post(name: FSWebSocketDidReceiveMessageNotification, object: self, userInfo: ["message":msgJSON])
}
func webSocket(_ webSocket: SRWebSocket!, didFailWithError error: Error!) {
NotificationCenter.default.post(name: FSWebSocketFailWithErrorNotification, object: self, userInfo: ["error": error])
// 连接失败:
if (error as NSError).code == 50{
// 断网,不重连
return
}
// 当前页面不需要使用websocket,不重连
// 重连次数超过限制,不重连
reconnect()
}
func webSocket(_ webSocket: SRWebSocket!, didReceivePong pongPayload: Data!) {
// 心跳包响应回调
}
func webSocket(_ webSocket: SRWebSocket!, didCloseWithCode code: Int, reason: String!, wasClean: Bool) {
// 连接被关闭
NotificationCenter.default.post(name: FSWebSocketDidCloseNotification, object: self, userInfo: ["code": code, "reason": reason, "wasClean": wasClean])
close()
}
}摘自链接:https://www.jianshu.com/p/934c0d79f75e
【性能优化】关键性能指标及测量标准
前言
随着时代的发展,业内曾经提出过很多性能优化相关的标准和规范,从最初2007年雅虎提出34条军规,到2020年google开始推广Web Vitals,优化技术已经有将近20多年的发展历史,如下图所示:

发展过程中产生了许多的性能指标、测量工具、优化手段等等,本文主要讲述关键性能指标及测量标准。
性能指标,顾名思义,就是性能优化过程中参考的一些标准。
进行性能优化,指标就是我们的一个抓手,首先你就要确定它的指标,然后才能根据指标去采取措施,否则就会像无头苍蝇一样乱撞,没有执行目标。
什么样的指标值得我们关注?
Web Vitals
Google在2020年推出了一个名为Web Vitals的新概念,着重评估一组页面访问体验钟的一部分关键指标,目的在于简化网络性能。每个指标代表页面体验的一个关键方面:加载、交互和视觉稳定性。

Web Vitals在感知的性能,交互性和令人愉悦的方面,可作为用户体验的简化基准。在考虑页面性能时,应该首先关注这一套较小的指标。
此外,Web Vitals代表了访问者在访问您的页面时首先在其视口中看到的内容,即首屏内容。他们首先看到的内容最终会影响他们对页面性能的看法。
首先,专注于这三个指标,可以使您获得可感知的和实际的性能可观的收益,然后再深入研究其他优化。
加载
所谓加载,就是进入页面时,页面内容的载入过程。比如,当你打开一些网站时,你会发现,有的网站首页上的文字、图片出现很缓慢,而有的则很快,这个内容出现的过程就是加载。加载缓慢严重消耗用户的耐心,会让用户离开页面。
这里我们拿淘宝首页的network信息观察一些指标:

如图所示,我们可以看到下方显示网页加载一共有201次请求(requests)、3.3MB资源量(resources),DOM完成的加载时间92ms(DOMContentLoaded)、总资源加载时间479ms(Load),这对一个电商网站来说已经很好了。
瀑布图
再来看瀑布图,nextwork中加载资源的列表右侧的Waterfall一栏显示的就是瀑布图,它可以非常直观的将网站的资源加载用自上而下的方式表达出来。我们可以从横向和纵向两个方向来解读它。
横向来看是具体资源的加载,如下图所示:


下面我们再来纵向看瀑布图,主要看2点:
- 资源之间的联系:如果下载发生了阻塞,很多资源的下载就会是串行处理的。如果是并行的,就可以加快下载过程。
- 关键时间节点:我们可以看到图中有红蓝两个颜色的两根线,蓝色的是DOM完成的加载时间,红色是页面中所有声明的资源加载完成的时间。

关键指标
那么这么多指标,到底哪些是最值得我们关注的呢?下面我来总结一下:
白屏时间(FP,First Paint):也叫首次绘制时间,对于应用页面,首次出现视觉上不同于跳转之前内容的时间点,或者说是页面发生第一次绘制的时间点,它的标准时间是 300ms。如果白屏时间过长,用户会认为我们的页面不可用,或者可用性差。如果超过一定时间(如 1s),用户注意力就会转移到其他页面。
首屏时间(FCP,First Contentful Paint):也叫首次有内容绘制时间,对于所有的网页应用,这是一个非常重要的指标。它是指从浏览器输入地址并回车后,到首屏内容渲染完毕的时间。这期间不需要滚动鼠标或者下拉页面,否则无效。也就是说,它是浏览器完成渲染DOM中第一部分内容(可能是文本、图像或其它任何元素)的时间点,此时用户应该在视觉上有直观的感受。
首次有意义绘制(FMP,First Meaningful Paint):指页面关键元素的渲染时间。这个概念并没有标准化定义,因为关键元素可以由开发者自行定义究竟什么是“有意义”的内容,只有开发者或者产品经理自己了解。
速度指数(Speed Index):指的是网页以多快的速度展示内容,标准时间是4s。
总下载时间(Load):页面所有资源加载完成所需要的时间。一般可以统计 window.onload,得到同步加载的资源全部加载完的耗时。如果页面中存在较多异步渲染,那么可以将异步渲染全部完成的时间作为总下载时间。
TTFB(Time To First Byte):是指网络请求被发起到从服务器接收到地一个字节的这段时间。其中包含了TCP连接时间、发送HTTP请求时间和获得相应消息第一个字节的时间。
TTFB这个参数比较重要,因为它可以给用户最直观的感受,如果TTFB很慢,说明资源一直没有返回,增加白屏时间,如果TTFB很快,资源回来之后就可以进行快速的解析和渲染。
那么影响TTFB的因素有哪些?
- 后台处理能力,服务器响应到底有多快
- 资源请求的网络状况,网络是否有延迟
首屏时间 vs 白屏时间
首屏时间 = 白屏时间 + 渲染时间。在加载性能指标方面,相比于白屏时间,首屏时间更重要。为什么?
从重要性角度看,打开页面后,第一眼看到的内容一般都非常关键,比如电商的头图、商品价格、购买按钮等。这些内容即便在最恶劣的网络环境下,我们也要确保用户能看得到。
从体验完整性角度看,进入页面后先是白屏,随着第一个字符加载,到首屏内容显示结束,我们才会认为加载完毕,用户可以使用了。白屏加载完成后,仅仅意味着页面内容开始加载,但我们还是没法完成诸如下单购买等实际操作,首屏时间结束后则可以。
DOMContentLoaded和Load事件的区别
其实从这两个事件的命名就能体会到,DOMContentLoaded 指的是文档中 DOM 加载内容加载完毕的时间,也就是说 HTML 结构已经是完整的了。但是我们知道,很多页面都包含图片、特殊字体、视频、音频等其他资源,由于这些资源由网络请求获取,需要额外的网络请求,因此DOM内容如加载完毕时,这些资源还没有请求或渲染完成。当页面上所有资源加载完成后,Load 事件才会被触发。
因此,在时间线上,Load 事件往往会落后于 DOMContentLoaded 事件。
交互/响应
所谓交互,就是用户点击网站或 App 的某个功能,页面给出的回应,也就是浏览器的响应时间。比如我们点击了一个“点赞”按钮,立刻给出了点赞数加一的展示,这就是交互体验好,反之如果很长时间都没回应,这就是交互体验不好。
关于交互指标,有的公司用 FID 指标 (First Input Delay,首次输入延迟), 指标必须尽量小于 100ms,如果过长会给人页面卡顿的感觉。还有的公司使用 PSI(Perceptual Speed Index,视觉变化率),衡量标准是小于20%。
一般来说,主要包括以下几个指标:
交互动作的反馈时间:也叫用户可交互时间,就是用户可以与应用进行加护的时间,一般来讲,我们认为是 DOMReady 的时间,因为我们通常会在这时绑定事件操作。如果页面中设计交互的脚本没有下载完成,那么当然没有达到所谓的用户可交互时间。那么如何定义 DOMReady 时间呢?这里我推荐大家看司徒正美的文章《何谓DOMReady》。
刷新率(FPS,Frame Per Second):也叫帧率,标准的刷新率指标是60帧/s,它可以决定画面是否足够流畅。
异步请求的完成时间:所有的异步请求能在1s中内请求回来。
关于帧率,我们可以用chorme Devtools来查看,打开控制台,点击快捷键command/ctrl+shift+P,弹出下面的弹窗,输入frame,点击FPS一栏,就会在页面左上角看到图2所示的监控台,显示网页交互过程中每一帧的绘制频率。

不同帧率的体验
- 帧率能够达到 50 ~ 60 FPS 的动画将会相当流畅,让人倍感舒适;
- 帧率在 30 ~ 50 FPS 之间的动画,因各人敏感程度不同,舒适度因人而异;
- 帧率在 30 FPS 以下的动画,让人感觉到明显的卡顿和不适感;
- 帧率波动很大的动画,亦会使人感觉到卡顿
现在网上很多关于浏览器reflow的文章都说给要少用offsetTop, offsetLeft 等获取布局信息的。因为这些属性需要触发一次浏览器的的Layout。也就是说在一帧内(16ms)会多了一次layout。如果Layout的次数太多,就会导致掉帧。
视觉稳定性
视觉稳定性指标CLS(Cumulative Layout Shift),也就是布局偏移量,它是指页面从一帧切换到另外一帧时,视线中不稳定元素的偏移情况。
比如,你想要购买的商品正在参加抢购活动,而且时间快要到了。在你正要点击页面链接购买的时候,原来的位置插入了一条 9.9 元包邮的商品广告。结果会怎样?你点成了那个广告商品。如果等你再返回购买的时候,你心仪商品的抢购活动结束了,你是不是很气?所以,CLS也非常重要。
一个好的CLS分数是75%以上的用户小于0.1,如图所示:

布局偏移的具体内容
布局偏移是由 Layout Instability API 定义的。这个API会在任意时间上报 layout-shift 的条目,当一个可见元素在两帧之间,改变了它的起始位置(默认的 writing mode 下指的是top和left属性)。这些元素被当成不稳定元素。
需要注意的是,布局偏移只发生在已经存在的元素改变起始位置的时候。如果一个新的元素被添加到dom上,或者已存在的元素改变它的尺寸,除非改变了其他元素的起始位置,否则都不算布局偏移。
布局偏移主要包含以下几项:
布局偏移分数:布局偏移的分数是两个度量的乘积:影响分数(impact fraction)和距离分数(distance fraction)。如果是一个很大的元素移动了较小的距离,实际影响并不大,所以分数需要依赖两个度量。
影响分数:影响分数测试的是两帧之间,不稳定元素在视图上的影响范围。
距离分数:距离分数测试的是两帧之间,不稳定元素在视图上移动的距离(水平和纵向取最大值)。如果有多个不稳定元素,也是取其中最大的一个。
动画和过渡:动画和过渡,如果做得好,对用户而言是一个不错的更新内容的方式,这样不会给用户“惊喜”。突然出现的或者预料之外的内容,会给用户一个很差的体验。但如果是一个动画或者过渡,用户可以很清楚的知道发生了什么,在状态变化的时候可以很好的引导用户。
CSS中的
transform属性可以让你在使用动画的时候不会产生布局偏移。
- 用
transform:scale()来替换width和height属性 - 用
transform:translate()来替换top,left,bottom,right属性
- 用
CLS是平时开发很少关注的点,页面视觉稳定性对很多web开发而言,可能没有加载性能那么关注度高,但对用户而言,这确实是很困扰的一点。平时开发中,尽可能的提醒自己,不管是产品交互图出来之后,或者是UI的视觉稿出来之后,如果出现了布局偏移的情况,都可以提出这方面的意见。开发过程中也尽可能的遵循上面提到的一些优化点,给用户一个稳定的视觉体验。
RAIL测量模型
RAIL模型是2015年google提出的一个可以量化的测量标准,通过RAIL模型可以指导性能优化的目标,让良好的用户体验成为可能。
Response 响应:是指用户操作网页的时候浏览器给到用户的反馈时间,其中处理事件应在50ms以内完成。
为什么是50ms?谷歌向向用户发起调研,将用户的反馈分成了几个组,经过研究得出用户能接受的反馈时间是100ms。
那么为什么我们要设置在50ms以内,因为100ms是用户输入到反馈的时间,但是浏览器处理反馈也需要时间,所以留给开发者优化处理事件的时间在50ms以内。如下图所示:

Animation - 页面中动画特效的流畅度,达到每10ms产生一帧。
根据研究得出,动画要达到60sps,即每秒60帧给人眼的感觉是流畅的,每一帧大概在16ms,去除浏览器绘制动画的6ms,开发者要保证每10ms产生一帧。
在这16ms内浏览器要完成的工作有:
- 脚本执行(JavaScript):脚本造成了需要重绘的改动,比如增删 DOM、请求动画等
- 样式计算(CSS Object Model):级联地生成每个节点的生效样式。
- 布局(Layout):计算布局,执行渲染算法
- 重绘(Paint):各层分别进行绘制(比如 3D 动画)
- 合成(Composite):将位图发送给合成线程。
Idle空闲 - 浏览器有足够的空闲时间,与响应想呼应。尽可能最大化空闲时间,不能让事件处理时间太长,超过50ms。
例如延迟加载可以用空闲时间去加载。但是如果需要前端做业务计算,就是不合理的。
Load - 网络加载时间,在5s内完成内容加载并可以交互。首先加载-解析-渲染的时间在5s,其次网络环境差的情况下,加载也会受到影响。
总结
至此,性能优化的指标我就介绍完了,现将关键指标总结如下:
- 性能优化的三个方向:加载、交互、视觉稳定性
- 加载的关键指标有:TTFB(请求等待时间)、FP(白屏时间)、FCP(首屏时间)、Speed Index(4s)
- 交互的关键指标:用户可交互时间、帧率(FPS)、异步请求完成时间
- 交互稳定性(CLS):布局偏移量中,布局偏移分数 = 影响分数 x 距离分数
- RAIL测量模型关注点:响应时间50ms、动画10ms/帧、浏览器空闲时间<50ms、网络加载时间5s
链接:https://juejin.cn/post/6956583036133572639
前端的你还不会优化你的图片资源?来看这一篇就够了!
优质的图片可以有效吸引用户,给用户良好的体验,所以随着互联网的发展,越来越多的产品开始使用图片来提升产品体验。相较于页面其他元素,图片的体积不容忽视。下图是截止 2019 年 6 月 HTTP Archive[1] 上统计的网站上各类资源加载的体积:
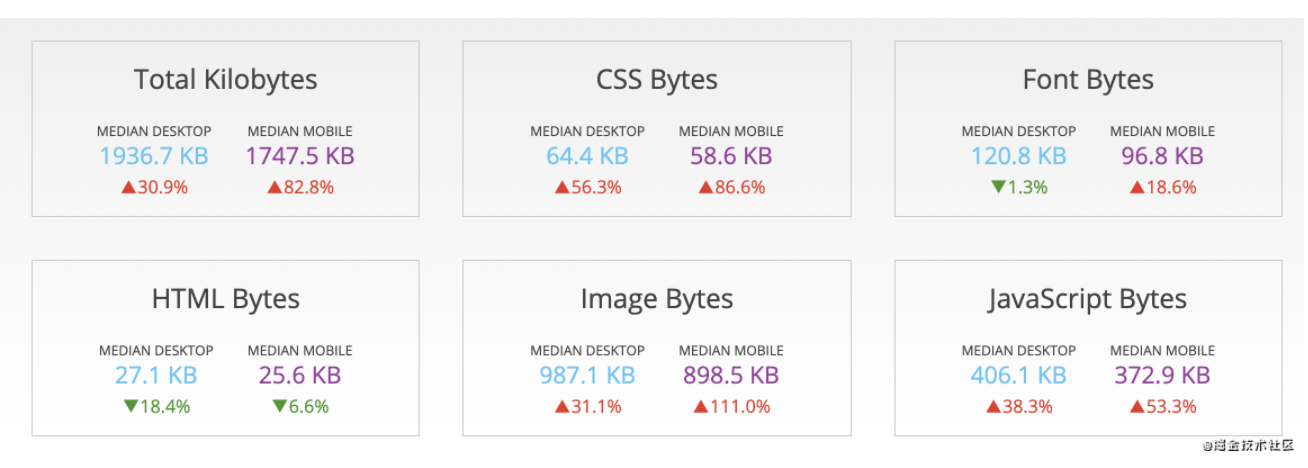
可以看到,图片占据了半壁江山。同样,在一篇 2018 年的文章中,也提到了图片在网站中体量的平均占比已经超过了 50%[2]。然而,随着平均加载图片总字节数的增加,图片的请求数却再减少,这也说明网站使用的图片质量和大小正在不断提高。
所以,如果单纯从加载的字节数这个维度来看性能优化,那么很多时候,优化图片带来的流量收益要远高于优化 JavaScript 脚本和 CSS 样式文件。下面我们就来看看,如何优化图片资源。
1. 优化请求数
1.1. 雪碧图
图片可以合并么?当然。最为常用的图片合并场景就是雪碧图(Sprite)[3]。
在网站上通常会有很多小的图标,不经优化的话,最直接的方式就是将这些小图标保存为一个个独立的图片文件,然后通过 CSS 将对应元素的背景图片设置为对应的图标图片。这么做的一个重要问题在于,页面加载时可能会同时请求非常多的小图标图片,这就会受到浏览器并发 HTTP 请求数的限制。我见过一个没有使用雪碧图的页面,首页加载时需要发送 20+ 请求来加载图标。将图标合并为一张大图可以实现「20+ → 1」的巨大缩减。
雪碧图的核心原理在于设置不同的背景偏移量,大致包含两点:
- 不同的图标元素都会将
background-url设置为合并后的雪碧图的 uri; - 不同的图标通过设置对应的
background-position来展示大图中对应的图标部分。
你可以用 Photoshop 这类工具自己制作雪碧图。当然比较推荐的还是将雪碧图的生成集成到前端自动化构建工具中,例如在 webpack 中使用 webpack-spritesmith,或者在 gulp 中使用 gulp.spritesmith。它们两者都是基于于 spritesmith 这个库,你也可以自己将这个库集成到你喜欢的构建工具中。
1.2. 懒加载
我们知道,一般来说我们访问一个页面,浏览器加载的整个页面其实是要比可视区域大很多的,也是什么我们会提出“首屏”的概念。这就导致其实很多图片是不在首屏中的,如果我们都加载的话,相当于是加载了用户不一定会看到图片。而图片体积一般都不小,这显然是一种流量的浪费。这种场景在一些带图片的长列表或者配图的博客中经常会遇到。
解决的核心思路就是图片懒加载 —— 尽量只加载用户正在浏览或者即将会浏览到的图片。实现上来说最简单的就是通过监听页面滚动,判断图片是否进入视野,从而真正去加载图片:
function loadIfNeeded($img) {
const bounding = $img..getBoundingClientRect();
if (
getComputedStyle($img).display !== 'none'
&& bounding.top <= window.innerHeight
&& bounding.bottom >= 0
) {
$img.src = $img.dataset.src;
$img.classList.remove('lazy');
}
}
// 这里使用了 throttle,你可以实现自己的 throttle,也可以使用 lodash
const lazy = throttle(function () {
const $imgList = document.querySelectorAll('.lazy');
if ($imgList.length === 0) {
document.removeEventListener('scroll', lazy);
window.removeEventListener('resize', lazy);
window.removeEventListener('orientationchange', lazy);
return;
}
$imgList.forEach(loadIfNeeded);
}, 200);
document.addEventListener('scroll', lazy);
window.addEventListener('resize', lazy);
window.addEventListener('orientationchange', lazy);对于页面上的元素只需要将原本的 src 值设置到 data-src 中即可,而 src 可以设置为一个统一的占位图。注意,由于页面滚动、缩放和横竖方向(移动端)都可能会改变可视区域,因此添加了三个监听。
当然,这是最传统的方法,现代浏览器还提供了一个更先进的 Intersection Observer API[4] 来做这个事,它可以通过更高效的方式来监听元素是否进入视口。考虑兼容性问题,在生产环境中建议使用对应的 polyfill。
如果想使用懒加载,还可以借助一些已有的工具库,例如 aFarkas/lazysizes、verlok/lazyload、tuupola/lazyload 等。
在使用懒加载时也有一些注意点:
- 首屏可以不需要懒加载,对首屏图片也使用懒加载会延迟图片的展示。
- 设置合理的占位图,避免图片加载后的页面“抖动”。
- 虽然目前基本所有用户都不会禁用 JavaScript,但还是建议做一些 JavaScript 不可用时的 backup。
对于占位图这块可以再补充一点。为了更好的用户体验,我们可以使用一个基于原图生成的体积小、清晰度低的图片作为占位图。这样一来不会增加太大的体积,二来会有很好的用户体验。LQIP (Low Quality Image Placeholders)[5] 就是这种技术。目前也已经有了 LQIP 和 SQIP(SVG-based LQIP) 的自动化工具可以直接使用。
如果你想了解更多关于图片懒加载的内容,这里有一篇更详尽的图片懒加载指南[6]。
1.3. CSS 中的图片懒加载
除了对于 <img> 元素的图片进行来加载,在 CSS 中使用的图片一样可以懒加载,最常见的场景就是 background-url
.login {
background-url: url(/static/img/login.png);
}对于上面这个样式规则,如果不应用到具体的元素,浏览器不会去下载该图片。所以你可以通过切换 className 的方式,放心得进行 CSS 中图片的懒加载。
1.4. 内联 base64
还有一种方式是将图片转为 base64 字符串,并将其内联到页面中返回,即将原 url 的值替换为 base64。这样,当浏览器解析到这个的图片 url 时,就不会去请求并下载图片,直接解析 base64 字符串即可。
但是这种方式的一个缺点在于相同的图片,相比使用二进制,变成 base64 后体积会增大 33%。而全部内联进页面后,也意味着原本可能并行加载的图片信息,都会被放在页面请求中(像当于是串行了)。同时这种方式也不利于复用独立的文件缓存。所以,使用 base64 需要权衡,常用于首屏加载 CRP 或者骨架图上的一些小图标。
2. 减小图片大小
2.1. 使用合适的图片格式
使用合适的图片格式不仅能帮助你减少不必要的请求流量,同时还可能提供更好的图片体验。
图片格式是一个比较大的话题,选择合适的格式[7]有利于性能优化。这里我们简单总结一些。
1) 使用 WebP:
考虑在网站上使用 WebP 格式[8]。在有损与无损压缩上,它的表现都会优于传统(JPEG/PNG)格式。WebP 无损压缩比 PNG 的体积小 26%,webP 的有损压缩比同质量的 JPEG 格式体积小 25-34%。同时 WebP 也支持透明度。下面提供了一种兼容性较好的写法。
<picture>
<source type="image/webp" srcset="/static/img/perf.webp">
<source type="image/jpeg" srcset="/static/img/perf.jpg">
<img src="/static/img/perf.jpg">
</picture>2) 使用 SVG 应对矢量图场景:
在一些需要缩放与高保真的情况,或者用作图标的场景下,使用 SVG 这种矢量图非常不错。有时使用 SVG 格式会比相同的 PNG 或 JPEG 更小。
3) 使用 video 替代 GIF:
在兼容性允许的情况下考虑,可以在想要动图效果时使用视频,通过静音(muted)的 video 来代替 GIF。相同的效果下,GIF 比视频(MPEG-4)大 5~20 倍。Smashing Magazine 上有篇文章[9]详细介绍使用方式。
4) 渐进式 JPEG:
基线 JPEG (baseline JPEG) 会从上往下逐步呈现,类似下面这种:

而另一种渐进式 JPEG (progressive JPEG)[10] 则会从模糊到逐渐清晰,使人的感受上会更加平滑。

不过渐进式 JPEG 的解码速度会慢于基线 JPEG,所以还是需要综合考虑 CPU、网络等情况,在实际的用户体验之上做权衡。
2.2. 图片质量的权衡
图片的压缩一般可以分为有损压缩(lossy compression)和无损压缩(lossless compression)。顾名思义,有损压缩下,会损失一定的图片质量,无损压缩则能够在保证图片质量的前提下压缩数据大小。不过,无损压缩一般可以带来更可观的体积缩减。在使用有损压缩时,一般我们可以指定一个 0-100 的压缩质量。在大多数情况下,相较于 100 质量系数的压缩,80~85 的质量系数可以带来 30~40% 的大小缩减,同时对图片效果影响较小,即人眼不易分辨出质量效果的差异。

处理图片压缩可以使用 imagemin 这样的工具,也可以进一步将它集成至 webpack、Gulp、Grunt 这样的自动化工具中。
2.3. 使用合适的大小和分辨率
由于移动端的发展,屏幕尺寸更加多样化了。同一套设计在不同尺寸、像素比的屏幕上可能需要不同像素大小的图片来保证良好的展示效果;此外,响应式设计也会对不同屏幕上最佳的图片尺寸有不同的要求。
以往我们可能会在 1280px 宽度的屏幕上和 640px 宽度的屏幕上都使用一张 400px 的图,但很可能在 640px 上我们只需要 200px 大小的图片。另一方面,对于如今盛行的“2 倍屏”、“3 倍屏”也需要使用不同像素大小的资源。
好在 HTML5 在 <img> 元素上为我们提供了 srcset 和 sizes 属性,可以让浏览器根据屏幕信息选择需要展示的图片。
<img srcset="small.jpg 480w, large.jpg 1080w" sizes="50w" src="large.jpg" >2.4. 删除冗余的图片信息
你也许不知道,很多图片含有一些非“视觉化”的元信息(metadata),带上它们可会导致体积增大与安全风险[12]。元信息包括图片的 DPI、相机品牌、拍摄时的 GPS 等,可能导致 JPEG 图片大小增加 15%。同时,其中的一些隐私信息也可能会带来安全风险。
所以如果不需要的情况下,可以使用像 imageOptim 这样的工具来移除隐私与非关键的元信息。
2.5 SVG 压缩
在 2.1. 中提到,合适的场景下可以使用 SVG。针对 SVG 我们也可以进行一些压缩。压缩包括了两个方面:
首先,与图片不同,图片是二进制形式的文件,而 SVG 作为一种 XML 文本,同样是适合使用 gzip 压缩的。
其次,SVG 本身的信息、数据是可以压缩的,例如用相比用 <path> 画一个椭圆,直接使用 <ellipse> 可以节省文本长度。关于信息的“压缩”还有更多可以优化的点[13]。SVGGO 是一个可以集成到我们构建流中的 NodeJS 工具,它能帮助我们进行 SVG 的优化。当然你也可以使用它提供的 Web 服务。
3. 缓存
与其他静态资源类似,我们仍然可以使用各类缓存策略来加速资源的加载。
图片作为现代 Web 应用的重要部分,在资源占用上同样也不可忽视。可以发现,在上面提及的各类优化措施中,同时附带了相应的工具或类库。平时我们主要的精力会放在 CSS 与 JavaScript 的优化上,因此在图片优化上可能概念较为薄弱,自动化程度较低。如果你希望更好得去贯彻图片的相关优化,非常建议将自动化工具引入到构建流程中。
除了上述的一些工具,这里再介绍两个非常好用的图片处理的自动化工具:Sharp 和 Jimp。
好了,我们的图片优化之旅就暂时到这了,下面就是字体资源了。
链接:https://juejin.cn/post/6962800616259190792
仅使用CSS就可以提高页面渲染速度的4个技巧
用户喜欢快速的网络应用,他们希望页面加载速度快,功能流畅。如果在滚动时有破损的动画或滞后,用户很有可能会离开你的网站。作为一名开发者,你可以做很多事情来改善用户体验。本文将重点介绍4个可以用来提高页面渲染速度的CSS技巧。
1. Content-visibility
一般来说,大多数Web应用都有复杂的UI元素,它的扩展范围超出了用户在浏览器视图中看到的内容。在这种情况下,我们可以使用内容可见性( content-visibility )来跳过屏幕外内容的渲染。如果你有大量的离屏内容,这将大大减少页面渲染时间。
这个功能是最新增加的功能之一,也是对提高渲染性能影响最大的功能之一。虽然 content-visibility 接受几个值,但我们可以在元素上使用 content-visibility: auto; 来获得直接的性能提升。
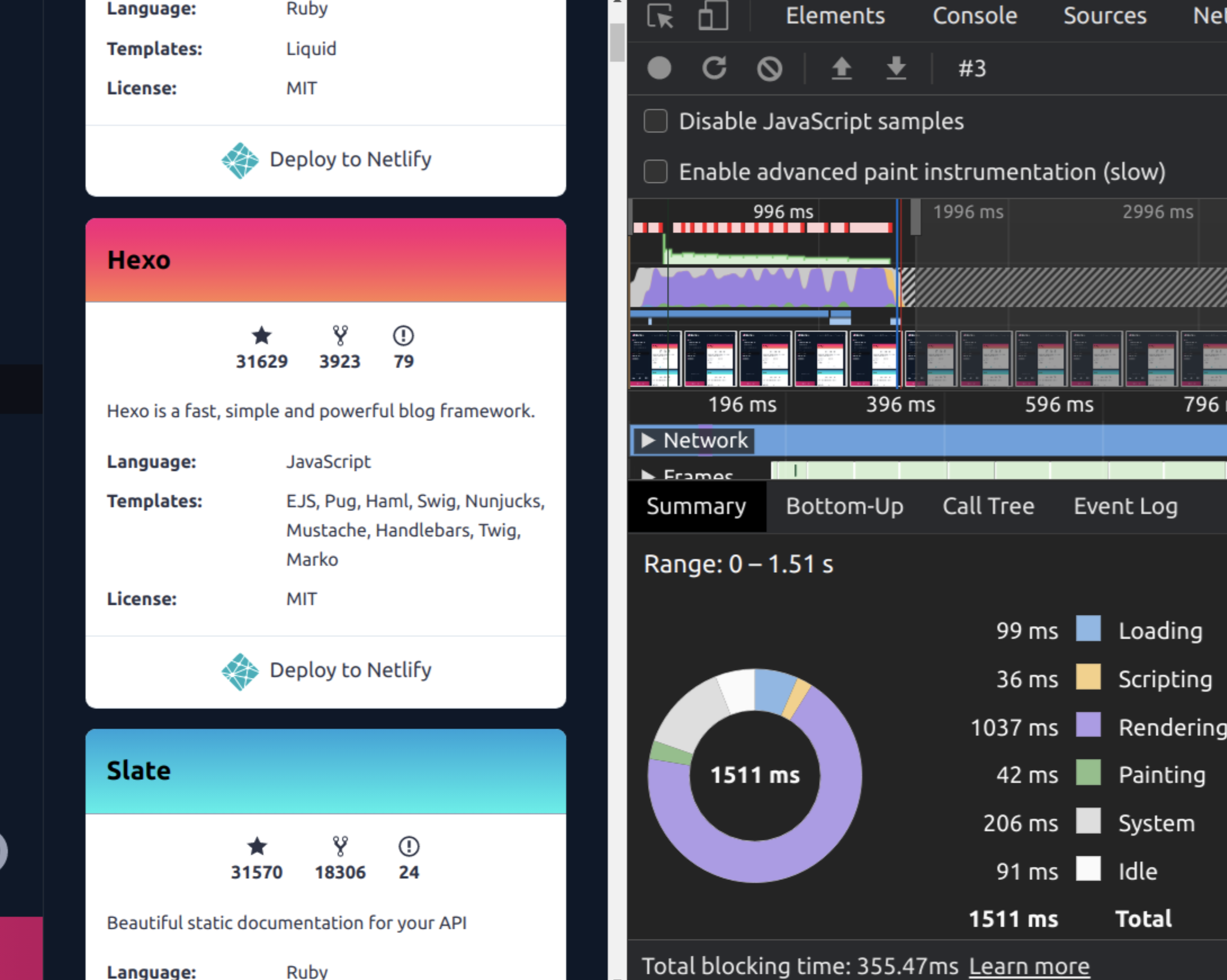
让我们考虑一下下面的页面,其中包含许多不同信息的卡片。虽然大约有12张卡适合屏幕,但列表中大约有375张卡。正如你所看到的,浏览器用了1037ms来渲染这个页面。
下一步,您可以向所有卡添加 content-visibility 。
在这个例子中,在页面中加入
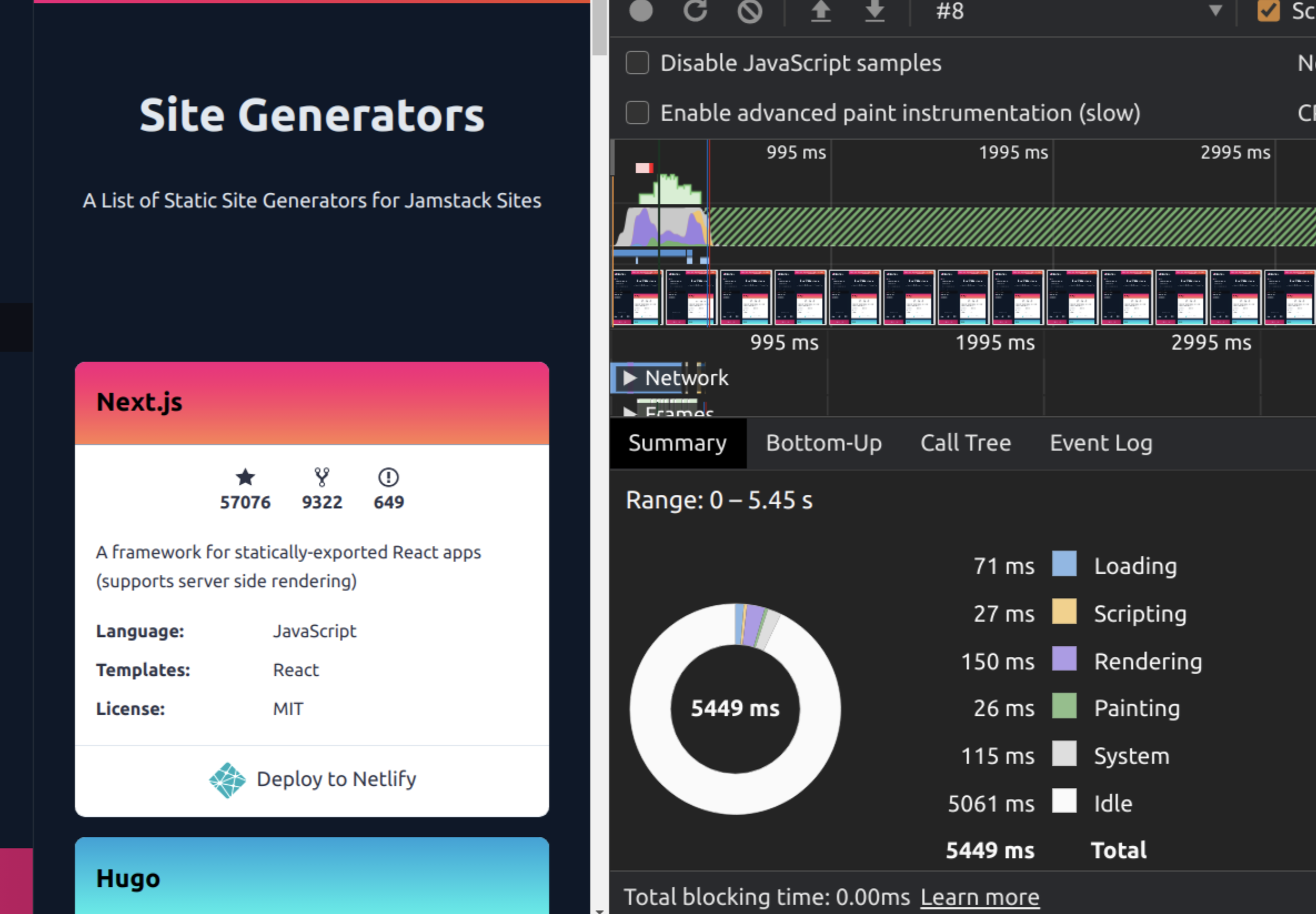
content-visibility后,渲染时间下降到150ms,这是6倍以上的性能提升。
正如你所看到的,内容可见性是相当强大的,对提高页面渲染时间非常有用。根据我们目前所讨论的东西,你一定是把它当成了页面渲染的银弹。
然而,有几个领域的内容可视性不佳。我想强调两点,供大家参考。
- 此功能仍处于试验阶段。 截至目前,Firefox(PC和Android版本)、IE(我认为他们没有计划在IE中添加这个功能)和,Safari(Mac和iOS)不支持内容可见性。
- 与滚动条行为有关的问题。 由于元素的初始渲染高度为0px,每当你向下滚动时,这些元素就会进入屏幕。实际内容会被渲染,元素的高度也会相应更新。这将使滚动条的行为以一种非预期的方式进行。
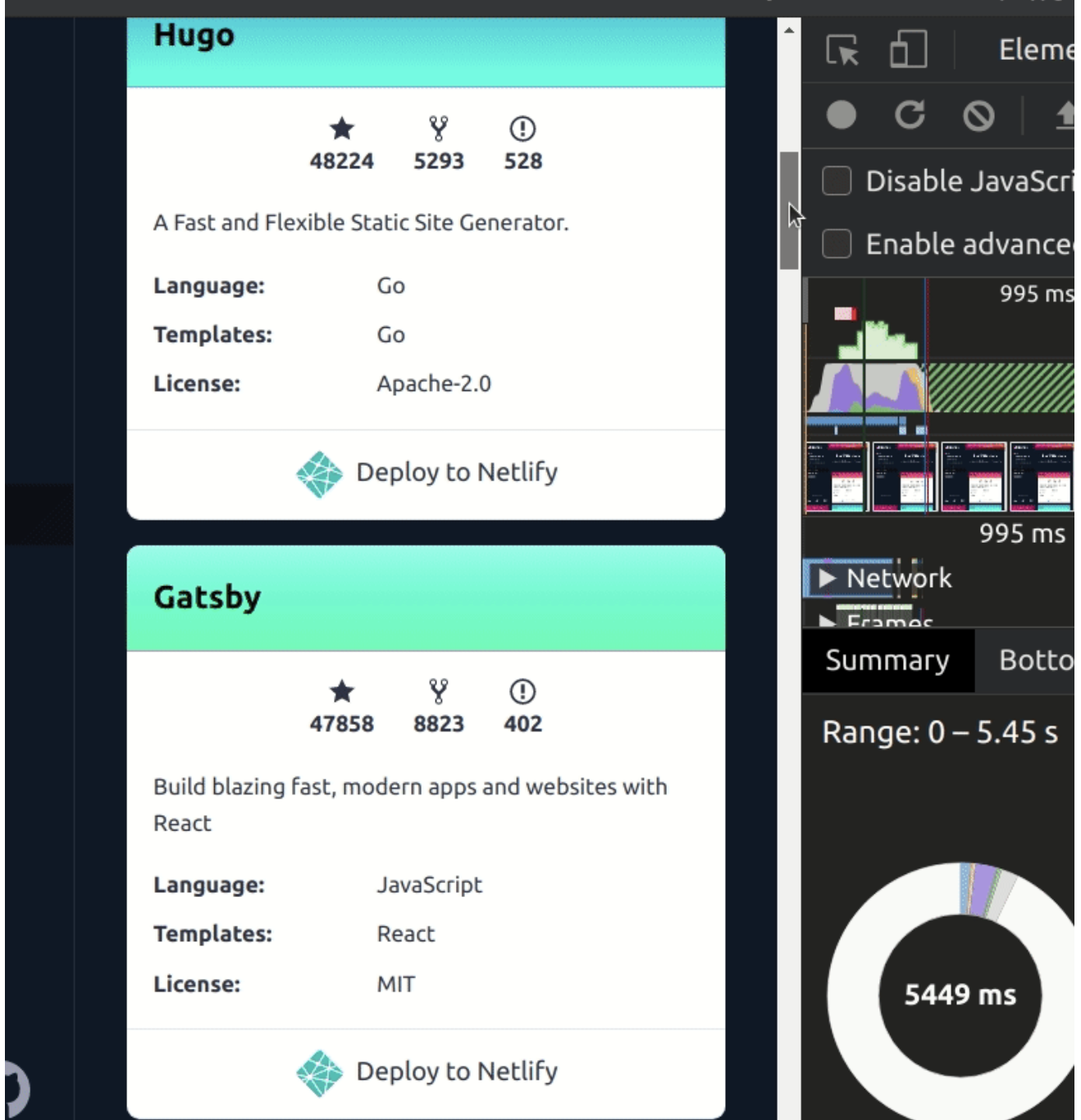
为了解决滚动条的问题,你可以使用另一个叫做 contain-intrinsic-size 的 CSS 属性。它指定了一个元素的自然大小,因此,元素将以给定的高度而不是0px呈现。
.element{
content-visibility: auto;
contain-intrinsic-size: 200px;
}然而,在实验时,我注意到,即使使用 conta-intrinsic-size,如果我们有大量的元素, content-visibility 设置为 auto ,你仍然会有较小的滚动条问题。
因此,我的建议是规划你的布局,将其分解成几个部分,然后在这些部分上使用内容可见性,以获得更好的滚动条行为。
2. Will-change 属性
浏览器上的动画并不是一件新鲜事。通常情况下,这些动画是和其他元素一起定期渲染的。不过,现在浏览器可以使用GPU来优化其中的一些动画操作。
通过will-change CSS属性,我们可以表明元素将修改特定的属性,让浏览器事先进行必要的优化。
下面发生的事情是,浏览器将为该元素创建一个单独的层。之后,它将该元素的渲染与其他优化一起委托给GPU。这将使动画更加流畅,因为GPU加速接管了动画的渲染。
// In stylesheet
.animating-element {
will-change: opacity;
}
// In HTML
<div class="animating-elememt">
Animating Child elements
</div>当在浏览器中渲染上述片段时,它将识别 will-change 属性并优化未来与不透明度相关的变化。
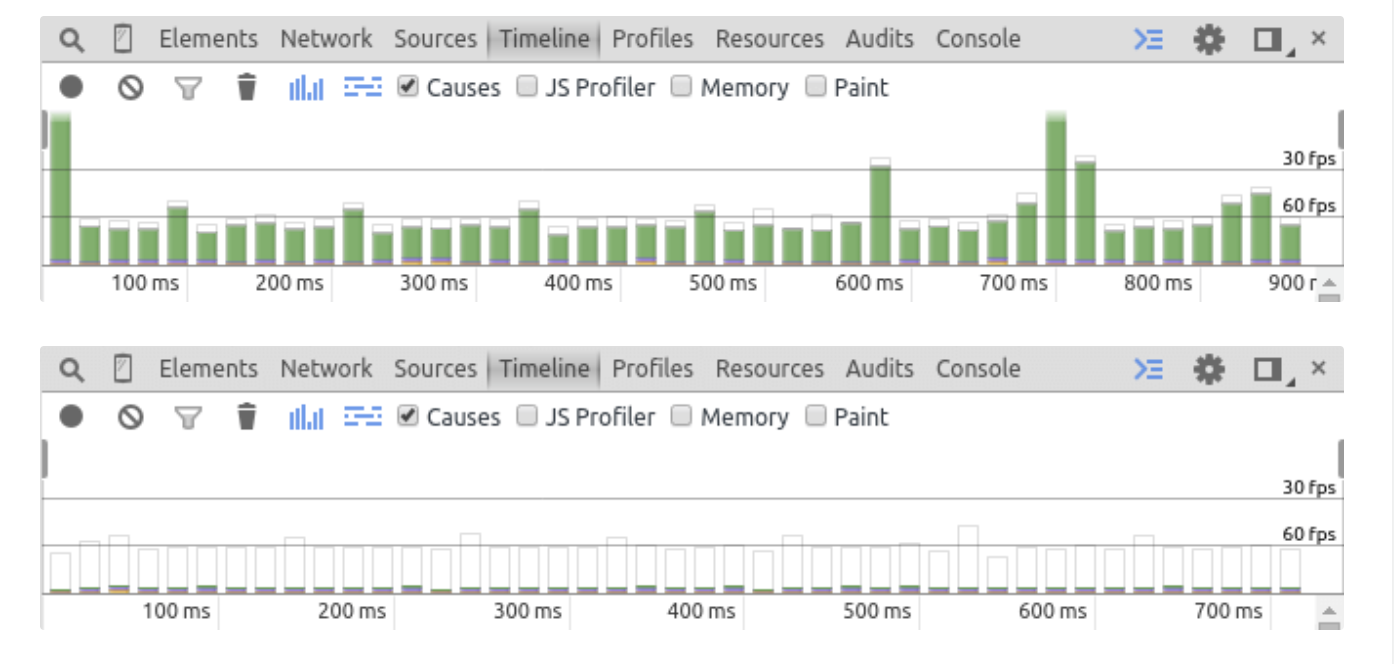
根据Maximillian Laumeister所做的性能基准,可以看到他通过这个单行的改变获得了超过120FPS的渲染速度,而最初的渲染速度大概在50FPS。
什么时候不是用will-change
虽然 will-change 的目的是为了提高性能,但如果你滥用它,它也会降低Web应用的性能。
**使用
will-change表示该元素在未来会发生变化。**因此,如果你试图将will-change和动画同时使用,它将不会给你带来优化。因此,建议在父元素上使用will-change,在子元素上使用动画。
.my-class{
will-change: opacity;
}
.child-class{
transition: opacity 1s ease-in-out;
}不要使用非动画元素。 当你在一个元素上使用
will-change时,浏览器会尝试通过将元素移动到一个新的图层并将转换工作交给GPU来优化它。如果您没有任何要转换的内容,则会导致资源浪费。
最后需要注意的是,建议在完成所有动画后,将元素的 will-change 删除。
3.减少渲染阻止时间
<link rel="stylesheet" href="styles.css">将其分解为多个样式表后:
<!-- style.css contains only the minimal styles needed for the page rendering -->
<link rel="stylesheet" href="styles.css" media="all" />
<!-- Following stylesheets have only the styles necessary for the form factor -->
<link rel="stylesheet" href="sm.css" media="(min-width: 20em)" />
<link rel="stylesheet" href="md.css" media="(min-width: 64em)" />
<link rel="stylesheet" href="lg.css" media="(min-width: 90em)" />
<link rel="stylesheet" href="ex.css" media="(min-width: 120em)" />
<link rel="stylesheet" href="print.css" media="print" />如您所见,根据样式因素分解样式表可以减少渲染阻止时间。
4.避免@import包含多个样式表
通过 @import,我们可以在另一个样式表中包含一个样式表。当我们在处理一个大型项目时,使用 @import 可以使代码更加简洁。
关于
@import的关键事实是,它是一个阻塞调用,因为它必须通过网络请求来获取文件,解析文件,并将其包含在样式表中。如果我们在样式表中嵌套了@import,就会妨碍渲染性能。
# style.css
@import url("windows.css");
# windows.css
@import url("componenets.css");
@import 相比,我们可以通过多个 link 来实现同样的功能,但性能要好得多,因为它允许我们并行加载样式表。
总结
除了我们在本文中讨论的4个方面,我们还有一些其他的方法可以使用CSS来提高网页的性能。CSS最近的一个特性: content-visibility,在未来的几年里看起来是如此的有前途,因为它给页面渲染带来了数倍的性能提升。
最重要的是,我们不需要写一条JavaScript语句就能获得所有的性能。
我相信你可以结合以上的一些功能,为终端用户构建性能更好的Web应用。希望这篇文章对你有用,如果你知道什么CSS技巧可以提高Web应用的性能,请在下面的评论中提及。谢谢大家。
链接:https://juejin.cn/post/6911203296078692359
任意组合判断还在用Switch?位运算符了解一下~
情景再现
很多时候,当我们写程序都会有这样的情况,就是代码多选操作.例如下面的操作.
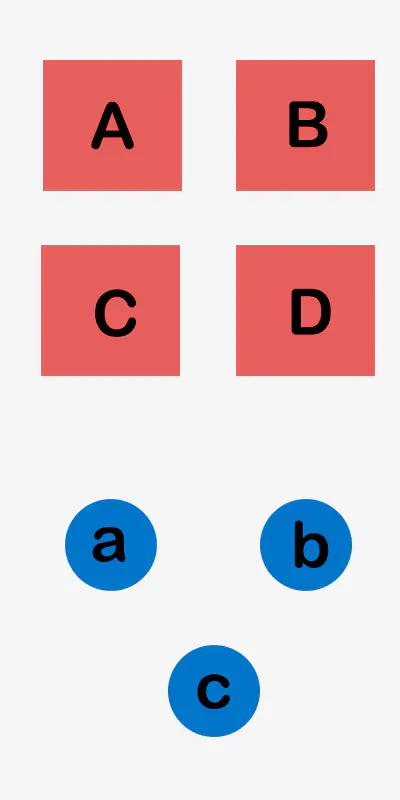
比如有四个视图View(分别为A,B,C,D);
当点击按钮a的时候,视图A,B背景色发生改变;
当点击按钮b的时候,视图A,B,D背景色发生改变;
当点击按钮c的时候,视图B,C,D背景色发生改变;
后续开发中可能有很多按钮和不同的组合形式.
这时候你会怎么办?
第一种方案: 所有的按钮就响应一个方法,里面使用if else等模块来区分不同的按钮事件.
思考问题: 后期如果增加一种按钮.你就需要增加一个if else,代码增加的同时,if else逻辑层级太多也不利于阅读.
第二种方案: if else性能太低?我们就使用Switch.配合着枚举值或者按钮的Tag值来做区别判断,枚举值可以定义成每一种组合形式都是一个枚举值.不同按钮相同的组合形式进入同样的模块.
思考问题: 虽然Switch使用break关键词相对于普通的if else有很大的性能提高,但是后期如果增加一种情况,仍然需要添加代码块.还是会增加代码量.
这时候我们总结一下上面倒是需要干什么,以及出现的问题.
需求: 组合是具有不确定性的,但是组合中的基本元素是确定的(A,B,C,D中的任意组合).
问题: 普通的方式不管if else或者Switch都可能会需要罗列出所有的组合形式,代码量很大,不符合代码规范.阅读起来也是相当的困难.
难道就没有更加优雅的方式来解决这个问题吗?这当然是有的,那就是我们的今天猪脚 位运算符.使用位运算符可以很好的帮助我们解决这一问题.但是在此之前我们需要先了解什么叫做位移运算符.
位运算符
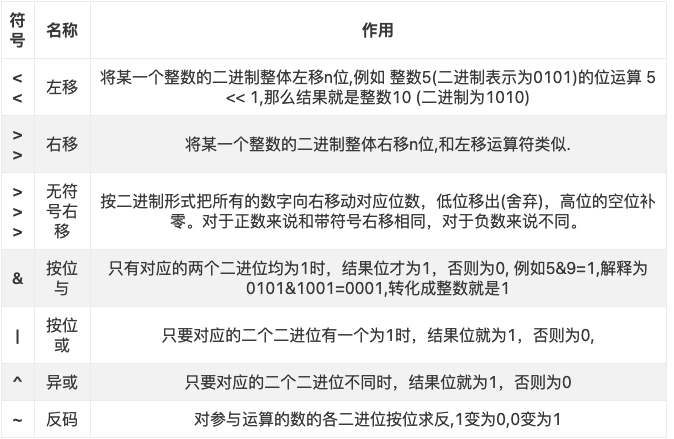
按位与和按位或举个例子来看下.
按位与
1001
&
0101
=0001按位或
1001
&
0101
=1101按位异或
1001
^
0101
=1100我们了解了位运算符,我们该如何解决最开始的那种问题呢?我们接着看~
解决问题
解决这种问题我们会用到 << 和& 以及 | 这三种位运算符.
首先定义一个ColorView视图,继承于UIView,然后在 .h 头文件定义枚举,并且ColorView持有枚举的属性.代码如下所示.
#import <UIKit/UIKit.h>
typedef enum : NSUInteger {
ColorViewStyleA = 1<<0,
ColorViewStyleB = 1<<1,
ColorViewStyleC = 1<<2,
ColorViewStyleD = 1<<3,
} ColorViewStyle;
@interface ColorView : UIView
@property(nonatomic,assign)ColorViewStyle style;
@property(nonatomic,copy)NSString *title;
@end然后在ViewController导入ColorView,并且声明一个属性needChangeColorStyle.用于判断需要做出修改的视图.
#import "ColorView.h"
@interface ViewController ()
@property(nonatomic,assign)ColorViewStyle needChangeColorStyle;
@end然后在ViewController创建ColorView和Button,这里由于时间原因,我就简写了.主要要给每种视图设置一个枚举值,作为识别码.
//创建ColorView
for (int i = 0; i < 4; i++) {
ColorView *colorView = [[ColorView alloc] initWithFrame:CGRectMake(viewWidth * i + distance *(i+1), 100, viewWidth, 100)];
............
switch (i) {
case 0:
colorView.style = ColorViewStyleA;
break;
case 1:
colorView.style = ColorViewStyleB;
break;
case 2:
colorView.style = ColorViewStyleC;
break;
case 3:
colorView.style = ColorViewStyleD;
break;
}
............
}
//创建按钮
for (int i = 0; i < 4; i++) {
............
}然后在按钮的点击方法 buttonAction 里面重置needChangeColorStyle的值,这里就需要使用到按位或进行枚举值的组合了.如下所示.
- (void)buttonAction:(UIButton *)sender {
//对 needChangeColorStyle 进行赋值,其实这步操作应该在一开始做的,这里是Demo,所以这么做了.
//赋值过程中使用了按位或运算符.整合可响应的View类型.
NSInteger tagIndex = sender.tag - 10000;
switch (tagIndex) {
case 0:
_needChangeColorStyle = ColorViewStyleA|ColorViewStyleB|ColorViewStyleD;
break;
case 1:
_needChangeColorStyle = ColorViewStyleB|ColorViewStyleC|ColorViewStyleD;
break;
case 2:
_needChangeColorStyle = ColorViewStyleA|ColorViewStyleB;
break;
case 3:
_needChangeColorStyle = ColorViewStyleD;
break;
}
[self colorViewsChangAction];
}最后在colorViewsChangAction方法中进行视图的操作选择.使用到了按位与运算.只要视图的style和_needChangeColorStyle有相交部分,那么两者按位与出来的数值一定是大于等于1的.这样就可以做包含操作了.代码日下所示.
- (void)colorViewsChangAction {
//遍历ColorView视图数组
for (ColorView *colorView in self.colorViews) {
//使用了按位与,查看两者是否具有相交部分.
if (_needChangeColorStyle & colorView.style) {
NSLog(@"%@ 做出了响应",colorView.title);
colorView.backgroundColor = [UIColor redColor];
} else {
colorView.backgroundColor = [UIColor orangeColor];
}
}
}这样我们就完成了使用位运算做任何组合判断的操作了,后期我们加一种按钮或者组合形式,只需要在 buttonAction 添加三行代码即可.其他都不用了,而且代码结构读起来非常的舒服.
当然了,在iOS原生框架也是有这样的操作的,例如对于贝塞尔曲线的指定角进行切边操作.枚举值也是带有位移运算的,枚举值如下所示.这时候可以仍然可以使用按位或组合任意形式的角.
typedef NS_OPTIONS(NSUInteger, UIRectCorner) {
UIRectCornerTopLeft = 1 << 0,
UIRectCornerTopRight = 1 << 1,
UIRectCornerBottomLeft = 1 << 2,
UIRectCornerBottomRight = 1 << 3,
UIRectCornerAllCorners = ~0UL
};总结
位运算符还有很多用途,这是最简单的用途而已,在安卓那边的话,如果枚举有性能问题,可以使用定义常量的形式来实现该目的,整体上是一致的,好了就说到这里,如果有任何问题,欢迎批评指导,谢谢.最后再把Demo发一遍.
转自:https://www.jianshu.com/p/5ed73f85ac37
收起阅读 »一种简单实用的 JS 动态加载方案
背景
在做 Web 应用的时候,你或许遇到过这样的场景:为了实现一个使用率很低的功能,却引入了超大的第三方库,导致项目打包后的 JS bundle 体积急剧膨胀。
我们有一些具体的案例,例如:
产品要求在项目中增加一个导出数据为 Excel 文件的功能,这个功能其实只有管理员才能看到,而且最多一周才会使用一次,绝对属于低频操作。
团队里的小伙伴为了实现这个功能,引入了 XLSX 这个库,JS bundle 体积因而增加了一倍,所有用户的体验都受到影响了。
XLSX 用来做 Excel 相关的操作是不错的选择,但因为新增低频操作影响全部用户却不值得。
除了导出 Excel 这种功能外,类似的场景还有使用 html2canvas 生成并下载海报,使用 fabric 动态生成图片等。
针对这种情况,你觉得该如何优化呢?
自动分包和动态加载
机智如你很快就想到使用 JS 动态加载,如果熟悉 React,还知道可以使用 react-loadable 来解决。
原理就是利用 React Code-Splitting,配合 Webpack 自动分包,动态加载。
这种方案可以,React 也推荐这么做,但是对于引用独立的第三方库这样的场景,还有更简单的方案。
更简单的方案
这些第三方库往往都提供了 umd 格式的 min.js,我们动态加载这些 min.js 就可以了。比如 XLSX,引入其 min.js 文件之后,就可以通过 window.XLSX 来实现 Excel 相关的操作。
此方案的优点有:
- 与框架无关,不需要和 React 等框架或 Webpack 等工具绑定
- 精细控制,React Code-Splitting 之类的方案只能到模块级别,想要在点击按钮后才动态加载较难实现
具体实现
我们重点需要实现一个 JS 动态加载器 AsyncLoader,代码如下:
function initLoader() {
// key 是对应 JS 执行后在 window 中添加的变量
const jsUrls = {
html2canvas: 'https://cdn.jsdelivr.net/npm/html2canvas@1.0.0-rc.7/dist/html2canvas.min.js',
XLSX: 'https://cdn.jsdelivr.net/npm/xlsx@0.16.9/dist/xlsx.min.js',
flvjs: 'https://cdn.jsdelivr.net/npm/flv.js@1.5.0/dist/flv.min.js',
domtoimage: 'https://cdn.jsdelivr.net/npm/dom-to-image@2.6.0/src/dom-to-image.min.js',
fabric: 'https://cdn.jsdelivr.net/npm/fabric@4.3.1/dist/fabric.min.js',
};
const loadScript = (src) => {
return new Promise((resolve, reject) => {
const script = document.createElement('script');
script.type = 'text/javascript';
script.onload = resolve;
script.onerror = reject;
script.crossOrigin = 'anonymous';
script.src = src;
if (document.head.append) {
document.head.append(script);
} else {
document.getElementsByTagName('head')[0].appendChild(script);
}
});
};
const loadByKey = (key) => {
// 判断对应变量在 window 是否存在,如果存在说明已加载,直接返回,这样可以避免多次重复加载
if (window[key]) {
return Promise.resolve();
} else {
if (Array.isArray(jsUrls[key])) {
return Promise.all(jsUrls[key].map(loadScript));
}
return loadScript(jsUrls[key]);
}
};
// 定义这些方法只是为了方便使用,其实 loadByKey 就够了。
const loadHtml2Canvas = () => {
return loadByKey('html2canvas');
};
const loadXlsx = () => {
return loadByKey('XLSX');
};
const loadFlvjs = () => {
return loadByKey('flvjs');
};
window.AsyncLoader = {
loadScript,
loadByKey,
loadHtml2Canvas,
loadXlsx,
loadFlvjs,
};
}
initLoader();使用方式
以 XLSX 为例,使用这种方式之后,我们不需要在顶部 import xlsx from 'xlsx',只有当用户点击 导出Excel 按钮的时候,才从 CDN 动态加载 xlsx.min.js,加载成功后使用 window.XLSX 即可,代码如下:
await window.AsyncLoader.loadXlsx().then(() => {
const XLSX = window.XLSX;
if (resp.data.signList && resp.data.signList.length > 0) {
const new_workbook = XLSX.utils.book_new();
resp.data.signList.map((item) => {
const header = ['班级/学校/单位', '姓名', '帐号', '签到时间'];
const { signRecords } = item;
signRecords.unshift(header);
const worksheet = XLSX.utils.aoa_to_sheet(signRecords);
XLSX.utils.book_append_sheet(new_workbook, worksheet, item.signName);
});
XLSX.writeFile(new_workbook, `${resp.data.fileName}.xlsx`);
} else {
const new_workbook = XLSX.utils.book_new();
const header = [['班级/学校/单位', '姓名', '帐号']];
const worksheet = XLSX.utils.aoa_to_sheet(header);
XLSX.utils.book_append_sheet(new_workbook, worksheet, '');
XLSX.writeFile(new_workbook, `${resp.data.fileName}.xlsx`);
}
});另一个动态加载 domtoimage 的示例
window.CommonJsLoader.loadByKey('domtoimage').then(() => {
const scale = 2;
window.domtoimage
.toPng(poster, {
height: poster.offsetHeight * scale,
width: poster.offsetWidth * scale,
style: {
zoom: 1,
transform: `scale(${scale})`,
transformOrigin: 'top left',
width: `${poster.offsetWidth}px`,
height: `${poster.offsetHeight}px`,
},
})
.then((dataUrl) => {
copyImage(dataUrl, liveData?.planName);
message.success(`${navigator.clipboard ? '复制' : '下载'}成功`);
});
});AsyncLoader 方案使用方便、理解简单,而且可以很好地利用 CDN 缓存,多个项目可以共用同样的 URL,进一步提高加载速度。而且这种方式使用的是原生 JS,在任何框架中都可以使用。
注意,如果你用 TypeScript 开发,这种方案或许会丢失一些智能提示,如果引入了对应的 @types/xxx 应该没影响。如果你特别在意开发时的智能提示,也可以在开发的过程中 import 对应的包,开发完成后才换成 AsyncLoader 方案。
Android基于微信 xlog 开源 日志框架
前言
之前写过一个 日志框架LogHelper ,是基于 Logger 开源库封装的,当时的因为项目本身的日志不是很多,完全可以使用,最近和其他公司合作,在一个新的项目上反馈,说在 大量log 的情况下会影响到手机主体功能的使用。从而让我对之前的日志行为做了一个深刻的反省随后在开发群中咨询了其他开发的小伙伴,如果追求性能,可以研究一下 微信的 xlog ,也是本篇博客的重点
xlog 是什么
xlog 是什么 这个问题 我这也是在【腾讯Bugly干货分享】微信mars 的高性能日志模块 xlog得到了答案
简单来说 ,就是腾讯团队分享的基于 c/c++ 高可靠性高性能的运行期日志组件
官网的 sample
知道了他是什么,就要只要他是怎么用的,打开github 找到官网Tencent/mars
使用非常简单
下载库
dependencies {
compile 'com.tencent.mars:mars-xlog:1.2.3'
}使用
System.loadLibrary("c++_shared");
System.loadLibrary("marsxlog");
final String SDCARD = Environment.getExternalStorageDirectory().getAbsolutePath();
final String logPath = SDCARD + "/marssample/log";
// this is necessary, or may crash for SIGBUS
final String cachePath = this.getFilesDir() + "/xlog"
//init xlog
if (BuildConfig.DEBUG) {
Xlog.appenderOpen(Xlog.LEVEL_DEBUG, Xlog.AppenderModeAsync, cachePath, logPath, "MarsSample", 0, "");
Xlog.setConsoleLogOpen(true);
} else {
Xlog.appenderOpen(Xlog.LEVEL_INFO, Xlog.AppenderModeAsync, cachePath, logPath, "MarsSample", 0, "");
Xlog.setConsoleLogOpen(false);
}
Log.setLogImp(new Xlog());OK 实现了他的功能
不要高兴的太早,后续的问题都头大
分析各个方法的作用
知道了最简单的用法,就想看看他支持哪些功能
按照官网的demo 首先分析一下appenderOpen
appenderOpen(int level, int mode, String cacheDir, String logDir, String nameprefix, int cacheDays, String pubkey)
level
日志级别 没啥好说的 XLog 中已经写得很清楚了
public static final int LEVEL_ALL = 0;
public static final int LEVEL_VERBOSE = 0;
public static final int LEVEL_DEBUG = 1;
public static final int LEVEL_INFO = 2;
public static final int LEVEL_WARNING = 3;
public static final int LEVEL_ERROR = 4;
public static final int LEVEL_FATAL = 5;
public static final int LEVEL_NONE = 6;值得注意的地方 debug 版本下建议把控制台日志打开,日志级别设为 Verbose 或者 Debug, release 版本建议把控制台日志关闭,日志级别使用 Info.
public static native void setLogLevel(int logLevel);这个在官网的 接入指南
这里也可以使用
方法设置
mode
写入的模式
- public static final int AppednerModeAsync = 0;
异步写入
- public static final int AppednerModeSync = 1;
同步写入
同步写入,可以理解为实时的日志,异步则不是
Release版本一定要用 AppednerModeAsync, Debug 版本两个都可以,但是使用 AppednerModeSync 可能会有卡顿
这里也可以使用
public static native void setAppenderMode(int mode);方法设置
cacheDir 设置缓存目录
缓存目录,当 logDir 不可写时候会写进这个目录,可选项,不选用请给 "", 如若要给,建议给应用的 /data/data/packname/files/log 目录。
会在目录下生成后缀为 .mmap3 的缓存文件,
logDir 设置写入的文件目录
真正的日志,后缀为 .xlog
日志写入目录,请给单独的目录,除了日志文件不要把其他文件放入该目录,不然可能会被日志的自动清理功能清理掉。
nameprefix 设置日志文件名的前缀
日志文件名的前缀,例如该值为TEST,生成的文件名为:TEST_20170102.xlog。
cacheDays
一般情况下填0即可。非0表示会在 _cachedir 目录下存放几天的日志。
这里的描述比较晦涩难懂,当我设置这个参数非0 的时候 会发现 原本设置在 logDir 目录下的文件 出现在了 cacheDir
例如 正常应该是
文件结构
- cacheDir
- log.mmap3
- logDir
- log_20200710.xlog
- log_20200711.xlog变成这样
- cacheDir
- log.mmap3
- log_20200710.xlog
- log_20200711.xlog
- logDir全部到了 cacheDir 下面
cacheDays 的意思是 在多少天以后 从缓存目录移到日志目录
pubkey 设置加密的 pubkey
这里涉及到了日志的加密与解密,下面会专门介绍
setMaxFileSize 设置文件大小
在 Xlog 下有一个 native 方法
public static native void setMaxFileSize(long size);
他表示 最大文件大小,这里需要说一下,原本的默认设置 是一天一个日志文件在 appender.h 描述的很清楚
/*
* By default, all logs will write to one file everyday. You can split logs to multi-file by changing max_file_size.
*
* @param _max_byte_size Max byte size of single log file, default is 0, meaning do not split.
*/
void appender_set_max_file_size(uint64_t _max_byte_size);默认情况下,所有日志每天都写入一个文件。可以通过更改max_file_size将日志分割为多个文件。单个日志文件的最大字节大小,默认为0,表示不分割
当超过设置的文件大小以后。文件会变成如下目录结构
- cacheDir
- log.mmap3
- logDir
- log_20200710.xlog
- log_20200710_1.xlog
- log_20200710_2.xlog在 appender.cc 对应的有如下逻辑,
static long __get_next_fileindex(const std::string& _fileprefix, const std::string& _fileext) {
...
return (filesize > sg_max_file_size) ? index + 1 : index;setConsoleLogOpen 设置是否在控制台答应日志
···java public static native void setConsoleLogOpen(boolean isOpen); ···
设置是否在控制台答应日志
setErrLogOpen
这个方法是没用的,一开始以为哪里继承的有问题,在查看源码的时候发现 他是一个空方法,没有应用
使用的话会导致程序异常,在自己编译的so 中我就把它给去掉了
setMaxAliveTime 设置单个文件最大保留时间
public static native void setMaxAliveTime(long duration);置单个文件最大保留时间 单位是秒,这个方法有3个需要注意的地方,
- 必须在 appenderOpen 方法之前才有效
- 最小的时间是 一天
- 默认的时间是10天
在 appender.cc 中可以看到
static const long kMaxLogAliveTime = 10 * 24 * 60 * 60; // 10 days in second
static const long kMinLogAliveTime = 24 * 60 * 60; // 1 days in second
static long sg_max_alive_time = kMaxLogAliveTime;
....
void appender_set_max_alive_duration(long _max_time) {
if (_max_time >= kMinLogAliveTime) {
sg_max_alive_time = _max_time;
}
}默认的时间是10天
appenderClose
在 文档中介绍说是在 程序退出时关闭日志 调用appenderClose的方法
然而在实际情况中 Application 类的 onTerminate() 只有在模拟器中才会生效,在真机中无效的,
如果在程序退出的时候没有触发 appenderClose 那么在下一次启动的时候,xlog 也会把日志写入到文件中
所以如何触发呢?
建议尽可能的去触发他 例如用户双击back 退出的情况下 你肯定是知道的 如果放在后台被杀死了,这个时候也真的没办法刷新,也没关系,上面也说了,再次启动的时候会刷新到日志中,
appenderFlush
当日志写入模式为异步时,调用该接口会把内存中的日志写入到文件。
isSync : true 为同步 flush,flush 结束后才会返回。 isSync : false 为异步 flush,不等待 flush 结束就返回。
日志文件的加密
这一块单独拿出来说明,是因为之前使用上遇到了坑
首先是这个 入参 PUB_KEY,一脸懵,是个啥,
在 mars/blob/master/mars/log/crypt/gen_key.py 这个就是能够获取到 PUB_KEY 的方法
运行如下
$ python gen_key.py
WARNING: Executing a script that is loading libcrypto in an unsafe way. This will fail in a future version of macOS. Set the LIBRESSL_REDIRECT_STUB_ABORT=1 in the environment to force this into an error.
save private key
471e607b1bb3760205f74a5e53d2764f795601e241ebc780c849e7fde1b4ce40
appender_open's parameter:
300330b09d9e771d6163bc53a4e23b188ac9b2f5c7150366835bce3a12b0c8d9c5ecb0b15274f12b2dffae7f4b11c3b3d340e0521e8690578f51813c93190e1e上面的 private key 自己保存好
appender_open's parameter: 就是需要的 PUB_KEY
日志文件的解密
上面已经知道如何加密了,现在了解一下如何解密
下载pyelliptic1
在Xlog 加密使用指引中能够看到
需要下载 pyelliptic1.5.7 然后编译 否则下面的命令会失败
直接解密脚本
xlog 很贴心的给我们提供了两个脚本
使用 decode_mars_nocrypt_log_file.py 解压没有加密的
python decode_mars_nocrypt_log_file [path]使用 decode_mars_crypt_log_file.py 加密的文件
在使用之前需要将 脚本中的
PRIV_KEY = "145aa7717bf9745b91e9569b80bbf1eedaa6cc6cd0e26317d810e35710f44cf8"
PUB_KEY = "572d1e2710ae5fbca54c76a382fdd44050b3a675cb2bf39feebe85ef63d947aff0fa4943f1112e8b6af34bebebbaefa1a0aae055d9259b89a1858f7cc9af9df1"
改成上面自己获取到的 key 否则是解压不出来的
python decode_mars_crypt_log_file.py ~/Desktop/log/log_20200710.xlog直接生成一个
- cacheDir
- log.mmap3
- logDir
- log_20200710.xlog
- log_20200710.xlog.log也可以自定义名字
python decode_mars_crypt_log_file.py ~/Desktop/log/log_20200710.xlog ~/Desktop/log/1.log- cacheDir
- log.mmap3
- logDir
- log_20200710.xlog
- 1.log修改日志的格式
打开我们解压好的日志查看
^^^^^^^^^^Oct 14 2019^^^20:27:59^^^^^^^^^^[17223,17223][2020-07-24 +0800 09:49:19]
get mmap time: 3
MARS_URL:
MARS_PATH: master
MARS_REVISION: 85b19f92
MARS_BUILD_TIME: 2019-10-14 20:27:57
MARS_BUILD_JOB:
log appender mode:0, use mmap:1
cache dir space info, capacity:57926635520 free:52452691968 available:52452691968
log dir space info, capacity:57926635520 free:52452691968 available:52452691968
[I][2020-07-24 +8.0 09:49:21.179][17223, 17223][TAG][, , 0][======================> 1
[I][2020-07-24 +8.0 09:49:21.180][17223, 17223][TAG][, , 0][======================> 2
[I][2020-07-24 +8.0 09:49:21.180][17223, 17223][TAG][, , 0][======================> 3
[I][2020-07-24 +8.0 09:49:21.180][17223, 17223][TAG][, , 0][======================> 4
[I][2020-07-24 +8.0 09:49:21.181][17223, 17223][TAG][, , 0][======================> 5
[I][2020-07-24 +8.0 09:49:21.181][17223, 17223][TAG][, , 0][======================> 6
[I][2020-07-24 +8.0 09:49:21.182][17223, 17223][TAG][, , 0][======================> 7
[I][2020-07-24 +8.0 09:49:21.182][17223, 17223][TAG][, , 0][======================> 8
[I][2020-07-24 +8.0 09:49:21.182][17223, 17223][TAG][, , 0][======================> 9
[I][2020-07-24 +8.0 09:49:21.183][17223, 17223][TAG][, , 0][======================> 10
[I][2020-07-24 +8.0 09:49:21.183][17223, 17223][TAG][, , 0][======================> 11
[I][2020-07-24 +8.0 09:49:21.183][17223, 17223][TAG][, , 0][======================> 12
[I][2020-07-24 +8.0 09:49:21.184][17223, 17223][TAG][, , 0][======================> 13
[I][2020-07-24 +8.0 09:49:21.184][17223, 17223][TAG][, , 0][======================> 14
[I][2020-07-24 +8.0 09:49:21.185][17223, 17223][TAG][, , 0][======================> 15
[I][2020-07-24 +8.0 09:49:21.185][17223, 17223][TAG][, , 0][======================> 16
[I][2020-07-24 +8.0 09:49:21.185][17223, 17223][TAG][, , 0][======================> 17我擦泪 除了我们需要的信息以外,还有这么多杂七杂八的信息,如何去掉,并且自己定义一下格式
这里就需要自己去编译 so 了,好在 xlog 已经给我们提供了很好的编译代码
对应的文档 本地编译
对于编译这块按照文档来就好了 需要注意的是
- 一定要用 ndk-r20 不要用最新版本的 21
- 一定用 Python2.7 mac 自带 不用要 Python3
去掉头文件
首先我们去到这个头文件,对于一个日志框架来着,这个没啥用
^^^^^^^^^^Oct 14 2019^^^20:27:59^^^^^^^^^^[17223,17223][2020-07-24 +0800 09:49:19]
get mmap time: 3
MARS_URL:
MARS_PATH: master
MARS_REVISION: 85b19f92
MARS_BUILD_TIME: 2019-10-14 20:27:57
MARS_BUILD_JOB:
log appender mode:0, use mmap:1
cache dir space info, capacity:57926635520 free:52452691968 available:52452691968
log dir space info, capacity:57926635520 free:52452691968 available:52452691968
在本机下载好的 mars 下,找到 appender.cc 将头文件去掉
修改日志格式
默认的格式很长
[I][2020-07-24 +8.0 09:49:21.179][17223, 17223][TAG][, , 0][======================> 1
[日志级别][时间][pid,tid][tag][filename,strFuncName,line][日志内容
是一个这样结构
比较乱,我们想要的日志 就时间,级别,日志内容 就行了
找到 formater.cc
将原本的
int ret = snprintf((char*)_log.PosPtr(), 1024, "[%s][%s][%" PRIdMAX ", %" PRIdMAX "%s][%s][%s, %s, %d][", // **CPPLINT SKIP**
_logbody ? levelStrings[_info->level] : levelStrings[kLevelFatal], temp_time,
_info->pid, _info->tid, _info->tid == _info->maintid ? "*" : "", _info->tag ? _info->tag : "",
filename, strFuncName, _info->line);改成
int ret = snprintf((char*)_log.PosPtr(), 1024, "[%s][%s]", // **CPPLINT SKIP**
temp_time, _logbody ? levelStrings[_info->level] : levelStrings[kLevelFatal] );就行了
然后从新编译,将so 翻入项目 在看一下现在的效果
[2020-07-24 +8.0 11:47:42.597][I]======================>9ok 打完收工
简单的封装一下
基本上分析和实现了我们需要的功能,那么把这部分简单的封装一下
放上核心的 Builder 源码可在下面自行查看
package com.allens.xlog
import android.content.Context
import com.tencent.mars.xlog.Log
import com.tencent.mars.xlog.Xlog
class Builder(context: Context) {
companion object {
//日志的tag
var tag = "log_tag"
}
//是否是debug 模式
private var debug = true
//是否打印控制台日志
private var consoleLogOpen = true
//是否每天一个日志文件
private var oneFileEveryday = true
//默认的位置
private val defCachePath = context.getExternalFilesDir(null)?.path + "/mmap"
// mmap 位置 默认缓存的位置
private var cachePath = defCachePath
//实际保存的log 位置
private var logPath = context.getExternalFilesDir(null)?.path + "/logDir"
//文件名称前缀 例如该值为TEST,生成的文件名为:TEST_20170102.xlog
private var namePreFix = "log"
//写入文件的模式
private var model = LogModel.Async
//最大文件大小
//默认情况下,所有日志每天都写入一个文件。可以通过更改max_file_size将日志分割为多个文件。
//单个日志文件的最大字节大小,默认为0,表示不分割
// 最大 当文件不能超过 10M
private var maxFileSize = 0L
//日志级别
//debug 版本下建议把控制台日志打开,日志级别设为 Verbose 或者 Debug, release 版本建议把控制台日志关闭,日志级别使用 Info.
private var logLevel = LogLevel.LEVEL_INFO
//通过 python gen_key.py 获取到的公钥
private var pubKey = ""
//单个文件最大保留时间 最小 1天 默认时间 10天
private var maxAliveTime = 10
//缓存的天数 一般情况下填0即可。非0表示会在 _cachedir 目录下存放几天的日志。
//原来缓存日期的意思是几天后从缓存目录移到日志目录
private var cacheDays = 0
fun setCachePath(cachePath: String): Builder {
this.cachePath = cachePath
return this
}
fun setLogPath(logPath: String): Builder {
this.logPath = logPath
return this
}
fun setNamePreFix(namePreFix: String): Builder {
this.namePreFix = namePreFix
return this
}
fun setModel(model: LogModel): Builder {
this.model = model
return this
}
fun setPubKey(key: String): Builder {
this.pubKey = key
return this
}
//原来缓存日期的意思是几天后从缓存目录移到日志目录 默认 0 即可
//如果想让文件保留多少天 用 [setMaxAliveTime] 方法即可
//大于 0 的时候 默认会放在缓存的位置上 [cachePath]
fun setCacheDays(days: Int): Builder {
if (days < 0) {
this.cacheDays = 0
} else {
this.cacheDays = days
}
return this
}
fun setDebug(debug: Boolean): Builder {
this.debug = debug
return this
}
fun setLogLevel(level: LogLevel): Builder {
this.logLevel = level
return this
}
fun setConsoleLogOpen(consoleLogOpen: Boolean): Builder {
this.consoleLogOpen = consoleLogOpen
return this
}
fun setTag(logTag: String): Builder {
tag = logTag
return this
}
/**
* [isOpen] true 设置每天一个日志文件
* false 那么 [setMaxFileSize] 生效
*/
fun setOneFileEveryday(isOpen: Boolean): Builder {
this.oneFileEveryday = isOpen
return this
}
fun setMaxFileSize(maxFileSize: Float): Builder {
when {
maxFileSize < 0 -> {
this.maxFileSize = 0L
}
maxFileSize > 10 -> {
this.maxFileSize = (10 * 1024 * 1024).toLong()
}
else -> {
this.maxFileSize = (maxFileSize * 1024 * 1024).toLong()
}
}
return this
}
/**
* [day] 设置单个文件的过期时间 默认10天 在程序启动30S 以后会检查过期文件
* 过期时间依据 当前系统时间 - 文件最后修改时间计算
* 默认 单个文件保存 10天
*/
fun setMaxAliveTime(day: Int): Builder {
when {
day < 0 -> {
this.maxAliveTime = 0
}
day > 10 -> {
this.maxAliveTime = 10
}
else -> {
this.maxAliveTime = day
}
}
return this
}
fun init() {
if (!debug) {
//判断如果是release 就强制使用 异步
model = LogModel.Async
//日志级别使用 Info
logLevel = LogLevel.LEVEL_INFO
}
if (cachePath.isEmpty()) {
//cachePath这个参数必传,而且要data下的私有文件目录,例如 /data/data/packagename/files/xlog, mmap文件会放在这个目录,如果传空串,可能会发生 SIGBUS 的crash。
cachePath = defCachePath
}
android.util.Log.i(tag, "Xlog=========================================>")
android.util.Log.i(
tag,
"info" + "\n"
+ "level:" + logLevel.level + "\n"
+ "model:" + model.model + "\n"
+ "cachePath:" + cachePath + "\n"
+ "logPath:" + logPath + "\n"
+ "namePreFix:" + namePreFix + "\n"
+ "cacheDays:" + cacheDays + "\n"
+ "pubKey:" + pubKey + "\n"
+ "consoleLogOpen:" + consoleLogOpen + "\n"
+ "maxFileSize:" + maxFileSize + "\n"
)
android.util.Log.i(tag, "Xlog=========================================<")
Xlog.setConsoleLogOpen(consoleLogOpen)
//每天一个日志文件
if (oneFileEveryday) {
Xlog.setMaxFileSize(0)
} else {
Xlog.setMaxFileSize(maxFileSize)
}
Xlog.setMaxAliveTime((maxAliveTime * 24 * 60 * 60).toLong())
Xlog.appenderOpen(
logLevel.level,
model.model,
cachePath,
logPath,
namePreFix,
cacheDays,
pubKey
)
Log.setLogImp(Xlog())
}
}下载
Step 1. Add the JitPack repository to your build file Add it in your root build.gradle at the end of repositories:
allprojects {
repositories {
...
maven { url 'https://www.jitpack.io' }
}
}
Step 2. Add the dependency
dependencies {
implementation 'com.github.JiangHaiYang01:XLogHelper:Tag'
}
添加 abiFilter
android {
compileSdkVersion 30
buildToolsVersion "30.0.1"
defaultConfig {
...
ndk {
abiFilter "armeabi-v7a"
}
}
...
}使用
初始化,建议放在 Application 中
XLogHelper.create(this)
.setModel(LogModel.Async)
.setTag("TAG")
.setConsoleLogOpen(true)
.setLogLevel(LogLevel.LEVEL_INFO)
.setNamePreFix("log")
.setPubKey("572d1e2710ae5fbca54c76a382fdd44050b3a675cb2bf39feebe85ef63d947aff0fa4943f1112e8b6af34bebebbaefa1a0aae055d9259b89a1858f7cc9af9df1")
.setMaxFileSize(1f)
.setOneFileEveryday(true)
.setCacheDays(0)
.setMaxAliveTime(2)
.init()
XLogHelper.i("======================> %s", i)
XLogHelper.e("======================> %s", i)
代码下载:
收起阅读 »作为iOSer,你还不会适配暗黑模式吗 ---- 如何适配暗黑模式(Dark Mode)
原理
1、将同一个资源,创建出两种模式的样式。系统根据当前选择的样式,自动获取该样式的资源
2、每次系统更新样式时,应用会调用当前所有存在的元素调用对应的一些重新方法,进行重绘视图,可以在对应的方法做相应的改动
资源文件适配
1、创建一个Assets文件(或在现有的Assets文件中)
2、新建一个图片资源文件(或者颜色资源文件、或者其他资源文件)
3、选中该资源文件, 打开 Xcode ->View ->Inspectors ->Show Attributes Inspectors (或者Option+Command+4)视图,将Apperances 选项 改为Any,Dark
4、执行完第三步,资源文件将会有多个容器框,分别为 Any Apperance 和 Dark Apperance. Any Apperance 应用于默认情况(Unspecified)与高亮情况(Light), Dark Apperance 应用于暗黑模式(Dark)
5、代码默认执行时,就可以正常通过名字使用了,系统会根据当前模式自动获取对应的资源文件
注意
同一工程内多个Assets文件在打包后,就会生成一个Assets.car 文件,所以要保证Assets内资源文件的名字不能相同
如何在代码里进行适配颜色(UIColor)
如何在代码里进行适配颜色(UIColor)
+ (UIColor *)colorWithDynamicProvider:(UIColor * (^)(UITraitCollection *))dynamicProvider API_AVAILABLE(ios(13.0), tvos(13.0)) API_UNAVAILABLE(watchos);
- (UIColor *)initWithDynamicProvider:(UIColor * (^)(UITraitCollection *))dynamicProvider API_AVAILABLE(ios(13.0), tvos(13.0)) API_UNAVAILABLE(watchos);eg.
[UIColor colorWithDynamicProvider:^UIColor * _Nonnull(UITraitCollection * _Nonnull trait) {
if (trait.userInterfaceStyle == UIUserInterfaceStyleDark) {
return UIColorRGB(0x000000);
} else {
return UIColorRGB(0xFFFFFF);
}
}];系统调用更新方法,自定义重绘视图
当用户更改外观时,系统会通知所有window与View需要更新样式,在此过程中iOS会触发以下方法, 完整的触发方法文档
UIView
traitCollectionDidChange(_:)
layoutSubviews()
draw(_:)
updateConstraints()
tintColorDidChange()UIViewController
traitCollectionDidChange(_:)
updateViewConstraints()
viewWillLayoutSubviews()
viewDidLayoutSubviews()UIPresentationController
traitCollectionDidChange(_:)
containerViewWillLayoutSubviews()
containerViewDidLayoutSubviews()如何不进行系统切换样式的适配
注意
苹果官方强烈建议适配 暗黑模式(Dark Mode)此功能也是为了开发者能慢慢将应用适配暗黑模式
所以想通过此功能不进行适配暗黑模式,预计将会被拒
全局关闭暗黑模式
1、在Info.plist 文件中,添加UIUserInterfaceStyle key 名字为 User Interface Style 值为String,
2、将UIUserInterfaceStyle key 的值设置为 Light
单个界面不遵循暗黑模式
1、UIViewController与UIView 都新增一个属性 overrideUserInterfaceStyle
2、将 overrideUserInterfaceStyle 设置为对应的模式,则强制限制该元素与其子元素以设置的模式进行展示,不跟随系统模式改变进行改变
1、设置 ViewController 的该属性, 将会影响视图控制器的视图和子视图控制器采用该样式
2、设置 View 的该属性, 将会影响视图及其所有子视图采用该样式
3、设置 Window 的该属性, 将会影响窗口中的所有内容都采用样式,包括根视图控制器和在该窗口中显示内容的所有演示控制器(UIPresentationController)
转自:https://www.jianshu.com/p/7925bd51d2d6
收起阅读 »[Android]使用函数指针实现native层异步回调
1. 前言
在上篇关于lambda表达式实现方式的文章中,有提到一个概念叫做MethodHandle,当时的解释是类似于C/C++的函数指针,但是文章发出后咨询友人的意见,发现很多人并不清楚函数指针是怎么用的,其实我本人也是只是知道这个概念,但是并没有实际使用过。仿佛冥冥中自有天意,前几天公司的项目正好用到了函数指针来做native层的事件回调,也让我理解了函数指针的妙用。但是关于C/C++我并不是特别熟练,于是将实现过程写了个DEMO,一是为了做个记录熟悉过程,二是以备后续使用。
2. 概念
如果在程序中定义了一个函数,那么在编译时系统就会为这个函数代码分配一段存储空间,这段存储空间的首地址称为这个函数的地址。而且函数名表示的就是这个地址。既然是地址我们就可以定义一个指针变量来存放,这个指针变量就叫作函数指针变量,简称函数指针。
那么这个指针变量怎么定义呢?虽然同样是指向一个地址,但指向函数的指针变量同我们之前讲的指向变量的指针变量的定义方式是不同的。例如:
int(*p)(int, int);
这个语句就定义了一个指向函数的指针变量 p。首先它是一个指针变量,所以要有一个“*”,即(p);其次前面的 int 表示这个指针变量可以指向返回值类型为 int 型的函数;后面括号中的两个 int 表示这个指针变量可以指向有两个参数且都是 int 型的函数。所以合起来这个语句的意思就是:定义了一个指针变量 p,该指针变量可以指向返回值类型为 int 型,且有两个整型参数的函数。p 的类型为 int()(int,int)。
所以函数指针的定义方式为:
函数返回值类型 (* 指针变量名) (函数参数列表);
“函数返回值类型”表示该指针变量可以指向具有什么返回值类型的函数;“函数参数列表”表示该指针变量可以指向具有什么参数列表的函数。这个参数列表中只需要写函数的参数类型即可。
我们看到,函数指针的定义就是将“函数声明”中的“函数名”改成“(*指针变量名)”。但是这里需要注意的是:“(*指针变量名)”两端的括号不能省略,括号改变了运算符的优先级。如果省略了括号,就不是定义函数指针而是一个函数声明了,即声明了一个返回值类型为指针型的函数。
那么怎么判断一个指针变量是指向变量的指针变量还是指向函数的指针变量呢?首先看变量名前面有没有“”,如果有“”说明是指针变量;其次看变量名的后面有没有带有形参类型的圆括号,如果有就是指向函数的指针变量,即函数指针,如果没有就是指向变量的指针变量。
3. 定义函数指针和枚举
假设native层有个耗时操作需要异步调用,我们在异步调用结束后通过回调通知业务层完成事件,那么这个时候就可以使用函数指针作为回调方法。
定义方式:
- 首先定义事件枚举:
enum EventEnum {
eeSleepWake,
};
- 其次,定义一个函数指针:
typedef void (*onSleepWake)(int code, void* sender);
这个函数指针可以指向一个返回值为void 参数分别为 int 和void型指针的函数,其中void型指针表示调用方的指针
- 定义一个结构体,包含函数指针和调用方的指针
struct EventData {
void* eventPointer;
void* sender;
};
- 注册事件持有类,使其成为单例
这个操作的部分代码:
class EventManager {
public:
static EventManager& singleton()
{
static EventManager sl;
return sl;
}
static EventManager& getInstance()
{
return singleton();
}
//注册事件
void addEvent(EventEnum eventEnum, void* event, void* sender);
EventData getEventData(EventEnum eventEnum);
private:
std::map<EventEnum, EventData> eventMap;
EventManager(){};
~EventManager(){};
};
- 实现事件注册函数
void EventManager::addEvent(EventEnum eventEnum, void* event, void* sender) {
if(event == nullptr || sender == nullptr) {
return;
}
EventData eventData;
eventData.eventPointer = event;
eventData.sender = sender;
eventMap.insert(std::pair<EventEnum, EventData>(eventEnum, eventData));
}
- 编写函数指针对应函数的具体实现
void eeSleepWakeCallback(int result, void* sender) {
JniTester *tester = (JniTester *) sender;
tester->onResultCallback(result);
}
- 在入口类中注册事件及其对应的枚举和函数
JniTester::JniTester() {
EventManager::getInstance().addEvent(eeSleepWake, (void*)eeSleepWakeCallback, this);
}
- 编写异步函数调用
···
void JniTester::getThreadResult() {
ThreadTest *test = new ThreadTest();
test->sleepThread();
}
···
耗时函数的具体实现:
void ThreadTest::sleepThread() {
std::thread cal_task(&ThreadTest::makeSleep, this);
cal_task.detach();
}
void ThreadTest::makeSleep() {
sleep(2);
}
这一步我们是通过新建一个线程,并让其等待2S来模拟异步耗时操作
4. 异步回调的实现
- 在java层编写java的回调方法
private OnResultCallback callback;
public void setOnResultCallback(OnResultCallback callback) {
this.callback = callback;
}
public interface OnResultCallback {
void onResult(int result);
}
- 在java曾编写java层回调的触发:
public void onResult(int result) {
if (this.callback != null) {
callback.onResult(result);
}
}
- native层异步动作完成的通知
通过向单例的事件持有类获取对应的事件枚举,获取到其对应的函数指针,并调用该函数指针实现:
void ThreadTest::makeSleep() {
sleep(2);
EventData eventData = EventManager::singleton().getEventData(eeSleepWake);
onSleepWake wake = (onSleepWake)eventData.eventPointer;
if(wake) {
wake(12345, eventData.sender);
}
}
因为我们在第三章节第7步注册的函数指针是eeSleepWakeCallback, 因此,这里会调用到这个函数:
void eeSleepWakeCallback(int result, void* sender) {
JniTester *tester = (JniTester *) sender;
tester->onResultCallback(result);
}
通过sender确定具体的对象,调用其onResultCallback函数
- onResultCallback函数的实现
void JniTester::onResultCallback(int result) {
JNIEnv *env = NULL;
int status = f_jvm->GetEnv((void **) &env, JNI_VERSION_1_4);
bool isInThread = false;
if (status < 0) {
isInThread = true;
f_jvm->AttachCurrentThread(&env, NULL);
}
if (f_cls != NULL) {
jmethodID id = env->GetMethodID(f_cls, "onResult", "(I)V");
if (id != NULL) {
env->CallVoidMethod(f_obj, id, result);
}
}
if (isInThread) {
f_jvm->DetachCurrentThread();
}
}
这里因为缺少java环境,因此我们需要将该线程挂载到jvm上执行,并获取对应的JNIEnv ,通过jnienv获取java层的回调触发方法onResult并执行。
5.效果
编写测试代码:
JniTester tester = new JniTester();
Log.d("zyl", "startTime = " + System.currentTimeMillis());
tester.setOnResultCallback(result -> {
Log.d("zyl", "endTime = " + System.currentTimeMillis());
Log.d("zyl", "result = " + result);
});
tester.requestData();
执行结果:
和预期一致,完美。
作者:dafasoft
链接:https://juejin.cn/post/6965699138163834910
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
当后端一次性丢给你10万条数据, 作为前端工程师的你,要怎么处理?
前段时间有朋友问我一个他们公司遇到的问题, 说是后端由于某种原因没有实现分页功能, 所以一次性返回了2万条数据,让前端用select组件展示到用户界面里. 我听完之后立马明白了他的困惑, 如果通过硬编码的方式去直接渲染这两万条数据到select中,肯定会卡死. 后面他还说需要支持搜索, 也是前端来实现,我顿时产生了兴趣. 当时想到的方案大致如下:
- 采用懒加载+分页(前端维护懒加载的数据分发和分页)
- 使用虚拟滚动技术(目前react的antd4.0已支持虚拟滚动的select长列表)
懒加载和分页方式一般用于做长列表优化, 类似于表格的分页功能, 具体思路就是用户每次只加载能看见的数据, 当滚动到底部时再去加载下一页的数据.
虚拟滚动技术也可以用来优化长列表, 其核心思路就是每次只渲染可视区域的列表数,当滚动后动态的追加元素并通过顶部padding来撑起整个滚动内容,实现思路也非常简单.
通过以上分析其实已经可以解决朋友的问题了,但是最为一名有追求的前端工程师, 笔者认真梳理了一下,并基于第一种方案抽象出一个实际的问题:
如何渲染大数据列表并支持搜索功能?
笔者将通过模拟不同段位前端工程师的实现方案, 来探索一下该问题的价值. 希望能对大家有所启发, 学会真正的深入思考.
正文
笔者将通过不同经验程序员的技术视角来分析以上问题, 接下来开始我们的表演.
在开始代码之前我们先做好基础准备, 笔者先用nodejs搭建一个数据服务器, 提供基本的数据请求,核心代码如下:
app.use(async (ctx, next) => {
if(ctx.url === '/api/getMock') {
let list = []
// 生成指定个数的随机字符串
function genrateRandomWords(n) {
let words = 'abcdefghijklmnopqrstuvwxyz你是好的嗯气短前端后端设计产品网但考虑到付款啦分手快乐的分类开发商的李开复封疆大吏师德师风吉林省附近',
len = words.length,
ret = ''
for(let i=0; i< n; i++) {
ret += words[Math.floor(Math.random() * len)]
}
return ret
}
// 生成10万条数据的list
for(let i = 0; i< 100000; i++) {
list.push({
name: `xu_0${i}`,
title: genrateRandomWords(12),
text: `我是第${i}项目, 赶快🌀吧~~`,
tid: `xx_${i}`
})
}
ctx.body = {
state: 200,
data: list
}
}
await next()
})初级工程师的方案
直接从后端请求数据, 渲染到页面的硬编码方案,思路如下:
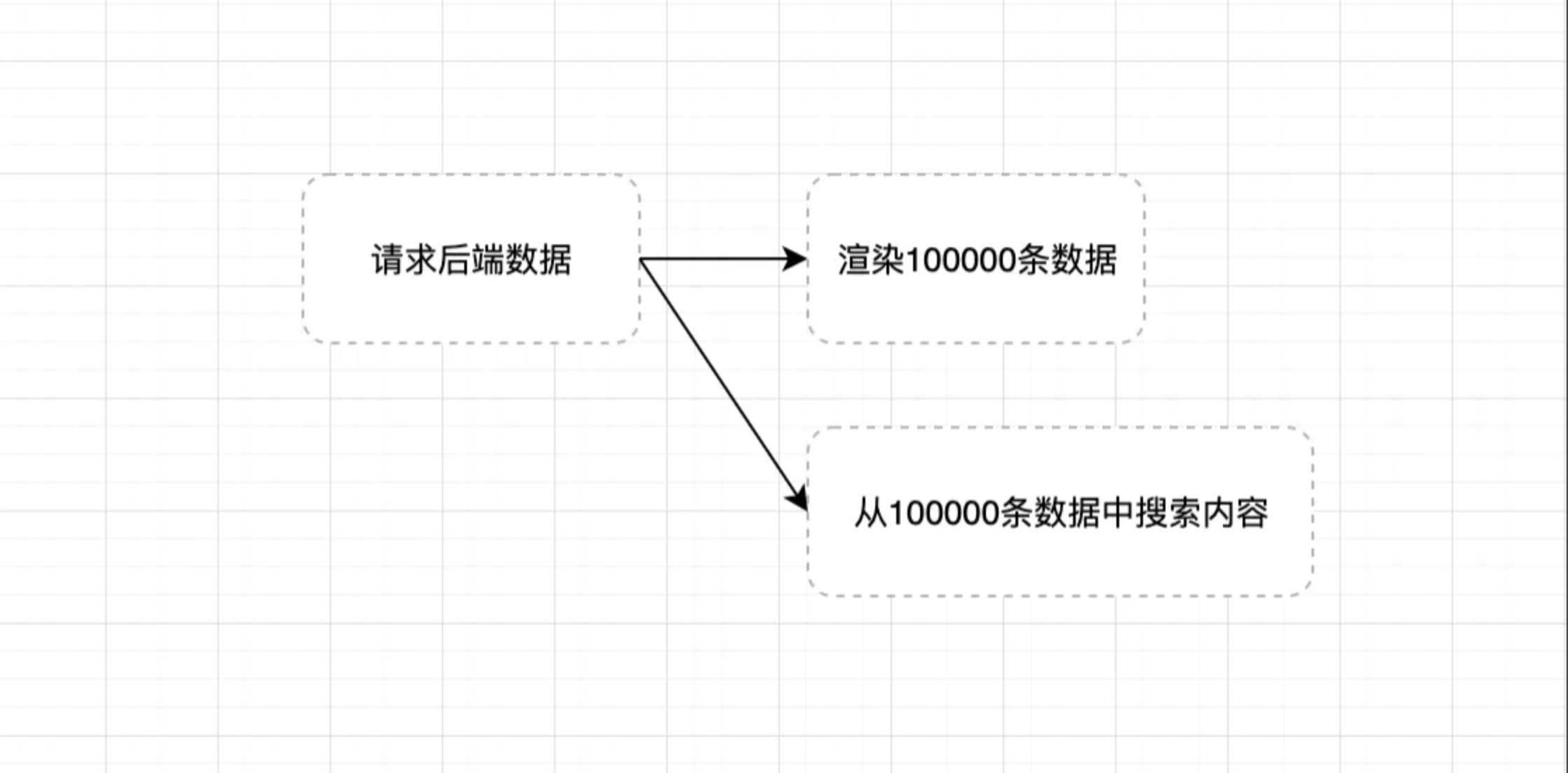
代码可能是这样的:
- 请求后端数据:
fetch(`${SERVER_URL}/api/getMock`).then(res => res.json()).then(res => {
if(res.state) {
data = res.data
setList(data)
}
})- 渲染页面
{
list.map((item, i) => {
return <div className={styles.item} key={item.tid}>
<div className={styles.tit}>{item.title} <span className={styles.label}>{item.name}</span></div>
<div>{item.text}</div>
</div>
})
}- 搜索数据
const handleSearch = (v) => {
let searchData = data.filter((item, i) => {
return item.title.indexOf(v) > -1
})
setList(searchData)
}这样做本质上是可以实现基本的需求,但是有明显的缺点,那就是数据一次性渲染到页面中, 数据量庞大将导致页面性能极具降低, 造成页面卡顿.
中级工程师的方案
作为一名有一定经验的前端开发工程师,一定对页面性能有所了解, 所以一定会熟悉防抖函数和节流函数, 并使用过诸如懒加载和分页这样的方案, 接下来我们看看中级工程师的方案:
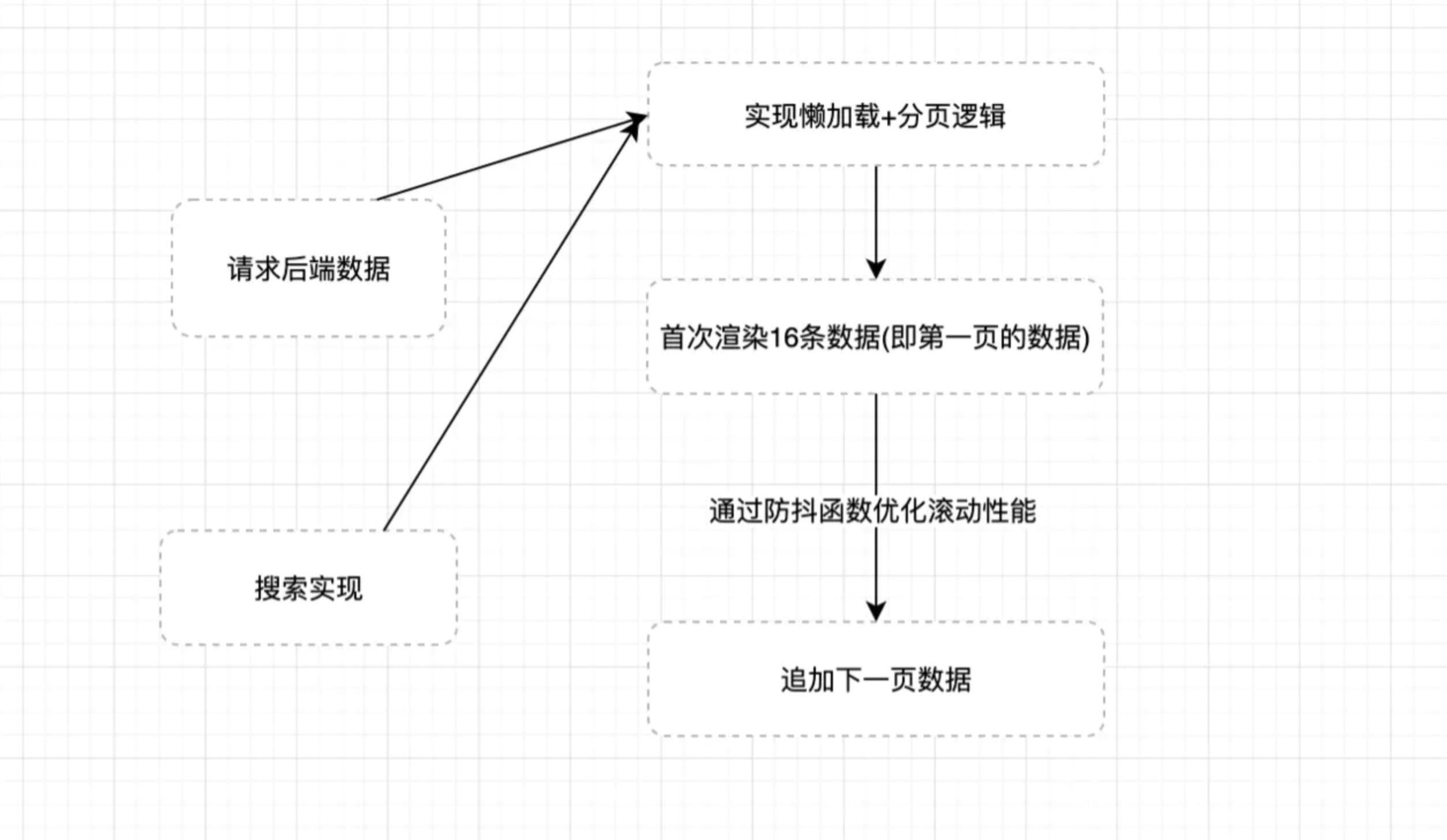
通过这个过程的优化, 代码已经基本可用了, 下面来介绍具体实现方案:
- 懒加载+分页方案 懒加载的实现主要是通过监听窗口的滚动, 当某一个占位元素可见之后去加载下一个数据,原理如下:

- 这里我们通过监听window的scroll事件以及对poll元素使用getBoundingClientRect来获取poll元素相对于可视窗口的距离, 从而自己实现一个懒加载方案.
在滚动的过程汇总我们还需要注意一个问题就是当用户往回滚动时, 实际上是不需要做任何处理的,所以我们需要加一个单向锁, 具体代码如下:
function scrollAndLoading() {
if(window.scrollY > prevY) { // 判断用户是否向下滚动
prevY = window.scrollY
if(poll.current.getBoundingClientRect().top <= window.innerHeight) {
// 请求下一页数据
}
}
}
useEffect(() => {
// something code
const getData = debounce(scrollAndLoading, 300)
window.addEventListener('scroll', getData, false)
return () => {
window.removeEventListener('scroll', getData, false)
}
}, [])其中prevY存储的是窗口上一次滚动的距离, 只有在向下滚动并且滚动高度大于上一次时才更新其值.
至于分页的逻辑, 原生javascript实现分页也很简单, 我们通过定义几个维度:
- curPage当前的页数
- pageSize 每一页展示的数量
- data 传入的数据量
有了这几个条件,我们的基本能分页功能就可以完成了. 前端分页的核心代码如下:
let data = [];
let curPage = 1;
let pageSize = 16;
let prevY = 0;
// other code...
function scrollAndLoading() {
if(window.scrollY > prevY) { // 判断用户是否向下滚动
prevY = window.scrollY
if(poll.current.getBoundingClientRect().top <= window.innerHeight) {
curPage++
setList(searchData.slice(0, pageSize * curPage))
}
}
}- 防抖函数实现 防抖函数因为比较简单, 这里直接上一个简单的防抖函数代码:
function debounce(fn, time) {
return function(args) {
let that = this
clearTimeout(fn.tid)
fn.tid = setTimeout(() => {
fn.call(that, args)
}, time);
}
}- 搜索实现 搜索功能代码如下:
const handleSearch = (v) => {
curPage = 1;
prevY = 0;
searchData = data.filter((item, i) => {
// 采用正则来做匹配, 后期支持前端模糊搜索
let reg = new RegExp(v, 'gi')
return reg.test(item.title)
})
setList(searchData.slice(0, pageSize * curPage))
}需要结合分页来实现, 所以这里为了不影响源数据, 我们采用临时数据searchData来存储. 效果如下:

搜索后

无论是搜索前还是搜索后, 都利用了懒加载, 所以再也不用担心数据量大带来的性能瓶颈了~
高级工程师的方案
作为一名久经战场的程序员, 我们应该考虑更优雅的实现方式,比如组件化, 算法优化, 多线程这类问题, 就比如我们问题中的大数据渲染, 我们也可以用虚拟长列表来更优雅简洁的来解决我们的需求. 至于虚拟长列表的实现笔者在开头已经点过,这里就不详细介绍了, 对于更大量的数据,比如100万(虽然实际开发中不会遇到这么无脑的场景),我们又该怎么处理呢?
第一个点我们可以使用js缓冲器来分片处理100万条数据, 思路代码如下:
function multistep(steps,args,callback){
var tasks = steps.concat();
setTimeout(function(){
var task = tasks.shift();
task.apply(null, args || []); //调用Apply参数必须是数组
if(tasks.length > 0){
setTimeout(arguments.callee, 25);
}else{
callback();
}
},25);
}这样就能比较大量计算导致的js进程阻塞问题了.更多性能优化方案可以参考笔者之前的文章:
我们还可以通过web worker来将需要在前端进行大量计算的逻辑移入进去, 保证js主进程的快速响应, 让web worker线程在后台计算, 计算完成后再通过web worker的通信机制来通知主进程, 比如模糊搜索等, 我们还可以对搜索算法进一步优化,比如二分法等,所以这些都是高级工程师该考虑的问题. 但是一定要分清场景, 寻找出性价比更高的方案.
链接:https://juejin.cn/post/6844904184689475592
收起阅读 »
一行可以让项目启动快70%以上的代码
前言
这两天闲来无事,想优化优化项目的启动时间,用了一个下午吧,将项目启动时间从48秒优化到14秒,大约70左右,效果还是有的,而且仅仅用了一行代码。
👇会讲一下找到这行代码的过程,如果没有耐心可以直接跳转到文章底部,直接看结论即可。
项目背景
项目就是简单的Vue项目,不过公司内部给vue-cli包了一层,不过影响不大。
别的也就没啥了,正常的H5网页,用的插件也不算多,为了控制项目体积。
项目分析
既然决定要优化了,首先要分析下项目,先用speed-measure-webpack-plugin和webpack-bundle-analyzer分析下,具体的配置这里就不多说了,很简单,网上一搜一大堆,这里直接看看结论。
首先是项目运行时间:
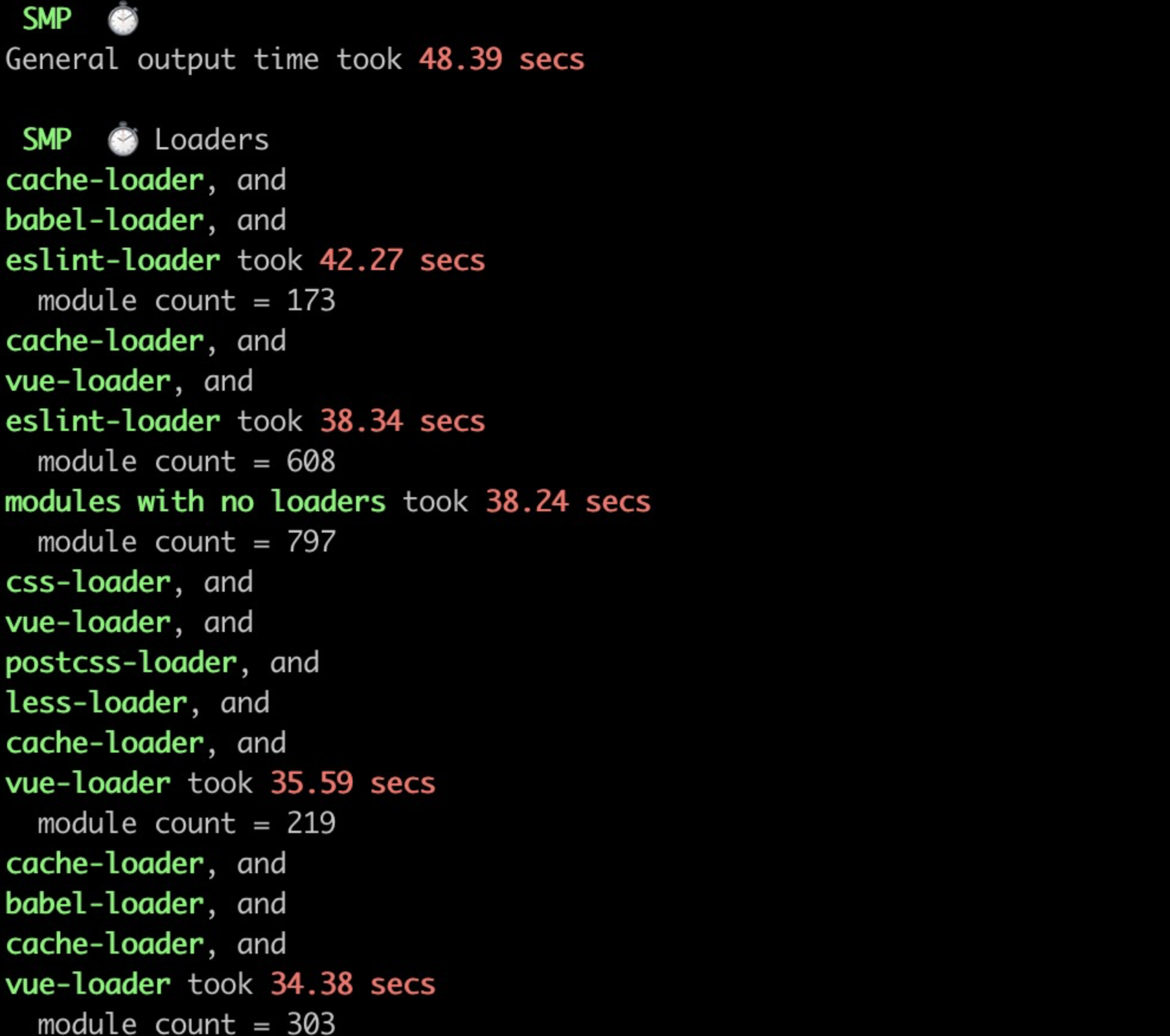
可以看到,基本上耗时大户就是eslint-loader和vue-loader了,二者一个耗时40多秒,一个耗时30多秒,非常的占用资源。
接下来再看看具体的包分析👇
这一看就很一下子定位到问题到根源了,右侧的chunk-vendors不用看,只看左侧的chunk-page,这里面的页面数量太多了,相应的文件也很多,这也就直接导致了eslint-loader和vue-loader耗时很久了,这么多文件,一个个检查耗时当然久了。
右侧其实还可以继续优化,但感觉没必要,swiper其实并不大。
那么现在就可以具体定位到问题了,由于项目是多SPA应用,致使.vue文件众多,在项目启动时进行eslint检查和加载耗时过长,导致项目启动时间较久。
解决方案
找到问题之后就得解决问题了,初步的解决方案有两个:
- 干掉
eslint,在本地编译时不检查 - 缓存
解决方案1必然是最简单的,但其实有点不合理,开着eslint就是为了规范代码格式,虽然在提交代码时也有对应的钩子来格式化代码,但在开发过程中进行提示可以更好的帮助我们形成合理的编码方式。
所以现在剩下的方案就只有进行缓存操作了,接下来笔者就开始找相关插件来更好的进行缓存了。
尝试解决
首先是hard-source-webpack-plugin,这插件为模块提供中间缓存步骤,但项目得跑两次,第一次构建时间正常,第二次大概能省去90%左右的时间。
这插件很多文章都有推荐,感觉很不错的样子,用起来也很简单,只需要👇:
plugins: [
new HardSourceWebpackPlugin()
]这就完事了。
就这么简单?确实是这么简单,但也不简单,如果到此为止,笔者也不会折腾一下午了。
就这么简单的一安装:
npm i hard-source-webpack-plugin -D然后像👆一样简单的配置,然后重启项目,您猜怎么着?
报错了!
原因是什么呢?
是因为speed-measure-webpack-plugin或者webpack-bundle-analyzer中的某一个,为什么呢?
原因笔者其实并不太清楚,因为启动的时候报的错是这样的:
Cannot find module 'webpack/lib/DependenciesBlockVariable'
哦呦,这个错有点小意外,怎么会突然报webpack的错呢?
笔者也是百思不得其解啊,去Google也没有人遇到这种问题。
不得已,只能去hard-source-webpack-plugin的github上看issue,发现其实有人遇到这个问题的,他们的解决方案就是降低webpack的版本,可笔者这里没办法这么做,因为都集成在vue-cli里了,而且这个还是公司内部包了一层的,这就根本不可能降版本了。
第一个转机
那还能怎么办呢?
实在没有办法了,笔者尝试搜索DependenciesBlockVariable的相关内容,这时事情发生了一丝微妙的变换,原来这个功能在webpack5中被移除了,难道是因为公司内部的vue-cli用的是webpack5.x版本?

笔者当即在node_modules里面找到了插件,然后查看了package.json文件,结果失望的发现webpack的版本是4.2.6,这就令人绝望了,难道真的不可以么?
既然打开了webpack的文档,那就好好看看吧。老实说这文档笔者已经看了N次了,真是每次看都有小惊喜,功能真是太多了。
翻着翻着就看到了这个小功能👇:

哦呦,还真有点小惊喜呦,这功能简直了,这不就是我想要的么?然后当机立断,往vue.config.js里一家,您猜怎么着?
成了!
虽然文档是webpack5.0的,但笔者发现4.x版本中也有这个功能,可能若一弱一些吧,多少能用啊。
重启了几次项目后发现启动时间已经稳定了,效果真的还不错呦~

直接给我干到了14秒,虽然有些不太稳定,但这已经是当前状态的最好解决方案了。
所以最后的代码就是:
chainWebpack: (config) => {
config.cache(true)
}用chainWebpack的原因是项目中其实没有独立的webpack.config.js文件,所以只能放在vue.config.js文件中,使用chainWebpack来将配置插入到webpack中去。
你以为事情到这里就结束了么?太简单了。
第二个转机
解决完问题后,当然要把speed-measure-webpack-plugin和webpack-bundle-analyzer这两个插件删掉了,然后整理整理代码,推上去完事。
可笔者还是不死心,为啥hard-source-webpack-plugin不好使呢?不应该啊,为啥别人都能用,自己的项目却用不了呢?
为了再次操作一手,也是为了更好的优化项目的启动时间,笔者再次安装了hard-source-webpack-plugin,并且对其进行了配置:
chainWebpack: (config) => {
config.plugin('cache').use(HardSourceWebpackPlugin)
}这次再一跑,您猜怎么着?
成了!
为了避免再次启动失败了,笔者这次没有使用speed-measure-webpack-plugin和webpack-bundle-analyzer这两个插件,所以启动时间也没法具体估计了,但目测时间再10秒以内,强啊。
所以说hard-source-webpack-plugin失败的原因可能就是那两个统计插件的原因了,得亏再试了一次,要不然就不明不白的GG了。
结论
这里的结论就很简单了,有两个版本。
首先,如果项目能使用hard-source-webpack-plugin就很方便了,用就完事了,啥事也不需要干,所以这一行代码是👇:
config.plugin('cache').use(HardSourceWebpackPlugin)大概真能快90%以上,官方并没有虚报时间。
其次,如果用不了hard-source-webpack-plugin那就放弃吧,尝试webpack自带的cache功能也是不错的,虽然比不上hard-source-webpack-plugin,但多少也能提升70%左右的启动时间,所以这一行代码是👇:
config.cache(true)并且不需要安装任何插件,一步到位。
这两种方法其实都是可行了,论稳定和效果的话hard-source-webpack-plugin还是更胜一筹,但cache胜在不用装额外的webpack插件,具体用什么就自己决定吧。
这里其实还是留了个坑,hard-source-webpack-plugin用不了的具体原因是什么呢?笔者只是猜测和speed-measure-webpack-plugin、webpack-bundle-analyzer这两个插件有关,但却不能肯定,如果有读者知道,欢迎在评论区留言或者私信笔者。
看了这么久,辛苦了!
链接:https://juejin.cn/post/6961203055257714702
SwiftUI-如何创建一个工程
2019年度WWDC全球开发者大会,更新旗下用于手机、电脑、智能手表和电视机顶盒的软件操作系统。此外还发布了计算机编程语言框架SwiftUI。SwiftUI是基于开发语言Swift建立的框架——SwiftUI。全新的SwiftUI可以用于watchOS、tvOS、macOS等苹果旗下系统。
在本文对于SwiftUI使用做一个简介。😊
环境:
1、macOS 15 Beta
2、Xcode 11.0 Beta
3、iOS 13.0 Beta
接下来我们尝试体验一下SwiftUI功能,如何使用SwiftUI实现一个TableView呢?
import SwiftUI
struct Hero: Identifiable {
let id: UUID = UUID()
let name: String
}
struct ContentView : View {
let heros = [
Hero(name: "邱少云"),
Hero(name: "黄继光"),
Hero(name: "董存瑞"),
Hero(name: "杨宝山"),
Hero(name: "毛岸英")
]
var body: some View {
List(heros) {
hero in
Text(hero.name)
}
}
}
#if DEBUG
struct ContentView_Previews : PreviewProvider {
static var previews: some View {
ContentView()
}
}
#endif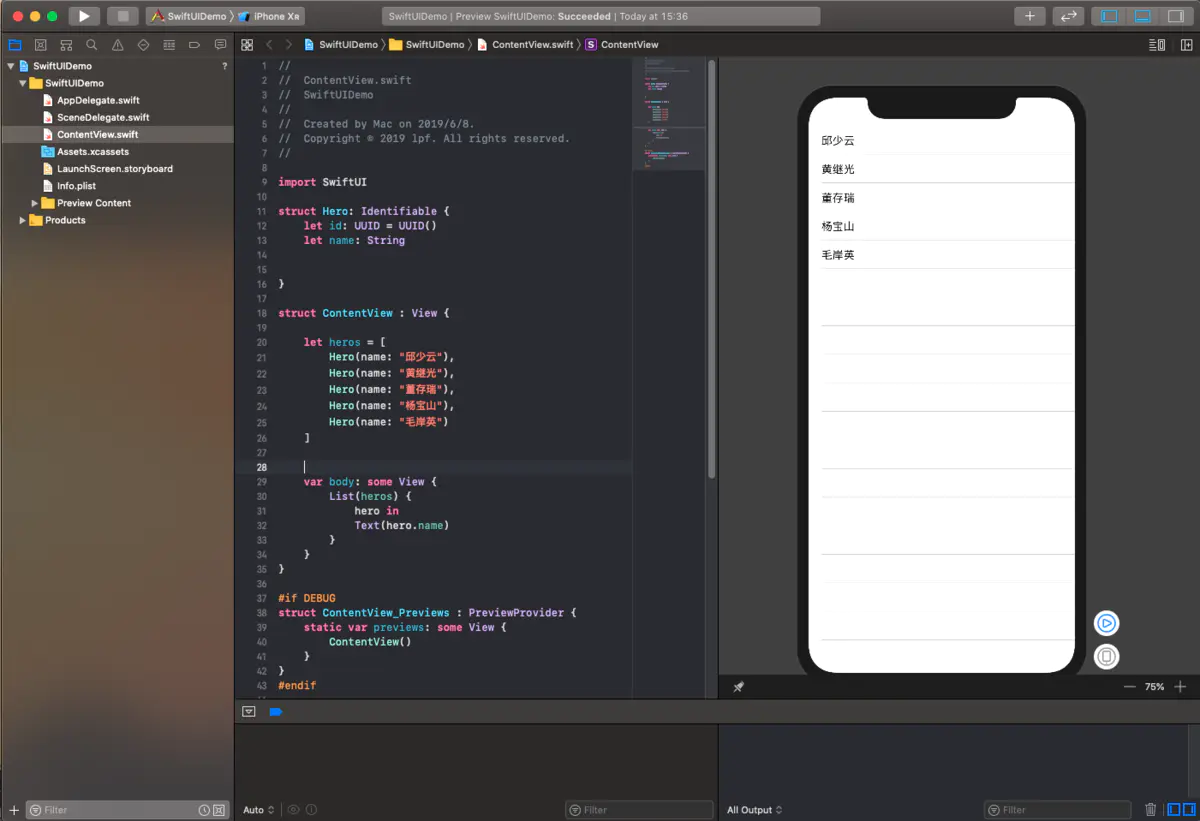
以上是我们实现的第一个SwiftUI程序是不是很直观?
接下来我们来了解一下程序的入口,同时解释一下他们之间如何联系的。
1、创建一个SwiftUI 工程
在Xcode-Beta 里创建工程和之前Xcode版本是一样的,我们选择 Single View App:
给工程命名同时选择使用SwiftUI
2、了解程序的入口
让我们从项目中删除尽可能多的代码和文件,看到什么程度还可以让它跑起来。刚开始创建工程是这样的:
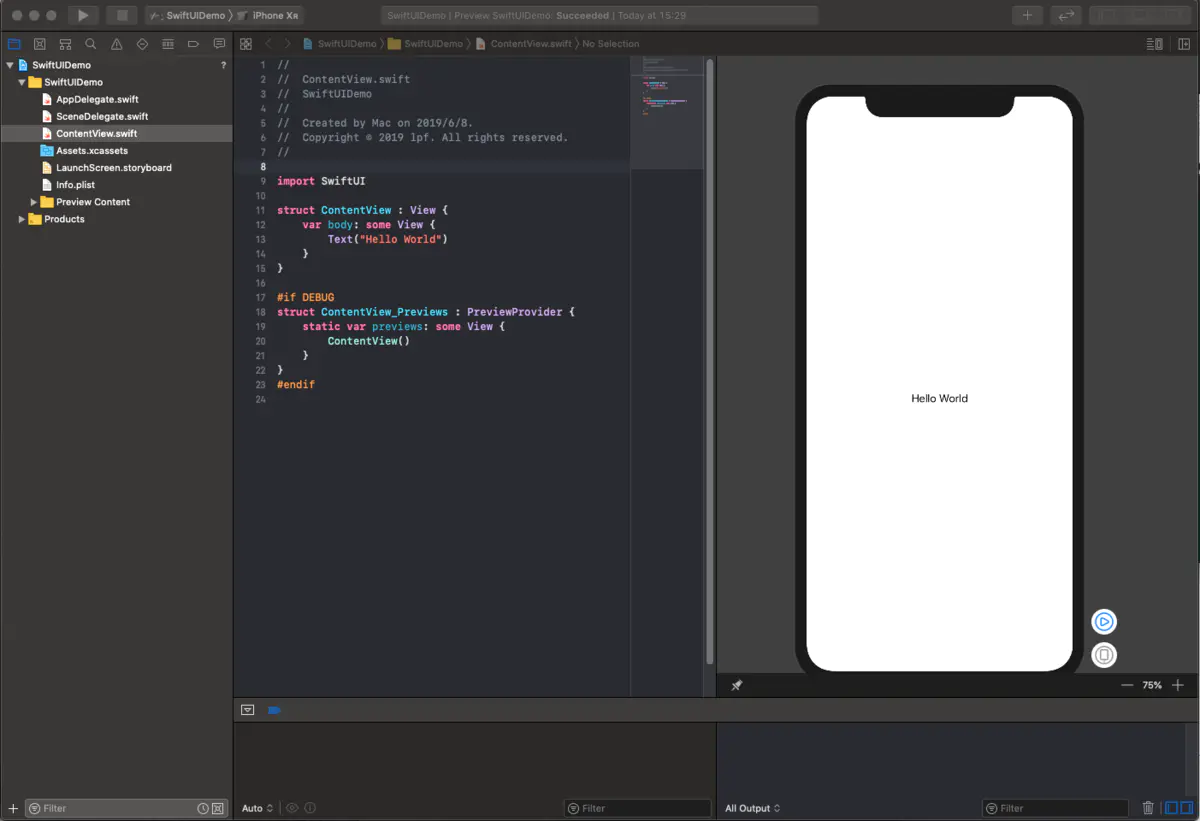
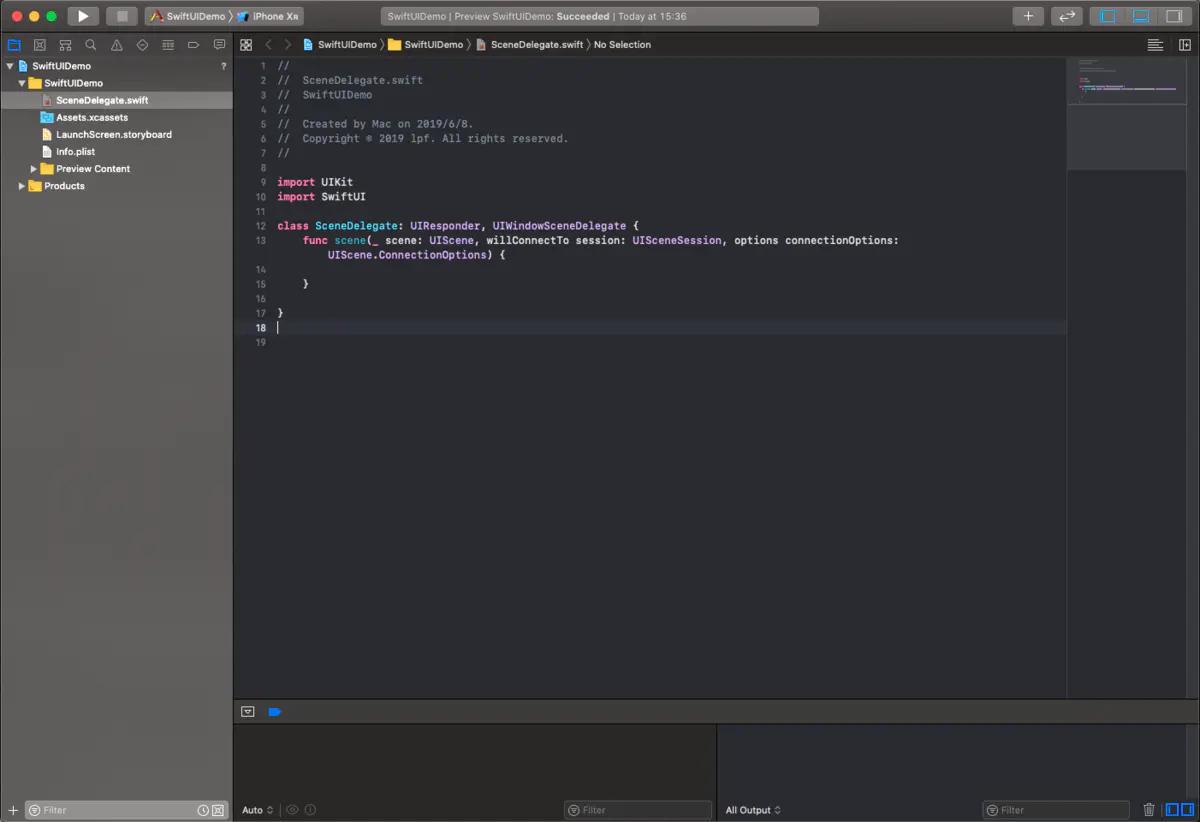
我们将AppDelegate.swift和ContentView.swift删除并移进回收站。并在SceneDelegate类的顶部添加@UIApplicationMain,让这个类遵循UIApplicationDelegate,删除SceneDelegate中除func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions)以外的方法,func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions)是程序的主入口。
现在如果选择iPhone XR进行运行,会显示黑屏。
3、创建一个新的Swift File或者直接选择SwiftUI View
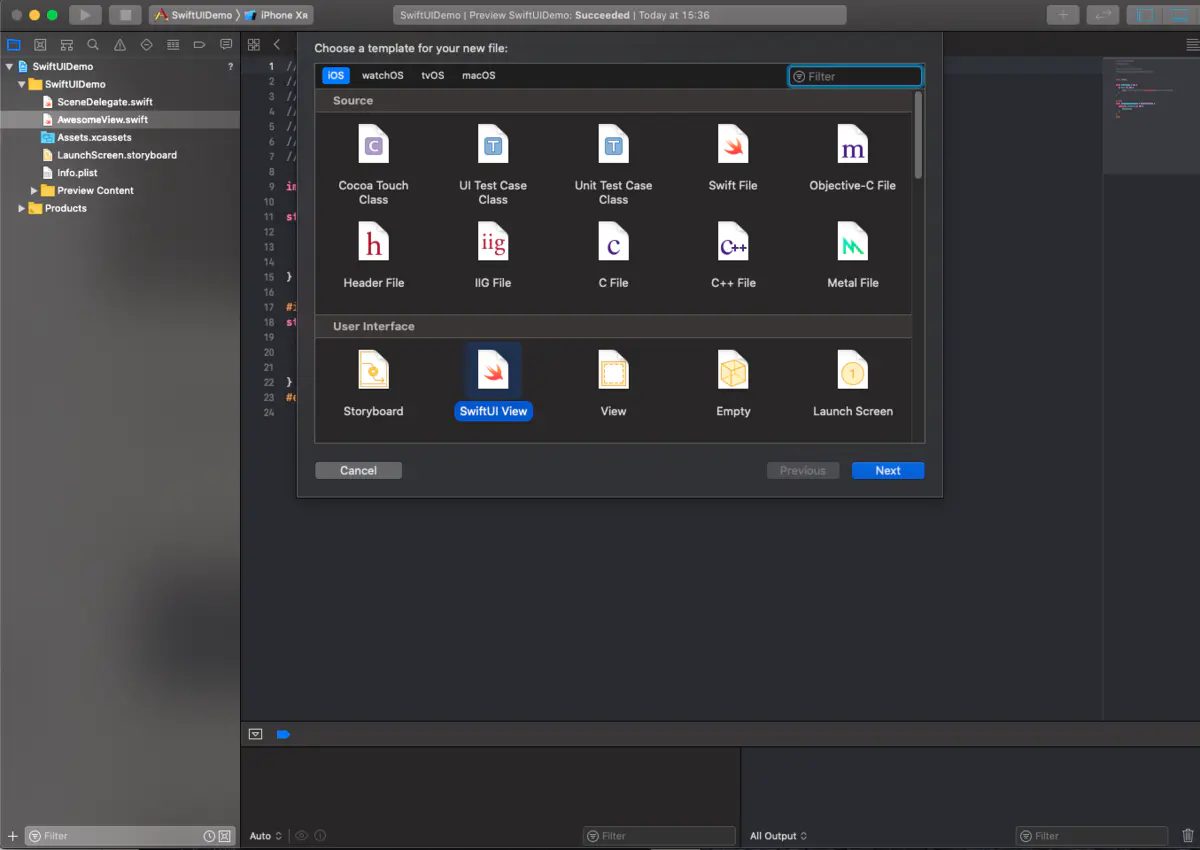
我们将新创建的Swift文件命名为 AwesomeView.swift,内部代码如下,和我们最初删除的ContentView.swift内容一样:
import SwiftUI
struct AwesomeView : View {
var body: some View {
Text(/*@START_MENU_TOKEN@*/"Hello World!"/*@END_MENU_TOKEN@*/)
}
}
#if DEBUG
struct AwesomeView_Previews : PreviewProvider {
static var previews: some View {
AwesomeView()
}
}
#endifAwesomeView.swift中有一个实现View协议的AwesomeView结构体,根据View协议,我们实现了body属性,Swift5.1中,我们不需要添加return关键字,函数或者闭包最后一行将自动返回。
这是我们写的第一个SwiftUI试图,接下来选择右上角,点击一个多条线按钮,选择Editor and Canvas
接下来点击Resume 或者 Try again 查看试图状态。
预览里将展示AwesomeView_Previews 结构体中闭包返回的所有试图预览。
在PreviewProvider里我们可以看到这段注释
Xcode statically discovers types that conform to `PreviewProvider` and
generates previews in the canvas for each provider it discovers.通过Xcode静态发现符合PreviewProvider协议的类型,并在画布中为它发现的每个provider生成预览。所以我们可以随意命名xxx_Previews并遵循PreviewProvider协议,就可以在画布上预览我们的视图。
我们可以编辑左边的代码,看右侧的画布是不是可以重载。😍
4、将SwiftUI View 定义为程序启动图
之前我们的跑起来的程序是黑屏,目前重新启动程序依然是黑屏。如何将我们定义的为根视图呢?其实我们之前删除代码是我们就注意到了在SceneDelegate.swift中有以下代码:
import UIKit
import SwiftUI
@UIApplicationMain
class SceneDelegate: UIResponder, UIWindowSceneDelegate, UIApplicationDelegate {
var window: UIWindow?
func scene(_ scene: UIScene, willConnectTo session: UISceneSession, options connectionOptions: UIScene.ConnectionOptions) {
// 实例化一个手机屏幕大小window
let window = UIWindow(frame: UIScreen.main.bounds)
// 实例化一个UIHostingController作为rootViewController
// UIHostingController保存SwiftUI视图,将AwesomeView作为根视图
window.rootViewController = UIHostingController(rootView: AwesomeView())
self.window = window
window.makeKeyAndVisible()
}
}现在运行程序我们就可以在模拟器中看到我们写的AwesomeView了。。。。
Xcode 是如何知道SceneDelegate.swift中的SceneDelegate作为程序启动根视图的类的呢?我们看一下工程中的info.plist
我们尝试修改一下Delegate Class Name将(PRODUCT_MODULE_NAME).SceneDelegate改为$(PRODUCT_MODULE_NAME).martinlasek,此时我们运行将会出现之前的黑屏情况,因为程序找不到martinlasek,
现在我们将SceneDelegate.swift中的SceneDelegate类重命名为martinlasek。然后我们再运行一次。在模拟器中我们再次看到了AwesomeView。
也就是说info.plist中的Delegate Class Name定义了根视图的类。
通过上面的一段内容你可以很轻松实现一个SwiftUI小程序。从现在开始你可以开启你的SwiftUI之旅了。
链接:https://www.jianshu.com/p/b4509d3d9766
收起阅读 »哇擦!他居然把 React 组件渲染到了命令行终端窗口里面
也许你之前听说过前端组件代码可以运行在浏览器,运行在移动端 App 里面,甚至可以直接在各种设备当中,但你有没有见过: 前端组件直接跑在命令行窗口里面,让前端代码构建出终端窗口的 GUI 界面和交互逻辑?
今天, 给大家分享一个非常有意思的开源项目: ink。它的作用就是将 React 组件渲染在终端窗口中,呈现出最后的命令行界面。
本文偏重实战,前面会带大家熟悉基本使用,然后会做一个基于实际场景的练手项目。
上手初体验
刚开始上手时,推荐使用官方的脚手架创建项目,省时省心。
npx create-ink-app --typescript然后运行这样一段代码:
import React, { useState, useEffect } from 'react'
import { render, Text} from 'ink'
const Counter = () => {
const [count, setCount] = useState(0)
useEffect(() => {
const timer = setInterval(() => {
setCount(count => ++count)
}, 100)
return () => {
clearInterval(timer)
}
})
return (
<Text color="green">
{count} tests passed
</Text>
)
}
render(<Counter />);会出现如下的界面:

并且数字一直递增! demo 虽小,但足以说明问题:
首先,这些文本输出都不是直接 console 出来的,而是通过
React 组件渲染出来的。
React 组件的
状态管理以及hooks 逻辑放到命令行的 GUI 当中仍然是生效的。
也就是说,前端的能力以及扩展到了命令行窗口当中了,这无疑是一项非常可怕的能力。著名的文档生成工具
Gatsby,包管理工具yarn2都使用了这项能力来完成终端 GUI 的搭建。
命令行工具项目实战
可能大家刚刚了解到这个工具,知道它的用途,但对于具体如何使用还是比较陌生。接下来让我们以一个实际的例子来进行实战,快速熟悉。代码仓库已经上传到 git,大家可以这个地址下面 fork 代码: github.com/sanyuan0704…
下面我们就来从头到尾开发这个项目。
项目背景
首先说一说项目的产生背景,在一个 TS 的业务项目当中,我们曾经碰到了一个问题:由于production模式下面,我们是采用先 tsc,拿到 js 产物代码,再用webpack打包这些产物。
但构建的时候直接报错了,原因就是 tsc 无法将 ts(x) 以外的资源文件移动到产物目录,以至于 webpack 在对于产物进行打包的时候,发现有些资源文件根本找不到!比如以前有这样一张图片的路径是这样—— src/asset/1.png,但这些在产物目录dist却没还有,因此 webpack 在打包 dist 目录下的代码时,会发现这张图片不存在,于是报错了。
解决思路
那如何来解决呢?
很显然,我们很难去扩展 tsc 的能力,现在最好的方式就是写个脚本手动将src下面的所有资源文件一一拷贝到dist目录,这样就能解决资源无法找到的问题。
一、拷贝文件逻辑
确定了解决思路之后,我们写下这样一段 ts 代码:
import { join, parse } from "path";
import { fdir } from 'fdir';
import fse from 'fs-extra'
const staticFiles = await new fdir()
.withFullPaths()
// 过滤掉 node_modules、ts、tsx
.filter(
(p) =>
!p.includes('node_modules') &&
!p.endsWith('.ts') &&
!p.endsWith('.tsx')
)
// 搜索 src 目录
.crawl(srcPath)
.withPromise() as string[]
await Promise.all(staticFiles.map(file => {
const targetFilePath = file.replace(srcPath, distPath);
// 创建目录并拷贝文件
return fse.mkdirp(parse(targetFilePath).dir)
.then(() => fse.copyFile(file, distPath))
);
}))代码使用了fdir这个库才搜索文件,非常好用的一个库,写法上也很优雅,推荐大家使用。
我们执行这段逻辑,成功将资源文件转移到到了产物目录中。
问题是解决掉了,但我们能不能封装一下这个逻辑,让它能够更方便地在其它项目当中复用,甚至直接提供给其他人复用呢?
接着,我想到了命令行工具。
二、命令行 GUI 搭建
接着我们使用 ink,也就是用 React 组件的方式来搭建命令行 GUI,根组件代码如下:
// index.tsx 引入代码省略
interface AppProps {
fileConsumer: FileCopyConsumer
}
const ACTIVE_TAB_NAME = {
STATE: "执行状态",
LOG: "执行日志"
}
const App: FC<AppProps> = ({ fileConsumer }) => {
const [activeTab, setActiveTab] = useState<string>(ACTIVE_TAB_NAME.STATE);
const handleTabChange = (name) => {
setActiveTab(name)
}
const WELCOME_TEXT = dedent`
欢迎来到 \`ink-copy\` 控制台!功能概览如下(按 **Tab** 切换):
`
return <>
<FullScreen>
<Box>
<Markdown>{WELCOME_TEXT}</Markdown>
</Box>
<Tabs onChange={handleTabChange}>
<Tab name={ACTIVE_TAB_NAME.STATE}>{ACTIVE_TAB_NAME.STATE}</Tab>
<Tab name={ACTIVE_TAB_NAME.LOG}>{ACTIVE_TAB_NAME.LOG}</Tab>
</Tabs>
<Box>
<Box display={ activeTab === ACTIVE_TAB_NAME.STATE ? 'flex': 'none'}>
<State />
</Box>
<Box display={ activeTab === ACTIVE_TAB_NAME.LOG ? 'flex': 'none'}>
<Log />
</Box>
</Box>
</FullScreen>
</>
};
export default App;可以看到,主要包含两大组件: State和Log,分别对应两个 Tab 栏。具体的代码大家去参考仓库即可,下面放出效果图:
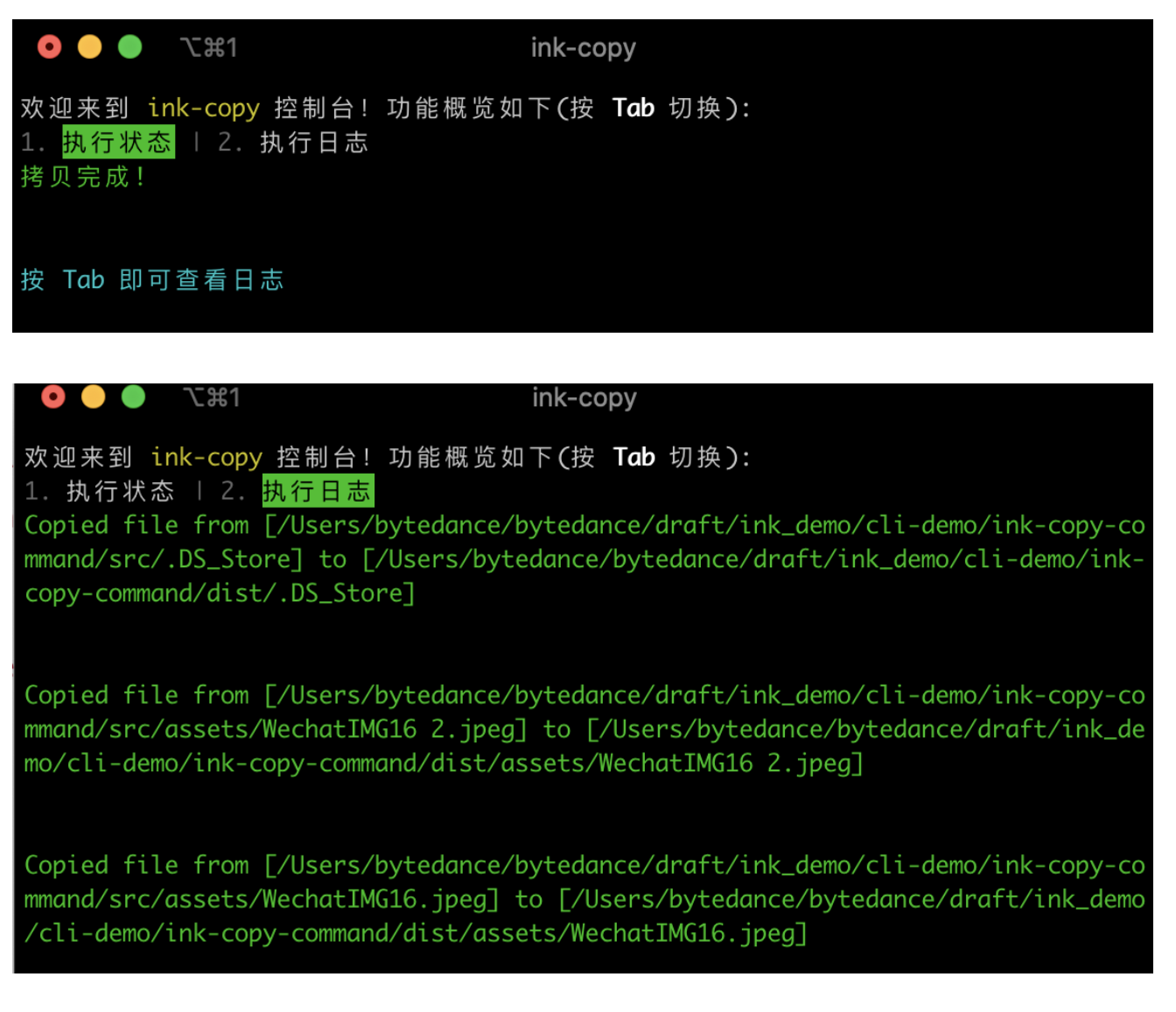
3. GUI 如何实时展示业务状态?
现在问题就来了,文件操作的逻辑开发完了,GUI 界面也搭建好了。那么现在如何将两者结合起来呢,也就是 GUI 如何实时地展示文件操作的状态呢?
对此,我们需要引入第三方,来进行这两个模块的通信。具体来讲,我们在文件操作的逻辑中维护一个 EventBus 对象,然后在 React 组件当中,通过 Context 的方式传入这个 EventBus。
从而完成 UI 和文件操作模块的通信。
现在我们开发一下这个 EventBus 对象,也就是下面的FileCopyConsumer:
export interface EventData {
kind: string;
payload: any;
}
export class FileCopyConsumer {
private callbacks: Function[];
constructor() {
this.callbacks = []
}
// 供 React 组件绑定回调
onEvent(fn: Function) {
this.callbacks.push(fn);
}
// 文件操作完成后调用
onDone(event: EventData) {
this.callbacks.forEach(callback => callback(event))
}
}接着在文件操作模块和 UI 模块当中,都需要做响应的适配,首先看看文件操作模块,我们做一下封装。
export class FileOperator {
fileConsumer: FileCopyConsumer;
srcPath: string;
targetPath: string;
constructor(srcPath ?: string, targetPath ?: string) {
// 初始化 EventBus 对象
this.fileConsumer = new FileCopyConsumer();
this.srcPath = srcPath ?? join(process.cwd(), 'src');
this.targetPath = targetPath ?? join(process.cwd(), 'dist');
}
async copyFiles() {
// 存储 log 信息
const stats = [];
// 在 src 中搜索文件
const staticFiles = ...
await Promise.all(staticFiles.map(file => {
// ...
// 存储 log
.then(() => stats.push(`Copied file from [${file}] to [${targetFilePath}]`));
}))
// 调用 onDone
this.fileConsumer.onDone({
kind: "finish",
payload: stats
})
}
}然后在初始化 FileOperator之后,将 fileConsumer通过 React Context 传入到组件当中,这样组件就能访问到fileConsumer,进而可以进行回调函数的绑定,代码演示如下:
// 组件当中拿到 fileConsumer & 绑定回调
export const State: FC<{}> = () => {
const context = useContext(Context);
const [finish, setFinish] = useState(false);
context?.fileConsumer.onEvent((data: EventData) => {
// 下面的逻辑在文件拷贝完成后执行
if (data.kind === 'finish') {
setTimeout(() => {
setFinish(true)
}, 2000)
}
})
return
//(JSX代码)
}这样,我们就成功地将 UI 和文件操作逻辑串联了起来。当然,篇幅所限,还有一些代码并没有展示出来,完整的代码都在 git 仓库当中。希望大家能 fork 下来好好体会一下整个项目的设计。
总体来说,React 组件代码能够跑在命令行终端,确实是一件激动人心的事情,给前端释放了更多想象的空间。本文对于这个能力的使用也只是冰山一角,更多使用姿势等待你去解锁,赶紧去玩一玩吧!
链接:https://juejin.cn/post/6952673382928220191
如何应用 SOLID 原则整理 React 代码之单一原则
SOLID 原则的主要是作为关心自己工作的软件专业人员的指导方针,另外还为那些以经得起时间考验的设计精美的代码库为荣的人。
今天,我们将从一个糟糕的代码示例开始,应用 SOLID 的第一个原则,看看它如何帮助我们编写小巧、漂亮、干净的并明确责任的 React 组件,。
什么是单一责任原则?
单一责任原则告诉我们的是,每个类或组件应该有一个单一的存在目的。
组件应该只做一件事,并且做得很好。
让我们重构一段糟糕但正常工作的代码,并使用这个原则使其更加清晰和完善。
让我们从一个糟糕的例子开始
首先让我们看看一些违反这一原则的代码,添加注释是为了更好地理解:
import React, {useEffect, useReducer, useState} from "react";
const initialState = {
isLoading: true
};
// 复杂的状态管理
function reducer(state, action) {
switch (action.type) {
case 'LOADING':
return {isLoading: true};
case 'FINISHED':
return {isLoading: false};
default:
return state;
}
}
export const SingleResponsibilityPrinciple = () => {
const [users , setUsers] = useState([])
const [filteredUsers , setFilteredUsers] = useState([])
const [state, dispatch] = useReducer(reducer, initialState);
const showDetails = (userId) => {
const user = filteredUsers.find(user => user.id===userId);
alert(user.contact)
}
// 远程数据获取
useEffect(() => {
dispatch({type:'LOADING'})
fetch('https://jsonplaceholder.typicode.com/users')
.then(response => response.json())
.then(json => {
dispatch({type:'FINISHED'})
setUsers(json)
})
},[])
// 数据处理
useEffect(() => {
const filteredUsers = users.map(user => {
return {
id: user.id,
name: user.name,
contact: `${user.phone} , ${user.email}`
};
});
setFilteredUsers(filteredUsers)
},[users])
// 复杂UI渲染
return <>
Users List
Loading state: {state.isLoading? 'Loading': 'Success'}
{users.map(user => {
return showDetails(user.id)}>
{user.name}
{user.email}
})}
}这段代码的作用
这是一个函数式组件,我们从远程数据源获取数据,再过滤数据,然后在 UI 中显示数据。我们还检测 API 调用的加载状态。
为了更好地理解这个例子,我把它简化了。但是你几乎可以在任何地方的同一个组件中找到它们!这里发生了很多事情:
远程数据的获取
数据过滤
复杂的状态管理
复杂的 UI 功能
因此,让我们探索如何改进代码的设计并使其紧凑。
1. 移动数据处理逻辑
不要将 HTTP 调用保留在组件中。这是经验之谈。您可以采用几种策略从组件中删除这些代码。
您至少应该创建一个自定义 Hook 并将数据获取逻辑移动到那里。例如,我们可以创建一个名为 useGetRemoteData 的 Hook,如下所示:
import {useEffect, useReducer, useState} from "react";
const initialState = {
isLoading: true
};
function reducer(state, action) {
switch (action.type) {
case 'LOADING':
return {isLoading: true};
case 'FINISHED':
return {isLoading: false};
default:
return state;
}
}
export const useGetRemoteData = (url) => {
const [users , setUsers] = useState([])
const [state, dispatch] = useReducer(reducer, initialState);
const [filteredUsers , setFilteredUsers] = useState([])
useEffect(() => {
dispatch({type:'LOADING'})
fetch('https://jsonplaceholder.typicode.com/users')
.then(response => response.json())
.then(json => {
dispatch({type:'FINISHED'})
setUsers(json)
})
},[])
useEffect(() => {
const filteredUsers = users.map(user => {
return {
id: user.id,
name: user.name,
contact: `${user.phone} , ${user.email}`
};
});
setFilteredUsers(filteredUsers)
},[users])
return {filteredUsers , isLoading: state.isLoading}
}现在我们的主要组件看起来像这样:
import React from "react";
import {useGetRemoteData} from "./useGetRemoteData";
export const SingleResponsibilityPrinciple = () => {
const {filteredUsers , isLoading} = useGetRemoteData()
const showDetails = (userId) => {
const user = filteredUsers.find(user => user.id===userId);
alert(user.contact)
}
return <>
Users List
Loading state: {isLoading? 'Loading': 'Success'}
{filteredUsers.map(user => {
return showDetails(user.id)}>
{user.name}
{user.email}
})}
}看看我们的组件现在是多么的小,多么的容易理解!这是在错综复杂的代码库中所能做的最简单、最重要的事情。
但我们可以做得更好。
2. 可重用的数据获取钩子
现在,当我们看到我们 useGetRemoteData Hook 时,我们看到这个 Hook 正在做两件事:
从远程数据源获取数据
过滤数据
让我们把获取远程数据的逻辑提取到一个单独的钩子,这个钩子的名字是 useHttpGetRequest,它把 URL 作为一个参数:
import {useEffect, useReducer, useState} from "react";
import {loadingReducer} from "./LoadingReducer";
const initialState = {
isLoading: true
};
export const useHttpGetRequest = (URL) => {
const [users , setUsers] = useState([])
const [state, dispatch] = useReducer(loadingReducer, initialState);
useEffect(() => {
dispatch({type:'LOADING'})
fetch(URL)
.then(response => response.json())
.then(json => {
dispatch({type:'FINISHED'})
setUsers(json)
})
},[])
return {users , isLoading: state.isLoading}
}我们还将 reducer 逻辑移除到一个单独的文件中:
export function loadingReducer(state, action) {
switch (action.type) {
case 'LOADING':
return {isLoading: true};
case 'FINISHED':
return {isLoading: false};
default:
return state;
}
}所以现在我们的 useGetRemoteData 变成了:
import {useEffect, useState} from "react";
import {useHttpGetRequest} from "./useHttpGet";
const REMOTE_URL = 'https://jsonplaceholder.typicode.com/users'
export const useGetRemoteData = () => {
const {users , isLoading} = useHttpGetRequest(REMOTE_URL)
const [filteredUsers , setFilteredUsers] = useState([])
useEffect(() => {
const filteredUsers = users.map(user => {
return {
id: user.id,
name: user.name,
contact: `${user.phone} , ${user.email}`
};
});
setFilteredUsers(filteredUsers)
},[users])
return {filteredUsers , isLoading}
}干净多了,对吧? 我们能做得更好吗? 当然,为什么不呢?
3. 分解 UI 组件
看看我们的组件,其中显示了用户的详细信息。我们可以为此创建一个可重用的 UserDetails 组件:
const UserDetails = (user) => {
const showDetails = (user) => {
alert(user.contact)
}
return showDetails(user)}>
{user.name}
{user.email}
}最后,我们的原始组件变成:
import React from "react";
import {useGetRemoteData} from "./useGetRemoteData";
export const Users = () => {
const {filteredUsers , isLoading} = useGetRemoteData()
return <>
Users List
Loading state: {isLoading? 'Loading': 'Success'}
{filteredUsers.map(user => )}
} 我们把代码从60行精简到了12行!我们创建了五个独立的组成部分,每个部分都有明确而单一的职责。
让我们回顾一下我们刚刚做了什么
让我们回顾一下我们的组件,看看我们是否实现了 SRP:
Users.js- 负责显示用户列表
UserDetails.jsー 负责显示用户的详细资料
useGetRemoteData.js- 负责过滤远程数据
useHttpGetrequest.js- 负责 HTTP 调用
LoadingReducer.js- 复杂的状态管理
当然,我们可以改进很多其他的东西,但是这应该是一个很好的起点。
链接:https://juejin.cn/post/6963480203637030926
React的性能优化(useMemo和useCallback)的使用
一、业务场景
React是一个用于构建用户界面的javascript的库,主要负责将数据转换为视图,保证数据和视图的统一,react在每次数据更新的时候都会重新render来保证数据和视图的统一,但是当父组件内部数据的变化,在父组件下挂载的所有子组件也会重新渲染,因为react默认会全部渲染所有的组件,包括子组件的子组件,这就造成不必要的浪费。
export default class Parent extends React.Component {
state = {
count: 0,
}
render() {
return(
<div>
我是父组件
<button onClick={() => this.setState({count: this.state.count++})}>点击按钮</button>
<Child />
</div>
)
}
}2、定义一个子组件
class Child extends React.Component {
render() {
console.log('我是子组件');
return (
<div>
我是子组件
<Grandson />
</div>
)
}
}3、定义一个孙子组件
class Grandson extends React.Component {
render() {
console.log('孙子组件')
return(<div>孙子组件</div>)
}
}4、上面几个组件是比较标准的
react的类组件,函数组件也是类似的,当你在父组件中点击按钮,其实你仅仅是想改变父组件内的count的值,但是你会发现每次点击的时候子组件和孙组件也会重新渲染,因为react并不知道是不是要渲染子组件,需要我们自己去判断。
一、类组件中使用shouldComponentUpdate生命周期钩子函数
1、在子组件中使用shouldComponentUpdate来判断是否要更新,
其实就是根据
this.props和函数参数中的nextProps中的参数来对比,如果返回false就不更新,如果返回ture就表示需要更新当前组件
class Child extends React.Component {
shouldComponentUpdate (nextProps, nextState) {
console.log(nextProps, this.props);
if (nextProps.count === this.props.count) {
return false;
} else {
return true;
}
}
...
}**注意点:**这里的count是要父组件给当前组件传递的参数(就是你要监听变化的的来更新当前组件),如果你写一个nextProps.name === this.props.name其实,父组件并没有给当前组件传递name那么下面都是返回false组件不更新
2、当子组件没更新,那么孙组件同样的不更新数据
二、使用PureComponet语法糖
其实
PureComponet就是一个语法糖,只是官方在底层帮你实现了shouldComponentUpdate方法而已,使用的时候只需要子类继承这个类就可以
1、子组件中继承
class Child extends React.PureComponent {
render() {
console.log('我是子组件');
return (
<div>
我是子组件
<Grandson />
</div>
)
}
}2、在父组件中使用
// 下面这种情况不会重新渲染子组件
<Child/>
// 下面这种情况下会重新渲染子组件
<Child count={this.state.count}/>三、memo的使用
当你子组件是类组件的时候可以使用
shouldComponentUpdate钩子函数或类组件继承PureComponent来实现不渲染子组件,但是对于函数组件来说是不能用这两个方法的,因此react官方给函数组件提供了memo来对函数组件包装下,实现不必要的渲染。
1、组件定义(这里也可以使用类组件)
function Child () {
console.log('我是子组件');
return (
<div>
子组件
</div>
)
}
function Parent () {
const [count, setCount] = useState(0);
return (
<div>
我是父组件-{count}
<button onClick={()=>setCount(count + 1)}>点击按钮</button>
<Child />
</div>
)
}2、这里我们父组件内部改变count并没有传递给子组件,但是子组件一样的重新渲染了,这并不是我们希望看到的,因为需要对子组件包装下
function Child () {
console.log('我是子组件');
return (
<div>
子组件
</div>
)
}
const ChildMemo = React.memo(Child);
function Parent () {
const [count, setCount] = useState(0);
return (
<div>
我是父组件-{count}
<button onClick={()=>setCount(count + 1)}>点击按钮</button>
{/* 这种情况下不会渲染子组件 */}
<ChildMemo />
{/* 这种情况下会渲染子组件 */}
<ChildMemo count={count}/>
</div>
)
}四、useMemo和useCallback的认识
1、
useMemo和useCallback都是具有缓存作用的,只是他们缓存对象不一样,一个是属性,一个是缓存函数,特点都是,当缓存依赖的没变,去获取还是获取曾经的缓存
2、
useMemo是对函数组件中的属性包装,返回一个具有缓存效果的新的属性,当依赖的属性没变化的时候,这个返回新属性就会从缓存中获取之前的。
3、
useCallback是对函数组件中的方法缓存,返回一个被缓存的方法
五、useMemo的使用(我们依赖借用子组件更新的来做)
1、根据上面的方式我们在父组件更新数据,观察子组件变化
const Child = (props) => {
console.log('重新渲染子组件', props);
return (
<div>子组件</div>
)
}
const ChildMemo = React.memo(Child);
const Parent = () => {
const [count, setCount] = useState(0);
const [number, setNumber]=useState(0)
const userInfo = {
age: count,
name: 'hello',
}
const btnHandler = () => {
setNumber(number+1);
}
return (
<div>
{number}-{count}
<button onClick={btnHandler}>按钮</button>
<ChildMemo userInfo={userInfo}/>
</div>
)
}上面发现我们仅仅是更新了number的值,传递给子组件的对象值并没有变化,但是每次子组件都重新更新了,虽然我们在子组件上用了React.memo包装还是不行,这是因为在父组件中每次重新渲染,对于对象来说会是重新一个新的对象了。因此子组件要重新更新,
2、使用useMemo对属性的包装
const userInfo = useMemo(() => {
return {
age: count,
name: 'hello',
};
}, [count]);使用useMemo包装后的对象,重新返回一个具有缓存效果的新对象,第二个参数表示依赖性,或者叫观察对象,当被观察的没变化,返回的就是缓存对象,如果被观察的变化了,那么就会返回新的,现在不管你怎么更新number的值,子组件都不会重新更新了
3、注意点:useMemo要配合React.memo来使用,不然传递到子组件也是不生效的
六、useCallback的使用
前面介绍了,useCallback是对一个方法的包装,返回一个具有缓存的方法,常见的使用场景是,父组件要传递一个方法给子组件
1、在不使用
useCallback的时候
const Child = (props) => {
console.log('渲染了子组件');
const { onClick } = props;
return (
<button onClick={onClick}>点击按钮获取值</button>
)
}
const ChildMemo = React.memo(Child);
const Parent = () => {
const [text, updateText] = useState('');
const textRef = useRef(text);
const handleSubmit = () => {
console.log('当前的值', text);
}
return(
<div>
我是父组件
<input type="text" value={text} onChange={(e) => updateText(e.target.value)}/>
<ChildMemo onClick={handleSubmit}/>
</div>
)
}结果是每次输入框输入值的时候,子组件就会重新渲染一次,其实子组件中仅仅是一个按钮,要获取最终输入的值,每次父组件输入值的时候,子组件就更新,很耗性能的
2、使用useCallback来包装一个方法
const Parent = () => {
const [text, updateText] = useState('');
const textRef = useRef();
// useCallback又依赖了textRef的变化,因此可以获取到最新的数据
const handleSubmit = useCallback(() => {
console.log('当前输入框的值:', textRef.current);
}, [textRef])
// 当text的值变化的时候就会给textRef的current重新赋值
useEffect(() => {
textRef.current = text;
}, [text]);
return(
<div>
我是父组件
<input type="text" value={text} onChange={(e) => updateText(e.target.value)}/>
<ChildMemo onClick={handleSubmit}/>
</div>
)
}原文:https://juejin.cn/post/6965302793242411021
收起阅读 »React22-diff算法
1.时间复杂度
最好的算法都是o(n3) n为元素个数 如果每个元素都去diff的话复杂度很高 所以react做出啦三个限制
1.只对同级元素进行diff,不用对另一个树的所有元素进行diff
2.tag不同的两个元素会产生不同的树,div变为p,react会销毁div及其子孙节点,新建p
3.通过key这个prop来暗示哪些子元素在不同渲染下保持稳定
举例说明第3点
// 更新前
<div>
<p >ka</p>
<h3 >song</h3>
</div>
// 更新后
<div>
<h3 >song</h3>
<p>ka</p>
</div>
这种情况下diff react会把p删除然后新建h3 插入 然后删除h3创建p在传入// 更新前
<div>
<p key="ka">ka</p>
<h3 key="song">song</h3>
</div>
// 更新后
<div>
<h3 key="song">song</h3>
<p key="ka">ka</p>
</div>
//有key的情况,p节点找到后面key相同的p节点所以节点可以复用 h3也可以复用 只需要做一个p append到h3后面的操作2.单一节点的diff
1.diff 就是对比jsx和currentfiber的对象生成workingprogress的fiber
2.dom节点是否可复用?1.type必须相同 2.key也必须相同 满足这两个才能复用 先检测key是否同再检测type是否同,可复用就复用这个fiber 不过是换属性而已
3.什么情况不能复用?
1.key不一样: 这函数一开始就判断key是否相同 不相同直接删除current的fiber,然后找兄弟节点去看是否key相同,为什么找兄弟节点呢 因为可能currentfiber有同级节点而jsx只是单个节点,还是会走到singleelement这个逻辑,所以要看currentfiber同级所有节点,不能旧删除是否可以复用。同时如果某个节点可以复用我们也需要将currentfiber的其他同级fiber删掉。都是为了下面这种情况。
如果都不一样则创建新的fiber
//current
<div></div>
<p></p>
//jsx
<p><p>2.type不一样:直接把current的该fiber和兄弟fiber全部删除,因为能判断到type的时候key已经相同啦,其他兄弟节点的key不可能相同,所以直接全部不可以复用。之前key不同还要看兄弟key是否相同。
3.多节点diff
什么时候执行多节点diff?当jsx此次为数组即可,无论currentfiber是不是数组
一共有三种情况
1.节点更新
//情况1—— 节点属性变化
// 之前
<ul>
<li key="0" className="before">0<li>
<li key="1">1<li>
</ul>
// 之后
<ul>
<li key="0" className="after">0<li>
<li key="1">1<li>
</ul>
//情况2—— 节点类型更新
// 之后
<ul>
<div key="0">0</div>
<li key="1">1<li>
</ul>2.节点新增或者减少
//情况1 —— 新增节点
// 之前
<ul>
<li key="0">0<li>
<li key="1">1<li>
</ul>
// 之后
<ul>
<li key="0">0<li>
<li key="1">1<li>
<li key="2">2<li>
</ul>
//情况2 —— 删除节点
// 之后
<ul>
<li key="1">1<li>
</ul>3.节点位置变化
// 之前
<ul>
<li key="0">0<li>
<li key="1">1<li>
</ul>
// 之后
<ul>
<li key="1">1<li>
<li key="0">0<li>
</ul>在我们做数组相关的算法题时,经常使用双指针从数组头和尾同时遍历以提高效率,但是这里却不行。
虽然本次更新的JSX对象 newChildren为数组形式,但是和newChildren中每个组件进行比较的是current fiber,同级的Fiber节点是由sibling指针链接形成的单链表,即不支持双指针遍历。
即 newChildren[0]与fiber比较,newChildren[1]与fiber.sibling比较。
所以无法使用双指针优化。
多节点diff 最终会产生一条fiber链表,不过最后返回的还是一个fiber(第一个fiber)作为child
基于以上原因,Diff算法的整体逻辑会经历两轮遍历:
第一轮遍历:处理更新的节点。 因为更新的概率是最大的
第二轮遍历:处理剩下的不属于更新的节点。
第一轮遍历
let i = 0,遍历newChildren,将newChildren[i]与oldFiber比较,判断DOM节点是否可复用。- 如果可复用,
i++,继续比较newChildren[i]与oldFiber.sibling,可以复用则继续遍历。 - 如果不可复用,分两种情况:
key不同导致不可复用,立即跳出整个遍历,第一轮遍历结束。(因为key不同是对应节点位置变化不属于更新节点,等到第二轮循环处理)key相同type不同导致不可复用,会将oldFiber标记为DELETION(这样在commit阶段就会删除这个dom),并继续遍历
- 如果
newChildren遍历完(即i === newChildren.length - 1)或者oldFiber遍历完(即oldFiber.sibling === null),跳出遍历,第一轮遍历结束。
function reconcileChildrenArray(
returnFiber: Fiber,
currentFirstChild: Fiber | null,
newChildren: Array<*>,
lanes: Lanes,
): Fiber | null {
// This algorithm can't optimize by searching from both ends since we
// don't have backpointers on fibers. I'm trying to see how far we can get
// with that model. If it ends up not being worth the tradeoffs, we can
// add it later.
// Even with a two ended optimization, we'd want to optimize for the case
// where there are few changes and brute force the comparison instead of
// going for the Map. It'd like to explore hitting that path first in
// forward-only mode and only go for the Map once we notice that we need
// lots of look ahead. This doesn't handle reversal as well as two ended
// search but that's unusual. Besides, for the two ended optimization to
// work on Iterables, we'd need to copy the whole set.
// In this first iteration, we'll just live with hitting the bad case
// (adding everything to a Map) in for every insert/move.
// If you change this code, also update reconcileChildrenIterator() which
// uses the same algorithm.
if (__DEV__) {
// First, validate keys.
let knownKeys = null;
for (let i = 0; i < newChildren.length; i++) {
const child = newChildren[i];
knownKeys = warnOnInvalidKey(child, knownKeys, returnFiber);
}
}
let resultingFirstChild: Fiber | null = null;//!返回的fiber
let previousNewFiber: Fiber | null = null;//!创建fiber链需要一个临时fiber来做连接
let oldFiber = currentFirstChild;//!遍历到的current的fiber(旧的fiber)
let lastPlacedIndex = 0;//!新创建的fiber节点对应的dom节点在页面中的位置 用来节点位置变化的
let newIdx = 0;//!遍历到的jsx数组的索引
let nextOldFiber = null;//!oldFiber的下一个fiber
//!第一轮循环 处理节点更新的情况
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {//!fiber的index标记为当前fiber在同级fiber中的位置
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
const newFiber = updateSlot(//!判断节点是否可以复用 这个函数主要看key是否相同 不相同直接返回null 相同则继续判断type是否相同 不相同则创建新的fiber返回 把旧的fiber打上delete的tag 新的fiber打上place的tag type也相同则可以复用fiber返回
returnFiber,
oldFiber,
newChildren[newIdx],
lanes,
);
if (newFiber === null) {
// TODO: This breaks on empty slots like null children. That's
// unfortunate because it triggers the slow path all the time. We need
// a better way to communicate whether this was a miss or null,
// boolean, undefined, etc.
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
if (oldFiber && newFiber.alternate === null) {
// We matched the slot, but we didn't reuse the existing fiber, so we
// need to delete the existing child.
deleteChild(returnFiber, oldFiber);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);//!给newfiber加上place的tag
if (previousNewFiber === null) {
// TODO: Move out of the loop. This only happens for the first run.
resultingFirstChild = newFiber;
} else {
// TODO: Defer siblings if we're not at the right index for this slot.
// I.e. if we had null values before, then we want to defer this
// for each null value. However, we also don't want to call updateSlot
// with the previous one.
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
//!新旧同时遍历完
if (newIdx === newChildren.length) {
// We've reached the end of the new children. We can delete the rest.
deleteRemainingChildren(returnFiber, oldFiber);
return resultingFirstChild;
}
//!老的遍历完 新的没遍历完 遍历剩下的jsx的newchildren
if (oldFiber === null) {
// If we don't have any more existing children we can choose a fast path
// since the rest will all be insertions.
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = createChild(returnFiber, newChildren[newIdx], lanes);
if (newFiber === null) {
continue;
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);//!直接把新的节点打上place 插入dom
if (previousNewFiber === null) {
// TODO: Move out of the loop. This only happens for the first run.
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
return resultingFirstChild;
}
//!老的没遍历完 新的也没遍历完 证明key不同跳出啦 要处理节点位置变化的情况 我们要找到key相同的复用 那么为了在o(1)时间内找到 我们用map(key:oldfiber.key->value:oldfiber)数据结构
// Add all children to a key map for quick lookups.
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
//!遍历剩下的newchldren
// Keep scanning and use the map to restore deleted items as moves.
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = updateFromMap(//!找到newchildren的key对应的oldfiber 复用/新建fiber返回
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes,
);
if (newFiber !== null) {
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
// The new fiber is a work in progress, but if there exists a
// current, that means that we reused the fiber. We need to delete
// it from the child list so that we don't add it to the deletion
// list.
existingChildren.delete(
newFiber.key === null ? newIdx : newFiber.key,//!从map中去掉已经找到key的oldfiber
);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);//!新的fiber标记为插入 注意位置 (oldindex<lastplaceindex) 移动位置插入 因为老的fiber的index位置比新的页面位置小 肯定要移动插入了
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
if (shouldTrackSideEffects) {
// Any existing children that weren't consumed above were deleted. We need
// to add them to the deletion list.
existingChildren.forEach(child => deleteChild(returnFiber, child));//!删除多余的oldfiber 因为新的children已经遍历完
}
return resultingFirstChild;
}原文:https://juejin.cn/post/6964653615256436750
收起阅读 »SwiftUI 入门指引教程
这是 WWDC2019 发布的 SwiftUI 布局框架的一些官方示例。
首先为了保证项目的正常运行,需要升级 Mac OS 至 10.15 beta 版,以及 Xcode 使用 Xcode 11 beta。
1.创建项目运行
首先创建一个新的项目,模板可以使用第一个Single View App,项目名称官方的Demo叫做Landmarks,勾选上Use SwiftUI如图。
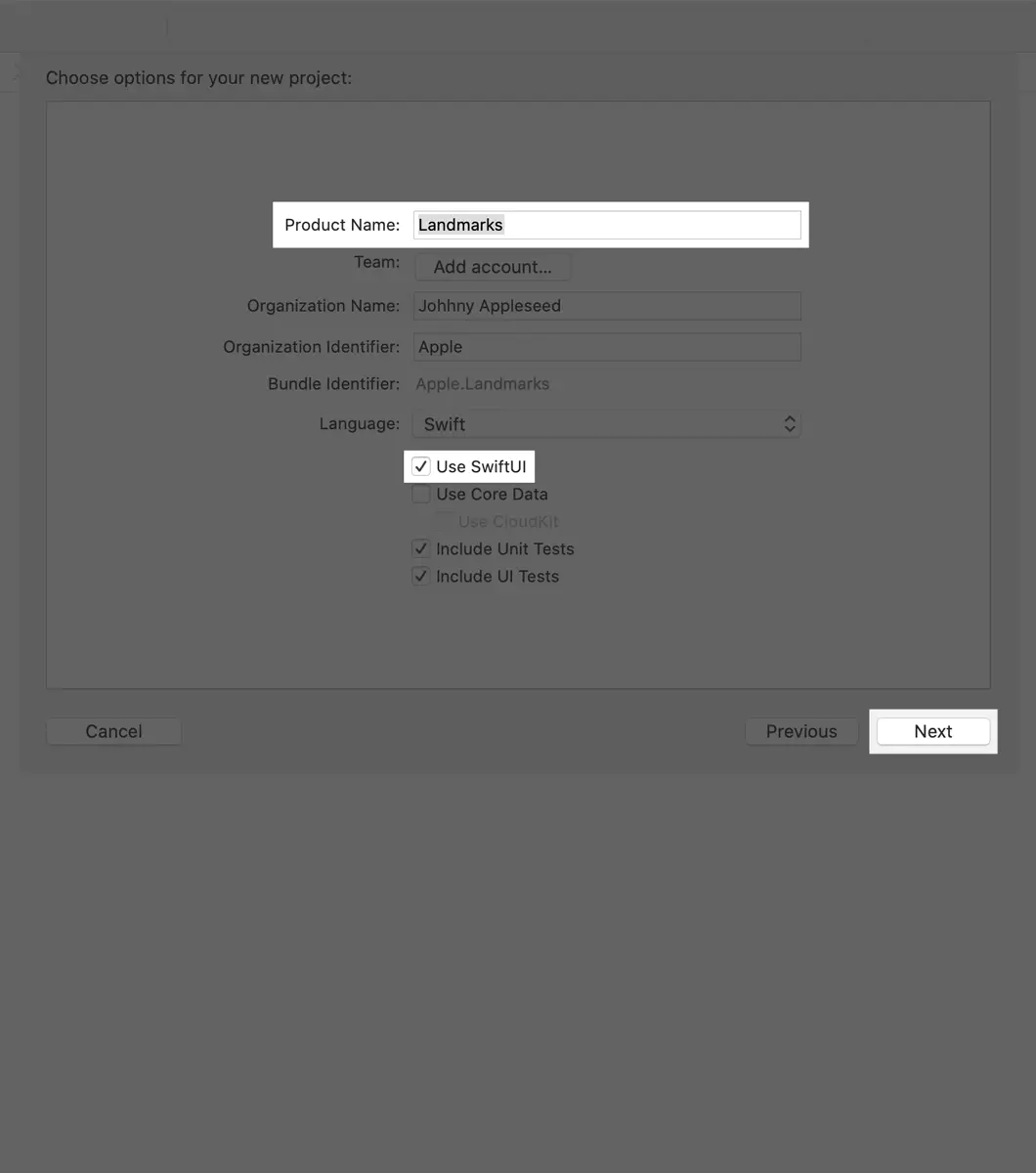
然后创建项目,点击打开 ContentView.swift,代码如下:
import SwiftUI
struct ContentView: View {
var body: some View {
Text("Hello World")
}
}
struct ContentView_Preview: PreviewProvider {
static var previews: some View {
ContentView()
}
}目前该类声明了两个 struct,第一个是该 View 的实现,第二个是为了实现该 View 的浏览。
然后在 canvas 视图上点击 Resume(如果找不到,打开 Editor > Editor and Canvas )。
然后修改 View 实现的代码,可以实时看到效果
struct ContentView: View {
var body: some View {
Text("Hello SwiftUI!")
}
}2、定制TextView
在之前的基础上,按住Command,并单击 Hello SwiftUI!,会弹出菜单,选择Inspect修改属性。
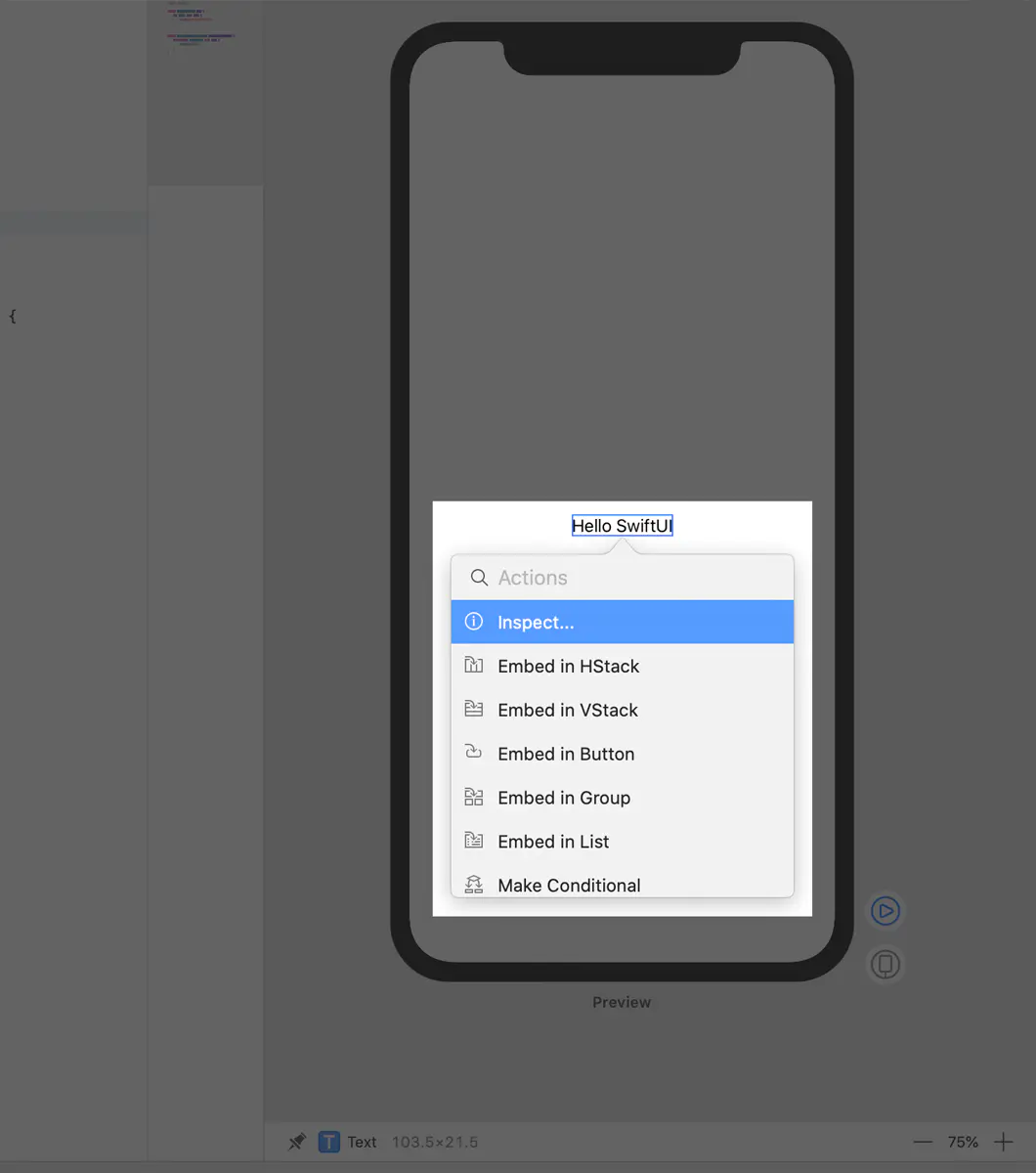
点击之后
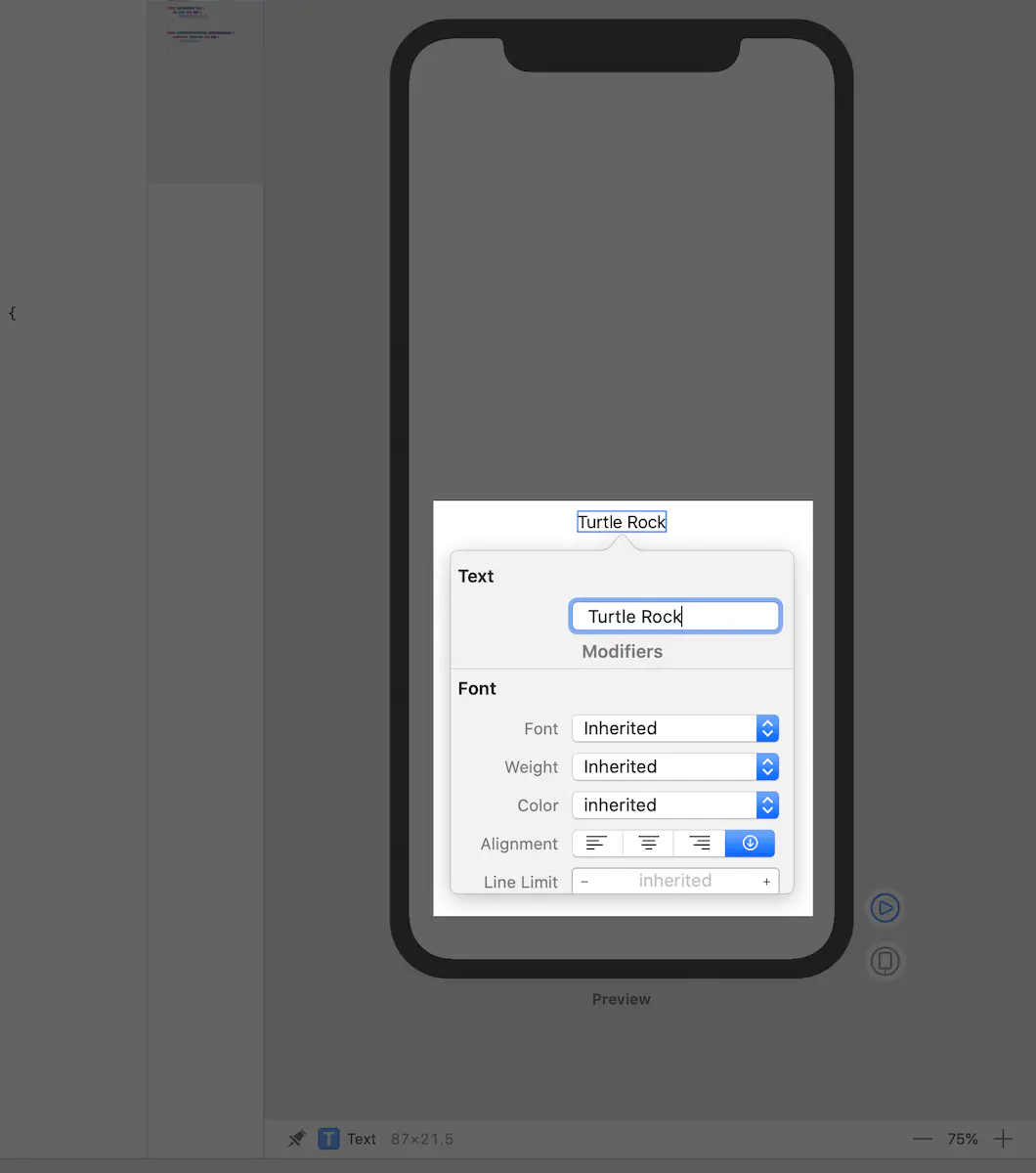
修改 Font 为 title。
然后手动修改UI代码,添加颜色为绿色:
struct ContentView: View {
var body: some View {
Text("Turtle Rock")
.font(.title)
.color(.green)
}
}接下来在代码中单击文本的声明Text("Turtle Rock"),可以看到弹出的菜单,点击检查器inspect,把颜色再改回黑色。
这个时候你会发现,Xcode会删除Text("Turtle Rock")这一行。
3、使用 Stack 去组合 View
这一部分会添加几个视图,并使用 Stack去组合。
单击 Text("Turtle Rock"),弹出的菜单中选择 Embed in VStack。
单击Xcode窗口右上角的加号按钮(+)打开库,然后在“Turtle Rock”文本视图后将Text视图拖到代码中的位置。
替换文本为 Joshua Tree National Park,设置字体为.subheadline。
然后编辑VStack的初始化方法,代码修改为 VStack(alignment: .leading) { 使得它左对齐。
然后在 canvas 里面 command 并单击 Joshua Tree National Park,选择 Embed in HStack 添加一个新的 textView,输入内容 California,设置字体为 .subheadline。
通过将 Spacer 添加到包含两个 Text 的水平堆栈,使得布局使用设备的整个宽度,如下:
struct ContentView: View {
var body: some View {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
}
}Spacer 会使用俯视图所有的空间,彻底的展开,不需要通过指定内容大小等属性。
最后,使用 padding()修饰符,添加到Stack的实现结束的地方,给界面留一些呼吸的空间。
struct ContentView: View {
var body: some View {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
}
}4、Image 添加图片
这一部分会添加一个独立的原型的自定义图片视图,将遮罩,边框和阴影应用于图像。
将图片添加到资源 asset 目录下。
创建一个新的额 SwiftUI 类,命名为 CircleImage.swift,并替换其实现如下,使用Image 的初始化方法 Image(_:)。
struct CircleImage: View {
var body: some View {
Image("turtlerock")
}
}Image初始化方法之后添加圆形剪裁形状,Circle 可以像这样用做于一个蒙版,或者用作一个试图内的原型的填充。
struct CircleImage: View {
var body: some View {
Image("turtlerock")
.clipShape(Circle())
}
}然后添加其余的属性,颜色,线宽和半径为10个单位的阴影:
struct CircleImage: View {
var body: some View {
Image("turtlerock")
.clipShape(Circle())
.overlay(
Circle().stroke(Color.gray, lineWidth: 4))
.shadow(radius: 10)
}
}5.组合成详情 View
在第一个 ContentView 类中插入一个新的 VStack 视图,位置如下:
struct ContentView: View {
var body: some View {
VStack {
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack(alignment: .top) {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
}
}
}添加一个 MapView,在新添加的 VStack 的下面,设置 MapView 的 Size, 如下:
struct ContentView: View {
var body: some View {
VStack {
MapView()
.frame(height: 300)
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)仅指定 height 参数的话,View 会自动调整其内容的宽度。在这种情况下,MapView 会扩展以填充可用空间。
点击 Live Preview 实时预览视图。
然后在 MapView 的下方,添加我们上一步实现的 CircleImage,并且设置向上的位置偏移量。
CircleImage()
.offset(y: -130)
.padding(.bottom, -130)在最外面的 VStack 的底部添加一个 spacer,把内容整个推到屏幕的上面。
最后:让 MapView 忽略上面的安全距离,在MapView下面插入 .edgesIgnoringSafeArea(.top),完整的类实现代码如下:
struct ContentView: View {
var body: some View {
VStack {
MapView()
.edgesIgnoringSafeArea(.top)
.frame(height: 300)
CircleImage()
.offset(y: -130)
.padding(.bottom, -130)
VStack(alignment: .leading) {
Text("Turtle Rock")
.font(.title)
HStack(alignment: .top) {
Text("Joshua Tree National Park")
.font(.subheadline)
Spacer()
Text("California")
.font(.subheadline)
}
}
.padding()
Spacer()
}
}
}
转自:https://www.jianshu.com/p/82524bf00b35
收起阅读 »使用react的7个避坑案例
React是个很受欢迎的前端框架。今天我们探索下React开发者应该注意的七个点。
1. 组件臃肿
React开发者没有创建必要的足够多的组件化,其实这个问题不局限于React开发者,很多Vue开发者也是。
当然,我们现在讨论的是React
在React中,我们可以创建一个很多内容的组件,来执行我们的各种任务,但是最好是保证组件精简 -- 一个组件关联一个函数。这样不仅节约你的时间,而且能帮你很好地定位问题。
比如下面的TodoList组件:
// ./components/TodoList.js
import React from 'react';
import { useTodoList } from '../hooks/useTodoList';
import { useQuery } from '../hooks/useQuery';
import TodoItem from './TodoItem';
import NewTodo from './NewTodo';
const TodoList = () => {
const { getQuery, setQuery } = useQuery();
const todos = useTodoList();
return (
<div>
<ul>
{todos.map(({ id, title, completed }) => (
<TodoItem key={id} id={id} title={title} completed={completed} />
))}
<NewTodo />
</ul>
<div>
Highlight Query for incomplete items:
<input value={getQuery()} onChange={e => setQuery(e.target.value)} />
</div>
</div>
);
};
export default TodoList;2. 直接更改state
在React中,状态应该是不变的。如果你直接修改state,会导致难以修改的性能问题。
比如下面例子:
const modifyPetsList = (element, id) => {
petsList[id].checked = element.target.checked;
setPetsList(petList)
}上面例子中,你想更改数组对象中checked键。但是你遇到一个问题:因为使用相同的引用更改了对象,React无法观察并触发重新渲染。
解决这个问题,我们应该使用setState()方法或者useState()钩子。
我们使用useState()方法来重写之前的例子。
const modifyPetsList = (element, id) => {
const { checked } = element.target;
setpetsList((pets) => {
return pets.map((pet, index) => {
if (id === index) {
pet = { ...pet, checked };
}
return pet;
});
});
};3. props该传数字类型的值却传了字符串,反之亦然
这是个很小的错误,不应该出现。
比如下面的例子:
class Arrival extends React.Component {
render() {
return (
<h1>
Hi! You arrived {this.props.position === 1 ? "first!" : "last!"} .
</h1>
);
}
}这里===对字符串'1'是无效的。而解决这个问题,需要我们在传递props值的时候用{}包裹。
修正如下:
// ❌
const element = <Arrival position='1' />;
// ✅
const element = <Arrival position={1} />;4. list组件中没使用key
假设我们需要渲染下面的列表项:
const lists = ['cat', 'dog', 'fish’];
render() {
return (
<ul>
{lists.map(listNo =>
<li>{listNo}</li>)}
</ul>
);
}当然,上面的代码可以运行。当列表比较庞杂并需要进行更改等操作的时候,就会带来渲染的问题。
React跟踪文档对象模型(DOM)上的所有列表元素。没有记录可以告知React,列表发生了什么改动。
解决这个问题,你需要添加keys在你的列表元素中。keys赋予每个元素唯一标识,这有助于React确定已添加,删除,修改了哪些项目。
如下:
<ul>
{lists.map(listNo =>
<li key={listNo}>{listNo}</li>)}
</ul>5. setState是异步操作
很容易忘记React中的state是异步操作的。如果你在设置一个值之后就去访问它,那么你可能不能立马获取到该值。
我们看看下面的例子:
handlePetsUpdate = (petCount) => {
this.setState({ petCount });
this.props.callback(this.state.petCount); // Old value
};你可以使用setState()的第二个参数,回调函数来处理。比如:
handlePetsUpdate = (petCount) => {
this.setState({ petCount }, () => {
this.props.callback(this.state.petCount); // Updated value
});
};6. 频繁使用Redux
在大型的React app中,很多开发者使用Redux来管理全局状态。
虽然Redux很有用,但是没必要使用它来管理每个状态。
如果我们的应用程序没有需要交换信息的并行级组件的时候,那么就不需要在项目中添加额外的库。比如我们想更改组件中的表单按钮状态的时候,我们更多的是优先考虑state方法或者useState钩子。
7. 组件没以大写字母开头命名
在JSX中,以小写开头的组件会向下编译为HTML元素。
所以我们应该避免下面的写法:
class demoComponentName extends React.Component {
}这将导致一个错误:如果你想渲染React组件,则需要以大写字母开头。
那么得采取下面这种写法:
class DemoComponentName extends React.Component {
}后话
上面的内容提取自Top 10 mistakes to avoid when using React,采用了意译的方式,提取了7条比较实用的内容。
原文:https://juejin.cn/post/6963032224316784654
收起阅读 »
SwiftUI官方教程解读
SwiftUI简介
SwiftUI是wwdc2019发布的一个新的UI框架,通过声明和修改视图来布局UI和创建流畅的动画效果。并且我们可以通过状态变量来进行数据绑定实现一次性布局;Xcode 11 内建了直观的新设计工具canvus,在整个开发过程中,预览可视化与代码可编辑性能同时支持并交互,让我们可以体验到代码和布局同步的乐趣;同时支持和UIkit的交互.
设计工具canvus
1、开发者可以在canvus中拖拽控件来构建界面, 所编辑的内容会立刻反应到代码上
2、切换不同的视图文件时canvus会切换到不同的界面
3、点击左下角的按钮钉我们可以把视图固定在活跃页面
4、选中canvus中的控件command+click可以调出inspect布局控件的属性
5、点击右上角的+可以获取新的控件并拖拽到对应的位置
6、在live状态下我们可以在canvus中调试点击等可交互效果 但不能缩放视图大小
每次修改或者增加属性需要点击resume刷新canvus
文件结构
创建一个SwiftUI文件,默认生成两个结构体。一个实现view的协议,在body属性里描述内容和布局;一个结构体声明预览的view 并进行初始化等信息,预览view是控制器的view时可以显示在多个模拟器设备,是控件view时可以设置frame,预览view是提供给canvus展示的,使用了#if DEBUG 指令,编译器会删除代码,不会随应用程序一起发布
struct LandmarksList_Previews: PreviewProvider {
static var previews: some View {
ForEach(["iPhone SE", "iPhone XS Max"].identified(by: \.self)) { deviceName in
LandmarkList()
.previewDevice(PreviewDevice(rawValue: deviceName))
.previewDisplayName(deviceName)
//.previewLayout(.fixed(width: 300, height: 70)) 设置view控件大小
}
.environmentObject(UserData())
}
}
#endif布局
普通的view:将多个视图组合并嵌入到堆栈中,这些堆栈将视图水平、垂直或者前后组合在一起
VStack { //这里的布局实现的是上图canvus中landMarkDetail的效果
MapView(coordinate: landmark.locationCoordinate)
.frame(height: 300)//不传width默认长度为整个界面
CircleImage(image: landmark.image(forSize: 250))
.offset(x: 0, y: -130)
.padding(.bottom, -130)
VStack(alignment: .leading) {
Text(landmark.name)
.font(.title)
HStack(alignment: .top) {
Text(landmark.park)
.font(.subheadline)
Spacer() //将水平的两个控件撑开
Text(landmark.state)
.font(.subheadline)
}
}
.padding()
Spacer()
}列表的布局:要求数据是可被标识的
(1)唯一标识每个元素的主键路径
List(landmarkData.identified(by: \.id)) { landmark in
LandmarkRow(landmark: landmark)
}(2)数据类型实现Identifiable protocol,持有一个id 属性
struct Landmark: Hashable, Codable, Identifiable {
var id: Int //
var name: String
fileprivate var imageName: String
fileprivate var coordinates: Coordinates
var state: String
var park: String
var category: Category
}
List(landmarkData) { landmark in
LandmarkRow(landmark: landmark)
} //直接传数据源导航
添加导航栏是将其嵌入到NavigationView中,点击跳转的控件包装在navigationButton中,以设置到目标视图的换位。navigationBarTitle设置导航栏的标题,navigationBarItems设置导航栏右边的item
NavigationView {//显示导航view
List {
//SwiftUI里面的类似switch的控件,可以在list中直接组合布局
Toggle(isOn: $showFavoritesOnly) {
Text("Favorites only")
}
ForEach(landmarkData) { landmark in
if !self.showFavoritesOnly || landmark.isFavorite {
//跳转到地标详细页面
NavigationButton(destination: LandmarkDetail(landmark: landmark)) {
LandmarkRow(landmark: landmark)
}
}
}
}
.navigationBarTitle(Text("Landmarks"))//导航标题
}
}实现modal出一个view
.navigationBarItems(trailing:
//点击navigationBarItems modal出profileHost页面
PresentationButton(
Image(systemName: "person.crop.circle")
.imageScale(.large)
.accessibility(label: Text("User Profile"))
.padding(),
destination: ProfileHost()
)
)程序运行是从sceneDelegate定义的根视图开始的, UIhostingController 是UIViewController的子类
动画效果
SwiftUI包括带有预定义或自定义的基本动画 以及弹簧和流体动画,可以调整动画速度,设置延迟,重复动画等等
可以通过在一个动画修改器后面添加另一个动画修改器来关闭动画
1、转场动画
系统转场动画调用: hikeDetail(hike.hike).transition(.slide)
自定义的转场动画:把转场动画作为AnyTransition类的类型属性 (方便点语法设置丰富自定义动画)
extension AnyTransition {
static var moveAndFade: AnyTransition {
let insertion = AnyTransition.move(edge: .trailing)
.combined(with: .opacity)
let removal = AnyTransition.scale()
.combined(with: .opacity)
return .asymmetric(insertion: insertion, removal: removal)
}
}HikeDetail(hike: hike).transition(.moveAndFade)调用转场动画;move(edge:)方法是让视图从同一边滑出来以及消失;asymmetric(insertion:removal:)设置出现和小时的不同的动画效果
2、阻尼动画
var animation: Animation { //定义成存储属性方便调用
Animation.spring(initialVelocity: 5)//重力效果,值越大,弹性越大
.speed(2)//动画时间,值越大动画速度越快
.delay(0.03 * Double(index))
}3、基础动画
Button(action: //点击按钮显示一个view带转场的动画效果
withAnimation {
self.showDetail.toggle()
}
}) {
Image(systemName: "chevron.right.circle")
.imageScale(.large)
//旋转90度
.rotationEffect(.degrees(showDetail ? 90 : 0))
//.animation(nil) //关闭前面的旋转90度的动画效果,只显示下面的动画
//选中的时候放大为原来的1.5倍
.scaleEffect(showDetail ? 1.5 : 1)
.padding()
// .animation(.basic()) 实现简单的基础动画
//.animation(.spring()) 阻尼动画
}给图片按钮加动画效果, 对应的会有旋转和缩放会有动画;加到action时,即使点击完成后的显示没有给image的可做动画属性加动画效果,全部都有动画,包含旋转缩放和转场动画
数据流
利用SwiftUI环境中的存储 ,把自定义数据对象绑定到view ,SwiftUI监视到可绑对象任何影响视图的更改并在更改后显示正确的视图
1、自定义绑定类型
声明为绑定类型 BindableObject ,PassthroughSubject是Combine框架的消息发布者, SwiftUI通过这个消息发布者订阅对象,并在数据发生变化的时候更新任何需要刷新的视图
import Combine
import SwiftUI
final class UserData: BindableObject {
let didChange = PassthroughSubject()
var showFavoritesOnly = false {
didSet {
didChange.send(self)
}
}
var landmarks = landmarkData {
didSet {
didChange.send(self)
}
}
} 当客户机需要更新数据的时候,可绑定对象通知其订阅者
eg:当其中一个属性发生更改时,在属性的didset里面通过didchange发布者发布更改
2、绑定属性
(1)state
@State var profile = Profile.default状态是随时间变化影响页面布局内容和行为的值
给定类型的持久值,视图通过该持久值读取和监视该值。状态实例不是值本身;它是读取和修改值的一种方法。若要访问状态的基础值,请使用其值属性。
(2)binding
@Binding var profile: Profile//向子视图传递数据(3)environmentObject :
@EnvironmentObject var userData: UserData存储在当前环境中的数据,跨视图传递,在初始化持有对象的时候使用environmentObject(_:)赋值可以和前面的自定义绑定类型一起使用
let window = UIWindow(frame: UIScreen.main.bounds)
window.rootViewController = UIHostingController(rootView: CategoryHome().environmentObject(UserData()))3、绑定行为
是对可变状态或数据的引用,用$的前缀访问状态变量或者其属性之一实现绑定控件 也可以访问绑定属性来实现绑定
与UIkit的交互
表示UIkit的view和controller 需要创建遵UIViewRepresentable或者UIViewControllerRepresentable协议的结构体,SwiftUI管理他们的生命周期并在需要的时候更新
实现协议方法:
//创建展示的UIViewController,调用一次
func makeUIViewController(context: Self.Context) -> Self.UIViewControllerType
//将展示的UIViewController更新到最新的版本
func updateUIViewController(_ uiViewController: Self.UIViewControllerType, context: Self.Context)
//创建协调器
func makeCoordinator() -> Self.Coordinator在结构体内嵌套定义一个coordinator类。SwiftUI管理coordinator并把它提供给context ,在makeUIView(context:)之前调用这个makeCoordinator()方法创建协调器,以便在配置视图控制器的时候可以访问coordinator对象
我们可以使用这个协调器来实现常见的Cocoa模式,例如委托、数据源和通过目标操作响应用户事件。
这里以用UIPageViewController实现轮播图为例,要注意其中的更新页面的逻辑~
pageview作为主view,组合一个PageControl 和 PageViewController实现图片轮播效果
PageView: @State var currentPage = 1 定义绑定属性 ,$currentPage实现绑定到PageViewController
PageViewController: @Binding var currentPage: Int 定义绑定属性,在更新的方法updateUIViewController里面绑定显示,点击pagecontrol的更新页面时pageviewcontroller可以更新到最新的页面
pagecontrol: @Binding var currentPage: Int定义绑定属性 ,updateUIView 绑定显示,pageview滑动更新页面 pagecontrol可以更新到正确的显示
struct PageView: View {
var viewControllers: [UIHostingController]
@State var currentPage = 1
init(_ views: [Page]) {//传入的view用SwiftUI的controller包装好后面传给pagecontroller
self.viewControllers = views.map { UIHostingController(rootView: $0) }
}
var body: some View {
ZStack(alignment: .bottomTrailing) {//将currentpage绑定起来了
PageViewController(controllers: viewControllers, currentPage: $currentPage)
PageControl(numberOfPages: viewControllers.count, currentPage: $currentPage)
.padding()
//Text("Current Page: \(currentPage)").padding(.trailing,30)
}
}
} import SwiftUI
import UIKit
struct PageViewController: UIViewControllerRepresentable {
var controllers: [UIViewController]
@Binding var currentPage: Int
func makeCoordinator() -> Coordinator {
Coordinator(self)
}
func makeUIViewController(context: Context) -> UIPageViewController {
let pageViewController = UIPageViewController(
transitionStyle: .scroll,
navigationOrientation: .horizontal)
pageViewController.dataSource = context.coordinator
pageViewController.delegate = context.coordinator
return pageViewController
}
func updateUIViewController(_ pageViewController: UIPageViewController, context: Context) {
//pageviewcontroller绑定currentpage显示当前的页面,pageView变化的时候,page更新页面
pageViewController.setViewControllers(
[controllers[currentPage]], direction: .forward, animated: true)
}
class Coordinator: NSObject, UIPageViewControllerDataSource, UIPageViewControllerDelegate {
var parent: PageViewController
init(_ pageViewController: PageViewController) {
self.parent = pageViewController
}
//左滑显示控制
func pageViewController(
_ pageViewController: UIPageViewController,
viewControllerBefore viewController: UIViewController) -> UIViewController? {
guard let index = parent.controllers.firstIndex(of: viewController) else {
return nil
}
if index == 0 {
return parent.controllers.last
}
return parent.controllers[index - 1]
}
// 右滑动显示控制
func pageViewController(
_ pageViewController: UIPageViewController,
viewControllerAfter viewController: UIViewController) -> UIViewController? {
guard let index = parent.controllers.firstIndex(of: viewController) else {
return nil
}
if index + 1 == parent.controllers.count {
return parent.controllers.first
}
return parent.controllers[index + 1]
}
func pageViewController(_ pageViewController: UIPageViewController, didFinishAnimating finished: Bool, previousViewControllers: [UIViewController], transitionCompleted completed: Bool) {
if completed,
let visibleViewController = pageViewController.viewControllers?.first,
let index = parent.controllers.firstIndex(of: visibleViewController) {
//当view滑动停止的时候告诉pageview当前页面的index(数据变化 pageview更新pagecontrol的展示)
parent.currentPage = index
}
}
}
}struct PageControl: UIViewRepresentable {
var numberOfPages: Int
@Binding var currentPage: Int
func makeCoordinator() -> Coordinator {
Coordinator(self)
}
func makeUIView(context: Context) -> UIPageControl {
let control = UIPageControl()
control.numberOfPages = numberOfPages
control.addTarget(
context.coordinator,
action: #selector(Coordinator.updateCurrentPage(sender:)),
for: .valueChanged)
return control
}
func updateUIView(_ uiView: UIPageControl, context: Context) {
uiView.currentPage = currentPage
}
class Coordinator: NSObject {
var control: PageControl
init(_ control: PageControl) {
self.control = control
}
@objc
func updateCurrentPage(sender: UIPageControl) {
control.currentPage = sender.currentPage
}
}
}: 当我们编辑一部分用户数据的时候,我们不希望在编辑数据完成的时候影响到其他的页面 那么我们需要创建一个副本数据, 当副本数据编辑完成的时候 用副本数据更新真正的数据, 使相关的页面变化 这部分的内容参见demo中profiles的部分;对于画图的部分demo中也有非常酷炫的示例,详情参见 HikeGraph、Badge(徽章)
参考资料
Apple官网教程 :https://developer.apple.com/tutorials/swiftui/creating-and-combining-views
demo下载
SwiftUI documentation
作者简介
就职于甜橙金融(翼支付)信息技术部,负责 iOS 客户端开发
转自:https://www.jianshu.com/p/ecfdbea7a0ed
收起阅读 »Swift 5—表达通过字符串插值
Swift的设计 - 首先是 - 是一种安全的语言。检查数字和集合是否有溢出,变量总是在第一次使用之前初始化,选项确保正确处理非值,并且相应地命名任何可能不安全的操作。
这些语言功能在很大程度上消除了一些最常见的编程错误,但我们不得不让我们guard失望。
今天,我想谈谈Swift 5中最激动人心的新功能之一:对字符串文字中的值如何通过协议进行插值的大修。很多人都对你可以用它做的很酷的事感到兴奋。(理所当然!我们将在短时间内完成所有这些工作)但我认为重要的是要更广泛地了解这一功能,以了解其影响的全部范围。ExpressibleByStringInterpolation
格式字符串很糟糕。
在不正确的NULL处理,缓冲区溢出和未初始化的变量之后, printf/scanf -style格式字符串可以说是C风格编程语言中最有问题的延迟。
在过去的20年中,安全专业人员已经记录了 数百个与格式字符串漏洞相关的漏洞。它是如此普遍,它被赋予了自己的 Common Weakness Enumeration常见的弱点列举类别。
他们不仅不安全,而且难以使用。是的,很难用。
考虑属性on ,它采用 格式字符串。如果我们想要创建一个包含其年份的日期的字符串表示,我们将使用,就像年份一样...... 对吗 dateFormat DateFormatter strftime "Y" "Y"
import Foundation
let formatter = DateFormatter()
formatter.dateFormat = "M/d/Y"
formatter.string(from: Date()) // "2/4/2019"这看起来确实如此,至少在今年的第一个360天。但是当我们跳到今年的最后一天时会发生什么?
let dateComponents = DateComponents(year: 2019,
month: 12,
day: 31)
let date = Calendar.current.date(from: dateComponents)!
formatter.string(from: date) // "12/31/2020" (😱)啊,啥? 结果"Y"是ISO周编号年的格式 ,它将在2019年12月31日返回2020,因为第二天是新年第一周的星期三。
我们真正想要的是"y"。
formatter.dateFormat = "M/d/y"
formatter.string(from: date) // 12/31/2019 (😄)格式化字符串是最难以使用的类型,因为它们很容易被错误地使用。日期格式字符串是最糟糕的,因为可能不清楚你做错了,直到为时已晚。它们是你的代码库中的字面时间炸弹。
现在花点时间(如果您还没有),"Y"在实际意图使用时,审核您的代码库以使用日期格式字符串"y"。
到目前为止,问题一直是API必须在危险但富有表现力的特定于域的语言特定领域的语言之间进行选择,例如格式字符串,以及正确但灵活性较低的方法调用。
Swift 5中的新功能,该协议允许这些类型的API既正确又富有表现力。在这样做的过程中,它推翻了几十年来有问题的行为。ExpressibleByStringInterpolation
所以不用多说,让我们来看看它是什么以及它是如何工作的:ExpressibleByStringInterpolation
ExpressibleByStringInterpolation
符合协议的类型可以自定义字符串文字中的内插值(即,转义的值)。
ExpressibleByStringInterpolation \(...)
您可以通过扩展默认String插值类型()或创建符合的新类型来利用此新协议。DefaultStringInterpolation ExpressibleByStringInterpolation
有关更多信息,请参阅Swift Evolution提议 SE-0228:“Fix ExpressibleByStringInterpolation”
扩展默认字符串插值
默认情况下,在Swift 5之前,字符串文字中的所有插值都直接发送到String初始值设定项。现在,您可以指定其他参数,就像调用方法一样(实际上,这就是您在幕后所做的事情)。ExpressibleByStringInterpolation
作为一个例子,让我们回顾以前的mixup "Y"和"y" ,看看这种混乱可能与避免。ExpressibleByStringInterpolation
通过扩展String默认插值类型(aptly-named ),我们可以定义一个名为的新方法。第一个未命名参数的类型确定哪些插值方法可用于要插值的值。在我们的例子中,我们将定义一个方法,该方法接受一个参数和一个 我们将用来指定哪个类型的附加参数DefaultStringInterpolation appendingInterpolation appendInterpolation Date component Calendar.Component
import Foundation
#if swift(<5)
#error("Download Xcode 10.2 Beta 2 to see this in action")
#endif
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
component: Calendar.Component)
{
let dateComponents =
Calendar.current.dateComponents([component],
from: value)
self.appendInterpolation(
dateComponents.value(for: component)!
)
}
}现在我们可以为每个单独的组件插入日期:
"\(date, component: .month)/\(date, component: .day)/\(date, component: .year)"
// "12/31/2019" (😊)这很冗长,是的。但是你永远不会误认为日历组件等同于你真正想要的东西:。.yearForWeekOfYear "Y" .year
但实际上,我们不应该像这样手工格式化日期。我们应该将责任委托给:DateFormatter
您可以像任何其他Swift方法一样重载插值,并使多个具有相同名称但不同类型的签名。例如,我们可以formatter为采用相应类型的日期和数字定义插值器。
import Foundation
extension DefaultStringInterpolation {
mutating func appendInterpolation(_ value: Date,
formatter: DateFormatter)
{
self.appendInterpolation(
formatter.string(from: value)
)
}
mutating func appendInterpolation<T>(_ value: T,
formatter: NumberFormatter)
where T : Numeric
{
self.appendInterpolation(
formatter.string(from: value as! NSNumber)!
)
}
}这允许与等效功能的一致接口,例如格式化插值日期和数字。
let dateFormatter = DateFormatter()
dateFormatter.dateStyle = .full
dateFormatter.timeStyle = .none
"Today is \(Date(), formatter: dateFormatter)"
// "Today is Monday, February 4, 2019"
let numberformatter = NumberFormatter()
numberformatter.numberStyle = .spellOut
"one plus one is \(1 + 1, formatter: numberformatter)"
// "one plus one is two"实现自定义字符串插值类型
除了扩展,您还可以在符合的自定义类型上定义自定义字符串插值行为。如果满足以下任何条件,您可以这样做:
DefaultStringInterpolation ExpressibleByStringInterpolation
1、您希望区分文字和插值段
2、您想限制可以插入的类型
3、您希望支持与默认情况下提供的不同的插值行为
3、您希望避免使用过多的API表面区域来增加内置字符串插值类型的负担
对于一个简单的例子,考虑一个转义XML中的值的自定义类型,类似于我们上周描述的一个记录器。我们的目标:提供了一个很好的模板的API,允许我们编写XML / HTML和在自动转义字符一样的方式插入值<和>。
我们将简单地用一个包含单个String值的包装器开始。
struct XMLEscapedString: LosslessStringConvertible {
var value: String
init?(_ value: String) {
self.value = value
}
var description: String {
return self.value
}
}我们在扩展中添加一致性,就像任何其他协议一样。它继承自,需要初始化程序。 本身需要一个初始化程序,它接受所需的关联类型的实例。ExpressibleByStringInterpolation ExpressibleByStringLiteral init(stringLiteral:) ExpressibleByStringInterpolation init(stringInterpolation:) StringInterpolation
此关联类型负责从字符串文字中收集所有文字段和插值。所有文字段都传递给方法。对于插值,编译器会找到与指定参数匹配的方法。在这种情况下,文字和插值都被收集到一个可变的字符串中。
StringInterpolation appendLiteral(_:)``appendInterpolation
这需要一个初始化器; 作为可选的优化,容量和插值计数可用于,例如,分配足够的空间来保存结果字符串。
StringInterpolationProtocol init(literalCapacity:interpolationCount:)
import Foundation
extension XMLEscapedString: ExpressibleByStringInterpolation {
init(stringLiteral value: String) {
self.init(value)!
}
init(stringInterpolation: StringInterpolation) {
self.init(stringInterpolation.value)!
}
struct StringInterpolation: StringInterpolationProtocol {
var value: String = ""
init(literalCapacity: Int, interpolationCount: Int) {
self.value.reserveCapacity(literalCapacity)
}
mutating func appendLiteral(_ literal: String) {
self.value.append(literal)
}
mutating func appendInterpolation<T>(_ value: T)
where T: CustomStringConvertible
{
let escaped = CFXMLCreateStringByEscapingEntities(
nil, value.description as NSString, nil
)! as NSString
self.value.append(escaped as String)
}
}
}完成所有这些后,我们现在可以使用自动转义插值的字符串文字进行初始化。(没有XSS漏洞利用给我们,谢谢!)XMLEscapedString
let name = "<bobby>"
let markup: XMLEscapedString = """
<p>Hello, \(name)!</p>
"""
print(markup)
// <p>Hello, <bobby>!</p>此功能的最佳部分之一是其实现的透明度。对于感觉非常神奇的行为,你永远不会想知道它是如何工作的。
将上面的字符串文字与下面的等效API调用进行比较:
var interpolation =
XMLEscapedString.StringInterpolation(literalCapacity: 15,
interpolationCount: 1)
interpolation.appendLiteral("<p>Hello, ")
interpolation.appendInterpolation(name)
interpolation.appendLiteral("!</p>")
let markup = XMLEscapedString(stringInterpolation: interpolation)
// <p>Hello, <bobby>!</p>阅读就像诗歌一样,不是吗?
有关更高级的示例,请查看Swift Strings Flight School指南示例代码中包含 的 Unicode样式操场
看看它是如何运作的,很难不去环顾四周,找到无数机会可以使用它:ExpressibleByStringInterpolation
1、格式化 字符串插值为日期和数字格式字符串提供了更安全,更易于理解的替代方法。
2、转义 无论是URL中的转义实体,XML文档,shell命令参数还是SQL查询中的值,可扩展字符串插值都可以无缝且自动地进行正确的行为。
3、装饰 使用字符串插值创建类型安全的DSL,用于为应用程序和终端输出创建属性字符串,使用ANSI控制序列来显示颜色和效果,或填充未加修饰的文本以匹配所需的对齐方式。
4、本地化 而不是依赖于扫描源代码以查找“NSLocalizedString”匹配的脚本,字符串插值允许我们构建利用编译器查找本地化字符串的所有实例的工具。
如果您考虑所有这些因素并考虑将来可能支持 编译时常量表达式,那么您发现Swift 5可能只是偶然发现了处理格式化的新方法。
转自:https://www.jianshu.com/p/14cb3d70d133
收起阅读 »Swift—文本输出流
print是Swift标准库中最常用的函数之一。实际上,这是程序员在编写“Hello,world!”时学习的第一个函数。令人惊讶的是,我们很少有人熟悉其他形式。
例如,您是否知道实际的签名print是 print(_:separator:terminator:)?或者它有一个名为print(_:separator:terminator:to:)?的变体 ?
令人震惊,我知道。
这就像了解你最好的朋友“Chaz” 的中间名,并且他的完整法定名称实际上是 “R”。巴克敏斯特小查尔斯拉格兰德“ - 哦,而且,他们一直都有一个完全相同的双胞胎。
一旦你花了一些时间来收集自己,请继续阅读,找出你之前认为不需要进一步介绍的功能的全部真相。
让我们首先仔细看看之前的函数声明:
func print<Target>(_ items: Any...,
separator: String = default,
terminator: String = default,
to output: inout Target)
where Target : TextOutputStream这个重载print 采用可变长度的参数列表,后跟separator和terminator参数 - 两者都有默认值。
1、separator是用于将每个元素的表示连接items 成单个字符串的字符串。默认情况下,这是一个空格(" ")。
2、terminator是附加到打印表示的末尾的字符串。默认情况下,这是换行符(\ n "\n")。
最后一个参数output 采用Target符合协议的泛型类型的可变实例。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
符合的类型的实例 可以传递给函数以从标准输出中捕获和重定向字符串。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream``print(_:to:)
实现自定义文本输出流类型
由于Unicode的多变性,您无法通过查看字符串来了解字符串中潜伏的字符。在 组合标记, 格式字符, 不支持的字符, 变体序列, 连字,有向图和其他表现形式之间,单个扩展字形集群可以包含远远超过眼睛的东西。
举个例子,让我们创建一个符合的自定义类型。我们不会逐字地将字符串写入标准输出,而是检查每个组成<dfn style="box-sizing: border-box;">代码点</dfn>。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
符合协议只是满足方法要求的问题。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream``write(_:)
protocol TextOutputStream {
mutating func write(_ string: String)
}在我们的实现中,我们迭代Unicode.Scalar传递的字符串中的每个值; 的enumerated()收集方法提供当前在每次循环偏移。在方法的顶部,guard如果字符串为空或换行符,则语句会提前解除(这会减少控制台中的噪音量)。
struct UnicodeLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n" else {
return
}
for (index, unicodeScalar) in
string.unicodeScalars.lazy.enumerated()
{
let name = unicodeScalar.name ?? ""
let codePoint = String(format: "U+X", unicodeScalar.value)
print("\(index): \(unicodeScalar) \(codePoint)\t\(name)")
}
}
}要使用我们的新类型,请初始化它并将其分配给变量(with ),以便它可以作为参数传递。任何时候我们想要获得字符串的X射线而不是仅仅打印它的表面表示,我们可以在我们的声明中添加一个额外的参数。Unicode<wbr style="box-sizing: border-box;">Logger``var``inout``print
这样做可以让我们揭示关于表情符号字符的秘密👨👩👧👧:它实际上是 由<abbr title="零宽度木匠" style="box-sizing: border-box;">ZWJ</abbr>字符加入的四个单独表情符号的 序列 - 总共七个代码点!<abbr title="零宽度木匠" style="box-sizing: border-box;"></abbr>
print("👨👩👧👧")
// Prints: "👨👩👧👧"
var logger = UnicodeLogger()
print("👨👩👧👧", to: &logger)
// Prints:
// 0: 👨 U+1F468 MAN
// 1: U+200D ZERO WIDTH JOINER
// 2: 👩 U+1F469 WOMAN
// 3: U+200D ZERO WIDTH JOINER
// 4: 👧 U+1F467 GIRL
// 5: U+200D ZERO WIDTH JOINER
// 6: 👧 U+1F467 GIRL在Swift 5.0中,您可以通过其Unicode properties属性访问标量值的名称。与此同时,我们可以使用 字符串变换 来为我们提取名称(我们只需要在两端去掉一些残骸)。
import Foundation
extension Unicode.Scalar {
var name: String? {
guard var escapedName =
"\(self)".applyingTransform(.toUnicodeName,
reverse: false)
else {
return nil
}
escapedName.removeFirst(3) // remove "\\N{"
escapedName.removeLast(1) // remove "}"
return escapedName
}
}有关更多信息,请参阅 SE-0211:“将Unicode属性添加到Unicode.Scalar”。
使用自定义文本输出流的想法
现在我们知道Swift标准库的一个不起眼的部分,我们可以用它做什么?
事实证明,有很多潜在的用例。为了更好地了解它们是什么,请考虑以下示例:Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
记录到标准错误
默认情况下,Swift print语句指向 <dfn style="box-sizing: border-box;">标准输出(stdout)</dfn>。如果您希望改为指向 <dfn style="box-sizing: border-box;">标准error(stderr)</dfn>,则可以创建新的文本输出流类型并按以下方式使用它:
import func Darwin.fputs
import var Darwin.stderr
struct StderrOutputStream: TextOutputStream {
mutating func write(_ string: String) {
fputs(string, stderr)
}
}
var standardError = StderrOutputStream()
print("Error!", to: &standardError)将输出写入文件
前面的写入示例stderr 可以概括为写入任何流或文件,而是通过创建输出流 (可以通过类型属性访问标准错误)。File<wbr style="box-sizing: border-box;">Handle
import Foundation
struct FileHandlerOutputStream: TextOutputStream {
private let fileHandle: FileHandle
let encoding: String.Encoding
init(_ fileHandle: FileHandle, encoding: String.Encoding = .utf8) {
self.fileHandle = fileHandle
self.encoding = encoding
}
mutating func write(_ string: String) {
if let data = string.data(using: encoding) {
fileHandle.write(data)
}
}
}按照这种方法,您可以自定义print写入文件而不是流。
let url = URL(fileURLWithPath: "/path/to/file.txt")
let fileHandle = try FileHandle(forWritingTo: url)
var output = FileHandlerOutputStream(fileHandle)
print("\(Date())", to: &output)转发流输出
作为最后一个例子,让我们想象一下你会发现自己经常将控制台输出复制粘贴到某个网站上的表单中的情况。不幸的是,该网站有试图解析无益的行为<,并>就好像它们是HTML。
每次发布到网站时,您都可以创建一个 自动处理该文本的内容,而不是采取额外的步骤来逃避文本(在这种情况下,我们使用我们发现深埋在Core Foundation中的XML转义函数)。Text<wbr style="box-sizing: border-box;">Output<wbr style="box-sizing: border-box;">Stream
import Foundation
struct XMLEscapingLogger: TextOutputStream {
mutating func write(_ string: String) {
guard !string.isEmpty && string != "\n",
let xmlEscaped = CFXMLCreateStringByEscapingEntities(nil, string as NSString, nil)
else {
return
}
print(xmlEscaped)
}
}
var logger = XMLEscapingLogger()
print("<3", to: &logger)
// Prints "<3"对于开发人员来说,打印是一种熟悉且便捷的方式,可以了解其代码的行为。它补充了更全面的技术,如日志框架和调试器,并且 - 在Swift的情况下 - 证明它本身就非常强大。
转自:https://www.jianshu.com/p/4901641b9c38
收起阅读 »90 行代码的webpack,你确定不学吗?
webpack 可以说是一个经久不衰的话题。其强大、灵活的功能曾极大地促进了前端工程化进程的发展,伴随了无数前端项目的起与落。其纷繁复杂的配置也曾让无数前端人望而却步,笑称需要一个新工种"webpack 配置工程师"。作为一个历史悠久,最常见、最经典的打包工具,webpack 极具讨论价值。理解 webpack,掌握 webpack,无论是在面试环节,还是在日常项目搭建、开发、优化环节,都能带来不少的收益。那么本文将从核心理念出发,带各位读者拨开 webpack 的外衣,看透其本质。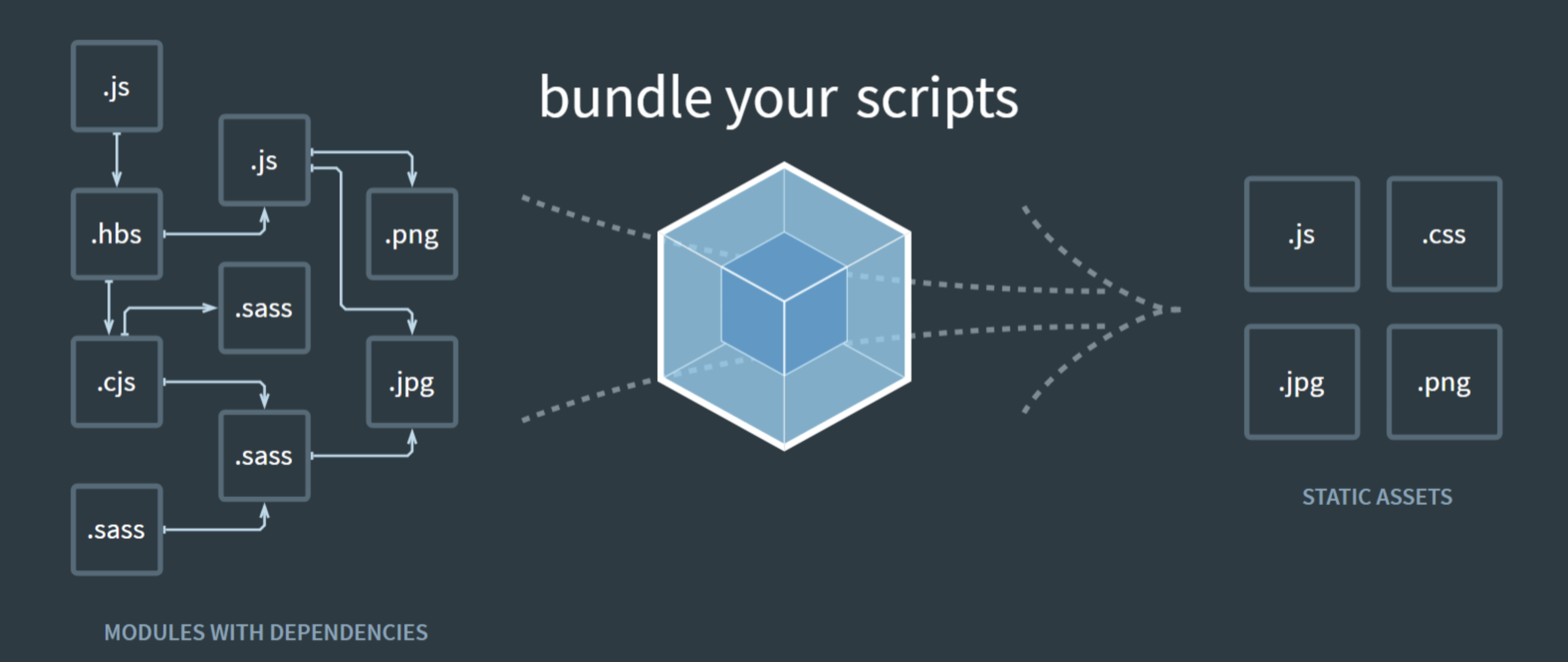
究竟是啥
其实这个问题在 webpack 官网的第一段就给出了明确的定义:
At its core, webpack is a static module bundler for modern JavaScript applications. When webpack processes your application, it internally builds a dependency graph which maps every module your project needs and generates one or more bundles.
其意为:
webpack 的核心是用于现代 JavaScript 应用程序的静态模块打包器。 当 webpack 处理您的应用程序时,它会在内部构建一个依赖关系图,该图映射您项目所需的每个模块并生成一个或多个包。
要素察觉:静态模块打包器、依赖关系图、生成一个或多个包。虽然如今的前端项目中,webpack 扮演着重要的角色,囊括了诸多功能,但从其本质上来讲,其仍然是一个“模块打包器”,将开发者的 JavaScript 模块打包成一个或多个 JavaScript 文件。
要干什么
那么,为什么需要一个模块打包器呢?webpack 仓库早年的 README 也给出了答案:
As developer you want to reuse existing code. As with node.js and web all file are already in the same language, but it is extra work to use your code with the node.js module system and the browser. The goal of
webpackis to bundle CommonJs modules into javascript files which can be loaded by<script>-tags.
可以看到,node.js 生态中积累了大量的 JavaScript 写的代码,却因为 node.js 端遵循的 CommonJS 模块化规范与浏览器端格格不入,导致代码无法得到复用,这是一个巨大的损失。于是 webpack 要做的就是将这些模块打包成可以在浏览器端使用 <script> 标签加载并运行的JavaScript 文件。
或许这并不是唯一解释 webpack 存在的原因,但足以给我们很大的启发——把 CommonJS 规范的代码转换成可在浏览器运行的 JavaScript 代码
怎么干的
既然浏览器端没有 CommonJS 规范,那就实现一个好了。从 webpack 打包出的产物,我们能看出思路。
新建三个文件观察其打包产物:
src/index.js
const printA = require('./a')
printA()src/a.js
const printB = require('./b')
module.exports = function printA() {
console.log('module a!')
printB()
}src/b.js
module.exports = function printB() {
console.log('module b!')
}执行 npx webpack --mode development 打包产出 dist/main.js 文件
上图中,使用了 webpack 打包 3 个简单的 js 文件 index.js/a.js/b.js, 其中 index.js 中依赖了 a.js, 而 a.js 中又依赖了 b.js, 形成一个完整依赖关系。
那么,webpack 又是如何知道文件之间的依赖关系的呢,如何收集被依赖的文件保证不遗漏呢?我们依然能从官方文档找到答案:
When webpack processes your application, it starts from a list of modules defined on the command line or in its configuration file. Starting from these entry points, webpack recursively builds a dependency graph that includes every module your application needs, then bundles all of those modules into a small number of bundles - often, just one - to be loaded by the browser.
也就是说,webpack 会从配置的入口开始,递归的构建一个应用程序所需要的模块的依赖树。我们知道,CommonJS 规范里,依赖某一个文件时,只需要使用 require 关键字将其引入即可,那么只要我们遇到require关键字,就去解析这个依赖,而这个依赖中可能又使用了 require 关键字继续引用另一个依赖,于是,就可以递归的根据 require 关键字找到所有的被依赖的文件,从而完成依赖树的构建了。
可以看到上图最终输出里,三个文件被以键值对的形式保存到 __webpack_modules__ 对象上, 对象的 key 为模块路径名,value 为一个被包装过的模块函数。函数拥有 module, module.exports, __webpack_require__ 三个参数。这使得每个模块都拥有使用 module.exports 导出本模块和使用 __webpack_require__ 引入其他模块的能力,同时保证了每个模块都处于一个隔离的函数作用域范围。
为什么 webpack要修改require关键字和require的路径?我们知道require是node环境自带的环境变量,可以直接使用,而在其他环境则没有这样一个变量,于是需要webpack提供这样的能力。只要提供了相似的能力,变量名叫 require还是 __webpack_require__其实无所谓。至于重写路径,当然是因为在node端系统会根据文件的路径加载,而在 webpack打包的文件中,使用原路径行不通,于是需要将路径重写为 __webpack_modules__ 的键,从而找到相应模块。
而下面的 __webpack_require__函数与 __webpack_module_cache__ 对象则完成了模块加载的职责。使用 __webpack_require__ 函数加载完成的模块被缓存到 __webpack_module_cache__ 对象上,以便下次如果有其他模块依赖此模块时,不需要重新运行模块的包装函数,减少执行效率的消耗。同时,如果多个文件之间存在循环依赖,比如 a.js 依赖了 b.js 文件, b.js 又依赖了 a.js,那么在 b.js 使用 __webpack_require__加载 a.js 时,会直接走进 if(cachedModule !== undefined) 分支然后 return已缓存过的 a.js 的引用,不会进一步执行 a.js 文件加载,从而避免了循环依赖无限递归的出现。
不能说这个由 webpack 实现的模块加载器与 CommonJS 规范一毛一样,只能说八九不离十吧。这样一来,打包后的 JavaScript 文件可以被 <script> 标签加载且运行在浏览器端了。
简易实现
了解了 webpack 处理后的 JavaScript 长成什么样子,我们梳理一下思路,依葫芦画瓢手动实现一个简易的打包器,帮助理解。
要做的事情有这么些:
- 读取入口文件,并收集依赖信息
- 递归地读取所有依赖模块,产出完整的依赖列表
- 将各模块内容打包成一块完整的可运行代码
话不多说,创建一个项目,并安装所需依赖
npm init -y
npm i @babel/core @babel/parser @babel/traverse webpack webpack-cli -D其中:
@babel/parser用于解析源代码,产出 AST@babel/traverse用于遍历 AST,找到require语句并修改成_require_,将引入路径改造为相对根的路径@babel/core用于将修改后的 AST 转换成新的代码输出
创建一个入口文件 myPack.js 并引入依赖
const fs = require('fs')
const path = require('path')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')紧接着,我们需要对某一个模块进行解析,并产出其模块信息,包括:模块路径、模块依赖、模块转换后代码
// 保存根路径,所有模块根据根路径产出相对路径
let root = process.cwd()
function readModuleInfo(filePath) {
// 准备好相对路径作为 module 的 key
filePath =
'./' + path.relative(root, path.resolve(filePath)).replace(/\\+/g, '/')
// 读取源码
const content = fs.readFileSync(filePath, 'utf-8')
// 转换出 AST
const ast = parser.parse(content)
// 遍历模块 AST,将依赖收集到 deps 数组中
const deps = []
traverse(ast, {
CallExpression: ({ node }) => {
// 如果是 require 语句,则收集依赖
if (node.callee.name === 'require') {
// 改造 require 关键字
node.callee.name = '_require_'
let moduleName = node.arguments[0].value
moduleName += path.extname(moduleName) ? '' : '.js'
moduleName = path.join(path.dirname(filePath), moduleName)
moduleName = './' + path.relative(root, moduleName).replace(/\\+/g, '/')
deps.push(moduleName)
// 改造依赖的路径
node.arguments[0].value = moduleName
}
},
})
// 编译回代码
const { code } = babel.transformFromAstSync(ast)
return {
filePath,
deps,
code,
}
}接下来,我们从入口出发递归地找到所有被依赖的模块,并构建成依赖树
function buildDependencyGraph(entry) {
// 获取入口模块信息
const entryInfo = readModuleInfo(entry)
// 项目依赖树
const graphArr = []
graphArr.push(entryInfo)
// 从入口模块触发,递归地找每个模块的依赖,并将每个模块信息保存到 graphArr
for (const module of graphArr) {
module.deps.forEach((depPath) => {
const moduleInfo = readModuleInfo(path.resolve(depPath))
graphArr.push(moduleInfo)
})
}
return graphArr
}经过上面一步,我们已经得到依赖树能够描述整个应用的依赖情况,最后我们只需要按照目标格式进行打包输出即可
function pack(graph, entry) {
const moduleArr = graph.map((module) => {
return (
`"${module.filePath}": function(module, exports, _require_) {
eval(\`` +
module.code +
`\`)
}`
)
})
const output = `;(() => {
var modules = {
${moduleArr.join(',\n')}
}
var modules_cache = {}
var _require_ = function(moduleId) {
if (modules_cache[moduleId]) return modules_cache[moduleId].exports
var module = modules_cache[moduleId] = {
exports: {}
}
modules[moduleId](module, module.exports, _require_)
return module.exports
}
_require_('${entry}')
})()`
return output
}直接使用字符串模板拼接成类 CommonJS 规范的模板,自动加载入口模块,并使用 IIFE 将代码包装,保证代码模块不会影响到全局作用域。
最后,编写一个入口函数 main 用以启动打包过程
function main(entry = './src/index.js', output = './dist.js') {
fs.writeFileSync(output, pack(buildDependencyGraph(entry), entry))
}
main()执行并验证结果
node myPack.js至此,我们使用了总共不到 90 行代码(包含注释),完成了一个极简的模块打包工具。虽然没有涉及任何 Webpack 源码, 但我们从打包器的设计原理入手,走过了打包工具的核心步骤,简易却不失完整。
总结
本文从 webpack 的设计理念和最终实现出发,梳理了其作为一个打包工具的核心能力,并使用一个简易版本实现帮助更直观的理解其本质。总的来说,webpack 作为打包工具无非是从应用入口出发,递归的找到所有依赖模块,并将他们解析输出成一个具备类 CommonJS 模块化规范的模块加载能力的 JavaScript 文件。
因其优秀的设计,在实际生产环节中,webapck 还能扩展出诸多强大的功能。然而其本质仍是模块打包器。不论是什么样的新特性或新能力,只要我们把握住打包工具的核心思想,任何问题终将迎刃而解。
链接:https://juejin.cn/post/6963820624623960101
使用vue+element开发一个谷歌插件
开始
{
"name": "testPlugin",
"description": "这是一个测试用例",
"version": "0.0.1",
"manifest_version": 2
}{
"name": "testPlugin",
"description": "这是一个测试用例",
"version": "0.0.1",
"manifest_version": 2,
"icons": {
"16": "icons/16.png",
"48": "icons/16.png"
}
}这时候在扩展程序中加载已解压的程序(就是我们创建的文件夹),就可以看到雏形了:

"browser_action": {
"default_title": "test plugin",
"default_icon": "icons/16.png",
"default_popup": "index.html"
}testPlugin创建index.html文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>test plugin</title>
</head>
<body>
<input id="name" placeholder="请输入"/>
</body>
</html>刷新插件,这时候点击浏览器中刚刚添加的插件的icon,就会弹出:

document.getElementById('button').onclick = function() {
alert(document.getElementById('name').value)
}<input id="name" placeholder="请输入"/>
<input id="button" type="button" value="点击"/>
<script src="js/index.js"></script>刷新插件

一个嵌入网页中的悬浮框
上述例子是点击icon浏览器右上角出现的小弹窗,
引入vue.js、element-ui
下载合适版本的vue.js和element-ui等插件,同样按照index.js一样的操作引入,如果没有下载单独js文件的地址,可以打开cdn地址直接将压缩后的代码复制。
manifest.json中添加:
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"css": [
"css/index.css"
],
"js": [
"js/vue.js",
"js/element.js",
"js/index.js"
],
"run_at": "document_idle"
}
],在index.js文件:
这里使用在head里插入link 的方式引入element-ui的css,减少插件包的一点大小,当然也可以像引入index.js那样在manifest.json中引入。
直接在index.js文件中写Vue实例,不过首先得创建挂载实例的节点:
let element = document.createElement('div')
let attr = document.createAttribute('id')
attr.value = 'appPlugin'
element.setAttributeNode(attr)
document.getElementsByTagName('body')[0].appendChild(element)
let link = document.createElement('link')
let linkAttr = document.createAttribute('rel')
linkAttr.value = 'stylesheet'
let linkHref = document.createAttribute('href')
linkHref.value = 'https://unpkg.com/element-ui/lib/theme-chalk/index.css'
link.setAttributeNode(linkAttr)
link.setAttributeNode(linkHref)
document.getElementsByTagName('head')[0].appendChild(link)
const vue = new Vue({
el: '#appPlugin',
template:`
<div class="app-plugin-content">{{text}}{{icon_post_message}}<el-button @click="Button">Button</el-button></div>
`,
data: function () {
return { text: 'hhhhhh', icon_post_message: '_icon_post_message', isOcContentPopShow: true }
},
mounted() {
console.log(this.text)
},
methods: {
Button() {
this.isOcContentPopShow = false
}
}
})让我们来写一个简易替换网页背景颜色工具
let element = document.createElement('div')
let attr = document.createAttribute('id')
attr.value = 'appPlugin'
element.setAttributeNode(attr)
document.getElementsByTagName('body')[0].appendChild(element)
let link = document.createElement('link')
let linkAttr = document.createAttribute('rel')
linkAttr.value = 'stylesheet'
let linkHref = document.createAttribute('href')
linkHref.value = 'https://unpkg.com/element-ui/lib/theme-chalk/index.css'
link.setAttributeNode(linkAttr)
link.setAttributeNode(linkHref)
document.getElementsByTagName('head')[0].appendChild(link)
const vue = new Vue({
el: '#appPlugin',
template: `
<div v-if="isOcContentPopShow" class="oc-move-page" id="oc_content_page">
<div class="oc-content-title" id="oc_content_title">颜色 <el-button type="text" icon="el-icon-close" @click="close"></el-button></div>
<div class="app-plugin-content">背景:<el-color-picker v-model="color1"></el-color-picker></div>
<div class="app-plugin-content">字体:<el-color-picker v-model="color2"></el-color-picker></div>
</div>
`,
data: function () {
return { color1: null, color2: null, documentArr: [], textArr: [], isOcContentPopShow: true }
},
watch: {
color1(val) {
let out = document.getElementById('oc_content_page')
let outC = document.getElementsByClassName('el-color-picker__panel')
this.documentArr.forEach(item => {
if(!out.contains(item) && !outC[0].contains(item) && !outC[1].contains(item)) {
item.style.cssText = `background-color: ${val}!important;color: ${this.color2}!important;`
}
})
},
color2(val) {
let out = document.getElementById('oc_content_page')
let outC = document.getElementsByClassName('el-color-picker__panel')[1]
this.textArr.forEach(item => {
if(!out.contains(item) && !outC.contains(item)) {
item.style.cssText = `color: ${val}!important;`
}
})
}
},
mounted() {
chrome.runtime.onConnect.addListener((res) => {
if (res.name === 'testPlugin') {
res.onMessage.addListener(mess => {
this.isOcContentPopShow = mess.isShow
})
}
})
this.$nextTick(() => {
let bodys = [...document.getElementsByTagName('body')]
let headers = [...document.getElementsByTagName('header')]
let divs = [...document.getElementsByTagName('div')]
let lis = [...document.getElementsByTagName('li')]
let articles = [...document.getElementsByTagName('article')]
let asides = [...document.getElementsByTagName('aside')]
let footers = [...document.getElementsByTagName('footer')]
let navs = [...document.getElementsByTagName('nav')]
this.documentArr = bodys.concat(headers, divs, lis, articles, asides, footers, navs)
let as = [...document.getElementsByTagName('a')]
let ps = [...document.getElementsByTagName('p')]
this.textArr = as.concat(ps)
})
},
methods: {
close() {
this.isOcContentPopShow = false
}
}
})index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>my plugin</title>
<link rel="stylesheet" href="css/index.css">
</head>
<body>
<div class="plugin">
<input id="plugin_button" type="button" value="打开" />
</div>
</body>
<script src="js/icon.js"></script>
</html>新建icon.js:
plugin_button.onclick = function () {
mess()
}
async function mess () {
const tabId = await getCurrentTabId()
const connect = chrome.tabs.connect(tabId, {name: 'testPlugin'});
connect.postMessage({isShow: true})
}
function getCurrentTabId() {
return new Promise((resolve, reject) => {
chrome.tabs.query({ active: true, currentWindow: true }, function (tabs) {
resolve(tabs.length ? tabs[0].id : null)
});
})
}新建index.css:
.oc-move-page{
width: 100px;
height: 200px;
background: white;
box-shadow: 0px 4px 8px rgba(0, 0, 0, 0.12);
border-radius: 8px;
position: fixed;
transform: translateY(-50%);
right: 0;
top: 50%;
z-index: 1000001;
}
.oc-move-page .oc-content-title{
text-align: left;
padding: 12px 16px;
font-weight: 600;
font-size: 18px;
border-bottom: 1px solid #DEE0E3;
}
.oc-move-page .app-plugin-content {
display: flex;
align-items: center;
margin-top: 10px;
}
.el-color-picker__panel {
right: 100px!important;
left: auto!important;
}
这样一个小尝试就完成了,当然如果有更多需求可以结合本地存储或者服务端来协作。
本文链接:https://blog.csdn.net/qq_26769677/article/details/116611072
手把手教你利用js给图片打马赛克
效果演示
Canvas简介
这个 HTML 元素是为了客户端矢量图形而设计的。它自己没有行为,但却把一个绘图 API 展现给客户端 JavaScript 以使脚本能够把想绘制的东西都绘制到一块画布上。
HTML5 标签用于绘制图像(通过脚本,通常是 JavaScript)
不过, 元素本身并没有绘制能力(它仅仅是图形的容器) - 您必须使用脚本来完成实际的绘图任务
getContext() 方法可返回一个对象,该对象提供了用于在画布上绘图的方法和属性
本手册提供完整的 getContext(“2d”) 对象属性和方法,可用于在画布上绘制文本、线条、矩形、圆形等等
标记和 SVG 以及 VML 之间的差异:
标记和 SVG 以及 VML 之间的一个重要的不同是, 有一个基于 JavaScript 的绘图 API,而 SVG 和 VML 使用一个 XML 文档来描述绘图。
这两种方式在功能上是等同的,任何一种都可以用另一种来模拟。从表面上看,它们很不相同,可是,每一种都有强项和弱点。例如,SVG 绘图很容易编辑,只要从其描述中移除元素就行。
要从同一图形的一个 标记中移除元素,往往需要擦掉绘图重新绘制它
知识点简介
let img = new Image()
//可以给图片一个链接
img.src = 'https://ss0.bdstatic.com/70cFuHSh_Q1YnxGkpoWK1HF6hhy/it/u=826495019,1749283937&fm=26&gp=0.jpg'
//或者本地已有图片的路径
//img.src = './download.jpg'
//添加到HTML中
document.body.appendChild(img)let ctx = Canvas.getContext(contextID)JavaScript 语法 1:
在画布上定位图像:context.drawImage(img,x,y);JavaScript 语法 2:
在画布上定位图像,并规定图像的宽度和高度:
context.drawImage(img,x,y,width,height);
JavaScript 语法 3:
剪切图像,并在画布上定位被剪切的部分:
context.drawImage(img,sx,sy,swidth,sheight,x,y,width,height);JavaScript 语法
getImageData() 方法返回 ImageData 对象,该对象拷贝了画布指定矩形的像素数据。
对于 ImageData 对象中的每个像素,都存在着四方面的信息,即 RGBA 值:
R - 红色 (0-255)
G - 绿色 (0-255)
B - 蓝色 (0-255)
A - alpha 通道 (0-255; 0 是透明的,255 是完全可见的)
color/alpha 以数组形式存在,并存储于 ImageData 对象的 data 属性中
var imgData=context.getImageData(x,y,width,height);putImageData() 方法将图像数据(从指定的 ImageData 对象)放回画布上。那我们开始搞起来吧
step-by-step
<body>
<img src="./download.jpg">
<button onclick="addCanvas()">生成Canvas</button>
<button onclick="generateImg()">生成图片</button>
</body>
接下来写addCanvas方法
function addCanvas() {
let bt = document.querySelector('button')
let img = new Image(); //1.准备赋值复制一份图片
img.src = './download.jpg';
img.onload = function() { //2.待图片加载完成
let width = this.width
let height = this.height
let canvas = document.createElement('canvas') //3.创建画布
let ctx = canvas.getContext("2d"); //4.获得该画布的内容
canvas.setAttribute('width', width) //5.为了统一,设置画布的宽高为图片的宽高
canvas.setAttribute('height', height)
ctx.drawImage(this, 0, 0, width, height); //5.在画布上绘制该图片
document.body.insertBefore(canvas, bt) //5.把canvas插入到按钮前面
}
}
嗯,我们已经成功走出了成功的一小步,接下来是干什么呢?…嗯,我们需要利用原生的onmouseup和onmousedown事件,代表我们按下鼠标这个过程,那么这两个事件添加到哪呢?
没错,既然我们要在canvas上进行马赛克操作,那我们必然要给canvas元素添加这两个事件
考虑到我们创建canvas的过程复杂了一点,我们做一个模块封装吧!
function addCanvas() {
let bt = document.querySelector('button')
let img = new Image();
img.src = './download.jpg'; //这里放自己的图片
img.onload = function() {
let width = this.width
let height = this.height
let {
canvas,
ctx
} = createCanvasAndCtx(width, height) //对象解构接收canvas和ctx
ctx.drawImage(this, 0, 0, width, height);
document.body.insertBefore(canvas, bt)
}
}
function createCanvasAndCtx(width, height) {
let canvas = document.createElement('canvas')
canvas.setAttribute('width', width)
canvas.setAttribute('height', height)
canvas.setAttribute('onmouseout', 'end()') //修补鼠标不在canvas上离开的补丁
canvas.setAttribute('onmousedown', 'start()') //添加鼠标按下
canvas.setAttribute('onmouseup', 'end()') //添加鼠标弹起
let ctx = canvas.getContext("2d");
return {
canvas,
ctx
}
}
function start() {
let canvas = document.querySelector('canvas')
canvas.onmousemove = () => {
console.log('你按下了并移动了鼠标')
}
}
function end() {
let canvas = document.querySelector('canvas')
canvas.onmousemove = null
}
function start() {
let img = document.querySelector('img')
let canvas = document.querySelector('canvas')
let ctx = canvas.getContext("2d");
imgData = ctx.getImageData(0, 0, img.clientWidth, img.clientHeight);
canvas.onmousemove = (e) => {
let w = imgData.width; //1.获取图片宽高
let h = imgData.height;
//马赛克的程度,数字越大越模糊
let num = 10;
//获取鼠标当前所在的像素RGBA
let color = getXY(imgData, e.offsetX, e.offsetY);
for (let k = 0; k < num; k++) {
for (let l = 0; l < num; l++) {
//设置imgData上坐标为(e.offsetX + l, e.offsetY + k)的的颜色
setXY(imgData, e.offsetX + l, e.offsetY + k, color);
}
}
//更新canvas数据
ctx.putImageData(imgData, 0, 0);
}
}
//这里为你提供了setXY和getXY两个函数,如果你有兴趣,可以去研究获取的原理
function setXY(obj, x, y, color) {
var w = obj.width;
var h = obj.height;
var d = obj.data;
obj.data[4 * (y * w + x)] = color[0];
obj.data[4 * (y * w + x) + 1] = color[1];
obj.data[4 * (y * w + x) + 2] = color[2];
obj.data[4 * (y * w + x) + 3] = color[3];
}
function getXY(obj, x, y) {
var w = obj.width;
var h = obj.height;
var d = obj.data;
var color = [];
color[0] = obj.data[4 * (y * w + x)];
color[1] = obj.data[4 * (y * w + x) + 1];
color[2] = obj.data[4 * (y * w + x) + 2];
color[3] = obj.data[4 * (y * w + x) + 3];
return color;
}function generateImg() {
let canvas = document.querySelector('canvas')
var newImg = new Image();
newImg.src = canvas.toDataURL("image/png");
document.body.insertBefore(newImg, canvas)
}完整代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<body>
<img src="./download.jpg">
<button onclick="addCanvas()">生成Canvas</button>
<button onclick="generateImg()">生成图片</button>
</body>
<script>
function addCanvas() {
let bt = document.querySelector('button')
let img = new Image();
img.src = './download.jpg'; //这里放自己的图片
img.onload = function() {
let width = this.width
let height = this.height
let {
canvas,
ctx
} = createCanvasAndCtx(width, height)
ctx.drawImage(this, 0, 0, width, height);
document.body.insertBefore(canvas, bt)
}
}
function createCanvasAndCtx(width, height) {
let canvas = document.createElement('canvas')
canvas.setAttribute('width', width)
canvas.setAttribute('height', height)
canvas.setAttribute('onmouseout', 'end()')
canvas.setAttribute('onmousedown', 'start()')
canvas.setAttribute('onmouseup', 'end()')
let ctx = canvas.getContext("2d");
return {
canvas,
ctx
}
}
function start() {
let img = document.querySelector('img')
let canvas = document.querySelector('canvas')
let ctx = canvas.getContext("2d");
imgData = ctx.getImageData(0, 0, img.clientWidth, img.clientHeight);
canvas.onmousemove = (e) => {
let w = imgData.width; //1.获取图片宽高
let h = imgData.height;
//马赛克的程度,数字越大越模糊
let num = 10;
//获取鼠标当前所在的像素RGBA
let color = getXY(imgData, e.offsetX, e.offsetY);
for (let k = 0; k < num; k++) {
for (let l = 0; l < num; l++) {
//设置imgData上坐标为(e.offsetX + l, e.offsetY + k)的的颜色
setXY(imgData, e.offsetX + l, e.offsetY + k, color);
}
}
//更新canvas数据
ctx.putImageData(imgData, 0, 0);
}
}
function generateImg() {
let canvas = document.querySelector('canvas')
var newImg = new Image();
newImg.src = canvas.toDataURL("image/png");
document.body.insertBefore(newImg, canvas)
}
function setXY(obj, x, y, color) {
var w = obj.width;
var h = obj.height;
var d = obj.data;
obj.data[4 * (y * w + x)] = color[0];
obj.data[4 * (y * w + x) + 1] = color[1];
obj.data[4 * (y * w + x) + 2] = color[2];
obj.data[4 * (y * w + x) + 3] = color[3];
}
function getXY(obj, x, y) {
var w = obj.width;
var h = obj.height;
var d = obj.data;
var color = [];
color[0] = obj.data[4 * (y * w + x)];
color[1] = obj.data[4 * (y * w + x) + 1];
color[2] = obj.data[4 * (y * w + x) + 2];
color[3] = obj.data[4 * (y * w + x) + 3];
return color;
}
function end() {
let canvas = document.querySelector('canvas')
canvas.onmousemove = null
}
</script>
</body>
</html>本文链接:https://blog.csdn.net/JKR10000/article/details/116803023
微信H5网页跳转小程序,这一篇就够了!
鉴于微信 开放标签说明文档 写的不是很清楚,大多数开发者看了以后表示:我从哪里来?要到哪里去?
所以鄙人记录下这篇文章,以便帮助到一些人。
静态网页跳转小程序
废话不多说,上才艺!
<html>
<head>
<meta charset="utf-8">
<meta name = "viewport" content = "width = device-width, initial-scale = 1.0, maximum-scale = 1.0, user-scalable = 0" />
<title>小程序跳转测试</title>
</head>
<body style="text-aligin:center;">
<wx-open-launch-weapp
id="launch-btn"
username="gh_e16de8f****" <!-- 这里填写小程序的原始ID -->
path="/pages/index/index.html"> <!-- 这里填写跳转对于小程序的页面 注意这里的 .html -->
<template>
<style>.btn { padding: 12px width:200px;height:50px;}</style>
<button class="btn">打开小程序</button>
</template>
</wx-open-launch-weapp>
<script src="/js/jquery-1.12.4.js"></script>
<script src="https://res.wx.qq.com/open/js/jweixin-1.6.0.js"></script> <!-- 至少必须是1.6版本 -->
<script>
$(function () {
//=== 这里仅仅是获取 config 的参数以及签名=== start
var url = location.href;
var functions = "updateAppMessageShareData";
$.get("https://xxx.com/wechat/jssdk/config", {"functions":functions}, function(response){
if(response.status == 0) {
var info = response.data;
wx.config({
debug: false,
appId: info.appId,
timestamp: info.timestamp,
nonceStr: info.nonceStr,
signature: info.signature,
jsApiList: info.jsApiList,
openTagList: ['wx-open-launch-weapp']//这里直接添加,什么都不用管
});
}
});
//=== 获取 config 的参数以及签名=== end
var btn = document.getElementById('launch-btn');
btn.addEventListener('launch', function (e) {
console.log('success');
});
btn.addEventListener('error', function (e) {
console.log('fail', e.detail);
});
});
</script>
</body>
</html>开放对象:
1、已认证的服务号,服务号绑定“JS接口安全域名”下的网页可使用此标签跳转任意合法合规的小程序。
2、已认证的非个人主体的小程序,使用小程序云开发的静态网站托管绑定的域名下的网页,可以使用此标签跳转任意合法合规的小程序。客户端要求
微信版本要求为:7.0.12及以上。 系统版本要求为:iOS 10.3及以上、Android 5.0及以上。
注意:微信开发者工具暂时不支持!所以建议直接使用手机访问进行测试。其他说明
这个功能其实很简单,并没有想象中那么复杂。 实质是在你能够做到自定义分享到朋友圈或朋友的基础上,config多了
openTagList: ['wx-open-launch-weapp']再者需要注意的是,path的页面url 必须带有 .html 带参数的话则参数跟在html的后面。
<wx-open-launch-weapp
id="launch-btn"
username="gh_e16de8f****" <!-- 这里填写小程序的原始ID -->
path="/pages/index/index.html">
<wx-open-launch-weapp
id="launch-btn"
username="gh_e16de8f****" <!-- 这里填写小程序的原始ID -->
path="/pages/index/index.html?id=123">VUE项目H5跳转
1、先请求接口配置微信需要的一些参数
// 需要先请求后端接口
let url = window.location.href.split("#")[0];
let shareConfig = await shareViewAPI.getWechatConfig({url});
let _this = this;
// 将接口返回的信息配置
wx.config({
debug: false,
appId: _this.app_id, // 必填,公众号的唯一标识
timestamp: shareConfig.timestamp, // 必填,生成签名的时间戳
nonceStr: shareConfig.nonceStr, // 必填,生成签名的随机串
signature: shareConfig.signature, // 必填,签名
jsApiList: ["onMenuShareAppMessage"], // 必填,如果只是为了跳转小程序,随便填个值都行
openTagList: ["wx-open-launch-weapp"] // 跳转小程序时必填
});2、在页面中添加wx-open-launch-weapp标签
<!-- 关于username 与 path的值 参考官方文档 -->
<wx-open-launch-weapp
id="launch-btn"
username="gh_***"
path="/pages/index/index.html"
@error="handleErrorFn"
@launch="handleLaunchFn"
>
<!-- vue中需要使用script标签代替template插槽 html中使用template -->
<script type="text/wxtag-template">
<p class="store-tool_tip">点击进入选基工具</p>
</script>
</wx-open-launch-weapp>methods: {
handleLaunchFn(e) {
console.log("success", e);
},
handleErrorFn(e) {
console.log("fail", e.detail);
}
}3、好啦
// 忽略打开微信小程序的组件
Vue.config.ignoredElements = ['wx-open-launch-weapp']独乐乐不如众乐乐,你的项目还在纠结用日志打印log么?Android开发okhttp3便捷拦截监听
SimpleInterceptor
SimpleInterceptor 是Android OkHttp客户端的的拦截接口工具,为的是方便测试或开发,快速查找问题。


环境要求
- Android 4.1+
- OkHttp 3.x or 4.x
- androidx
git地址
github地址 :https://github.com/smartbackme/SimpleInterceptor
国内访问地址: https://gitee.com/dileber/SimpleInterceptor
如果觉得不错 github 给个星
警告:
使用此拦截器时生成和存储的数据可能包含敏感信息,如授权或Cookie头,以及请求和响应主体的内容。
由此,其只能用于调试过程,不可发布到线上
配置
project : build.gradle
buildscript {
repositories {
maven { url 'https://www.jitpack.io' }
}
版本于okhttp关联:
如果app 集成的是okhttp3 3.+版本那么请选用 3.0版本代码
如果app 集成的是okhttp3 4.+版本那么请选用 4.0版本代码
okhttp3 3.+
dependencies {
debugImplementation 'com.github.smartbackme.SimpleInterceptor:simpleinterceptor-debug:3.0'
releaseImplementation 'com.github.smartbackme.SimpleInterceptor:simpleinterceptor-release:3.0'
}
or
okhttp3 4.+
dependencies {
debugImplementation 'com.github.smartbackme.SimpleInterceptor:simpleinterceptor-debug:4.0'
releaseImplementation 'com.github.smartbackme.SimpleInterceptor:simpleinterceptor-release:4.0'
}
使用:
OkHttpClient.Builder()
.addInterceptor(SimpleInterceptor(context))
.build()
下载地址:dileber-SimpleInterceptor-master.zip
收起阅读 »
ORCharts:环形图、饼状图、扇形图
本文为ORCharts:环形图、饼状图、扇形图 部分, 做详细说明
相关连接
GitHub
ORCharts
ORCharts:曲线图、折线图
效果预览

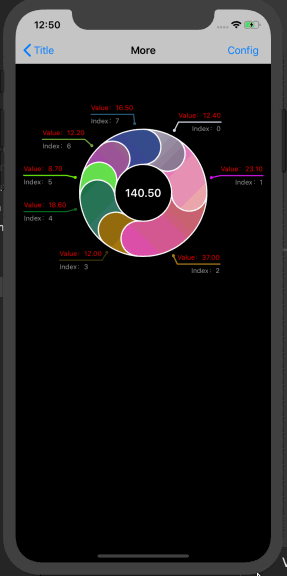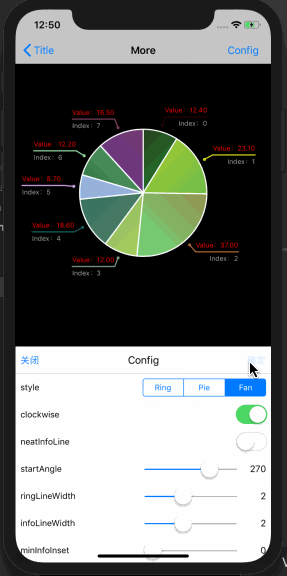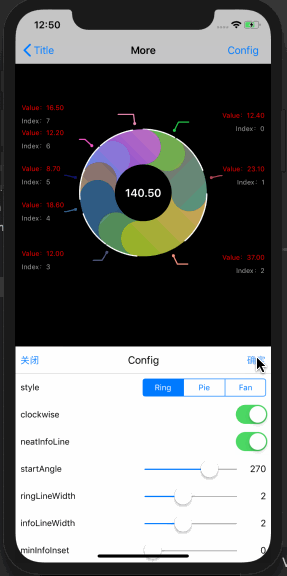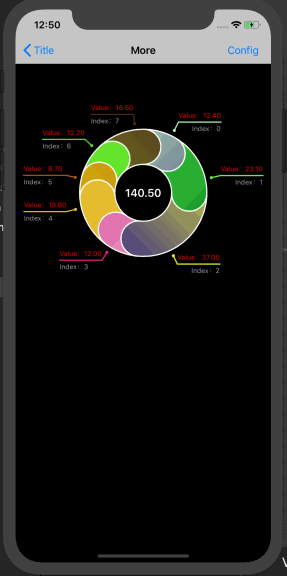
安装
pod 'ORCharts/Ring'使用
Use Interface Builder
1、 在XIB或Storyboard拖拽一个 UIView 到你需要展示的位置
2、 修改Class为 ORRingChartView
3、 设置 dataSource
代码
@property (nonatomic, strong) ORRingChartView *ringChartView;_ringChartView = [[ORRingChartView alloc] initWithFrame:CGRectMake(0, 0, 375, 375)];
_ringChartView.dataSource = self;
[self.view addSubview:_ringChartView];在数据改变或是配置改变的时候reloadData
[_ringChartView reloadData];style
ORRingChartStyleRing:环形图(默认)
ORRingChartStylePie:饼状图
ORRingChartStyleFan:扇形图
_ringChart.style = ORRingChartStylePie;代理相关
ORRingChartViewDatasource
1、@required
必须实现方法,数据个数以及对应数据,类似tableView
- (NSInteger)numberOfRingsOfChartView:(ORRingChartView *)chartView;
- (CGFloat)chartView:(ORRingChartView *)chartView valueAtRingIndex:(NSInteger)index;2、@optional,对应Index数据视图的渐变色,默认为随机色
- (NSArray <UIColor *> *)chartView:(ORRingChartView *)chartView graidentColorsAtRingIndex:(NSInteger)index;对应Index数据视图的线条颜色,默认为白色
- (UIColor *)chartView:(ORRingChartView *)chartView lineColorForRingAtRingIndex:(NSInteger)index;对应Index数据的信息线条颜色,默认为graidentColors的第一个颜色
- (UIColor *)chartView:(ORRingChartView *)chartView lineColorForInfoLineAtRingIndex:(NSInteger)index;中心视图,默认nil,返回的时候需要设置视图大小
- (UIView *)viewForRingCenterOfChartView:(ORRingChartView *)chartView;对应Index数据的顶部信息视图,默认nil,返回的时候需要设置视图大小
- (UIView *)chartView:(ORRingChartView *)chartView viewForTopInfoAtRingIndex:(NSInteger)index;对应Index数据的底部信息视图,默认nil,返回的时候需要设置视图大小
- (UIView *)chartView:(ORRingChartView *)chartView viewForBottomInfoAtRingIndex:(NSInteger)index;配置相关
以下是配置中部分属性图解
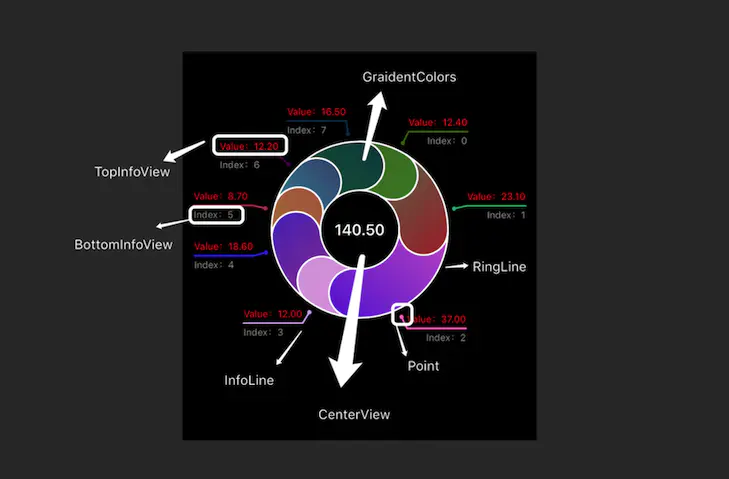
配置修改方式
_ringChart.config.neatInfoLine = YES;
_ringChart.config.ringLineWidth = 2;
_ringChart.config.animateDuration = 1;
[_ringChart reloadData];以下为配置具体说明
1、整体
clockwise:图表绘制方向是否为顺时针,默认YES
animateDuration:动画时长 ,设置0,则没有动画,默认1
neatInfoLine:infoLine 两边对齐、等宽,默认NO
startAngle:图表绘制起始角度,默认 M_PI * 3 / 2
ringLineWidth:ringLine宽度,默认2
infoLineWidth:infoLine宽度,默认2
2、偏移、边距配置
minInfoInset:infoView的内容偏移,值越大,infoView越宽,默认0
infoLineMargin:infoLine 至 周边 的距离,默认10
infoLineInMargin:infoLine 至 环形图的距离,默认 10
infoLineBreakMargin:infoLine折线距离,默认 15
infoViewMargin:infoLine 至 infoView的距离,默认5
3、其他
pointWidth:infoline 末尾圆点宽度,默认 5
ringWidth:环形图,圆环宽度, 如果设置了 centerView 则无效,默认60
文末
GitHub传送门
有任何问题,可在本文下方评论,或是GitHub上提出issue
如有可取之处, 记得 star
转自:https://www.jianshu.com/p/317a79890984
收起阅读 »Swift手势密码库,用这一个就够了!
一个轻量级、面对协议编程、高度自定义的 图形解锁/手势解锁 / 手势密码 / 图案密码 / 九宫格密码
相比于其他同类三方库有哪些优势:
1、完全面对协议编程,支持高度自定义网格视图和连接线视图,轻松实现各类不同需求;
2、默认支持多种配置效果,支持大部分主流效果,引入就可以搞定需求;
3、源码采用Swift5编写,通过泛型、枚举、函数式编程优化代码,具有更高的学习价值;
4、后期会持续迭代,不断添加主流效果;
Github地址
效果预览
1. 箭头
2. 中间点自动链接

3. 小灰点

4. 小白点
5. 荧光蓝
6. fill白色

7. 阴影

8. 图片

9. 旋转(鸡你太美)

10. 破折线
11. 图片连接线(箭头)

12. 图片连接线(小鱼儿)

13. 设置密码

14. 修改密码

15. 验证密码

使用
初始化PatternLockViewConfig
方式一:使用LockConfig
LockConfig是默认提供的类,实现了PatternLockViewConfig协议。可以直接通过LockConfig的属性进行自定义。
let config = LockConfig()
config.gridSize = CGSize(width: 70, height: 70)
config.matrix = Matrix(row: 3, column: 3)
config.errorDisplayDuration = 1方式二:新建实现PatternLockViewConfig协议的类
该方式可以将所有配置细节聚集到自定义类的内部,外部只需要初始化自定义类即可。详情请参考demo里面的ArrowConfig类。这样有个好处就是,多个地方都需要用到同样配置的时候,只需要初始化相同的类,而不用像使用LockConfig那样,复制属性配置代码。
struct ArrowConfig: PatternLockViewConfig {
var matrix: Matrix = Matrix(row: 3, column: 3)
var gridSize: CGSize = CGSize(width: 70, height: 70)
var connectLine: ConnectLine?
var autoMediumGridsConnect: Bool = false
//其他属性配置!只是示例,就不显示所有配置项,影响文档长度
}配置GridView
config.initGridClosure = {(matrix) -> PatternLockGrid in
let gridView = GridView()
let outerStrokeLineWidthStatus = GridPropertyStatus<CGFloat>.init(normal: 1, connect: 2, error: 2)
let outerStrokeColorStatus = GridPropertyStatus<UIColor>(normal: tintColor, connect: tintColor, error: .red)
gridView.outerRoundConfig = RoundConfig(radius: 33, lineWidthStatus: outerStrokeLineWidthStatus, lineColorStatus: outerStrokeColorStatus, fillColorStatus: nil)
let innerFillColorStatus = GridPropertyStatus<UIColor>(normal: nil, connect: tintColor, error: .red)
gridView.innerRoundConfig = RoundConfig(radius: 10, lineWidthStatus: nil, lineColorStatus: nil, fillColorStatus: innerFillColorStatus)
return gridView
}配置ConnectLine
let lineView = ConnectLineView()
lineView.lineColorStatus = .init(normal: tintColor, error: .red)
lineView.triangleColorStatus = .init(normal: tintColor, error: .red)
lineView.isTriangleHidden = false
lineView.lineWidth = 3
config.connectLine = lineView初始化PatternLockView
lockView = PatternLockView(config: config)
lockView.delegate = self
view.addSubview(lockView)结构

完全遵从面对协议开发。
PatternLockView依赖于配置协议PatternLockViewConfig。
配置协议配置网格协议PatternLockGrid和连接线协议ConnectLine。
转自:https://www.jianshu.com/p/f8aa805057fc
收起阅读 »这是一个围绕SQLite的Objective-C封装
FMDB
安装
如果尚未执行此操作,则可能需要初始化项目,以使其Podfile为您生成模板:
$ pod init然后,编辑Podfile,并添加FMDB:
# Uncomment the next line to define a global platform for your project
# platform :ios, '9.0'
target 'MyApp' do
# Comment the next line if you're not using Swift and don't want to use dynamic frameworks
use_frameworks!
# Pods for MyApp2
pod 'FMDB'
# pod 'FMDB/FTS' # FMDB with FTS
# pod 'FMDB/standalone' # FMDB with latest SQLite amalgamation source
# pod 'FMDB/standalone/FTS' # FMDB with latest SQLite amalgamation source and FTS
# pod 'FMDB/SQLCipher' # FMDB with SQLCipher
end
$ pod install然后打开.xcworkspace而不是.xcodeproj。
Carthage 安装
$ echo ' github "ccgus/fmdb" ' > ./Cartfile
$ carthage update您可以在Cocoa项目中使用任何一种样式。FMDB会在编译时确定您正在使用哪个,并做正确的事。
自定义功能
过去,编写自定义函数时,通常必须包含自己的@autoreleasepool块,以避免在编写通过大表扫描的函数时出现问题。现在,FMDB将自动将其包装在自动释放池中,因此您不必这样做。
另外,过去,在检索传递给函数的值时,您必须下拉至SQLite C API并包含您自己的sqlite3_value_XXX调用。现在有FMDatabase方法valueInt,valueString等等,这样你就可以留内斯威夫特和/或Objective-C中,而无需自行调用C函数。同样,指定的返回值时,你不再需要调用sqlite3_result_XXXC API,而是你可以使用FMDatabase方法resultInt,resultString等有一个新enum的valueType叫SqliteValueType,可用于检查传递给自定义函数参数的类型。
queue.inTransaction { db, rollback in
do {
guard let db == db else {
// handle error here
return
}
try db.executeUpdate("INSERT INTO foo (bar) VALUES (?)", values: [1])
try db.executeUpdate("INSERT INTO foo (bar) VALUES (?)", values: [2])
} catch {
rollback?.pointee = true
}
}然后,您可以在SQL中使用该函数(在这种情况下,匹配“ Jose”和“José”):
SELECT * FROM employees WHERE RemoveDiacritics(first_name) LIKE 'jose'
API变更
除了makeFunctionNamed上面提到的以外,还有一些其他的API更改。具体来说,
为了与API的其余部分保持一致,方法
objectForColumnName和UTF8StringForColumnName已重命名为objectForColumn和UTF8StringForColumn。注意,如果将无效的列名/索引传递给它,则
objectForColumn(和相关的下标运算符)现在返回nil。它曾经返回NSNull。为了避免与混乱
FMDatabaseQueue的方法inTransaction,其中执行交易,该FMDatabase方法以确定是否是在交易与否,inTransaction已被替换为只读属性,isInTransaction。几种功能都被转换为性能,即,
databasePath,maxBusyRetryTimeInterval,shouldCacheStatements,sqliteHandle,hasOpenResultSets,lastInsertRowId,changes,goodConnection,columnCount,resultDictionary,applicationID,applicationIDString,userVersion,countOfCheckedInDatabases,countOfCheckedOutDatabases,和countOfOpenDatabases。对于Objective-C用户而言,这几乎没有实质性影响,但是对于Swift用户而言,它带来了更为自然的界面。注意:对于Objective-C开发人员,以前版本的FMDB公开了许多ivars(但是我们希望您无论如何都不要直接使用它们!),但是这些实现的详细信息不再公开。
URL方法
为了适应Apple从路径到URL的转变,现在存在NSURL各种init方法的再现形式,以前只接受路径。
用法
FMDB中有三个主要类:
FMDatabase-表示单个SQLite数据库。用于执行SQL语句。FMResultSet-表示在上执行查询的结果FMDatabase。FMDatabaseQueue-如果要在多个线程上执行查询和更新,则需要使用此类。在下面的“线程安全”部分中对此进行了描述。
数据库创建
使用FMDatabase指向SQLite数据库文件的路径创建。此路径可以是以下三个路径之一:
- 文件系统路径。该文件不必在磁盘上存在。如果它不存在,则会为您创建。
- 空字符串(
@"")。在临时位置创建一个空数据库。FMDatabase关闭连接后,将删除该数据库。 NULL。创建一个内存数据库。FMDatabase关闭连接后,该数据库将被销毁。
(有关临时和内存数据库的更多信息,请阅读有关此主题的sqlite文档:https : //www.sqlite.org/inmemorydb.html)
NSString * path = [ NSTemporaryDirectory()stringByAppendingPathComponent:@“ tmp.db ” ];
FMDatabase * db = [FMDatabase databaseWithPath: path];与数据库进行交互之前,必须先将其打开。如果没有足够的资源或权限打开和/或创建数据库,则打开失败。
if(![db open ]){
db = nil;
}执行更新
任何不是该SELECT语句的SQL语句都可以视为更新。这包括CREATE,UPDATE,INSERT,ALTER,COMMIT,BEGIN,DETACH,DELETE,DROP,END,EXPLAIN,VACUUM,和REPLACE语句(以及许多其他)。基本上,如果您的SQL语句不是以开头SELECT,则它是一条更新语句。
执行更新将返回单个值a BOOL。返回值YES表示更新已成功执行,返回值NO表示遇到某些错误。您可以调用-lastErrorMessage和-lastErrorCode方法来检索更多信息。
执行查询
一个SELECT语句是一个查询和通过的一个执行-executeQuery...方法。
FMResultSet如果成功,则执行查询将返回一个对象,如果nil失败,则返回一个对象。您应该使用-lastErrorMessage和-lastErrorCode方法来确定查询失败的原因。
为了遍历查询结果,可以使用while()循环。您还需要从一条记录“步入”到另一条记录。使用FMDB,最简单的方法是这样的:
FMResultSet *s = [db executeQuery:@"SELECT * FROM myTable"];
while ([s next]) {
//retrieve values for each record
}
-[FMResultSet next]在尝试访问查询中返回的值之前,必须始终调用它,即使您只希望得到一个值:
FMResultSet *s = [db executeQuery:@"SELECT COUNT(*) FROM myTable"];
if ([s next]) {
int totalCount = [s intForColumnIndex:0];
}
[s close]; // Call the -close method on the FMResultSet if you cannot confirm whether the result set is exhausted.
FMResultSet 有许多方法可以检索适当格式的数据:
intForColumn:longForColumn:longLongIntForColumn:boolForColumn:doubleForColumn:stringForColumn:dateForColumn:dataForColumn:dataNoCopyForColumn:UTF8StringForColumn:objectForColumn:
这些方法中的每一个都还具有一个{type}ForColumnIndex:变体,用于根据结果中列的位置而不是列名来检索数据。
通常情况下,有没有必要-close的FMResultSet自己,因为当任一结果集耗尽出现这种情况。但是,如果仅提取单个请求或其他没有耗尽结果集的请求,则需要在上调用-close方法FMResultSet。
在数据库上执行完查询和更新后,应-close建立FMDatabase连接,以便SQLite放弃其在操作过程中获取的任何资源。
iOS 方便操作 CoreData 的快捷方式
MagicalRecord
MagicalRecord的灵感来自Ruby on Rails的Active Record获取。该代码的目标是:
- 清理我的核心数据相关代码
- 允许清晰,简单的单行读取
- 当需要优化请求时,仍允许修改NSFetchRequest
项目状况
该项目的活动已停止,已由Core Data本身取代。我们提供的最新版本是:
- MagicalRecord 2.4.0是一个稳定的版本,可从标签'2.4.0'或中获得
pod 'MagicalRecord', :git => 'https://github.com/magicalpanda/MagicalRecord'。 - 实验版本MagicalRecord 3.0.0,有两种版本,一种是branch
release/3.0,另一种是branchmaintenance/3.0。
使用CocoaPods
在您的项目中集成MagicalRecord的最简单方法之一是使用CocoaPods:
将以下行添加到您的
Podfile:一种。清楚的
荚 'MagicalRecord' , :GIT中 => 'https://github.com/magicalpanda/MagicalRecord'b。使用CocoaLumberjack作为记录器
荚 'MagicalRecord / CocoaLumberjack' , :GIT中 => 'https://github.com/magicalpanda/MagicalRecord'在您的项目目录中,运行
pod update现在,您应该能够添加
#import到目标的任何源文件中,并开始使用MagicalRecord!
使用Xcode
作为Git子模块将MagicalRecord添加到您的项目中:
$ cd MyXcodeProjectFolder
$ git submodule add https://github.com/magicalpanda/MagicalRecord.git Vendor/MagicalRecord
$ git commit -m "Add MagicalRecord submodule"
拖动
Vendor/MagicalRecord/MagicalRecord.xcproj到您现有的Xcode项目导航到项目的设置,然后选择要将MagicalRecord添加到的目标
导航到“构建阶段”,然后展开“使用库链接二进制文件”部分
单击+,然后找到适合您目标平台的MagicalRecord框架版本
现在,您应该能够添加
#import到目标的任何源文件中,并开始使用MagicalRecord!
注意请注意,如果将Xcode的链接框架自动设置为“否”,则可能需要将CoreData.framework添加到iOS上的项目中,因为UIKit默认情况下不包括Core Data。在OS X上,Cocoa包含核心数据。
类别方法
//目标C
#进口 < MagicalRecord / MagicalRecord.h >
#进口 < MagicalRecord / MagicalRecord + ShorthandMethods.h >
#进口 < MagicalRecord / MagicalRecordShorthandMethodAliases.h >如果您使用的是Swift,则需要将这些导入添加到目标的Objective-C桥接标头中。
一旦包含了标题,就应该在设置/使用MagicalRecord之前调用+[MagicalRecord enableShorthandMethods]class方法:
// Objective-C-
( void)theMethodWhereYouSetupMagicalRecord
{
[MagicalRecord enableShorthandMethods ];
//按照常规设置MagicalRecord
}//斯威夫特
func theMethodWhereYouSetupMagicalRecord(){
MagicalRecord。enableShorthandMethods()
//照常设置MagicalRecord在vue项目中使用骨架屏
现在的应用开发,基本上都是前后端分离的,前端主流框架有SPA、MPA等,那么解决页面渲染、白屏时间成为首要关注的点
webpack可以按需加载,减小首屏需要加载代码的体积;
使用CDN技术、静态代码等缓存技术,可以减小加载渲染的时长
问题:但是首页依然存在加载、渲染等待时长的问题。那么如何从视觉效果上减小首屏白屏的时间呢?
骨架屏:举个例子:其实就是在模版文件中id=app容器下面写想要展示的效果,在new Vue(option)之后,该id下的内容就被替换了( 这时候,可能Vue编译生成的内容还没有挂载。因为new Vue的时候会进行一系列的初始化,这也需要耗费时间的)。这样就可以从视觉上减小白屏的时间
骨架屏的实现方式
1、直接在模版文件id=app容器下面,写进想要展示的效果html
2、直接在模板文件id=app容器下面,用图片展示
3、使用vue ssr提供的webpack插件
4、自动生成并且自动插入静态骨架屏
方式1和方式2存在的缺陷:针对不同入口,展示的效果都一样,导致不能灵活的针对不同的入口,展示不同的样式
方式3可以针对不同的入口展示不同的效果。(实质也是先通过ssr生成一个json文件,然后将json文件内容注入到模板文件的id=app容器下)
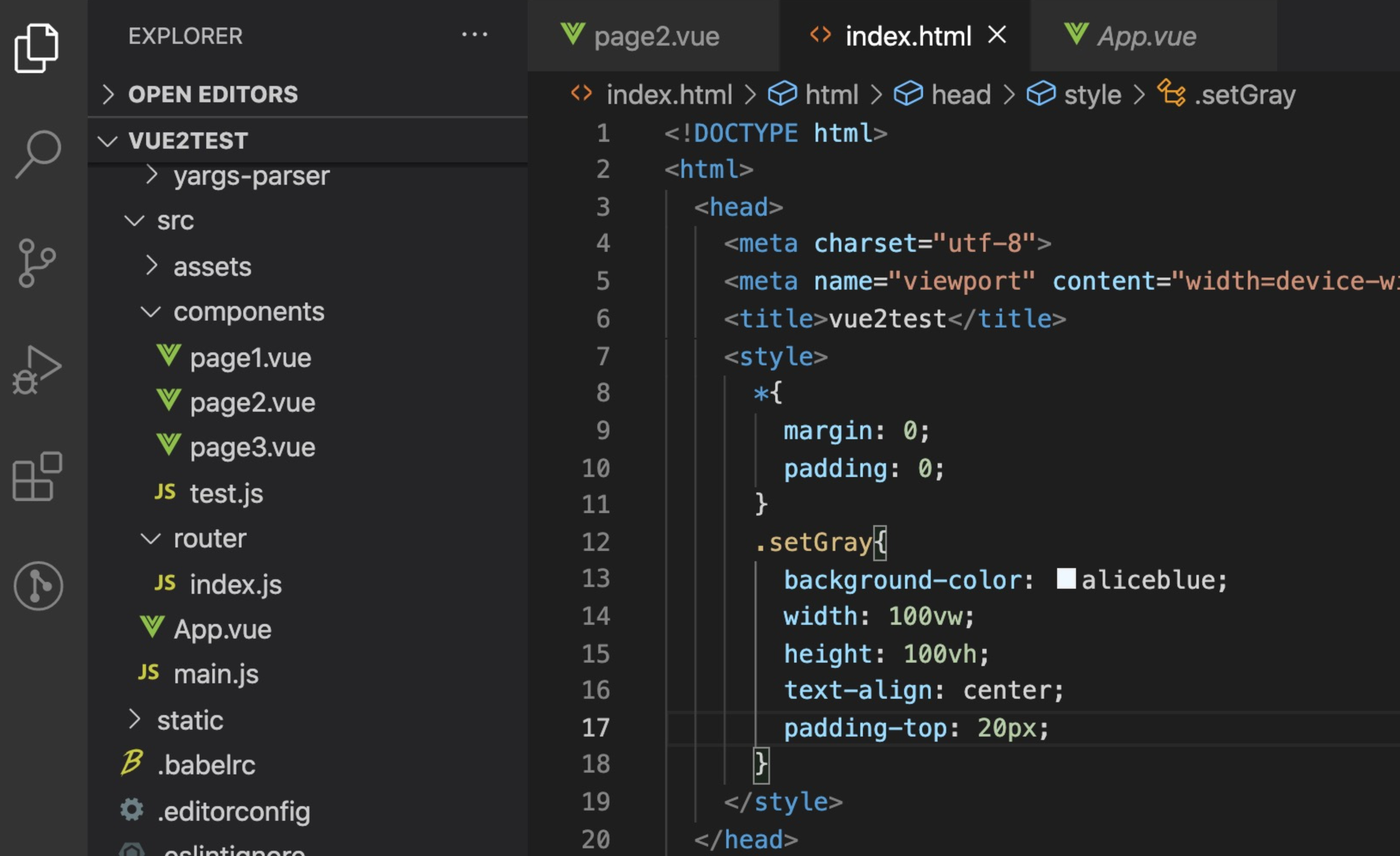

在方案一的基础上,将骨架屏的代码抽离出来,不在模版文件里面书写代码,而是在vue文件里面书写效果代码,这样便于维护
1、在根目录下建一个skeleton文件夹,在该目录下创建文件App.vue文件(根组件,类似Vue项目的App.vue)、home.skeleton.vue(首页骨架屏展示效果的代码,类似Vue项目写的路由页面)、skeleton-entry.js(入口文件类似Vue项目的入口文件)、plugin/server-plugin.js(vue-server-renderer包提供了server-plugin插件,从里面将代码拷贝出来)
home.skeleton.vue(首页骨架屏展示效果的代码)
<template>
<div class="skeleton-home">
<div>加载中...</div>
</div>
</template>
<style>
.skeleton-home {
width: 100vw;
height: 100vh;
background-color: #eaeaea;
}
</style>App.vue(根组件)
<template>
<div id="app">
<!-- 根组件 -->
<home style="display:none" id="homeSkeleton"></home>
</div>
</template>
<script>
import home from './home.skeleton.vue'
export default{
components: {
home
}
}
</script>
<style>
#app {
font-family: 'Avenir', Helvetica, Arial, sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
text-align: center;
color: #2c3e50;
}
*{
padding: 0;
margin: 0;
}
</style>skeleton-entry.js(入口文件)
// 入口文件
import Vue from 'vue'
import App from './App.vue'
let skeleton = new Vue({
render(h) {
return h(App)
}
})
export default skeletonplugin/server-plugin.js(vue-server-renderer包提供了server-plugin插件)
'use strict';
/* */
var isJS = function (file) { return /\.js(\?[^.]+)?$/.test(file); };
var ref = require('chalk');
var red = ref.red;
var yellow = ref.yellow;
var prefix = "[vue-server-renderer-webpack-plugin]";
var warn = exports.warn = function (msg) { return console.error(red((prefix + " " + msg + "\n"))); };
var tip = exports.tip = function (msg) { return console.log(yellow((prefix + " " + msg + "\n"))); };
var validate = function (compiler) {
if (compiler.options.target !== 'node') {
warn('webpack config `target` should be "node".');
}
if (compiler.options.output && compiler.options.output.libraryTarget !== 'commonjs2') {
warn('webpack config `output.libraryTarget` should be "commonjs2".');
}
if (!compiler.options.externals) {
tip(
'It is recommended to externalize dependencies in the server build for ' +
'better build performance.'
);
}
};
var VueSSRServerPlugin = function VueSSRServerPlugin (options) {
if ( options === void 0 ) options = {};
this.options = Object.assign({
filename: 'vue-ssr-server-bundle.json'
}, options);
};
VueSSRServerPlugin.prototype.apply = function apply (compiler) {
var this$1 = this;
validate(compiler);
compiler.plugin('emit', function (compilation, cb) {
var stats = compilation.getStats().toJson();
var entryName = Object.keys(stats.entrypoints)[0];
var entryAssets = stats.entrypoints[entryName].assets.filter(isJS);
if (entryAssets.length > 1) {
throw new Error(
"Server-side bundle should have one single entry file. " +
"Avoid using CommonsChunkPlugin in the server config."
)
}
var entry = entryAssets[0];
if (!entry || typeof entry !== 'string') {
throw new Error(
("Entry \"" + entryName + "\" not found. Did you specify the correct entry option?")
)
}
var bundle = {
entry: entry,
files: {},
maps: {}
};
stats.assets.forEach(function (asset) {
if (asset.name.match(/\.js$/)) {
bundle.files[asset.name] = compilation.assets[asset.name].source();
} else if (asset.name.match(/\.js\.map$/)) {
bundle.maps[asset.name.replace(/\.map$/, '')] = JSON.parse(compilation.assets[asset.name].source());
}
// do not emit anything else for server
delete compilation.assets[asset.name];
});
var json = JSON.stringify(bundle, null, 2);
var filename = this$1.options.filename;
compilation.assets[filename] = {
source: function () { return json; },
size: function () { return json.length; }
};
cb();
});
};
module.exports = VueSSRServerPlugin;'use strict'
const path = require('path')
const nodeExternals = require('webpack-node-externals')
const VueSSRServerPlugin = require('../skeleton/plugin/server-plugin')
module.exports = {
// 这允许 webpack 以 Node 适用方式(Node-appropriate fashion)处理动态导入(dynamic import),
// 并且还会在编译 Vue 组件时,
// 告知 `vue-loader` 输送面向服务器代码(server-oriented code)。
target: 'node',
// 对 bundle renderer 提供 source map 支持
devtool: 'source-map',
// 将 entry 指向应用程序的 server entry 文件
entry: path.resolve(__dirname, '../skeleton/skeleton-entry.js'),
output: {
path: path.resolve(__dirname, '../skeleton'), // 生成的文件的目录
publicPath: '/skeleton/',
filename: '[name].js',
libraryTarget: 'commonjs2' // 此处告知 server bundle 使用 Node 风格导出模块(Node-style exports)
},
module: {
rules: [
{
test: /\.vue$/,
loader: 'vue-loader',
options: {
compilerOptions: {
preserveWhitespace: false
}
}
},
{
test: /\.css$/,
use: ['vue-style-loader', 'css-loader']
}
]
},
performance: {
hints: false
},
// https://webpack.js.org/configuration/externals/#function
// https://github.com/liady/webpack-node-externals
// 外置化应用程序依赖模块。可以使服务器构建速度更快,
// 并生成较小的 bundle 文件。
externals: nodeExternals({
// 不要外置化 webpack 需要处理的依赖模块。
// 你可以在这里添加更多的文件类型。例如,未处理 *.vue 原始文件,
// 你还应该将修改 `global`(例如 polyfill)的依赖模块列入白名单
allowlist: /\.css$/
}),
// 这是将服务器的整个输出
// 构建为单个 JSON 文件的插件。
// 不配置filename,则默认文件名为 `vue-ssr-server-bundle.json`
plugins: [
new VueSSRServerPlugin({
filename: 'skeleton.json'
})
]
}"scripts": {
"create-skeleton": "webpack --progress --config build/webpack.skeleton.conf.js",
"fill-skeleton": "node ./skeleton/skeleton.js"
}npm run create-skeleton
// 将生成的skeleton.json的内容填充到模板文件中
const fs = require('fs')
const { resolve } = require('path')
const createBundleRenderer = require('vue-server-renderer').createBundleRenderer
// 读取skeleton.json,以skeleton/index.html为模版写入内容
const renderer = createBundleRenderer(resolve(__dirname, '../skeleton/skeleton.json'), {
template: fs.readFileSync(resolve(__dirname, '../skeleton/index.html'), 'utf-8')
})
// 把上一步模版完成的内容写入根目录下的模版文件'index.html'
renderer.renderToString({}, (err, html) => {
if (err) {
return console.log(err)
}
console.log('render complete!')
fs.writeFileSync('index.html', html, 'utf-8')
})"fill-skeleton": "node ./skeleton/skeleton.js"iOS超方便的多样式提示框
MBProgressHUD
MBProgressHUD是一个iOS嵌入式类,在后台线程中完成工作时显示带有指示符和/或标签的半透明HUD。HUD旨在代替未记录的,UIKit UIProgressHUD具有某些附加功能的专用显示器。要求
MBProgressHUD适用于iOS 9.0+。它取决于以下Apple框架,大多数Xcode模板应已包含以下框架:
- Foundation.framework
- UIKit.framework
- CoreGraphics.framework
您将需要最新的开发人员工具才能进行构建MBProgressHUD。较旧的Xcode版本可能会起作用,但不会明确维护兼容性。
将MBProgressHUD添加到您的项目
CocoaPods
pod 'MBProgressHUD', '~> 1.2.0'- 通过运行安装pod
pod install。 - 随需包含MBProgressHUD
#import "MBProgressHUD.h"。
Carthage
- MBProgressHUD添加到您的Cartfile。例如,
github "jdg/MBProgressHUD" ~> 1.2.0 - run
carthage update - 将MBProgressHUD添加到您的项目中。
SwiftPM / Accio
.package(url: "https://github.com/jdg/MBProgressHUD.git", .upToNextMajor(from: "1.2.0")),
.target(name: "App", dependencies: ["MBProgressHUD"]),
然后在Xcode 11+(SwiftPM)中打开您的项目或运行accio update(Accio)。
源文件
或者,您可以直接将MBProgressHUD.h和MBProgressHUD.m源文件添加到您的项目中。
- 下载最新的代码版本,或将存储库作为git子模块添加到git跟踪的项目中。
- 打开Xcode中的项目,然后拖放
MBProgressHUD.h和MBProgressHUD.m到您的项目(使用“产品导航视图”)。当询问是否从项目外部提取代码存档时,请确保选择复制项目。 - 随需包含MBProgressHUD
#import "MBProgressHUD.h"。
在运行长时间运行的任务时处理MBProgressHUD时需要遵循的主要原则是使主线程保持无工作状态,因此可以及时更新UI。因此,建议使用MBProgressHUD的方法是在主线程上进行设置,然后将要执行的任务旋转到新线程上。
[MBProgressHUD showHUDAddedTo:self.view animated:YES];
dispatch_async(dispatch_get_global_queue( DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
// Do something...
dispatch_async(dispatch_get_main_queue(), ^{
[MBProgressHUD hideHUDForView:self.view animated:YES];
});
});MBProgressHUD *hud = [MBProgressHUD showHUDAddedTo:self.view animated:YES];
hud.mode = MBProgressHUDModeAnnularDeterminate;
hud.label.text = @"Loading";
[self doSomethingInBackgroundWithProgressCallback:^(float progress) {
hud.progress = progress;
} completionCallback:^{
[hud hideAnimated:YES];
}];MBProgressHUD *hud = [MBProgressHUD showHUDAddedTo:self.view animated:YES];
hud.mode = MBProgressHUDModeAnnularDeterminate;
hud.label.text = @"Loading";
NSProgress *progress = [self doSomethingInBackgroundCompletion:^{
[hud hideAnimated:YES];
}];
hud.progressObject = progress;[MBProgressHUD showHUDAddedTo:self.view animated:YES];
dispatch_time_t popTime = dispatch_time(DISPATCH_TIME_NOW, 0.01 * NSEC_PER_SEC);
dispatch_after(popTime, dispatch_get_main_queue(), ^(void){
// Do something...
[MBProgressHUD hideHUDForView:self.view animated:YES];
});520和女朋友搞点不一样的礼物, html+css+js做一个网页版坦克大战游戏
坦克游戏玩法及介绍

打开这个首页很简单,基本是上面这个样子,然后选择两个人回车就可以进行玩耍了,这个游戏需要两个人一起操作,玩家1(我): 使用WASD四个键进行上左下右方向的控制,通过space键进行设计射击。玩家2(女朋友):通过方向键上下左右控制方向,通过enter键盘射击。基本上我控制整个电脑键盘的左边,她控制电脑键盘的右边。通过N键进行下一关,P键选择上一关。再键盘上显示如下。



项目结构

<!DOCTYPE html>
<html lang="zh" class="no-js demo-1">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="js/jquery.min.js"></script>
<script src="js/Helper.js"></script>
<script src="js/keyboard.js"></script>
<script src="js/const.js"></script>
<script src="js/level.js"></script>
<script src="js/crackAnimation.js"></script>
<script src="js/prop.js"></script>
<script src="js/bullet.js"></script>
<script src="js/tank.js"></script>
<script src="js/num.js"></script>
<script src="js/menu.js"></script>
<script src="js/map.js"></script>
<script src="js/Collision.js"></script>
<script src="js/stage.js"></script>
<script src="js/main.js"></script>
<link rel="stylesheet" type="text/css" href="css/default.css" />
<style type="text/css">
#canvasDiv canvas{
position:absolute;
}
</style>
</head>
<body>
<div class="container">
<head><h3>操作说明:玩家1:WASD上左下右,space射击;玩家2:方向键,enter射击。n下一关,p上一关。</h3></head>
<div class="main clearfix">
<div id="canvasDiv" >
<canvas id="wallCanvas" ></canvas>
<canvas id="tankCanvas" ></canvas>
<canvas id="grassCanvas" ></canvas>
<canvas id="overCanvas" ></canvas>
<canvas id="stageCanvas" ></canvas>
</div>
</div>
</div><!-- /container -->
<div style="text-align:center;">
<p>来源:<a href="https://sunmenglei.blog.csdn.net/" target="_blank">孙叫兽的博客</a></p>
</div>
</body>
</html>css
*, *:after, *:before { -webkit-box-sizing: border-box; -moz-box-sizing: border-box; box-sizing: border-box; }
body, html { font-size: 100%; padding: 0; margin: 0; height: 100%;}
/* Clearfix hack by Nicolas Gallagher: http://nicolasgallagher.com/micro-clearfix-hack/ */
.clearfix:before, .clearfix:after { content: " "; display: table; }
.clearfix:after { clear: both; }
body {
font-family: "Helvetica Neue",Helvetica,Arial,'Microsoft YaHei',sans-serif,'Lato', Calibri;
color: #777;
background: #f6f6f6;
}
a {
color: #555;
text-decoration: none;
outline: none;
}
a:hover,
a:active {
color: #777;
}
a img {
border: none;
}
/* Header Style */
.main,
.container > header {
margin: 0 auto;
/*padding: 2em;*/
}
.container {
height: 100%;
}
.container > header {
padding-top: 20px;
padding-bottom: 20px;
text-align: center;
background: rgba(0,0,0,0.01);
}
.container > header h1 {
font-size: 2.625em;
line-height: 1.3;
margin: 0;
font-weight: 300;
}
.container > header span {
display: block;
font-size: 60%;
opacity: 0.3;
padding: 0 0 0.6em 0.1em;
}
/* Main Content */
.main {
/*max-width: 69em;*/
width: 100%;
height: 100%;
overflow: hidden;
}
.demo-scroll{
overflow-y: scroll;
width: 100%;
height: 100%;
}
.column {
float: left;
width: 50%;
padding: 0 2em;
min-height: 300px;
position: relative;
}
.column:nth-child(2) {
box-shadow: -1px 0 0 rgba(0,0,0,0.1);
}
.column p {
font-weight: 300;
font-size: 2em;
padding: 0;
margin: 0;
text-align: right;
line-height: 1.5;
}
/* To Navigation Style */
.htmleaf-top {
background: #fff;
background: rgba(255, 255, 255, 0.6);
text-transform: uppercase;
width: 100%;
font-size: 0.69em;
line-height: 2.2;
}
.htmleaf-top a {
padding: 0 1em;
letter-spacing: 0.1em;
color: #888;
display: inline-block;
}
.htmleaf-top a:hover {
background: rgba(255,255,255,0.95);
color: #333;
}
.htmleaf-top span.right {
float: right;
}
.htmleaf-top span.right a {
float: left;
display: block;
}
.htmleaf-icon:before {
font-family: 'codropsicons';
margin: 0 4px;
speak: none;
font-style: normal;
font-weight: normal;
font-variant: normal;
text-transform: none;
line-height: 1;
-webkit-font-smoothing: antialiased;
}
/* Demo Buttons Style */
.htmleaf-demos {
padding-top: 1em;
font-size: 0.9em;
}
.htmleaf-demos a {
display: inline-block;
margin: 0.2em;
padding: 0.45em 1em;
background: #999;
color: #fff;
font-weight: 700;
border-radius: 2px;
}
.htmleaf-demos a:hover,
.htmleaf-demos a.current-demo,
.htmleaf-demos a.current-demo:hover {
opacity: 0.6;
}
.htmleaf-nav {
text-align: center;
}
.htmleaf-nav a {
display: inline-block;
margin: 20px auto;
padding: 0.3em;
}
.bb-custom-wrapper {
width: 420px;
position: relative;
margin: 0 auto 40px;
text-align: center;
}
/* Demo Styles */
.demo-1 body {
color: #87968e;
background: #fff2e3;
}
.demo-1 a {
color: #72b890;
}
.demo-1 .htmleaf-demos a {
background: #72b890;
color: #fff;
}
.demo-2 body {
color: #fff;
background: #c05d8e;
}
.demo-2 a {
color: #d38daf;
}
.demo-2 a:hover,
.demo-2 a:active {
color: #fff;
}
.demo-2 .htmleaf-demos a {
background: #883b61;
color: #fff;
}
.demo-2 .htmleaf-top a:hover {
background: rgba(255,255,255,0.3);
color: #333;
}
.demo-3 body {
color: #87968e;
background: #fff2e3;
}
.demo-3 a {
color: #ea5381;
}
.demo-3 .htmleaf-demos a {
background: #ea5381;
color: #fff;
}
.demo-4 body {
color: #999;
background: #fff2e3;
overflow: hidden;
}
.demo-4 a {
color: #1baede;
}
.demo-4 a:hover,
.demo-4 a:active {
opacity: 0.6;
}
.demo-4 .htmleaf-demos a {
background: #1baede;
color: #fff;
}
.demo-5 body {
background: #fffbd6;
}
/****/
.related {
/*margin-top: 5em;*/
color: #fff;
background: #333;
text-align: center;
font-size: 1.25em;
padding: 3em 0;
overflow: hidden;
}
.related a {
display: inline-block;
text-align: left;
margin: 20px auto;
padding: 10px 20px;
opacity: 0.8;
-webkit-transition: opacity 0.3s;
transition: opacity 0.3s;
-webkit-backface-visibility: hidden;
}
.related a:hover,
.related a:active {
opacity: 1;
}
.related a img {
max-width: 100%;
}
.related a h3 {
font-weight: 300;
margin-top: 0.15em;
color: #fff;
}
@media screen and (max-width: 40em) {
.htmleaf-icon span {
display: none;
}
.htmleaf-icon:before {
font-size: 160%;
line-height: 2;
}
}
@media screen and (max-width: 46.0625em) {
.column {
width: 100%;
min-width: auto;
min-height: auto;
padding: 1em;
}
.column p {
text-align: left;
font-size: 1.5em;
}
.column:nth-child(2) {
box-shadow: 0 -1px 0 rgba(0,0,0,0.1);
}
}
@media screen and (max-width: 25em) {
.htmleaf-icon span {
display: none;
}
}核心js
/**
* 检测2个物体是否碰撞
* @param object1 物体1
* @param object2 物体2
* @param overlap 允许重叠的大小
* @returns {Boolean} 如果碰撞了,返回true
*/
function CheckIntersect(object1, object2, overlap)
{
// x-轴 x-轴
// A1------>B1 C1 A2------>B2 C2
// +--------+ ^ +--------+ ^
// | object1| | y-轴 | object2| | y-轴
// | | | | | |
// +--------+ D1 +--------+ D2
//
//overlap是重叠的区域值
A1 = object1.x + overlap;
B1 = object1.x + object1.size - overlap;
C1 = object1.y + overlap;
D1 = object1.y + object1.size - overlap;
A2 = object2.x + overlap;
B2 = object2.x + object2.size - overlap;
C2 = object2.y + overlap;
D2 = object2.y + object2.size - overlap;
//假如他们在x-轴重叠
if(A1 >= A2 && A1 <= B2
|| B1 >= A2 && B1 <= B2)
{
//判断y-轴重叠
if(C1 >= C2 && C1 <= D2 || D1 >= C2 && D1 <= D2)
{
return true;
}
}
return false;
}
/**
* 坦克与地图块碰撞
* @param tank 坦克对象
* @param mapobj 地图对象
* @returns {Boolean} 如果碰撞,返回true
*/
function tankMapCollision(tank,mapobj){
//移动检测,记录最后一次的移动方向,根据方向判断+-overlap,
var tileNum = 0;//需要检测的tile数
var rowIndex = 0;//map中的行索引
var colIndex = 0;//map中的列索引
var overlap = 3;//允许重叠的大小
//根据tank的x、y计算出map中的row和col
if(tank.dir == UP){
rowIndex = parseInt((tank.tempY + overlap - mapobj.offsetY)/mapobj.tileSize);
colIndex = parseInt((tank.tempX + overlap- mapobj.offsetX)/mapobj.tileSize);
}else if(tank.dir == DOWN){
//向下,即dir==1的时候,行索引的计算需要+tank.Height
rowIndex = parseInt((tank.tempY - overlap - mapobj.offsetY + tank.size)/mapobj.tileSize);
colIndex = parseInt((tank.tempX + overlap- mapobj.offsetX)/mapobj.tileSize);
}else if(tank.dir == LEFT){
rowIndex = parseInt((tank.tempY + overlap- mapobj.offsetY)/mapobj.tileSize);
colIndex = parseInt((tank.tempX + overlap - mapobj.offsetX)/mapobj.tileSize);
}else if(tank.dir == RIGHT){
rowIndex = parseInt((tank.tempY + overlap- mapobj.offsetY)/mapobj.tileSize);
//向右,即dir==3的时候,列索引的计算需要+tank.Height
colIndex = parseInt((tank.tempX - overlap - mapobj.offsetX + tank.size)/mapobj.tileSize);
}
if(rowIndex >= mapobj.HTileCount || rowIndex < 0 || colIndex >= mapobj.wTileCount || colIndex < 0){
return true;
}
if(tank.dir == UP || tank.dir == DOWN){
var tempWidth = parseInt(tank.tempX - map.offsetX - (colIndex)*mapobj.tileSize + tank.size - overlap);//去除重叠部分
if(tempWidth % mapobj.tileSize == 0 ){
tileNum = parseInt(tempWidth/mapobj.tileSize);
}else{
tileNum = parseInt(tempWidth/mapobj.tileSize) + 1;
}
for(var i=0;i<tileNum && colIndex+i < mapobj.wTileCount ;i++){
var mapContent = mapobj.mapLevel[rowIndex][colIndex+i];
if(mapContent == WALL || mapContent == GRID || mapContent == WATER || mapContent == HOME || mapContent == ANOTHREHOME){
if(tank.dir == UP){
tank.y = mapobj.offsetY + rowIndex * mapobj.tileSize + mapobj.tileSize - overlap;
}else if(tank.dir == DOWN){
tank.y = mapobj.offsetY + rowIndex * mapobj.tileSize - tank.size + overlap;
}
return true;
}
}
}else{
var tempHeight = parseInt(tank.tempY - map.offsetY - (rowIndex)*mapobj.tileSize + tank.size - overlap);//去除重叠部分
if(tempHeight % mapobj.tileSize == 0 ){
tileNum = parseInt(tempHeight/mapobj.tileSize);
}else{
tileNum = parseInt(tempHeight/mapobj.tileSize) + 1;
}
for(var i=0;i<tileNum && rowIndex+i < mapobj.HTileCount;i++){
var mapContent = mapobj.mapLevel[rowIndex+i][colIndex];
if(mapContent == WALL || mapContent == GRID || mapContent == WATER || mapContent == HOME || mapContent == ANOTHREHOME){
if(tank.dir == LEFT){
tank.x = mapobj.offsetX + colIndex * mapobj.tileSize + mapobj.tileSize - overlap;
}else if(tank.dir == RIGHT){
tank.x = mapobj.offsetX + colIndex * mapobj.tileSize - tank.size + overlap;
}
return true;
}
}
}
return false;
}
/**
* 子弹与地图块的碰撞
* @param bullet 子弹对象
* @param mapobj 地图对象
*/
function bulletMapCollision(bullet,mapobj){
var tileNum = 0;//需要检测的tile数
var rowIndex = 0;//map中的行索引
var colIndex = 0;//map中的列索引
var mapChangeIndex = [];//map中需要更新的索引数组
var result = false;//是否碰撞
//根据bullet的x、y计算出map中的row和col
if(bullet.dir == UP){
rowIndex = parseInt((bullet.y - mapobj.offsetY)/mapobj.tileSize);
colIndex = parseInt((bullet.x - mapobj.offsetX)/mapobj.tileSize);
}else if(bullet.dir == DOWN){
//向下,即dir==1的时候,行索引的计算需要+bullet.Height
rowIndex = parseInt((bullet.y - mapobj.offsetY + bullet.size)/mapobj.tileSize);
colIndex = parseInt((bullet.x - mapobj.offsetX)/mapobj.tileSize);
}else if(bullet.dir == LEFT){
rowIndex = parseInt((bullet.y - mapobj.offsetY)/mapobj.tileSize);
colIndex = parseInt((bullet.x - mapobj.offsetX)/mapobj.tileSize);
}else if(bullet.dir == RIGHT){
rowIndex = parseInt((bullet.y - mapobj.offsetY)/mapobj.tileSize);
//向右,即dir==3的时候,列索引的计算需要+bullet.Height
colIndex = parseInt((bullet.x - mapobj.offsetX + bullet.size)/mapobj.tileSize);
}
if(rowIndex >= mapobj.HTileCount || rowIndex < 0 || colIndex >= mapobj.wTileCount || colIndex < 0){
return true;
}
if(bullet.dir == UP || bullet.dir == DOWN){
var tempWidth = parseInt(bullet.x - map.offsetX - (colIndex)*mapobj.tileSize + bullet.size);
if(tempWidth % mapobj.tileSize == 0 ){
tileNum = parseInt(tempWidth/mapobj.tileSize);
}else{
tileNum = parseInt(tempWidth/mapobj.tileSize) + 1;
}
for(var i=0;i<tileNum && colIndex+i < mapobj.wTileCount ;i++){
var mapContent = mapobj.mapLevel[rowIndex][colIndex+i];
if(mapContent == WALL || mapContent == GRID || mapContent == HOME || mapContent == ANOTHREHOME){
//bullet.distroy();
result = true;
if(mapContent == WALL){
//墙被打掉
mapChangeIndex.push([rowIndex,colIndex+i]);
}else if(mapContent == GRID){
}else{
isGameOver = true;
break;
}
}
}
}else{
var tempHeight = parseInt(bullet.y - map.offsetY - (rowIndex)*mapobj.tileSize + bullet.size);
if(tempHeight % mapobj.tileSize == 0 ){
tileNum = parseInt(tempHeight/mapobj.tileSize);
}else{
tileNum = parseInt(tempHeight/mapobj.tileSize) + 1;
}
for(var i=0;i<tileNum && rowIndex+i < mapobj.HTileCount;i++){
var mapContent = mapobj.mapLevel[rowIndex+i][colIndex];
if(mapContent == WALL || mapContent == GRID || mapContent == HOME || mapContent == ANOTHREHOME){
//bullet.distroy();
result = true;
if(mapContent == WALL){
//墙被打掉
mapChangeIndex.push([rowIndex+i,colIndex]);
}else if(mapContent == GRID){
}else{
isGameOver = true;
break;
}
}
}
}
//更新地图
map.updateMap(mapChangeIndex,0);
return result;
}原文地址:https://blog.csdn.net/weixin_41937552/article/details/116559485
知乎 iOS 客户端工程化工具 Venom
前言
知乎 iOS 客户端从一开始围绕问答社区到目前涵盖 Feed,会员,商业,文章,想法等多个业务线的综合内容生产与消费平台。项目的复杂程度已经在超级 App 的范畴。单周发布与业务并行开发也逐渐变成主流。同时在知乎 iOS 平台,技术选型一直也都比较开(sui)放(yi)。较早了引入了 Swift 进行业务开发,列表引入了需要 OC++ 的 ComponentKit 作为核心引擎。所以在这种多业务方团队,技术形态复杂,组件仓库数量多等场景下,也同样遇到了各种超级 App 团队都面临的一些问题。
问题如下:
如何统一开发环境
提高编译速度
提高打包速度
二进制组件调试
多组件联合调试
多组件联合打包
约束组件依赖关系等
当然在思考解决上面这些问题前,知乎 iOS 项目也同样经历过组件化的工作。与众多组件化拆分方案殊途同归,进行了业务划分,主仓库代码清空,业务线及 SDK 进行独立仓库管理。引入基于路由,基于协议声明的组件间通信等机制等,这里就不多赘述了。
简介
核心介绍的项目名称为 Venom,灵感来源于电影《毒液》。Venom 的用户端是一款为开发人员打造 Mac App,应用内置了工程构建需要的全套 Ruby Gem 和 Cocoapods 等其相关构建环境。核心目标是解决工程构建,二进制构建,组件管理,调试工具等一系列开发过程中的繁琐耗时任务。
所以当一台全新的 Mac 电脑希望运行工程时, 只需要 3 步:
1、安装 Venom For Mac 客户端。
2、使用 Venom 打开工程点击 Make 按钮。
3、构建完成点击 XCode 按钮打开工程。(当然默认己装 XCode )
从此告别 ruby,cocoapods 版本不对,gem 问题,bundle 问题以及权限问题等困扰。因为构建环境内置,使得构建环境与工程师本地环境隔离,极大的降低了工程 setup 的成本。
完整的 Venom 包含了 3 个部分:
1、Venom App
2、Venom 内核
3、Venom Server
下面会着重介绍客户端和内核相关的技术方案,数据服务目前仅为组件的附加信息提供 API 支持。
Venom 内核介绍
在引入 Venom 前,一直使用 Cocoapods 的 Podfile 进行组件的引用。但如果希望对 pod 命令的 DSL 进行扩展,发现是不够方便的。索性在 Cocoapods 上层建立自己的组件描述文件,每一个描述文件最终都会被转化为一次 podfile 的 pod 调用。

如上图,使用 Venom 方式集成的项目,由在 VenomFiles 目录内的组建描述文件组成。
组件描述文件
VenomFile.new do |v| v.name = 'XXModuleA' v.git = 'git@git.abc.abc.com:Team-iOS-Module/XXModule.git' v.tag = '1.0.0' v.binary = false v.use_module_map = true v.XX...end组件描述文件可以理解是 pod 命令的一个超集,在包含了 pod 的原有功能基础上,扩展其他功能(胶水代码创建,二进制化与源码切换等)。
组件调试
同时在与 VenomFile 同级别还设计了一个 Customization.yml 的文件。当开发过程中,需要对某个组件进行源码二进制的切换,或者源码路径的切换,版本引用的切换等,不会直接改动 VenomFile,会改动 Customization.yml 来进行。在构建过程中的优先,Customization.yml > Venomfile 。为了每个工程师的改动不会互相影响,Customization.yml 是非 git 托管的。而 VenomFiles 内的文件只有更新版本号或其他配置改动,才会更新。
构建过程
所有组件都通过一个个 Venomfile 文件方式管理在主工程仓库中,通过目录对组件进行层级划分管理。

原来的 Podfile 文件通过嵌入 Venom 进行构建职责的接管。
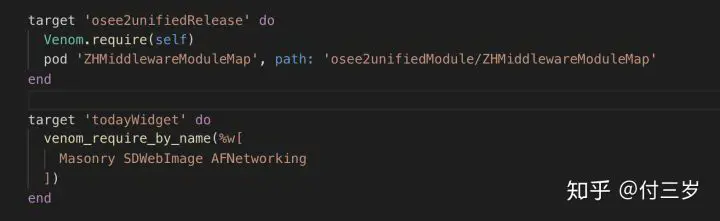
使用 Venom 后 pod install 的实际过程就如下图:
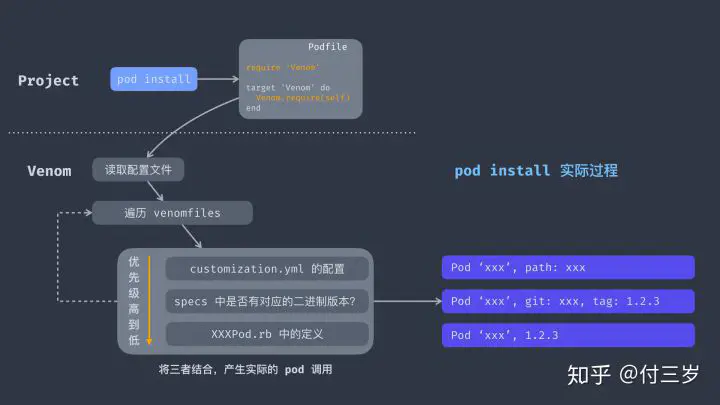
整体上来看, Venom 内核提供了一套扩展 pod 属性的描述文件,开发阶段通过 customization.yml 进行可配置的构建。构建过程中,依赖 Venomfile 文件的唯一标识进行二进制库和源码的关联。通过对 Cocoapods 构建过程的 hook 实现二进制与源码的引用切换。二进制化方案可参考 :
Xinyu Zhao:知乎 iOS 基于 CocoaPods 实现的二进制化方案
命令接口
Venom 内核除了主要的构建职责,还提供了一系列的 ipc 命令。通过这些 ipc 命令,上层的 Venom 客户端就可以更容易的操作每个组件,进行定制化的开发组织。来构建工程。
例如:
// 修改组件二进制使用方式,使用二进制venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --binary// 修改组件二进制使用方式,使用源码venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --source// 修改 yml 文件中指定组件的路径venom ipc customization \ --path /Users/abc/Developer/zhihu/abc/def \ --edit \ --name ZHModuleABC \ --pod_path /path/to/ZHModuleABC// reset 某个组件在 customization 中的 change,不指定 name 参数会给整个文件置成空venom ipc customization \ --path /xxx \ --reset \ --name ZHModuleABCVenom App 介绍
通过对 Venom 内核的简单介绍,其实可以认为,只通过命令行版的工具,就可以达到用到的大部分功能。但因为实际开发情况一般不会一个人一次只处理一个模块,所以希望以一种所见即所得方式来让业务工程师不用关心下层的逻辑,学习命令。可以快速建立起开发环境是我们的主要目标。
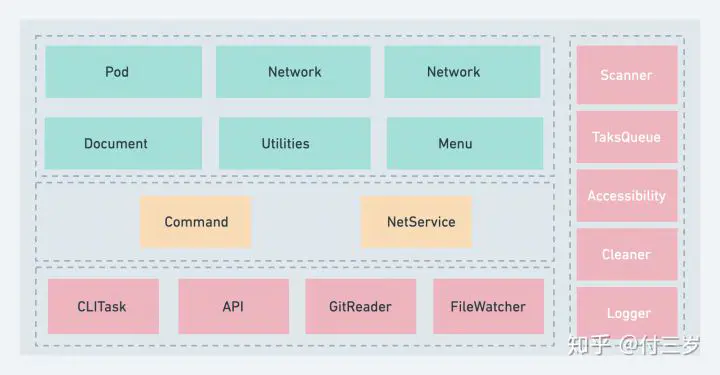
<center style="color: rgb(74, 74, 74); font-family: Avenir, Tahoma, Arial, "PingFang SC", "Lantinghei SC", "Microsoft Yahei", "Hiragino Sans GB", "Microsoft Sans Serif", "WenQuanYi Micro Hei", Helvetica, sans-serif; font-size: 16px; font-style: normal; font-variant-ligatures: normal; font-variant-caps: normal; font-weight: 400; letter-spacing: normal; orphans: 2; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px; -webkit-text-stroke-width: 0px; background-color: rgb(255, 255, 255); text-decoration-style: initial; text-decoration-color: initial;">客户端主要模块</center>
Venom App 内置了全套的 guby gem 环境来运行命令。通过 CLITask 来访问 Venom-core 以及 git 等其他命令(venom 内核一样内置在 Venom App 内)。
核心功能
开发组件关联
正常情况下 clone 下来的主工程(壳工程)内是没有代码的,只有空的工程文件和组件描述文件。Venom 工具划分了 2 个区域,普通组件和定制组件。
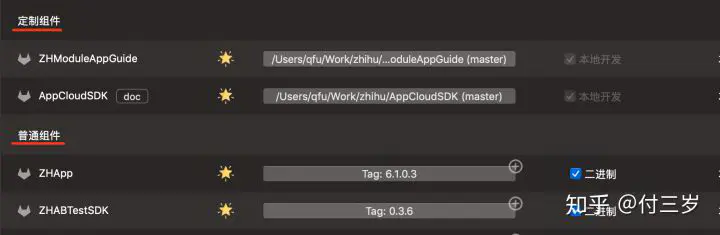
因为每个开发者维护的组件其实是有限的几个,一般都会将源码放在固定目录,所以通过设置客户端的自动扫描路径。在 Venom 界面上,如果在扫码路径下发现了相关组件,则可以一键关联本地目录组件,这样组件会切换到定制组件的模式进行开发。
特定版本关联
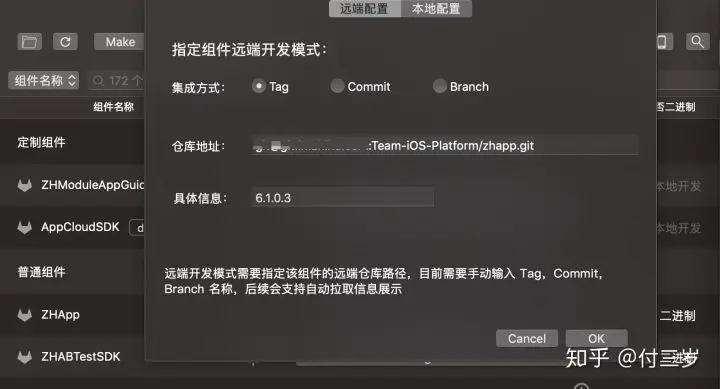
在开发过程中,有时需要对某一个依赖库的特定版本进行调试或连调。所以也支持通过 tag,commit,branch 等方式,进行特定源码的切换和关联。
源码与二进制切换

某些特殊场景下,可能希望工程以所有组件都是源代码方式构建,排查问题。那么也可以通过 2 种不同的构建模式一键切换。(当然全源码构建一次需要十足的耐心)
二进制模式下搜索与调试
二进制化后,大部分情况下都工作在二进制模式下,但有时在进行源码搜索时,希望可以全局搜索。所以在构建过程中,会把当前版本的源码目录也引用到工程目录下。

所以在工程进行检索代码时,是完全没问题的。有了源码,在云端进行二进制打包时,通过 fdebug-prefix-map ( Clang command line argument reference )这个参数重新在二进制文件中改写 Debug 模式的源代码路径。这样即使在二进制模式下,也可以直接关联源码进行断点调试。
组件依赖关系分析
当组件很多后,就会出现一些工程师对组件所处层级不够了解,导致出现依赖混乱的问题。所以在构建结束后会通过对组件层级的检查,进行组件依赖层级的判断。
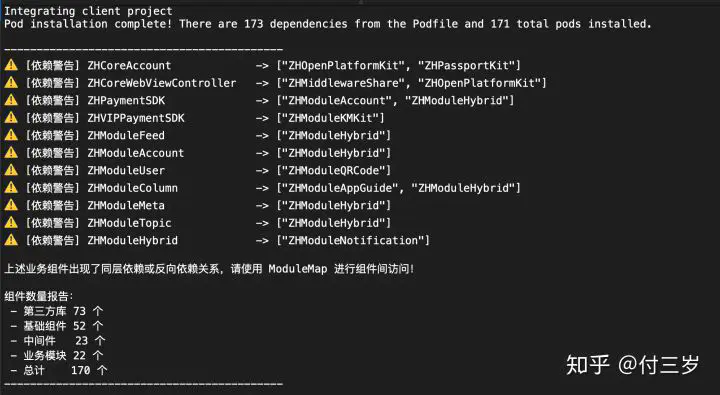
总结
在推进所有工程师使用 Venom 客户端后,相当于在开发环节有了一个强有力的抓手。由于 App 的自动更新功能,可以在平台下提供给开发者更多的工具,而开发者只需要更新客户端使用。通过工具化客户端的开发,我们重构了原有散落在各处的脚步,工具集中整合在一起。使得开发工具维护更统一,更新也更及时,开发人员上手成本也更低。
Venom 核心承担的是开发环境管理,工程组织与构建管理,提高工程效率工作。但上线后,我们还陆续在此基础上提供了一些其他功能。
1、多仓库 MR 自动填充提交
2、本地非独立业务仓库单元测试
3、个人开发者账号真机调试
4、无用图片扫描工具
5、轻量的 app 网络和日志查看等
转自:https://www.jianshu.com/p/b65d7bb7fa32
vue 事件总线EventBus的概念、使用以及注意点
前言
vue组件中的数据传递最最常见的就是父子组件之间的传递。父传子通过props向下传递数据给子组件;子传父通过$emit发送事件,并携带数据给父组件。而有时两个组件之间毫无关系,或者他们之间的结构复杂,如何传递数据呢?这时就要用到 vue 中的事件总线 EventBus的概念
正文
EventBus的简介
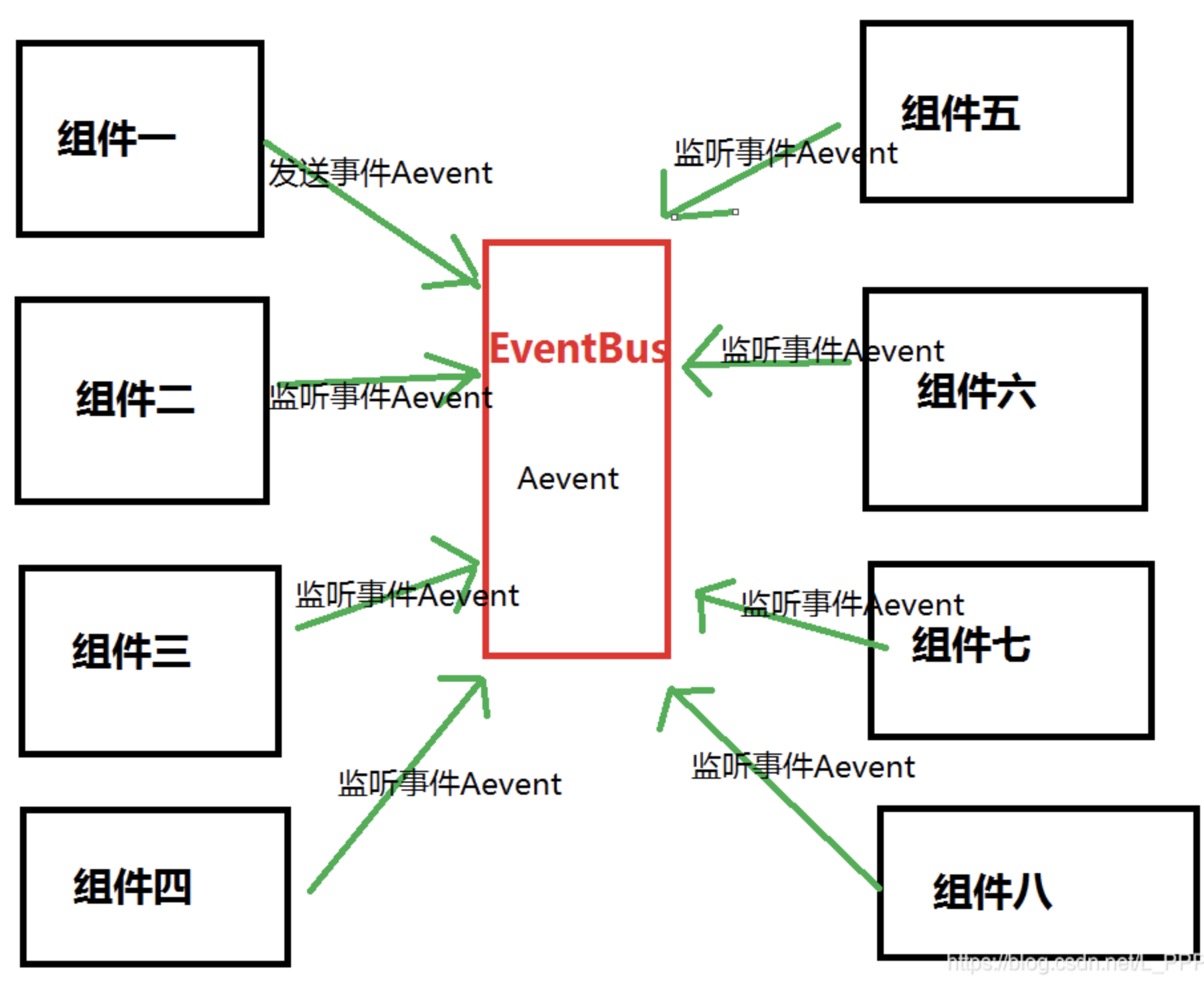
EventBus的使用
一、初始化
import Vue from 'vue'
//因为是全局的一个'仓库',所以初始化要在全局初始化
const EventBus = new Vue()//在已经创建好的Vue实例原型中创建一个EventBus
Vue.prototype.$EventBus = new Vue()二、向EventBus发送事件
发送事件的语法:this.$EventBus.$emit(发送的事件名,传递的参数)
已经创建好EventBus后我们就需要向它发送需要传递的事件,以便其他组件可以向EventBus获取。
例子:有两个组件A和B需要通信,他们不是父子组件关系,B事件需要获得A事件里的一组数据data
<!-- A.vue 这里是以模块化的方式讲解的,即A组件和B组件分别各自
一个.vue文件,所以代码中会有导入的语法-->
<template>
<button @click="sendMsg">发送MsgA</button>
</template>
<script>
export default {
data(){
return{
MsgA: 'A组件中的Msg'
}
},
methods: {
sendMsg() {
/*调用全局Vue实例中的$EventBus事件总线中的$emit属性,发送事
件"aMsg",并携带A组件中的Msg*/
this.$EventBus.$emit("aMsg", this.MsgA);
}
}
};
</script>三、接收事件
<!-- B.vue -->
<template>
<!-- 展示msgB -->
<p>{{msgB}}</p>
</template>
<script>
export default {
data(){
return {
//初始化一个msgB
msgB: ''
}
},
mounted() {
/*调用全局Vue实例中的$EventBus事件总线中的$on属性,监听A组件发送
到事件总线中的aMsg事件*/
this.$EventBus.$on("aMsg", (data) => {
//将A组件传递过来的参数data赋值给msgB
this.msgB = data;
});
}
};
</script>
这样,B组件就轻松接收到了A组件传递过来的参数,并成功展示了该参数,这样是不是就很简单的解决了各组件之间的通讯呢?虽然EventBus是一个很轻便的方法,任何数据都可以往里传,然后被别的组件获取,但是如果用不好,容易出现很严重的BUG,所以接下来我们就来讲解一下移除监听事件。
四、移除监听事件
在上一个例子中,我们A组件向事件总线发送了一个事件aMsg并传递了参数MsgA,然后B组件对该事件进行了监听,并获取了传递过来的参数。但是,这时如果我们离开B组件,然后再次进入B组件时,又会触发一次对事件aMsg的监听,这时时间总线里就有两个监听了,如果反复进入B组件多次,那么就会对aMsg进行多次的监听。
总而言之,A组件只向EventBus发送了一次事件,但B组件却进行了多次监听,EventBus容器中有很多个一模一样的事件监听器这时就会出现,事件只触发一次,但监听事件中的回调函数执行了很多次
<!-- B.vue -->
<template>
<!-- 展示msgB -->
<p>{{msgB}}</p>
</template>
<script>
export default {
data(){
return {
//初始化一个msgB
msgB: ''
}
},
mounted() {
/*调用全局Vue实例中的$EventBus事件总线中的$on属性,监听A组件发送
到事件总线中的aMsg事件*/
this.$EventBus.$on("aMsg", (data) => {
//将A组件传递过来的参数data赋值给msgB
this.msgB = data;
});
},
beforeDestroy(){
//移除监听事件"aMsg"
this.$EventBus.$off("aMsg")
}
};
</script>结束语
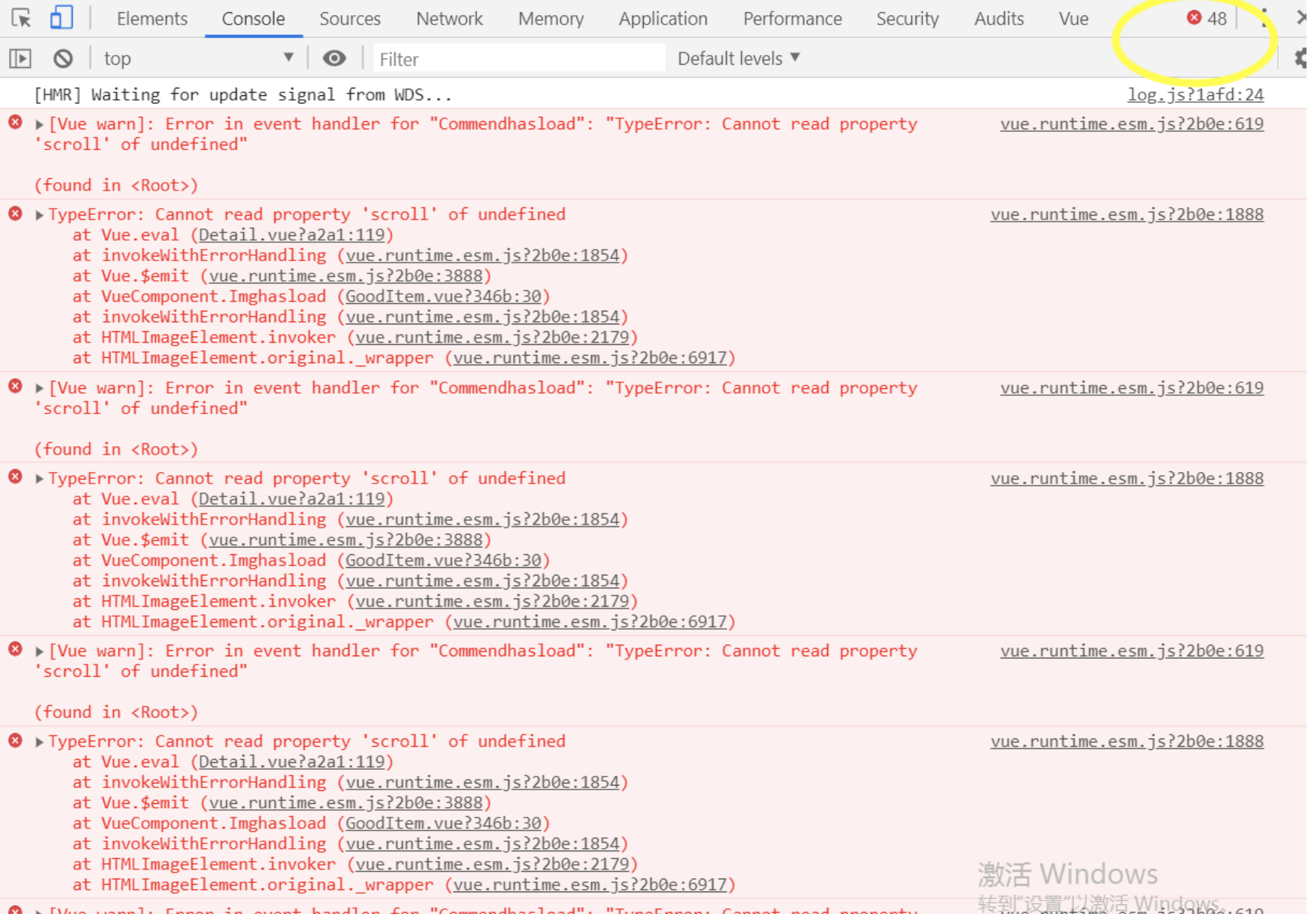
无废话快速上手React路由
安装
// npm
npm install react-router-dom
// yarn
yarn add react-router-domreact-router相关标签
import {
BrowserRouter,
HashRouter,
Route,
Redirect,
Switch,
Link,
NavLink,
withRouter,
} from 'react-router-dom'简单路由跳转
import {
BrowserRouter as Router,
Route,
Link
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
<Link to="/home" className="link">跳转Home页面</Link>
<Link to="/about" className="link">跳转About页面</Link>
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
</Router>
</div>
);
}
export default App;嵌套路由跳转
import {
BrowserRouter as Router,
Route,
Link,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
<Link to="/home">跳转Home页面</Link>
<Link to="/about">跳转About页面</Link>
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
</Router>
</div>
);
}
export default App;然后 Home 组件中同样也想设置两个路由组件的匹配路径,分别是 /home/one 和 /home/two,此时就可以看出,这个 /home/one 和 /home/two 为上一级路由 /home 的二级嵌套路由,代码如下:
import React from 'react'
import {
Route,
Link,
} from 'react-router-dom'
import One from './one'
import Two from './two'
function Home () {
return (
<>
我是Home页面
<Link to="/home/one">跳转到Home/one页面</Link>
<Link to="/home/two">跳转到Home/two页面</Link>
<Route path="/home/one" component={One}/>
<Route path="/home/two" component={Two}/>
</>
)
}
export default Home特别注意: Home 组件中的路由组件 One 的二级路由路径匹配必须要写 /home/one ,而不是 /one ,不要以为 One 组件看似在 Home 组件内就可以简写成 /one
动态链接
import {
BrowserRouter as Router,
Route,
NavLink
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
<NavLink to="/home" className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
</Router>
</div>
);
}
export default App;
/* 设置active类的样式 */
.active {
font-weight: blod;
color: red;
}路由匹配优化
import {
BrowserRouter as Router,
Route,
NavLink,
Switch,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
<NavLink to="/home" className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<Switch>
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
<Route path="/home" component={Home}/>
<Route path="/home" component={Home}/>
{/* 此处省略一万个Route组件 */}
<Route path="/home" component={Home}/>
</Switch>
</Router>
</div>
);
}
export default App;重定向
import {
BrowserRouter as Router,
Route,
NavLink,
Switch,
Redirect,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
<NavLink to="/home" className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<NavLink to="/shop" className="link">跳转Shop页面</NavLink> {/* 点击,跳转到/shop,但该路径没有设置 */}
<Switch>
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
<Redirect to="/home" /> {/* 当以上Route组件都匹配失败时,重定向到/home */}
</Switch>
</Router>
</div>
);
}
export default App;路由传参
第一种
import {
BrowserRouter as Router,
Route,
NavLink,
Switch,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
{/* 在 /home 的路径上携带了 张三、18 共两个参数 */}
<NavLink to="/home/张三/18" className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<Switch>
{/* 在 /home 匹配路径上相同的位置接收了 name、age 两个参数 */}
<Route path="/home/:name/:age" component={Home}/>
<Route path="/about" component={About}/>
</Switch>
</Router>
</div>
);
}
export default App;第二种
import {
BrowserRouter as Router,
Route,
NavLink,
Switch,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
{/* 在跳转路径后面以?开头传递两个参数,分别为name=张三、age=18 */}
<NavLink to="/home?name=张三&age=18" className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<Switch>
{/* 此处无需做接收操作 */}
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
</Switch>
</Router>
</div>
);
}
export default App;第三种
import {
BrowserRouter as Router,
Route,
NavLink,
Switch,
} from 'react-router-dom'
import Home from './home'
import About from './about'
function App() {
return (
<div className="App">
<Router>
{/* 以对象的形式描述to属性,路径属性名为pathname,参数属性名为state */}
<NavLink to={{pathname: "/home", state: {name: '张三', age: 18}}} className="link">跳转Home页面</NavLink>
<NavLink to="/about" className="link">跳转About页面</NavLink>
<Switch>
{/* 此处无需特地接收属性 */}
<Route path="/home" component={Home}/>
<Route path="/about" component={About}/>
</Switch>
</Router>
</div>
);
}
export default App;函数式路由
push
import React from 'react'
function Home (props) {
let pushLink = () => {
props.history.push('/about')
}
return (
<div className="a">
我是Home页面
<button onClick={pushLink}>跳转到about页面</button>
</div>
)
}
export default Homereplace
import React from 'react'
function Home (props) {
let replaceLink = () => {
props.history.replace('/about')
}
return (
<div className="a">
我是Home页面
<button onClick={replaceLink}>跳转到about页面</button>
</div>
)
}
export default HomegoForward
goBack
go
收起阅读 »vue数据可视化界面,智慧图表。Echarts,以及git
一、数据图表
1.1HighChart
兼容 IE6+、完美支持移动端、图表类型丰富、方便快捷的 HTML5 交互性图表库下载
一、通过CDN
https://code.highcharts.com.cn/index.html
二、通过NPM下载(用的比较多)
npm install highcharts
三、通过官网下载
https://www.highcharts.com.cn/download
通过引入库的方式引入到本地基本应用
Document
1.2Echarts(用的更多一些)
一、通过CDN
jsdelivr.com/package/npm/echarts
二、通过NPM(通过NPM)
npm install echarts
三、通过官网
https://echarts.apache.org/zh/download.html
四、通过github
https://github.com/apache/echarts/releases1.3如何在vue脚手架中引入Echarts
//全局引入echart
import * as echarts from 'echarts'
Vue.prototype.$echarts = echartshome.vue
二、git代码管理
2.1代码管理工具
svn (小乌龟)
https://tortoisesvn.net/
git (命令)
github(所有开源项目的归属地)
https://github.com/
码云
https://gitee.com/
git软件
https://git-scm.com/
无论是gihub还是码云,他们都是用git命令去操作的。所以命令都一样
git软件的安装,下一步,下一步,傻瓜式安装即可
装成功的状态: 鼠标右键看到 git Bash Here 就OK2.2创建一个远程仓库 (新项目)
一、登录github/码云输入用户名密码
二、新建一个远程仓库,在官网右上角(点击+ )
三、创建一个仓库名称,添加仓库描述,创建一个公有的仓库,不需要为仓库创建其他内容一、在本地创建一个文件夹,创建相关的基本骨架
二、初始化当前文件夹变成本地仓库(会出现一个.git的隐藏文件)
git init
三、本地的所有内容上传到暂缓区
git add .
四、提交的时候要做记录
git commit -m '尽量写英文,非要写写中文也可以'
五、链接远程仓库
git remote add origin https://gitee.com/zhangzhangzhangdada/shop-admin.git
六、把暂缓区的内容推送到远程仓库 (master 默认的分支名字)
git push -u origin master原文:https://blog.csdn.net/weixin_49030317/article/details/116666179
收起阅读 »JavaScript解密之旅-----数组的遍历方法总结
数组的循环
一、forEach()
二、map()
三、filter()
四、reduce()与reduceRight()
五、every()
六、some()
七、find()与findIndex()
八、 for in
九、 for of
十、 for
总结
数组的循环
一、forEach()
对数组进行遍历循环,对数组中的每一项运行给定函数。这个方法没有返回值。
参数都是function类型,默认有传参,参数分别为:遍历的数组内容;第对应的数组索引,数组本身。
var arr = [1, 2, 3, 4, 5];
arr.forEach(function (item, index, arr) {
console.log(item, index, arr);
// item:遍历的数组内容,index:第对应的数组索引,arr:数组本身。
});二、map()
var arr = [1, 2, 3, 4, 5];
var arr2 = arr.map(function (item) {
return item * item;
});
console.log(arr2); //[1, 4, 9, 16, 25]三、filter()
var arr = [1, 2, 3, 4, 5];
var arr2 = arr.filter(function (x, index) {
return x % 2 == 0 || index >= 2;
});
console.log(arr2); // [2,3,4,5]四、reduce()与reduceRight()
// reduce()
let array = [1, 2, 3, 4, 5];
let arrayNew = array.reduce((x, y) => {
console.log("x===>" + x);
console.log("y===>" + y);
console.log("x+y===>", Number(x) + Number(y));
return x + y;
});
console.log("arrayNew", arrayNew); // 15
console.log(array); // [1, 2, 3, 4, 5]
// reduceRight() 只是执行数组顺序为倒序五、every()
var arr = [1, 2, 3, 4, 5];
var arr2 = arr.every(function (x) {
return x < 8;
});
console.log(arr2); //true
var arr3 = arr.every(function (x) {
return x < 3;
});
console.log(arr3); // false六、some()
var arr = [1, 2, 3, 4, 5];
var arr2 = arr.some(function(x) {
return x < 3;
});
console.log(arr2); //true
var arr3 = arr.some(function(x) {
return x > 6;
});
console.log(arr3); // false七、find()与findIndex()
// find()
let arr = [1, 2, 3, 4, 5];
let res = arr.find(function (val, index, arr) {
return val > 3;
});
console.log(res); //4
// findIndex
let arr = [1, 2, 3, 4, 5];
let res = arr.findIndex(function (val, index, arr) {
return val > 3;
});
console.log(res); //3八、 for in
var arr = [
{ id: 1, name: "程序员" },
{ id: 2, name: "掉头发" },
{ id: 3, name: "你不信" },
{ id: 4, name: "薅一下" },
];
var arrNew = [];
for (var key in arr) {
console.log(key);
console.log(arr[key]);
arrNew.push(arr[key].id);
}
console.log(arrNew);九、 for of
var arr = [
{ name: "程序员" },
{ name: "掉头发" },
{ name: "你不信" },
{ name: "薅一下" },
];
// key()是对键名的遍历;
// value()是对键值的遍历;
// entries()是对键值对的遍历;
for (let item of arr) {
console.log(item);
}
// 输出数组索引
for (let item of arr.keys()) {
console.log(item);
}
// 输出内容和索引
for (let [item, val] of arr.entries()) {
console.table(item + ":" + val);
}十、 for
var arr = [
{ name: "程序员" },
{ name: "掉头发" },
{ name: "你不信" },
{ name: "薅一下" },
];
for (let index = 0; index < arr.length; index++) {
const element = arr[index];
console.log(element )
}总结
Android炫酷的粒子动画!
一、总述
ParticleTextView 是一个 Android 平台的自定义 view 组件,可以用彩色粒子组成指定的文字,并配合多种动画效果和配置属性,呈现出丰富的视觉效果。

二、使用
1. 引入依赖
compile 'yasic.library.ParticleTextView:particletextview:0.0.6'
2. 加入到布局文件中
<com.yasic.library.particletextview.View.ParticleTextView
android:id="@+id/particleTextView"
android:layout_width="match_parent"
android:layout_height="match_parent" />3. 实例化配置信息类 ParticleTextViewConfig
ParticleTextView particleTextView = (ParticleTextView) findViewById(R.id.particleTextView);
RandomMovingStrategy randomMovingStrategy = new RandomMovingStrategy();
ParticleTextViewConfig config = new ParticleTextViewConfig.Builder()
.setRowStep(8)
.setColumnStep(8)
.setTargetText("Random")
.setReleasing(0.2)
.setParticleRadius(4)
.setMiniDistance(0.1)
.setTextSize(150)
.setMovingStrategy(randomMovingStrategy)
.instance();
particleTextView.setConfig(config);4. 启动动画
particleTextView.startAnimation();5. 暂停动画
particleTextView1.stopAnimation();三、API说明
粒子移动轨迹策略 MovingStrategy
移动轨迹策略继承自抽象类 MovingStrategy,可以自己继承并实现其中的 setMovingPath 方法,以下是自带的几种移动轨迹策略
- CornerStrategy

- HorizontalStrategy

- BidiHorizontalStrategy

- VerticalStrategy

- BidiVerticalStrategy
配置信息类 ParticleTextViewConfig
配置信息类采用工厂模式创建,以下属性均为可选属性。
- 设置显示的文字
setTargetText(String targetText)- 设置文字大小
setTextSize(int textSize)- 设置粒子半径
setParticleRadius(float radius)- 设置横向和纵向像素采样间隔
采样间隔越小生成的粒子数目越多,但绘制帧数也随之降低,建议结合文字大小与粒子半径进行调节。
setColumnStep(int columnStep)
setRowStep(int rowStep)- 设置粒子运动速度
setReleasing(double releasing)指定时刻,粒子的运动速度由下列公式决定,其中 Vx 和 Vy 分别是 X 与 Y 方向上的运动速度,target 与 source 分别是粒子的目的坐标与当前坐标
Vx = (targetX - sourceX) * releasing
Vy = (targetY - sourceY) * releasing
- 设置最小判决距离
当粒子与目的坐标距离小于最小判决距离时将直接移动到目的坐标,从而减少不明显的动画过程。
setMiniDistance(double miniDistance)- 设置粒子颜色域
默认使用完全随机的颜色域
setParticleColorArray(String[] particleColorArray)- 设置粒子移动轨迹策略
默认使用随机分布式策略
setMovingStrategy(MovingStrategy movingStrategy)- 设置不同路径间动画的间隔时间
delay < 0 时动画不循环
setDelay(Long delay)ParticleTextView类
- 指定配置信息类
setConfig(ParticleTextViewConfig config)
- 开启动画
void startAnimation()
- 停止动画
void stopAnimation()
- 获取动画是否暂停
暂停是指动画完成了一段路径后的暂留状态
boolean isAnimationPause()
- 获取动画是否停止
停止是指动画完成了一次完整路径后的停止状态
boolean isAnimationStop()
ParticleTextSurfaceView 类
继承自 SurfaceView 类,利用子线程进行 Canvas 绘制,在多个组件渲染情况下效率更高。所有 API 与 ParticleTextView 类一致。
代码下载:ParticleTextView-master.zip
收起阅读 »
无敌的 iOS 网络通信库
RestKit是一个现代的Objective-C框架,用于在iOS和Mac OS X上实现RESTful Web服务客户端。它提供了一个强大的对象映射引擎,该引擎与Core Data无缝集成,并提供了一组简单的网络原语,用于映射建立在顶部的HTTP请求和响应。的AFNetworking。它具有一组经过精心设计的优雅API,这些API使访问和建模RESTful资源感到不可思议。例如,以下是访问Twitter公共时间轴并将JSON内容转换为Tweet对象数组的方法:
@interface RKTweet : NSObject
@property (nonatomic, copy) NSNumber *userID;
@property (nonatomic, copy) NSString *username;
@property (nonatomic, copy) NSString *text;
@end
RKObjectMapping *mapping = [RKObjectMapping mappingForClass:[RKTweet class]];
[mapping addAttributeMappingsFromDictionary:@{
@"user.name": @"username",
@"user.id": @"userID",
@"text": @"text"
}];
RKResponseDescriptor *responseDescriptor = [RKResponseDescriptor responseDescriptorWithMapping:mapping method:RKRequestMethodAny pathPattern:nil keyPath:nil statusCodes:nil];
NSURL *url = [NSURL URLWithString:@"http://api.twitter.com/1/statuses/public_timeline.json"];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
RKObjectRequestOperation *operation = [[RKObjectRequestOperation alloc] initWithRequest:request responseDescriptors:@[responseDescriptor]];
[operation setCompletionBlockWithSuccess:^(RKObjectRequestOperation *operation, RKMappingResult *result) {
NSLog(@"The public timeline Tweets: %@", [result array]);
} failure:nil];
[operation start];
概述
RestKit被设计为模块化的,每个模块都致力于在整个框架以及与主机平台之间维护最少的依赖关系集。库的核心是对象映射引擎,该引擎负责在表示形式之间转换对象(例如JSON / XML <->本地域对象)。
API快速入门
RestKit分为几个模块,这些模块将映射引擎与HTTP和Core Data集成完全分开,以提供最大的灵活性。每个模块中的键类在下面突出显示,并且每个模块都超链接到源代码中包含的README.md。
| 对象映射 | |
|---|---|
| RKObjectMapping | 封装用于转换由键-值编码键路径表示的对象表示的配置。 |
| RKAttributeMapping | 根据源和目标键路径指定对象或实体映射中的属性之间的所需转换。 |
| RKRelationshipMapping | 根据源和目标键路径以及用来映射子对象属性的RKObjectMapping指定嵌套的一个或多个子对象的所需映射。 |
| RK动态映射 | 指定一个灵活的映射,在该映射中,关于要使用哪个RKObjectMapping来处理给定文档的决策将推迟到运行时。 |
| RKMapperOperation | 提供用于将反序列化文档映射到一组本地域对象的接口。 |
| RKMappingOperation | 一个的NSOperation执行使用对象表示之间的映射RKObjectMapping。 |
| 联网 | |
| RKRequestDescriptor | 描述可以针对给定对象类型从应用程序发送到远程Web应用程序的请求。 |
| RKResponseDescriptor | 根据对象映射,键路径,用于匹配URL的SOCKit模式以及一组状态码(它们定义了适合映射的情况)描述了可以从远程Web应用程序返回的对象可映射响应。给定的响应。 |
| RKObjectParameterization | 执行给定对象到NSDictionary表示形式的映射,该表示形式适合用作HTTP请求的参数。 |
| RKObjectRequestOperation | 一个NSOperation,它使用一组RKResponseDescriptor对象中表示的配置来发送HTTP请求并在已解析的响应主体上执行对象映射。 |
| RKResponseMapperOperation | 一个的NSOperation提供用于对象映射的支撑NSHTTPURLResponse使用一组RKResponseDescriptor对象。 |
| RKObjectManager | 捕获使用对象映射通过HTTP与RESTful Web应用程序通信的常见模式,包括:
|
| 路由器 | 从基本URL和一组RKRoute对象生成NSURL对象,这些对象描述了应用程序使用的相对路径。 |
| RKRoute | 描述给定对象类型和HTTP方法的单个相对路径,对象的关系或符号名。 |
| 核心数据 | |
| RKManagedObjectStore | 封装核心数据配置,包括NSManagedObjectModel,NSPersistentStoreCoordinator和一对NSManagedObjectContext对象。 |
| RKEntityMapping | 为映射建模,以将对象表示形式转换为给定NSEntityDescription的NSManagedObject实例。 |
| RKConnectionDescription | 描述用于使用外键属性在Core Data实体之间建立关系的映射。 |
| RKManagedObjectRequestOperation | 一个的NSOperation子类发送所解析响应身体的HTTP请求和执行对象映射来创建NSManagedObject情况下,使用建立对象之间的关系RKConnectionDescription了孤立的对象的对象清洗,并且在远程后端系统不再存在。 |
| RKManagedObjectImporter | 针对以下两种情况,使用RKEntityMapping对象提供对托管对象的批量映射的支持:
|
| 搜索 | |
| RKSearchIndexer | 提供对在Core Data中为应用程序中实体的字符串属性生成全文可搜索索引的支持。 |
| RKSearchPredicate | 生成给定文本字符串的NSCompoundPredicate,该字符串将搜索通过RKSearchIndexer跨任何索引实体建立的索引。 |
| 测验 | |
| RKMappingTest | 给定已解析的文档以及对象或实体映射,为单元测试对象映射配置提供支持。根据预期的关键路径映射和/或预期的转换结果来配置预期。 |
| RKTestFixture | 提供一个接口,可轻松生成用于单元测试的测试夹具数据。 |
| RKTestFactory | 提供对创建用于测试的对象的支持。 |
例子
对象请求
//从/articles/1234.json获取单个Article并将其映射到一个对象
// JSON看起来像{“ article”:{“ title”:“ My Article”,“ author”:“ Blake”,“ body” :“非常酷!”}}
RKObjectMapping *映射= [RKObjectMapping mappingForClass: [Article class ]];
[映射addAttributeMappingsFromArray: @ [ @“标题”,@“作者”,@“正文” ]];
NSIndexSet * statusCodes = RKStatusCodeIndexSetForClass(RKStatusCodeClassSuccessful); // 2xx中的任何内容
RKResponseDescriptor * responseDescriptor = [RKResponseDescriptor responseDescriptorWithMapping:映射方法: RKRequestMethodAny pathPattern:@“ / articles /:articleID ” keyPath:@“ article ” statusCodes: statusCodes];
NSURLRequest * request = [ NSURLRequest requestWithURL: [ NSURL URLWithString:@“ http://restkit.org/articles/1234.json ” ]];
RKObjectRequestOperation * operation = [[RKObjectRequestOperation alloc ] initWithRequest:请求responseDescriptors: @ [responseDescriptor]];
[操作setCompletionBlockWithSuccess: ^(RKObjectRequestOperation *操作,RKMappingResult *结果){
Article *文章= [结果firstObject ];
NSLog(@“映射文章:%@ ”,文章);
}错误: ^(RKObjectRequestOperation * operation,NSError * error){
NSLog(@“失败,错误:%@ ”,[error localizedDescription ]);
}];
[操作开始];托管对象请求
//从/articles/888.json获取文章及其类别,并映射到Core Data实体
// // JSON类似于{“ article”:{“ title”:“ My Article”,“ author”:“ Blake”,“正文”:“非常酷!”,“类别”:[{“ id”:1,“名称”:“核心数据”]}
NSManagedObjectModel * managedObjectModel = [ NSManagedObjectModel mergedModelFromBundles:nil ];
RKManagedObjectStore * managedObjectStore = [[RKManagedObjectStore alloc ] initWithManagedObjectModel: managedObjectModel];
NSError *错误= nil ;
布尔成功= RKEnsureDirectoryExistsAtPath(RKApplicationDataDirectory(),&error);
如果(!成功){
RKLogError(@“无法在路径' %@ ':%@ ”上创建应用程序数据目录,RKApplicationDataDirectory(),错误);
}
NSString * path = [ RKApplicationDataDirectory()stringByAppendingPathComponent:@“ Store.sqlite ” ];
NSPersistentStore * persistentStore = [managedObjectStore addSQLitePersistentStoreAtPath:SeedDatabaseAtPath的路径:nil withConfiguration:nil 选项:nil 错误:&error];
if(!persistentStore){
RKLogError(@“无法在路径' %@ ':%@ ”上添加持久性存储,路径错误);
}
[managedObjectStore createManagedObjectContexts ];
RKEntityMapping * categoryMapping = [RKEntityMapping mappingForEntityForName:@“ Category ” inManagedObjectStore: managedObjectStore];
[categoryMapping addAttributeMappingsFromDictionary: @ { “ id ”:“ categoryID ”,@“ name ”:“ name ” }]];
RKEntityMapping * articleMapping = [RKEntityMapping mappingForEntityForName:@“ Article ” inManagedObjectStore: managedObjectStore];
[articleMapping addAttributeMappingsFromArray: @ [ @“标题”,@“作者”,@“正文” ]];
[articleMapping addPropertyMapping: [RKRelationshipMapping relationshipMappingFromKeyPath:@“类别” toKeyPath:@“类别” withMapping: categoryMapping]];
NSIndexSet * statusCodes = RKStatusCodeIndexSetForClass(RKStatusCodeClassSuccessful); // 2xx中的任何内容
RKResponseDescriptor * responseDescriptor = [RKResponseDescriptor responseDescriptorWithMapping: articleMapping方法: RKRequestMethodAny pathPattern:@“ / articles /:articleID ” keyPath:@“ article ” statusCodes: statusCodes];
NSURLRequest * request = [ NSURLRequest requestWithURL: [ NSURL URLWithString:@“ http://restkit.org/articles/888.json ” ]];
RKManagedObjectRequestOperation * operation = [[RKManagedObjectRequestOperation alloc ] initWithRequest:请求responseDescriptors: @ [responseDescriptor]];
operation.managedObjectContext = managedObjectStore.mainQueueManagedObjectContext;
operation.managedObjectCache = managedObjectStore.managedObjectCache;
[操作setCompletionBlockWithSuccess: ^(RKObjectRequestOperation *操作,RKMappingResult *结果){
Article *文章= [结果firstObject ];
NSLog(@“映射文章:%@ ”,文章);
NSLog(@“映射类别:%@ ”,[article.categories anyObject ]);
}错误: ^(RKObjectRequestOperation * operation,NSError * error){
NSLog(@“失败,错误:%@ ”,[error localizedDescription ]);
}];
NSOperationQueue * operationQueue = [ NSOperationQueue new ];
[operationQueue addOperation:操作];将客户端错误响应映射到NSError
// GET /articles/error.json返回422(不可处理的实体)
// JSON看起来像{“ errors”:“发生某些错误”}
//您可以将错误映射到任何类,但是会免费提供`RKErrorMessage`
RKObjectMapping * errorMapping = [RKObjectMapping mappingForClass: [RKErrorMessage类]];
//源键路径上包含错误的整个值映射到消息
[errorMapping addPropertyMapping: [RKAttributeMapping attributeMappingFromKeyPath:nil toKeyPath:@“ errorMessage ” ]];
NSIndexSet * statusCodes = RKStatusCodeIndexSetForClass(RKStatusCodeClassClientError);
//在4xx状态码范围内的任意响应于与“错误”键路径使用该映射
RKResponseDescriptor * errorDescriptor = [RKResponseDescriptor responseDescriptorWithMapping: errorMapping方法: RKRequestMethodAny pathPattern:零 的keyPath:@ “错误” statusCodes: statusCodes];
NSURLRequest * request = [ NSURLRequest requestWithURL: [ NSURL URLWithString:@“ http://restkit.org/articles/error.json ” ]];
RKObjectRequestOperation * operation = [[RKObjectRequestOperation alloc ] initWithRequest:请求responseDescriptors: @ [errorDescriptor]];
[operation setCompletionBlockWithSuccess:无 故障: ^(RKObjectRequestOperation * operation,NSError * error){
//错误所映射到的类的“ description”方法用于构造localizedDescription
NSLog的值(@“加载了此错误:%@ “,[错误localizedDescription ]);
//您可以通过`userInfo`
RKErrorMessage * errorMessage = [[error.userInfo objectForKey: RKObjectMapperErrorObjectsKey] firstObject ];访问用于构造NSError的模型对象。
}];在对象管理器中集中配置
//设置文章和错误响应描述符
//成功的JSON类似于{“ article”:{“ title”:“ My Article”,“ author”:“ Blake”,“ body”:“非常酷!”}}
RKObjectMapping *映射= [RKObjectMapping mappingForClass: [Article class ]];
[映射addAttributeMappingsFromArray: @ [ @“标题”,@“作者”,@“正文” ]];
NSIndexSet * statusCodes = RKStatusCodeIndexSetForClass(RKStatusCodeClassSuccessful); // 2xx中的任何内容
RKResponseDescriptor * articleDescriptor = [RKResponseDescriptor responseDescriptorWithMapping:映射方法: RKRequestMethodAny pathPattern:@“ / articles ” keyPath:@“ article ” statusCodes: statusCodes];
//错误JSON看起来像{“错误”:“发生某些错误”}
RKObjectMapping * errorMapping = [RKObjectMapping mappingForClass: [RKErrorMessage类]];
//源键路径上包含错误的整个值映射到消息
[errorMapping addPropertyMapping: [RKAttributeMapping attributeMappingFromKeyPath:nil toKeyPath:@“ errorMessage ” ]];
NSIndexSet * statusCodes = RKStatusCodeIndexSetForClass(RKStatusCodeClassClientError);
// 4xx状态码范围内带有“错误”键路径的任何响应都使用此映射
RKResponseDescriptor * errorDescriptor = [RKResponseDescriptor responseDescriptorWithMapping: errorMapping方法: RKRequestMethodAny pathPattern:nil keyPath:@“ errors ” statusCodes: statusCodes];
//将描述符添加到管理器
RKObjectManager * manager = [RKObjectManager managerWithBaseURL: [ NSURL URLWithString:@“ http://restkit.org ” ]];
[manager addResponseDescriptorsFromArray: @ [articleDescriptor,errorDescriptor]];
[manager getObjectsAtPath:@“ /articles/555.json ” 参数:无 成功: ^(RKObjectRequestOperation * operation,RKMappingResult * mappingResult){
//处理articleDescriptor
}失败: ^(RKObjectRequestOperation * operation,NSError * error){
//传输错误或服务器错误,由errorDescriptor
}]处理;要求
RestKit需要iOS 8.0或更高版本或Mac OS X 10.9或更高版本。
RestKit中使用了多个第三方开源库,包括:
- AFNetworking-网络支持
- LibComponentLogging-日志支持
- SOCKit-字符串<->对象编码
- iso8601parser-支持解析和生成ISO- 8601日期
必须将以下Cocoa框架链接到应用程序目标中,以进行正确的编译:
- iOS上的CFNetwork.framework
- CoreData.framework
- Security.framework
- iOS上的MobileCoreServices.framework或OS X上的CoreServices.framework
并且必须设置以下链接器标志:
- -ObjC
- -all_load
$ cd /path/to/MyProject
$ touch Podfile
$ edit Podfile
target "YOUR PROJECT" do
platform :ios, '7.0'
# Or platform :osx, '10.7'
pod 'RestKit', '~> 0.24.0'
end
# Testing and Search are optional components
pod 'RestKit/Testing', '~> 0.24.0'
pod 'RestKit/Search', '~> 0.24.0'
更多实例及常见问题:https://github.com/RestKit/RestKit
一个开源的iOS框架,用于基于GPU的图像和视频处理
概述
GPUImage框架是BSD许可的iOS库,可让您将GPU加速的滤镜和其他效果应用于图像,实时摄像机视频和电影。与Core Image(iOS 5.0的一部分)相比,GPUImage允许您编写自己的自定义过滤器,支持部署到iOS 4.0并具有更简单的界面。但是,它目前缺少Core Image的一些更高级的功能,例如面部检测。
对于诸如处理图像或实时视频帧之类的大规模并行操作,GPU比CPU具有一些明显的性能优势。在iPhone 4上,简单的图像过滤器在GPU上的执行速度比基于CPU的等效过滤器快100倍以上。
但是,在GPU上运行自定义滤镜需要大量代码才能为这些滤镜设置和维护OpenGL ES 2.0渲染目标。我创建了一个示例项目来做到这一点:
http://www.sunsetlakesoftware.com/2010/10/22/gpu-accelerated-video-processing-mac-and-ios
并发现我在创建过程中必须编写许多样板代码。因此,我将这个框架整合在一起,该框架封装了处理图像和视频时遇到的许多常见任务,并且使您不必担心OpenGL ES 2.0的基础。
在处理视频时,此框架与Core Image相比具有优势,在iPhone 4上仅花费2.5 ms即可从相机上传帧,应用伽玛滤镜和显示,而使用Core Image进行相同操作则需要106 ms。基于CPU的处理需要460毫秒,因此使GPUImage在此硬件上进行此操作的速度比Core Image快40倍,比与CPU绑定的处理快184倍。在iPhone 4S上,在这种情况下,GPUImage仅比Core Image快4倍,比CPU绑定处理快102倍。但是,对于更高半径的高斯模糊等更复杂的操作,Core Image当前超过GPUImage。
技术要求
- OpenGL ES 2.0:使用此功能的应用程序将无法在原始iPhone,iPhone 3G以及第一代和第二代iPod touch上运行
- iOS 4.1作为部署目标(4.0没有电影阅读所需的某些扩展)。如果您希望在拍摄静态照片时显示实时视频预览,则需要iOS 4.3作为部署目标。
- iOS 5.0 SDK构建
- 设备必须具有摄像头才能使用与摄像头相关的功能(显然)
- 该框架使用自动引用计数(ARC),但如果将其添加为子项目,则应同时支持使用ARC和手动引用计数的项目,如下所述。对于针对iOS 4.x的手动引用计数应用程序,您需要在应用程序项目的“其他链接器标志”中添加-fobjc-arc。
通用架构
GPUImage使用OpenGL ES 2.0着色器以比在CPU绑定例程中更快的速度执行图像和视频操作。但是,它在简化的Objective-C界面中隐藏了与OpenGL ES API交互的复杂性。通过此接口,您可以定义图像和视频的输入源,将过滤器成串连接,并将处理后的图像或视频发送到屏幕,UIImage或磁盘上的电影。
视频图像或视频帧是从源对象上传的,源对象是GPUImageOutput的子类。其中包括GPUImageVideoCamera(用于来自iOS相机的实时视频),GPUImageStillCamera(用于使用相机拍摄照片),GPUImagePicture(用于静止图像)和GPUImageMovie(用于电影)。源对象将静止图像帧作为纹理上传到OpenGL ES,然后将这些纹理移交给处理链中的下一个对象。
链中的滤镜和其他后续元素符合GPUImageInput协议,该协议使它们可以从链中的上一个链接中获取或处理纹理,并对它们进行处理。距离目标更远一步的对象被视为目标,可以通过将多个目标添加到单个输出或过滤器来分支处理。
例如,如果某个应用程序从摄像机中获取实时视频,然后将该视频转换为棕褐色调,然后在屏幕上显示该视频,则会建立一个类似于以下内容的链:
GPUImageVideoCamera -> GPUImageSepiaFilter -> GPUImageView 将静态库添加到您的iOS项目
注意:如果要在Swift项目中使用它,则需要使用“将其添加为框架”部分中的步骤,而不要使用以下步骤。Swift需要第三方代码模块。
一旦有了该框架的最新源代码,就可以很容易地将其添加到您的应用程序中。首先将GPUImage.xcodeproj文件拖动到应用程序的Xcode项目中,以将框架嵌入项目中。接下来,转到应用程序的目标,然后将GPUImage添加为目标依赖项。最后,您需要将libGPUImage.a库从GPUImage框架的Products文件夹拖到应用程序目标的Link Binary With Libraries构建阶段。
GPUImage需要将其他一些框架链接到您的应用程序,因此您需要在应用程序目标中添加以下内容作为链接库:
- CoreMedia
- CoreVideo
- OpenGLES
- AVFoundation
- QuartzCore
您还需要找到框架标头,因此在项目的构建设置中,将“标头搜索路径”设置为从应用程序到GPUImage源目录内的framework /子目录的相对路径。使此标头搜索路径是递归的。
要在您的应用程序中使用GPUImage类,只需使用以下内容包括核心框架头即可:
#import "GPUImage.h"
注意:如果尝试使用Interface Builder构建接口时,如果遇到错误“ Interface Builder中的未知类GPUImageView”或类似错误,则可能需要在项目的构建设置中将-ObjC添加到Other Linker Flags。
另外,如果您需要将其部署到iOS 4.x,则似乎当前版本的Xcode(4.3)要求您在最终应用程序中弱链接Core Video框架,否则会崩溃并显示消息“找不到符号” :_CVOpenGLESTextureCacheCreate”,当您创建要上传到App Store或临时分发的归档文件时。为此,请转到项目的“构建阶段”选项卡,展开“使用库链接二进制文件”组,然后在列表中找到CoreVideo.framework。将列表最右边的设置从“必需”更改为“可选”。
此外,这是一个支持ARC的框架,因此,如果要在针对iOS 4.x的手动引用计数应用程序中使用此框架,则还需要将-fobjc-arc添加到“其他链接器标志”中。
在命令行上构建静态库
如果您不想将项目作为依赖项包含在应用程序的Xcode项目中,则可以为iOS Simulator或设备构建通用静态库。为此,请build.sh在命令行上运行。生成的库和头文件将位于build/Release-iphone。您也可以通过更改中的IOSSDK_VER变量来更改iOS SDK的build.sh版本(可以使用找到所有可用版本xcodebuild -showsdks)。
将此作为框架(模块)添加到Mac或iOS项目
Xcode 6和iOS 8和Mac一样,都支持使用完整的框架,从而简化了将其添加到应用程序中的过程。要将其添加到您的应用程序中,建议将.xcodeproj项目文件拖到您的应用程序项目中(就像在静态库目标中一样)。
对于您的应用程序,转到其目标构建设置,然后选择“构建阶段”选项卡。在“目标依赖项”分组下,在iOS上添加GPUImageFramework(而不是在构建静态库的GPUImage上),或者在Mac上添加GPUImage。在“使用库链接二进制文件”部分下,添加GPUImage.framework。
这将导致GPUImage构建为框架。在Xcode 6下,它也将作为模块构建,从而允许您在Swift项目中使用它。如上设置时,您只需要使用
import GPUImage
把它拉进去。
然后,您需要添加一个新的“复制文件”构建阶段,将“目标”设置为“框架”,然后向其添加GPUImage.framework构建产品。这将使框架与您的应用程序捆绑在一起(否则,在执行时,您将看到神秘的“ dyld:库未加载:@ rpath / GPUImage.framework / GPUImage”错误)。
过滤实况视频
要从iOS设备的摄像头过滤实时视频,可以使用以下代码:
GPUImageVideoCamera *videoCamera = [[GPUImageVideoCamera alloc] initWithSessionPreset:AVCaptureSessionPreset640x480 cameraPosition:AVCaptureDevicePositionBack];
videoCamera.outputImageOrientation = UIInterfaceOrientationPortrait;
GPUImageFilter *customFilter = [[GPUImageFilter alloc] initWithFragmentShaderFromFile:@"CustomShader"];
GPUImageView *filteredVideoView = [[GPUImageView alloc] initWithFrame:CGRectMake(0.0, 0.0, viewWidth, viewHeight)];
// Add the view somewhere so it's visible
[videoCamera addTarget:customFilter];
[customFilter addTarget:filteredVideoView];
[videoCamera startCameraCapture];
这会使用尝试以640x480捕获的预设来设置来自iOS设备的背面摄像头的视频源。该视频是通过处于纵向模式的界面捕获的,在该模式下,横向安装的摄像机需要在显示之前旋转其视频帧。然后,使用文件CustomShader.fsh中的代码将自定义滤镜设置为来自摄像机的视频帧的目标。最终,这些过滤后的视频帧将在UIView子类的帮助下显示在屏幕上,该子类可以呈现此管道产生的过滤后的OpenGL ES纹理。
可以通过设置GPUImageView的fillMode属性来更改其填充模式,这样,如果源视频的长宽比与视图的长宽比不同,则视频将被拉伸,以黑条居中或缩放以填充。
对于混合滤镜和其他吸收多个图像的滤镜,您可以创建多个输出并将单个滤镜添加为这两个输出的目标。将输出添加为目标的顺序将影响混合或以其他方式处理输入图像的顺序。
另外,如果您希望启用麦克风音频捕获以录制到电影中,则需要将相机的audioEncodingTarget设置为您的电影编写者,如下所示:
videoCamera.audioEncodingTarget = movieWriter;
捕获和过滤静止照片
要捕获和过滤静态照片,可以使用与过滤视频类似的过程。您可以使用GPUImageStillCamera代替GPUImageVideoCamera:
stillCamera = [[GPUImageStillCamera alloc] init];
stillCamera.outputImageOrientation = UIInterfaceOrientationPortrait;
filter = [[GPUImageGammaFilter alloc] init];
[stillCamera addTarget:filter];
GPUImageView *filterView = (GPUImageView *)self.view;
[filter addTarget:filterView];
[stillCamera startCameraCapture];
这将为您提供静态相机预览视频的实时,经过过滤的提要。请注意,此预览视频仅在iOS 4.3及更高版本上提供,因此,如果您希望具有此功能,则可能需要将其设置为部署目标。
一旦要捕获照片,就可以使用如下所示的回调块:
[stillCamera capturePhotoProcessedUpToFilter:filter withCompletionHandler:^(UIImage *processedImage, NSError *error){
NSData *dataForJPEGFile = UIImageJPEGRepresentation(processedImage, 0.8);
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES);
NSString *documentsDirectory = [paths objectAtIndex:0];
NSError *error2 = nil;
if (![dataForJPEGFile writeToFile:[documentsDirectory stringByAppendingPathComponent:@"FilteredPhoto.jpg"] options:NSAtomicWrite error:&error2])
{
return;
}
}];
上面的代码捕获由预览视图中使用的相同滤镜链处理的原尺寸照片,并将该照片以JPEG格式保存到磁盘中,位于应用程序的文档目录中。
请注意,由于纹理大小的限制,该框架目前无法在较旧的设备(iPhone 4S,iPad 2或Retina iPad之前的设备)上处理宽度大于2048像素或高的图像。这意味着其相机输出的静态照片大于该尺寸的iPhone 4将无法捕获此类照片。正在实施一种切片机制来解决此问题。所有其他设备都应该能够使用此方法捕获和过滤照片。
处理静止图像
有两种方法可以处理静止图像并创建结果。实现此目的的第一种方法是创建一个静止图像源对象并手动创建一个滤镜链:
UIImage *inputImage = [UIImage imageNamed:@"Lambeau.jpg"];
GPUImagePicture *stillImageSource = [[GPUImagePicture alloc] initWithImage:inputImage];
GPUImageSepiaFilter *stillImageFilter = [[GPUImageSepiaFilter alloc] init];
[stillImageSource addTarget:stillImageFilter];
[stillImageFilter useNextFrameForImageCapture];
[stillImageSource processImage];
UIImage *currentFilteredVideoFrame = [stillImageFilter imageFromCurrentFramebuffer];
请注意,要从过滤器手动捕获图像,需要设置-useNextFrameForImageCapture以便告诉过滤器以后需要从其捕获。默认情况下,GPUImage重用过滤器中的帧缓冲区以节省内存,因此,如果您需要保留过滤器的帧缓冲区以进行手动图像捕获,则需要提前告知它。
对于要应用于图像的单个滤镜,只需执行以下操作:
GPUImageSepiaFilter *stillImageFilter2 = [[GPUImageSepiaFilter alloc] init];
UIImage *quickFilteredImage = [stillImageFilter2 imageByFilteringImage:inputImage];
编写自定义过滤器
与iOS(从iOS 5.0开始)上的Core Image相比,此框架的一大优势是能够编写自己的自定义图像和视频处理过滤器。这些过滤器作为OpenGL ES 2.0片段着色器提供,以类似C的OpenGL着色语言编写。
自定义过滤器使用以下代码初始化
GPUImageFilter *customFilter = [[GPUImageFilter alloc] initWithFragmentShaderFromFile:@"CustomShader"];
其中片段着色器使用的扩展名是.fsh。此外,如果您不希望将片段着色器发送到应用程序包中,则可以使用-initWithFragmentShaderFromString:初始值设定项将片段着色器提供为字符串。
片段着色器对在该滤镜阶段要渲染的每个像素执行其计算。他们使用OpenGL阴影语言(GLSL)进行此操作,这是一种类似于C的语言,并附加了2-D和3-D图形。以下棕褐色调滤镜是片段着色器的一个示例:
varying highp vec2 textureCoordinate;
uniform sampler2D inputImageTexture;
void main()
{
lowp vec4 textureColor = texture2D(inputImageTexture, textureCoordinate);
lowp vec4 outputColor;
outputColor.r = (textureColor.r * 0.393) + (textureColor.g * 0.769) + (textureColor.b * 0.189);
outputColor.g = (textureColor.r * 0.349) + (textureColor.g * 0.686) + (textureColor.b * 0.168);
outputColor.b = (textureColor.r * 0.272) + (textureColor.g * 0.534) + (textureColor.b * 0.131);
outputColor.a = 1.0;
gl_FragColor = outputColor;
}
为了使图像过滤器可在GPUImage框架中使用,需要前两行采用textureCoordinate变化(对于纹理中的当前坐标,归一化为1.0)和inputImageTexture统一(对于实际的输入图像帧纹理) 。
着色器的其余部分在传入的纹理中的该位置捕获像素的颜色,以产生棕褐色调的方式对其进行操作,并将该像素颜色写出以用于下一步处理管道。
将片段着色器添加到Xcode项目时要注意的一件事是Xcode认为它们是源代码文件。要解决此问题,您需要将着色器从“编译源”构建阶段手动移至“复制捆绑包资源”,以便使着色器包含在应用程序捆绑包中。
过滤和重新编码电影
可以通过GPUImageMovie类将电影加载到框架中,进行过滤,然后使用GPUImageMovieWriter将其写出。GPUImageMovieWriter的速度也足够快,可以以640x480的速度从iPhone 4的摄像头实时录制视频,因此可以将直接过滤的视频源输入其中。目前,GPUImageMovieWriter的速度足以在iPhone 4上以高达20 FPS的速度录制实时720p视频,而在iPhone 4S(以及新iPad)上以30 FPS的速度录制720p和1080p的视频。
以下是如何加载示例电影,将其通过像素化滤镜传递,然后将结果记录为480 x 640 h.264电影的示例:
movieFile = [[GPUImageMovie alloc] initWithURL:sampleURL];
pixellateFilter = [[GPUImagePixellateFilter alloc] init];
[movieFile addTarget:pixellateFilter];
NSString *pathToMovie = [NSHomeDirectory() stringByAppendingPathComponent:@"Documents/Movie.m4v"];
unlink([pathToMovie UTF8String]);
NSURL *movieURL = [NSURL fileURLWithPath:pathToMovie];
movieWriter = [[GPUImageMovieWriter alloc] initWithMovieURL:movieURL size:CGSizeMake(480.0, 640.0)];
[pixellateFilter addTarget:movieWriter];
movieWriter.shouldPassthroughAudio = YES;
movieFile.audioEncodingTarget = movieWriter;
[movieFile enableSynchronizedEncodingUsingMovieWriter:movieWriter];
[movieWriter startRecording];
[movieFile startProcessing];
录制完成后,您需要从筛选器链中删除电影录像机,并使用如下代码关闭录制:
[pixellateFilter removeTarget:movieWriter];
[movieWriter finishRecording];
电影必须先完成,然后才能使用,因此,如果在此之前将其中断,则录制将丢失。
与OpenGL ES交互
GPUImage可以分别通过使用其GPUImageTextureOutput和GPUImageTextureInput类从OpenGL ES导出和导入纹理。这样,您就可以记录来自OpenGL ES场景的电影,该电影使用绑定的纹理渲染到帧缓冲区对象,或者过滤视频或图像,然后将它们作为纹理显示在OpenGL ES中,以在场景中显示。
使用此方法的一个警告是,必须通过共享组或类似方式在GPUImage的OpenGL ES上下文和任何其他上下文之间共享这些过程中使用的纹理。
内置过滤器
当前有125个内置过滤器,分为以下类别:
色彩调整
GPUImageBrightnessFilter:调整图像的亮度
- 亮度:调整后的亮度(-1.0-1.0,默认值为0.0)
GPUImageExposureFilter:调整图像的曝光
- 曝光:调整后的曝光(-10.0-10.0,默认值为0.0)
GPUImageContrastFilter:调整图像的对比度
- 对比度:调整后的对比度(0.0-4.0,默认值为1.0)
GPUImageSaturationFilter:调整图像的饱和度
- 饱和度:应用于图像的饱和度或去饱和度(0.0-2.0,默认值为1.0)
GPUImageGammaFilter:调整图像的灰度系数
- gamma:要应用的gamma调整(0.0-3.0,默认值为1.0)
GPUImageLevelsFilter:类似Photoshop的色阶调整。min,max,minOut和maxOut参数在[0,1]范围内浮动。如果来自Photoshop的参数在[0,255]范围内,则必须首先将它们转换为[0,1]。gamma / mid参数是一个float> =0。它与Photoshop中的值匹配。如果要对RGB以及各个通道应用级别,则需要两次使用此滤镜-首先用于单个通道,然后用于所有通道。
GPUImageColorMatrixFilter:通过将矩阵应用于图像来变换图像的颜色
- colorMatrix:一个4x4矩阵,用于转换图像中的每种颜色
- 强度:新转换的颜色替换每个像素的原始颜色的程度
GPUImageRGBFilter:调整图像的各个RGB通道
- 红色:每个色彩通道相乘的归一化值。范围从0.0开始,默认值为1.0。
- 绿色:
- 蓝色:
GPUImageHueFilter:调整图像的色调
- 色调:色调角度,以度为单位。默认为90度
GPUImageVibranceFilter:调整图像的鲜艳度
- vibrance:要应用的vibrance调整,默认设置为0.0,建议的最小/最大值分别为-1.2和1.2。
GPUImageWhiteBalanceFilter:调整图像的白平衡。
- temperature:调整图像所用的温度,以ºK为单位。值4000非常凉爽,而7000非常温暖。默认值为5000。请注意,在4000和5000之间的比例在视觉上与在5000和7000之间的比例几乎相同。
- 色调:用于调整图像的色调。值-200表示非常绿色,而200表示非常粉红色。默认值为0。
GPUImageToneCurveFilter:基于样条曲线为每个颜色通道调整图像的颜色。
- redControlPoints:
- greenControlPoints:
- blueControlPoints:
- rgbCompositeControlPoints:色调曲线采用一系列控制点,这些控制点定义了每个颜色分量或复合物中所有三个分量的样条曲线。这些以NSValue包裹的CGPoints的形式存储在NSArray中,其标准化的X和Y坐标为0-1。默认值为(0,0),(0.5,0.5),(1,1)。
GPUImageHighlightShadowFilter:调整图像的阴影和高光
- 阴影:增加阴影以使阴影变淡,从0.0到1.0,默认值为0.0。
- Highlights:从1.0降低到0.0,以1.0为默认值将高光变暗。
GPUImageHighlightShadowTintFilter:允许您使用颜色和强度独立地着色图像的阴影和高光
- shadowTintColor:阴影色调RGB颜色(GPUVector4)。默认值:(
{1.0f, 0.0f, 0.0f, 1.0f}红色)。 - highlightTintColor:高亮色调RGB颜色(GPUVector4)。默认值:(
{0.0f, 0.0f, 1.0f, 1.0f}蓝色)。 - shadowTintIntensity:阴影着色强度,从0.0到1.0。默认值:0.0
- highlightTintIntensity:突出显示色调强度,从0.0到1.0,默认值为0.0。
- shadowTintColor:阴影色调RGB颜色(GPUVector4)。默认值:(
GPUImageLookupFilter:使用RGB颜色查找图像来重新映射图像中的颜色。首先,使用您最喜欢的照片编辑应用程序将滤镜应用于GPUImage / framework / Resources中的lookup.png。为了使其正常工作,每个像素的颜色都不得依赖于其他像素(例如,模糊将不起作用)。如果需要更复杂的过滤器,则可以根据需要创建任意多个查找表。准备就绪后,将新的lookup.png文件用作GPUImageLookupFilter的第二个输入。
GPUImageAmatorkaFilter:基于Amatorka的Photoshop动作的照片滤镜:http ://amatorka.deviantart.com/art/Amatorka-Action-2-121069631 。如果要使用此效果,则必须将GPUImage Resources文件夹中的lookup_amatorka.png添加到应用程序包中。
GPUImageMissEtikateFilter:基于Etikate小姐的Photoshop动作的照片滤镜:http ://miss-etikate.deviantart.com/art/Photoshop-Action-15-120151961 。如果要使用此效果,则必须将GPUImage Resources文件夹中的lookup_miss_etikate.png添加到应用程序包中。
GPUImageSoftEleganceFilter:另一个基于查找的颜色重新映射滤镜。如果要使用此效果,则必须将GPUImage Resources文件夹中的lookup_soft_elegance_1.png和lookup_soft_elegance_2.png添加到应用程序包中。
GPUImageSkinToneFilter:肤色调整滤镜,可影响浅色肤色的唯一范围,并相应地调整粉红色/绿色或粉红色/橙色范围。默认值针对白皙的皮肤,但可以根据需要进行调整。
- skinToneAdjust:调整肤色的量。默认值:0.0,建议的最小/最大值:分别为-0.3和0.3。
- skinHue:要检测的皮肤色调。默认值:0.05(白皙至泛红皮肤)。
- skinHueThreshold:皮肤色调的变化量。默认值:40.0。
- maxHueShift:允许的最大色相偏移量。默认值:0.25
- maxSaturationShift =要移动的最大饱和量(使用橙色时)。默认值:0.4
- upperSkinToneColor =
GPUImageSkinToneUpperColorGreen或GPUImageSkinToneUpperColorOrange
GPUImageColorInvertFilter:反转图像的颜色
GPUImageGrayscaleFilter:将图像转换为灰度(饱和度滤镜的实现速度稍快,但无法改变颜色的贡献)
GPUImageMonochromeFilter:根据每个像素的亮度,将图像转换为单色版本
- strength:特定颜色替换正常图像颜色的程度(0.0-1.0,默认值为1.0)
- color:用作效果基础的颜色,默认为(0.6,0.45,0.3,1.0)。
GPUImageFalseColorFilter:使用图像的亮度在两种用户指定的颜色之间进行混合
- firstColor:第一种和第二种颜色分别指定什么颜色替换图像的暗区和亮区。默认值为(0.0,0.0,0.5)amd(1.0,0.0,0.0)。
- secondColor:
GPUImageHazeFilter:用于添加或删除雾度(类似于UV滤镜)
- distance:所应用颜色的强度。默认值为0。最佳值为-.3到.3。
- 斜率:颜色变化的量。默认值为0。最佳值为-.3到.3。
GPUImageSepiaFilter:简单的棕褐色调滤镜
- 强度:棕褐色替换正常图像颜色的程度(0.0-1.0,默认值为1.0)
GPUImageOpacityFilter:调整传入图像的Alpha通道
- opacity:将每个像素的输入Alpha通道乘以(0.0-1.0,默认值为1.0)的值
GPUImageSolidColorGenerator:这会输出生成的纯色图像。您需要使用-forceProcessingAtSize定义图像大小:
- color:用于填充图像的颜色,采用四部分格式。
GPUImageLuminanceThresholdFilter:亮度高于阈值的像素将显示为白色,而低于阈值的像素将为黑色
- threshold:亮度阈值,从0.0到1.0,默认值为0.5
GPUImageAdaptiveThresholdFilter:确定像素周围的局部亮度,如果像素低于该局部亮度,则将其变为黑色,如果高于该像素,则将其变为白色。这对于在变化的光照条件下挑选文本很有用。
- blurRadiusInPixels:背景平均模糊半径(以像素为单位)的倍数,默认为4。
GPUImageAverageLuminanceThresholdFilter:这将应用阈值操作,其中将根据场景的平均亮度连续调整阈值。
- thresholdMultiplier:这是平均亮度将被乘以达到最终使用阈值的一个因素。默认情况下,该值为1.0。
GPUImageHistogramFilter:这将分析传入的图像并创建一个输出直方图,其输出每个颜色值的频率。该滤波器的输出是一个3像素高,256像素宽的图像,其中心(垂直)像素包含与发生各种颜色值的频率相对应的像素。每个颜色值占据256个宽度位置之一,从左侧的0到右侧的255。可以为单个颜色通道(kGPUImageHistogramRed,kGPUImageHistogramGreen,kGPUImageHistogramBlue),图像亮度(kGPUImageHistogramLuminance)或一次为所有三个颜色通道(kGPUImageHistogramRGB)生成此直方图。
- downsamplingFactor:不是决定对每个像素进行采样,而是决定要对图像的哪个部分进行采样。默认情况下,它是16,最小值为1。这是防止饱和直方图的必要条件,直方图在每种颜色值变得过载之前只能记录256个像素。
GPUImageHistogramGenerator:这是一个特殊的过滤器,主要用于与GPUImageHistogramFilter一起使用。它生成由GPUImageHistogramFilter生成的颜色直方图的输出表示形式,但可以重新用于显示其他类型的值。它获取图像并查看中心(垂直)像素。然后,它将RGB分量的数值绘制在输出纹理的单独的彩色图形中。您可能需要为此过滤器设置一个大小,以使其输出可见。
GPUImageAverageColor:通过对图像中每个像素的RGBA分量求平均值,此处理输入图像并确定场景的平均颜色。约简过程用于在GPU上逐步对源图像进行下采样,然后在CPU上进行短暂的平均计算。该过滤器的输出毫无意义,但是您需要将colorAverageProcessingFinishedBlock属性设置为一个包含四个颜色分量和一个帧时间并对它们执行某些操作的块。
GPUImageLuminosity:与GPUImageAverageColor一样,这会将图像降低到其平均亮度。您需要设置luminosityProcessingFinishedBlock来处理此过滤器的输出,该过滤器仅返回一个发光度值和一个帧时间。
GPUImageChromaKeyFilter:对于图像中的给定颜色,将alpha通道设置为0。这与GPUImageChromaKeyBlendFilter相似,只是不将第二个图像混合为匹配的颜色,而不会在第二个图像中取而代之颜色透明。
- thresholdSensitivity:颜色匹配需要与要替换的目标颜色之间的接近程度(默认值为0.4)
- 平滑:混合颜色时的平滑程度(默认值为0.1)
图像处理
GPUImageTransformFilter:这会将任意2D或3D变换应用于图像
- affineTransform:这需要一个CGAffineTransform来调整二维图像
- transform3D:这需要一个CATransform3D来处理3-D图像
- ignoreAspectRatio:默认情况下,将保持变换图像的纵横比,但是可以将其设置为YES,以使变换与纵横比无关
GPUImageCropFilter:将图像裁剪到特定区域,然后仅将该区域传递到滤镜的下一个阶段
- cropRegion:要裁剪出图像的矩形区域,将其标准化为0.0-1.0的坐标。(0.0,0.0)位置在图像的左上方。
GPUImageLanczosResamplingFilter:这使您可以使用Lanczos重采样对图像进行上采样或下采样,其质量明显优于标准线性或三线性插值。只需使用-forceProcessingAtSize:即可设置过滤器的目标输出分辨率,然后将针对该新大小重新采样图像。
GPUImageSharpenFilter:锐化图像
- 清晰度:要应用的清晰度调整(-4.0-4.0,默认值为0.0)
GPUImageUnsharpMaskFilter:应用不清晰的蒙版
- blurRadiusInPixels:基础高斯模糊的模糊半径。默认值为4.0。
- 强度:锐化的强度,从在多达0.0,与1.0的默认
GPUImageGaussianBlurFilter:硬件优化的可变半径高斯模糊
- texelSpacingMultiplier:像素间距的乘数,范围从0.0开始,默认值为1.0。进行调整可能会稍微增加模糊强度,但会在结果中引入伪影。强烈建议您先使用其他参数,然后再触摸此参数。
- blurRadiusInPixels:用于模糊的半径(以像素为单位),默认值为2.0。这将调整高斯分布函数中的sigma变量。
- blurRadiusAsFractionOfImageWidth:
- blurRadiusAsFractionOfImageHeight:设置这些属性将允许模糊半径随图像的大小缩放
- blurPasses:顺序模糊传入图像的次数。通过的次数越多,过滤器的速度就越慢。
GPUImageBoxBlurFilter:硬件优化的可变半径框模糊
- texelSpacingMultiplier:像素间距的乘数,范围从0.0开始,默认值为1.0。进行调整可能会稍微增加模糊强度,但会在结果中引入伪影。强烈建议您先使用其他参数,然后再触摸此参数。
- blurRadiusInPixels:用于模糊的半径(以像素为单位),默认值为2.0。这将调整高斯分布函数中的sigma变量。
- blurRadiusAsFractionOfImageWidth:
- blurRadiusAsFractionOfImageHeight:设置这些属性将允许模糊半径随图像的大小缩放
- blurPasses:顺序模糊传入图像的次数。通过的次数越多,过滤器的速度就越慢。
GPUImageSingleComponentGaussianBlurFilter:对GPUImageGaussianBlurFilter的修改,仅对红色组件起作用
- texelSpacingMultiplier:像素间距的乘数,范围从0.0开始,默认值为1.0。进行调整可能会稍微增加模糊强度,但会在结果中引入伪影。强烈建议您先使用其他参数,然后再触摸此参数。
- blurRadiusInPixels:用于模糊的半径(以像素为单位),默认值为2.0。这将调整高斯分布函数中的sigma变量。
- blurRadiusAsFractionOfImageWidth:
- blurRadiusAsFractionOfImageHeight:设置这些属性将允许模糊半径随图像的大小缩放
- blurPasses:顺序模糊传入图像的次数。通过的次数越多,过滤器的速度就越慢。
GPUImageGaussianSelectiveBlurFilter:高斯模糊,可将焦点保留在圆形区域内
- blurRadiusInPixels:用于模糊的半径(以像素为单位),默认值为5.0。这将调整高斯分布函数中的sigma变量。
- excludeCircleRadius:从模糊中排除的圆形区域的半径
- excludeCirclePoint:从模糊中排除的圆形区域的中心
- excludeBlurSize:模糊部分和透明圆之间的区域大小
- AspectRatio:图像的纵横比,用于调整对焦区域的圆度。默认情况下,它与图像的宽高比匹配,但是您可以覆盖此值。
GPUImageGaussianBlurPositionFilter:GPUImageGaussianSelectiveBlurFilter的反函数,仅在特定圆圈内应用模糊
- blurSize:模糊大小的乘数,范围从0.0开始,默认为1.0
- blurCenter:模糊的中心,默认为0.5、0.5
- blurRadius:模糊的半径,默认为1.0
GPUImageiOSBlurFilter:尝试在控制中心等地方复制iOS 7上使用的背景模糊。
- blurRadiusInPixels:用于模糊的半径(以像素为单位),默认值为12.0。这将调整高斯分布函数中的sigma变量。
- 饱和度:饱和度范围从0.0(完全饱和)到2.0(最大饱和度),正常水平为0.8
- 下采样:下采样然后上采样传入图像的程度,以最小化高斯模糊内的计算,默认值为4.0。
GPUImageMedianFilter:获取3x3区域中三个颜色分量的中值
GPUImageBilateralFilter:双向模糊,它尝试在保留锐利边缘的同时模糊相似的颜色值
- texelSpacingMultiplier:texel读取之间的间隔的乘数,范围从0.0开始,默认为4.0
- distanceNormalizationFactor:中心颜色和样本颜色之间的距离的归一化因子,默认值为8.0。
GPUImageTiltShiftFilter:模拟的倾斜移位镜头效果
- blurRadiusInPixels:基础模糊的半径,以像素为单位。默认情况下是7.0。
- topFocusLevel:图像中对焦区域顶部的标准化位置,此值应小于bottomFocusLevel,默认值为0.4
- bottomFocusLevel:图像中对焦区域底部的标准化位置,此值应高于topFocusLevel,默认值为0.6
- focusFallOffRate:图像从对焦区域模糊的速率,默认为0.2
GPUImage3x3ConvolutionFilter:对图像运行3x3卷积内核
- convolutionKernel:卷积内核是一个3x3的值矩阵,适用于该像素及其周围的8个像素。矩阵以行优先顺序指定,左上像素为one.one,右下像素为three.three。如果矩阵中的值之和不等于1.0,则图像可能变亮或变暗。
GPUImageSobelEdgeDetectionFilter:Sobel边缘检测,边缘以白色突出显示
- texelWidth:
- texelHeight:这些参数影响检测到的边缘的可见性
- edgeStrength:调整滤镜的动态范围。较高的值会导致边缘更牢固,但会饱和强度颜色空间。默认值为1.0。
GPUImagePrewittEdgeDetectionFilter:Prewitt边缘检测,边缘以白色突出显示
- texelWidth:
- texelHeight:这些参数影响检测到的边缘的可见性
- edgeStrength:调整滤镜的动态范围。较高的值会导致边缘更牢固,但会饱和强度颜色空间。默认值为1.0。
GPUImageThresholdEdgeDetectionFilter:执行Sobel边缘检测,但是应用阈值而不是给出逐渐的强度值
- texelWidth:
- texelHeight:这些参数影响检测到的边缘的可见性
- edgeStrength:调整滤镜的动态范围。较高的值会导致边缘更牢固,但会饱和强度颜色空间。默认值为1.0。
- threshold:高于此阈值的任何边缘将为黑色,低于白色的任何边缘。范围从0.0到1.0,默认值为0.8
GPUImageCannyEdgeDetectionFilter:这使用完整的Canny流程突出显示一像素宽的边缘
- texelWidth:
- texelHeight:这些参数影响检测到的边缘的可见性
- blurRadiusInPixels:高斯模糊的基础模糊半径。默认值为2.0。
- blurTexelSpacingMultiplier:基础的模糊纹理像素间距乘数。默认值为1.0。
- upperThreshold:任何梯度幅度大于此阈值的边都将通过并显示在最终结果中。默认值为0.4。
- lowerThreshold:任何梯度幅度低于此阈值的边将失败,并从最终结果中删除。默认值为0.1。
GPUImageHarrisCornerDetectionFilter:在输入图像上运行哈里斯角点检测算法,并生成一个图像,这些角点为白色像素,其他所有颜色均为黑色。可以设置cornersDetectedBlock,并且在回调中将为您提供您要执行的所有其他操作的角列表(以标准化的0..1 X,Y坐标表示)。
- blurRadiusInPixels:基础高斯模糊的半径。默认值为2.0。
- 敏感度:一个内部比例因子,用于调整在滤镜中生成的边角图的动态范围。默认值为5.0。
- threshold:检测到一个点作为拐角的阈值。根据尺寸,光线条件和iOS设备摄像头类型的不同,此方法可能会有很大的不同,因此可能需要一些试验才能确定适合您的情况。默认值为0.20。
Runtime底层原理--动态方法解析总结
方法的底层会编译成消息,消息进行递归,先从实例方法开始查找,到父类最后到NSObject。如果在汇编部分快速查找没有找到IMP,就会进入C/C++中的动态方法解析进入lookUpImpOrForward方法进行递归。
动态方法解析
动态方法解析分为实例方法和类方法两种。
实例方法查找imp流程和动态方法解析
比如执行一个Student实例方法eat,会先去这个类中查找是否有该方法(sel),如果有则进行存储以便下次直接从汇编部分快速查找。
// Try this class's cache.
// Student元类 - 父类 (根元类) -- NSObject
// resovleInstance 防止递归 --
imp = cache_getImp(cls, sel);
if (imp) goto done;
// Try this class's method lists.
{
Method meth = getMethodNoSuper_nolock(cls, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, cls);
imp = meth->imp;
goto done;
}
}如果没有sel那么接下来去父类(直到NSObject)的缓存和方法列表找查找。如果在父类中找到先缓存再执行done.
// 元类的父类 - NSObject 是否有 实例方法
for (Class curClass = cls->superclass;
curClass != nil;
curClass = curClass->superclass)
{
// Halt if there is a cycle in the superclass chain.
if (--attempts == 0) {
_objc_fatal("Memory corruption in class list.");
}
// Superclass cache.
imp = cache_getImp(curClass, sel);
if (imp) {
if (imp != (IMP)_objc_msgForward_impcache) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, imp, sel, inst, curClass);
goto done;
}如果最终还是没找到,则会进入动态方法解析_class_resolveMethod,先判断当前cls对象是不是元类,也就是如果是对象方法会走到_class_resolveInstanceMethod方法,
/***********************************************************************
* _class_resolveMethod
* Call +resolveClassMethod or +resolveInstanceMethod.
* Returns nothing; any result would be potentially out-of-date already.
* Does not check if the method already exists.
**********************************************************************/
void _class_resolveMethod(Class cls, SEL sel, id inst)
{
if (! cls->isMetaClass()) {
// try [cls resolveInstanceMethod:sel]
_class_resolveInstanceMethod(cls, sel, inst);
}
else {
// try [nonMetaClass resolveClassMethod:sel]
// and [cls resolveInstanceMethod:sel]
_class_resolveClassMethod(cls, sel, inst);
if (!lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
_class_resolveInstanceMethod(cls, sel, inst);
}
}
}如果元类,那么执行_class_resolveInstanceMethod(cls, sel, inst)方法,该方法会执行lookUpImpOrNil(cls->ISA(), SEL_resolveInstanceMethod, cls, NO/*initialize*/, YES/*cache*/, NO/*resolver*/),查找当前的cls的isa是否实现了resolveInstanceMethod,也就是是否有自定义实现、是否重写了。如果查到了就会给类对象发送消息objc_msgSend,调起resolveInstanceMethod方法
/***********************************************************************
* lookUpImpOrNil.
* Like lookUpImpOrForward, but returns nil instead of _objc_msgForward_impcache
**********************************************************************/
IMP lookUpImpOrNil(Class cls, SEL sel, id inst,
bool initialize, bool cache, bool resolver)
{
IMP imp = lookUpImpOrForward(cls, sel, inst, initialize, cache, resolver);
if (imp == _objc_msgForward_impcache) return nil;
else return imp;
}lookUpImpOrNil的内部是通过lookUpImpOrForward方法进行查找,再次回到递归调用。
如果还是没查到,这里就不会再次进入动态方法解析(注:如果再次进入动态方法解析会形成死递归),首先对cls的元类进行查找,然后元类的父类,也就是根元类(系统默认实现的虚拟的)进行查找、最终到NSObjece,只不过NSObjece中默认实现resolveInstanceMethod方法返回NO,也就是此时在元类进行查找的时候找到了resolveInstanceMethod方法,并停止继续查找,这就是为什么动态方法解析后的递归没有再次进入动态方法解析的原因。如果最终还是没有找到SEL_resolveInstanceMethod则说明程序有问题,直接返回。下面是isa走位图:

如果找到的imp不是转发的imp,则返回imp。
举个例子:
在Student中有个对象run方法,但是并没有实现,当调用run方法时,最终没有找到imp会崩溃。通过动态方法解析,实现run方法
#pragma mark - 动态方法解析
+ (BOOL)resolveInstanceMethod:(SEL)sel {
NSLog(@"动态方法解析 - %@",self);
if (sel == @selector(run)) {
// 我们动态解析对象方法
NSLog(@"对象方法 run 解析走这里");
SEL readSEL = @selector(readBook);
Method readM= class_getInstanceMethod(self, readSEL);
IMP readImp = method_getImplementation(readM);
const char *type = method_getTypeEncoding(readM);
return class_addMethod(self, sel, readImp, type);
}
return [super resolveInstanceMethod:sel];
}此时只是给对象方法添加了一个imp,接下来再次进入查找imp流程,重复之前的操作,只不过现在对象方法已经有了imp。
/***********************************************************************
* _class_resolveInstanceMethod
* Call +resolveInstanceMethod, looking for a method to be added to class cls.
* cls may be a metaclass or a non-meta class.
* Does not check if the method already exists.
**********************************************************************/
static void _class_resolveInstanceMethod(Class cls, SEL sel, id inst)
{
if (! lookUpImpOrNil(cls->ISA(), SEL_resolveInstanceMethod, cls,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
// Resolver not implemented.
return;
}
BOOL (*msg)(Class, SEL, SEL) = (typeof(msg))objc_msgSend;
bool resolved = msg(cls, SEL_resolveInstanceMethod, sel);
// Cache the result (good or bad) so the resolver doesn't fire next time.
// +resolveInstanceMethod adds to self a.k.a. cls
IMP imp = lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/);
// ...省略N行代码动态方法解析的实质: 经过漫长的查找并没有找到sel的imp,系统会发送resolveInstanceMethod消息,为了防止系统崩溃,可以在该方法内对sel添加imp,系统会自动再次查找imp。
类方法查找imp流程和动态方法解析
类方法查找imp流程和实例方法查找imp前面流程一样,也是从汇编部分快速查找,之后判断cls是不是元类,在元类方法列表中查找,如果元类中没有当前的sel,就去元类的父类中查找,还没有就去根元类的父类NSObject中查找,此时查找的就是NSObject中是否有这个实例对象方法,如果NSObject中也没有就会进入动态方法解析_class_resolveMethod。类对象这里的cls和对象方法不一样,因为cls是元类所以直接走_class_resolveClassMethod方法。进入_class_resolveClassMethod方法还是先判断resolveClassMethod方法是否有实现,之后发送消息objc_msgSend,这里和实例方法有所区别,类方法会执行_class_getNonMetaClass方法,内部实现getNonMetaClass,getNonMetaClass会判断当前cls是不是NSObject,判断当前的cls是不是根元类,也就是自己,接下来判断inst类对象,判断inst类对象的isa如果不是元类,那么返回类对象的父类,不是就返回类对象。在_class_resolveClassMethod方法中添加了imp后还是和实例方法一样,再次进入重新查找流程,此时如果还是没有,那么类方法还会再一次的进入_class_resolveInstanceMethod方法,和实例方法不同的是resolveInstanceMethod方法内部的cls是元类,所以找的方法也就是- (BOOL)resolveClassMethod:(SEL)sel,可以在NSObject中添加+ (BOOL)resolveClassMethod:(SEL)sel方法,这样无论类方法还是实例方法都会走到这里,可以作为防崩溃的处理。
/***********************************************************************
* getNonMetaClass
* Return the ordinary class for this class or metaclass.
* `inst` is an instance of `cls` or a subclass thereof, or nil.
* Non-nil inst is faster.
* Used by +initialize.
* Locking: runtimeLock must be read- or write-locked by the caller
**********************************************************************/
static Class getNonMetaClass(Class metacls, id inst)
{
static int total, named, secondary, sharedcache;
runtimeLock.assertLocked();
realizeClass(metacls);
total++;
// return cls itself if it's already a non-meta class
if (!metacls->isMetaClass()) return metacls;
// metacls really is a metaclass
// special case for root metaclass
// where inst == inst->ISA() == metacls is possible
if (metacls->ISA() == metacls) {
Class cls = metacls->superclass;
assert(cls->isRealized());
assert(!cls->isMetaClass());
assert(cls->ISA() == metacls);
if (cls->ISA() == metacls) return cls;
}
// use inst if available
if (inst) {
Class cls = (Class)inst;
realizeClass(cls);
// cls may be a subclass - find the real class for metacls
while (cls && cls->ISA() != metacls) {
cls = cls->superclass;
realizeClass(cls);
}
if (cls) {
assert(!cls->isMetaClass());
assert(cls->ISA() == metacls);
return cls;
}我们在Student类中添加未实现的类方法walk,在NSObject类中添加一个对象方法walk,运行程序不会崩溃。类方法先递归,开始找父类,最终在NSObject类中好到对象方法walk。
TIP:对象方法存储在类中,类方法存储在元类里面,类对象以实例方法的形式存储在元类中。可以通过输出class_getInstanceMethod方法和class_getClassMethod方法的imp指针来验证,当然源码也可以解释在cls的元类中查找实例方法
/***********************************************************************
* class_getClassMethod. Return the class method for the specified
* class and selector.
**********************************************************************/
Method class_getClassMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
return class_getInstanceMethod(cls->getMeta(), sel);
}还可以通过LLDB进行验证,动态方法解析的时候执行lookUpImpOrForward(Class cls, SEL sel, id inst, bool initialize, bool cache, bool resolver)方法,这里的cls就是inst的元类
# define ISA_MASK 0x00007ffffffffff8ULL
// -------------------------------------------------
#if SUPPORT_NONPOINTER_ISA
inline Class
objc_object::ISA()
{
assert(!isTaggedPointer());
#if SUPPORT_INDEXED_ISA
if (isa.nonpointer) {
uintptr_t slot = isa.indexcls;
return classForIndex((unsigned)slot);
}
return (Class)isa.bits;
#else
return (Class)(isa.bits & ISA_MASK);
#endif
}这里看到初始化的时候isa.bits & ISA_MASK,我们先后打印cls和inst的信息,也可以验证当前指针指向当前的元类。

动态方法解析作用
适用于重定向,也可以做防崩溃处理,也可以做一些错误日志收集等等。动态方法解析本质就是提供机会(任何没有实现的方法都可以重新实现)。
转自:https://www.jianshu.com/p/a7db9f0c82d6
收起阅读 »7种经常使用的Vue.js模式?你居然还不知道!!
说实话,阅读文档并不是我们大多数人喜欢的事情,但当使用像Vue这样不断发展的现代前端框架时,很多东西会随着每一个新版本的发布而改变,你可能会错过一些后来推出的新的闪亮功能。让我们看一下那些有趣但不那么流行的功能和优化的写法。请记住,所有这些都是Vue文档的一部分。
7种Vue.js模式
1.处理加载状态
在大型应用程序中,我们可能需要将应用程序划分为更小的块,只有在需要时才从服务器加载组件。为了使这一点更容易,Vue允许你将你的组件定义为一个工厂函数,它异步解析你的组件定义。Vue只有在需要渲染组件时才会触发工厂函数,并将缓存结果,以便将来重新渲染。2.3版本的新功能是,异步组件工厂也可以返回一个如下格式的对象。
const AsyncComponent = () => ({
// 要加载的组件(应为Promise)
component: import('./MyComponent.vue'),
// 异步组件正在加载时要使用的组件
loading: LoadingComponent,
// 加载失败时使用的组件
error: ErrorComponent,
// 显示加载组件之前的延迟。默认值:200ms。
delay: 200,
// 如果提供并超过了超时,则会显示error组件。默认值:无穷。
timeout: 3000
})通过这种方法,你有额外的加载和错误状态、组件获取的延迟和超时等选项。
2.廉价的“v-once”静态组件
在Vue中渲染纯HTML元素的速度非常快,但有时你可能有一个包含大量静态内容的组件。在这种情况下,你可以通过在根元素中添加 v-once 指令来确保它只被评估一次,然后进行缓存,就像这样。
Vue.component('terms-of-service', {
template: `
<div v-once>
<h1>Terms of Service</h1>
... a lot of static content ...
</div>
`
})3.递归组件
name: 'stack-overflow',
template: '<div><stack-overflow></stack-overflow></div>'像上面这样的组件会导致“超过最大堆栈大小”的错误,所以要确保递归调用是有条件的即(使用 v-if 最终将为 false)
4.内联模板
当特殊属性 inline-template 存在于一个子组件上时,该组件将使用它的内部内容作为它的模板,而不是将其视为分布式内容,这允许更灵活的模板编写。
<my-component inline-template>
<div>
<p>These are compiled as the component's own template.</p>
<p>Not parent's transclusion content.</p>
</div>
</my-component>5.动态指令参数
指令参数可以是动态的。例如,在 v-mydirective:[argument]=“value" 中, argument 可以根据组件实例中的数据属性更新!这使得我们的自定义指令可以灵活地在整个应用程序中使用。
这是一条指令,其中可以根据组件实例更新动态参数:
<div id="dynamicexample">
<h3>Scroll down inside this section ↓</h3>
<p v-pin:[direction]="200">I am pinned onto the page at 200px to the left.</p>
</div>
Vue.directive('pin', {
bind: function (el, binding, vnode) {
el.style.position = 'fixed'
var s = (binding.arg == 'left' ? 'left' : 'top')
el.style[s] = binding.value + 'px'
}
})
new Vue({
el: '#dynamicexample',
data: function () {
return {
direction: 'left'
}
}
})6.事件和键修饰符
on: {
'!click': this.doThisInCapturingMode,
'~keyup': this.doThisOnce,
'~!mouseover': this.doThisOnceInCapturingMode
}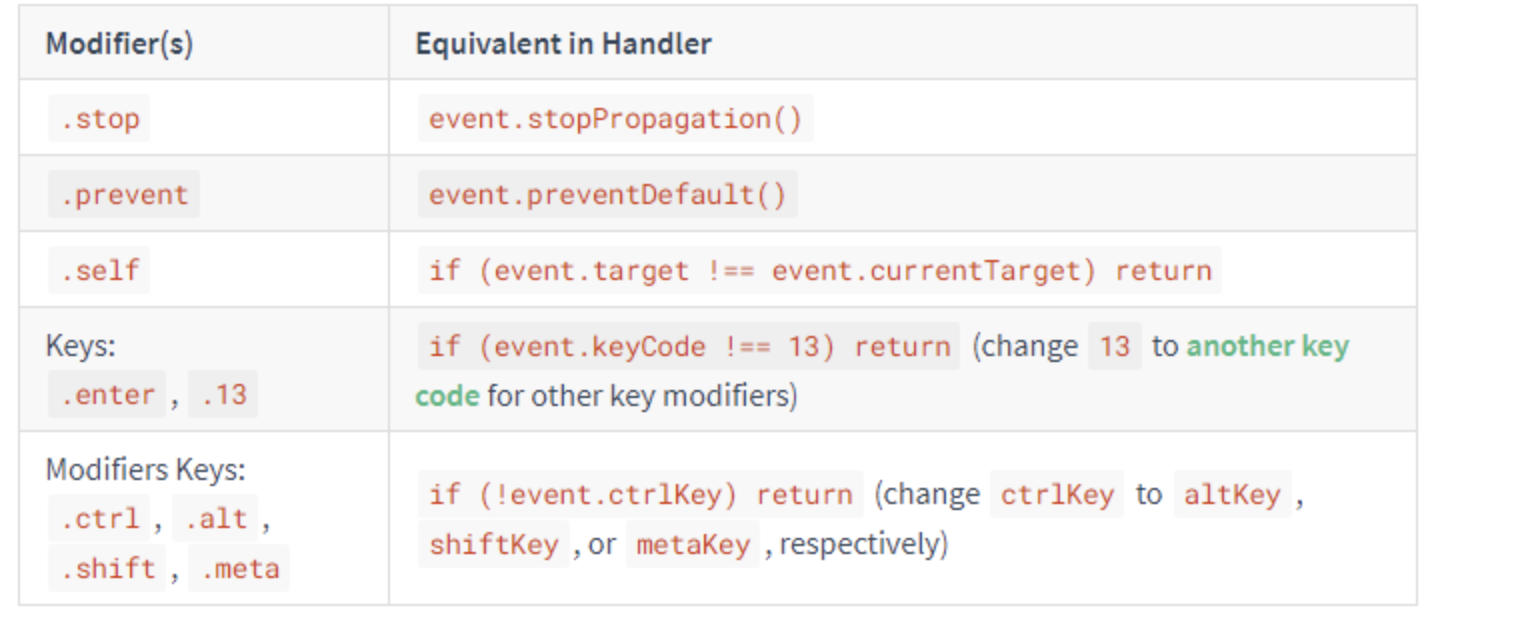
7.依赖注入(Provide/Inject)
有几种方法可以让两个组件在 Vue 中进行通信,它们各有优缺点。在2.2版本中引入的一种新方法是使用Provide/Inject的依赖注入。
这对选项一起使用,允许一个祖先组件作为其所有子孙的依赖注入器,无论组件层次结构有多深,只要它们在同一个父链上。如果你熟悉React,这与React的上下文功(context)能非常相似。
// parent component providing 'foo'
var Provider = {
provide: {
foo: 'bar'
},
// ...
}
// child component injecting 'foo'
var Child = {
inject: ['foo'],
created () {
console.log(this.foo) // => "bar"
}
// ...
}iOS Files文件应用程序开发
前言:
最近在做一个项目,需要用到文件选取、上传、下载功能,首先想到的就是iOS11自带的“文件”应用。“文件”算是一个中转站,是iOS系统的文件管理器,可以为各个项目提供私有的文件夹,进行文件管理。
iOS11已经提供了相当完善的接口,本文基于此开发过程的总结,给出iOS11的桌面“文件”应用程序进行相关开发的经验。文中若有错漏之处,恳请大家批评指正。
两种开发模式
1、将qq或微信的文档拷贝到自己项目中,即拷贝模式;
2、将qq或微信的文档存储到“文件”中,即存储模式
拷贝模式开发步骤:
(1)打开项目中的info.plist,添加“Document Types”键值:
(2)项目运行安装到真机上。打开微信或qq里的文档,从右上角的“...”按钮选择“用其他应用打开”;

(3)此时将看到自己的项目已经存在其他应用的列表上,选择“拷贝到xxx”,选择拷贝到自己开发的项目;
(4)点击“拷贝到xxx”后,将跳转到自己项目中。需要在自己项目的AppDelegate.m文件中处理回调;
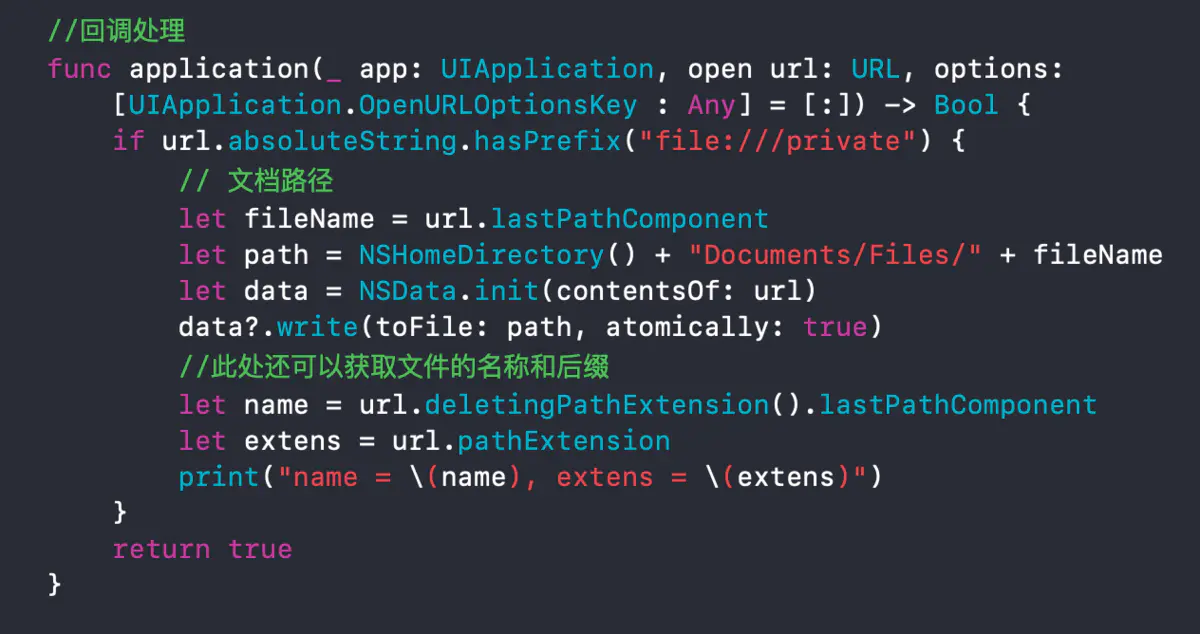
(5)后续步骤可以做一个本地文件管理界面(类似相册图片的九宫格展示,或者列表形式),进行本地文件管理,读取、上传、下载,这里就不展开讨论了。
存储模式的开发步骤:
(1)打开项目中的info.plist,添加“Supports Document Browser”键值:

(2)项目运行安装到真机上。打开微信或qq里的文档,从右上角的“...”按钮选择“用其他应用打开”;
(3)在弹窗中选择存储到“文件”,将文件存储到系统的“文件”应用程序;
(4)在打开的“文件”应用程序中,选择添加到自己的项目;
(5)在项目中编写代码,获取“文件”应用程序中刚刚的存储文件,代码如下:
(6)运行代码,将项目安装到真机上,进入代码所在的页面,打开“文件”面板,即可看到在“文件”里的本项目名称的文件夹,选择刚才的文件即可。
转自:https://www.jianshu.com/p/e1e57f8e86c5
收起阅读 »vue传值方式总结 (十二种方法)
一.父传子传递
//父组件
<template>
<div>
<i>父组件</i>
<!--页面使用-->
<son :data='name'></son>
</div>
</template>
<script>
import son from "./son.vue";//导入父组件
export default {
components: { son },//注册组件
name: "父组件",
data() {
return {
name: "Frazier", //父组件定义变量
};
},
};
</script>//子组件
<template>
<div>{{data}}</div>
</template>
<script>
export default {
components: { },
name: '子组件',
props:["data"],
};
</script>二.子传父传递
//父组件
<template>
<div>
<i>父组件</i>
<!--页面使用-->
<son @lcclick="lcclick"></son>//自定义一个事件
</div>
</template>
<script>
import son from "./son.vue"; //导入父组件
export default {
components: { son }, //注册组件
name: "父组件",
data() {
return {};
},
methods: {
lcclick(){
alert('子传父')
}
},
};
</script>//子组件
<template>
<div>
<button @click="lcalter">点我</button>
</div>
</template>
<script>
export default {
components: { },
name: '子组件',
methods: {
lcalter(){
this.$emit('lcclick')//通过emit来触发事件
}
},
};
</script>三.兄弟组件通信(bus总线)
(1)在src中新建一个Bus.js的文件,然后导出一个空的vue实例
(2)在传输数据的一方引入Bus.js 然后通过Bus.e m i t ( “ 事 件 名 ” , " 参 数 " ) 来 来 派 发 事 件 , 数 据 是 以 emit(“事件名”,"参数")来来派发事件,数据是以emit(“事件名”,"参数")来来派发事件,数据是以emit()的参 数形式来传递
(3)在接受的数据的一方 引入 Bus.js 然后通过 Bus.$on(“事件名”,(data)=>{data是接受的数据})
图片示例:


四.ref/refs(父子组件通信)
//父组件
<template>
<div>
<button @click="sayHello">sayHello</button>
<child ref="childForRef"></child>
</div>
</template>
<script>
import child from './child.vue'
export default {
components: { child },
data () {
return {
childForRef: null,
}
},
mounted() {
this.childForRef = this.$refs.childForRef;
console.log(this.childForRef.name);
},
methods: {
sayHello() {
this.childForRef.sayHello()
}
}
}
</script>//子组件
<template>
<div>child 的内容</div>
</template>
<script>
export default {
data () {
return {
name: '我是 child',
}
},
methods: {
sayHello () {
console.log('hello');
alert('hello');
}
}
}
</script>五.Vuex通信
//父组件
template>
<div id="app">
<ChildA/>
<ChildB/>
</div>
</template>
<script>
import ChildA from './ChildA' // 导入A组件
import ChildB from './ChildB' // 导入B组件
export default {
components: {ChildA, ChildB} // 注册组件
}
</script>//子组件A
<template>
<div id="childA">
<h1>我是A组件</h1>
<button @click="transform">点我让B组件接收到数据</button>
<p>因为点了B,所以信息发生了变化:{{BMessage}}</p>
</div>
</template>
<script>
export default {
data() {
return {
AMessage: 'Hello,B组件,我是A组件'
}
},
computed: {
BMessage() {
// 这里存储从store里获取的B组件的数据
return this.$store.state.BMsg
}
},
methods: {
transform() {
// 触发receiveAMsg,将A组件的数据存放到store里去
this.$store.commit('receiveAMsg', {
AMsg: this.AMessage
})
}
}
}
</script>//子组件B
<template>
<div id="childB">
<h1>我是B组件</h1>
<button @click="transform">点我让A组件接收到数据</button>
<p>点了A,我的信息发生了变化:{{AMessage}}</p>
</div>
</template>
<script>
export default {
data() {
return {
BMessage: 'Hello,A组件,我是B组件'
}
},
computed: {
AMessage() {
// 这里存储从store里获取的A组件的数据
return this.$store.state.AMsg
}
},
methods: {
transform() {
// 触发receiveBMsg,将B组件的数据存放到store里去
this.$store.commit('receiveBMsg', {
BMsg: this.BMessage
})
}
}
}
</script>//vuex
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
const state = {
AMsg: '',
BMsg: ''
}
const mutations = {
receiveAMsg(state, payload) {
// 将A组件的数据存放于state
state.AMsg = payload.AMsg
},
receiveBMsg(state, payload) {
// 将B组件的数据存放于state
state.BMsg = payload.BMsg
}
}
export default new Vuex.Store({
state,
mutations
})六.$parent
通过parent可以获父组件实例 ,然 后通过这个实例就可以访问父组件的属 性和方法 ,它还有一个兄弟parent可以获父组件实例,然后通过这个实例就可以访问父组件的属性和方法,它还有一个兄弟parent可以获父组件实例,然后通过这个实例就可以访问父组件的属性和方法,它还有一个兄弟root,可以获取根组件实例。
代码示例:
// 获父组件的数据
this.$parent.foo
// 写入父组件的数据
this.$parent.foo = 2
// 访问父组件的计算属性
this.$parent.bar
// 调用父组件的方法
this.$parent.baz()
//在子组件传给父组件例子中,可以使用this.$parent.getNum(100)传值给父组件。七.sessionStorage传值
// 保存数据到 sessionStorage
sessionStorage.setItem('key', 'value');
// 从 sessionStorage 获取数据
let data = sessionStorage.getItem('key');
// 从 sessionStorage 删除保存的数据
sessionStorage.removeItem('key');
// 从 sessionStorage 删除所有保存的数据
sessionStorage.clear();注意:里面存的是键值对,只能是字符串类型,如果要存对象的话,需要使用 let objStr = JSON.stringify(obj) 转成字符串然后再存储(使用的时候 let obj = JSON.parse(objStr) 解析为对象)。
推荐一个库 good-storage ,它封装了sessionStorage ,可以直接用它的API存对象
//localStorage
storage.set(key,val)
storage.get(key, def)
//sessionStorage
storage.session.set(key, val)
storage.session.get(key, val)八.路由传值
使用问号传值
A页面跳转B页面时使用 this.r o u t e r . p u s h ( ’ / B ? n a m e = d a n s e e k ’ ) B 页 面 可 以 使 用 t h i s . router.push(’/B?name=danseek’) B页面可以使用 this.router.push(’/B?name=danseek’)B页面可以使用this.route.query.name 来获取A页面传过来的值
上面要注意router和route的区别
使用冒号传值
配置如下路由:
{
path: '/b/:name',
name: 'b',
component: () => import( '../views/B.vue')
},在B页面可以通过 this.$route.params.name 来获取路由传入的name的值
使用父子组件传值
由于router-view本身也是一个组件,所以我们也可以使用父子组件传值方式传值,然后在对应的子页面里加上props,因为type更新后没有刷新路由,所以不能直接在子页面的mounted钩子里直接获取最新type的值,而要使用watch
<router-view :type="type"></router-view>
// 子页面
props: ['type']
watch: {
type(){
// console.log("在这个方法可以时刻获取最新的数据:type=",this.type)
},
},九.祖传孙 $attrs
<template>
<section>
<parent name="grandParent" sex="男" age="88" hobby="code" @sayKnow="sayKnow"></parent>
</section>
</template>
<script>
import Parent from './Parent'
export default {
name: "GrandParent",
components: {
Parent
},
data() {
return {}
},
methods: {
sayKnow(val){
console.log(val)
}
},
mounted() {
}
}
</script>template>
<section>
<p>父组件收到</p>
<p>祖父的名字:{{name}}</p>
<children v-bind="$attrs" v-on="$listeners"></children>
</section>
</template>
<script>
import Children from './Children'
export default {
name: "Parent",
components: {
Children
},
// 父组件接收了name,所以name值是不会传到子组件的
props:['name'],
data() {
return {}
},
methods: {},
mounted() {
}
}
</script><template>
<section>
<p>子组件收到</p>
<p>祖父的名字:{{name}}</p>
<p>祖父的性别:{{sex}}</p>
<p>祖父的年龄:{{age}}</p>
<p>祖父的爱好:{{hobby}}</p>
<button @click="sayKnow">我知道啦</button>
</section>
</template>
<script>
export default {
name: "Children",
components: {},
// 由于父组件已经接收了name属性,所以name不会传到子组件了
props:['sex','age','hobby','name'],
data() {
return {}
},
methods: {
sayKnow(){
this.$emit('sayKnow','我知道啦')
}
},
mounted() {
}
}
</script>十.孙传祖使用$listeners
<template>
<div id="app">
<children-one @eventOne="eventOne"></children-one>
{{ msg }}
</div>
</template>
<script>
import ChildrenOne from '../src/components/children.vue'
export default {
name: 'App',
components: {
ChildrenOne,
},
data() {
return {
msg: ''
}
},
methods: {
eventOne(value) {
this.msg = value
}
}
}
</script>//父组件
<template>
<div>
<children-two v-on="$listeners"></children-two>
</div>
</template>
<script>
import ChildrenTwo from './childrenTwo.vue'
export default {
name: 'childrenOne',
components: {
ChildrenTwo
}
}
</script>//子组建
<template>
<div>
<button @click="setMsg">点击传给祖父</button>
</div>
</template>
<script>
export default {
name: 'children',
methods: {
setMsg() {
this.$emit('eventOne', '123')
}
}
}
</script>十一.promise传参
//类似与这样使用,但实际上后面两个参数无法获取
promise = new Promise((resolve,reject)=>{
let a = 1
let b = 2
let c = 3
resolve(a,b,c)
})
promise.then((a,b,c)=>{
console.log(a,b,c)
})resolve() 只能接受并处理一个参数,多余的参数会被忽略掉。
如果想多个用数组,或者对象方式。。
数组
promise = new Promise((resolve,reject)=>{
resolve([1,2,3])
})
promise.then((arr)=>{
console.log(arr[0],arr[1],arr[2])
})对象
promise = new Promise((resolve,reject)=>{
resolve({a:1,b:2,c:3})
})
promise.then(obj=>{
console.log(obj.a,obj.b,obj.c)
})十二.全局变量
本文链接:https://blog.csdn.net/Frazier1995/article/details/116069811
前端必须要了解的一些知识 (十一)
六种基本数据类型
undefined
null
string
boolean
number
symbol(ES6)- 一种引用类型
- Object
string
- length属性
- prototype 添加的方法或属性在所有的实例上共享
- charAt(index) 返回值
- charCodeAt(index) 返回字符的Unicode编码
- indexOf(searchVal,index) 值所在的位置 param2是从位置开始算
- search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符
var str = 'abcDEF';
console.log(str.search('c')); //返回2
console.log(str.search('d')); //返回-1
console.log(str.search(/d/i)); //返回3Object
- 对象可以通过执行new操作符后跟要创建的对象类型的名称来创建。
前端错误的分类
即时运行错误:代码错误
资源加载错误
错误的捕获方式
代码错误
try...catch
window.onerror资源错误
object.onerror(不会冒泡到window):节点上绑定error事件
performance.getEntries:获取资源的加载时长
error的事件捕获:用捕获不用冒泡可以监控
上报错误的基本原理
1.ajax通讯方式上报
2.image对象上报
跨域的代码错误怎么捕获

![]()
前端必须要了解的一些知识 (十)
console.log(1)
setTimeout(){
console.log(2)
}
console.log(3)
1,3,2

console.log(A)
while(true){
}
console.log(B)
//只输出A while是个同步队列 。 进入死循环
----------------------------
console.log(A)
settimeout(){
console.log(B)
}
while(true){
}
//仍然只输出A 。 同步没执行完不会执行异步
-----------------------------
for(var i=0;i<4;i++){
settimeout(()=>{
console.log(i)
},1000)
}
//4次4




前端必须要了解的一些知识 (九)









