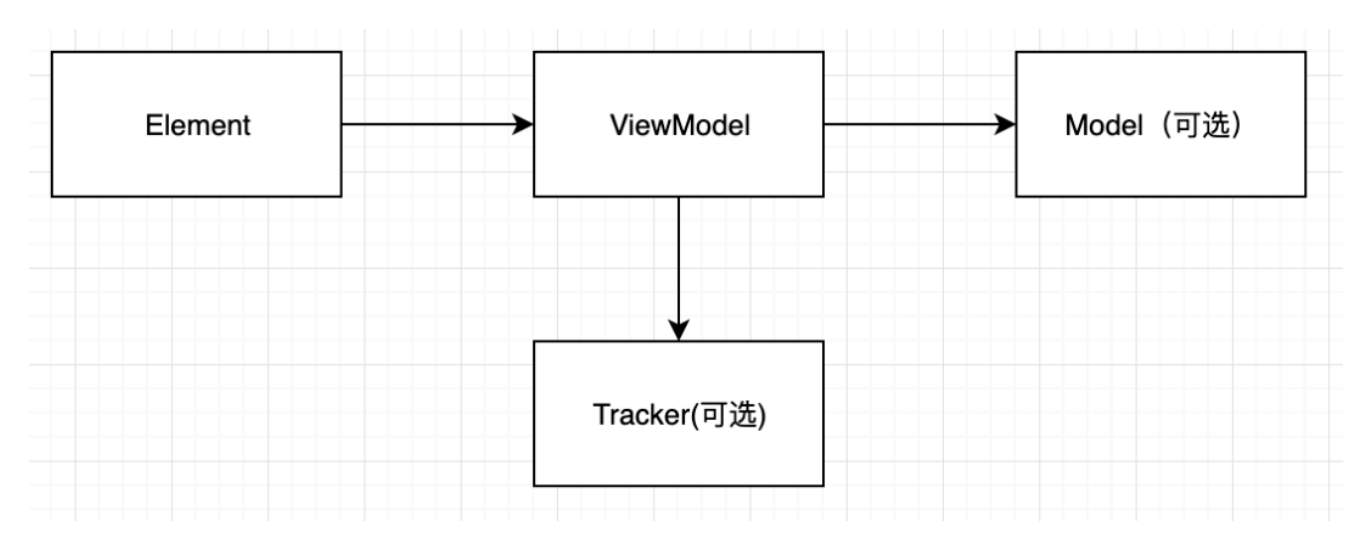
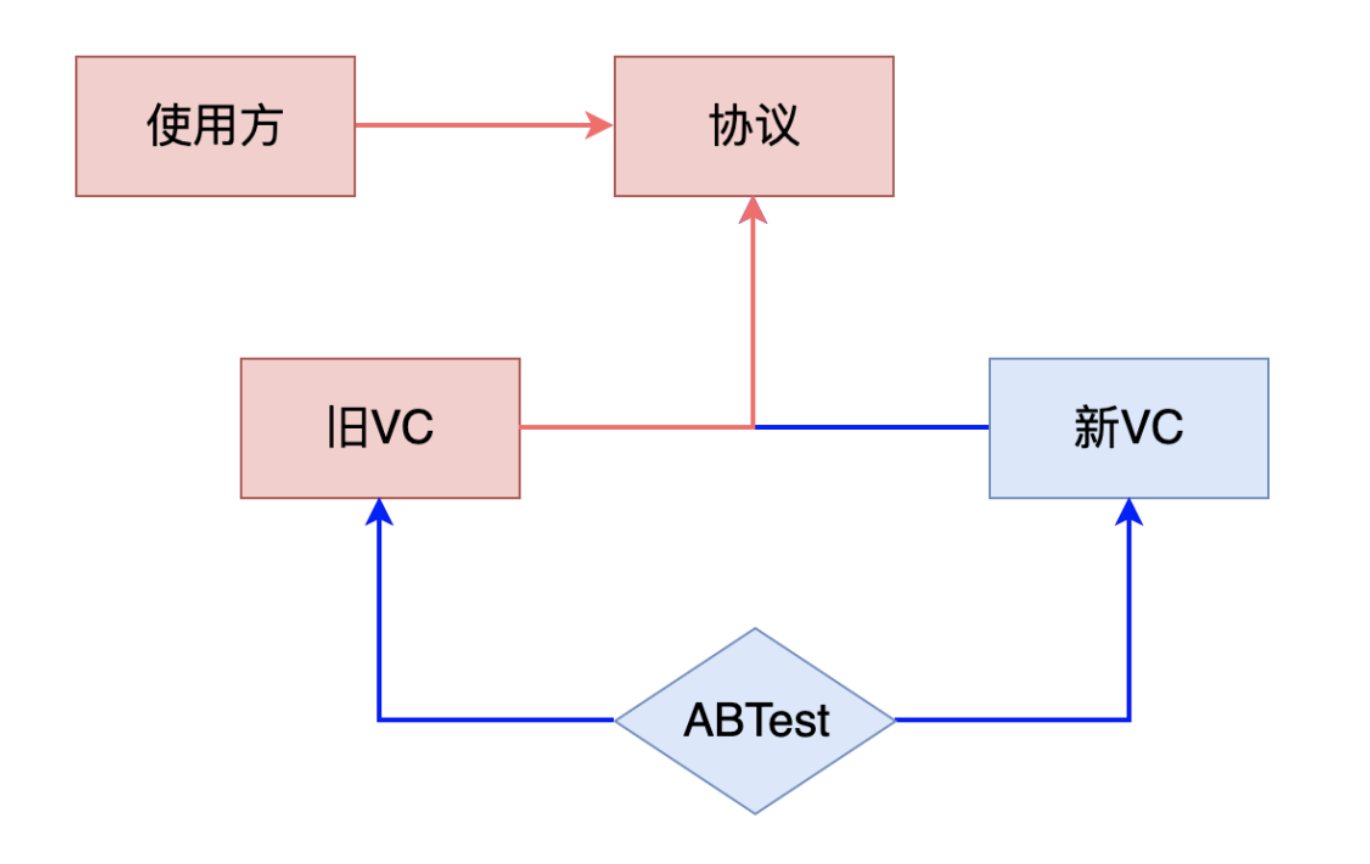
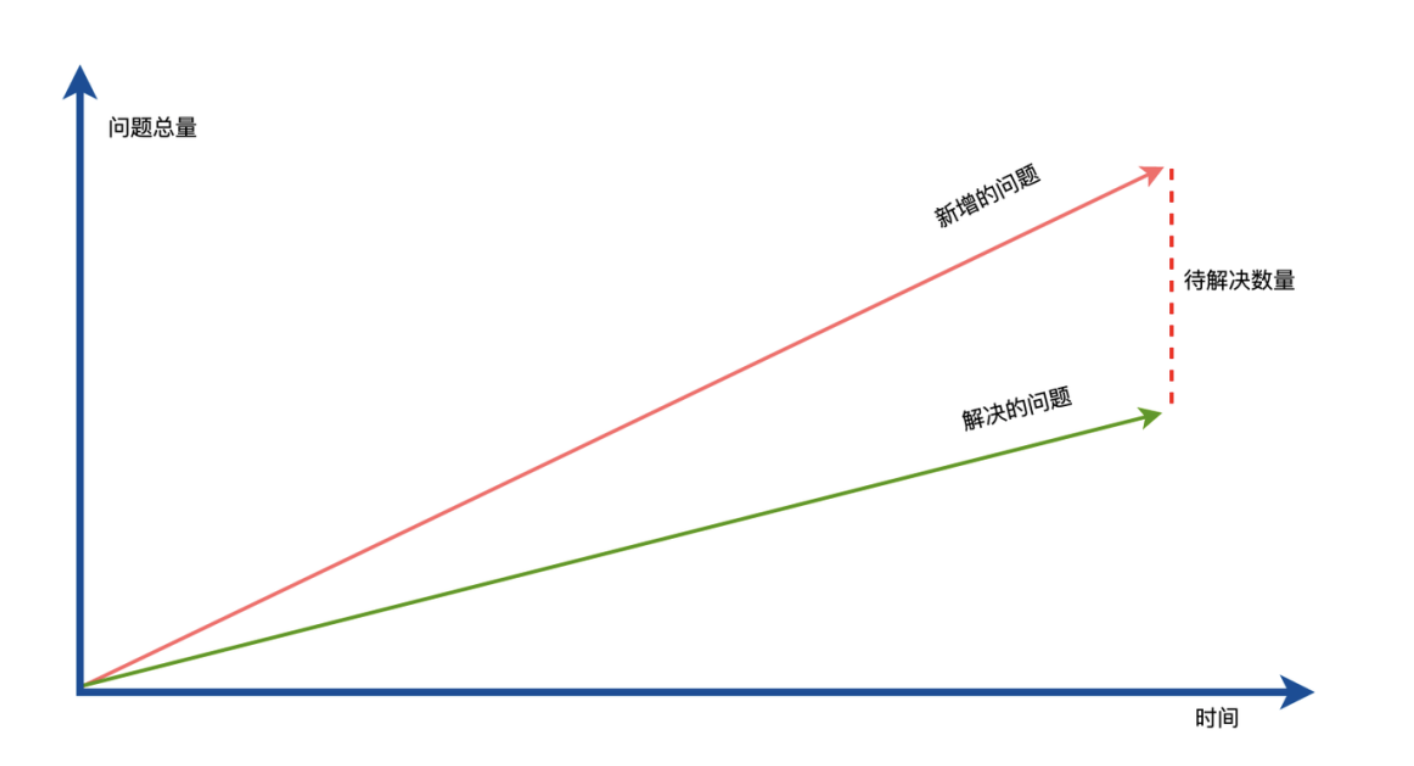
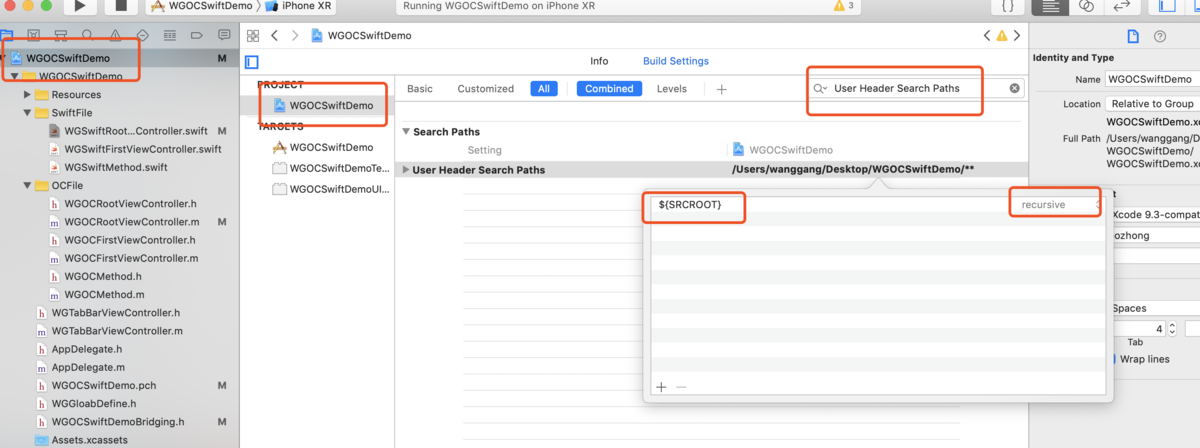
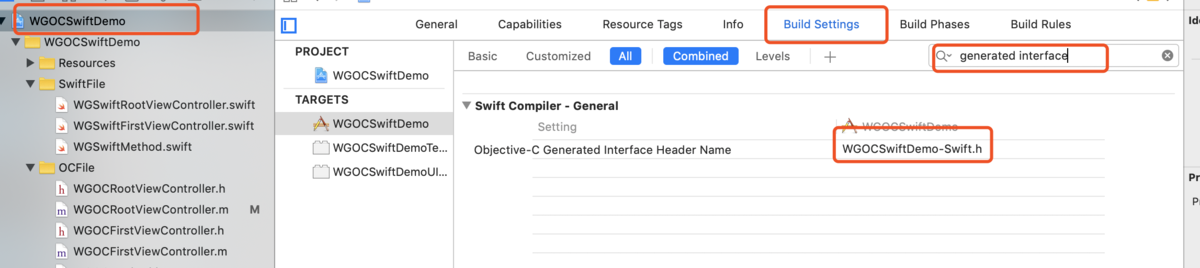
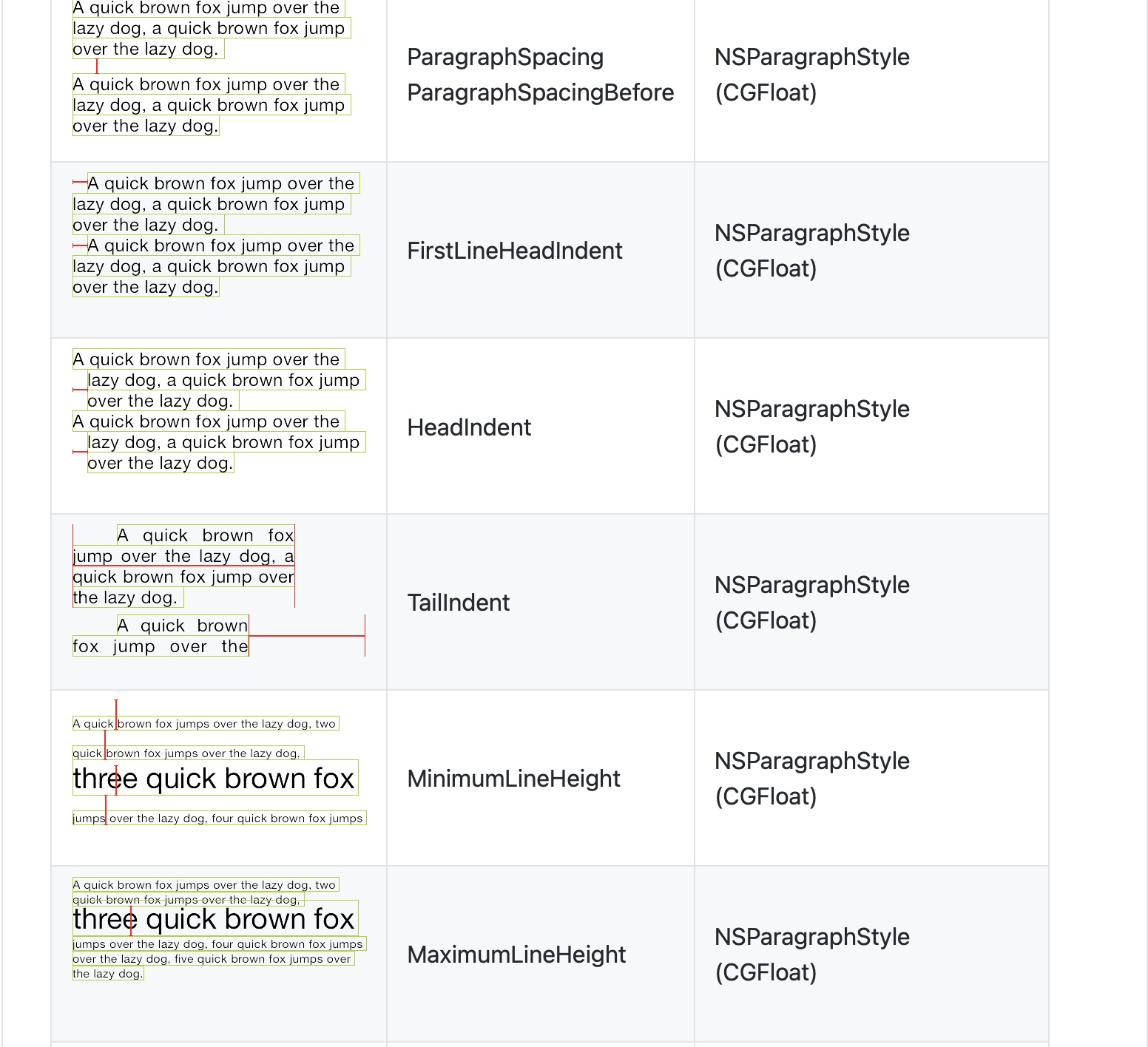
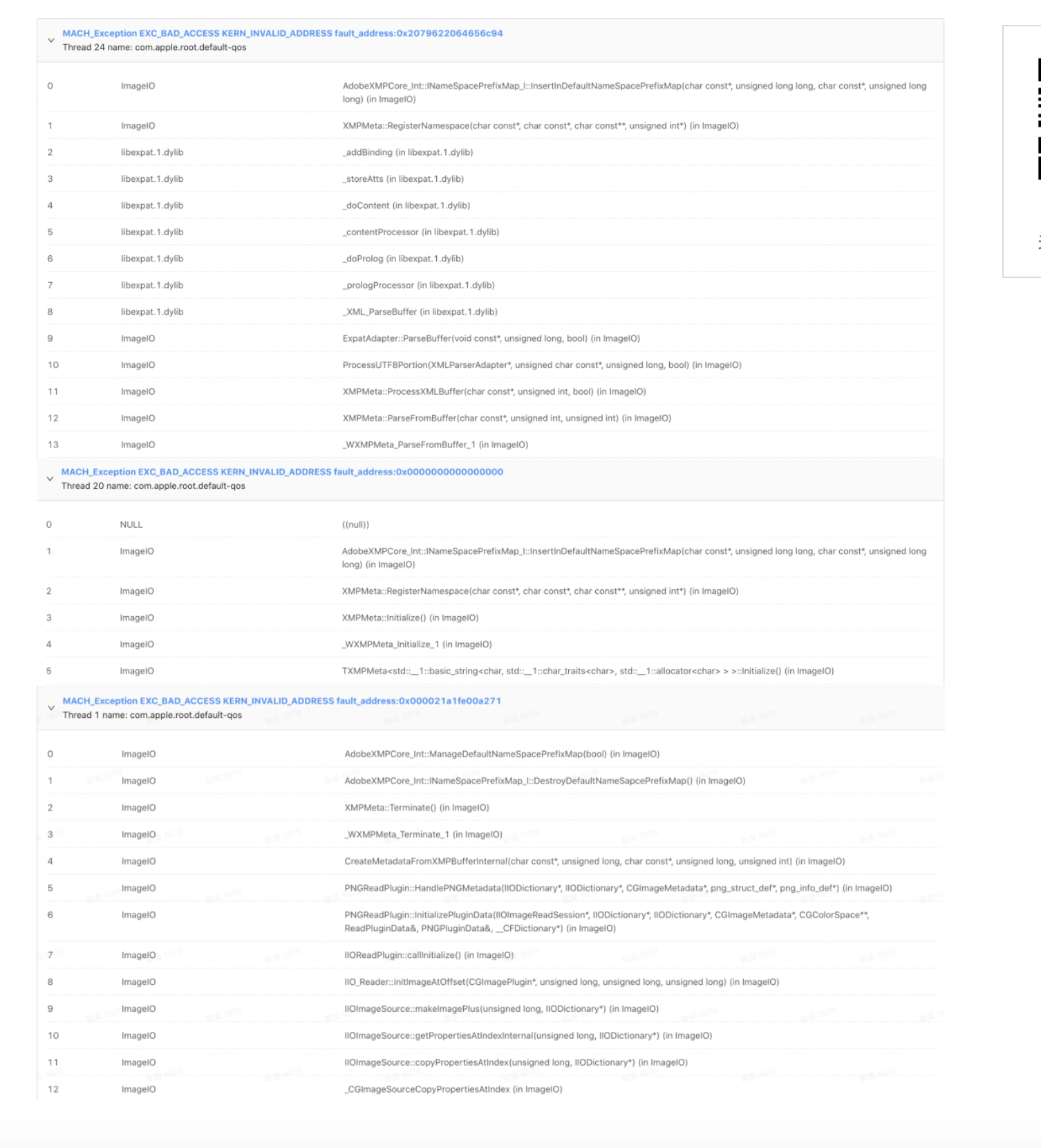
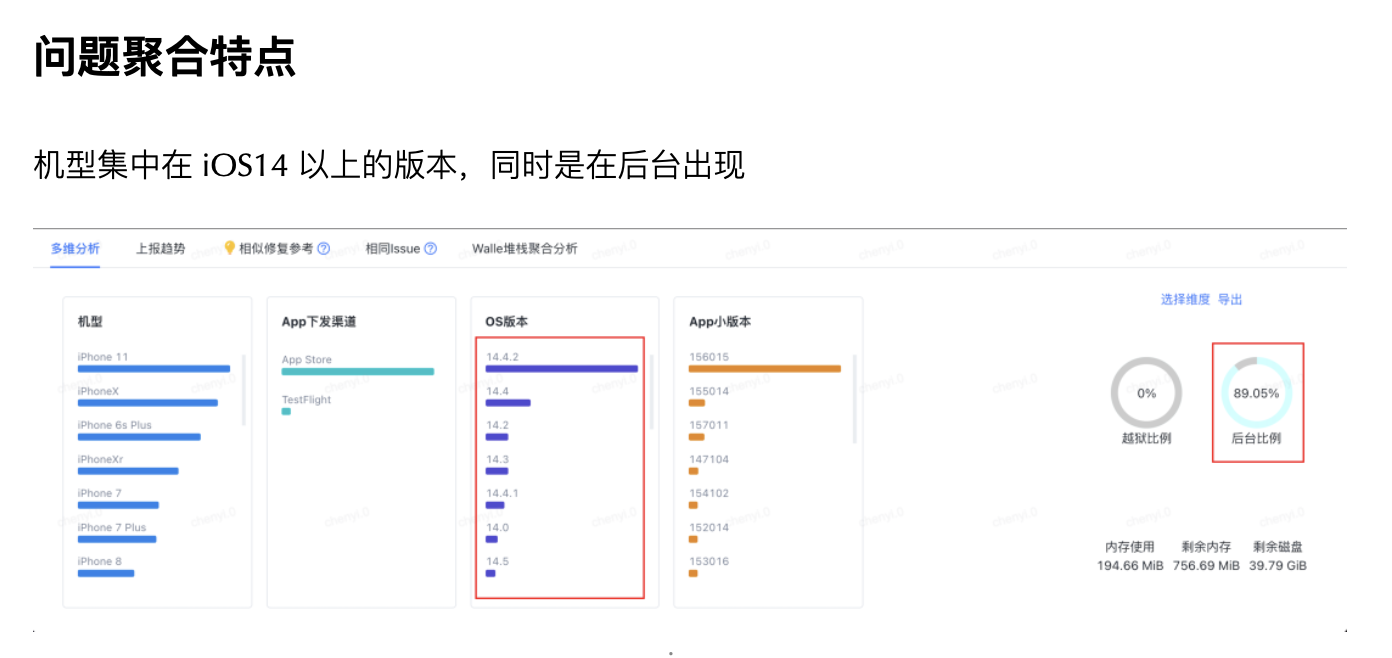
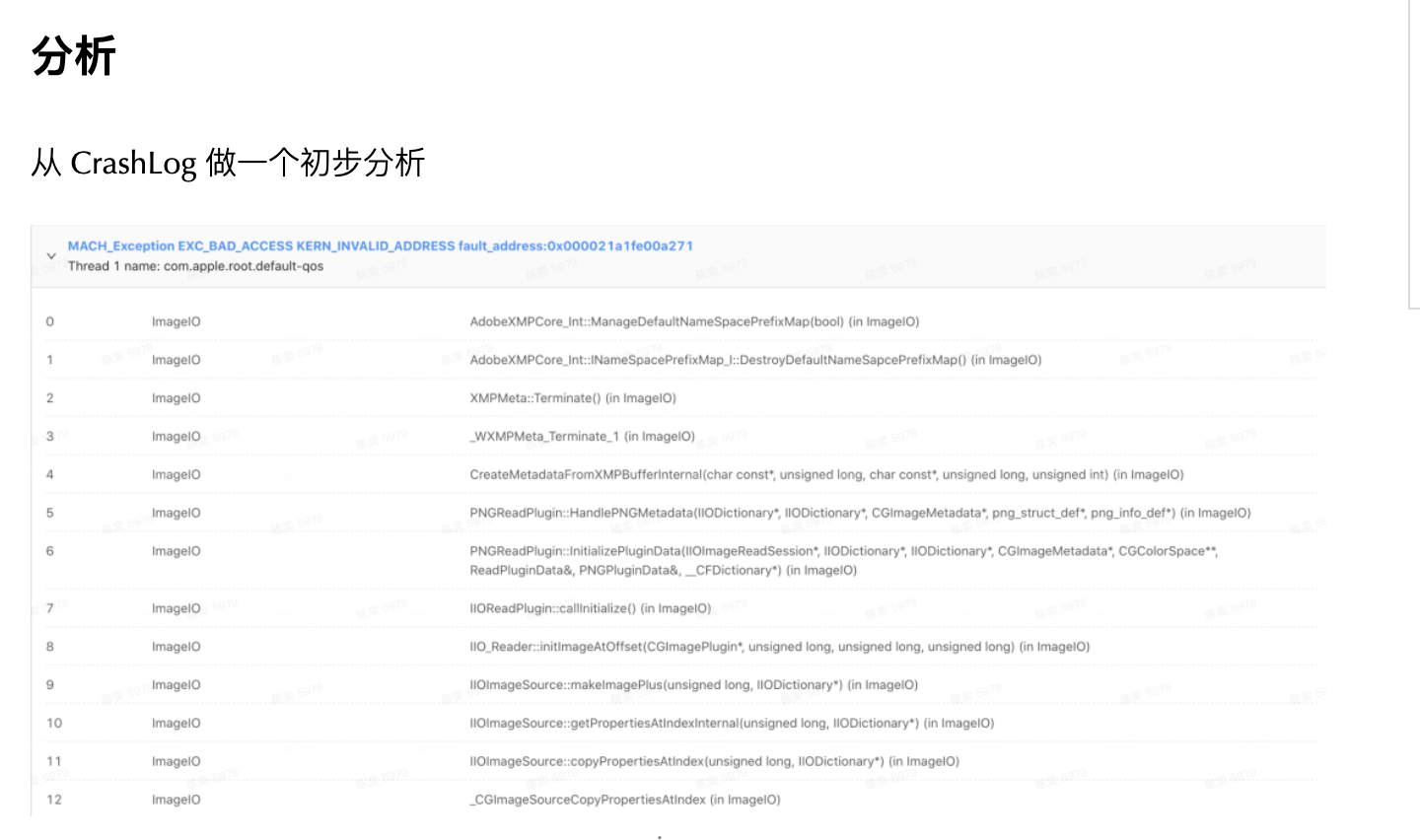
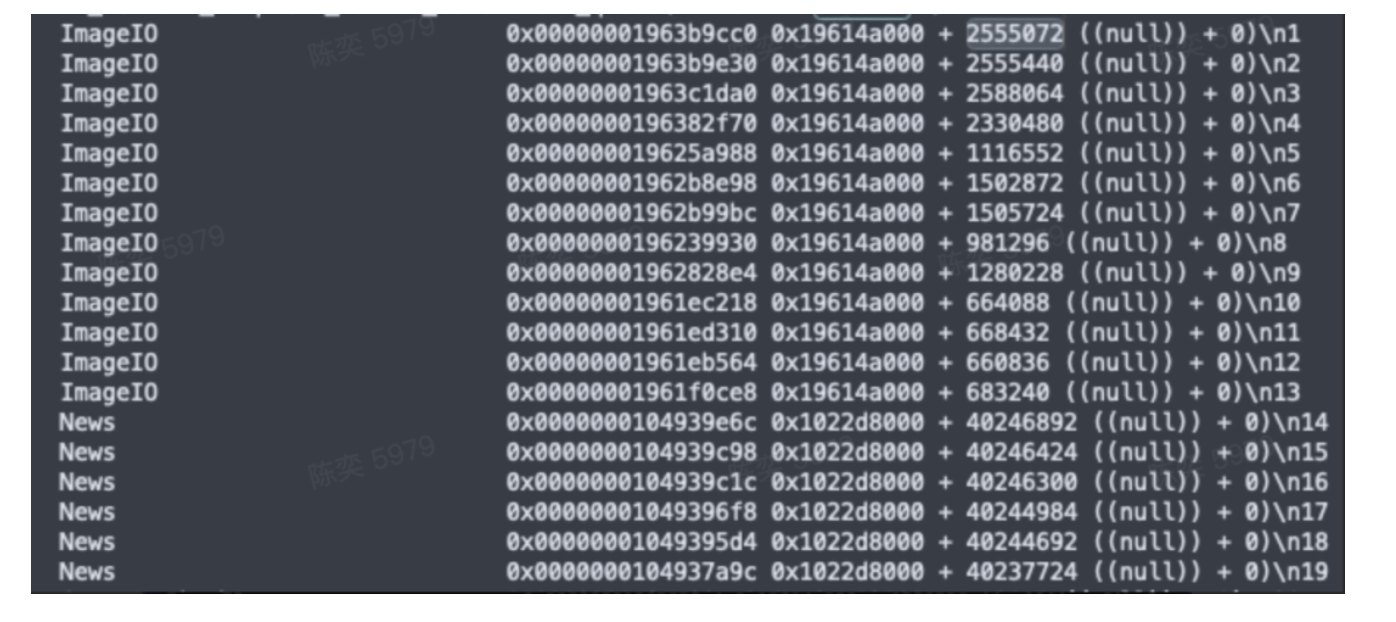
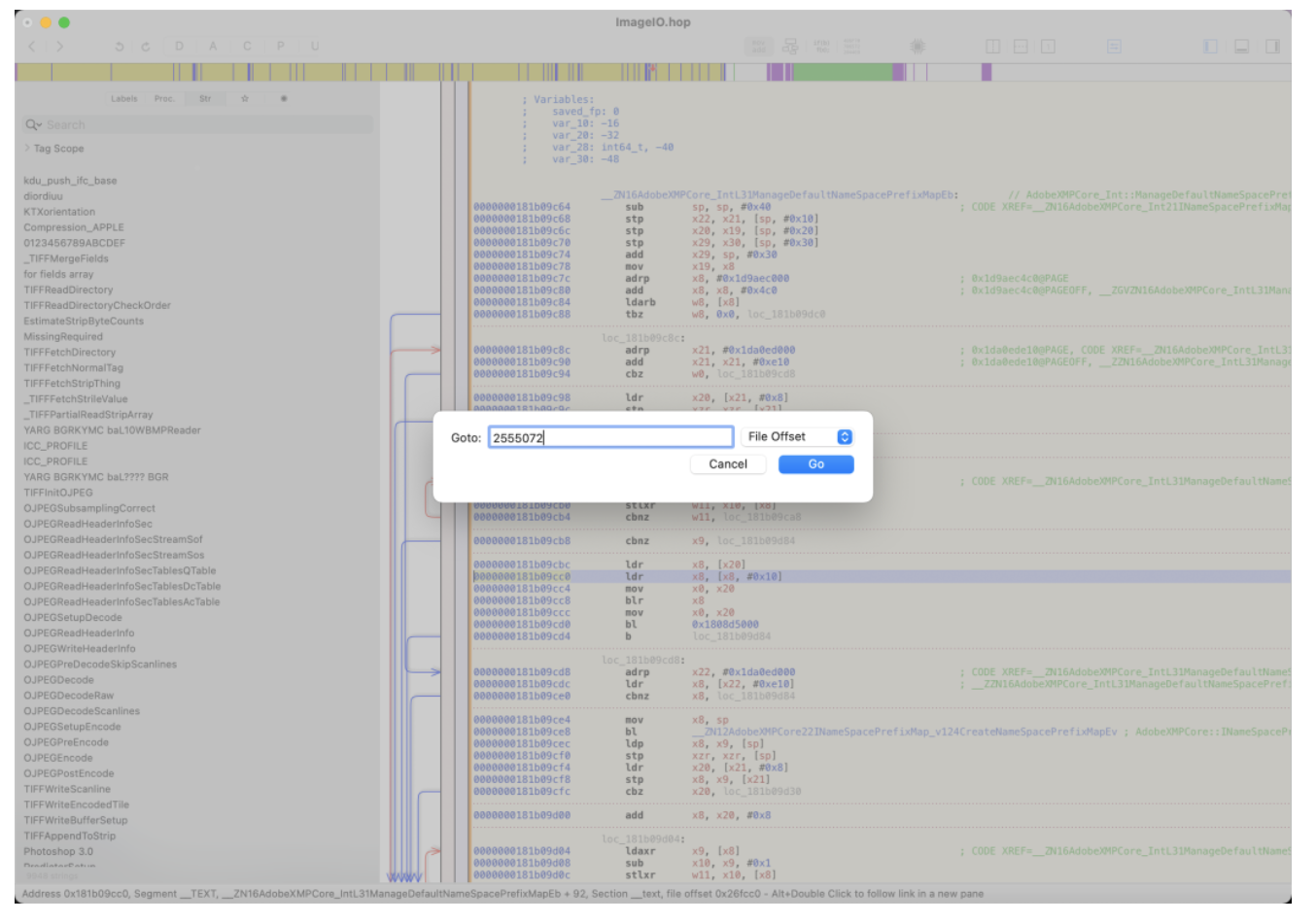
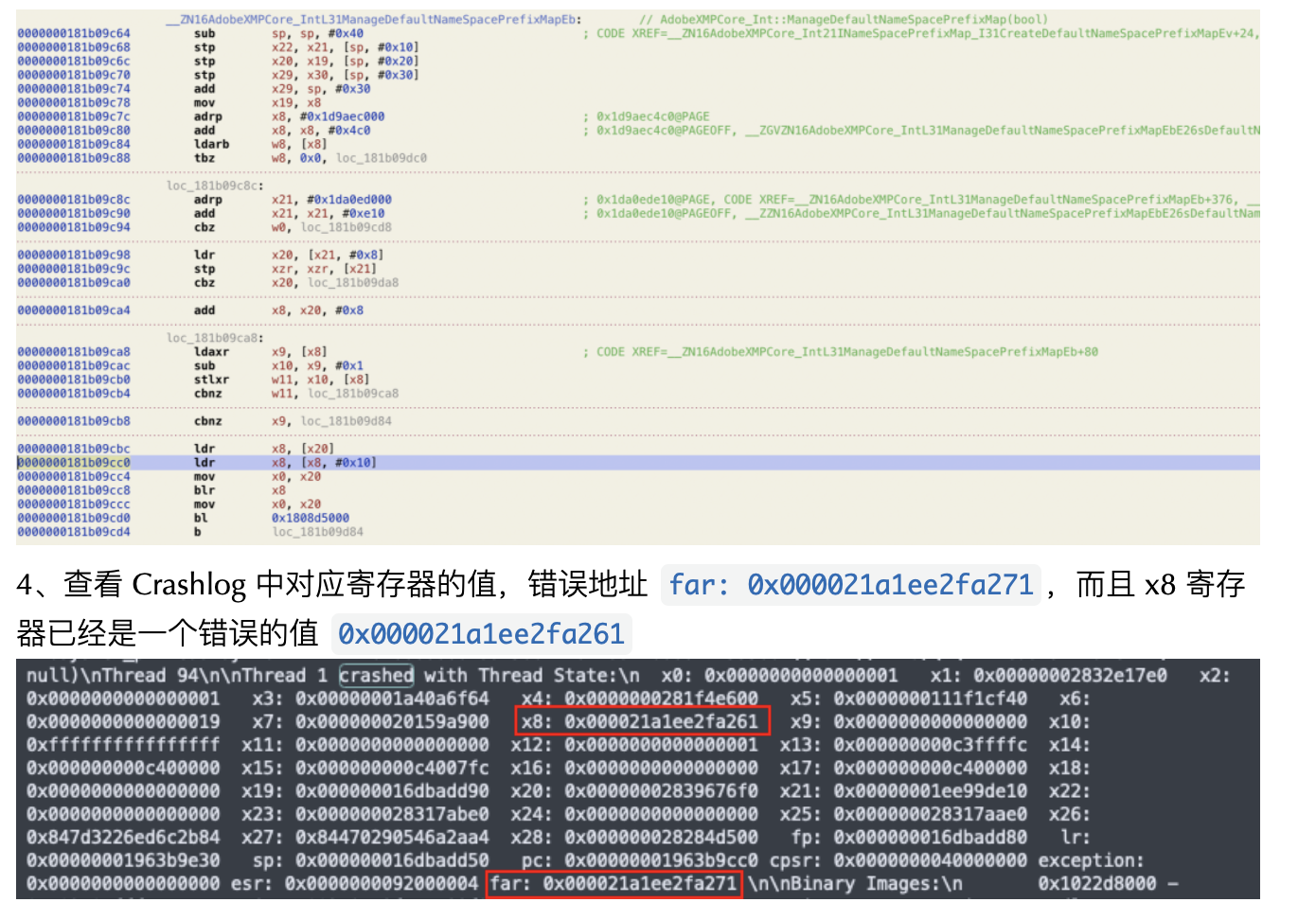
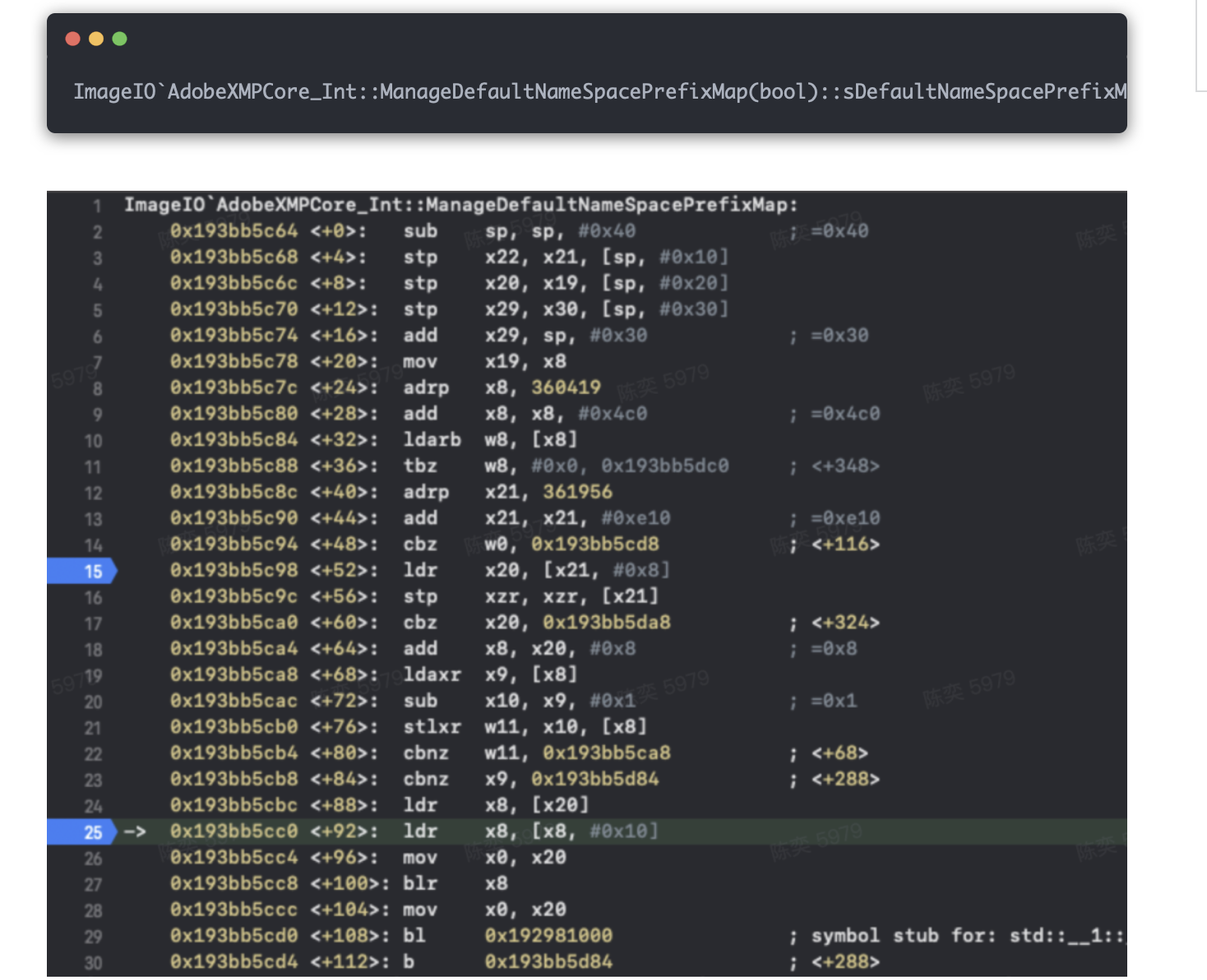
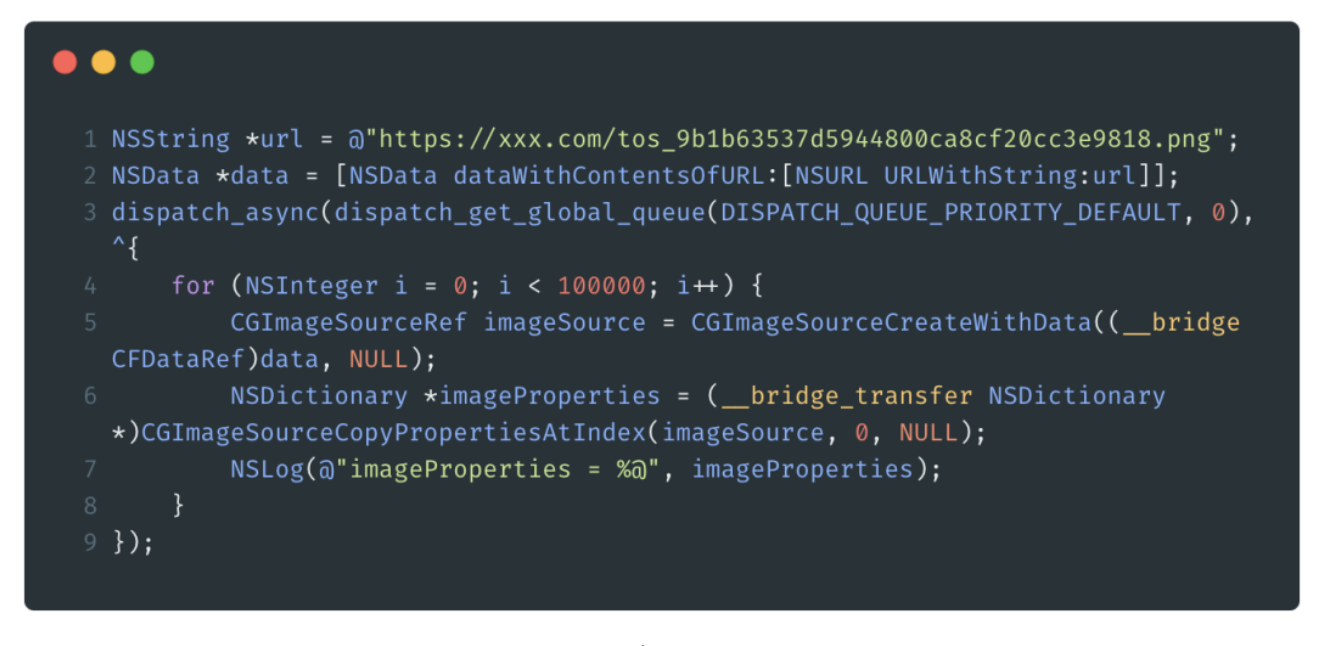
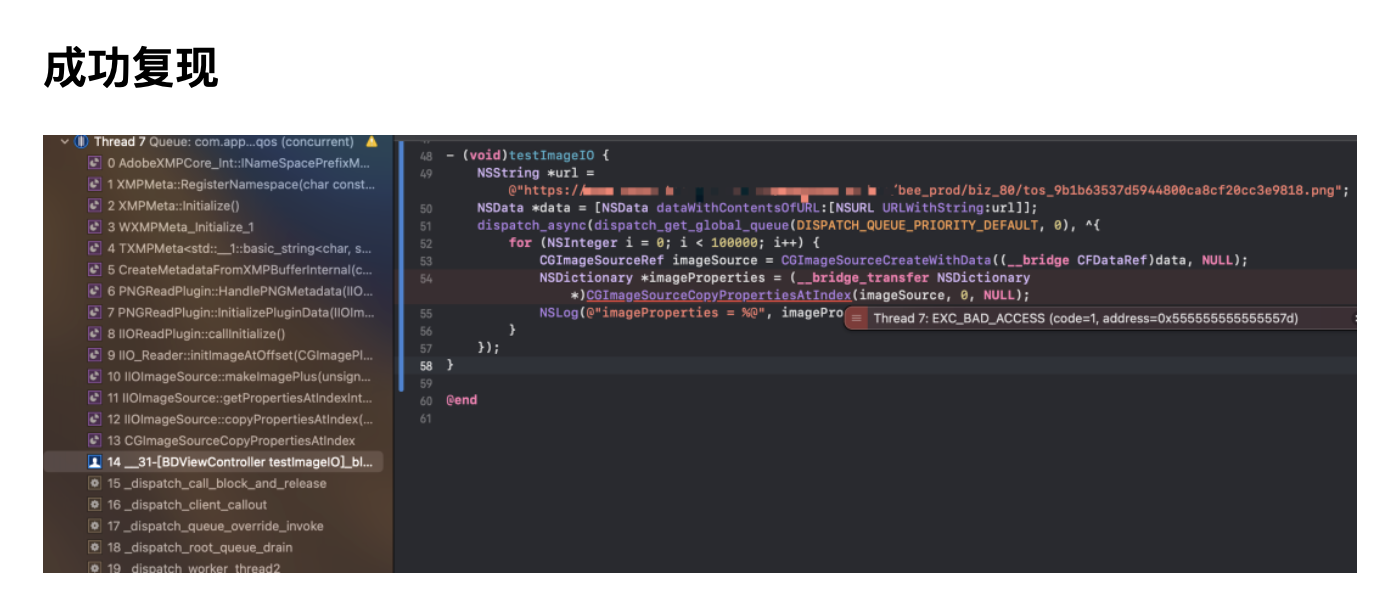
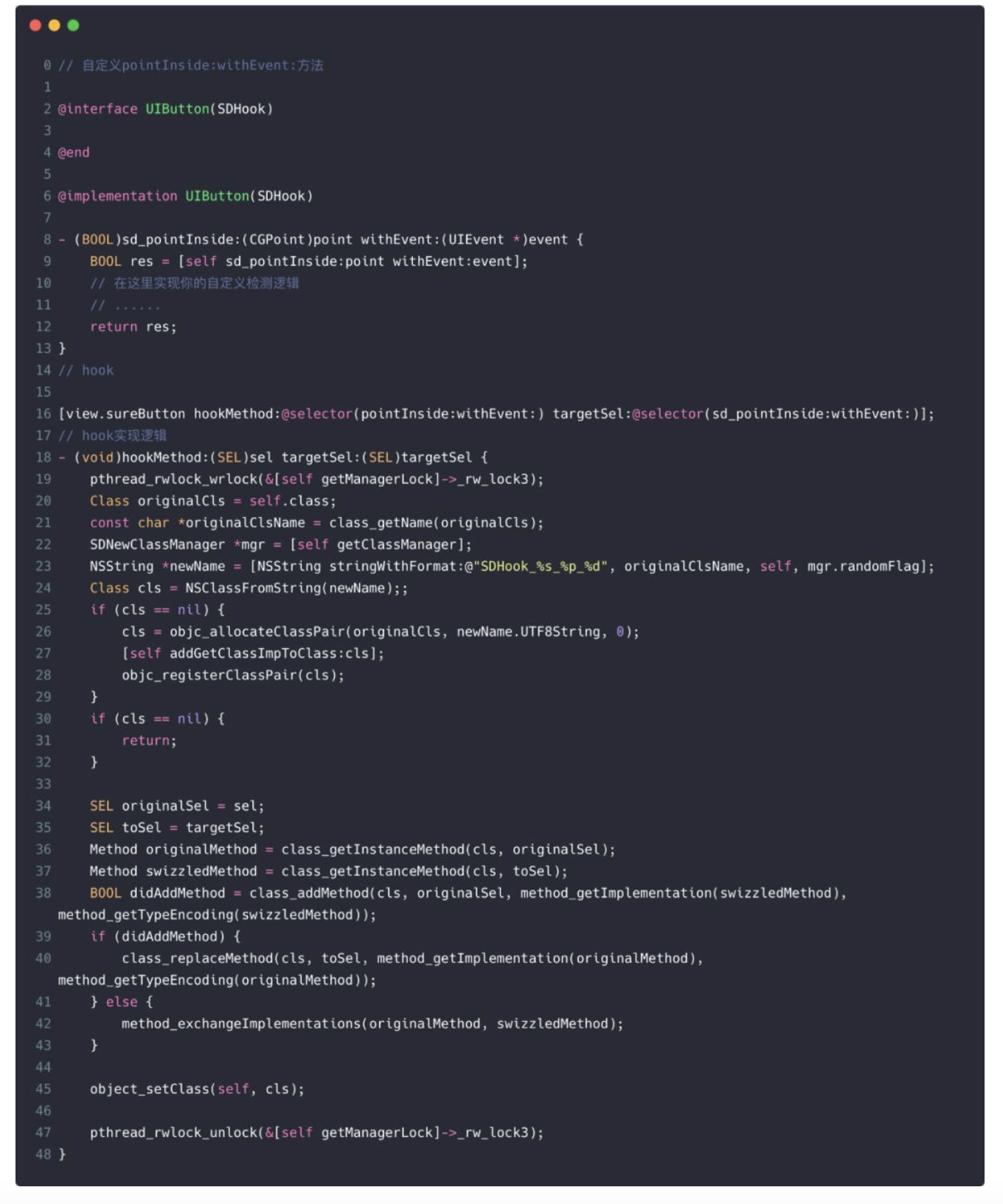
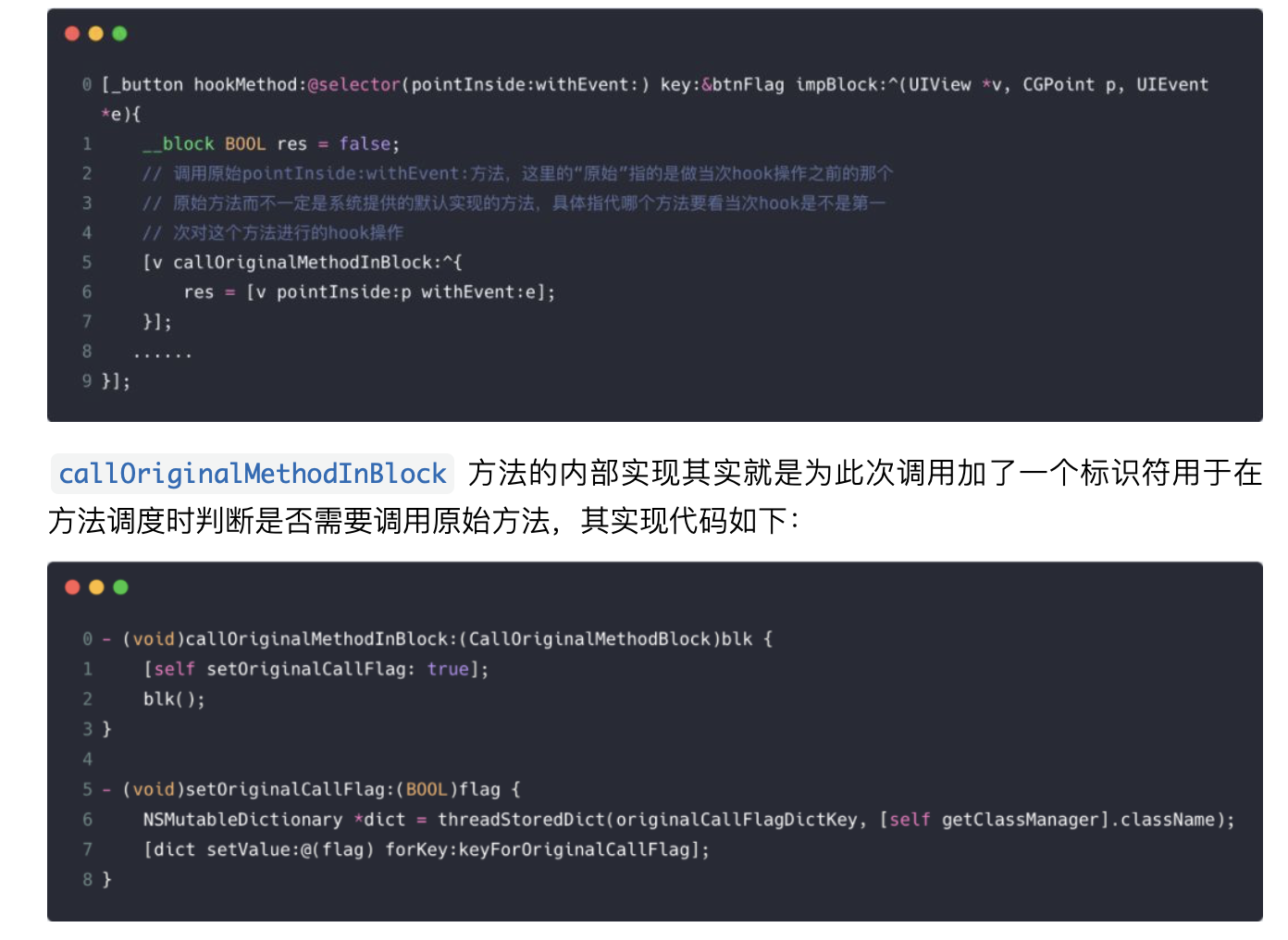
随着 Web 技术的不断发展,浏览器的功能也越来越强大。这些年出现了很多在线 Web 设计工具,比如在线 PS、在线海报设计器或在线自定义表单设计器等。这些 Web 设计器允许用户在完成设计之后,把生成的文件保存到本地,其中有一部分设计器就是利用浏览器提供的 Web API 来实现客户端文件下载。下面阿宝哥先来介绍客户端下载中,最常见的 a 标签下载 方案。
而图片下载的功能是借助 dataUrlToBlob 和 saveFile 这两个函数来实现。它们分别用于实现 Data URLs => Blob 的转换和文件的保存,具体的代码如下所示:
function dataUrlToBlob(base64, mimeType) {
let bytes = window.atob(base64.split(",")[1]);
let ab = new ArrayBuffer(bytes.length);
let ia = new Uint8Array(ab);
for (let i = 0; i < bytes.length; i++) {
ia[i] = bytes.charCodeAt(i);
}
return new Blob([ab], { type: mimeType });
}
// 保存文件
function saveFile(blob, filename) {
const a = document.createElement("a");
a.download = filename;
a.href = URL.createObjectURL(blob);
a.click();
URL.revokeObjectURL(a.href)
}
在 文件上传,搞懂这8种场景就够了 这篇文章中,阿宝哥介绍了如何利用 JSZip 这个库提供的 API,把待上传目录下的所有文件压缩成 ZIP 文件,然后再把生成的 ZIP 文件上传到服务器。同样,利用 JSZip 这个库,我们可以实现在客户端同时下载多个文件,然后把已下载的文件压缩成 Zip 包,并下载到本地的功能。对应的操作流程如下图所示:
在以上 Gif 图中,阿宝哥演示了把 3 张素材图,打包成 Zip 文件并下载到本地的过程。接下来,我们来介绍如何使用 JSZip 这个库实现以上的功能。
//显示PopupWindow publicvoidshowAtLocation(View parent, int gravity, int x, int y) {
mParentRootView = new WeakReference<>(parent.getRootView());
showAtLocation(parent.getWindowToken(), gravity, x, y);
}
//显示PopupWindow publicvoidshowAtLocation(IBinder token, int gravity, int x, int y) { if (isShowing() || mContentView == null) { return;
}
platform :ios, '11.0' project 'iOSPlayground.xcodeproj' target 'iOSPlayground'do pod 'SDWebImage', '~> 5.6.0' pod 'SDWebImageLottieCoder', '~> 0.1.0' pod 'SDWebImageWebPCoder', '~> 0.6.1' end
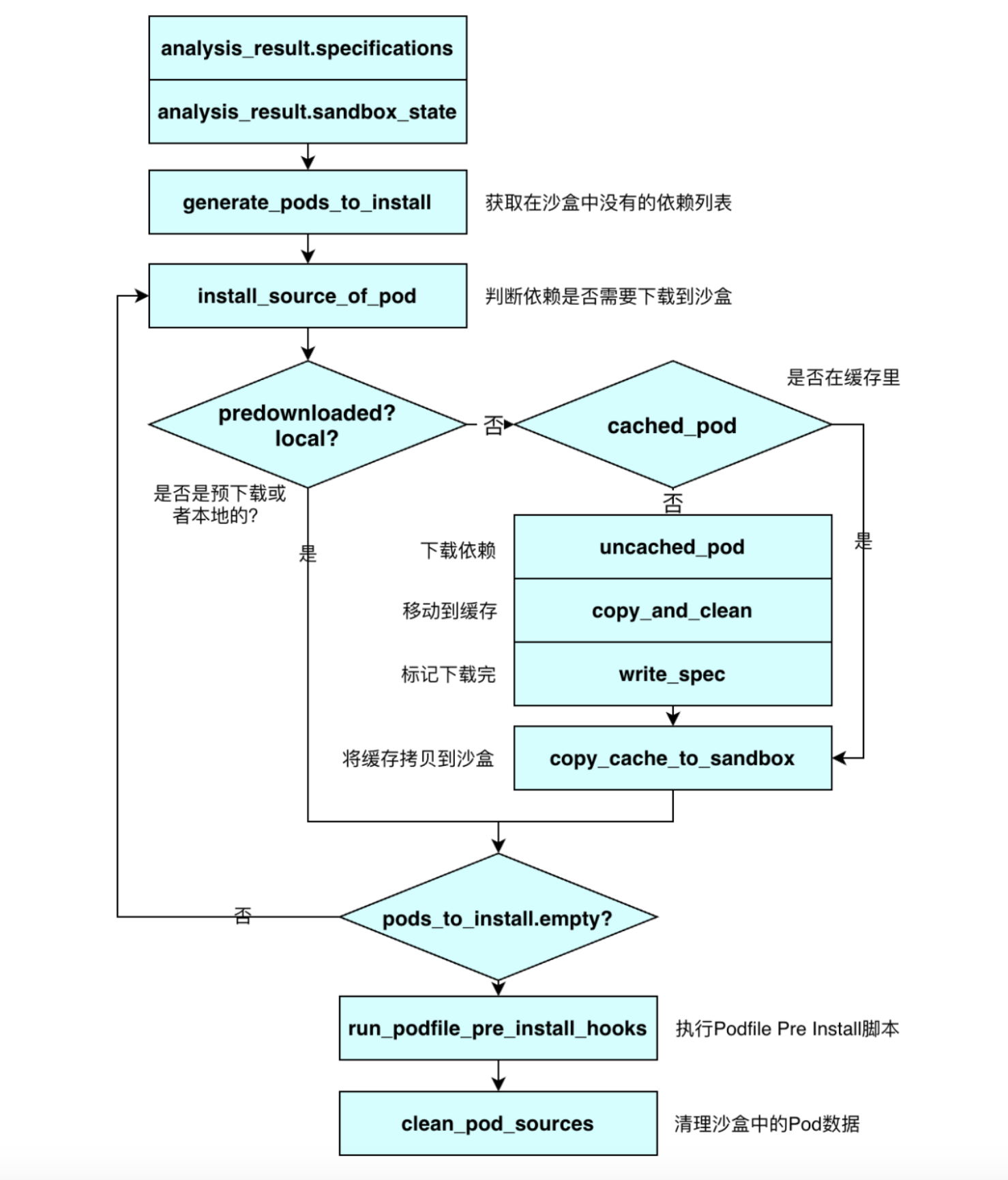
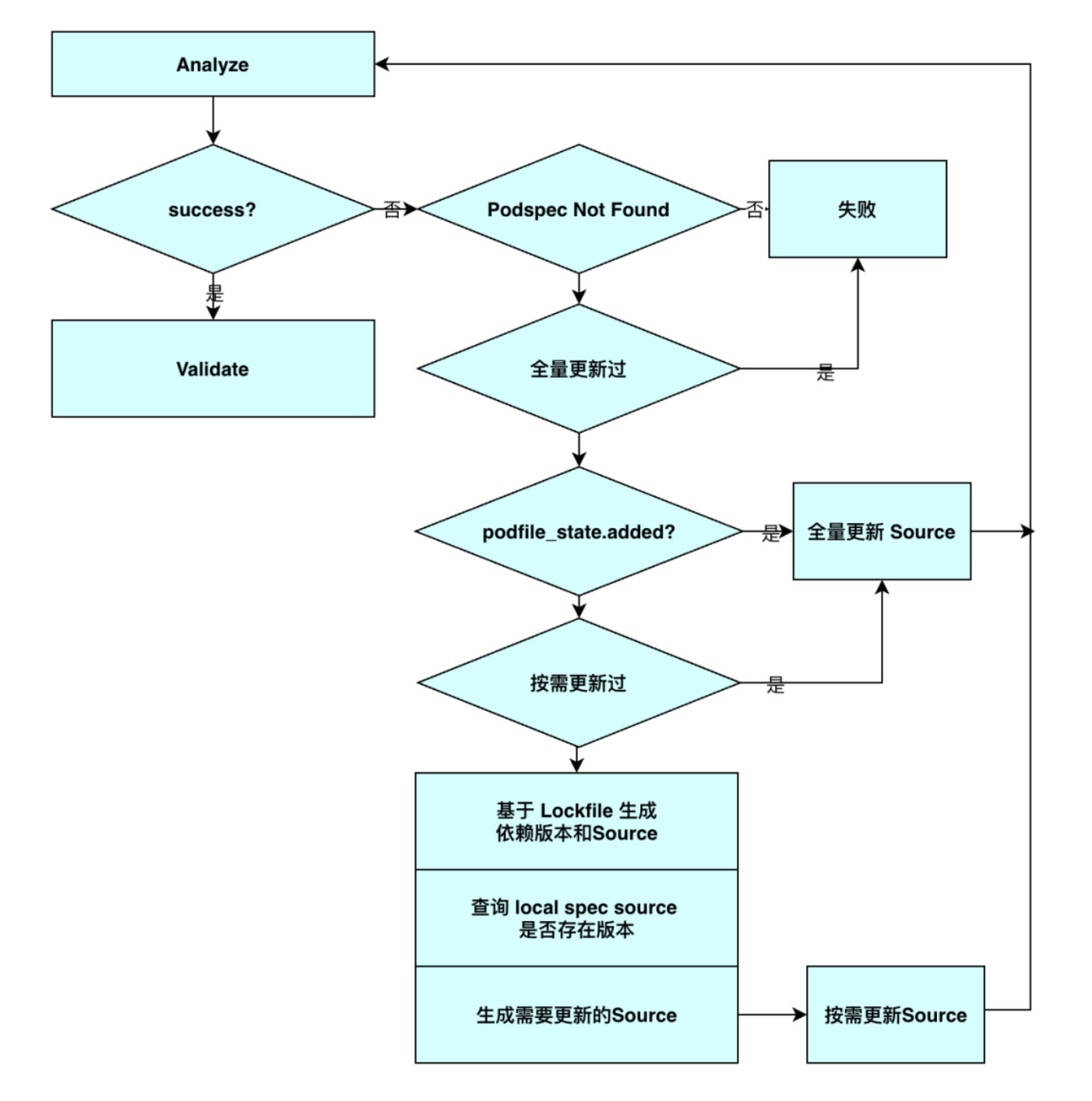
然后执行 Pod install 命令 bundle exec pod install,CocoaPods 开始为你构建多依赖的开发环境;整个 Pod Install 流程最核心的就是 ::Pod::Installer 类,Pod Install 命令会初始化并配置 Installer,然后执行 install! 流程,install! 流程主要包括 6 个环节
def install! prepare resolve_dependencies # 依赖决议 download_dependencies # 依赖下载 validate_targets # Pods 校验 generate_pods_project # Pods Project 生成 if installation_options.integrate_targets? integrate_user_project # User Project 整合 else UI.section 'Skipping User Project Integration' end perform_post_install_actions # 收尾 end
下面会对这 5 个流程做一些简单分析,为了简单起见,我们会忽略一些细节。
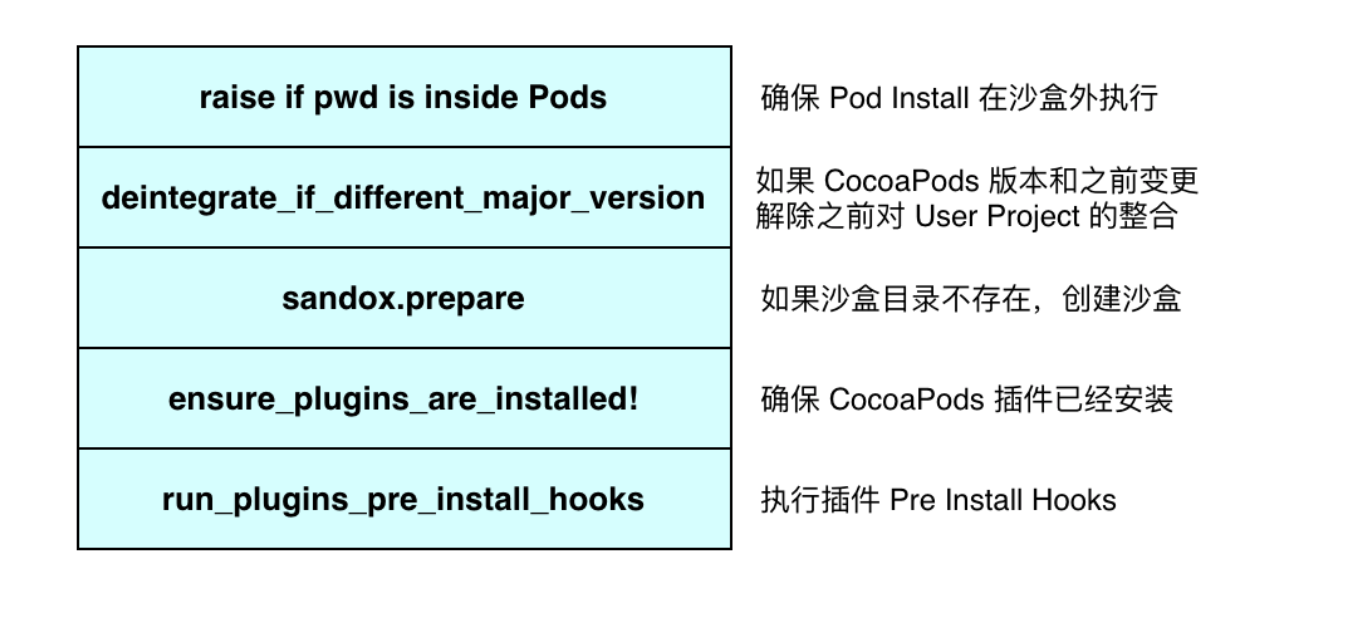
准备阶段
这个流程主要是在 Pod Install 前做一些环境检查,并且初始化 Pod Install 的执行环境。
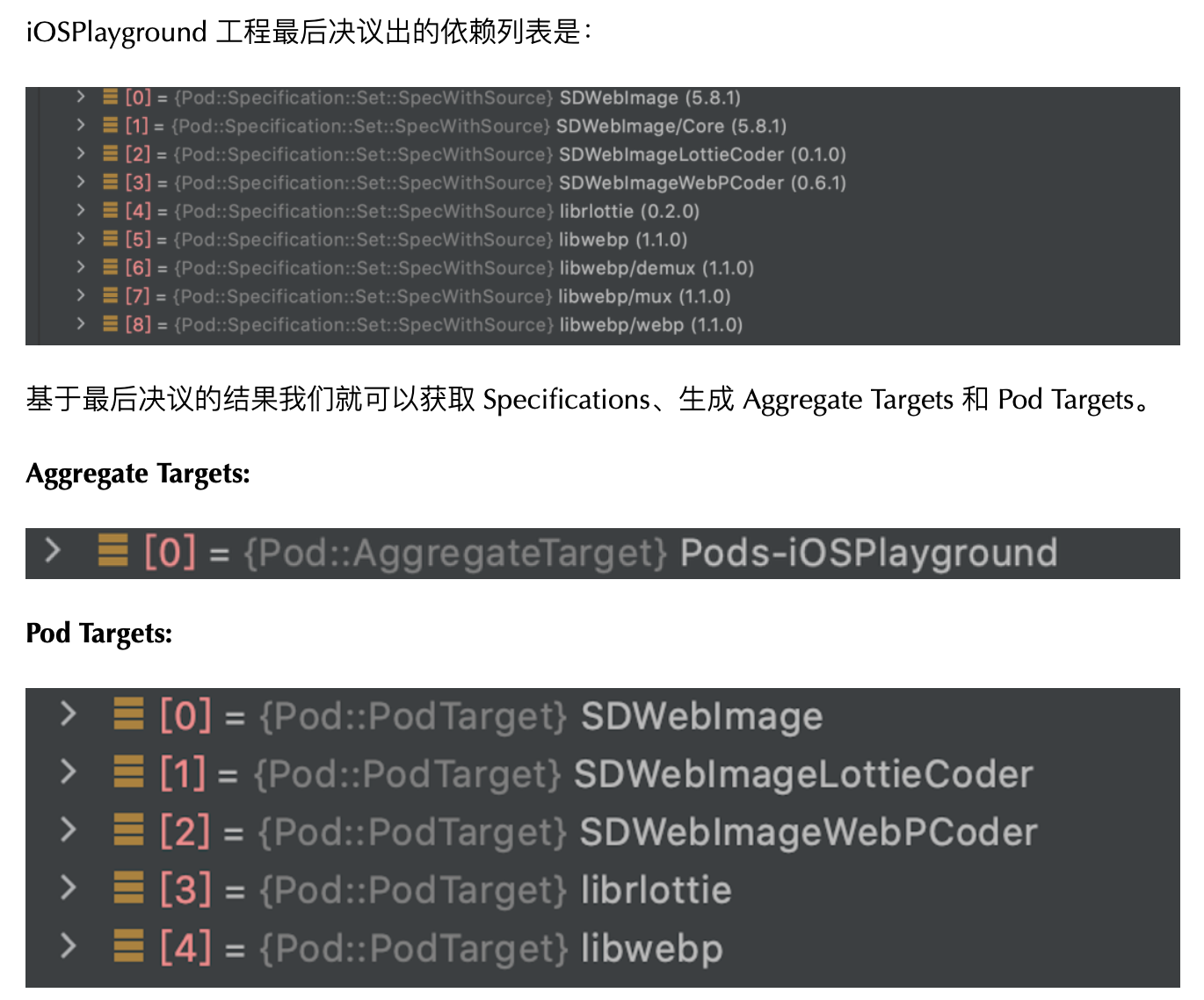
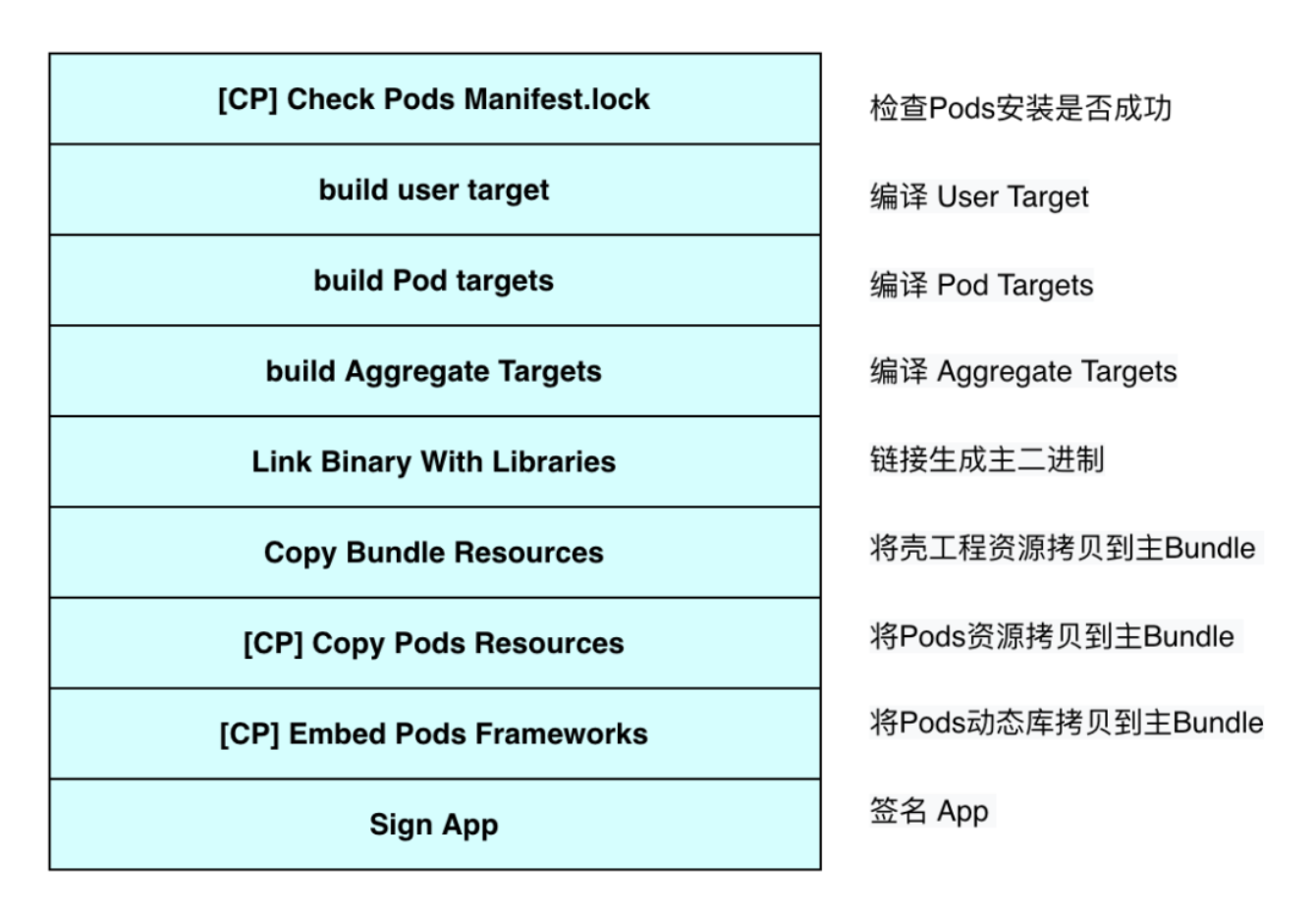
Pod Install 执行完成后,就将 User Target 整合到了 CocoaPods 环境中。User Target 依赖 Aggregate Target,Aggregate Target 依赖所有 Pod Targets,Pod Targets 按照 Pod 描述文件(Podspec)中的依赖关系进行依赖,这些依赖关系保证了编译顺序
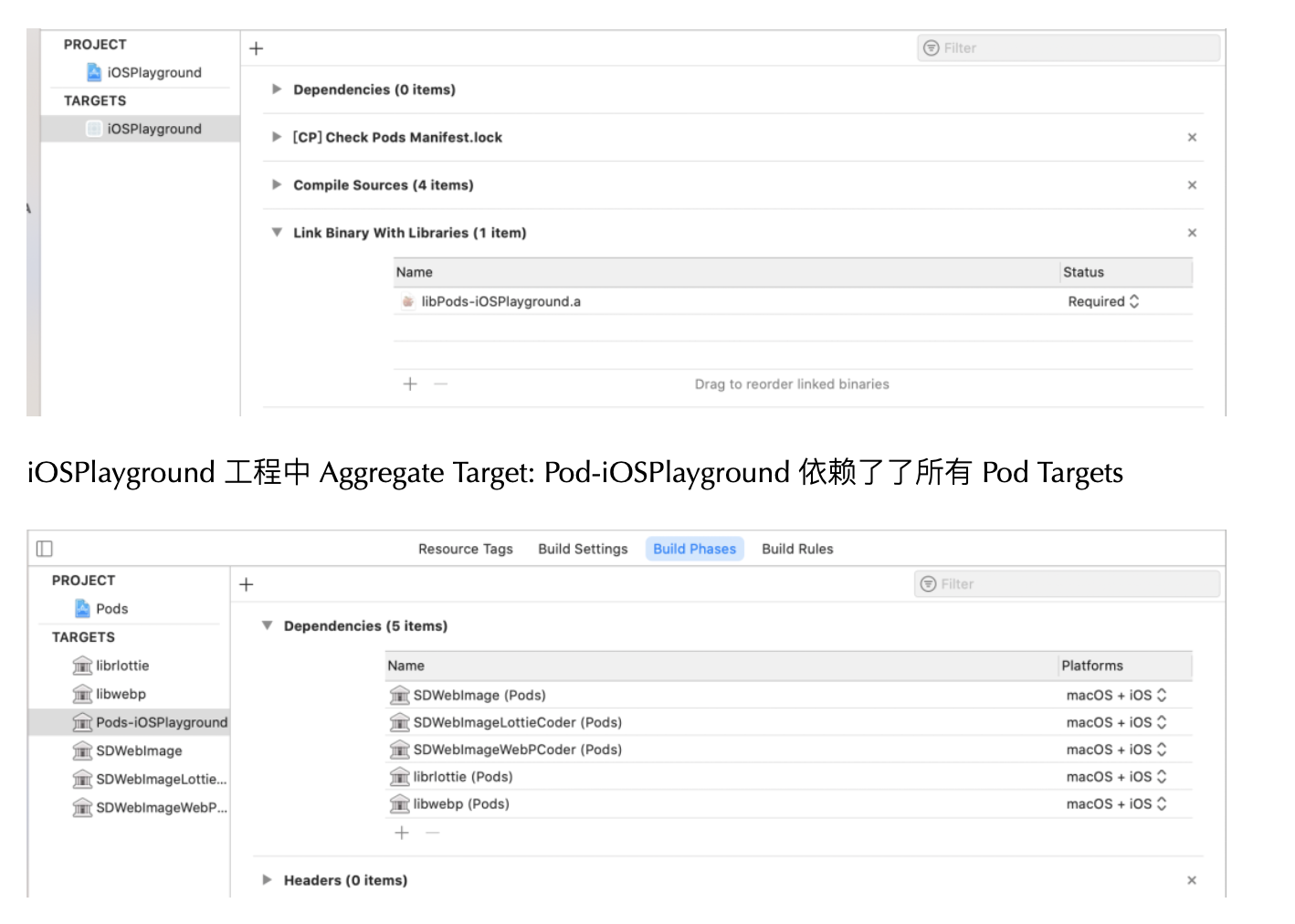
iOSPlayground 工程中 User Target: iOSPlayground 依赖了 Aggregate Target 的产物 libPods-iOSPlayground.a
CocoaPods 的依赖版本决议流程是基于 Molinillo 的,Molinillo 是基于 DAG 来进行依赖解析的,通过构建图可以方便的进行依赖关系查找、依赖环查找、版本降级等。但是使用图来进行解析是有成本的,实际上大部分的本地依赖决议场景并不需要这么复杂,Podfile.lock 中的版本就是决议后的版本,大部分的研发流程直接使用 Podfile.lock 进行线性决议就可以,这可以大幅加快决议速度。
Specification 缓存
依赖分析流程中,CocoaPods 需要获取满足约束的 Specifications,1.7.5 上的流程是获取一个组件的所有版本的 Specifications 并缓存,然后从 Specifications 中筛选出满足约束的 Specifications。对于复杂的项目来说,往往对一个依赖的约束来自于多个组件,比如 A 依赖 F(>=0),B 依赖 F (>=0),在分析完 A 对 F 的依赖后,在处理 B 对 F 的依赖时,还是需要进行一次全量比较。通过优化 Specification 缓存层可以减少这部分耗时,直接返回。
module Pod::Specification::Set def all_specifications(warn_for_multiple_pod_sources, requirement) @all_specifications ||= {} @all_specifications[requirement] ||= begin #... end end end
module Pod::Requirement def eql?(other) @requirements.eql? other.requirements end end
循环依赖发现
当出现循环依赖时,CocoaPods 会报错,但报错信息只有谁和谁之间存在循环依赖,比如:
There is a circular dependency between A/S1 and D/S1
随着工程的复杂度提高,对于复杂的循环依赖关系,比如 A/S1 -> B -> C-> D/S2 -> D/S1 -> A/S1, 基于上面的信息我们很难找到真正的链路,而且循环依赖往往不止一条,subspec、default spec 等设置也提高了问题定位的复杂度。我们优化了循环依赖的报错,当出现循环依赖的时候,比如 A 和 D 之间有环,我们会查找 A -> D/S1 之前所有的路径,并打印出来:
There is a circular dependency between A/S1 and D/S1 Possible Paths:A/S1 -> B -> C-> D/S2 -> D/S1 -> A/S1 A/S1 -> B -> C -> C2 -> D/S2 -> D/S1 -> A/S1 A/S1 -> B -> C -> C3 -> C2 -> D/S2 -> D/S1 -> A/S1
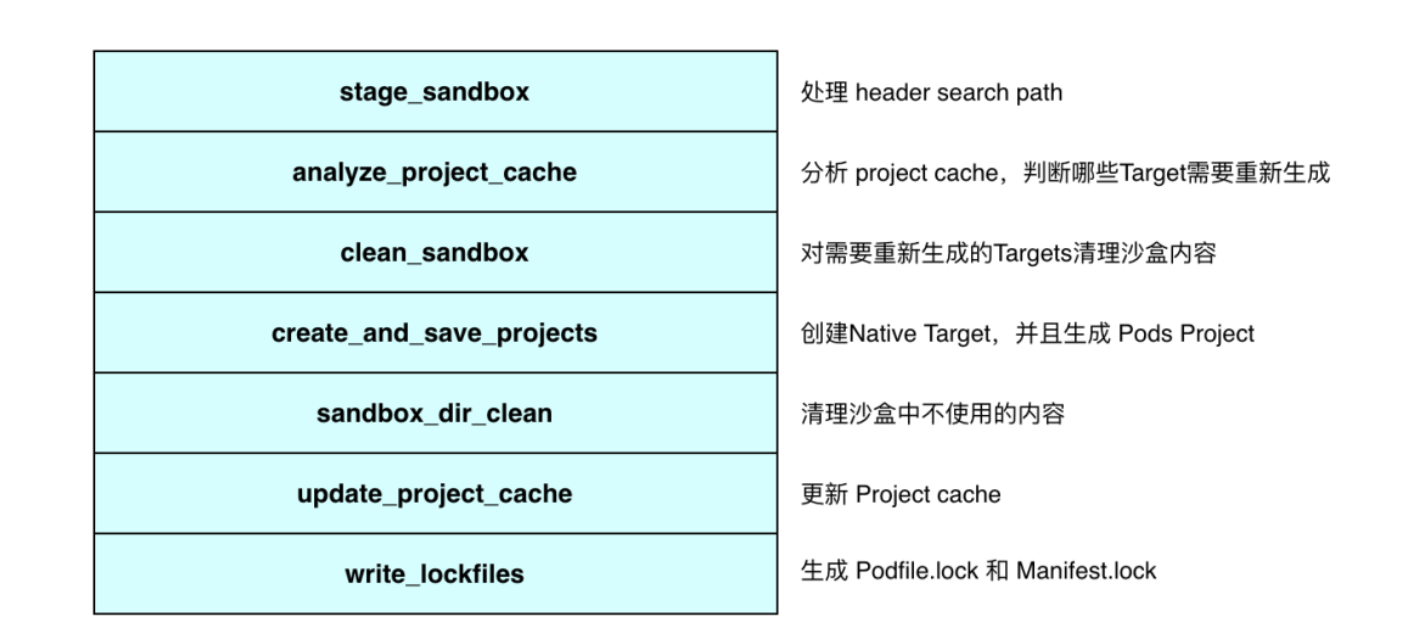
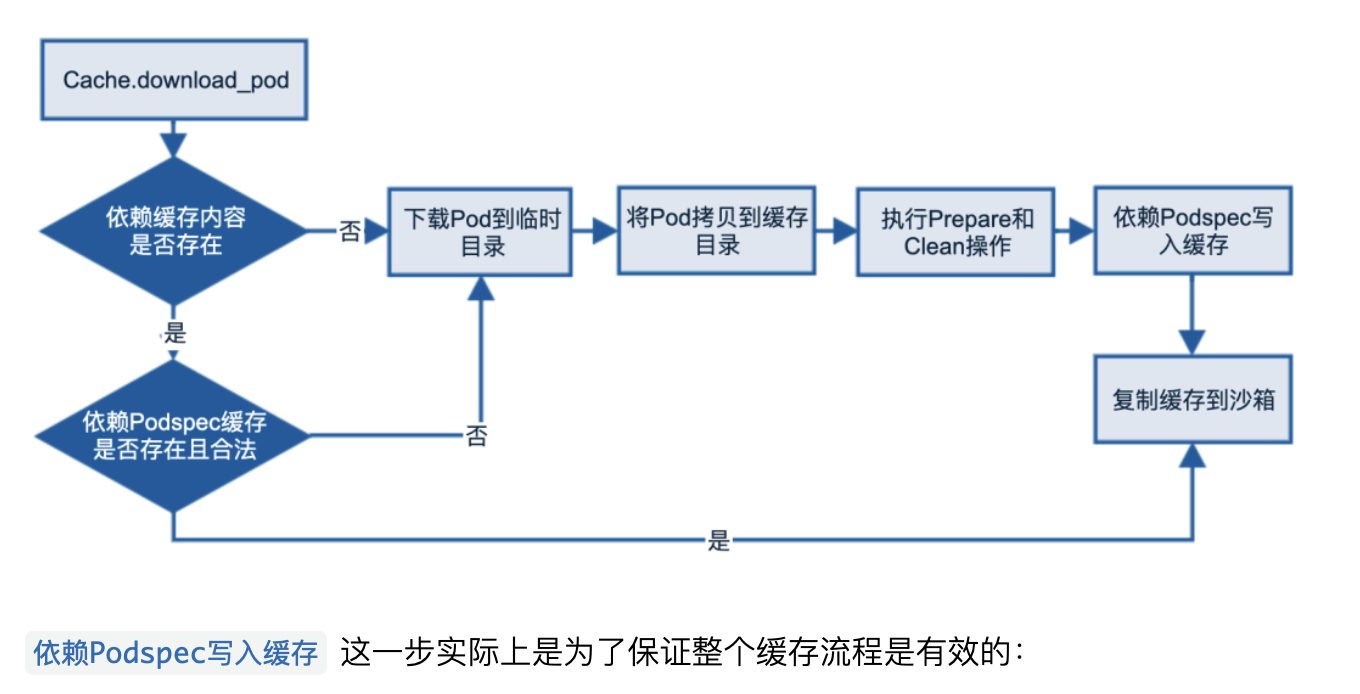
在 Pods 工程生成流程中有三个流程会比较耗时,这些数据每次 Pod Install 都需要重新生成:
Pod 目录下的文件和目录列表,需要对目录下的所有节点做遍历;
Pod 目录下的动态库列表,需要分析二进制格式,判断是否为动态库;
Pod 文件的访问策略缓存 glob_cache,这个 glob_cache 是用于访问组件仓库中不同类型文件的,比如 source files、headers、frameworks、bundles 等。
但其实这些数据对固定版本的依赖都是唯一的,如果可以缓存一份就可以避免二次生成导致的额外耗时,我们补充了这个缓存层,以抖音为例子,使 Pod Clean Install 减少了 36%,Pod No-clean Install 减少了 42%
添加 FileAccessors 缓存层后,在效率上获得提升的同时,在稳定性上也获得了提升。因为在本地记录了 Pod 完整的文件结构,因此我们可以对 Pod 的内容做检查,避免 Pod 内容被删除导致构建失败。比如研发同学误删了缓存中的二进制库,CocoaPods 默认是难以发现的,需要延迟到链接阶段报 Symbol Not Found 的错误,但是基于 FileAccessors 缓存层,我们可以在 Pod Install 流程对 Pod 内容做检查,提前暴露出二进制库缺失,触发重新下载。
提高编译并发度
Pod Target 的依赖关系会保证 Target 按顺序编译,但是会导致 Target 编译的并发度下降,一定程度上降低了编译效率。其实生成静态库的 Pod Target 不需要按顺序进行编译,因为静态库编译不依赖产物,只是在最后进行链接。通过移除静态库的 Pod Target 对其他 Target 的依赖,可以提高整体的编译效率。
在 Multi Project 下,「Dependency Subproject」会导致索引混乱,移除静态库的 Pod Target 对其他 Target 的依赖后,我们也可以删除 Dependent Pod Subproject,减少 Xcode 检索问题。
Arguments Too Long
超大型工程在编译时稳定性降低,往往会因为工程放置的目录长产生一些未定义错误,其中错误比较大的来源就是 Arguments Too Long,表现为:
Build operation failed without specifying any errors ;Verify final result code for completed build operation
组件化的一个目标是业务代码按架构设计拆分成组件 Pod。但如果在一个组件中新增文件,比如在组件 A 中新增文件,依赖组件 A 的组件 B 是不能直接访问新增文件的头文件的,需要重新执行 Pod Install,这样会影响整体的研发效率。
为什么组件 B 不能够访问组件 A 的新增文件?在 Pod Install 后,组件 A 公共访问的头文件被索引在 Pods/Headers/Public/A/ 目录下,组件 B 的 HEADER_SEARCH_PATH 中配置了 Pods/Headers/Public/A/,因此就可以在组件 B 的代码里引入组件 A 的头文件。新增头文件的头文件没有在目录中索引,所以组件 B 就访问不到了。只需要在添加文件后,建立新增头文件的索引到 Pods/Headers/Public/A/目录下,就可以为组件 B 提供组件 A 新增文件的访问能力,这样就不需要重新 Pod Install 了。
Lockfile 生成
在依赖管理的部分场景中,我们只需要进行依赖决议,重新生成 Podfile.lock,但通过 Pod Install 生成是需要执行依赖下载及后续流程的,这些流程是比较耗时的,为了支持 Podfile.lock 的快速生成,可以对 install 命令做了简化,在依赖决议后就可以直接生成 Podfile.lock:
class Pod::Installer def quick_generate_lockfile! # 初始化 sandbox 环境 quick_prepare_env quick_resolve_dependencies quick_write_lockfiles end end
首先我们假设所有数据都是二维空间下的点,我们从图中这个R8区域说起,也就是那个shape of data object。别把那一块不规则图形看成一个数据,我们把它看作是多个数据围成的一个区域。为了实现R树结构,我们用一个最小边界矩形恰好框住这个不规则区域,这样,我们就构造出了一个区域:R8。R8的特点很明显,就是正正好好框住所有在此区域中的数据。其他实线包围住的区域,如R9,R10,R12等都是同样的道理。这样一来,我们一共得到了12个最最基本的最小矩形。这些矩形都将被存储在子结点中。
但最近在暑期实习的日子里,我特意留心观察了一下身边的实习生同学使用工具的习惯。我发现自己在大学认为高效率的工作模式,他们无论在意识层面还是在使用层面上对工具的掌握都有些蹩脚。特别是有部分同学 Mac 也没有怎么接触过,算是效率领域的门外汉了。所以本着做个负责的好师兄的态度,我将自己对工具使用的经验,分享给大家。也算是抛砖引玉,和大家一起聊聊有哪些 NB 又和好玩的工具。
需要注意的是:我这里主要以 Mac Apple 生态作为基调,但我相信工具和效率提升的思想是不变的,Win 下也有具体的工具可以替代,所以 Win 的同学也可以认真找一找,评论回复一下 Win 下的替代方案吧 🙏🏻
当然,👇 的工具,我没有办法在这种汇总类的文章里面讲透彻,所以都「点到为止」,给了相关扩展阅读的文章,所以感兴趣的话大家再外链出去研究一番,或者自行 Google 社区的优质资源 ~
主打 Mac 上的自动化流程。通过 👇 这种可视化编程的思路,创建一种动作流。比如我想实现通过 Cmd + Alt + B 搜索 Chrome 书签 🔖。社区的小伙伴们就已经帮我们实现了一套工作流。我们可以直接在 Alfred 的社区 Packtal 等论坛去下载已经实现的 Workflow 去实现这些日常生活中的小自动化流程。
再比如上面的:
ChromeHistory:搜索 Chrome 历史记录(在 Alfred 搜索中)
GithubRepos:浏览搜索自己的 GithubRepo
Colors:快速转换前端颜色(前端同学一定知道为什么这个常用)🙈
... 等等等等
我们也可以定义自己的工作流来自动化一些流程,我用自身的一个 Case 来说,我会定义很多快捷键来绑定我自己的日常操作。比如:
function compose(...fns) {
return function composed(result){
// 拷贝一份保存函数的数组
var list = fns.slice();
while (list.length > 0) {
// 将最后一个函数从列表尾部拿出
// 并执行它
result = list.pop()( result );
}
return result;
};
}
// ES6 箭头函数形式写法
var compose =
(...fns) =>
result => {
var list = fns.slice();
while (list.length > 0) {
// 将最后一个函数从列表尾部拿出
// 并执行它
result = list.pop()( result );
}
return result;
};
var error:NSError? let possibleCameraInput: AnyObject? = AVCaptureDeviceInput.deviceInputWithDevice(backCameraDevice, error: &error) if let backCameraInput = possibleCameraInput as? AVCaptureDeviceInput { if self.session.canAddInput(backCameraInput) { self.session.addInput(backCameraInput) } }
var pointInPreview = focusTapGR.locationInView(focusTapGR.view) var pointInCamera = previewLayer.captureDevicePointOfInterestForPoint(pointInPreview) ...// 锁定,配置
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
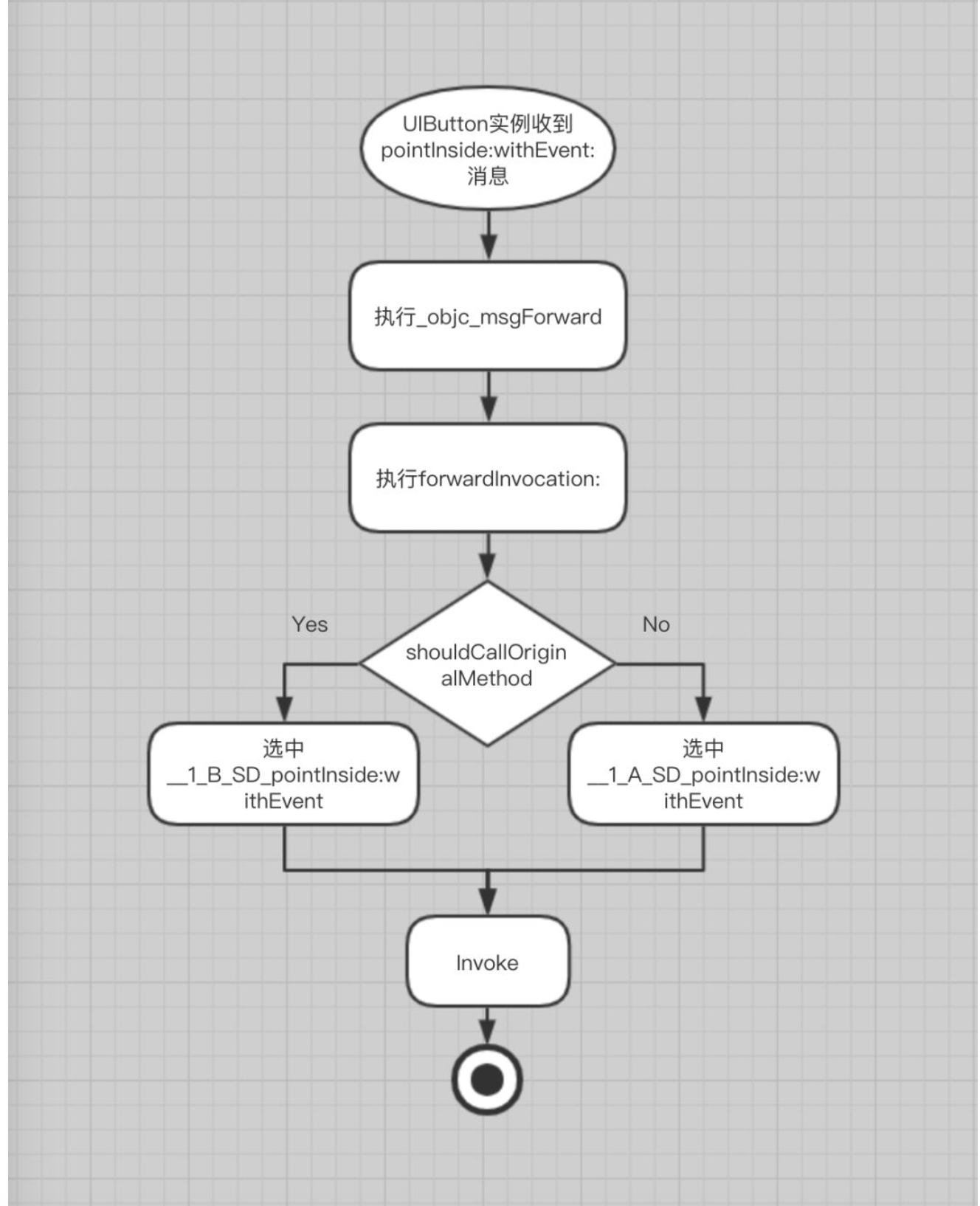
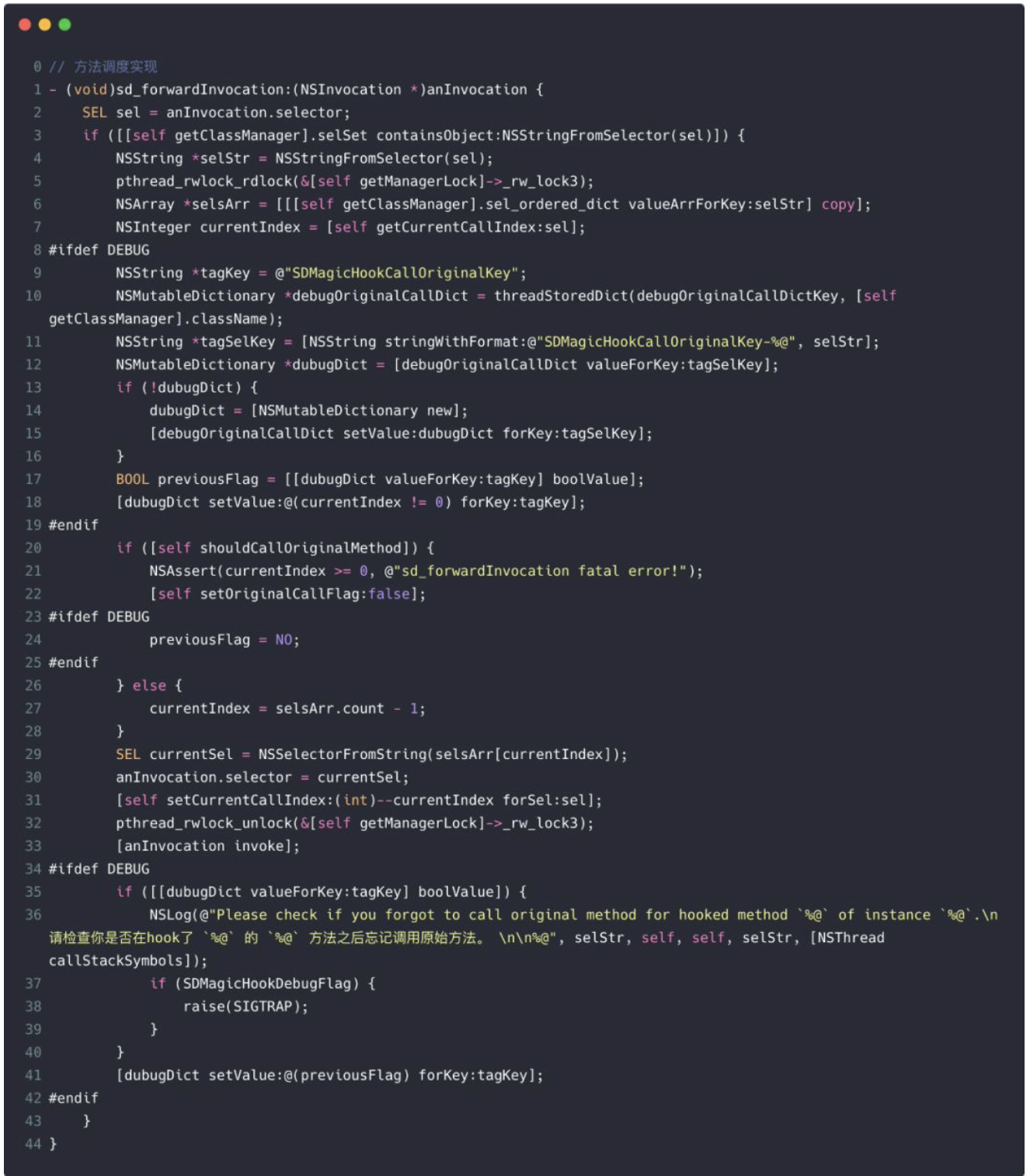
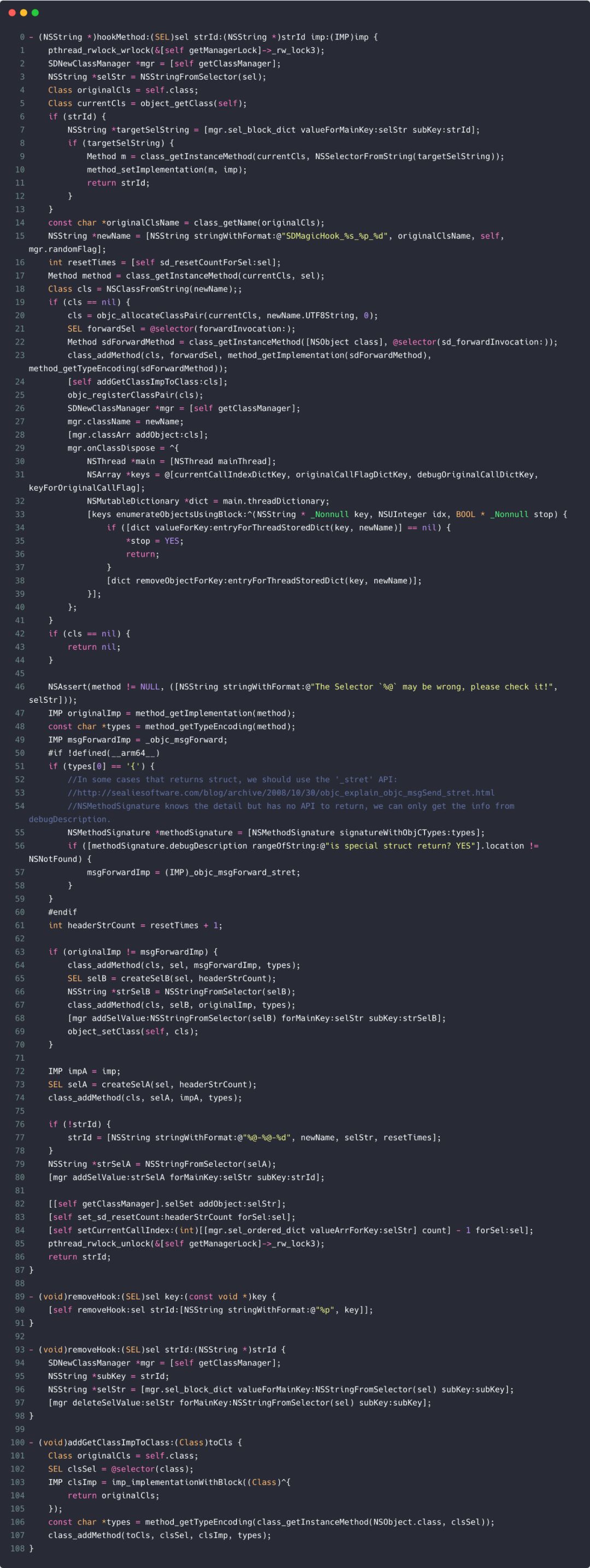
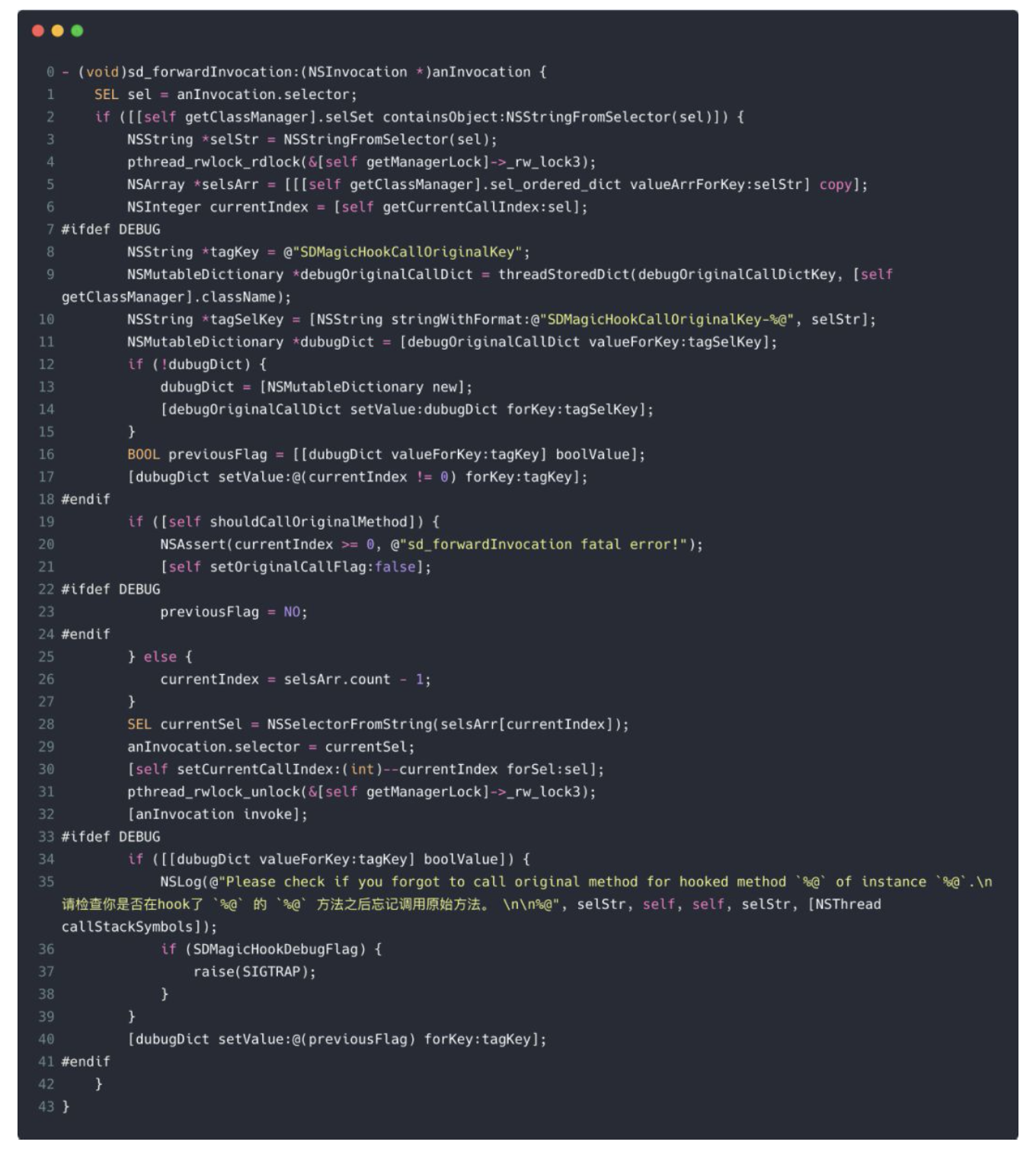
动态类型就是说运行时才确定对象的真正类型。例如我们可以向一个 id 类型的对象发送任何消息,这在编译期都是合法的,因为类型是可以动态确定的,消息真正起作用的时机也是在运行时这个对象的类型确定以后,这个下面就会讲到。我们甚至可以在运行时动态修改一个对象的 isa 指针从而修改其类型,OC 中 KVO 的实现正是对动态类型的典型应用。
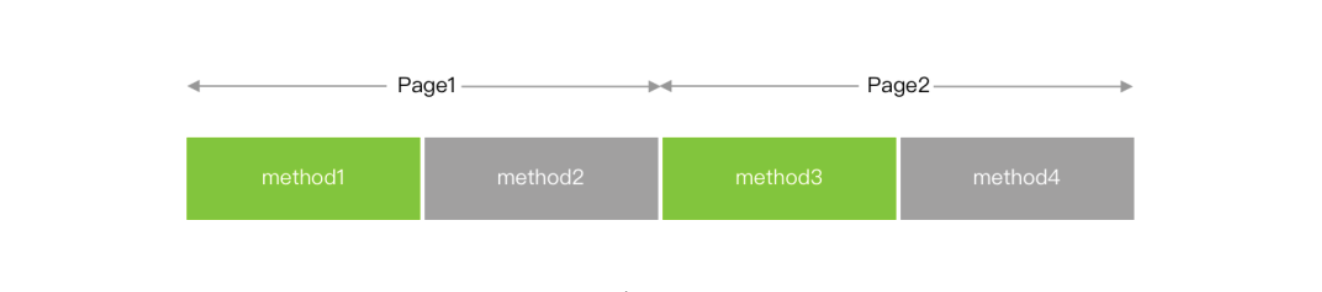
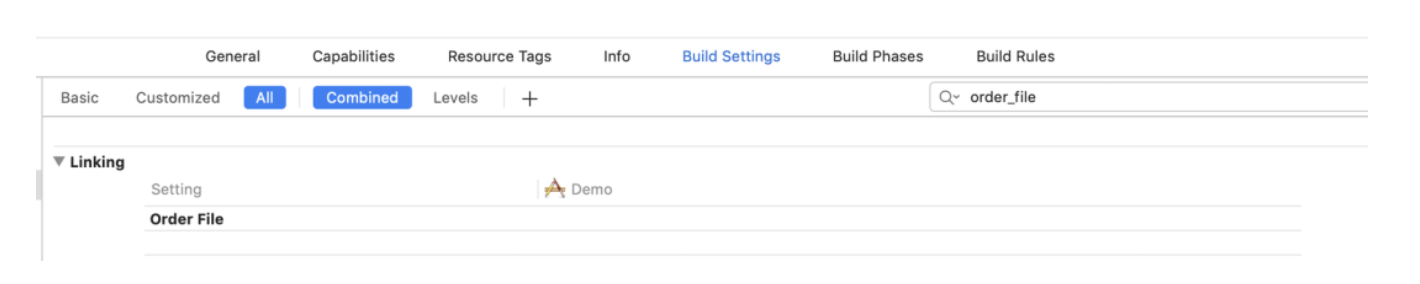
Alters the order in which functions and data are laid out. For each section in the output file, any symbol in that section that are specified in the order file file is moved to the start of its section and laid out in the same order as in the order file file.
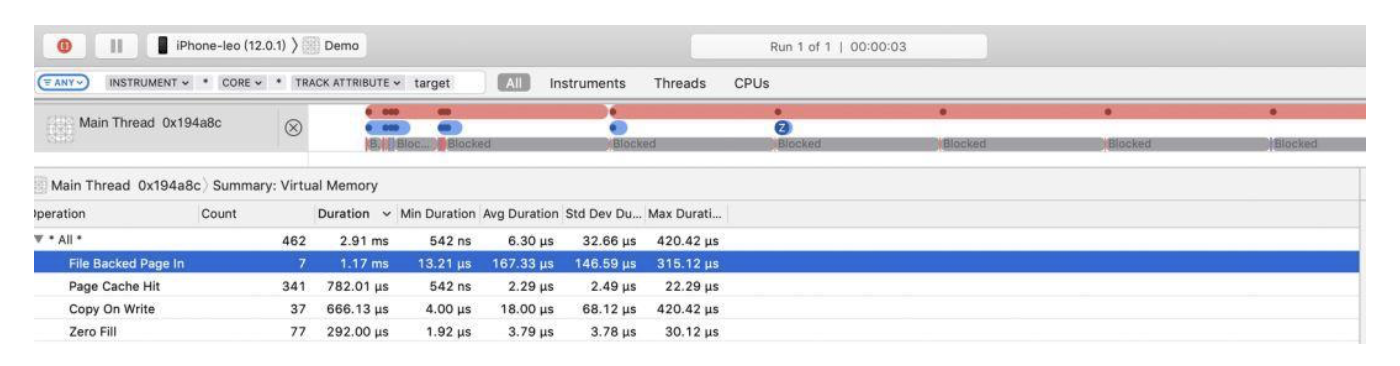
程序的运行是出于满足人们对某种逻辑需求的处理,在计算机上表现为可执行指令,正常情况下我们期望的指令是按逻辑的顺序依次执行的,而实际情况由于某些指令是耗时操作,不能立即返回结果而造成了阻塞,导致程序无法继续执行。这种情况多见于一些io操作。这时,对于用户层面来说,我们可以选择stop the world,等待操作完成返回结果后再继续操作,也可以选择继续去执行其他操作,等事件返回结果后再通知回来。这就是从用户角度来看的同步与异步。
Future<void> main() async { var startTime = DateTime.now().second; var bannerList = getBannerList(); var homeTabList = getHomeTabList(); var homeMsgList = getHomeMsgList();
@Override
protected void measureChildWithMargins(View child, int parentWidthMeasureSpec, int widthUsed, int parentHeightMeasureSpec, int heightUsed) {
child.measure(parentWidthMeasureSpec, parentHeightMeasureSpec);
}
@Override
public boolean onMeasureChild(
@NonNull CoordinatorLayout parent,
@NonNull T child,
int parentWidthMeasureSpec,
int widthUsed,
int parentHeightMeasureSpec,
int heightUsed) {
final CoordinatorLayout.LayoutParams lp =
(CoordinatorLayout.LayoutParams) child.getLayoutParams();
if (lp.height == CoordinatorLayout.LayoutParams.WRAP_CONTENT) {
// If the view is set to wrap on it's height, CoordinatorLayout by default will
// cap the view at the CoL's height. Since the AppBarLayout can scroll, this isn't
// what we actually want, so we measure it ourselves with an unspecified spec to
// allow the child to be larger than it's parent
parent.onMeasureChild(
child,
parentWidthMeasureSpec,
widthUsed,
MeasureSpec.makeMeasureSpec(0, MeasureSpec.UNSPECIFIED),
heightUsed);
return true;
}
// Let the parent handle it as normal
return super.onMeasureChild(
parent, child, parentWidthMeasureSpec, widthUsed, parentHeightMeasureSpec, heightUsed);
}
override fun onInterceptTouchEvent(e: MotionEvent?): Boolean {
if (e!!.action == MotionEvent.ACTION_DOWN) {
val childRecyclerView = findCurrentChildRecyclerView()
@JvmOverloads
fun addHeaderView(view: View, index: Int = -1, orientation: Int = LinearLayout.VERTICAL): Int {
if (!this::mHeaderLayout.isInitialized) {
mHeaderLayout = LinearLayout(view.context)
mHeaderLayout.orientation = orientation
mHeaderLayout.layoutParams = if (orientation == LinearLayout.VERTICAL) {
RecyclerView.LayoutParams(MATCH_PARENT, WRAP_CONTENT)
} else {
RecyclerView.LayoutParams(WRAP_CONTENT, MATCH_PARENT)
}
}
val childCount = mHeaderLayout.childCount
var mIndex = index
if (index < 0 || index > childCount) {
mIndex = childCount
}
mHeaderLayout.addView(view, mIndex)
if (mHeaderLayout.childCount == 1) {
val position = headerViewPosition
if (position != -1) {
notifyItemInserted(position)
}
}
return mIndex
}
companionobject { privateconstval TAG = "dispatch_result"
fungetInstance(activity: FragmentActivity): DispatchResultFragment =
activity.run { val fragmentManager = supportFragmentManager var fragment = fragmentManager.findFragmentByTag(TAG) as DispatchResultFragment? if (fragment == null) {
fragment = DispatchResultFragment()
fragmentManager.beginTransaction().add(fragment, TAG).commitAllowingStateLoss()
fragmentManager.executePendingTransactions()
}
fragment
}
}
}
如果觉得 Activity Result API 比较复杂,也可以拷贝这个去用。不过 requestCode 处理得不够好,而且很多功能需要自己额外去实现,用起来可能没那么方便。
<div id="box">
<input type="button" id="add" value="添加" />
<input type="button" id="remove" value="删除" />
<input type="button" id="move" value="移动" />
<input type="button" id="select" value="选择" />
</div>
方式一:需要4次dom操作
window.onload = function () {
var Add = document.getElementById("add");
var Remove = document.getElementById("remove");
var Move = document.getElementById("move");
var Select = document.getElementById("select");
Add.onclick = function () { alert('添加'); }; Remove.onclick = function () { alert('删除'); }; Move.onclick = function () { alert('移动'); }; Select.onclick = function () { alert('选择'); } }
方式二:委托它们父级代为执行事件
window.onload = function(){
var oBox = document.getElementById("box");
oBox.onclick = function (ev) {
var ev = ev || window.event;
var target = ev.target || ev.srcElement;
if(target.nodeName.toLocaleLowerCase() == 'input'){
switch(target.id){
case 'add' :
alert('添加');
break;
case 'remove' :
alert('删除');
break;
case 'move' :
alert('移动');
break;
case 'select' :
alert('选择');
break;
}
}
}
}
用事件委托就可以只用一次dom操作就能完成所有的效果,比上面的性能肯定是要好一些的
3. 事件捕获
会从document开始触发,一级一级往下传递,依次触发,直到真正事件目标为止。
<div> <button> <p>点击捕获</p> </button></div> <script> var oP = document.querySelector('p'); var oB = document.querySelector('button'); var oD = document.querySelector('div'); var oBody = document.querySelector('body'); oP.addEventListener('click', function () { console.log('p标签被点击') }, true); oB.addEventListener('click', function () { console.log("button被点击") }, true); oD.addEventListener('click', function () { console.log('div被点击') }, true); oBody.addEventListener('click', function () { console.log('body被点击') }, true); </script> 点击<p>点击捕获</p>,打印的顺序是:body=>div=>button=>p</body>
DocumentFragment,文档片段接口,一个没有父对象的最小文档对象。它被作为一个轻量版的 Document使用,就像标准的document一样,存储由节点(nodes)组成的文档结构。与document相比,最大的区别是DocumentFragment不是真实 DOM 树的一部分,它的变化不会触发 DOM 树的重新渲染,且不会导致性能等问题。
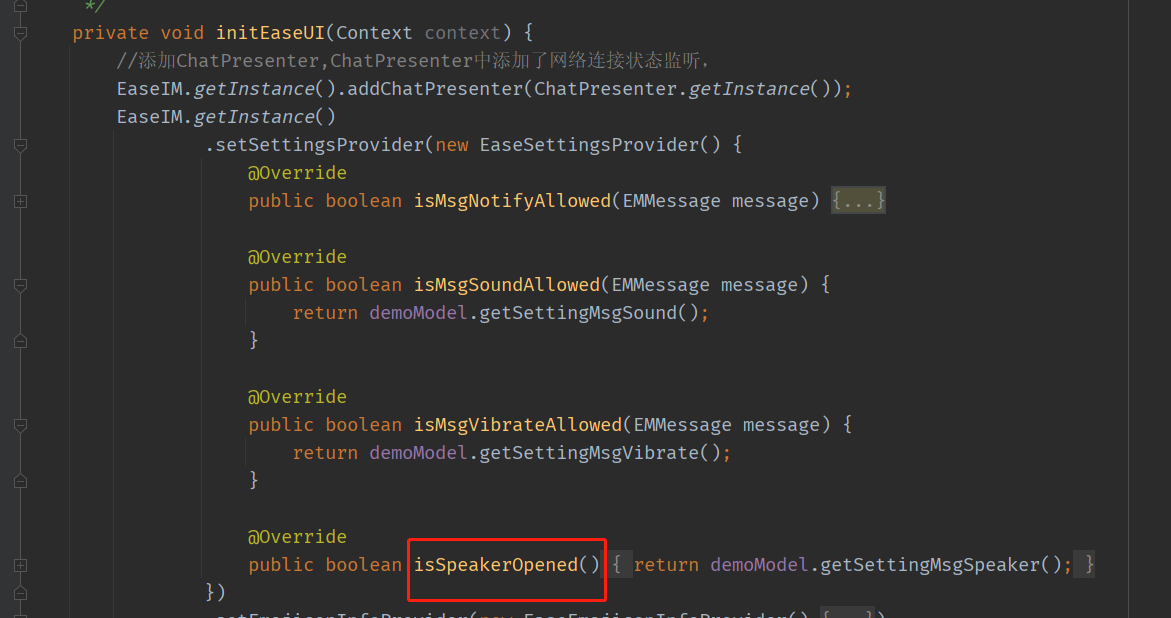
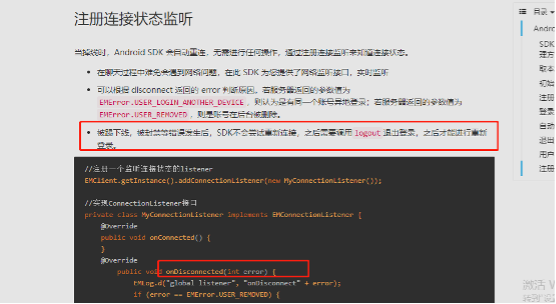
10. 创建聊天室,显示you hava no permission to do this 创建聊天室,只能使用rest接口去创建。 参考文档:https://docs-im.easemob.com/im/server/basics/chatroom#创建聊天室 11. 设置的自动同意添加好友,为什么添加之后好友列表里查找不到? 回答:用户A添加 用户 B为好友,如果用户B是离线状态的话,用户A的好友列表是里不显示用户B的,用户 B上线之后,用户A的好友列表中会出现用户B。
1.通过EMGroupOptions的extField设置的扩展字段。 2.从服务器获取群组信息,获取getExtension EMGroup group = EMClient.getInstance().groupManager().getGroupFromServer(groupId);group.getExtension();
28.oppo推送报空指针 Process: com.example.is, PID: 24696 java.lang.NullPointerException: Attempt to invoke virtual method 'android.content.pm.PackageManager android.content.Context.getPackageManager()' on a null object reference at com.heytap.mcssdk.d.a(Unknown Source:7) at com.heytap.mcssdk.d.l(Unknown Source:6) at com.heytap.mcssdk.d.n(Unknown Source:0) at com.heytap.msp.push.HeytapPushManager.isSupportPush(Unknown Source:4) at com.hyphenate.push.platform.oppo.a.b(Unknown Source:0) at com.hyphenate.push.platform.a.a(Unknown Source:6) at com.hyphenate.push.EMPushHelper.a(Unknown Source:145) at com.hyphenate.push.EMPushHelper.register(Unknown Source:35) at com.hyphenate.chat.EMClient$7.run(Unknown Source:204) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641) at java.lang.Thread.run(Thread.java:919)
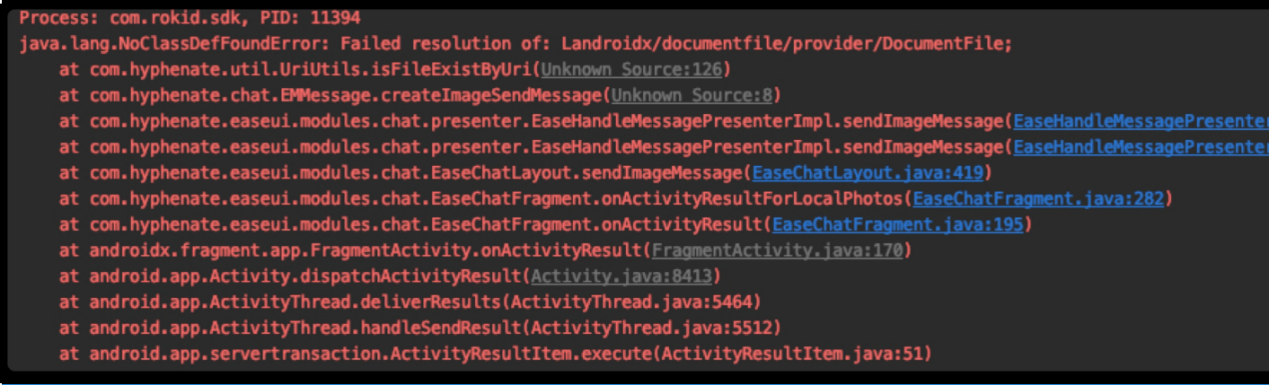
java.lang.RuntimeException:Unable to start receiver com.hyphenate.chat.EMMonitorReceiver: java.lang.IllegalStateException: Not allowed to start service Intent { cmp=com.ant.health/com.hyphenate.chat.EMChatService }: app is in background uid UidRecord{ab5b452 u0a320 RCVR idle change:uncached procs:1 seq(0,0,0)}
// 壳子工程的Application @ShellApp public class MyApplication extends Application {
@Override public void onCreate() { super.onCreate(); } } // 其他Module的Application @ModuleApp(priority = 1) public class Module1App extends Application { private static final String TAG = "Lobster";
@AppInstance public static Application mApplication1;
@Override public void onCreate() { super.onCreate(); Log.i(TAG , "Module1App->onCreate"); } } // 其他Module的Application @ModuleApp(priority = 2) public class Module2App extends Application { private static final String TAG = "Lobster"; @AppInstance public static Application mApplication2;
@Override public void onCreate() { super.onCreate(); Log.i(TAG , "Module2App->onCreate"); Toast.makeText(mApplication2, "I come from Module2App", Toast.LENGTH_SHORT).show(); } }
privateintmeasureSize(int defaultSize, int measureSpec){ int mode = MeasureSpec.getMode(measureSpec); int size = MeasureSpec.getSize(measureSpec); int result = defaultSize; switch (mode) { case MeasureSpec.UNSPECIFIED:
result = defaultSize; break; case MeasureSpec.AT_MOST: case MeasureSpec.EXACTLY:
result = size; break;
} return result;
}